Pipeline(steps=[('featureunion-1',\n",
" FeatureUnion(transformer_list=[('pipeline-1',\n",
" Pipeline(steps=[('columntransformer',\n",
" ColumnTransformer(transformers=[('passthrough',\n",
" 'passthrough',\n",
" <sklearn.compose._column_transformer.make_column_selector object at 0x7d34eb307cd0>)])),\n",
" ('simpleimputer',\n",
" SimpleImputer(fill_value='missing',\n",
" strategy='constant')),\n",
" ('onehotencode...\n",
" VarianceThreshold(threshold=0.1557560591318)),\n",
" ('featureunion-2',\n",
" FeatureUnion(transformer_list=[('pipeline-1',\n",
" Pipeline(steps=[('passthrough',\n",
" Passthrough())])),\n",
" ('pipeline-2',\n",
" Pipeline(steps=[('polynomialfeatures',\n",
" PolynomialFeatures())])),\n",
" ('pipeline-3',\n",
" Pipeline(steps=[('zerocount',\n",
" ZeroCount())]))])),\n",
" ('randomforestclassifier',\n",
" RandomForestClassifier(criterion='log_loss',\n",
" n_estimators=80))])In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.Pipeline(steps=[('featureunion-1',\n",
" FeatureUnion(transformer_list=[('pipeline-1',\n",
" Pipeline(steps=[('columntransformer',\n",
" ColumnTransformer(transformers=[('passthrough',\n",
" 'passthrough',\n",
" <sklearn.compose._column_transformer.make_column_selector object at 0x7d34eb307cd0>)])),\n",
" ('simpleimputer',\n",
" SimpleImputer(fill_value='missing',\n",
" strategy='constant')),\n",
" ('onehotencode...\n",
" VarianceThreshold(threshold=0.1557560591318)),\n",
" ('featureunion-2',\n",
" FeatureUnion(transformer_list=[('pipeline-1',\n",
" Pipeline(steps=[('passthrough',\n",
" Passthrough())])),\n",
" ('pipeline-2',\n",
" Pipeline(steps=[('polynomialfeatures',\n",
" PolynomialFeatures())])),\n",
" ('pipeline-3',\n",
" Pipeline(steps=[('zerocount',\n",
" ZeroCount())]))])),\n",
" ('randomforestclassifier',\n",
" RandomForestClassifier(criterion='log_loss',\n",
" n_estimators=80))])FeatureUnion(transformer_list=[('pipeline-1',\n",
" Pipeline(steps=[('columntransformer',\n",
" ColumnTransformer(transformers=[('passthrough',\n",
" 'passthrough',\n",
" <sklearn.compose._column_transformer.make_column_selector object at 0x7d34eb307cd0>)])),\n",
" ('simpleimputer',\n",
" SimpleImputer(fill_value='missing',\n",
" strategy='constant')),\n",
" ('onehotencoder',\n",
" OneHotEncoder(drop='first',\n",
" sparse_output=False))])),\n",
" ('pipeline-2',\n",
" Pipeline(steps=[('columntransformer',\n",
" ColumnTransformer(transformers=[('passthrough',\n",
" 'passthrough',\n",
" <sklearn.compose._column_transformer.make_column_selector object at 0x7d34eb307d30>)])),\n",
" ('simpleimputer',\n",
" SimpleImputer(strategy='median'))]))])FeatureUnion(transformer_list=[('pipeline-1',\n",
" Pipeline(steps=[('passthrough',\n",
" Passthrough())])),\n",
" ('pipeline-2',\n",
" Pipeline(steps=[('polynomialfeatures',\n",
" PolynomialFeatures())])),\n",
" ('pipeline-3',\n",
" Pipeline(steps=[('zerocount', ZeroCount())]))])
⚠️ Warning
This documentation is for the archived version of TPOT, which is no longer maintained. For the latest version, click here.
# TPOT API
## Classification
class tpot.TPOTClassifier(generations=100, population_size=100,
offspring_size=None, mutation_rate=0.9,
crossover_rate=0.1,
scoring='accuracy', cv=5,
subsample=1.0, n_jobs=1,
max_time_mins=None, max_eval_time_mins=5,
random_state=None, config_dict=None,
template=None,
warm_start=False,
memory=None,
use_dask=False,
periodic_checkpoint_folder=None,
early_stop=None,
verbosity=0,
disable_update_check=False,
log_file=None
)
Automated machine learning for supervised classification tasks.
The TPOTClassifier performs an intelligent search over machine learning pipelines that can contain supervised classification models,
preprocessors, feature selection techniques, and any other estimator or transformer that follows the [scikit-learn API](http://scikit-learn.org/stable/developers/contributing.html#apis-of-scikit-learn-objects).
The TPOTClassifier will also search over the hyperparameters of all objects in the pipeline.
By default, TPOTClassifier will search over a broad range of supervised classification algorithms, transformers, and their parameters.
However, the algorithms, transformers, and hyperparameters that the TPOTClassifier searches over can be fully customized using the `config_dict` parameter.
Read more in the [User Guide](using/#tpot-with-code).
| Parameters: |
generations: int or None optional (default=100)
Number of iterations to the run pipeline optimization process. It must be a positive number or None. If None, the parameter max_time_mins must be defined as the runtime limit.
Generally, TPOT will work better when you give it more generations (and therefore time) to optimize the pipeline.
TPOT will evaluate population_size + generations × offspring_size pipelines in total.
population_size: int, optional (default=100)
Number of individuals to retain in the genetic programming population every generation. Must be a positive number.
Generally, TPOT will work better when you give it more individuals with which to optimize the pipeline.
offspring_size: int, optional (default=None)
Number of offspring to produce in each genetic programming generation. Must be a positive number. By default, the number of offspring is equal to the number of population size.
mutation_rate: float, optional (default=0.9)
Mutation rate for the genetic programming algorithm in the range [0.0, 1.0]. This parameter tells the GP algorithm how many pipelines to apply random changes to every generation.
mutation_rate + crossover_rate cannot exceed 1.0.
We recommend using the default parameter unless you understand how the mutation rate affects GP algorithms.
crossover_rate: float, optional (default=0.1)
Crossover rate for the genetic programming algorithm in the range [0.0, 1.0]. This parameter tells the genetic programming algorithm how many pipelines to "breed" every generation.
mutation_rate + crossover_rate cannot exceed 1.0.
We recommend using the default parameter unless you understand how the crossover rate affects GP algorithms.
scoring: string or callable, optional (default='accuracy')
Function used to evaluate the quality of a given pipeline for the classification problem. The following built-in scoring functions can be used:
'accuracy', 'adjusted_rand_score', 'average_precision', 'balanced_accuracy', 'f1', 'f1_macro', 'f1_micro', 'f1_samples', 'f1_weighted', 'neg_log_loss', 'precision' etc. (suffixes apply as with ‘f1’), 'recall' etc. (suffixes apply as with ‘f1’), ‘jaccard’ etc. (suffixes apply as with ‘f1’), 'roc_auc', ‘roc_auc_ovr’, ‘roc_auc_ovo’, ‘roc_auc_ovr_weighted’, ‘roc_auc_ovo_weighted’
If you would like to use a custom scorer, you can pass the callable object/function with signature scorer(estimator, X, y).
See the section on scoring functions for more details.
cv: int, cross-validation generator, or an iterable, optional (default=5)
Cross-validation strategy used when evaluating pipelines.
Possible inputs:
- integer, to specify the number of folds in an unshuffled StratifiedKFold,
- An object to be used as a cross-validation generator, or
- An iterable yielding train/test splits.
subsample: float, optional (default=1.0)
Fraction of training samples that are used during the TPOT optimization process. Must be in the range (0.0, 1.0].
Setting subsample=0.5 tells TPOT to use a random subsample of half of the training data. This subsample will remain the same during the entire pipeline optimization process.
n_jobs: integer, optional (default=1)
Number of processes to use in parallel for evaluating pipelines during the TPOT optimization process.
Setting n_jobs=-1 will use as many cores as available on the computer. For n_jobs below -1, (n_cpus + 1 + n_jobs) are used. Thus for n_jobs = -2, all CPUs but one are used. Beware that using multiple processes on the same machine may cause memory issues for large datasets.
max_time_mins: integer or None, optional (default=None)
How many minutes TPOT has to optimize the pipeline.
If not None, this setting will allow TPOT to run until max_time_mins minutes elapsed and then stop. TPOT will stop earlier if generations is set and all generations are already evaluated.
max_eval_time_mins: float, optional (default=5)
How many minutes TPOT has to evaluate a single pipeline.
Setting this parameter to higher values will allow TPOT to evaluate more complex pipelines, but will also allow TPOT to run longer. Use this parameter to help prevent TPOT from wasting time on evaluating time-consuming pipelines.
random_state: integer or None, optional (default=None)
The seed of the pseudo random number generator used in TPOT.
Use this parameter to make sure that TPOT will give you the same results each time you run it against the same data set with that seed.
config_dict: Python dictionary, string, or None, optional (default=None)
A configuration dictionary for customizing the operators and parameters that TPOT searches in the optimization process.
Possible inputs are:
- Python dictionary, TPOT will use your custom configuration,
- string 'TPOT light', TPOT will use a built-in configuration with only fast models and preprocessors, or
- string 'TPOT MDR', TPOT will use a built-in configuration specialized for genomic studies, or
- string 'TPOT sparse': TPOT will use a configuration dictionary with a one-hot encoder and the operators normally included in TPOT that also support sparse matrices, or
- None, TPOT will use the default TPOTClassifier configuration.
See the built-in configurations section for the list of configurations included with TPOT, and the custom configuration section for more information and examples of how to create your own TPOT configurations.
template: string (default=None)
Template of predefined pipeline structure. The option is for specifying a desired structure for the machine learning pipeline evaluated in TPOT.
So far this option only supports linear pipeline structure. Each step in the pipeline should be a main class of operators (Selector, Transformer, Classifier) or a specific operator (e.g. `SelectPercentile`) defined in TPOT operator configuration. If one step is a main class, TPOT will randomly assign all subclass operators (subclasses of [`SelectorMixin`](https://github.com/scikit-learn/scikit-learn/blob/master/sklearn/feature_selection/base.py#L17), [`TransformerMixin`](https://scikit-learn.org/stable/modules/generated/sklearn.base.TransformerMixin.html), [`ClassifierMixin`](https://scikit-learn.org/stable/modules/generated/sklearn.base.ClassifierMixin.html) in scikit-learn) to that step. Steps in the template are delimited by "-", e.g. "SelectPercentile-Transformer-Classifier". By default value of template is None, TPOT generates tree-based pipeline randomly.
See the template option in tpot section for more details.
warm_start: boolean, optional (default=False)
Flag indicating whether the TPOT instance will reuse the population from previous calls to fit().
Setting warm_start=True can be useful for running TPOT for a short time on a dataset, checking the results, then resuming the TPOT run from where it left off.
memory: a joblib.Memory object or string, optional (default=None)
If supplied, pipeline will cache each transformer after calling fit. This feature is used to avoid computing the fit transformers within a pipeline if the parameters and input data are identical with another fitted pipeline during optimization process. More details about memory caching in scikit-learn documentation
Possible inputs are:
- String 'auto': TPOT uses memory caching with a temporary directory and cleans it up upon shutdown, or
- Path of a caching directory, TPOT uses memory caching with the provided directory and TPOT does NOT clean the caching directory up upon shutdown, or
- Memory object, TPOT uses the instance of joblib.Memory for memory caching and TPOT does NOT clean the caching directory up upon shutdown, or
- None, TPOT does not use memory caching.
use_dask: boolean, optional (default: False)
Whether to use Dask-ML's pipeline optimiziations. This avoid re-fitting
the same estimator on the same split of data multiple times. It
will also provide more detailed diagnostics when using Dask's
distributed scheduler.
See avoid repeated work for more details.
periodic_checkpoint_folder: path string, optional (default: None)
If supplied, a folder in which TPOT will periodically save pipelines in pareto front so far while optimizing.
Currently once per generation but not more often than once per 30 seconds.
Useful in multiple cases:
- Sudden death before TPOT could save optimized pipeline
- Track its progress
- Grab pipelines while it's still optimizing
early_stop: integer, optional (default: None)
How many generations TPOT checks whether there is no improvement in optimization process.
Ends the optimization process if there is no improvement in the given number of generations.
verbosity: integer, optional (default=0)
How much information TPOT communicates while it's running.
Possible inputs are:
- 0, TPOT will print nothing,
- 1, TPOT will print minimal information,
- 2, TPOT will print more information and provide a progress bar, or
- 3, TPOT will print everything and provide a progress bar.
disable_update_check: boolean, optional (default=False)
Flag indicating whether the TPOT version checker should be disabled.
The update checker will tell you when a new version of TPOT has been released.
log_file: file-like class (io.TextIOWrapper or io.StringIO) or string, optional (default: None)
Save progress content to a file.
If it is a string for the path and file name of the desired output file,
TPOT will create the file and write log into it.
If it is None, TPOT will output log into sys.stdout
|
| Attributes: |
fitted_pipeline_: scikit-learn Pipeline object
The best pipeline that TPOT discovered during the pipeline optimization process, fitted on the entire training dataset.
pareto_front_fitted_pipelines_: Python dictionary
Dictionary containing the all pipelines on the TPOT Pareto front, where the key is the string representation of the pipeline and the value is the corresponding pipeline fitted on the entire training dataset.
The TPOT Pareto front provides a trade-off between pipeline complexity (i.e., the number of steps in the pipeline) and the predictive performance of the pipeline.
Note: pareto_front_fitted_pipelines_ is only available when verbosity=3.
evaluated_individuals_: Python dictionary
Dictionary containing all pipelines that were evaluated during the pipeline optimization process, where the key is the string representation of the pipeline and the value is a tuple containing (# of steps in pipeline, accuracy metric for the pipeline).
This attribute is primarily for internal use, but may be useful for looking at the other pipelines that TPOT evaluated.
|
Example
```Python
from tpot import TPOTClassifier
from sklearn.datasets import load_digits
from sklearn.model_selection import train_test_split
digits = load_digits()
X_train, X_test, y_train, y_test = train_test_split(digits.data, digits.target,
train_size=0.75, test_size=0.25)
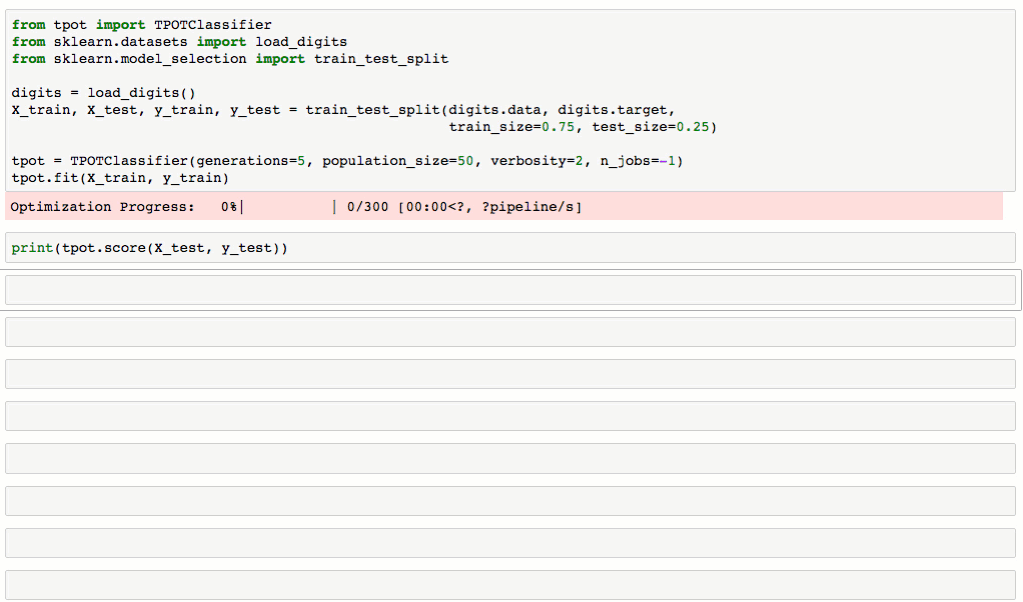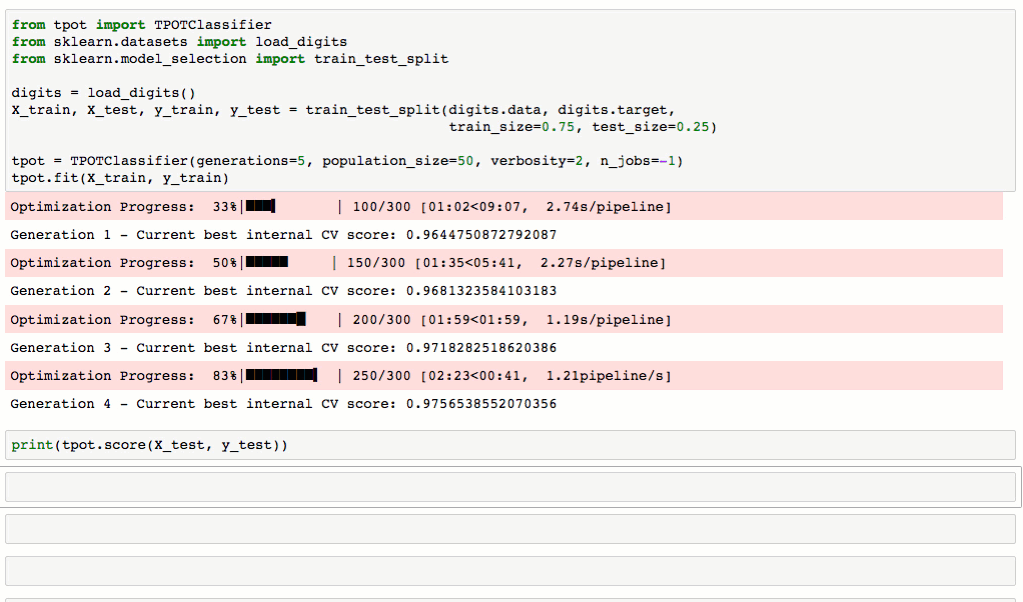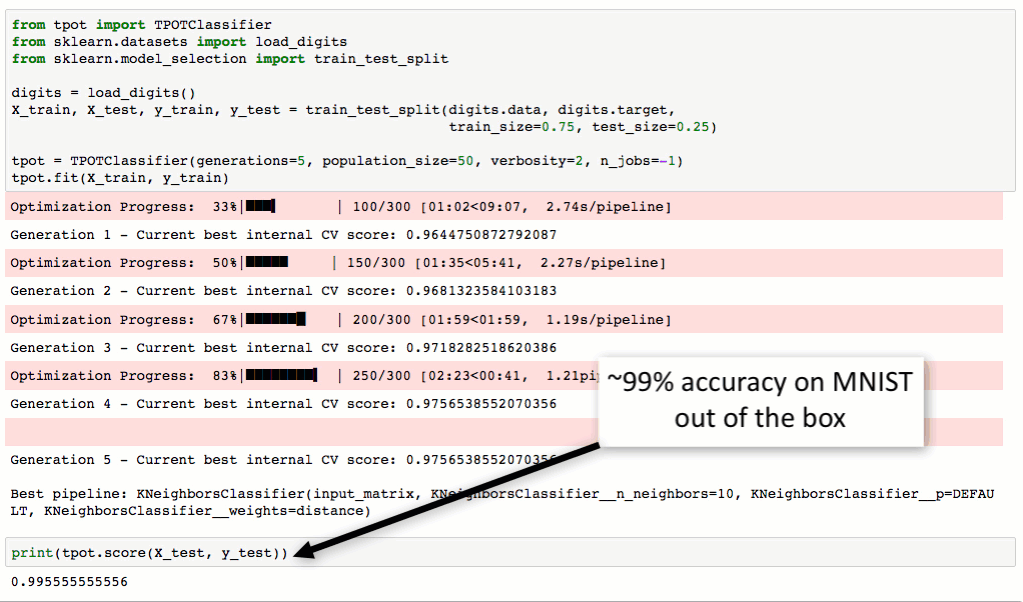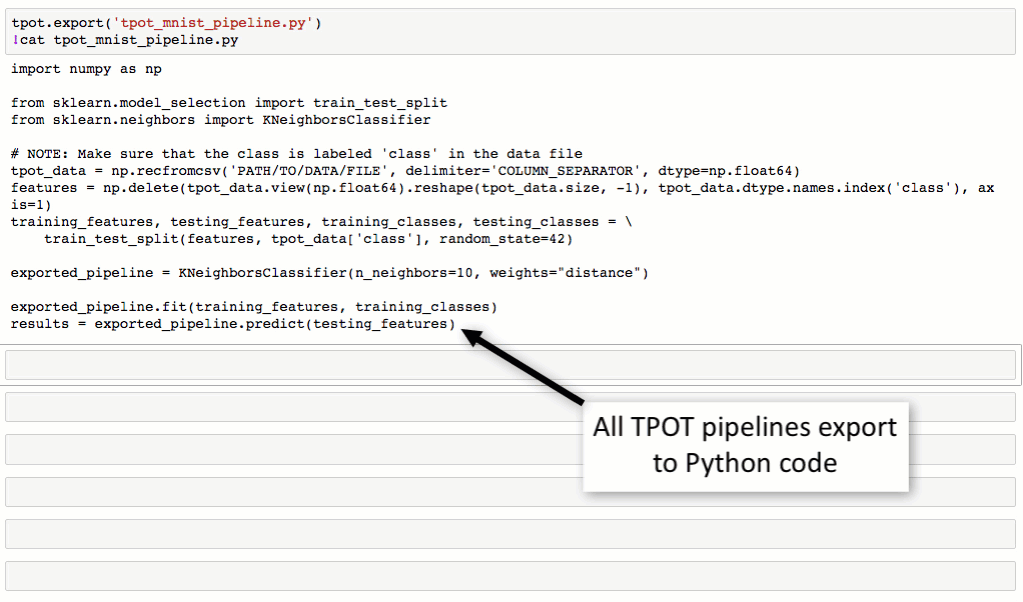
tpot = TPOTClassifier(generations=5, population_size=50, verbosity=2)
tpot.fit(X_train, y_train)
print(tpot.score(X_test, y_test))
tpot.export('tpot_digits_pipeline.py')
```
Functions
| fit(features, classes[, sample_weight, groups]) |
Run the TPOT optimization process on the given training data. |
| predict(features) |
Use the optimized pipeline to predict the classes for a feature set. |
| predict_proba(features) |
Use the optimized pipeline to estimate the class probabilities for a feature set. |
| score(testing_features, testing_classes) |
Returns the optimized pipeline's score on the given testing data using the user-specified scoring function. |
| export(output_file_name) |
Export the optimized pipeline as Python code. |
```Python
fit(features, classes, sample_weight=None, groups=None)
```
Run the TPOT optimization process on the given training data.
Uses genetic programming to optimize a machine learning pipeline that maximizes the score on the provided features and target. This pipeline optimization procedure uses internal k-fold cross-validaton to avoid overfitting on the provided data. At the end of the pipeline optimization procedure, the best pipeline is then trained on the entire set of provided samples.
| Parameters: |
features: array-like {n_samples, n_features}
Feature matrix
TPOT and all scikit-learn algorithms assume that the features will be numerical and there will be no missing values.
As such, when a feature matrix is provided to TPOT, all missing values will automatically be replaced (i.e., imputed)
using median value imputation.
If you wish to use a different imputation strategy than median imputation, please make sure to apply imputation to your feature set prior to passing it to TPOT.
classes: array-like {n_samples}
List of class labels for prediction
sample_weight: array-like {n_samples}, optional
Per-sample weights. Higher weights indicate more importance. If specified, sample_weight will be passed to any pipeline element whose fit() function accepts a sample_weight argument. By default, using sample_weight does not affect tpot's scoring functions, which determine preferences between pipelines.
groups: array-like, with shape {n_samples, }, optional
Group labels for the samples used when performing cross-validation.
This parameter should only be used in conjunction with sklearn's Group cross-validation functions, such as sklearn.model_selection.GroupKFold.
|
| Returns: |
self: object
Returns a copy of the fitted TPOT object
|
Use the optimized pipeline to predict the classes for a feature set.
| Parameters: |
features: array-like {n_samples, n_features}
Feature matrix
|
| Returns: |
predictions: array-like {n_samples}
Predicted classes for the samples in the feature matrix
|
Use the optimized pipeline to estimate the class probabilities for a feature set.
Note: This function will only work for pipelines whose final classifier supports the
predict_proba function. TPOT will raise an error otherwise.
| Parameters: |
features: array-like {n_samples, n_features}
Feature matrix
|
| Returns: |
predictions: array-like {n_samples, n_classes}
The class probabilities of the input samples
|
Returns the optimized pipeline's score on the given testing data using the user-specified scoring function.
The default scoring function for TPOTClassifier is 'accuracy'.
| Parameters: |
testing_features: array-like {n_samples, n_features}
Feature matrix of the testing set
testing_classes: array-like {n_samples}
List of class labels for prediction in the testing set
|
| Returns: |
accuracy_score: float
The estimated test set accuracy according to the user-specified scoring function.
|
Export the optimized pipeline as Python code.
See the
usage documentation for example usage of the export function.
| Parameters: |
output_file_name: string
String containing the path and file name of the desired output file
data_file_path: string
By default, the path of input dataset is 'PATH/TO/DATA/FILE' by default. If data_file_path is another string, the path will be replaced.
|
| Returns: |
exported_code_string: string
The whole pipeline text as a string should be returned if output_file_name is not specified.
|
class tpot.TPOTRegressor(generations=100, population_size=100,
offspring_size=None, mutation_rate=0.9,
crossover_rate=0.1,
scoring='neg_mean_squared_error', cv=5,
subsample=1.0, n_jobs=1,
max_time_mins=None, max_eval_time_mins=5,
random_state=None, config_dict=None,
template=None,
warm_start=False,
memory=None,
use_dask=False,
periodic_checkpoint_folder=None,
early_stop=None,
verbosity=0,
disable_update_check=False)
Automated machine learning for supervised regression tasks.
The TPOTRegressor performs an intelligent search over machine learning pipelines that can contain supervised regression models,
preprocessors, feature selection techniques, and any other estimator or transformer that follows the [scikit-learn API](http://scikit-learn.org/stable/developers/contributing.html#apis-of-scikit-learn-objects).
The TPOTRegressor will also search over the hyperparameters of all objects in the pipeline.
By default, TPOTRegressor will search over a broad range of supervised regression models, transformers, and their hyperparameters.
However, the models, transformers, and parameters that the TPOTRegressor searches over can be fully customized using the `config_dict` parameter.
Read more in the [User Guide](using/#tpot-with-code).
| Parameters: |
generations: int or None, optional (default=100)
Number of iterations to the run pipeline optimization process. It must be a positive number or None. If None, the parameter max_time_mins must be defined as the runtime limit.
Generally, TPOT will work better when you give it more generations (and therefore time) to optimize the pipeline.
TPOT will evaluate population_size + generations × offspring_size pipelines in total.
population_size: int, optional (default=100)
Number of individuals to retain in the genetic programming population every generation. Must be a positive number.
Generally, TPOT will work better when you give it more individuals with which to optimize the pipeline.
offspring_size: int, optional (default=None)
Number of offspring to produce in each genetic programming generation. Must be a positive number. By default, the number of offspring is equal to the number of population size.
mutation_rate: float, optional (default=0.9)
Mutation rate for the genetic programming algorithm in the range [0.0, 1.0]. This parameter tells the GP algorithm how many pipelines to apply random changes to every generation.
mutation_rate + crossover_rate cannot exceed 1.0.
We recommend using the default parameter unless you understand how the mutation rate affects GP algorithms.
crossover_rate: float, optional (default=0.1)
Crossover rate for the genetic programming algorithm in the range [0.0, 1.0]. This parameter tells the genetic programming algorithm how many pipelines to "breed" every generation.
mutation_rate + crossover_rate cannot exceed 1.0.
We recommend using the default parameter unless you understand how the crossover rate affects GP algorithms.
scoring: string or callable, optional (default='neg_mean_squared_error')
Function used to evaluate the quality of a given pipeline for the regression problem. The following built-in scoring functions can be used:
'neg_median_absolute_error', 'neg_mean_absolute_error', 'neg_mean_squared_error', 'r2'
Note that we recommend using the neg version of mean squared error and related metrics so TPOT will minimize (instead of maximize) the metric.
If you would like to use a custom scorer, you can pass the callable object/function with signature scorer(estimator, X, y).
See the section on scoring functions for more details.
cv: int, cross-validation generator, or an iterable, optional (default=5)
Cross-validation strategy used when evaluating pipelines.
Possible inputs:
- integer, to specify the number of folds in an unshuffled KFold,
- An object to be used as a cross-validation generator, or
- An iterable yielding train/test splits.
subsample: float, optional (default=1.0)
Fraction of training samples that are used during the TPOT optimization process. Must be in the range (0.0, 1.0].
Setting subsample=0.5 tells TPOT to use a random subsample of half of the training data. This subsample will remain the same during the entire pipeline optimization process.
n_jobs: integer, optional (default=1)
Number of processes to use in parallel for evaluating pipelines during the TPOT optimization process.
Setting n_jobs=-1 will use as many cores as available on the computer. For n_jobs below -1, (n_cpus + 1 + n_jobs) are used. Thus for n_jobs = -2, all CPUs but one are used. Beware that using multiple processes on the same machine may cause memory issues for large datasets
max_time_mins: integer or None, optional (default=None)
How many minutes TPOT has to optimize the pipeline.
If not None, this setting will allow TPOT to run until max_time_mins minutes elapsed and then stop. TPOT will stop earlier if generations is set and all generations are already evaluated.
max_eval_time_mins: float, optional (default=5)
How many minutes TPOT has to evaluate a single pipeline.
Setting this parameter to higher values will allow TPOT to evaluate more complex pipelines, but will also allow TPOT to run longer. Use this parameter to help prevent TPOT from wasting time on evaluating time-consuming pipelines.
random_state: integer or None, optional (default=None)
The seed of the pseudo random number generator used in TPOT.
Use this parameter to make sure that TPOT will give you the same results each time you run it against the same data set with that seed.
config_dict: Python dictionary, string, or None, optional (default=None)
A configuration dictionary for customizing the operators and parameters that TPOT searches in the optimization process.
Possible inputs are:
- Python dictionary, TPOT will use your custom configuration,
- string 'TPOT light', TPOT will use a built-in configuration with only fast models and preprocessors, or
- string 'TPOT MDR', TPOT will use a built-in configuration specialized for genomic studies, or
- string 'TPOT sparse': TPOT will use a configuration dictionary with a one-hot encoder and the operators normally included in TPOT that also support sparse matrices, or
- None, TPOT will use the default TPOTRegressor configuration.
See the built-in configurations section for the list of configurations included with TPOT, and the custom configuration section for more information and examples of how to create your own TPOT configurations.
template: string (default=None)
Template of predefined pipeline structure. The option is for specifying a desired structure for the machine learning pipeline evaluated in TPOT.
So far this option only supports linear pipeline structure. Each step in the pipeline should be a main class of operators (Selector, Transformer or Regressor) or a specific operator (e.g. `SelectPercentile`) defined in TPOT operator configuration. If one step is a main class, TPOT will randomly assign all subclass operators (subclasses of [`SelectorMixin`](https://github.com/scikit-learn/scikit-learn/blob/master/sklearn/feature_selection/base.py#L17), [`TransformerMixin`](https://scikit-learn.org/stable/modules/generated/sklearn.base.TransformerMixin.html) or [`RegressorMixin`](https://scikit-learn.org/stable/modules/generated/sklearn.base.RegressorMixin.html) in scikit-learn) to that step. Steps in the template are delimited by "-", e.g. "SelectPercentile-Transformer-Regressor". By default value of template is None, TPOT generates tree-based pipeline randomly.
See the template option in tpot section for more details.
warm_start: boolean, optional (default=False)
Flag indicating whether the TPOT instance will reuse the population from previous calls to fit().
Setting warm_start=True can be useful for running TPOT for a short time on a dataset, checking the results, then resuming the TPOT run from where it left off.
memory: a joblib.Memory object or string, optional (default=None)
If supplied, pipeline will cache each transformer after calling fit. This feature is used to avoid computing the fit transformers within a pipeline if the parameters and input data are identical with another fitted pipeline during optimization process. More details about memory caching in scikit-learn documentation
Possible inputs are:
- String 'auto': TPOT uses memory caching with a temporary directory and cleans it up upon shutdown, or
- Path of a caching directory, TPOT uses memory caching with the provided directory and TPOT does NOT clean the caching directory up upon shutdown, or
- Memory object, TPOT uses the instance of joblib.Memory for memory caching and TPOT does NOT clean the caching directory up upon shutdown, or
- None, TPOT does not use memory caching.
use_dask: boolean, optional (default: False)
Whether to use Dask-ML's pipeline optimiziations. This avoid re-fitting
the same estimator on the same split of data multiple times. It
will also provide more detailed diagnostics when using Dask's
distributed scheduler.
See avoid repeated work for more details.
periodic_checkpoint_folder: path string, optional (default: None)
If supplied, a folder in which TPOT will periodically save pipelines in pareto front so far while optimizing.
Currently once per generation but not more often than once per 30 seconds.
Useful in multiple cases:
- Sudden death before TPOT could save optimized pipeline
- Track its progress
- Grab pipelines while it's still optimizing
early_stop: integer, optional (default: None)
How many generations TPOT checks whether there is no improvement in optimization process.
Ends the optimization process if there is no improvement in the given number of generations.
verbosity: integer, optional (default=0)
How much information TPOT communicates while it's running.
Possible inputs are:
- 0, TPOT will print nothing,
- 1, TPOT will print minimal information,
- 2, TPOT will print more information and provide a progress bar, or
- 3, TPOT will print everything and provide a progress bar.
disable_update_check: boolean, optional (default=False)
Flag indicating whether the TPOT version checker should be disabled.
The update checker will tell you when a new version of TPOT has been released.
|
| Attributes: |
fitted_pipeline_: scikit-learn Pipeline object
The best pipeline that TPOT discovered during the pipeline optimization process, fitted on the entire training dataset.
pareto_front_fitted_pipelines_: Python dictionary
Dictionary containing the all pipelines on the TPOT Pareto front, where the key is the string representation of the pipeline and the value is the corresponding pipeline fitted on the entire training dataset.
The TPOT Pareto front provides a trade-off between pipeline complexity (i.e., the number of steps in the pipeline) and the predictive performance of the pipeline.
Note: _pareto_front_fitted_pipelines is only available when verbosity=3.
evaluated_individuals_: Python dictionary
Dictionary containing all pipelines that were evaluated during the pipeline optimization process, where the key is the string representation of the pipeline and the value is a tuple containing (# of steps in pipeline, accuracy metric for the pipeline).
This attribute is primarily for internal use, but may be useful for looking at the other pipelines that TPOT evaluated.
|
Example
```Python
from tpot import TPOTRegressor
from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
digits = load_boston()
X_train, X_test, y_train, y_test = train_test_split(digits.data, digits.target,
train_size=0.75, test_size=0.25)
tpot = TPOTRegressor(generations=5, population_size=50, verbosity=2)
tpot.fit(X_train, y_train)
print(tpot.score(X_test, y_test))
tpot.export('tpot_boston_pipeline.py')
```
Functions
| fit(features, target[, sample_weight, groups]) |
Run the TPOT optimization process on the given training data. |
| predict(features) |
Use the optimized pipeline to predict the target values for a feature set. |
| score(testing_features, testing_target) |
Returns the optimized pipeline's score on the given testing data using the user-specified scoring function. |
| export(output_file_name) |
Export the optimized pipeline as Python code. |
```Python
fit(features, target, sample_weight=None, groups=None)
```
Run the TPOT optimization process on the given training data.
Uses genetic programming to optimize a machine learning pipeline that maximizes the score on the provided features and target. This pipeline optimization procedure uses internal k-fold cross-validaton to avoid overfitting on the provided data. At the end of the pipeline optimization procedure, the best pipeline is then trained on the entire set of provided samples.
| Parameters: |
features: array-like {n_samples, n_features}
Feature matrix
TPOT and all scikit-learn algorithms assume that the features will be numerical and there will be no missing values.
As such, when a feature matrix is provided to TPOT, all missing values will automatically be replaced (i.e., imputed)
using median value imputation.
If you wish to use a different imputation strategy than median imputation, please make sure to apply imputation to your feature set prior to passing it to TPOT.
target: array-like {n_samples}
List of target labels for prediction
sample_weight: array-like {n_samples}, optional
Per-sample weights. Higher weights indicate more importance. If specified, sample_weight will be passed to any pipeline element whose fit() function accepts a sample_weight argument. By default, using sample_weight does not affect tpot's scoring functions, which determine preferences between pipelines.
groups: array-like, with shape {n_samples, }, optional
Group labels for the samples used when performing cross-validation.
This parameter should only be used in conjunction with sklearn's Group cross-validation functions, such as sklearn.model_selection.GroupKFold.
|
| Returns: |
self: object
Returns a copy of the fitted TPOT object
|
Use the optimized pipeline to predict the target values for a feature set.
| Parameters: |
features: array-like {n_samples, n_features}
Feature matrix
|
| Returns: |
predictions: array-like {n_samples}
Predicted target values for the samples in the feature matrix
|
Returns the optimized pipeline's score on the given testing data using the user-specified scoring function.
The default scoring function for TPOTRegressor is 'mean_squared_error'.
| Parameters: |
testing_features: array-like {n_samples, n_features}
Feature matrix of the testing set
testing_target: array-like {n_samples}
List of target labels for prediction in the testing set
|
| Returns: |
accuracy_score: float
The estimated test set accuracy according to the user-specified scoring function.
|
Export the optimized pipeline as Python code.
See the
usage documentation for example usage of the export function.
| Parameters: |
output_file_name: string
String containing the path and file name of the desired output file
data_file_path: string
By default, the path of input dataset is 'PATH/TO/DATA/FILE' by default. If data_file_path is another string, the path will be replaced.
|
| Returns: |
exported_code_string: string
The whole pipeline text as a string should be returned if output_file_name is not specified.
|
⚠️ Warning
This documentation is for the archived version of TPOT, which is no longer maintained. For the latest version, click here.
# Citing TPOT
If you use TPOT in a scientific publication, please consider citing at least one of the following papers:
Trang T. Le, Weixuan Fu and Jason H. Moore (2020). [Scaling tree-based automated machine learning to biomedical big data with a feature set selector](https://academic.oup.com/bioinformatics/article/36/1/250/5511404). *Bioinformatics*.36(1): 250-256.
BibTeX entry:
```bibtex
@article{le2020scaling,
title={Scaling tree-based automated machine learning to biomedical big data with a feature set selector},
author={Le, Trang T and Fu, Weixuan and Moore, Jason H},
journal={Bioinformatics},
volume={36},
number={1},
pages={250--256},
year={2020},
publisher={Oxford University Press}
}
```
Randal S. Olson, Ryan J. Urbanowicz, Peter C. Andrews, Nicole A. Lavender, La Creis Kidd, and Jason H. Moore (2016). [Automating biomedical data science through tree-based pipeline optimization](http://link.springer.com/chapter/10.1007/978-3-319-31204-0_9). *Applications of Evolutionary Computation*, pages 123-137.
BibTeX entry:
```bibtex
@inbook{Olson2016EvoBio,
author={Olson, Randal S. and Urbanowicz, Ryan J. and Andrews, Peter C. and Lavender, Nicole A. and Kidd, La Creis and Moore, Jason H.},
editor={Squillero, Giovanni and Burelli, Paolo},
chapter={Automating Biomedical Data Science Through Tree-Based Pipeline Optimization},
title={Applications of Evolutionary Computation: 19th European Conference, EvoApplications 2016, Porto, Portugal, March 30 -- April 1, 2016, Proceedings, Part I},
year={2016},
publisher={Springer International Publishing},
pages={123--137},
isbn={978-3-319-31204-0},
doi={10.1007/978-3-319-31204-0_9},
url={http://dx.doi.org/10.1007/978-3-319-31204-0_9}
}
```
Evaluation of a Tree-based Pipeline Optimization Tool for Automating Data Science
Randal S. Olson, Nathan Bartley, Ryan J. Urbanowicz, and Jason H. Moore (2016). [Evaluation of a Tree-based Pipeline Optimization Tool for Automating Data Science](http://dl.acm.org/citation.cfm?id=2908918). *Proceedings of GECCO 2016*, pages 485-492.
BibTeX entry:
```bibtex
@inproceedings{OlsonGECCO2016,
author = {Olson, Randal S. and Bartley, Nathan and Urbanowicz, Ryan J. and Moore, Jason H.},
title = {Evaluation of a Tree-based Pipeline Optimization Tool for Automating Data Science},
booktitle = {Proceedings of the Genetic and Evolutionary Computation Conference 2016},
series = {GECCO '16},
year = {2016},
isbn = {978-1-4503-4206-3},
location = {Denver, Colorado, USA},
pages = {485--492},
numpages = {8},
url = {http://doi.acm.org/10.1145/2908812.2908918},
doi = {10.1145/2908812.2908918},
acmid = {2908918},
publisher = {ACM},
address = {New York, NY, USA},
}
```
Alternatively, you can cite the repository directly with the following DOI:
[DOI](https://zenodo.org/badge/latestdoi/20747/rhiever/tpot)
================================================
FILE: docs/archived/contributing.md
================================================
⚠️ Warning
This documentation is for the archived version of TPOT, which is no longer maintained. For the latest version, click here.
# Contribution Guide
We welcome you to [check the existing issues](https://github.com/EpistasisLab/tpot/issues/) for bugs or enhancements to work on. If you have an idea for an extension to TPOT, please [file a new issue](https://github.com/EpistasisLab/tpot/issues/new) so we can discuss it.
## Project layout
The latest stable release of TPOT is on the [master branch](https://github.com/EpistasisLab/tpot/tree/master), whereas the latest version of TPOT in development is on the [development branch](https://github.com/EpistasisLab/tpot/tree/development). Make sure you are looking at and working on the correct branch if you're looking to contribute code.
In terms of directory structure:
* All of TPOT's code sources are in the `tpot` directory
* The documentation sources are in the `docs_sources` directory
* Images in the documentation are in the `images` directory
* Tutorials for TPOT are in the `tutorials` directory
* Unit tests for TPOT are in the `tests.py` file
Make sure to familiarize yourself with the project layout before making any major contributions, and especially make sure to send all code changes to the `development` branch.
## How to contribute
The preferred way to contribute to TPOT is to fork the
[main repository](https://github.com/EpistasisLab/tpot/) on
GitHub:
1. Fork the [project repository](https://github.com/EpistasisLab/tpot):
click on the 'Fork' button near the top of the page. This creates
a copy of the code under your account on the GitHub server.
2. Clone this copy to your local disk:
$ git clone git@github.com:YourUsername/tpot.git
$ cd tpot
3. Create a branch to hold your changes:
$ git checkout -b my-contribution
4. Make sure your local environment is setup correctly for development. Installation instructions are almost identical to [the user instructions](installing.md) except that TPOT should *not* be installed. If you have TPOT installed on your computer then make sure you are using a virtual environment that does not have TPOT installed. Furthermore, you should make sure you have installed the `nose` package into your development environment so that you can test changes locally.
$ conda install nose
5. Start making changes on your newly created branch, remembering to never work on the ``master`` branch! Work on this copy on your computer using Git to do the version control.
6. Once some changes are saved locally, you can use your tweaked version of TPOT by navigating to the project's base directory and running TPOT directly from the command line:
$ python -m tpot.driver
or by running script that imports and uses the TPOT module with code similar to `from tpot import TPOTClassifier`
7. To check your changes haven't broken any existing tests and to check new tests you've added pass run the following (note, you must have the `nose` package installed within your dev environment for this to work):
$ nosetests -s -v
8. When you're done editing and local testing, run:
$ git add modified_files
$ git commit
to record your changes in Git, then push them to GitHub with:
$ git push -u origin my-contribution
Finally, go to the web page of your fork of the TPOT repo, and click 'Pull Request' (PR) to send your changes to the maintainers for review. Make sure that you send your PR to the `development` branch, as the `master` branch is reserved for the latest stable release. This will start the CI server to check all the project's unit tests run and send an email to the maintainers.
(If any of the above seems like magic to you, then look up the
[Git documentation](http://git-scm.com/documentation) on the web.)
## Before submitting your pull request
Before you submit a pull request for your contribution, please work through this checklist to make sure that you have done everything necessary so we can efficiently review and accept your changes.
If your contribution changes TPOT in any way:
* Update the [documentation](https://github.com/EpistasisLab/tpot/tree/master/docs_sources) so all of your changes are reflected there.
* Update the [README](https://github.com/EpistasisLab/tpot/blob/master/README.md) if anything there has changed.
If your contribution involves any code changes:
* Update the [project unit tests](https://github.com/EpistasisLab/tpot/tree/master/tests) to test your code changes.
* Make sure that your code is properly commented with [docstrings](https://www.python.org/dev/peps/pep-0257/) and comments explaining your rationale behind non-obvious coding practices.
* If your code affected any of the pipeline operators, make sure that the corresponding [export functionality](https://github.com/EpistasisLab/tpot/blob/master/tpot/export_utils.py) reflects those changes.
If your contribution requires a new library dependency:
* Double-check that the new dependency is easy to install via `pip` or Anaconda and supports both Python 2 and 3. If the dependency requires a complicated installation, then we most likely won't merge your changes because we want to keep TPOT easy to install.
* Add the required version of the library to [.travis.yml](https://github.com/EpistasisLab/tpot/blob/master/.travis.yml#L7)
* Add a line to pip install the library to [.travis_install.sh](https://github.com/EpistasisLab/tpot/blob/master/ci/.travis_install.sh#L46)
* Add a line to print the version of the library to [.travis_install.sh](https://github.com/EpistasisLab/tpot/blob/master/ci/.travis_install.sh#L63)
* Similarly add a line to print the version of the library to [.travis_test.sh](https://github.com/EpistasisLab/tpot/blob/master/ci/.travis_test.sh#L13)
## After submitting your pull request
After submitting your pull request, [Travis-CI](https://travis-ci.com/) will automatically run unit tests on your changes and make sure that your updated code builds and runs on Python 2 and 3. We also use services that automatically check code quality and test coverage.
Check back shortly after submitting your pull request to make sure that your code passes these checks. If any of the checks come back with a red X, then do your best to address the errors.
================================================
FILE: docs/archived/css/archived.css
================================================
.md-grid {
max-width: 100%;
}
================================================
FILE: docs/archived/examples.md
================================================
⚠️ Warning
This documentation is for the archived version of TPOT, which is no longer maintained. For the latest version, click here.
# Overview
The following sections illustrate the usage of TPOT with various datasets, each
belonging to a typical class of machine learning tasks.
| Dataset | Task | Task class | Dataset description | Jupyter notebook |
| ------- | ----------------------- | ---------------------- |:-------------------:|:------------------------------------------------------------------------------------------:|
| Iris | flower classification | classification | [link](https://archive.ics.uci.edu/ml/datasets/iris) | [link](https://github.com/EpistasisLab/tpot/blob/master/tutorials/IRIS.ipynb) |
| Optical Recognition of Handwritten Digits | digit recognition | (image) classification | [link](https://scikit-learn.org/stable/datasets/index.html#digits-dataset) | [link](https://github.com/EpistasisLab/tpot/blob/master/tutorials/Digits.ipynb) |
| Boston | housing prices modeling | regression | [link](https://www.cs.toronto.edu/~delve/data/boston/bostonDetail.html) | N/A |
| Titanic | survival analysis | classification | [link](https://www.kaggle.com/c/titanic/data) | [link](https://github.com/EpistasisLab/tpot/blob/master/tutorials/Titanic_Kaggle.ipynb) |
| Bank Marketing | subscription prediction | classification | [link](https://archive.ics.uci.edu/ml/datasets/Bank+Marketing) | [link](https://github.com/EpistasisLab/tpot/blob/master/tutorials/Portuguese%20Bank%20Marketing/Portuguese%20Bank%20Marketing%20Strategy.ipynb) |
| MAGIC Gamma Telescope | event detection | classification | [link](https://archive.ics.uci.edu/ml/datasets/MAGIC+Gamma+Telescope) | [link](https://github.com/EpistasisLab/tpot/blob/master/tutorials/MAGIC%20Gamma%20Telescope/MAGIC%20Gamma%20Telescope.ipynb) |
| cuML Classification Example | random classification problem | classification | [link](https://scikit-learn.org/stable/modules/generated/sklearn.datasets.make_classification.html) | [link](https://github.com/EpistasisLab/tpot/blob/master/tutorials/cuML_Classification_Example.ipynb) |
| cuML Regression Example | random regression problem | regression | [link](https://scikit-learn.org/stable/modules/generated/sklearn.datasets.make_regression.html) | [link](https://github.com/EpistasisLab/tpot/blob/master/tutorials/cuML_Regression_Example.ipynb) |
**Notes:**
- For details on how the `fit()`, `score()` and `export()` methods work, refer to the [usage documentation](/using/).
- Upon re-running the experiments, your resulting pipelines _may_ differ (to some extent) from the ones demonstrated here.
## Iris flower classification
The following code illustrates how TPOT can be employed for performing a simple _classification task_ over the Iris dataset.
```Python
from tpot import TPOTClassifier
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
import numpy as np
iris = load_iris()
X_train, X_test, y_train, y_test = train_test_split(iris.data.astype(np.float64),
iris.target.astype(np.float64), train_size=0.75, test_size=0.25, random_state=42)
tpot = TPOTClassifier(generations=5, population_size=50, verbosity=2, random_state=42)
tpot.fit(X_train, y_train)
print(tpot.score(X_test, y_test))
tpot.export('tpot_iris_pipeline.py')
```
Running this code should discover a pipeline (exported as `tpot_iris_pipeline.py`) that achieves about 97% test accuracy:
```Python
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import Normalizer
from tpot.export_utils import set_param_recursive
# NOTE: Make sure that the outcome column is labeled 'target' in the data file
tpot_data = pd.read_csv('PATH/TO/DATA/FILE', sep='COLUMN_SEPARATOR', dtype=np.float64)
features = tpot_data.drop('target', axis=1)
training_features, testing_features, training_target, testing_target = \
train_test_split(features, tpot_data['target'], random_state=42)
# Average CV score on the training set was: 0.9826086956521738
exported_pipeline = make_pipeline(
Normalizer(norm="l2"),
KNeighborsClassifier(n_neighbors=5, p=2, weights="distance")
)
# Fix random state for all the steps in exported pipeline
set_param_recursive(exported_pipeline.steps, 'random_state', 42)
exported_pipeline.fit(training_features, training_target)
results = exported_pipeline.predict(testing_features)
```
## Digits dataset
Below is a minimal working example with the optical recognition of handwritten digits dataset, which is an _image classification problem_.
```Python
from tpot import TPOTClassifier
from sklearn.datasets import load_digits
from sklearn.model_selection import train_test_split
digits = load_digits()
X_train, X_test, y_train, y_test = train_test_split(digits.data, digits.target,
train_size=0.75, test_size=0.25, random_state=42)
tpot = TPOTClassifier(generations=5, population_size=50, verbosity=2, random_state=42)
tpot.fit(X_train, y_train)
print(tpot.score(X_test, y_test))
tpot.export('tpot_digits_pipeline.py')
```
Running this code should discover a pipeline (exported as `tpot_digits_pipeline.py`) that achieves about 98% test accuracy:
```Python
import numpy as np
import pandas as pd
from sklearn.ensemble import RandomForestClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.pipeline import make_pipeline, make_union
from sklearn.preprocessing import PolynomialFeatures
from tpot.builtins import StackingEstimator
from tpot.export_utils import set_param_recursive
# NOTE: Make sure that the outcome column is labeled 'target' in the data file
tpot_data = pd.read_csv('PATH/TO/DATA/FILE', sep='COLUMN_SEPARATOR', dtype=np.float64)
features = tpot_data.drop('target', axis=1)
training_features, testing_features, training_target, testing_target = \
train_test_split(features, tpot_data['target'], random_state=42)
# Average CV score on the training set was: 0.9799428471757372
exported_pipeline = make_pipeline(
PolynomialFeatures(degree=2, include_bias=False, interaction_only=False),
StackingEstimator(estimator=LogisticRegression(C=0.1, dual=False, penalty="l1")),
RandomForestClassifier(bootstrap=True, criterion="entropy", max_features=0.35000000000000003, min_samples_leaf=20, min_samples_split=19, n_estimators=100)
)
# Fix random state for all the steps in exported pipeline
set_param_recursive(exported_pipeline.steps, 'random_state', 42)
exported_pipeline.fit(training_features, training_target)
results = exported_pipeline.predict(testing_features)
```
## Boston housing prices modeling
The following code illustrates how TPOT can be employed for performing a _regression task_ over the Boston housing prices dataset.
```Python
from tpot import TPOTRegressor
from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
housing = load_boston()
X_train, X_test, y_train, y_test = train_test_split(housing.data, housing.target,
train_size=0.75, test_size=0.25, random_state=42)
tpot = TPOTRegressor(generations=5, population_size=50, verbosity=2, random_state=42)
tpot.fit(X_train, y_train)
print(tpot.score(X_test, y_test))
tpot.export('tpot_boston_pipeline.py')
```
Running this code should discover a pipeline (exported as `tpot_boston_pipeline.py`) that achieves at least 10 mean squared error (MSE) on the test set:
```Python
import numpy as np
import pandas as pd
from sklearn.ensemble import ExtraTreesRegressor
from sklearn.model_selection import train_test_split
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import PolynomialFeatures
from tpot.export_utils import set_param_recursive
# NOTE: Make sure that the outcome column is labeled 'target' in the data file
tpot_data = pd.read_csv('PATH/TO/DATA/FILE', sep='COLUMN_SEPARATOR', dtype=np.float64)
features = tpot_data.drop('target', axis=1)
training_features, testing_features, training_target, testing_target = \
train_test_split(features, tpot_data['target'], random_state=42)
# Average CV score on the training set was: -10.812040755234403
exported_pipeline = make_pipeline(
PolynomialFeatures(degree=2, include_bias=False, interaction_only=False),
ExtraTreesRegressor(bootstrap=False, max_features=0.5, min_samples_leaf=2, min_samples_split=3, n_estimators=100)
)
# Fix random state for all the steps in exported pipeline
set_param_recursive(exported_pipeline.steps, 'random_state', 42)
exported_pipeline.fit(training_features, training_target)
results = exported_pipeline.predict(testing_features)
```
## Titanic survival analysis
To see the TPOT applied the Titanic Kaggle dataset, see the Jupyter notebook [here](https://github.com/EpistasisLab/tpot/blob/master/tutorials/Titanic_Kaggle.ipynb). This example shows how to take a messy dataset and preprocess it such that it can be used in scikit-learn and TPOT.
## Portuguese Bank Marketing
The corresponding Jupyter notebook, containing the associated data preprocessing and analysis, can be found [here](https://github.com/EpistasisLab/tpot/blob/master/tutorials/Portuguese%20Bank%20Marketing/Portuguese%20Bank%20Marketing%20Stratergy.ipynb).
## MAGIC Gamma Telescope
The corresponding Jupyter notebook, containing the associated data preprocessing and analysis, can be found [here](https://github.com/EpistasisLab/tpot/blob/master/tutorials/MAGIC%20Gamma%20Telescope/MAGIC%20Gamma%20Telescope.ipynb).
## Neural network classifier using TPOT-NN
By loading the TPOT-NN configuration dictionary, PyTorch estimators will be included for classification. Users can also create their own NN configuration dictionary that includes `tpot.builtins.PytorchLRClassifier` and/or `tpot.builtins.PytorchMLPClassifier`, or they can specify them using a template string, as shown in the following example:
```Python
from tpot import TPOTClassifier
from sklearn.datasets import make_blobs
from sklearn.model_selection import train_test_split
X, y = make_blobs(n_samples=100, centers=2, n_features=3, random_state=42)
X_train, X_test, y_train, y_test = train_test_split(X, y, train_size=0.75, test_size=0.25)
clf = TPOTClassifier(config_dict='TPOT NN', template='Selector-Transformer-PytorchLRClassifier',
verbosity=2, population_size=10, generations=10)
clf.fit(X_train, y_train)
print(clf.score(X_test, y_test))
clf.export('tpot_nn_demo_pipeline.py')
```
This example is somewhat trivial, but it should result in nearly 100% classification accuracy.
================================================
FILE: docs/archived/index.md
================================================
⚠️ Warning
This documentation is for the archived version of TPOT, which is no longer maintained. For the latest version, click here.
 Consider TPOT your **Data Science Assistant**. TPOT is a Python Automated Machine Learning tool that optimizes machine learning pipelines using genetic programming.
Consider TPOT your **Data Science Assistant**. TPOT is a Python Automated Machine Learning tool that optimizes machine learning pipelines using genetic programming.
TPOT will automate the most tedious part of machine learning by intelligently exploring thousands of possible pipelines to find the best one for your data.
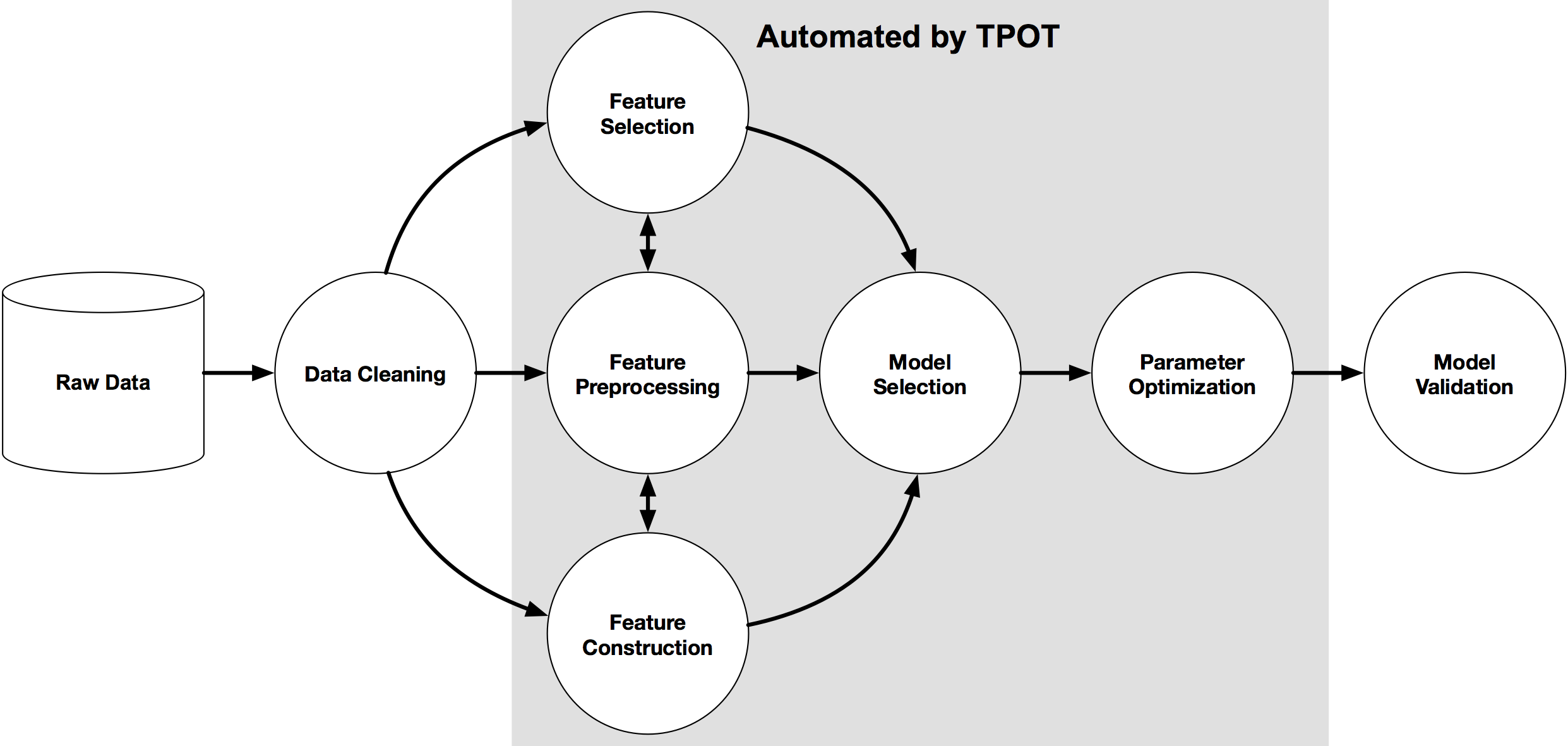 An example machine learning pipeline
An example machine learning pipeline
Once TPOT is finished searching (or you get tired of waiting), it provides you with the Python code for the best pipeline it found so you can tinker with the pipeline from there.
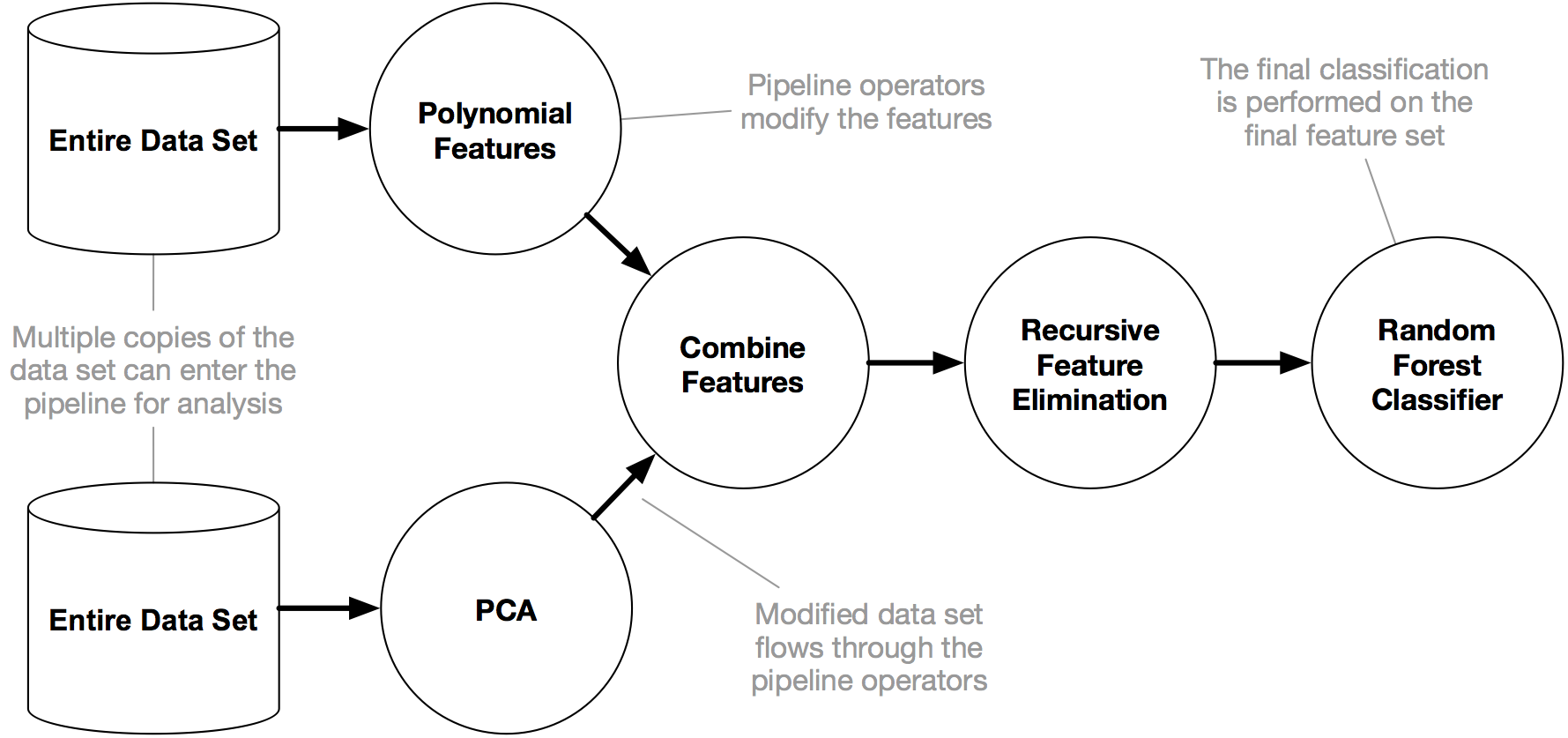 An example TPOT pipeline
An example TPOT pipeline
TPOT is built on top of scikit-learn, so all of the code it generates should look familiar... if you're familiar with scikit-learn, anyway.
**TPOT is still under active development** and we encourage you to check back on this repository regularly for updates.
================================================
FILE: docs/archived/installing.md
================================================
⚠️ Warning
This documentation is for the archived version of TPOT, which is no longer maintained. For the latest version, click here.
# Installation
TPOT is built on top of several existing Python libraries, including:
* [NumPy](http://www.numpy.org/)
* [SciPy](https://www.scipy.org/)
* [scikit-learn](http://www.scikit-learn.org/)
* [DEAP](https://github.com/DEAP/deap)
* [update_checker](https://github.com/bboe/update_checker)
* [tqdm](https://github.com/tqdm/tqdm)
* [stopit](https://github.com/glenfant/stopit)
* [pandas](http://pandas.pydata.org)
* [joblib](https://joblib.readthedocs.io/en/latest/)
* [xgboost](https://xgboost.readthedocs.io/en/latest/)
Most of the necessary Python packages can be installed via the [Anaconda Python distribution](https://www.anaconda.com/products/individual), which we strongly recommend that you use. **Support for Python 3.4 and below has been officially dropped since version 0.11.0.**
You can install TPOT using `pip` or `conda-forge`.
## pip
NumPy, SciPy, scikit-learn, pandas, joblib, and PyTorch can be installed in Anaconda via the command:
```Shell
conda install numpy scipy scikit-learn pandas joblib pytorch
```
DEAP, update_checker, tqdm, stopit and xgboost can be installed with `pip` via the command:
```Shell
pip install deap update_checker tqdm stopit xgboost
```
**Windows users: pip installation may not work on some Windows environments, and it may cause unexpected errors.** If you have issues installing XGBoost, check the [XGBoost installation documentation](http://xgboost.readthedocs.io/en/latest/build.html).
If you plan to use [Dask](http://dask.pydata.org/en/latest/) for parallel training, make sure to install [dask[delay] and dask[dataframe]](https://docs.dask.org/en/latest/install.html) and [dask_ml](https://dask-ml.readthedocs.io/en/latest/install.html). **It is noted that dask-ml>=1.7 requires distributed>=2.4.0 and scikit-learn>=0.23.0.**
```Shell
pip install dask[delayed] dask[dataframe] dask-ml fsspec>=0.3.3 distributed>=2.10.0
```
If you plan to use the [TPOT-MDR configuration](https://arxiv.org/abs/1702.01780), make sure to install [scikit-mdr](https://github.com/EpistasisLab/scikit-mdr) and [scikit-rebate](https://github.com/EpistasisLab/scikit-rebate):
```Shell
pip install scikit-mdr skrebate
```
To enable support for [PyTorch](https://pytorch.org/)-based neural networks (TPOT-NN), you will need to install PyTorch. TPOT-NN will work with either CPU or GPU PyTorch, but we strongly recommend using a GPU version, if possible, as CPU PyTorch models tend to train very slowly.
We recommend following [PyTorch's installation instructions](https://pytorch.org/get-started/locally/) customized for your operating system and Python distribution.
Finally to install TPOT itself, run the following command:
```Shell
pip install tpot
```
## conda-forge
To install tpot and its core dependencies you can use:
```Shell
conda install -c conda-forge tpot
```
To install additional dependencies you can use:
```Shell
conda install -c conda-forge tpot xgboost dask dask-ml scikit-mdr skrebate
```
As mentioned above, we recommend following [PyTorch's installation instructions](https://pytorch.org/get-started/locally/) for installing it to enable support for [PyTorch](https://pytorch.org/)-based neural networks (TPOT-NN).
## Installation for using TPOT-cuML configuration
With "TPOT cuML" configuration (see built-in configurations), TPOT will search over a restricted configuration using the GPU-accelerated estimators in [RAPIDS cuML](https://github.com/rapidsai/cuml) and [DMLC XGBoost](https://github.com/dmlc/xgboost). **This configuration requires an NVIDIA Pascal architecture or better GPU with [compute capability 6.0+](https://developer.nvidia.com/cuda-gpus), and that the library cuML is installed.** With this configuration, all model training and predicting will be GPU-accelerated. This configuration is particularly useful for medium-sized and larger datasets on which CPU-based estimators are a common bottleneck, and works for both the `TPOTClassifier` and `TPOTRegressor`.
Please download this conda environment yml file to install TPOT for using TPOT-cuML configuration.
```
conda env create -f tpot-cuml.yml -n tpot-cuml
conda activate tpot-cuml
```
## Installation problems
Please [file a new issue](https://github.com/EpistasisLab/tpot/issues/new) if you run into installation problems.
================================================
FILE: docs/archived/related.md
================================================
⚠️ Warning
This documentation is for the archived version of TPOT, which is no longer maintained. For the latest version, click here.
Other Automated Machine Learning (AutoML) tools and related projects:
| Name |
Language |
License |
Description |
| Auto-WEKA |
Java |
GPL-v3 |
Automated model selection and hyper-parameter tuning for Weka models. |
| auto-sklearn |
Python |
BSD-3-Clause |
An automated machine learning toolkit and a drop-in replacement for a scikit-learn estimator. |
| auto_ml |
Python |
MIT |
Automated machine learning for analytics & production. Supports manual feature type declarations. |
| H2O AutoML |
Java with Python, Scala & R APIs and web GUI |
Apache 2.0 |
Automated: data prep, hyperparameter tuning, random grid search and stacked ensembles in a distributed ML platform. |
| devol |
Python |
MIT |
Automated deep neural network design via genetic programming. |
| MLBox |
Python |
BSD-3-Clause |
Accurate hyper-parameter optimization in high-dimensional space with support for distributed computing. |
| Recipe |
C |
GPL-v3 |
Machine-learning pipeline optimization through genetic programming. Uses grammars to define pipeline structure. |
| Xcessiv |
Python |
Apache 2.0 |
A web-based application for quick, scalable, and automated hyper-parameter tuning and stacked ensembling in Python. |
| GAMA |
Python |
Apache 2.0 |
Machine-learning pipeline optimization through asynchronous evaluation based genetic programming. |
================================================
FILE: docs/archived/releases.md
================================================
⚠️ Warning
This documentation is for the archived version of TPOT, which is no longer maintained. For the latest version, click here.
# Release Notes
## Version 0.12.0
- Fix numpy compatibility
- Dask optimizations
- Minor bug fixes
## Version 0.11.7
- Fix compatibility issue with scikit-learn 0.24 and xgboost 1.3.0
- Fix a bug causing that TPOT does not work when classifying more than 50 classes
- Add initial support `Resampler` from `imblearn`
- Fix minor bugs
## Version 0.11.6
- Fix a bug causing point mutation function does not work properly with using `template` option
- Add a new built configuration called "TPOT cuML" which TPOT will search over a restricted configuration using the GPU-accelerated estimators in [RAPIDS cuML](https://github.com/rapidsai/cuml) and [DMLC XGBoost](https://github.com/dmlc/xgboost). **This configuration requires an NVIDIA Pascal architecture or better GPU with [compute capability 6.0+](https://developer.nvidia.com/cuda-gpus), and that the library cuML is installed.**
- Add string path support for log/log_file parameter
- Fix a bug in version 0.11.5 causing no update in stdout after each generation
- Fix minor bugs
## Version 0.11.5
- Make `Pytorch` as an optional dependency
- Refine installation documentation
## Version 0.11.4
- Add a new built configuration "TPOT NN" which includes all operators in "Default TPOT" plus additional neural network estimators written in PyTorch (currently `tpot.builtins.PytorchLRClassifier` and `tpot.builtins.PytorchMLPClassifier` for classification tasks only)
- Refine `log_file` parameter's behavior
## Version 0.11.3
- Fix a bug in TPOTRegressor in v0.11.2
- Add `-log` option in command line interface to save process log to a file.
## Version 0.11.2
- Fix `early_stop` parameter does not work properly
- TPOT built-in `OneHotEncoder` can refit to different datasets
- Fix the issue that the attribute `evaluated_individuals_` cannot record correct generation info.
- Add a new parameter `log_file` to output logs to a file instead of `sys.stdout`
- Fix some code quality issues and mistakes in documentations
- Fix minor bugs
## Version 0.11.1
- Fix compatibility issue with scikit-learn v0.22
- `warm_start` now saves both Primitive Sets and evaluated_pipelines_ from previous runs;
- Fix the error that TPOT assign wrong fitness scores to non-evaluated pipelines (interrupted by `max_min_mins` or `KeyboardInterrupt`) ;
- Fix the bug that mutation operator cannot generate new pipeline when template is not default value and `warm_start` is True;
- Fix the bug that `max_time_mins` cannot stop optimization process when search space is limited.
- Fix a bug in exported codes when the exported pipeline is only 1 estimator
- Fix spelling mistakes in documentations
- Fix some code quality issues
## Version 0.11.0
- **Support for Python 3.4 and below has been officially dropped.** Also support for scikit-learn 0.20 or below has been dropped.
- The support of a metric function with the signature `score_func(y_true, y_pred)` for `scoring parameter` has been dropped.
- Refine `StackingEstimator` for not stacking NaN/Infinity predication probabilities.
- Fix a bug that population doesn't persist by `warm_start=True` when `max_time_mins` is not default value.
- Now the `random_state` parameter in TPOT is used for pipeline evaluation instead of using a fixed random seed of 42 before. The `set_param_recursive` function has been moved to `export_utils.py` and it can be used in exported codes for setting `random_state` recursively in scikit-learn Pipeline. It is used to set `random_state` in `fitted_pipeline_` attribute and exported pipelines.
- TPOT can independently use `generations` and `max_time_mins` to limit the optimization process through using one of the parameters or both.
- `.export()` function will return string of exported pipeline if output filename is not specified.
- Add [`SGDClassifier`](https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.SGDClassifier.html) and [`SGDRegressor`](https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.SGDRegressor.html) into TPOT default configs.
- Documentation has been updated
- Fix minor bugs.
## Version 0.10.2
- **TPOT v0.10.2 is the last version to support Python 2.7 and Python 3.4.**
- Minor updates for fixing compatibility issues with the latest version of scikit-learn (version > 0.21) and xgboost (v0.90)
- Default value of `template` parameter is changed to `None` instead.
- Fix errors in documentation
## Version 0.10.1
- Add `data_file_path` option into `expert` function for replacing `'PATH/TO/DATA/FILE'` to customized dataset path in exported scripts. (Related issue #838)
- Change python version in CI tests to 3.7
- Add CI tests for macOS.
## Version 0.10.0
- Add a new `template` option to specify a desired structure for machine learning pipeline in TPOT. Check [TPOT API](https://epistasislab.github.io/tpot/api/) (it will be updated once it is merge to master branch).
- Add `FeatureSetSelector` operator into TPOT for feature selection based on *priori* export knowledge. Please check our [preprint paper](https://www.biorxiv.org/content/10.1101/502484v1.article-info) for more details (*Note: it was named `DatasetSelector` in 1st version paper but we will rename to FeatureSetSelector in next version of the paper*)
- Refine `n_jobs` parameter to accept value below -1. For n_jobs below -1, (n_cpus + 1 + n_jobs) are used. Thus for n_jobs = -2, all CPUs but one are used.
- Now `memory` parameter can create memory cache directory if it does not exist.
- Fix minor bugs.
## Version 0.9.6
- Fix a bug causing that `max_time_mins` parameter doesn't work when `use_dask=True` in TPOT 0.9.5
- Now TPOT saves best pareto values best pareto pipeline s in checkpoint folder
- TPOT raises `ImportError` if operators in the TPOT configuration are not available when `verbosity>2`
- Thank @PGijsbers for the suggestions. Now TPOT can save scores of individuals already evaluated in any generation even the evaluation process of that generation is interrupted/stopped. But it is noted that, in this case, TPOT will raise this **warning message**: `WARNING: TPOT may not provide a good pipeline if TPOT is stopped/interrupted in a early generation.`, because the pipelines in early generation, e.g. 1st generation, are evolved/modified very limited times via evolutionary algorithm.
- Fix bugs in configuration of `TPOTRegressor`
- Error fixes in documentation
## Version 0.9.5
- **TPOT now supports integration with Dask for parallelization + smart caching**. Big thanks to the Dask dev team for making this happen!
- TPOT now supports for imputation/sparse matrices into `predict` and `predict_proba` functions.
- `TPOTClassifier` and `TPOTRegressor` now follows scikit-learn estimator API.
- We refined scoring parameter in TPOT API for accepting [`Scorer` object](http://jaquesgrobler.github.io/online-sklearn-build/modules/generated/sklearn.metrics.Scorer.html).
- We refined parameters in VarianceThreshold and FeatureAgglomeration.
- TPOT now supports using memory caching within a Pipeline via an optional `memory` parameter.
- We improved documentation of TPOT.
## Version 0.9
* **TPOT now supports sparse matrices** with a new built-in TPOT configuration, "TPOT sparse". We are using a custom OneHotEncoder implementation that supports missing values and continuous features.
* We have added an "early stopping" option for stopping the optimization process if no improvement is made within a set number of generations. Look up the `early_stop` parameter to access this functionality.
* TPOT now reduces the number of duplicated pipelines between generations, which saves you time during the optimization process.
* TPOT now supports custom scoring functions via the command-line mode.
* We have added a new optional argument, `periodic_checkpoint_folder`, that allows TPOT to periodically save the best pipeline so far to a local folder during optimization process.
* TPOT no longer uses `sklearn.externals.joblib` when `n_jobs=1` to avoid the potential freezing issue [that scikit-learn suffers from](http://scikit-learn.org/stable/faq.html#why-do-i-sometime-get-a-crash-freeze-with-n-jobs-1-under-osx-or-linux).
* We have added `pandas` as a dependency to read input datasets instead of `numpy.recfromcsv`. NumPy's `recfromcsv` function is unable to parse datasets with complex data types.
* Fixed a bug that `DEFAULT` in the parameter(s) of nested estimator raises `KeyError` when exporting pipelines.
* Fixed a bug related to setting `random_state` in nested estimators. The issue would happen with pipeline with `SelectFromModel` (`ExtraTreesClassifier` as nested estimator) or `StackingEstimator` if nested estimator has `random_state` parameter.
* Fixed a bug in the missing value imputation function in TPOT to impute along columns instead rows.
* Refined input checking for sparse matrices in TPOT.
* Refined the TPOT pipeline mutation operator.
## Version 0.8
* **TPOT now detects whether there are missing values in your dataset** and replaces them with the median value of the column.
* TPOT now allows you to set a `group` parameter in the `fit` function so you can use the [GroupKFold](http://scikit-learn.org/stable/modules/generated/sklearn.model_selection.GroupKFold.html) cross-validation strategy.
* TPOT now allows you to set a subsample ratio of the training instance with the `subsample` parameter. For example, setting `subsample`=0.5 tells TPOT to create a fixed subsample of half of the training data for the pipeline optimization process. This parameter can be useful for speeding up the pipeline optimization process, but may give less accurate performance estimates from cross-validation.
* **TPOT now has more [built-in configurations](/using/#built-in-tpot-configurations)**, including TPOT MDR and TPOT light, for both classification and regression problems.
* `TPOTClassifier` and `TPOTRegressor` now expose three useful internal attributes, `fitted_pipeline_`, `pareto_front_fitted_pipelines_`, and `evaluated_individuals_`. These attributes are described in the [API documentation](/api/).
* Oh, **TPOT now has [thorough API documentation](/api/)**. Check it out!
* Fixed a reproducibility issue where setting `random_seed` didn't necessarily result in the same results every time. This bug was present since TPOT v0.7.
* Refined input checking in TPOT.
* Removed Python 2 uncompliant code.
## Version 0.7
* **TPOT now has multiprocessing support.** TPOT allows you to use multiple processes in parallel to accelerate the pipeline optimization process in TPOT with the `n_jobs` parameter.
* TPOT now allows you to **customize the operators and parameters considered during the optimization process**, which can be accomplished with the new `config_dict` parameter. The format of this customized dictionary can be found in the [online documentation](/using/#customizing-tpots-operators-and-parameters), along with a list of [built-in configurations](/using/#built-in-tpot-configurations).
* TPOT now allows you to **specify a time limit for evaluating a single pipeline** (default limit is 5 minutes) in optimization process with the `max_eval_time_mins` parameter, so TPOT won't spend hours evaluating overly-complex pipelines.
* We tweaked TPOT's underlying evolutionary optimization algorithm to work even better, including using the [mu+lambda algorithm](http://deap.readthedocs.io/en/master/api/algo.html#deap.algorithms.eaMuPlusLambda). This algorithm gives you more control of how many pipelines are generated every iteration with the `offspring_size` parameter.
* Refined the default operators and parameters in TPOT, so TPOT 0.7 should work even better than 0.6.
* TPOT now supports sample weights in the fitness function if some if your samples are more important to classify correctly than others. The sample weights option works the same as in scikit-learn, e.g., `tpot.fit(x_train, y_train, sample_weights=sample_weights)`.
* The default scoring metric in TPOT has been changed from balanced accuracy to accuracy, the same default metric for classification algorithms in scikit-learn. Balanced accuracy can still be used by setting `scoring='balanced_accuracy'` when creating a TPOT instance.
## Version 0.6
* **TPOT now supports regression problems!** We have created two separate `TPOTClassifier` and `TPOTRegressor` classes to support classification and regression problems, respectively. The [command-line interface](/using/#tpot-on-the-command-line) also supports this feature through the `-mode` parameter.
* TPOT now allows you to **specify a time limit** for the optimization process with the `max_time_mins` parameter, so you don't need to guess how long TPOT will take any more to recommend a pipeline to you.
* Added a new operator that performs feature selection using [ExtraTrees](http://scikit-learn.org/stable/modules/ensemble.html#extremely-randomized-trees) feature importance scores.
* **[XGBoost](https://github.com/dmlc/xgboost) has been added as an optional dependency to TPOT.** If you have XGBoost installed, TPOT will automatically detect your installation and use the `XGBoostClassifier` and `XGBoostRegressor` in its pipelines.
* TPOT now offers a verbosity level of 3 ("science mode"), which outputs the entire Pareto front instead of only the current best score. This feature may be useful for users looking to make a trade-off between pipeline complexity and score.
## Version 0.5
* Major refactor: Each operator is defined in a separate class file. Hooray for easier-to-maintain code!
* TPOT now **exports directly to scikit-learn Pipelines** instead of hacky code.
* Internal representation of individuals now uses scikit-learn pipelines.
* Parameters for each operator have been optimized so TPOT spends less time exploring useless parameters.
* We have removed pandas as a dependency and instead use numpy matrices to store the data.
* TPOT now uses **k-fold cross-validation** when evaluating pipelines, with a default k = 3. This k parameter can be tuned when creating a new TPOT instance.
* Improved **scoring function support**: Even though TPOT uses balanced accuracy by default, you can now have TPOT use [any of the scoring functions](http://scikit-learn.org/stable/modules/model_evaluation.html#common-cases-predefined-values) that `cross_val_score` supports.
* Added the scikit-learn [Normalizer](http://scikit-learn.org/stable/modules/generated/sklearn.preprocessing.Normalizer.html) preprocessor.
* [Minor text fixes.](http://knowyourmeme.com/memes/pokemon-go-updates-controversy)
## Version 0.4
In TPOT 0.4, we've made some major changes to the internals of TPOT and added some convenience functions. We've summarized the changes below.
- Added new sklearn models and preprocessors
- AdaBoostClassifier
- BernoulliNB
- ExtraTreesClassifier
- GaussianNB
- MultinomialNB
- LinearSVC
- PassiveAggressiveClassifier
- GradientBoostingClassifier
- RBFSampler
- FastICA
- FeatureAgglomeration
- Nystroem
- Added operator that inserts virtual features for the count of features with values of zero
- Reworked parameterization of TPOT operators
- Reduced parameter search space with information from a scikit-learn benchmark
- TPOT no longer generates arbitrary parameter values, but uses a fixed parameter set instead
- Removed XGBoost as a dependency
- Too many users were having install issues with XGBoost
- Replaced with scikit-learn's GradientBoostingClassifier
- Improved descriptiveness of TPOT command line parameter documentation
- Removed min/max/avg details during fit() when verbosity > 1
- Replaced with tqdm progress bar
- Added tqdm as a dependency
- Added
fit_predict() convenience function
- Added
get_params() function so TPOT can operate in scikit-learn's cross_val_score & related functions
## Version 0.3
* We revised the internal optimization process of TPOT to make it more efficient, in particular in regards to the model parameters that TPOT optimizes over.
## Version 0.2
* TPOT now has the ability to export the optimized pipelines to sklearn code.
* Logistic regression, SVM, and k-nearest neighbors classifiers were added as pipeline operators. Previously, TPOT only included decision tree and random forest classifiers.
* TPOT can now use arbitrary scoring functions for the optimization process.
* TPOT now performs multi-objective Pareto optimization to balance model complexity (i.e., # of pipeline operators) and the score of the pipeline.
## Version 0.1
* First public release of TPOT.
* Optimizes pipelines with decision trees and random forest classifiers as the model, and uses a handful of feature preprocessors.
================================================
FILE: docs/archived/support.md
================================================
⚠️ Warning
This documentation is for the archived version of TPOT, which is no longer maintained. For the latest version, click here.
TPOT was developed in the [Computational Genetics Lab](http://epistasis.org/) at the [University of Pennsylvania](https://www.upenn.edu/) with funding from the [NIH](http://www.nih.gov/) under grant R01 AI117694. We are incredibly grateful for the support of the NIH and the University of Pennsylvania during the development of this project.
The TPOT logo was designed by Todd Newmuis, who generously donated his time to the project.
================================================
FILE: docs/archived/using.md
================================================
⚠️ Warning
This documentation is for the archived version of TPOT, which is no longer maintained. For the latest version, click here.
# Using TPOT
## What to expect from AutoML software
Automated machine learning (AutoML) takes a higher-level approach to machine learning than most practitioners are used to,
so we've gathered a handful of guidelines on what to expect when running AutoML software such as TPOT.
AutoML algorithms aren't intended to run for only a few minutes
Of course, you *can* run TPOT for only a few minutes and it will find a reasonably good pipeline for your dataset.
However, if you don't run TPOT for long enough, it may not find the best possible pipeline for your dataset. It may even not
find any suitable pipeline at all, in which case a `RuntimeError('A pipeline has not yet been optimized. Please call fit() first.')`
will be raised.
Often it is worthwhile to run multiple instances of TPOT in parallel for a long time (hours to days) to allow TPOT to thoroughly search
the pipeline space for your dataset.
AutoML algorithms can take a long time to finish their search
AutoML algorithms aren't as simple as fitting one model on the dataset; they are considering multiple machine learning algorithms
(random forests, linear models, SVMs, etc.) in a pipeline with multiple preprocessing steps (missing value imputation, scaling,
PCA, feature selection, etc.), the hyperparameters for all of the models and preprocessing steps, as well as multiple ways
to ensemble or stack the algorithms within the pipeline.
As such, TPOT will take a while to run on larger datasets, but it's important to realize why. With the default TPOT settings
(100 generations with 100 population size), TPOT will evaluate 10,000 pipeline configurations before finishing.
To put this number into context, think about a grid search of 10,000 hyperparameter combinations for a machine learning algorithm
and how long that grid search will take. That is 10,000 model configurations to evaluate with 10-fold cross-validation,
which means that roughly 100,000 models are fit and evaluated on the training data in one grid search.
That's a time-consuming procedure, even for simpler models like decision trees.
Typical TPOT runs will take hours to days to finish (unless it's a small dataset), but you can always interrupt
the run partway through and see the best results so far. TPOT also [provides](/tpot/api/) a `warm_start` parameter that
lets you restart a TPOT run from where it left off.
AutoML algorithms can recommend different solutions for the same dataset
If you're working with a reasonably complex dataset or run TPOT for a short amount of time, different TPOT runs
may result in different pipeline recommendations. TPOT's optimization algorithm is stochastic in nature, which means
that it uses randomness (in part) to search the possible pipeline space. When two TPOT runs recommend different
pipelines, this means that the TPOT runs didn't converge due to lack of time *or* that multiple pipelines
perform more-or-less the same on your dataset.
This is actually an advantage over fixed grid search techniques: TPOT is meant to be an assistant that gives
you ideas on how to solve a particular machine learning problem by exploring pipeline configurations that you
might have never considered, then leaves the fine-tuning to more constrained parameter tuning techniques such
as grid search.
## TPOT with code
We've taken care to design the TPOT interface to be as similar as possible to scikit-learn.
TPOT can be imported just like any regular Python module. To import TPOT, type:
```Python
from tpot import TPOTClassifier
```
then create an instance of TPOT as follows:
```Python
pipeline_optimizer = TPOTClassifier()
```
It's also possible to use TPOT for regression problems with the `TPOTRegressor` class. Other than the class name,
a `TPOTRegressor` is used the same way as a `TPOTClassifier`. You can read more about the `TPOTClassifier` and `TPOTRegressor` classes in the [API documentation](/tpot/api/).
Some example code with custom TPOT parameters might look like:
```Python
pipeline_optimizer = TPOTClassifier(generations=5, population_size=20, cv=5,
random_state=42, verbosity=2)
```
Now TPOT is ready to optimize a pipeline for you. You can tell TPOT to optimize a pipeline based on a data set with the `fit` function:
```Python
pipeline_optimizer.fit(X_train, y_train)
```
The `fit` function initializes the genetic programming algorithm to find the highest-scoring pipeline based on average k-fold cross-validation
Then, the pipeline is trained on the entire set of provided samples, and the TPOT instance can be used as a fitted model.
You can then proceed to evaluate the final pipeline on the testing set with the `score` function:
```Python
print(pipeline_optimizer.score(X_test, y_test))
```
Finally, you can tell TPOT to export the corresponding Python code for the optimized pipeline to a text file with the `export` function:
```Python
pipeline_optimizer.export('tpot_exported_pipeline.py')
```
Once this code finishes running, `tpot_exported_pipeline.py` will contain the Python code for the optimized pipeline.
Below is a full example script using TPOT to optimize a pipeline, score it, and export the best pipeline to a file.
```Python
from tpot import TPOTClassifier
from sklearn.datasets import load_digits
from sklearn.model_selection import train_test_split
digits = load_digits()
X_train, X_test, y_train, y_test = train_test_split(digits.data, digits.target,
train_size=0.75, test_size=0.25)
pipeline_optimizer = TPOTClassifier(generations=5, population_size=20, cv=5,
random_state=42, verbosity=2)
pipeline_optimizer.fit(X_train, y_train)
print(pipeline_optimizer.score(X_test, y_test))
pipeline_optimizer.export('tpot_exported_pipeline.py')
```
Check our [examples](/tpot/examples/) to see TPOT applied to some specific data sets.
## TPOT on the command line
To use TPOT via the command line, enter the following command with a path to the data file:
```Shell
tpot /path_to/data_file.csv
```
An example command-line call to TPOT may look like:
```Shell
tpot data/mnist.csv -is , -target class -o tpot_exported_pipeline.py -g 5 -p 20 -cv 5 -s 42 -v 2
```
TPOT offers several arguments that can be provided at the command line. To see brief descriptions of these arguments,
enter the following command:
```Shell
tpot --help
```
Detailed descriptions of the command-line arguments are below.
| Argument |
Parameter |
Valid values |
Effect |
| -is |
INPUT_SEPARATOR |
Any string |
Character used to separate columns in the input file. |
| -target |
TARGET_NAME |
Any string |
Name of the target column in the input file. |
| -mode |
TPOT_MODE |
['classification', 'regression'] |
Whether TPOT is being used for a supervised classification or regression problem. |
| -o |
OUTPUT_FILE |
String path to a file |
File to export the code for the final optimized pipeline. |
| -g |
GENERATIONS |
Any positive integer or None |
Number of iterations to run the pipeline optimization process. It must be a positive number or None. If None, the parameter max_time_mins must be defined as the runtime limit. Generally, TPOT will work better when you give it more generations (and therefore time) to optimize the pipeline.
TPOT will evaluate POPULATION_SIZE + GENERATIONS x OFFSPRING_SIZE pipelines in total. |
| -p |
POPULATION_SIZE |
Any positive integer |
Number of individuals to retain in the GP population every generation. Generally, TPOT will work better when you give it more individuals (and therefore time) to optimize the pipeline.
TPOT will evaluate POPULATION_SIZE + GENERATIONS x OFFSPRING_SIZE pipelines in total. |
| -os |
OFFSPRING_SIZE |
Any positive integer |
Number of offspring to produce in each GP generation.
By default, OFFSPRING_SIZE = POPULATION_SIZE. |
| -mr |
MUTATION_RATE |
[0.0, 1.0] |
GP mutation rate in the range [0.0, 1.0]. This tells the GP algorithm how many pipelines to apply random changes to every generation.
We recommend using the default parameter unless you understand how the mutation rate affects GP algorithms. |
| -xr |
CROSSOVER_RATE |
[0.0, 1.0] |
GP crossover rate in the range [0.0, 1.0]. This tells the GP algorithm how many pipelines to "breed" every generation.
We recommend using the default parameter unless you understand how the crossover rate affects GP algorithms. |
| -scoring |
SCORING_FN |
'accuracy', 'adjusted_rand_score', 'average_precision', 'balanced_accuracy',
'f1',
'f1_macro', 'f1_micro', 'f1_samples', 'f1_weighted', 'neg_log_loss', 'neg_mean_absolute_error',
'neg_mean_squared_error', 'neg_median_absolute_error', 'precision', 'precision_macro', 'precision_micro',
'precision_samples', 'precision_weighted',
'r2', 'recall', 'recall_macro', 'recall_micro', 'recall_samples',
'recall_weighted', 'roc_auc', 'my_module.scorer_name*' |
Function used to evaluate the quality of a given pipeline for the problem. By default, accuracy is used for classification and mean squared error (MSE) is used for regression.
TPOT assumes that any function with "error" or "loss" in the name is meant to be minimized, whereas any other functions will be maximized.
my_module.scorer_name: You can also specify your own function or a full python path to an existing one.
See the section on scoring functions for more details. |
| -cv |
CV |
Any integer > 1 |
Number of folds to evaluate each pipeline over in k-fold cross-validation during the TPOT optimization process. |
-sub |
SUBSAMPLE |
(0.0, 1.0] |
Subsample ratio of the training instance. Setting it to 0.5 means that TPOT randomly collects half of training samples for pipeline optimization process. |
| -njobs |
NUM_JOBS |
Any positive integer or -1 |
Number of CPUs for evaluating pipelines in parallel during the TPOT optimization process.
Assigning this to -1 will use as many cores as available on the computer. For n_jobs below -1, (n_cpus + 1 + n_jobs) are used. Thus for n_jobs = -2, all CPUs but one are used. |
| -maxtime |
MAX_TIME_MINS |
Any positive integer |
How many minutes TPOT has to optimize the pipeline.
How many minutes TPOT has to optimize the pipeline.If not None, this setting will allow TPOT to run until max_time_mins minutes elapsed and then stop. TPOT will stop earlier if generationsis set and all generations are already evaluated. |
| -maxeval |
MAX_EVAL_MINS |
Any positive float |
How many minutes TPOT has to evaluate a single pipeline.
Setting this parameter to higher values will allow TPOT to consider more complex pipelines but will also allow TPOT to run longer. |
| -s |
RANDOM_STATE |
Any positive integer |
Random number generator seed for reproducibility.
Set this seed if you want your TPOT run to be reproducible with the same seed and data set in the future. |
| -config |
CONFIG_FILE |
String or file path |
Operators and parameter configurations in TPOT:
- Path for configuration file: TPOT will use the path to a configuration file for customizing the operators and parameters that TPOT uses in the optimization process
- string 'TPOT light', TPOT will use a built-in configuration with only fast models and preprocessors
- string 'TPOT MDR', TPOT will use a built-in configuration specialized for genomic studies
- string 'TPOT sparse': TPOT will use a configuration dictionary with a one-hot encoder and the operators normally included in TPOT that also support sparse matrices.
See the built-in configurations section for the list of configurations included with TPOT, and the custom configuration section for more information and examples of how to create your own TPOT configurations.
|
| -template |
TEMPLATE |
String |
Template of predefined pipeline structure. The option is for specifying a desired structure for the machine learning pipeline evaluated in TPOT. So far this option only supports linear pipeline structure. Each step in the pipeline should be a main class of operators (Selector, Transformer, Classifier or Regressor) or a specific operator (e.g. `SelectPercentile`) defined in TPOT operator configuration. If one step is a main class, TPOT will randomly assign all subclass operators (subclasses of [`SelectorMixin`](https://github.com/scikit-learn/scikit-learn/blob/master/sklearn/feature_selection/base.py#L17), [`TransformerMixin`](https://scikit-learn.org/stable/modules/generated/sklearn.base.TransformerMixin.html), [`ClassifierMixin`](https://scikit-learn.org/stable/modules/generated/sklearn.base.ClassifierMixin.html) or [`RegressorMixin`](https://scikit-learn.org/stable/modules/generated/sklearn.base.RegressorMixin.html) in scikit-learn) to that step. Steps in the template are delimited by "-", e.g. "SelectPercentile-Transformer-Classifier". By default value of template is None, TPOT generates tree-based pipeline randomly.
See the template option in tpot section for more details.
|
| -memory |
MEMORY |
String or file path |
If supplied, pipeline will cache each transformer after calling fit. This feature is used to avoid computing the fit transformers within a pipeline if the parameters and input data are identical with another fitted pipeline during optimization process. Memory caching mode in TPOT:
- Path for a caching directory: TPOT uses memory caching with the provided directory and TPOT does NOT clean the caching directory up upon shutdown.
- string 'auto': TPOT uses memory caching with a temporary directory and cleans it up upon shutdown.
|
| -cf |
CHECKPOINT_FOLDER |
Folder path |
If supplied, a folder you created, in which tpot will periodically save pipelines in pareto front so far while optimizing.
This is useful in multiple cases:
- sudden death before tpot could save an optimized pipeline
- progress tracking
- grabbing a pipeline while tpot is working
Example:
mkdir my_checkpoints
-cf ./my_checkpoints
|
| -es |
EARLY_STOP |
Any positive integer |
How many generations TPOT checks whether there is no improvement in optimization process.
End optimization process if there is no improvement in the set number of generations.
|
| -v |
VERBOSITY |
{0, 1, 2, 3} |
How much information TPOT communicates while it is running.
0 = none, 1 = minimal, 2 = high, 3 = all.
A setting of 2 or higher will add a progress bar during the optimization procedure. |
| -log |
LOG |
Folder path |
Save progress content to a file. |
| --no-update-check |
Flag indicating whether the TPOT version checker should be disabled. |
| --version |
Show TPOT's version number and exit. |
| --help |
Show TPOT's help documentation and exit. |
## Scoring functions
TPOT makes use of `sklearn.model_selection.cross_val_score` for evaluating pipelines, and as such offers the same support for scoring functions. There are two ways to make use of scoring functions with TPOT:
- You can pass in a string to the `scoring` parameter from the list above. Any other strings will cause TPOT to throw an exception.
- You can pass the callable object/function with signature `scorer(estimator, X, y)`, where `estimator` is trained estimator to use for scoring, `X` are features that will be passed to `estimator.predict` and `y` are target values for `X`. To do this, you should implement your own function. See the example below for further explanation.
```Python
from tpot import TPOTClassifier
from sklearn.datasets import load_digits
from sklearn.model_selection import train_test_split
from sklearn.metrics import make_scorer
digits = load_digits()
X_train, X_test, y_train, y_test = train_test_split(digits.data, digits.target,
train_size=0.75, test_size=0.25)
# Make a custom metric function
def my_custom_accuracy(y_true, y_pred):
return float(sum(y_pred == y_true)) / len(y_true)
# Make a custom a scorer from the custom metric function
# Note: greater_is_better=False in make_scorer below would mean that the scoring function should be minimized.
my_custom_scorer = make_scorer(my_custom_accuracy, greater_is_better=True)
tpot = TPOTClassifier(generations=5, population_size=20, verbosity=2,
scoring=my_custom_scorer)
tpot.fit(X_train, y_train)
print(tpot.score(X_test, y_test))
tpot.export('tpot_digits_pipeline.py')
```
* **my_module.scorer_name**: You can also use a custom `score_func(y_true, y_pred)` or `scorer(estimator, X, y)` function through the command line by adding the argument `-scoring my_module.scorer` to your command-line call. TPOT will import your module and use the custom scoring function from there. TPOT will include your current working directory when importing the module, so you can place it in the same directory where you are going to run TPOT.
Example: `-scoring sklearn.metrics.auc` will use the function auc from sklearn.metrics module.
## Built-in TPOT configurations
TPOT comes with a handful of default operators and parameter configurations that we believe work well for optimizing machine learning pipelines. Below is a list of the current built-in configurations that come with TPOT.
| Configuration Name |
Description |
Operators |
| Default TPOT |
TPOT will search over a broad range of preprocessors, feature constructors, feature selectors, models, and parameters to find a series of operators that minimize the error of the model predictions. Some of these operators are complex and may take a long time to run, especially on larger datasets.
Note: This is the default configuration for TPOT. To use this configuration, use the default value (None) for the config_dict parameter. |
Classification
Regression |
| TPOT light |
TPOT will search over a restricted range of preprocessors, feature constructors, feature selectors, models, and parameters to find a series of operators that minimize the error of the model predictions. Only simpler and fast-running operators will be used in these pipelines, so TPOT light is useful for finding quick and simple pipelines for a classification or regression problem.
This configuration works for both the TPOTClassifier and TPOTRegressor. |
Classification
Regression |
| TPOT MDR |
TPOT will search over a series of feature selectors and Multifactor Dimensionality Reduction models to find a series of operators that maximize prediction accuracy. The TPOT MDR configuration is specialized for genome-wide association studies (GWAS), and is described in detail online here.
Note that TPOT MDR may be slow to run because the feature selection routines are computationally expensive, especially on large datasets. |
Classification
Regression |
| TPOT sparse |
TPOT uses a configuration dictionary with a one-hot encoder and the operators normally included in TPOT that also support sparse matrices.
This configuration works for both the TPOTClassifier and TPOTRegressor. |
Classification
Regression |
| TPOT NN |
TPOT uses the same configuration as "Default TPOT" plus additional neural network estimators written in PyTorch (currently only `tpot.builtins.PytorchLRClassifier` and `tpot.builtins.PytorchMLPClassifier`).
Currently only classification is supported, but future releases will include regression estimators. |
Classification |
| TPOT cuML |
TPOT will search over a restricted configuration using the GPU-accelerated estimators in RAPIDS cuML and DMLC XGBoost. This configuration requires an NVIDIA Pascal architecture or better GPU with compute capability 6.0+, and that the library cuML is installed. With this configuration, all model training and predicting will be GPU-accelerated.
This configuration is particularly useful for medium-sized and larger datasets on which CPU-based estimators are a common bottleneck, and works for both the TPOTClassifier and TPOTRegressor. |
Classification
Regression |
To use any of these configurations, simply pass the string name of the configuration to the `config_dict` parameter (or `-config` on the command line). For example, to use the "TPOT light" configuration:
```Python
from tpot import TPOTClassifier
from sklearn.datasets import load_digits
from sklearn.model_selection import train_test_split
digits = load_digits()
X_train, X_test, y_train, y_test = train_test_split(digits.data, digits.target,
train_size=0.75, test_size=0.25)
tpot = TPOTClassifier(generations=5, population_size=20, verbosity=2,
config_dict='TPOT light')
tpot.fit(X_train, y_train)
print(tpot.score(X_test, y_test))
tpot.export('tpot_digits_pipeline.py')
```
## Customizing TPOT's operators and parameters
Beyond the default configurations that come with TPOT, in some cases it is useful to limit the algorithms and parameters that TPOT considers. For that reason, we allow users to provide TPOT with a custom configuration for its operators and parameters.
The custom TPOT configuration must be in nested dictionary format, where the first level key is the path and name of the operator (e.g., `sklearn.naive_bayes.MultinomialNB`) and the second level key is the corresponding parameter name for that operator (e.g., `fit_prior`). The second level key should point to a list of parameter values for that parameter, e.g., `'fit_prior': [True, False]`.
For a simple example, the configuration could be:
```Python
tpot_config = {
'sklearn.naive_bayes.GaussianNB': {
},
'sklearn.naive_bayes.BernoulliNB': {
'alpha': [1e-3, 1e-2, 1e-1, 1., 10., 100.],
'fit_prior': [True, False]
},
'sklearn.naive_bayes.MultinomialNB': {
'alpha': [1e-3, 1e-2, 1e-1, 1., 10., 100.],
'fit_prior': [True, False]
}
}
```
in which case TPOT would only consider pipelines containing `GaussianNB`, `BernoulliNB`, `MultinomialNB`, and tune those algorithm's parameters in the ranges provided. This dictionary can be passed directly within the code to the `TPOTClassifier`/`TPOTRegressor` `config_dict` parameter, described above. For example:
```Python
from tpot import TPOTClassifier
from sklearn.datasets import load_digits
from sklearn.model_selection import train_test_split
digits = load_digits()
X_train, X_test, y_train, y_test = train_test_split(digits.data, digits.target,
train_size=0.75, test_size=0.25)
tpot_config = {
'sklearn.naive_bayes.GaussianNB': {
},
'sklearn.naive_bayes.BernoulliNB': {
'alpha': [1e-3, 1e-2, 1e-1, 1., 10., 100.],
'fit_prior': [True, False]
},
'sklearn.naive_bayes.MultinomialNB': {
'alpha': [1e-3, 1e-2, 1e-1, 1., 10., 100.],
'fit_prior': [True, False]
}
}
tpot = TPOTClassifier(generations=5, population_size=20, verbosity=2,
config_dict=tpot_config)
tpot.fit(X_train, y_train)
print(tpot.score(X_test, y_test))
tpot.export('tpot_digits_pipeline.py')
```
Command-line users must create a separate `.py` file with the custom configuration and provide the path to the file to the `tpot` call. For example, if the simple example configuration above is saved in `tpot_classifier_config.py`, that configuration could be used on the command line with the command:
```
tpot data/mnist.csv -is , -target class -config tpot_classifier_config.py -g 5 -p 20 -v 2 -o tpot_exported_pipeline.py
```
When using the command-line interface, the configuration file specified in the `-config` parameter *must* name its custom TPOT configuration `tpot_config`. Otherwise, TPOT will not be able to locate the configuration dictionary.
For more detailed examples of how to customize TPOT's operator configuration, see the default configurations for [classification](https://github.com/EpistasisLab/tpot/blob/master/tpot/config/classifier.py) and [regression](https://github.com/EpistasisLab/tpot/blob/master/tpot/config/regressor.py) in TPOT's source code.
Note that you must have all of the corresponding packages for the operators installed on your computer, otherwise TPOT will not be able to use them. For example, if XGBoost is not installed on your computer, then TPOT will simply not import nor use XGBoost in the pipelines it considers.
## Template option in TPOT
Template option provides a way to specify a desired structure for machine learning pipeline, which may reduce TPOT computation time and potentially provide more interpretable results. Current implementation only supports linear pipelines.
Below is a simple example to use `template` option. The pipelines generated/evaluated in TPOT will follow this structure: 1st step is a feature selector (a subclass of [`SelectorMixin`](https://github.com/scikit-learn/scikit-learn/blob/master/sklearn/feature_selection/base.py#L17)), 2nd step is a feature transformer (a subclass of [`TransformerMixin`](https://scikit-learn.org/stable/modules/generated/sklearn.base.TransformerMixin.html)) and 3rd step is a classifier for classification (a subclass of [`ClassifierMixin`](https://scikit-learn.org/stable/modules/generated/sklearn.base.ClassifierMixin.html)). The last step must be `Classifier` for `TPOTClassifier`'s template but `Regressor` for `TPOTRegressor`. **Note: although `SelectorMixin` is subclass of `TransformerMixin` in scikit-learn, but `Transformer` in this option excludes those subclasses of `SelectorMixin`.**
```Python
tpot_obj = TPOTClassifier(
template='Selector-Transformer-Classifier'
)
```
If a specific operator, e.g. `SelectPercentile`, is preferred for usage in the 1st step of the pipeline, the template can be defined like 'SelectPercentile-Transformer-Classifier'.
## FeatureSetSelector in TPOT
`FeatureSetSelector` is a special new operator in TPOT. This operator enables feature selection based on *priori* expert knowledge. For example, in RNA-seq gene expression analysis, this operator can be used to select one or more gene (feature) set(s) based on GO (Gene Ontology) terms or annotated gene sets Molecular Signatures Database ([MSigDB](http://software.broadinstitute.org/gsea/msigdb/index.jsp)) in the 1st step of pipeline via `template` option above, in order to reduce dimensions and TPOT computation time. This operator requires a dataset list in csv format. In this csv file, there are only three columns: 1st column is feature set names, 2nd column is the total number of features in one set and 3rd column is a list of feature names (if input X is pandas.DataFrame) or indexes (if input X is numpy.ndarray) delimited by ";". Below is an example how to use this operator in TPOT.
Please check our [preprint paper](https://www.biorxiv.org/content/10.1101/502484v1.article-info) for more details.
```Python
from tpot import TPOTClassifier
import numpy as np
import pandas as pd
from tpot.config import classifier_config_dict
test_data = pd.read_csv("https://raw.githubusercontent.com/EpistasisLab/tpot/master/tests/tests.csv")
test_X = test_data.drop("class", axis=1)
test_y = test_data['class']
# add FeatureSetSelector into tpot configuration
classifier_config_dict['tpot.builtins.FeatureSetSelector'] = {
'subset_list': ['https://raw.githubusercontent.com/EpistasisLab/tpot/master/tests/subset_test.csv'],
'sel_subset': [0,1] # select only one feature set, a list of index of subset in the list above
#'sel_subset': list(combinations(range(3), 2)) # select two feature sets
}
tpot = TPOTClassifier(generations=5,
population_size=50, verbosity=2,
template='FeatureSetSelector-Transformer-Classifier',
config_dict=classifier_config_dict)
tpot.fit(test_X, test_y)
```
## Pipeline caching in TPOT
With the `memory` parameter, pipelines can cache the results of each transformer after fitting them. This feature is used to avoid repeated computation by transformers within a pipeline if the parameters and input data are identical to another fitted pipeline during optimization process. TPOT allows users to specify a custom directory path or [`joblib.Memory`](https://joblib.readthedocs.io/en/latest/generated/joblib.Memory.html) in case they want to re-use the memory cache in future TPOT runs (or a `warm_start` run).
There are three methods for enabling memory caching in TPOT:
```Python
from tpot import TPOTClassifier
from tempfile import mkdtemp
from joblib import Memory
from shutil import rmtree
# Method 1, auto mode: TPOT uses memory caching with a temporary directory and cleans it up upon shutdown
tpot = TPOTClassifier(memory='auto')
# Method 2, with a custom directory for memory caching
tpot = TPOTClassifier(memory='/to/your/path')
# Method 3, with a Memory object
cachedir = mkdtemp() # Create a temporary folder
memory = Memory(cachedir=cachedir, verbose=0)
tpot = TPOTClassifier(memory=memory)
# Clear the cache directory when you don't need it anymore
rmtree(cachedir)
```
**Note: TPOT does NOT clean up memory caches if users set a custom directory path or Memory object. We recommend that you clean up the memory caches when you don't need it anymore.**
## Crash/freeze issue with n_jobs > 1 under OSX or Linux
Internally, TPOT uses [joblib](http://joblib.readthedocs.io/) to fit estimators in parallel.
This is the same parallelization framework used by scikit-learn. But it may crash/freeze with n_jobs > 1 under OSX or Linux [as scikit-learn does](http://scikit-learn.org/stable/faq.html#why-do-i-sometime-get-a-crash-freeze-with-n-jobs-1-under-osx-or-linux), especially with large datasets.
One solution is to configure Python's `multiprocessing` module to use the `forkserver` start method (instead of the default `fork`) to manage the process pools. You can enable the `forkserver` mode globally for your program by putting the following codes into your main script:
```Python
import multiprocessing
# other imports, custom code, load data, define model...
if __name__ == '__main__':
multiprocessing.set_start_method('forkserver')
# call scikit-learn utils or tpot utils with n_jobs > 1 here
```
More information about these start methods can be found in the [multiprocessing documentation](https://docs.python.org/3/library/multiprocessing.html#contexts-and-start-methods).
## Parallel Training with Dask
For large problems or working on Jupyter notebook, we highly recommend that you can distribute the work on a [Dask](http://dask.pydata.org/en/latest/) cluster.
The [dask-examples binder](https://mybinder.org/v2/gh/dask/dask-examples/master?filepath=machine-learning%2Ftpot.ipynb) has a runnable example
with a small dask cluster.
To use your Dask cluster to fit a TPOT model, specify the ``use_dask`` keyword when you create the TPOT estimator. **Note: if `use_dask=True`, TPOT will use as many cores as available on the your Dask cluster. If `n_jobs` is specified, then it will control the chunk size (10*`n_jobs` if it is less then offspring size) of parallel training.**
```python
estimator = TPOTEstimator(use_dask=True, n_jobs=-1)
```
This will use all the workers on your cluster to do the training, and use [Dask-ML's pipeline rewriting](https://dask-ml.readthedocs.io/en/latest/hyper-parameter-search.html#avoid-repeated-work) to avoid re-fitting estimators multiple times on the same set of data.
It will also provide fine-grained diagnostics in the [distributed scheduler UI](https://distributed.readthedocs.io/en/latest/web.html).
Alternatively, Dask implements a joblib backend.
You can instruct TPOT to use the distributed backend during training by specifying a `joblib.parallel_backend`:
```python
import joblib
import distributed.joblib
from dask.distributed import Client
# connect to the cluster
client = Client('schedueler-address')
# create the estimator normally
estimator = TPOTClassifier(n_jobs=-1)
# perform the fit in this context manager
with joblib.parallel_backend("dask"):
estimator.fit(X, y)
```
See [dask's distributed joblib integration](https://distributed.readthedocs.io/en/latest/joblib.html) for more.
## Neural Networks in TPOT (`tpot.nn`)
Support for neural network models and deep learning is an experimental feature newly added to TPOT. Available neural network architectures are provided by the `tpot.nn` module. Unlike regular `sklearn` estimators, these models need to be written by hand, and must also inherit the appropriate base classes provided by `sklearn` for all of their built-in modules. In other words, they need implement methods like `.fit()`, `fit_transform()`, `get_params()`, etc., as described in detail on [Developing scikit-learn estimators](https://scikit-learn.org/stable/developers/develop.html).
### Telling TPOT to use built-in PyTorch neural network models
Mainly due to the issues described below, TPOT won't use its neural network models unless you explicitly tell it to do so. This is done as follows:
- Use `import tpot.nn` before instantiating any TPOT estimators.
- Use a configuration dictionary that includes one or more `tpot.nn` estimators, either by writing one manually, including one from a file, or by importing the configuration in `tpot/config/classifier_nn.py`. A very simple example that will force TPOT to only use a PyTorch-based logistic regression classifier as its main estimator is as follows:
```python
tpot_config = {
'tpot.nn.PytorchLRClassifier': {
'learning_rate': [1e-3, 1e-2, 1e-1, 0.5, 1.]
}
}
```
- Alternatively, use a template string including `PytorchLRClassifier` or `PytorchMLPClassifier` while loading the TPOT-NN configuration dictionary.
Neural network models are notorious for being extremely sensitive to their initialization parameters, so you may need to heavily adjust `tpot.nn` configuration dictionaries in order to attain good performance on your dataset.
A simple example of using TPOT-NN is shown in [examples](/tpot/examples/).
### Important caveats
- Neural network models (especially when they reach moderately large sizes) take a notoriously large amount of time and computing power to train. You should expect `tpot.nn` neural networks to train several orders of magnitude slower than their `sklearn` alternatives. This can be alleviated somewhat by training the models on computers with CUDA-enabled GPUs.
- TPOT will occasionally learn pipelines that stack several `sklearn` estimators. Mathematically, these can be nearly identical to some deep learning models. For example, by stacking several `sklearn.linear_model.LogisticRegression`s, you end up with a very close approximation of a Multilayer Perceptron; one of the simplest and most well known deep learning architectures. TPOT's genetic programming algorithms generally optimize these 'networks' much faster than PyTorch, which typically uses a more brute-force convex optimization approach.
- The problem of 'black box' model introspection is one of the most substantial criticisms and challenges of deep learning. This problem persists in `tpot.nn`, whereas TPOT's default estimators often are far easier to introspect.
================================================
FILE: docs/cite.md
================================================
# Citing TPOT
If you use TPOT in a scientific publication, please consider citing at least one of the following papers:
Hernandez, J. G., Saini, A. K., Ghosh, A., & Moore, J. H. (2025). [The tree-based pipeline optimization tool: Tackling biomedical research problems with genetic programming and automated machine learning](https://www.cell.com/patterns/fulltext/S2666-3899(25)00162-X). Patterns, 6(7).
BibTeX entry:
```bibtext
@article{hernandez2025tree,
title={The tree-based pipeline optimization tool: Tackling biomedical research problems with genetic programming and automated machine learning},
author={Hernandez, Jose Guadalupe and Saini, Anil Kumar and Ghosh, Attri and Moore, Jason H},
journal={Patterns},
volume={6},
number={7},
year={2025},
publisher={Elsevier}
}
```
Ribeiro, P., Saini, A., Moran, J., Matsumoto, N., Choi, H., Hernandez, M., & Moore, J. H. (2024). [TPOT2: A New Graph-Based Implementation of the Tree-Based Pipeline Optimization Tool for Automated Machine Learning](https://link.springer.com/chapter/10.1007/978-981-99-8413-8_1). In Genetic programming theory and practice XX (pp. 1-17). Singapore: Springer Nature Singapore.
BitTex entry:
```bibtex
@incollection{ribeiro2024tpot2,
title={TPOT2: A New Graph-Based Implementation of the Tree-Based Pipeline Optimization Tool for Automated Machine Learning},
author={Ribeiro, Pedro and Saini, Anil and Moran, Jay and Matsumoto, Nicholas and Choi, Hyunjun and Hernandez, Miguel and Moore, Jason H},
booktitle={Genetic programming theory and practice XX},
pages={1--17},
year={2024},
publisher={Springer}
}
```
Randal S. Olson, Ryan J. Urbanowicz, Peter C. Andrews, Nicole A. Lavender, La Creis Kidd, and Jason H. Moore (2016). [Automating biomedical data science through tree-based pipeline optimization](http://link.springer.com/chapter/10.1007/978-3-319-31204-0_9). *Applications of Evolutionary Computation*, pages 123-137.
BibTeX entry:
```bibtex
@inbook{Olson2016EvoBio,
author={Olson, Randal S. and Urbanowicz, Ryan J. and Andrews, Peter C. and Lavender, Nicole A. and Kidd, La Creis and Moore, Jason H.},
editor={Squillero, Giovanni and Burelli, Paolo},
chapter={Automating Biomedical Data Science Through Tree-Based Pipeline Optimization},
title={Applications of Evolutionary Computation: 19th European Conference, EvoApplications 2016, Porto, Portugal, March 30 -- April 1, 2016, Proceedings, Part I},
year={2016},
publisher={Springer International Publishing},
pages={123--137},
isbn={978-3-319-31204-0},
doi={10.1007/978-3-319-31204-0_9},
url={http://dx.doi.org/10.1007/978-3-319-31204-0_9}
}
```
Randal S. Olson, Nathan Bartley, Ryan J. Urbanowicz, and Jason H. Moore (2016). [Evaluation of a Tree-based Pipeline Optimization Tool for Automating Data Science](http://dl.acm.org/citation.cfm?id=2908918). *Proceedings of GECCO 2016*, pages 485-492.
BibTeX entry:
```bibtex
@inproceedings{OlsonGECCO2016,
author = {Olson, Randal S. and Bartley, Nathan and Urbanowicz, Ryan J. and Moore, Jason H.},
title = {Evaluation of a Tree-based Pipeline Optimization Tool for Automating Data Science},
booktitle = {Proceedings of the Genetic and Evolutionary Computation Conference 2016},
series = {GECCO '16},
year = {2016},
isbn = {978-1-4503-4206-3},
location = {Denver, Colorado, USA},
pages = {485--492},
numpages = {8},
url = {http://doi.acm.org/10.1145/2908812.2908918},
doi = {10.1145/2908812.2908918},
acmid = {2908918},
publisher = {ACM},
address = {New York, NY, USA},
}
```
================================================
FILE: docs/contribute.md
================================================
# Contributing
We welcome you to check the existing issues for bugs or enhancements to work on. If you have an idea for an extension to TPOT, please file a new issue so we can discuss it.
# Contribution Guide
We welcome you to [check the existing issues](https://github.com/EpistasisLab/tpot/issues/) for bugs or enhancements to work on. If you have an idea for an extension to TPOT, please [file a new issue](https://github.com/EpistasisLab/tpot/issues/new) so we can discuss it.
## Project layout
Both the latest stable release and the development version of TPOT are on the [main branch](https://github.com/EpistasisLab/tpot/tree/main). Ensure you are working from the correct commit when contributing.
In terms of directory structure:
* All of TPOT's code sources are in the `tpot` directory
* The documentation sources are in the `docs_sources` directory
* Images in the documentation are in the `images` directory
* Tutorials for TPOT are in the `tutorials` directory
* Unit tests for TPOT are in the `tests.py` file
Make sure to familiarize yourself with the project layout before making any major contributions, and especially make sure to send all code changes to the `main` branch.
## How to contribute
The preferred way to contribute to TPOT is to fork the
[main repository](https://github.com/EpistasisLab/tpot/) on
GitHub:
1. Fork the [project repository](https://github.com/EpistasisLab/tpot):
click on the 'Fork' button near the top of the page. This creates
a copy of the code under your account on the GitHub server.
2. Clone this copy to your local disk:
$ git clone git@github.com:YourUsername/tpot.git
$ cd tpot
3. Create a branch to hold your changes:
$ git checkout main
$ git pull origin main
$ git checkout -b my-contribution
4. Make sure your local environment is setup correctly for development. Set up your local environment following the [Developer Installation instructions](installing.md#developerlatest-branch-installation). Ensure you also install `pytest` (`conda install pytest` or `pip install pytest`) into your development environment so that you can test changes locally.
5. Start making changes on your newly created branch. Work on this copy on your computer using Git to do the version control.
6. Check your changes haven't broken any existing tests and pass all your new tests. Navigate the terminal into the `tpot/tpot/` folder and run the command `pytest` to start all tests. (note, you must have the `pytest` package installed within your dev environment for this to work):
$ pytest
7. When you're done editing and local testing, run:
$ git add modified_files
$ git commit
to record your changes in Git, then push them to GitHub with:
$ git push -u origin my-contribution
Finally, go to the web page of your fork of the TPOT repo, and click 'Pull Request' (PR) to send your changes to the maintainers for review. Make sure that you send your PR to the `main` branch. This will start the CI server to check all the project's unit tests run and send an email to the maintainers.
(If any of the above seems like magic to you, then look up the
[Git documentation](http://git-scm.com/documentation) on the web.)
## Before submitting your pull request
Before you submit a pull request for your contribution, please work through this checklist to make sure that you have done everything necessary so we can efficiently review and accept your changes.
If your contribution changes TPOT in any way:
* Update the [documentation](https://github.com/EpistasisLab/tpot/tree/main/docs) so all of your changes are reflected there.
* Update the [README](https://github.com/EpistasisLab/tpot/blob/main/README.md) if anything there has changed.
If your contribution involves any code changes:
* Update the [project unit tests](https://github.com/EpistasisLab/tpot/tree/main/tpot/tests) to test your code changes.
* Make sure that your code is properly commented with [docstrings](https://www.python.org/dev/peps/pep-0257/) and comments explaining your rationale behind non-obvious coding practices.
If your contribution requires a new library dependency:
* Double-check that the new dependency is easy to install via `pip` or Anaconda. If the dependency requires a complicated installation, then we most likely won't merge your changes because we want to keep TPOT easy to install.
## After submitting your pull request
After submitting your pull request, GitHub will automatically run unit tests on your changes and make sure that your updated code builds and runs. We also use services that automatically check code quality and test coverage.
Check back shortly after submitting your pull request to make sure that your code passes these checks. If any of the checks come back with a red X, then do your best to address the errors.
================================================
FILE: docs/css/extra.css
================================================
.md-grid {
max-width: 100%;
}
================================================
FILE: docs/index.md
================================================
{%
include-markdown "../README.md"
%}
================================================
FILE: docs/installation.md
================================================
# Installation
TPOT requires a working installation of Python.
### Creating a conda environment (optional)
We recommend using conda environments for installing TPOT, though it would work equally well if manually installed without it.
[More information on making anaconda environments found here.](https://conda.io/projects/conda/en/latest/user-guide/tasks/manage-environments.html)
```
conda create --name tpotenv python=3.13
conda activate tpotenv
```
### Note for M1 Mac or other Arm-based CPU users
You need to install the lightgbm package directly from conda using the following command before installing TPOT.
This is to ensure that you get the version that is compatible with your system.
```
conda install --yes -c conda-forge 'lightgbm>=3.3.3'
```
### Developer/Latest Branch Installation
```
pip install -e /path/to/tpotrepo
```
If you downloaded with git pull, then the repository folder will be named TPOT. (Note: this folder is the one that includes setup.py inside of it and not the folder of the same name inside it).
If you downloaded as a zip, the folder may be called tpot-main.
================================================
FILE: docs/related.md
================================================
Other Automated Machine Learning (AutoML) tools and related projects:
| Name |
Language |
License |
Description |
| Auto-WEKA |
Java |
GPL-v3 |
Automated model selection and hyper-parameter tuning for Weka models. |
| auto-sklearn |
Python |
BSD-3-Clause |
An automated machine learning toolkit and a drop-in replacement for a scikit-learn estimator. |
| auto_ml |
Python |
MIT |
Automated machine learning for analytics & production. Supports manual feature type declarations. |
| H2O AutoML |
Java with Python, Scala & R APIs and web GUI |
Apache 2.0 |
Automated: data prep, hyperparameter tuning, random grid search and stacked ensembles in a distributed ML platform. |
| devol |
Python |
MIT |
Automated deep neural network design via genetic programming. |
| MLBox |
Python |
BSD-3-Clause |
Accurate hyper-parameter optimization in high-dimensional space with support for distributed computing. |
| Recipe |
C |
GPL-v3 |
Machine-learning pipeline optimization through genetic programming. Uses grammars to define pipeline structure. |
| Xcessiv |
Python |
Apache 2.0 |
A web-based application for quick, scalable, and automated hyper-parameter tuning and stacked ensembling in Python. |
| GAMA |
Python |
Apache 2.0 |
Machine-learning pipeline optimization through asynchronous evaluation based genetic programming. |
| PyMoo |
Python |
Apache 2.0 |
Multi-objective optimization in Python. |
| Karoo GP |
Python |
MIT |
A Python based genetic programming application suite with support for symbolic regression and classification. |
| MABE |
C++ |
See here |
A Python based genetic programming application suite with support for symbolic regression and classification. |
| SBBFramework |
Python |
BSD-2-Clause |
Python implementation of Symbiotic Bid-Based (SBB) framework for problem decomposition using Genetic Programming (GP). |
| Tiny GP |
Python |
GPL-v3 |
A minimalistic program implementing Koza-style (tree-based) genetic programming to solve a symbolic regression problem. |
| Baikal |
Python |
BSD-3-Clause |
A graph-based functional API for building complex scikit-learn pipelines. |
| skdag |
Python |
MIT |
A more flexible alternative to scikit-learn Pipelines. |
| d6tflow |
Python |
MIT |
A python library which makes building complex data science workflows easy, fast and intuitive. |
================================================
FILE: docs/requirements_docs.txt
================================================
griffe==1.3.1
mike==2.1.3
mkdocs==1.6.1
mkdocs-include-markdown-plugin==6.2.2
mkdocs-jupyter==0.25.0
mkdocs-material==9.5.35
mkdocstrings==0.26.1
mkdocstrings-python==1.11.1
nbconvert==7.16.5
================================================
FILE: docs/scripts/build_docs_sources.sh
================================================
#!/bin/bash
function iterate_files() {
local directory="$1"
base_dir="docs/documentation"
for file in "$directory"/*; do
if [ -f "$file" ] && [[ "$file" == *.py ]] && [ "$(basename "$file")" != "__init__.py" ] && \
! echo "$file" | grep -q "test" && [ "$(basename "$file")" != "graph_utils.py" ]; then
directories=$base_dir/$(dirname "$file")
file_name=$(basename "$file")
md_file=$directories/"${file_name%.*}".md
mkdir -p $directories && touch $md_file
include_line=$(dirname "$file")
include_line="${include_line//\//.}"."${file_name%.*}"
echo "::: $include_line" > $md_file
elif [ -d "$file" ]; then
iterate_files "$file"
fi
done
}
iterate_files "tpot"
================================================
FILE: docs/scripts/build_mkdocs.sh
================================================
#!/bin/bash
cat > mkdocs.yml <> mkdocs.yml
echo " - tpot_api/estimator.md" >> mkdocs.yml
echo " - tpot_api/classifier.md" >> mkdocs.yml
echo " - tpot_api/regressor.md" >> mkdocs.yml
echo " - Examples:" >> mkdocs.yml
for file in docs/Tutorial/*.ipynb; do
base=$(basename $file .ipynb)
echo " - Tutorial/$base.ipynb" >> mkdocs.yml
done
echo " - Documentation:" >> mkdocs.yml
function iterate_source_files() {
local directory="$1"
for file in "$directory"/*; do
if [ -f "$file" ] && [[ "$file" == *.md ]]; then
slash_count=$(echo "$file" | grep -o '/' | wc -l)
num_spaces=$((slash_count * 2))
spaces=$(printf "%*s" $num_spaces)
echo "$spaces- ${file#*/}" >> mkdocs.yml
fi
done
for file in "$directory"/*; do
if [ -d "$file" ]; then
slash_count=$(echo "$file" | grep -o '/' | wc -l)
num_spaces=$((slash_count * 2))
spaces=$(printf "%*s" $num_spaces)
last_dir=$(basename "$file")
echo "$spaces- $last_dir:" >> mkdocs.yml
iterate_source_files "$file"
fi
done
}
iterate_source_files "docs/documentation"
# make these static instead
# for file in docs/*.md; do
# base=$(basename $file .md)
# if [ "$base" == "index" ]; then
# continue
# fi
# echo " - $base.md" >> mkdocs.yml
# done
echo " - contribute.md" >> mkdocs.yml
echo " - cite.md" >> mkdocs.yml
echo " - support.md" >> mkdocs.yml
echo " - related.md" >> mkdocs.yml
# moved to the top
# # test docstring
# # echo " - Tutorials:" >> mkdocs.yml
# for file in docs/tutorial/*.ipynb; do
# base=$(basename $file .ipynb)
# echo " - tutorial/$base.ipynb" >> mkdocs.yml
# done
================================================
FILE: docs/scripts/build_tutorial_toc_not_used.sh
================================================
#!/bin/bash
for file in docs/tutorial/*.html; do
base=$(basename "$file" .html)
echo "" > "docs/tutorial/$base.md"
done
================================================
FILE: docs/support.md
================================================
# Support
TPOT was developed in the [Artificial Intelligence Innovation (A2I) Lab](http://epistasis.org/) at Cedars-Sinai with funding from the [NIH](http://www.nih.gov/) under grants U01 AG066833 and R01 LM010098. We are incredibly grateful for the support of the NIH and the Cedars-Sinai during the development of this project.
The TPOT logo was designed by Todd Newmuis, who generously donated his time to the project.
================================================
FILE: docs/tpot_api/classifier.md
================================================
::: tpot.tpot_estimator.templates.tpottemplates.TPOTClassifier
================================================
FILE: docs/tpot_api/estimator.md
================================================
::: tpot.tpot_estimator.estimator
================================================
FILE: docs/tpot_api/regressor.md
================================================
::: tpot.tpot_estimator.templates.tpottemplates.TPOTRegressor
================================================
FILE: docs/using.md
================================================
# Using TPOT
See the Tutorials Folder for more instructions and examples.
## Best Practices
### 1
TPOT uses dask for parallel processing. When Python is parallelized, each module is imported within each processes. Therefore it is important to protect all code within a `if __name__ == "__main__"` when running TPOT from a script. This is not required when running TPOT from a notebook.
For example:
```
#my_analysis.py
import tpot
if __name__ == "__main__":
X, y = load_my_data()
est = tpot.TPOTClassifier()
est.fit(X,y)
#rest of analysis
```
### 2
When designing custom objective functions, avoid the use of global variables.
Don't Do:
```
global_X = [[1,2],[4,5]]
global_y = [0,1]
def foo(est):
return my_scorer(est, X=global_X, y=global_y)
```
Instead use a partial
```
from functools import partial
def foo_scorer(est, X, y):
return my_scorer(est, X, y)
if __name__=='__main__':
X = [[1,2],[4,5]]
y = [0,1]
final_scorer = partial(foo_scorer, X=X, y=y)
```
Similarly when using lambda functions.
Dont Do:
```
def new_objective(est, a, b)
#definition
a = 100
b = 20
bad_function = lambda est : new_objective(est=est, a=a, b=b)
```
Do:
```
def new_objective(est, a, b)
#definition
a = 100
b = 20
good_function = lambda est, a=a, b=b : new_objective(est=est, a=a, b=b)
```
## Tips
TPOT will not check if your data is correctly formatted. It will assume that you have passed in operators that can handle the type of data that was passed in. For instance, if you pass in a pandas dataframe with categorical features and missing data, then you should also include in your configuration operators that can handle those feautures of the data. Alternatively, if you pass in `preprocessing = True`, TPOT will impute missing values, one hot encode categorical features, then standardize the data. (Note that this is currently fitted and transformed on the entire training set before splitting for CV. Later there will be an option to apply per fold, and have the parameters be learnable.)
Setting `verbose` to 5 can be helpful during debugging as it will print out the error generated by failing pipelines.
================================================
FILE: mkdocs_archived.yml
================================================
site_name: TPOT
site_url: http://epistasislab.github.io/tpot
site_author: Randal S. Olson
site_description: Documentation for TPOT, a Python Automated Machine Learning tool that optimizes machine learning pipelines using genetic programming.
repo_url: https://github.com/epistasislab/tpot
edit_uri: edit/master/docs/archived/
docs_dir: docs/archived/
site_dir: target/archived_site
#theme: readthedocs
theme:
name: material
logo: assets/tpot-logo.jpg
favicon: assets/favicon.ico
features:
- toc.integrate
- navigation.top
palette:
# light mode
- scheme: default
primary: grey
toggle:
icon: material/brightness-7
name: Switch to dark mode
# dark mode
- scheme: slate
primary: grey
toggle:
icon: material/brightness-4
name: Switch to light mode
extra:
version:
provider: mike
extra_css:
- css/archived.css
markdown_extensions:
- tables
- fenced_code
- pymdownx.highlight:
anchor_linenums: true
- pymdownx.inlinehilite
- pymdownx.snippets
- pymdownx.superfences
plugins:
- include-markdown
copyright: Developed by Randal S. Olson and others at the University of Pennsylvania
nav:
- Home: index.md
- Installation: installing.md
- Using TPOT: using.md
- TPOT API: api.md
- Examples: examples.md
- Contributing: contributing.md
- Release Notes: releases.md
- Citing TPOT: citing.md
- Support: support.md
- Related: related.md
================================================
FILE: pyproject.toml
================================================
[build-system]
requires = ["setuptools>=61", "setuptools_scm>=7.0", "wheel"]
build-backend = "setuptools.build_meta"
[project]
name = "TPOT"
description = "Tree-based Pipeline Optimization Tool"
readme = "README.md"
requires-python = ">=3.10,<3.14"
license = { text = "LGPL-3.0" }
authors = [
{ name = "Pedro Ribeiro" }
]
keywords = [
"pipeline optimization",
"hyperparameter optimization",
"data science",
"machine learning",
"genetic programming",
"evolutionary computation"
]
classifiers = [
"Intended Audience :: Science/Research",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Topic :: Scientific/Engineering :: Artificial Intelligence"
]
dependencies = [
"numpy>=1.26.4",
"scipy>=1.3.1",
"scikit-learn>=1.6",
"update_checker>=0.16",
"tqdm>=4.36.1",
"stopit>=1.1.1",
"pandas>=2.2.0",
"joblib>=1.1.1",
"xgboost>=3.0.0",
"matplotlib>=3.6.2",
"traitlets>=5.8.0",
"lightgbm>=3.3.3",
"optuna>=3.0.5",
"networkx>=3.0",
"dask>=2024.4.2",
"distributed>=2024.4.2",
"dask-expr>=1.0.12",
"dask-jobqueue>=0.8.5",
"func_timeout>=4.3.5",
"configspace>=1.1.1",
"dill>=0.3.9",
"seaborn>=0.13.2",
]
dynamic = ["version"]
[project.optional-dependencies]
skrebate = ["skrebate>=0.3.4"]
mdr = ["scikit-mdr>=0.4.4"]
sklearnex = ["scikit-learn-intelex>=2023.2.1"]
amltk = ["amltk>=1.12.1"]
testing = [
"pytest>=6.0",
"pytest-cov>=2.0",
"mypy>=0.910",
"flake8>=3.9",
"tox>=3.24"
]
[project.urls]
Homepage = "https://github.com/EpistasisLab/tpot"
[project.scripts]
tpot = "tpot:main"
[tool.setuptools]
packages = ["tpot"]
zip-safe = true
[tool.setuptools.package-data]
tpot = ["py.typed"]
[tool.flake8]
max-line-length = 120
[tool.setuptools_scm]
# setuptools_scm gets the version from Git tags, e.g git tag v1.1.0
# then python -m build embeds the version into the package
================================================
FILE: tox.ini
================================================
[tox]
minversion = 3.28.0
# flake8 and mypy outputs severla errors, so we disable them for now
# envlist = py310, flake8, mypy
envlist = py310, py311, py312, py313
isolated_build = true
skip_missing_interpreters = true
[gh-actions]
python =
3.10: py310
3.11: py311
3.12: py312
3.13: py313
# 3.10: py310, flake8, mypy
[testenv]
setenv =
PYTHONPATH = {toxinidir}
extras = testing
deps =
setuptools>=65.0.0
commands =
pytest --basetemp={envtmpdir}
[testenv:flake8]
basepython = python3.10
deps = flake8
commands = flake8 tpot
[testenv:mypy]
basepython = python3.10
extras = testing
deps =
setuptools>=65.0.0
commands = mypy tpot
================================================
FILE: tpot/__init__.py
================================================
"""
This file is part of the TPOT library.
The current version of TPOT was developed at Cedars-Sinai by:
- Pedro Henrique Ribeiro (https://github.com/perib, https://www.linkedin.com/in/pedro-ribeiro/)
- Anil Saini (anil.saini@cshs.org)
- Jose Hernandez (jgh9094@gmail.com)
- Jay Moran (jay.moran@cshs.org)
- Nicholas Matsumoto (nicholas.matsumoto@cshs.org)
- Hyunjun Choi (hyunjun.choi@cshs.org)
- Gabriel Ketron (gabriel.ketron@cshs.org)
- Miguel E. Hernandez (miguel.e.hernandez@cshs.org)
- Jason Moore (moorejh28@gmail.com)
The original version of TPOT was primarily developed at the University of Pennsylvania by:
- Randal S. Olson (rso@randalolson.com)
- Weixuan Fu (weixuanf@upenn.edu)
- Daniel Angell (dpa34@drexel.edu)
- Jason Moore (moorejh28@gmail.com)
- and many more generous open-source contributors
TPOT is free software: you can redistribute it and/or modify
it under the terms of the GNU Lesser General Public License as
published by the Free Software Foundation, either version 3 of
the License, or (at your option) any later version.
TPOT is distributed in the hope that it will be useful,
but WITHOUT ANY WARRANTY; without even the implied warranty of
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
GNU Lesser General Public License for more details.
You should have received a copy of the GNU Lesser General Public
License along with TPOT. If not, see .
"""
#TODO: are all the imports in the init files done correctly?
#TODO clean up import organization
from .individual import BaseIndividual
from .graphsklearn import GraphPipeline
from .population import Population
from . import builtin_modules
from . import config
from . import search_spaces
from . import utils
from . import evolvers
from . import objectives
from . import selectors
from . import tpot_estimator
from . import old_config_utils
from .tpot_estimator import TPOTClassifier, TPOTRegressor, TPOTEstimator, TPOTEstimatorSteadyState
from update_checker import update_check
from ._version import __version__
update_check("tpot",__version__)
================================================
FILE: tpot/_version.py
================================================
try:
from importlib.metadata import version
except ImportError:
from importlib_metadata import version # for Python < 3.8
__version__ = version("tpot")
================================================
FILE: tpot/builtin_modules/__init__.py
================================================
from .feature_set_selector import FeatureSetSelector
from .zero_count import ZeroCount
from .column_one_hot_encoder import ColumnOneHotEncoder, ColumnOrdinalEncoder
from .arithmetictransformer import ArithmeticTransformer
from .arithmetictransformer import AddTransformer, mul_neg_1_Transformer, MulTransformer, SafeReciprocalTransformer, EQTransformer, NETransformer, GETransformer, GTTransformer, LETransformer, LTTransformer, MinTransformer, MaxTransformer, ZeroTransformer, OneTransformer, NTransformer
from .passthrough import Passthrough, SkipTransformer
from .imputer import ColumnSimpleImputer
from .estimatortransformer import EstimatorTransformer
from .passkbinsdiscretizer import PassKBinsDiscretizer
try:
from .nn import PytorchLRClassifier, PytorchMLPClassifier
except (ModuleNotFoundError, ImportError):
pass
# import warnings
# warnings.warn("Warning: optional dependency `torch` is not available. - skipping import of NN models.")
================================================
FILE: tpot/builtin_modules/arithmetictransformer.py
================================================
"""
This file is part of the TPOT library.
The current version of TPOT was developed at Cedars-Sinai by:
- Pedro Henrique Ribeiro (https://github.com/perib, https://www.linkedin.com/in/pedro-ribeiro/)
- Anil Saini (anil.saini@cshs.org)
- Jose Hernandez (jgh9094@gmail.com)
- Jay Moran (jay.moran@cshs.org)
- Nicholas Matsumoto (nicholas.matsumoto@cshs.org)
- Hyunjun Choi (hyunjun.choi@cshs.org)
- Gabriel Ketron (gabriel.ketron@cshs.org)
- Miguel E. Hernandez (miguel.e.hernandez@cshs.org)
- Jason Moore (moorejh28@gmail.com)
The original version of TPOT was primarily developed at the University of Pennsylvania by:
- Randal S. Olson (rso@randalolson.com)
- Weixuan Fu (weixuanf@upenn.edu)
- Daniel Angell (dpa34@drexel.edu)
- Jason Moore (moorejh28@gmail.com)
- and many more generous open-source contributors
TPOT is free software: you can redistribute it and/or modify
it under the terms of the GNU Lesser General Public License as
published by the Free Software Foundation, either version 3 of
the License, or (at your option) any later version.
TPOT is distributed in the hope that it will be useful,
but WITHOUT ANY WARRANTY; without even the implied warranty of
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
GNU Lesser General Public License for more details.
You should have received a copy of the GNU Lesser General Public
License along with TPOT. If not, see .
"""
import random
import numpy as np
from sklearn.base import TransformerMixin, BaseEstimator
#operations are done along axis
#TODO potentially we could do operations on every combo (mul would be all possible pairs multiplied with each other)
class ArithmeticTransformer(TransformerMixin, BaseEstimator):
#functions = ["add", "mul_neg_1", "mul", "safe_reciprocal", "eq","ne","ge","gt","le","lt", "min","max","0","1"]
def __init__(self, function,):
"""
A transformer that applies a function to the input array along axis 1.
Parameters
----------
function : str
The function to apply to the input array. The following functions are supported:
- 'add' : Add all elements along axis 1
- 'mul_neg_1' : Multiply all elements along axis 1 by -1
- 'mul' : Multiply all elements along axis 1
- 'safe_reciprocal' : Take the reciprocal of all elements along axis 1, with a safe division by zero
- 'eq' : Check if all elements along axis 1 are equal
- 'ne' : Check if all elements along axis 1 are not equal
- 'ge' : Check if all elements along axis 1 are greater than or equal to 0
- 'gt' : Check if all elements along axis 1 are greater than 0
- 'le' : Check if all elements along axis 1 are less than or equal to 0
- 'lt' : Check if all elements along axis 1 are less than 0
- 'min' : Take the minimum of all elements along axis 1
- 'max' : Take the maximum of all elements along axis 1
- '0' : Return an array of zeros
- '1' : Return an array of ones
"""
self.function = function
def fit(self, X, y=None):
return self
def transform(self, X):
transformed_X = np.array(self.transform_helper(np.array(X)))
if transformed_X.dtype != float:
transformed_X = transformed_X.astype(float)
return transformed_X
def transform_helper(self, X):
X = np.array(X)
if len(X.shape) == 1:
X = np.expand_dims(X,0)
if self.function == "add":
return np.expand_dims(np.sum(X,1),1)
elif self.function == "mul_neg_1":
return X*-1
elif self.function == "mul":
return np.expand_dims(np.prod(X,1),1)
elif self.function == "safe_reciprocal":
results = np.divide(1.0, X.astype(float), out=np.zeros_like(X).astype(float), where=X!=0) #TODO remove astypefloat?
return results
elif self.function == "eq":
return np.expand_dims(np.all(X == X[0,:], axis = 1),1).astype(float)
elif self.function == "ne":
return 1- np.expand_dims(np.all(X == X[0,:], axis = 1),1).astype(float)
#TODO these could be "sorted order"
elif self.function == "ge":
result = X >= 0
return result.astype(float)
elif self.function == "gt":
result = X > 0
return result.astype(float)
elif self.function == "le":
result = X <= 0
return result.astype(float)
elif self.function == "lt":
result = X < 0
return result.astype(float)
elif self.function == "min":
return np.expand_dims(np.amin(X,1),1)
elif self.function == "max":
return np.expand_dims(np.amax(X,1),1)
elif self.function == "0":
return np.zeros((X.shape[0],1))
elif self.function == "1":
return np.ones((X.shape[0],1))
def issorted(x, rev=False):
if rev:
s = sorted(x)
s.reverse()
if s == x:
return True
else:
if sorted(x) == x:
return True
return False
class AddTransformer(TransformerMixin, BaseEstimator):
def __init__(self):
"""
A transformer that adds all elements along axis 1.
"""
pass
def fit(self, X, y=None):
return self
def transform(self, X):
transformed_X = np.array(self.transform_helper(np.array(X)))
if transformed_X.dtype != float:
transformed_X = transformed_X.astype(float)
return transformed_X
def transform_helper(self, X):
X = np.array(X)
if len(X.shape) == 1:
X = np.expand_dims(X,0)
return np.expand_dims(np.sum(X,1),1)
class mul_neg_1_Transformer(TransformerMixin, BaseEstimator):
def __init__(self):
"""
A transformer that multiplies all elements by -1.
"""
pass
def fit(self, X, y=None):
return self
def transform(self, X):
transformed_X = np.array(self.transform_helper(np.array(X)))
if transformed_X.dtype != float:
transformed_X = transformed_X.astype(float)
return transformed_X
def transform_helper(self, X):
X = np.array(X)
if len(X.shape) == 1:
X = np.expand_dims(X,0)
return X*-1
class MulTransformer(TransformerMixin, BaseEstimator):
def __init__(self):
"""
A transformer that multiplies all elements along axis 1.
"""
pass
def fit(self, X, y=None):
return self
def transform(self, X):
transformed_X = np.array(self.transform_helper(np.array(X)))
if transformed_X.dtype != float:
transformed_X = transformed_X.astype(float)
return transformed_X
def transform_helper(self, X):
X = np.array(X)
if len(X.shape) == 1:
X = np.expand_dims(X,0)
return np.expand_dims(np.prod(X,1),1)
class SafeReciprocalTransformer(TransformerMixin, BaseEstimator):
def __init__(self):
"""
A transformer that takes the reciprocal of all elements, with a safe division by zero.
"""
pass
def fit(self, X, y=None):
return self
def transform(self, X):
transformed_X = np.array(self.transform_helper(np.array(X)))
if transformed_X.dtype != float:
transformed_X = transformed_X.astype(float)
return transformed_X
def transform_helper(self, X):
X = np.array(X)
if len(X.shape) == 1:
X = np.expand_dims(X,0)
return np.divide(1.0, X.astype(float), out=np.zeros_like(X).astype(float), where=X!=0) #TODO remove astypefloat?
class EQTransformer(TransformerMixin, BaseEstimator):
def __init__(self):
"""
A transformer that takes checks if all elements in a row are equal.
"""
pass
def fit(self, X, y=None):
return self
def transform(self, X):
transformed_X = np.array(self.transform_helper(np.array(X)))
if transformed_X.dtype != float:
transformed_X = transformed_X.astype(float)
return transformed_X
def transform_helper(self, X):
X = np.array(X)
if len(X.shape) == 1:
X = np.expand_dims(X,0)
return np.expand_dims(np.all(X == X[0,:], axis = 1),1).astype(float)
class NETransformer(TransformerMixin, BaseEstimator):
def __init__(self):
"""
A transformer that takes checks if all elements in a row are not equal.
"""
pass
def fit(self, X, y=None):
return self
def transform(self, X):
transformed_X = np.array(self.transform_helper(np.array(X)))
if transformed_X.dtype != float:
transformed_X = transformed_X.astype(float)
return transformed_X
def transform_helper(self, X):
X = np.array(X)
if len(X.shape) == 1:
X = np.expand_dims(X,0)
return 1- np.expand_dims(np.all(X == X[0,:], axis = 1),1).astype(float)
class GETransformer(TransformerMixin, BaseEstimator):
def __init__(self):
"""
A transformer that takes checks if all elements in a row are greater than or equal to 0.
"""
pass
def fit(self, X, y=None):
return self
def transform(self, X):
transformed_X = np.array(self.transform_helper(np.array(X)))
if transformed_X.dtype != float:
transformed_X = transformed_X.astype(float)
return transformed_X
def transform_helper(self, X):
X = np.array(X)
if len(X.shape) == 1:
X = np.expand_dims(X,0)
result = X >= 0
return result.astype(float)
class GTTransformer(TransformerMixin, BaseEstimator):
def __init__(self):
"""
A transformer that takes checks if all elements in a row are greater than 0.
"""
pass
def fit(self, X, y=None):
return self
def transform(self, X):
transformed_X = np.array(self.transform_helper(np.array(X)))
if transformed_X.dtype != float:
transformed_X = transformed_X.astype(float)
return transformed_X
def transform_helper(self, X):
X = np.array(X)
if len(X.shape) == 1:
X = np.expand_dims(X,0)
result = X > 0
return result.astype(float)
class LETransformer(TransformerMixin, BaseEstimator):
def __init__(self):
"""
A transformer that takes checks if all elements in a row are less than or equal to 0.
"""
pass
def fit(self, X, y=None):
return self
def transform(self, X):
transformed_X = np.array(self.transform_helper(np.array(X)))
if transformed_X.dtype != float:
transformed_X = transformed_X.astype(float)
return transformed_X
def transform_helper(self, X):
X = np.array(X)
if len(X.shape) == 1:
X = np.expand_dims(X,0)
result = X <= 0
return result.astype(float)
class LTTransformer(TransformerMixin, BaseEstimator):
def __init__(self):
"""
A transformer that takes checks if all elements in a row are less than 0.
"""
pass
def fit(self, X, y=None):
return self
def transform(self, X):
transformed_X = np.array(self.transform_helper(np.array(X)))
if transformed_X.dtype != float:
transformed_X = transformed_X.astype(float)
return transformed_X
def transform_helper(self, X):
X = np.array(X)
if len(X.shape) == 1:
X = np.expand_dims(X,0)
result = X < 0
return result.astype(float)
class MinTransformer(TransformerMixin, BaseEstimator):
def __init__(self):
"""
A transformer that takes the minimum of all elements in a row.
"""
pass
def fit(self, X, y=None):
return self
def transform(self, X):
transformed_X = np.array(self.transform_helper(np.array(X)))
if transformed_X.dtype != float:
transformed_X = transformed_X.astype(float)
return transformed_X
def transform_helper(self, X):
X = np.array(X)
if len(X.shape) == 1:
X = np.expand_dims(X,0)
return np.expand_dims(np.amin(X,1),1)
class MaxTransformer(TransformerMixin, BaseEstimator):
def __init__(self):
"""
A transformer that takes the maximum of all elements in a row.
"""
pass
def fit(self, X, y=None):
return self
def transform(self, X):
transformed_X = np.array(self.transform_helper(np.array(X)))
if transformed_X.dtype != float:
transformed_X = transformed_X.astype(float)
return transformed_X
def transform_helper(self, X):
X = np.array(X)
if len(X.shape) == 1:
X = np.expand_dims(X,0)
return np.expand_dims(np.amax(X,1),1)
class ZeroTransformer(TransformerMixin, BaseEstimator):
def __init__(self):
"""
A transformer that returns an array of zeros.
"""
pass
def fit(self, X, y=None):
return self
def transform(self, X):
transformed_X = np.array(self.transform_helper(np.array(X)))
if transformed_X.dtype != float:
transformed_X = transformed_X.astype(float)
return transformed_X
def transform_helper(self, X):
X = np.array(X)
if len(X.shape) == 1:
X = np.expand_dims(X,0)
return np.zeros((X.shape[0],1))
class OneTransformer(TransformerMixin, BaseEstimator):
def __init__(self):
"""
A transformer that returns an array of ones.
"""
pass
def fit(self, X, y=None):
return self
def transform(self, X):
transformed_X = np.array(self.transform_helper(np.array(X)))
if transformed_X.dtype != float:
transformed_X = transformed_X.astype(float)
return transformed_X
def transform_helper(self, X):
X = np.array(X)
if len(X.shape) == 1:
X = np.expand_dims(X,0)
return np.ones((X.shape[0],1))
class NTransformer(TransformerMixin, BaseEstimator):
def __init__(self, n):
"""
A transformer that returns an array of n.
"""
self.n = n
def fit(self, X, y=None):
return self
def transform(self, X):
transformed_X = np.array(self.transform_helper(np.array(X)))
if transformed_X.dtype != float:
transformed_X = transformed_X.astype(float)
return transformed_X
def transform_helper(self, X):
X = np.array(X)
if len(X.shape) == 1:
X = np.expand_dims(X,0)
return np.ones((X.shape[0],1))*self.n
================================================
FILE: tpot/builtin_modules/column_one_hot_encoder.py
================================================
"""
This file is part of the TPOT library.
The current version of TPOT was developed at Cedars-Sinai by:
- Pedro Henrique Ribeiro (https://github.com/perib, https://www.linkedin.com/in/pedro-ribeiro/)
- Anil Saini (anil.saini@cshs.org)
- Jose Hernandez (jgh9094@gmail.com)
- Jay Moran (jay.moran@cshs.org)
- Nicholas Matsumoto (nicholas.matsumoto@cshs.org)
- Hyunjun Choi (hyunjun.choi@cshs.org)
- Gabriel Ketron (gabriel.ketron@cshs.org)
- Miguel E. Hernandez (miguel.e.hernandez@cshs.org)
- Jason Moore (moorejh28@gmail.com)
The original version of TPOT was primarily developed at the University of Pennsylvania by:
- Randal S. Olson (rso@randalolson.com)
- Weixuan Fu (weixuanf@upenn.edu)
- Daniel Angell (dpa34@drexel.edu)
- Jason Moore (moorejh28@gmail.com)
- and many more generous open-source contributors
TPOT is free software: you can redistribute it and/or modify
it under the terms of the GNU Lesser General Public License as
published by the Free Software Foundation, either version 3 of
the License, or (at your option) any later version.
TPOT is distributed in the hope that it will be useful,
but WITHOUT ANY WARRANTY; without even the implied warranty of
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
GNU Lesser General Public License for more details.
You should have received a copy of the GNU Lesser General Public
License along with TPOT. If not, see .
"""
import numpy as np
from scipy import sparse
from sklearn.base import TransformerMixin, BaseEstimator
from sklearn.utils import check_array
from sklearn.preprocessing import OneHotEncoder, OrdinalEncoder
import sklearn
import pandas as pd
from pandas.api.types import is_numeric_dtype
def auto_select_categorical_features(X, min_unique=10,):
if isinstance(X, pd.DataFrame):
return [col for col in X.columns if len(X[col].unique()) < min_unique]
else:
return [i for i in range(X.shape[1]) if len(np.unique(X[:, i])) < min_unique]
def _X_selected(X, selected):
"""Split X into selected features and other features"""
if isinstance(X, pd.DataFrame):
X_sel = X[selected]
X_not_sel = X.drop(selected, axis=1)
else:
X_sel = X[:, selected]
X_not_sel = np.delete(X, selected, axis=1)
return X_sel, X_not_sel
class ColumnOneHotEncoder(TransformerMixin, BaseEstimator ):
def __init__(self, columns='auto', drop=None, handle_unknown='infrequent_if_exist', sparse_output=False, min_frequency=None,max_categories=None):
'''
A wrapper for OneHotEncoder that allows for onehot encoding of specific columns in a DataFrame or np array.
Parameters
----------
columns : str, list, default='auto'
Determines which columns to onehot encode with sklearn.preprocessing.OneHotEncoder.
- 'auto' : Automatically select categorical features based on columns with less than 10 unique values
- 'categorical' : Automatically select categorical features
- 'numeric' : Automatically select numeric features
- 'all' : Select all features
- list : A list of columns to select
drop, handle_unknown, sparse_output, min_frequency, max_categories : see sklearn.preprocessing.OneHotEncoder
'''
self.columns = columns
self.drop = drop
self.handle_unknown = handle_unknown
self.sparse_output = sparse_output
self.min_frequency = min_frequency
self.max_categories = max_categories
def fit(self, X, y=None):
"""Fit OneHotEncoder to X, then transform X.
Equivalent to self.fit(X).transform(X), but more convenient and more
efficient. See fit for the parameters, transform for the return value.
Parameters
----------
X : array-like or sparse matrix, shape=(n_samples, n_features)
Dense array or sparse matrix.
y: array-like {n_samples,} (Optional, ignored)
Feature labels
"""
if (self.columns == "categorical" or self.columns == "numeric") and not isinstance(X, pd.DataFrame):
raise ValueError(f"Invalid value for columns: {self.columns}. "
"Only 'all' or is supported for np arrays")
if self.columns == "categorical":
self.columns_ = list(X.select_dtypes(exclude='number').columns)
elif self.columns == "numeric":
self.columns_ = [col for col in X.columns if is_numeric_dtype(X[col])]
elif self.columns == "auto":
self.columns_ = auto_select_categorical_features(X)
elif self.columns == "all":
if isinstance(X, pd.DataFrame):
self.columns_ = X.columns
else:
self.columns_ = list(range(X.shape[1]))
elif isinstance(self.columns, list):
self.columns_ = self.columns
else:
raise ValueError(f"Invalid value for columns: {self.columns}")
if len(self.columns_) == 0:
return self
self.enc = sklearn.preprocessing.OneHotEncoder( categories='auto',
drop = self.drop,
handle_unknown = self.handle_unknown,
sparse_output = self.sparse_output,
min_frequency = self.min_frequency,
max_categories = self.max_categories)
#TODO make this more consistent with sklearn baseimputer/baseencoder
if isinstance(X, pd.DataFrame):
self.enc.set_output(transform="pandas")
for col in X.columns:
# check if the column name is not a string
if not isinstance(col, str):
# if it's not a string, rename the column with "X" prefix
X.rename(columns={col: f"X{col}"}, inplace=True)
if len(self.columns_) == X.shape[1]:
X_sel = self.enc.fit(X)
else:
X_sel, X_not_sel = _X_selected(X, self.columns_)
X_sel = self.enc.fit(X_sel)
return self
def transform(self, X):
"""Transform X using one-hot encoding.
Parameters
----------
X : array-like or sparse matrix, shape=(n_samples, n_features)
Dense array or sparse matrix.
Returns
-------
X_out : sparse matrix if sparse=True else a 2-d array, dtype=int
Transformed input.
"""
if len(self.columns_) == 0:
return X
#TODO make this more consistent with sklearn baseimputer/baseencoder
if isinstance(X, pd.DataFrame):
for col in X.columns:
# check if the column name is not a string
if not isinstance(col, str):
# if it's not a string, rename the column with "X" prefix
X.rename(columns={col: f"X{col}"}, inplace=True)
if len(self.columns_) == X.shape[1]:
return self.enc.transform(X)
else:
X_sel, X_not_sel= _X_selected(X, self.columns_)
X_sel = self.enc.transform(X_sel)
#If X is dataframe
if isinstance(X, pd.DataFrame):
X_sel = pd.DataFrame(X_sel, columns=self.enc.get_feature_names_out())
return pd.concat([X_not_sel.reset_index(drop=True), X_sel.reset_index(drop=True)], axis=1)
else:
return np.hstack((X_not_sel, X_sel))
class ColumnOrdinalEncoder(TransformerMixin, BaseEstimator ):
def __init__(self, columns='auto', handle_unknown='error', unknown_value = -1, encoded_missing_value = np.nan, min_frequency=None,max_categories=None):
'''
Parameters
----------
columns : str, list, default='auto'
Determines which columns to onehot encode with sklearn.preprocessing.OneHotEncoder.
- 'auto' : Automatically select categorical features based on columns with less than 10 unique values
- 'categorical' : Automatically select categorical features
- 'numeric' : Automatically select numeric features
- 'all' : Select all features
- list : A list of columns to select
drop, handle_unknown, sparse_output, min_frequency, max_categories : see sklearn.preprocessing.OneHotEncoder
'''
self.columns = columns
self.handle_unknown = handle_unknown
self.unknown_value = unknown_value
self.encoded_missing_value = encoded_missing_value
self.min_frequency = min_frequency
self.max_categories = max_categories
def fit(self, X, y=None):
"""Fit OneHotEncoder to X, then transform X.
Equivalent to self.fit(X).transform(X), but more convenient and more
efficient. See fit for the parameters, transform for the return value.
Parameters
----------
X : array-like or sparse matrix, shape=(n_samples, n_features)
Dense array or sparse matrix.
y: array-like {n_samples,} (Optional, ignored)
Feature labels
"""
if (self.columns == "categorical" or self.columns == "numeric") and not isinstance(X, pd.DataFrame):
raise ValueError(f"Invalid value for columns: {self.columns}. "
"Only 'all' or is supported for np arrays")
if self.columns == "categorical":
self.columns_ = list(X.select_dtypes(exclude='number').columns)
elif self.columns == "numeric":
self.columns_ = [col for col in X.columns if is_numeric_dtype(X[col])]
elif self.columns == "auto":
self.columns_ = auto_select_categorical_features(X)
elif self.columns == "all":
if isinstance(X, pd.DataFrame):
self.columns_ = X.columns
else:
self.columns_ = list(range(X.shape[1]))
elif isinstance(self.columns, list):
self.columns_ = self.columns
else:
raise ValueError(f"Invalid value for columns: {self.columns}")
if len(self.columns_) == 0:
return self
self.enc = sklearn.preprocessing.OrdinalEncoder(categories='auto',
handle_unknown = self.handle_unknown,
unknown_value = self.unknown_value,
encoded_missing_value = self.encoded_missing_value,
min_frequency = self.min_frequency,
max_categories = self.max_categories)
#TODO make this more consistent with sklearn baseimputer/baseencoder
'''
if isinstance(X, pd.DataFrame):
self.enc.set_output(transform="pandas")
for col in X.columns:
# check if the column name is not a string
if not isinstance(col, str):
# if it's not a string, rename the column with "X" prefix
X.rename(columns={col: f"X{col}"}, inplace=True)
'''
if len(self.columns_) == X.shape[1]:
X_sel = self.enc.fit(X)
else:
X_sel, X_not_sel = _X_selected(X, self.columns_)
X_sel = self.enc.fit(X_sel)
return self
def transform(self, X):
"""Transform X using one-hot encoding.
Parameters
----------
X : array-like or sparse matrix, shape=(n_samples, n_features)
Dense array or sparse matrix.
Returns
-------
X_out : sparse matrix if sparse=True else a 2-d array, dtype=int
Transformed input.
"""
if len(self.columns_) == 0:
return X
#TODO make this more consistent with sklearn baseimputer/baseencoder
'''
if isinstance(X, pd.DataFrame):
for col in X.columns:
# check if the column name is not a string
if not isinstance(col, str):
# if it's not a string, rename the column with "X" prefix
X.rename(columns={col: f"X{col}"}, inplace=True)
'''
if len(self.columns_) == X.shape[1]:
return self.enc.transform(X)
else:
X_sel, X_not_sel= _X_selected(X, self.columns_)
X_sel = self.enc.transform(X_sel)
#If X is dataframe
if isinstance(X, pd.DataFrame):
X_sel = pd.DataFrame(X_sel, columns=self.enc.get_feature_names_out())
return pd.concat([X_not_sel.reset_index(drop=True), X_sel.reset_index(drop=True)], axis=1)
else:
return np.hstack((X_not_sel, X_sel))
================================================
FILE: tpot/builtin_modules/estimatortransformer.py
================================================
"""
This file is part of the TPOT library.
The current version of TPOT was developed at Cedars-Sinai by:
- Pedro Henrique Ribeiro (https://github.com/perib, https://www.linkedin.com/in/pedro-ribeiro/)
- Anil Saini (anil.saini@cshs.org)
- Jose Hernandez (jgh9094@gmail.com)
- Jay Moran (jay.moran@cshs.org)
- Nicholas Matsumoto (nicholas.matsumoto@cshs.org)
- Hyunjun Choi (hyunjun.choi@cshs.org)
- Gabriel Ketron (gabriel.ketron@cshs.org)
- Miguel E. Hernandez (miguel.e.hernandez@cshs.org)
- Jason Moore (moorejh28@gmail.com)
The original version of TPOT was primarily developed at the University of Pennsylvania by:
- Randal S. Olson (rso@randalolson.com)
- Weixuan Fu (weixuanf@upenn.edu)
- Daniel Angell (dpa34@drexel.edu)
- Jason Moore (moorejh28@gmail.com)
- and many more generous open-source contributors
TPOT is free software: you can redistribute it and/or modify
it under the terms of the GNU Lesser General Public License as
published by the Free Software Foundation, either version 3 of
the License, or (at your option) any later version.
TPOT is distributed in the hope that it will be useful,
but WITHOUT ANY WARRANTY; without even the implied warranty of
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
GNU Lesser General Public License for more details.
You should have received a copy of the GNU Lesser General Public
License along with TPOT. If not, see .
"""
from numpy import ndarray
from sklearn.base import TransformerMixin, BaseEstimator
from sklearn.model_selection import cross_val_predict
from sklearn.utils.validation import check_is_fitted
from sklearn.utils.metaestimators import available_if
import numpy as np
from sklearn.utils.validation import check_is_fitted
class EstimatorTransformer(TransformerMixin, BaseEstimator ):
def __init__(self, estimator, method='auto', passthrough=False, cross_val_predict_cv=None):
"""
A class for using a sklearn estimator as a transformer. When calling fit_transform, this class returns the out put of cross_val_predict
and trains the estimator on the full dataset. When calling transform, this class uses the estimator fit on the full dataset to transform the data.
Parameters
----------
estimator : sklear.base. BaseEstimator
The estimator to use as a transformer.
method : str, default='auto'
The method to use for the transformation. If 'auto', will try to use predict_proba, decision_function, or predict in that order.
- predict_proba: use the predict_proba method of the estimator.
- decision_function: use the decision_function method of the estimator.
- predict: use the predict method of the estimator.
passthrough : bool, default=False
Whether to pass the original input through.
cross_val_predict_cv : int, default=0
Number of folds to use for the cross_val_predict function for inner classifiers and regressors. Estimators will still be fit on the full dataset, but the following node will get the outputs from cross_val_predict.
- 0-1 : When set to 0 or 1, the cross_val_predict function will not be used. The next layer will get the outputs from fitting and transforming the full dataset.
- >=2 : When fitting pipelines with inner classifiers or regressors, they will still be fit on the full dataset.
However, the output to the next node will come from cross_val_predict with the specified number of folds.
"""
self.estimator = estimator
self.method = method
self.passthrough = passthrough
self.cross_val_predict_cv = cross_val_predict_cv
def fit(self, X, y=None):
self.estimator.fit(X, y)
return self
def transform(self, X, y=None):
#Does not do cross val predict, just uses the estimator to transform the data. This is used for the actual transformation in practice, so the real transformation without fitting is needed
if self.method == 'auto':
if hasattr(self.estimator, 'predict_proba'):
method = 'predict_proba'
elif hasattr(self.estimator, 'decision_function'):
method = 'decision_function'
elif hasattr(self.estimator, 'predict'):
method = 'predict'
else:
raise ValueError('Estimator has no valid method')
else:
method = self.method
output = getattr(self.estimator, method)(X)
output=np.array(output)
if len(output.shape) == 1:
output = output.reshape(-1,1)
if self.passthrough:
return np.hstack((output, X))
else:
return output
def fit_transform(self, X, y=None):
#Does use cross_val_predict if cross_val_predict_cv is greater than 0. this function is only used in training the model.
self.estimator.fit(X,y)
if self.method == 'auto':
if hasattr(self.estimator, 'predict_proba'):
method = 'predict_proba'
elif hasattr(self.estimator, 'decision_function'):
method = 'decision_function'
elif hasattr(self.estimator, 'predict'):
method = 'predict'
else:
raise ValueError('Estimator has no valid method')
else:
method = self.method
if self.cross_val_predict_cv is not None:
output = cross_val_predict(self.estimator, X, y=y, cv=self.cross_val_predict_cv)
else:
output = getattr(self.estimator, method)(X)
#reshape if needed
if len(output.shape) == 1:
output = output.reshape(-1,1)
output=np.array(output)
if self.passthrough:
return np.hstack((output, X))
else:
return output
def _estimator_has(attr):
'''Check if we can delegate a method to the underlying estimator.
First, we check the first fitted final estimator if available, otherwise we
check the unfitted final estimator.
'''
return lambda self: (self.estimator is not None and
hasattr(self.estimator, attr)
)
@available_if(_estimator_has('predict'))
def predict(self, X, **predict_params):
check_is_fitted(self.estimator)
#X = check_array(X)
preds = self.estimator.predict(X,**predict_params)
return preds
@available_if(_estimator_has('predict_proba'))
def predict_proba(self, X, **predict_params):
check_is_fitted(self.estimator)
#X = check_array(X)
return self.estimator.predict_proba(X,**predict_params)
@available_if(_estimator_has('decision_function'))
def decision_function(self, X, **predict_params):
check_is_fitted(self.estimator)
#X = check_array(X)
return self.estimator.decision_function(X,**predict_params)
def __sklearn_is_fitted__(self):
"""
Check fitted status and return a Boolean value.
"""
return check_is_fitted(self.estimator)
# @property
# def _estimator_type(self):
# return self.estimator._estimator_type
@property
def classes_(self):
"""The classes labels. Only exist if the last step is a classifier."""
return self.estimator._classes
================================================
FILE: tpot/builtin_modules/feature_encoding_frequency_selector.py
================================================
"""
From https://github.com/EpistasisLab/autoqtl
"""
import numpy as np
from sklearn.base import BaseEstimator
from sklearn.feature_selection._base import SelectorMixin
class FeatureEncodingFrequencySelector(SelectorMixin, BaseEstimator):
"""Feature selector based on Encoding Frequency. Encoding frequency is the frequency of each unique element(0/1/2/3) present in a feature set.
Features are selected on the basis of a threshold assigned for encoding frequency. If frequency of any unique element is less than or equal to threshold, the feature is removed. """
@property
def __name__(self):
"""Instance name is the same as the class name. """
return self.__class__.__name__
def __init__(self, threshold):
"""Create a FeatureEncodingFrequencySelector object.
Parameters
----------
threshold : float, required
Threshold value for allele frequency. If frequency of A or frequency of a is less than the threshold value then the feature is dropped.
Returns
-------
None
"""
self.threshold = threshold
"""def fit(self, X, y=None):
Fit FeatureAlleleFrequencySelector for feature selection
Parameters
----------
X : numpy ndarray, {n_samples, n_features}
The training input samples.
y : numpy array {n_samples,}
The training target values.
Returns
-------
self : object
Returns a copy of the estimator
self.selected_feature_indexes = []
self.no_of_features = X.shape[1]
# Finding the no of alleles in each feature column
for i in range(0, X.shape[1]):
no_of_AA_featurewise = np.count_nonzero(X[:,i]==0)
no_of_Aa_featurewise = np.count_nonzero(X[:,i]==1)
no_of_aa_featurewise = np.count_nonzero(X[:,i]==2)
frequency_A_featurewise = (2*no_of_AA_featurewise + no_of_Aa_featurewise) / (2*no_of_AA_featurewise +
2*no_of_Aa_featurewise + 2*no_of_aa_featurewise)
frequency_a_featurewise = 1 - frequency_A_featurewise
if(not(frequency_A_featurewise <= self.threshold) and not(frequency_a_featurewise <= self.threshold)):
self.selected_feature_indexes.append(i)
return self"""
"""def transform(self, X):
Make subset after fit
Parameters
----------
X : numpy ndarray, {n_samples, n_features}
New data, where n_samples is the number of samples and n_features is the number of features.
Returns
-------
X_transformed : numpy ndarray, {n_samples, n_features}
The transformed feature set.
X_transformed = X[:, self.selected_feature_indexes]
return X_transformed"""
def fit(self, X, y=None) :
"""Fit FeatureEncodingFrequencySelector for feature selection. This function gets the appropriate features. """
self.selected_feature_indexes = []
self.no_of_original_features = X.shape[1]
# Finding the frequency of all the unique elements present featurewise in the input variable X
for i in range(0, X.shape[1]):
unique, counts = np.unique(X[:,i], return_counts=True)
element_count_dict_featurewise = dict(zip(unique, counts))
element_frequency_dict_featurewise = {}
feature_column_selected = True
for x in unique:
x_frequency_featurewise = element_count_dict_featurewise[x] / sum(counts)
element_frequency_dict_featurewise[x] = x_frequency_featurewise
for frequency in element_frequency_dict_featurewise.values():
if frequency <= self.threshold :
feature_column_selected = False
break
if feature_column_selected == True :
self.selected_feature_indexes.append(i)
if not len(self.selected_feature_indexes):
"""msg = "No feature in X meets the encoding frequency threshold {0:.5f}"
raise ValueError(msg.format(self.threshold))"""
for i in range(0, X.shape[1]):
self.selected_feature_indexes.append(i)
return self
def transform(self, X):
""" Make subset after fit. This function returns a transformed version of X. """
X_transformed = X[:, self.selected_feature_indexes]
return X_transformed
def _get_support_mask(self):
"""
Get the boolean mask indicating which features are selected
It is the abstractmethod
Returns
-------
support : boolean array of shape [# input features]
An element is True iff its corresponding feature is selected for retention.
"""
n_features = self.no_of_original_features
mask = np.zeros(n_features, dtype=bool)
mask[np.asarray(self.selected_feature_indexes)] = True
return mask
================================================
FILE: tpot/builtin_modules/feature_set_selector.py
================================================
"""
This file is part of the TPOT library.
The current version of TPOT was developed at Cedars-Sinai by:
- Pedro Henrique Ribeiro (https://github.com/perib, https://www.linkedin.com/in/pedro-ribeiro/)
- Anil Saini (anil.saini@cshs.org)
- Jose Hernandez (jgh9094@gmail.com)
- Jay Moran (jay.moran@cshs.org)
- Nicholas Matsumoto (nicholas.matsumoto@cshs.org)
- Hyunjun Choi (hyunjun.choi@cshs.org)
- Gabriel Ketron (gabriel.ketron@cshs.org)
- Miguel E. Hernandez (miguel.e.hernandez@cshs.org)
- Jason Moore (moorejh28@gmail.com)
The original version of TPOT was primarily developed at the University of Pennsylvania by:
- Randal S. Olson (rso@randalolson.com)
- Weixuan Fu (weixuanf@upenn.edu)
- Daniel Angell (dpa34@drexel.edu)
- Jason Moore (moorejh28@gmail.com)
- and many more generous open-source contributors
TPOT is free software: you can redistribute it and/or modify
it under the terms of the GNU Lesser General Public License as
published by the Free Software Foundation, either version 3 of
the License, or (at your option) any later version.
TPOT is distributed in the hope that it will be useful,
but WITHOUT ANY WARRANTY; without even the implied warranty of
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
GNU Lesser General Public License for more details.
You should have received a copy of the GNU Lesser General Public
License along with TPOT. If not, see .
"""
#TODO handle sparse input?
import numpy as np
import pandas as pd
import os, os.path
from sklearn.base import BaseEstimator
from sklearn.feature_selection._base import SelectorMixin
#TODO clean this up and make sure it works
class FeatureSetSelector(SelectorMixin, BaseEstimator):
"""
Select predefined feature subsets.
"""
def __init__(self, sel_subset=None, name=None):
"""Create a FeatureSetSelector object.
Parameters
----------
sel_subset: list or int
If X is a dataframe, items in sel_subset list must correspond to column names
If X is a numpy array, items in sel_subset list must correspond to column indexes
int: index of a single column
Returns
-------
None
"""
self.name = name
self.sel_subset = sel_subset
def fit(self, X, y=None):
"""Fit FeatureSetSelector for feature selection
Parameters
----------
X: array-like of shape (n_samples, n_features)
The training input samples.
y: array-like, shape (n_samples,)
The target values (integers that correspond to classes in classification, real numbers in regression).
Returns
-------
self: object
Returns a copy of the estimator
"""
if isinstance(self.sel_subset, int) or isinstance(self.sel_subset, str):
self.sel_subset = [self.sel_subset]
#generate self.feat_list_idx
if isinstance(X, pd.DataFrame):
self.feature_names_in_ = X.columns.tolist()
self.feat_list_idx = sorted([self.feature_names_in_.index(feat) for feat in self.sel_subset])
elif isinstance(X, np.ndarray):
self.feature_names_in_ = None#list(range(X.shape[1]))
self.feat_list_idx = sorted(self.sel_subset)
n_features = X.shape[1]
self.mask = np.zeros(n_features, dtype=bool)
self.mask[np.asarray(self.feat_list_idx)] = True
return self
#TODO keep returned as dataframe if input is dataframe? may not be consistent with sklearn
# def transform(self, X):
def __sklearn_tags__(self):
tags = super().__sklearn_tags__()
tags.input_tags.allow_nan = True
tags.target_tags.required = False # formally requires_y
return tags
def _get_support_mask(self):
"""
Get the boolean mask indicating which features are selected
Returns
-------
support : boolean array of shape [# input features]
An element is True iff its corresponding feature is selected for
retention.
"""
return self.mask
================================================
FILE: tpot/builtin_modules/feature_transformers.py
================================================
# -*- coding: utf-8 -*-
"""
This file is part of the TPOT library.
The current version of TPOT was developed at Cedars-Sinai by:
- Pedro Henrique Ribeiro (https://github.com/perib, https://www.linkedin.com/in/pedro-ribeiro/)
- Anil Saini (anil.saini@cshs.org)
- Jose Hernandez (jgh9094@gmail.com)
- Jay Moran (jay.moran@cshs.org)
- Nicholas Matsumoto (nicholas.matsumoto@cshs.org)
- Hyunjun Choi (hyunjun.choi@cshs.org)
- Gabriel Ketron (gabriel.ketron@cshs.org)
- Miguel E. Hernandez (miguel.e.hernandez@cshs.org)
- Jason Moore (moorejh28@gmail.com)
The original version of TPOT was primarily developed at the University of Pennsylvania by:
- Randal S. Olson (rso@randalolson.com)
- Weixuan Fu (weixuanf@upenn.edu)
- Daniel Angell (dpa34@drexel.edu)
- Jason Moore (moorejh28@gmail.com)
- and many more generous open-source contributors
TPOT is free software: you can redistribute it and/or modify
it under the terms of the GNU Lesser General Public License as
published by the Free Software Foundation, either version 3 of
the License, or (at your option) any later version.
TPOT is distributed in the hope that it will be useful,
but WITHOUT ANY WARRANTY; without even the implied warranty of
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
GNU Lesser General Public License for more details.
You should have received a copy of the GNU Lesser General Public
License along with TPOT. If not, see .
"""
import numpy as np
from sklearn.base import TransformerMixin, BaseEstimator
from sklearn.utils import check_array
from sklearn.decomposition import PCA
from .one_hot_encoder import OneHotEncoder, auto_select_categorical_features, _X_selected
class CategoricalSelector(TransformerMixin, BaseEstimator ):
"""Meta-transformer for selecting categorical features and transform them using OneHotEncoder.
Parameters
----------
threshold : int, default=10
Maximum number of unique values per feature to consider the feature
to be categorical.
minimum_fraction: float, default=None
Minimum fraction of unique values in a feature to consider the feature
to be categorical.
"""
def __init__(self, threshold=10, minimum_fraction=None):
"""Create a CategoricalSelector object."""
self.threshold = threshold
self.minimum_fraction = minimum_fraction
def fit(self, X, y=None):
"""Do nothing and return the estimator unchanged
This method is just there to implement the usual API and hence
work in pipelines.
Parameters
----------
X : array-like
"""
X = check_array(X, accept_sparse='csr')
return self
def transform(self, X):
"""Select categorical features and transform them using OneHotEncoder.
Parameters
----------
X: numpy ndarray, {n_samples, n_components}
New data, where n_samples is the number of samples and n_components is the number of components.
Returns
-------
array-like, {n_samples, n_components}
"""
selected = auto_select_categorical_features(X, threshold=self.threshold)
X_sel, _, n_selected, _ = _X_selected(X, selected)
if n_selected == 0:
# No features selected.
raise ValueError('No categorical feature was found!')
else:
ohe = OneHotEncoder(categorical_features='all', sparse=False, minimum_fraction=self.minimum_fraction)
return ohe.fit_transform(X_sel)
class ContinuousSelector(TransformerMixin, BaseEstimator ):
"""Meta-transformer for selecting continuous features and transform them using PCA.
Parameters
----------
threshold : int, default=10
Maximum number of unique values per feature to consider the feature
to be categorical.
svd_solver : string {'auto', 'full', 'arpack', 'randomized'}
auto :
the solver is selected by a default policy based on `X.shape` and
`n_components`: if the input data is larger than 500x500 and the
number of components to extract is lower than 80% of the smallest
dimension of the data, then the more efficient 'randomized'
method is enabled. Otherwise the exact full SVD is computed and
optionally truncated afterwards.
full :
run exact full SVD calling the standard LAPACK solver via
`scipy.linalg.svd` and select the components by postprocessing
arpack :
run SVD truncated to n_components calling ARPACK solver via
`scipy.sparse.linalg.svds`. It requires strictly
0 < n_components < X.shape[1]
randomized :
run randomized SVD by the method of Halko et al.
iterated_power : int >= 0, or 'auto', (default 'auto')
Number of iterations for the power method computed by
svd_solver == 'randomized'.
"""
def __init__(self, threshold=10, svd_solver='randomized' ,iterated_power='auto', random_state=42):
"""Create a ContinuousSelector object."""
self.threshold = threshold
self.svd_solver = svd_solver
self.iterated_power = iterated_power
self.random_state = random_state
def fit(self, X, y=None):
"""Do nothing and return the estimator unchanged
This method is just there to implement the usual API and hence
work in pipelines.
Parameters
----------
X : array-like
"""
X = check_array(X)
return self
def transform(self, X):
"""Select continuous features and transform them using PCA.
Parameters
----------
X: numpy ndarray, {n_samples, n_components}
New data, where n_samples is the number of samples and n_components is the number of components.
Returns
-------
array-like, {n_samples, n_components}
"""
selected = auto_select_categorical_features(X, threshold=self.threshold)
_, X_sel, n_selected, _ = _X_selected(X, selected)
if n_selected == 0:
# No features selected.
raise ValueError('No continuous feature was found!')
else:
pca = PCA(svd_solver=self.svd_solver, iterated_power=self.iterated_power, random_state=self.random_state)
return pca.fit_transform(X_sel)
================================================
FILE: tpot/builtin_modules/genetic_encoders.py
================================================
"""
Code from https://github.com/EpistasisLab/autoqtl
This file contains the class definition for all the genetic encoders.
All the genetic encoder classes inherit the Scikit learn BaseEstimator and TransformerMixin classes to follow the Scikit-learn paradigm.
"""
import numpy as np
from sklearn.base import TransformerMixin, BaseEstimator
from sklearn.utils import check_array
class DominantEncoder(TransformerMixin, BaseEstimator ):
"""This class contains the function definition for encoding the input features as a Dominant genetic model.
The encoding used is AA(0)->1, Aa(1)->1, aa(2)->0. """
def fit(self, X, y=None):
"""Do nothing and return the estimator unchanged.
Dummy function to fit in with the sklearn API and hence work in pipelines.
Parameters
----------
X : array-like
"""
return self
def transform(self, X, y=None):
"""Transform the data by applying the Dominant encoding.
Parameters
----------
X : numpy ndarray, {n_samples, n_components}
New data, where n_samples is the number of samples (number of individuals)
and n_components is the number of components (number of features).
y : None
Unused
Returns
-------
X_transformed: numpy ndarray, {n_samples, n_components}
The encoded feature set
"""
X = check_array(X)
map = {0: 1, 1: 1, 2: 0}
mapping_function = np.vectorize(lambda i: map[i] if i in map else i)
X_transformed = mapping_function(X)
return X_transformed
class RecessiveEncoder(TransformerMixin, BaseEstimator ):
"""This class contains the function definition for encoding the input features as a Recessive genetic model.
The encoding used is AA(0)->0, Aa(1)->1, aa(2)->1. """
def fit(self, X, y=None):
"""Do nothing and return the estimator unchanged.
Dummy function to fit in with the sklearn API and hence work in pipelines.
Parameters
----------
X : array-like
"""
return self
def transform(self, X, y=None):
"""Transform the data by applying the Recessive encoding.
Parameters
----------
X : numpy ndarray, {n_samples, n_components}
New data, where n_samples is the number of samples (number of individuals)
and n_components is the number of components (number of features).
y : None
Unused
Returns
-------
X_transformed: numpy ndarray, {n_samples, n_components}
The encoded feature set
"""
X = check_array(X)
map = {0: 0, 1: 1, 2: 1}
mapping_function = np.vectorize(lambda i: map[i] if i in map else i)
X_transformed = mapping_function(X)
return X_transformed
class HeterosisEncoder(TransformerMixin, BaseEstimator ):
"""This class contains the function definition for encoding the input features as a Heterozygote Advantage genetic model.
The encoding used is AA(0)->0, Aa(1)->1, aa(2)->0. """
def fit(self, X, y=None):
"""Do nothing and return the estimator unchanged.
Dummy function to fit in with the sklearn API and hence work in pipelines.
Parameters
----------
X : array-like
"""
return self
def transform(self, X, y=None):
"""Transform the data by applying the Heterosis encoding.
Parameters
----------
X : numpy ndarray, {n_samples, n_components}
New data, where n_samples is the number of samples (number of individuals)
and n_components is the number of components (number of features).
y : None
Unused
Returns
-------
X_transformed: numpy ndarray, {n_samples, n_components}
The encoded feature set
"""
X = check_array(X)
map = {0: 0, 1: 1, 2: 0}
mapping_function = np.vectorize(lambda i: map[i] if i in map else i)
X_transformed = mapping_function(X)
return X_transformed
class UnderDominanceEncoder(TransformerMixin, BaseEstimator ):
"""This class contains the function definition for encoding the input features as a Under Dominance genetic model.
The encoding used is AA(0)->2, Aa(1)->0, aa(2)->1. """
def fit(self, X, y=None):
"""Do nothing and return the estimator unchanged.
Dummy function to fit in with the sklearn API and hence work in pipelines.
Parameters
----------
X : array-like
"""
return self
def transform(self, X, y=None):
"""Transform the data by applying the Heterosis encoding.
Parameters
----------
X : numpy ndarray, {n_samples, n_components}
New data, where n_samples is the number of samples (number of individuals)
and n_components is the number of components (number of features).
y : None
Unused
Returns
-------
X_transformed: numpy ndarray, {n_samples, n_components}
The encoded feature set
"""
X = check_array(X)
map = {0: 2, 1: 0, 2: 1}
mapping_function = np.vectorize(lambda i: map[i] if i in map else i)
X_transformed = mapping_function(X)
return X_transformed
class OverDominanceEncoder(TransformerMixin, BaseEstimator ):
"""This class contains the function definition for encoding the input features as a Over Dominance genetic model.
The encoding used is AA(0)->1, Aa(1)->2, aa(2)->0. """
def fit(self, X, y=None):
"""Do nothing and return the estimator unchanged.
Dummy function to fit in with the sklearn API and hence work in pipelines.
Parameters
----------
X : array-like
"""
return self
def transform(self, X, y=None):
"""Transform the data by applying the Heterosis encoding.
Parameters
----------
X : numpy ndarray, {n_samples, n_components}
New data, where n_samples is the number of samples (number of individuals)
and n_components is the number of components (number of features).
y : None
Unused
Returns
-------
X_transformed: numpy ndarray, {n_samples, n_components}
The encoded feature set
"""
X = check_array(X)
map = {0: 1, 1: 2, 2: 0}
mapping_function = np.vectorize(lambda i: map[i] if i in map else i)
X_transformed = mapping_function(X)
return X_transformed
================================================
FILE: tpot/builtin_modules/imputer.py
================================================
"""
This file is part of the TPOT library.
The current version of TPOT was developed at Cedars-Sinai by:
- Pedro Henrique Ribeiro (https://github.com/perib, https://www.linkedin.com/in/pedro-ribeiro/)
- Anil Saini (anil.saini@cshs.org)
- Jose Hernandez (jgh9094@gmail.com)
- Jay Moran (jay.moran@cshs.org)
- Nicholas Matsumoto (nicholas.matsumoto@cshs.org)
- Hyunjun Choi (hyunjun.choi@cshs.org)
- Gabriel Ketron (gabriel.ketron@cshs.org)
- Miguel E. Hernandez (miguel.e.hernandez@cshs.org)
- Jason Moore (moorejh28@gmail.com)
The original version of TPOT was primarily developed at the University of Pennsylvania by:
- Randal S. Olson (rso@randalolson.com)
- Weixuan Fu (weixuanf@upenn.edu)
- Daniel Angell (dpa34@drexel.edu)
- Jason Moore (moorejh28@gmail.com)
- and many more generous open-source contributors
TPOT is free software: you can redistribute it and/or modify
it under the terms of the GNU Lesser General Public License as
published by the Free Software Foundation, either version 3 of
the License, or (at your option) any later version.
TPOT is distributed in the hope that it will be useful,
but WITHOUT ANY WARRANTY; without even the implied warranty of
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
GNU Lesser General Public License for more details.
You should have received a copy of the GNU Lesser General Public
License along with TPOT. If not, see .
"""
#TODO support np arrays
import numpy as np
from scipy import sparse
from sklearn.base import TransformerMixin, BaseEstimator
from sklearn.utils import check_array
from sklearn.preprocessing import OneHotEncoder
import sklearn
import sklearn.impute
import pandas as pd
from pandas.api.types import is_numeric_dtype
import sklearn.compose
class ColumnSimpleImputer(TransformerMixin, BaseEstimator ):
def __init__(self, columns="all",
missing_values=np.nan,
strategy="mean",
fill_value=None,
copy=True,
add_indicator=False,
keep_empty_features=False,):
""""
A wrapper for SimpleImputer that allows for imputation of specific columns in a DataFrame or np array.
Passes through columns that are not imputed.
Parameters
----------
columns : str, list, default='all'
Determines which columns to impute with sklearn.impute.SimpleImputer.
- 'categorical' : Automatically select categorical features
- 'numeric' : Automatically select numeric features
- 'all' : Select all features
- list : A list of columns to select
# See documentation from sklearn.impute.SimpleImputer for the following parameters
missing_values, strategy, fill_value, copy, add_indicator, keep_empty_features
"""
self.columns = columns
self.missing_values = missing_values
self.strategy = strategy
self.fill_value = fill_value
self.copy = copy
self.add_indicator = add_indicator
self.keep_empty_features = keep_empty_features
def fit(self, X, y=None):
if (self.columns == "categorical" or self.columns == "numeric") and not isinstance(X, pd.DataFrame):
raise ValueError(f"Invalid value for columns: {self.columns}. "
"Only 'all' or is supported for np arrays")
if self.columns == "categorical":
self.columns_ = list(X.select_dtypes(exclude='number').columns)
elif self.columns == "numeric":
self.columns_ = [col for col in X.columns if is_numeric_dtype(X[col])]
elif self.columns == "all":
if isinstance(X, pd.DataFrame):
self.columns_ = X.columns
else:
self.columns_ = list(range(X.shape[1]))
elif isinstance(self.columns, list):
self.columns_ = self.columns
else:
raise ValueError(f"Invalid value for columns: {self.columns}")
if len(self.columns_) == 0:
return self
self.imputer = sklearn.impute.SimpleImputer(missing_values=self.missing_values,
strategy=self.strategy,
fill_value=self.fill_value,
copy=self.copy,
add_indicator=self.add_indicator,
keep_empty_features=self.keep_empty_features)
if isinstance(X, pd.DataFrame):
self.imputer.set_output(transform="pandas")
if isinstance(X, pd.DataFrame):
self.imputer.fit(X[self.columns_], y)
else:
self.imputer.fit(X[:, self.columns_], y)
return self
def transform(self, X):
if len(self.columns_) == 0:
return X
if isinstance(X, pd.DataFrame):
X = X.copy()
X[self.columns_] = self.imputer.transform(X[self.columns_])
return X
else:
X = np.copy(X)
X[:, self.columns_] = self.imputer.transform(X[:, self.columns_])
return X
================================================
FILE: tpot/builtin_modules/nn.py
================================================
# -*- coding: utf-8 -*-
"""
This file is part of the TPOT library.
The current version of TPOT was developed at Cedars-Sinai by:
- Pedro Henrique Ribeiro (https://github.com/perib, https://www.linkedin.com/in/pedro-ribeiro/)
- Anil Saini (anil.saini@cshs.org)
- Jose Hernandez (jgh9094@gmail.com)
- Jay Moran (jay.moran@cshs.org)
- Nicholas Matsumoto (nicholas.matsumoto@cshs.org)
- Hyunjun Choi (hyunjun.choi@cshs.org)
- Gabriel Ketron (gabriel.ketron@cshs.org)
- Miguel E. Hernandez (miguel.e.hernandez@cshs.org)
- Jason Moore (moorejh28@gmail.com)
The original version of TPOT was primarily developed at the University of Pennsylvania by:
- Randal S. Olson (rso@randalolson.com)
- Weixuan Fu (weixuanf@upenn.edu)
- Daniel Angell (dpa34@drexel.edu)
- Jason Moore (moorejh28@gmail.com)
- and many more generous open-source contributors
TPOT is free software: you can redistribute it and/or modify
it under the terms of the GNU Lesser General Public License as
published by the Free Software Foundation, either version 3 of
the License, or (at your option) any later version.
TPOT is distributed in the hope that it will be useful,
but WITHOUT ANY WARRANTY; without even the implied warranty of
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
GNU Lesser General Public License for more details.
You should have received a copy of the GNU Lesser General Public
License along with TPOT. If not, see .
"""
# Note: There are quite a few pylint messages disabled in this file. In
# general, this usually should be avoided. However, in some cases it is
# necessary: e.g., we use `X` and `y` to refer to data and labels in compliance
# with the scikit-learn API, but pylint doesn't like short variable names.
# pylint: disable=redefined-outer-name
# pylint: disable=not-callable
from abc import abstractmethod
import numpy as np
from sklearn.base import BaseEstimator, ClassifierMixin
from sklearn.utils.validation import check_X_y, assert_all_finite, check_array, check_is_fitted
from sklearn.utils.multiclass import type_of_target
try:
import torch
from torch import nn
from torch.autograd import Variable
from torch.optim import Adam
from torch.utils.data import TensorDataset, DataLoader
except ModuleNotFoundError:
raise
def _pytorch_model_is_fully_initialized(clf: BaseEstimator):
if all([
hasattr(clf, 'network'),
hasattr(clf, 'loss_function'),
hasattr(clf, 'optimizer'),
hasattr(clf, 'data_loader'),
hasattr(clf, 'train_dset_len'),
hasattr(clf, 'device')
]):
return True
else:
return False
def _get_cuda_device_if_available():
if torch.cuda.is_available():
return torch.device('cuda')
else:
return torch.device('cpu')
class PytorchEstimator(BaseEstimator):
"""Base class for Pytorch-based estimators (currently only classifiers) for
use in TPOT.
In the future, these will be merged into TPOT's main code base.
"""
@abstractmethod
def fit(self, X, y): # pragma: no cover
pass
@abstractmethod
def transform(self, X): # pragma: no cover
pass
def predict(self, X):
return self.transform(X)
def fit_transform(self, X, y):
self.fit(X, y)
return self.transform(X)
def set_params(self, **parameters):
for parameter, value in parameters.items():
setattr(self, parameter, value)
return self
class PytorchClassifier(ClassifierMixin, PytorchEstimator):
@abstractmethod
def _init_model(self, X, y): # pragma: no cover
pass
def fit(self, X, y):
"""Generalizable method for fitting a PyTorch estimator to a training
set.
Parameters
----------
X : array-like of shape (n_samples, n_features)
Training vector, where n_samples is the number of samples and
n_features is the number of features.
y : array-like of shape (n_samples,)
Target vector relative to X.
Returns
-------
self
Fitted estimator.
"""
self._init_model(X, y)
assert _pytorch_model_is_fully_initialized(self)
for epoch in range(self.num_epochs):
for i, (samples, labels) in enumerate(self.data_loader):
samples = samples.to(self.device)
labels = labels.to(self.device)
self.optimizer.zero_grad()
outputs = self.network(samples)
loss = self.loss_function(outputs, labels)
loss.backward()
self.optimizer.step()
if self.verbose and ((i + 1) % 100 == 0):
print(
"Epoch: [%d/%d], Step: [%d/%d], Loss: %.4f"
% (
epoch + 1,
self.num_epochs,
i + 1,
self.train_dset_len // self.batch_size,
loss.item(),
)
)
# pylint: disable=attribute-defined-outside-init
self.is_fitted_ = True
return self
def validate_inputs(self, X, y):
# Things we don't want to allow until we've tested them:
# - Sparse inputs
# - Multiclass outputs (e.g., more than 2 classes in `y`)
# - Non-finite inputs
# - Complex inputs
X, y = check_X_y(X, y, accept_sparse=False, allow_nd=False)
# Throw a ValueError if X or y contains NaN or infinity.
assert_all_finite(X)
assert_all_finite(y)
if type_of_target(y) != 'binary':
raise ValueError("Non-binary targets not supported")
if np.any(np.iscomplex(X)) or np.any(np.iscomplex(y)):
raise ValueError("Complex data not supported")
if np.issubdtype(X.dtype, np.object_) or np.issubdtype(y.dtype, np.object_):
try:
X = X.astype(float)
y = y.astype(int)
except (TypeError, ValueError):
raise ValueError("argument must be a string.* number")
return (X, y)
def predict(self, X):
X = check_array(X, accept_sparse=True)
check_is_fitted(self, 'is_fitted_')
X = torch.tensor(X, dtype=torch.float32).to(self.device)
predictions = np.empty(len(X), dtype=int)
for i, rows in enumerate(X):
rows = Variable(rows.view(-1, self.input_size))
outputs = self.network(rows)
_, predicted = torch.max(outputs.data, 1)
predictions[i] = int(predicted)
return predictions.reshape(-1, 1)
def transform(self, X):
return self.predict(X)
class _LR(nn.Module):
# pylint: disable=arguments-differ
def __init__(self, input_size, num_classes):
super(_LR, self).__init__()
self.linear = nn.Linear(input_size, num_classes)
def forward(self, x):
out = self.linear(x)
return out
class _MLP(nn.Module):
# pylint: disable=arguments-differ
def __init__(self, input_size, num_classes):
super(_MLP, self).__init__()
self.hidden_size = round((input_size+num_classes)/2)
self.fc1 = nn.Linear(input_size, self.hidden_size)
self.relu = nn.Tanh()
self.fc2 = nn.Linear(self.hidden_size, num_classes)
def forward(self, x):
hidden = self.fc1(x)
r1 = self.relu(hidden)
out = self.fc2(r1)
return out
class PytorchLRClassifier(PytorchClassifier):
"""Logistic Regression classifier, implemented in PyTorch, for use with
TPOT.
For examples on standalone use (i.e., non-TPOT) refer to:
https://github.com/trang1618/tpot-nn/blob/master/tpot_nn/estimator_sandbox.py
"""
def __init__(
self,
num_epochs=10,
batch_size=16,
learning_rate=0.02,
weight_decay=1e-4,
verbose=False
):
self.num_epochs = num_epochs
self.batch_size = batch_size
self.learning_rate = learning_rate
self.weight_decay = weight_decay
self.verbose = verbose
self.input_size = None
self.num_classes = None
self.network = None
self.loss_function = None
self.optimizer = None
self.data_loader = None
self.train_dset_len = None
self.device = None
def _init_model(self, X, y):
device = _get_cuda_device_if_available()
X, y = self.validate_inputs(X, y)
self.input_size = X.shape[-1]
self.num_classes = len(set(y))
X = torch.tensor(X, dtype=torch.float32)
y = torch.tensor(y, dtype=torch.long)
train_dset = TensorDataset(X, y)
# Set parameters of the network
self.network = _LR(self.input_size, self.num_classes).to(device)
self.loss_function = nn.CrossEntropyLoss()
self.optimizer = Adam(self.network.parameters(), lr=self.learning_rate, weight_decay=self.weight_decay)
self.data_loader = DataLoader(
train_dset, batch_size=self.batch_size, shuffle=True, num_workers=2
)
self.train_dset_len = len(train_dset)
self.device = device
def __sklearn_tags__(self):
tags = super().__sklearn_tags__()
tags.non_deterministic = True
tags.target_tags.single_output = True
return tags
class PytorchMLPClassifier(PytorchClassifier):
"""Multilayer Perceptron, implemented in PyTorch, for use with TPOT.
"""
def __init__(
self,
num_epochs=10,
batch_size=8,
learning_rate=0.01,
weight_decay=0,
verbose=False
):
self.num_epochs = num_epochs
self.batch_size = batch_size
self.learning_rate = learning_rate
self.weight_decay = weight_decay
self.verbose = verbose
self.input_size = None
self.num_classes = None
self.network = None
self.loss_function = None
self.optimizer = None
self.data_loader = None
self.train_dset_len = None
self.device = None
def _init_model(self, X, y):
device = _get_cuda_device_if_available()
X, y = self.validate_inputs(X, y)
self.input_size = X.shape[-1]
self.num_classes = len(set(y))
X = torch.tensor(X, dtype=torch.float32)
y = torch.tensor(y, dtype=torch.long)
train_dset = TensorDataset(X, y)
# Set parameters of the network
self.network = _MLP(self.input_size, self.num_classes).to(device)
self.loss_function = nn.CrossEntropyLoss()
self.optimizer = Adam(self.network.parameters(), lr=self.learning_rate, weight_decay=self.weight_decay)
self.data_loader = DataLoader(
train_dset, batch_size=self.batch_size, shuffle=True, num_workers=2
)
self.train_dset_len = len(train_dset)
self.device = device
def __sklearn_tags__(self):
tags = super().__sklearn_tags__()
tags.non_deterministic = True
tags.target_tags.single_output = True
return tags
================================================
FILE: tpot/builtin_modules/passkbinsdiscretizer.py
================================================
"""
This file is part of the TPOT library.
The current version of TPOT was developed at Cedars-Sinai by:
- Pedro Henrique Ribeiro (https://github.com/perib, https://www.linkedin.com/in/pedro-ribeiro/)
- Anil Saini (anil.saini@cshs.org)
- Jose Hernandez (jgh9094@gmail.com)
- Jay Moran (jay.moran@cshs.org)
- Nicholas Matsumoto (nicholas.matsumoto@cshs.org)
- Hyunjun Choi (hyunjun.choi@cshs.org)
- Gabriel Ketron (gabriel.ketron@cshs.org)
- Miguel E. Hernandez (miguel.e.hernandez@cshs.org)
- Jason Moore (moorejh28@gmail.com)
The original version of TPOT was primarily developed at the University of Pennsylvania by:
- Randal S. Olson (rso@randalolson.com)
- Weixuan Fu (weixuanf@upenn.edu)
- Daniel Angell (dpa34@drexel.edu)
- Jason Moore (moorejh28@gmail.com)
- and many more generous open-source contributors
TPOT is free software: you can redistribute it and/or modify
it under the terms of the GNU Lesser General Public License as
published by the Free Software Foundation, either version 3 of
the License, or (at your option) any later version.
TPOT is distributed in the hope that it will be useful,
but WITHOUT ANY WARRANTY; without even the implied warranty of
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
GNU Lesser General Public License for more details.
You should have received a copy of the GNU Lesser General Public
License along with TPOT. If not, see .
"""
import pandas as pd
from sklearn.base import TransformerMixin, BaseEstimator
from sklearn.compose import ColumnTransformer
from sklearn.preprocessing import KBinsDiscretizer
import numpy as np
def select_features(X, min_unique=10,):
"""
Given a DataFrame or numpy array, return a list of column indices that have more than min_unique unique values.
Parameters
----------
X: DataFrame or numpy array
Data to select features from
min_unique: int, default=10
Minimum number of unique values a column must have to be selected
Returns
-------
list
List of column indices that have more than min_unique unique values
"""
if isinstance(X, pd.DataFrame):
return [col for col in X.columns if len(X[col].unique()) > min_unique]
else:
return [i for i in range(X.shape[1]) if len(np.unique(X[:, i])) > min_unique]
class PassKBinsDiscretizer(TransformerMixin, BaseEstimator ):
def __init__(self, n_bins=5, encode='onehot-dense', strategy='quantile', subsample=None, random_state=None):
self.n_bins = n_bins
self.encode = encode
self.strategy = strategy
self.subsample = subsample
self.random_state = random_state
"""
Same as sklearn.preprocessing.KBinsDiscretizer, but passes through columns that are not discretized due to having fewer than n_bins unique values instead of ignoring them.
See sklearn.preprocessing.KBinsDiscretizer for more information.
"""
def fit(self, X, y=None):
# Identify columns with more than n unique values
# Create a ColumnTransformer to select and discretize the chosen columns
self.selected_columns_ = select_features(X, min_unique=10)
if isinstance(X, pd.DataFrame):
self.not_selected_columns_ = [col for col in X.columns if col not in self.selected_columns_]
else:
self.not_selected_columns_ = [i for i in range(X.shape[1]) if i not in self.selected_columns_]
enc = KBinsDiscretizer(n_bins=self.n_bins, encode=self.encode, strategy=self.strategy, subsample=self.subsample, random_state=self.random_state)
self.transformer = ColumnTransformer([
('discretizer', enc, self.selected_columns_),
('passthrough', 'passthrough', self.not_selected_columns_)
])
self.transformer.fit(X)
return self
def transform(self, X):
return self.transformer.transform(X)
================================================
FILE: tpot/builtin_modules/passthrough.py
================================================
"""
This file is part of the TPOT library.
The current version of TPOT was developed at Cedars-Sinai by:
- Pedro Henrique Ribeiro (https://github.com/perib, https://www.linkedin.com/in/pedro-ribeiro/)
- Anil Saini (anil.saini@cshs.org)
- Jose Hernandez (jgh9094@gmail.com)
- Jay Moran (jay.moran@cshs.org)
- Nicholas Matsumoto (nicholas.matsumoto@cshs.org)
- Hyunjun Choi (hyunjun.choi@cshs.org)
- Gabriel Ketron (gabriel.ketron@cshs.org)
- Miguel E. Hernandez (miguel.e.hernandez@cshs.org)
- Jason Moore (moorejh28@gmail.com)
The original version of TPOT was primarily developed at the University of Pennsylvania by:
- Randal S. Olson (rso@randalolson.com)
- Weixuan Fu (weixuanf@upenn.edu)
- Daniel Angell (dpa34@drexel.edu)
- Jason Moore (moorejh28@gmail.com)
- and many more generous open-source contributors
TPOT is free software: you can redistribute it and/or modify
it under the terms of the GNU Lesser General Public License as
published by the Free Software Foundation, either version 3 of
the License, or (at your option) any later version.
TPOT is distributed in the hope that it will be useful,
but WITHOUT ANY WARRANTY; without even the implied warranty of
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
GNU Lesser General Public License for more details.
You should have received a copy of the GNU Lesser General Public
License along with TPOT. If not, see .
"""
from sklearn.base import TransformerMixin, BaseEstimator
import numpy as np
class Passthrough(TransformerMixin,BaseEstimator):
"""
A transformer that does nothing. It just passes the input array as is.
"""
def fit(self, X=None, y=None):
"""
Nothing to fit, just returns self.
"""
return self
def transform(self, X):
"""
returns the input array as is.
"""
return X
class SkipTransformer(TransformerMixin,BaseEstimator):
"""
A transformer returns an empty array. When combined with FeatureUnion, it can be used to skip a branch.
"""
def fit(self, X=None, y=None):
"""
Nothing to fit, just returns self.
"""
return self
def transform(self, X):
"""
returns an empty array.
"""
return np.array([]).reshape(X.shape[0],0)
================================================
FILE: tpot/builtin_modules/tests/feature_set_selector_tests.py
================================================
"""
This file is part of the TPOT library.
The current version of TPOT was developed at Cedars-Sinai by:
- Pedro Henrique Ribeiro (https://github.com/perib, https://www.linkedin.com/in/pedro-ribeiro/)
- Anil Saini (anil.saini@cshs.org)
- Jose Hernandez (jgh9094@gmail.com)
- Jay Moran (jay.moran@cshs.org)
- Nicholas Matsumoto (nicholas.matsumoto@cshs.org)
- Hyunjun Choi (hyunjun.choi@cshs.org)
- Gabriel Ketron (gabriel.ketron@cshs.org)
- Miguel E. Hernandez (miguel.e.hernandez@cshs.org)
- Jason Moore (moorejh28@gmail.com)
The original version of TPOT was primarily developed at the University of Pennsylvania by:
- Randal S. Olson (rso@randalolson.com)
- Weixuan Fu (weixuanf@upenn.edu)
- Daniel Angell (dpa34@drexel.edu)
- Jason Moore (moorejh28@gmail.com)
- and many more generous open-source contributors
TPOT is free software: you can redistribute it and/or modify
it under the terms of the GNU Lesser General Public License as
published by the Free Software Foundation, either version 3 of
the License, or (at your option) any later version.
TPOT is distributed in the hope that it will be useful,
but WITHOUT ANY WARRANTY; without even the implied warranty of
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
GNU Lesser General Public License for more details.
You should have received a copy of the GNU Lesser General Public
License along with TPOT. If not, see .
"""
import numpy as np
import pandas as pd
from tpot.config.custom_modules import FeatureSetSelector
from nose.tools import assert_raises
test_data = pd.read_csv("tests/tests.csv")
test_X = test_data.drop("class", axis=1)
def test_FeatureSetSelector_1():
"""Assert that the StackingEstimator returns transformed X based on test feature list 1."""
ds = FeatureSetSelector(subset_list="tests/subset_test.csv", sel_subset="test_subset_1")
ds.fit(test_X, y=None)
transformed_X = ds.transform(test_X)
assert transformed_X.shape[0] == test_X.shape[0]
assert transformed_X.shape[1] != test_X.shape[1]
assert transformed_X.shape[1] == 5
assert np.array_equal(transformed_X, test_X[ds.feat_list].values)
def test_FeatureSetSelector_2():
"""Assert that the StackingEstimator returns transformed X based on test feature list 2."""
ds = FeatureSetSelector(subset_list="tests/subset_test.csv", sel_subset="test_subset_2")
ds.fit(test_X, y=None)
transformed_X = ds.transform(test_X)
assert transformed_X.shape[0] == test_X.shape[0]
assert transformed_X.shape[1] != test_X.shape[1]
assert transformed_X.shape[1] == 6
assert np.array_equal(transformed_X, test_X[ds.feat_list].values)
def test_FeatureSetSelector_3():
"""Assert that the StackingEstimator returns transformed X based on 2 subsets' names"""
ds = FeatureSetSelector(subset_list="tests/subset_test.csv", sel_subset=["test_subset_1", "test_subset_2"])
ds.fit(test_X, y=None)
transformed_X = ds.transform(test_X)
assert transformed_X.shape[0] == test_X.shape[0]
assert transformed_X.shape[1] != test_X.shape[1]
assert transformed_X.shape[1] == 7
assert np.array_equal(transformed_X, test_X[ds.feat_list].values)
def test_FeatureSetSelector_4():
"""Assert that the StackingEstimator returns transformed X based on 2 subsets' indexs"""
ds = FeatureSetSelector(subset_list="tests/subset_test.csv", sel_subset=[0, 1])
ds.fit(test_X, y=None)
transformed_X = ds.transform(test_X)
assert transformed_X.shape[0] == test_X.shape[0]
assert transformed_X.shape[1] != test_X.shape[1]
assert transformed_X.shape[1] == 7
assert np.array_equal(transformed_X, test_X[ds.feat_list].values)
def test_FeatureSetSelector_5():
"""Assert that the StackingEstimator returns transformed X seleced based on test feature list 1's index."""
ds = FeatureSetSelector(subset_list="tests/subset_test.csv", sel_subset=0)
ds.fit(test_X, y=None)
transformed_X = ds.transform(test_X)
assert transformed_X.shape[0] == test_X.shape[0]
assert transformed_X.shape[1] != test_X.shape[1]
assert transformed_X.shape[1] == 5
assert np.array_equal(transformed_X, test_X[ds.feat_list].values)
def test_FeatureSetSelector_6():
"""Assert that the _get_support_mask function returns correct mask."""
ds = FeatureSetSelector(subset_list="tests/subset_test.csv", sel_subset="test_subset_1")
ds.fit(test_X, y=None)
mask = ds._get_support_mask()
get_mask = ds.get_support()
assert mask.shape[0] == 30
assert np.count_nonzero(mask) == 5
assert np.array_equal(get_mask, mask)
def test_FeatureSetSelector_7():
"""Assert that the StackingEstimator works as expected when input X is np.array."""
ds = FeatureSetSelector(subset_list="tests/subset_test.csv", sel_subset="test_subset_1")
ds.fit(test_X.values, y=None)
transformed_X = ds.transform(test_X.values)
str_feat_list = [str(i+2) for i in ds.feat_list_idx]
assert transformed_X.shape[0] == test_X.shape[0]
assert transformed_X.shape[1] != test_X.shape[1]
assert transformed_X.shape[1] == 5
assert np.array_equal(transformed_X, test_X.values[:, ds.feat_list_idx])
assert np.array_equal(transformed_X, test_X[str_feat_list].values)
def test_FeatureSetSelector_8():
"""Assert that the StackingEstimator rasies ValueError when features are not available."""
ds = FeatureSetSelector(subset_list="tests/subset_test.csv", sel_subset="test_subset_4")
assert_raises(ValueError, ds.fit, test_X)
def test_FeatureSetSelector_9():
"""Assert that the StackingEstimator __name__ returns correct class name."""
ds = FeatureSetSelector(subset_list="tests/subset_test.csv", sel_subset="test_subset_4")
assert ds.__name__ == 'FeatureSetSelector'
================================================
FILE: tpot/builtin_modules/zero_count.py
================================================
"""
This file is part of the TPOT library.
The current version of TPOT was developed at Cedars-Sinai by:
- Pedro Henrique Ribeiro (https://github.com/perib, https://www.linkedin.com/in/pedro-ribeiro/)
- Anil Saini (anil.saini@cshs.org)
- Jose Hernandez (jgh9094@gmail.com)
- Jay Moran (jay.moran@cshs.org)
- Nicholas Matsumoto (nicholas.matsumoto@cshs.org)
- Hyunjun Choi (hyunjun.choi@cshs.org)
- Gabriel Ketron (gabriel.ketron@cshs.org)
- Miguel E. Hernandez (miguel.e.hernandez@cshs.org)
- Jason Moore (moorejh28@gmail.com)
The original version of TPOT was primarily developed at the University of Pennsylvania by:
- Randal S. Olson (rso@randalolson.com)
- Weixuan Fu (weixuanf@upenn.edu)
- Daniel Angell (dpa34@drexel.edu)
- Jason Moore (moorejh28@gmail.com)
- and many more generous open-source contributors
TPOT is free software: you can redistribute it and/or modify
it under the terms of the GNU Lesser General Public License as
published by the Free Software Foundation, either version 3 of
the License, or (at your option) any later version.
TPOT is distributed in the hope that it will be useful,
but WITHOUT ANY WARRANTY; without even the implied warranty of
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
GNU Lesser General Public License for more details.
You should have received a copy of the GNU Lesser General Public
License along with TPOT. If not, see .
"""
import numpy as np
from sklearn.base import TransformerMixin, BaseEstimator
from sklearn.utils import check_array
class ZeroCount(TransformerMixin, BaseEstimator ):
"""Adds the count of zeros and count of non-zeros per sample as features."""
def fit(self, X, y=None):
"""Dummy function to fit in with the sklearn API."""
return self
def transform(self, X, y=None):
"""Transform data by adding two virtual features.
Parameters
----------
X: numpy ndarray, {n_samples, n_components}
New data, where n_samples is the number of samples and n_components
is the number of components.
y: None
Unused
Returns
-------
X_transformed: array-like, shape (n_samples, n_features)
The transformed feature set
"""
X = check_array(X)
n_features = X.shape[1]
X_transformed = np.copy(X)
non_zero_vector = np.count_nonzero(X_transformed, axis=1)
non_zero = np.reshape(non_zero_vector, (-1, 1))
zero_col = np.reshape(n_features - non_zero_vector, (-1, 1))
X_transformed = np.hstack((non_zero, X_transformed))
X_transformed = np.hstack((zero_col, X_transformed))
return X_transformed
================================================
FILE: tpot/config/__init__.py
================================================
"""
This file is part of the TPOT library.
The current version of TPOT was developed at Cedars-Sinai by:
- Pedro Henrique Ribeiro (https://github.com/perib, https://www.linkedin.com/in/pedro-ribeiro/)
- Anil Saini (anil.saini@cshs.org)
- Jose Hernandez (jgh9094@gmail.com)
- Jay Moran (jay.moran@cshs.org)
- Nicholas Matsumoto (nicholas.matsumoto@cshs.org)
- Hyunjun Choi (hyunjun.choi@cshs.org)
- Gabriel Ketron (gabriel.ketron@cshs.org)
- Miguel E. Hernandez (miguel.e.hernandez@cshs.org)
- Jason Moore (moorejh28@gmail.com)
The original version of TPOT was primarily developed at the University of Pennsylvania by:
- Randal S. Olson (rso@randalolson.com)
- Weixuan Fu (weixuanf@upenn.edu)
- Daniel Angell (dpa34@drexel.edu)
- Jason Moore (moorejh28@gmail.com)
- and many more generous open-source contributors
TPOT is free software: you can redistribute it and/or modify
it under the terms of the GNU Lesser General Public License as
published by the Free Software Foundation, either version 3 of
the License, or (at your option) any later version.
TPOT is distributed in the hope that it will be useful,
but WITHOUT ANY WARRANTY; without even the implied warranty of
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
GNU Lesser General Public License for more details.
You should have received a copy of the GNU Lesser General Public
License along with TPOT. If not, see .
"""
from .get_configspace import get_search_space
================================================
FILE: tpot/config/autoqtl_builtins.py
================================================
"""
This file is part of the TPOT library.
The current version of TPOT was developed at Cedars-Sinai by:
- Pedro Henrique Ribeiro (https://github.com/perib, https://www.linkedin.com/in/pedro-ribeiro/)
- Anil Saini (anil.saini@cshs.org)
- Jose Hernandez (jgh9094@gmail.com)
- Jay Moran (jay.moran@cshs.org)
- Nicholas Matsumoto (nicholas.matsumoto@cshs.org)
- Hyunjun Choi (hyunjun.choi@cshs.org)
- Gabriel Ketron (gabriel.ketron@cshs.org)
- Miguel E. Hernandez (miguel.e.hernandez@cshs.org)
- Jason Moore (moorejh28@gmail.com)
The original version of TPOT was primarily developed at the University of Pennsylvania by:
- Randal S. Olson (rso@randalolson.com)
- Weixuan Fu (weixuanf@upenn.edu)
- Daniel Angell (dpa34@drexel.edu)
- Jason Moore (moorejh28@gmail.com)
- and many more generous open-source contributors
TPOT is free software: you can redistribute it and/or modify
it under the terms of the GNU Lesser General Public License as
published by the Free Software Foundation, either version 3 of
the License, or (at your option) any later version.
TPOT is distributed in the hope that it will be useful,
but WITHOUT ANY WARRANTY; without even the implied warranty of
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
GNU Lesser General Public License for more details.
You should have received a copy of the GNU Lesser General Public
License along with TPOT. If not, see .
"""
from tpot.builtin_modules import genetic_encoders
from tpot.builtin_modules import feature_encoding_frequency_selector
import sklearn
import numpy as np
from ConfigSpace import ConfigurationSpace
from ConfigSpace import ConfigurationSpace, Integer, Float, Categorical, Normal
FeatureEncodingFrequencySelector_ConfigurationSpace = ConfigurationSpace(
space = {
'threshold': Float("threshold", bounds=(0, .35))
}
)
# genetic_encoders.DominantEncoder : {},
# genetic_encoders.RecessiveEncoder : {},
# genetic_encoders.HeterosisEncoder : {},
# genetic_encoders.UnderDominanceEncoder : {},
# genetic_encoders.OverDominanceEncoder : {},
================================================
FILE: tpot/config/classifiers.py
================================================
"""
This file is part of the TPOT library.
The current version of TPOT was developed at Cedars-Sinai by:
- Pedro Henrique Ribeiro (https://github.com/perib, https://www.linkedin.com/in/pedro-ribeiro/)
- Anil Saini (anil.saini@cshs.org)
- Jose Hernandez (jgh9094@gmail.com)
- Jay Moran (jay.moran@cshs.org)
- Nicholas Matsumoto (nicholas.matsumoto@cshs.org)
- Hyunjun Choi (hyunjun.choi@cshs.org)
- Gabriel Ketron (gabriel.ketron@cshs.org)
- Miguel E. Hernandez (miguel.e.hernandez@cshs.org)
- Jason Moore (moorejh28@gmail.com)
The original version of TPOT was primarily developed at the University of Pennsylvania by:
- Randal S. Olson (rso@randalolson.com)
- Weixuan Fu (weixuanf@upenn.edu)
- Daniel Angell (dpa34@drexel.edu)
- Jason Moore (moorejh28@gmail.com)
- and many more generous open-source contributors
TPOT is free software: you can redistribute it and/or modify
it under the terms of the GNU Lesser General Public License as
published by the Free Software Foundation, either version 3 of
the License, or (at your option) any later version.
TPOT is distributed in the hope that it will be useful,
but WITHOUT ANY WARRANTY; without even the implied warranty of
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
GNU Lesser General Public License for more details.
You should have received a copy of the GNU Lesser General Public
License along with TPOT. If not, see .
"""
from ConfigSpace import ConfigurationSpace
from ConfigSpace import ConfigurationSpace, Integer, Float, Categorical, Normal
from ConfigSpace import EqualsCondition, OrConjunction, NotEqualsCondition, InCondition
import numpy as np
import sklearn
def get_LogisticRegression_ConfigurationSpace(random_state, n_jobs=1):
dual = False
space = {"solver":"saga",
"max_iter":1000,
"n_jobs":n_jobs,
"dual":dual,
}
penalty = Categorical('penalty', ['l1', 'l2',"elasticnet"], default='l2')
C = Float('C', (0.01, 1e5), log=True)
l1_ratio = Float('l1_ratio', (0.0, 1.0))
class_weight = Categorical('class_weight', [None, 'balanced'])
l1_ratio_condition = EqualsCondition(l1_ratio, penalty, 'elasticnet')
if random_state is not None: #This is required because configspace doesn't allow None as a value
space['random_state'] = random_state
cs = ConfigurationSpace(space)
cs.add([penalty, C, l1_ratio, class_weight])
cs.add([l1_ratio_condition])
return cs
def get_KNeighborsClassifier_ConfigurationSpace(n_samples, n_jobs=1):
return ConfigurationSpace(
space = {
'n_neighbors': Integer("n_neighbors", bounds=(1, min(100,n_samples)), log=True),
'weights': Categorical("weights", ['uniform', 'distance']),
'p': Integer("p", bounds=(1, 3)),
'n_jobs': n_jobs,
}
)
def get_BaggingClassifier_ConfigurationSpace(random_state, n_jobs=1):
space = {
'n_estimators': Integer("n_estimators", bounds=(3, 100)),
'max_samples': Float("max_samples", bounds=(0.1, 1.0)),
'max_features': Float("max_features", bounds=(0.1, 1.0)),
'bootstrap_features': Categorical("bootstrap_features", [True, False]),
'n_jobs': n_jobs,
}
if random_state is not None: #This is required because configspace doesn't allow None as a value
space['random_state'] = random_state
bootstrap = Categorical("bootstrap", [True, False])
oob_score = Categorical("oob_score", [True, False])
oob_condition = EqualsCondition(oob_score, bootstrap, True)
cs = ConfigurationSpace(
space = space
)
cs.add([bootstrap, oob_score])
cs.add([oob_condition])
return cs
def get_DecisionTreeClassifier_ConfigurationSpace(n_featues, random_state):
space = {
'criterion': Categorical("criterion", ['gini', 'entropy']),
'max_depth': Integer("max_depth", bounds=(1, min(20,2*n_featues))), #max of 20? log scale?
'min_samples_split': Integer("min_samples_split", bounds=(2, 20)),
'min_samples_leaf': Integer("min_samples_leaf", bounds=(1, 20)),
'max_features': Categorical("max_features", [None, 'sqrt', 'log2']),
'min_weight_fraction_leaf': 0.0,
'class_weight' : Categorical('class_weight', [None, 'balanced']),
}
if random_state is not None: #This is required because configspace doesn't allow None as a value
space['random_state'] = random_state
return ConfigurationSpace(
space = space
)
#TODO Does not support predict_proba
def get_LinearSVC_ConfigurationSpace(random_state):
space = {"dual":"auto"}
penalty = Categorical('penalty', ['l1', 'l2'])
C = Float('C', (0.01, 1e5), log=True)
loss = Categorical('loss', ['hinge', 'squared_hinge'])
loss_condition = EqualsCondition(loss, penalty, 'l2')
if random_state is not None: #This is required because configspace doesn't allow None as a value
space['random_state'] = random_state
cs = ConfigurationSpace(space)
cs.add([penalty, C, loss])
cs.add([loss_condition])
return cs
def get_SVC_ConfigurationSpace(random_state):
space = {
'max_iter': 3000,
'probability':True}
kernel = Categorical("kernel", ['poly', 'rbf', 'sigmoid', 'linear'])
C = Float('C', (0.01, 1e5), log=True)
degree = Integer("degree", bounds=(1, 5))
gamma = Float("gamma", bounds=(1e-5, 8), log=True)
shrinking = Categorical("shrinking", [True, False])
coef0 = Float("coef0", bounds=(-1, 1))
class_weight = Categorical('class_weight', [None, 'balanced'])
degree_condition = EqualsCondition(degree, kernel, 'poly')
gamma_condition = InCondition(gamma, kernel, ['rbf', 'poly'])
coef0_condition = InCondition(coef0, kernel, ['poly', 'sigmoid'])
if random_state is not None: #This is required because configspace doesn't allow None as a value
space['random_state'] = random_state
cs = ConfigurationSpace(space)
cs.add([kernel, C, coef0, degree, gamma, shrinking, class_weight])
cs.add([degree_condition, gamma_condition, coef0_condition])
return cs
def get_RandomForestClassifier_ConfigurationSpace( random_state, n_jobs=1):
space = {
'n_estimators': 128, #as recommended by Oshiro et al. (2012
'max_features': Float("max_features", bounds=(0.01,1), log=True), #log scale like autosklearn?
'criterion': Categorical("criterion", ['gini', 'entropy']),
'min_samples_split': Integer("min_samples_split", bounds=(2, 20)),
'min_samples_leaf': Integer("min_samples_leaf", bounds=(1, 20)),
'bootstrap': Categorical("bootstrap", [True, False]),
'class_weight': Categorical("class_weight", [None, 'balanced']),
'n_jobs': n_jobs,
}
if random_state is not None: #This is required because configspace doesn't allow None as a value
space['random_state'] = random_state
return ConfigurationSpace(
space = space
)
def get_XGBClassifier_ConfigurationSpace(random_state, n_jobs=1):
space = {
'n_estimators': 100,
'learning_rate': Float("learning_rate", bounds=(1e-3, 1), log=True),
'subsample': Float("subsample", bounds=(0.5, 1.0)),
'min_child_weight': Integer("min_child_weight", bounds=(1, 21)),
'gamma': Float("gamma", bounds=(1e-4, 20), log=True),
'max_depth': Integer("max_depth", bounds=(3, 18)),
'reg_alpha': Float("reg_alpha", bounds=(1e-4, 100), log=True),
'reg_lambda': Float("reg_lambda", bounds=(1e-4, 1), log=True),
'n_jobs': n_jobs,
'nthread': 1,
'verbosity': 0,
}
if random_state is not None: #This is required because configspace doesn't allow None as a value
space['random_state'] = random_state
return ConfigurationSpace(
space = space
)
def get_LGBMClassifier_ConfigurationSpace(random_state, n_jobs=1):
space = {
'boosting_type': Categorical("boosting_type", ['gbdt', 'dart', 'goss']),
'num_leaves': Integer("num_leaves", bounds=(2, 256)),
'max_depth': Integer("max_depth", bounds=(1, 10)),
'n_estimators': Integer("n_estimators", bounds=(10, 100)),
'class_weight': Categorical("class_weight", [None, 'balanced']),
'verbose':-1,
'n_jobs': n_jobs,
}
if random_state is not None: #This is required because configspace doesn't allow None as a value
space['random_state'] = random_state
return ConfigurationSpace(
space=space
)
def get_ExtraTreesClassifier_ConfigurationSpace(random_state, n_jobs=1):
space = {
'n_estimators': 100,
'criterion': Categorical("criterion", ["gini", "entropy"]),
'max_features': Float("max_features", bounds=(0.01, 1.00)),
'min_samples_split': Integer("min_samples_split", bounds=(2, 20)),
'min_samples_leaf': Integer("min_samples_leaf", bounds=(1, 20)),
'bootstrap': Categorical("bootstrap", [True, False]),
'class_weight': Categorical("class_weight", [None, 'balanced']),
'n_jobs': n_jobs,
}
if random_state is not None: #This is required because configspace doesn't allow None as a value
space['random_state'] = random_state
return ConfigurationSpace(
space = space
)
def get_SGDClassifier_ConfigurationSpace(random_state, n_jobs=1):
space = {
'loss': Categorical("loss", ['modified_huber']), #don't include hinge because we have LinearSVC, don't include log because we have LogisticRegression. TODO 'squared_hinge'? doesn't support predict proba
'penalty': 'elasticnet',
'alpha': Float("alpha", bounds=(1e-5, 0.01), log=True),
'l1_ratio': Float("l1_ratio", bounds=(0.0, 1.0)),
'eta0': Float("eta0", bounds=(0.01, 1.0)),
'n_jobs': n_jobs,
'fit_intercept': Categorical("fit_intercept", [True]),
'class_weight': Categorical("class_weight", [None, 'balanced']),
}
if random_state is not None: #This is required because configspace doesn't allow None as a value
space['random_state'] = random_state
power_t = Float("power_t", bounds=(1e-5, 100.0), log=True)
learning_rate = Categorical("learning_rate", ['invscaling', 'constant', "optimal"])
powertcond = EqualsCondition(power_t, learning_rate, 'invscaling')
cs = ConfigurationSpace(
space = space
)
cs.add([power_t, learning_rate])
cs.add([powertcond])
return cs
GaussianNB_ConfigurationSpace = {}
def get_BernoulliNB_ConfigurationSpace():
return ConfigurationSpace(
space = {
'alpha': Float("alpha", bounds=(1e-2, 100), log=True),
'fit_prior': Categorical("fit_prior", [True, False]),
}
)
def get_MultinomialNB_ConfigurationSpace():
return ConfigurationSpace(
space = {
'alpha': Float("alpha", bounds=(1e-3, 100), log=True),
'fit_prior': Categorical("fit_prior", [True, False]),
}
)
def get_AdaBoostClassifier_ConfigurationSpace(random_state):
space = {
'n_estimators': Integer("n_estimators", bounds=(50, 500)),
'learning_rate': Float("learning_rate", bounds=(0.01, 2), log=True),
}
if random_state is not None: #This is required because configspace doesn't allow None as a value
space['random_state'] = random_state
return ConfigurationSpace(
space = space
)
def get_QuadraticDiscriminantAnalysis_ConfigurationSpace():
return ConfigurationSpace(
space = {
'reg_param': Float("reg_param", bounds=(0, 1)),
}
)
def get_PassiveAggressiveClassifier_ConfigurationSpace(random_state):
space = {
'C': Float("C", bounds=(1e-5, 10), log=True),
'loss': Categorical("loss", ['hinge', 'squared_hinge']),
'average': Categorical("average", [True, False]),
}
if random_state is not None: #This is required because configspace doesn't allow None as a value
space['random_state'] = random_state
return ConfigurationSpace(
space = space
)
#TODO support auto shrinkage when solver is svd. may require custom node
def get_LinearDiscriminantAnalysis_ConfigurationSpace():
solver = Categorical("solver", ['svd', 'lsqr', 'eigen'])
shrinkage = Float("shrinkage", bounds=(0, 1))
shrinkcond = NotEqualsCondition(shrinkage, solver, 'svd')
cs = ConfigurationSpace()
cs.add([solver, shrinkage])
cs.add([shrinkcond])
return cs
#### Gradient Boosting Classifiers
def get_GradientBoostingClassifier_ConfigurationSpace(n_classes, random_state):
early_stop = Categorical("early_stop", ["off", "valid", "train"])
n_iter_no_change = Integer("n_iter_no_change",bounds=(1,20))
validation_fraction = Float("validation_fraction", bounds=(0.01, 0.4))
n_iter_no_change_cond = InCondition(n_iter_no_change, early_stop, ["valid", "train"] )
validation_fraction_cond = EqualsCondition(validation_fraction, early_stop, "valid")
space = {
'learning_rate': Float("learning_rate", bounds=(1e-3, 1), log=True),
'min_samples_leaf': Integer("min_samples_leaf", bounds=(1, 200)),
'min_samples_split': Integer("min_samples_split", bounds=(2, 20)),
'subsample': Float("subsample", bounds=(0.1, 1.0)),
'max_features': Float("max_features", bounds=(0.01, 1.00)),
'max_leaf_nodes': Integer("max_leaf_nodes", bounds=(3, 2047)),
'max_depth':None, # 'max_depth': Integer("max_depth", bounds=(1, 2*n_features)),
'tol': 1e-4,
}
if n_classes == 2:
space['loss']= Categorical("loss", ['log_loss', 'exponential'])
else:
space['loss'] = "log_loss"
if random_state is not None: #This is required because configspace doesn't allow None as a value
space['random_state'] = random_state
cs = ConfigurationSpace(
space = space
)
cs.add([n_iter_no_change, validation_fraction, early_stop ])
cs.add([validation_fraction_cond, n_iter_no_change_cond])
return cs
def GradientBoostingClassifier_hyperparameter_parser(params):
final_params = {
'loss': params['loss'],
'learning_rate': params['learning_rate'],
'min_samples_leaf': params['min_samples_leaf'],
'min_samples_split': params['min_samples_split'],
'max_features': params['max_features'],
'max_leaf_nodes': params['max_leaf_nodes'],
'max_depth': params['max_depth'],
'tol': params['tol'],
'subsample': params['subsample']
}
if 'random_state' in params:
final_params['random_state'] = params['random_state']
if params['early_stop'] == 'off':
final_params['n_iter_no_change'] = None
final_params['validation_fraction'] = None
elif params['early_stop'] == 'valid':
#this is required because in crossover, its possible that n_iter_no_change is not in the params
if 'n_iter_no_change' not in params:
final_params['n_iter_no_change'] = 10
else:
final_params['n_iter_no_change'] = params['n_iter_no_change']
if 'validation_fraction' not in params:
final_params['validation_fraction'] = 0.1
else:
final_params['validation_fraction'] = params['validation_fraction']
elif params['early_stop'] == 'train':
if 'n_iter_no_change' not in params:
final_params['n_iter_no_change'] = 10
final_params['validation_fraction'] = None
return final_params
#only difference is l2_regularization
def get_HistGradientBoostingClassifier_ConfigurationSpace(random_state):
early_stop = Categorical("early_stop", ["off", "valid", "train"])
n_iter_no_change = Integer("n_iter_no_change",bounds=(1,20))
validation_fraction = Float("validation_fraction", bounds=(0.01, 0.4))
n_iter_no_change_cond = InCondition(n_iter_no_change, early_stop, ["valid", "train"] )
validation_fraction_cond = EqualsCondition(validation_fraction, early_stop, "valid")
space = {
'learning_rate': Float("learning_rate", bounds=(1e-3, 1), log=True),
'min_samples_leaf': Integer("min_samples_leaf", bounds=(1, 200)),
'max_features': Float("max_features", bounds=(0.1,1.0)),
'max_leaf_nodes': Integer("max_leaf_nodes", bounds=(3, 2047)),
'max_depth':None, # 'max_depth': Integer("max_depth", bounds=(1, 2*n_features)),
'l2_regularization': Float("l2_regularization", bounds=(1e-10, 1), log=True),
'tol': 1e-4,
}
if random_state is not None: #This is required because configspace doesn't allow None as a value
space['random_state'] = random_state
cs = ConfigurationSpace(
space = space
)
cs.add([n_iter_no_change, validation_fraction, early_stop ])
cs.add([validation_fraction_cond, n_iter_no_change_cond])
return cs
def HistGradientBoostingClassifier_hyperparameter_parser(params):
final_params = {
'learning_rate': params['learning_rate'],
'min_samples_leaf': params['min_samples_leaf'],
'max_features': params['max_features'],
'max_leaf_nodes': params['max_leaf_nodes'],
'max_depth': params['max_depth'],
'tol': params['tol'],
'l2_regularization': params['l2_regularization']
}
if 'random_state' in params:
final_params['random_state'] = params['random_state']
if params['early_stop'] == 'off':
# final_params['n_iter_no_change'] = 0
final_params['validation_fraction'] = None
final_params['early_stopping'] = False
elif params['early_stop'] == 'valid':
#this is required because in crossover, its possible that n_iter_no_change is not in the params
if 'n_iter_no_change' not in params:
final_params['n_iter_no_change'] = 10
else:
final_params['n_iter_no_change'] = params['n_iter_no_change']
if 'validation_fraction' not in params:
final_params['validation_fraction'] = 0.1
else:
final_params['validation_fraction'] = params['validation_fraction']
final_params['early_stopping'] = True
elif params['early_stop'] == 'train':
if 'n_iter_no_change' not in params:
final_params['n_iter_no_change'] = 10
else:
final_params['n_iter_no_change'] = params['n_iter_no_change']
final_params['validation_fraction'] = None
final_params['early_stopping'] = True
return final_params
###
def get_MLPClassifier_ConfigurationSpace(random_state):
space = {"n_iter_no_change":32}
if random_state is not None: #This is required because configspace doesn't allow None as a value
space['random_state'] = random_state
cs = ConfigurationSpace(
space = space
)
n_hidden_layers = Integer("n_hidden_layers", bounds=(1, 3))
n_nodes_per_layer = Integer("n_nodes_per_layer", bounds=(16, 512))
activation = Categorical("activation", ["identity", "logistic",'tanh', 'relu'])
alpha = Float("alpha", bounds=(1e-4, 1e-1), log=True)
early_stopping = Categorical("early_stopping", [True,False])
learning_rate_init = Float("learning_rate_init", bounds=(1e-4, 1e-1), log=True)
learning_rate = Categorical("learning_rate", ['constant', 'invscaling', 'adaptive'])
cs.add([n_hidden_layers, n_nodes_per_layer, activation, alpha, learning_rate, early_stopping, learning_rate_init])
return cs
def MLPClassifier_hyperparameter_parser(params):
hyperparameters = {
'n_iter_no_change': params['n_iter_no_change'],
'hidden_layer_sizes' : [params['n_nodes_per_layer']]*params['n_hidden_layers'],
'activation': params['activation'],
'alpha': params['alpha'],
'early_stopping': params['early_stopping'],
'learning_rate_init': params['learning_rate_init'],
'learning_rate': params['learning_rate'],
}
if 'random_state' in params:
hyperparameters['random_state'] = params['random_state']
return hyperparameters
###
###
def get_GaussianProcessClassifier_ConfigurationSpace(n_features, random_state):
space = {
'n_features': n_features,
'alpha': Float("alpha", bounds=(1e-10, 1.0), log=True),
'thetaL': Float("thetaL", bounds=(1e-10, 1e-3), log=True),
'thetaU': Float("thetaU", bounds=(1.0, 100000), log=True),
}
if random_state is not None: #This is required because configspace doesn't allow None as a value
space['random_state'] = random_state
return ConfigurationSpace(
space = space
)
def GaussianProcessClassifier_hyperparameter_parser(params):
kernel = sklearn.gaussian_process.kernels.RBF(
length_scale = [1.0]*params['n_features'],
length_scale_bounds=[(params['thetaL'], params['thetaU'])] * params['n_features'],
)
final_params = {"kernel": kernel,
"n_restarts_optimizer": 10,
"optimizer": "fmin_l_bfgs_b",
"copy_X_train": True,
}
if "random_state" in params:
final_params['random_state'] = params['random_state']
return final_params
================================================
FILE: tpot/config/classifiers_sklearnex.py
================================================
"""
This file is part of the TPOT library.
The current version of TPOT was developed at Cedars-Sinai by:
- Pedro Henrique Ribeiro (https://github.com/perib, https://www.linkedin.com/in/pedro-ribeiro/)
- Anil Saini (anil.saini@cshs.org)
- Jose Hernandez (jgh9094@gmail.com)
- Jay Moran (jay.moran@cshs.org)
- Nicholas Matsumoto (nicholas.matsumoto@cshs.org)
- Hyunjun Choi (hyunjun.choi@cshs.org)
- Gabriel Ketron (gabriel.ketron@cshs.org)
- Miguel E. Hernandez (miguel.e.hernandez@cshs.org)
- Jason Moore (moorejh28@gmail.com)
The original version of TPOT was primarily developed at the University of Pennsylvania by:
- Randal S. Olson (rso@randalolson.com)
- Weixuan Fu (weixuanf@upenn.edu)
- Daniel Angell (dpa34@drexel.edu)
- Jason Moore (moorejh28@gmail.com)
- and many more generous open-source contributors
TPOT is free software: you can redistribute it and/or modify
it under the terms of the GNU Lesser General Public License as
published by the Free Software Foundation, either version 3 of
the License, or (at your option) any later version.
TPOT is distributed in the hope that it will be useful,
but WITHOUT ANY WARRANTY; without even the implied warranty of
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
GNU Lesser General Public License for more details.
You should have received a copy of the GNU Lesser General Public
License along with TPOT. If not, see .
"""
from ConfigSpace import ConfigurationSpace
from ConfigSpace import ConfigurationSpace, Integer, Float, Categorical, Normal
def get_RandomForestClassifier_ConfigurationSpace(random_state, n_jobs=1):
space = {
'n_estimators': 100, #TODO make this a higher number? learned?
'bootstrap': Categorical("bootstrap", [True, False]),
'min_samples_split': Integer("min_samples_split", bounds=(2, 20)),
'min_samples_leaf': Integer("min_samples_leaf", bounds=(1, 20)),
'n_jobs': n_jobs,
}
if random_state is not None: #This is required because configspace doesn't allow None as a value
space['random_state'] = random_state
return ConfigurationSpace(
space = space
)
def get_KNeighborsClassifier_ConfigurationSpace(n_samples):
return ConfigurationSpace(
space = {
'n_neighbors': Integer("n_neighbors", bounds=(1, max(n_samples, 100)), log=True),
'weights': Categorical("weights", ['uniform', 'distance']),
}
)
#TODO add conditionals
def get_LogisticRegression_ConfigurationSpace(random_state):
space = {
'solver': Categorical("solver", ['liblinear', 'sag', 'saga']),
'penalty': Categorical("penalty", ['l1', 'l2']),
'dual': Categorical("dual", [True, False]),
'C': Float("C", bounds=(1e-4, 1e4), log=True),
'max_iter': 1000,
}
if random_state is not None: #This is required because configspace doesn't allow None as a value
space['random_state'] = random_state
return ConfigurationSpace(
space = space
)
def get_SVC_ConfigurationSpace(random_state):
space = {
'kernel': Categorical("kernel", ['poly', 'rbf', 'linear', 'sigmoid']),
'C': Float("C", bounds=(1e-4, 25), log=True),
'degree': Integer("degree", bounds=(1, 4)),
'max_iter': 3000,
'tol': 0.001,
'probability': Categorical("probability", [True]), # configspace doesn't allow bools as a default value? but does allow them as a value inside a Categorical
}
if random_state is not None: #This is required because configspace doesn't allow None as a value
space['random_state'] = random_state
return ConfigurationSpace(
space = space
)
def get_NuSVC_ConfigurationSpace(random_state):
space = {
'nu': Float("nu", bounds=(0.05, 1.0)),
'kernel': Categorical("kernel", ['poly', 'rbf', 'linear', 'sigmoid']),
#'C': Float("C", bounds=(1e-4, 25), log=True),
'degree': Integer("degree", bounds=(1, 4)),
'class_weight': Categorical("class_weight", [None, 'balanced']),
'max_iter': 3000,
'tol': 0.005,
'probability': Categorical("probability", [True]), # configspace doesn't allow bools as a default value? but does allow them as a value inside a Categorical
}
if random_state is not None: #This is required because configspace doesn't allow None as a value
space['random_state'] = random_state
return ConfigurationSpace(
space = space
)
================================================
FILE: tpot/config/get_configspace.py
================================================
"""
This file is part of the TPOT library.
The current version of TPOT was developed at Cedars-Sinai by:
- Pedro Henrique Ribeiro (https://github.com/perib, https://www.linkedin.com/in/pedro-ribeiro/)
- Anil Saini (anil.saini@cshs.org)
- Jose Hernandez (jgh9094@gmail.com)
- Jay Moran (jay.moran@cshs.org)
- Nicholas Matsumoto (nicholas.matsumoto@cshs.org)
- Hyunjun Choi (hyunjun.choi@cshs.org)
- Gabriel Ketron (gabriel.ketron@cshs.org)
- Miguel E. Hernandez (miguel.e.hernandez@cshs.org)
- Jason Moore (moorejh28@gmail.com)
The original version of TPOT was primarily developed at the University of Pennsylvania by:
- Randal S. Olson (rso@randalolson.com)
- Weixuan Fu (weixuanf@upenn.edu)
- Daniel Angell (dpa34@drexel.edu)
- Jason Moore (moorejh28@gmail.com)
- and many more generous open-source contributors
TPOT is free software: you can redistribute it and/or modify
it under the terms of the GNU Lesser General Public License as
published by the Free Software Foundation, either version 3 of
the License, or (at your option) any later version.
TPOT is distributed in the hope that it will be useful,
but WITHOUT ANY WARRANTY; without even the implied warranty of
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
GNU Lesser General Public License for more details.
You should have received a copy of the GNU Lesser General Public
License along with TPOT. If not, see .
"""
import importlib.util
import sys
import numpy as np
import warnings
import importlib.util
from ..search_spaces.nodes import EstimatorNode
from ..search_spaces.pipelines import ChoicePipeline, WrapperPipeline
from . import classifiers
from . import transformers
from . import selectors
from . import regressors
from . import autoqtl_builtins
from . import imputers
from . import mdr_configs
from . import special_configs
from . import classifiers_sklearnex
from . import regressors_sklearnex
from ConfigSpace import ConfigurationSpace
from ConfigSpace import ConfigurationSpace, Integer, Float, Categorical, Normal
#autoqtl_builtins
from tpot.builtin_modules import genetic_encoders, feature_encoding_frequency_selector
from tpot.builtin_modules import AddTransformer, mul_neg_1_Transformer, MulTransformer, SafeReciprocalTransformer, EQTransformer, NETransformer, GETransformer, GTTransformer, LETransformer, LTTransformer, MinTransformer, MaxTransformer, ZeroTransformer, OneTransformer, NTransformer
from tpot.builtin_modules.genetic_encoders import DominantEncoder, RecessiveEncoder, HeterosisEncoder, UnderDominanceEncoder, OverDominanceEncoder
from tpot.builtin_modules import ZeroCount, ColumnOneHotEncoder, ColumnOrdinalEncoder, PassKBinsDiscretizer
from tpot.builtin_modules import Passthrough, SkipTransformer
from sklearn.linear_model import SGDClassifier, LogisticRegression, SGDRegressor, Ridge, Lasso, ElasticNet, Lars, LassoLars, LassoLarsCV, RidgeCV, ElasticNetCV, PassiveAggressiveClassifier, ARDRegression
from sklearn.ensemble import BaggingClassifier, RandomForestClassifier, ExtraTreesClassifier, GradientBoostingClassifier, ExtraTreesRegressor, ExtraTreesClassifier, AdaBoostRegressor, AdaBoostClassifier, GradientBoostingRegressor,RandomForestRegressor, BaggingRegressor, ExtraTreesRegressor, HistGradientBoostingClassifier, HistGradientBoostingRegressor
from sklearn.neural_network import MLPClassifier, MLPRegressor
from sklearn.tree import DecisionTreeClassifier, DecisionTreeRegressor
from xgboost import XGBClassifier, XGBRegressor
from sklearn.neighbors import KNeighborsClassifier, KNeighborsRegressor
from sklearn.svm import SVC, SVR, LinearSVR, LinearSVC
from lightgbm import LGBMClassifier, LGBMRegressor
import sklearn
import sklearn.calibration as calibration
from sklearn.naive_bayes import GaussianNB, BernoulliNB, MultinomialNB
from sklearn.decomposition import FastICA, PCA
from sklearn.cluster import FeatureAgglomeration
from sklearn.kernel_approximation import Nystroem, RBFSampler
from sklearn.preprocessing import StandardScaler, PowerTransformer, QuantileTransformer, RobustScaler, PolynomialFeatures, Normalizer, MinMaxScaler, MaxAbsScaler, Binarizer, KBinsDiscretizer
from sklearn.feature_selection import SelectFwe, SelectPercentile, VarianceThreshold, RFE, SelectFromModel
from sklearn.feature_selection import f_classif, f_regression #TODO create a selectomixin using these?
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis, QuadraticDiscriminantAnalysis
from sklearn.gaussian_process import GaussianProcessRegressor, GaussianProcessClassifier
from sklearn.experimental import enable_iterative_imputer
from sklearn.impute import SimpleImputer, IterativeImputer, KNNImputer
import sklearn.calibration
import importlib.util
# Check if skrebate is installed
is_skrebate_installed = importlib.util.find_spec("skrebate") is not None
# Check if sklearnx is installed
is_sklearnx_installed = importlib.util.find_spec("sklearnx") is not None
all_methods = [SGDClassifier, RandomForestClassifier, ExtraTreesClassifier, GradientBoostingClassifier, MLPClassifier, DecisionTreeClassifier, XGBClassifier, KNeighborsClassifier, SVC, LogisticRegression, LGBMClassifier, LinearSVC, GaussianNB, BernoulliNB, MultinomialNB, ExtraTreesRegressor, RandomForestRegressor, GradientBoostingRegressor, BaggingRegressor, DecisionTreeRegressor, KNeighborsRegressor, XGBRegressor, ZeroCount, ColumnOneHotEncoder, ColumnOrdinalEncoder, Binarizer, FastICA, FeatureAgglomeration, MaxAbsScaler, MinMaxScaler, Normalizer, Nystroem, PCA, PolynomialFeatures, RBFSampler, RobustScaler, StandardScaler, SelectFwe, SelectPercentile, VarianceThreshold, SGDRegressor, Ridge, Lasso, ElasticNet, Lars, LassoLars, LassoLarsCV, RidgeCV, SVR, LinearSVR, AdaBoostRegressor, GradientBoostingRegressor, RandomForestRegressor, BaggingRegressor, ExtraTreesRegressor, DecisionTreeRegressor, KNeighborsRegressor, ElasticNetCV,
AdaBoostClassifier,MLPRegressor,
GaussianProcessRegressor, HistGradientBoostingClassifier, HistGradientBoostingRegressor,
AddTransformer, mul_neg_1_Transformer, MulTransformer, SafeReciprocalTransformer, EQTransformer, NETransformer, GETransformer, GTTransformer, LETransformer, LTTransformer, MinTransformer, MaxTransformer, ZeroTransformer, OneTransformer, NTransformer,
PowerTransformer, QuantileTransformer,ARDRegression, QuadraticDiscriminantAnalysis, PassiveAggressiveClassifier, LinearDiscriminantAnalysis,
DominantEncoder, RecessiveEncoder, HeterosisEncoder, UnderDominanceEncoder, OverDominanceEncoder,
GaussianProcessClassifier, BaggingClassifier,LGBMRegressor,
Passthrough,SkipTransformer,
PassKBinsDiscretizer,
SimpleImputer, IterativeImputer, KNNImputer,
KBinsDiscretizer,
]
#if mdr is installed
if importlib.util.find_spec('mdr') is not None:
from mdr import MDR, ContinuousMDR
all_methods.append(MDR)
all_methods.append(ContinuousMDR)
if importlib.util.find_spec('skrebate') is not None:
from skrebate import ReliefF, SURF, SURFstar, MultiSURF
all_methods.append(ReliefF)
all_methods.append(SURF)
all_methods.append(SURFstar)
all_methods.append(MultiSURF)
STRING_TO_CLASS = {
t.__name__: t for t in all_methods
}
if importlib.util.find_spec('sklearnex') is not None:
import sklearnex
import sklearnex.linear_model
import sklearnex.svm
import sklearnex.ensemble
import sklearnex.neighbors
sklearnex_methods = []
sklearnex_methods.append(sklearnex.linear_model.LinearRegression)
sklearnex_methods.append(sklearnex.linear_model.Ridge)
sklearnex_methods.append(sklearnex.linear_model.Lasso)
sklearnex_methods.append(sklearnex.linear_model.ElasticNet)
sklearnex_methods.append(sklearnex.svm.SVR)
sklearnex_methods.append(sklearnex.svm.NuSVR)
sklearnex_methods.append(sklearnex.ensemble.RandomForestRegressor)
sklearnex_methods.append(sklearnex.neighbors.KNeighborsRegressor)
sklearnex_methods.append(sklearnex.ensemble.RandomForestClassifier)
sklearnex_methods.append(sklearnex.neighbors.KNeighborsClassifier)
sklearnex_methods.append(sklearnex.svm.SVC)
sklearnex_methods.append(sklearnex.svm.NuSVC)
sklearnex_methods.append(sklearnex.linear_model.LogisticRegression)
STRING_TO_CLASS.update({f"{t.__name__}_sklearnex": t for t in sklearnex_methods})
# not including "PassiveAggressiveClassifier" in classifiers since it is mainly for larger than memory datasets/online use cases
# TODO need to subclass "GaussianProcessClassifier" and 'GaussianProcessRegressor'. These require n_features as a parameter for the kernel, but n_features may be different depending on selection functions or transformations previously in the pipeline.
GROUPNAMES = {
"selectors": ["SelectFwe", "SelectPercentile", "VarianceThreshold",],
"selectors_classification": ["SelectFwe", "SelectPercentile", "VarianceThreshold", "RFE_classification", "SelectFromModel_classification"],
"selectors_regression": ["SelectFwe", "SelectPercentile", "VarianceThreshold", "RFE_regression", "SelectFromModel_regression"],
"classifiers" : ["LGBMClassifier", "BaggingClassifier", 'AdaBoostClassifier', 'BernoulliNB', 'DecisionTreeClassifier', 'ExtraTreesClassifier', 'GaussianNB', 'HistGradientBoostingClassifier', 'KNeighborsClassifier','LinearDiscriminantAnalysis', 'LogisticRegression', 'MLPClassifier', 'MultinomialNB', "QuadraticDiscriminantAnalysis", 'RandomForestClassifier', 'SGDClassifier', 'XGBClassifier'],
"regressors" : ["LGBMRegressor", 'AdaBoostRegressor', "ARDRegression", 'DecisionTreeRegressor', 'ExtraTreesRegressor', 'HistGradientBoostingRegressor', 'KNeighborsRegressor', 'LinearSVR', "MLPRegressor", 'RandomForestRegressor', 'SGDRegressor', 'XGBRegressor'],
"transformers": ["KBinsDiscretizer", "Binarizer", "PCA", "ZeroCount", "FastICA", "FeatureAgglomeration", "Nystroem", "RBFSampler", "QuantileTransformer", "PowerTransformer", "ColumnOneHotEncoder", "ColumnOrdinalEncoder"],
"scalers": ["MinMaxScaler", "RobustScaler", "StandardScaler", "MaxAbsScaler", "Normalizer", ],
"all_transformers" : ["transformers", "scalers"],
"arithmatic": ["AddTransformer", "mul_neg_1_Transformer", "MulTransformer", "SafeReciprocalTransformer", "EQTransformer", "NETransformer", "GETransformer", "GTTransformer", "LETransformer", "LTTransformer", "MinTransformer", "MaxTransformer"],
"imputers": ["SimpleImputer", "IterativeImputer", "KNNImputer"],
"genetic_encoders": ["DominantEncoder", "RecessiveEncoder", "HeterosisEncoder", "UnderDominanceEncoder", "OverDominanceEncoder"],
"genetic encoders" : ["DominantEncoder", "RecessiveEncoder", "HeterosisEncoder", "UnderDominanceEncoder", "OverDominanceEncoder"]
}
# Add skrebate-related entries if skrebate is installed
if is_skrebate_installed:
GROUPNAMES["skrebate"] = ["ReliefF", "SURF", "SURFstar", "MultiSURF"]
# Add sklearnx-related entries if sklearnx is installed
if is_sklearnx_installed:
GROUPNAMES["classifiers_sklearnex"] = ["RandomForestClassifier_sklearnex", "LogisticRegression_sklearnex", "KNeighborsClassifier_sklearnex", "SVC_sklearnex","NuSVC_sklearnex"],
GROUPNAMES["regressors_sklearnex"] = ["LinearRegression_sklearnex", "Ridge_sklearnex", "Lasso_sklearnex", "ElasticNet_sklearnex", "SVR_sklearnex", "NuSVR_sklearnex", "RandomForestRegressor_sklearnex", "KNeighborsRegressor_sklearnex"],
def get_configspace(name, n_classes=3, n_samples=1000, n_features=100, random_state=None, n_jobs=1):
"""
This function returns the ConfigSpace.ConfigurationSpace with the hyperparameter ranges for the given
scikit-learn method. It also uses the n_classes, n_samples, n_features, and random_state to set the
hyperparameters that depend on these values.
Parameters
----------
name : str
The str name of the scikit-learn method for which to create the ConfigurationSpace. (e.g. 'RandomForestClassifier' for sklearn.ensemble.RandomForestClassifier)
n_classes : int
The number of classes in the target variable. Default is 3.
n_samples : int
The number of samples in the dataset. Default is 1000.
n_features : int
The number of features in the dataset. Default is 100.
random_state : int
The random_state to use in the ConfigurationSpace. Default is None.
If None, the random_state hyperparameter is not included in the ConfigurationSpace.
Use this to set the random state for the individual methods if you want to ensure reproducibility.
n_jobs : int (default=1)
Sets the n_jobs parameter for estimators that have it. Default is 1.
"""
match name:
#autoqtl_builtins.py
case "FeatureEncodingFrequencySelector":
return autoqtl_builtins.FeatureEncodingFrequencySelector_ConfigurationSpace
case "DominantEncoder":
return {}
case "RecessiveEncoder":
return {}
case "HeterosisEncoder":
return {}
case "UnderDominanceEncoder":
return {}
case "OverDominanceEncoder":
return {}
case "Passthrough":
return {}
case "SkipTransformer":
return {}
#classifiers.py
case "LinearDiscriminantAnalysis":
return classifiers.get_LinearDiscriminantAnalysis_ConfigurationSpace()
case "AdaBoostClassifier":
return classifiers.get_AdaBoostClassifier_ConfigurationSpace(random_state=random_state)
case "LogisticRegression":
return classifiers.get_LogisticRegression_ConfigurationSpace(random_state=random_state, n_jobs=n_jobs)
case "KNeighborsClassifier":
return classifiers.get_KNeighborsClassifier_ConfigurationSpace(n_samples=n_samples, n_jobs=n_jobs)
case "DecisionTreeClassifier":
return classifiers.get_DecisionTreeClassifier_ConfigurationSpace(n_featues=n_features, random_state=random_state)
case "SVC":
return classifiers.get_SVC_ConfigurationSpace(random_state=random_state)
case "LinearSVC":
return classifiers.get_LinearSVC_ConfigurationSpace(random_state=random_state)
case "RandomForestClassifier":
return classifiers.get_RandomForestClassifier_ConfigurationSpace(random_state=random_state, n_jobs=n_jobs)
case "GradientBoostingClassifier":
return classifiers.get_GradientBoostingClassifier_ConfigurationSpace(n_classes=n_classes, random_state=random_state)
case "HistGradientBoostingClassifier":
return classifiers.get_HistGradientBoostingClassifier_ConfigurationSpace(random_state=random_state)
case "XGBClassifier":
return classifiers.get_XGBClassifier_ConfigurationSpace(random_state=random_state, n_jobs=n_jobs)
case "LGBMClassifier":
return classifiers.get_LGBMClassifier_ConfigurationSpace(random_state=random_state, n_jobs=n_jobs)
case "ExtraTreesClassifier":
return classifiers.get_ExtraTreesClassifier_ConfigurationSpace(random_state=random_state, n_jobs=n_jobs)
case "SGDClassifier":
return classifiers.get_SGDClassifier_ConfigurationSpace(random_state=random_state, n_jobs=n_jobs)
case "MLPClassifier":
return classifiers.get_MLPClassifier_ConfigurationSpace(random_state=random_state)
case "BernoulliNB":
return classifiers.get_BernoulliNB_ConfigurationSpace()
case "MultinomialNB":
return classifiers.get_MultinomialNB_ConfigurationSpace()
case "GaussianNB":
return {}
case "LassoLarsCV":
return {}
case "ElasticNetCV":
return regressors.ElasticNetCV_configspace
case "RidgeCV":
return {}
case "PassiveAggressiveClassifier":
return classifiers.get_PassiveAggressiveClassifier_ConfigurationSpace(random_state=random_state)
case "QuadraticDiscriminantAnalysis":
return classifiers.get_QuadraticDiscriminantAnalysis_ConfigurationSpace()
case "GaussianProcessClassifier":
return classifiers.get_GaussianProcessClassifier_ConfigurationSpace(n_features=n_features, random_state=random_state)
case "BaggingClassifier":
return classifiers.get_BaggingClassifier_ConfigurationSpace(random_state=random_state, n_jobs=n_jobs)
#regressors.py
case "RandomForestRegressor":
return regressors.get_RandomForestRegressor_ConfigurationSpace(random_state=random_state, n_jobs=n_jobs)
case "SGDRegressor":
return regressors.get_SGDRegressor_ConfigurationSpace(random_state=random_state)
case "Ridge":
return regressors.get_Ridge_ConfigurationSpace(random_state=random_state)
case "Lasso":
return regressors.get_Lasso_ConfigurationSpace(random_state=random_state)
case "ElasticNet":
return regressors.get_ElasticNet_ConfigurationSpace(random_state=random_state)
case "Lars":
return regressors.get_Lars_ConfigurationSpace(random_state=random_state)
case "OthogonalMatchingPursuit":
return regressors.get_OthogonalMatchingPursuit_ConfigurationSpace()
case "BayesianRidge":
return regressors.get_BayesianRidge_ConfigurationSpace()
case "LassoLars":
return regressors.get_LassoLars_ConfigurationSpace(random_state=random_state)
case "BaggingRegressor":
return regressors.get_BaggingRegressor_ConfigurationSpace(random_state=random_state)
case "ARDRegression":
return regressors.get_ARDRegression_ConfigurationSpace()
case "TheilSenRegressor":
return regressors.get_TheilSenRegressor_ConfigurationSpace(random_state=random_state)
case "Perceptron":
return regressors.get_Perceptron_ConfigurationSpace(random_state=random_state)
case "DecisionTreeRegressor":
return regressors.get_DecisionTreeRegressor_ConfigurationSpace(random_state=random_state)
case "LinearSVR":
return regressors.get_LinearSVR_ConfigurationSpace(random_state=random_state)
case "SVR":
return regressors.get_SVR_ConfigurationSpace()
case "XGBRegressor":
return regressors.get_XGBRegressor_ConfigurationSpace(random_state=random_state, n_jobs=n_jobs)
case "AdaBoostRegressor":
return regressors.get_AdaBoostRegressor_ConfigurationSpace(random_state=random_state)
case "ExtraTreesRegressor":
return regressors.get_ExtraTreesRegressor_ConfigurationSpace(random_state=random_state, n_jobs=n_jobs)
case "GradientBoostingRegressor":
return regressors.get_GradientBoostingRegressor_ConfigurationSpace(random_state=random_state)
case "HistGradientBoostingRegressor":
return regressors.get_HistGradientBoostingRegressor_ConfigurationSpace(random_state=random_state)
case "MLPRegressor":
return regressors.get_MLPRegressor_ConfigurationSpace(random_state=random_state)
case "KNeighborsRegressor":
return regressors.get_KNeighborsRegressor_ConfigurationSpace(n_samples=n_samples, n_jobs=n_jobs)
case "GaussianProcessRegressor":
return regressors.get_GaussianProcessRegressor_ConfigurationSpace(n_features=n_features, random_state=random_state)
case "LGBMRegressor":
return regressors.get_LGBMRegressor_ConfigurationSpace(random_state=random_state, n_jobs=n_jobs)
case "BaggingRegressor":
return regressors.get_BaggingRegressor_ConfigurationSpace(random_state=random_state, n_jobs=n_jobs)
#transformers.py
case "Binarizer":
return transformers.Binarizer_configspace
case "Normalizer":
return transformers.Normalizer_configspace
case "PCA":
return transformers.PCA_configspace
case "ZeroCount":
return transformers.ZeroCount_configspace
case "FastICA":
return transformers.get_FastICA_configspace(n_features=n_features, random_state=random_state)
case "FeatureAgglomeration":
return transformers.get_FeatureAgglomeration_configspace(n_features=n_features)
case "Nystroem":
return transformers.get_Nystroem_configspace(n_features=n_features, random_state=random_state)
case "RBFSampler":
return transformers.get_RBFSampler_configspace(n_features=n_features, random_state=random_state)
case "MinMaxScaler":
return {}
case "PowerTransformer":
return {}
case "QuantileTransformer":
return transformers.get_QuantileTransformer_configspace(n_samples=n_samples, random_state=random_state)
case "RobustScaler":
return transformers.RobustScaler_configspace
case "MaxAbsScaler":
return {}
case "PolynomialFeatures":
return transformers.PolynomialFeatures_configspace
case "StandardScaler":
return {}
case "PassKBinsDiscretizer":
return transformers.get_passkbinsdiscretizer_configspace(random_state=random_state)
case "KBinsDiscretizer":
return transformers.get_passkbinsdiscretizer_configspace(random_state=random_state)
case "ColumnOneHotEncoder":
return {}
case "ColumnOrdinalEncoder":
return {}
#selectors.py
case "SelectFwe":
return selectors.SelectFwe_configspace
case "SelectPercentile":
return selectors.SelectPercentile_configspace
case "VarianceThreshold":
return selectors.VarianceThreshold_configspace
case "RFE":
return selectors.RFE_configspace_part
case "SelectFromModel":
return selectors.SelectFromModel_configspace_part
#special_configs.py
case "AddTransformer":
return {}
case "mul_neg_1_Transformer":
return {}
case "MulTransformer":
return {}
case "SafeReciprocalTransformer":
return {}
case "EQTransformer":
return {}
case "NETransformer":
return {}
case "GETransformer":
return {}
case "GTTransformer":
return {}
case "LETransformer":
return {}
case "LTTransformer":
return {}
case "MinTransformer":
return {}
case "MaxTransformer":
return {}
case "ZeroTransformer":
return {}
case "OneTransformer":
return {}
case "NTransformer":
return ConfigurationSpace(
space = {
'n': Float("n", bounds=(-1e2, 1e2)),
}
)
#imputers.py
case "SimpleImputer":
return imputers.simple_imputer_cs
case "IterativeImputer":
return imputers.get_IterativeImputer_config_space(n_features=n_features, random_state=random_state)
case "IterativeImputer_no_estimator":
return imputers.get_IterativeImputer_config_space_no_estimator(n_features=n_features, random_state=random_state)
case "KNNImputer":
return imputers.get_KNNImputer_config_space(n_samples=n_samples)
#mdr_configs.py
case "MDR":
return mdr_configs.MDR_configspace
case "ContinuousMDR":
return mdr_configs.MDR_configspace
case "ReliefF":
return mdr_configs.get_skrebate_ReliefF_config_space(n_features=n_features)
case "SURF":
return mdr_configs.get_skrebate_SURF_config_space(n_features=n_features)
case "SURFstar":
return mdr_configs.get_skrebate_SURFstar_config_space(n_features=n_features)
case "MultiSURF":
return mdr_configs.get_skrebate_MultiSURF_config_space(n_features=n_features)
#classifiers_sklearnex.py
case "RandomForestClassifier_sklearnex":
return classifiers_sklearnex.get_RandomForestClassifier_ConfigurationSpace(random_state=random_state, n_jobs=n_jobs)
case "LogisticRegression_sklearnex":
return classifiers_sklearnex.get_LogisticRegression_ConfigurationSpace(random_state=random_state)
case "KNeighborsClassifier_sklearnex":
return classifiers_sklearnex.get_KNeighborsClassifier_ConfigurationSpace(n_samples=n_samples)
case "SVC_sklearnex":
return classifiers_sklearnex.get_SVC_ConfigurationSpace(random_state=random_state)
case "NuSVC_sklearnex":
return classifiers_sklearnex.get_NuSVC_ConfigurationSpace(random_state=random_state)
#regressors_sklearnex.py
case "LinearRegression_sklearnex":
return {}
case "Ridge_sklearnex":
return regressors_sklearnex.get_Ridge_ConfigurationSpace(random_state=random_state)
case "Lasso_sklearnex":
return regressors_sklearnex.get_Lasso_ConfigurationSpace(random_state=random_state)
case "ElasticNet_sklearnex":
return regressors_sklearnex.get_ElasticNet_ConfigurationSpace(random_state=random_state)
case "SVR_sklearnex":
return regressors_sklearnex.get_SVR_ConfigurationSpace(random_state=random_state)
case "NuSVR_sklearnex":
return regressors_sklearnex.get_NuSVR_ConfigurationSpace(random_state=random_state)
case "RandomForestRegressor_sklearnex":
return regressors_sklearnex.get_RandomForestRegressor_ConfigurationSpace(random_state=random_state)
case "KNeighborsRegressor_sklearnex":
return regressors_sklearnex.get_KNeighborsRegressor_ConfigurationSpace(n_samples=n_samples)
#raise error
raise ValueError(f"Could not find configspace for {name}")
def flatten_group_names(name):
#if string
if isinstance(name, str):
if name in GROUPNAMES:
return flatten_group_names(GROUPNAMES[name])
else:
return name
flattened_list = []
for key in name:
if key in GROUPNAMES:
flattened_list.extend(flatten_group_names(GROUPNAMES[key]))
else:
flattened_list.append(key)
return flattened_list
def get_search_space(name, n_classes=3, n_samples=1000, n_features=100, random_state=None, return_choice_pipeline=True, base_node=EstimatorNode, n_jobs=1):
"""
Returns a TPOT search space for a given scikit-learn method or group of methods.
Parameters
----------
name : str or list
The name of the scikit-learn method or group of methods for which to create the search space.
- str: The name of the scikit-learn method. (e.g. 'RandomForestClassifier' for sklearn.ensemble.RandomForestClassifier)
Alternatively, the name of a group of methods. (e.g. 'classifiers' for all classifiers).
- list: A list of scikit-learn method names. (e.g. ['RandomForestClassifier', 'ExtraTreesClassifier'])
n_classes : int (default=3)
The number of classes in the target variable.
n_samples : int (default=1000)
The number of samples in the dataset.
n_features : int (default=100)
The number of features in the dataset.
random_state : int (default=None)
A fixed random_state to pass through to all methods that have a random_state hyperparameter.
return_choice_pipeline : bool (default=True)
If False, returns a list of TPOT.search_spaces.nodes.EstimatorNode objects.
If True, returns a single TPOT.search_spaces.pipelines.ChoicePipeline that includes and samples from all EstimatorNodes.
base_node: TPOT.search_spaces.base.SearchSpace (default=TPOT.search_spaces.nodes.EstimatorNode)
The SearchSpace to pass the configuration space to. If you want to experiment with custom mutation/crossover operators, you can pass a custom SearchSpace node here.
n_jobs : int (default=1)
Sets the n_jobs parameter for estimators that have it. Default is 1.
Returns
-------
Returns an SearchSpace object that can be optimized by TPOT.
- TPOT.search_spaces.nodes.EstimatorNode (or base_node) if there is only one search space.
- List of TPOT.search_spaces.nodes.EstimatorNode (or base_node) objects if there are multiple search spaces.
- TPOT.search_spaces.pipelines.ChoicePipeline object if return_choice_pipeline is True.
Note: for some special cases with methods using wrapped estimators, the returned search space is a TPOT.search_spaces.pipelines.WrapperPipeline object.
"""
name = flatten_group_names(name)
#if list of names, return a list of EstimatorNodes
if isinstance(name, list) or isinstance(name, np.ndarray):
search_spaces = [get_search_space(n, n_classes=n_classes, n_samples=n_samples, n_features=n_features, random_state=random_state, return_choice_pipeline=False, base_node=base_node, n_jobs=n_jobs) for n in name]
#remove Nones
search_spaces = [s for s in search_spaces if s is not None]
if return_choice_pipeline:
return ChoicePipeline(search_spaces=np.hstack(search_spaces))
else:
return np.hstack(search_spaces)
# if name in GROUPNAMES:
# name_list = GROUPNAMES[name]
# return get_search_space(name_list, n_classes=n_classes, n_samples=n_samples, n_features=n_features, random_state=random_state, return_choice_pipeline=return_choice_pipeline, base_node=base_node)
return get_node(name, n_classes=n_classes, n_samples=n_samples, n_features=n_features, random_state=random_state, base_node=base_node, n_jobs=n_jobs)
def get_node(name, n_classes=3, n_samples=100, n_features=100, random_state=None, base_node=EstimatorNode, n_jobs=1):
"""
Helper function for get_search_space. Returns a single EstimatorNode for the given scikit-learn method. Also includes special cases for nodes that require custom parsing of the hyperparameters or methods that wrap other methods.
Parameters
----------
name : str or list
The name of the scikit-learn method or group of methods for which to create the search space.
- str: The name of the scikit-learn method. (e.g. 'RandomForestClassifier' for sklearn.ensemble.RandomForestClassifier)
Alternatively, the name of a group of methods. (e.g. 'classifiers' for all classifiers).
- list: A list of scikit-learn method names. (e.g. ['RandomForestClassifier', 'ExtraTreesClassifier'])
n_classes : int (default=3)
The number of classes in the target variable.
n_samples : int (default=1000)
The number of samples in the dataset.
n_features : int (default=100)
The number of features in the dataset.
random_state : int (default=None)
A fixed random_state to pass through to all methods that have a random_state hyperparameter.
return_choice_pipeline : bool (default=True)
If False, returns a list of TPOT.search_spaces.nodes.EstimatorNode objects.
If True, returns a single TPOT.search_spaces.pipelines.ChoicePipeline that includes and samples from all EstimatorNodes.
base_node: TPOT.search_spaces.base.SearchSpace (default=TPOT.search_spaces.nodes.EstimatorNode)
The SearchSpace to pass the configuration space to. If you want to experiment with custom mutation/crossover operators, you can pass a custom SearchSpace node here.
n_jobs : int (default=1)
Sets the n_jobs parameter for estimators that have it. Default is 1.
Returns
-------
Returns an SearchSpace object that can be optimized by TPOT.
- TPOT.search_spaces.nodes.EstimatorNode (or base_node).
- TPOT.search_spaces.pipelines.WrapperPipeline object if the method requires a wrapped estimator.
"""
if name == "LinearSVC_wrapped":
ext = get_node("LinearSVC", n_classes=n_classes, n_samples=n_samples, random_state=random_state, n_jobs=n_jobs)
return WrapperPipeline(estimator_search_space=ext, method=sklearn.calibration.CalibratedClassifierCV, space={})
if name == "RFE_classification":
rfe_sp = get_configspace(name="RFE", n_classes=n_classes, n_samples=n_samples, random_state=random_state, n_jobs=n_jobs)
ext = get_node("ExtraTreesClassifier", n_classes=n_classes, n_samples=n_samples, random_state=random_state, n_jobs=n_jobs)
return WrapperPipeline(estimator_search_space=ext, method=RFE, space=rfe_sp)
if name == "RFE_regression":
rfe_sp = get_configspace(name="RFE", n_classes=n_classes, n_samples=n_samples, random_state=random_state, n_jobs=n_jobs)
ext = get_node("ExtraTreesRegressor", n_classes=n_classes, n_samples=n_samples, random_state=random_state, n_jobs=n_jobs)
return WrapperPipeline(estimator_search_space=ext, method=RFE, space=rfe_sp)
if name == "SelectFromModel_classification":
sfm_sp = get_configspace(name="SelectFromModel", n_classes=n_classes, n_samples=n_samples, random_state=random_state, n_jobs=n_jobs)
ext = get_node("ExtraTreesClassifier", n_classes=n_classes, n_samples=n_samples, random_state=random_state, n_jobs=n_jobs)
return WrapperPipeline(estimator_search_space=ext, method=SelectFromModel, space=sfm_sp)
if name == "SelectFromModel_regression":
sfm_sp = get_configspace(name="SelectFromModel", n_classes=n_classes, n_samples=n_samples, random_state=random_state, n_jobs=n_jobs)
ext = get_node("ExtraTreesRegressor", n_classes=n_classes, n_samples=n_samples, random_state=random_state, n_jobs=n_jobs)
return WrapperPipeline(estimator_search_space=ext, method=SelectFromModel, space=sfm_sp)
# TODO Add IterativeImputer with more estimator methods
if name == "IterativeImputer_learned_estimators":
iteative_sp = get_configspace(name="IterativeImputer_no_estimator", n_features=n_features, random_state=random_state, n_jobs=n_jobs)
regressor_searchspace = get_node("ExtraTreesRegressor", n_classes=n_classes, n_samples=n_samples, random_state=random_state, n_jobs=n_jobs)
return WrapperPipeline(estimator_search_space=regressor_searchspace, method=IterativeImputer, space=iteative_sp)
#these are nodes that have special search spaces which require custom parsing of the hyperparameters
if name == "IterativeImputer":
configspace = get_configspace(name, n_classes=n_classes, n_samples=n_samples, random_state=random_state, n_jobs=n_jobs)
return EstimatorNode(STRING_TO_CLASS[name], configspace, hyperparameter_parser=imputers.IterativeImputer_hyperparameter_parser)
if name == "RobustScaler":
configspace = get_configspace(name, n_classes=n_classes, n_samples=n_samples, random_state=random_state, n_jobs=n_jobs)
return base_node(STRING_TO_CLASS[name], configspace, hyperparameter_parser=transformers.robust_scaler_hyperparameter_parser)
if name == "GradientBoostingClassifier":
configspace = get_configspace(name, n_classes=n_classes, n_samples=n_samples, random_state=random_state, n_jobs=n_jobs)
return base_node(STRING_TO_CLASS[name], configspace, hyperparameter_parser=classifiers.GradientBoostingClassifier_hyperparameter_parser)
if name == "HistGradientBoostingClassifier":
configspace = get_configspace(name, n_classes=n_classes, n_samples=n_samples, random_state=random_state, n_jobs=n_jobs)
return base_node(STRING_TO_CLASS[name], configspace, hyperparameter_parser=classifiers.HistGradientBoostingClassifier_hyperparameter_parser)
if name == "GradientBoostingRegressor":
configspace = get_configspace(name, n_classes=n_classes, n_samples=n_samples, random_state=random_state, n_jobs=n_jobs)
return base_node(STRING_TO_CLASS[name], configspace, hyperparameter_parser=regressors.GradientBoostingRegressor_hyperparameter_parser)
if name == "HistGradientBoostingRegressor":
configspace = get_configspace(name, n_classes=n_classes, n_samples=n_samples, random_state=random_state, n_jobs=n_jobs)
return base_node(STRING_TO_CLASS[name], configspace, hyperparameter_parser=regressors.HistGradientBoostingRegressor_hyperparameter_parser)
if name == "MLPClassifier":
configspace = get_configspace(name, n_classes=n_classes, n_samples=n_samples, random_state=random_state, n_jobs=n_jobs)
return base_node(STRING_TO_CLASS[name], configspace, hyperparameter_parser=classifiers.MLPClassifier_hyperparameter_parser)
if name == "MLPRegressor":
configspace = get_configspace(name, n_classes=n_classes, n_samples=n_samples, random_state=random_state, n_jobs=n_jobs)
return base_node(STRING_TO_CLASS[name], configspace, hyperparameter_parser=regressors.MLPRegressor_hyperparameter_parser)
if name == "GaussianProcessRegressor":
configspace = get_configspace(name, n_classes=n_classes, n_samples=n_samples, random_state=random_state, n_jobs=n_jobs)
return base_node(STRING_TO_CLASS[name], configspace, hyperparameter_parser=regressors.GaussianProcessRegressor_hyperparameter_parser)
if name == "GaussianProcessClassifier":
configspace = get_configspace(name, n_classes=n_classes, n_samples=n_samples, random_state=random_state, n_jobs=n_jobs)
return base_node(STRING_TO_CLASS[name], configspace, hyperparameter_parser=classifiers.GaussianProcessClassifier_hyperparameter_parser)
if name == "FeatureAgglomeration":
configspace = get_configspace(name, n_classes=n_classes, n_samples=n_samples, random_state=random_state, n_jobs=n_jobs)
return base_node(STRING_TO_CLASS[name], configspace, hyperparameter_parser=transformers.FeatureAgglomeration_hyperparameter_parser)
configspace = get_configspace(name, n_classes=n_classes, n_samples=n_samples, n_features=n_features, random_state=random_state, n_jobs=n_jobs)
if configspace is None:
#raise warning
warnings.warn(f"Could not find configspace for {name}")
return None
return base_node(STRING_TO_CLASS[name], configspace)
================================================
FILE: tpot/config/imputers.py
================================================
"""
This file is part of the TPOT library.
The current version of TPOT was developed at Cedars-Sinai by:
- Pedro Henrique Ribeiro (https://github.com/perib, https://www.linkedin.com/in/pedro-ribeiro/)
- Anil Saini (anil.saini@cshs.org)
- Jose Hernandez (jgh9094@gmail.com)
- Jay Moran (jay.moran@cshs.org)
- Nicholas Matsumoto (nicholas.matsumoto@cshs.org)
- Hyunjun Choi (hyunjun.choi@cshs.org)
- Gabriel Ketron (gabriel.ketron@cshs.org)
- Miguel E. Hernandez (miguel.e.hernandez@cshs.org)
- Jason Moore (moorejh28@gmail.com)
The original version of TPOT was primarily developed at the University of Pennsylvania by:
- Randal S. Olson (rso@randalolson.com)
- Weixuan Fu (weixuanf@upenn.edu)
- Daniel Angell (dpa34@drexel.edu)
- Jason Moore (moorejh28@gmail.com)
- and many more generous open-source contributors
TPOT is free software: you can redistribute it and/or modify
it under the terms of the GNU Lesser General Public License as
published by the Free Software Foundation, either version 3 of
the License, or (at your option) any later version.
TPOT is distributed in the hope that it will be useful,
but WITHOUT ANY WARRANTY; without even the implied warranty of
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
GNU Lesser General Public License for more details.
You should have received a copy of the GNU Lesser General Public
License along with TPOT. If not, see .
"""
import sklearn
import sklearn.ensemble
import sklearn.linear_model
import sklearn.neighbors
from ConfigSpace import ConfigurationSpace
from ConfigSpace import ConfigurationSpace, Integer, Float, Categorical, Normal
from ConfigSpace import EqualsCondition
simple_imputer_cs = ConfigurationSpace(
space = {
'strategy' : Categorical('strategy',
['mean','median', 'most_frequent', 'constant']
),
#'add_indicator' : Categorical('add_indicator', [True, False]),
#Removed add_indicator, it appends a mask next to the rest of the data
# and can cause errors. gk
}
)
#test
def get_IterativeImputer_config_space(n_features, random_state):
space = { 'initial_strategy' : Categorical('initial_strategy',
['mean', 'median',
'most_frequent', 'constant']),
'n_nearest_features' : Integer('n_nearest_features',
bounds=(1, n_features)),
'imputation_order' : Categorical('imputation_order',
['ascending', 'descending',
'roman', 'arabic', 'random']),
}
estimator = Categorical('estimator', ['Bayesian', 'RFR', 'Ridge', 'KNN'])
sample_posterior = Categorical('sample_posterior', [True, False])
sampling_condition = EqualsCondition(sample_posterior, estimator, 'Bayesian')
if random_state is not None:
#This is required because configspace doesn't allow None as a value
space['random_state'] = random_state
cs = ConfigurationSpace(space=space)
cs.add([estimator, sample_posterior])
cs.add([sampling_condition])
return cs
def get_IterativeImputer_config_space_no_estimator(n_features, random_state):
space = { 'initial_strategy' : Categorical('initial_strategy',
['mean', 'median',
'most_frequent', 'constant']),
'n_nearest_features' : Integer('n_nearest_features',
bounds=(1, n_features)),
'imputation_order' : Categorical('imputation_order',
['ascending', 'descending',
'roman', 'arabic', 'random']),
}
if random_state is not None:
#This is required because configspace doesn't allow None as a value
space['random_state'] = random_state
cs = ConfigurationSpace(space=space)
return cs
def get_KNNImputer_config_space(n_samples):
space = {
'n_neighbors': Integer('n_neighbors', bounds=(1, max(n_samples,100))),
'weights': Categorical('weights', ['uniform', 'distance'])
}
return ConfigurationSpace(
space=space
)
def IterativeImputer_hyperparameter_parser(params):
est = params['estimator']
match est:
case 'Bayesian':
estimator = sklearn.linear_model.BayesianRidge()
case 'RFR':
estimator = sklearn.ensemble.RandomForestRegressor()
case 'Ridge':
estimator = sklearn.linear_model.Ridge()
case 'KNN':
estimator = sklearn.neighbors.KNeighborsRegressor()
final_params = {
'estimator' : estimator,
'initial_strategy' : params['initial_strategy'],
'n_nearest_features' : params['n_nearest_features'],
'imputation_order' : params['imputation_order'],
}
if 'sample_posterior' in params:
final_params['sample_posterior'] = params['sample_posterior']
if 'random_state' in params:
final_params['random_state'] = params['random_state']
return final_params
================================================
FILE: tpot/config/mdr_configs.py
================================================
"""
This file is part of the TPOT library.
The current version of TPOT was developed at Cedars-Sinai by:
- Pedro Henrique Ribeiro (https://github.com/perib, https://www.linkedin.com/in/pedro-ribeiro/)
- Anil Saini (anil.saini@cshs.org)
- Jose Hernandez (jgh9094@gmail.com)
- Jay Moran (jay.moran@cshs.org)
- Nicholas Matsumoto (nicholas.matsumoto@cshs.org)
- Hyunjun Choi (hyunjun.choi@cshs.org)
- Gabriel Ketron (gabriel.ketron@cshs.org)
- Miguel E. Hernandez (miguel.e.hernandez@cshs.org)
- Jason Moore (moorejh28@gmail.com)
The original version of TPOT was primarily developed at the University of Pennsylvania by:
- Randal S. Olson (rso@randalolson.com)
- Weixuan Fu (weixuanf@upenn.edu)
- Daniel Angell (dpa34@drexel.edu)
- Jason Moore (moorejh28@gmail.com)
- and many more generous open-source contributors
TPOT is free software: you can redistribute it and/or modify
it under the terms of the GNU Lesser General Public License as
published by the Free Software Foundation, either version 3 of
the License, or (at your option) any later version.
TPOT is distributed in the hope that it will be useful,
but WITHOUT ANY WARRANTY; without even the implied warranty of
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
GNU Lesser General Public License for more details.
You should have received a copy of the GNU Lesser General Public
License along with TPOT. If not, see .
"""
from ConfigSpace import ConfigurationSpace
from ConfigSpace import ConfigurationSpace, Integer, Float, Categorical, Normal
#MDR
MDR_configspace = ConfigurationSpace(
space = {
'tie_break': Categorical('tie_break', [0,1]),
'default_label': Categorical('default_label', [0,1]),
}
)
def get_skrebate_ReliefF_config_space(n_features):
return ConfigurationSpace(
space = {
'n_features_to_select': Integer('n_features_to_select', bounds=(1, n_features), log=True),
'n_neighbors': Integer('n_neighbors', bounds=(2,500), log=True),
}
)
def get_skrebate_SURF_config_space(n_features):
return ConfigurationSpace(
space = {
'n_features_to_select': Integer('n_features_to_select', bounds=(1, n_features), log=True),
}
)
def get_skrebate_SURFstar_config_space(n_features):
return ConfigurationSpace(
space = {
'n_features_to_select': Integer('n_features_to_select', bounds=(1, n_features), log=True),
}
)
def get_skrebate_MultiSURF_config_space(n_features):
return ConfigurationSpace(
space = {
'n_features_to_select': Integer('n_features_to_select', bounds=(1, n_features), log=True),
}
)
================================================
FILE: tpot/config/regressors.py
================================================
"""
This file is part of the TPOT library.
The current version of TPOT was developed at Cedars-Sinai by:
- Pedro Henrique Ribeiro (https://github.com/perib, https://www.linkedin.com/in/pedro-ribeiro/)
- Anil Saini (anil.saini@cshs.org)
- Jose Hernandez (jgh9094@gmail.com)
- Jay Moran (jay.moran@cshs.org)
- Nicholas Matsumoto (nicholas.matsumoto@cshs.org)
- Hyunjun Choi (hyunjun.choi@cshs.org)
- Gabriel Ketron (gabriel.ketron@cshs.org)
- Miguel E. Hernandez (miguel.e.hernandez@cshs.org)
- Jason Moore (moorejh28@gmail.com)
The original version of TPOT was primarily developed at the University of Pennsylvania by:
- Randal S. Olson (rso@randalolson.com)
- Weixuan Fu (weixuanf@upenn.edu)
- Daniel Angell (dpa34@drexel.edu)
- Jason Moore (moorejh28@gmail.com)
- and many more generous open-source contributors
TPOT is free software: you can redistribute it and/or modify
it under the terms of the GNU Lesser General Public License as
published by the Free Software Foundation, either version 3 of
the License, or (at your option) any later version.
TPOT is distributed in the hope that it will be useful,
but WITHOUT ANY WARRANTY; without even the implied warranty of
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
GNU Lesser General Public License for more details.
You should have received a copy of the GNU Lesser General Public
License along with TPOT. If not, see .
"""
import sklearn
from ConfigSpace import ConfigurationSpace
from ConfigSpace import ConfigurationSpace, Integer, Float, Categorical, Normal
from ConfigSpace import EqualsCondition, OrConjunction, NotEqualsCondition, InCondition
import numpy as np
#TODO: fill in remaining
#TODO check for places were we could use log scaling
ElasticNetCV_configspace = {
"l1_ratio" : np.arange(0.0, 1.01, 0.05),
}
def get_RandomForestRegressor_ConfigurationSpace(random_state, n_jobs=1):
space = {
'n_estimators': 100,
'criterion': Categorical("criterion", ['friedman_mse', 'poisson', 'absolute_error', 'squared_error']),
'max_features': Float("max_features", bounds=(0.05, 1.0)),
'bootstrap': Categorical("bootstrap", [True, False]),
'min_samples_split': Integer("min_samples_split", bounds=(2, 21)),
'min_samples_leaf': Integer("min_samples_leaf", bounds=(1, 21)),
'n_jobs': n_jobs,
}
if random_state is not None: #This is required because configspace doesn't allow None as a value
space['random_state'] = random_state
return ConfigurationSpace(
space = space
)
def get_SGDRegressor_ConfigurationSpace(random_state):
space = {
'alpha': Float("alpha", bounds=(1e-7, 1e-1), log=True),
'average': Categorical("average", [True, False]),
'fit_intercept': Categorical("fit_intercept", [True]),
}
if random_state is not None: #This is required because configspace doesn't allow None as a value
space['random_state'] = random_state
cs = ConfigurationSpace(
space = space
)
l1_ratio = Float("l1_ratio", bounds=(1e-7, 1.0), log=True)
penalty = Categorical("penalty", ["l1", "l2", "elasticnet"])
epsilon = Float("epsilon", bounds=(1e-5, 1e-1), log=True)
loss = Categorical("loss", ['epsilon_insensitive', 'squared_epsilon_insensitive', 'huber', 'squared_error'])
eta0 = Float("eta0", bounds=(1e-7, 1e-1), log=True)
learning_rate = Categorical("learning_rate", ['optimal', 'invscaling', 'constant'])
power_t = Float("power_t", bounds=(1e-5, 1.0), log=True)
elasticnet = EqualsCondition(l1_ratio, penalty, "elasticnet")
epsilon_condition = InCondition(
epsilon,
loss,
["huber", "epsilon_insensitive", "squared_epsilon_insensitive"],
)
eta0_in_inv_con = InCondition(eta0, learning_rate, ["invscaling", "constant"])
power_t_condition = EqualsCondition(power_t, learning_rate, "invscaling")
cs.add(
[l1_ratio, penalty, epsilon, loss, eta0, learning_rate, power_t]
)
cs.add(
[elasticnet, epsilon_condition, power_t_condition, eta0_in_inv_con]
)
return cs
def get_Ridge_ConfigurationSpace(random_state):
space = {
'alpha': Float("alpha", bounds=(0.0, 1.0)),
'fit_intercept': Categorical("fit_intercept", [True]),
'tol': Float("tol", bounds=(1e-5, 1e-1), log=True),
'solver': Categorical("solver", ['auto', 'svd', 'cholesky', 'lsqr', 'sparse_cg', 'sag', 'saga']),
}
if random_state is not None: #This is required because configspace doesn't allow None as a value
space['random_state'] = random_state
return ConfigurationSpace(
space = space
)
def get_Lasso_ConfigurationSpace(random_state):
space = {
'alpha': Float("alpha", bounds=(0.0, 1.0)),
'fit_intercept': Categorical("fit_intercept", [True]),
'tol': 0.0001,
}
if random_state is not None: #This is required because configspace doesn't allow None as a value
space['random_state'] = random_state
return ConfigurationSpace(
space = space
)
def get_ElasticNet_ConfigurationSpace(random_state):
space = {
'alpha': Float("alpha", bounds=(0.0, 1.0)),
'l1_ratio': Float("l1_ratio", bounds=(0.0, 1.0)),
}
if random_state is not None: #This is required because configspace doesn't allow None as a value
space['random_state'] = random_state
return ConfigurationSpace(
space = space
)
def get_Lars_ConfigurationSpace(random_state):
space = {
}
if random_state is not None: #This is required because configspace doesn't allow None as a value
space['random_state'] = random_state
return ConfigurationSpace(
space = space
)
def get_OthogonalMatchingPursuit_ConfigurationSpace():
return ConfigurationSpace(
space = {
}
)
def get_BayesianRidge_ConfigurationSpace():
return ConfigurationSpace(
space = {
'tol': 0.0001,
'alpha_1': Float("alpha_1", bounds=(1e-6, 1e-1), log=True),
'alpha_2': Float("alpha_2", bounds=(1e-6, 1e-1), log=True),
'lambda_1': Float("lambda_1", bounds=(1e-6, 1e-1), log=True),
'lambda_2': Float("lambda_2", bounds=(1e-6, 1e-1), log=True),
}
)
def get_LassoLars_ConfigurationSpace(random_state):
space = {
'alpha': Float("alpha", bounds=(0.0, 1.0)),
'eps': Float("eps", bounds=(1e-5, 1e-1), log=True),
}
if random_state is not None: #This is required because configspace doesn't allow None as a value
space['random_state'] = random_state
return ConfigurationSpace(
space = space
)
def get_BaggingRegressor_ConfigurationSpace(random_state):
space = {
'max_samples': Float("max_samples", bounds=(0.05, 1.00)),
'max_features': Float("max_features", bounds=(0.05, 1.00)),
'bootstrap': Categorical("bootstrap", [True, False]),
'bootstrap_features': Categorical("bootstrap_features", [True, False]),
}
if random_state is not None: #This is required because configspace doesn't allow None as a value
space['random_state'] = random_state
return ConfigurationSpace(
space = space
)
def get_ARDRegression_ConfigurationSpace():
return ConfigurationSpace(
space = {
'alpha_1': Float("alpha_1", bounds=(1e-10, 1e-3), log=True),
'alpha_2': Float("alpha_2", bounds=(1e-10, 1e-3), log=True),
'lambda_1': Float("lambda_1", bounds=(1e-10, 1e-3), log=True),
'lambda_2': Float("lambda_2", bounds=(1e-10, 1e-3), log=True),
'threshold_lambda': Integer("threshold_lambda", bounds=(1e3, 1e5)),
}
)
def get_TheilSenRegressor_ConfigurationSpace(random_state):
space = {
'n_subsamples': Integer("n_subsamples", bounds=(10, 10000)),
'max_subpopulation': Integer("max_subpopulation", bounds=(10, 1000)),
}
if random_state is not None: #This is required because configspace doesn't allow None as a value
space['random_state'] = random_state
return ConfigurationSpace(
space = space
)
def get_Perceptron_ConfigurationSpace(random_state):
space = {
'penalty': Categorical("penalty", [None, 'l2', 'l1', 'elasticnet']),
'alpha': Float("alpha", bounds=(1e-5, 1e-1), log=True),
'l1_ratio': Float("l1_ratio", bounds=(0.0, 1.0)),
'learning_rate': Categorical("learning_rate", ['constant', 'optimal', 'invscaling']),
'validation_fraction': Float("validation_fraction", bounds=(0.05, 1.00)),
}
if random_state is not None: #This is required because configspace doesn't allow None as a value
space['random_state'] = random_state
return ConfigurationSpace(
space = space
)
def get_DecisionTreeRegressor_ConfigurationSpace(random_state):
space = {
'criterion': Categorical("criterion", ['friedman_mse', 'poisson', 'absolute_error', 'squared_error']),
# 'max_depth': Integer("max_depth", bounds=(1, n_features*2)),
'min_samples_split': Integer("min_samples_split", bounds=(2, 21)),
'min_samples_leaf': Integer("min_samples_leaf", bounds=(1, 21)),
}
if random_state is not None: #This is required because configspace doesn't allow None as a value
space['random_state'] = random_state
return ConfigurationSpace(
space = space
)
def get_KNeighborsRegressor_ConfigurationSpace(n_samples, n_jobs=1):
return ConfigurationSpace(
space = {
'n_neighbors': Integer("n_neighbors", bounds=(1, min(100,n_samples))),
'weights': Categorical("weights", ['uniform', 'distance']),
'p': Integer("p", bounds=(1, 3)),
'n_jobs': n_jobs,
}
)
def get_LinearSVR_ConfigurationSpace(random_state):
space = {
'epsilon': Float("epsilon", bounds=(1e-4, 1.0), log=True),
'C': Float('C', (0.01, 1e5), log=True),
'dual': "auto",
'loss': Categorical("loss", ['epsilon_insensitive', 'squared_epsilon_insensitive']),
}
if random_state is not None: #This is required because configspace doesn't allow None as a value
space['random_state'] = random_state
return ConfigurationSpace(
space = space
)
#add coef0?
def get_SVR_ConfigurationSpace():
space = {
'epislon': Float("epsilon", bounds=(1e-4, 1.0), log=True),
'shrinking': Categorical("shrinking", [True, False]),
'C': Float('C', (0.01, 1e5), log=True),
'max_iter': 3000,
'tol': 0.005,
}
cs = ConfigurationSpace(
space = space
)
kernel = Categorical("kernel", ['poly', 'rbf', 'linear', 'sigmoid'])
degree = Integer("degree", bounds=(1, 5))
gamma = Float("gamma", bounds=(1e-5, 10.0), log=True)
coef0 = Float("coef0", bounds=(-1, 1))
degree_condition = EqualsCondition(degree, kernel, 'poly')
gamma_condition = InCondition(gamma, kernel, ['poly', 'rbf',])
coef0_condition = InCondition(coef0, kernel, ['poly', 'sigmoid'])
cs.add([kernel, degree, gamma, coef0])
cs.add([degree_condition,gamma_condition])
return cs
def get_XGBRegressor_ConfigurationSpace(random_state, n_jobs=1):
space = {
'n_estimators': 100,
'learning_rate': Float("learning_rate", bounds=(1e-3, 1), log=True),
'subsample': Float("subsample", bounds=(0.5, 1.0)),
'min_child_weight': Integer("min_child_weight", bounds=(1, 21)),
'gamma': Float("gamma", bounds=(1e-4, 20), log=True),
'max_depth': Integer("max_depth", bounds=(3, 18)),
'reg_alpha': Float("reg_alpha", bounds=(1e-4, 100), log=True),
'reg_lambda': Float("reg_lambda", bounds=(1e-4, 1), log=True),
'n_jobs': n_jobs,
'nthread': 1,
'verbosity': 0,
'objective': 'reg:squarederror',
}
if random_state is not None: #This is required because configspace doesn't allow None as a value
space['random_state'] = random_state
return ConfigurationSpace(
space = space
)
def get_AdaBoostRegressor_ConfigurationSpace(random_state):
space = {
'n_estimators': Integer("n_estimators", bounds=(50, 500)),
'learning_rate': Float("learning_rate", bounds=(1e-3, 2.0), log=True),
'loss': Categorical("loss", ['linear', 'square', 'exponential']),
}
if random_state is not None: #This is required because configspace doesn't allow None as a value
space['random_state'] = random_state
return ConfigurationSpace(
space = space
)
def get_ExtraTreesRegressor_ConfigurationSpace(random_state, n_jobs=1):
space = {
'n_estimators': 100,
'criterion': Categorical("criterion", ['friedman_mse', 'poisson', 'absolute_error', 'squared_error']),
'max_features': Float("max_features", bounds=(0.05, 1.0)),
'min_samples_split': Integer("min_samples_split", bounds=(2, 21)),
'min_samples_leaf': Integer("min_samples_leaf", bounds=(1, 21)),
'bootstrap': Categorical("bootstrap", [True, False]),
'n_jobs': n_jobs,
}
if random_state is not None: #This is required because configspace doesn't allow None as a value
space['random_state'] = random_state
return ConfigurationSpace(
space = space
)
###
def get_GaussianProcessRegressor_ConfigurationSpace(n_features, random_state):
space = {
'n_features': n_features,
'alpha': Float("alpha", bounds=(1e-10, 1.0), log=True),
'thetaL': Float("thetaL", bounds=(1e-10, 1e-3), log=True),
'thetaU': Float("thetaU", bounds=(1.0, 100000), log=True),
}
if random_state is not None: #This is required because configspace doesn't allow None as a value
space['random_state'] = random_state
return ConfigurationSpace(
space = space
)
def GaussianProcessRegressor_hyperparameter_parser(params):
kernel = sklearn.gaussian_process.kernels.RBF(
length_scale = [1.0]*params['n_features'],
length_scale_bounds=[(params['thetaL'], params['thetaU'])] * params['n_features'],
)
final_params = {"kernel": kernel,
"alpha": params['alpha'],
"n_restarts_optimizer": 10,
"optimizer": "fmin_l_bfgs_b",
"normalize_y": True,
"copy_X_train": True,
}
if "random_state" in params:
final_params['random_state'] = params['random_state']
return final_params
###
def get_GradientBoostingRegressor_ConfigurationSpace(random_state):
early_stop = Categorical("early_stop", ["off", "valid", "train"])
n_iter_no_change = Integer("n_iter_no_change",bounds=(1,20))
validation_fraction = Float("validation_fraction", bounds=(0.01, 0.4))
n_iter_no_change_cond = InCondition(n_iter_no_change, early_stop, ["valid", "train"] )
validation_fraction_cond = EqualsCondition(validation_fraction, early_stop, "valid")
space = {
'loss': Categorical("loss", ['log_loss', 'exponential']),
'learning_rate': Float("learning_rate", bounds=(1e-3, 1), log=True),
'min_samples_leaf': Integer("min_samples_leaf", bounds=(1, 200)),
'min_samples_split': Integer("min_samples_split", bounds=(2, 20)),
'subsample': Float("subsample", bounds=(0.1, 1.0)),
'max_features': Float("max_features", bounds=(0.01, 1.00)),
'max_leaf_nodes': Integer("max_leaf_nodes", bounds=(3, 2047)),
'max_depth':None, #'max_depth': Integer("max_depth", bounds=(1, 2*n_features)),
'tol': 1e-4,
}
if random_state is not None: #This is required because configspace doesn't allow None as a value
space['random_state'] = random_state
cs = ConfigurationSpace(
space = space
)
cs.add([n_iter_no_change, validation_fraction, early_stop ])
cs.add([validation_fraction_cond, n_iter_no_change_cond])
return cs
def GradientBoostingRegressor_hyperparameter_parser(params):
final_params = {
'loss': params['loss'],
'learning_rate': params['learning_rate'],
'min_samples_leaf': params['min_samples_leaf'],
'min_samples_split': params['min_samples_split'],
'max_features': params['max_features'],
'max_leaf_nodes': params['max_leaf_nodes'],
'max_depth': params['max_depth'],
'tol': params['tol'],
'subsample': params['subsample']
}
if 'random_state' in params:
final_params['random_state'] = params['random_state']
if params['early_stop'] == 'off':
final_params['n_iter_no_change'] = None
final_params['validation_fraction'] = None
elif params['early_stop'] == 'valid':
#this is required because in crossover, its possible that n_iter_no_change is not in the params
if 'n_iter_no_change' not in params:
final_params['n_iter_no_change'] = 10
else:
final_params['n_iter_no_change'] = params['n_iter_no_change']
if 'validation_fraction' not in params:
final_params['validation_fraction'] = 0.1
else:
final_params['validation_fraction'] = params['validation_fraction']
elif params['early_stop'] == 'train':
if 'n_iter_no_change' not in params:
final_params['n_iter_no_change'] = 10
else:
final_params['n_iter_no_change'] = params['n_iter_no_change']
final_params['validation_fraction'] = None
return final_params
#only difference is l2_regularization
def get_HistGradientBoostingRegressor_ConfigurationSpace(random_state):
early_stop = Categorical("early_stop", ["off", "valid", "train"])
n_iter_no_change = Integer("n_iter_no_change",bounds=(1,20))
validation_fraction = Float("validation_fraction", bounds=(0.01, 0.4))
n_iter_no_change_cond = InCondition(n_iter_no_change, early_stop, ["valid", "train"] )
validation_fraction_cond = EqualsCondition(validation_fraction, early_stop, "valid")
space = {
'loss': Categorical("loss", ['log_loss', 'exponential']),
'learning_rate': Float("learning_rate", bounds=(1e-3, 1), log=True),
'min_samples_leaf': Integer("min_samples_leaf", bounds=(1, 200)),
'max_features': Float("max_features", bounds=(0.1,1.0)),
'max_leaf_nodes': Integer("max_leaf_nodes", bounds=(3, 2047)),
'max_depth':None, #'max_depth': Integer("max_depth", bounds=(1, 2*n_features)),
'l2_regularization': Float("l2_regularization", bounds=(1e-10, 1), log=True),
'tol': 1e-4,
}
if random_state is not None: #This is required because configspace doesn't allow None as a value
space['random_state'] = random_state
cs = ConfigurationSpace(
space = space
)
cs.add([n_iter_no_change, validation_fraction, early_stop ])
cs.add([validation_fraction_cond, n_iter_no_change_cond])
return cs
def HistGradientBoostingRegressor_hyperparameter_parser(params):
final_params = {
'learning_rate': params['learning_rate'],
'min_samples_leaf': params['min_samples_leaf'],
'max_features': params['max_features'],
'max_leaf_nodes': params['max_leaf_nodes'],
'max_depth': params['max_depth'],
'tol': params['tol'],
'l2_regularization': params['l2_regularization']
}
if 'random_state' in params:
final_params['random_state'] = params['random_state']
if params['early_stop'] == 'off':
# final_params['n_iter_no_change'] = 0
# final_params['validation_fraction'] = None
final_params['early_stopping'] = False
elif params['early_stop'] == 'valid':
if 'n_iter_no_change' not in params:
final_params['n_iter_no_change'] = 10
else:
final_params['n_iter_no_change'] = params['n_iter_no_change']
if 'validation_fraction' not in params:
final_params['validation_fraction'] = 0.1
else:
final_params['validation_fraction'] = params['validation_fraction']
final_params['early_stopping'] = True
elif params['early_stop'] == 'train':
if 'n_iter_no_change' not in params:
final_params['n_iter_no_change'] = 10
else:
final_params['n_iter_no_change'] = params['n_iter_no_change']
final_params['validation_fraction'] = None
final_params['early_stopping'] = True
return final_params
###
def get_MLPRegressor_ConfigurationSpace(random_state):
space = {"n_iter_no_change":32}
if random_state is not None: #This is required because configspace doesn't allow None as a value
space['random_state'] = random_state
cs = ConfigurationSpace(
space = space
)
n_hidden_layers = Integer("n_hidden_layers", bounds=(1, 3))
n_nodes_per_layer = Integer("n_nodes_per_layer", bounds=(16, 512))
activation = Categorical("activation", ['tanh', 'relu'])
alpha = Float("alpha", bounds=(1e-7, 1e-1), log=True)
learning_rate = Float("learning_rate", bounds=(1e-4, 1e-1), log=True)
early_stopping = Categorical("early_stopping", [True,False])
learning_rate_init = Float("learning_rate_init", bounds=(1e-4, 1e-1), log=True)
learning_rate = Categorical("learning_rate", ['constant', 'invscaling', 'adaptive'])
cs.add([n_hidden_layers, n_nodes_per_layer, activation, alpha, learning_rate, early_stopping, learning_rate_init])
return cs
def MLPRegressor_hyperparameter_parser(params):
hyperparameters = {
'n_iter_no_change': params['n_iter_no_change'],
'hidden_layer_sizes' : [params['n_nodes_per_layer']]*params['n_hidden_layers'],
'activation': params['activation'],
'alpha': params['alpha'],
'early_stopping': params['early_stopping'],
'learning_rate_init': params['learning_rate_init'],
'learning_rate': params['learning_rate'],
}
if 'random_state' in params:
hyperparameters['random_state'] = params['random_state']
return hyperparameters
def get_BaggingRegressor_ConfigurationSpace(random_state, n_jobs=1):
space = {
'n_estimators': Integer("n_estimators", bounds=(3, 100)),
'max_samples': Float("max_samples", bounds=(0.1, 1.0)),
'max_features': Float("max_features", bounds=(0.1, 1.0)),
'bootstrap_features': Categorical("bootstrap_features", [True, False]),
'n_jobs': n_jobs,
}
if random_state is not None: #This is required because configspace doesn't allow None as a value
space['random_state'] = random_state
bootstrap = Categorical("bootstrap", [True, False])
oob_score = Categorical("oob_score", [True, False])
oob_condition = EqualsCondition(oob_score, bootstrap, True)
cs = ConfigurationSpace(
space = space
)
cs.add([bootstrap, oob_score])
cs.add([oob_condition])
return cs
def get_LGBMRegressor_ConfigurationSpace(random_state, n_jobs=1):
space = {
'boosting_type': Categorical("boosting_type", ['gbdt', 'dart', 'goss']),
'num_leaves': Integer("num_leaves", bounds=(2, 256)),
'max_depth': Integer("max_depth", bounds=(1, 10)),
'n_estimators': Integer("n_estimators", bounds=(10, 100)),
'verbose':-1,
'n_jobs': n_jobs,
}
if random_state is not None: #This is required because configspace doesn't allow None as a value
space['random_state'] = random_state
return ConfigurationSpace(
space=space
)
================================================
FILE: tpot/config/regressors_sklearnex.py
================================================
"""
This file is part of the TPOT library.
The current version of TPOT was developed at Cedars-Sinai by:
- Pedro Henrique Ribeiro (https://github.com/perib, https://www.linkedin.com/in/pedro-ribeiro/)
- Anil Saini (anil.saini@cshs.org)
- Jose Hernandez (jgh9094@gmail.com)
- Jay Moran (jay.moran@cshs.org)
- Nicholas Matsumoto (nicholas.matsumoto@cshs.org)
- Hyunjun Choi (hyunjun.choi@cshs.org)
- Gabriel Ketron (gabriel.ketron@cshs.org)
- Miguel E. Hernandez (miguel.e.hernandez@cshs.org)
- Jason Moore (moorejh28@gmail.com)
The original version of TPOT was primarily developed at the University of Pennsylvania by:
- Randal S. Olson (rso@randalolson.com)
- Weixuan Fu (weixuanf@upenn.edu)
- Daniel Angell (dpa34@drexel.edu)
- Jason Moore (moorejh28@gmail.com)
- and many more generous open-source contributors
TPOT is free software: you can redistribute it and/or modify
it under the terms of the GNU Lesser General Public License as
published by the Free Software Foundation, either version 3 of
the License, or (at your option) any later version.
TPOT is distributed in the hope that it will be useful,
but WITHOUT ANY WARRANTY; without even the implied warranty of
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
GNU Lesser General Public License for more details.
You should have received a copy of the GNU Lesser General Public
License along with TPOT. If not, see .
"""
from ConfigSpace import ConfigurationSpace
from ConfigSpace import ConfigurationSpace, Integer, Float, Categorical, Normal
def get_RandomForestRegressor_ConfigurationSpace(random_state):
space = {
'n_estimators': 100,
'max_features': Float("max_features", bounds=(0.05, 1.0)),
'bootstrap': Categorical("bootstrap", [True, False]),
'min_samples_split': Integer("min_samples_split", bounds=(2, 21)),
'min_samples_leaf': Integer("min_samples_leaf", bounds=(1, 21)),
}
if random_state is not None: #This is required because configspace doesn't allow None as a value
space['random_state'] = random_state
return ConfigurationSpace(
space = space
)
def get_KNeighborsRegressor_ConfigurationSpace(n_samples):
return ConfigurationSpace(
space = {
'n_neighbors': Integer("n_neighbors", bounds=(1, max(n_samples, 100))),
'weights': Categorical("weights", ['uniform', 'distance']),
}
)
def get_Ridge_ConfigurationSpace(random_state):
space = {
'alpha': Float("alpha", bounds=(0.0, 1.0)),
'fit_intercept': Categorical("fit_intercept", [True]),
'tol': Float("tol", bounds=(1e-5, 1e-1)),
}
if random_state is not None: #This is required because configspace doesn't allow None as a value
space['random_state'] = random_state
return ConfigurationSpace(
space = space
)
def get_Lasso_ConfigurationSpace(random_state):
space = {
'alpha': Float("alpha", bounds=(0.0, 1.0)),
'fit_intercept': Categorical("fit_intercept", [True]),
'precompute': Categorical("precompute", [True, False, 'auto']),
'tol': 0.001,
'positive': Categorical("positive", [True, False]),
'selection': Categorical("selection", ['cyclic', 'random']),
}
if random_state is not None: #This is required because configspace doesn't allow None as a value
space['random_state'] = random_state
return ConfigurationSpace(
space = space
)
def get_ElasticNet_ConfigurationSpace(random_state):
space = {
'alpha': Float("alpha", bounds=(0.0, 1.0)),
'l1_ratio': Float("l1_ratio", bounds=(0.0, 1.0)),
}
if random_state is not None: #This is required because configspace doesn't allow None as a value
space['random_state'] = random_state
return ConfigurationSpace(
space = space
)
def get_SVR_ConfigurationSpace(random_state):
space = {
'kernel': Categorical("kernel", ['poly', 'rbf', 'linear', 'sigmoid']),
'C': Float("C", bounds=(1e-4, 25), log=True),
'degree': Integer("degree", bounds=(1, 4)),
'max_iter': 3000,
'tol': 0.001,
}
if random_state is not None: #This is required because configspace doesn't allow None as a value
space['random_state'] = random_state
return ConfigurationSpace(
space = space
)
def get_NuSVR_ConfigurationSpace(random_state):
space = {
'nu': Float("nu", bounds=(0.05, 1.0)),
'kernel': Categorical("kernel", ['poly', 'rbf', 'linear', 'sigmoid']),
'C': Float("C", bounds=(1e-4, 25), log=True),
'degree': Integer("degree", bounds=(1, 4)),
'max_iter': 3000,
'tol': 0.005,
}
if random_state is not None: #This is required because configspace doesn't allow None as a value
space['random_state'] = random_state
return ConfigurationSpace(
space = space
)
================================================
FILE: tpot/config/selectors.py
================================================
"""
This file is part of the TPOT library.
The current version of TPOT was developed at Cedars-Sinai by:
- Pedro Henrique Ribeiro (https://github.com/perib, https://www.linkedin.com/in/pedro-ribeiro/)
- Anil Saini (anil.saini@cshs.org)
- Jose Hernandez (jgh9094@gmail.com)
- Jay Moran (jay.moran@cshs.org)
- Nicholas Matsumoto (nicholas.matsumoto@cshs.org)
- Hyunjun Choi (hyunjun.choi@cshs.org)
- Gabriel Ketron (gabriel.ketron@cshs.org)
- Miguel E. Hernandez (miguel.e.hernandez@cshs.org)
- Jason Moore (moorejh28@gmail.com)
The original version of TPOT was primarily developed at the University of Pennsylvania by:
- Randal S. Olson (rso@randalolson.com)
- Weixuan Fu (weixuanf@upenn.edu)
- Daniel Angell (dpa34@drexel.edu)
- Jason Moore (moorejh28@gmail.com)
- and many more generous open-source contributors
TPOT is free software: you can redistribute it and/or modify
it under the terms of the GNU Lesser General Public License as
published by the Free Software Foundation, either version 3 of
the License, or (at your option) any later version.
TPOT is distributed in the hope that it will be useful,
but WITHOUT ANY WARRANTY; without even the implied warranty of
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
GNU Lesser General Public License for more details.
You should have received a copy of the GNU Lesser General Public
License along with TPOT. If not, see .
"""
#TODO: how to best support transformers/selectors that take other transformers with their own hyperparameters?
import numpy as np
import sklearn
from ConfigSpace import ConfigurationSpace
from ConfigSpace import ConfigurationSpace, Integer, Float, Categorical, Normal
SelectFwe_configspace = ConfigurationSpace(
space = {
'alpha': Float('alpha', bounds=(1e-4, 0.05), log=True),
}
)
SelectPercentile_configspace = ConfigurationSpace(
space = {
'percentile': Float('percentile', bounds=(1, 100.0)),
}
)
VarianceThreshold_configspace = ConfigurationSpace(
space = {
'threshold': Float('threshold', bounds=(1e-4, .2), log=True),
}
)
# Note the RFE_configspace_part and SelectFromModel_configspace_part are not complete, they both require the estimator to be set.
# These are indended to be used with the Wrapped search space.
RFE_configspace_part = ConfigurationSpace(
space = {
'step': Float('step', bounds=(1e-4, 1.0)),
}
)
SelectFromModel_configspace_part = ConfigurationSpace(
space = {
'threshold': Float('threshold', bounds=(1e-4, 1.0), log=True),
}
)
================================================
FILE: tpot/config/special_configs.py
================================================
"""
This file is part of the TPOT library.
The current version of TPOT was developed at Cedars-Sinai by:
- Pedro Henrique Ribeiro (https://github.com/perib, https://www.linkedin.com/in/pedro-ribeiro/)
- Anil Saini (anil.saini@cshs.org)
- Jose Hernandez (jgh9094@gmail.com)
- Jay Moran (jay.moran@cshs.org)
- Nicholas Matsumoto (nicholas.matsumoto@cshs.org)
- Hyunjun Choi (hyunjun.choi@cshs.org)
- Gabriel Ketron (gabriel.ketron@cshs.org)
- Miguel E. Hernandez (miguel.e.hernandez@cshs.org)
- Jason Moore (moorejh28@gmail.com)
The original version of TPOT was primarily developed at the University of Pennsylvania by:
- Randal S. Olson (rso@randalolson.com)
- Weixuan Fu (weixuanf@upenn.edu)
- Daniel Angell (dpa34@drexel.edu)
- Jason Moore (moorejh28@gmail.com)
- and many more generous open-source contributors
TPOT is free software: you can redistribute it and/or modify
it under the terms of the GNU Lesser General Public License as
published by the Free Software Foundation, either version 3 of
the License, or (at your option) any later version.
TPOT is distributed in the hope that it will be useful,
but WITHOUT ANY WARRANTY; without even the implied warranty of
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
GNU Lesser General Public License for more details.
You should have received a copy of the GNU Lesser General Public
License along with TPOT. If not, see .
"""
from tpot.builtin_modules import ArithmeticTransformer, FeatureSetSelector
from functools import partial
import pandas as pd
import numpy as np
from tpot.builtin_modules import AddTransformer, mul_neg_1_Transformer, MulTransformer, SafeReciprocalTransformer, EQTransformer, NETransformer, GETransformer, GTTransformer, LETransformer, LTTransformer, MinTransformer, MaxTransformer, ZeroTransformer, OneTransformer, NTransformer
from ConfigSpace import ConfigurationSpace
from ConfigSpace import ConfigurationSpace, Integer, Float, Categorical, Normal
def get_ArithmeticTransformer_ConfigurationSpace():
return ConfigurationSpace(
space = {
'function': Categorical("function", ["add", "mul_neg_1", "mul", "safe_reciprocal", "eq","ne","ge","gt","le","lt", "min","max","0","1"]),
}
)
# AddTransformer: {}
# mul_neg_1_Transformer: {}
# MulTransformer: {}
# SafeReciprocalTransformer: {}
# EQTransformer: {}
# NETransformer: {}
# GETransformer: {}
# GTTransformer: {}
# LETransformer: {}
# LTTransformer: {}
# MinTransformer: {}
# MaxTransformer: {}
================================================
FILE: tpot/config/template_search_spaces.py
================================================
"""
This file is part of the TPOT library.
The current version of TPOT was developed at Cedars-Sinai by:
- Pedro Henrique Ribeiro (https://github.com/perib, https://www.linkedin.com/in/pedro-ribeiro/)
- Anil Saini (anil.saini@cshs.org)
- Jose Hernandez (jgh9094@gmail.com)
- Jay Moran (jay.moran@cshs.org)
- Nicholas Matsumoto (nicholas.matsumoto@cshs.org)
- Hyunjun Choi (hyunjun.choi@cshs.org)
- Gabriel Ketron (gabriel.ketron@cshs.org)
- Miguel E. Hernandez (miguel.e.hernandez@cshs.org)
- Jason Moore (moorejh28@gmail.com)
The original version of TPOT was primarily developed at the University of Pennsylvania by:
- Randal S. Olson (rso@randalolson.com)
- Weixuan Fu (weixuanf@upenn.edu)
- Daniel Angell (dpa34@drexel.edu)
- Jason Moore (moorejh28@gmail.com)
- and many more generous open-source contributors
TPOT is free software: you can redistribute it and/or modify
it under the terms of the GNU Lesser General Public License as
published by the Free Software Foundation, either version 3 of
the License, or (at your option) any later version.
TPOT is distributed in the hope that it will be useful,
but WITHOUT ANY WARRANTY; without even the implied warranty of
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
GNU Lesser General Public License for more details.
You should have received a copy of the GNU Lesser General Public
License along with TPOT. If not, see .
"""
import tpot
from tpot.search_spaces.pipelines import *
from tpot.search_spaces.nodes import *
from .get_configspace import get_search_space
import sklearn.model_selection
import sklearn
def get_linear_search_space(classification=True, inner_predictors=True, cross_val_predict_cv=0, **get_search_space_params ):
if classification:
selectors = get_search_space(["selectors","selectors_classification", "Passthrough"], **get_search_space_params)
estimators = get_search_space(["classifiers"], **get_search_space_params)
else:
selectors = get_search_space(["selectors","selectors_regression", "Passthrough"], **get_search_space_params)
estimators = get_search_space(["regressors"], **get_search_space_params)
# this allows us to wrap the classifiers in the EstimatorTransformer
# this is necessary so that classifiers can be used inside of sklearn pipelines
wrapped_estimators = WrapperPipeline(tpot.builtin_modules.EstimatorTransformer, {'cross_val_predict_cv':cross_val_predict_cv}, estimators)
scalers = get_search_space(["scalers","Passthrough"], **get_search_space_params)
transformers_layer =UnionPipeline([
ChoicePipeline([
DynamicUnionPipeline(get_search_space(["transformers"],**get_search_space_params)),
get_search_space("SkipTransformer", **get_search_space_params),
]),
get_search_space("Passthrough", **get_search_space_params)
]
)
inner_estimators_layer = UnionPipeline([
ChoicePipeline([
DynamicUnionPipeline(wrapped_estimators),
get_search_space("SkipTransformer", **get_search_space_params),
]),
get_search_space("Passthrough", **get_search_space_params)]
)
if inner_predictors:
search_space = SequentialPipeline(search_spaces=[
scalers,
selectors,
transformers_layer,
inner_estimators_layer,
estimators,
])
else:
search_space = SequentialPipeline(search_spaces=[
scalers,
selectors,
transformers_layer,
estimators,
])
return search_space
def get_graph_search_space(classification=True, inner_predictors=True, cross_val_predict_cv=0, **get_search_space_params ):
if classification:
root_search_space = get_search_space(["classifiers"], **get_search_space_params)
inner_search_space = tpot.config.get_search_space(["transformers","scalers","selectors_classification"],**get_search_space_params)
else:
root_search_space = get_search_space(["regressors"], **get_search_space_params)
if classification:
if inner_predictors:
inner_search_space = tpot.config.get_search_space(["classifiers","transformers","scalers","selectors_classification"],**get_search_space_params)
else:
inner_search_space = tpot.config.get_search_space(["transformers","scalers","selectors_classification"],**get_search_space_params)
else:
if inner_predictors:
inner_search_space = tpot.config.get_search_space(["regressors", "transformers","scalers","selectors_regression"],**get_search_space_params)
else:
inner_search_space = tpot.config.get_search_space(["transformers","scalers","selectors_regression"],**get_search_space_params)
search_space = tpot.search_spaces.pipelines.GraphSearchPipeline(
root_search_space= root_search_space,
leaf_search_space = None,
inner_search_space = inner_search_space,
cross_val_predict_cv=cross_val_predict_cv,
max_size=15,
)
return search_space
def get_graph_search_space_light(classification=True, inner_predictors=True, cross_val_predict_cv=0, **get_search_space_params ):
if classification:
root_search_space = get_search_space(['BernoulliNB', 'DecisionTreeClassifier', 'GaussianNB', 'KNeighborsClassifier', 'LogisticRegression', 'MultinomialNB'], **get_search_space_params)
else:
root_search_space = get_search_space(["RidgeCV", "LinearSVR", "LassoLarsCV", "KNeighborsRegressor", "DecisionTreeRegressor", "ElasticNetCV"], **get_search_space_params)
if classification:
if inner_predictors:
inner_search_space = tpot.config.get_search_space(['BernoulliNB', 'DecisionTreeClassifier', 'GaussianNB', 'KNeighborsClassifier', 'LogisticRegression', 'MultinomialNB',"transformers","scalers","SelectFwe", "SelectPercentile", "VarianceThreshold"],**get_search_space_params)
else:
inner_search_space = tpot.config.get_search_space(["transformers","scalers","SelectFwe", "SelectPercentile", "VarianceThreshold"],**get_search_space_params)
else:
if inner_predictors:
inner_search_space = tpot.config.get_search_space(["RidgeCV", "LinearSVR", "LassoLarsCV", "KNeighborsRegressor", "DecisionTreeRegressor", "ElasticNetCV", "transformers","scalers", "SelectFwe", "SelectPercentile", "VarianceThreshold"],**get_search_space_params)
else:
inner_search_space = tpot.config.get_search_space(["transformers", "scalers", "SelectFwe", "SelectPercentile", "VarianceThreshold"],**get_search_space_params)
search_space = tpot.search_spaces.pipelines.GraphSearchPipeline(
root_search_space= root_search_space,
leaf_search_space = None,
inner_search_space = inner_search_space,
cross_val_predict_cv=cross_val_predict_cv,
max_size=15,
)
return search_space
def get_light_search_space(classification=True, inner_predictors=False, cross_val_predict_cv=0, **get_search_space_params ):
selectors = get_search_space(["SelectFwe", "SelectPercentile", "VarianceThreshold","Passthrough"], **get_search_space_params)
if classification:
estimators = get_search_space(['BernoulliNB', 'DecisionTreeClassifier', 'GaussianNB', 'KNeighborsClassifier', 'LogisticRegression', 'MultinomialNB'], **get_search_space_params)
else:
estimators = get_search_space(["RidgeCV", "LinearSVR", "LassoLarsCV", "KNeighborsRegressor", "DecisionTreeRegressor", "ElasticNetCV"], **get_search_space_params)
# this allows us to wrap the classifiers in the EstimatorTransformer
# this is necessary so that classifiers can be used inside of sklearn pipelines
wrapped_estimators = WrapperPipeline(tpot.builtin_modules.EstimatorTransformer, {'cross_val_predict_cv':cross_val_predict_cv}, estimators)
scalers = get_search_space(["scalers","Passthrough"], **get_search_space_params)
transformers_layer =UnionPipeline([
ChoicePipeline([
DynamicUnionPipeline(get_search_space(["transformers"],**get_search_space_params)),
get_search_space("SkipTransformer", **get_search_space_params),
]),
get_search_space("Passthrough", **get_search_space_params)
]
)
inner_estimators_layer = UnionPipeline([
ChoicePipeline([
DynamicUnionPipeline(wrapped_estimators),
get_search_space("SkipTransformer", **get_search_space_params),
]),
get_search_space("Passthrough", **get_search_space_params)]
)
if inner_predictors:
search_space = SequentialPipeline(search_spaces=[
scalers,
selectors,
transformers_layer,
inner_estimators_layer,
estimators,
])
else:
search_space = SequentialPipeline(search_spaces=[
scalers,
selectors,
transformers_layer,
estimators,
])
return search_space
def get_mdr_search_space(classification=True, **get_search_space_params ):
if classification:
mdr_sp = DynamicLinearPipeline(get_search_space(["ReliefF", "SURF", "SURFstar", "MultiSURF", "MDR"], **get_search_space_params), max_length=10)
estimators = get_search_space(['LogisticRegression'], **get_search_space_params)
else:
mdr_sp = DynamicLinearPipeline(get_search_space(["ReliefF", "SURF", "SURFstar", "MultiSURF", "ContinuousMDR"], **get_search_space_params), max_length=10)
estimators = get_search_space(["ElasticNetCV"], **get_search_space_params)
search_space = SequentialPipeline(search_spaces=[
mdr_sp,
estimators,
])
return search_space
def get_template_search_spaces(search_space, classification=True, inner_predictors=None, cross_val_predict_cv=None, **get_search_space_params):
"""
Returns a search space which can be optimized by TPOT.
Parameters
----------
search_space: str or SearchSpace
The default search space to use. If a string, it should be one of the following:
- 'linear': A search space for linear pipelines
- 'linear-light': A search space for linear pipelines with a smaller, faster search space
- 'graph': A search space for graph pipelines
- 'graph-light': A search space for graph pipelines with a smaller, faster search space
- 'mdr': A search space for MDR pipelines
If a SearchSpace object, it should be a valid search space object for TPOT.
classification: bool, default=True
Whether the problem is a classification problem or a regression problem.
inner_predictors: bool, default=None
Whether to include additional classifiers/regressors before the final classifier/regressor (allowing for ensembles).
Defaults to False for 'linear-light' and 'graph-light' search spaces, and True otherwise. (Not used for 'mdr' search space)
cross_val_predict_cv: int, default=None
The number of folds to use for cross_val_predict.
Defaults to 0 for 'linear-light' and 'graph-light' search spaces, and 5 otherwise. (Not used for 'mdr' search space)
get_search_space_params: dict
Additional parameters to pass to the get_search_space function.
"""
if inner_predictors is None:
if search_space == "light" or search_space == "graph_light":
inner_predictors = False
else:
inner_predictors = True
if cross_val_predict_cv is None:
if search_space == "light" or search_space == "graph_light":
cross_val_predict_cv = 0
else:
if classification:
cross_val_predict_cv = sklearn.model_selection.StratifiedKFold(n_splits=5, shuffle=True, random_state=42)
else:
cross_val_predict_cv = sklearn.model_selection.KFold(n_splits=5, shuffle=True, random_state=42)
if isinstance(search_space, str):
if search_space == "linear":
return get_linear_search_space(classification, inner_predictors, cross_val_predict_cv=cross_val_predict_cv, **get_search_space_params)
elif search_space == "graph":
return get_graph_search_space(classification, inner_predictors, cross_val_predict_cv=cross_val_predict_cv, **get_search_space_params)
elif search_space == "graph-light":
return get_graph_search_space_light(classification, inner_predictors, cross_val_predict_cv=cross_val_predict_cv, **get_search_space_params)
elif search_space == "linear-light":
return get_light_search_space(classification, inner_predictors, cross_val_predict_cv=cross_val_predict_cv, **get_search_space_params)
elif search_space == "mdr":
return get_mdr_search_space(classification, **get_search_space_params)
else:
raise ValueError("Invalid search space")
else:
return search_space
================================================
FILE: tpot/config/tests/__init__.py
================================================
================================================
FILE: tpot/config/tests/test_get_configspace.py
================================================
import pytest
import tpot
import sys
from sklearn.datasets import load_iris
import random
import sklearn
import warnings
import tpot.config
from ..get_configspace import STRING_TO_CLASS, GROUPNAMES
import importlib.util
def test_loop_through_all_hyperparameters():
n_classes=3
n_samples=100
n_features=100
random_state=None
for class_name, _ in STRING_TO_CLASS.items():
print(class_name)
estnode_gen = tpot.config.get_search_space(class_name, n_classes=n_classes, n_samples=n_samples, n_features=n_features, random_state=random_state)
#generate 100 random hyperparameters and make sure they are all valid
for i in range(25):
estnode = estnode_gen.generate()
est = estnode.export_pipeline()
@pytest.mark.skipif(sys.platform == 'darwin', reason="sklearnex dependency not available on macOS")
def test_loop_through_groupnames():
n_classes=3
n_samples=100
n_features=100
random_state=None
# Check if skrebate is installed
is_skrebate_installed = importlib.util.find_spec("skrebate") is not None
# Check if sklearnx is installed
is_sklearnx_installed = importlib.util.find_spec("sklearnx") is not None
if is_skrebate_installed:
warnings.warn("skrebate not installed, skipping those estimators")
if is_sklearnx_installed:
warnings.warn("sklearnx not installed, skipping those estimators")
for groupname, group in GROUPNAMES.items():
for class_name in group:
print(class_name)
estnode_gen = tpot.config.get_search_space(class_name, n_classes=n_classes, n_samples=n_samples, n_features=n_features, random_state=random_state)
#generate 10 random hyperparameters and make sure they are all valid
for i in range(25):
estnode = estnode_gen.generate()
est = estnode.export_pipeline()
================================================
FILE: tpot/config/transformers.py
================================================
"""
This file is part of the TPOT library.
The current version of TPOT was developed at Cedars-Sinai by:
- Pedro Henrique Ribeiro (https://github.com/perib, https://www.linkedin.com/in/pedro-ribeiro/)
- Anil Saini (anil.saini@cshs.org)
- Jose Hernandez (jgh9094@gmail.com)
- Jay Moran (jay.moran@cshs.org)
- Nicholas Matsumoto (nicholas.matsumoto@cshs.org)
- Hyunjun Choi (hyunjun.choi@cshs.org)
- Gabriel Ketron (gabriel.ketron@cshs.org)
- Miguel E. Hernandez (miguel.e.hernandez@cshs.org)
- Jason Moore (moorejh28@gmail.com)
The original version of TPOT was primarily developed at the University of Pennsylvania by:
- Randal S. Olson (rso@randalolson.com)
- Weixuan Fu (weixuanf@upenn.edu)
- Daniel Angell (dpa34@drexel.edu)
- Jason Moore (moorejh28@gmail.com)
- and many more generous open-source contributors
TPOT is free software: you can redistribute it and/or modify
it under the terms of the GNU Lesser General Public License as
published by the Free Software Foundation, either version 3 of
the License, or (at your option) any later version.
TPOT is distributed in the hope that it will be useful,
but WITHOUT ANY WARRANTY; without even the implied warranty of
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
GNU Lesser General Public License for more details.
You should have received a copy of the GNU Lesser General Public
License along with TPOT. If not, see .
"""
from ConfigSpace import ConfigurationSpace
from ConfigSpace import ConfigurationSpace, Integer, Float, Categorical, Normal
from ConfigSpace import EqualsCondition, OrConjunction, NotEqualsCondition, InCondition
import numpy as np
Binarizer_configspace = ConfigurationSpace(
space = {
'threshold': Float('threshold', bounds=(0.0, 1.0)),
}
)
Normalizer_configspace = ConfigurationSpace(
space={'norm': Categorical('norm', ['l1', 'l2', 'max'])}
)
PCA_configspace = ConfigurationSpace(
space={'n_components': Float('n_components', bounds=(0.5, 0.999))}
)
ZeroCount_configspace = {}
PolynomialFeatures_configspace = ConfigurationSpace(
space = {
'degree': Integer('degree', bounds=(2, 3)),
'interaction_only': Categorical('interaction_only', [True, False]),
}
)
OneHotEncoder_configspace = {} #TODO include the parameter for max unique values
OrdinalEncoder_configspace = {} #TODO include the parameter for max unique values
def get_FastICA_configspace(n_features=100, random_state=None):
space = {
'n_components': Integer('n_components', bounds=(1, n_features)),
'algorithm': Categorical('algorithm', ['parallel', 'deflation']),
'whiten':'unit-variance',
}
if random_state is not None: #This is required because configspace doesn't allow None as a value
space['random_state'] = random_state
return ConfigurationSpace(
space = space
)
def get_FeatureAgglomeration_configspace(n_features):
linkage = Categorical('linkage', ['ward', 'complete', 'average'])
metric = Categorical('metric', ['euclidean', 'l1', 'l2', 'manhattan', 'cosine'])
n_clusters = Integer('n_clusters', bounds=(2, min(n_features,400)))
pooling_func = Categorical('pooling_func', ['mean', 'median', 'max'])
metric_condition = NotEqualsCondition(metric, linkage, 'ward')
cs = ConfigurationSpace()
cs.add([linkage, metric, n_clusters, pooling_func])
cs.add(metric_condition)
return cs
def FeatureAgglomeration_hyperparameter_parser(params):
new_params = params.copy()
if "pooling_func" in new_params:
if new_params["pooling_func"] == "mean":
new_params["pooling_func"] = np.mean
elif new_params["pooling_func"] == "median":
new_params["pooling_func"] = np.median
elif new_params["pooling_func"] == "max":
new_params["pooling_func"] = np.max
elif new_params["pooling_func"] == "min":
new_params["pooling_func"] = np.min
return new_params
def get_Nystroem_configspace(n_features=100, random_state=None,):
space = {
'gamma': Float('gamma', bounds=(0.0, 1.0)),
'kernel': Categorical('kernel', ['rbf', 'cosine', 'chi2', 'laplacian', 'polynomial', 'poly', 'linear', 'additive_chi2', 'sigmoid']),
'n_components': Integer('n_components', bounds=(1, n_features)),
}
if random_state is not None: #This is required because configspace doesn't allow None as a value
space['random_state'] = random_state
return ConfigurationSpace(
space = space
)
def get_RBFSampler_configspace(n_features=100, random_state=None):
space = {
'gamma': Float('gamma', bounds=(0.0, 1.0)),
'n_components': Integer('n_components', bounds=(1, n_features)),
}
if random_state is not None: #This is required because configspace doesn't allow None as a value
space['random_state'] = random_state
return ConfigurationSpace(
space = space
)
def get_QuantileTransformer_configspace(random_state=None, n_samples=1000):
space = {
'n_quantiles': Integer('n_quantiles', bounds=(10, n_samples)),
'output_distribution': Categorical('output_distribution', ['uniform', 'normal']),
}
if random_state is not None: #This is required because configspace doesn't allow None as a value
space['random_state'] = random_state
return ConfigurationSpace(
space = space
)
def get_passkbinsdiscretizer_configspace(random_state=None):
space = {
'n_bins': Integer('n_bins', bounds=(3, 100)),
'encode': 'onehot-dense',
'strategy': Categorical('strategy', ['uniform', 'quantile', 'kmeans']),
# 'subsample': Categorical('subsample', ['auto', 'warn', 'ignore']),
}
if random_state is not None: #This is required because configspace doesn't allow None as a value
space['random_state'] = random_state
return ConfigurationSpace(
space = space
)
### ROBUST SCALER
RobustScaler_configspace = ConfigurationSpace({
"q_min": Float("q_min", bounds=(0.001, 0.3)),
"q_max": Float("q_max", bounds=(0.7, 0.999)),
})
def robust_scaler_hyperparameter_parser(params):
return {"quantile_range": (params["q_min"], params["q_max"])}
================================================
FILE: tpot/evolvers/__init__.py
================================================
from .base_evolver import *
from .steady_state_evolver import *
================================================
FILE: tpot/evolvers/base_evolver.py
================================================
"""
This file is part of the TPOT library.
The current version of TPOT was developed at Cedars-Sinai by:
- Pedro Henrique Ribeiro (https://github.com/perib, https://www.linkedin.com/in/pedro-ribeiro/)
- Anil Saini (anil.saini@cshs.org)
- Jose Hernandez (jgh9094@gmail.com)
- Jay Moran (jay.moran@cshs.org)
- Nicholas Matsumoto (nicholas.matsumoto@cshs.org)
- Hyunjun Choi (hyunjun.choi@cshs.org)
- Gabriel Ketron (gabriel.ketron@cshs.org)
- Miguel E. Hernandez (miguel.e.hernandez@cshs.org)
- Jason Moore (moorejh28@gmail.com)
The original version of TPOT was primarily developed at the University of Pennsylvania by:
- Randal S. Olson (rso@randalolson.com)
- Weixuan Fu (weixuanf@upenn.edu)
- Daniel Angell (dpa34@drexel.edu)
- Jason Moore (moorejh28@gmail.com)
- and many more generous open-source contributors
TPOT is free software: you can redistribute it and/or modify
it under the terms of the GNU Lesser General Public License as
published by the Free Software Foundation, either version 3 of
the License, or (at your option) any later version.
TPOT is distributed in the hope that it will be useful,
but WITHOUT ANY WARRANTY; without even the implied warranty of
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
GNU Lesser General Public License for more details.
You should have received a copy of the GNU Lesser General Public
License along with TPOT. If not, see .
"""
#All abstract methods in the Evolutionary_Optimization module
from abc import abstractmethod
import tpot
import typing
import tqdm
from tpot import BaseIndividual
import time
import numpy as np
import copy
import scipy
import os
import pickle
import statistics
from tqdm.dask import TqdmCallback
import distributed
from dask.distributed import Client
from dask.distributed import LocalCluster
from tpot.selectors import survival_select_NSGA2, tournament_selection_dominated
import math
from tpot.utils.utils import get_thresholds, beta_interpolation, remove_items, equalize_list
import gc
# Evolvers allow you to pass in custom mutation and crossover functions. By default,
# the evolver will just use these functions to call ind.mutate or ind.crossover
def ind_mutate(ind, rng):
"""
Calls the ind.mutate method on the individual
Parameters
----------
ind : tpot.BaseIndividual
The individual to mutate
rng : int or numpy.random.Generator
A numpy random generator to use for reproducibility
"""
rng = np.random.default_rng(rng)
return ind.mutate(rng=rng)
def ind_crossover(ind1, ind2, rng):
"""
Calls the ind1.crossover(ind2, rng=rng)
Parameters
----------
ind1 : tpot.BaseIndividual
ind2 : tpot.BaseIndividual
rng : int or numpy.random.Generator
A numpy random generator to use for reproducibility
"""
rng = np.random.default_rng(rng)
return ind1.crossover(ind2, rng=rng)
class BaseEvolver():
def __init__( self,
individual_generator ,
objective_functions,
objective_function_weights,
objective_names = None,
objective_kwargs = None,
bigger_is_better = True,
population_size = 50,
initial_population_size = None,
population_scaling = .5,
generations_until_end_population = 1,
generations = 50,
early_stop = None,
early_stop_tol = 0.001,
max_time_mins=float("inf"),
max_eval_time_mins=5,
n_jobs=1,
memory_limit="4GB",
client=None,
survival_percentage = 1,
crossover_probability=.2,
mutate_probability=.7,
mutate_then_crossover_probability=.05,
crossover_then_mutate_probability=.05,
mutation_functions = [ind_mutate],
crossover_functions = [ind_crossover],
mutation_function_weights = None,
crossover_function_weights = None,
n_parents=2,
survival_selector = survival_select_NSGA2,
parent_selector = tournament_selection_dominated,
budget_range = None,
budget_scaling = .5,
generations_until_end_budget = 1,
stepwise_steps = 5,
threshold_evaluation_pruning = None,
threshold_evaluation_scaling = .5,
min_history_threshold = 20,
selection_evaluation_pruning = None,
selection_evaluation_scaling = .5,
evaluation_early_stop_steps = None,
final_score_strategy = "mean",
verbose = 0,
periodic_checkpoint_folder = None,
callback = None,
rng=None,
) -> None:
"""
Uses mutation, crossover, and optimization functions to evolve a population of individuals towards the given objective functions.
Parameters
----------
individual_generator : generator
Generator that yields new base individuals. Used to generate initial population.
objective_functions : list of callables
list of functions that get applied to the individual and return a float or list of floats
If an objective function returns multiple values, they are all concatenated in order
with respect to objective_function_weights and early_stop_tol.
objective_function_weights : list of floats
list of weights for each objective function. Sign flips whether bigger is better or not
objective_names : list of strings, default=None
Names of the objectives. If None, objective0, objective1, etc. will be used
objective_kwargs : dict, default=None
Dictionary of keyword arguments to pass to the objective function
bigger_is_better : bool, default=True
If True, the objective function is maximized. If False, the objective function is minimized. Use negative weights to reverse the direction.
population_size : int, default=50
Size of the population
initial_population_size : int, default=None
Size of the initial population. If None, population_size will be used.
population_scaling : int, default=0.5
Scaling factor to use when determining how fast we move the threshold moves from the start to end percentile.
generations_until_end_population : int, default=1
Number of generations until the population size reaches population_size
generations : int, default=50
Number of generations to run
early_stop : int, default=None
Number of generations without improvement before early stopping. All objectives must have converged within the tolerance for this to be triggered. In general a value of around 5-20 is good.
early_stop_tol : float, list of floats, or None, default=0.001
-list of floats
list of tolerances for each objective function. If the difference between the best score and the current score is less than the tolerance, the individual is considered to have converged
If an index of the list is None, that item will not be used for early stopping
-int
If an int is given, it will be used as the tolerance for all objectives
max_time_mins : float, default=float("inf")
Maximum time to run the optimization. If none or inf, will run until the end of the generations.
max_eval_time_mins : float, default=10
Maximum time to evaluate a single individual. If none or inf, there will be no time limit per evaluation.
n_jobs : int, default=1
Number of processes to run in parallel.
memory_limit : str, default=None
Memory limit for each job. See Dask [LocalCluster documentation](https://distributed.dask.org/en/stable/api.html#distributed.Client) for more information.
client : dask.distributed.Client, default=None
A dask client to use for parallelization. If not None, this will override the n_jobs and memory_limit parameters. If None, will create a new client with num_workers=n_jobs and memory_limit=memory_limit.
survival_percentage : float, default=1
Percentage of the population size to utilize for mutation and crossover at the beginning of the generation. The rest are discarded. Individuals are selected with the selector passed into survival_selector. The value of this parameter must be between 0 and 1, inclusive.
For example, if the population size is 100 and the survival percentage is .5, 50 individuals will be selected with NSGA2 from the existing population. These will be used for mutation and crossover to generate the next 100 individuals for the next generation. The remainder are discarded from the live population. In the next generation, there will now be the 50 parents + the 100 individuals for a total of 150. Surivival percentage is based of the population size parameter and not the existing population size (current population size when using successive halving). Therefore, in the next generation we will still select 50 individuals from the currently existing 150.
crossover_probability : float, default=.2
Probability of generating a new individual by crossover between two individuals.
mutate_probability : float, default=.7
Probability of generating a new individual by crossover between one individuals.
mutate_then_crossover_probability : float, default=.05
Probability of generating a new individual by mutating two individuals followed by crossover.
crossover_then_mutate_probability : float, default=.05
Probability of generating a new individual by crossover between two individuals followed by a mutation of the resulting individual.
n_parents : int, default=2
Number of parents to use for crossover. Must be greater than 1.
survival_selector : function, default=survival_select_NSGA2
Function to use to select individuals for survival. Must take a matrix of scores and return selected indexes.
Used to selected population_size * survival_percentage individuals at the start of each generation to use for mutation and crossover.
parent_selector : function, default=parent_select_NSGA2
Function to use to select pairs parents for crossover and individuals for mutation. Must take a matrix of scores and return selected indexes.
budget_range : list [start, end], default=None
This parameter is used for the successive halving algorithm.
A starting and ending budget to use for the budget scaling. The evolver will interpolate between these values over the generations_until_end_budget.
Use is dependent on the objective functions. (In TPOTEstimator this corresponds to the percentage of the data to sample.)
budget_scaling float : [0,1], default=0.5
A scaling factor to use when determining how fast we move the budget from the start to end budget.
generations_until_end_budget : int, default=1
The number of generations to run before reaching the max budget.
stepwise_steps : int, default=1
The number of staircase steps to take when interpolating the budget and population size.
threshold_evaluation_pruning : list [start, end], default=None
Starting and ending percentile to use as a threshold for the evaluation early stopping. The evolver will interpolate between these values over the evaluation_early_stop_steps.
Values between 0 and 100.
At each step of the evaluation, a threshold is calculated based on the previous evaluations. All individuals that are below the performance threshold are not evaluated for further steps.
For example, if the threshold is set to the 90th percentile of the previous evaluations, all individuals that are below the 90th percentile are not evaluated further. This can save computation by not evaluating all individuals for all steps of cross validation.
threshold_evaluation_scaling : float [0,inf), default=0.5
A scaling factor to use when determining how fast we move the threshold moves from the start to end percentile.
Must be greater than zero. Higher numbers will move the threshold to the end faster.
min_history_threshold : int, default=0
The minimum number of previous scores needed before using threshold early stopping.
selection_evaluation_pruning : list, default=None
A lower and upper percent of the population size to select each round of CV.
Values between 0 and 1.
Selects a percentage of the population to evaluate at each step of the evaluation.
For example, one strategy is to evaluate different steps of cross validation one at a time, and only select the best N individuals for subsequent steps.
This can save computation by not evaluating all individuals for all steps of cross validation. By default this selection is done with the NSGA2 selector.
selection_evaluation_scaling : float, default=0.5
A scaling factor to use when determining how fast we move the threshold moves from the start to end percentile.
Must be greater than zero. Higher numbers will move the threshold to the end faster.
evaluation_early_stop_steps : int, default=1
The number of steps that will be taken from the objective function. (e.g., the number of CV folds to evaluate)
final_score_strategy : str, default="mean"
The strategy to use when determining the final score for an individual.
"mean": The mean of all objective scores
"last": The score returned by the last call. Currently each objective is evaluated with a clone of the individual.
verbose : int, default=0
How much information to print during the optimization process. Higher values include the information from lower values.
0. nothing
1. progress bar
2. evaluations progress bar
3. best individual
4. warnings
>=5. full warnings trace
periodic_checkpoint_folder : str, default=None
Folder to save the population to periodically. If None, no periodic saving will be done.
If provided, training will resume from this checkpoint.
callback : tpot.CallBackInterface, default=None
Callback object. Not implemented
rng : Numpy.Random.Generator, None, default=None
An object for reproducability of experiments. This value will be passed to numpy.random.default_rng() to create an instnce of the genrator to pass to other classes
- Numpy.Random.Generator
Will be used to create and lock in Generator instance with 'numpy.random.default_rng()'. Note this will be the same Generator passed in.
- None
Will be used to create Generator for 'numpy.random.default_rng()' where a fresh, unpredictable entropy will be pulled from the OS
Attributes
----------
population : tpot.Population
The population of individuals.
Use population.population to access the individuals in the current population.
Use population.evaluated_individuals to access a data frame of all individuals that have been explored.
"""
self.rng = np.random.default_rng(rng)
if threshold_evaluation_pruning is not None or selection_evaluation_pruning is not None:
if evaluation_early_stop_steps is None:
raise ValueError("evaluation_early_stop_steps must be set when using threshold_evaluation_pruning or selection_evaluation_pruning")
self.individual_generator = individual_generator
self.population_size = population_size
self.objective_functions = objective_functions
self.objective_function_weights = np.array(objective_function_weights)
self.bigger_is_better = bigger_is_better
if not bigger_is_better:
self.objective_function_weights = np.array(self.objective_function_weights)*-1
self.initial_population_size = initial_population_size
if self.initial_population_size is None:
self.cur_population_size = population_size
else:
self.cur_population_size = initial_population_size
self.population_scaling = population_scaling
self.generations_until_end_population = generations_until_end_population
self.population_size_list = None
self.periodic_checkpoint_folder = periodic_checkpoint_folder
self.verbose = verbose
self.callback = callback
self.generations = generations
self.n_jobs = n_jobs
if max_time_mins is None:
self.max_time_mins = float("inf")
else:
self.max_time_mins = max_time_mins
self.max_eval_time_mins = max_eval_time_mins
self.generation = 0
self.threshold_evaluation_pruning =threshold_evaluation_pruning
self.threshold_evaluation_scaling = max(0.00001,threshold_evaluation_scaling )
self.min_history_threshold = min_history_threshold
self.selection_evaluation_pruning = selection_evaluation_pruning
self.selection_evaluation_scaling = max(0.00001,selection_evaluation_scaling )
self.evaluation_early_stop_steps = evaluation_early_stop_steps
self.final_score_strategy = final_score_strategy
self.budget_range = budget_range
self.budget_scaling = budget_scaling
self.generations_until_end_budget = generations_until_end_budget
self.stepwise_steps = stepwise_steps
self.memory_limit = memory_limit
self.client = client
self.survival_selector=survival_selector
self.parent_selector=parent_selector
self.survival_percentage = survival_percentage
total_var_p = crossover_probability + mutate_probability + mutate_then_crossover_probability + crossover_then_mutate_probability
self.crossover_probability = crossover_probability / total_var_p
self.mutate_probability = mutate_probability / total_var_p
self.mutate_then_crossover_probability= mutate_then_crossover_probability / total_var_p
self.crossover_then_mutate_probability= crossover_then_mutate_probability / total_var_p
self.mutation_functions = mutation_functions
self.crossover_functions = crossover_functions
if mutation_function_weights is None:
self.mutation_function_weights = [1 for _ in range(len(mutation_functions))]
else:
self.mutation_function_weights = mutation_function_weights
if mutation_function_weights is None:
self.crossover_function_weights = [1 for _ in range(len(mutation_functions))]
else:
self.crossover_function_weights = crossover_function_weights
self.n_parents = n_parents
if objective_kwargs is None:
self.objective_kwargs = {}
else:
self.objective_kwargs = objective_kwargs
# if objective_kwargs is None:
# self.objective_kwargs = [{}] * len(self.objective_functions)
# elif isinstance(objective_kwargs, dict):
# self.objective_kwargs = [objective_kwargs] * len(self.objective_functions)
# else:
# self.objective_kwargs = objective_kwargs
###########
if self.initial_population_size != self.population_size:
self.population_size_list = beta_interpolation(start=self.cur_population_size, end=self.population_size, scale=self.population_scaling, n=generations_until_end_population, n_steps=self.stepwise_steps)
self.population_size_list = np.round(self.population_size_list).astype(int)
if self.budget_range is None:
self.budget_list = None
else:
self.budget_list = beta_interpolation(start=self.budget_range[0], end=self.budget_range[1], n=self.generations_until_end_budget, scale=self.budget_scaling, n_steps=self.stepwise_steps)
if objective_names is None:
self.objective_names = ["objective"+str(i) for i in range(len(objective_function_weights))]
else:
self.objective_names = objective_names
if self.budget_list is not None:
if len(self.budget_list) <= self.generation:
self.budget = self.budget_list[-1]
else:
self.budget = self.budget_list[self.generation]
else:
self.budget = None
self.early_stop_tol = early_stop_tol
self.early_stop = early_stop
if isinstance(self.early_stop_tol, float):
self.early_stop_tol = [self.early_stop_tol for _ in range(len(self.objective_names))]
self.early_stop_tol = [np.inf if tol is None else tol for tol in self.early_stop_tol]
self.population = None
self.population_file = None
if self.periodic_checkpoint_folder is not None:
self.population_file = os.path.join(self.periodic_checkpoint_folder, "population.pkl")
if not os.path.exists(self.periodic_checkpoint_folder):
os.makedirs(self.periodic_checkpoint_folder)
if os.path.exists(self.population_file):
self.population = pickle.load(open(self.population_file, "rb"))
if len(self.population.evaluated_individuals)>0 and "Generation" in self.population.evaluated_individuals.columns:
self.generation = self.population.evaluated_individuals['Generation'].max() + 1 #TODO check if this is empty?
init_names = self.objective_names
if self.budget_range is not None:
init_names = init_names + ["Budget"]
if self.population is None:
self.population = tpot.Population(column_names=init_names)
initial_population = [next(self.individual_generator) for _ in range(self.cur_population_size)]
self.population.add_to_population(initial_population, self.rng)
self.population.update_column(self.population.population, column_names="Generation", data=self.generation)
def optimize(self, generations=None):
"""
Creates an initial population and runs the evolutionary algorithm for the given number of generations.
If generations is None, will use self.generations.
Parameters
----------
generations : int, default=None
Number of generations to run. If None, will use self.generations.
"""
if self.client is not None: #If user passed in a client manually
self._client = self.client
else:
if self.verbose >= 4:
silence_logs = 30
elif self.verbose >=5:
silence_logs = 40
else:
silence_logs = 50
self._cluster = LocalCluster(n_workers=self.n_jobs, #if no client is passed in and no global client exists, create our own
threads_per_worker=1,
silence_logs=silence_logs,
processes=True,
memory_limit=self.memory_limit)
self._client = Client(self._cluster)
if generations is None:
generations = self.generations
start_time = time.time()
generations_without_improvement = np.array([0 for _ in range(len(self.objective_function_weights))])
best_scores = [-np.inf for _ in range(len(self.objective_function_weights))]
self.scheduled_timeout_time = time.time() + self.max_time_mins*60
try:
#for gen in tnrange(generations,desc="Generation", disable=self.verbose<1):
done = False
gen = 0
if self.verbose >= 1:
if generations is None or np.isinf(generations):
pbar = tqdm.tqdm(total=0)
else:
pbar = tqdm.tqdm(total=generations)
pbar.set_description("Generation")
while not done:
# Generation 0 is the initial population
if self.generation == 0:
if self.population_file is not None:
pickle.dump(self.population, open(self.population_file, "wb"))
self.evaluate_population()
if self.population_file is not None:
pickle.dump(self.population, open(self.population_file, "wb"))
attempts = 2
while len(self.population.population) == 0 and attempts > 0:
new_initial_population = [next(self.individual_generator) for _ in range(self.cur_population_size)]
self.population.add_to_population(new_initial_population, rng=self.rng)
attempts -= 1
self.evaluate_population()
if len(self.population.population) == 0:
raise Exception("No individuals could be evaluated in the initial population. This may indicate a bug in the configuration, included models, or objective functions. Set verbose>=4 to see the errors that caused individuals to fail.")
self.generation += 1
# Generation 1 is the first generation after the initial population
else:
if time.time() - start_time > self.max_time_mins*60:
if self.population.evaluated_individuals[self.objective_names].isnull().all().iloc[0]:
raise Exception("No individuals could be evaluated in the initial population as the max_eval_mins time limit was reached before any individuals could be evaluated.")
break
self.step()
if self.verbose >= 3:
sign = np.sign(self.objective_function_weights)
valid_df = self.population.evaluated_individuals[~self.population.evaluated_individuals[self.objective_names].isin(["TIMEOUT","INVALID"]).any(axis=1)][self.objective_names]*sign
cur_best_scores = valid_df.max(axis=0)*sign
cur_best_scores = cur_best_scores.to_numpy()
print("Generation: ", self.generation)
for i, obj in enumerate(self.objective_names):
print(f"Best {obj} score: {cur_best_scores[i]}")
if self.early_stop:
if self.budget is None or self.budget>=self.budget_range[-1]: #self.budget>=1:
#get sign of objective_function_weights
sign = np.sign(self.objective_function_weights)
#get best score for each objective
valid_df = self.population.evaluated_individuals[~self.population.evaluated_individuals[self.objective_names].isin(["TIMEOUT","INVALID"]).any(axis=1)][self.objective_names]*sign
cur_best_scores = valid_df.max(axis=0)
cur_best_scores = cur_best_scores.to_numpy()
#cur_best_scores = self.population.get_column(self.population.population, column_names=self.objective_names).max(axis=0)*sign #TODO this assumes the current population is the best
improved = ( np.array(cur_best_scores) - np.array(best_scores) >= np.array(self.early_stop_tol) )
not_improved = np.logical_not(improved)
generations_without_improvement = generations_without_improvement * not_improved + not_improved #set to zero if not improved, else increment
pass
#update best score
best_scores = [max(best_scores[i], cur_best_scores[i]) for i in range(len(self.objective_names))]
if all(generations_without_improvement>self.early_stop):
if self.verbose >= 3:
print("Early stop")
break
#save population
if self.population_file is not None: # and time.time() - last_save_time > 60*10:
pickle.dump(self.population, open(self.population_file, "wb"))
gen += 1
if self.verbose >= 1:
pbar.update(1)
if generations is not None and gen >= generations:
done = True
except KeyboardInterrupt:
if self.verbose >= 3:
print("KeyboardInterrupt")
self.population.remove_invalid_from_population(column_names=self.objective_names, invalid_value="INVALID")
self.population.remove_invalid_from_population(column_names=self.objective_names, invalid_value="TIMEOUT")
self.population.remove_invalid_from_population(column_names="Eval Error", invalid_value="INVALID")
self.population.remove_invalid_from_population(column_names="Eval Error", invalid_value="TIMEOUT")
if self.population_file is not None:
pickle.dump(self.population, open(self.population_file, "wb"))
if self.client is None: #If we created our own client, close it
self._client.close()
self._cluster.close()
tpot.utils.get_pareto_frontier(self.population.evaluated_individuals, column_names=self.objective_names, weights=self.objective_function_weights)
def step(self,):
"""
Runs a single generation of the evolutionary algorithm. This includes selecting individuals for survival, generating offspring, and evaluating the offspring.
"""
if self.population_size_list is not None:
if self.generation < len(self.population_size_list):
self.cur_population_size = self.population_size_list[self.generation]
else:
self.cur_population_size = self.population_size
if self.budget_list is not None:
if len(self.budget_list) <= self.generation:
self.budget = self.budget_range[-1]
else:
self.budget = self.budget_list[self.generation]
else:
self.budget = None
if self.survival_selector is not None:
n_survivors = max(1,int(self.cur_population_size*self.survival_percentage)) #always keep at least one individual
self.population.survival_select( selector=self.survival_selector,
weights=self.objective_function_weights,
columns_names=self.objective_names,
n_survivors=n_survivors,
inplace=True,
rng=self.rng,)
self.generate_offspring()
self.evaluate_population()
self.generation += 1
def generate_offspring(self, ): #your EA Algorithm goes here
"""
Create population_size new individuals from the current population.
This includes selecting parents, applying mutation and crossover, and adding the new individuals to the population.
"""
parents = self.population.parent_select(selector=self.parent_selector, weights=self.objective_function_weights, columns_names=self.objective_names, k=self.cur_population_size, n_parents=2, rng=self.rng)
p = np.array([self.crossover_probability, self.mutate_then_crossover_probability, self.crossover_then_mutate_probability, self.mutate_probability])
p = p / p.sum()
var_op_list = self.rng.choice(["crossover", "mutate_then_crossover", "crossover_then_mutate", "mutate"], size=self.cur_population_size, p=p)
for i, op in enumerate(var_op_list):
if op == "mutate":
parents[i] = parents[i][0] #mutations take a single individual
offspring = self.population.create_offspring2(parents, var_op_list, self.mutation_functions, self.mutation_function_weights, self.crossover_functions, self.crossover_function_weights, add_to_population=True, keep_repeats=False, mutate_until_unique=True, rng=self.rng)
self.population.update_column(offspring, column_names="Generation", data=self.generation, )
# Gets a list of unevaluated individuals in the livepopulation, evaluates them, and removes failed attempts
# TODO This could probably be an independent function?
def evaluate_population(self,):
"""
Evaluates the individuals in the population that have not been evaluated yet.
"""
#Update the sliding scales and thresholds
# Save population, TODO remove some of these
if self.population_file is not None: # and time.time() - last_save_time > 60*10:
pickle.dump(self.population, open(self.population_file, "wb"))
last_save_time = time.time()
#Get the current thresholds per step
self.thresholds = None
if self.threshold_evaluation_pruning is not None:
old_data = self.population.evaluated_individuals[self.objective_names]
old_data = old_data[old_data[self.objective_names].notnull().all(axis=1)]
if len(old_data) >= self.min_history_threshold:
self.thresholds = np.array([get_thresholds(old_data[obj_name],
start=self.threshold_evaluation_pruning[0],
end=self.threshold_evaluation_pruning[1],
scale=self.threshold_evaluation_scaling,
n=self.evaluation_early_stop_steps)
for obj_name in self.objective_names]).T
#Get the selectors survival rates per step
if self.selection_evaluation_pruning is not None:
lower = self.cur_population_size*self.selection_evaluation_pruning[0]
upper = self.cur_population_size*self.selection_evaluation_pruning[1]
#survival_counts = self.cur_population_size*(scipy.special.betainc(1,self.selection_evaluation_scaling,np.linspace(0,1,self.evaluation_early_stop_steps))*(upper-lower)+lower)
survival_counts = np.array(beta_interpolation(start=lower, end=upper, scale=self.selection_evaluation_scaling, n=self.evaluation_early_stop_steps, n_steps=self.evaluation_early_stop_steps))
self.survival_counts = survival_counts.astype(int)
else:
self.survival_counts = None
if self.evaluation_early_stop_steps is not None:
if self.survival_counts is None:
#TODO if we are not using selection method for each step, we can create single threads that run all steps for an individual. No need to come back each step.
self.evaluate_population_selection_early_stop(survival_counts=self.survival_counts, thresholds=self.thresholds, budget=self.budget)
else:
#parallelize one step at a time. After each step, come together and select the next individuals to run the next step on.
self.evaluate_population_selection_early_stop(survival_counts=self.survival_counts, thresholds=self.thresholds, budget=self.budget)
else:
self.evaluate_population_full(budget=self.budget)
# Save population, TODO remove some of these
if self.population_file is not None: # and time.time() - last_save_time > 60*10:
pickle.dump(self.population, open(self.population_file, "wb"))
last_save_time = time.time()
def evaluate_population_full(self, budget=None):
"""
Evaluates all individuals in the population that have not been evaluated yet.
This is the normal/default strategy for evaluating individuals without any early stopping of individual evaluation functions. (e.g., no threshold or selection early stopping). Early stopping by generation is still possible.
"""
individuals_to_evaluate = self.get_unevaluated_individuals(self.objective_names, budget=budget,)
#print("evaluating this many individuals: ", len(individuals_to_evaluate))
if len(individuals_to_evaluate) == 0:
if self.verbose > 3:
print("No new individuals to evaluate")
return
if self.max_eval_time_mins is not None:
theoretical_timeout = self.max_eval_time_mins * math.ceil(len(individuals_to_evaluate) / self.n_jobs)
theoretical_timeout = theoretical_timeout*2
else:
theoretical_timeout = np.inf
scheduled_timeout_time_left = self.scheduled_timeout_time - time.time()
parallel_timeout = min(theoretical_timeout, scheduled_timeout_time_left)
if parallel_timeout < 0:
parallel_timeout = 10
scores, start_times, end_times, eval_errors = tpot.utils.eval_utils.parallel_eval_objective_list(individuals_to_evaluate, self.objective_functions, verbose=self.verbose, max_eval_time_mins=self.max_eval_time_mins, budget=budget, n_expected_columns=len(self.objective_names), client=self._client, scheduled_timeout_time=self.scheduled_timeout_time, **self.objective_kwargs)
self.population.update_column(individuals_to_evaluate, column_names=self.objective_names, data=scores)
if budget is not None:
self.population.update_column(individuals_to_evaluate, column_names="Budget", data=budget)
self.population.update_column(individuals_to_evaluate, column_names="Submitted Timestamp", data=start_times)
self.population.update_column(individuals_to_evaluate, column_names="Completed Timestamp", data=end_times)
self.population.update_column(individuals_to_evaluate, column_names="Eval Error", data=eval_errors)
self.population.remove_invalid_from_population(column_names="Eval Error")
self.population.remove_invalid_from_population(column_names="Eval Error", invalid_value="TIMEOUT")
def get_unevaluated_individuals(self, column_names, budget=None, individual_list=None):
"""
This function is used to get a list of individuals in the current population that have not been evaluated yet.
Parameters
----------
column_names : list of strings
Names of the columns to check for unevaluated individuals (generally objective functions).
budget : float, default=None
Budget to use when checking for unevaluated individuals. If None, will not check the budget column.
Finds individuals who have not been evaluated with the given budget on column names.
individual_list : list of individuals, default=None
List of individuals to check for unevaluated individuals. If None, will use the current population.
"""
if individual_list is not None:
cur_pop = np.array(individual_list)
else:
cur_pop = np.array(self.population.population)
if all([name_step in self.population.evaluated_individuals.columns for name_step in column_names]):
if budget is not None:
offspring_scores = self.population.get_column(cur_pop, column_names=column_names+["Budget"], to_numpy=False)
#Individuals are unevaluated if we have a higher budget OR if any of the objectives are nan
unevaluated_filter = lambda i: any(offspring_scores.loc[offspring_scores.index[i]][column_names].isna()) or (offspring_scores.loc[offspring_scores.index[i]]["Budget"] < budget)
else:
offspring_scores = self.population.get_column(cur_pop, column_names=column_names, to_numpy=False)
unevaluated_filter = lambda i: any(offspring_scores.loc[offspring_scores.index[i]][column_names].isna())
unevaluated_individuals_this_step = [i for i in range(len(cur_pop)) if unevaluated_filter(i)]
return cur_pop[unevaluated_individuals_this_step]
else: #if column names are not in the evaluated_individuals, then we have not evaluated any individuals yet
for name_step in column_names:
self.population.evaluated_individuals[name_step] = np.nan
return cur_pop
def evaluate_population_selection_early_stop(self,survival_counts, thresholds=None, budget=None):
"""
This function tries to save computation by partially evaluating the individuals and then selecting which individuals to evaluate further based on the results of the partial evaluation.
Two strategies are implemented:
1. Selection early stopping: Selects a percentage of the population to evaluate at each step of the evaluation.
for example, one strategy is to evaluate different steps of cross validation one at a time, and only select the best N individuals for subsequent steps.
This can save computation by not evaluating all individuals for all steps of cross validation. By default this selection is done with the NSGA2 selector.
2. Threshold early stopping: At each step of the evaluation, a threshold is calculated based on the previous evaluations. All individuals that are below the performance threshold are not evaluated for further steps.
For example, if the threshold is set to the 90th percentile of the previous evaluations, all individuals that are below the 90th percentile are not evaluated further. This can save computation by not evaluating all individuals for all steps of cross validation.
Both of these strategies can be used simultaneously. Individuals must pass both the selection and threshold criteria to be evaluated further.
Parameters
----------
survival_counts : list of ints, default=None
Number of individuals to select for survival at each step of the evaluation. If None, will not use selection early stopping.
For example: [10, 5, 2] would select 10 individuals for the first step, 5 for the second, and 2 for the third.
thresholds : list of floats, default=None
Thresholds to use for early stopping at each step of the evaluation. If None, will not use threshold early stopping.
budget : float, default=None
Budget to use when evaluating individuals. Use is dependent on the objective functions. (In TPOTEstimator this corresponds to the percentage of the data to sample.)
"""
survival_selector = tpot.selectors.survival_select_NSGA2
################
objective_function_signs = np.sign(self.objective_function_weights)
cur_individuals = self.population.population.copy()
all_step_names = []
for step in range(self.evaluation_early_stop_steps):
if budget is None:
this_step_names = [f"{n}_step_{step}" for n in self.objective_names]
else:
this_step_names = [f"{n}_budget_{budget}_step_{step}" for n in self.objective_names]
all_step_names.append(this_step_names)
unevaluated_individuals_this_step = self.get_unevaluated_individuals(this_step_names, budget=None, individual_list=cur_individuals)
if len(unevaluated_individuals_this_step) == 0:
if self.verbose > 3:
print("No new individuals to evaluate")
continue
if self.max_eval_time_mins is not None:
theoretical_timeout = self.max_eval_time_mins * math.ceil(len(unevaluated_individuals_this_step) / self.n_jobs)*60
theoretical_timeout = theoretical_timeout*2
else:
theoretical_timeout = np.inf
scheduled_timeout_time_left = self.scheduled_timeout_time - time.time()
parallel_timeout = min(theoretical_timeout, scheduled_timeout_time_left)
if parallel_timeout < 0:
parallel_timeout = 10
scores, start_times, end_times, eval_errors = tpot.utils.eval_utils.parallel_eval_objective_list(individual_list=unevaluated_individuals_this_step,
objective_list=self.objective_functions,
verbose=self.verbose,
max_eval_time_mins=self.max_eval_time_mins,
step=step,
budget = self.budget,
generation = self.generation,
n_expected_columns=len(self.objective_names),
client=self._client,
scheduled_timeout_time=self.scheduled_timeout_time,
**self.objective_kwargs,
)
self.population.update_column(unevaluated_individuals_this_step, column_names=this_step_names, data=scores)
self.population.update_column(unevaluated_individuals_this_step, column_names="Submitted Timestamp", data=start_times)
self.population.update_column(unevaluated_individuals_this_step, column_names="Completed Timestamp", data=end_times)
self.population.update_column(unevaluated_individuals_this_step, column_names="Eval Error", data=eval_errors)
self.population.remove_invalid_from_population(column_names="Eval Error")
self.population.remove_invalid_from_population(column_names="Eval Error", invalid_value="TIMEOUT")
#remove invalids:
invalids = []
#find indeces of invalids
for j in range(len(scores)):
if any([s=="INVALID" for s in scores[j]]):
invalids.append(j)
for j in range(len(scores)):
if any([s=="TIMEOUT" for s in scores[j]]):
invalids.append(j)
#already evaluated
already_evaluated = list(set(cur_individuals) - set(unevaluated_individuals_this_step))
#evaluated and valid
valid_evaluations_this_step = remove_items(unevaluated_individuals_this_step,invalids)
#update cur_individuals with current individuals with valid scores
cur_individuals = np.concatenate([already_evaluated, valid_evaluations_this_step])
#Get average scores
#array of shape (steps, individuals, objectives)
offspring_scores = [self.population.get_column(cur_individuals, column_names=step_names) for step_names in all_step_names]
offspring_scores = np.array(offspring_scores)
if self.final_score_strategy == 'mean':
offspring_scores = offspring_scores.mean(axis=0)
elif self.final_score_strategy == 'last':
offspring_scores = offspring_scores[-1]
#remove individuals with nan scores
invalids = []
for i in range(len(offspring_scores)):
if any(np.isnan(offspring_scores[i])):
invalids.append(i)
cur_individuals = remove_items(cur_individuals,invalids)
offspring_scores = remove_items(offspring_scores,invalids)
#if last step, add the final metrics
if step == self.evaluation_early_stop_steps-1:
self.population.update_column(cur_individuals, column_names=self.objective_names, data=offspring_scores)
if budget is not None:
self.population.update_column(cur_individuals, column_names="Budget", data=budget)
return
#If we have more threads than remaining individuals, we may as well evaluate the extras too
if self.n_jobs < len(cur_individuals):
#Remove based on thresholds
if thresholds is not None:
threshold = thresholds[step]
invalids = []
for i in range(len(offspring_scores)):
if all([s*w>t*w for s,t,w in zip(offspring_scores[i],threshold,objective_function_signs) ]):
invalids.append(i)
if len(invalids) > 0:
max_to_remove = min(len(cur_individuals) - self.n_jobs, len(invalids))
if max_to_remove < len(invalids):
# invalids = np.random.choice(invalids, max_to_remove, replace=False)
invalids = self.rng.choice(invalids, max_to_remove, replace=False)
cur_individuals = remove_items(cur_individuals,invalids)
offspring_scores = remove_items(offspring_scores,invalids)
# Remove based on selection
if survival_counts is not None:
if step < self.evaluation_early_stop_steps - 1 and survival_counts[step]>1: #don't do selection for the last loop since they are completed
k = survival_counts[step] + len(invalids) #TODO can remove the min if the selections method can ignore k>population size
if len(cur_individuals)> 1 and k > self.n_jobs and k < len(cur_individuals):
weighted_scores = np.array([s * self.objective_function_weights for s in offspring_scores ])
new_population_index = survival_selector(weighted_scores, k=k)
cur_individuals = np.array(cur_individuals)[new_population_index]
offspring_scores = offspring_scores[new_population_index]
================================================
FILE: tpot/evolvers/steady_state_evolver.py
================================================
"""
This file is part of the TPOT library.
The current version of TPOT was developed at Cedars-Sinai by:
- Pedro Henrique Ribeiro (https://github.com/perib, https://www.linkedin.com/in/pedro-ribeiro/)
- Anil Saini (anil.saini@cshs.org)
- Jose Hernandez (jgh9094@gmail.com)
- Jay Moran (jay.moran@cshs.org)
- Nicholas Matsumoto (nicholas.matsumoto@cshs.org)
- Hyunjun Choi (hyunjun.choi@cshs.org)
- Gabriel Ketron (gabriel.ketron@cshs.org)
- Miguel E. Hernandez (miguel.e.hernandez@cshs.org)
- Jason Moore (moorejh28@gmail.com)
The original version of TPOT was primarily developed at the University of Pennsylvania by:
- Randal S. Olson (rso@randalolson.com)
- Weixuan Fu (weixuanf@upenn.edu)
- Daniel Angell (dpa34@drexel.edu)
- Jason Moore (moorejh28@gmail.com)
- and many more generous open-source contributors
TPOT is free software: you can redistribute it and/or modify
it under the terms of the GNU Lesser General Public License as
published by the Free Software Foundation, either version 3 of
the License, or (at your option) any later version.
TPOT is distributed in the hope that it will be useful,
but WITHOUT ANY WARRANTY; without even the implied warranty of
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
GNU Lesser General Public License for more details.
You should have received a copy of the GNU Lesser General Public
License along with TPOT. If not, see .
"""
#All abstract methods in the Evolutionary_Optimization module
import tpot
import typing
import tqdm
import time
import numpy as np
import os
import pickle
from tqdm.dask import TqdmCallback
import distributed
from dask.distributed import Client
from dask.distributed import LocalCluster
from tpot.selectors import survival_select_NSGA2, tournament_selection_dominated
import math
from tpot.utils.utils import get_thresholds, beta_interpolation, remove_items, equalize_list
import dask
import warnings
import gc
# Evolvers allow you to pass in custom mutation and crossover functions. By default,
# the evolver will just use these functions to call ind.mutate or ind.crossover
def ind_mutate(ind, rng):
"""
Calls the ind.mutate method on the individual
Parameters
----------
ind : tpot.BaseIndividual
The individual to mutate
rng : int or numpy.random.Generator
A numpy random generator to use for reproducibility
"""
rng = np.random.default_rng(rng)
return ind.mutate(rng=rng)
def ind_crossover(ind1, ind2, rng):
"""
Calls the ind1.crossover(ind2, rng=rng)
Parameters
----------
ind1 : tpot.BaseIndividual
ind2 : tpot.BaseIndividual
rng : int or numpy.random.Generator
A numpy random generator to use for reproducibility
"""
rng = np.random.default_rng(rng)
return ind1.crossover(ind2, rng=rng)
class SteadyStateEvolver():
def __init__( self,
individual_generator ,
objective_functions,
objective_function_weights,
objective_names = None,
objective_kwargs = None,
bigger_is_better = True,
initial_population_size = 50,
population_size = 300,
max_evaluated_individuals = None,
early_stop = None,
early_stop_mins = None,
early_stop_tol = 0.001,
max_time_mins=float("inf"),
max_eval_time_mins=10,
n_jobs=1,
memory_limit="4GB",
client=None,
crossover_probability=.2,
mutate_probability=.7,
mutate_then_crossover_probability=.05,
crossover_then_mutate_probability=.05,
n_parents=2,
survival_selector = survival_select_NSGA2,
parent_selector = tournament_selection_dominated,
budget_range = None,
budget_scaling = .5,
individuals_until_end_budget = 1,
stepwise_steps = 5,
verbose = 0,
periodic_checkpoint_folder = None,
callback = None,
rng=None
) -> None:
"""
Whereas the base_evolver uses a generational approach, the steady state evolver continuously generates individuals as resources become available.
This evolver will simultaneously evaluated n_jobs individuals. As soon as one individual is evaluated, the current population is updated with survival_selector,
a new individual is generated from parents selected with parent_selector, and the new individual is immediately submitted for evaluation.
In contrast, the base_evolver batches evaluations in generations, and only updates the population and creates new individuals after all individuals in the current generation are evaluated.
In practice, this means that steady state evolver is more likely to use all cores at all times, allowing for flexibility is duration of evaluations and number of evaluations. However, it
may also generate less diverse populations as a result.
Parameters
----------
individual_generator : generator
Generator that yields new base individuals. Used to generate initial population.
objective_functions : list of callables
list of functions that get applied to the individual and return a float or list of floats
If an objective function returns multiple values, they are all concatenated in order
with respect to objective_function_weights and early_stop_tol.
objective_function_weights : list of floats
list of weights for each objective function. Sign flips whether bigger is better or not
objective_names : list of strings, default=None
Names of the objectives. If None, objective0, objective1, etc. will be used
objective_kwargs : dict, default=None
Dictionary of keyword arguments to pass to the objective function
bigger_is_better : bool, default=True
If True, the objective function is maximized. If False, the objective function is minimized. Use negative weights to reverse the direction.
initial_population_size : int, default=50
Number of random individuals to generate in the initial population. These will all be randomly sampled, all other subsequent individuals will be generated from the population.
population_size : int, default=50
Note: This is different from the base_evolver.
In steady_state_evolver, the population_size is the number of individuals to keep in the live population. This is the total number of best individuals (as determined by survival_selector) to keep in the population.
New individuals are generated from this population size.
In base evolver, this is also the number of individuals to generate in each generation, however, here, we generate individuals as resources become available so there is no concept of a generation.
It is recommended to use a higher population_size to ensure diversity in the population.
max_evaluated_individuals : int, default=None
Maximum number of individuals to evaluate after which training is terminated. If None, will evaluate until time limit is reached.
early_stop : int, default=None
If the best individual has not improved in this many evaluations, stop training.
Note: Also different from base_evolver. In base evolver, this is the number of generations without improvement. Here, it is the number of individuals evaluated without improvement. Naturally, a higher value is recommended.
early_stop_mins : int, default=None
If the best individual has not improved in this many minutes, stop training.
early_stop_tol : float, list of floats, or None, default=0.001
-list of floats
list of tolerances for each objective function. If the difference between the best score and the current score is less than the tolerance, the individual is considered to have converged
If an index of the list is None, that item will not be used for early stopping
-int
If an int is given, it will be used as the tolerance for all objectives
max_time_mins : float, default=float("inf")
Maximum time to run the optimization. If none or inf, will run until the end of the generations.
max_eval_time_mins : float, default=10
Maximum time to evaluate a single individual. If none or inf, there will be no time limit per evaluation.
n_jobs : int, default=1
Number of processes to run in parallel.
memory_limit : str, default=None
Memory limit for each job. See Dask [LocalCluster documentation](https://distributed.dask.org/en/stable/api.html#distributed.Client) for more information.
client : dask.distributed.Client, default=None
A dask client to use for parallelization. If not None, this will override the n_jobs and memory_limit parameters. If None, will create a new client with num_workers=n_jobs and memory_limit=memory_limit.
crossover_probability : float, default=.2
Probability of generating a new individual by crossover between two individuals.
mutate_probability : float, default=.7
Probability of generating a new individual by crossover between one individuals.
mutate_then_crossover_probability : float, default=.05
Probability of generating a new individual by mutating two individuals followed by crossover.
crossover_then_mutate_probability : float, default=.05
Probability of generating a new individual by crossover between two individuals followed by a mutation of the resulting individual.
n_parents : int, default=2
Number of parents to use for crossover. Must be greater than 1.
survival_selector : function, default=survival_select_NSGA2
Function to use to select individuals for survival. Must take a matrix of scores and return selected indexes.
Used to selected population_size * survival_percentage individuals at the start of each generation to use for mutation and crossover.
parent_selector : function, default=parent_select_NSGA2
Function to use to select pairs parents for crossover and individuals for mutation. Must take a matrix of scores and return selected indexes.
budget_range : list [start, end], default=None
This parameter is used for the successive halving algorithm.
A starting and ending budget to use for the budget scaling. The evolver will interpolate between these values over the generations_until_end_budget.
Use is dependent on the objective functions. (In TPOTEstimator this corresponds to the percentage of the data to sample.)
budget_scaling float : [0,1], default=0.5
A scaling factor to use when determining how fast we move the budget from the start to end budget.
evaluations_until_end_budget : int, default=1
The number of evaluations to run before reaching the max budget.
stepwise_steps : int, default=1
The number of staircase steps to take when interpolating the budget.
verbose : int, default=0
How much information to print during the optimization process. Higher values include the information from lower values.
0. nothing
1. progress bar
2. evaluations progress bar
3. best individual
4. warnings
>=5. full warnings trace
periodic_checkpoint_folder : str, default=None
Folder to save the population to periodically. If None, no periodic saving will be done.
If provided, training will resume from this checkpoint.
callback : tpot.CallBackInterface, default=None
Callback object. Not implemented
rng : Numpy.Random.Generator, None, default=None
An object for reproducability of experiments. This value will be passed to numpy.random.default_rng() to create an instnce of the genrator to pass to other classes
- Numpy.Random.Generator
Will be used to create and lock in Generator instance with 'numpy.random.default_rng()'. Note this will be the same Generator passed in.
- None
Will be used to create Generator for 'numpy.random.default_rng()' where a fresh, unpredictable entropy will be pulled from the OS
Attributes
----------
population : tpot.Population
The population of individuals.
Use population.population to access the individuals in the current population.
Use population.evaluated_individuals to access a data frame of all individuals that have been explored.
"""
self.rng = np.random.default_rng(rng)
self.max_evaluated_individuals = max_evaluated_individuals
self.individuals_until_end_budget = individuals_until_end_budget
self.individual_generator = individual_generator
self.population_size = population_size
self.objective_functions = objective_functions
self.objective_function_weights = np.array(objective_function_weights)
self.bigger_is_better = bigger_is_better
if not bigger_is_better:
self.objective_function_weights = np.array(self.objective_function_weights)*-1
self.population_size_list = None
self.periodic_checkpoint_folder = periodic_checkpoint_folder
self.verbose = verbose
self.callback = callback
self.n_jobs = n_jobs
if max_time_mins is None:
self.max_time_mins = float("inf")
else:
self.max_time_mins = max_time_mins
#functools requires none for infinite time, doesn't support inf
if max_eval_time_mins is not None and math.isinf(max_eval_time_mins ):
self.max_eval_time_mins = None
else:
self.max_eval_time_mins = max_eval_time_mins
self.initial_population_size = initial_population_size
self.budget_range = budget_range
self.budget_scaling = budget_scaling
self.stepwise_steps = stepwise_steps
self.memory_limit = memory_limit
self.client = client
self.survival_selector=survival_selector
self.parent_selector=parent_selector
total_var_p = crossover_probability + mutate_probability + mutate_then_crossover_probability + crossover_then_mutate_probability
self.crossover_probability = crossover_probability / total_var_p
self.mutate_probability = mutate_probability / total_var_p
self.mutate_then_crossover_probability= mutate_then_crossover_probability / total_var_p
self.crossover_then_mutate_probability= crossover_then_mutate_probability / total_var_p
self.n_parents = n_parents
if objective_kwargs is None:
self.objective_kwargs = {}
else:
self.objective_kwargs = objective_kwargs
###########
if self.budget_range is None:
self.budget_list = None
else:
self.budget_list = beta_interpolation(start=self.budget_range[0], end=self.budget_range[1], n=self.generations_until_end_budget, scale=self.budget_scaling, n_steps=self.stepwise_steps)
if objective_names is None:
self.objective_names = ["objective"+str(i) for i in range(len(objective_function_weights))]
else:
self.objective_names = objective_names
if self.budget_list is not None:
if len(self.budget_list) <= self.generation:
self.budget = self.budget_list[-1]
else:
self.budget = self.budget_list[self.generation]
else:
self.budget = None
self.early_stop_tol = early_stop_tol
self.early_stop_mins = early_stop_mins
self.early_stop = early_stop
if isinstance(self.early_stop_tol, float):
self.early_stop_tol = [self.early_stop_tol for _ in range(len(self.objective_names))]
self.early_stop_tol = [np.inf if tol is None else tol for tol in self.early_stop_tol]
self.population = None
self.population_file = None
if self.periodic_checkpoint_folder is not None:
self.population_file = os.path.join(self.periodic_checkpoint_folder, "population.pkl")
if not os.path.exists(self.periodic_checkpoint_folder):
os.makedirs(self.periodic_checkpoint_folder)
if os.path.exists(self.population_file):
self.population = pickle.load(open(self.population_file, "rb"))
init_names = self.objective_names
if self.budget_range is not None:
init_names = init_names + ["Budget"]
if self.population is None:
self.population = tpot.Population(column_names=init_names)
initial_population = [next(self.individual_generator) for _ in range(self.initial_population_size)]
self.population.add_to_population(initial_population, rng=self.rng)
def optimize(self):
"""
Creates an initial population and runs the evolutionary algorithm for the given number of generations.
If generations is None, will use self.generations.
"""
#intialize the client
if self.client is not None: #If user passed in a client manually
self._client = self.client
else:
if self.verbose >= 4:
silence_logs = 30
elif self.verbose >=5:
silence_logs = 40
else:
silence_logs = 50
self._cluster = LocalCluster(n_workers=self.n_jobs, #if no client is passed in and no global client exists, create our own
threads_per_worker=1,
silence_logs=silence_logs,
processes=False,
memory_limit=self.memory_limit)
self._client = Client(self._cluster)
self.max_queue_size = len(self._client.cluster.workers)
#set up logging params
evaluated_count = 0
generations_without_improvement = np.array([0 for _ in range(len(self.objective_function_weights))])
timestamp_of_last_improvement = np.array([time.time() for _ in range(len(self.objective_function_weights))])
best_scores = [-np.inf for _ in range(len(self.objective_function_weights))]
scheduled_timeout_time = time.time() + self.max_time_mins*60
budget = None
submitted_futures = {}
submitted_inds = set()
start_time = time.time()
try:
if self.verbose >= 1:
if self.max_evaluated_individuals is not None:
pbar = tqdm.tqdm(total=self.max_evaluated_individuals, miniters=1)
else:
pbar = tqdm.tqdm(total=0, miniters=1)
pbar.set_description("Evaluations")
#submit initial population
individuals_to_evaluate = self.get_unevaluated_individuals(self.objective_names, budget=budget,)
for individual in individuals_to_evaluate:
if len(submitted_futures) >= self.max_queue_size:
break
future = self._client.submit(tpot.utils.eval_utils.eval_objective_list, individual, self.objective_functions, verbose=self.verbose, max_eval_time_mins=self.max_eval_time_mins, **self.objective_kwargs)
submitted_futures[future] = {"individual": individual,
"time": time.time(),
"budget": budget,}
submitted_inds.add(individual.unique_id())
self.population.update_column(individual, column_names="Submitted Timestamp", data=time.time())
done = False
start_time = time.time()
enough_parents_evaluated=False
while not done:
###############################
# Step 1: Check for finished futures
###############################
#wait for at least one future to finish or timeout
try:
if self.max_eval_time_mins is None or math.isinf(self.max_eval_time_mins):
next(distributed.as_completed(submitted_futures, timeout=5*60))
else:
next(distributed.as_completed(submitted_futures, timeout=self.max_eval_time_mins*60))
except dask.distributed.TimeoutError:
pass
except dask.distributed.CancelledError:
pass
#Loop through all futures, collect completed and timeout futures.
for completed_future in list(submitted_futures.keys()):
eval_error = None
#get scores and update
if completed_future.done(): #if future is done
#If the future is done but threw and error, record the error
if completed_future.exception() or completed_future.status == "error": #if the future is done and threw an error
print("Exception in future")
print(completed_future.exception())
scores = [np.nan for _ in range(len(self.objective_names))]
eval_error = "INVALID"
elif completed_future.cancelled(): #if the future is done and was cancelled
print("Cancelled future (likely memory related)")
scores = [np.nan for _ in range(len(self.objective_names))]
eval_error = "INVALID"
self._client.run(gc.collect)
else: #if the future is done and did not throw an error, get the scores
try:
scores = completed_future.result()
#check if scores contain "INVALID" or "TIMEOUT"
if "INVALID" in scores:
eval_error = "INVALID"
scores = [np.nan]
elif "TIMEOUT" in scores:
eval_error = "TIMEOUT"
scores = [np.nan]
except Exception as e:
print("Exception in future, but not caught by dask")
print(e)
print(completed_future.exception())
print(completed_future)
print("status", completed_future.status)
print("done", completed_future.done())
print("cancelld ", completed_future.cancelled())
scores = [np.nan for _ in range(len(self.objective_names))]
eval_error = "INVALID"
completed_future.release() #release the future
else: #if future is not done
if (self.max_eval_time_mins is not None) and (not math.isinf(self.max_eval_time_mins)): #if max_eval_time_mins is set to a value
#check if the future has been running for too long, cancel the future
if time.time() - submitted_futures[completed_future]["time"] > self.max_eval_time_mins*1.25*60:
completed_future.cancel()
completed_future.release() #release the future
if self.verbose >= 4:
print(f'WARNING AN INDIVIDUAL TIMED OUT (Fallback): \n {submitted_futures[completed_future]} \n')
scores = [np.nan for _ in range(len(self.objective_names))]
eval_error = "TIMEOUT"
else:
continue #otherwise, continue to next future
else:
#this future is not done and we don't have a time limit so let it keep goooooiiiinnnggggg
#there must be another future that did complete
continue
#update population
this_individual = submitted_futures[completed_future]["individual"]
this_budget = submitted_futures[completed_future]["budget"]
this_time = submitted_futures[completed_future]["time"]
if len(scores) < len(self.objective_names):
scores = [scores[0] for _ in range(len(self.objective_names))]
self.population.update_column(this_individual, column_names=self.objective_names, data=scores)
self.population.update_column(this_individual, column_names="Completed Timestamp", data=time.time())
self.population.update_column(this_individual, column_names="Eval Error", data=eval_error)
if budget is not None:
self.population.update_column(this_individual, column_names="Budget", data=this_budget)
submitted_futures.pop(completed_future)
submitted_inds.add(this_individual.unique_id())
if self.verbose >= 1:
pbar.update(1)
#now we have a list of completed futures
self.population.remove_invalid_from_population(column_names="Eval Error", invalid_value="INVALID")
self.population.remove_invalid_from_population(column_names="Eval Error", invalid_value="TIMEOUT")
#I am not entirely sure if this is necessary. I believe that calling release on the futures should be enough to free up memory. If memory issues persist, this may be a good place to start.
#client.run(gc.collect) #run garbage collection to free up memory
###############################
# Step 2: Early Stopping
###############################
if self.verbose >= 3:
sign = np.sign(self.objective_function_weights)
valid_df = self.population.evaluated_individuals[~self.population.evaluated_individuals[["Eval Error"]].isin(["TIMEOUT","INVALID"]).any(axis=1)][self.objective_names]*sign
cur_best_scores = valid_df.max(axis=0)*sign
cur_best_scores = cur_best_scores.to_numpy()
for i, obj in enumerate(self.objective_names):
print(f"Best {obj} score: {cur_best_scores[i]}")
if self.early_stop or self.early_stop_mins:
if self.budget is None or self.budget>=self.budget_range[-1]: #self.budget>=1:
#get sign of objective_function_weights
sign = np.sign(self.objective_function_weights)
#get best score for each objective
valid_df = self.population.evaluated_individuals[~self.population.evaluated_individuals[["Eval Error"]].isin(["TIMEOUT","INVALID"]).any(axis=1)][self.objective_names]*sign
cur_best_scores = valid_df.max(axis=0)
cur_best_scores = cur_best_scores.to_numpy()
#cur_best_scores = self.population.get_column(self.population.population, column_names=self.objective_names).max(axis=0)*sign #TODO this assumes the current population is the best
improved = ( np.array(cur_best_scores) - np.array(best_scores) >= np.array(self.early_stop_tol) )
not_improved = np.logical_not(improved)
generations_without_improvement = generations_without_improvement * not_improved + not_improved #set to zero if not improved, else increment
timestamp_of_last_improvement = timestamp_of_last_improvement * not_improved + time.time()*improved #set to current time if improved
pass
#update best score
best_scores = [max(best_scores[i], cur_best_scores[i]) for i in range(len(self.objective_names))]
if self.early_stop:
if all(generations_without_improvement>self.early_stop):
if self.verbose >= 3:
print(f"Early stop ({self.early_stop} individuals evaluated without improvement)")
break
if self.early_stop_mins:
if any(time.time() - timestamp_of_last_improvement > self.early_stop_mins*60):
if self.verbose >= 3:
print(f"Early stop ({self.early_stop_mins} seconds passed without improvement)")
break
#if we evaluated enough individuals or time is up, stop
if self.max_time_mins is not None and time.time() - start_time > self.max_time_mins*60:
if self.verbose >= 3:
print("Time limit reached")
done = True
break
if self.max_evaluated_individuals is not None and len(self.population.evaluated_individuals.dropna(subset=self.objective_names)) >= self.max_evaluated_individuals:
print("Evaluated enough individuals")
done = True
break
###############################
# Step 3: Submit unevaluated individuals from the initial population
###############################
individuals_to_evaluate = self.get_unevaluated_individuals(self.objective_names, budget=budget,)
individuals_to_evaluate = [ind for ind in individuals_to_evaluate if ind.unique_id() not in submitted_inds]
for individual in individuals_to_evaluate:
if self.max_queue_size > len(submitted_futures):
future = self._client.submit(tpot.utils.eval_utils.eval_objective_list, individual, self.objective_functions, verbose=self.verbose, max_eval_time_mins=self.max_eval_time_mins,**self.objective_kwargs)
submitted_futures[future] = {"individual": individual,
"time": time.time(),
"budget": budget,}
submitted_inds.add(individual.unique_id())
self.population.update_column(individual, column_names="Submitted Timestamp", data=time.time())
###############################
# Step 4: Survival Selection
###############################
if self.survival_selector is not None:
parents_df = self.population.get_column(self.population.population, column_names=self.objective_names + ["Individual"], to_numpy=False)
evaluated = parents_df[~parents_df[self.objective_names].isna().any(axis=1)]
if len(evaluated) > self.population_size:
unevaluated = parents_df[parents_df[self.objective_names].isna().any(axis=1)]
cur_evaluated_population = parents_df["Individual"].to_numpy()
if len(cur_evaluated_population) > self.population_size:
scores = evaluated[self.objective_names].to_numpy()
weighted_scores = scores * self.objective_function_weights
new_population_index = np.ravel(self.survival_selector(weighted_scores, k=self.population_size, rng=self.rng)) #TODO make it clear that we are concatenating scores...
#set new population
try:
cur_evaluated_population = np.array(cur_evaluated_population)[new_population_index]
cur_evaluated_population = np.concatenate([cur_evaluated_population, unevaluated["Individual"].to_numpy()])
self.population.set_population(cur_evaluated_population, rng=self.rng)
except Exception as e:
print("Exception in survival selection")
print(e)
print("new_population_index", new_population_index)
print("cur_evaluated_population", cur_evaluated_population)
print("unevaluated", unevaluated)
print("evaluated", evaluated)
print("scores", scores)
print("weighted_scores", weighted_scores)
print("self.objective_function_weights", self.objective_function_weights)
print("self.population_size", self.population_size)
print("parents_df", parents_df)
###############################
# Step 5: Parent Selection and Variation
###############################
n_individuals_to_submit = self.max_queue_size - len(submitted_futures)
if n_individuals_to_submit > 0:
#count non-nan values in the objective columns
if not enough_parents_evaluated:
parents_df = self.population.get_column(self.population.population, column_names=self.objective_names, to_numpy=False)
scores = parents_df[self.objective_names[0]].to_numpy()
#count non-nan values in the objective columns
n_evaluated = np.count_nonzero(~np.isnan(scores))
if n_evaluated >0 :
enough_parents_evaluated=True
# parents_df = self.population.get_column(self.population.population, column_names=self.objective_names+ ["Individual"], to_numpy=False)
# parents_df = parents_df[~parents_df[self.objective_names].isin(["TIMEOUT","INVALID"]).any(axis=1)]
# parents_df = parents_df[~parents_df[self.objective_names].isna().any(axis=1)]
# cur_evaluated_population = parents_df["Individual"].to_numpy()
# if len(cur_evaluated_population) > 0:
# scores = parents_df[self.objective_names].to_numpy()
# weighted_scores = scores * self.objective_function_weights
# #number of crossover pairs and mutation only parent to generate
# if len(parents_df) < 2:
# var_ops = ["mutate" for _ in range(n_individuals_to_submit)]
# else:
# var_ops = [self.rng.choice(["crossover","mutate_then_crossover","crossover_then_mutate",'mutate'],p=[self.crossover_probability,self.mutate_then_crossover_probability, self.crossover_then_mutate_probability,self.mutate_probability]) for _ in range(n_individuals_to_submit)]
# parents = []
# for op in var_ops:
# if op == "mutate":
# parents.extend(np.array(cur_evaluated_population)[self.parent_selector(weighted_scores, k=1, n_parents=1, rng=self.rng)])
# else:
# parents.extend(np.array(cur_evaluated_population)[self.parent_selector(weighted_scores, k=1, n_parents=2, rng=self.rng)])
# #_offspring = self.population.create_offspring2(parents, var_ops, rng=self.rng, add_to_population=True)
# offspring = self.population.create_offspring2(parents, var_ops, [ind_mutate], None, [ind_crossover], None, add_to_population=True, keep_repeats=False, mutate_until_unique=True, rng=self.rng)
if enough_parents_evaluated:
parents = self.population.parent_select(selector=self.parent_selector, weights=self.objective_function_weights, columns_names=self.objective_names, k=n_individuals_to_submit, n_parents=2, rng=self.rng)
p = np.array([self.crossover_probability, self.mutate_then_crossover_probability, self.crossover_then_mutate_probability, self.mutate_probability])
p = p / p.sum()
var_op_list = self.rng.choice(["crossover", "mutate_then_crossover", "crossover_then_mutate", "mutate"], size=n_individuals_to_submit, p=p)
for i, op in enumerate(var_op_list):
if op == "mutate":
parents[i] = parents[i][0] #mutations take a single individual
offspring = self.population.create_offspring2(parents, var_op_list, [ind_mutate], None, [ind_crossover], None, add_to_population=True, keep_repeats=False, mutate_until_unique=True, rng=self.rng)
# If we don't have enough evaluated individuals to use as parents for variation, we create new individuals randomly
# This can happen if the individuals in the initial population are invalid
elif len(submitted_futures) < self.max_queue_size:
initial_population = self.population.evaluated_individuals.iloc[:self.initial_population_size*3]
invalid_initial_population = initial_population[initial_population[["Eval Error"]].isin(["TIMEOUT","INVALID"]).any(axis=1)]
if len(invalid_initial_population) >= self.initial_population_size*3: #if all individuals in the 3*initial population are invalid
raise Exception("No individuals could be evaluated in the initial population. This may indicate a bug in the configuration, included models, or objective functions. Set verbose>=4 to see the errors that caused individuals to fail.")
n_individuals_to_create = self.max_queue_size - len(submitted_futures)
initial_population = [next(self.individual_generator) for _ in range(n_individuals_to_create)]
self.population.add_to_population(initial_population, rng=self.rng)
###############################
# Step 6: Add Unevaluated Individuals Generated by Variation
###############################
individuals_to_evaluate = self.get_unevaluated_individuals(self.objective_names, budget=budget,)
individuals_to_evaluate = [ind for ind in individuals_to_evaluate if ind.unique_id() not in submitted_inds]
for individual in individuals_to_evaluate:
if self.max_queue_size > len(submitted_futures):
future = self._client.submit(tpot.utils.eval_utils.eval_objective_list, individual, self.objective_functions, verbose=self.verbose, max_eval_time_mins=self.max_eval_time_mins,**self.objective_kwargs)
submitted_futures[future] = {"individual": individual,
"time": time.time(),
"budget": budget,}
submitted_inds.add(individual.unique_id())
self.population.update_column(individual, column_names="Submitted Timestamp", data=time.time())
#Checkpointing
if self.population_file is not None: # and time.time() - last_save_time > 60*10:
pickle.dump(self.population, open(self.population_file, "wb"))
except KeyboardInterrupt:
if self.verbose >= 3:
print("KeyboardInterrupt")
###############################
# Step 7: Cleanup
###############################
self.population.remove_invalid_from_population(column_names="Eval Error", invalid_value="INVALID")
self.population.remove_invalid_from_population(column_names="Eval Error", invalid_value="TIMEOUT")
#done, cleanup futures
for future in submitted_futures.keys():
future.cancel()
future.release() #release the future
#I am not entirely sure if this is necessary. I believe that calling release on the futures should be enough to free up memory. If memory issues persist, this may be a good place to start.
#client.run(gc.collect) #run garbage collection to free up memory
#checkpoint
if self.population_file is not None:
pickle.dump(self.population, open(self.population_file, "wb"))
if self.client is None: #If we created our own client, close it
self._client.close()
self._cluster.close()
tpot.utils.get_pareto_frontier(self.population.evaluated_individuals, column_names=self.objective_names, weights=self.objective_function_weights)
def get_unevaluated_individuals(self, column_names, budget=None, individual_list=None):
"""
This function is used to get a list of individuals in the current population that have not been evaluated yet.
Parameters
----------
column_names : list of strings
Names of the columns to check for unevaluated individuals (generally objective functions).
budget : float, default=None
Budget to use when checking for unevaluated individuals. If None, will not check the budget column.
Finds individuals who have not been evaluated with the given budget on column names.
individual_list : list of individuals, default=None
List of individuals to check for unevaluated individuals. If None, will use the current population.
"""
if individual_list is not None:
cur_pop = np.array(individual_list)
else:
cur_pop = np.array(self.population.population)
if all([name_step in self.population.evaluated_individuals.columns for name_step in column_names]):
if budget is not None:
offspring_scores = self.population.get_column(cur_pop, column_names=column_names+["Budget"], to_numpy=False)
#Individuals are unevaluated if we have a higher budget OR if any of the objectives are nan
unevaluated_filter = lambda i: any(offspring_scores.loc[offspring_scores.index[i]][column_names].isna()) or (offspring_scores.loc[offspring_scores.index[i]]["Budget"] < budget)
else:
offspring_scores = self.population.get_column(cur_pop, column_names=column_names, to_numpy=False)
unevaluated_filter = lambda i: any(offspring_scores.loc[offspring_scores.index[i]][column_names].isna())
unevaluated_individuals_this_step = [i for i in range(len(cur_pop)) if unevaluated_filter(i)]
return cur_pop[unevaluated_individuals_this_step]
else: #if column names are not in the evaluated_individuals, then we have not evaluated any individuals yet
for name_step in column_names:
self.population.evaluated_individuals[name_step] = np.nan
return cur_pop
================================================
FILE: tpot/graphsklearn.py
================================================
"""
This file is part of the TPOT library.
The current version of TPOT was developed at Cedars-Sinai by:
- Pedro Henrique Ribeiro (https://github.com/perib, https://www.linkedin.com/in/pedro-ribeiro/)
- Anil Saini (anil.saini@cshs.org)
- Jose Hernandez (jgh9094@gmail.com)
- Jay Moran (jay.moran@cshs.org)
- Nicholas Matsumoto (nicholas.matsumoto@cshs.org)
- Hyunjun Choi (hyunjun.choi@cshs.org)
- Gabriel Ketron (gabriel.ketron@cshs.org)
- Miguel E. Hernandez (miguel.e.hernandez@cshs.org)
- Jason Moore (moorejh28@gmail.com)
The original version of TPOT was primarily developed at the University of Pennsylvania by:
- Randal S. Olson (rso@randalolson.com)
- Weixuan Fu (weixuanf@upenn.edu)
- Daniel Angell (dpa34@drexel.edu)
- Jason Moore (moorejh28@gmail.com)
- and many more generous open-source contributors
TPOT is free software: you can redistribute it and/or modify
it under the terms of the GNU Lesser General Public License as
published by the Free Software Foundation, either version 3 of
the License, or (at your option) any later version.
TPOT is distributed in the hope that it will be useful,
but WITHOUT ANY WARRANTY; without even the implied warranty of
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
GNU Lesser General Public License for more details.
You should have received a copy of the GNU Lesser General Public
License along with TPOT. If not, see .
"""
from functools import partial
import numpy as np
import networkx as nx
import matplotlib.pyplot as plt
import sklearn
from sklearn.utils.metaestimators import available_if
import pandas as pd
from sklearn.utils.metaestimators import _BaseComposition
from sklearn.utils.validation import check_memory
from sklearn.preprocessing import LabelEncoder
from sklearn.base import is_classifier, is_regressor
from sklearn.utils._tags import get_tags
import copy
#labels - str
#attributes - "instance" -> instance of the type
def plot(graph: nx.DiGraph):
G = graph.reverse()
try:
pos = nx.planar_layout(G) # positions for all nodes
except:
pos = nx.shell_layout(G)
# nodes
options = {'edgecolors': 'tab:gray', 'node_size': 800, 'alpha': 0.9}
nx.draw_networkx_nodes(G, pos, nodelist=list(G.nodes), node_color='tab:red', **options)
# edges
nx.draw_networkx_edges(G, pos, width=3.0, arrows=True)
# some math labels
labels = {}
for i, n in enumerate(G.nodes):
labels[n] = n#.__class__.__name__
nx.draw_networkx_labels(G, pos, labels, font_size=7, font_color='black')
plt.tight_layout()
plt.axis('off')
plt.show()
#copied from https://github.com/scikit-learn/scikit-learn/blob/36958fb240fbe435673a9e3c52e769f01f36bec0/sklearn/ensemble/_stacking.py#L121
def _method_name(name, estimator, method):
if estimator == 'drop':
return None
if method == 'auto':
if hasattr(estimator, 'predict_proba'):
return 'predict_proba'
elif hasattr(estimator, 'decision_function'):
return 'decision_function'
else:
return 'predict'
else:
if not hasattr(estimator, method):
raise ValueError(
'Underlying estimator {} does not implement the method {}.'.format(
name, method
)
)
return method
def estimator_fit_transform_override_cross_val_predict(estimator, X, y, cv=5, method='auto', **fit_params):
method = _method_name(name=estimator.__class__.__name__, estimator=estimator, method=method)
if (isinstance(cv, int) and cv>1) or (not isinstance(cv, int) and cv is not None):
preds = sklearn.model_selection.cross_val_predict(estimator=estimator, X=X, y=y, cv=cv, method=method, **fit_params)
estimator.fit(X,y, **fit_params)
else:
estimator.fit(X,y, **fit_params)
func = getattr(estimator,method)
preds = func(X)
return preds, estimator
# https://github.com/scikit-learn/scikit-learn/blob/7db5b6a98/sklearn/pipeline.py#L883
def _fit_transform_one(model, X, y, fit_transform=True, **fit_params):
"""Fit and transform one step in a pipeline."""
if fit_transform and hasattr(model, "fit_transform"):
res = model.fit_transform(X, y, **fit_params)
else:
res = model.fit(X, y, **fit_params).transform(X)
#return model
return res, model
#TODO: make sure predict proba doesn't return p and 1-p for nclasses=2
def fit_sklearn_digraph(graph: nx.DiGraph,
X,
y,
method='auto',
cross_val_predict_cv = 0, #func(est,X,y) -> transformed_X
memory = None,
topo_sort = None,
):
memory = check_memory(memory)
fit_transform_one_cached = memory.cache(_fit_transform_one)
estimator_fit_transform_override_cross_val_predict_cached = memory.cache(estimator_fit_transform_override_cross_val_predict)
if topo_sort is None:
topo_sort = list(nx.topological_sort(graph))
topo_sort.reverse()
transformed_steps = {}
for i in range(len(topo_sort)):
node = topo_sort[i]
instance = graph.nodes[node]["instance"]
if len(list(get_ordered_successors(graph, node))) == 0: #If this node had no inputs use X
this_X = X
else: #in node has inputs, get those
this_X = np.hstack([transformed_steps[child] for child in get_ordered_successors(graph, node)])
# Removed so that the cache is the same for all models. Not including transform would index it seperately
#if i == len(topo_sort)-1: #last method doesn't need transformed.
# instance.fit(this_X, y)
if is_classifier(instance) or is_regressor(instance):
transformed, instance = estimator_fit_transform_override_cross_val_predict_cached(instance, this_X, y, cv=cross_val_predict_cv, method=method)
else:
transformed, instance = fit_transform_one_cached(instance, this_X, y)#instance.fit_transform(this_X,y)
graph.nodes[node]["instance"] = instance
if len(transformed.shape) == 1:
transformed = transformed.reshape(-1, 1)
transformed_steps[node] = transformed
#TODO add attribute to decide 'method' for each node
#TODO make more memory efficient. Free memory when a transformation is no longer needed
#TODO better handle multiple roots
def transform_sklearn_digraph(graph: nx.DiGraph,
X,
method = 'auto',
output_nodes = None,
topo_sort = None,):
if graph.number_of_nodes() == 1: #TODO make this better...
return X
if topo_sort is None:
topo_sort = list(nx.topological_sort(graph))
topo_sort.reverse()
transformed_steps = {}
for i in range(len(topo_sort)):
node = topo_sort[i]
instance = graph.nodes[node]["instance"]
if len(list(get_ordered_successors(graph, node))) == 0:
this_X = X
else:
this_X = np.hstack([transformed_steps[child] for child in get_ordered_successors(graph, node)])
if is_classifier(instance) or is_regressor(instance):
this_method = _method_name(instance.__class__.__name__, instance, method)
transformed = getattr(instance, this_method)(this_X)
else:
transformed = instance.transform(this_X)
if len(transformed.shape) == 1:
transformed = transformed.reshape(-1, 1)
transformed_steps[node] = transformed
if output_nodes is None:
return transformed_steps
else:
return {n: transformed_steps[n] for n in output_nodes}
def get_inputs_to_node(graph: nx.DiGraph,
X,
node,
method = 'auto',
topo_sort = None,
):
if len(list(get_ordered_successors(graph, node))) == 0:
this_X = X
else:
transformed_steps = transform_sklearn_digraph(graph,
X,
method,
topo_sort = topo_sort,
)
this_X = np.hstack([transformed_steps[child] for child in get_ordered_successors(graph, node)])
return this_X
def _estimator_has(attr):
'''Check if we can delegate a method to the underlying estimator.
First, we check the first fitted final estimator if available, otherwise we
check the unfitted final estimator.
'''
def check(self):
return hasattr(self.graph.nodes[self.root]["instance"], attr)
return check
def setup_ordered_successors(graph: nx.DiGraph):
for node in graph.nodes:
graph.nodes[node]["successors"] = sorted(list(graph.successors(node)))
def get_ordered_successors(graph: nx.DiGraph, node):
return graph.nodes[node]["successors"]
#TODO make sure it meets all requirements for basecomposition
class GraphPipeline(_BaseComposition):
def __init__(
self,
graph,
cross_val_predict_cv=0, #signature function(estimator, X, y=none)
method='auto',
memory=None,
use_label_encoder=False,
**kwargs,
):
super().__init__(**kwargs)
'''
An sklearn baseestimator that uses genetic programming to optimize a pipeline.
Parameters
----------
graph: networkx.DiGraph
A directed graph where the nodes are sklearn estimators and the edges are the inputs to those estimators.
cross_val_predict_cv: int, cross-validation generator or an iterable, optional
Determines the cross-validation splitting strategy used in inner classifiers or regressors
method: str, optional
The prediction method to use for the inner classifiers or regressors. If 'auto', it will try to use predict_proba, decision_function, or predict in that order.
memory: str or object with the joblib.Memory interface, optional
Used to cache the input and outputs of nodes to prevent refitting or computationally heavy transformations. By default, no caching is performed. If a string is given, it is the path to the caching directory.
use_label_encoder: bool, optional
If True, the label encoder is used to encode the labels to be 0 to N. If False, the label encoder is not used.
Mainly useful for classifiers (XGBoost) that require labels to be ints from 0 to N.
Can also be a sklearn.preprocessing.LabelEncoder object. If so, that label encoder is used.
'''
self.graph = graph
self.cross_val_predict_cv = cross_val_predict_cv
self.method = method
self.memory = memory
self.use_label_encoder = use_label_encoder
setup_ordered_successors(graph)
self.topo_sorted_nodes = list(nx.topological_sort(self.graph))
self.topo_sorted_nodes.reverse()
self.root = self.topo_sorted_nodes[-1]
if self.use_label_encoder:
if type(self.use_label_encoder) == LabelEncoder:
self.label_encoder = self.use_label_encoder
else:
self.label_encoder = LabelEncoder()
#TODO clean this up
try:
nx.find_cycle(self.G)
raise BaseException
except:
pass
def __str__(self):
if len(self.graph.edges) > 0:
return str(self.graph.edges)
else:
return str(self.graph.nodes)
def fit(self, X, y):
if self.use_label_encoder:
if type(self.use_label_encoder) == LabelEncoder:
y = self.label_encoder.transform(y)
else:
y = self.label_encoder.fit_transform(y)
fit_sklearn_digraph( graph=self.graph,
X=X,
y=y,
method=self.method,
cross_val_predict_cv = self.cross_val_predict_cv,
memory = self.memory,
topo_sort = self.topo_sorted_nodes,
)
return self
def plot(self, ):
plot(graph = self.graph)
def __sklearn_is_fitted__(self):
'''Indicate whether pipeline has been fit.'''
try:
# check if the last step of the pipeline is fitted
# we only check the last step since if the last step is fit, it
# means the previous steps should also be fit. This is faster than
# checking if every step of the pipeline is fit.
sklearn.utils.validation.check_is_fitted(self.graph.nodes[self.root]["instance"])
return True
except sklearn.exceptions.NotFittedError:
return False
@available_if(_estimator_has('predict'))
def predict(self, X, **predict_params):
this_X = get_inputs_to_node(self.graph,
X,
self.root,
method = self.method,
topo_sort = self.topo_sorted_nodes,
)
preds = self.graph.nodes[self.root]["instance"].predict(this_X, **predict_params)
if self.use_label_encoder:
preds = self.label_encoder.inverse_transform(preds)
return preds
@available_if(_estimator_has('predict_proba'))
def predict_proba(self, X, **predict_params):
this_X = get_inputs_to_node(self.graph,
X,
self.root,
method = self.method,
topo_sort = self.topo_sorted_nodes,
)
return self.graph.nodes[self.root]["instance"].predict_proba(this_X, **predict_params)
@available_if(_estimator_has('decision_function'))
def decision_function(self, X, **predict_params):
this_X = get_inputs_to_node(self.graph,
X,
self.root,
method = self.method,
topo_sort = self.topo_sorted_nodes,
)
return self.graph.nodes[self.root]["instance"].decision_function(this_X, **predict_params)
@available_if(_estimator_has('transform'))
def transform(self, X, **predict_params):
this_X = get_inputs_to_node(self.graph,
X,
self.root,
method = self.method,
topo_sort = self.topo_sorted_nodes,
)
return self.graph.nodes[self.root]["instance"].transform(this_X, **predict_params)
@property
def classes_(self):
"""The classes labels. Only exist if the last step is a classifier."""
if self.use_label_encoder:
return self.label_encoder.classes_
else:
return self.graph.nodes[self.root]["instance"].classes_
@property
def _estimator_type(self):
return self.graph.nodes[self.root]["instance"]._estimator_type
def __sklearn_tags__(self):
tags = super().__sklearn_tags__()
final_step = self.graph.nodes[self.root]["instance"]
try:
last_step_tags = final_step.__sklearn_tags__()
except:
last_step_tags = get_tags(final_step)
tags.estimator_type = last_step_tags.estimator_type
tags.target_tags.multi_output = last_step_tags.target_tags.multi_output
tags.classifier_tags = copy.deepcopy(last_step_tags.classifier_tags)
tags.regressor_tags = copy.deepcopy(last_step_tags.regressor_tags)
tags.transformer_tags = copy.deepcopy(last_step_tags.transformer_tags)
tags.input_tags.sparse = all(
self.graph.nodes[step]['instance'].__sklearn_tags__().input_tags.sparse
for step in self.topo_sorted_nodes
)
tags.input_tags.pairwise = last_step_tags.input_tags.pairwise
return tags
================================================
FILE: tpot/individual.py
================================================
"""
This file is part of the TPOT library.
The current version of TPOT was developed at Cedars-Sinai by:
- Pedro Henrique Ribeiro (https://github.com/perib, https://www.linkedin.com/in/pedro-ribeiro/)
- Anil Saini (anil.saini@cshs.org)
- Jose Hernandez (jgh9094@gmail.com)
- Jay Moran (jay.moran@cshs.org)
- Nicholas Matsumoto (nicholas.matsumoto@cshs.org)
- Hyunjun Choi (hyunjun.choi@cshs.org)
- Gabriel Ketron (gabriel.ketron@cshs.org)
- Miguel E. Hernandez (miguel.e.hernandez@cshs.org)
- Jason Moore (moorejh28@gmail.com)
The original version of TPOT was primarily developed at the University of Pennsylvania by:
- Randal S. Olson (rso@randalolson.com)
- Weixuan Fu (weixuanf@upenn.edu)
- Daniel Angell (dpa34@drexel.edu)
- Jason Moore (moorejh28@gmail.com)
- and many more generous open-source contributors
TPOT is free software: you can redistribute it and/or modify
it under the terms of the GNU Lesser General Public License as
published by the Free Software Foundation, either version 3 of
the License, or (at your option) any later version.
TPOT is distributed in the hope that it will be useful,
but WITHOUT ANY WARRANTY; without even the implied warranty of
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
GNU Lesser General Public License for more details.
You should have received a copy of the GNU Lesser General Public
License along with TPOT. If not, see .
"""
from abc import abstractmethod
import types
import numpy as np
import copy
import copy
import typing
class BaseIndividual:
def __init__(self) -> None:
self.mutation_list = []
self.crossover_list = []
def mutate(self, rng=None):
rng = np.random.default_rng(rng)
mutation_list_copy = self.mutation_list.copy()
rng.shuffle(mutation_list_copy)
for func in mutation_list_copy:
if func():
return True
return False
def crossover(self, ind2, rng=None):
rng = np.random.default_rng(rng)
crossover_list_copy = self.crossover_list.copy()
rng.shuffle(crossover_list_copy)
for func in crossover_list_copy:
if func(ind2):
return True
return False
# a guided change of an individual when given an objective function
def optimize(self, objective_function, rng=None , steps=5):
rng = np.random.default_rng(rng)
for _ in range(steps):
self.mutate(rng=rng)
#Return a hashable unique to this individual setup
#For use when evaluating whether or not an individual is 'the same' and another individual
def unique_id(self):
return self
#TODO https://www.pythontutorial.net/python-oop/python-__hash__/
#python hashing and __eq__ functions look into
#whether or not this would be a better way of doing things
# #TODO: use this instead of unique_id()?
# #unique_id() and __repr__ could have different levels of specificity.
# def __repr__(self) -> str:
# pass
# def __hash__(self) -> int:
# pass
# def __eq__(self, other):
# self.unique_id() == other.unique_id()
================================================
FILE: tpot/logbook.py
================================================
"""
This file is part of the TPOT library.
The current version of TPOT was developed at Cedars-Sinai by:
- Pedro Henrique Ribeiro (https://github.com/perib, https://www.linkedin.com/in/pedro-ribeiro/)
- Anil Saini (anil.saini@cshs.org)
- Jose Hernandez (jgh9094@gmail.com)
- Jay Moran (jay.moran@cshs.org)
- Nicholas Matsumoto (nicholas.matsumoto@cshs.org)
- Hyunjun Choi (hyunjun.choi@cshs.org)
- Gabriel Ketron (gabriel.ketron@cshs.org)
- Miguel E. Hernandez (miguel.e.hernandez@cshs.org)
- Jason Moore (moorejh28@gmail.com)
The original version of TPOT was primarily developed at the University of Pennsylvania by:
- Randal S. Olson (rso@randalolson.com)
- Weixuan Fu (weixuanf@upenn.edu)
- Daniel Angell (dpa34@drexel.edu)
- Jason Moore (moorejh28@gmail.com)
- and many more generous open-source contributors
TPOT is free software: you can redistribute it and/or modify
it under the terms of the GNU Lesser General Public License as
published by the Free Software Foundation, either version 3 of
the License, or (at your option) any later version.
TPOT is distributed in the hope that it will be useful,
but WITHOUT ANY WARRANTY; without even the implied warranty of
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
GNU Lesser General Public License for more details.
You should have received a copy of the GNU Lesser General Public
License along with TPOT. If not, see .
"""
class CallBackInterface():
def __init__(self) -> None:
pass
def step_callback(self, population):
pass
def population_mutate_callback(self, offspring, parent=None):
pass
def population_crossover_callback(self, offspring, parent=None):
pass
def evolutionary_algorithm_step_callback(self, population):
pass
class Logbook():
pass
================================================
FILE: tpot/objectives/__init__.py
================================================
from .average_path_length import average_path_length_objective
from .number_of_nodes import number_of_nodes_objective
from .number_of_leaves import number_of_leaves_scorer, number_of_leaves_objective
from .complexity import complexity_scorer
#these scorers are calculated per fold of CV on the fitted pipeline for that fold
SCORERS = {
"complexity_scorer": complexity_scorer
}
#these objectives are calculated once on unfitted models as secondary objectives
OBJECTIVES = { "average_path_length_objective": average_path_length_objective,
"number_of_nodes_objective": number_of_nodes_objective,
"number_of_leaves_objective": number_of_leaves_objective
}
================================================
FILE: tpot/objectives/average_path_length.py
================================================
"""
This file is part of the TPOT library.
The current version of TPOT was developed at Cedars-Sinai by:
- Pedro Henrique Ribeiro (https://github.com/perib, https://www.linkedin.com/in/pedro-ribeiro/)
- Anil Saini (anil.saini@cshs.org)
- Jose Hernandez (jgh9094@gmail.com)
- Jay Moran (jay.moran@cshs.org)
- Nicholas Matsumoto (nicholas.matsumoto@cshs.org)
- Hyunjun Choi (hyunjun.choi@cshs.org)
- Gabriel Ketron (gabriel.ketron@cshs.org)
- Miguel E. Hernandez (miguel.e.hernandez@cshs.org)
- Jason Moore (moorejh28@gmail.com)
The original version of TPOT was primarily developed at the University of Pennsylvania by:
- Randal S. Olson (rso@randalolson.com)
- Weixuan Fu (weixuanf@upenn.edu)
- Daniel Angell (dpa34@drexel.edu)
- Jason Moore (moorejh28@gmail.com)
- and many more generous open-source contributors
TPOT is free software: you can redistribute it and/or modify
it under the terms of the GNU Lesser General Public License as
published by the Free Software Foundation, either version 3 of
the License, or (at your option) any later version.
TPOT is distributed in the hope that it will be useful,
but WITHOUT ANY WARRANTY; without even the implied warranty of
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
GNU Lesser General Public License for more details.
You should have received a copy of the GNU Lesser General Public
License along with TPOT. If not, see .
"""
import networkx as nx
import numpy as np
def average_path_length_objective(graph_pipeline):
"""
Computes the average shortest path from all nodes to the root/final estimator (only supported for GraphPipeline)
Parameters
----------
graph_pipeline: GraphPipeline
The pipeline to compute the average path length for
"""
path_lengths = nx.shortest_path_length(graph_pipeline.graph, source=graph_pipeline.root)
return np.mean(np.array(list(path_lengths.values())))+1
================================================
FILE: tpot/objectives/complexity.py
================================================
"""
This file is part of the TPOT library.
The current version of TPOT was developed at Cedars-Sinai by:
- Pedro Henrique Ribeiro (https://github.com/perib, https://www.linkedin.com/in/pedro-ribeiro/)
- Anil Saini (anil.saini@cshs.org)
- Jose Hernandez (jgh9094@gmail.com)
- Jay Moran (jay.moran@cshs.org)
- Nicholas Matsumoto (nicholas.matsumoto@cshs.org)
- Hyunjun Choi (hyunjun.choi@cshs.org)
- Gabriel Ketron (gabriel.ketron@cshs.org)
- Miguel E. Hernandez (miguel.e.hernandez@cshs.org)
- Jason Moore (moorejh28@gmail.com)
The original version of TPOT was primarily developed at the University of Pennsylvania by:
- Randal S. Olson (rso@randalolson.com)
- Weixuan Fu (weixuanf@upenn.edu)
- Daniel Angell (dpa34@drexel.edu)
- Jason Moore (moorejh28@gmail.com)
- and many more generous open-source contributors
TPOT is free software: you can redistribute it and/or modify
it under the terms of the GNU Lesser General Public License as
published by the Free Software Foundation, either version 3 of
the License, or (at your option) any later version.
TPOT is distributed in the hope that it will be useful,
but WITHOUT ANY WARRANTY; without even the implied warranty of
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
GNU Lesser General Public License for more details.
You should have received a copy of the GNU Lesser General Public
License along with TPOT. If not, see .
"""
from tpot import GraphPipeline
import numpy as np
import sklearn
import warnings
from functools import reduce # Valid in Python 2.6+, required in Python 3
import operator
from sklearn.multiclass import OneVsOneClassifier, OneVsRestClassifier
from sklearn.linear_model import SGDClassifier, LogisticRegression, SGDRegressor, Ridge, Lasso, ElasticNet, Lars, LassoLars, LassoLarsCV, RidgeCV, ElasticNetCV, PassiveAggressiveClassifier, ARDRegression
from sklearn.ensemble import BaggingClassifier, RandomForestClassifier, ExtraTreesClassifier, GradientBoostingClassifier, ExtraTreesRegressor, ExtraTreesClassifier, AdaBoostRegressor, AdaBoostClassifier, GradientBoostingRegressor,RandomForestRegressor, BaggingRegressor, ExtraTreesRegressor, HistGradientBoostingClassifier, HistGradientBoostingRegressor
from sklearn.neural_network import MLPClassifier, MLPRegressor
from sklearn.tree import DecisionTreeClassifier, DecisionTreeRegressor
from xgboost import XGBClassifier, XGBRegressor
from sklearn.neighbors import KNeighborsClassifier, KNeighborsRegressor
from sklearn.svm import SVC, SVR, LinearSVR, LinearSVC
from lightgbm import LGBMClassifier, LGBMRegressor
from sklearn.naive_bayes import GaussianNB, BernoulliNB, MultinomialNB
from sklearn.ensemble import StackingClassifier, StackingRegressor, VotingClassifier, VotingRegressor
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis, QuadraticDiscriminantAnalysis
from sklearn.gaussian_process import GaussianProcessRegressor, GaussianProcessClassifier
# MultinomialNB: params_MultinomialNB,
from sklearn.base import is_classifier, is_regressor
#https://scikit-learn.org/stable/auto_examples/applications/plot_model_complexity_influence.html
def _count_nonzero_coefficients_and_intercept(est):
n_coef = np.count_nonzero(est.coef_)
if hasattr(est, 'intercept_'):
n_coef += np.count_nonzero(est.intercept_)
return n_coef
#https://stackoverflow.com/questions/51139875/sklearn-randomforestregressor-number-of-trainable-parameters
def tree_complexity(tree):
return tree.tree_.node_count * 5 #each node has 5 parameters
#https://stackoverflow.com/questions/51139875/sklearn-randomforestregressor-number-of-trainable-parameters
def forest_complexity(forest):
all_trees = np.array(forest.estimators_)
if len(all_trees.shape)>1:
all_trees = all_trees.ravel()
return sum(tree_complexity(tree) for tree in all_trees)
def histgradientboosting_complexity(forest):
all_trees = np.array(forest._predictors)
if len(all_trees.shape)>1:
all_trees = all_trees.ravel()
return sum(len(tree.nodes)*5 for tree in all_trees)
def knn_complexity(knn):
return knn.n_neighbors
def support_vector_machine_complexity(svm):
count = 0
count += sum(svm.n_support_)
if svm.kernel == 'linear':
count += np.count_nonzero(svm.coef_)
return count
def sklearn_MLP_complexity(mlp):
n_layers = len(mlp.coefs_)
n_params = 0
for i in range(n_layers):
n_params += len(mlp.coefs_[i]) + len(mlp.intercepts_[i])
return n_params
def calculate_xgb_model_complexity(est):
df = est.get_booster().trees_to_dataframe()
cols_to_remove = ['Tree','Node', 'ID', 'count', 'Gain', 'Cover']
#keeps ['Feature', 'Split', 'Yes', 'No', 'Missing', 'Category']
#category is the specific category for a given feature. takes the place of split for categorical features
for col in cols_to_remove:
if col in df.columns:
df = df.drop(col, axis=1)
df = ~df.isna()
return df.sum().sum()
def BernoulliNB_Complexity(model):
num_coefficients = len(model.class_log_prior_) + len(model.feature_log_prob_)
return num_coefficients
def GaussianNB_Complexity(model):
num_coefficients = len(model.class_prior_) + len(model.theta_) + len(model.var_)
return num_coefficients
def MultinomialNB_Complexity(model):
num_coefficients = len(model.class_log_prior_) + len(model.feature_log_prob_)
return num_coefficients
def BaggingComplexity(est):
return sum([calculate_model_complexity(bagged) for bagged in est.estimators_])
def lightgbm_complexity(est):
df = est.booster_.trees_to_dataframe()
#remove tree_index and node_depth
cols_to_remove = ['node_index','tree_index', 'node_depth', 'count', 'parent_index']
for col in cols_to_remove:
if col in df.columns:
df = df.drop(col, axis=1)
s = df.shape
return s[0] * s[1]
def QuadraticDiscriminantAnalysis_complexity(est):
count = reduce(operator.mul,np.array(est.rotations_).shape) + reduce(operator.mul,np.array(est.scalings_).shape) + reduce(operator.mul,np.array(est.means_).shape) + reduce(operator.mul,np.array(est.priors_).shape)
return count
#TODO consider the complexity of the kernel?
def gaussian_process_classifier_complexity(est):
if isinstance(est.base_estimator_, OneVsOneClassifier) or isinstance(est.base_estimator_, OneVsRestClassifier):
count = 0
for clf in est.base_estimator_.estimators_:
count += len(clf.pi_)
return count
return len(est.base_estimator_.pi_)
#TODO consider the complexity of the kernel?
def gaussian_process_regressor_complexity(est):
return len(est.alpha_)
def adaboost_complexity(est):
return len(est.estimator_weights_) + sum(calculate_model_complexity(bagged) for bagged in est.estimators_)
def ensemble_complexity(est):
return sum(calculate_model_complexity(bagged) for bagged in est.estimators_)
complexity_objective_per_estimator = { LogisticRegression: _count_nonzero_coefficients_and_intercept,
SGDClassifier: _count_nonzero_coefficients_and_intercept,
LinearSVC : _count_nonzero_coefficients_and_intercept,
LinearSVR : _count_nonzero_coefficients_and_intercept,
ARDRegression: _count_nonzero_coefficients_and_intercept, #When predicting mean, only coef and intercept used. Though there are more params for the variance/covariance matrix
LinearDiscriminantAnalysis: _count_nonzero_coefficients_and_intercept,
QuadraticDiscriminantAnalysis: QuadraticDiscriminantAnalysis_complexity,
SGDRegressor: _count_nonzero_coefficients_and_intercept,
Ridge: _count_nonzero_coefficients_and_intercept,
Lasso: _count_nonzero_coefficients_and_intercept,
ElasticNet: _count_nonzero_coefficients_and_intercept,
Lars: _count_nonzero_coefficients_and_intercept,
LassoLars: _count_nonzero_coefficients_and_intercept,
LassoLarsCV: _count_nonzero_coefficients_and_intercept,
RidgeCV: _count_nonzero_coefficients_and_intercept,
ElasticNetCV: _count_nonzero_coefficients_and_intercept,
PassiveAggressiveClassifier: _count_nonzero_coefficients_and_intercept,
KNeighborsClassifier: knn_complexity,
KNeighborsRegressor: knn_complexity,
DecisionTreeClassifier: tree_complexity,
DecisionTreeRegressor: tree_complexity,
GradientBoostingRegressor: forest_complexity,
GradientBoostingClassifier: forest_complexity,
RandomForestClassifier : forest_complexity,
RandomForestRegressor: forest_complexity,
HistGradientBoostingClassifier: histgradientboosting_complexity,
HistGradientBoostingRegressor: histgradientboosting_complexity,
ExtraTreesRegressor: forest_complexity,
ExtraTreesClassifier: forest_complexity,
XGBClassifier: calculate_xgb_model_complexity,
XGBRegressor: calculate_xgb_model_complexity,
SVC : support_vector_machine_complexity,
SVR : support_vector_machine_complexity,
MLPClassifier: sklearn_MLP_complexity,
MLPRegressor: sklearn_MLP_complexity,
BaggingRegressor: BaggingComplexity,
BaggingClassifier: BaggingComplexity,
BernoulliNB: BernoulliNB_Complexity,
GaussianNB: GaussianNB_Complexity,
MultinomialNB: MultinomialNB_Complexity,
LGBMClassifier: lightgbm_complexity,
LGBMRegressor: lightgbm_complexity,
GaussianProcessClassifier: gaussian_process_classifier_complexity,
GaussianProcessRegressor: gaussian_process_regressor_complexity,
AdaBoostClassifier: adaboost_complexity,
AdaBoostRegressor: adaboost_complexity,
# StackingClassifier: ensemble_complexity,
# StackingRegressor: ensemble_complexity,
# VotingClassifier: ensemble_complexity,
# VotingRegressor: ensemble_complexity
}
def calculate_model_complexity(est):
if isinstance(est, sklearn.pipeline.Pipeline):
return sum(calculate_model_complexity(estimator) for _,estimator in est.steps)
if isinstance(est, sklearn.pipeline.FeatureUnion):
return sum(calculate_model_complexity(estimator) for _,estimator in est.transformer_list)
if isinstance(est, GraphPipeline):
return sum(calculate_model_complexity(est.graph.nodes[node]['instance']) for node in est.graph.nodes)
model_type = type(est)
if is_classifier(est) or is_regressor(est):
if model_type not in complexity_objective_per_estimator:
warnings.warn(f"Complexity objective not defined for this classifier/regressor: {model_type}")
if model_type in complexity_objective_per_estimator:
return complexity_objective_per_estimator[model_type](est)
#else, if is subclass of sklearn selector
elif issubclass(model_type, sklearn.feature_selection.SelectorMixin):
return 0
else:
return 1
def complexity_scorer(est, X=None, y=None):
"""
Estimates the number of learned parameters across all classifiers and regressors in the pipelines.
Additionally, currently transformers add 1 point and selectors add 0 points (since they don't affect the complexity of the "final" predictive pipeline.
Parameters
----------
est: sklearn.base.BaseEstimator
The estimator or pipeline to compute the complexity for
X: array-like
The input samples (unused)
y: array-like
The target values (unused)
"""
return calculate_model_complexity(est)
================================================
FILE: tpot/objectives/number_of_leaves.py
================================================
"""
This file is part of the TPOT library.
The current version of TPOT was developed at Cedars-Sinai by:
- Pedro Henrique Ribeiro (https://github.com/perib, https://www.linkedin.com/in/pedro-ribeiro/)
- Anil Saini (anil.saini@cshs.org)
- Jose Hernandez (jgh9094@gmail.com)
- Jay Moran (jay.moran@cshs.org)
- Nicholas Matsumoto (nicholas.matsumoto@cshs.org)
- Hyunjun Choi (hyunjun.choi@cshs.org)
- Gabriel Ketron (gabriel.ketron@cshs.org)
- Miguel E. Hernandez (miguel.e.hernandez@cshs.org)
- Jason Moore (moorejh28@gmail.com)
The original version of TPOT was primarily developed at the University of Pennsylvania by:
- Randal S. Olson (rso@randalolson.com)
- Weixuan Fu (weixuanf@upenn.edu)
- Daniel Angell (dpa34@drexel.edu)
- Jason Moore (moorejh28@gmail.com)
- and many more generous open-source contributors
TPOT is free software: you can redistribute it and/or modify
it under the terms of the GNU Lesser General Public License as
published by the Free Software Foundation, either version 3 of
the License, or (at your option) any later version.
TPOT is distributed in the hope that it will be useful,
but WITHOUT ANY WARRANTY; without even the implied warranty of
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
GNU Lesser General Public License for more details.
You should have received a copy of the GNU Lesser General Public
License along with TPOT. If not, see .
"""
def number_of_leaves_scorer(est,X=None, y=None):
return len([v for v, d in est.graph.out_degree() if d == 0])
def number_of_leaves_objective(est):
"""
Calculates the number of leaves (input nodes) in a GraphPipeline
Parameters
----------
est: GraphPipeline
The pipeline to compute the number of leaves for
"""
return len([v for v, d in est.graph.out_degree() if d == 0])
================================================
FILE: tpot/objectives/number_of_nodes.py
================================================
"""
This file is part of the TPOT library.
The current version of TPOT was developed at Cedars-Sinai by:
- Pedro Henrique Ribeiro (https://github.com/perib, https://www.linkedin.com/in/pedro-ribeiro/)
- Anil Saini (anil.saini@cshs.org)
- Jose Hernandez (jgh9094@gmail.com)
- Jay Moran (jay.moran@cshs.org)
- Nicholas Matsumoto (nicholas.matsumoto@cshs.org)
- Hyunjun Choi (hyunjun.choi@cshs.org)
- Gabriel Ketron (gabriel.ketron@cshs.org)
- Miguel E. Hernandez (miguel.e.hernandez@cshs.org)
- Jason Moore (moorejh28@gmail.com)
The original version of TPOT was primarily developed at the University of Pennsylvania by:
- Randal S. Olson (rso@randalolson.com)
- Weixuan Fu (weixuanf@upenn.edu)
- Daniel Angell (dpa34@drexel.edu)
- Jason Moore (moorejh28@gmail.com)
- and many more generous open-source contributors
TPOT is free software: you can redistribute it and/or modify
it under the terms of the GNU Lesser General Public License as
published by the Free Software Foundation, either version 3 of
the License, or (at your option) any later version.
TPOT is distributed in the hope that it will be useful,
but WITHOUT ANY WARRANTY; without even the implied warranty of
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
GNU Lesser General Public License for more details.
You should have received a copy of the GNU Lesser General Public
License along with TPOT. If not, see .
"""
from ..graphsklearn import GraphPipeline
from sklearn.pipeline import Pipeline
import sklearn
def number_of_nodes_objective(est):
"""
Calculates the number of leaves (input nodes) in an sklearn pipeline
Parameters
----------
est: GraphPipeline | Pipeline | FeatureUnion | BaseEstimator
The pipeline to compute the number of nodes from.
"""
if isinstance(est, GraphPipeline):
return sum(number_of_nodes_objective(est.graph.nodes[node]["instance"]) for node in est.graph.nodes)
if isinstance(est, Pipeline):
return sum(number_of_nodes_objective(estimator) for _,estimator in est.steps)
if isinstance(est, sklearn.pipeline.FeatureUnion):
return sum(number_of_nodes_objective(estimator) for _,estimator in est.transformer_list)
return 1
================================================
FILE: tpot/objectives/tests/test_complexity_objective.py
================================================
================================================
FILE: tpot/objectives/tests/test_number_of_nodes.py
================================================
import pytest
import tpot
from sklearn.datasets import load_iris
import random
import sklearn
from sklearn.svm import SVC
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.pipeline import Pipeline
import networkx as nx
import tpot
from tpot import GraphPipeline
import sklearn.metrics
def test_number_of_nodes_objective_Graphpipeline():
g = nx.DiGraph()
g.add_node("scaler", instance=StandardScaler())
g.add_node("svc", instance=SVC())
g.add_node("LogisticRegression", instance=LogisticRegression())
g.add_node("LogisticRegression2", instance=LogisticRegression())
g.add_edge("svc","scaler")
g.add_edge("LogisticRegression", "scaler")
g.add_edge("LogisticRegression2", "LogisticRegression")
g.add_edge("LogisticRegression2", "svc")
est = GraphPipeline(g)
assert tpot.objectives.number_of_nodes.number_of_nodes_objective(est) == 4
def test_number_of_nodes_objective_Pipeline():
pipe = Pipeline([("scaler", StandardScaler()), ("svc", SVC())])
assert tpot.objectives.number_of_nodes.number_of_nodes_objective(pipe) == 2
def test_number_of_nodes_objective_not_pipeline_or_graphpipeline():
assert tpot.objectives.number_of_nodes.number_of_nodes_objective(SVC()) == 1
assert tpot.objectives.number_of_nodes.number_of_nodes_objective(StandardScaler()) == 1
assert tpot.objectives.number_of_nodes.number_of_nodes_objective(LogisticRegression()) == 1
def test_number_of_nodes_objective_pipeline_in_graphpipeline():
g = nx.DiGraph()
g.add_node("scaler", instance=StandardScaler())
g.add_node("pipe", instance=Pipeline([("scaler", StandardScaler()), ("svc", SVC())]))
g.add_edge("pipe","scaler")
est = GraphPipeline(g)
assert tpot.objectives.number_of_nodes.number_of_nodes_objective(est) == 3
def test_number_of_nodes_objective_graphpipeline_in_pipeline():
pipe = Pipeline([("scaler", StandardScaler()), ("svc", SVC())])
g = nx.DiGraph()
g.add_node("scaler", instance=StandardScaler())
g.add_node("svc", instance=SVC())
g.add_node("LogisticRegression", instance=LogisticRegression())
g.add_node("LogisticRegression2", instance=LogisticRegression())
g.add_edge("svc","scaler")
g.add_edge("LogisticRegression", "scaler")
g.add_edge("LogisticRegression2", "LogisticRegression")
g.add_edge("LogisticRegression2", "svc")
est = GraphPipeline(g)
pipe.steps.append(("graphpipe", est))
assert tpot.objectives.number_of_nodes.number_of_nodes_objective(pipe) == 6
def test_number_of_nodes_objective_graphpipeline_in_graphpipeline():
g = nx.DiGraph()
g.add_node("scaler", instance=StandardScaler())
g.add_node("svc", instance=SVC())
g.add_node("LogisticRegression", instance=LogisticRegression())
g.add_node("LogisticRegression2", instance=LogisticRegression())
g.add_edge("svc","scaler")
g.add_edge("LogisticRegression", "scaler")
g.add_edge("LogisticRegression2", "LogisticRegression")
g.add_edge("LogisticRegression2", "svc")
est = GraphPipeline(g)
g2 = nx.DiGraph()
g2.add_node("g1", instance=est)
g2.add_node("svc", instance=SVC())
g2.add_node("LogisticRegression", instance=LogisticRegression())
g2.add_node("LogisticRegression2", instance=LogisticRegression())
g2.add_edge("svc","g1")
g2.add_edge("LogisticRegression", "g1")
g2.add_edge("LogisticRegression2", "LogisticRegression")
g2.add_edge("LogisticRegression2", "svc")
est2 = GraphPipeline(g2)
assert tpot.objectives.number_of_nodes.number_of_nodes_objective(est2) == 7
def test_number_of_nodes_objective_pipeline_in_pipeline():
pipe = Pipeline([("scaler", StandardScaler()), ("svc", SVC())])
pipe2 = Pipeline([("pipe", pipe), ("svc", SVC())])
assert tpot.objectives.number_of_nodes.number_of_nodes_objective(pipe2) == 3
================================================
FILE: tpot/old_config_utils/__init__.py
================================================
"""
This file is part of the TPOT library.
The current version of TPOT was developed at Cedars-Sinai by:
- Pedro Henrique Ribeiro (https://github.com/perib, https://www.linkedin.com/in/pedro-ribeiro/)
- Anil Saini (anil.saini@cshs.org)
- Jose Hernandez (jgh9094@gmail.com)
- Jay Moran (jay.moran@cshs.org)
- Nicholas Matsumoto (nicholas.matsumoto@cshs.org)
- Hyunjun Choi (hyunjun.choi@cshs.org)
- Gabriel Ketron (gabriel.ketron@cshs.org)
- Miguel E. Hernandez (miguel.e.hernandez@cshs.org)
- Jason Moore (moorejh28@gmail.com)
The original version of TPOT was primarily developed at the University of Pennsylvania by:
- Randal S. Olson (rso@randalolson.com)
- Weixuan Fu (weixuanf@upenn.edu)
- Daniel Angell (dpa34@drexel.edu)
- Jason Moore (moorejh28@gmail.com)
- and many more generous open-source contributors
TPOT is free software: you can redistribute it and/or modify
it under the terms of the GNU Lesser General Public License as
published by the Free Software Foundation, either version 3 of
the License, or (at your option) any later version.
TPOT is distributed in the hope that it will be useful,
but WITHOUT ANY WARRANTY; without even the implied warranty of
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
GNU Lesser General Public License for more details.
You should have received a copy of the GNU Lesser General Public
License along with TPOT. If not, see .
"""
from .old_config_utils import convert_config_dict_to_list, convert_config_dict_to_choicepipeline, convert_config_dict_to_graphpipeline, convert_config_dict_to_linearpipeline
================================================
FILE: tpot/old_config_utils/old_config_utils.py
================================================
"""
This file is part of the TPOT library.
The current version of TPOT was developed at Cedars-Sinai by:
- Pedro Henrique Ribeiro (https://github.com/perib, https://www.linkedin.com/in/pedro-ribeiro/)
- Anil Saini (anil.saini@cshs.org)
- Jose Hernandez (jgh9094@gmail.com)
- Jay Moran (jay.moran@cshs.org)
- Nicholas Matsumoto (nicholas.matsumoto@cshs.org)
- Hyunjun Choi (hyunjun.choi@cshs.org)
- Gabriel Ketron (gabriel.ketron@cshs.org)
- Miguel E. Hernandez (miguel.e.hernandez@cshs.org)
- Jason Moore (moorejh28@gmail.com)
The original version of TPOT was primarily developed at the University of Pennsylvania by:
- Randal S. Olson (rso@randalolson.com)
- Weixuan Fu (weixuanf@upenn.edu)
- Daniel Angell (dpa34@drexel.edu)
- Jason Moore (moorejh28@gmail.com)
- and many more generous open-source contributors
TPOT is free software: you can redistribute it and/or modify
it under the terms of the GNU Lesser General Public License as
published by the Free Software Foundation, either version 3 of
the License, or (at your option) any later version.
TPOT is distributed in the hope that it will be useful,
but WITHOUT ANY WARRANTY; without even the implied warranty of
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
GNU Lesser General Public License for more details.
You should have received a copy of the GNU Lesser General Public
License along with TPOT. If not, see .
"""
from ConfigSpace import ConfigurationSpace
from ConfigSpace import ConfigurationSpace, Integer, Float, Categorical, Normal
from ConfigSpace import EqualsCondition, OrConjunction, NotEqualsCondition, InCondition
from ..search_spaces.nodes import EstimatorNode
from ..search_spaces.pipelines import WrapperPipeline, ChoicePipeline, GraphSearchPipeline, SequentialPipeline, DynamicLinearPipeline
import ConfigSpace
import sklearn
from functools import partial
import inspect
import numpy as np
def load_get_module_from_string(module_string):
"""
Takes a string in the form of 'module.submodule.class' and returns the class.
Parameters
----------
module_string : str
The string representation of the module and class to load.
Returns
-------
class
The class that was loaded from the module string.
"""
module_name, class_name = module_string.rsplit('.', 1)
module = __import__(module_name, fromlist=[class_name])
return getattr(module, class_name)
def hyperparameter_parser(hdict, function_params_conversion_dict):
d = hdict.copy()
d.update(function_params_conversion_dict)
return d
def get_node_space(module_string, params):
"""
Create the search space for a single node in the TPOT config.
Parameters
----------
module_string : str
The string representation of the module and class to load. E.g. 'sklearn.ensemble.RandomForestClassifier'
params : dict
The dictionary representation of the hyperparameter search space for the module_string.
Returns
-------
EstimatorNode or WrapperPipeline
"""
method = load_get_module_from_string(module_string)
config_space = ConfigurationSpace()
sub_space = None
sub_space_name = None
function_params_conversion_dict = {}
if params is None:
return EstimatorNode(method=method, space=config_space)
for param_name, param in params.items():
if param is None:
config_space.add(Categorical(param_name, [None]))
if isinstance(param, range):
param = list(param)
if isinstance(param, list) or isinstance(param, np.ndarray):
if len(param) == 1:
p = param[0]
config_space.add(ConfigSpace.hyperparameters.Constant(param_name, p))
else:
config_space.add(Categorical(param_name, param))
# if all(isinstance(i, int) for i in param):
# config_space.add_hyperparameter(Integer(param_name, (min(param), max(param))))
# elif all(isinstance(i, float) for i in param):
# config_space.add_hyperparameter(Float(param_name, (min(param), max(param))))
# else:
# config_space.add_hyperparameter(Categorical(param_name, param))
elif isinstance(param, dict): #TPOT1 config dicts have dictionaries for values of hyperparameters that are either a function or an estimator
if len(param) > 1:
raise ValueError(f"Multiple items in dictionary entry for {param_name}")
key = list(param.keys())[0]
innermethod = load_get_module_from_string(key)
if inspect.isclass(innermethod) and issubclass(innermethod, sklearn.base.BaseEstimator): #is an estimator
if sub_space is None:
sub_space_name = param_name
sub_space = get_node_space(key, param[key])
else:
raise ValueError("Only multiple hyperparameters are estimators. Only one parameter ")
else: #assume the key is a function and ignore the value
function_params_conversion_dict[param_name] = innermethod
else:
# config_space.add_hyperparameter(Categorical(param_name, param))
config_space.add(ConfigSpace.hyperparameters.Constant(param_name, param))
parser=None
if len(function_params_conversion_dict) > 0:
parser = partial(hyperparameter_parser, function_params_conversion_dict)
if sub_space is None:
if parser is not None:
return EstimatorNode(method=method, space=config_space, hyperparameter_parser=parser)
else:
return EstimatorNode(method=method, space=config_space)
else:
if parser is not None:
return WrapperPipeline(method=method, space=config_space, estimator_search_space=sub_space, wrapped_param_name=sub_space_name, hyperparameter_parser=parser)
else:
return WrapperPipeline(method=method, space=config_space, estimator_search_space=sub_space, wrapped_param_name=sub_space_name)
### Below are the functions that convert the old config dicts to the new search spaces to be used by users.
def convert_config_dict_to_list(config_dict):
"""
Takes in a TPOT config dictionary and returns a list of search spaces (EstimatorNode, WrapperPipeline)
Parameters
----------
config_dict : dict
The dictionary representation of the TPOT config.
Returns
-------
list
A list of search spaces (EstimatorNode, WrapperPipeline) that represent the config_dict.
"""
search_spaces = []
for key, value in config_dict.items():
search_spaces.append(get_node_space(key, value))
return search_spaces
def convert_config_dict_to_choicepipeline(config_dict):
"""
Takes in a TPOT config dictionary and returns a ChoicePipeline search space that represents the config_dict.
This space will sample from all included modules in the config_dict.
Parameters
----------
config_dict : dict
The dictionary representation of the TPOT config.
Returns
-------
ChoicePipeline
A ChoicePipeline search space that represents the config_dict.
"""
search_spaces = []
for key, value in config_dict.items():
search_spaces.append(get_node_space(key, value))
return ChoicePipeline(search_spaces)
#Note doesn't convert estimators so they passthrough inputs like in TPOT1
def convert_config_dict_to_graphpipeline(config_dict):
"""
Takes in a TPOT config dictionary and returns a GraphSearchPipeline search space that represents the config_dict.
This space will sample from all included modules in the config_dict. It will also identify classifiers/regressors to set the search space for the root node.
Note doesn't convert estimators so they passthrough inputs like in TPOT1
Parameters
----------
config_dict : dict
The dictionary representation of the TPOT config.
Returns
-------
GraphSearchPipeline
A GraphSearchPipeline search space that represents the config_dict.
"""
root_search_spaces = []
inner_search_spaces = []
for key, value in config_dict.items():
#if root
if issubclass(load_get_module_from_string(key), sklearn.base.ClassifierMixin) or issubclass(load_get_module_from_string(key), sklearn.base.RegressorMixin):
root_search_spaces.append(get_node_space(key, value))
else:
inner_search_spaces.append(get_node_space(key, value))
if len(root_search_spaces) == 0:
Warning("No classifiers or regressors found, allowing any estimator to be the root node")
root_search_spaces = inner_search_spaces
#merge inner and root search spaces
inner_space = np.concatenate([root_search_spaces,inner_search_spaces])
root_space = ChoicePipeline(root_search_spaces)
inner_space = ChoicePipeline(inner_search_spaces)
final_space = GraphSearchPipeline(root_search_space=root_space, inner_search_space=inner_space)
return final_space
#Note doesn't convert estimators so they passthrough inputs like in TPOT1
def convert_config_dict_to_linearpipeline(config_dict):
"""
Takes in a TPOT config dictionary and returns a GraphSearchPipeline search space that represents the config_dict.
This space will sample from all included modules in the config_dict. It will also identify classifiers/regressors to set the search space for the root node.
Note doesn't convert estimators so they passthrough inputs like in TPOT1
Parameters
----------
config_dict : dict
The dictionary representation of the TPOT config.
Returns
-------
GraphSearchPipeline
A GraphSearchPipeline search space that represents the config_dict.
"""
root_search_spaces = []
inner_search_spaces = []
for key, value in config_dict.items():
#if root
if issubclass(load_get_module_from_string(key), sklearn.base.ClassifierMixin) or issubclass(load_get_module_from_string(key), sklearn.base.RegressorMixin):
root_search_spaces.append(get_node_space(key, value))
else:
inner_search_spaces.append(get_node_space(key, value))
if len(root_search_spaces) == 0:
Warning("No classifiers or regressors found, allowing any estimator to be the root node")
root_search_spaces = inner_search_spaces
#merge inner and root search spaces
inner_space = np.concatenate([root_search_spaces,inner_search_spaces])
root_space = ChoicePipeline(root_search_spaces)
inner_space = ChoicePipeline(inner_search_spaces)
final_space = SequentialPipeline([
DynamicLinearPipeline(inner_space, 10),
root_space
])
return final_space
================================================
FILE: tpot/population.py
================================================
"""
This file is part of the TPOT library.
The current version of TPOT was developed at Cedars-Sinai by:
- Pedro Henrique Ribeiro (https://github.com/perib, https://www.linkedin.com/in/pedro-ribeiro/)
- Anil Saini (anil.saini@cshs.org)
- Jose Hernandez (jgh9094@gmail.com)
- Jay Moran (jay.moran@cshs.org)
- Nicholas Matsumoto (nicholas.matsumoto@cshs.org)
- Hyunjun Choi (hyunjun.choi@cshs.org)
- Gabriel Ketron (gabriel.ketron@cshs.org)
- Miguel E. Hernandez (miguel.e.hernandez@cshs.org)
- Jason Moore (moorejh28@gmail.com)
The original version of TPOT was primarily developed at the University of Pennsylvania by:
- Randal S. Olson (rso@randalolson.com)
- Weixuan Fu (weixuanf@upenn.edu)
- Daniel Angell (dpa34@drexel.edu)
- Jason Moore (moorejh28@gmail.com)
- and many more generous open-source contributors
TPOT is free software: you can redistribute it and/or modify
it under the terms of the GNU Lesser General Public License as
published by the Free Software Foundation, either version 3 of
the License, or (at your option) any later version.
TPOT is distributed in the hope that it will be useful,
but WITHOUT ANY WARRANTY; without even the implied warranty of
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
GNU Lesser General Public License for more details.
You should have received a copy of the GNU Lesser General Public
License along with TPOT. If not, see .
"""
import numpy as np
import copy
import copy
import typing
import tpot
from tpot import BaseIndividual
from traitlets import Bool
import collections
import pandas as pd
from joblib import Parallel, delayed
import copy
import pickle
import dask
def mutate(individual, rng):
rng = np.random.default_rng(rng)
if isinstance(individual, collections.abc.Iterable):
for ind in individual:
ind.mutate(rng=rng)
else:
individual.mutate(rng=rng)
return individual
def crossover(parents, rng):
rng = np.random.default_rng(rng)
parents[0].crossover(parents[1], rng=rng)
return parents[0]
def mutate_and_crossover(parents, rng):
rng = np.random.default_rng(rng)
parents[0].crossover(parents[1], rng=rng)
parents[0].mutate(rng=rng)
parents[1].mutate(rng=rng)
return parents
def crossover_and_mutate(parents, rng):
rng = np.random.default_rng(rng)
for p in parents:
p.mutate(rng=rng)
parents[0].crossover(parents[1], rng=rng)
return parents[0]
built_in_var_ops_dict = {"mutate":mutate,
"crossover":crossover,
"mutate_then_crossover":mutate_and_crossover,
"crossover_then_mutate":crossover_and_mutate}
class Population():
'''
Primary usage is to keep track of evaluated individuals
Parameters
----------
initial_population : {list of BaseIndividuals}, default=None
Initial population to start with. If None, start with an empty population.
use_unique_id : {Bool}, default=True
If True, individuals are treated as unique if they have the same unique_id().
If False, all new individuals are treated as unique.
callback : {function}, default=None
NOT YET IMPLEMENTED
A function to call after each generation. The function should take a Population object as its only argument.
Attributes
----------
population : {list of BaseIndividuals}
The current population of individuals. Contains the live instances of BaseIndividuals.
evaluated_individuals : {dict}
A dictionary of dictionaries. The keys are the unique_id() or self of each BaseIndividual.
Can be thought of as a table with the unique_id() as the row index and the inner dictionary keys as the columns.
'''
def __init__( self,
column_names: typing.List[str] = None,
n_jobs: int = 1,
callback=None,
) -> None:
if column_names is not None:
column_names = column_names+["Parents", "Variation_Function"]
else:
column_names = ["Parents", "Variation_Function"]
self.evaluated_individuals = pd.DataFrame(columns=column_names)
self.evaluated_individuals["Parents"] = self.evaluated_individuals["Parents"].astype('object')
self.use_unique_id = True #Todo clean this up. perhaps pull unique_id() out of baseestimator and have it be supplied as a function
self.n_jobs = n_jobs
self.callback=callback
self.population = []
def survival_select(self, selector, weights, columns_names, n_survivors, rng, inplace=True):
rng = np.random.default_rng(rng)
weighted_scores = self.get_column(self.population, column_names=columns_names) * weights
new_population_index = np.ravel(selector(weighted_scores, k=n_survivors, rng=rng)) #TODO make it clear that we are concatenating scores...
new_population = np.array(self.population)[new_population_index]
if inplace:
self.set_population(new_population, rng=rng)
return new_population
def parent_select(self, selector, weights, columns_names, k, n_parents, rng):
rng = np.random.default_rng(rng)
weighted_scores = self.get_column(self.population, column_names=columns_names) * weights
parents_index = selector(weighted_scores, k=k, n_parents=n_parents, rng=rng)
parents = np.array(self.population)[parents_index]
return parents
#remove individuals that either do not have a column_name value or a nan in that value
#TODO take into account when the value is not a list/tuple?
#TODO make invalid a global variable?
def remove_invalid_from_population(self, column_names, invalid_value = "INVALID"):
'''
Remove individuals from the live population if either do not have a value in the column_name column or if the value contains np.nan.
Parameters
----------
column_name : {str}
The name of the column to check for np.nan values.
Returns
-------
None
'''
if isinstance(column_names, str): #TODO check this
column_names = [column_names]
is_valid = lambda ind: ind.unique_id() not in self.evaluated_individuals.index or invalid_value not in self.evaluated_individuals.loc[ind.unique_id(),column_names].to_list()
self.population = [ind for ind in self.population if is_valid(ind)]
# takes the list of individuals and adds it to the live population list.
# if keep_repeats is False, repeated individuals are not added to the population
# returns a list of individuals added to the live population
#TODO make keep repeats allow for previously evaluated individuals,
#but make sure that the live population only includes one of each, no repeats
def add_to_population(self, individuals: typing.List[BaseIndividual], rng, keep_repeats=False, mutate_until_unique=True):
'''
Add individuals to the live population. Add individuals to the evaluated_individuals if they are not already there.
Parameters:
-----------
individuals : {list of BaseIndividuals}
The individuals to add to the live population.
keep_repeats : {bool}, default=False
If True, allow the population to have repeated individuals.
If False, only add individuals that have not yet been added to geneology.
'''
rng = np.random.default_rng(rng)
if not isinstance(individuals, collections.abc.Iterable):
individuals = [individuals]
new_individuals = []
#TODO check for proper inputs
for individual in individuals:
key = individual.unique_id()
if key not in self.evaluated_individuals.index: #If its new, we always add it
self.evaluated_individuals.loc[key] = np.nan
self.evaluated_individuals.loc[key,"Individual"] = copy.deepcopy(individual)
self.population.append(individual)
new_individuals.append(individual)
else:#If its old
if keep_repeats: #If we want to keep repeats, we add it
self.population.append(individual)
new_individuals.append(individual)
elif mutate_until_unique: #If its old and we don't want repeats, we can optionally mutate it until it is unique
for _ in range(20):
individual = copy.deepcopy(individual)
individual.mutate(rng=rng)
key = individual.unique_id()
if key not in self.evaluated_individuals.index:
self.evaluated_individuals.loc[key] = np.nan
self.evaluated_individuals.loc[key,"Individual"] = copy.deepcopy(individual)
self.population.append(individual)
new_individuals.append(individual)
break
return new_individuals
def update_column(self, individual, column_names, data):
'''
Update the column_name column in the evaluated_individuals with the data.
If the data is a list, it must be the same length as the evaluated_individuals.
If the data is a single value, it will be applied to all individuals in the evaluated_individuals.
'''
if isinstance(individual, collections.abc.Iterable):
if self.use_unique_id:
key = [ind.unique_id() for ind in individual]
else:
key = individual
else:
if self.use_unique_id:
key = individual.unique_id()
else:
key = individual
self.evaluated_individuals.loc[key,column_names] = data
def get_column(self, individual, column_names=None, to_numpy=True):
'''
Update the column_name column in the evaluated_individuals with the data.
If the data is a list, it must be the same length as the evaluated_individuals.
If the data is a single value, it will be applied to all individuals in the evaluated_individuals.
'''
if isinstance(individual, collections.abc.Iterable):
if self.use_unique_id:
key = [ind.unique_id() for ind in individual]
else:
key = individual
else:
if self.use_unique_id:
key = individual.unique_id()
else:
key = individual
if column_names is not None:
slice = self.evaluated_individuals.loc[key,column_names]
else:
slice = self.evaluated_individuals.loc[key]
if to_numpy:
slice.reset_index(drop=True, inplace=True)
return slice.to_numpy()
else:
return slice
#returns the individuals without a 'column' as a key in geneology
#TODO make sure not to get repeats in this list even if repeats are in the "live" population
def get_unevaluated_individuals(self, column_names, individual_list=None):
if individual_list is None:
individual_list = self.population
if self.use_unique_id:
unevaluated_filter = lambda individual: individual.unique_id() not in self.evaluated_individuals.index or any(self.evaluated_individuals.loc[individual.unique_id(), column_names].isna())
else:
unevaluated_filter = lambda individual: individual not in self.evaluated_individuals.index or any(self.evaluated_individuals.loc[individual.unique_id(), column_names].isna())
return [individual for individual in individual_list if unevaluated_filter(individual)]
# def get_valid_evaluated_individuals_df(self, column_names_to_check, invalid_values=["TIMEOUT","INVALID"]):
# '''
# Returns a dataframe of the evaluated individuals that do no have invalid_values in column_names_to_check.
# '''
# return self.evaluated_individuals[~self.evaluated_individuals[column_names_to_check].isin(invalid_values).any(axis=1)]
#the live population empied and is set to new_population
def set_population(self, new_population, rng, keep_repeats=True):
'''
sets population to new population
for selection?
'''
rng = np.random.default_rng(rng)
self.population = []
self.add_to_population(new_population, rng=rng, keep_repeats=keep_repeats)
#TODO should we just generate one offspring per crossover?
def create_offspring(self, parents_list, var_op_list, rng, add_to_population=True, keep_repeats=False, mutate_until_unique=True, n_jobs=1):
'''
parents_list: a list of lists of parents.
var_op_list: a list of var_ops to apply to each list of parents. Should be the same length as parents_list.
for example:
parents_list = [[parent1, parent2], [parent3]]
var_op_list = ["crossover", "mutate"]
This will apply crossover to parent1 and parent2 and mutate to parent3.
Creates offspring from parents using the var_op_list.
If string, will use a built in method
- "crossover" : crossover
- "mutate" : mutate
- "mutate_and_crossover" : mutate_and_crossover
- "cross_and_mutate" : cross_and_mutate
'''
rng = np.random.default_rng(rng)
new_offspring = []
all_offspring = parallel_create_offspring(parents_list, var_op_list, rng=rng, n_jobs=n_jobs)
for parents, offspring, var_op in zip(parents_list, all_offspring, var_op_list):
# if var_op in built_in_var_ops_dict:
# var_op = built_in_var_ops_dict[var_op]
# offspring = copy.deepcopy(parents)
# offspring = var_op(offspring)
# if isinstance(offspring, collections.abc.Iterable):
# offspring = offspring[0]
if add_to_population:
added = self.add_to_population(offspring, rng=rng, keep_repeats=keep_repeats, mutate_until_unique=mutate_until_unique)
if len(added) > 0:
for new_child in added:
parent_keys = [parent.unique_id() for parent in parents]
if not pd.api.types.is_object_dtype(self.evaluated_individuals["Parents"]): #TODO Is there a cleaner way of doing this? Not required for some python environments?
self.evaluated_individuals["Parents"] = self.evaluated_individuals["Parents"].astype('object')
if not pd.api.types.is_object_dtype(self.evaluated_individuals["Variation_Function"]):#TODO Is there a cleaner way of doing this? Not required for some python environments?
self.evaluated_individuals["Variation_Function"] = self.evaluated_individuals["Variation_Function"].astype('object')
self.evaluated_individuals.at[new_child.unique_id(),"Parents"] = tuple(parent_keys)
#if var_op is a function
if hasattr(var_op, '__call__'):
self.evaluated_individuals.at[new_child.unique_id(),"Variation_Function"] = var_op.__name__
else:
self.evaluated_individuals.at[new_child.unique_id(),"Variation_Function"] = str(var_op)
new_offspring.append(new_child)
else:
new_offspring.append(offspring)
return new_offspring
#TODO should we just generate one offspring per crossover?
def create_offspring2(self, parents_list, var_op_list, mutation_functions,mutation_function_weights, crossover_functions,crossover_function_weights, rng, add_to_population=True, keep_repeats=False, mutate_until_unique=True):
rng = np.random.default_rng(rng)
new_offspring = []
all_offspring = []
chosen_ops = []
for parents, var_op in zip(parents_list,var_op_list):
#TODO put this loop in population class
if var_op == "mutate":
mutation_op = rng.choice(mutation_functions, p=mutation_function_weights)
all_offspring.append(copy_and_mutate(parents[0], mutation_op, rng=rng))
chosen_ops.append(mutation_op.__name__)
elif var_op == "crossover":
crossover_op = rng.choice(crossover_functions, p=crossover_function_weights)
all_offspring.append(copy_and_crossover(parents, crossover_op, rng=rng))
chosen_ops.append(crossover_op.__name__)
elif var_op == "mutate_then_crossover":
mutation_op1 = rng.choice(mutation_functions, p=mutation_function_weights)
mutation_op2 = rng.choice(mutation_functions, p=mutation_function_weights)
crossover_op = rng.choice(crossover_functions, p=crossover_function_weights)
p1 = copy_and_mutate(parents[0], mutation_op1, rng=rng)
p2 = copy_and_mutate(parents[1], mutation_op2, rng=rng)
crossover_op(p1,p2,rng=rng)
all_offspring.append(p1)
chosen_ops.append(f"{mutation_op1.__name__} , {mutation_op2.__name__} , {crossover_op.__name__}")
elif var_op == "crossover_then_mutate":
crossover_op = rng.choice(crossover_functions, p=crossover_function_weights)
child = copy_and_crossover(parents, crossover_op, rng=rng)
mutation_op = rng.choice(mutation_functions, p=mutation_function_weights)
mutation_op(child, rng=rng)
all_offspring.append(child)
chosen_ops.append(f"{crossover_op.__name__} , {mutation_op.__name__}")
for parents, offspring, var_op in zip(parents_list, all_offspring, chosen_ops):
# if var_op in built_in_var_ops_dict:
# var_op = built_in_var_ops_dict[var_op]
# offspring = copy.deepcopy(parents)
# offspring = var_op(offspring)
# if isinstance(offspring, collections.abc.Iterable):
# offspring = offspring[0]
if add_to_population:
added = self.add_to_population(offspring, rng=rng, keep_repeats=keep_repeats, mutate_until_unique=mutate_until_unique)
if len(added) > 0:
for new_child in added:
parent_keys = [parent.unique_id() for parent in parents]
if not pd.api.types.is_object_dtype(self.evaluated_individuals["Parents"]): #TODO Is there a cleaner way of doing this? Not required for some python environments?
self.evaluated_individuals["Parents"] = self.evaluated_individuals["Parents"].astype('object')
self.evaluated_individuals.at[new_child.unique_id(),"Parents"] = tuple(parent_keys)
#check if Variation_Function variable is an object type
if not pd.api.types.is_object_dtype(self.evaluated_individuals["Variation_Function"]): #TODO Is there a cleaner way of doing this? Not required for some python environments?
self.evaluated_individuals["Variation_Function"] = self.evaluated_individuals["Variation_Function"].astype('object')
#if var_op is a function
if hasattr(var_op, '__call__'):
self.evaluated_individuals.at[new_child.unique_id(),"Variation_Function"] = var_op.__name__
else:
self.evaluated_individuals.at[new_child.unique_id(),"Variation_Function"] = str(var_op)
new_offspring.append(new_child)
else:
new_offspring.append(offspring)
return new_offspring
def get_id(individual):
return individual.unique_id()
def parallel_create_offspring(parents_list, var_op_list, rng, n_jobs=1):
rng = np.random.default_rng(rng)
if n_jobs == 1:
return nonparallel_create_offpring(parents_list, var_op_list, rng=rng)
else:
delayed_offspring = []
for parents, var_op in zip(parents_list,var_op_list):
#TODO put this loop in population class
if var_op in built_in_var_ops_dict:
var_op = built_in_var_ops_dict[var_op]
delayed_offspring.append(dask.delayed(copy_and_change)(parents, var_op, rng=rng))
offspring = dask.compute(*delayed_offspring,
num_workers=n_jobs, threads_per_worker=1)
return offspring
def nonparallel_create_offpring(parents_list, var_op_list, rng, n_jobs=1):
rng = np.random.default_rng(rng)
offspring = []
for parents, var_op in zip(parents_list,var_op_list):
#TODO put this loop in population class
if var_op in built_in_var_ops_dict:
var_op = built_in_var_ops_dict[var_op]
offspring.append(copy_and_change(parents, var_op, rng=rng))
return offspring
def copy_and_change(parents, var_op, rng):
rng = np.random.default_rng(rng)
offspring = copy.deepcopy(parents)
offspring = var_op(offspring, rng=rng)
if isinstance(offspring, collections.abc.Iterable):
offspring = offspring[0]
return offspring
def copy_and_mutate(parents, var_op, rng):
rng = np.random.default_rng(rng)
offspring = copy.deepcopy(parents)
var_op(offspring, rng=rng)
if isinstance(offspring, collections.abc.Iterable):
offspring = offspring[0]
return offspring
def copy_and_crossover(parents, var_op, rng):
rng = np.random.default_rng(rng)
offspring = copy.deepcopy(parents)
var_op(offspring[0],offspring[1], rng=rng)
return offspring[0]
def parallel_get_id(n_jobs, individual_list):
id_list = Parallel(n_jobs=n_jobs)(delayed(get_id)(ind) for ind in individual_list)
return id_list
================================================
FILE: tpot/search_spaces/__init__.py
================================================
from .base import *
from . import nodes
from . import pipelines
================================================
FILE: tpot/search_spaces/base.py
================================================
"""
This file is part of the TPOT library.
The current version of TPOT was developed at Cedars-Sinai by:
- Pedro Henrique Ribeiro (https://github.com/perib, https://www.linkedin.com/in/pedro-ribeiro/)
- Anil Saini (anil.saini@cshs.org)
- Jose Hernandez (jgh9094@gmail.com)
- Jay Moran (jay.moran@cshs.org)
- Nicholas Matsumoto (nicholas.matsumoto@cshs.org)
- Hyunjun Choi (hyunjun.choi@cshs.org)
- Gabriel Ketron (gabriel.ketron@cshs.org)
- Miguel E. Hernandez (miguel.e.hernandez@cshs.org)
- Jason Moore (moorejh28@gmail.com)
The original version of TPOT was primarily developed at the University of Pennsylvania by:
- Randal S. Olson (rso@randalolson.com)
- Weixuan Fu (weixuanf@upenn.edu)
- Daniel Angell (dpa34@drexel.edu)
- Jason Moore (moorejh28@gmail.com)
- and many more generous open-source contributors
TPOT is free software: you can redistribute it and/or modify
it under the terms of the GNU Lesser General Public License as
published by the Free Software Foundation, either version 3 of
the License, or (at your option) any later version.
TPOT is distributed in the hope that it will be useful,
but WITHOUT ANY WARRANTY; without even the implied warranty of
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
GNU Lesser General Public License for more details.
You should have received a copy of the GNU Lesser General Public
License along with TPOT. If not, see .
"""
import tpot
import sklearn
from sklearn.base import BaseEstimator
import sklearn
import networkx as nx
from . import graph_utils
from typing import final
class SklearnIndividual(tpot.BaseIndividual):
def __init_subclass__(cls):
cls.crossover = cls.validate_same_type(cls.crossover)
def __init__(self,) -> None:
super().__init__()
def mutate(self, rng=None):
return
def crossover(self, other, rng=None, **kwargs):
return
@final
def validate_same_type(func):
def wrapper(self, other, rng=None, **kwargs):
if not isinstance(other, type(self)):
return False
return func(self, other, rng=rng, **kwargs)
return wrapper
def export_pipeline(self, **kwargs) -> BaseEstimator:
return
def unique_id(self):
"""
Returns a unique identifier for the individual. Used for preventing duplicate individuals from being evaluated.
"""
return self
#TODO currently TPOT population class manually uses the unique_id to generate the index for the population data frame.
#alternatively, the index could be the individual itself, with the __eq__ and __hash__ methods implemented.
# Though this breaks the graphpipeline. When a mutation is called, it changes the __eq__ and __hash__ outputs.
# Since networkx uses the hash and eq to determine if a node is already in the graph, this causes the graph thing that
# This is a new node not in the graph. But this could be changed if when the graphpipeline mutates nodes,
# it "replaces" the existing node with the mutated node. This would require a change in the graphpipeline class.
# def __eq__(self, other):
# return self.unique_id() == other.unique_id()
# def __hash__(self):
# return hash(self.unique_id())
#number of components in the pipeline
def get_size(self):
return 1
@final
def export_flattened_graphpipeline(self, **graphpipeline_kwargs) -> tpot.GraphPipeline:
return flatten_to_graphpipeline(self.export_pipeline(), **graphpipeline_kwargs)
class SearchSpace():
def __init__(self,):
pass
def generate(self, rng=None) -> SklearnIndividual:
pass
def flatten_graphpipeline(est):
flattened_full_graph = est.graph.copy()
#put ests into the node label from the attributes
flattened_full_graph = nx.relabel_nodes(flattened_full_graph, {n: flattened_full_graph.nodes[n]['instance'] for n in flattened_full_graph.nodes})
remove_list = []
for node in flattened_full_graph.nodes:
if isinstance(node, nx.DiGraph):
flattened = flatten_any(node)
roots = graph_utils.get_roots(flattened)
leaves = graph_utils.get_leaves(flattened)
n1_s = flattened_full_graph.successors(node)
n1_p = flattened_full_graph.predecessors(node)
remove_list.append(node)
flattened_full_graph = nx.compose(flattened_full_graph, flattened)
flattened_full_graph.add_edges_from([ (n2, n) for n in n1_s for n2 in leaves])
flattened_full_graph.add_edges_from([ (n, n2) for n in n1_p for n2 in roots])
for node in remove_list:
flattened_full_graph.remove_node(node)
return flattened_full_graph
def flatten_pipeline(est):
graph = nx.DiGraph()
steps = [flatten_any(s[1]) for s in est.steps]
#add steps to graph and connect them
for s in steps:
graph = nx.compose(graph, s)
#connect leaves of each step to the roots of the next step
for i in range(len(steps)-1):
roots = graph_utils.get_roots(steps[i])
leaves = graph_utils.get_leaves(steps[i+1])
graph.add_edges_from([ (l,r) for l in leaves for r in roots])
return graph
def flatten_estimator(est):
graph = nx.DiGraph()
graph.add_node(est)
return graph
def flatten_any(est):
if isinstance(est, tpot.GraphPipeline):
return flatten_graphpipeline(est)
elif isinstance(est, sklearn.pipeline.Pipeline):
return flatten_pipeline(est)
else:
return flatten_estimator(est)
def flatten_to_graphpipeline(est, **graphpipeline_kwargs):
#rename nodes to string representation of the instance and put the instance in the node attributes
flattened_full_graph = flatten_any(est)
instance_to_label = {}
label_to_instance = {}
for node in flattened_full_graph.nodes:
found_unique_label = False
i=1
while not found_unique_label:
new_label = f"{node.__class__.__name__}_{i}"
if new_label not in label_to_instance:
found_unique_label = True
i+=1
label_to_instance[new_label] = node
instance_to_label[node] = new_label
flattened_full_graph = nx.relabel_nodes(flattened_full_graph, instance_to_label)
for label, instance in label_to_instance.items():
flattened_full_graph.nodes[label]["instance"] = instance
return tpot.GraphPipeline(flattened_full_graph, **graphpipeline_kwargs)
================================================
FILE: tpot/search_spaces/graph_utils.py
================================================
"""
This file is part of the TPOT library.
The current version of TPOT was developed at Cedars-Sinai by:
- Pedro Henrique Ribeiro (https://github.com/perib, https://www.linkedin.com/in/pedro-ribeiro/)
- Anil Saini (anil.saini@cshs.org)
- Jose Hernandez (jgh9094@gmail.com)
- Jay Moran (jay.moran@cshs.org)
- Nicholas Matsumoto (nicholas.matsumoto@cshs.org)
- Hyunjun Choi (hyunjun.choi@cshs.org)
- Gabriel Ketron (gabriel.ketron@cshs.org)
- Miguel E. Hernandez (miguel.e.hernandez@cshs.org)
- Jason Moore (moorejh28@gmail.com)
The original version of TPOT was primarily developed at the University of Pennsylvania by:
- Randal S. Olson (rso@randalolson.com)
- Weixuan Fu (weixuanf@upenn.edu)
- Daniel Angell (dpa34@drexel.edu)
- Jason Moore (moorejh28@gmail.com)
- and many more generous open-source contributors
TPOT is free software: you can redistribute it and/or modify
it under the terms of the GNU Lesser General Public License as
published by the Free Software Foundation, either version 3 of
the License, or (at your option) any later version.
TPOT is distributed in the hope that it will be useful,
but WITHOUT ANY WARRANTY; without even the implied warranty of
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
GNU Lesser General Public License for more details.
You should have received a copy of the GNU Lesser General Public
License along with TPOT. If not, see .
"""
import networkx as nx
import numpy as np
def remove_and_stitch(graph, node):
successors = graph.successors(node)
predecessors = graph.predecessors(node)
graph.remove_node(node)
for s in successors:
for p in predecessors:
graph.add_edge(p,s)
def remove_nodes_disconnected_from_node(graph, node):
descendants = nx.descendants(graph, node)
for n in list(graph.nodes):
if n not in descendants and n is not node:
graph.remove_node(n)
#graph.remove_nodes_from([n for n in graph.nodes if n not in nx.descendants(graph, node) and n is not node])
def get_roots(graph):
return [v for v, d in graph.in_degree() if d == 0]
def get_leaves(graph):
return [v for v, d in graph.out_degree() if d == 0]
def get_max_path_through_node(graph, root, node):
if len(list(graph.successors(node)))==0:
return get_max_path_size(graph, root, node)
else:
leaves = [n for n in nx.descendants(graph,node) if len(list(graph.successors(n)))==0]
return max([get_max_path_size(graph, root, l) for l in leaves])
def get_max_path_size(graph, fromnode1,tonode2, return_path=False):
if fromnode1 is tonode2:
if return_path:
return [fromnode1]
return 1
else:
max_length_path = max(nx.all_simple_paths(graph, fromnode1, tonode2), key=lambda x: len(x))
if return_path:
return max_length_path
return len(max_length_path) #gets the max path and finds the length of that path
def invert_dictionary(d):
inv_map = {}
for k, v in d.items():
inv_map.setdefault(v, set()).add(k)
return inv_map
def select_nodes_same_depth(g1, node1, g2, node2, rng=None):
rng = np.random.default_rng(rng)
g1_nodes = nx.shortest_path_length(g1, source=node1)
g2_nodes = nx.shortest_path_length(g2, source=node2)
max_depth = max(list(g1_nodes.values()) + list(g2_nodes.values()))
g1_nodes = invert_dictionary(g1_nodes)
g2_nodes = invert_dictionary(g2_nodes)
# depth_number_of_nodes = []
# for i in range(max_depth+1):
# n = 0
# if i in g1_nodes and i in g2_nodes:
# depth_number_of_nodes.append(len(g1_nodes[i])+len(g1_nodes[i]))
# else:
# break
possible_pairs = []
for i in range(max_depth+1):
if i in g1_nodes and i in g2_nodes:
for n1 in g1_nodes[i]:
for n2 in g2_nodes[i]:
possible_pairs.append( (n1,n2) )
rng.shuffle(possible_pairs)
for p in possible_pairs:
yield p[0], p[1]
def select_nodes_randomly(g1, g2, rng=None):
rng = np.random.default_rng(rng)
sorted_self_nodes_list = list(g1.nodes)
rng.shuffle(sorted_self_nodes_list)
sorted_other_nodes_list = list(g2.nodes)
rng.shuffle(sorted_other_nodes_list)
for node1 in sorted_self_nodes_list:
for node2 in sorted_other_nodes_list:
if node1 is node2:
continue
yield node1, node2
================================================
FILE: tpot/search_spaces/nodes/__init__.py
================================================
"""
This file is part of the TPOT library.
The current version of TPOT was developed at Cedars-Sinai by:
- Pedro Henrique Ribeiro (https://github.com/perib, https://www.linkedin.com/in/pedro-ribeiro/)
- Anil Saini (anil.saini@cshs.org)
- Jose Hernandez (jgh9094@gmail.com)
- Jay Moran (jay.moran@cshs.org)
- Nicholas Matsumoto (nicholas.matsumoto@cshs.org)
- Hyunjun Choi (hyunjun.choi@cshs.org)
- Gabriel Ketron (gabriel.ketron@cshs.org)
- Miguel E. Hernandez (miguel.e.hernandez@cshs.org)
- Jason Moore (moorejh28@gmail.com)
The original version of TPOT was primarily developed at the University of Pennsylvania by:
- Randal S. Olson (rso@randalolson.com)
- Weixuan Fu (weixuanf@upenn.edu)
- Daniel Angell (dpa34@drexel.edu)
- Jason Moore (moorejh28@gmail.com)
- and many more generous open-source contributors
TPOT is free software: you can redistribute it and/or modify
it under the terms of the GNU Lesser General Public License as
published by the Free Software Foundation, either version 3 of
the License, or (at your option) any later version.
TPOT is distributed in the hope that it will be useful,
but WITHOUT ANY WARRANTY; without even the implied warranty of
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
GNU Lesser General Public License for more details.
You should have received a copy of the GNU Lesser General Public
License along with TPOT. If not, see .
"""
from .estimator_node import *
from .genetic_feature_selection import *
from .fss_node import *
================================================
FILE: tpot/search_spaces/nodes/estimator_node.py
================================================
"""
This file is part of the TPOT library.
The current version of TPOT was developed at Cedars-Sinai by:
- Pedro Henrique Ribeiro (https://github.com/perib, https://www.linkedin.com/in/pedro-ribeiro/)
- Anil Saini (anil.saini@cshs.org)
- Jose Hernandez (jgh9094@gmail.com)
- Jay Moran (jay.moran@cshs.org)
- Nicholas Matsumoto (nicholas.matsumoto@cshs.org)
- Hyunjun Choi (hyunjun.choi@cshs.org)
- Gabriel Ketron (gabriel.ketron@cshs.org)
- Miguel E. Hernandez (miguel.e.hernandez@cshs.org)
- Jason Moore (moorejh28@gmail.com)
The original version of TPOT was primarily developed at the University of Pennsylvania by:
- Randal S. Olson (rso@randalolson.com)
- Weixuan Fu (weixuanf@upenn.edu)
- Daniel Angell (dpa34@drexel.edu)
- Jason Moore (moorejh28@gmail.com)
- and many more generous open-source contributors
TPOT is free software: you can redistribute it and/or modify
it under the terms of the GNU Lesser General Public License as
published by the Free Software Foundation, either version 3 of
the License, or (at your option) any later version.
TPOT is distributed in the hope that it will be useful,
but WITHOUT ANY WARRANTY; without even the implied warranty of
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
GNU Lesser General Public License for more details.
You should have received a copy of the GNU Lesser General Public
License along with TPOT. If not, see .
"""
# try https://automl.github.io/ConfigSpace/main/api/hyperparameters.html
import numpy as np
from ..base import SklearnIndividual, SearchSpace
from ConfigSpace import ConfigurationSpace
from typing import final
def default_hyperparameter_parser(params:dict) -> dict:
return params
class EstimatorNodeIndividual(SklearnIndividual):
"""
Note that ConfigurationSpace does not support None as a parameter. Instead, use the special string "". TPOT will automatically replace instances of this string with the Python None.
Parameters
----------
method : type
The class of the estimator to be used
space : ConfigurationSpace|dict
The hyperparameter space to be used. If a dict is passed, hyperparameters are fixed and not learned.
"""
def __init__(self, method: type,
space: ConfigurationSpace|dict, #TODO If a dict is passed, hyperparameters are fixed and not learned. Is this confusing? Should we make a second node type?
hyperparameter_parser: callable = None,
rng=None) -> None:
super().__init__()
self.method = method
self.space = space
if hyperparameter_parser is None:
self.hyperparameter_parser = default_hyperparameter_parser
else:
self.hyperparameter_parser = hyperparameter_parser
if isinstance(space, dict):
self.hyperparameters = space
else:
rng = np.random.default_rng(rng)
self.space.seed(rng.integers(0, 2**32))
self.hyperparameters = dict(self.space.sample_configuration())
def mutate(self, rng=None):
if isinstance(self.space, dict):
return False
rng = np.random.default_rng(rng)
self.space.seed(rng.integers(0, 2**32))
self.hyperparameters = dict(self.space.sample_configuration())
return True
def crossover(self, other, rng=None):
if isinstance(self.space, dict):
return False
rng = np.random.default_rng(rng)
if self.method != other.method:
return False
#loop through hyperparameters, randomly swap items in self.hyperparameters with items in other.hyperparameters
for hyperparameter in self.space:
if rng.choice([True, False]):
if hyperparameter in other.hyperparameters:
self.hyperparameters[hyperparameter] = other.hyperparameters[hyperparameter]
return True
@final #this method should not be overridden, instead override hyperparameter_parser
def export_pipeline(self, **kwargs):
return self.method(**self.hyperparameter_parser(self.hyperparameters))
def unique_id(self):
#return a dictionary of the method and the hyperparameters
method_str = self.method.__name__
params = list(self.hyperparameters.keys())
params = sorted(params)
id_str = f"{method_str}({', '.join([f'{param}={self.hyperparameters[param]}' for param in params])})"
return id_str
class EstimatorNode(SearchSpace):
def __init__(self, method, space, hyperparameter_parser=default_hyperparameter_parser):
self.method = method
self.space = space
self.hyperparameter_parser = hyperparameter_parser
def generate(self, rng=None):
return EstimatorNodeIndividual(self.method, self.space, hyperparameter_parser=self.hyperparameter_parser, rng=rng)
================================================
FILE: tpot/search_spaces/nodes/estimator_node_gradual.py
================================================
"""
This file is part of the TPOT library.
The current version of TPOT was developed at Cedars-Sinai by:
- Pedro Henrique Ribeiro (https://github.com/perib, https://www.linkedin.com/in/pedro-ribeiro/)
- Anil Saini (anil.saini@cshs.org)
- Jose Hernandez (jgh9094@gmail.com)
- Jay Moran (jay.moran@cshs.org)
- Nicholas Matsumoto (nicholas.matsumoto@cshs.org)
- Hyunjun Choi (hyunjun.choi@cshs.org)
- Gabriel Ketron (gabriel.ketron@cshs.org)
- Miguel E. Hernandez (miguel.e.hernandez@cshs.org)
- Jason Moore (moorejh28@gmail.com)
The original version of TPOT was primarily developed at the University of Pennsylvania by:
- Randal S. Olson (rso@randalolson.com)
- Weixuan Fu (weixuanf@upenn.edu)
- Daniel Angell (dpa34@drexel.edu)
- Jason Moore (moorejh28@gmail.com)
- and many more generous open-source contributors
TPOT is free software: you can redistribute it and/or modify
it under the terms of the GNU Lesser General Public License as
published by the Free Software Foundation, either version 3 of
the License, or (at your option) any later version.
TPOT is distributed in the hope that it will be useful,
but WITHOUT ANY WARRANTY; without even the implied warranty of
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
GNU Lesser General Public License for more details.
You should have received a copy of the GNU Lesser General Public
License along with TPOT. If not, see .
"""
# try https://automl.github.io/ConfigSpace/main/api/hyperparameters.html
import numpy as np
from tpot.search_spaces.base import SklearnIndividual, SearchSpace
from ConfigSpace import ConfigurationSpace
from typing import final
import ConfigSpace
def default_hyperparameter_parser(params:dict) -> dict:
return params
# NOTE: This is not the default, currently experimental
class EstimatorNodeIndividual_gradual(SklearnIndividual):
"""
Note that ConfigurationSpace does not support None as a parameter. Instead, use the special string "". TPOT will automatically replace instances of this string with the Python None.
Parameters
----------
method : type
The class of the estimator to be used
space : ConfigurationSpace|dict
The hyperparameter space to be used. If a dict is passed, hyperparameters are fixed and not learned.
"""
def __init__(self, method: type,
space: ConfigurationSpace|dict, #TODO If a dict is passed, hyperparameters are fixed and not learned. Is this confusing? Should we make a second node type?
hyperparameter_parser: callable = None,
rng=None) -> None:
super().__init__()
self.method = method
self.space = space
if hyperparameter_parser is None:
self.hyperparameter_parser = default_hyperparameter_parser
else:
self.hyperparameter_parser = hyperparameter_parser
if isinstance(space, dict):
self.hyperparameters = space
else:
rng = np.random.default_rng(rng)
self.space.seed(rng.integers(0, 2**32))
self.hyperparameters = dict(self.space.sample_configuration())
def mutate(self, rng=None):
if isinstance(self.space, dict):
return False
self.hyperparameters = gradual_hyperparameter_update(params=self.hyperparameters, configspace=self.space, rng=rng)
return True
def crossover(self, other, rng=None):
if isinstance(self.space, dict):
return False
rng = np.random.default_rng(rng)
if self.method != other.method:
return False
#loop through hyperparameters, randomly swap items in self.hyperparameters with items in other.hyperparameters
for hyperparameter in self.space:
if rng.choice([True, False]):
if hyperparameter in other.hyperparameters:
self.hyperparameters[hyperparameter] = other.hyperparameters[hyperparameter]
return True
@final #this method should not be overridden, instead override hyperparameter_parser
def export_pipeline(self, **kwargs):
return self.method(**self.hyperparameter_parser(self.hyperparameters))
def unique_id(self):
#return a dictionary of the method and the hyperparameters
method_str = self.method.__name__
params = list(self.hyperparameters.keys())
params = sorted(params)
id_str = f"{method_str}({', '.join([f'{param}={self.hyperparameters[param]}' for param in params])})"
return id_str
def gradual_hyperparameter_update(params:dict, configspace:ConfigurationSpace, rng=None):
rng = np.random.default_rng(rng)
configspace.seed(rng.integers(0, 2**32))
new_params = dict(configspace.sample_configuration())
for param in list(new_params.keys()):
#if parameter is float, multiply by normal distribution
if param not in params:
continue
try:
if issubclass(type(configspace[param]), ConfigSpace.hyperparameters.hyperparameter.FloatHyperparameter):
if configspace[param].log:
new_params[param] = params[param] * rng.lognormal(0, 1)
else:
new_params[param] = params[param] + rng.normal(0, .1)* (configspace[param].upper-configspace[param].lower)
# if check if above or below min and cap
if new_params[param] < configspace[param].lower:
new_params[param] = configspace[param].lower
elif new_params[param] > configspace[param].upper:
new_params[param] = configspace[param].upper
#if parameter is integer, add normal distribution
elif issubclass(type(configspace[param]), ConfigSpace.hyperparameters.hyperparameter.IntegerHyperparameter):
new_params[param] = params[param] * rng.normal(0, 1)
# if check if above or below min and cap
if new_params[param] < configspace[param].lower:
new_params[param] = configspace[param].lower
elif new_params[param] > configspace[param].upper:
new_params[param] = configspace[param].upper
new_params[param] = int(new_params[param])
# TODO : add support for categorical hyperparameters
else:
new_params[param] = params[param]
except:
pass
return new_params
class EstimatorNode_gradual(SearchSpace):
def __init__(self, method, space, hyperparameter_parser=default_hyperparameter_parser):
self.method = method
self.space = space
self.hyperparameter_parser = hyperparameter_parser
def generate(self, rng=None):
return EstimatorNodeIndividual_gradual(self.method, self.space, hyperparameter_parser=self.hyperparameter_parser, rng=rng)
================================================
FILE: tpot/search_spaces/nodes/fss_node.py
================================================
"""
This file is part of the TPOT library.
The current version of TPOT was developed at Cedars-Sinai by:
- Pedro Henrique Ribeiro (https://github.com/perib, https://www.linkedin.com/in/pedro-ribeiro/)
- Anil Saini (anil.saini@cshs.org)
- Jose Hernandez (jgh9094@gmail.com)
- Jay Moran (jay.moran@cshs.org)
- Nicholas Matsumoto (nicholas.matsumoto@cshs.org)
- Hyunjun Choi (hyunjun.choi@cshs.org)
- Gabriel Ketron (gabriel.ketron@cshs.org)
- Miguel E. Hernandez (miguel.e.hernandez@cshs.org)
- Jason Moore (moorejh28@gmail.com)
The original version of TPOT was primarily developed at the University of Pennsylvania by:
- Randal S. Olson (rso@randalolson.com)
- Weixuan Fu (weixuanf@upenn.edu)
- Daniel Angell (dpa34@drexel.edu)
- Jason Moore (moorejh28@gmail.com)
- and many more generous open-source contributors
TPOT is free software: you can redistribute it and/or modify
it under the terms of the GNU Lesser General Public License as
published by the Free Software Foundation, either version 3 of
the License, or (at your option) any later version.
TPOT is distributed in the hope that it will be useful,
but WITHOUT ANY WARRANTY; without even the implied warranty of
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
GNU Lesser General Public License for more details.
You should have received a copy of the GNU Lesser General Public
License along with TPOT. If not, see .
"""
from numpy import iterable
import tpot
import numpy as np
import sklearn
import sklearn.datasets
import numpy as np
import pandas as pd
import os, os.path
from sklearn.base import BaseEstimator
from sklearn.feature_selection._base import SelectorMixin
from ..base import SklearnIndividual, SearchSpace
from ...builtin_modules.feature_set_selector import FeatureSetSelector
class FSSIndividual(SklearnIndividual):
def __init__( self,
subsets,
rng=None,
):
"""
An individual for representing a specific FeatureSetSelector.
The FeatureSetSelector selects a feature list of list of predefined feature subsets.
This instance will select one set initially. Mutation and crossover can swap the selected subset with another.
Parameters
----------
subsets : str or list, default=None
Sets the subsets that the FeatureSetSeletor will select from if set as an option in one of the configuration dictionaries.
Features are defined by column names if using a Pandas data frame, or ints corresponding to indexes if using numpy arrays.
- str : If a string, it is assumed to be a path to a csv file with the subsets.
The first column is assumed to be the name of the subset and the remaining columns are the features in the subset.
- list or np.ndarray : If a list or np.ndarray, it is assumed to be a list of subsets (i.e a list of lists).
- dict : A dictionary where keys are the names of the subsets and the values are the list of features.
- int : If an int, it is assumed to be the number of subsets to generate. Each subset will contain one feature.
- None : If None, each column will be treated as a subset. One column will be selected per subset.
rng : int, np.random.Generator, optional
The random number generator. The default is None.
Only used to select the first subset.
Returns
-------
None
"""
subsets = subsets
rng = np.random.default_rng(rng)
if isinstance(subsets, str):
df = pd.read_csv(subsets,header=None,index_col=0)
df['features'] = df.apply(lambda x: list([x[c] for c in df.columns]),axis=1)
self.subset_dict = {}
for row in df.index:
self.subset_dict[row] = df.loc[row]['features']
elif isinstance(subsets, dict):
self.subset_dict = subsets
elif isinstance(subsets, list) or isinstance(subsets, np.ndarray):
self.subset_dict = {str(i):subsets[i] for i in range(len(subsets))}
elif isinstance(subsets, int):
self.subset_dict = {"{0}".format(i):i for i in range(subsets)}
else:
raise ValueError("Subsets must be a string, dictionary, list, int, or numpy array")
self.names_list = list(self.subset_dict.keys())
self.selected_subset_name = rng.choice(self.names_list)
self.sel_subset = self.subset_dict[self.selected_subset_name]
def mutate(self, rng=None):
rng = np.random.default_rng(rng)
#get list of names not including the current one
names = [name for name in self.names_list if name != self.selected_subset_name]
self.selected_subset_name = rng.choice(names)
self.sel_subset = self.subset_dict[self.selected_subset_name]
def crossover(self, other, rng=None):
self.selected_subset_name = other.selected_subset_name
self.sel_subset = other.sel_subset
def export_pipeline(self, **kwargs):
return FeatureSetSelector(sel_subset=self.sel_subset, name=self.selected_subset_name)
def unique_id(self):
id_str = "FeatureSetSelector({0})".format(self.selected_subset_name)
return id_str
class FSSNode(SearchSpace):
def __init__(self,
subsets,
):
"""
A search space for a FeatureSetSelector.
The FeatureSetSelector selects a feature list of list of predefined feature subsets.
Parameters
----------
subsets : str or list, default=None
Sets the subsets that the FeatureSetSeletor will select from if set as an option in one of the configuration dictionaries.
Features are defined by column names if using a Pandas data frame, or ints corresponding to indexes if using numpy arrays.
- str : If a string, it is assumed to be a path to a csv file with the subsets.
The first column is assumed to be the name of the subset and the remaining columns are the features in the subset.
- list or np.ndarray : If a list or np.ndarray, it is assumed to be a list of subsets (i.e a list of lists).
- dict : A dictionary where keys are the names of the subsets and the values are the list of features.
- int : If an int, it is assumed to be the number of subsets to generate. Each subset will contain one feature.
- None : If None, each column will be treated as a subset. One column will be selected per subset.
Returns
-------
None
"""
self.subsets = subsets
def generate(self, rng=None) -> SklearnIndividual:
return FSSIndividual(
subsets=self.subsets,
rng=rng,
)
================================================
FILE: tpot/search_spaces/nodes/genetic_feature_selection.py
================================================
"""
This file is part of the TPOT library.
The current version of TPOT was developed at Cedars-Sinai by:
- Pedro Henrique Ribeiro (https://github.com/perib, https://www.linkedin.com/in/pedro-ribeiro/)
- Anil Saini (anil.saini@cshs.org)
- Jose Hernandez (jgh9094@gmail.com)
- Jay Moran (jay.moran@cshs.org)
- Nicholas Matsumoto (nicholas.matsumoto@cshs.org)
- Hyunjun Choi (hyunjun.choi@cshs.org)
- Gabriel Ketron (gabriel.ketron@cshs.org)
- Miguel E. Hernandez (miguel.e.hernandez@cshs.org)
- Jason Moore (moorejh28@gmail.com)
The original version of TPOT was primarily developed at the University of Pennsylvania by:
- Randal S. Olson (rso@randalolson.com)
- Weixuan Fu (weixuanf@upenn.edu)
- Daniel Angell (dpa34@drexel.edu)
- Jason Moore (moorejh28@gmail.com)
- and many more generous open-source contributors
TPOT is free software: you can redistribute it and/or modify
it under the terms of the GNU Lesser General Public License as
published by the Free Software Foundation, either version 3 of
the License, or (at your option) any later version.
TPOT is distributed in the hope that it will be useful,
but WITHOUT ANY WARRANTY; without even the implied warranty of
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
GNU Lesser General Public License for more details.
You should have received a copy of the GNU Lesser General Public
License along with TPOT. If not, see .
"""
from numpy import iterable
import tpot
import numpy as np
import sklearn
import sklearn.datasets
import numpy as np
import pandas as pd
import os, os.path
from sklearn.base import BaseEstimator
from sklearn.feature_selection._base import SelectorMixin
from ..base import SklearnIndividual, SearchSpace
class MaskSelector(SelectorMixin, BaseEstimator):
"""Select predefined feature subsets."""
def __init__(self, mask, set_output_transform=None):
self.mask = mask
self.set_output_transform = set_output_transform
if set_output_transform is not None:
self.set_output(transform=set_output_transform)
def fit(self, X, y=None):
self.n_features_in_ = X.shape[1]
if isinstance(X, pd.DataFrame):
self.feature_names_in_ = X.columns
# self.set_output(transform="pandas")
self.is_fitted_ = True #so sklearn knows it's fitted
return self
def __sklearn_tags__(self):
tags = super().__sklearn_tags__()
tags.input_tags.allow_nan = True
tags.target_tags.required = False # formally requires_y
return tags
def _get_support_mask(self):
return np.array(self.mask)
def get_feature_names_out(self, input_features=None):
return self.feature_names_in_[self.get_support()]
class GeneticFeatureSelectorIndividual(SklearnIndividual):
def __init__( self,
mask,
start_p=0.2,
mutation_rate = 0.5,
crossover_rate = 0.5,
mutation_rate_rate = 0,
crossover_rate_rate = 0,
rng=None,
):
self.start_p = start_p
self.mutation_rate = mutation_rate
self.crossover_rate = crossover_rate
self.mutation_rate_rate = mutation_rate_rate
self.crossover_rate_rate = crossover_rate_rate
rng = np.random.default_rng(rng)
if isinstance(mask, int):
#list of random bollean values
self.mask = rng.choice([True, False], size=mask, p=[self.start_p,1-self.start_p])
else:
self.mask = mask
# check if there are no features selected, if so select one
if sum(self.mask) == 0:
index = rng.choice(len(self.mask))
self.mask[index] = True
self.mutation_list = [self._mutate_add, self._mutate_remove]
self.crossover_list = [self._crossover_swap]
def mutate(self, rng=None):
rng = np.random.default_rng(rng)
if rng.uniform() < self.mutation_rate_rate:
self.mutation_rate = self.mutation_rate * rng.uniform(0.5, 2)
self.mutation_rate = min(self.mutation_rate, 2)
self.mutation_rate = max(self.mutation_rate, 1/len(self.mask))
return rng.choice(self.mutation_list)(rng)
def crossover(self, other, rng=None):
rng = np.random.default_rng(rng)
if rng.uniform() < self.crossover_rate_rate:
self.crossover_rate = self.crossover_rate * rng.uniform(0.5, 2)
self.crossover_rate = min(self.crossover_rate, .6)
self.crossover_rate = max(self.crossover_rate, 1/len(self.mask))
return rng.choice(self.crossover_list)(other, rng)
# def _mutate_add(self, rng=None):
# rng = np.random.default_rng(rng)
# add_mask = rng.choice([True, False], size=self.mask.shape, p=[self.mutation_rate,1-self.mutation_rate])
# self.mask = np.logical_or(self.mask, add_mask)
# return True
# def _mutate_remove(self, rng=None):
# rng = np.random.default_rng(rng)
# add_mask = rng.choice([False, True], size=self.mask.shape, p=[self.mutation_rate,1-self.mutation_rate])
# self.mask = np.logical_and(self.mask, add_mask)
# return True
def _mutate_add(self, rng=None):
rng = np.random.default_rng(rng)
num_pos = np.sum(self.mask)
num_neg = len(self.mask) - num_pos
if num_neg == 0:
return False
to_add = int(self.mutation_rate * num_pos)
to_add = max(to_add, 1)
p = to_add / num_neg
p = min(p, 1)
add_mask = rng.choice([True, False], size=self.mask.shape, p=[p,1-p])
if sum(np.logical_or(self.mask, add_mask)) == 0:
pass
self.mask = np.logical_or(self.mask, add_mask)
return True
def _mutate_remove(self, rng=None):
rng = np.random.default_rng(rng)
num_pos = np.sum(self.mask)
if num_pos == 1:
return False
num_neg = len(self.mask) - num_pos
to_remove = int(self.mutation_rate * num_pos)
to_remove = max(to_remove, 1)
p = to_remove / num_pos
p = min(p, .5)
remove_mask = rng.choice([True, False], size=self.mask.shape, p=[p,1-p])
self.mask = np.logical_and(self.mask, remove_mask)
if sum(self.mask) == 0:
index = rng.choice(len(self.mask))
self.mask[index] = True
return True
def _crossover_swap(self, ss2, rng=None):
rng = np.random.default_rng(rng)
mask = rng.choice([True, False], size=self.mask.shape, p=[self.crossover_rate,1-self.crossover_rate])
self.mask = np.where(mask, self.mask, ss2.mask)
def export_pipeline(self, **kwargs):
return MaskSelector(mask=self.mask)
def unique_id(self):
mask_idexes = np.where(self.mask)[0]
id_str = ','.join([str(i) for i in mask_idexes])
return id_str
class GeneticFeatureSelectorNode(SearchSpace):
def __init__(self,
n_features,
start_p=0.2,
mutation_rate = 0.1,
crossover_rate = 0.1,
mutation_rate_rate = 0, # These are still experimental but seem to help. Theory is that it takes slower steps as it gets closer to the optimal solution.
crossover_rate_rate = 0,# Otherwise is mutation_rate is too small, it takes forever, and if its too large, it never converges.
):
"""
A node that generates a GeneticFeatureSelectorIndividual. Uses genetic algorithm to select novel subsets of features.
Parameters
----------
n_features : int
Number of features in the dataset.
start_p : float
Probability of selecting a given feature for the initial subset of features.
mutation_rate : float
Probability of adding/removing a feature from the subset of features.
crossover_rate : float
Probability of swapping a feature between two subsets of features.
mutation_rate_rate : float
Probability of changing the mutation rate. (experimental)
crossover_rate_rate : float
Probability of changing the crossover rate. (experimental)
"""
self.n_features = n_features
self.start_p = start_p
self.mutation_rate = mutation_rate
self.crossover_rate = crossover_rate
self.mutation_rate_rate = mutation_rate_rate
self.crossover_rate_rate = crossover_rate_rate
def generate(self, rng=None) -> SklearnIndividual:
return GeneticFeatureSelectorIndividual( mask=self.n_features,
start_p=self.start_p,
mutation_rate=self.mutation_rate,
crossover_rate=self.crossover_rate,
mutation_rate_rate=self.mutation_rate_rate,
crossover_rate_rate=self.crossover_rate_rate,
rng=rng
)
================================================
FILE: tpot/search_spaces/pipelines/__init__.py
================================================
from .choice import *
from .dynamic_linear import *
from .sequential import *
from .graph import *
from .tree import *
from .wrapper import *
from .dynamicunion import *
from .union import *
================================================
FILE: tpot/search_spaces/pipelines/choice.py
================================================
"""
This file is part of the TPOT library.
The current version of TPOT was developed at Cedars-Sinai by:
- Pedro Henrique Ribeiro (https://github.com/perib, https://www.linkedin.com/in/pedro-ribeiro/)
- Anil Saini (anil.saini@cshs.org)
- Jose Hernandez (jgh9094@gmail.com)
- Jay Moran (jay.moran@cshs.org)
- Nicholas Matsumoto (nicholas.matsumoto@cshs.org)
- Hyunjun Choi (hyunjun.choi@cshs.org)
- Gabriel Ketron (gabriel.ketron@cshs.org)
- Miguel E. Hernandez (miguel.e.hernandez@cshs.org)
- Jason Moore (moorejh28@gmail.com)
The original version of TPOT was primarily developed at the University of Pennsylvania by:
- Randal S. Olson (rso@randalolson.com)
- Weixuan Fu (weixuanf@upenn.edu)
- Daniel Angell (dpa34@drexel.edu)
- Jason Moore (moorejh28@gmail.com)
- and many more generous open-source contributors
TPOT is free software: you can redistribute it and/or modify
it under the terms of the GNU Lesser General Public License as
published by the Free Software Foundation, either version 3 of
the License, or (at your option) any later version.
TPOT is distributed in the hope that it will be useful,
but WITHOUT ANY WARRANTY; without even the implied warranty of
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
GNU Lesser General Public License for more details.
You should have received a copy of the GNU Lesser General Public
License along with TPOT. If not, see .
"""
import tpot
import numpy as np
import pandas as pd
import sklearn
from tpot import config
from typing import Generator, List, Tuple, Union
import random
from ..base import SklearnIndividual, SearchSpace
class ChoicePipelineIndividual(SklearnIndividual):
def __init__(self, search_spaces : List[SearchSpace], rng=None) -> None:
super().__init__()
rng = np.random.default_rng(rng)
self.search_spaces = search_spaces
self.node = rng.choice(self.search_spaces).generate(rng=rng)
def mutate(self, rng=None):
rng = np.random.default_rng(rng)
if rng.choice([True, False]):
return self._mutate_select_new_node(rng)
else:
return self._mutate_node(rng)
def _mutate_select_new_node(self, rng=None):
rng = np.random.default_rng(rng)
self.node = rng.choice(self.search_spaces).generate(rng=rng)
return True
def _mutate_node(self, rng=None):
return self.node.mutate(rng)
def crossover(self, other, rng=None):
return self.node.crossover(other.node, rng)
def export_pipeline(self, **kwargs):
return self.node.export_pipeline(**kwargs)
def unique_id(self):
return self.node.unique_id()
class ChoicePipeline(SearchSpace):
def __init__(self, search_spaces : List[SearchSpace] ) -> None:
self.search_spaces = search_spaces
"""
Takes in a list of search spaces. Will select one node from the search space.
"""
def generate(self, rng=None):
rng = np.random.default_rng(rng)
return ChoicePipelineIndividual(self.search_spaces, rng=rng)
================================================
FILE: tpot/search_spaces/pipelines/dynamic_linear.py
================================================
"""
This file is part of the TPOT library.
The current version of TPOT was developed at Cedars-Sinai by:
- Pedro Henrique Ribeiro (https://github.com/perib, https://www.linkedin.com/in/pedro-ribeiro/)
- Anil Saini (anil.saini@cshs.org)
- Jose Hernandez (jgh9094@gmail.com)
- Jay Moran (jay.moran@cshs.org)
- Nicholas Matsumoto (nicholas.matsumoto@cshs.org)
- Hyunjun Choi (hyunjun.choi@cshs.org)
- Gabriel Ketron (gabriel.ketron@cshs.org)
- Miguel E. Hernandez (miguel.e.hernandez@cshs.org)
- Jason Moore (moorejh28@gmail.com)
The original version of TPOT was primarily developed at the University of Pennsylvania by:
- Randal S. Olson (rso@randalolson.com)
- Weixuan Fu (weixuanf@upenn.edu)
- Daniel Angell (dpa34@drexel.edu)
- Jason Moore (moorejh28@gmail.com)
- and many more generous open-source contributors
TPOT is free software: you can redistribute it and/or modify
it under the terms of the GNU Lesser General Public License as
published by the Free Software Foundation, either version 3 of
the License, or (at your option) any later version.
TPOT is distributed in the hope that it will be useful,
but WITHOUT ANY WARRANTY; without even the implied warranty of
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
GNU Lesser General Public License for more details.
You should have received a copy of the GNU Lesser General Public
License along with TPOT. If not, see .
"""
import tpot
import numpy as np
import pandas as pd
import sklearn
from tpot import config
from typing import Generator, List, Tuple, Union
import random
from ..base import SklearnIndividual, SearchSpace
import copy
from ..tuple_index import TupleIndex
class DynamicLinearPipelineIndividual(SklearnIndividual):
# takes in a single search space.
# will produce a pipeline of variable length. Each step in the pipeline will be pulled from the search space provided.
def __init__(self, search_space : SearchSpace, max_length: int , rng=None) -> None:
super().__init__()
rng = np.random.default_rng(rng)
self.search_space = search_space
self.min_length = 1
self.max_length = max_length
self.pipeline = self._generate_pipeline(rng)
def _generate_pipeline(self, rng=None):
rng = np.random.default_rng(rng)
pipeline = []
length = rng.integers(self.min_length, self.max_length)
length = min(length, 3)
for _ in range(length):
pipeline.append(self.search_space.generate(rng))
return pipeline
def mutate(self, rng=None):
rng = np.random.default_rng(rng)
options = []
if len(self.pipeline) > self.min_length:
options.append(self._mutate_remove_node)
if len(self.pipeline) < self.max_length:
options.append(self._mutate_add_node)
options.append(self._mutate_step)
return rng.choice(options)(rng)
def _mutate_add_node(self, rng=None):
rng = np.random.default_rng(rng)
new_node = self.search_space.generate(rng)
idx = rng.integers(len(self.pipeline))
self.pipeline.insert(idx, new_node)
def _mutate_remove_node(self, rng=None):
rng = np.random.default_rng(rng)
idx = rng.integers(len(self.pipeline))
self.pipeline.pop(idx)
def _mutate_step(self, rng=None):
#choose a random step in the pipeline and mutate it
rng = np.random.default_rng(rng)
step = rng.choice(self.pipeline)
return step.mutate(rng)
def crossover(self, other, rng=None):
#swap a random step in the pipeline with the corresponding step in the other pipeline
rng = np.random.default_rng(rng)
cx_funcs = [self._crossover_swap_multiple_nodes, self._crossover_node]
rng.shuffle(cx_funcs)
for cx_func in cx_funcs:
if cx_func(other, rng):
return True
return False
def _crossover_swap_multiple_nodes(self, other, rng):
rng = np.random.default_rng(rng)
max_steps = int(min(len(self.pipeline), len(other.pipeline))/2)
max_steps = max(max_steps, 1)
if max_steps == 1:
n_steps_to_swap = 1
else:
n_steps_to_swap = rng.integers(1, max_steps)
other_indexes_to_take = rng.choice(len(other.pipeline), n_steps_to_swap, replace=False)
self_indexes_to_replace = rng.choice(len(self.pipeline), n_steps_to_swap, replace=False)
# self.pipeline[self_indexes_to_replace], other.pipeline[other_indexes_to_take] = other.pipeline[other_indexes_to_take], self.pipeline[self_indexes_to_replace]
for self_idx, other_idx in zip(self_indexes_to_replace, other_indexes_to_take):
self.pipeline[self_idx], other.pipeline[other_idx] = other.pipeline[other_idx], self.pipeline[self_idx]
return True
def _crossover_swap_node(self, other, rng):
if len(self.pipeline) != len(other.pipeline):
return False
if len(self.pipeline) < 2:
return False
rng = np.random.default_rng(rng)
idx = rng.integers(1,len(self.pipeline))
self.pipeline[idx], other.pipeline[idx] = other.pipeline[idx], self.pipeline[idx]
return True
def _crossover_node(self, other, rng):
rng = np.random.default_rng(rng)
pipeline1_indexes= list(range(len(self.pipeline)))
pipeline2_indexes= list(range(len(other.pipeline)))
rng.shuffle(pipeline1_indexes)
rng.shuffle(pipeline2_indexes)
crossover_success = False
for idx1, idx2 in zip(pipeline1_indexes, pipeline2_indexes):
if self.pipeline[idx1].crossover(other.pipeline[idx2], rng):
crossover_success = True
return crossover_success
def export_pipeline(self, memory=None, **kwargs):
return sklearn.pipeline.make_pipeline(*[step.export_pipeline(memory=memory, **kwargs) for step in self.pipeline], memory=memory)
def unique_id(self):
l = [step.unique_id() for step in self.pipeline]
l = ["DynamicLinearPipeline"] + l
return TupleIndex(tuple(l))
class DynamicLinearPipeline(SearchSpace):
def __init__(self, search_space : SearchSpace, max_length: int ) -> None:
self.search_space = search_space
self.max_length = max_length
"""
Takes in a single search space. Will produce a linear pipeline of variable length. Each step in the pipeline will be pulled from the search space provided.
"""
def generate(self, rng=None):
rng = np.random.default_rng(rng)
return DynamicLinearPipelineIndividual(self.search_space, self.max_length, rng=rng)
================================================
FILE: tpot/search_spaces/pipelines/dynamicunion.py
================================================
"""
This file is part of the TPOT library.
The current version of TPOT was developed at Cedars-Sinai by:
- Pedro Henrique Ribeiro (https://github.com/perib, https://www.linkedin.com/in/pedro-ribeiro/)
- Anil Saini (anil.saini@cshs.org)
- Jose Hernandez (jgh9094@gmail.com)
- Jay Moran (jay.moran@cshs.org)
- Nicholas Matsumoto (nicholas.matsumoto@cshs.org)
- Hyunjun Choi (hyunjun.choi@cshs.org)
- Gabriel Ketron (gabriel.ketron@cshs.org)
- Miguel E. Hernandez (miguel.e.hernandez@cshs.org)
- Jason Moore (moorejh28@gmail.com)
The original version of TPOT was primarily developed at the University of Pennsylvania by:
- Randal S. Olson (rso@randalolson.com)
- Weixuan Fu (weixuanf@upenn.edu)
- Daniel Angell (dpa34@drexel.edu)
- Jason Moore (moorejh28@gmail.com)
- and many more generous open-source contributors
TPOT is free software: you can redistribute it and/or modify
it under the terms of the GNU Lesser General Public License as
published by the Free Software Foundation, either version 3 of
the License, or (at your option) any later version.
TPOT is distributed in the hope that it will be useful,
but WITHOUT ANY WARRANTY; without even the implied warranty of
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
GNU Lesser General Public License for more details.
You should have received a copy of the GNU Lesser General Public
License along with TPOT. If not, see .
"""
import tpot
import numpy as np
import pandas as pd
import sklearn
from tpot import config
from typing import Generator, List, Tuple, Union
import random
from ..base import SklearnIndividual, SearchSpace
from ..tuple_index import TupleIndex
class DynamicUnionPipelineIndividual(SklearnIndividual):
"""
Takes in one search space.
Will produce a FeatureUnion of up to max_estimators number of steps.
The output of the FeatureUnion will the all of the steps concatenated together.
"""
def __init__(self, search_space : SearchSpace, max_estimators=None, allow_repeats=False, rng=None) -> None:
super().__init__()
self.search_space = search_space
if max_estimators is None:
self.max_estimators = np.inf
else:
self.max_estimators = max_estimators
self.allow_repeats = allow_repeats
self.union_dict = {}
if self.max_estimators == np.inf:
init_max = 3
else:
init_max = self.max_estimators
rng = np.random.default_rng(rng)
for _ in range(rng.integers(1, init_max)):
self._mutate_add_step(rng)
def mutate(self, rng=None):
rng = np.random.default_rng(rng)
mutation_funcs = [self._mutate_add_step, self._mutate_remove_step, self._mutate_replace_step, self._mutate_note]
rng.shuffle(mutation_funcs)
for mutation_func in mutation_funcs:
if mutation_func(rng):
return True
def _mutate_add_step(self, rng):
rng = np.random.default_rng(rng)
max_attempts = 10
if len(self.union_dict) < self.max_estimators:
for _ in range(max_attempts):
new_step = self.search_space.generate(rng)
if new_step.unique_id() not in self.union_dict:
self.union_dict[new_step.unique_id()] = new_step
return True
return False
def _mutate_remove_step(self, rng):
rng = np.random.default_rng(rng)
if len(self.union_dict) > 1:
self.union_dict.pop( rng.choice(list(self.union_dict.keys())))
return True
return False
def _mutate_replace_step(self, rng):
rng = np.random.default_rng(rng)
changed = self._mutate_remove_step(rng) or self._mutate_add_step(rng)
return changed
#TODO mutate one step or multiple?
def _mutate_note(self, rng):
rng = np.random.default_rng(rng)
changed = False
values = list(self.union_dict.values())
for step in values:
if rng.random() < 0.5:
changed = step.mutate(rng) or changed
self.union_dict = {step.unique_id(): step for step in values}
return changed
def crossover(self, other, rng=None):
rng = np.random.default_rng(rng)
cx_funcs = [self._crossover_swap_multiple_nodes, self._crossover_node]
rng.shuffle(cx_funcs)
for cx_func in cx_funcs:
if cx_func(other, rng):
return True
return False
def _crossover_swap_multiple_nodes(self, other, rng):
rng = np.random.default_rng(rng)
self_values = list(self.union_dict.values())
other_values = list(other.union_dict.values())
rng.shuffle(self_values)
rng.shuffle(other_values)
self_idx = rng.integers(0,len(self_values))
other_idx = rng.integers(0,len(other_values))
#Note that this is not one-point-crossover since the sequence doesn't matter. this is just a quick way to swap multiple random items
self_values[:self_idx], other_values[:other_idx] = other_values[:other_idx], self_values[:self_idx]
self.union_dict = {step.unique_id(): step for step in self_values}
other.union_dict = {step.unique_id(): step for step in other_values}
return True
def _crossover_node(self, other, rng):
rng = np.random.default_rng(rng)
changed = False
self_values = list(self.union_dict.values())
other_values = list(other.union_dict.values())
rng.shuffle(self_values)
rng.shuffle(other_values)
for self_step, other_step in zip(self_values, other_values):
if rng.random() < 0.5:
changed = self_step.crossover(other_step, rng) or changed
self.union_dict = {step.unique_id(): step for step in self_values}
other.union_dict = {step.unique_id(): step for step in other_values}
return changed
def export_pipeline(self, **kwargs):
values = list(self.union_dict.values())
return sklearn.pipeline.make_union(*[step.export_pipeline(**kwargs) for step in values])
def unique_id(self):
values = list(self.union_dict.values())
l = [step.unique_id() for step in values]
# if all items are strings, then sort them
if all([isinstance(x, str) for x in l]):
l.sort()
l = ["FeatureUnion"] + l
return TupleIndex(frozenset(l))
class DynamicUnionPipeline(SearchSpace):
def __init__(self, search_space : SearchSpace, max_estimators=None, allow_repeats=False ) -> None:
"""
Takes in a list of search spaces. will produce a pipeline of Sequential length. Each step in the pipeline will correspond to the the search space provided in the same index.
"""
self.search_space = search_space
self.max_estimators = max_estimators
self.allow_repeats = allow_repeats
def generate(self, rng=None):
rng = np.random.default_rng(rng)
return DynamicUnionPipelineIndividual(self.search_space, max_estimators=self.max_estimators, allow_repeats=self.allow_repeats, rng=rng)
================================================
FILE: tpot/search_spaces/pipelines/graph.py
================================================
"""
This file is part of the TPOT library.
The current version of TPOT was developed at Cedars-Sinai by:
- Pedro Henrique Ribeiro (https://github.com/perib, https://www.linkedin.com/in/pedro-ribeiro/)
- Anil Saini (anil.saini@cshs.org)
- Jose Hernandez (jgh9094@gmail.com)
- Jay Moran (jay.moran@cshs.org)
- Nicholas Matsumoto (nicholas.matsumoto@cshs.org)
- Hyunjun Choi (hyunjun.choi@cshs.org)
- Gabriel Ketron (gabriel.ketron@cshs.org)
- Miguel E. Hernandez (miguel.e.hernandez@cshs.org)
- Jason Moore (moorejh28@gmail.com)
The original version of TPOT was primarily developed at the University of Pennsylvania by:
- Randal S. Olson (rso@randalolson.com)
- Weixuan Fu (weixuanf@upenn.edu)
- Daniel Angell (dpa34@drexel.edu)
- Jason Moore (moorejh28@gmail.com)
- and many more generous open-source contributors
TPOT is free software: you can redistribute it and/or modify
it under the terms of the GNU Lesser General Public License as
published by the Free Software Foundation, either version 3 of
the License, or (at your option) any later version.
TPOT is distributed in the hope that it will be useful,
but WITHOUT ANY WARRANTY; without even the implied warranty of
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
GNU Lesser General Public License for more details.
You should have received a copy of the GNU Lesser General Public
License along with TPOT. If not, see .
"""
import tpot
import numpy as np
from typing import Generator, List, Tuple, Union
from ..base import SklearnIndividual, SearchSpace
import networkx as nx
import copy
import matplotlib.pyplot as plt
import itertools
from ..graph_utils import *
from ..nodes.estimator_node import EstimatorNodeIndividual
from typing import Union, Callable
import sklearn
from functools import partial
import random
class GraphPipelineIndividual(SklearnIndividual):
"""
Defines a search space of pipelines in the shape of a Directed Acyclic Graphs. The search spaces for root, leaf, and inner nodes can be defined separately if desired.
Each graph will have a single root serving as the final estimator which is drawn from the `root_search_space`. If the `leaf_search_space` is defined, all leaves
in the pipeline will be drawn from that search space. If the `leaf_search_space` is not defined, all leaves will be drawn from the `inner_search_space`.
Nodes that are not leaves or roots will be drawn from the `inner_search_space`. If the `inner_search_space` is not defined, there will be no inner nodes.
`cross_val_predict_cv`, `method`, `memory`, and `use_label_encoder` are passed to the GraphPipeline object when the pipeline is exported and not directly used in the search space.
Exports to a GraphPipeline object.
Parameters
----------
root_search_space: SearchSpace
The search space for the root node of the graph. This node will be the final estimator in the pipeline.
inner_search_space: SearchSpace, optional
The search space for the inner nodes of the graph. If not defined, there will be no inner nodes.
leaf_search_space: SearchSpace, optional
The search space for the leaf nodes of the graph. If not defined, the leaf nodes will be drawn from the inner_search_space.
crossover_same_depth: bool, optional
If True, crossover will only occur between nodes at the same depth in the graph. If False, crossover will occur between nodes at any depth.
cross_val_predict_cv: int, cross-validation generator or an iterable, optional
Determines the cross-validation splitting strategy used in inner classifiers or regressors
method: str, optional
The prediction method to use for the inner classifiers or regressors. If 'auto', it will try to use predict_proba, decision_function, or predict in that order.
memory: str or object with the joblib.Memory interface, optional
Used to cache the input and outputs of nodes to prevent refitting or computationally heavy transformations. By default, no caching is performed. If a string is given, it is the path to the caching directory.
use_label_encoder: bool, optional
If True, the label encoder is used to encode the labels to be 0 to N. If False, the label encoder is not used.
Mainly useful for classifiers (XGBoost) that require labels to be ints from 0 to N.
Can also be a sklearn.preprocessing.LabelEncoder object. If so, that label encoder is used.
rng: int, RandomState instance or None, optional
Seed for sampling the first graph instance.
"""
def __init__(
self,
root_search_space: SearchSpace,
leaf_search_space: SearchSpace = None,
inner_search_space: SearchSpace = None,
max_size: int = np.inf,
crossover_same_depth: bool = False,
cross_val_predict_cv: Union[int, Callable] = 0, #signature function(estimator, X, y=none)
method: str = 'auto',
use_label_encoder: bool = False,
rng=None):
super().__init__()
self.__debug = False
rng = np.random.default_rng(rng)
self.root_search_space = root_search_space
self.leaf_search_space = leaf_search_space
self.inner_search_space = inner_search_space
self.max_size = max_size
self.crossover_same_depth = crossover_same_depth
self.cross_val_predict_cv = cross_val_predict_cv
self.method = method
self.use_label_encoder = use_label_encoder
self.root = self.root_search_space.generate(rng)
self.graph = nx.DiGraph()
self.graph.add_node(self.root)
if self.leaf_search_space is not None:
self.leaf = self.leaf_search_space.generate(rng)
self.graph.add_node(self.leaf)
self.graph.add_edge(self.root, self.leaf)
if self.inner_search_space is None and self.leaf_search_space is None:
self.mutate_methods_list = [self._mutate_node]
self.crossover_methods_list = [self._crossover_swap_branch,]#[self._crossover_swap_branch, self._crossover_swap_node, self._crossover_take_branch] #TODO self._crossover_nodes,
else:
self.mutate_methods_list = [self._mutate_insert_leaf, self._mutate_insert_inner_node, self._mutate_remove_node, self._mutate_node, self._mutate_insert_bypass_node]
self.crossover_methods_list = [self._crossover_swap_branch, self._crossover_nodes, self._crossover_take_branch ]#[self._crossover_swap_branch, self._crossover_swap_node, self._crossover_take_branch] #TODO self._crossover_nodes,
self.merge_duplicated_nodes_toggle = True
self.graphkey = None
def mutate(self, rng=None):
rng = np.random.default_rng(rng)
rng.shuffle(self.mutate_methods_list)
for mutate_method in self.mutate_methods_list:
if mutate_method(rng=rng):
if self.merge_duplicated_nodes_toggle:
self._merge_duplicated_nodes()
if self.__debug:
print(mutate_method)
if self.root not in self.graph.nodes:
print('lost root something went wrong with ', mutate_method)
if len(self.graph.predecessors(self.root)) > 0:
print('root has parents ', mutate_method)
if any([n in nx.ancestors(self.graph,n) for n in self.graph.nodes]):
print('a node is connecting to itself...')
if self.__debug:
try:
nx.find_cycle(self.graph)
print('something went wrong with ', mutate_method)
except:
pass
self.graphkey = None
return False
def _mutate_insert_leaf(self, rng=None):
rng = np.random.default_rng(rng)
if self.max_size > self.graph.number_of_nodes():
sorted_nodes_list = list(self.graph.nodes)
rng.shuffle(sorted_nodes_list) #TODO: sort by number of children and/or parents? bias model one way or another
for node in sorted_nodes_list:
#if leafs are protected, check if node is a leaf
#if node is a leaf, skip because we don't want to add node on top of node
if (self.leaf_search_space is not None #if leafs are protected
and len(list(self.graph.successors(node))) == 0 #if node is leaf
and len(list(self.graph.predecessors(node))) > 0 #except if node is root, in which case we want to add a leaf even if it happens to be a leaf too
):
continue
#If node *is* the root or is not a leaf, add leaf node. (dont want to add leaf on top of leaf)
if self.leaf_search_space is not None:
new_node = self.leaf_search_space.generate(rng)
else:
new_node = self.inner_search_space.generate(rng)
self.graph.add_node(new_node)
self.graph.add_edge(node, new_node)
return True
return False
def _mutate_insert_inner_node(self, rng=None):
"""
Finds an edge in the graph and inserts a new node between the two nodes. Removes the edge between the two nodes.
"""
rng = np.random.default_rng(rng)
if self.max_size > self.graph.number_of_nodes():
sorted_nodes_list = list(self.graph.nodes)
sorted_nodes_list2 = list(self.graph.nodes)
rng.shuffle(sorted_nodes_list) #TODO: sort by number of children and/or parents? bias model one way or another
rng.shuffle(sorted_nodes_list2)
for node in sorted_nodes_list:
#loop through children of node
for child_node in list(self.graph.successors(node)):
if child_node is not node and child_node not in nx.ancestors(self.graph, node):
if self.leaf_search_space is not None:
#If if we are protecting leafs, dont add connection into a leaf
if len(list(nx.descendants(self.graph,node))) ==0 :
continue
new_node = self.inner_search_space.generate(rng)
self.graph.add_node(new_node)
self.graph.add_edges_from([(node, new_node), (new_node, child_node)])
self.graph.remove_edge(node, child_node)
return True
return False
def _mutate_remove_node(self, rng=None):
'''
Removes a randomly chosen node and connects its parents to its children.
If the node is the only leaf for an inner node and 'leaf_search_space' is not none, we do not remove it.
'''
rng = np.random.default_rng(rng)
nodes_list = list(self.graph.nodes)
nodes_list.remove(self.root)
leaves = get_leaves(self.graph)
while len(nodes_list) > 0:
node = rng.choice(nodes_list)
nodes_list.remove(node)
if self.leaf_search_space is not None and len(list(nx.descendants(self.graph,node))) == 0 : #if the node is a leaf
if len(leaves) <= 1:
continue #dont remove the last leaf
leaf_parents = self.graph.predecessors(node)
# if any of the parents of the node has one one child, continue
if any([len(list(self.graph.successors(lp))) < 2 for lp in leaf_parents]): #dont remove a leaf if it is the only input into another node.
continue
remove_and_stitch(self.graph, node)
remove_nodes_disconnected_from_node(self.graph, self.root)
return True
else:
remove_and_stitch(self.graph, node)
remove_nodes_disconnected_from_node(self.graph, self.root)
return True
return False
def _mutate_node(self, rng=None):
'''
Mutates the hyperparameters for a randomly chosen node in the graph.
'''
rng = np.random.default_rng(rng)
sorted_nodes_list = list(self.graph.nodes)
rng.shuffle(sorted_nodes_list)
completed_one = False
for node in sorted_nodes_list:
if node.mutate(rng):
return True
return False
def _mutate_remove_edge(self, rng=None):
'''
Deletes an edge as long as deleting that edge does not make the graph disconnected.
'''
rng = np.random.default_rng(rng)
sorted_nodes_list = list(self.graph.nodes)
rng.shuffle(sorted_nodes_list)
for child_node in sorted_nodes_list:
parents = list(self.graph.predecessors(child_node))
if len(parents) > 1: # if it has more than one parent, you can remove an edge (if this is the only child of a node, it will become a leaf)
for parent_node in parents:
# if removing the egde will make the parent_node a leaf node, skip
if self.leaf_search_space is not None and len(list(self.graph.successors(parent_node))) < 2:
continue
self.graph.remove_edge(parent_node, child_node)
return True
return False
def _mutate_add_edge(self, rng=None):
'''
Randomly add an edge from a node to another node that is not an ancestor of the first node.
'''
rng = np.random.default_rng(rng)
sorted_nodes_list = list(self.graph.nodes)
rng.shuffle(sorted_nodes_list)
for child_node in sorted_nodes_list:
for parent_node in sorted_nodes_list:
if self.leaf_search_space is not None:
if len(list(self.graph.successors(parent_node))) == 0:
continue
# skip if
# - parent and child are the same node
# - edge already exists
# - child is an ancestor of parent
if (child_node is not parent_node) and not self.graph.has_edge(parent_node,child_node) and (child_node not in nx.ancestors(self.graph, parent_node)):
self.graph.add_edge(parent_node,child_node)
return True
return False
def _mutate_insert_bypass_node(self, rng=None):
"""
Pick two nodes (doesn't necessarily need to be connected). Create a new node. connect one node to the new node and the new node to the other node.
Does not remove any edges.
"""
rng = np.random.default_rng(rng)
if self.max_size > self.graph.number_of_nodes():
sorted_nodes_list = list(self.graph.nodes)
sorted_nodes_list2 = list(self.graph.nodes)
rng.shuffle(sorted_nodes_list) #TODO: sort by number of children and/or parents? bias model one way or another
rng.shuffle(sorted_nodes_list2)
for node in sorted_nodes_list:
for child_node in sorted_nodes_list2:
if child_node is not node and child_node not in nx.ancestors(self.graph, node):
if self.leaf_search_space is not None:
#If if we are protecting leafs, dont add connection into a leaf
if len(list(nx.descendants(self.graph,node))) ==0 :
continue
new_node = self.inner_search_space.generate(rng)
self.graph.add_node(new_node)
self.graph.add_edges_from([(node, new_node), (new_node, child_node)])
return True
return False
def crossover(self, ind2, rng=None):
'''
self is the first individual, ind2 is the second individual
If crossover_same_depth, it will select graphindividuals at the same recursive depth.
Otherwise, it will select graphindividuals randomly from the entire graph and its subgraphs.
This does not impact graphs without subgraphs. And it does not impacts nodes that are not graphindividuals. Cros
'''
rng = np.random.default_rng(rng)
rng.shuffle(self.crossover_methods_list)
finished = False
for crossover_method in self.crossover_methods_list:
if crossover_method(ind2, rng=rng):
self._merge_duplicated_nodes()
finished = True
break
if self.__debug:
try:
nx.find_cycle(self.graph)
print('something went wrong with ', crossover_method)
except:
pass
if finished:
self.graphkey = None
return finished
def _crossover_swap_branch(self, G2, rng=None):
'''
swaps a branch from parent1 with a branch from parent2. does not modify parent2
'''
rng = np.random.default_rng(rng)
if self.crossover_same_depth:
pair_gen = select_nodes_same_depth(self.graph, self.root, G2.graph, G2.root, rng=rng)
else:
pair_gen = select_nodes_randomly(self.graph, G2.graph, rng=rng)
for node1, node2 in pair_gen:
#TODO: if root is in inner_search_space, then do use it?
if node1 is self.root or node2 is G2.root: #dont want to add root as inner node
continue
#check if node1 is a leaf and leafs are protected, don't add an input to the leave
if self.leaf_search_space is not None: #if we are protecting leaves,
node1_is_leaf = len(list(self.graph.successors(node1))) == 0
node2_is_leaf = len(list(G2.graph.successors(node2))) == 0
#if not ((node1_is_leaf and node1_is_leaf) or (not node1_is_leaf and not node2_is_leaf)): #if node1 is a leaf
#if (node1_is_leaf and (not node2_is_leaf)) or ( (not node1_is_leaf) and node2_is_leaf):
if not node1_is_leaf:
#only continue if node1 and node2 are both leaves or both not leaves
continue
temp_graph_1 = self.graph.copy()
temp_graph_1.remove_node(node1)
remove_nodes_disconnected_from_node(temp_graph_1, self.root)
#isolating the branch
branch2 = G2.graph.copy()
n2_descendants = nx.descendants(branch2,node2)
for n in list(branch2.nodes):
if n not in n2_descendants and n is not node2: #removes all nodes not in the branch
branch2.remove_node(n)
branch2 = copy.deepcopy(branch2)
branch2_root = get_roots(branch2)[0]
temp_graph_1.add_edges_from(branch2.edges)
for p in list(self.graph.predecessors(node1)):
temp_graph_1.add_edge(p,branch2_root)
if temp_graph_1.number_of_nodes() > self.max_size:
continue
self.graph = temp_graph_1
return True
return False
def _crossover_take_branch(self, G2, rng=None):
'''
Takes a subgraph from Parent2 and add it to a randomly chosen node in Parent1.
'''
rng = np.random.default_rng(rng)
if self.crossover_same_depth:
pair_gen = select_nodes_same_depth(self.graph, self.root, G2.graph, G2.root, rng=rng)
else:
pair_gen = select_nodes_randomly(self.graph, G2.graph, rng=rng)
for node1, node2 in pair_gen:
#TODO: if root is in inner_search_space, then do use it?
if node2 is G2.root: #dont want to add root as inner node
continue
#check if node1 is a leaf and leafs are protected, don't add an input to the leave
if self.leaf_search_space is not None and len(list(self.graph.successors(node1))) == 0:
continue
#icheck if node2 is graph individual
# if isinstance(node2,GraphIndividual):
# if not ((isinstance(node2,GraphIndividual) and ("Recursive" in self.inner_search_space or "Recursive" in self.leaf_search_space))):
# continue
#isolating the branch
branch2 = G2.graph.copy()
n2_descendants = nx.descendants(branch2,node2)
for n in list(branch2.nodes):
if n not in n2_descendants and n is not node2: #removes all nodes not in the branch
branch2.remove_node(n)
#if node1 plus node2 branch has more than max_children, skip
if branch2.number_of_nodes() + self.graph.number_of_nodes() > self.max_size:
continue
branch2 = copy.deepcopy(branch2)
branch2_root = get_roots(branch2)[0]
self.graph.add_edges_from(branch2.edges)
self.graph.add_edge(node1,branch2_root)
return True
return False
def _crossover_nodes(self, G2, rng=None):
'''
Swaps the hyperparamters of one randomly chosen node in Parent1 with the hyperparameters of randomly chosen node in Parent2.
'''
rng = np.random.default_rng(rng)
if self.crossover_same_depth:
pair_gen = select_nodes_same_depth(self.graph, self.root, G2.graph, G2.root, rng=rng)
else:
pair_gen = select_nodes_randomly(self.graph, G2.graph, rng=rng)
for node1, node2 in pair_gen:
#if both nodes are leaves
if len(list(self.graph.successors(node1)))==0 and len(list(G2.graph.successors(node2)))==0:
if node1.crossover(node2):
return True
#if both nodes are inner nodes
if len(list(self.graph.successors(node1)))>0 and len(list(G2.graph.successors(node2)))>0:
if len(list(self.graph.predecessors(node1)))>0 and len(list(G2.graph.predecessors(node2)))>0:
if node1.crossover(node2):
return True
#if both nodes are root nodes
if node1 is self.root and node2 is G2.root:
if node1.crossover(node2):
return True
return False
#not including the nodes, just their children
#Finds leaves attached to nodes and swaps them
def _crossover_swap_leaf_at_node(self, G2, rng=None):
rng = np.random.default_rng(rng)
if self.crossover_same_depth:
pair_gen = select_nodes_same_depth(self.graph, self.root, G2.graph, G2.root, rng=rng)
else:
pair_gen = select_nodes_randomly(self.graph, G2.graph, rng=rng)
success = False
for node1, node2 in pair_gen:
# if leaves are protected node1 and node2 must both be leaves or both be inner nodes
if self.leaf_search_space is not None and not (len(list(self.graph.successors(node1)))==0 ^ len(list(G2.graph.successors(node2)))==0):
continue
#self_leafs = [c for c in nx.descendants(self.graph,node1) if len(list(self.graph.successors(c)))==0 and c is not node1]
node_leafs = [c for c in nx.descendants(G2.graph,node2) if len(list(G2.graph.successors(c)))==0 and c is not node2]
# if len(self_leafs) >0:
# for c in self_leafs:
# if random.choice([True,False]):
# self.graph.remove_node(c)
# G2.graph.add_edge(node2, c)
# success = True
if len(node_leafs) >0:
for c in node_leafs:
if rng.choice([True,False]):
G2.graph.remove_node(c)
self.graph.add_edge(node1, c)
success = True
return success
#TODO edit so that G2 is not modified
def _crossover_swap_node(self, G2, rng=None):
'''
Swaps randomly chosen node from Parent1 with a randomly chosen node from Parent2.
'''
rng = np.random.default_rng(rng)
if self.crossover_same_depth:
pair_gen = select_nodes_same_depth(self.graph, self.root, G2.graph, G2.root, rng=rng)
else:
pair_gen = select_nodes_randomly(self.graph, G2.graph, rng=rng)
for node1, node2 in pair_gen:
if node1 is self.root or node2 is G2.root: #TODO: allow root
continue
#if leaves are protected
if self.leaf_search_space is not None:
#if one node is a leaf, the other must be a leaf
if not((len(list(self.graph.successors(node1)))==0) ^ (len(list(G2.graph.successors(node2)))==0)):
continue #only continue if both are leaves, or both are not leaves
n1_s = self.graph.successors(node1)
n1_p = self.graph.predecessors(node1)
n2_s = G2.graph.successors(node2)
n2_p = G2.graph.predecessors(node2)
self.graph.remove_node(node1)
G2.graph.remove_node(node2)
self.graph.add_node(node2)
self.graph.add_edges_from([ (node2, n) for n in n1_s])
G2.graph.add_edges_from([ (node1, n) for n in n2_s])
self.graph.add_edges_from([ (n, node2) for n in n1_p])
G2.graph.add_edges_from([ (n, node1) for n in n2_p])
return True
return False
def _merge_duplicated_nodes(self):
graph_changed = False
merged = False
while(not merged):
node_list = list(self.graph.nodes)
merged = True
for node, other_node in itertools.product(node_list, node_list):
if node is other_node:
continue
#If nodes are same class/hyperparameters
if node.unique_id() == other_node.unique_id():
node_children = set(self.graph.successors(node))
other_node_children = set(self.graph.successors(other_node))
#if nodes have identical children, they can be merged
if node_children == other_node_children:
for other_node_parent in list(self.graph.predecessors(other_node)):
if other_node_parent not in self.graph.predecessors(node):
self.graph.add_edge(other_node_parent,node)
self.graph.remove_node(other_node)
merged=False
graph_changed = True
break
return graph_changed
def export_pipeline(self, memory=None, **kwargs):
estimator_graph = self.graph.copy()
#mapping = {node:node.method_class(**node.hyperparameters) for node in estimator_graph}
label_remapping = {}
label_to_instance = {}
for node in estimator_graph:
this_pipeline_node = node.export_pipeline(memory=memory, **kwargs)
found_unique_label = False
i=1
while not found_unique_label:
label = "{0}_{1}".format(this_pipeline_node.__class__.__name__, i)
if label not in label_to_instance:
found_unique_label = True
else:
i+=1
label_remapping[node] = label
label_to_instance[label] = this_pipeline_node
estimator_graph = nx.relabel_nodes(estimator_graph, label_remapping)
for label, instance in label_to_instance.items():
estimator_graph.nodes[label]["instance"] = instance
return tpot.GraphPipeline(graph=estimator_graph, memory=memory, use_label_encoder=self.use_label_encoder, method=self.method, cross_val_predict_cv=self.cross_val_predict_cv)
def plot(self):
G = self.graph.reverse()
#TODO clean this up
try:
pos = nx.planar_layout(G) # positions for all nodes
except:
pos = nx.shell_layout(G)
# nodes
options = {'edgecolors': 'tab:gray', 'node_size': 800, 'alpha': 0.9}
nodelist = list(G.nodes)
node_color = [plt.cm.Set1(G.nodes[n]['recursive depth']) for n in G]
fig, ax = plt.subplots()
nx.draw(G, pos, nodelist=nodelist, node_color=node_color, ax=ax, **options)
'''edgelist = []
for n in n1.node_set:
for child in n.children:
edgelist.append((n,child))'''
# edges
#nx.draw_networkx_edges(G, pos, width=3.0, arrows=True)
'''nx.draw_networkx_edges(
G,
pos,
edgelist=[edgelist],
width=8,
alpha=0.5,
edge_color='tab:red',
)'''
# some math labels
labels = {}
for i, n in enumerate(G.nodes):
labels[n] = n.method_class.__name__ + "\n" + str(n.hyperparameters)
nx.draw_networkx_labels(G, pos, labels,ax=ax, font_size=7, font_color='black')
plt.tight_layout()
plt.axis('off')
plt.show()
def unique_id(self):
if self.graphkey is None:
#copy self.graph
new_graph = self.graph.copy()
for n in new_graph.nodes:
new_graph.nodes[n]['label'] = n.unique_id()
new_graph = nx.convert_node_labels_to_integers(new_graph)
self.graphkey = GraphKey(new_graph)
return self.graphkey
class GraphSearchPipeline(SearchSpace):
def __init__(self,
root_search_space: SearchSpace,
leaf_search_space: SearchSpace = None,
inner_search_space: SearchSpace = None,
max_size: int = np.inf,
crossover_same_depth: bool = False,
cross_val_predict_cv: Union[int, Callable] = 0, #signature function(estimator, X, y=none)
method: str = 'auto',
use_label_encoder: bool = False):
"""
Defines a search space of pipelines in the shape of a Directed Acyclic Graphs. The search spaces for root, leaf, and inner nodes can be defined separately if desired.
Each graph will have a single root serving as the final estimator which is drawn from the `root_search_space`. If the `leaf_search_space` is defined, all leaves
in the pipeline will be drawn from that search space. If the `leaf_search_space` is not defined, all leaves will be drawn from the `inner_search_space`.
Nodes that are not leaves or roots will be drawn from the `inner_search_space`. If the `inner_search_space` is not defined, there will be no inner nodes.
`cross_val_predict_cv`, `method`, `memory`, and `use_label_encoder` are passed to the GraphPipeline object when the pipeline is exported and not directly used in the search space.
Exports to a GraphPipeline object.
Parameters
----------
root_search_space: SearchSpace
The search space for the root node of the graph. This node will be the final estimator in the pipeline.
inner_search_space: SearchSpace, optional
The search space for the inner nodes of the graph. If not defined, there will be no inner nodes.
leaf_search_space: SearchSpace, optional
The search space for the leaf nodes of the graph. If not defined, the leaf nodes will be drawn from the inner_search_space.
crossover_same_depth: bool, optional
If True, crossover will only occur between nodes at the same depth in the graph. If False, crossover will occur between nodes at any depth.
cross_val_predict_cv : int, default=0
Number of folds to use for the cross_val_predict function for inner classifiers and regressors. Estimators will still be fit on the full dataset, but the following node will get the outputs from cross_val_predict.
- 0-1 : When set to 0 or 1, the cross_val_predict function will not be used. The next layer will get the outputs from fitting and transforming the full dataset.
- >=2 : When fitting pipelines with inner classifiers or regressors, they will still be fit on the full dataset.
However, the output to the next node will come from cross_val_predict with the specified number of folds.
method: str, optional
The prediction method to use for the inner classifiers or regressors. If 'auto', it will try to use predict_proba, decision_function, or predict in that order.
memory: str or object with the joblib.Memory interface, optional
Used to cache the input and outputs of nodes to prevent refitting or computationally heavy transformations. By default, no caching is performed. If a string is given, it is the path to the caching directory.
use_label_encoder: bool, optional
If True, the label encoder is used to encode the labels to be 0 to N. If False, the label encoder is not used.
Mainly useful for classifiers (XGBoost) that require labels to be ints from 0 to N.
Can also be a sklearn.preprocessing.LabelEncoder object. If so, that label encoder is used.
"""
self.root_search_space = root_search_space
self.leaf_search_space = leaf_search_space
self.inner_search_space = inner_search_space
self.max_size = max_size
self.crossover_same_depth = crossover_same_depth
self.cross_val_predict_cv = cross_val_predict_cv
self.method = method
self.use_label_encoder = use_label_encoder
def generate(self, rng=None):
rng = np.random.default_rng(rng)
ind = GraphPipelineIndividual(self.root_search_space, self.leaf_search_space, self.inner_search_space, self.max_size, self.crossover_same_depth,
self.cross_val_predict_cv, self.method, self.use_label_encoder, rng=rng)
# if user specified limit, grab a random number between that limit
if self.max_size is None or self.max_size == np.inf:
n_nodes = rng.integers(1, 5)
else:
n_nodes = min(rng.integers(1, self.max_size), 5)
starting_ops = []
if self.inner_search_space is not None:
starting_ops.append(ind._mutate_insert_inner_node)
if self.leaf_search_space is not None or self.inner_search_space is not None:
starting_ops.append(ind._mutate_insert_leaf)
n_nodes -= 1
if len(starting_ops) > 0:
for _ in range(n_nodes-1):
func = rng.choice(starting_ops)
func(rng=rng)
ind._merge_duplicated_nodes()
return ind
class GraphKey():
'''
A class that can be used as a key for a graph.
Parameters
----------
graph : (nx.Graph)
The graph to use as a key. Node Attributes are used for the hash.
matched_label : (str)
The node attribute to consider for the hash.
'''
def __init__(self, graph, matched_label='label') -> None:#['hyperparameters', 'method_class']) -> None:
self.graph = graph
self.matched_label = matched_label
self.node_match = partial(node_match, matched_labels=[matched_label])
self.key = int(nx.weisfeiler_lehman_graph_hash(self.graph, node_attr=self.matched_label),16) #hash(tuple(sorted([val for (node, val) in self.graph.degree()])))
#If hash is different, node is definitely different
# https://arxiv.org/pdf/2002.06653.pdf
def __hash__(self) -> int:
return self.key
#If hash is same, use __eq__ to know if they are actually different
def __eq__(self, other):
return nx.is_isomorphic(self.graph, other.graph, node_match=self.node_match)
def node_match(n1,n2, matched_labels):
return all( [ n1[m] == n2[m] for m in matched_labels])
================================================
FILE: tpot/search_spaces/pipelines/sequential.py
================================================
"""
This file is part of the TPOT library.
The current version of TPOT was developed at Cedars-Sinai by:
- Pedro Henrique Ribeiro (https://github.com/perib, https://www.linkedin.com/in/pedro-ribeiro/)
- Anil Saini (anil.saini@cshs.org)
- Jose Hernandez (jgh9094@gmail.com)
- Jay Moran (jay.moran@cshs.org)
- Nicholas Matsumoto (nicholas.matsumoto@cshs.org)
- Hyunjun Choi (hyunjun.choi@cshs.org)
- Gabriel Ketron (gabriel.ketron@cshs.org)
- Miguel E. Hernandez (miguel.e.hernandez@cshs.org)
- Jason Moore (moorejh28@gmail.com)
The original version of TPOT was primarily developed at the University of Pennsylvania by:
- Randal S. Olson (rso@randalolson.com)
- Weixuan Fu (weixuanf@upenn.edu)
- Daniel Angell (dpa34@drexel.edu)
- Jason Moore (moorejh28@gmail.com)
- and many more generous open-source contributors
TPOT is free software: you can redistribute it and/or modify
it under the terms of the GNU Lesser General Public License as
published by the Free Software Foundation, either version 3 of
the License, or (at your option) any later version.
TPOT is distributed in the hope that it will be useful,
but WITHOUT ANY WARRANTY; without even the implied warranty of
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
GNU Lesser General Public License for more details.
You should have received a copy of the GNU Lesser General Public
License along with TPOT. If not, see .
"""
import tpot
import numpy as np
import pandas as pd
import sklearn
from tpot import config
from typing import Generator, List, Tuple, Union
import random
from ..base import SklearnIndividual, SearchSpace
from ..tuple_index import TupleIndex
class SequentialPipelineIndividual(SklearnIndividual):
# takes in a list of search spaces. each space is a list of SearchSpaces.
# will produce a pipeline of Sequential length. Each step in the pipeline will correspond to the the search space provided in the same index.
def __init__(self, search_spaces : List[SearchSpace], rng=None) -> None:
super().__init__()
self.search_spaces = search_spaces
self.pipeline = []
for space in self.search_spaces:
self.pipeline.append(space.generate(rng))
self.pipeline = np.array(self.pipeline)
#TODO, mutate all steps or just one?
def mutate(self, rng=None):
# mutated = False
# for step in self.pipeline:
# if rng.random() < 0.5:
# if step.mutate(rng):
# mutated = True
# return mutated
rng = np.random.default_rng(rng)
step = rng.choice(self.pipeline)
return step.mutate(rng)
def crossover(self, other, rng=None):
#swap a random step in the pipeline with the corresponding step in the other pipeline
if len(self.pipeline) != len(other.pipeline):
return False
rng = np.random.default_rng(rng)
cx_funcs = [self._crossover_swap_multiple_nodes, self._crossover_swap_segment, self._crossover_node]
rng.shuffle(cx_funcs)
for cx_func in cx_funcs:
if cx_func(other, rng):
return True
return False
def _crossover_swap_node(self, other, rng):
if len(self.pipeline) != len(other.pipeline):
return False
rng = np.random.default_rng(rng)
idx = rng.integers(1,len(self.pipeline))
self.pipeline[idx], other.pipeline[idx] = other.pipeline[idx], self.pipeline[idx]
return True
def _crossover_swap_multiple_nodes(self, other, rng):
if len(self.pipeline) != len(other.pipeline):
return False
if len(self.pipeline) < 2:
return False
rng = np.random.default_rng(rng)
max_steps = int(min(len(self.pipeline), len(other.pipeline))/2)
max_steps = max(max_steps, 1)
if max_steps == 1:
n_steps_to_swap = 1
else:
n_steps_to_swap = rng.integers(1, max_steps)
indexes_to_swap = rng.choice(len(other.pipeline), n_steps_to_swap, replace=False)
for idx in indexes_to_swap:
self.pipeline[idx], other.pipeline[idx] = other.pipeline[idx], self.pipeline[idx]
return True
def _crossover_swap_segment(self, other, rng):
if len(self.pipeline) != len(other.pipeline):
return False
if len(self.pipeline) < 2:
return False
rng = np.random.default_rng(rng)
idx = rng.integers(1,len(self.pipeline))
left = rng.choice([True, False])
if left:
self.pipeline[:idx], other.pipeline[:idx] = other.pipeline[:idx], self.pipeline[:idx]
else:
self.pipeline[idx:], other.pipeline[idx:] = other.pipeline[idx:], self.pipeline[idx:]
return True
def _crossover_node(self, other, rng):
rng = np.random.default_rng(rng)
# crossover_success = False
# for idx in range(len(self.pipeline)):
# if rng.random() < 0.5:
# if self.pipeline[idx].crossover(other.pipeline[idx], rng):
# crossover_success = True
# return crossover_success
crossover_success = False
for idx in range(len(self.pipeline)):
if rng.random() < 0.5:
if self.pipeline[idx].crossover(other.pipeline[idx], rng):
crossover_success = True
return crossover_success
def export_pipeline(self, memory=None, **kwargs):
return sklearn.pipeline.make_pipeline(*[step.export_pipeline(memory=memory, **kwargs) for step in self.pipeline], memory=memory)
def unique_id(self):
l = [step.unique_id() for step in self.pipeline]
l = ["SequentialPipeline"] + l
return TupleIndex(tuple(l))
class SequentialPipeline(SearchSpace):
def __init__(self, search_spaces : List[SearchSpace] ) -> None:
"""
Takes in a list of search spaces. will produce a pipeline of Sequential length. Each step in the pipeline will correspond to the the search space provided in the same index.
"""
self.search_spaces = search_spaces
def generate(self, rng=None):
rng = np.random.default_rng(rng)
return SequentialPipelineIndividual(self.search_spaces, rng=rng)
================================================
FILE: tpot/search_spaces/pipelines/tests/test_graphspace.py
================================================
# Test all nodes have all dictionaries
import pytest
import tpot
import tpot
from ConfigSpace import ConfigurationSpace
from ConfigSpace import ConfigurationSpace, Integer, Float, Categorical, Normal
from sklearn.neighbors import KNeighborsClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeClassifier
from sklearn.preprocessing import StandardScaler
def test_merge_duplicate_nodes():
knn_configspace = {}
standard_scaler_configspace = {}
knn_node = tpot.search_spaces.nodes.EstimatorNode(
method = KNeighborsClassifier,
space = knn_configspace,
)
scaler_node = tpot.search_spaces.nodes.EstimatorNode(
method = StandardScaler,
space = standard_scaler_configspace,
)
graph_search_space = tpot.search_spaces.pipelines.GraphSearchPipeline(
root_search_space= knn_node,
leaf_search_space = scaler_node,
inner_search_space = None,
max_size = 10,
)
ind = graph_search_space.generate()
# all of these leaves should be identical
ind._mutate_insert_leaf()
ind._mutate_insert_leaf()
ind._mutate_insert_leaf()
ind._mutate_insert_leaf()
ind._merge_duplicated_nodes()
assert len(ind.graph.nodes) == 2
================================================
FILE: tpot/search_spaces/pipelines/tree.py
================================================
"""
This file is part of the TPOT library.
The current version of TPOT was developed at Cedars-Sinai by:
- Pedro Henrique Ribeiro (https://github.com/perib, https://www.linkedin.com/in/pedro-ribeiro/)
- Anil Saini (anil.saini@cshs.org)
- Jose Hernandez (jgh9094@gmail.com)
- Jay Moran (jay.moran@cshs.org)
- Nicholas Matsumoto (nicholas.matsumoto@cshs.org)
- Hyunjun Choi (hyunjun.choi@cshs.org)
- Gabriel Ketron (gabriel.ketron@cshs.org)
- Miguel E. Hernandez (miguel.e.hernandez@cshs.org)
- Jason Moore (moorejh28@gmail.com)
The original version of TPOT was primarily developed at the University of Pennsylvania by:
- Randal S. Olson (rso@randalolson.com)
- Weixuan Fu (weixuanf@upenn.edu)
- Daniel Angell (dpa34@drexel.edu)
- Jason Moore (moorejh28@gmail.com)
- and many more generous open-source contributors
TPOT is free software: you can redistribute it and/or modify
it under the terms of the GNU Lesser General Public License as
published by the Free Software Foundation, either version 3 of
the License, or (at your option) any later version.
TPOT is distributed in the hope that it will be useful,
but WITHOUT ANY WARRANTY; without even the implied warranty of
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
GNU Lesser General Public License for more details.
You should have received a copy of the GNU Lesser General Public
License along with TPOT. If not, see .
"""
import tpot
import numpy as np
import pandas as pd
import sklearn
from tpot import config
from typing import Generator, List, Tuple, Union
import random
from ..base import SklearnIndividual, SearchSpace
import networkx as nx
import copy
import matplotlib.pyplot as plt
from .graph import GraphPipelineIndividual
from ..graph_utils import *
class TreePipelineIndividual(GraphPipelineIndividual):
def __init__(self,
**kwargs) -> None:
super().__init__(**kwargs)
self.crossover_methods_list = [self._crossover_swap_branch, self._crossover_swap_node, self._crossover_nodes]
self.mutate_methods_list = [self._mutate_insert_leaf, self._mutate_insert_inner_node, self._mutate_remove_node, self._mutate_node]
self.merge_duplicated_nodes_toggle = False
class TreePipeline(SearchSpace):
def __init__(self, root_search_space : SearchSpace,
leaf_search_space : SearchSpace = None,
inner_search_space : SearchSpace =None,
min_size: int = 2,
max_size: int = 10,
crossover_same_depth=False) -> None:
"""
Generates a pipeline of variable length. Pipeline will have a tree structure similar to TPOT1.
"""
self.search_space = root_search_space
self.leaf_search_space = leaf_search_space
self.inner_search_space = inner_search_space
self.min_size = min_size
self.max_size = max_size
self.crossover_same_depth = crossover_same_depth
def generate(self, rng=None):
rng = np.random.default_rng(rng)
return TreePipelineIndividual(self.search_space, self.leaf_search_space, self.inner_search_space, self.min_size, self.max_size, self.crossover_same_depth, rng=rng)
================================================
FILE: tpot/search_spaces/pipelines/union.py
================================================
"""
This file is part of the TPOT library.
The current version of TPOT was developed at Cedars-Sinai by:
- Pedro Henrique Ribeiro (https://github.com/perib, https://www.linkedin.com/in/pedro-ribeiro/)
- Anil Saini (anil.saini@cshs.org)
- Jose Hernandez (jgh9094@gmail.com)
- Jay Moran (jay.moran@cshs.org)
- Nicholas Matsumoto (nicholas.matsumoto@cshs.org)
- Hyunjun Choi (hyunjun.choi@cshs.org)
- Gabriel Ketron (gabriel.ketron@cshs.org)
- Miguel E. Hernandez (miguel.e.hernandez@cshs.org)
- Jason Moore (moorejh28@gmail.com)
The original version of TPOT was primarily developed at the University of Pennsylvania by:
- Randal S. Olson (rso@randalolson.com)
- Weixuan Fu (weixuanf@upenn.edu)
- Daniel Angell (dpa34@drexel.edu)
- Jason Moore (moorejh28@gmail.com)
- and many more generous open-source contributors
TPOT is free software: you can redistribute it and/or modify
it under the terms of the GNU Lesser General Public License as
published by the Free Software Foundation, either version 3 of
the License, or (at your option) any later version.
TPOT is distributed in the hope that it will be useful,
but WITHOUT ANY WARRANTY; without even the implied warranty of
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
GNU Lesser General Public License for more details.
You should have received a copy of the GNU Lesser General Public
License along with TPOT. If not, see .
"""
import tpot
import numpy as np
import pandas as pd
import sklearn
from tpot import config
from typing import Generator, List, Tuple, Union
import random
from ..base import SklearnIndividual, SearchSpace
from ..tuple_index import TupleIndex
class UnionPipelineIndividual(SklearnIndividual):
"""
Takes in a list of search spaces. each space is a list of SearchSpaces.
Will produce a FeatureUnion pipeline. Each step in the pipeline will correspond to the the search space provided in the same index.
The resulting pipeline will be a FeatureUnion of the steps in the pipeline.
"""
def __init__(self, search_spaces : List[SearchSpace], rng=None) -> None:
super().__init__()
self.search_spaces = search_spaces
self.pipeline = []
for space in self.search_spaces:
self.pipeline.append(space.generate(rng))
def mutate(self, rng=None):
rng = np.random.default_rng(rng)
step = rng.choice(self.pipeline)
return step.mutate(rng)
def crossover(self, other, rng=None):
#swap a random step in the pipeline with the corresponding step in the other pipeline
rng = np.random.default_rng(rng)
cx_funcs = [self._crossover_node, self._crossover_swap_node]
rng.shuffle(cx_funcs)
for cx_func in cx_funcs:
if cx_func(other, rng):
return True
return False
def _crossover_swap_node(self, other, rng):
rng = np.random.default_rng(rng)
idx = rng.integers(1,len(self.pipeline))
self.pipeline[idx], other.pipeline[idx] = other.pipeline[idx], self.pipeline[idx]
return True
def _crossover_node(self, other, rng):
rng = np.random.default_rng(rng)
crossover_success = False
for idx in range(len(self.pipeline)):
if rng.random() < 0.5:
if self.pipeline[idx].crossover(other.pipeline[idx], rng):
crossover_success = True
return crossover_success
def export_pipeline(self, **kwargs):
return sklearn.pipeline.make_union(*[step.export_pipeline(**kwargs) for step in self.pipeline])
def unique_id(self):
l = [step.unique_id() for step in self.pipeline]
l = ["FeatureUnion"] + l
return TupleIndex(tuple(l))
class UnionPipeline(SearchSpace):
def __init__(self, search_spaces : List[SearchSpace] ) -> None:
"""
Takes in a list of search spaces. will produce a pipeline of Sequential length. Each step in the pipeline will correspond to the the search space provided in the same index.
"""
self.search_spaces = search_spaces
def generate(self, rng=None):
rng = np.random.default_rng(rng)
return UnionPipelineIndividual(self.search_spaces, rng=rng)
================================================
FILE: tpot/search_spaces/pipelines/wrapper.py
================================================
"""
This file is part of the TPOT library.
The current version of TPOT was developed at Cedars-Sinai by:
- Pedro Henrique Ribeiro (https://github.com/perib, https://www.linkedin.com/in/pedro-ribeiro/)
- Anil Saini (anil.saini@cshs.org)
- Jose Hernandez (jgh9094@gmail.com)
- Jay Moran (jay.moran@cshs.org)
- Nicholas Matsumoto (nicholas.matsumoto@cshs.org)
- Hyunjun Choi (hyunjun.choi@cshs.org)
- Gabriel Ketron (gabriel.ketron@cshs.org)
- Miguel E. Hernandez (miguel.e.hernandez@cshs.org)
- Jason Moore (moorejh28@gmail.com)
The original version of TPOT was primarily developed at the University of Pennsylvania by:
- Randal S. Olson (rso@randalolson.com)
- Weixuan Fu (weixuanf@upenn.edu)
- Daniel Angell (dpa34@drexel.edu)
- Jason Moore (moorejh28@gmail.com)
- and many more generous open-source contributors
TPOT is free software: you can redistribute it and/or modify
it under the terms of the GNU Lesser General Public License as
published by the Free Software Foundation, either version 3 of
the License, or (at your option) any later version.
TPOT is distributed in the hope that it will be useful,
but WITHOUT ANY WARRANTY; without even the implied warranty of
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
GNU Lesser General Public License for more details.
You should have received a copy of the GNU Lesser General Public
License along with TPOT. If not, see .
"""
import numpy as np
import pandas as pd
import sklearn
from tpot import config
from typing import Generator, List, Tuple, Union
import random
from ..base import SklearnIndividual, SearchSpace
from ConfigSpace import ConfigurationSpace
from ..tuple_index import TupleIndex
class WrapperPipelineIndividual(SklearnIndividual):
def __init__(
self,
method: type,
space: ConfigurationSpace,
estimator_search_space: SearchSpace,
hyperparameter_parser: callable = None,
wrapped_param_name: str = None,
rng=None) -> None:
super().__init__()
self.method = method
self.space = space
self.estimator_search_space = estimator_search_space
self.hyperparameters_parser = hyperparameter_parser
self.wrapped_param_name = wrapped_param_name
rng = np.random.default_rng(rng)
self.node = self.estimator_search_space.generate(rng)
if isinstance(space, dict):
self.hyperparameters = space
else:
rng = np.random.default_rng(rng)
self.space.seed(rng.integers(0, 2**32))
self.hyperparameters = dict(self.space.sample_configuration())
def mutate(self, rng=None):
rng = np.random.default_rng(rng)
if rng.choice([True, False]):
return self._mutate_hyperparameters(rng)
else:
return self._mutate_node(rng)
def _mutate_hyperparameters(self, rng=None):
if isinstance(self.space, dict):
return False
rng = np.random.default_rng(rng)
self.space.seed(rng.integers(0, 2**32))
self.hyperparameters = dict(self.space.sample_configuration())
return True
def _mutate_node(self, rng=None):
return self.node.mutate(rng)
def crossover(self, other, rng=None):
rng = np.random.default_rng(rng)
if rng.choice([True, False]):
return self._crossover_hyperparameters(other, rng)
else:
self.node.crossover(other.estimator_search_space, rng)
def _crossover_hyperparameters(self, other, rng=None):
if isinstance(self.space, dict):
return False
rng = np.random.default_rng(rng)
if self.method != other.method:
return False
#loop through hyperparameters, randomly swap items in self.hyperparameters with items in other.hyperparameters
for hyperparameter in self.space:
if rng.choice([True, False]):
if hyperparameter in other.hyperparameters:
self.hyperparameters[hyperparameter] = other.hyperparameters[hyperparameter]
return True
def export_pipeline(self, **kwargs):
if self.hyperparameters_parser is not None:
final_params = self.hyperparameters_parser(self.hyperparameters)
else:
final_params = self.hyperparameters
est = self.node.export_pipeline(**kwargs)
wrapped_est = self.method(est, **final_params)
return wrapped_est
def unique_id(self):
#return a dictionary of the method and the hyperparameters
method_str = self.method.__name__
params = list(self.hyperparameters.keys())
params = sorted(params)
id_str = f"{method_str}({', '.join([f'{param}={self.hyperparameters[param]}' for param in params])})"
return TupleIndex(("WrapperPipeline", id_str, self.node.unique_id()))
class WrapperPipeline(SearchSpace):
def __init__(
self,
method: type,
space: ConfigurationSpace,
estimator_search_space: SearchSpace,
hyperparameter_parser: callable = None,
wrapped_param_name: str = None
) -> None:
"""
This search space is for wrapping a sklearn estimator with a method that takes another estimator and hyperparameters as arguments.
For example, this can be used with sklearn.ensemble.BaggingClassifier or sklearn.ensemble.AdaBoostClassifier.
"""
self.estimator_search_space = estimator_search_space
self.method = method
self.space = space
self.hyperparameter_parser=hyperparameter_parser
self.wrapped_param_name = wrapped_param_name
def generate(self, rng=None):
rng = np.random.default_rng(rng)
return WrapperPipelineIndividual(method=self.method, space=self.space, estimator_search_space=self.estimator_search_space, hyperparameter_parser=self.hyperparameter_parser, wrapped_param_name=self.wrapped_param_name, rng=rng)
================================================
FILE: tpot/search_spaces/tests/test_search_spaces.py
================================================
"""
This file is part of the TPOT library.
The current version of TPOT was developed at Cedars-Sinai by:
- Pedro Henrique Ribeiro (https://github.com/perib, https://www.linkedin.com/in/pedro-ribeiro/)
- Anil Saini (anil.saini@cshs.org)
- Jose Hernandez (jgh9094@gmail.com)
- Jay Moran (jay.moran@cshs.org)
- Nicholas Matsumoto (nicholas.matsumoto@cshs.org)
- Hyunjun Choi (hyunjun.choi@cshs.org)
- Gabriel Ketron (gabriel.ketron@cshs.org)
- Miguel E. Hernandez (miguel.e.hernandez@cshs.org)
- Jason Moore (moorejh28@gmail.com)
The original version of TPOT was primarily developed at the University of Pennsylvania by:
- Randal S. Olson (rso@randalolson.com)
- Weixuan Fu (weixuanf@upenn.edu)
- Daniel Angell (dpa34@drexel.edu)
- Jason Moore (moorejh28@gmail.com)
- and many more generous open-source contributors
TPOT is free software: you can redistribute it and/or modify
it under the terms of the GNU Lesser General Public License as
published by the Free Software Foundation, either version 3 of
the License, or (at your option) any later version.
TPOT is distributed in the hope that it will be useful,
but WITHOUT ANY WARRANTY; without even the implied warranty of
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
GNU Lesser General Public License for more details.
You should have received a copy of the GNU Lesser General Public
License along with TPOT. If not, see .
"""
# Test all nodes have all dictionaries
import pytest
import tpot
import tpot
from ConfigSpace import ConfigurationSpace
from ConfigSpace import ConfigurationSpace, Integer, Float, Categorical, Normal
from sklearn.neighbors import KNeighborsClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeClassifier
from sklearn.preprocessing import StandardScaler
def test_EstimatorNodeCrossover():
knn_configspace = {}
standard_scaler_configspace = {}
knn_node = tpot.search_spaces.nodes.EstimatorNode(
method = KNeighborsClassifier,
space = knn_configspace,
)
knnind1 = knn_node.generate()
knnind2 = knn_node.generate()
for i in range(0,10):
knnind1.mutate()
knnind2.mutate()
knnind1.crossover(knnind2)
def test_ValueError_different_types():
knn_node = tpot.config.get_search_space(["KNeighborsClassifier"])
sfm_wrapper_node = tpot.config.get_search_space(["SelectFromModel_classification"])
for i in range(10):
ind1 = knn_node.generate()
ind2 = sfm_wrapper_node.generate()
assert not ind1.crossover(ind2)
assert not ind2.crossover(ind1)
if __name__ == "__main__":
test_EstimatorNodeCrossover()
test_ValueError_different_types()
================================================
FILE: tpot/search_spaces/tuple_index.py
================================================
"""
This file is part of the TPOT library.
The current version of TPOT was developed at Cedars-Sinai by:
- Pedro Henrique Ribeiro (https://github.com/perib, https://www.linkedin.com/in/pedro-ribeiro/)
- Anil Saini (anil.saini@cshs.org)
- Jose Hernandez (jgh9094@gmail.com)
- Jay Moran (jay.moran@cshs.org)
- Nicholas Matsumoto (nicholas.matsumoto@cshs.org)
- Hyunjun Choi (hyunjun.choi@cshs.org)
- Gabriel Ketron (gabriel.ketron@cshs.org)
- Miguel E. Hernandez (miguel.e.hernandez@cshs.org)
- Jason Moore (moorejh28@gmail.com)
The original version of TPOT was primarily developed at the University of Pennsylvania by:
- Randal S. Olson (rso@randalolson.com)
- Weixuan Fu (weixuanf@upenn.edu)
- Daniel Angell (dpa34@drexel.edu)
- Jason Moore (moorejh28@gmail.com)
- and many more generous open-source contributors
TPOT is free software: you can redistribute it and/or modify
it under the terms of the GNU Lesser General Public License as
published by the Free Software Foundation, either version 3 of
the License, or (at your option) any later version.
TPOT is distributed in the hope that it will be useful,
but WITHOUT ANY WARRANTY; without even the implied warranty of
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
GNU Lesser General Public License for more details.
You should have received a copy of the GNU Lesser General Public
License along with TPOT. If not, see .
"""
import numpy as np
class TupleIndex():
"""
TPOT uses tuples to create a unique id for some pipeline search spaces. However, tuples sometimes don't interact correctly with pandas indexes.
This class is a wrapper around a tuple that allows it to be used as a key in a dictionary, without it being an itereable.
An alternative could be to make unique id return a string, but this would not work with graphpipelines, which require a special object.
This class allows linear pipelines to contain graph pipelines while still being able to be used as a key in a dictionary.
"""
def __init__(self, tup):
self.tup = tup
def __eq__(self,other) -> bool:
return self.tup == other
def __hash__(self) -> int:
return self.tup.__hash__()
def __str__(self) -> str:
return self.tup.__str__()
def __repr__(self) -> str:
return self.tup.__repr__()
================================================
FILE: tpot/selectors/__init__.py
================================================
from .lexicase_selection import lexicase_selection
from .max_weighted_average_selector import max_weighted_average_selector
from .random_selector import random_selector
from .tournament_selection import tournament_selection
from .tournament_selection_dominated import tournament_selection_dominated
from .nsgaii import nondominated_sorting, crowding_distance, dominates, survival_select_NSGA2
from .map_elites_selection import map_elites_survival_selector, map_elites_parent_selector
SELECTORS = {"lexicase":lexicase_selection,
"max_weighted_average":max_weighted_average_selector,
"random":random_selector,
"tournament":tournament_selection,
"tournament_dominated":tournament_selection_dominated,
"nsgaii":survival_select_NSGA2,
"map_elites_survival":map_elites_survival_selector,
"map_elites_parent":map_elites_parent_selector,
}
================================================
FILE: tpot/selectors/lexicase_selection.py
================================================
"""
This file is part of the TPOT library.
The current version of TPOT was developed at Cedars-Sinai by:
- Pedro Henrique Ribeiro (https://github.com/perib, https://www.linkedin.com/in/pedro-ribeiro/)
- Anil Saini (anil.saini@cshs.org)
- Jose Hernandez (jgh9094@gmail.com)
- Jay Moran (jay.moran@cshs.org)
- Nicholas Matsumoto (nicholas.matsumoto@cshs.org)
- Hyunjun Choi (hyunjun.choi@cshs.org)
- Gabriel Ketron (gabriel.ketron@cshs.org)
- Miguel E. Hernandez (miguel.e.hernandez@cshs.org)
- Jason Moore (moorejh28@gmail.com)
The original version of TPOT was primarily developed at the University of Pennsylvania by:
- Randal S. Olson (rso@randalolson.com)
- Weixuan Fu (weixuanf@upenn.edu)
- Daniel Angell (dpa34@drexel.edu)
- Jason Moore (moorejh28@gmail.com)
- and many more generous open-source contributors
TPOT is free software: you can redistribute it and/or modify
it under the terms of the GNU Lesser General Public License as
published by the Free Software Foundation, either version 3 of
the License, or (at your option) any later version.
TPOT is distributed in the hope that it will be useful,
but WITHOUT ANY WARRANTY; without even the implied warranty of
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
GNU Lesser General Public License for more details.
You should have received a copy of the GNU Lesser General Public
License along with TPOT. If not, see .
"""
import numpy as np
def lexicase_selection(scores, k, n_parents=1, rng=None):
"""
Select the best individual according to Lexicase Selection, *k* times.
The returned list contains the indices of the chosen *individuals*.
Parameters
----------
scores : np.ndarray
The score matrix, where rows the individuals and the columns are the corresponds to scores on different objectives.
k : int
The number of individuals to select.
n_parents : int, optional
The number of parents to select per individual. The default is 1.
rng : int, np.random.Generator, optional
The random number generator. The default is None.
Returns
-------
A array of indices of selected individuals of shape (k, n_parents).
"""
rng = np.random.default_rng(rng)
chosen =[]
for i in range(k*n_parents):
candidates = list(range(len(scores)))
cases = list(range(len(scores[0])))
rng.shuffle(cases)
while len(cases) > 0 and len(candidates) > 1:
best_val_for_case = max(scores[candidates,cases[0]])
candidates = [x for x in candidates if scores[x, cases[0]] == best_val_for_case]
cases.pop(0)
chosen.append(rng.choice(candidates))
return np.reshape(chosen, (k, n_parents))
================================================
FILE: tpot/selectors/map_elites_selection.py
================================================
"""
This file is part of the TPOT library.
The current version of TPOT was developed at Cedars-Sinai by:
- Pedro Henrique Ribeiro (https://github.com/perib, https://www.linkedin.com/in/pedro-ribeiro/)
- Anil Saini (anil.saini@cshs.org)
- Jose Hernandez (jgh9094@gmail.com)
- Jay Moran (jay.moran@cshs.org)
- Nicholas Matsumoto (nicholas.matsumoto@cshs.org)
- Hyunjun Choi (hyunjun.choi@cshs.org)
- Gabriel Ketron (gabriel.ketron@cshs.org)
- Miguel E. Hernandez (miguel.e.hernandez@cshs.org)
- Jason Moore (moorejh28@gmail.com)
The original version of TPOT was primarily developed at the University of Pennsylvania by:
- Randal S. Olson (rso@randalolson.com)
- Weixuan Fu (weixuanf@upenn.edu)
- Daniel Angell (dpa34@drexel.edu)
- Jason Moore (moorejh28@gmail.com)
- and many more generous open-source contributors
TPOT is free software: you can redistribute it and/or modify
it under the terms of the GNU Lesser General Public License as
published by the Free Software Foundation, either version 3 of
the License, or (at your option) any later version.
TPOT is distributed in the hope that it will be useful,
but WITHOUT ANY WARRANTY; without even the implied warranty of
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
GNU Lesser General Public License for more details.
You should have received a copy of the GNU Lesser General Public
License along with TPOT. If not, see .
"""
import numpy as np
#TODO make these functions take in a predetermined set of bins rather than calculating a new set each time
def create_nd_matrix(matrix, grid_steps=None, bins=None):
"""
Create an n-dimensional matrix with the highest score for each cell
Parameters
----------
matrix : np.ndarray
The score matrix, where the first column is the score and the rest are the features for the map-elites algorithm.
grid_steps : int, optional
The number of steps to use for each feature to automatically create the bin thresholds. The default is None.
bins : list, optional
A list of lists containing the bin edges for each feature (other than the score). The default is None.
Returns
-------
np.ndarray
An n-dimensional matrix with the highest score for each cell and the index of the individual with that score.
The value in the cell is a dictionary with the keys "score" and "idx" containing the score and index of the individual respectively.
"""
if grid_steps is not None and bins is not None:
raise ValueError("Either grid_steps or bins must be provided but not both")
# Extract scores and features
scores = matrix[:, 0]
features = matrix[:, 1:]
# Determine the min and max of each feature
min_vals = np.min(features, axis=0)
max_vals = np.max(features, axis=0)
# Create bins for each feature
if bins is None:
bins = [np.linspace(min_vals[i], max_vals[i], grid_steps) for i in range(len(min_vals))]
# Initialize n-dimensional matrix with negative infinity
nd_matrix = np.full([len(b)+1 for b in bins], {"score": -np.inf, "idx": None})
# Fill in each cell with the highest score for that cell
for idx, (score, feature) in enumerate(zip(scores, features)):
indices = [np.digitize(f, bin) for f, bin in zip(feature, bins)]
cur_score = nd_matrix[tuple(indices)]["score"]
if score > cur_score:
nd_matrix[tuple(indices)] = {"score": score, "idx": idx}
return nd_matrix
def manhattan(a, b):
"""
Calculate the Manhattan distance between two points.
Parameters
----------
a : np.ndarray
The first point.
b : np.ndarray
The second point.
Returns
-------
float
The Manhattan distance between the two points.
"""
return sum(abs(val1-val2) for val1, val2 in zip(a,b))
def map_elites_survival_selector(scores, k=None, rng=None, grid_steps= 10, bins=None):
"""
Takes a matrix of scores and returns the indexes of the individuals that are in the best cells of the map-elites grid.
Can either take a grid_steps parameter to automatically create the bins or a bins parameter to specify the bins manually.
Parameters
----------
scores : np.ndarray
The score matrix, where the first column is the score and the rest are the features for the map-elites algorithm.
k : int, optional
The number of individuals to select. The default is None.
rng : int, np.random.Generator, optional
The random number generator. The default is None.
grid_steps : int, optional
The number of steps to use for each feature to automatically create the bin thresholds. The default is None.
bins : list, optional
A list of lists containing the bin edges for each feature (other than the score). The default is None.
Returns
-------
np.ndarray
An array of indexes of the individuals in the best cells of the map-elites grid (without repeats).
"""
if grid_steps is not None and bins is not None:
raise ValueError("Either grid_steps or bins must be provided but not both")
rng = np.random.default_rng(rng)
scores = np.array(scores)
#create grid
matrix = create_nd_matrix(scores, grid_steps=grid_steps, bins=bins)
matrix = matrix.flatten()
indexes = [cell["idx"] for cell in matrix if cell["idx"] is not None]
return np.unique(indexes)
def map_elites_parent_selector(scores, k, n_parents=1, rng=None, manhattan_distance = 2, grid_steps= 10, bins=None):
"""
A parent selection algorithm for the map-elites algorithm. First creates a grid of the best individuals per cell and then selects parents based on the Manhattan distance between the cells of the best individuals.
Parameters
----------
scores : np.ndarray
The score matrix, where the first column is the score and the rest are the features for the map-elites algorithm.
k : int
The number of individuals to select.
n_parents : int, optional
The number of parents to select per individual. The default is 1.
rng : int, np.random.Generator, optional
The random number generator. The default is None.
manhattan_distance : int, optional
The maximum Manhattan distance between parents. The default is 2. If no parents are found within this distance, the distance is increased by 1 until at least one other parent is found.
grid_steps : int, optional
The number of steps to use for each feature to automatically create the bin thresholds. The default is None.
bins : list, optional
A list of lists containing the bin edges for each feature (other than the score). The default is None.
Returns
-------
np.ndarray
An array of indexes of the parents selected for each individual
"""
if grid_steps is not None and bins is not None:
raise ValueError("Either grid_steps or bins must be provided but not both")
rng = np.random.default_rng(rng)
scores = np.array(scores)
#create grid
matrix = create_nd_matrix(scores, grid_steps=grid_steps, bins=bins)
#return true if cell is not empty
f = np.vectorize(lambda x: x["idx"] is not None)
valid_coordinates = np.array(np.where(f(matrix))).T
idx_to_coordinates = {matrix[tuple(coordinates)]["idx"]: coordinates for coordinates in valid_coordinates}
idxes = [idx for idx in idx_to_coordinates.keys()] #all the indexes of best score per cell
distance_matrix = np.zeros((len(idxes), len(idxes)))
for i, idx1 in enumerate(idxes):
for j, idx2 in enumerate(idxes):
distance_matrix[i][j] = manhattan(idx_to_coordinates[idx1], idx_to_coordinates[idx2])
parents = []
for i in range(k):
#randomly select a cell
idx = rng.choice(idxes) #select random parent
#get the distance from this parent to all other parents
dm_idx = idxes.index(idx)
row = distance_matrix[dm_idx]
#get all second parents that are within manhattan distance. if none are found increase the distance
candidates = []
while len(candidates) == 0:
candidates = np.where(row <= manhattan_distance)[0]
#remove self from candidates
candidates = candidates[candidates != dm_idx]
manhattan_distance += 1
if manhattan_distance > np.max(distance_matrix):
break
if len(candidates) == 0:
parents.append([idx, idx]) #if no other parents are found, select the same parent twice. weird to crossover with itself though
else:
this_parents = [idx]
for p in range(n_parents-1):
idx2_cords = rng.choice(candidates)
this_parents.append(idxes[idx2_cords])
parents.append(this_parents)
return np.array(parents)
def get_bins_quantiles(arr, k=None, q=None):
"""
Takes a matrix and returns the bin thresholds based on quantiles.
Parameters
----------
arr : np.ndarray
The matrix to calculate the bins for.
k : int, optional
The number of bins to create. This parameter creates k equally spaced quantiles.
For example, k=3 will create quantiles at array([0.25, 0.5 , 0.75]).
q : np.ndarray, optional
Custom quantiles to use for the bins. This parameter creates bins based on the quantiles of the data. The default is None.
"""
bins = []
if q is not None and k is not None:
raise ValueError("Only one of k or q can be specified")
if q is not None:
final_q = q
elif k is not None:
final_q = np.linspace(0, 1, k+2)[1:-1]
for i in range(arr.shape[1]):
bins.append(np.quantile(arr[:,i], final_q))
return bins
def get_bins(arr, k):
"""
Get equally spaced bin thresholds between the min and max values for the array of scores.
Parameters
----------
arr : np.ndarray
The list of values to calculate the bins for.
k : int
The number of bins to create.
Returns
-------
list
A list of bin thresholds calculated to be k equally spaced bins between the min and max of the array.
"""
min_vals = np.min(arr, axis=0)
max_vals = np.max(arr, axis=0)
[np.linspace(min_vals[i], max_vals[i], k) for i in range(len(min_vals))]
================================================
FILE: tpot/selectors/max_weighted_average_selector.py
================================================
"""
This file is part of the TPOT library.
The current version of TPOT was developed at Cedars-Sinai by:
- Pedro Henrique Ribeiro (https://github.com/perib, https://www.linkedin.com/in/pedro-ribeiro/)
- Anil Saini (anil.saini@cshs.org)
- Jose Hernandez (jgh9094@gmail.com)
- Jay Moran (jay.moran@cshs.org)
- Nicholas Matsumoto (nicholas.matsumoto@cshs.org)
- Hyunjun Choi (hyunjun.choi@cshs.org)
- Gabriel Ketron (gabriel.ketron@cshs.org)
- Miguel E. Hernandez (miguel.e.hernandez@cshs.org)
- Jason Moore (moorejh28@gmail.com)
The original version of TPOT was primarily developed at the University of Pennsylvania by:
- Randal S. Olson (rso@randalolson.com)
- Weixuan Fu (weixuanf@upenn.edu)
- Daniel Angell (dpa34@drexel.edu)
- Jason Moore (moorejh28@gmail.com)
- and many more generous open-source contributors
TPOT is free software: you can redistribute it and/or modify
it under the terms of the GNU Lesser General Public License as
published by the Free Software Foundation, either version 3 of
the License, or (at your option) any later version.
TPOT is distributed in the hope that it will be useful,
but WITHOUT ANY WARRANTY; without even the implied warranty of
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
GNU Lesser General Public License for more details.
You should have received a copy of the GNU Lesser General Public
License along with TPOT. If not, see .
"""
import numpy as np
def max_weighted_average_selector(scores,k, n_parents=1, rng=None):
"""
Select the best individual according to Max Weighted Average Selection, *k* times.
Parameters
----------
scores : np.ndarray
The score matrix, where rows the individuals and the columns are the corresponds to scores on different objectives.
k : int
The number of individuals to select.
n_parents : int, optional
The number of parents to select per individual. The default is 1.
rng : int, np.random.Generator, optional
The random number generator. The default is None.
Returns
-------
A array of indices of selected individuals of shape (k, n_parents).
"""
ave_scores = [np.nanmean(s ) for s in scores ] #TODO make this more efficient
chosen = np.argsort(ave_scores)[::-1][0:k] #TODO check this behavior with nans
return np.reshape(chosen, (k, n_parents))
================================================
FILE: tpot/selectors/nsgaii.py
================================================
"""
This file is part of the TPOT library.
The current version of TPOT was developed at Cedars-Sinai by:
- Pedro Henrique Ribeiro (https://github.com/perib, https://www.linkedin.com/in/pedro-ribeiro/)
- Anil Saini (anil.saini@cshs.org)
- Jose Hernandez (jgh9094@gmail.com)
- Jay Moran (jay.moran@cshs.org)
- Nicholas Matsumoto (nicholas.matsumoto@cshs.org)
- Hyunjun Choi (hyunjun.choi@cshs.org)
- Gabriel Ketron (gabriel.ketron@cshs.org)
- Miguel E. Hernandez (miguel.e.hernandez@cshs.org)
- Jason Moore (moorejh28@gmail.com)
The original version of TPOT was primarily developed at the University of Pennsylvania by:
- Randal S. Olson (rso@randalolson.com)
- Weixuan Fu (weixuanf@upenn.edu)
- Daniel Angell (dpa34@drexel.edu)
- Jason Moore (moorejh28@gmail.com)
- and many more generous open-source contributors
TPOT is free software: you can redistribute it and/or modify
it under the terms of the GNU Lesser General Public License as
published by the Free Software Foundation, either version 3 of
the License, or (at your option) any later version.
TPOT is distributed in the hope that it will be useful,
but WITHOUT ANY WARRANTY; without even the implied warranty of
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
GNU Lesser General Public License for more details.
You should have received a copy of the GNU Lesser General Public
License along with TPOT. If not, see .
"""
import numpy as np
# Deb, Pratab, Agarwal, and Meyarivan, “A fast elitist non-dominated sorting genetic algorithm for multi-objective optimization: NSGA-II”, 2002.
# chatgpt
def nondominated_sorting(matrix):
"""
Returns the indices of the non-dominated rows in the scores matrix.
Rows are considered samples, and columns are considered objectives.
Parameters
----------
matrix : np.ndarray
The score matrix, where rows the individuals and the columns are the corresponds to scores on different objectives.
Returns
-------
list
A list of lists of indices of the non-dominated rows in the scores matrix.
"""
# Initialize the front list and the rank list
# Initialize the current front
fronts = {0:set()}
# Initialize the list of dominated points
dominated = [set() for _ in range(len(matrix))] #si the set of solutions which solution i dominates
# Initialize the list of points that dominate the current point
dominating = [0 for _ in range(len(matrix))] #ni the number of solutions that denominate solution i
# Iterate over all points
for p, p_scores in enumerate(matrix):
# Iterate over all other points
for q, q_scores in enumerate(matrix):
# If the current point dominates the other point, increment the count of points dominated by the current point
if dominates(p_scores, q_scores):
dominated[p].add(q)
# If the current point is dominated by the other point, add it to the list of dominated points
elif dominates(q_scores, p_scores):
dominating[p] += 1
if dominating[p] == 0:
fronts[0].add(p)
i=0
# Iterate until all points have been added to a front
while len(fronts[i]) > 0:
H = set()
for p in fronts[i]:
for q in dominated[p]:
dominating[q] -= 1
if dominating[q] == 0:
H.add(q)
i += 1
fronts[i] = H
return [fronts[j] for j in range(i)]
def dominates(list1, list2):
"""
returns true is all values in list1 are not strictly worse than list2 AND at least one item in list1 is better than list2
Parameters
----------
list1 : list
The first list of values to compare.
list2 : list
The second list of values to compare.
Returns
-------
bool
True if all values in list1 are not strictly worse than list2 AND at least one item in list1 is better than list2, False otherwise.
"""
return all(list1[i] >= list2[i] for i in range(len(list1))) and any(list1[i] > list2[i] for i in range(len(list1)))
#adapted from deap + gtp
#bigger is better
def crowding_distance(matrix):
"""
Takes a matrix of scores and returns the crowding distance for each point.
Parameters
----------
matrix : np.ndarray
The score matrix, where rows the individuals and the columns are the corresponds to scores on different objectives.
Returns
-------
list
A list of the crowding distances for each point in the score matrix.
"""
matrix = np.array(matrix)
# Initialize the crowding distance for each point to zero
crowding_distances = [0 for _ in range(len(matrix))]
# Iterate over each objective
for objective_i in range(matrix.shape[1]):
# Sort the points according to the current objective
sorted_i = matrix[:, objective_i].argsort()
# Set the crowding distance of the first and last points to infinity
crowding_distances[sorted_i[0]] = float("inf")
crowding_distances[sorted_i[-1]] = float("inf")
if matrix[sorted_i[0]][objective_i] == matrix[sorted_i[-1]][objective_i]: # https://github.com/DEAP/deap/blob/f2a570567fa3dce156d7cfb0c50bc72f133258a1/deap/tools/emo.py#L135
continue
norm = matrix.shape[1] * float(matrix[sorted_i[0]][objective_i] - matrix[sorted_i[-1]][objective_i])
for prev, cur, following in zip(sorted_i[:-2], sorted_i[1:-1], sorted_i[2:]):
crowding_distances[cur] += (matrix[following][objective_i] - matrix[prev][objective_i]) / norm
return crowding_distances
def survival_select_NSGA2(scores, k, rng=None):
"""
Select the top k individuals from the scores matrix using the NSGA-II algorithm.
Parameters
----------
scores : np.ndarray
The score matrix, where rows the individuals and the columns are the corresponds to scores on different objectives.
k : int
The number of individuals to select.
rng : int, np.random.Generator, optional
The random number generator. The default is None.
Returns
-------
list
A list of indices of the selected individuals (without repeats).
"""
pareto_fronts = nondominated_sorting(scores)
# chosen = list(itertools.chain.from_iterable(fronts))
# if len(chosen) >= k:
# return chosen[0:k]
chosen = []
current_front_number = 0
while len(chosen) < k and current_front_number < len(pareto_fronts):
current_front = np.array(list(pareto_fronts[current_front_number]))
front_scores = [scores[i] for i in current_front]
crowding_distances = crowding_distance(front_scores)
sorted_indeces = current_front[np.argsort(crowding_distances)[::-1]]
chosen.extend(sorted_indeces[0:(k-len(chosen))])
current_front_number += 1
return chosen
================================================
FILE: tpot/selectors/random_selector.py
================================================
"""
This file is part of the TPOT library.
The current version of TPOT was developed at Cedars-Sinai by:
- Pedro Henrique Ribeiro (https://github.com/perib, https://www.linkedin.com/in/pedro-ribeiro/)
- Anil Saini (anil.saini@cshs.org)
- Jose Hernandez (jgh9094@gmail.com)
- Jay Moran (jay.moran@cshs.org)
- Nicholas Matsumoto (nicholas.matsumoto@cshs.org)
- Hyunjun Choi (hyunjun.choi@cshs.org)
- Gabriel Ketron (gabriel.ketron@cshs.org)
- Miguel E. Hernandez (miguel.e.hernandez@cshs.org)
- Jason Moore (moorejh28@gmail.com)
The original version of TPOT was primarily developed at the University of Pennsylvania by:
- Randal S. Olson (rso@randalolson.com)
- Weixuan Fu (weixuanf@upenn.edu)
- Daniel Angell (dpa34@drexel.edu)
- Jason Moore (moorejh28@gmail.com)
- and many more generous open-source contributors
TPOT is free software: you can redistribute it and/or modify
it under the terms of the GNU Lesser General Public License as
published by the Free Software Foundation, either version 3 of
the License, or (at your option) any later version.
TPOT is distributed in the hope that it will be useful,
but WITHOUT ANY WARRANTY; without even the implied warranty of
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
GNU Lesser General Public License for more details.
You should have received a copy of the GNU Lesser General Public
License along with TPOT. If not, see .
"""
import numpy as np
def random_selector(scores, k, n_parents=1, rng=None, ):
"""
Randomly selects indeces of individuals from the scores matrix.
Parameters
----------
scores : np.ndarray
The score matrix, where rows the individuals and the columns are the corresponds to scores on different objectives.
k : int
The number of individuals to select.
n_parents : int, optional
The number of parents to select per individual. The default is 1.
rng : int, np.random.Generator, optional
The random number generator. The default is None.
Returns
-------
A array of indices of randomly selected individuals (with replacement) of shape (k, n_parents).
"""
rng = np.random.default_rng(rng)
chosen = rng.choice(list(range(0,len(scores))), size=k*n_parents)
return np.reshape(chosen, (k, n_parents))
================================================
FILE: tpot/selectors/tournament_selection.py
================================================
"""
This file is part of the TPOT library.
The current version of TPOT was developed at Cedars-Sinai by:
- Pedro Henrique Ribeiro (https://github.com/perib, https://www.linkedin.com/in/pedro-ribeiro/)
- Anil Saini (anil.saini@cshs.org)
- Jose Hernandez (jgh9094@gmail.com)
- Jay Moran (jay.moran@cshs.org)
- Nicholas Matsumoto (nicholas.matsumoto@cshs.org)
- Hyunjun Choi (hyunjun.choi@cshs.org)
- Gabriel Ketron (gabriel.ketron@cshs.org)
- Miguel E. Hernandez (miguel.e.hernandez@cshs.org)
- Jason Moore (moorejh28@gmail.com)
The original version of TPOT was primarily developed at the University of Pennsylvania by:
- Randal S. Olson (rso@randalolson.com)
- Weixuan Fu (weixuanf@upenn.edu)
- Daniel Angell (dpa34@drexel.edu)
- Jason Moore (moorejh28@gmail.com)
- and many more generous open-source contributors
TPOT is free software: you can redistribute it and/or modify
it under the terms of the GNU Lesser General Public License as
published by the Free Software Foundation, either version 3 of
the License, or (at your option) any later version.
TPOT is distributed in the hope that it will be useful,
but WITHOUT ANY WARRANTY; without even the implied warranty of
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
GNU Lesser General Public License for more details.
You should have received a copy of the GNU Lesser General Public
License along with TPOT. If not, see .
"""
import numpy as np
def tournament_selection(scores, k, n_parents=1, rng=None, tournament_size=2, score_index=0):
"""
Select the best individual among *tournsize* randomly chosen
individuals, *k* times. The returned list contains the indices of the chosen *individuals*.
Parameters
----------
scores : np.ndarray
The score matrix, where rows the individuals and the columns are the corresponds to scores on different objectives.
k : int
The number of individuals to select.
n_parents : int, optional
The number of parents to select per individual. The default is 1.
rng : int, np.random.Generator, optional
The random number generator. The default is None.
tournament_size : int, optional
The number of individuals participating in each tournament.
score_index : int, str, optional
The index of the score to use for selection. If "average" is passed, the average score is used. The default is 0 (only the first score is used).
Returns
-------
A array of indices of selected individuals of shape (k, n_parents).
"""
rng = np.random.default_rng(rng)
if isinstance(score_index,int):
key=lambda x:x[1][score_index]
elif score_index == "average":
key=lambda x:np.mean(x[1])
chosen = []
for i in range(k*n_parents):
aspirants_idx =[rng.choice(len(scores)) for i in range(tournament_size)]
aspirants = list(zip(aspirants_idx, scores[aspirants_idx])) # Zip indices and elements together
chosen.append(max(aspirants, key=key)[0]) # Retrun the index of the maximum element
return np.reshape(chosen, (k, n_parents))
================================================
FILE: tpot/selectors/tournament_selection_dominated.py
================================================
"""
This file is part of the TPOT library.
The current version of TPOT was developed at Cedars-Sinai by:
- Pedro Henrique Ribeiro (https://github.com/perib, https://www.linkedin.com/in/pedro-ribeiro/)
- Anil Saini (anil.saini@cshs.org)
- Jose Hernandez (jgh9094@gmail.com)
- Jay Moran (jay.moran@cshs.org)
- Nicholas Matsumoto (nicholas.matsumoto@cshs.org)
- Hyunjun Choi (hyunjun.choi@cshs.org)
- Gabriel Ketron (gabriel.ketron@cshs.org)
- Miguel E. Hernandez (miguel.e.hernandez@cshs.org)
- Jason Moore (moorejh28@gmail.com)
The original version of TPOT was primarily developed at the University of Pennsylvania by:
- Randal S. Olson (rso@randalolson.com)
- Weixuan Fu (weixuanf@upenn.edu)
- Daniel Angell (dpa34@drexel.edu)
- Jason Moore (moorejh28@gmail.com)
- and many more generous open-source contributors
TPOT is free software: you can redistribute it and/or modify
it under the terms of the GNU Lesser General Public License as
published by the Free Software Foundation, either version 3 of
the License, or (at your option) any later version.
TPOT is distributed in the hope that it will be useful,
but WITHOUT ANY WARRANTY; without even the implied warranty of
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
GNU Lesser General Public License for more details.
You should have received a copy of the GNU Lesser General Public
License along with TPOT. If not, see .
"""
import numpy as np
from.nsgaii import nondominated_sorting, crowding_distance, dominates
#based on deap
def tournament_selection_dominated(scores, k, n_parents=2, rng=None):
"""
Select the best individual among 2 randomly chosen
individuals, *k* times. Selection is first attempted by checking if one individual dominates the other. Otherwise one with the highest crowding distance is selected.
The returned list contains the indices of the chosen *individuals*.
Parameters
----------
scores : np.ndarray
The score matrix, where rows the individuals and the columns are the corresponds to scores on different objectives.
k : int
The number of individuals to select.
n_parents : int, optional
The number of parents to select per individual. The default is 2.
rng : int, np.random.Generator, optional
The random number generator. The default is None.
Returns
-------
A array of indices of selected individuals of shape (k, n_parents).
"""
rng = np.random.default_rng(rng)
pareto_fronts = nondominated_sorting(scores)
# chosen = list(itertools.chain.from_iterable(fronts))
# if len(chosen) >= k:
# return chosen[0:k]
crowding_dict = {}
chosen = []
current_front_number = 0
while current_front_number < len(pareto_fronts):
current_front = np.array(list(pareto_fronts[current_front_number]))
front_scores = [scores[i] for i in current_front]
crowding_distances = crowding_distance(front_scores)
for i, crowding in zip(current_front,crowding_distances):
crowding_dict[i] = crowding
current_front_number += 1
chosen = []
for i in range(k*n_parents):
asp1 = rng.choice(len(scores))
asp2 = rng.choice(len(scores))
if dominates(scores[asp1], scores[asp2]):
chosen.append(asp1)
elif dominates(scores[asp2], scores[asp1]):
chosen.append(asp2)
elif crowding_dict[asp1] > crowding_dict[asp2]:
chosen.append(asp1)
elif crowding_dict[asp1] < crowding_dict[asp2]:
chosen.append(asp2)
else:
chosen.append(rng.choice([asp1,asp2]))
return np.reshape(chosen, (k, n_parents))
================================================
FILE: tpot/tests/__init__.py
================================================
================================================
FILE: tpot/tests/conftest.py
================================================
"""
This file is part of the TPOT library.
The current version of TPOT was developed at Cedars-Sinai by:
- Pedro Henrique Ribeiro (https://github.com/perib, https://www.linkedin.com/in/pedro-ribeiro/)
- Anil Saini (anil.saini@cshs.org)
- Jose Hernandez (jgh9094@gmail.com)
- Jay Moran (jay.moran@cshs.org)
- Nicholas Matsumoto (nicholas.matsumoto@cshs.org)
- Hyunjun Choi (hyunjun.choi@cshs.org)
- Gabriel Ketron (gabriel.ketron@cshs.org)
- Miguel E. Hernandez (miguel.e.hernandez@cshs.org)
- Jason Moore (moorejh28@gmail.com)
The original version of TPOT was primarily developed at the University of Pennsylvania by:
- Randal S. Olson (rso@randalolson.com)
- Weixuan Fu (weixuanf@upenn.edu)
- Daniel Angell (dpa34@drexel.edu)
- Jason Moore (moorejh28@gmail.com)
- and many more generous open-source contributors
TPOT is free software: you can redistribute it and/or modify
it under the terms of the GNU Lesser General Public License as
published by the Free Software Foundation, either version 3 of
the License, or (at your option) any later version.
TPOT is distributed in the hope that it will be useful,
but WITHOUT ANY WARRANTY; without even the implied warranty of
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
GNU Lesser General Public License for more details.
You should have received a copy of the GNU Lesser General Public
License along with TPOT. If not, see .
"""
import pytest
import sys
@pytest.fixture
def capture_stdout(monkeypatch):
buffer = {"stdout": "", "write_calls": 0}
def fake_write(s):
buffer["stdout"] += s
buffer["write_calls"] += 1
monkeypatch.setattr(sys.stdout, "write", fake_write)
return buffer
================================================
FILE: tpot/tests/test_estimators.py
================================================
"""
This file is part of the TPOT library.
The current version of TPOT was developed at Cedars-Sinai by:
- Pedro Henrique Ribeiro (https://github.com/perib, https://www.linkedin.com/in/pedro-ribeiro/)
- Anil Saini (anil.saini@cshs.org)
- Jose Hernandez (jgh9094@gmail.com)
- Jay Moran (jay.moran@cshs.org)
- Nicholas Matsumoto (nicholas.matsumoto@cshs.org)
- Hyunjun Choi (hyunjun.choi@cshs.org)
- Gabriel Ketron (gabriel.ketron@cshs.org)
- Miguel E. Hernandez (miguel.e.hernandez@cshs.org)
- Jason Moore (moorejh28@gmail.com)
The original version of TPOT was primarily developed at the University of Pennsylvania by:
- Randal S. Olson (rso@randalolson.com)
- Weixuan Fu (weixuanf@upenn.edu)
- Daniel Angell (dpa34@drexel.edu)
- Jason Moore (moorejh28@gmail.com)
- and many more generous open-source contributors
TPOT is free software: you can redistribute it and/or modify
it under the terms of the GNU Lesser General Public License as
published by the Free Software Foundation, either version 3 of
the License, or (at your option) any later version.
TPOT is distributed in the hope that it will be useful,
but WITHOUT ANY WARRANTY; without even the implied warranty of
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
GNU Lesser General Public License for more details.
You should have received a copy of the GNU Lesser General Public
License along with TPOT. If not, see .
"""
import pytest
import tpot
from sklearn.datasets import load_iris
import random
import sklearn
@pytest.fixture
def sample_dataset():
X_train, y_train = load_iris(return_X_y=True)
return X_train, y_train
#standard test
@pytest.fixture
def tpot_estimator():
n_classes=3
n_samples=100
n_features=100
search_space = tpot.search_spaces.pipelines.GraphSearchPipeline(
root_search_space= tpot.config.get_search_space("classifiers", n_samples=n_samples, n_features=n_features, n_classes=n_classes),
leaf_search_space = None,
inner_search_space = tpot.config.get_search_space(["selectors","transformers"],n_samples=n_samples, n_features=n_features, n_classes=n_classes),
max_size = 10,
)
return tpot.TPOTEstimator(
search_space=search_space,
population_size=10,
generations=2,
scorers=['roc_auc_ovr'],
scorers_weights=[1],
classification=True,
n_jobs=4,
early_stop=5,
other_objective_functions= [],
other_objective_functions_weights=[],
max_time_mins=20/60,
verbose=3)
@pytest.fixture
def tpot_classifier():
return tpot.tpot_estimator.templates.TPOTClassifier(max_time_mins=60/60,verbose=0)
@pytest.fixture
def tpot_regressor():
return tpot.tpot_estimator.templates.TPOTRegressor(max_time_mins=60/60,verbose=0)
@pytest.fixture
def tpot_estimator_with_pipeline(tpot_estimator,sample_dataset):
tpot_estimator.fit(sample_dataset[0], sample_dataset[1])
return tpot_estimator
def test_tpot_estimator_predict(tpot_estimator_with_pipeline,sample_dataset):
#X_test = [[1, 2, 3], [4, 5, 6]]
X_test = sample_dataset[0]
y_pred = tpot_estimator_with_pipeline.predict(X_test)
assert len(y_pred) == len(X_test)
assert tpot_estimator_with_pipeline.fitted_pipeline_ is not None
def test_tpot_estimator_generations_type():
with pytest.raises(TypeError):
tpot.TPOTEstimator(generations="two", population_size=10, verbosity=2)
def test_tpot_estimator_population_size_type():
with pytest.raises(TypeError):
tpot.TPOTEstimator(generations=2, population_size='ten', verbosity=2)
def test_tpot_estimator_verbosity_type():
with pytest.raises(TypeError):
tpot.TPOTEstimator(generations=2, population_size=10, verbosity='high')
def test_tpot_estimator_scoring_type():
with pytest.raises(TypeError):
tpot.TPOTEstimator(generations=2, population_size=10, verbosity=2, scoring=0.5)
def test_tpot_estimator_cv_type():
with pytest.raises(TypeError):
tpot.TPOTEstimator(generations=2, population_size=10, verbosity=2, cv='kfold')
def test_tpot_estimator_n_jobs_type():
with pytest.raises(TypeError):
tpot.TPOTEstimator(generations=2, population_size=10, verbosity=2, n_jobs='all')
def test_tpot_estimator_config_dict_type():
with pytest.raises(TypeError):
tpot.TPOTEstimator(generations=2, population_size=10, verbosity=2, config_dict='config')
def test_tpot_classifier_fit(tpot_classifier,sample_dataset):
#load iris dataset
X_train = sample_dataset[0]
y_train = sample_dataset[1]
tpot_classifier.fit(X_train, y_train)
assert tpot_classifier.fitted_pipeline_ is not None
def test_tpot_regressor_fit(tpot_regressor):
scorer = sklearn.metrics.get_scorer('neg_mean_squared_error')
X, y = sklearn.datasets.load_diabetes(return_X_y=True)
X_train, X_test, y_train, y_test = sklearn.model_selection.train_test_split(X, y, train_size=0.05, test_size=0.95)
tpot_regressor.fit(X_train, y_train)
assert tpot_regressor.fitted_pipeline_ is not None
================================================
FILE: tpot/tests/test_hello_world.py
================================================
"""
Test hello world.
Notes:
parameterizing the test_input and expected values allows tests continue running even if one fails.
xfail marks a test as expected to fail. This is useful for tests that are not yet implemented.
fixtures are used to setup and teardown tests. They are useful for tests that require a lot of setup.
We can implement fixtures if we need them.
"""
import pytest
@pytest.mark.parametrize("test_input,expected", [
("Hello World", "Hello World"),
])
def test_hello_world(test_input, expected):
assert test_input is expected
def test_print(capture_stdout):
print("Hello World")
assert capture_stdout["stdout"] == "Hello World\n"
================================================
FILE: tpot/tpot_estimator/__init__.py
================================================
"""
This file is part of the TPOT library.
The current version of TPOT was developed at Cedars-Sinai by:
- Pedro Henrique Ribeiro (https://github.com/perib, https://www.linkedin.com/in/pedro-ribeiro/)
- Anil Saini (anil.saini@cshs.org)
- Jose Hernandez (jgh9094@gmail.com)
- Jay Moran (jay.moran@cshs.org)
- Nicholas Matsumoto (nicholas.matsumoto@cshs.org)
- Hyunjun Choi (hyunjun.choi@cshs.org)
- Gabriel Ketron (gabriel.ketron@cshs.org)
- Miguel E. Hernandez (miguel.e.hernandez@cshs.org)
- Jason Moore (moorejh28@gmail.com)
The original version of TPOT was primarily developed at the University of Pennsylvania by:
- Randal S. Olson (rso@randalolson.com)
- Weixuan Fu (weixuanf@upenn.edu)
- Daniel Angell (dpa34@drexel.edu)
- Jason Moore (moorejh28@gmail.com)
- and many more generous open-source contributors
TPOT is free software: you can redistribute it and/or modify
it under the terms of the GNU Lesser General Public License as
published by the Free Software Foundation, either version 3 of
the License, or (at your option) any later version.
TPOT is distributed in the hope that it will be useful,
but WITHOUT ANY WARRANTY; without even the implied warranty of
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
GNU Lesser General Public License for more details.
You should have received a copy of the GNU Lesser General Public
License along with TPOT. If not, see .
"""
from .estimator import TPOTEstimator
from .steady_state_estimator import TPOTEstimatorSteadyState
from .templates import TPOTClassifier, TPOTRegressor
================================================
FILE: tpot/tpot_estimator/cross_val_utils.py
================================================
"""
This file is part of the TPOT library.
The current version of TPOT was developed at Cedars-Sinai by:
- Pedro Henrique Ribeiro (https://github.com/perib, https://www.linkedin.com/in/pedro-ribeiro/)
- Anil Saini (anil.saini@cshs.org)
- Jose Hernandez (jgh9094@gmail.com)
- Jay Moran (jay.moran@cshs.org)
- Nicholas Matsumoto (nicholas.matsumoto@cshs.org)
- Hyunjun Choi (hyunjun.choi@cshs.org)
- Gabriel Ketron (gabriel.ketron@cshs.org)
- Miguel E. Hernandez (miguel.e.hernandez@cshs.org)
- Jason Moore (moorejh28@gmail.com)
The original version of TPOT was primarily developed at the University of Pennsylvania by:
- Randal S. Olson (rso@randalolson.com)
- Weixuan Fu (weixuanf@upenn.edu)
- Daniel Angell (dpa34@drexel.edu)
- Jason Moore (moorejh28@gmail.com)
- and many more generous open-source contributors
TPOT is free software: you can redistribute it and/or modify
it under the terms of the GNU Lesser General Public License as
published by the Free Software Foundation, either version 3 of
the License, or (at your option) any later version.
TPOT is distributed in the hope that it will be useful,
but WITHOUT ANY WARRANTY; without even the implied warranty of
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
GNU Lesser General Public License for more details.
You should have received a copy of the GNU Lesser General Public
License along with TPOT. If not, see .
"""
import time
import sklearn.metrics
from collections.abc import Iterable
import pandas as pd
import sklearn
import numpy as np
def cross_val_score_objective(estimator, X, y, scorers, cv, fold=None):
"""
Compute the cross validated scores for a estimator. Only fits the estimator once per fold, and loops over the scorers to evaluate the estimator.
Parameters
----------
estimator: sklearn.base.BaseEstimator
The estimator to fit and score.
X: np.ndarray or pd.DataFrame
The feature matrix.
y: np.ndarray or pd.Series
The target vector.
scorers: list or scorer
The scorers to use.
If a list, will loop over the scorers and return a list of scorers.
If a single scorer, will return a single score.
cv: sklearn cross-validator
The cross-validator to use. For example, sklearn.model_selection.KFold or sklearn.model_selection.StratifiedKFold.
fold: int, optional
The fold to return the scores for. If None, will return the mean of all the scores (per scorer). Default is None.
Returns
-------
scores: np.ndarray or float
The scores for the estimator per scorer. If fold is None, will return the mean of all the scores (per scorer).
Returns a list if multiple scorers are used, otherwise returns a float for the single scorer.
"""
#check if scores is not iterable
if not isinstance(scorers, Iterable):
scorers = [scorers]
scores = []
if fold is None:
for train_index, test_index in cv.split(X, y):
this_fold_estimator = sklearn.base.clone(estimator)
if isinstance(X, pd.DataFrame) or isinstance(X, pd.Series):
X_train, X_test = X.iloc[train_index], X.iloc[test_index]
else:
X_train, X_test = X[train_index], X[test_index]
if isinstance(y, pd.DataFrame) or isinstance(y, pd.Series):
y_train, y_test = y.iloc[train_index], y.iloc[test_index]
else:
y_train, y_test = y[train_index], y[test_index]
start = time.time()
this_fold_estimator.fit(X_train,y_train)
duration = time.time() - start
this_fold_scores = [sklearn.metrics.get_scorer(scorer)(this_fold_estimator, X_test, y_test) for scorer in scorers]
scores.append(this_fold_scores)
del this_fold_estimator
del X_train
del X_test
del y_train
del y_test
return np.mean(scores,0)
else:
this_fold_estimator = sklearn.base.clone(estimator)
train_index, test_index = list(cv.split(X, y))[fold]
if isinstance(X, pd.DataFrame) or isinstance(X, pd.Series):
X_train, X_test = X.iloc[train_index], X.iloc[test_index]
else:
X_train, X_test = X[train_index], X[test_index]
if isinstance(y, pd.DataFrame) or isinstance(y, pd.Series):
y_train, y_test = y.iloc[train_index], y.iloc[test_index]
else:
y_train, y_test = y[train_index], y[test_index]
start = time.time()
this_fold_estimator.fit(X_train,y_train)
duration = time.time() - start
this_fold_scores = [sklearn.metrics.get_scorer(scorer)(this_fold_estimator, X_test, y_test) for scorer in scorers]
return this_fold_scores
================================================
FILE: tpot/tpot_estimator/estimator.py
================================================
"""
This file is part of the TPOT library.
The current version of TPOT was developed at Cedars-Sinai by:
- Pedro Henrique Ribeiro (https://github.com/perib, https://www.linkedin.com/in/pedro-ribeiro/)
- Anil Saini (anil.saini@cshs.org)
- Jose Hernandez (jgh9094@gmail.com)
- Jay Moran (jay.moran@cshs.org)
- Nicholas Matsumoto (nicholas.matsumoto@cshs.org)
- Hyunjun Choi (hyunjun.choi@cshs.org)
- Gabriel Ketron (gabriel.ketron@cshs.org)
- Miguel E. Hernandez (miguel.e.hernandez@cshs.org)
- Jason Moore (moorejh28@gmail.com)
The original version of TPOT was primarily developed at the University of Pennsylvania by:
- Randal S. Olson (rso@randalolson.com)
- Weixuan Fu (weixuanf@upenn.edu)
- Daniel Angell (dpa34@drexel.edu)
- Jason Moore (moorejh28@gmail.com)
- and many more generous open-source contributors
TPOT is free software: you can redistribute it and/or modify
it under the terms of the GNU Lesser General Public License as
published by the Free Software Foundation, either version 3 of
the License, or (at your option) any later version.
TPOT is distributed in the hope that it will be useful,
but WITHOUT ANY WARRANTY; without even the implied warranty of
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
GNU Lesser General Public License for more details.
You should have received a copy of the GNU Lesser General Public
License along with TPOT. If not, see .
"""
from sklearn.base import BaseEstimator
from sklearn.utils.metaestimators import available_if
import numpy as np
import sklearn.metrics
import tpot.config
from sklearn.utils.validation import check_is_fitted
from tpot.selectors import survival_select_NSGA2, tournament_selection_dominated
from sklearn.preprocessing import LabelEncoder
import pandas as pd
from sklearn.model_selection import train_test_split
import tpot
from dask.distributed import Client
from dask.distributed import LocalCluster
from sklearn.preprocessing import LabelEncoder
import warnings
import math
from .estimator_utils import *
from dask import config as cfg
from sklearn.experimental import enable_iterative_imputer
from ..config.template_search_spaces import get_template_search_spaces
import warnings
from sklearn.utils._tags import get_tags
import copy
def set_dask_settings():
cfg.set({'distributed.scheduler.worker-ttl': None})
cfg.set({'distributed.scheduler.allowed-failures':1})
#TODO inherit from _BaseComposition?
class TPOTEstimator(BaseEstimator):
def __init__(self,
search_space,
scorers,
scorers_weights,
classification,
cv = 10,
other_objective_functions=[],
other_objective_functions_weights = [],
objective_function_names = None,
bigger_is_better = True,
export_graphpipeline = False,
memory = None,
categorical_features = None,
preprocessing = False,
population_size = 50,
initial_population_size = None,
population_scaling = .5,
generations_until_end_population = 1,
generations = None,
max_time_mins=60,
max_eval_time_mins=10,
validation_strategy = "none",
validation_fraction = .2,
disable_label_encoder = False,
#early stopping parameters
early_stop = None,
scorers_early_stop_tol = 0.001,
other_objectives_early_stop_tol =None,
threshold_evaluation_pruning = None,
threshold_evaluation_scaling = .5,
selection_evaluation_pruning = None,
selection_evaluation_scaling = .5,
min_history_threshold = 20,
#evolver parameters
survival_percentage = 1,
crossover_probability=.2,
mutate_probability=.7,
mutate_then_crossover_probability=.05,
crossover_then_mutate_probability=.05,
survival_selector = survival_select_NSGA2,
parent_selector = tournament_selection_dominated,
#budget parameters
budget_range = None,
budget_scaling = .5,
generations_until_end_budget = 1,
stepwise_steps = 5,
#dask parameters
n_jobs=1,
memory_limit = None,
client = None,
processes = True,
#debugging and logging parameters
warm_start = False,
periodic_checkpoint_folder = None,
callback = None,
verbose = 0,
scatter = True,
# random seed for random number generator (rng)
random_state = None,
):
'''
An sklearn baseestimator that uses genetic programming to optimize a pipeline.
Parameters
----------
search_space : (String, tpot.search_spaces.SearchSpace)
- String : The default search space to use for the optimization.
| String | Description |
| :--- | :----: |
| linear | A linear pipeline with the structure of "Selector->(transformers+Passthrough)->(classifiers/regressors+Passthrough)->final classifier/regressor." For both the transformer and inner estimator layers, TPOT may choose one or more transformers/classifiers, or it may choose none. The inner classifier/regressor layer is optional. |
| linear-light | Same search space as linear, but without the inner classifier/regressor layer and with a reduced set of faster running estimators. |
| graph | TPOT will optimize a pipeline in the shape of a directed acyclic graph. The nodes of the graph can include selectors, scalers, transformers, or classifiers/regressors (inner classifiers/regressors can optionally be not included). This will return a custom GraphPipeline rather than an sklearn Pipeline. More details in Tutorial 6. |
| graph-light | Same as graph search space, but without the inner classifier/regressors and with a reduced set of faster running estimators. |
| mdr |TPOT will search over a series of feature selectors and Multifactor Dimensionality Reduction models to find a series of operators that maximize prediction accuracy. The TPOT MDR configuration is specialized for genome-wide association studies (GWAS), and is described in detail online here.
Note that TPOT MDR may be slow to run because the feature selection routines are computationally expensive, especially on large datasets. |
- SearchSpace : The search space to use for the optimization. This should be an instance of a SearchSpace.
The search space to use for the optimization. This should be an instance of a SearchSpace.
TPOT has groups of search spaces found in the following folders, tpot.search_spaces.nodes for the nodes in the pipeline and tpot.search_spaces.pipelines for the pipeline structure.
scorers : (list, scorer)
A scorer or list of scorers to be used in the cross-validation process.
see https://scikit-learn.org/stable/modules/model_evaluation.html
scorers_weights : list
A list of weights to be applied to the scorers during the optimization process.
classification : bool
If True, the problem is treated as a classification problem. If False, the problem is treated as a regression problem.
Used to determine the CV strategy.
cv : int, cross-validator
- (int): Number of folds to use in the cross-validation process. By uses the sklearn.model_selection.KFold cross-validator for regression and StratifiedKFold for classification. In both cases, shuffled is set to True.
- (sklearn.model_selection.BaseCrossValidator): A cross-validator to use in the cross-validation process.
- max_depth (int): The maximum depth from any node to the root of the pipelines to be generated.
other_objective_functions : list, default=[]
A list of other objective functions to apply to the pipeline. The function takes a single parameter for the graphpipeline estimator and returns either a single score or a list of scores.
other_objective_functions_weights : list, default=[]
A list of weights to be applied to the other objective functions.
objective_function_names : list, default=None
A list of names to be applied to the objective functions. If None, will use the names of the objective functions.
bigger_is_better : bool, default=True
If True, the objective function is maximized. If False, the objective function is minimized. Use negative weights to reverse the direction.
memory: Memory object or string, default=None
If supplied, pipeline will cache each transformer after calling fit with joblib.Memory. This feature
is used to avoid computing the fit transformers within a pipeline if the parameters
and input data are identical with another fitted pipeline during optimization process.
- String 'auto':
TPOT uses memory caching with a temporary directory and cleans it up upon shutdown.
- String path of a caching directory
TPOT uses memory caching with the provided directory and TPOT does NOT clean
the caching directory up upon shutdown. If the directory does not exist, TPOT will
create it.
- Memory object:
TPOT uses the instance of joblib.Memory for memory caching,
and TPOT does NOT clean the caching directory up upon shutdown.
- None:
TPOT does not use memory caching.
categorical_features: list or None
Categorical columns to inpute and/or one hot encode during the preprocessing step. Used only if preprocessing is not False.
- None : If None, TPOT will automatically use object columns in pandas dataframes as objects for one hot encoding in preprocessing.
- List of categorical features. If X is a dataframe, this should be a list of column names. If X is a numpy array, this should be a list of column indices
preprocessing : bool or BaseEstimator/Pipeline,
EXPERIMENTAL - will be changed in future versions
A pipeline that will be used to preprocess the data before CV. Note that the parameters for these steps are not optimized. Add them to the search space to be optimized.
- bool : If True, will use a default preprocessing pipeline which includes imputation followed by one hot encoding.
- Pipeline : If an instance of a pipeline is given, will use that pipeline as the preprocessing pipeline.
population_size : int, default=50
Size of the population
initial_population_size : int, default=None
Size of the initial population. If None, population_size will be used.
population_scaling : int, default=0.5
Scaling factor to use when determining how fast we move the threshold moves from the start to end percentile.
generations_until_end_population : int, default=1
Number of generations until the population size reaches population_size
generations : int, default=None
Number of generations to run
max_time_mins : float, default=60
Maximum time to run the optimization. If none or inf, will run until the end of the generations.
max_eval_time_mins : float, default=10
Maximum time to evaluate a single individual. If none or inf, there will be no time limit per evaluation.
validation_strategy : str, default='none'
EXPERIMENTAL The validation strategy to use for selecting the final pipeline from the population. TPOT may overfit the cross validation score. A second validation set can be used to select the final pipeline.
- 'auto' : Automatically determine the validation strategy based on the dataset shape.
- 'reshuffled' : Use the same data for cross validation and final validation, but with different splits for the folds. This is the default for small datasets.
- 'split' : Use a separate validation set for final validation. Data will be split according to validation_fraction. This is the default for medium datasets.
- 'none' : Do not use a separate validation set for final validation. Select based on the original cross-validation score. This is the default for large datasets.
validation_fraction : float, default=0.2
EXPERIMENTAL The fraction of the dataset to use for the validation set when validation_strategy is 'split'. Must be between 0 and 1.
disable_label_encoder : bool, default=False
If True, TPOT will check if the target needs to be relabeled to be sequential ints from 0 to N. This is necessary for XGBoost compatibility. If the labels need to be encoded, TPOT will use sklearn.preprocessing.LabelEncoder to encode the labels. The encoder can be accessed via the self.label_encoder_ attribute.
If False, no additional label encoders will be used.
early_stop : int, default=None
Number of generations without improvement before early stopping. All objectives must have converged within the tolerance for this to be triggered. In general a value of around 5-20 is good.
scorers_early_stop_tol :
-list of floats
list of tolerances for each scorer. If the difference between the best score and the current score is less than the tolerance, the individual is considered to have converged
If an index of the list is None, that item will not be used for early stopping
-int
If an int is given, it will be used as the tolerance for all objectives
other_objectives_early_stop_tol :
-list of floats
list of tolerances for each of the other objective function. If the difference between the best score and the current score is less than the tolerance, the individual is considered to have converged
If an index of the list is None, that item will not be used for early stopping
-int
If an int is given, it will be used as the tolerance for all objectives
threshold_evaluation_pruning : list [start, end], default=None
starting and ending percentile to use as a threshold for the evaluation early stopping.
Values between 0 and 100.
threshold_evaluation_scaling : float [0,inf), default=0.5
A scaling factor to use when determining how fast we move the threshold moves from the start to end percentile.
Must be greater than zero. Higher numbers will move the threshold to the end faster.
selection_evaluation_pruning : list, default=None
A lower and upper percent of the population size to select each round of CV.
Values between 0 and 1.
selection_evaluation_scaling : float, default=0.5
A scaling factor to use when determining how fast we move the threshold moves from the start to end percentile.
Must be greater than zero. Higher numbers will move the threshold to the end faster.
min_history_threshold : int, default=0
The minimum number of previous scores needed before using threshold early stopping.
survival_percentage : float, default=1
Percentage of the population size to utilize for mutation and crossover at the beginning of the generation. The rest are discarded. Individuals are selected with the selector passed into survival_selector. The value of this parameter must be between 0 and 1, inclusive.
For example, if the population size is 100 and the survival percentage is .5, 50 individuals will be selected with NSGA2 from the existing population. These will be used for mutation and crossover to generate the next 100 individuals for the next generation. The remainder are discarded from the live population. In the next generation, there will now be the 50 parents + the 100 individuals for a total of 150. Surivival percentage is based of the population size parameter and not the existing population size (current population size when using successive halving). Therefore, in the next generation we will still select 50 individuals from the currently existing 150.
crossover_probability : float, default=.2
Probability of generating a new individual by crossover between two individuals.
mutate_probability : float, default=.7
Probability of generating a new individual by crossover between one individuals.
mutate_then_crossover_probability : float, default=.05
Probability of generating a new individual by mutating two individuals followed by crossover.
crossover_then_mutate_probability : float, default=.05
Probability of generating a new individual by crossover between two individuals followed by a mutation of the resulting individual.
survival_selector : function, default=survival_select_NSGA2
Function to use to select individuals for survival. Must take a matrix of scores and return selected indexes.
Used to selected population_size * survival_percentage individuals at the start of each generation to use for mutation and crossover.
parent_selector : function, default=parent_select_NSGA2
Function to use to select pairs parents for crossover and individuals for mutation. Must take a matrix of scores and return selected indexes.
budget_range : list [start, end], default=None
A starting and ending budget to use for the budget scaling.
budget_scaling float : [0,1], default=0.5
A scaling factor to use when determining how fast we move the budget from the start to end budget.
generations_until_end_budget : int, default=1
The number of generations to run before reaching the max budget.
stepwise_steps : int, default=1
The number of staircase steps to take when scaling the budget and population size.
n_jobs : int, default=1
Number of processes to run in parallel.
memory_limit : str, default=None
Memory limit for each job. See Dask [LocalCluster documentation](https://distributed.dask.org/en/stable/api.html#distributed.Client) for more information.
client : dask.distributed.Client, default=None
A dask client to use for parallelization. If not None, this will override the n_jobs and memory_limit parameters. If None, will create a new client with num_workers=n_jobs and memory_limit=memory_limit.
processes : bool, default=True
If True, will use multiprocessing to parallelize the optimization process. If False, will use threading.
True seems to perform better. However, False is required for interactive debugging.
warm_start : bool, default=False
If True, will use the continue the evolutionary algorithm from the last generation of the previous run.
periodic_checkpoint_folder : str, default=None
Folder to save the population to periodically. If None, no periodic saving will be done.
If provided, training will resume from this checkpoint.
callback : tpot.CallBackInterface, default=None
Callback object. Not implemented
verbose : int, default=1
How much information to print during the optimization process. Higher values include the information from lower values.
0. nothing
1. progress bar
3. best individual
4. warnings
>=5. full warnings trace
6. evaluations progress bar. (Temporary: This used to be 2. Currently, using evaluation progress bar may prevent some instances were we terminate a generation early due to it reaching max_time_mins in the middle of a generation OR a pipeline failed to be terminated normally and we need to manually terminate it.)
scatter : bool, default=True
If True, will scatter the data to the dask workers. If False, will not scatter the data. This can be useful for debugging.
random_state : int, None, default=None
A seed for reproducability of experiments. This value will be passed to numpy.random.default_rng() to create an instnce of the genrator to pass to other classes
- int
Will be used to create and lock in Generator instance with 'numpy.random.default_rng()'
- None
Will be used to create Generator for 'numpy.random.default_rng()' where a fresh, unpredictable entropy will be pulled from the OS
Attributes
----------
fitted_pipeline_ : GraphPipeline
A fitted instance of the GraphPipeline that inherits from sklearn BaseEstimator. This is fitted on the full X, y passed to fit.
evaluated_individuals : A pandas data frame containing data for all evaluated individuals in the run.
Columns:
- *objective functions : The first few columns correspond to the passed in scorers and objective functions
- Parents : A tuple containing the indexes of the pipelines used to generate the pipeline of that row. If NaN, this pipeline was generated randomly in the initial population.
- Variation_Function : Which variation function was used to mutate or crossover the parents. If NaN, this pipeline was generated randomly in the initial population.
- Individual : The internal representation of the individual that is used during the evolutionary algorithm. This is not an sklearn BaseEstimator.
- Generation : The generation the pipeline first appeared.
- Pareto_Front : The nondominated front that this pipeline belongs to. 0 means that its scores is not strictly dominated by any other individual.
To save on computational time, the best frontier is updated iteratively each generation.
The pipelines with the 0th pareto front do represent the exact best frontier. However, the pipelines with pareto front >= 1 are only in reference to the other pipelines in the final population.
All other pipelines are set to NaN.
- Instance : The unfitted GraphPipeline BaseEstimator.
- *validation objective functions : Objective function scores evaluated on the validation set.
- Validation_Pareto_Front : The full pareto front calculated on the validation set. This is calculated for all pipelines with Pareto_Front equal to 0. Unlike the Pareto_Front which only calculates the frontier and the final population, the Validation Pareto Front is calculated for all pipelines tested on the validation set.
pareto_front : The same pandas dataframe as evaluated individuals, but containing only the frontier pareto front pipelines.
'''
# sklearn BaseEstimator must have a corresponding attribute for each parameter.
# These should not be modified once set.
self.scorers = scorers
self.scorers_weights = scorers_weights
self.classification = classification
self.cv = cv
self.other_objective_functions = other_objective_functions
self.other_objective_functions_weights = other_objective_functions_weights
self.objective_function_names = objective_function_names
self.bigger_is_better = bigger_is_better
self.search_space = search_space
self.export_graphpipeline = export_graphpipeline
self.memory = memory
self.categorical_features = categorical_features
self.preprocessing = preprocessing
self.validation_strategy = validation_strategy
self.validation_fraction = validation_fraction
self.disable_label_encoder = disable_label_encoder
self.population_size = population_size
self.initial_population_size = initial_population_size
self.population_scaling = population_scaling
self.generations_until_end_population = generations_until_end_population
self.generations = generations
self.early_stop = early_stop
self.scorers_early_stop_tol = scorers_early_stop_tol
self.other_objectives_early_stop_tol = other_objectives_early_stop_tol
self.max_time_mins = max_time_mins
self.max_eval_time_mins = max_eval_time_mins
self.n_jobs= n_jobs
self.memory_limit = memory_limit
self.client = client
self.survival_percentage = survival_percentage
self.crossover_probability = crossover_probability
self.mutate_probability = mutate_probability
self.mutate_then_crossover_probability= mutate_then_crossover_probability
self.crossover_then_mutate_probability= crossover_then_mutate_probability
self.survival_selector=survival_selector
self.parent_selector=parent_selector
self.budget_range = budget_range
self.budget_scaling = budget_scaling
self.generations_until_end_budget = generations_until_end_budget
self.stepwise_steps = stepwise_steps
self.threshold_evaluation_pruning =threshold_evaluation_pruning
self.threshold_evaluation_scaling = threshold_evaluation_scaling
self.min_history_threshold = min_history_threshold
self.selection_evaluation_pruning = selection_evaluation_pruning
self.selection_evaluation_scaling = selection_evaluation_scaling
self.warm_start = warm_start
self.verbose = verbose
self.periodic_checkpoint_folder = periodic_checkpoint_folder
self.callback = callback
self.processes = processes
self.scatter = scatter
timer_set = self.max_time_mins != float("inf") and self.max_time_mins is not None
if self.generations is not None and timer_set:
warnings.warn("Both generations and max_time_mins are set. TPOT will terminate when the first condition is met.")
# create random number generator based on rngseed
self.rng = np.random.default_rng(random_state)
# save random state passed to us for other functions that use random_state
self.random_state = random_state
#Initialize other used params
if self.initial_population_size is None:
self._initial_population_size = self.population_size
else:
self._initial_population_size = self.initial_population_size
if isinstance(self.scorers, str):
self._scorers = [self.scorers]
elif callable(self.scorers):
self._scorers = [self.scorers]
else:
self._scorers = self.scorers
self._scorers = [sklearn.metrics.get_scorer(scoring) for scoring in self._scorers]
self._scorers_early_stop_tol = self.scorers_early_stop_tol
self._evolver = tpot.evolvers.BaseEvolver
self.objective_function_weights = [*scorers_weights, *other_objective_functions_weights]
if self.objective_function_names is None:
obj_names = [f.__name__ for f in other_objective_functions]
else:
obj_names = self.objective_function_names
self.objective_names = [f._score_func.__name__ if hasattr(f,"_score_func") else f.__name__ for f in self._scorers] + obj_names
if not isinstance(self.other_objectives_early_stop_tol, list):
self._other_objectives_early_stop_tol = [self.other_objectives_early_stop_tol for _ in range(len(self.other_objective_functions))]
else:
self._other_objectives_early_stop_tol = self.other_objectives_early_stop_tol
if not isinstance(self._scorers_early_stop_tol, list):
self._scorers_early_stop_tol = [self._scorers_early_stop_tol for _ in range(len(self._scorers))]
else:
self._scorers_early_stop_tol = self._scorers_early_stop_tol
self.early_stop_tol = [*self._scorers_early_stop_tol, *self._other_objectives_early_stop_tol]
self._evolver_instance = None
self.evaluated_individuals = None
self.label_encoder_ = None
set_dask_settings()
def fit(self, X, y):
if self.client is not None: #If user passed in a client manually
_client = self.client
else:
if self.verbose >= 4:
silence_logs = 30
elif self.verbose >=5:
silence_logs = 40
else:
silence_logs = 50
cluster = LocalCluster(n_workers=self.n_jobs, #if no client is passed in and no global client exists, create our own
threads_per_worker=1,
processes=self.processes,
silence_logs=silence_logs,
memory_limit=self.memory_limit)
_client = Client(cluster)
if self.classification and not self.disable_label_encoder and not check_if_y_is_encoded(y):
warnings.warn("Labels are not encoded as ints from 0 to N. For compatibility with some classifiers such as sklearn, TPOT has encoded y with the sklearn LabelEncoder. When using pipelines outside the main TPOT estimator class, you can encode the labels with est.label_encoder_")
self.label_encoder_ = LabelEncoder()
y = self.label_encoder_.fit_transform(y)
self.evaluated_individuals = None
#determine validation strategy
if self.validation_strategy == 'auto':
nrows = X.shape[0]
ncols = X.shape[1]
if nrows/ncols < 20:
validation_strategy = 'reshuffled'
elif nrows/ncols < 100:
validation_strategy = 'split'
else:
validation_strategy = 'none'
else:
validation_strategy = self.validation_strategy
if validation_strategy == 'split':
if self.classification:
X, X_val, y, y_val = train_test_split(X, y, test_size=self.validation_fraction, stratify=y, random_state=self.random_state)
else:
X, X_val, y, y_val = train_test_split(X, y, test_size=self.validation_fraction, random_state=self.random_state)
X_original = X
y_original = y
if isinstance(self.cv, int) or isinstance(self.cv, float):
n_folds = self.cv
else:
n_folds = self.cv.get_n_splits(X, y)
if self.classification:
X, y = remove_underrepresented_classes(X, y, n_folds)
if self.preprocessing:
#X = pd.DataFrame(X)
if not isinstance(self.preprocessing, bool) and isinstance(self.preprocessing, sklearn.base.BaseEstimator):
self._preprocessing_pipeline = sklearn.base.clone(self.preprocessing)
#TODO: check if there are missing values in X before imputation. If not, don't include imputation in pipeline. Check if there are categorical columns. If not, don't include one hot encoding in pipeline
else: #if self.preprocessing is True or not a sklearn estimator
pipeline_steps = []
if self.categorical_features is not None: #if categorical features are specified, use those
pipeline_steps.append(("impute_categorical", tpot.builtin_modules.ColumnSimpleImputer(self.categorical_features, strategy='most_frequent')))
pipeline_steps.append(("impute_numeric", tpot.builtin_modules.ColumnSimpleImputer("numeric", strategy='mean')))
pipeline_steps.append(("ColumnOneHotEncoder", tpot.builtin_modules.ColumnOneHotEncoder(self.categorical_features, min_frequency=0.0001))) # retain wrong param fix
else:
if isinstance(X, pd.DataFrame):
categorical_columns = X.select_dtypes(include=['object']).columns
if len(categorical_columns) > 0:
pipeline_steps.append(("impute_categorical", tpot.builtin_modules.ColumnSimpleImputer("categorical", strategy='most_frequent')))
pipeline_steps.append(("impute_numeric", tpot.builtin_modules.ColumnSimpleImputer("numeric", strategy='mean')))
pipeline_steps.append(("ColumnOneHotEncoder", tpot.builtin_modules.ColumnOneHotEncoder("categorical", min_frequency=0.0001))) # retain wrong param fix
else:
pipeline_steps.append(("impute_numeric", tpot.builtin_modules.ColumnSimpleImputer("all", strategy='mean')))
else:
pipeline_steps.append(("impute_numeric", tpot.builtin_modules.ColumnSimpleImputer("all", strategy='mean')))
self._preprocessing_pipeline = sklearn.pipeline.Pipeline(pipeline_steps)
X = self._preprocessing_pipeline.fit_transform(X, y)
else:
self._preprocessing_pipeline = None
#_, y = sklearn.utils.check_X_y(X, y, y_numeric=True)
#Set up the configuation dictionaries and the search spaces
#check if self.cv is a number
if isinstance(self.cv, int) or isinstance(self.cv, float):
if self.classification:
self.cv_gen = sklearn.model_selection.StratifiedKFold(n_splits=self.cv, shuffle=True, random_state=self.random_state)
else:
self.cv_gen = sklearn.model_selection.KFold(n_splits=self.cv, shuffle=True, random_state=self.random_state)
else:
self.cv_gen = sklearn.model_selection.check_cv(self.cv, y, classifier=self.classification)
n_samples= int(math.floor(X.shape[0]/n_folds))
n_features=X.shape[1]
if isinstance(X, pd.DataFrame):
self.feature_names = X.columns
else:
self.feature_names = None
def objective_function(pipeline_individual,
X,
y,
is_classification=self.classification,
scorers= self._scorers,
cv=self.cv_gen,
other_objective_functions=self.other_objective_functions,
export_graphpipeline=self.export_graphpipeline,
memory=self.memory,
**kwargs):
return objective_function_generator(
pipeline_individual,
X,
y,
is_classification=is_classification,
scorers= scorers,
cv=cv,
other_objective_functions=other_objective_functions,
export_graphpipeline=export_graphpipeline,
memory=memory,
**kwargs,
)
if self.threshold_evaluation_pruning is not None or self.selection_evaluation_pruning is not None:
evaluation_early_stop_steps = self.cv
else:
evaluation_early_stop_steps = None
if self.scatter:
X_future = _client.scatter(X)
y_future = _client.scatter(y)
else:
X_future = X
y_future = y
if self.classification:
n_classes = len(np.unique(y))
else:
n_classes = None
get_search_space_params = {"n_classes": n_classes,
"n_samples":len(y),
"n_features":X.shape[1],
"random_state":self.random_state}
self._search_space = get_template_search_spaces(self.search_space, classification=self.classification, inner_predictors=True, **get_search_space_params)
# TODO : Add check for empty values in X and if so, add imputation to the search space
# make this depend on self.preprocessing
# if check_empty_values(X):
# from sklearn.experimental import enable_iterative_imputer
# from ConfigSpace import ConfigurationSpace
# from ConfigSpace import ConfigurationSpace, Integer, Float, Categorical, Normal
# iterative_imputer_cs = ConfigurationSpace(
# space = {
# 'n_nearest_features' : Categorical('n_nearest_features', [100]),
# 'initial_strategy' : Categorical('initial_strategy', ['mean','median', 'most_frequent', ]),
# 'add_indicator' : Categorical('add_indicator', [True, False]),
# }
# )
# imputation_search = tpot.search_spaces.pipelines.ChoicePipeline([
# tpot.config.get_search_space("SimpleImputer"),
# tpot.search_spaces.nodes.EstimatorNode(sklearn.impute.IterativeImputer, iterative_imputer_cs)
# ])
# self.search_space_final = tpot.search_spaces.pipelines.SequentialPipeline(search_spaces=[ imputation_search, self._search_space], memory="sklearn_pipeline_memory")
# else:
# self.search_space_final = self._search_space
self.search_space_final = self._search_space
def ind_generator(rng):
rng = np.random.default_rng(rng)
while True:
yield self.search_space_final.generate(rng)
#If warm start and we have an evolver instance, use the existing one
if not(self.warm_start and self._evolver_instance is not None):
self._evolver_instance = self._evolver( individual_generator=ind_generator(self.rng),
objective_functions= [objective_function],
objective_function_weights = self.objective_function_weights,
objective_names=self.objective_names,
bigger_is_better = self.bigger_is_better,
population_size= self.population_size,
generations=self.generations,
initial_population_size = self._initial_population_size,
n_jobs=self.n_jobs,
verbose = self.verbose,
max_time_mins = self.max_time_mins ,
max_eval_time_mins = self.max_eval_time_mins,
periodic_checkpoint_folder = self.periodic_checkpoint_folder,
threshold_evaluation_pruning = self.threshold_evaluation_pruning,
threshold_evaluation_scaling = self.threshold_evaluation_scaling,
min_history_threshold = self.min_history_threshold,
selection_evaluation_pruning = self.selection_evaluation_pruning,
selection_evaluation_scaling = self.selection_evaluation_scaling,
evaluation_early_stop_steps = evaluation_early_stop_steps,
early_stop_tol = self.early_stop_tol,
early_stop= self.early_stop,
budget_range = self.budget_range,
budget_scaling = self.budget_scaling,
generations_until_end_budget = self.generations_until_end_budget,
population_scaling = self.population_scaling,
generations_until_end_population = self.generations_until_end_population,
stepwise_steps = self.stepwise_steps,
client = _client,
objective_kwargs = {"X": X_future, "y": y_future},
survival_selector=self.survival_selector,
parent_selector=self.parent_selector,
survival_percentage = self.survival_percentage,
crossover_probability = self.crossover_probability,
mutate_probability = self.mutate_probability,
mutate_then_crossover_probability= self.mutate_then_crossover_probability,
crossover_then_mutate_probability= self.crossover_then_mutate_probability,
rng=self.rng,
)
self._evolver_instance.optimize()
#self._evolver_instance.population.update_pareto_fronts(self.objective_names, self.objective_function_weights)
self.make_evaluated_individuals()
tpot.utils.get_pareto_frontier(self.evaluated_individuals, column_names=self.objective_names, weights=self.objective_function_weights)
if validation_strategy == 'reshuffled':
best_pareto_front_idx = list(self.pareto_front.index)
best_pareto_front = list(self.pareto_front.loc[best_pareto_front_idx]['Individual'])
#reshuffle rows
X, y = sklearn.utils.shuffle(X, y, random_state=self.random_state)
if self.scatter:
X_future = _client.scatter(X)
y_future = _client.scatter(y)
else:
X_future = X
y_future = y
val_objective_function_list = [lambda ind,
X,
y,
is_classification=self.classification,
scorers= self._scorers,
cv=self.cv_gen,
other_objective_functions=self.other_objective_functions,
export_graphpipeline=self.export_graphpipeline,
memory=self.memory,
**kwargs: objective_function_generator(
ind,
X,
y,
is_classification=is_classification,
scorers= scorers,
cv=cv,
other_objective_functions=other_objective_functions,
export_graphpipeline=export_graphpipeline,
memory=memory,
**kwargs,
)]
objective_kwargs = {"X": X_future, "y": y_future}
val_scores, start_times, end_times, eval_errors = tpot.utils.eval_utils.parallel_eval_objective_list(best_pareto_front, val_objective_function_list, verbose=self.verbose, max_eval_time_mins=self.max_eval_time_mins, n_expected_columns=len(self.objective_names), client=_client, **objective_kwargs)
val_objective_names = ['validation_'+name for name in self.objective_names]
self.objective_names_for_selection = val_objective_names
self.evaluated_individuals.loc[best_pareto_front_idx,val_objective_names] = val_scores
self.evaluated_individuals.loc[best_pareto_front_idx,'validation_start_times'] = start_times
self.evaluated_individuals.loc[best_pareto_front_idx,'validation_end_times'] = end_times
self.evaluated_individuals.loc[best_pareto_front_idx,'validation_eval_errors'] = eval_errors
self.evaluated_individuals["Validation_Pareto_Front"] = tpot.utils.get_pareto_frontier(self.evaluated_individuals, column_names=val_objective_names, weights=self.objective_function_weights)
elif validation_strategy == 'split':
if self.scatter:
X_future = _client.scatter(X)
y_future = _client.scatter(y)
X_val_future = _client.scatter(X_val)
y_val_future = _client.scatter(y_val)
else:
X_future = X
y_future = y
X_val_future = X_val
y_val_future = y_val
objective_kwargs = {"X": X_future, "y": y_future, "X_val" : X_val_future, "y_val":y_val_future }
best_pareto_front_idx = list(self.pareto_front.index)
best_pareto_front = list(self.pareto_front.loc[best_pareto_front_idx]['Individual'])
val_objective_function_list = [lambda ind,
X,
y,
X_val,
y_val,
scorers= self._scorers,
other_objective_functions=self.other_objective_functions,
export_graphpipeline=self.export_graphpipeline,
memory=self.memory,
**kwargs: val_objective_function_generator(
ind,
X,
y,
X_val,
y_val,
scorers= scorers,
other_objective_functions=other_objective_functions,
export_graphpipeline=export_graphpipeline,
memory=memory,
**kwargs,
)]
val_scores, start_times, end_times, eval_errors = tpot.utils.eval_utils.parallel_eval_objective_list(best_pareto_front, val_objective_function_list, verbose=self.verbose, max_eval_time_mins=self.max_eval_time_mins, n_expected_columns=len(self.objective_names), client=_client, **objective_kwargs)
val_objective_names = ['validation_'+name for name in self.objective_names]
self.objective_names_for_selection = val_objective_names
self.evaluated_individuals.loc[best_pareto_front_idx,val_objective_names] = val_scores
self.evaluated_individuals.loc[best_pareto_front_idx,'validation_start_times'] = start_times
self.evaluated_individuals.loc[best_pareto_front_idx,'validation_end_times'] = end_times
self.evaluated_individuals.loc[best_pareto_front_idx,'validation_eval_errors'] = eval_errors
self.evaluated_individuals["Validation_Pareto_Front"] = tpot.utils.get_pareto_frontier(self.evaluated_individuals, column_names=val_objective_names, weights=self.objective_function_weights)
else:
self.objective_names_for_selection = self.objective_names
val_scores = self.evaluated_individuals[self.evaluated_individuals[self.objective_names_for_selection].isna().all(1).ne(True)][self.objective_names_for_selection]
weighted_scores = val_scores*self.objective_function_weights
if self.bigger_is_better:
best_indices = list(weighted_scores.sort_values(by=self.objective_names_for_selection, ascending=False).index)
else:
best_indices = list(weighted_scores.sort_values(by=self.objective_names_for_selection, ascending=True).index)
for best_idx in best_indices:
best_individual = self.evaluated_individuals.loc[best_idx]['Individual']
self.selected_best_score = self.evaluated_individuals.loc[best_idx]
#TODO
#best_individual_pipeline = best_individual.export_pipeline(memory=self.memory, cross_val_predict_cv=self.cross_val_predict_cv)
if self.export_graphpipeline:
best_individual_pipeline = best_individual.export_flattened_graphpipeline(memory=self.memory)
else:
best_individual_pipeline = best_individual.export_pipeline(memory=self.memory)
if self.preprocessing:
self.fitted_pipeline_ = sklearn.pipeline.make_pipeline(sklearn.base.clone(self._preprocessing_pipeline), best_individual_pipeline )
else:
self.fitted_pipeline_ = best_individual_pipeline
try:
self.fitted_pipeline_.fit(X_original,y_original) #TODO use y_original as well?
break
except Exception as e:
if self.verbose >= 4:
warnings.warn("Final pipeline failed to fit. Rarely, the pipeline might work on the objective function but fail on the full dataset. Generally due to interactions with different features being selected or transformations having different properties. Trying next pipeline")
print(e)
continue
if self.client is None: #no client was passed in
#close cluster and client
# _client.close()
# cluster.close()
try:
_client.shutdown()
cluster.close()
#catch exception
except Exception as e:
print("Error shutting down client and cluster")
Warning(e)
return self
def _estimator_has(attr):
'''Check if we can delegate a method to the underlying estimator.
First, we check the first fitted final estimator if available, otherwise we
check the unfitted final estimator.
'''
return lambda self: (self.fitted_pipeline_ is not None and
hasattr(self.fitted_pipeline_, attr)
)
@available_if(_estimator_has('predict'))
def predict(self, X, **predict_params):
check_is_fitted(self)
#X = check_array(X)
preds = self.fitted_pipeline_.predict(X,**predict_params)
if self.classification and self.label_encoder_:
preds = self.label_encoder_.inverse_transform(preds)
return preds
@available_if(_estimator_has('predict_proba'))
def predict_proba(self, X, **predict_params):
check_is_fitted(self)
#X = check_array(X)
return self.fitted_pipeline_.predict_proba(X,**predict_params)
@available_if(_estimator_has('decision_function'))
def decision_function(self, X, **predict_params):
check_is_fitted(self)
#X = check_array(X)
return self.fitted_pipeline_.decision_function(X,**predict_params)
@available_if(_estimator_has('transform'))
def transform(self, X, **predict_params):
check_is_fitted(self)
#X = check_array(X)
return self.fitted_pipeline_.transform(X,**predict_params)
@property
def classes_(self):
"""The classes labels. Only exist if the last step is a classifier."""
if self.label_encoder_:
return self.label_encoder_.classes_
else:
return self.fitted_pipeline_.classes_
@property
def _estimator_type(self):
return self.fitted_pipeline_._estimator_type
def __sklearn_tags__(self):
if hasattr(self, 'fitted_pipeline_'): #if fitted
try:
tags = copy.deepcopy(self.fitted_pipeline_.__sklearn_tags__())
except:
tags = copy.deepcopy(get_tags(self.fitted_pipeline_))
else: #if not fitted
tags = super().__sklearn_tags__()
if self.random_state is None:
tags.non_deterministic = False
if self.classification:
if tags.classifier_tags is None:
tags.classifier_tags = sklearn.utils.ClassifierTags()
tags.classifier_tags.multi_class = True
tags.classifier_tags.multi_label = True
return tags
def make_evaluated_individuals(self):
#check if _evolver_instance exists
if self.evaluated_individuals is None:
self.evaluated_individuals = self._evolver_instance.population.evaluated_individuals.copy()
objects = list(self.evaluated_individuals.index)
object_to_int = dict(zip(objects, range(len(objects))))
self.evaluated_individuals = self.evaluated_individuals.set_index(self.evaluated_individuals.index.map(object_to_int))
self.evaluated_individuals['Parents'] = self.evaluated_individuals['Parents'].apply(lambda row: convert_parents_tuples_to_integers(row, object_to_int))
self.evaluated_individuals["Instance"] = self.evaluated_individuals["Individual"].apply(lambda ind: apply_make_pipeline(ind, preprocessing_pipeline=self._preprocessing_pipeline, export_graphpipeline=self.export_graphpipeline, memory=self.memory))
return self.evaluated_individuals
@property
def pareto_front(self):
#check if _evolver_instance exists
if self.evaluated_individuals is None:
return None
else:
if "Pareto_Front" not in self.evaluated_individuals:
return self.evaluated_individuals
else:
return self.evaluated_individuals[self.evaluated_individuals["Pareto_Front"]==1]
def check_empty_values(data):
"""
Checks for empty values in a dataset.
Args:
data (numpy.ndarray or pandas.DataFrame): The dataset to check.
Returns:
bool: True if the dataset contains empty values, False otherwise.
"""
if isinstance(data, pd.DataFrame):
return data.isnull().values.any()
elif isinstance(data, np.ndarray):
return np.isnan(data).any()
else:
raise ValueError("Unsupported data type")
================================================
FILE: tpot/tpot_estimator/estimator_utils.py
================================================
"""
This file is part of the TPOT library.
The current version of TPOT was developed at Cedars-Sinai by:
- Pedro Henrique Ribeiro (https://github.com/perib, https://www.linkedin.com/in/pedro-ribeiro/)
- Anil Saini (anil.saini@cshs.org)
- Jose Hernandez (jgh9094@gmail.com)
- Jay Moran (jay.moran@cshs.org)
- Nicholas Matsumoto (nicholas.matsumoto@cshs.org)
- Hyunjun Choi (hyunjun.choi@cshs.org)
- Gabriel Ketron (gabriel.ketron@cshs.org)
- Miguel E. Hernandez (miguel.e.hernandez@cshs.org)
- Jason Moore (moorejh28@gmail.com)
The original version of TPOT was primarily developed at the University of Pennsylvania by:
- Randal S. Olson (rso@randalolson.com)
- Weixuan Fu (weixuanf@upenn.edu)
- Daniel Angell (dpa34@drexel.edu)
- Jason Moore (moorejh28@gmail.com)
- and many more generous open-source contributors
TPOT is free software: you can redistribute it and/or modify
it under the terms of the GNU Lesser General Public License as
published by the Free Software Foundation, either version 3 of
the License, or (at your option) any later version.
TPOT is distributed in the hope that it will be useful,
but WITHOUT ANY WARRANTY; without even the implied warranty of
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
GNU Lesser General Public License for more details.
You should have received a copy of the GNU Lesser General Public
License along with TPOT. If not, see .
"""
import numpy as np
import sklearn
import sklearn.base
import tpot
import pandas as pd
from .cross_val_utils import cross_val_score_objective
def convert_parents_tuples_to_integers(row, object_to_int):
"""
Helper function to convert the parent rows into integers representing the index of the parent in the population.
Original pandas dataframe using a custom index for the parents. This function converts the custom index to an integer index for easier manipulation by end users.
Parameters
----------
row: list, np.ndarray, tuple
The row to convert.
object_to_int: dict
A dictionary mapping the object to an integer index.
Returns
-------
tuple
The row with the custom index converted to an integer index.
"""
if type(row) == list or type(row) == np.ndarray or type(row) == tuple:
return tuple(object_to_int[obj] for obj in row)
else:
return np.nan
#TODO add kwargs
def apply_make_pipeline(ind, preprocessing_pipeline=None, export_graphpipeline=False, **pipeline_kwargs):
"""
Helper function to create a column of sklearn pipelines from the tpot individual class.
Parameters
----------
ind: tpot.SklearnIndividual
The individual to convert to a pipeline.
preprocessing_pipeline: sklearn.pipeline.Pipeline, optional
The preprocessing pipeline to include before the individual's pipeline.
export_graphpipeline: bool, default=False
Force the pipeline to be exported as a graph pipeline. Flattens all nested pipelines, FeatureUnions, and GraphPipelines into a single GraphPipeline.
pipeline_kwargs: dict
Keyword arguments to pass to the export_pipeline or export_flattened_graphpipeline method.
Returns
-------
sklearn estimator
"""
try:
if export_graphpipeline:
est = ind.export_flattened_graphpipeline(**pipeline_kwargs)
else:
est = ind.export_pipeline(**pipeline_kwargs)
if preprocessing_pipeline is None:
return est
else:
return sklearn.pipeline.make_pipeline(sklearn.base.clone(preprocessing_pipeline), est)
except:
return None
def objective_function_generator(pipeline, x,y, scorers, cv, other_objective_functions, step=None, budget=None, is_classification=True, export_graphpipeline=False, **pipeline_kwargs):
"""
Uses cross validation to evaluate the pipeline using the scorers, and concatenates results with scores from standalone other objective functions.
Parameters
----------
pipeline: tpot.SklearnIndividual
The individual to evaluate.
x: np.ndarray
The feature matrix.
y: np.ndarray
The target vector.
scorers: list
The scorers to use for cross validation.
cv: int, float, or sklearn cross-validator
The cross-validator to use. For example, sklearn.model_selection.KFold or sklearn.model_selection.StratifiedKFold.
If an int, will use sklearn.model_selection.KFold with n_splits=cv.
other_objective_functions: list
A list of standalone objective functions to evaluate the pipeline. With signature obj(pipeline) -> float. or obj(pipeline) -> np.ndarray
These functions take in the unfitted estimator.
step: int, optional
The fold to return the scores for. If None, will return the mean of all the scores (per scorer). Default is None.
budget: float, optional
The budget to subsample the data. If None, will use the full dataset. Default is None.
Will subsample budget*len(x) samples.
is_classification: bool, default=True
If True, will stratify the subsampling. Default is True.
export_graphpipeline: bool, default=False
Force the pipeline to be exported as a graph pipeline. Flattens all nested sklearn pipelines, FeatureUnions, and GraphPipelines into a single GraphPipeline.
pipeline_kwargs: dict
Keyword arguments to pass to the export_pipeline or export_flattened_graphpipeline method.
Returns
-------
np.ndarray
The concatenated scores for the pipeline. The first len(scorers) elements are the cross validation scores, and the remaining elements are the standalone objective functions.
"""
if export_graphpipeline:
pipeline = pipeline.export_flattened_graphpipeline(**pipeline_kwargs)
else:
pipeline = pipeline.export_pipeline(**pipeline_kwargs)
if budget is not None and budget < 1:
if is_classification:
x,y = sklearn.utils.resample(x,y, stratify=y, n_samples=int(budget*len(x)), replace=False, random_state=1)
else:
x,y = sklearn.utils.resample(x,y, n_samples=int(budget*len(x)), replace=False, random_state=1)
if isinstance(cv, int) or isinstance(cv, float):
n_splits = cv
else:
n_splits = cv.n_splits
if len(scorers) > 0:
cv_obj_scores = cross_val_score_objective(sklearn.base.clone(pipeline),x,y,scorers=scorers, cv=cv , fold=step)
else:
cv_obj_scores = []
if other_objective_functions is not None and len(other_objective_functions) >0:
other_scores = [obj(sklearn.base.clone(pipeline)) for obj in other_objective_functions]
#flatten
other_scores = np.array(other_scores).flatten().tolist()
else:
other_scores = []
return np.concatenate([cv_obj_scores,other_scores])
def val_objective_function_generator(pipeline, X_train, y_train, X_test, y_test, scorers, other_objective_functions, export_graphpipeline=False, **pipeline_kwargs):
"""
Trains a pipeline on a training set and evaluates it on a test set using the scorers and other objective functions.
Parameters
----------
pipeline: tpot.SklearnIndividual
The individual to evaluate.
X_train: np.ndarray
The feature matrix of the training set.
y_train: np.ndarray
The target vector of the training set.
X_test: np.ndarray
The feature matrix of the test set.
y_test: np.ndarray
The target vector of the test set.
scorers: list
The scorers to use for cross validation.
other_objective_functions: list
A list of standalone objective functions to evaluate the pipeline. With signature obj(pipeline) -> float. or obj(pipeline) -> np.ndarray
These functions take in the unfitted estimator.
export_graphpipeline: bool, default=False
Force the pipeline to be exported as a graph pipeline. Flattens all nested sklearn pipelines, FeatureUnions, and GraphPipelines into a single GraphPipeline.
pipeline_kwargs: dict
Keyword arguments to pass to the export_pipeline or export_flattened_graphpipeline method.
Returns
-------
np.ndarray
The concatenated scores for the pipeline. The first len(scorers) elements are the cross validation scores, and the remaining elements are the standalone objective functions.
"""
#subsample the data
if export_graphpipeline:
pipeline = pipeline.export_flattened_graphpipeline(**pipeline_kwargs)
else:
pipeline = pipeline.export_pipeline(**pipeline_kwargs)
fitted_pipeline = sklearn.base.clone(pipeline)
fitted_pipeline.fit(X_train, y_train)
if len(scorers) > 0:
scores =[sklearn.metrics.get_scorer(scorer)(fitted_pipeline, X_test, y_test) for scorer in scorers]
other_scores = []
if other_objective_functions is not None and len(other_objective_functions) >0:
other_scores = [obj(sklearn.base.clone(pipeline)) for obj in other_objective_functions]
return np.concatenate([scores,other_scores])
def remove_underrepresented_classes(x, y, min_count):
"""
Helper function to remove classes with less than min_count samples from the dataset.
Parameters
----------
x: np.ndarray or pd.DataFrame
The feature matrix.
y: np.ndarray or pd.Series
The target vector.
min_count: int
The minimum number of samples to keep a class.
Returns
-------
np.ndarray, np.ndarray
The feature matrix and target vector with rows from classes with less than min_count samples removed.
"""
if isinstance(y, (np.ndarray, pd.Series)):
unique, counts = np.unique(y, return_counts=True)
if min(counts) >= min_count:
return x, y
keep_classes = unique[counts >= min_count]
mask = np.isin(y, keep_classes)
x = x[mask]
y = y[mask]
elif isinstance(y, pd.DataFrame):
counts = y.apply(pd.Series.value_counts)
if min(counts) >= min_count:
return x, y
keep_classes = counts.index[counts >= min_count].tolist()
mask = y.isin(keep_classes).all(axis=1)
x = x[mask]
y = y[mask]
else:
raise TypeError("y must be a numpy array or a pandas Series/DataFrame")
return x, y
def convert_to_float(x):
try:
return float(x)
except ValueError:
return x
def check_if_y_is_encoded(y):
'''
Checks if the target y is composed of sequential ints from 0 to N.
XGBoost requires the target to be encoded in this way.
Parameters
----------
y: np.ndarray
The target vector.
Returns
-------
bool
True if the target is encoded as sequential ints from 0 to N, False otherwise
'''
y = sorted(set(y))
return all(i == j for i, j in enumerate(y))
================================================
FILE: tpot/tpot_estimator/steady_state_estimator.py
================================================
"""
This file is part of the TPOT library.
The current version of TPOT was developed at Cedars-Sinai by:
- Pedro Henrique Ribeiro (https://github.com/perib, https://www.linkedin.com/in/pedro-ribeiro/)
- Anil Saini (anil.saini@cshs.org)
- Jose Hernandez (jgh9094@gmail.com)
- Jay Moran (jay.moran@cshs.org)
- Nicholas Matsumoto (nicholas.matsumoto@cshs.org)
- Hyunjun Choi (hyunjun.choi@cshs.org)
- Gabriel Ketron (gabriel.ketron@cshs.org)
- Miguel E. Hernandez (miguel.e.hernandez@cshs.org)
- Jason Moore (moorejh28@gmail.com)
The original version of TPOT was primarily developed at the University of Pennsylvania by:
- Randal S. Olson (rso@randalolson.com)
- Weixuan Fu (weixuanf@upenn.edu)
- Daniel Angell (dpa34@drexel.edu)
- Jason Moore (moorejh28@gmail.com)
- and many more generous open-source contributors
TPOT is free software: you can redistribute it and/or modify
it under the terms of the GNU Lesser General Public License as
published by the Free Software Foundation, either version 3 of
the License, or (at your option) any later version.
TPOT is distributed in the hope that it will be useful,
but WITHOUT ANY WARRANTY; without even the implied warranty of
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
GNU Lesser General Public License for more details.
You should have received a copy of the GNU Lesser General Public
License along with TPOT. If not, see .
"""
from sklearn.base import BaseEstimator
from sklearn.utils.metaestimators import available_if
import numpy as np
import sklearn.metrics
import tpot.config
from sklearn.utils.validation import check_is_fitted
from tpot.selectors import survival_select_NSGA2, tournament_selection_dominated
from sklearn.preprocessing import LabelEncoder
from sklearn.utils.multiclass import unique_labels
import pandas as pd
from sklearn.model_selection import train_test_split
import tpot
from dask.distributed import Client
from dask.distributed import LocalCluster
import math
from dask import config as cfg
from .estimator_utils import *
import warnings
from sklearn.utils._tags import get_tags
import copy
from ..config.template_search_spaces import get_template_search_spaces
def set_dask_settings():
cfg.set({'distributed.scheduler.worker-ttl': None})
cfg.set({'distributed.scheduler.allowed-failures':1})
#TODO inherit from _BaseComposition?
class TPOTEstimatorSteadyState(BaseEstimator):
def __init__(self,
search_space,
scorers= [],
scorers_weights = [],
classification = False,
cv = 10,
other_objective_functions=[], #tpot.objectives.estimator_objective_functions.number_of_nodes_objective],
other_objective_functions_weights = [],
objective_function_names = None,
bigger_is_better = True,
export_graphpipeline = False,
memory = None,
categorical_features = None,
subsets = None,
preprocessing = False,
validation_strategy = "none",
validation_fraction = .2,
disable_label_encoder = False,
initial_population_size = 50,
population_size = 50,
max_evaluated_individuals = None,
early_stop = None,
early_stop_mins = None,
scorers_early_stop_tol = 0.001,
other_objectives_early_stop_tol = None,
max_time_mins=None,
max_eval_time_mins=10,
n_jobs=1,
memory_limit = None,
client = None,
crossover_probability=.2,
mutate_probability=.7,
mutate_then_crossover_probability=.05,
crossover_then_mutate_probability=.05,
survival_selector = survival_select_NSGA2,
parent_selector = tournament_selection_dominated,
budget_range = None,
budget_scaling = .5,
individuals_until_end_budget = 1,
stepwise_steps = 5,
warm_start = False,
verbose = 0,
periodic_checkpoint_folder = None,
callback = None,
processes = True,
scatter = True,
# random seed for random number generator (rng)
random_state = None,
optuna_optimize_pareto_front = False,
optuna_optimize_pareto_front_trials = 100,
optuna_optimize_pareto_front_timeout = 60*10,
optuna_storage = "sqlite:///optuna.db",
):
'''
An sklearn baseestimator that uses genetic programming to optimize a pipeline.
Parameters
----------
scorers : (list, scorer)
A scorer or list of scorers to be used in the cross-validation process.
see https://scikit-learn.org/stable/modules/model_evaluation.html
scorers_weights : list
A list of weights to be applied to the scorers during the optimization process.
classification : bool
If True, the problem is treated as a classification problem. If False, the problem is treated as a regression problem.
Used to determine the CV strategy.
cv : int, cross-validator
- (int): Number of folds to use in the cross-validation process. By uses the sklearn.model_selection.KFold cross-validator for regression and StratifiedKFold for classification. In both cases, shuffled is set to True.
- (sklearn.model_selection.BaseCrossValidator): A cross-validator to use in the cross-validation process.
other_objective_functions : list, default=[]
A list of other objective functions to apply to the pipeline. The function takes a single parameter for the graphpipeline estimator and returns either a single score or a list of scores.
other_objective_functions_weights : list, default=[]
A list of weights to be applied to the other objective functions.
objective_function_names : list, default=None
A list of names to be applied to the objective functions. If None, will use the names of the objective functions.
bigger_is_better : bool, default=True
If True, the objective function is maximized. If False, the objective function is minimized. Use negative weights to reverse the direction.
max_size : int, default=np.inf
The maximum number of nodes of the pipelines to be generated.
linear_pipeline : bool, default=False
If True, the pipelines generated will be linear. If False, the pipelines generated will be directed acyclic graphs.
root_config_dict : dict, default='auto'
The configuration dictionary to use for the root node of the model.
If 'auto', will use "classifiers" if classification=True, else "regressors".
- 'selectors' : A selection of sklearn Selector methods.
- 'classifiers' : A selection of sklearn Classifier methods.
- 'regressors' : A selection of sklearn Regressor methods.
- 'transformers' : A selection of sklearn Transformer methods.
- 'arithmetic_transformer' : A selection of sklearn Arithmetic Transformer methods that replicate symbolic classification/regression operators.
- 'passthrough' : A node that just passes though the input. Useful for passing through raw inputs into inner nodes.
- 'feature_set_selector' : A selector that pulls out specific subsets of columns from the data. Only well defined as a leaf.
Subsets are set with the subsets parameter.
- 'skrebate' : Includes ReliefF, SURF, SURFstar, MultiSURF.
- 'MDR' : Includes MDR.
- 'ContinuousMDR' : Includes ContinuousMDR.
- 'genetic encoders' : Includes Genetic Encoder methods as used in AutoQTL.
- 'FeatureEncodingFrequencySelector': Includes FeatureEncodingFrequencySelector method as used in AutoQTL.
- list : a list of strings out of the above options to include the corresponding methods in the configuration dictionary.
inner_config_dict : dict, default=["selectors", "transformers"]
The configuration dictionary to use for the inner nodes of the model generation.
Default ["selectors", "transformers"]
- 'selectors' : A selection of sklearn Selector methods.
- 'classifiers' : A selection of sklearn Classifier methods.
- 'regressors' : A selection of sklearn Regressor methods.
- 'transformers' : A selection of sklearn Transformer methods.
- 'arithmetic_transformer' : A selection of sklearn Arithmetic Transformer methods that replicate symbolic classification/regression operators.
- 'passthrough' : A node that just passes though the input. Useful for passing through raw inputs into inner nodes.
- 'feature_set_selector' : A selector that pulls out specific subsets of columns from the data. Only well defined as a leaf.
Subsets are set with the subsets parameter.
- 'skrebate' : Includes ReliefF, SURF, SURFstar, MultiSURF.
- 'MDR' : Includes MDR.
- 'ContinuousMDR' : Includes ContinuousMDR.
- 'genetic encoders' : Includes Genetic Encoder methods as used in AutoQTL.
- 'FeatureEncodingFrequencySelector': Includes FeatureEncodingFrequencySelector method as used in AutoQTL.
- list : a list of strings out of the above options to include the corresponding methods in the configuration dictionary.
- None : If None and max_depth>1, the root_config_dict will be used for the inner nodes as well.
leaf_config_dict : dict, default=None
The configuration dictionary to use for the leaf node of the model. If set, leaf nodes must be from this dictionary.
Otherwise leaf nodes will be generated from the root_config_dict.
Default None
- 'selectors' : A selection of sklearn Selector methods.
- 'classifiers' : A selection of sklearn Classifier methods.
- 'regressors' : A selection of sklearn Regressor methods.
- 'transformers' : A selection of sklearn Transformer methods.
- 'arithmetic_transformer' : A selection of sklearn Arithmetic Transformer methods that replicate symbolic classification/regression operators.
- 'passthrough' : A node that just passes though the input. Useful for passing through raw inputs into inner nodes.
- 'feature_set_selector' : A selector that pulls out specific subsets of columns from the data. Only well defined as a leaf.
Subsets are set with the subsets parameter.
- 'skrebate' : Includes ReliefF, SURF, SURFstar, MultiSURF.
- 'MDR' : Includes MDR.
- 'ContinuousMDR' : Includes ContinuousMDR.
- 'genetic encoders' : Includes Genetic Encoder methods as used in AutoQTL.
- 'FeatureEncodingFrequencySelector': Includes FeatureEncodingFrequencySelector method as used in AutoQTL.
- list : a list of strings out of the above options to include the corresponding methods in the configuration dictionary.
- None : If None, a leaf will not be required (i.e. the pipeline can be a single root node). Leaf nodes will be generated from the inner_config_dict.
categorical_features: list or None
Categorical columns to inpute and/or one hot encode during the preprocessing step. Used only if preprocessing is not False.
- None : If None, TPOT will automatically use object columns in pandas dataframes as objects for one hot encoding in preprocessing.
- List of categorical features. If X is a dataframe, this should be a list of column names. If X is a numpy array, this should be a list of column indices
memory: Memory object or string, default=None
If supplied, pipeline will cache each transformer after calling fit with joblib.Memory. This feature
is used to avoid computing the fit transformers within a pipeline if the parameters
and input data are identical with another fitted pipeline during optimization process.
- String 'auto':
TPOT uses memory caching with a temporary directory and cleans it up upon shutdown.
- String path of a caching directory
TPOT uses memory caching with the provided directory and TPOT does NOT clean
the caching directory up upon shutdown. If the directory does not exist, TPOT will
create it.
- Memory object:
TPOT uses the instance of joblib.Memory for memory caching,
and TPOT does NOT clean the caching directory up upon shutdown.
- None:
TPOT does not use memory caching.
preprocessing : bool or BaseEstimator/Pipeline,
EXPERIMENTAL
A pipeline that will be used to preprocess the data before CV.
- bool : If True, will use a default preprocessing pipeline.
- Pipeline : If an instance of a pipeline is given, will use that pipeline as the preprocessing pipeline.
validation_strategy : str, default='none'
EXPERIMENTAL The validation strategy to use for selecting the final pipeline from the population. TPOT may overfit the cross validation score. A second validation set can be used to select the final pipeline.
- 'auto' : Automatically determine the validation strategy based on the dataset shape.
- 'reshuffled' : Use the same data for cross validation and final validation, but with different splits for the folds. This is the default for small datasets.
- 'split' : Use a separate validation set for final validation. Data will be split according to validation_fraction. This is the default for medium datasets.
- 'none' : Do not use a separate validation set for final validation. Select based on the original cross-validation score. This is the default for large datasets.
validation_fraction : float, default=0.2
EXPERIMENTAL The fraction of the dataset to use for the validation set when validation_strategy is 'split'. Must be between 0 and 1.
disable_label_encoder : bool, default=False
If True, TPOT will check if the target needs to be relabeled to be sequential ints from 0 to N. This is necessary for XGBoost compatibility. If the labels need to be encoded, TPOT will use sklearn.preprocessing.LabelEncoder to encode the labels. The encoder can be accessed via the self.label_encoder_ attribute.
If False, no additional label encoders will be used.
population_size : int, default=50
Size of the population
initial_population_size : int, default=50
Size of the initial population. If None, population_size will be used.
population_scaling : int, default=0.5
Scaling factor to use when determining how fast we move the threshold moves from the start to end percentile.
generations_until_end_population : int, default=1
Number of generations until the population size reaches population_size
generations : int, default=50
Number of generations to run
early_stop : int, default=None
Number of evaluated individuals without improvement before early stopping. Counted across all objectives independently. Triggered when all objectives have not improved by the given number of individuals.
early_stop_mins : float, default=None
Number of seconds without improvement before early stopping. All objectives must not have improved for the given number of seconds for this to be triggered.
scorers_early_stop_tol :
-list of floats
list of tolerances for each scorer. If the difference between the best score and the current score is less than the tolerance, the individual is considered to have converged
If an index of the list is None, that item will not be used for early stopping
-int
If an int is given, it will be used as the tolerance for all objectives
other_objectives_early_stop_tol :
-list of floats
list of tolerances for each of the other objective function. If the difference between the best score and the current score is less than the tolerance, the individual is considered to have converged
If an index of the list is None, that item will not be used for early stopping
-int
If an int is given, it will be used as the tolerance for all objectives
max_time_mins : float, default=float("inf")
Maximum time to run the optimization. If none or inf, will run until the end of the generations.
max_eval_time_mins : float, default=10
Maximum time to evaluate a single individual. If none or inf, there will be no time limit per evaluation.
n_jobs : int, default=1
Number of processes to run in parallel.
memory_limit : str, default=None
Memory limit for each job. See Dask [LocalCluster documentation](https://distributed.dask.org/en/stable/api.html#distributed.Client) for more information.
client : dask.distributed.Client, default=None
A dask client to use for parallelization. If not None, this will override the n_jobs and memory_limit parameters. If None, will create a new client with num_workers=n_jobs and memory_limit=memory_limit.
crossover_probability : float, default=.2
Probability of generating a new individual by crossover between two individuals.
mutate_probability : float, default=.7
Probability of generating a new individual by crossover between one individuals.
mutate_then_crossover_probability : float, default=.05
Probability of generating a new individual by mutating two individuals followed by crossover.
crossover_then_mutate_probability : float, default=.05
Probability of generating a new individual by crossover between two individuals followed by a mutation of the resulting individual.
survival_selector : function, default=survival_select_NSGA2
Function to use to select individuals for survival. Must take a matrix of scores and return selected indexes.
Used to selected population_size individuals at the start of each generation to use for mutation and crossover.
parent_selector : function, default=parent_select_NSGA2
Function to use to select pairs parents for crossover and individuals for mutation. Must take a matrix of scores and return selected indexes.
budget_range : list [start, end], default=None
A starting and ending budget to use for the budget scaling.
budget_scaling float : [0,1], default=0.5
A scaling factor to use when determining how fast we move the budget from the start to end budget.
individuals_until_end_budget : int, default=1
The number of generations to run before reaching the max budget.
stepwise_steps : int, default=1
The number of staircase steps to take when scaling the budget and population size.
threshold_evaluation_pruning : list [start, end], default=None
starting and ending percentile to use as a threshold for the evaluation early stopping.
Values between 0 and 100.
threshold_evaluation_scaling : float [0,inf), default=0.5
A scaling factor to use when determining how fast we move the threshold moves from the start to end percentile.
Must be greater than zero. Higher numbers will move the threshold to the end faster.
min_history_threshold : int, default=0
The minimum number of previous scores needed before using threshold early stopping.
selection_evaluation_pruning : list, default=None
A lower and upper percent of the population size to select each round of CV.
Values between 0 and 1.
selection_evaluation_scaling : float, default=0.5
A scaling factor to use when determining how fast we move the threshold moves from the start to end percentile.
Must be greater than zero. Higher numbers will move the threshold to the end faster.
n_initial_optimizations : int, default=0
Number of individuals to optimize before starting the evolution.
optimization_cv : int
Number of folds to use for the optuna optimization's internal cross-validation.
max_optimize_time_seconds : float, default=60*5
Maximum time to run an optimization
optimization_steps : int, default=10
Number of steps per optimization
warm_start : bool, default=False
If True, will use the continue the evolutionary algorithm from the last generation of the previous run.
verbose : int, default=1
How much information to print during the optimization process. Higher values include the information from lower values.
0. nothing
1. progress bar
3. best individual
4. warnings
>=5. full warnings trace
random_state : int, None, default=None
A seed for reproducability of experiments. This value will be passed to numpy.random.default_rng() to create an instnce of the genrator to pass to other classes
- int
Will be used to create and lock in Generator instance with 'numpy.random.default_rng()'
- None
Will be used to create Generator for 'numpy.random.default_rng()' where a fresh, unpredictable entropy will be pulled from the OS
periodic_checkpoint_folder : str, default=None
Folder to save the population to periodically. If None, no periodic saving will be done.
If provided, training will resume from this checkpoint.
callback : tpot.CallBackInterface, default=None
Callback object. Not implemented
processes : bool, default=True
If True, will use multiprocessing to parallelize the optimization process. If False, will use threading.
True seems to perform better. However, False is required for interactive debugging.
Attributes
----------
fitted_pipeline_ : GraphPipeline
A fitted instance of the GraphPipeline that inherits from sklearn BaseEstimator. This is fitted on the full X, y passed to fit.
evaluated_individuals : A pandas data frame containing data for all evaluated individuals in the run.
Columns:
- *objective functions : The first few columns correspond to the passed in scorers and objective functions
- Parents : A tuple containing the indexes of the pipelines used to generate the pipeline of that row. If NaN, this pipeline was generated randomly in the initial population.
- Variation_Function : Which variation function was used to mutate or crossover the parents. If NaN, this pipeline was generated randomly in the initial population.
- Individual : The internal representation of the individual that is used during the evolutionary algorithm. This is not an sklearn BaseEstimator.
- Generation : The generation the pipeline first appeared.
- Pareto_Front : The nondominated front that this pipeline belongs to. 0 means that its scores is not strictly dominated by any other individual.
To save on computational time, the best frontier is updated iteratively each generation.
The pipelines with the 0th pareto front do represent the exact best frontier. However, the pipelines with pareto front >= 1 are only in reference to the other pipelines in the final population.
All other pipelines are set to NaN.
- Instance : The unfitted GraphPipeline BaseEstimator.
- *validation objective functions : Objective function scores evaluated on the validation set.
- Validation_Pareto_Front : The full pareto front calculated on the validation set. This is calculated for all pipelines with Pareto_Front equal to 0. Unlike the Pareto_Front which only calculates the frontier and the final population, the Validation Pareto Front is calculated for all pipelines tested on the validation set.
pareto_front : The same pandas dataframe as evaluated individuals, but containing only the frontier pareto front pipelines.
'''
# sklearn BaseEstimator must have a corresponding attribute for each parameter.
# These should not be modified once set.
self.search_space = search_space
self.scorers = scorers
self.scorers_weights = scorers_weights
self.classification = classification
self.cv = cv
self.other_objective_functions = other_objective_functions
self.other_objective_functions_weights = other_objective_functions_weights
self.objective_function_names = objective_function_names
self.bigger_is_better = bigger_is_better
self.export_graphpipeline = export_graphpipeline
self.memory = memory
self.categorical_features = categorical_features
self.preprocessing = preprocessing
self.validation_strategy = validation_strategy
self.validation_fraction = validation_fraction
self.disable_label_encoder = disable_label_encoder
self.population_size = population_size
self.initial_population_size = initial_population_size
self.early_stop = early_stop
self.early_stop_mins = early_stop_mins
self.scorers_early_stop_tol = scorers_early_stop_tol
self.other_objectives_early_stop_tol = other_objectives_early_stop_tol
self.max_time_mins = max_time_mins
self.max_eval_time_mins = max_eval_time_mins
self.n_jobs= n_jobs
self.memory_limit = memory_limit
self.client = client
self.crossover_probability = crossover_probability
self.mutate_probability = mutate_probability
self.mutate_then_crossover_probability= mutate_then_crossover_probability
self.crossover_then_mutate_probability= crossover_then_mutate_probability
self.survival_selector=survival_selector
self.parent_selector=parent_selector
self.budget_range = budget_range
self.budget_scaling = budget_scaling
self.individuals_until_end_budget = individuals_until_end_budget
self.stepwise_steps = stepwise_steps
self.warm_start = warm_start
self.verbose = verbose
self.periodic_checkpoint_folder = periodic_checkpoint_folder
self.callback = callback
self.processes = processes
self.scatter = scatter
self.optuna_optimize_pareto_front = optuna_optimize_pareto_front
self.optuna_optimize_pareto_front_trials = optuna_optimize_pareto_front_trials
self.optuna_optimize_pareto_front_timeout = optuna_optimize_pareto_front_timeout
self.optuna_storage = optuna_storage
# create random number generator based on rngseed
self.rng = np.random.default_rng(random_state)
# save random state passed to us for other functions that use random_state
self.random_state = random_state
self.max_evaluated_individuals = max_evaluated_individuals
#Initialize other used params
if self.initial_population_size is None:
self._initial_population_size = self.population_size
else:
self._initial_population_size = self.initial_population_size
if isinstance(self.scorers, str):
self._scorers = [self.scorers]
elif callable(self.scorers):
self._scorers = [self.scorers]
else:
self._scorers = self.scorers
self._scorers = [sklearn.metrics.get_scorer(scoring) for scoring in self._scorers]
self._scorers_early_stop_tol = self.scorers_early_stop_tol
self._evolver = tpot.evolvers.SteadyStateEvolver
self.objective_function_weights = [*scorers_weights, *other_objective_functions_weights]
if self.objective_function_names is None:
obj_names = [f.__name__ for f in other_objective_functions]
else:
obj_names = self.objective_function_names
self.objective_names = [f._score_func.__name__ if hasattr(f,"_score_func") else f.__name__ for f in self._scorers] + obj_names
if not isinstance(self.other_objectives_early_stop_tol, list):
self._other_objectives_early_stop_tol = [self.other_objectives_early_stop_tol for _ in range(len(self.other_objective_functions))]
else:
self._other_objectives_early_stop_tol = self.other_objectives_early_stop_tol
if not isinstance(self._scorers_early_stop_tol, list):
self._scorers_early_stop_tol = [self._scorers_early_stop_tol for _ in range(len(self._scorers))]
else:
self._scorers_early_stop_tol = self._scorers_early_stop_tol
self.early_stop_tol = [*self._scorers_early_stop_tol, *self._other_objectives_early_stop_tol]
self._evolver_instance = None
self.evaluated_individuals = None
self.label_encoder_ = None
set_dask_settings()
def fit(self, X, y):
if self.client is not None: #If user passed in a client manually
_client = self.client
else:
if self.verbose >= 4:
silence_logs = 30
elif self.verbose >=5:
silence_logs = 40
else:
silence_logs = 50
cluster = LocalCluster(n_workers=self.n_jobs, #if no client is passed in and no global client exists, create our own
threads_per_worker=1,
processes=self.processes,
silence_logs=silence_logs,
memory_limit=self.memory_limit)
_client = Client(cluster)
if self.classification and not self.disable_label_encoder and not check_if_y_is_encoded(y):
warnings.warn("Labels are not encoded as ints from 0 to N. For compatibility with some classifiers such as sklearn, TPOT has encoded y with the sklearn LabelEncoder. When using pipelines outside the main TPOT estimator class, you can encode the labels with est.label_encoder_")
self.label_encoder_ = LabelEncoder()
y = self.label_encoder_.fit_transform(y)
self.evaluated_individuals = None
#determine validation strategy
if self.validation_strategy == 'auto':
nrows = X.shape[0]
ncols = X.shape[1]
if nrows/ncols < 20:
validation_strategy = 'reshuffled'
elif nrows/ncols < 100:
validation_strategy = 'split'
else:
validation_strategy = 'none'
else:
validation_strategy = self.validation_strategy
if validation_strategy == 'split':
if self.classification:
X, X_val, y, y_val = train_test_split(X, y, test_size=self.validation_fraction, stratify=y, random_state=self.random_state)
else:
X, X_val, y, y_val = train_test_split(X, y, test_size=self.validation_fraction, random_state=self.random_state)
X_original = X
y_original = y
if isinstance(self.cv, int) or isinstance(self.cv, float):
n_folds = self.cv
else:
n_folds = self.cv.get_n_splits(X, y)
if self.classification:
X, y = remove_underrepresented_classes(X, y, n_folds)
if self.preprocessing:
#X = pd.DataFrame(X)
if not isinstance(self.preprocessing, bool) and isinstance(self.preprocessing, sklearn.base.BaseEstimator):
self._preprocessing_pipeline = self.preprocessing
#TODO: check if there are missing values in X before imputation. If not, don't include imputation in pipeline. Check if there are categorical columns. If not, don't include one hot encoding in pipeline
else: #if self.preprocessing is True or not a sklearn estimator
pipeline_steps = []
if self.categorical_features is not None: #if categorical features are specified, use those
pipeline_steps.append(("impute_categorical", tpot.builtin_modules.ColumnSimpleImputer(self.categorical_features, strategy='most_frequent')))
pipeline_steps.append(("impute_numeric", tpot.builtin_modules.ColumnSimpleImputer("numeric", strategy='mean')))
pipeline_steps.append(("ColumnOneHotEncoder", tpot.builtin_modules.ColumnOneHotEncoder(self.categorical_features, strategy='most_frequent')))
else:
if isinstance(X, pd.DataFrame):
categorical_columns = X.select_dtypes(include=['object']).columns
if len(categorical_columns) > 0:
pipeline_steps.append(("impute_categorical", tpot.builtin_modules.ColumnSimpleImputer("categorical", strategy='most_frequent')))
pipeline_steps.append(("impute_numeric", tpot.builtin_modules.ColumnSimpleImputer("numeric", strategy='mean')))
pipeline_steps.append(("ColumnOneHotEncoder", tpot.builtin_modules.ColumnOneHotEncoder("categorical", strategy='most_frequent')))
else:
pipeline_steps.append(("impute_numeric", tpot.builtin_modules.ColumnSimpleImputer("all", strategy='mean')))
else:
pipeline_steps.append(("impute_numeric", tpot.builtin_modules.ColumnSimpleImputer("all", strategy='mean')))
self._preprocessing_pipeline = sklearn.pipeline.Pipeline(pipeline_steps)
X = self._preprocessing_pipeline.fit_transform(X, y)
else:
self._preprocessing_pipeline = None
#_, y = sklearn.utils.check_X_y(X, y, y_numeric=True)
#Set up the configuation dictionaries and the search spaces
#check if self.cv is a number
if isinstance(self.cv, int) or isinstance(self.cv, float):
if self.classification:
self.cv_gen = sklearn.model_selection.StratifiedKFold(n_splits=self.cv, shuffle=True, random_state=self.random_state)
else:
self.cv_gen = sklearn.model_selection.KFold(n_splits=self.cv, shuffle=True, random_state=self.random_state)
else:
self.cv_gen = sklearn.model_selection.check_cv(self.cv, y, classifier=self.classification)
n_samples= int(math.floor(X.shape[0]/n_folds))
n_features=X.shape[1]
if isinstance(X, pd.DataFrame):
self.feature_names = X.columns
else:
self.feature_names = None
def objective_function(pipeline_individual,
X,
y,
is_classification=self.classification,
scorers= self._scorers,
cv=self.cv_gen,
other_objective_functions=self.other_objective_functions,
export_graphpipeline=self.export_graphpipeline,
memory=self.memory,
**kwargs):
return objective_function_generator(
pipeline_individual,
X,
y,
is_classification=is_classification,
scorers= scorers,
cv=cv,
other_objective_functions=other_objective_functions,
export_graphpipeline=export_graphpipeline,
memory=memory,
**kwargs,
)
if self.classification:
n_classes = len(np.unique(y))
else:
n_classes = None
get_search_space_params = {"n_classes": n_classes,
"n_samples":len(y),
"n_features":X.shape[1],
"random_state":self.random_state}
self._search_space = get_template_search_spaces(self.search_space, classification=self.classification, inner_predictors=True, **get_search_space_params)
def ind_generator(rng):
rng = np.random.default_rng(rng)
while True:
yield self._search_space.generate(rng)
if self.scatter:
X_future = _client.scatter(X)
y_future = _client.scatter(y)
else:
X_future = X
y_future = y
#If warm start and we have an evolver instance, use the existing one
if not(self.warm_start and self._evolver_instance is not None):
self._evolver_instance = self._evolver( individual_generator=ind_generator(self.rng),
objective_functions= [objective_function],
objective_function_weights = self.objective_function_weights,
objective_names=self.objective_names,
bigger_is_better = self.bigger_is_better,
population_size= self.population_size,
initial_population_size = self._initial_population_size,
n_jobs=self.n_jobs,
verbose = self.verbose,
max_time_mins = self.max_time_mins ,
max_eval_time_mins = self.max_eval_time_mins,
periodic_checkpoint_folder = self.periodic_checkpoint_folder,
early_stop_tol = self.early_stop_tol,
early_stop= self.early_stop,
early_stop_mins = self.early_stop_mins,
budget_range = self.budget_range,
budget_scaling = self.budget_scaling,
individuals_until_end_budget = self.individuals_until_end_budget,
stepwise_steps = self.stepwise_steps,
client = _client,
objective_kwargs = {"X": X_future, "y": y_future},
survival_selector=self.survival_selector,
parent_selector=self.parent_selector,
crossover_probability = self.crossover_probability,
mutate_probability = self.mutate_probability,
mutate_then_crossover_probability= self.mutate_then_crossover_probability,
crossover_then_mutate_probability= self.crossover_then_mutate_probability,
max_evaluated_individuals = self.max_evaluated_individuals,
rng=self.rng,
)
self._evolver_instance.optimize()
#self._evolver_instance.population.update_pareto_fronts(self.objective_names, self.objective_function_weights)
self.make_evaluated_individuals()
if self.optuna_optimize_pareto_front:
pareto_front_inds = self.pareto_front['Individual'].values
all_graphs, all_scores = tpot.individual_representations.graph_pipeline_individual.simple_parallel_optuna(pareto_front_inds, objective_function, self.objective_function_weights, _client, storage=self.optuna_storage, steps=self.optuna_optimize_pareto_front_trials, verbose=self.verbose, max_eval_time_mins=self.max_eval_time_mins, max_time_mins=self.optuna_optimize_pareto_front_timeout, **{"X": X, "y": y})
all_scores = tpot.utils.eval_utils.process_scores(all_scores, len(self.objective_function_weights))
if len(all_graphs) > 0:
df = pd.DataFrame(np.column_stack((all_graphs, all_scores,np.repeat("Optuna",len(all_graphs)))), columns=["Individual"] + self.objective_names +["Parents"])
for obj in self.objective_names:
df[obj] = df[obj].apply(convert_to_float)
self.evaluated_individuals = pd.concat([self.evaluated_individuals, df], ignore_index=True)
else:
print("WARNING NO OPTUNA TRIALS COMPLETED")
tpot.utils.get_pareto_frontier(self.evaluated_individuals, column_names=self.objective_names, weights=self.objective_function_weights)
if validation_strategy == 'reshuffled':
best_pareto_front_idx = list(self.pareto_front.index)
best_pareto_front = list(self.pareto_front.loc[best_pareto_front_idx]['Individual'])
#reshuffle rows
X, y = sklearn.utils.shuffle(X, y, random_state=self.random_state)
if self.scatter:
X_future = _client.scatter(X)
y_future = _client.scatter(y)
else:
X_future = X
y_future = y
val_objective_function_list = [lambda ind,
X,
y,
is_classification=self.classification,
scorers= self._scorers,
cv=self.cv_gen,
other_objective_functions=self.other_objective_functions,
export_graphpipeline=self.export_graphpipeline,
memory=self.memory,
**kwargs: objective_function_generator(
ind,
X,
y,
is_classification=is_classification,
scorers= scorers,
cv=cv,
other_objective_functions=other_objective_functions,
export_graphpipeline=export_graphpipeline,
memory=memory,
**kwargs,
)]
objective_kwargs = {"X": X_future, "y": y_future}
val_scores, start_times, end_times, eval_errors = tpot.utils.eval_utils.parallel_eval_objective_list(best_pareto_front, val_objective_function_list, verbose=self.verbose, max_eval_time_mins=self.max_eval_time_mins, n_expected_columns=len(self.objective_names), client=_client, **objective_kwargs)
val_objective_names = ['validation_'+name for name in self.objective_names]
self.objective_names_for_selection = val_objective_names
self.evaluated_individuals.loc[best_pareto_front_idx,val_objective_names] = val_scores
self.evaluated_individuals.loc[best_pareto_front_idx,'validation_start_times'] = start_times
self.evaluated_individuals.loc[best_pareto_front_idx,'validation_end_times'] = end_times
self.evaluated_individuals.loc[best_pareto_front_idx,'validation_eval_errors'] = eval_errors
self.evaluated_individuals["Validation_Pareto_Front"] = tpot.utils.get_pareto_frontier(self.evaluated_individuals, column_names=val_objective_names, weights=self.objective_function_weights)
elif validation_strategy == 'split':
if self.scatter:
X_future = _client.scatter(X)
y_future = _client.scatter(y)
X_val_future = _client.scatter(X_val)
y_val_future = _client.scatter(y_val)
else:
X_future = X
y_future = y
X_val_future = X_val
y_val_future = y_val
objective_kwargs = {"X": X_future, "y": y_future, "X_val" : X_val_future, "y_val":y_val_future }
best_pareto_front_idx = list(self.pareto_front.index)
best_pareto_front = list(self.pareto_front.loc[best_pareto_front_idx]['Individual'])
val_objective_function_list = [lambda ind,
X,
y,
X_val,
y_val,
scorers= self._scorers,
other_objective_functions=self.other_objective_functions,
export_graphpipeline=self.export_graphpipeline,
memory=self.memory,
**kwargs: val_objective_function_generator(
ind,
X,
y,
X_val,
y_val,
scorers= scorers,
other_objective_functions=other_objective_functions,
export_graphpipeline=export_graphpipeline,
memory=memory,
**kwargs,
)]
val_scores, start_times, end_times, eval_errors = tpot.utils.eval_utils.parallel_eval_objective_list(best_pareto_front, val_objective_function_list, verbose=self.verbose, max_eval_time_mins=self.max_eval_time_mins, n_expected_columns=len(self.objective_names), client=_client, **objective_kwargs)
val_objective_names = ['validation_'+name for name in self.objective_names]
self.objective_names_for_selection = val_objective_names
self.evaluated_individuals.loc[best_pareto_front_idx,val_objective_names] = val_scores
self.evaluated_individuals.loc[best_pareto_front_idx,'validation_start_times'] = start_times
self.evaluated_individuals.loc[best_pareto_front_idx,'validation_end_times'] = end_times
self.evaluated_individuals.loc[best_pareto_front_idx,'validation_eval_errors'] = eval_errors
self.evaluated_individuals["Validation_Pareto_Front"] = tpot.utils.get_pareto_frontier(self.evaluated_individuals, column_names=val_objective_names, weights=self.objective_function_weights)
else:
self.objective_names_for_selection = self.objective_names
val_scores = self.evaluated_individuals[self.evaluated_individuals[self.objective_names_for_selection].isin(["TIMEOUT","INVALID"]).any(axis=1).ne(True)][self.objective_names_for_selection].astype(float)
weighted_scores = val_scores*self.objective_function_weights
if self.bigger_is_better:
best_indices = list(weighted_scores.sort_values(by=self.objective_names_for_selection, ascending=False).index)
else:
best_indices = list(weighted_scores.sort_values(by=self.objective_names_for_selection, ascending=True).index)
for best_idx in best_indices:
best_individual = self.evaluated_individuals.loc[best_idx]['Individual']
self.selected_best_score = self.evaluated_individuals.loc[best_idx]
#TODO
#best_individual_pipeline = best_individual.export_pipeline(memory=self.memory, cross_val_predict_cv=self.cross_val_predict_cv)
if self.export_graphpipeline:
best_individual_pipeline = best_individual.export_flattened_graphpipeline(memory=self.memory)
else:
best_individual_pipeline = best_individual.export_pipeline(memory=self.memory)
if self.preprocessing:
self.fitted_pipeline_ = sklearn.pipeline.make_pipeline(sklearn.base.clone(self._preprocessing_pipeline), best_individual_pipeline )
else:
self.fitted_pipeline_ = best_individual_pipeline
try:
self.fitted_pipeline_.fit(X_original,y_original) #TODO use y_original as well?
break
except Exception as e:
if self.verbose >= 4:
warnings.warn("Final pipeline failed to fit. Rarely, the pipeline might work on the objective function but fail on the full dataset. Generally due to interactions with different features being selected or transformations having different properties. Trying next pipeline")
print(e)
continue
if self.client is None: #no client was passed in
#close cluster and client
# _client.close()
# cluster.close()
try:
_client.shutdown()
cluster.close()
#catch exception
except Exception as e:
print("Error shutting down client and cluster")
Warning(e)
return self
def _estimator_has(attr):
'''Check if we can delegate a method to the underlying estimator.
First, we check the first fitted final estimator if available, otherwise we
check the unfitted final estimator.
'''
return lambda self: (self.fitted_pipeline_ is not None and
hasattr(self.fitted_pipeline_, attr)
)
@available_if(_estimator_has('predict'))
def predict(self, X, **predict_params):
check_is_fitted(self)
#X = check_array(X)
preds = self.fitted_pipeline_.predict(X,**predict_params)
if self.classification and self.label_encoder_:
preds = self.label_encoder_.inverse_transform(preds)
return preds
@available_if(_estimator_has('predict_proba'))
def predict_proba(self, X, **predict_params):
check_is_fitted(self)
#X = check_array(X)
return self.fitted_pipeline_.predict_proba(X,**predict_params)
@available_if(_estimator_has('decision_function'))
def decision_function(self, X, **predict_params):
check_is_fitted(self)
#X = check_array(X)
return self.fitted_pipeline_.decision_function(X,**predict_params)
@available_if(_estimator_has('transform'))
def transform(self, X, **predict_params):
check_is_fitted(self)
#X = check_array(X)
return self.fitted_pipeline_.transform(X,**predict_params)
@property
def classes_(self):
"""The classes labels. Only exist if the last step is a classifier."""
if self.label_encoder_:
return self.label_encoder_.classes_
else:
return self.fitted_pipeline_.classes_
@property
def _estimator_type(self):
return self.fitted_pipeline_._estimator_type
def __sklearn_tags__(self):
if hasattr(self, 'fitted_pipeline_'): #if fitted
try:
tags = copy.deepcopy(self.fitted_pipeline_.__sklearn_tags__())
except:
tags = copy.deepcopy(get_tags(self.fitted_pipeline_))
else: #if not fitted
tags = super().__sklearn_tags__()
if self.random_state is None:
tags.non_deterministic = False
if self.classification:
if tags.classifier_tags is None:
tags.classifier_tags = sklearn.utils.ClassifierTags()
tags.classifier_tags.multi_class = True
tags.classifier_tags.multi_label = True
return tags
def make_evaluated_individuals(self):
#check if _evolver_instance exists
if self.evaluated_individuals is None:
self.evaluated_individuals = self._evolver_instance.population.evaluated_individuals.copy()
objects = list(self.evaluated_individuals.index)
object_to_int = dict(zip(objects, range(len(objects))))
self.evaluated_individuals = self.evaluated_individuals.set_index(self.evaluated_individuals.index.map(object_to_int))
self.evaluated_individuals['Parents'] = self.evaluated_individuals['Parents'].apply(lambda row: convert_parents_tuples_to_integers(row, object_to_int))
self.evaluated_individuals["Instance"] = self.evaluated_individuals["Individual"].apply(lambda ind: apply_make_pipeline(ind, preprocessing_pipeline=self._preprocessing_pipeline, export_graphpipeline=self.export_graphpipeline, memory=self.memory))
return self.evaluated_individuals
@property
def pareto_front(self):
#check if _evolver_instance exists
if self.evaluated_individuals is None:
return None
else:
if "Pareto_Front" not in self.evaluated_individuals:
return self.evaluated_individuals
else:
return self.evaluated_individuals[self.evaluated_individuals["Pareto_Front"]==1]
================================================
FILE: tpot/tpot_estimator/templates/__init__.py
================================================
from .tpottemplates import *
================================================
FILE: tpot/tpot_estimator/templates/tpot_autoimputer.py
================================================
================================================
FILE: tpot/tpot_estimator/templates/tpottemplates.py
================================================
"""
This file is part of the TPOT library.
The current version of TPOT was developed at Cedars-Sinai by:
- Pedro Henrique Ribeiro (https://github.com/perib, https://www.linkedin.com/in/pedro-ribeiro/)
- Anil Saini (anil.saini@cshs.org)
- Jose Hernandez (jgh9094@gmail.com)
- Jay Moran (jay.moran@cshs.org)
- Nicholas Matsumoto (nicholas.matsumoto@cshs.org)
- Hyunjun Choi (hyunjun.choi@cshs.org)
- Gabriel Ketron (gabriel.ketron@cshs.org)
- Miguel E. Hernandez (miguel.e.hernandez@cshs.org)
- Jason Moore (moorejh28@gmail.com)
The original version of TPOT was primarily developed at the University of Pennsylvania by:
- Randal S. Olson (rso@randalolson.com)
- Weixuan Fu (weixuanf@upenn.edu)
- Daniel Angell (dpa34@drexel.edu)
- Jason Moore (moorejh28@gmail.com)
- and many more generous open-source contributors
TPOT is free software: you can redistribute it and/or modify
it under the terms of the GNU Lesser General Public License as
published by the Free Software Foundation, either version 3 of
the License, or (at your option) any later version.
TPOT is distributed in the hope that it will be useful,
but WITHOUT ANY WARRANTY; without even the implied warranty of
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
GNU Lesser General Public License for more details.
You should have received a copy of the GNU Lesser General Public
License along with TPOT. If not, see .
"""
import tpot
import numpy as np
import pandas as pd
from ..estimator import TPOTEstimator
from sklearn.utils.validation import check_X_y, check_array, check_is_fitted
from tpot.selectors import survival_select_NSGA2, tournament_selection_dominated
#TODO These do not follow sklearn conventions of __init__
from ...config.template_search_spaces import get_template_search_spaces
class TPOTRegressor(TPOTEstimator):
def __init__( self,
search_space = "linear",
scorers=['neg_mean_squared_error'],
scorers_weights=[1],
cv = 10, #remove this and use a value based on dataset size?
other_objective_functions=[], #tpot.objectives.estimator_objective_functions.number_of_nodes_objective],
other_objective_functions_weights = [],
objective_function_names = None,
bigger_is_better = True,
categorical_features = None,
memory = None,
preprocessing = False,
max_time_mins=60,
max_eval_time_mins=10,
n_jobs = 1,
validation_strategy = "none",
validation_fraction = .2,
early_stop = None,
warm_start = False,
periodic_checkpoint_folder = None,
verbose = 2,
memory_limit = None,
client = None,
random_state=None,
allow_inner_regressors=None,
**tpotestimator_kwargs,
):
'''
An sklearn baseestimator that uses genetic programming to optimize a regression pipeline.
For more parameters, see the TPOTEstimator class.
Parameters
----------
search_space : (String, tpot.search_spaces.SearchSpace)
- String : The default search space to use for the optimization.
| String | Description |
| :--- | :----: |
| linear | A linear pipeline with the structure of "Selector->(transformers+Passthrough)->(classifiers/regressors+Passthrough)->final classifier/regressor." For both the transformer and inner estimator layers, TPOT may choose one or more transformers/classifiers, or it may choose none. The inner classifier/regressor layer is optional. |
| linear-light | Same search space as linear, but without the inner classifier/regressor layer and with a reduced set of faster running estimators. |
| graph | TPOT will optimize a pipeline in the shape of a directed acyclic graph. The nodes of the graph can include selectors, scalers, transformers, or classifiers/regressors (inner classifiers/regressors can optionally be not included). This will return a custom GraphPipeline rather than an sklearn Pipeline. More details in Tutorial 6. |
| graph-light | Same as graph search space, but without the inner classifier/regressors and with a reduced set of faster running estimators. |
| mdr |TPOT will search over a series of feature selectors and Multifactor Dimensionality Reduction models to find a series of operators that maximize prediction accuracy. The TPOT MDR configuration is specialized for genome-wide association studies (GWAS), and is described in detail online here.
Note that TPOT MDR may be slow to run because the feature selection routines are computationally expensive, especially on large datasets. |
- SearchSpace : The search space to use for the optimization. This should be an instance of a SearchSpace.
The search space to use for the optimization. This should be an instance of a SearchSpace.
TPOT has groups of search spaces found in the following folders, tpot.search_spaces.nodes for the nodes in the pipeline and tpot.search_spaces.pipelines for the pipeline structure.
scorers : (list, scorer)
A scorer or list of scorers to be used in the cross-validation process.
see https://scikit-learn.org/stable/modules/model_evaluation.html
scorers_weights : list
A list of weights to be applied to the scorers during the optimization process.
classification : bool
If True, the problem is treated as a classification problem. If False, the problem is treated as a regression problem.
Used to determine the CV strategy.
cv : int, cross-validator
- (int): Number of folds to use in the cross-validation process. By uses the sklearn.model_selection.KFold cross-validator for regression and StratifiedKFold for classification. In both cases, shuffled is set to True.
- (sklearn.model_selection.BaseCrossValidator): A cross-validator to use in the cross-validation process.
- max_depth (int): The maximum depth from any node to the root of the pipelines to be generated.
other_objective_functions : list, default=[]
A list of other objective functions to apply to the pipeline. The function takes a single parameter for the graphpipeline estimator and returns either a single score or a list of scores.
other_objective_functions_weights : list, default=[]
A list of weights to be applied to the other objective functions.
objective_function_names : list, default=None
A list of names to be applied to the objective functions. If None, will use the names of the objective functions.
bigger_is_better : bool, default=True
If True, the objective function is maximized. If False, the objective function is minimized. Use negative weights to reverse the direction.
categorical_features : list or None
Categorical columns to inpute and/or one hot encode during the preprocessing step. Used only if preprocessing is not False.
categorical_features: list or None
Categorical columns to inpute and/or one hot encode during the preprocessing step. Used only if preprocessing is not False.
- None : If None, TPOT will automatically use object columns in pandas dataframes as objects for one hot encoding in preprocessing.
- List of categorical features. If X is a dataframe, this should be a list of column names. If X is a numpy array, this should be a list of column indices
memory: Memory object or string, default=None
If supplied, pipeline will cache each transformer after calling fit with joblib.Memory. This feature
is used to avoid computing the fit transformers within a pipeline if the parameters
and input data are identical with another fitted pipeline during optimization process.
- String 'auto':
TPOT uses memory caching with a temporary directory and cleans it up upon shutdown.
- String path of a caching directory
TPOT uses memory caching with the provided directory and TPOT does NOT clean
the caching directory up upon shutdown. If the directory does not exist, TPOT will
create it.
- Memory object:
TPOT uses the instance of joblib.Memory for memory caching,
and TPOT does NOT clean the caching directory up upon shutdown.
- None:
TPOT does not use memory caching.
preprocessing : bool or BaseEstimator/Pipeline,
EXPERIMENTAL
A pipeline that will be used to preprocess the data before CV. Note that the parameters for these steps are not optimized. Add them to the search space to be optimized.
- bool : If True, will use a default preprocessing pipeline which includes imputation followed by one hot encoding.
- Pipeline : If an instance of a pipeline is given, will use that pipeline as the preprocessing pipeline.
max_time_mins : float, default=float("inf")
Maximum time to run the optimization. If none or inf, will run until the end of the generations.
max_eval_time_mins : float, default=60*5
Maximum time to evaluate a single individual. If none or inf, there will be no time limit per evaluation.
n_jobs : int, default=1
Number of processes to run in parallel.
validation_strategy : str, default='none'
EXPERIMENTAL The validation strategy to use for selecting the final pipeline from the population. TPOT may overfit the cross validation score. A second validation set can be used to select the final pipeline.
- 'auto' : Automatically determine the validation strategy based on the dataset shape.
- 'reshuffled' : Use the same data for cross validation and final validation, but with different splits for the folds. This is the default for small datasets.
- 'split' : Use a separate validation set for final validation. Data will be split according to validation_fraction. This is the default for medium datasets.
- 'none' : Do not use a separate validation set for final validation. Select based on the original cross-validation score. This is the default for large datasets.
validation_fraction : float, default=0.2
EXPERIMENTAL The fraction of the dataset to use for the validation set when validation_strategy is 'split'. Must be between 0 and 1.
early_stop : int, default=None
Number of generations without improvement before early stopping. All objectives must have converged within the tolerance for this to be triggered. In general a value of around 5-20 is good.
warm_start : bool, default=False
If True, will use the continue the evolutionary algorithm from the last generation of the previous run.
periodic_checkpoint_folder : str, default=None
Folder to save the population to periodically. If None, no periodic saving will be done.
If provided, training will resume from this checkpoint.
verbose : int, default=1
How much information to print during the optimization process. Higher values include the information from lower values.
0. nothing
1. progress bar
3. best individual
4. warnings
>=5. full warnings trace
6. evaluations progress bar. (Temporary: This used to be 2. Currently, using evaluation progress bar may prevent some instances were we terminate a generation early due to it reaching max_time_mins in the middle of a generation OR a pipeline failed to be terminated normally and we need to manually terminate it.)
memory_limit : str, default=None
Memory limit for each job. See Dask [LocalCluster documentation](https://distributed.dask.org/en/stable/api.html#distributed.Client) for more information.
client : dask.distributed.Client, default=None
A dask client to use for parallelization. If not None, this will override the n_jobs and memory_limit parameters. If None, will create a new client with num_workers=n_jobs and memory_limit=memory_limit.
random_state : int, None, default=None
A seed for reproducability of experiments. This value will be passed to numpy.random.default_rng() to create an instnce of the genrator to pass to other classes
- int
Will be used to create and lock in Generator instance with 'numpy.random.default_rng()'
- None
Will be used to create Generator for 'numpy.random.default_rng()' where a fresh, unpredictable entropy will be pulled from the OS
allow_inner_regressors : bool, default=True
If True, the search space will include ensembled regressors.
Attributes
----------
fitted_pipeline_ : GraphPipeline
A fitted instance of the GraphPipeline that inherits from sklearn BaseEstimator. This is fitted on the full X, y passed to fit.
evaluated_individuals : A pandas data frame containing data for all evaluated individuals in the run.
Columns:
- *objective functions : The first few columns correspond to the passed in scorers and objective functions
- Parents : A tuple containing the indexes of the pipelines used to generate the pipeline of that row. If NaN, this pipeline was generated randomly in the initial population.
- Variation_Function : Which variation function was used to mutate or crossover the parents. If NaN, this pipeline was generated randomly in the initial population.
- Individual : The internal representation of the individual that is used during the evolutionary algorithm. This is not an sklearn BaseEstimator.
- Generation : The generation the pipeline first appeared.
- Pareto_Front : The nondominated front that this pipeline belongs to. 0 means that its scores is not strictly dominated by any other individual.
To save on computational time, the best frontier is updated iteratively each generation.
The pipelines with the 0th pareto front do represent the exact best frontier. However, the pipelines with pareto front >= 1 are only in reference to the other pipelines in the final population.
All other pipelines are set to NaN.
- Instance : The unfitted GraphPipeline BaseEstimator.
- *validation objective functions : Objective function scores evaluated on the validation set.
- Validation_Pareto_Front : The full pareto front calculated on the validation set. This is calculated for all pipelines with Pareto_Front equal to 0. Unlike the Pareto_Front which only calculates the frontier and the final population, the Validation Pareto Front is calculated for all pipelines tested on the validation set.
pareto_front : The same pandas dataframe as evaluated individuals, but containing only the frontier pareto front pipelines.
'''
self.search_space = search_space
self.scorers = scorers
self.scorers_weights = scorers_weights
self.cv = cv
self.other_objective_functions = other_objective_functions
self.other_objective_functions_weights = other_objective_functions_weights
self.objective_function_names = objective_function_names
self.bigger_is_better = bigger_is_better
self.categorical_features = categorical_features
self.memory = memory
self.preprocessing = preprocessing
self.max_time_mins = max_time_mins
self.max_eval_time_mins = max_eval_time_mins
self.n_jobs = n_jobs
self.validation_strategy = validation_strategy
self.validation_fraction = validation_fraction
self.early_stop = early_stop
self.warm_start = warm_start
self.periodic_checkpoint_folder = periodic_checkpoint_folder
self.verbose = verbose
self.memory_limit = memory_limit
self.client = client
self.random_state = random_state
self.allow_inner_regressors = allow_inner_regressors
self.tpotestimator_kwargs = tpotestimator_kwargs
self.initialized = False
def fit(self, X, y):
if not self.initialized:
get_search_space_params = {"n_classes": None,
"n_samples":len(y),
"n_features":X.shape[1],
"random_state":self.random_state}
search_space = get_template_search_spaces(self.search_space, classification=False, inner_predictors=self.allow_inner_regressors, **get_search_space_params)
super(TPOTRegressor,self).__init__(
search_space=search_space,
scorers=self.scorers,
scorers_weights=self.scorers_weights,
cv=self.cv,
other_objective_functions=self.other_objective_functions, #tpot.objectives.estimator_objective_functions.number_of_nodes_objective],
other_objective_functions_weights = self.other_objective_functions_weights,
objective_function_names = self.objective_function_names,
bigger_is_better = self.bigger_is_better,
categorical_features = self.categorical_features,
memory = self.memory,
preprocessing = self.preprocessing,
max_time_mins=self.max_time_mins,
max_eval_time_mins=self.max_eval_time_mins,
n_jobs=self.n_jobs,
validation_strategy = self.validation_strategy,
validation_fraction = self.validation_fraction,
early_stop = self.early_stop,
warm_start = self.warm_start,
periodic_checkpoint_folder = self.periodic_checkpoint_folder,
verbose = self.verbose,
classification=False,
memory_limit = self.memory_limit,
client = self.client,
random_state=self.random_state,
**self.tpotestimator_kwargs)
self.initialized = True
return super().fit(X,y)
class TPOTClassifier(TPOTEstimator):
def __init__( self,
search_space = "linear",
scorers=['roc_auc_ovr'],
scorers_weights=[1],
cv = 10,
other_objective_functions=[], #tpot.objectives.estimator_objective_functions.number_of_nodes_objective],
other_objective_functions_weights = [],
objective_function_names = None,
bigger_is_better = True,
categorical_features = None,
memory = None,
preprocessing = False,
max_time_mins=60,
max_eval_time_mins=10,
n_jobs = 1,
validation_strategy = "none",
validation_fraction = .2,
early_stop = None,
warm_start = False,
periodic_checkpoint_folder = None,
verbose = 2,
memory_limit = None,
client = None,
random_state=None,
allow_inner_classifiers=None,
**tpotestimator_kwargs,
):
"""
An sklearn baseestimator that uses genetic programming to optimize a classification pipeline.
For more parameters, see the TPOTEstimator class.
Parameters
----------
search_space : (String, tpot.search_spaces.SearchSpace)
- String : The default search space to use for the optimization.
| String | Description |
| :--- | :----: |
| linear | A linear pipeline with the structure of "Selector->(transformers+Passthrough)->(classifiers/regressors+Passthrough)->final classifier/regressor." For both the transformer and inner estimator layers, TPOT may choose one or more transformers/classifiers, or it may choose none. The inner classifier/regressor layer is optional. |
| linear-light | Same search space as linear, but without the inner classifier/regressor layer and with a reduced set of faster running estimators. |
| graph | TPOT will optimize a pipeline in the shape of a directed acyclic graph. The nodes of the graph can include selectors, scalers, transformers, or classifiers/regressors (inner classifiers/regressors can optionally be not included). This will return a custom GraphPipeline rather than an sklearn Pipeline. More details in Tutorial 6. |
| graph-light | Same as graph search space, but without the inner classifier/regressors and with a reduced set of faster running estimators. |
| mdr |TPOT will search over a series of feature selectors and Multifactor Dimensionality Reduction models to find a series of operators that maximize prediction accuracy. The TPOT MDR configuration is specialized for genome-wide association studies (GWAS), and is described in detail online here.
Note that TPOT MDR may be slow to run because the feature selection routines are computationally expensive, especially on large datasets. |
- SearchSpace : The search space to use for the optimization. This should be an instance of a SearchSpace.
The search space to use for the optimization. This should be an instance of a SearchSpace.
TPOT has groups of search spaces found in the following folders, tpot.search_spaces.nodes for the nodes in the pipeline and tpot.search_spaces.pipelines for the pipeline structure.
scorers : (list, scorer)
A scorer or list of scorers to be used in the cross-validation process.
see https://scikit-learn.org/stable/modules/model_evaluation.html
scorers_weights : list
A list of weights to be applied to the scorers during the optimization process.
classification : bool
If True, the problem is treated as a classification problem. If False, the problem is treated as a regression problem.
Used to determine the CV strategy.
cv : int, cross-validator
- (int): Number of folds to use in the cross-validation process. By uses the sklearn.model_selection.KFold cross-validator for regression and StratifiedKFold for classification. In both cases, shuffled is set to True.
- (sklearn.model_selection.BaseCrossValidator): A cross-validator to use in the cross-validation process.
- max_depth (int): The maximum depth from any node to the root of the pipelines to be generated.
other_objective_functions : list, default=[]
A list of other objective functions to apply to the pipeline. The function takes a single parameter for the graphpipeline estimator and returns either a single score or a list of scores.
other_objective_functions_weights : list, default=[]
A list of weights to be applied to the other objective functions.
objective_function_names : list, default=None
A list of names to be applied to the objective functions. If None, will use the names of the objective functions.
bigger_is_better : bool, default=True
If True, the objective function is maximized. If False, the objective function is minimized. Use negative weights to reverse the direction.
categorical_features : list or None
Categorical columns to inpute and/or one hot encode during the preprocessing step. Used only if preprocessing is not False.
categorical_features: list or None
Categorical columns to inpute and/or one hot encode during the preprocessing step. Used only if preprocessing is not False.
- None : If None, TPOT will automatically use object columns in pandas dataframes as objects for one hot encoding in preprocessing.
- List of categorical features. If X is a dataframe, this should be a list of column names. If X is a numpy array, this should be a list of column indices
memory: Memory object or string, default=None
If supplied, pipeline will cache each transformer after calling fit with joblib.Memory. This feature
is used to avoid computing the fit transformers within a pipeline if the parameters
and input data are identical with another fitted pipeline during optimization process.
- String 'auto':
TPOT uses memory caching with a temporary directory and cleans it up upon shutdown.
- String path of a caching directory
TPOT uses memory caching with the provided directory and TPOT does NOT clean
the caching directory up upon shutdown. If the directory does not exist, TPOT will
create it.
- Memory object:
TPOT uses the instance of joblib.Memory for memory caching,
and TPOT does NOT clean the caching directory up upon shutdown.
- None:
TPOT does not use memory caching.
preprocessing : bool or BaseEstimator/Pipeline,
EXPERIMENTAL
A pipeline that will be used to preprocess the data before CV. Note that the parameters for these steps are not optimized. Add them to the search space to be optimized.
- bool : If True, will use a default preprocessing pipeline which includes imputation followed by one hot encoding.
- Pipeline : If an instance of a pipeline is given, will use that pipeline as the preprocessing pipeline.
max_time_mins : float, default=float("inf")
Maximum time to run the optimization. If none or inf, will run until the end of the generations.
max_eval_time_mins : float, default=60*5
Maximum time to evaluate a single individual. If none or inf, there will be no time limit per evaluation.
n_jobs : int, default=1
Number of processes to run in parallel.
validation_strategy : str, default='none'
EXPERIMENTAL The validation strategy to use for selecting the final pipeline from the population. TPOT may overfit the cross validation score. A second validation set can be used to select the final pipeline.
- 'auto' : Automatically determine the validation strategy based on the dataset shape.
- 'reshuffled' : Use the same data for cross validation and final validation, but with different splits for the folds. This is the default for small datasets.
- 'split' : Use a separate validation set for final validation. Data will be split according to validation_fraction. This is the default for medium datasets.
- 'none' : Do not use a separate validation set for final validation. Select based on the original cross-validation score. This is the default for large datasets.
validation_fraction : float, default=0.2
EXPERIMENTAL The fraction of the dataset to use for the validation set when validation_strategy is 'split'. Must be between 0 and 1.
early_stop : int, default=None
Number of generations without improvement before early stopping. All objectives must have converged within the tolerance for this to be triggered. In general a value of around 5-20 is good.
warm_start : bool, default=False
If True, will use the continue the evolutionary algorithm from the last generation of the previous run.
periodic_checkpoint_folder : str, default=None
Folder to save the population to periodically. If None, no periodic saving will be done.
If provided, training will resume from this checkpoint.
verbose : int, default=1
How much information to print during the optimization process. Higher values include the information from lower values.
0. nothing
1. progress bar
3. best individual
4. warnings
>=5. full warnings trace
6. evaluations progress bar. (Temporary: This used to be 2. Currently, using evaluation progress bar may prevent some instances were we terminate a generation early due to it reaching max_time_mins in the middle of a generation OR a pipeline failed to be terminated normally and we need to manually terminate it.)
memory_limit : str, default=None
Memory limit for each job. See Dask [LocalCluster documentation](https://distributed.dask.org/en/stable/api.html#distributed.Client) for more information.
client : dask.distributed.Client, default=None
A dask client to use for parallelization. If not None, this will override the n_jobs and memory_limit parameters. If None, will create a new client with num_workers=n_jobs and memory_limit=memory_limit.
random_state : int, None, default=None
A seed for reproducability of experiments. This value will be passed to numpy.random.default_rng() to create an instnce of the genrator to pass to other classes
- int
Will be used to create and lock in Generator instance with 'numpy.random.default_rng()'
- None
Will be used to create Generator for 'numpy.random.default_rng()' where a fresh, unpredictable entropy will be pulled from the OS
allow_inner_classifiers : bool, default=True
If True, the search space will include ensembled classifiers.
Attributes
----------
fitted_pipeline_ : GraphPipeline
A fitted instance of the GraphPipeline that inherits from sklearn BaseEstimator. This is fitted on the full X, y passed to fit.
evaluated_individuals : A pandas data frame containing data for all evaluated individuals in the run.
Columns:
- *objective functions : The first few columns correspond to the passed in scorers and objective functions
- Parents : A tuple containing the indexes of the pipelines used to generate the pipeline of that row. If NaN, this pipeline was generated randomly in the initial population.
- Variation_Function : Which variation function was used to mutate or crossover the parents. If NaN, this pipeline was generated randomly in the initial population.
- Individual : The internal representation of the individual that is used during the evolutionary algorithm. This is not an sklearn BaseEstimator.
- Generation : The generation the pipeline first appeared.
- Pareto_Front : The nondominated front that this pipeline belongs to. 0 means that its scores is not strictly dominated by any other individual.
To save on computational time, the best frontier is updated iteratively each generation.
The pipelines with the 0th pareto front do represent the exact best frontier. However, the pipelines with pareto front >= 1 are only in reference to the other pipelines in the final population.
All other pipelines are set to NaN.
- Instance : The unfitted GraphPipeline BaseEstimator.
- *validation objective functions : Objective function scores evaluated on the validation set.
- Validation_Pareto_Front : The full pareto front calculated on the validation set. This is calculated for all pipelines with Pareto_Front equal to 0. Unlike the Pareto_Front which only calculates the frontier and the final population, the Validation Pareto Front is calculated for all pipelines tested on the validation set.
pareto_front : The same pandas dataframe as evaluated individuals, but containing only the frontier pareto front pipelines.
"""
self.search_space = search_space
self.scorers = scorers
self.scorers_weights = scorers_weights
self.cv = cv
self.other_objective_functions = other_objective_functions
self.other_objective_functions_weights = other_objective_functions_weights
self.objective_function_names = objective_function_names
self.bigger_is_better = bigger_is_better
self.categorical_features = categorical_features
self.memory = memory
self.preprocessing = preprocessing
self.max_time_mins = max_time_mins
self.max_eval_time_mins = max_eval_time_mins
self.n_jobs = n_jobs
self.validation_strategy = validation_strategy
self.validation_fraction = validation_fraction
self.early_stop = early_stop
self.warm_start = warm_start
self.periodic_checkpoint_folder = periodic_checkpoint_folder
self.verbose = verbose
self.memory_limit = memory_limit
self.client = client
self.random_state = random_state
self.tpotestimator_kwargs = tpotestimator_kwargs
self.allow_inner_classifiers = allow_inner_classifiers
self.initialized = False
def fit(self, X, y):
if not self.initialized:
get_search_space_params = {"n_classes": len(np.unique(y)),
"n_samples":len(y),
"n_features":X.shape[1],
"random_state":self.random_state}
search_space = get_template_search_spaces(self.search_space, classification=True, inner_predictors=self.allow_inner_classifiers, **get_search_space_params)
super(TPOTClassifier,self).__init__(
search_space=search_space,
scorers=self.scorers,
scorers_weights=self.scorers_weights,
cv = self.cv,
other_objective_functions=self.other_objective_functions, #tpot.objectives.estimator_objective_functions.number_of_nodes_objective],
other_objective_functions_weights = self.other_objective_functions_weights,
objective_function_names = self.objective_function_names,
bigger_is_better = self.bigger_is_better,
categorical_features = self.categorical_features,
memory = self.memory,
preprocessing = self.preprocessing,
max_time_mins=self.max_time_mins,
max_eval_time_mins=self.max_eval_time_mins,
n_jobs=self.n_jobs,
validation_strategy = self.validation_strategy,
validation_fraction = self.validation_fraction,
early_stop = self.early_stop,
warm_start = self.warm_start,
periodic_checkpoint_folder = self.periodic_checkpoint_folder,
verbose = self.verbose,
classification=True,
memory_limit = self.memory_limit,
client = self.client,
random_state=self.random_state,
**self.tpotestimator_kwargs)
self.initialized = True
return super().fit(X,y)
def predict(self, X, **predict_params):
check_is_fitted(self)
#X=check_array(X)
return self.fitted_pipeline_.predict(X,**predict_params)
================================================
FILE: tpot/tpot_estimator/tests/__init__.py
================================================
"""
This file is part of the TPOT library.
The current version of TPOT was developed at Cedars-Sinai by:
- Pedro Henrique Ribeiro (https://github.com/perib, https://www.linkedin.com/in/pedro-ribeiro/)
- Anil Saini (anil.saini@cshs.org)
- Jose Hernandez (jgh9094@gmail.com)
- Jay Moran (jay.moran@cshs.org)
- Nicholas Matsumoto (nicholas.matsumoto@cshs.org)
- Hyunjun Choi (hyunjun.choi@cshs.org)
- Gabriel Ketron (gabriel.ketron@cshs.org)
- Miguel E. Hernandez (miguel.e.hernandez@cshs.org)
- Jason Moore (moorejh28@gmail.com)
The original version of TPOT was primarily developed at the University of Pennsylvania by:
- Randal S. Olson (rso@randalolson.com)
- Weixuan Fu (weixuanf@upenn.edu)
- Daniel Angell (dpa34@drexel.edu)
- Jason Moore (moorejh28@gmail.com)
- and many more generous open-source contributors
TPOT is free software: you can redistribute it and/or modify
it under the terms of the GNU Lesser General Public License as
published by the Free Software Foundation, either version 3 of
the License, or (at your option) any later version.
TPOT is distributed in the hope that it will be useful,
but WITHOUT ANY WARRANTY; without even the implied warranty of
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
GNU Lesser General Public License for more details.
You should have received a copy of the GNU Lesser General Public
License along with TPOT. If not, see .
"""
================================================
FILE: tpot/tpot_estimator/tests/test_estimator_utils.py
================================================
"""
This file is part of the TPOT library.
The current version of TPOT was developed at Cedars-Sinai by:
- Pedro Henrique Ribeiro (https://github.com/perib, https://www.linkedin.com/in/pedro-ribeiro/)
- Anil Saini (anil.saini@cshs.org)
- Jose Hernandez (jgh9094@gmail.com)
- Jay Moran (jay.moran@cshs.org)
- Nicholas Matsumoto (nicholas.matsumoto@cshs.org)
- Hyunjun Choi (hyunjun.choi@cshs.org)
- Gabriel Ketron (gabriel.ketron@cshs.org)
- Miguel E. Hernandez (miguel.e.hernandez@cshs.org)
- Jason Moore (moorejh28@gmail.com)
The original version of TPOT was primarily developed at the University of Pennsylvania by:
- Randal S. Olson (rso@randalolson.com)
- Weixuan Fu (weixuanf@upenn.edu)
- Daniel Angell (dpa34@drexel.edu)
- Jason Moore (moorejh28@gmail.com)
- and many more generous open-source contributors
TPOT is free software: you can redistribute it and/or modify
it under the terms of the GNU Lesser General Public License as
published by the Free Software Foundation, either version 3 of
the License, or (at your option) any later version.
TPOT is distributed in the hope that it will be useful,
but WITHOUT ANY WARRANTY; without even the implied warranty of
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
GNU Lesser General Public License for more details.
You should have received a copy of the GNU Lesser General Public
License along with TPOT. If not, see .
"""
import pytest
import numpy as np
import pandas as pd
from ..estimator_utils import *
def test_remove_underrepresented_classes():
x = np.array([[1, 2], [3, 4], [5, 6], [7, 8]])
y = np.array([0, 1, 0, 2])
min_count = 2
x_result, y_result = remove_underrepresented_classes(x, y, min_count)
np.testing.assert_array_equal(x_result, np.array([[1, 2], [5, 6]]))
np.testing.assert_array_equal(y_result, np.array([0, 0]))
x = pd.DataFrame({'a': [1, 2], 'b': [3, 4], 'c': [5, 6], 'd': [7, 8]}).T
y = pd.Series([0, 1, 0, 2])
min_count = 2
x_result, y_result = remove_underrepresented_classes(x, y, min_count)
pd.testing.assert_frame_equal(x_result, pd.DataFrame({'a': [1, 2], 'c': [5, 6]}).T)
pd.testing.assert_series_equal(y_result, pd.Series([0, 1, 0, 2])[[0,2]])
x = np.array([[1, 2], [3, 4], [5, 6], [7, 8]])
y = np.array([0, 1, 0, 1])
min_count = 2
x_result, y_result = remove_underrepresented_classes(x, y, min_count)
np.testing.assert_array_equal(x_result, np.array([[1, 2], [3, 4], [5, 6], [7, 8]]))
np.testing.assert_array_equal(y_result, np.array([0, 1, 0, 1]))
x = pd.DataFrame({'a': [1, 2], 'b': [3, 4], 'c': [5, 6], 'd': [7, 8]}).T
y = pd.Series([0, 1, 0, 1])
min_count = 2
x_result, y_result = remove_underrepresented_classes(x, y, min_count)
pd.testing.assert_frame_equal(x_result, pd.DataFrame({'a': [1, 2], 'b': [3, 4], 'c': [5, 6], 'd': [7, 8]}).T)
pd.testing.assert_series_equal(y_result, pd.Series([0, 1, 0, 1]))
def test_check_if_y_is_encoded():
assert check_if_y_is_encoded([0, 1, 2, 3]) == True
assert check_if_y_is_encoded([0, 1, 3, 4]) == False
assert check_if_y_is_encoded([0, 2, 3]) == False
assert check_if_y_is_encoded([0]) == True
assert check_if_y_is_encoded([0,0,0,0,1,1,1,1]) == True
assert check_if_y_is_encoded([0,0,0,0,1,1,1,1,3]) == False
assert check_if_y_is_encoded([1,1,1,1,2,2,2,2]) == False
================================================
FILE: tpot/utils/__init__.py
================================================
"""
This file is part of the TPOT library.
The current version of TPOT was developed at Cedars-Sinai by:
- Pedro Henrique Ribeiro (https://github.com/perib, https://www.linkedin.com/in/pedro-ribeiro/)
- Anil Saini (anil.saini@cshs.org)
- Jose Hernandez (jgh9094@gmail.com)
- Jay Moran (jay.moran@cshs.org)
- Nicholas Matsumoto (nicholas.matsumoto@cshs.org)
- Hyunjun Choi (hyunjun.choi@cshs.org)
- Gabriel Ketron (gabriel.ketron@cshs.org)
- Miguel E. Hernandez (miguel.e.hernandez@cshs.org)
- Jason Moore (moorejh28@gmail.com)
The original version of TPOT was primarily developed at the University of Pennsylvania by:
- Randal S. Olson (rso@randalolson.com)
- Weixuan Fu (weixuanf@upenn.edu)
- Daniel Angell (dpa34@drexel.edu)
- Jason Moore (moorejh28@gmail.com)
- and many more generous open-source contributors
TPOT is free software: you can redistribute it and/or modify
it under the terms of the GNU Lesser General Public License as
published by the Free Software Foundation, either version 3 of
the License, or (at your option) any later version.
TPOT is distributed in the hope that it will be useful,
but WITHOUT ANY WARRANTY; without even the implied warranty of
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
GNU Lesser General Public License for more details.
You should have received a copy of the GNU Lesser General Public
License along with TPOT. If not, see .
"""
from . import eval_utils
from .utils import *
# If amltk is installed, import the parser
try:
from .amltk_parser import tpot_parser
except ImportError:
# Handle the case when amltk is not installed
pass
# print("amltk is not installed. Please install it to use tpot_parser.")
# Optional: raise an exception or provide alternative functionality
================================================
FILE: tpot/utils/amltk_parser.py
================================================
"""
This file is part of the TPOT library.
The current version of TPOT was developed at Cedars-Sinai by:
- Pedro Henrique Ribeiro (https://github.com/perib, https://www.linkedin.com/in/pedro-ribeiro/)
- Anil Saini (anil.saini@cshs.org)
- Jose Hernandez (jgh9094@gmail.com)
- Jay Moran (jay.moran@cshs.org)
- Nicholas Matsumoto (nicholas.matsumoto@cshs.org)
- Hyunjun Choi (hyunjun.choi@cshs.org)
- Gabriel Ketron (gabriel.ketron@cshs.org)
- Miguel E. Hernandez (miguel.e.hernandez@cshs.org)
- Jason Moore (moorejh28@gmail.com)
The original version of TPOT was primarily developed at the University of Pennsylvania by:
- Randal S. Olson (rso@randalolson.com)
- Weixuan Fu (weixuanf@upenn.edu)
- Daniel Angell (dpa34@drexel.edu)
- Jason Moore (moorejh28@gmail.com)
- and many more generous open-source contributors
TPOT is free software: you can redistribute it and/or modify
it under the terms of the GNU Lesser General Public License as
published by the Free Software Foundation, either version 3 of
the License, or (at your option) any later version.
TPOT is distributed in the hope that it will be useful,
but WITHOUT ANY WARRANTY; without even the implied warranty of
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
GNU Lesser General Public License for more details.
You should have received a copy of the GNU Lesser General Public
License along with TPOT. If not, see .
"""
from amltk.pipeline import Choice, Component, Sequential, Node, Fixed, Split, Join, Searchable
from tpot.search_spaces.pipelines import SequentialPipeline, ChoicePipeline, UnionPipeline
from tpot.search_spaces.nodes import EstimatorNode
from ConfigSpace import ConfigurationSpace
def component_to_estimatornode(component: Component) -> EstimatorNode:
method = component.item
space_dict = {}
if component.space is not None:
space_dict.update(component.space)
if component.config is not None:
space_dict.update(component.config)
space = ConfigurationSpace(component.space)
tpot_sp = EstimatorNode(method=method, space=space)
return tpot_sp
def fixed_to_estimatornode(node: Fixed) -> EstimatorNode:
method = node.item
#check if method is a class or an object
if not isinstance(method, type):
method = type(method)
#if baseestimator, get params
if hasattr(node.item, 'get_params'):
space_dict = node.item.get_params(deep=False)
else:
space_dict = {}
if node.space is not None:
space_dict.update(node.space)
if node.config is not None:
space_dict.update(node.config)
tpot_sp = EstimatorNode(method=method, space=space_dict)
return tpot_sp
def sequential_to_sequentialpipeline(sequential: Sequential) -> SequentialPipeline:
nodes = [tpot_parser(node) for node in sequential.nodes]
tpot_sp = SequentialPipeline(search_spaces=nodes)
return tpot_sp
def choice_to_choicepipeline(choice: Choice) -> ChoicePipeline:
nodes = [tpot_parser(node) for node in choice.nodes]
tpot_sp = ChoicePipeline(search_spaces=nodes)
return tpot_sp
def split_to_unionpipeline(split: Split) -> UnionPipeline:
nodes = [tpot_parser(node) for node in split.nodes]
tpot_sp = UnionPipeline(search_spaces=nodes)
return tpot_sp
def tpot_parser(
node: Node,
):
"""
Convert amltk pipeline search space into a tpot pipeline search space.
Parameters
----------
node: amltk.pipeline.Node
The node to convert.
Returns
-------
tpot.search_spaces.base.SearchSpace
The equivalent TPOT search space which can be optimized by TPOT.
"""
if isinstance(node, Component):
return component_to_estimatornode(node)
elif isinstance(node, Sequential):
return sequential_to_sequentialpipeline(node)
elif isinstance(node, Choice):
return choice_to_choicepipeline(node)
elif isinstance(node, Fixed):
return fixed_to_estimatornode(node)
elif isinstance(node, Split):
return split_to_unionpipeline(node)
else:
raise ValueError(f"Node type {type(node)} not supported")
================================================
FILE: tpot/utils/eval_utils.py
================================================
"""
This file is part of the TPOT library.
The current version of TPOT was developed at Cedars-Sinai by:
- Pedro Henrique Ribeiro (https://github.com/perib, https://www.linkedin.com/in/pedro-ribeiro/)
- Anil Saini (anil.saini@cshs.org)
- Jose Hernandez (jgh9094@gmail.com)
- Jay Moran (jay.moran@cshs.org)
- Nicholas Matsumoto (nicholas.matsumoto@cshs.org)
- Hyunjun Choi (hyunjun.choi@cshs.org)
- Gabriel Ketron (gabriel.ketron@cshs.org)
- Miguel E. Hernandez (miguel.e.hernandez@cshs.org)
- Jason Moore (moorejh28@gmail.com)
The original version of TPOT was primarily developed at the University of Pennsylvania by:
- Randal S. Olson (rso@randalolson.com)
- Weixuan Fu (weixuanf@upenn.edu)
- Daniel Angell (dpa34@drexel.edu)
- Jason Moore (moorejh28@gmail.com)
- and many more generous open-source contributors
TPOT is free software: you can redistribute it and/or modify
it under the terms of the GNU Lesser General Public License as
published by the Free Software Foundation, either version 3 of
the License, or (at your option) any later version.
TPOT is distributed in the hope that it will be useful,
but WITHOUT ANY WARRANTY; without even the implied warranty of
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
GNU Lesser General Public License for more details.
You should have received a copy of the GNU Lesser General Public
License along with TPOT. If not, see .
"""
import types
from abc import abstractmethod
import numpy as np
from joblib import Parallel, delayed
import traceback
from collections.abc import Iterable
import warnings
from stopit import threading_timeoutable, TimeoutException
from tpot.selectors import survival_select_NSGA2
import time
import dask
import stopit
from dask.diagnostics import ProgressBar
from tqdm.dask import TqdmCallback
from dask.distributed import progress
import distributed
import func_timeout
import gc
import math
def process_scores(scores, n):
'''
Purpose: This function processes a list of scores to ensure that each score list has the same length, n. If a score list is shorter than n, the function fills the list with either "TIMEOUT" or "INVALID" values.
Parameters:
scores: A list of score lists. Each score list represents a set of scores for a particular player or team. The score lists may have different lengths.
n: An integer representing the desired length for each score list.
Returns:
The scores list, after processing.
'''
for i in range(len(scores)):
if len(scores[i]) < n:
if "TIMEOUT" in scores[i]:
scores[i] = ["TIMEOUT" for j in range(n)]
else:
scores[i] = ["INVALID" for j in range(n)]
return scores
def objective_nan_wrapper( individual,
objective_function,
verbose=0,
max_eval_time_mins=None,
**objective_kwargs):
with warnings.catch_warnings(record=True) as w: #catches all warnings in w so it can be supressed by verbose
try:
if max_eval_time_mins is None or math.isinf(max_eval_time_mins):
value = objective_function(individual, **objective_kwargs)
else:
value = func_timeout.func_timeout(max_eval_time_mins*60, objective_function, args=[individual], kwargs=objective_kwargs)
if not isinstance(value, Iterable):
value = [value]
if len(w) and verbose>=4:
warnings.warn(w[0].message)
return value
except func_timeout.exceptions.FunctionTimedOut:
if verbose >= 4:
print(f'WARNING AN INDIVIDUAL TIMED OUT: \n {individual} \n')
return ["TIMEOUT"]
except Exception as e:
if verbose == 4:
print(f'WARNING THIS INDIVIDUAL CAUSED AND EXCEPTION \n {individual} \n {e} \n')
if verbose >= 5:
trace = traceback.format_exc()
print(f'WARNING THIS INDIVIDUAL CAUSED AND EXCEPTION \n {individual} \n {e} \n {trace}')
return ["INVALID"]
def eval_objective_list(ind, objective_list, verbose=0,**objective_kwargs):
scores = np.concatenate([objective_nan_wrapper(ind, obj, verbose,**objective_kwargs) for obj in objective_list ])
return scores
def parallel_eval_objective_list(individual_list,
objective_list,
verbose=0,
max_eval_time_mins=None,
n_expected_columns=None,
client=None,
scheduled_timeout_time=None,
**objective_kwargs):
individual_stack = list(individual_list)
max_queue_size = len(client.cluster.workers)
submitted_futures = {}
scores_dict = {}
submitted_inds = set()
global_timeout_triggered = False
while len(submitted_futures) < max_queue_size and len(individual_stack)>0:
individual = individual_stack.pop()
future = client.submit(eval_objective_list, individual, objective_list, verbose=verbose, max_eval_time_mins=max_eval_time_mins,**objective_kwargs)
submitted_futures[future] = {"individual": individual,
"time": time.time(),}
submitted_inds.add(individual.unique_id())
while len(individual_stack)>0 or len(submitted_futures)>0:
#wait for at least one future to finish or timeout
try:
if max_eval_time_mins is None or math.isinf(max_eval_time_mins):
next(distributed.as_completed(submitted_futures))
else:
next(distributed.as_completed(submitted_futures, timeout=max_eval_time_mins*60))
except dask.distributed.TimeoutError:
pass
except dask.distributed.CancelledError:
pass
global_timeout_triggered = scheduled_timeout_time is not None and time.time() > scheduled_timeout_time
#Loop through all futures, collect completed and timeout futures.
for completed_future in list(submitted_futures.keys()):
#get scores and update
if completed_future.done(): #if future is done
#If the future is done but threw and error, record the error
if completed_future.exception() or completed_future.status == "error": #if the future is done and threw an error
print("Exception in future")
print(completed_future.exception())
scores = [np.nan for _ in range(n_expected_columns)]
eval_error = "INVALID"
elif completed_future.cancelled(): #if the future is done and was cancelled
print("Cancelled future (likely memory related)")
scores = [np.nan for _ in range(n_expected_columns)]
eval_error = "INVALID"
client.run(gc.collect)
else: #if the future is done and did not throw an error, get the scores
try:
scores = completed_future.result()
#check if scores contain "INVALID" or "TIMEOUT"
if "INVALID" in scores:
eval_error = "INVALID"
scores = [np.nan for _ in range(n_expected_columns)]
elif "TIMEOUT" in scores:
eval_error = "TIMEOUT"
scores = [np.nan for _ in range(n_expected_columns)]
else:
eval_error = None
except Exception as e:
print("Exception in future, but not caught by dask")
print(e)
print(completed_future.exception())
print(completed_future)
print("status", completed_future.status)
print("done", completed_future.done())
print("cancelld ", completed_future.cancelled())
scores = [np.nan for _ in range(n_expected_columns)]
eval_error = "INVALID"
completed_future.release() #release the future
else: #if future is not done
# check if the future has been running for too long, cancel the future
# we multiply max_eval_time_mins by 1.25 since the objective function in the future should be able to cancel itself. This is a backup in case it doesn't.
if max_eval_time_mins is not None and time.time() - submitted_futures[completed_future]["time"] > max_eval_time_mins*1.25*60:
completed_future.cancel()
completed_future.release()
if verbose >= 4:
print(f'WARNING AN INDIVIDUAL TIMED OUT (Fallback): \n {submitted_futures[completed_future]} \n')
scores = [np.nan for _ in range(n_expected_columns)]
eval_error = "TIMEOUT"
elif global_timeout_triggered:
completed_future.cancel()
completed_future.release()
if verbose >= 4:
print(f'WARNING AN INDIVIDUAL TIMED OUT (max_time_mins): \n {submitted_futures[completed_future]} \n')
scores = [np.nan for _ in range(n_expected_columns)]
eval_error = None #eval error is None because these individuals were not evaluated or did not have time to reach max_eval_time_mins. this allows them to be reused if warm_start=True
else:
continue #otherwise, continue to next future
#log scores
cur_individual = submitted_futures[completed_future]["individual"]
scores_dict[cur_individual] = {"scores": scores,
"start_time": submitted_futures[completed_future]["time"],
"end_time": time.time(),
"eval_error": eval_error,
}
#update submitted futures
submitted_futures.pop(completed_future)
#I am not entirely sure if this is necessary. I believe that calling release on the futures should be enough to free up memory. If memory issues persist, this may be a good place to start.
#client.run(gc.collect) #run garbage collection to free up memory
#break if timeout
if global_timeout_triggered:
while len(individual_stack) > 0:
individual = individual_stack.pop()
scores_dict[individual] = {"scores": [np.nan for _ in range(n_expected_columns)],
"start_time": time.time(),
"end_time": time.time(),
"eval_error": None,
}
break
#submit new futures
while len(submitted_futures) < max_queue_size and len(individual_stack)>0:
individual = individual_stack.pop()
future = client.submit(eval_objective_list, individual, objective_list, verbose=verbose, timeout=max_eval_time_mins*60,**objective_kwargs)
submitted_futures[future] = {"individual": individual,
"time": time.time(),}
submitted_inds.add(individual.unique_id())
#I am not entirely sure if this is necessary. I believe that calling release on the futures should be enough to free up memory. If memory issues persist, this may be a good place to start.
#client.run(gc.collect) #run garbage collection to free up memory
#collect remaining futures
final_scores = [scores_dict[individual]["scores"] for individual in individual_list]
final_start_times = [scores_dict[individual]["start_time"] for individual in individual_list]
final_end_times = [scores_dict[individual]["end_time"] for individual in individual_list]
final_eval_errors = [scores_dict[individual]["eval_error"] for individual in individual_list]
final_scores = process_scores(final_scores, n_expected_columns)
return final_scores, final_start_times, final_end_times, final_eval_errors
###################
# Parallel optimization
#############
@threading_timeoutable(np.nan) #TODO timeout behavior
def optimize_objective(ind, objective, steps=5, verbose=0):
with warnings.catch_warnings(record=True) as w: #catches all warnings in w so it can be supressed by verbose
try:
value = ind.optimize(objective, steps=steps)
if not isinstance(value, Iterable):
value = [value]
if len(w) and verbose>=2:
warnings.warn(w[0].message)
return value
except Exception as e:
if verbose >= 2:
print('WARNING THIS INDIVIDUAL CAUSED AND EXCEPTION')
print(e)
print()
if verbose >= 3:
print(traceback.format_exc())
print()
return [np.nan]
def parallel_optimize_objective(individual_list,
objective,
n_jobs = 1,
verbose=0,
steps=5,
timeout=None,
**objective_kwargs, ):
Parallel(n_jobs=n_jobs)(delayed(optimize_objective)(ind, objective, steps, verbose, timeout=timeout) for ind in individual_list ) #TODO: parallelize
================================================
FILE: tpot/utils/utils.py
================================================
"""
This file is part of the TPOT library.
The current version of TPOT was developed at Cedars-Sinai by:
- Pedro Henrique Ribeiro (https://github.com/perib, https://www.linkedin.com/in/pedro-ribeiro/)
- Anil Saini (anil.saini@cshs.org)
- Jose Hernandez (jgh9094@gmail.com)
- Jay Moran (jay.moran@cshs.org)
- Nicholas Matsumoto (nicholas.matsumoto@cshs.org)
- Hyunjun Choi (hyunjun.choi@cshs.org)
- Gabriel Ketron (gabriel.ketron@cshs.org)
- Miguel E. Hernandez (miguel.e.hernandez@cshs.org)
- Jason Moore (moorejh28@gmail.com)
The original version of TPOT was primarily developed at the University of Pennsylvania by:
- Randal S. Olson (rso@randalolson.com)
- Weixuan Fu (weixuanf@upenn.edu)
- Daniel Angell (dpa34@drexel.edu)
- Jason Moore (moorejh28@gmail.com)
- and many more generous open-source contributors
TPOT is free software: you can redistribute it and/or modify
it under the terms of the GNU Lesser General Public License as
published by the Free Software Foundation, either version 3 of
the License, or (at your option) any later version.
TPOT is distributed in the hope that it will be useful,
but WITHOUT ANY WARRANTY; without even the implied warranty of
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
GNU Lesser General Public License for more details.
You should have received a copy of the GNU Lesser General Public
License along with TPOT. If not, see .
"""
import numpy as np
import scipy
import statistics
import tpot
import pandas as pd
def get_thresholds(scores, start=0, end=1, scale=.5, n=10,):
thresh = beta_interpolation(start=start, end=end, scale=scale, n=n)
return [np.percentile(scores, t) for t in thresh]
def equalize_list(lst, n_steps):
step_size = len(lst) / n_steps
new_lst = []
for i in range(n_steps):
start_index = int(i * step_size)
end_index = int((i+1) * step_size)
if i == 0: # First segment
step_lst = [lst[start_index]] * (end_index - start_index)
elif i == n_steps-1: # Last segment
step_lst = [lst[-1]] * (end_index - start_index)
else: # Middle segment
segment = lst[start_index:end_index]
median_value = statistics.median(segment)
step_lst = [median_value] * (end_index - start_index)
new_lst.extend(step_lst)
return new_lst
def beta_interpolation(start=0, end=1, scale=1, n=10, n_steps=None):
if n_steps is None:
n_steps = n
if n_steps > n:
n_steps = n
if scale <= 0:
scale = 0.0001
if scale >= 1:
scale = 0.9999
alpha = 3 * scale
beta = 3 - alpha
x = np.linspace(0,1,n)
values = scipy.special.betainc(alpha,beta,x)*(end-start)+start
if n_steps is not None:
return equalize_list(values, n_steps)
else:
return values
#thanks chat gtp
def remove_items(items, indexes_to_remove):
items = items.copy()
#if items is a numpy array, we need to convert to a list
if type(items) == np.ndarray:
items = items.tolist()
for index in sorted(indexes_to_remove, reverse=True):
del items[index]
return np.array(items)
# https://stackoverflow.com/questions/32791911/fast-calculation-of-pareto-front-in-python
# bigger is better
def is_pareto_efficient(scores, return_mask = True):
"""
Find the pareto-efficient points
:param scores: An (n_points, n_scores) array
:param return_mask: True to return a mask
:return: An array of indices of pareto-efficient points.
If return_mask is True, this will be an (n_points, ) boolean array
Otherwise it will be a (n_efficient_points, ) integer array of indices.
"""
is_efficient = np.arange(scores.shape[0])
n_points = scores.shape[0]
next_point_index = 0 # Next index in the is_efficient array to search for
while next_point_indexscores[next_point_index], axis=1)
nondominated_point_mask[next_point_index] = True
is_efficient = is_efficient[nondominated_point_mask] # Remove dominated points
scores = scores[nondominated_point_mask]
next_point_index = np.sum(nondominated_point_mask[:next_point_index])+1
if return_mask:
is_efficient_mask = np.zeros(n_points, dtype = bool)
is_efficient_mask[is_efficient] = True
return is_efficient_mask
else:
return is_efficient
def get_pareto_frontier(df, column_names, weights):
# dftmp = df[~df[column_names].isin(invalid_values).any(axis=1)]
dftmp = df[df[column_names].notnull().all(axis=1)]
if "Budget" in dftmp.columns:
#get rows with the max budget
dftmp = dftmp[dftmp["Budget"]==dftmp["Budget"].max()]
indexes = dftmp[~dftmp[column_names].isna().any(axis=1)].index.values
weighted_scores = df.loc[indexes][column_names].to_numpy() * weights
mask = is_pareto_efficient(weighted_scores, return_mask = True)
df["Pareto_Front"] = np.nan #TODO this will get deprecated
df.loc[indexes[mask], "Pareto_Front"] = 1
def get_pareto_front(df, column_names, weights):
dftmp = df[df[column_names].notnull().all(axis=1)]
if "Budget" in dftmp.columns:
#get rows with the max budget
dftmp = dftmp[dftmp["Budget"]==dftmp["Budget"].max()]
indexes = dftmp[~dftmp[column_names].isna().any(axis=1)].index.values
weighted_scores = df.loc[indexes][column_names].to_numpy() * weights
pareto_fronts = tpot.selectors.nondominated_sorting(weighted_scores)
df = pd.DataFrame(index=df.index,columns=["Pareto_Front"], data=[])
df["Pareto_Front"] = np.nan
for i, front in enumerate(pareto_fronts):
for index in front:
df.loc[indexes[index], "Pareto_Front"] = i+1
return df["Pareto_Front"]