Copy disabled (too large)
Download .txt
Showing preview only (44,925K chars total). Download the full file to get everything.
Repository: HaozheZhao/UltraEdit
Branch: main
Commit: 1af5f0478d56
Files: 1598
Total size: 42.3 MB
Directory structure:
gitextract_dp4dknxa/
├── .gitignore
├── README.md
├── app.py
├── data_generation/
│ ├── Grounded-Segment-Anything/
│ │ ├── .gitignore
│ │ ├── .gitmodules
│ │ ├── CITATION.cff
│ │ ├── Dockerfile
│ │ ├── EfficientSAM/
│ │ │ ├── EdgeSAM/
│ │ │ │ ├── common.py
│ │ │ │ ├── rep_vit.py
│ │ │ │ └── setup_edge_sam.py
│ │ │ ├── FastSAM/
│ │ │ │ └── tools.py
│ │ │ ├── LightHQSAM/
│ │ │ │ ├── setup_light_hqsam.py
│ │ │ │ └── tiny_vit_sam.py
│ │ │ ├── MobileSAM/
│ │ │ │ ├── setup_mobile_sam.py
│ │ │ │ └── tiny_vit_sam.py
│ │ │ ├── README.md
│ │ │ ├── RepViTSAM/
│ │ │ │ ├── repvit.py
│ │ │ │ └── setup_repvit_sam.py
│ │ │ ├── grounded_edge_sam.py
│ │ │ ├── grounded_efficient_sam.py
│ │ │ ├── grounded_fast_sam.py
│ │ │ ├── grounded_light_hqsam.py
│ │ │ ├── grounded_mobile_sam.py
│ │ │ └── grounded_repvit_sam.py
│ │ ├── GroundingDINO/
│ │ │ ├── LICENSE
│ │ │ ├── README.md
│ │ │ ├── demo/
│ │ │ │ ├── gradio_app.py
│ │ │ │ └── inference_on_a_image.py
│ │ │ ├── groundingdino/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── config/
│ │ │ │ │ ├── GroundingDINO_SwinB.py
│ │ │ │ │ └── GroundingDINO_SwinT_OGC.py
│ │ │ │ ├── datasets/
│ │ │ │ │ ├── __init__.py
│ │ │ │ │ └── transforms.py
│ │ │ │ ├── models/
│ │ │ │ │ ├── GroundingDINO/
│ │ │ │ │ │ ├── __init__.py
│ │ │ │ │ │ ├── backbone/
│ │ │ │ │ │ │ ├── __init__.py
│ │ │ │ │ │ │ ├── backbone.py
│ │ │ │ │ │ │ ├── position_encoding.py
│ │ │ │ │ │ │ └── swin_transformer.py
│ │ │ │ │ │ ├── bertwarper.py
│ │ │ │ │ │ ├── csrc/
│ │ │ │ │ │ │ ├── MsDeformAttn/
│ │ │ │ │ │ │ │ ├── ms_deform_attn.h
│ │ │ │ │ │ │ │ ├── ms_deform_attn_cpu.cpp
│ │ │ │ │ │ │ │ ├── ms_deform_attn_cpu.h
│ │ │ │ │ │ │ │ ├── ms_deform_attn_cuda.cu
│ │ │ │ │ │ │ │ ├── ms_deform_attn_cuda.h
│ │ │ │ │ │ │ │ └── ms_deform_im2col_cuda.cuh
│ │ │ │ │ │ │ ├── cuda_version.cu
│ │ │ │ │ │ │ └── vision.cpp
│ │ │ │ │ │ ├── fuse_modules.py
│ │ │ │ │ │ ├── groundingdino.py
│ │ │ │ │ │ ├── ms_deform_attn.py
│ │ │ │ │ │ ├── transformer.py
│ │ │ │ │ │ ├── transformer_vanilla.py
│ │ │ │ │ │ └── utils.py
│ │ │ │ │ ├── __init__.py
│ │ │ │ │ └── registry.py
│ │ │ │ ├── util/
│ │ │ │ │ ├── __init__.py
│ │ │ │ │ ├── box_ops.py
│ │ │ │ │ ├── get_tokenlizer.py
│ │ │ │ │ ├── inference.py
│ │ │ │ │ ├── logger.py
│ │ │ │ │ ├── misc.py
│ │ │ │ │ ├── slconfig.py
│ │ │ │ │ ├── slio.py
│ │ │ │ │ ├── time_counter.py
│ │ │ │ │ ├── utils.py
│ │ │ │ │ ├── visualizer.py
│ │ │ │ │ └── vl_utils.py
│ │ │ │ └── version.py
│ │ │ ├── pyproject.toml
│ │ │ ├── requirements.txt
│ │ │ ├── setup.py
│ │ │ ├── sub_8_new_83748.err
│ │ │ └── submit_gpu_task_83747.err
│ │ ├── LICENSE
│ │ ├── Makefile
│ │ ├── README.md
│ │ ├── automatic_label_demo.py
│ │ ├── automatic_label_ram_demo.py
│ │ ├── automatic_label_simple_demo.py
│ │ ├── automatic_label_tag2text_demo.py
│ │ ├── chatbot.py
│ │ ├── cog.yaml
│ │ ├── gradio_app.py
│ │ ├── grounded_sam.ipynb
│ │ ├── grounded_sam_3d_box.ipynb
│ │ ├── grounded_sam_colab_demo.ipynb
│ │ ├── grounded_sam_demo.py
│ │ ├── grounded_sam_inpainting_demo.py
│ │ ├── grounded_sam_osx_demo.py
│ │ ├── grounded_sam_simple_demo.py
│ │ ├── grounded_sam_visam.py
│ │ ├── grounded_sam_whisper_demo.py
│ │ ├── grounded_sam_whisper_inpainting_demo.py
│ │ ├── grounding_dino_demo.py
│ │ ├── playground/
│ │ │ ├── DeepFloyd/
│ │ │ │ ├── README.md
│ │ │ │ ├── dream.py
│ │ │ │ ├── inpaint.py
│ │ │ │ └── style_transfer.py
│ │ │ ├── ImageBind_SAM/
│ │ │ │ ├── README.md
│ │ │ │ ├── audio_referring_seg_demo.py
│ │ │ │ ├── data.py
│ │ │ │ ├── demo.py
│ │ │ │ ├── image_referring_seg_demo.py
│ │ │ │ ├── models/
│ │ │ │ │ ├── __init__.py
│ │ │ │ │ ├── helpers.py
│ │ │ │ │ ├── imagebind_model.py
│ │ │ │ │ ├── multimodal_preprocessors.py
│ │ │ │ │ └── transformer.py
│ │ │ │ ├── text_referring_seg_demo.py
│ │ │ │ └── utils.py
│ │ │ ├── LaMa/
│ │ │ │ ├── README.md
│ │ │ │ ├── lama_inpaint_demo.py
│ │ │ │ └── sam_lama.py
│ │ │ ├── PaintByExample/
│ │ │ │ ├── README.md
│ │ │ │ ├── paint_by_example.py
│ │ │ │ └── sam_paint_by_example.py
│ │ │ ├── README.md
│ │ │ └── RePaint/
│ │ │ ├── README.md
│ │ │ └── repaint.py
│ │ ├── predict.py
│ │ ├── requirements.txt
│ │ ├── segment_anything/
│ │ │ ├── .flake8
│ │ │ ├── CODE_OF_CONDUCT.md
│ │ │ ├── CONTRIBUTING.md
│ │ │ ├── LICENSE
│ │ │ ├── README.md
│ │ │ ├── linter.sh
│ │ │ ├── notebooks/
│ │ │ │ ├── automatic_mask_generator_example.ipynb
│ │ │ │ ├── onnx_model_example.ipynb
│ │ │ │ └── predictor_example.ipynb
│ │ │ ├── scripts/
│ │ │ │ ├── amg.py
│ │ │ │ └── export_onnx_model.py
│ │ │ ├── segment_anything/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── automatic_mask_generator.py
│ │ │ │ ├── build_sam.py
│ │ │ │ ├── build_sam_hq.py
│ │ │ │ ├── modeling/
│ │ │ │ │ ├── __init__.py
│ │ │ │ │ ├── common.py
│ │ │ │ │ ├── image_encoder.py
│ │ │ │ │ ├── mask_decoder.py
│ │ │ │ │ ├── mask_decoder_hq.py
│ │ │ │ │ ├── prompt_encoder.py
│ │ │ │ │ ├── sam.py
│ │ │ │ │ └── transformer.py
│ │ │ │ ├── predictor.py
│ │ │ │ └── utils/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── amg.py
│ │ │ │ ├── onnx.py
│ │ │ │ └── transforms.py
│ │ │ ├── setup.cfg
│ │ │ └── setup.py
│ │ └── voxelnext_3d_box/
│ │ ├── README.md
│ │ ├── __init__.py
│ │ ├── config.yaml
│ │ ├── model.py
│ │ ├── models/
│ │ │ ├── __init__.py
│ │ │ ├── data_processor.py
│ │ │ ├── mean_vfe.py
│ │ │ ├── spconv_backbone_voxelnext.py
│ │ │ └── voxelnext_head.py
│ │ ├── requirements.txt
│ │ └── utils/
│ │ ├── centernet_utils.py
│ │ ├── config.py
│ │ └── image_projection.py
│ ├── data_generation.py
│ ├── ldm/
│ │ ├── data/
│ │ │ ├── __init__.py
│ │ │ ├── base.py
│ │ │ ├── imagenet.py
│ │ │ └── lsun.py
│ │ ├── lr_scheduler.py
│ │ ├── models/
│ │ │ ├── autoencoder.py
│ │ │ └── diffusion/
│ │ │ ├── __init__.py
│ │ │ ├── classifier.py
│ │ │ ├── ddim.py
│ │ │ ├── ddpm.py
│ │ │ ├── dpm_solver/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── dpm_solver.py
│ │ │ │ └── sampler.py
│ │ │ └── plms.py
│ │ ├── modules/
│ │ │ ├── attention.py
│ │ │ ├── diffusionmodules/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── model.py
│ │ │ │ ├── openaimodel.py
│ │ │ │ └── util.py
│ │ │ ├── distributions/
│ │ │ │ ├── __init__.py
│ │ │ │ └── distributions.py
│ │ │ ├── ema.py
│ │ │ ├── encoders/
│ │ │ │ ├── __init__.py
│ │ │ │ └── modules.py
│ │ │ ├── image_degradation/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── bsrgan.py
│ │ │ │ ├── bsrgan_light.py
│ │ │ │ └── utils_image.py
│ │ │ ├── losses/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── contperceptual.py
│ │ │ │ └── vqperceptual.py
│ │ │ └── x_transformer.py
│ │ └── util.py
│ ├── metrics/
│ │ ├── clip_similarity.py
│ │ └── compute_metrics.py
│ ├── processors.py
│ ├── prompt_to_prompt_pipeline.py
│ ├── run_inpainting_multiiple_objects.sh
│ ├── run_sdxl_turbo_p2p_i2i_8gpu.sh
│ ├── sdxl_p2p_pipeline.py
│ └── util.py
├── diffusers/
│ ├── .github/
│ │ ├── ISSUE_TEMPLATE/
│ │ │ ├── bug-report.yml
│ │ │ ├── config.yml
│ │ │ ├── feature_request.md
│ │ │ ├── feedback.md
│ │ │ ├── new-model-addition.yml
│ │ │ └── translate.md
│ │ ├── PULL_REQUEST_TEMPLATE.md
│ │ ├── actions/
│ │ │ └── setup-miniconda/
│ │ │ └── action.yml
│ │ └── workflows/
│ │ ├── benchmark.yml
│ │ ├── build_docker_images.yml
│ │ ├── build_documentation.yml
│ │ ├── build_pr_documentation.yml
│ │ ├── mirror_community_pipeline.yml
│ │ ├── nightly_tests.yml
│ │ ├── notify_slack_about_release.yml
│ │ ├── pr_dependency_test.yml
│ │ ├── pr_flax_dependency_test.yml
│ │ ├── pr_test_fetcher.yml
│ │ ├── pr_test_peft_backend.yml
│ │ ├── pr_tests.yml
│ │ ├── pr_torch_dependency_test.yml
│ │ ├── push_tests.yml
│ │ ├── push_tests_fast.yml
│ │ ├── push_tests_mps.yml
│ │ ├── pypi_publish.yaml
│ │ ├── run_tests_from_a_pr.yml
│ │ ├── ssh-runner.yml
│ │ ├── stale.yml
│ │ ├── trufflehog.yml
│ │ ├── typos.yml
│ │ ├── update_metadata.yml
│ │ └── upload_pr_documentation.yml
│ ├── .gitignore
│ ├── CITATION.cff
│ ├── CODE_OF_CONDUCT.md
│ ├── CONTRIBUTING.md
│ ├── LICENSE
│ ├── MANIFEST.in
│ ├── Makefile
│ ├── PHILOSOPHY.md
│ ├── README.md
│ ├── _typos.toml
│ ├── benchmarks/
│ │ ├── base_classes.py
│ │ ├── benchmark_controlnet.py
│ │ ├── benchmark_ip_adapters.py
│ │ ├── benchmark_sd_img.py
│ │ ├── benchmark_sd_inpainting.py
│ │ ├── benchmark_t2i_adapter.py
│ │ ├── benchmark_t2i_lcm_lora.py
│ │ ├── benchmark_text_to_image.py
│ │ ├── push_results.py
│ │ ├── run_all.py
│ │ └── utils.py
│ ├── docker/
│ │ ├── diffusers-doc-builder/
│ │ │ └── Dockerfile
│ │ ├── diffusers-flax-cpu/
│ │ │ └── Dockerfile
│ │ ├── diffusers-flax-tpu/
│ │ │ └── Dockerfile
│ │ ├── diffusers-onnxruntime-cpu/
│ │ │ └── Dockerfile
│ │ ├── diffusers-onnxruntime-cuda/
│ │ │ └── Dockerfile
│ │ ├── diffusers-pytorch-compile-cuda/
│ │ │ └── Dockerfile
│ │ ├── diffusers-pytorch-cpu/
│ │ │ └── Dockerfile
│ │ ├── diffusers-pytorch-cuda/
│ │ │ └── Dockerfile
│ │ └── diffusers-pytorch-xformers-cuda/
│ │ └── Dockerfile
│ ├── docs/
│ │ ├── README.md
│ │ ├── TRANSLATING.md
│ │ └── source/
│ │ ├── _config.py
│ │ ├── en/
│ │ │ ├── _toctree.yml
│ │ │ ├── advanced_inference/
│ │ │ │ └── outpaint.md
│ │ │ ├── api/
│ │ │ │ ├── activations.md
│ │ │ │ ├── attnprocessor.md
│ │ │ │ ├── configuration.md
│ │ │ │ ├── image_processor.md
│ │ │ │ ├── internal_classes_overview.md
│ │ │ │ ├── loaders/
│ │ │ │ │ ├── ip_adapter.md
│ │ │ │ │ ├── lora.md
│ │ │ │ │ ├── peft.md
│ │ │ │ │ ├── single_file.md
│ │ │ │ │ ├── textual_inversion.md
│ │ │ │ │ └── unet.md
│ │ │ │ ├── logging.md
│ │ │ │ ├── models/
│ │ │ │ │ ├── asymmetricautoencoderkl.md
│ │ │ │ │ ├── autoencoder_tiny.md
│ │ │ │ │ ├── autoencoderkl.md
│ │ │ │ │ ├── consistency_decoder_vae.md
│ │ │ │ │ ├── controlnet.md
│ │ │ │ │ ├── dit_transformer2d.md
│ │ │ │ │ ├── hunyuan_transformer2d.md
│ │ │ │ │ ├── overview.md
│ │ │ │ │ ├── pixart_transformer2d.md
│ │ │ │ │ ├── prior_transformer.md
│ │ │ │ │ ├── sd3_transformer2d.md
│ │ │ │ │ ├── transformer2d.md
│ │ │ │ │ ├── transformer_temporal.md
│ │ │ │ │ ├── unet-motion.md
│ │ │ │ │ ├── unet.md
│ │ │ │ │ ├── unet2d-cond.md
│ │ │ │ │ ├── unet2d.md
│ │ │ │ │ ├── unet3d-cond.md
│ │ │ │ │ ├── uvit2d.md
│ │ │ │ │ └── vq.md
│ │ │ │ ├── normalization.md
│ │ │ │ ├── outputs.md
│ │ │ │ ├── pipelines/
│ │ │ │ │ ├── amused.md
│ │ │ │ │ ├── animatediff.md
│ │ │ │ │ ├── attend_and_excite.md
│ │ │ │ │ ├── audioldm.md
│ │ │ │ │ ├── audioldm2.md
│ │ │ │ │ ├── auto_pipeline.md
│ │ │ │ │ ├── blip_diffusion.md
│ │ │ │ │ ├── consistency_models.md
│ │ │ │ │ ├── controlnet.md
│ │ │ │ │ ├── controlnet_sdxl.md
│ │ │ │ │ ├── controlnetxs.md
│ │ │ │ │ ├── controlnetxs_sdxl.md
│ │ │ │ │ ├── dance_diffusion.md
│ │ │ │ │ ├── ddim.md
│ │ │ │ │ ├── ddpm.md
│ │ │ │ │ ├── deepfloyd_if.md
│ │ │ │ │ ├── diffedit.md
│ │ │ │ │ ├── dit.md
│ │ │ │ │ ├── hunyuandit.md
│ │ │ │ │ ├── i2vgenxl.md
│ │ │ │ │ ├── kandinsky.md
│ │ │ │ │ ├── kandinsky3.md
│ │ │ │ │ ├── kandinsky_v22.md
│ │ │ │ │ ├── latent_consistency_models.md
│ │ │ │ │ ├── latent_diffusion.md
│ │ │ │ │ ├── ledits_pp.md
│ │ │ │ │ ├── marigold.md
│ │ │ │ │ ├── musicldm.md
│ │ │ │ │ ├── overview.md
│ │ │ │ │ ├── paint_by_example.md
│ │ │ │ │ ├── panorama.md
│ │ │ │ │ ├── pia.md
│ │ │ │ │ ├── pix2pix.md
│ │ │ │ │ ├── pixart.md
│ │ │ │ │ ├── pixart_sigma.md
│ │ │ │ │ ├── self_attention_guidance.md
│ │ │ │ │ ├── semantic_stable_diffusion.md
│ │ │ │ │ ├── shap_e.md
│ │ │ │ │ ├── stable_cascade.md
│ │ │ │ │ ├── stable_diffusion/
│ │ │ │ │ │ ├── adapter.md
│ │ │ │ │ │ ├── depth2img.md
│ │ │ │ │ │ ├── gligen.md
│ │ │ │ │ │ ├── image_variation.md
│ │ │ │ │ │ ├── img2img.md
│ │ │ │ │ │ ├── inpaint.md
│ │ │ │ │ │ ├── k_diffusion.md
│ │ │ │ │ │ ├── latent_upscale.md
│ │ │ │ │ │ ├── ldm3d_diffusion.md
│ │ │ │ │ │ ├── overview.md
│ │ │ │ │ │ ├── sdxl_turbo.md
│ │ │ │ │ │ ├── stable_diffusion_2.md
│ │ │ │ │ │ ├── stable_diffusion_3.md
│ │ │ │ │ │ ├── stable_diffusion_safe.md
│ │ │ │ │ │ ├── stable_diffusion_xl.md
│ │ │ │ │ │ ├── svd.md
│ │ │ │ │ │ ├── text2img.md
│ │ │ │ │ │ └── upscale.md
│ │ │ │ │ ├── stable_unclip.md
│ │ │ │ │ ├── text_to_video.md
│ │ │ │ │ ├── text_to_video_zero.md
│ │ │ │ │ ├── unclip.md
│ │ │ │ │ ├── unidiffuser.md
│ │ │ │ │ ├── value_guided_sampling.md
│ │ │ │ │ └── wuerstchen.md
│ │ │ │ ├── schedulers/
│ │ │ │ │ ├── cm_stochastic_iterative.md
│ │ │ │ │ ├── consistency_decoder.md
│ │ │ │ │ ├── ddim.md
│ │ │ │ │ ├── ddim_inverse.md
│ │ │ │ │ ├── ddpm.md
│ │ │ │ │ ├── deis.md
│ │ │ │ │ ├── dpm_discrete.md
│ │ │ │ │ ├── dpm_discrete_ancestral.md
│ │ │ │ │ ├── dpm_sde.md
│ │ │ │ │ ├── edm_euler.md
│ │ │ │ │ ├── edm_multistep_dpm_solver.md
│ │ │ │ │ ├── euler.md
│ │ │ │ │ ├── euler_ancestral.md
│ │ │ │ │ ├── flow_match_euler_discrete.md
│ │ │ │ │ ├── heun.md
│ │ │ │ │ ├── ipndm.md
│ │ │ │ │ ├── lcm.md
│ │ │ │ │ ├── lms_discrete.md
│ │ │ │ │ ├── multistep_dpm_solver.md
│ │ │ │ │ ├── multistep_dpm_solver_inverse.md
│ │ │ │ │ ├── overview.md
│ │ │ │ │ ├── pndm.md
│ │ │ │ │ ├── repaint.md
│ │ │ │ │ ├── score_sde_ve.md
│ │ │ │ │ ├── score_sde_vp.md
│ │ │ │ │ ├── singlestep_dpm_solver.md
│ │ │ │ │ ├── stochastic_karras_ve.md
│ │ │ │ │ ├── tcd.md
│ │ │ │ │ ├── unipc.md
│ │ │ │ │ └── vq_diffusion.md
│ │ │ │ ├── utilities.md
│ │ │ │ └── video_processor.md
│ │ │ ├── conceptual/
│ │ │ │ ├── contribution.md
│ │ │ │ ├── ethical_guidelines.md
│ │ │ │ ├── evaluation.md
│ │ │ │ └── philosophy.md
│ │ │ ├── index.md
│ │ │ ├── installation.md
│ │ │ ├── optimization/
│ │ │ │ ├── coreml.md
│ │ │ │ ├── deepcache.md
│ │ │ │ ├── fp16.md
│ │ │ │ ├── habana.md
│ │ │ │ ├── memory.md
│ │ │ │ ├── mps.md
│ │ │ │ ├── onnx.md
│ │ │ │ ├── open_vino.md
│ │ │ │ ├── tgate.md
│ │ │ │ ├── tome.md
│ │ │ │ ├── torch2.0.md
│ │ │ │ └── xformers.md
│ │ │ ├── quicktour.md
│ │ │ ├── stable_diffusion.md
│ │ │ ├── training/
│ │ │ │ ├── adapt_a_model.md
│ │ │ │ ├── controlnet.md
│ │ │ │ ├── create_dataset.md
│ │ │ │ ├── custom_diffusion.md
│ │ │ │ ├── ddpo.md
│ │ │ │ ├── distributed_inference.md
│ │ │ │ ├── dreambooth.md
│ │ │ │ ├── instructpix2pix.md
│ │ │ │ ├── kandinsky.md
│ │ │ │ ├── lcm_distill.md
│ │ │ │ ├── lora.md
│ │ │ │ ├── overview.md
│ │ │ │ ├── sdxl.md
│ │ │ │ ├── t2i_adapters.md
│ │ │ │ ├── text2image.md
│ │ │ │ ├── text_inversion.md
│ │ │ │ ├── unconditional_training.md
│ │ │ │ └── wuerstchen.md
│ │ │ ├── tutorials/
│ │ │ │ ├── autopipeline.md
│ │ │ │ ├── basic_training.md
│ │ │ │ ├── fast_diffusion.md
│ │ │ │ ├── tutorial_overview.md
│ │ │ │ └── using_peft_for_inference.md
│ │ │ └── using-diffusers/
│ │ │ ├── callback.md
│ │ │ ├── conditional_image_generation.md
│ │ │ ├── controlling_generation.md
│ │ │ ├── controlnet.md
│ │ │ ├── custom_pipeline_overview.md
│ │ │ ├── depth2img.md
│ │ │ ├── diffedit.md
│ │ │ ├── image_quality.md
│ │ │ ├── img2img.md
│ │ │ ├── inference_with_lcm.md
│ │ │ ├── inference_with_tcd_lora.md
│ │ │ ├── inpaint.md
│ │ │ ├── ip_adapter.md
│ │ │ ├── kandinsky.md
│ │ │ ├── loading.md
│ │ │ ├── loading_adapters.md
│ │ │ ├── marigold_usage.md
│ │ │ ├── merge_loras.md
│ │ │ ├── other-formats.md
│ │ │ ├── overview_techniques.md
│ │ │ ├── push_to_hub.md
│ │ │ ├── reusing_seeds.md
│ │ │ ├── scheduler_features.md
│ │ │ ├── schedulers.md
│ │ │ ├── sdxl.md
│ │ │ ├── sdxl_turbo.md
│ │ │ ├── shap-e.md
│ │ │ ├── stable_diffusion_jax_how_to.md
│ │ │ ├── svd.md
│ │ │ ├── t2i_adapter.md
│ │ │ ├── text-img2vid.md
│ │ │ ├── textual_inversion_inference.md
│ │ │ ├── unconditional_image_generation.md
│ │ │ ├── weighted_prompts.md
│ │ │ └── write_own_pipeline.md
│ │ ├── ja/
│ │ │ ├── _toctree.yml
│ │ │ ├── index.md
│ │ │ ├── installation.md
│ │ │ ├── quicktour.md
│ │ │ ├── stable_diffusion.md
│ │ │ └── tutorials/
│ │ │ ├── autopipeline.md
│ │ │ └── tutorial_overview.md
│ │ ├── ko/
│ │ │ ├── _toctree.yml
│ │ │ ├── api/
│ │ │ │ └── pipelines/
│ │ │ │ └── stable_diffusion/
│ │ │ │ └── stable_diffusion_xl.md
│ │ │ ├── conceptual/
│ │ │ │ ├── contribution.md
│ │ │ │ ├── ethical_guidelines.md
│ │ │ │ ├── evaluation.md
│ │ │ │ └── philosophy.md
│ │ │ ├── in_translation.md
│ │ │ ├── index.md
│ │ │ ├── installation.md
│ │ │ ├── optimization/
│ │ │ │ ├── coreml.md
│ │ │ │ ├── fp16.md
│ │ │ │ ├── habana.md
│ │ │ │ ├── mps.md
│ │ │ │ ├── onnx.md
│ │ │ │ ├── open_vino.md
│ │ │ │ ├── opt_overview.md
│ │ │ │ ├── tome.md
│ │ │ │ ├── torch2.0.md
│ │ │ │ └── xformers.md
│ │ │ ├── quicktour.md
│ │ │ ├── stable_diffusion.md
│ │ │ ├── training/
│ │ │ │ ├── adapt_a_model.md
│ │ │ │ ├── controlnet.md
│ │ │ │ ├── create_dataset.md
│ │ │ │ ├── custom_diffusion.md
│ │ │ │ ├── distributed_inference.md
│ │ │ │ ├── dreambooth.md
│ │ │ │ ├── instructpix2pix.md
│ │ │ │ ├── lora.md
│ │ │ │ ├── overview.md
│ │ │ │ ├── text2image.md
│ │ │ │ ├── text_inversion.md
│ │ │ │ └── unconditional_training.md
│ │ │ ├── tutorials/
│ │ │ │ ├── basic_training.md
│ │ │ │ └── tutorial_overview.md
│ │ │ └── using-diffusers/
│ │ │ ├── conditional_image_generation.md
│ │ │ ├── contribute_pipeline.md
│ │ │ ├── control_brightness.md
│ │ │ ├── controlling_generation.md
│ │ │ ├── custom_pipeline_examples.md
│ │ │ ├── custom_pipeline_overview.md
│ │ │ ├── depth2img.md
│ │ │ ├── img2img.md
│ │ │ ├── inpaint.md
│ │ │ ├── loading.md
│ │ │ ├── loading_overview.md
│ │ │ ├── other-formats.md
│ │ │ ├── pipeline_overview.md
│ │ │ ├── reproducibility.md
│ │ │ ├── reusing_seeds.md
│ │ │ ├── schedulers.md
│ │ │ ├── stable_diffusion_jax_how_to.md
│ │ │ ├── textual_inversion_inference.md
│ │ │ ├── unconditional_image_generation.md
│ │ │ ├── using_safetensors.md
│ │ │ ├── weighted_prompts.md
│ │ │ └── write_own_pipeline.md
│ │ ├── pt/
│ │ │ ├── _toctree.yml
│ │ │ ├── index.md
│ │ │ ├── installation.md
│ │ │ └── quicktour.md
│ │ └── zh/
│ │ ├── _toctree.yml
│ │ ├── index.md
│ │ ├── installation.md
│ │ ├── quicktour.md
│ │ └── stable_diffusion.md
│ ├── examples/
│ │ ├── README.md
│ │ ├── advanced_diffusion_training/
│ │ │ ├── README.md
│ │ │ ├── requirements.txt
│ │ │ ├── train_dreambooth_lora_sd15_advanced.py
│ │ │ └── train_dreambooth_lora_sdxl_advanced.py
│ │ ├── amused/
│ │ │ ├── README.md
│ │ │ └── train_amused.py
│ │ ├── community/
│ │ │ ├── README.md
│ │ │ ├── README_community_scripts.md
│ │ │ ├── bit_diffusion.py
│ │ │ ├── checkpoint_merger.py
│ │ │ ├── clip_guided_images_mixing_stable_diffusion.py
│ │ │ ├── clip_guided_stable_diffusion.py
│ │ │ ├── clip_guided_stable_diffusion_img2img.py
│ │ │ ├── composable_stable_diffusion.py
│ │ │ ├── ddim_noise_comparative_analysis.py
│ │ │ ├── dps_pipeline.py
│ │ │ ├── edict_pipeline.py
│ │ │ ├── fresco_v2v.py
│ │ │ ├── gluegen.py
│ │ │ ├── hd_painter.py
│ │ │ ├── iadb.py
│ │ │ ├── imagic_stable_diffusion.py
│ │ │ ├── img2img_inpainting.py
│ │ │ ├── instaflow_one_step.py
│ │ │ ├── interpolate_stable_diffusion.py
│ │ │ ├── ip_adapter_face_id.py
│ │ │ ├── kohya_hires_fix.py
│ │ │ ├── latent_consistency_img2img.py
│ │ │ ├── latent_consistency_interpolate.py
│ │ │ ├── latent_consistency_txt2img.py
│ │ │ ├── llm_grounded_diffusion.py
│ │ │ ├── lpw_stable_diffusion.py
│ │ │ ├── lpw_stable_diffusion_onnx.py
│ │ │ ├── lpw_stable_diffusion_xl.py
│ │ │ ├── magic_mix.py
│ │ │ ├── marigold_depth_estimation.py
│ │ │ ├── masked_stable_diffusion_img2img.py
│ │ │ ├── mixture_canvas.py
│ │ │ ├── mixture_tiling.py
│ │ │ ├── multilingual_stable_diffusion.py
│ │ │ ├── one_step_unet.py
│ │ │ ├── pipeline_animatediff_controlnet.py
│ │ │ ├── pipeline_animatediff_img2video.py
│ │ │ ├── pipeline_demofusion_sdxl.py
│ │ │ ├── pipeline_fabric.py
│ │ │ ├── pipeline_null_text_inversion.py
│ │ │ ├── pipeline_prompt2prompt.py
│ │ │ ├── pipeline_sdxl_style_aligned.py
│ │ │ ├── pipeline_stable_diffusion_boxdiff.py
│ │ │ ├── pipeline_stable_diffusion_pag.py
│ │ │ ├── pipeline_stable_diffusion_upscale_ldm3d.py
│ │ │ ├── pipeline_stable_diffusion_xl_controlnet_adapter.py
│ │ │ ├── pipeline_stable_diffusion_xl_controlnet_adapter_inpaint.py
│ │ │ ├── pipeline_stable_diffusion_xl_differential_img2img.py
│ │ │ ├── pipeline_stable_diffusion_xl_instandid_img2img.py
│ │ │ ├── pipeline_stable_diffusion_xl_instantid.py
│ │ │ ├── pipeline_stable_diffusion_xl_ipex.py
│ │ │ ├── pipeline_zero1to3.py
│ │ │ ├── regional_prompting_stable_diffusion.py
│ │ │ ├── rerender_a_video.py
│ │ │ ├── run_onnx_controlnet.py
│ │ │ ├── run_tensorrt_controlnet.py
│ │ │ ├── scheduling_ufogen.py
│ │ │ ├── sd_text2img_k_diffusion.py
│ │ │ ├── sde_drag.py
│ │ │ ├── seed_resize_stable_diffusion.py
│ │ │ ├── speech_to_image_diffusion.py
│ │ │ ├── stable_diffusion_comparison.py
│ │ │ ├── stable_diffusion_controlnet_img2img.py
│ │ │ ├── stable_diffusion_controlnet_inpaint.py
│ │ │ ├── stable_diffusion_controlnet_inpaint_img2img.py
│ │ │ ├── stable_diffusion_controlnet_reference.py
│ │ │ ├── stable_diffusion_ipex.py
│ │ │ ├── stable_diffusion_mega.py
│ │ │ ├── stable_diffusion_reference.py
│ │ │ ├── stable_diffusion_repaint.py
│ │ │ ├── stable_diffusion_tensorrt_img2img.py
│ │ │ ├── stable_diffusion_tensorrt_inpaint.py
│ │ │ ├── stable_diffusion_tensorrt_txt2img.py
│ │ │ ├── stable_diffusion_xl_reference.py
│ │ │ ├── stable_unclip.py
│ │ │ ├── text_inpainting.py
│ │ │ ├── tiled_upscaling.py
│ │ │ ├── unclip_image_interpolation.py
│ │ │ ├── unclip_text_interpolation.py
│ │ │ └── wildcard_stable_diffusion.py
│ │ ├── conftest.py
│ │ ├── consistency_distillation/
│ │ │ ├── README.md
│ │ │ ├── README_sdxl.md
│ │ │ ├── requirements.txt
│ │ │ ├── test_lcm_lora.py
│ │ │ ├── train_lcm_distill_lora_sd_wds.py
│ │ │ ├── train_lcm_distill_lora_sdxl.py
│ │ │ ├── train_lcm_distill_lora_sdxl_wds.py
│ │ │ ├── train_lcm_distill_sd_wds.py
│ │ │ └── train_lcm_distill_sdxl_wds.py
│ │ ├── controlnet/
│ │ │ ├── README.md
│ │ │ ├── README_sdxl.md
│ │ │ ├── requirements.txt
│ │ │ ├── requirements_flax.txt
│ │ │ ├── requirements_sdxl.txt
│ │ │ ├── test_controlnet.py
│ │ │ ├── train_controlnet.py
│ │ │ ├── train_controlnet_flax.py
│ │ │ └── train_controlnet_sdxl.py
│ │ ├── custom_diffusion/
│ │ │ ├── README.md
│ │ │ ├── requirements.txt
│ │ │ ├── retrieve.py
│ │ │ ├── test_custom_diffusion.py
│ │ │ └── train_custom_diffusion.py
│ │ ├── dreambooth/
│ │ │ ├── README.md
│ │ │ ├── README_sd3.md
│ │ │ ├── README_sdxl.md
│ │ │ ├── requirements.txt
│ │ │ ├── requirements_flax.txt
│ │ │ ├── requirements_sd3.txt
│ │ │ ├── requirements_sdxl.txt
│ │ │ ├── test_dreambooth.py
│ │ │ ├── test_dreambooth_lora.py
│ │ │ ├── test_dreambooth_lora_edm.py
│ │ │ ├── train_dreambooth.py
│ │ │ ├── train_dreambooth_flax.py
│ │ │ ├── train_dreambooth_lora.py
│ │ │ ├── train_dreambooth_lora_sd3.py
│ │ │ ├── train_dreambooth_lora_sdxl.py
│ │ │ └── train_dreambooth_sd3.py
│ │ ├── inference/
│ │ │ ├── README.md
│ │ │ ├── image_to_image.py
│ │ │ └── inpainting.py
│ │ ├── instruct_pix2pix/
│ │ │ ├── README.md
│ │ │ ├── README_sdxl.md
│ │ │ ├── requirements.txt
│ │ │ ├── test_instruct_pix2pix.py
│ │ │ ├── train_instruct_pix2pix.py
│ │ │ └── train_instruct_pix2pix_sdxl.py
│ │ ├── kandinsky2_2/
│ │ │ └── text_to_image/
│ │ │ ├── README.md
│ │ │ ├── requirements.txt
│ │ │ ├── train_text_to_image_decoder.py
│ │ │ ├── train_text_to_image_lora_decoder.py
│ │ │ ├── train_text_to_image_lora_prior.py
│ │ │ └── train_text_to_image_prior.py
│ │ ├── reinforcement_learning/
│ │ │ ├── README.md
│ │ │ └── run_diffuser_locomotion.py
│ │ ├── research_projects/
│ │ │ ├── README.md
│ │ │ ├── colossalai/
│ │ │ │ ├── README.md
│ │ │ │ ├── inference.py
│ │ │ │ ├── requirement.txt
│ │ │ │ └── train_dreambooth_colossalai.py
│ │ │ ├── consistency_training/
│ │ │ │ ├── README.md
│ │ │ │ ├── requirements.txt
│ │ │ │ └── train_cm_ct_unconditional.py
│ │ │ ├── controlnet/
│ │ │ │ └── train_controlnet_webdataset.py
│ │ │ ├── diffusion_dpo/
│ │ │ │ ├── README.md
│ │ │ │ ├── requirements.txt
│ │ │ │ ├── train_diffusion_dpo.py
│ │ │ │ └── train_diffusion_dpo_sdxl.py
│ │ │ ├── diffusion_orpo/
│ │ │ │ ├── README.md
│ │ │ │ ├── requirements.txt
│ │ │ │ ├── train_diffusion_orpo_sdxl_lora.py
│ │ │ │ └── train_diffusion_orpo_sdxl_lora_wds.py
│ │ │ ├── dreambooth_inpaint/
│ │ │ │ ├── README.md
│ │ │ │ ├── requirements.txt
│ │ │ │ ├── train_dreambooth_inpaint.py
│ │ │ │ └── train_dreambooth_inpaint_lora.py
│ │ │ ├── geodiff/
│ │ │ │ ├── README.md
│ │ │ │ └── geodiff_molecule_conformation.ipynb
│ │ │ ├── gligen/
│ │ │ │ ├── README.md
│ │ │ │ ├── dataset.py
│ │ │ │ ├── demo.ipynb
│ │ │ │ ├── make_datasets.py
│ │ │ │ ├── requirements.txt
│ │ │ │ └── train_gligen_text.py
│ │ │ ├── instructpix2pix_lora/
│ │ │ │ ├── README.md
│ │ │ │ └── train_instruct_pix2pix_lora.py
│ │ │ ├── intel_opts/
│ │ │ │ ├── README.md
│ │ │ │ ├── inference_bf16.py
│ │ │ │ ├── textual_inversion/
│ │ │ │ │ ├── README.md
│ │ │ │ │ ├── requirements.txt
│ │ │ │ │ └── textual_inversion_bf16.py
│ │ │ │ └── textual_inversion_dfq/
│ │ │ │ ├── README.md
│ │ │ │ ├── requirements.txt
│ │ │ │ ├── text2images.py
│ │ │ │ └── textual_inversion.py
│ │ │ ├── lora/
│ │ │ │ ├── README.md
│ │ │ │ ├── requirements.txt
│ │ │ │ └── train_text_to_image_lora.py
│ │ │ ├── multi_subject_dreambooth/
│ │ │ │ ├── README.md
│ │ │ │ ├── requirements.txt
│ │ │ │ └── train_multi_subject_dreambooth.py
│ │ │ ├── multi_subject_dreambooth_inpainting/
│ │ │ │ ├── README.md
│ │ │ │ ├── requirements.txt
│ │ │ │ └── train_multi_subject_dreambooth_inpainting.py
│ │ │ ├── multi_token_textual_inversion/
│ │ │ │ ├── README.md
│ │ │ │ ├── multi_token_clip.py
│ │ │ │ ├── requirements.txt
│ │ │ │ ├── requirements_flax.txt
│ │ │ │ ├── textual_inversion.py
│ │ │ │ └── textual_inversion_flax.py
│ │ │ ├── onnxruntime/
│ │ │ │ ├── README.md
│ │ │ │ ├── text_to_image/
│ │ │ │ │ ├── README.md
│ │ │ │ │ ├── requirements.txt
│ │ │ │ │ └── train_text_to_image.py
│ │ │ │ ├── textual_inversion/
│ │ │ │ │ ├── README.md
│ │ │ │ │ ├── requirements.txt
│ │ │ │ │ └── textual_inversion.py
│ │ │ │ └── unconditional_image_generation/
│ │ │ │ ├── README.md
│ │ │ │ ├── requirements.txt
│ │ │ │ └── train_unconditional.py
│ │ │ ├── promptdiffusion/
│ │ │ │ ├── README.md
│ │ │ │ ├── convert_original_promptdiffusion_to_diffusers.py
│ │ │ │ ├── pipeline_prompt_diffusion.py
│ │ │ │ └── promptdiffusioncontrolnet.py
│ │ │ ├── rdm/
│ │ │ │ ├── README.md
│ │ │ │ ├── pipeline_rdm.py
│ │ │ │ └── retriever.py
│ │ │ ├── realfill/
│ │ │ │ ├── README.md
│ │ │ │ ├── infer.py
│ │ │ │ ├── requirements.txt
│ │ │ │ └── train_realfill.py
│ │ │ ├── scheduled_huber_loss_training/
│ │ │ │ ├── README.md
│ │ │ │ ├── dreambooth/
│ │ │ │ │ ├── train_dreambooth.py
│ │ │ │ │ ├── train_dreambooth_lora.py
│ │ │ │ │ └── train_dreambooth_lora_sdxl.py
│ │ │ │ └── text_to_image/
│ │ │ │ ├── train_text_to_image.py
│ │ │ │ ├── train_text_to_image_lora.py
│ │ │ │ ├── train_text_to_image_lora_sdxl.py
│ │ │ │ └── train_text_to_image_sdxl.py
│ │ │ └── sdxl_flax/
│ │ │ ├── README.md
│ │ │ ├── sdxl_single.py
│ │ │ └── sdxl_single_aot.py
│ │ ├── t2i_adapter/
│ │ │ ├── README.md
│ │ │ ├── README_sdxl.md
│ │ │ ├── requirements.txt
│ │ │ ├── test_t2i_adapter.py
│ │ │ └── train_t2i_adapter_sdxl.py
│ │ ├── test_examples_utils.py
│ │ ├── text_to_image/
│ │ │ ├── README.md
│ │ │ ├── README_sdxl.md
│ │ │ ├── requirements.txt
│ │ │ ├── requirements_flax.txt
│ │ │ ├── requirements_sdxl.txt
│ │ │ ├── test_text_to_image.py
│ │ │ ├── test_text_to_image_lora.py
│ │ │ ├── train_text_to_image.py
│ │ │ ├── train_text_to_image_flax.py
│ │ │ ├── train_text_to_image_lora.py
│ │ │ ├── train_text_to_image_lora_sdxl.py
│ │ │ └── train_text_to_image_sdxl.py
│ │ ├── textual_inversion/
│ │ │ ├── README.md
│ │ │ ├── README_sdxl.md
│ │ │ ├── requirements.txt
│ │ │ ├── requirements_flax.txt
│ │ │ ├── test_textual_inversion.py
│ │ │ ├── test_textual_inversion_sdxl.py
│ │ │ ├── textual_inversion.py
│ │ │ ├── textual_inversion_flax.py
│ │ │ └── textual_inversion_sdxl.py
│ │ ├── unconditional_image_generation/
│ │ │ ├── README.md
│ │ │ ├── requirements.txt
│ │ │ ├── test_unconditional.py
│ │ │ └── train_unconditional.py
│ │ ├── vqgan/
│ │ │ ├── README.md
│ │ │ ├── discriminator.py
│ │ │ ├── requirements.txt
│ │ │ ├── test_vqgan.py
│ │ │ └── train_vqgan.py
│ │ └── wuerstchen/
│ │ └── text_to_image/
│ │ ├── README.md
│ │ ├── __init__.py
│ │ ├── modeling_efficient_net_encoder.py
│ │ ├── requirements.txt
│ │ ├── train_text_to_image_lora_prior.py
│ │ └── train_text_to_image_prior.py
│ ├── pyproject.toml
│ ├── scripts/
│ │ ├── __init__.py
│ │ ├── change_naming_configs_and_checkpoints.py
│ │ ├── conversion_ldm_uncond.py
│ │ ├── convert_amused.py
│ │ ├── convert_animatediff_motion_lora_to_diffusers.py
│ │ ├── convert_animatediff_motion_module_to_diffusers.py
│ │ ├── convert_asymmetric_vqgan_to_diffusers.py
│ │ ├── convert_blipdiffusion_to_diffusers.py
│ │ ├── convert_consistency_decoder.py
│ │ ├── convert_consistency_to_diffusers.py
│ │ ├── convert_dance_diffusion_to_diffusers.py
│ │ ├── convert_ddpm_original_checkpoint_to_diffusers.py
│ │ ├── convert_diffusers_sdxl_lora_to_webui.py
│ │ ├── convert_diffusers_to_original_sdxl.py
│ │ ├── convert_diffusers_to_original_stable_diffusion.py
│ │ ├── convert_dit_to_diffusers.py
│ │ ├── convert_gligen_to_diffusers.py
│ │ ├── convert_i2vgen_to_diffusers.py
│ │ ├── convert_if.py
│ │ ├── convert_k_upscaler_to_diffusers.py
│ │ ├── convert_kakao_brain_unclip_to_diffusers.py
│ │ ├── convert_kandinsky3_unet.py
│ │ ├── convert_kandinsky_to_diffusers.py
│ │ ├── convert_ldm_original_checkpoint_to_diffusers.py
│ │ ├── convert_lora_safetensor_to_diffusers.py
│ │ ├── convert_models_diffuser_to_diffusers.py
│ │ ├── convert_ms_text_to_video_to_diffusers.py
│ │ ├── convert_music_spectrogram_to_diffusers.py
│ │ ├── convert_ncsnpp_original_checkpoint_to_diffusers.py
│ │ ├── convert_original_audioldm2_to_diffusers.py
│ │ ├── convert_original_audioldm_to_diffusers.py
│ │ ├── convert_original_controlnet_to_diffusers.py
│ │ ├── convert_original_musicldm_to_diffusers.py
│ │ ├── convert_original_stable_diffusion_to_diffusers.py
│ │ ├── convert_original_t2i_adapter.py
│ │ ├── convert_pixart_alpha_to_diffusers.py
│ │ ├── convert_pixart_sigma_to_diffusers.py
│ │ ├── convert_shap_e_to_diffusers.py
│ │ ├── convert_stable_cascade.py
│ │ ├── convert_stable_cascade_lite.py
│ │ ├── convert_stable_diffusion_checkpoint_to_onnx.py
│ │ ├── convert_stable_diffusion_controlnet_to_onnx.py
│ │ ├── convert_stable_diffusion_controlnet_to_tensorrt.py
│ │ ├── convert_svd_to_diffusers.py
│ │ ├── convert_tiny_autoencoder_to_diffusers.py
│ │ ├── convert_unclip_txt2img_to_image_variation.py
│ │ ├── convert_unidiffuser_to_diffusers.py
│ │ ├── convert_vae_diff_to_onnx.py
│ │ ├── convert_vae_pt_to_diffusers.py
│ │ ├── convert_versatile_diffusion_to_diffusers.py
│ │ ├── convert_vq_diffusion_to_diffusers.py
│ │ ├── convert_wuerstchen.py
│ │ ├── convert_zero123_to_diffusers.py
│ │ ├── generate_logits.py
│ │ └── log_reports.py
│ ├── setup.py
│ ├── src/
│ │ └── diffusers/
│ │ ├── __init__.py
│ │ ├── callbacks.py
│ │ ├── commands/
│ │ │ ├── __init__.py
│ │ │ ├── diffusers_cli.py
│ │ │ ├── env.py
│ │ │ └── fp16_safetensors.py
│ │ ├── configuration_utils.py
│ │ ├── dependency_versions_check.py
│ │ ├── dependency_versions_table.py
│ │ ├── experimental/
│ │ │ ├── README.md
│ │ │ ├── __init__.py
│ │ │ └── rl/
│ │ │ ├── __init__.py
│ │ │ └── value_guided_sampling.py
│ │ ├── image_processor.py
│ │ ├── loaders/
│ │ │ ├── __init__.py
│ │ │ ├── autoencoder.py
│ │ │ ├── controlnet.py
│ │ │ ├── ip_adapter.py
│ │ │ ├── lora.py
│ │ │ ├── lora_conversion_utils.py
│ │ │ ├── peft.py
│ │ │ ├── single_file.py
│ │ │ ├── single_file_model.py
│ │ │ ├── single_file_utils.py
│ │ │ ├── textual_inversion.py
│ │ │ ├── unet.py
│ │ │ ├── unet_loader_utils.py
│ │ │ └── utils.py
│ │ ├── models/
│ │ │ ├── README.md
│ │ │ ├── __init__.py
│ │ │ ├── activations.py
│ │ │ ├── adapter.py
│ │ │ ├── attention.py
│ │ │ ├── attention_flax.py
│ │ │ ├── attention_processor.py
│ │ │ ├── autoencoders/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── autoencoder_asym_kl.py
│ │ │ │ ├── autoencoder_kl.py
│ │ │ │ ├── autoencoder_kl_temporal_decoder.py
│ │ │ │ ├── autoencoder_tiny.py
│ │ │ │ ├── consistency_decoder_vae.py
│ │ │ │ ├── vae.py
│ │ │ │ └── vq_model.py
│ │ │ ├── controlnet.py
│ │ │ ├── controlnet_flax.py
│ │ │ ├── controlnet_xs.py
│ │ │ ├── downsampling.py
│ │ │ ├── embeddings.py
│ │ │ ├── embeddings_flax.py
│ │ │ ├── lora.py
│ │ │ ├── model_loading_utils.py
│ │ │ ├── modeling_flax_pytorch_utils.py
│ │ │ ├── modeling_flax_utils.py
│ │ │ ├── modeling_outputs.py
│ │ │ ├── modeling_pytorch_flax_utils.py
│ │ │ ├── modeling_utils.py
│ │ │ ├── normalization.py
│ │ │ ├── resnet.py
│ │ │ ├── resnet_flax.py
│ │ │ ├── transformers/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── dit_transformer_2d.py
│ │ │ │ ├── dual_transformer_2d.py
│ │ │ │ ├── hunyuan_transformer_2d.py
│ │ │ │ ├── pixart_transformer_2d.py
│ │ │ │ ├── prior_transformer.py
│ │ │ │ ├── t5_film_transformer.py
│ │ │ │ ├── transformer_2d.py
│ │ │ │ ├── transformer_sd3.py
│ │ │ │ └── transformer_temporal.py
│ │ │ ├── unets/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── unet_1d.py
│ │ │ │ ├── unet_1d_blocks.py
│ │ │ │ ├── unet_2d.py
│ │ │ │ ├── unet_2d_blocks.py
│ │ │ │ ├── unet_2d_blocks_flax.py
│ │ │ │ ├── unet_2d_condition.py
│ │ │ │ ├── unet_2d_condition_flax.py
│ │ │ │ ├── unet_3d_blocks.py
│ │ │ │ ├── unet_3d_condition.py
│ │ │ │ ├── unet_i2vgen_xl.py
│ │ │ │ ├── unet_kandinsky3.py
│ │ │ │ ├── unet_motion_model.py
│ │ │ │ ├── unet_spatio_temporal_condition.py
│ │ │ │ ├── unet_stable_cascade.py
│ │ │ │ └── uvit_2d.py
│ │ │ ├── upsampling.py
│ │ │ ├── vae_flax.py
│ │ │ └── vq_model.py
│ │ ├── optimization.py
│ │ ├── pipelines/
│ │ │ ├── README.md
│ │ │ ├── __init__.py
│ │ │ ├── amused/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── pipeline_amused.py
│ │ │ │ ├── pipeline_amused_img2img.py
│ │ │ │ └── pipeline_amused_inpaint.py
│ │ │ ├── animatediff/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── pipeline_animatediff.py
│ │ │ │ ├── pipeline_animatediff_sdxl.py
│ │ │ │ ├── pipeline_animatediff_video2video.py
│ │ │ │ └── pipeline_output.py
│ │ │ ├── audioldm/
│ │ │ │ ├── __init__.py
│ │ │ │ └── pipeline_audioldm.py
│ │ │ ├── audioldm2/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── modeling_audioldm2.py
│ │ │ │ └── pipeline_audioldm2.py
│ │ │ ├── auto_pipeline.py
│ │ │ ├── blip_diffusion/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── blip_image_processing.py
│ │ │ │ ├── modeling_blip2.py
│ │ │ │ ├── modeling_ctx_clip.py
│ │ │ │ └── pipeline_blip_diffusion.py
│ │ │ ├── consistency_models/
│ │ │ │ ├── __init__.py
│ │ │ │ └── pipeline_consistency_models.py
│ │ │ ├── controlnet/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── multicontrolnet.py
│ │ │ │ ├── pipeline_controlnet.py
│ │ │ │ ├── pipeline_controlnet_blip_diffusion.py
│ │ │ │ ├── pipeline_controlnet_img2img.py
│ │ │ │ ├── pipeline_controlnet_inpaint.py
│ │ │ │ ├── pipeline_controlnet_inpaint_sd_xl.py
│ │ │ │ ├── pipeline_controlnet_sd_xl.py
│ │ │ │ ├── pipeline_controlnet_sd_xl_img2img.py
│ │ │ │ └── pipeline_flax_controlnet.py
│ │ │ ├── controlnet_xs/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── pipeline_controlnet_xs.py
│ │ │ │ └── pipeline_controlnet_xs_sd_xl.py
│ │ │ ├── dance_diffusion/
│ │ │ │ ├── __init__.py
│ │ │ │ └── pipeline_dance_diffusion.py
│ │ │ ├── ddim/
│ │ │ │ ├── __init__.py
│ │ │ │ └── pipeline_ddim.py
│ │ │ ├── ddpm/
│ │ │ │ ├── __init__.py
│ │ │ │ └── pipeline_ddpm.py
│ │ │ ├── deepfloyd_if/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── pipeline_if.py
│ │ │ │ ├── pipeline_if_img2img.py
│ │ │ │ ├── pipeline_if_img2img_superresolution.py
│ │ │ │ ├── pipeline_if_inpainting.py
│ │ │ │ ├── pipeline_if_inpainting_superresolution.py
│ │ │ │ ├── pipeline_if_superresolution.py
│ │ │ │ ├── pipeline_output.py
│ │ │ │ ├── safety_checker.py
│ │ │ │ ├── timesteps.py
│ │ │ │ └── watermark.py
│ │ │ ├── deprecated/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── alt_diffusion/
│ │ │ │ │ ├── __init__.py
│ │ │ │ │ ├── modeling_roberta_series.py
│ │ │ │ │ ├── pipeline_alt_diffusion.py
│ │ │ │ │ ├── pipeline_alt_diffusion_img2img.py
│ │ │ │ │ └── pipeline_output.py
│ │ │ │ ├── audio_diffusion/
│ │ │ │ │ ├── __init__.py
│ │ │ │ │ ├── mel.py
│ │ │ │ │ └── pipeline_audio_diffusion.py
│ │ │ │ ├── latent_diffusion_uncond/
│ │ │ │ │ ├── __init__.py
│ │ │ │ │ └── pipeline_latent_diffusion_uncond.py
│ │ │ │ ├── pndm/
│ │ │ │ │ ├── __init__.py
│ │ │ │ │ └── pipeline_pndm.py
│ │ │ │ ├── repaint/
│ │ │ │ │ ├── __init__.py
│ │ │ │ │ └── pipeline_repaint.py
│ │ │ │ ├── score_sde_ve/
│ │ │ │ │ ├── __init__.py
│ │ │ │ │ └── pipeline_score_sde_ve.py
│ │ │ │ ├── spectrogram_diffusion/
│ │ │ │ │ ├── __init__.py
│ │ │ │ │ ├── continuous_encoder.py
│ │ │ │ │ ├── midi_utils.py
│ │ │ │ │ ├── notes_encoder.py
│ │ │ │ │ └── pipeline_spectrogram_diffusion.py
│ │ │ │ ├── stable_diffusion_variants/
│ │ │ │ │ ├── __init__.py
│ │ │ │ │ ├── pipeline_cycle_diffusion.py
│ │ │ │ │ ├── pipeline_onnx_stable_diffusion_inpaint_legacy.py
│ │ │ │ │ ├── pipeline_stable_diffusion_inpaint_legacy.py
│ │ │ │ │ ├── pipeline_stable_diffusion_model_editing.py
│ │ │ │ │ ├── pipeline_stable_diffusion_paradigms.py
│ │ │ │ │ └── pipeline_stable_diffusion_pix2pix_zero.py
│ │ │ │ ├── stochastic_karras_ve/
│ │ │ │ │ ├── __init__.py
│ │ │ │ │ └── pipeline_stochastic_karras_ve.py
│ │ │ │ ├── versatile_diffusion/
│ │ │ │ │ ├── __init__.py
│ │ │ │ │ ├── modeling_text_unet.py
│ │ │ │ │ ├── pipeline_versatile_diffusion.py
│ │ │ │ │ ├── pipeline_versatile_diffusion_dual_guided.py
│ │ │ │ │ ├── pipeline_versatile_diffusion_image_variation.py
│ │ │ │ │ └── pipeline_versatile_diffusion_text_to_image.py
│ │ │ │ └── vq_diffusion/
│ │ │ │ ├── __init__.py
│ │ │ │ └── pipeline_vq_diffusion.py
│ │ │ ├── dit/
│ │ │ │ ├── __init__.py
│ │ │ │ └── pipeline_dit.py
│ │ │ ├── free_init_utils.py
│ │ │ ├── hunyuandit/
│ │ │ │ ├── __init__.py
│ │ │ │ └── pipeline_hunyuandit.py
│ │ │ ├── i2vgen_xl/
│ │ │ │ ├── __init__.py
│ │ │ │ └── pipeline_i2vgen_xl.py
│ │ │ ├── kandinsky/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── pipeline_kandinsky.py
│ │ │ │ ├── pipeline_kandinsky_combined.py
│ │ │ │ ├── pipeline_kandinsky_img2img.py
│ │ │ │ ├── pipeline_kandinsky_inpaint.py
│ │ │ │ ├── pipeline_kandinsky_prior.py
│ │ │ │ └── text_encoder.py
│ │ │ ├── kandinsky2_2/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── pipeline_kandinsky2_2.py
│ │ │ │ ├── pipeline_kandinsky2_2_combined.py
│ │ │ │ ├── pipeline_kandinsky2_2_controlnet.py
│ │ │ │ ├── pipeline_kandinsky2_2_controlnet_img2img.py
│ │ │ │ ├── pipeline_kandinsky2_2_img2img.py
│ │ │ │ ├── pipeline_kandinsky2_2_inpainting.py
│ │ │ │ ├── pipeline_kandinsky2_2_prior.py
│ │ │ │ └── pipeline_kandinsky2_2_prior_emb2emb.py
│ │ │ ├── kandinsky3/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── convert_kandinsky3_unet.py
│ │ │ │ ├── pipeline_kandinsky3.py
│ │ │ │ └── pipeline_kandinsky3_img2img.py
│ │ │ ├── latent_consistency_models/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── pipeline_latent_consistency_img2img.py
│ │ │ │ └── pipeline_latent_consistency_text2img.py
│ │ │ ├── latent_diffusion/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── pipeline_latent_diffusion.py
│ │ │ │ └── pipeline_latent_diffusion_superresolution.py
│ │ │ ├── ledits_pp/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── pipeline_leditspp_stable_diffusion.py
│ │ │ │ ├── pipeline_leditspp_stable_diffusion_xl.py
│ │ │ │ └── pipeline_output.py
│ │ │ ├── marigold/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── marigold_image_processing.py
│ │ │ │ ├── pipeline_marigold_depth.py
│ │ │ │ └── pipeline_marigold_normals.py
│ │ │ ├── musicldm/
│ │ │ │ ├── __init__.py
│ │ │ │ └── pipeline_musicldm.py
│ │ │ ├── onnx_utils.py
│ │ │ ├── paint_by_example/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── image_encoder.py
│ │ │ │ └── pipeline_paint_by_example.py
│ │ │ ├── pia/
│ │ │ │ ├── __init__.py
│ │ │ │ └── pipeline_pia.py
│ │ │ ├── pipeline_flax_utils.py
│ │ │ ├── pipeline_loading_utils.py
│ │ │ ├── pipeline_utils.py
│ │ │ ├── pixart_alpha/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── pipeline_pixart_alpha.py
│ │ │ │ └── pipeline_pixart_sigma.py
│ │ │ ├── semantic_stable_diffusion/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── pipeline_output.py
│ │ │ │ └── pipeline_semantic_stable_diffusion.py
│ │ │ ├── shap_e/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── camera.py
│ │ │ │ ├── pipeline_shap_e.py
│ │ │ │ ├── pipeline_shap_e_img2img.py
│ │ │ │ └── renderer.py
│ │ │ ├── stable_cascade/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── pipeline_stable_cascade.py
│ │ │ │ ├── pipeline_stable_cascade_combined.py
│ │ │ │ └── pipeline_stable_cascade_prior.py
│ │ │ ├── stable_diffusion/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── clip_image_project_model.py
│ │ │ │ ├── convert_from_ckpt.py
│ │ │ │ ├── pipeline_flax_stable_diffusion.py
│ │ │ │ ├── pipeline_flax_stable_diffusion_img2img.py
│ │ │ │ ├── pipeline_flax_stable_diffusion_inpaint.py
│ │ │ │ ├── pipeline_onnx_stable_diffusion.py
│ │ │ │ ├── pipeline_onnx_stable_diffusion_img2img.py
│ │ │ │ ├── pipeline_onnx_stable_diffusion_inpaint.py
│ │ │ │ ├── pipeline_onnx_stable_diffusion_upscale.py
│ │ │ │ ├── pipeline_output.py
│ │ │ │ ├── pipeline_stable_diffusion.py
│ │ │ │ ├── pipeline_stable_diffusion_depth2img.py
│ │ │ │ ├── pipeline_stable_diffusion_image_variation.py
│ │ │ │ ├── pipeline_stable_diffusion_img2img.py
│ │ │ │ ├── pipeline_stable_diffusion_inpaint.py
│ │ │ │ ├── pipeline_stable_diffusion_instruct_pix2pix.py
│ │ │ │ ├── pipeline_stable_diffusion_latent_upscale.py
│ │ │ │ ├── pipeline_stable_diffusion_upscale.py
│ │ │ │ ├── pipeline_stable_unclip.py
│ │ │ │ ├── pipeline_stable_unclip_img2img.py
│ │ │ │ ├── safety_checker.py
│ │ │ │ ├── safety_checker_flax.py
│ │ │ │ └── stable_unclip_image_normalizer.py
│ │ │ ├── stable_diffusion_3/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── pipeline_output.py
│ │ │ │ ├── pipeline_stable_diffusion_3.py
│ │ │ │ ├── pipeline_stable_diffusion_3_img2img.py
│ │ │ │ └── pipeline_stable_diffusion_3_instructpix2pix.py
│ │ │ ├── stable_diffusion_attend_and_excite/
│ │ │ │ ├── __init__.py
│ │ │ │ └── pipeline_stable_diffusion_attend_and_excite.py
│ │ │ ├── stable_diffusion_diffedit/
│ │ │ │ ├── __init__.py
│ │ │ │ └── pipeline_stable_diffusion_diffedit.py
│ │ │ ├── stable_diffusion_gligen/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── pipeline_stable_diffusion_gligen.py
│ │ │ │ └── pipeline_stable_diffusion_gligen_text_image.py
│ │ │ ├── stable_diffusion_k_diffusion/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── pipeline_stable_diffusion_k_diffusion.py
│ │ │ │ └── pipeline_stable_diffusion_xl_k_diffusion.py
│ │ │ ├── stable_diffusion_ldm3d/
│ │ │ │ ├── __init__.py
│ │ │ │ └── pipeline_stable_diffusion_ldm3d.py
│ │ │ ├── stable_diffusion_panorama/
│ │ │ │ ├── __init__.py
│ │ │ │ └── pipeline_stable_diffusion_panorama.py
│ │ │ ├── stable_diffusion_safe/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── pipeline_output.py
│ │ │ │ ├── pipeline_stable_diffusion_safe.py
│ │ │ │ └── safety_checker.py
│ │ │ ├── stable_diffusion_sag/
│ │ │ │ ├── __init__.py
│ │ │ │ └── pipeline_stable_diffusion_sag.py
│ │ │ ├── stable_diffusion_xl/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── pipeline_flax_stable_diffusion_xl.py
│ │ │ │ ├── pipeline_output.py
│ │ │ │ ├── pipeline_stable_diffusion_xl.py
│ │ │ │ ├── pipeline_stable_diffusion_xl_img2img.py
│ │ │ │ ├── pipeline_stable_diffusion_xl_inpaint.py
│ │ │ │ ├── pipeline_stable_diffusion_xl_instruct_pix2pix.py
│ │ │ │ └── watermark.py
│ │ │ ├── stable_video_diffusion/
│ │ │ │ ├── __init__.py
│ │ │ │ └── pipeline_stable_video_diffusion.py
│ │ │ ├── t2i_adapter/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── pipeline_stable_diffusion_adapter.py
│ │ │ │ └── pipeline_stable_diffusion_xl_adapter.py
│ │ │ ├── text_to_video_synthesis/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── pipeline_output.py
│ │ │ │ ├── pipeline_text_to_video_synth.py
│ │ │ │ ├── pipeline_text_to_video_synth_img2img.py
│ │ │ │ ├── pipeline_text_to_video_zero.py
│ │ │ │ └── pipeline_text_to_video_zero_sdxl.py
│ │ │ ├── unclip/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── pipeline_unclip.py
│ │ │ │ ├── pipeline_unclip_image_variation.py
│ │ │ │ └── text_proj.py
│ │ │ ├── unidiffuser/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── modeling_text_decoder.py
│ │ │ │ ├── modeling_uvit.py
│ │ │ │ └── pipeline_unidiffuser.py
│ │ │ └── wuerstchen/
│ │ │ ├── __init__.py
│ │ │ ├── modeling_paella_vq_model.py
│ │ │ ├── modeling_wuerstchen_common.py
│ │ │ ├── modeling_wuerstchen_diffnext.py
│ │ │ ├── modeling_wuerstchen_prior.py
│ │ │ ├── pipeline_wuerstchen.py
│ │ │ ├── pipeline_wuerstchen_combined.py
│ │ │ └── pipeline_wuerstchen_prior.py
│ │ ├── py.typed
│ │ ├── schedulers/
│ │ │ ├── README.md
│ │ │ ├── __init__.py
│ │ │ ├── deprecated/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── scheduling_karras_ve.py
│ │ │ │ └── scheduling_sde_vp.py
│ │ │ ├── scheduling_amused.py
│ │ │ ├── scheduling_consistency_decoder.py
│ │ │ ├── scheduling_consistency_models.py
│ │ │ ├── scheduling_ddim.py
│ │ │ ├── scheduling_ddim_flax.py
│ │ │ ├── scheduling_ddim_inverse.py
│ │ │ ├── scheduling_ddim_parallel.py
│ │ │ ├── scheduling_ddpm.py
│ │ │ ├── scheduling_ddpm_flax.py
│ │ │ ├── scheduling_ddpm_parallel.py
│ │ │ ├── scheduling_ddpm_wuerstchen.py
│ │ │ ├── scheduling_deis_multistep.py
│ │ │ ├── scheduling_dpmsolver_multistep.py
│ │ │ ├── scheduling_dpmsolver_multistep_flax.py
│ │ │ ├── scheduling_dpmsolver_multistep_inverse.py
│ │ │ ├── scheduling_dpmsolver_sde.py
│ │ │ ├── scheduling_dpmsolver_singlestep.py
│ │ │ ├── scheduling_edm_dpmsolver_multistep.py
│ │ │ ├── scheduling_edm_euler.py
│ │ │ ├── scheduling_euler_ancestral_discrete.py
│ │ │ ├── scheduling_euler_discrete.py
│ │ │ ├── scheduling_euler_discrete_flax.py
│ │ │ ├── scheduling_flow_match_euler_discrete.py
│ │ │ ├── scheduling_heun_discrete.py
│ │ │ ├── scheduling_ipndm.py
│ │ │ ├── scheduling_k_dpm_2_ancestral_discrete.py
│ │ │ ├── scheduling_k_dpm_2_discrete.py
│ │ │ ├── scheduling_karras_ve_flax.py
│ │ │ ├── scheduling_lcm.py
│ │ │ ├── scheduling_lms_discrete.py
│ │ │ ├── scheduling_lms_discrete_flax.py
│ │ │ ├── scheduling_pndm.py
│ │ │ ├── scheduling_pndm_flax.py
│ │ │ ├── scheduling_repaint.py
│ │ │ ├── scheduling_sasolver.py
│ │ │ ├── scheduling_sde_ve.py
│ │ │ ├── scheduling_sde_ve_flax.py
│ │ │ ├── scheduling_tcd.py
│ │ │ ├── scheduling_unclip.py
│ │ │ ├── scheduling_unipc_multistep.py
│ │ │ ├── scheduling_utils.py
│ │ │ ├── scheduling_utils_flax.py
│ │ │ └── scheduling_vq_diffusion.py
│ │ ├── training_utils.py
│ │ ├── utils/
│ │ │ ├── __init__.py
│ │ │ ├── accelerate_utils.py
│ │ │ ├── constants.py
│ │ │ ├── deprecation_utils.py
│ │ │ ├── doc_utils.py
│ │ │ ├── dummy_flax_and_transformers_objects.py
│ │ │ ├── dummy_flax_objects.py
│ │ │ ├── dummy_note_seq_objects.py
│ │ │ ├── dummy_onnx_objects.py
│ │ │ ├── dummy_pt_objects.py
│ │ │ ├── dummy_torch_and_librosa_objects.py
│ │ │ ├── dummy_torch_and_scipy_objects.py
│ │ │ ├── dummy_torch_and_torchsde_objects.py
│ │ │ ├── dummy_torch_and_transformers_and_k_diffusion_objects.py
│ │ │ ├── dummy_torch_and_transformers_and_onnx_objects.py
│ │ │ ├── dummy_torch_and_transformers_objects.py
│ │ │ ├── dummy_transformers_and_torch_and_note_seq_objects.py
│ │ │ ├── dynamic_modules_utils.py
│ │ │ ├── export_utils.py
│ │ │ ├── hub_utils.py
│ │ │ ├── import_utils.py
│ │ │ ├── loading_utils.py
│ │ │ ├── logging.py
│ │ │ ├── model_card_template.md
│ │ │ ├── outputs.py
│ │ │ ├── peft_utils.py
│ │ │ ├── pil_utils.py
│ │ │ ├── state_dict_utils.py
│ │ │ ├── testing_utils.py
│ │ │ ├── torch_utils.py
│ │ │ └── versions.py
│ │ └── video_processor.py
│ ├── subd_112030.err
│ ├── subh_112029.err
│ ├── tests/
│ │ ├── __init__.py
│ │ ├── conftest.py
│ │ ├── fixtures/
│ │ │ ├── custom_pipeline/
│ │ │ │ ├── pipeline.py
│ │ │ │ └── what_ever.py
│ │ │ └── elise_format0.mid
│ │ ├── lora/
│ │ │ ├── test_lora_layers_sd.py
│ │ │ ├── test_lora_layers_sd3.py
│ │ │ ├── test_lora_layers_sdxl.py
│ │ │ └── utils.py
│ │ ├── models/
│ │ │ ├── __init__.py
│ │ │ ├── autoencoders/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── test_models_vae.py
│ │ │ │ ├── test_models_vae_flax.py
│ │ │ │ └── test_models_vq.py
│ │ │ ├── test_activations.py
│ │ │ ├── test_attention_processor.py
│ │ │ ├── test_layers_utils.py
│ │ │ ├── test_modeling_common.py
│ │ │ ├── test_modeling_common_flax.py
│ │ │ ├── transformers/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── test_models_dit_transformer2d.py
│ │ │ │ ├── test_models_pixart_transformer2d.py
│ │ │ │ ├── test_models_prior.py
│ │ │ │ └── test_models_transformer_sd3.py
│ │ │ └── unets/
│ │ │ ├── __init__.py
│ │ │ ├── test_models_unet_1d.py
│ │ │ ├── test_models_unet_2d.py
│ │ │ ├── test_models_unet_2d_condition.py
│ │ │ ├── test_models_unet_2d_flax.py
│ │ │ ├── test_models_unet_3d_condition.py
│ │ │ ├── test_models_unet_controlnetxs.py
│ │ │ ├── test_models_unet_motion.py
│ │ │ ├── test_models_unet_spatiotemporal.py
│ │ │ ├── test_unet_2d_blocks.py
│ │ │ └── test_unet_blocks_common.py
│ │ ├── others/
│ │ │ ├── test_check_copies.py
│ │ │ ├── test_check_dummies.py
│ │ │ ├── test_config.py
│ │ │ ├── test_dependencies.py
│ │ │ ├── test_ema.py
│ │ │ ├── test_hub_utils.py
│ │ │ ├── test_image_processor.py
│ │ │ ├── test_outputs.py
│ │ │ ├── test_training.py
│ │ │ ├── test_utils.py
│ │ │ └── test_video_processor.py
│ │ ├── pipelines/
│ │ │ ├── __init__.py
│ │ │ ├── amused/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── test_amused.py
│ │ │ │ ├── test_amused_img2img.py
│ │ │ │ └── test_amused_inpaint.py
│ │ │ ├── animatediff/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── test_animatediff.py
│ │ │ │ ├── test_animatediff_sdxl.py
│ │ │ │ └── test_animatediff_video2video.py
│ │ │ ├── audioldm/
│ │ │ │ ├── __init__.py
│ │ │ │ └── test_audioldm.py
│ │ │ ├── audioldm2/
│ │ │ │ ├── __init__.py
│ │ │ │ └── test_audioldm2.py
│ │ │ ├── blipdiffusion/
│ │ │ │ ├── __init__.py
│ │ │ │ └── test_blipdiffusion.py
│ │ │ ├── consistency_models/
│ │ │ │ ├── __init__.py
│ │ │ │ └── test_consistency_models.py
│ │ │ ├── controlnet/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── test_controlnet.py
│ │ │ │ ├── test_controlnet_blip_diffusion.py
│ │ │ │ ├── test_controlnet_img2img.py
│ │ │ │ ├── test_controlnet_inpaint.py
│ │ │ │ ├── test_controlnet_inpaint_sdxl.py
│ │ │ │ ├── test_controlnet_sdxl.py
│ │ │ │ ├── test_controlnet_sdxl_img2img.py
│ │ │ │ └── test_flax_controlnet.py
│ │ │ ├── controlnet_xs/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── test_controlnetxs.py
│ │ │ │ └── test_controlnetxs_sdxl.py
│ │ │ ├── dance_diffusion/
│ │ │ │ ├── __init__.py
│ │ │ │ └── test_dance_diffusion.py
│ │ │ ├── ddim/
│ │ │ │ ├── __init__.py
│ │ │ │ └── test_ddim.py
│ │ │ ├── ddpm/
│ │ │ │ ├── __init__.py
│ │ │ │ └── test_ddpm.py
│ │ │ ├── deepfloyd_if/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── test_if.py
│ │ │ │ ├── test_if_img2img.py
│ │ │ │ ├── test_if_img2img_superresolution.py
│ │ │ │ ├── test_if_inpainting.py
│ │ │ │ ├── test_if_inpainting_superresolution.py
│ │ │ │ └── test_if_superresolution.py
│ │ │ ├── dit/
│ │ │ │ ├── __init__.py
│ │ │ │ └── test_dit.py
│ │ │ ├── hunyuan_dit/
│ │ │ │ ├── __init__.py
│ │ │ │ └── test_hunyuan_dit.py
│ │ │ ├── i2vgen_xl/
│ │ │ │ ├── __init__.py
│ │ │ │ └── test_i2vgenxl.py
│ │ │ ├── ip_adapters/
│ │ │ │ └── test_ip_adapter_stable_diffusion.py
│ │ │ ├── kandinsky/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── test_kandinsky.py
│ │ │ │ ├── test_kandinsky_combined.py
│ │ │ │ ├── test_kandinsky_img2img.py
│ │ │ │ ├── test_kandinsky_inpaint.py
│ │ │ │ └── test_kandinsky_prior.py
│ │ │ ├── kandinsky2_2/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── test_kandinsky.py
│ │ │ │ ├── test_kandinsky_combined.py
│ │ │ │ ├── test_kandinsky_controlnet.py
│ │ │ │ ├── test_kandinsky_controlnet_img2img.py
│ │ │ │ ├── test_kandinsky_img2img.py
│ │ │ │ ├── test_kandinsky_inpaint.py
│ │ │ │ ├── test_kandinsky_prior.py
│ │ │ │ └── test_kandinsky_prior_emb2emb.py
│ │ │ ├── kandinsky3/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── test_kandinsky3.py
│ │ │ │ └── test_kandinsky3_img2img.py
│ │ │ ├── latent_consistency_models/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── test_latent_consistency_models.py
│ │ │ │ └── test_latent_consistency_models_img2img.py
│ │ │ ├── latent_diffusion/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── test_latent_diffusion.py
│ │ │ │ └── test_latent_diffusion_superresolution.py
│ │ │ ├── ledits_pp/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── test_ledits_pp_stable_diffusion.py
│ │ │ │ └── test_ledits_pp_stable_diffusion_xl.py
│ │ │ ├── marigold/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── test_marigold_depth.py
│ │ │ │ └── test_marigold_normals.py
│ │ │ ├── musicldm/
│ │ │ │ ├── __init__.py
│ │ │ │ └── test_musicldm.py
│ │ │ ├── paint_by_example/
│ │ │ │ ├── __init__.py
│ │ │ │ └── test_paint_by_example.py
│ │ │ ├── pia/
│ │ │ │ ├── __init__.py
│ │ │ │ └── test_pia.py
│ │ │ ├── pipeline_params.py
│ │ │ ├── pixart_alpha/
│ │ │ │ ├── __init__.py
│ │ │ │ └── test_pixart.py
│ │ │ ├── pixart_sigma/
│ │ │ │ ├── __init__.py
│ │ │ │ └── test_pixart.py
│ │ │ ├── pndm/
│ │ │ │ ├── __init__.py
│ │ │ │ └── test_pndm.py
│ │ │ ├── semantic_stable_diffusion/
│ │ │ │ ├── __init__.py
│ │ │ │ └── test_semantic_diffusion.py
│ │ │ ├── shap_e/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── test_shap_e.py
│ │ │ │ └── test_shap_e_img2img.py
│ │ │ ├── stable_cascade/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── test_stable_cascade_combined.py
│ │ │ │ ├── test_stable_cascade_decoder.py
│ │ │ │ └── test_stable_cascade_prior.py
│ │ │ ├── stable_diffusion/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── test_onnx_stable_diffusion.py
│ │ │ │ ├── test_onnx_stable_diffusion_img2img.py
│ │ │ │ ├── test_onnx_stable_diffusion_inpaint.py
│ │ │ │ ├── test_onnx_stable_diffusion_upscale.py
│ │ │ │ ├── test_stable_diffusion.py
│ │ │ │ ├── test_stable_diffusion_img2img.py
│ │ │ │ ├── test_stable_diffusion_inpaint.py
│ │ │ │ └── test_stable_diffusion_instruction_pix2pix.py
│ │ │ ├── stable_diffusion_2/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── test_stable_diffusion.py
│ │ │ │ ├── test_stable_diffusion_attend_and_excite.py
│ │ │ │ ├── test_stable_diffusion_depth.py
│ │ │ │ ├── test_stable_diffusion_diffedit.py
│ │ │ │ ├── test_stable_diffusion_flax.py
│ │ │ │ ├── test_stable_diffusion_flax_inpaint.py
│ │ │ │ ├── test_stable_diffusion_inpaint.py
│ │ │ │ ├── test_stable_diffusion_latent_upscale.py
│ │ │ │ ├── test_stable_diffusion_upscale.py
│ │ │ │ └── test_stable_diffusion_v_pred.py
│ │ │ ├── stable_diffusion_3/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── test_pipeline_stable_diffusion_3.py
│ │ │ │ └── test_pipeline_stable_diffusion_3_img2img.py
│ │ │ ├── stable_diffusion_adapter/
│ │ │ │ ├── __init__.py
│ │ │ │ └── test_stable_diffusion_adapter.py
│ │ │ ├── stable_diffusion_gligen/
│ │ │ │ ├── __init__.py
│ │ │ │ └── test_stable_diffusion_gligen.py
│ │ │ ├── stable_diffusion_gligen_text_image/
│ │ │ │ ├── __init__.py
│ │ │ │ └── test_stable_diffusion_gligen_text_image.py
│ │ │ ├── stable_diffusion_image_variation/
│ │ │ │ ├── __init__.py
│ │ │ │ └── test_stable_diffusion_image_variation.py
│ │ │ ├── stable_diffusion_k_diffusion/
│ │ │ │ ├── __init__.py
│ │ │ │ └── test_stable_diffusion_k_diffusion.py
│ │ │ ├── stable_diffusion_ldm3d/
│ │ │ │ ├── __init__.py
│ │ │ │ └── test_stable_diffusion_ldm3d.py
│ │ │ ├── stable_diffusion_panorama/
│ │ │ │ ├── __init__.py
│ │ │ │ └── test_stable_diffusion_panorama.py
│ │ │ ├── stable_diffusion_safe/
│ │ │ │ ├── __init__.py
│ │ │ │ └── test_safe_diffusion.py
│ │ │ ├── stable_diffusion_sag/
│ │ │ │ ├── __init__.py
│ │ │ │ └── test_stable_diffusion_sag.py
│ │ │ ├── stable_diffusion_xl/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── test_stable_diffusion_xl.py
│ │ │ │ ├── test_stable_diffusion_xl_adapter.py
│ │ │ │ ├── test_stable_diffusion_xl_img2img.py
│ │ │ │ ├── test_stable_diffusion_xl_inpaint.py
│ │ │ │ ├── test_stable_diffusion_xl_instruction_pix2pix.py
│ │ │ │ └── test_stable_diffusion_xl_k_diffusion.py
│ │ │ ├── stable_unclip/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── test_stable_unclip.py
│ │ │ │ └── test_stable_unclip_img2img.py
│ │ │ ├── stable_video_diffusion/
│ │ │ │ ├── __init__.py
│ │ │ │ └── test_stable_video_diffusion.py
│ │ │ ├── test_pipeline_utils.py
│ │ │ ├── test_pipelines.py
│ │ │ ├── test_pipelines_auto.py
│ │ │ ├── test_pipelines_combined.py
│ │ │ ├── test_pipelines_common.py
│ │ │ ├── test_pipelines_flax.py
│ │ │ ├── test_pipelines_onnx_common.py
│ │ │ ├── text_to_video_synthesis/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── test_text_to_video.py
│ │ │ │ ├── test_text_to_video_zero.py
│ │ │ │ ├── test_text_to_video_zero_sdxl.py
│ │ │ │ └── test_video_to_video.py
│ │ │ ├── unclip/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── test_unclip.py
│ │ │ │ └── test_unclip_image_variation.py
│ │ │ ├── unidiffuser/
│ │ │ │ ├── __init__.py
│ │ │ │ └── test_unidiffuser.py
│ │ │ └── wuerstchen/
│ │ │ ├── __init__.py
│ │ │ ├── test_wuerstchen_combined.py
│ │ │ ├── test_wuerstchen_decoder.py
│ │ │ └── test_wuerstchen_prior.py
│ │ ├── schedulers/
│ │ │ ├── __init__.py
│ │ │ ├── test_scheduler_consistency_model.py
│ │ │ ├── test_scheduler_ddim.py
│ │ │ ├── test_scheduler_ddim_inverse.py
│ │ │ ├── test_scheduler_ddim_parallel.py
│ │ │ ├── test_scheduler_ddpm.py
│ │ │ ├── test_scheduler_ddpm_parallel.py
│ │ │ ├── test_scheduler_deis.py
│ │ │ ├── test_scheduler_dpm_multi.py
│ │ │ ├── test_scheduler_dpm_multi_inverse.py
│ │ │ ├── test_scheduler_dpm_sde.py
│ │ │ ├── test_scheduler_dpm_single.py
│ │ │ ├── test_scheduler_edm_dpmsolver_multistep.py
│ │ │ ├── test_scheduler_edm_euler.py
│ │ │ ├── test_scheduler_euler.py
│ │ │ ├── test_scheduler_euler_ancestral.py
│ │ │ ├── test_scheduler_flax.py
│ │ │ ├── test_scheduler_heun.py
│ │ │ ├── test_scheduler_ipndm.py
│ │ │ ├── test_scheduler_kdpm2_ancestral.py
│ │ │ ├── test_scheduler_kdpm2_discrete.py
│ │ │ ├── test_scheduler_lcm.py
│ │ │ ├── test_scheduler_lms.py
│ │ │ ├── test_scheduler_pndm.py
│ │ │ ├── test_scheduler_sasolver.py
│ │ │ ├── test_scheduler_score_sde_ve.py
│ │ │ ├── test_scheduler_tcd.py
│ │ │ ├── test_scheduler_unclip.py
│ │ │ ├── test_scheduler_unipc.py
│ │ │ ├── test_scheduler_vq_diffusion.py
│ │ │ └── test_schedulers.py
│ │ └── single_file/
│ │ ├── __init__.py
│ │ ├── single_file_testing_utils.py
│ │ ├── test_model_controlnet_single_file.py
│ │ ├── test_model_sd_cascade_unet_single_file.py
│ │ ├── test_model_vae_single_file.py
│ │ ├── test_stable_diffusion_controlnet_img2img_single_file.py
│ │ ├── test_stable_diffusion_controlnet_inpaint_single_file.py
│ │ ├── test_stable_diffusion_controlnet_single_file.py
│ │ ├── test_stable_diffusion_img2img_single_file.py
│ │ ├── test_stable_diffusion_inpaint_single_file.py
│ │ ├── test_stable_diffusion_single_file.py
│ │ ├── test_stable_diffusion_upscale_single_file.py
│ │ ├── test_stable_diffusion_xl_adapter_single_file.py
│ │ ├── test_stable_diffusion_xl_controlnet_single_file.py
│ │ ├── test_stable_diffusion_xl_img2img_single_file.py
│ │ ├── test_stable_diffusion_xl_instruct_pix2pix.py
│ │ └── test_stable_diffusion_xl_single_file.py
│ └── utils/
│ ├── check_config_docstrings.py
│ ├── check_copies.py
│ ├── check_doc_toc.py
│ ├── check_dummies.py
│ ├── check_inits.py
│ ├── check_repo.py
│ ├── check_table.py
│ ├── custom_init_isort.py
│ ├── fetch_latest_release_branch.py
│ ├── fetch_torch_cuda_pipeline_test_matrix.py
│ ├── get_modified_files.py
│ ├── notify_slack_about_release.py
│ ├── overwrite_expected_slice.py
│ ├── print_env.py
│ ├── release.py
│ ├── stale.py
│ ├── tests_fetcher.py
│ └── update_metadata.py
├── example.py
├── requirements.txt
├── scripts/
│ ├── run_sft_512_sd3_stage1.sh
│ ├── run_sft_512_sdxl_stage1.sh
│ ├── run_sft_512_sdxl_with_mask_stage2.sh
│ └── run_sft_512_with_mask_sd3_stage2.sh
└── traning/
├── train_sd3_pix2pix.py
└── train_sdxl_pix2pix.py
================================================
FILE CONTENTS
================================================
================================================
FILE: .gitignore
================================================
# Byte-compiled / optimized / DLL files
__pycache__/
*.py[cod]
*$py.class
# C extensions
*.so
# Distribution / packaging
.Python
build/
develop-eggs/
dist/
downloads/
eggs/
.eggs/
lib/
lib64/
parts/
sdist/
var/
wheels/
share/python-wheels/
*.egg-info/
.installed.cfg
*.egg
MANIFEST
# PyInstaller
# Usually these files are written by a python script from a template
# before PyInstaller builds the exe, so as to inject date/other infos into it.
*.manifest
*.spec
# Installer logs
pip-log.txt
pip-delete-this-directory.txt
# Unit test / coverage reports
htmlcov/
.tox/
.nox/
.coverage
.coverage.*
.cache
nosetests.xml
coverage.xml
*.cover
*.py,cover
.hypothesis/
.pytest_cache/
cover/
# Translations
*.mo
*.pot
# Django stuff:
*.log
local_settings.py
db.sqlite3
db.sqlite3-journal
# Flask stuff:
instance/
.webassets-cache
# Scrapy stuff:
.scrapy
# Sphinx documentation
docs/_build/
# PyBuilder
.pybuilder/
target/
# Jupyter Notebook
.ipynb_checkpoints
# IPython
profile_default/
ipython_config.py
# pyenv
# For a library or package, you might want to ignore these files since the code is
# intended to run in multiple environments; otherwise, check them in:
# .python-version
# pipenv
# According to pypa/pipenv#598, it is recommended to include Pipfile.lock in version control.
# However, in case of collaboration, if having platform-specific dependencies or dependencies
# having no cross-platform support, pipenv may install dependencies that don't work, or not
# install all needed dependencies.
#Pipfile.lock
# poetry
# Similar to Pipfile.lock, it is generally recommended to include poetry.lock in version control.
# This is especially recommended for binary packages to ensure reproducibility, and is more
# commonly ignored for libraries.
# https://python-poetry.org/docs/basic-usage/#commit-your-poetrylock-file-to-version-control
#poetry.lock
# pdm
# Similar to Pipfile.lock, it is generally recommended to include pdm.lock in version control.
#pdm.lock
# pdm stores project-wide configurations in .pdm.toml, but it is recommended to not include it
# in version control.
# https://pdm.fming.dev/latest/usage/project/#working-with-version-control
.pdm.toml
.pdm-python
.pdm-build/
# PEP 582; used by e.g. github.com/David-OConnor/pyflow and github.com/pdm-project/pdm
__pypackages__/
# Celery stuff
celerybeat-schedule
celerybeat.pid
# SageMath parsed files
*.sage.py
# Environments
.env
.venv
env/
venv/
ENV/
env.bak/
venv.bak/
# Spyder project settings
.spyderproject
.spyproject
# Rope project settings
.ropeproject
# mkdocs documentation
/site
# mypy
.mypy_cache/
.dmypy.json
dmypy.json
# Pyre type checker
.pyre/
# pytype static type analyzer
.pytype/
# Cython debug symbols
cython_debug/
*.jsonl
# PyCharm
# JetBrains specific template is maintained in a separate JetBrains.gitignore that can
# be found at https://github.com/github/gitignore/blob/main/Global/JetBrains.gitignore
# and can be added to the global gitignore or merged into this file. For a more nuclear
# option (not recommended) you can uncomment the following to ignore the entire idea folder.
#.idea/
================================================
FILE: README.md
================================================
<h1 align="center">UltraEdit</h1>
<p align="center">
<a href="https://arxiv.org/abs/2407.05282">
<img alt="Static Badge" src="https://img.shields.io/badge/arXiv-2407.05282-red"></a>
<a href="https://huggingface.co/spaces/jeasinema/UltraEdit-SD3">
<img alt="Static Badge" src="https://img.shields.io/badge/Demo-Gradio-green">
</a>
<a href="https://huggingface.co/datasets/BleachNick/UltraEdit">
<img alt="Static Badge" src="https://img.shields.io/badge/Dataset-HuggingFace-blue">
</a>
<a href="https://ultra-editing.github.io/">
<img alt="Static Badge" src="https://img.shields.io/badge/Page-Link-pink">
</a>
<a href="https://huggingface.co/BleachNick/SD3_UltraEdit_w_mask">
<img alt="Static Badge" src="https://img.shields.io/badge/Model-HuggingFace-yellow">
</a>
</p>
This repository contains code, models, and datasets for UltraEdit.
## Introduction
**UltraEdit**, a large-scale (~4M editing samples), automatically generated dataset for instruction-based image editing. Our key idea is to address the drawbacks in existing image editing datasets like InstructPix2Pix and MagicBrush, and provide a systematic approach to producing massive and high-quality image editing samples.
**UltraEdit** offers several distinct advantages:
1. It features a broader range of editing instructions by leveraging the creativity of large language models (LLMs) alongside in-context editing examples from human raters.
2. Its data sources are based on real images, including photographs and artworks, which provide greater diversity and reduced bias compared to datasets solely generated by text-to-image models.
3. It also supports region-based editing, enhanced by high-quality, automatically produced region annotations.
Our experiments show that canonical diffusion-based editing baselines trained on **UltraEdit** set new records on various benchmarks.
Our analysis further confirms the crucial role of real image anchors and region-based editing data.
## Training
**Setup:**
```
pip install -r requirements
cd diffusers && pip install -e .
```
### Training with stable-diffusion3
**Stage 1: Free-form image editing**
```shell
bash scripts/run_sft_512_sd3_stage1.sh
```
**Stage 2: Mix training**
```shell
bash scripts/run_sft_512_with_mask_sd3_stage2.sh
```
### Training with stable-diffusion-xl
**Stage 1: Free-form image editing**
```shell
bash scripts/run_sft_512_sdxl_stage1.sh
```
[//]: # (**Stage 2: Mix training**)
[//]: # ()
[//]: # (```shell)
[//]: # (bash scripts/run_sft_512_with_mask_sd3_stage2.sh)
[//]: # (```)
### Training with stable-diffusion1.5
**Stage 1: Free-form image editing**
```shell
bash scripts/run_sft_512_sd15_stage1.sh
```
**Stage 2: Mix training**
```shell
bash scripts/run_sft_512_with_mask_sd15_stage2.sh
```
## Example
Below is an example of how to use our pipeline for image editing. Given an input image and a mask image, the model can generate the edited result according to the provided prompt.
<p float="left">
<img src="images/input.png" width="200" />
<img src="images/mask_img.png" width="200" style="border-left:1px solid black;" />
<img src="images/editing_result.png" width="200" style="border-left:1px solid black;" />
</p>
```python
# For Editing with SD3
import torch
from diffusers import StableDiffusion3InstructPix2PixPipeline
from diffusers.utils import load_image
import requests
import PIL.Image
import PIL.ImageOps
pipe = StableDiffusion3InstructPix2PixPipeline.from_pretrained("BleachNick/SD3_UltraEdit_w_mask", torch_dtype=torch.float16)
pipe = pipe.to("cuda")
prompt="What if the horse wears a hat?"
img = load_image("input.png").resize((512, 512))
mask_img = load_image("mask_img.png").resize(img.size)
# For free form Editing, seed a blank mask
# mask_img = PIL.Image.new("RGB", img.size, (255, 255, 255))
image = pipe(
prompt,
image=img,
mask_img=mask_img,
negative_prompt="",
num_inference_steps=50,
image_guidance_scale=1.5,
guidance_scale=7.5,
).images[0]
image.save("edited_image.png")
# display image
```
## Citation
If you find our work useful, please kindly cite
```bib
@misc{zhao2024ultraeditinstructionbasedfinegrainedimage,
title={UltraEdit: Instruction-based Fine-Grained Image Editing at Scale},
author={Haozhe Zhao and Xiaojian Ma and Liang Chen and Shuzheng Si and Rujie Wu and Kaikai An and Peiyu Yu and Minjia Zhang and Qing Li and Baobao Chang},
year={2024},
eprint={2407.05282},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2407.05282},
}
```
[//]: # ()
[//]: # (## License)
[//]: # ()
[//]: # (This project is licensed under the terms of the MIT license. See the [LICENSE](LICENSE.md) file for details.)
[//]: # ()
[//]: # (## Contact)
[//]: # ()
[//]: # (For any questions or issues, please open an issue on GitHub or contact us at support@example.com.)
================================================
FILE: app.py
================================================
# import spaces
import torch
from diffusers import StableDiffusion3InstructPix2PixPipeline, SD3Transformer2DModel
import gradio as gr
import PIL.Image
import numpy as np
from PIL import Image, ImageOps
pipe = StableDiffusion3InstructPix2PixPipeline.from_pretrained("BleachNick/SD3_UltraEdit_w_mask",
torch_dtype=torch.float16)
pipe = pipe.to("cuda")
# @spaces.GPU(duration=120)
def generate(image_mask, prompt, num_inference_steps=50, image_guidance_scale=1.6, guidance_scale=7.5, seed=255):
def is_blank_mask(mask_img):
mask_array = np.array(mask_img.convert('L')) # Convert to luminance to simplify the check
return np.all(mask_array == 0)
seed = int(seed)
generator = torch.manual_seed(seed)
img = image_mask["background"].convert("RGB")
mask_img = image_mask["layers"][0].getchannel('A').convert("RGB")
desired_size = (512, 512)
img = ImageOps.fit(img, desired_size, method=Image.LANCZOS, centering=(0.5, 0.5))
mask_img = ImageOps.fit(mask_img, desired_size, method=Image.LANCZOS, centering=(0.5, 0.5))
if is_blank_mask(mask_img):
mask_img = PIL.Image.new('RGB', img.size, color=(255, 255, 255))
editing_mode = "Free-form"
else:
editing_mode = "Region-based"
mask_img = mask_img.convert('RGB')
image = pipe(
prompt,
image=img,
mask_img=mask_img,
num_inference_steps=num_inference_steps,
image_guidance_scale=image_guidance_scale,
guidance_scale=guidance_scale,
generator=generator
).images[0]
return image, f"Editing Mode: {editing_mode}"
example_lists = [
[['UltraEdit/images/example_images/1-input.png', 'UltraEdit/images/example_images/1-mask.png',
'UltraEdit/images/example_images/1-merged.png'], "Add a moon in the sky", 20, 1.5, 12.5, 255],
[['UltraEdit/images/example_images/1-input.png', 'UltraEdit/images/example_images/1-input.png',
'UltraEdit/images/example_images/1-input.png'], "Add a moon in the sky", 20, 1.5, 6.5, 255],
[['UltraEdit/images/example_images/2-input.png', 'UltraEdit/images/example_images/2-mask.png',
'UltraEdit/images/example_images/2-merged.png'], "add cherry blossoms", 20, 1.5, 12.5, 255],
[['UltraEdit/images/example_images/3-input.png', 'UltraEdit/images/example_images/3-mask.png',
'UltraEdit/images/example_images/3-merged.png'],
"Please dress her in a short purple wedding dress adorned with white floral embroidery.", 20, 1.5, 6.5, 255],
[['UltraEdit/images/example_images/4-input.png', 'UltraEdit/images/example_images/4-mask.png',
'UltraEdit/images/example_images/4-merged.png'], "give her a chief's headdress.", 20, 1.5, 7.5, 24555]
]
mask_ex_list = []
for exp in example_lists:
ex_dict = {}
ex_dict['background'] = exp[0][0]
ex_dict['layers'] = [exp[0][1], exp[0][2]]
ex_dict['composite'] = exp[0][2]
re_list = [ex_dict, exp[1], exp[2], exp[3], exp[4], exp[5]]
mask_ex_list.append(re_list)
image_mask_input = gr.ImageMask(sources='upload', type="pil", label="Input Image: Mask with pen or leave unmasked",
transforms=(), layers=False)
prompt_input = gr.Textbox(label="Prompt")
num_inference_steps_input = gr.Slider(minimum=0, maximum=100, value=50, label="Number of Inference Steps")
image_guidance_scale_input = gr.Slider(minimum=0.0, maximum=2.5, value=1.5, label="Image Guidance Scale")
guidance_scale_input = gr.Slider(minimum=0.0, maximum=17.5, value=12.5, label="Guidance Scale")
seed_input = gr.Textbox(value="255", label="Random Seed")
inputs = [image_mask_input, prompt_input, num_inference_steps_input, image_guidance_scale_input, guidance_scale_input,
seed_input]
outputs = [gr.Image(label="Generated Image"), gr.Text(label="Editing Mode")]
article_html = """
<div style="text-align: center; max-width: 1000px; margin: 20px auto; font-family: Arial, sans-serif;">
<h2 style="font-weight: 900; font-size: 2.5rem; margin-bottom: 0.5rem;">
🖼️ UltraEdit for Fine-Grained Image Editing
</h2>
<div style="margin-bottom: 1rem;">
<h3 style="font-weight: 500; font-size: 1.25rem; margin: 0;"></h3>
<p style="font-weight: 400; font-size: 1rem; margin: 0.5rem 0;">
Haozhe Zhao<sup>1*</sup>, Xiaojian Ma<sup>2*</sup>, Liang Chen<sup>1</sup>, Shuzheng Si<sup>1</sup>, Rujie Wu<sup>1</sup>,
Kaikai An<sup>1</sup>, Peiyu Yu<sup>3</sup>, Minjia Zhang<sup>4</sup>, Qing Li<sup>2</sup>, Baobao Chang<sup>2</sup>
</p>
<p style="font-weight: 400; font-size: 1rem; margin: 0;">
<sup>1</sup>Peking University, <sup>2</sup>BIGAI, <sup>3</sup>UCLA, <sup>4</sup>UIUC
</p>
</div>
<div style="margin: 1rem 0; display: flex; justify-content: center; gap: 1.5rem; flex-wrap: wrap;">
<a href="https://huggingface.co/datasets/BleachNick/UltraEdit" style="display: flex; align-items: center; text-decoration: none; color: blue; font-weight: bold; gap: 0.5rem;">
<img src="https://huggingface.co/front/assets/huggingface_logo-noborder.svg" alt="Dataset_4M" style="height: 20px; vertical-align: middle;"> Dataset
</a>
<a href="https://huggingface.co/datasets/BleachNick/UltraEdit_500k" style="display: flex; align-items: center; text-decoration: none; color: blue; font-weight: bold; gap: 0.5rem;">
<img src="https://huggingface.co/front/assets/huggingface_logo-noborder.svg" alt="Dataset_500k" style="height: 20px; vertical-align: middle;"> Dataset_500k
</a>
<a href="https://ultra-editing.github.io/" style="display: flex; align-items: center; text-decoration: none; color: blue; font-weight: bold; gap: 0.5rem;">
<span style="font-size: 20px; vertical-align: middle;">🔗</span> Page
</a>
<a href="https://huggingface.co/BleachNick/SD3_UltraEdit_w_mask" style="display: flex; align-items: center; text-decoration: none; color: blue; font-weight: bold; gap: 0.5rem;">
<img src="https://huggingface.co/front/assets/huggingface_logo-noborder.svg" alt="Checkpoint" style="height: 20px; vertical-align: middle;"> Checkpoint
</a>
<a href="https://github.com/HaozheZhao/UltraEdit" style="display: flex; align-items: center; text-decoration: none; color: blue; font-weight: bold; gap: 0.5rem;">
<img src="https://upload.wikimedia.org/wikipedia/commons/9/91/Octicons-mark-github.svg" alt="GitHub" style="height: 20px; vertical-align: middle;"> GitHub
</a>
</div>
<div style="text-align: left; margin: 0 auto; font-size: 1rem; line-height: 1.5;">
<p>
<b>UltraEdit</b> is a dataset designed for fine-grained, instruction-based image editing. It contains over 4 million free-form image editing samples and more than 100,000 region-based image editing samples, automatically generated with real images as anchors.
</p>
<p>
This demo allows you to perform image editing using the <a href="https://huggingface.co/stabilityai/stable-diffusion-3-medium-diffusers" style="color: blue; text-decoration: none;">Stable Diffusion 3</a> model trained with this extensive dataset. It supports both free-form (without mask) and region-based (with mask) image editing. Use the sliders to adjust the inference steps and guidance scales, and provide a seed for reproducibility. The image guidance scale of 1.5 and text guidance scale of 7.5 / 12.5 is a good start for free-form/region-based image editing.
</p>
<p>
<b>Usage Instructions:</b> You need to upload the images and prompts for editing. Use the pen tool to mark the areas you want to edit. If no region is marked, it will resort to free-form editing.
</p>
</div>
</div>
"""
html = '''
<div style="text-align: left; margin-top: 2rem; font-size: 0.85rem; color: gray;">
<b>Limitations:</b>
<ul>
<li>We have not conducted any NSFW checks;</li>
<li>Due to the bias of the generated models, the model performance is still weak when dealing with high-frequency information such as <b>human facial expressions or text in the images</b>;</li>
<li>We unified the free-form and region-based image editing by adding an extra channel of the mask image to the dataset. When doing free-form image editing, the network receives a blank mask.</li>
<li>The generation result is sensitive to the guidance scale. For text guidance, based on experience, free-form image editing will perform better with a relatively low guidance score (7.5 or lower), while region-based image editing will perform better with a higher guidance score.</li>
</ul>
</div>
'''
demo = gr.Interface(
fn=generate,
inputs=inputs,
outputs=outputs,
description=article_html,
article=html,
examples=mask_ex_list
)
demo.queue().launch()
================================================
FILE: data_generation/Grounded-Segment-Anything/.gitignore
================================================
# Byte-compiled / optimized / DLL files
__pycache__/
*.py[cod]
*$py.class
# C extensions
*.so
# Distribution / packaging
.Python
build/
develop-eggs/
dist/
downloads/
eggs/
.eggs/
lib/
lib64/
parts/
sdist/
var/
wheels/
pip-wheel-metadata/
share/python-wheels/
*.egg-info/
.installed.cfg
*.egg
MANIFEST
# PyInstaller
# Usually these files are written by a python script from a template
# before PyInstaller builds the exe, so as to inject date/other infos into it.
*.manifest
*.spec
# Installer logs
pip-log.txt
pip-delete-this-directory.txt
# Unit test / coverage reports
htmlcov/
.tox/
.nox/
.coverage
.coverage.*
.cache
nosetests.xml
coverage.xml
*.cover
*.py,cover
.hypothesis/
.pytest_cache/
# Translations
*.mo
*.pot
# Django stuff:
*.log
local_settings.py
db.sqlite3
db.sqlite3-journal
# Flask stuff:
instance/
.webassets-cache
# Scrapy stuff:
.scrapy
# Sphinx documentation
docs/_build/
# PyBuilder
target/
# Jupyter Notebook
.ipynb_checkpoints
# IPython
profile_default/
ipython_config.py
# pyenv
.python-version
# pipenv
# According to pypa/pipenv#598, it is recommended to include Pipfile.lock in version control.
# However, in case of collaboration, if having platform-specific dependencies or dependencies
# having no cross-platform support, pipenv may install dependencies that don't work, or not
# install all needed dependencies.
#Pipfile.lock
# PEP 582; used by e.g. github.com/David-OConnor/pyflow
__pypackages__/
# Celery stuff
celerybeat-schedule
celerybeat.pid
# SageMath parsed files
*.sage.py
# Environments
.env
.venv
env/
venv/
ENV/
env.bak/
venv.bak/
# Spyder project settings
.spyderproject
.spyproject
# Rope project settings
.ropeproject
# mkdocs documentation
/site
# mypy
.mypy_cache/
.dmypy.json
dmypy.json
# Pyre type checker
.pyre/
# checkpoint
*.pth
outputs/
.idea/
================================================
FILE: data_generation/Grounded-Segment-Anything/.gitmodules
================================================
[submodule "grounded-sam-osx"]
path = grounded-sam-osx
url = https://github.com/linjing7/grounded-sam-osx.git
[submodule "VISAM"]
path = VISAM
url = https://github.com/BingfengYan/VISAM
================================================
FILE: data_generation/Grounded-Segment-Anything/CITATION.cff
================================================
cff-version: 1.2.0
message: "If you use this software, please cite it as below."
authors:
- name: "Grounded-SAM Contributors"
title: "Grounded-Segment-Anything"
date-released: 2023-04-06
url: "https://github.com/IDEA-Research/Grounded-Segment-Anything"
license: Apache-2.0
================================================
FILE: data_generation/Grounded-Segment-Anything/Dockerfile
================================================
FROM pytorch/pytorch:1.13.1-cuda11.6-cudnn8-devel
# Arguments to build Docker Image using CUDA
ARG USE_CUDA=0
ARG TORCH_ARCH=
ENV AM_I_DOCKER True
ENV BUILD_WITH_CUDA "${USE_CUDA}"
ENV TORCH_CUDA_ARCH_LIST "${TORCH_ARCH}"
ENV CUDA_HOME /usr/local/cuda-11.6/
RUN mkdir -p /home/appuser/Grounded-Segment-Anything
COPY . /home/appuser/Grounded-Segment-Anything/
RUN apt-get update && apt-get install --no-install-recommends wget ffmpeg=7:* \
libsm6=2:* libxext6=2:* git=1:* nano=2.* \
vim=2:* -y \
&& apt-get clean && apt-get autoremove && rm -rf /var/lib/apt/lists/*
WORKDIR /home/appuser/Grounded-Segment-Anything
RUN python -m pip install --no-cache-dir -e segment_anything
# When using build isolation, PyTorch with newer CUDA is installed and can't compile GroundingDINO
RUN python -m pip install --no-cache-dir wheel
RUN python -m pip install --no-cache-dir --no-build-isolation -e GroundingDINO
WORKDIR /home/appuser
RUN pip install --no-cache-dir diffusers[torch]==0.15.1 opencv-python==4.7.0.72 \
pycocotools==2.0.6 matplotlib==3.5.3 \
onnxruntime==1.14.1 onnx==1.13.1 ipykernel==6.16.2 scipy gradio openai
================================================
FILE: data_generation/Grounded-Segment-Anything/EfficientSAM/EdgeSAM/common.py
================================================
# Copyright (c) Meta Platforms, Inc. and affiliates.
# All rights reserved.
# This source code is licensed under the license found in the
# LICENSE file in the root directory of this source tree.
import torch
import torch.nn as nn
import torch.nn.functional as F
from typing import Type
class MLPBlock(nn.Module):
def __init__(
self,
embedding_dim: int,
mlp_dim: int,
act: Type[nn.Module] = nn.GELU,
) -> None:
super().__init__()
self.lin1 = nn.Linear(embedding_dim, mlp_dim)
self.lin2 = nn.Linear(mlp_dim, embedding_dim)
self.act = act()
def forward(self, x: torch.Tensor) -> torch.Tensor:
return self.lin2(self.act(self.lin1(x)))
# From https://github.com/facebookresearch/detectron2/blob/main/detectron2/layers/batch_norm.py # noqa
# Itself from https://github.com/facebookresearch/ConvNeXt/blob/d1fa8f6fef0a165b27399986cc2bdacc92777e40/models/convnext.py#L119 # noqa
class LayerNorm2d(nn.Module):
def __init__(self, num_channels: int, eps: float = 1e-6) -> None:
super().__init__()
self.weight = nn.Parameter(torch.ones(num_channels))
self.bias = nn.Parameter(torch.zeros(num_channels))
self.eps = eps
def forward(self, x: torch.Tensor) -> torch.Tensor:
u = x.mean(1, keepdim=True)
s = (x - u).pow(2).mean(1, keepdim=True)
x = (x - u) / torch.sqrt(s + self.eps)
x = self.weight[:, None, None] * x + self.bias[:, None, None]
return x
def val2list(x: list or tuple or any, repeat_time=1) -> list:
if isinstance(x, (list, tuple)):
return list(x)
return [x for _ in range(repeat_time)]
def val2tuple(x: list or tuple or any, min_len: int = 1, idx_repeat: int = -1) -> tuple:
x = val2list(x)
# repeat elements if necessary
if len(x) > 0:
x[idx_repeat:idx_repeat] = [x[idx_repeat] for _ in range(min_len - len(x))]
return tuple(x)
def list_sum(x: list) -> any:
return x[0] if len(x) == 1 else x[0] + list_sum(x[1:])
def resize(
x: torch.Tensor,
size: any or None = None,
scale_factor=None,
mode: str = "bicubic",
align_corners: bool or None = False,
) -> torch.Tensor:
if mode in ["bilinear", "bicubic"]:
return F.interpolate(
x,
size=size,
scale_factor=scale_factor,
mode=mode,
align_corners=align_corners,
)
elif mode in ["nearest", "area"]:
return F.interpolate(x, size=size, scale_factor=scale_factor, mode=mode)
else:
raise NotImplementedError(f"resize(mode={mode}) not implemented.")
class UpSampleLayer(nn.Module):
def __init__(
self,
mode="bicubic",
size=None,
factor=2,
align_corners=False,
):
super(UpSampleLayer, self).__init__()
self.mode = mode
self.size = val2list(size, 2) if size is not None else None
self.factor = None if self.size is not None else factor
self.align_corners = align_corners
def forward(self, x: torch.Tensor) -> torch.Tensor:
return resize(x, self.size, self.factor, self.mode, self.align_corners)
class OpSequential(nn.Module):
def __init__(self, op_list):
super(OpSequential, self).__init__()
valid_op_list = []
for op in op_list:
if op is not None:
valid_op_list.append(op)
self.op_list = nn.ModuleList(valid_op_list)
def forward(self, x: torch.Tensor) -> torch.Tensor:
for op in self.op_list:
x = op(x)
return x
================================================
FILE: data_generation/Grounded-Segment-Anything/EfficientSAM/EdgeSAM/rep_vit.py
================================================
import torch.nn as nn
from EdgeSAM.common import LayerNorm2d, UpSampleLayer, OpSequential
__all__ = ['rep_vit_m1', 'rep_vit_m2', 'rep_vit_m3', 'RepViT']
m1_cfgs = [
# k, t, c, SE, HS, s
[3, 2, 48, 1, 0, 1],
[3, 2, 48, 0, 0, 1],
[3, 2, 48, 0, 0, 1],
[3, 2, 96, 0, 0, 2],
[3, 2, 96, 1, 0, 1],
[3, 2, 96, 0, 0, 1],
[3, 2, 96, 0, 0, 1],
[3, 2, 192, 0, 1, 2],
[3, 2, 192, 1, 1, 1],
[3, 2, 192, 0, 1, 1],
[3, 2, 192, 1, 1, 1],
[3, 2, 192, 0, 1, 1],
[3, 2, 192, 1, 1, 1],
[3, 2, 192, 0, 1, 1],
[3, 2, 192, 1, 1, 1],
[3, 2, 192, 0, 1, 1],
[3, 2, 192, 1, 1, 1],
[3, 2, 192, 0, 1, 1],
[3, 2, 192, 1, 1, 1],
[3, 2, 192, 0, 1, 1],
[3, 2, 192, 1, 1, 1],
[3, 2, 192, 0, 1, 1],
[3, 2, 192, 0, 1, 1],
[3, 2, 384, 0, 1, 2],
[3, 2, 384, 1, 1, 1],
[3, 2, 384, 0, 1, 1]
]
m2_cfgs = [
# k, t, c, SE, HS, s
[3, 2, 64, 1, 0, 1],
[3, 2, 64, 0, 0, 1],
[3, 2, 64, 0, 0, 1],
[3, 2, 128, 0, 0, 2],
[3, 2, 128, 1, 0, 1],
[3, 2, 128, 0, 0, 1],
[3, 2, 128, 0, 0, 1],
[3, 2, 256, 0, 1, 2],
[3, 2, 256, 1, 1, 1],
[3, 2, 256, 0, 1, 1],
[3, 2, 256, 1, 1, 1],
[3, 2, 256, 0, 1, 1],
[3, 2, 256, 1, 1, 1],
[3, 2, 256, 0, 1, 1],
[3, 2, 256, 1, 1, 1],
[3, 2, 256, 0, 1, 1],
[3, 2, 256, 1, 1, 1],
[3, 2, 256, 0, 1, 1],
[3, 2, 256, 1, 1, 1],
[3, 2, 256, 0, 1, 1],
[3, 2, 256, 0, 1, 1],
[3, 2, 512, 0, 1, 2],
[3, 2, 512, 1, 1, 1],
[3, 2, 512, 0, 1, 1]
]
m3_cfgs = [
# k, t, c, SE, HS, s
[3, 2, 64, 1, 0, 1],
[3, 2, 64, 0, 0, 1],
[3, 2, 64, 1, 0, 1],
[3, 2, 64, 0, 0, 1],
[3, 2, 64, 0, 0, 1],
[3, 2, 128, 0, 0, 2],
[3, 2, 128, 1, 0, 1],
[3, 2, 128, 0, 0, 1],
[3, 2, 128, 1, 0, 1],
[3, 2, 128, 0, 0, 1],
[3, 2, 128, 0, 0, 1],
[3, 2, 256, 0, 1, 2],
[3, 2, 256, 1, 1, 1],
[3, 2, 256, 0, 1, 1],
[3, 2, 256, 1, 1, 1],
[3, 2, 256, 0, 1, 1],
[3, 2, 256, 1, 1, 1],
[3, 2, 256, 0, 1, 1],
[3, 2, 256, 1, 1, 1],
[3, 2, 256, 0, 1, 1],
[3, 2, 256, 1, 1, 1],
[3, 2, 256, 0, 1, 1],
[3, 2, 256, 1, 1, 1],
[3, 2, 256, 0, 1, 1],
[3, 2, 256, 1, 1, 1],
[3, 2, 256, 0, 1, 1],
[3, 2, 256, 1, 1, 1],
[3, 2, 256, 0, 1, 1],
[3, 2, 256, 1, 1, 1],
[3, 2, 256, 0, 1, 1],
[3, 2, 256, 0, 1, 1],
[3, 2, 512, 0, 1, 2],
[3, 2, 512, 1, 1, 1],
[3, 2, 512, 0, 1, 1]
]
def _make_divisible(v, divisor, min_value=None):
"""
This function is taken from the original tf repo.
It ensures that all layers have a channel number that is divisible by 8
It can be seen here:
https://github.com/tensorflow/models/blob/master/research/slim/nets/mobilenet/mobilenet.py
:param v:
:param divisor:
:param min_value:
:return:
"""
if min_value is None:
min_value = divisor
new_v = max(min_value, int(v + divisor / 2) // divisor * divisor)
# Make sure that round down does not go down by more than 10%.
if new_v < 0.9 * v:
new_v += divisor
return new_v
from timm.models.layers import SqueezeExcite
import torch
class Conv2d_BN(torch.nn.Sequential):
def __init__(self, a, b, ks=1, stride=1, pad=0, dilation=1,
groups=1, bn_weight_init=1, resolution=-10000):
super().__init__()
self.add_module('c', torch.nn.Conv2d(
a, b, ks, stride, pad, dilation, groups, bias=False))
self.add_module('bn', torch.nn.BatchNorm2d(b))
torch.nn.init.constant_(self.bn.weight, bn_weight_init)
torch.nn.init.constant_(self.bn.bias, 0)
@torch.no_grad()
def fuse(self):
c, bn = self._modules.values()
w = bn.weight / (bn.running_var + bn.eps) ** 0.5
w = c.weight * w[:, None, None, None]
b = bn.bias - bn.running_mean * bn.weight / \
(bn.running_var + bn.eps) ** 0.5
m = torch.nn.Conv2d(w.size(1) * self.c.groups, w.size(
0), w.shape[2:], stride=self.c.stride, padding=self.c.padding, dilation=self.c.dilation,
groups=self.c.groups,
device=c.weight.device)
m.weight.data.copy_(w)
m.bias.data.copy_(b)
return m
class Residual(torch.nn.Module):
def __init__(self, m, drop=0.):
super().__init__()
self.m = m
self.drop = drop
def forward(self, x):
if self.training and self.drop > 0:
return x + self.m(x) * torch.rand(x.size(0), 1, 1, 1,
device=x.device).ge_(self.drop).div(1 - self.drop).detach()
else:
return x + self.m(x)
@torch.no_grad()
def fuse(self):
if isinstance(self.m, Conv2d_BN):
m = self.m.fuse()
assert (m.groups == m.in_channels)
identity = torch.ones(m.weight.shape[0], m.weight.shape[1], 1, 1)
identity = torch.nn.functional.pad(identity, [1, 1, 1, 1])
m.weight += identity.to(m.weight.device)
return m
elif isinstance(self.m, torch.nn.Conv2d):
m = self.m
assert (m.groups != m.in_channels)
identity = torch.ones(m.weight.shape[0], m.weight.shape[1], 1, 1)
identity = torch.nn.functional.pad(identity, [1, 1, 1, 1])
m.weight += identity.to(m.weight.device)
return m
else:
return self
class RepVGGDW(torch.nn.Module):
def __init__(self, ed) -> None:
super().__init__()
self.conv = Conv2d_BN(ed, ed, 3, 1, 1, groups=ed)
self.conv1 = Conv2d_BN(ed, ed, 1, 1, 0, groups=ed)
self.dim = ed
def forward(self, x):
return self.conv(x) + self.conv1(x) + x
@torch.no_grad()
def fuse(self):
conv = self.conv.fuse()
conv1 = self.conv1.fuse()
conv_w = conv.weight
conv_b = conv.bias
conv1_w = conv1.weight
conv1_b = conv1.bias
conv1_w = torch.nn.functional.pad(conv1_w, [1, 1, 1, 1])
identity = torch.nn.functional.pad(torch.ones(conv1_w.shape[0], conv1_w.shape[1], 1, 1, device=conv1_w.device),
[1, 1, 1, 1])
final_conv_w = conv_w + conv1_w + identity
final_conv_b = conv_b + conv1_b
conv.weight.data.copy_(final_conv_w)
conv.bias.data.copy_(final_conv_b)
return conv
class RepViTBlock(nn.Module):
def __init__(self, inp, hidden_dim, oup, kernel_size, stride, use_se, use_hs, skip_downsample=False):
super(RepViTBlock, self).__init__()
assert stride in [1, 2]
self.identity = stride == 1 and inp == oup
assert (hidden_dim == 2 * inp)
if stride == 2:
if skip_downsample:
stride = 1
self.token_mixer = nn.Sequential(
Conv2d_BN(inp, inp, kernel_size, stride, (kernel_size - 1) // 2, groups=inp),
SqueezeExcite(inp, 0.25) if use_se else nn.Identity(),
Conv2d_BN(inp, oup, ks=1, stride=1, pad=0)
)
self.channel_mixer = Residual(nn.Sequential(
# pw
Conv2d_BN(oup, 2 * oup, 1, 1, 0),
nn.GELU() if use_hs else nn.GELU(),
# pw-linear
Conv2d_BN(2 * oup, oup, 1, 1, 0, bn_weight_init=0),
))
else:
assert (self.identity)
self.token_mixer = nn.Sequential(
RepVGGDW(inp),
SqueezeExcite(inp, 0.25) if use_se else nn.Identity(),
)
self.channel_mixer = Residual(nn.Sequential(
# pw
Conv2d_BN(inp, hidden_dim, 1, 1, 0),
nn.GELU() if use_hs else nn.GELU(),
# pw-linear
Conv2d_BN(hidden_dim, oup, 1, 1, 0, bn_weight_init=0),
))
def forward(self, x):
return self.channel_mixer(self.token_mixer(x))
from timm.models.vision_transformer import trunc_normal_
class BN_Linear(torch.nn.Sequential):
def __init__(self, a, b, bias=True, std=0.02):
super().__init__()
self.add_module('bn', torch.nn.BatchNorm1d(a))
self.add_module('l', torch.nn.Linear(a, b, bias=bias))
trunc_normal_(self.l.weight, std=std)
if bias:
torch.nn.init.constant_(self.l.bias, 0)
@torch.no_grad()
def fuse(self):
bn, l = self._modules.values()
w = bn.weight / (bn.running_var + bn.eps) ** 0.5
b = bn.bias - self.bn.running_mean * \
self.bn.weight / (bn.running_var + bn.eps) ** 0.5
w = l.weight * w[None, :]
if l.bias is None:
b = b @ self.l.weight.T
else:
b = (l.weight @ b[:, None]).view(-1) + self.l.bias
m = torch.nn.Linear(w.size(1), w.size(0), device=l.weight.device)
m.weight.data.copy_(w)
m.bias.data.copy_(b)
return m
class RepViT(nn.Module):
arch_settings = {
'm1': m1_cfgs,
'm2': m2_cfgs,
'm3': m3_cfgs
}
def __init__(self, arch, img_size=1024, upsample_mode='bicubic'):
super(RepViT, self).__init__()
# setting of inverted residual blocks
self.cfgs = self.arch_settings[arch]
self.img_size = img_size
# building first layer
input_channel = self.cfgs[0][2]
patch_embed = torch.nn.Sequential(Conv2d_BN(3, input_channel // 2, 3, 2, 1), torch.nn.GELU(),
Conv2d_BN(input_channel // 2, input_channel, 3, 2, 1))
layers = [patch_embed]
# building inverted residual blocks
block = RepViTBlock
self.stage_idx = []
prev_c = input_channel
for idx, (k, t, c, use_se, use_hs, s) in enumerate(self.cfgs):
output_channel = _make_divisible(c, 8)
exp_size = _make_divisible(input_channel * t, 8)
skip_downsample = False
if c != prev_c:
self.stage_idx.append(idx - 1)
prev_c = c
layers.append(block(input_channel, exp_size, output_channel, k, s, use_se, use_hs, skip_downsample))
input_channel = output_channel
self.stage_idx.append(idx)
self.features = nn.ModuleList(layers)
stage2_channels = _make_divisible(self.cfgs[self.stage_idx[2]][2], 8)
stage3_channels = _make_divisible(self.cfgs[self.stage_idx[3]][2], 8)
self.fuse_stage2 = nn.Conv2d(stage2_channels, 256, kernel_size=1, bias=False)
self.fuse_stage3 = OpSequential([
nn.Conv2d(stage3_channels, 256, kernel_size=1, bias=False),
UpSampleLayer(factor=2, mode=upsample_mode),
])
self.neck = nn.Sequential(
nn.Conv2d(256, 256, kernel_size=1, bias=False),
LayerNorm2d(256),
nn.Conv2d(256, 256, kernel_size=3, padding=1, bias=False),
LayerNorm2d(256),
)
def forward(self, x):
counter = 0
output_dict = dict()
# patch_embed
x = self.features[0](x)
output_dict['stem'] = x
# stages
for idx, f in enumerate(self.features[1:]):
x = f(x)
if idx in self.stage_idx:
output_dict[f'stage{counter}'] = x
counter += 1
x = self.fuse_stage2(output_dict['stage2']) + self.fuse_stage3(output_dict['stage3'])
x = self.neck(x)
# hack this place because we modified the predictor of SAM for HQ-SAM in
# segment_anything/segment_anything/predictor.py line 91 to return intern features of the backbone
# self.features, self.interm_features = self.model.image_encoder(input_image)
return x, None
def rep_vit_m1(img_size=1024, **kwargs):
return RepViT('m1', img_size, **kwargs)
def rep_vit_m2(img_size=1024, **kwargs):
return RepViT('m2', img_size, **kwargs)
def rep_vit_m3(img_size=1024, **kwargs):
return RepViT('m3', img_size, **kwargs)
================================================
FILE: data_generation/Grounded-Segment-Anything/EfficientSAM/EdgeSAM/setup_edge_sam.py
================================================
# Copyright (c) Meta Platforms, Inc. and affiliates.
# All rights reserved.
# This source code is licensed under the license found in the
# LICENSE file in the root directory of this source tree.
import torch
from functools import partial
from segment_anything.modeling import ImageEncoderViT, MaskDecoder, PromptEncoder, Sam, TwoWayTransformer
from EdgeSAM.rep_vit import RepViT
prompt_embed_dim = 256
image_size = 1024
vit_patch_size = 16
image_embedding_size = image_size // vit_patch_size
def build_edge_sam(checkpoint=None, upsample_mode="bicubic"):
image_encoder = RepViT(
arch="m1",
img_size=image_size,
upsample_mode=upsample_mode
)
return _build_sam(image_encoder, checkpoint)
sam_model_registry = {
"default": build_edge_sam,
"edge_sam": build_edge_sam,
}
def _build_sam_encoder(
encoder_embed_dim,
encoder_depth,
encoder_num_heads,
encoder_global_attn_indexes,
):
image_encoder = ImageEncoderViT(
depth=encoder_depth,
embed_dim=encoder_embed_dim,
img_size=image_size,
mlp_ratio=4,
norm_layer=partial(torch.nn.LayerNorm, eps=1e-6),
num_heads=encoder_num_heads,
patch_size=vit_patch_size,
qkv_bias=True,
use_rel_pos=True,
global_attn_indexes=encoder_global_attn_indexes,
window_size=14,
out_chans=prompt_embed_dim,
)
return image_encoder
def _build_sam(
image_encoder,
checkpoint=None,
):
sam = Sam(
image_encoder=image_encoder,
prompt_encoder=PromptEncoder(
embed_dim=prompt_embed_dim,
image_embedding_size=(image_embedding_size, image_embedding_size),
input_image_size=(image_size, image_size),
mask_in_chans=16,
),
mask_decoder=MaskDecoder(
num_multimask_outputs=3,
transformer=TwoWayTransformer(
depth=2,
embedding_dim=prompt_embed_dim,
mlp_dim=2048,
num_heads=8,
),
transformer_dim=prompt_embed_dim,
iou_head_depth=3,
iou_head_hidden_dim=256,
),
pixel_mean=[123.675, 116.28, 103.53],
pixel_std=[58.395, 57.12, 57.375],
)
sam.eval()
if checkpoint is not None:
with open(checkpoint, "rb") as f:
state_dict = torch.load(f, map_location="cpu")
sam.load_state_dict(state_dict)
return sam
================================================
FILE: data_generation/Grounded-Segment-Anything/EfficientSAM/FastSAM/tools.py
================================================
import numpy as np
from PIL import Image
import matplotlib.pyplot as plt
import cv2
import torch
import os
import clip
def convert_box_xywh_to_xyxy(box):
x1 = box[0]
y1 = box[1]
x2 = box[0] + box[2]
y2 = box[1] + box[3]
return [x1, y1, x2, y2]
def segment_image(image, bbox):
image_array = np.array(image)
segmented_image_array = np.zeros_like(image_array)
x1, y1, x2, y2 = bbox
segmented_image_array[y1:y2, x1:x2] = image_array[y1:y2, x1:x2]
segmented_image = Image.fromarray(segmented_image_array)
black_image = Image.new("RGB", image.size, (255, 255, 255))
# transparency_mask = np.zeros_like((), dtype=np.uint8)
transparency_mask = np.zeros(
(image_array.shape[0], image_array.shape[1]), dtype=np.uint8
)
transparency_mask[y1:y2, x1:x2] = 255
transparency_mask_image = Image.fromarray(transparency_mask, mode="L")
black_image.paste(segmented_image, mask=transparency_mask_image)
return black_image
def format_results(result, filter=0):
annotations = []
n = len(result.masks.data)
for i in range(n):
annotation = {}
mask = result.masks.data[i] == 1.0
if torch.sum(mask) < filter:
continue
annotation["id"] = i
annotation["segmentation"] = mask.cpu().numpy()
annotation["bbox"] = result.boxes.data[i]
annotation["score"] = result.boxes.conf[i]
annotation["area"] = annotation["segmentation"].sum()
annotations.append(annotation)
return annotations
def filter_masks(annotations): # filte the overlap mask
annotations.sort(key=lambda x: x["area"], reverse=True)
to_remove = set()
for i in range(0, len(annotations)):
a = annotations[i]
for j in range(i + 1, len(annotations)):
b = annotations[j]
if i != j and j not in to_remove:
# check if
if b["area"] < a["area"]:
if (a["segmentation"] & b["segmentation"]).sum() / b[
"segmentation"
].sum() > 0.8:
to_remove.add(j)
return [a for i, a in enumerate(annotations) if i not in to_remove], to_remove
def get_bbox_from_mask(mask):
mask = mask.astype(np.uint8)
contours, hierarchy = cv2.findContours(
mask, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE
)
x1, y1, w, h = cv2.boundingRect(contours[0])
x2, y2 = x1 + w, y1 + h
if len(contours) > 1:
for b in contours:
x_t, y_t, w_t, h_t = cv2.boundingRect(b)
# 将多个bbox合并成一个
x1 = min(x1, x_t)
y1 = min(y1, y_t)
x2 = max(x2, x_t + w_t)
y2 = max(y2, y_t + h_t)
h = y2 - y1
w = x2 - x1
return [x1, y1, x2, y2]
def fast_process(
annotations, args, mask_random_color, bbox=None, points=None, edges=False
):
if isinstance(annotations[0], dict):
annotations = [annotation["segmentation"] for annotation in annotations]
result_name = os.path.basename(args.img_path)
image = cv2.imread(args.img_path)
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
original_h = image.shape[0]
original_w = image.shape[1]
plt.figure(figsize=(original_w/100, original_h/100))
plt.imshow(image)
if args.better_quality == True:
if isinstance(annotations[0], torch.Tensor):
annotations = np.array(annotations.cpu())
for i, mask in enumerate(annotations):
mask = cv2.morphologyEx(
mask.astype(np.uint8), cv2.MORPH_CLOSE, np.ones((3, 3), np.uint8)
)
annotations[i] = cv2.morphologyEx(
mask.astype(np.uint8), cv2.MORPH_OPEN, np.ones((8, 8), np.uint8)
)
if args.device == "cpu":
annotations = np.array(annotations)
fast_show_mask(
annotations,
plt.gca(),
random_color=mask_random_color,
bbox=bbox,
points=points,
pointlabel=args.point_label,
retinamask=args.retina,
target_height=original_h,
target_width=original_w,
)
else:
if isinstance(annotations[0], np.ndarray):
annotations = torch.from_numpy(annotations)
fast_show_mask_gpu(
annotations,
plt.gca(),
random_color=args.randomcolor,
bbox=bbox,
points=points,
pointlabel=args.point_label,
retinamask=args.retina,
target_height=original_h,
target_width=original_w,
)
if isinstance(annotations, torch.Tensor):
annotations = annotations.cpu().numpy()
if args.withContours == True:
contour_all = []
temp = np.zeros((original_h, original_w, 1))
for i, mask in enumerate(annotations):
if type(mask) == dict:
mask = mask["segmentation"]
annotation = mask.astype(np.uint8)
if args.retina == False:
annotation = cv2.resize(
annotation,
(original_w, original_h),
interpolation=cv2.INTER_NEAREST,
)
contours, hierarchy = cv2.findContours(
annotation, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE
)
for contour in contours:
contour_all.append(contour)
cv2.drawContours(temp, contour_all, -1, (255, 255, 255), 2)
color = np.array([0 / 255, 0 / 255, 255 / 255, 0.8])
contour_mask = temp / 255 * color.reshape(1, 1, -1)
plt.imshow(contour_mask)
save_path = args.output
if not os.path.exists(save_path):
os.makedirs(save_path)
plt.axis("off")
fig = plt.gcf()
plt.draw()
buf = fig.canvas.tostring_rgb()
cols, rows = fig.canvas.get_width_height()
img_array = np.fromstring(buf, dtype=np.uint8).reshape(rows, cols, 3)
return img_array
# cv2.imwrite(os.path.join(save_path, result_name), cv2.cvtColor(img_array, cv2.COLOR_RGB2BGR))
# CPU post process
def fast_show_mask(
annotation,
ax,
random_color=False,
bbox=None,
points=None,
pointlabel=None,
retinamask=True,
target_height=960,
target_width=960,
):
msak_sum = annotation.shape[0]
height = annotation.shape[1]
weight = annotation.shape[2]
# 将annotation 按照面积 排序
areas = np.sum(annotation, axis=(1, 2))
sorted_indices = np.argsort(areas)
annotation = annotation[sorted_indices]
index = (annotation != 0).argmax(axis=0)
if random_color == True:
color = np.random.random((msak_sum, 1, 1, 3))
else:
color = np.ones((msak_sum, 1, 1, 3)) * np.array(
[30 / 255, 144 / 255, 255 / 255]
)
transparency = np.ones((msak_sum, 1, 1, 1)) * 0.6
visual = np.concatenate([color, transparency], axis=-1)
mask_image = np.expand_dims(annotation, -1) * visual
show = np.zeros((height, weight, 4))
h_indices, w_indices = np.meshgrid(
np.arange(height), np.arange(weight), indexing="ij"
)
indices = (index[h_indices, w_indices], h_indices, w_indices, slice(None))
# 使用向量化索引更新show的值
show[h_indices, w_indices, :] = mask_image[indices]
if bbox is not None:
x1, y1, x2, y2 = bbox
ax.add_patch(
plt.Rectangle(
(x1, y1), x2 - x1, y2 - y1, fill=False, edgecolor="b", linewidth=1
)
)
# draw point
if points is not None:
plt.scatter(
[point[0] for i, point in enumerate(points) if pointlabel[i] == 1],
[point[1] for i, point in enumerate(points) if pointlabel[i] == 1],
s=20,
c="y",
)
plt.scatter(
[point[0] for i, point in enumerate(points) if pointlabel[i] == 0],
[point[1] for i, point in enumerate(points) if pointlabel[i] == 0],
s=20,
c="m",
)
if retinamask == False:
show = cv2.resize(
show, (target_width, target_height), interpolation=cv2.INTER_NEAREST
)
ax.imshow(show)
def fast_show_mask_gpu(
annotation,
ax,
random_color=False,
bbox=None,
points=None,
pointlabel=None,
retinamask=True,
target_height=960,
target_width=960,
):
msak_sum = annotation.shape[0]
height = annotation.shape[1]
weight = annotation.shape[2]
areas = torch.sum(annotation, dim=(1, 2))
sorted_indices = torch.argsort(areas, descending=False)
annotation = annotation[sorted_indices]
# 找每个位置第一个非零值下标
index = (annotation != 0).to(torch.long).argmax(dim=0)
if random_color == True:
color = torch.rand((msak_sum, 1, 1, 3)).to(annotation.device)
else:
color = torch.ones((msak_sum, 1, 1, 3)).to(annotation.device) * torch.tensor(
[30 / 255, 144 / 255, 255 / 255]
).to(annotation.device)
transparency = torch.ones((msak_sum, 1, 1, 1)).to(annotation.device) * 0.6
visual = torch.cat([color, transparency], dim=-1)
mask_image = torch.unsqueeze(annotation, -1) * visual
# 按index取数,index指每个位置选哪个batch的数,把mask_image转成一个batch的形式
show = torch.zeros((height, weight, 4)).to(annotation.device)
h_indices, w_indices = torch.meshgrid(
torch.arange(height), torch.arange(weight), indexing="ij"
)
indices = (index[h_indices, w_indices], h_indices, w_indices, slice(None))
# 使用向量化索引更新show的值
show[h_indices, w_indices, :] = mask_image[indices]
show_cpu = show.cpu().numpy()
if bbox is not None:
x1, y1, x2, y2 = bbox
ax.add_patch(
plt.Rectangle(
(x1, y1), x2 - x1, y2 - y1, fill=False, edgecolor="b", linewidth=1
)
)
# draw point
if points is not None:
plt.scatter(
[point[0] for i, point in enumerate(points) if pointlabel[i] == 1],
[point[1] for i, point in enumerate(points) if pointlabel[i] == 1],
s=20,
c="y",
)
plt.scatter(
[point[0] for i, point in enumerate(points) if pointlabel[i] == 0],
[point[1] for i, point in enumerate(points) if pointlabel[i] == 0],
s=20,
c="m",
)
if retinamask == False:
show_cpu = cv2.resize(
show_cpu, (target_width, target_height), interpolation=cv2.INTER_NEAREST
)
ax.imshow(show_cpu)
# clip
@torch.no_grad()
def retriev(
model, preprocess, elements, search_text: str, device
) -> int:
preprocessed_images = [preprocess(image).to(device) for image in elements]
tokenized_text = clip.tokenize([search_text]).to(device)
stacked_images = torch.stack(preprocessed_images)
image_features = model.encode_image(stacked_images)
text_features = model.encode_text(tokenized_text)
image_features /= image_features.norm(dim=-1, keepdim=True)
text_features /= text_features.norm(dim=-1, keepdim=True)
probs = 100.0 * image_features @ text_features.T
return probs[:, 0].softmax(dim=0)
def crop_image(annotations, image_path):
image = Image.open(image_path)
ori_w, ori_h = image.size
mask_h, mask_w = annotations[0]["segmentation"].shape
if ori_w != mask_w or ori_h != mask_h:
image = image.resize((mask_w, mask_h))
cropped_boxes = []
cropped_images = []
not_crop = []
filter_id = []
# annotations, _ = filter_masks(annotations)
# filter_id = list(_)
for _, mask in enumerate(annotations):
if np.sum(mask["segmentation"]) <= 100:
filter_id.append(_)
continue
bbox = get_bbox_from_mask(mask["segmentation"]) # mask 的 bbox
cropped_boxes.append(segment_image(image, bbox)) # 保存裁剪的图片
# cropped_boxes.append(segment_image(image,mask["segmentation"]))
cropped_images.append(bbox) # 保存裁剪的图片的bbox
return cropped_boxes, cropped_images, not_crop, filter_id, annotations
def box_prompt(masks, bbox, target_height, target_width):
h = masks.shape[1]
w = masks.shape[2]
if h != target_height or w != target_width:
bbox = [
int(bbox[0] * w / target_width),
int(bbox[1] * h / target_height),
int(bbox[2] * w / target_width),
int(bbox[3] * h / target_height),
]
bbox[0] = round(bbox[0]) if round(bbox[0]) > 0 else 0
bbox[1] = round(bbox[1]) if round(bbox[1]) > 0 else 0
bbox[2] = round(bbox[2]) if round(bbox[2]) < w else w
bbox[3] = round(bbox[3]) if round(bbox[3]) < h else h
# IoUs = torch.zeros(len(masks), dtype=torch.float32)
bbox_area = (bbox[3] - bbox[1]) * (bbox[2] - bbox[0])
masks_area = torch.sum(masks[:, bbox[1] : bbox[3], bbox[0] : bbox[2]], dim=(1, 2))
orig_masks_area = torch.sum(masks, dim=(1, 2))
union = bbox_area + orig_masks_area - masks_area
IoUs = masks_area / union
max_iou_index = torch.argmax(IoUs)
return masks[max_iou_index].cpu().numpy(), max_iou_index
def point_prompt(masks, points, pointlabel, target_height, target_width): # numpy 处理
h = masks[0]["segmentation"].shape[0]
w = masks[0]["segmentation"].shape[1]
if h != target_height or w != target_width:
points = [
[int(point[0] * w / target_width), int(point[1] * h / target_height)]
for point in points
]
onemask = np.zeros((h, w))
for i, annotation in enumerate(masks):
if type(annotation) == dict:
mask = annotation["segmentation"]
else:
mask = annotation
for i, point in enumerate(points):
if mask[point[1], point[0]] == 1 and pointlabel[i] == 1:
onemask += mask
if mask[point[1], point[0]] == 1 and pointlabel[i] == 0:
onemask -= mask
onemask = onemask >= 1
return onemask, 0
def text_prompt(annotations, args):
cropped_boxes, cropped_images, not_crop, filter_id, annotaions = crop_image(
annotations, args.img_path
)
clip_model, preprocess = clip.load("ViT-B/32", device=args.device)
scores = retriev(
clip_model, preprocess, cropped_boxes, args.text_prompt, device=args.device
)
max_idx = scores.argsort()
max_idx = max_idx[-1]
max_idx += sum(np.array(filter_id) <= int(max_idx))
return annotaions[max_idx]["segmentation"], max_idx
================================================
FILE: data_generation/Grounded-Segment-Anything/EfficientSAM/LightHQSAM/setup_light_hqsam.py
================================================
from LightHQSAM.tiny_vit_sam import TinyViT
from segment_anything.modeling import MaskDecoderHQ, PromptEncoder, Sam, TwoWayTransformer
def setup_model():
prompt_embed_dim = 256
image_size = 1024
vit_patch_size = 16
image_embedding_size = image_size // vit_patch_size
mobile_sam = Sam(
image_encoder=TinyViT(img_size=1024, in_chans=3, num_classes=1000,
embed_dims=[64, 128, 160, 320],
depths=[2, 2, 6, 2],
num_heads=[2, 4, 5, 10],
window_sizes=[7, 7, 14, 7],
mlp_ratio=4.,
drop_rate=0.,
drop_path_rate=0.0,
use_checkpoint=False,
mbconv_expand_ratio=4.0,
local_conv_size=3,
layer_lr_decay=0.8
),
prompt_encoder=PromptEncoder(
embed_dim=prompt_embed_dim,
image_embedding_size=(image_embedding_size, image_embedding_size),
input_image_size=(image_size, image_size),
mask_in_chans=16,
),
mask_decoder=MaskDecoderHQ(
num_multimask_outputs=3,
transformer=TwoWayTransformer(
depth=2,
embedding_dim=prompt_embed_dim,
mlp_dim=2048,
num_heads=8,
),
transformer_dim=prompt_embed_dim,
iou_head_depth=3,
iou_head_hidden_dim=256,
vit_dim=160,
),
pixel_mean=[123.675, 116.28, 103.53],
pixel_std=[58.395, 57.12, 57.375],
)
return mobile_sam
================================================
FILE: data_generation/Grounded-Segment-Anything/EfficientSAM/LightHQSAM/tiny_vit_sam.py
================================================
# --------------------------------------------------------
# TinyViT Model Architecture
# Copyright (c) 2022 Microsoft
# Adapted from LeViT and Swin Transformer
# LeViT: (https://github.com/facebookresearch/levit)
# Swin: (https://github.com/microsoft/swin-transformer)
# Build the TinyViT Model
# --------------------------------------------------------
import itertools
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.utils.checkpoint as checkpoint
from timm.models.layers import DropPath as TimmDropPath,\
to_2tuple, trunc_normal_
from timm.models.registry import register_model
from typing import Tuple
class Conv2d_BN(torch.nn.Sequential):
def __init__(self, a, b, ks=1, stride=1, pad=0, dilation=1,
groups=1, bn_weight_init=1):
super().__init__()
self.add_module('c', torch.nn.Conv2d(
a, b, ks, stride, pad, dilation, groups, bias=False))
bn = torch.nn.BatchNorm2d(b)
torch.nn.init.constant_(bn.weight, bn_weight_init)
torch.nn.init.constant_(bn.bias, 0)
self.add_module('bn', bn)
@torch.no_grad()
def fuse(self):
c, bn = self._modules.values()
w = bn.weight / (bn.running_var + bn.eps)**0.5
w = c.weight * w[:, None, None, None]
b = bn.bias - bn.running_mean * bn.weight / \
(bn.running_var + bn.eps)**0.5
m = torch.nn.Conv2d(w.size(1) * self.c.groups, w.size(
0), w.shape[2:], stride=self.c.stride, padding=self.c.padding, dilation=self.c.dilation, groups=self.c.groups)
m.weight.data.copy_(w)
m.bias.data.copy_(b)
return m
class DropPath(TimmDropPath):
def __init__(self, drop_prob=None):
super().__init__(drop_prob=drop_prob)
self.drop_prob = drop_prob
def __repr__(self):
msg = super().__repr__()
msg += f'(drop_prob={self.drop_prob})'
return msg
class PatchEmbed(nn.Module):
def __init__(self, in_chans, embed_dim, resolution, activation):
super().__init__()
img_size: Tuple[int, int] = to_2tuple(resolution)
self.patches_resolution = (img_size[0] // 4, img_size[1] // 4)
self.num_patches = self.patches_resolution[0] * \
self.patches_resolution[1]
self.in_chans = in_chans
self.embed_dim = embed_dim
n = embed_dim
self.seq = nn.Sequential(
Conv2d_BN(in_chans, n // 2, 3, 2, 1),
activation(),
Conv2d_BN(n // 2, n, 3, 2, 1),
)
def forward(self, x):
return self.seq(x)
class MBConv(nn.Module):
def __init__(self, in_chans, out_chans, expand_ratio,
activation, drop_path):
super().__init__()
self.in_chans = in_chans
self.hidden_chans = int(in_chans * expand_ratio)
self.out_chans = out_chans
self.conv1 = Conv2d_BN(in_chans, self.hidden_chans, ks=1)
self.act1 = activation()
self.conv2 = Conv2d_BN(self.hidden_chans, self.hidden_chans,
ks=3, stride=1, pad=1, groups=self.hidden_chans)
self.act2 = activation()
self.conv3 = Conv2d_BN(
self.hidden_chans, out_chans, ks=1, bn_weight_init=0.0)
self.act3 = activation()
self.drop_path = DropPath(
drop_path) if drop_path > 0. else nn.Identity()
def forward(self, x):
shortcut = x
x = self.conv1(x)
x = self.act1(x)
x = self.conv2(x)
x = self.act2(x)
x = self.conv3(x)
x = self.drop_path(x)
x += shortcut
x = self.act3(x)
return x
class PatchMerging(nn.Module):
def __init__(self, input_resolution, dim, out_dim, activation):
super().__init__()
self.input_resolution = input_resolution
self.dim = dim
self.out_dim = out_dim
self.act = activation()
self.conv1 = Conv2d_BN(dim, out_dim, 1, 1, 0)
stride_c=2
if(out_dim==320 or out_dim==448 or out_dim==576):
stride_c=1
self.conv2 = Conv2d_BN(out_dim, out_dim, 3, stride_c, 1, groups=out_dim)
self.conv3 = Conv2d_BN(out_dim, out_dim, 1, 1, 0)
def forward(self, x):
if x.ndim == 3:
H, W = self.input_resolution
B = len(x)
# (B, C, H, W)
x = x.view(B, H, W, -1).permute(0, 3, 1, 2)
x = self.conv1(x)
x = self.act(x)
x = self.conv2(x)
x = self.act(x)
x = self.conv3(x)
x = x.flatten(2).transpose(1, 2)
return x
class ConvLayer(nn.Module):
def __init__(self, dim, input_resolution, depth,
activation,
drop_path=0., downsample=None, use_checkpoint=False,
out_dim=None,
conv_expand_ratio=4.,
):
super().__init__()
self.dim = dim
self.input_resolution = input_resolution
self.depth = depth
self.use_checkpoint = use_checkpoint
# build blocks
self.blocks = nn.ModuleList([
MBConv(dim, dim, conv_expand_ratio, activation,
drop_path[i] if isinstance(drop_path, list) else drop_path,
)
for i in range(depth)])
# patch merging layer
if downsample is not None:
self.downsample = downsample(
input_resolution, dim=dim, out_dim=out_dim, activation=activation)
else:
self.downsample = None
def forward(self, x):
for blk in self.blocks:
if self.use_checkpoint:
x = checkpoint.checkpoint(blk, x)
else:
x = blk(x)
if self.downsample is not None:
x = self.downsample(x)
return x
class Mlp(nn.Module):
def __init__(self, in_features, hidden_features=None,
out_features=None, act_layer=nn.GELU, drop=0.):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.norm = nn.LayerNorm(in_features)
self.fc1 = nn.Linear(in_features, hidden_features)
self.fc2 = nn.Linear(hidden_features, out_features)
self.act = act_layer()
self.drop = nn.Dropout(drop)
def forward(self, x):
x = self.norm(x)
x = self.fc1(x)
x = self.act(x)
x = self.drop(x)
x = self.fc2(x)
x = self.drop(x)
return x
class Attention(torch.nn.Module):
def __init__(self, dim, key_dim, num_heads=8,
attn_ratio=4,
resolution=(14, 14),
):
super().__init__()
# (h, w)
assert isinstance(resolution, tuple) and len(resolution) == 2
self.num_heads = num_heads
self.scale = key_dim ** -0.5
self.key_dim = key_dim
self.nh_kd = nh_kd = key_dim * num_heads
self.d = int(attn_ratio * key_dim)
self.dh = int(attn_ratio * key_dim) * num_heads
self.attn_ratio = attn_ratio
h = self.dh + nh_kd * 2
self.norm = nn.LayerNorm(dim)
self.qkv = nn.Linear(dim, h)
self.proj = nn.Linear(self.dh, dim)
points = list(itertools.product(
range(resolution[0]), range(resolution[1])))
N = len(points)
attention_offsets = {}
idxs = []
for p1 in points:
for p2 in points:
offset = (abs(p1[0] - p2[0]), abs(p1[1] - p2[1]))
if offset not in attention_offsets:
attention_offsets[offset] = len(attention_offsets)
idxs.append(attention_offsets[offset])
self.attention_biases = torch.nn.Parameter(
torch.zeros(num_heads, len(attention_offsets)))
self.register_buffer('attention_bias_idxs',
torch.LongTensor(idxs).view(N, N),
persistent=False)
@torch.no_grad()
def train(self, mode=True):
super().train(mode)
if mode and hasattr(self, 'ab'):
del self.ab
else:
self.register_buffer('ab',
self.attention_biases[:, self.attention_bias_idxs],
persistent=False)
def forward(self, x): # x (B,N,C)
B, N, _ = x.shape
# Normalization
x = self.norm(x)
qkv = self.qkv(x)
# (B, N, num_heads, d)
q, k, v = qkv.view(B, N, self.num_heads, -
1).split([self.key_dim, self.key_dim, self.d], dim=3)
# (B, num_heads, N, d)
q = q.permute(0, 2, 1, 3)
k = k.permute(0, 2, 1, 3)
v = v.permute(0, 2, 1, 3)
attn = (
(q @ k.transpose(-2, -1)) * self.scale
+
(self.attention_biases[:, self.attention_bias_idxs]
if self.training else self.ab)
)
attn = attn.softmax(dim=-1)
x = (attn @ v).transpose(1, 2).reshape(B, N, self.dh)
x = self.proj(x)
return x
class TinyViTBlock(nn.Module):
r""" TinyViT Block.
Args:
dim (int): Number of input channels.
input_resolution (tuple[int, int]): Input resolution.
num_heads (int): Number of attention heads.
window_size (int): Window size.
mlp_ratio (float): Ratio of mlp hidden dim to embedding dim.
drop (float, optional): Dropout rate. Default: 0.0
drop_path (float, optional): Stochastic depth rate. Default: 0.0
local_conv_size (int): the kernel size of the convolution between
Attention and MLP. Default: 3
activation: the activation function. Default: nn.GELU
"""
def __init__(self, dim, input_resolution, num_heads, window_size=7,
mlp_ratio=4., drop=0., drop_path=0.,
local_conv_size=3,
activation=nn.GELU,
):
super().__init__()
self.dim = dim
self.input_resolution = input_resolution
self.num_heads = num_heads
assert window_size > 0, 'window_size must be greater than 0'
self.window_size = window_size
self.mlp_ratio = mlp_ratio
self.drop_path = DropPath(
drop_path) if drop_path > 0. else nn.Identity()
assert dim % num_heads == 0, 'dim must be divisible by num_heads'
head_dim = dim // num_heads
window_resolution = (window_size, window_size)
self.attn = Attention(dim, head_dim, num_heads,
attn_ratio=1, resolution=window_resolution)
mlp_hidden_dim = int(dim * mlp_ratio)
mlp_activation = activation
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim,
act_layer=mlp_activation, drop=drop)
pad = local_conv_size // 2
self.local_conv = Conv2d_BN(
dim, dim, ks=local_conv_size, stride=1, pad=pad, groups=dim)
def forward(self, x):
H, W = self.input_resolution
B, L, C = x.shape
assert L == H * W, "input feature has wrong size"
res_x = x
if H == self.window_size and W == self.window_size:
x = self.attn(x)
else:
x = x.view(B, H, W, C)
pad_b = (self.window_size - H %
self.window_size) % self.window_size
pad_r = (self.window_size - W %
self.window_size) % self.window_size
padding = pad_b > 0 or pad_r > 0
if padding:
x = F.pad(x, (0, 0, 0, pad_r, 0, pad_b))
pH, pW = H + pad_b, W + pad_r
nH = pH // self.window_size
nW = pW // self.window_size
# window partition
x = x.view(B, nH, self.window_size, nW, self.window_size, C).transpose(2, 3).reshape(
B * nH * nW, self.window_size * self.window_size, C)
x = self.attn(x)
# window reverse
x = x.view(B, nH, nW, self.window_size, self.window_size,
C).transpose(2, 3).reshape(B, pH, pW, C)
if padding:
x = x[:, :H, :W].contiguous()
x = x.view(B, L, C)
x = res_x + self.drop_path(x)
x = x.transpose(1, 2).reshape(B, C, H, W)
x = self.local_conv(x)
x = x.view(B, C, L).transpose(1, 2)
x = x + self.drop_path(self.mlp(x))
return x
def extra_repr(self) -> str:
return f"dim={self.dim}, input_resolution={self.input_resolution}, num_heads={self.num_heads}, " \
f"window_size={self.window_size}, mlp_ratio={self.mlp_ratio}"
class BasicLayer(nn.Module):
""" A basic TinyViT layer for one stage.
Args:
dim (int): Number of input channels.
input_resolution (tuple[int]): Input resolution.
depth (int): Number of blocks.
num_heads (int): Number of attention heads.
window_size (int): Local window size.
mlp_ratio (float): Ratio of mlp hidden dim to embedding dim.
drop (float, optional): Dropout rate. Default: 0.0
drop_path (float | tuple[float], optional): Stochastic depth rate. Default: 0.0
downsample (nn.Module | None, optional): Downsample layer at the end of the layer. Default: None
use_checkpoint (bool): Whether to use checkpointing to save memory. Default: False.
local_conv_size: the kernel size of the depthwise convolution between attention and MLP. Default: 3
activation: the activation function. Default: nn.GELU
out_dim: the output dimension of the layer. Default: dim
"""
def __init__(self, dim, input_resolution, depth, num_heads, window_size,
mlp_ratio=4., drop=0.,
drop_path=0., downsample=None, use_checkpoint=False,
local_conv_size=3,
activation=nn.GELU,
out_dim=None,
):
super().__init__()
self.dim = dim
self.input_resolution = input_resolution
self.depth = depth
self.use_checkpoint = use_checkpoint
# build blocks
self.blocks = nn.ModuleList([
TinyViTBlock(dim=dim, input_resolution=input_resolution,
num_heads=num_heads, window_size=window_size,
mlp_ratio=mlp_ratio,
drop=drop,
drop_path=drop_path[i] if isinstance(
drop_path, list) else drop_path,
local_conv_size=local_conv_size,
activation=activation,
)
for i in range(depth)])
# patch merging layer
if downsample is not None:
self.downsample = downsample(
input_resolution, dim=dim, out_dim=out_dim, activation=activation)
else:
self.downsample = None
def forward(self, x):
for blk in self.blocks:
if self.use_checkpoint:
x = checkpoint.checkpoint(blk, x)
else:
x = blk(x)
if self.downsample is not None:
x = self.downsample(x)
return x
def extra_repr(self) -> str:
return f"dim={self.dim}, input_resolution={self.input_resolution}, depth={self.depth}"
class LayerNorm2d(nn.Module):
def __init__(self, num_channels: int, eps: float = 1e-6) -> None:
super().__init__()
self.weight = nn.Parameter(torch.ones(num_channels))
self.bias = nn.Parameter(torch.zeros(num_channels))
self.eps = eps
def forward(self, x: torch.Tensor) -> torch.Tensor:
u = x.mean(1, keepdim=True)
s = (x - u).pow(2).mean(1, keepdim=True)
x = (x - u) / torch.sqrt(s + self.eps)
x = self.weight[:, None, None] * x + self.bias[:, None, None]
return x
class TinyViT(nn.Module):
def __init__(self, img_size=224, in_chans=3, num_classes=1000,
embed_dims=[96, 192, 384, 768], depths=[2, 2, 6, 2],
num_heads=[3, 6, 12, 24],
window_sizes=[7, 7, 14, 7],
mlp_ratio=4.,
drop_rate=0.,
drop_path_rate=0.1,
use_checkpoint=False,
mbconv_expand_ratio=4.0,
local_conv_size=3,
layer_lr_decay=1.0,
):
super().__init__()
self.img_size=img_size
self.num_classes = num_classes
self.depths = depths
self.num_layers = len(depths)
self.mlp_ratio = mlp_ratio
activation = nn.GELU
self.patch_embed = PatchEmbed(in_chans=in_chans,
embed_dim=embed_dims[0],
resolution=img_size,
activation=activation)
patches_resolution = self.patch_embed.patches_resolution
self.patches_resolution = patches_resolution
# stochastic depth
dpr = [x.item() for x in torch.linspace(0, drop_path_rate,
sum(depths))] # stochastic depth decay rule
# build layers
self.layers = nn.ModuleList()
for i_layer in range(self.num_layers):
kwargs = dict(dim=embed_dims[i_layer],
input_resolution=(patches_resolution[0] // (2 ** (i_layer-1 if i_layer == 3 else i_layer)),
patches_resolution[1] // (2 ** (i_layer-1 if i_layer == 3 else i_layer))),
# input_resolution=(patches_resolution[0] // (2 ** i_layer),
# patches_resolution[1] // (2 ** i_layer)),
depth=depths[i_layer],
drop_path=dpr[sum(depths[:i_layer]):sum(depths[:i_layer + 1])],
downsample=PatchMerging if (
i_layer < self.num_layers - 1) else None,
use_checkpoint=use_checkpoint,
out_dim=embed_dims[min(
i_layer + 1, len(embed_dims) - 1)],
activation=activation,
)
if i_layer == 0:
layer = ConvLayer(
conv_expand_ratio=mbconv_expand_ratio,
**kwargs,
)
else:
layer = BasicLayer(
num_heads=num_heads[i_layer],
window_size=window_sizes[i_layer],
mlp_ratio=self.mlp_ratio,
drop=drop_rate,
local_conv_size=local_conv_size,
**kwargs)
self.layers.append(layer)
# Classifier head
self.norm_head = nn.LayerNorm(embed_dims[-1])
self.head = nn.Linear(
embed_dims[-1], num_classes) if num_classes > 0 else torch.nn.Identity()
# init weights
self.apply(self._init_weights)
self.set_layer_lr_decay(layer_lr_decay)
self.neck = nn.Sequential(
nn.Conv2d(
embed_dims[-1],
256,
kernel_size=1,
bias=False,
),
LayerNorm2d(256),
nn.Conv2d(
256,
256,
kernel_size=3,
padding=1,
bias=False,
),
LayerNorm2d(256),
)
def set_layer_lr_decay(self, layer_lr_decay):
decay_rate = layer_lr_decay
# layers -> blocks (depth)
depth = sum(self.depths)
lr_scales = [decay_rate ** (depth - i - 1) for i in range(depth)]
#print("LR SCALES:", lr_scales)
def _set_lr_scale(m, scale):
for p in m.parameters():
p.lr_scale = scale
self.patch_embed.apply(lambda x: _set_lr_scale(x, lr_scales[0]))
i = 0
for layer in self.layers:
for block in layer.blocks:
block.apply(lambda x: _set_lr_scale(x, lr_scales[i]))
i += 1
if layer.downsample is not None:
layer.downsample.apply(
lambda x: _set_lr_scale(x, lr_scales[i - 1]))
assert i == depth
for m in [self.norm_head, self.head]:
m.apply(lambda x: _set_lr_scale(x, lr_scales[-1]))
for k, p in self.named_parameters():
p.param_name = k
def _check_lr_scale(m):
for p in m.parameters():
assert hasattr(p, 'lr_scale'), p.param_name
self.apply(_check_lr_scale)
def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
@torch.jit.ignore
def no_weight_decay_keywords(self):
return {'attention_biases'}
def forward_features(self, x):
# x: (N, C, H, W)
x = self.patch_embed(x)
x = self.layers[0](x)
start_i = 1
interm_embeddings=[]
for i in range(start_i, len(self.layers)):
layer = self.layers[i]
x = layer(x)
# print('x shape:', x.shape, '---i:', i)
if i == 1:
interm_embeddings.append(x.view(x.shape[0], 64, 64, -1))
B,_,C=x.size()
x = x.view(B, 64, 64, C)
x=x.permute(0, 3, 1, 2)
x=self.neck(x)
return x, interm_embeddings
def forward(self, x):
x, interm_embeddings = self.forward_features(x)
#x = self.norm_head(x)
#x = self.head(x)
# print('come to here is correct'* 3)
return x, interm_embeddings
_checkpoint_url_format = \
'https://github.com/wkcn/TinyViT-model-zoo/releases/download/checkpoints/{}.pth'
_provided_checkpoints = {
'tiny_vit_5m_224': 'tiny_vit_5m_22kto1k_distill',
'tiny_vit_11m_224': 'tiny_vit_11m_22kto1k_distill',
'tiny_vit_21m_224': 'tiny_vit_21m_22kto1k_distill',
'tiny_vit_21m_384': 'tiny_vit_21m_22kto1k_384_distill',
'tiny_vit_21m_512': 'tiny_vit_21m_22kto1k_512_distill',
}
def register_tiny_vit_model(fn):
'''Register a TinyViT model
It is a wrapper of `register_model` with loading the pretrained checkpoint.
'''
def fn_wrapper(pretrained=False, **kwargs):
model = fn()
if pretrained:
model_name = fn.__name__
assert model_name in _provided_checkpoints, \
f'Sorry that the checkpoint `{model_name}` is not provided yet.'
url = _checkpoint_url_format.format(
_provided_checkpoints[model_name])
checkpoint = torch.hub.load_state_dict_from_url(
url=url,
map_location='cpu', check_hash=False,
)
model.load_state_dict(checkpoint['model'])
return model
# rename the name of fn_wrapper
fn_wrapper.__name__ = fn.__name__
return register_model(fn_wrapper)
@register_tiny_vit_model
def tiny_vit_5m_224(pretrained=False, num_classes=1000, drop_path_rate=0.0):
return TinyViT(
num_classes=num_classes,
embed_dims=[64, 128, 160, 320],
depths=[2, 2, 6, 2],
num_heads=[2, 4, 5, 10],
window_sizes=[7, 7, 14, 7],
drop_path_rate=drop_path_rate,
)
@register_tiny_vit_model
def tiny_vit_11m_224(pretrained=False, num_classes=1000, drop_path_rate=0.1):
return TinyViT(
num_classes=num_classes,
embed_dims=[64, 128, 256, 448],
depths=[2, 2, 6, 2],
num_heads=[2, 4, 8, 14],
window_sizes=[7, 7, 14, 7],
drop_path_rate=drop_path_rate,
)
@register_tiny_vit_model
def tiny_vit_21m_224(pretrained=False, num_classes=1000, drop_path_rate=0.2):
return TinyViT(
num_classes=num_classes,
embed_dims=[96, 192, 384, 576],
depths=[2, 2, 6, 2],
num_heads=[3, 6, 12, 18],
window_sizes=[7, 7, 14, 7],
drop_path_rate=drop_path_rate,
)
@register_tiny_vit_model
def tiny_vit_21m_384(pretrained=False, num_classes=1000, drop_path_rate=0.1):
return TinyViT(
img_size=384,
num_classes=num_classes,
embed_dims=[96, 192, 384, 576],
depths=[2, 2, 6, 2],
num_heads=[3, 6, 12, 18],
window_sizes=[12, 12, 24, 12],
drop_path_rate=drop_path_rate,
)
@register_tiny_vit_model
def tiny_vit_21m_512(pretrained=False, num_classes=1000, drop_path_rate=0.1):
return TinyViT(
img_size=512,
num_classes=num_classes,
embed_dims=[96, 192, 384, 576],
depths=[2, 2, 6, 2],
num_heads=[3, 6, 12, 18],
window_sizes=[16, 16, 32, 16],
drop_path_rate=drop_path_rate,
)
================================================
FILE: data_generation/Grounded-Segment-Anything/EfficientSAM/MobileSAM/setup_mobile_sam.py
================================================
from MobileSAM.tiny_vit_sam import TinyViT
from segment_anything.modeling import MaskDecoder, PromptEncoder, Sam, TwoWayTransformer
def setup_model():
prompt_embed_dim = 256
image_size = 1024
vit_patch_size = 16
image_embedding_size = image_size // vit_patch_size
mobile_sam = Sam(
image_encoder=TinyViT(img_size=1024, in_chans=3, num_classes=1000,
embed_dims=[64, 128, 160, 320],
depths=[2, 2, 6, 2],
num_heads=[2, 4, 5, 10],
window_sizes=[7, 7, 14, 7],
mlp_ratio=4.,
drop_rate=0.,
drop_path_rate=0.0,
use_checkpoint=False,
mbconv_expand_ratio=4.0,
local_conv_size=3,
layer_lr_decay=0.8
),
prompt_encoder=PromptEncoder(
embed_dim=prompt_embed_dim,
image_embedding_size=(image_embedding_size, image_embedding_size),
input_image_size=(image_size, image_size),
mask_in_chans=16,
),
mask_decoder=MaskDecoder(
num_multimask_outputs=3,
transformer=TwoWayTransformer(
depth=2,
embedding_dim=prompt_embed_dim,
mlp_dim=2048,
num_heads=8,
),
transformer_dim=prompt_embed_dim,
iou_head_depth=3,
iou_head_hidden_dim=256,
),
pixel_mean=[123.675, 116.28, 103.53],
pixel_std=[58.395, 57.12, 57.375],
)
return mobile_sam
================================================
FILE: data_generation/Grounded-Segment-Anything/EfficientSAM/MobileSAM/tiny_vit_sam.py
================================================
# --------------------------------------------------------
# TinyViT Model Architecture
# Copyright (c) 2022 Microsoft
# Adapted from LeViT and Swin Transformer
# LeViT: (https://github.com/facebookresearch/levit)
# Swin: (https://github.com/microsoft/swin-transformer)
# Build the TinyViT Model
# --------------------------------------------------------
import itertools
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.utils.checkpoint as checkpoint
from timm.models.layers import DropPath as TimmDropPath,\
to_2tuple, trunc_normal_
from timm.models.registry import register_model
from typing import Tuple
class Conv2d_BN(torch.nn.Sequential):
def __init__(self, a, b, ks=1, stride=1, pad=0, dilation=1,
groups=1, bn_weight_init=1):
super().__init__()
self.add_module('c', torch.nn.Conv2d(
a, b, ks, stride, pad, dilation, groups, bias=False))
bn = torch.nn.BatchNorm2d(b)
torch.nn.init.constant_(bn.weight, bn_weight_init)
torch.nn.init.constant_(bn.bias, 0)
self.add_module('bn', bn)
@torch.no_grad()
def fuse(self):
c, bn = self._modules.values()
w = bn.weight / (bn.running_var + bn.eps)**0.5
w = c.weight * w[:, None, None, None]
b = bn.bias - bn.running_mean * bn.weight / \
(bn.running_var + bn.eps)**0.5
m = torch.nn.Conv2d(w.size(1) * self.c.groups, w.size(
0), w.shape[2:], stride=self.c.stride, padding=self.c.padding, dilation=self.c.dilation, groups=self.c.groups)
m.weight.data.copy_(w)
m.bias.data.copy_(b)
return m
class DropPath(TimmDropPath):
def __init__(self, drop_prob=None):
super().__init__(drop_prob=drop_prob)
self.drop_prob = drop_prob
def __repr__(self):
msg = super().__repr__()
msg += f'(drop_prob={self.drop_prob})'
return msg
class PatchEmbed(nn.Module):
def __init__(self, in_chans, embed_dim, resolution, activation):
super().__init__()
img_size: Tuple[int, int] = to_2tuple(resolution)
self.patches_resolution = (img_size[0] // 4, img_size[1] // 4)
self.num_patches = self.patches_resolution[0] * \
self.patches_resolution[1]
self.in_chans = in_chans
self.embed_dim = embed_dim
n = embed_dim
self.seq = nn.Sequential(
Conv2d_BN(in_chans, n // 2, 3, 2, 1),
activation(),
Conv2d_BN(n // 2, n, 3, 2, 1),
)
def forward(self, x):
return self.seq(x)
class MBConv(nn.Module):
def __init__(self, in_chans, out_chans, expand_ratio,
activation, drop_path):
super().__init__()
self.in_chans = in_chans
self.hidden_chans = int(in_chans * expand_ratio)
self.out_chans = out_chans
self.conv1 = Conv2d_BN(in_chans, self.hidden_chans, ks=1)
self.act1 = activation()
self.conv2 = Conv2d_BN(self.hidden_chans, self.hidden_chans,
ks=3, stride=1, pad=1, groups=self.hidden_chans)
self.act2 = activation()
self.conv3 = Conv2d_BN(
self.hidden_chans, out_chans, ks=1, bn_weight_init=0.0)
self.act3 = activation()
self.drop_path = DropPath(
drop_path) if drop_path > 0. else nn.Identity()
def forward(self, x):
shortcut = x
x = self.conv1(x)
x = self.act1(x)
x = self.conv2(x)
x = self.act2(x)
x = self.conv3(x)
x = self.drop_path(x)
x += shortcut
x = self.act3(x)
return x
class PatchMerging(nn.Module):
def __init__(self, input_resolution, dim, out_dim, activation):
super().__init__()
self.input_resolution = input_resolution
self.dim = dim
self.out_dim = out_dim
self.act = activation()
self.conv1 = Conv2d_BN(dim, out_dim, 1, 1, 0)
stride_c=2
if(out_dim==320 or out_dim==448 or out_dim==576):#handongshen 576
stride_c=1
self.conv2 = Conv2d_BN(out_dim, out_dim, 3, stride_c, 1, groups=out_dim)
self.conv3 = Conv2d_BN(out_dim, out_dim, 1, 1, 0)
def forward(self, x):
if x.ndim == 3:
H, W = self.input_resolution
B = len(x)
# (B, C, H, W)
x = x.view(B, H, W, -1).permute(0, 3, 1, 2)
x = self.conv1(x)
x = self.act(x)
x = self.conv2(x)
x = self.act(x)
x = self.conv3(x)
x = x.flatten(2).transpose(1, 2)
return x
class ConvLayer(nn.Module):
def __init__(self, dim, input_resolution, depth,
activation,
drop_path=0., downsample=None, use_checkpoint=False,
out_dim=None,
conv_expand_ratio=4.,
):
super().__init__()
self.dim = dim
self.input_resolution = input_resolution
self.depth = depth
self.use_checkpoint = use_checkpoint
# build blocks
self.blocks = nn.ModuleList([
MBConv(dim, dim, conv_expand_ratio, activation,
drop_path[i] if isinstance(drop_path, list) else drop_path,
)
for i in range(depth)])
# patch merging layer
if downsample is not None:
self.downsample = downsample(
input_resolution, dim=dim, out_dim=out_dim, activation=activation)
else:
self.downsample = None
def forward(self, x):
for blk in self.blocks:
if self.use_checkpoint:
x = checkpoint.checkpoint(blk, x)
else:
x = blk(x)
if self.downsample is not None:
x = self.downsample(x)
return x
class Mlp(nn.Module):
def __init__(self, in_features, hidden_features=None,
out_features=None, act_layer=nn.GELU, drop=0.):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.norm = nn.LayerNorm(in_features)
self.fc1 = nn.Linear(in_features, hidden_features)
self.fc2 = nn.Linear(hidden_features, out_features)
self.act = act_layer()
self.drop = nn.Dropout(drop)
def forward(self, x):
x = self.norm(x)
x = self.fc1(x)
x = self.act(x)
x = self.drop(x)
x = self.fc2(x)
x = self.drop(x)
return x
class Attention(torch.nn.Module):
def __init__(self, dim, key_dim, num_heads=8,
attn_ratio=4,
resolution=(14, 14),
):
super().__init__()
# (h, w)
assert isinstance(resolution, tuple) and len(resolution) == 2
self.num_heads = num_heads
self.scale = key_dim ** -0.5
self.key_dim = key_dim
self.nh_kd = nh_kd = key_dim * num_heads
self.d = int(attn_ratio * key_dim)
self.dh = int(attn_ratio * key_dim) * num_heads
self.attn_ratio = attn_ratio
h = self.dh + nh_kd * 2
self.norm = nn.LayerNorm(dim)
self.qkv = nn.Linear(dim, h)
self.proj = nn.Linear(self.dh, dim)
points = list(itertools.product(
range(resolution[0]), range(resolution[1])))
N = len(points)
attention_offsets = {}
idxs = []
for p1 in points:
for p2 in points:
offset = (abs(p1[0] - p2[0]), abs(p1[1] - p2[1]))
if offset not in attention_offsets:
attention_offsets[offset] = len(attention_offsets)
idxs.append(attention_offsets[offset])
self.attention_biases = torch.nn.Parameter(
torch.zeros(num_heads, len(attention_offsets)))
self.register_buffer('attention_bias_idxs',
torch.LongTensor(idxs).view(N, N),
persistent=False)
@torch.no_grad()
def train(self, mode=True):
super().train(mode)
if mode and hasattr(self, 'ab'):
del self.ab
else:
self.ab = self.attention_biases[:, self.attention_bias_idxs]
def forward(self, x): # x (B,N,C)
B, N, _ = x.shape
# Normalization
x = self.norm(x)
qkv = self.qkv(x)
# (B, N, num_heads, d)
q, k, v = qkv.view(B, N, self.num_heads, -
1).split([self.key_dim, self.key_dim, self.d], dim=3)
# (B, num_heads, N, d)
q = q.permute(0, 2, 1, 3)
k = k.permute(0, 2, 1, 3)
v = v.permute(0, 2, 1, 3)
attn = (
(q @ k.transpose(-2, -1)) * self.scale
+
(self.attention_biases[:, self.attention_bias_idxs]
if self.training else self.ab)
)
attn = attn.softmax(dim=-1)
x = (attn @ v).transpose(1, 2).reshape(B, N, self.dh)
x = self.proj(x)
return x
class TinyViTBlock(nn.Module):
r""" TinyViT Block.
Args:
dim (int): Number of input channels.
input_resolution (tuple[int, int]): Input resulotion.
num_heads (int): Number of attention heads.
window_size (int): Window size.
mlp_ratio (float): Ratio of mlp hidden dim to embedding dim.
drop (float, optional): Dropout rate. Default: 0.0
drop_path (float, optional): Stochastic depth rate. Default: 0.0
local_conv_size (int): the kernel size of the convolution between
Attention and MLP. Default: 3
activation: the activation function. Default: nn.GELU
"""
def __init__(self, dim, input_resolution, num_heads, window_size=7,
mlp_ratio=4., drop=0., drop_path=0.,
local_conv_size=3,
activation=nn.GELU,
):
super().__init__()
self.dim = dim
self.input_resolution = input_resolution
self.num_heads = num_heads
assert window_size > 0, 'window_size must be greater than 0'
self.window_size = window_size
self.mlp_ratio = mlp_ratio
self.drop_path = DropPath(
drop_path) if drop_path > 0. else nn.Identity()
assert dim % num_heads == 0, 'dim must be divisible by num_heads'
head_dim = dim // num_heads
window_resolution = (window_size, window_size)
self.attn = Attention(dim, head_dim, num_heads,
attn_ratio=1, resolution=window_resolution)
mlp_hidden_dim = int(dim * mlp_ratio)
mlp_activation = activation
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim,
act_layer=mlp_activation, drop=drop)
pad = local_conv_size // 2
self.local_conv = Conv2d_BN(
dim, dim, ks=local_conv_size, stride=1, pad=pad, groups=dim)
def forward(self, x):
H, W = self.input_resolution
B, L, C = x.shape
assert L == H * W, "input feature has wrong size"
res_x = x
if H == self.window_size and W == self.window_size:
x = self.attn(x)
else:
x = x.view(B, H, W, C)
pad_b = (self.window_size - H %
self.window_size) % self.window_size
pad_r = (self.window_size - W %
self.window_size) % self.window_size
padding = pad_b > 0 or pad_r > 0
if padding:
x = F.pad(x, (0, 0, 0, pad_r, 0, pad_b))
pH, pW = H + pad_b, W + pad_r
nH = pH // self.window_size
nW = pW // self.window_size
# window partition
x = x.view(B, nH, self.window_size, nW, self.window_size, C).transpose(2, 3).reshape(
B * nH * nW, self.window_size * self.window_size, C)
x = self.attn(x)
# window reverse
x = x.view(B, nH, nW, self.window_size, self.window_size,
C).transpose(2, 3).reshape(B, pH, pW, C)
if padding:
x = x[:, :H, :W].contiguous()
x = x.view(B, L, C)
x = res_x + self.drop_path(x)
x = x.transpose(1, 2).reshape(B, C, H, W)
x = self.local_conv(x)
x = x.view(B, C, L).transpose(1, 2)
x = x + self.drop_path(self.mlp(x))
return x
def extra_repr(self) -> str:
return f"dim={self.dim}, input_resolution={self.input_resolution}, num_heads={self.num_heads}, " \
f"window_size={self.window_size}, mlp_ratio={self.mlp_ratio}"
class BasicLayer(nn.Module):
""" A basic TinyViT layer for one stage.
Args:
dim (int): Number of input channels.
input_resolution (tuple[int]): Input resolution.
depth (int): Number of blocks.
num_heads (int): Number of attention heads.
window_size (int): Local window size.
mlp_ratio (float): Ratio of mlp hidden dim to embedding dim.
drop (float, optional): Dropout rate. Default: 0.0
drop_path (float | tuple[float], optional): Stochastic depth rate. Default: 0.0
downsample (nn.Module | None, optional): Downsample layer at the end of the layer. Default: None
use_checkpoint (bool): Whether to use checkpointing to save memory. Default: False.
local_conv_size: the kernel size of the depthwise convolution between attention and MLP. Default: 3
activation: the activation function. Default: nn.GELU
out_dim: the output dimension of the layer. Default: dim
"""
def __init__(self, dim, input_resolution, depth, num_heads, window_size,
mlp_ratio=4., drop=0.,
drop_path=0., downsample=None, use_checkpoint=False,
local_conv_size=3,
activation=nn.GELU,
out_dim=None,
):
super().__init__()
self.dim = dim
self.input_resolution = input_resolution
self.depth = depth
self.use_checkpoint = use_checkpoint
# build blocks
self.blocks = nn.ModuleList([
TinyViTBlock(dim=dim, input_resolution=input_resolution,
num_heads=num_heads, window_size=window_size,
mlp_ratio=mlp_ratio,
drop=drop,
drop_path=drop_path[i] if isinstance(
drop_path, list) else drop_path,
local_conv_size=local_conv_size,
activation=activation,
)
for i in range(depth)])
# patch merging layer
if downsample is not None:
self.downsample = downsample(
input_resolution, dim=dim, out_dim=out_dim, activation=activation)
else:
self.downsample = None
def forward(self, x):
for blk in self.blocks:
if self.use_checkpoint:
x = checkpoint.checkpoint(blk, x)
else:
x = blk(x)
if self.downsample is not None:
x = self.downsample(x)
return x
def extra_repr(self) -> str:
return f"dim={self.dim}, input_resolution={self.input_resolution}, depth={self.depth}"
class LayerNorm2d(nn.Module):
def __init__(self, num_channels: int, eps: float = 1e-6) -> None:
super().__init__()
self.weight = nn.Parameter(torch.ones(num_channels))
self.bias = nn.Parameter(torch.zeros(num_channels))
self.eps = eps
def forward(self, x: torch.Tensor) -> torch.Tensor:
u = x.mean(1, keepdim=True)
s = (x - u).pow(2).mean(1, keepdim=True)
x = (x - u) / torch.sqrt(s + self.eps)
x = self.weight[:, None, None] * x + self.bias[:, None, None]
return x
class TinyViT(nn.Module):
def __init__(self, img_size=224, in_chans=3, num_classes=1000,
embed_dims=[96, 192, 384, 768], depths=[2, 2, 6, 2],
num_heads=[3, 6, 12, 24],
window_sizes=[7, 7, 14, 7],
mlp_ratio=4.,
drop_rate=0.,
drop_path_rate=0.1,
use_checkpoint=False,
mbconv_expand_ratio=4.0,
local_conv_size=3,
layer_lr_decay=1.0,
):
super().__init__()
self.img_size=img_size
self.num_classes = num_classes
self.depths = depths
self.num_layers = len(depths)
self.mlp_ratio = mlp_ratio
activation = nn.GELU
self.patch_embed = PatchEmbed(in_chans=in_chans,
embed_dim=embed_dims[0],
resolution=img_size,
activation=activation)
patches_resolution = self.patch_embed.patches_resolution
self.patches_resolution = patches_resolution
# stochastic depth
dpr = [x.item() for x in torch.linspace(0, drop_path_rate,
sum(depths))] # stochastic depth decay rule
# build layers
self.layers = nn.ModuleList()
for i_layer in range(self.num_layers):
kwargs = dict(dim=embed_dims[i_layer],
input_resolution=(patches_resolution[0] // (2 ** (i_layer-1 if i_layer == 3 else i_layer)),
patches_resolution[1] // (2 ** (i_layer-1 if i_layer == 3 else i_layer))),
# input_resolution=(patches_resolution[0] // (2 ** i_layer),
# patches_resolution[1] // (2 ** i_layer)),
depth=depths[i_layer],
drop_path=dpr[sum(depths[:i_layer]):sum(depths[:i_layer + 1])],
downsample=PatchMerging if (
i_layer < self.num_layers - 1) else None,
use_checkpoint=use_checkpoint,
out_dim=embed_dims[min(
i_layer + 1, len(embed_dims) - 1)],
activation=activation,
)
if i_layer == 0:
layer = ConvLayer(
conv_expand_ratio=mbconv_expand_ratio,
**kwargs,
)
else:
layer = BasicLayer(
num_heads=num_heads[i_layer],
window_size=window_sizes[i_layer],
mlp_ratio=self.mlp_ratio,
drop=drop_rate,
local_conv_size=local_conv_size,
**kwargs)
self.layers.append(layer)
# Classifier head
self.norm_head = nn.LayerNorm(embed_dims[-1])
self.head = nn.Linear(
embed_dims[-1], num_classes) if num_classes > 0 else torch.nn.Identity()
# init weights
self.apply(self._init_weights)
self.set_layer_lr_decay(layer_lr_decay)
self.neck = nn.Sequential(
nn.Conv2d(
embed_dims[-1],#handongshen
256,
kernel_size=1,
bias=False,
),
LayerNorm2d(256),
nn.Conv2d(
256,
256,
kernel_size=3,
padding=1,
bias=False,
),
LayerNorm2d(256),
)
def set_layer_lr_decay(self, layer_lr_decay):
decay_rate = layer_lr_decay
# layers -> blocks (depth)
depth = sum(self.depths)
lr_scales = [decay_rate ** (depth - i - 1) for i in range(depth)]
print("LR SCALES:", lr_scales)
def _set_lr_scale(m, scale):
for p in m.parameters():
p.lr_scale = scale
self.patch_embed.apply(lambda x: _set_lr_scale(x, lr_scales[0]))
i = 0
for layer in self.layers:
for block in layer.blocks:
block.apply(lambda x: _set_lr_scale(x, lr_scales[i]))
i += 1
if layer.downsample is not None:
layer.downsample.apply(
lambda x: _set_lr_scale(x, lr_scales[i - 1]))
assert i == depth
for m in [self.norm_head, self.head]:
m.apply(lambda x: _set_lr_scale(x, lr_scales[-1]))
for k, p in self.named_parameters():
p.param_name = k
def _check_lr_scale(m):
for p in m.parameters():
assert hasattr(p, 'lr_scale'), p.param_name
self.apply(_check_lr_scale)
def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
@torch.jit.ignore
def no_weight_decay_keywords(self):
return {'attention_biases'}
def forward_features(self, x):
# x: (N, C, H, W)
x = self.patch_embed(x)
x = self.layers[0](x)
start_i = 1
for i in range(start_i, len(self.layers)):
layer = self.layers[i]
x = layer(x)
B,_,C=x.size()
x = x.view(B, 64, 64, C)
x=x.permute(0, 3, 1, 2)
x=self.neck(x)
return x
def forward(self, x):
x = self.forward_features(x)
# We have made some hack changes here to make it compatible with SAM-HQ
return x, None
_checkpoint_url_format = \
'https://github.com/wkcn/TinyViT-model-zoo/releases/download/checkpoints/{}.pth'
_provided_checkpoints = {
'tiny_vit_5m_224': 'tiny_vit_5m_22kto1k_distill',
'tiny_vit_11m_224': 'tiny_vit_11m_22kto1k_distill',
'tiny_vit_21m_224': 'tiny_vit_21m_22kto1k_distill',
'tiny_vit_21m_384': 'tiny_vit_21m_22kto1k_384_distill',
'tiny_vit_21m_512': 'tiny_vit_21m_22kto1k_512_distill',
}
def register_tiny_vit_model(fn):
'''Register a TinyViT model
It is a wrapper of `register_model` with loading the pretrained checkpoint.
'''
def fn_wrapper(pretrained=False, **kwargs):
model = fn()
if pretrained:
model_name = fn.__name__
assert model_name in _provided_checkpoints, \
f'Sorry that the checkpoint `{model_name}` is not provided yet.'
url = _checkpoint_url_format.format(
_provided_checkpoints[model_name])
checkpoint = torch.hub.load_state_dict_from_url(
url=url,
map_location='cpu', check_hash=False,
)
model.load_state_dict(checkpoint['model'])
return model
# rename the name of fn_wrapper
fn_wrapper.__name__ = fn.__name__
return register_model(fn_wrapper)
@register_tiny_vit_model
def tiny_vit_5m_224(pretrained=False, num_classes=1000, drop_path_rate=0.0):
return TinyViT(
num_classes=num_classes,
embed_dims=[64, 128, 160, 320],
depths=[2, 2, 6, 2],
num_heads=[2, 4, 5, 10],
window_sizes=[7, 7, 14, 7],
drop_path_rate=drop_path_rate,
)
@register_tiny_vit_model
def tiny_vit_11m_224(pretrained=False, num_classes=1000, drop_path_rate=0.1):
return TinyViT(
num_classes=num_classes,
embed_dims=[64, 128, 256, 448],
depths=[2, 2, 6, 2],
num_heads=[2, 4, 8, 14],
window_sizes=[7, 7, 14, 7],
drop_path_rate=drop_path_rate,
)
@register_tiny_vit_model
def tiny_vit_21m_224(pretrained=False, num_classes=1000, drop_path_rate=0.2):
return TinyViT(
num_classes=num_classes,
embed_dims=[96, 192, 384, 576],
depths=[2, 2, 6, 2],
num_heads=[3, 6, 12, 18],
window_sizes=[7, 7, 14, 7],
drop_path_rate=drop_path_rate,
)
@register_tiny_vit_model
def tiny_vit_21m_384(pretrained=False, num_classes=1000, drop_path_rate=0.1):
return TinyViT(
img_size=384,
num_classes=num_classes,
embed_dims=[96, 192, 384, 576],
depths=[2, 2, 6, 2],
num_heads=[3, 6, 12, 18],
window_sizes=[12, 12, 24, 12],
drop_path_rate=drop_path_rate,
)
@register_tiny_vit_model
def tiny_vit_21m_512(pretrained=False, num_classes=1000, drop_path_rate=0.1):
return TinyViT(
img_size=512,
num_classes=num_classes,
embed_dims=[96, 192, 384, 576],
depths=[2, 2, 6, 2],
num_heads=[3, 6, 12, 18],
window_sizes=[16, 16, 32, 16],
drop_path_rate=drop_path_rate,
)
================================================
FILE: data_generation/Grounded-Segment-Anything/EfficientSAM/README.md
================================================
## Efficient Grounded-SAM
We're going to combine [Grounding-DINO](https://github.com/IDEA-Research/GroundingDINO) with efficient SAM variants for faster annotating.
<!-- Combining [Grounding-DINO](https://github.com/IDEA-Research/GroundingDINO) and [Fast-SAM](https://github.com/CASIA-IVA-Lab/FastSAM) for faster zero-shot detect and segment anything. -->
### Table of Contents
- [Installation](#installation)
- [Efficient SAM Series](#efficient-sams)
- [Run Grounded-FastSAM Demo](#run-grounded-fastsam-demo)
- [Run Grounded-MobileSAM Demo](#run-grounded-mobilesam-demo)
- [Run Grounded-LightHQSAM Demo](#run-grounded-light-hqsam-demo)
- [Run Grounded-Efficient-SAM Demo](#run-grounded-efficient-sam-demo)
- [Run Grounded-Edge-SAM Demo](#run-grounded-edge-sam-demo)
- [Run Grounded-RepViT-SAM Demo](#run-grounded-repvit-sam-demo)
### Installation
- Install [Grounded-SAM](https://github.com/IDEA-Research/Grounded-Segment-Anything#installation)
- Install [Fast-SAM](https://github.com/CASIA-IVA-Lab/FastSAM#installation)
- Note that we may use the sam image as the demo image in order to compare the inference results of different efficient-sam variants.
### Efficient SAMs
Here's the list of Efficient SAM variants:
<div align="center">
| Title | Intro | Description | Links |
|:----:|:----:|:----:|:----:|
| [FastSAM](https://arxiv.org/pdf/2306.12156.pdf) |  | The Fast Segment Anything Model(FastSAM) is a CNN Segment Anything Model trained by only 2% of the SA-1B dataset published by SAM authors. The FastSAM achieve a comparable performance with the SAM method at 50× higher run-time speed. | [[Github](https://github.com/CASIA-IVA-Lab/FastSAM)] [[Demo](https://huggingface.co/spaces/An-619/FastSAM)] |
| [MobileSAM](https://arxiv.org/pdf/2306.14289.pdf) |  | MobileSAM performs on par with the original SAM (at least visually) and keeps exactly the same pipeline as the original SAM except for a change on the image encoder. Specifically, we replace the original heavyweight ViT-H encoder (632M) with a much smaller Tiny-ViT (5M). On a single GPU, MobileSAM runs around 12ms per image: 8ms on the image encoder and 4ms on the mask decoder. | [[Github](https://github.com/ChaoningZhang/MobileSAM)] |
| [Light-HQSAM](https://arxiv.org/pdf/2306.01567.pdf) | 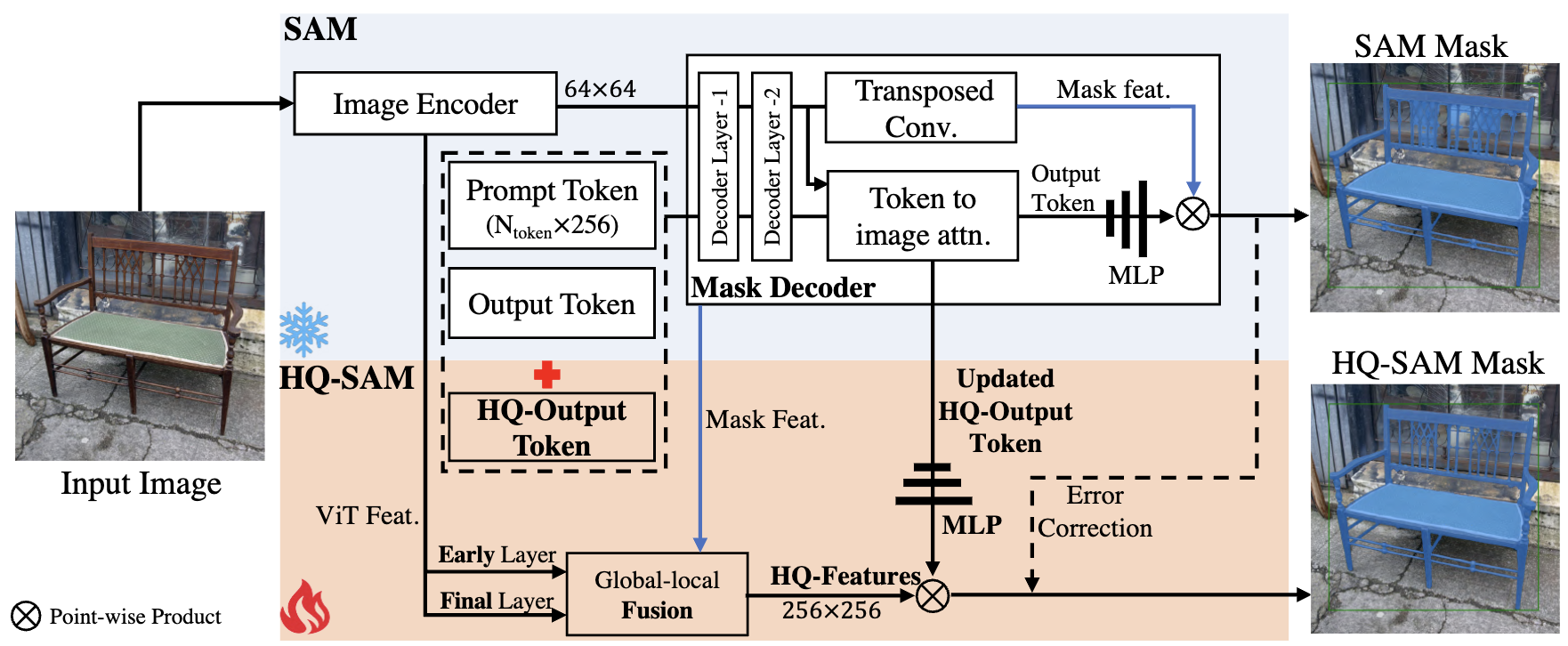 | Light HQ-SAM is based on the tiny vit image encoder provided by MobileSAM. We design a learnable High-Quality Output Token, which is injected into SAM's mask decoder and is responsible for predicting the high-quality mask. Instead of only applying it on mask-decoder features, we first fuse them with ViT features for improved mask details. Refer to [Light HQ-SAM vs. MobileSAM](https://github.com/SysCV/sam-hq#light-hq-sam-vs-mobilesam-on-coco) for more details. | [[Github](https://github.com/SysCV/sam-hq)] |
| [Efficient-SAM](https://github.com/yformer/EfficientSAM) | 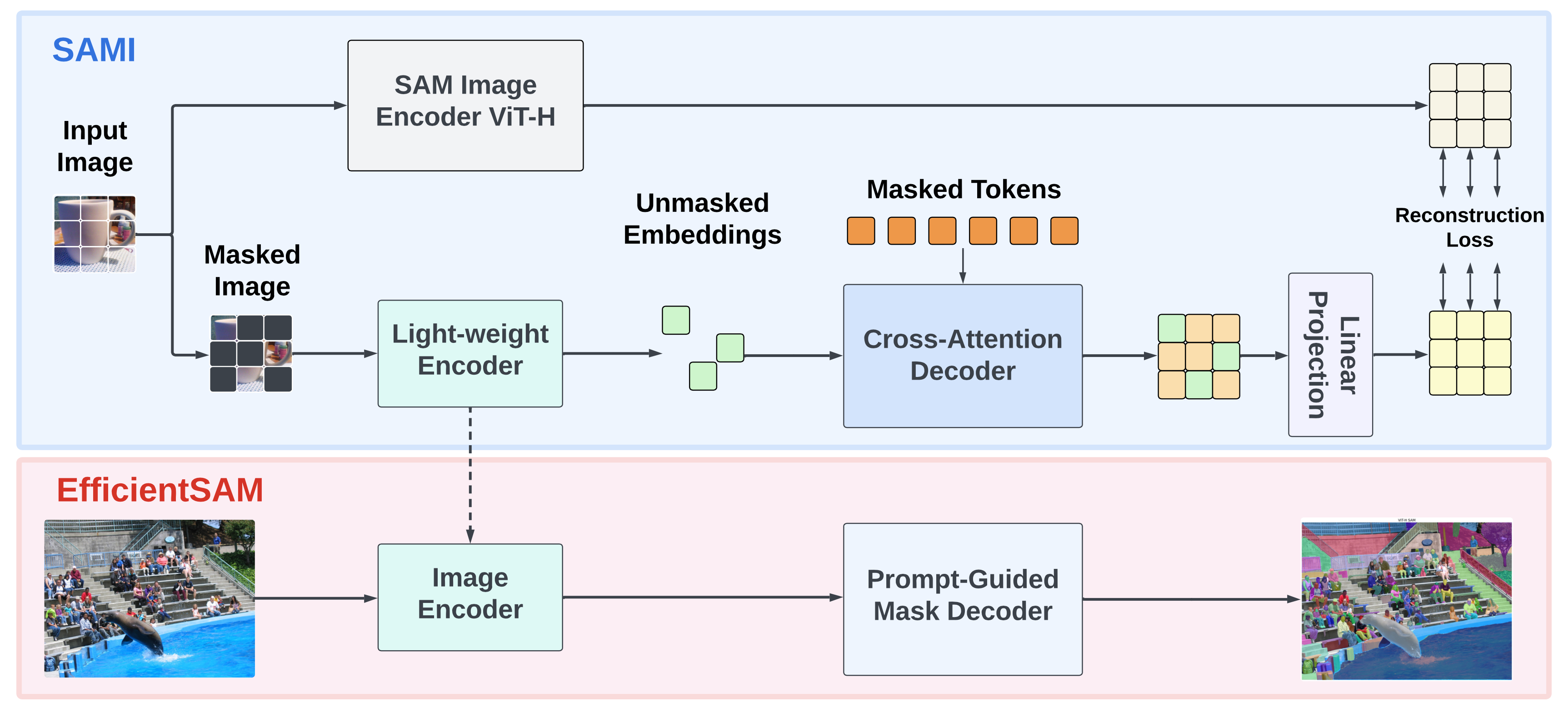 |Segment Anything Model (SAM) has emerged as a powerful tool for numerous vision applications. However, the huge computation cost of SAM model has limited its applications to wider real-world applications. To address this limitation, we propose EfficientSAMs, light-weight SAM models that exhibit decent performance with largely reduced complexity. Our idea is based on leveraging masked image pretraining, SAMI, which learns to reconstruct features from SAM image encoder for effective visual representation learning. Further, we take SAMI-pretrained light-weight image encoders and mask decoder to build EfficientSAMs, and finetune the models on SA-1B for segment anything task. Refer to [EfficientSAM arXiv](https://arxiv.org/pdf/2312.00863.pdf) for more details.| [[Github](https://github.com/yformer/EfficientSAM)] |
| [Edge-SAM](https://github.com/chongzhou96/EdgeSAM) | 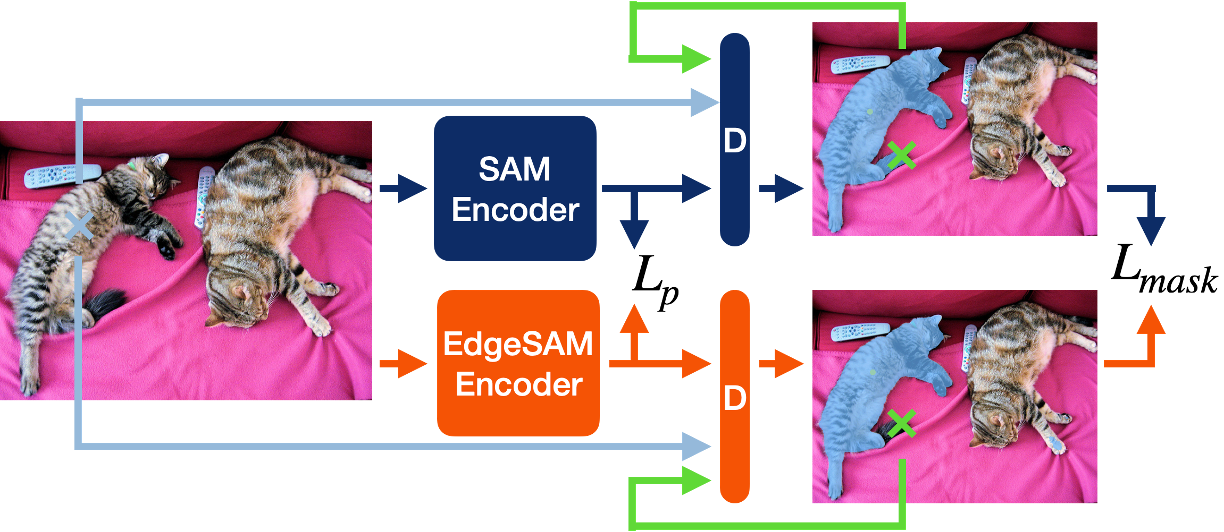 | EdgeSAM involves distilling the original ViT-based SAM image encoder into a purely CNN-based architecture, better suited for edge devices. We carefully benchmark various distillation strategies and demonstrate that task-agnostic encoder distillation fails to capture the full knowledge embodied in SAM. Refer to [Edge-SAM arXiv](https://arxiv.org/abs/2312.06660) for more details. | [[Github](https://github.com/chongzhou96/EdgeSAM)] |
| [RepViT-SAM](https://github.com/THU-MIG/RepViT/tree/main/sam) |  | Recently, RepViT achieves the state-of-the-art performance and latency trade-off on mobile devices by incorporating efficient architectural designs of ViTs into CNNs. Here, to achieve real-time segmenting anything on mobile devices, following MobileSAM, we replace the heavyweight image encoder in SAM with RepViT model, ending up with the RepViT-SAM model. Extensive experiments show that RepViT-SAM can enjoy significantly better zero-shot transfer capability than MobileSAM, along with nearly 10× faster inference speed. Refer to [RepViT-SAM arXiv](https://arxiv.org/pdf/2312.05760.pdf) for more details. | [[Github](https://github.com/THU-MIG/RepViT)] |
</div>
### Run Grounded-FastSAM Demo
- Firstly, download the pretrained Fast-SAM weight [here](https://github.com/CASIA-IVA-Lab/FastSAM#model-checkpoints)
- Run the demo with the following script:
```bash
cd Grounded-Segment-Anything
python EfficientSAM/grounded_fast_sam.py --model_path "./FastSAM-x.pt" --img_path "assets/demo4.jpg" --text "the black dog." --output "./output/"
```
- And the results will be saved in `./output/` as:
<div style="text-align: center">
| Input | Text | Output |
|:---:|:---:|:---:|
| | "The black dog." |  |
</div>
**Note**: Due to the post process of FastSAM, only one box can be annotated at a time, if there're multiple box prompts, we simply save multiple annotate images to `./output` now, which will be modified in the future release.
### Run Grounded-MobileSAM Demo
- Firstly, download the pretrained MobileSAM weight [here](https://github.com/ChaoningZhang/MobileSAM/tree/master/weights)
- Run the demo with the following script:
```bash
cd Grounded-Segment-Anything
python EfficientSAM/grounded_mobile_sam.py --MOBILE_SAM_CHECKPOINT_PATH "./EfficientSAM/mobile_sam.pt" --SOURCE_IMAGE_PATH "./assets/demo2.jpg" --CAPTION "the running dog"
```
- And the result will be saved as `./gronded_mobile_sam_anontated_image.jpg` as:
<div style="text-align: center">
| Input | Text | Output |
|:---:|:---:|:---:|
| | "the running dog" |  |
</div>
### Run Grounded-Light-HQSAM Demo
- Firstly, download the pretrained Light-HQSAM weight [here](https://github.com/SysCV/sam-hq#model-checkpoints)
- Run the demo with the following script:
```bash
cd Grounded-Segment-Anything
python EfficientSAM/grounded_light_hqsam.py
```
- And the result will be saved as `./gronded_light_hqsam_anontated_image.jpg` as:
<div style="text-align: center">
| Input | Text | Output |
|:---:|:---:|:---:|
| | "bench" |  |
</div>
### Run Grounded-Efficient-SAM Demo
- Download the pretrained EfficientSAM checkpoint from [here](https://github.com/yformer/EfficientSAM#model) and put it under `Grounded-Segment-Anything/EfficientSAM`
- Run the demo with the following script:
```bash
cd Grounded-Segment-Anything
python EfficientSAM/grounded_efficient_sam.py
```
- And the result will be saved as `./gronded_efficient_sam_anontated_image.jpg` as:
<div style="text-align: center">
| Input | Text | Output |
|:---:|:---:|:---:|
| | "bench" |  |
</div>
### Run Grounded-Edge-SAM Demo
- Download the pretrained [Edge-SAM](https://github.com/chongzhou96/EdgeSAM) checkpoint follow the [official instruction](https://github.com/chongzhou96/EdgeSAM?tab=readme-ov-file#usage-) as:
```bash
cd Grounded-Segment-Anything
wget -P EfficientSAM/ https://huggingface.co/spaces/chongzhou/EdgeSAM/resolve/main/weights/edge_sam.pth
wget -P EfficientSAM/ https://huggingface.co/spaces/chongzhou/EdgeSAM/resolve/main/weights/edge_sam_3x.pth
```
- Run the demo with the following script:
```bash
cd Grounded-Segment-Anything
python EfficientSAM/grounded_edge_sam.py
```
- And the result will be saved as `./gronded_edge_sam_anontated_image.jpg` as:
<div style="text-align: center">
| Input | Text | Output |
|:---:|:---:|:---:|
| | "bench" |  |
</div>
### Run Grounded-RepViT-SAM Demo
- Download the pretrained [RepViT-SAM](https://github.com/THU-MIG/RepViT) checkpoint follow the [official instruction](https://github.com/THU-MIG/RepViT/tree/main/sam#installation) as:
```bash
cd Grounded-Segment-Anything
wget -P EfficientSAM/ https://github.com/THU-MIG/RepViT/releases/download/v1.0/repvit_sam.pt
```
- Run the demo with the following script:
```bash
cd Grounded-Segment-Anything
python EfficientSAM/grounded_repvit_sam.py
```
- And the result will be saved as `./gronded_repvit_sam_anontated_image.jpg` as:
<div style="text-align: center">
| Input | Text | Output |
|:---:|:---:|:---:|
| | "bench" |  |
</div>
================================================
FILE: data_generation/Grounded-Segment-Anything/EfficientSAM/RepViTSAM/repvit.py
================================================
import torch.nn as nn
__all__ = ['repvit_m1']
def _make_divisible(v, divisor, min_value=None):
"""
This function is taken from the original tf repo.
It ensures that all layers have a channel number that is divisible by 8
It can be seen here:
https://github.com/tensorflow/models/blob/master/research/slim/nets/mobilenet/mobilenet.py
:param v:
:param divisor:
:param min_value:
:return:
"""
if min_value is None:
min_value = divisor
new_v = max(min_value, int(v + divisor / 2) // divisor * divisor)
# Make sure that round down does not go down by more than 10%.
if new_v < 0.9 * v:
new_v += divisor
return new_v
from timm.models.layers import SqueezeExcite
import torch
# From https://github.com/facebookresearch/detectron2/blob/main/detectron2/layers/batch_norm.py # noqa
# Itself from https://github.com/facebookresearch/ConvNeXt/blob/d1fa8f6fef0a165b27399986cc2bdacc92777e40/models/convnext.py#L119 # noqa
class LayerNorm2d(nn.Module):
def __init__(self, num_channels: int, eps: float = 1e-6) -> None:
super().__init__()
self.weight = nn.Parameter(torch.ones(num_channels))
self.bias = nn.Parameter(torch.zeros(num_channels))
self.eps = eps
def forward(self, x: torch.Tensor) -> torch.Tensor:
u = x.mean(1, keepdim=True)
s = (x - u).pow(2).mean(1, keepdim=True)
x = (x - u) / torch.sqrt(s + self.eps)
x = self.weight[:, None, None] * x + self.bias[:, None, None]
return x
class Conv2d_BN(torch.nn.Sequential):
def __init__(self, a, b, ks=1, stride=1, pad=0, dilation=1,
groups=1, bn_weight_init=1, resolution=-10000):
super().__init__()
self.add_module('c', torch.nn.Conv2d(
a, b, ks, stride, pad, dilation, groups, bias=False))
self.add_module('bn', torch.nn.BatchNorm2d(b))
torch.nn.init.constant_(self.bn.weight, bn_weight_init)
torch.nn.init.constant_(self.bn.bias, 0)
@torch.no_grad()
def fuse(self):
c, bn = self._modules.values()
w = bn.weight / (bn.running_var + bn.eps)**0.5
w = c.weight * w[:, None, None, None]
b = bn.bias - bn.running_mean * bn.weight / \
(bn.running_var + bn.eps)**0.5
m = torch.nn.Conv2d(w.size(1) * self.c.groups, w.size(
0), w.shape[2:], stride=self.c.stride, padding=self.c.padding, dilation=self.c.dilation, groups=self.c.groups,
device=c.weight.device)
m.weight.data.copy_(w)
m.bias.data.copy_(b)
return m
class Residual(torch.nn.Module):
def __init__(self, m, drop=0.):
super().__init__()
self.m = m
self.drop = drop
def forward(self, x):
if self.training and self.drop > 0:
return x + self.m(x) * torch.rand(x.size(0), 1, 1, 1,
device=x.device).ge_(self.drop).div(1 - self.drop).detach()
else:
return x + self.m(x)
@torch.no_grad()
def fuse(self):
if isinstance(self.m, Conv2d_BN):
m = self.m.fuse()
assert(m.groups == m.in_channels)
identity = torch.ones(m.weight.shape[0], m.weight.shape[1], 1, 1)
identity = torch.nn.functional.pad(identity, [1,1,1,1])
m.weight += identity.to(m.weight.device)
return m
elif isinstance(self.m, torch.nn.Conv2d):
m = self.m
assert(m.groups != m.in_channels)
identity = torch.ones(m.weight.shape[0], m.weight.shape[1], 1, 1)
identity = torch.nn.functional.pad(identity, [1,1,1,1])
m.weight += identity.to(m.weight.device)
return m
else:
return self
class RepVGGDW(torch.nn.Module):
def __init__(self, ed) -> None:
super().__init__()
self.conv = Conv2d_BN(ed, ed, 3, 1, 1, groups=ed)
self.conv1 = torch.nn.Conv2d(ed, ed, 1, 1, 0, groups=ed)
self.dim = ed
self.bn = torch.nn.BatchNorm2d(ed)
def forward(self, x):
return self.bn((self.conv(x) + self.conv1(x)) + x)
@torch.no_grad()
def fuse(self):
conv = self.conv.fuse()
conv1 = self.conv1
conv_w = conv.weight
conv_b = conv.bias
conv1_w = conv1.weight
conv1_b = conv1.bias
conv1_w = torch.nn.functional.pad(conv1_w, [1,1,1,1])
identity = torch.nn.functional.pad(torch.ones(conv1_w.shape[0], conv1_w.shape[1], 1, 1, device=conv1_w.device), [1,1,1,1])
final_conv_w = conv_w + conv1_w + identity
final_conv_b = conv_b + conv1_b
conv.weight.data.copy_(final_conv_w)
conv.bias.data.copy_(final_conv_b)
bn = self.bn
w = bn.weight / (bn.running_var + bn.eps)**0.5
w = conv.weight * w[:, None, None, None]
b = bn.bias + (conv.bias - bn.running_mean) * bn.weight / \
(bn.running_var + bn.eps)**0.5
conv.weight.data.copy_(w)
conv.bias.data.copy_(b)
return conv
class RepViTBlock(nn.Module):
def __init__(self, inp, hidden_dim, oup, kernel_size, stride, use_se, use_hs):
super(RepViTBlock, self).__init__()
assert stride in [1, 2]
self.identity = stride == 1 and inp == oup
assert(hidden_dim == 2 * inp)
if stride == 2:
self.token_mixer = nn.Sequential(
Conv2d_BN(inp, inp, kernel_size, stride if inp != 320 else 1, (kernel_size - 1) // 2, groups=inp),
SqueezeExcite(inp, 0.25) if use_se else nn.Identity(),
Conv2d_BN(inp, oup, ks=1, stride=1, pad=0)
)
self.channel_mixer = Residual(nn.Sequential(
# pw
Conv2d_BN(oup, 2 * oup, 1, 1, 0),
nn.GELU() if use_hs else nn.GELU(),
# pw-linear
Conv2d_BN(2 * oup, oup, 1, 1, 0, bn_weight_init=0),
))
else:
# assert(self.identity)
self.token_mixer = nn.Sequential(
RepVGGDW(inp),
SqueezeExcite(inp, 0.25) if use_se else nn.Identity(),
)
if self.identity:
self.channel_mixer = Residual(nn.Sequential(
# pw
Conv2d_BN(inp, hidden_dim, 1, 1, 0),
nn.GELU() if use_hs else nn.GELU(),
# pw-linear
Conv2d_BN(hidden_dim, oup, 1, 1, 0, bn_weight_init=0),
))
else:
self.channel_mixer = nn.Sequential(
# pw
Conv2d_BN(inp, hidden_dim, 1, 1, 0),
nn.GELU() if use_hs else nn.GELU(),
# pw-linear
Conv2d_BN(hidden_dim, oup, 1, 1, 0, bn_weight_init=0),
)
def forward(self, x):
return self.channel_mixer(self.token_mixer(x))
from timm.models.vision_transformer import trunc_normal_
class BN_Linear(torch.nn.Sequential):
def __init__(self, a, b, bias=True, std=0.02):
super().__init__()
self.add_module('bn', torch.nn.BatchNorm1d(a))
self.add_module('l', torch.nn.Linear(a, b, bias=bias))
trunc_normal_(self.l.weight, std=std)
if bias:
torch.nn.init.constant_(self.l.bias, 0)
@torch.no_grad()
def fuse(self):
bn, l = self._modules.values()
w = bn.weight / (bn.running_var + bn.eps)**0.5
b = bn.bias - self.bn.running_mean * \
self.bn.weight / (bn.running_var + bn.eps)**0.5
w = l.weight * w[None, :]
if l.bias is None:
b = b @ self.l.weight.T
else:
b = (l.weight @ b[:, None]).view(-1) + self.l.bias
m = torch.nn.Linear(w.size(1), w.size(0), device=l.weight.device)
m.weight.data.copy_(w)
m.bias.data.copy_(b)
return m
class Classfier(nn.Module):
def __init__(self, dim, num_classes, distillation=True):
super().__init__()
self.classifier = BN_Linear(dim, num_classes) if num_classes > 0 else torch.nn.Identity()
self.distillation = distillation
if distillation:
self.classifier_dist = BN_Linear(dim, num_classes) if num_classes > 0 else torch.nn.Identity()
def forward(self, x):
if self.distillation:
x = self.classifier(x), self.classifier_dist(x)
if not self.training:
x = (x[0] + x[1]) / 2
else:
x = self.classifier(x)
return x
@torch.no_grad()
def fuse(self):
classifier = self.classifier.fuse()
if self.distillation:
classifier_dist = self.classifier_dist.fuse()
classifier.weight += classifier_dist.weight
classifier.bias += classifier_dist.bias
classifier.weight /= 2
classifier.bias /= 2
return classifier
else:
return classifier
class RepViT(nn.Module):
def __init__(self, cfgs, num_classes=1000, distillation=False, img_size=1024):
super(RepViT, self).__init__()
# setting of inverted residual blocks
self.cfgs = cfgs
self.img_size = img_size
# building first layer
input_channel = self.cfgs[0][2]
patch_embed = torch.nn.Sequential(Conv2d_BN(3, input_channel // 2, 3, 2, 1), torch.nn.GELU(),
Conv2d_BN(input_channel // 2, input_channel, 3, 2, 1))
layers = [patch_embed]
# building inverted residual blocks
block = RepViTBlock
for k, t, c, use_se, use_hs, s in self.cfgs:
output_channel = _make_divisible(c, 8)
exp_size = _make_divisible(input_channel * t, 8)
layers.append(block(input_channel, exp_size, output_channel, k, s, use_se, use_hs))
input_channel = output_channel
self.features = nn.ModuleList(layers)
# self.classifier = Classfier(output_channel, num_classes, distillation)
self.neck = nn.Sequential(
nn.Conv2d(
output_channel,
256,
kernel_size=1,
bias=False,
),
LayerNorm2d(256),
nn.Conv2d(
256,
256,
kernel_size=3,
padding=1,
bias=False,
),
LayerNorm2d(256),
)
def forward(self, x):
# x = self.features(x)
for f in self.features:
x = f(x)
# x = torch.nn.functional.adaptive_avg_pool2d(x, 1).flatten(1)
x = self.neck(x)
return x, None
from timm.models import register_model
@register_model
def repvit(pretrained=False, num_classes = 1000, distillation=False, **kwargs):
"""
Constructs a MobileNetV3-Large model
"""
cfgs = [
# k, t, c, SE, HS, s
[3, 2, 80, 1, 0, 1],
[3, 2, 80, 0, 0, 1],
[3, 2, 80, 1, 0, 1],
[3, 2, 80, 0, 0, 1],
[3, 2, 80, 1, 0, 1],
[3, 2, 80, 0, 0, 1],
[3, 2, 80, 0, 0, 1],
[3, 2, 160, 0, 0, 2],
[3, 2, 160, 1, 0, 1],
[3, 2, 160, 0, 0, 1],
[3, 2, 160, 1, 0, 1],
[3, 2, 160, 0, 0, 1],
[3, 2, 160, 1, 0, 1],
[3, 2, 160, 0, 0, 1],
[3, 2, 160, 0, 0, 1],
[3, 2, 320, 0, 1, 2],
[3, 2, 320, 1, 1, 1],
[3, 2, 320, 0, 1, 1],
[3, 2, 320, 1, 1, 1],
[3, 2, 320, 0, 1, 1],
[3, 2, 320, 1, 1, 1],
[3, 2, 320, 0, 1, 1],
[3, 2, 320, 1, 1, 1],
[3, 2, 320, 0, 1, 1],
[3, 2, 320, 1, 1, 1],
[3, 2, 320, 0, 1, 1],
[3, 2, 320, 1, 1, 1],
[3, 2, 320, 0, 1, 1],
[3, 2, 320, 1, 1, 1],
[3, 2, 320, 0, 1, 1],
[3, 2, 320, 1, 1, 1],
[3, 2, 320, 0, 1, 1],
[3, 2, 320, 1, 1, 1],
[3, 2, 320, 0, 1, 1],
[3, 2, 320, 1, 1, 1],
[3, 2, 320, 0, 1, 1],
[3, 2, 320, 1, 1, 1],
[3, 2, 320, 0, 1, 1],
[3, 2, 320, 1, 1, 1],
[3, 2, 320, 0, 1, 1],
[3, 2, 320, 1, 1, 1],
[3, 2, 320, 0, 1, 1],
[3, 2, 320, 1, 1, 1],
[3, 2, 320, 0, 1, 1],
[3, 2, 320, 1, 1, 1],
[3, 2, 320, 0, 1, 1],
[3, 2, 320, 1, 1, 1],
[3, 2, 320, 0, 1, 1],
[3, 2, 320, 1, 1, 1],
[3, 2, 320, 0, 1, 1],
# [3, 2, 320, 1, 1, 1],
# [3, 2, 320, 0, 1, 1],
[3, 2, 320, 0, 1, 1],
[3, 2, 640, 0, 1, 2],
[3, 2, 640, 1, 1, 1],
[3, 2, 640, 0, 1, 1],
# [3, 2, 640, 1, 1, 1],
# [3, 2, 640, 0, 1, 1]
]
return RepViT(cfgs, num_classes=num_classes, distillation=distillation)
================================================
FILE: data_generation/Grounded-Segment-Anything/EfficientSAM/RepViTSAM/setup_repvit_sam.py
================================================
# Copyright (c) Meta Platforms, Inc. and affiliates.
# All rights reserved.
# This source code is licensed under the license found in the
# LICENSE file in the root directory of this source tree.
import torch
from functools import partial
from segment_anything.modeling import ImageEncoderViT, MaskDecoder, PromptEncoder, Sam, TwoWayTransformer
from RepViTSAM import repvit
from timm.models import create_model
def build_sam_repvit(checkpoint=None):
prompt_embed_dim = 256
image_size = 1024
vit_patch_size = 16
image_embedding_size = image_size // vit_patch_size
repvit_sam = Sam(
image_encoder=create_model('repvit'),
prompt_encoder=PromptEncoder(
embed_dim=prompt_embed_dim,
image_embedding_size=(image_embedding_size, image_embedding_size),
input_image_size=(image_size, image_size),
mask_in_chans=16,
),
mask_decoder=MaskDecoder(
num_multimask_outputs=3,
transformer=TwoWayTransformer(
depth=2,
embedding_dim=prompt_embed_dim,
mlp_dim=2048,
num_heads=8,
),
transformer_dim=prompt_embed_dim,
iou_head_depth=3,
iou_head_hidden_dim=256,
),
pixel_mean=[123.675, 116.28, 103.53],
pixel_std=[58.395, 57.12, 57.375],
)
repvit_sam.eval()
if checkpoint is not None:
with open(checkpoint, "rb") as f:
state_dict = torch.load(f)
repvit_sam.load_state_dict(state_dict)
return repvit_sam
from functools import partial
sam_model_registry = {
"repvit": partial(build_sam_repvit),
}
================================================
FILE: data_generation/Grounded-Segment-Anything/EfficientSAM/grounded_edge_sam.py
================================================
import cv2
import numpy as np
import supervision as sv
import torch
import torchvision
from groundingdino.util.inference import Model
from segment_anything import SamPredictor
from EdgeSAM.setup_edge_sam import build_edge_sam
DEVICE = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# GroundingDINO config and checkpoint
GROUNDING_DINO_CONFIG_PATH = "GroundingDINO/groundingdino/config/GroundingDINO_SwinT_OGC.py"
GROUNDING_DINO_CHECKPOINT_PATH = "./groundingdino_swint_ogc.pth"
# Building GroundingDINO inference model
grounding_dino_model = Model(model_config_path=GROUNDING_DINO_CONFIG_PATH, model_checkpoint_path=GROUNDING_DINO_CHECKPOINT_PATH)
# Building MobileSAM predictor
EdgeSAM_CHECKPOINT_PATH = "./EfficientSAM/edge_sam_3x.pth"
edge_sam = build_edge_sam(checkpoint=EdgeSAM_CHECKPOINT_PATH)
edge_sam.to(device=DEVICE)
sam_predictor = SamPredictor(edge_sam)
# Predict classes and hyper-param for GroundingDINO
SOURCE_IMAGE_PATH = "./EfficientSAM/LightHQSAM/example_light_hqsam.png"
CLASSES = ["bench"]
BOX_THRESHOLD = 0.25
TEXT_THRESHOLD = 0.25
NMS_THRESHOLD = 0.8
# load image
image = cv2.imread(SOURCE_IMAGE_PATH)
# detect objects
detections = grounding_dino_model.predict_with_classes(
image=image,
classes=CLASSES,
box_threshold=BOX_THRESHOLD,
text_threshold=TEXT_THRESHOLD
)
# annotate image with detections
box_annotator = sv.BoxAnnotator()
labels = [
f"{CLASSES[class_id]} {confidence:0.2f}"
for _, _, confidence, class_id, _, _
in detections]
annotated_frame = box_annotator.annotate(scene=image.copy(), detections=detections, labels=labels)
# save the annotated grounding dino image
cv2.imwrite("EfficientSAM/LightHQSAM/groundingdino_annotated_image.jpg", annotated_frame)
# NMS post process
print(f"Before NMS: {len(detections.xyxy)} boxes")
nms_idx = torchvision.ops.nms(
torch.from_numpy(detections.xyxy),
torch.from_numpy(detections.confidence),
NMS_THRESHOLD
).numpy().tolist()
detections.xyxy = detections.xyxy[nms_idx]
detections.confidence = detections.confidence[nms_idx]
detections.class_id = detections.class_id[nms_idx]
print(f"After NMS: {len(detections.xyxy)} boxes")
# Prompting SAM with detected boxes
def segment(sam_predictor: SamPredictor, image: np.ndarray, xyxy: np.ndarray) -> np.ndarray:
sam_predictor.set_image(image)
result_masks = []
for box in xyxy:
masks, scores, logits = sam_predictor.predict(
box=box,
multimask_output=False,
hq_token_only=True,
)
index = np.argmax(scores)
result_masks.append(masks[index])
return np.array(result_masks)
# convert detections to masks
detections.mask = segment(
sam_predictor=sam_predictor,
image=cv2.cvtColor(image, cv2.COLOR_BGR2RGB),
xyxy=detections.xyxy
)
# annotate image with detections
box_annotator = sv.BoxAnnotator()
mask_annotator = sv.MaskAnnotator()
labels = [
f"{CLASSES[class_id]} {confidence:0.2f}"
for _, _, confidence, class_id, _, _
in detections]
annotated_image = mask_annotator.annotate(scene=image.copy(), detections=detections)
annotated_image = box_annotator.annotate(scene=annotated_image, detections=detections, labels=labels)
# save the annotated grounded-sam image
cv2.imwrite("EfficientSAM/grounded_edge_sam_annotated_image.jpg", annotated_image)
================================================
FILE: data_generation/Grounded-Segment-Anything/EfficientSAM/grounded_efficient_sam.py
================================================
import cv2
import numpy as np
import supervision as sv
import torch
import torchvision
from torchvision.transforms import ToTensor
from groundingdino.util.inference import Model
DEVICE = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# GroundingDINO config and checkpoint
GROUNDING_DINO_CONFIG_PATH = "GroundingDINO/groundingdino/config/GroundingDINO_SwinT_OGC.py"
GROUNDING_DINO_CHECKPOINT_PATH = "./groundingdino_swint_ogc.pth"
# Building GroundingDINO inference model
grounding_dino_model = Model(model_config_path=GROUNDING_DINO_CONFIG_PATH, model_checkpoint_path=GROUNDING_DINO_CHECKPOINT_PATH)
# Building MobileSAM predictor
EFFICIENT_SAM_CHECHPOINT_PATH = "./EfficientSAM/efficientsam_s_gpu.jit"
efficientsam = torch.jit.load(EFFICIENT_SAM_CHECHPOINT_PATH)
# Predict classes and hyper-param for GroundingDINO
SOURCE_IMAGE_PATH = "./EfficientSAM/LightHQSAM/example_light_hqsam.png"
CLASSES = ["bench"]
BOX_THRESHOLD = 0.25
TEXT_THRESHOLD = 0.25
NMS_THRESHOLD = 0.8
# load image
image = cv2.imread(SOURCE_IMAGE_PATH)
# detect objects
detections = grounding_dino_model.predict_with_classes(
image=image,
classes=CLASSES,
box_threshold=BOX_THRESHOLD,
text_threshold=TEXT_THRESHOLD
)
# annotate image with detections
box_annotator = sv.BoxAnnotator()
labels = [
f"{CLASSES[class_id]} {confidence:0.2f}"
for _, _, confidence, class_id, _, _
in detections]
annotated_frame = box_annotator.annotate(scene=image.copy(), detections=detections, labels=labels)
# save the annotated grounding dino image
cv2.imwrite("EfficientSAM/LightHQSAM/groundingdino_annotated_image.jpg", annotated_frame)
# NMS post process
print(f"Before NMS: {len(detections.xyxy)} boxes")
nms_idx = torchvision.ops.nms(
torch.from_numpy(detections.xyxy),
torch.from_numpy(detections.confidence),
NMS_THRESHOLD
).numpy().tolist()
detections.xyxy = detections.xyxy[nms_idx]
detections.confidence = detections.confidence[nms_idx]
detections.class_id = detections.class_id[nms_idx]
print(f"After NMS: {len(detections.xyxy)} boxes")
def efficient_sam_box_prompt_segment(image, pts_sampled, model):
bbox = torch.reshape(torch.tensor(pts_sampled), [1, 1, 2, 2])
bbox_labels = torch.reshape(torch.tensor([2, 3]), [1, 1, 2])
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
img_tensor = ToTensor()(image)
predicted_logits, predicted_iou = model(
img_tensor[None, ...].cuda(),
bbox.cuda(),
bbox_labels.cuda(),
)
predicted_logits = predicted_logits.cpu()
all_masks = torch.ge(torch.sigmoid(predicted_logits[0, 0, :, :, :]), 0.5).numpy()
predicted_iou = predicted_iou[0, 0, ...].cpu().detach().numpy()
max_predicted_iou = -1
selected_mask_using_predicted_iou = None
for m in range(all_masks.shape[0]):
curr_predicted_iou = predicted_iou[m]
if (
curr_predicted_iou > max_predicted_iou
or selected_mask_using_predicted_iou is None
):
max_predicted_iou = curr_predicted_iou
selected_mask_using_predicted_iou = all_masks[m]
return selected_mask_using_predicted_iou
# collect segment results from EfficientSAM
result_masks = []
for box in detections.xyxy:
mask = efficient_sam_box_prompt_segment(image, box, efficientsam)
result_masks.append(mask)
detections.mask = np.array(result_masks)
# annotate image with detections
box_annotator = sv.BoxAnnotator()
mask_annotator = sv.MaskAnnotator()
labels = [
f"{CLASSES[class_id]} {confidence:0.2f}"
for _, _, confidence, class_id, _, _
in detections]
annotated_image = mask_annotator.annotate(scene=image.copy(), detections=detections)
annotated_image = box_annotator.annotate(scene=annotated_image, detections=detections, labels=labels)
# save the annotated grounded-sam image
cv2.imwrite("EfficientSAM/gronded_efficient_sam_anontated_image.jpg", annotated_image)
================================================
FILE: data_generation/Grounded-Segment-Anything/EfficientSAM/grounded_fast_sam.py
================================================
import argparse
import cv2
from ultralytics import YOLO
from FastSAM.tools import *
from groundingdino.util.inference import load_model, load_image, predict, annotate, Model
from torchvision.ops import box_convert
import ast
def parse_args():
parser = argparse.ArgumentParser()
parser.add_argument(
"--model_path", type=str, default="./FastSAM/FastSAM-x.pt", help="model"
)
parser.add_argument(
"--img_path", type=str, default="./images/dogs.jpg", help="path to image file"
)
parser.add_argument(
"--text", type=str, default="the black dog.", help="text prompt for GroundingDINO"
)
parser.add_argument("--imgsz", type=int, default=1024, help="image size")
parser.add_argument(
"--iou",
type=float,
default=0.9,
help="iou threshold for filtering the annotations",
)
parser.add_argument(
"--conf", type=float, default=0.4, help="object confidence threshold"
)
parser.add_argument(
"--output", type=str, default="./output/", help="image save path"
)
parser.add_argument(
"--randomcolor", type=bool, default=True, help="mask random color"
)
parser.add_argument(
"--point_prompt", type=str, default="[[0,0]]", help="[[x1,y1],[x2,y2]]"
)
parser.add_argument(
"--point_label",
type=str,
default="[0]",
help="[1,0] 0:background, 1:foreground",
)
parser.add_argument("--box_prompt", type=str, default="[0,0,0,0]", help="[x,y,w,h]")
parser.add_argument(
"--better_quality",
type=str,
default=False,
help="better quality using morphologyEx",
)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
parser.add_argument(
"--device", type=str, default=device, help="cuda:[0,1,2,3,4] or cpu"
)
parser.add_argument(
"--retina",
type=bool,
default=True,
help="draw high-resolution segmentation masks",
)
parser.add_argument(
"--withContours", type=bool, default=False, help="draw the edges of the masks"
)
return parser.parse_args()
def main(args):
# Image Path
img_path = args.img_path
text = args.text
# path to save img
save_path = args.output
if not os.path.exists(save_path):
os.makedirs(save_path)
basename = os.path.basename(args.img_path).split(".")[0]
# Build Fast-SAM Model
# ckpt_path = "/comp_robot/rentianhe/code/Grounded-Segment-Anything/FastSAM/FastSAM-x.pt"
model = YOLO(args.model_path)
results = model(
args.img_path,
imgsz=args.imgsz,
device=args.device,
retina_masks=args.retina,
iou=args.iou,
conf=args.conf,
max_det=100,
)
# Build GroundingDINO Model
groundingdino_config = "GroundingDINO/groundingdino/config/GroundingDINO_SwinT_OGC.py"
groundingdino_ckpt_path = "./groundingdino_swint_ogc.pth"
image_source, image = load_image(img_path)
model = load_model(groundingdino_config, groundingdino_ckpt_path)
boxes, logits, phrases = predict(
model=model,
image=image,
caption=text,
box_threshold=0.3,
text_threshold=0.25,
device=args.device,
)
# Grounded-Fast-SAM
ori_img = cv2.imread(img_path)
ori_h = ori_img.shape[0]
ori_w = ori_img.shape[1]
# Save each frame due to the post process from FastSAM
boxes = boxes * torch.Tensor([ori_w, ori_h, ori_w, ori_h])
print(f"Detected Boxes: {len(boxes)}")
boxes = box_convert(boxes=boxes, in_fmt="cxcywh", out_fmt="xyxy").cpu().numpy().tolist()
for box_idx in range(len(boxes)):
mask, _ = box_prompt(
results[0].masks.data,
boxes[box_idx],
ori_h,
ori_w,
)
annotations = np.array([mask])
img_array = fast_process(
annotations=annotations,
args=args,
mask_random_color=True,
bbox=boxes[box_idx],
)
cv2.imwrite(os.path.join(save_path, basename + f"_{str(box_idx)}_caption_{phrases[box_idx]}.jpg"), cv2.cvtColor(img_array, cv2.COLOR_RGB2BGR))
if __name__ == "__main__":
args = parse_args()
main(args)
================================================
FILE: data_generation/Grounded-Segment-Anything/EfficientSAM/grounded_light_hqsam.py
================================================
import cv2
import numpy as np
import supervision as sv
import torch
import torchvision
from groundingdino.util.inference import Model
from segment_anything import SamPredictor
from LightHQSAM.setup_light_hqsam import setup_model
DEVICE = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# GroundingDINO config and checkpoint
GROUNDING_DINO_CONFIG_PATH = "GroundingDINO/groundingdino/config/GroundingDINO_SwinT_OGC.py"
GROUNDING_DINO_CHECKPOINT_PATH = "./groundingdino_swint_ogc.pth"
# Building GroundingDINO inference model
grounding_dino_model = Model(model_config_path=GROUNDING_DINO_CONFIG_PATH, model_checkpoint_path=GROUNDING_DINO_CHECKPOINT_PATH)
# Building MobileSAM predictor
HQSAM_CHECKPOINT_PATH = "./EfficientSAM/sam_hq_vit_tiny.pth"
checkpoint = torch.load(HQSAM_CHECKPOINT_PATH)
light_hqsam = setup_model()
light_hqsam.load_state_dict(checkpoint, strict=True)
light_hqsam.to(device=DEVICE)
sam_predictor = SamPredictor(light_hqsam)
# Predict classes and hyper-param for GroundingDINO
SOURCE_IMAGE_PATH = "./EfficientSAM/LightHQSAM/example_light_hqsam.png"
CLASSES = ["bench"]
BOX_THRESHOLD = 0.25
TEXT_THRESHOLD = 0.25
NMS_THRESHOLD = 0.8
# load image
image = cv2.imread(SOURCE_IMAGE_PATH)
# detect objects
detections = grounding_dino_model.predict_with_classes(
image=image,
classes=CLASSES,
box_threshold=BOX_THRESHOLD,
text_threshold=TEXT_THRESHOLD
)
# annotate image with detections
box_annotator = sv.BoxAnnotator()
labels = [
f"{CLASSES[class_id]} {confidence:0.2f}"
for _, _, confidence, class_id, _, _
in detections]
annotated_frame = box_annotator.annotate(scene=image.copy(), detections=detections, labels=labels)
# save the annotated grounding dino image
cv2.imwrite("EfficientSAM/LightHQSAM/groundingdino_annotated_image.jpg", annotated_frame)
# NMS post process
print(f"Before NMS: {len(detections.xyxy)} boxes")
nms_idx = torchvision.ops.nms(
torch.from_numpy(detections.xyxy),
torch.from_numpy(detections.confidence),
NMS_THRESHOLD
).numpy().tolist()
detections.xyxy = detections.xyxy[nms_idx]
detections.confidence = detections.confidence[nms_idx]
detections.class_id = detections.class_id[nms_idx]
print(f"After NMS: {len(detections.xyxy)} boxes")
# Prompting SAM with detected boxes
def segment(sam_predictor: SamPredictor, image: np.ndarray, xyxy: np.ndarray) -> np.ndarray:
sam_predictor.set_image(image)
result_masks = []
for box in xyxy:
masks, scores, logits = sam_predictor.predict(
box=box,
multimask_output=False,
hq_token_only=True,
)
index = np.argmax(scores)
result_masks.append(masks[index])
return np.array(result_masks)
# convert detections to masks
detections.mask = segment(
sam_predictor=sam_predictor,
image=cv2.cvtColor(image, cv2.COLOR_BGR2RGB),
xyxy=detections.xyxy
)
# annotate image with detections
box_annotator = sv.BoxAnnotator()
mask_annotator = sv.MaskAnnotator()
labels = [
f"{CLASSES[class_id]} {confidence:0.2f}"
for _, _, confidence, class_id, _, _
in detections]
annotated_image = mask_annotator.annotate(scene=image.copy(), detections=detections)
annotated_image = box_annotator.annotate(scene=annotated_image, detections=detections, labels=labels)
# save the annotated grounded-sam image
cv2.imwrite("EfficientSAM/LightHQSAM/grounded_light_hqsam_annotated_image.jpg", annotated_image)
================================================
FILE: data_generation/Grounded-Segment-Anything/EfficientSAM/grounded_mobile_sam.py
================================================
import cv2
import numpy as np
import supervision as sv
import argparse
import torch
import torchvision
from groundingdino.util.inference import Model
from segment_anything import SamPredictor
from MobileSAM.setup_mobile_sam import setup_model
def parse_args():
parser = argparse.ArgumentParser()
parser.add_argument(
"--MOBILE_SAM_CHECKPOINT_PATH", type=str, default="./EfficientSAM/mobile_sam.pt", help="model"
)
parser.add_argument(
"--SOURCE_IMAGE_PATH", type=str, default="./assets/demo2.jpg", help="path to image file"
)
parser.add_argument(
"--CAPTION", type=str, default="The running dog", help="text prompt for GroundingDINO"
)
parser.add_argument(
"--OUT_FILE_BOX", type=str, default="groundingdino_annotated_image.jpg", help="the output filename"
)
parser.add_argument(
"--OUT_FILE_SEG", type=str, default="grounded_mobile_sam_annotated_image.jpg", help="the output filename"
)
parser.add_argument(
"--OUT_FILE_BIN_MASK", type=str, default="grounded_mobile_sam_bin_mask.jpg", help="the output filename"
)
parser.add_argument("--BOX_THRESHOLD", type=float, default=0.25, help="")
parser.add_argument("--TEXT_THRESHOLD", type=float, default=0.25, help="")
parser.add_argument("--NMS_THRESHOLD", type=float, default=0.8, help="")
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
parser.add_argument(
"--DEVICE", type=str, default=device, help="cuda:[0,1,2,3,4] or cpu"
)
return parser.parse_args()
def main(args):
DEVICE = args.DEVICE
# GroundingDINO config and checkpoint
GROUNDING_DINO_CONFIG_PATH = "GroundingDINO/groundingdino/config/GroundingDINO_SwinT_OGC.py"
GROUNDING_DINO_CHECKPOINT_PATH = "./groundingdino_swint_ogc.pth"
# Building GroundingDINO inference model
grounding_dino_model = Model(model_config_path=GROUNDING_DINO_CONFIG_PATH, model_checkpoint_path=GROUNDING_DINO_CHECKPOINT_PATH)
# Building MobileSAM predictor
MOBILE_SAM_CHECKPOINT_PATH = args.MOBILE_SAM_CHECKPOINT_PATH
checkpoint = torch.load(MOBILE_SAM_CHECKPOINT_PATH)
mobile_sam = setup_model()
mobile_sam.load_state_dict(checkpoint, strict=True)
mobile_sam.to(device=DEVICE)
sam_predictor = SamPredictor(mobile_sam)
# Predict classes and hyper-param for GroundingDINO
SOURCE_IMAGE_PATH = args.SOURCE_IMAGE_PATH
CLASSES = [args.CAPTION]
BOX_THRESHOLD = args.BOX_THRESHOLD
TEXT_THRESHOLD = args.TEXT_THRESHOLD
NMS_THRESHOLD = args.NMS_THRESHOLD
# load image
image = cv2.imread(SOURCE_IMAGE_PATH)
# detect objects
detections = grounding_dino_model.predict_with_classes(
image=image,
classes=CLASSES,
box_threshold=BOX_THRESHOLD,
text_threshold=TEXT_THRESHOLD
)
# annotate image with detections
box_annotator = sv.BoxAnnotator()
labels = [
f"{CLASSES[class_id]} {confidence:0.2f}"
for _, _, confidence, class_id, _, _
in detections]
annotated_frame = box_annotator.annotate(scene=image.copy(), detections=detections, labels=labels)
# save the annotated grounding dino image
cv2.imwrite(args.OUT_FILE_BOX, annotated_frame)
# NMS post process
print(f"Before NMS: {len(detections.xyxy)} boxes")
nms_idx = torchvision.ops.nms(
torch.from_numpy(detections.xyxy),
torch.from_numpy(detections.confidence),
NMS_THRESHOLD
).numpy().tolist()
detections.xyxy = detections.xyxy[nms_idx]
detections.confidence = detections.confidence[nms_idx]
detections.class_id = detections.class_id[nms_idx]
print(f"After NMS: {len(detections.xyxy)} boxes")
# Prompting SAM with detected boxes
def segment(sam_predictor: SamPredictor, image: np.ndarray, xyxy: np.ndarray) -> np.ndarray:
sam_predictor.set_image(image)
result_masks = []
for box in xyxy:
masks, scores, logits = sam_predictor.predict(
box=box,
multimask_output=True
)
index = np.argmax(scores)
result_masks.append(masks[index])
return np.array(result_masks)
# convert detections to masks
detections.mask = segment(
sam_predictor=sam_predictor,
image=cv2.cvtColor(image, cv2.COLOR_BGR2RGB),
xyxy=detections.xyxy
)
binary_mask = detections.mask[0].astype(np.uint8)*255
cv2.imwrite(args.OUT_FILE_BIN_MASK, binary_mask)
# annotate image with detections
box_annotator = sv.BoxAnnotator()
mask_annotator = sv.MaskAnnotator()
labels = [
f"{CLASSES[class_id]} {confidence:0.2f}"
for _, _, confidence, class_id, _, _
in detections]
annotated_image = mask_annotator.annotate(scene=image.copy(), detections=detections)
annotated_image = box_annotator.annotate(scene=annotated_image, detections=detections, labels=labels)
# save the annotated grounded-sam image
cv2.imwrite(args.OUT_FILE_SEG, annotated_image)
if __name__ == "__main__":
args = parse_args()
main(args)
================================================
FILE: data_generation/Grounded-Segment-Anything/EfficientSAM/grounded_repvit_sam.py
================================================
import cv2
import numpy as np
import supervision as sv
import torch
import torchvision
from groundingdino.util.inference import Model
from segment_anything import SamPredictor
from RepViTSAM.setup_repvit_sam import build_sam_repvit
DEVICE = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# GroundingDINO config and checkpoint
GROUNDING_DINO_CONFIG_PATH = "GroundingDINO/groundingdino/config/GroundingDINO_SwinT_OGC.py"
GROUNDING_DINO_CHECKPOINT_PATH = "./groundingdino_swint_ogc.pth"
# Building GroundingDINO inference model
grounding_dino_model = Model(model_config_path=GROUNDING_DINO_CONFIG_PATH, model_checkpoint_path=GROUNDING_DINO_CHECKPOINT_PATH)
# Building MobileSAM predictor
RepViTSAM_CHECKPOINT_PATH = "./EfficientSAM/repvit_sam.pt"
repvit_sam = build_sam_repvit(checkpoint=RepViTSAM_CHECKPOINT_PATH)
repvit_sam.to(device=DEVICE)
sam_predictor = SamPredictor(repvit_sam)
# Predict classes and hyper-param for GroundingDINO
SOURCE_IMAGE_PATH = "./EfficientSAM/LightHQSAM/example_light_hqsam.png"
CLASSES = ["bench"]
BOX_THRESHOLD = 0.25
TEXT_THRESHOLD = 0.25
NMS_THRESHOLD = 0.8
# load image
image = cv2.imread(SOURCE_IMAGE_PATH)
# detect objects
detections = grounding_dino_model.predict_with_classes(
image=image,
classes=CLASSES,
box_threshold=BOX_THRESHOLD,
text_threshold=TEXT_THRESHOLD
)
# annotate image with detections
box_annotator = sv.BoxAnnotator()
labels = [
f"{CLASSES[class_id]} {confidence:0.2f}"
for _, _, confidence, class_id, _, _
in detections]
annotated_frame = box_annotator.annotate(scene=image.copy(), detections=detections, labels=labels)
# save the annotated grounding dino image
cv2.imwrite("EfficientSAM/LightHQSAM/groundingdino_annotated_image.jpg", annotated_frame)
# NMS post process
print(f"Before NMS: {len(detections.xyxy)} boxes")
nms_idx = torchvision.ops.nms(
torch.from_numpy(detections.xyxy),
torch.from_numpy(detections.confidence),
NMS_THRESHOLD
).numpy().tolist()
detections.xyxy = detections.xyxy[nms_idx]
detections.confidence = detections.confidence[nms_idx]
detections.class_id = detections.class_id[nms_idx]
print(f"After NMS: {len(detections.xyxy)} boxes")
# Prompting SAM with detected boxes
def segment(sam_predictor: SamPredictor, image: np.ndarray, xyxy: np.ndarray) -> np.ndarray:
sam_predictor.set_image(image)
result_masks = []
for box in xyxy:
masks, scores, logits = sam_predictor.predict(
box=box,
multimask_output=False,
hq_token_only=True,
)
index = np.argmax(scores)
result_masks.append(masks[index])
return np.array(result_masks)
# convert detections to masks
detections.mask = segment(
sam_predictor=sam_predictor,
image=cv2.cvtColor(image, cv2.COLOR_BGR2RGB),
xyxy=detections.xyxy
)
# annotate image with detections
box_annotator = sv.BoxAnnotator()
mask_annotator = sv.MaskAnnotator()
labels = [
f"{CLASSES[class_id]} {confidence:0.2f}"
for _, _, confidence, class_id, _, _
in detections]
annotated_image = mask_annotator.annotate(scene=image.copy(), detections=detections)
annotated_image = box_annotator.annotate(scene=annotated_image, detections=detections, labels=labels)
# save the annotated grounded-sam image
cv2.imwrite("EfficientSAM/grounded_repvit_sam_annotated_image.jpg", annotated_image)
================================================
FILE: data_generation/Grounded-Segment-Anything/GroundingDINO/LICENSE
================================================
Apache License
Version 2.0, January 2004
http://www.apache.org/licenses/
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
1. Definitions.
"License" shall mean the terms and conditions for use, reproduction,
and distribution as defined by Sections 1 through 9 of this document.
"Licensor" shall mean the copyright owner or entity authorized by
the copyright owner that is granting the License.
"Legal Entity" shall mean the union of the acting entity and all
other entities that control, are controlled by, or are under common
control with that entity. For the purposes of this definition,
"control" means (i) the power, direct or indirect, to cause the
direction or management of such entity, whether by contract or
otherwise, or (ii) ownership of fifty percent (50%) or more of the
outstanding shares, or (iii) beneficial ownership of such entity.
"You" (or "Your") shall mean an individual or Legal Entity
exercising permissions granted by this License.
"Source" form shall mean the preferred form for making modifications,
including but not limited to software source code, documentation
source, and configuration files.
"Object" form shall mean any form resulting from mechanical
transformation or translation of a Source form, including but
not limited to compiled object code, generated documentation,
and conversions to other media types.
"Work" shall mean the work of authorship, whether in Source or
Object form, made available under the License, as indicated by a
copyright notice that is included in or attached to the work
(an example is provided in the Appendix below).
"Derivative Works" shall mean any work, whether in Source or Object
form, that is based on (or derived from) the Work and for which the
editorial revisions, annotations, elaborations, or other modifications
represent, as a whole, an original work of authorship. For the purposes
of this License, Derivative Works shall not include works that remain
separable from, or merely link (or bind by name) to the interfaces of,
the Work and Derivative Works thereof.
"Contribution" shall mean any work of authorship, including
the original version of the Work and any modifications or additions
to that Work or Derivative Works thereof, that is intentionally
submitted to Licensor for inclusion in the Work by the copyright owner
or by an individual or Legal Entity authorized to submit on behalf of
the copyright owner. For the purposes of this definition, "submitted"
means any form of electronic, verbal, or written communication sent
to the Licensor or its representatives, including but not limited to
communication on electronic mailing lists, source code control systems,
and issue tracking systems that are managed by, or on behalf of, the
Licensor for the purpose of discussing and improving the Work, but
excluding communication that is conspicuously marked or otherwise
designated in writing by the copyright owner as "Not a Contribution."
"Contributor" shall mean Licensor and any individual or Legal Entity
on behalf of whom a Contribution has been received by Licensor and
subsequently incorporated within the Work.
2. Grant of Copyright License. Subject to the terms and conditions of
this License, each Contributor hereby grants to You a perpetual,
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
copyright license to reproduce, prepare Derivative Works of,
publicly display, publicly perform, sublicense, and distribute the
Work and such Derivative Works in Source or Object form.
3. Grant of Patent License. Subject to the terms and conditions of
this License, each Contributor hereby grants to You a perpetual,
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
(except as stated in this section) patent license to make, have made,
use, offer to sell, sell, import, and otherwise transfer the Work,
where such license applies only to those patent claims licensable
by such Contributor that are necessarily infringed by their
Contribution(s) alone or by combination of their Contribution(s)
with the Work to which such Contribution(s) was submitted. If You
institute patent litigation against any entity (including a
cross-claim or counterclaim in a lawsuit) alleging that the Work
or a Contribution incorporated within the Work constitutes direct
or contributory patent infringement, then any patent licenses
granted to You under this License for that Work shall terminate
as of the date such litigation is filed.
4. Redistribution. You may reproduce and distribute copies of the
Work or Derivative Works thereof in any medium, with or without
modifications, and in Source or Object form, provided that You
meet the following conditions:
(a) You must give any other recipients of the Work or
Derivative Works a copy of this License; and
(b) You must cause any modified files to carry prominent notices
stating that You changed the files; and
(c) You must retain, in the Source form of any Derivative Works
that You distribute, all copyright, patent, trademark, and
attribution notices from the Source form of the Work,
excluding those notices that do not pertain to any part of
the Derivative Works; and
(d) If the Work includes a "NOTICE" text file as part of its
distribution, then any Derivative Works that You distribute must
include a readable copy of the attribution notices contained
within such NOTICE file, excluding those notices that do not
pertain to any part of the Derivative Works, in at least one
of the following places: within a NOTICE text file distributed
as part of the Derivative Works; within the Source form or
documentation, if provided along with the Derivative Works; or,
within a display generated by the Derivative Works, if and
wherever such third-party notices normally appear. The contents
of the NOTICE file are for informational purposes only and
do not modify the License. You may add Your own attribution
notices within Derivative Works that You distribute, alongside
or as an addendum to the NOTICE text from the Work, provided
that such additional attribution notices cannot be construed
as modifying the License.
You may add Your own copyright statement to Your modifications and
may provide additional or different license terms and conditions
for use, reproduction, or distribution of Your modifications, or
for any such Derivative Works as a whole, provided Your use,
reproduction, and distribution of the Work otherwise complies with
the conditions stated in this License.
5. Submission of Contributions. Unless You explicitly state otherwise,
any Contribution intentionally submitted for inclusion in the Work
by You to the Licensor shall be under the terms and conditions of
this License, without any additional terms or conditions.
Notwithstanding the above, nothing herein shall supersede or modify
the terms of any separate license agreement you may have executed
with Licensor regarding such Contributions.
6. Trademarks. This License does not grant permission to use the trade
names, trademarks, service marks, or product names of the Licensor,
except as required for reasonable and customary use in describing the
origin of the Work and reproducing the content of the NOTICE file.
7. Disclaimer of Warranty. Unless required by applicable law or
agreed to in writing, Licensor provides the Work (and each
Contributor provides its Contributions) on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
implied, including, without limitation, any warranties or conditions
of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
PARTICULAR PURPOSE. You are solely responsible for determining the
appropriateness of using or redistributing the Work and assume any
risks associated with Your exercise of permissions under this License.
8. Limitation of Liability. In no event and under no legal theory,
whether in tort (including negligence), contract, or otherwise,
unless required by applicable law (such as deliberate and grossly
negligent acts) or agreed to in writing, shall any Contributor be
liable to You for damages, including any direct, indirect, special,
incidental, or consequential damages of any character arising as a
result of this License or out of the use or inability to use the
Work (including but not limited to damages for loss of goodwill,
work stoppage, computer failure or malfunction, or any and all
other commercial damages or losses), even if such Contributor
has been advised of the possibility of such damages.
9. Accepting Warranty or Additional Liability. While redistributing
the Work or Derivative Works thereof, You may choose to offer,
and charge a fee for, acceptance of support, warranty, indemnity,
or other liability obligations and/or rights consistent with this
License. However, in accepting such obligations, You may act only
on Your own behalf and on Your sole responsibility, not on behalf
of any other Contributor, and only if You agree to indemnify,
defend, and hold each Contributor harmless for any liability
incurred by, or claims asserted against, such Contributor by reason
of your accepting any such warranty or additional liability.
END OF TERMS AND CONDITIONS
APPENDIX: How to apply the Apache License to your work.
To apply the Apache License to your work, attach the following
boilerplate notice, with the fields enclosed by brackets "[]"
replaced with your own identifying information. (Don't include
the brackets!) The text should be enclosed in the appropriate
comment syntax for the file format. We also recommend that a
file or class name and description of purpose be included on the
same "printed page" as the copyright notice for easier
identification within third-party archives.
Copyright 2020 - present, Facebook, Inc
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
================================================
FILE: data_generation/Grounded-Segment-Anything/GroundingDINO/README.md
================================================
# Grounding DINO
---
[](https://arxiv.org/abs/2303.05499)
[](https://youtu.be/wxWDt5UiwY8)
[](https://colab.research.google.com/github/roboflow-ai/notebooks/blob/main/notebooks/zero-shot-object-detection-with-grounding-dino.ipynb)
[](https://youtu.be/cMa77r3YrDk)
[](https://huggingface.co/spaces/ShilongLiu/Grounding_DINO_demo)
[](https://paperswithcode.com/sota/zero-shot-object-detection-on-mscoco?p=grounding-dino-marrying-dino-with-grounded) \
[](https://paperswithcode.com/sota/zero-shot-object-detection-on-odinw?p=grounding-dino-marrying-dino-with-grounded) \
[](https://paperswithcode.com/sota/object-detection-on-coco-minival?p=grounding-dino-marrying-dino-with-grounded) \
[](https://paperswithcode.com/sota/object-detection-on-coco?p=grounding-dino-marrying-dino-with-grounded)
Official PyTorch implementation of [Grounding DINO](https://arxiv.org/abs/2303.05499), a stronger open-set object detector. Code is available now!
## Highlight
- **Open-Set Detection.** Detect **everything** with language!
- **High Performancce.** COCO zero-shot **52.5 AP** (training without COCO data!). COCO fine-tune **63.0 AP**.
- **Flexible.** Collaboration with Stable Diffusion for Image Editting.
## News
[2023/03/28] A YouTube [video](https://youtu.be/cMa77r3YrDk) about Grounding DINO and basic object detection prompt engineering. [[SkalskiP](https://github.com/SkalskiP)] \
[2023/03/28] Add a [demo](https://huggingface.co/spaces/ShilongLiu/Grounding_DINO_demo) on Hugging Face Space! \
[2023/03/27] Support CPU-only mode. Now the model can run on machines without GPUs.\
[2023/03/25] A [demo](https://colab.research.google.com/github/roboflow-ai/notebooks/blob/main/notebooks/zero-shot-object-detection-with-grounding-dino.ipynb) for Grounding DINO is available at Colab. [[SkalskiP](https://github.com/SkalskiP)] \
[2023/03/22] Code is available Now!
<details open>
<summary><font size="4">
Description
</font></summary>
<img src=".asset/hero_figure.png" alt="ODinW" width="100%">
</details>
## TODO
- [x] Release inference code and demo.
- [x] Release checkpoints.
- [ ] Grounding DINO with Stable Diffusion and GLIGEN demos.
- [ ] Release training codes.
## Install
If you have a CUDA environment, please make sure the environment variable `CUDA_HOME` is set. It will be compiled under CPU-only mode if no CUDA available.
```bash
pip install -e .
```
## Demo
```bash
CUDA_VISIBLE_DEVICES=6 python demo/inference_on_a_image.py \
-c /path/to/config \
-p /path/to/checkpoint \
-i .asset/cats.png \
-o "outputs/0" \
-t "cat ear." \
[--cpu-only] # open it for cpu mode
```
See the `demo/inference_on_a_image.py` for more details.
**Web UI**
We also provide a demo code to integrate Grounding DINO with Gradio Web UI. See the file `demo/gradio_app.py` for more details.
## Checkpoints
<!-- insert a table -->
<table>
<thead>
<tr style="text-align: right;">
<th></th>
<th>name</th>
<th>backbone</th>
<th>Data</th>
<th>box AP on COCO</th>
<th>Checkpoint</th>
<th>Config</th>
</tr>
</thead>
<tbody>
<tr>
<th>1</th>
<td>GroundingDINO-T</td>
<td>Swin-T</td>
<td>O365,GoldG,Cap4M</td>
<td>48.4 (zero-shot) / 57.2 (fine-tune)</td>
<td><a href="https://github.com/IDEA-Research/GroundingDINO/releases/download/v0.1.0-alpha/groundingdino_swint_ogc.pth">Github link</a> | <a href="https://huggingface.co/ShilongLiu/GroundingDINO/resolve/main/groundingdino_swint_ogc.pth">HF link</a></td>
<td><a href="https://github.com/IDEA-Research/GroundingDINO/blob/main/groundingdino/config/GroundingDINO_SwinT_OGC.py">link</a></td>
</tr>
</tbody>
</table>
## Results
<details open>
<summary><font size="4">
COCO Object Detection Results
</font></summary>
<img src=".asset/COCO.png" alt="COCO" width="100%">
</details>
<details open>
<summary><font size="4">
ODinW Object Detection Results
</font></summary>
<img src=".asset/ODinW.png" alt="ODinW" width="100%">
</details>
<details open>
<summary><font size="4">
Marrying Grounding DINO with <a href="https://github.com/Stability-AI/StableDiffusion">Stable Diffusion</a> for Image Editing
</font></summary>
<img src=".asset/GD_SD.png" alt="GD_SD" width="100%">
</details>
<details open>
<summary><font size="4">
Marrying Grounding DINO with <a href="https://github.com/gligen/GLIGEN">GLIGEN</a> for more Detailed Image Editing
</font></summary>
<img src=".asset/GD_GLIGEN.png" alt="GD_GLIGEN" width="100%">
</details>
## Model
Includes: a text backbone, an image backbone, a feature enhancer, a language-guided query selection, and a cross-modality decoder.

## Acknowledgement
Our model is related to [DINO](https://github.com/IDEA-Research/DINO) and [GLIP](https://github.com/microsoft/GLIP). Thanks for their great work!
We also thank great previous work including DETR, Deformable DETR, SMCA, Conditional DETR, Anchor DETR, Dynamic DETR, DAB-DETR, DN-DETR, etc. More related work are available at [Awesome Detection Transformer](https://github.com/IDEACVR/awesome-detection-transformer). A new toolbox [detrex](https://github.com/IDEA-Research/detrex) is available as well.
Thanks [Stable Diffusion](https://github.com/Stability-AI/StableDiffusion) and [GLIGEN](https://github.com/gligen/GLIGEN) for their awesome models.
## Citation
If you find our work helpful for your research, please consider citing the following BibTeX entry.
```bibtex
@inproceedings{ShilongLiu2023GroundingDM,
title={Grounding DINO: Marrying DINO with Grounded Pre-Training for Open-Set Object Detection},
author={Shilong Liu and Zhaoyang Zeng and Tianhe Ren and Feng Li and Hao Zhang and Jie Yang and Chunyuan Li and Jianwei Yang and Hang Su and Jun Zhu and Lei Zhang},
year={2023}
}
```
================================================
FILE: data_generation/Grounded-Segment-Anything/GroundingDINO/demo/gradio_app.py
================================================
import argparse
from functools import partial
import cv2
import requests
import os
from io import BytesIO
from PIL import Image
import numpy as np
from pathlib import Path
import warnings
import torch
# prepare the environment
os.system("python setup.py build develop --user")
os.system("pip install packaging==21.3")
os.system("pip install gradio")
warnings.filterwarnings("ignore")
import gradio as gr
from groundingdino.models import build_model
from groundingdino.util.slconfig import SLConfig
from groundingdino.util.utils import clean_state_dict
from groundingdino.util.inference import annotate, load_image, predict
import groundingdino.datasets.transforms as T
from huggingface_hub import hf_hub_download
# Use this command for evaluate the GLIP-T model
config_file = "groundingdino/config/GroundingDINO_SwinT_OGC.py"
ckpt_repo_id = "ShilongLiu/GroundingDINO"
ckpt_filenmae = "groundingdino_swint_ogc.pth"
def load_model_hf(model_config_path, repo_id, filename, device='cpu'):
args = SLConfig.fromfile(model_config_path)
model = build_model(args)
args.device = device
cache_file = hf_hub_download(repo_id=repo_id, filename=filename)
checkpoint = torch.load(cache_file, map_location='cpu')
log = model.load_state_dict(clean_state_dict(checkpoint['model']), strict=False)
print("Model loaded from {} \n => {}".format(cache_file, log))
_ = model.eval()
return model
def image_transform_grounding(init_image):
transform = T.Compose([
T.RandomResize([800], max_size=1333),
T.ToTensor(),
T.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
image, _ = transform(init_image, None) # 3, h, w
return init_image, image
def image_transform_grounding_for_vis(init_image):
transform = T.Compose([
T.RandomResize([800], max_size=1333),
])
image, _ = transform(init_image, None) # 3, h, w
return image
model = load_model_hf(config_file, ckpt_repo_id, ckpt_filenmae)
def run_grounding(input_image, grounding_caption, box_threshold, text_threshold):
init_image = input_image.convert("RGB")
original_size = init_image.size
_, image_tensor = image_transform_grounding(init_image)
image_pil: Image = image_transform_grounding_for_vis(init_image)
# run grounidng
boxes, logits, phrases = predict(model, image_tensor, grounding_caption, box_threshold, text_threshold, device='cpu')
annotated_frame = annotate(image_source=np.asarray(image_pil), boxes=boxes, logits=logits, phrases=phrases)
image_with_box = Image.fromarray(cv2.cvtColor(annotated_frame, cv2.COLOR_BGR2RGB))
return image_with_box
if __name__ == "__main__":
parser = argparse.ArgumentParser("Grounding DINO demo", add_help=True)
parser.add_argument("--debug", action="store_true", help="using debug mode")
parser.add_argument("--share", action="store_true", help="share the app")
args = parser.parse_args()
block = gr.Blocks().queue()
with block:
gr.Markdown("# [Grounding DINO](https://github.com/IDEA-Research/GroundingDINO)")
gr.Markdown("### Open-World Detection with Grounding DINO")
with gr.Row():
with gr.Column():
input_image = gr.Image(source='upload', type="pil")
grounding_caption = gr.Textbox(label="Detection Prompt")
run_button = gr.Button(label="Run")
with gr.Accordion("Advanced options", open=False):
box_threshold = gr.Slider(
label="Box Threshold", minimum=0.0, maximum=1.0, value=0.25, step=0.001
)
text_threshold = gr.Slider(
label="Text Threshold", minimum=0.0, maximum=1.0, value=0.25, step=0.001
)
with gr.Column():
gallery = gr.outputs.Image(
type="pil",
# label="grounding results"
).style(full_width=True, full_height=True)
# gallery = gr.Gallery(label="Generated images", show_label=False).style(
# grid=[1], height="auto", container=True, full_width=True, full_height=True)
run_button.click(fn=run_grounding, inputs=[
input_image, grounding_caption, box_threshold, text_threshold], outputs=[gallery])
block.launch(server_name='0.0.0.0', server_port=7579, debug=args.debug, share=args.share)
================================================
FILE: data_generation/Grounded-Segment-Anything/GroundingDINO/demo/inference_on_a_image.py
================================================
import argparse
import os
import sys
import numpy as np
import torch
from PIL import Image, ImageDraw, ImageFont
import groundingdino.datasets.transforms as T
from groundingdino.models import build_model
from groundingdino.util import box_ops
from groundingdino.util.slconfig import SLConfig
from groundingdino.util.utils import clean_state_dict, get_phrases_from_posmap
def plot_boxes_to_image(image_pil, tgt):
H, W = tgt["size"]
boxes = tgt["boxes"]
labels = tgt["labels"]
assert len(boxes) == len(labels), "boxes and labels must have same length"
draw = ImageDraw.Draw(image_pil)
mask = Image.new("L", image_pil.size, 0)
mask_draw = ImageDraw.Draw(mask)
# draw boxes and masks
for box, label in zip(boxes, labels):
# from 0..1 to 0..W, 0..H
box = box * torch.Tensor([W, H, W, H])
# from xywh to xyxy
box[:2] -= box[2:] / 2
box[2:] += box[:2]
# random color
color = tuple(np.random.randint(0, 255, size=3).tolist())
# draw
x0, y0, x1, y1 = box
x0, y0, x1, y1 = int(x0), int(y0), int(x1), int(y1)
draw.rectangle([x0, y0, x1, y1], outline=color, width=6)
# draw.text((x0, y0), str(label), fill=color)
font = ImageFont.load_default()
if hasattr(font, "getbbox"):
bbox = draw.textbbox((x0, y0), str(label), font)
else:
w, h = draw.textsize(str(label), font)
bbox = (x0, y0, w + x0, y0 + h)
# bbox = draw.textbbox((x0, y0), str(label))
draw.rectangle(bbox, fill=color)
draw.text((x0, y0), str(label), fill="white")
mask_draw.rectangle([x0, y0, x1, y1], fill=255, width=6)
return image_pil, mask
def load_image(image_path):
# load image
image_pil = Image.open(image_path).convert("RGB") # load image
transform = T.Compose(
[
T.RandomResize([800], max_size=1333),
T.ToTensor(),
T.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]),
]
)
image, _ = transform(image_pil, None) # 3, h, w
return image_pil, image
def load_model(model_config_path, model_checkpoint_path, cpu_only=False):
args = SLConfig.fromfile(model_config_path)
args.device = "cuda" if not cpu_only else "cpu"
model = build_model(args)
checkpoint = torch.load(model_checkpoint_path, map_location="cpu")
load_res = model.load_state_dict(clean_state_dict(checkpoint["model"]), strict=False)
print(load_res)
_ = model.eval()
return model
def get_grounding_output(model, image, caption, box_threshold, text_threshold, with_logits=True, cpu_only=False):
caption = caption.lower()
caption = caption.strip()
if not caption.endswith("."):
caption = caption + "."
device = "cuda" if not cpu_only else "cpu"
model = model.to(device)
image = image.to(device)
with torch.no_grad():
outputs = model(image[None], captions=[caption])
logits = outputs["pred_logits"].cpu().sigmoid()[0] # (nq, 256)
boxes = outputs["pred_boxes"].cpu()[0] # (nq, 4)
logits.shape[0]
# filter output
logits_filt = logits.clone()
boxes_filt = boxes.clone()
filt_mask = logits_filt.max(dim=1)[0] > box_threshold
logits_filt = logits_filt[filt_mask] # num_filt, 256
boxes_filt = boxes_filt[filt_mask] # num_filt, 4
logits_filt.shape[0]
# get phrase
tokenlizer = model.tokenizer
tokenized = tokenlizer(caption)
# build pred
pred_phrases = []
for logit, box in zip(logits_filt, boxes_filt):
pred_phrase = get_phrases_from_posmap(logit > text_threshold, tokenized, tokenlizer)
if with_logits:
pred_phrases.append(pred_phrase + f"({str(logit.max().item())[:4]})")
else:
pred_phrases.append(pred_phrase)
return boxes_filt, pred_phrases
if __name__ == "__main__":
parser = argparse.ArgumentParser("Grounding DINO example", add_help=True)
parser.add_argument("--config_file", "-c", type=str, required=True, help="path to config file")
parser.add_argument(
"--checkpoint_path", "-p", type=str, required=True, help="path to checkpoint file"
)
parser.add_argument("--image_path", "-i", type=str, required=True, help="path to image file")
parser.add_argument("--text_prompt", "-t", type=str, required=True, help="text prompt")
parser.add_argument(
"--output_dir", "-o", type=str, default="outputs", required=True, help="output directory"
)
parser.add_argument("--box_threshold", type=float, default=0.3, help="box threshold")
parser.add_argument("--text_threshold", type=float, default=0.25, help="text threshold")
parser.add_argument("--cpu-only", action="store_true", help="running on cpu only!, default=False")
args = parser.parse_args()
# cfg
config_file = args.config_file # change the path of the model config file
checkpoint_path = args.checkpoint_path # change the path of the model
image_path = args.image_path
text_prompt = args.text_prompt
output_dir = args.output_dir
box_threshold = args.box_threshold
text_threshold = args.text_threshold
# make dir
os.makedirs(output_dir, exist_ok=True)
# load image
image_pil, image = load_image(image_path)
# load model
model = load_model(config_file, checkpoint_path, cpu_only=args.cpu_only)
# visualize raw image
image_pil.save(os.path.join(output_dir, "raw_image.jpg"))
# run model
boxes_filt, pred_phrases = get_grounding_output(
model, image, text_prompt, box_threshold, text_threshold, cpu_only=args.cpu_only
)
# visualize pred
size = image_pil.size
pred_dict = {
"boxes": boxes_filt,
"size": [size[1], size[0]], # H,W
"labels": pred_phrases,
}
# import ipdb; ipdb.set_trace()
image_with_box = plot_boxes_to_image(image_pil, pred_dict)[0]
image_with_box.save(os.path.join(output_dir, "pred.jpg"))
================================================
FILE: data_generation/Grounded-Segment-Anything/GroundingDINO/groundingdino/__init__.py
================================================
================================================
FILE: data_generation/Grounded-Segment-Anything/GroundingDINO/groundingdino/config/GroundingDINO_SwinB.py
================================================
batch_size = 1
modelname = "groundingdino"
backbone = "swin_B_384_22k"
position_embedding = "sine"
pe_temperatureH = 20
pe_temperatureW = 20
return_interm_indices = [1, 2, 3]
backbone_freeze_keywords = None
enc_layers = 6
dec_layers = 6
pre_norm = False
dim_feedforward = 2048
hidden_dim = 256
dropout = 0.0
nheads = 8
num_queries = 900
query_dim = 4
num_patterns = 0
num_feature_levels = 4
enc_n_points = 4
dec_n_points = 4
two_stage_type = "standard"
two_stage_bbox_embed_share = False
two_stage_class_embed_share = False
transformer_activation = "relu"
dec_pred_bbox_embed_share = True
dn_box_noise_scale = 1.0
dn_label_noise_ratio = 0.5
dn_label_coef = 1.0
dn_bbox_coef = 1.0
embed_init_tgt = True
dn_labelbook_size = 2000
max_text_len = 256
text_encoder_type = "bert-base-uncased"
use_text_enhancer = True
use_fusion_layer = True
use_checkpoint = True
use_transformer_ckpt = True
use_text_cross_attention = True
text_dropout = 0.0
fusion_dropout = 0.0
fusion_droppath = 0.1
sub_sentence_present = True
================================================
FILE: data_generation/Grounded-Segment-Anything/GroundingDINO/groundingdino/config/GroundingDINO_SwinT_OGC.py
================================================
batch_size = 1
modelname = "groundingdino"
backbone = "swin_T_224_1k"
position_embedding = "sine"
pe_temperatureH = 20
pe_temperatureW = 20
return_interm_indices = [1, 2, 3]
backbone_freeze_keywords = None
enc_layers = 6
dec_layers = 6
pre_norm = False
dim_feedforward = 2048
hidden_dim = 256
dropout = 0.0
nheads = 8
num_queries = 900
query_dim = 4
num_patterns = 0
num_feature_levels = 4
enc_n_points = 4
dec_n_points = 4
two_stage_type = "standard"
two_stage_bbox_embed_share = False
two_stage_class_embed_share = False
transformer_activation = "relu"
dec_pred_bbox_embed_share = True
dn_box_noise_scale = 1.0
dn_label_noise_ratio = 0.5
dn_label_coef = 1.0
dn_bbox_coef = 1.0
embed_init_tgt = True
dn_labelbook_size = 2000
max_text_len = 256
text_encoder_type = "bert-base-uncased"
use_text_enhancer = True
use_fusion_layer = True
use_checkpoint = True
use_transformer_ckpt = True
use_text_cross_attention = True
text_dropout = 0.0
fusion_dropout = 0.0
fusion_droppath = 0.1
sub_sentence_present = True
================================================
FILE: data_generation/Grounded-Segment-Anything/GroundingDINO/groundingdino/datasets/__init__.py
================================================
================================================
FILE: data_generation/Grounded-Segment-Anything/GroundingDINO/groundingdino/datasets/transforms.py
================================================
# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved
"""
Transforms and data augmentation for both image + bbox.
"""
import os
import random
import PIL
import torch
import torchvision.transforms as T
import torchvision.transforms.functional as F
from groundingdino.util.box_ops import box_xyxy_to_cxcywh
from groundingdino.util.misc import interpolate
def crop(image, target, region):
cropped_image = F.crop(image, *region)
target = target.copy()
i, j, h, w = region
# should we do something wrt the original size?
target["size"] = torch.tensor([h, w])
fields = ["labels", "area", "iscrowd", "positive_map"]
if "boxes" in target:
boxes = target["boxes"]
max_size = torch.as_tensor([w, h], dtype=torch.float32)
cropped_boxes = boxes - torch.as_tensor([j, i, j, i])
cropped_boxes = torch.min(cropped_boxes.reshape(-1, 2, 2), max_size)
cropped_boxes = cropped_boxes.clamp(min=0)
area = (cropped_boxes[:, 1, :] - cropped_boxes[:, 0, :]).prod(dim=1)
target["boxes"] = cropped_boxes.reshape(-1, 4)
target["area"] = area
fields.append("boxes")
if "masks" in target:
# FIXME should we update the area here if there are no boxes?
target["masks"] = target["masks"][:, i : i + h, j : j + w]
fields.append("masks")
# remove elements for which the boxes or masks that have zero area
if "boxes" in target or "masks" in target:
# favor boxes selection when defining which elements to keep
# this is compatible with previous implementation
if "boxes" in target:
cropped_boxes = target["boxes"].reshape(-1, 2, 2)
keep = torch.all(cropped_boxes[:, 1, :] > cropped_boxes[:, 0, :], dim=1)
else:
keep = target["masks"].flatten(1).any(1)
for field in fields:
if field in target:
target[field] = target[field][keep]
if os.environ.get("IPDB_SHILONG_DEBUG", None) == "INFO":
# for debug and visualization only.
if "strings_positive" in target:
target["strings_positive"] = [
_i for _i, _j in zip(target["strings_positive"], keep) if _j
]
return cropped_image, target
def hflip(image, target):
flipped_image = F.hflip(image)
w, h = image.size
target = target.copy()
if "boxes" in target:
boxes = target["boxes"]
boxes = boxes[:, [2, 1, 0, 3]] * torch.as_tensor([-1, 1, -1, 1]) + torch.as_tensor(
[w, 0, w, 0]
)
target["boxes"] = boxes
if "masks" in target:
target["masks"] = target["masks"].flip(-1)
return flipped_image, target
def resize(image, target, size, max_size=None):
# size can be min_size (scalar) or (w, h) tuple
def get_size_with_aspect_ratio(image_size, size, max_size=None):
w, h = image_size
if max_size is not None:
min_original_size = float(min((w, h)))
max_original_size = float(max((w, h)))
if max_original_size / min_original_size * size > max_size:
size = int(round(max_size * min_original_size / max_original_size))
if (w <= h and w == size) or (h <= w and h == size):
return (h, w)
if w < h:
ow = size
oh = int(size * h / w)
else:
oh = size
ow = int(size * w / h)
return (oh, ow)
def get_size(image_size, size, max_size=None):
if isinstance(size, (list, tuple)):
return size[::-1]
else:
return get_size_with_aspect_ratio(image_size, size, max_size)
size = get_size(image.size, size, max_size)
rescaled_image = F.resize(image, size)
if target is None:
return rescaled_image, None
ratios = tuple(float(s) / float(s_orig) for s, s_orig in zip(rescaled_image.size, image.size))
ratio_width, ratio_height = ratios
target = target.copy()
if "boxes" in target:
boxes = target["boxes"]
scaled_boxes = boxes * torch.as_tensor(
[ratio_width, ratio_height, ratio_width, ratio_height]
)
target["boxes"] = scaled_boxes
if "area" in target:
area = target["area"]
scaled_area = area * (ratio_width * ratio_height)
target["area"] = scaled_area
h, w = size
target["size"] = torch.tensor([h, w])
if "masks" in target:
target["masks"] = (
interpolate(target["masks"][:, None].float(), size, mode="nearest")[:, 0] > 0.5
)
return rescaled_image, target
def pad(image, target, padding):
# assumes that we only pad on the bottom right corners
padded_image = F.pad(image, (0, 0, padding[0], padding[1]))
if target is None:
return padded_image, None
target = target.copy()
# should we do something wrt the original size?
target["size"] = torch.tensor(padded_image.size[::-1])
if "masks" in target:
target["masks"] = torch.nn.functional.pad(target["masks"], (0, padding[0], 0, padding[1]))
return padded_image, target
class ResizeDebug(object):
def __init__(self, size):
self.size = size
def __call__(self, img, target):
return resize(img, target, self.size)
class RandomCrop(object):
def __init__(self, size):
self.size = size
def __call__(self, img, target):
region = T.RandomCrop.get_params(img, self.size)
return crop(img, target, region)
class RandomSizeCrop(object):
def __init__(self, min_size: int, max_size: int, respect_boxes: bool = False):
# respect_boxes: True to keep all boxes
# False to tolerence box filter
self.min_size = min_size
self.max_size = max_size
self.respect_boxes = respect_boxes
def __call__(self, img: PIL.Image.Image, target: dict):
init_boxes = len(target["boxes"])
max_patience = 10
for i in range(max_patience):
w = random.randint(self.min_size, min(img.width, self.max_size))
h = random.randint(self.min_size, min(img.height, self.max_size))
region = T.RandomCrop.get_params(img, [h, w])
result_img, result_target = crop(img, target, region)
if (
not self.respect_boxes
or len(result_target["boxes"]) == init_boxes
or i == max_patience - 1
):
return result_img, result_target
return result_img, result_target
class CenterCrop(object):
def __init__(self, size):
self.size = size
def __call__(self, img, target):
image_width, image_height = img.size
crop_height, crop_width = self.size
crop_top = int(round((image_height - crop_height) / 2.0))
crop_left = int(round((image_width - crop_width) / 2.0))
return crop(img, target, (crop_top, crop_left, crop_height, crop_width))
class RandomHorizontalFlip(object):
def __init__(self, p=0.5):
self.p = p
def __call__(self, img, target):
if random.random() < self.p:
return hflip(img, target)
return img, target
class RandomResize(object):
def __init__(self, sizes, max_size=None):
assert isinstance(sizes, (list, tuple))
self.sizes = sizes
self.max_size = max_size
def __call__(self, img, target=None):
size = random.choice(self.sizes)
return resize(img, target, size, self.max_size)
class RandomPad(object):
def __init__(self, max_pad):
self.max_pad = max_pad
def __call__(self, img, target):
pad_x = random.randint(0, self.max_pad)
pad_y = random.randint(0, self.max_pad)
return pad(img, target, (pad_x, pad_y))
class RandomSelect(object):
"""
Randomly selects between transforms1 and transforms2,
with probability p for transforms1 and (1 - p) for transforms2
"""
def __init__(self, transforms1, transforms2, p=0.5):
self.transforms1 = transforms1
self.transforms2 = transforms2
self.p = p
def __call__(self, img, target):
if random.random() < self.p:
return self.transforms1(img, target)
return self.transforms2(img, target)
class ToTensor(object):
def __call__(self, img, target):
return F.to_tensor(img), target
class RandomErasing(object):
def __init__(self, *args, **kwargs):
self.eraser = T.RandomErasing(*args, **kwargs)
def __call__(self, img, target):
return self.eraser(img), target
class Normalize(object):
def __init__(self, mean, std):
self.mean = mean
self.std = std
def __call__(self, image, target=None):
image = F.normalize(image, mean=self.mean, std=self.std)
if target is None:
return image, None
target = target.copy()
h, w = image.shape[-2:]
if "boxes" in target:
boxes = target["boxes"]
boxes = box_xyxy_to_cxcywh(boxes)
boxes = boxes / torch.tensor([w, h, w, h], dtype=torch.float32)
target
gitextract_dp4dknxa/
├── .gitignore
├── README.md
├── app.py
├── data_generation/
│ ├── Grounded-Segment-Anything/
│ │ ├── .gitignore
│ │ ├── .gitmodules
│ │ ├── CITATION.cff
│ │ ├── Dockerfile
│ │ ├── EfficientSAM/
│ │ │ ├── EdgeSAM/
│ │ │ │ ├── common.py
│ │ │ │ ├── rep_vit.py
│ │ │ │ └── setup_edge_sam.py
│ │ │ ├── FastSAM/
│ │ │ │ └── tools.py
│ │ │ ├── LightHQSAM/
│ │ │ │ ├── setup_light_hqsam.py
│ │ │ │ └── tiny_vit_sam.py
│ │ │ ├── MobileSAM/
│ │ │ │ ├── setup_mobile_sam.py
│ │ │ │ └── tiny_vit_sam.py
│ │ │ ├── README.md
│ │ │ ├── RepViTSAM/
│ │ │ │ ├── repvit.py
│ │ │ │ └── setup_repvit_sam.py
│ │ │ ├── grounded_edge_sam.py
│ │ │ ├── grounded_efficient_sam.py
│ │ │ ├── grounded_fast_sam.py
│ │ │ ├── grounded_light_hqsam.py
│ │ │ ├── grounded_mobile_sam.py
│ │ │ └── grounded_repvit_sam.py
│ │ ├── GroundingDINO/
│ │ │ ├── LICENSE
│ │ │ ├── README.md
│ │ │ ├── demo/
│ │ │ │ ├── gradio_app.py
│ │ │ │ └── inference_on_a_image.py
│ │ │ ├── groundingdino/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── config/
│ │ │ │ │ ├── GroundingDINO_SwinB.py
│ │ │ │ │ └── GroundingDINO_SwinT_OGC.py
│ │ │ │ ├── datasets/
│ │ │ │ │ ├── __init__.py
│ │ │ │ │ └── transforms.py
│ │ │ │ ├── models/
│ │ │ │ │ ├── GroundingDINO/
│ │ │ │ │ │ ├── __init__.py
│ │ │ │ │ │ ├── backbone/
│ │ │ │ │ │ │ ├── __init__.py
│ │ │ │ │ │ │ ├── backbone.py
│ │ │ │ │ │ │ ├── position_encoding.py
│ │ │ │ │ │ │ └── swin_transformer.py
│ │ │ │ │ │ ├── bertwarper.py
│ │ │ │ │ │ ├── csrc/
│ │ │ │ │ │ │ ├── MsDeformAttn/
│ │ │ │ │ │ │ │ ├── ms_deform_attn.h
│ │ │ │ │ │ │ │ ├── ms_deform_attn_cpu.cpp
│ │ │ │ │ │ │ │ ├── ms_deform_attn_cpu.h
│ │ │ │ │ │ │ │ ├── ms_deform_attn_cuda.cu
│ │ │ │ │ │ │ │ ├── ms_deform_attn_cuda.h
│ │ │ │ │ │ │ │ └── ms_deform_im2col_cuda.cuh
│ │ │ │ │ │ │ ├── cuda_version.cu
│ │ │ │ │ │ │ └── vision.cpp
│ │ │ │ │ │ ├── fuse_modules.py
│ │ │ │ │ │ ├── groundingdino.py
│ │ │ │ │ │ ├── ms_deform_attn.py
│ │ │ │ │ │ ├── transformer.py
│ │ │ │ │ │ ├── transformer_vanilla.py
│ │ │ │ │ │ └── utils.py
│ │ │ │ │ ├── __init__.py
│ │ │ │ │ └── registry.py
│ │ │ │ ├── util/
│ │ │ │ │ ├── __init__.py
│ │ │ │ │ ├── box_ops.py
│ │ │ │ │ ├── get_tokenlizer.py
│ │ │ │ │ ├── inference.py
│ │ │ │ │ ├── logger.py
│ │ │ │ │ ├── misc.py
│ │ │ │ │ ├── slconfig.py
│ │ │ │ │ ├── slio.py
│ │ │ │ │ ├── time_counter.py
│ │ │ │ │ ├── utils.py
│ │ │ │ │ ├── visualizer.py
│ │ │ │ │ └── vl_utils.py
│ │ │ │ └── version.py
│ │ │ ├── pyproject.toml
│ │ │ ├── requirements.txt
│ │ │ ├── setup.py
│ │ │ ├── sub_8_new_83748.err
│ │ │ └── submit_gpu_task_83747.err
│ │ ├── LICENSE
│ │ ├── Makefile
│ │ ├── README.md
│ │ ├── automatic_label_demo.py
│ │ ├── automatic_label_ram_demo.py
│ │ ├── automatic_label_simple_demo.py
│ │ ├── automatic_label_tag2text_demo.py
│ │ ├── chatbot.py
│ │ ├── cog.yaml
│ │ ├── gradio_app.py
│ │ ├── grounded_sam.ipynb
│ │ ├── grounded_sam_3d_box.ipynb
│ │ ├── grounded_sam_colab_demo.ipynb
│ │ ├── grounded_sam_demo.py
│ │ ├── grounded_sam_inpainting_demo.py
│ │ ├── grounded_sam_osx_demo.py
│ │ ├── grounded_sam_simple_demo.py
│ │ ├── grounded_sam_visam.py
│ │ ├── grounded_sam_whisper_demo.py
│ │ ├── grounded_sam_whisper_inpainting_demo.py
│ │ ├── grounding_dino_demo.py
│ │ ├── playground/
│ │ │ ├── DeepFloyd/
│ │ │ │ ├── README.md
│ │ │ │ ├── dream.py
│ │ │ │ ├── inpaint.py
│ │ │ │ └── style_transfer.py
│ │ │ ├── ImageBind_SAM/
│ │ │ │ ├── README.md
│ │ │ │ ├── audio_referring_seg_demo.py
│ │ │ │ ├── data.py
│ │ │ │ ├── demo.py
│ │ │ │ ├── image_referring_seg_demo.py
│ │ │ │ ├── models/
│ │ │ │ │ ├── __init__.py
│ │ │ │ │ ├── helpers.py
│ │ │ │ │ ├── imagebind_model.py
│ │ │ │ │ ├── multimodal_preprocessors.py
│ │ │ │ │ └── transformer.py
│ │ │ │ ├── text_referring_seg_demo.py
│ │ │ │ └── utils.py
│ │ │ ├── LaMa/
│ │ │ │ ├── README.md
│ │ │ │ ├── lama_inpaint_demo.py
│ │ │ │ └── sam_lama.py
│ │ │ ├── PaintByExample/
│ │ │ │ ├── README.md
│ │ │ │ ├── paint_by_example.py
│ │ │ │ └── sam_paint_by_example.py
│ │ │ ├── README.md
│ │ │ └── RePaint/
│ │ │ ├── README.md
│ │ │ └── repaint.py
│ │ ├── predict.py
│ │ ├── requirements.txt
│ │ ├── segment_anything/
│ │ │ ├── .flake8
│ │ │ ├── CODE_OF_CONDUCT.md
│ │ │ ├── CONTRIBUTING.md
│ │ │ ├── LICENSE
│ │ │ ├── README.md
│ │ │ ├── linter.sh
│ │ │ ├── notebooks/
│ │ │ │ ├── automatic_mask_generator_example.ipynb
│ │ │ │ ├── onnx_model_example.ipynb
│ │ │ │ └── predictor_example.ipynb
│ │ │ ├── scripts/
│ │ │ │ ├── amg.py
│ │ │ │ └── export_onnx_model.py
│ │ │ ├── segment_anything/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── automatic_mask_generator.py
│ │ │ │ ├── build_sam.py
│ │ │ │ ├── build_sam_hq.py
│ │ │ │ ├── modeling/
│ │ │ │ │ ├── __init__.py
│ │ │ │ │ ├── common.py
│ │ │ │ │ ├── image_encoder.py
│ │ │ │ │ ├── mask_decoder.py
│ │ │ │ │ ├── mask_decoder_hq.py
│ │ │ │ │ ├── prompt_encoder.py
│ │ │ │ │ ├── sam.py
│ │ │ │ │ └── transformer.py
│ │ │ │ ├── predictor.py
│ │ │ │ └── utils/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── amg.py
│ │ │ │ ├── onnx.py
│ │ │ │ └── transforms.py
│ │ │ ├── setup.cfg
│ │ │ └── setup.py
│ │ └── voxelnext_3d_box/
│ │ ├── README.md
│ │ ├── __init__.py
│ │ ├── config.yaml
│ │ ├── model.py
│ │ ├── models/
│ │ │ ├── __init__.py
│ │ │ ├── data_processor.py
│ │ │ ├── mean_vfe.py
│ │ │ ├── spconv_backbone_voxelnext.py
│ │ │ └── voxelnext_head.py
│ │ ├── requirements.txt
│ │ └── utils/
│ │ ├── centernet_utils.py
│ │ ├── config.py
│ │ └── image_projection.py
│ ├── data_generation.py
│ ├── ldm/
│ │ ├── data/
│ │ │ ├── __init__.py
│ │ │ ├── base.py
│ │ │ ├── imagenet.py
│ │ │ └── lsun.py
│ │ ├── lr_scheduler.py
│ │ ├── models/
│ │ │ ├── autoencoder.py
│ │ │ └── diffusion/
│ │ │ ├── __init__.py
│ │ │ ├── classifier.py
│ │ │ ├── ddim.py
│ │ │ ├── ddpm.py
│ │ │ ├── dpm_solver/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── dpm_solver.py
│ │ │ │ └── sampler.py
│ │ │ └── plms.py
│ │ ├── modules/
│ │ │ ├── attention.py
│ │ │ ├── diffusionmodules/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── model.py
│ │ │ │ ├── openaimodel.py
│ │ │ │ └── util.py
│ │ │ ├── distributions/
│ │ │ │ ├── __init__.py
│ │ │ │ └── distributions.py
│ │ │ ├── ema.py
│ │ │ ├── encoders/
│ │ │ │ ├── __init__.py
│ │ │ │ └── modules.py
│ │ │ ├── image_degradation/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── bsrgan.py
│ │ │ │ ├── bsrgan_light.py
│ │ │ │ └── utils_image.py
│ │ │ ├── losses/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── contperceptual.py
│ │ │ │ └── vqperceptual.py
│ │ │ └── x_transformer.py
│ │ └── util.py
│ ├── metrics/
│ │ ├── clip_similarity.py
│ │ └── compute_metrics.py
│ ├── processors.py
│ ├── prompt_to_prompt_pipeline.py
│ ├── run_inpainting_multiiple_objects.sh
│ ├── run_sdxl_turbo_p2p_i2i_8gpu.sh
│ ├── sdxl_p2p_pipeline.py
│ └── util.py
├── diffusers/
│ ├── .github/
│ │ ├── ISSUE_TEMPLATE/
│ │ │ ├── bug-report.yml
│ │ │ ├── config.yml
│ │ │ ├── feature_request.md
│ │ │ ├── feedback.md
│ │ │ ├── new-model-addition.yml
│ │ │ └── translate.md
│ │ ├── PULL_REQUEST_TEMPLATE.md
│ │ ├── actions/
│ │ │ └── setup-miniconda/
│ │ │ └── action.yml
│ │ └── workflows/
│ │ ├── benchmark.yml
│ │ ├── build_docker_images.yml
│ │ ├── build_documentation.yml
│ │ ├── build_pr_documentation.yml
│ │ ├── mirror_community_pipeline.yml
│ │ ├── nightly_tests.yml
│ │ ├── notify_slack_about_release.yml
│ │ ├── pr_dependency_test.yml
│ │ ├── pr_flax_dependency_test.yml
│ │ ├── pr_test_fetcher.yml
│ │ ├── pr_test_peft_backend.yml
│ │ ├── pr_tests.yml
│ │ ├── pr_torch_dependency_test.yml
│ │ ├── push_tests.yml
│ │ ├── push_tests_fast.yml
│ │ ├── push_tests_mps.yml
│ │ ├── pypi_publish.yaml
│ │ ├── run_tests_from_a_pr.yml
│ │ ├── ssh-runner.yml
│ │ ├── stale.yml
│ │ ├── trufflehog.yml
│ │ ├── typos.yml
│ │ ├── update_metadata.yml
│ │ └── upload_pr_documentation.yml
│ ├── .gitignore
│ ├── CITATION.cff
│ ├── CODE_OF_CONDUCT.md
│ ├── CONTRIBUTING.md
│ ├── LICENSE
│ ├── MANIFEST.in
│ ├── Makefile
│ ├── PHILOSOPHY.md
│ ├── README.md
│ ├── _typos.toml
│ ├── benchmarks/
│ │ ├── base_classes.py
│ │ ├── benchmark_controlnet.py
│ │ ├── benchmark_ip_adapters.py
│ │ ├── benchmark_sd_img.py
│ │ ├── benchmark_sd_inpainting.py
│ │ ├── benchmark_t2i_adapter.py
│ │ ├── benchmark_t2i_lcm_lora.py
│ │ ├── benchmark_text_to_image.py
│ │ ├── push_results.py
│ │ ├── run_all.py
│ │ └── utils.py
│ ├── docker/
│ │ ├── diffusers-doc-builder/
│ │ │ └── Dockerfile
│ │ ├── diffusers-flax-cpu/
│ │ │ └── Dockerfile
│ │ ├── diffusers-flax-tpu/
│ │ │ └── Dockerfile
│ │ ├── diffusers-onnxruntime-cpu/
│ │ │ └── Dockerfile
│ │ ├── diffusers-onnxruntime-cuda/
│ │ │ └── Dockerfile
│ │ ├── diffusers-pytorch-compile-cuda/
│ │ │ └── Dockerfile
│ │ ├── diffusers-pytorch-cpu/
│ │ │ └── Dockerfile
│ │ ├── diffusers-pytorch-cuda/
│ │ │ └── Dockerfile
│ │ └── diffusers-pytorch-xformers-cuda/
│ │ └── Dockerfile
│ ├── docs/
│ │ ├── README.md
│ │ ├── TRANSLATING.md
│ │ └── source/
│ │ ├── _config.py
│ │ ├── en/
│ │ │ ├── _toctree.yml
│ │ │ ├── advanced_inference/
│ │ │ │ └── outpaint.md
│ │ │ ├── api/
│ │ │ │ ├── activations.md
│ │ │ │ ├── attnprocessor.md
│ │ │ │ ├── configuration.md
│ │ │ │ ├── image_processor.md
│ │ │ │ ├── internal_classes_overview.md
│ │ │ │ ├── loaders/
│ │ │ │ │ ├── ip_adapter.md
│ │ │ │ │ ├── lora.md
│ │ │ │ │ ├── peft.md
│ │ │ │ │ ├── single_file.md
│ │ │ │ │ ├── textual_inversion.md
│ │ │ │ │ └── unet.md
│ │ │ │ ├── logging.md
│ │ │ │ ├── models/
│ │ │ │ │ ├── asymmetricautoencoderkl.md
│ │ │ │ │ ├── autoencoder_tiny.md
│ │ │ │ │ ├── autoencoderkl.md
│ │ │ │ │ ├── consistency_decoder_vae.md
│ │ │ │ │ ├── controlnet.md
│ │ │ │ │ ├── dit_transformer2d.md
│ │ │ │ │ ├── hunyuan_transformer2d.md
│ │ │ │ │ ├── overview.md
│ │ │ │ │ ├── pixart_transformer2d.md
│ │ │ │ │ ├── prior_transformer.md
│ │ │ │ │ ├── sd3_transformer2d.md
│ │ │ │ │ ├── transformer2d.md
│ │ │ │ │ ├── transformer_temporal.md
│ │ │ │ │ ├── unet-motion.md
│ │ │ │ │ ├── unet.md
│ │ │ │ │ ├── unet2d-cond.md
│ │ │ │ │ ├── unet2d.md
│ │ │ │ │ ├── unet3d-cond.md
│ │ │ │ │ ├── uvit2d.md
│ │ │ │ │ └── vq.md
│ │ │ │ ├── normalization.md
│ │ │ │ ├── outputs.md
│ │ │ │ ├── pipelines/
│ │ │ │ │ ├── amused.md
│ │ │ │ │ ├── animatediff.md
│ │ │ │ │ ├── attend_and_excite.md
│ │ │ │ │ ├── audioldm.md
│ │ │ │ │ ├── audioldm2.md
│ │ │ │ │ ├── auto_pipeline.md
│ │ │ │ │ ├── blip_diffusion.md
│ │ │ │ │ ├── consistency_models.md
│ │ │ │ │ ├── controlnet.md
│ │ │ │ │ ├── controlnet_sdxl.md
│ │ │ │ │ ├── controlnetxs.md
│ │ │ │ │ ├── controlnetxs_sdxl.md
│ │ │ │ │ ├── dance_diffusion.md
│ │ │ │ │ ├── ddim.md
│ │ │ │ │ ├── ddpm.md
│ │ │ │ │ ├── deepfloyd_if.md
│ │ │ │ │ ├── diffedit.md
│ │ │ │ │ ├── dit.md
│ │ │ │ │ ├── hunyuandit.md
│ │ │ │ │ ├── i2vgenxl.md
│ │ │ │ │ ├── kandinsky.md
│ │ │ │ │ ├── kandinsky3.md
│ │ │ │ │ ├── kandinsky_v22.md
│ │ │ │ │ ├── latent_consistency_models.md
│ │ │ │ │ ├── latent_diffusion.md
│ │ │ │ │ ├── ledits_pp.md
│ │ │ │ │ ├── marigold.md
│ │ │ │ │ ├── musicldm.md
│ │ │ │ │ ├── overview.md
│ │ │ │ │ ├── paint_by_example.md
│ │ │ │ │ ├── panorama.md
│ │ │ │ │ ├── pia.md
│ │ │ │ │ ├── pix2pix.md
│ │ │ │ │ ├── pixart.md
│ │ │ │ │ ├── pixart_sigma.md
│ │ │ │ │ ├── self_attention_guidance.md
│ │ │ │ │ ├── semantic_stable_diffusion.md
│ │ │ │ │ ├── shap_e.md
│ │ │ │ │ ├── stable_cascade.md
│ │ │ │ │ ├── stable_diffusion/
│ │ │ │ │ │ ├── adapter.md
│ │ │ │ │ │ ├── depth2img.md
│ │ │ │ │ │ ├── gligen.md
│ │ │ │ │ │ ├── image_variation.md
│ │ │ │ │ │ ├── img2img.md
│ │ │ │ │ │ ├── inpaint.md
│ │ │ │ │ │ ├── k_diffusion.md
│ │ │ │ │ │ ├── latent_upscale.md
│ │ │ │ │ │ ├── ldm3d_diffusion.md
│ │ │ │ │ │ ├── overview.md
│ │ │ │ │ │ ├── sdxl_turbo.md
│ │ │ │ │ │ ├── stable_diffusion_2.md
│ │ │ │ │ │ ├── stable_diffusion_3.md
│ │ │ │ │ │ ├── stable_diffusion_safe.md
│ │ │ │ │ │ ├── stable_diffusion_xl.md
│ │ │ │ │ │ ├── svd.md
│ │ │ │ │ │ ├── text2img.md
│ │ │ │ │ │ └── upscale.md
│ │ │ │ │ ├── stable_unclip.md
│ │ │ │ │ ├── text_to_video.md
│ │ │ │ │ ├── text_to_video_zero.md
│ │ │ │ │ ├── unclip.md
│ │ │ │ │ ├── unidiffuser.md
│ │ │ │ │ ├── value_guided_sampling.md
│ │ │ │ │ └── wuerstchen.md
│ │ │ │ ├── schedulers/
│ │ │ │ │ ├── cm_stochastic_iterative.md
│ │ │ │ │ ├── consistency_decoder.md
│ │ │ │ │ ├── ddim.md
│ │ │ │ │ ├── ddim_inverse.md
│ │ │ │ │ ├── ddpm.md
│ │ │ │ │ ├── deis.md
│ │ │ │ │ ├── dpm_discrete.md
│ │ │ │ │ ├── dpm_discrete_ancestral.md
│ │ │ │ │ ├── dpm_sde.md
│ │ │ │ │ ├── edm_euler.md
│ │ │ │ │ ├── edm_multistep_dpm_solver.md
│ │ │ │ │ ├── euler.md
│ │ │ │ │ ├── euler_ancestral.md
│ │ │ │ │ ├── flow_match_euler_discrete.md
│ │ │ │ │ ├── heun.md
│ │ │ │ │ ├── ipndm.md
│ │ │ │ │ ├── lcm.md
│ │ │ │ │ ├── lms_discrete.md
│ │ │ │ │ ├── multistep_dpm_solver.md
│ │ │ │ │ ├── multistep_dpm_solver_inverse.md
│ │ │ │ │ ├── overview.md
│ │ │ │ │ ├── pndm.md
│ │ │ │ │ ├── repaint.md
│ │ │ │ │ ├── score_sde_ve.md
│ │ │ │ │ ├── score_sde_vp.md
│ │ │ │ │ ├── singlestep_dpm_solver.md
│ │ │ │ │ ├── stochastic_karras_ve.md
│ │ │ │ │ ├── tcd.md
│ │ │ │ │ ├── unipc.md
│ │ │ │ │ └── vq_diffusion.md
│ │ │ │ ├── utilities.md
│ │ │ │ └── video_processor.md
│ │ │ ├── conceptual/
│ │ │ │ ├── contribution.md
│ │ │ │ ├── ethical_guidelines.md
│ │ │ │ ├── evaluation.md
│ │ │ │ └── philosophy.md
│ │ │ ├── index.md
│ │ │ ├── installation.md
│ │ │ ├── optimization/
│ │ │ │ ├── coreml.md
│ │ │ │ ├── deepcache.md
│ │ │ │ ├── fp16.md
│ │ │ │ ├── habana.md
│ │ │ │ ├── memory.md
│ │ │ │ ├── mps.md
│ │ │ │ ├── onnx.md
│ │ │ │ ├── open_vino.md
│ │ │ │ ├── tgate.md
│ │ │ │ ├── tome.md
│ │ │ │ ├── torch2.0.md
│ │ │ │ └── xformers.md
│ │ │ ├── quicktour.md
│ │ │ ├── stable_diffusion.md
│ │ │ ├── training/
│ │ │ │ ├── adapt_a_model.md
│ │ │ │ ├── controlnet.md
│ │ │ │ ├── create_dataset.md
│ │ │ │ ├── custom_diffusion.md
│ │ │ │ ├── ddpo.md
│ │ │ │ ├── distributed_inference.md
│ │ │ │ ├── dreambooth.md
│ │ │ │ ├── instructpix2pix.md
│ │ │ │ ├── kandinsky.md
│ │ │ │ ├── lcm_distill.md
│ │ │ │ ├── lora.md
│ │ │ │ ├── overview.md
│ │ │ │ ├── sdxl.md
│ │ │ │ ├── t2i_adapters.md
│ │ │ │ ├── text2image.md
│ │ │ │ ├── text_inversion.md
│ │ │ │ ├── unconditional_training.md
│ │ │ │ └── wuerstchen.md
│ │ │ ├── tutorials/
│ │ │ │ ├── autopipeline.md
│ │ │ │ ├── basic_training.md
│ │ │ │ ├── fast_diffusion.md
│ │ │ │ ├── tutorial_overview.md
│ │ │ │ └── using_peft_for_inference.md
│ │ │ └── using-diffusers/
│ │ │ ├── callback.md
│ │ │ ├── conditional_image_generation.md
│ │ │ ├── controlling_generation.md
│ │ │ ├── controlnet.md
│ │ │ ├── custom_pipeline_overview.md
│ │ │ ├── depth2img.md
│ │ │ ├── diffedit.md
│ │ │ ├── image_quality.md
│ │ │ ├── img2img.md
│ │ │ ├── inference_with_lcm.md
│ │ │ ├── inference_with_tcd_lora.md
│ │ │ ├── inpaint.md
│ │ │ ├── ip_adapter.md
│ │ │ ├── kandinsky.md
│ │ │ ├── loading.md
│ │ │ ├── loading_adapters.md
│ │ │ ├── marigold_usage.md
│ │ │ ├── merge_loras.md
│ │ │ ├── other-formats.md
│ │ │ ├── overview_techniques.md
│ │ │ ├── push_to_hub.md
│ │ │ ├── reusing_seeds.md
│ │ │ ├── scheduler_features.md
│ │ │ ├── schedulers.md
│ │ │ ├── sdxl.md
│ │ │ ├── sdxl_turbo.md
│ │ │ ├── shap-e.md
│ │ │ ├── stable_diffusion_jax_how_to.md
│ │ │ ├── svd.md
│ │ │ ├── t2i_adapter.md
│ │ │ ├── text-img2vid.md
│ │ │ ├── textual_inversion_inference.md
│ │ │ ├── unconditional_image_generation.md
│ │ │ ├── weighted_prompts.md
│ │ │ └── write_own_pipeline.md
│ │ ├── ja/
│ │ │ ├── _toctree.yml
│ │ │ ├── index.md
│ │ │ ├── installation.md
│ │ │ ├── quicktour.md
│ │ │ ├── stable_diffusion.md
│ │ │ └── tutorials/
│ │ │ ├── autopipeline.md
│ │ │ └── tutorial_overview.md
│ │ ├── ko/
│ │ │ ├── _toctree.yml
│ │ │ ├── api/
│ │ │ │ └── pipelines/
│ │ │ │ └── stable_diffusion/
│ │ │ │ └── stable_diffusion_xl.md
│ │ │ ├── conceptual/
│ │ │ │ ├── contribution.md
│ │ │ │ ├── ethical_guidelines.md
│ │ │ │ ├── evaluation.md
│ │ │ │ └── philosophy.md
│ │ │ ├── in_translation.md
│ │ │ ├── index.md
│ │ │ ├── installation.md
│ │ │ ├── optimization/
│ │ │ │ ├── coreml.md
│ │ │ │ ├── fp16.md
│ │ │ │ ├── habana.md
│ │ │ │ ├── mps.md
│ │ │ │ ├── onnx.md
│ │ │ │ ├── open_vino.md
│ │ │ │ ├── opt_overview.md
│ │ │ │ ├── tome.md
│ │ │ │ ├── torch2.0.md
│ │ │ │ └── xformers.md
│ │ │ ├── quicktour.md
│ │ │ ├── stable_diffusion.md
│ │ │ ├── training/
│ │ │ │ ├── adapt_a_model.md
│ │ │ │ ├── controlnet.md
│ │ │ │ ├── create_dataset.md
│ │ │ │ ├── custom_diffusion.md
│ │ │ │ ├── distributed_inference.md
│ │ │ │ ├── dreambooth.md
│ │ │ │ ├── instructpix2pix.md
│ │ │ │ ├── lora.md
│ │ │ │ ├── overview.md
│ │ │ │ ├── text2image.md
│ │ │ │ ├── text_inversion.md
│ │ │ │ └── unconditional_training.md
│ │ │ ├── tutorials/
│ │ │ │ ├── basic_training.md
│ │ │ │ └── tutorial_overview.md
│ │ │ └── using-diffusers/
│ │ │ ├── conditional_image_generation.md
│ │ │ ├── contribute_pipeline.md
│ │ │ ├── control_brightness.md
│ │ │ ├── controlling_generation.md
│ │ │ ├── custom_pipeline_examples.md
│ │ │ ├── custom_pipeline_overview.md
│ │ │ ├── depth2img.md
│ │ │ ├── img2img.md
│ │ │ ├── inpaint.md
│ │ │ ├── loading.md
│ │ │ ├── loading_overview.md
│ │ │ ├── other-formats.md
│ │ │ ├── pipeline_overview.md
│ │ │ ├── reproducibility.md
│ │ │ ├── reusing_seeds.md
│ │ │ ├── schedulers.md
│ │ │ ├── stable_diffusion_jax_how_to.md
│ │ │ ├── textual_inversion_inference.md
│ │ │ ├── unconditional_image_generation.md
│ │ │ ├── using_safetensors.md
│ │ │ ├── weighted_prompts.md
│ │ │ └── write_own_pipeline.md
│ │ ├── pt/
│ │ │ ├── _toctree.yml
│ │ │ ├── index.md
│ │ │ ├── installation.md
│ │ │ └── quicktour.md
│ │ └── zh/
│ │ ├── _toctree.yml
│ │ ├── index.md
│ │ ├── installation.md
│ │ ├── quicktour.md
│ │ └── stable_diffusion.md
│ ├── examples/
│ │ ├── README.md
│ │ ├── advanced_diffusion_training/
│ │ │ ├── README.md
│ │ │ ├── requirements.txt
│ │ │ ├── train_dreambooth_lora_sd15_advanced.py
│ │ │ └── train_dreambooth_lora_sdxl_advanced.py
│ │ ├── amused/
│ │ │ ├── README.md
│ │ │ └── train_amused.py
│ │ ├── community/
│ │ │ ├── README.md
│ │ │ ├── README_community_scripts.md
│ │ │ ├── bit_diffusion.py
│ │ │ ├── checkpoint_merger.py
│ │ │ ├── clip_guided_images_mixing_stable_diffusion.py
│ │ │ ├── clip_guided_stable_diffusion.py
│ │ │ ├── clip_guided_stable_diffusion_img2img.py
│ │ │ ├── composable_stable_diffusion.py
│ │ │ ├── ddim_noise_comparative_analysis.py
│ │ │ ├── dps_pipeline.py
│ │ │ ├── edict_pipeline.py
│ │ │ ├── fresco_v2v.py
│ │ │ ├── gluegen.py
│ │ │ ├── hd_painter.py
│ │ │ ├── iadb.py
│ │ │ ├── imagic_stable_diffusion.py
│ │ │ ├── img2img_inpainting.py
│ │ │ ├── instaflow_one_step.py
│ │ │ ├── interpolate_stable_diffusion.py
│ │ │ ├── ip_adapter_face_id.py
│ │ │ ├── kohya_hires_fix.py
│ │ │ ├── latent_consistency_img2img.py
│ │ │ ├── latent_consistency_interpolate.py
│ │ │ ├── latent_consistency_txt2img.py
│ │ │ ├── llm_grounded_diffusion.py
│ │ │ ├── lpw_stable_diffusion.py
│ │ │ ├── lpw_stable_diffusion_onnx.py
│ │ │ ├── lpw_stable_diffusion_xl.py
│ │ │ ├── magic_mix.py
│ │ │ ├── marigold_depth_estimation.py
│ │ │ ├── masked_stable_diffusion_img2img.py
│ │ │ ├── mixture_canvas.py
│ │ │ ├── mixture_tiling.py
│ │ │ ├── multilingual_stable_diffusion.py
│ │ │ ├── one_step_unet.py
│ │ │ ├── pipeline_animatediff_controlnet.py
│ │ │ ├── pipeline_animatediff_img2video.py
│ │ │ ├── pipeline_demofusion_sdxl.py
│ │ │ ├── pipeline_fabric.py
│ │ │ ├── pipeline_null_text_inversion.py
│ │ │ ├── pipeline_prompt2prompt.py
│ │ │ ├── pipeline_sdxl_style_aligned.py
│ │ │ ├── pipeline_stable_diffusion_boxdiff.py
│ │ │ ├── pipeline_stable_diffusion_pag.py
│ │ │ ├── pipeline_stable_diffusion_upscale_ldm3d.py
│ │ │ ├── pipeline_stable_diffusion_xl_controlnet_adapter.py
│ │ │ ├── pipeline_stable_diffusion_xl_controlnet_adapter_inpaint.py
│ │ │ ├── pipeline_stable_diffusion_xl_differential_img2img.py
│ │ │ ├── pipeline_stable_diffusion_xl_instandid_img2img.py
│ │ │ ├── pipeline_stable_diffusion_xl_instantid.py
│ │ │ ├── pipeline_stable_diffusion_xl_ipex.py
│ │ │ ├── pipeline_zero1to3.py
│ │ │ ├── regional_prompting_stable_diffusion.py
│ │ │ ├── rerender_a_video.py
│ │ │ ├── run_onnx_controlnet.py
│ │ │ ├── run_tensorrt_controlnet.py
│ │ │ ├── scheduling_ufogen.py
│ │ │ ├── sd_text2img_k_diffusion.py
│ │ │ ├── sde_drag.py
│ │ │ ├── seed_resize_stable_diffusion.py
│ │ │ ├── speech_to_image_diffusion.py
│ │ │ ├── stable_diffusion_comparison.py
│ │ │ ├── stable_diffusion_controlnet_img2img.py
│ │ │ ├── stable_diffusion_controlnet_inpaint.py
│ │ │ ├── stable_diffusion_controlnet_inpaint_img2img.py
│ │ │ ├── stable_diffusion_controlnet_reference.py
│ │ │ ├── stable_diffusion_ipex.py
│ │ │ ├── stable_diffusion_mega.py
│ │ │ ├── stable_diffusion_reference.py
│ │ │ ├── stable_diffusion_repaint.py
│ │ │ ├── stable_diffusion_tensorrt_img2img.py
│ │ │ ├── stable_diffusion_tensorrt_inpaint.py
│ │ │ ├── stable_diffusion_tensorrt_txt2img.py
│ │ │ ├── stable_diffusion_xl_reference.py
│ │ │ ├── stable_unclip.py
│ │ │ ├── text_inpainting.py
│ │ │ ├── tiled_upscaling.py
│ │ │ ├── unclip_image_interpolation.py
│ │ │ ├── unclip_text_interpolation.py
│ │ │ └── wildcard_stable_diffusion.py
│ │ ├── conftest.py
│ │ ├── consistency_distillation/
│ │ │ ├── README.md
│ │ │ ├── README_sdxl.md
│ │ │ ├── requirements.txt
│ │ │ ├── test_lcm_lora.py
│ │ │ ├── train_lcm_distill_lora_sd_wds.py
│ │ │ ├── train_lcm_distill_lora_sdxl.py
│ │ │ ├── train_lcm_distill_lora_sdxl_wds.py
│ │ │ ├── train_lcm_distill_sd_wds.py
│ │ │ └── train_lcm_distill_sdxl_wds.py
│ │ ├── controlnet/
│ │ │ ├── README.md
│ │ │ ├── README_sdxl.md
│ │ │ ├── requirements.txt
│ │ │ ├── requirements_flax.txt
│ │ │ ├── requirements_sdxl.txt
│ │ │ ├── test_controlnet.py
│ │ │ ├── train_controlnet.py
│ │ │ ├── train_controlnet_flax.py
│ │ │ └── train_controlnet_sdxl.py
│ │ ├── custom_diffusion/
│ │ │ ├── README.md
│ │ │ ├── requirements.txt
│ │ │ ├── retrieve.py
│ │ │ ├── test_custom_diffusion.py
│ │ │ └── train_custom_diffusion.py
│ │ ├── dreambooth/
│ │ │ ├── README.md
│ │ │ ├── README_sd3.md
│ │ │ ├── README_sdxl.md
│ │ │ ├── requirements.txt
│ │ │ ├── requirements_flax.txt
│ │ │ ├── requirements_sd3.txt
│ │ │ ├── requirements_sdxl.txt
│ │ │ ├── test_dreambooth.py
│ │ │ ├── test_dreambooth_lora.py
│ │ │ ├── test_dreambooth_lora_edm.py
│ │ │ ├── train_dreambooth.py
│ │ │ ├── train_dreambooth_flax.py
│ │ │ ├── train_dreambooth_lora.py
│ │ │ ├── train_dreambooth_lora_sd3.py
│ │ │ ├── train_dreambooth_lora_sdxl.py
│ │ │ └── train_dreambooth_sd3.py
│ │ ├── inference/
│ │ │ ├── README.md
│ │ │ ├── image_to_image.py
│ │ │ └── inpainting.py
│ │ ├── instruct_pix2pix/
│ │ │ ├── README.md
│ │ │ ├── README_sdxl.md
│ │ │ ├── requirements.txt
│ │ │ ├── test_instruct_pix2pix.py
│ │ │ ├── train_instruct_pix2pix.py
│ │ │ └── train_instruct_pix2pix_sdxl.py
│ │ ├── kandinsky2_2/
│ │ │ └── text_to_image/
│ │ │ ├── README.md
│ │ │ ├── requirements.txt
│ │ │ ├── train_text_to_image_decoder.py
│ │ │ ├── train_text_to_image_lora_decoder.py
│ │ │ ├── train_text_to_image_lora_prior.py
│ │ │ └── train_text_to_image_prior.py
│ │ ├── reinforcement_learning/
│ │ │ ├── README.md
│ │ │ └── run_diffuser_locomotion.py
│ │ ├── research_projects/
│ │ │ ├── README.md
│ │ │ ├── colossalai/
│ │ │ │ ├── README.md
│ │ │ │ ├── inference.py
│ │ │ │ ├── requirement.txt
│ │ │ │ └── train_dreambooth_colossalai.py
│ │ │ ├── consistency_training/
│ │ │ │ ├── README.md
│ │ │ │ ├── requirements.txt
│ │ │ │ └── train_cm_ct_unconditional.py
│ │ │ ├── controlnet/
│ │ │ │ └── train_controlnet_webdataset.py
│ │ │ ├── diffusion_dpo/
│ │ │ │ ├── README.md
│ │ │ │ ├── requirements.txt
│ │ │ │ ├── train_diffusion_dpo.py
│ │ │ │ └── train_diffusion_dpo_sdxl.py
│ │ │ ├── diffusion_orpo/
│ │ │ │ ├── README.md
│ │ │ │ ├── requirements.txt
│ │ │ │ ├── train_diffusion_orpo_sdxl_lora.py
│ │ │ │ └── train_diffusion_orpo_sdxl_lora_wds.py
│ │ │ ├── dreambooth_inpaint/
│ │ │ │ ├── README.md
│ │ │ │ ├── requirements.txt
│ │ │ │ ├── train_dreambooth_inpaint.py
│ │ │ │ └── train_dreambooth_inpaint_lora.py
│ │ │ ├── geodiff/
│ │ │ │ ├── README.md
│ │ │ │ └── geodiff_molecule_conformation.ipynb
│ │ │ ├── gligen/
│ │ │ │ ├── README.md
│ │ │ │ ├── dataset.py
│ │ │ │ ├── demo.ipynb
│ │ │ │ ├── make_datasets.py
│ │ │ │ ├── requirements.txt
│ │ │ │ └── train_gligen_text.py
│ │ │ ├── instructpix2pix_lora/
│ │ │ │ ├── README.md
│ │ │ │ └── train_instruct_pix2pix_lora.py
│ │ │ ├── intel_opts/
│ │ │ │ ├── README.md
│ │ │ │ ├── inference_bf16.py
│ │ │ │ ├── textual_inversion/
│ │ │ │ │ ├── README.md
│ │ │ │ │ ├── requirements.txt
│ │ │ │ │ └── textual_inversion_bf16.py
│ │ │ │ └── textual_inversion_dfq/
│ │ │ │ ├── README.md
│ │ │ │ ├── requirements.txt
│ │ │ │ ├── text2images.py
│ │ │ │ └── textual_inversion.py
│ │ │ ├── lora/
│ │ │ │ ├── README.md
│ │ │ │ ├── requirements.txt
│ │ │ │ └── train_text_to_image_lora.py
│ │ │ ├── multi_subject_dreambooth/
│ │ │ │ ├── README.md
│ │ │ │ ├── requirements.txt
│ │ │ │ └── train_multi_subject_dreambooth.py
│ │ │ ├── multi_subject_dreambooth_inpainting/
│ │ │ │ ├── README.md
│ │ │ │ ├── requirements.txt
│ │ │ │ └── train_multi_subject_dreambooth_inpainting.py
│ │ │ ├── multi_token_textual_inversion/
│ │ │ │ ├── README.md
│ │ │ │ ├── multi_token_clip.py
│ │ │ │ ├── requirements.txt
│ │ │ │ ├── requirements_flax.txt
│ │ │ │ ├── textual_inversion.py
│ │ │ │ └── textual_inversion_flax.py
│ │ │ ├── onnxruntime/
│ │ │ │ ├── README.md
│ │ │ │ ├── text_to_image/
│ │ │ │ │ ├── README.md
│ │ │ │ │ ├── requirements.txt
│ │ │ │ │ └── train_text_to_image.py
│ │ │ │ ├── textual_inversion/
│ │ │ │ │ ├── README.md
│ │ │ │ │ ├── requirements.txt
│ │ │ │ │ └── textual_inversion.py
│ │ │ │ └── unconditional_image_generation/
│ │ │ │ ├── README.md
│ │ │ │ ├── requirements.txt
│ │ │ │ └── train_unconditional.py
│ │ │ ├── promptdiffusion/
│ │ │ │ ├── README.md
│ │ │ │ ├── convert_original_promptdiffusion_to_diffusers.py
│ │ │ │ ├── pipeline_prompt_diffusion.py
│ │ │ │ └── promptdiffusioncontrolnet.py
│ │ │ ├── rdm/
│ │ │ │ ├── README.md
│ │ │ │ ├── pipeline_rdm.py
│ │ │ │ └── retriever.py
│ │ │ ├── realfill/
│ │ │ │ ├── README.md
│ │ │ │ ├── infer.py
│ │ │ │ ├── requirements.txt
│ │ │ │ └── train_realfill.py
│ │ │ ├── scheduled_huber_loss_training/
│ │ │ │ ├── README.md
│ │ │ │ ├── dreambooth/
│ │ │ │ │ ├── train_dreambooth.py
│ │ │ │ │ ├── train_dreambooth_lora.py
│ │ │ │ │ └── train_dreambooth_lora_sdxl.py
│ │ │ │ └── text_to_image/
│ │ │ │ ├── train_text_to_image.py
│ │ │ │ ├── train_text_to_image_lora.py
│ │ │ │ ├── train_text_to_image_lora_sdxl.py
│ │ │ │ └── train_text_to_image_sdxl.py
│ │ │ └── sdxl_flax/
│ │ │ ├── README.md
│ │ │ ├── sdxl_single.py
│ │ │ └── sdxl_single_aot.py
│ │ ├── t2i_adapter/
│ │ │ ├── README.md
│ │ │ ├── README_sdxl.md
│ │ │ ├── requirements.txt
│ │ │ ├── test_t2i_adapter.py
│ │ │ └── train_t2i_adapter_sdxl.py
│ │ ├── test_examples_utils.py
│ │ ├── text_to_image/
│ │ │ ├── README.md
│ │ │ ├── README_sdxl.md
│ │ │ ├── requirements.txt
│ │ │ ├── requirements_flax.txt
│ │ │ ├── requirements_sdxl.txt
│ │ │ ├── test_text_to_image.py
│ │ │ ├── test_text_to_image_lora.py
│ │ │ ├── train_text_to_image.py
│ │ │ ├── train_text_to_image_flax.py
│ │ │ ├── train_text_to_image_lora.py
│ │ │ ├── train_text_to_image_lora_sdxl.py
│ │ │ └── train_text_to_image_sdxl.py
│ │ ├── textual_inversion/
│ │ │ ├── README.md
│ │ │ ├── README_sdxl.md
│ │ │ ├── requirements.txt
│ │ │ ├── requirements_flax.txt
│ │ │ ├── test_textual_inversion.py
│ │ │ ├── test_textual_inversion_sdxl.py
│ │ │ ├── textual_inversion.py
│ │ │ ├── textual_inversion_flax.py
│ │ │ └── textual_inversion_sdxl.py
│ │ ├── unconditional_image_generation/
│ │ │ ├── README.md
│ │ │ ├── requirements.txt
│ │ │ ├── test_unconditional.py
│ │ │ └── train_unconditional.py
│ │ ├── vqgan/
│ │ │ ├── README.md
│ │ │ ├── discriminator.py
│ │ │ ├── requirements.txt
│ │ │ ├── test_vqgan.py
│ │ │ └── train_vqgan.py
│ │ └── wuerstchen/
│ │ └── text_to_image/
│ │ ├── README.md
│ │ ├── __init__.py
│ │ ├── modeling_efficient_net_encoder.py
│ │ ├── requirements.txt
│ │ ├── train_text_to_image_lora_prior.py
│ │ └── train_text_to_image_prior.py
│ ├── pyproject.toml
│ ├── scripts/
│ │ ├── __init__.py
│ │ ├── change_naming_configs_and_checkpoints.py
│ │ ├── conversion_ldm_uncond.py
│ │ ├── convert_amused.py
│ │ ├── convert_animatediff_motion_lora_to_diffusers.py
│ │ ├── convert_animatediff_motion_module_to_diffusers.py
│ │ ├── convert_asymmetric_vqgan_to_diffusers.py
│ │ ├── convert_blipdiffusion_to_diffusers.py
│ │ ├── convert_consistency_decoder.py
│ │ ├── convert_consistency_to_diffusers.py
│ │ ├── convert_dance_diffusion_to_diffusers.py
│ │ ├── convert_ddpm_original_checkpoint_to_diffusers.py
│ │ ├── convert_diffusers_sdxl_lora_to_webui.py
│ │ ├── convert_diffusers_to_original_sdxl.py
│ │ ├── convert_diffusers_to_original_stable_diffusion.py
│ │ ├── convert_dit_to_diffusers.py
│ │ ├── convert_gligen_to_diffusers.py
│ │ ├── convert_i2vgen_to_diffusers.py
│ │ ├── convert_if.py
│ │ ├── convert_k_upscaler_to_diffusers.py
│ │ ├── convert_kakao_brain_unclip_to_diffusers.py
│ │ ├── convert_kandinsky3_unet.py
│ │ ├── convert_kandinsky_to_diffusers.py
│ │ ├── convert_ldm_original_checkpoint_to_diffusers.py
│ │ ├── convert_lora_safetensor_to_diffusers.py
│ │ ├── convert_models_diffuser_to_diffusers.py
│ │ ├── convert_ms_text_to_video_to_diffusers.py
│ │ ├── convert_music_spectrogram_to_diffusers.py
│ │ ├── convert_ncsnpp_original_checkpoint_to_diffusers.py
│ │ ├── convert_original_audioldm2_to_diffusers.py
│ │ ├── convert_original_audioldm_to_diffusers.py
│ │ ├── convert_original_controlnet_to_diffusers.py
│ │ ├── convert_original_musicldm_to_diffusers.py
│ │ ├── convert_original_stable_diffusion_to_diffusers.py
│ │ ├── convert_original_t2i_adapter.py
│ │ ├── convert_pixart_alpha_to_diffusers.py
│ │ ├── convert_pixart_sigma_to_diffusers.py
│ │ ├── convert_shap_e_to_diffusers.py
│ │ ├── convert_stable_cascade.py
│ │ ├── convert_stable_cascade_lite.py
│ │ ├── convert_stable_diffusion_checkpoint_to_onnx.py
│ │ ├── convert_stable_diffusion_controlnet_to_onnx.py
│ │ ├── convert_stable_diffusion_controlnet_to_tensorrt.py
│ │ ├── convert_svd_to_diffusers.py
│ │ ├── convert_tiny_autoencoder_to_diffusers.py
│ │ ├── convert_unclip_txt2img_to_image_variation.py
│ │ ├── convert_unidiffuser_to_diffusers.py
│ │ ├── convert_vae_diff_to_onnx.py
│ │ ├── convert_vae_pt_to_diffusers.py
│ │ ├── convert_versatile_diffusion_to_diffusers.py
│ │ ├── convert_vq_diffusion_to_diffusers.py
│ │ ├── convert_wuerstchen.py
│ │ ├── convert_zero123_to_diffusers.py
│ │ ├── generate_logits.py
│ │ └── log_reports.py
│ ├── setup.py
│ ├── src/
│ │ └── diffusers/
│ │ ├── __init__.py
│ │ ├── callbacks.py
│ │ ├── commands/
│ │ │ ├── __init__.py
│ │ │ ├── diffusers_cli.py
│ │ │ ├── env.py
│ │ │ └── fp16_safetensors.py
│ │ ├── configuration_utils.py
│ │ ├── dependency_versions_check.py
│ │ ├── dependency_versions_table.py
│ │ ├── experimental/
│ │ │ ├── README.md
│ │ │ ├── __init__.py
│ │ │ └── rl/
│ │ │ ├── __init__.py
│ │ │ └── value_guided_sampling.py
│ │ ├── image_processor.py
│ │ ├── loaders/
│ │ │ ├── __init__.py
│ │ │ ├── autoencoder.py
│ │ │ ├── controlnet.py
│ │ │ ├── ip_adapter.py
│ │ │ ├── lora.py
│ │ │ ├── lora_conversion_utils.py
│ │ │ ├── peft.py
│ │ │ ├── single_file.py
│ │ │ ├── single_file_model.py
│ │ │ ├── single_file_utils.py
│ │ │ ├── textual_inversion.py
│ │ │ ├── unet.py
│ │ │ ├── unet_loader_utils.py
│ │ │ └── utils.py
│ │ ├── models/
│ │ │ ├── README.md
│ │ │ ├── __init__.py
│ │ │ ├── activations.py
│ │ │ ├── adapter.py
│ │ │ ├── attention.py
│ │ │ ├── attention_flax.py
│ │ │ ├── attention_processor.py
│ │ │ ├── autoencoders/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── autoencoder_asym_kl.py
│ │ │ │ ├── autoencoder_kl.py
│ │ │ │ ├── autoencoder_kl_temporal_decoder.py
│ │ │ │ ├── autoencoder_tiny.py
│ │ │ │ ├── consistency_decoder_vae.py
│ │ │ │ ├── vae.py
│ │ │ │ └── vq_model.py
│ │ │ ├── controlnet.py
│ │ │ ├── controlnet_flax.py
│ │ │ ├── controlnet_xs.py
│ │ │ ├── downsampling.py
│ │ │ ├── embeddings.py
│ │ │ ├── embeddings_flax.py
│ │ │ ├── lora.py
│ │ │ ├── model_loading_utils.py
│ │ │ ├── modeling_flax_pytorch_utils.py
│ │ │ ├── modeling_flax_utils.py
│ │ │ ├── modeling_outputs.py
│ │ │ ├── modeling_pytorch_flax_utils.py
│ │ │ ├── modeling_utils.py
│ │ │ ├── normalization.py
│ │ │ ├── resnet.py
│ │ │ ├── resnet_flax.py
│ │ │ ├── transformers/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── dit_transformer_2d.py
│ │ │ │ ├── dual_transformer_2d.py
│ │ │ │ ├── hunyuan_transformer_2d.py
│ │ │ │ ├── pixart_transformer_2d.py
│ │ │ │ ├── prior_transformer.py
│ │ │ │ ├── t5_film_transformer.py
│ │ │ │ ├── transformer_2d.py
│ │ │ │ ├── transformer_sd3.py
│ │ │ │ └── transformer_temporal.py
│ │ │ ├── unets/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── unet_1d.py
│ │ │ │ ├── unet_1d_blocks.py
│ │ │ │ ├── unet_2d.py
│ │ │ │ ├── unet_2d_blocks.py
│ │ │ │ ├── unet_2d_blocks_flax.py
│ │ │ │ ├── unet_2d_condition.py
│ │ │ │ ├── unet_2d_condition_flax.py
│ │ │ │ ├── unet_3d_blocks.py
│ │ │ │ ├── unet_3d_condition.py
│ │ │ │ ├── unet_i2vgen_xl.py
│ │ │ │ ├── unet_kandinsky3.py
│ │ │ │ ├── unet_motion_model.py
│ │ │ │ ├── unet_spatio_temporal_condition.py
│ │ │ │ ├── unet_stable_cascade.py
│ │ │ │ └── uvit_2d.py
│ │ │ ├── upsampling.py
│ │ │ ├── vae_flax.py
│ │ │ └── vq_model.py
│ │ ├── optimization.py
│ │ ├── pipelines/
│ │ │ ├── README.md
│ │ │ ├── __init__.py
│ │ │ ├── amused/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── pipeline_amused.py
│ │ │ │ ├── pipeline_amused_img2img.py
│ │ │ │ └── pipeline_amused_inpaint.py
│ │ │ ├── animatediff/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── pipeline_animatediff.py
│ │ │ │ ├── pipeline_animatediff_sdxl.py
│ │ │ │ ├── pipeline_animatediff_video2video.py
│ │ │ │ └── pipeline_output.py
│ │ │ ├── audioldm/
│ │ │ │ ├── __init__.py
│ │ │ │ └── pipeline_audioldm.py
│ │ │ ├── audioldm2/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── modeling_audioldm2.py
│ │ │ │ └── pipeline_audioldm2.py
│ │ │ ├── auto_pipeline.py
│ │ │ ├── blip_diffusion/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── blip_image_processing.py
│ │ │ │ ├── modeling_blip2.py
│ │ │ │ ├── modeling_ctx_clip.py
│ │ │ │ └── pipeline_blip_diffusion.py
│ │ │ ├── consistency_models/
│ │ │ │ ├── __init__.py
│ │ │ │ └── pipeline_consistency_models.py
│ │ │ ├── controlnet/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── multicontrolnet.py
│ │ │ │ ├── pipeline_controlnet.py
│ │ │ │ ├── pipeline_controlnet_blip_diffusion.py
│ │ │ │ ├── pipeline_controlnet_img2img.py
│ │ │ │ ├── pipeline_controlnet_inpaint.py
│ │ │ │ ├── pipeline_controlnet_inpaint_sd_xl.py
│ │ │ │ ├── pipeline_controlnet_sd_xl.py
│ │ │ │ ├── pipeline_controlnet_sd_xl_img2img.py
│ │ │ │ └── pipeline_flax_controlnet.py
│ │ │ ├── controlnet_xs/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── pipeline_controlnet_xs.py
│ │ │ │ └── pipeline_controlnet_xs_sd_xl.py
│ │ │ ├── dance_diffusion/
│ │ │ │ ├── __init__.py
│ │ │ │ └── pipeline_dance_diffusion.py
│ │ │ ├── ddim/
│ │ │ │ ├── __init__.py
│ │ │ │ └── pipeline_ddim.py
│ │ │ ├── ddpm/
│ │ │ │ ├── __init__.py
│ │ │ │ └── pipeline_ddpm.py
│ │ │ ├── deepfloyd_if/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── pipeline_if.py
│ │ │ │ ├── pipeline_if_img2img.py
│ │ │ │ ├── pipeline_if_img2img_superresolution.py
│ │ │ │ ├── pipeline_if_inpainting.py
│ │ │ │ ├── pipeline_if_inpainting_superresolution.py
│ │ │ │ ├── pipeline_if_superresolution.py
│ │ │ │ ├── pipeline_output.py
│ │ │ │ ├── safety_checker.py
│ │ │ │ ├── timesteps.py
│ │ │ │ └── watermark.py
│ │ │ ├── deprecated/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── alt_diffusion/
│ │ │ │ │ ├── __init__.py
│ │ │ │ │ ├── modeling_roberta_series.py
│ │ │ │ │ ├── pipeline_alt_diffusion.py
│ │ │ │ │ ├── pipeline_alt_diffusion_img2img.py
│ │ │ │ │ └── pipeline_output.py
│ │ │ │ ├── audio_diffusion/
│ │ │ │ │ ├── __init__.py
│ │ │ │ │ ├── mel.py
│ │ │ │ │ └── pipeline_audio_diffusion.py
│ │ │ │ ├── latent_diffusion_uncond/
│ │ │ │ │ ├── __init__.py
│ │ │ │ │ └── pipeline_latent_diffusion_uncond.py
│ │ │ │ ├── pndm/
│ │ │ │ │ ├── __init__.py
│ │ │ │ │ └── pipeline_pndm.py
│ │ │ │ ├── repaint/
│ │ │ │ │ ├── __init__.py
│ │ │ │ │ └── pipeline_repaint.py
│ │ │ │ ├── score_sde_ve/
│ │ │ │ │ ├── __init__.py
│ │ │ │ │ └── pipeline_score_sde_ve.py
│ │ │ │ ├── spectrogram_diffusion/
│ │ │ │ │ ├── __init__.py
│ │ │ │ │ ├── continuous_encoder.py
│ │ │ │ │ ├── midi_utils.py
│ │ │ │ │ ├── notes_encoder.py
│ │ │ │ │ └── pipeline_spectrogram_diffusion.py
│ │ │ │ ├── stable_diffusion_variants/
│ │ │ │ │ ├── __init__.py
│ │ │ │ │ ├── pipeline_cycle_diffusion.py
│ │ │ │ │ ├── pipeline_onnx_stable_diffusion_inpaint_legacy.py
│ │ │ │ │ ├── pipeline_stable_diffusion_inpaint_legacy.py
│ │ │ │ │ ├── pipeline_stable_diffusion_model_editing.py
│ │ │ │ │ ├── pipeline_stable_diffusion_paradigms.py
│ │ │ │ │ └── pipeline_stable_diffusion_pix2pix_zero.py
│ │ │ │ ├── stochastic_karras_ve/
│ │ │ │ │ ├── __init__.py
│ │ │ │ │ └── pipeline_stochastic_karras_ve.py
│ │ │ │ ├── versatile_diffusion/
│ │ │ │ │ ├── __init__.py
│ │ │ │ │ ├── modeling_text_unet.py
│ │ │ │ │ ├── pipeline_versatile_diffusion.py
│ │ │ │ │ ├── pipeline_versatile_diffusion_dual_guided.py
│ │ │ │ │ ├── pipeline_versatile_diffusion_image_variation.py
│ │ │ │ │ └── pipeline_versatile_diffusion_text_to_image.py
│ │ │ │ └── vq_diffusion/
│ │ │ │ ├── __init__.py
│ │ │ │ └── pipeline_vq_diffusion.py
│ │ │ ├── dit/
│ │ │ │ ├── __init__.py
│ │ │ │ └── pipeline_dit.py
│ │ │ ├── free_init_utils.py
│ │ │ ├── hunyuandit/
│ │ │ │ ├── __init__.py
│ │ │ │ └── pipeline_hunyuandit.py
│ │ │ ├── i2vgen_xl/
│ │ │ │ ├── __init__.py
│ │ │ │ └── pipeline_i2vgen_xl.py
│ │ │ ├── kandinsky/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── pipeline_kandinsky.py
│ │ │ │ ├── pipeline_kandinsky_combined.py
│ │ │ │ ├── pipeline_kandinsky_img2img.py
│ │ │ │ ├── pipeline_kandinsky_inpaint.py
│ │ │ │ ├── pipeline_kandinsky_prior.py
│ │ │ │ └── text_encoder.py
│ │ │ ├── kandinsky2_2/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── pipeline_kandinsky2_2.py
│ │ │ │ ├── pipeline_kandinsky2_2_combined.py
│ │ │ │ ├── pipeline_kandinsky2_2_controlnet.py
│ │ │ │ ├── pipeline_kandinsky2_2_controlnet_img2img.py
│ │ │ │ ├── pipeline_kandinsky2_2_img2img.py
│ │ │ │ ├── pipeline_kandinsky2_2_inpainting.py
│ │ │ │ ├── pipeline_kandinsky2_2_prior.py
│ │ │ │ └── pipeline_kandinsky2_2_prior_emb2emb.py
│ │ │ ├── kandinsky3/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── convert_kandinsky3_unet.py
│ │ │ │ ├── pipeline_kandinsky3.py
│ │ │ │ └── pipeline_kandinsky3_img2img.py
│ │ │ ├── latent_consistency_models/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── pipeline_latent_consistency_img2img.py
│ │ │ │ └── pipeline_latent_consistency_text2img.py
│ │ │ ├── latent_diffusion/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── pipeline_latent_diffusion.py
│ │ │ │ └── pipeline_latent_diffusion_superresolution.py
│ │ │ ├── ledits_pp/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── pipeline_leditspp_stable_diffusion.py
│ │ │ │ ├── pipeline_leditspp_stable_diffusion_xl.py
│ │ │ │ └── pipeline_output.py
│ │ │ ├── marigold/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── marigold_image_processing.py
│ │ │ │ ├── pipeline_marigold_depth.py
│ │ │ │ └── pipeline_marigold_normals.py
│ │ │ ├── musicldm/
│ │ │ │ ├── __init__.py
│ │ │ │ └── pipeline_musicldm.py
│ │ │ ├── onnx_utils.py
│ │ │ ├── paint_by_example/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── image_encoder.py
│ │ │ │ └── pipeline_paint_by_example.py
│ │ │ ├── pia/
│ │ │ │ ├── __init__.py
│ │ │ │ └── pipeline_pia.py
│ │ │ ├── pipeline_flax_utils.py
│ │ │ ├── pipeline_loading_utils.py
│ │ │ ├── pipeline_utils.py
│ │ │ ├── pixart_alpha/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── pipeline_pixart_alpha.py
│ │ │ │ └── pipeline_pixart_sigma.py
│ │ │ ├── semantic_stable_diffusion/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── pipeline_output.py
│ │ │ │ └── pipeline_semantic_stable_diffusion.py
│ │ │ ├── shap_e/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── camera.py
│ │ │ │ ├── pipeline_shap_e.py
│ │ │ │ ├── pipeline_shap_e_img2img.py
│ │ │ │ └── renderer.py
│ │ │ ├── stable_cascade/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── pipeline_stable_cascade.py
│ │ │ │ ├── pipeline_stable_cascade_combined.py
│ │ │ │ └── pipeline_stable_cascade_prior.py
│ │ │ ├── stable_diffusion/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── clip_image_project_model.py
│ │ │ │ ├── convert_from_ckpt.py
│ │ │ │ ├── pipeline_flax_stable_diffusion.py
│ │ │ │ ├── pipeline_flax_stable_diffusion_img2img.py
│ │ │ │ ├── pipeline_flax_stable_diffusion_inpaint.py
│ │ │ │ ├── pipeline_onnx_stable_diffusion.py
│ │ │ │ ├── pipeline_onnx_stable_diffusion_img2img.py
│ │ │ │ ├── pipeline_onnx_stable_diffusion_inpaint.py
│ │ │ │ ├── pipeline_onnx_stable_diffusion_upscale.py
│ │ │ │ ├── pipeline_output.py
│ │ │ │ ├── pipeline_stable_diffusion.py
│ │ │ │ ├── pipeline_stable_diffusion_depth2img.py
│ │ │ │ ├── pipeline_stable_diffusion_image_variation.py
│ │ │ │ ├── pipeline_stable_diffusion_img2img.py
│ │ │ │ ├── pipeline_stable_diffusion_inpaint.py
│ │ │ │ ├── pipeline_stable_diffusion_instruct_pix2pix.py
│ │ │ │ ├── pipeline_stable_diffusion_latent_upscale.py
│ │ │ │ ├── pipeline_stable_diffusion_upscale.py
│ │ │ │ ├── pipeline_stable_unclip.py
│ │ │ │ ├── pipeline_stable_unclip_img2img.py
│ │ │ │ ├── safety_checker.py
│ │ │ │ ├── safety_checker_flax.py
│ │ │ │ └── stable_unclip_image_normalizer.py
│ │ │ ├── stable_diffusion_3/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── pipeline_output.py
│ │ │ │ ├── pipeline_stable_diffusion_3.py
│ │ │ │ ├── pipeline_stable_diffusion_3_img2img.py
│ │ │ │ └── pipeline_stable_diffusion_3_instructpix2pix.py
│ │ │ ├── stable_diffusion_attend_and_excite/
│ │ │ │ ├── __init__.py
│ │ │ │ └── pipeline_stable_diffusion_attend_and_excite.py
│ │ │ ├── stable_diffusion_diffedit/
│ │ │ │ ├── __init__.py
│ │ │ │ └── pipeline_stable_diffusion_diffedit.py
│ │ │ ├── stable_diffusion_gligen/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── pipeline_stable_diffusion_gligen.py
│ │ │ │ └── pipeline_stable_diffusion_gligen_text_image.py
│ │ │ ├── stable_diffusion_k_diffusion/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── pipeline_stable_diffusion_k_diffusion.py
│ │ │ │ └── pipeline_stable_diffusion_xl_k_diffusion.py
│ │ │ ├── stable_diffusion_ldm3d/
│ │ │ │ ├── __init__.py
│ │ │ │ └── pipeline_stable_diffusion_ldm3d.py
│ │ │ ├── stable_diffusion_panorama/
│ │ │ │ ├── __init__.py
│ │ │ │ └── pipeline_stable_diffusion_panorama.py
│ │ │ ├── stable_diffusion_safe/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── pipeline_output.py
│ │ │ │ ├── pipeline_stable_diffusion_safe.py
│ │ │ │ └── safety_checker.py
│ │ │ ├── stable_diffusion_sag/
│ │ │ │ ├── __init__.py
│ │ │ │ └── pipeline_stable_diffusion_sag.py
│ │ │ ├── stable_diffusion_xl/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── pipeline_flax_stable_diffusion_xl.py
│ │ │ │ ├── pipeline_output.py
│ │ │ │ ├── pipeline_stable_diffusion_xl.py
│ │ │ │ ├── pipeline_stable_diffusion_xl_img2img.py
│ │ │ │ ├── pipeline_stable_diffusion_xl_inpaint.py
│ │ │ │ ├── pipeline_stable_diffusion_xl_instruct_pix2pix.py
│ │ │ │ └── watermark.py
│ │ │ ├── stable_video_diffusion/
│ │ │ │ ├── __init__.py
│ │ │ │ └── pipeline_stable_video_diffusion.py
│ │ │ ├── t2i_adapter/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── pipeline_stable_diffusion_adapter.py
│ │ │ │ └── pipeline_stable_diffusion_xl_adapter.py
│ │ │ ├── text_to_video_synthesis/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── pipeline_output.py
│ │ │ │ ├── pipeline_text_to_video_synth.py
│ │ │ │ ├── pipeline_text_to_video_synth_img2img.py
│ │ │ │ ├── pipeline_text_to_video_zero.py
│ │ │ │ └── pipeline_text_to_video_zero_sdxl.py
│ │ │ ├── unclip/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── pipeline_unclip.py
│ │ │ │ ├── pipeline_unclip_image_variation.py
│ │ │ │ └── text_proj.py
│ │ │ ├── unidiffuser/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── modeling_text_decoder.py
│ │ │ │ ├── modeling_uvit.py
│ │ │ │ └── pipeline_unidiffuser.py
│ │ │ └── wuerstchen/
│ │ │ ├── __init__.py
│ │ │ ├── modeling_paella_vq_model.py
│ │ │ ├── modeling_wuerstchen_common.py
│ │ │ ├── modeling_wuerstchen_diffnext.py
│ │ │ ├── modeling_wuerstchen_prior.py
│ │ │ ├── pipeline_wuerstchen.py
│ │ │ ├── pipeline_wuerstchen_combined.py
│ │ │ └── pipeline_wuerstchen_prior.py
│ │ ├── py.typed
│ │ ├── schedulers/
│ │ │ ├── README.md
│ │ │ ├── __init__.py
│ │ │ ├── deprecated/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── scheduling_karras_ve.py
│ │ │ │ └── scheduling_sde_vp.py
│ │ │ ├── scheduling_amused.py
│ │ │ ├── scheduling_consistency_decoder.py
│ │ │ ├── scheduling_consistency_models.py
│ │ │ ├── scheduling_ddim.py
│ │ │ ├── scheduling_ddim_flax.py
│ │ │ ├── scheduling_ddim_inverse.py
│ │ │ ├── scheduling_ddim_parallel.py
│ │ │ ├── scheduling_ddpm.py
│ │ │ ├── scheduling_ddpm_flax.py
│ │ │ ├── scheduling_ddpm_parallel.py
│ │ │ ├── scheduling_ddpm_wuerstchen.py
│ │ │ ├── scheduling_deis_multistep.py
│ │ │ ├── scheduling_dpmsolver_multistep.py
│ │ │ ├── scheduling_dpmsolver_multistep_flax.py
│ │ │ ├── scheduling_dpmsolver_multistep_inverse.py
│ │ │ ├── scheduling_dpmsolver_sde.py
│ │ │ ├── scheduling_dpmsolver_singlestep.py
│ │ │ ├── scheduling_edm_dpmsolver_multistep.py
│ │ │ ├── scheduling_edm_euler.py
│ │ │ ├── scheduling_euler_ancestral_discrete.py
│ │ │ ├── scheduling_euler_discrete.py
│ │ │ ├── scheduling_euler_discrete_flax.py
│ │ │ ├── scheduling_flow_match_euler_discrete.py
│ │ │ ├── scheduling_heun_discrete.py
│ │ │ ├── scheduling_ipndm.py
│ │ │ ├── scheduling_k_dpm_2_ancestral_discrete.py
│ │ │ ├── scheduling_k_dpm_2_discrete.py
│ │ │ ├── scheduling_karras_ve_flax.py
│ │ │ ├── scheduling_lcm.py
│ │ │ ├── scheduling_lms_discrete.py
│ │ │ ├── scheduling_lms_discrete_flax.py
│ │ │ ├── scheduling_pndm.py
│ │ │ ├── scheduling_pndm_flax.py
│ │ │ ├── scheduling_repaint.py
│ │ │ ├── scheduling_sasolver.py
│ │ │ ├── scheduling_sde_ve.py
│ │ │ ├── scheduling_sde_ve_flax.py
│ │ │ ├── scheduling_tcd.py
│ │ │ ├── scheduling_unclip.py
│ │ │ ├── scheduling_unipc_multistep.py
│ │ │ ├── scheduling_utils.py
│ │ │ ├── scheduling_utils_flax.py
│ │ │ └── scheduling_vq_diffusion.py
│ │ ├── training_utils.py
│ │ ├── utils/
│ │ │ ├── __init__.py
│ │ │ ├── accelerate_utils.py
│ │ │ ├── constants.py
│ │ │ ├── deprecation_utils.py
│ │ │ ├── doc_utils.py
│ │ │ ├── dummy_flax_and_transformers_objects.py
│ │ │ ├── dummy_flax_objects.py
│ │ │ ├── dummy_note_seq_objects.py
│ │ │ ├── dummy_onnx_objects.py
│ │ │ ├── dummy_pt_objects.py
│ │ │ ├── dummy_torch_and_librosa_objects.py
│ │ │ ├── dummy_torch_and_scipy_objects.py
│ │ │ ├── dummy_torch_and_torchsde_objects.py
│ │ │ ├── dummy_torch_and_transformers_and_k_diffusion_objects.py
│ │ │ ├── dummy_torch_and_transformers_and_onnx_objects.py
│ │ │ ├── dummy_torch_and_transformers_objects.py
│ │ │ ├── dummy_transformers_and_torch_and_note_seq_objects.py
│ │ │ ├── dynamic_modules_utils.py
│ │ │ ├── export_utils.py
│ │ │ ├── hub_utils.py
│ │ │ ├── import_utils.py
│ │ │ ├── loading_utils.py
│ │ │ ├── logging.py
│ │ │ ├── model_card_template.md
│ │ │ ├── outputs.py
│ │ │ ├── peft_utils.py
│ │ │ ├── pil_utils.py
│ │ │ ├── state_dict_utils.py
│ │ │ ├── testing_utils.py
│ │ │ ├── torch_utils.py
│ │ │ └── versions.py
│ │ └── video_processor.py
│ ├── subd_112030.err
│ ├── subh_112029.err
│ ├── tests/
│ │ ├── __init__.py
│ │ ├── conftest.py
│ │ ├── fixtures/
│ │ │ ├── custom_pipeline/
│ │ │ │ ├── pipeline.py
│ │ │ │ └── what_ever.py
│ │ │ └── elise_format0.mid
│ │ ├── lora/
│ │ │ ├── test_lora_layers_sd.py
│ │ │ ├── test_lora_layers_sd3.py
│ │ │ ├── test_lora_layers_sdxl.py
│ │ │ └── utils.py
│ │ ├── models/
│ │ │ ├── __init__.py
│ │ │ ├── autoencoders/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── test_models_vae.py
│ │ │ │ ├── test_models_vae_flax.py
│ │ │ │ └── test_models_vq.py
│ │ │ ├── test_activations.py
│ │ │ ├── test_attention_processor.py
│ │ │ ├── test_layers_utils.py
│ │ │ ├── test_modeling_common.py
│ │ │ ├── test_modeling_common_flax.py
│ │ │ ├── transformers/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── test_models_dit_transformer2d.py
│ │ │ │ ├── test_models_pixart_transformer2d.py
│ │ │ │ ├── test_models_prior.py
│ │ │ │ └── test_models_transformer_sd3.py
│ │ │ └── unets/
│ │ │ ├── __init__.py
│ │ │ ├── test_models_unet_1d.py
│ │ │ ├── test_models_unet_2d.py
│ │ │ ├── test_models_unet_2d_condition.py
│ │ │ ├── test_models_unet_2d_flax.py
│ │ │ ├── test_models_unet_3d_condition.py
│ │ │ ├── test_models_unet_controlnetxs.py
│ │ │ ├── test_models_unet_motion.py
│ │ │ ├── test_models_unet_spatiotemporal.py
│ │ │ ├── test_unet_2d_blocks.py
│ │ │ └── test_unet_blocks_common.py
│ │ ├── others/
│ │ │ ├── test_check_copies.py
│ │ │ ├── test_check_dummies.py
│ │ │ ├── test_config.py
│ │ │ ├── test_dependencies.py
│ │ │ ├── test_ema.py
│ │ │ ├── test_hub_utils.py
│ │ │ ├── test_image_processor.py
│ │ │ ├── test_outputs.py
│ │ │ ├── test_training.py
│ │ │ ├── test_utils.py
│ │ │ └── test_video_processor.py
│ │ ├── pipelines/
│ │ │ ├── __init__.py
│ │ │ ├── amused/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── test_amused.py
│ │ │ │ ├── test_amused_img2img.py
│ │ │ │ └── test_amused_inpaint.py
│ │ │ ├── animatediff/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── test_animatediff.py
│ │ │ │ ├── test_animatediff_sdxl.py
│ │ │ │ └── test_animatediff_video2video.py
│ │ │ ├── audioldm/
│ │ │ │ ├── __init__.py
│ │ │ │ └── test_audioldm.py
│ │ │ ├── audioldm2/
│ │ │ │ ├── __init__.py
│ │ │ │ └── test_audioldm2.py
│ │ │ ├── blipdiffusion/
│ │ │ │ ├── __init__.py
│ │ │ │ └── test_blipdiffusion.py
│ │ │ ├── consistency_models/
│ │ │ │ ├── __init__.py
│ │ │ │ └── test_consistency_models.py
│ │ │ ├── controlnet/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── test_controlnet.py
│ │ │ │ ├── test_controlnet_blip_diffusion.py
│ │ │ │ ├── test_controlnet_img2img.py
│ │ │ │ ├── test_controlnet_inpaint.py
│ │ │ │ ├── test_controlnet_inpaint_sdxl.py
│ │ │ │ ├── test_controlnet_sdxl.py
│ │ │ │ ├── test_controlnet_sdxl_img2img.py
│ │ │ │ └── test_flax_controlnet.py
│ │ │ ├── controlnet_xs/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── test_controlnetxs.py
│ │ │ │ └── test_controlnetxs_sdxl.py
│ │ │ ├── dance_diffusion/
│ │ │ │ ├── __init__.py
│ │ │ │ └── test_dance_diffusion.py
│ │ │ ├── ddim/
│ │ │ │ ├── __init__.py
│ │ │ │ └── test_ddim.py
│ │ │ ├── ddpm/
│ │ │ │ ├── __init__.py
│ │ │ │ └── test_ddpm.py
│ │ │ ├── deepfloyd_if/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── test_if.py
│ │ │ │ ├── test_if_img2img.py
│ │ │ │ ├── test_if_img2img_superresolution.py
│ │ │ │ ├── test_if_inpainting.py
│ │ │ │ ├── test_if_inpainting_superresolution.py
│ │ │ │ └── test_if_superresolution.py
│ │ │ ├── dit/
│ │ │ │ ├── __init__.py
│ │ │ │ └── test_dit.py
│ │ │ ├── hunyuan_dit/
│ │ │ │ ├── __init__.py
│ │ │ │ └── test_hunyuan_dit.py
│ │ │ ├── i2vgen_xl/
│ │ │ │ ├── __init__.py
│ │ │ │ └── test_i2vgenxl.py
│ │ │ ├── ip_adapters/
│ │ │ │ └── test_ip_adapter_stable_diffusion.py
│ │ │ ├── kandinsky/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── test_kandinsky.py
│ │ │ │ ├── test_kandinsky_combined.py
│ │ │ │ ├── test_kandinsky_img2img.py
│ │ │ │ ├── test_kandinsky_inpaint.py
│ │ │ │ └── test_kandinsky_prior.py
│ │ │ ├── kandinsky2_2/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── test_kandinsky.py
│ │ │ │ ├── test_kandinsky_combined.py
│ │ │ │ ├── test_kandinsky_controlnet.py
│ │ │ │ ├── test_kandinsky_controlnet_img2img.py
│ │ │ │ ├── test_kandinsky_img2img.py
│ │ │ │ ├── test_kandinsky_inpaint.py
│ │ │ │ ├── test_kandinsky_prior.py
│ │ │ │ └── test_kandinsky_prior_emb2emb.py
│ │ │ ├── kandinsky3/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── test_kandinsky3.py
│ │ │ │ └── test_kandinsky3_img2img.py
│ │ │ ├── latent_consistency_models/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── test_latent_consistency_models.py
│ │ │ │ └── test_latent_consistency_models_img2img.py
│ │ │ ├── latent_diffusion/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── test_latent_diffusion.py
│ │ │ │ └── test_latent_diffusion_superresolution.py
│ │ │ ├── ledits_pp/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── test_ledits_pp_stable_diffusion.py
│ │ │ │ └── test_ledits_pp_stable_diffusion_xl.py
│ │ │ ├── marigold/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── test_marigold_depth.py
│ │ │ │ └── test_marigold_normals.py
│ │ │ ├── musicldm/
│ │ │ │ ├── __init__.py
│ │ │ │ └── test_musicldm.py
│ │ │ ├── paint_by_example/
│ │ │ │ ├── __init__.py
│ │ │ │ └── test_paint_by_example.py
│ │ │ ├── pia/
│ │ │ │ ├── __init__.py
│ │ │ │ └── test_pia.py
│ │ │ ├── pipeline_params.py
│ │ │ ├── pixart_alpha/
│ │ │ │ ├── __init__.py
│ │ │ │ └── test_pixart.py
│ │ │ ├── pixart_sigma/
│ │ │ │ ├── __init__.py
│ │ │ │ └── test_pixart.py
│ │ │ ├── pndm/
│ │ │ │ ├── __init__.py
│ │ │ │ └── test_pndm.py
│ │ │ ├── semantic_stable_diffusion/
│ │ │ │ ├── __init__.py
│ │ │ │ └── test_semantic_diffusion.py
│ │ │ ├── shap_e/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── test_shap_e.py
│ │ │ │ └── test_shap_e_img2img.py
│ │ │ ├── stable_cascade/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── test_stable_cascade_combined.py
│ │ │ │ ├── test_stable_cascade_decoder.py
│ │ │ │ └── test_stable_cascade_prior.py
│ │ │ ├── stable_diffusion/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── test_onnx_stable_diffusion.py
│ │ │ │ ├── test_onnx_stable_diffusion_img2img.py
│ │ │ │ ├── test_onnx_stable_diffusion_inpaint.py
│ │ │ │ ├── test_onnx_stable_diffusion_upscale.py
│ │ │ │ ├── test_stable_diffusion.py
│ │ │ │ ├── test_stable_diffusion_img2img.py
│ │ │ │ ├── test_stable_diffusion_inpaint.py
│ │ │ │ └── test_stable_diffusion_instruction_pix2pix.py
│ │ │ ├── stable_diffusion_2/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── test_stable_diffusion.py
│ │ │ │ ├── test_stable_diffusion_attend_and_excite.py
│ │ │ │ ├── test_stable_diffusion_depth.py
│ │ │ │ ├── test_stable_diffusion_diffedit.py
│ │ │ │ ├── test_stable_diffusion_flax.py
│ │ │ │ ├── test_stable_diffusion_flax_inpaint.py
│ │ │ │ ├── test_stable_diffusion_inpaint.py
│ │ │ │ ├── test_stable_diffusion_latent_upscale.py
│ │ │ │ ├── test_stable_diffusion_upscale.py
│ │ │ │ └── test_stable_diffusion_v_pred.py
│ │ │ ├── stable_diffusion_3/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── test_pipeline_stable_diffusion_3.py
│ │ │ │ └── test_pipeline_stable_diffusion_3_img2img.py
│ │ │ ├── stable_diffusion_adapter/
│ │ │ │ ├── __init__.py
│ │ │ │ └── test_stable_diffusion_adapter.py
│ │ │ ├── stable_diffusion_gligen/
│ │ │ │ ├── __init__.py
│ │ │ │ └── test_stable_diffusion_gligen.py
│ │ │ ├── stable_diffusion_gligen_text_image/
│ │ │ │ ├── __init__.py
│ │ │ │ └── test_stable_diffusion_gligen_text_image.py
│ │ │ ├── stable_diffusion_image_variation/
│ │ │ │ ├── __init__.py
│ │ │ │ └── test_stable_diffusion_image_variation.py
│ │ │ ├── stable_diffusion_k_diffusion/
│ │ │ │ ├── __init__.py
│ │ │ │ └── test_stable_diffusion_k_diffusion.py
│ │ │ ├── stable_diffusion_ldm3d/
│ │ │ │ ├── __init__.py
│ │ │ │ └── test_stable_diffusion_ldm3d.py
│ │ │ ├── stable_diffusion_panorama/
│ │ │ │ ├── __init__.py
│ │ │ │ └── test_stable_diffusion_panorama.py
│ │ │ ├── stable_diffusion_safe/
│ │ │ │ ├── __init__.py
│ │ │ │ └── test_safe_diffusion.py
│ │ │ ├── stable_diffusion_sag/
│ │ │ │ ├── __init__.py
│ │ │ │ └── test_stable_diffusion_sag.py
│ │ │ ├── stable_diffusion_xl/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── test_stable_diffusion_xl.py
│ │ │ │ ├── test_stable_diffusion_xl_adapter.py
│ │ │ │ ├── test_stable_diffusion_xl_img2img.py
│ │ │ │ ├── test_stable_diffusion_xl_inpaint.py
│ │ │ │ ├── test_stable_diffusion_xl_instruction_pix2pix.py
│ │ │ │ └── test_stable_diffusion_xl_k_diffusion.py
│ │ │ ├── stable_unclip/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── test_stable_unclip.py
│ │ │ │ └── test_stable_unclip_img2img.py
│ │ │ ├── stable_video_diffusion/
│ │ │ │ ├── __init__.py
│ │ │ │ └── test_stable_video_diffusion.py
│ │ │ ├── test_pipeline_utils.py
│ │ │ ├── test_pipelines.py
│ │ │ ├── test_pipelines_auto.py
│ │ │ ├── test_pipelines_combined.py
│ │ │ ├── test_pipelines_common.py
│ │ │ ├── test_pipelines_flax.py
│ │ │ ├── test_pipelines_onnx_common.py
│ │ │ ├── text_to_video_synthesis/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── test_text_to_video.py
│ │ │ │ ├── test_text_to_video_zero.py
│ │ │ │ ├── test_text_to_video_zero_sdxl.py
│ │ │ │ └── test_video_to_video.py
│ │ │ ├── unclip/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── test_unclip.py
│ │ │ │ └── test_unclip_image_variation.py
│ │ │ ├── unidiffuser/
│ │ │ │ ├── __init__.py
│ │ │ │ └── test_unidiffuser.py
│ │ │ └── wuerstchen/
│ │ │ ├── __init__.py
│ │ │ ├── test_wuerstchen_combined.py
│ │ │ ├── test_wuerstchen_decoder.py
│ │ │ └── test_wuerstchen_prior.py
│ │ ├── schedulers/
│ │ │ ├── __init__.py
│ │ │ ├── test_scheduler_consistency_model.py
│ │ │ ├── test_scheduler_ddim.py
│ │ │ ├── test_scheduler_ddim_inverse.py
│ │ │ ├── test_scheduler_ddim_parallel.py
│ │ │ ├── test_scheduler_ddpm.py
│ │ │ ├── test_scheduler_ddpm_parallel.py
│ │ │ ├── test_scheduler_deis.py
│ │ │ ├── test_scheduler_dpm_multi.py
│ │ │ ├── test_scheduler_dpm_multi_inverse.py
│ │ │ ├── test_scheduler_dpm_sde.py
│ │ │ ├── test_scheduler_dpm_single.py
│ │ │ ├── test_scheduler_edm_dpmsolver_multistep.py
│ │ │ ├── test_scheduler_edm_euler.py
│ │ │ ├── test_scheduler_euler.py
│ │ │ ├── test_scheduler_euler_ancestral.py
│ │ │ ├── test_scheduler_flax.py
│ │ │ ├── test_scheduler_heun.py
│ │ │ ├── test_scheduler_ipndm.py
│ │ │ ├── test_scheduler_kdpm2_ancestral.py
│ │ │ ├── test_scheduler_kdpm2_discrete.py
│ │ │ ├── test_scheduler_lcm.py
│ │ │ ├── test_scheduler_lms.py
│ │ │ ├── test_scheduler_pndm.py
│ │ │ ├── test_scheduler_sasolver.py
│ │ │ ├── test_scheduler_score_sde_ve.py
│ │ │ ├── test_scheduler_tcd.py
│ │ │ ├── test_scheduler_unclip.py
│ │ │ ├── test_scheduler_unipc.py
│ │ │ ├── test_scheduler_vq_diffusion.py
│ │ │ └── test_schedulers.py
│ │ └── single_file/
│ │ ├── __init__.py
│ │ ├── single_file_testing_utils.py
│ │ ├── test_model_controlnet_single_file.py
│ │ ├── test_model_sd_cascade_unet_single_file.py
│ │ ├── test_model_vae_single_file.py
│ │ ├── test_stable_diffusion_controlnet_img2img_single_file.py
│ │ ├── test_stable_diffusion_controlnet_inpaint_single_file.py
│ │ ├── test_stable_diffusion_controlnet_single_file.py
│ │ ├── test_stable_diffusion_img2img_single_file.py
│ │ ├── test_stable_diffusion_inpaint_single_file.py
│ │ ├── test_stable_diffusion_single_file.py
│ │ ├── test_stable_diffusion_upscale_single_file.py
│ │ ├── test_stable_diffusion_xl_adapter_single_file.py
│ │ ├── test_stable_diffusion_xl_controlnet_single_file.py
│ │ ├── test_stable_diffusion_xl_img2img_single_file.py
│ │ ├── test_stable_diffusion_xl_instruct_pix2pix.py
│ │ └── test_stable_diffusion_xl_single_file.py
│ └── utils/
│ ├── check_config_docstrings.py
│ ├── check_copies.py
│ ├── check_doc_toc.py
│ ├── check_dummies.py
│ ├── check_inits.py
│ ├── check_repo.py
│ ├── check_table.py
│ ├── custom_init_isort.py
│ ├── fetch_latest_release_branch.py
│ ├── fetch_torch_cuda_pipeline_test_matrix.py
│ ├── get_modified_files.py
│ ├── notify_slack_about_release.py
│ ├── overwrite_expected_slice.py
│ ├── print_env.py
│ ├── release.py
│ ├── stale.py
│ ├── tests_fetcher.py
│ └── update_metadata.py
├── example.py
├── requirements.txt
├── scripts/
│ ├── run_sft_512_sd3_stage1.sh
│ ├── run_sft_512_sdxl_stage1.sh
│ ├── run_sft_512_sdxl_with_mask_stage2.sh
│ └── run_sft_512_with_mask_sd3_stage2.sh
└── traning/
├── train_sd3_pix2pix.py
└── train_sdxl_pix2pix.py
Showing preview only (1,233K chars total). Download the full file or copy to clipboard to get everything.
SYMBOL INDEX (14100 symbols across 926 files)
FILE: app.py
function generate (line 16) | def generate(image_mask, prompt, num_inference_steps=50, image_guidance_...
FILE: data_generation/Grounded-Segment-Anything/EfficientSAM/EdgeSAM/common.py
class MLPBlock (line 14) | class MLPBlock(nn.Module):
method __init__ (line 15) | def __init__(
method forward (line 26) | def forward(self, x: torch.Tensor) -> torch.Tensor:
class LayerNorm2d (line 32) | class LayerNorm2d(nn.Module):
method __init__ (line 33) | def __init__(self, num_channels: int, eps: float = 1e-6) -> None:
method forward (line 39) | def forward(self, x: torch.Tensor) -> torch.Tensor:
function val2list (line 47) | def val2list(x: list or tuple or any, repeat_time=1) -> list:
function val2tuple (line 53) | def val2tuple(x: list or tuple or any, min_len: int = 1, idx_repeat: int...
function list_sum (line 63) | def list_sum(x: list) -> any:
function resize (line 67) | def resize(
class UpSampleLayer (line 88) | class UpSampleLayer(nn.Module):
method __init__ (line 89) | def __init__(
method forward (line 102) | def forward(self, x: torch.Tensor) -> torch.Tensor:
class OpSequential (line 106) | class OpSequential(nn.Module):
method __init__ (line 107) | def __init__(self, op_list):
method forward (line 115) | def forward(self, x: torch.Tensor) -> torch.Tensor:
FILE: data_generation/Grounded-Segment-Anything/EfficientSAM/EdgeSAM/rep_vit.py
function _make_divisible (line 103) | def _make_divisible(v, divisor, min_value=None):
class Conv2d_BN (line 128) | class Conv2d_BN(torch.nn.Sequential):
method __init__ (line 129) | def __init__(self, a, b, ks=1, stride=1, pad=0, dilation=1,
method fuse (line 139) | def fuse(self):
class Residual (line 154) | class Residual(torch.nn.Module):
method __init__ (line 155) | def __init__(self, m, drop=0.):
method forward (line 160) | def forward(self, x):
method fuse (line 168) | def fuse(self):
class RepVGGDW (line 187) | class RepVGGDW(torch.nn.Module):
method __init__ (line 188) | def __init__(self, ed) -> None:
method forward (line 194) | def forward(self, x):
method fuse (line 198) | def fuse(self):
class RepViTBlock (line 220) | class RepViTBlock(nn.Module):
method __init__ (line 221) | def __init__(self, inp, hidden_dim, oup, kernel_size, stride, use_se, ...
method forward (line 257) | def forward(self, x):
class BN_Linear (line 264) | class BN_Linear(torch.nn.Sequential):
method __init__ (line 265) | def __init__(self, a, b, bias=True, std=0.02):
method fuse (line 274) | def fuse(self):
class RepViT (line 290) | class RepViT(nn.Module):
method __init__ (line 297) | def __init__(self, arch, img_size=1024, upsample_mode='bicubic'):
method forward (line 339) | def forward(self, x):
function rep_vit_m1 (line 361) | def rep_vit_m1(img_size=1024, **kwargs):
function rep_vit_m2 (line 365) | def rep_vit_m2(img_size=1024, **kwargs):
function rep_vit_m3 (line 369) | def rep_vit_m3(img_size=1024, **kwargs):
FILE: data_generation/Grounded-Segment-Anything/EfficientSAM/EdgeSAM/setup_edge_sam.py
function build_edge_sam (line 21) | def build_edge_sam(checkpoint=None, upsample_mode="bicubic"):
function _build_sam_encoder (line 35) | def _build_sam_encoder(
function _build_sam (line 58) | def _build_sam(
FILE: data_generation/Grounded-Segment-Anything/EfficientSAM/FastSAM/tools.py
function convert_box_xywh_to_xyxy (line 10) | def convert_box_xywh_to_xyxy(box):
function segment_image (line 18) | def segment_image(image, bbox):
function format_results (line 35) | def format_results(result, filter=0):
function filter_masks (line 53) | def filter_masks(annotations): # filte the overlap mask
function get_bbox_from_mask (line 71) | def get_bbox_from_mask(mask):
function fast_process (line 91) | def fast_process(
function fast_show_mask (line 180) | def fast_show_mask(
function fast_show_mask_gpu (line 246) | def fast_show_mask_gpu(
function retriev (line 313) | def retriev(
function crop_image (line 327) | def crop_image(annotations, image_path):
function box_prompt (line 351) | def box_prompt(masks, bbox, target_height, target_width):
function point_prompt (line 379) | def point_prompt(masks, points, pointlabel, target_height, target_width)...
function text_prompt (line 402) | def text_prompt(annotations, args):
FILE: data_generation/Grounded-Segment-Anything/EfficientSAM/LightHQSAM/setup_light_hqsam.py
function setup_model (line 4) | def setup_model():
FILE: data_generation/Grounded-Segment-Anything/EfficientSAM/LightHQSAM/tiny_vit_sam.py
class Conv2d_BN (line 21) | class Conv2d_BN(torch.nn.Sequential):
method __init__ (line 22) | def __init__(self, a, b, ks=1, stride=1, pad=0, dilation=1,
method fuse (line 33) | def fuse(self):
class DropPath (line 46) | class DropPath(TimmDropPath):
method __init__ (line 47) | def __init__(self, drop_prob=None):
method __repr__ (line 51) | def __repr__(self):
class PatchEmbed (line 57) | class PatchEmbed(nn.Module):
method __init__ (line 58) | def __init__(self, in_chans, embed_dim, resolution, activation):
method forward (line 73) | def forward(self, x):
class MBConv (line 77) | class MBConv(nn.Module):
method __init__ (line 78) | def __init__(self, in_chans, out_chans, expand_ratio,
method forward (line 99) | def forward(self, x):
class PatchMerging (line 118) | class PatchMerging(nn.Module):
method __init__ (line 119) | def __init__(self, input_resolution, dim, out_dim, activation):
method forward (line 133) | def forward(self, x):
class ConvLayer (line 150) | class ConvLayer(nn.Module):
method __init__ (line 151) | def __init__(self, dim, input_resolution, depth,
method forward (line 178) | def forward(self, x):
class Mlp (line 189) | class Mlp(nn.Module):
method __init__ (line 190) | def __init__(self, in_features, hidden_features=None,
method forward (line 201) | def forward(self, x):
class Attention (line 212) | class Attention(torch.nn.Module):
method __init__ (line 213) | def __init__(self, dim, key_dim, num_heads=8,
method train (line 251) | def train(self, mode=True):
method forward (line 260) | def forward(self, x): # x (B,N,C)
class TinyViTBlock (line 287) | class TinyViTBlock(nn.Module):
method __init__ (line 303) | def __init__(self, dim, input_resolution, num_heads, window_size=7,
method forward (line 335) | def forward(self, x):
method extra_repr (line 378) | def extra_repr(self) -> str:
class BasicLayer (line 383) | class BasicLayer(nn.Module):
method __init__ (line 402) | def __init__(self, dim, input_resolution, depth, num_heads, window_size,
method forward (line 436) | def forward(self, x):
method extra_repr (line 446) | def extra_repr(self) -> str:
class LayerNorm2d (line 449) | class LayerNorm2d(nn.Module):
method __init__ (line 450) | def __init__(self, num_channels: int, eps: float = 1e-6) -> None:
method forward (line 456) | def forward(self, x: torch.Tensor) -> torch.Tensor:
class TinyViT (line 462) | class TinyViT(nn.Module):
method __init__ (line 463) | def __init__(self, img_size=224, in_chans=3, num_classes=1000,
method set_layer_lr_decay (line 553) | def set_layer_lr_decay(self, layer_lr_decay):
method _init_weights (line 587) | def _init_weights(self, m):
method no_weight_decay_keywords (line 597) | def no_weight_decay_keywords(self):
method forward_features (line 600) | def forward_features(self, x):
method forward (line 621) | def forward(self, x):
function register_tiny_vit_model (line 640) | def register_tiny_vit_model(fn):
function tiny_vit_5m_224 (line 666) | def tiny_vit_5m_224(pretrained=False, num_classes=1000, drop_path_rate=0...
function tiny_vit_11m_224 (line 678) | def tiny_vit_11m_224(pretrained=False, num_classes=1000, drop_path_rate=...
function tiny_vit_21m_224 (line 690) | def tiny_vit_21m_224(pretrained=False, num_classes=1000, drop_path_rate=...
function tiny_vit_21m_384 (line 702) | def tiny_vit_21m_384(pretrained=False, num_classes=1000, drop_path_rate=...
function tiny_vit_21m_512 (line 715) | def tiny_vit_21m_512(pretrained=False, num_classes=1000, drop_path_rate=...
FILE: data_generation/Grounded-Segment-Anything/EfficientSAM/MobileSAM/setup_mobile_sam.py
function setup_model (line 4) | def setup_model():
FILE: data_generation/Grounded-Segment-Anything/EfficientSAM/MobileSAM/tiny_vit_sam.py
class Conv2d_BN (line 21) | class Conv2d_BN(torch.nn.Sequential):
method __init__ (line 22) | def __init__(self, a, b, ks=1, stride=1, pad=0, dilation=1,
method fuse (line 33) | def fuse(self):
class DropPath (line 46) | class DropPath(TimmDropPath):
method __init__ (line 47) | def __init__(self, drop_prob=None):
method __repr__ (line 51) | def __repr__(self):
class PatchEmbed (line 57) | class PatchEmbed(nn.Module):
method __init__ (line 58) | def __init__(self, in_chans, embed_dim, resolution, activation):
method forward (line 73) | def forward(self, x):
class MBConv (line 77) | class MBConv(nn.Module):
method __init__ (line 78) | def __init__(self, in_chans, out_chans, expand_ratio,
method forward (line 99) | def forward(self, x):
class PatchMerging (line 118) | class PatchMerging(nn.Module):
method __init__ (line 119) | def __init__(self, input_resolution, dim, out_dim, activation):
method forward (line 133) | def forward(self, x):
class ConvLayer (line 150) | class ConvLayer(nn.Module):
method __init__ (line 151) | def __init__(self, dim, input_resolution, depth,
method forward (line 178) | def forward(self, x):
class Mlp (line 189) | class Mlp(nn.Module):
method __init__ (line 190) | def __init__(self, in_features, hidden_features=None,
method forward (line 201) | def forward(self, x):
class Attention (line 212) | class Attention(torch.nn.Module):
method __init__ (line 213) | def __init__(self, dim, key_dim, num_heads=8,
method train (line 251) | def train(self, mode=True):
method forward (line 258) | def forward(self, x): # x (B,N,C)
class TinyViTBlock (line 285) | class TinyViTBlock(nn.Module):
method __init__ (line 301) | def __init__(self, dim, input_resolution, num_heads, window_size=7,
method forward (line 333) | def forward(self, x):
method extra_repr (line 376) | def extra_repr(self) -> str:
class BasicLayer (line 381) | class BasicLayer(nn.Module):
method __init__ (line 400) | def __init__(self, dim, input_resolution, depth, num_heads, window_size,
method forward (line 434) | def forward(self, x):
method extra_repr (line 444) | def extra_repr(self) -> str:
class LayerNorm2d (line 447) | class LayerNorm2d(nn.Module):
method __init__ (line 448) | def __init__(self, num_channels: int, eps: float = 1e-6) -> None:
method forward (line 454) | def forward(self, x: torch.Tensor) -> torch.Tensor:
class TinyViT (line 460) | class TinyViT(nn.Module):
method __init__ (line 461) | def __init__(self, img_size=224, in_chans=3, num_classes=1000,
method set_layer_lr_decay (line 551) | def set_layer_lr_decay(self, layer_lr_decay):
method _init_weights (line 585) | def _init_weights(self, m):
method no_weight_decay_keywords (line 595) | def no_weight_decay_keywords(self):
method forward_features (line 598) | def forward_features(self, x):
method forward (line 614) | def forward(self, x):
function register_tiny_vit_model (line 632) | def register_tiny_vit_model(fn):
function tiny_vit_5m_224 (line 658) | def tiny_vit_5m_224(pretrained=False, num_classes=1000, drop_path_rate=0...
function tiny_vit_11m_224 (line 670) | def tiny_vit_11m_224(pretrained=False, num_classes=1000, drop_path_rate=...
function tiny_vit_21m_224 (line 682) | def tiny_vit_21m_224(pretrained=False, num_classes=1000, drop_path_rate=...
function tiny_vit_21m_384 (line 694) | def tiny_vit_21m_384(pretrained=False, num_classes=1000, drop_path_rate=...
function tiny_vit_21m_512 (line 707) | def tiny_vit_21m_512(pretrained=False, num_classes=1000, drop_path_rate=...
FILE: data_generation/Grounded-Segment-Anything/EfficientSAM/RepViTSAM/repvit.py
function _make_divisible (line 7) | def _make_divisible(v, divisor, min_value=None):
class LayerNorm2d (line 32) | class LayerNorm2d(nn.Module):
method __init__ (line 33) | def __init__(self, num_channels: int, eps: float = 1e-6) -> None:
method forward (line 39) | def forward(self, x: torch.Tensor) -> torch.Tensor:
class Conv2d_BN (line 46) | class Conv2d_BN(torch.nn.Sequential):
method __init__ (line 47) | def __init__(self, a, b, ks=1, stride=1, pad=0, dilation=1,
method fuse (line 57) | def fuse(self):
class Residual (line 70) | class Residual(torch.nn.Module):
method __init__ (line 71) | def __init__(self, m, drop=0.):
method forward (line 76) | def forward(self, x):
method fuse (line 84) | def fuse(self):
class RepVGGDW (line 103) | class RepVGGDW(torch.nn.Module):
method __init__ (line 104) | def __init__(self, ed) -> None:
method forward (line 111) | def forward(self, x):
method fuse (line 115) | def fuse(self):
class RepViTBlock (line 144) | class RepViTBlock(nn.Module):
method __init__ (line 145) | def __init__(self, inp, hidden_dim, oup, kernel_size, stride, use_se, ...
method forward (line 188) | def forward(self, x):
class BN_Linear (line 192) | class BN_Linear(torch.nn.Sequential):
method __init__ (line 193) | def __init__(self, a, b, bias=True, std=0.02):
method fuse (line 202) | def fuse(self):
class Classfier (line 217) | class Classfier(nn.Module):
method __init__ (line 218) | def __init__(self, dim, num_classes, distillation=True):
method forward (line 225) | def forward(self, x):
method fuse (line 235) | def fuse(self):
class RepViT (line 247) | class RepViT(nn.Module):
method __init__ (line 248) | def __init__(self, cfgs, num_classes=1000, distillation=False, img_siz...
method forward (line 288) | def forward(self, x):
function repvit (line 299) | def repvit(pretrained=False, num_classes = 1000, distillation=False, **k...
FILE: data_generation/Grounded-Segment-Anything/EfficientSAM/RepViTSAM/setup_repvit_sam.py
function build_sam_repvit (line 13) | def build_sam_repvit(checkpoint=None):
FILE: data_generation/Grounded-Segment-Anything/EfficientSAM/grounded_edge_sam.py
function segment (line 75) | def segment(sam_predictor: SamPredictor, image: np.ndarray, xyxy: np.nda...
FILE: data_generation/Grounded-Segment-Anything/EfficientSAM/grounded_efficient_sam.py
function efficient_sam_box_prompt_segment (line 71) | def efficient_sam_box_prompt_segment(image, pts_sampled, model):
FILE: data_generation/Grounded-Segment-Anything/EfficientSAM/grounded_fast_sam.py
function parse_args (line 9) | def parse_args():
function main (line 68) | def main(args):
FILE: data_generation/Grounded-Segment-Anything/EfficientSAM/grounded_light_hqsam.py
function segment (line 77) | def segment(sam_predictor: SamPredictor, image: np.ndarray, xyxy: np.nda...
FILE: data_generation/Grounded-Segment-Anything/EfficientSAM/grounded_mobile_sam.py
function parse_args (line 12) | def parse_args():
function main (line 42) | def main(args):
FILE: data_generation/Grounded-Segment-Anything/EfficientSAM/grounded_repvit_sam.py
function segment (line 75) | def segment(sam_predictor: SamPredictor, image: np.ndarray, xyxy: np.nda...
FILE: data_generation/Grounded-Segment-Anything/GroundingDINO/demo/gradio_app.py
function load_model_hf (line 42) | def load_model_hf(model_config_path, repo_id, filename, device='cpu'):
function image_transform_grounding (line 54) | def image_transform_grounding(init_image):
function image_transform_grounding_for_vis (line 63) | def image_transform_grounding_for_vis(init_image):
function run_grounding (line 72) | def run_grounding(input_image, grounding_caption, box_threshold, text_th...
FILE: data_generation/Grounded-Segment-Anything/GroundingDINO/demo/inference_on_a_image.py
function plot_boxes_to_image (line 16) | def plot_boxes_to_image(image_pil, tgt):
function load_image (line 57) | def load_image(image_path):
function load_model (line 72) | def load_model(model_config_path, model_checkpoint_path, cpu_only=False):
function get_grounding_output (line 83) | def get_grounding_output(model, image, caption, box_threshold, text_thre...
FILE: data_generation/Grounded-Segment-Anything/GroundingDINO/groundingdino/datasets/transforms.py
function crop (line 17) | def crop(image, target, region):
function hflip (line 68) | def hflip(image, target):
function resize (line 87) | def resize(image, target, size, max_size=None):
function pad (line 149) | def pad(image, target, padding):
class ResizeDebug (line 162) | class ResizeDebug(object):
method __init__ (line 163) | def __init__(self, size):
method __call__ (line 166) | def __call__(self, img, target):
class RandomCrop (line 170) | class RandomCrop(object):
method __init__ (line 171) | def __init__(self, size):
method __call__ (line 174) | def __call__(self, img, target):
class RandomSizeCrop (line 179) | class RandomSizeCrop(object):
method __init__ (line 180) | def __init__(self, min_size: int, max_size: int, respect_boxes: bool =...
method __call__ (line 187) | def __call__(self, img: PIL.Image.Image, target: dict):
class CenterCrop (line 204) | class CenterCrop(object):
method __init__ (line 205) | def __init__(self, size):
method __call__ (line 208) | def __call__(self, img, target):
class RandomHorizontalFlip (line 216) | class RandomHorizontalFlip(object):
method __init__ (line 217) | def __init__(self, p=0.5):
method __call__ (line 220) | def __call__(self, img, target):
class RandomResize (line 226) | class RandomResize(object):
method __init__ (line 227) | def __init__(self, sizes, max_size=None):
method __call__ (line 232) | def __call__(self, img, target=None):
class RandomPad (line 237) | class RandomPad(object):
method __init__ (line 238) | def __init__(self, max_pad):
method __call__ (line 241) | def __call__(self, img, target):
class RandomSelect (line 247) | class RandomSelect(object):
method __init__ (line 253) | def __init__(self, transforms1, transforms2, p=0.5):
method __call__ (line 258) | def __call__(self, img, target):
class ToTensor (line 264) | class ToTensor(object):
method __call__ (line 265) | def __call__(self, img, target):
class RandomErasing (line 269) | class RandomErasing(object):
method __init__ (line 270) | def __init__(self, *args, **kwargs):
method __call__ (line 273) | def __call__(self, img, target):
class Normalize (line 277) | class Normalize(object):
method __init__ (line 278) | def __init__(self, mean, std):
method __call__ (line 282) | def __call__(self, image, target=None):
class Compose (line 296) | class Compose(object):
method __init__ (line 297) | def __init__(self, transforms):
method __call__ (line 300) | def __call__(self, image, target):
method __repr__ (line 305) | def __repr__(self):
FILE: data_generation/Grounded-Segment-Anything/GroundingDINO/groundingdino/models/GroundingDINO/backbone/backbone.py
class FrozenBatchNorm2d (line 33) | class FrozenBatchNorm2d(torch.nn.Module):
method __init__ (line 42) | def __init__(self, n):
method _load_from_state_dict (line 49) | def _load_from_state_dict(
method forward (line 60) | def forward(self, x):
class BackboneBase (line 73) | class BackboneBase(nn.Module):
method __init__ (line 74) | def __init__(
method forward (line 107) | def forward(self, tensor_list: NestedTensor):
class Backbone (line 119) | class Backbone(BackboneBase):
method __init__ (line 122) | def __init__(
class Joiner (line 146) | class Joiner(nn.Sequential):
method __init__ (line 147) | def __init__(self, backbone, position_embedding):
method forward (line 150) | def forward(self, tensor_list: NestedTensor):
function build_backbone (line 162) | def build_backbone(args):
FILE: data_generation/Grounded-Segment-Anything/GroundingDINO/groundingdino/models/GroundingDINO/backbone/position_encoding.py
class PositionEmbeddingSine (line 30) | class PositionEmbeddingSine(nn.Module):
method __init__ (line 36) | def __init__(self, num_pos_feats=64, temperature=10000, normalize=Fals...
method forward (line 47) | def forward(self, tensor_list: NestedTensor):
class PositionEmbeddingSineHW (line 78) | class PositionEmbeddingSineHW(nn.Module):
method __init__ (line 84) | def __init__(
method forward (line 98) | def forward(self, tensor_list: NestedTensor):
class PositionEmbeddingLearned (line 134) | class PositionEmbeddingLearned(nn.Module):
method __init__ (line 139) | def __init__(self, num_pos_feats=256):
method reset_parameters (line 145) | def reset_parameters(self):
method forward (line 149) | def forward(self, tensor_list: NestedTensor):
function build_position_encoding (line 171) | def build_position_encoding(args):
FILE: data_generation/Grounded-Segment-Anything/GroundingDINO/groundingdino/models/GroundingDINO/backbone/swin_transformer.py
class Mlp (line 24) | class Mlp(nn.Module):
method __init__ (line 27) | def __init__(
method forward (line 38) | def forward(self, x):
function window_partition (line 47) | def window_partition(x, window_size):
function window_reverse (line 61) | def window_reverse(windows, window_size, H, W):
class WindowAttention (line 77) | class WindowAttention(nn.Module):
method __init__ (line 90) | def __init__(
method forward (line 134) | def forward(self, x, mask=None):
class SwinTransformerBlock (line 177) | class SwinTransformerBlock(nn.Module):
method __init__ (line 194) | def __init__(
method forward (line 238) | def forward(self, x, mask_matrix):
class PatchMerging (line 301) | class PatchMerging(nn.Module):
method __init__ (line 308) | def __init__(self, dim, norm_layer=nn.LayerNorm):
method forward (line 314) | def forward(self, x, H, W):
class BasicLayer (line 343) | class BasicLayer(nn.Module):
method __init__ (line 361) | def __init__(
method forward (line 409) | def forward(self, x, H, W):
class PatchEmbed (line 459) | class PatchEmbed(nn.Module):
method __init__ (line 468) | def __init__(self, patch_size=4, in_chans=3, embed_dim=96, norm_layer=...
method forward (line 482) | def forward(self, x):
class SwinTransformer (line 501) | class SwinTransformer(nn.Module):
method __init__ (line 530) | def __init__(
method _freeze_stages (line 636) | def _freeze_stages(self):
method forward_raw (line 678) | def forward_raw(self, x):
method forward (line 712) | def forward(self, tensor_list: NestedTensor):
method train (line 756) | def train(self, mode=True):
function build_swin_transformer (line 762) | def build_swin_transformer(modelname, pretrain_img_size, **kw):
FILE: data_generation/Grounded-Segment-Anything/GroundingDINO/groundingdino/models/GroundingDINO/bertwarper.py
class BertModelWarper (line 17) | class BertModelWarper(nn.Module):
method __init__ (line 18) | def __init__(self, bert_model):
method forward (line 31) | def forward(
class TextEncoderShell (line 169) | class TextEncoderShell(nn.Module):
method __init__ (line 170) | def __init__(self, text_encoder):
method forward (line 175) | def forward(self, **kw):
function generate_masks_with_special_tokens (line 180) | def generate_masks_with_special_tokens(tokenized, special_tokens_list, t...
function generate_masks_with_special_tokens_and_transfer_map (line 224) | def generate_masks_with_special_tokens_and_transfer_map(tokenized, speci...
FILE: data_generation/Grounded-Segment-Anything/GroundingDINO/groundingdino/models/GroundingDINO/csrc/MsDeformAttn/ms_deform_attn.h
function namespace (line 19) | namespace groundingdino {
FILE: data_generation/Grounded-Segment-Anything/GroundingDINO/groundingdino/models/GroundingDINO/csrc/MsDeformAttn/ms_deform_attn_cpu.cpp
type groundingdino (line 16) | namespace groundingdino {
function ms_deform_attn_cpu_forward (line 18) | at::Tensor
function ms_deform_attn_cpu_backward (line 30) | std::vector<at::Tensor>
FILE: data_generation/Grounded-Segment-Anything/GroundingDINO/groundingdino/models/GroundingDINO/csrc/MsDeformAttn/ms_deform_attn_cpu.h
function namespace (line 14) | namespace groundingdino {
FILE: data_generation/Grounded-Segment-Anything/GroundingDINO/groundingdino/models/GroundingDINO/csrc/MsDeformAttn/ms_deform_attn_cuda.h
function namespace (line 14) | namespace groundingdino {
FILE: data_generation/Grounded-Segment-Anything/GroundingDINO/groundingdino/models/GroundingDINO/csrc/vision.cpp
type groundingdino (line 5) | namespace groundingdino {
function get_cuda_version (line 11) | std::string get_cuda_version() {
function get_compiler_version (line 32) | std::string get_compiler_version() {
function PYBIND11_MODULE (line 53) | PYBIND11_MODULE(TORCH_EXTENSION_NAME, m) {
FILE: data_generation/Grounded-Segment-Anything/GroundingDINO/groundingdino/models/GroundingDINO/fuse_modules.py
class FeatureResizer (line 14) | class FeatureResizer(nn.Module):
method __init__ (line 20) | def __init__(self, input_feat_size, output_feat_size, dropout, do_ln=T...
method forward (line 28) | def forward(self, encoder_features):
function l1norm (line 36) | def l1norm(X, dim, eps=1e-8):
function l2norm (line 43) | def l2norm(X, dim, eps=1e-8):
function func_attention (line 50) | def func_attention(query, context, smooth=1, raw_feature_norm="softmax",...
class BiMultiHeadAttention (line 99) | class BiMultiHeadAttention(nn.Module):
method __init__ (line 100) | def __init__(self, v_dim, l_dim, embed_dim, num_heads, dropout=0.1, cf...
method _shape (line 129) | def _shape(self, tensor: torch.Tensor, seq_len: int, bsz: int):
method _reset_parameters (line 132) | def _reset_parameters(self):
method forward (line 146) | def forward(self, v, l, attention_mask_v=None, attention_mask_l=None):
class BiAttentionBlock (line 252) | class BiAttentionBlock(nn.Module):
method __init__ (line 253) | def __init__(
method forward (line 286) | def forward(self, v, l, attention_mask_v=None, attention_mask_l=None):
FILE: data_generation/Grounded-Segment-Anything/GroundingDINO/groundingdino/models/GroundingDINO/groundingdino.py
class GroundingDINO (line 51) | class GroundingDINO(nn.Module):
method __init__ (line 54) | def __init__(
method _reset_parameters (line 203) | def _reset_parameters(self):
method init_ref_points (line 209) | def init_ref_points(self, use_num_queries):
method forward (line 212) | def forward(self, samples: NestedTensor, targets: List = None, **kw):
method _set_aux_loss (line 352) | def _set_aux_loss(self, outputs_class, outputs_coord):
function build_groundingdino (line 363) | def build_groundingdino(args):
FILE: data_generation/Grounded-Segment-Anything/GroundingDINO/groundingdino/models/GroundingDINO/ms_deform_attn.py
function _is_power_of_2 (line 35) | def _is_power_of_2(n):
class MultiScaleDeformableAttnFunction (line 41) | class MultiScaleDeformableAttnFunction(Function):
method forward (line 43) | def forward(
method backward (line 72) | def backward(ctx, grad_output):
function multi_scale_deformable_attn_pytorch (line 93) | def multi_scale_deformable_attn_pytorch(
class MultiScaleDeformableAttention (line 136) | class MultiScaleDeformableAttention(nn.Module):
method __init__ (line 154) | def __init__(
method _reset_parameters (line 194) | def _reset_parameters(self):
method init_weights (line 197) | def init_weights(self):
method freeze_sampling_offsets (line 222) | def freeze_sampling_offsets(self):
method freeze_attention_weights (line 227) | def freeze_attention_weights(self):
method forward (line 232) | def forward(
function create_dummy_class (line 363) | def create_dummy_class(klass, dependency, message=""):
function create_dummy_func (line 392) | def create_dummy_func(func, dependency, message=""):
FILE: data_generation/Grounded-Segment-Anything/GroundingDINO/groundingdino/models/GroundingDINO/transformer.py
class Transformer (line 40) | class Transformer(nn.Module):
method __init__ (line 41) | def __init__(
method _reset_parameters (line 189) | def _reset_parameters(self):
method get_valid_ratio (line 199) | def get_valid_ratio(self, mask):
method init_ref_points (line 208) | def init_ref_points(self, use_num_queries):
method forward (line 211) | def forward(self, srcs, masks, refpoint_embed, pos_embeds, tgt, attn_m...
class TransformerEncoder (line 406) | class TransformerEncoder(nn.Module):
method __init__ (line 407) | def __init__(
method get_reference_points (line 466) | def get_reference_points(spatial_shapes, valid_ratios, device):
method forward (line 482) | def forward(
class TransformerDecoder (line 599) | class TransformerDecoder(nn.Module):
method __init__ (line 600) | def __init__(
method forward (line 634) | def forward(
class DeformableTransformerEncoderLayer (line 739) | class DeformableTransformerEncoderLayer(nn.Module):
method __init__ (line 740) | def __init__(
method with_pos_embed (line 772) | def with_pos_embed(tensor, pos):
method forward_ffn (line 775) | def forward_ffn(self, src):
method forward (line 781) | def forward(
class DeformableTransformerDecoderLayer (line 803) | class DeformableTransformerDecoderLayer(nn.Module):
method __init__ (line 804) | def __init__(
method rm_self_attn_modules (line 853) | def rm_self_attn_modules(self):
method with_pos_embed (line 859) | def with_pos_embed(tensor, pos):
method forward_ffn (line 862) | def forward_ffn(self, tgt):
method forward (line 869) | def forward(
function build_transformer (line 931) | def build_transformer(args):
FILE: data_generation/Grounded-Segment-Anything/GroundingDINO/groundingdino/models/GroundingDINO/transformer_vanilla.py
class TextTransformer (line 33) | class TextTransformer(nn.Module):
method __init__ (line 34) | def __init__(self, num_layers, d_model=256, nheads=8, dim_feedforward=...
method forward (line 47) | def forward(self, memory_text: torch.Tensor, text_attention_mask: torc...
class TransformerEncoderLayer (line 72) | class TransformerEncoderLayer(nn.Module):
method __init__ (line 73) | def __init__(
method with_pos_embed (line 98) | def with_pos_embed(self, tensor, pos: Optional[Tensor]):
method forward (line 101) | def forward(
FILE: data_generation/Grounded-Segment-Anything/GroundingDINO/groundingdino/models/GroundingDINO/utils.py
function _get_clones (line 16) | def _get_clones(module, N, layer_share=False):
function get_sine_pos_embed (line 24) | def get_sine_pos_embed(
function gen_encoder_output_proposals (line 56) | def gen_encoder_output_proposals(
class RandomBoxPerturber (line 120) | class RandomBoxPerturber:
method __init__ (line 121) | def __init__(
method __call__ (line 128) | def __call__(self, refanchors: Tensor) -> Tensor:
function sigmoid_focal_loss (line 139) | def sigmoid_focal_loss(
class MLP (line 172) | class MLP(nn.Module):
method __init__ (line 175) | def __init__(self, input_dim, hidden_dim, output_dim, num_layers):
method forward (line 183) | def forward(self, x):
function _get_activation_fn (line 189) | def _get_activation_fn(activation, d_model=256, batch_dim=0):
function gen_sineembed_for_position (line 205) | def gen_sineembed_for_position(pos_tensor):
class ContrastiveEmbed (line 235) | class ContrastiveEmbed(nn.Module):
method __init__ (line 236) | def __init__(self, max_text_len=256):
method forward (line 244) | def forward(self, x, text_dict):
FILE: data_generation/Grounded-Segment-Anything/GroundingDINO/groundingdino/models/__init__.py
function build_model (line 11) | def build_model(args):
FILE: data_generation/Grounded-Segment-Anything/GroundingDINO/groundingdino/models/registry.py
class Registry (line 18) | class Registry(object):
method __init__ (line 19) | def __init__(self, name):
method __repr__ (line 23) | def __repr__(self):
method __len__ (line 29) | def __len__(self):
method name (line 33) | def name(self):
method module_dict (line 37) | def module_dict(self):
method get (line 40) | def get(self, key):
method registe_with_name (line 43) | def registe_with_name(self, module_name=None, force=False):
method register (line 46) | def register(self, module_build_function, module_name=None, force=False):
FILE: data_generation/Grounded-Segment-Anything/GroundingDINO/groundingdino/util/box_ops.py
function box_cxcywh_to_xyxy (line 9) | def box_cxcywh_to_xyxy(x):
function box_xyxy_to_cxcywh (line 15) | def box_xyxy_to_cxcywh(x):
function box_iou (line 22) | def box_iou(boxes1, boxes2):
function generalized_box_iou (line 39) | def generalized_box_iou(boxes1, boxes2):
function box_iou_pairwise (line 66) | def box_iou_pairwise(boxes1, boxes2):
function generalized_box_iou_pairwise (line 82) | def generalized_box_iou_pairwise(boxes1, boxes2):
function masks_to_boxes (line 107) | def masks_to_boxes(masks):
FILE: data_generation/Grounded-Segment-Anything/GroundingDINO/groundingdino/util/get_tokenlizer.py
function get_tokenlizer (line 4) | def get_tokenlizer(text_encoder_type):
function get_pretrained_language_model (line 21) | def get_pretrained_language_model(text_encoder_type):
FILE: data_generation/Grounded-Segment-Anything/GroundingDINO/groundingdino/util/inference.py
function preprocess_caption (line 22) | def preprocess_caption(caption: str) -> str:
function load_model (line 29) | def load_model(model_config_path: str, model_checkpoint_path: str, devic...
function load_image (line 39) | def load_image(image_path: str) -> Tuple[np.array, torch.Tensor]:
function predict (line 53) | def predict(
function annotate (line 88) | def annotate(image_source: np.ndarray, boxes: torch.Tensor, logits: torc...
class Model (line 111) | class Model:
method __init__ (line 113) | def __init__(
method predict_with_caption (line 126) | def predict_with_caption(
method predict_with_classes (line 167) | def predict_with_classes(
method preprocess_image (line 213) | def preprocess_image(image_bgr: np.ndarray) -> torch.Tensor:
method post_process_result (line 226) | def post_process_result(
method phrases2classes (line 238) | def phrases2classes(phrases: List[str], classes: List[str]) -> np.ndar...
method find_index (line 249) | def find_index(string, lst):
FILE: data_generation/Grounded-Segment-Anything/GroundingDINO/groundingdino/util/logger.py
class _ColorfulFormatter (line 10) | class _ColorfulFormatter(logging.Formatter):
method __init__ (line 11) | def __init__(self, *args, **kwargs):
method formatMessage (line 18) | def formatMessage(self, record):
function setup_logger (line 32) | def setup_logger(output=None, distributed_rank=0, *, color=True, name="i...
function _cached_log_stream (line 92) | def _cached_log_stream(filename):
FILE: data_generation/Grounded-Segment-Anything/GroundingDINO/groundingdino/util/misc.py
class SmoothedValue (line 33) | class SmoothedValue(object):
method __init__ (line 38) | def __init__(self, window_size=20, fmt=None):
method update (line 46) | def update(self, value, n=1):
method synchronize_between_processes (line 51) | def synchronize_between_processes(self):
method median (line 65) | def median(self):
method avg (line 72) | def avg(self):
method global_avg (line 77) | def global_avg(self):
method max (line 85) | def max(self):
method value (line 89) | def value(self):
method __str__ (line 92) | def __str__(self):
function _get_global_gloo_group (line 103) | def _get_global_gloo_group():
function all_gather_cpu (line 115) | def all_gather_cpu(data):
function all_gather (line 173) | def all_gather(data):
function reduce_dict (line 220) | def reduce_dict(input_dict, average=True):
class MetricLogger (line 247) | class MetricLogger(object):
method __init__ (line 248) | def __init__(self, delimiter="\t"):
method update (line 252) | def update(self, **kwargs):
method __getattr__ (line 259) | def __getattr__(self, attr):
method __str__ (line 266) | def __str__(self):
method synchronize_between_processes (line 275) | def synchronize_between_processes(self):
method add_meter (line 279) | def add_meter(self, name, meter):
method log_every (line 282) | def log_every(self, iterable, print_freq, header=None, logger=None):
function get_sha (line 362) | def get_sha():
function collate_fn (line 383) | def collate_fn(batch):
function _max_by_axis (line 390) | def _max_by_axis(the_list):
class NestedTensor (line 399) | class NestedTensor(object):
method __init__ (line 400) | def __init__(self, tensors, mask: Optional[Tensor]):
method imgsize (line 416) | def imgsize(self):
method to (line 425) | def to(self, device):
method to_img_list_single (line 436) | def to_img_list_single(self, tensor, mask):
method to_img_list (line 443) | def to_img_list(self):
method device (line 460) | def device(self):
method decompose (line 463) | def decompose(self):
method __repr__ (line 466) | def __repr__(self):
method shape (line 470) | def shape(self):
function nested_tensor_from_tensor_list (line 474) | def nested_tensor_from_tensor_list(tensor_list: List[Tensor]):
function _onnx_nested_tensor_from_tensor_list (line 502) | def _onnx_nested_tensor_from_tensor_list(tensor_list: List[Tensor]) -> N...
function setup_for_distributed (line 532) | def setup_for_distributed(is_master):
function is_dist_avail_and_initialized (line 548) | def is_dist_avail_and_initialized():
function get_world_size (line 556) | def get_world_size():
function get_rank (line 562) | def get_rank():
function is_main_process (line 568) | def is_main_process():
function save_on_master (line 572) | def save_on_master(*args, **kwargs):
function init_distributed_mode (line 577) | def init_distributed_mode(args):
function accuracy (line 638) | def accuracy(output, target, topk=(1,)):
function accuracy_onehot (line 657) | def accuracy_onehot(pred, gt):
function interpolate (line 669) | def interpolate(input, size=None, scale_factor=None, mode="nearest", ali...
class color_sys (line 687) | class color_sys:
method __init__ (line 688) | def __init__(self, num_colors) -> None:
method __call__ (line 700) | def __call__(self, idx):
function inverse_sigmoid (line 704) | def inverse_sigmoid(x, eps=1e-3):
function clean_state_dict (line 711) | def clean_state_dict(state_dict):
FILE: data_generation/Grounded-Segment-Anything/GroundingDINO/groundingdino/util/slconfig.py
function check_file_exist (line 21) | def check_file_exist(filename, msg_tmpl='file "{}" does not exist'):
class ConfigDict (line 26) | class ConfigDict(Dict):
method __missing__ (line 27) | def __missing__(self, name):
method __getattr__ (line 30) | def __getattr__(self, name):
class SLConfig (line 42) | class SLConfig(object):
method _validate_py_syntax (line 68) | def _validate_py_syntax(filename):
method _file2dict (line 77) | def _file2dict(filename):
method _merge_a_into_b (line 140) | def _merge_a_into_b(a, b):
method fromfile (line 184) | def fromfile(filename):
method __init__ (line 188) | def __init__(self, cfg_dict=None, cfg_text=None, filename=None):
method filename (line 209) | def filename(self):
method text (line 213) | def text(self):
method pretty_text (line 217) | def pretty_text(self):
method __repr__ (line 310) | def __repr__(self):
method __len__ (line 313) | def __len__(self):
method __getattr__ (line 316) | def __getattr__(self, name):
method __getitem__ (line 329) | def __getitem__(self, name):
method __setattr__ (line 332) | def __setattr__(self, name, value):
method __setitem__ (line 337) | def __setitem__(self, name, value):
method __iter__ (line 342) | def __iter__(self):
method dump (line 345) | def dump(self, file=None):
method merge_from_dict (line 353) | def merge_from_dict(self, options):
method __setstate__ (line 386) | def __setstate__(self, state):
method copy (line 389) | def copy(self):
method deepcopy (line 392) | def deepcopy(self):
class DictAction (line 396) | class DictAction(Action):
method _parse_int_float_bool (line 404) | def _parse_int_float_bool(val):
method __call__ (line 419) | def __call__(self, parser, namespace, values, option_string=None):
FILE: data_generation/Grounded-Segment-Anything/GroundingDINO/groundingdino/util/slio.py
class BaseFileHandler (line 23) | class BaseFileHandler(metaclass=ABCMeta):
method load_from_fileobj (line 25) | def load_from_fileobj(self, file, **kwargs):
method dump_to_fileobj (line 29) | def dump_to_fileobj(self, obj, file, **kwargs):
method dump_to_str (line 33) | def dump_to_str(self, obj, **kwargs):
method load_from_path (line 36) | def load_from_path(self, filepath, mode="r", **kwargs):
method dump_to_path (line 40) | def dump_to_path(self, obj, filepath, mode="w", **kwargs):
class JsonHandler (line 45) | class JsonHandler(BaseFileHandler):
method load_from_fileobj (line 46) | def load_from_fileobj(self, file):
method dump_to_fileobj (line 49) | def dump_to_fileobj(self, obj, file, **kwargs):
method dump_to_str (line 52) | def dump_to_str(self, obj, **kwargs):
class PickleHandler (line 56) | class PickleHandler(BaseFileHandler):
method load_from_fileobj (line 57) | def load_from_fileobj(self, file, **kwargs):
method load_from_path (line 60) | def load_from_path(self, filepath, **kwargs):
method dump_to_str (line 63) | def dump_to_str(self, obj, **kwargs):
method dump_to_fileobj (line 67) | def dump_to_fileobj(self, obj, file, **kwargs):
method dump_to_path (line 71) | def dump_to_path(self, obj, filepath, **kwargs):
class YamlHandler (line 75) | class YamlHandler(BaseFileHandler):
method load_from_fileobj (line 76) | def load_from_fileobj(self, file, **kwargs):
method dump_to_fileobj (line 80) | def dump_to_fileobj(self, obj, file, **kwargs):
method dump_to_str (line 84) | def dump_to_str(self, obj, **kwargs):
function is_str (line 102) | def is_str(x):
function slload (line 110) | def slload(file, file_format=None, **kwargs):
function sldump (line 143) | def sldump(obj, file=None, file_format=None, **kwargs):
FILE: data_generation/Grounded-Segment-Anything/GroundingDINO/groundingdino/util/time_counter.py
class TimeCounter (line 5) | class TimeCounter:
method __init__ (line 6) | def __init__(self) -> None:
method clear (line 9) | def clear(self):
method timeit (line 13) | def timeit(self, name):
class TimeHolder (line 19) | class TimeHolder:
method __init__ (line 20) | def __init__(self) -> None:
method update (line 23) | def update(self, _timedict: dict):
method final_res (line 29) | def final_res(self):
method __str__ (line 32) | def __str__(self):
class AverageMeter (line 36) | class AverageMeter(object):
method __init__ (line 39) | def __init__(self, name, fmt=":f", val_only=False):
method reset (line 45) | def reset(self):
method update (line 51) | def update(self, val, n=1):
method __str__ (line 57) | def __str__(self):
FILE: data_generation/Grounded-Segment-Anything/GroundingDINO/groundingdino/util/utils.py
function slprint (line 15) | def slprint(x, name="x"):
function clean_state_dict (line 29) | def clean_state_dict(state_dict):
function renorm (line 38) | def renorm(
class CocoClassMapper (line 66) | class CocoClassMapper:
method __init__ (line 67) | def __init__(self) -> None:
method origin2compact (line 153) | def origin2compact(self, idx):
method compact2origin (line 156) | def compact2origin(self, idx):
function to_device (line 160) | def to_device(item, device):
function get_gaussian_mean (line 174) | def get_gaussian_mean(x, axis, other_axis, softmax=True):
function get_expected_points_from_map (line 200) | def get_expected_points_from_map(hm, softmax=True):
class Embedder (line 222) | class Embedder:
method __init__ (line 223) | def __init__(self, **kwargs):
method create_embedding_fn (line 227) | def create_embedding_fn(self):
method embed (line 251) | def embed(self, inputs):
function get_embedder (line 255) | def get_embedder(multires, i=0):
class APOPMeter (line 275) | class APOPMeter:
method __init__ (line 276) | def __init__(self) -> None:
method update (line 282) | def update(self, pred, gt):
method update_cm (line 293) | def update_cm(self, tp, fp, tn, fn):
function inverse_sigmoid (line 300) | def inverse_sigmoid(x, eps=1e-5):
function get_raw_dict (line 307) | def get_raw_dict(args):
function stat_tensors (line 325) | def stat_tensors(tensor):
class NiceRepr (line 340) | class NiceRepr:
method __nice__ (line 374) | def __nice__(self):
method __repr__ (line 384) | def __repr__(self):
method __str__ (line 394) | def __str__(self):
function ensure_rng (line 405) | def ensure_rng(rng=None):
function random_boxes (line 436) | def random_boxes(num=1, scale=1, rng=None):
class ModelEma (line 473) | class ModelEma(torch.nn.Module):
method __init__ (line 474) | def __init__(self, model, decay=0.9997, device=None):
method _update (line 487) | def _update(self, model, update_fn):
method update (line 496) | def update(self, model):
method set (line 499) | def set(self, model):
class BestMetricSingle (line 503) | class BestMetricSingle:
method __init__ (line 504) | def __init__(self, init_res=0.0, better="large") -> None:
method isbetter (line 512) | def isbetter(self, new_res, old_res):
method update (line 518) | def update(self, new_res, ep):
method __str__ (line 525) | def __str__(self) -> str:
method __repr__ (line 528) | def __repr__(self) -> str:
method summary (line 531) | def summary(self) -> dict:
class BestMetricHolder (line 538) | class BestMetricHolder:
method __init__ (line 539) | def __init__(self, init_res=0.0, better="large", use_ema=False) -> None:
method update (line 546) | def update(self, new_res, epoch, is_ema=False):
method summary (line 560) | def summary(self):
method __repr__ (line 570) | def __repr__(self) -> str:
method __str__ (line 573) | def __str__(self) -> str:
function targets_to (line 577) | def targets_to(targets: List[Dict[str, Any]], device):
function get_phrases_from_posmap (line 599) | def get_phrases_from_posmap(
FILE: data_generation/Grounded-Segment-Anything/GroundingDINO/groundingdino/util/visualizer.py
function renorm (line 22) | def renorm(
class ColorMap (line 50) | class ColorMap:
method __init__ (line 51) | def __init__(self, basergb=[255, 255, 0]):
method __call__ (line 54) | def __call__(self, attnmap):
function rainbow_text (line 66) | def rainbow_text(x, y, ls, lc, **kw):
class COCOVisualizer (line 95) | class COCOVisualizer:
method __init__ (line 96) | def __init__(self, coco=None, tokenlizer=None) -> None:
method visualize (line 99) | def visualize(self, img, tgt, caption=None, dpi=180, savedir="vis"):
method addtgt (line 135) | def addtgt(self, tgt):
method showAnns (line 225) | def showAnns(self, anns, draw_bbox=False):
FILE: data_generation/Grounded-Segment-Anything/GroundingDINO/groundingdino/util/vl_utils.py
function create_positive_map_from_span (line 8) | def create_positive_map_from_span(tokenized, token_span, max_text_len=256):
function build_captions_and_token_span (line 49) | def build_captions_and_token_span(cat_list, force_lowercase):
function build_id2posspan_and_caption (line 90) | def build_id2posspan_and_caption(category_dict: dict):
FILE: data_generation/Grounded-Segment-Anything/GroundingDINO/setup.py
function write_version_file (line 44) | def write_version_file():
function get_extensions (line 56) | def get_extensions():
function parse_requirements (line 114) | def parse_requirements(fname="requirements.txt", with_version=True):
FILE: data_generation/Grounded-Segment-Anything/automatic_label_demo.py
function load_image (line 33) | def load_image(image_path):
function generate_caption (line 48) | def generate_caption(raw_image, device):
function generate_tags (line 59) | def generate_tags(caption, split=',', max_tokens=100, model="gpt-3.5-tur...
function check_caption (line 82) | def check_caption(caption, pred_phrases, max_tokens=100, model="gpt-3.5-...
function load_model (line 107) | def load_model(model_config_path, model_checkpoint_path, device):
function get_grounding_output (line 118) | def get_grounding_output(model, image, caption, box_threshold, text_thre...
function show_mask (line 153) | def show_mask(mask, ax, random_color=False):
function show_box (line 163) | def show_box(box, ax, label):
function save_mask_data (line 170) | def save_mask_data(output_dir, caption, mask_list, box_list, label_list):
FILE: data_generation/Grounded-Segment-Anything/automatic_label_ram_demo.py
function load_image (line 36) | def load_image(image_path):
function check_tags_chinese (line 51) | def check_tags_chinese(tags_chinese, pred_phrases, max_tokens=100, model...
function load_model (line 76) | def load_model(model_config_path, model_checkpoint_path, device):
function get_grounding_output (line 87) | def get_grounding_output(model, image, caption, box_threshold, text_thre...
function show_mask (line 122) | def show_mask(mask, ax, random_color=False):
function show_box (line 132) | def show_box(box, ax, label):
function save_mask_data (line 139) | def save_mask_data(output_dir, tags_chinese, mask_list, box_list, label_...
FILE: data_generation/Grounded-Segment-Anything/automatic_label_simple_demo.py
function segment (line 135) | def segment(sam_predictor: SamPredictor, image: np.ndarray, xyxy: np.nda...
FILE: data_generation/Grounded-Segment-Anything/automatic_label_tag2text_demo.py
function load_image (line 34) | def load_image(image_path):
function generate_caption (line 49) | def generate_caption(raw_image, device):
function generate_tags (line 60) | def generate_tags(caption, split=',', max_tokens=100, model="gpt-3.5-tur...
function check_caption (line 83) | def check_caption(caption, pred_phrases, max_tokens=100, model="gpt-3.5-...
function load_model (line 108) | def load_model(model_config_path, model_checkpoint_path, device):
function get_grounding_output (line 119) | def get_grounding_output(model, image, caption, box_threshold, text_thre...
function show_mask (line 154) | def show_mask(mask, ax, random_color=False):
function show_box (line 164) | def show_box(box, ax, label):
function save_mask_data (line 171) | def save_mask_data(output_dir, caption, mask_list, box_list, label_list):
FILE: data_generation/Grounded-Segment-Anything/chatbot.py
function seed_everything (line 131) | def seed_everything(seed):
function prompts (line 139) | def prompts(name, description):
function blend_gt2pt (line 148) | def blend_gt2pt(old_image, new_image, sigma=0.15, steps=100):
function cut_dialogue_history (line 205) | def cut_dialogue_history(history_memory, keep_last_n_words=500):
function get_new_image_name (line 221) | def get_new_image_name(org_img_name, func_name="update"):
class MaskFormer (line 238) | class MaskFormer:
method __init__ (line 239) | def __init__(self, device):
method inference (line 245) | def inference(self, image_path, text):
class ImageEditing (line 268) | class ImageEditing:
method __init__ (line 269) | def __init__(self, device):
method inference_replace (line 283) | def inference_replace(self, inputs):
class InstructPix2Pix (line 299) | class InstructPix2Pix:
method __init__ (line 300) | def __init__(self, device):
method inference (line 314) | def inference(self, inputs):
class Text2Image (line 327) | class Text2Image:
method __init__ (line 328) | def __init__(self, device):
method inference (line 343) | def inference(self, text):
class ImageCaptioning (line 353) | class ImageCaptioning:
method __init__ (line 354) | def __init__(self, device):
method inference (line 365) | def inference(self, image_path):
class Image2Canny (line 373) | class Image2Canny:
method __init__ (line 374) | def __init__(self, device):
method inference (line 384) | def inference(self, inputs):
class CannyText2Image (line 397) | class CannyText2Image:
method __init__ (line 398) | def __init__(self, device):
method inference (line 419) | def inference(self, inputs):
class Image2Line (line 434) | class Image2Line:
method __init__ (line 435) | def __init__(self, device):
method inference (line 444) | def inference(self, inputs):
class LineText2Image (line 453) | class LineText2Image:
method __init__ (line 454) | def __init__(self, device):
method inference (line 477) | def inference(self, inputs):
class Image2Hed (line 492) | class Image2Hed:
method __init__ (line 493) | def __init__(self, device):
method inference (line 502) | def inference(self, inputs):
class HedText2Image (line 511) | class HedText2Image:
method __init__ (line 512) | def __init__(self, device):
method inference (line 535) | def inference(self, inputs):
class Image2Scribble (line 550) | class Image2Scribble:
method __init__ (line 551) | def __init__(self, device):
method inference (line 560) | def inference(self, inputs):
class ScribbleText2Image (line 569) | class ScribbleText2Image:
method __init__ (line 570) | def __init__(self, device):
method inference (line 591) | def inference(self, inputs):
class Image2Pose (line 606) | class Image2Pose:
method __init__ (line 607) | def __init__(self, device):
method inference (line 615) | def inference(self, inputs):
class PoseText2Image (line 624) | class PoseText2Image:
method __init__ (line 625) | def __init__(self, device):
method inference (line 649) | def inference(self, inputs):
class Image2Seg (line 664) | class Image2Seg:
method __init__ (line 665) | def __init__(self, device):
method inference (line 713) | def inference(self, inputs):
class SegText2Image (line 731) | class SegText2Image:
method __init__ (line 732) | def __init__(self, device):
method inference (line 753) | def inference(self, inputs):
class Image2Depth (line 768) | class Image2Depth:
method __init__ (line 769) | def __init__(self, device):
method inference (line 777) | def inference(self, inputs):
class DepthText2Image (line 790) | class DepthText2Image:
method __init__ (line 791) | def __init__(self, device):
method inference (line 812) | def inference(self, inputs):
class Image2Normal (line 827) | class Image2Normal:
method __init__ (line 828) | def __init__(self, device):
method inference (line 837) | def inference(self, inputs):
class NormalText2Image (line 861) | class NormalText2Image:
method __init__ (line 862) | def __init__(self, device):
method inference (line 883) | def inference(self, inputs):
class VisualQuestionAnswering (line 898) | class VisualQuestionAnswering:
method __init__ (line 899) | def __init__(self, device):
method inference (line 911) | def inference(self, inputs):
class InfinityOutPainting (line 922) | class InfinityOutPainting:
method __init__ (line 924) | def __init__(self, ImageCaptioning, ImageEditing, VisualQuestionAnswer...
method get_BLIP_vqa (line 933) | def get_BLIP_vqa(self, image, question):
method get_BLIP_caption (line 941) | def get_BLIP_caption(self, image):
method check_prompt (line 948) | def check_prompt(self, prompt):
method get_imagine_caption (line 954) | def get_imagine_caption(self, image, imagine):
method resize_image (line 971) | def resize_image(self, image, max_size=1000000, multiple=8):
method dowhile (line 978) | def dowhile(self, original_img, tosize, expand_ratio, imagine, usr_pro...
method inference (line 1006) | def inference(self, inputs):
class Grounded_dino_sam_inpainting (line 1020) | class Grounded_dino_sam_inpainting:
method __init__ (line 1021) | def __init__(self, device):
method inference_caption (line 1045) | def inference_caption(self, image_path):
method _detect_object (line 1052) | def _detect_object(self, image_path, text_prompt, func_name):
method inference_detect_one_object (line 1079) | def inference_detect_one_object(self, inputs):
method inference_detect_multi_object (line 1093) | def inference_detect_multi_object(self, inputs):
method inference_segment_anything (line 1106) | def inference_segment_anything(self, image_path):
method _segment_object (line 1129) | def _segment_object(self, image_path, text_prompt, func_name):
method inference_segment_one_object (line 1187) | def inference_segment_one_object(self, inputs):
method inference_segment_multi_object (line 1201) | def inference_segment_multi_object(self, inputs):
method inference_auto_segment_object (line 1213) | def inference_auto_segment_object(self, image_path):
method _inpainting (line 1227) | def _inpainting(self, image_path, to_be_replaced_txt, replace_with_txt...
method inference_replace (line 1267) | def inference_replace(self, inputs):
class ConversationBot (line 1277) | class ConversationBot:
method __init__ (line 1278) | def __init__(self, load_dict):
method run_text (line 1306) | def run_text(self, text, state):
method run_image (line 1316) | def run_image(self, image, state, txt, lang):
method init_agent (line 1350) | def init_agent(self, openai_api_key, lang):
function speech_recognition (line 1373) | def speech_recognition(speech_file):
FILE: data_generation/Grounded-Segment-Anything/gradio_app.py
function show_anns (line 34) | def show_anns(anns):
function generate_caption (line 59) | def generate_caption(processor, blip_model, raw_image):
function generate_tags (line 66) | def generate_tags(caption, split=',', max_tokens=100, model="gpt-3.5-tur...
function transform_image (line 83) | def transform_image(image_pil):
function load_model (line 96) | def load_model(model_config_path, model_checkpoint_path, device):
function get_grounding_output (line 107) | def get_grounding_output(model, image, caption, box_threshold, text_thre...
function draw_mask (line 143) | def draw_mask(mask, draw, random_color=False):
function draw_box (line 154) | def draw_box(box, draw, label):
function run_grounded_sam (line 189) | def run_grounded_sam(input_image, text_prompt, task_type, inpaint_prompt...
FILE: data_generation/Grounded-Segment-Anything/grounded_sam_demo.py
function load_image (line 32) | def load_image(image_path):
function load_model (line 47) | def load_model(model_config_path, model_checkpoint_path, device):
function get_grounding_output (line 58) | def get_grounding_output(model, image, caption, box_threshold, text_thre...
function show_mask (line 93) | def show_mask(mask, ax, random_color=False):
function show_box (line 103) | def show_box(box, ax, label):
function save_mask_data (line 110) | def save_mask_data(output_dir, mask_list, box_list, label_list):
FILE: data_generation/Grounded-Segment-Anything/grounded_sam_inpainting_demo.py
function load_image (line 31) | def load_image(image_path):
function load_model (line 46) | def load_model(model_config_path, model_checkpoint_path, device):
function get_grounding_output (line 57) | def get_grounding_output(model, image, caption, box_threshold, text_thre...
function show_mask (line 92) | def show_mask(mask, ax, random_color=False):
function show_box (line 102) | def show_box(box, ax, label):
FILE: data_generation/Grounded-Segment-Anything/grounded_sam_osx_demo.py
function load_image (line 35) | def load_image(image_path):
function load_model (line 50) | def load_model(model_config_path, model_checkpoint_path, device):
function get_grounding_output (line 61) | def get_grounding_output(model, image, caption, box_threshold, text_thre...
function show_mask (line 97) | def show_mask(mask, ax, random_color=False):
function show_box (line 106) | def show_box(box, ax, label):
function save_mask_data (line 116) | def save_mask_data(output_dir, mask_list, box_list, label_list):
function bbox_resize (line 144) | def bbox_resize(bbox, scale=1.0):
function mesh_recovery (line 150) | def mesh_recovery(original_img, bboxes):
FILE: data_generation/Grounded-Segment-Anything/grounded_sam_simple_demo.py
function segment (line 76) | def segment(sam_predictor: SamPredictor, image: np.ndarray, xyxy: np.nda...
FILE: data_generation/Grounded-Segment-Anything/grounded_sam_visam.py
class Colors (line 28) | class Colors:
method __init__ (line 30) | def __init__(self):
method __call__ (line 37) | def __call__(self, i, bgr=False):
method hex2rgb (line 42) | def hex2rgb(h): # rgb order (PIL)
class ListImgDataset (line 49) | class ListImgDataset(Dataset):
method __init__ (line 50) | def __init__(self, mot_path, img_list, det_db) -> None:
method load_img_from_file (line 64) | def load_img_from_file(self, f_path):
method init_img (line 79) | def init_img(self, img, proposals):
method __len__ (line 92) | def __len__(self):
method __getitem__ (line 95) | def __getitem__(self, index):
class Detector (line 100) | class Detector(object):
method __init__ (line 101) | def __init__(self, args, model, vid, sam_predictor=None):
method filter_dt_by_score (line 123) | def filter_dt_by_score(dt_instances: Instances, prob_threshold: float)...
method filter_dt_by_area (line 129) | def filter_dt_by_area(dt_instances: Instances, area_threshold: float) ...
method detect (line 135) | def detect(self, prob_threshold=0.6, area_threshold=100, vis=False):
class RuntimeTrackerBase (line 205) | class RuntimeTrackerBase(object):
method __init__ (line 206) | def __init__(self, score_thresh=0.6, filter_score_thresh=0.5, miss_tol...
method clear (line 212) | def clear(self):
method update (line 215) | def update(self, track_instances: Instances):
FILE: data_generation/Grounded-Segment-Anything/grounded_sam_whisper_demo.py
function load_image (line 28) | def load_image(image_path):
function load_model (line 43) | def load_model(model_config_path, model_checkpoint_path, device):
function get_grounding_output (line 54) | def get_grounding_output(model, image, caption, box_threshold, text_thre...
function show_mask (line 88) | def show_mask(mask, ax, random_color=False):
function show_box (line 98) | def show_box(box, ax, label):
function save_mask_data (line 105) | def save_mask_data(output_dir, mask_list, box_list, label_list):
function speech_recognition (line 134) | def speech_recognition(speech_file, model):
FILE: data_generation/Grounded-Segment-Anything/grounded_sam_whisper_inpainting_demo.py
function load_image (line 38) | def load_image(image_path):
function load_model (line 53) | def load_model(model_config_path, model_checkpoint_path, device):
function get_grounding_output (line 64) | def get_grounding_output(model, image, caption, box_threshold, text_thre...
function show_mask (line 99) | def show_mask(mask, ax, random_color=False):
function show_box (line 109) | def show_box(box, ax, label):
function speech_recognition (line 116) | def speech_recognition(speech_file, model):
function filter_prompts_with_chatgpt (line 138) | def filter_prompts_with_chatgpt(caption, max_tokens=100, model="gpt-3.5-...
FILE: data_generation/Grounded-Segment-Anything/playground/DeepFloyd/inpaint.py
function download_image (line 10) | def download_image(url):
FILE: data_generation/Grounded-Segment-Anything/playground/ImageBind_SAM/audio_referring_seg_demo.py
function retriev_vision_and_audio (line 57) | def retriev_vision_and_audio(elements, audio_list):
FILE: data_generation/Grounded-Segment-Anything/playground/ImageBind_SAM/data.py
function waveform2melspec (line 29) | def waveform2melspec(waveform, sample_rate, num_mel_bins, target_length):
function get_clip_timepoints (line 68) | def get_clip_timepoints(clip_sampler, duration):
function load_and_transform_vision_data_from_pil_image (line 78) | def load_and_transform_vision_data_from_pil_image(img_list, device):
function load_and_transform_vision_data (line 102) | def load_and_transform_vision_data(image_paths, device):
function load_and_transform_text (line 129) | def load_and_transform_text(text, device):
function load_and_transform_audio_data (line 138) | def load_and_transform_audio_data(
function get_clip_timepoints (line 188) | def get_clip_timepoints(clip_sampler, duration):
function crop_boxes (line 199) | def crop_boxes(boxes, x_offset, y_offset):
function uniform_crop (line 218) | def uniform_crop(images, size, spatial_idx, boxes=None, scale_size=None):
class SpatialCrop (line 277) | class SpatialCrop(nn.Module):
method __init__ (line 286) | def __init__(self, crop_size: int = 224, num_crops: int = 3):
method forward (line 298) | def forward(self, videos):
function load_and_transform_video_data (line 320) | def load_and_transform_video_data(
FILE: data_generation/Grounded-Segment-Anything/playground/ImageBind_SAM/demo.py
function retriev_vision_and_text (line 58) | def retriev_vision_and_text(elements, text_list):
function retriev_vision_and_audio (line 68) | def retriev_vision_and_audio(elements, audio_list):
FILE: data_generation/Grounded-Segment-Anything/playground/ImageBind_SAM/image_referring_seg_demo.py
function retriev_vision_and_vision (line 65) | def retriev_vision_and_vision(elements):
FILE: data_generation/Grounded-Segment-Anything/playground/ImageBind_SAM/models/helpers.py
class Normalize (line 17) | class Normalize(nn.Module):
method __init__ (line 18) | def __init__(self, dim: int) -> None:
method forward (line 22) | def forward(self, x):
class LearnableLogitScaling (line 26) | class LearnableLogitScaling(nn.Module):
method __init__ (line 27) | def __init__(
method forward (line 43) | def forward(self, x):
method extra_repr (line 46) | def extra_repr(self):
class EinOpsRearrange (line 51) | class EinOpsRearrange(nn.Module):
method __init__ (line 52) | def __init__(self, rearrange_expr: str, **kwargs) -> None:
method forward (line 57) | def forward(self, x):
class VerboseNNModule (line 62) | class VerboseNNModule(nn.Module):
method get_readable_tensor_repr (line 68) | def get_readable_tensor_repr(name: str, tensor: torch.Tensor) -> str:
method extra_repr (line 81) | def extra_repr(self) -> str:
function cast_if_src_dtype (line 100) | def cast_if_src_dtype(
class QuickGELU (line 110) | class QuickGELU(nn.Module):
method forward (line 112) | def forward(self, x: torch.Tensor):
class SelectElement (line 116) | class SelectElement(nn.Module):
method __init__ (line 117) | def __init__(self, index) -> None:
method forward (line 121) | def forward(self, x):
class SelectEOSAndProject (line 126) | class SelectEOSAndProject(nn.Module):
method __init__ (line 131) | def __init__(self, proj: nn.Module) -> None:
method forward (line 135) | def forward(self, x, seq_len):
FILE: data_generation/Grounded-Segment-Anything/playground/ImageBind_SAM/models/imagebind_model.py
class ImageBindModel (line 48) | class ImageBindModel(nn.Module):
method __init__ (line 49) | def __init__(
method _create_modality_preprocessors (line 142) | def _create_modality_preprocessors(
method _create_modality_trunks (line 276) | def _create_modality_trunks(
method _create_modality_heads (line 377) | def _create_modality_heads(
method _create_modality_postprocessors (line 429) | def _create_modality_postprocessors(self, out_embed_dim):
method forward (line 455) | def forward(self, inputs):
function imagebind_huge (line 490) | def imagebind_huge(pretrained=False):
FILE: data_generation/Grounded-Segment-Anything/playground/ImageBind_SAM/models/multimodal_preprocessors.py
function get_sinusoid_encoding_table (line 27) | def get_sinusoid_encoding_table(n_position, d_hid):
function interpolate_pos_encoding_2d (line 46) | def interpolate_pos_encoding_2d(target_spatial_size, pos_embed):
function interpolate_pos_encoding (line 66) | def interpolate_pos_encoding(
function _get_pos_embedding (line 105) | def _get_pos_embedding(
class PatchEmbedGeneric (line 122) | class PatchEmbedGeneric(nn.Module):
method __init__ (line 127) | def __init__(self, proj_stem, norm_layer: Optional[nn.Module] = None):
method get_patch_layout (line 138) | def get_patch_layout(self, img_size):
method forward (line 152) | def forward(self, x):
class SpatioTemporalPosEmbeddingHelper (line 161) | class SpatioTemporalPosEmbeddingHelper(VerboseNNModule):
method __init__ (line 162) | def __init__(
method get_pos_embedding (line 184) | def get_pos_embedding(self, vision_input, all_vision_tokens):
class RGBDTPreprocessor (line 196) | class RGBDTPreprocessor(VerboseNNModule):
method __init__ (line 197) | def __init__(
method init_parameters (line 237) | def init_parameters(self, init_param_style):
method tokenize_input_and_cls_pos (line 256) | def tokenize_input_and_cls_pos(self, input, stem, mask):
method forward (line 274) | def forward(self, vision=None, depth=None, patch_mask=None):
class AudioPreprocessor (line 302) | class AudioPreprocessor(RGBDTPreprocessor):
method __init__ (line 303) | def __init__(self, audio_stem: PatchEmbedGeneric, **kwargs) -> None:
method forward (line 306) | def forward(self, audio=None):
class ThermalPreprocessor (line 310) | class ThermalPreprocessor(RGBDTPreprocessor):
method __init__ (line 311) | def __init__(self, thermal_stem: PatchEmbedGeneric, **kwargs) -> None:
method forward (line 314) | def forward(self, thermal=None):
function build_causal_attention_mask (line 318) | def build_causal_attention_mask(context_length):
class TextPreprocessor (line 327) | class TextPreprocessor(VerboseNNModule):
method __init__ (line 328) | def __init__(
method init_parameters (line 363) | def init_parameters(self, init_param_style="openclip"):
method forward (line 379) | def forward(self, text):
class Im2Video (line 407) | class Im2Video(nn.Module):
method __init__ (line 410) | def __init__(self, time_dim=2):
method forward (line 414) | def forward(self, x):
class PadIm2Video (line 424) | class PadIm2Video(Im2Video):
method __init__ (line 425) | def __init__(self, ntimes, pad_type, time_dim=2):
method forward (line 432) | def forward(self, x):
function bytes_to_unicode (line 448) | def bytes_to_unicode():
function get_pairs (line 474) | def get_pairs(word):
function basic_clean (line 486) | def basic_clean(text):
function whitespace_clean (line 492) | def whitespace_clean(text):
class SimpleTokenizer (line 498) | class SimpleTokenizer(object):
method __init__ (line 499) | def __init__(self, bpe_path: str, context_length=77):
method bpe (line 526) | def bpe(self, token):
method encode (line 567) | def encode(self, text):
method decode (line 577) | def decode(self, tokens):
method __call__ (line 586) | def __call__(self, texts, context_length=None):
class IMUPreprocessor (line 607) | class IMUPreprocessor(VerboseNNModule):
method __init__ (line 608) | def __init__(
method init_parameters (line 637) | def init_parameters(self, init_param_style):
method tokenize_input_and_cls_pos (line 652) | def tokenize_input_and_cls_pos(self, input, stem):
method forward (line 667) | def forward(self, imu):
FILE: data_generation/Grounded-Segment-Anything/playground/ImageBind_SAM/models/transformer.py
class Attention (line 27) | class Attention(nn.Module):
method __init__ (line 28) | def __init__(
method forward (line 49) | def forward(self, x):
class Mlp (line 72) | class Mlp(nn.Module):
method __init__ (line 73) | def __init__(
method forward (line 89) | def forward(self, x):
class MultiheadAttention (line 98) | class MultiheadAttention(nn.MultiheadAttention):
method forward (line 99) | def forward(self, x: torch.Tensor, attn_mask: torch.Tensor):
class ViTAttention (line 103) | class ViTAttention(Attention):
method forward (line 104) | def forward(self, x: torch.Tensor, attn_mask: torch.Tensor):
class BlockWithMasking (line 109) | class BlockWithMasking(nn.Module):
method __init__ (line 110) | def __init__(
method forward (line 163) | def forward(self, x: torch.Tensor, attn_mask: torch.Tensor):
class SimpleTransformer (line 180) | class SimpleTransformer(nn.Module):
method __init__ (line 181) | def __init__(
method _init_weights (line 234) | def _init_weights(self, m):
method forward (line 249) | def forward(
FILE: data_generation/Grounded-Segment-Anything/playground/ImageBind_SAM/text_referring_seg_demo.py
function retriev_vision_and_text (line 57) | def retriev_vision_and_text(elements, text_list):
FILE: data_generation/Grounded-Segment-Anything/playground/ImageBind_SAM/utils.py
function segment_image (line 4) | def segment_image(image, segmentation_mask):
function convert_box_xywh_to_xyxy (line 17) | def convert_box_xywh_to_xyxy(box):
function get_indices_of_values_above_threshold (line 25) | def get_indices_of_values_above_threshold(values, threshold):
FILE: data_generation/Grounded-Segment-Anything/playground/LaMa/lama_inpaint_demo.py
function download_image (line 9) | def download_image(url):
FILE: data_generation/Grounded-Segment-Anything/playground/LaMa/sam_lama.py
function download_image (line 18) | def download_image(url):
function dilate_mask (line 73) | def dilate_mask(mask, dilate_factor=15):
function save_array_to_img (line 82) | def save_array_to_img(img_arr, img_p):
FILE: data_generation/Grounded-Segment-Anything/playground/PaintByExample/paint_by_example.py
function download_image (line 13) | def download_image(url):
FILE: data_generation/Grounded-Segment-Anything/playground/PaintByExample/sam_paint_by_example.py
function download_image (line 16) | def download_image(url):
FILE: data_generation/Grounded-Segment-Anything/playground/RePaint/repaint.py
function download_image (line 10) | def download_image(url):
FILE: data_generation/Grounded-Segment-Anything/predict.py
class ModelOutput (line 42) | class ModelOutput(BaseModel):
class Predictor (line 49) | class Predictor(BasePredictor):
method setup (line 50) | def setup(self):
method predict (line 87) | def predict(
function get_grounding_output (line 205) | def get_grounding_output(
function load_image (line 244) | def load_image(image_path):
function load_model (line 259) | def load_model(model_config_path, model_checkpoint_path, device):
function show_mask (line 272) | def show_mask(mask, ax, random_color=False):
function show_box (line 282) | def show_box(box, ax, label):
FILE: data_generation/Grounded-Segment-Anything/segment_anything/scripts/amg.py
function write_masks_to_folder (line 152) | def write_masks_to_folder(masks: List[Dict[str, Any]], path: str) -> None:
function get_amg_kwargs (line 177) | def get_amg_kwargs(args):
function main (line 195) | def main(args: argparse.Namespace) -> None:
FILE: data_generation/Grounded-Segment-Anything/segment_anything/scripts/export_onnx_model.py
function run_export (line 97) | def run_export(
function to_numpy (line 173) | def to_numpy(tensor):
FILE: data_generation/Grounded-Segment-Anything/segment_anything/segment_anything/automatic_mask_generator.py
class SamAutomaticMaskGenerator (line 35) | class SamAutomaticMaskGenerator:
method __init__ (line 36) | def __init__(
method generate (line 137) | def generate(self, image: np.ndarray) -> List[Dict[str, Any]]:
method _generate_masks (line 197) | def _generate_masks(self, image: np.ndarray) -> MaskData:
method _process_crop (line 225) | def _process_crop(
method _process_batch (line 266) | def _process_batch(
method postprocess_small_regions (line 324) | def postprocess_small_regions(
FILE: data_generation/Grounded-Segment-Anything/segment_anything/segment_anything/build_sam.py
function build_sam_vit_h (line 14) | def build_sam_vit_h(checkpoint=None):
function build_sam_vit_l (line 27) | def build_sam_vit_l(checkpoint=None):
function build_sam_vit_b (line 37) | def build_sam_vit_b(checkpoint=None):
function _build_sam (line 55) | def _build_sam(
FILE: data_generation/Grounded-Segment-Anything/segment_anything/segment_anything/build_sam_hq.py
function build_sam_hq_vit_h (line 14) | def build_sam_hq_vit_h(checkpoint=None):
function build_sam_hq_vit_l (line 27) | def build_sam_hq_vit_l(checkpoint=None):
function build_sam_hq_vit_b (line 37) | def build_sam_hq_vit_b(checkpoint=None):
function _build_sam (line 55) | def _build_sam(
FILE: data_generation/Grounded-Segment-Anything/segment_anything/segment_anything/modeling/common.py
class MLPBlock (line 13) | class MLPBlock(nn.Module):
method __init__ (line 14) | def __init__(
method forward (line 25) | def forward(self, x: torch.Tensor) -> torch.Tensor:
class LayerNorm2d (line 31) | class LayerNorm2d(nn.Module):
method __init__ (line 32) | def __init__(self, num_channels: int, eps: float = 1e-6) -> None:
method forward (line 38) | def forward(self, x: torch.Tensor) -> torch.Tensor:
FILE: data_generation/Grounded-Segment-Anything/segment_anything/segment_anything/modeling/image_encoder.py
class ImageEncoderViT (line 17) | class ImageEncoderViT(nn.Module):
method __init__ (line 18) | def __init__(
method forward (line 106) | def forward(self, x: torch.Tensor) -> torch.Tensor:
class Block (line 122) | class Block(nn.Module):
method __init__ (line 125) | def __init__(
method forward (line 169) | def forward(self, x: torch.Tensor) -> torch.Tensor:
class Attention (line 188) | class Attention(nn.Module):
method __init__ (line 191) | def __init__(
method forward (line 227) | def forward(self, x: torch.Tensor) -> torch.Tensor:
function window_partition (line 246) | def window_partition(x: torch.Tensor, window_size: int) -> Tuple[torch.T...
function window_unpartition (line 270) | def window_unpartition(
function get_rel_pos (line 295) | def get_rel_pos(q_size: int, k_size: int, rel_pos: torch.Tensor) -> torc...
function add_decomposed_rel_pos (line 328) | def add_decomposed_rel_pos(
class PatchEmbed (line 367) | class PatchEmbed(nn.Module):
method __init__ (line 372) | def __init__(
method forward (line 394) | def forward(self, x: torch.Tensor) -> torch.Tensor:
FILE: data_generation/Grounded-Segment-Anything/segment_anything/segment_anything/modeling/mask_decoder.py
class MaskDecoder (line 16) | class MaskDecoder(nn.Module):
method __init__ (line 17) | def __init__(
method forward (line 71) | def forward(
method predict_masks (line 114) | def predict_masks(
class MLP (line 156) | class MLP(nn.Module):
method __init__ (line 157) | def __init__(
method forward (line 173) | def forward(self, x):
FILE: data_generation/Grounded-Segment-Anything/segment_anything/segment_anything/modeling/mask_decoder_hq.py
class MaskDecoderHQ (line 17) | class MaskDecoderHQ(nn.Module):
method __init__ (line 18) | def __init__(
method forward (line 99) | def forward(
method predict_masks (line 158) | def predict_masks(
class MLP (line 210) | class MLP(nn.Module):
method __init__ (line 211) | def __init__(
method forward (line 227) | def forward(self, x):
FILE: data_generation/Grounded-Segment-Anything/segment_anything/segment_anything/modeling/prompt_encoder.py
class PromptEncoder (line 16) | class PromptEncoder(nn.Module):
method __init__ (line 17) | def __init__(
method get_dense_pe (line 62) | def get_dense_pe(self) -> torch.Tensor:
method _embed_points (line 73) | def _embed_points(
method _embed_boxes (line 93) | def _embed_boxes(self, boxes: torch.Tensor) -> torch.Tensor:
method _embed_masks (line 102) | def _embed_masks(self, masks: torch.Tensor) -> torch.Tensor:
method _get_batch_size (line 107) | def _get_batch_size(
method _get_device (line 125) | def _get_device(self) -> torch.device:
method forward (line 128) | def forward(
class PositionEmbeddingRandom (line 171) | class PositionEmbeddingRandom(nn.Module):
method __init__ (line 176) | def __init__(self, num_pos_feats: int = 64, scale: Optional[float] = N...
method _pe_encoding (line 185) | def _pe_encoding(self, coords: torch.Tensor) -> torch.Tensor:
method forward (line 194) | def forward(self, size: Tuple[int, int]) -> torch.Tensor:
method forward_with_coords (line 207) | def forward_with_coords(
FILE: data_generation/Grounded-Segment-Anything/segment_anything/segment_anything/modeling/sam.py
class Sam (line 18) | class Sam(nn.Module):
method __init__ (line 22) | def __init__(
method device (line 50) | def device(self) -> Any:
method forward (line 54) | def forward(
method postprocess_masks (line 133) | def postprocess_masks(
method preprocess (line 164) | def preprocess(self, x: torch.Tensor) -> torch.Tensor:
FILE: data_generation/Grounded-Segment-Anything/segment_anything/segment_anything/modeling/transformer.py
class TwoWayTransformer (line 16) | class TwoWayTransformer(nn.Module):
method __init__ (line 17) | def __init__(
method forward (line 62) | def forward(
class TwoWayAttentionBlock (line 109) | class TwoWayAttentionBlock(nn.Module):
method __init__ (line 110) | def __init__(
method forward (line 151) | def forward(
class Attention (line 185) | class Attention(nn.Module):
method __init__ (line 191) | def __init__(
method _separate_heads (line 208) | def _separate_heads(self, x: Tensor, num_heads: int) -> Tensor:
method _recombine_heads (line 213) | def _recombine_heads(self, x: Tensor) -> Tensor:
method forward (line 218) | def forward(self, q: Tensor, k: Tensor, v: Tensor) -> Tensor:
FILE: data_generation/Grounded-Segment-Anything/segment_anything/segment_anything/predictor.py
class SamPredictor (line 17) | class SamPredictor:
method __init__ (line 18) | def __init__(
method set_image (line 34) | def set_image(
method set_torch_image (line 65) | def set_torch_image(
method predict (line 94) | def predict(
method predict_torch (line 173) | def predict_torch(
method get_image_embedding (line 252) | def get_image_embedding(self) -> torch.Tensor:
method device (line 266) | def device(self) -> torch.device:
method reset_image (line 269) | def reset_image(self) -> None:
FILE: data_generation/Grounded-Segment-Anything/segment_anything/segment_anything/utils/amg.py
class MaskData (line 16) | class MaskData:
method __init__ (line 22) | def __init__(self, **kwargs) -> None:
method __setitem__ (line 29) | def __setitem__(self, key: str, item: Any) -> None:
method __delitem__ (line 35) | def __delitem__(self, key: str) -> None:
method __getitem__ (line 38) | def __getitem__(self, key: str) -> Any:
method items (line 41) | def items(self) -> ItemsView[str, Any]:
method filter (line 44) | def filter(self, keep: torch.Tensor) -> None:
method cat (line 59) | def cat(self, new_stats: "MaskData") -> None:
method to_numpy (line 72) | def to_numpy(self) -> None:
function is_box_near_crop_edge (line 78) | def is_box_near_crop_edge(
function box_xyxy_to_xywh (line 91) | def box_xyxy_to_xywh(box_xyxy: torch.Tensor) -> torch.Tensor:
function batch_iterator (line 98) | def batch_iterator(batch_size: int, *args) -> Generator[List[Any], None,...
function mask_to_rle_pytorch (line 107) | def mask_to_rle_pytorch(tensor: torch.Tensor) -> List[Dict[str, Any]]:
function rle_to_mask (line 138) | def rle_to_mask(rle: Dict[str, Any]) -> np.ndarray:
function area_from_rle (line 152) | def area_from_rle(rle: Dict[str, Any]) -> int:
function calculate_stability_score (line 156) | def calculate_stability_score(
function build_point_grid (line 179) | def build_point_grid(n_per_side: int) -> np.ndarray:
function build_all_layer_point_grids (line 189) | def build_all_layer_point_grids(
function generate_crop_boxes (line 200) | def generate_crop_boxes(
function uncrop_boxes_xyxy (line 237) | def uncrop_boxes_xyxy(boxes: torch.Tensor, crop_box: List[int]) -> torch...
function uncrop_points (line 246) | def uncrop_points(points: torch.Tensor, crop_box: List[int]) -> torch.Te...
function uncrop_masks (line 255) | def uncrop_masks(
function remove_small_regions (line 267) | def remove_small_regions(
function coco_encode_rle (line 294) | def coco_encode_rle(uncompressed_rle: Dict[str, Any]) -> Dict[str, Any]:
function batched_mask_to_box (line 303) | def batched_mask_to_box(masks: torch.Tensor) -> torch.Tensor:
FILE: data_generation/Grounded-Segment-Anything/segment_anything/segment_anything/utils/onnx.py
class SamOnnxModel (line 17) | class SamOnnxModel(nn.Module):
method __init__ (line 25) | def __init__(
method resize_longest_image_size (line 42) | def resize_longest_image_size(
method _embed_points (line 51) | def _embed_points(self, point_coords: torch.Tensor, point_labels: torc...
method _embed_masks (line 69) | def _embed_masks(self, input_mask: torch.Tensor, has_mask_input: torch...
method mask_postprocessing (line 76) | def mask_postprocessing(self, masks: torch.Tensor, orig_im_size: torch...
method select_masks (line 92) | def select_masks(
method forward (line 108) | def forward(
FILE: data_generation/Grounded-Segment-Anything/segment_anything/segment_anything/utils/transforms.py
class ResizeLongestSide (line 16) | class ResizeLongestSide:
method __init__ (line 23) | def __init__(self, target_length: int) -> None:
method apply_image (line 26) | def apply_image(self, image: np.ndarray) -> np.ndarray:
method apply_coords (line 33) | def apply_coords(self, coords: np.ndarray, original_size: Tuple[int, ....
method apply_boxes (line 47) | def apply_boxes(self, boxes: np.ndarray, original_size: Tuple[int, ......
method apply_image_torch (line 55) | def apply_image_torch(self, image: torch.Tensor) -> torch.Tensor:
method apply_coords_torch (line 67) | def apply_coords_torch(
method apply_boxes_torch (line 83) | def apply_boxes_torch(
method get_preprocess_shape (line 94) | def get_preprocess_shape(oldh: int, oldw: int, long_side_length: int) ...
FILE: data_generation/Grounded-Segment-Anything/voxelnext_3d_box/model.py
class VoxelNeXt (line 12) | class VoxelNeXt(nn.Module):
method __init__ (line 13) | def __init__(self, model_cfg):
class Model (line 39) | class Model(nn.Module):
method __init__ (line 40) | def __init__(self, model_cfg, device="cuda"):
method image_embedding (line 56) | def image_embedding(self, image):
method point_embedding (line 59) | def point_embedding(self, data_dict, image_id):
method generate_3D_box (line 85) | def generate_3D_box(self, lidar2img_rt, mask, voxel_coords, pred_dicts...
method forward (line 118) | def forward(self, image, point_dict, prompt_point, lidar2img_rt, image...
FILE: data_generation/Grounded-Segment-Anything/voxelnext_3d_box/models/data_processor.py
function mask_points_by_range (line 12) | def mask_points_by_range(points, limit_range):
class VoxelGeneratorWrapper (line 18) | class VoxelGeneratorWrapper():
method __init__ (line 19) | def __init__(self, vsize_xyz, coors_range_xyz, num_point_features, max...
method generate (line 47) | def generate(self, points):
class DataProcessor (line 66) | class DataProcessor(object):
method __init__ (line 67) | def __init__(self, processor_configs, point_cloud_range, training, num...
method mask_points_and_boxes_outside_range (line 81) | def mask_points_and_boxes_outside_range(self, data_dict=None, config=N...
method shuffle_points (line 91) | def shuffle_points(self, data_dict=None, config=None):
method transform_points_to_voxels_placeholder (line 103) | def transform_points_to_voxels_placeholder(self, data_dict=None, confi...
method double_flip (line 113) | def double_flip(self, points):
method transform_points_to_voxels (line 129) | def transform_points_to_voxels(self, data_dict=None, config=None):
method sample_points (line 156) | def sample_points(self, data_dict=None, config=None):
method calculate_grid_size (line 188) | def calculate_grid_size(self, data_dict=None, config=None):
method forward (line 196) | def forward(self, data_dict):
FILE: data_generation/Grounded-Segment-Anything/voxelnext_3d_box/models/mean_vfe.py
class MeanVFE (line 4) | class MeanVFE(nn.Module):
method __init__ (line 5) | def __init__(self):
method forward (line 8) | def forward(self, batch_dict, **kwargs):
FILE: data_generation/Grounded-Segment-Anything/voxelnext_3d_box/models/spconv_backbone_voxelnext.py
function replace_feature (line 9) | def replace_feature(out, new_features):
function post_act_block (line 13) | def post_act_block(in_channels, out_channels, kernel_size, indice_key=No...
class SparseBasicBlock (line 35) | class SparseBasicBlock(spconv.SparseModule):
method __init__ (line 38) | def __init__(self, inplanes, planes, stride=1, norm_fn=None, downsampl...
method forward (line 55) | def forward(self, x):
class VoxelResBackBone8xVoxelNeXt (line 74) | class VoxelResBackBone8xVoxelNeXt(nn.Module):
method __init__ (line 75) | def __init__(self, input_channels, grid_size, **kwargs):
method bev_out (line 153) | def bev_out(self, x_conv, index):
method track_voxels_2d (line 174) | def track_voxels_2d(self, x, x_downsample, index, kernel_size=3):
method index_from_sparse (line 214) | def index_from_sparse(self, feature, indices, x_target, _2d=False):
method forward (line 229) | def forward(self, batch_dict):
FILE: data_generation/Grounded-Segment-Anything/voxelnext_3d_box/models/voxelnext_head.py
class SeparateHead (line 10) | class SeparateHead(nn.Module):
method __init__ (line 11) | def __init__(self, input_channels, sep_head_dict, kernel_size, use_bia...
method forward (line 30) | def forward(self, x):
class VoxelNeXtHead (line 38) | class VoxelNeXtHead(nn.Module):
method __init__ (line 39) | def __init__(self, class_names, point_cloud_range, voxel_size, kernel_...
method generate_predicted_boxes (line 76) | def generate_predicted_boxes(self, batch_size, pred_dicts, voxel_indic...
method _get_voxel_infos (line 137) | def _get_voxel_infos(self, x):
method forward (line 152) | def forward(self, data_dict):
FILE: data_generation/Grounded-Segment-Anything/voxelnext_3d_box/utils/centernet_utils.py
function _topk_1d (line 6) | def _topk_1d(scores, batch_size, batch_idx, obj, K=40, nuscenes=False):
function gather_feat_idx (line 40) | def gather_feat_idx(feats, inds, batch_size, batch_idx):
function decode_bbox_from_voxels_nuscenes (line 53) | def decode_bbox_from_voxels_nuscenes(batch_size, indices, obj, rot_cos, ...
FILE: data_generation/Grounded-Segment-Anything/voxelnext_3d_box/utils/config.py
function merge_new_config (line 4) | def merge_new_config(config, new_config):
function cfg_from_yaml_file (line 23) | def cfg_from_yaml_file(cfg_file, config):
FILE: data_generation/Grounded-Segment-Anything/voxelnext_3d_box/utils/image_projection.py
function get_data_info (line 5) | def get_data_info(info, cam_type):
function _proj_voxel_image (line 23) | def _proj_voxel_image(voxel_coords, lidar2img_rt, voxel_size, point_clou...
function _draw_image (line 41) | def _draw_image(points_image, image_path, depth):
function _draw_mask (line 51) | def _draw_mask(image_path, mask, color=None):
function _draw_3dbox (line 62) | def _draw_3dbox(box, lidar2img_rt, image, mask=None, color=None, output_...
FILE: data_generation/data_generation.py
function generate_Contours_mask (line 59) | def generate_Contours_mask(pil_img):
function find_contours_number (line 92) | def find_contours_number(mask_image: np.array):
function check_mask_size (line 96) | def check_mask_size(mask, min_size=0.01, max_size=0.9):
function create_mask_image (line 105) | def create_mask_image(image_source, detected_boxes):
function to_pil (line 133) | def to_pil(image: torch.Tensor) -> Image.Image:
function gd_load_image (line 138) | def gd_load_image(image_path) -> Tuple[np.array, torch.Tensor]:
function load_image (line 157) | def load_image(image_path, target_size=512):
function compare_prompts (line 188) | def compare_prompts(prompt1, prompt2):
function generate_images (line 194) | def generate_images(args,pipe, prompts, init_image, cross_attention_kwar...
function generate_contour_mask (line 260) | def generate_contour_mask(mask):
function detect (line 277) | def detect(image, text_prompt, model, box_threshold = 0.3, text_threshol...
function segment (line 287) | def segment(image, sam_model, boxes,device):
function save_tsv (line 302) | def save_tsv(args, shard_id, shard, device, global_data):
class NoneImageDataset (line 789) | class NoneImageDataset(Dataset):
method __init__ (line 790) | def __init__(self, url_data):
method __len__ (line 793) | def __len__(self):
method __getitem__ (line 796) | def __getitem__(self, idx):
class OpenImageDataset (line 803) | class OpenImageDataset(Dataset):
method __init__ (line 804) | def __init__(self, url_data):
method __len__ (line 807) | def __len__(self):
method __getitem__ (line 810) | def __getitem__(self, idx):
class RegionDataset (line 834) | class RegionDataset(Dataset):
method __init__ (line 835) | def __init__(self, url_data):
method __len__ (line 838) | def __len__(self):
method __getitem__ (line 841) | def __getitem__(self, idx):
function collate_fn (line 885) | def collate_fn(batch):
function load_jsonl (line 930) | def load_jsonl(file_path):
function load_json (line 936) | def load_json(file_path):
function load_groundingdino_model (line 939) | def load_groundingdino_model(model_config_path, model_checkpoint_path, d...
function main (line 949) | def main():
FILE: data_generation/ldm/data/base.py
class Txt2ImgIterableBaseDataset (line 5) | class Txt2ImgIterableBaseDataset(IterableDataset):
method __init__ (line 9) | def __init__(self, num_records=0, valid_ids=None, size=256):
method __len__ (line 18) | def __len__(self):
method __iter__ (line 22) | def __iter__(self):
FILE: data_generation/ldm/data/imagenet.py
function synset2idx (line 20) | def synset2idx(path_to_yaml="data/index_synset.yaml"):
class ImageNetBase (line 26) | class ImageNetBase(Dataset):
method __init__ (line 27) | def __init__(self, config=None):
method __len__ (line 39) | def __len__(self):
method __getitem__ (line 42) | def __getitem__(self, i):
method _prepare (line 45) | def _prepare(self):
method _filter_relpaths (line 48) | def _filter_relpaths(self, relpaths):
method _prepare_synset_to_human (line 66) | def _prepare_synset_to_human(self):
method _prepare_idx_to_synset (line 74) | def _prepare_idx_to_synset(self):
method _prepare_human_to_integer_label (line 80) | def _prepare_human_to_integer_label(self):
method _load (line 93) | def _load(self):
class ImageNetTrain (line 134) | class ImageNetTrain(ImageNetBase):
method __init__ (line 145) | def __init__(self, process_images=True, data_root=None, **kwargs):
method _prepare (line 150) | def _prepare(self):
class ImageNetValidation (line 197) | class ImageNetValidation(ImageNetBase):
method __init__ (line 211) | def __init__(self, process_images=True, data_root=None, **kwargs):
method _prepare (line 216) | def _prepare(self):
class ImageNetSR (line 272) | class ImageNetSR(Dataset):
method __init__ (line 273) | def __init__(self, size=None,
method __len__ (line 336) | def __len__(self):
method __getitem__ (line 339) | def __getitem__(self, i):
class ImageNetSRTrain (line 375) | class ImageNetSRTrain(ImageNetSR):
method __init__ (line 376) | def __init__(self, **kwargs):
method get_base (line 379) | def get_base(self):
class ImageNetSRValidation (line 386) | class ImageNetSRValidation(ImageNetSR):
method __init__ (line 387) | def __init__(self, **kwargs):
method get_base (line 390) | def get_base(self):
FILE: data_generation/ldm/data/lsun.py
class LSUNBase (line 9) | class LSUNBase(Dataset):
method __init__ (line 10) | def __init__(self,
method __len__ (line 36) | def __len__(self):
method __getitem__ (line 39) | def __getitem__(self, i):
class LSUNChurchesTrain (line 62) | class LSUNChurchesTrain(LSUNBase):
method __init__ (line 63) | def __init__(self, **kwargs):
class LSUNChurchesValidation (line 67) | class LSUNChurchesValidation(LSUNBase):
method __init__ (line 68) | def __init__(self, flip_p=0., **kwargs):
class LSUNBedroomsTrain (line 73) | class LSUNBedroomsTrain(LSUNBase):
method __init__ (line 74) | def __init__(self, **kwargs):
class LSUNBedroomsValidation (line 78) | class LSUNBedroomsValidation(LSUNBase):
method __init__ (line 79) | def __init__(self, flip_p=0.0, **kwargs):
class LSUNCatsTrain (line 84) | class LSUNCatsTrain(LSUNBase):
method __init__ (line 85) | def __init__(self, **kwargs):
class LSUNCatsValidation (line 89) | class LSUNCatsValidation(LSUNBase):
method __init__ (line 90) | def __init__(self, flip_p=0., **kwargs):
FILE: data_generation/ldm/lr_scheduler.py
class LambdaWarmUpCosineScheduler (line 4) | class LambdaWarmUpCosineScheduler:
method __init__ (line 8) | def __init__(self, warm_up_steps, lr_min, lr_max, lr_start, max_decay_...
method schedule (line 17) | def schedule(self, n, **kwargs):
method __call__ (line 32) | def __call__(self, n, **kwargs):
class LambdaWarmUpCosineScheduler2 (line 36) | class LambdaWarmUpCosineScheduler2:
method __init__ (line 41) | def __init__(self, warm_up_steps, f_min, f_max, f_start, cycle_lengths...
method find_in_interval (line 52) | def find_in_interval(self, n):
method schedule (line 59) | def schedule(self, n, **kwargs):
method __call__ (line 77) | def __call__(self, n, **kwargs):
class LambdaLinearScheduler (line 81) | class LambdaLinearScheduler(LambdaWarmUpCosineScheduler2):
method schedule (line 83) | def schedule(self, n, **kwargs):
FILE: data_generation/ldm/models/autoencoder.py
class VQModel (line 14) | class VQModel(pl.LightningModule):
method __init__ (line 15) | def __init__(self,
method ema_scope (line 64) | def ema_scope(self, context=None):
method init_from_ckpt (line 78) | def init_from_ckpt(self, path, ignore_keys=list()):
method on_train_batch_end (line 92) | def on_train_batch_end(self, *args, **kwargs):
method encode (line 96) | def encode(self, x):
method encode_to_prequant (line 102) | def encode_to_prequant(self, x):
method decode (line 107) | def decode(self, quant):
method decode_code (line 112) | def decode_code(self, code_b):
method forward (line 117) | def forward(self, input, return_pred_indices=False):
method get_input (line 124) | def get_input(self, batch, k):
method training_step (line 142) | def training_step(self, batch, batch_idx, optimizer_idx):
method validation_step (line 164) | def validation_step(self, batch, batch_idx):
method _validation_step (line 170) | def _validation_step(self, batch, batch_idx, suffix=""):
method configure_optimizers (line 197) | def configure_optimizers(self):
method get_last_layer (line 230) | def get_last_layer(self):
method log_images (line 233) | def log_images(self, batch, only_inputs=False, plot_ema=False, **kwargs):
method to_rgb (line 255) | def to_rgb(self, x):
class VQModelInterface (line 264) | class VQModelInterface(VQModel):
method __init__ (line 265) | def __init__(self, embed_dim, *args, **kwargs):
method encode (line 269) | def encode(self, x):
method decode (line 274) | def decode(self, h, force_not_quantize=False):
class AutoencoderKL (line 285) | class AutoencoderKL(pl.LightningModule):
method __init__ (line 286) | def __init__(self,
method init_from_ckpt (line 313) | def init_from_ckpt(self, path, ignore_keys=list()):
method encode (line 324) | def encode(self, x):
method decode (line 330) | def decode(self, z):
method forward (line 335) | def forward(self, input, sample_posterior=True):
method get_input (line 344) | def get_input(self, batch, k):
method training_step (line 351) | def training_step(self, batch, batch_idx, optimizer_idx):
method validation_step (line 372) | def validation_step(self, batch, batch_idx):
method configure_optimizers (line 386) | def configure_optimizers(self):
method get_last_layer (line 397) | def get_last_layer(self):
method log_images (line 401) | def log_images(self, batch, only_inputs=False, **kwargs):
method to_rgb (line 417) | def to_rgb(self, x):
class IdentityFirstStage (line 426) | class IdentityFirstStage(torch.nn.Module):
method __init__ (line 427) | def __init__(self, *args, vq_interface=False, **kwargs):
method encode (line 431) | def encode(self, x, *args, **kwargs):
method decode (line 434) | def decode(self, x, *args, **kwargs):
method quantize (line 437) | def quantize(self, x, *args, **kwargs):
method forward (line 442) | def forward(self, x, *args, **kwargs):
FILE: data_generation/ldm/models/diffusion/classifier.py
function disabled_train (line 22) | def disabled_train(self, mode=True):
class NoisyLatentImageClassifier (line 28) | class NoisyLatentImageClassifier(pl.LightningModule):
method __init__ (line 30) | def __init__(self,
method init_from_ckpt (line 70) | def init_from_ckpt(self, path, ignore_keys=list(), only_model=False):
method load_diffusion (line 88) | def load_diffusion(self):
method load_classifier (line 95) | def load_classifier(self, ckpt_path, pool):
method get_x_noisy (line 110) | def get_x_noisy(self, x, t, noise=None):
method forward (line 120) | def forward(self, x_noisy, t, *args, **kwargs):
method get_input (line 124) | def get_input(self, batch, k):
method get_conditioning (line 133) | def get_conditioning(self, batch, k=None):
method compute_top_k (line 150) | def compute_top_k(self, logits, labels, k, reduction="mean"):
method on_train_epoch_start (line 157) | def on_train_epoch_start(self):
method write_logs (line 162) | def write_logs(self, loss, logits, targets):
method shared_step (line 179) | def shared_step(self, batch, t=None):
method training_step (line 198) | def training_step(self, batch, batch_idx):
method reset_noise_accs (line 202) | def reset_noise_accs(self):
method on_validation_start (line 206) | def on_validation_start(self):
method validation_step (line 210) | def validation_step(self, batch, batch_idx):
method configure_optimizers (line 220) | def configure_optimizers(self):
method log_images (line 238) | def log_images(self, batch, N=8, *args, **kwargs):
FILE: data_generation/ldm/models/diffusion/ddim.py
class DDIMSampler (line 12) | class DDIMSampler(object):
method __init__ (line 13) | def __init__(self, model, schedule="linear", **kwargs):
method register_buffer (line 19) | def register_buffer(self, name, attr):
method make_schedule (line 25) | def make_schedule(self, ddim_num_steps, ddim_discretize="uniform", ddi...
method sample (line 57) | def sample(self,
method ddim_sampling (line 114) | def ddim_sampling(self, cond, shape,
method p_sample_ddim (line 166) | def p_sample_ddim(self, x, c, t, index, repeat_noise=False, use_origin...
method stochastic_encode (line 207) | def stochastic_encode(self, x0, t, use_original_steps=False, noise=None):
method decode (line 223) | def decode(self, x_latent, cond, t_start, unconditional_guidance_scale...
FILE: data_generation/ldm/models/diffusion/ddpm.py
function disabled_train (line 34) | def disabled_train(self, mode=True):
function uniform_on_device (line 40) | def uniform_on_device(r1, r2, shape, device):
class DDPM (line 44) | class DDPM(pl.LightningModule):
method __init__ (line 46) | def __init__(self,
method register_schedule (line 117) | def register_schedule(self, given_betas=None, beta_schedule="linear", ...
method ema_scope (line 172) | def ema_scope(self, context=None):
method init_from_ckpt (line 186) | def init_from_ckpt(self, path, ignore_keys=list(), only_model=False):
method q_mean_variance (line 204) | def q_mean_variance(self, x_start, t):
method predict_start_from_noise (line 216) | def predict_start_from_noise(self, x_t, t, noise):
method q_posterior (line 222) | def q_posterior(self, x_start, x_t, t):
method p_mean_variance (line 231) | def p_mean_variance(self, x, t, clip_denoised: bool):
method p_sample (line 244) | def p_sample(self, x, t, clip_denoised=True, repeat_noise=False):
method p_sample_loop (line 253) | def p_sample_loop(self, shape, return_intermediates=False):
method sample (line 268) | def sample(self, batch_size=16, return_intermediates=False):
method q_sample (line 274) | def q_sample(self, x_start, t, noise=None):
method get_loss (line 279) | def get_loss(self, pred, target, mean=True):
method p_losses (line 294) | def p_losses(self, x_start, t, noise=None):
method forward (line 323) | def forward(self, x, *args, **kwargs):
method get_input (line 329) | def get_input(self, batch, k):
method shared_step (line 337) | def shared_step(self, batch):
method training_step (line 342) | def training_step(self, batch, batch_idx):
method validation_step (line 358) | def validation_step(self, batch, batch_idx):
method on_train_batch_end (line 366) | def on_train_batch_end(self, *args, **kwargs):
method _get_rows_from_list (line 370) | def _get_rows_from_list(self, samples):
method log_images (line 378) | def log_images(self, batch, N=8, n_row=2, sample=True, return_keys=Non...
method configure_optimizers (line 415) | def configure_optimizers(self):
class LatentDiffusion (line 424) | class LatentDiffusion(DDPM):
method __init__ (line 426) | def __init__(self,
method make_cond_schedule (line 471) | def make_cond_schedule(self, ):
method on_train_batch_start (line 478) | def on_train_batch_start(self, batch, batch_idx, dataloader_idx):
method register_schedule (line 493) | def register_schedule(self,
method instantiate_first_stage (line 502) | def instantiate_first_stage(self, config):
method instantiate_cond_stage (line 509) | def instantiate_cond_stage(self, config):
method _get_denoise_row_from_list (line 530) | def _get_denoise_row_from_list(self, samples, desc='', force_no_decode...
method get_first_stage_encoding (line 542) | def get_first_stage_encoding(self, encoder_posterior):
method get_learned_conditioning (line 551) | def get_learned_conditioning(self, c):
method meshgrid (line 564) | def meshgrid(self, h, w):
method delta_border (line 571) | def delta_border(self, h, w):
method get_weighting (line 585) | def get_weighting(self, h, w, Ly, Lx, device):
method get_fold_unfold (line 601) | def get_fold_unfold(self, x, kernel_size, stride, uf=1, df=1): # todo...
method get_input (line 654) | def get_input(self, batch, k, return_first_stage_outputs=False, force_...
method decode_first_stage (line 706) | def decode_first_stage(self, z, predict_cids=False, force_not_quantize...
method differentiable_decode_first_stage (line 766) | def differentiable_decode_first_stage(self, z, predict_cids=False, for...
method encode_first_stage (line 826) | def encode_first_stage(self, x):
method shared_step (line 865) | def shared_step(self, batch, **kwargs):
method forward (line 870) | def forward(self, x, c, *args, **kwargs):
method _rescale_annotations (line 881) | def _rescale_annotations(self, bboxes, crop_coordinates): # TODO: mov...
method apply_model (line 891) | def apply_model(self, x_noisy, t, cond, return_ids=False):
method _predict_eps_from_xstart (line 994) | def _predict_eps_from_xstart(self, x_t, t, pred_xstart):
method _prior_bpd (line 998) | def _prior_bpd(self, x_start):
method p_losses (line 1012) | def p_losses(self, x_start, cond, t, noise=None):
method p_mean_variance (line 1047) | def p_mean_variance(self, x, c, t, clip_denoised: bool, return_codeboo...
method p_sample (line 1079) | def p_sample(self, x, c, t, clip_denoised=False, repeat_noise=False,
method progressive_denoising (line 1110) | def progressive_denoising(self, cond, shape, verbose=True, callback=No...
method p_sample_loop (line 1166) | def p_sample_loop(self, cond, shape, return_intermediates=False,
method sample (line 1217) | def sample(self, cond, batch_size=16, return_intermediates=False, x_T=...
method sample_log (line 1235) | def sample_log(self,cond,batch_size,ddim, ddim_steps,**kwargs):
method log_images (line 1251) | def log_images(self, batch, N=8, n_row=4, sample=True, ddim_steps=200,...
method configure_optimizers (line 1361) | def configure_optimizers(self):
method to_rgb (line 1386) | def to_rgb(self, x):
class DiffusionWrapper (line 1395) | class DiffusionWrapper(pl.LightningModule):
method __init__ (line 1396) | def __init__(self, diff_model_config, conditioning_key):
method forward (line 1402) | def forward(self, x, t, c_concat: list = None, c_crossattn: list = None):
class Layout2ImgDiffusion (line 1424) | class Layout2ImgDiffusion(LatentDiffusion):
method __init__ (line 1426) | def __init__(self, cond_stage_key, *args, **kwargs):
method log_images (line 1430) | def log_images(self, batch, N=8, *args, **kwargs):
FILE: data_generation/ldm/models/diffusion/dpm_solver/dpm_solver.py
class NoiseScheduleVP (line 6) | class NoiseScheduleVP:
method __init__ (line 7) | def __init__(
method marginal_log_mean_coeff (line 125) | def marginal_log_mean_coeff(self, t):
method marginal_alpha (line 138) | def marginal_alpha(self, t):
method marginal_std (line 144) | def marginal_std(self, t):
method marginal_lambda (line 150) | def marginal_lambda(self, t):
method inverse_lambda (line 158) | def inverse_lambda(self, lamb):
function model_wrapper (line 177) | def model_wrapper(
class DPM_Solver (line 351) | class DPM_Solver:
method __init__ (line 352) | def __init__(self, model_fn, noise_schedule, predict_x0=False, thresho...
method noise_prediction_fn (line 380) | def noise_prediction_fn(self, x, t):
method data_prediction_fn (line 386) | def data_prediction_fn(self, x, t):
method model_fn (line 401) | def model_fn(self, x, t):
method get_time_steps (line 410) | def get_time_steps(self, skip_type, t_T, t_0, N, device):
method get_orders_and_timesteps_for_singlestep_solver (line 439) | def get_orders_and_timesteps_for_singlestep_solver(self, steps, order,...
method denoise_to_zero_fn (line 498) | def denoise_to_zero_fn(self, x, s):
method dpm_solver_first_update (line 504) | def dpm_solver_first_update(self, x, s, t, model_s=None, return_interm...
method singlestep_dpm_solver_second_update (line 551) | def singlestep_dpm_solver_second_update(self, x, s, t, r1=0.5, model_s...
method singlestep_dpm_solver_third_update (line 633) | def singlestep_dpm_solver_third_update(self, x, s, t, r1=1./3., r2=2./...
method multistep_dpm_solver_second_update (line 755) | def multistep_dpm_solver_second_update(self, x, model_prev_list, t_pre...
method multistep_dpm_solver_third_update (line 812) | def multistep_dpm_solver_third_update(self, x, model_prev_list, t_prev...
method singlestep_dpm_solver_update (line 859) | def singlestep_dpm_solver_update(self, x, s, t, order, return_intermed...
method multistep_dpm_solver_update (line 885) | def multistep_dpm_solver_update(self, x, model_prev_list, t_prev_list,...
method dpm_solver_adaptive (line 909) | def dpm_solver_adaptive(self, x, order, t_T, t_0, h_init=0.05, atol=0....
method sample (line 965) | def sample(self, x, steps=20, t_start=None, t_end=None, order=3, skip_...
function interpolate_fn (line 1132) | def interpolate_fn(x, xp, yp):
function expand_dims (line 1174) | def expand_dims(v, dims):
FILE: data_generation/ldm/models/diffusion/dpm_solver/sampler.py
class DPMSolverSampler (line 8) | class DPMSolverSampler(object):
method __init__ (line 9) | def __init__(self, model, **kwargs):
method register_buffer (line 15) | def register_buffer(self, name, attr):
method sample (line 22) | def sample(self,
FILE: data_generation/ldm/models/diffusion/plms.py
class PLMSSampler (line 11) | class PLMSSampler(object):
method __init__ (line 12) | def __init__(self, model, schedule="linear", **kwargs):
method register_buffer (line 18) | def register_buffer(self, name, attr):
method make_schedule (line 24) | def make_schedule(self, ddim_num_steps, ddim_discretize="uniform", ddi...
method sample (line 58) | def sample(self,
method plms_sampling (line 115) | def plms_sampling(self, cond, shape,
method p_sample_plms (line 173) | def p_sample_plms(self, x, c, t, index, repeat_noise=False, use_origin...
FILE: data_generation/ldm/modules/attention.py
function exists (line 11) | def exists(val):
function uniq (line 15) | def uniq(arr):
function default (line 19) | def default(val, d):
function max_neg_value (line 25) | def max_neg_value(t):
function init_ (line 29) | def init_(tensor):
class GEGLU (line 37) | class GEGLU(nn.Module):
method __init__ (line 38) | def __init__(self, dim_in, dim_out):
method forward (line 42) | def forward(self, x):
class FeedForward (line 47) | class FeedForward(nn.Module):
method __init__ (line 48) | def __init__(self, dim, dim_out=None, mult=4, glu=False, dropout=0.):
method forward (line 63) | def forward(self, x):
function zero_module (line 67) | def zero_module(module):
function Normalize (line 76) | def Normalize(in_channels):
class LinearAttention (line 80) | class LinearAttention(nn.Module):
method __init__ (line 81) | def __init__(self, dim, heads=4, dim_head=32):
method forward (line 88) | def forward(self, x):
class SpatialSelfAttention (line 99) | class SpatialSelfAttention(nn.Module):
method __init__ (line 100) | def __init__(self, in_channels):
method forward (line 126) | def forward(self, x):
class CrossAttention (line 152) | class CrossAttention(nn.Module):
method __init__ (line 153) | def __init__(self, query_dim, context_dim=None, heads=8, dim_head=64, ...
method forward (line 170) | def forward(self, x, context=None, mask=None):
class BasicTransformerBlock (line 196) | class BasicTransformerBlock(nn.Module):
method __init__ (line 197) | def __init__(self, dim, n_heads, d_head, dropout=0., context_dim=None,...
method forward (line 208) | def forward(self, x, context=None):
method _forward (line 211) | def _forward(self, x, context=None):
class SpatialTransformer (line 218) | class SpatialTransformer(nn.Module):
method __init__ (line 226) | def __init__(self, in_channels, n_heads, d_head,
method forward (line 250) | def forward(self, x, context=None):
FILE: data_generation/ldm/modules/diffusionmodules/model.py
function get_timestep_embedding (line 12) | def get_timestep_embedding(timesteps, embedding_dim):
function nonlinearity (line 33) | def nonlinearity(x):
function Normalize (line 38) | def Normalize(in_channels, num_groups=32):
class Upsample (line 42) | class Upsample(nn.Module):
method __init__ (line 43) | def __init__(self, in_channels, with_conv):
method forward (line 53) | def forward(self, x):
class Downsample (line 60) | class Downsample(nn.Module):
method __init__ (line 61) | def __init__(self, in_channels, with_conv):
method forward (line 72) | def forward(self, x):
class ResnetBlock (line 82) | class ResnetBlock(nn.Module):
method __init__ (line 83) | def __init__(self, *, in_channels, out_channels=None, conv_shortcut=Fa...
method forward (line 121) | def forward(self, x, temb):
class LinAttnBlock (line 144) | class LinAttnBlock(LinearAttention):
method __init__ (line 146) | def __init__(self, in_channels):
class AttnBlock (line 150) | class AttnBlock(nn.Module):
method __init__ (line 151) | def __init__(self, in_channels):
method forward (line 178) | def forward(self, x):
function make_attn (line 205) | def make_attn(in_channels, attn_type="vanilla"):
class Model (line 216) | class Model(nn.Module):
method __init__ (line 217) | def __init__(self, *, ch, out_ch, ch_mult=(1,2,4,8), num_res_blocks,
method forward (line 316) | def forward(self, x, t=None, context=None):
method get_last_layer (line 364) | def get_last_layer(self):
class Encoder (line 368) | class Encoder(nn.Module):
method __init__ (line 369) | def __init__(self, *, ch, out_ch, ch_mult=(1,2,4,8), num_res_blocks,
method forward (line 434) | def forward(self, x):
class Decoder (line 462) | class Decoder(nn.Module):
method __init__ (line 463) | def __init__(self, *, ch, out_ch, ch_mult=(1,2,4,8), num_res_blocks,
method forward (line 535) | def forward(self, z):
class SimpleDecoder (line 571) | class SimpleDecoder(nn.Module):
method __init__ (line 572) | def __init__(self, in_channels, out_channels, *args, **kwargs):
method forward (line 594) | def forward(self, x):
class UpsampleDecoder (line 607) | class UpsampleDecoder(nn.Module):
method __init__ (line 608) | def __init__(self, in_channels, out_channels, ch, num_res_blocks, reso...
method forward (line 641) | def forward(self, x):
class LatentRescaler (line 655) | class LatentRescaler(nn.Module):
method __init__ (line 656) | def __init__(self, factor, in_channels, mid_channels, out_channels, de...
method forward (line 680) | def forward(self, x):
class MergedRescaleEncoder (line 692) | class MergedRescaleEncoder(nn.Module):
method __init__ (line 693) | def __init__(self, in_channels, ch, resolution, out_ch, num_res_blocks,
method forward (line 705) | def forward(self, x):
class MergedRescaleDecoder (line 711) | class MergedRescaleDecoder(nn.Module):
method __init__ (line 712) | def __init__(self, z_channels, out_ch, resolution, num_res_blocks, att...
method forward (line 722) | def forward(self, x):
class Upsampler (line 728) | class Upsampler(nn.Module):
method __init__ (line 729) | def __init__(self, in_size, out_size, in_channels, out_channels, ch_mu...
method forward (line 741) | def forward(self, x):
class Resize (line 747) | class Resize(nn.Module):
method __init__ (line 748) | def __init__(self, in_channels=None, learned=False, mode="bilinear"):
method forward (line 763) | def forward(self, x, scale_factor=1.0):
class FirstStagePostProcessor (line 770) | class FirstStagePostProcessor(nn.Module):
method __init__ (line 772) | def __init__(self, ch_mult:list, in_channels,
method instantiate_pretrained (line 807) | def instantiate_pretrained(self, config):
method encode_with_pretrained (line 816) | def encode_with_pretrained(self,x):
method forward (line 822) | def forward(self,x):
FILE: data_generation/ldm/modules/diffusionmodules/openaimodel.py
function convert_module_to_f16 (line 24) | def convert_module_to_f16(x):
function convert_module_to_f32 (line 27) | def convert_module_to_f32(x):
class AttentionPool2d (line 32) | class AttentionPool2d(nn.Module):
method __init__ (line 37) | def __init__(
method forward (line 51) | def forward(self, x):
class TimestepBlock (line 62) | class TimestepBlock(nn.Module):
method forward (line 68) | def forward(self, x, emb):
class TimestepEmbedSequential (line 74) | class TimestepEmbedSequential(nn.Sequential, TimestepBlock):
method forward (line 80) | def forward(self, x, emb, context=None):
class Upsample (line 91) | class Upsample(nn.Module):
method __init__ (line 100) | def __init__(self, channels, use_conv, dims=2, out_channels=None, padd...
method forward (line 109) | def forward(self, x):
class TransposedUpsample (line 121) | class TransposedUpsample(nn.Module):
method __init__ (line 123) | def __init__(self, channels, out_channels=None, ks=5):
method forward (line 130) | def forward(self,x):
class Downsample (line 134) | class Downsample(nn.Module):
method __init__ (line 143) | def __init__(self, channels, use_conv, dims=2, out_channels=None,paddi...
method forward (line 158) | def forward(self, x):
class ResBlock (line 163) | class ResBlock(TimestepBlock):
method __init__ (line 179) | def __init__(
method forward (line 243) | def forward(self, x, emb):
method _forward (line 255) | def _forward(self, x, emb):
class AttentionBlock (line 278) | class AttentionBlock(nn.Module):
method __init__ (line 285) | def __init__(
method forward (line 314) | def forward(self, x):
method _forward (line 318) | def _forward(self, x):
function count_flops_attn (line 327) | def count_flops_attn(model, _x, y):
class QKVAttentionLegacy (line 347) | class QKVAttentionLegacy(nn.Module):
method __init__ (line 352) | def __init__(self, n_heads):
method forward (line 356) | def forward(self, qkv):
method count_flops (line 375) | def count_flops(model, _x, y):
class QKVAttention (line 379) | class QKVAttention(nn.Module):
method __init__ (line 384) | def __init__(self, n_heads):
method forward (line 388) | def forward(self, qkv):
method count_flops (line 409) | def count_flops(model, _x, y):
class UNetModel (line 413) | class UNetModel(nn.Module):
method __init__ (line 443) | def __init__(
method convert_to_fp16 (line 694) | def convert_to_fp16(self):
method convert_to_fp32 (line 702) | def convert_to_fp32(self):
method forward (line 710) | def forward(self, x, timesteps=None, context=None, y=None,**kwargs):
class EncoderUNetModel (line 745) | class EncoderUNetModel(nn.Module):
method __init__ (line 751) | def __init__(
method convert_to_fp16 (line 924) | def convert_to_fp16(self):
method convert_to_fp32 (line 931) | def convert_to_fp32(self):
method forward (line 938) | def forward(self, x, timesteps):
FILE: data_generation/ldm/modules/diffusionmodules/util.py
function make_beta_schedule (line 21) | def make_beta_schedule(schedule, n_timestep, linear_start=1e-4, linear_e...
function make_ddim_timesteps (line 46) | def make_ddim_timesteps(ddim_discr_method, num_ddim_timesteps, num_ddpm_...
function make_ddim_sampling_parameters (line 63) | def make_ddim_sampling_parameters(alphacums, ddim_timesteps, eta, verbos...
function betas_for_alpha_bar (line 77) | def betas_for_alpha_bar(num_diffusion_timesteps, alpha_bar, max_beta=0.9...
function extract_into_tensor (line 96) | def extract_into_tensor(a, t, x_shape):
function checkpoint (line 102) | def checkpoint(func, inputs, params, flag):
class CheckpointFunction (line 119) | class CheckpointFunction(torch.autograd.Function):
method forward (line 121) | def forward(ctx, run_function, length, *args):
method backward (line 131) | def backward(ctx, *output_grads):
function timestep_embedding (line 151) | def timestep_embedding(timesteps, dim, max_period=10000, repeat_only=Fal...
function zero_module (line 174) | def zero_module(module):
function scale_module (line 183) | def scale_module(module, scale):
function mean_flat (line 192) | def mean_flat(tensor):
function normalization (line 199) | def normalization(channels):
class SiLU (line 209) | class SiLU(nn.Module):
method forward (line 210) | def forward(self, x):
class GroupNorm32 (line 214) | class GroupNorm32(nn.GroupNorm):
method forward (line 215) | def forward(self, x):
function conv_nd (line 218) | def conv_nd(dims, *args, **kwargs):
function linear (line 231) | def linear(*args, **kwargs):
function avg_pool_nd (line 238) | def avg_pool_nd(dims, *args, **kwargs):
class HybridConditioner (line 251) | class HybridConditioner(nn.Module):
method __init__ (line 253) | def __init__(self, c_concat_config, c_crossattn_config):
method forward (line 258) | def forward(self, c_concat, c_crossattn):
function noise_like (line 264) | def noise_like(shape, device, repeat=False):
FILE: data_generation/ldm/modules/distributions/distributions.py
class AbstractDistribution (line 5) | class AbstractDistribution:
method sample (line 6) | def sample(self):
method mode (line 9) | def mode(self):
class DiracDistribution (line 13) | class DiracDistribution(AbstractDistribution):
method __init__ (line 14) | def __init__(self, value):
method sample (line 17) | def sample(self):
method mode (line 20) | def mode(self):
class DiagonalGaussianDistribution (line 24) | class DiagonalGaussianDistribution(object):
method __init__ (line 25) | def __init__(self, parameters, deterministic=False):
method sample (line 35) | def sample(self):
method kl (line 39) | def kl(self, other=None):
method nll (line 53) | def nll(self, sample, dims=[1,2,3]):
method mode (line 61) | def mode(self):
function normal_kl (line 65) | def normal_kl(mean1, logvar1, mean2, logvar2):
FILE: data_generation/ldm/modules/ema.py
class LitEma (line 5) | class LitEma(nn.Module):
method __init__ (line 6) | def __init__(self, model, decay=0.9999, use_num_upates=True):
method forward (line 25) | def forward(self,model):
method copy_to (line 46) | def copy_to(self, model):
method store (line 55) | def store(self, parameters):
method restore (line 64) | def restore(self, parameters):
FILE: data_generation/ldm/modules/encoders/modules.py
class AbstractEncoder (line 12) | class AbstractEncoder(nn.Module):
method __init__ (line 13) | def __init__(self):
method encode (line 16) | def encode(self, *args, **kwargs):
class ClassEmbedder (line 21) | class ClassEmbedder(nn.Module):
method __init__ (line 22) | def __init__(self, embed_dim, n_classes=1000, key='class'):
method forward (line 27) | def forward(self, batch, key=None):
class TransformerEmbedder (line 36) | class TransformerEmbedder(AbstractEncoder):
method __init__ (line 38) | def __init__(self, n_embed, n_layer, vocab_size, max_seq_len=77, devic...
method forward (line 44) | def forward(self, tokens):
method encode (line 49) | def encode(self, x):
class BERTTokenizer (line 53) | class BERTTokenizer(AbstractEncoder):
method __init__ (line 55) | def __init__(self, device="cuda", vq_interface=True, max_length=77):
method forward (line 63) | def forward(self, text):
method encode (line 70) | def encode(self, text):
method decode (line 76) | def decode(self, text):
class BERTEmbedder (line 80) | class BERTEmbedder(AbstractEncoder):
method __init__ (line 82) | def __init__(self, n_embed, n_layer, vocab_size=30522, max_seq_len=77,
method forward (line 93) | def forward(self, text):
method encode (line 101) | def encode(self, text):
class SpatialRescaler (line 106) | class SpatialRescaler(nn.Module):
method __init__ (line 107) | def __init__(self,
method forward (line 125) | def forward(self,x):
method encode (line 134) | def encode(self, x):
class FrozenCLIPEmbedder (line 137) | class FrozenCLIPEmbedder(AbstractEncoder):
method __init__ (line 139) | def __init__(self, version="/home/zhaohaozhe/model2/clip-vit-large-pat...
method freeze (line 147) | def freeze(self):
method forward (line 152) | def forward(self, text):
method encode (line 161) | def encode(self, text):
class FrozenCLIPTextEmbedder (line 165) | class FrozenCLIPTextEmbedder(nn.Module):
method __init__ (line 169) | def __init__(self, version='ViT-L/14', device="cuda", max_length=77, n...
method freeze (line 177) | def freeze(self):
method forward (line 182) | def forward(self, text):
method encode (line 189) | def encode(self, text):
class FrozenClipImageEmbedder (line 197) | class FrozenClipImageEmbedder(nn.Module):
method __init__ (line 201) | def __init__(
method preprocess (line 216) | def preprocess(self, x):
method forward (line 226) | def forward(self, x):
FILE: data_generation/ldm/modules/image_degradation/bsrgan.py
function modcrop_np (line 29) | def modcrop_np(img, sf):
function analytic_kernel (line 49) | def analytic_kernel(k):
function anisotropic_Gaussian (line 65) | def anisotropic_Gaussian(ksize=15, theta=np.pi, l1=6, l2=6):
function gm_blur_kernel (line 86) | def gm_blur_kernel(mean, cov, size=15):
function shift_pixel (line 99) | def shift_pixel(x, sf, upper_left=True):
function blur (line 128) | def blur(x, k):
function gen_kernel (line 145) | def gen_kernel(k_size=np.array([15, 15]), scale_factor=np.array([4, 4]),...
function fspecial_gaussian (line 187) | def fspecial_gaussian(hsize, sigma):
function fspecial_laplacian (line 201) | def fspecial_laplacian(alpha):
function fspecial (line 210) | def fspecial(filter_type, *args, **kwargs):
function bicubic_degradation (line 228) | def bicubic_degradation(x, sf=3):
function srmd_degradation (line 240) | def srmd_degradation(x, k, sf=3):
function dpsr_degradation (line 262) | def dpsr_degradation(x, k, sf=3):
function classical_degradation (line 284) | def classical_degradation(x, k, sf=3):
function add_sharpening (line 299) | def add_sharpening(img, weight=0.5, radius=50, threshold=10):
function add_blur (line 325) | def add_blur(img, sf=4):
function add_resize (line 339) | def add_resize(img, sf=4):
function add_Gaussian_noise (line 369) | def add_Gaussian_noise(img, noise_level1=2, noise_level2=25):
function add_speckle_noise (line 386) | def add_speckle_noise(img, noise_level1=2, noise_level2=25):
function add_Poisson_noise (line 404) | def add_Poisson_noise(img):
function add_JPEG_noise (line 418) | def add_JPEG_noise(img):
function random_crop (line 427) | def random_crop(lq, hq, sf=4, lq_patchsize=64):
function degradation_bsrgan (line 438) | def degradation_bsrgan(img, sf=4, lq_patchsize=72, isp_model=None):
function degradation_bsrgan_variant (line 530) | def degradation_bsrgan_variant(image, sf=4, isp_model=None):
function degradation_bsrgan_plus (line 617) | def degradation_bsrgan_plus(img, sf=4, shuffle_prob=0.5, use_sharp=True,...
FILE: data_generation/ldm/modules/image_degradation/bsrgan_light.py
function modcrop_np (line 29) | def modcrop_np(img, sf):
function analytic_kernel (line 49) | def analytic_kernel(k):
function anisotropic_Gaussian (line 65) | def anisotropic_Gaussian(ksize=15, theta=np.pi, l1=6, l2=6):
function gm_blur_kernel (line 86) | def gm_blur_kernel(mean, cov, size=15):
function shift_pixel (line 99) | def shift_pixel(x, sf, upper_left=True):
function blur (line 128) | def blur(x, k):
function gen_kernel (line 145) | def gen_kernel(k_size=np.array([15, 15]), scale_factor=np.array([4, 4]),...
function fspecial_gaussian (line 187) | def fspecial_gaussian(hsize, sigma):
function fspecial_laplacian (line 201) | def fspecial_laplacian(alpha):
function fspecial (line 210) | def fspecial(filter_type, *args, **kwargs):
function bicubic_degradation (line 228) | def bicubic_degradation(x, sf=3):
function srmd_degradation (line 240) | def srmd_degradation(x, k, sf=3):
function dpsr_degradation (line 262) | def dpsr_degradation(x, k, sf=3):
function classical_degradation (line 284) | def classical_degradation(x, k, sf=3):
function add_sharpening (line 299) | def add_sharpening(img, weight=0.5, radius=50, threshold=10):
function add_blur (line 325) | def add_blur(img, sf=4):
function add_resize (line 343) | def add_resize(img, sf=4):
function add_Gaussian_noise (line 373) | def add_Gaussian_noise(img, noise_level1=2, noise_level2=25):
function add_speckle_noise (line 390) | def add_speckle_noise(img, noise_level1=2, noise_level2=25):
function add_Poisson_noise (line 408) | def add_Poisson_noise(img):
function add_JPEG_noise (line 422) | def add_JPEG_noise(img):
function random_crop (line 431) | def random_crop(lq, hq, sf=4, lq_patchsize=64):
function degradation_bsrgan (line 442) | def degradation_bsrgan(img, sf=4, lq_patchsize=72, isp_model=None):
function degradation_bsrgan_variant (line 534) | def degradation_bsrgan_variant(image, sf=4, isp_model=None):
FILE: data_generation/ldm/modules/image_degradation/utils_image.py
function is_image_file (line 29) | def is_image_file(filename):
function get_timestamp (line 33) | def get_timestamp():
function imshow (line 37) | def imshow(x, title=None, cbar=False, figsize=None):
function surf (line 47) | def surf(Z, cmap='rainbow', figsize=None):
function get_image_paths (line 67) | def get_image_paths(dataroot):
function _get_paths_from_images (line 74) | def _get_paths_from_images(path):
function patches_from_image (line 93) | def patches_from_image(img, p_size=512, p_overlap=64, p_max=800):
function imssave (line 112) | def imssave(imgs, img_path):
function split_imageset (line 125) | def split_imageset(original_dataroot, taget_dataroot, n_channels=3, p_si...
function mkdir (line 153) | def mkdir(path):
function mkdirs (line 158) | def mkdirs(paths):
function mkdir_and_rename (line 166) | def mkdir_and_rename(path):
function imread_uint (line 185) | def imread_uint(path, n_channels=3):
function imsave (line 203) | def imsave(img, img_path):
function imwrite (line 209) | def imwrite(img, img_path):
function read_img (line 220) | def read_img(path):
function uint2single (line 249) | def uint2single(img):
function single2uint (line 254) | def single2uint(img):
function uint162single (line 259) | def uint162single(img):
function single2uint16 (line 264) | def single2uint16(img):
function uint2tensor4 (line 275) | def uint2tensor4(img):
function uint2tensor3 (line 282) | def uint2tensor3(img):
function tensor2uint (line 289) | def tensor2uint(img):
function single2tensor3 (line 302) | def single2tensor3(img):
function single2tensor4 (line 307) | def single2tensor4(img):
function tensor2single (line 312) | def tensor2single(img):
function tensor2single3 (line 320) | def tensor2single3(img):
function single2tensor5 (line 329) | def single2tensor5(img):
function single32tensor5 (line 333) | def single32tensor5(img):
function single42tensor4 (line 337) | def single42tensor4(img):
function tensor2img (line 342) | def tensor2img(tensor, out_type=np.uint8, min_max=(0, 1)):
function augment_img (line 380) | def augment_img(img, mode=0):
function augment_img_tensor4 (line 401) | def augment_img_tensor4(img, mode=0):
function augment_img_tensor (line 422) | def augment_img_tensor(img, mode=0):
function augment_img_np3 (line 441) | def augment_img_np3(img, mode=0):
function augment_imgs (line 469) | def augment_imgs(img_list, hflip=True, rot=True):
function modcrop (line 494) | def modcrop(img_in, scale):
function shave (line 510) | def shave(img_in, border=0):
function rgb2ycbcr (line 529) | def rgb2ycbcr(img, only_y=True):
function ycbcr2rgb (line 553) | def ycbcr2rgb(img):
function bgr2ycbcr (line 573) | def bgr2ycbcr(img, only_y=True):
function channel_convert (line 597) | def channel_convert(in_c, tar_type, img_list):
function calculate_psnr (line 621) | def calculate_psnr(img1, img2, border=0):
function calculate_ssim (line 642) | def calculate_ssim(img1, img2, border=0):
function ssim (line 669) | def ssim(img1, img2):
function cubic (line 700) | def cubic(x):
function calculate_weights_indices (line 708) | def calculate_weights_indices(in_length, out_length, scale, kernel, kern...
function imresize (line 766) | def imresize(img, scale, antialiasing=True):
function imresize_np (line 839) | def imresize_np(img, scale, antialiasing=True):
FILE: data_generation/ldm/modules/losses/contperceptual.py
class LPIPSWithDiscriminator (line 7) | class LPIPSWithDiscriminator(nn.Module):
method __init__ (line 8) | def __init__(self, disc_start, logvar_init=0.0, kl_weight=1.0, pixello...
method calculate_adaptive_weight (line 32) | def calculate_adaptive_weight(self, nll_loss, g_loss, last_layer=None):
method forward (line 45) | def forward(self, inputs, reconstructions, posteriors, optimizer_idx,
FILE: data_generation/ldm/modules/losses/vqperceptual.py
function hinge_d_loss_with_exemplar_weights (line 11) | def hinge_d_loss_with_exemplar_weights(logits_real, logits_fake, weights):
function adopt_weight (line 20) | def adopt_weight(weight, global_step, threshold=0, value=0.):
function measure_perplexity (line 26) | def measure_perplexity(predicted_indices, n_embed):
function l1 (line 35) | def l1(x, y):
function l2 (line 39) | def l2(x, y):
class VQLPIPSWithDiscriminator (line 43) | class VQLPIPSWithDiscriminator(nn.Module):
method __init__ (line 44) | def __init__(self, disc_start, codebook_weight=1.0, pixelloss_weight=1.0,
method calculate_adaptive_weight (line 85) | def calculate_adaptive_weight(self, nll_loss, g_loss, last_layer=None):
method forward (line 98) | def forward(self, codebook_loss, inputs, reconstructions, optimizer_idx,
FILE: data_generation/ldm/modules/x_transformer.py
class AbsolutePositionalEmbedding (line 25) | class AbsolutePositionalEmbedding(nn.Module):
method __init__ (line 26) | def __init__(self, dim, max_seq_len):
method init_ (line 31) | def init_(self):
method forward (line 34) | def forward(self, x):
class FixedPositionalEmbedding (line 39) | class FixedPositionalEmbedding(nn.Module):
method __init__ (line 40) | def __init__(self, dim):
method forward (line 45) | def forward(self, x, seq_dim=1, offset=0):
function exists (line 54) | def exists(val):
function default (line 58) | def default(val, d):
function always (line 64) | def always(val):
function not_equals (line 70) | def not_equals(val):
function equals (line 76) | def equals(val):
function max_neg_value (line 82) | def max_neg_value(tensor):
function pick_and_pop (line 88) | def pick_and_pop(keys, d):
function group_dict_by_key (line 93) | def group_dict_by_key(cond, d):
function string_begins_with (line 102) | def string_begins_with(prefix, str):
function group_by_key_prefix (line 106) | def group_by_key_prefix(prefix, d):
function groupby_prefix_and_trim (line 110) | def groupby_prefix_and_trim(prefix, d):
class Scale (line 117) | class Scale(nn.Module):
method __init__ (line 118) | def __init__(self, value, fn):
method forward (line 123) | def forward(self, x, **kwargs):
class Rezero (line 128) | class Rezero(nn.Module):
method __init__ (line 129) | def __init__(self, fn):
method forward (line 134) | def forward(self, x, **kwargs):
class ScaleNorm (line 139) | class ScaleNorm(nn.Module):
method __init__ (line 140) | def __init__(self, dim, eps=1e-5):
method forward (line 146) | def forward(self, x):
class RMSNorm (line 151) | class RMSNorm(nn.Module):
method __init__ (line 152) | def __init__(self, dim, eps=1e-8):
method forward (line 158) | def forward(self, x):
class Residual (line 163) | class Residual(nn.Module):
method forward (line 164) | def forward(self, x, residual):
class GRUGating (line 168) | class GRUGating(nn.Module):
method __init__ (line 169) | def __init__(self, dim):
method forward (line 173) | def forward(self, x, residual):
class GEGLU (line 184) | class GEGLU(nn.Module):
method __init__ (line 185) | def __init__(self, dim_in, dim_out):
method forward (line 189) | def forward(self, x):
class FeedForward (line 194) | class FeedForward(nn.Module):
method __init__ (line 195) | def __init__(self, dim, dim_out=None, mult=4, glu=False, dropout=0.):
method forward (line 210) | def forward(self, x):
class Attention (line 215) | class Attention(nn.Module):
method __init__ (line 216) | def __init__(
method forward (line 268) | def forward(
class AttentionLayers (line 370) | class AttentionLayers(nn.Module):
method __init__ (line 371) | def __init__(
method forward (line 481) | def forward(
class Encoder (line 541) | class Encoder(AttentionLayers):
method __init__ (line 542) | def __init__(self, **kwargs):
class TransformerWrapper (line 548) | class TransformerWrapper(nn.Module):
method __init__ (line 549) | def __init__(
method init_ (line 595) | def init_(self):
method forward (line 598) | def forward(
FILE: data_generation/ldm/util.py
function log_txt_as_img (line 17) | def log_txt_as_img(wh, xc, size=10):
function ismap (line 41) | def ismap(x):
function isimage (line 47) | def isimage(x):
function exists (line 53) | def exists(x):
function default (line 57) | def default(val, d):
function mean_flat (line 63) | def mean_flat(tensor):
function count_params (line 71) | def count_params(model, verbose=False):
function instantiate_from_config (line 78) | def instantiate_from_config(config):
function get_obj_from_str (line 88) | def get_obj_from_str(string, reload=False):
function _do_parallel_data_prefetch (line 96) | def _do_parallel_data_prefetch(func, Q, data, idx, idx_to_fn=False):
function parallel_data_prefetch (line 108) | def parallel_data_prefetch(
FILE: data_generation/metrics/clip_similarity.py
class ClipSimilarity (line 14) | class ClipSimilarity(nn.Module):
method __init__ (line 15) | def __init__(self, name: str = "ViT-L/14"):
method encode_text (line 28) | def encode_text(self, text: list[str]) -> torch.Tensor:
method encode_image (line 34) | def encode_image(self, image: torch.Tensor) -> torch.Tensor: # Input ...
method get_dinov2_embedding (line 41) | def get_dinov2_embedding(self, image: torch.Tensor) -> torch.Tensor:
method get_ssim_sim (line 47) | def get_ssim_sim(self, image1,image2):
method forward (line 62) | def forward(
FILE: data_generation/metrics/compute_metrics.py
class CFGDenoiser (line 34) | class CFGDenoiser(nn.Module):
method __init__ (line 35) | def __init__(self, model):
method forward (line 39) | def forward(self, z, sigma, cond, uncond, text_cfg_scale, image_cfg_sc...
function load_model_from_config (line 50) | def load_model_from_config(config, ckpt, vae_ckpt=None, verbose=False):
class ImageEditor (line 73) | class ImageEditor(nn.Module):
method __init__ (line 74) | def __init__(self, config, ckpt, vae_ckpt=None):
method forward (line 84) | def forward(
function compute_metrics (line 117) | def compute_metrics(config,
function plot_metrics (line 186) | def plot_metrics(metrics_file, output_path):
function main (line 205) | def main():
FILE: data_generation/processors.py
class P2PCrossAttnProcessor (line 11) | class P2PCrossAttnProcessor:
method __init__ (line 12) | def __init__(self, controller, place_in_unet):
method __call__ (line 17) | def __call__(self, attn: Attention, hidden_states, encoder_hidden_stat...
function create_controller (line 48) | def create_controller(
class AttentionControl (line 129) | class AttentionControl(abc.ABC):
method step_callback (line 130) | def step_callback(self, x_t):
method between_steps (line 133) | def between_steps(self):
method num_uncond_att_layers (line 137) | def num_uncond_att_layers(self):
method forward (line 141) | def forward(self, attn, is_cross: bool, place_in_unet: str):
method __call__ (line 144) | def __call__(self, attn, is_cross: bool, place_in_unet: str):
method reset (line 155) | def reset(self):
method __init__ (line 159) | def __init__(self, attn_res=None):
class EmptyControl (line 166) | class EmptyControl(AttentionControl):
method forward (line 167) | def forward(self, attn, is_cross: bool, place_in_unet: str):
class AttentionStore (line 171) | class AttentionStore(AttentionControl):
method get_empty_store (line 173) | def get_empty_store():
method forward (line 176) | def forward(self, attn, is_cross: bool, place_in_unet: str):
method between_steps (line 182) | def between_steps(self):
method get_average_attention (line 191) | def get_average_attention(self):
method reset (line 197) | def reset(self):
method __init__ (line 202) | def __init__(self, attn_res=None):
class LocalBlend (line 209) | class LocalBlend:
method __call__ (line 210) | def __call__(self, x_t, attention_store):
method __init__ (line 229) | def __init__(
class AttentionControlEdit (line 246) | class AttentionControlEdit(AttentionStore, abc.ABC):
method step_callback (line 247) | def step_callback(self, x_t):
method replace_self_attention (line 252) | def replace_self_attention(self, attn_base, att_replace):
method replace_cross_attention (line 259) | def replace_cross_attention(self, attn_base, att_replace):
method forward (line 262) | def forward(self, attn, is_cross: bool, place_in_unet: str):
method __init__ (line 280) | def __init__(
class AttentionReplace (line 307) | class AttentionReplace(AttentionControlEdit):
method replace_cross_attention (line 308) | def replace_cross_attention(self, attn_base, att_replace):
method __init__ (line 311) | def __init__(
class AttentionRefine (line 328) | class AttentionRefine(AttentionControlEdit):
method replace_cross_attention (line 329) | def replace_cross_attention(self, attn_base, att_replace):
method __init__ (line 334) | def __init__(
class AttentionReweight (line 353) | class AttentionReweight(AttentionControlEdit):
method replace_cross_attention (line 354) | def replace_cross_attention(self, attn_base, att_replace):
method __init__ (line 360) | def __init__(
function update_alpha_time_word (line 381) | def update_alpha_time_word(
function get_time_words_attention_alpha (line 395) | def get_time_words_attention_alpha(
function get_word_inds (line 416) | def get_word_inds(text: str, word_place: int, tokenizer):
function get_replacement_mapper_ (line 438) | def get_replacement_mapper_(x: str, y: str, tokenizer, max_len=77):
function get_replacement_mapper (line 477) | def get_replacement_mapper(prompts, tokenizer, max_len=77):
function get_equalizer (line 487) | def get_equalizer(
class ScoreParams (line 501) | class ScoreParams:
method __init__ (line 502) | def __init__(self, gap, match, mismatch):
method mis_match_char (line 507) | def mis_match_char(self, x, y):
function get_matrix (line 514) | def get_matrix(size_x, size_y, gap):
function get_traceback_matrix (line 521) | def get_traceback_matrix(size_x, size_y):
function global_align (line 529) | def global_align(x, y, score):
function get_aligned_sequences (line 547) | def get_aligned_sequences(x, y, trace_back):
function get_mapper (line 575) | def get_mapper(x: str, y: str, tokenizer, max_len=77):
function get_refinement_mapper (line 589) | def get_refinement_mapper(prompts, tokenizer, max_len=77):
FILE: data_generation/prompt_to_prompt_pipeline.py
function rescale_noise_cfg (line 7) | def rescale_noise_cfg(noise_cfg, noise_pred_text, guidance_rescale=0.0):
class Prompt2PromptPipeline (line 21) | class Prompt2PromptPipeline(StableDiffusionXLPipeline):
method check_inputs (line 49) | def check_inputs(
method _aggregate_and_get_attention_maps_per_token (line 122) | def _aggregate_and_get_attention_maps_per_token(self, with_softmax):
method _get_attention_maps_list (line 134) | def _get_attention_maps_list(
method __call__ (line 148) | def __call__(
method register_attention_control (line 452) | def register_attention_control(self, controller):
FILE: data_generation/sdxl_p2p_pipeline.py
function rescale_noise_cfg (line 10) | def rescale_noise_cfg(noise_cfg, noise_pred_text, guidance_rescale=0.0):
class Prompt2PromptPipeline (line 24) | class Prompt2PromptPipeline(StableDiffusionXLPipeline):
method check_inputs (line 52) | def check_inputs(
method _aggregate_and_get_attention_maps_per_token (line 125) | def _aggregate_and_get_attention_maps_per_token(self, with_softmax):
method _get_attention_maps_list (line 137) | def _get_attention_maps_list(
method __call__ (line 151) | def __call__(
method register_attention_control (line 455) | def register_attention_control(self, controller):
function retrieve_timesteps (line 486) | def retrieve_timesteps(
class Prompt2PromptImg2ImgPipeline (line 529) | class Prompt2PromptImg2ImgPipeline(StableDiffusionXLImg2ImgPipeline):
method check_inputs (line 557) | def check_inputs(
method _aggregate_and_get_attention_maps_per_token (line 624) | def _aggregate_and_get_attention_maps_per_token(self, with_softmax):
method _get_attention_maps_list (line 636) | def _get_attention_maps_list(
method __call__ (line 650) | def __call__(
method register_attention_control (line 1040) | def register_attention_control(self, controller):
class Prompt2PromptInpaintPipeline (line 1068) | class Prompt2PromptInpaintPipeline(StableDiffusionXLInpaintPipeline):
method check_inputs (line 1096) | def check_inputs(
method _aggregate_and_get_attention_maps_per_token (line 1175) | def _aggregate_and_get_attention_maps_per_token(self, with_softmax):
method _get_attention_maps_list (line 1187) | def _get_attention_maps_list(
method __call__ (line 1201) | def __call__(
method register_attention_control (line 1776) | def register_attention_control(self, controller):
FILE: data_generation/util.py
class P2PCrossAttnProcessor (line 11) | class P2PCrossAttnProcessor:
method __init__ (line 12) | def __init__(self, controller, place_in_unet):
method __call__ (line 17) | def __call__(self, attn: Attention, hidden_states, encoder_hidden_stat...
function create_controller (line 48) | def create_controller(
class AttentionControl (line 129) | class AttentionControl(abc.ABC):
method step_callback (line 130) | def step_callback(self, x_t):
method between_steps (line 133) | def between_steps(self):
method num_uncond_att_layers (line 137) | def num_uncond_att_layers(self):
method forward (line 141) | def forward(self, attn, is_cross: bool, place_in_unet: str):
method __call__ (line 144) | def __call__(self, attn, is_cross: bool, place_in_unet: str):
method reset (line 155) | def reset(self):
method __init__ (line 159) | def __init__(self, attn_res=None):
class EmptyControl (line 166) | class EmptyControl(AttentionControl):
method forward (line 167) | def forward(self, attn, is_cross: bool, place_in_unet: str):
class AttentionStore (line 171) | class AttentionStore(AttentionControl):
method get_empty_store (line 173) | def get_empty_store():
method forward (line 176) | def forward(self, attn, is_cross: bool, place_in_unet: str):
method between_steps (line 182) | def between_steps(self):
method get_average_attention (line 191) | def get_average_attention(self):
method reset (line 197) | def reset(self):
method __init__ (line 202) | def __init__(self, attn_res=None):
class LocalBlend (line 209) | class LocalBlend:
method __call__ (line 210) | def __call__(self, x_t, attention_store):
method __init__ (line 229) | def __init__(
class AttentionControlEdit (line 246) | class AttentionControlEdit(AttentionStore, abc.ABC):
method step_callback (line 247) | def step_callback(self, x_t):
method replace_self_attention (line 252) | def replace_self_attention(self, attn_base, att_replace):
method replace_cross_attention (line 259) | def replace_cross_attention(self, attn_base, att_replace):
method forward (line 262) | def forward(self, attn, is_cross: bool, place_in_unet: str):
method __init__ (line 280) | def __init__(
class AttentionReplace (line 307) | class AttentionReplace(AttentionControlEdit):
method replace_cross_attention (line 308) | def replace_cross_attention(self, attn_base, att_replace):
method __init__ (line 314) | def __init__(
class AttentionRefine (line 332) | class AttentionRefine(AttentionControlEdit):
method replace_cross_attention (line 333) | def replace_cross_attention(self, attn_base, att_replace):
method __init__ (line 338) | def __init__(
class AttentionReweight (line 357) | class AttentionReweight(AttentionControlEdit):
method replace_cross_attention (line 358) | def replace_cross_attention(self, attn_base, att_replace):
method __init__ (line 364) | def __init__(
function update_alpha_time_word (line 385) | def update_alpha_time_word(
function get_time_words_attention_alpha (line 399) | def get_time_words_attention_alpha(
function get_word_inds (line 420) | def get_word_inds(text: str, word_place: int, tokenizer):
function get_replacement_mapper_ (line 442) | def get_replacement_mapper_(x: str, y: str, tokenizer, max_len=77):
function get_replacement_mapper (line 482) | def get_replacement_mapper(prompts, tokenizer, max_len=77,torch_dtype=to...
function get_equalizer (line 500) | def get_equalizer(
class ScoreParams (line 514) | class ScoreParams:
method __init__ (line 515) | def __init__(self, gap, match, mismatch):
method mis_match_char (line 520) | def mis_match_char(self, x, y):
function get_matrix (line 527) | def get_matrix(size_x, size_y, gap):
function get_traceback_matrix (line 534) | def get_traceback_matrix(size_x, size_y):
function global_align (line 542) | def global_align(x, y, score):
function get_aligned_sequences (line 560) | def get_aligned_sequences(x, y, trace_back):
function get_mapper (line 588) | def get_mapper(x: str, y: str, tokenizer, max_len=77):
function get_refinement_mapper (line 602) | def get_refinement_mapper(prompts, tokenizer, max_len=77):
FILE: diffusers/benchmarks/base_classes.py
class BaseBenchmak (line 49) | class BaseBenchmak:
method __init__ (line 52) | def __init__(self, args):
method run_inference (line 55) | def run_inference(self, args):
method benchmark (line 58) | def benchmark(self, args):
method get_result_filepath (line 61) | def get_result_filepath(self, args):
class TextToImageBenchmark (line 73) | class TextToImageBenchmark(BaseBenchmak):
method __init__ (line 76) | def __init__(self, args):
method run_inference (line 97) | def run_inference(self, pipe, args):
method benchmark (line 104) | def benchmark(self, args):
class TurboTextToImageBenchmark (line 124) | class TurboTextToImageBenchmark(TextToImageBenchmark):
method __init__ (line 125) | def __init__(self, args):
method run_inference (line 128) | def run_inference(self, pipe, args):
class LCMLoRATextToImageBenchmark (line 137) | class LCMLoRATextToImageBenchmark(TextToImageBenchmark):
method __init__ (line 140) | def __init__(self, args):
method get_result_filepath (line 147) | def get_result_filepath(self, args):
method run_inference (line 158) | def run_inference(self, pipe, args):
method benchmark (line 166) | def benchmark(self, args):
class ImageToImageBenchmark (line 186) | class ImageToImageBenchmark(TextToImageBenchmark):
method __init__ (line 191) | def __init__(self, args):
method run_inference (line 195) | def run_inference(self, pipe, args):
class TurboImageToImageBenchmark (line 204) | class TurboImageToImageBenchmark(ImageToImageBenchmark):
method __init__ (line 205) | def __init__(self, args):
method run_inference (line 208) | def run_inference(self, pipe, args):
class InpaintingBenchmark (line 219) | class InpaintingBenchmark(ImageToImageBenchmark):
method __init__ (line 224) | def __init__(self, args):
method run_inference (line 229) | def run_inference(self, pipe, args):
class IPAdapterTextToImageBenchmark (line 239) | class IPAdapterTextToImageBenchmark(TextToImageBenchmark):
method __init__ (line 243) | def __init__(self, args):
method run_inference (line 259) | def run_inference(self, pipe, args):
class ControlNetBenchmark (line 268) | class ControlNetBenchmark(TextToImageBenchmark):
method __init__ (line 276) | def __init__(self, args):
method run_inference (line 294) | def run_inference(self, pipe, args):
class ControlNetSDXLBenchmark (line 303) | class ControlNetSDXLBenchmark(ControlNetBenchmark):
method __init__ (line 307) | def __init__(self, args):
class T2IAdapterBenchmark (line 311) | class T2IAdapterBenchmark(ControlNetBenchmark):
method __init__ (line 319) | def __init__(self, args):
class T2IAdapterSDXLBenchmark (line 338) | class T2IAdapterSDXLBenchmark(T2IAdapterBenchmark):
method __init__ (line 345) | def __init__(self, args):
FILE: diffusers/benchmarks/push_results.py
function has_previous_benchmark (line 13) | def has_previous_benchmark() -> str:
function filter_float (line 22) | def filter_float(value):
function push_to_hf_dataset (line 28) | def push_to_hf_dataset():
FILE: diffusers/benchmarks/run_all.py
class SubprocessCallException (line 14) | class SubprocessCallException(Exception):
function run_command (line 19) | def run_command(command: List[str], return_stdout=False):
function main (line 36) | def main():
FILE: diffusers/benchmarks/utils.py
class BenchmarkInfo (line 35) | class BenchmarkInfo:
function flush (line 40) | def flush():
function bytes_to_giga_bytes (line 48) | def bytes_to_giga_bytes(bytes):
function benchmark_fn (line 52) | def benchmark_fn(f, *args, **kwargs):
function generate_csv_dict (line 61) | def generate_csv_dict(
function write_to_csv (line 80) | def write_to_csv(file_name: str, data_dict: Dict[str, Union[str, bool, f...
function collate_csv (line 88) | def collate_csv(input_files: List[str], output_file: str):
FILE: diffusers/examples/advanced_diffusion_training/train_dreambooth_lora_sd15_advanced.py
function save_model_card (line 79) | def save_model_card(
function import_model_class_from_model_name_or_path (line 209) | def import_model_class_from_model_name_or_path(
function parse_args (line 229) | def parse_args(input_args=None):
class TokenEmbeddingsHandler (line 712) | class TokenEmbeddingsHandler:
method __init__ (line 713) | def __init__(self, text_encoders, tokenizers):
method initialize_new_tokens (line 721) | def initialize_new_tokens(self, inserting_toks: List[str]):
method save_embeddings (line 762) | def save_embeddings(self, file_path: str):
method dtype (line 782) | def dtype(self):
method device (line 786) | def device(self):
method retract_embeddings (line 790) | def retract_embeddings(self):
class DreamBoothDataset (line 811) | class DreamBoothDataset(Dataset):
method __init__ (line 817) | def __init__(
method __len__ (line 928) | def __len__(self):
method __getitem__ (line 931) | def __getitem__(self, index):
function collate_fn (line 966) | def collate_fn(examples, with_prior_preservation=False):
class PromptDataset (line 983) | class PromptDataset(Dataset):
method __init__ (line 986) | def __init__(self, prompt, num_samples):
method __len__ (line 990) | def __len__(self):
method __getitem__ (line 993) | def __getitem__(self, index):
function tokenize_prompt (line 1000) | def tokenize_prompt(tokenizer, prompt, add_special_tokens=False):
function encode_prompt (line 1014) | def encode_prompt(text_encoders, tokenizers, prompt, text_input_ids_list...
function main (line 1031) | def main(args):
FILE: diffusers/examples/advanced_diffusion_training/train_dreambooth_lora_sdxl_advanced.py
function determine_scheduler_type (line 86) | def determine_scheduler_type(pretrained_model_name_or_path, revision):
function save_model_card (line 100) | def save_model_card(
function import_model_class_from_model_name_or_path (line 231) | def import_model_class_from_model_name_or_path(
function parse_args (line 251) | def parse_args(input_args=None):
function is_belong_to_blocks (line 766) | def is_belong_to_blocks(key, blocks):
function get_unet_lora_target_modules (line 776) | def get_unet_lora_target_modules(unet, use_blora, target_blocks=None):
class TokenEmbeddingsHandler (line 800) | class TokenEmbeddingsHandler:
method __init__ (line 801) | def __init__(self, text_encoders, tokenizers):
method initialize_new_tokens (line 809) | def initialize_new_tokens(self, inserting_toks: List[str]):
method save_embeddings (line 849) | def save_embeddings(self, file_path: str):
method dtype (line 869) | def dtype(self):
method device (line 873) | def device(self):
method retract_embeddings (line 877) | def retract_embeddings(self):
class DreamBoothDataset (line 898) | class DreamBoothDataset(Dataset):
method __init__ (line 904) | def __init__(
method __len__ (line 1080) | def __len__(self):
method __getitem__ (line 1083) | def __getitem__(self, index):
function collate_fn (line 1112) | def collate_fn(examples, with_prior_preservation=False):
class PromptDataset (line 1138) | class PromptDataset(Dataset):
method __init__ (line 1141) | def __init__(self, prompt, num_samples):
method __len__ (line 1145) | def __len__(self):
method __getitem__ (line 1148) | def __getitem__(self, index):
function tokenize_prompt (line 1155) | def tokenize_prompt(tokenizer, prompt, add_special_tokens=False):
function encode_prompt (line 1169) | def encode_prompt(text_encoders, tokenizers, prompt, text_input_ids_list...
function main (line 1197) | def main(args):
FILE: diffusers/examples/amused/train_amused.py
function parse_args (line 54) | def parse_args():
class InstanceDataRootDataset (line 301) | class InstanceDataRootDataset(Dataset):
method __init__ (line 302) | def __init__(
method __len__ (line 312) | def __len__(self):
method __getitem__ (line 315) | def __getitem__(self, index):
class InstanceDataImageDataset (line 325) | class InstanceDataImageDataset(Dataset):
method __init__ (line 326) | def __init__(
method __len__ (line 335) | def __len__(self):
method __getitem__ (line 340) | def __getitem__(self, index):
class HuggingFaceDataset (line 344) | class HuggingFaceDataset(Dataset):
method __init__ (line 345) | def __init__(
method __len__ (line 361) | def __len__(self):
method __getitem__ (line 364) | def __getitem__(self, index):
function process_image (line 379) | def process_image(image, size):
function tokenize_prompt (line 402) | def tokenize_prompt(tokenizer, prompt):
function encode_prompt (line 412) | def encode_prompt(text_encoder, input_ids):
function main (line 419) | def main(args):
function save_checkpoint (line 946) | def save_checkpoint(args, accelerator, global_step):
FILE: diffusers/examples/community/bit_diffusion.py
function decimal_to_bits (line 15) | def decimal_to_bits(x, bits=BITS):
function bits_to_decimal (line 31) | def bits_to_decimal(x, bits=BITS):
function ddim_bit_scheduler_step (line 45) | def ddim_bit_scheduler_step(
function ddpm_bit_scheduler_step (line 135) | def ddpm_bit_scheduler_step(
class BitDiffusion (line 213) | class BitDiffusion(DiffusionPipeline):
method __init__ (line 214) | def __init__(
method __call__ (line 229) | def __call__(
FILE: diffusers/examples/community/checkpoint_merger.py
class CheckpointMergerPipeline (line 15) | class CheckpointMergerPipeline(DiffusionPipeline):
method __init__ (line 36) | def __init__(self):
method _compare_model_configs (line 40) | def _compare_model_configs(self, dict0, dict1):
method _remove_meta_keys (line 51) | def _remove_meta_keys(self, config_dict: Dict):
method merge (line 62) | def merge(self, pretrained_model_name_or_path_list: List[Union[str, os...
method weighted_sum (line 268) | def weighted_sum(theta0, theta1, theta2, alpha):
method sigmoid (line 273) | def sigmoid(theta0, theta1, theta2, alpha):
method inv_sigmoid (line 279) | def inv_sigmoid(theta0, theta1, theta2, alpha):
method add_difference (line 286) | def add_difference(theta0, theta1, theta2, alpha):
FILE: diffusers/examples/community/clip_guided_images_mixing_stable_diffusion.py
function preprocess (line 26) | def preprocess(image, w, h):
function slerp (line 44) | def slerp(t, v0, v1, DOT_THRESHOLD=0.9995):
function spherical_dist_loss (line 69) | def spherical_dist_loss(x, y):
function set_requires_grad (line 75) | def set_requires_grad(model, value):
class CLIPGuidedImagesMixingStableDiffusion (line 80) | class CLIPGuidedImagesMixingStableDiffusion(DiffusionPipeline, StableDif...
method __init__ (line 81) | def __init__(
method freeze_vae (line 116) | def freeze_vae(self):
method unfreeze_vae (line 119) | def unfreeze_vae(self):
method freeze_unet (line 122) | def freeze_unet(self):
method unfreeze_unet (line 125) | def unfreeze_unet(self):
method get_timesteps (line 128) | def get_timesteps(self, num_inference_steps, strength, device):
method prepare_latents (line 137) | def prepare_latents(self, image, timestep, batch_size, dtype, device, ...
method get_image_description (line 163) | def get_image_description(self, image):
method get_clip_image_embeddings (line 170) | def get_clip_image_embeddings(self, image, batch_size):
method cond_fn (line 179) | def cond_fn(
method __call__ (line 234) | def __call__(
FILE: diffusers/examples/community/clip_guided_stable_diffusion.py
class MakeCutouts (line 22) | class MakeCutouts(nn.Module):
method __init__ (line 23) | def __init__(self, cut_size, cut_power=1.0):
method forward (line 29) | def forward(self, pixel_values, num_cutouts):
function spherical_dist_loss (line 43) | def spherical_dist_loss(x, y):
function set_requires_grad (line 49) | def set_requires_grad(model, value):
class CLIPGuidedStableDiffusion (line 54) | class CLIPGuidedStableDiffusion(DiffusionPipeline, StableDiffusionMixin):
method __init__ (line 60) | def __init__(
method freeze_vae (line 92) | def freeze_vae(self):
method unfreeze_vae (line 95) | def unfreeze_vae(self):
method freeze_unet (line 98) | def freeze_unet(self):
method unfreeze_unet (line 101) | def unfreeze_unet(self):
method cond_fn (line 105) | def cond_fn(
method __call__ (line 169) | def __call__(
FILE: diffusers/examples/community/clip_guided_stable_diffusion_img2img.py
function preprocess (line 78) | def preprocess(image, w, h):
class MakeCutouts (line 96) | class MakeCutouts(nn.Module):
method __init__ (line 97) | def __init__(self, cut_size, cut_power=1.0):
method forward (line 103) | def forward(self, pixel_values, num_cutouts):
function spherical_dist_loss (line 117) | def spherical_dist_loss(x, y):
function set_requires_grad (line 123) | def set_requires_grad(model, value):
class CLIPGuidedStableDiffusion (line 128) | class CLIPGuidedStableDiffusion(DiffusionPipeline, StableDiffusionMixin):
method __init__ (line 134) | def __init__(
method freeze_vae (line 166) | def freeze_vae(self):
method unfreeze_vae (line 169) | def unfreeze_vae(self):
method freeze_unet (line 172) | def freeze_unet(self):
method unfreeze_unet (line 175) | def unfreeze_unet(self):
method get_timesteps (line 178) | def get_timesteps(self, num_inference_steps, strength, device):
method prepare_latents (line 187) | def prepare_latents(self, image, timestep, batch_size, num_images_per_...
method cond_fn (line 240) | def cond_fn(
method __call__ (line 304) | def __call__(
FILE: diffusers/examples/community/composable_stable_diffusion.py
class ComposableStableDiffusionPipeline (line 42) | class ComposableStableDiffusionPipeline(DiffusionPipeline, StableDiffusi...
method __init__ (line 72) | def __init__(
method _encode_prompt (line 168) | def _encode_prompt(self, prompt, device, num_images_per_prompt, do_cla...
method run_safety_checker (line 273) | def run_safety_checker(self, image, device, dtype):
method decode_latents (line 283) | def decode_latents(self, latents):
method prepare_extra_step_kwargs (line 291) | def prepare_extra_step_kwargs(self, generator, eta):
method check_inputs (line 308) | def check_inputs(self, prompt, height, width, callback_steps):
method prepare_latents (line 323) | def prepare_latents(self, batch_size, num_channels_latents, height, wi...
method __call__ (line 346) | def __call__(
FILE: diffusers/examples/community/ddim_noise_comparative_analysis.py
function preprocess (line 35) | def preprocess(image):
class DDIMNoiseComparativeAnalysisPipeline (line 46) | class DDIMNoiseComparativeAnalysisPipeline(DiffusionPipeline):
method __init__ (line 58) | def __init__(self, unet, scheduler):
method check_inputs (line 66) | def check_inputs(self, strength):
method get_timesteps (line 70) | def get_timesteps(self, num_inference_steps, strength, device):
method prepare_latents (line 79) | def prepare_latents(self, image, timestep, batch_size, dtype, device, ...
method __call__ (line 104) | def __call__(
FILE: diffusers/examples/community/dps_pipeline.py
class DPSPipeline (line 27) | class DPSPipeline(DiffusionPipeline):
method __init__ (line 44) | def __init__(self, unet, scheduler):
method __call__ (line 49) | def __call__(
class SuperResolutionOperator (line 167) | class SuperResolutionOperator(nn.Module):
method __init__ (line 168) | def __init__(self, in_shape, scale_factor):
method forward (line 371) | def forward(self, data, **kwargs):
class GaussialBlurOperator (line 375) | class GaussialBlurOperator(nn.Module):
method __init__ (line 376) | def __init__(self, kernel_size, intensity):
method forward (line 421) | def forward(self, data, **kwargs):
method transpose (line 424) | def transpose(self, data, **kwargs):
method get_kernel (line 427) | def get_kernel(self):
function RMSELoss (line 431) | def RMSELoss(yhat, y):
FILE: diffusers/examples/community/edict_pipeline.py
class EDICTPipeline (line 15) | class EDICTPipeline(DiffusionPipeline):
method __init__ (line 16) | def __init__(
method _encode_prompt (line 41) | def _encode_prompt(
method denoise_mixing_layer (line 73) | def denoise_mixing_layer(self, x: torch.Tensor, y: torch.Tensor):
method noise_mixing_layer (line 79) | def noise_mixing_layer(self, x: torch.Tensor, y: torch.Tensor):
method _get_alpha_and_beta (line 85) | def _get_alpha_and_beta(self, t: torch.Tensor):
method noise_step (line 93) | def noise_step(
method denoise_step (line 112) | def denoise_step(
method decode_latents (line 131) | def decode_latents(self, latents: torch.Tensor):
method prepare_latents (line 138) | def prepare_latents(
method __call__ (line 189) | def __call__(
FILE: diffusers/examples/community/fresco_v2v.py
function clear_cache (line 52) | def clear_cache():
function coords_grid (line 57) | def coords_grid(b, h, w, homogeneous=False, device=None):
function bilinear_sample (line 76) | def bilinear_sample(img, sample_coords, mode="bilinear", padding_mode="z...
class Dilate (line 100) | class Dilate:
method __init__ (line 101) | def __init__(self, kernel_size=7, channels=1, device="cpu"):
method __call__ (line 110) | def __call__(self, x):
function flow_warp (line 115) | def flow_warp(feature, flow, mask=False, mode="bilinear", padding_mode="...
function forward_backward_consistency_check (line 124) | def forward_backward_consistency_check(fwd_flow, bwd_flow, alpha=0.01, b...
function numpy2tensor (line 146) | def numpy2tensor(img):
function calc_mean_std (line 153) | def calc_mean_std(feat, eps=1e-5, chunk=1):
function adaptive_instance_normalization (line 165) | def adaptive_instance_normalization(content_feat, style_feat, chunk=1):
function optimize_feature (line 175) | def optimize_feature(
function warp_tensor (line 263) | def warp_tensor(sample, flows, occs, saliency, unet_chunk_size):
function my_forward (line 300) | def my_forward(
function get_single_mapping_ind (line 641) | def get_single_mapping_ind(bwd_flow, bwd_occ, imgs, scale=1.0):
function get_mapping_ind (line 697) | def get_mapping_ind(bwd_flows, bwd_occs, imgs, scale=1.0):
function apply_FRESCO_opt (line 736) | def apply_FRESCO_opt(
function get_intraframe_paras (line 757) | def get_intraframe_paras(pipe, imgs, frescoProc, prompt_embeds, do_class...
function get_flow_and_interframe_paras (line 806) | def get_flow_and_interframe_paras(flow_model, imgs):
class AttentionControl (line 863) | class AttentionControl:
method __init__ (line 872) | def __init__(self):
method get_empty_store (line 886) | def get_empty_store():
method clear_store (line 891) | def clear_store(self):
method enable_store (line 899) | def enable_store(self):
method disable_store (line 902) | def disable_store(self):
method enable_intraattn (line 906) | def enable_intraattn(self):
method disable_intraattn (line 913) | def disable_intraattn(self):
method disable_cfattn (line 918) | def disable_cfattn(self):
method enable_cfattn (line 922) | def enable_cfattn(self, attn_mask=None):
method disable_interattn (line 936) | def disable_interattn(self):
method enable_interattn (line 940) | def enable_interattn(self, interattn_paras=None):
method disable_controller (line 954) | def disable_controller(self):
method enable_controller (line 959) | def enable_controller(self, interattn_paras=None, attn_mask=None):
method forward (line 964) | def forward(self, context):
method __call__ (line 976) | def __call__(self, context):
class FRESCOAttnProcessor2_0 (line 981) | class FRESCOAttnProcessor2_0:
method __init__ (line 1002) | def __init__(self, unet_chunk_size=2, controller=None):
method __call__ (line 1008) | def __call__(
function apply_FRESCO_attn (line 1193) | def apply_FRESCO_attn(pipe):
function retrieve_latents (line 1209) | def retrieve_latents(
function prepare_image (line 1222) | def prepare_image(image):
class FrescoV2VPipeline (line 1246) | class FrescoV2VPipeline(StableDiffusionControlNetImg2ImgPipeline):
method __init__ (line 1289) | def __init__(
method _encode_prompt (line 1383) | def _encode_prompt(
method encode_prompt (line 1416) | def encode_prompt(
method encode_image (line 1598) | def encode_image(self, image, device, num_images_per_prompt, output_hi...
method prepare_ip_adapter_image_embeds (line 1623) | def prepare_ip_adapter_image_embeds(
method run_safety_checker (line 1675) | def run_safety_checker(self, image, device, dtype):
method decode_latents (line 1690) | def decode_latents(self, latents):
method prepare_extra_step_kwargs (line 1702) | def prepare_extra_step_kwargs(self, generator, eta):
method check_inputs (line 1719) | def check_inputs(
method check_image (line 1877) | def check_image(self, image, prompt, prompt_embeds):
method prepare_control_image (line 1915) | def prepare_control_image(
method get_timesteps (line 1946) | def get_timesteps(self, num_inference_steps, strength, device):
method prepare_latents (line 1958) | def prepare_latents(
method guidance_scale (line 2024) | def guidance_scale(self):
method clip_skip (line 2028) | def clip_skip(self):
method do_classifier_free_guidance (line 2035) | def do_classifier_free_guidance(self):
method cross_attention_kwargs (line 2039) | def cross_attention_kwargs(self):
method num_timesteps (line 2043) | def num_timesteps(self):
method __call__ (line 2047) | def __call__(
FILE: diffusers/examples/community/gluegen.py
class TranslatorBase (line 29) | class TranslatorBase(nn.Module):
method __init__ (line 30) | def __init__(self, num_tok, dim, dim_out, mult=2):
method forward (line 58) | def forward(self, x):
class TranslatorBaseNoLN (line 78) | class TranslatorBaseNoLN(nn.Module):
method __init__ (line 79) | def __init__(self, num_tok, dim, dim_out, mult=2):
method forward (line 101) | def forward(self, x):
class TranslatorNoLN (line 121) | class TranslatorNoLN(nn.Module):
method __init__ (line 122) | def __init__(self, num_tok, dim, dim_out, mult=2, depth=5):
method forward (line 130) | def forward(self, x):
function rescale_noise_cfg (line 139) | def rescale_noise_cfg(noise_cfg, noise_pred_text, guidance_rescale=0.0):
function retrieve_timesteps (line 153) | def retrieve_timesteps(
class GlueGenStableDiffusionPipeline (line 197) | class GlueGenStableDiffusionPipeline(DiffusionPipeline, StableDiffusionM...
method __init__ (line 198) | def __init__(
method load_language_adapter (line 228) | def load_language_adapter(
method _adapt_language (line 245) | def _adapt_language(self, prompt_embeds: torch.Tensor):
method encode_prompt (line 250) | def encode_prompt(
method run_safety_checker (line 433) | def run_safety_checker(self, image, device, dtype):
method prepare_extra_step_kwargs (line 447) | def prepare_extra_step_kwargs(self, generator, eta):
method check_inputs (line 464) | def check_inputs(
method prepare_latents (line 502) | def prepare_latents(self, batch_size, num_channels_latents, height, wi...
method get_guidance_scale_embedding (line 525) | def get_guidance_scale_embedding(self, w, embedding_dim=512, dtype=tor...
method guidance_scale (line 554) | def guidance_scale(self):
method guidance_rescale (line 558) | def guidance_rescale(self):
method clip_skip (line 562) | def clip_skip(self):
method do_classifier_free_guidance (line 569) | def do_classifier_free_guidance(self):
method cross_attention_kwargs (line 573) | def cross_attention_kwargs(self):
method num_timesteps (line 577) | def num_timesteps(self):
method interrupt (line 581) | def interrupt(self):
method __call__ (line 585) | def __call__(
FILE: diffusers/examples/community/hd_painter.py
class RASGAttnProcessor (line 20) | class RASGAttnProcessor:
method __init__ (line 21) | def __init__(self, mask, token_idx, scale_factor):
method __call__ (line 28) | def __call__(
class PAIntAAttnProcessor (line 100) | class PAIntAAttnProcessor:
method __init__ (line 101) | def __init__(self, transformer_block, mask, token_idx, do_classifier_f...
method __call__ (line 111) | def __call__(
class StableDiffusionHDPainterPipeline (line 401) | class StableDiffusionHDPainterPipeline(StableDiffusionInpaintPipeline):
method get_tokenized_prompt (line 402) | def get_tokenized_prompt(self, prompt):
method init_attn_processors (line 406) | def init_attn_processors(
method __call__ (line 452) | def __call__(
class GaussianSmoothing (line 896) | class GaussianSmoothing(nn.Module):
method __init__ (line 910) | def __init__(self, channels, kernel_size, sigma, dim=2):
method forward (line 944) | def forward(self, input):
function get_attention_scores (line 955) | def get_attention_scores(
FILE: diffusers/examples/community/iadb.py
class IADBScheduler (line 11) | class IADBScheduler(SchedulerMixin, ConfigMixin):
method step (line 18) | def step(
method set_timesteps (line 51) | def set_timesteps(self, num_inference_steps: int):
method add_noise (line 54) | def add_noise(
method __len__ (line 62) | def __len__(self):
class IADBPipeline (line 66) | class IADBPipeline(DiffusionPipeline):
method __init__ (line 78) | def __init__(self, unet, scheduler):
method __call__ (line 84) | def __call__(
FILE: diffusers/examples/community/imagic_stable_diffusion.py
function preprocess (line 51) | def preprocess(image):
class ImagicStableDiffusionPipeline (line 61) | class ImagicStableDiffusionPipeline(DiffusionPipeline, StableDiffusionMi...
method __init__ (line 89) | def __init__(
method train (line 110) | def train(
method __call__ (line 311) | def __call__(
FILE: diffusers/examples/community/img2img_inpainting.py
function prepare_mask_and_masked_image (line 21) | def prepare_mask_and_masked_image(image, mask):
function check_size (line 38) | def check_size(image, height, width):
function overlay_inner_image (line 48) | def overlay_inner_image(image, inner_image, paste_offset: Tuple[int] = (...
class ImageToImageInpaintingPipeline (line 58) | class ImageToImageInpaintingPipeline(DiffusionPipeline):
method __init__ (line 86) | def __init__(
method __call__ (line 133) | def __call__(
FILE: diffusers/examples/community/instaflow_one_step.py
function rescale_noise_cfg (line 41) | def rescale_noise_cfg(noise_cfg, noise_pred_text, guidance_rescale=0.0):
class InstaFlowPipeline (line 55) | class InstaFlowPipeline(
method __init__ (line 95) | def __init__(
method _encode_prompt (line 185) | def _encode_prompt(
method encode_prompt (line 215) | def encode_prompt(
method run_safety_checker (line 374) | def run_safety_checker(self, image, device, dtype):
method decode_latents (line 388) | def decode_latents(self, latents):
method merge_dW_to_unet (line 399) | def merge_dW_to_unet(pipe, dW_dict, alpha=1.0):
method prepare_extra_step_kwargs (line 406) | def prepare_extra_step_kwargs(self, generator, eta):
method check_inputs (line 423) | def check_inputs(
method prepare_latents (line 470) | def prepare_latents(self, batch_size, num_channels_latents, height, wi...
method __call__ (line 493) | def __call__(
FILE: diffusers/examples/community/interpolate_stable_diffusion.py
function slerp (line 22) | def slerp(t, v0, v1, DOT_THRESHOLD=0.9995):
class StableDiffusionWalkPipeline (line 49) | class StableDiffusionWalkPipeline(DiffusionPipeline, StableDiffusionMixin):
method __init__ (line 77) | def __init__(
method __call__ (line 124) | def __call__(
method embed_text (line 377) | def embed_text(self, text):
method get_noise (line 390) | def get_noise(self, seed, dtype=torch.float32, height=512, width=512):
method walk (line 399) | def walk(
FILE: diffusers/examples/community/ip_adapter_face_id.py
class IPAdapterFullImageProjection (line 55) | class IPAdapterFullImageProjection(nn.Module):
method __init__ (line 56) | def __init__(self, image_embed_dim=1024, cross_attention_dim=1024, mul...
method forward (line 65) | def forward(self, image_embeds: torch.Tensor):
function rescale_noise_cfg (line 71) | def rescale_noise_cfg(noise_cfg, noise_pred_text, guidance_rescale=0.0):
function retrieve_timesteps (line 85) | def retrieve_timesteps(
class IPAdapterFaceIDStableDiffusionPipeline (line 129) | class IPAdapterFaceIDStableDiffusionPipeline(
method __init__ (line 175) | def __init__(
method load_ip_adapter_face_id (line 267) | def load_ip_adapter_face_id(self, pretrained_model_name_or_path_or_dic...
method convert_ip_adapter_image_proj_to_diffusers (line 306) | def convert_ip_adapter_image_proj_to_diffusers(self, state_dict):
method _load_ip_adapter_weights (line 330) | def _load_ip_adapter_weights(self, state_dict):
method set_ip_adapter_scale (line 442) | def set_ip_adapter_scale(self, scale):
method _encode_prompt (line 448) | def _encode_prompt(
method encode_prompt (line 480) | def encode_prompt(
method run_safety_checker (line 661) | def run_safety_checker(self, image, device, dtype):
method decode_latents (line 675) | def decode_latents(self, latents):
method prepare_extra_step_kwargs (line 686) | def prepare_extra_step_kwargs(self, generator, eta):
method check_inputs (line 703) | def check_inputs(
method prepare_latents (line 755) | def prepare_latents(self, batch_size, num_channels_latents, height, wi...
method get_guidance_scale_embedding (line 778) | def get_guidance_scale_embedding(self, w, embedding_dim=512, dtype=tor...
method guidance_scale (line 807) | def guidance_scale(self):
method guidance_rescale (line 811) | def guidance_rescale(self):
method clip_skip (line 815) | def clip_skip(self):
method do_classifier_free_guidance (line 822) | def do_classifier_free_guidance(self):
method cross_attention_kwargs (line 826) | def cross_attention_kwargs(self):
method num_timesteps (line 830) | def num_timesteps(self):
method interrupt (line 834) | def interrupt(self):
method __call__ (line 838) | def __call__(
FILE: diffusers/examples/community/kohya_hires_fix.py
class UNet2DConditionModelHighResFix (line 35) | class UNet2DConditionModelHighResFix(UNet2DConditionModel):
method __init__ (line 49) | def __init__(self, high_res_fix: List[Dict] = [{"timestep": 600, "scal...
method _resize (line 55) | def _resize(cls, sample, target=None, scale_factor=1, mode="bicubic"):
method forward (line 68) | def forward(
method from_unet (line 361) | def from_unet(cls, unet: UNet2DConditionModel, high_res_fix: list):
class StableDiffusionHighResFixPipeline (line 390) | class StableDiffusionHighResFixPipeline(StableDiffusionPipeline):
method __init__ (line 430) | def __init__(
FILE: diffusers/examples/community/latent_consistency_img2img.py
class LatentConsistencyModelImg2ImgPipeline (line 39) | class LatentConsistencyModelImg2ImgPipeline(DiffusionPipeline):
method __init__ (line 42) | def __init__(
method _encode_prompt (line 75) | def _encode_prompt(
method run_safety_checker (line 153) | def run_safety_checker(self, image, device, dtype):
method prepare_latents (line 167) | def prepare_latents(
method get_w_embedding (line 243) | def get_w_embedding(self, w, embedding_dim=512, dtype=torch.float32):
method get_timesteps (line 266) | def get_timesteps(self, num_inference_steps, strength, device):
method __call__ (line 276) | def __call__(
class LCMSchedulerOutput (line 394) | class LCMSchedulerOutput(BaseOutput):
function betas_for_alpha_bar (line 411) | def betas_for_alpha_bar(
function rescale_zero_terminal_snr (line 451) | def rescale_zero_terminal_snr(betas):
class LCMSchedulerWithTimestamp (line 484) | class LCMSchedulerWithTimestamp(SchedulerMixin, ConfigMixin):
method __init__ (line 539) | def __init__(
method scale_model_input (line 590) | def scale_model_input(self, sample: torch.Tensor, timestep: Optional[i...
method _get_variance (line 605) | def _get_variance(self, timestep, prev_timestep):
method _threshold_sample (line 616) | def _threshold_sample(self, sample: torch.Tensor) -> torch.Tensor:
method set_timesteps (line 649) | def set_timesteps(
method get_scalings_for_boundary_condition_discrete (line 678) | def get_scalings_for_boundary_condition_discrete(self, t):
method step (line 686) | def step(
method add_noise (line 778) | def add_noise(
method get_velocity (line 802) | def get_velocity(self, sample: torch.Tensor, noise: torch.Tensor, time...
method __len__ (line 820) | def __len__(self):
FILE: diffusers/examples/community/latent_consistency_interpolate.py
function lerp (line 76) | def lerp(
function slerp (line 126) | def slerp(
class LatentConsistencyModelWalkPipeline (line 192) | class LatentConsistencyModelWalkPipeline(
method __init__ (line 234) | def __init__(
method encode_prompt (line 277) | def encode_prompt(
method run_safety_checker (line 459) | def run_safety_checker(self, image, device, dtype):
method prepare_latents (line 474) | def prepare_latents(self, batch_size, num_channels_latents, height, wi...
method get_guidance_scale_embedding (line 496) | def get_guidance_scale_embedding(self, w, embedding_dim=512, dtype=tor...
method prepare_extra_step_kwargs (line 525) | def prepare_extra_step_kwargs(self, generator, eta):
method check_inputs (line 543) | def check_inputs(
method interpolate_embedding (line 581) | def interpolate_embedding(
method interpolate_latent (line 612) | def interpolate_latent(
method guidance_scale (line 638) | def guidance_scale(self):
method cross_attention_kwargs (line 642) | def cross_attention_kwargs(self):
method clip_skip (line 646) | def clip_skip(self):
method num_timesteps (line 650) | def num_timesteps(self):
method __call__ (line 655) | def __call__(
FILE: diffusers/examples/community/latent_consistency_txt2img.py
class LatentConsistencyModelPipeline (line 37) | class LatentConsistencyModelPipeline(DiffusionPipeline):
method __init__ (line 40) | def __init__(
method _encode_prompt (line 73) | def _encode_prompt(
method run_safety_checker (line 151) | def run_safety_checker(self, image, device, dtype):
method prepare_latents (line 165) | def prepare_latents(self, batch_size, num_channels_latents, height, wi...
method get_w_embedding (line 180) | def get_w_embedding(self, w, embedding_dim=512, dtype=torch.float32):
method __call__ (line 204) | def __call__(
class LCMSchedulerOutput (line 309) | class LCMSchedulerOutput(BaseOutput):
function betas_for_alpha_bar (line 326) | def betas_for_alpha_bar(
function rescale_zero_terminal_snr (line 366) | def rescale_zero_terminal_snr(betas):
class LCMScheduler (line 399) | class LCMScheduler(SchedulerMixin, ConfigMixin):
method __init__ (line 451) | def __init__(
method scale_model_input (line 502) | def scale_model_input(self, sample: torch.Tensor, timestep: Optional[i...
method _get_variance (line 517) | def _get_variance(self, timestep, prev_timestep):
method _threshold_sample (line 528) | def _threshold_sample(self, sample: torch.Tensor) -> torch.Tensor:
method set_timesteps (line 561) | def set_timesteps(self, num_inference_steps: int, lcm_origin_steps: in...
method get_scalings_for_boundary_condition_discrete (line 586) | def get_scalings_for_boundary_condition_discrete(self, t):
method step (line 594) | def step(
method add_noise (line 686) | def add_noise(
method get_velocity (line 710) | def get_velocity(self, sample: torch.Tensor, noise: torch.Tensor, time...
method __len__ (line 728) | def __len__(self):
FILE: diffusers/examples/community/llm_grounded_diffusion.py
function convert_attn_keys (line 123) | def convert_attn_keys(key):
function scale_proportion (line 136) | def scale_proportion(obj_box, H, W):
class AttnProcessorWithHook (line 149) | class AttnProcessorWithHook(AttnProcessor2_0):
method __init__ (line 150) | def __init__(
method __call__ (line 167) | def __call__(
class LLMGroundedDiffusionPipeline (line 270) | class LLMGroundedDiffusionPipeline(
method __init__ (line 319) | def __init__(
method attn_hook (line 416) | def attn_hook(self, name, query, key, value, attention_probs):
method convert_box (line 421) | def convert_box(cls, box, height, width):
method _parse_response_with_negative (line 431) | def _parse_response_with_negative(cls, text):
method parse_llm_response (line 469) | def parse_llm_response(cls, response, canvas_height=512, canvas_width=...
method check_inputs (line 480) | def check_inputs(
method register_attn_hooks (line 538) | def register_attn_hooks(self, unet):
method enable_fuser (line 573) | def enable_fuser(self, enabled=True):
method enable_attn_hook (line 578) | def enable_attn_hook(self, enabled=True):
method get_token_map (line 583) | def get_token_map(self, prompt, padding="do_not_pad", verbose=False):
method get_phrase_indices (line 599) | def get_phrase_indices(
method add_ca_loss_per_attn_map_to_loss (line 648) | def add_ca_loss_per_attn_map_to_loss(
method compute_ca_loss (line 701) | def compute_ca_loss(
method __call__ (line 745) | def __call__(
method latent_lmd_guidance (line 1082) | def latent_lmd_guidance(
method _encode_prompt (line 1190) | def _encode_prompt(
method encode_prompt (line 1223) | def encode_prompt(
method encode_image (line 1407) | def encode_image(self, image, device, num_images_per_prompt):
method run_safety_checker (line 1421) | def run_safety_checker(self, image, device, dtype):
method decode_latents (line 1436) | def decode_latents(self, latents):
method prepare_extra_step_kwargs (line 1448) | def prepare_extra_step_kwargs(self, generator, eta):
method prepare_latents (line 1466) | def prepare_latents(
method get_guidance_scale_embedding (line 1499) | def get_guidance_scale_embedding(self, w, embedding_dim=512, dtype=tor...
method guidance_scale (line 1529) | def guidance_scale(self):
method guidance_rescale (line 1534) | def guidance_rescale(self):
method clip_skip (line 1539) | def clip_skip(self):
method do_classifier_free_guidance (line 1547) | def do_classifier_free_guidance(self):
method cross_attention_kwargs (line 1552) | def cross_attention_kwargs(self):
method num_timesteps (line 1557) | def num_timesteps(self):
FILE: diffusers/examples/community/lpw_stable_diffusion.py
function parse_prompt_attention (line 51) | def parse_prompt_attention(text):
function get_prompts_with_weights (line 137) | def get_prompts_with_weights(pipe: DiffusionPipeline, prompt: List[str],...
function pad_tokens_and_weights (line 172) | def pad_tokens_and_weights(tokens, weights, max_length, bos, eos, pad, n...
function get_unweighted_text_embeddings (line 197) | def get_unweighted_text_embeddings(
function get_weighted_text_embeddings (line 237) | def get_weighted_text_embeddings(
function preprocess_image (line 370) | def preprocess_image(image, batch_size):
function preprocess_mask (line 380) | def preprocess_mask(mask, batch_size, scale_factor=8):
class StableDiffusionLongPromptWeightingPipeline (line 411) | class StableDiffusionLongPromptWeightingPipeline(
method __init__ (line 446) | def __init__(
method _encode_prompt (line 538) | def _encode_prompt(
method check_inputs (line 615) | def check_inputs(
method get_timesteps (line 666) | def get_timesteps(self, num_inference_steps, strength, device, is_text...
method run_safety_checker (line 678) | def run_safety_checker(self, image, device, dtype):
method decode_latents (line 688) | def decode_latents(self, latents):
method prepare_extra_step_kwargs (line 696) | def prepare_extra_step_kwargs(self, generator, eta):
method prepare_latents (line 713) | def prepare_latents(
method __call__ (line 766) | def __call__(
method text2img (line 1024) | def text2img(
method img2img (line 1138) | def img2img(
method inpaint (line 1250) | def inpaint(
FILE: diffusers/examples/community/lpw_stable_diffusion_onnx.py
function parse_prompt_attention (line 78) | def parse_prompt_attention(text):
function get_prompts_with_weights (line 164) | def get_prompts_with_weights(pipe, prompt: List[str], max_length: int):
function pad_tokens_and_weights (line 199) | def pad_tokens_and_weights(tokens, weights, max_length, bos, eos, pad, n...
function get_unweighted_text_embeddings (line 224) | def get_unweighted_text_embeddings(
function get_weighted_text_embeddings (line 265) | def get_weighted_text_embeddings(
function preprocess_image (line 407) | def preprocess_image(image):
function preprocess_mask (line 416) | def preprocess_mask(mask, scale_factor=8):
class OnnxStableDiffusionLongPromptWeightingPipeline (line 428) | class OnnxStableDiffusionLongPromptWeightingPipeline(OnnxStableDiffusion...
method __init__ (line 439) | def __init__(
method __init__ (line 466) | def __init__(
method __init__additional__ (line 489) | def __init__additional__(self):
method _encode_prompt (line 493) | def _encode_prompt(
method check_inputs (line 544) | def check_inputs(self, prompt, height, width, strength, callback_steps):
method get_timesteps (line 562) | def get_timesteps(self, num_inference_steps, strength, is_text2img):
method run_safety_checker (line 575) | def run_safety_checker(self, image):
method decode_latents (line 593) | def decode_latents(self, latents):
method prepare_extra_step_kwargs (line 604) | def prepare_extra_step_kwargs(self, generator, eta):
method prepare_latents (line 621) | def prepare_latents(self, image, timestep, batch_size, height, width, ...
method __call__ (line 654) | def __call__(
method text2img (line 870) | def text2img(
method img2img (line 962) | def img2img(
method inpaint (line 1053) | def inpaint(
FILE: diffusers/examples/community/lpw_stable_diffusion_xl.py
function parse_prompt_attention (line 51) | def parse_prompt_attention(text):
function get_prompts_tokens_with_weights (line 153) | def get_prompts_tokens_with_weights(clip_tokenizer: CLIPTokenizer, promp...
function group_tokens_and_weights (line 203) | def group_tokens_and_weights(token_ids: list, weights: list, pad_last_bl...
function get_weighted_text_embeddings_sdxl (line 255) | def get_weighted_text_embeddings_sdxl(
function rescale_noise_cfg (line 474) | def rescale_noise_cfg(noise_cfg, noise_pred_text, guidance_rescale=0.0):
function retrieve_latents (line 489) | def retrieve_latents(
function retrieve_timesteps (line 503) | def retrieve_timesteps(
class SDXLLongPromptWeightingPipeline (line 547) | class SDXLLongPromptWeightingPipeline(
method __init__ (line 615) | def __init__(
method enable_model_cpu_offload (line 657) | def enable_model_cpu_offload(self, gpu_id=0):
method encode_prompt (line 688) | def encode_prompt(
method encode_image (line 880) | def encode_image(self, image, device, num_images_per_prompt, output_hi...
method prepare_extra_step_kwargs (line 905) | def prepare_extra_step_kwargs(self, generator, eta):
method check_inputs (line 922) | def check_inputs(
method get_timesteps (line 1005) | def get_timesteps(self, num_inference_steps, strength, device, denoisi...
method prepare_latents (line 1041) | def prepare_latents(
method _encode_vae_image (line 1197) | def _encode_vae_image(self, image: torch.Tensor, generator: torch.Gene...
method prepare_mask_latents (line 1220) | def prepare_mask_latents(
method _get_add_time_ids (line 1273) | def _get_add_time_ids(self, original_size, crops_coords_top_left, targ...
method upcast_vae (line 1290) | def upcast_vae(self):
method get_guidance_scale_embedding (line 1310) | def get_guidance_scale_embedding(self, w, embedding_dim=512, dtype=tor...
method guidance_scale (line 1339) | def guidance_scale(self):
method guidance_rescale (line 1343) | def guidance_rescale(self):
method clip_skip (line 1347) | def clip_skip(self):
method do_classifier_free_guidance (line 1354) | def do_classifier_free_guidance(self):
method cross_attention_kwargs (line 1358) | def cross_attention_kwargs(self):
method denoising_end (line 1362) | def denoising_end(self):
method denoising_start (line 1366) | def denoising_start(self):
method num_timesteps (line 1370) | def num_timesteps(self):
method __call__ (line 1375) | def __call__(
method text2img (line 1913) | def text2img(
method img2img (line 1986) | def img2img(
method inpaint (line 2063) | def inpaint(
method load_lora_weights (line 2145) | def load_lora_weights(self, pretrained_model_name_or_path_or_dict: Uni...
method save_lora_weights (line 2177) | def save_lora_weights(
method _remove_text_encoder_monkey_patch (line 2210) | def _remove_text_encoder_monkey_patch(self):
FILE: diffusers/examples/community/magic_mix.py
class MagicMixPipeline (line 19) | class MagicMixPipeline(Diffusi
Copy disabled (too large)
Download .json
Condensed preview — 1598 files, each showing path, character count, and a content snippet. Download the .json file for the full structured content (45,493K chars).
[
{
"path": ".gitignore",
"chars": 3147,
"preview": "# Byte-compiled / optimized / DLL files\n__pycache__/\n*.py[cod]\n*$py.class\n\n# C extensions\n*.so\n\n# Distribution / packagi"
},
{
"path": "README.md",
"chars": 4907,
"preview": "<h1 align=\"center\">UltraEdit</h1>\n\n<p align=\"center\">\n\n<a href=\"https://arxiv.org/abs/2407.05282\">\n<img alt=\"Static Badg"
},
{
"path": "app.py",
"chars": 8899,
"preview": "# import spaces\r\nimport torch\r\nfrom diffusers import StableDiffusion3InstructPix2PixPipeline, SD3Transformer2DModel\r\nimp"
},
{
"path": "data_generation/Grounded-Segment-Anything/.gitignore",
"chars": 1836,
"preview": "# Byte-compiled / optimized / DLL files\n__pycache__/\n*.py[cod]\n*$py.class\n\n# C extensions\n*.so\n\n# Distribution / packagi"
},
{
"path": "data_generation/Grounded-Segment-Anything/.gitmodules",
"chars": 191,
"preview": "\n[submodule \"grounded-sam-osx\"]\n\tpath = grounded-sam-osx\n\turl = https://github.com/linjing7/grounded-sam-osx.git\n[submod"
},
{
"path": "data_generation/Grounded-Segment-Anything/CITATION.cff",
"chars": 275,
"preview": "cff-version: 1.2.0\nmessage: \"If you use this software, please cite it as below.\"\nauthors:\n - name: \"Grounded-SAM Contri"
},
{
"path": "data_generation/Grounded-Segment-Anything/Dockerfile",
"chars": 1140,
"preview": "FROM pytorch/pytorch:1.13.1-cuda11.6-cudnn8-devel\n\n# Arguments to build Docker Image using CUDA\nARG USE_CUDA=0\nARG TORCH"
},
{
"path": "data_generation/Grounded-Segment-Anything/EfficientSAM/EdgeSAM/common.py",
"chars": 3642,
"preview": "# Copyright (c) Meta Platforms, Inc. and affiliates.\n# All rights reserved.\n\n# This source code is licensed under the li"
},
{
"path": "data_generation/Grounded-Segment-Anything/EfficientSAM/EdgeSAM/rep_vit.py",
"chars": 12019,
"preview": "import torch.nn as nn\nfrom EdgeSAM.common import LayerNorm2d, UpSampleLayer, OpSequential\n\n__all__ = ['rep_vit_m1', 'rep"
},
{
"path": "data_generation/Grounded-Segment-Anything/EfficientSAM/EdgeSAM/setup_edge_sam.py",
"chars": 2473,
"preview": "# Copyright (c) Meta Platforms, Inc. and affiliates.\n# All rights reserved.\n\n# This source code is licensed under the li"
},
{
"path": "data_generation/Grounded-Segment-Anything/EfficientSAM/FastSAM/tools.py",
"chars": 14404,
"preview": "import numpy as np\nfrom PIL import Image\nimport matplotlib.pyplot as plt\nimport cv2\nimport torch\nimport os\nimport clip\n\n"
},
{
"path": "data_generation/Grounded-Segment-Anything/EfficientSAM/LightHQSAM/setup_light_hqsam.py",
"chars": 1676,
"preview": "from LightHQSAM.tiny_vit_sam import TinyViT\nfrom segment_anything.modeling import MaskDecoderHQ, PromptEncoder, Sam, Two"
},
{
"path": "data_generation/Grounded-Segment-Anything/EfficientSAM/LightHQSAM/tiny_vit_sam.py",
"chars": 25091,
"preview": "# --------------------------------------------------------\n# TinyViT Model Architecture\n# Copyright (c) 2022 Microsoft\n#"
},
{
"path": "data_generation/Grounded-Segment-Anything/EfficientSAM/MobileSAM/setup_mobile_sam.py",
"chars": 1642,
"preview": "from MobileSAM.tiny_vit_sam import TinyViT\nfrom segment_anything.modeling import MaskDecoder, PromptEncoder, Sam, TwoWay"
},
{
"path": "data_generation/Grounded-Segment-Anything/EfficientSAM/MobileSAM/tiny_vit_sam.py",
"chars": 24771,
"preview": "# --------------------------------------------------------\n# TinyViT Model Architecture\n# Copyright (c) 2022 Microsoft\n#"
},
{
"path": "data_generation/Grounded-Segment-Anything/EfficientSAM/README.md",
"chars": 10243,
"preview": "## Efficient Grounded-SAM\n\nWe're going to combine [Grounding-DINO](https://github.com/IDEA-Research/GroundingDINO) with "
},
{
"path": "data_generation/Grounded-Segment-Anything/EfficientSAM/RepViTSAM/repvit.py",
"chars": 13003,
"preview": "import torch.nn as nn\n\n\n__all__ = ['repvit_m1']\n\n\ndef _make_divisible(v, divisor, min_value=None):\n \"\"\"\n This func"
},
{
"path": "data_generation/Grounded-Segment-Anything/EfficientSAM/RepViTSAM/setup_repvit_sam.py",
"chars": 1765,
"preview": "# Copyright (c) Meta Platforms, Inc. and affiliates.\n# All rights reserved.\n\n# This source code is licensed under the li"
},
{
"path": "data_generation/Grounded-Segment-Anything/EfficientSAM/grounded_edge_sam.py",
"chars": 3349,
"preview": "import cv2\nimport numpy as np\nimport supervision as sv\n\nimport torch\nimport torchvision\n\nfrom groundingdino.util.inferen"
},
{
"path": "data_generation/Grounded-Segment-Anything/EfficientSAM/grounded_efficient_sam.py",
"chars": 3914,
"preview": "import cv2\nimport numpy as np\nimport supervision as sv\n\nimport torch\nimport torchvision\nfrom torchvision.transforms impo"
},
{
"path": "data_generation/Grounded-Segment-Anything/EfficientSAM/grounded_fast_sam.py",
"chars": 4274,
"preview": "import argparse\nimport cv2\nfrom ultralytics import YOLO\nfrom FastSAM.tools import *\nfrom groundingdino.util.inference im"
},
{
"path": "data_generation/Grounded-Segment-Anything/EfficientSAM/grounded_light_hqsam.py",
"chars": 3438,
"preview": "import cv2\nimport numpy as np\nimport supervision as sv\n\nimport torch\nimport torchvision\n\nfrom groundingdino.util.inferen"
},
{
"path": "data_generation/Grounded-Segment-Anything/EfficientSAM/grounded_mobile_sam.py",
"chars": 4963,
"preview": "import cv2\nimport numpy as np\nimport supervision as sv\nimport argparse\nimport torch\nimport torchvision\n\nfrom groundingdi"
},
{
"path": "data_generation/Grounded-Segment-Anything/EfficientSAM/grounded_repvit_sam.py",
"chars": 3367,
"preview": "import cv2\nimport numpy as np\nimport supervision as sv\n\nimport torch\nimport torchvision\n\nfrom groundingdino.util.inferen"
},
{
"path": "data_generation/Grounded-Segment-Anything/GroundingDINO/LICENSE",
"chars": 11354,
"preview": " Apache License\n Version 2.0, January 2004\n "
},
{
"path": "data_generation/Grounded-Segment-Anything/GroundingDINO/README.md",
"chars": 6751,
"preview": "# Grounding DINO \n\n---\n\n[](https://arxiv.org/abs/2303."
},
{
"path": "data_generation/Grounded-Segment-Anything/GroundingDINO/demo/gradio_app.py",
"chars": 4463,
"preview": "import argparse\nfrom functools import partial\nimport cv2\nimport requests\nimport os\nfrom io import BytesIO\nfrom PIL impor"
},
{
"path": "data_generation/Grounded-Segment-Anything/GroundingDINO/demo/inference_on_a_image.py",
"chars": 6001,
"preview": "import argparse\nimport os\nimport sys\n\nimport numpy as np\nimport torch\nfrom PIL import Image, ImageDraw, ImageFont\n\nimpor"
},
{
"path": "data_generation/Grounded-Segment-Anything/GroundingDINO/groundingdino/__init__.py",
"chars": 0,
"preview": ""
},
{
"path": "data_generation/Grounded-Segment-Anything/GroundingDINO/groundingdino/config/GroundingDINO_SwinB.py",
"chars": 1007,
"preview": "batch_size = 1\nmodelname = \"groundingdino\"\nbackbone = \"swin_B_384_22k\"\nposition_embedding = \"sine\"\npe_temperatureH = 20\n"
},
{
"path": "data_generation/Grounded-Segment-Anything/GroundingDINO/groundingdino/config/GroundingDINO_SwinT_OGC.py",
"chars": 1006,
"preview": "batch_size = 1\nmodelname = \"groundingdino\"\nbackbone = \"swin_T_224_1k\"\nposition_embedding = \"sine\"\npe_temperatureH = 20\np"
},
{
"path": "data_generation/Grounded-Segment-Anything/GroundingDINO/groundingdino/datasets/__init__.py",
"chars": 0,
"preview": ""
},
{
"path": "data_generation/Grounded-Segment-Anything/GroundingDINO/groundingdino/datasets/transforms.py",
"chars": 9711,
"preview": "# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved\n\"\"\"\nTransforms and data augmentation for both ima"
},
{
"path": "data_generation/Grounded-Segment-Anything/GroundingDINO/groundingdino/models/GroundingDINO/__init__.py",
"chars": 823,
"preview": "# ------------------------------------------------------------------------\n# Grounding DINO\n# url: https://github.com/ID"
},
{
"path": "data_generation/Grounded-Segment-Anything/GroundingDINO/groundingdino/models/GroundingDINO/backbone/__init__.py",
"chars": 37,
"preview": "from .backbone import build_backbone\n"
},
{
"path": "data_generation/Grounded-Segment-Anything/GroundingDINO/groundingdino/models/GroundingDINO/backbone/backbone.py",
"chars": 7972,
"preview": "# ------------------------------------------------------------------------\n# Grounding DINO\n# url: https://github.com/ID"
},
{
"path": "data_generation/Grounded-Segment-Anything/GroundingDINO/groundingdino/models/GroundingDINO/backbone/position_encoding.py",
"chars": 6866,
"preview": "# ------------------------------------------------------------------------\n# Grounding DINO\n# url: https://github.com/ID"
},
{
"path": "data_generation/Grounded-Segment-Anything/GroundingDINO/groundingdino/models/GroundingDINO/backbone/swin_transformer.py",
"chars": 29354,
"preview": "# ------------------------------------------------------------------------\n# Grounding DINO\n# url: https://github.com/ID"
},
{
"path": "data_generation/Grounded-Segment-Anything/GroundingDINO/groundingdino/models/GroundingDINO/bertwarper.py",
"chars": 12242,
"preview": "# ------------------------------------------------------------------------\n# Grounding DINO\n# url: https://github.com/ID"
},
{
"path": "data_generation/Grounded-Segment-Anything/GroundingDINO/groundingdino/models/GroundingDINO/csrc/MsDeformAttn/ms_deform_attn.h",
"chars": 1883,
"preview": "/*!\n**************************************************************************************************\n* Deformable DETR"
},
{
"path": "data_generation/Grounded-Segment-Anything/GroundingDINO/groundingdino/models/GroundingDINO/csrc/MsDeformAttn/ms_deform_attn_cpu.cpp",
"chars": 1311,
"preview": "/*!\n**************************************************************************************************\n* Deformable DETR"
},
{
"path": "data_generation/Grounded-Segment-Anything/GroundingDINO/groundingdino/models/GroundingDINO/csrc/MsDeformAttn/ms_deform_attn_cpu.h",
"chars": 1194,
"preview": "/*!\n**************************************************************************************************\n* Deformable DETR"
},
{
"path": "data_generation/Grounded-Segment-Anything/GroundingDINO/groundingdino/models/GroundingDINO/csrc/MsDeformAttn/ms_deform_attn_cuda.cu",
"chars": 7367,
"preview": "/*!\n**************************************************************************************************\n* Deformable DETR"
},
{
"path": "data_generation/Grounded-Segment-Anything/GroundingDINO/groundingdino/models/GroundingDINO/csrc/MsDeformAttn/ms_deform_attn_cuda.h",
"chars": 1195,
"preview": "/*!\n**************************************************************************************************\n* Deformable DETR"
},
{
"path": "data_generation/Grounded-Segment-Anything/GroundingDINO/groundingdino/models/GroundingDINO/csrc/MsDeformAttn/ms_deform_im2col_cuda.cuh",
"chars": 54694,
"preview": "/*!\n**************************************************************************\n* Deformable DETR\n* Copyright (c) 2020 Se"
},
{
"path": "data_generation/Grounded-Segment-Anything/GroundingDINO/groundingdino/models/GroundingDINO/csrc/cuda_version.cu",
"chars": 140,
"preview": "#include <cuda_runtime_api.h>\n\nnamespace groundingdino {\nint get_cudart_version() {\n return CUDART_VERSION;\n}\n} // name"
},
{
"path": "data_generation/Grounded-Segment-Anything/GroundingDINO/groundingdino/models/GroundingDINO/csrc/vision.cpp",
"chars": 1419,
"preview": "// Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved\n\n#include \"MsDeformAttn/ms_deform_attn.h\"\n\nnames"
},
{
"path": "data_generation/Grounded-Segment-Anything/GroundingDINO/groundingdino/models/GroundingDINO/fuse_modules.py",
"chars": 11825,
"preview": "# ------------------------------------------------------------------------\n# Grounding DINO\n# url: https://github.com/ID"
},
{
"path": "data_generation/Grounded-Segment-Anything/GroundingDINO/groundingdino/models/GroundingDINO/groundingdino.py",
"chars": 16691,
"preview": "# ------------------------------------------------------------------------\n# Grounding DINO\n# url: https://github.com/ID"
},
{
"path": "data_generation/Grounded-Segment-Anything/GroundingDINO/groundingdino/models/GroundingDINO/ms_deform_attn.py",
"chars": 15527,
"preview": "# ------------------------------------------------------------------------\n# Grounding DINO\n# url: https://github.com/ID"
},
{
"path": "data_generation/Grounded-Segment-Anything/GroundingDINO/groundingdino/models/GroundingDINO/transformer.py",
"chars": 36865,
"preview": "# ------------------------------------------------------------------------\n# Grounding DINO\n# url: https://github.com/ID"
},
{
"path": "data_generation/Grounded-Segment-Anything/GroundingDINO/groundingdino/models/GroundingDINO/transformer_vanilla.py",
"chars": 4020,
"preview": "# ------------------------------------------------------------------------\n# Grounding DINO\n# url: https://github.com/ID"
},
{
"path": "data_generation/Grounded-Segment-Anything/GroundingDINO/groundingdino/models/GroundingDINO/utils.py",
"chars": 10203,
"preview": "# ------------------------------------------------------------------------\n# Grounding DINO\n# url: https://github.com/ID"
},
{
"path": "data_generation/Grounded-Segment-Anything/GroundingDINO/groundingdino/models/__init__.py",
"chars": 754,
"preview": "# ------------------------------------------------------------------------\n# Grounding DINO\n# url: https://github.com/ID"
},
{
"path": "data_generation/Grounded-Segment-Anything/GroundingDINO/groundingdino/models/registry.py",
"chars": 2143,
"preview": "# ------------------------------------------------------------------------\n# Grounding DINO\n# url: https://github.com/ID"
},
{
"path": "data_generation/Grounded-Segment-Anything/GroundingDINO/groundingdino/util/__init__.py",
"chars": 71,
"preview": "# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved\n"
},
{
"path": "data_generation/Grounded-Segment-Anything/GroundingDINO/groundingdino/util/box_ops.py",
"chars": 3905,
"preview": "# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved\n\"\"\"\nUtilities for bounding box manipulation and G"
},
{
"path": "data_generation/Grounded-Segment-Anything/GroundingDINO/groundingdino/util/get_tokenlizer.py",
"chars": 1335,
"preview": "from transformers import AutoTokenizer, BertModel, BertTokenizer, RobertaModel, RobertaTokenizerFast\n\n\ndef get_tokenlize"
},
{
"path": "data_generation/Grounded-Segment-Anything/GroundingDINO/groundingdino/util/inference.py",
"chars": 8705,
"preview": "from typing import Tuple, List\n\nimport re\nimport cv2\nimport numpy as np\nimport supervision as sv\nimport torch\nfrom PIL i"
},
{
"path": "data_generation/Grounded-Segment-Anything/GroundingDINO/groundingdino/util/logger.py",
"chars": 3303,
"preview": "# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved\nimport functools\nimport logging\nimport os\nimport "
},
{
"path": "data_generation/Grounded-Segment-Anything/GroundingDINO/groundingdino/util/misc.py",
"chars": 23348,
"preview": "# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved\n\"\"\"\nMisc functions, including distributed helpers"
},
{
"path": "data_generation/Grounded-Segment-Anything/GroundingDINO/groundingdino/util/slconfig.py",
"chars": 14401,
"preview": "# ==========================================================\n# Modified from mmcv\n# ===================================="
},
{
"path": "data_generation/Grounded-Segment-Anything/GroundingDINO/groundingdino/util/slio.py",
"chars": 5377,
"preview": "# ==========================================================\n# Modified from mmcv\n# ===================================="
},
{
"path": "data_generation/Grounded-Segment-Anything/GroundingDINO/groundingdino/util/time_counter.py",
"chars": 1567,
"preview": "import json\nimport time\n\n\nclass TimeCounter:\n def __init__(self) -> None:\n pass\n\n def clear(self):\n "
},
{
"path": "data_generation/Grounded-Segment-Anything/GroundingDINO/groundingdino/util/utils.py",
"chars": 17712,
"preview": "import argparse\nimport json\nimport warnings\nfrom collections import OrderedDict\nfrom copy import deepcopy\nfrom typing im"
},
{
"path": "data_generation/Grounded-Segment-Anything/GroundingDINO/groundingdino/util/visualizer.py",
"chars": 12047,
"preview": "# -*- coding: utf-8 -*-\n\"\"\"\n@File : visualizer.py\n@Time : 2022/04/05 11:39:33\n@Author : Shilong Liu \n@Conta"
},
{
"path": "data_generation/Grounded-Segment-Anything/GroundingDINO/groundingdino/util/vl_utils.py",
"chars": 3489,
"preview": "import os\nimport random\nfrom typing import List\n\nimport torch\n\n\ndef create_positive_map_from_span(tokenized, token_span,"
},
{
"path": "data_generation/Grounded-Segment-Anything/GroundingDINO/groundingdino/version.py",
"chars": 22,
"preview": "__version__ = '0.1.0'\n"
},
{
"path": "data_generation/Grounded-Segment-Anything/GroundingDINO/pyproject.toml",
"chars": 118,
"preview": "[build-system]\nrequires = [\n \"setuptools\",\n \"torch\",\n \"wheel\",\n \"torch\"\n]\nbuild-backend = \"setuptools.build_meta\"\n"
},
{
"path": "data_generation/Grounded-Segment-Anything/GroundingDINO/requirements.txt",
"chars": 91,
"preview": "torch\ntorchvision\ntransformers\naddict\nyapf\ntimm\nnumpy\nopencv-python\nsupervision\npycocotools"
},
{
"path": "data_generation/Grounded-Segment-Anything/GroundingDINO/setup.py",
"chars": 7646,
"preview": "# coding=utf-8\n# Copyright 2022 The IDEA Authors. All rights reserved.\n#\n# Licensed under the Apache License, Version 2."
},
{
"path": "data_generation/Grounded-Segment-Anything/GroundingDINO/sub_8_new_83748.err",
"chars": 90,
"preview": "slurmstepd: error: *** JOB 83748 ON dgx-hyperplane18 CANCELLED AT 2024-04-16T17:44:38 ***\n"
},
{
"path": "data_generation/Grounded-Segment-Anything/GroundingDINO/submit_gpu_task_83747.err",
"chars": 90,
"preview": "slurmstepd: error: *** JOB 83747 ON dgx-hyperplane16 CANCELLED AT 2024-04-10T01:07:12 ***\n"
},
{
"path": "data_generation/Grounded-Segment-Anything/LICENSE",
"chars": 11350,
"preview": " Apache License\n Version 2.0, January 2004\n "
},
{
"path": "data_generation/Grounded-Segment-Anything/Makefile",
"chars": 1469,
"preview": "# Get version of CUDA and enable it for compilation if CUDA > 11.0\n# This solves https://github.com/IDEA-Research/Ground"
},
{
"path": "data_generation/Grounded-Segment-Anything/README.md",
"chars": 44814,
"preview": "\n\n# Grounded-Segment-Anything\n["
},
{
"path": "data_generation/Grounded-Segment-Anything/automatic_label_demo.py",
"chars": 11886,
"preview": "import argparse\nimport os\nimport copy\n\nimport numpy as np\nimport json\nimport torch\nimport torchvision\nfrom PIL import Im"
},
{
"path": "data_generation/Grounded-Segment-Anything/automatic_label_ram_demo.py",
"chars": 11586,
"preview": "import argparse\nimport os\n\nimport numpy as np\nimport json\nimport torch\nimport torchvision\nfrom PIL import Image\nimport l"
},
{
"path": "data_generation/Grounded-Segment-Anything/automatic_label_simple_demo.py",
"chars": 5004,
"preview": "import cv2\nimport numpy as np\nimport supervision as sv\nfrom typing import List\nfrom PIL import Image\n\nimport torch\n\nfrom"
},
{
"path": "data_generation/Grounded-Segment-Anything/automatic_label_tag2text_demo.py",
"chars": 12878,
"preview": "import argparse\nimport os\nimport copy\n\nimport numpy as np\nimport json\nimport torch\nimport torchvision\nfrom PIL import Im"
},
{
"path": "data_generation/Grounded-Segment-Anything/chatbot.py",
"chars": 80155,
"preview": "# coding: utf-8\nimport os\nimport gradio as gr\nimport random\nimport torch\nimport cv2\nimport re\nimport uuid\nfrom PIL impor"
},
{
"path": "data_generation/Grounded-Segment-Anything/cog.yaml",
"chars": 630,
"preview": "# Configuration for Cog ⚙️\n# Reference: https://github.com/replicate/cog/blob/main/docs/yaml.md\n\nbuild:\n gpu: true\n cu"
},
{
"path": "data_generation/Grounded-Segment-Anything/gradio_app.py",
"chars": 15546,
"preview": "import os\nimport random\nimport cv2\nfrom scipy import ndimage\n\nimport gradio as gr\nimport argparse\nimport litellm\n\nimport"
},
{
"path": "data_generation/Grounded-Segment-Anything/grounded_sam.ipynb",
"chars": 2223704,
"preview": "{\n \"cells\": [\n {\n \"attachments\": {},\n \"cell_type\": \"markdown\",\n \"metadata\": {},\n \"source\": [\n \"# Grounded Se"
},
{
"path": "data_generation/Grounded-Segment-Anything/grounded_sam_3d_box.ipynb",
"chars": 2080873,
"preview": "{\n \"cells\": [\n {\n \"cell_type\": \"markdown\",\n \"id\": \"199d1e0a\",\n \"metadata\": {},\n \"source\": [\n \"# Segement Ant"
},
{
"path": "data_generation/Grounded-Segment-Anything/grounded_sam_colab_demo.ipynb",
"chars": 2882284,
"preview": "{\n \"nbformat\": 4,\n \"nbformat_minor\": 0,\n \"metadata\": {\n \"colab\": {\n \"provenance\": [],\n \"authorship_tag\":"
},
{
"path": "data_generation/Grounded-Segment-Anything/grounded_sam_demo.py",
"chars": 8188,
"preview": "import argparse\nimport os\nimport sys\n\nimport numpy as np\nimport json\nimport torch\nfrom PIL import Image\n\nsys.path.append"
},
{
"path": "data_generation/Grounded-Segment-Anything/grounded_sam_inpainting_demo.py",
"chars": 7789,
"preview": "import argparse\nimport os\nimport copy\n\nimport numpy as np\nimport torch\nfrom PIL import Image, ImageDraw, ImageFont\n\n# Gr"
},
{
"path": "data_generation/Grounded-Segment-Anything/grounded_sam_osx_demo.py",
"chars": 10825,
"preview": "import torchvision.transforms as transforms\nfrom torch.nn.parallel.data_parallel import DataParallel\nimport torch.backen"
},
{
"path": "data_generation/Grounded-Segment-Anything/grounded_sam_simple_demo.py",
"chars": 3284,
"preview": "import cv2\nimport numpy as np\nimport supervision as sv\n\nimport torch\nimport torchvision\n\nfrom groundingdino.util.inferen"
},
{
"path": "data_generation/Grounded-Segment-Anything/grounded_sam_visam.py",
"chars": 10520,
"preview": "\nfrom copy import deepcopy\nimport json\n\nimport os\nimport argparse\nimport torchvision.transforms.functional as F\nimport t"
},
{
"path": "data_generation/Grounded-Segment-Anything/grounded_sam_whisper_demo.py",
"chars": 8907,
"preview": "import argparse\nimport os\nimport copy\n\nimport numpy as np\nimport json\nimport torch\nimport torchvision\nfrom PIL import Im"
},
{
"path": "data_generation/Grounded-Segment-Anything/grounded_sam_whisper_inpainting_demo.py",
"chars": 11022,
"preview": "import argparse\nimport os\nfrom warnings import warn\n\nimport numpy as np\nimport torch\nfrom PIL import Image, ImageDraw, I"
},
{
"path": "data_generation/Grounded-Segment-Anything/grounding_dino_demo.py",
"chars": 890,
"preview": "from groundingdino.util.inference import load_model, load_image, predict, annotate, Model\nimport cv2\n\n\nCONFIG_PATH = \"Gr"
},
{
"path": "data_generation/Grounded-Segment-Anything/playground/DeepFloyd/README.md",
"chars": 8745,
"preview": "## DeepFloyd\n\n:grapes: [[Official Project Page](https://github.com/deep-floyd/IF)] :apple:[[Official Online Demo]"
},
{
"path": "data_generation/Grounded-Segment-Anything/playground/DeepFloyd/dream.py",
"chars": 1715,
"preview": "from deepfloyd_if.modules import IFStageI, IFStageII, StableStageIII\nfrom deepfloyd_if.modules.t5 import T5Embedder\nfrom"
},
{
"path": "data_generation/Grounded-Segment-Anything/playground/DeepFloyd/inpaint.py",
"chars": 1916,
"preview": "import PIL\nimport requests\nfrom io import BytesIO\nfrom torchvision.transforms import ToTensor\n\nfrom deepfloyd_if.modules"
},
{
"path": "data_generation/Grounded-Segment-Anything/playground/DeepFloyd/style_transfer.py",
"chars": 1221,
"preview": "from PIL import Image\n\nfrom deepfloyd_if.modules import IFStageI, IFStageII\nfrom deepfloyd_if.modules.t5 import T5Embedd"
},
{
"path": "data_generation/Grounded-Segment-Anything/playground/ImageBind_SAM/README.md",
"chars": 3067,
"preview": "## ImageBind with SAM\n\nThis is an experimental demo aims to combine [ImageBind](https://github.com/facebookresearch/Imag"
},
{
"path": "data_generation/Grounded-Segment-Anything/playground/ImageBind_SAM/audio_referring_seg_demo.py",
"chars": 2795,
"preview": "import data\nimport cv2\nimport torch\nfrom PIL import Image, ImageDraw\nfrom tqdm import tqdm\nfrom models import imagebind_"
},
{
"path": "data_generation/Grounded-Segment-Anything/playground/ImageBind_SAM/data.py",
"chars": 12567,
"preview": "#!/usr/bin/env python3\n# Portions Copyright (c) Meta Platforms, Inc. and affiliates.\n# All rights reserved.\n\n# This sour"
},
{
"path": "data_generation/Grounded-Segment-Anything/playground/ImageBind_SAM/demo.py",
"chars": 4202,
"preview": "import data\nimport cv2\nimport torch\nimport numpy as np\nfrom PIL import Image, ImageDraw\nfrom tqdm import tqdm\nfrom model"
},
{
"path": "data_generation/Grounded-Segment-Anything/playground/ImageBind_SAM/image_referring_seg_demo.py",
"chars": 3085,
"preview": "import data\nimport cv2\nimport torch\nfrom PIL import Image, ImageDraw\nfrom tqdm import tqdm\nfrom models import imagebind_"
},
{
"path": "data_generation/Grounded-Segment-Anything/playground/ImageBind_SAM/models/__init__.py",
"chars": 0,
"preview": ""
},
{
"path": "data_generation/Grounded-Segment-Anything/playground/ImageBind_SAM/models/helpers.py",
"chars": 3983,
"preview": "#!/usr/bin/env python3\n# Portions Copyright (c) Meta Platforms, Inc. and affiliates.\n# All rights reserved.\n\n# This sour"
},
{
"path": "data_generation/Grounded-Segment-Anything/playground/ImageBind_SAM/models/imagebind_model.py",
"chars": 16446,
"preview": "#!/usr/bin/env python3\n# Portions Copyright (c) Meta Platforms, Inc. and affiliates.\n# All rights reserved.\n\n# This sour"
},
{
"path": "data_generation/Grounded-Segment-Anything/playground/ImageBind_SAM/models/multimodal_preprocessors.py",
"chars": 23090,
"preview": "#!/usr/bin/env python3\n# Portions Copyright (c) Meta Platforms, Inc. and affiliates.\n# All rights reserved.\n\n# This sour"
},
{
"path": "data_generation/Grounded-Segment-Anything/playground/ImageBind_SAM/models/transformer.py",
"chars": 9748,
"preview": "#!/usr/bin/env python3\n# Portions Copyright (c) Meta Platforms, Inc. and affiliates.\n# All rights reserved.\n\n# This sour"
},
{
"path": "data_generation/Grounded-Segment-Anything/playground/ImageBind_SAM/text_referring_seg_demo.py",
"chars": 2759,
"preview": "import data\nimport cv2\nimport torch\nfrom PIL import Image, ImageDraw\nfrom tqdm import tqdm\nfrom models import imagebind_"
},
{
"path": "data_generation/Grounded-Segment-Anything/playground/ImageBind_SAM/utils.py",
"chars": 932,
"preview": "from PIL import Image\nimport numpy as np\n\ndef segment_image(image, segmentation_mask):\n image_array = np.array(image)"
},
{
"path": "data_generation/Grounded-Segment-Anything/playground/LaMa/README.md",
"chars": 4319,
"preview": "## LaMa: Resolution-robust Large Mask Inpainting with Fourier Convolutions\n\n:grapes: [[Official Project Page](https://ad"
},
{
"path": "data_generation/Grounded-Segment-Anything/playground/LaMa/lama_inpaint_demo.py",
"chars": 896,
"preview": "import cv2\nimport PIL\nimport requests\nimport numpy as np\nfrom lama_cleaner.model.lama import LaMa\nfrom lama_cleaner.sche"
},
{
"path": "data_generation/Grounded-Segment-Anything/playground/LaMa/sam_lama.py",
"chars": 2579,
"preview": "# !pip install diffusers transformers\n\nimport requests\nimport cv2\nimport numpy as np\nimport PIL\nfrom PIL import Image\nfr"
},
{
"path": "data_generation/Grounded-Segment-Anything/playground/PaintByExample/README.md",
"chars": 4837,
"preview": "## Paint by Example: Exemplar-based Image Editing with Diffusion Models\n\n:grapes: [[Official Project Page](https://githu"
},
{
"path": "data_generation/Grounded-Segment-Anything/playground/PaintByExample/paint_by_example.py",
"chars": 1592,
"preview": "# !pip install diffusers transformers\n\nimport PIL\nimport requests\nimport torch\nfrom io import BytesIO\nfrom diffusers imp"
},
{
"path": "data_generation/Grounded-Segment-Anything/playground/PaintByExample/sam_paint_by_example.py",
"chars": 2377,
"preview": "# !pip install diffusers transformers\n\nimport requests\nimport torch\nimport numpy as np\nfrom PIL import Image\nfrom io imp"
},
{
"path": "data_generation/Grounded-Segment-Anything/playground/README.md",
"chars": 995,
"preview": "## Playground\n\nWe will try more interesting **base models** and **build more fun demos** in the playground. In the playg"
},
{
"path": "data_generation/Grounded-Segment-Anything/playground/RePaint/README.md",
"chars": 2776,
"preview": "## RePaint: Inpainting using Denoising Diffusion Probabilistic Models\n\n:grapes: [[Official Project Page](https://github."
},
{
"path": "data_generation/Grounded-Segment-Anything/playground/RePaint/repaint.py",
"chars": 1356,
"preview": "from io import BytesIO\n\nimport torch\n\nimport PIL\nimport requests\nfrom diffusers import RePaintPipeline, RePaintScheduler"
},
{
"path": "data_generation/Grounded-Segment-Anything/predict.py",
"chars": 9123,
"preview": "# Prediction interface for Cog ⚙️\n# https://github.com/replicate/cog/blob/main/docs/python.md\n\nimport os\nimport json\nfro"
},
{
"path": "data_generation/Grounded-Segment-Anything/requirements.txt",
"chars": 215,
"preview": "addict\ndiffusers\ngradio\nhuggingface_hub\nmatplotlib\nnumpy\nonnxruntime\nopencv_python\nPillow\npycocotools\nPyYAML\nrequests\nse"
},
{
"path": "data_generation/Grounded-Segment-Anything/segment_anything/.flake8",
"chars": 211,
"preview": "[flake8]\nignore = W503, E203, E221, C901, C408, E741, C407, B017, F811, C101, EXE001, EXE002\nmax-line-length = 100\nmax-c"
},
{
"path": "data_generation/Grounded-Segment-Anything/segment_anything/CODE_OF_CONDUCT.md",
"chars": 3541,
"preview": "# Code of Conduct\n\n## Our Pledge\n\nIn the interest of fostering an open and welcoming environment, we as\ncontributors and"
},
{
"path": "data_generation/Grounded-Segment-Anything/segment_anything/CONTRIBUTING.md",
"chars": 1400,
"preview": "# Contributing to segment-anything\nWe want to make contributing to this project as easy and transparent as\npossible.\n\n##"
},
{
"path": "data_generation/Grounded-Segment-Anything/segment_anything/LICENSE",
"chars": 11357,
"preview": " Apache License\n Version 2.0, January 2004\n "
},
{
"path": "data_generation/Grounded-Segment-Anything/segment_anything/README.md",
"chars": 5657,
"preview": "# Segment Anything\n\n**[Meta AI Research, FAIR](https://ai.facebook.com/research/)**\n\n[Alexander Kirillov](https://alexan"
},
{
"path": "data_generation/Grounded-Segment-Anything/segment_anything/linter.sh",
"chars": 564,
"preview": "#!/bin/bash -e\n# Copyright (c) Facebook, Inc. and its affiliates.\n\n{\n black --version | grep -E \"23\\.\" > /dev/null\n} ||"
},
{
"path": "data_generation/Grounded-Segment-Anything/segment_anything/notebooks/automatic_mask_generator_example.ipynb",
"chars": 4381140,
"preview": "{\n \"cells\": [\n {\n \"cell_type\": \"code\",\n \"execution_count\": 1,\n \"id\": \"5fa21d44\",\n \"metadata\": {},\n \"outputs\":"
},
{
"path": "data_generation/Grounded-Segment-Anything/segment_anything/notebooks/onnx_model_example.ipynb",
"chars": 22507,
"preview": "{\n \"cells\": [\n {\n \"cell_type\": \"code\",\n \"execution_count\": null,\n \"id\": \"901c8ef3\",\n \"metadata\": {},\n \"output"
},
{
"path": "data_generation/Grounded-Segment-Anything/segment_anything/notebooks/predictor_example.ipynb",
"chars": 8381065,
"preview": "{\n \"cells\": [\n {\n \"cell_type\": \"code\",\n \"execution_count\": 1,\n \"id\": \"f400486b\",\n \"metadata\": {},\n \"outputs\":"
},
{
"path": "data_generation/Grounded-Segment-Anything/segment_anything/scripts/amg.py",
"chars": 7038,
"preview": "# Copyright (c) Meta Platforms, Inc. and affiliates.\n# All rights reserved.\n\n# This source code is licensed under the li"
},
{
"path": "data_generation/Grounded-Segment-Anything/segment_anything/scripts/export_onnx_model.py",
"chars": 6296,
"preview": "# Copyright (c) Meta Platforms, Inc. and affiliates.\n# All rights reserved.\n\n# This source code is licensed under the li"
},
{
"path": "data_generation/Grounded-Segment-Anything/segment_anything/segment_anything/__init__.py",
"chars": 574,
"preview": "# Copyright (c) Meta Platforms, Inc. and affiliates.\n# All rights reserved.\n\n# This source code is licensed under the li"
},
{
"path": "data_generation/Grounded-Segment-Anything/segment_anything/segment_anything/automatic_mask_generator.py",
"chars": 15132,
"preview": "# Copyright (c) Meta Platforms, Inc. and affiliates.\n# All rights reserved.\n\n# This source code is licensed under the li"
},
{
"path": "data_generation/Grounded-Segment-Anything/segment_anything/segment_anything/build_sam.py",
"chars": 2929,
"preview": "# Copyright (c) Meta Platforms, Inc. and affiliates.\n# All rights reserved.\n\n# This source code is licensed under the li"
},
{
"path": "data_generation/Grounded-Segment-Anything/segment_anything/segment_anything/build_sam_hq.py",
"chars": 3380,
"preview": "# Copyright (c) Meta Platforms, Inc. and affiliates.\n# All rights reserved.\n\n# This source code is licensed under the li"
},
{
"path": "data_generation/Grounded-Segment-Anything/segment_anything/segment_anything/modeling/__init__.py",
"chars": 428,
"preview": "# Copyright (c) Meta Platforms, Inc. and affiliates.\n# All rights reserved.\n\n# This source code is licensed under the li"
},
{
"path": "data_generation/Grounded-Segment-Anything/segment_anything/segment_anything/modeling/common.py",
"chars": 1479,
"preview": "# Copyright (c) Meta Platforms, Inc. and affiliates.\n# All rights reserved.\n\n# This source code is licensed under the li"
},
{
"path": "data_generation/Grounded-Segment-Anything/segment_anything/segment_anything/modeling/image_encoder.py",
"chars": 14548,
"preview": "# Copyright (c) Meta Platforms, Inc. and affiliates.\n# All rights reserved.\n\n# This source code is licensed under the li"
},
{
"path": "data_generation/Grounded-Segment-Anything/segment_anything/segment_anything/modeling/mask_decoder.py",
"chars": 6684,
"preview": "# Copyright (c) Meta Platforms, Inc. and affiliates.\n# All rights reserved.\n\n# This source code is licensed under the li"
},
{
"path": "data_generation/Grounded-Segment-Anything/segment_anything/segment_anything/modeling/mask_decoder_hq.py",
"chars": 9783,
"preview": "# Copyright (c) Meta Platforms, Inc. and affiliates.\n# Modified by HQ-SAM team\n# All rights reserved.\n\n# This source cod"
},
{
"path": "data_generation/Grounded-Segment-Anything/segment_anything/segment_anything/modeling/prompt_encoder.py",
"chars": 8594,
"preview": "# Copyright (c) Meta Platforms, Inc. and affiliates.\n# All rights reserved.\n\n# This source code is licensed under the li"
},
{
"path": "data_generation/Grounded-Segment-Anything/segment_anything/segment_anything/modeling/sam.py",
"chars": 7225,
"preview": "# Copyright (c) Meta Platforms, Inc. and affiliates.\n# All rights reserved.\n\n# This source code is licensed under the li"
},
{
"path": "data_generation/Grounded-Segment-Anything/segment_anything/segment_anything/modeling/transformer.py",
"chars": 8396,
"preview": "# Copyright (c) Meta Platforms, Inc. and affiliates.\n# All rights reserved.\n\n# This source code is licensed under the li"
},
{
"path": "data_generation/Grounded-Segment-Anything/segment_anything/segment_anything/predictor.py",
"chars": 11934,
"preview": "# Copyright (c) Meta Platforms, Inc. and affiliates.\n# All rights reserved.\n\n# This source code is licensed under the li"
},
{
"path": "data_generation/Grounded-Segment-Anything/segment_anything/segment_anything/utils/__init__.py",
"chars": 197,
"preview": "# Copyright (c) Meta Platforms, Inc. and affiliates.\n# All rights reserved.\n\n# This source code is licensed under the li"
},
{
"path": "data_generation/Grounded-Segment-Anything/segment_anything/segment_anything/utils/amg.py",
"chars": 12711,
"preview": "# Copyright (c) Meta Platforms, Inc. and affiliates.\n# All rights reserved.\n\n# This source code is licensed under the li"
},
{
"path": "data_generation/Grounded-Segment-Anything/segment_anything/segment_anything/utils/onnx.py",
"chars": 5790,
"preview": "# Copyright (c) Meta Platforms, Inc. and affiliates.\n# All rights reserved.\n\n# This source code is licensed under the li"
},
{
"path": "data_generation/Grounded-Segment-Anything/segment_anything/segment_anything/utils/transforms.py",
"chars": 3968,
"preview": "# Copyright (c) Meta Platforms, Inc. and affiliates.\n# All rights reserved.\n\n# This source code is licensed under the li"
},
{
"path": "data_generation/Grounded-Segment-Anything/segment_anything/setup.cfg",
"chars": 371,
"preview": "[isort]\nline_length=100\nmulti_line_output=3\ninclude_trailing_comma=True\nknown_standard_library=numpy,setuptools\nskip_glo"
},
{
"path": "data_generation/Grounded-Segment-Anything/segment_anything/setup.py",
"chars": 541,
"preview": "# Copyright (c) Meta Platforms, Inc. and affiliates.\n# All rights reserved.\n\n# This source code is licensed under the li"
},
{
"path": "data_generation/Grounded-Segment-Anything/voxelnext_3d_box/README.md",
"chars": 4097,
"preview": "# 3D-Box via Segment Anything\n\nWe extend [Segment Anything](https://github.com/facebookresearch/segment-anything) to 3D "
},
{
"path": "data_generation/Grounded-Segment-Anything/voxelnext_3d_box/__init__.py",
"chars": 0,
"preview": ""
},
{
"path": "data_generation/Grounded-Segment-Anything/voxelnext_3d_box/config.yaml",
"chars": 1545,
"preview": "SAM_TYPE: \"vit_h\"\nSAM_CHECKPOINT: \"sam_vit_h_4b8939.pth\"\n\nPOINT_CLOUD_RANGE: [-51.2, -51.2, -5.0, 51.2, 51.2, 3.0]\nUSED_"
},
{
"path": "data_generation/Grounded-Segment-Anything/voxelnext_3d_box/model.py",
"chars": 6391,
"preview": "import numpy as np\nimport torch\nimport torch.nn as nn\nfrom .models.data_processor import DataProcessor\nfrom .models.mean"
},
{
"path": "data_generation/Grounded-Segment-Anything/voxelnext_3d_box/models/__init__.py",
"chars": 0,
"preview": ""
},
{
"path": "data_generation/Grounded-Segment-Anything/voxelnext_3d_box/models/data_processor.py",
"chars": 8514,
"preview": "from functools import partial\n\nimport numpy as np\n\ntv = None\ntry:\n import cumm.tensorview as tv\nexcept:\n pass\n\n\nde"
},
{
"path": "data_generation/Grounded-Segment-Anything/voxelnext_3d_box/models/mean_vfe.py",
"chars": 827,
"preview": "import torch\nimport torch.nn as nn\n\nclass MeanVFE(nn.Module):\n def __init__(self):\n super().__init__()\n\n de"
},
{
"path": "data_generation/Grounded-Segment-Anything/voxelnext_3d_box/models/spconv_backbone_voxelnext.py",
"chars": 12210,
"preview": "from functools import partial\nimport torch\nimport torch.nn as nn\n\nimport spconv.pytorch as spconv\nfrom spconv.core impor"
},
{
"path": "data_generation/Grounded-Segment-Anything/voxelnext_3d_box/models/voxelnext_head.py",
"chars": 7275,
"preview": "import numpy as np\nimport torch\nimport torch.nn as nn\nfrom voxelnext_3d_box.utils import centernet_utils\nimport spconv.p"
},
{
"path": "data_generation/Grounded-Segment-Anything/voxelnext_3d_box/requirements.txt",
"chars": 93,
"preview": "numpy\ntorch\ntorchvision\neasydict\npyyaml\nopencv-python\npycocotools\nmatplotlib\nonnxruntime\nonnx"
},
{
"path": "data_generation/Grounded-Segment-Anything/voxelnext_3d_box/utils/centernet_utils.py",
"chars": 4915,
"preview": "# This file is modified from https://github.com/tianweiy/CenterPoint\n\nimport torch\n\n\ndef _topk_1d(scores, batch_size, ba"
},
{
"path": "data_generation/Grounded-Segment-Anything/voxelnext_3d_box/utils/config.py",
"chars": 960,
"preview": "import yaml\nfrom easydict import EasyDict\n\ndef merge_new_config(config, new_config):\n if '_BASE_CONFIG_' in new_confi"
},
{
"path": "data_generation/Grounded-Segment-Anything/voxelnext_3d_box/utils/image_projection.py",
"chars": 4465,
"preview": "import torch\nimport numpy as np\nimport cv2\n\ndef get_data_info(info, cam_type):\n\n cam_info = info[cam_type]\n\n lidar"
},
{
"path": "data_generation/data_generation.py",
"chars": 51387,
"preview": "\nimport base64\n\nimport io\nimport multiprocessing\nimport os\nimport random\nimport traceback\nfrom argparse import ArgumentP"
},
{
"path": "data_generation/ldm/data/__init__.py",
"chars": 0,
"preview": ""
},
{
"path": "data_generation/ldm/data/base.py",
"chars": 693,
"preview": "from abc import abstractmethod\nfrom torch.utils.data import Dataset, ConcatDataset, ChainDataset, IterableDataset\n\n\nclas"
},
{
"path": "data_generation/ldm/data/imagenet.py",
"chars": 15497,
"preview": "import os, yaml, pickle, shutil, tarfile, glob\nimport cv2\nimport albumentations\nimport PIL\nimport numpy as np\nimport tor"
},
{
"path": "data_generation/ldm/data/lsun.py",
"chars": 3274,
"preview": "import os\nimport numpy as np\nimport PIL\nfrom PIL import Image\nfrom torch.utils.data import Dataset\nfrom torchvision impo"
},
{
"path": "data_generation/ldm/lr_scheduler.py",
"chars": 3882,
"preview": "import numpy as np\n\n\nclass LambdaWarmUpCosineScheduler:\n \"\"\"\n note: use with a base_lr of 1.0\n \"\"\"\n def __in"
},
{
"path": "data_generation/ldm/models/autoencoder.py",
"chars": 17619,
"preview": "import torch\nimport pytorch_lightning as pl\nimport torch.nn.functional as F\nfrom contextlib import contextmanager\n\nfrom "
},
{
"path": "data_generation/ldm/models/diffusion/__init__.py",
"chars": 0,
"preview": ""
},
{
"path": "data_generation/ldm/models/diffusion/classifier.py",
"chars": 10276,
"preview": "import os\nimport torch\nimport pytorch_lightning as pl\nfrom omegaconf import OmegaConf\nfrom torch.nn import functional as"
},
{
"path": "data_generation/ldm/models/diffusion/ddim.py",
"chars": 12797,
"preview": "\"\"\"SAMPLING ONLY.\"\"\"\n\nimport torch\nimport numpy as np\nfrom tqdm import tqdm\nfrom functools import partial\n\nfrom ldm.modu"
},
{
"path": "data_generation/ldm/models/diffusion/ddpm.py",
"chars": 67425,
"preview": "\"\"\"\nwild mixture of\nhttps://github.com/lucidrains/denoising-diffusion-pytorch/blob/7706bdfc6f527f58d33f84b7b522e61e6e316"
},
{
"path": "data_generation/ldm/models/diffusion/dpm_solver/__init__.py",
"chars": 37,
"preview": "from .sampler import DPMSolverSampler"
},
{
"path": "data_generation/ldm/models/diffusion/dpm_solver/dpm_solver.py",
"chars": 64057,
"preview": "import torch\nimport torch.nn.functional as F\nimport math\n\n\nclass NoiseScheduleVP:\n def __init__(\n self,\n "
},
{
"path": "data_generation/ldm/models/diffusion/dpm_solver/sampler.py",
"chars": 2908,
"preview": "\"\"\"SAMPLING ONLY.\"\"\"\n\nimport torch\n\nfrom .dpm_solver import NoiseScheduleVP, model_wrapper, DPM_Solver\n\n\nclass DPMSolver"
},
{
"path": "data_generation/ldm/models/diffusion/plms.py",
"chars": 12450,
"preview": "\"\"\"SAMPLING ONLY.\"\"\"\n\nimport torch\nimport numpy as np\nfrom tqdm import tqdm\nfrom functools import partial\n\nfrom ldm.modu"
},
{
"path": "data_generation/ldm/modules/attention.py",
"chars": 8531,
"preview": "from inspect import isfunction\nimport math\nimport torch\nimport torch.nn.functional as F\nfrom torch import nn, einsum\nfro"
},
{
"path": "data_generation/ldm/modules/diffusionmodules/__init__.py",
"chars": 0,
"preview": ""
},
{
"path": "data_generation/ldm/modules/diffusionmodules/model.py",
"chars": 33409,
"preview": "# pytorch_diffusion + derived encoder decoder\nimport math\nimport torch\nimport torch.nn as nn\nimport numpy as np\nfrom ein"
},
{
"path": "data_generation/ldm/modules/diffusionmodules/openaimodel.py",
"chars": 34953,
"preview": "from abc import abstractmethod\nfrom functools import partial\nimport math\nfrom typing import Iterable\n\nimport numpy as np"
},
{
"path": "data_generation/ldm/modules/diffusionmodules/util.py",
"chars": 9561,
"preview": "# adopted from\n# https://github.com/openai/improved-diffusion/blob/main/improved_diffusion/gaussian_diffusion.py\n# and\n#"
},
{
"path": "data_generation/ldm/modules/distributions/__init__.py",
"chars": 0,
"preview": ""
},
{
"path": "data_generation/ldm/modules/distributions/distributions.py",
"chars": 2970,
"preview": "import torch\nimport numpy as np\n\n\nclass AbstractDistribution:\n def sample(self):\n raise NotImplementedError()\n"
},
{
"path": "data_generation/ldm/modules/ema.py",
"chars": 2982,
"preview": "import torch\nfrom torch import nn\n\n\nclass LitEma(nn.Module):\n def __init__(self, model, decay=0.9999, use_num_upates="
},
{
"path": "data_generation/ldm/modules/encoders/__init__.py",
"chars": 0,
"preview": ""
},
{
"path": "data_generation/ldm/modules/encoders/modules.py",
"chars": 8171,
"preview": "import torch\nimport torch.nn as nn\nfrom functools import partial\nimport clip\nfrom einops import rearrange, repeat\nfrom t"
},
{
"path": "data_generation/ldm/modules/image_degradation/__init__.py",
"chars": 208,
"preview": "from ldm.modules.image_degradation.bsrgan import degradation_bsrgan_variant as degradation_fn_bsr\nfrom ldm.modules.image"
},
{
"path": "data_generation/ldm/modules/image_degradation/bsrgan.py",
"chars": 25198,
"preview": "# -*- coding: utf-8 -*-\n\"\"\"\n# --------------------------------------------\n# Super-Resolution\n# ------------------------"
},
{
"path": "data_generation/ldm/modules/image_degradation/bsrgan_light.py",
"chars": 22238,
"preview": "# -*- coding: utf-8 -*-\nimport numpy as np\nimport cv2\nimport torch\n\nfrom functools import partial\nimport random\nfrom sci"
},
{
"path": "data_generation/ldm/modules/image_degradation/utils_image.py",
"chars": 29022,
"preview": "import os\nimport math\nimport random\nimport numpy as np\nimport torch\nimport cv2\nfrom torchvision.utils import make_grid\nf"
},
{
"path": "data_generation/ldm/modules/losses/__init__.py",
"chars": 68,
"preview": "from ldm.modules.losses.contperceptual import LPIPSWithDiscriminator"
},
{
"path": "data_generation/ldm/modules/losses/contperceptual.py",
"chars": 5581,
"preview": "import torch\nimport torch.nn as nn\n\nfrom taming.modules.losses.vqperceptual import * # TODO: taming dependency yes/no?\n"
},
{
"path": "data_generation/ldm/modules/losses/vqperceptual.py",
"chars": 7941,
"preview": "import torch\nfrom torch import nn\nimport torch.nn.functional as F\nfrom einops import repeat\n\nfrom taming.modules.discrim"
},
{
"path": "data_generation/ldm/modules/x_transformer.py",
"chars": 20168,
"preview": "\"\"\"shout-out to https://github.com/lucidrains/x-transformers/tree/main/x_transformers\"\"\"\nimport torch\nfrom torch import "
},
{
"path": "data_generation/ldm/util.py",
"chars": 5857,
"preview": "import importlib\n\nimport torch\nimport numpy as np\nfrom collections import abc\nfrom einops import rearrange\nfrom functool"
},
{
"path": "data_generation/metrics/clip_similarity.py",
"chars": 3882,
"preview": "from __future__ import annotations\n\nimport clip\nimport torch\nimport torch.nn as nn\nimport torch.nn.functional as F\nfrom "
},
{
"path": "data_generation/metrics/compute_metrics.py",
"chars": 8188,
"preview": "from __future__ import annotations\n\nimport math\nimport random\nimport sys\nfrom argparse import ArgumentParser\n\nimport ein"
}
]
// ... and 1398 more files (download for full content)
About this extraction
This page contains the full source code of the HaozheZhao/UltraEdit GitHub repository, extracted and formatted as plain text for AI agents and large language models (LLMs). The extraction includes 1598 files (42.3 MB), approximately 11.2M tokens, and a symbol index with 14100 extracted functions, classes, methods, constants, and types. Use this with OpenClaw, Claude, ChatGPT, Cursor, Windsurf, or any other AI tool that accepts text input. You can copy the full output to your clipboard or download it as a .txt file.
Extracted by GitExtract — free GitHub repo to text converter for AI. Built by Nikandr Surkov.