以下是实现该算法的代码
```js
function sort(array) {
checkArray(array);
quickSort(array, 0, array.length - 1);
return array;
}
function quickSort(array, left, right) {
if (left < right) {
swap(array, , right)
// 随机取值,然后和末尾交换,这样做比固定取一个位置的复杂度略低
let indexs = part(array, parseInt(Math.random() * (right - left + 1)) + left, right);
quickSort(array, left, indexs[0]);
quickSort(array, indexs[1] + 1, right);
}
}
function part(array, left, right) {
let less = left - 1;
let more = right;
while (left < more) {
if (array[left] < array[right]) {
// 当前值比基准值小,`less` 和 `left` 都加一
++less;
++left;
} else if (array[left] > array[right]) {
// 当前值比基准值大,将当前值和右边的值交换
// 并且不改变 `left`,因为当前换过来的值还没有判断过大小
swap(array, --more, left);
} else {
// 和基准值相同,只移动下标
left++;
}
}
// 将基准值和比基准值大的第一个值交换位置
// 这样数组就变成 `[比基准值小, 基准值, 比基准值大]`
swap(array, right, more);
return [less, more];
}
```
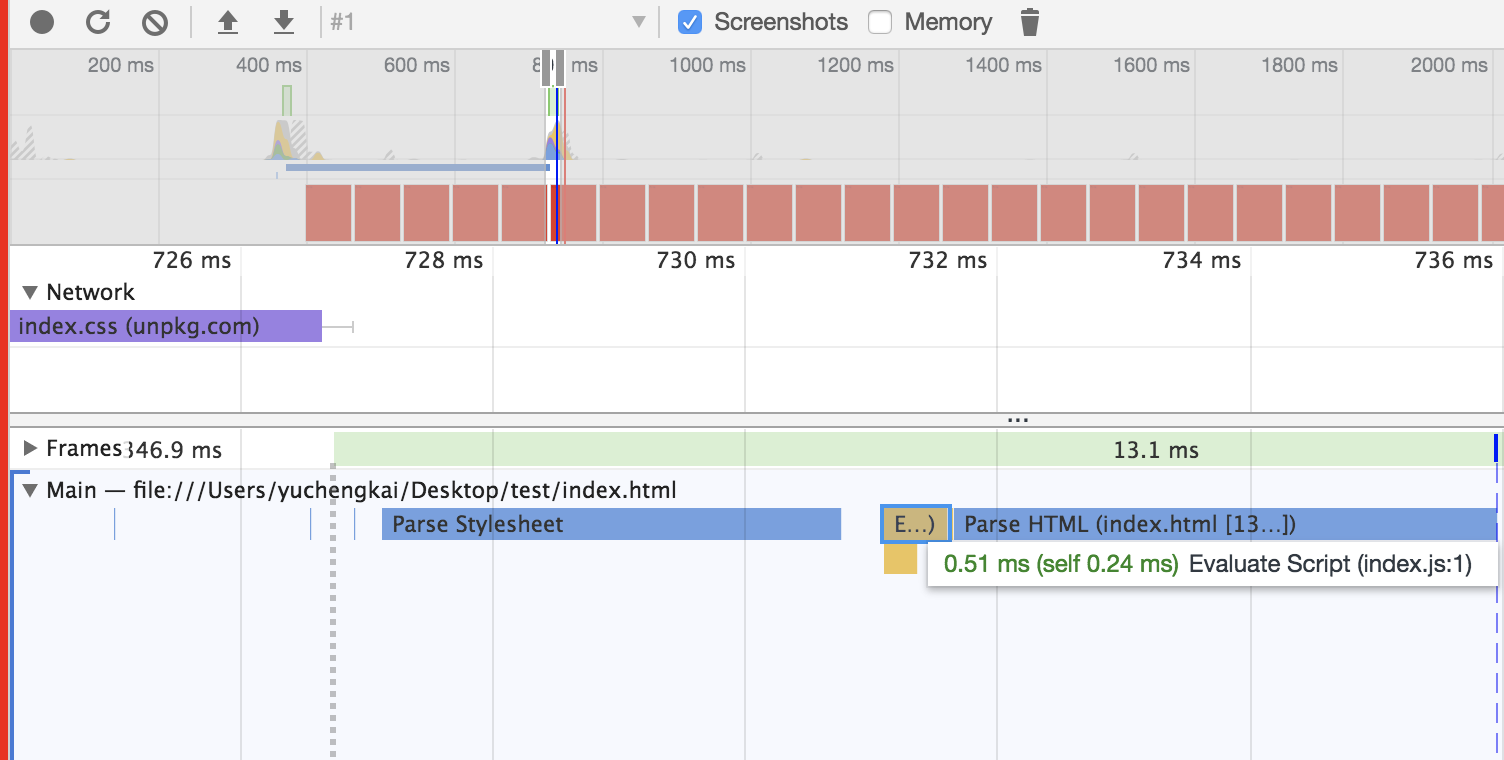
该算法的复杂度和归并排序是相同的,但是额外空间复杂度比归并排序少,只需 O(logN),并且相比归并排序来说,所需的常数时间也更少。
### 面试题
**Sort Colors**:该题目来自 [LeetCode](https://leetcode.com/problems/sort-colors/description/),题目需要我们将 `[2,0,2,1,1,0]` 排序成 `[0,0,1,1,2,2]` ,这个问题就可以使用三路快排的思想。
以下是代码实现
```js
var sortColors = function(nums) {
let left = -1;
let right = nums.length;
let i = 0;
// 下标如果遇到 right,说明已经排序完成
while (i < right) {
if (nums[i] == 0) {
swap(nums, i++, ++left);
} else if (nums[i] == 1) {
i++;
} else {
swap(nums, i, --right);
}
}
};
```
**Kth Largest Element in an Array**:该题目来自 [LeetCode](https://leetcode.com/problems/kth-largest-element-in-an-array/description/),题目需要找出数组中第 K 大的元素,这问题也可以使用快排的思路。并且因为是找出第 K 大元素,所以在分离数组的过程中,可以找出需要的元素在哪边,然后只需要排序相应的一边数组就好。
以下是代码实现
```js
var findKthLargest = function(nums, k) {
let l = 0
let r = nums.length - 1
// 得出第 K 大元素的索引位置
k = nums.length - k
while (l < r) {
// 分离数组后获得比基准树大的第一个元素索引
let index = part(nums, l, r)
// 判断该索引和 k 的大小
if (index < k) {
l = index + 1
} else if (index > k) {
r = index - 1
} else {
break
}
}
return nums[k]
};
function part(array, left, right) {
let less = left - 1;
let more = right;
while (left < more) {
if (array[left] < array[right]) {
++less;
++left;
} else if (array[left] > array[right]) {
swap(array, --more, left);
} else {
left++;
}
}
swap(array, right, more);
return more;
}
```
## 堆排序
堆排序利用了二叉堆的特性来做,二叉堆通常用数组表示,并且二叉堆是一颗完全二叉树(所有叶节点(最底层的节点)都是从左往右顺序排序,并且其他层的节点都是满的)。二叉堆又分为大根堆与小根堆。
- 大根堆是某个节点的所有子节点的值都比他小
- 小根堆是某个节点的所有子节点的值都比他大
堆排序的原理就是组成一个大根堆或者小根堆。以小根堆为例,某个节点的左边子节点索引是 `i * 2 + 1`,右边是 `i * 2 + 2`,父节点是 `(i - 1) /2`。
1. 首先遍历数组,判断该节点的父节点是否比他小,如果小就交换位置并继续判断,直到他的父节点比他大
2. 重新以上操作 1,直到数组首位是最大值
3. 然后将首位和末尾交换位置并将数组长度减一,表示数组末尾已是最大值,不需要再比较大小
4. 对比左右节点哪个大,然后记住大的节点的索引并且和父节点对比大小,如果子节点大就交换位置
5. 重复以上操作 3 - 4 直到整个数组都是大根堆。
以下是实现该算法的代码
```js
function heap(array) {
checkArray(array);
// 将最大值交换到首位
for (let i = 0; i < array.length; i++) {
heapInsert(array, i);
}
let size = array.length;
// 交换首位和末尾
swap(array, 0, --size);
while (size > 0) {
heapify(array, 0, size);
swap(array, 0, --size);
}
return array;
}
function heapInsert(array, index) {
// 如果当前节点比父节点大,就交换
while (array[index] > array[parseInt((index - 1) / 2)]) {
swap(array, index, parseInt((index - 1) / 2));
// 将索引变成父节点
index = parseInt((index - 1) / 2);
}
}
function heapify(array, index, size) {
let left = index * 2 + 1;
while (left < size) {
// 判断左右节点大小
let largest =
left + 1 < size && array[left] < array[left + 1] ? left + 1 : left;
// 判断子节点和父节点大小
largest = array[index] < array[largest] ? largest : index;
if (largest === index) break;
swap(array, index, largest);
index = largest;
left = index * 2 + 1;
}
}
```
以上代码实现了小根堆,如果需要实现大根堆,只需要把节点对比反一下就好。
该算法的复杂度是 O(logN)
## 系统自带排序实现
每个语言的排序内部实现都是不同的。
对于 JS 来说,数组长度大于 10 会采用快排,否则使用插入排序 [源码实现](https://github.com/v8/v8/blob/ad82a40509c5b5b4680d4299c8f08d6c6d31af3c/src/js/array.js#L760:7) 。选择插入排序是因为虽然时间复杂度很差,但是在数据量很小的情况下和 `O(N * logN) `相差无几,然而插入排序需要的常数时间很小,所以相对别的排序来说更快。
对于 Java 来说,还会考虑内部的元素的类型。对于存储对象的数组来说,会采用稳定性好的算法。稳定性的意思就是对于相同值来说,相对顺序不能改变。
# 链表
## 反转单向链表
该题目来自 [LeetCode](https://leetcode.com/problems/reverse-linked-list/description/),题目需要将一个单向链表反转。思路很简单,使用三个变量分别表示当前节点和当前节点的前后节点,虽然这题很简单,但是却是一道面试常考题
以下是实现该算法的代码
```js
var reverseList = function(head) {
// 判断下变量边界问题
if (!head || !head.next) return head
// 初始设置为空,因为第一个节点反转后就是尾部,尾部节点指向 null
let pre = null
let current = head
let next
// 判断当前节点是否为空
// 不为空就先获取当前节点的下一节点
// 然后把当前节点的 next 设为上一个节点
// 然后把 current 设为下一个节点,pre 设为当前节点
while(current) {
next = current.next
current.next = pre
pre = current
current = next
}
return pre
};
```
# 树
## 二叉树的先序,中序,后序遍历
先序遍历表示先访问根节点,然后访问左节点,最后访问右节点。
中序遍历表示先访问左节点,然后访问根节点,最后访问右节点。
后序遍历表示先访问左节点,然后访问右节点,最后访问根节点。
### 递归实现
递归实现相当简单,代码如下
```js
function TreeNode(val) {
this.val = val;
this.left = this.right = null;
}
var traversal = function(root) {
if (root) {
// 先序
console.log(root);
traversal(root.left);
// 中序
// console.log(root);
traversal(root.right);
// 后序
// console.log(root);
}
};
```
对于递归的实现来说,只需要理解每个节点都会被访问三次就明白为什么这样实现了。
### 非递归实现
非递归实现使用了栈的结构,通过栈的先进后出模拟递归实现。
以下是先序遍历代码实现
```js
function pre(root) {
if (root) {
let stack = [];
// 先将根节点 push
stack.push(root);
// 判断栈中是否为空
while (stack.length > 0) {
// 弹出栈顶元素
root = stack.pop();
console.log(root);
// 因为先序遍历是先左后右,栈是先进后出结构
// 所以先 push 右边再 push 左边
if (root.right) {
stack.push(root.right);
}
if (root.left) {
stack.push(root.left);
}
}
}
}
```
以下是中序遍历代码实现
```js
function mid(root) {
if (root) {
let stack = [];
// 中序遍历是先左再根最后右
// 所以首先应该先把最左边节点遍历到底依次 push 进栈
// 当左边没有节点时,就打印栈顶元素,然后寻找右节点
// 对于最左边的叶节点来说,可以把它看成是两个 null 节点的父节点
// 左边打印不出东西就把父节点拿出来打印,然后再看右节点
while (stack.length > 0 || root) {
if (root) {
stack.push(root);
root = root.left;
} else {
root = stack.pop();
console.log(root);
root = root.right;
}
}
}
}
```
以下是后序遍历代码实现,该代码使用了两个栈来实现遍历,相比一个栈的遍历来说要容易理解很多
```js
function pos(root) {
if (root) {
let stack1 = [];
let stack2 = [];
// 后序遍历是先左再右最后根
// 所以对于一个栈来说,应该先 push 根节点
// 然后 push 右节点,最后 push 左节点
stack1.push(root);
while (stack1.length > 0) {
root = stack1.pop();
stack2.push(root);
if (root.left) {
stack1.push(root.left);
}
if (root.right) {
stack1.push(root.right);
}
}
while (stack2.length > 0) {
console.log(s2.pop());
}
}
}
```
## 中序遍历的前驱后继节点
实现这个算法的前提是节点有一个 `parent` 的指针指向父节点,根节点指向 `null` 。
如图所示,该树的中序遍历结果是 `4, 2, 5, 1, 6, 3, 7`
### 前驱节点
对于节点 `2` 来说,他的前驱节点就是 `4` ,按照中序遍历原则,可以得出以下结论
1. 如果选取的节点的左节点不为空,就找该左节点最右的节点。对于节点 `1` 来说,他有左节点 `2` ,那么节点 `2` 的最右节点就是 `5`
2. 如果左节点为空,且目标节点是父节点的右节点,那么前驱节点为父节点。对于节点 `5` 来说,没有左节点,且是节点 `2` 的右节点,所以节点 `2` 是前驱节点
3. 如果左节点为空,且目标节点是父节点的左节点,向上寻找到第一个是父节点的右节点的节点。对于节点 `6` 来说,没有左节点,且是节点 `3` 的左节点,所以向上寻找到节点 `1` ,发现节点 `3` 是节点 `1` 的右节点,所以节点 `1` 是节点 `6` 的前驱节点
以下是算法实现
```js
function predecessor(node) {
if (!node) return
// 结论 1
if (node.left) {
return getRight(node.left)
} else {
let parent = node.parent
// 结论 2 3 的判断
while(parent && parent.right === node) {
node = parent
parent = node.parent
}
return parent
}
}
function getRight(node) {
if (!node) return
node = node.right
while(node) node = node.right
return node
}
```
### 后继节点
对于节点 `2` 来说,他的后继节点就是 `5` ,按照中序遍历原则,可以得出以下结论
1. 如果有右节点,就找到该右节点的最左节点。对于节点 `1` 来说,他有右节点 `3` ,那么节点 `3` 的最左节点就是 `6`
2. 如果没有右节点,就向上遍历直到找到一个节点是父节点的左节点。对于节点 `5` 来说,没有右节点,就向上寻找到节点 `2` ,该节点是父节点 `1` 的左节点,所以节点 `1` 是后继节点
以下是算法实现
```js
function successor(node) {
if (!node) return
// 结论 1
if (node.right) {
return getLeft(node.right)
} else {
// 结论 2
let parent = node.parent
// 判断 parent 为空
while(parent && parent.left === node) {
node = parent
parent = node.parent
}
return parent
}
}
function getLeft(node) {
if (!node) return
node = node.left
while(node) node = node.left
return node
}
```
## 树的深度
**树的最大深度**:该题目来自 [Leetcode](https://leetcode.com/problems/maximum-depth-of-binary-tree/description/),题目需要求出一颗二叉树的最大深度
以下是算法实现
```js
var maxDepth = function(root) {
if (!root) return 0
return Math.max(maxDepth(root.left), maxDepth(root.right)) + 1
};
```
对于该递归函数可以这样理解:一旦没有找到节点就会返回 0,每弹出一次递归函数就会加一,树有三层就会得到3。
# 动态规划
动态规划背后的基本思想非常简单。就是将一个问题拆分为子问题,一般来说这些子问题都是非常相似的,那么我们可以通过只解决一次每个子问题来达到减少计算量的目的。
一旦得出每个子问题的解,就存储该结果以便下次使用。
## 斐波那契数列
斐波那契数列就是从 0 和 1 开始,后面的数都是前两个数之和
0,1,1,2,3,5,8,13,21,34,55,89....
那么显然易见,我们可以通过递归的方式来完成求解斐波那契数列
```js
function fib(n) {
if (n < 2 && n >= 0) return n
return fib(n - 1) + fib(n - 2)
}
fib(10)
```
以上代码已经可以完美的解决问题。但是以上解法却存在很严重的性能问题,当 n 越大的时候,需要的时间是指数增长的,这时候就可以通过动态规划来解决这个问题。
动态规划的本质其实就是两点
1. 自底向上分解子问题
2. 通过变量存储已经计算过的解
根据上面两点,我们的斐波那契数列的动态规划思路也就出来了
1. 斐波那契数列从 0 和 1 开始,那么这就是这个子问题的最底层
2. 通过数组来存储每一位所对应的斐波那契数列的值
```js
function fib(n) {
let array = new Array(n + 1).fill(null)
array[0] = 0
array[1] = 1
for (let i = 2; i <= n; i++) {
array[i] = array[i - 1] + array[i - 2]
}
return array[n]
}
fib(10)
```
## 0 - 1背包问题
该问题可以描述为:给定一组物品,每种物品都有自己的重量和价格,在限定的总重量内,我们如何选择,才能使得物品的总价格最高。每个问题只能放入至多一次。
假设我们有以下物品
| 物品 ID / 重量 | 价值 |
| :------------: | :--: |
| 1 | 3 |
| 2 | 7 |
| 3 | 12 |
对于一个总容量为 5 的背包来说,我们可以放入重量 2 和 3 的物品来达到背包内的物品总价值最高。
对于这个问题来说,子问题就两个,分别是放物品和不放物品,可以通过以下表格来理解子问题
| 物品 ID / 剩余容量 | 0 | 1 | 2 | 3 | 4 | 5 |
| :----------------: | :--: | :--: | :--: | :--: | :--: | :--: |
| 1 | 0 | 3 | 3 | 3 | 3 | 3 |
| 2 | 0 | 3 | 7 | 10 | 10 | 10 |
| 3 | 0 | 3 | 7 | 12 | 15 | 19 |
直接来分析能放三种物品的情况,也就是最后一行
- 当容量少于 3 时,只取上一行对应的数据,因为当前容量不能容纳物品 3
- 当容量 为 3 时,考虑两种情况,分别为放入物品 3 和不放物品 3
- 不放物品 3 的情况下,总价值为 10
- 放入物品 3 的情况下,总价值为 12,所以应该放入物品 3
- 当容量 为 4 时,考虑两种情况,分别为放入物品 3 和不放物品 3
- 不放物品 3 的情况下,总价值为 10
- 放入物品 3 的情况下,和放入物品 1 的价值相加,得出总价值为 15,所以应该放入物品 3
- 当容量 为 5 时,考虑两种情况,分别为放入物品 3 和不放物品 3
- 不放物品 3 的情况下,总价值为 10
- 放入物品 3 的情况下,和放入物品 2 的价值相加,得出总价值为 19,所以应该放入物品 3
以下代码对照上表更容易理解
```js
/**
* @param {*} w 物品重量
* @param {*} v 物品价值
* @param {*} C 总容量
* @returns
*/
function knapsack(w, v, C) {
let length = w.length
if (length === 0) return 0
// 对照表格,生成的二维数组,第一维代表物品,第二维代表背包剩余容量
// 第二维中的元素代表背包物品总价值
let array = new Array(length).fill(new Array(C + 1).fill(null))
// 完成底部子问题的解
for (let i = 0; i <= C; i++) {
// 对照表格第一行, array[0] 代表物品 1
// i 代表剩余总容量
// 当剩余总容量大于物品 1 的重量时,记录下背包物品总价值,否则价值为 0
array[0][i] = i >= w[0] ? v[0] : 0
}
// 自底向上开始解决子问题,从物品 2 开始
for (let i = 1; i < length; i++) {
for (let j = 0; j <= C; j++) {
// 这里求解子问题,分别为不放当前物品和放当前物品
// 先求不放当前物品的背包总价值,这里的值也就是对应表格中上一行对应的值
array[i][j] = array[i - 1][j]
// 判断当前剩余容量是否可以放入当前物品
if (j >= w[i]) {
// 可以放入的话,就比大小
// 放入当前物品和不放入当前物品,哪个背包总价值大
array[i][j] = Math.max(array[i][j], v[i] + array[i - 1][j - w[i]])
}
}
}
return array[length - 1][C]
}
```
## 最长递增子序列
最长递增子序列意思是在一组数字中,找出最长一串递增的数字,比如
0, 3, 4, 17, 2, 8, 6, 10
对于以上这串数字来说,最长递增子序列就是 0, 3, 4, 8, 10,可以通过以下表格更清晰的理解
| 数字 | 0 | 3 | 4 | 17 | 2 | 8 | 6 | 10 |
| :--: | :--: | :--: | :--: | :--: | :--: | :--: | :--: | :--: |
| 长度 | 1 | 2 | 3 | 4 | 2 | 4 | 4 | 5 |
通过以上表格可以很清晰的发现一个规律,找出刚好比当前数字小的数,并且在小的数组成的长度基础上加一。
这个问题的动态思路解法很简单,直接上代码
```js
function lis(n) {
if (n.length === 0) return 0
// 创建一个和参数相同大小的数组,并填充值为 1
let array = new Array(n.length).fill(1)
// 从索引 1 开始遍历,因为数组已经所有都填充为 1 了
for (let i = 1; i < n.length; i++) {
// 从索引 0 遍历到 i
// 判断索引 i 上的值是否大于之前的值
for (let j = 0; j < i; j++) {
if (n[i] > n[j]) {
array[i] = Math.max(array[i], 1 + array[j])
}
}
}
let res = 1
for (let i = 0; i < array.length; i++) {
res = Math.max(res, array[i])
}
return res
}
```
# 字符串相关
在字符串相关算法中,Trie 树可以解决解决很多问题,同时具备良好的空间和时间复杂度,比如以下问题
- 词频统计
- 前缀匹配
如果你对于 Trie 树还不怎么了解,可以前往 [这里](../DataStruct/dataStruct-zh.md#trie) 阅读
================================================
FILE: Algorithm/algorithm-en.md
================================================
# Time Complexity
The worst time complexity is often used to measure the quality of an algorithm.
The constant time O(1) means that this operation has nothing to do with the amount of data. It is a fixed-time operation, such as arithmetic operation.
For an algorithm, it is possible to calculate the operation numbers of `aN + 1`, N represents the amount of data. Then the time complexity of the algorithm is O(N). Because when we calculate the time complexity, the amount of data is usually very large, when low-order terms and constant terms are negligible.
Of course, it may happen that both algorithms are O(N) time complexity, then comparing the low-order terms and the constant terms of the two algorithms.
# Bit Operation
Bit operation is useful in algorithms and can be much faster than arithmetic operations.
Before learning bit operation, you should know how decimal converts to binary and how binary turns to decimal. Here is a simple calculation method.
- Decimal `33` can be seen as `32 + 1` and `33` should be six-bit binary (Because 33 is approximately 32, and 32 is the fifth power of 2, so it is six bit), so the decimal `33` is `100001`, as long as it is the power of 2, then it is 1 otherwise it is 0.
- Then binary `100001` is the same, the first is `2^5`, the last is `2^0`, and the sum is 33
## Shift Arithmetic Left <<
```js
10 << 1 // -> 20
```
Shift arithmetic left is to move all the binary to the left, `10` is represented as `1010` in binary, after shifting one bit to the left becomes `10100`, and converted to decimal is 20, so the left shift can be basically regarded as the following formula `a << b => a * (2 ^ b)`.
## Shift Arithmetic Right >>
```js
10 >> 1 // -> 5
```
The bitwise right shift moves all the binary digits to the right and remove the extra left digit. `10` is represented as `1010` in binary, and becomes `101` after shifting one bit to the right, and becomes 5 in decimal value, so the right shift is basically the following formula: `a >> b => a / (2 ^ b)`.
Right shift is very useful, for example, you can calculate the intermediate value in the binary algorithm.
```js
13 >> 1 // -> 6
```
## Bitwise Operation
**Bitwise And**
Each bit is 1, and the result is 1
```js
8 & 7 // -> 0
// 1000 & 0111 -> 0000 -> 0
```
**Bitwise Or**
One of bit is 1, and the result is 1
```js
8 | 7 // -> 15
// 1000 | 0111 -> 1111 -> 15
```
**Bitwise XOR**
Each bit is different, and the result is 1
```js
8 ^ 7 // -> 15
8 ^ 8 // -> 0
// 1000 ^ 0111 -> 1111 -> 15
// 1000 ^ 1000 -> 0000 -> 0
```
From the above code, we can find that the bitwise XOR is the not carry addition.
**Interview Question**:Not using arithmetic operation to get the sum of two numbers
This question can use bitwise XOR, because bitwise XOR is not carry addition, `8 ^ 8 = 0`, but if carry it will be 16 , so we only need to XOR the two numbers and then carry. So, if both bit is 1, and there should be a carry 1 on the left, so the following formula can be obtained `a + b = a ^ b + (a & b) << 1` , then simulate addition by recursive.
```js
function sum(a, b) {
if (a == 0) return b
if (b == 0) return a
let newA = a ^ b
let newB = (a & b) << 1
return sum(newA, newB)
}
```
# Sort
The following two functions will be used in sorting commonly, so I don't write them one by one.
```js
function checkArray(array) {
if (!array || array.length <= 2) return
}
function swap(array, left, right) {
let rightValue = array[right]
array[right] = array[left]
array[left] = rightValue
}
```
## Bubble Sort
The principle of bubble sort is as follows, starting with the first element, and comparing the current element with the next index element. If the current element is larger, then swap them and repeat until the last element is compared, then the last element at this time is the largest number in the array. The above operation is repeated in the next round, but the last element is already the maximum number, so there is no need to compare the last element, only the position of `length - 1` is needed.
The following code is implement of the algorithm.
```js
function bubble(array) {
checkArray(array);
for (let i = array.length - 1; i > 0; i--) {
// Traversing from 0 to `length - 1`
for (let j = 0; j < i; j++) {
if (array[j] > array[j + 1]) swap(array, j, j + 1)
}
}
return array;
}
```
The operation numbers of the algorithm is an arithmetic progression `n + (n - 1) + (n - 2) + 1` . After removing the constant part, the time complexity is `O(n * n)`.
## Insert Sort
The principle of insert sort is as follows. The first element is default as the sorted element, taking the next element and comparing it to the current element, swapping them if the current element is larger. Then the first element is the minimum number at this time, so the next operation starts from the third element, and repeats the previous operation.
The following code is implement of the algorithm.
```js
function insertion(array) {
checkArray(array);
for (let i = 1; i < array.length; i++) {
for (let j = i - 1; j >= 0 && array[j] > array[j + 1]; j--)
swap(array, j, j + 1);
}
return array;
}
```
The operation numbers of the algorithm is an arithmetic progression `n + (n - 1) + (n - 2) + 1` . After removing the constant part, the time complexity is `O(n * n)`.
## Select Sort
The principle of select sort is as follows. Traverse the array, set the index of minimum to 0. If the extracted value is smaller than the current minimum, replace the minimum index. After the traversal is completed, the value on the first element and the minimum index are exchanged. After the above operation, the first element is the minimum value in the array, and the next operation starts from index 1 and repeats the previous opration.
The following code is implement of the algorithm.
```js
function selection(array) {
checkArray(array);
for (let i = 0; i < array.length - 1; i++) {
let minIndex = i;
for (let j = i + 1; j < array.length; j++) {
minIndex = array[j] < array[minIndex] ? j : minIndex;
}
swap(array, i, minIndex);
}
return array;
}
```
The operation numbers of the algorithm is an arithmetic progression `n + (n - 1) + (n - 2) + 1` . After removing the constant part, the time complexity is `O(n * n)`.
## Merge Sort
The principle of merge sort is as follows. Divide the array into two parts by recursion until one array contains at most two elements, then sort the array and merge them into a sorted array. Suppose I have a set of array `[3, 1, 2, 8, 9, 7, 6]`, the intermediate index is 3, and the array `[3, 1, 2, 8]` is sorted first. On this left array, continue splitting until the array becomes two elements (if the array length is odd, there will be a array containing only one element). Then sort the array `[3, 1]` and `[2, 8]`, and then sort the array `[1, 3, 2, 8]`, this time the left array is sorted, then sort the right array according to the above method, and finally sort the array `[1, 2, 3, 8]` and `[6, 7, 9]`.
The following code is implement of the algorithm.
```js
function sort(array) {
checkArray(array);
mergeSort(array, 0, array.length - 1);
return array;
}
function mergeSort(array, left, right) {
// The left and right indexes are the same.
// means there is only one element.
if (left === right) return;
// Equivalent to `left + (right - left) / 2`
// More secure than `(left + right) / 2`,
// and the index will not out of bounds
// Bit operations are used because bit operations
// are faster than arithmetic operation
let mid = parseInt(left + ((right - left) >> 1));
mergeSort(array, left, mid);
mergeSort(array, mid + 1, right);
let help = [];
let i = 0;
let p1 = left;
let p2 = mid + 1;
while (p1 <= mid && p2 <= right) {
help[i++] = array[p1] < array[p2] ? array[p1++] : array[p2++];
}
while (p1 <= mid) {
help[i++] = array[p1++];
}
while (p2 <= right) {
help[i++] = array[p2++];
}
for (let i = 0; i < help.length; i++) {
array[left + i] = help[i];
}
return array;
}
```
The above algorithm uses the idea of recursion. The essence of recursion is pushed into stack. Whenever a function is executed recursively, the information of the function (such as parameters, internal variables, the number of rows has executed) is pushed into stack until a termination condition is encountered, then pop stack and continue execute the function. The call trajectory for the above recursive function is as follows.
```js
mergeSort(data, 0, 6) // mid = 3
mergeSort(data, 0, 3) // mid = 1
mergeSort(data, 0, 1) // mid = 0
mergeSort(data, 0, 0) // return to the previous step
mergeSort(data, 1, 1) // return to the previous step
// Sort p1 = 0, p2 = mid + 1 = 1
// Fall back to `mergeSort(data, 0, 3)`
// and perform the next recursion
mergeSort(2, 3) // mid = 2
mergeSort(3, 3) // return to the previous step
// Sort p1 = 2, p2 = mid + 1 = 3
// Fall back to `mergeSort(data, 0, 3)` and execution merge logic
// Sort p1 = 0, p2 = mid + 1 = 2
// Execution completed
// The array on the left is sorted,
// and the right side is also sorted like this
```
The operation numbers of the algorithm can be calculated as follows: recursively twice and each time the amount of data is half of the array, and finally the entire array is iterated once, so the expression `2T(N / 2) + T(N) `( T represent time and N represent data amount). According to the expression, the [formula](https://www.wikiwand.com/en/Master_theorem_(analysis_of_algorithms)) can be applied to get a time complexity of `O(N * logN)`.
## Quick Sort
The principle of quick sort is as follows. Randomly select a value in the array as the reference value, and compare the value with the reference value from left to right.Move the value to the left of the array if it is smaller than the reference value, and the larger one move to the right. The reference value is exchanged with the value which first larger than the reference value after the comparison completed. Then divide the array into two parts through the position of the reference value and continue the recursive operation.
The following code is implement of the algorithm.
```js
function sort(array) {
checkArray(array);
quickSort(array, 0, array.length - 1);
return array;
}
function quickSort(array, left, right) {
if (left < right) {
swap(array, , right)
// Randomly take values and then swap it with the end,
// which is slightly less complex than take a fixed position
let indexs = part(array, parseInt(Math.random() * (right - left + 1)) + left, right);
quickSort(array, left, indexs[0]);
quickSort(array, indexs[1] + 1, right);
}
}
function part(array, left, right) {
let less = left - 1;
let more = right;
while (left < more) {
if (array[left] < array[right]) {
// The current value is smaller than the reference value,
// and both `less` and `left` are added one.
++less;
++left;
} else if (array[left] > array[right]) {
// The current value is larger than the reference value,
// and the current value is exchanged with
// the value on the right.
// And don't change `left`, because the current value
// has not been judged yet.
swap(array, --more, left);
} else {
// Same as the reference value, only move the index
left++;
}
}
// Exchange the reference value with the value
// which is first larger than the reference value.
// Thus the array becomes `[less than the reference value,
// the reference value, larger than the reference value]`.
swap(array, right, more);
return [less, more];
}
```
The time complexity is same as merge sort, but the extra space complexity is less than the merge sort, only `O(logN)` is needed, and the constant time also smaller than the merge sort.
### Interview Question
**Sort Colors**:The topic is from [LeetCode](https://leetcode.com/problems/sort-colors/description/),The problem requires us to sort `[2,0,2,1,1,0]` into `[0,0,1,1,2,2]`, and this problem can use the idea of three-way quicksort.
The following code is implement of the algorithm.
```js
var sortColors = function(nums) {
let left = -1;
let right = nums.length;
let i = 0;
// If the index encounters right,
// it indicates that the sort has been completed.
while (i < right) {
if (nums[i] == 0) {
swap(nums, i++, ++left);
} else if (nums[i] == 1) {
i++;
} else {
swap(nums, i, --right);
}
}
};
```
**Kth Largest Element in an Array**:The topic is from [LeetCode](https://leetcode.com/problems/kth-largest-element-in-an-array/description/),The problem needs to find the Kth largest element in the array. This problem can also use the idea of quicksort. And because it is to find out the Kth element, in the process of separating the array, you can find out which side of the element you need, and then just sort the corresponding side array.
The following code is implement of the algorithm.
```js
var findKthLargest = function(nums, k) {
let l = 0
let r = nums.length - 1
// Get the index of the Kth largest element
k = nums.length - k
while (l < r) {
// After separating the array, get the element
// which first larger than the reference element
let index = part(nums, l, r)
// Compare the index with the k
if (index < k) {
l = index + 1
} else if (index > k) {
r = index - 1
} else {
break
}
}
return nums[k]
};
function part(array, left, right) {
let less = left - 1;
let more = right;
while (left < more) {
if (array[left] < array[right]) {
++less;
++left;
} else if (array[left] > array[right]) {
swap(array, --more, left);
} else {
left++;
}
}
swap(array, right, more);
return more;
}
```
## Heap Sort
Heap sort takes advantage of the characteristics with the binary heap, which is usually represented by an array, and the binary heap is a complete binary tree (all leaf nodes (the lowest node) are sorted from left to right, and others nodes are all full). The binary heap is divided into max-head and min-heap.
- A max-heap is all child nodes value smaller than the node value.
- A min-heap is all child nodes value larger than the node value.
The principle of heap sort is to compose a max-heap or a min-heap. Taking a min-heap as an example, the index of the left child node is `i * 2 + 1`, and the right node is `i * 2 + 2`, and the parent node is `(i - 1) / 2`.
1. First at all traverse the array to determine if the parent node is smaller than current node. If true, swap the position and continue to judge until his parent node is larger than him.
2. Repeat the above operation 1, until the first position of the array is the maximum.
3. Then swap the first and last position and minus 1with the length of the array, indicating that the end of the array is the maximum, it is no need to compare with it.
4. Compare with the left and right nodes, then remember the index of the larger node and compare it with the parent node. If the child node is larger, then swap them.
5. Repeat the above steps 3 - 4 until the whole array is a max-heap.
The following code is implement of the algorithm.
```js
function heap(array) {
checkArray(array);
// Exchange the maximum value to the first position
for (let i = 0; i < array.length; i++) {
heapInsert(array, i);
}
let size = array.length;
// Exchange first and last position
swap(array, 0, --size);
while (size > 0) {
heapify(array, 0, size);
swap(array, 0, --size);
}
return array;
}
function heapInsert(array, index) {
// Exchange them if current node larger than parent node
while (array[index] > array[parseInt((index - 1) / 2)]) {
swap(array, index, parseInt((index - 1) / 2));
// Change the index to the parent node
index = parseInt((index - 1) / 2);
}
}
function heapify(array, index, size) {
let left = index * 2 + 1;
while (left < size) {
// Judge the size of the left and right node
let largest =
left + 1 < size && array[left] < array[left + 1] ? left + 1 : left;
// Judge the size of the child and parent node
largest = array[index] < array[largest] ? largest : index;
if (largest === index) break;
swap(array, index, largest);
index = largest;
left = index * 2 + 1;
}
}
```
The above code implements a min-heap. If you need to implement a max-heap, you only need to reverse the comparison.
The time complexity of the algorithm is `O(logN)`.
## System Comes With Sorting Implementation
The internal implementation of sorting for each language is different.
For JS, it will use quick sort if array length greater than 10, otherwise will use insert sort [Source implementation](https://github.com/v8/v8/blob/ad82a40509c5b5b4680d4299c8f08d6c6d31af3c/src/js/array.js#L760:7) . The insert sort is chosen because although the time complexity is very poor, it is almost the same as `O(N * logN)` when the amount of data is small, but the constant time required for insert sort is small, so it is faster than other sorts.
For Java, the type of elements inside is also considered. For arrays that store objects, a stable algorithm is used. Stability means that the relative order cannot be changed for the same value.
# Linked List
## Reverse Singly Linked List
The topic is from [LeetCode](https://leetcode.com/problems/reverse-linked-list/description/),The problem needs to reverse a singly linked list. The idea is very simple. Use three variables to represent the current node and the previous and next nodes of current node. Although this question is very simple, it is an regular interview question.
The following code is implement of the algorithm.
```js
var reverseList = function(head) {
// Judge the problem of variable boundary
if (!head || !head.next) return head
// The initial setting is empty because the first node is the tail when it is inverted, and the tail node points to null
let pre = null
let current = head
let next
// Judge if the current node is empty
// Get the next node of the current node if it is not empty
// Then set the next node of current to the previous node.
// Then set current to the next node and pre to the current node
while(current) {
next = current.next
current.next = pre
pre = current
current = next
}
return pre
};
```
# Tree
## Preorder, Inorder, Postorder Traversal of Binary Tree
Preorder traversal means that the root node is accessed first, then the left node is accessed, and the right node is accessed last.
Inorder traversal means that the left node is accessed first, then the root node is accessed, and the right node is accessed last.
Postorder traversal means that the left node is accessed first, then the right node is accessed, and the root node is accessed last.
### Recursive Implementation
Recursive implementation is quite simple, the code is as follows.
```js
function TreeNode(val) {
this.val = val;
this.left = this.right = null;
}
var traversal = function(root) {
if (root) {
// Preorder
console.log(root);
traversal(root.left);
// Inorder
// console.log(root);
traversal(root.right);
// Postorder
// console.log(root);
}
};
```
For recursive implementation, you only need to understand that each node will be accessed three times so you will understand why this is done.
### Non-Recursive Implementation
The non-recursive implementation uses the structure of the stack, realize the recursive implementation by implementing the FILO of the stack.
The following code is implementation of the preorder traversal.
```js
function pre(root) {
if (root) {
let stack = [];
// Push the root node first
stack.push(root);
// Determine if the stack is empty
while (stack.length > 0) {
// Pop the top element
root = stack.pop();
console.log(root);
// Because the preorder traversal is first left and then right,
// the stack is a structure of FILO.
// So push the right node and then push the left node.
if (root.right) {
stack.push(root.right);
}
if (root.left) {
stack.push(root.left);
}
}
}
}
```
The following code is implementation of the inorder traversal.
```js
function mid(root) {
if (root) {
let stack = [];
// The inorder traversal is first left, then root and last right node
// So first should traverse the left node and push it to the stack.
// When there is no node on the left,
// the top node is printed and then find the right node.
// For the leftmost leaf node,
// you can think of it as the parent of two null nodes.
// If you can't print anything on the left,
// take the parent node out and print it, then look at the right node.
while (stack.length > 0 || root) {
if (root) {
stack.push(root);
root = root.left;
} else {
root = stack.pop();
console.log(root);
root = root.right;
}
}
}
}
```
The following code is the postorder traversal implementation that uses two stacks to implement traversal, which is easier to understand than a stack traversal.
```js
function pos(root) {
if (root) {
let stack1 = [];
let stack2 = [];
// Postorder traversal is first left, then right and last root node
// So for a stack, you should first push the root node
// Then push the right node, and finally push the left node
stack1.push(root);
while (stack1.length > 0) {
root = stack1.pop();
stack2.push(root);
if (root.left) {
stack1.push(root.left);
}
if (root.right) {
stack1.push(root.right);
}
}
while (stack2.length > 0) {
console.log(s2.pop());
}
}
}
```
## Predecessor and Successor Nodes of the Inorder Traversal
The premise of implementing this algorithm is that the node has a `parent` pointer to the parent node and a root node to `null` .
As shown, the tree's inorder traversal result is `4, 2, 5, 1, 6, 3, 7`
### Predecessor Node
For node `2`, his predecessor node is`4 `. According to the principle of inorder traversal, the following conclusions can be drawn.
1. If the left node of the selected node is not empty, look for the rightmost node of the left node. For node `1`, he has left node `2`, then the rightmost node of node `2` is `5`
2. If the left node is empty and the target node is the right node of the parent node, then the predecessor node is the parent node. For node `5`, there is no left node and it is the right node of node `2`, so node `2` is the precursor node.
3. If the left node is empty and the target node is the left node of the parent node, look up the first node that is the right node of the parent node. For node `6`, there is no left node, and it is the left node of node `3`. So look up to node `1` and find that node `3` is the right node of node `1`, so node `1` is the predecessor of node `6`.
The following code is implement of the algorithm.
```js
function predecessor(node) {
if (!node) return
// Conclusion 1
if (node.left) {
return getRight(node.left)
} else {
let parent = node.parent
// Conclusion 2 3 judgment
while(parent && parent.right === node) {
node = parent
parent = node.parent
}
return parent
}
}
function getRight(node) {
if (!node) return
node = node.right
while(node) node = node.right
return node
}
```
### Successor Node
For node `2`, his successor is `5`, according to the principle of inorder traversal, you can draw the following conclusions.
1. If there is a right node, the leftmost node of the right node will be found. For node `1`, he has a right node `3`, then the leftmost node of node `3` is `6`.
2. If there is no right node, it traverses up until it finds a node that is the left node of the parent node. For node `5`, if there is no right node, it will look up to node `2`, which is the left node of parent node `1`, so node `1` is the successor node.
The following code is implement of the algorithm.
```js
function successor(node) {
if (!node) return
// Conclusion 1
if (node.right) {
return getLeft(node.right)
} else {
// Conclusion 2
let parent = node.parent
// Judge parent if it is empty
while(parent && parent.left === node) {
node = parent
parent = node.parent
}
return parent
}
}
function getLeft(node) {
if (!node) return
node = node.left
while(node) node = node.left
return node
}
```
## Depth of the Tree
**Maximum Depth of the Tree**:The topic comes from [Leetcode](https://leetcode.com/problems/maximum-depth-of-binary-tree/description/),The problem needs to find the maximum depth of a binary tree.
The following code is implement of the algorithm.
```js
var maxDepth = function(root) {
if (!root) return 0
return Math.max(maxDepth(root.left), maxDepth(root.right)) + 1
};
```
For this recursive function, you can understand that if you don't find the node, it will return 0. Each time you pop up, the recursive function will add one. If you have three layers, you will get 3.
# Dynamic Programming
The basic principle behind dynamic programming is very simple. It split a problem into sub-problems. Generally speaking, these sub-problems are very similar. Then we can reduce the amount of calculation by solving only one sub-problem once.
Once the solution for each sub-problem is derived, the result is stored for next use.
## Fibonacci Sequence
The Fibonacci sequence starts with 0 and 1, and the following numbers are the sum of the first two numbers.
0,1,1,2,3,5,8,13,21,34,55,89....
So obviously easy to see, we can complete the Fibonacci sequence by recursively.
```js
function fib(n) {
if (n < 2 && n >= 0) return n
return fib(n - 1) + fib(n - 2)
}
fib(10)
```
The above code has been able to solve the problem perfectly. However, the above solution has serious performance problems. When n is larger, the time required is exponentially increasing. At this time, dynamic programming can solve this problem.
The essence of dynamic programming is actually two points.
1. Bottom-up decomposition problem
2. Store the already calculated solution by variable
According to the above two points, the dynamic programming of our Fibonacci sequence is coming out.
1. The Fibonacci sequence starts with 0 and 1, then this is the bottom of the sub-problem
2. Store the value of the corresponding Fibonacci sequence for each bit through an array
```js
function fib(n) {
let array = new Array(n + 1).fill(null)
array[0] = 0
array[1] = 1
for (let i = 2; i <= n; i++) {
array[i] = array[i - 1] + array[i - 2]
}
return array[n]
}
fib(10)
```
## 0 - 1 Backpack Problem
The problem can be described as: given a group of goods, each good has its own weight and price, How can we choose to make the highest total price of the good within a limited total weight. Each question can only be placed at most once.
Suppose we have the following goods.
| Goods ID / Weight | Value |
| :---------------: | :---: |
| 1 | 3 |
| 2 | 7 |
| 3 | 12 |
For a backpack with a total capacity of 5, we can put goods with weight 2 and 3 to achieve the highest total value of the goods in the backpack.
For this problem, there are two sub-problems, one is placing goods and another is not. You can use the following table to understand sub-questions.
| Goods ID / The remaining capacity | 0 | 1 | 2 | 3 | 4 | 5 |
| :-------------------------------: | :--: | :--: | :--: | :--: | :--: | :--: |
| 1 | 0 | 3 | 3 | 3 | 3 | 3 |
| 2 | 0 | 3 | 7 | 10 | 10 | 10 |
| 3 | 0 | 3 | 7 | 12 | 15 | 19 |
Directly analyze the situation where three goods can be placed, that is the last line.
- When the capacity is less than 3, only the data corresponding to the previous row is taken because the current capacity cannot accommodate the good 3
- When the capacity is 3, consider two cases, placing the good 3 and another is not placing the good 3
- In the case of not placing good 3, the total value is 10
- In the case of placing good 3, the total value is 12, so goods should be placed 3
- When the capacity is 4, consider two cases, placing goods 3 and another is not placing goods 3
- In the case of not placing good 3, the total value is 10
- In the case of placing good 3, add the value of good 1 to get the total value of 15, so it should be placed in good 3
- When the capacity is 5, consider two cases, placing the good 3 and not placing the good 3
- In the case of not placing good 3, the total value is 10
- In the case of placing good 3, add the value of good 2 to get the total value of 19, so it should be placed in good 3
It is easier to understand the following code with the above table.
```js
/**
* @param {*} w Good weight
* @param {*} v Good value
* @param {*} C Total capacity
* @returns
*/
function knapsack(w, v, C) {
let length = w.length
if (length === 0) return 0
// Compare to the table, the generated two-dimensional array,
// the first dimension represents the good,
// and the second dimension represents the remaining capacity of the backpack.
// The elements in the second dimension represent the total value of the backpack good
let array = new Array(length).fill(new Array(C + 1).fill(null))
// Complete the solution of the bottom sub-problem
for (let i = 0; i <= C; i++) {
// Compare to the first line of the table, array[0] represents the good 1
// i represents the total remaining capacity
// When the remaining total capacity is greater than the weight of the good 1,
// record the total value of the backpack good, otherwise the value is 0.
array[0][i] = i >= w[0] ? v[0] : 0
}
// Solve sub-problems from bottom to up, starting with good 2
for (let i = 1; i < length; i++) {
for (let j = 0; j <= C; j++) {
// Solve the sub-problems here,
// divided into not to put the current good and put the current good
// First solve the total value of the backpack with not putting the current good.
// The value here is the value corresponding to the previous line in the corresponding table.
array[i][j] = array[i - 1][j]
// Determine whether the current remaining capacity can be placed in the current good.
if (j >= w[i]) {
// If you can put it, and then compare it.
// Put the current item and not put the current item,
// which backpack has a max total value
array[i][j] = Math.max(array[i][j], v[i] + array[i - 1][j - w[i]])
}
}
}
return array[length - 1][C]
}
```
## Longest Increasing Subsequence
The longest incrementing subsequence means finding out the longest incremental numbers in a set of numbers, such as
0, 3, 4, 17, 2, 8, 6, 10
For the above numbers, the longest increment subsequence is 0, 3, 4, 8, 10, which can be understood more clearly by the following table.
| Number | 0 | 3 | 4 | 17 | 2 | 8 | 6 | 10 |
| :----: | :--: | :--: | :--: | :--: | :--: | :--: | :--: | :--: |
| Length | 1 | 2 | 3 | 4 | 2 | 4 | 4 | 5 |
Through the above table, you can clearly find a rule, find out the number just smaller than the current number, and add one based on the length of the small number.
The dynamic solution to this problem is very simple, directly on the code.
```js
function lis(n) {
if (n.length === 0) return 0
// Create an array of the same size as the parameter and fill it with a value of 1
let array = new Array(n.length).fill(1)
// Traversing from index 1, because the array has all been filled with 1
for (let i = 1; i < n.length; i++) {
// Traversing from index 0 to i
// Determine if the value on index i is greater than the previous value
for (let j = 0; j < i; j++) {
if (n[i] > n[j]) {
array[i] = Math.max(array[i], 1 + array[j])
}
}
}
let res = 1
for (let i = 0; i < array.length; i++) {
res = Math.max(res, array[i])
}
return res
}
```
# String Related
In the string correlation algorithm, Trie tree can solve many problems, and has good space and time complexity, such as the following problems.
- Word frequency statistics
- Prefix matching
If you don't know much about the Trie tree, you can go [here](../DataStruct/dataStruct-zh.md#trie) to read
================================================
FILE: Browser/browser-ch.md
================================================
**Table of Contents** *generated with [DocToc](https://github.com/thlorenz/doctoc)*
- [事件机制](#%E4%BA%8B%E4%BB%B6%E6%9C%BA%E5%88%B6)
- [事件触发三阶段](#%E4%BA%8B%E4%BB%B6%E8%A7%A6%E5%8F%91%E4%B8%89%E9%98%B6%E6%AE%B5)
- [注册事件](#%E6%B3%A8%E5%86%8C%E4%BA%8B%E4%BB%B6)
- [事件代理](#%E4%BA%8B%E4%BB%B6%E4%BB%A3%E7%90%86)
- [跨域](#%E8%B7%A8%E5%9F%9F)
- [JSONP](#jsonp)
- [CORS](#cors)
- [document.domain](#documentdomain)
- [postMessage](#postmessage)
- [Event loop](#event-loop)
- [Node 中的 Event loop](#node-%E4%B8%AD%E7%9A%84-event-loop)
- [timer](#timer)
- [I/O](#io)
- [idle, prepare](#idle-prepare)
- [poll](#poll)
- [check](#check)
- [close callbacks](#close-callbacks)
- [存储](#%E5%AD%98%E5%82%A8)
- [cookie,localStorage,sessionStorage,indexDB](#cookielocalstoragesessionstorageindexdb)
- [Service Worker](#service-worker)
- [渲染机制](#%E6%B8%B2%E6%9F%93%E6%9C%BA%E5%88%B6)
- [Load 和 DOMContentLoaded 区别](#load-%E5%92%8C-domcontentloaded-%E5%8C%BA%E5%88%AB)
- [图层](#%E5%9B%BE%E5%B1%82)
- [重绘(Repaint)和回流(Reflow)](#%E9%87%8D%E7%BB%98repaint%E5%92%8C%E5%9B%9E%E6%B5%81reflow)
- [减少重绘和回流](#%E5%87%8F%E5%B0%91%E9%87%8D%E7%BB%98%E5%92%8C%E5%9B%9E%E6%B5%81)
# 事件机制
## 事件触发三阶段
事件触发有三个阶段
- `window` 往事件触发处传播,遇到注册的捕获事件会触发
- 传播到事件触发处时触发注册的事件
- 从事件触发处往 `window` 传播,遇到注册的冒泡事件会触发
事件触发一般来说会按照上面的顺序进行,但是也有特例,如果给一个目标节点同时注册冒泡和捕获事件,事件触发会按照注册的顺序执行。
```js
// 以下会先打印冒泡然后是捕获
node.addEventListener('click',(event) =>{
console.log('冒泡')
},false);
node.addEventListener('click',(event) =>{
console.log('捕获 ')
},true)
```
## 注册事件
通常我们使用 `addEventListener` 注册事件,该函数的第三个参数可以是布尔值,也可以是对象。对于布尔值 `useCapture` 参数来说,该参数默认值为 `false` 。`useCapture` 决定了注册的事件是捕获事件还是冒泡事件。对于对象参数来说,可以使用以下几个属性
- `capture`,布尔值,和 `useCapture` 作用一样
- `once`,布尔值,值为 `true` 表示该回调只会调用一次,调用后会移除监听
- `passive`,布尔值,表示永远不会调用 `preventDefault`
一般来说,我们只希望事件只触发在目标上,这时候可以使用 `stopPropagation` 来阻止事件的进一步传播。通常我们认为 `stopPropagation` 是用来阻止事件冒泡的,其实该函数也可以阻止捕获事件。`stopImmediatePropagation` 同样也能实现阻止事件,但是还能阻止该事件目标执行别的注册事件。
```js
node.addEventListener('click',(event) =>{
event.stopImmediatePropagation()
console.log('冒泡')
},false);
// 点击 node 只会执行上面的函数,该函数不会执行
node.addEventListener('click',(event) => {
console.log('捕获 ')
},true)
```
## 事件代理
如果一个节点中的子节点是动态生成的,那么子节点需要注册事件的话应该注册在父节点上
```html
1
2
3
4
5
```
事件代理的方式相对于直接给目标注册事件来说,有以下优点
- 节省内存
- 不需要给子节点注销事件
# 跨域
因为浏览器出于安全考虑,有同源策略。也就是说,如果协议、域名或者端口有一个不同就是跨域,Ajax 请求会失败。
我们可以通过以下几种常用方法解决跨域的问题
## JSONP
JSONP 的原理很简单,就是利用 `
```
JSONP 使用简单且兼容性不错,但是只限于 `get` 请求。
在开发中可能会遇到多个 JSONP 请求的回调函数名是相同的,这时候就需要自己封装一个 JSONP,以下是简单实现
```js
function jsonp(url, jsonpCallback, success) {
let script = document.createElement("script");
script.src = url;
script.async = true;
script.type = "text/javascript";
window[jsonpCallback] = function(data) {
success && success(data);
};
document.body.appendChild(script);
}
jsonp(
"http://xxx",
"callback",
function(value) {
console.log(value);
}
);
```
## CORS
CORS需要浏览器和后端同时支持。IE 8 和 9 需要通过 `XDomainRequest` 来实现。
浏览器会自动进行 CORS 通信,实现CORS通信的关键是后端。只要后端实现了 CORS,就实现了跨域。
服务端设置 `Access-Control-Allow-Origin` 就可以开启 CORS。 该属性表示哪些域名可以访问资源,如果设置通配符则表示所有网站都可以访问资源。
## document.domain
该方式只能用于二级域名相同的情况下,比如 `a.test.com` 和 `b.test.com` 适用于该方式。
只需要给页面添加 `document.domain = 'test.com'` 表示二级域名都相同就可以实现跨域
## postMessage
这种方式通常用于获取嵌入页面中的第三方页面数据。一个页面发送消息,另一个页面判断来源并接收消息
```js
// 发送消息端
window.parent.postMessage('message', 'http://test.com');
// 接收消息端
var mc = new MessageChannel();
mc.addEventListener('message', (event) => {
var origin = event.origin || event.originalEvent.origin;
if (origin === 'http://test.com') {
console.log('验证通过')
}
});
```
# Event loop
众所周知 JS 是门非阻塞单线程语言,因为在最初 JS 就是为了和浏览器交互而诞生的。如果 JS 是门多线程的语言话,我们在多个线程中处理 DOM 就可能会发生问题(一个线程中新加节点,另一个线程中删除节点),当然可以引入读写锁解决这个问题。
JS 在执行的过程中会产生执行环境,这些执行环境会被顺序的加入到执行栈中。如果遇到异步的代码,会被挂起并加入到 Task(有多种 task) 队列中。一旦执行栈为空,Event Loop 就会从 Task 队列中拿出需要执行的代码并放入执行栈中执行,所以本质上来说 JS 中的异步还是同步行为。
```js
console.log('script start');
setTimeout(function() {
console.log('setTimeout');
}, 0);
console.log('script end');
```
以上代码虽然 `setTimeout` 延时为 0,其实还是异步。这是因为 HTML5 标准规定这个函数第二个参数不得小于 4 毫秒,不足会自动增加。所以 `setTimeout` 还是会在 `script end` 之后打印。
不同的任务源会被分配到不同的 Task 队列中,任务源可以分为 微任务(microtask) 和 宏任务(macrotask)。在 ES6 规范中,microtask 称为 `jobs`,macrotask 称为 `task`。
```js
console.log('script start');
setTimeout(function() {
console.log('setTimeout');
}, 0);
new Promise((resolve) => {
console.log('Promise')
resolve()
}).then(function() {
console.log('promise1');
}).then(function() {
console.log('promise2');
});
console.log('script end');
// script start => Promise => script end => promise1 => promise2 => setTimeout
```
以上代码虽然 `setTimeout` 写在 `Promise` 之前,但是因为 `Promise` 属于微任务而 `setTimeout` 属于宏任务,所以会有以上的打印。
微任务包括 `process.nextTick` ,`promise` ,`Object.observe` ,`MutationObserver`
宏任务包括 `script` , `setTimeout` ,`setInterval` ,`setImmediate` ,`I/O` ,`UI rendering`
很多人有个误区,认为微任务快于宏任务,其实是错误的。因为宏任务中包括了 `script` ,浏览器会先执行一个宏任务,接下来有异步代码的话就先执行微任务。
所以正确的一次 Event loop 顺序是这样的
1. 执行同步代码,这属于宏任务
2. 执行栈为空,查询是否有微任务需要执行
3. 执行所有微任务
4. 必要的话渲染 UI
5. 然后开始下一轮 Event loop,执行宏任务中的异步代码
通过上述的 Event loop 顺序可知,如果宏任务中的异步代码有大量的计算并且需要操作 DOM 的话,为了更快的 界面响应,我们可以把操作 DOM 放入微任务中。
## Node 中的 Event loop
Node 中的 Event loop 和浏览器中的不相同。
Node 的 Event loop 分为6个阶段,它们会按照顺序反复运行
```
┌───────────────────────┐
┌─>│ timers │
│ └──────────┬────────────┘
│ ┌──────────┴────────────┐
│ │ I/O callbacks │
│ └──────────┬────────────┘
│ ┌──────────┴────────────┐
│ │ idle, prepare │
│ └──────────┬────────────┘ ┌───────────────┐
│ ┌──────────┴────────────┐ │ incoming: │
│ │ poll │<──connections─── │
│ └──────────┬────────────┘ │ data, etc. │
│ ┌──────────┴────────────┐ └───────────────┘
│ │ check │
│ └──────────┬────────────┘
│ ┌──────────┴────────────┐
└──┤ close callbacks │
└───────────────────────┘
```
### timer
timers 阶段会执行 `setTimeout` 和 `setInterval`
一个 `timer` 指定的时间并不是准确时间,而是在达到这个时间后尽快执行回调,可能会因为系统正在执行别的事务而延迟。
下限的时间有一个范围:`[1, 2147483647]` ,如果设定的时间不在这个范围,将被设置为1。
### I/O
I/O 阶段会执行除了 close 事件,定时器和 `setImmediate` 的回调
### idle, prepare
idle, prepare 阶段内部实现
### poll
poll 阶段很重要,这一阶段中,系统会做两件事情
1. 执行到点的定时器
2. 执行 poll 队列中的事件
并且当 poll 中没有定时器的情况下,会发现以下两件事情
- 如果 poll 队列不为空,会遍历回调队列并同步执行,直到队列为空或者系统限制
- 如果 poll 队列为空,会有两件事发生
- 如果有 `setImmediate` 需要执行,poll 阶段会停止并且进入到 check 阶段执行 `setImmediate`
- 如果没有 `setImmediate` 需要执行,会等待回调被加入到队列中并立即执行回调
如果有别的定时器需要被执行,会回到 timer 阶段执行回调。
### check
check 阶段执行 `setImmediate`
### close callbacks
close callbacks 阶段执行 close 事件
并且在 Node 中,有些情况下的定时器执行顺序是随机的
```js
setTimeout(() => {
console.log('setTimeout');
}, 0);
setImmediate(() => {
console.log('setImmediate');
})
// 这里可能会输出 setTimeout,setImmediate
// 可能也会相反的输出,这取决于性能
// 因为可能进入 event loop 用了不到 1 毫秒,这时候会执行 setImmediate
// 否则会执行 setTimeout
```
当然在这种情况下,执行顺序是相同的
```js
var fs = require('fs')
fs.readFile(__filename, () => {
setTimeout(() => {
console.log('timeout');
}, 0);
setImmediate(() => {
console.log('immediate');
});
});
// 因为 readFile 的回调在 poll 中执行
// 发现有 setImmediate ,所以会立即跳到 check 阶段执行回调
// 再去 timer 阶段执行 setTimeout
// 所以以上输出一定是 setImmediate,setTimeout
```
上面介绍的都是 macrotask 的执行情况,microtask 会在以上每个阶段完成后立即执行。
```js
setTimeout(()=>{
console.log('timer1')
Promise.resolve().then(function() {
console.log('promise1')
})
}, 0)
setTimeout(()=>{
console.log('timer2')
Promise.resolve().then(function() {
console.log('promise2')
})
}, 0)
// 以上代码在浏览器和 node 中打印情况是不同的
// 浏览器中一定打印 timer1, promise1, timer2, promise2
// node 中可能打印 timer1, timer2, promise1, promise2
// 也可能打印 timer1, promise1, timer2, promise2
```
Node 中的 `process.nextTick` 会先于其他 microtask 执行。
```js
setTimeout(() => {
console.log("timer1");
Promise.resolve().then(function() {
console.log("promise1");
});
}, 0);
process.nextTick(() => {
console.log("nextTick");
});
// nextTick, timer1, promise1
```
# 存储
## cookie,localStorage,sessionStorage,indexDB
| 特性 | cookie | localStorage | sessionStorage | indexDB |
| :----------: | :----------------------------------------: | :----------------------: | :------------: | :----------------------: |
| 数据生命周期 | 一般由服务器生成,可以设置过期时间 | 除非被清理,否则一直存在 | 页面关闭就清理 | 除非被清理,否则一直存在 |
| 数据存储大小 | 4K | 5M | 5M | 无限 |
| 与服务端通信 | 每次都会携带在 header 中,对于请求性能影响 | 不参与 | 不参与 | 不参与 |
从上表可以看到,`cookie` 已经不建议用于存储。如果没有大量数据存储需求的话,可以使用 `localStorage` 和 `sessionStorage` 。对于不怎么改变的数据尽量使用 `localStorage` 存储,否则可以用 `sessionStorage` 存储。
对于 `cookie`,我们还需要注意安全性。
| 属性 | 作用 |
| :-------: | :----------------------------------------------------------: |
| value | 如果用于保存用户登录态,应该将该值加密,不能使用明文的用户标识 |
| http-only | 不能通过 JS 访问 Cookie,减少 XSS 攻击 |
| secure | 只能在协议为 HTTPS 的请求中携带 |
| same-site | 规定浏览器不能在跨域请求中携带 Cookie,减少 CSRF 攻击 |
## Service Worker
> Service workers 本质上充当Web应用程序与浏览器之间的代理服务器,也可以在网络可用时作为浏览器和网络间的代理。它们旨在(除其他之外)使得能够创建有效的离线体验,拦截网络请求并基于网络是否可用以及更新的资源是否驻留在服务器上来采取适当的动作。他们还允许访问推送通知和后台同步API。
目前该技术通常用来做缓存文件,提高首屏速度,可以试着来实现这个功能。
```js
// index.js
if (navigator.serviceWorker) {
navigator.serviceWorker
.register("sw.js")
.then(function(registration) {
console.log("service worker 注册成功");
})
.catch(function(err) {
console.log("servcie worker 注册失败");
});
}
// sw.js
// 监听 `install` 事件,回调中缓存所需文件
self.addEventListener("install", e => {
e.waitUntil(
caches.open("my-cache").then(function(cache) {
return cache.addAll(["./index.html", "./index.js"]);
})
);
});
// 拦截所有请求事件
// 如果缓存中已经有请求的数据就直接用缓存,否则去请求数据
self.addEventListener("fetch", e => {
e.respondWith(
caches.match(e.request).then(function(response) {
if (response) {
return response;
}
console.log("fetch source");
})
);
});
```
打开页面,可以在开发者工具中的 `Application` 看到 Service Worker 已经启动了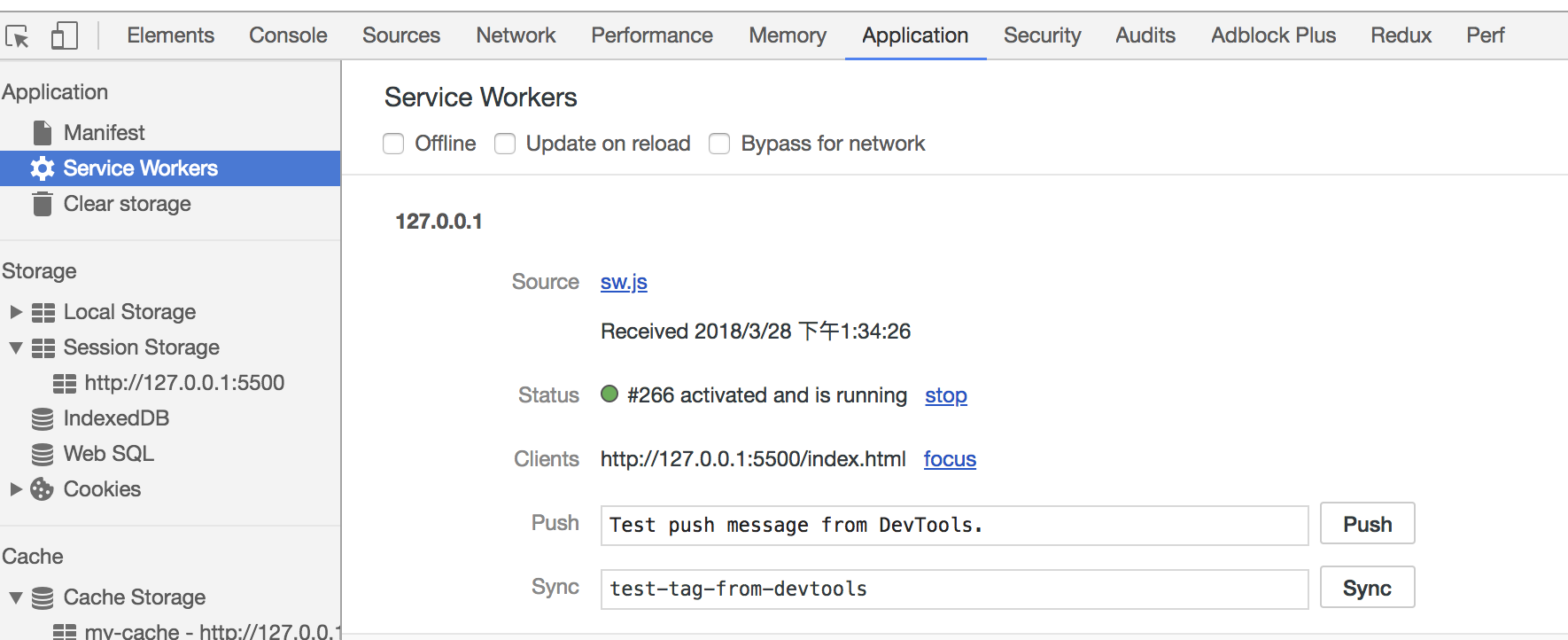
在 Cache 中也可以发现我们所需的文件已被缓存
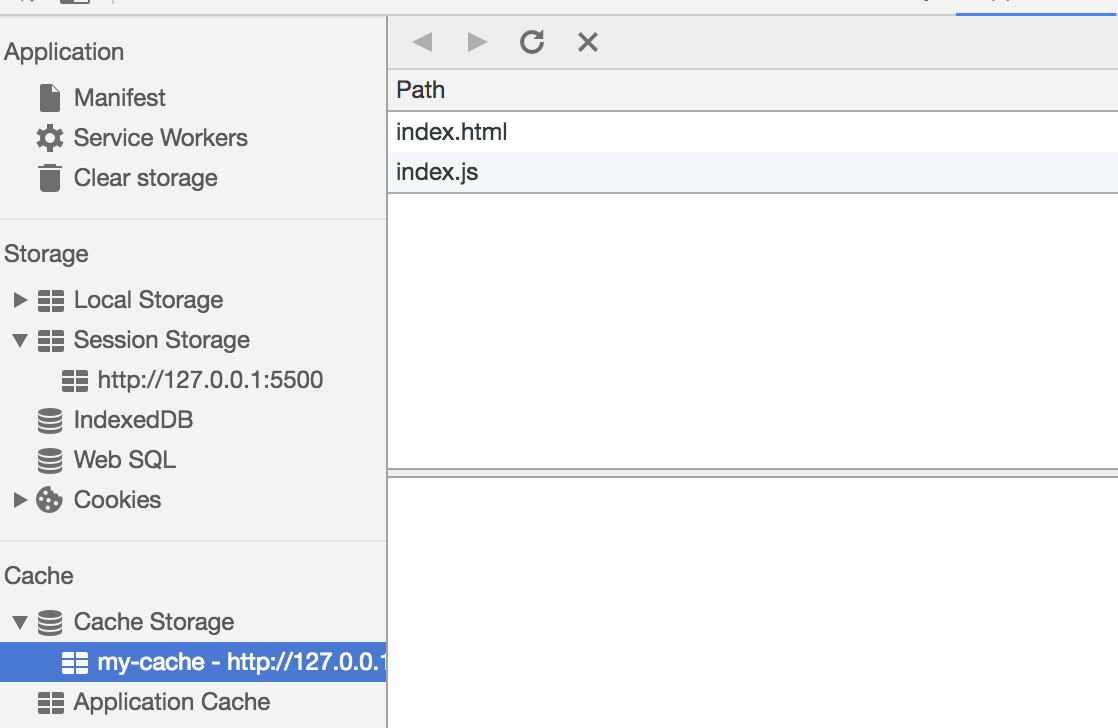
当我们重新刷新页面可以发现我们缓存的数据是从 Service Worker 中读取的

# 渲染机制
浏览器的渲染机制一般分为以下几个步骤
1. 处理 HTML 并构建 DOM 树。
2. 处理 CSS 构建 CSSOM 树。
3. 将 DOM 与 CSSOM 合并成一个渲染树。
4. 根据渲染树来布局,计算每个节点的位置。
5. 调用 GPU 绘制,合成图层,显示在屏幕上。
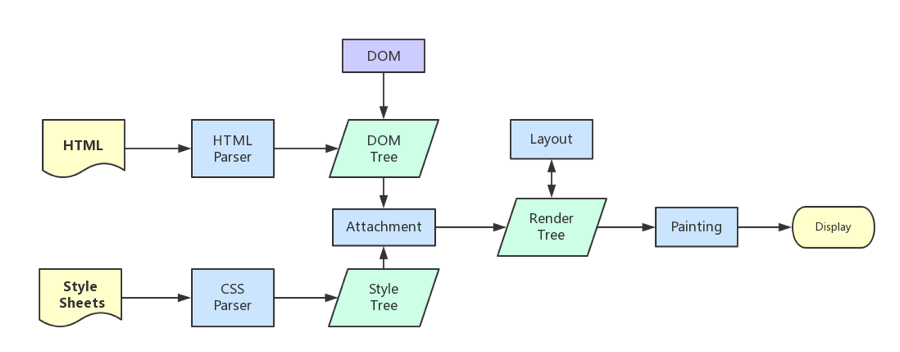
在构建 CSSOM 树时,会阻塞渲染,直至 CSSOM 树构建完成。并且构建 CSSOM 树是一个十分消耗性能的过程,所以应该尽量保证层级扁平,减少过度层叠,越是具体的 CSS 选择器,执行速度越慢。
当 HTML 解析到 script 标签时,会暂停构建 DOM,完成后才会从暂停的地方重新开始。也就是说,如果你想首屏渲染的越快,就越不应该在首屏就加载 JS 文件。并且 CSS 也会影响 JS 的执行,只有当解析完样式表才会执行 JS,所以也可以认为这种情况下,CSS 也会暂停构建 DOM。
## Load 和 DOMContentLoaded 区别
Load 事件触发代表页面中的 DOM,CSS,JS,图片已经全部加载完毕。
DOMContentLoaded 事件触发代表初始的 HTML 被完全加载和解析,不需要等待 CSS,JS,图片加载。
## 图层
一般来说,可以把普通文档流看成一个图层。特定的属性可以生成一个新的图层。**不同的图层渲染互不影响**,所以对于某些频繁需要渲染的建议单独生成一个新图层,提高性能。**但也不能生成过多的图层,会引起反作用。**
通过以下几个常用属性可以生成新图层
- 3D 变换:`translate3d`、`translateZ`
- `will-change`
- `video`、`iframe` 标签
- 通过动画实现的 `opacity` 动画转换
- `position: fixed`
## 重绘(Repaint)和回流(Reflow)
重绘和回流是渲染步骤中的一小节,但是这两个步骤对于性能影响很大。
- 重绘是当节点需要更改外观而不会影响布局的,比如改变 `color` 就叫称为重绘
- 回流是布局或者几何属性需要改变就称为回流。
回流必定会发生重绘,重绘不一定会引发回流。回流所需的成本比重绘高的多,改变深层次的节点很可能导致父节点的一系列回流。
所以以下几个动作可能会导致性能问题:
- 改变 window 大小
- 改变字体
- 添加或删除样式
- 文字改变
- 定位或者浮动
- 盒模型
很多人不知道的是,重绘和回流其实和 Event loop 有关。
1. 当 Event loop 执行完 Microtasks 后,会判断 document 是否需要更新。因为浏览器是 60Hz 的刷新率,每 16ms 才会更新一次。
2. 然后判断是否有 `resize` 或者 `scroll` ,有的话会去触发事件,所以 `resize` 和 `scroll` 事件也是至少 16ms 才会触发一次,并且自带节流功能。
3. 判断是否触发了 media query
4. 更新动画并且发送事件
5. 判断是否有全屏操作事件
6. 执行 `requestAnimationFrame` 回调
7. 执行 `IntersectionObserver` 回调,该方法用于判断元素是否可见,可以用于懒加载上,但是兼容性不好
8. 更新界面
9. 以上就是一帧中可能会做的事情。如果在一帧中有空闲时间,就会去执行 `requestIdleCallback` 回调。
以上内容来自于 [HTML 文档](https://html.spec.whatwg.org/multipage/webappapis.html#event-loop-processing-model)
## 减少重绘和回流
- 使用 `translate` 替代 `top`
```html
```
- 使用 `visibility` 替换 `display: none` ,因为前者只会引起重绘,后者会引发回流(改变了布局)
- 把 DOM 离线后修改,比如:先把 DOM 给 `display:none` (有一次 Reflow),然后你修改100次,然后再把它显示出来
- 不要把 DOM 结点的属性值放在一个循环里当成循环里的变量
```js
for(let i = 0; i < 1000; i++) {
// 获取 offsetTop 会导致回流,因为需要去获取正确的值
console.log(document.querySelector('.test').style.offsetTop)
}
```
- 不要使用 table 布局,可能很小的一个小改动会造成整个 table 的重新布局
- 动画实现的速度的选择,动画速度越快,回流次数越多,也可以选择使用 `requestAnimationFrame`
- CSS 选择符从右往左匹配查找,避免 DOM 深度过深
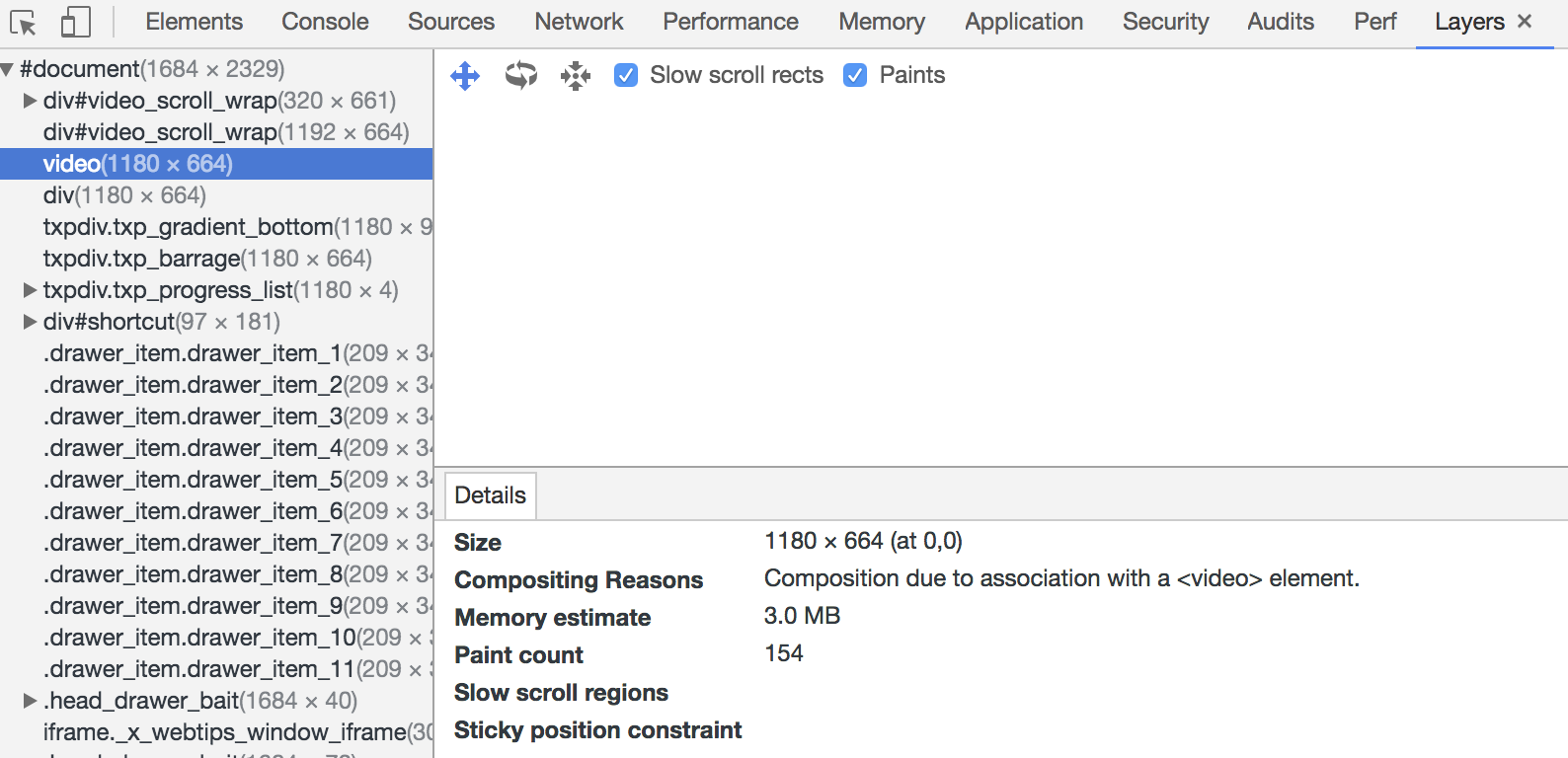
- 将频繁运行的动画变为图层,图层能够阻止该节点回流影响别的元素。比如对于 `video` 标签,浏览器会自动将该节点变为图层。
================================================
FILE: Browser/browser-en.md
================================================
**Table of Contents** *generated with [DocToc](https://github.com/thlorenz/doctoc)*
- [Event mechanism](#event-mechanism)
- [The three phases of event propagation](#the-three-phases-of-event-propagation)
- [Event Registration](#event-registration)
- [Event Delegation](#event-delegation)
- [Cross Domain](#cross-domain)
- [JSONP](#jsonp)
- [CORS](#cors)
- [document.domain](#documentdomain)
- [postMessage](#postmessage)
- [Event Loop](#event-loop)
- [Event Loop in Node](#event-loop-in-node)
- [timer](#timer)
- [pending callbacks](#pending-callbacks)
- [idle, prepare](#idle-prepare)
- [poll](#poll)
- [check](#check)
- [close callbacks](#close-callbacks)
- [Storage](#storage)
- [cookie,localStorage,sessionStorage,indexDB](#cookielocalstoragesessionstorageindexdb)
- [Service Worker](#service-worker)
- [Rendering mechanism](#rendering-mechanism)
- [Difference between Load & DOMContentLoaded](#difference-between-load--domcontentloaded)
- [Layers](#layers)
- [Repaint & Reflow](#repaint--reflow)
- [Minimize Repaint & Reflow](#minimize-repaint--reflow)
# Event mechanism
## The three phases of event propagation
Event propagation has three phases:
- The event object propagates from the Window to the target’s parent. Capturing events will trigger.
- The event object arrives at the event object’s event target. Events registered to target will trigger.
- The event object propagates from the target's parent up to the Window. Bubbling events will trigger.
Event propagation generally follows the above sequence, but there are exceptions. If a target node is registered for both bubbling and capturing events, events are invoked in the order they were registered.
```js
// The following code will print bubbling first and then trigger capture events
node.addEventListener('click',(event) =>{
console.log('bubble')
},false);
node.addEventListener('click',(event) =>{
console.log('capture')
},true)
```
## Event Registration
Usually, we use `addEventListener` to register an event, and the `useCapture` is a function parameter, which receives a Boolean value, the default value is `false`. `useCapture` determines whether the registered event is a capturing event or a bubbling event. For the object parameter, you can use the following properties:
- `capture`, Boolean value, same as `useCapture`
- `once`, Boolean value, `true` indicating that the callback should be called at most once, after invoked the listener will be removed
- `passive`, Boolean, means it will never call `preventDefault`
Generally speaking, we only want the event to trigger on the target. To achieve this we can use `stopPropagation` to prevent the propagation of the event. Usually, we would think that `stopPropagation` is used to stop the event bubbling, but this function can also prevent the event capturing. `stopImmediatePropagation` can achieve the same effects, and it can also prevent other listeners of the same event from being called.
```js
node.addEventListener('click',(event) =>{
event.stopImmediatePropagation()
console.log('bubbling')
},false);
// Clicking node will only execute the above function, this function will not execute
node.addEventListener('click',(event) => {
console.log('capture ')
},true)
```
## Event Delegation
If a child node inside a parent node is dynamically generated, events on the child node should be added to parent node:
```html
1
2
3
4
5
```
Event delegation has the following advantages over adding events straight to child nodes:
- Save memory
- No need remove event listeners on child nodes
# Cross Domain
Browsers have the same-origin policy for security reasons. In other words, if the protocol, domain name or port has one difference, that would be cross-domain, and the Ajax request will fail.
We can solve the cross-domain issues through following methods:
## JSONP
The principle of JSONP is very simple, that is to make use of the `
```
JSONP is simple to use and has good compatibility, but is limited to `get` requests.
You may encounter the situation where you have the same callback names in multiple JSONP requests. In this situation you need to encapsulate JSONP. The following is a simple implementation:
```js
function jsonp(url, jsonpCallback, success) {
let script = document.createElement("script");
script.src = url;
script.async = true;
script.type = "text/javascript";
window[jsonpCallback] = function(data) {
success && success(data);
};
document.body.appendChild(script);
}
jsonp(
"http://xxx",
"callback",
function(value) {
console.log(value);
}
);
```
## CORS
CORS requires browser and backend support at the same time. Internet Explorer 8 and 9 expose CORS via the XDomainRequest object.
The browser will automatically perform CORS. The key to implementing CORS is the backend. As long as the backend implements CORS, it enables cross-domain.
The server sets `Access-Control-Allow-Origin` to enable CORS. This property specifies which domains can access the resource. If set to wildcard, all websites can access the resource.
## document.domain
This can only be used for the same second-level domain, for example, `a.test.com` and `b.test.com` are suitable for this case.
Set `document.domain = 'test.com'` would enable CORS within the same second-level domain.
## postMessage
This method is usually used to get data from embedded third-party page. One page sends a message, the other page checks the source and receives the message:
```js
// send of page
window.parent.postMessage('message', 'http://test.com');
// receive of page
var mc = new MessageChannel();
mc.addEventListener('message', (event) => {
var origin = event.origin || event.originalEvent.origin;
if (origin === 'http://test.com') {
console.log('success')
}
});
```
# Event Loop
As we all know, JS is a non-blocking and single-threaded language, because JS was born to interact with the browser in the beginning. If JS was a multi-threaded language, we might have problems handling DOM in multiple threads (imagine adding nodes in a thread and deleting nodes in another thread at the same time), however we could introduce a read-write lock to solve this problem.
Execution context, generated during JS execution, will be pushed into call stack sequentially. Asynchronous codes will hang up and get pushed into the task queues (there are multiple kinds of tasks). Once the call stack is empty, the Event Loop will process the next message in the task queues and push it into the call stack for execution, thus essentially the asynchronous operation in JS is actually synchronous.
```js
console.log('script start');
setTimeout(function() {
console.log('setTimeout');
}, 0);
console.log('script end');
```
The above code is asynchronous, even though the `setTimeout` delay is 0. That’s because the HTML5 standard stipulates that the second parameter of the function `setTimeout` must not be less than 4 milliseconds, otherwise it will automatically . So `setTimeout` is still logged after `script end`.
Different tasks are assigned to different Task queues. Tasks can be divided into `microtasks` and `macrotasks`. In the ES6 specification, a `microtask` is called a `job` and a `macrotask` is called a `task`.
```js
console.log('script start');
setTimeout(function() {
console.log('setTimeout');
}, 0);
new Promise((resolve) => {
console.log('Promise')
resolve()
}).then(function() {
console.log('promise1');
}).then(function() {
console.log('promise2');
});
console.log('script end');
// script start => Promise => script end => promise1 => promise2 => setTimeout
```
Although `setTimeout` is set before `Promise`, the above printing still occurs because `Promise` belongs to microtask and `setTimeout` belongs to macrotask.
Microtasks include `process.nextTick`, `promise`, `Object.observe` and `MutationObserver`.
Macrotasks include `script`, `setTimeout`, `setInterval`, `setImmediate`, `I/O` and `UI rendering`.
Many people have the misunderstanding that microtasks always get executed before macrotasks and this is incorrect. Because the macrotask includes `script`, the browser will perform this macrotask first, followed by any microtasks in asynchronous codes.
So the correct sequence of an event loop looks like this:
1. Execute synchronous codes, which belongs to macrotask
2. Once call stack is empty, query if any microtasks need to be executed
3. Execute all the microtasks
4. If necessary, render the UI
5. Then start the next round of the Event loop, and execute the asynchronous operations in the macrotask
According to the above sequence of the event loop, if the asynchronous codes in the macrotask have a large number of calculations and need to operate on DOM, we can put DOM operation into microtask for faster interface response.
## Event Loop in Node
The event loop in Node is not the same as in the browser.
The event loop in Node is divided into 6 phases, and they will be executed in order repeatedly:
```
┌───────────────────────┐
┌─>│ timers │
│ └──────────┬────────────┘
│ ┌──────────┴────────────┐
│ │ pending callbacks │
│ └──────────┬────────────┘
│ ┌──────────┴────────────┐
│ │ idle, prepare │
│ └──────────┬────────────┘ ┌───────────────┐
│ ┌──────────┴────────────┐ │ incoming: │
│ │ poll │<──---| connections │
│ └──────────┬────────────┘ │ data, etc. │
│ ┌──────────┴────────────┐ └───────────────┘
│ │ check │
│ └──────────┬────────────┘
│ ┌──────────┴────────────┐
└──┤ close callbacks │
└───────────────────────┘
```
### timer
The `timer` phase executes the callbacks of `setTimeout` and `setInterval`.
`Timer` specifies the time that callbacks will run as early as they can be scheduled, after the specified amount of time has passed rather than the exact time a person wants it to be executed.
The lower bound time has a range: `[1, 2147483647]`. If the set time is not in this range, it will be set to 1.
### pending callbacks
This phase executes I/O callbacks deferred to the next loop iteration.
### idle, prepare
The `idle, prepare` phase is for internal implementation.
### poll
This phase retrieves new I/O events; execute I/O related callbacks (almost all with the exception of close callbacks, the ones scheduled by timers, and setImmediate()); node will block here when appropriate.
The `poll` phase has two main functions:
1. Calculating how long it should block and poll for I/O, then
2. Processing events in the poll queue.
When the event loop enters the `poll` phase and there are no timers scheduled, one of two things will happen:
- If the `poll` queue is not empty, the event loop will iterate through its queue of callbacks executing them synchronously until either the queue has been exhausted, or the system-dependent hard limit is reached.
- If the `poll` queue is empty, one of two more things will happen:
1. If scripts have been scheduled by `setImmediate`. the event loop will end the `poll` phase and continue to the check phase to execute those scheduled scripts.
2. If scripts have not been scheduled by `setImmediate`, the event loop will wait for callbacks to be added to the queue, then execute them immediately.
Once the `poll` queue is empty the event loop will check for timers whose time thresholds have been reached. If one or more timers are ready, the event loop will wrap back to the timers phase to execute those timers' callbacks.
### check
The `check` phase executes the callbacks of `setImmediate`.
### close callbacks
The `close` event will be emitted in this phase.
And in Node, the order of execution of timers is random in some cases:
```js
setTimeout(() => {
console.log('setTimeout');
}, 0);
setImmediate(() => {
console.log('setImmediate');
})
// Here, it may log setTimeout => setImmediate
// It is also possible to log the opposite result, which depends on performance
// Because it may take less than 1 millisecond to enter the event loop, `setImmediate` would be executed at this time.
// Otherwise it will execute `setTimeout`
```
Certainly, in this case, the execution order is the same:
```js
var fs = require('fs')
fs.readFile(__filename, () => {
setTimeout(() => {
console.log('timeout');
}, 0);
setImmediate(() => {
console.log('immediate');
});
});
// Because the callback of `readFile` was executed in `poll` phase
// Founding `setImmediate`,it immediately jumps to the `check` phase to execute the callback
// and then goes to the `timer` phase to execute `setTimeout`
// so the above output must be `setImmediate` => `setTimeout`
```
The above is the implementation of the macrotask. The microtask will be executed immediately after each phase is completed.
```js
setTimeout(()=>{
console.log('timer1')
Promise.resolve().then(function() {
console.log('promise1')
})
}, 0)
setTimeout(()=>{
console.log('timer2')
Promise.resolve().then(function() {
console.log('promise2')
})
}, 0)
// The log result is different, when the above code is executed in browser and node
// In browser, it will log: timer1 => promise1 => timer2 => promise2
// In node, it may log: timer1 => timer2 => promise1 => promise2
// or timer1, promise1, timer2, promise2
```
`process.nextTick` in Node will be executed before other microtasks.
```js
setTimeout(() => {
console.log("timer1");
Promise.resolve().then(function() {
console.log("promise1");
});
}, 0);
process.nextTick(() => {
console.log("nextTick");
});
// nextTick => timer1 => promise1
```
# Storage
## cookie,localStorage,sessionStorage,indexDB
| features | cookie | localStorage | sessionStorage | indexDB |
| :---------------------: | :----------------------------------------------------------: | :---------------------------------------: | :----------------------------------------------------------: | :---------------------------------------: |
| Life cycle of data | generally generated by the server, but you can set the expiration time | unless cleared manually, it always exists | once the browser tab is closed, it will be cleaned up immediately | unless cleared manually, it always exists |
| Storage size of data | 4K | 5M | 5M | unlimited |
| Communication with server | it is carried in the header everytime, and has a performance impact on the request | doesn't participate | doesn't participate | doesn't participate |
As we can see from the above table, `cookies` are no longer recommended for storage. We can use `localStorage` and `sessionStorage` if we don't have much data to store. Use `localStorage` to store data that doesn't change much, otherwise `sessionStorage` can be used.
For `cookies`, we also need pay attention to security issue.
| attribute | effect |
| :-------: | :----------------------------------------------------------: |
| value | the value should be encrypted if used to save the login state, and the cleartext user ID shouldn't be used |
| http-only | cookies cannot be accessed through JS, for reducing XSS attack |
| secure | cookies can only be carried in requests with HTTPS protocol |
| same-site | browsers cannot pass cookies in cross-origin requests, for reducing CSRF attacks |
## Service Worker
> Service workers essentially act as proxy servers that sit between web applications, the browser and the network (when available). They are intended, among other things, to enable the creation of effective offline experiences, intercept network requests and take appropriate action based on whether the network is available, and update assets residing on the server. They will also allow access to push notifications and background sync APIs.
At present, this technology is usually used to cache files and increase the render speed of the first screen. We can try to implement this function:
```js
// index.js
if (navigator.serviceWorker) {
navigator.serviceWorker
.register("sw.js")
.then(function(registration) {
console.log("service worker register success");
})
.catch(function(err) {
console.log("servcie worker register error");
});
}
// sw.js
// Listen for the `install` event, and cache the required files in the callback
self.addEventListener("install", e => {
e.waitUntil(
caches.open("my-cache").then(function(cache) {
return cache.addAll(["./index.html", "./index.js"]);
})
);
});
// intercept all the request events
// use the cache directly if the requested data already existed in the cache; otherwise, send requests for data
self.addEventListener("fetch", e => {
e.respondWith(
caches.match(e.request).then(function(response) {
if (response) {
return response;
}
console.log("fetch source");
})
);
});
```
Open the page, we can see that the Service Worker has started in the `Application` pane of devTools:
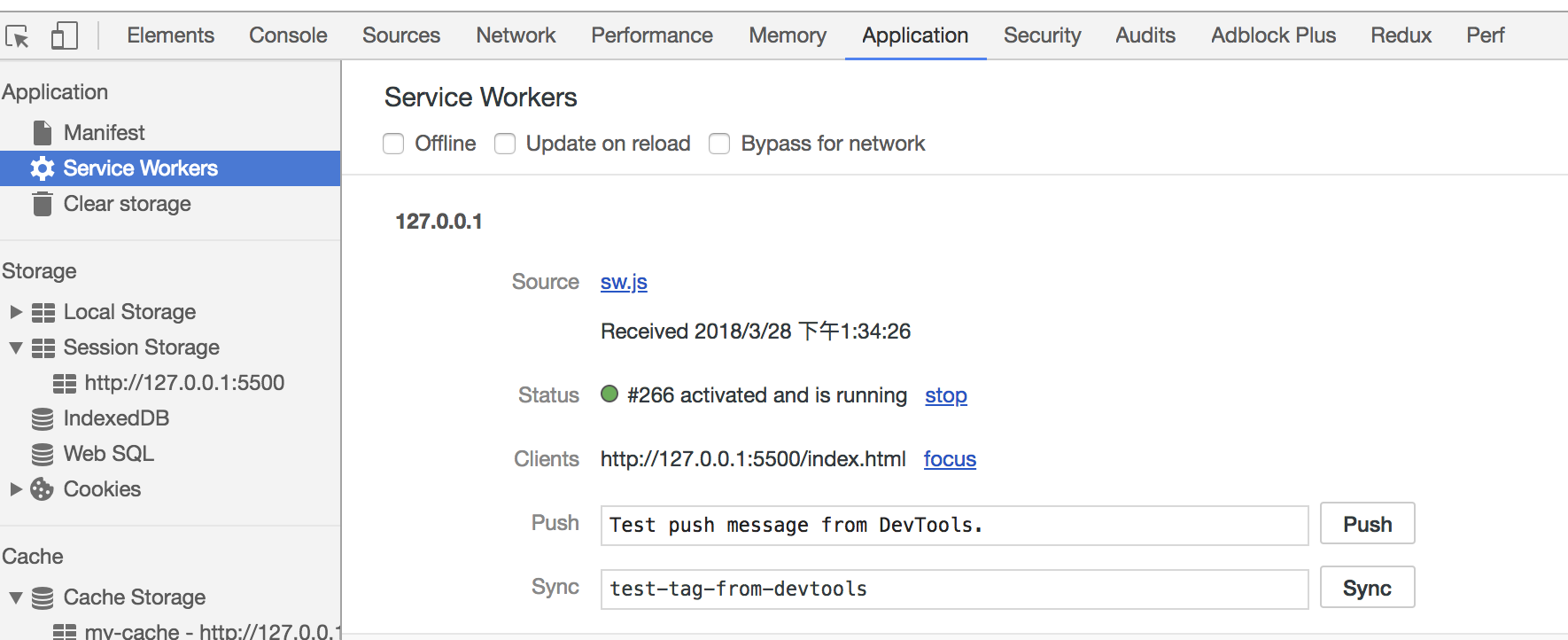
In the Cache pane, we can also find that the files we need have been cached:

Refreshing the page, we can see that our cached data is read from the Service Worker:

# Rendering mechanism
The mechanism of the browser engine usually has the following steps:
1. Parse HTML to construct the DOM tree.
2. Parse CSS to construct the CSSOM tree.
3. Create the render tree by combining the DOM & CSSOM.
4. Run layout based on the render tree, then calculate each node's exact coordinates on the screen.
5. Paint elements by GPU, composite layers and display on the screen.
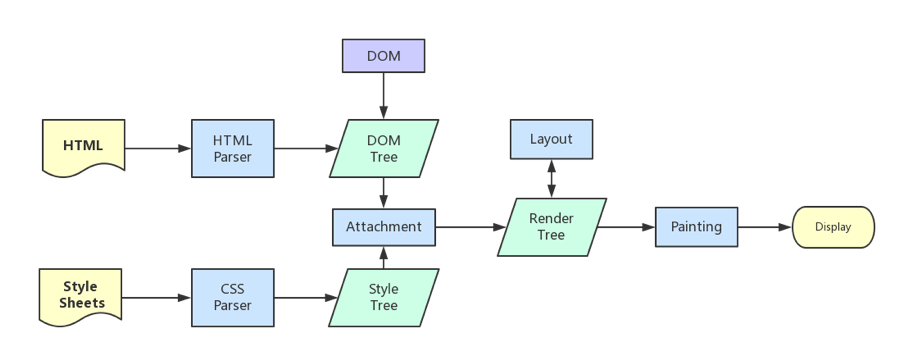
When building the CSSOM tree, the rendering is blocked until the CSSOM tree is built. And building the CSSOM tree is a very cost-intensive process, so you should try to ensure that the level is flat and reduce excessive cascading. The more specific the CSS selector is, the slower the execution.
When the HTML is parsing the script tag, the DOM is paused and will restart from the paused position. In other words, the faster you want to render the first screen, the less you should load the JS file on the first screen. And CSS will also affect the execution of JS. JS will only be executed when the stylesheet is parsed. Therefore, it can be considered that CSS will also suspend the DOM in this case.
## Difference between Load & DOMContentLoaded
**Load** event occurs when all the resources (e.g. DOM、CSS、JS、pictures) have been loaded.
**DOMContentLoaded** event occurs as soon as the HTML of the pages has been loaded, no matter whether the other resources have been loaded.
## Layers
Generally,we can treat the document flow as a single layer. Some special attributes also could create a new layer. **Different Layers are independent**. So, it is recommended to create a new layer to render some elements which changes frequently. **But it is also a bad idea to create too many layers.**
The following attributes usually can create a new layer:
- 3Dtranslate: `translate3d`, `translateZ`
- `will-change`
- tags like: `video`, `iframe`
- animation achieved by `opacity`
- `position: fixed`
## Repaint & Reflow
Repaint and Reflow is a small step in the main rendering flow, but they have a great impact on the performance.
- Repaint occurs when the node changes but doesn't affect the layout, e.g. `color`.
- Reflow occurs when the node changes caused by layout or the geometry attributes.
Reflow will trigger a Repaint, but the opposite is not necessarily true. Reflow is much more expensive than Repaint. The changes in deep level node's attributes may cause a series of changes of its ancestral nodes.
Actions like the following may cause performance problems:
- change the window's size
- change font-family
- add or delete styles
- change texts
- change position & float
- change box model
You may not know that Repaint and Reflow has something to do with the **Event Loop**.
- In a event loop, when a microtask finishes, the engine will check whether the document needs update. As the refresh rate of the browse is 60Hz, this means it will update every 16ms.
- Then browser would check whether there are events like `resize` or `scroll` and if true, trigger the handlers. So the handlers of resize and scroll will be invoked every 16ms, which means automatic throttling.
- Evaluate media queries and report changes.
- Update animations and send events.
- Check whether this is a full-screen event.
- Execute `requestAnimationFrame` callback.
- Execute `IntersectionObserver` callback, which is used to determine whether an element should be displaying, usually in lazy-load, but has poor compatibility.
- Update the screen.
- The above events may occur in every frame. If there is idle time, the `requestIdleCallback` callback will be called.
All of the above are from [HTML Documents](https://html.spec.whatwg.org/multipage/webappapis.html#event-loop-processing-model).
## Minimize Repaint & Reflow
- Use `translate` instead of `top`:
```html
```
- Use `visibility` instead of `display: none`, because the former will only cause Repaint while the latter will cause Reflow, which changes the layout.
- Change the DOM when it is offline, e.g. change the DOM 100 times after set it `display: none` and then show it on screen. During this process there is only one Reflow.
- Do not put an attribute of a node inside a loop:
```js
for(let i = 0; i < 1000; i++) {
// it will cause the reflow to get offsetTop, because it need to calculate the right value
console.log(document.querySelector('.test').style.offsetTop)
}
```
- Do not use table to construct the layout, because even a little change will cause the re-construct.
- Animation speed matters: the faster it goes, the more Reflow. You can also utilize `requestAnimationFrame`.
- The css selector will search to match from right to left, so you'd better avoid deep level DOM node.
- As we know that the layer will prevent the changed node from affecting others, so it is good practice to create a new layer for animations with high frequency.
================================================
FILE: Career/How-to-use-your-time-correctly.md
================================================
**Table of Contents** *generated with [DocToc](https://github.com/thlorenz/doctoc)*
- [花时间补基础,读文档](#%E8%8A%B1%E6%97%B6%E9%97%B4%E8%A1%A5%E5%9F%BA%E7%A1%80%E8%AF%BB%E6%96%87%E6%A1%A3)
- [学会搜索](#%E5%AD%A6%E4%BC%9A%E6%90%9C%E7%B4%A2)
- [学点英语](#%E5%AD%A6%E7%82%B9%E8%8B%B1%E8%AF%AD)
- [画个图,想一想再做](#%E7%94%BB%E4%B8%AA%E5%9B%BE%E6%83%B3%E4%B8%80%E6%83%B3%E5%86%8D%E5%81%9A)
- [利用好下班时间学习](#%E5%88%A9%E7%94%A8%E5%A5%BD%E4%B8%8B%E7%8F%AD%E6%97%B6%E9%97%B4%E5%AD%A6%E4%B9%A0)
- [列好 ToDo](#%E5%88%97%E5%A5%BD-todo)
- [反思和整理](#%E5%8F%8D%E6%80%9D%E5%92%8C%E6%95%B4%E7%90%86)
你是否时常会焦虑时间过的很快,没时间学习,本文将会分享一些个人的见解。
### 花时间补基础,读文档
在工作中我们时常会花很多时间去 debug,但是你是否发现很多问题最终只是你基础不扎实或者文档没有仔细看。
基础是你技术的基石,一定要花时间打好基础,而不是追各种新的技术。一旦你的基础扎实,学习各种新的技术也肯定不在话下,因为新的技术,究其根本都是相通的。
文档同样也是一门技术的基础。一个优秀的库,开发人员肯定已经把如何使用这个库都写在文档中了,仔细阅读文档一定会是少写 bug 的最省事路子。
### 学会搜索
如果你还在使用百度搜索编程问题,请尽快抛弃这个垃圾搜索引擎。同样一个关键字,使用百度和谷歌,谷歌基本完胜的。即使你使用中文在谷歌中搜索,得到的结果也往往是谷歌占优,所以如果你想迅速的通过搜索引擎来解决问题,那一定是谷歌。
### 学点英语
说到英语,一定是大家所最不想听的。其实我一直认为程序员学习英语是简单的,因为我们工作中是一直接触着英语,并且看懂技术文章,文档所需要的单词量是极少的。我时常在群里看到大家发出一个问题的截图问什么原因,其实在截图中英语已经很明白的说明了问题的所在,如果你的英语过关,完全不需要浪费时间来提问和搜索。所以我认为学点英语也是节省时间中很重要的一点。
那么如何去学习呢,chrome 装个翻译插件,直接拿英文文档或文章读,不会的就直接划词翻译,然后记录下这个单词并背诵。每天花半小时看点英文文档和文章,坚持两个月,你的英语水平不说别的,看文档和文章绝对不会有难题了。这一定是一个很划算的个人时间投资,花点时间学习英语,能为你将来的技术之路铺平很多坎。
### 画个图,想一想再做
你是否遇到过这种问题,需求一下来,看一眼,然后马上就按照设计稿开始做了,可能中间出个问题导致你需要返工。
如果你存在这样的问题,我很推荐在看到设计稿和需求的时候花点时间想一想,画一画。考虑一下设计稿中是否可以找到可以拆分出来的复用组件,是否存在之前写过的组件。该如何组织这个界面,数据的流转是怎么样的。然后画一下这个页面的需求,最后再动手做。
### 利用好下班时间学习
说到下班时间,那可能就有人说了公司很迟下班,这其实是国内很普遍的情况。但是我认为正常的加班是可以的,但是强制的加班就是在损耗你的身体和前途。
可以这么说,大部分的 996 公司,加班的这些时间并不会增加你的技术,无非就是在写一些重复的业务逻辑。也许你可以拿到更多的钱,但是代价是身体还有前途。程序员是靠技术吃饭的,如果你长久呆在一个长时间加班的公司,不能增长你的技术还要吞噬你的下班学习时间,那么你一定会废掉的。如果你遇到了这种情况,只能推荐尽快跳槽到非 996 的公司。
那么如果你有足够的下班时间,一定要花上 1, 2 小时去学习,上班大家基本都一样,技术的精进就是看下班以后的那几个小时了。如果你能利用好下班时间来学习,坚持下去,时间一定会给你很好的答复。
### 列好 ToDo
我喜欢规划好一段时间内要做的事情,并且要把事情拆分为小点。给 ToDo 列好优先级,紧急的优先级最高。相同优先级的我喜欢先做简单的,因为这样一旦完成就能划掉一个,提高成就感。
### 反思和整理
每周末都会花上点时间整理下本周记录的笔记和看到的不错文章。然后考虑下本周完成的工作和下周准备要完成的工作。
================================================
FILE: DataStruct/dataStruct-en.md
================================================
**Table of Contents** *generated with [DocToc](https://github.com/thlorenz/doctoc)*
- [Stack](#stack)
- [Conception](#conception)
- [Implementation](#implementation)
- [Application](#application)
- [Queues](#queues)
- [concept](#concept)
- [implementation](#implementation)
- [Singly-linked Queue](#singly-linked-queue)
- [Circular Queue](#circular-queue)
- [Linked List](#linked-list)
- [Concept](#concept)
- [Implementation](#implementation-1)
- [Tree](#tree)
- [Binary Tree](#binary-tree)
- [Binary Search Tree](#binary-search-tree)
- [Implementation](#implementation-2)
- [AVL Tree](#avl-tree)
- [Concept](#concept-1)
- [Implementation](#implementation-3)
- [Trie](#trie)
- [Concept](#concept-2)
- [Implementation](#implementation-4)
- [Disjoint Set](#disjoint-set)
- [Concept](#concept-3)
- [Implementation](#implementation-5)
- [Heap](#heap)
- [Concept](#concept-4)
- [Implementation of Max Binary Heap](#implementation-of-max-binary-heap)
# Stack
## Conception
A stack is the basic data structure that can be logically thought of as a linear structure.
Insertion and deletion of items at the top of the stack and the operation should obey the rules LIFO(Last In First Out).

## Implementation
Each data structure can be implemented by the different method. We can treat stack as a subclass of Array. So we take the array for example here.
```js
class Stack {
constructor() {
this.stack = []
}
push(item) {
this.stack.push(item)
}
pop() {
this.stack.pop()
}
peek() {
return this.stack[this.getCount() - 1]
}
getCount() {
return this.stack.length
}
isEmpty() {
return this.getCount() === 0
}
}
```
## Application
We choose [the NO.20 topic in LeetCode](https://leetcode.com/problems/valid-parentheses/submissions/1)
Our goal is to match the brackets. We can use the features of the stack to implement it.
```js
var isValid = function (s) {
let map = {
'(': -1,
')': 1,
'[': -2,
']': 2,
'{': -3,
'}': 3
}
let stack = []
for (let i = 0; i < s.length; i++) {
if (map[s[i]] < 0) {
stack.push(s[i])
} else {
let last = stack.pop()
if (map[last] + map[s[i]] != 0) return false
}
}
if (stack.length > 0) return false
return true
};
```
# Queues
## concept
A queue is a linear data structure. The insertion takes place at one end while the deletion occurs the other one. And the operation should obey the rules FIFO(First In First Out).

## implementation
Here, we'll talk two implementations of the queue: Singly-linked Queue and Circular Queue.
### Singly-linked Queue
```js
class Queue {
constructor() {
this.queue = []
}
enQueue(item) {
this.queue.push(item)
}
deQueue() {
return this.queue.shift()
}
getHeader() {
return this.queue[0]
}
getLength() {
return this.queue.length
}
isEmpty() {
return this.getLength() === 0
}
}
```
It is an O(n) operation to enqueue in a Singly-linked Queue, while it is an average O(1) in a Circular Queue. So here comes the Circular Queue.
### Circular Queue
```js
class SqQueue {
constructor(length) {
this.queue = new Array(length + 1)
// head of the queue
this.first = 0
// tail of the queue
this.last = 0
// size of the queue
this.size = 0
}
enQueue(item) {
// the array need to expand if last + 1 is the head
// `% this.queue.length` is to avoid index out of bounds
if (this.first === (this.last + 1) % this.queue.length) {
this.resize(this.getLength() * 2 + 1)
}
this.queue[this.last] = item
this.size++
this.last = (this.last + 1) % this.queue.length
}
deQueue() {
if (this.isEmpty()) {
throw Error('Queue is empty')
}
let r = this.queue[this.first]
this.queue[this.first] = null
this.first = (this.first + 1) % this.queue.length
this.size--
// if the size of queue is too small
// reduce the size half when the real size is quarter of the length and the length is not 2
if (this.size === this.getLength() / 4 && this.getLength() / 2 !== 0) {
this.resize(this.getLength() / 2)
}
return r
}
getHeader() {
if (this.isEmpty()) {
throw Error('Queue is empty')
}
return this.queue[this.first]
}
getLength() {
return this.queue.length - 1
}
isEmpty() {
return this.first === this.last
}
resize(length) {
let q = new Array(length)
for (let i = 0; i < length; i++) {
q[i] = this.queue[(i + this.first) % this.queue.length]
}
this.queue = q
this.first = 0
this.last = this.size
}
}
```
# Linked List
## Concept
The linked list is a linear data structure and born to be recursive structure. It can fully use the memory of the computer and manage the memory dynamically and flexibly. But Nodes in the linked list must be read in order from the beginning which can be random in the array, and it uses more memory than the array because of the storage used by their pointers.

## Implementation
Singly-linked list
```javascript
class Node {
constructor(v, next) {
this.value = v
this.next = next
}
}
class LinkList {
constructor() {
// size
this.size = 0
// virtual head
this.dummyNode = new Node(null, null)
}
find(header, index, currentIndex) {
if (index === currentIndex) return header
return this.find(header.next, index, currentIndex + 1)
}
addNode(v, index) {
this.checkIndex(index)
// the next of the node inserted should be previous node'next
// and the previous node's next should point to the node insert,
// except inserted to tail which next is null
let prev = this.find(this.dummyNode, index, 0)
prev.next = new Node(v, prev.next)
this.size++
return prev.next
}
insertNode(v, index) {
return this.addNode(v, index)
}
addToFirst(v) {
return this.addNode(v, 0)
}
addToLast(v) {
return this.addNode(v, this.size)
}
removeNode(index, isLast) {
this.checkIndex(index)
index = isLast ? index - 1 : index
let prev = this.find(this.dummyNode, index, 0)
let node = prev.next
prev.next = node.next
node.next = null
this.size--
return node
}
removeFirstNode() {
return this.removeNode(0)
}
removeLastNode() {
return this.removeNode(this.size, true)
}
checkIndex(index) {
if (index < 0 || index > this.size) throw Error('Index error')
}
getNode(index) {
this.checkIndex(index)
if (this.isEmpty()) return
return this.find(this.dummyNode, index, 0).next
}
isEmpty() {
return this.size === 0
}
getSize() {
return this.size
}
}
```
# Tree
## Binary Tree
Binary Tree is a common one of the many structures of the tree. And it is born to be recursive.
Binary tree start at a root node and each node consists of two child-nodes at most: left node and right node. The nodes in the bottom are usually called leaf nodes, and when the leaf nodes is full, we call the Full Binary Tree.
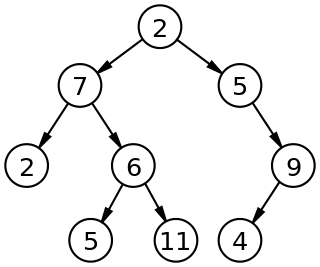
## Binary Search Tree
Binary Search Tree (BST) is one of the binary trees, so it has all the features of the binary tree. But different with the binary tree, the value in any node is larger than the values in all nodes in that node's left subtree and smaller than the values in all nodes in that node's right subtree.
This storage method is very suitable for data search. As shown below, when you need to find 6, because the value you need to find is larger than the value of the root node, you only need to find it in the right subtree of the root node, which greatly improves the search efficiency.
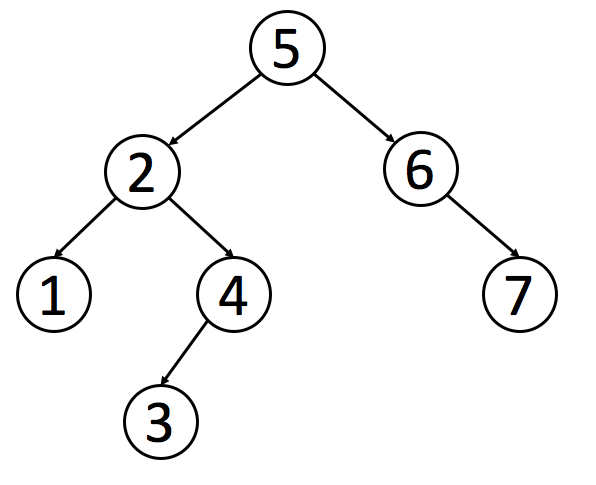
### Implementation
```js
class Node {
constructor(value) {
this.value = value
this.left = null
this.right = null
}
}
class BST {
constructor() {
this.root = null
this.size = 0
}
getSize() {
return this.size
}
isEmpty() {
return this.size === 0
}
addNode(v) {
this.root = this._addChild(this.root, v)
}
// make comparison to the value of the node when insertion
_addChild(node, v) {
if (!node) {
this.size++
return new Node(v)
}
if (node.value > v) {
node.left = this._addChild(node.left, v)
} else if (node.value < v) {
node.right = this._addChild(node.right, v)
}
return node
}
}
```
Above is the basic implementation of BST, the implementation of traversing tree are as follows.
There are three ways for traversing trees: Preorder Traversal, In order Traversal, PostOrder Traversal. The difference of these ways is the time when to visit the root node. In the process of traversing the tree, each node traverses three times, traversing itself, traversing the left subtree and traversing the right subtree. If you need to implement pre-order traversal, you only need to operate the first time when traversing to the node.
Following are the implementation by recursive, if you want to find the non-recursive, [click here](../Algorithm/algorithm-ch.md#%E9%9D%9E%E9%80%92%E5%BD%92%E5%AE%9E%E7%8E%B0)
```js
// Preorder traversal can be used to print the structure of the tree
// first root then left, and the right is last
traversal() {
this._pre(this.root)
}
_pre(node) {
if (node) {
console.log(node.value)
this._pre(node.left)
this._pre(node.right)
}
}
// Inorder traversal can be used to order
// you can sort the value of BST only by one time of Inorder traversal
// first left , then root and right is last
midTraversal() {
this._mid(this.root)
}
_mid(node) {
if (node) {
this._mid(node.left)
console.log(node.value)
this._mid(node.right)
}
}
// Postorder traversal can be used in the case that you want to
// operate the child node first and then the parent node
// first left, then right and the root is last
backTraversal() {
this._back(this.root)
}
_back(node) {
if (node) {
this._back(node.left)
this._back(node.right)
console.log(node.value)
}
}
```
These three ways belong to Deep First Search. Meanwhile, there is Breadth First Search, which traverse the node layer by layer. We can implement it in the queue.
```js
breadthTraversal() {
if (!this.root) return null
let q = new Queue()
// enqueue the root node
q.enQueue(this.root)
// whether the queue is empty, if true, the traverse is finished.
while (!q.isEmpty()) {
// dequeue the head, and whether it has child-node,
// if true, enqueue th left and the right
let n = q.deQueue()
if (n.left) q.enQueue(n.left)
if (n.right) q.enQueue(n.right)
}
}
```
We will introduce how to find the smallest and the biggest in the tree. Because of the feature of the BST, the smallest must be on the left while the biggest is on the right.
```js
getMin() {
return this._getMin(this.root).value
}
_getMin(node) {
if (!node.left) return node
return this._getMin(node.left)
}
getMax() {
return this._getMax(this.root).value
}
_getMax(node) {
if (!node.right) return node
return this._getMin(node.right)
}
```
**Round up and Round down** Since these two operations are opposite, the code is similar, here we'll talk about round down. According to the feature of the BST, the target must be on the left. We only need to traverse the left nodes until the current node is no bigger than the target. And then adjudge if there have right nodes, if do, continue the judgment recursively.
```js
floor(v) {
let node = this._floor(this.root, v)
return node ? node.value : null
}
_floor(node, v) {
if (!node) return null
if (node.value === v) return v
// if the current node is bigger than the target, continue
if (node.value > v) {
return this._floor(node.left, v)
}
// whether the current node has the right subtree
let right = this._floor(node.right, v)
if (right) return right
return node
}
```
**Rank** get the rank of the given value or get the value of the given rank, and these two operations are also similar. We as usual only introduce the operation of the latter. We should retrofit the code to add a property `size` to each node which indicates how many subnodes a node has, include itself.
```js
class Node {
constructor(value) {
this.value = value
this.left = null
this.right = null
// add code
this.size = 1
}
}
// add code
_getSize(node) {
return node ? node.size : 0
}
_addChild(node, v) {
if (!node) {
return new Node(v)
}
if (node.value > v) {
// edit code
node.size++
node.left = this._addChild(node.left, v)
} else if (node.value < v) {
// edit code
node.size++
node.right = this._addChild(node.right, v)
}
return node
}
select(k) {
let node = this._select(this.root, k)
return node ? node.value : null
}
_select(node, k) {
if (!node) return null
// get the size of the node in the left subtree
let size = node.left ? node.left.size : 0
// if size is bigger than k, the target is in the left side
if (size > k) return this._select(node.left, k)
// if the size is smaller than k, the target is in the right side
// there is need to recalculate the k
if (size < k) return this._select(node.right, k - size - 1)
return node
}
```
Here come the most difficult parts in BST: delete nodes, include the following cases:
- the target node has no subtree
- the target node has only one subtree
- the target node has two subtrees
The first and the second is easy to resolve, while the last is a little difficult.
So let us implement the simple operation at first: delete the minimum node. It could not appear in the third case, and the operation delete the largest node is opposite, so there is no need to talk.
```js
delectMin() {
this.root = this._delectMin(this.root)
console.log(this.root)
}
_delectMin(node) {
// rescursive the left subtree
// if the left subtree is null, check if the right is exist
// if true, take the right subtree in place of the delect node
if ((node != null) & !node.left) return node.right
node.left = this._delectMin(node.left)
// update the size at last
node.size = this._getSize(node.left) + this._getSize(node.right) + 1
return node
}
```
The last, how to delete a random node. T.Hibbard put forward the solution in 1962 which can be used to solve the third case.
In this situation, we should get the descendant node of the current node which is the smallest node in the current node's right subtree and replace the target node by it. And then assign the descendant node with the subtree of the target, and give the right subtree without decent node to the left subtree.
Since the root node is bigger than all the nodes in left subtree, while less than all the nodes in the right subtree. When you want to delete a root node, you need to pick a suitable node to take place, which should bigger than the root node that means it must come from the right subtree. Then the smallest node would be picked with the limit that all the nodes in the right subtree should bigger than the root node.
```js
delect(v) {
this.root = this._delect(this.root, v)
}
_delect(node, v) {
if (!node) return null
// if the target is less than the current node, serach in the left subtree
if (node.value < v) {
node.right = this._delect(node.right, v)
} else if (node.value > v) {
// if the target is bigger than the current node, serach in the right subtree
node.left = this._delect(node.left, v)
} else {
// in this case, the target has been found
// check if the node has subtree
// if true, return the subtree, same operation with `_delectMin`
if (!node.left) return node.right
if (!node.right) return node.left
// in this case, the node has both subtree
// get the decendent node of the current node,
// which is the smallest node in the right subtree
let min = this._getMin(node.right)
// delete the smallest after got it
// Then assign the subtree after deleting the node to the smallest node
min.right = this._delectMin(node.right)
// subtree is the same
min.left = node.left
node = min
}
// update size
node.size = this._getSize(node.left) + this._getSize(node.right) + 1
return node
}
```
## AVL Tree
### Concept
BST is limited in the production because it is not the strict O(log N) and sometimes it will degenerate to a linked list, e.g., insertion of an ascending order number list.
AVL tree improved the BST, the difference between the left subtree height and the right subtree height in each node is less than 1, which can ensure that the time complexity is strict O(log N). Based on this, the insertion and deletion may need to rotate the tree to balance the height.
### Implementation
Since improved from the BST, some codes in AVL are repeated, which we will not analysis again.
Four cases are in the node insertion of AVL tree.

As for l-l(left-left), the new node T1 is in the left side of the node X. The tree cannot keep balance by now, so there need to rotate. After rotating, the tree should still obey the rules the mid is bigger than the left and less than the right according to the features of the BST.
before rotating: T1 < X < T2 < Y < T3 < Z < T4, after rotating, the node Y is the root, so we need to add the right subtree of Y to the left of the Z and update the height of the nodes.
The same situation to the r-r, opposite to the l-l, we do not talk more.
As for the l-r, the new node is on the right side of the node X, and we need to rotate twice.
First, rotate the left node to the left, after that the case change to l-l, we can handle it like l-l.
```js
class Node {
constructor(value) {
this.value = value
this.left = null
this.right = null
this.height = 1
}
}
class AVL {
constructor() {
this.root = null
}
addNode(v) {
this.root = this._addChild(this.root, v)
}
_addChild(node, v) {
if (!node) {
return new Node(v)
}
if (node.value > v) {
node.left = this._addChild(node.left, v)
} else if (node.value < v) {
node.right = this._addChild(node.right, v)
} else {
node.value = v
}
node.height =
1 + Math.max(this._getHeight(node.left), this._getHeight(node.right))
let factor = this._getBalanceFactor(node)
// when need right-rotate, the height of the left subtree must higher than right
if (factor > 1 && this._getBalanceFactor(node.left) >= 0) {
return this._rightRotate(node)
}
// when need left-rotate, the height of the left subtree must lower than right
if (factor < -1 && this._getBalanceFactor(node.right) <= 0) {
return this._leftRotate(node)
}
// l-r
// left subtree is higher than right,
// and the right subtree of the left subtree of the node
// is higher than the left subtree of the left subtree of the node
if (factor > 1 && this._getBalanceFactor(node.left) < 0) {
node.left = this._leftRotate(node.left)
return this._rightRotate(node)
}
// r-l
// left subtree is lower than right,
// and the right subtree of the right subtree of the node
// is lower than the left subtree of the right subtree of the node
if (factor < -1 && this._getBalanceFactor(node.right) > 0) {
node.right = this._rightRotate(node.right)
return this._leftRotate(node)
}
return node
}
_getHeight(node) {
if (!node) return 0
return node.height
}
_getBalanceFactor(node) {
return this._getHeight(node.left) - this._getHeight(node.right)
}
// right-rotate
// 5 2
// / \ / \
// 2 6 ==> 1 5
// / \ / / \
// 1 3 new 3 6
// /
// new
_rightRotate(node) {
// new root after rotate
let newRoot = node.left
// node need to be moved
let moveNode = newRoot.right
// right node of the node 2 change to node 5
newRoot.right = node
// left node of node 5 change to node 3
node.left = moveNode
// update the height
node.height =
1 + Math.max(this._getHeight(node.left), this._getHeight(node.right))
newRoot.height =
1 +
Math.max(this._getHeight(newRoot.left), this._getHeight(newRoot.right))
return newRoot
}
// left-rotate
// 4 6
// / \ / \
// 2 6 ==> 4 7
// / \ / \ \
// 5 7 2 5 new
// \
// new
_leftRotate(node) {
// new root after rotate
let newRoot = node.right
// node need to be moved
let moveNode = newRoot.left
// left node of the node 6 change to node 4
newRoot.left = node
// right node of the node 4 change to node 5
node.right = moveNode
// update the height
node.height =
1 + Math.max(this._getHeight(node.left), this._getHeight(node.right))
newRoot.height =
1 +
Math.max(this._getHeight(newRoot.left), this._getHeight(newRoot.right))
return newRoot
}
}
```
# Trie
## Concept
In computer science, a trie, also called digital tree and sometimes radix tree or prefix tree (as prefixes can search them), is a kind of search tree—an ordered tree data structure that is used to store a dynamic set or associative array where the keys are usually strings.
Simply, this data structure is used to search string easily, with the following features:
- the root is on behalf of the empty string, and each node has N links (N is 26 in searching English character), each link represents a character.
- all nodes do not store a character, and only the path store, this is different from other tree structures.
- the character in the path from the root to the random node can combine to the strings corresponding to the node
## Implementation
Generally, the implementation of the trie is much more simple than others, let's take the English character searching for example.
```js
class TrieNode {
constructor() {
// the times of each character travels through the node
this.path = 0
// the amount of the string to the node
this.end = 0
// links
this.next = new Array(26).fill(null)
}
}
class Trie {
constructor() {
// root node, empty string
this.root = new TrieNode()
}
// insert string
insert(str) {
if (!str) return
let node = this.root
for (let i = 0; i < str.length; i++) {
// get the index of the character
let index = str[i].charCodeAt() - 'a'.charCodeAt()
// create if without the index
if (!node.next[index]) {
node.next[index] = new TrieNode()
}
node.path += 1
node = node.next[index]
}
node.end += 1
}
// The number of times the search string appears
search(str) {
if (!str) return
let node = this.root
for (let i = 0; i < str.length; i++) {
let index = str[i].charCodeAt() - 'a'.charCodeAt()
// if the index does node exists, there is no string to be search
if (!node.next[index]) {
return 0
}
node = node.next[index]
}
return node.end
}
// delete the string
delete(str) {
if (!this.search(str)) return
let node = this.root
for (let i = 0; i < str.length; i++) {
let index = str[i].charCodeAt() - 'a'.charCodeAt()
// if the path is 0, this means no string pass
// delete it
if (--node.next[index].path == 0) {
node.next[index] = null
return
}
node = node.next[index]
}
node.end -= 1
}
}
```
# Disjoint Set
## Concept
Disjoint Set is a special data structure of the tree. Each node in this structure has a parent node, if there is only the current node, then the pointer of the parent node points to itself.
Two important operations are in this structure,
- Find: find the member of the set to which the element belongs, and it can be used to determine whether the two elements belong to the same set
- Union: combine two sets to a new set
## Implementation
```js
class DisjointSet {
// init sample
constructor(count) {
// each node's parenet node is iteself when initialization
this.parent = new Array(count)
// record the deepth of the tree to optimize the complexity of query
this.rank = new Array(count)
for (let i = 0; i < count; i++) {
this.parent[i] = i
this.rank[i] = 1
}
}
find(p) {
// check whether the parent node of the current node is itself, if false, means has not found yet
// uglify the path for optimization
// assume the parent node of the current node is A
// mount the current node to the parent node of A to deeply optimize
while (p != this.parent[p]) {
this.parent[p] = this.parent[this.parent[p]]
p = this.parent[p]
}
return p
}
isConnected(p, q) {
return this.find(p) === this.find(q)
}
// combine
union(p, q) {
// find the parent node of the two number
let i = this.find(p)
let j = this.find(q)
if (i === j) return
// compare the deepth of the two trees
// if the deepth is equal, add as you wish
if (this.rank[i] < this.rank[j]) {
this.parent[i] = j
} else if (this.rank[i] > this.rank[j]) {
this.parent[j] = i
} else {
this.parent[i] = j
this.rank[j] += 1
}
}
}
```
# Heap
## Concept
Heap is usually treated as a tree-based array list.
It is implemented by constructure binary heap, one of the BST. Features are as follows:
- each node either larger or less than all its child-nodes
- heap is always a full-tree
We call the heap **Max Binary Heap** that its root value is the largest, while the heap with the smallest root value is called **Min Binary Heap**.
Priority Queue also can be implemented by the heap, with the same operation.
## Implementation of Max Binary Heap
The index of the left-child of each node is `i * 2 + 1`, while the right's is `i * 2 + 2`, and the parent's is `(i - 1) / 2`
There are two central operations in the heap, `shiftUp` and `shiftDown`. The former is used for insertion, and the latter is to delete the root node.
The key of `shiftUp` is to compare with the parent node bubbly and exchange the position if it is larger than the parent.
As for `shiftDown`, first exchange root and the tail node, and then delete the tail. After that, Compare with the parent node and both child-nodes circularly, if the child-node is larger, assign the parent node with the larger node.

```js
class MaxHeap {
constructor() {
this.heap = []
}
size() {
return this.heap.length
}
empty() {
return this.size() == 0
}
add(item) {
this.heap.push(item)
this._shiftUp(this.size() - 1)
}
removeMax() {
this._shiftDown(0)
}
getParentIndex(k) {
return parseInt((k - 1) / 2)
}
getLeftIndex(k) {
return k * 2 + 1
}
_shiftUp(k) {
// exchange if the current node is bigger than the parent node
while (this.heap[k] > this.heap[this.getParentIndex(k)]) {
this._swap(k, this.getParentIndex(k))
// update the index to the parent node's
k = this.getParentIndex(k)
}
}
_shiftDown(k) {
// exchange the head and tail, then delete the tail
this._swap(k, this.size() - 1)
this.heap.splice(this.size() - 1, 1)
// check whether the node has left child-node,
// the right must exist because of full-tree
while (this.getLeftIndex(k) < this.size()) {
let j = this.getLeftIndex(k)
// check whether the right child exits, and whether it is largger than the left
if (j + 1 < this.size() && this.heap[j + 1] > this.heap[j]) j++
// check whether the parenet node is largger than both child-nodes
if (this.heap[k] >= this.heap[j]) break
this._swap(k, j)
k = j
}
}
_swap(left, right) {
let rightValue = this.heap[right]
this.heap[right] = this.heap[left]
this.heap[left] = rightValue
}
}
```
```js
class MaxHeap {
constructor() {
this.heap = []
}
size() {
return this.heap.length
}
empty() {
return this.size() == 0
}
add(item) {
this.heap.push(item)
this._shiftUp(this.size() - 1)
}
removeMax() {
this._shiftDown(0)
}
getParentIndex(k) {
return parseInt((k - 1) / 2)
}
getLeftIndex(k) {
return k * 2 + 1
}
_shiftUp(k) {
// exchange if the current node is bigger than the parent node
while (this.heap[k] > this.heap[this.getParentIndex(k)]) {
this._swap(k, this.getParentIndex(k))
// update the index to the parent node's
k = this.getParentIndex(k)
}
}
_shiftDown(k) {
// exchange the head and delete the tail
this._swap(k, this.size() - 1)
this.heap.splice(this.size() - 1, 1)
// check if the node has left child-node, the right must exist if true according to the binary heap
while (this.getLeftIndex(k) < this.size()) {
let j = this.getLeftIndex(k)
// check if the right child exits, and whether it is largger than the left
if (j + 1 < this.size() && this.heap[j + 1] > this.heap[j]) j++
// check if the parenet node is largger than both child-nodes
if (this.heap[k] >= this.heap[j]) break
this._swap(k, j)
k = j
}
}
_swap(left, right) {
let rightValue = this.heap[right]
this.heap[right] = this.heap[left]
this.heap[left] = rightValue
}
}
```
================================================
FILE: DataStruct/dataStruct-zh.md
================================================
**Table of Contents** *generated with [DocToc](https://github.com/thlorenz/doctoc)*
- [栈](#%E6%A0%88)
- [概念](#%E6%A6%82%E5%BF%B5)
- [实现](#%E5%AE%9E%E7%8E%B0)
- [应用](#%E5%BA%94%E7%94%A8)
- [队列](#%E9%98%9F%E5%88%97)
- [概念](#%E6%A6%82%E5%BF%B5-1)
- [实现](#%E5%AE%9E%E7%8E%B0-1)
- [单链队列](#%E5%8D%95%E9%93%BE%E9%98%9F%E5%88%97)
- [循环队列](#%E5%BE%AA%E7%8E%AF%E9%98%9F%E5%88%97)
- [链表](#%E9%93%BE%E8%A1%A8)
- [概念](#%E6%A6%82%E5%BF%B5-2)
- [实现](#%E5%AE%9E%E7%8E%B0-2)
- [树](#%E6%A0%91)
- [二叉树](#%E4%BA%8C%E5%8F%89%E6%A0%91)
- [二分搜索树](#%E4%BA%8C%E5%88%86%E6%90%9C%E7%B4%A2%E6%A0%91)
- [实现](#%E5%AE%9E%E7%8E%B0-3)
- [AVL 树](#avl-%E6%A0%91)
- [概念](#%E6%A6%82%E5%BF%B5-3)
- [实现](#%E5%AE%9E%E7%8E%B0-4)
- [Trie](#trie)
- [概念](#%E6%A6%82%E5%BF%B5-4)
- [实现](#%E5%AE%9E%E7%8E%B0-5)
- [并查集](#%E5%B9%B6%E6%9F%A5%E9%9B%86)
- [概念](#%E6%A6%82%E5%BF%B5-5)
- [实现](#%E5%AE%9E%E7%8E%B0-6)
- [堆](#%E5%A0%86)
- [概念](#%E6%A6%82%E5%BF%B5-6)
- [实现大根堆](#%E5%AE%9E%E7%8E%B0%E5%A4%A7%E6%A0%B9%E5%A0%86)
# 栈
## 概念
栈是一个线性结构,在计算机中是一个相当常见的数据结构。
栈的特点是只能在某一端添加或删除数据,遵循先进后出的原则

## 实现
每种数据结构都可以用很多种方式来实现,其实可以把栈看成是数组的一个子集,所以这里使用数组来实现
```js
class Stack {
constructor() {
this.stack = []
}
push(item) {
this.stack.push(item)
}
pop() {
this.stack.pop()
}
peek() {
return this.stack[this.getCount() - 1]
}
getCount() {
return this.stack.length
}
isEmpty() {
return this.getCount() === 0
}
}
```
## 应用
选取了 [LeetCode 上序号为 20 的题目](https://leetcode.com/problems/valid-parentheses/submissions/1)
题意是匹配括号,可以通过栈的特性来完成这道题目
```js
var isValid = function (s) {
let map = {
'(': -1,
')': 1,
'[': -2,
']': 2,
'{': -3,
'}': 3
}
let stack = []
for (let i = 0; i < s.length; i++) {
if (map[s[i]] < 0) {
stack.push(s[i])
} else {
let last = stack.pop()
if (map[last] + map[s[i]] != 0) return false
}
}
if (stack.length > 0) return false
return true
};
```
# 队列
## 概念
队列一个线性结构,特点是在某一端添加数据,在另一端删除数据,遵循先进先出的原则。

## 实现
这里会讲解两种实现队列的方式,分别是单链队列和循环队列。
### 单链队列
```js
class Queue {
constructor() {
this.queue = []
}
enQueue(item) {
this.queue.push(item)
}
deQueue() {
return this.queue.shift()
}
getHeader() {
return this.queue[0]
}
getLength() {
return this.queue.length
}
isEmpty() {
return this.getLength() === 0
}
}
```
因为单链队列在出队操作的时候需要 O(n) 的时间复杂度,所以引入了循环队列。循环队列的出队操作平均是 O(1) 的时间复杂度。
## 循环队列
```js
class SqQueue {
constructor(length) {
this.queue = new Array(length + 1)
// 队头
this.first = 0
// 队尾
this.last = 0
// 当前队列大小
this.size = 0
}
enQueue(item) {
// 判断队尾 + 1 是否为队头
// 如果是就代表需要扩容数组
// % this.queue.length 是为了防止数组越界
if (this.first === (this.last + 1) % this.queue.length) {
this.resize(this.getLength() * 2 + 1)
}
this.queue[this.last] = item
this.size++
this.last = (this.last + 1) % this.queue.length
}
deQueue() {
if (this.isEmpty()) {
throw Error('Queue is empty')
}
let r = this.queue[this.first]
this.queue[this.first] = null
this.first = (this.first + 1) % this.queue.length
this.size--
// 判断当前队列大小是否过小
// 为了保证不浪费空间,在队列空间等于总长度四分之一时
// 且不为 2 时缩小总长度为当前的一半
if (this.size === this.getLength() / 4 && this.getLength() / 2 !== 0) {
this.resize(this.getLength() / 2)
}
return r
}
getHeader() {
if (this.isEmpty()) {
throw Error('Queue is empty')
}
return this.queue[this.first]
}
getLength() {
return this.queue.length - 1
}
isEmpty() {
return this.first === this.last
}
resize(length) {
let q = new Array(length)
for (let i = 0; i < length; i++) {
q[i] = this.queue[(i + this.first) % this.queue.length]
}
this.queue = q
this.first = 0
this.last = this.size
}
}
```
# 链表
## 概念
链表是一个线性结构,同时也是一个天然的递归结构。链表结构可以充分利用计算机内存空间,实现灵活的内存动态管理。但是链表失去了数组随机读取的优点,同时链表由于增加了结点的指针域,空间开销比较大。

## 实现
单向链表
```javascript
class Node {
constructor(v, next) {
this.value = v
this.next = next
}
}
class LinkList {
constructor() {
// 链表长度
this.size = 0
// 虚拟头部
this.dummyNode = new Node(null, null)
}
find(header, index, currentIndex) {
if (index === currentIndex) return header
return this.find(header.next, index, currentIndex + 1)
}
addNode(v, index) {
this.checkIndex(index)
// 当往链表末尾插入时,prev.next 为空
// 其他情况时,因为要插入节点,所以插入的节点
// 的 next 应该是 prev.next
// 然后设置 prev.next 为插入的节点
let prev = this.find(this.dummyNode, index, 0)
prev.next = new Node(v, prev.next)
this.size++
return prev.next
}
insertNode(v, index) {
return this.addNode(v, index)
}
addToFirst(v) {
return this.addNode(v, 0)
}
addToLast(v) {
return this.addNode(v, this.size)
}
removeNode(index, isLast) {
this.checkIndex(index)
index = isLast ? index - 1 : index
let prev = this.find(this.dummyNode, index, 0)
let node = prev.next
prev.next = node.next
node.next = null
this.size--
return node
}
removeFirstNode() {
return this.removeNode(0)
}
removeLastNode() {
return this.removeNode(this.size, true)
}
checkIndex(index) {
if (index < 0 || index > this.size) throw Error('Index error')
}
getNode(index) {
this.checkIndex(index)
if (this.isEmpty()) return
return this.find(this.dummyNode, index, 0).next
}
isEmpty() {
return this.size === 0
}
getSize() {
return this.size
}
}
```
# 树
## 二叉树
树拥有很多种结构,二叉树是树中最常用的结构,同时也是一个天然的递归结构。
二叉树拥有一个根节点,每个节点至多拥有两个子节点,分别为:左节点和右节点。树的最底部节点称之为叶节点,当一颗树的叶数量数量为满时,该树可以称之为满二叉树。

## 二分搜索树
二分搜索树也是二叉树,拥有二叉树的特性。但是区别在于二分搜索树每个节点的值都比他的左子树的值大,比右子树的值小。
这种存储方式很适合于数据搜索。如下图所示,当需要查找 6 的时候,因为需要查找的值比根节点的值大,所以只需要在根节点的右子树上寻找,大大提高了搜索效率。
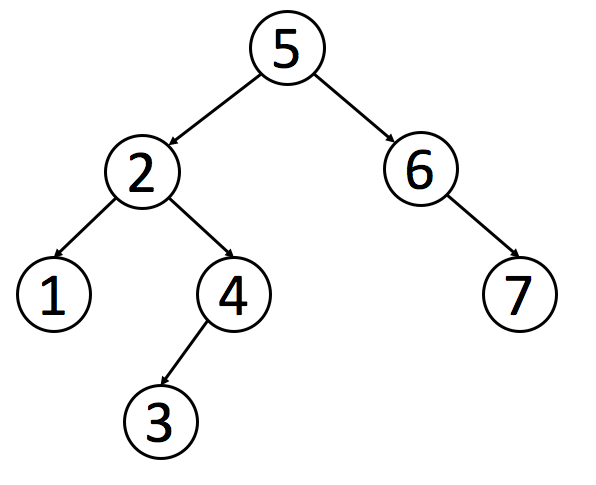
### 实现
```js
class Node {
constructor(value) {
this.value = value
this.left = null
this.right = null
}
}
class BST {
constructor() {
this.root = null
this.size = 0
}
getSize() {
return this.size
}
isEmpty() {
return this.size === 0
}
addNode(v) {
this.root = this._addChild(this.root, v)
}
// 添加节点时,需要比较添加的节点值和当前
// 节点值的大小
_addChild(node, v) {
if (!node) {
this.size++
return new Node(v)
}
if (node.value > v) {
node.left = this._addChild(node.left, v)
} else if (node.value < v) {
node.right = this._addChild(node.right, v)
}
return node
}
}
```
以上是最基本的二分搜索树实现,接下来实现树的遍历。
对于树的遍历来说,有三种遍历方法,分别是先序遍历、中序遍历、后序遍历。三种遍历的区别在于何时访问节点。在遍历树的过程中,每个节点都会遍历三次,分别是遍历到自己,遍历左子树和遍历右子树。如果需要实现先序遍历,那么只需要第一次遍历到节点时进行操作即可。
以下都是递归实现,如果你想学习非递归实现,可以 [点击这里阅读](../Algorithm/algorithm-ch.md#%E9%9D%9E%E9%80%92%E5%BD%92%E5%AE%9E%E7%8E%B0)
```js
// 先序遍历可用于打印树的结构
// 先序遍历先访问根节点,然后访问左节点,最后访问右节点。
preTraversal() {
this._pre(this.root)
}
_pre(node) {
if (node) {
console.log(node.value)
this._pre(node.left)
this._pre(node.right)
}
}
// 中序遍历可用于排序
// 对于 BST 来说,中序遍历可以实现一次遍历就
// 得到有序的值
// 中序遍历表示先访问左节点,然后访问根节点,最后访问右节点。
midTraversal() {
this._mid(this.root)
}
_mid(node) {
if (node) {
this._mid(node.left)
console.log(node.value)
this._mid(node.right)
}
}
// 后序遍历可用于先操作子节点
// 再操作父节点的场景
// 后序遍历表示先访问左节点,然后访问右节点,最后访问根节点。
backTraversal() {
this._back(this.root)
}
_back(node) {
if (node) {
this._back(node.left)
this._back(node.right)
console.log(node.value)
}
}
```
以上的这几种遍历都可以称之为深度遍历,对应的还有种遍历叫做广度遍历,也就是一层层地遍历树。对于广度遍历来说,我们需要利用之前讲过的队列结构来完成。
```js
breadthTraversal() {
if (!this.root) return null
let q = new Queue()
// 将根节点入队
q.enQueue(this.root)
// 循环判断队列是否为空,为空
// 代表树遍历完毕
while (!q.isEmpty()) {
// 将队首出队,判断是否有左右子树
// 有的话,就先左后右入队
let n = q.deQueue()
console.log(n.value)
if (n.left) q.enQueue(n.left)
if (n.right) q.enQueue(n.right)
}
}
```
接下来先介绍如何在树中寻找最小值或最大数。因为二分搜索树的特性,所以最小值一定在根节点的最左边,最大值相反
```js
getMin() {
return this._getMin(this.root).value
}
_getMin(node) {
if (!node.left) return node
return this._getMin(node.left)
}
getMax() {
return this._getMax(this.root).value
}
_getMax(node) {
if (!node.right) return node
return this._getMin(node.right)
}
```
**向上取整和向下取整**,这两个操作是相反的,所以代码也是类似的,这里只介绍如何向下取整。既然是向下取整,那么根据二分搜索树的特性,值一定在根节点的左侧。只需要一直遍历左子树直到当前节点的值不再大于等于需要的值,然后判断节点是否还拥有右子树。如果有的话,继续上面的递归判断。
```js
floor(v) {
let node = this._floor(this.root, v)
return node ? node.value : null
}
_floor(node, v) {
if (!node) return null
if (node.value === v) return v
// 如果当前节点值还比需要的值大,就继续递归
if (node.value > v) {
return this._floor(node.left, v)
}
// 判断当前节点是否拥有右子树
let right = this._floor(node.right, v)
if (right) return right
return node
}
```
**排名**,这是用于获取给定值的排名或者排名第几的节点的值,这两个操作也是相反的,所以这个只介绍如何获取排名第几的节点的值。对于这个操作而言,我们需要略微的改造点代码,让每个节点拥有一个 `size` 属性。该属性表示该节点下有多少子节点(包含自身)。
```js
class Node {
constructor(value) {
this.value = value
this.left = null
this.right = null
// 修改代码
this.size = 1
}
}
// 新增代码
_getSize(node) {
return node ? node.size : 0
}
_addChild(node, v) {
if (!node) {
return new Node(v)
}
if (node.value > v) {
// 修改代码
node.size++
node.left = this._addChild(node.left, v)
} else if (node.value < v) {
// 修改代码
node.size++
node.right = this._addChild(node.right, v)
}
return node
}
select(k) {
let node = this._select(this.root, k)
return node ? node.value : null
}
_select(node, k) {
if (!node) return null
// 先获取左子树下有几个节点
let size = node.left ? node.left.size : 0
// 判断 size 是否大于 k
// 如果大于 k,代表所需要的节点在左节点
if (size > k) return this._select(node.left, k)
// 如果小于 k,代表所需要的节点在右节点
// 注意这里需要重新计算 k,减去根节点除了右子树的节点数量
if (size < k) return this._select(node.right, k - size - 1)
return node
}
```
接下来讲解的是二分搜索树中最难实现的部分:删除节点。因为对于删除节点来说,会存在以下几种情况
- 需要删除的节点没有子树
- 需要删除的节点只有一条子树
- 需要删除的节点有左右两条树
对于前两种情况很好解决,但是第三种情况就有难度了,所以先来实现相对简单的操作:删除最小节点,对于删除最小节点来说,是不存在第三种情况的,删除最大节点操作是和删除最小节点相反的,所以这里也就不再赘述。
```js
delectMin() {
this.root = this._delectMin(this.root)
console.log(this.root)
}
_delectMin(node) {
// 一直递归左子树
// 如果左子树为空,就判断节点是否拥有右子树
// 有右子树的话就把需要删除的节点替换为右子树
if ((node != null) & !node.left) return node.right
node.left = this._delectMin(node.left)
// 最后需要重新维护下节点的 `size`
node.size = this._getSize(node.left) + this._getSize(node.right) + 1
return node
}
```
最后讲解的就是如何删除任意节点了。对于这个操作,T.Hibbard 在 1962 年提出了解决这个难题的办法,也就是如何解决第三种情况。
当遇到这种情况时,需要取出当前节点的后继节点(也就是当前节点右子树的最小节点)来替换需要删除的节点。然后将需要删除节点的左子树赋值给后继结点,右子树删除后继结点后赋值给他。
你如果对于这个解决办法有疑问的话,可以这样考虑。因为二分搜索树的特性,父节点一定比所有左子节点大,比所有右子节点小。那么当需要删除父节点时,势必需要拿出一个比父节点大的节点来替换父节点。这个节点肯定不存在于左子树,必然存在于右子树。然后又需要保持父节点都是比右子节点小的,那么就可以取出右子树中最小的那个节点来替换父节点。
```js
delect(v) {
this.root = this._delect(this.root, v)
}
_delect(node, v) {
if (!node) return null
// 寻找的节点比当前节点小,去左子树找
if (node.value < v) {
node.right = this._delect(node.right, v)
} else if (node.value > v) {
// 寻找的节点比当前节点大,去右子树找
node.left = this._delect(node.left, v)
} else {
// 进入这个条件说明已经找到节点
// 先判断节点是否拥有拥有左右子树中的一个
// 是的话,将子树返回出去,这里和 `_delectMin` 的操作一样
if (!node.left) return node.right
if (!node.right) return node.left
// 进入这里,代表节点拥有左右子树
// 先取出当前节点的后继结点,也就是取当前节点右子树的最小值
let min = this._getMin(node.right)
// 取出最小值后,删除最小值
// 然后把删除节点后的子树赋值给最小值节点
min.right = this._delectMin(node.right)
// 左子树不动
min.left = node.left
node = min
}
// 维护 size
node.size = this._getSize(node.left) + this._getSize(node.right) + 1
return node
}
```
## AVL 树
### 概念
二分搜索树实际在业务中是受到限制的,因为并不是严格的 O(logN),在极端情况下会退化成链表,比如加入一组升序的数字就会造成这种情况。
AVL 树改进了二分搜索树,在 AVL 树中任意节点的左右子树的高度差都不大于 1,这样保证了时间复杂度是严格的 O(logN)。基于此,对 AVL 树增加或删除节点时可能需要旋转树来达到高度的平衡。
### 实现
因为 AVL 树是改进了二分搜索树,所以部分代码是于二分搜索树重复的,对于重复内容不作再次解析。
对于 AVL 树来说,添加节点会有四种情况
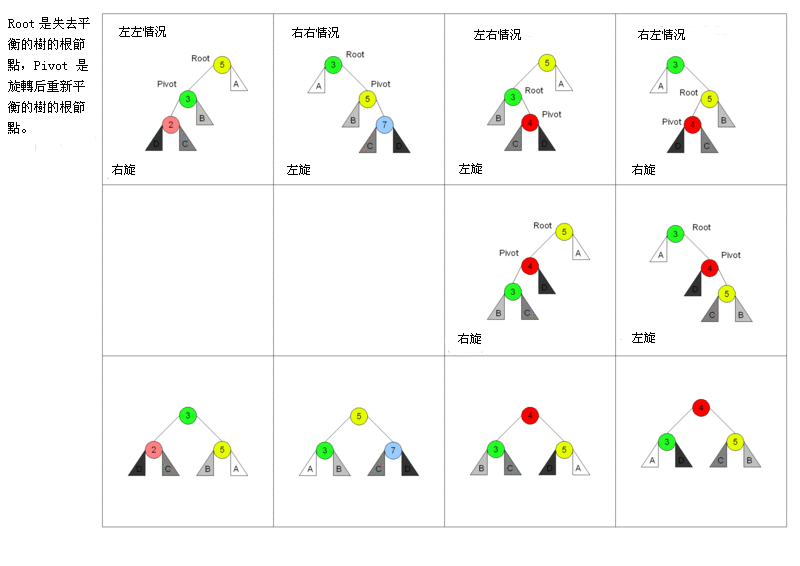
对于左左情况来说,新增加的节点位于节点 2 的左侧,这时树已经不平衡,需要旋转。因为搜索树的特性,节点比左节点大,比右节点小,所以旋转以后也要实现这个特性。
旋转之前:new < 2 < C < 3 < B < 5 < A,右旋之后节点 3 为根节点,这时候需要将节点 3 的右节点加到节点 5 的左边,最后还需要更新节点的高度。
对于右右情况来说,相反于左左情况,所以不再赘述。
对于左右情况来说,新增加的节点位于节点 4 的右侧。对于这种情况,需要通过两次旋转来达到目的。
首先对节点的左节点左旋,这时树满足左左的情况,再对节点进行一次右旋就可以达到目的。
```js
class Node {
constructor(value) {
this.value = value
this.left = null
this.right = null
this.height = 1
}
}
class AVL {
constructor() {
this.root = null
}
addNode(v) {
this.root = this._addChild(this.root, v)
}
_addChild(node, v) {
if (!node) {
return new Node(v)
}
if (node.value > v) {
node.left = this._addChild(node.left, v)
} else if (node.value < v) {
node.right = this._addChild(node.right, v)
} else {
node.value = v
}
node.height =
1 + Math.max(this._getHeight(node.left), this._getHeight(node.right))
let factor = this._getBalanceFactor(node)
// 当需要右旋时,根节点的左树一定比右树高度高
if (factor > 1 && this._getBalanceFactor(node.left) >= 0) {
return this._rightRotate(node)
}
// 当需要左旋时,根节点的左树一定比右树高度矮
if (factor < -1 && this._getBalanceFactor(node.right) <= 0) {
return this._leftRotate(node)
}
// 左右情况
// 节点的左树比右树高,且节点的左树的右树比节点的左树的左树高
if (factor > 1 && this._getBalanceFactor(node.left) < 0) {
node.left = this._leftRotate(node.left)
return this._rightRotate(node)
}
// 右左情况
// 节点的左树比右树矮,且节点的右树的右树比节点的右树的左树矮
if (factor < -1 && this._getBalanceFactor(node.right) > 0) {
node.right = this._rightRotate(node.right)
return this._leftRotate(node)
}
return node
}
_getHeight(node) {
if (!node) return 0
return node.height
}
_getBalanceFactor(node) {
return this._getHeight(node.left) - this._getHeight(node.right)
}
// 节点右旋
// 5 2
// / \ / \
// 2 6 ==> 1 5
// / \ / / \
// 1 3 new 3 6
// /
// new
_rightRotate(node) {
// 旋转后新根节点
let newRoot = node.left
// 需要移动的节点
let moveNode = newRoot.right
// 节点 2 的右节点改为节点 5
newRoot.right = node
// 节点 5 左节点改为节点 3
node.left = moveNode
// 更新树的高度
node.height =
1 + Math.max(this._getHeight(node.left), this._getHeight(node.right))
newRoot.height =
1 +
Math.max(this._getHeight(newRoot.left), this._getHeight(newRoot.right))
return newRoot
}
// 节点左旋
// 4 6
// / \ / \
// 2 6 ==> 4 7
// / \ / \ \
// 5 7 2 5 new
// \
// new
_leftRotate(node) {
// 旋转后新根节点
let newRoot = node.right
// 需要移动的节点
let moveNode = newRoot.left
// 节点 6 的左节点改为节点 4
newRoot.left = node
// 节点 4 右节点改为节点 5
node.right = moveNode
// 更新树的高度
node.height =
1 + Math.max(this._getHeight(node.left), this._getHeight(node.right))
newRoot.height =
1 +
Math.max(this._getHeight(newRoot.left), this._getHeight(newRoot.right))
return newRoot
}
}
```
# Trie
## 概念
在计算机科学,**trie**,又称**前缀树**或**字典树**,是一种有序树,用于保存关联数组,其中的键通常是字符串。
简单点来说,这个结构的作用大多是为了方便搜索字符串,该树有以下几个特点
- 根节点代表空字符串,每个节点都有 N(假如搜索英文字符,就有 26 条) 条链接,每条链接代表一个字符
- 节点不存储字符,只有路径才存储,这点和其他的树结构不同
- 从根节点开始到任意一个节点,将沿途经过的字符连接起来就是该节点对应的字符串
、
## 实现
总得来说 Trie 的实现相比别的树结构来说简单的很多,实现就以搜索英文字符为例。
```js
class TrieNode {
constructor() {
// 代表每个字符经过节点的次数
this.path = 0
// 代表到该节点的字符串有几个
this.end = 0
// 链接
this.next = new Array(26).fill(null)
}
}
class Trie {
constructor() {
// 根节点,代表空字符
this.root = new TrieNode()
}
// 插入字符串
insert(str) {
if (!str) return
let node = this.root
for (let i = 0; i < str.length; i++) {
// 获得字符先对应的索引
let index = str[i].charCodeAt() - 'a'.charCodeAt()
// 如果索引对应没有值,就创建
if (!node.next[index]) {
node.next[index] = new TrieNode()
}
node.path += 1
node = node.next[index]
}
node.end += 1
}
// 搜索字符串出现的次数
search(str) {
if (!str) return
let node = this.root
for (let i = 0; i < str.length; i++) {
let index = str[i].charCodeAt() - 'a'.charCodeAt()
// 如果索引对应没有值,代表没有需要搜素的字符串
if (!node.next[index]) {
return 0
}
node = node.next[index]
}
return node.end
}
// 删除字符串
delete(str) {
if (!this.search(str)) return
let node = this.root
for (let i = 0; i < str.length; i++) {
let index = str[i].charCodeAt() - 'a'.charCodeAt()
// 如果索引对应的节点的 Path 为 0,代表经过该节点的字符串
// 已经一个,直接删除即可
if (--node.next[index].path == 0) {
node.next[index] = null
return
}
node = node.next[index]
}
node.end -= 1
}
}
```
# 并查集
## 概念
并查集是一种特殊的树结构,用于处理一些不交集的合并及查询问题。该结构中每个节点都有一个父节点,如果只有当前一个节点,那么该节点的父节点指向自己。
这个结构中有两个重要的操作,分别是:
- Find:确定元素属于哪一个子集。它可以被用来确定两个元素是否属于同一子集。
- Union:将两个子集合并成同一个集合。

## 实现
```js
class DisjointSet {
// 初始化样本
constructor(count) {
// 初始化时,每个节点的父节点都是自己
this.parent = new Array(count)
// 用于记录树的深度,优化搜索复杂度
this.rank = new Array(count)
for (let i = 0; i < count; i++) {
this.parent[i] = i
this.rank[i] = 1
}
}
find(p) {
// 寻找当前节点的父节点是否为自己,不是的话表示还没找到
// 开始进行路径压缩优化
// 假设当前节点父节点为 A
// 将当前节点挂载到 A 节点的父节点上,达到压缩深度的目的
while (p != this.parent[p]) {
this.parent[p] = this.parent[this.parent[p]]
p = this.parent[p]
}
return p
}
isConnected(p, q) {
return this.find(p) === this.find(q)
}
// 合并
union(p, q) {
// 找到两个数字的父节点
let i = this.find(p)
let j = this.find(q)
if (i === j) return
// 判断两棵树的深度,深度小的加到深度大的树下面
// 如果两棵树深度相等,那就无所谓怎么加
if (this.rank[i] < this.rank[j]) {
this.parent[i] = j
} else if (this.rank[i] > this.rank[j]) {
this.parent[j] = i
} else {
this.parent[i] = j
this.rank[j] += 1
}
}
}
```
# 堆
## 概念
堆通常是一个可以被看做一棵树的数组对象。
堆的实现通过构造**二叉堆**,实为二叉树的一种。这种数据结构具有以下性质。
- 任意节点小于(或大于)它的所有子节点
- 堆总是一棵完全树。即除了最底层,其他层的节点都被元素填满,且最底层从左到右填入。
将根节点最大的堆叫做**最大堆**或**大根堆**,根节点最小的堆叫做**最小堆**或**小根堆**。
优先队列也完全可以用堆来实现,操作是一模一样的。
## 实现大根堆
堆的每个节点的左边子节点索引是 `i * 2 + 1`,右边是 `i * 2 + 2`,父节点是 `(i - 1) /2`。
堆有两个核心的操作,分别是 `shiftUp` 和 `shiftDown` 。前者用于添加元素,后者用于删除根节点。
`shiftUp` 的核心思路是一路将节点与父节点对比大小,如果比父节点大,就和父节点交换位置。
`shiftDown` 的核心思路是先将根节点和末尾交换位置,然后移除末尾元素。接下来循环判断父节点和两个子节点的大小,如果子节点大,就把最大的子节点和父节点交换。
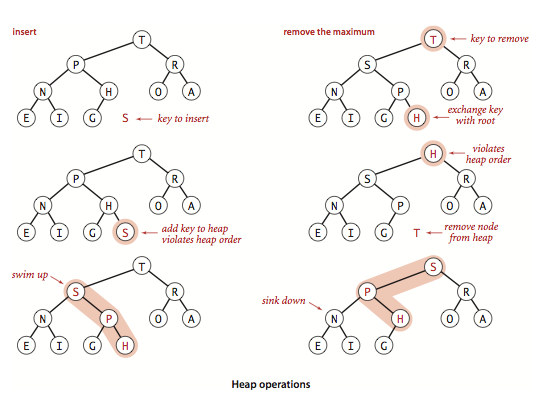
```js
class MaxHeap {
constructor() {
this.heap = []
}
size() {
return this.heap.length
}
empty() {
return this.size() == 0
}
add(item) {
this.heap.push(item)
this._shiftUp(this.size() - 1)
}
removeMax() {
this._shiftDown(0)
}
getParentIndex(k) {
return parseInt((k - 1) / 2)
}
getLeftIndex(k) {
return k * 2 + 1
}
_shiftUp(k) {
// 如果当前节点比父节点大,就交换
while (this.heap[k] > this.heap[this.getParentIndex(k)]) {
this._swap(k, this.getParentIndex(k))
// 将索引变成父节点
k = this.getParentIndex(k)
}
}
_shiftDown(k) {
// 交换首位并删除末尾
this._swap(k, this.size() - 1)
this.heap.splice(this.size() - 1, 1)
// 判断节点是否有左孩子,因为二叉堆的特性,有右必有左
while (this.getLeftIndex(k) < this.size()) {
let j = this.getLeftIndex(k)
// 判断是否有右孩子,并且右孩子是否大于左孩子
if (j + 1 < this.size() && this.heap[j + 1] > this.heap[j]) j++
// 判断父节点是否已经比子节点都大
if (this.heap[k] >= this.heap[j]) break
this._swap(k, j)
k = j
}
}
_swap(left, right) {
let rightValue = this.heap[right]
this.heap[right] = this.heap[left]
this.heap[left] = rightValue
}
}
```
================================================
FILE: Framework/framework-br.md
================================================
**Table of Contents** *generated with [DocToc](https://github.com/thlorenz/doctoc)*
- [MVVM](#mvvm)
- [Verificação suja](#dirty-checking)
- [Sequestro de dados](#data-hijacking)
- [Proxy vs. Obeject.defineProperty](#proxy-vs-obejectdefineproperty)
- [Princípios de rota](#routing-principle)
- [Virtual Dom](#virtual-dom)
- [Por que Virtual Dom é preciso](#why-virtual-dom-is-needed)
- [Intrudução ao algoritmo do Virtual Dom](#virtual-dom-algorithm-introduction)
- [Implementação do algoritimo do Virtual Dom](#virtual-dom-algorithm-implementation)
- [recursão da árvore](#recursion-of-the-tree)
- [varificando mudança de propriedades](#checking-property-changes)
- [Implementação do algoritimo para detectar mudanças de lista](#algorithm-implementation-for-detecting-list-changes)
- [Iterando e marcando elementos filhos](#iterating-and-marking-child-elements)
- [Diferença de renderização](#rendering-difference)
- [Fim](#the-end)
# MVVM
MVVM consiste dos três seguintes conceitos
* View: Interface
* Model:Modelo de dados
* ViewModel:Como uma ponte responsável pela comunicação entre a View e o Model
Na época do JQuery, se você precisar atualizar a UI, você precisar obter o DOM correspondente e então atualizar a UI, então os dados e as regras de negócio estão fortemente acoplados com a página.
No MVVM, o UI é condizudo pelos dados. Uma vez que o dado mudou, a UI correspondente será atualizada. Se a UI mudar, o dado correspondente também ira mudar. Dessas forma, nos preocupamos apenas com o fluxo de dados no processamento do negócio sem lidar com a página diretamente. ViewModel apenas se preocupa com o processamento de dados e regras de negócio e não se preocupa como a View manipula os dados. Nesse caso, nós podemos separar a View da Model. Se qualquer uma das partes mudarem, isso não necessariamente precisa mudar na outra parte, e qualquer lógica reusável pode ser colocado na ViewModel, permitindo multiplas View reusarem esse ViewModel.
No MVVM, o núcleo é two-way binding de dados, tal como a verificação suja do Angular e sequestro de dados no Vue.
## Verificação Suja
Quando o evento especificado é disparado, ele irá entrar na verificação suja e chamar o laço `$digest` caminhando através de todos os dados observados para determinar se o valor atual é diferente do valor anterior. Se a mudança é detectada, irá chamar a função `$watch`, e então chamar o laço `$digest` novamente até que nenhuma mudança seja encontrada. O ciclo vai de pelo menos de duas vezes até dez vezes.
Embora a verificação suja ser ineficiente, ele consegue completar a tarefa sem se preocupar sobre como o dado mudou, mas o two-way binding no `Vue` é problemático. E a verificação suja consegue alcançar detecção de lotes de valores atualizados, e então unificar atualizações na UI, com grandeza reduzindo o número de operações no DOM. Assim sendo, ineficiência é relativa, e é assim que o benevolente vê o sábio e a sabedoria.
## Sequesto de dados
Vue internamente usa `Obeject.defineProperty()` para implementar o two-way binding, do qual permite você escutar por eventos de `set` e `get`.
```js
var data = { name: 'yck' }
observe(data)
let name = data.name // -> ontém o valor
data.name = 'yyy' // -> muda o valor
function observe(obj) {
// juiz do tipo
if (!obj || typeof obj !== 'object') {
return
}
Object.keys(obj).forEach(key => {
defineReactive(obj, key, obj[key])
})
}
function defineReactive(obj, key, val) {
// recurse as propriedades dos filhos
observe(val)
Object.defineProperty(obj, key, {
enumerable: true,
configurable: true,
get: function reactiveGetter() {
console.log('get value')
return val
},
set: function reactiveSetter(newVal) {
console.log('change value')
val = newVal
}
})
}
```
O código acima é uma simples implementação de como escutar os eventos `set` e `get` dos dados, mas isso não é o suficiente. Você também precisa adicionar um Publish/Subscribe para as propriedades quando apropriado.
```html
{{name}}
```
::: v-pre
Nesse processo, análisando o código do modelo, como acima, quando encontrando `{{name}}`, adicione um publish/subscribe para a propriedade `name`
:::
```js
// dissociar por Dep
class Dep {
constructor() {
this.subs = []
}
addSub(sub) {
// Sub é uma instância do observador
this.subs.push(sub)
}
notify() {
this.subs.forEach(sub => {
sub.update()
})
}
}
// Propriedade global, configura o observador com essa propriedade
Dep.target = null
function update(value) {
document.querySelector('div').innerText = value
}
class Watcher {
constructor(obj, key, cb) {
// Aponte Dep.target para se mesmo
// Então dispare o getter para a propriedade adicionar o ouvinte
// Finalmente, set Dep.target como null
Dep.target = this
this.cb = cb
this.obj = obj
this.key = key
this.value = obj[key]
Dep.target = null
}
update() {
// obtenha o novo valor
this.value = this.obj[this.key]
// update Dom with the update method
// atualize o DOM com o método de atualizar
this.cb(this.value)
}
}
var data = { name: 'yck' }
observe(data)
// Simulando a ação disparada analisando o `{{name}}`
new Watcher(data, 'name', update)
// atualiza o DOM innerText
data.name = 'yyy'
```
Next, improve on the `defineReactive` function.
```js
function defineReactive(obj, key, val) {
// recurse as propriedades do filho
observe(val)
let dp = new Dep()
Object.defineProperty(obj, key, {
enumerable: true,
configurable: true,
get: function reactiveGetter() {
console.log('get value')
// Adiciona o Watcher para inscrição
if (Dep.target) {
dp.addSub(Dep.target)
}
return val
},
set: function reactiveSetter(newVal) {
console.log('change value')
val = newVal
// Execute o método de atualização do Watcher
dp.notify()
}
})
}
```
A implementação acima é um simples two-way binding. A idéia central é manualmente disparar o getter das propriedades para adicionar o Publish/Subscribe.
## Proxy vs. Obeject.defineProperty
Apesar do `Obeject.defineProperty` ser capaz de implementar o two-way binding, ele ainda é falho.
* Ele consegue implementar apenas o sequestro de dados nas propriedades,
* ele não consegue escutar a mudança de dados para arrays
Apesar de Vue conseguir detectar mudanças em um array de dados, é na verdade um hack e é falho.
```js
const arrayProto = Array.prototype
export const arrayMethods = Object.create(arrayProto)
// hack as seguintes funções
const methodsToPatch = [
'push',
'pop',
'shift',
'unshift',
'splice',
'sort',
'reverse'
]
methodsToPatch.forEach(function (method) {
// obter a função nativa
const original = arrayProto[method]
def(arrayMethods, method, function mutator (...args) {
// chama a função nativa
const result = original.apply(this, args)
const ob = this.__ob__
let inserted
switch (method) {
case 'push':
case 'unshift':
inserted = args
break
case 'splice':
inserted = args.slice(2)
break
}
if (inserted) ob.observeArray(inserted)
// dispara uma atualização
ob.dep.notify()
return result
})
})
```
Por outro lado, `Proxy` não tem o problema acima. Ele suporta nativamente a escuta para mudança no array e consegue interceptar o objeto completo diretamente, então Vue irá também substituir `Obeject.defineProperty` por `Proxy` na próxima grande versão.
```js
let onWatch = (obj, setBind, getLogger) => {
let handler = {
get(target, property, receiver) {
getLogger(target, property)
return Reflect.get(target, property, receiver);
},
set(target, property, value, receiver) {
setBind(value);
return Reflect.set(target, property, value);
}
};
return new Proxy(obj, handler);
};
let obj = { a: 1 }
let value
let p = onWatch(obj, (v) => {
value = v
}, (target, property) => {
console.log(`Get '${property}' = ${target[property]}`);
})
p.a = 2 // vincula `value` para `2`
p.a // -> obtém 'a' = 2
```
# Princípio de rotas
As rotas no front-end é atualmente simples de implementar. A essência é escutar as mudanças na URL, então coincidir com as regras de roteamento, exibindo a página correspondente, e não precisa atualizar. Atualmente, existe apenas duas implementações de rotas usados pela página única.
- modo hash
- modo history
`www.test.com/#/` é a hash URL. Quando o valor depois do hash `#` muda, nenhuma request será enviada ao servidor. Você pode escutar as mudanças na URL através do evento `hashchange`, e então pular para a página correspondente.
O modo history é uma nova funcionalidade do HTML5, do qual é muito mais lindo que o Hash URL.
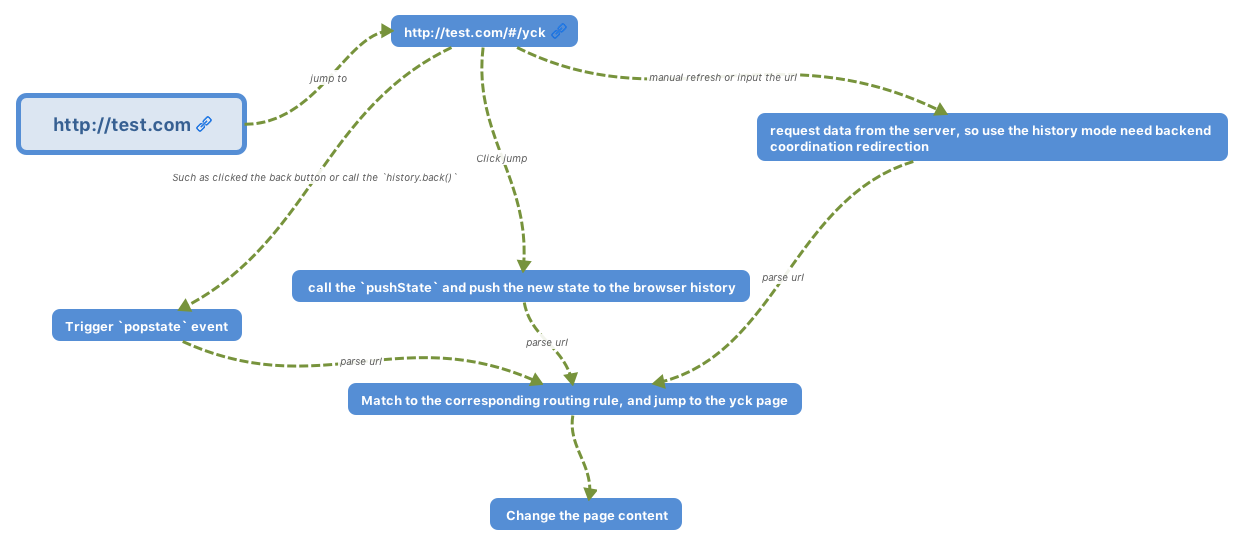
# Virtual Dom
[source code](https://github.com/KieSun/My-wheels/tree/master/Virtual%20Dom)
## Por que Virtual Dom é preciso
Como nós sabemos, modificar o DOM é uma tarefa custosa. Poderiamos considerar usar objetos JS para simular objetos DOM, desde de que operando em objetos JS é economizado muito mais tempo que operar no DOM.
Por exemplo
```js
// Vamos assumir que esse array simula um ul do qual cotém 5 li's.
[1, 2, 3, 4, 5]
// usando esse para substituir a ul acima.
[1, 2, 5, 4]
```
A partir do exemplo acima, é aparente que a terceira li foi removida, e a quarta e quinta mudaram suas posições
Se a operação anterior for aplicada no DOM, nós temos o seguinte código:
```js
// removendo a terceira li
ul.childNodes[2].remove()
// trocando internamente as posições do quarto e quinto elemento
let fromNode = ul.childNodes[4]
let toNode = node.childNodes[3]
let cloneFromNode = fromNode.cloneNode(true)
let cloenToNode = toNode.cloneNode(true)
ul.replaceChild(cloneFromNode, toNode)
ul.replaceChild(cloenToNode, fromNode)
```
De fato, nas operações atuais, nós precisamos de um identificador para cada nó, como um index para verificar se os dois nós são idênticos. Esse é o motivo de ambos Vue e React sugerirem na documentação oficial usar identificadores `key` para os nós em uma lista para garantir eficiência.
Elementos do DOM não só podem ser simulados, mas eles também podem ser renderizados por objetos JS.
Abaixo está uma simples implementação de um objeto JS simulando um elemento DOM.
```js
export default class Element {
/**
* @param {String} tag 'div'
* @param {Object} props { class: 'item' }
* @param {Array} children [ Element1, 'text']
* @param {String} key option
*/
constructor(tag, props, children, key) {
this.tag = tag
this.props = props
if (Array.isArray(children)) {
this.children = children
} else if (isString(children)) {
this.key = children
this.children = null
}
if (key) this.key = key
}
// renderização
render() {
let root = this._createElement(
this.tag,
this.props,
this.children,
this.key
)
document.body.appendChild(root)
return root
}
create() {
return this._createElement(this.tag, this.props, this.children, this.key)
}
// criando um elemento
_createElement(tag, props, child, key) {
// criando um elemento com tag
let el = document.createElement(tag)
// definindo propriedades em um elemento
for (const key in props) {
if (props.hasOwnProperty(key)) {
const value = props[key]
el.setAttribute(key, value)
}
}
if (key) {
el.setAttribute('key', key)
}
// adicionando nós filhos recursivamente
if (child) {
child.forEach(element => {
let child
if (element instanceof Element) {
child = this._createElement(
element.tag,
element.props,
element.children,
element.key
)
} else {
child = document.createTextNode(element)
}
el.appendChild(child)
})
}
return el
}
}
```
## Introdução ao algoritmo de Virtual Dom
O próximo passo depois de usar JS para implementar elementos DOM é detectar mudanças no objeto.
DOM é uma árvore de multi-ramifacações. Se nós compararmos a antiga e a nova árvore completamente, o tempo de complexidade seria O(n ^ 3), o que é simplesmente inaceitável. Assim sendo, o time do React otimizou esse algoritimo para alcançar uma complexidade O(n) para detectar as mudanças.
A chave para alcançar O(n) é apenas comparar os
nós no mesmo nível em vez de através dos níveis. Isso funciona porque no uso atual nós raramente movemos elementos DOM através dos níveis.
Nós então temos dois passos do algoritmo.
- Do topo para fundo, da esquerda para direita itera o objeto, primeira pesquisa de profundidade. Nesse passo adicionamos um índice para cada nó, renderizando as diferenças depois.
- sempre que um nó tiver um elemento filho, nós verificamos se o elemento filho mudou.
## Implementação do algoritmo do Virtual Dom
### recursão da árvore
Primeiro vamos implementar o algoritmo de recursão da árvore. Antes de fazer isso, vamos considerar os diferentes casos de comparar dois nós.
1. novos nós `tagName` ou `key` são diferentes do antigo. Isso significa que o nó antigo é substituido, e nós não temos que recorrer no nó mais porque a subárvore foi completamente removida.
2. novos nós `tagName` e `key` (talvez inexistente) são a mesma do antigo. Nós começamos a recursar na subárvore.
3. não aparece novo nó. Não é preciso uma operação.
```js
import { StateEnums, isString, move } from './util'
import Element from './element'
export default function diff(oldDomTree, newDomTree) {
// para gravar mudanças
let pathchs = {}
// o índice começa no 0
dfs(oldDomTree, newDomTree, 0, pathchs)
return pathchs
}
function dfs(oldNode, newNode, index, patches) {
// para salvar as mudanças na subárvore
let curPatches = []
// três casos
// 1. não é novo nó, não faça nada
// 2. novos nós tagName e `key` são diferentes dos antigos, substitua
// 3. novos nós tagName e key são o mesmo do antigo, comece a recursão
if (!newNode) {
} else if (newNode.tag === oldNode.tag && newNode.key === oldNode.key) {
// verifique se as propriedades mudaram
let props = diffProps(oldNode.props, newNode.props)
if (props.length) curPatches.push({ type: StateEnums.ChangeProps, props })
// recurse a subárvore
diffChildren(oldNode.children, newNode.children, index, patches)
} else {
// diferentes nós, substitua
curPatches.push({ type: StateEnums.Replace, node: newNode })
}
if (curPatches.length) {
if (patches[index]) {
patches[index] = patches[index].concat(curPatches)
} else {
patches[index] = curPatches
}
}
}
```
### verificando mudança das propriedades
Nós temos também três passos para verificar por mudanças nas propriedades
1. itere a lista de propriedades antiga, verifique se a propriedade ainda existe na nova lista de propriedade.
2. itere a nova lista de propriedades, verifique se existe mudanças para propriedades existente nas duas listas.
3. no segundo passo, também verifique se a propriedade não existe na lista de propriedades antiga.
```js
function diffProps(oldProps, newProps) {
// três passos para checar as props
// itere oldProps para remover propriedades
// itere newProps para mudar os valores das propriedades
// por último verifique se novas propriedades foram adicionadas
let change = []
for (const key in oldProps) {
if (oldProps.hasOwnProperty(key) && !newProps[key]) {
change.push({
prop: key
})
}
}
for (const key in newProps) {
if (newProps.hasOwnProperty(key)) {
const prop = newProps[key]
if (oldProps[key] && oldProps[key] !== newProps[key]) {
change.push({
prop: key,
value: newProps[key]
})
} else if (!oldProps[key]) {
change.push({
prop: key,
value: newProps[key]
})
}
}
}
return change
}
```
### Implementação do Algoritmo de detecção de mudanças na lista
Esse algoritmo é o núcle do Virtual Dom. Vamos descer a lista.
O passo principal é similar a verificação de mudanças nas propriedades. Também existe três passos.
1. itere a antiga lista de nós, verifique se ao nó ainda existe na nova lista.
2. itere a nova lista de nós, verifiquen se existe algum novo nó.
3. para o seguindo passo, também verifique se o nó moveu.
PS: esse algoritmo apenas manipula nós com `key`s.
```js
function listDiff(oldList, newList, index, patches) {
// para fazer a iteração mais conveniente, primeiro pegue todas as chaves de ambas as listas
let oldKeys = getKeys(oldList)
let newKeys = getKeys(newList)
let changes = []
// para salvar o dado do nó depois das mudanças
// existe varia vantagem de usar esse array para salvar
// 1. nós conseguimos obter corretamente o index de nós deletados
// 2. precisamos apenas opera no DOM uma vez para interexchanged os nós
// 3. precisamos apenas iterar para verificar na função `diffChildren`
// nós não precisamos verificar de novo para nós existente nas duas listas
let list = []
oldList &&
oldList.forEach(item => {
let key = item.key
if (isString(item)) {
key = item
}
// verificando se o novo filho tem o nó atual
// se não, então delete
let index = newKeys.indexOf(key)
if (index === -1) {
list.push(null)
} else list.push(key)
})
// array depois de alterações iterativas
let length = list.length
// uma vez deletando um array de elementos, o índice muda
// removemos de trás para ter certeza que os índices permanecem o mesmo
for (let i = length - 1; i >= 0; i--) {
// verifica se o elemento atual é null, se sim então significa que precisamos remover ele
if (!list[i]) {
list.splice(i, 1)
changes.push({
type: StateEnums.Remove,
index: i
})
}
}
// itere a nova lista, verificando se um nó é adicionado ou movido
// também adicione ou mova nós para `list`
newList &&
newList.forEach((item, i) => {
let key = item.key
if (isString(item)) {
key = item
}
// verifique se o filho antigo tem o nó atual
let index = list.indexOf(key)
// se não então precisamos inserir
if (index === -1 || key == null) {
changes.push({
type: StateEnums.Insert,
node: item,
index: i
})
list.splice(i, 0, key)
} else {
// encontrado o nó, precisamos verificar se ele precisar ser movido.
if (index !== i) {
changes.push({
type: StateEnums.Move,
from: index,
to: i
})
move(list, index, i)
}
}
})
return { changes, list }
}
function getKeys(list) {
let keys = []
let text
list &&
list.forEach(item => {
let key
if (isString(item)) {
key = [item]
} else if (item instanceof Element) {
key = item.key
}
keys.push(key)
})
return keys
}
```
### Iterando e marcando elementos filho
Para essa função, existe duas principais funcionalidades.
1. verificando diferenças entre duas listas
2. marcando nós
No geral, a implementação das funcionalidades são simples.
```js
function diffChildren(oldChild, newChild, index, patches) {
let { changes, list } = listDiff(oldChild, newChild, index, patches)
if (changes.length) {
if (patches[index]) {
patches[index] = patches[index].concat(changes)
} else {
patches[index] = changes
}
}
// marcando o ultimo nó iterado
let last = null
oldChild &&
oldChild.forEach((item, i) => {
let child = item && item.children
if (child) {
index =
last && last.children ? index + last.children.length + 1 : index + 1
let keyIndex = list.indexOf(item.key)
let node = newChild[keyIndex]
// só itera nós existentes em ambas as listas
// não precisamos visitar os adicionados ou removidos
if (node) {
dfs(item, node, index, patches)
}
} else index += 1
last = item
})
}
```
### Renderizando diferenças
A partir dos algoritmos anteriores, nós já obtemos as diferenças entre duas árvores. Depois de saber as diferenças, precisamos atualizar o DOM localmente. Vamos dar uma olhada no último passo do algoritmo do Virtual Dom.
Há duas funcionalidades principais para isso
1. Busca profunda na árvore e extrair os nós que precisam ser modificados.
2. Atualize o DOM local
Esse pedaço de código é bastante fácil de entender como um todo.
```js
let index = 0
export default function patch(node, patchs) {
let changes = patchs[index]
let childNodes = node && node.childNodes
// essa busca profunda é a mesma do algoritmo de diff
if (!childNodes) index += 1
if (changes && changes.length && patchs[index]) {
changeDom(node, changes)
}
let last = null
if (childNodes && childNodes.length) {
childNodes.forEach((item, i) => {
index =
last && last.children ? index + last.children.length + 1 : index + 1
patch(item, patchs)
last = item
})
}
}
function changeDom(node, changes, noChild) {
changes &&
changes.forEach(change => {
let { type } = change
switch (type) {
case StateEnums.ChangeProps:
let { props } = change
props.forEach(item => {
if (item.value) {
node.setAttribute(item.prop, item.value)
} else {
node.removeAttribute(item.prop)
}
})
break
case StateEnums.Remove:
node.childNodes[change.index].remove()
break
case StateEnums.Insert:
let dom
if (isString(change.node)) {
dom = document.createTextNode(change.node)
} else if (change.node instanceof Element) {
dom = change.node.create()
}
node.insertBefore(dom, node.childNodes[change.index])
break
case StateEnums.Replace:
node.parentNode.replaceChild(change.node.create(), node)
break
case StateEnums.Move:
let fromNode = node.childNodes[change.from]
let toNode = node.childNodes[change.to]
let cloneFromNode = fromNode.cloneNode(true)
let cloenToNode = toNode.cloneNode(true)
node.replaceChild(cloneFromNode, toNode)
node.replaceChild(cloenToNode, fromNode)
break
default:
break
}
})
}
```
## Fim
A implementação dos algoritimos do Virtual Dom contém os três seguintes passos:
1. Simular a criação de objetos DOM através do JS
2. Verifica a diferança entre dois objetos
2. Renderiza a diferença
```js
let test4 = new Element('div', { class: 'my-div' }, ['test4'])
let test5 = new Element('ul', { class: 'my-div' }, ['test5'])
let test1 = new Element('div', { class: 'my-div' }, [test4])
let test2 = new Element('div', { id: '11' }, [test5, test4])
let root = test1.render()
let pathchs = diff(test1, test2)
console.log(pathchs)
setTimeout(() => {
console.log('start updating')
patch(root, pathchs)
console.log('end updating')
}, 1000)
```
Embora a implementação atual seja simples, isso não é definitivamente o suficiente para ententer os algoritmos do Virtual Dom.
================================================
FILE: Framework/framework-en.md
================================================
**Table of Contents** *generated with [DocToc](https://github.com/thlorenz/doctoc)*
- [MVVM](#mvvm)
- [Dirty Checking](#dirty-checking)
- [Data hijacking](#data-hijacking)
- [Proxy vs. Object.defineProperty](#proxy-vs-objectdefineproperty)
- [Routing principle](#routing-principle)
- [Virtual Dom](#virtual-dom)
- [Why Virtual Dom is needed](#why-virtual-dom-is-needed)
- [Virtual Dom algorithm introduction](#virtual-dom-algorithm-introduction)
- [Virtual Dom algorithm implementation](#virtual-dom-algorithm-implementation)
- [recursion of the tree](#recursion-of-the-tree)
- [checking property changes](#checking-property-changes)
- [Algorithm Implementation for Detecting List Changes](#algorithm-implementation-for-detecting-list-changes)
- [Iterating and Marking Child Elements](#iterating-and-marking-child-elements)
- [Rendering Difference](#rendering-difference)
- [The End](#the-end)
# MVVM
MVVM consists of the following three contents
* View: interface
* Model:Data model
* ViewModel:As a bridge responsible for communicating View and Model
In the JQuery period, if you need to refresh the UI, you need to get the corresponding DOM and then update the UI, so the data and business logic are strongly-coupled with the page.
In MVVM, the UI is driven by data. Once the data is changed, the corresponding UI will be refreshed. If the UI changes, the corresponding data will also be changed. In this way, we can only care about the data flow in business processing without dealing with the page directly. ViewModel only cares about the processing of data and business and does not care how View handles data. In this case, we can separate the View from the Model. If either party changes, it does not necessarily need to change the other party, and some reusable logic can be placed in a ViewModel, allowing multiple Views to reuse this ViewModel.
In MVVM, the core is the two-way binding of data, such as dirty checking by Angular and data hijacking in Vue.
## Dirty Checking
When the specified event is triggered, it will enter the dirty checking and call the `$digest` loop to walk through all the data observers to determine whether the current value is different from the previous value. If a change is detected, it will call the `$watch` function, and then call the `$digest` loop again until no changes are found. The cycle is at least two times, up to ten times.
Although dirty checking has inefficiencies, it can complete the task without caring about how the data is changed, but the two-way binding in `Vue` is problematic. And dirty checking can achieve batch detection of updated values, and then unified update UI, greatly reducing the number of operating DOM. Therefore, inefficiency is also relative, and this is what the benevolent sees the wise and sees wisdom.
## Data hijacking
Vue internally uses `Object.defineProperty()` to implement two-way binding, which allows you to listen for events of `set` and `get`.
```js
var data = { name: 'yck' }
observe(data)
let name = data.name // -> get value
data.name = 'yyy' // -> change value
function observe(obj) {
// judge the type
if (!obj || typeof obj !== 'object') {
return
}
Object.keys(obj).forEach(key => {
defineReactive(obj, key, obj[key])
})
}
function defineReactive(obj, key, val) {
// recurse the properties of child
observe(val)
Object.defineProperty(obj, key, {
enumerable: true,
configurable: true,
get: function reactiveGetter() {
console.log('get value')
return val
},
set: function reactiveSetter(newVal) {
console.log('change value')
val = newVal
}
})
}
```
The above code simply implements how to listen for the `set` and `get` events of the data, but that's not enough. You also need to add a Publish/Subscribe to the property when appropriate.
```html
{{name}}
```
::: v-pre
In the process of parsing the template code like above, when encountering `{{name}}`, add a publish/subscribe to the property `name`
:::
```js
// decouple by Dep
class Dep {
constructor() {
this.subs = []
}
addSub(sub) {
// Sub is an instance of Watcher
this.subs.push(sub)
}
notify() {
this.subs.forEach(sub => {
sub.update()
})
}
}
// Global property, configure Watcher with this property
Dep.target = null
function update(value) {
document.querySelector('div').innerText = value
}
class Watcher {
constructor(obj, key, cb) {
// Point Dep.target to itself
// Then trigger the getter of the property to add the listener
// Finally, set Dep.target as null
Dep.target = this
this.cb = cb
this.obj = obj
this.key = key
this.value = obj[key]
Dep.target = null
}
update() {
// get the new value
this.value = this.obj[this.key]
// update Dom with the update method
this.cb(this.value)
}
}
var data = { name: 'yck' }
observe(data)
// Simulate the action triggered by parsing the `{{name}}`
new Watcher(data, 'name', update)
// update Dom innerText
data.name = 'yyy'
```
Next, improve on the `defineReactive` function.
```js
function defineReactive(obj, key, val) {
// recurse the properties of child
observe(val)
let dp = new Dep()
Object.defineProperty(obj, key, {
enumerable: true,
configurable: true,
get: function reactiveGetter() {
console.log('get value')
// Add Watcher to the subscription
if (Dep.target) {
dp.addSub(Dep.target)
}
return val
},
set: function reactiveSetter(newVal) {
console.log('change value')
val = newVal
// Execute the update method of Watcher
dp.notify()
}
})
}
```
The above implements a simple two-way binding. The core idea is to manually trigger the getter of the property to add the Publish/Subscribe.
## Proxy vs. Object.defineProperty
Although `Object.defineProperty` has been able to implement two-way binding, it is still flawed.
* It can only implement data hijacking on properties, so it needs deep traversal of the entire object
* it can't listen to changes in data for arrays
Although Vue can detect the changes in array data, it is actually a hack and is flawed.
```js
const arrayProto = Array.prototype
export const arrayMethods = Object.create(arrayProto)
// hack the following functions
const methodsToPatch = [
'push',
'pop',
'shift',
'unshift',
'splice',
'sort',
'reverse'
]
methodsToPatch.forEach(function (method) {
// get the native function
const original = arrayProto[method]
def(arrayMethods, method, function mutator (...args) {
// call the native function
const result = original.apply(this, args)
const ob = this.__ob__
let inserted
switch (method) {
case 'push':
case 'unshift':
inserted = args
break
case 'splice':
inserted = args.slice(2)
break
}
if (inserted) ob.observeArray(inserted)
// trigger the update
ob.dep.notify()
return result
})
})
```
On the other hand, `Proxy` doesn't have the above problem. It natively supports listening to array changes and can intercept the entire object directly, so Vue will also replace `Object.defineProperty` with `Proxy` in the next big version.
```js
let onWatch = (obj, setBind, getLogger) => {
let handler = {
get(target, property, receiver) {
getLogger(target, property)
return Reflect.get(target, property, receiver);
},
set(target, property, value, receiver) {
setBind(value);
return Reflect.set(target, property, value);
}
};
return new Proxy(obj, handler);
};
let obj = { a: 1 }
let value
let p = onWatch(obj, (v) => {
value = v
}, (target, property) => {
console.log(`Get '${property}' = ${target[property]}`);
})
p.a = 2 // bind `value` to `2`
p.a // -> Get 'a' = 2
```
# Routing principle
The front-end routing is actually very simple to implement. The essence is to listen to changes in the URL, then match the routing rules, display the corresponding page, and no need to refresh. Currently, there are only two implementations of the route used by a single page.
- hash mode
- history mode
`www.test.com/#/` is the hash URL. When the hash value after `#` changes, no request will be sent to server. You can listen to the URL change through the `hashchange` event, and then jump to the corresponding page.

History mode is a new feature of HTML5, which is more beautiful than Hash URL.
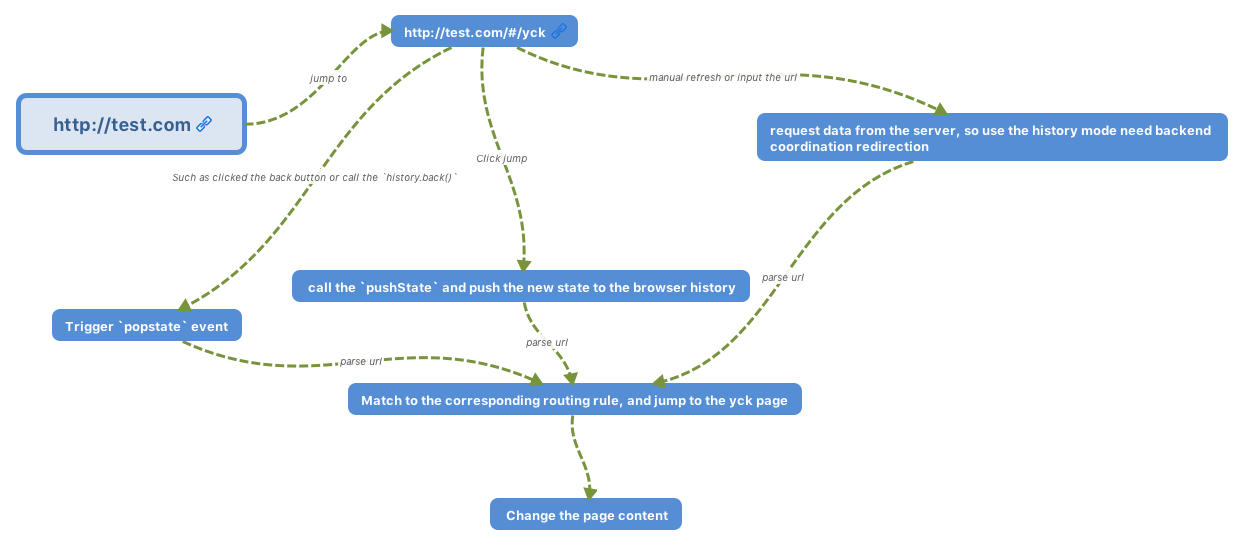
# Virtual Dom
[source code](https://github.com/KieSun/My-wheels/tree/master/Virtual%20Dom)
## Why Virtual Dom is needed
As we know, modifying DOM is a costly task. We could consider using JS objects to simulate DOM objects, since operating on JS objects is much more time saving than operating on DOM.
For example
```js
// Let's assume this array simulates a ul which contains five li's.
[1, 2, 3, 4, 5]
// using this to replace the ul above.
[1, 2, 5, 4]
```
From the above example, it's apparent that the first ul's 3rd li is removed, and the 4th and the 5th are exchanged positions.
If the previous operation is applied to DOM, we have the following code:
```js
// removing the 3rd li
ul.childNodes[2].remove()
// interexchanging positions between the 4th and the 5th
let fromNode = ul.childNodes[4]
let toNode = node.childNodes[3]
let cloneFromNode = fromNode.cloneNode(true)
let cloneToNode = toNode.cloneNode(true)
ul.replaceChild(cloneFromNode, toNode)
ul.replaceChild(cloneToNode, fromNode)
```
Of course, in actual operations, we need an identifier for each node, as an index for checking if two nodes are identical. This is why both Vue and React's official documentation suggests using a unique identifier `key` for nodes in a list to ensure efficiency.
DOM element can not only be simulated, but they can also be rendered by JS objects.
Below is a simple implementation of a JS object simulating a DOM element.
```js
export default class Element {
/**
* @param {String} tag 'div'
* @param {Object} props { class: 'item' }
* @param {Array} children [ Element1, 'text']
* @param {String} key option
*/
constructor(tag, props, children, key) {
this.tag = tag
this.props = props
if (Array.isArray(children)) {
this.children = children
} else if (isString(children)) {
this.key = children
this.children = null
}
if (key) this.key = key
}
// render
render() {
let root = this._createElement(
this.tag,
this.props,
this.children,
this.key
)
document.body.appendChild(root)
return root
}
create() {
return this._createElement(this.tag, this.props, this.children, this.key)
}
// create an element
_createElement(tag, props, child, key) {
// create an element with tag
let el = document.createElement(tag)
// set properties on the element
for (const key in props) {
if (props.hasOwnProperty(key)) {
const value = props[key]
el.setAttribute(key, value)
}
}
if (key) {
el.setAttribute('key', key)
}
// add children nodes recursively
if (child) {
child.forEach(element => {
let child
if (element instanceof Element) {
child = this._createElement(
element.tag,
element.props,
element.children,
element.key
)
} else {
child = document.createTextNode(element)
}
el.appendChild(child)
})
}
return el
}
}
```
## Virtual Dom algorithm introduction
The next step after using JS to implement DOM element is to detect object changes.
DOM is a multi-branching tree. If we were to compare the old and the new trees thoroughly, the time complexity would be O(n ^ 3), which is simply unacceptable. Therefore, the React team optimized their algorithm to achieve an O(n) complexity for detecting changes.
The key to achieving O(n) is to only compare the nodes on the same level rather than across levels. This works because in actual usage we rarely move DOM elements across levels.
We then have two steps of the algorithm.
- from top to bottom, from left to right to iterate the object, aka depth first search. This step adds an index to every node, for rendering the differences later.
- whenever a node has a child element, we check whether the child element changed.
## Virtual Dom algorithm implementation
### recursion of the tree
First let's implement the recursion algorithm of the tree. Before doing that, let's consider the different cases of comparing two nodes.
1. new node's `tagName` or `key` is different from that of the old one. This means the old node is replaced, and we don't have to recurse on the node any more because the whole subtree is removed.
2. new node's `tagName` and `key` (maybe nonexistent) are the same as the old's. We start recursing on the subtree.
3. no new node appears. No operation needed.
```js
import { StateEnums, isString, move } from './util'
import Element from './element'
export default function diff(oldDomTree, newDomTree) {
// for recording changes
let patches = {}
// the index starts at 0
dfs(oldDomTree, newDomTree, 0, patches)
return patches
}
function dfs(oldNode, newNode, index, patches) {
// for saving the subtree changes
let curPatches = []
// three cases
// 1. no new node, do nothing
// 2. new nodes' tagName and `key` are different from the old one's, replace
// 3. new nodes' tagName and key are the same as the old one's, start recursing
if (!newNode) {
} else if (newNode.tag === oldNode.tag && newNode.key === oldNode.key) {
// check whether properties changed
let props = diffProps(oldNode.props, newNode.props)
if (props.length) curPatches.push({ type: StateEnums.ChangeProps, props })
// recurse the subtree
diffChildren(oldNode.children, newNode.children, index, patches)
} else {
// different node, replace
curPatches.push({ type: StateEnums.Replace, node: newNode })
}
if (curPatches.length) {
if (patches[index]) {
patches[index] = patches[index].concat(curPatches)
} else {
patches[index] = curPatches
}
}
}
```
### checking property changes
We also have three steps for checking for property changes
1. iterate the old property list, check if the property still exists in the new property list.
2. iterate the new property list, check if there are changes for properties existing in both lists.
3. for the second step, also check if a property doesn't exist in the old property list.
```js
function diffProps(oldProps, newProps) {
// three steps for checking for props
// iterate oldProps for removed properties
// iterate newProps for changed property values
// lastly check if new properties are added
let change = []
for (const key in oldProps) {
if (oldProps.hasOwnProperty(key) && !newProps[key]) {
change.push({
prop: key
})
}
}
for (const key in newProps) {
if (newProps.hasOwnProperty(key)) {
const prop = newProps[key]
if (oldProps[key] && oldProps[key] !== newProps[key]) {
change.push({
prop: key,
value: newProps[key]
})
} else if (!oldProps[key]) {
change.push({
prop: key,
value: newProps[key]
})
}
}
}
return change
}
```
### Algorithm Implementation for Detecting List Changes
This algorithm is the core of the Virtual Dom. Let's go down the list.
The main steps are similar to checking property changes. There are also three steps.
1. iterate the old node list, check if the node still exists in the new list.
2. iterate the new node list, check if there is any new node.
3. for the second step, also check if a node moved.
PS: this algorithm only handles nodes with `key`s.
```js
function listDiff(oldList, newList, index, patches) {
// to make the iteration more convenient, first take all keys from both lists
let oldKeys = getKeys(oldList)
let newKeys = getKeys(newList)
let changes = []
// for saving the node data after changes
// there are several advantages of using this array to save
// 1. we can correctly obtain the index of the deleted node
// 2. we only need to operate on the DOM once for interexchanged nodes
// 3. we only need to iterate for the checking in the `diffChildren` function
// we don't need to check again for nodes existing in both lists
let list = []
oldList &&
oldList.forEach(item => {
let key = item.key
if (isString(item)) {
key = item
}
// checking if the new children has the current node
// if not then delete
let index = newKeys.indexOf(key)
if (index === -1) {
list.push(null)
} else list.push(key)
})
// array after iterative changes
let length = list.length
// since deleting array elements changes the indices
// we remove from the back to make sure indices stay the same
for (let i = length - 1; i >= 0; i--) {
// check if the current element is null, if so then it means we need to remove it
if (!list[i]) {
list.splice(i, 1)
changes.push({
type: StateEnums.Remove,
index: i
})
}
}
// iterate the new list, check if a node is added or moved
// also add and move nodes for `list`
newList &&
newList.forEach((item, i) => {
let key = item.key
if (isString(item)) {
key = item
}
// check if the old children has the current node
let index = list.indexOf(key)
// if not then we need to insert
if (index === -1 || key == null) {
changes.push({
type: StateEnums.Insert,
node: item,
index: i
})
list.splice(i, 0, key)
} else {
// found the node, need to check if it needs to be moved.
if (index !== i) {
changes.push({
type: StateEnums.Move,
from: index,
to: i
})
move(list, index, i)
}
}
})
return { changes, list }
}
function getKeys(list) {
let keys = []
let text
list &&
list.forEach(item => {
let key
if (isString(item)) {
key = [item]
} else if (item instanceof Element) {
key = item.key
}
keys.push(key)
})
return keys
}
```
### Iterating and Marking Child Elements
For this function, there are two main functionalities.
1. checking differences between two lists
2. marking nodes
In general, the functionalities implemented are simple.
```js
function diffChildren(oldChild, newChild, index, patches) {
let { changes, list } = listDiff(oldChild, newChild, index, patches)
if (changes.length) {
if (patches[index]) {
patches[index] = patches[index].concat(changes)
} else {
patches[index] = changes
}
}
// marking last iterated node
let last = null
oldChild &&
oldChild.forEach((item, i) => {
let child = item && item.children
if (child) {
index =
last && last.children ? index + last.children.length + 1 : index + 1
let keyIndex = list.indexOf(item.key)
let node = newChild[keyIndex]
// only iterate nodes existing in both lists
// no need to visit the added or removed ones
if (node) {
dfs(item, node, index, patches)
}
} else index += 1
last = item
})
}
```
### Rendering Difference
From the earlier algorithms, we can already get the differences between two trees. After knowing the differences, we need to locally update DOM. Let's take a look at the last step of Virtual Dom algorithms.
Two main functionalities for this function
1. Deep search the tree and extract the nodes needing modifications
2. Locally update DOM
This code snippet is pretty easy to understand as a whole.
```js
let index = 0
export default function patch(node, patches) {
let changes = patches[index]
let childNodes = node && node.childNodes
// this deep search is the same as the one in diff algorithm
if (!childNodes) index += 1
if (changes && changes.length && patches[index]) {
changeDom(node, changes)
}
let last = null
if (childNodes && childNodes.length) {
childNodes.forEach((item, i) => {
index =
last && last.children ? index + last.children.length + 1 : index + 1
patch(item, patches)
last = item
})
}
}
function changeDom(node, changes, noChild) {
changes &&
changes.forEach(change => {
let { type } = change
switch (type) {
case StateEnums.ChangeProps:
let { props } = change
props.forEach(item => {
if (item.value) {
node.setAttribute(item.prop, item.value)
} else {
node.removeAttribute(item.prop)
}
})
break
case StateEnums.Remove:
node.childNodes[change.index].remove()
break
case StateEnums.Insert:
let dom
if (isString(change.node)) {
dom = document.createTextNode(change.node)
} else if (change.node instanceof Element) {
dom = change.node.create()
}
node.insertBefore(dom, node.childNodes[change.index])
break
case StateEnums.Replace:
node.parentNode.replaceChild(change.node.create(), node)
break
case StateEnums.Move:
let fromNode = node.childNodes[change.from]
let toNode = node.childNodes[change.to]
let cloneFromNode = fromNode.cloneNode(true)
let cloneToNode = toNode.cloneNode(true)
node.replaceChild(cloneFromNode, toNode)
node.replaceChild(cloneToNode, fromNode)
break
default:
break
}
})
}
```
## The End
The implementation of the Virtual Dom algorithms contains the following three steps:
1. Simulate the creation of DOM objects through JS
2. Check differences between two objects
3. Render the differences
```js
let test4 = new Element('div', { class: 'my-div' }, ['test4'])
let test5 = new Element('ul', { class: 'my-div' }, ['test5'])
let test1 = new Element('div', { class: 'my-div' }, [test4])
let test2 = new Element('div', { id: '11' }, [test5, test4])
let root = test1.render()
let patches = diff(test1, test2)
console.log(patches)
setTimeout(() => {
console.log('start updating')
patch(root, patches)
console.log('end updating')
}, 1000)
```
Although the current implementation is simple, it's definitely enough for understanding Virtual Dom algorithms.
================================================
FILE: Framework/framework-zh.md
================================================
**Table of Contents** *generated with [DocToc](https://github.com/thlorenz/doctoc)*
- [MVVM](#mvvm)
- [脏数据检测](#%E8%84%8F%E6%95%B0%E6%8D%AE%E6%A3%80%E6%B5%8B)
- [数据劫持](#%E6%95%B0%E6%8D%AE%E5%8A%AB%E6%8C%81)
- [Proxy 与 Object.defineProperty 对比](#proxy-%E4%B8%8E-objectdefineproperty-%E5%AF%B9%E6%AF%94)
- [路由原理](#%E8%B7%AF%E7%94%B1%E5%8E%9F%E7%90%86)
- [Virtual Dom](#virtual-dom)
- [为什么需要 Virtual Dom](#%E4%B8%BA%E4%BB%80%E4%B9%88%E9%9C%80%E8%A6%81-virtual-dom)
- [Virtual Dom 算法简述](#virtual-dom-%E7%AE%97%E6%B3%95%E7%AE%80%E8%BF%B0)
- [Virtual Dom 算法实现](#virtual-dom-%E7%AE%97%E6%B3%95%E5%AE%9E%E7%8E%B0)
- [树的递归](#%E6%A0%91%E7%9A%84%E9%80%92%E5%BD%92)
- [判断属性的更改](#%E5%88%A4%E6%96%AD%E5%B1%9E%E6%80%A7%E7%9A%84%E6%9B%B4%E6%94%B9)
- [判断列表差异算法实现](#%E5%88%A4%E6%96%AD%E5%88%97%E8%A1%A8%E5%B7%AE%E5%BC%82%E7%AE%97%E6%B3%95%E5%AE%9E%E7%8E%B0)
- [遍历子元素打标识](#%E9%81%8D%E5%8E%86%E5%AD%90%E5%85%83%E7%B4%A0%E6%89%93%E6%A0%87%E8%AF%86)
- [渲染差异](#%E6%B8%B2%E6%9F%93%E5%B7%AE%E5%BC%82)
- [最后](#%E6%9C%80%E5%90%8E)
# MVVM
MVVM 由以下三个内容组成
- View:界面
- Model:数据模型
- ViewModel:作为桥梁负责沟通 View 和 Model
在 JQuery 时期,如果需要刷新 UI 时,需要先取到对应的 DOM 再更新 UI,这样数据和业务的逻辑就和页面有强耦合。
在 MVVM 中,UI 是通过数据驱动的,数据一旦改变就会相应的刷新对应的 UI,UI 如果改变,也会改变对应的数据。这种方式就可以在业务处理中只关心数据的流转,而无需直接和页面打交道。ViewModel 只关心数据和业务的处理,不关心 View 如何处理数据,在这种情况下,View 和 Model 都可以独立出来,任何一方改变了也不一定需要改变另一方,并且可以将一些可复用的逻辑放在一个 ViewModel 中,让多个 View 复用这个 ViewModel。
在 MVVM 中,最核心的也就是数据双向绑定,例如 Angluar 的脏数据检测,Vue 中的数据劫持。
## 脏数据检测
当触发了指定事件后会进入脏数据检测,这时会调用 `$digest` 循环遍历所有的数据观察者,判断当前值是否和先前的值有区别,如果检测到变化的话,会调用 `$watch` 函数,然后再次调用 `$digest` 循环直到发现没有变化。循环至少为二次 ,至多为十次。
脏数据检测虽然存在低效的问题,但是不关心数据是通过什么方式改变的,都可以完成任务,但是这在 Vue 中的双向绑定是存在问题的。并且脏数据检测可以实现批量检测出更新的值,再去统一更新 UI,大大减少了操作 DOM 的次数。所以低效也是相对的,这就仁者见仁智者见智了。
## 数据劫持
Vue 内部使用了 `Object.defineProperty()` 来实现双向绑定,通过这个函数可以监听到 `set` 和 `get` 的事件。
```js
var data = { name: 'yck' }
observe(data)
let name = data.name // -> get value
data.name = 'yyy' // -> change value
function observe(obj) {
// 判断类型
if (!obj || typeof obj !== 'object') {
return
}
Object.keys(obj).forEach(key => {
defineReactive(obj, key, obj[key])
})
}
function defineReactive(obj, key, val) {
// 递归子属性
observe(val)
Object.defineProperty(obj, key, {
enumerable: true,
configurable: true,
get: function reactiveGetter() {
console.log('get value')
return val
},
set: function reactiveSetter(newVal) {
console.log('change value')
val = newVal
}
})
}
```
以上代码简单的实现了如何监听数据的 `set` 和 `get` 的事件,但是仅仅如此是不够的,还需要在适当的时候给属性添加发布订阅
```html
{{name}}
```
::: v-pre
在解析如上模板代码时,遇到 `{{name}}` 就会给属性 `name` 添加发布订阅。
:::
```js
// 通过 Dep 解耦
class Dep {
constructor() {
this.subs = []
}
addSub(sub) {
// sub 是 Watcher 实例
this.subs.push(sub)
}
notify() {
this.subs.forEach(sub => {
sub.update()
})
}
}
// 全局属性,通过该属性配置 Watcher
Dep.target = null
function update(value) {
document.querySelector('div').innerText = value
}
class Watcher {
constructor(obj, key, cb) {
// 将 Dep.target 指向自己
// 然后触发属性的 getter 添加监听
// 最后将 Dep.target 置空
Dep.target = this
this.cb = cb
this.obj = obj
this.key = key
this.value = obj[key]
Dep.target = null
}
update() {
// 获得新值
this.value = this.obj[this.key]
// 调用 update 方法更新 Dom
this.cb(this.value)
}
}
var data = { name: 'yck' }
observe(data)
// 模拟解析到 `{{name}}` 触发的操作
new Watcher(data, 'name', update)
// update Dom innerText
data.name = 'yyy'
```
接下来,对 `defineReactive` 函数进行改造
```js
function defineReactive(obj, key, val) {
// 递归子属性
observe(val)
let dp = new Dep()
Object.defineProperty(obj, key, {
enumerable: true,
configurable: true,
get: function reactiveGetter() {
console.log('get value')
// 将 Watcher 添加到订阅
if (Dep.target) {
dp.addSub(Dep.target)
}
return val
},
set: function reactiveSetter(newVal) {
console.log('change value')
val = newVal
// 执行 watcher 的 update 方法
dp.notify()
}
})
}
```
以上实现了一个简易的双向绑定,核心思路就是手动触发一次属性的 getter 来实现发布订阅的添加。
## Proxy 与 Object.defineProperty 对比
`Object.defineProperty` 虽然已经能够实现双向绑定了,但是他还是有缺陷的。
1. 只能对属性进行数据劫持,所以需要深度遍历整个对象
2. 对于数组不能监听到数据的变化
虽然 Vue 中确实能检测到数组数据的变化,但是其实是使用了 hack 的办法,并且也是有缺陷的。
```js
const arrayProto = Array.prototype
export const arrayMethods = Object.create(arrayProto)
// hack 以下几个函数
const methodsToPatch = [
'push',
'pop',
'shift',
'unshift',
'splice',
'sort',
'reverse'
]
methodsToPatch.forEach(function (method) {
// 获得原生函数
const original = arrayProto[method]
def(arrayMethods, method, function mutator (...args) {
// 调用原生函数
const result = original.apply(this, args)
const ob = this.__ob__
let inserted
switch (method) {
case 'push':
case 'unshift':
inserted = args
break
case 'splice':
inserted = args.slice(2)
break
}
if (inserted) ob.observeArray(inserted)
// 触发更新
ob.dep.notify()
return result
})
})
```
反观 Proxy 就没以上的问题,原生支持监听数组变化,并且可以直接对整个对象进行拦截,所以 Vue 也将在下个大版本中使用 Proxy 替换 Object.defineProperty
```js
let onWatch = (obj, setBind, getLogger) => {
let handler = {
get(target, property, receiver) {
getLogger(target, property)
return Reflect.get(target, property, receiver);
},
set(target, property, value, receiver) {
setBind(value);
return Reflect.set(target, property, value);
}
};
return new Proxy(obj, handler);
};
let obj = { a: 1 }
let value
let p = onWatch(obj, (v) => {
value = v
}, (target, property) => {
console.log(`Get '${property}' = ${target[property]}`);
})
p.a = 2 // bind `value` to `2`
p.a // -> Get 'a' = 2
```
# 路由原理
前端路由实现起来其实很简单,本质就是监听 URL 的变化,然后匹配路由规则,显示相应的页面,并且无须刷新。目前单页面使用的路由就只有两种实现方式
- hash 模式
- history 模式
`www.test.com/#/` 就是 Hash URL,当 `#` 后面的哈希值发生变化时,不会向服务器请求数据,可以通过 `hashchange` 事件来监听到 URL 的变化,从而进行跳转页面。
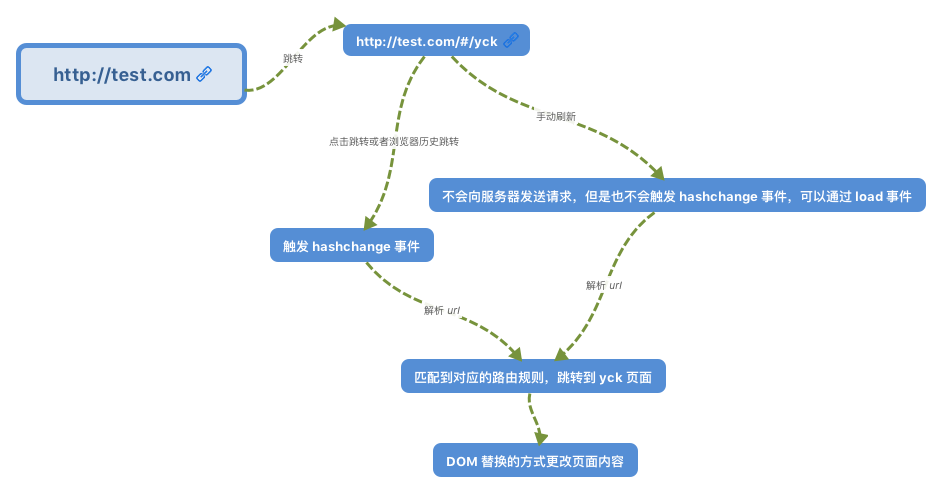
History 模式是 HTML5 新推出的功能,比之 Hash URL 更加美观
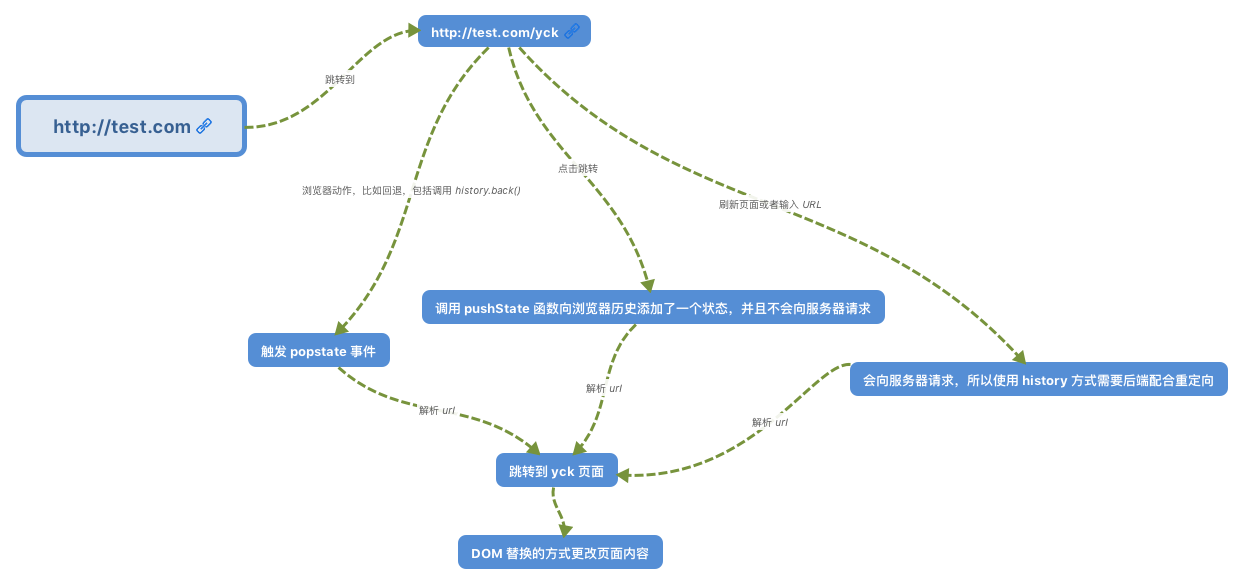
# Virtual Dom
[代码地址](https://github.com/KieSun/My-wheels/tree/master/Virtual%20Dom)
## 为什么需要 Virtual Dom
众所周知,操作 DOM 是很耗费性能的一件事情,既然如此,我们可以考虑通过 JS 对象来模拟 DOM 对象,毕竟操作 JS 对象比操作 DOM 省时的多。
举个例子
```js
// 假设这里模拟一个 ul,其中包含了 5 个 li
[1, 2, 3, 4, 5]
// 这里替换上面的 li
[1, 2, 5, 4]
```
从上述例子中,我们一眼就可以看出先前的 ul 中的第三个 li 被移除了,四五替换了位置。
如果以上操作对应到 DOM 中,那么就是以下代码
```js
// 删除第三个 li
ul.childNodes[2].remove()
// 将第四个 li 和第五个交换位置
let fromNode = ul.childNodes[4]
let toNode = node.childNodes[3]
let cloneFromNode = fromNode.cloneNode(true)
let cloenToNode = toNode.cloneNode(true)
ul.replaceChild(cloneFromNode, toNode)
ul.replaceChild(cloenToNode, fromNode)
```
当然在实际操作中,我们还需要给每个节点一个标识,作为判断是同一个节点的依据。所以这也是 Vue 和 React 中官方推荐列表里的节点使用唯一的 `key` 来保证性能。
那么既然 DOM 对象可以通过 JS 对象来模拟,反之也可以通过 JS 对象来渲染出对应的 DOM
以下是一个 JS 对象模拟 DOM 对象的简单实现
```js
export default class Element {
/**
* @param {String} tag 'div'
* @param {Object} props { class: 'item' }
* @param {Array} children [ Element1, 'text']
* @param {String} key option
*/
constructor(tag, props, children, key) {
this.tag = tag
this.props = props
if (Array.isArray(children)) {
this.children = children
} else if (isString(children)) {
this.key = children
this.children = null
}
if (key) this.key = key
}
// 渲染
render() {
let root = this._createElement(
this.tag,
this.props,
this.children,
this.key
)
document.body.appendChild(root)
return root
}
create() {
return this._createElement(this.tag, this.props, this.children, this.key)
}
// 创建节点
_createElement(tag, props, child, key) {
// 通过 tag 创建节点
let el = document.createElement(tag)
// 设置节点属性
for (const key in props) {
if (props.hasOwnProperty(key)) {
const value = props[key]
el.setAttribute(key, value)
}
}
if (key) {
el.setAttribute('key', key)
}
// 递归添加子节点
if (child) {
child.forEach(element => {
let child
if (element instanceof Element) {
child = this._createElement(
element.tag,
element.props,
element.children,
element.key
)
} else {
child = document.createTextNode(element)
}
el.appendChild(child)
})
}
return el
}
}
```
## Virtual Dom 算法简述
既然我们已经通过 JS 来模拟实现了 DOM,那么接下来的难点就在于如何判断旧的对象和新的对象之间的差异。
DOM 是多叉树的结构,如果需要完整的对比两颗树的差异,那么需要的时间复杂度会是 O(n ^ 3),这个复杂度肯定是不能接受的。于是 React 团队优化了算法,实现了 O(n) 的复杂度来对比差异。
实现 O(n) 复杂度的关键就是只对比同层的节点,而不是跨层对比,这也是考虑到在实际业务中很少会去跨层的移动 DOM 元素。
所以判断差异的算法就分为了两步
- 首先从上至下,从左往右遍历对象,也就是树的深度遍历,这一步中会给每个节点添加索引,便于最后渲染差异
- 一旦节点有子元素,就去判断子元素是否有不同
## Virtual Dom 算法实现
### 树的递归
首先我们来实现树的递归算法,在实现该算法前,先来考虑下两个节点对比会有几种情况
1. 新的节点的 `tagName` 或者 `key` 和旧的不同,这种情况代表需要替换旧的节点,并且也不再需要遍历新旧节点的子元素了,因为整个旧节点都被删掉了
2. 新的节点的 `tagName` 和 `key`(可能都没有)和旧的相同,开始遍历子树
3. 没有新的节点,那么什么都不用做
```js
import { StateEnums, isString, move } from './util'
import Element from './element'
export default function diff(oldDomTree, newDomTree) {
// 用于记录差异
let pathchs = {}
// 一开始的索引为 0
dfs(oldDomTree, newDomTree, 0, pathchs)
return pathchs
}
function dfs(oldNode, newNode, index, patches) {
// 用于保存子树的更改
let curPatches = []
// 需要判断三种情况
// 1.没有新的节点,那么什么都不用做
// 2.新的节点的 tagName 和 `key` 和旧的不同,就替换
// 3.新的节点的 tagName 和 key(可能都没有) 和旧的相同,开始遍历子树
if (!newNode) {
} else if (newNode.tag === oldNode.tag && newNode.key === oldNode.key) {
// 判断属性是否变更
let props = diffProps(oldNode.props, newNode.props)
if (props.length) curPatches.push({ type: StateEnums.ChangeProps, props })
// 遍历子树
diffChildren(oldNode.children, newNode.children, index, patches)
} else {
// 节点不同,需要替换
curPatches.push({ type: StateEnums.Replace, node: newNode })
}
if (curPatches.length) {
if (patches[index]) {
patches[index] = patches[index].concat(curPatches)
} else {
patches[index] = curPatches
}
}
}
```
### 判断属性的更改
判断属性的更改也分三个步骤
1. 遍历旧的属性列表,查看每个属性是否还存在于新的属性列表中
2. 遍历新的属性列表,判断两个列表中都存在的属性的值是否有变化
3. 在第二步中同时查看是否有属性不存在与旧的属性列列表中
```js
function diffProps(oldProps, newProps) {
// 判断 Props 分以下三步骤
// 先遍历 oldProps 查看是否存在删除的属性
// 然后遍历 newProps 查看是否有属性值被修改
// 最后查看是否有属性新增
let change = []
for (const key in oldProps) {
if (oldProps.hasOwnProperty(key) && !newProps[key]) {
change.push({
prop: key
})
}
}
for (const key in newProps) {
if (newProps.hasOwnProperty(key)) {
const prop = newProps[key]
if (oldProps[key] && oldProps[key] !== newProps[key]) {
change.push({
prop: key,
value: newProps[key]
})
} else if (!oldProps[key]) {
change.push({
prop: key,
value: newProps[key]
})
}
}
}
return change
}
```
### 判断列表差异算法实现
这个算法是整个 Virtual Dom 中最核心的算法,且让我一一为你道来。
这里的主要步骤其实和判断属性差异是类似的,也是分为三步
1. 遍历旧的节点列表,查看每个节点是否还存在于新的节点列表中
2. 遍历新的节点列表,判断是否有新的节点
3. 在第二步中同时判断节点是否有移动
PS:该算法只对有 `key` 的节点做处理
```js
function listDiff(oldList, newList, index, patches) {
// 为了遍历方便,先取出两个 list 的所有 keys
let oldKeys = getKeys(oldList)
let newKeys = getKeys(newList)
let changes = []
// 用于保存变更后的节点数据
// 使用该数组保存有以下好处
// 1.可以正确获得被删除节点索引
// 2.交换节点位置只需要操作一遍 DOM
// 3.用于 `diffChildren` 函数中的判断,只需要遍历
// 两个树中都存在的节点,而对于新增或者删除的节点来说,完全没必要
// 再去判断一遍
let list = []
oldList &&
oldList.forEach(item => {
let key = item.key
if (isString(item)) {
key = item
}
// 寻找新的 children 中是否含有当前节点
// 没有的话需要删除
let index = newKeys.indexOf(key)
if (index === -1) {
list.push(null)
} else list.push(key)
})
// 遍历变更后的数组
let length = list.length
// 因为删除数组元素是会更改索引的
// 所有从后往前删可以保证索引不变
for (let i = length - 1; i >= 0; i--) {
// 判断当前元素是否为空,为空表示需要删除
if (!list[i]) {
list.splice(i, 1)
changes.push({
type: StateEnums.Remove,
index: i
})
}
}
// 遍历新的 list,判断是否有节点新增或移动
// 同时也对 `list` 做节点新增和移动节点的操作
newList &&
newList.forEach((item, i) => {
let key = item.key
if (isString(item)) {
key = item
}
// 寻找旧的 children 中是否含有当前节点
let index = list.indexOf(key)
// 没找到代表新节点,需要插入
if (index === -1 || key == null) {
changes.push({
type: StateEnums.Insert,
node: item,
index: i
})
list.splice(i, 0, key)
} else {
// 找到了,需要判断是否需要移动
if (index !== i) {
changes.push({
type: StateEnums.Move,
from: index,
to: i
})
move(list, index, i)
}
}
})
return { changes, list }
}
function getKeys(list) {
let keys = []
let text
list &&
list.forEach(item => {
let key
if (isString(item)) {
key = [item]
} else if (item instanceof Element) {
key = item.key
}
keys.push(key)
})
return keys
}
```
### 遍历子元素打标识
对于这个函数来说,主要功能就两个
1. 判断两个列表差异
2. 给节点打上标记
总体来说,该函数实现的功能很简单
```js
function diffChildren(oldChild, newChild, index, patches) {
let { changes, list } = listDiff(oldChild, newChild, index, patches)
if (changes.length) {
if (patches[index]) {
patches[index] = patches[index].concat(changes)
} else {
patches[index] = changes
}
}
// 记录上一个遍历过的节点
let last = null
oldChild &&
oldChild.forEach((item, i) => {
let child = item && item.children
if (child) {
index =
last && last.children ? index + last.children.length + 1 : index + 1
let keyIndex = list.indexOf(item.key)
let node = newChild[keyIndex]
// 只遍历新旧中都存在的节点,其他新增或者删除的没必要遍历
if (node) {
dfs(item, node, index, patches)
}
} else index += 1
last = item
})
}
```
### 渲染差异
通过之前的算法,我们已经可以得出两个树的差异了。既然知道了差异,就需要局部去更新 DOM 了,下面就让我们来看看 Virtual Dom 算法的最后一步骤
这个函数主要两个功能
1. 深度遍历树,将需要做变更操作的取出来
2. 局部更新 DOM
整体来说这部分代码还是很好理解的
```js
let index = 0
export default function patch(node, patchs) {
let changes = patchs[index]
let childNodes = node && node.childNodes
// 这里的深度遍历和 diff 中是一样的
if (!childNodes) index += 1
if (changes && changes.length && patchs[index]) {
changeDom(node, changes)
}
let last = null
if (childNodes && childNodes.length) {
childNodes.forEach((item, i) => {
index =
last && last.children ? index + last.children.length + 1 : index + 1
patch(item, patchs)
last = item
})
}
}
function changeDom(node, changes, noChild) {
changes &&
changes.forEach(change => {
let { type } = change
switch (type) {
case StateEnums.ChangeProps:
let { props } = change
props.forEach(item => {
if (item.value) {
node.setAttribute(item.prop, item.value)
} else {
node.removeAttribute(item.prop)
}
})
break
case StateEnums.Remove:
node.childNodes[change.index].remove()
break
case StateEnums.Insert:
let dom
if (isString(change.node)) {
dom = document.createTextNode(change.node)
} else if (change.node instanceof Element) {
dom = change.node.create()
}
node.insertBefore(dom, node.childNodes[change.index])
break
case StateEnums.Replace:
node.parentNode.replaceChild(change.node.create(), node)
break
case StateEnums.Move:
let fromNode = node.childNodes[change.from]
let toNode = node.childNodes[change.to]
let cloneFromNode = fromNode.cloneNode(true)
let cloenToNode = toNode.cloneNode(true)
node.replaceChild(cloneFromNode, toNode)
node.replaceChild(cloenToNode, fromNode)
break
default:
break
}
})
}
```
## 最后
Virtual Dom 算法的实现也就是以下三步
1. 通过 JS 来模拟创建 DOM 对象
2. 判断两个对象的差异
3. 渲染差异
```js
let test4 = new Element('div', { class: 'my-div' }, ['test4'])
let test5 = new Element('ul', { class: 'my-div' }, ['test5'])
let test1 = new Element('div', { class: 'my-div' }, [test4])
let test2 = new Element('div', { id: '11' }, [test5, test4])
let root = test1.render()
let pathchs = diff(test1, test2)
console.log(pathchs)
setTimeout(() => {
console.log('开始更新')
patch(root, pathchs)
console.log('结束更新')
}, 1000)
```
当然目前的实现还略显粗糙,但是对于理解 Virtual Dom 算法来说已经是完全足够的了。
================================================
FILE: Framework/react-br.md
================================================
**Table of Contents** *generated with [DocToc](https://github.com/thlorenz/doctoc)*
- [React Lifecycle analysis](#react-lifecycle-analysis)
- [The usage advice of Lifecycle methods in React V16](#the-usage-advice-of--lifecycle-methods-in-react-v16)
- [setState](#setstate)
- [Redux Source Code Analysis](#redux-source-code-analysis)
# Análise do Ciclo de vida React
O Fiber foi introduzido no lançamento da V16. O mecanismo afeta alguma das chamadas do ciclo de vida até certo ponto e foi introduzida duas novas APIs para resolver problemas.
Nas versões anteriores, se eu tiver um componente composto complexo e então mudar o `state` na camada mais alta do componente, a pilha de chamada poderia ser grande.
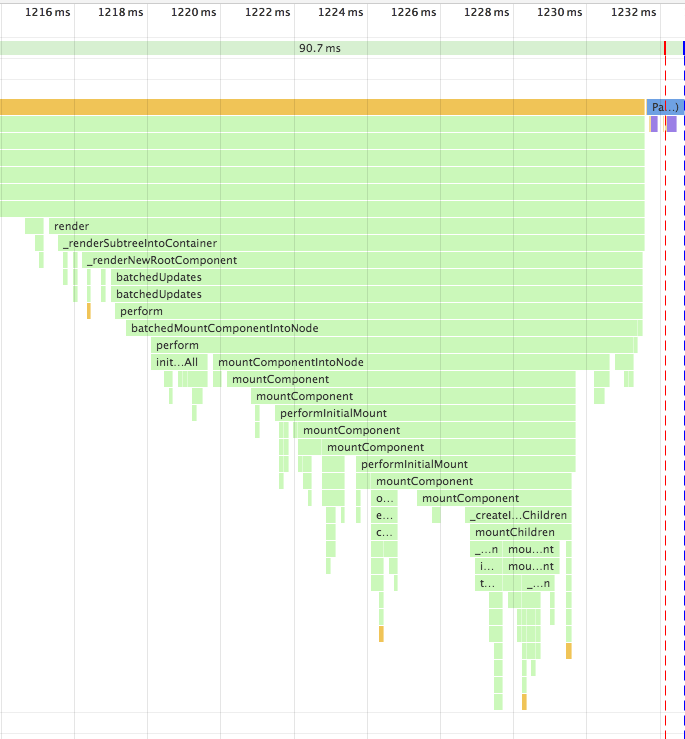
Se a pilha de chamada for muito longa, e complicadas operações estiverem no meio, isso pode causar um bloqueio a thread principal por um longe tempo, resultando em uma experiência ruim para o usuário. Fiber nasceu para resolver esse problema.
Fiber é na essência uma pilha virtual de quadros, e o novo agendador espontaneamente agenda esses quadros de acordo
com sua prioridade, desse modo, mudando a renderização síncrona anterior para renderização assíncrona, e segmentando a atualização sem afetar a experiência.
React tem seu proprio conjunto de lógica sobre como priorizar. Para coisas que requerem alta performance em tempo-real, tal como animação, que significa isso deve ser renderizado uma vez dentro de 16 ms para garantir que não está emperrando, React pausa o update a cada 16 ms (dentro de 16 ms) e retorna para continuar renderizando a animação.
Para renderização assíncrona, existe agora dois estagios de renderização: `reconciliation` e `commit`. O primeiro processo pode ser interrompido, enquanto o último não poder ser suspenso, e a interface será atualizada até isso ser completo.
**Reconciliation** etapa
- `componentWillMount`
- `componentWillReceiveProps`
- `shouldComponentUpdate`
- `componentWillUpdate`
**Commit** etapa
- `componentDidMount`
- `componentDidUpdate`
- `componentWillUnmount`
Pelo fato que a fase de `reconciliation` pode ser interrompida, as funções do ciclo de vida que executaram na fase de `reconciliation` podem ser chamadas multiplas vezes, o que pode causar vários bugs. Então para essas funções, exceto para `shouldComponentUpdate`, devemos evitar assim que possivel, e uma nova API está introduzida na V16 para resolver esse problema.
`getDerivedStateFromProps` é usado para substituir `componentWillReceiveProps`, do qual é chamado durando a inicialização e atualização
```js
class ExampleComponent extends React.Component {
// Inicializa o state no construtor,
// Ou com a propriedade initializer.
state = {};
static getDerivedStateFromProps(nextProps, prevState) {
if (prevState.someMirroredValue !== nextProps.someValue) {
return {
derivedData: computeDerivedState(nextProps),
someMirroredValue: nextProps.someValue
};
}
// Retorna nulo para indicar que não há mudança no state.
return null;
}
}
```
`getSnapshotBeforeUpdate` é usado para substituir o `componentWillUpdate`, do qual é chamado depois do `update` mas antes do DOM atualizar para leitura o último dado do DOM.
## O conselho usado nos métodos do ciclo de vida no React V16
```js
class ExampleComponent extends React.Component {
// Usado para iniciar o state
constructor() {}
// Usado para substituir o `componentWillReceiveProps`, do qual ira ser chamado quando inicializado e `update`
// Porque a função é estática, você não pode acessar o `this`
// Se você precisar comparar `prevProps`, você precisa manter ele separado no `state`
static getDerivedStateFromProps(nextProps, prevState) {}
// Determina se você precisa atualizar os componentes, usado na maioria das vezes para otimização de performance do componente
shouldComponentUpdate(nextProps, nextState) {}
// Chamado depois do componente ser montado
// Pode requisitar ou subscrever nessa função
componentDidMount() {}
// Obter o último dado do DOM
getSnapshotBeforeUpdate() {}
// É sobre o componente ser destruido
// Pode remover subscrições, timers, etc.
componentWillUnmount() {}
// Chamado depois do componente ser destruido
componentDidUnMount() {}
// Chamado depois da atualização do componente
componentDidUpdate() {}
// renderiza o componente
render() {}
// As seguintes funções não são recomendadas
UNSAFE_componentWillMount() {}
UNSAFE_componentWillUpdate(nextProps, nextState) {}
UNSAFE_componentWillReceiveProps(nextProps) {}
}
```
# setState
`setState` é uma API que é frequentemente usada no React, mas ele tem alguns problemas que podem levar a erros. O centro das razões é que a API é assíncrona.
Primeiro, chamando `setState` não casa mudança imediata no `state`, e se você chamar multiplos `setState` de uma vez, o resultado pode não ser como o esperado.
```js
handle() {
// Iniciado o `count` em 0
console.log(this.state.count) // -> 0
this.setState({ count: this.state.count + 1 })
this.setState({ count: this.state.count + 1 })
this.setState({ count: this.state.count + 1 })
console.log(this.state.count) // -> 0
}
```
Primeiro, ambos os prints são 0, porque o `setState` é uma API assíncrona e irá apenas executar depois do código síncrono terminar sua execução. O motivo para o `setState` ser assíncrono é que `setState` pode causar repintar no DOM. Se a chamada repintar imediatamente depois da chamada, a chamada vai causar uma perca de performance desnecessária. Desenhando para ser assíncrono, você pode colocar multiplas chamadas dentro da fila e unificar os processos de atualização quando apropriado.
Segundo, apesar do `setState` ser chamado três vezes, o valor do `count` ainda é 1. Porque multiplas chamadas são fundidas em uma, o `state` só vai mudar quando a atualização terminar, e três chamadas são equivalente para o seguinte código.
```js
Object.assign(
{},
{ count: this.state.count + 1 },
{ count: this.state.count + 1 },
{ count: this.state.count + 1 },
)
```
De fato, você pode também chamar `setState` três vezes da seguinte maneira para fazer `count` 3
```js
handle() {
this.setState((prevState) => ({ count: prevState.count + 1 }))
this.setState((prevState) => ({ count: prevState.count + 1 }))
this.setState((prevState) => ({ count: prevState.count + 1 }))
}
```
Se você quer acessar o `state` correto depois de cada chamada ao `setState`, você pode fazer isso com o seguinte código:
```js
handle() {
this.setState((prevState) => ({ count: prevState.count + 1 }), () => {
console.log(this.state)
})
}
```
# Análise de código do Redux
Vamos dar uma olhada na função `combineReducers` primeiro.
```js
// passe um objeto
export default function combineReducers(reducers) {
// capture as chaves desse objeto
const reducerKeys = Object.keys(reducers)
// reducers depois filtrados
const finalReducers = {}
// obtenha os valores correspondentes para cada chave
// no ambiente de desenvolvimento, verifique se o valor é undefined
// então coloque os valores do tipo de função dentro do finalReducers
for (let i = 0; i < reducerKeys.length; i++) {
const key = reducerKeys[i]
if (process.env.NODE_ENV !== 'production') {
if (typeof reducers[key] === 'undefined') {
warning(`No reducer provided for key "${key}"`)
}
}
if (typeof reducers[key] === 'function') {
finalReducers[key] = reducers[key]
}
}
// obtenha as chaves dos reducers depois de filtrado
const finalReducerKeys = Object.keys(finalReducers)
// no ambiente de desenvolvimento verifique e salvo as chaves inesperadas em cache para alertas futuros
let unexpectedKeyCache
if (process.env.NODE_ENV !== 'production') {
unexpectedKeyCache = {}
}
let shapeAssertionError
try {
// explicações de funções estão abaixo
assertReducerShape(finalReducers)
} catch (e) {
shapeAssertionError = e
}
// combineReducers retorna outra função, que é reduzido depois de fundido
// essa função retorna o state raiz
// também percena que um encerramento é usado aqui. A função usa algumas propriedades externas
return function combination(state = {}, action) {
if (shapeAssertionError) {
throw shapeAssertionError
}
// explicações das funções estão abaixo
if (process.env.NODE_ENV !== 'production') {
const warningMessage = getUnexpectedStateShapeWarningMessage(
state,
finalReducers,
action,
unexpectedKeyCache
)
if (warningMessage) {
warning(warningMessage)
}
}
// if state changed
let hasChanged = false
// state depois das mudanças
const nextState = {}
for (let i = 0; i < finalReducerKeys.length; i++) {
// obter a chave com index
const key = finalReducerKeys[i]
// obter a função de reducer correspondente com a chave
const reducer = finalReducers[key]
// a chave na arvore do state é a mesma chave no finalReducers
// então a chave passada nos parametros para o combineReducers representa cada reducer assim como cada state
const previousStateForKey = state[key]
// execute as funções reducer para pegar o state correspondente a chave
const nextStateForKey = reducer(previousStateForKey, action)
// verifique o valor do state, reporte erros se ele não estiver undefined
if (typeof nextStateForKey === 'undefined') {
const errorMessage = getUndefinedStateErrorMessage(key, action)
throw new Error(errorMessage)
}
// coloque o valor dentro do nextState
nextState[key] = nextStateForKey
// se o state mudaou
hasChanged = hasChanged || nextStateForKey !== previousStateForKey
}
// enquanto o state mudar, retorne um novo state
return hasChanged ? nextState : state
}
}
```
`combineReducers` é simples e generico. Resumindo, ele aceita um objeto e retorna uma função depois processado os parâmetros. Essa função tem um objeto finalReducers que armazena os parametros processados. O objeto é então iterado, cada função reducer nela é executada, e o novo state é executado.
Vamos então olhar as duas funções usadas no combineReducers.
```js
// a primeira função usada para lançar os erros
function assertReducerShape(reducers) {
// iterar nós paramêtros no combineReducers
Object.keys(reducers).forEach(key => {
const reducer = reducers[key]
// passar uma ação
const initialState = reducer(undefined, { type: ActionTypes.INIT })
// lança um erro se o state estiver undefined
if (typeof initialState === 'undefined') {
throw new Error(
`Reducer "${key}" retorna undefined durante a inicialização. ` +
`Se o state passado para o reducer for undefined, você deve ` +
`explicitamente retornar o state inicial. O state inicial não deve ` +
`ser undefined. Se você não quer definir um valor para esse reducer, ` +
`você pode user null ao invés de undefined.`
)
}
// processe novamente, considerando o caso que o usuário retornou um valor para ActionTypes.INIT no reducer
// passa uma ação aleatória e verificar se o valor é undefined
const type =
'@@redux/PROBE_UNKNOWN_ACTION_' +
Math.random()
.toString(36)
.substring(7)
.split('')
.join('.')
if (typeof reducer(undefined, { type }) === 'undefined') {
throw new Error(
`Reducer "${key}" retorna undefined quando sondado com um tipo aleatório. ` +
`Não tente manipular ${
ActionTypes.INIT
} ou outras ações no "redux/*" ` +
`namespace.Eles são considerados privado. Ao invés, você deve retornar o ` +
`state atual para qualquer action desconhecida, a menos que esteja undefined, ` +
`nesse caso você deve retorna o state inicial, independemente do ` +
`tipo da ação. O state inicial não deve ser undefined, mas pode ser null.`
)
}
})
}
function getUnexpectedStateShapeWarningMessage(
inputState,
reducers,
action,
unexpectedKeyCache
) {
// aqui os reducers já estão no finalReducers
const reducerKeys = Object.keys(reducers)
const argumentName =
action && action.type === ActionTypes.INIT
? 'preloadedState argumento passado para o createStore'
: 'state anterior recebido pelo reducer'
// se finalReducers estiver vázio
if (reducerKeys.length === 0) {
return (
'Store não tem um reducer válido. Certifique-se de que um argumento foi passado ' +
'para o combineReducers é um objeto do qual os valores são reducers.'
)
}
// se o state passado não é um objeto
if (!isPlainObject(inputState)) {
return (
`O ${argumentName} tem um tipo inesperado de "` +
{}.toString.call(inputState).match(/\s([a-z|A-Z]+)/)[1] +
`". O argumento esperado deve ser um objeto com as seguintes ` +
`chaves: "${reducerKeys.join('", "')}"`
)
}
// compara as chaves do state a do finalReducers e filtra as chaves extras
const unexpectedKeys = Object.keys(inputState).filter(
key => !reducers.hasOwnProperty(key) && !unexpectedKeyCache[key]
)
unexpectedKeys.forEach(key => {
unexpectedKeyCache[key] = true
})
if (action && action.type === ActionTypes.REPLACE) return
// se unexpectedKeys não estiver vázia
if (unexpectedKeys.length > 0) {
return (
`Inesperada ${unexpectedKeys.length > 1 ? 'chaves' : 'chave'} ` +
`"${unexpectedKeys.join('", "')}" encontrada em ${argumentName}. ` +
`Esperado encontrar uma das chaves do reducer conhecida ao invés: ` +
`"${reducerKeys.join('", "')}". Chaves inesperadas serão ignoradas.`
)
}
}
```
Vamos então dar uma olhada na função `compose`
```js
// Essa função é bem elegante. Ela nos permite empilhar diversas funções passando a
// referências da função. O termo é chamado de Higher-order function.
// chama funções a partir da direita para esquerda com funções reduce
// por exemplo, no objeto acima
compose(
applyMiddleware(thunkMiddleware),
window.devToolsExtension ? window.devToolsExtension() : f => f
)
// Com compose ele retorna dentro do applyMiddleware(thunkMiddleware)(window.devToolsExtension()())
// então você deveria retorna uma função quando window.devToolsExtension não for encontrada
export default function compose(...funcs) {
if (funcs.length === 0) {
return arg => arg
}
if (funcs.length === 1) {
return funcs[0]
}
return funcs.reduce((a, b) => (...args) => a(b(...args)))
}
```
Vamos então analisar pare do código da função `createStore`
```js
export default function createStore(reducer, preloadedState, enhancer) {
// normalmente preloadedState é raramente usado
// verificar o tipo, é o segundo parâmetro da função e não existe terceiro parâmetro, então troque as posições
if (typeof preloadedState === 'function' && typeof enhancer === 'undefined') {
enhancer = preloadedState
preloadedState = undefined
}
// verifique se enhancer é uma função
if (typeof enhancer !== 'undefined') {
if (typeof enhancer !== 'function') {
throw new Error('É esperado que enhancer seja uma função.')
}
// se não existe um tipo error, primeiro execute o enhancer, então execute o createStore
return enhancer(createStore)(reducer, preloadedState)
}
// verifique se o reducer é uma função
if (typeof reducer !== 'function') {
throw new Error('É esperado que o reducer seja uma função.')
}
// reducer atual
let currentReducer = reducer
// state atual
let currentState = preloadedState
// atual listener array
let currentListeners = []
// esse é um design muito importante. O proposito é que o currentListeners array seja invariante quando os listeners estiverem sendo interado
// Nós podemos considerar se apenas um currentListeners existe. Se nós executarmos o subscribe novamente em alguma execução do subscribe, ou unsubscribe isso mudaria o tamanho do currentListeners array, então devemos ter um index erro
let nextListeners = currentListeners
// se o reducer está executando
let isDispatching = false
// se o currentListeners é o mesmo que o nextListeners, atribua o valor de volta
function ensureCanMutateNextListeners() {
if (nextListeners === currentListeners) {
nextListeners = currentListeners.slice()
}
}
// ......
}
```
Vamos dar uma olhada na função `applyMiddleware`
Antes eu preciso introduzir um conceito chamado Currying. Currying é uma tecnologia para mudar uma função com multiplos parâmetros em uma série de funções com um único parâmetro.
```js
function add(a,b) { return a + b }
add(1, 2) => 3
// para a função abaixo, nós usamos Currying igual a
function add(a) {
return b => {
return a + b
}
}
add(1)(2) => 3
// você pode entender Currying como:
// nós armazenamos uma variável do lado de fora com um closure, e retornamos uma função que leva um parâmetro. Nessa função, nós usamos a variável armazenada e retornamos um valor.
```
```js
// essa função deve ser a parte mais obstrusa de todo código
// essa função retorna um função Curried
// assim sendo a função deve se chamada como: applyMiddleware(...middlewares)(createStore)(...args)
export default function applyMiddleware(...middlewares) {
return createStore => (...args) => {
// aqui nós executamos createStore, e passamos o parâmetro passado por último a função applyMiddleware
const store = createStore(...args)
let dispatch = () => {
throw new Error(
`Dispatching while constructing your middleware is not allowed. ` +
`Other middleware would not be applied to this dispatch.`
)
}
let chain = []
// todo middleware deve ter essas duas funções
const middlewareAPI = {
getState: store.getState,
dispatch: (...args) => dispatch(...args)
}
// passar cada middleware nos middlewares para o middlewareAPI
chain = middlewares.map(middleware => middleware(middlewareAPI))
// assim como antes, chame cada middleware da esquerda para direita, e passo para o store.dispatch
dispatch = compose(...chain)(store.dispatch)
// essa parte é um pouco abstrata, nós iremos analisar juntos com o código do redux-thunk
// createThunkMiddleware retorna uma função de 3-nível, o primeiro nível aceita um parâmetro middlewareAPI
// o segundo nível aceita store.dispatch
// o terceiro nível aceita parâmentros no dispatch
{function createThunkMiddleware(extraArgument) {
return ({ dispatch, getState }) => next => action => {
// verifique se o parâmetro no dispatch é uma função
if (typeof action === 'function') {
// se assim for, passe esses parâmetros, até as acões não sejam mais uma função, então execute dispatch({type: 'XXX'})
return action(dispatch, getState, extraArgument);
}
return next(action);
};
}
const thunk = createThunkMiddleware();
export default thunk;}
// retorn o middleware-empowered dispatch e o resto das propriedades no store.
return {
...store,
dispatch
}
}
}
```
Agora nós passamos a parte difícil. Vamos olhar uma parte mais fácil.
```js
// Não há muito para dizer aqui, retorne o state atual, mas nós não podemos chamar essa função quando o reducer estiver executando
function getState() {
if (isDispatching) {
throw new Error(
'You may not call store.getState() while the reducer is executing. ' +
'The reducer has already received the state as an argument. ' +
'Pass it down from the top reducer instead of reading it from the store.'
)
}
return currentState
}
// aceita uma função parâmetro
function subscribe(listener) {
if (typeof listener !== 'function') {
throw new Error('Expected listener to be a function.')
}
// a maior parte desse design já foi coberto na descrição sobre nextListeners. Não há muito para falar sobre.
if (isDispatching) {
throw new Error(
'You may not call store.subscribe() while the reducer is executing. ' +
'If you would like to be notified after the store has been updated, subscribe from a ' +
'component and invoke store.getState() in the callback to access the latest state. ' +
'See http://redux.js.org/docs/api/Store.html#subscribe for more details.'
)
}
let isSubscribed = true
ensureCanMutateNextListeners()
nextListeners.push(listener)
// retorne a função de cancelar a subscription
return function unsubscribe() {
if (!isSubscribed) {
return
}
if (isDispatching) {
throw new Error(
'You may not unsubscribe from a store listener while the reducer is executing. ' +
'See http://redux.js.org/docs/api/Store.html#subscribe for more details.'
)
}
isSubscribed = false
ensureCanMutateNextListeners()
const index = nextListeners.indexOf(listener)
nextListeners.splice(index, 1)
}
}
function dispatch(action) {
// o prototype dispatch vai verificar se a ação é um objeto
if (!isPlainObject(action)) {
throw new Error(
'Actions must be plain objects. ' +
'Use custom middleware for async actions.'
)
}
if (typeof action.type === 'undefined') {
throw new Error(
'Actions may not have an undefined "type" property. ' +
'Have you misspelled a constant?'
)
}
// perceba que você não pode chamar uma função dispatch nos reducers
// isso causaria um estouro de pilha
if (isDispatching) {
throw new Error('Reducers may not dispatch actions.')
}
// execute a função composta depois do combineReducers
try {
isDispatching = true
currentState = currentReducer(currentState, action)
} finally {
isDispatching = false
}
// itere nos currentListeners e execute as funções salvas no array de funções
const listeners = (currentListeners = nextListeners)
for (let i = 0; i < listeners.length; i++) {
const listener = listeners[i]
listener()
}
return action
}
// no fim do createStore, invoce uma ação dispatch({ type: ActionTypes.INIT });
// para inicializar o state
```
================================================
FILE: Framework/react-en.md
================================================
**Table of Contents** *generated with [DocToc](https://github.com/thlorenz/doctoc)*
- [React Lifecycle analysis](#react-lifecycle-analysis)
- [The usage advice of Lifecycle methods in React V16](#the-usage-advice-of--lifecycle-methods-in-react-v16)
- [setState](#setstate)
- [Redux Source Code Analysis](#redux-source-code-analysis)
# React Lifecycle analysis
The Fiber mechanism was introduced in the V16 release. The mechanism affects some of the lifecycle calls to a certain extent and introduces two new APIs to solve the problems.
In previous versions, if you had a very complex composite component and then changed the `state` of the topmost component, the call stack might be long.
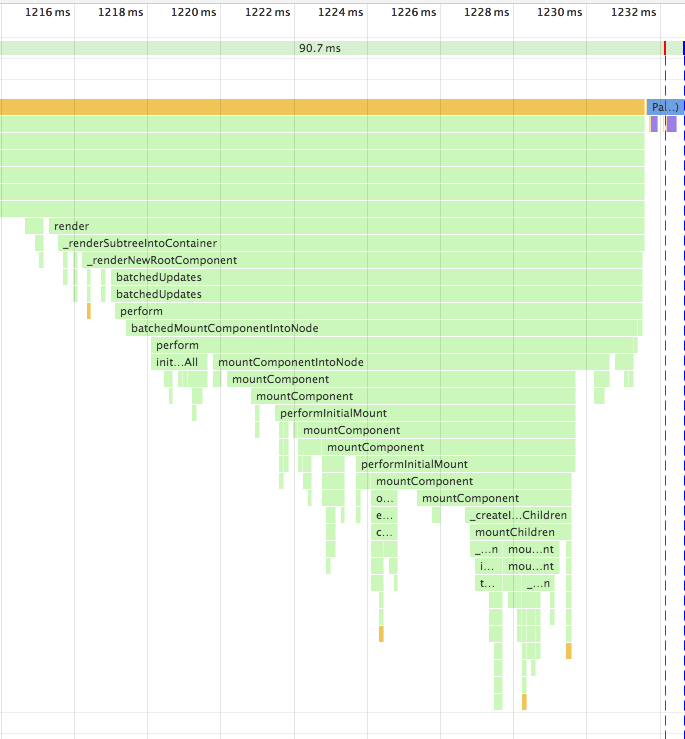
If the call stack is too long, and complicated operations are performed in the middle, it may cause the main thread to be blocked for a long time, resulting in a bad user experience. Fiber is born to solve this problem.
Fiber is essentially a virtual stack frame, and the new scheduler freely schedules these frames according to their priority, thereby changing the previous synchronous rendering to asynchronous rendering, and segmenting the update without affecting the experience.
React has its own set of logic on how to prioritize. For things that require high real-time performance, such as animation, which means it must be rendered once within 16 ms to ensure that it is not stuck, React pauses the update every 16 ms (within 16ms) and returns to continue rendering the animation.
For asynchronous rendering, there are now two stages of rendering: `reconciliation` and `commit`. The former process can be interrupted, while the latter cannot be suspended, and the interface will be updated until it is completed.
**Reconciliation** stage
- `componentWillMount`
- `componentWillReceiveProps`
- `shouldComponentUpdate`
- `componentWillUpdate`
**Commit** stage
- `componentDidMount`
- `componentDidUpdate`
- `componentWillUnmount`
Because the `reconciliation` phase can be interrupted, the lifecycle functions that will be executed in the `reconciliation` phase may be called multiple times, which may cause bugs. So for these functions, except for `shouldComponentUpdate`, should be avoided as much as possible, and a new API is introduced in V16 to solve this problem.
`getDerivedStateFromProps` is used to replace `componentWillReceiveProps` , which is called during initialization and update
```js
class ExampleComponent extends React.Component {
// Initialize state in constructor,
// Or with a property initializer.
state = {};
static getDerivedStateFromProps(nextProps, prevState) {
if (prevState.someMirroredValue !== nextProps.someValue) {
return {
derivedData: computeDerivedState(nextProps),
someMirroredValue: nextProps.someValue
};
}
// Return null to indicate no change to state.
return null;
}
}
```
`getSnapshotBeforeUpdate` is used to replace `componentWillUpdate`, which is called after the `update` but before the DOM update to read the latest DOM data.
## The usage advice of Lifecycle methods in React V16
```js
class ExampleComponent extends React.Component {
// Used to initialize the state
constructor() {}
// Used to replace `componentWillReceiveProps` , which will be called when initializing and `update`
// Because the function is static, you can't get `this`
// If need to compare `prevProps`, you need to maintain it separately in `state`
static getDerivedStateFromProps(nextProps, prevState) {}
// Determine whether you need to update components, mostly for component performance optimization
shouldComponentUpdate(nextProps, nextState) {}
// Called after the component is mounted
// Can request or subscribe in this function
componentDidMount() {}
// Used to get the latest DOM data
getSnapshotBeforeUpdate() {}
// Component is about to be destroyed
// Can remove subscriptions, timers, etc. here
componentWillUnmount() {}
// Called after the component is destroyed
componentDidUnMount() {}
// Called after component update
componentDidUpdate() {}
// render component
render() {}
// The following functions are not recommended
UNSAFE_componentWillMount() {}
UNSAFE_componentWillUpdate(nextProps, nextState) {}
UNSAFE_componentWillReceiveProps(nextProps) {}
}
```
# setState
`setState` is an API that is often used in React, but it has some problems that can lead to mistakes. The core reason is that the API is asynchronous.
First, calling `setState` does not immediately cause a change to `state`, and if you call multiple `setState` at a time, the result may not be as you expect.
```js
handle() {
// Initialize `count` to 0
console.log(this.state.count) // -> 0
this.setState({ count: this.state.count + 1 })
this.setState({ count: this.state.count + 1 })
this.setState({ count: this.state.count + 1 })
console.log(this.state.count) // -> 0
}
```
First, both prints are 0, because `setState` is an asynchronous API and will only execute after the sync code has finished running. The reason for `setState` is asynchronous is that `setState` may cause repainting of the DOM. If the call is repainted immediately after the call, the call will cause unnecessary performance loss. Designed to be asynchronous, you can put multiple calls into a queue and unify the update process when appropriate.
Second, although `setState` is called three times, the value of `count` is still 1. Because multiple calls are merged into one, only `state` will change when the update ends, and three calls are equivalent to the following code.
```js
Object.assign(
{},
{ count: this.state.count + 1 },
{ count: this.state.count + 1 },
{ count: this.state.count + 1 },
)
```
Of course, you can also call `setState` three times by the following way to make `count` 3
```js
handle() {
this.setState((prevState) => ({ count: prevState.count + 1 }))
this.setState((prevState) => ({ count: prevState.count + 1 }))
this.setState((prevState) => ({ count: prevState.count + 1 }))
}
```
If you want to get the correct `state` after each call to `setState`, you can do it with the following code:
```js
handle() {
this.setState((prevState) => ({ count: prevState.count + 1 }), () => {
console.log(this.state)
})
}
```
# Redux Source Code Analysis
Let's take a look at the `combineReducers` function first.
```js
// pass an object
export default function combineReducers(reducers) {
// get this object's keys
const reducerKeys = Object.keys(reducers)
// reducers after filtering
const finalReducers = {}
// get the values corresponding to every key
// in dev environment, check if the value is undefined
// then put function type values into finalReducers
for (let i = 0; i < reducerKeys.length; i++) {
const key = reducerKeys[i]
if (process.env.NODE_ENV !== 'production') {
if (typeof reducers[key] === 'undefined') {
warning(`No reducer provided for key "${key}"`)
}
}
if (typeof reducers[key] === 'function') {
finalReducers[key] = reducers[key]
}
}
// get the keys of the reducers after filtering
const finalReducerKeys = Object.keys(finalReducers)
// in dev environment check and save unexpected key to cache for warnings later
let unexpectedKeyCache
if (process.env.NODE_ENV !== 'production') {
unexpectedKeyCache = {}
}
let shapeAssertionError
try {
// explanations of the function is below
assertReducerShape(finalReducers)
} catch (e) {
shapeAssertionError = e
}
// combineReducers returns another function, which is reducer after merging
// this function returns the root state
// also notice a closure is used here. The function uses some outside properties
return function combination(state = {}, action) {
if (shapeAssertionError) {
throw shapeAssertionError
}
// explanations of the function is below
if (process.env.NODE_ENV !== 'production') {
const warningMessage = getUnexpectedStateShapeWarningMessage(
state,
finalReducers,
action,
unexpectedKeyCache
)
if (warningMessage) {
warning(warningMessage)
}
}
// if state changed
let hasChanged = false
// state after changes
const nextState = {}
for (let i = 0; i < finalReducerKeys.length; i++) {
// get the key with index
const key = finalReducerKeys[i]
// get the corresponding reducer function with key
const reducer = finalReducers[key]
// the key in state tree is the same as the key in finalReducers
// so the key of the parameter passed to combineReducers represents each reducer as well as each state
const previousStateForKey = state[key]
// execute reducer function to get the state corresponding to the key
const nextStateForKey = reducer(previousStateForKey, action)
// check the value of state, report error if it's undefined
if (typeof nextStateForKey === 'undefined') {
const errorMessage = getUndefinedStateErrorMessage(key, action)
throw new Error(errorMessage)
}
// put the value into nextState
nextState[key] = nextStateForKey
// if state changed
hasChanged = hasChanged || nextStateForKey !== previousStateForKey
}
// as long as state changed, return the new state
return hasChanged ? nextState : state
}
}
```
`combineReducers` is simple in general. In short, it accepts an object and return a function after processing the parameters. This function has an object finalReducers that stores the processed parameters. The object is then itereated on, each reducer function in it is executed, and the new state is returned.
Let's then take a look at the two functions used in combineReducers.
```js
// the first function used to throw errors
function assertReducerShape(reducers) {
// iterate on the parameters in combineReducers
Object.keys(reducers).forEach(key => {
const reducer = reducers[key]
// pass an action
const initialState = reducer(undefined, { type: ActionTypes.INIT })
// throw an error if the state is undefined
if (typeof initialState === 'undefined') {
throw new Error(
`Reducer "${key}" returned undefined during initialization. ` +
`If the state passed to the reducer is undefined, you must ` +
`explicitly return the initial state. The initial state may ` +
`not be undefined. If you don't want to set a value for this reducer, ` +
`you can use null instead of undefined.`
)
}
// process again, considering the case that the user returned a value for ActionTypes.INIT in the reducer
// pass a random action and check if the value is undefined
const type =
'@@redux/PROBE_UNKNOWN_ACTION_' +
Math.random()
.toString(36)
.substring(7)
.split('')
.join('.')
if (typeof reducer(undefined, { type }) === 'undefined') {
throw new Error(
`Reducer "${key}" returned undefined when probed with a random type. ` +
`Don't try to handle ${
ActionTypes.INIT
} or other actions in "redux/*" ` +
`namespace. They are considered private. Instead, you must return the ` +
`current state for any unknown actions, unless it is undefined, ` +
`in which case you must return the initial state, regardless of the ` +
`action type. The initial state may not be undefined, but can be null.`
)
}
})
}
function getUnexpectedStateShapeWarningMessage(
inputState,
reducers,
action,
unexpectedKeyCache
) {
// here the reducers is already finalReducers
const reducerKeys = Object.keys(reducers)
const argumentName =
action && action.type === ActionTypes.INIT
? 'preloadedState argument passed to createStore'
: 'previous state received by the reducer'
// if finalReducers is empty
if (reducerKeys.length === 0) {
return (
'Store does not have a valid reducer. Make sure the argument passed ' +
'to combineReducers is an object whose values are reducers.'
)
}
// if the state passed is not an object
if (!isPlainObject(inputState)) {
return (
`The ${argumentName} has unexpected type of "` +
{}.toString.call(inputState).match(/\s([a-z|A-Z]+)/)[1] +
`". Expected argument to be an object with the following ` +
`keys: "${reducerKeys.join('", "')}"`
)
}
// compare the keys of the state and of finalReducers and filter out the extra keys
const unexpectedKeys = Object.keys(inputState).filter(
key => !reducers.hasOwnProperty(key) && !unexpectedKeyCache[key]
)
unexpectedKeys.forEach(key => {
unexpectedKeyCache[key] = true
})
if (action && action.type === ActionTypes.REPLACE) return
// if unexpectedKeys is not empty
if (unexpectedKeys.length > 0) {
return (
`Unexpected ${unexpectedKeys.length > 1 ? 'keys' : 'key'} ` +
`"${unexpectedKeys.join('", "')}" found in ${argumentName}. ` +
`Expected to find one of the known reducer keys instead: ` +
`"${reducerKeys.join('", "')}". Unexpected keys will be ignored.`
)
}
}
```
Let's then take a look at `compose` function
```js
// This function is quite elegant. It let us stack several functions via passing the references of functions. The term is called Higher-order function.
// call functions from the right to the left with reduce function
// for the example in the project above
compose(
applyMiddleware(thunkMiddleware),
window.devToolsExtension ? window.devToolsExtension() : f => f
)
// with compose it turns into applyMiddleware(thunkMiddleware)(window.devToolsExtension()())
// so you should return a function when window.devToolsExtension is not found
export default function compose(...funcs) {
if (funcs.length === 0) {
return arg => arg
}
if (funcs.length === 1) {
return funcs[0]
}
return funcs.reduce((a, b) => (...args) => a(b(...args)))
}
```
Let's then analyze part of the source code of `createStore` function
```js
export default function createStore(reducer, preloadedState, enhancer) {
// normally preloadedState is rarely used
// check type, is the second parameter is a function and there is no third parameter, then exchange positions
if (typeof preloadedState === 'function' && typeof enhancer === 'undefined') {
enhancer = preloadedState
preloadedState = undefined
}
// check if enhancer is a function
if (typeof enhancer !== 'undefined') {
if (typeof enhancer !== 'function') {
throw new Error('Expected the enhancer to be a function.')
}
// if there is no type error, first execute enhancer, then execute createStore
return enhancer(createStore)(reducer, preloadedState)
}
// check if reducer is a function
if (typeof reducer !== 'function') {
throw new Error('Expected the reducer to be a function.')
}
// current reducer
let currentReducer = reducer
// current state
let currentState = preloadedState
// current listener array
let currentListeners = []
// this is a very important design. The purpose is that currentListeners array is an invariant when the listeners are iterated every time
// we can consider if only currentListeners exists. If we execute subscribe again in some subscribe execution, or unsubscribe, it would change the length of the currentListeners array, so there might be an index error
let nextListeners = currentListeners
// if reducer is executing
let isDispatching = false
// if currentListeners is the same as nextListeners, assign the value back
function ensureCanMutateNextListeners() {
if (nextListeners === currentListeners) {
nextListeners = currentListeners.slice()
}
}
// ......
}
```
We look at `applyMiddleware` function next
Before that I need to introduce a concept called function Currying. Currying is a technology for changing a function with multiple parameters to a series of functions with a single parameter.
```js
function add(a,b) { return a + b }
add(1, 2) => 3
// for the above function, we can use Currying like so
function add(a) {
return b => {
return a + b
}
}
add(1)(2) => 3
// you can understand Currying like this:
// we store an outside variable with a closure, and return a function that takes a parameter. In this function, we use the stored variable and return the value.
```
```js
// this function should be the most abstruse part of the whole source code
// this function returns a function Curried
// therefore the funciton should be called like so: applyMiddleware(...middlewares)(createStore)(...args)
export default function applyMiddleware(...middlewares) {
return createStore => (...args) => {
// here we execute createStore, and pass the parameters passed lastly to the applyMiddleware function
const store = createStore(...args)
let dispatch = () => {
throw new Error(
`Dispatching while constructing your middleware is not allowed. ` +
`Other middleware would not be applied to this dispatch.`
)
}
let chain = []
// every middleware should have these two functions
const middlewareAPI = {
getState: store.getState,
dispatch: (...args) => dispatch(...args)
}
// pass every middleware in middlewares to middlewareAPI
chain = middlewares.map(middleware => middleware(middlewareAPI))
// same as before, calle very middleWare from right to left, and pass to store.dispatch
dispatch = compose(...chain)(store.dispatch)
// this piece is a little abstract, we'll analyze together with the code of redux-thunk
// createThunkMiddleware returns a 3-level function, the first level accepts a middlewareAPI parameter
// the second level accepts store.dispatch
// the third level accepts parameters in dispatch
{function createThunkMiddleware(extraArgument) {
return ({ dispatch, getState }) => next => action => {
// check if the parameters in dispatch is a function
if (typeof action === 'function') {
// if so, pass those parameters, until action is no longer a function, then execute dispatch({type: 'XXX'})
return action(dispatch, getState, extraArgument);
}
return next(action);
};
}
const thunk = createThunkMiddleware();
export default thunk;}
// return the middleware-empowered dispatch and the rest of the properties in store.
return {
...store,
dispatch
}
}
}
```
Now we've passed the hardest part. Let's take a look at some easier pieces.
```js
// Not much to say here, return the current state, but we can't call this function when reducer is running
function getState() {
if (isDispatching) {
throw new Error(
'You may not call store.getState() while the reducer is executing. ' +
'The reducer has already received the state as an argument. ' +
'Pass it down from the top reducer instead of reading it from the store.'
)
}
return currentState
}
// accept a function parameter
function subscribe(listener) {
if (typeof listener !== 'function') {
throw new Error('Expected listener to be a function.')
}
// the major design of this part is already covered in the description of nextListeners. Not much to talk about otherwise
if (isDispatching) {
throw new Error(
'You may not call store.subscribe() while the reducer is executing. ' +
'If you would like to be notified after the store has been updated, subscribe from a ' +
'component and invoke store.getState() in the callback to access the latest state. ' +
'See http://redux.js.org/docs/api/Store.html#subscribe for more details.'
)
}
let isSubscribed = true
ensureCanMutateNextListeners()
nextListeners.push(listener)
// return a cancel subscription function
return function unsubscribe() {
if (!isSubscribed) {
return
}
if (isDispatching) {
throw new Error(
'You may not unsubscribe from a store listener while the reducer is executing. ' +
'See http://redux.js.org/docs/api/Store.html#subscribe for more details.'
)
}
isSubscribed = false
ensureCanMutateNextListeners()
const index = nextListeners.indexOf(listener)
nextListeners.splice(index, 1)
}
}
function dispatch(action) {
// the prototype dispatch will check if action is an object
if (!isPlainObject(action)) {
throw new Error(
'Actions must be plain objects. ' +
'Use custom middleware for async actions.'
)
}
if (typeof action.type === 'undefined') {
throw new Error(
'Actions may not have an undefined "type" property. ' +
'Have you misspelled a constant?'
)
}
// note that you can't call dispatch function in reducers
// it would cause a stack overflow
if (isDispatching) {
throw new Error('Reducers may not dispatch actions.')
}
// execute the composed function after combineReducers
try {
isDispatching = true
currentState = currentReducer(currentState, action)
} finally {
isDispatching = false
}
// iterate on currentListeners and execute saved functions in the array
const listeners = (currentListeners = nextListeners)
for (let i = 0; i < listeners.length; i++) {
const listener = listeners[i]
listener()
}
return action
}
// at the end of createStore, invoke an action dispatch({ type: ActionTypes.INIT });
// to initialize state
```
================================================
FILE: Framework/react-zh.md
================================================
**Table of Contents** *generated with [DocToc](https://github.com/thlorenz/doctoc)*
- [React 生命周期分析](#react-%E7%94%9F%E5%91%BD%E5%91%A8%E6%9C%9F%E5%88%86%E6%9E%90)
- [V16 生命周期函数用法建议](#v16-%E7%94%9F%E5%91%BD%E5%91%A8%E6%9C%9F%E5%87%BD%E6%95%B0%E7%94%A8%E6%B3%95%E5%BB%BA%E8%AE%AE)
- [setState](#setstate)
- [Redux 源码分析](#redux-%E6%BA%90%E7%A0%81%E5%88%86%E6%9E%90)
# React 生命周期分析
在 V16 版本中引入了 Fiber 机制。这个机制一定程度上的影响了部分生命周期的调用,并且也引入了新的 2 个 API 来解决问题。
在之前的版本中,如果你拥有一个很复杂的复合组件,然后改动了最上层组件的 `state`,那么调用栈可能会很长

调用栈过长,再加上中间进行了复杂的操作,就可能导致长时间阻塞主线程,带来不好的用户体验。Fiber 就是为了解决该问题而生。
Fiber 本质上是一个虚拟的堆栈帧,新的调度器会按照优先级自由调度这些帧,从而将之前的同步渲染改成了异步渲染,在不影响体验的情况下去分段计算更新。
对于如何区别优先级,React 有自己的一套逻辑。对于动画这种实时性很高的东西,也就是 16 ms 必须渲染一次保证不卡顿的情况下,React 会每 16 ms(以内) 暂停一下更新,返回来继续渲染动画。
对于异步渲染,现在渲染有两个阶段:`reconciliation` 和 `commit` 。前者过程是可以打断的,后者不能暂停,会一直更新界面直到完成。
**Reconciliation** 阶段
- `componentWillMount`
- `componentWillReceiveProps`
- `shouldComponentUpdate`
- `componentWillUpdate`
**Commit** 阶段
- `componentDidMount`
- `componentDidUpdate`
- `componentWillUnmount`
因为 `reconciliation` 阶段是可以被打断的,所以 `reconciliation` 阶段会执行的生命周期函数就可能会出现调用多次的情况,从而引起 Bug。所以对于 `reconciliation` 阶段调用的几个函数,除了 `shouldComponentUpdate` 以外,其他都应该避免去使用,并且 V16 中也引入了新的 API 来解决这个问题。
`getDerivedStateFromProps` 用于替换 `componentWillReceiveProps` ,该函数会在初始化和 `update` 时被调用
```js
class ExampleComponent extends React.Component {
// Initialize state in constructor,
// Or with a property initializer.
state = {};
static getDerivedStateFromProps(nextProps, prevState) {
if (prevState.someMirroredValue !== nextProps.someValue) {
return {
derivedData: computeDerivedState(nextProps),
someMirroredValue: nextProps.someValue
};
}
// Return null to indicate no change to state.
return null;
}
}
```
`getSnapshotBeforeUpdate` 用于替换 `componentWillUpdate` ,该函数会在 `update` 后 DOM 更新前被调用,用于读取最新的 DOM 数据。
## V16 生命周期函数用法建议
```js
class ExampleComponent extends React.Component {
// 用于初始化 state
constructor() {}
// 用于替换 `componentWillReceiveProps` ,该函数会在初始化和 `update` 时被调用
// 因为该函数是静态函数,所以取不到 `this`
// 如果需要对比 `prevProps` 需要单独在 `state` 中维护
static getDerivedStateFromProps(nextProps, prevState) {}
// 判断是否需要更新组件,多用于组件性能优化
shouldComponentUpdate(nextProps, nextState) {}
// 组件挂载后调用
// 可以在该函数中进行请求或者订阅
componentDidMount() {}
// 用于获得最新的 DOM 数据
getSnapshotBeforeUpdate() {}
// 组件即将销毁
// 可以在此处移除订阅,定时器等等
componentWillUnmount() {}
// 组件销毁后调用
componentDidUnMount() {}
// 组件更新后调用
componentDidUpdate() {}
// 渲染组件函数
render() {}
// 以下函数不建议使用
UNSAFE_componentWillMount() {}
UNSAFE_componentWillUpdate(nextProps, nextState) {}
UNSAFE_componentWillReceiveProps(nextProps) {}
}
```
# setState
`setState` 在 React 中是经常使用的一个 API,但是它存在一些问题,可能会导致犯错,核心原因就是因为这个 API 是异步的。
首先 `setState` 的调用并不会马上引起 `state` 的改变,并且如果你一次调用了多个 `setState` ,那么结果可能并不如你期待的一样。
```js
handle() {
// 初始化 `count` 为 0
console.log(this.state.count) // -> 0
this.setState({ count: this.state.count + 1 })
this.setState({ count: this.state.count + 1 })
this.setState({ count: this.state.count + 1 })
console.log(this.state.count) // -> 0
}
```
第一,两次的打印都为 0,因为 `setState` 是个异步 API,只有同步代码运行完毕才会执行。`setState` 异步的原因我认为在于,`setState` 可能会导致 DOM 的重绘,如果调用一次就马上去进行重绘,那么调用多次就会造成不必要的性能损失。设计成异步的话,就可以将多次调用放入一个队列中,在恰当的时候统一进行更新过程。
第二,虽然调用了三次 `setState` ,但是 `count` 的值还是为 1。因为多次调用会合并为一次,只有当更新结束后 `state` 才会改变,三次调用等同于如下代码
```js
Object.assign(
{},
{ count: this.state.count + 1 },
{ count: this.state.count + 1 },
{ count: this.state.count + 1 },
)
```
当然你也可以通过以下方式来实现调用三次 `setState` 使得 `count` 为 3
```js
handle() {
this.setState((prevState) => ({ count: prevState.count + 1 }))
this.setState((prevState) => ({ count: prevState.count + 1 }))
this.setState((prevState) => ({ count: prevState.count + 1 }))
}
```
如果你想在每次调用 `setState` 后获得正确的 `state` ,可以通过如下代码实现
```js
handle() {
this.setState((prevState) => ({ count: prevState.count + 1 }), () => {
console.log(this.state)
})
}
```
# Redux 源码分析
首先让我们来看下 `combineReducers` 函数
```js
// 传入一个 object
export default function combineReducers(reducers) {
// 获取该 Object 的 key 值
const reducerKeys = Object.keys(reducers)
// 过滤后的 reducers
const finalReducers = {}
// 获取每一个 key 对应的 value
// 在开发环境下判断值是否为 undefined
// 然后将值类型是函数的值放入 finalReducers
for (let i = 0; i < reducerKeys.length; i++) {
const key = reducerKeys[i]
if (process.env.NODE_ENV !== 'production') {
if (typeof reducers[key] === 'undefined') {
warning(`No reducer provided for key "${key}"`)
}
}
if (typeof reducers[key] === 'function') {
finalReducers[key] = reducers[key]
}
}
// 拿到过滤后的 reducers 的 key 值
const finalReducerKeys = Object.keys(finalReducers)
// 在开发环境下判断,保存不期望 key 的缓存用以下面做警告
let unexpectedKeyCache
if (process.env.NODE_ENV !== 'production') {
unexpectedKeyCache = {}
}
let shapeAssertionError
try {
// 该函数解析在下面
assertReducerShape(finalReducers)
} catch (e) {
shapeAssertionError = e
}
// combineReducers 函数返回一个函数,也就是合并后的 reducer 函数
// 该函数返回总的 state
// 并且你也可以发现这里使用了闭包,函数里面使用到了外面的一些属性
return function combination(state = {}, action) {
if (shapeAssertionError) {
throw shapeAssertionError
}
// 该函数解析在下面
if (process.env.NODE_ENV !== 'production') {
const warningMessage = getUnexpectedStateShapeWarningMessage(
state,
finalReducers,
action,
unexpectedKeyCache
)
if (warningMessage) {
warning(warningMessage)
}
}
// state 是否改变
let hasChanged = false
// 改变后的 state
const nextState = {}
for (let i = 0; i < finalReducerKeys.length; i++) {
// 拿到相应的 key
const key = finalReducerKeys[i]
// 获得 key 对应的 reducer 函数
const reducer = finalReducers[key]
// state 树下的 key 是与 finalReducers 下的 key 相同的
// 所以你在 combineReducers 中传入的参数的 key 即代表了 各个 reducer 也代表了各个 state
const previousStateForKey = state[key]
// 然后执行 reducer 函数获得该 key 值对应的 state
const nextStateForKey = reducer(previousStateForKey, action)
// 判断 state 的值,undefined 的话就报错
if (typeof nextStateForKey === 'undefined') {
const errorMessage = getUndefinedStateErrorMessage(key, action)
throw new Error(errorMessage)
}
// 然后将 value 塞进去
nextState[key] = nextStateForKey
// 如果 state 改变
hasChanged = hasChanged || nextStateForKey !== previousStateForKey
}
// state 只要改变过,就返回新的 state
return hasChanged ? nextState : state
}
}
```
`combineReducers` 函数总的来说很简单,总结来说就是接收一个对象,将参数过滤后返回一个函数。该函数里有一个过滤参数后的对象 finalReducers,遍历该对象,然后执行对象中的每一个 reducer 函数,最后将新的 state 返回。
接下来让我们来看看 combinrReducers 中用到的两个函数
```js
// 这是执行的第一个用于抛错的函数
function assertReducerShape(reducers) {
// 将 combineReducers 中的参数遍历
Object.keys(reducers).forEach(key => {
const reducer = reducers[key]
// 给他传入一个 action
const initialState = reducer(undefined, { type: ActionTypes.INIT })
// 如果得到的 state 为 undefined 就抛错
if (typeof initialState === 'undefined') {
throw new Error(
`Reducer "${key}" returned undefined during initialization. ` +
`If the state passed to the reducer is undefined, you must ` +
`explicitly return the initial state. The initial state may ` +
`not be undefined. If you don't want to set a value for this reducer, ` +
`you can use null instead of undefined.`
)
}
// 再过滤一次,考虑到万一你在 reducer 中给 ActionTypes.INIT 返回了值
// 传入一个随机的 action 判断值是否为 undefined
const type =
'@@redux/PROBE_UNKNOWN_ACTION_' +
Math.random()
.toString(36)
.substring(7)
.split('')
.join('.')
if (typeof reducer(undefined, { type }) === 'undefined') {
throw new Error(
`Reducer "${key}" returned undefined when probed with a random type. ` +
`Don't try to handle ${
ActionTypes.INIT
} or other actions in "redux/*" ` +
`namespace. They are considered private. Instead, you must return the ` +
`current state for any unknown actions, unless it is undefined, ` +
`in which case you must return the initial state, regardless of the ` +
`action type. The initial state may not be undefined, but can be null.`
)
}
})
}
function getUnexpectedStateShapeWarningMessage(
inputState,
reducers,
action,
unexpectedKeyCache
) {
// 这里的 reducers 已经是 finalReducers
const reducerKeys = Object.keys(reducers)
const argumentName =
action && action.type === ActionTypes.INIT
? 'preloadedState argument passed to createStore'
: 'previous state received by the reducer'
// 如果 finalReducers 为空
if (reducerKeys.length === 0) {
return (
'Store does not have a valid reducer. Make sure the argument passed ' +
'to combineReducers is an object whose values are reducers.'
)
}
// 如果你传入的 state 不是对象
if (!isPlainObject(inputState)) {
return (
`The ${argumentName} has unexpected type of "` +
{}.toString.call(inputState).match(/\s([a-z|A-Z]+)/)[1] +
`". Expected argument to be an object with the following ` +
`keys: "${reducerKeys.join('", "')}"`
)
}
// 将参入的 state 于 finalReducers 下的 key 做比较,过滤出多余的 key
const unexpectedKeys = Object.keys(inputState).filter(
key => !reducers.hasOwnProperty(key) && !unexpectedKeyCache[key]
)
unexpectedKeys.forEach(key => {
unexpectedKeyCache[key] = true
})
if (action && action.type === ActionTypes.REPLACE) return
// 如果 unexpectedKeys 有值的话
if (unexpectedKeys.length > 0) {
return (
`Unexpected ${unexpectedKeys.length > 1 ? 'keys' : 'key'} ` +
`"${unexpectedKeys.join('", "')}" found in ${argumentName}. ` +
`Expected to find one of the known reducer keys instead: ` +
`"${reducerKeys.join('", "')}". Unexpected keys will be ignored.`
)
}
}
```
接下来让我们先来看看 `compose` 函数
```js
// 这个函数设计的很巧妙,通过传入函数引用的方式让我们完成多个函数的嵌套使用,术语叫做高阶函数
// 通过使用 reduce 函数做到从右至左调用函数
// 对于上面项目中的例子
compose(
applyMiddleware(thunkMiddleware),
window.devToolsExtension ? window.devToolsExtension() : f => f
)
// 经过 compose 函数变成了 applyMiddleware(thunkMiddleware)(window.devToolsExtension()())
// 所以在找不到 window.devToolsExtension 时你应该返回一个函数
export default function compose(...funcs) {
if (funcs.length === 0) {
return arg => arg
}
if (funcs.length === 1) {
return funcs[0]
}
return funcs.reduce((a, b) => (...args) => a(b(...args)))
}
```
然后我们来解析 `createStore` 函数的部分代码
```js
export default function createStore(reducer, preloadedState, enhancer) {
// 一般 preloadedState 用的少,判断类型,如果第二个参数是函数且没有第三个参数,就调换位置
if (typeof preloadedState === 'function' && typeof enhancer === 'undefined') {
enhancer = preloadedState
preloadedState = undefined
}
// 判断 enhancer 是否是函数
if (typeof enhancer !== 'undefined') {
if (typeof enhancer !== 'function') {
throw new Error('Expected the enhancer to be a function.')
}
// 类型没错的话,先执行 enhancer,然后再执行 createStore 函数
return enhancer(createStore)(reducer, preloadedState)
}
// 判断 reducer 是否是函数
if (typeof reducer !== 'function') {
throw new Error('Expected the reducer to be a function.')
}
// 当前 reducer
let currentReducer = reducer
// 当前状态
let currentState = preloadedState
// 当前监听函数数组
let currentListeners = []
// 这是一个很重要的设计,为的就是每次在遍历监听器的时候保证 currentListeners 数组不变
// 可以考虑下只存在 currentListeners 的情况,如果我在某个 subscribe 中再次执行 subscribe
// 或者 unsubscribe,这样会导致当前的 currentListeners 数组大小发生改变,从而可能导致
// 索引出错
let nextListeners = currentListeners
// reducer 是否正在执行
let isDispatching = false
// 如果 currentListeners 和 nextListeners 相同,就赋值回去
function ensureCanMutateNextListeners() {
if (nextListeners === currentListeners) {
nextListeners = currentListeners.slice()
}
}
// ......
}
```
接下来先来介绍 `applyMiddleware` 函数
在这之前我需要先来介绍一下函数柯里化,柯里化是一种将使用多个参数的一个函数转换成一系列使用一个参数的函数的技术。
```js
function add(a,b) { return a + b }
add(1, 2) => 3
// 对于以上函数如果使用柯里化可以这样改造
function add(a) {
return b => {
return a + b
}
}
add(1)(2) => 3
// 你可以这样理解函数柯里化,通过闭包保存了外部的一个变量,然后返回一个接收参数的函数,在该函数中使用了保存的变量,然后再返回值。
```
```js
// 这个函数应该是整个源码中最难理解的一块了
// 该函数返回一个柯里化的函数
// 所以调用这个函数应该这样写 applyMiddleware(...middlewares)(createStore)(...args)
export default function applyMiddleware(...middlewares) {
return createStore => (...args) => {
// 这里执行 createStore 函数,把 applyMiddleware 函数最后次调用的参数传进来
const store = createStore(...args)
let dispatch = () => {
throw new Error(
`Dispatching while constructing your middleware is not allowed. ` +
`Other middleware would not be applied to this dispatch.`
)
}
let chain = []
// 每个中间件都应该有这两个函数
const middlewareAPI = {
getState: store.getState,
dispatch: (...args) => dispatch(...args)
}
// 把 middlewares 中的每个中间件都传入 middlewareAPI
chain = middlewares.map(middleware => middleware(middlewareAPI))
// 和之前一样,从右至左调用每个中间件,然后传入 store.dispatch
dispatch = compose(...chain)(store.dispatch)
// 这里只看这部分代码有点抽象,我这里放入 redux-thunk 的代码来结合分析
// createThunkMiddleware返回了3层函数,第一层函数接收 middlewareAPI 参数
// 第二次函数接收 store.dispatch
// 第三层函数接收 dispatch 中的参数
{function createThunkMiddleware(extraArgument) {
return ({ dispatch, getState }) => next => action => {
// 判断 dispatch 中的参数是否为函数
if (typeof action === 'function') {
// 是函数的话再把这些参数传进去,直到 action 不为函数,执行 dispatch({tyep: 'XXX'})
return action(dispatch, getState, extraArgument);
}
return next(action);
};
}
const thunk = createThunkMiddleware();
export default thunk;}
// 最后把经过中间件加强后的 dispatch 于剩余 store 中的属性返回,这样你的 dispatch
return {
...store,
dispatch
}
}
}
```
好了,我们现在将困难的部分都攻克了,来看一些简单的代码
```js
// 这个没啥好说的,就是把当前的 state 返回,但是当正在执行 reducer 时不能执行该方法
function getState() {
if (isDispatching) {
throw new Error(
'You may not call store.getState() while the reducer is executing. ' +
'The reducer has already received the state as an argument. ' +
'Pass it down from the top reducer instead of reading it from the store.'
)
}
return currentState
}
// 接收一个函数参数
function subscribe(listener) {
if (typeof listener !== 'function') {
throw new Error('Expected listener to be a function.')
}
// 这部分最主要的设计 nextListeners 已经讲过,其他基本没什么好说的
if (isDispatching) {
throw new Error(
'You may not call store.subscribe() while the reducer is executing. ' +
'If you would like to be notified after the store has been updated, subscribe from a ' +
'component and invoke store.getState() in the callback to access the latest state. ' +
'See http://redux.js.org/docs/api/Store.html#subscribe for more details.'
)
}
let isSubscribed = true
ensureCanMutateNextListeners()
nextListeners.push(listener)
// 返回一个取消订阅函数
return function unsubscribe() {
if (!isSubscribed) {
return
}
if (isDispatching) {
throw new Error(
'You may not unsubscribe from a store listener while the reducer is executing. ' +
'See http://redux.js.org/docs/api/Store.html#subscribe for more details.'
)
}
isSubscribed = false
ensureCanMutateNextListeners()
const index = nextListeners.indexOf(listener)
nextListeners.splice(index, 1)
}
}
function dispatch(action) {
// 原生的 dispatch 会判断 action 是否为对象
if (!isPlainObject(action)) {
throw new Error(
'Actions must be plain objects. ' +
'Use custom middleware for async actions.'
)
}
if (typeof action.type === 'undefined') {
throw new Error(
'Actions may not have an undefined "type" property. ' +
'Have you misspelled a constant?'
)
}
// 注意在 Reducers 中是不能执行 dispatch 函数的
// 因为你一旦在 reducer 函数中执行 dispatch,会引发死循环
if (isDispatching) {
throw new Error('Reducers may not dispatch actions.')
}
// 执行 combineReducers 组合后的函数
try {
isDispatching = true
currentState = currentReducer(currentState, action)
} finally {
isDispatching = false
}
// 然后遍历 currentListeners,执行数组中保存的函数
const listeners = (currentListeners = nextListeners)
for (let i = 0; i < listeners.length; i++) {
const listener = listeners[i]
listener()
}
return action
}
// 然后在 createStore 末尾会发起一个 action dispatch({ type: ActionTypes.INIT });
// 用以初始化 state
```
================================================
FILE: Framework/vue-br.md
================================================
**Table of Contents** *generated with [DocToc](https://github.com/thlorenz/doctoc)*
- [Análises do princípio NextTick](#nexttick-principle-analysis)
- [Análises do ciclo de vid](#lifecycle-analysis)
# Análises do princípio NextTick
`nextTick` permiti-nos adiar a callback ser executada depois da próxima atualizada do ciclo do DOM, para obter a atualização.
Antes da versão 2.4, Vue usou micro tarefas, mas prioridade das micro tarefas é bem alta, e em alguns casos, isso deve ser mais rápido que o evento de bubbling, mas se você usar macro tarefas, pode haver alguns problemas de performance na renderização. Então na nova versão, micro tarefas são usadas por padrão, mas macro tarefas serão usadas em casos especiais, como v-on.
Para implementar macro tarefas, você primeiro deve determinar se o `setImmediate` pode ser usado, se não, abaixe para `MessageChannel`. Se não novamente, use `setTimeout`.
```js
if (typeof setImmediate !== 'undefined' && isNative(setImmediate)) {
macroTimerFunc = () => {
setImmediate(flushCallbacks)
}
} else if (
typeof MessageChannel !== 'undefined' &&
(isNative(MessageChannel) ||
// PhantomJS
MessageChannel.toString() === '[object MessageChannelConstructor]')
) {
const channel = new MessageChannel()
const port = channel.port2
channel.port1.onmessage = flushCallbacks
macroTimerFunc = () => {
port.postMessage(1)
}
} else {
/* istanbul ignore next */
macroTimerFunc = () => {
setTimeout(flushCallbacks, 0)
}
}
```
`nextTick` também suporta o uso de `Promise`, do qual ira determinar se a `Promise` está implementada.
```js
export function nextTick(cb?: Function, ctx?: Object) {
let _resolve
// Consolide funções de callback dentro do de um array
callbacks.push(() => {
if (cb) {
try {
cb.call(ctx)
} catch (e) {
handleError(e, ctx, 'nextTick')
}
} else if (_resolve) {
_resolve(ctx)
}
})
if (!pending) {
pending = true
if (useMacroTask) {
macroTimerFunc()
} else {
microTimerFunc()
}
}
// Determina se a Promisse pode ser usada
// Atribuir _resolve se possivel
// Desta maneira a função callback pode ser chamada em forma de promise
if (!cb && typeof Promise !== 'undefined') {
return new Promise(resolve => {
_resolve = resolve
})
}
}
```
# Análise do Ciclo de Vida
A função do ciclo de vida é a função gancho que o componente vai disparar quando inicializar ou atualizar os dados.
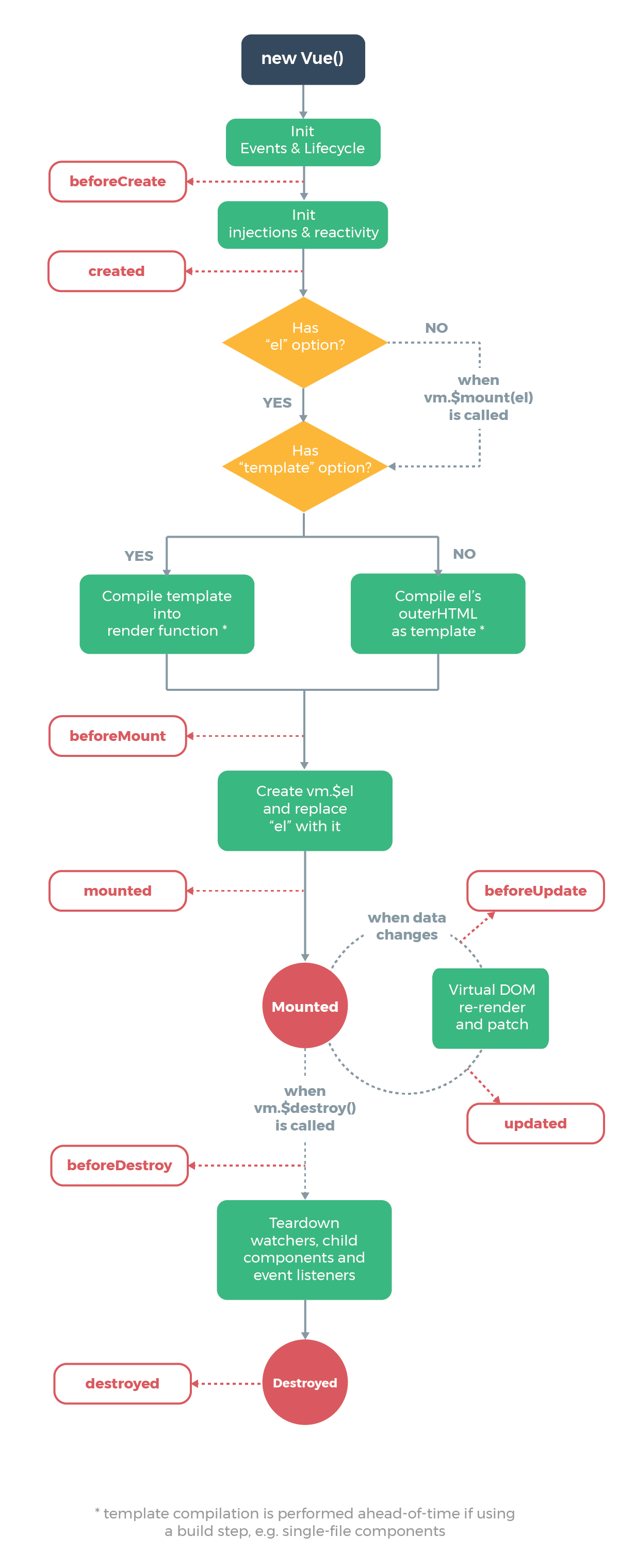
O seguinte código irá ser chamado na inicialização, e o ciclo de vida vai ser chamado pelo `callHook`
```js
Vue.prototype._init = function(options) {
initLifecycle(vm)
initEvents(vm)
initRender(vm)
callHook(vm, 'beforeCreate') // não consegue receber dados das props
initInjections(vm)
initState(vm)
initProvide(vm)
callHook(vm, 'created')
}
```
Ele pode ser encontrado no código acima quando `beforeCreate` é chamado, o dado no `props` ou `data` não pode ser obtido porque a inicialização desse dado está no `initState`.
No próximo, a função montadora vai ser chamada
```js
export function mountComponent {
callHook(vm, 'beforeMount')
// ...
if (vm.$vnode == null) {
vm._isMounted = true
callHook(vm, 'mounted')
}
}
```
`beforeMount` vai ser executado antes de montar uma instância, então comece a criar o VDOM e substituir ele com o DOM real, e finalmente chame o gancho `mounted`. E há um julgamente lógico aqui, que se ele for um `new Vue({}) ` externo, `$vnode` não existe, então o gancho `mounted` será executado diretamente. Se existe um componente filho, ele vai ser montado recursivamente, apenas quando todos os componentes filhos forem montados, o gancho de montar o componente raíz vai ser executado.
Próximo, isso vem para a função gancho que vai ser chamada quando os dados forem atualizados.
```js
function flushSchedulerQueue() {
// ...
for (index = 0; index < queue.length; index++) {
watcher = queue[index]
if (watcher.before) {
watcher.before() // chama `beforeUpdate`
}
id = watcher.id
has[id] = null
watcher.run()
// no dev build, verifca e para check and stop circular updates.
if (process.env.NODE_ENV !== 'production' && has[id] != null) {
circular[id] = (circular[id] || 0) + 1
if (circular[id] > MAX_UPDATE_COUNT) {
warn(
'You may have an infinite update loop ' +
(watcher.user
? `in watcher with expression "${watcher.expression}"`
: `in a component render function.`),
watcher.vm
)
break
}
}
}
callUpdatedHooks(updatedQueue)
}
function callUpdatedHooks(queue) {
let i = queue.length
while (i--) {
const watcher = queue[i]
const vm = watcher.vm
if (vm._watcher === watcher && vm._isMounted) {
callHook(vm, 'updated')
}
}
}
```
Existem duas funções do ciclo de vida que não são mencionada no diagrama acima, `activated` e `deactivated`, e apenas o componente `kee-alive` possui esses dois ciclos. Componente encapsulado com `keep-alive` não serão destruídos durante o switch, mas sera cacheado em memória e executado a função gancho `deactivated`, e executar a função `actived` depois de coincidir o cache e a renderização.
Finalmente, vamos olhar a função gancho usada para destruir o componente.
```js
Vue.prototype.$destroy = function() {
// ...
callHook(vm, 'beforeDestroy')
vm._isBeingDestroyed = true
// remove-se mesmo a partir do pai
const parent = vm.$parent
if (parent && !parent._isBeingDestroyed && !vm.$options.abstract) {
remove(parent.$children, vm)
}
// destroi watchers
if (vm._watcher) {
vm._watcher.teardown()
}
let i = vm._watchers.length
while (i--) {
vm._watchers[i].teardown()
}
// remove a referência a partir do dado ob
// objeto congelados não devem ter um observador.
if (vm._data.__ob__) {
vm._data.__ob__.vmCount--
}
// chame o último gancho...
vm._isDestroyed = true
// invoque ganchos destruídos na árvore atualmente renderizada
// dispare o gancho destruído
callHook(vm, 'destroyed')
// desligo todos os ouvintes da instância.
vm.$off()
// remove __vue__ reference
// remove __vue__ reference
if (vm.$el) {
vm.$el.__vue__ = null
}
// lance uma referência circular (#6759)
if (vm.$vnode) {
vm.$vnode.parent = null
}
}
```
A função `beforeDestroy` será chamada antes da operação de destruir ser desempenhada, e então uma série de operações de destruição são desempenhadas. Se existe um componente filho, eles serão destruidos recursivamente, e apenas quando todos os componente filhos são destruídos, o gancho `destroyed` do componente raíz será executado.
================================================
FILE: Framework/vue-en.md
================================================
**Table of Contents** *generated with [DocToc](https://github.com/thlorenz/doctoc)*
- [NextTick principle analysis](#nexttick-principle-analysis)
- [Lifecycle analysis](#lifecycle-analysis)
# NextTick principle analysis
`nextTick` allows us to defer the callback to be executed after the next DOM update cycle, to get the updated DOM.
Before version 2.4, Vue used microtasks, but the priority of microtasks is too high, and in some cases, it may faster than event bubbling, but if you use macrotasks, there may be some issues of rendering performance. So in the new version, microtasks will be used by default, but macrotasks will be used in special cases, such as v-on.
For implementing macrotasks, you will first determine if `setImmediate` can be used, if not, downgrade to `MessageChannel`. If not again, use `setTimeout`.
```js
if (typeof setImmediate !== 'undefined' && isNative(setImmediate)) {
macroTimerFunc = () => {
setImmediate(flushCallbacks)
}
} else if (
typeof MessageChannel !== 'undefined' &&
(isNative(MessageChannel) ||
// PhantomJS
MessageChannel.toString() === '[object MessageChannelConstructor]')
) {
const channel = new MessageChannel()
const port = channel.port2
channel.port1.onmessage = flushCallbacks
macroTimerFunc = () => {
port.postMessage(1)
}
} else {
/* istanbul ignore next */
macroTimerFunc = () => {
setTimeout(flushCallbacks, 0)
}
}
```
`nextTick` also supports the use of `Promise`, which will determine whether `Promise` is implemented.
```js
export function nextTick(cb?: Function, ctx?: Object) {
let _resolve
// Consolidate callback functions into an array
callbacks.push(() => {
if (cb) {
try {
cb.call(ctx)
} catch (e) {
handleError(e, ctx, 'nextTick')
}
} else if (_resolve) {
_resolve(ctx)
}
})
if (!pending) {
pending = true
if (useMacroTask) {
macroTimerFunc()
} else {
microTimerFunc()
}
}
// Determine if Promise can be used
// Assign _resolve if possible
// This way the callback function can be called in the way of promise
if (!cb && typeof Promise !== 'undefined') {
return new Promise(resolve => {
_resolve = resolve
})
}
}
```
# Lifecycle analysis
The lifecycle function is the hook function that the component will trigger when it initializes or updates the data.
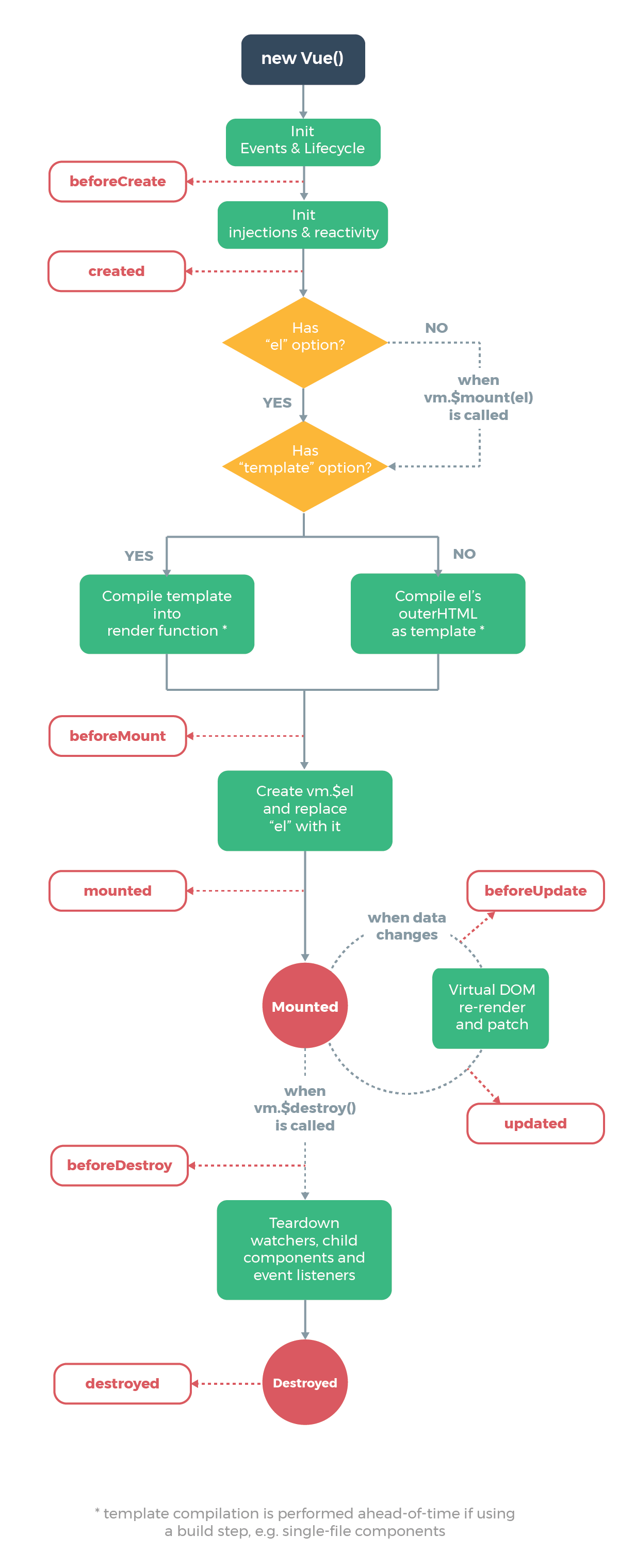
The following code will be called at initialization, and lifecycle is called by `callHook`
```js
Vue.prototype._init = function(options) {
initLifecycle(vm)
initEvents(vm)
initRender(vm)
callHook(vm, 'beforeCreate') // can not get props data
initInjections(vm)
initState(vm)
initProvide(vm)
callHook(vm, 'created')
}
```
It can be found that in the above code when `beforeCreate` is called, the data in `props` or `data` cannot be obtained because the initialization of these data is in `initState`.
Next, the mount function will be called
```js
export function mountComponent {
callHook(vm, 'beforeMount')
// ...
if (vm.$vnode == null) {
vm._isMounted = true
callHook(vm, 'mounted')
}
}
```
`beforeMount` will be executed before mounting the instance, then starts to create the VDOM and replace it with the real DOM, and finally call the `mounted` hook. And there’s a judgment logic here that if it is an external `new Vue({}) `, `$vnode` doesn’t exist, so the `mounted` hook will be executed directly. If there are child components, they will be mounted recursively, only when all the child components are mounted, the mount hooks of the root components will be executed.
Next, it comes to the hook function that will be called when the data is updated.
```js
function flushSchedulerQueue() {
// ...
for (index = 0; index < queue.length; index++) {
watcher = queue[index]
if (watcher.before) {
watcher.before() // call `beforeUpdate`
}
id = watcher.id
has[id] = null
watcher.run()
// in dev build, check and stop circular updates.
if (process.env.NODE_ENV !== 'production' && has[id] != null) {
circular[id] = (circular[id] || 0) + 1
if (circular[id] > MAX_UPDATE_COUNT) {
warn(
'You may have an infinite update loop ' +
(watcher.user
? `in watcher with expression "${watcher.expression}"`
: `in a component render function.`),
watcher.vm
)
break
}
}
}
callUpdatedHooks(updatedQueue)
}
function callUpdatedHooks(queue) {
let i = queue.length
while (i--) {
const watcher = queue[i]
const vm = watcher.vm
if (vm._watcher === watcher && vm._isMounted) {
callHook(vm, 'updated')
}
}
}
```
There are two lifecycle functions that aren’t mentioned in the above diagram, `activated` and `deactivated`, and only the `kee-alive` component has these two life cycles. Components wrapped with `keep-alive` will not be destroyed during the switch, but be cached in memory and execute the `deactivated` hook function, and execute the `actived` hook function after matching the cache and rendering.
Finally, let’s see the hook function that used to destroy the component.
```js
Vue.prototype.$destroy = function() {
// ...
callHook(vm, 'beforeDestroy')
vm._isBeingDestroyed = true
// remove self from parent
const parent = vm.$parent
if (parent && !parent._isBeingDestroyed && !vm.$options.abstract) {
remove(parent.$children, vm)
}
// teardown watchers
if (vm._watcher) {
vm._watcher.teardown()
}
let i = vm._watchers.length
while (i--) {
vm._watchers[i].teardown()
}
// remove reference from data ob
// frozen object may not have observer.
if (vm._data.__ob__) {
vm._data.__ob__.vmCount--
}
// call the last hook...
vm._isDestroyed = true
// invoke destroy hooks on current rendered tree
vm.__patch__(vm._vnode, null)
// fire destroyed hook
callHook(vm, 'destroyed')
// turn off all instance listeners.
vm.$off()
// remove __vue__ reference
if (vm.$el) {
vm.$el.__vue__ = null
}
// release circular reference (#6759)
if (vm.$vnode) {
vm.$vnode.parent = null
}
}
```
The `beforeDestroy` hook function will be called before the destroy operation is performed, and then a series of destruction operations are performed. If there are child components, they will be destroyed recursively, and only when all the child components are destroyed, the hook `destroyed` of the root component will be executed.
================================================
FILE: Framework/vue-zh.md
================================================
**Table of Contents** *generated with [DocToc](https://github.com/thlorenz/doctoc)*
- [NextTick 原理分析](#nexttick-%E5%8E%9F%E7%90%86%E5%88%86%E6%9E%90)
- [生命周期分析](#%E7%94%9F%E5%91%BD%E5%91%A8%E6%9C%9F%E5%88%86%E6%9E%90)
- [VueRouter 源码解析](#vuerouter-%E6%BA%90%E7%A0%81%E8%A7%A3%E6%9E%90)
- [重要函数思维导图](#%E9%87%8D%E8%A6%81%E5%87%BD%E6%95%B0%E6%80%9D%E7%BB%B4%E5%AF%BC%E5%9B%BE)
- [路由注册](#%E8%B7%AF%E7%94%B1%E6%B3%A8%E5%86%8C)
- [VueRouter 实例化](#vuerouter-%E5%AE%9E%E4%BE%8B%E5%8C%96)
- [创建路由匹配对象](#%E5%88%9B%E5%BB%BA%E8%B7%AF%E7%94%B1%E5%8C%B9%E9%85%8D%E5%AF%B9%E8%B1%A1)
- [路由初始化](#%E8%B7%AF%E7%94%B1%E5%88%9D%E5%A7%8B%E5%8C%96)
- [路由跳转](#%E8%B7%AF%E7%94%B1%E8%B7%B3%E8%BD%AC)
# NextTick 原理分析
`nextTick` 可以让我们在下次 DOM 更新循环结束之后执行延迟回调,用于获得更新后的 DOM。
在 Vue 2.4 之前都是使用的 microtasks,但是 microtasks 的优先级过高,在某些情况下可能会出现比事件冒泡更快的情况,但如果都使用 macrotasks 又可能会出现渲染的性能问题。所以在新版本中,会默认使用 microtasks,但在特殊情况下会使用 macrotasks,比如 v-on。
对于实现 macrotasks ,会先判断是否能使用 `setImmediate` ,不能的话降级为 `MessageChannel` ,以上都不行的话就使用 `setTimeout`
```js
if (typeof setImmediate !== 'undefined' && isNative(setImmediate)) {
macroTimerFunc = () => {
setImmediate(flushCallbacks)
}
} else if (
typeof MessageChannel !== 'undefined' &&
(isNative(MessageChannel) ||
// PhantomJS
MessageChannel.toString() === '[object MessageChannelConstructor]')
) {
const channel = new MessageChannel()
const port = channel.port2
channel.port1.onmessage = flushCallbacks
macroTimerFunc = () => {
port.postMessage(1)
}
} else {
/* istanbul ignore next */
macroTimerFunc = () => {
setTimeout(flushCallbacks, 0)
}
}
```
`nextTick` 同时也支持 Promise 的使用,会判断是否实现了 Promise
```js
export function nextTick(cb?: Function, ctx?: Object) {
let _resolve
// 将回调函数整合进一个数组中
callbacks.push(() => {
if (cb) {
try {
cb.call(ctx)
} catch (e) {
handleError(e, ctx, 'nextTick')
}
} else if (_resolve) {
_resolve(ctx)
}
})
if (!pending) {
pending = true
if (useMacroTask) {
macroTimerFunc()
} else {
microTimerFunc()
}
}
// 判断是否可以使用 Promise
// 可以的话给 _resolve 赋值
// 这样回调函数就能以 promise 的方式调用
if (!cb && typeof Promise !== 'undefined') {
return new Promise(resolve => {
_resolve = resolve
})
}
}
```
# 生命周期分析
生命周期函数就是组件在初始化或者数据更新时会触发的钩子函数。
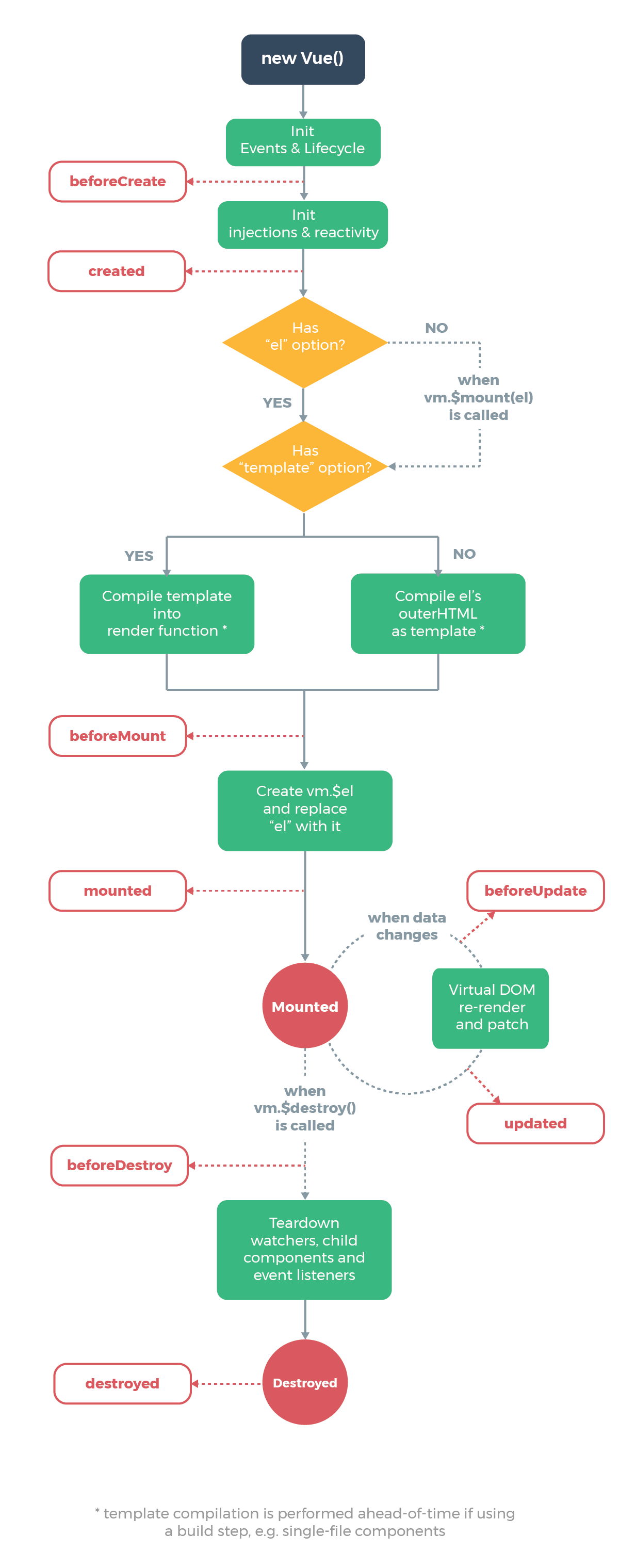
在初始化时,会调用以下代码,生命周期就是通过 `callHook` 调用的
```js
Vue.prototype._init = function(options) {
initLifecycle(vm)
initEvents(vm)
initRender(vm)
callHook(vm, 'beforeCreate') // 拿不到 props data
initInjections(vm)
initState(vm)
initProvide(vm)
callHook(vm, 'created')
}
```
可以发现在以上代码中,`beforeCreate` 调用的时候,是获取不到 props 或者 data 中的数据的,因为这些数据的初始化都在 `initState` 中。
接下来会执行挂载函数
```js
export function mountComponent {
callHook(vm, 'beforeMount')
// ...
if (vm.$vnode == null) {
vm._isMounted = true
callHook(vm, 'mounted')
}
}
```
`beforeMount` 就是在挂载前执行的,然后开始创建 VDOM 并替换成真实 DOM,最后执行 `mounted` 钩子。这里会有个判断逻辑,如果是外部 `new Vue({}) ` 的话,不会存在 `$vnode` ,所以直接执行 ``mounted`` 钩子了。如果有子组件的话,会递归挂载子组件,只有当所有子组件全部挂载完毕,才会执行根组件的挂载钩子。
接下来是数据更新时会调用的钩子函数
```js
function flushSchedulerQueue() {
// ...
for (index = 0; index < queue.length; index++) {
watcher = queue[index]
if (watcher.before) {
watcher.before() // 调用 beforeUpdate
}
id = watcher.id
has[id] = null
watcher.run()
// in dev build, check and stop circular updates.
if (process.env.NODE_ENV !== 'production' && has[id] != null) {
circular[id] = (circular[id] || 0) + 1
if (circular[id] > MAX_UPDATE_COUNT) {
warn(
'You may have an infinite update loop ' +
(watcher.user
? `in watcher with expression "${watcher.expression}"`
: `in a component render function.`),
watcher.vm
)
break
}
}
}
callUpdatedHooks(updatedQueue)
}
function callUpdatedHooks(queue) {
let i = queue.length
while (i--) {
const watcher = queue[i]
const vm = watcher.vm
if (vm._watcher === watcher && vm._isMounted) {
callHook(vm, 'updated')
}
}
}
```
上图还有两个生命周期没有说,分别为 `activated` 和 `deactivated` ,这两个钩子函数是 `keep-alive` 组件独有的。用 `keep-alive` 包裹的组件在切换时不会进行销毁,而是缓存到内存中并执行 `deactivated` 钩子函数,命中缓存渲染后会执行 `actived` 钩子函数。
最后就是销毁组件的钩子函数了
```js
Vue.prototype.$destroy = function() {
// ...
callHook(vm, 'beforeDestroy')
vm._isBeingDestroyed = true
// remove self from parent
const parent = vm.$parent
if (parent && !parent._isBeingDestroyed && !vm.$options.abstract) {
remove(parent.$children, vm)
}
// teardown watchers
if (vm._watcher) {
vm._watcher.teardown()
}
let i = vm._watchers.length
while (i--) {
vm._watchers[i].teardown()
}
// remove reference from data ob
// frozen object may not have observer.
if (vm._data.__ob__) {
vm._data.__ob__.vmCount--
}
// call the last hook...
vm._isDestroyed = true
// invoke destroy hooks on current rendered tree
vm.__patch__(vm._vnode, null)
// fire destroyed hook
callHook(vm, 'destroyed')
// turn off all instance listeners.
vm.$off()
// remove __vue__ reference
if (vm.$el) {
vm.$el.__vue__ = null
}
// release circular reference (#6759)
if (vm.$vnode) {
vm.$vnode.parent = null
}
}
```
在执行销毁操作前会调用 `beforeDestroy` 钩子函数,然后进行一系列的销毁操作,如果有子组件的话,也会递归销毁子组件,所有子组件都销毁完毕后才会执行根组件的 `destroyed` 钩子函数。
# VueRouter 源码解析
## 重要函数思维导图
以下思维导图罗列了源码中重要的一些函数
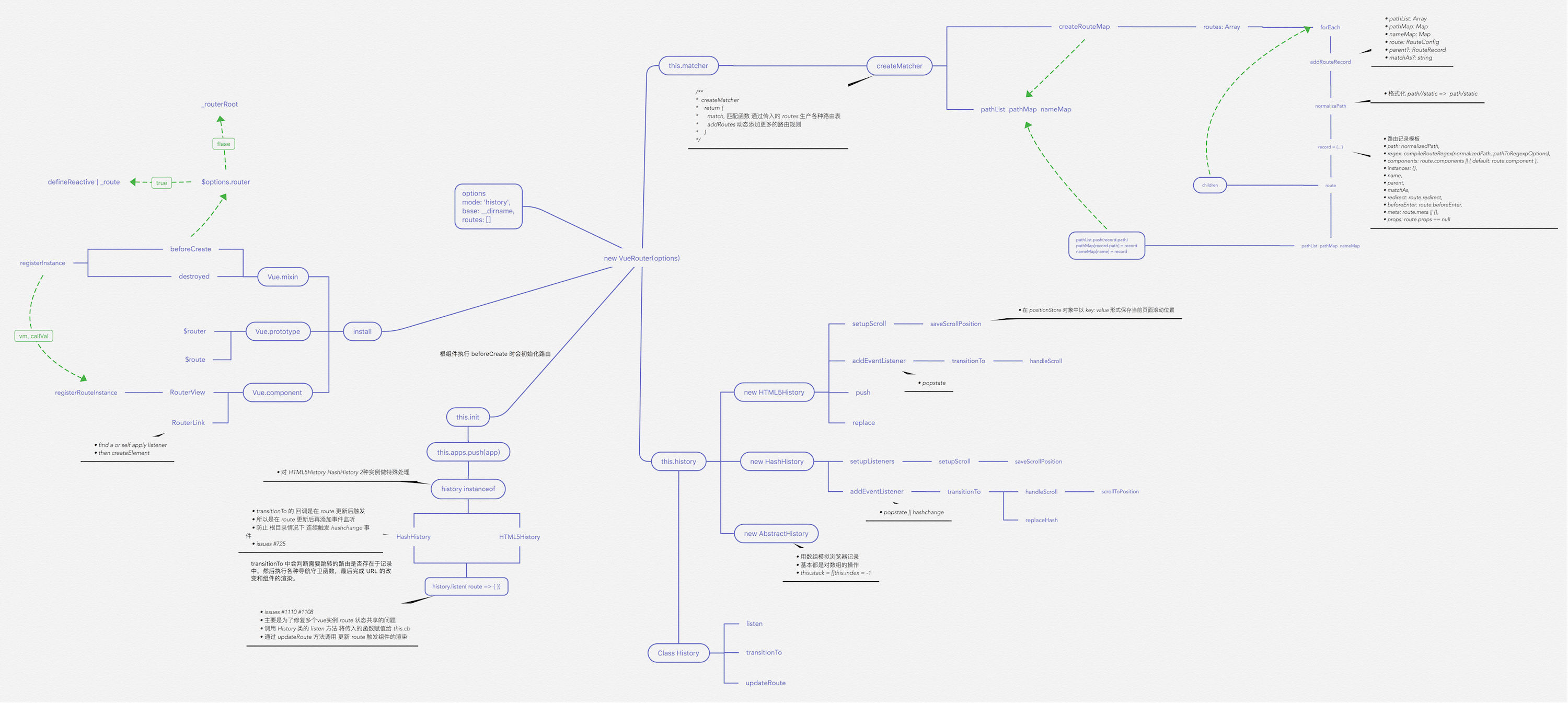
## 路由注册
在开始之前,推荐大家 clone 一份源码对照着看。因为篇幅较长,函数间的跳转也很多。
使用路由之前,需要调用 `Vue.use(VueRouter)`,这是因为让插件可以使用 Vue
```js
export function initUse (Vue: GlobalAPI) {
Vue.use = function (plugin: Function | Object) {
// 判断重复安装插件
const installedPlugins = (this._installedPlugins || (this._installedPlugins = []))
if (installedPlugins.indexOf(plugin) > -1) {
return this
}
const args = toArray(arguments, 1)
// 插入 Vue
args.unshift(this)
// 一般插件都会有一个 install 函数
// 通过该函数让插件可以使用 Vue
if (typeof plugin.install === 'function') {
plugin.install.apply(plugin, args)
} else if (typeof plugin === 'function') {
plugin.apply(null, args)
}
installedPlugins.push(plugin)
return this
}
}
```
接下来看下 `install` 函数的部分实现
```js
export function install (Vue) {
// 确保 install 调用一次
if (install.installed && _Vue === Vue) return
install.installed = true
// 把 Vue 赋值给全局变量
_Vue = Vue
const registerInstance = (vm, callVal) => {
let i = vm.$options._parentVnode
if (isDef(i) && isDef(i = i.data) && isDef(i = i.registerRouteInstance)) {
i(vm, callVal)
}
}
// 给每个组件的钩子函数混入实现
// 可以发现在 `beforeCreate` 钩子执行时
// 会初始化路由
Vue.mixin({
beforeCreate () {
// 判断组件是否存在 router 对象,该对象只在根组件上有
if (isDef(this.$options.router)) {
// 根路由设置为自己
this._routerRoot = this
this._router = this.$options.router
// 初始化路由
this._router.init(this)
// 很重要,为 _route 属性实现双向绑定
// 触发组件渲染
Vue.util.defineReactive(this, '_route', this._router.history.current)
} else {
// 用于 router-view 层级判断
this._routerRoot = (this.$parent && this.$parent._routerRoot) || this
}
registerInstance(this, this)
},
destroyed () {
registerInstance(this)
}
})
// 全局注册组件 router-link 和 router-view
Vue.component('RouterView', View)
Vue.component('RouterLink', Link)
}
```
对于路由注册来说,核心就是调用 `Vue.use(VueRouter)`,使得 VueRouter 可以使用 Vue。然后通过 Vue 来调用 VueRouter 的 `install` 函数。在该函数中,核心就是给组件混入钩子函数和全局注册两个路由组件。
## VueRouter 实例化
在安装插件后,对 VueRouter 进行实例化。
```js
const Home = { template: '
home
' }
const Foo = { template: '
foo
' }
const Bar = { template: '
bar
' }
// 3. Create the router
const router = new VueRouter({
mode: 'hash',
base: __dirname,
routes: [
{ path: '/', component: Home }, // all paths are defined without the hash.
{ path: '/foo', component: Foo },
{ path: '/bar', component: Bar }
]
})
```
来看一下 VueRouter 的构造函数
```js
constructor(options: RouterOptions = {}) {
// ...
// 路由匹配对象
this.matcher = createMatcher(options.routes || [], this)
// 根据 mode 采取不同的路由方式
let mode = options.mode || 'hash'
this.fallback =
mode === 'history' && !supportsPushState && options.fallback !== false
if (this.fallback) {
mode = 'hash'
}
if (!inBrowser) {
mode = 'abstract'
}
this.mode = mode
switch (mode) {
case 'history':
this.history = new HTML5History(this, options.base)
break
case 'hash':
this.history = new HashHistory(this, options.base, this.fallback)
break
case 'abstract':
this.history = new AbstractHistory(this, options.base)
break
default:
if (process.env.NODE_ENV !== 'production') {
assert(false, `invalid mode: ${mode}`)
}
}
}
```
在实例化 VueRouter 的过程中,核心是创建一个路由匹配对象,并且根据 mode 来采取不同的路由方式。
## 创建路由匹配对象
```js
export function createMatcher (
routes: Array,
router: VueRouter
): Matcher {
// 创建路由映射表
const { pathList, pathMap, nameMap } = createRouteMap(routes)
function addRoutes (routes) {
createRouteMap(routes, pathList, pathMap, nameMap)
}
// 路由匹配
function match (
raw: RawLocation,
currentRoute?: Route,
redirectedFrom?: Location
): Route {
//...
}
return {
match,
addRoutes
}
}
```
`createMatcher` 函数的作用就是创建路由映射表,然后通过闭包的方式让 `addRoutes` 和 `match` 函数能够使用路由映射表的几个对象,最后返回一个 `Matcher` 对象。
接下来看 `createMatcher` 函数时如何创建映射表的
```js
export function createRouteMap (
routes: Array,
oldPathList?: Array,
oldPathMap?: Dictionary,
oldNameMap?: Dictionary
): {
pathList: Array;
pathMap: Dictionary;
nameMap: Dictionary;
} {
// 创建映射表
const pathList: Array = oldPathList || []
const pathMap: Dictionary = oldPathMap || Object.create(null)
const nameMap: Dictionary = oldNameMap || Object.create(null)
// 遍历路由配置,为每个配置添加路由记录
routes.forEach(route => {
addRouteRecord(pathList, pathMap, nameMap, route)
})
// 确保通配符在最后
for (let i = 0, l = pathList.length; i < l; i++) {
if (pathList[i] === '*') {
pathList.push(pathList.splice(i, 1)[0])
l--
i--
}
}
return {
pathList,
pathMap,
nameMap
}
}
// 添加路由记录
function addRouteRecord (
pathList: Array,
pathMap: Dictionary,
nameMap: Dictionary,
route: RouteConfig,
parent?: RouteRecord,
matchAs?: string
) {
// 获得路由配置下的属性
const { path, name } = route
const pathToRegexpOptions: PathToRegexpOptions = route.pathToRegexpOptions || {}
// 格式化 url,替换 /
const normalizedPath = normalizePath(
path,
parent,
pathToRegexpOptions.strict
)
// 生成记录对象
const record: RouteRecord = {
path: normalizedPath,
regex: compileRouteRegex(normalizedPath, pathToRegexpOptions),
components: route.components || { default: route.component },
instances: {},
name,
parent,
matchAs,
redirect: route.redirect,
beforeEnter: route.beforeEnter,
meta: route.meta || {},
props: route.props == null
? {}
: route.components
? route.props
: { default: route.props }
}
if (route.children) {
// 递归路由配置的 children 属性,添加路由记录
route.children.forEach(child => {
const childMatchAs = matchAs
? cleanPath(`${matchAs}/${child.path}`)
: undefined
addRouteRecord(pathList, pathMap, nameMap, child, record, childMatchAs)
})
}
// 如果路由有别名的话
// 给别名也添加路由记录
if (route.alias !== undefined) {
const aliases = Array.isArray(route.alias)
? route.alias
: [route.alias]
aliases.forEach(alias => {
const aliasRoute = {
path: alias,
children: route.children
}
addRouteRecord(
pathList,
pathMap,
nameMap,
aliasRoute,
parent,
record.path || '/' // matchAs
)
})
}
// 更新映射表
if (!pathMap[record.path]) {
pathList.push(record.path)
pathMap[record.path] = record
}
// 命名路由添加记录
if (name) {
if (!nameMap[name]) {
nameMap[name] = record
} else if (process.env.NODE_ENV !== 'production' && !matchAs) {
warn(
false,
`Duplicate named routes definition: ` +
`{ name: "${name}", path: "${record.path}" }`
)
}
}
}
```
以上就是创建路由匹配对象的全过程,通过用户配置的路由规则来创建对应的路由映射表。
## 路由初始化
当根组件调用 `beforeCreate` 钩子函数时,会执行以下代码
```js
beforeCreate () {
// 只有根组件有 router 属性,所以根组件初始化时会初始化路由
if (isDef(this.$options.router)) {
this._routerRoot = this
this._router = this.$options.router
this._router.init(this)
Vue.util.defineReactive(this, '_route', this._router.history.current)
} else {
this._routerRoot = (this.$parent && this.$parent._routerRoot) || this
}
registerInstance(this, this)
}
```
接下来看下路由初始化会做些什么
```js
init(app: any /* Vue component instance */) {
// 保存组件实例
this.apps.push(app)
// 如果根组件已经有了就返回
if (this.app) {
return
}
this.app = app
// 赋值路由模式
const history = this.history
// 判断路由模式,以哈希模式为例
if (history instanceof HTML5History) {
history.transitionTo(history.getCurrentLocation())
} else if (history instanceof HashHistory) {
// 添加 hashchange 监听
const setupHashListener = () => {
history.setupListeners()
}
// 路由跳转
history.transitionTo(
history.getCurrentLocation(),
setupHashListener,
setupHashListener
)
}
// 该回调会在 transitionTo 中调用
// 对组件的 _route 属性进行赋值,触发组件渲染
history.listen(route => {
this.apps.forEach(app => {
app._route = route
})
})
}
```
在路由初始化时,核心就是进行路由的跳转,改变 URL 然后渲染对应的组件。接下来来看一下路由是如何进行跳转的。
## 路由跳转
```js
transitionTo (location: RawLocation, onComplete?: Function, onAbort?: Function) {
// 获取匹配的路由信息
const route = this.router.match(location, this.current)
// 确认切换路由
this.confirmTransition(route, () => {
// 以下为切换路由成功或失败的回调
// 更新路由信息,对组件的 _route 属性进行赋值,触发组件渲染
// 调用 afterHooks 中的钩子函数
this.updateRoute(route)
// 添加 hashchange 监听
onComplete && onComplete(route)
// 更新 URL
this.ensureURL()
// 只执行一次 ready 回调
if (!this.ready) {
this.ready = true
this.readyCbs.forEach(cb => { cb(route) })
}
}, err => {
// 错误处理
if (onAbort) {
onAbort(err)
}
if (err && !this.ready) {
this.ready = true
this.readyErrorCbs.forEach(cb => { cb(err) })
}
})
}
```
在路由跳转中,需要先获取匹配的路由信息,所以先来看下如何获取匹配的路由信息
```js
function match (
raw: RawLocation,
currentRoute?: Route,
redirectedFrom?: Location
): Route {
// 序列化 url
// 比如对于该 url 来说 /abc?foo=bar&baz=qux#hello
// 会序列化路径为 /abc
// 哈希为 #hello
// 参数为 foo: 'bar', baz: 'qux'
const location = normalizeLocation(raw, currentRoute, false, router)
const { name } = location
// 如果是命名路由,就判断记录中是否有该命名路由配置
if (name) {
const record = nameMap[name]
// 没找到表示没有匹配的路由
if (!record) return _createRoute(null, location)
const paramNames = record.regex.keys
.filter(key => !key.optional)
.map(key => key.name)
// 参数处理
if (typeof location.params !== 'object') {
location.params = {}
}
if (currentRoute && typeof currentRoute.params === 'object') {
for (const key in currentRoute.params) {
if (!(key in location.params) && paramNames.indexOf(key) > -1) {
location.params[key] = currentRoute.params[key]
}
}
}
if (record) {
location.path = fillParams(record.path, location.params, `named route "${name}"`)
return _createRoute(record, location, redirectedFrom)
}
} else if (location.path) {
// 非命名路由处理
location.params = {}
for (let i = 0; i < pathList.length; i++) {
// 查找记录
const path = pathList[i]
const record = pathMap[path]
// 如果匹配路由,则创建路由
if (matchRoute(record.regex, location.path, location.params)) {
return _createRoute(record, location, redirectedFrom)
}
}
}
// 没有匹配的路由
return _createRoute(null, location)
}
```
接下来看看如何创建路由
```js
// 根据条件创建不同的路由
function _createRoute(
record: ?RouteRecord,
location: Location,
redirectedFrom?: Location
): Route {
if (record && record.redirect) {
return redirect(record, redirectedFrom || location)
}
if (record && record.matchAs) {
return alias(record, location, record.matchAs)
}
return createRoute(record, location, redirectedFrom, router)
}
export function createRoute (
record: ?RouteRecord,
location: Location,
redirectedFrom?: ?Location,
router?: VueRouter
): Route {
const stringifyQuery = router && router.options.stringifyQuery
// 克隆参数
let query: any = location.query || {}
try {
query = clone(query)
} catch (e) {}
// 创建路由对象
const route: Route = {
name: location.name || (record && record.name),
meta: (record && record.meta) || {},
path: location.path || '/',
hash: location.hash || '',
query,
params: location.params || {},
fullPath: getFullPath(location, stringifyQuery),
matched: record ? formatMatch(record) : []
}
if (redirectedFrom) {
route.redirectedFrom = getFullPath(redirectedFrom, stringifyQuery)
}
// 让路由对象不可修改
return Object.freeze(route)
}
// 获得包含当前路由的所有嵌套路径片段的路由记录
// 包含从根路由到当前路由的匹配记录,从上至下
function formatMatch(record: ?RouteRecord): Array {
const res = []
while (record) {
res.unshift(record)
record = record.parent
}
return res
}
```
至此匹配路由已经完成,我们回到 `transitionTo` 函数中,接下来执行 `confirmTransition`
```js
transitionTo (location: RawLocation, onComplete?: Function, onAbort?: Function) {
// 确认切换路由
this.confirmTransition(route, () => {}
}
confirmTransition(route: Route, onComplete: Function, onAbort?: Function) {
const current = this.current
// 中断跳转路由函数
const abort = err => {
if (isError(err)) {
if (this.errorCbs.length) {
this.errorCbs.forEach(cb => {
cb(err)
})
} else {
warn(false, 'uncaught error during route navigation:')
console.error(err)
}
}
onAbort && onAbort(err)
}
// 如果是相同的路由就不跳转
if (
isSameRoute(route, current) &&
route.matched.length === current.matched.length
) {
this.ensureURL()
return abort()
}
// 通过对比路由解析出可复用的组件,需要渲染的组件,失活的组件
const { updated, deactivated, activated } = resolveQueue(
this.current.matched,
route.matched
)
function resolveQueue(
current: Array,
next: Array
): {
updated: Array,
activated: Array,
deactivated: Array
} {
let i
const max = Math.max(current.length, next.length)
for (i = 0; i < max; i++) {
// 当前路由路径和跳转路由路径不同时跳出遍历
if (current[i] !== next[i]) {
break
}
}
return {
// 可复用的组件对应路由
updated: next.slice(0, i),
// 需要渲染的组件对应路由
activated: next.slice(i),
// 失活的组件对应路由
deactivated: current.slice(i)
}
}
// 导航守卫数组
const queue: Array = [].concat(
// 失活的组件钩子
extractLeaveGuards(deactivated),
// 全局 beforeEach 钩子
this.router.beforeHooks,
// 在当前路由改变,但是该组件被复用时调用
extractUpdateHooks(updated),
// 需要渲染组件 enter 守卫钩子
activated.map(m => m.beforeEnter),
// 解析异步路由组件
resolveAsyncComponents(activated)
)
// 保存路由
this.pending = route
// 迭代器,用于执行 queue 中的导航守卫钩子
const iterator = (hook: NavigationGuard, next) => {
// 路由不相等就不跳转路由
if (this.pending !== route) {
return abort()
}
try {
// 执行钩子
hook(route, current, (to: any) => {
// 只有执行了钩子函数中的 next,才会继续执行下一个钩子函数
// 否则会暂停跳转
// 以下逻辑是在判断 next() 中的传参
if (to === false || isError(to)) {
// next(false)
this.ensureURL(true)
abort(to)
} else if (
typeof to === 'string' ||
(typeof to === 'object' &&
(typeof to.path === 'string' || typeof to.name === 'string'))
) {
// next('/') 或者 next({ path: '/' }) -> 重定向
abort()
if (typeof to === 'object' && to.replace) {
this.replace(to)
} else {
this.push(to)
}
} else {
// 这里执行 next
// 也就是执行下面函数 runQueue 中的 step(index + 1)
next(to)
}
})
} catch (e) {
abort(e)
}
}
// 经典的同步执行异步函数
runQueue(queue, iterator, () => {
const postEnterCbs = []
const isValid = () => this.current === route
// 当所有异步组件加载完成后,会执行这里的回调,也就是 runQueue 中的 cb()
// 接下来执行 需要渲染组件的导航守卫钩子
const enterGuards = extractEnterGuards(activated, postEnterCbs, isValid)
const queue = enterGuards.concat(this.router.resolveHooks)
runQueue(queue, iterator, () => {
// 跳转完成
if (this.pending !== route) {
return abort()
}
this.pending = null
onComplete(route)
if (this.router.app) {
this.router.app.$nextTick(() => {
postEnterCbs.forEach(cb => {
cb()
})
})
}
})
})
}
export function runQueue (queue: Array, fn: Function, cb: Function) {
const step = index => {
// 队列中的函数都执行完毕,就执行回调函数
if (index >= queue.length) {
cb()
} else {
if (queue[index]) {
// 执行迭代器,用户在钩子函数中执行 next() 回调
// 回调中判断传参,没有问题就执行 next(),也就是 fn 函数中的第二个参数
fn(queue[index], () => {
step(index + 1)
})
} else {
step(index + 1)
}
}
}
// 取出队列中第一个钩子函数
step(0)
}
```
接下来介绍导航守卫
```js
const queue: Array = [].concat(
// 失活的组件钩子
extractLeaveGuards(deactivated),
// 全局 beforeEach 钩子
this.router.beforeHooks,
// 在当前路由改变,但是该组件被复用时调用
extractUpdateHooks(updated),
// 需要渲染组件 enter 守卫钩子
activated.map(m => m.beforeEnter),
// 解析异步路由组件
resolveAsyncComponents(activated)
)
```
第一步是先执行失活组件的钩子函数
```js
function extractLeaveGuards(deactivated: Array): Array {
// 传入需要执行的钩子函数名
return extractGuards(deactivated, 'beforeRouteLeave', bindGuard, true)
}
function extractGuards(
records: Array,
name: string,
bind: Function,
reverse?: boolean
): Array {
const guards = flatMapComponents(records, (def, instance, match, key) => {
// 找出组件中对应的钩子函数
const guard = extractGuard(def, name)
if (guard) {
// 给每个钩子函数添加上下文对象为组件自身
return Array.isArray(guard)
? guard.map(guard => bind(guard, instance, match, key))
: bind(guard, instance, match, key)
}
})
// 数组降维,并且判断是否需要翻转数组
// 因为某些钩子函数需要从子执行到父
return flatten(reverse ? guards.reverse() : guards)
}
export function flatMapComponents (
matched: Array,
fn: Function
): Array {
// 数组降维
return flatten(matched.map(m => {
// 将组件中的对象传入回调函数中,获得钩子函数数组
return Object.keys(m.components).map(key => fn(
m.components[key],
m.instances[key],
m, key
))
}))
}
```
第二步执行全局 beforeEach 钩子函数
```js
beforeEach(fn: Function): Function {
return registerHook(this.beforeHooks, fn)
}
function registerHook(list: Array, fn: Function): Function {
list.push(fn)
return () => {
const i = list.indexOf(fn)
if (i > -1) list.splice(i, 1)
}
}
```
在 VueRouter 类中有以上代码,每当给 VueRouter 实例添加 beforeEach 函数时就会将函数 push 进 beforeHooks 中。
第三步执行 `beforeRouteUpdate` 钩子函数,调用方式和第一步相同,只是传入的函数名不同,在该函数中可以访问到 `this` 对象。
第四步执行 `beforeEnter` 钩子函数,该函数是路由独享的钩子函数。
第五步是解析异步组件。
```js
export function resolveAsyncComponents (matched: Array): Function {
return (to, from, next) => {
let hasAsync = false
let pending = 0
let error = null
// 该函数作用之前已经介绍过了
flatMapComponents(matched, (def, _, match, key) => {
// 判断是否是异步组件
if (typeof def === 'function' && def.cid === undefined) {
hasAsync = true
pending++
// 成功回调
// once 函数确保异步组件只加载一次
const resolve = once(resolvedDef => {
if (isESModule(resolvedDef)) {
resolvedDef = resolvedDef.default
}
// 判断是否是构造函数
// 不是的话通过 Vue 来生成组件构造函数
def.resolved = typeof resolvedDef === 'function'
? resolvedDef
: _Vue.extend(resolvedDef)
// 赋值组件
// 如果组件全部解析完毕,继续下一步
match.components[key] = resolvedDef
pending--
if (pending <= 0) {
next()
}
})
// 失败回调
const reject = once(reason => {
const msg = `Failed to resolve async component ${key}: ${reason}`
process.env.NODE_ENV !== 'production' && warn(false, msg)
if (!error) {
error = isError(reason)
? reason
: new Error(msg)
next(error)
}
})
let res
try {
// 执行异步组件函数
res = def(resolve, reject)
} catch (e) {
reject(e)
}
if (res) {
// 下载完成执行回调
if (typeof res.then === 'function') {
res.then(resolve, reject)
} else {
const comp = res.component
if (comp && typeof comp.then === 'function') {
comp.then(resolve, reject)
}
}
}
}
})
// 不是异步组件直接下一步
if (!hasAsync) next()
}
}
```
以上就是第一个 `runQueue` 中的逻辑,第五步完成后会执行第一个 `runQueue` 中回调函数
```js
// 该回调用于保存 `beforeRouteEnter` 钩子中的回调函数
const postEnterCbs = []
const isValid = () => this.current === route
// beforeRouteEnter 导航守卫钩子
const enterGuards = extractEnterGuards(activated, postEnterCbs, isValid)
// beforeResolve 导航守卫钩子
const queue = enterGuards.concat(this.router.resolveHooks)
runQueue(queue, iterator, () => {
if (this.pending !== route) {
return abort()
}
this.pending = null
// 这里会执行 afterEach 导航守卫钩子
onComplete(route)
if (this.router.app) {
this.router.app.$nextTick(() => {
postEnterCbs.forEach(cb => {
cb()
})
})
}
})
```
第六步是执行 `beforeRouteEnter` 导航守卫钩子,`beforeRouteEnter` 钩子不能访问 `this` 对象,因为钩子在导航确认前被调用,需要渲染的组件还没被创建。但是该钩子函数是唯一一个支持在回调中获取 `this` 对象的函数,回调会在路由确认执行。
```js
beforeRouteEnter (to, from, next) {
next(vm => {
// 通过 `vm` 访问组件实例
})
}
```
下面来看看是如何支持在回调中拿到 `this` 对象的
```js
function extractEnterGuards(
activated: Array,
cbs: Array,
isValid: () => boolean
): Array {
// 这里和之前调用导航守卫基本一致
return extractGuards(
activated,
'beforeRouteEnter',
(guard, _, match, key) => {
return bindEnterGuard(guard, match, key, cbs, isValid)
}
)
}
function bindEnterGuard(
guard: NavigationGuard,
match: RouteRecord,
key: string,
cbs: Array,
isValid: () => boolean
): NavigationGuard {
return function routeEnterGuard(to, from, next) {
return guard(to, from, cb => {
// 判断 cb 是否是函数
// 是的话就 push 进 postEnterCbs
next(cb)
if (typeof cb === 'function') {
cbs.push(() => {
// 循环直到拿到组件实例
poll(cb, match.instances, key, isValid)
})
}
})
}
}
// 该函数是为了解决 issus #750
// 当 router-view 外面包裹了 mode 为 out-in 的 transition 组件
// 会在组件初次导航到时获得不到组件实例对象
function poll(
cb: any, // somehow flow cannot infer this is a function
instances: Object,
key: string,
isValid: () => boolean
) {
if (
instances[key] &&
!instances[key]._isBeingDestroyed // do not reuse being destroyed instance
) {
cb(instances[key])
} else if (isValid()) {
// setTimeout 16ms 作用和 nextTick 基本相同
setTimeout(() => {
poll(cb, instances, key, isValid)
}, 16)
}
}
```
第七步是执行 `beforeResolve` 导航守卫钩子,如果注册了全局 `beforeResolve` 钩子就会在这里执行。
第八步就是导航确认,调用 `afterEach` 导航守卫钩子了。
以上都执行完成后,会触发组件的渲染
```js
history.listen(route => {
this.apps.forEach(app => {
app._route = route
})
})
```
以上回调会在 `updateRoute` 中调用
```js
updateRoute(route: Route) {
const prev = this.current
this.current = route
this.cb && this.cb(route)
this.router.afterHooks.forEach(hook => {
hook && hook(route, prev)
})
}
```
至此,路由跳转已经全部分析完毕。核心就是判断需要跳转的路由是否存在于记录中,然后执行各种导航守卫函数,最后完成 URL 的改变和组件的渲染。
================================================
FILE: Git/git-en.md
================================================
**Table of Contents** *generated with [DocToc](https://github.com/thlorenz/doctoc)*
- [Merge with Rebase](#merge-with-rebase)
- [stash](#stash)
- [reflog](#reflog)
- [Reset](#reset)
This is not for rookie, we'll introduce something about more advanced.
## Merge with Rebase
This command shows no difference with the command `merge`.
We usually use `merge` to merge the code from one branch to `master` , like this:
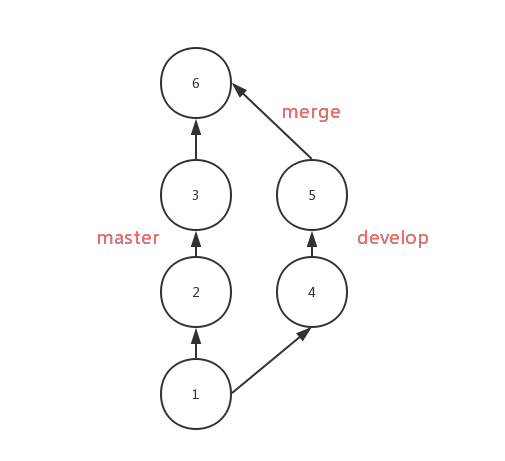
After using `rebase ` , the commits from `develop` will be moved to the third `commit` of the `master` in order, as follows:
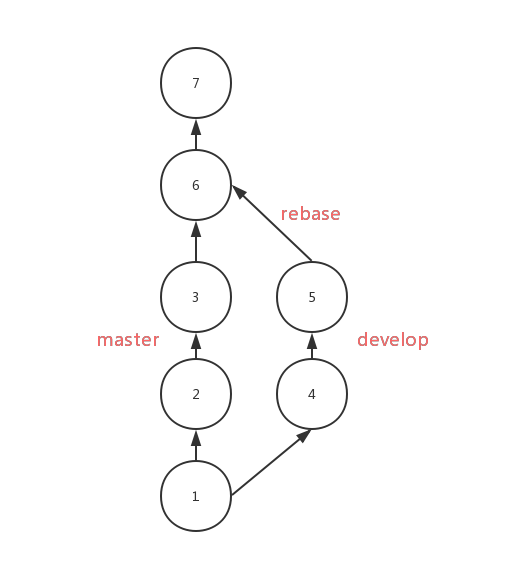
Compare with `merge`, the result of `rebase` is very clear with a single flow. But if there is any conflict, you'll be in trouble to solving them. You have to solve them one by one , while you only need to solve them one-time if using `merge`.
You should use `rebase` on the local branchs which need be rebased. If you need to `rebase` the `develop` to the `master`, you should do as follows:
```shell
## branch develop
git rebase master
git checkout master
## move HEAD on `master` to the latest commit
git merge develop
```
## stash
Use `git stash` to save the current state of the working directory while you want to check out branch, if you don't want to use `commit`.
```shell
git stash
```
This command can record the current state of the working directory, if you want to recover it, you can do like this:
```shell
git stash pop
```
then you'll back to the exactly state before.
## reflog
This command will show you the records of HEAD's trace. If you delete a branch by mistake, you can examine the hashs of HEAD by using `reflog`.

According to the picture, the last movement of HEAD is just after `merge`, and then the `new` branch was deleted, so we can get the branch back by the following command:
```shell
git checkout 37d9aca
git checkout -b new
```
PS:`reflog` is time-bound, it can only record the state over a period of time.
## Reset
If you want to delete the last commit, you can do like this:
```shell
git reset --hard HEAD^
```
But this command doesn't delete the commit, it just reset the HEAD and branch.
================================================
FILE: Git/git-zh.md
================================================
**Table of Contents** *generated with [DocToc](https://github.com/thlorenz/doctoc)*
- [Rebase 合并](#rebase-%E5%90%88%E5%B9%B6)
- [stash](#stash)
- [reflog](#reflog)
- [Reset](#reset)
本文不会介绍 Git 的基本操作,会对一些高级操作进行说明。
## Rebase 合并
该命令可以让和 `merge` 命令得到的结果基本是一致的。
通常使用 `merge` 操作将分支上的代码合并到 `master` 中,分支样子如下所示
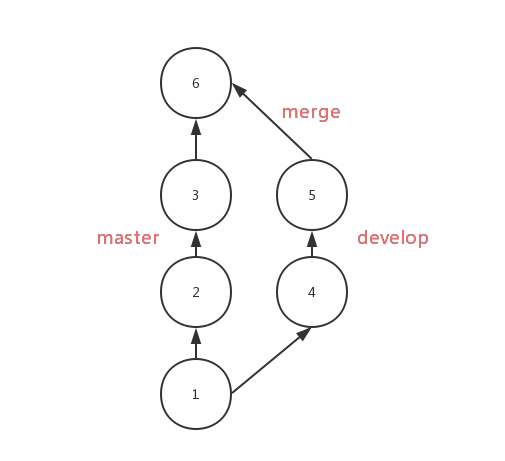
使用 `rebase` 后,会将 `develop` 上的 `commit` 按顺序移到 `master` 的第三个 `commit` 后面,分支样子如下所示
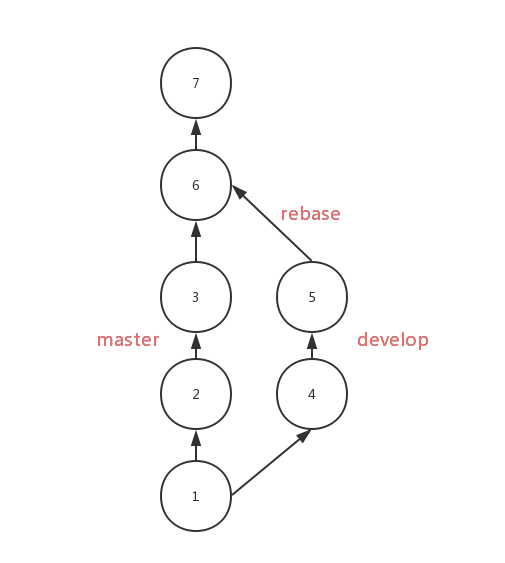
Rebase 对比 merge,优势在于合并后的结果很清晰,只有一条线,劣势在于如果一旦出现冲突,解决冲突很麻烦,可能要解决多个冲突,但是 merge 出现冲突只需要解决一次。
使用 rebase 应该在需要被 rebase 的分支上操作,并且该分支是本地分支。如果 `develop` 分支需要 rebase 到 `master` 上去,那么应该如下操作
```shell
## branch develop
git rebase master
git checkout master
## 用于将 `master` 上的 HEAD 移动到最新的 commit
git merge develop
```
## stash
`stash` 用于临时保存工作目录的改动。开发中可能会遇到代码写一半需要切分支打包的问题,如果这时候你不想 `commit` 的话,就可以使用该命令。
```shell
git stash
```
使用该命令可以暂存你的工作目录,后面想恢复工作目录,只需要使用
```shell
git stash pop
```
这样你之前临时保存的代码又回来了
## reflog
`reflog` 可以看到 HEAD 的移动记录,假如之前误删了一个分支,可以通过 `git reflog` 看到移动 HEAD 的哈希值

从图中可以看出,HEAD 的最后一次移动行为是 `merge` 后,接下来分支 `new` 就被删除了,那么我们可以通过以下命令找回 `new` 分支
```shell
git checkout 37d9aca
git checkout -b new
```
PS:`reflog` 记录是时效的,只会保存一段时间内的记录。
## Reset
如果你想删除刚写的 commit,就可以通过以下命令实现
```shell
git reset --hard HEAD^
```
但是 `reset` 的本质并不是删除了 commit,而是重新设置了 HEAD 和它指向的 branch。
================================================
FILE: JS/JS-br.md
================================================
**Table of Contents** *generated with [DocToc](https://github.com/thlorenz/doctoc)*
- [Tipos incorporados](#tipos-incorporados)
- [Conversão de Tipos](#conversão-de-tipos)
- [Convertendo para boleano](#convertendo-para-boleano)
- [De objetos para tipos primitivos](#de-objetos-para-tipos-primitivos)
- [Operadores aritméticos](#operadores-aritméticos)
- [`==` operador](#-operador)
- [Operador de comparação](#operador-de-comparação)
- [Typeof](#typeof)
- [New](#new)
- [This](#this)
- [Instanceof](#instanceof)
- [Scope](#scope)
- [Closure](#closure)
- [Prototypes](#prototypes)
- [Herança](#herança)
- [Cópia rasa e profunda](#cópia-rasa-e-profunda)
- [Cópia rasa](#cópia-rasa)
- [Cópia profunda](#cópia-profunda)
- [Modularização](#modularização)
- [CommonJS](#commonjs)
- [AMD](#amd)
- [A diferença entre call apply bind](#a-diferença-entre-call-apply-bind)
- [simulação para implementar `call` e `apply`](#simulação-para-implementar--call-e--apply)
- [Implementação de Promise](#implementação-de-promise)
- [Implementação do Generator](#implementação-do-generator)
- [Debouncing](#debouncing)
- [Throttle](#throttle)
- [Map、FlatMap e Reduce](#mapflatmap-e-reduce)
- [Async e await](#async-e-await)
- [Proxy](#proxy)
- [Por que 0.1 + 0.2 != 0.3](#por-que-01--02--03)
- [Expressões regulares](#expressões-regulares)
- [Metacaracteres](#metacaracteres)
- [Flags](#flags)
- [Character Shorthands](#character-shorthands)
# Tipos incorporados
O JavaScript define sete tipos incorporados, dos quais podem ser divididos em duas categorias `Primitive Type` e `Object`.
Existem seis tipos primitivos: `null`, `undefined`, `boolean`, `number`, `string` e `symbol `.
Em JavaScript, não existe inteiros de verdade, todos os números são implementados em dupla-precisão 64-bit em formato binário IEEE 754. Quando nós usamos números de pontos flutuantes, iremos ter alguns efeitos colaterais. Aqui está um exemplo desses efeitos colaterais.
```js
0.1 + 0.2 == 0.3 // false
```
Para tipos primitivos, quando usamos literais para inicializar uma variável, ela tem apenas um valor literal, ela não tem um tipo. Isso será convertido para o tipo correspondente apenas quando necessário.
```js
let a = 111 // apenas literais, não um número
a.toString() // convertido para o objeto quando necessário
```
Objeto é um tipo de referência. Nós iremos encontrar problemas sobre cópia rasa e cópia profunda quando usando ele.
```js
let a = { name: 'FE' }
let b = a
b.name = 'EF'
console.log(a.name) // EF
```
# Conversão de Tipos
## Convertendo para Boleano
Quando a condição é julgada, que não seja `undefined`, `null`, `false`, `NaN`, `''`, `0`, `-0`, os esses valores, incluindo objetos, são convertidos para `true`.
## De objetos para tipos primitivos
Quando objetos são convertidos, `valueOf` e `toString` serão chamados, respectivamente em ordem. Esses dois métodos também são sobrescritos.
```js
let a = {
valueOf() {
return 0
}
}
```
## Operadores Aritméticos
Apenas para adicão, se um dos parâmentros for uma string, o outro será convertido para uma string também. Para todas as outras operações, enquanto se um dos parâmetros for um número, o outro será convertido para um número.
Adicões invocaram três tipos de conversões de tipos: para tipos primitivos, para números e string:
```js
1 + '1' // '11'
2 * '2' // 4
[1, 2] + [2, 1] // '1,22,1'
// [1, 2].toString() -> '1,2'
// [2, 1].toString() -> '2,1'
// '1,2' + '2,1' = '1,22,1'
```
Observe a expressão `'a' + + 'b'` para adição:
```js
'a' + + 'b' // -> "aNaN"
// uma vez que + 'b' -> NaN
// Você deve ter visto + '1' -> 1
```
## `==` operador

`toPrimitive` na figura acima é convertido objetos para tipos primitivos.
`===` é geralmente recomendado para comparar valores. Contudo, se você gostaria de checar o valor `null`, você pode usar `xx == null`.
Vamos dar uma olhada no exemplo `[] == ![] // -> true`. O processo seguinte explica por que a expressão é `true`:
```js
// [] convertendo para true, então pegue o oposto para false
[] == false
// com #8
[] == ToNumber(false)
[] == 0
// com #10
ToPrimitive([]) == 0
// [].toString() -> ''
'' == 0
// com #6
0 == 0 // -> true
```
## Operador de comparação
1. Se for um objeto, `toPrimitive` é usado.
2. Se for uma string, o caractere índice `unicode` é usado.
# Typeof
`typeof` também permite exibir o tipo correto de tipos primitivos, exceto `null`:
```js
typeof 1 // 'number'
typeof '1' // 'string'
typeof undefined // 'undefined'
typeof true // 'boolean'
typeof Symbol() // 'symbol'
typeof b // b não foi declarado, mas ainda pode ser exibido como undefined
```
Para objeto, `typeof` irá sempre exibir `object`, exceto **function**:
```js
typeof [] // 'object'
typeof {} // 'object'
typeof console.log // 'function'
```
Quanto a `null`, ele é sempre tratado como um `object` pelo `typeof`, apesar de ser um tipo primitivo, e esse é um bug que que existe a um bom tempo.
```js
typeof null // 'object'
```
Por que isso acontece? Porque a versão inicial do JS era baseada em sistemas de 32-bits, do qual armazenava a informação do tipo de variável em bits mais baixos por considerações de performance. Essas começam com objetos `000`, e todos os bits de `null` são zero, então isso é erroneamente tratado como um objeto. Apesar do código atual verificar se os tipos internos mudaram, esse bug foi passado para baixo.
Nós podemos usar `Object.prototype.toString.call(xx)` se quisermos pegar o tipo de dado correto da variável, e então obtemos uma string como `[object Type]`:
```js
let a
// Podemos declarar `undefined` da seguinte maneira
a === undefined
// mas a palavra não reservada `undefined` pode ser re assinada em versões antigas dos browsers
let undefined = 1
// vai dar errado declarar assim
// então nós podemos usar o seguinte método, com menos código
// ele sempre vai retornar `undefined`, tanto faz vir seguido de `void`
a === void 0
```
# New
1. Crie um novo objeto
2. Encadei o prototype
3. Ligue o this
4. Retorne um novo objeto
Os quatro passos acima vão acontecer no processo chamado `new`. Podemos também tentar implementar o `new ` nós mesmos:
```js
function create() {
// Crie um objeto vázio
let obj = new Object()
// Obtenha o construtor
let Ctor = [].shift.call(arguments)
// Encadeie para o prototype
obj.__proto__ = Ctor.prototype
// Ligue o this, execute o construtor
let result = Con.apply(obj, arguments)
// Tenha certeza que o novo é um objeto
return typeof result === 'object'? result : obj
}
```
Instância de um novo objeto são todas criadas com `new`, seja ele `function Foo()`, ou `let a = { b: 1 }` .
É recomendado criar os objetos usando notação literal (seja por questões de performance ou legibilidade), uma vez que é necessário um look-up para `Object` atravessar o escopo encadeado quando criando um objeto usando `new Object()`, mas você não precisa ter esse tipo de probelma quando usando literais.
```js
function Foo() {}
// Função são sintáticamente amigáveis
// Internamente é equivalente a new Function()
let a = { b: 1 }
// Dentro desse lireal, `new Object()` também é usado
```
Para `new`, também precisamos prestar atenção ao operador precedente:
```js
function Foo() {
return this;
}
Foo.getName = function () {
console.log('1');
};
Foo.prototype.getName = function () {
console.log('2');
};
new Foo.getName(); // -> 1
new Foo().getName(); // -> 2
```
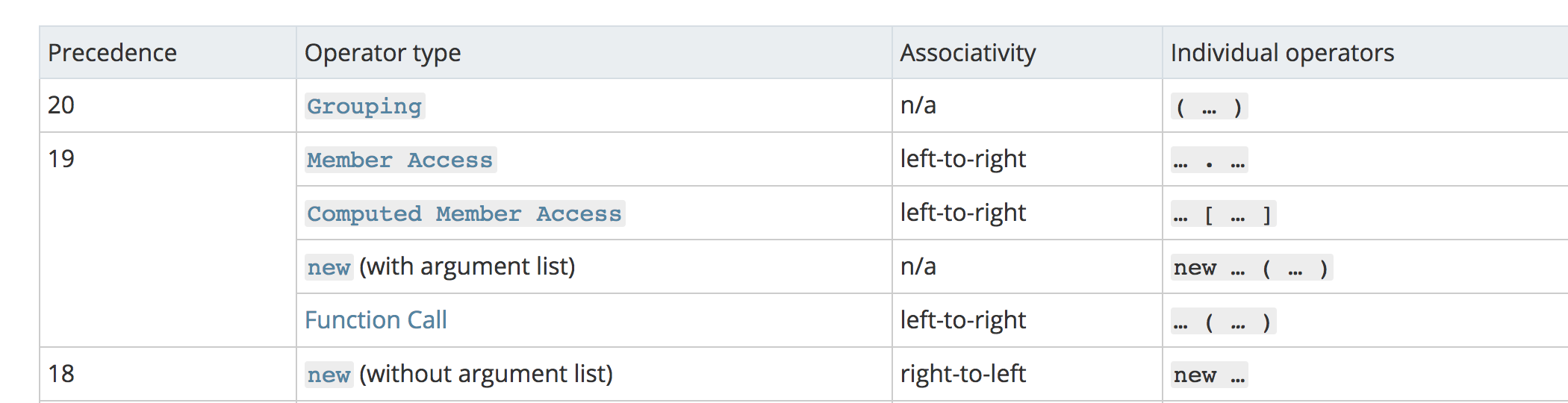
Como você pode ver na imagem acima, `new Foo()` possui uma alta prioridade sobre `new Foo`, então podemos dividir a ordem de execução do código acima assim:
```js
new (Foo.getName());
(new Foo()).getName();
```
Para a primeira função, `Foo.getName()` é executado primeiro, então o resultado é 1;
Para mais tarte, ele primeiro executa `new Foo()` para criar uma instância, então encontrar a função `getName` no `Foo` via cadeia de prototype, então o resultado é 2.
# This
`This`, um conceito que é confuso para maioria das pessoas, atualmente não é difícil de entender enquanto você lembrar as seguintes regras:
```js
function foo() {
console.log(this.a);
}
var a = 1;
foo();
var obj = {
a: 2,
foo: foo
};
obj.foo();
// Nas duas situações acima, `this` depende apenas do objeto ser chamado antes da função,
// e o segundo caso tem uma alta prioriade sobre o primeiro caso.
// o seguinte cenário tem uma alta prioridade, `this` só ficará ligado para c,
// e não existe uma maneira de mudar o que `this` está limitado
var c = new foo();
c.a = 3;
console.log(c.a);
// finalmente, usando `call`, `apply`, `bind` para mudar o que o `this` é obrigado,
// em outro cenário onde essa prioridade é apenas o segundo `new`
```
Entendendo sobre as várias situações acima, nós não vamos ser confundidos pelo `this` na maioria dos casos. Depois, vamos dar uma olhada no `this` nas arrow functions:
```js
function a() {
return () => {
return () => {
console.log(this);
};
};
}
console.log(a()()());
```
Atualmente, as arrow function não tem o `this`, `this` na função acima apenas depende da primeira função externa que não é uma arrow function. Nesse caso, `this` é o padrão para `window` porque chamando `a` iguala a primeira condição nos códigos acima. Também, o que o `this` está ligado não ira ser mudado por qualquer código uma vez que o `this` estiver ligado em um contexto.
# Instanceof
O operador `instanceof` consegue checar corretamente o tipo dos objetos, porque o seu mecanismo interno encontra se o tipo do `prototype` pode ser encontrado na cadeia de prototype do objeto.
vamos tentar implementar ele:
```js
function instanceof(left, right) {
// obtenha o type do `prototype`
let prototype = right.prototype
// obtenha o `prototype` do objeto
left = left.__proto__
// verifique se o tipo do objeto é igual ao prototype do tipo
while (true) {
if (left === null)
return false
if (prototype === left)
return true
left = left.__proto__
}
}
```
# Scope
Executar código JS deveria gerar execução do contexto, enquanto o código não é escrito na função, ele faz parte da execução do contexto global. O código na função vai gerar executação do contexto da função. Existe também uma execução do contexto do `eval`, do qual basicamente não é mais usado, então você pode pensar apenas em duas execuções de contexto.
O atributo `[[Scope]]` é gerado no primeiro estágio de geração de contexto, que é um ponteiro, corresponde a linked list do escopo, e o JS vai procurar variáveis através dessas linked list no contexto global.
Vamos olhar um exemplo common, `var`:
```js
b() // chama b
console.log(a) // undefined
var a = 'Hello world'
function b() {
console.log('call b')
}
```
Ele sabe que funcões e variáveis são içadas acima em relação aos outputs. A explicação usual para o hoisting diz que as declarações são ‘movidas’ para o topo do código, e não existe nada de errado com isso e é fácil de todo mundo entender. Mas para um explicação mais precisa deveria ser algo como:
Haveria dois estágios quando a execução do contexto é gerada. O primeiro estágio é o estágio de criação(para ser mais epecífico, o passo de geração variáveis objeto), no qual o interpretador de JS deveria encontrar variáveis e funções que precisam ser içadas, e aloca memória para eles atecipadamente, então as funções deveriam ser guardadas na memória internamente, mas variáveis seriam apenas declaradas e assinadas para `undefined`, assim sendo, nós podemos usar elas adiante no segundo estágio (a execução do código no estágio)
No processo de içar, a mesma função deveria sobrescrever a última função, e funções tem alta prioridade sobre variáveis içadas.
```js
b() // chama segundo b
function b() {
console.log('chama b primeiro')
}
function b() {
console.log('chama b segundo')
}
var b = 'Hello world'
```
Usando `var` é mais provável error-prone, portanto ES6 introduziu uma nova palava-chave `let`. `let` tem uma característica importante que ela não pode ser usada antes de declarada, que conflita com o ditado comum que `let` não tem a habilidade de içar. De fato, `let` iça a declaracão, mas não é assinada, por causa da **temporal dead zone**.
# Closure
A definição de closure é simples: a função A retorna a função B, e a função b consegue acessar as variáveis da função A, portanto a função B é chamada de closure.
```js
function A() {
let a = 1
function B() {
console.log(a)
}
return B
}
```
Se você estiver se perguntando por que a função B também consegue se referenciar as variáveis da função A enquanto a função A aparece a partir da stack de chamadas? Porque as variáveis na função A são guardadas na pilha nesse momento. O motor atual do JS consegue indentificar quais variáveis precisam ser salvas na heap e quais precisam ser salvas na stack por análise de fuga.
Uma pergunta classica de entrevista é usando closure em loops para resolver o problema de usar `var` para definir funções:
```js
for ( var i=1; i<=5; i++) {
setTimeout( function timer() {
console.log( i );
}, i*1000 );
)
```
Em primeirio lugar, todos os loops vão ser executados completamente porque `setTimeout` é uma função assíncrona, e nesse momento `i` é 6, então isso vai exibir um bando de 6.
Existe três soluções, closure é a primeira:
```js
for (var i = 1; i <= 5; i++) {
(function(j) {
setTimeout(function timer() {
console.log(j);
}, j * 1000);
})(i);
}
```
A segunda é fazer o uso do terceiro parâmetro do `setTimeout`:
```js
for ( var i=1; i<=5; i++) {
setTimeout( function timer(j) {
console.log( j );
}, i*1000, i);
}
```
A terceira é definir o `i` usando `let`:
```js
for ( let i=1; i<=5; i++) {
setTimeout( function timer() {
console.log( i );
}, i*1000 );
}
```
Para `let`, ele vai criar um escopo de block-level, do qual é equivalente a:
```js
{
// Forma o escopo block-level
let i = 0
{
let ii = i
setTimeout( function timer() {
console.log( i );
}, i*1000 );
}
i++
{
let ii = i
}
i++
{
let ii = i
}
...
}
```
# Prototypes
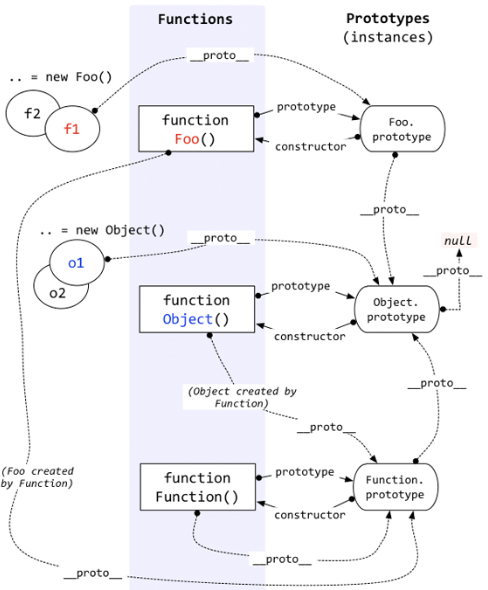
Cada função, além de `Function.prototype.bind()`, tem uma propriedade interna, denotado como `prototype`, do qual é uma referência para o prototype.
Cada objeto tem uma propriedade interna, denotada como `__proto__`, que é uma referência para o prototype do construtor que criou o objeto. Essa propriedade é atualmente referenciada ao `[[prototype]]`, mas o `[[prototype]]` é uma propriedade interna que nós não podemos acessar, então usamos o `__proto__` para acessar ele.
Objetos podem usar `__proto__` para procurar propriedade que não fazem parte do objeto, e `__proto__` conecta os objetos juntos para formar uma cadeida de prototype.
# Herança
No ES5, podemos resolve os problema de herança usando os seguintes passos:
```js
function Super() {}
Super.prototype.getNumber = function() {
return 1
}
function Sub() {}
let s = new Sub()
Sub.prototype = Object.create(Super.prototype, {
constructor: {
value: Sub,
enumerable: false,
writable: true,
configurable: true
}
})
```
A idéia de herança implementada acima é para definir o `prototype` da classe filho como o `prototype` da classe pai.
No ES6, podemos facilmente resolver esse problema com a sintaxe `class`:
```js
class MyDate extends Date {
test() {
return this.getTime()
}
}
let myDate = new MyDate()
myDate.test()
```
Contudo, ES6 não é compátivel com todos os navegadores, então usamos o Babel para compilar esser código.
Se chamar `myDate.test()` com o código compilado, você vai ficar surpreso de ver que existe um erro:

Porque existem restrições no baixo nível do JS, se a instância não for construida pelo `Date`, ele não pode chamar funções no `Date`, que também explica a partir de outro aspecto que herança de `Class` no ES6 é diferente das heranças gerais na sintaxe do ES5.
Uma vez o baixo nível dos limites do JS que a instância deve ser construido pelo `Date`, nós podemos tentar outra maneira de implementar herança:
```js
function MyData() {
}
MyData.prototype.test = function () {
return this.getTime()
}
let d = new Date()
Object.setPrototypeOf(d, MyData.prototype)
Object.setPrototypeOf(MyData.prototype, Date.prototype)
```
A implementação da idéia acima sobre herança: primeiro cria uma instância da classe do pai => muda o original `__proto__` de instância, conectado ao `prototype` da classe do filho => muda o `__proto__` da classe do filho `prototype` para o `prototype` da classe do pai.
A herança de implementação com o método acima pode perfeitamente resolver a restrição no baixo nível do JS.
# Cópia rasa e profunda
```js
let a = {
age: 1
}
let b = a
a.age = 2
console.log(b.age) // 2
```
A partir do exemplo acima, nós podemos ver que se você assinar um objeto para uma variável, então os valores dos dois vão ter a mesma referência, um muda o outro muda adequadamente.
Geralmente, nós não queremos que tal problema apareça durante o desensolvimento, portanto podemos usar a cópia rasa para resolver esse problema.
## Cópia rasa
Primeiramente podemos resolver o problema através do `Object.assign`:
```js
let a = {
age: 1
}
let b = Object.assign({}, a)
a.age = 2
console.log(b.age) // 1
```
Certamente, podemos usar o spread operator (...) para resolver o problema:
```js
let a = {
age: 1
}
let b = {...a}
a.age = 2
console.log(b.age) // 1
```
Geralmente, a cópia rasa pode resolver a maioria dos problemas, mas precisamos da cópia profunda quando encontrado a seguinte situação:
```js
let a = {
age: 1,
jobs: {
first: 'FE'
}
}
let b = {...a}
a.jobs.first = 'native'
console.log(b.jobs.first) // native
```
A cópia rasa resolve apenas o problema na primeira camada. Se o objeto contém objetos, então ele retorna para o topico inicial que os dois valores compartilham a mesma referência. Para resolver esse problema, precisamos introduzir a cópia profunda.
## Cópia profunda
O problema pode geralmente ser resolvido por `JSON.parse(JSON.stringify(object))`
```js
let a = {
age: 1,
jobs: {
first: 'FE'
}
}
let b = JSON.parse(JSON.stringify(a))
a.jobs.first = 'native'
console.log(b.jobs.first) // FE
```
Mas esse método também tem seus limites:
* ignora `undefined`
* incapaz de serializar função
* incapaz de resolver referência circular de um objeto
```js
let obj = {
a: 1,
b: {
c: 2,
d: 3,
},
}
obj.c = obj.b
obj.e = obj.a
obj.b.c = obj.c
obj.b.d = obj.b
obj.b.e = obj.b.c
let newObj = JSON.parse(JSON.stringify(obj))
console.log(newObj)
```
Se um objto é uma referência circular como o exemplo acima, você vai encontrar o método `JSON.parse(JSON.stringify(object))` ele não pode fazer a cópia profunda desse objeto:

Quando lidando com uma função ou `undefined`, o objeto pode não ser serializado adequedamente.
```js
let a = {
age: undefined,
sex: Symbol('male'),
jobs: function() {},
name: 'yck'
}
let b = JSON.parse(JSON.stringify(a))
console.log(b) // {name: "yck"}
```
No caso acima, você pode perceber que o método ignora a função e `undefined`.
A maioria dos dados conseguem ser serializados, então esse método resolve a maioria dos problemas, e como uma função embutida, ele tem uma performance melhor quando lidando com a cópia profunda. Certamente, você pode usar [the deep copy function of `lodash` ](https://lodash.com/docs#cloneDeep) quando sues dados contém os três casos acima.
Se o objeto que você quer copiar contém um tipo embutido mas não contém uma função, você pode usar `MessageChannel`
```js
function structuralClone(obj) {
return new Promise(resolve => {
const {port1, port2} = new MessageChannel();
port2.onmessage = ev => resolve(ev.data);
port1.postMessage(obj);
});
}
var obj = {a: 1, b: {
c: b
}}
// preste atenção que esse método é assíncrono
// ele consegue manipular `undefined` e referência circular do objeto
(async () => {
const clone = await structuralClone(obj)
})()
```
# Modularização
Com o Babel, nós conseguimos usar a ES6 modularização:
```js
// arquivo a.js
export function a() {}
export function b() {}
// arquivo b.js
export default function() {}
import {a, b} from './a.js'
import XXX from './b.js'
```
## CommonJS
`CommonJS` é uma aspecto único do Node. É preciso `Browserify` para o `CommonJS` ser usado nos navegadores.
```js
// a.js
module.exports = {
a: 1
}
// ou
exports.a = 1
// b.js
var module = require('./a.js')
module.a // -> log 1
```
No código acima, `module.exports` e `exports` podem causar confusão. Vamos dar uma olhada na implementação interna:
```js
var module = require('./a.js')
module.a
// esse é o empacotador atual de uma função a ser executada imediatamente, de modo que não precisamos bagunçar as variáveis globais.
// O que é importante aqui é que o módulo é apenas uma variável do Node.
module.exports = {
a: 1
}
// implementação básica
var module = {
exports: {} // exporta em um objeto vázio
}
// Esse é o por que o exports e module.exports tem usos similares.
var exports = module.exports
var load = function (module) {
// to be exported
var a = 1
module.exports = a
return module.exports
};
```
Vamos então falar sobre `module.exports` e `exports`, que tem uso similar, mas um não atribui um valor para `exports` diretamente. A tarefa seria um no-op.
A diferença entre as modularizações no `CommonJS` a no ES6 são:
- O antigo suporta importes dinamico, que é `require(${path}/xx.js)`; o último não suporta isso ainda, mas
existem propostas.
- O antigo usa importes síncronos. Desde de que usado no servidor os arquivos são locais, não importa muito mesmo se o import síncrono bloqueia a main thread. O último usa importe assíncrono, porque ele é usado no navegador em que os arquivos baixados são precisos. O processo de renderização seria afetado muito se assíncrono importe for usado.
- O anterior copia os valores quando exportando. Mesmo se o valor exportado mudou, os valores importados não irão mudar. Portanto, se os valores devem ser atualizados, outro importe precisa acontecer. Contudo, o último usa ligações em tempo real, os valores importados são importados no mesmo endereço de memória, então o valor importado muda junto com os importados.
- Em execução o último é compilado para `require/exports`.
## AMD
AMD é apresentado por `RequireJS`.
```js
// AMD
define(['./a', './b'], function(a, b) {
a.do()
b.do()
})
define(function(require, exports, module) {
var a = require('./a')
a.doSomething()
var b = require('./b')
b.doSomething()
})
```
# A diferença entre call apply bind
Primeiro, vamos falar a diferença entre os dois antigos.
Ambos `call` e `apply` são usados para mudar o que o `this` se refere. Seu papel é o mesmo, mas a maneira de passar os parâmetros é diferente.
Além do primeiro parâmetro, `call` também aceita uma lista de argumentos, enquanto `apply` aceita um único array de argumentos.
```js
let a = {
value: 1
}
function getValue(name, age) {
console.log(name)
console.log(age)
console.log(this.value)
}
getValue.call(a, 'yck', '24')
getValue.apply(a, ['yck', '24'])
```
## simulação para implementar `call` e `apply`
Consideramos implementar eles a partir das seguintes regras:
* Se o primeiro parâmetro não foi passado, então o primeiro será o padrão `window`;
* Mude a referência do `this`, que faz um novo objeto capaz de executar a função. Então vamos pensar assim: adicione a função para um novo objeto e então delete ele depois da execução.
```js
Function.prototype.myCall = function (context) {
var context = context || window
// Adiciona uma propriedade ao `context`
// getValue.call(a, 'yck', '24') => a.fn = getValue
context.fn = this
// pega os parâmentros do `context`
var args = [...arguments].slice(1)
// getValue.call(a, 'yck', '24') => a.fn('yck', '24')
var result = context.fn(...args)
// deleta fn
delete context.fn
return result
}
```
O exemplo acima é a idéia central da simulação do `call`, e a implementação do `apply` é similar.
```js
Function.prototype.myApply = function (context) {
var context = context || window
context.fn = this
var result
// Existe a necessidade de determinar se guarda o segundo parâmentro
// Se o segundo parâmetro existir, espalhe ele
if (arguments[1]) {
result = context.fn(...arguments[1])
} else {
result = context.fn()
}
delete context.fn
return result
}
```
A regra do `bind` é a mesma das outras duas, exceto que ela retorna uma função. E nós podemos implementar currying com o `bind`
vamos simular o `bind`:
```js
Function.prototype.myBind = function (context) {
if (typeof this !== 'function') {
throw new TypeError('Error')
}
var _this = this
var args = [...arguments].slice(1)
// retorna uma função
return function F() {
// Nós podemos usar `new F()` porque ele retorna uma função, então precisamos determinar
if (this instanceof F) {
return new _this(...args, ...arguments)
}
return _this.apply(context, args.concat(...arguments))
}
}
```
# Implementação de Promise
`Promise` é a nova sintaxe introduzida pelo ES6, que resolve os problemas de callback hell.
Promise pode ser visto como um estado de máquina e o seu estado inicial é `pending`. Nós podemos mudar o estado para `resolved` ou `rejected` usando as funções `resolve` e `reject`. Uma vez que o state mudou, ele não pode mudar novamente.
A função `then` retorna uma instância da Promise, do qual é uma nova instância ao invés do anterior. E existe por que a especificação de estado da Promise que adiciona para o estado `pending`, outro estado não pode ser mudado, e multiplas chamadas a função `then` serão insignificantes se a mesma instância for retornada.
Para `then`, ele pode essencialmente ser visto como flatMap`:
```js
// árvore de estados
const PENDING = 'pending';
const RESOLVED = 'resolved';
const REJECTED = 'rejected';
// promise aceita um argumento na função que será executada imediatamente.
function MyPromise(fn) {
let _this = this;
_this.currentState = PENDING;
_this.value = undefined;
// Save o callback do `then`, apenas em cache quando o estado da promise for pending,
// no máximo será cacheado em cada instância
_this.resolvedCallbacks = [];
_this.rejectedCallbacks = [];
_this.resolve = function(value) {
// execute assícronamente para garantir a ordem de execução
setTimeout(() => {
if (value instanceof MyPromise) {
// se o valor é uma Promise, execute recursivamente
return value.then(_this.resolve, _this.reject)
}
if (_this.currentState === PENDING) {
_this.currentState = RESOLVED;
_this.value = value;
_this.resolvedCallbacks.forEach(cb => cb());
}
})
}
_this.reject = function(reason) {
// execute assícronamente para garantir a ordem de execução
setTimeout(() => {
if (_this.currentState === PENDING) {
_this.currentState = REJECTED;
_this.value = reason;
_this.rejectedCallbacks.forEach(cb => cb());
}
})
}
// para resolver o seguinte problema
// `new Promise(() => throw Error('error))`
try {
fn(_this.resolve, _this.reject);
} catch (e) {
_this.reject(e);
}
}
MyPromise.prototype.then = function(onResolved, onRejected) {
const self = this;
// especificação 2.2.7, `then` deve retornar uma nova promise
let promise2;
// especificação 2.2, ambos `onResolved` e `onRejected` são argumentos opcionais
// isso deveria ser ignorado se `onResolved` ou `onRjected` não for uma função,
// do qual implementa a penetrar a passagem desse valor
// `Promise.resolve(4).then().then((value) => console.log(value))`
onResolved = typeof onResolved === 'function' ? onResolved : v => v;
onRejected = typeof onRejected === 'function' ? onRejected : r => throw r;
if (self.currentState === RESOLVED) {
return (promise2 = new MyPromise((resolve, reject) => {
// especificação 2.2.4, encapsula eles com `setTimeout`,
// em ordem para garantir que `onFulfilled` e `onRjected` executam assícronamente
setTimeout(() => {
try {
let x = onResolved(self.value);
resolutionProcedure(promise2, x, resolve, reject);
} catch (reason) {
reject(reason);
}
});
}));
}
if (self.currentState === REJECTED) {
return (promise2 = new MyPromise((resolve, reject) => {
// execute `onRejected` assícronamente
setTimeout(() => {
try {
let x = onRejected(self.value);
resolutionProcedure(promise2, x, resolve, reject);
} catch (reason) {
reject(reason);
}
});
}))
}
if (self.currentState === PENDING) {
return (promise2 = new MyPromise((resolve, reject) => {
self.resolvedCallbacks.push(() => {
// Considerando que isso deve lançar um erro, encapsule eles com `try/catch`
try {
let x = onResolved(self.value);
resolutionProcedure(promise2, x, resolve, reject);
} catch (r) {
reject(r);
}
});
self.rejectedCallbacks.push(() => {
try {
let x = onRejected(self.value);
resolutionProcedure(promise2, x, resolve, reject);
} catch (r) {
reject(r);
}
})
}))
}
}
// especificação 2.3
function resolutionProcedure(promise2, x, resolve, reject) {
// especificação 2.3.1,`x` e `promise2` não podem ser referenciados para o mesmo objeto,
// evitando referência circular
if (promise2 === x) {
return reject(new TypeError('Error'));
}
// especificação 2.3.2, se `x` é uma Promise e o estado é `pending`,
// a promisse deve permanecer, se não, ele deve ser executado.
if (x instanceof MyPromise) {
if (x.currentState === PENDING) {
// chame a função `resolutionProcedure` novamente para
// confirmar o tipo de argumento que x resolve
// Se for um tipo primitivo, irá ser resolvido novamente
// passando o valor para o próximo `then`.
x.then((value) => {
resolutionProcedure(promise2, value, resolve, reject);
}, reject)
} else {
x.then(resolve, reject);
}
return;
}
// especificação 2.3.3.3.3
// se ambos `reject` e `resolve` forem executado, a primeira execução
// de sucesso tem precedência, e qualquer execução é ignorada
let called = false;
// especificação 2.3.3, determina se `x` é um objeto ou uma função
if (x !== null && (typeof x === 'object' || typeof x === 'function')) {
// especificação 2.3.3.2, se não conseguir obter o `then`, execute o `reject`
try {
// especificação 2.3.3.1
let then = x.then;
// se `then` é uma função, chame o `x.then`
if (typeof then === 'function') {
// especificação 2.3.3.3
then.call(x, y => {
if (called) return;
called = true;
// especificação 2.3.3.3.1
resolutionProcedure(promise2, y, resolve, reject);
}, e => {
if (called) return;
called = true;
reject(e);
});
} else {
// especificação 2.3.3.4
resolve(x);
}
} catch (e) {
if (called) return;
called = true;
reject(e);
}
} else {
// especificação 2.3.4, `x` pertence ao tipo primitivo de dados
resolve(x);
}
}
```
O código acima, que é implementado baseado em Promise / A+ especificação, pode passar os testes completos de `promises-aplus-tests`
# Implementação do Generator
Generator é uma funcionalidade sintática adicionada no ES6. Similar a `Promise`, pode ser usado para programação assíncrona.
```js
// * significa que isso é uma função Generator
// yield dentro de um bloco pode ser usado para pausar a execução
// next consegue resumir a execução
function* test() {
let a = 1 + 2;
yield 2;
yield 3;
}
let b = test();
console.log(b.next()); // > { value: 2, done: false }
console.log(b.next()); // > { value: 3, done: false }
console.log(b.next()); // > { value: undefined, done: true }
```
Como podemos dizer no código acima, a função com um `*` teria a execução da função `next`. Em outras palavras, a execução de função retorna um objeto. Toda chamada a função `next` pode continuar a execução do código pausado. Um simples implementação da função Generator é mostrada abaixo:
```js
// cb é a função 'test' compilada
function generator(cb) {
return (function() {
var object = {
next: 0,
stop: function() {}
};
return {
next: function() {
var ret = cb(object);
if (ret === undefined) return { value: undefined, done: true };
return {
value: ret,
done: false
};
}
};
})();
}
// Depois da compilação do babel's, a função 'test' retorna dentro dessa:
function test() {
var a;
return generator(function(_context) {
while (1) {
switch ((_context.prev = _context.next)) {
// yield separa o código em diversos blocos
// cada chamada 'next' executa um bloco de código
// e indica o próximo bloco a ser executado
case 0:
a = 1 + 2;
_context.next = 4;
return 2;
case 4:
_context.next = 6;
return 3;
// execução completa
case 6:
case "end":
return _context.stop();
}
}
});
}
```
# Debouncing
Tendo você encontrado esse problema e seu dia-a-dia no desenvolvimento: como fazer uma computação complexa em um evento de scroll ou prevenir o "segundo clique acidental" no butão?
Esses requisitos podem ser alcançados com funcões debouncing. Especialmente para o primeiro, se uma computação complexa estiver sendo chamado em frequentes eventos de callbacks, existe uma grande chance que a página se torne lenta. É melhor combinar essas multiplas computações e uma, e apenas operar em determinado periodo de tempo. Desde que existe muitas bibliotecas que implementam debouncing, nós não construimos nosso próprio aqui e vamos pegar o código do underscore para explicar o debouncing:
```js
/**
* função underscore debouncing. Quando a função callback é chamada em série, a funcão vai executar apenas quando o tempo ideal é maior ou igual ao `wait`.
*
* @param {function} func função callback
* @param {number} wait tamanho do intervalo de espera
* @param {boolean} immediate quando definido para true, func é executada imadiatamente
* @return {function} retorna a função a ser chamada pelo cliente
*/
_.debounce = function(func, wait, immediate) {
var timeout, args, context, timestamp, result;
var later = function() {
// compara now para o último timestamp
var last = _.now() - timestamp;
// se o tempo de intervalo atual é menor então o set interval é maior que 0, então reinicie o timer.
if (last < wait && last >= 0) {
timeout = setTimeout(later, wait - last);
} else {
// senão é o momento de executar a função callback
timeout = null;
if (!immediate) {
result = func.apply(context, args);
if (!timeout) context = args = null;
}
}
};
return function() {
context = this;
args = arguments;
// obtendo o timestamp
timestamp = _.now();
// se o timer não existir então execute a função imediatamente
var callNow = immediate && !timeout;
// se o time não existe então crie um
if (!timeout) timeout = setTimeout(later, wait);
if (callNow) {
// se a função imediata é precisa, use aplly para começar a função
result = func.apply(context, args);
context = args = null;
}
return result;
};
};
```
A implementação completa da ƒunção não é tão difícil.
- Para a implementação de proteger contra clicks acidentais: enquanto eu começar o time e o time existir, não importa quantas vezes eu clicar o butão, a função de callback não será executada. Contudo quando o time termina, é setado para `null`, outro click é permitido.
- Para a implementação da executação da função de atraso: toda chamada para a função debouncing vai disparar um tempo de intervalo equivalente entre a chamada tual e a última chamada. Se o intervalo é menor que o requerido, outro time será cirado, e o atraso é atribuido ao set interval menos o tempo anterior. Quando o tempo passa, a função de callback é executada.
# Throttle
`Debounce` e `Throttle` possuem naturezas diferentes. `Debounce` é para tornar multiplas execuções na última execução, e `Throttle` é para tornar multiplas execuções em uma execução de intervalos regulares.
```js
// Os dois primeiro parâmetros com debounce são a mesma função
// options: você pode passar duas propriedades
// trailing: o último tempo não é executado
// leading: o primeiro tempo não é executado
// As duas propriedades não coexistem, contudo a função não será executada
_.throttle = function(func, wait, options) {
var context, args, result;
var timeout = null;
// timestamp anterior
var previous = 0;
// Defina vázio se as opções não forem passadas
if (!options) options = {};
// Função Timer callback
var later = function() {
// se você definiu `leading`, então defina `previous` para zero
// O primeiro if da seguinte função é usada
previous = options.leading === false ? 0 : _.now();
// O primeiro é prevenindo memory leaks e o segundo é julgado os seguintes timers quando configurado `timeout` para null
timeout = null;
result = func.apply(context, args);
if (!timeout) context = args = null;
};
return function() {
// Obtenha o timestamp atual
var now = _.now();
// Deve ser verdado quando entrar pela primeira vez
// Se você não precisa executar essa função na primeira vez
// Defina o último timestamp para o atual
// Então ele será maior que 0 quando o termo remanecente for calculado da próxima vez
if (!previous && options.leading === false)
previous = now;
var remaining = wait - (now - previous);
context = this;
args = arguments;
// Essa condição só será preenchida se definido para `trailing`
// Essa condição só será preenchida no ínicio se não definido `leading`
// Outro ponto, você deve pensar que essa condição não será preenchida se você ligar o timer
// De fato, será assim até entrar porque o atraso do timer não é acurado
// Isso é muito como se você setar a 2 segundos, mas ele precisa 2.2 segundos para disparar, então o tempo será preenchido nessa condição
if (remaining <= 0 || remaining > wait) {
// Limpe se existe um timer e ele chama a callback duas vezes
if (timeout) {
clearTimeout(timeout);
timeout = null;
}
previous = now;
result = func.apply(context, args);
if (!timeout) context = args = null;
} else if (!timeout && options.trailing !== false) {
// Julge se o timer e trailing forem definidos
// E você não pode defirnor leading e trailing no mesmo instante
timeout = setTimeout(later, remaining);
}
return result;
};
};
```
# Map、FlatMap e Reduce
O efeito do `Map` é para gerar um novo array, iterando sobre o array original, tomando cada elemento para fazer alguma transformação, e então `append` para um novo array.
```js
[1, 2, 3].map((v) => v + 1)
// -> [2, 3, 4]
```
`Map` tem três parâmetros, nomeando o índice atual do elemento, o índice, o array original.
```js
['1','2','3'].map(parseInt)
// parseInt('1', 0) -> 1
// parseInt('2', 1) -> NaN
// parseInt('3', 2) -> NaN
```
O efeito do `FlatMap` é quase o mesmo do `Map`, mas o array original será substituído para um array multidimensional. Você pode pensar no `FlatMap` com um `map` e um `flatten`, que atualmente não é suportado nos navegadores.
```js
[1, [2], 3].flatMap((v) => v + 1)
// -> [2, 3, 4]
```
Você pode alcançar isso quando você quer reduzir completamente dimensões de um array multidimensional:
```js
const flattenDeep = (arr) => Array.isArray(arr)
? arr.reduce( (a, b) => [...a, ...flattenDeep(b)] , [])
: [arr]
flattenDeep([1, [[2], [3, [4]], 5]])
```
O efeito do `Reduce` é para combinar os valores em um array e pegar o valor final:
```js
function a() {
console.log(1);
}
function b() {
console.log(2);
}
[a, b].reduce((a, b) => a(b()))
// -> 2 1
```
# Async e await
A função `async` vai retornar uma `Promise`:
```js
async function test() {
return "1";
}
console.log(test()); // -> Promise {: "1"}
```
Você pode pensar em `async` como uma função encapsuladora usando `Promise.resolve()`.
`await` pode ser usado apenas em funcões `async`:
```js
function sleep() {
return new Promise(resolve => {
setTimeout(() => {
console.log('finish')
resolve("sleep");
}, 2000);
});
}
async function test() {
let value = await sleep();
console.log("object");
}
test()
```
O código acime vai exibir `finish` antes de exibir `object`. Porque `await` espera pela funcão `sleep` `resolve`, mesmo se a sincronização de código estiver seguida, ele não executa antes do código assíncrono ser executado.
A vantagem do `async` e `await` comparado ao uso direto da `Promise` mente em manipular a cadeia de chamada do `then`, que pode produzir código claro e acurado. A desvantagem é que uso indevido do `await` pode causar problemas de performance porque `await` bloqueia o código. Possivelmente o código assíncrono não depende do anterior, mas ele ainda precisa esperar o anterir ser completo, ocasionando perda de concorrência.
Vamos dar uma olhada em um código que usa `await`:
```js
var a = 0
var b = async () => {
a = a + await 10
console.log('2', a) // -> '2' 10
a = (await 10) + a
console.log('3', a) // -> '3' 20
}
b()
a++
console.log('1', a) // -> '1' 1
```
Você pode ter dúvidas sobre o código acima, aqui nós explicamos o príncipio:
- Primeiro a função `b` é executada. A variável `a` ainda é zero antes da execução do `await 10`, porque os `Generators` são implementados dentro do `await` e `Generators` matém as coisas na pilha, então nesse momento `a = 0` é salvo
- Porque `await` é uma operação assíncrona, `console.log('1', a)` será executada primeiro.
- Nesse ponto, o código síncrono é completado e o código assíncrono é iniciado. O valor salvo é usado. Nesse instante, `a = 10`
- Então chega a execução usual do código
# Proxy
Proxy é uma nova funcionalidade desde o ES6. Ele costuma ser usado para definir operações em objetos:
```js
let p = new Proxy(target, handler);
// `target` representa o objeto que precisamos adicionar o proxy
// `handler` operações customizadas no objeto
```
Proxy podem ser conveniente para implementação de data bindind e listening:
```js
let onWatch = (obj, setBind, getLogger) => {
let handler = {
get(target, property, receiver) {
getLogger(target, property)
return Reflect.get(target, property, receiver);
},
set(target, property, value, receiver) {
setBind(value);
return Reflect.set(target, property, value);
}
};
return new Proxy(obj, handler);
};
let obj = { a: 1 }
let value
let p = onWatch(obj, (v) => {
value = v
}, (target, property) => {
console.log(`Get '${property}' = ${target[property]}`);
})
p.a = 2 // liga `value` para `2`
p.a // -> obtém 'a' = 2
```
# Por que 0.1 + 0.2 != 0.3
Porque JS usa a precisão-dupla do IEEE 754 versão (64-bit). Toda linguagem que usa esse padrão tem esse problema.
Como nós sabemos, computadores usam binários para representar decimais, então `0.1` em binário é representado como
```js
// (0011) representa o ciclo
0.1 = 2^-4 * 1.10011(0011)
```
Como nós chegamos a esse número binário? Podemos tentar computar ele como abaixo:
Computações binária em números flutuantes são diferentes daqueles em inteiros. Por multiplicação, apenas bits flutuantes são computados, enquanto bits do tipo inteiro são usados pelos binários para cada bit. Então o primeiro bit é usado como o bit mais significante. Assim sendo nós obtemos 0.1 = 2^-4 * 1.10011(0011)`.
`0.2` é similar. Nós apenas precisamos passear na primeira multiplicação e obter `0.2 = 2^-3 * 1.10011(0011)`
Voltando a precisão dupla pelo padrão IEE 754. Entre o 64 bits, um bit é usado para assinatura, 11 é usado para bits inteiros, e o outros 52 bits são floats. Uma vez que `0.1` e `0.2` são ciclos infinitos de binários, o último bit do float precisa indicar se volta (mesmo como o arredendomaneto em decimal).
Depois do arredondamento, `2^-4 * 1.10011...001` se torna `2^-4 * 1.10011(0011 * 12 vezes)010`. Depois de adicionado esses dois binários obtemos `2^-2 * 1.0011(0011 * 11 vezes)0100`, que é `0.30000000000000004` em decimal.
A solução nativa pra esse problema é mostrado abaixo:
```js
parseFloat((0.1 + 0.2).toFixed(10))
```
# Expressões Regulares
## Metacaracteres
| Metacaractere | Efeito |
| :-----------: | :----------------------------------------------------------: |
| . | corresponde a qualquer caractere exceto de terminadores de linhas: \n, \r, \u2028 or \u2029. |
| [] | corresponde a qualquer coisa dentro dos colchetes. Por exemplo, [0-9] corresponde a qualquer número |
| ^ | ^9 significa corresponder qualquer coisa que começa com '9'; [`^`9] significa não corresponder aos caracteres exceto '9' nos colchetes |
| {1, 2} | corresponde 1 ou 2 caracteres digitais |
| (yck) | corresponde apenas strings com o mesmo 'yck' |
| \| | corresponde a qualquer caractere antes e depois \| |
| \ | caracter de escape |
| * | corresponde a expressão precedente 0 ou mais vezes |
| + | corresponde a expressão precedente 1 ou mais vezes |
| ? | o caractere antes do '?' é opcional |
## Bandeiras
| Bandeira | Efeito |
| :------: | :--------------: |
| i | pesquisa insensível a maiúsculas e minúsculas |
| g | corresponde globalmente |
| m | multilinha |
## Caracteres Atalhos
| Atalho | Efeito |
| :--: | :------------------------: |
| \w | caracteres alfanuméricos, caracteres sublinhados |
| \W | o oposto do acima |
| \s | qualquer caractere em branco |
| \S | o oposto do acima |
| \d | números |
| \D | o oposto do acima |
| \b | inicio ou fim da palavra |
| \B | o oposto do acima |
================================================
FILE: JS/JS-ch.md
================================================
**Table of Contents** *generated with [DocToc](https://github.com/thlorenz/doctoc)*
- [内置类型](#%E5%86%85%E7%BD%AE%E7%B1%BB%E5%9E%8B)
- [Typeof](#typeof)
- [类型转换](#%E7%B1%BB%E5%9E%8B%E8%BD%AC%E6%8D%A2)
- [转Boolean](#%E8%BD%ACboolean)
- [对象转基本类型](#%E5%AF%B9%E8%B1%A1%E8%BD%AC%E5%9F%BA%E6%9C%AC%E7%B1%BB%E5%9E%8B)
- [四则运算符](#%E5%9B%9B%E5%88%99%E8%BF%90%E7%AE%97%E7%AC%A6)
- [`==` 操作符](#-%E6%93%8D%E4%BD%9C%E7%AC%A6)
- [比较运算符](#%E6%AF%94%E8%BE%83%E8%BF%90%E7%AE%97%E7%AC%A6)
- [原型](#%E5%8E%9F%E5%9E%8B)
- [new](#new)
- [instanceof](#instanceof)
- [this](#this)
- [执行上下文](#%E6%89%A7%E8%A1%8C%E4%B8%8A%E4%B8%8B%E6%96%87)
- [闭包](#%E9%97%AD%E5%8C%85)
- [深浅拷贝](#%E6%B7%B1%E6%B5%85%E6%8B%B7%E8%B4%9D)
- [浅拷贝](#%E6%B5%85%E6%8B%B7%E8%B4%9D)
- [深拷贝](#%E6%B7%B1%E6%8B%B7%E8%B4%9D)
- [模块化](#%E6%A8%A1%E5%9D%97%E5%8C%96)
- [CommonJS](#commonjs)
- [AMD](#amd)
- [防抖](#%E9%98%B2%E6%8A%96)
- [节流](#%E8%8A%82%E6%B5%81)
- [继承](#%E7%BB%A7%E6%89%BF)
- [call, apply, bind 区别](#call-apply-bind-%E5%8C%BA%E5%88%AB)
- [模拟实现 call 和 apply](#%E6%A8%A1%E6%8B%9F%E5%AE%9E%E7%8E%B0-call-%E5%92%8C-apply)
- [Promise 实现](#promise-%E5%AE%9E%E7%8E%B0)
- [Generator 实现](#generator-%E5%AE%9E%E7%8E%B0)
- [Map、FlatMap 和 Reduce](#mapflatmap-%E5%92%8C-reduce)
- [async 和 await](#async-%E5%92%8C-await)
- [Proxy](#proxy)
- [为什么 0.1 + 0.2 != 0.3](#%E4%B8%BA%E4%BB%80%E4%B9%88-01--02--03)
- [正则表达式](#%E6%AD%A3%E5%88%99%E8%A1%A8%E8%BE%BE%E5%BC%8F)
- [元字符](#%E5%85%83%E5%AD%97%E7%AC%A6)
- [修饰语](#%E4%BF%AE%E9%A5%B0%E8%AF%AD)
- [字符简写](#%E5%AD%97%E7%AC%A6%E7%AE%80%E5%86%99)
- [V8 下的垃圾回收机制](#v8-%E4%B8%8B%E7%9A%84%E5%9E%83%E5%9C%BE%E5%9B%9E%E6%94%B6%E6%9C%BA%E5%88%B6)
- [新生代算法](#%E6%96%B0%E7%94%9F%E4%BB%A3%E7%AE%97%E6%B3%95)
- [老生代算法](#%E8%80%81%E7%94%9F%E4%BB%A3%E7%AE%97%E6%B3%95)
# 内置类型
JS 中分为七种内置类型,七种内置类型又分为两大类型:基本类型和对象(Object)。
基本类型有六种: `null`,`undefined`,`boolean`,`number`,`string`,`symbol`。
其中 JS 的数字类型是浮点类型的,没有整型。并且浮点类型基于 IEEE 754标准实现,在使用中会遇到某些 [Bug](#%E4%B8%BA%E4%BB%80%E4%B9%88-01--02--03)。`NaN` 也属于 `number` 类型,并且 `NaN` 不等于自身。
对于基本类型来说,如果使用字面量的方式,那么这个变量只是个字面量,只有在必要的时候才会转换为对应的类型
```js
let a = 111 // 这只是字面量,不是 number 类型
a.toString() // 使用时候才会转换为对象类型
```
对象(Object)是引用类型,在使用过程中会遇到浅拷贝和深拷贝的问题。
```js
let a = { name: 'FE' }
let b = a
b.name = 'EF'
console.log(a.name) // EF
```
# Typeof
`typeof` 对于基本类型,除了 `null` 都可以显示正确的类型
```js
typeof 1 // 'number'
typeof '1' // 'string'
typeof undefined // 'undefined'
typeof true // 'boolean'
typeof Symbol() // 'symbol'
typeof b // b 没有声明,但是还会显示 undefined
```
`typeof` 对于对象,除了函数都会显示 `object`
```js
typeof [] // 'object'
typeof {} // 'object'
typeof console.log // 'function'
```
对于 `null` 来说,虽然它是基本类型,但是会显示 `object`,这是一个存在很久了的 Bug
```js
typeof null // 'object'
```
PS:为什么会出现这种情况呢?因为在 JS 的最初版本中,使用的是 32 位系统,为了性能考虑使用低位存储了变量的类型信息,`000` 开头代表是对象,然而 `null` 表示为全零,所以将它错误的判断为 `object` 。虽然现在的内部类型判断代码已经改变了,但是对于这个 Bug 却是一直流传下来。
如果我们想获得一个变量的正确类型,可以通过 `Object.prototype.toString.call(xx)`。这样我们就可以获得类似 `[object Type]` 的字符串。
```js
let a
// 我们也可以这样判断 undefined
a === undefined
// 但是 undefined 不是保留字,能够在低版本浏览器被赋值
let undefined = 1
// 这样判断就会出错
// 所以可以用下面的方式来判断,并且代码量更少
// 因为 void 后面随便跟上一个组成表达式
// 返回就是 undefined
a === void 0
```
# 类型转换
## 转Boolean
在条件判断时,除了 `undefined`, `null`, `false`, `NaN`, `''`, `0`, `-0`,其他所有值都转为 `true`,包括所有对象。
## 对象转基本类型
对象在转换基本类型时,首先会调用 `valueOf` 然后调用 `toString`。并且这两个方法你是可以重写的。
```js
let a = {
valueOf() {
return 0
}
}
```
当然你也可以重写 `Symbol.toPrimitive` ,该方法在转基本类型时调用优先级最高。
```js
let a = {
valueOf() {
return 0;
},
toString() {
return '1';
},
[Symbol.toPrimitive]() {
return 2;
}
}
1 + a // => 3
'1' + a // => '12'
```
## 四则运算符
只有当加法运算时,其中一方是字符串类型,就会把另一个也转为字符串类型。其他运算只要其中一方是数字,那么另一方就转为数字。并且加法运算会触发三种类型转换:将值转换为原始值,转换为数字,转换为字符串。
```js
1 + '1' // '11'
2 * '2' // 4
[1, 2] + [2, 1] // '1,22,1'
// [1, 2].toString() -> '1,2'
// [2, 1].toString() -> '2,1'
// '1,2' + '2,1' = '1,22,1'
```
对于加号需要注意这个表达式 `'a' + + 'b'`
```js
'a' + + 'b' // -> "aNaN"
// 因为 + 'b' -> NaN
// 你也许在一些代码中看到过 + '1' -> 1
```
## `==` 操作符

上图中的 `toPrimitive` 就是对象转基本类型。
这里来解析一道题目 `[] == ![] // -> true` ,下面是这个表达式为何为 `true` 的步骤
```js
// [] 转成 true,然后取反变成 false
[] == false
// 根据第 8 条得出
[] == ToNumber(false)
[] == 0
// 根据第 10 条得出
ToPrimitive([]) == 0
// [].toString() -> ''
'' == 0
// 根据第 6 条得出
0 == 0 // -> true
```
## 比较运算符
1. 如果是对象,就通过 `toPrimitive` 转换对象
2. 如果是字符串,就通过 `unicode` 字符索引来比较
# 原型
每个函数都有 `prototype` 属性,除了 `Function.prototype.bind()`,该属性指向原型。
每个对象都有 `__proto__` 属性,指向了创建该对象的构造函数的原型。其实这个属性指向了 `[[prototype]]`,但是 `[[prototype]]` 是内部属性,我们并不能访问到,所以使用 `_proto_` 来访问。
对象可以通过 `__proto__` 来寻找不属于该对象的属性,`__proto__` 将对象连接起来组成了原型链。
如果你想更进一步的了解原型,可以仔细阅读 [深度解析原型中的各个难点](https://github.com/KieSun/Blog/issues/2)。
# new
1. 新生成了一个对象
2. 链接到原型
3. 绑定 this
4. 返回新对象
在调用 `new` 的过程中会发生以上四件事情,我们也可以试着来自己实现一个 `new`
```js
function create() {
// 创建一个空的对象
let obj = new Object()
// 获得构造函数
let Con = [].shift.call(arguments)
// 链接到原型
obj.__proto__ = Con.prototype
// 绑定 this,执行构造函数
let result = Con.apply(obj, arguments)
// 确保 new 出来的是个对象
return typeof result === 'object' ? result : obj
}
```
对于实例对象来说,都是通过 `new` 产生的,无论是 `function Foo()` 还是 `let a = { b : 1 }` 。
对于创建一个对象来说,更推荐使用字面量的方式创建对象(无论性能上还是可读性)。因为你使用 `new Object()` 的方式创建对象需要通过作用域链一层层找到 `Object`,但是你使用字面量的方式就没这个问题。
```js
function Foo() {}
// function 就是个语法糖
// 内部等同于 new Function()
let a = { b: 1 }
// 这个字面量内部也是使用了 new Object()
```
对于 `new` 来说,还需要注意下运算符优先级。
```js
function Foo() {
return this;
}
Foo.getName = function () {
console.log('1');
};
Foo.prototype.getName = function () {
console.log('2');
};
new Foo.getName(); // -> 1
new Foo().getName(); // -> 2
```
从上图可以看出,`new Foo() ` 的优先级大于 `new Foo` ,所以对于上述代码来说可以这样划分执行顺序
```js
new (Foo.getName());
(new Foo()).getName();
```
对于第一个函数来说,先执行了 `Foo.getName()` ,所以结果为 1;对于后者来说,先执行 `new Foo()` 产生了一个实例,然后通过原型链找到了 `Foo` 上的 `getName` 函数,所以结果为 2。
# instanceof
`instanceof` 可以正确的判断对象的类型,因为内部机制是通过判断对象的原型链中是不是能找到类型的 `prototype`。
我们也可以试着实现一下 `instanceof`
```js
function instanceof(left, right) {
// 获得类型的原型
let prototype = right.prototype
// 获得对象的原型
left = left.__proto__
// 判断对象的类型是否等于类型的原型
while (true) {
if (left === null)
return false
if (prototype === left)
return true
left = left.__proto__
}
}
```
# this
`this` 是很多人会混淆的概念,但是其实他一点都不难,你只需要记住几个规则就可以了。
```js
function foo() {
console.log(this.a)
}
var a = 1
foo()
var obj = {
a: 2,
foo: foo
}
obj.foo()
// 以上两者情况 `this` 只依赖于调用函数前的对象,优先级是第二个情况大于第一个情况
// 以下情况是优先级最高的,`this` 只会绑定在 `c` 上,不会被任何方式修改 `this` 指向
var c = new foo()
c.a = 3
console.log(c.a)
// 还有种就是利用 call,apply,bind 改变 this,这个优先级仅次于 new
```
以上几种情况明白了,很多代码中的 `this` 应该就没什么问题了,下面让我们看看箭头函数中的 `this`
```js
function a() {
return () => {
return () => {
console.log(this)
}
}
}
console.log(a()()())
```
箭头函数其实是没有 `this` 的,这个函数中的 `this` 只取决于他外面的第一个不是箭头函数的函数的 `this`。在这个例子中,因为调用 `a` 符合前面代码中的第一个情况,所以 `this` 是 `window`。并且 `this` 一旦绑定了上下文,就不会被任何代码改变。
# 执行上下文
当执行 JS 代码时,会产生三种执行上下文
- 全局执行上下文
- 函数执行上下文
- eval 执行上下文
每个执行上下文中都有三个重要的属性
- 变量对象(VO),包含变量、函数声明和函数的形参,该属性只能在全局上下文中访问
- 作用域链(JS 采用词法作用域,也就是说变量的作用域是在定义时就决定了)
- this
```js
var a = 10
function foo(i) {
var b = 20
}
foo()
```
对于上述代码,执行栈中有两个上下文:全局上下文和函数 `foo` 上下文。
```js
stack = [
globalContext,
fooContext
]
```
对于全局上下文来说,VO 大概是这样的
```js
globalContext.VO === globe
globalContext.VO = {
a: undefined,
foo: ,
}
```
对于函数 `foo` 来说,VO 不能访问,只能访问到活动对象(AO)
```js
fooContext.VO === foo.AO
fooContext.AO {
i: undefined,
b: undefined,
arguments: <>
}
// arguments 是函数独有的对象(箭头函数没有)
// 该对象是一个伪数组,有 `length` 属性且可以通过下标访问元素
// 该对象中的 `callee` 属性代表函数本身
// `caller` 属性代表函数的调用者
```
对于作用域链,可以把它理解成包含自身变量对象和上级变量对象的列表,通过 `[[Scope]]` 属性查找上级变量
```js
fooContext.[[Scope]] = [
globalContext.VO
]
fooContext.Scope = fooContext.[[Scope]] + fooContext.VO
fooContext.Scope = [
fooContext.VO,
globalContext.VO
]
```
接下来让我们看一个老生常谈的例子,`var`
```js
b() // call b
console.log(a) // undefined
var a = 'Hello world'
function b() {
console.log('call b')
}
```
想必以上的输出大家肯定都已经明白了,这是因为函数和变量提升的原因。通常提升的解释是说将声明的代码移动到了顶部,这其实没有什么错误,便于大家理解。但是更准确的解释应该是:在生成执行上下文时,会有两个阶段。第一个阶段是创建的阶段(具体步骤是创建 VO),JS 解释器会找出需要提升的变量和函数,并且给他们提前在内存中开辟好空间,函数的话会将整个函数存入内存中,变量只声明并且赋值为 undefined,所以在第二个阶段,也就是代码执行阶段,我们可以直接提前使用。
在提升的过程中,相同的函数会覆盖上一个函数,并且函数优先于变量提升
```js
b() // call b second
function b() {
console.log('call b fist')
}
function b() {
console.log('call b second')
}
var b = 'Hello world'
```
`var` 会产生很多错误,所以在 ES6中引入了 `let`。`let` 不能在声明前使用,但是这并不是常说的 `let` 不会提升,`let` 提升了声明但没有赋值,因为临时死区导致了并不能在声明前使用。
对于非匿名的立即执行函数需要注意以下一点
```js
var foo = 1
(function foo() {
foo = 10
console.log(foo)
}()) // -> ƒ foo() { foo = 10 ; console.log(foo) }
```
因为当 JS 解释器在遇到非匿名的立即执行函数时,会创建一个辅助的特定对象,然后将函数名称作为这个对象的属性,因此函数内部才可以访问到 `foo`,但是这个值又是只读的,所以对它的赋值并不生效,所以打印的结果还是这个函数,并且外部的值也没有发生更改。
```js
specialObject = {};
Scope = specialObject + Scope;
foo = new FunctionExpression;
foo.[[Scope]] = Scope;
specialObject.foo = foo; // {DontDelete}, {ReadOnly}
delete Scope[0]; // remove specialObject from the front of scope chain
```
# 闭包
闭包的定义很简单:函数 A 返回了一个函数 B,并且函数 B 中使用了函数 A 的变量,函数 B 就被称为闭包。
```js
function A() {
let a = 1
function B() {
console.log(a)
}
return B
}
```
你是否会疑惑,为什么函数 A 已经弹出调用栈了,为什么函数 B 还能引用到函数 A 中的变量。因为函数 A 中的变量这时候是存储在堆上的。现在的 JS 引擎可以通过逃逸分析辨别出哪些变量需要存储在堆上,哪些需要存储在栈上。
经典面试题,循环中使用闭包解决 `var` 定义函数的问题
```Js
for ( var i=1; i<=5; i++) {
setTimeout( function timer() {
console.log( i );
}, i*1000 );
}
```
首先因为 `setTimeout` 是个异步函数,所有会先把循环全部执行完毕,这时候 `i` 就是 6 了,所以会输出一堆 6。
解决办法两种,第一种使用闭包
```js
for (var i = 1; i <= 5; i++) {
(function(j) {
setTimeout(function timer() {
console.log(j);
}, j * 1000);
})(i);
}
```
第二种就是使用 `setTimeout ` 的第三个参数
```js
for ( var i=1; i<=5; i++) {
setTimeout( function timer(j) {
console.log( j );
}, i*1000, i);
}
```
第三种就是使用 `let` 定义 `i` 了
```js
for ( let i=1; i<=5; i++) {
setTimeout( function timer() {
console.log( i );
}, i*1000 );
}
```
因为对于 `let` 来说,他会创建一个块级作用域,相当于
```js
{ // 形成块级作用域
let i = 0
{
let ii = i
setTimeout( function timer() {
console.log( ii );
}, i*1000 );
}
i++
{
let ii = i
}
i++
{
let ii = i
}
...
}
```
# 深浅拷贝
```js
let a = {
age: 1
}
let b = a
a.age = 2
console.log(b.age) // 2
```
从上述例子中我们可以发现,如果给一个变量赋值一个对象,那么两者的值会是同一个引用,其中一方改变,另一方也会相应改变。
通常在开发中我们不希望出现这样的问题,我们可以使用浅拷贝来解决这个问题。
## 浅拷贝
首先可以通过 `Object.assign` 来解决这个问题。
```js
let a = {
age: 1
}
let b = Object.assign({}, a)
a.age = 2
console.log(b.age) // 1
```
当然我们也可以通过展开运算符(…)来解决
```js
let a = {
age: 1
}
let b = {...a}
a.age = 2
console.log(b.age) // 1
```
通常浅拷贝就能解决大部分问题了,但是当我们遇到如下情况就需要使用到深拷贝了
```js
let a = {
age: 1,
jobs: {
first: 'FE'
}
}
let b = {...a}
a.jobs.first = 'native'
console.log(b.jobs.first) // native
```
浅拷贝只解决了第一层的问题,如果接下去的值中还有对象的话,那么就又回到刚开始的话题了,两者享有相同的引用。要解决这个问题,我们需要引入深拷贝。
## 深拷贝
这个问题通常可以通过 `JSON.parse(JSON.stringify(object))` 来解决。
```js
let a = {
age: 1,
jobs: {
first: 'FE'
}
}
let b = JSON.parse(JSON.stringify(a))
a.jobs.first = 'native'
console.log(b.jobs.first) // FE
```
但是该方法也是有局限性的:
- 会忽略 `undefined`
- 会忽略 `symbol`
- 不能序列化函数
- 不能解决循环引用的对象
```js
let obj = {
a: 1,
b: {
c: 2,
d: 3,
},
}
obj.c = obj.b
obj.e = obj.a
obj.b.c = obj.c
obj.b.d = obj.b
obj.b.e = obj.b.c
let newObj = JSON.parse(JSON.stringify(obj))
console.log(newObj)
```
如果你有这么一个循环引用对象,你会发现你不能通过该方法深拷贝

在遇到函数、 `undefined` 或者 `symbol` 的时候,该对象也不能正常的序列化
```js
let a = {
age: undefined,
sex: Symbol('male'),
jobs: function() {},
name: 'yck'
}
let b = JSON.parse(JSON.stringify(a))
console.log(b) // {name: "yck"}
```
你会发现在上述情况中,该方法会忽略掉函数和 `undefined` 。
但是在通常情况下,复杂数据都是可以序列化的,所以这个函数可以解决大部分问题,并且该函数是内置函数中处理深拷贝性能最快的。当然如果你的数据中含有以上三种情况下,可以使用 [lodash 的深拷贝函数](https://lodash.com/docs#cloneDeep)。
如果你所需拷贝的对象含有内置类型并且不包含函数,可以使用 `MessageChannel`
```js
function structuralClone(obj) {
return new Promise(resolve => {
const {port1, port2} = new MessageChannel();
port2.onmessage = ev => resolve(ev.data);
port1.postMessage(obj);
});
}
var obj = {a: 1, b: {
c: b
}}
// 注意该方法是异步的
// 可以处理 undefined 和循环引用对象
(async () => {
const clone = await structuralClone(obj)
})()
```
# 模块化
在有 Babel 的情况下,我们可以直接使用 ES6 的模块化
```js
// file a.js
export function a() {}
export function b() {}
// file b.js
export default function() {}
import {a, b} from './a.js'
import XXX from './b.js'
```
## CommonJS
`CommonJs` 是 Node 独有的规范,浏览器中使用就需要用到 `Browserify` 解析了。
```js
// a.js
module.exports = {
a: 1
}
// or
exports.a = 1
// b.js
var module = require('./a.js')
module.a // -> log 1
```
在上述代码中,`module.exports` 和 `exports` 很容易混淆,让我们来看看大致内部实现
```js
var module = require('./a.js')
module.a
// 这里其实就是包装了一层立即执行函数,这样就不会污染全局变量了,
// 重要的是 module 这里,module 是 Node 独有的一个变量
module.exports = {
a: 1
}
// 基本实现
var module = {
exports: {} // exports 就是个空对象
}
// 这个是为什么 exports 和 module.exports 用法相似的原因
var exports = module.exports
var load = function (module) {
// 导出的东西
var a = 1
module.exports = a
return module.exports
};
```
再来说说 `module.exports` 和 `exports`,用法其实是相似的,但是不能对 `exports` 直接赋值,不会有任何效果。
对于 `CommonJS` 和 ES6 中的模块化的两者区别是:
- 前者支持动态导入,也就是 `require(${path}/xx.js)`,后者目前不支持,但是已有提案
- 前者是同步导入,因为用于服务端,文件都在本地,同步导入即使卡住主线程影响也不大。而后者是异步导入,因为用于浏览器,需要下载文件,如果也采用同步导入会对渲染有很大影响
- 前者在导出时都是值拷贝,就算导出的值变了,导入的值也不会改变,所以如果想更新值,必须重新导入一次。但是后者采用实时绑定的方式,导入导出的值都指向同一个内存地址,所以导入值会跟随导出值变化
- 后者会编译成 `require/exports` 来执行的
## AMD
AMD 是由 `RequireJS` 提出的
```js
// AMD
define(['./a', './b'], function(a, b) {
a.do()
b.do()
})
define(function(require, exports, module) {
var a = require('./a')
a.doSomething()
var b = require('./b')
b.doSomething()
})
```
# 防抖
你是否在日常开发中遇到一个问题,在滚动事件中需要做个复杂计算或者实现一个按钮的防二次点击操作。
这些需求都可以通过函数防抖动来实现。尤其是第一个需求,如果在频繁的事件回调中做复杂计算,很有可能导致页面卡顿,不如将多次计算合并为一次计算,只在一个精确点做操作。
PS:防抖和节流的作用都是防止函数多次调用。区别在于,假设一个用户一直触发这个函数,且每次触发函数的间隔小于wait,防抖的情况下只会调用一次,而节流的 情况会每隔一定时间(参数wait)调用函数。
我们先来看一个袖珍版的防抖理解一下防抖的实现:
```js
// func是用户传入需要防抖的函数
// wait是等待时间
const debounce = (func, wait = 50) => {
// 缓存一个定时器id
let timer = 0
// 这里返回的函数是每次用户实际调用的防抖函数
// 如果已经设定过定时器了就清空上一次的定时器
// 开始一个新的定时器,延迟执行用户传入的方法
return function(...args) {
if (timer) clearTimeout(timer)
timer = setTimeout(() => {
func.apply(this, args)
}, wait)
}
}
// 不难看出如果用户调用该函数的间隔小于wait的情况下,上一次的时间还未到就被清除了,并不会执行函数
```
这是一个简单版的防抖,但是有缺陷,这个防抖只能在最后调用。一般的防抖会有immediate选项,表示是否立即调用。这两者的区别,举个栗子来说:
- 例如在搜索引擎搜索问题的时候,我们当然是希望用户输入完最后一个字才调用查询接口,这个时候适用`延迟执行`的防抖函数,它总是在一连串(间隔小于wait的)函数触发之后调用。
- 例如用户给interviewMap点star的时候,我们希望用户点第一下的时候就去调用接口,并且成功之后改变star按钮的样子,用户就可以立马得到反馈是否star成功了,这个情况适用`立即执行`的防抖函数,它总是在第一次调用,并且下一次调用必须与前一次调用的时间间隔大于wait才会触发。
下面我们来实现一个带有立即执行选项的防抖函数
```js
// 这个是用来获取当前时间戳的
function now() {
return +new Date()
}
/**
* 防抖函数,返回函数连续调用时,空闲时间必须大于或等于 wait,func 才会执行
*
* @param {function} func 回调函数
* @param {number} wait 表示时间窗口的间隔
* @param {boolean} immediate 设置为ture时,是否立即调用函数
* @return {function} 返回客户调用函数
*/
function debounce (func, wait = 50, immediate = true) {
let timer, context, args
// 延迟执行函数
const later = () => setTimeout(() => {
// 延迟函数执行完毕,清空缓存的定时器序号
timer = null
// 延迟执行的情况下,函数会在延迟函数中执行
// 使用到之前缓存的参数和上下文
if (!immediate) {
func.apply(context, args)
context = args = null
}
}, wait)
// 这里返回的函数是每次实际调用的函数
return function(...params) {
// 如果没有创建延迟执行函数(later),就创建一个
if (!timer) {
timer = later()
// 如果是立即执行,调用函数
// 否则缓存参数和调用上下文
if (immediate) {
func.apply(this, params)
} else {
context = this
args = params
}
// 如果已有延迟执行函数(later),调用的时候清除原来的并重新设定一个
// 这样做延迟函数会重新计时
} else {
clearTimeout(timer)
timer = later()
}
}
}
```
整体函数实现的不难,总结一下。
- 对于按钮防点击来说的实现:如果函数是立即执行的,就立即调用,如果函数是延迟执行的,就缓存上下文和参数,放到延迟函数中去执行。一旦我开始一个定时器,只要我定时器还在,你每次点击我都重新计时。一旦你点累了,定时器时间到,定时器重置为 `null`,就可以再次点击了。
- 对于延时执行函数来说的实现:清除定时器ID,如果是延迟调用就调用函数
# 节流
防抖动和节流本质是不一样的。防抖动是将多次执行变为最后一次执行,节流是将多次执行变成每隔一段时间执行。
```js
/**
* underscore 节流函数,返回函数连续调用时,func 执行频率限定为 次 / wait
*
* @param {function} func 回调函数
* @param {number} wait 表示时间窗口的间隔
* @param {object} options 如果想忽略开始函数的的调用,传入{leading: false}。
* 如果想忽略结尾函数的调用,传入{trailing: false}
* 两者不能共存,否则函数不能执行
* @return {function} 返回客户调用函数
*/
_.throttle = function(func, wait, options) {
var context, args, result;
var timeout = null;
// 之前的时间戳
var previous = 0;
// 如果 options 没传则设为空对象
if (!options) options = {};
// 定时器回调函数
var later = function() {
// 如果设置了 leading,就将 previous 设为 0
// 用于下面函数的第一个 if 判断
previous = options.leading === false ? 0 : _.now();
// 置空一是为了防止内存泄漏,二是为了下面的定时器判断
timeout = null;
result = func.apply(context, args);
if (!timeout) context = args = null;
};
return function() {
// 获得当前时间戳
var now = _.now();
// 首次进入前者肯定为 true
// 如果需要第一次不执行函数
// 就将上次时间戳设为当前的
// 这样在接下来计算 remaining 的值时会大于0
if (!previous && options.leading === false) previous = now;
// 计算剩余时间
var remaining = wait - (now - previous);
context = this;
args = arguments;
// 如果当前调用已经大于上次调用时间 + wait
// 或者用户手动调了时间
// 如果设置了 trailing,只会进入这个条件
// 如果没有设置 leading,那么第一次会进入这个条件
// 还有一点,你可能会觉得开启了定时器那么应该不会进入这个 if 条件了
// 其实还是会进入的,因为定时器的延时
// 并不是准确的时间,很可能你设置了2秒
// 但是他需要2.2秒才触发,这时候就会进入这个条件
if (remaining <= 0 || remaining > wait) {
// 如果存在定时器就清理掉否则会调用二次回调
if (timeout) {
clearTimeout(timeout);
timeout = null;
}
previous = now;
result = func.apply(context, args);
if (!timeout) context = args = null;
} else if (!timeout && options.trailing !== false) {
// 判断是否设置了定时器和 trailing
// 没有的话就开启一个定时器
// 并且不能不能同时设置 leading 和 trailing
timeout = setTimeout(later, remaining);
}
return result;
};
};
```
# 继承
在 ES5 中,我们可以使用如下方式解决继承的问题
```js
function Super() {}
Super.prototype.getNumber = function() {
return 1
}
function Sub() {}
let s = new Sub()
Sub.prototype = Object.create(Super.prototype, {
constructor: {
value: Sub,
enumerable: false,
writable: true,
configurable: true
}
})
```
以上继承实现思路就是将子类的原型设置为父类的原型
在 ES6 中,我们可以通过 `class` 语法轻松解决这个问题
```js
class MyDate extends Date {
test() {
return this.getTime()
}
}
let myDate = new MyDate()
myDate.test()
```
但是 ES6 不是所有浏览器都兼容,所以我们需要使用 Babel 来编译这段代码。
如果你使用编译过得代码调用 `myDate.test()` 你会惊奇地发现出现了报错

因为在 JS 底层有限制,如果不是由 `Date` 构造出来的实例的话,是不能调用 `Date` 里的函数的。所以这也侧面的说明了:**ES6 中的 `class` 继承与 ES5 中的一般继承写法是不同的**。
既然底层限制了实例必须由 `Date` 构造出来,那么我们可以改变下思路实现继承
```js
function MyData() {
}
MyData.prototype.test = function () {
return this.getTime()
}
let d = new Date()
Object.setPrototypeOf(d, MyData.prototype)
Object.setPrototypeOf(MyData.prototype, Date.prototype)
```
以上继承实现思路:**先创建父类实例** => 改变实例原先的 `_proto__` 转而连接到子类的 `prototype` => 子类的 `prototype` 的 `__proto__` 改为父类的 `prototype`。
通过以上方法实现的继承就可以完美解决 JS 底层的这个限制。
# call, apply, bind 区别
首先说下前两者的区别。
`call` 和 `apply` 都是为了解决改变 `this` 的指向。作用都是相同的,只是传参的方式不同。
除了第一个参数外,`call` 可以接收一个参数列表,`apply` 只接受一个参数数组。
```js
let a = {
value: 1
}
function getValue(name, age) {
console.log(name)
console.log(age)
console.log(this.value)
}
getValue.call(a, 'yck', '24')
getValue.apply(a, ['yck', '24'])
```
## 模拟实现 call 和 apply
可以从以下几点来考虑如何实现
- 不传入第一个参数,那么默认为 `window`
- 改变了 this 指向,让新的对象可以执行该函数。那么思路是否可以变成给新的对象添加一个函数,然后在执行完以后删除?
```js
Function.prototype.myCall = function (context) {
var context = context || window
// 给 context 添加一个属性
// getValue.call(a, 'yck', '24') => a.fn = getValue
context.fn = this
// 将 context 后面的参数取出来
var args = [...arguments].slice(1)
// getValue.call(a, 'yck', '24') => a.fn('yck', '24')
var result = context.fn(...args)
// 删除 fn
delete context.fn
return result
}
```
以上就是 `call` 的思路,`apply` 的实现也类似
```js
Function.prototype.myApply = function (context) {
var context = context || window
context.fn = this
var result
// 需要判断是否存储第二个参数
// 如果存在,就将第二个参数展开
if (arguments[1]) {
result = context.fn(...arguments[1])
} else {
result = context.fn()
}
delete context.fn
return result
}
```
`bind` 和其他两个方法作用也是一致的,只是该方法会返回一个函数。并且我们可以通过 `bind` 实现柯里化。
同样的,也来模拟实现下 `bind`
```js
Function.prototype.myBind = function (context) {
if (typeof this !== 'function') {
throw new TypeError('Error')
}
var _this = this
var args = [...arguments].slice(1)
// 返回一个函数
return function F() {
// 因为返回了一个函数,我们可以 new F(),所以需要判断
if (this instanceof F) {
return new _this(...args, ...arguments)
}
return _this.apply(context, args.concat(...arguments))
}
}
```
# Promise 实现
Promise 是 ES6 新增的语法,解决了回调地狱的问题。
可以把 Promise 看成一个状态机。初始是 `pending` 状态,可以通过函数 `resolve` 和 `reject` ,将状态转变为 `resolved` 或者 `rejected` 状态,状态一旦改变就不能再次变化。
`then` 函数会返回一个 Promise 实例,并且该返回值是一个新的实例而不是之前的实例。因为 Promise 规范规定除了 `pending` 状态,其他状态是不可以改变的,如果返回的是一个相同实例的话,多个 `then` 调用就失去意义了。
对于 `then` 来说,本质上可以把它看成是 `flatMap`
```js
// 三种状态
const PENDING = "pending";
const RESOLVED = "resolved";
const REJECTED = "rejected";
// promise 接收一个函数参数,该函数会立即执行
function MyPromise(fn) {
let _this = this;
_this.currentState = PENDING;
_this.value = undefined;
// 用于保存 then 中的回调,只有当 promise
// 状态为 pending 时才会缓存,并且每个实例至多缓存一个
_this.resolvedCallbacks = [];
_this.rejectedCallbacks = [];
_this.resolve = function (value) {
if (value instanceof MyPromise) {
// 如果 value 是个 Promise,递归执行
return value.then(_this.resolve, _this.reject)
}
setTimeout(() => { // 异步执行,保证执行顺序
if (_this.currentState === PENDING) {
_this.currentState = RESOLVED;
_this.value = value;
_this.resolvedCallbacks.forEach(cb => cb());
}
})
};
_this.reject = function (reason) {
setTimeout(() => { // 异步执行,保证执行顺序
if (_this.currentState === PENDING) {
_this.currentState = REJECTED;
_this.value = reason;
_this.rejectedCallbacks.forEach(cb => cb());
}
})
}
// 用于解决以下问题
// new Promise(() => throw Error('error))
try {
fn(_this.resolve, _this.reject);
} catch (e) {
_this.reject(e);
}
}
MyPromise.prototype.then = function (onResolved, onRejected) {
var self = this;
// 规范 2.2.7,then 必须返回一个新的 promise
var promise2;
// 规范 2.2.onResolved 和 onRejected 都为可选参数
// 如果类型不是函数需要忽略,同时也实现了透传
// Promise.resolve(4).then().then((value) => console.log(value))
onResolved = typeof onResolved === 'function' ? onResolved : v => v;
onRejected = typeof onRejected === 'function' ? onRejected : r => throw r;
if (self.currentState === RESOLVED) {
return (promise2 = new MyPromise(function (resolve, reject) {
// 规范 2.2.4,保证 onFulfilled,onRjected 异步执行
// 所以用了 setTimeout 包裹下
setTimeout(function () {
try {
var x = onResolved(self.value);
resolutionProcedure(promise2, x, resolve, reject);
} catch (reason) {
reject(reason);
}
});
}));
}
if (self.currentState === REJECTED) {
return (promise2 = new MyPromise(function (resolve, reject) {
setTimeout(function () {
// 异步执行onRejected
try {
var x = onRejected(self.value);
resolutionProcedure(promise2, x, resolve, reject);
} catch (reason) {
reject(reason);
}
});
}));
}
if (self.currentState === PENDING) {
return (promise2 = new MyPromise(function (resolve, reject) {
self.resolvedCallbacks.push(function () {
// 考虑到可能会有报错,所以使用 try/catch 包裹
try {
var x = onResolved(self.value);
resolutionProcedure(promise2, x, resolve, reject);
} catch (r) {
reject(r);
}
});
self.rejectedCallbacks.push(function () {
try {
var x = onRejected(self.value);
resolutionProcedure(promise2, x, resolve, reject);
} catch (r) {
reject(r);
}
});
}));
}
};
// 规范 2.3
function resolutionProcedure(promise2, x, resolve, reject) {
// 规范 2.3.1,x 不能和 promise2 相同,避免循环引用
if (promise2 === x) {
return reject(new TypeError("Error"));
}
// 规范 2.3.2
// 如果 x 为 Promise,状态为 pending 需要继续等待否则执行
if (x instanceof MyPromise) {
if (x.currentState === PENDING) {
x.then(function (value) {
// 再次调用该函数是为了确认 x resolve 的
// 参数是什么类型,如果是基本类型就再次 resolve
// 把值传给下个 then
resolutionProcedure(promise2, value, resolve, reject);
}, reject);
} else {
x.then(resolve, reject);
}
return;
}
// 规范 2.3.3.3.3
// reject 或者 resolve 其中一个执行过得话,忽略其他的
let called = false;
// 规范 2.3.3,判断 x 是否为对象或者函数
if (x !== null && (typeof x === "object" || typeof x === "function")) {
// 规范 2.3.3.2,如果不能取出 then,就 reject
try {
// 规范 2.3.3.1
let then = x.then;
// 如果 then 是函数,调用 x.then
if (typeof then === "function") {
// 规范 2.3.3.3
then.call(
x,
y => {
if (called) return;
called = true;
// 规范 2.3.3.3.1
resolutionProcedure(promise2, y, resolve, reject);
},
e => {
if (called) return;
called = true;
reject(e);
}
);
} else {
// 规范 2.3.3.4
resolve(x);
}
} catch (e) {
if (called) return;
called = true;
reject(e);
}
} else {
// 规范 2.3.4,x 为基本类型
resolve(x);
}
}
```
以上就是根据 Promise / A+ 规范来实现的代码,可以通过 `promises-aplus-tests` 的完整测试
# Generator 实现
Generator 是 ES6 中新增的语法,和 Promise 一样,都可以用来异步编程
```js
// 使用 * 表示这是一个 Generator 函数
// 内部可以通过 yield 暂停代码
// 通过调用 next 恢复执行
function* test() {
let a = 1 + 2;
yield 2;
yield 3;
}
let b = test();
console.log(b.next()); // > { value: 2, done: false }
console.log(b.next()); // > { value: 3, done: false }
console.log(b.next()); // > { value: undefined, done: true }
```
从以上代码可以发现,加上 `*` 的函数执行后拥有了 `next` 函数,也就是说函数执行后返回了一个对象。每次调用 `next` 函数可以继续执行被暂停的代码。以下是 Generator 函数的简单实现
```js
// cb 也就是编译过的 test 函数
function generator(cb) {
return (function() {
var object = {
next: 0,
stop: function() {}
};
return {
next: function() {
var ret = cb(object);
if (ret === undefined) return { value: undefined, done: true };
return {
value: ret,
done: false
};
}
};
})();
}
// 如果你使用 babel 编译后可以发现 test 函数变成了这样
function test() {
var a;
return generator(function(_context) {
while (1) {
switch ((_context.prev = _context.next)) {
// 可以发现通过 yield 将代码分割成几块
// 每次执行 next 函数就执行一块代码
// 并且表明下次需要执行哪块代码
case 0:
a = 1 + 2;
_context.next = 4;
return 2;
case 4:
_context.next = 6;
return 3;
// 执行完毕
case 6:
case "end":
return _context.stop();
}
}
});
}
```
# Map、FlatMap 和 Reduce
`Map` 作用是生成一个新数组,遍历原数组,将每个元素拿出来做一些变换然后 `append` 到新的数组中。
```js
[1, 2, 3].map((v) => v + 1)
// -> [2, 3, 4]
```
`Map` 有三个参数,分别是当前索引元素,索引,原数组
```js
['1','2','3'].map(parseInt)
// parseInt('1', 0) -> 1
// parseInt('2', 1) -> NaN
// parseInt('3', 2) -> NaN
```
`FlatMap` 和 `map` 的作用几乎是相同的,但是对于多维数组来说,会将原数组降维。可以将 `FlatMap` 看成是 `map` + `flatten` ,目前该函数在浏览器中还不支持。
```js
[1, [2], 3].flatMap((v) => v + 1)
// -> [2, 3, 4]
```
如果想将一个多维数组彻底的降维,可以这样实现
```js
const flattenDeep = (arr) => Array.isArray(arr)
? arr.reduce( (a, b) => [...a, ...flattenDeep(b)] , [])
: [arr]
flattenDeep([1, [[2], [3, [4]], 5]])
```
`Reduce` 作用是数组中的值组合起来,最终得到一个值
```js
function a() {
console.log(1);
}
function b() {
console.log(2);
}
[a, b].reduce((a, b) => a(b()))
// -> 2 1
```
# async 和 await
一个函数如果加上 `async` ,那么该函数就会返回一个 `Promise`
```js
async function test() {
return "1";
}
console.log(test()); // -> Promise {: "1"}
```
可以把 `async` 看成将函数返回值使用 `Promise.resolve()` 包裹了下。
`await` 只能在 `async` 函数中使用
```js
function sleep() {
return new Promise(resolve => {
setTimeout(() => {
console.log('finish')
resolve("sleep");
}, 2000);
});
}
async function test() {
let value = await sleep();
console.log("object");
}
test()
```
上面代码会先打印 `finish` 然后再打印 `object` 。因为 `await` 会等待 `sleep` 函数 `resolve` ,所以即使后面是同步代码,也不会先去执行同步代码再来执行异步代码。
`async 和 await` 相比直接使用 `Promise` 来说,优势在于处理 `then` 的调用链,能够更清晰准确的写出代码。缺点在于滥用 `await` 可能会导致性能问题,因为 `await` 会阻塞代码,也许之后的异步代码并不依赖于前者,但仍然需要等待前者完成,导致代码失去了并发性。
下面来看一个使用 `await` 的代码。
```js
var a = 0
var b = async () => {
a = a + await 10
console.log('2', a) // -> '2' 10
a = (await 10) + a
console.log('3', a) // -> '3' 20
}
b()
a++
console.log('1', a) // -> '1' 1
```
对于以上代码你可能会有疑惑,这里说明下原理
- 首先函数 `b` 先执行,在执行到 `await 10` 之前变量 `a` 还是 0,因为在 `await` 内部实现了 `generators` ,`generators` 会保留堆栈中东西,所以这时候 `a = 0` 被保存了下来
- 因为 `await` 是异步操作,遇到`await`就会立即返回一个`pending`状态的`Promise`对象,暂时返回执行代码的控制权,使得函数外的代码得以继续执行,所以会先执行 `console.log('1', a)`
- 这时候同步代码执行完毕,开始执行异步代码,将保存下来的值拿出来使用,这时候 `a = 10`
- 然后后面就是常规执行代码了
# Proxy
Proxy 是 ES6 中新增的功能,可以用来自定义对象中的操作
```js
let p = new Proxy(target, handler);
// `target` 代表需要添加代理的对象
// `handler` 用来自定义对象中的操作
```
可以很方便的使用 Proxy 来实现一个数据绑定和监听
```js
let onWatch = (obj, setBind, getLogger) => {
let handler = {
get(target, property, receiver) {
getLogger(target, property)
return Reflect.get(target, property, receiver);
},
set(target, property, value, receiver) {
setBind(value);
return Reflect.set(target, property, value);
}
};
return new Proxy(obj, handler);
};
let obj = { a: 1 }
let value
let p = onWatch(obj, (v) => {
value = v
}, (target, property) => {
console.log(`Get '${property}' = ${target[property]}`);
})
p.a = 2 // bind `value` to `2`
p.a // -> Get 'a' = 2
```
# 为什么 0.1 + 0.2 != 0.3
因为 JS 采用 IEEE 754 双精度版本(64位),并且只要采用 IEEE 754 的语言都有该问题。
我们都知道计算机表示十进制是采用二进制表示的,所以 `0.1` 在二进制表示为
```js
// (0011) 表示循环
0.1 = 2^-4 * 1.10011(0011)
```
那么如何得到这个二进制的呢,我们可以来演算下
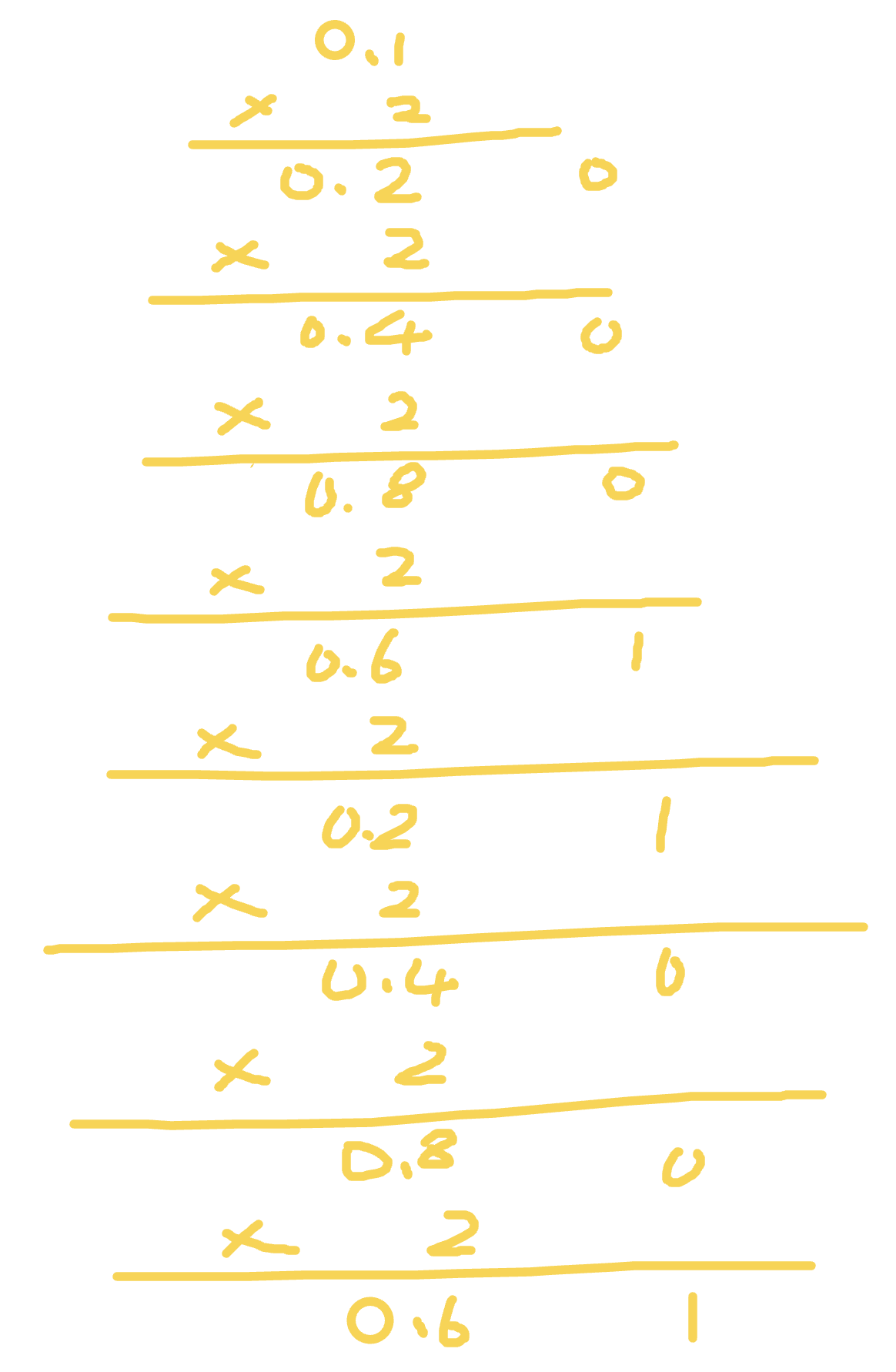
小数算二进制和整数不同。乘法计算时,只计算小数位,整数位用作每一位的二进制,并且得到的第一位为最高位。所以我们得出 `0.1 = 2^-4 * 1.10011(0011)`,那么 `0.2` 的演算也基本如上所示,只需要去掉第一步乘法,所以得出 `0.2 = 2^-3 * 1.10011(0011)`。
回来继续说 IEEE 754 双精度。六十四位中符号位占一位,整数位占十一位,其余五十二位都为小数位。因为 `0.1` 和 `0.2` 都是无限循环的二进制了,所以在小数位末尾处需要判断是否进位(就和十进制的四舍五入一样)。
所以 `2^-4 * 1.10011...001` 进位后就变成了 `2^-4 * 1.10011(0011 * 12次)010` 。那么把这两个二进制加起来会得出 `2^-2 * 1.0011(0011 * 11次)0100` , 这个值算成十进制就是 `0.30000000000000004`
下面说一下原生解决办法,如下代码所示
```js
parseFloat((0.1 + 0.2).toFixed(10))
```
# 正则表达式
## 元字符
| 元字符 | 作用 |
| :----: | :----------------------------------------------------------: |
| . | 匹配任意字符除了换行符和回车符 |
| [] | 匹配方括号内的任意字符。比如 [0-9] 就可以用来匹配任意数字 |
| ^ | ^9,这样使用代表匹配以 9 开头。[`^`9],这样使用代表不匹配方括号内除了 9 的字符 |
| {1, 2} | 匹配 1 到 2 位字符 |
| (yck) | 只匹配和 yck 相同字符串 |
| \| | 匹配 \| 前后任意字符 |
| \ | 转义 |
| * | 只匹配出现 0 次及以上 * 前的字符 |
| + | 只匹配出现 1 次及以上 + 前的字符 |
| ? | ? 之前字符可选 |
## 修饰语
| 修饰语 | 作用 |
| :----: | :--------: |
| i | 忽略大小写 |
| g | 全局搜索 |
| m | 多行 |
## 字符简写
| 简写 | 作用 |
| :--: | :------------------: |
| \w | 匹配字母数字或下划线 |
| \W | 和上面相反 |
| \s | 匹配任意的空白符 |
| \S | 和上面相反 |
| \d | 匹配数字 |
| \D | 和上面相反 |
| \b | 匹配单词的开始或结束 |
| \B | 和上面相反 |
# V8 下的垃圾回收机制
V8 实现了准确式 GC,GC 算法采用了分代式垃圾回收机制。因此,V8 将内存(堆)分为新生代和老生代两部分。
## 新生代算法
新生代中的对象一般存活时间较短,使用 Scavenge GC 算法。
在新生代空间中,内存空间分为两部分,分别为 From 空间和 To 空间。在这两个空间中,必定有一个空间是使用的,另一个空间是空闲的。新分配的对象会被放入 From 空间中,当 From 空间被占满时,新生代 GC 就会启动了。算法会检查 From 空间中存活的对象并复制到 To 空间中,如果有失活的对象就会销毁。当复制完成后将 From 空间和 To 空间互换,这样 GC 就结束了。
## 老生代算法
老生代中的对象一般存活时间较长且数量也多,使用了两个算法,分别是标记清除算法和标记压缩算法。
在讲算法前,先来说下什么情况下对象会出现在老生代空间中:
- 新生代中的对象是否已经经历过一次 Scavenge 算法,如果经历过的话,会将对象从新生代空间移到老生代空间中。
- To 空间的对象占比大小超过 25 %。在这种情况下,为了不影响到内存分配,会将对象从新生代空间移到老生代空间中。
老生代中的空间很复杂,有如下几个空间
```c++
enum AllocationSpace {
// TODO(v8:7464): Actually map this space's memory as read-only.
RO_SPACE, // 不变的对象空间
NEW_SPACE, // 新生代用于 GC 复制算法的空间
OLD_SPACE, // 老生代常驻对象空间
CODE_SPACE, // 老生代代码对象空间
MAP_SPACE, // 老生代 map 对象
LO_SPACE, // 老生代大空间对象
NEW_LO_SPACE, // 新生代大空间对象
FIRST_SPACE = RO_SPACE,
LAST_SPACE = NEW_LO_SPACE,
FIRST_GROWABLE_PAGED_SPACE = OLD_SPACE,
LAST_GROWABLE_PAGED_SPACE = MAP_SPACE
};
```
在老生代中,以下情况会先启动标记清除算法:
- 某一个空间没有分块的时候
- 空间中被对象超过一定限制
- 空间不能保证新生代中的对象移动到老生代中
在这个阶段中,会遍历堆中所有的对象,然后标记活的对象,在标记完成后,销毁所有没有被标记的对象。在标记大型对内存时,可能需要几百毫秒才能完成一次标记。这就会导致一些性能上的问题。为了解决这个问题,2011 年,V8 从 stop-the-world 标记切换到增量标志。在增量标记期间,GC 将标记工作分解为更小的模块,可以让 JS 应用逻辑在模块间隙执行一会,从而不至于让应用出现停顿情况。但在 2018 年,GC 技术又有了一个重大突破,这项技术名为并发标记。该技术可以让 GC 扫描和标记对象时,同时允许 JS 运行,你可以点击 [该博客](https://v8project.blogspot.com/2018/06/concurrent-marking.html) 详细阅读。
清除对象后会造成堆内存出现碎片的情况,当碎片超过一定限制后会启动压缩算法。在压缩过程中,将活的对象像一端移动,直到所有对象都移动完成然后清理掉不需要的内存。
================================================
FILE: JS/JS-en.md
================================================
**Table of Contents** *generated with [DocToc](https://github.com/thlorenz/doctoc)*
- [Built-in Types](#built-in-types)
- [Type Conversion](#type-conversion)
- [Converting to Boolean](#converting-to-boolean)
- [Objects to Primitive Types](#objects-to-primitive-types)
- [Arithmetic Operators](#arithmetic-operators)
- [`==` operator](#-operator)
- [Comparison Operator](#comparison-operator)
- [Typeof](#typeof)
- [New](#new)
- [This](#this)
- [Instanceof](#instanceof)
- [Scope](#scope)
- [Closure](#closure)
- [Prototypes](#prototypes)
- [Inheritance](#inheritance)
- [Deep and Shallow Copy](#deep-and-shallow-copy)
- [Shallow copy](#shallow-copy)
- [Deep copy](#deep-copy)
- [Modularization](#modularization)
- [CommonJS](#commonjs)
- [AMD](#amd)
- [The differences between call, apply, bind](#the-differences-between-call-apply-bind)
- [simulation to implement `call` and `apply`](#simulation-to-implement--call-and--apply)
- [Promise implementation](#promise-implementation)
- [Generator Implementation](#generator-implementation)
- [Debouncing](#debouncing)
- [Throttle](#throttle)
- [Map、FlatMap and Reduce](#mapflatmap-and-reduce)
- [Async and await](#async-and-await)
- [Proxy](#proxy)
- [Why 0.1 + 0.2 != 0.3](#why-01--02--03)
- [Regular Expressions](#regular-expressions)
- [Metacharacters](#metacharacters)
- [Flags](#flags)
- [Character Shorthands](#character-shorthands)
# Built-in Types
JavaScript defines seven built-in types, which can be broken down into two categories: `Primitive Type` and `Object`.
There are six primitive types: `null`, `undefined`, `boolean`, `number`, `string` and `symbol `.
In JavaScript, there are no true integers, all numbers are implemented in double-precision 64-bit binary format IEEE 754. When we use binary floating-point numbers, it will have some side effects. Here is an example of these side effects.
```js
0.1 + 0.2 == 0.3 // false
```
For the primitive data types, when we use literals to initialize a variable, the variable only has the literals as its value, it doesn’t have a type. It will be converted to the corresponding type only when necessary.
```js
let a = 111 // only literals, not a number
a.toString() // converted to object when necessary
```
Object is a reference type. We will encouter problems about shallow copy and deep copy when using it.
```js
let a = { name: 'FE' }
let b = a
b.name = 'EF'
console.log(a.name) // EF
```
# Type Conversion
## Converting to Boolean
When the condition is judged, other than `undefined`, `null`, `false`, `NaN`, `''`, `0`, `-0`, all of the values, including objects, are converted to `true`.
## Objects to Primitive Types
When objects are converted, `valueOf` and `toString` will be called, respectively in order. These two methods can also be overridden.
```js
let a = {
valueOf() {
return 0
}
}
```
## Arithmetic Operators
Only for additions, if one of the parameters is a string, the other one will be converted to string as well. For all other operations, as long as one of the parameters is a number, the other one will be converted to a number.
Additions will invoke three types of type conversions: to primitive types, to numbers and to string:
```js
1 + '1' // '11'
2 * '2' // 4
[1, 2] + [2, 1] // '1,22,1'
// [1, 2].toString() -> '1,2'
// [2, 1].toString() -> '2,1'
// '1,2' + '2,1' = '1,22,1'
```
Note the expression `'a' + + 'b'` for addition:
```js
'a' + + 'b' // -> "aNaN"
// since + 'b' -> NaN
// You might have seen + '1' -> 1
```
## `==` operator

`toPrimitive` in above figure is converting objects to primitive types.
`===` is usually recommended to compare values. However, if you would like to check for `null` value, you can use `xx == null`.
Let's take a look at an example `[] == ![] // -> true`. The following process explains why the expression evaluates to `true`:
```js
// [] converting to true, then take the opposite to false
[] == false
// with #8
[] == ToNumber(false)
[] == 0
// with #10
ToPrimitive([]) == 0
// [].toString() -> ''
'' == 0
// with #6
0 == 0 // -> true
```
## Comparison Operator
1. If it's an object, `toPrimitive` is used.
2. If it's a string, `unicode` character index is used.
# Typeof
`typeof` can always display the correct type of primitive types, except `null`:
```js
typeof 1 // 'number'
typeof '1' // 'string'
typeof undefined // 'undefined'
typeof true // 'boolean'
typeof Symbol() // 'symbol'
typeof b // b is not declared,but it still can be displayed as undefined
```
For object, `typeof` will always display `object`, except **function**:
```js
typeof [] // 'object'
typeof {} // 'object'
typeof console.log // 'function'
```
As for `null`, it is always be treated as an `object` by `typeof`,although it is a primitive data type, and this is a bug that has been around for a long time.
```js
typeof null // 'object'
```
Why does this happen? Because the initial version of JS was based on 32-bit systems, which stored type information of variables in the lower bits for performance considerations. Those start with `000` are objects, and all the bits of `null` are zero, so it is erroneously treated as an object. Although the current code of checking internal types has changed, this bug has been passed down.
We can use `Object.prototype.toString.call(xx)` if we want to get the correct data type of a variable, and then we can get a string like `[object Type]`:
```js
let a
// We can also judge `undefined` like this
a === undefined
// But the nonreserved word `undefined` can be re-assigned in a lower version browser
let undefined = 1
// it will go wrong to judge like this
// So we can use the following method, with less code
// it will always return `undefined`, whatever follows `void `
a === void 0
```
# New
1. Create a new object
2. Chained to prototype
3. Bind this
4. Return a new object
The above four steps will happen in the process of calling `new`. We can also try to implement `new ` by ourselves:
```js
function create() {
// Create an empty object
let obj = new Object()
// Get the constructor
let Ctor = [].shift.call(arguments)
// Chained to prototype
obj.__proto__ = Ctor.prototype
// Bind this, Execute the constructor
let result = Con.apply(obj, arguments)
// Make sure the new one is an object
return typeof result === 'object'? result : obj
}
```
Instances of object are all created with `new`, whether it's `function Foo()` , or `let a = { b: 1 }` .
It is recommended to create objects using the literal notation (whether it's for performance or readability), since a look-up is needed for `Object` through the scope chain when creating an object using `new Object()`, but you don't have this kind of problem when using literals.
```js
function Foo() {}
// Function is a syntactic sugar
// Internally equivalent to new Function()
let a = { b: 1 }
// Inside this literal, `new Object()` is also used
```
For `new`, we also need pay attention to the operator precedence:
```js
function Foo() {
return this;
}
Foo.getName = function () {
console.log('1');
};
Foo.prototype.getName = function () {
console.log('2');
};
new Foo.getName(); // -> 1
new Foo().getName(); // -> 2
```
As you can see from the above image, `new Foo()` has a higher priority than `new Foo`, so we can divide the execution order of the above code like this:
```js
new (Foo.getName());
(new Foo()).getName();
```
For the first function, `Foo.getName()` is executed first, so the result is 1;
As for the latter, it first executes `new Foo()` to create an instance, then finds the `getName` function on `Foo` via the prototype chain, so the result is 2.
# This
`This`, a concept that is confusing to many people, is actually not difficult to understand as long as you remember the following rules:
```js
function foo() {
console.log(this.a);
}
var a = 1;
foo();
var obj = {
a: 2,
foo: foo
};
obj.foo();
// In the above two situations, `this` only depends on the object before calling the function,
// and the second case has higher priority than the first case .
// the following scenario has the highest priority,`this` will only be bound to c,
// and there's no way to change what `this` is bound to .
var c = new foo();
c.a = 3;
console.log(c.a);
// finally, using `call`, `apply`, `bind` to change what `this` is bound to,
// is another scenario where its priority is only second to `new`
```
Understanding the above several situations, we won’t be confused by `this` under most circumstances. Next, let’s take a look at `this` in arrow functions:
```js
function a() {
return () => {
return () => {
console.log(this);
};
};
}
console.log(a()()());
```
Actually, the arrow function does not have `this`, `this` in the above function only depends on the first outer function that is not an arrow function. For this case, `this` is default to `window` because calling `a` matches the first condition in the above codes. Also, what `this` is bound to will not be changed by any codes once `this` is bound to the context.
# Instanceof
The `instanceof` operator can correctly check the type of objects, because its internal mechanism is to find out if `prototype` of this type can be found in the prototype chain of the object.
let’s try to implement it:
```js
function instanceof(left, right) {
// get the `prototype` of the type
let prototype = right.prototype
// get the `prototype` of the object
left = left.__proto__
// check if the type of the object is equal to the prototype of the type
while (true) {
if (left === null)
return false
if (prototype === left)
return true
left = left.__proto__
}
}
```
# Scope
Executing JS code would generate execution context, as long as code is not written in a function, it belongs to the global execution context. Code in a function will generate function execution context. There’s also an `eval` execution context, which basically is not used anymore, so you can think of only two execution contexts.
The `[[Scope]]` attribute is generated in the first stage of generating execution context, which is a pointer, corresponds to the linked list of the scope, and JS will look up variables through this linked list up to the global context.
Let's look at a common example , `var`:
```js
b() // call b
console.log(a) // undefined
var a = 'Hello world'
function b() {
console.log('call b')
}
```
It’s known that function and variable hoisting is the real reason for the above outputs. The usual explanation for hoisting says that the declarations are ‘moved’ to the top of the code, and there is nothing wrong with that and it’s easy for everyone to understand. But a more accurate explanation should be something like this:
There would be two stages when the execution context is generated. The first stage is the stage of creation(to be specific, the step of generating variable objects), in which the JS interpreter would find out variables and functions that need to be hoisted, and allocate memory for them in advance, then functions would be stored into memory entirely, but variables would only be declared and assigned to `undefined`, therefore, we can use them in advance in the second stage (the code execution stage).
In the process of hoisting, the same function would overwrite the last function, and functions have higher priority than variables hoisting.
```js
b() // call b second
function b() {
console.log('call b fist')
}
function b() {
console.log('call b second')
}
var b = 'Hello world'
```
Using `var` is more likely error-prone, thus ES6 introduces a new keyword `let`. `let` has an important feature that it can’t be used before declared, which conflicts the common saying that `let` doesn’t have the ability of hoisting. In fact, `let` hoists declaration, but is not assigned, because the **temporal dead zone**.
# Closure
The definition of closure is simple: function A returns a function B, and function B can access variables of function A, thus function B is called a closure.
```js
function A() {
let a = 1
function B() {
console.log(a)
}
return B
}
```
Are you wondering why function B can also refer to variables in function A while function A has been popped up from the call stack? Because variables in function A are stored on the heap at this time. The current JS engine can identify which variables need to be stored on the heap and which need to be stored on the stack by escape analysis.
A classic interview question is using closures in loops to solve the problem of using `var` to define functions:
```js
for ( var i=1; i<=5; i++) {
setTimeout( function timer() {
console.log( i );
}, i*1000 );
)
```
First of all, all loops will be executed completely because `setTimeout` is an asynchronous function, and at that time `i` is 6, so it will print a bunch of 6.
There are three solutions,closure is the first one:
```js
for (var i = 1; i <= 5; i++) {
(function(j) {
setTimeout(function timer() {
console.log(j);
}, j * 1000);
})(i);
}
```
The second one is to make use of the third parameter of `setTimeout`:
```js
for ( var i=1; i<=5; i++) {
setTimeout( function timer(j) {
console.log( j );
}, i*1000, i);
}
```
The third is to define `i` using `let`:
```js
for ( let i=1; i<=5; i++) {
setTimeout( function timer() {
console.log( i );
}, i*1000 );
}
```
For `let`, it will create a block-level scope, which is equivalent to:
```js
{
// Form block-level scope
let i = 0
{
let ii = i
setTimeout( function timer() {
console.log( i );
}, i*1000 );
}
i++
{
let ii = i
}
i++
{
let ii = i
}
...
}
```
# Prototypes
Each function, besides `Function.prototype.bind()`, has an internal property, denoted as `prototype`, which is a reference to the prototype.
Each object has an internal property, denoted as `__proto__`, which is a reference to the prototype of the constructor that creates the object. This property actually refers to `[[prototype]]`, but `[[prototype]]` is an internal property that we can’t access, so we use `__proto__` to access it.
Objects can use `__proto__` to look up properties that do not belong to the object, and `__proto__` connects objects together to form a prototype chain.
# Inheritance
In ES5, we can solve the problems of inheritance by using the following ways:
```js
function Super() {}
Super.prototype.getNumber = function() {
return 1
}
function Sub() {}
let s = new Sub()
Sub.prototype = Object.create(Super.prototype, {
constructor: {
value: Sub,
enumerable: false,
writable: true,
configurable: true
}
})
```
The above idea of inheritance implementation is to set the `prototype` of the child class as the `prototype` of the parent class.
In ES6, we can easily solve this problem with the `class` syntax:
```js
class MyDate extends Date {
test() {
return this.getTime()
}
}
let myDate = new MyDate()
myDate.test()
```
However, ES6 is not compatible with all browsers, so we need to use Babel to compile this code.
If call `myDate.test()` with compiled code, you’ll be surprised to see that there’s an error:

Because there are restrictions on the low-level of JS, if the instance isn’t constructed by `Date`, it can’t call functions in `Date`, which also explains from another aspect that `Class` inheritance in ES6 is different from the general inheritance in ES5 syntax.
Since the low-level of JS limits that the instance must be constructed by `Date` , we can try another way to implement inheritance:
```js
function MyData() {
}
MyData.prototype.test = function () {
return this.getTime()
}
let d = new Date()
Object.setPrototypeOf(d, MyData.prototype)
Object.setPrototypeOf(MyData.prototype, Date.prototype)
```
The implementation idea of the above inheritance: first create the instance of parent class => change the original `__proto__` of the instance, connect it to the `prototype` of child class => change the `__proto__` of child class’s `prototype` to the `prototype` of parent class.
The inheritance implement with the above method can perfectly solve the restriction on low-level of JS.
# Deep and Shallow Copy
```js
let a = {
age: 1
}
let b = a
a.age = 2
console.log(b.age) // 2
```
From the above example, we can see that if you assign an object to a variable, then the values of both will be the same reference, one changes, the other changes accordingly.
Usually, we don't want such problem to appear during development, thus we can use shallow copy to solve this problem.
## Shallow copy
Firstly we can solve the problem by `Object.assign`:
```js
let a = {
age: 1
}
let b = Object.assign({}, a)
a.age = 2
console.log(b.age) // 1
```
Certainly, we can use the spread operator (...) to solve the problem:
```js
let a = {
age: 1
}
let b = {...a}
a.age = 2
console.log(b.age) // 1
```
Usually, shallow copy can solve most problems, but we need deep copy when encountering the following situation:
```js
let a = {
age: 1,
jobs: {
first: 'FE'
}
}
let b = {...a}
a.jobs.first = 'native'
console.log(b.jobs.first) // native
```
The shallow copy only solves the problem of the first layer. If the object contains objects, then it returns to the beginning topic that both values share the same reference. To solve this problem, we need to introduce deep copy.
## Deep copy
The problem can usually be solved by `JSON.parse(JSON.stringify(object))`
```js
let a = {
age: 1,
jobs: {
first: 'FE'
}
}
let b = JSON.parse(JSON.stringify(a))
a.jobs.first = 'native'
console.log(b.jobs.first) // FE
```
But this method also has its limits:
* ignore `undefined`
* ignore `symbol`
* unable to serialize function
* unable to resolve circular references in an object
```js
let obj = {
a: 1,
b: {
c: 2,
d: 3,
},
}
obj.c = obj.b
obj.e = obj.a
obj.b.c = obj.c
obj.b.d = obj.b
obj.b.e = obj.b.c
let newObj = JSON.parse(JSON.stringify(obj))
console.log(newObj)
```
If an object is circularly referenced like the above example, you’ll find the method `JSON.parse(JSON.stringify(object))` can’t make a deep copy of this object:

When dealing with function, `undefined` or `symbol`, the object can also not be serialized properly.
```js
let a = {
age: undefined,
sex: Symbol('male'),
jobs: function() {},
name: 'yck'
}
let b = JSON.parse(JSON.stringify(a))
console.log(b) // {name: "yck"}
```
In above case, you can see that the method ignores function and `undefined`.
Most often complex data can be serialized, so this method can solve most problems, and as a built-in function, it has the fastest performance when dealing with deep copy. Certainly, you can use [the deep copy function of `lodash` ](https://lodash.com/docs#cloneDeep) when your data contains the above three cases.
If the object you want to copy contains a built-in type but doesn’t contain a function, you can use `MessageChannel`
```js
function structuralClone(obj) {
return new Promise(resolve => {
const {port1, port2} = new MessageChannel();
port2.onmessage = ev => resolve(ev.data);
port1.postMessage(obj);
});
}
var obj = {a: 1, b: {
c: b
}}
// pay attention that this method is asynchronous
// it can handle `undefined` and circular reference object
(async () => {
const clone = await structuralClone(obj)
})()
```
# Modularization
With Babel, we can directly use ES6's modularization:
```js
// file a.js
export function a() {}
export function b() {}
// file b.js
export default function() {}
import {a, b} from './a.js'
import XXX from './b.js'
```
## CommonJS
`CommonJS` is Node's unique feature. `Browserify` is needed for `CommonJS` to be used in browsers.
```js
// a.js
module.exports = {
a: 1
}
// or
exports.a = 1
// b.js
var module = require('./a.js')
module.a // -> log 1
```
In the code above, `module.exports` and `exports` can cause confusions. Let us take a peek at the internal implementations:
```js
var module = require('./a.js')
module.a
// this is actually a wrapper of a function to be executed immediately so that we don't mess up the global variables.
// what's important here is that module is a Node only variable.
module.exports = {
a: 1
}
// basic implementation
var module = {
exports: {} // exports is an empty object
}
// This is why exports and module.exports have similar usage.
var exports = module.exports
var load = function (module) {
// to be exported
var a = 1
module.exports = a
return module.exports
};
```
Let's then talk about `module.exports` and `exports`, which have similar usage, but one cannot assign a value to `exports` directly. The assignment would be a no-op.
The differences between the modularizations in `CommonJS` and in ES6 are:
- The former supports dynamic imports, which is `require(${path}/xx.js)`; the latter doesn't support it yet, but there have been proposals.
- The former uses synchronous imports. Since it is used on the server end and files are local, it doesn't matter much even if the synchronous imports block the main thread. The latter uses asynchronous imports, because it is used in browsers in which file downloads are needed. Rendering process would be affected much if synchronous import was used.
- The former copies the values when exporting. Even if the values exported change, the values imported will not change. Therefore, if values shall be updated, another import needs to happen. However, the latter uses realtime bindings, the values imported and exported point to the same memory addresses, so the imported values change along with the exported ones.
- In execution the latter is compiled to `require/exports`.
## AMD
AMD is brought forward by `RequireJS`.
```js
// AMD
define(['./a', './b'], function(a, b) {
a.do()
b.do()
})
define(function(require, exports, module) {
var a = require('./a')
a.doSomething()
var b = require('./b')
b.doSomething()
})
```
# The differences between call, apply, bind
Firstly, let’s tell the difference between the former two.
Both `call` and `apply` are used to change what `this` refers to. Their role is the same, but the way to pass parameters is different.
In addition to the first parameter, `call` can accept an argument list, while `apply` accepts a single array of arguments.
```js
let a = {
value: 1
}
function getValue(name, age) {
console.log(name)
console.log(age)
console.log(this.value)
}
getValue.call(a, 'yck', '24')
getValue.apply(a, ['yck', '24'])
```
## simulation to implement `call` and `apply`
We can consider how to implement them from the following rules:
* If the first parameter isn’t passed, then the first parameter will default to `window`;
* Change what `this` refers to, which makes new object capable of executing the function. Then let’s think like this: add a function to a new object and then delete it after the execution.
```js
Function.prototype.myCall = function (context) {
var context = context || window
// Add an property to the `context`
// getValue.call(a, 'yck', '24') => a.fn = getValue
context.fn = this
// take out the rest parameters of `context`
var args = [...arguments].slice(1)
// getValue.call(a, 'yck', '24') => a.fn('yck', '24')
var result = context.fn(...args)
// delete fn
delete context.fn
return result
}
```
The above is the main idea of simulating `call`, and the implementation of `apply` is similar.
```js
Function.prototype.myApply = function (context) {
var context = context || window
context.fn = this
var result
// There's a need to determine whether to store the second parameter
// If the second parameter exists, spread it
if (arguments[1]) {
result = context.fn(...arguments[1])
} else {
result = context.fn()
}
delete context.fn
return result
}
```
The role of `bind` is the same as the other two, except that it returns a function. And we can implement currying with `bind`
let’s simulate `bind`:
```js
Function.prototype.myBind = function (context) {
if (typeof this !== 'function') {
throw new TypeError('Error')
}
var _this = this
var args = [...arguments].slice(1)
// return a function
return function F() {
// we can use `new F()` because it returns a function, so we need to determine
if (this instanceof F) {
return new _this(...args, ...arguments)
}
return _this.apply(context, args.concat(...arguments))
}
}
```
# Promise implementation
`Promise` is a new syntax introduced by ES6, which resolves the problem of callback hell.
Promise can be seen as a state machine and it's initial state is `pending`. We can change the state to `resolved` or `rejected` by using the `resolve` and `reject` functions. Once the state is changed, it cannot be changed again.
The function `then` returns a Promise instance, which is a new instance instead of the previous one. And that's because the Promise specification states that in addition to the `pending` state, other states cannot be changed, and multiple calls of function `then` will be meaningless if the same instance is returned.
For `then`, it can essentially be seen as `flatMap`:
```js
// three states
const PENDING = 'pending';
const RESOLVED = 'resolved';
const REJECTED = 'rejected';
// promise accepts a function argument that will execute immediately.
function MyPromise(fn) {
let _this = this;
_this.currentState = PENDING;
_this.value = undefined;
// To save the callback of `then`,only cached when the state of the promise is pending,
// at most one will be cached in every instance
_this.resolvedCallbacks = [];
_this.rejectedCallbacks = [];
_this.resolve = function(value) {
// execute asynchronously to guarantee the execution order
setTimeout(() => {
if (value instanceof MyPromise) {
// if value is a Promise, execute recursively
return value.then(_this.resolve, _this.reject)
}
if (_this.currentState === PENDING) {
_this.currentState = RESOLVED;
_this.value = value;
_this.resolvedCallbacks.forEach(cb => cb());
}
})
}
_this.reject = function(reason) {
// execute asynchronously to guarantee the execution order
setTimeout(() => {
if (_this.currentState === PENDING) {
_this.currentState = REJECTED;
_this.value = reason;
_this.rejectedCallbacks.forEach(cb => cb());
}
})
}
// to solve the following problem
// `new Promise(() => throw Error('error))`
try {
fn(_this.resolve, _this.reject);
} catch (e) {
_this.reject(e);
}
}
MyPromise.prototype.then = function(onResolved, onRejected) {
const self = this;
// specification 2.2.7, `then` must return a new promise
let promise2;
// specification 2.2, both `onResolved` and `onRejected` are optional arguments
// it should be ignored if `onResolved` or `onRjected` is not a function,
// which implements the penetrate pass of it's value
// `Promise.resolve(4).then().then((value) => console.log(value))`
onResolved = typeof onResolved === 'function' ? onResolved : v => v;
onRejected = typeof onRejected === 'function' ? onRejected : r => throw r;
if (self.currentState === RESOLVED) {
return (promise2 = new MyPromise((resolve, reject) => {
// specification 2.2.4, wrap them with `setTimeout`,
// in order to insure that `onFulfilled` and `onRjected` execute asynchronously
setTimeout(() => {
try {
let x = onResolved(self.value);
resolutionProcedure(promise2, x, resolve, reject);
} catch (reason) {
reject(reason);
}
});
}));
}
if (self.currentState === REJECTED) {
return (promise2 = new MyPromise((resolve, reject) => {
// execute `onRejected` asynchronously
setTimeout(() => {
try {
let x = onRejected(self.value);
resolutionProcedure(promise2, x, resolve, reject);
} catch (reason) {
reject(reason);
}
});
}))
}
if (self.currentState === PENDING) {
return (promise2 = new MyPromise((resolve, reject) => {
self.resolvedCallbacks.push(() => {
// Considering that it may throw error, wrap them with `try/catch`
try {
let x = onResolved(self.value);
resolutionProcedure(promise2, x, resolve, reject);
} catch (r) {
reject(r);
}
});
self.rejectedCallbacks.push(() => {
try {
let x = onRejected(self.value);
resolutionProcedure(promise2, x, resolve, reject);
} catch (r) {
reject(r);
}
})
}))
}
}
// specification 2.3
function resolutionProcedure(promise2, x, resolve, reject) {
// specification 2.3.1,`x` and `promise2` can't refer to the same object,
// avoiding the circular references
if (promise2 === x) {
return reject(new TypeError('Error'));
}
// specification 2.3.2, if `x` is a Promise and the state is `pending`,
// the promise must remain, If not, it should execute.
if (x instanceof MyPromise) {
if (x.currentState === PENDING) {
// call the function `resolutionProcedure` again to
// confirm the type of the argument that x resolves
// If it's a primitive type, it will be resolved again to
// pass the value to next `then`.
x.then((value) => {
resolutionProcedure(promise2, value, resolve, reject);
}, reject)
} else {
x.then(resolve, reject);
}
return;
}
// specification 2.3.3.3.3
// if both `reject` and `resolve` are executed, the first successful
// execution takes precedence, and any further executions are ignored
let called = false;
// specification 2.3.3, determine whether `x` is an object or a function
if (x !== null && (typeof x === 'object' || typeof x === 'function')) {
// specification 2.3.3.2, if can't get `then`, execute the `reject`
try {
// specification 2.3.3.1
let then = x.then;
// if `then` is a function, call the `x.then`
if (typeof then === 'function') {
// specification 2.3.3.3
then.call(x, y => {
if (called) return;
called = true;
// specification 2.3.3.3.1
resolutionProcedure(promise2, y, resolve, reject);
}, e => {
if (called) return;
called = true;
reject(e);
});
} else {
// specification 2.3.3.4
resolve(x);
}
} catch (e) {
if (called) return;
called = true;
reject(e);
}
} else {
// specification 2.3.4, `x` belongs to primitive data type
resolve(x);
}
}
```
The above codes, which is implemented based on the Promise / A+ specification, can pass the full test of `promises-aplus-tests`
# Generator Implementation
Generator is an added syntactic feature in ES6. Similar to `Promise`, it can be used for asynchronous programming.
```js
// * means this is a Generator function
// yield within the block can be used to pause the execution
// next can resume execution
function* test() {
let a = 1 + 2;
yield 2;
yield 3;
}
let b = test();
console.log(b.next()); // > { value: 2, done: false }
console.log(b.next()); // > { value: 3, done: false }
console.log(b.next()); // > { value: undefined, done: true }
```
As we can tell from the above code, a function with a `*` would have the `next` function execution. In other words, the execution of the function returns an object. Every call to the `next` function can resume executing the paused code. A simple implementation of the Generator function is shown below:
```js
// cb is the compiled 'test' function
function generator(cb) {
return (function() {
var object = {
next: 0,
stop: function() {}
};
return {
next: function() {
var ret = cb(object);
if (ret === undefined) return { value: undefined, done: true };
return {
value: ret,
done: false
};
}
};
})();
}
// After babel's compilation, 'test' function turns into this:
function test() {
var a;
return generator(function(_context) {
while (1) {
switch ((_context.prev = _context.next)) {
// yield splits the code into several blocks
// every 'next' call executes one block of clode
// and indicates the next block to execute
case 0:
a = 1 + 2;
_context.next = 4;
return 2;
case 4:
_context.next = 6;
return 3;
// execution complete
case 6:
case "end":
return _context.stop();
}
}
});
}
```
# Debouncing
Have you ever encountered this problem in your development: how to do a complex computation in a scrolling event or to prevent the "second accidental click" on a button?
These requirements can be achieved with function debouncing. Especially for the first one, if complex computations are carried out in frequent event callbacks, there's a large chance that the page becomes laggy. It's better to combine multiple computations into a single one, and only operate at particular time. Since there are many libraries that implement debouncing, we won't build our own here and will just take underscore's source code to explain debouncing:
```js
/**
* underscore's debouncing function. When the callback function is called in series, func will only execute when the idel time is larger or equal to `wait`.
*
* @param {function} func callback function
* @param {number} wait length of waiting intervals
* @param {boolean} immediate when set to true, func is executed immediately
* @return {function} returns the function to be called by the client
*/
_.debounce = function(func, wait, immediate) {
var timeout, args, context, timestamp, result;
var later = function() {
// compare now to the last timestamp
var last = _.now() - timestamp;
// if the current time interval is smaller than the set interval and larger than 0, then reset the timer.
if (last < wait && last >= 0) {
timeout = setTimeout(later, wait - last);
} else {
// otherwise it's time to execute the callback function
timeout = null;
if (!immediate) {
result = func.apply(context, args);
if (!timeout) context = args = null;
}
}
};
return function() {
context = this;
args = arguments;
// obtain the timestamp
timestamp = _.now();
// if the timer doesn't exist then execute the function immediately
var callNow = immediate && !timeout;
// if the timer doesn't exist then create one
// else clear the current timer and reset a new timer
if (timeout) clearTimeout(timeout);
timeout = setTimeout(later, wait);
if (callNow) {
// if the immediate execution is needed, use apply to start the function
result = func.apply(context, args);
context = args = null;
}
return result;
};
};
```
The complete function implementation is not too difficult. Let's summarize here.
- For the implementation of protecting against accidental clicks: as long as I start a timer and the timer is there, no matter how you click the button, the callback function won't be executed. Whenever the timer ends and is set to `null`, another click is allowed.
- For the implementation of a delayed function execution: every call to the debouncing function will trigger an evaluation of time interval between the current call and the last one. If the interval is less than the required, another timer will be created, and the delay is set to the set interval minus the previous elapsed time. When the time's up, the corresponding callback function is executed.
# Throttle
`Debounce` and `Throttle` are different in nature. `Debounce` is to turn multiple executions into one last execution, and `Throttle` is to turn multiple executions into executions at regular intervals.
```js
// The first two parameters with debounce are the same function
// options: You can pass two properties
// trailing: Last time does not execute
// leading: First time does not execute
// The two properties cannot coexist, otherwise the function cannot be executed
_.throttle = function(func, wait, options) {
var context, args, result;
var timeout = null;
// Previous timestamp
var previous = 0;
// Set empty if options is not passed
if (!options) options = {};
// Timer callback function
var later = function() {
// If you set `leading`, then set `previous` to zero
// The first `if` statement of the following function is used
previous = options.leading === false ? 0 : _.now();
// The first is prevented memory leaks and the second is judged the following timers when setting `timeout` to null
timeout = null;
result = func.apply(context, args);
if (!timeout) context = args = null;
};
return function() {
// Get current timestamp
var now = _.now();
// It must be true when it entering firstly
// If you do not need to execute the function firstly
// Set the last timestamp to current
// Then it will be greater than 0 when the remaining time is calculated next
if (!previous && options.leading === false)
previous = now;
var remaining = wait - (now - previous);
context = this;
args = arguments;
// This condition will only be entered if it set `trailing`
// This condition will be entered firstly if it not set `leading`
// Another point, you may think that this condition will not be entered if you turn on the timer
// In fact, it will still enter because the timer delay is not accurate
// It is very likely that you set 2 seconds, but it needs 2.2 seconds to trigger, then this time will enter this condition
if (remaining <= 0 || remaining > wait) {
// Clean up if there exist a timer otherwise it call twice callback
if (timeout) {
clearTimeout(timeout);
timeout = null;
}
previous = now;
result = func.apply(context, args);
if (!timeout) context = args = null;
} else if (!timeout && options.trailing !== false) {
// Judgment whether timer and trailing are set
// And you can't set leading and trailing at the same time
timeout = setTimeout(later, remaining);
}
return result;
};
};
```
# Map、FlatMap and Reduce
The effect of `Map` is to generate a new array, iterate over the original array, take each element out to do some transformation, and then `append` to the new array.
```js
[1, 2, 3].map((v) => v + 1)
// -> [2, 3, 4]
```
`Map` has three parameters, namely the current index element, the index, the original array.
```js
['1','2','3'].map(parseInt)
// parseInt('1', 0) -> 1
// parseInt('2', 1) -> NaN
// parseInt('3', 2) -> NaN
```
The effect of `FlatMap` is almost the same with a `Map`, but the original array will be flatten for multidimensional arrays. You can think of `FlatMap` as a `map` and a `flatten`, which is currently not supported in browsers.
```js
[1, [2], 3].flatMap((v) => v + 1)
// -> [2, 3, 4]
```
You can achieve this when you want to completely reduce the dimensions of a multidimensional array:
```js
const flattenDeep = (arr) => Array.isArray(arr)
? arr.reduce( (a, b) => [...a, ...flattenDeep(b)] , [])
: [arr]
flattenDeep([1, [[2], [3, [4]], 5]])
```
The effect of `Reduce` is to combine the values in the array and get a final value:
```js
function a() {
console.log(1);
}
function b() {
console.log(2);
}
[a, b].reduce((a, b) => a(b()))
// -> 2 1
```
# Async and await
`async` function will return a `Promise`:
```js
async function test() {
return "1";
}
console.log(test()); // -> Promise {: "1"}
```
You can think of `async` as wrapping a function using `Promise.resolve()`.
`await` can only be used in `async` functions:
```js
function sleep() {
return new Promise(resolve => {
setTimeout(() => {
console.log('finish')
resolve("sleep");
}, 2000);
});
}
async function test() {
let value = await sleep();
console.log("object");
}
test()
```
The above code will print `finish` before printing `object`. Because `await` waits for the `sleep` function `resolve`, even if the synchronization code is followed, it is not executed before the asynchronous code is executed.
The advantage of `async` and `await` compared to the direct use of `Promise` lies in handling the call chain of `then`, which can produce clear and accurate code. The downside is that misuse of `await` can cause performance problems because `await` blocks the code. Perhaps the asynchronous code does not depend on the former, but it still needs to wait for the former to complete, causing the code to lose concurrency.
Let's look at a code that uses `await`:
```js
var a = 0
var b = async () => {
a = a + await 10
console.log('2', a) // -> '2' 10
a = (await 10) + a
console.log('3', a) // -> '3' 20
}
b()
a++
console.log('1', a) // -> '1' 1
```
You may have doubts about the above code, here we explain the principle:
- First the function `b` is executed. The variable `a` is still 0 before execution `await 10`, Because the `Generators` are implemented inside `await` and `Generators` will keep things in the stack, so at this time `a = 0` is saved
- Because `await` is an asynchronous operation, it will immediately return a `pending` state `Promise` object when it encounter `await`, and temporarily returning control of the execution code, so that the code outside the function can continue to be executed. `console.log('1', a)` will be executed first.
- At this point, the synchronous code is completed and asynchronous code is started. The saved value is used. At this time, `a = 10`
- Then comes the usual code execution
# Proxy
Proxy is a new feature since ES6. It can be used to define operations in objects:
```js
let p = new Proxy(target, handler);
// `target` represents the object of need to add the proxy
// `handler` customizes operations in the object
```
Proxy can be handy for implementation of data binding and listening:
```js
let onWatch = (obj, setBind, getLogger) => {
let handler = {
get(target, property, receiver) {
getLogger(target, property)
return Reflect.get(target, property, receiver);
},
set(target, property, value, receiver) {
setBind(value);
return Reflect.set(target, property, value);
}
};
return new Proxy(obj, handler);
};
let obj = { a: 1 }
let value
let p = onWatch(obj, (v) => {
value = v
}, (target, property) => {
console.log(`Get '${property}' = ${target[property]}`);
})
p.a = 2 // bind `value` to `2`
p.a // -> Get 'a' = 2
```
# Why 0.1 + 0.2 != 0.3
Because JS uses the IEEE 754 double-precision version (64-bit). Every language that uses this standard has this problem.
As we know, computers use binaries to represent decimals, so `0.1` in binary is represented as
```js
// (0011) represents cycle
0.1 = 2^-4 * 1.10011(0011)
```
How do we come to this binary number? We can try computing it as below:
Binary computations in float numbers are different from those in integers. For multiplications, only the float bits are computed, while the integer bits are used for the binaries for each bit. Then the first bit is used as the most significant bit. Therefore we get `0.1 = 2^-4 * 1.10011(0011)`.
`0.2` is similar. We just need to get rid of the first multiplcation and get `0.2 = 2^-3 * 1.10011(0011)`.
Back to the double float for IEEE 754 standard. Among the 64 bits, one bit is used for signing, 11 used for integer bits, and the rest 52 bits are floats. Since `0.1` and `0.2` are infinitely cycling binaries, the last bit of the floats needs to indicate whether to round (same as rounding in decimals).
After rounding, `2^-4 * 1.10011...001` becomes `2^-4 * 1.10011(0011 * 12 times)010`. After adding these two binaries we get `2^-2 * 1.0011(0011 * 11 times)0100`, which is `0.30000000000000004` in decimals.
The native solution to this problem is shown below:
```js
parseFloat((0.1 + 0.2).toFixed(10))
```
# Regular Expressions
## Metacharacters
| Metacharacter | Effect |
| :-----------: | :----------------------------------------------------------: |
| . | matches any character except line terminators: \n, \r, \u2028 or \u2029. |
| [] | matches anything within the brackets. For example, [0-9] can match any number |
| ^ | ^9 means matching anything that starts with '9'; [`^`9] means not matching characters except '9' in between brackets |
| {1, 2} | matches 1 or 2 digit characters |
| (yck) | only matches strings the same as 'yck' |
| \| | matches any character before and after \| |
| \ | escape character |
| * | matches the preceding expression 0 or more times |
| + | matches the preceding expression 1 or more times |
| ? | the character before '?' is optional |
## Flags
| Flag | Effect |
| :------: | :--------------: |
| i | case-insensitive search |
| g | matches globally |
| m | multiline |
## Character Shorthands
| shorthand | Effect |
| :--: | :------------------------: |
| \w | alphanumeric characters, underline character |
| \W | the opposite of the above |
| \s | any blank character |
| \S | the opposite of the above |
| \d | numbers |
| \D | the opposite of the above |
| \b | start or end of a word |
| \B | the opposite of the above |
================================================
FILE: LICENSE
================================================
MIT License
Copyright (c) 2018 YuChengKai
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE.
================================================
FILE: MP/mp-ch.md
================================================
- [小程序-登录](#小程序-登录)
- [unionid和openid](#unionid和openid)
- [关键Api](#关键api)
- [登录流程设计](#登录流程设计)
- [利用现有登录体系](#利用现有登录体系)
- [利用OpenId 创建用户体系](#利用openid-创建用户体系)
- [利用 Unionid 创建用户体系](#利用-unionid-创建用户体系)
- [注意事项](#注意事项)
- [小程序-图片导出](#小程序-图片导出)
- [基本原理](#基本原理)
- [如何优雅实现](#如何优雅实现)
- [注意事项](#注意事项-1)
- [小程序-数据统计](#小程序-数据统计)
- [设计一个埋点sdk](#设计一个埋点sdk)
- [分析接口](#分析接口)
- [微信自定义数据分析](#分析接口)
- [小程序-工程化](#小程序-工程化)
- [工程化做什么](#工程化做什么)
- [方案选型](#方案选型)
- [具体开发思路](#具体开发思路)
- [小程序-持续集成](#小程序-持续集成)
- [规范化的开发流程](#规范化的开发流程)
- [如何做小程序的持续集成](#如何做小程序的持续集成)
- [准备工作](#准备工作)
- [开发小程序的集成脚本](#开发小程序的集成脚本可以使用各种语言shell-js-python)
- [集成](#集成)
- [总结](#总结)
- [小程序架构](#小程序架构)
- [下载小程序完整包](#下载小程序完整包)
- [App Service - Life Cylce](#app-service---life-cylce)
- [面试题](#面试题)
- [View - WXML](#view---wxml)
- [View - WXSS](#view---wxss)
- [支持大部分CSS特性](#支持大部分css特性)
- [尺寸单位 rpx](#尺寸单位-rpx)
- [样式导入](#样式导入)
- [内联样式](#内联样式)
- [全局样式与局部样式](#全局样式与局部样式)
- [iconfont](#iconfont)
- [View - Component](#view---component)
- [View - Native Component](#view---native-component)
- [目前小程序的问题或限制](#目前小程序的问题或限制)
- [小程序HTTP2支持情况](#小程序http2支持情况)
- [HTTP2支持情况:模拟器与真机均不支持](#http2支持情况模拟器与真机均不支持)
- [HTTP2服务器需要对小程序做兼容性适配](#http2服务器需要对小程序做兼容性适配)
- [授权获取用户信息流程](#授权获取用户信息流程)
- [性能优化](#性能优化)
- [加载优化](#加载优化)
- [使用分包加载优化](#使用分包加载优化)
- [渲染性能优化](#渲染性能优化)
- [官方小程序技术能力规划](#官方小程序技术能力规划)
- [自定义组件2.0](#自定义组件20)
- [npm支持](#npm支持)
- [官方自定义组件](#官方自定义组件)
- [添加体验评分](#添加体验评分)
- [原生组件同层渲染](#原生组件同层渲染)
- [wepy vs mpvue](#wepy-vs-mpvue)
- [数据流管理](#数据流管理)
- [组件化](#组件化)
- [工程化](#工程化)
- [综合比较](#综合比较)
- [选型的个人看法](#选型的个人看法)
- [mpvue](#mpvue)
- [框架原理](#框架原理)
- [mpvue-loader](#mpvue-loader)
- [compiler](#compiler)
- [runtime](#runtime)
- [Class和Style为什么暂不支持组件](#class和style为什么暂不支持组件)
- [分包加载](#分包加载)
- [问题与展望](#问题与展望)
- [小程序-学习](#小程序-学习)
- [学习建议](#学习建议)
- [如何解决遇到的问题](#如何解决遇到的问题)
- [总结](#总结-1)
- [参考链接](#参考链接)
# 小程序-登录
## unionid和openid
了解小程序登录之前,我们写了解下小程序/公众号登录涉及到两个最关键的用户标识:
- `OpenId` 是一个用户对于一个小程序/公众号的标识,开发者可以通过这个标识识别出用户。
- `UnionId` 是一个用户对于同主体微信小程序/公众号/APP的标识,开发者需要在微信开放平台下绑定相同账号的主体。开发者可通过UnionId,实现多个小程序、公众号、甚至APP 之间的数据互通了。
## 关键Api
- [`wx.login`](https://developers.weixin.qq.com/miniprogram/dev/api/api-login.html) 官方提供的登录能力
- [`wx.checkSession`](https://developers.weixin.qq.com/miniprogram/dev/api/signature.html#wxchecksessionobject) 校验用户当前的session_key是否有效
- [`wx.authorize`](https://developers.weixin.qq.com/miniprogram/dev/api/authorize.html) 提前向用户发起授权请求
- [`wx.getUserInfo`](https://developers.weixin.qq.com/miniprogram/dev/api/api-login.html) 获取用户基本信息
## 登录流程设计
以下从笔者接触过的几种登录流程来做阐述:
### 利用现有登录体系
直接复用现有系统的登录体系,只需要在小程序端设计用户名,密码/验证码输入页面,便可以简便的实现登录,只需要保持良好的用户体验即可。
### 利用OpenId 创建用户体系
👆提过,`OpenId` 是一个小程序对于一个用户的标识,利用这一点我们可以轻松的实现一套基于小程序的用户体系,值得一提的是这种用户体系对用户的打扰最低,可以实现静默登录。具体步骤如下:
1. 小程序客户端通过 `wx.login` 获取 code
2. 传递 code 向服务端,服务端拿到 code 调用微信登录凭证校验接口,微信服务器返回 `openid` 和会话密钥 `session_key` ,此时开发者服务端便可以利用 `openid` 生成用户入库,再向小程序客户端返回自定义登录态
3. 小程序客户端缓存 (通过`storage`)自定义登录态(token),后续调用接口时携带该登录态作为用户身份标识即可
### 利用 Unionid 创建用户体系
如果想实现多个小程序,公众号,已有登录系统的数据互通,可以通过获取到用户 unionid 的方式建立用户体系。因为 unionid 在同一开放平台下的所所有应用都是相同的,通过 `unionid` 建立的用户体系即可实现全平台数据的互通,更方便的接入原有的功能,那如何获取 `unionid` 呢,有以下两种方式:
1. 如果户关注了某个相同主体公众号,或曾经在某个相同主体App、公众号上进行过微信登录授权,通过 `wx.login` 可以直接获取 到 `unionid`
2. 结合 `wx.getUserInfo` 和 `