|
|
██████╗ ███████╗███████╗██████╗ ██████╗ ██████╗ ██████╗ ███████╗
██╔══██╗██╔════╝██╔════╝██╔══██╗██╔════╝██╔═══██╗██╔══██╗██╔════╝
██║ ██║█████╗ █████╗ ██████╔╝██║ ██║ ██║██║ ██║█████╗
██║ ██║██╔══╝ ██╔══╝ ██╔═══╝ ██║ ██║ ██║██║ ██║██╔══╝
██████╔╝███████╗███████╗██║ ╚██████╗╚██████╔╝██████╔╝███████╗
╚═════╝ ╚══════╝╚══════╝╚═╝ ╚═════╝ ╚═════╝ ╚═════╝ ╚══════╝
|

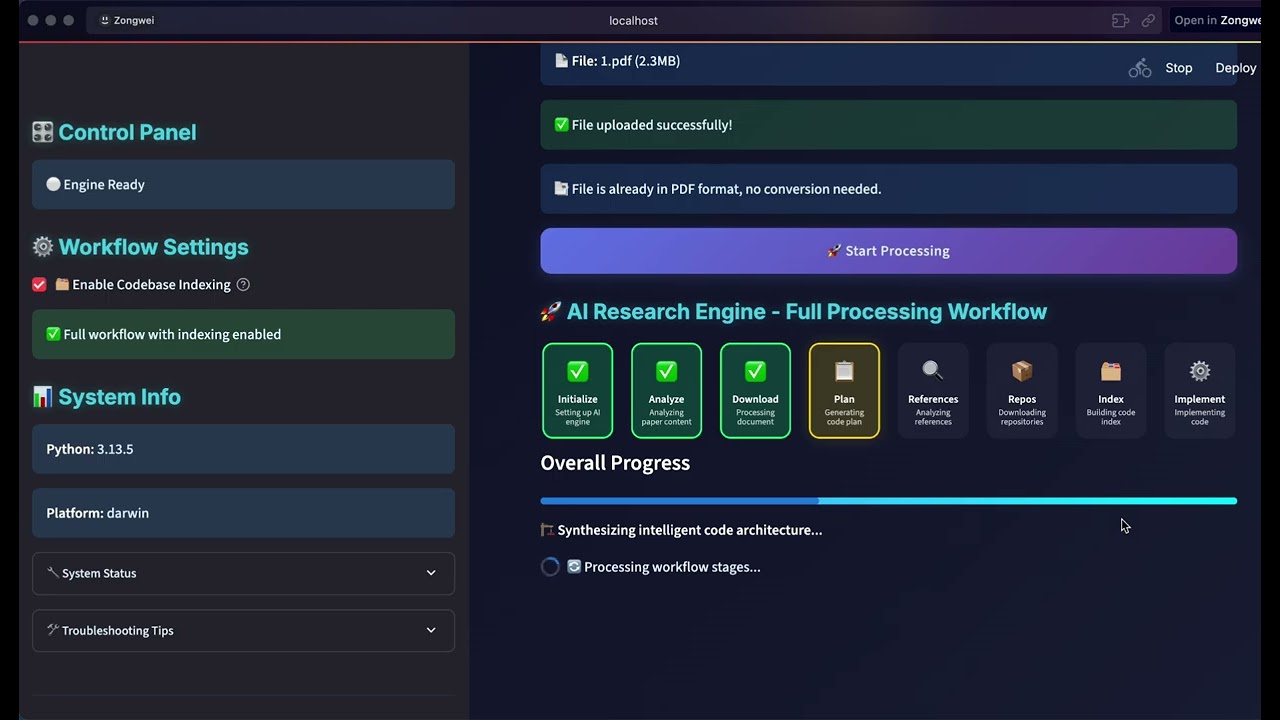
#### 🖥️ **CLI Interface**
**Terminal-Based Development**

🚀 Advanced Terminal Experience
*Professional terminal interface for advanced users and CI/CD integration*
⚡ Fast command-line workflow 🔧 Developer-friendly interface 📊 Real-time progress tracking |
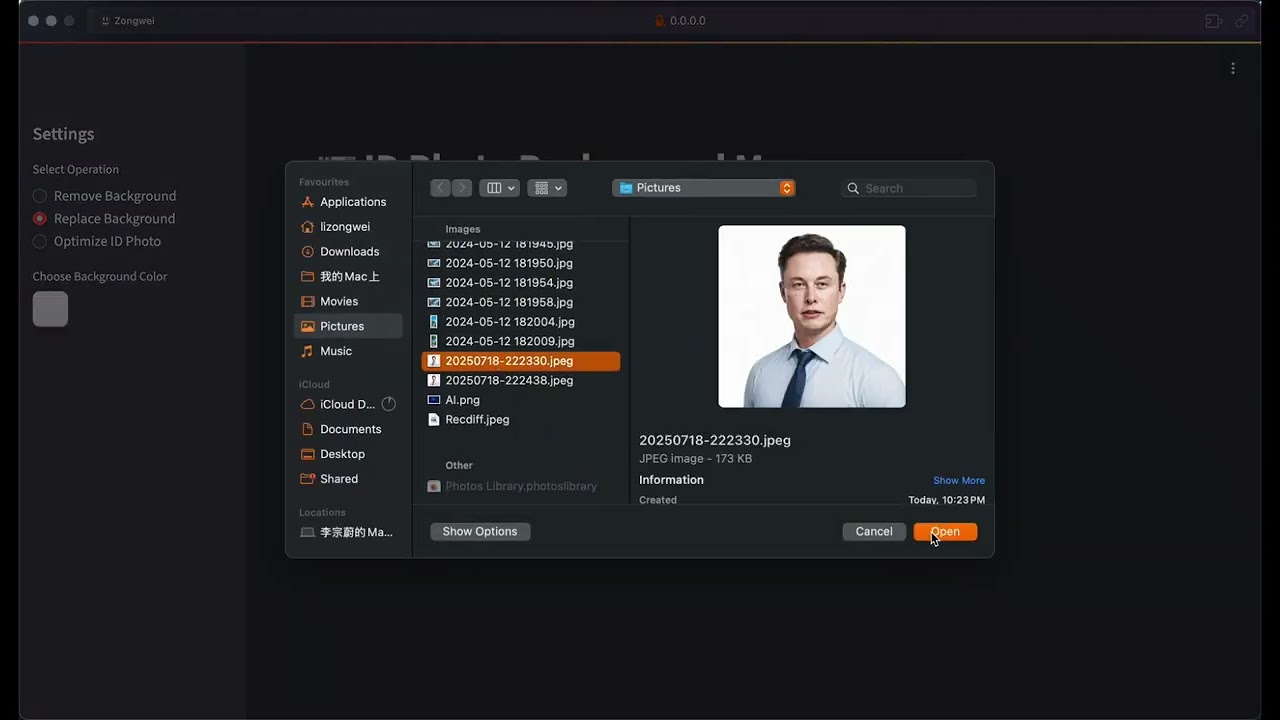
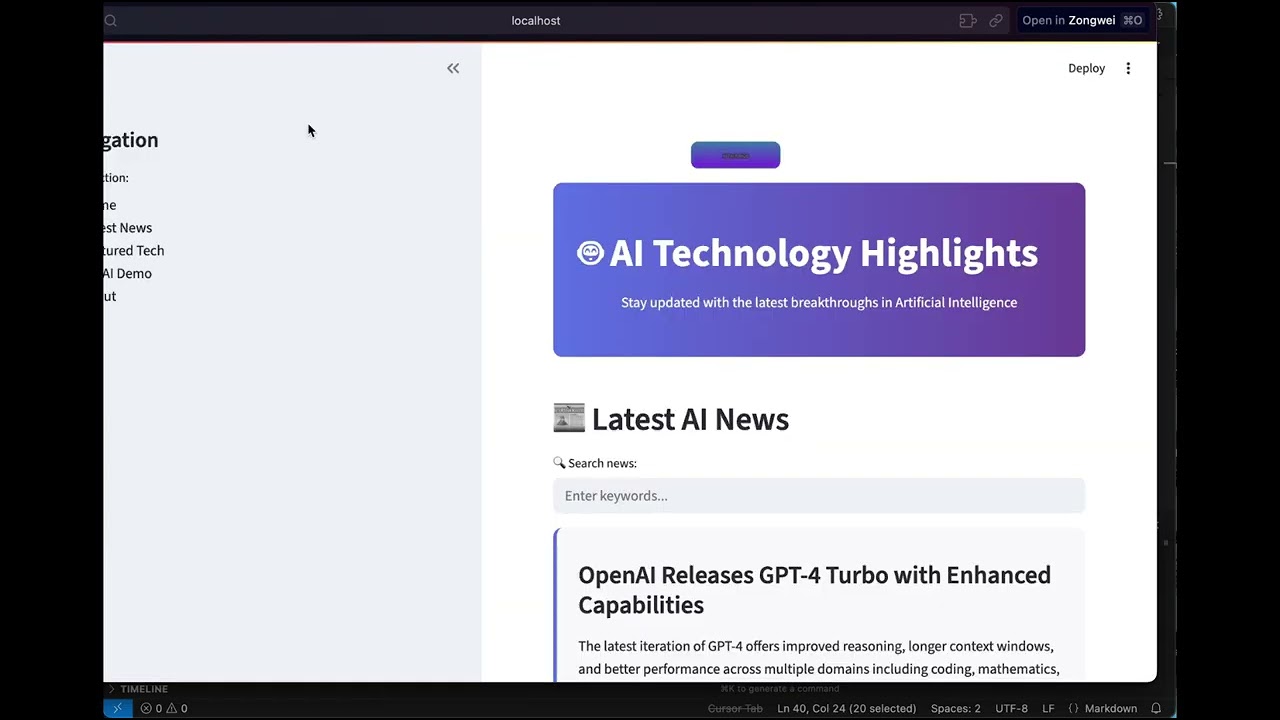
#### 🌐 **Web Interface**
**Visual Interactive Experience**

🎨 Modern Web Dashboard
*Beautiful web interface with streamlined workflow for all skill levels*
🖱️ Intuitive drag-and-drop 📱 Responsive design 🎯 Visual progress tracking |
### 🎬 **Introduction Video**
 *🎯 **Watch our complete introduction** - See how DeepCode transforms research papers and natural language into production-ready code*
*🎯 **Watch our complete introduction** - See how DeepCode transforms research papers and natural language into production-ready code*
---
> *"Where AI Agents Transform Ideas into Production-Ready Code"*






 ================================================
FILE: nanobot/Dockerfile
================================================
FROM ghcr.io/astral-sh/uv:python3.12-bookworm-slim
# Install Node.js 20 for the WhatsApp bridge
RUN apt-get update && \
apt-get install -y --no-install-recommends curl ca-certificates gnupg git && \
mkdir -p /etc/apt/keyrings && \
curl -fsSL https://deb.nodesource.com/gpgkey/nodesource-repo.gpg.key | gpg --dearmor -o /etc/apt/keyrings/nodesource.gpg && \
echo "deb [signed-by=/etc/apt/keyrings/nodesource.gpg] https://deb.nodesource.com/node_20.x nodistro main" > /etc/apt/sources.list.d/nodesource.list && \
apt-get update && \
apt-get install -y --no-install-recommends nodejs && \
apt-get purge -y gnupg && \
apt-get autoremove -y && \
rm -rf /var/lib/apt/lists/*
WORKDIR /app
# Install Python dependencies first (cached layer)
# Note: build context is DeepCode root, so paths start with nanobot/
COPY nanobot/pyproject.toml nanobot/README.md nanobot/LICENSE ./
RUN mkdir -p nanobot bridge && touch nanobot/__init__.py && \
uv pip install --system --no-cache . && \
rm -rf nanobot bridge
# Copy the full source and install
COPY nanobot/nanobot/ nanobot/
COPY nanobot/bridge/ bridge/
RUN uv pip install --system --no-cache .
# Build the WhatsApp bridge
WORKDIR /app/bridge
RUN npm install && npm run build
WORKDIR /app
# Create config directory
RUN mkdir -p /root/.nanobot
# Gateway default port
EXPOSE 18790
ENTRYPOINT ["nanobot"]
CMD ["gateway"]
================================================
FILE: nanobot/LICENSE
================================================
MIT License
Copyright (c) 2025 nanobot contributors
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE.
================================================
FILE: nanobot/README.md
================================================
================================================
FILE: nanobot/Dockerfile
================================================
FROM ghcr.io/astral-sh/uv:python3.12-bookworm-slim
# Install Node.js 20 for the WhatsApp bridge
RUN apt-get update && \
apt-get install -y --no-install-recommends curl ca-certificates gnupg git && \
mkdir -p /etc/apt/keyrings && \
curl -fsSL https://deb.nodesource.com/gpgkey/nodesource-repo.gpg.key | gpg --dearmor -o /etc/apt/keyrings/nodesource.gpg && \
echo "deb [signed-by=/etc/apt/keyrings/nodesource.gpg] https://deb.nodesource.com/node_20.x nodistro main" > /etc/apt/sources.list.d/nodesource.list && \
apt-get update && \
apt-get install -y --no-install-recommends nodejs && \
apt-get purge -y gnupg && \
apt-get autoremove -y && \
rm -rf /var/lib/apt/lists/*
WORKDIR /app
# Install Python dependencies first (cached layer)
# Note: build context is DeepCode root, so paths start with nanobot/
COPY nanobot/pyproject.toml nanobot/README.md nanobot/LICENSE ./
RUN mkdir -p nanobot bridge && touch nanobot/__init__.py && \
uv pip install --system --no-cache . && \
rm -rf nanobot bridge
# Copy the full source and install
COPY nanobot/nanobot/ nanobot/
COPY nanobot/bridge/ bridge/
RUN uv pip install --system --no-cache .
# Build the WhatsApp bridge
WORKDIR /app/bridge
RUN npm install && npm run build
WORKDIR /app
# Create config directory
RUN mkdir -p /root/.nanobot
# Gateway default port
EXPOSE 18790
ENTRYPOINT ["nanobot"]
CMD ["gateway"]
================================================
FILE: nanobot/LICENSE
================================================
MIT License
Copyright (c) 2025 nanobot contributors
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE.
================================================
FILE: nanobot/README.md
================================================





