Repository: HIT-SCIR/ltp4j
Branch: master
Commit: 548bd38dffaa
Files: 39
Total size: 84.0 KB
Directory structure:
gitextract_trfcfd8n/
├── .gitignore
├── .gitmodules
├── .travis.yml
├── CMakeLists.txt
├── README.md
├── aol.properties
├── appveyor.yml
├── doc/
│ ├── api.rst
│ ├── background.rst
│ ├── conf.py
│ ├── index.rst
│ ├── install.rst
│ ├── ltp4j-document-1.0.md
│ ├── make.bat
│ ├── requirements.txt
│ └── run.rst
├── examples/
│ ├── Console.java
│ └── example
├── pom.xml
└── src/
├── main/
│ ├── c++/
│ │ ├── edu_hit_ir_ltp4j_NER.cpp
│ │ ├── edu_hit_ir_ltp4j_Parser.cpp
│ │ ├── edu_hit_ir_ltp4j_Postagger.cpp
│ │ ├── edu_hit_ir_ltp4j_SRL.cpp
│ │ ├── edu_hit_ir_ltp4j_Segmentor.cpp
│ │ ├── edu_hit_ir_ltp4j_SplitSentence.cpp
│ │ └── string_to_jstring.hpp
│ └── java/
│ └── edu/
│ └── hit/
│ └── ir/
│ └── ltp4j/
│ ├── NER.java
│ ├── Pair.java
│ ├── Parser.java
│ ├── Postagger.java
│ ├── SRL.java
│ ├── Segmentor.java
│ └── SplitSentence.java
└── test/
├── c++/
│ └── main.cpp
└── java/
└── edu/
└── hit/
└── ir/
└── ltp4j/
└── test/
├── NERTest.java
├── ParserTest.java
├── PostaggerTest.java
├── SRLTest.java
└── SegmentorTest.java
================================================
FILE CONTENTS
================================================
================================================
FILE: .gitignore
================================================
###########
# data #
###########
ltp_data
###########
# outputs #
###########
output
CMakeFiles
cmake_install.cmake
CmakeCache.txt
Makefile
libs
target
###########
# IDEs #
###########
.idea
================================================
FILE: .gitmodules
================================================
[submodule "src/main/c++/ltp"]
path = src/main/c++/ltp
url = https://github.com/HIT-SCIR/ltp.git
================================================
FILE: .travis.yml
================================================
language:
- cpp
- java
os:
- linux
- osx
before_script:
- if [[ "$TRAVIS_OS_NAME" == "osx" && -z "$JAVA_HOME" && -x "/usr/libexec/java_home" ]] ; then export JAVA_HOME=$(/usr/libexec/java_home); fi
- git submodule init
- git submodule update
script:
- mvn -Dmaven.test.skip=true
================================================
FILE: CMakeLists.txt
================================================
cmake_minimum_required (VERSION 2.8.0)
project ("ltp4j")
find_package(JNI)
set (LTP_HOME "${PROJECT_SOURCE_DIR}/ltp" CACHE STRING "Use to specified ltp path") # change it to your ltp root
set (LIBRARY_OUTPUT_PATH ${PROJECT_SOURCE_DIR}/libs)
set (JNI_SOURCE_DIR ${PROJECT_SOURCE_DIR}/jni)
include_directories (
${JNI_SOURCE_DIR}
${LTP_HOME}/include
${JNI_INCLUDE_DIRS})
#if(WIN32)
# include_directories ($ENV{JAVA_HOME}/include/win32)
#else(WIN32)
# include_directories ($ENV{JAVA_HOME}/include/linux)
#endif(WIN32)
if(APPLE)
set(CMAKE_CXX_FLAGS "-stdlib=libstdc++")
endif(APPLE)
if(WIN32)
link_directories (${LTP_HOME}/lib/Debug)
else(WIN32)
link_directories (${LTP_HOME}/lib)
endif(WIN32)
add_library (split_sentence_jni SHARED
${JNI_SOURCE_DIR}/split_sentence_jni.cpp)
target_link_libraries (split_sentence_jni splitsnt)
add_library (segmentor_jni SHARED ${JNI_SOURCE_DIR}/segment_jni.cpp)
target_link_libraries (segmentor_jni segmentor)
add_library(postagger_jni SHARED ${JNI_SOURCE_DIR}/postag_jni.cpp)
target_link_libraries (postagger_jni postagger)
add_library (ner_jni SHARED ${JNI_SOURCE_DIR}/ner_jni.cpp)
target_link_libraries (ner_jni ner)
add_library (parser_jni SHARED ${JNI_SOURCE_DIR}/parser_jni.cpp)
target_link_libraries (parser_jni parser)
add_library (srl_jni SHARED ${JNI_SOURCE_DIR}/srl_jni.cpp)
target_link_libraries (srl_jni srl)
# -----------------------------------------------
# TOOLKIT
================================================
FILE: README.md
================================================
ltp4jbeta: Language Technology Platform For Java
============================================
[](https://travis-ci.org/HIT-SCIR/ltp4j)
[](http://ltp4j.readthedocs.org/en/neoltp4j/?badge=neoltp4j)
# LTP 4.0
LTP 4.0 的支持请移步[libltp](https://github.com/HIT-SCIR/libltp)仓库
# 更新
1. ltp4j 现已经更新对 LTP 3.4.0的支持。
2. 项目改用 maven 构建、编译。具体使用方法参见文档。
# 简介
ltp4j是语言技术平台[(Language Technology Platform, LTP)](https://github.com/HIT-SCIR/ltp)接口的一个Java封装。
本项目旨在使Java用户可以本地调用LTP。
本项目仍在开发之中,欢迎反馈bug。
# 文档
请参考在线文档:[ltp4j使用文档](http://ltp4j.readthedocs.io)
================================================
FILE: aol.properties
================================================
amd64.Windows.msvc.cpp.defines=Windows WIN32 _WINDOWS NOMINMAX BOOST_ALL_NO_LIB
amd64.Windows.msvc.c.defines=Windows WIN32 _WINDOWS NOMINMAX BOOST_ALL_NO_LIB
================================================
FILE: appveyor.yml
================================================
version: '{build}'
image:
- Visual Studio 2015
- Visual Studio 2017
platform: x64
install:
- ps: |
Add-Type -AssemblyName System.IO.Compression.FileSystem
if (!(Test-Path -Path "C:\maven" )) {
(new-object System.Net.WebClient).DownloadFile(
'http://www.us.apache.org/dist/maven/maven-3/3.3.9/binaries/apache-maven-3.3.9-bin.zip',
'C:\maven-bin.zip'
)
[System.IO.Compression.ZipFile]::ExtractToDirectory("C:\maven-bin.zip", "C:\maven")
}
- cmd: SET PATH=C:\maven\apache-maven-3.3.9\bin;%JAVA_HOME%\bin;%PATH%
- cmd: SET MAVEN_OPTS=-XX:MaxPermSize=2g -Xmx4g
- cmd: SET JAVA_OPTS=-XX:MaxPermSize=2g -Xmx4g
build_script:
- git submodule init
- git submodule update
- mvn -Dmaven.test.skip=true
cache:
- C:\maven\
- C:\Users\appveyor\.m2
================================================
FILE: doc/api.rst
================================================
编程接口
========
.. java:package:: edu.hit.ir.ltp4j
分词接口
--------
.. java:type:: public class Segmentor
分词主要提供三个接口:
.. java:method:: public final native int create(String modelPath)
功能:
读取模型文件,初始化分词器。
参数:
+---------------------+------------------------------------------------------------+
| 参数名 | 参数描述 |
+=====================+============================================================+
| String modelPath | 指定模型文件的路径 |
+---------------------+------------------------------------------------------------+
.. java:method:: public final native void release()
功能:
释放模型文件,销毁分词器。
.. java:method:: public final native int segment(String sent, List words)
功能:
调用分词接口。
参数:
+---------------------+------------------------------------------------------------+
| 参数名 | 参数描述 |
+=====================+============================================================+
| String sent | 待分词句子 |
+---------------------+------------------------------------------------------------+
| List words | 结果分词序列 |
+---------------------+------------------------------------------------------------+
**示例程序**
.. code:: java
import java.util.ArrayList;
import java.util.List;
import edu.hit.ir.ltp4j.*;
public class TestSegment {
public static void main(String[] args) {
if(Segmentor.create("../../../ltp_data/cws.model")<0){
System.err.println("load failed");
return;
}
String sent = "我是中国人";
List words = new ArrayList();
int size = Segmentor.segment(sent,words);
for(int i = 0; i words, List tags)
功能:
调用词性标注接口
参数:
+--------------------+--------------------------------------------------------------------+
| 参数名 | 参数描述 |
+====================+====================================================================+
| List words | 待标注的词序列 |
+--------------------+--------------------------------------------------------------------+
| List tags | 词性标注结果,序列中的第i个元素是第i个词的词性 |
+--------------------+--------------------------------------------------------------------+
**示例程序**
.. code:: java
import java.util.ArrayList;
import java.util.List;
import edu.hit.ir.ltp4j.*;
public class TestPostag {
public static void main(String[] args) {
if(Postagger.create("../../../ltp_data/pos.model")<0) {
System.err.println("load failed");
return;
}
List words= new ArrayList();
words.add("我"); words.add("是");
words.add("中国"); words.add("人");
List postags= new ArrayList();
int size = Postagger.postag(words,postags);
for(int i = 0; i < size; i++) {
System.out.print(words.get(i)+"_"+postags.get(i));
if(i==size-1) {
System.out.println();
} else {
System.out.print("|");
}
}
Postagger.release();
}
}
命名实体识别接口
------------------
.. java:type:: public class NER
命名实体识别主要提供三个接口:
.. java:method:: public final native int create(String modelPath)
功能:
读取模型文件,初始化命名实体识别器
参数:
+----------------------------------------+--------------------------------------------------------------------+
| 参数名 | 参数描述 |
+========================================+====================================================================+
| const char * path | 命名实体识别模型路径 |
+----------------------------------------+--------------------------------------------------------------------+
返回值:
返回一个指向词性标注器的指针。
.. java:method:: public final native void release()
功能:
释放模型文件,销毁命名实体识别器。
.. java:method:: public final native int recognize(List words, List postags, List ners)
功能:
调用命名实体识别接口
参数:
+----------------------+----------------------------------------------------------------------------------------+
| 参数名 | 参数描述 |
+======================+========================================================================================+
| List words | 待识别的词序列 |
+----------------------+----------------------------------------------------------------------------------------+
| List postags | 待识别的词的词性序列 |
+----------------------+----------------------------------------------------------------------------------------+
| List ners | | 命名实体识别结果, |
| | | 命名实体识别的结果为O时表示这个词不是命名实体, |
| | | 否则为{POS}-{TYPE}形式的标记,POS代表这个词在命名实体中的位置,TYPE表示命名实体类型 |
+----------------------+----------------------------------------------------------------------------------------+
**示例程序**
.. code:: java
import java.util.ArrayList;
import java.util.List;
import edu.hit.ir.ltp4j.*;
public class TestNer {
public static void main(String[] args) {
if(NER.create("../../../ltp_data/ner.model")<0) {
System.err.println("load failed");
return;
}
List words = new ArrayList();
List tags = new ArrayList();
List ners = new ArrayList();
words.add("中国");tags.add("ns");
words.add("国际");tags.add("n");
words.add("广播");tags.add("n");
words.add("电台");tags.add("n");
words.add("创办");tags.add("v");
words.add("于");tags.add("p");
words.add("1941年");tags.add("m");
words.add("12月");tags.add("m");
words.add("3日");tags.add("m");
words.add("。");tags.add("wp");
NER.recognize(words, tags, ners);
for (int i = 0; i < words.size(); i++) {
System.out.println(ners.get(i));
}
NER.release();
}
}
依存句法分析接口
-----------------
.. java:type:: public class Parser
依存句法分析主要提供三个接口:
.. java:method:: public final native int create(String modelPath)
功能:
读取模型文件,初始化依存句法分析器
参数:
+---------------------------------------+--------------------------------------------------------------------+
| 参数名 | 参数描述 |
+=======================================+====================================================================+
| String modelPath | 依存句法分析模型路径 |
+---------------------------------------+--------------------------------------------------------------------+
.. java:method:: public final native void release()
功能:
释放模型文件,销毁依存句法分析器。
.. java:method:: public final native int parse(List words, List tags, List heads, List deprels)
功能:
调用依存句法分析接口
参数:
+----------------------+--------------------------------------------------------------------+
| 参数名 | 参数描述 |
+======================+====================================================================+
| List words | 待分析的词序列 |
+----------------------+--------------------------------------------------------------------+
| List tags | 待分析的词的词性序列 |
+----------------------+--------------------------------------------------------------------+
| List heads | 结果依存弧,heads[i]代表第i个词的父亲节点的编号 |
+----------------------+--------------------------------------------------------------------+
| List deprels | 结果依存弧关系类型 |
+----------------------+--------------------------------------------------------------------+
**示例程序**
.. code:: java
import java.util.ArrayList;
import java.util.List;
import edu.hit.ir.ltp4j.*;
public class TestParse {
public static void main(String[] args){
Parser parser = new Parser();
if(parser.create("./model/ltp_data/parser.model") < 0){
throw new RuntimeException("fail to load parser model");
}
List words = new ArrayList<>();
List postags = new ArrayList<>();
words.add("一把手"); postags.add("n");
words.add("亲自"); postags.add("d");
words.add("过河"); postags.add("v");
words.add("。"); postags.add("wp");
List heads = new ArrayList<>();
List deprels = new ArrayList<>();
parser.parse(words, postags, heads, deprels);
for(int i=0; i words, List tags, List heads, List deprels, List>>>> srls)
功能:
调用命名实体识别接口
参数:
+---------------------------------------------------+-----------------------------------------------------------+
| 参数名 | 参数描述 |
+===================================================+===========================================================+
| List words | 输入的词序列 |
+---------------------------------------------------+-----------------------------------------------------------+
| List tags | 输入的词性序列 |
+---------------------------------------------------+-----------------------------------------------------------+
| List heads | 这个词的父节点的编号 [#f1]_ |
+---------------------------------------------------+-----------------------------------------------------------+
| List deprels | 这个词的父节点的依存关系类型 |
+---------------------------------------------------+-----------------------------------------------------------+
| List>>>> srls | 结果语义角色标注 |
+---------------------------------------------------+-----------------------------------------------------------+
常见问题
--------
.. rubric:: 注
.. [#f1] 编号从0记起
================================================
FILE: doc/background.rst
================================================
简介与背景知识
==============
ltp4j是 `语言技术平台 (Language Technology Platform, LTP) `_ 接口的一个Java封装。 本项目旨在使Java用户可以本地调用LTP。
在使用ltp4j之前,您需要简要了解
* 什么是语言技术平台,它能否帮助您解决问题
* 如何安装语言技术平台
* 语言技术平台提供哪些编程接口
如果您对这些问题不了解,请首先阅读我们提供的有关语言技术平台的 `文档 `_ 。在本文档的后续中,我们假定您已经阅读并成功编译并使用语言技术平台。
ltj4j的基本实现思路是依靠JNI技术实现在Java中调用C/C++动态库。我们建议您使用几分钟了解 `Java调用C/C++动态库 `_ 的实践方式。
ltp4j整个项目由两部分组成,他们分别是:
* ltp4j.jar:Java接口程序。
* C++代理程序:ltp4j加载的ltp动态库。
================================================
FILE: doc/conf.py
================================================
# -*- coding: utf-8 -*-
#
# LTP documentation build configuration file, created by
# sphinx-quickstart on Mon Jan 19 17:24:17 2015.
#
# This file is execfile()d with the current directory set to its
# containing dir.
#
# Note that not all possible configuration values are present in this
# autogenerated file.
#
# All configuration values have a default; values that are commented out
# serve to show the default.
import sys
import os
# If extensions (or modules to document with autodoc) are in another directory,
# add these directories to sys.path here. If the directory is relative to the
# documentation root, use os.path.abspath to make it absolute, like shown here.
#sys.path.insert(0, os.path.abspath('.'))
# -- General configuration ------------------------------------------------
# If your documentation needs a minimal Sphinx version, state it here.
#needs_sphinx = '1.0'
# Add any Sphinx extension module names here, as strings. They can be
# extensions coming with Sphinx (named 'sphinx.ext.*') or your custom
# ones.
extensions = ['javasphinx']
# Add any paths that contain templates here, relative to this directory.
templates_path = ['_templates']
# The suffix of source filenames.
source_suffix = '.rst'
# The encoding of source files.
#source_encoding = 'utf-8-sig'
# The master toctree document.
master_doc = 'index'
# General information about the project.
project = u'ltp4j'
copyright = u'2016, HIT-SCIR'
# The version info for the project you're documenting, acts as replacement for
# |version| and |release|, also used in various other places throughout the
# built documents.
#
# The short X.Y version.
version = '0.1'
# The full version, including alpha/beta/rc tags.
release = '0.1-SNAPSHORT'
# The language for content autogenerated by Sphinx. Refer to documentation
# for a list of supported languages.
#language = None
# There are two options for replacing |today|: either, you set today to some
# non-false value, then it is used:
#today = ''
# Else, today_fmt is used as the format for a strftime call.
#today_fmt = '%B %d, %Y'
# List of patterns, relative to source directory, that match files and
# directories to ignore when looking for source files.
exclude_patterns = ['_build']
# The reST default role (used for this markup: `text`) to use for all
# documents.
#default_role = None
# If true, '()' will be appended to :func: etc. cross-reference text.
#add_function_parentheses = True
# If true, the current module name will be prepended to all description
# unit titles (such as .. function::).
#add_module_names = True
# If true, sectionauthor and moduleauthor directives will be shown in the
# output. They are ignored by default.
#show_authors = False
# The name of the Pygments (syntax highlighting) style to use.
pygments_style = 'sphinx'
# A list of ignored prefixes for module index sorting.
#modindex_common_prefix = []
# If true, keep warnings as "system message" paragraphs in the built documents.
#keep_warnings = False
# -- Options for HTML output ----------------------------------------------
# The theme to use for HTML and HTML Help pages. See the documentation for
# a list of builtin themes.
html_theme = 'alabaster'
# Theme options are theme-specific and customize the look and feel of a theme
# further. For a list of options available for each theme, see the
# documentation.
#html_theme_options = {}
# Add any paths that contain custom themes here, relative to this directory.
#html_theme_path = []
# The name for this set of Sphinx documents. If None, it defaults to
# " v documentation".
#html_title = None
# A shorter title for the navigation bar. Default is the same as html_title.
#html_short_title = None
# The name of an image file (relative to this directory) to place at the top
# of the sidebar.
#html_logo = None
# The name of an image file (within the static path) to use as favicon of the
# docs. This file should be a Windows icon file (.ico) being 16x16 or 32x32
# pixels large.
#html_favicon = None
# Add any paths that contain custom static files (such as style sheets) here,
# relative to this directory. They are copied after the builtin static files,
# so a file named "default.css" will overwrite the builtin "default.css".
html_static_path = ['_static']
# Add any extra paths that contain custom files (such as robots.txt or
# .htaccess) here, relative to this directory. These files are copied
# directly to the root of the documentation.
#html_extra_path = []
# If not '', a 'Last updated on:' timestamp is inserted at every page bottom,
# using the given strftime format.
#html_last_updated_fmt = '%b %d, %Y'
# If true, SmartyPants will be used to convert quotes and dashes to
# typographically correct entities.
#html_use_smartypants = True
# Custom sidebar templates, maps document names to template names.
#html_sidebars = {}
# Additional templates that should be rendered to pages, maps page names to
# template names.
#html_additional_pages = {}
# If false, no module index is generated.
#html_domain_indices = True
# If false, no index is generated.
#html_use_index = True
# If true, the index is split into individual pages for each letter.
#html_split_index = False
# If true, links to the reST sources are added to the pages.
#html_show_sourcelink = True
# If true, "Created using Sphinx" is shown in the HTML footer. Default is True.
#html_show_sphinx = True
# If true, "(C) Copyright ..." is shown in the HTML footer. Default is True.
#html_show_copyright = True
# If true, an OpenSearch description file will be output, and all pages will
# contain a tag referring to it. The value of this option must be the
# base URL from which the finished HTML is served.
#html_use_opensearch = ''
# This is the file name suffix for HTML files (e.g. ".xhtml").
#html_file_suffix = None
# Output file base name for HTML help builder.
htmlhelp_basename = 'LTPdoc'
# -- Options for LaTeX output ---------------------------------------------
latex_elements = {
# The paper size ('letterpaper' or 'a4paper').
#'papersize': 'letterpaper',
# The font size ('10pt', '11pt' or '12pt').
#'pointsize': '10pt',
# Additional stuff for the LaTeX preamble.
#'preamble': '',
}
# Grouping the document tree into LaTeX files. List of tuples
# (source start file, target name, title,
# author, documentclass [howto, manual, or own class]).
latex_documents = [
('index', 'LTP.tex', u'LTP Documentation',
u'HIT-SCIR', 'manual'),
]
# The name of an image file (relative to this directory) to place at the top of
# the title page.
#latex_logo = None
# For "manual" documents, if this is true, then toplevel headings are parts,
# not chapters.
#latex_use_parts = False
# If true, show page references after internal links.
#latex_show_pagerefs = False
# If true, show URL addresses after external links.
#latex_show_urls = False
# Documents to append as an appendix to all manuals.
#latex_appendices = []
# If false, no module index is generated.
#latex_domain_indices = True
# -- Options for manual page output ---------------------------------------
# One entry per manual page. List of tuples
# (source start file, name, description, authors, manual section).
man_pages = [
('index', 'ltp', u'LTP Documentation',
[u'HIT-SCIR'], 1)
]
# If true, show URL addresses after external links.
#man_show_urls = False
# -- Options for Texinfo output -------------------------------------------
# Grouping the document tree into Texinfo files. List of tuples
# (source start file, target name, title, author,
# dir menu entry, description, category)
texinfo_documents = [
('index', 'ltp4j', u'ltp4j Documentation',
u'HIT-SCIR', 'ltp4j', 'One line description of project.',
'Miscellaneous'),
]
# Documents to append as an appendix to all manuals.
#texinfo_appendices = []
# If false, no module index is generated.
#texinfo_domain_indices = True
# How to display URL addresses: 'footnote', 'no', or 'inline'.
#texinfo_show_urls = 'footnote'
# If true, do not generate a @detailmenu in the "Top" node's menu.
#texinfo_no_detailmenu = False
================================================
FILE: doc/index.rst
================================================
.. ltpdoctest documentation master file, created by
sphinx-quickstart on Wed Jan 14 22:35:55 2015.
You can adapt this file completely to your liking, but it should at least
contain the root `toctree` directive.
.. include:: background.rst
目录
=====
.. toctree::
:maxdepth: 2
install
run
api
索引及表格
==================
* :ref:`genindex`
* :ref:`search`
================================================
FILE: doc/install.rst
================================================
.. _install-label:
编译ltp4j
=========
如果您需要使用ltp4j,必须拥有两部分内容
* ltp4j.jar与C++代理程序
* LTP模型文件
其中,LTP模型文件可以从 `百度云 `_,当前ltp4j对应的模型版本为3.3.1。本文档将着重介绍如何编译ltp4j.jar与其C++代理程序。
安装Maven
---------
ltp4j使用 `apache maven `_ 进行构建。在构建ltp4j之前,您首先需要安装maven。安装方法请参考: `安装apache maven `_。
编译ltp4j
---------
在确保安装maven的前提下(即 `mvn -h` 具有输出结果),您可以按照如下方式构建ltp4j。
1. 在命令行下进入ltp4j所在文件夹
2. `git submodule init`
3. `git submodule update`
4. `mvn -Dmaven.test.skip=true`
如果您编译提示成功同时项目根目录下包含 `target/ltp4j-{version}.jar`,证明已经编译成功。
nar-maven-plugin
~~~~~~~~~~~~~~~~
本部分将介绍编译ltp4j的一些技术考虑,与编译ltp4j无关。对这部分不感兴趣的用户可以忽略这部分文档。
ltp4j的基本技术考虑是 **使用户使用最简单的技术手段编译使用ltp4j** 。所以我们选择了maven作为构建工具,希望可以通过一条指令完成编译过程。
如前文所述,ltp4j需要ltp4j.jar及其C++代理程序两部分。
为了在maven中既能够使用java编译器编译jar又能够使用C++编译器编译C++代理程序,我们经过调研,决定使用 `nar-maven-plugin `_ 。这一maven插件使我们可以在不同的系统架构下编译C++的代码 (AOL)。
在使用过程中,我们发现了这一插件的一系列bug,并通过贡献代码的方式进行了解决。
编译结果
--------
nar-maven-plugin的编译结果随操作系统的不同而存在差异。其生成的ltp4j.jar以及代理文件可以从如下路径找到
* jar:`./target/ltp4j-{version}.jar`
* 代理程序:`./target/ltp4j-{version}-{AOL}-jni/`
其中,`vesion` 代表ltp4j的版本。`AOL` 代表 **体系结构-系统-链接器** 。
举例来讲,
* Windows 64位系统使用MSVC编译对应的AOL为:amd64-Windows-msvc
* Ubuntu 64位系统使用gnuc++编译对应的AOL为:amd64-Linux-gpp
编译结果示例
~~~~~~~~~~~~
**64位Linux g++**
.. code:: shell
$ find target/ -type f -name "*.jar" -or -name "*.so"
target/ltp4j-0.1.0-SNAPSHOT.jar
target/nar/ltp4j-0.1.0-SNAPSHOT-amd64-Linux-gpp-jni/lib/amd64-Linux-gpp/jni/libltp4j-0.1.0-SNAPSHOT.so
**64位windows MSVC**
.. code:: shell
$ find target/ -type f -name "*.jar" -or -name "*.dll"
target/ltp4j-0.1.0-SNAPSHOT.jar
target/nar/ltp4j-0.1.0-SNAPSHOT-amd64-Windows-msvc-jni/lib/amd64-Windows-msvc/jni/ltp4j-0.1.0-SNAPSHOT.dll
常见问题
--------
================================================
FILE: doc/ltp4j-document-1.0.md
================================================
ltp4j 文档
===============
ltp4j是[语言技术平台(Language Technology Platform, LTP)](https://github.com/HIT-SCIR/ltp)的Java封装。
关于LTP更多的信息,欢迎访问LTP项目主页。
### 作者
* 韩冰 << bhan@ir.hit.edu.cn >> 2014-05-15 创建文档
# 简介与背景知识
ltp4j是[语言技术平台(Language Technology Platform, LTP)](https://github.com/HIT-SCIR/ltp)接口的一个Java封装。
本项目旨在使Java用户可以本地调用LTP。
在使用ltp4j之前,您需要简要了解
* [什么是语言技术平台](https://github.com/HIT-SCIR/ltp/blob/master/doc/ltp-document-3.0.md#%E7%AE%80%E4%BB%8B),它能否帮助您解决问题
* [如何安装语言技术平台](https://github.com/HIT-SCIR/ltp/blob/master/doc/ltp-document-3.0.md#%E5%A6%82%E4%BD%95%E5%AE%89%E8%A3%85ltp)
* [语言技术平台提供哪些编程接口](https://github.com/HIT-SCIR/ltp/blob/master/doc/ltp-document-3.0.md#%E7%BC%96%E7%A8%8B%E6%8E%A5%E5%8F%A3)
如果您对这些问题不了解,请首先阅读我们提供的有关语言技术平台的文档。
在本文档的后续中,我们假定您已经阅读并成功编译并使用语言技术平台。
ltp4j主要依靠JNI实现。整个项目由两部分组成,他们分别是:
* __ltp4j.jar__:Java接口程序,利用ant能够直接编译构建为ltp4j.jar,方便用户导入使用。
* C++代理程序,在项目/jni/目录下实现Java接口中的功能,利用CMake编译构建为动态库。
# 安装
在这一章节中,我们假定您下载并将LTP放置于`/path/to/your/ltp-project`路径下;
而ltp4j放置于`/path/to/your/ltp4j-project`路径下。
## 编译ltp4j.jar
### 命令行方式
ltp4j.jar使用ant编译工具编译。 在命令行环境下,可以在项目根目录(`/path/to/your/ltp4j-project`)下使用
```
ant
```
命令编译。编译成功后,将在`build_jar/jar`下产生`ltp4j.jar`文件。
### Eclipse
如果使用Eclipse,可以按照_"File > New > Project... > Java Project from Existing Ant Buildfile"_的方式从build.xml中创建项目。
选择next后,在Ant buildfile:一栏中填入build.xml的路径,`/path/to/your/ltp4j-project/build.xml`(window用户请添加盘符并将/改为\\),如下图所示。
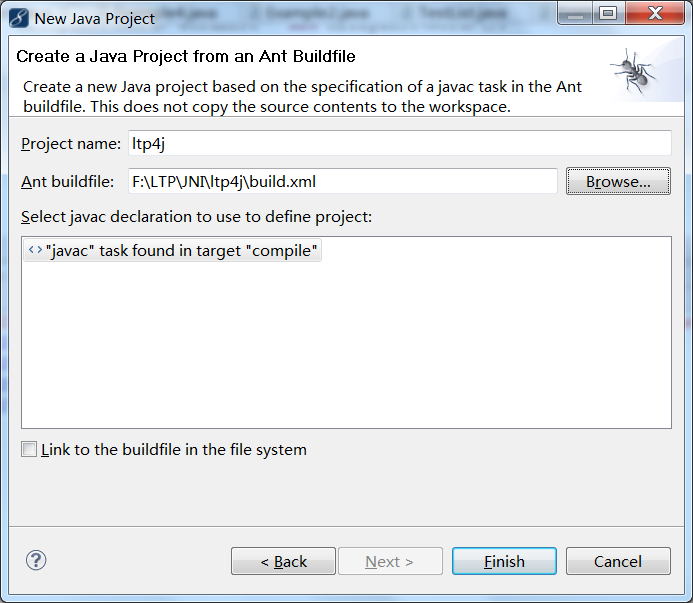
点击Finish就导入了项目。
在导入项目后,右键build.xml选择2 Ant Build。 在弹出的对话框中的选择main选项卡,并在`Base Directory:`中填入项目路径`/path/to/your/ltp4j-project/`。
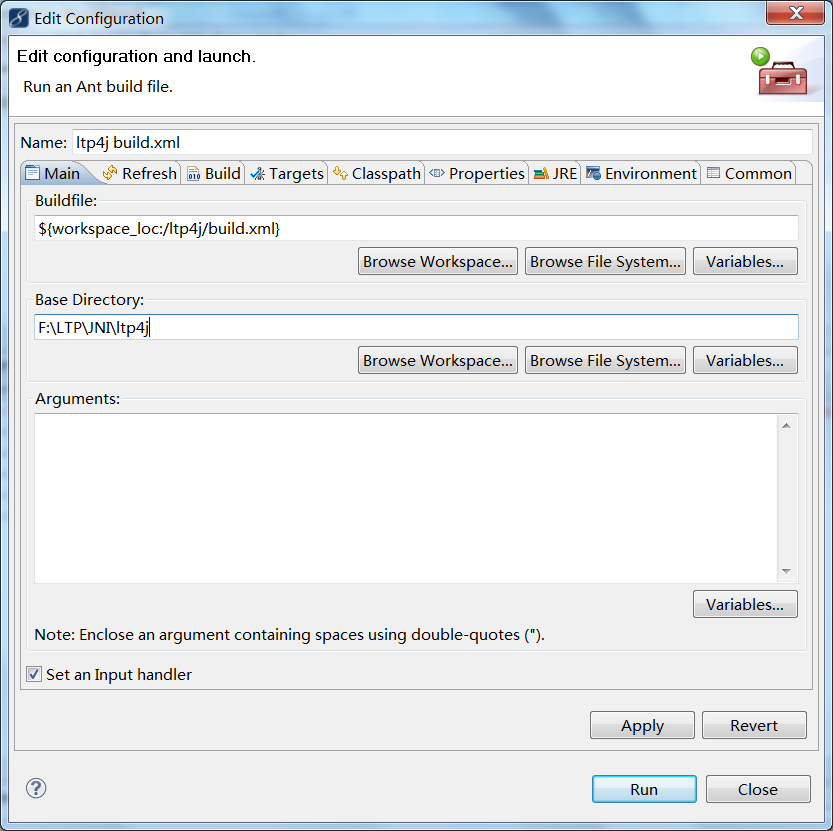
填好后执行run,build/jar下产生名为ltp4j.jar的jar文件。
### Intellij Idea
配置maven。点击右侧的MavenProject。导入pom.xml。
## 编译C++代理程序
代理程序jni动态库依赖于ltp的动态库,请先行编译LTP。
### 安装CMake
ltp4j使用的C++代理程序使用编译工具CMake构建项目。
在编译代理程序之前,你需要首先安装CMake。
CMake的网站在[这里](http://www.cmake.org)。如果你是Windows用户,请下载CMake的二进制安装包;
如果你是Linux,Mac OS或Cygwin的用户,可以通过编译源码的方式安装CMake,当然,你也可以使用Linux的软件源来安装。
### Windows(MSVC)编译
第一步:配置ltp的安装路径
因为jni依赖于ltp编译产生的动态库,所以在编译过程中需要给出ltp的路径。
请修改`/path/to/your/ltp4j-project/CMakeLists.txt`中的`LTP_HOME`的值为您的LTP项目的路径(`/path/to/your/ltp-project`),
对应修改的代码为:
```set (LTP_HOME "/path/to/your/ltp-project/")```
第二步:构建VC Project
在项目文件夹下新建一个名为build的文件夹,使用CMake Gui,在source code中填入项目文件夹,在binaries中填入build文件夹。然后Configure -> Generate。
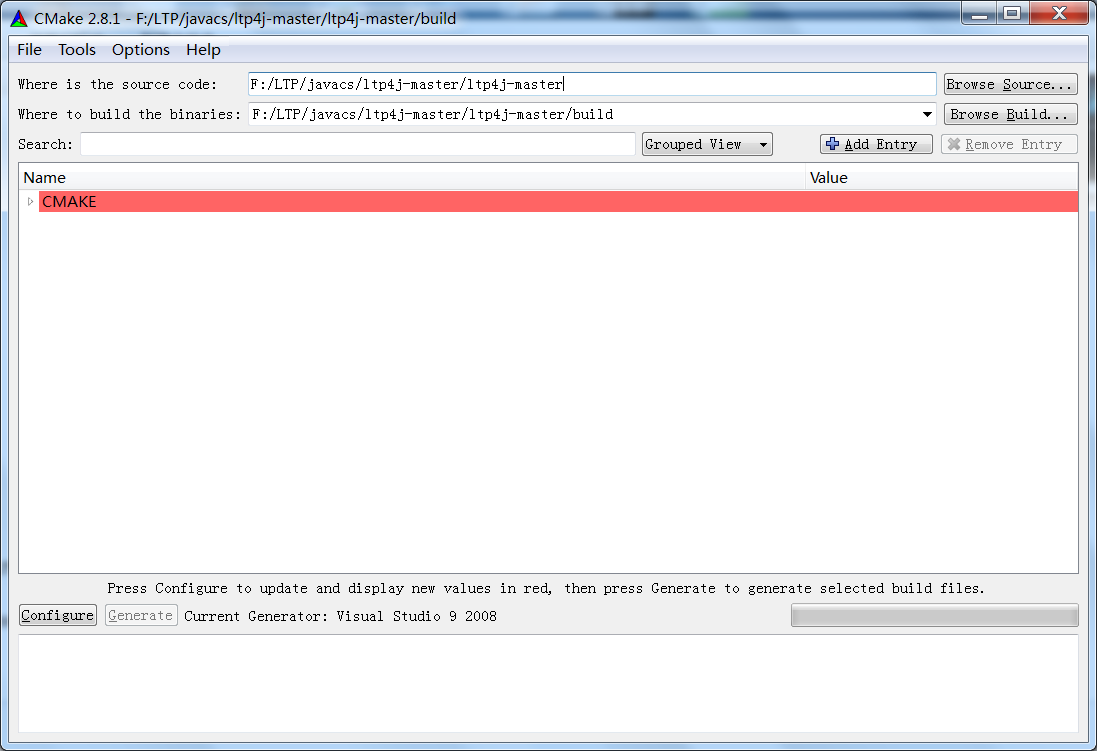
或者在命令行build 路径下运行
```
cmake ..
```
第二步:编译
### Linux,Mac OSX和Cygwin编译
Linux、Mac OSX(*)和Cygwin的用户,可以直接在项目根目录下使用命令
```
cmake .
make
```
进行编译。
编译成功后,会在libs文件夹下生成以下一些动态库(**)
| 程序名 | 说明 |
| ------ | ---- |
| split_sentence_jni.so | 分句动态库 |
| segmentor_jni.so | 分词动态库 |
| postagger_jni.so| 词性标注动态库 |
| parser_jni.so | 依存句法分析动态库 |
| ner_jni.so | 命名实体识别动态库 |
| srl_jni.so | 语义角色标注动态库 |
###注意事项
* **该处编译需要设置Java环境变量JAVA_HOME**。
* **需要保持c++编译器与JDK同是32位或者64位,否则JVM不能加载生成的动态库**
#开始使用
构建需要在本地使用ltp的工程
* 导入ltp4j.jar
* windows下将libs文件夹中生成的所有动态库、以及原ltp lib文件夹下的splitsnt、segmentor、postagger、ner、parser、srl 6个动态库拷贝到项目根目录
* linux下export LD_LIBRARY_PATH=#jni动态库路径#
接下来便可仿照下面各个接口的例子使用ltp啦。
#编程接口
## 分词接口
edu.ir.hit.ltp4j.Segmentor
分词主要提供四个接口:
**int create(带外部词典)**
功能:
读取模型文件,初始化分词器。
参数:
| 参数名 | 参数描述 |
|--------|----------|
|String path | 指定模型文件的路径 |
|String lexicon_path | 指定外部词典路径。如果lexicon_path为NULL,则不加载外部词典 |
返回值:
成功加载模型返回1,否则返回-1。
**int create**
功能:
读取模型文件,初始化分词器。
参数:
| 参数名 | 参数描述 |
|--------|----------|
|String path | 指定模型文件的路径 |
返回值:
成功加载模型返回1,否则返回-1。
**void release**
功能:
释放模型文件,销毁分词器。
参数:无
返回值:无
**int Segment**
功能:
调用分词接口。
参数:
| 参数名 | 参数描述 |
|--------|----------|
|String | 待分词句子 |
|java.util.List< String > words| 结果分词序列 |
返回值:
返回结果中词的个数。
### 示例程序
一个简单的实例程序可以说明分词接口的用法:
```
import java.util.ArrayList;
import java.util.List;
import edu.hit.ir.ltp4j.*;
public class TestSegment {
public static void main(String[] args) {
if(Segmentor.create("../../../ltp_data/cws.model")<0){
System.err.println("load failed");
return;
}
String sent = "我是中国人";
List words = new ArrayList();
int size = Segmentor.segment(sent,words);
for(int i = 0; i words | 待标注的词序列 |
|java.util.List< String > tags | 词性标注结果,序列中的第i个元素是第i个词的词性 |
返回值:
返回结果中词的个数
### 示例程序
一个简单的实例程序可以说明词性标注接口的用法:
```
import java.util.ArrayList;
import java.util.ArrayList;
import java.util.List;
import edu.hit.ir.ltp4j.*;
public class TestPostag {
public static void main(String[] args) {
if(Postagger.create("../../../ltp_data/pos.model")<0) {
System.err.println("load failed");
return;
}
List words= new ArrayList();
words.add("我"); words.add("是");
words.add("中国"); words.add("人");
List postags= new ArrayList();
int size = Postagger.postag(words,postags);
for(int i = 0; i < size; i++) {
System.out.print(words.get(i)+"_"+postags.get(i));
if(i==size-1) {
System.out.println();
} else {
System.out.print("|");
}
}
Postagger.release();
}
}
```
## 命名实体识别接口
edu.ir.hit.ltp4j.NER
命名实体识别主要提供三个接口:
**int create**
功能:
参数:
| 参数名 | 参数描述 |
|-------|----------|
| String path | 命名实体识别模型路径 |
返回值:
成功加载模型返回1,否则返回-1。
**void release**
功能:
释放模型文件,销毁命名实体识别器。
参数:无
返回值:无
**int recognize**
功能:
调用命名实体识别接口
参数:
|参数名 | 参数描述 |
|-------|----------|
|java.util.List< String > words | 待识别的词序列 |
|java.util.List< String > postags | 待识别的词的词性序列 |
|java.util.List< String > tags | 命名实体识别结果,命名实体识别的结果为O时表示这个词不是命名实体,否则为{POS}-{TYPE}形式的标记,POS代表这个词在命名实体中的位置,TYPE表示命名实体类型 |
返回值:
返回结果中词的个数
### 示例程序
import java.util.ArrayList;
import java.util.List;
import edu.hit.ir.ltp4j.*;
public class TestNer {
public static void main(String[] args) {
if(NER.create("../../../ltp_data/ner.model")<0) {
System.err.println("load failed");
return;
}
List words = new ArrayList();
List tags = new ArrayList();
List ners = new ArrayList();
words.add("中国");tags.add("ns");
words.add("国际");tags.add("n");
words.add("广播");tags.add("n");
words.add("电台");tags.add("n");
words.add("创办");tags.add("v");
words.add("于");tags.add("p");
words.add("1941年");tags.add("m");
words.add("12月");tags.add("m");
words.add("3日");tags.add("m");
words.add("。");tags.add("wp");
NER.recognize(words, tags, ners);
for (int i = 0; i < words.size(); i++) {
System.out.println(ners.get(i));
}
NER.release();
}
}
## 依存句法分析接口
edu.ir.hit.ltp4j.Parser
依存句法分析主要提供三个接口:
**int create**
功能:
读取模型文件,初始化依存句法分析器
参数:
|参数名 | 参数描述 |
|---|---|
|String path | 依存句法分析模型路径 |
返回值:
成功加载模型返回1,否则返回-1。
**void release**
功能:
释放模型文件,销毁依存句法分析器。
参数:无
返回值:无
**int parse**
功能:
调用依存句法分析接口
参数:
|参数名 | 参数描述 |
|---|---|
|java.util.List< String > words | 待分析的词序列 |
|java.util.List< String > postags | 待分析的词的词性序列 |
|java.util.List< Integer > heads | 结果依存弧,heads[i]代表第i个词的父亲节点的编号 |
|java.util.List< String > deprels | 结果依存弧关系类型 |
返回值:
返回结果中词的个数
### 示例程序
一个简单的实例程序可以说明依存句法分析接口的用法:
import java.util.ArrayList;
import java.util.List;
import edu.hit.ir.ltp4j.*;
public class TestParser {
public static void main(String[] args) {
if(Parser.create("../../../ltp_data/parser.model")<0) {
System.err.println("load failed");
return;
}
List words = new ArrayList();
List tags = new ArrayList();
words.add("一把手");tags.add("n");
words.add("亲自");tags.add("d");
words.add("过问");tags.add("v");
words.add("。");tags.add("wp");
List heads = new ArrayList();
List deprels = new ArrayList();
int size = Parser.parse(words,tags,heads,deprels);
for(int i = 0;i words | 待分析的词序列 |
|java.util.List< String > postags | 待分析的词的词性序列 |
|java.util.List< String > ners| 待分析的命名实体序列
|java.util.List< Integer > heads | 待分析的依存弧,heads[i]代表第i个词的父亲节点的编号 |
|java.util.List< String > deprels | 待分析的依存弧关系类型 |
| List< Pair< Integer, List< Pair< String, Pair< Integer, Integer > > > > > srls | 结果语义角色标注 |
返回值:
返回角色个数
### 示例程序
一个简单的实例程序可以说明依存句法分析接口的用法:
import java.util.ArrayList;
import java.util.List;
import edu.hit.ir.ltp4j.*;
public class TestSrl {
public static void main(String[] args) {
SRL.create("../../../ltp_data/pisrl.model");
ArrayList words = new ArrayList();
words.add("一把手");
words.add("亲自");
words.add("过问");
words.add("。");
ArrayList tags = new ArrayList();
tags.add("n");
tags.add("d");
tags.add("v");
tags.add("wp");
ArrayList heads = new ArrayList();
heads.add(2);
heads.add(2);
heads.add(-1);
heads.add(2);
ArrayList deprels = new ArrayList();
deprels.add("SBV");
deprels.add("ADV");
deprels.add("HED");
deprels.add("WP");
List>>>> srls = new ArrayList>>>>();
SRL.srl(words, tags, heads, deprels, srls);
for (int i = 0; i < srls.size(); ++i) {
System.out.println(srls.get(i).first + ":");
for (int j = 0; j < srls.get(i).second.size(); ++j) {
System.out.println(" tpye = "+ srls.get(i).second.get(j).first + " beg = "+ srls.get(i).second.get(j).second.first + " end = "+ srls.get(i).second.get(j).second.second);
}
}
SRL.release();
}
}
###注意事项
* **对于一个包含N个词的句子,句法分析返回的父节点范围在0至N之间,而语义角色标注的输入需要在-1至N-1之间。因此,若要在句法分析后进行语义角色标注,需要把heads作减一操作。**
================================================
FILE: doc/make.bat
================================================
@ECHO OFF
REM Command file for Sphinx documentation
if "%SPHINXBUILD%" == "" (
set SPHINXBUILD=sphinx-build
)
set BUILDDIR=_build
set ALLSPHINXOPTS=-d %BUILDDIR%/doctrees %SPHINXOPTS% .
set I18NSPHINXOPTS=%SPHINXOPTS% .
if NOT "%PAPER%" == "" (
set ALLSPHINXOPTS=-D latex_paper_size=%PAPER% %ALLSPHINXOPTS%
set I18NSPHINXOPTS=-D latex_paper_size=%PAPER% %I18NSPHINXOPTS%
)
if "%1" == "" goto help
if "%1" == "help" (
:help
echo.Please use `make ^` where ^ is one of
echo. html to make standalone HTML files
echo. dirhtml to make HTML files named index.html in directories
echo. singlehtml to make a single large HTML file
echo. pickle to make pickle files
echo. json to make JSON files
echo. htmlhelp to make HTML files and a HTML help project
echo. qthelp to make HTML files and a qthelp project
echo. devhelp to make HTML files and a Devhelp project
echo. epub to make an epub
echo. latex to make LaTeX files, you can set PAPER=a4 or PAPER=letter
echo. text to make text files
echo. man to make manual pages
echo. texinfo to make Texinfo files
echo. gettext to make PO message catalogs
echo. changes to make an overview over all changed/added/deprecated items
echo. xml to make Docutils-native XML files
echo. pseudoxml to make pseudoxml-XML files for display purposes
echo. linkcheck to check all external links for integrity
echo. doctest to run all doctests embedded in the documentation if enabled
goto end
)
if "%1" == "clean" (
for /d %%i in (%BUILDDIR%\*) do rmdir /q /s %%i
del /q /s %BUILDDIR%\*
goto end
)
%SPHINXBUILD% 2> nul
if errorlevel 9009 (
echo.
echo.The 'sphinx-build' command was not found. Make sure you have Sphinx
echo.installed, then set the SPHINXBUILD environment variable to point
echo.to the full path of the 'sphinx-build' executable. Alternatively you
echo.may add the Sphinx directory to PATH.
echo.
echo.If you don't have Sphinx installed, grab it from
echo.http://sphinx-doc.org/
exit /b 1
)
if "%1" == "html" (
%SPHINXBUILD% -b html %ALLSPHINXOPTS% %BUILDDIR%/html
if errorlevel 1 exit /b 1
echo.
echo.Build finished. The HTML pages are in %BUILDDIR%/html.
goto end
)
if "%1" == "dirhtml" (
%SPHINXBUILD% -b dirhtml %ALLSPHINXOPTS% %BUILDDIR%/dirhtml
if errorlevel 1 exit /b 1
echo.
echo.Build finished. The HTML pages are in %BUILDDIR%/dirhtml.
goto end
)
if "%1" == "singlehtml" (
%SPHINXBUILD% -b singlehtml %ALLSPHINXOPTS% %BUILDDIR%/singlehtml
if errorlevel 1 exit /b 1
echo.
echo.Build finished. The HTML pages are in %BUILDDIR%/singlehtml.
goto end
)
if "%1" == "pickle" (
%SPHINXBUILD% -b pickle %ALLSPHINXOPTS% %BUILDDIR%/pickle
if errorlevel 1 exit /b 1
echo.
echo.Build finished; now you can process the pickle files.
goto end
)
if "%1" == "json" (
%SPHINXBUILD% -b json %ALLSPHINXOPTS% %BUILDDIR%/json
if errorlevel 1 exit /b 1
echo.
echo.Build finished; now you can process the JSON files.
goto end
)
if "%1" == "htmlhelp" (
%SPHINXBUILD% -b htmlhelp %ALLSPHINXOPTS% %BUILDDIR%/htmlhelp
if errorlevel 1 exit /b 1
echo.
echo.Build finished; now you can run HTML Help Workshop with the ^
.hhp project file in %BUILDDIR%/htmlhelp.
goto end
)
if "%1" == "qthelp" (
%SPHINXBUILD% -b qthelp %ALLSPHINXOPTS% %BUILDDIR%/qthelp
if errorlevel 1 exit /b 1
echo.
echo.Build finished; now you can run "qcollectiongenerator" with the ^
.qhcp project file in %BUILDDIR%/qthelp, like this:
echo.^> qcollectiongenerator %BUILDDIR%\qthelp\LTP.qhcp
echo.To view the help file:
echo.^> assistant -collectionFile %BUILDDIR%\qthelp\LTP.ghc
goto end
)
if "%1" == "devhelp" (
%SPHINXBUILD% -b devhelp %ALLSPHINXOPTS% %BUILDDIR%/devhelp
if errorlevel 1 exit /b 1
echo.
echo.Build finished.
goto end
)
if "%1" == "epub" (
%SPHINXBUILD% -b epub %ALLSPHINXOPTS% %BUILDDIR%/epub
if errorlevel 1 exit /b 1
echo.
echo.Build finished. The epub file is in %BUILDDIR%/epub.
goto end
)
if "%1" == "latex" (
%SPHINXBUILD% -b latex %ALLSPHINXOPTS% %BUILDDIR%/latex
if errorlevel 1 exit /b 1
echo.
echo.Build finished; the LaTeX files are in %BUILDDIR%/latex.
goto end
)
if "%1" == "latexpdf" (
%SPHINXBUILD% -b latex %ALLSPHINXOPTS% %BUILDDIR%/latex
cd %BUILDDIR%/latex
make all-pdf
cd %BUILDDIR%/..
echo.
echo.Build finished; the PDF files are in %BUILDDIR%/latex.
goto end
)
if "%1" == "latexpdfja" (
%SPHINXBUILD% -b latex %ALLSPHINXOPTS% %BUILDDIR%/latex
cd %BUILDDIR%/latex
make all-pdf-ja
cd %BUILDDIR%/..
echo.
echo.Build finished; the PDF files are in %BUILDDIR%/latex.
goto end
)
if "%1" == "text" (
%SPHINXBUILD% -b text %ALLSPHINXOPTS% %BUILDDIR%/text
if errorlevel 1 exit /b 1
echo.
echo.Build finished. The text files are in %BUILDDIR%/text.
goto end
)
if "%1" == "man" (
%SPHINXBUILD% -b man %ALLSPHINXOPTS% %BUILDDIR%/man
if errorlevel 1 exit /b 1
echo.
echo.Build finished. The manual pages are in %BUILDDIR%/man.
goto end
)
if "%1" == "texinfo" (
%SPHINXBUILD% -b texinfo %ALLSPHINXOPTS% %BUILDDIR%/texinfo
if errorlevel 1 exit /b 1
echo.
echo.Build finished. The Texinfo files are in %BUILDDIR%/texinfo.
goto end
)
if "%1" == "gettext" (
%SPHINXBUILD% -b gettext %I18NSPHINXOPTS% %BUILDDIR%/locale
if errorlevel 1 exit /b 1
echo.
echo.Build finished. The message catalogs are in %BUILDDIR%/locale.
goto end
)
if "%1" == "changes" (
%SPHINXBUILD% -b changes %ALLSPHINXOPTS% %BUILDDIR%/changes
if errorlevel 1 exit /b 1
echo.
echo.The overview file is in %BUILDDIR%/changes.
goto end
)
if "%1" == "linkcheck" (
%SPHINXBUILD% -b linkcheck %ALLSPHINXOPTS% %BUILDDIR%/linkcheck
if errorlevel 1 exit /b 1
echo.
echo.Link check complete; look for any errors in the above output ^
or in %BUILDDIR%/linkcheck/output.txt.
goto end
)
if "%1" == "doctest" (
%SPHINXBUILD% -b doctest %ALLSPHINXOPTS% %BUILDDIR%/doctest
if errorlevel 1 exit /b 1
echo.
echo.Testing of doctests in the sources finished, look at the ^
results in %BUILDDIR%/doctest/output.txt.
goto end
)
if "%1" == "xml" (
%SPHINXBUILD% -b xml %ALLSPHINXOPTS% %BUILDDIR%/xml
if errorlevel 1 exit /b 1
echo.
echo.Build finished. The XML files are in %BUILDDIR%/xml.
goto end
)
if "%1" == "pseudoxml" (
%SPHINXBUILD% -b pseudoxml %ALLSPHINXOPTS% %BUILDDIR%/pseudoxml
if errorlevel 1 exit /b 1
echo.
echo.Build finished. The pseudo-XML files are in %BUILDDIR%/pseudoxml.
goto end
)
:end
================================================
FILE: doc/requirements.txt
================================================
javasphinx
================================================
FILE: doc/run.rst
================================================
运行
====
以编译运行examples/Test.java为例。
概念
~~~~
**version与aol**
version是当前ltp4j的版本号,aol是使用ltp4j机器的`架构-系统-链接器`
在命令行条件下可以用如下命令获得
.. code:: shell
# get version
version=`egrep '' pom.xml | head -1 | tr -d ' ' | sed 's///g' | sed 's/<\/version>//g'`
# get aol
aol=`ls target/ltp4j-${version}-*-jni.nar | sed "s/target\/ltp4j-${version}-//g" | sed "s/-jni.nar//g"`
在其他条件下可以根据编译步骤生成的的nar文件进行判断。
具体来讲编译步骤生成的nar文件的格式为`target/ltp4j-${version}-${aol}-jni.jar`。
**运行jni的必要条件**
1. 添加ltp4j.jar到java项目的classpath里
2. 添加c++代理程序的路径到java.library.path里
命令行
~~~~~~
.. code:: shell
# get version
version=`egrep '' pom.xml | head -1 | tr -d ' ' | sed 's///g' | sed 's/<\/version>//g'`
# get aol
aol=`ls target/ltp4j-${version}-*-jni.nar | sed "s/target\/ltp4j-${version}-//g" | sed "s/-jni.nar//g"`
# compile
javac -cp "target/ltp4j-${version}.jar" examples/Test.java
# run, specifying java.library.path, Test accept input from stdin
cat examples/example | java -Djava.library.path=target/nar/ltp4j-$version-$aol-jni/lib/$aol/jni/ \
-cp "target/ltp4j-${version}.jar:examples" Test \
--segment-model=ltp_data/cws.model \
--postag-model=ltp_data/pos.model \
--ner-model=ltp_data/ner.model \
--parser-model=ltp_data/parser.model \
--srl-dir=ltp_data/srl/
Eclipse
~~~~~~~
1. File -> New -> Java Project, 在Project name处填入ltp4jtest
2. 右键examples项目下的src文件夹,在弹出菜单下选择New -> Class,Name处填入Test
3. 将examples/Test.java填入Test中
4. 右键examples项目下的Properties,
1. 选择 `Java Build Path`
2. 选择 `Libraries` 选项卡
3. 选择 `Add External JAR...` 选择编译出的ltp4j-$version.jar文件 [添加ltp4.jar]
4. 点击 > 箭头展开添加的ltp4j-$version.jar,在Native library location中选择C++代理程序的路径 [添加java.library.path]
如图所示:
.. image:: _static/eclipse.gif
参考: `How to set the java.library.path from Eclipse `_
Intellij
~~~~~~~~
参考:`How to set the java.library.path in intelliJ Idea `_
常见问题
~~~~~~~~
================================================
FILE: examples/Console.java
================================================
import java.util.Scanner;
import java.util.ArrayList;
import java.util.List;
import edu.hit.ir.ltp4j.SplitSentence;
import edu.hit.ir.ltp4j.Segmentor;
import edu.hit.ir.ltp4j.Postagger;
import edu.hit.ir.ltp4j.NER;
import edu.hit.ir.ltp4j.Parser;
import edu.hit.ir.ltp4j.SRL;
import edu.hit.ir.ltp4j.Pair;
public class Console {
private String segmentModel;
private String postagModel;
private String NERModel;
private String parserModel;
private String SRLModel;
private SplitSentence sentenceSplitApp;
private Segmentor segmentorApp;
private Postagger postaggerApp;
private NER nerApp;
private Parser parserApp;
private SRL srlApp;
private boolean ParseArguments(String[] args) {
if (args.length == 1 && (args[0].equals("--help") || args[0].equals("-h"))) {
Usage();
return false;
}
for (int i = 0; i < args.length; ++ i) {
if (args[i].startsWith("--segment-model=")) {
segmentModel = args[i].split("=")[1];
} else if (args[i].startsWith("--postag-model=")) {
postagModel = args[i].split("=")[1];
} else if (args[i].startsWith("--ner-model=")) {
NERModel = args[i].split("=")[1];
} else if (args[i].startsWith("--parser-model=")) {
parserModel = args[i].split("=")[1];
} else if (args[i].startsWith("--srl-model=")) {
SRLModel = args[i].split("=")[1];
} else {
throw new IllegalArgumentException("Unknown options " + args[i]);
}
}
if (segmentModel == null || postagModel == null || NERModel == null ||
parserModel == null || SRLModel == null) {
Usage();
throw new IllegalArgumentException("");
}
sentenceSplitApp = new SplitSentence();
segmentorApp = new Segmentor();
segmentorApp.create(segmentModel);
postaggerApp = new Postagger();
postaggerApp.create(postagModel);
nerApp = new NER();
nerApp.create(NERModel);
parserApp = new Parser();
parserApp.create(parserModel);
srlApp = new SRL();
srlApp.create(SRLModel);
return true;
}
public void Usage() {
System.err.println("An command line example for ltp4j - The Java embedding of LTP");
System.err.println("Sentences are inputted from stdin.");
System.err.println("");
System.err.println("Usage:");
System.err.println("");
System.err.println(" java -cp --segment-model= \\");
System.err.println(" --postag-model= \\");
System.err.println(" --ner-model= \\");
System.err.println(" --parser-model= \\");
System.err.println(" --srl-model=");
}
private String join(ArrayList payload, String conjunction) {
StringBuilder sb = new StringBuilder();
if (payload == null || payload.size() == 0) {
return "";
}
sb.append(payload.get(0));
for (int i = 1; i < payload.size(); ++ i) {
sb.append(conjunction).append(payload.get(i));
}
return sb.toString();
}
public void Analyse(String sent) {
ArrayList sents = new ArrayList();
sentenceSplitApp.splitSentence(sent, sents);
for(int m = 0; m < sents.size(); m++) {
ArrayList words = new ArrayList();
ArrayList postags = new ArrayList();
ArrayList ners = new ArrayList();
ArrayList heads = new ArrayList();
ArrayList deprels = new ArrayList();
List>>>> srls =
new ArrayList>>>>();
System.out.println("#" + (m + 1));
System.out.println("Sentence : " + sents.get(m));
segmentorApp.segment(sents.get(m), words);
System.out.println("Segment Result : " + join(words, "\t"));
postaggerApp.postag(words, postags);
System.out.print("Postag Result : ");
System.out.println(join(postags, "\t"));
nerApp.recognize(words, postags, ners);
System.out.print("NER Result : ");
System.out.println(join(ners, "\t"));
parserApp.parse(words, postags, heads, deprels);
int size = heads.size();
StringBuilder sb = new StringBuilder();
sb.append(heads.get(0)).append(":").append(deprels.get(0));
for(int i = 1; i < heads.size(); i++) {
sb.append("\t").append(heads.get(i)).append(":").append(deprels.get(i));
}
System.out.print("Parse Result : ");
System.out.println(sb.toString());
for (int i = 0; i < heads.size(); i++) {
heads.set(i, heads.get(i) - 1);
}
srlApp.srl(words,postags,heads,deprels,srls);
size = srls.size();
System.out.print("SRL Result : ");
if (size == 0) {
System.out.println();
}
for (int i = 0; i < srls.size(); i++) {
System.out.print(srls.get(i).first + " ->");
for (int j = 0; j < srls.get(i).second.size(); j++) {
System.out.print(srls.get(i).second.get(j).first
+ ": beg = " + srls.get(i).second.get(j).second.first
+ " end = " + srls.get(i).second.get(j).second.second + ";");
}
System.out.println();
}
}
}
public void release(){
segmentorApp.release();
postaggerApp.release();
nerApp.release();
parserApp.release();
srlApp.release();
}
public static void main(String[] args) {
Console console = new Console();
try {
if (!console.ParseArguments(args)) {
return;
}
Scanner input = new Scanner(System.in);
String sent;
try {
System.out.print(">>> ");
while((sent = input.nextLine()) != null) {
if (sent.length() > 0) {
console.Analyse(sent);
}
System.out.print(">>> ");
}
} catch(Exception e) {
console.release();
}
} catch (IllegalArgumentException e) {
}
}
}
================================================
FILE: examples/example
================================================
中国进出口银行与中国银行加强合作
================================================
FILE: pom.xml
================================================
4.0.0
edu.hit.ir.ltp4j
ltp4j
0.1.0-SNAPSHOT
nar
hitscir-ltp4j
Language Technology Platform for Java
http://github.com/HIT-SCIR/ltp4j
UTF-8
true
The Apache License, Version 2.0
http://www.apache.org/licenses/LICENSE-2.0.txt
sonatype-nexus-snapshots
Sonatype Nexus Snapshots
https://oss.sonatype.org/content/repositories/snapshots/
sonatype-nexus-staging
Nexus Release Repository
https://oss.sonatype.org/service/local/staging/deploy/maven2/
junit
junit
4.7
test
install
maven-dependency-plugin
maven-compiler-plugin
com.github.maven-nar
nar-maven-plugin
3.5.0
true
src/main/c++
ltp/examples/*
ltp/src/console/*
ltp/src/ltp/*
ltp/src/segmentor/io.cpp
ltp/src/segmentor/otcws.cpp
ltp/src/segmentor/segmentor_frontend.cpp
ltp/src/segmentor/customized_segmentor_frontend.cpp
ltp/src/postagger/io.cpp
ltp/src/postagger/otpos.cpp
ltp/src/postagger/postagger_frontend.cpp
ltp/src/ner/io.cpp
ltp/src/ner/otner.cpp
ltp/src/ner/ner_frontend.cpp
ltp/src/parser/*
ltp/src/parser.n/io.cpp
ltp/src/parser.n/main.cpp
ltp/src/parser.n/parser_frontend.cpp
ltp/src/srl/**/process/*
ltp/src/srl/*/pred.cpp
ltp/src/srl/*/train.cpp
ltp/src/srl/tool/merge.cpp
ltp/src/server/*
ltp/src/xml4nlp/*
ltp/src/unittest/*
ltp/thirdparty/eigen/unsupported/**/*
ltp/thirdparty/dynet/dynet/cuda.cc
ltp/thirdparty/tinyxml/*
ltp/thirdparty/tinythreadpp/*
ltp/thirdparty/maxent/train.cpp
ltp/thirdparty/maxent/predict.cpp
ltp/thirdparty/gtest/**/*
src/main/c++/ltp/src
src/main/c++/ltp/src/srl
src/main/c++/ltp/src/srl/common
src/main/c++/ltp/src/srl/include
src/main/c++/ltp/src/utils
src/main/c++/ltp/thirdparty/boost/include
src/main/c++/ltp/thirdparty/maxent
src/main/c++/ltp/thirdparty/eigen
src/main/c++/ltp/thirdparty/dynet
src/main/c++/ltp/thirdparty/jsoncpp/include
false
**/*
jni
edu.hit.ir.ltp4j
false
Segmentor
Postagger
NER
Parser
SRL
================================================
FILE: src/main/c++/edu_hit_ir_ltp4j_NER.cpp
================================================
#include "ner/ner_dll.h"
#include "edu_hit_ir_ltp4j_NER.h"
#include "string_to_jstring.hpp"
#include
#include
#include
static void * ner = NULL;
JNIEXPORT jint JNICALL Java_edu_hit_ir_ltp4j_NER_create
(JNIEnv * env, jobject obj, jstring model_path) {
const char * str = env->GetStringUTFChars( model_path , 0);
if (!ner) {
ner = ner_create_recognizer(str);
} else {
ner_release_recognizer(ner);
ner = ner_create_recognizer(str);
}
env->ReleaseStringUTFChars( model_path, str);
if (ner) {
return 1;
}
return -1;
}
JNIEXPORT jint JNICALL Java_edu_hit_ir_ltp4j_NER_recognize
(JNIEnv * env, jobject obj, jobject array_words, jobject array_tags, jobject array_ners) {
jclass array_list = env->GetObjectClass(array_words);
jmethodID list_add = env->GetMethodID(array_list,"add","(Ljava/lang/Object;)Z");
jmethodID list_get = env->GetMethodID(array_list,"get","(I)Ljava/lang/Object;");
jmethodID list_size = env->GetMethodID(array_list,"size","()I");
std::vector words,tags,ners;
int size_words = env->CallIntMethod(array_words,list_size);
int size_tags = env->CallIntMethod(array_tags,list_size);
if (size_words!=size_tags) {
return 0;
}
for (int i = 0; i < size_words; i++) {
jobject tmp = env->CallObjectMethod(array_words,list_get,i);
jstring s = reinterpret_cast (tmp);
const char * st = env->GetStringUTFChars(s,0);
std::string s_s(st);
words.push_back(s_s);
env->ReleaseStringUTFChars( s, st);
}
for (int i = 0; i < size_tags; i++) {
jobject tmp = env->CallObjectMethod(array_tags,list_get,i);
jstring s = reinterpret_cast (tmp);
const char * st = env->GetStringUTFChars(s,0);
std::string s_s(st);
tags.push_back(s_s);
env->ReleaseStringUTFChars( s, st);
}
int len = ner_recognize(ner,words,tags,ners);
for (int i = 0; i < len; i++) {
jobject tmp = stringToJstring(env,ners[i].c_str());
env->CallBooleanMethod(array_ners,list_add,tmp);
}
return len;
}
JNIEXPORT void JNICALL Java_edu_hit_ir_ltp4j_NER_release
(JNIEnv * env, jobject obj) {
ner_release_recognizer(ner);
ner = NULL;
}
================================================
FILE: src/main/c++/edu_hit_ir_ltp4j_Parser.cpp
================================================
#include "edu_hit_ir_ltp4j_Parser.h"
#include "parser/parser_dll.h"
#include "string_to_jstring.hpp"
#include
#include
#include
#include
static void * parser = NULL;
JNIEXPORT jint JNICALL Java_edu_hit_ir_ltp4j_Parser_create
(JNIEnv * env, jobject obj, jstring model_path) {
const char * str = env->GetStringUTFChars( model_path , 0);
if(!parser){
parser = parser_create_parser(str);
}
env->ReleaseStringUTFChars( model_path, str);
if(parser) {
return 1;
}
return -1;
}
JNIEXPORT jint JNICALL Java_edu_hit_ir_ltp4j_Parser_parse
(JNIEnv * env, jobject obj, jobject array_words, jobject array_tags, jobject array_heads, jobject array_deprels) {
jclass array_list = env->GetObjectClass(array_words);
jclass integer = env->FindClass("java/lang/Integer");
jmethodID list_add = env->GetMethodID(array_list, "add", "(Ljava/lang/Object;)Z");
jmethodID list_get = env->GetMethodID(array_list, "get", "(I)Ljava/lang/Object;");
jmethodID list_size = env->GetMethodID(array_list, "size", "()I");
jmethodID integer_init =env->GetMethodID(integer, "", "(I)V");
std::vector words,tags,deprels;
std::vector heads;
int size_words = env->CallIntMethod(array_words,list_size);
int size_tags = env->CallIntMethod(array_tags,list_size);
if (size_words!=size_tags) {
return -1;
}
for (int i = 0; i < size_words; i++) {
jobject tmp = env->CallObjectMethod(array_words,list_get,i);
jstring s = reinterpret_cast (tmp);
const char * st = env->GetStringUTFChars(s,0);
std::string s_s(st);
words.push_back(s_s);
env->ReleaseStringUTFChars( s, st);
}
for (int i = 0; i < size_tags; i++) {
jobject tmp = env->CallObjectMethod(array_tags,list_get,i);
jstring s = reinterpret_cast (tmp);
const char * st = env->GetStringUTFChars(s,0);
std::string s_s(st);
tags.push_back(s_s);
env->ReleaseStringUTFChars( s, st);
}
int len = parser_parse(parser,words,tags,heads,deprels);
if (len < 0) {
return -1;
}
size_t size = heads.size();
for (size_t i = 0; iNewObject(integer,integer_init,heads.at(i));
env->CallBooleanMethod(array_heads,list_add, integer_object);
}
for (size_t i = 0;iCallBooleanMethod(array_deprels,list_add,tmp);
}
return len;
}
JNIEXPORT void JNICALL Java_edu_hit_ir_ltp4j_Parser_release
(JNIEnv * env, jobject obj) {
parser_release_parser(parser);
parser = NULL;
}
================================================
FILE: src/main/c++/edu_hit_ir_ltp4j_Postagger.cpp
================================================
#include "postagger/postag_dll.h"
#include "edu_hit_ir_ltp4j_Postagger.h"
#include "string_to_jstring.hpp"
#include
#include
#include
#include
static void * postagger = NULL;
JNIEXPORT jint JNICALL Java_edu_hit_ir_ltp4j_Postagger_create__Ljava_lang_String_2
(JNIEnv * env, jobject obj, jstring model_path) {
const char* str = env->GetStringUTFChars( model_path , 0);
if(!postagger){
postagger = postagger_create_postagger(str);
} else {
postagger_release_postagger(postagger);
postagger = postagger_create_postagger(str);
}
env->ReleaseStringUTFChars( model_path, str);
if (postagger) {
return 1;
}
return -1;
}
JNIEXPORT jint JNICALL Java_edu_hit_ir_ltp4j_Postagger_create__Ljava_lang_String_2Ljava_lang_String_2
(JNIEnv * env, jobject obj, jstring model_path, jstring lexicon_path) {
const char * model = env->GetStringUTFChars( model_path , 0);
const char * lexicon = env->GetStringUTFChars( lexicon_path , 0);
if(!postagger){
postagger = postagger_create_postagger(model,lexicon);
} else {
postagger_release_postagger(postagger);
postagger = postagger_create_postagger(model,lexicon);
}
env->ReleaseStringUTFChars( model_path, model);
env->ReleaseStringUTFChars( lexicon_path, lexicon);
if(postagger) {
return 1;
}
return -1;
}
JNIEXPORT jint JNICALL Java_edu_hit_ir_ltp4j_Postagger_postag
(JNIEnv * env, jobject obj, jobject array_words, jobject array_postags) {
jclass array_list = env->GetObjectClass(array_words);
jmethodID list_add = env->GetMethodID(array_list, "add", "(Ljava/lang/Object;)Z");
jmethodID list_get = env->GetMethodID(array_list, "get", "(I)Ljava/lang/Object;");
jmethodID list_size = env->GetMethodID(array_list, "size", "()I");
std::vector words, postags;
int size = env->CallIntMethod(array_words,list_size);
for (int i = 0; i < size ; i++) {
jobject tmp = env->CallObjectMethod(array_words,list_get,i);
jstring s = reinterpret_cast (tmp);
const char * st = env->GetStringUTFChars(s,0);
std::string s_s(st);
words.push_back(s_s);
env->ReleaseStringUTFChars( s, st);
}
int len = postagger_postag(postagger,words,postags);
for (int i = 0; i < len; i++) {
jobject tmp = stringToJstring(env,postags[i].c_str());
env->CallBooleanMethod(array_postags,list_add,tmp);
}
return len;
}
JNIEXPORT void JNICALL Java_edu_hit_ir_ltp4j_Postagger_release
(JNIEnv * env, jobject obj) {
postagger_release_postagger(postagger);
postagger = NULL;
}
================================================
FILE: src/main/c++/edu_hit_ir_ltp4j_SRL.cpp
================================================
#include "edu_hit_ir_ltp4j_SRL.h"
#include "srl/SRL_DLL.h"
#include "string_to_jstring.hpp"
#include
#include
#include
#include
JNIEXPORT jint JNICALL Java_edu_hit_ir_ltp4j_SRL_create
(JNIEnv * env, jobject obj, jstring model_path){
const char * str = env->GetStringUTFChars( model_path , 0);
std::string path(str);
int tag = srl_load_resource(path);
env->ReleaseStringUTFChars( model_path, str);
if(0==tag) {
return 1;
}
return -1;
}
JNIEXPORT jint JNICALL Java_edu_hit_ir_ltp4j_SRL_srl
(JNIEnv * env, jclass obj, jobject array_words, jobject array_tags, jobject array_heads, jobject array_deprels, jobject srl_result){
jclass array_list = env->GetObjectClass(array_words);
jmethodID list_construct = env->GetMethodID(array_list,"","()V");
jmethodID list_add = env->GetMethodID(array_list, "add", "(Ljava/lang/Object;)Z");
jmethodID list_get = env->GetMethodID(array_list, "get", "(I)Ljava/lang/Object;");
jmethodID list_size = env->GetMethodID(array_list, "size", "()I");
jclass integer = env->FindClass("java/lang/Integer");
jmethodID integer_construct =env->GetMethodID(integer,"","(I)V");
jmethodID integer_int =env->GetMethodID(integer,"intValue","()I");
jclass pair = env->FindClass("edu/hit/ir/ltp4j/Pair");
jmethodID pair_construct = env->GetMethodID(pair, "",
"(Ljava/lang/Object;Ljava/lang/Object;)V");
std::vector words,tags,deprels;
std::vector heads;
std::vector > parsers;
std::vector<
std::pair<
int,
std::vector<
std::pair >
>
>
> srls;
unsigned size_words = env->CallIntMethod(array_words, list_size);
for(unsigned i = 0; i < size_words; i++){
jobject tmp = env->CallObjectMethod(array_words,list_get,i);
jstring s = reinterpret_cast (tmp);
const char * st = env->GetStringUTFChars(s,0);
std::string s_s(st);
words.push_back(s_s);
env->ReleaseStringUTFChars( s, st);
}
unsigned size_tags = env->CallIntMethod(array_tags, list_size);
for(unsigned i = 0;iCallObjectMethod(array_tags,list_get,i);
jstring s = reinterpret_cast (tmp);
const char * st = env->GetStringUTFChars(s,0);
std::string s_s(st);
tags.push_back(s_s);
env->ReleaseStringUTFChars( s, st);
}
unsigned size_heads = env->CallIntMethod(array_heads,list_size);
for(unsigned i = 0; i < size_heads; i++){
jobject tmp = env->CallObjectMethod(array_heads,list_get,i);
int digit = env->CallIntMethod(tmp,integer_int);
heads.push_back(digit);
}
unsigned size_deprels = env->CallIntMethod(array_deprels,list_size);
for(unsigned i = 0;iCallObjectMethod(array_deprels,list_get,i);
jstring s = reinterpret_cast (tmp);
const char * st = env->GetStringUTFChars(s,0);
std::string s_s(st);
deprels.push_back(s_s);
env->ReleaseStringUTFChars( s, st);
}
for(unsigned i = 0; i < size_heads; i++){
parsers.push_back(make_pair(heads.at(i),deprels.at(i)));
}
int len = srl_dosrl(words,tags,parsers,srls);
if(len<0)
return -1;
for(unsigned i = 0;iNewObject(integer,integer_construct,srls[i].first);
jobject args = env->NewObject(array_list,list_construct);
for(unsigned j = 0;jNewObject(integer,integer_construct,srls[i].second[j].second.first);
jobject end = env->NewObject(integer,integer_construct,srls[i].second[j].second.second);
jobject bound = env->NewObject(pair,pair_construct,start,end);
jobject rels = stringToJstring(env,srls[i].second[j].first.c_str());
jobject inner = env->NewObject(pair,pair_construct,rels,bound);
env->CallBooleanMethod(args,list_add,inner);
}
jobject outer = env->NewObject(pair,pair_construct,trigger,args);
env->CallBooleanMethod(srl_result,list_add,outer);
}
return (int)srls.size();
}
JNIEXPORT void JNICALL Java_edu_hit_ir_ltp4j_SRL_release
(JNIEnv * env, jobject obj) {
srl_release_resource();
}
================================================
FILE: src/main/c++/edu_hit_ir_ltp4j_Segmentor.cpp
================================================
#include "segmentor/segment_dll.h"
#include "edu_hit_ir_ltp4j_Segmentor.h"
#include "string_to_jstring.hpp"
#include
#include
#include
static void* segmentor = NULL;
JNIEXPORT jint JNICALL Java_edu_hit_ir_ltp4j_Segmentor_create__Ljava_lang_String_2
(JNIEnv* env, jobject obj, jstring model_path) {
const char* str = env->GetStringUTFChars( model_path , 0);
if(!segmentor){
segmentor = segmentor_create_segmentor(str);
} else{
segmentor_release_segmentor(segmentor);
segmentor = segmentor_create_segmentor(str);
}
env->ReleaseStringUTFChars( model_path, str);
if(segmentor) {
return 1;
}
return -1;
}
JNIEXPORT jint JNICALL Java_edu_hit_ir_ltp4j_Segmentor_create__Ljava_lang_String_2Ljava_lang_String_2
(JNIEnv* env, jobject obj, jstring model_path, jstring lexicon_path) {
const char* str_model = env->GetStringUTFChars( model_path , 0);
const char* str_lexicon = env->GetStringUTFChars( lexicon_path , 0);
if(!segmentor){
segmentor = segmentor_create_segmentor(str_model,str_lexicon);
} else{
segmentor_release_segmentor(segmentor);
segmentor = segmentor_create_segmentor(str_model,str_lexicon);
}
env->ReleaseStringUTFChars( model_path, str_model);
env->ReleaseStringUTFChars( lexicon_path, str_lexicon);
if(segmentor) {
return 1;
}
return -1;
}
JNIEXPORT jint JNICALL Java_edu_hit_ir_ltp4j_Segmentor_segment
(JNIEnv* env, jobject obj, jstring sent, jobject array_words) {
jclass array_list = env->GetObjectClass(array_words);
jmethodID list_add = env->GetMethodID(array_list, "add", "(Ljava/lang/Object;)Z");
const char* str_sent = env->GetStringUTFChars( sent , 0);
std::string sentence(str_sent);
std::vector words;
int len = segmentor_segment(segmentor, sentence, words);
for(int i = 0; i < len; i++) {
jobject tmp = stringToJstring(env,words[i].c_str());
env->CallBooleanMethod(array_words,list_add,tmp);
}
env->ReleaseStringUTFChars(sent, str_sent);
return len;
}
JNIEXPORT void JNICALL Java_edu_hit_ir_ltp4j_Segmentor_release
(JNIEnv* env, jobject obj) {
segmentor_release_segmentor(segmentor);
segmentor = NULL;
}
================================================
FILE: src/main/c++/edu_hit_ir_ltp4j_SplitSentence.cpp
================================================
#include "edu_hit_ir_ltp4j_SplitSentence.h"
#include "splitsnt/SplitSentence.h"
#include "string_to_jstring.hpp"
#include
#include
#include
#include
using namespace std;
JNIEXPORT void JNICALL Java_edu_hit_ir_ltp4j_SplitSentence_splitSentence
(JNIEnv * env, jobject obj, jstring sent, jobject array_sents){
const char * str = env->GetStringUTFChars(sent,0);
string s_s(str);
jclass array_list = env->GetObjectClass(array_sents);
jmethodID list_add = env->GetMethodID(array_list,"add","(Ljava/lang/Object;)Z");
vector sents;
SplitSentence(s_s,sents);
for (unsigned i = 0; i < sents.size(); i++) {
jobject tmp = stringToJstring(env,sents[i].c_str());
env->CallBooleanMethod(array_sents,list_add,tmp);
}
env->ReleaseStringUTFChars(sent,str);
}
================================================
FILE: src/main/c++/string_to_jstring.hpp
================================================
#include
#include
#include
inline jstring stringToJstring(JNIEnv* env, const char* pat) {
jclass strClass = env->FindClass("Ljava/lang/String;");
jmethodID ctorID = env->GetMethodID(strClass, "", "([BLjava/lang/String;)V");
jbyteArray bytes = env->NewByteArray( (jsize)strlen(pat) );
env->SetByteArrayRegion(bytes, 0, (jsize)strlen(pat), (jbyte*)pat);
jstring encoding = env->NewStringUTF("utf-8");
return (jstring)env->NewObject(strClass, ctorID, bytes, encoding);
}
================================================
FILE: src/main/java/edu/hit/ir/ltp4j/NER.java
================================================
package edu.hit.ir.ltp4j;
import java.util.List;
public class NER {
static {
NarSystem.loadLibrary();
}
public final native int create(String modelPath);
public final native int recognize(List words,
List postags, List ners);
public final native void release();
}
================================================
FILE: src/main/java/edu/hit/ir/ltp4j/Pair.java
================================================
package edu.hit.ir.ltp4j;
public class Pair {
public final F first;
public final S second;
/**
* Constructor for a Pair.
*
* @param first
* the first object in the Pair
* @param second
* the second object in the pair
*/
public Pair(F first, S second) {
this.first = first;
this.second = second;
}
/**
* Compute a hash code using the hash codes of the underlying objects
*
* @return a hashcode of the Pair
*/
@Override
public int hashCode() {
return (first == null ? 0 : first.hashCode())
^ (second == null ? 0 : second.hashCode());
}
public boolean equals(Object o) {
if (!(o instanceof Pair)) {
return false;
}
Pair p = (Pair) o;
return (p.first.equals(first)) && (p.second.equals(second));
}
/**
* Convenience method for creating an appropriately typed pair.
*
* @param a
* the first object in the Pair
* @param b
* the second object in the pair
* @return a Pair that is templatized with the types of a and b
*/
public static Pair create(A a, B b) {
return new Pair(a, b);
}
}
================================================
FILE: src/main/java/edu/hit/ir/ltp4j/Parser.java
================================================
package edu.hit.ir.ltp4j;
import java.util.List;
public class Parser {
static {
NarSystem.loadLibrary();
}
public final native int create(String modelPath);
public final native int parse(List words,
List tags, List heads,
List deprels);
public final native void release();
}
================================================
FILE: src/main/java/edu/hit/ir/ltp4j/Postagger.java
================================================
package edu.hit.ir.ltp4j;
import java.util.List;
public class Postagger {
static {
NarSystem.loadLibrary();
}
public final native int create(String modelPath);
public final native int create(String modelPath, String lexiconPath);
public final native int postag(List words,
List tags);
public final native void release();
}
================================================
FILE: src/main/java/edu/hit/ir/ltp4j/SRL.java
================================================
package edu.hit.ir.ltp4j;
import java.util.List;
public class SRL {
static {
NarSystem.loadLibrary();
}
public final native int create(String modelPath);
public final native int srl(
List words,
List tags,
List heads,
List deprels,
List>>>> srls);
public final native void release();
}
================================================
FILE: src/main/java/edu/hit/ir/ltp4j/Segmentor.java
================================================
package edu.hit.ir.ltp4j;
import java.util.List;
public class Segmentor {
static {
NarSystem.loadLibrary();
}
public final native int create(String modelPath);
public final native int create(String modelPath, String lexiconPath);
public final native int segment(String sent, List words);
public final native void release();
}
================================================
FILE: src/main/java/edu/hit/ir/ltp4j/SplitSentence.java
================================================
package edu.hit.ir.ltp4j;
import java.util.List;
public class SplitSentence{
static {
NarSystem.loadLibrary();
}
public final native void splitSentence(String sent,List sents);
}
================================================
FILE: src/test/c++/main.cpp
================================================
#include
int main(int argc, char* argv[]) {
return 0;
}
================================================
FILE: src/test/java/edu/hit/ir/ltp4j/test/NERTest.java
================================================
package edu.hit.ir.ltp4j.test;
import edu.hit.ir.ltp4j.NER;
import java.util.List;
import java.util.ArrayList;
import org.junit.Assert;
import org.junit.Test;
public class NERTest {
@Test public final void testNERCreate()
throws Exception
{
NER app = new NER();
Assert.assertEquals( 1, app.create("ltp_data/ner.model") );
}
@Test public final void testNERRecognize()
throws Exception
{
NER app = new NER();
app.create("ltp_data/ner.model");
List words = new ArrayList();
List tags = new ArrayList();
words.add("中国"); tags.add("ns");
words.add("进出口"); tags.add("n");
words.add("银行"); tags.add("n");
words.add("与"); tags.add("p");
words.add("中国"); tags.add("ns");
words.add("银行"); tags.add("n");
words.add("加强"); tags.add("v");
words.add("合作"); tags.add("v");
List result = new ArrayList();
app.recognize(words, tags, result);
Assert.assertEquals( 8, result.size() );
Assert.assertEquals( "B-Ni", result.get(0) );
Assert.assertEquals( "I-Ni", result.get(1) );
Assert.assertEquals( "E-Ni", result.get(2) );
Assert.assertEquals( "O", result.get(3) );
Assert.assertEquals( "B-Ni", result.get(4) );
Assert.assertEquals( "E-Ni", result.get(5) );
Assert.assertEquals( "O", result.get(6) );
Assert.assertEquals( "O", result.get(7) );
}
}
================================================
FILE: src/test/java/edu/hit/ir/ltp4j/test/ParserTest.java
================================================
package edu.hit.ir.ltp4j.test;
import edu.hit.ir.ltp4j.Parser;
import java.util.List;
import java.util.ArrayList;
import org.junit.Assert;
import org.junit.Test;
public class ParserTest {
@Test public final void testParserCreate()
throws Exception
{
Parser app = new Parser();
Assert.assertEquals( 1, app.create("ltp_data/parser.model") );
}
@Test public final void testParserParse()
throws Exception
{
Parser app = new Parser();
app.create("ltp_data/parser.model");
List words = new ArrayList();
List tags = new ArrayList();
words.add("中国"); tags.add("ns");
words.add("进出口"); tags.add("n");
words.add("银行"); tags.add("n");
words.add("与"); tags.add("p");
words.add("中国"); tags.add("ns");
words.add("银行"); tags.add("n");
words.add("加强"); tags.add("v");
words.add("合作"); tags.add("v");
List heads = new ArrayList();
List deprels = new ArrayList();
app.parse(words, tags, heads, deprels);
Assert.assertEquals( 8, heads.size() ); Assert.assertEquals( 8, deprels.size() );
Assert.assertTrue( 3 == heads.get(0) ); Assert.assertEquals( "ATT", deprels.get(0) );
Assert.assertTrue( 3 == heads.get(1) ); Assert.assertEquals( "ATT", deprels.get(1) );
Assert.assertTrue( 7 == heads.get(2) ); Assert.assertEquals( "SBV", deprels.get(2) );
Assert.assertTrue( 3 == heads.get(3) ); Assert.assertEquals( "ADV", deprels.get(3) );
Assert.assertTrue( 6 == heads.get(4) ); Assert.assertEquals( "ATT", deprels.get(4) );
Assert.assertTrue( 4 == heads.get(5) ); Assert.assertEquals( "POB", deprels.get(5) );
Assert.assertTrue( 0 == heads.get(6) ); Assert.assertEquals( "HED", deprels.get(6) );
Assert.assertTrue( 7 == heads.get(7) ); Assert.assertEquals( "VOB", deprels.get(7) );
}
}
================================================
FILE: src/test/java/edu/hit/ir/ltp4j/test/PostaggerTest.java
================================================
package edu.hit.ir.ltp4j.test;
import edu.hit.ir.ltp4j.Postagger;
import java.util.List;
import java.util.ArrayList;
import org.junit.Assert;
import org.junit.Test;
public class PostaggerTest {
@Test public final void testPostaggerCreate()
throws Exception
{
Postagger app = new Postagger();
Assert.assertEquals( 1, app.create("ltp_data/pos.model") );
}
@Test public final void testPostaggerPostag()
throws Exception
{
Postagger app = new Postagger();
app.create("ltp_data/pos.model");
List words = new ArrayList();
words.add("中国");
words.add("进出口");
words.add("银行");
words.add("与");
words.add("中国");
words.add("银行");
words.add("加强");
words.add("合作");
List result = new ArrayList();
app.postag(words, result);
Assert.assertEquals( 8, result.size() );
Assert.assertEquals( "ns", result.get(0) );
Assert.assertEquals( "n", result.get(1) );
Assert.assertEquals( "n", result.get(2) );
Assert.assertEquals( "p", result.get(3) );
Assert.assertEquals( "ns", result.get(4) );
Assert.assertEquals( "n", result.get(5) );
Assert.assertEquals( "v", result.get(6) );
Assert.assertEquals( "v", result.get(7) );
}
}
================================================
FILE: src/test/java/edu/hit/ir/ltp4j/test/SRLTest.java
================================================
package edu.hit.ir.ltp4j.test;
import edu.hit.ir.ltp4j.SRL;
import org.junit.Assert;
import org.junit.Test;
public class SRLTest {
@Test public final void testSRLCreate()
throws Exception
{
SRL app = new SRL();
Assert.assertEquals( 1, app.create("ltp_data/pisrl.model") );
}
}
================================================
FILE: src/test/java/edu/hit/ir/ltp4j/test/SegmentorTest.java
================================================
package edu.hit.ir.ltp4j.test;
import edu.hit.ir.ltp4j.Segmentor;
import java.util.List;
import java.util.ArrayList;
import org.junit.Assert;
import org.junit.Test;
public class SegmentorTest {
@Test public final void testSegmentorCreate()
throws Exception
{
Segmentor app = new Segmentor();
Assert.assertEquals( 1, app.create("ltp_data/cws.model") );
}
@Test public final void testSegmentorSegment()
throws Exception
{
Segmentor app = new Segmentor();
app.create("ltp_data/cws.model");
List result = new ArrayList();
app.segment("中国进出口银行与中国银行加强合作", result);
Assert.assertEquals( 8, result.size() );
Assert.assertEquals( "中国", result.get(0) );
Assert.assertEquals( "进出口", result.get(1) );
Assert.assertEquals( "银行", result.get(2) );
Assert.assertEquals( "与", result.get(3) );
Assert.assertEquals( "中国", result.get(4) );
Assert.assertEquals( "银行", result.get(5) );
Assert.assertEquals( "加强", result.get(6) );
Assert.assertEquals( "合作", result.get(7) );
}
}