[
{
"path": ".gitignore",
"content": "\n###########\n# data #\n###########\nltp_data\n\n###########\n# outputs #\n###########\noutput\nCMakeFiles\ncmake_install.cmake\nCmakeCache.txt\nMakefile\nlibs\ntarget\n\n###########\n# IDEs #\n###########\n.idea\n"
},
{
"path": ".gitmodules",
"content": "[submodule \"src/main/c++/ltp\"]\n\tpath = src/main/c++/ltp\n\turl = https://github.com/HIT-SCIR/ltp.git\n"
},
{
"path": ".travis.yml",
"content": "language:\n - cpp\n - java\n\nos:\n - linux\n - osx\n\nbefore_script:\n - if [[ \"$TRAVIS_OS_NAME\" == \"osx\" && -z \"$JAVA_HOME\" && -x \"/usr/libexec/java_home\" ]] ; then export JAVA_HOME=$(/usr/libexec/java_home); fi\n - git submodule init\n - git submodule update\n\nscript:\n - mvn -Dmaven.test.skip=true\n"
},
{
"path": "CMakeLists.txt",
"content": "cmake_minimum_required (VERSION 2.8.0)\nproject (\"ltp4j\")\n\nfind_package(JNI)\nset (LTP_HOME \"${PROJECT_SOURCE_DIR}/ltp\" CACHE STRING \"Use to specified ltp path\") # change it to your ltp root\nset (LIBRARY_OUTPUT_PATH ${PROJECT_SOURCE_DIR}/libs)\nset (JNI_SOURCE_DIR ${PROJECT_SOURCE_DIR}/jni)\n\ninclude_directories (\n ${JNI_SOURCE_DIR}\n ${LTP_HOME}/include\n ${JNI_INCLUDE_DIRS})\n\n#if(WIN32)\n# include_directories ($ENV{JAVA_HOME}/include/win32)\n#else(WIN32)\n# include_directories ($ENV{JAVA_HOME}/include/linux)\n#endif(WIN32)\n\nif(APPLE)\n set(CMAKE_CXX_FLAGS \"-stdlib=libstdc++\")\nendif(APPLE)\n\nif(WIN32)\n link_directories (${LTP_HOME}/lib/Debug)\nelse(WIN32)\n link_directories (${LTP_HOME}/lib)\nendif(WIN32)\n\nadd_library (split_sentence_jni SHARED\n ${JNI_SOURCE_DIR}/split_sentence_jni.cpp)\ntarget_link_libraries (split_sentence_jni splitsnt)\n\nadd_library (segmentor_jni SHARED ${JNI_SOURCE_DIR}/segment_jni.cpp)\ntarget_link_libraries (segmentor_jni segmentor)\n\nadd_library(postagger_jni SHARED ${JNI_SOURCE_DIR}/postag_jni.cpp)\ntarget_link_libraries (postagger_jni postagger)\n\nadd_library (ner_jni SHARED ${JNI_SOURCE_DIR}/ner_jni.cpp)\ntarget_link_libraries (ner_jni ner)\n\nadd_library (parser_jni SHARED ${JNI_SOURCE_DIR}/parser_jni.cpp)\ntarget_link_libraries (parser_jni parser)\n\nadd_library (srl_jni SHARED ${JNI_SOURCE_DIR}/srl_jni.cpp)\ntarget_link_libraries (srl_jni srl)\n\n# -----------------------------------------------\n# TOOLKIT\n"
},
{
"path": "README.md",
"content": "ltp4jbeta: Language Technology Platform For Java\n============================================\n\n[](https://travis-ci.org/HIT-SCIR/ltp4j)\n[](http://ltp4j.readthedocs.org/en/neoltp4j/?badge=neoltp4j)\n\n# LTP 4.0\nLTP 4.0 的支持请移步[libltp](https://github.com/HIT-SCIR/libltp)仓库\n\n# 更新\n\n1. ltp4j 现已经更新对 LTP 3.4.0的支持。\n2. 项目改用 maven 构建、编译。具体使用方法参见文档。\n\n# 简介\n\nltp4j是语言技术平台[(Language Technology Platform, LTP)](https://github.com/HIT-SCIR/ltp)接口的一个Java封装。\n本项目旨在使Java用户可以本地调用LTP。\n本项目仍在开发之中,欢迎反馈bug。\n\n# 文档\n\n请参考在线文档:[ltp4j使用文档](http://ltp4j.readthedocs.io)\n\n"
},
{
"path": "aol.properties",
"content": "amd64.Windows.msvc.cpp.defines=Windows WIN32 _WINDOWS NOMINMAX BOOST_ALL_NO_LIB\namd64.Windows.msvc.c.defines=Windows WIN32 _WINDOWS NOMINMAX BOOST_ALL_NO_LIB\n\n"
},
{
"path": "appveyor.yml",
"content": "version: '{build}'\n\nimage:\n - Visual Studio 2015\n - Visual Studio 2017\n\nplatform: x64\n\ninstall:\n - ps: |\n Add-Type -AssemblyName System.IO.Compression.FileSystem\n if (!(Test-Path -Path \"C:\\maven\" )) {\n (new-object System.Net.WebClient).DownloadFile(\n 'http://www.us.apache.org/dist/maven/maven-3/3.3.9/binaries/apache-maven-3.3.9-bin.zip',\n 'C:\\maven-bin.zip'\n )\n [System.IO.Compression.ZipFile]::ExtractToDirectory(\"C:\\maven-bin.zip\", \"C:\\maven\")\n }\n - cmd: SET PATH=C:\\maven\\apache-maven-3.3.9\\bin;%JAVA_HOME%\\bin;%PATH%\n - cmd: SET MAVEN_OPTS=-XX:MaxPermSize=2g -Xmx4g\n - cmd: SET JAVA_OPTS=-XX:MaxPermSize=2g -Xmx4g\n\nbuild_script:\n - git submodule init\n - git submodule update\n - mvn -Dmaven.test.skip=true\n\ncache:\n - C:\\maven\\\n - C:\\Users\\appveyor\\.m2\n"
},
{
"path": "doc/api.rst",
"content": "编程接口\n========\n\n.. java:package:: edu.hit.ir.ltp4j\n\n分词接口\n--------\n\n.. java:type:: public class Segmentor\n\n分词主要提供三个接口:\n\n.. java:method:: public final native int create(String modelPath)\n\n 功能:\n\n 读取模型文件,初始化分词器。\n\n 参数:\n\n +---------------------+------------------------------------------------------------+\n | 参数名 | 参数描述 |\n +=====================+============================================================+\n | String modelPath | 指定模型文件的路径 |\n +---------------------+------------------------------------------------------------+\n \n\n.. java:method:: public final native void release()\n\n 功能:\n\n 释放模型文件,销毁分词器。\n\n.. java:method:: public final native int segment(String sent, List words)\n\n 功能:\n\n 调用分词接口。\n\n 参数:\n\n +---------------------+------------------------------------------------------------+\n | 参数名 | 参数描述 |\n +=====================+============================================================+\n | String sent | 待分词句子 |\n +---------------------+------------------------------------------------------------+\n | List words | 结果分词序列 |\n +---------------------+------------------------------------------------------------+\n\n\n**示例程序**\n\n.. code:: java\n\n import java.util.ArrayList;\n import java.util.List;\n import edu.hit.ir.ltp4j.*;\n\n public class TestSegment {\n public static void main(String[] args) {\n if(Segmentor.create(\"../../../ltp_data/cws.model\")<0){\n System.err.println(\"load failed\");\n return;\n }\n\n String sent = \"我是中国人\";\n List words = new ArrayList();\n int size = Segmentor.segment(sent,words);\n\n for(int i = 0; i words, List tags)\n\n 功能:\n\n 调用词性标注接口\n\n 参数:\n\n +--------------------+--------------------------------------------------------------------+\n | 参数名 | 参数描述 |\n +====================+====================================================================+\n | List words | 待标注的词序列 |\n +--------------------+--------------------------------------------------------------------+\n | List tags | 词性标注结果,序列中的第i个元素是第i个词的词性 |\n +--------------------+--------------------------------------------------------------------+\n\n**示例程序**\n\n.. code:: java\n\n import java.util.ArrayList;\n import java.util.List;\n import edu.hit.ir.ltp4j.*;\n\n public class TestPostag {\n public static void main(String[] args) {\n if(Postagger.create(\"../../../ltp_data/pos.model\")<0) {\n System.err.println(\"load failed\");\n return;\n }\n\n List words= new ArrayList();\n words.add(\"我\"); words.add(\"是\");\n words.add(\"中国\"); words.add(\"人\");\n List postags= new ArrayList();\n\n int size = Postagger.postag(words,postags);\n for(int i = 0; i < size; i++) {\n System.out.print(words.get(i)+\"_\"+postags.get(i));\n if(i==size-1) {\n System.out.println();\n } else {\n System.out.print(\"|\");\n }\n }\n Postagger.release();\n }\n }\n\n\n命名实体识别接口\n------------------\n\n.. java:type:: public class NER\n\n命名实体识别主要提供三个接口:\n\n.. java:method:: public final native int create(String modelPath)\n\n 功能:\n\n 读取模型文件,初始化命名实体识别器\n\n 参数:\n\n +----------------------------------------+--------------------------------------------------------------------+\n | 参数名 | 参数描述 |\n +========================================+====================================================================+\n | const char * path | 命名实体识别模型路径 |\n +----------------------------------------+--------------------------------------------------------------------+\n\n 返回值:\n\n 返回一个指向词性标注器的指针。\n\n.. java:method:: public final native void release()\n\n 功能:\n\n 释放模型文件,销毁命名实体识别器。\n\n\n.. java:method:: public final native int recognize(List words, List postags, List ners)\n\n 功能:\n\n 调用命名实体识别接口\n\n 参数:\n\n +----------------------+----------------------------------------------------------------------------------------+\n | 参数名 | 参数描述 |\n +======================+========================================================================================+\n | List words | 待识别的词序列 |\n +----------------------+----------------------------------------------------------------------------------------+\n | List postags | 待识别的词的词性序列 |\n +----------------------+----------------------------------------------------------------------------------------+\n | List ners | | 命名实体识别结果, |\n | | | 命名实体识别的结果为O时表示这个词不是命名实体, |\n | | | 否则为{POS}-{TYPE}形式的标记,POS代表这个词在命名实体中的位置,TYPE表示命名实体类型 |\n +----------------------+----------------------------------------------------------------------------------------+\n\n\n**示例程序**\n\n.. code:: java\n\n import java.util.ArrayList;\n import java.util.List;\n import edu.hit.ir.ltp4j.*;\n\n public class TestNer {\n\n public static void main(String[] args) {\n if(NER.create(\"../../../ltp_data/ner.model\")<0) {\n System.err.println(\"load failed\");\n return; \n }\n List words = new ArrayList();\n List tags = new ArrayList();\n List ners = new ArrayList();\n words.add(\"中国\");tags.add(\"ns\");\n words.add(\"国际\");tags.add(\"n\");\n words.add(\"广播\");tags.add(\"n\");\n words.add(\"电台\");tags.add(\"n\");\n words.add(\"创办\");tags.add(\"v\");\n words.add(\"于\");tags.add(\"p\");\n words.add(\"1941年\");tags.add(\"m\");\n words.add(\"12月\");tags.add(\"m\");\n words.add(\"3日\");tags.add(\"m\");\n words.add(\"。\");tags.add(\"wp\");\n\n NER.recognize(words, tags, ners);\n\n for (int i = 0; i < words.size(); i++) {\n System.out.println(ners.get(i));\n }\n\n NER.release();\n\n }\n }\n\n依存句法分析接口\n-----------------\n\n.. java:type:: public class Parser\n\n依存句法分析主要提供三个接口:\n\n.. java:method:: public final native int create(String modelPath)\n\n 功能:\n\n 读取模型文件,初始化依存句法分析器\n\n 参数:\n\n +---------------------------------------+--------------------------------------------------------------------+\n | 参数名 | 参数描述 |\n +=======================================+====================================================================+\n | String modelPath | 依存句法分析模型路径 |\n +---------------------------------------+--------------------------------------------------------------------+\n\n.. java:method:: public final native void release()\n\n 功能:\n\n 释放模型文件,销毁依存句法分析器。\n\n.. java:method:: public final native int parse(List words, List tags, List heads, List deprels)\n\n 功能:\n\n 调用依存句法分析接口\n\n 参数:\n\n +----------------------+--------------------------------------------------------------------+\n | 参数名 | 参数描述 |\n +======================+====================================================================+\n | List words | 待分析的词序列 |\n +----------------------+--------------------------------------------------------------------+\n | List tags | 待分析的词的词性序列 |\n +----------------------+--------------------------------------------------------------------+\n | List heads | 结果依存弧,heads[i]代表第i个词的父亲节点的编号 |\n +----------------------+--------------------------------------------------------------------+\n | List deprels | 结果依存弧关系类型 |\n +----------------------+--------------------------------------------------------------------+\n\n\n**示例程序**\n\n.. code:: java\n\n import java.util.ArrayList;\n import java.util.List;\n import edu.hit.ir.ltp4j.*;\n\n public class TestParse {\n\n public static void main(String[] args){\n Parser parser = new Parser();\n if(parser.create(\"./model/ltp_data/parser.model\") < 0){\n throw new RuntimeException(\"fail to load parser model\");\n }\n List words = new ArrayList<>();\n List postags = new ArrayList<>();\n words.add(\"一把手\"); postags.add(\"n\");\n words.add(\"亲自\"); postags.add(\"d\");\n words.add(\"过河\"); postags.add(\"v\");\n words.add(\"。\"); postags.add(\"wp\");\n\n List heads = new ArrayList<>();\n List deprels = new ArrayList<>();\n\n parser.parse(words, postags, heads, deprels);\n\n for(int i=0; i words, List tags, List heads, List deprels, List>>>> srls)\n\n 功能:\n\n 调用命名实体识别接口\n\n 参数:\n\n +---------------------------------------------------+-----------------------------------------------------------+\n | 参数名 | 参数描述 |\n +===================================================+===========================================================+\n | List words | 输入的词序列 |\n +---------------------------------------------------+-----------------------------------------------------------+\n | List tags | 输入的词性序列 |\n +---------------------------------------------------+-----------------------------------------------------------+\n | List heads | 这个词的父节点的编号 [#f1]_ |\n +---------------------------------------------------+-----------------------------------------------------------+\n | List deprels | 这个词的父节点的依存关系类型 |\n +---------------------------------------------------+-----------------------------------------------------------+\n | List>>>> srls | 结果语义角色标注 |\n +---------------------------------------------------+-----------------------------------------------------------+\n\n常见问题\n--------\n\n.. rubric:: 注\n\n.. [#f1] 编号从0记起"
},
{
"path": "doc/background.rst",
"content": "简介与背景知识\n==============\n\nltp4j是 `语言技术平台 (Language Technology Platform, LTP) `_ 接口的一个Java封装。 本项目旨在使Java用户可以本地调用LTP。\n\n在使用ltp4j之前,您需要简要了解\n\n* 什么是语言技术平台,它能否帮助您解决问题\n* 如何安装语言技术平台\n* 语言技术平台提供哪些编程接口\n\n如果您对这些问题不了解,请首先阅读我们提供的有关语言技术平台的 `文档 `_ 。在本文档的后续中,我们假定您已经阅读并成功编译并使用语言技术平台。\n\n\nltj4j的基本实现思路是依靠JNI技术实现在Java中调用C/C++动态库。我们建议您使用几分钟了解 `Java调用C/C++动态库 `_ 的实践方式。\n\nltp4j整个项目由两部分组成,他们分别是:\n\n* ltp4j.jar:Java接口程序。\n* C++代理程序:ltp4j加载的ltp动态库。\n\n"
},
{
"path": "doc/conf.py",
"content": "# -*- coding: utf-8 -*-\n#\n# LTP documentation build configuration file, created by\n# sphinx-quickstart on Mon Jan 19 17:24:17 2015.\n#\n# This file is execfile()d with the current directory set to its\n# containing dir.\n#\n# Note that not all possible configuration values are present in this\n# autogenerated file.\n#\n# All configuration values have a default; values that are commented out\n# serve to show the default.\n\nimport sys\nimport os\n\n# If extensions (or modules to document with autodoc) are in another directory,\n# add these directories to sys.path here. If the directory is relative to the\n# documentation root, use os.path.abspath to make it absolute, like shown here.\n#sys.path.insert(0, os.path.abspath('.'))\n\n# -- General configuration ------------------------------------------------\n\n# If your documentation needs a minimal Sphinx version, state it here.\n#needs_sphinx = '1.0'\n\n# Add any Sphinx extension module names here, as strings. They can be\n# extensions coming with Sphinx (named 'sphinx.ext.*') or your custom\n# ones.\nextensions = ['javasphinx']\n\n# Add any paths that contain templates here, relative to this directory.\ntemplates_path = ['_templates']\n\n# The suffix of source filenames.\nsource_suffix = '.rst'\n\n# The encoding of source files.\n#source_encoding = 'utf-8-sig'\n\n# The master toctree document.\nmaster_doc = 'index'\n\n# General information about the project.\nproject = u'ltp4j'\ncopyright = u'2016, HIT-SCIR'\n\n# The version info for the project you're documenting, acts as replacement for\n# |version| and |release|, also used in various other places throughout the\n# built documents.\n#\n# The short X.Y version.\nversion = '0.1'\n# The full version, including alpha/beta/rc tags.\nrelease = '0.1-SNAPSHORT'\n\n# The language for content autogenerated by Sphinx. Refer to documentation\n# for a list of supported languages.\n#language = None\n\n# There are two options for replacing |today|: either, you set today to some\n# non-false value, then it is used:\n#today = ''\n# Else, today_fmt is used as the format for a strftime call.\n#today_fmt = '%B %d, %Y'\n\n# List of patterns, relative to source directory, that match files and\n# directories to ignore when looking for source files.\nexclude_patterns = ['_build']\n\n# The reST default role (used for this markup: `text`) to use for all\n# documents.\n#default_role = None\n\n# If true, '()' will be appended to :func: etc. cross-reference text.\n#add_function_parentheses = True\n\n# If true, the current module name will be prepended to all description\n# unit titles (such as .. function::).\n#add_module_names = True\n\n# If true, sectionauthor and moduleauthor directives will be shown in the\n# output. They are ignored by default.\n#show_authors = False\n\n# The name of the Pygments (syntax highlighting) style to use.\npygments_style = 'sphinx'\n\n# A list of ignored prefixes for module index sorting.\n#modindex_common_prefix = []\n\n# If true, keep warnings as \"system message\" paragraphs in the built documents.\n#keep_warnings = False\n\n\n# -- Options for HTML output ----------------------------------------------\n\n# The theme to use for HTML and HTML Help pages. See the documentation for\n# a list of builtin themes.\nhtml_theme = 'alabaster'\n\n# Theme options are theme-specific and customize the look and feel of a theme\n# further. For a list of options available for each theme, see the\n# documentation.\n#html_theme_options = {}\n\n# Add any paths that contain custom themes here, relative to this directory.\n#html_theme_path = []\n\n# The name for this set of Sphinx documents. If None, it defaults to\n# \" v documentation\".\n#html_title = None\n\n# A shorter title for the navigation bar. Default is the same as html_title.\n#html_short_title = None\n\n# The name of an image file (relative to this directory) to place at the top\n# of the sidebar.\n#html_logo = None\n\n# The name of an image file (within the static path) to use as favicon of the\n# docs. This file should be a Windows icon file (.ico) being 16x16 or 32x32\n# pixels large.\n#html_favicon = None\n\n# Add any paths that contain custom static files (such as style sheets) here,\n# relative to this directory. They are copied after the builtin static files,\n# so a file named \"default.css\" will overwrite the builtin \"default.css\".\nhtml_static_path = ['_static']\n\n# Add any extra paths that contain custom files (such as robots.txt or\n# .htaccess) here, relative to this directory. These files are copied\n# directly to the root of the documentation.\n#html_extra_path = []\n\n# If not '', a 'Last updated on:' timestamp is inserted at every page bottom,\n# using the given strftime format.\n#html_last_updated_fmt = '%b %d, %Y'\n\n# If true, SmartyPants will be used to convert quotes and dashes to\n# typographically correct entities.\n#html_use_smartypants = True\n\n# Custom sidebar templates, maps document names to template names.\n#html_sidebars = {}\n\n# Additional templates that should be rendered to pages, maps page names to\n# template names.\n#html_additional_pages = {}\n\n# If false, no module index is generated.\n#html_domain_indices = True\n\n# If false, no index is generated.\n#html_use_index = True\n\n# If true, the index is split into individual pages for each letter.\n#html_split_index = False\n\n# If true, links to the reST sources are added to the pages.\n#html_show_sourcelink = True\n\n# If true, \"Created using Sphinx\" is shown in the HTML footer. Default is True.\n#html_show_sphinx = True\n\n# If true, \"(C) Copyright ...\" is shown in the HTML footer. Default is True.\n#html_show_copyright = True\n\n# If true, an OpenSearch description file will be output, and all pages will\n# contain a tag referring to it. The value of this option must be the\n# base URL from which the finished HTML is served.\n#html_use_opensearch = ''\n\n# This is the file name suffix for HTML files (e.g. \".xhtml\").\n#html_file_suffix = None\n\n# Output file base name for HTML help builder.\nhtmlhelp_basename = 'LTPdoc'\n\n\n# -- Options for LaTeX output ---------------------------------------------\n\nlatex_elements = {\n# The paper size ('letterpaper' or 'a4paper').\n#'papersize': 'letterpaper',\n\n# The font size ('10pt', '11pt' or '12pt').\n#'pointsize': '10pt',\n\n# Additional stuff for the LaTeX preamble.\n#'preamble': '',\n}\n\n# Grouping the document tree into LaTeX files. List of tuples\n# (source start file, target name, title,\n# author, documentclass [howto, manual, or own class]).\nlatex_documents = [\n ('index', 'LTP.tex', u'LTP Documentation',\n u'HIT-SCIR', 'manual'),\n]\n\n# The name of an image file (relative to this directory) to place at the top of\n# the title page.\n#latex_logo = None\n\n# For \"manual\" documents, if this is true, then toplevel headings are parts,\n# not chapters.\n#latex_use_parts = False\n\n# If true, show page references after internal links.\n#latex_show_pagerefs = False\n\n# If true, show URL addresses after external links.\n#latex_show_urls = False\n\n# Documents to append as an appendix to all manuals.\n#latex_appendices = []\n\n# If false, no module index is generated.\n#latex_domain_indices = True\n\n\n# -- Options for manual page output ---------------------------------------\n\n# One entry per manual page. List of tuples\n# (source start file, name, description, authors, manual section).\nman_pages = [\n ('index', 'ltp', u'LTP Documentation',\n [u'HIT-SCIR'], 1)\n]\n\n# If true, show URL addresses after external links.\n#man_show_urls = False\n\n\n# -- Options for Texinfo output -------------------------------------------\n\n# Grouping the document tree into Texinfo files. List of tuples\n# (source start file, target name, title, author,\n# dir menu entry, description, category)\ntexinfo_documents = [\n ('index', 'ltp4j', u'ltp4j Documentation',\n u'HIT-SCIR', 'ltp4j', 'One line description of project.',\n 'Miscellaneous'),\n]\n\n# Documents to append as an appendix to all manuals.\n#texinfo_appendices = []\n\n# If false, no module index is generated.\n#texinfo_domain_indices = True\n\n# How to display URL addresses: 'footnote', 'no', or 'inline'.\n#texinfo_show_urls = 'footnote'\n\n# If true, do not generate a @detailmenu in the \"Top\" node's menu.\n#texinfo_no_detailmenu = False\n\n\n"
},
{
"path": "doc/index.rst",
"content": ".. ltpdoctest documentation master file, created by\n sphinx-quickstart on Wed Jan 14 22:35:55 2015.\n You can adapt this file completely to your liking, but it should at least\n contain the root `toctree` directive.\n\n.. include:: background.rst\n\n目录\n=====\n\n.. toctree::\n :maxdepth: 2\n\n install\n run\n api\n\n\n索引及表格\n==================\n\n* :ref:`genindex`\n* :ref:`search`\n\n"
},
{
"path": "doc/install.rst",
"content": ".. _install-label:\n\n编译ltp4j\n=========\n\n如果您需要使用ltp4j,必须拥有两部分内容\n\n* ltp4j.jar与C++代理程序\n* LTP模型文件\n\n其中,LTP模型文件可以从 `百度云 `_,当前ltp4j对应的模型版本为3.3.1。本文档将着重介绍如何编译ltp4j.jar与其C++代理程序。\n\n安装Maven\n---------\n\nltp4j使用 `apache maven `_ 进行构建。在构建ltp4j之前,您首先需要安装maven。安装方法请参考: `安装apache maven `_。\n\n编译ltp4j\n---------\n\n在确保安装maven的前提下(即 `mvn -h` 具有输出结果),您可以按照如下方式构建ltp4j。\n\n1. 在命令行下进入ltp4j所在文件夹\n2. `git submodule init`\n3. `git submodule update`\n4. `mvn -Dmaven.test.skip=true`\n\n如果您编译提示成功同时项目根目录下包含 `target/ltp4j-{version}.jar`,证明已经编译成功。\n\nnar-maven-plugin\n~~~~~~~~~~~~~~~~\n\n本部分将介绍编译ltp4j的一些技术考虑,与编译ltp4j无关。对这部分不感兴趣的用户可以忽略这部分文档。\n\nltp4j的基本技术考虑是 **使用户使用最简单的技术手段编译使用ltp4j** 。所以我们选择了maven作为构建工具,希望可以通过一条指令完成编译过程。\n如前文所述,ltp4j需要ltp4j.jar及其C++代理程序两部分。\n为了在maven中既能够使用java编译器编译jar又能够使用C++编译器编译C++代理程序,我们经过调研,决定使用 `nar-maven-plugin `_ 。这一maven插件使我们可以在不同的系统架构下编译C++的代码 (AOL)。\n在使用过程中,我们发现了这一插件的一系列bug,并通过贡献代码的方式进行了解决。\n\n\n编译结果\n--------\n\nnar-maven-plugin的编译结果随操作系统的不同而存在差异。其生成的ltp4j.jar以及代理文件可以从如下路径找到\n\n* jar:`./target/ltp4j-{version}.jar`\n* 代理程序:`./target/ltp4j-{version}-{AOL}-jni/`\n\n其中,`vesion` 代表ltp4j的版本。`AOL` 代表 **体系结构-系统-链接器** 。\n举例来讲,\n\n* Windows 64位系统使用MSVC编译对应的AOL为:amd64-Windows-msvc\n* Ubuntu 64位系统使用gnuc++编译对应的AOL为:amd64-Linux-gpp\n\n编译结果示例\n~~~~~~~~~~~~\n\n**64位Linux g++**\n\n.. code:: shell\n\n $ find target/ -type f -name \"*.jar\" -or -name \"*.so\"\n target/ltp4j-0.1.0-SNAPSHOT.jar\n target/nar/ltp4j-0.1.0-SNAPSHOT-amd64-Linux-gpp-jni/lib/amd64-Linux-gpp/jni/libltp4j-0.1.0-SNAPSHOT.so\n\n\n**64位windows MSVC**\n\n.. code:: shell\n\n $ find target/ -type f -name \"*.jar\" -or -name \"*.dll\"\n target/ltp4j-0.1.0-SNAPSHOT.jar\n target/nar/ltp4j-0.1.0-SNAPSHOT-amd64-Windows-msvc-jni/lib/amd64-Windows-msvc/jni/ltp4j-0.1.0-SNAPSHOT.dll\n\n\n常见问题\n--------\n\n"
},
{
"path": "doc/ltp4j-document-1.0.md",
"content": "ltp4j 文档\n===============\n\nltp4j是[语言技术平台(Language Technology Platform, LTP)](https://github.com/HIT-SCIR/ltp)的Java封装。\n关于LTP更多的信息,欢迎访问LTP项目主页。\n\n### 作者\n* 韩冰 << bhan@ir.hit.edu.cn >> 2014-05-15 创建文档\n\n# 简介与背景知识\nltp4j是[语言技术平台(Language Technology Platform, LTP)](https://github.com/HIT-SCIR/ltp)接口的一个Java封装。\n本项目旨在使Java用户可以本地调用LTP。\n\n在使用ltp4j之前,您需要简要了解\n* [什么是语言技术平台](https://github.com/HIT-SCIR/ltp/blob/master/doc/ltp-document-3.0.md#%E7%AE%80%E4%BB%8B),它能否帮助您解决问题\n* [如何安装语言技术平台](https://github.com/HIT-SCIR/ltp/blob/master/doc/ltp-document-3.0.md#%E5%A6%82%E4%BD%95%E5%AE%89%E8%A3%85ltp)\n* [语言技术平台提供哪些编程接口](https://github.com/HIT-SCIR/ltp/blob/master/doc/ltp-document-3.0.md#%E7%BC%96%E7%A8%8B%E6%8E%A5%E5%8F%A3)\n\n如果您对这些问题不了解,请首先阅读我们提供的有关语言技术平台的文档。\n在本文档的后续中,我们假定您已经阅读并成功编译并使用语言技术平台。\n\nltp4j主要依靠JNI实现。整个项目由两部分组成,他们分别是:\n\n* __ltp4j.jar__:Java接口程序,利用ant能够直接编译构建为ltp4j.jar,方便用户导入使用。\n* C++代理程序,在项目/jni/目录下实现Java接口中的功能,利用CMake编译构建为动态库。\n\n# 安装\n\n在这一章节中,我们假定您下载并将LTP放置于`/path/to/your/ltp-project`路径下;\n而ltp4j放置于`/path/to/your/ltp4j-project`路径下。\n\n## 编译ltp4j.jar\n\n### 命令行方式\n\nltp4j.jar使用ant编译工具编译。 在命令行环境下,可以在项目根目录(`/path/to/your/ltp4j-project`)下使用\n\n```\nant\n```\n命令编译。编译成功后,将在`build_jar/jar`下产生`ltp4j.jar`文件。\n\n### Eclipse\n\n如果使用Eclipse,可以按照_\"File > New > Project... > Java Project from Existing Ant Buildfile\"_的方式从build.xml中创建项目。 \n选择next后,在Ant buildfile:一栏中填入build.xml的路径,`/path/to/your/ltp4j-project/build.xml`(window用户请添加盘符并将/改为\\\\),如下图所示。\n\n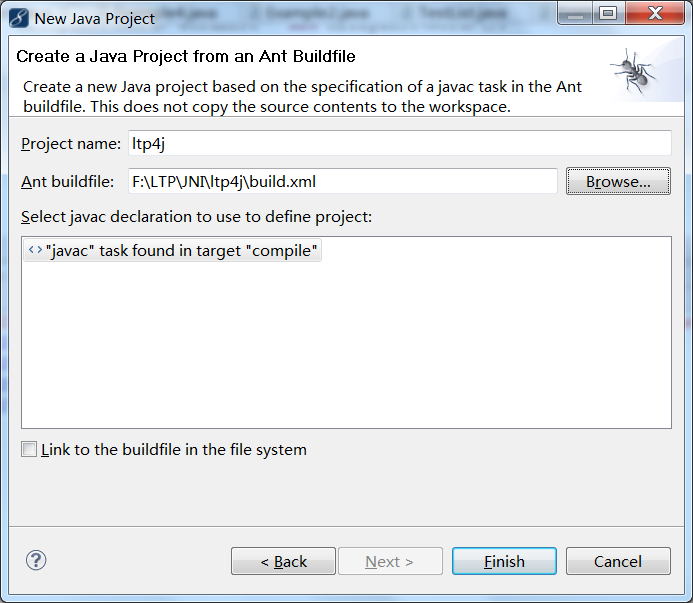\n\n点击Finish就导入了项目。\n\n在导入项目后,右键build.xml选择2 Ant Build。 在弹出的对话框中的选择main选项卡,并在`Base Directory:`中填入项目路径`/path/to/your/ltp4j-project/`。\n\n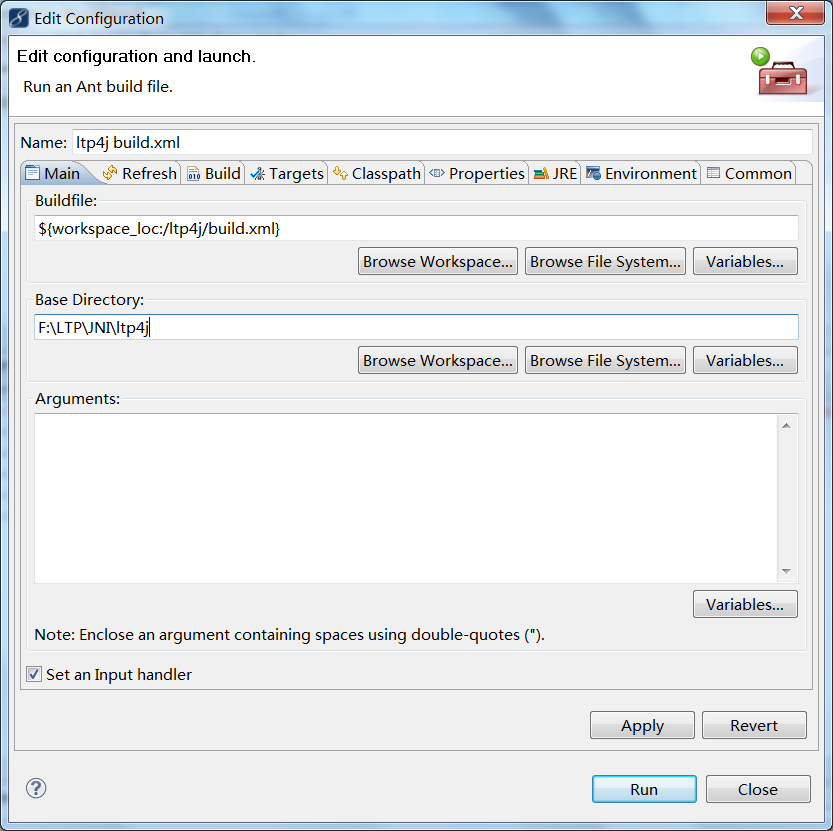\n\n填好后执行run,build/jar下产生名为ltp4j.jar的jar文件。\n\n### Intellij Idea\n\n配置maven。点击右侧的MavenProject。导入pom.xml。\n\n## 编译C++代理程序\n\n代理程序jni动态库依赖于ltp的动态库,请先行编译LTP。\n\n### 安装CMake\nltp4j使用的C++代理程序使用编译工具CMake构建项目。\n在编译代理程序之前,你需要首先安装CMake。\nCMake的网站在[这里](http://www.cmake.org)。如果你是Windows用户,请下载CMake的二进制安装包;\n如果你是Linux,Mac OS或Cygwin的用户,可以通过编译源码的方式安装CMake,当然,你也可以使用Linux的软件源来安装。\n\n### Windows(MSVC)编译\n\n第一步:配置ltp的安装路径\n\n因为jni依赖于ltp编译产生的动态库,所以在编译过程中需要给出ltp的路径。\n请修改`/path/to/your/ltp4j-project/CMakeLists.txt`中的`LTP_HOME`的值为您的LTP项目的路径(`/path/to/your/ltp-project`),\n对应修改的代码为:\n\n```set (LTP_HOME \"/path/to/your/ltp-project/\")```\n\n第二步:构建VC Project\n\n在项目文件夹下新建一个名为build的文件夹,使用CMake Gui,在source code中填入项目文件夹,在binaries中填入build文件夹。然后Configure -> Generate。\n\n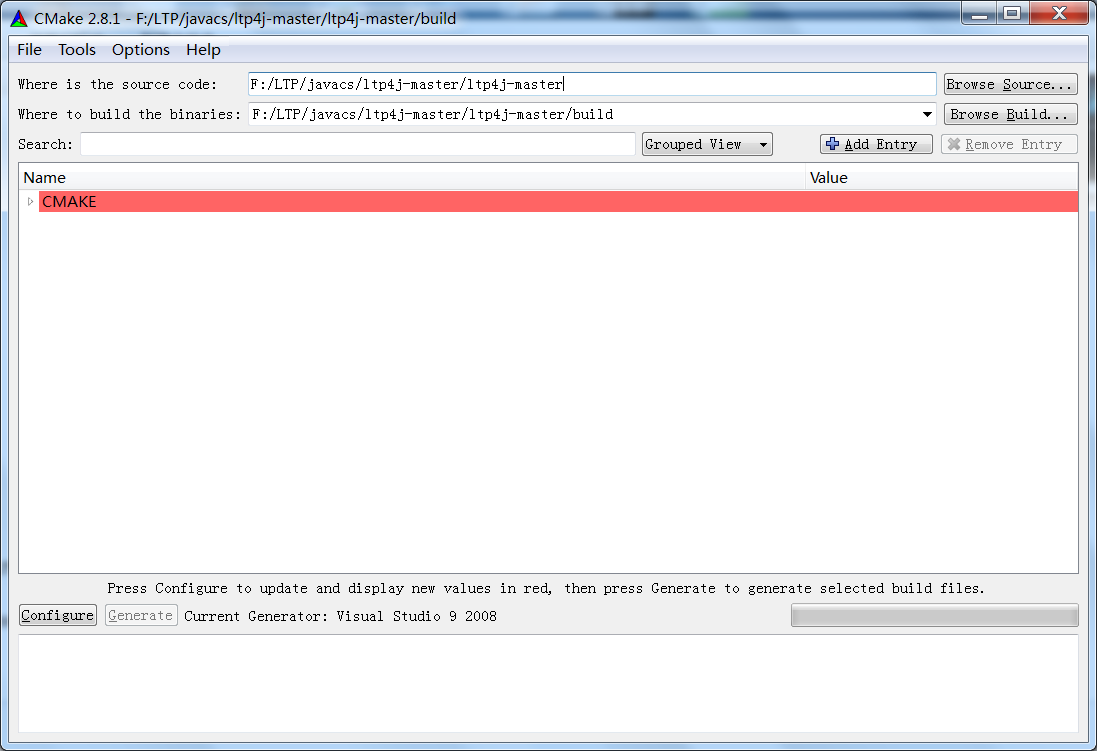\n\n或者在命令行build 路径下运行\n\n```\ncmake ..\n```\n\n第二步:编译\n\n### Linux,Mac OSX和Cygwin编译\nLinux、Mac OSX(*)和Cygwin的用户,可以直接在项目根目录下使用命令\n\n```\ncmake .\nmake\n```\n\n进行编译。\n\n编译成功后,会在libs文件夹下生成以下一些动态库(**)\n\n| 程序名 | 说明 |\n| ------ | ---- |\n| split_sentence_jni.so | 分句动态库 |\n| segmentor_jni.so | 分词动态库 |\n| postagger_jni.so| 词性标注动态库 |\n| parser_jni.so | 依存句法分析动态库 |\n| ner_jni.so | 命名实体识别动态库 |\n| srl_jni.so | 语义角色标注动态库 |\n\n###注意事项\n\n* **该处编译需要设置Java环境变量JAVA_HOME**。\n* **需要保持c++编译器与JDK同是32位或者64位,否则JVM不能加载生成的动态库**\n\n#开始使用\n\n构建需要在本地使用ltp的工程\n* 导入ltp4j.jar\n* windows下将libs文件夹中生成的所有动态库、以及原ltp lib文件夹下的splitsnt、segmentor、postagger、ner、parser、srl 6个动态库拷贝到项目根目录\n* linux下export LD_LIBRARY_PATH=#jni动态库路径#\n\n接下来便可仿照下面各个接口的例子使用ltp啦。\n\n#编程接口\n\n## 分词接口\n\nedu.ir.hit.ltp4j.Segmentor\n\n分词主要提供四个接口:\n\n**int create(带外部词典)**\n\n功能:\n\n读取模型文件,初始化分词器。\n\n参数:\n\n| 参数名 | 参数描述 |\n|--------|----------|\n|String path | 指定模型文件的路径 |\n|String lexicon_path | 指定外部词典路径。如果lexicon_path为NULL,则不加载外部词典 |\n\n返回值:\n\n成功加载模型返回1,否则返回-1。\n\n**int create**\n\n功能:\n\n读取模型文件,初始化分词器。\n\n参数:\n\n| 参数名 | 参数描述 |\n|--------|----------|\n|String path | 指定模型文件的路径 |\n\n\n返回值:\n\n成功加载模型返回1,否则返回-1。\n\n\n**void release**\n\n功能:\n\n释放模型文件,销毁分词器。\n\n参数:无\n\n返回值:无\n\n**int Segment**\n\n功能:\n\n调用分词接口。\n\n参数:\n\n| 参数名 | 参数描述 |\n|--------|----------|\n|String | 待分词句子 |\n|java.util.List< String > words| 结果分词序列 |\n\n返回值:\n\n返回结果中词的个数。\n\n### 示例程序\n\n一个简单的实例程序可以说明分词接口的用法:\n\n```\nimport java.util.ArrayList;\nimport java.util.List;\nimport edu.hit.ir.ltp4j.*;\n\npublic class TestSegment {\n public static void main(String[] args) {\n if(Segmentor.create(\"../../../ltp_data/cws.model\")<0){\n System.err.println(\"load failed\");\n return;\n }\n\n String sent = \"我是中国人\";\n List words = new ArrayList();\n int size = Segmentor.segment(sent,words);\n\n for(int i = 0; i words | 待标注的词序列 |\n|java.util.List< String > tags | 词性标注结果,序列中的第i个元素是第i个词的词性 |\n\n返回值:\n\n返回结果中词的个数\n\n### 示例程序\n\n一个简单的实例程序可以说明词性标注接口的用法:\n\n```\nimport java.util.ArrayList;\nimport java.util.ArrayList;\nimport java.util.List;\nimport edu.hit.ir.ltp4j.*;\n\npublic class TestPostag {\n public static void main(String[] args) {\n if(Postagger.create(\"../../../ltp_data/pos.model\")<0) {\n System.err.println(\"load failed\");\n return;\n }\n \n List words= new ArrayList();\n words.add(\"我\"); words.add(\"是\");\n words.add(\"中国\"); words.add(\"人\");\n List postags= new ArrayList();\n\n int size = Postagger.postag(words,postags);\n for(int i = 0; i < size; i++) {\n System.out.print(words.get(i)+\"_\"+postags.get(i));\n if(i==size-1) {\n System.out.println();\n } else {\n System.out.print(\"|\");\n }\n }\n Postagger.release();\n }\n}\n```\n\n## 命名实体识别接口\n\nedu.ir.hit.ltp4j.NER\n\n命名实体识别主要提供三个接口:\n\n**int create**\n\n功能:\n\n参数:\n\n| 参数名 | 参数描述 |\n|-------|----------|\n| String path | 命名实体识别模型路径 |\n\n返回值:\n\n成功加载模型返回1,否则返回-1。\n\n**void release**\n\n功能:\n\n释放模型文件,销毁命名实体识别器。\n\n参数:无\n\n返回值:无\n\n**int recognize**\n\n功能:\n\n调用命名实体识别接口\n\n参数:\n\n|参数名 | 参数描述 |\n|-------|----------|\n|java.util.List< String > words | 待识别的词序列 |\n|java.util.List< String > postags | 待识别的词的词性序列 |\n|java.util.List< String > tags | 命名实体识别结果,命名实体识别的结果为O时表示这个词不是命名实体,否则为{POS}-{TYPE}形式的标记,POS代表这个词在命名实体中的位置,TYPE表示命名实体类型 |\n\n返回值:\n\n返回结果中词的个数\n\n### 示例程序\n import java.util.ArrayList;\n import java.util.List;\n import edu.hit.ir.ltp4j.*;\n\n public class TestNer {\n\n public static void main(String[] args) {\n if(NER.create(\"../../../ltp_data/ner.model\")<0) {\n System.err.println(\"load failed\");\n return; \n }\n List words = new ArrayList();\n List tags = new ArrayList();\n List ners = new ArrayList();\n words.add(\"中国\");tags.add(\"ns\");\n words.add(\"国际\");tags.add(\"n\");\n words.add(\"广播\");tags.add(\"n\");\n words.add(\"电台\");tags.add(\"n\");\n words.add(\"创办\");tags.add(\"v\");\n words.add(\"于\");tags.add(\"p\");\n words.add(\"1941年\");tags.add(\"m\");\n words.add(\"12月\");tags.add(\"m\");\n words.add(\"3日\");tags.add(\"m\");\n words.add(\"。\");tags.add(\"wp\");\n\n NER.recognize(words, tags, ners);\n\n for (int i = 0; i < words.size(); i++) {\n System.out.println(ners.get(i));\n }\n\n NER.release();\n\n }\n }\n\n## 依存句法分析接口\nedu.ir.hit.ltp4j.Parser\n依存句法分析主要提供三个接口:\n\n**int create**\n\n功能:\n\n读取模型文件,初始化依存句法分析器\n\n参数:\n\n|参数名 | 参数描述 |\n|---|---|\n|String path | 依存句法分析模型路径 |\n\n返回值:\n\n成功加载模型返回1,否则返回-1。\n\n**void release**\n\n功能:\n\n释放模型文件,销毁依存句法分析器。\n\n参数:无\n\n返回值:无\n\n**int parse**\n\n功能:\n\n调用依存句法分析接口\n\n参数:\n\n|参数名 | 参数描述 |\n|---|---|\n|java.util.List< String > words | 待分析的词序列 |\n|java.util.List< String > postags | 待分析的词的词性序列 |\n|java.util.List< Integer > heads | 结果依存弧,heads[i]代表第i个词的父亲节点的编号 |\n|java.util.List< String > deprels | 结果依存弧关系类型 |\n\n返回值:\n\n返回结果中词的个数\n\n### 示例程序\n\n一个简单的实例程序可以说明依存句法分析接口的用法:\n\n import java.util.ArrayList;\n import java.util.List;\n import edu.hit.ir.ltp4j.*;\n\n\n public class TestParser {\n\n public static void main(String[] args) {\n if(Parser.create(\"../../../ltp_data/parser.model\")<0) {\n System.err.println(\"load failed\");\n return;\n }\n List words = new ArrayList();\n List tags = new ArrayList();\n words.add(\"一把手\");tags.add(\"n\");\n words.add(\"亲自\");tags.add(\"d\");\n words.add(\"过问\");tags.add(\"v\");\n words.add(\"。\");tags.add(\"wp\");\n List heads = new ArrayList();\n List deprels = new ArrayList();\n\n int size = Parser.parse(words,tags,heads,deprels);\n\n for(int i = 0;i words | 待分析的词序列 |\n|java.util.List< String > postags | 待分析的词的词性序列 |\n|java.util.List< String > ners| 待分析的命名实体序列\n|java.util.List< Integer > heads | 待分析的依存弧,heads[i]代表第i个词的父亲节点的编号 |\n|java.util.List< String > deprels | 待分析的依存弧关系类型 |\n| List< Pair< Integer, List< Pair< String, Pair< Integer, Integer > > > > > srls | 结果语义角色标注 |\n\n返回值:\n\n返回角色个数\n\n### 示例程序\n\n一个简单的实例程序可以说明依存句法分析接口的用法:\n\n import java.util.ArrayList;\n import java.util.List;\n import edu.hit.ir.ltp4j.*;\n\n public class TestSrl {\n\n public static void main(String[] args) {\n SRL.create(\"../../../ltp_data/pisrl.model\");\n ArrayList words = new ArrayList();\n words.add(\"一把手\");\n words.add(\"亲自\");\n words.add(\"过问\");\n words.add(\"。\");\n ArrayList tags = new ArrayList();\n tags.add(\"n\");\n tags.add(\"d\");\n tags.add(\"v\");\n tags.add(\"wp\");\n ArrayList heads = new ArrayList();\n heads.add(2);\n heads.add(2);\n heads.add(-1);\n heads.add(2);\n ArrayList deprels = new ArrayList();\n deprels.add(\"SBV\");\n deprels.add(\"ADV\");\n deprels.add(\"HED\");\n deprels.add(\"WP\");\n List>>>> srls = new ArrayList>>>>();\n SRL.srl(words, tags, heads, deprels, srls);\n for (int i = 0; i < srls.size(); ++i) {\n System.out.println(srls.get(i).first + \":\");\n for (int j = 0; j < srls.get(i).second.size(); ++j) {\n System.out.println(\" tpye = \"+ srls.get(i).second.get(j).first + \" beg = \"+ srls.get(i).second.get(j).second.first + \" end = \"+ srls.get(i).second.get(j).second.second);\n }\n }\n SRL.release();\n }\n\n }\n \n###注意事项\n\n* **对于一个包含N个词的句子,句法分析返回的父节点范围在0至N之间,而语义角色标注的输入需要在-1至N-1之间。因此,若要在句法分析后进行语义角色标注,需要把heads作减一操作。**\n"
},
{
"path": "doc/make.bat",
"content": "@ECHO OFF\n\nREM Command file for Sphinx documentation\n\nif \"%SPHINXBUILD%\" == \"\" (\n\tset SPHINXBUILD=sphinx-build\n)\nset BUILDDIR=_build\nset ALLSPHINXOPTS=-d %BUILDDIR%/doctrees %SPHINXOPTS% .\nset I18NSPHINXOPTS=%SPHINXOPTS% .\nif NOT \"%PAPER%\" == \"\" (\n\tset ALLSPHINXOPTS=-D latex_paper_size=%PAPER% %ALLSPHINXOPTS%\n\tset I18NSPHINXOPTS=-D latex_paper_size=%PAPER% %I18NSPHINXOPTS%\n)\n\nif \"%1\" == \"\" goto help\n\nif \"%1\" == \"help\" (\n\t:help\n\techo.Please use `make ^` where ^ is one of\n\techo. html to make standalone HTML files\n\techo. dirhtml to make HTML files named index.html in directories\n\techo. singlehtml to make a single large HTML file\n\techo. pickle to make pickle files\n\techo. json to make JSON files\n\techo. htmlhelp to make HTML files and a HTML help project\n\techo. qthelp to make HTML files and a qthelp project\n\techo. devhelp to make HTML files and a Devhelp project\n\techo. epub to make an epub\n\techo. latex to make LaTeX files, you can set PAPER=a4 or PAPER=letter\n\techo. text to make text files\n\techo. man to make manual pages\n\techo. texinfo to make Texinfo files\n\techo. gettext to make PO message catalogs\n\techo. changes to make an overview over all changed/added/deprecated items\n\techo. xml to make Docutils-native XML files\n\techo. pseudoxml to make pseudoxml-XML files for display purposes\n\techo. linkcheck to check all external links for integrity\n\techo. doctest to run all doctests embedded in the documentation if enabled\n\tgoto end\n)\n\nif \"%1\" == \"clean\" (\n\tfor /d %%i in (%BUILDDIR%\\*) do rmdir /q /s %%i\n\tdel /q /s %BUILDDIR%\\*\n\tgoto end\n)\n\n\n%SPHINXBUILD% 2> nul\nif errorlevel 9009 (\n\techo.\n\techo.The 'sphinx-build' command was not found. Make sure you have Sphinx\n\techo.installed, then set the SPHINXBUILD environment variable to point\n\techo.to the full path of the 'sphinx-build' executable. Alternatively you\n\techo.may add the Sphinx directory to PATH.\n\techo.\n\techo.If you don't have Sphinx installed, grab it from\n\techo.http://sphinx-doc.org/\n\texit /b 1\n)\n\nif \"%1\" == \"html\" (\n\t%SPHINXBUILD% -b html %ALLSPHINXOPTS% %BUILDDIR%/html\n\tif errorlevel 1 exit /b 1\n\techo.\n\techo.Build finished. The HTML pages are in %BUILDDIR%/html.\n\tgoto end\n)\n\nif \"%1\" == \"dirhtml\" (\n\t%SPHINXBUILD% -b dirhtml %ALLSPHINXOPTS% %BUILDDIR%/dirhtml\n\tif errorlevel 1 exit /b 1\n\techo.\n\techo.Build finished. The HTML pages are in %BUILDDIR%/dirhtml.\n\tgoto end\n)\n\nif \"%1\" == \"singlehtml\" (\n\t%SPHINXBUILD% -b singlehtml %ALLSPHINXOPTS% %BUILDDIR%/singlehtml\n\tif errorlevel 1 exit /b 1\n\techo.\n\techo.Build finished. The HTML pages are in %BUILDDIR%/singlehtml.\n\tgoto end\n)\n\nif \"%1\" == \"pickle\" (\n\t%SPHINXBUILD% -b pickle %ALLSPHINXOPTS% %BUILDDIR%/pickle\n\tif errorlevel 1 exit /b 1\n\techo.\n\techo.Build finished; now you can process the pickle files.\n\tgoto end\n)\n\nif \"%1\" == \"json\" (\n\t%SPHINXBUILD% -b json %ALLSPHINXOPTS% %BUILDDIR%/json\n\tif errorlevel 1 exit /b 1\n\techo.\n\techo.Build finished; now you can process the JSON files.\n\tgoto end\n)\n\nif \"%1\" == \"htmlhelp\" (\n\t%SPHINXBUILD% -b htmlhelp %ALLSPHINXOPTS% %BUILDDIR%/htmlhelp\n\tif errorlevel 1 exit /b 1\n\techo.\n\techo.Build finished; now you can run HTML Help Workshop with the ^\n.hhp project file in %BUILDDIR%/htmlhelp.\n\tgoto end\n)\n\nif \"%1\" == \"qthelp\" (\n\t%SPHINXBUILD% -b qthelp %ALLSPHINXOPTS% %BUILDDIR%/qthelp\n\tif errorlevel 1 exit /b 1\n\techo.\n\techo.Build finished; now you can run \"qcollectiongenerator\" with the ^\n.qhcp project file in %BUILDDIR%/qthelp, like this:\n\techo.^> qcollectiongenerator %BUILDDIR%\\qthelp\\LTP.qhcp\n\techo.To view the help file:\n\techo.^> assistant -collectionFile %BUILDDIR%\\qthelp\\LTP.ghc\n\tgoto end\n)\n\nif \"%1\" == \"devhelp\" (\n\t%SPHINXBUILD% -b devhelp %ALLSPHINXOPTS% %BUILDDIR%/devhelp\n\tif errorlevel 1 exit /b 1\n\techo.\n\techo.Build finished.\n\tgoto end\n)\n\nif \"%1\" == \"epub\" (\n\t%SPHINXBUILD% -b epub %ALLSPHINXOPTS% %BUILDDIR%/epub\n\tif errorlevel 1 exit /b 1\n\techo.\n\techo.Build finished. The epub file is in %BUILDDIR%/epub.\n\tgoto end\n)\n\nif \"%1\" == \"latex\" (\n\t%SPHINXBUILD% -b latex %ALLSPHINXOPTS% %BUILDDIR%/latex\n\tif errorlevel 1 exit /b 1\n\techo.\n\techo.Build finished; the LaTeX files are in %BUILDDIR%/latex.\n\tgoto end\n)\n\nif \"%1\" == \"latexpdf\" (\n\t%SPHINXBUILD% -b latex %ALLSPHINXOPTS% %BUILDDIR%/latex\n\tcd %BUILDDIR%/latex\n\tmake all-pdf\n\tcd %BUILDDIR%/..\n\techo.\n\techo.Build finished; the PDF files are in %BUILDDIR%/latex.\n\tgoto end\n)\n\nif \"%1\" == \"latexpdfja\" (\n\t%SPHINXBUILD% -b latex %ALLSPHINXOPTS% %BUILDDIR%/latex\n\tcd %BUILDDIR%/latex\n\tmake all-pdf-ja\n\tcd %BUILDDIR%/..\n\techo.\n\techo.Build finished; the PDF files are in %BUILDDIR%/latex.\n\tgoto end\n)\n\nif \"%1\" == \"text\" (\n\t%SPHINXBUILD% -b text %ALLSPHINXOPTS% %BUILDDIR%/text\n\tif errorlevel 1 exit /b 1\n\techo.\n\techo.Build finished. The text files are in %BUILDDIR%/text.\n\tgoto end\n)\n\nif \"%1\" == \"man\" (\n\t%SPHINXBUILD% -b man %ALLSPHINXOPTS% %BUILDDIR%/man\n\tif errorlevel 1 exit /b 1\n\techo.\n\techo.Build finished. The manual pages are in %BUILDDIR%/man.\n\tgoto end\n)\n\nif \"%1\" == \"texinfo\" (\n\t%SPHINXBUILD% -b texinfo %ALLSPHINXOPTS% %BUILDDIR%/texinfo\n\tif errorlevel 1 exit /b 1\n\techo.\n\techo.Build finished. The Texinfo files are in %BUILDDIR%/texinfo.\n\tgoto end\n)\n\nif \"%1\" == \"gettext\" (\n\t%SPHINXBUILD% -b gettext %I18NSPHINXOPTS% %BUILDDIR%/locale\n\tif errorlevel 1 exit /b 1\n\techo.\n\techo.Build finished. The message catalogs are in %BUILDDIR%/locale.\n\tgoto end\n)\n\nif \"%1\" == \"changes\" (\n\t%SPHINXBUILD% -b changes %ALLSPHINXOPTS% %BUILDDIR%/changes\n\tif errorlevel 1 exit /b 1\n\techo.\n\techo.The overview file is in %BUILDDIR%/changes.\n\tgoto end\n)\n\nif \"%1\" == \"linkcheck\" (\n\t%SPHINXBUILD% -b linkcheck %ALLSPHINXOPTS% %BUILDDIR%/linkcheck\n\tif errorlevel 1 exit /b 1\n\techo.\n\techo.Link check complete; look for any errors in the above output ^\nor in %BUILDDIR%/linkcheck/output.txt.\n\tgoto end\n)\n\nif \"%1\" == \"doctest\" (\n\t%SPHINXBUILD% -b doctest %ALLSPHINXOPTS% %BUILDDIR%/doctest\n\tif errorlevel 1 exit /b 1\n\techo.\n\techo.Testing of doctests in the sources finished, look at the ^\nresults in %BUILDDIR%/doctest/output.txt.\n\tgoto end\n)\n\nif \"%1\" == \"xml\" (\n\t%SPHINXBUILD% -b xml %ALLSPHINXOPTS% %BUILDDIR%/xml\n\tif errorlevel 1 exit /b 1\n\techo.\n\techo.Build finished. The XML files are in %BUILDDIR%/xml.\n\tgoto end\n)\n\nif \"%1\" == \"pseudoxml\" (\n\t%SPHINXBUILD% -b pseudoxml %ALLSPHINXOPTS% %BUILDDIR%/pseudoxml\n\tif errorlevel 1 exit /b 1\n\techo.\n\techo.Build finished. The pseudo-XML files are in %BUILDDIR%/pseudoxml.\n\tgoto end\n)\n\n:end\n"
},
{
"path": "doc/requirements.txt",
"content": "javasphinx\n"
},
{
"path": "doc/run.rst",
"content": "运行\n====\n\n以编译运行examples/Test.java为例。\n\n概念\n~~~~\n\n**version与aol**\n\nversion是当前ltp4j的版本号,aol是使用ltp4j机器的`架构-系统-链接器`\n\n在命令行条件下可以用如下命令获得\n\n.. code:: shell\n\n # get version\n version=`egrep '' pom.xml | head -1 | tr -d ' ' | sed 's///g' | sed 's/<\\/version>//g'`\n \n # get aol\n aol=`ls target/ltp4j-${version}-*-jni.nar | sed \"s/target\\/ltp4j-${version}-//g\" | sed \"s/-jni.nar//g\"`\n\n \n在其他条件下可以根据编译步骤生成的的nar文件进行判断。\n具体来讲编译步骤生成的nar文件的格式为`target/ltp4j-${version}-${aol}-jni.jar`。\n\n**运行jni的必要条件**\n\n1. 添加ltp4j.jar到java项目的classpath里\n2. 添加c++代理程序的路径到java.library.path里\n\n命令行\n~~~~~~\n\n.. code:: shell\n\n # get version\n version=`egrep '' pom.xml | head -1 | tr -d ' ' | sed 's///g' | sed 's/<\\/version>//g'`\n \n # get aol\n aol=`ls target/ltp4j-${version}-*-jni.nar | sed \"s/target\\/ltp4j-${version}-//g\" | sed \"s/-jni.nar//g\"`\n\n # compile\n javac -cp \"target/ltp4j-${version}.jar\" examples/Test.java\n \n # run, specifying java.library.path, Test accept input from stdin\n cat examples/example | java -Djava.library.path=target/nar/ltp4j-$version-$aol-jni/lib/$aol/jni/ \\\n -cp \"target/ltp4j-${version}.jar:examples\" Test \\\n --segment-model=ltp_data/cws.model \\\n --postag-model=ltp_data/pos.model \\\n --ner-model=ltp_data/ner.model \\\n --parser-model=ltp_data/parser.model \\\n --srl-dir=ltp_data/srl/\n\nEclipse\n~~~~~~~\n\n1. File -> New -> Java Project, 在Project name处填入ltp4jtest\n2. 右键examples项目下的src文件夹,在弹出菜单下选择New -> Class,Name处填入Test\n3. 将examples/Test.java填入Test中\n4. 右键examples项目下的Properties,\n 1. 选择 `Java Build Path`\n 2. 选择 `Libraries` 选项卡\n 3. 选择 `Add External JAR...` 选择编译出的ltp4j-$version.jar文件 [添加ltp4.jar]\n 4. 点击 > 箭头展开添加的ltp4j-$version.jar,在Native library location中选择C++代理程序的路径 [添加java.library.path]\n\n如图所示:\n\n.. image:: _static/eclipse.gif\n \n参考: `How to set the java.library.path from Eclipse `_\n\nIntellij\n~~~~~~~~\n\n参考:`How to set the java.library.path in intelliJ Idea `_\n\n常见问题\n~~~~~~~~\n\n"
},
{
"path": "examples/Console.java",
"content": "import java.util.Scanner;\nimport java.util.ArrayList;\nimport java.util.List;\nimport edu.hit.ir.ltp4j.SplitSentence;\nimport edu.hit.ir.ltp4j.Segmentor;\nimport edu.hit.ir.ltp4j.Postagger;\nimport edu.hit.ir.ltp4j.NER;\nimport edu.hit.ir.ltp4j.Parser;\nimport edu.hit.ir.ltp4j.SRL;\nimport edu.hit.ir.ltp4j.Pair;\n\npublic class Console {\n private String segmentModel;\n private String postagModel;\n private String NERModel;\n private String parserModel;\n private String SRLModel;\n\n private SplitSentence sentenceSplitApp;\n private Segmentor segmentorApp;\n private Postagger postaggerApp;\n private NER nerApp;\n private Parser parserApp;\n private SRL srlApp;\n\n private boolean ParseArguments(String[] args) {\n if (args.length == 1 && (args[0].equals(\"--help\") || args[0].equals(\"-h\"))) {\n Usage();\n return false;\n }\n\n for (int i = 0; i < args.length; ++ i) {\n if (args[i].startsWith(\"--segment-model=\")) {\n segmentModel = args[i].split(\"=\")[1];\n } else if (args[i].startsWith(\"--postag-model=\")) {\n postagModel = args[i].split(\"=\")[1];\n } else if (args[i].startsWith(\"--ner-model=\")) {\n NERModel = args[i].split(\"=\")[1];\n } else if (args[i].startsWith(\"--parser-model=\")) {\n parserModel = args[i].split(\"=\")[1];\n } else if (args[i].startsWith(\"--srl-model=\")) {\n SRLModel = args[i].split(\"=\")[1];\n } else {\n throw new IllegalArgumentException(\"Unknown options \" + args[i]);\n }\n }\n\n if (segmentModel == null || postagModel == null || NERModel == null ||\n parserModel == null || SRLModel == null) {\n Usage();\n throw new IllegalArgumentException(\"\");\n }\n\n sentenceSplitApp = new SplitSentence();\n\n segmentorApp = new Segmentor();\n segmentorApp.create(segmentModel);\n\n postaggerApp = new Postagger();\n postaggerApp.create(postagModel);\n\n nerApp = new NER();\n nerApp.create(NERModel);\n\n parserApp = new Parser();\n parserApp.create(parserModel);\n\n srlApp = new SRL();\n srlApp.create(SRLModel);\n\n return true;\n }\n\n public void Usage() {\n System.err.println(\"An command line example for ltp4j - The Java embedding of LTP\");\n System.err.println(\"Sentences are inputted from stdin.\");\n System.err.println(\"\");\n System.err.println(\"Usage:\");\n System.err.println(\"\");\n System.err.println(\" java -cp --segment-model= \\\\\");\n System.err.println(\" --postag-model= \\\\\");\n System.err.println(\" --ner-model= \\\\\");\n System.err.println(\" --parser-model= \\\\\");\n System.err.println(\" --srl-model=\");\n }\n\n private String join(ArrayList payload, String conjunction) {\n StringBuilder sb = new StringBuilder();\n if (payload == null || payload.size() == 0) {\n return \"\";\n }\n sb.append(payload.get(0));\n for (int i = 1; i < payload.size(); ++ i) {\n sb.append(conjunction).append(payload.get(i));\n }\n return sb.toString();\n }\n\n\n public void Analyse(String sent) {\n ArrayList sents = new ArrayList();\n sentenceSplitApp.splitSentence(sent, sents);\n\n for(int m = 0; m < sents.size(); m++) {\n ArrayList words = new ArrayList();\n ArrayList postags = new ArrayList();\n ArrayList ners = new ArrayList();\n ArrayList heads = new ArrayList();\n ArrayList deprels = new ArrayList();\n List>>>> srls =\n new ArrayList>>>>();\n\n System.out.println(\"#\" + (m + 1));\n System.out.println(\"Sentence : \" + sents.get(m));\n\n segmentorApp.segment(sents.get(m), words);\n System.out.println(\"Segment Result : \" + join(words, \"\\t\"));\n\n postaggerApp.postag(words, postags);\n System.out.print(\"Postag Result : \");\n System.out.println(join(postags, \"\\t\"));\n\n nerApp.recognize(words, postags, ners);\n System.out.print(\"NER Result : \");\n System.out.println(join(ners, \"\\t\"));\n\n parserApp.parse(words, postags, heads, deprels);\n int size = heads.size();\n StringBuilder sb = new StringBuilder();\n sb.append(heads.get(0)).append(\":\").append(deprels.get(0));\n for(int i = 1; i < heads.size(); i++) {\n sb.append(\"\\t\").append(heads.get(i)).append(\":\").append(deprels.get(i));\n }\n System.out.print(\"Parse Result : \");\n System.out.println(sb.toString());\n\n for (int i = 0; i < heads.size(); i++) {\n heads.set(i, heads.get(i) - 1);\n }\n\n srlApp.srl(words,postags,heads,deprels,srls);\n\n size = srls.size();\n System.out.print(\"SRL Result : \");\n if (size == 0) {\n System.out.println();\n }\n for (int i = 0; i < srls.size(); i++) {\n System.out.print(srls.get(i).first + \" ->\");\n for (int j = 0; j < srls.get(i).second.size(); j++) {\n System.out.print(srls.get(i).second.get(j).first\n + \": beg = \" + srls.get(i).second.get(j).second.first\n + \" end = \" + srls.get(i).second.get(j).second.second + \";\");\n }\n System.out.println();\n }\n }\n }\n\n public void release(){\n segmentorApp.release();\n postaggerApp.release();\n nerApp.release();\n parserApp.release();\n srlApp.release();\n }\n\n public static void main(String[] args) {\n Console console = new Console();\n\n try {\n if (!console.ParseArguments(args)) {\n return;\n }\n\n Scanner input = new Scanner(System.in);\n String sent;\n try {\n System.out.print(\">>> \");\n while((sent = input.nextLine()) != null) {\n if (sent.length() > 0) {\n console.Analyse(sent);\n }\n System.out.print(\">>> \");\n }\n } catch(Exception e) {\n console.release();\n }\n } catch (IllegalArgumentException e) {\n }\n }\n}\n"
},
{
"path": "examples/example",
"content": "中国进出口银行与中国银行加强合作\n"
},
{
"path": "pom.xml",
"content": "\n 4.0.0\n edu.hit.ir.ltp4j\n ltp4j\n 0.1.0-SNAPSHOT\n nar\n hitscir-ltp4j\n Language Technology Platform for Java\n http://github.com/HIT-SCIR/ltp4j\n\n \n UTF-8\n true\n \n\n \n \n The Apache License, Version 2.0\n http://www.apache.org/licenses/LICENSE-2.0.txt\n \n \n\n \n \n sonatype-nexus-snapshots\n Sonatype Nexus Snapshots\n https://oss.sonatype.org/content/repositories/snapshots/\n \n \n sonatype-nexus-staging\n Nexus Release Repository\n https://oss.sonatype.org/service/local/staging/deploy/maven2/\n \n \n\n \n \n junit\n junit\n 4.7\n test\n \n \n\n \n install\n \n \n maven-dependency-plugin\n \n \n maven-compiler-plugin\n \n \n com.github.maven-nar\n nar-maven-plugin\n 3.5.0\n true\n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n src/main/c++\n \n ltp/examples/*\n ltp/src/console/*\n ltp/src/ltp/*\n ltp/src/segmentor/io.cpp\n ltp/src/segmentor/otcws.cpp\n ltp/src/segmentor/segmentor_frontend.cpp\n ltp/src/segmentor/customized_segmentor_frontend.cpp\n ltp/src/postagger/io.cpp\n ltp/src/postagger/otpos.cpp\n ltp/src/postagger/postagger_frontend.cpp\n ltp/src/ner/io.cpp\n ltp/src/ner/otner.cpp\n ltp/src/ner/ner_frontend.cpp\n ltp/src/parser/*\n ltp/src/parser.n/io.cpp\n ltp/src/parser.n/main.cpp\n ltp/src/parser.n/parser_frontend.cpp\n ltp/src/srl/**/process/*\n ltp/src/srl/*/pred.cpp\n ltp/src/srl/*/train.cpp\n ltp/src/srl/tool/merge.cpp\n ltp/src/server/*\n ltp/src/xml4nlp/*\n ltp/src/unittest/*\n ltp/thirdparty/eigen/unsupported/**/*\n ltp/thirdparty/dynet/dynet/cuda.cc\n ltp/thirdparty/tinyxml/*\n ltp/thirdparty/tinythreadpp/*\n ltp/thirdparty/maxent/train.cpp\n ltp/thirdparty/maxent/predict.cpp\n ltp/thirdparty/gtest/**/*\n \n \n src/main/c++/ltp/src\n src/main/c++/ltp/src/srl\n src/main/c++/ltp/src/srl/common\n src/main/c++/ltp/src/srl/include\n src/main/c++/ltp/src/utils\n src/main/c++/ltp/thirdparty/boost/include\n src/main/c++/ltp/thirdparty/maxent\n src/main/c++/ltp/thirdparty/eigen\n src/main/c++/ltp/thirdparty/dynet\n src/main/c++/ltp/thirdparty/jsoncpp/include\n \n false\n \n \n \n \n \n \n \n \n \n \n **/*\n \n \n \n \n jni\n edu.hit.ir.ltp4j\n false\n \n \n \n \n \n \n \n \n \n Segmentor\n Postagger\n NER\n Parser\n SRL\n \n \n \n \n \n \n\n"
},
{
"path": "src/main/c++/edu_hit_ir_ltp4j_NER.cpp",
"content": "#include \"ner/ner_dll.h\"\n#include \"edu_hit_ir_ltp4j_NER.h\"\n#include \"string_to_jstring.hpp\"\n#include \n#include \n#include \n\nstatic void * ner = NULL;\n\nJNIEXPORT jint JNICALL Java_edu_hit_ir_ltp4j_NER_create\n (JNIEnv * env, jobject obj, jstring model_path) {\n const char * str = env->GetStringUTFChars( model_path , 0);\n\n if (!ner) {\n ner = ner_create_recognizer(str);\n } else {\n ner_release_recognizer(ner);\n ner = ner_create_recognizer(str);\n }\n\n env->ReleaseStringUTFChars( model_path, str); \n if (ner) {\n return 1;\n }\n return -1;\n}\n\nJNIEXPORT jint JNICALL Java_edu_hit_ir_ltp4j_NER_recognize\n (JNIEnv * env, jobject obj, jobject array_words, jobject array_tags, jobject array_ners) {\n\n jclass array_list = env->GetObjectClass(array_words);\n\n jmethodID list_add = env->GetMethodID(array_list,\"add\",\"(Ljava/lang/Object;)Z\");\n jmethodID list_get = env->GetMethodID(array_list,\"get\",\"(I)Ljava/lang/Object;\");\n jmethodID list_size = env->GetMethodID(array_list,\"size\",\"()I\");\n\n std::vector words,tags,ners;\n\n int size_words = env->CallIntMethod(array_words,list_size);\n int size_tags = env->CallIntMethod(array_tags,list_size);\n\n if (size_words!=size_tags) {\n return 0;\n }\n\n for (int i = 0; i < size_words; i++) {\n jobject tmp = env->CallObjectMethod(array_words,list_get,i);\n jstring s = reinterpret_cast (tmp);\n const char * st = env->GetStringUTFChars(s,0);\n std::string s_s(st);\n words.push_back(s_s);\n env->ReleaseStringUTFChars( s, st);\n }\n\n for (int i = 0; i < size_tags; i++) {\n jobject tmp = env->CallObjectMethod(array_tags,list_get,i);\n jstring s = reinterpret_cast (tmp);\n const char * st = env->GetStringUTFChars(s,0);\n std::string s_s(st);\n tags.push_back(s_s);\n env->ReleaseStringUTFChars( s, st); \n }\n\n int len = ner_recognize(ner,words,tags,ners);\n\n for (int i = 0; i < len; i++) {\n jobject tmp = stringToJstring(env,ners[i].c_str());\n env->CallBooleanMethod(array_ners,list_add,tmp);\n }\n return len;\n}\n\nJNIEXPORT void JNICALL Java_edu_hit_ir_ltp4j_NER_release\n (JNIEnv * env, jobject obj) {\n ner_release_recognizer(ner);\n ner = NULL;\n}\n\n\n"
},
{
"path": "src/main/c++/edu_hit_ir_ltp4j_Parser.cpp",
"content": "#include \"edu_hit_ir_ltp4j_Parser.h\"\n#include \"parser/parser_dll.h\"\n#include \"string_to_jstring.hpp\"\n#include \n#include \n#include \n#include \n\nstatic void * parser = NULL;\n\nJNIEXPORT jint JNICALL Java_edu_hit_ir_ltp4j_Parser_create\n (JNIEnv * env, jobject obj, jstring model_path) {\n\n const char * str = env->GetStringUTFChars( model_path , 0);\n\n if(!parser){\n parser = parser_create_parser(str);\n }\n\n env->ReleaseStringUTFChars( model_path, str);\n\n if(parser) {\n return 1;\n }\n\n return -1;\n}\n\nJNIEXPORT jint JNICALL Java_edu_hit_ir_ltp4j_Parser_parse\n (JNIEnv * env, jobject obj, jobject array_words, jobject array_tags, jobject array_heads, jobject array_deprels) {\n\n jclass array_list = env->GetObjectClass(array_words);\n jclass integer = env->FindClass(\"java/lang/Integer\");\n\n jmethodID list_add = env->GetMethodID(array_list, \"add\", \"(Ljava/lang/Object;)Z\");\n jmethodID list_get = env->GetMethodID(array_list, \"get\", \"(I)Ljava/lang/Object;\");\n jmethodID list_size = env->GetMethodID(array_list, \"size\", \"()I\");\n jmethodID integer_init =env->GetMethodID(integer, \"\", \"(I)V\");\n\n std::vector words,tags,deprels;\n std::vector heads;\n\n int size_words = env->CallIntMethod(array_words,list_size);\n int size_tags = env->CallIntMethod(array_tags,list_size);\n\n if (size_words!=size_tags) {\n return -1;\n }\n\n for (int i = 0; i < size_words; i++) {\n jobject tmp = env->CallObjectMethod(array_words,list_get,i);\n jstring s = reinterpret_cast (tmp);\n const char * st = env->GetStringUTFChars(s,0);\n std::string s_s(st);\n words.push_back(s_s);\n env->ReleaseStringUTFChars( s, st);\n }\n\n for (int i = 0; i < size_tags; i++) {\n jobject tmp = env->CallObjectMethod(array_tags,list_get,i);\n jstring s = reinterpret_cast (tmp);\n const char * st = env->GetStringUTFChars(s,0);\n std::string s_s(st);\n tags.push_back(s_s);\n env->ReleaseStringUTFChars( s, st); \n }\n\n int len = parser_parse(parser,words,tags,heads,deprels);\n\n if (len < 0) {\n return -1;\n }\n\n size_t size = heads.size();\n for (size_t i = 0; iNewObject(integer,integer_init,heads.at(i));\n env->CallBooleanMethod(array_heads,list_add, integer_object);\n }\n\n for (size_t i = 0;iCallBooleanMethod(array_deprels,list_add,tmp);\n }\n\n return len;\n}\n\nJNIEXPORT void JNICALL Java_edu_hit_ir_ltp4j_Parser_release\n (JNIEnv * env, jobject obj) {\n parser_release_parser(parser);\n parser = NULL;\n}\n\n"
},
{
"path": "src/main/c++/edu_hit_ir_ltp4j_Postagger.cpp",
"content": "#include \"postagger/postag_dll.h\"\n#include \"edu_hit_ir_ltp4j_Postagger.h\"\n#include \"string_to_jstring.hpp\"\n#include \n#include \n#include \n#include \n\nstatic void * postagger = NULL;\n\nJNIEXPORT jint JNICALL Java_edu_hit_ir_ltp4j_Postagger_create__Ljava_lang_String_2\n (JNIEnv * env, jobject obj, jstring model_path) {\n const char* str = env->GetStringUTFChars( model_path , 0);\n\n if(!postagger){\n postagger = postagger_create_postagger(str);\n } else {\n postagger_release_postagger(postagger);\n postagger = postagger_create_postagger(str);\n }\n\n env->ReleaseStringUTFChars( model_path, str);\n\n if (postagger) {\n return 1;\n }\n return -1;\n}\n\nJNIEXPORT jint JNICALL Java_edu_hit_ir_ltp4j_Postagger_create__Ljava_lang_String_2Ljava_lang_String_2\n (JNIEnv * env, jobject obj, jstring model_path, jstring lexicon_path) {\n\n const char * model = env->GetStringUTFChars( model_path , 0);\n const char * lexicon = env->GetStringUTFChars( lexicon_path , 0);\n\n if(!postagger){\n postagger = postagger_create_postagger(model,lexicon);\n } else {\n postagger_release_postagger(postagger);\n postagger = postagger_create_postagger(model,lexicon);\n }\n\n env->ReleaseStringUTFChars( model_path, model);\n env->ReleaseStringUTFChars( lexicon_path, lexicon);\n\n if(postagger) {\n return 1;\n }\n return -1;\n}\n\n\nJNIEXPORT jint JNICALL Java_edu_hit_ir_ltp4j_Postagger_postag\n (JNIEnv * env, jobject obj, jobject array_words, jobject array_postags) {\n jclass array_list = env->GetObjectClass(array_words);\n\n jmethodID list_add = env->GetMethodID(array_list, \"add\", \"(Ljava/lang/Object;)Z\");\n jmethodID list_get = env->GetMethodID(array_list, \"get\", \"(I)Ljava/lang/Object;\");\n jmethodID list_size = env->GetMethodID(array_list, \"size\", \"()I\");\n\n std::vector words, postags;\n\n int size = env->CallIntMethod(array_words,list_size);\n\n for (int i = 0; i < size ; i++) {\n jobject tmp = env->CallObjectMethod(array_words,list_get,i);\n jstring s = reinterpret_cast (tmp);\n const char * st = env->GetStringUTFChars(s,0);\n std::string s_s(st);\n words.push_back(s_s);\n env->ReleaseStringUTFChars( s, st);\n }\n\n int len = postagger_postag(postagger,words,postags);\n\n for (int i = 0; i < len; i++) {\n jobject tmp = stringToJstring(env,postags[i].c_str());\n env->CallBooleanMethod(array_postags,list_add,tmp);\n }\n\n return len;\n}\n\nJNIEXPORT void JNICALL Java_edu_hit_ir_ltp4j_Postagger_release\n (JNIEnv * env, jobject obj) {\n postagger_release_postagger(postagger);\n postagger = NULL;\n}\n\n\n\n"
},
{
"path": "src/main/c++/edu_hit_ir_ltp4j_SRL.cpp",
"content": "#include \"edu_hit_ir_ltp4j_SRL.h\"\n#include \"srl/SRL_DLL.h\"\n#include \"string_to_jstring.hpp\"\n#include \n#include \n#include \n#include \n\nJNIEXPORT jint JNICALL Java_edu_hit_ir_ltp4j_SRL_create\n (JNIEnv * env, jobject obj, jstring model_path){\n const char * str = env->GetStringUTFChars( model_path , 0);\n std::string path(str);\n int tag = srl_load_resource(path);\n env->ReleaseStringUTFChars( model_path, str); \n if(0==tag) {\n return 1;\n }\n return -1;\n}\n\nJNIEXPORT jint JNICALL Java_edu_hit_ir_ltp4j_SRL_srl\n(JNIEnv * env, jclass obj, jobject array_words, jobject array_tags, jobject array_heads, jobject array_deprels, jobject srl_result){\n jclass array_list = env->GetObjectClass(array_words);\n jmethodID list_construct = env->GetMethodID(array_list,\"\",\"()V\");\n jmethodID list_add = env->GetMethodID(array_list, \"add\", \"(Ljava/lang/Object;)Z\");\n jmethodID list_get = env->GetMethodID(array_list, \"get\", \"(I)Ljava/lang/Object;\");\n jmethodID list_size = env->GetMethodID(array_list, \"size\", \"()I\");\n\n jclass integer = env->FindClass(\"java/lang/Integer\");\n jmethodID integer_construct =env->GetMethodID(integer,\"\",\"(I)V\");\n jmethodID integer_int =env->GetMethodID(integer,\"intValue\",\"()I\");\n\n jclass pair = env->FindClass(\"edu/hit/ir/ltp4j/Pair\");\n jmethodID pair_construct = env->GetMethodID(pair, \"\",\n \"(Ljava/lang/Object;Ljava/lang/Object;)V\");\n\n std::vector words,tags,deprels;\n std::vector heads;\n std::vector > parsers;\n std::vector<\n std::pair<\n int,\n std::vector<\n std::pair >\n >\n >\n > srls;\n\n unsigned size_words = env->CallIntMethod(array_words, list_size);\n for(unsigned i = 0; i < size_words; i++){\n jobject tmp = env->CallObjectMethod(array_words,list_get,i);\n jstring s = reinterpret_cast (tmp);\n const char * st = env->GetStringUTFChars(s,0);\n std::string s_s(st);\n words.push_back(s_s);\n env->ReleaseStringUTFChars( s, st);\n }\n\n unsigned size_tags = env->CallIntMethod(array_tags, list_size);\n for(unsigned i = 0;iCallObjectMethod(array_tags,list_get,i);\n jstring s = reinterpret_cast (tmp);\n const char * st = env->GetStringUTFChars(s,0);\n std::string s_s(st);\n tags.push_back(s_s);\n env->ReleaseStringUTFChars( s, st); \n }\n\n\n unsigned size_heads = env->CallIntMethod(array_heads,list_size);\n for(unsigned i = 0; i < size_heads; i++){\n jobject tmp = env->CallObjectMethod(array_heads,list_get,i);\n int digit = env->CallIntMethod(tmp,integer_int);\n heads.push_back(digit);\n }\n\n unsigned size_deprels = env->CallIntMethod(array_deprels,list_size);\n for(unsigned i = 0;iCallObjectMethod(array_deprels,list_get,i);\n jstring s = reinterpret_cast (tmp);\n const char * st = env->GetStringUTFChars(s,0);\n std::string s_s(st);\n deprels.push_back(s_s);\n env->ReleaseStringUTFChars( s, st); \n }\n\n for(unsigned i = 0; i < size_heads; i++){\n parsers.push_back(make_pair(heads.at(i),deprels.at(i)));\n }\n\n int len = srl_dosrl(words,tags,parsers,srls);\n\n if(len<0)\n return -1;\n\n for(unsigned i = 0;iNewObject(integer,integer_construct,srls[i].first);\n jobject args = env->NewObject(array_list,list_construct);\n\n for(unsigned j = 0;jNewObject(integer,integer_construct,srls[i].second[j].second.first);\n jobject end = env->NewObject(integer,integer_construct,srls[i].second[j].second.second);\n\n jobject bound = env->NewObject(pair,pair_construct,start,end);\n\n jobject rels = stringToJstring(env,srls[i].second[j].first.c_str());\n jobject inner = env->NewObject(pair,pair_construct,rels,bound);\n env->CallBooleanMethod(args,list_add,inner);\n }\n\n jobject outer = env->NewObject(pair,pair_construct,trigger,args);\n env->CallBooleanMethod(srl_result,list_add,outer);\n }\n\n return (int)srls.size();\n}\n\nJNIEXPORT void JNICALL Java_edu_hit_ir_ltp4j_SRL_release\n (JNIEnv * env, jobject obj) {\n srl_release_resource();\n}\n\n"
},
{
"path": "src/main/c++/edu_hit_ir_ltp4j_Segmentor.cpp",
"content": "#include \"segmentor/segment_dll.h\"\r\n#include \"edu_hit_ir_ltp4j_Segmentor.h\"\r\n#include \"string_to_jstring.hpp\"\r\n#include \r\n#include \r\n#include \r\n\r\nstatic void* segmentor = NULL;\r\n\r\nJNIEXPORT jint JNICALL Java_edu_hit_ir_ltp4j_Segmentor_create__Ljava_lang_String_2\r\n (JNIEnv* env, jobject obj, jstring model_path) {\r\n const char* str = env->GetStringUTFChars( model_path , 0);\r\n\r\n if(!segmentor){\r\n segmentor = segmentor_create_segmentor(str);\r\n } else{\r\n segmentor_release_segmentor(segmentor);\r\n segmentor = segmentor_create_segmentor(str);\r\n }\r\n\r\n env->ReleaseStringUTFChars( model_path, str);\r\n\r\n if(segmentor) {\r\n return 1;\r\n }\r\n\r\n return -1;\r\n}\r\n\r\nJNIEXPORT jint JNICALL Java_edu_hit_ir_ltp4j_Segmentor_create__Ljava_lang_String_2Ljava_lang_String_2\r\n (JNIEnv* env, jobject obj, jstring model_path, jstring lexicon_path) {\r\n\r\n const char* str_model = env->GetStringUTFChars( model_path , 0);\r\n const char* str_lexicon = env->GetStringUTFChars( lexicon_path , 0);\r\n\r\n if(!segmentor){\r\n segmentor = segmentor_create_segmentor(str_model,str_lexicon);\r\n } else{\r\n segmentor_release_segmentor(segmentor);\r\n segmentor = segmentor_create_segmentor(str_model,str_lexicon);\r\n }\r\n\r\n env->ReleaseStringUTFChars( model_path, str_model);\r\n env->ReleaseStringUTFChars( lexicon_path, str_lexicon);\r\n\r\n if(segmentor) {\r\n return 1;\r\n }\r\n return -1;\r\n}\r\n\r\nJNIEXPORT jint JNICALL Java_edu_hit_ir_ltp4j_Segmentor_segment\r\n (JNIEnv* env, jobject obj, jstring sent, jobject array_words) {\r\n\r\n jclass array_list = env->GetObjectClass(array_words);\r\n jmethodID list_add = env->GetMethodID(array_list, \"add\", \"(Ljava/lang/Object;)Z\");\r\n\r\n const char* str_sent = env->GetStringUTFChars( sent , 0);\r\n std::string sentence(str_sent);\r\n std::vector words;\r\n\r\n int len = segmentor_segment(segmentor, sentence, words);\r\n\r\n for(int i = 0; i < len; i++) {\r\n jobject tmp = stringToJstring(env,words[i].c_str());\r\n env->CallBooleanMethod(array_words,list_add,tmp);\r\n }\r\n env->ReleaseStringUTFChars(sent, str_sent);\r\n return len;\r\n}\r\n\r\nJNIEXPORT void JNICALL Java_edu_hit_ir_ltp4j_Segmentor_release\r\n (JNIEnv* env, jobject obj) {\r\n segmentor_release_segmentor(segmentor);\r\n segmentor = NULL;\r\n}\r\n\r\n\r\n"
},
{
"path": "src/main/c++/edu_hit_ir_ltp4j_SplitSentence.cpp",
"content": "#include \"edu_hit_ir_ltp4j_SplitSentence.h\"\n#include \"splitsnt/SplitSentence.h\"\n#include \"string_to_jstring.hpp\"\n#include \n#include \n#include \n#include \n\nusing namespace std;\n\nJNIEXPORT void JNICALL Java_edu_hit_ir_ltp4j_SplitSentence_splitSentence\n (JNIEnv * env, jobject obj, jstring sent, jobject array_sents){\n const char * str = env->GetStringUTFChars(sent,0);\n string s_s(str);\n\n jclass array_list = env->GetObjectClass(array_sents);\n jmethodID list_add = env->GetMethodID(array_list,\"add\",\"(Ljava/lang/Object;)Z\");\n\n vector sents;\n SplitSentence(s_s,sents);\n\n for (unsigned i = 0; i < sents.size(); i++) {\n jobject tmp = stringToJstring(env,sents[i].c_str());\n env->CallBooleanMethod(array_sents,list_add,tmp);\n }\n\n env->ReleaseStringUTFChars(sent,str);\n}\n"
},
{
"path": "src/main/c++/string_to_jstring.hpp",
"content": "#include \n#include \n#include \n\ninline jstring stringToJstring(JNIEnv* env, const char* pat) {\n jclass strClass = env->FindClass(\"Ljava/lang/String;\");\n jmethodID ctorID = env->GetMethodID(strClass, \"\", \"([BLjava/lang/String;)V\");\n jbyteArray bytes = env->NewByteArray( (jsize)strlen(pat) );\n env->SetByteArrayRegion(bytes, 0, (jsize)strlen(pat), (jbyte*)pat);\n jstring encoding = env->NewStringUTF(\"utf-8\"); \n return (jstring)env->NewObject(strClass, ctorID, bytes, encoding);\n}\n"
},
{
"path": "src/main/java/edu/hit/ir/ltp4j/NER.java",
"content": "package edu.hit.ir.ltp4j;\nimport java.util.List;\n\npublic class NER {\n static {\n NarSystem.loadLibrary();\n }\n\n public final native int create(String modelPath);\n public final native int recognize(List words,\n List postags, List ners);\n public final native void release();\n}\n\n"
},
{
"path": "src/main/java/edu/hit/ir/ltp4j/Pair.java",
"content": "package edu.hit.ir.ltp4j;\npublic class Pair {\n public final F first;\n public final S second;\n\n /**\n * Constructor for a Pair.\n * \n * @param first\n * the first object in the Pair\n * @param second\n * the second object in the pair\n */\n public Pair(F first, S second) {\n this.first = first;\n this.second = second;\n }\n\n /**\n * Compute a hash code using the hash codes of the underlying objects\n * \n * @return a hashcode of the Pair\n */\n @Override\n public int hashCode() {\n return (first == null ? 0 : first.hashCode())\n ^ (second == null ? 0 : second.hashCode());\n }\n\n public boolean equals(Object o) {\n if (!(o instanceof Pair)) {\n return false;\n }\n Pair p = (Pair) o;\n return (p.first.equals(first)) && (p.second.equals(second));\n }\n\n /**\n * Convenience method for creating an appropriately typed pair.\n * \n * @param a\n * the first object in the Pair\n * @param b\n * the second object in the pair\n * @return a Pair that is templatized with the types of a and b\n */\n public static Pair create(A a, B b) {\n return new Pair(a, b);\n }\n}\n"
},
{
"path": "src/main/java/edu/hit/ir/ltp4j/Parser.java",
"content": "package edu.hit.ir.ltp4j;\nimport java.util.List;\n\npublic class Parser {\n static {\n NarSystem.loadLibrary();\n }\n\n public final native int create(String modelPath);\n public final native int parse(List words,\n List tags, List heads,\n List deprels);\n public final native void release();\n}\n\n"
},
{
"path": "src/main/java/edu/hit/ir/ltp4j/Postagger.java",
"content": "package edu.hit.ir.ltp4j;\nimport java.util.List;\n\npublic class Postagger {\n static {\n NarSystem.loadLibrary();\n }\n\n public final native int create(String modelPath);\n public final native int create(String modelPath, String lexiconPath);\n public final native int postag(List words,\n List tags);\n public final native void release();\n}\n\n"
},
{
"path": "src/main/java/edu/hit/ir/ltp4j/SRL.java",
"content": "package edu.hit.ir.ltp4j;\nimport java.util.List;\n\npublic class SRL {\n static {\n NarSystem.loadLibrary();\n }\n\n public final native int create(String modelPath);\n public final native int srl(\n List words,\n List tags,\n List heads,\n List deprels,\n List>>>> srls);\n public final native void release();\n}\n\n"
},
{
"path": "src/main/java/edu/hit/ir/ltp4j/Segmentor.java",
"content": "package edu.hit.ir.ltp4j;\nimport java.util.List;\n\npublic class Segmentor {\n static {\n NarSystem.loadLibrary();\n }\n\n public final native int create(String modelPath);\n public final native int create(String modelPath, String lexiconPath);\n public final native int segment(String sent, List words);\n public final native void release();\n}\n\n"
},
{
"path": "src/main/java/edu/hit/ir/ltp4j/SplitSentence.java",
"content": "package edu.hit.ir.ltp4j;\nimport java.util.List;\n\npublic class SplitSentence{\n static {\n NarSystem.loadLibrary();\n }\n\n public final native void splitSentence(String sent,List sents);\n}\n"
},
{
"path": "src/test/c++/main.cpp",
"content": "#include \n\nint main(int argc, char* argv[]) {\n return 0;\n}\n"
},
{
"path": "src/test/java/edu/hit/ir/ltp4j/test/NERTest.java",
"content": "package edu.hit.ir.ltp4j.test;\n\nimport edu.hit.ir.ltp4j.NER;\nimport java.util.List;\nimport java.util.ArrayList;\nimport org.junit.Assert;\nimport org.junit.Test;\n\npublic class NERTest {\n @Test public final void testNERCreate() \n throws Exception\n {\n NER app = new NER();\n Assert.assertEquals( 1, app.create(\"ltp_data/ner.model\") );\n }\n \n @Test public final void testNERRecognize()\n throws Exception\n {\n NER app = new NER();\n app.create(\"ltp_data/ner.model\");\n \n List words = new ArrayList();\n List tags = new ArrayList();\n \n words.add(\"中国\"); tags.add(\"ns\");\n words.add(\"进出口\"); tags.add(\"n\");\n words.add(\"银行\"); tags.add(\"n\");\n words.add(\"与\"); tags.add(\"p\");\n words.add(\"中国\"); tags.add(\"ns\");\n words.add(\"银行\"); tags.add(\"n\");\n words.add(\"加强\"); tags.add(\"v\");\n words.add(\"合作\"); tags.add(\"v\");\n \n List result = new ArrayList();\n app.recognize(words, tags, result);\n \n Assert.assertEquals( 8, result.size() );\n Assert.assertEquals( \"B-Ni\", result.get(0) );\n Assert.assertEquals( \"I-Ni\", result.get(1) );\n Assert.assertEquals( \"E-Ni\", result.get(2) );\n Assert.assertEquals( \"O\", result.get(3) );\n Assert.assertEquals( \"B-Ni\", result.get(4) );\n Assert.assertEquals( \"E-Ni\", result.get(5) );\n Assert.assertEquals( \"O\", result.get(6) );\n Assert.assertEquals( \"O\", result.get(7) );\n }\n}\n"
},
{
"path": "src/test/java/edu/hit/ir/ltp4j/test/ParserTest.java",
"content": "package edu.hit.ir.ltp4j.test;\n\nimport edu.hit.ir.ltp4j.Parser;\nimport java.util.List;\nimport java.util.ArrayList;\nimport org.junit.Assert;\nimport org.junit.Test;\n\npublic class ParserTest {\n @Test public final void testParserCreate() \n throws Exception\n {\n Parser app = new Parser();\n Assert.assertEquals( 1, app.create(\"ltp_data/parser.model\") );\n }\n \n @Test public final void testParserParse()\n throws Exception\n {\n Parser app = new Parser();\n app.create(\"ltp_data/parser.model\");\n \n List words = new ArrayList();\n List tags = new ArrayList();\n \n words.add(\"中国\"); tags.add(\"ns\");\n words.add(\"进出口\"); tags.add(\"n\");\n words.add(\"银行\"); tags.add(\"n\");\n words.add(\"与\"); tags.add(\"p\");\n words.add(\"中国\"); tags.add(\"ns\");\n words.add(\"银行\"); tags.add(\"n\");\n words.add(\"加强\"); tags.add(\"v\");\n words.add(\"合作\"); tags.add(\"v\");\n\n List heads = new ArrayList();\n List deprels = new ArrayList();\n \n app.parse(words, tags, heads, deprels);\n\n Assert.assertEquals( 8, heads.size() ); Assert.assertEquals( 8, deprels.size() );\n Assert.assertTrue( 3 == heads.get(0) ); Assert.assertEquals( \"ATT\", deprels.get(0) );\n Assert.assertTrue( 3 == heads.get(1) ); Assert.assertEquals( \"ATT\", deprels.get(1) );\n Assert.assertTrue( 7 == heads.get(2) ); Assert.assertEquals( \"SBV\", deprels.get(2) );\n Assert.assertTrue( 3 == heads.get(3) ); Assert.assertEquals( \"ADV\", deprels.get(3) );\n Assert.assertTrue( 6 == heads.get(4) ); Assert.assertEquals( \"ATT\", deprels.get(4) );\n Assert.assertTrue( 4 == heads.get(5) ); Assert.assertEquals( \"POB\", deprels.get(5) );\n Assert.assertTrue( 0 == heads.get(6) ); Assert.assertEquals( \"HED\", deprels.get(6) );\n Assert.assertTrue( 7 == heads.get(7) ); Assert.assertEquals( \"VOB\", deprels.get(7) );\n }\n}\n"
},
{
"path": "src/test/java/edu/hit/ir/ltp4j/test/PostaggerTest.java",
"content": "package edu.hit.ir.ltp4j.test;\n\nimport edu.hit.ir.ltp4j.Postagger;\nimport java.util.List;\nimport java.util.ArrayList;\nimport org.junit.Assert;\nimport org.junit.Test;\n\npublic class PostaggerTest {\n @Test public final void testPostaggerCreate() \n throws Exception\n {\n Postagger app = new Postagger();\n Assert.assertEquals( 1, app.create(\"ltp_data/pos.model\") );\n }\n\n @Test public final void testPostaggerPostag() \n throws Exception\n {\n Postagger app = new Postagger();\n app.create(\"ltp_data/pos.model\");\n\n List words = new ArrayList();\n\n words.add(\"中国\");\n words.add(\"进出口\");\n words.add(\"银行\");\n words.add(\"与\");\n words.add(\"中国\");\n words.add(\"银行\");\n words.add(\"加强\");\n words.add(\"合作\");\n\n List result = new ArrayList();\n\n app.postag(words, result);\n Assert.assertEquals( 8, result.size() );\n Assert.assertEquals( \"ns\", result.get(0) );\n Assert.assertEquals( \"n\", result.get(1) );\n Assert.assertEquals( \"n\", result.get(2) );\n Assert.assertEquals( \"p\", result.get(3) );\n Assert.assertEquals( \"ns\", result.get(4) );\n Assert.assertEquals( \"n\", result.get(5) );\n Assert.assertEquals( \"v\", result.get(6) );\n Assert.assertEquals( \"v\", result.get(7) );\n }\n}\n"
},
{
"path": "src/test/java/edu/hit/ir/ltp4j/test/SRLTest.java",
"content": "package edu.hit.ir.ltp4j.test;\n\nimport edu.hit.ir.ltp4j.SRL;\nimport org.junit.Assert;\nimport org.junit.Test;\n\npublic class SRLTest {\n @Test public final void testSRLCreate() \n throws Exception\n {\n SRL app = new SRL();\n Assert.assertEquals( 1, app.create(\"ltp_data/pisrl.model\") );\n }\n}\n"
},
{
"path": "src/test/java/edu/hit/ir/ltp4j/test/SegmentorTest.java",
"content": "package edu.hit.ir.ltp4j.test;\n\nimport edu.hit.ir.ltp4j.Segmentor;\nimport java.util.List;\nimport java.util.ArrayList;\nimport org.junit.Assert;\nimport org.junit.Test;\n\npublic class SegmentorTest {\n @Test public final void testSegmentorCreate() \n throws Exception\n {\n Segmentor app = new Segmentor();\n Assert.assertEquals( 1, app.create(\"ltp_data/cws.model\") );\n }\n\n @Test public final void testSegmentorSegment()\n throws Exception\n {\n Segmentor app = new Segmentor();\n app.create(\"ltp_data/cws.model\");\n\n List result = new ArrayList();\n app.segment(\"中国进出口银行与中国银行加强合作\", result);\n\n Assert.assertEquals( 8, result.size() );\n Assert.assertEquals( \"中国\", result.get(0) );\n Assert.assertEquals( \"进出口\", result.get(1) );\n Assert.assertEquals( \"银行\", result.get(2) );\n Assert.assertEquals( \"与\", result.get(3) );\n Assert.assertEquals( \"中国\", result.get(4) );\n Assert.assertEquals( \"银行\", result.get(5) );\n Assert.assertEquals( \"加强\", result.get(6) );\n Assert.assertEquals( \"合作\", result.get(7) );\n }\n}\n"
}
]