.\r\n\t\t:params bit_rate: {'MD 128k': 128000, 'HD 320k': 320000}\r\n\t\t:return: 歌曲下载地址\r\n\t\t\"\"\"\r\n\r\n\t\turl = 'http://music.163.com/weapi/song/enhance/player/url?csrf_token='\r\n\t\tcsrf = ''\r\n\t\tparams = {'ids': [song_id], 'br': bit_rate, 'csrf_token': csrf}\r\n\t\tresult = self.post_request(url, params)\r\n\t\t# 歌曲下载地址\r\n\t\tsong_url = result['data'][0]['url']\r\n\r\n\t\t# 歌曲不存在\r\n\t\tif song_url is None:\r\n\t\t\tclick.echo('Song {} is not available due to copyright issue.'.format(song_id))\r\n\t\telse:\r\n\t\t\treturn song_url\r\n\r\n\tdef get_song_by_url(self, song_url, song_name, song_num, folder):\r\n\t\t\"\"\"\r\n\t\t下载歌曲到本地\r\n\t\t:params song_url: 歌曲下载地址\r\n\t\t:params song_name: 歌曲名字\r\n\t\t:params song_num: 下载的歌曲数\r\n\t\t:params folder: 保存路径\r\n\t\t\"\"\"\r\n\t\tif not os.path.exists(folder):\r\n\t\t\tos.makedirs(folder)\r\n\t\tfpath = os.path.join(folder, str(song_num) + '_' + song_name + '.mp3')\r\n\t\tif sys.platform == 'win32' or sys.platform == 'cygwin':\r\n\t\t\tvalid_name = re.sub(r'[<>:\"/\\\\|?*]', '', song_name)\r\n\t\t\tif valid_name != song_name:\r\n\t\t\t\tclick.echo('{} will be saved as: {}.mp3'.format(song_name, valid_name))\r\n\t\t\t\tfpath = os.path.join(folder, str(song_num) + '_' + valid_name + '.mp3')\r\n\t\t\r\n\t\tif not os.path.exists(fpath):\r\n\t\t\tresp = self.download_session.get(song_url, timeout=self.timeout, stream=True)\r\n\t\t\tlength = int(resp.headers.get('content-length'))\r\n\t\t\tlabel = 'Downloading {} {}kb'.format(song_name, int(length/1024))\r\n\r\n\t\t\twith click.progressbar(length=length, label=label) as progressbar:\r\n\t\t\t\twith open(fpath, 'wb') as song_file:\r\n\t\t\t\t\tfor chunk in resp.iter_content(chunk_size=1024):\r\n\t\t\t\t\t\tif chunk:\r\n\t\t\t\t\t\t\tsong_file.write(chunk)\r\n\t\t\t\t\t\t\tprogressbar.update(1024)\r\n\r\n\r\nclass Netease():\r\n\t\"\"\"\r\n\t网易云音乐下载\r\n\t\"\"\"\r\n\tdef __init__(self, timeout, folder, quiet, cookie_path):\r\n\t\tself.crawler = Crawler(timeout, cookie_path)\r\n\t\tself.folder = '.' if folder is None else folder\r\n\t\tself.quiet = quiet\r\n\r\n\tdef download_song_by_search(self, song_name, song_num):\r\n\t\t\"\"\"\r\n\t\t根据歌曲名进行搜索\r\n\t\t:params song_name: 歌曲名字\r\n\t\t:params song_num: 下载的歌曲数\r\n\t\t\"\"\"\r\n\r\n\t\ttry:\r\n\t\t\tsong = self.crawler.search_song(song_name, song_num, self.quiet)\r\n\t\texcept:\r\n\t\t\tclick.echo('download_song_by_serach error')\r\n\t\t# 如果找到了音乐, 则下载\r\n\t\tif song != None:\r\n\t\t\tself.download_song_by_id(song.song_id, song.song_name, song.song_num, self.folder)\r\n\r\n\tdef download_song_by_id(self, song_id, song_name, song_num, folder='.'):\r\n\t\t\"\"\"\r\n\t\t通过歌曲的ID下载\r\n\t\t:params song_id: 歌曲ID\r\n\t\t:params song_name: 歌曲名\r\n\t\t:params song_num: 下载的歌曲数\r\n\t\t:params folder: 保存地址\r\n\t\t\"\"\"\r\n\t\ttry:\r\n\t\t\turl = self.crawler.get_song_url(song_id)\r\n\t\t\t# 去掉非法字符\r\n\t\t\tsong_name = song_name.replace('/', '')\r\n\t\t\tsong_name = song_name.replace('.', '')\r\n\t\t\tself.crawler.get_song_by_url(url, song_name, song_num, folder)\r\n\r\n\t\texcept:\r\n\t\t\tclick.echo('download_song_by_id error')\r\n\r\n\r\nif __name__ == '__main__':\r\n\ttimeout = 60\r\n\toutput = 'Musics'\r\n\tquiet = True\r\n\tcookie_path = 'Cookie'\r\n\tnetease = Netease(timeout, output, quiet, cookie_path)\r\n\tmusic_list_name = 'music_list.txt'\r\n\t# 如果music列表存在, 那么开始下载\r\n\tif os.path.exists(music_list_name):\r\n\t\twith open(music_list_name, 'r') as f:\r\n\t\t\tmusic_list = list(map(lambda x: x.strip(), f.readlines()))\r\n\t\tfor song_num, song_name in enumerate(music_list):\r\n\t\t\tnetease.download_song_by_search(song_name,song_num + 1)\r\n\telse:\r\n\t\tclick.echo('music_list.txt not exist.')"
},
{
"path": "Netease/music_list.txt",
"content": "風見鶏\n外婆的话【不才】\nWe Don't Talk Anymore\n【电吉他】《青鸟》\n小棋童\n千本桜(古筝版)\n妄为\n借我\n你到底有没有爱过我\n七月上\n"
},
{
"path": "README.md",
"content": "# 注:2020年最新连载教程请移步:[Python Spider 2020](https://github.com/Jack-Cherish/python-spider/tree/master/2020 \"Python Spider 2020\")\n\n免责声明:\n\n大家请以学习为目的使用本仓库,爬虫违法违规的案件:https://github.com/HiddenStrawberry/Crawler_Illegal_Cases_In_China\n\n本仓库的所有内容仅供学习和参考之用,禁止用于商业用途。任何人或组织不得将本仓库的内容用于非法用途或侵犯他人合法权益。本仓库所涉及的爬虫技术仅用于学习和研究,不得用于对其他平台进行大规模爬虫或其他非法行为。对于因使用本仓库内容而引起的任何法律责任,本仓库不承担任何责任。使用本仓库的内容即表示您同意本免责声明的所有条款和条件。\n\n# Python Spider\n\n原创文章每周最少两篇,**后续最新文章**会在[【公众号】](https://cuijiahua.com/wp-content/uploads/2020/05/gzh-w.jpg)首发,视频[【B站】](https://space.bilibili.com/331507846)首发,大家可以加我[【微信】](https://cuijiahua.com/wp-content/uploads/2020/05/gzh-w.jpg)进**交流群**,技术交流或提意见都可以,欢迎**Star**!\n\n\n  \n
\n  \n
\n  \n
\n  \n
\n  \n
\n  \n
\n  \n
\n
\n\n## 声明\n\n* 代码、教程**仅限于学习交流,请勿用于任何商业用途!**\n\n## 目录\n\n* [爬虫小工具](#爬虫小工具)\n * [文件下载小助手](https://github.com/Jack-Cherish/python-spider/blob/master/downloader.py \"悬停显示\")\n* [爬虫实战](#爬虫实战)\n * [笔趣看小说下载](https://github.com/Jack-Cherish/python-spider/blob/master/biqukan.py \"悬停显示\")\n * [百度文库免费文章下载助手_rev1](https://github.com/Jack-Cherish/python-spider/blob/master/baiduwenku.py \"悬停显示\")\n * [百度文库免费文章下载助手_rev2](https://github.com/Jack-Cherish/python-spider/blob/master/baiduwenku_pro_1.py \"悬停显示\")\n * [《帅啊》网帅哥图片下载](https://github.com/Jack-Cherish/python-spider/blob/master/shuaia.py \"悬停显示\")\n * [构建代理IP池](https://github.com/Jack-Cherish/python-spider/blob/master/daili.py \"悬停显示\")\n * [《火影忍者》漫画下载](https://github.com/Jack-Cherish/python-spider/tree/master/cartoon \"悬停显示\")\n * [财务报表下载小助手](https://github.com/Jack-Cherish/python-spider/blob/master/financical.py \"悬停显示\")\n * [一小时入门网络爬虫](https://github.com/Jack-Cherish/python-spider/tree/master/one_hour_spider \"悬停显示\")\n * [抖音App视频下载](https://github.com/Jack-Cherish/python-spider/tree/master/douyin \"悬停显示\")\n * [GEETEST验证码识别](https://github.com/Jack-Cherish/python-spider/blob/master/geetest.py \"悬停显示\")\n * [12306抢票小助手](https://github.com/Jack-Cherish/python-spider/blob/master/12306.py \"悬停显示\")\n * [百万英雄答题辅助系统](https://github.com/Jack-Cherish/python-spider/tree/master/baiwan \"悬停显示\") \n * [网易云音乐免费音乐批量下载](https://github.com/Jack-Cherish/python-spider/tree/master/Netease \"悬停显示\")\n * [B站免费视频和弹幕批量下载](https://github.com/Jack-Cherish/python-spider/tree/master/bilibili \"悬停显示\")\n * [京东商品晒单图下载](https://github.com/Jack-Cherish/python-spider/tree/master/dingdong \"悬停显示\")\n * [正方教务管理系统个人信息查询](https://github.com/Jack-Cherish/python-spider/tree/master/zhengfang_system_spider \"悬停显示\")\n* [其它](#其它)\n\n## 爬虫小工具\n\n* downloader.py:文件下载小助手\n\n\t一个可以用于下载图片、视频、文件的小工具,有下载进度显示功能。稍加修改即可添加到自己的爬虫中。\n\t\n\t动态示意图:\n\t\n\t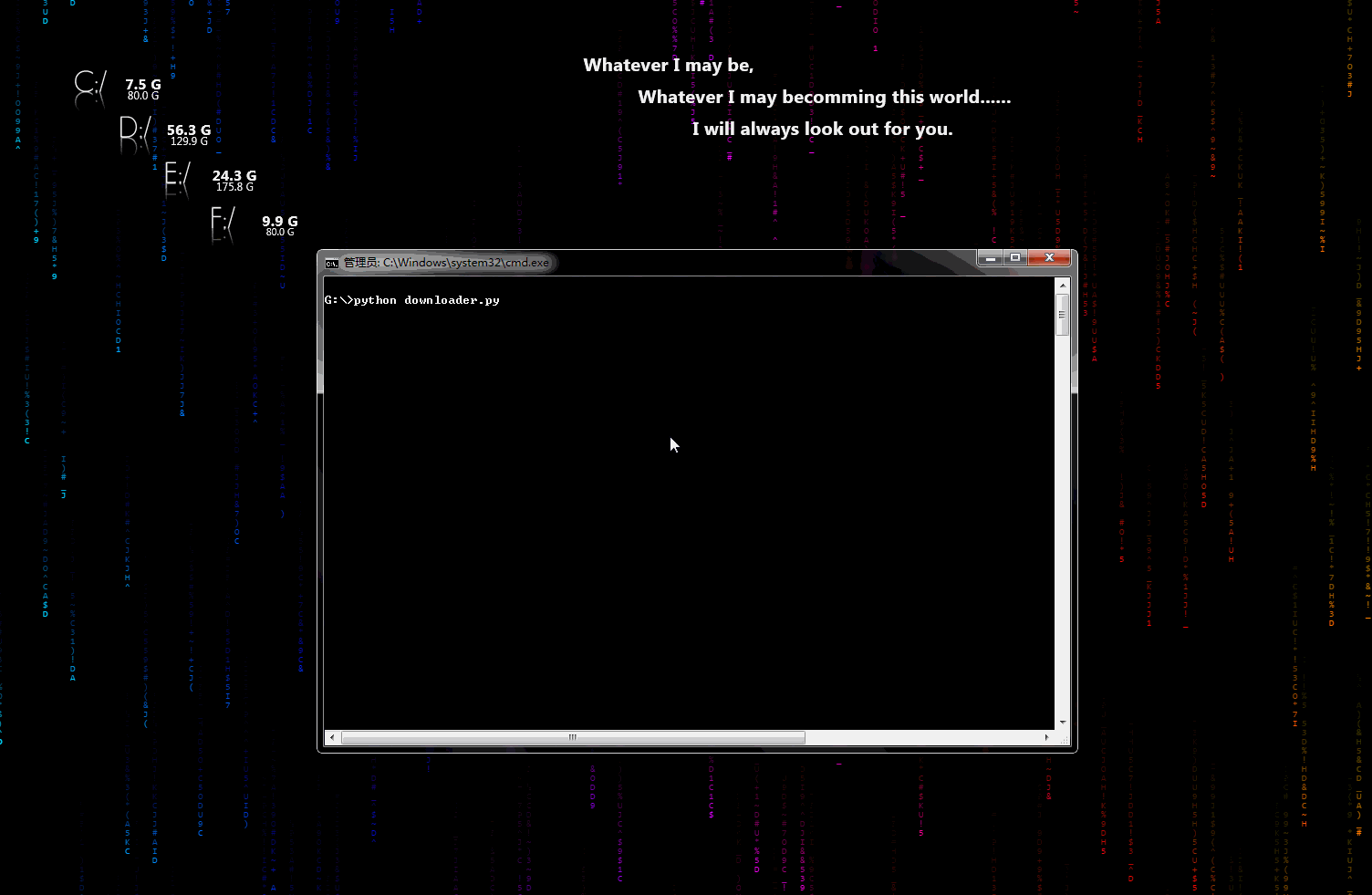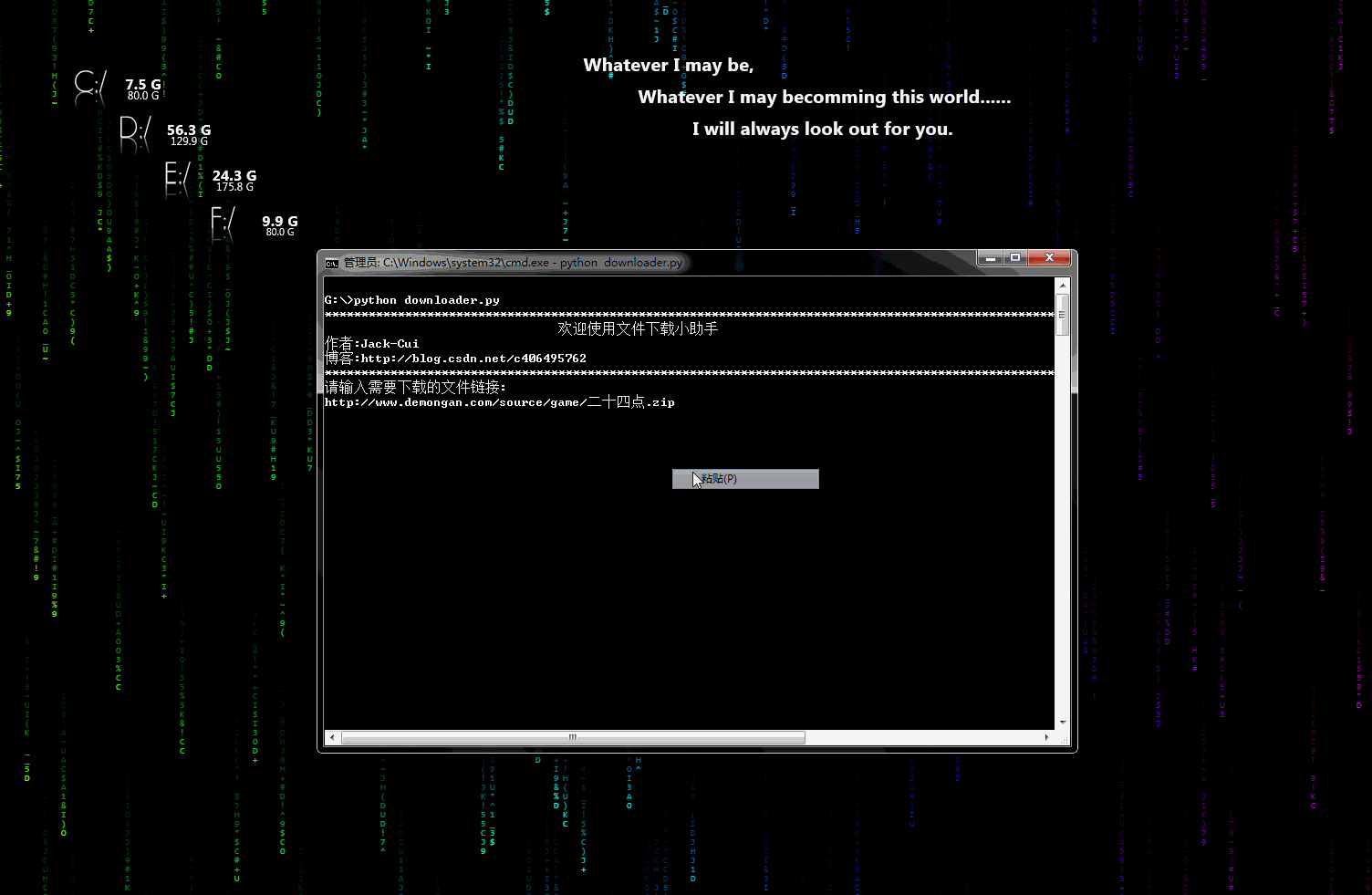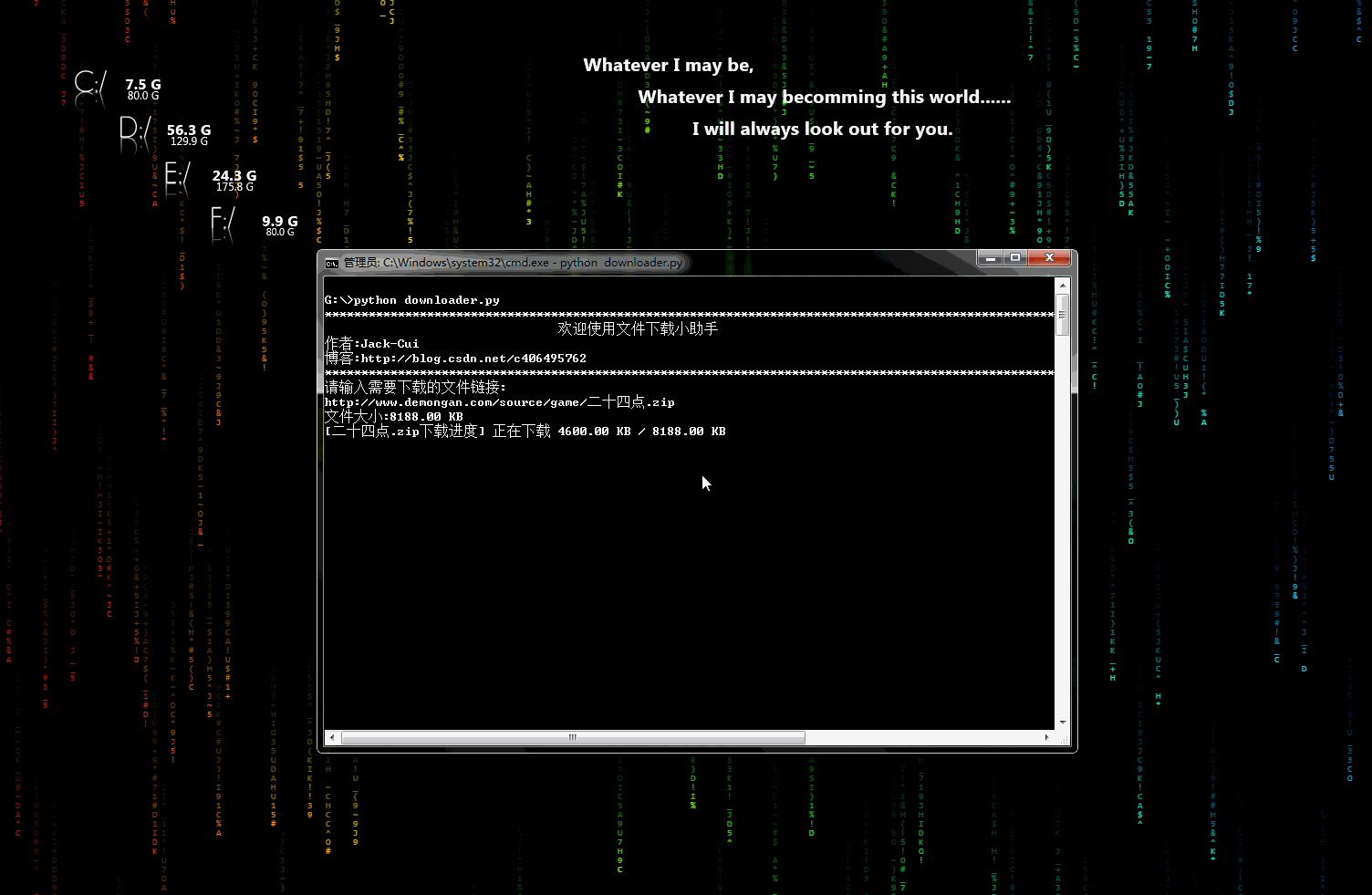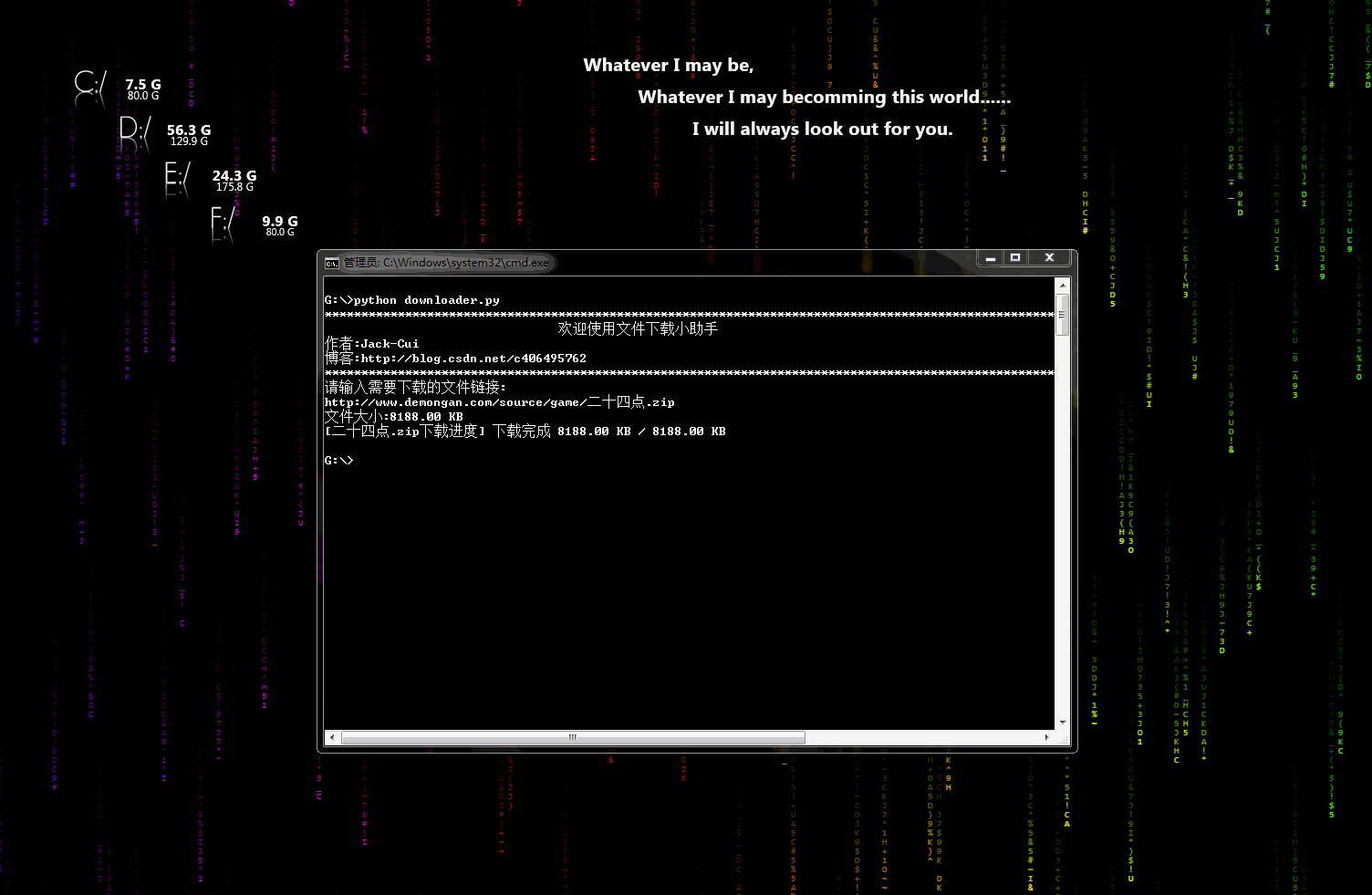\n\n## 爬虫实战\n \n * biqukan.py:《笔趣看》盗版小说网站,爬取小说工具\n\n\t第三方依赖库安装:\n\n\t\tpip3 install beautifulsoup4\n\n\t使用方法:\n\n\t\tpython biqukan.py\n\n * baiduwenku.py: 百度文库word文章爬取\n\t\n\t原理说明:http://blog.csdn.net/c406495762/article/details/72331737\n\t\n\t代码不完善,没有进行打包,不具通用性,纯属娱乐。\n\t\n * shuaia.py: 爬取《帅啊》网,帅哥图片\n\n\t《帅啊》网URL:http://www.shuaia.net/index.html\n\n\t原理说明:http://blog.csdn.net/c406495762/article/details/72597755\n\t\n\t第三方依赖库安装:\n\t\n\t\tpip3 install requests beautifulsoup4\n\t\t\n * daili.py: 构建代理IP池\n\n\t原理说明:http://blog.csdn.net/c406495762/article/details/72793480\n\t\n\t\n * carton: 使用Scrapy爬取《火影忍者》漫画\n\n\t代码可以爬取整个《火影忍者》漫画所有章节的内容,保存到本地。更改地址,可以爬取其他漫画。保存地址可以在settings.py中修改。\n\t\n\t动漫网站:http://comic.kukudm.com/\n\t\n\t原理说明:http://blog.csdn.net/c406495762/article/details/72858983\n\t\n * hero.py: 《王者荣耀》推荐出装查询小助手\n\n\t网页爬取已经会了,想过爬取手机APP里的内容吗?\n\t\n\t原理说明:http://blog.csdn.net/c406495762/article/details/76850843\n\t\n * financical.py: 财务报表下载小助手\n\n\t爬取的数据存入数据库会吗?《跟股神巴菲特学习炒股之财务报表入库(MySQL)》也许能给你一些思路。\n\t\n\t原理说明:http://blog.csdn.net/c406495762/article/details/77801899\n\t\n\t动态示意图:\n\t\n\t\n\t\n * one_hour_spider:一小时入门Python3网络爬虫。\n\n\t原理说明:\n\t\n\t * 知乎:https://zhuanlan.zhihu.com/p/29809609\n\t * CSDN:http://blog.csdn.net/c406495762/article/details/78123502\n\t\n\t本次实战内容有:\n\t\n\t * 网络小说下载(静态网站)-biqukan\n\t * 优美壁纸下载(动态网站)-unsplash\n\t * 视频下载\n\t \n * douyin.py:抖音App视频下载\n \n\t抖音App的视频下载,就是普通的App爬取。\n\n\t原理说明:\n\t\n\t * 个人网站:http://cuijiahua.com/blog/2018/03/spider-5.html\n\t\n * douyin_pro:抖音App视频下载(升级版)\n \n\t抖音App的视频下载,添加视频解析网站,支持无水印视频下载,使用第三方平台解析。\n\n\t原理说明:\n\t\n\t * 个人网站:http://cuijiahua.com/blog/2018/03/spider-5.html\n\t \n * douyin:抖音App视频下载(升级版2)\n \n\t抖音App的视频下载,添加视频解析网站,支持无水印视频下载,通过url解析,无需第三方平台。\n\t\n\t原理说明:\n\t\n\t * 个人网站:http://cuijiahua.com/blog/2018/03/spider-5.html\n\t \n\t动态示意图:\n\t\n\t\n\t\n * geetest.py:GEETEST验证码识别\n \n \t原理说明:\n\t\n\t 无\n\t\n * 12306.py:用Python抢火车票简单代码\n \n\t可以自己慢慢丰富,蛮简单,有爬虫基础很好操作,没有原理说明。\n\t\n * baiwan:百万英雄辅助答题\n \n\t效果图:\n\t\n\t\n\t\n\t原理说明:\n\t\n\t* 个人网站:http://cuijiahua.com/blog/2018/01/spider_3.html\n\t\n \t功能介绍:\n\t\n\t服务器端,使用Python(baiwan.py)通过抓包获得的接口获取答题数据,解析之后通过百度知道搜索接口匹配答案,将最终匹配的结果写入文件(file.txt)。\n\t\n\t手机抓包不会的朋友,可以看下我的早期[手机APP抓包教程](http://blog.csdn.net/c406495762/article/details/76850843 \"悬停显示\")。\n\t\n\tNode.js(app.js)每隔1s读取一次file.txt文件,并将读取结果通过socket.io推送给客户端(index.html)。\n\t\n\t亲测答题延时在3s左右。\n\t\n\t声明:没做过后端和前端,花了一天时间,现学现卖弄好的,javascript也是现看现用,百度的程序,调试调试而已。可能有很多用法比较low的地方,用法不对,请勿见怪,有大牛感兴趣,可以自行完善。\n\n * Netease:根据歌单下载网易云音乐\n \t\n\t效果图:\n\t\n\t\n\t\n\t原理说明:\n\t\n\t暂无\n\t\n\t功能介绍:\n\t\n\t根据music_list.txt文件里的歌单的信息下载网易云音乐,将自己喜欢的音乐进行批量下载。\n\n * bilibili:B站视频和弹幕批量下载\n \t\n\t原理说明:\n\t\n\t暂无\n\t\n\t使用说明:\n\t\n python bilibili.py -d 猫 -k 猫 -p 10\n\n 三个参数:\n -d\t保存视频的文件夹名\n -k\tB站搜索的关键字\n -p\t下载搜索结果前多少页\n\t\n * jingdong:京东商品晒单图下载\n \n \t效果图:\n\t\n\t\n \t\n\t原理说明:\n\t\n\t暂无\n\t\n\t使用说明:\n\t\n python jd.py -k 芒果\n\t\n 三个参数:\n -d\t保存图片的路径,默认为fd.py文件所在文件夹\n -k\t搜索关键词\n -n \t下载商品的晒单图个数,即n个商店的晒单图\n\n * zhengfang_system_spider:对正方教务管理系统个人课表,个人学生成绩,绩点等简单爬取\n \n \t效果图:\n\t\n\t\n \t\n\t原理说明:\n\t\n\t暂无\n\t\n\t使用说明:\n\t\n cd zhengfang_system_spider\n pip install -r requirements.txt\n python spider.py\n\n## 其它\n\n * 欢迎 Pull requests,感谢贡献。\n \n 更多精彩,敬请期待!\n\n \n\n \n"
},
{
"path": "baiduwenku.py",
"content": "# -*- coding:UTF-8 -*-\nfrom selenium import webdriver\nfrom bs4 import BeautifulSoup\nimport re\nimport time\n\nif __name__ == '__main__':\n\n\toptions = webdriver.ChromeOptions()\n\toptions.add_argument('user-agent=\"Mozilla/5.0 (Linux; Android 4.0.4; Galaxy Nexus Build/IMM76B) AppleWebKit/535.19 (KHTML, like Gecko) Chrome/18.0.1025.133 Mobile Safari/535.19\"')\n\tdriver = webdriver.Chrome('J:\\迅雷下载\\chromedriver.exe', chrome_options=options)\n\tdriver.get('https://wenku.baidu.com/view/aa31a84bcf84b9d528ea7a2c.html')\n\n\thtml = driver.page_source\n\tbf1 = BeautifulSoup(html, 'lxml')\n\tresult = bf1.find_all(class_='rtcspage')\n\tbf2 = BeautifulSoup(str(result[0]), 'lxml')\n\ttitle = bf2.div.div.h1.string\n\tpagenum = bf2.find_all(class_='size')\n\tpagenum = BeautifulSoup(str(pagenum), 'lxml').span.string\n\tpagepattern = re.compile('页数:(\\d+)页')\n\tnum = int(pagepattern.findall(pagenum)[0])\n\tprint('文章标题:%s' % title)\n\tprint('文章页数:%d' % num)\n\n\n\twhile True:\n\t\tnum = num / 5.0\n\t\thtml = driver.page_source\n\t\tbf1 = BeautifulSoup(html, 'lxml')\n\t\tresult = bf1.find_all(class_='rtcspage')\n\t\tfor each_result in result:\n\t\t\tbf2 = BeautifulSoup(str(each_result), 'lxml')\n\t\t\ttexts = bf2.find_all('p')\n\t\t\tfor each_text in texts:\n\t\t\t\tmain_body = BeautifulSoup(str(each_text), 'lxml')\n\t\t\t\tfor each in main_body.find_all(True):\n\t\t\t\t\tif each.name == 'span':\n\t\t\t\t\t\tprint(each.string.replace('\\xa0',''),end='')\n\t\t\t\t\telif each.name == 'br':\n\t\t\t\t\t\tprint('')\n\t\t\tprint('\\n')\n\t\tif num > 1:\n\t\t\tpage = driver.find_elements_by_xpath(\"//div[@class='page']\")\n\t\t\tdriver.execute_script('arguments[0].scrollIntoView();', page[-1]) #拖动到可见的元素去\n\t\t\tnextpage = driver.find_element_by_xpath(\"//a[@data-fun='next']\")\n\t\t\tnextpage.click()\n\t\t\ttime.sleep(3)\n\t\telse:\n\t\t\tbreak"
},
{
"path": "baiduwenku_pro_1.py",
"content": "import requests\nimport re\nimport json\nimport os\n\nsession = requests.session()\n\n\ndef fetch_url(url):\n return session.get(url).content.decode('gbk')\n\n\ndef get_doc_id(url):\n return re.findall('view/(.*).html', url)[0]\n\n\ndef parse_type(content):\n return re.findall(r\"docType.*?\\:.*?\\'(.*?)\\'\\,\", content)[0]\n\n\ndef parse_title(content):\n return re.findall(r\"title.*?\\:.*?\\'(.*?)\\'\\,\", content)[0]\n\n\ndef parse_doc(content):\n result = ''\n url_list = re.findall('(https.*?0.json.*?)\\\\\\\\x22}', content)\n url_list = [addr.replace(\"\\\\\\\\\\\\/\", \"/\") for addr in url_list]\n for url in url_list[:-5]:\n content = fetch_url(url)\n y = 0\n txtlists = re.findall('\"c\":\"(.*?)\".*?\"y\":(.*?),', content)\n for item in txtlists:\n if not y == item[1]:\n y = item[1]\n n = '\\n'\n else:\n n = ''\n result += n\n result += item[0].encode('utf-8').decode('unicode_escape', 'ignore')\n return result\n\n\ndef parse_txt(doc_id):\n content_url = 'https://wenku.baidu.com/api/doc/getdocinfo?callback=cb&doc_id=' + doc_id\n content = fetch_url(content_url)\n md5 = re.findall('\"md5sum\":\"(.*?)\"', content)[0]\n pn = re.findall('\"totalPageNum\":\"(.*?)\"', content)[0]\n rsign = re.findall('\"rsign\":\"(.*?)\"', content)[0]\n content_url = 'https://wkretype.bdimg.com/retype/text/' + doc_id + '?rn=' + pn + '&type=txt' + md5 + '&rsign=' + rsign\n content = json.loads(fetch_url(content_url))\n result = ''\n for item in content:\n for i in item['parags']:\n result += i['c'].replace('\\\\r', '\\r').replace('\\\\n', '\\n')\n return result\n\n\ndef parse_other(doc_id):\n content_url = \"https://wenku.baidu.com/browse/getbcsurl?doc_id=\" + doc_id + \"&pn=1&rn=99999&type=ppt\"\n content = fetch_url(content_url)\n url_list = re.findall('{\"zoom\":\"(.*?)\",\"page\"', content)\n url_list = [item.replace(\"\\\\\", '') for item in url_list]\n if not os.path.exists(doc_id):\n os.mkdir(doc_id)\n for index, url in enumerate(url_list):\n content = session.get(url).content\n path = os.path.join(doc_id, str(index) + '.jpg')\n with open(path, 'wb') as f:\n f.write(content)\n print(\"图片保存在\" + doc_id + \"文件夹\")\n\n\ndef save_file(filename, content):\n with open(filename, 'w', encoding='utf8') as f:\n f.write(content)\n print('已保存为:' + filename)\n\n\n# test_txt_url = 'https://wenku.baidu.com/view/cbb4af8b783e0912a3162a89.html?from=search'\n# test_ppt_url = 'https://wenku.baidu.com/view/2b7046e3f78a6529657d5376.html?from=search'\n# test_pdf_url = 'https://wenku.baidu.com/view/dd6e15c1227916888586d795.html?from=search'\n# test_xls_url = 'https://wenku.baidu.com/view/eb4a5bb7312b3169a551a481.html?from=search'\ndef main():\n url = input('请输入要下载的文库URL地址')\n content = fetch_url(url)\n doc_id = get_doc_id(url)\n type = parse_type(content)\n title = parse_title(content)\n if type == 'doc':\n result = parse_doc(content)\n save_file(title + '.txt', result)\n elif type == 'txt':\n result = parse_txt(doc_id)\n save_file(title + '.txt', result)\n else:\n parse_other(doc_id)\n\n\nif __name__ == \"__main__\":\n main()\n"
},
{
"path": "baiwan/app.js",
"content": "var http = require('http');\nvar fs = require('fs');\nvar schedule = require(\"node-schedule\"); \nvar message = {};\nvar count = 0;\nvar server = http.createServer(function (req,res){\n fs.readFile('./index.html',function(error,data){\n res.writeHead(200,{'Content-Type':'text/html'});\n res.end(data,'utf-8');\n });\n}).listen(80);\nconsole.log('Server running!');\nvar lineReader = require('line-reader');\nfunction messageGet(){\n lineReader.eachLine('file.txt', function(line, last) {\n count++;\n var name = 'line' + count;\n console.log(name);\n\tconsole.log(line);\n message[name] = line;\n }); \n if(count == 25){\n \tcount = 0;\n }\n else{\n \tfor(var i = count+1; i <= 25; i++){\n \t var name = 'line' + i;\n message[name] = 'f';\n\t}\n \tcount = 0;\n }\n}\nvar io = require('socket.io').listen(server);\nvar rule = new schedule.RecurrenceRule();\nvar times = [];\nfor(var i=1; i<1800; i++){\n times.push(i);\n}\nrule.second = times;\nschedule.scheduleJob(rule, function(){\n messageGet();\n});\nio.sockets.on('connection',function(socket){\n // console.log('User connected' + count + 'user(s) present');\n socket.emit('users',message);\n socket.broadcast.emit('users',message);\n\n socket.on('disconnect',function(){\n console.log('User disconnected');\n //socket.broadcast.emit('users',message); \n });\n});\n"
},
{
"path": "baiwan/baiwan.py",
"content": "# -*-coding:utf-8 -*-\nimport requests\nfrom lxml import etree\nfrom bs4 import BeautifulSoup\nimport urllib\nimport time, re, types, os\n\n\n\"\"\"\n代码写的匆忙,本来想再重构下,完善好注释再发,但是比较忙,想想算了,所以自行完善吧!写法很不规范,勿见怪。\n\n作者: Jack Cui\nWebsite:http://cuijiahua.com\n注: 本软件仅用于学习交流,请勿用于任何商业用途!\n\"\"\"\n\nclass BaiWan():\n\tdef __init__(self):\n\t\t# 百度知道搜索接口\n\t\tself.baidu = 'http://zhidao.baidu.com/search?'\n\t\t# 百万英雄及接口,每个人的接口都不一样,里面包含的手机信息,因此不公布,请自行抓包,有疑问欢迎留言:http://cuijiahua.com/liuyan.html\n\t\tself.api = 'https://api-spe-ttl.ixigua.com/xxxxxxx={}'.format(int(time.time()*1000))\n\n\t# 获取答案并解析问题\n\tdef get_question(self):\n\t\tto = True\n\t\twhile to:\n\t\t\tlist_dir = os.listdir('./')\n\t\t\tif 'question.txt' not in list_dir:\n\t\t\t\tfw = open('question.txt', 'w')\n\t\t\t\tfw.write('百万英雄尚未出题请稍后!')\n\t\t\t\tfw.close()\t\t\n\t\t\tgo = True\n\t\t\twhile go:\n\t\t\t\treq = requests.get(self.api, verify=False)\n\t\t\t\treq.encoding = 'utf-8'\n\t\t\t\thtml = req.text\n\n\t\t\t\tprint(html)\n\t\t\t\tif '*' in html:\n\t\t\t\t\tquestion_start = html.index('*')\n\t\t\t\t\ttry:\n\t\t\t\t\t\t\n\t\t\t\t\t\tquestion_end = html.index('?')\n\t\t\t\t\texcept:\n\t\t\t\t\t\tquestion_end = html.index('?')\n\t\t\t\t\tquestion = html[question_start:question_end][2:]\n\t\t\t\t\tif question != None:\n\t\t\t\t\t\tfr = open('question.txt', 'r')\n\t\t\t\t\t\ttext = fr.readline()\n\t\t\t\t\t\tfr.close()\n\t\t\t\t\t\tif text != question:\n\t\t\t\t\t\t\tprint(question)\n\t\t\t\t\t\t\tgo = False\n\t\t\t\t\t\t\twith open('question.txt', 'w') as f:\n\t\t\t\t\t\t\t\tf.write(question)\n\t\t\t\t\t\telse:\n\t\t\t\t\t\t\ttime.sleep(1)\n\t\t\t\t\telse:\n\t\t\t\t\t\tto = False\n\t\t\t\telse:\n\t\t\t\t\tto = False\n\n\t\t\ttemp = re.findall(r'[\\u4e00-\\u9fa5a-zA-Z0-9\\+\\-\\*/]', html[question_end+1:])\n\t\t\tb_index = []\n\t\t\tprint(temp)\n\n\t\t\tfor index, each in enumerate(temp):\n\t\t\t\tif each == 'B':\n\t\t\t\t\tb_index.append(index)\n\t\t\t\telif each == 'P' and (len(temp) - index) <= 3 :\n\t\t\t\t\tb_index.append(index)\n\t\t\t\t\tbreak\n\n\t\t\tif len(b_index) == 4:\n\t\t\t\ta = ''.join(temp[b_index[0] + 1:b_index[1]])\n\t\t\t\tb = ''.join(temp[b_index[1] + 1:b_index[2]])\n\t\t\t\tc = ''.join(temp[b_index[2] + 1:b_index[3]])\n\t\t\t\talternative_answers = [a,b,c]\n\n\t\t\t\tif '下列' in question:\n\t\t\t\t\tquestion = a + ' ' + b + ' ' + c + ' ' + question.replace('下列', '')\n\t\t\t\telif '以下' in question:\n\t\t\t\t\tquestion = a + ' ' + b + ' ' + c + ' ' + question.replace('以下', '')\n\t\t\telse:\n\t\t\t\talternative_answers = []\n\t\t\t# 根据问题和备选答案搜索答案\n\t\t\tself.search(question, alternative_answers)\n\t\t\ttime.sleep(1)\n\n\tdef search(self, question, alternative_answers):\n\t\tprint(question)\n\t\tprint(alternative_answers)\n\t\tinfos = {\"word\":question}\n\t\t# 调用百度接口\n\t\turl = self.baidu + 'lm=0&rn=10&pn=0&fr=search&ie=gbk&' + urllib.parse.urlencode(infos, encoding='GB2312')\n\t\tprint(url)\n\t\theaders = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.86 Safari/537.36',\n\t\t}\n\t\tsess = requests.Session()\n\t\treq = sess.get(url = url, headers=headers, verify=False)\n\t\treq.encoding = 'gbk'\n\t\t# print(req.text)\n\t\tbf = BeautifulSoup(req.text, 'lxml')\n\t\tanswers = bf.find_all('dd',class_='dd answer')\n\t\tfor answer in answers:\n\t\t\tprint(answer.text)\n\n\t\t# 推荐答案\n\t\trecommend = ''\n\t\tif alternative_answers != []:\n\t\t\tbest = []\n\t\t\tprint('\\n')\n\t\t\tfor answer in answers:\n\t\t\t\t# print(answer.text)\n\t\t\t\tfor each_answer in alternative_answers:\n\t\t\t\t\tif each_answer in answer.text:\n\t\t\t\t\t\tbest.append(each_answer)\n\t\t\t\t\t\tprint(each_answer,end=' ')\n\t\t\t\t\t\t# print(answer.text)\n\t\t\t\t\t\tprint('\\n')\n\t\t\t\t\t\tbreak\n\t\t\tstatistics = {}\n\t\t\tfor each in best:\n\t\t\t\tif each not in statistics.keys():\n\t\t\t\t\tstatistics[each] = 1\n\t\t\t\telse:\n\t\t\t\t\tstatistics[each] += 1\n\t\t\terrors = ['没有', '不是', '不对', '不正确','错误','不包括','不包含','不在','错']\n\t\t\terror_list = list(map(lambda x: x in question, errors))\n\t\t\tprint(error_list)\n\t\t\tif sum(error_list) >= 1:\n\t\t\t\tfor each_answer in alternative_answers:\n\t\t\t\t\tif each_answer not in statistics.items():\n\t\t\t\t\t\trecommend = each_answer\n\t\t\t\t\t\tprint('推荐答案:', recommend)\n\t\t\t\t\t\tbreak\n\t\t\telif statistics != {}:\n\t\t\t\trecommend = sorted(statistics.items(), key=lambda e:e[1], reverse=True)[0][0]\n\t\t\t\tprint('推荐答案:', recommend)\n\n\t\t# 写入文件\n\t\twith open('file.txt', 'w') as f:\n\t\t\tf.write('问题:' + question)\n\t\t\tf.write('\\n')\n\t\t\tf.write('*' * 50)\n\t\t\tf.write('\\n')\n\t\t\tif alternative_answers != []:\n\t\t\t\tf.write('选项:')\n\t\t\t\tfor i in range(len(alternative_answers)):\n\t\t\t\t\tf.write(alternative_answers[i])\n\t\t\t\t\tf.write(' ')\n\t\t\tf.write('\\n')\n\t\t\tf.write('*' * 50)\n\t\t\tf.write('\\n')\n\t\t\tf.write('参考答案:\\n')\n\t\t\tfor answer in answers:\n\t\t\t\tf.write(answer.text)\n\t\t\t\tf.write('\\n')\n\t\t\tf.write('*' * 50)\n\t\t\tf.write('\\n')\n\t\t\tif recommend != '':\n\t\t\t\tf.write('最终答案请自行斟酌!\\t')\n\t\t\t\tf.write('推荐答案:' + sorted(statistics.items(), key=lambda e:e[1], reverse=True)[0][0])\n\n\nif __name__ == '__main__':\n\tbw = BaiWan()\n\tbw.get_question()"
},
{
"path": "baiwan/file.txt",
"content": "⣺Ǽ¼\n**************************************************\nѡ723 81 101 \n**************************************************\nο𰸣\n\nƼ\n81 ÿİһйžգҲСһڡ August 1, anniversary of the founding of the Chinese People's Liberation Army֪Ⱦ뵽http://baike.baidu.com/view/23211.htm\n[ϸ]\n\nãйžĽÿİһգưһڣİһպ\n𣺽81գ71ա ÿ81йžգ׳ơһڡ192781գй챱ˣܶ Ҷͦ е쵼£ڽϲװ壬췴Թ...\n730\n𣺰һǽڣǰһ첻731ô\n192781һϲ,йװɵĵһǹ,־йй쵼װʱ,־й͵ӵĵÿİһйž\nԴйʱй쵼ϲ塣192781յϲ壬йװɵĵһǹ־йй쵼װʱڣ־й͵ӵĵ 19337£...\nԪ1181101\n𣺰һŽ\n 201581 ũ ʮ 201681 ũ إ ÿİһйžգҲСһڡ1933711գлάʱίԱ630յĽ飬81...\n**************************************************\nմã\tƼ𰸣81"
},
{
"path": "baiwan/index.html",
"content": "\n\n \n \n \n Jack Cui答题辅助系统\n \n \n
\n"
},
{
"path": "baiduwenku.py",
"content": "# -*- coding:UTF-8 -*-\nfrom selenium import webdriver\nfrom bs4 import BeautifulSoup\nimport re\nimport time\n\nif __name__ == '__main__':\n\n\toptions = webdriver.ChromeOptions()\n\toptions.add_argument('user-agent=\"Mozilla/5.0 (Linux; Android 4.0.4; Galaxy Nexus Build/IMM76B) AppleWebKit/535.19 (KHTML, like Gecko) Chrome/18.0.1025.133 Mobile Safari/535.19\"')\n\tdriver = webdriver.Chrome('J:\\迅雷下载\\chromedriver.exe', chrome_options=options)\n\tdriver.get('https://wenku.baidu.com/view/aa31a84bcf84b9d528ea7a2c.html')\n\n\thtml = driver.page_source\n\tbf1 = BeautifulSoup(html, 'lxml')\n\tresult = bf1.find_all(class_='rtcspage')\n\tbf2 = BeautifulSoup(str(result[0]), 'lxml')\n\ttitle = bf2.div.div.h1.string\n\tpagenum = bf2.find_all(class_='size')\n\tpagenum = BeautifulSoup(str(pagenum), 'lxml').span.string\n\tpagepattern = re.compile('页数:(\\d+)页')\n\tnum = int(pagepattern.findall(pagenum)[0])\n\tprint('文章标题:%s' % title)\n\tprint('文章页数:%d' % num)\n\n\n\twhile True:\n\t\tnum = num / 5.0\n\t\thtml = driver.page_source\n\t\tbf1 = BeautifulSoup(html, 'lxml')\n\t\tresult = bf1.find_all(class_='rtcspage')\n\t\tfor each_result in result:\n\t\t\tbf2 = BeautifulSoup(str(each_result), 'lxml')\n\t\t\ttexts = bf2.find_all('p')\n\t\t\tfor each_text in texts:\n\t\t\t\tmain_body = BeautifulSoup(str(each_text), 'lxml')\n\t\t\t\tfor each in main_body.find_all(True):\n\t\t\t\t\tif each.name == 'span':\n\t\t\t\t\t\tprint(each.string.replace('\\xa0',''),end='')\n\t\t\t\t\telif each.name == 'br':\n\t\t\t\t\t\tprint('')\n\t\t\tprint('\\n')\n\t\tif num > 1:\n\t\t\tpage = driver.find_elements_by_xpath(\"//div[@class='page']\")\n\t\t\tdriver.execute_script('arguments[0].scrollIntoView();', page[-1]) #拖动到可见的元素去\n\t\t\tnextpage = driver.find_element_by_xpath(\"//a[@data-fun='next']\")\n\t\t\tnextpage.click()\n\t\t\ttime.sleep(3)\n\t\telse:\n\t\t\tbreak"
},
{
"path": "baiduwenku_pro_1.py",
"content": "import requests\nimport re\nimport json\nimport os\n\nsession = requests.session()\n\n\ndef fetch_url(url):\n return session.get(url).content.decode('gbk')\n\n\ndef get_doc_id(url):\n return re.findall('view/(.*).html', url)[0]\n\n\ndef parse_type(content):\n return re.findall(r\"docType.*?\\:.*?\\'(.*?)\\'\\,\", content)[0]\n\n\ndef parse_title(content):\n return re.findall(r\"title.*?\\:.*?\\'(.*?)\\'\\,\", content)[0]\n\n\ndef parse_doc(content):\n result = ''\n url_list = re.findall('(https.*?0.json.*?)\\\\\\\\x22}', content)\n url_list = [addr.replace(\"\\\\\\\\\\\\/\", \"/\") for addr in url_list]\n for url in url_list[:-5]:\n content = fetch_url(url)\n y = 0\n txtlists = re.findall('\"c\":\"(.*?)\".*?\"y\":(.*?),', content)\n for item in txtlists:\n if not y == item[1]:\n y = item[1]\n n = '\\n'\n else:\n n = ''\n result += n\n result += item[0].encode('utf-8').decode('unicode_escape', 'ignore')\n return result\n\n\ndef parse_txt(doc_id):\n content_url = 'https://wenku.baidu.com/api/doc/getdocinfo?callback=cb&doc_id=' + doc_id\n content = fetch_url(content_url)\n md5 = re.findall('\"md5sum\":\"(.*?)\"', content)[0]\n pn = re.findall('\"totalPageNum\":\"(.*?)\"', content)[0]\n rsign = re.findall('\"rsign\":\"(.*?)\"', content)[0]\n content_url = 'https://wkretype.bdimg.com/retype/text/' + doc_id + '?rn=' + pn + '&type=txt' + md5 + '&rsign=' + rsign\n content = json.loads(fetch_url(content_url))\n result = ''\n for item in content:\n for i in item['parags']:\n result += i['c'].replace('\\\\r', '\\r').replace('\\\\n', '\\n')\n return result\n\n\ndef parse_other(doc_id):\n content_url = \"https://wenku.baidu.com/browse/getbcsurl?doc_id=\" + doc_id + \"&pn=1&rn=99999&type=ppt\"\n content = fetch_url(content_url)\n url_list = re.findall('{\"zoom\":\"(.*?)\",\"page\"', content)\n url_list = [item.replace(\"\\\\\", '') for item in url_list]\n if not os.path.exists(doc_id):\n os.mkdir(doc_id)\n for index, url in enumerate(url_list):\n content = session.get(url).content\n path = os.path.join(doc_id, str(index) + '.jpg')\n with open(path, 'wb') as f:\n f.write(content)\n print(\"图片保存在\" + doc_id + \"文件夹\")\n\n\ndef save_file(filename, content):\n with open(filename, 'w', encoding='utf8') as f:\n f.write(content)\n print('已保存为:' + filename)\n\n\n# test_txt_url = 'https://wenku.baidu.com/view/cbb4af8b783e0912a3162a89.html?from=search'\n# test_ppt_url = 'https://wenku.baidu.com/view/2b7046e3f78a6529657d5376.html?from=search'\n# test_pdf_url = 'https://wenku.baidu.com/view/dd6e15c1227916888586d795.html?from=search'\n# test_xls_url = 'https://wenku.baidu.com/view/eb4a5bb7312b3169a551a481.html?from=search'\ndef main():\n url = input('请输入要下载的文库URL地址')\n content = fetch_url(url)\n doc_id = get_doc_id(url)\n type = parse_type(content)\n title = parse_title(content)\n if type == 'doc':\n result = parse_doc(content)\n save_file(title + '.txt', result)\n elif type == 'txt':\n result = parse_txt(doc_id)\n save_file(title + '.txt', result)\n else:\n parse_other(doc_id)\n\n\nif __name__ == \"__main__\":\n main()\n"
},
{
"path": "baiwan/app.js",
"content": "var http = require('http');\nvar fs = require('fs');\nvar schedule = require(\"node-schedule\"); \nvar message = {};\nvar count = 0;\nvar server = http.createServer(function (req,res){\n fs.readFile('./index.html',function(error,data){\n res.writeHead(200,{'Content-Type':'text/html'});\n res.end(data,'utf-8');\n });\n}).listen(80);\nconsole.log('Server running!');\nvar lineReader = require('line-reader');\nfunction messageGet(){\n lineReader.eachLine('file.txt', function(line, last) {\n count++;\n var name = 'line' + count;\n console.log(name);\n\tconsole.log(line);\n message[name] = line;\n }); \n if(count == 25){\n \tcount = 0;\n }\n else{\n \tfor(var i = count+1; i <= 25; i++){\n \t var name = 'line' + i;\n message[name] = 'f';\n\t}\n \tcount = 0;\n }\n}\nvar io = require('socket.io').listen(server);\nvar rule = new schedule.RecurrenceRule();\nvar times = [];\nfor(var i=1; i<1800; i++){\n times.push(i);\n}\nrule.second = times;\nschedule.scheduleJob(rule, function(){\n messageGet();\n});\nio.sockets.on('connection',function(socket){\n // console.log('User connected' + count + 'user(s) present');\n socket.emit('users',message);\n socket.broadcast.emit('users',message);\n\n socket.on('disconnect',function(){\n console.log('User disconnected');\n //socket.broadcast.emit('users',message); \n });\n});\n"
},
{
"path": "baiwan/baiwan.py",
"content": "# -*-coding:utf-8 -*-\nimport requests\nfrom lxml import etree\nfrom bs4 import BeautifulSoup\nimport urllib\nimport time, re, types, os\n\n\n\"\"\"\n代码写的匆忙,本来想再重构下,完善好注释再发,但是比较忙,想想算了,所以自行完善吧!写法很不规范,勿见怪。\n\n作者: Jack Cui\nWebsite:http://cuijiahua.com\n注: 本软件仅用于学习交流,请勿用于任何商业用途!\n\"\"\"\n\nclass BaiWan():\n\tdef __init__(self):\n\t\t# 百度知道搜索接口\n\t\tself.baidu = 'http://zhidao.baidu.com/search?'\n\t\t# 百万英雄及接口,每个人的接口都不一样,里面包含的手机信息,因此不公布,请自行抓包,有疑问欢迎留言:http://cuijiahua.com/liuyan.html\n\t\tself.api = 'https://api-spe-ttl.ixigua.com/xxxxxxx={}'.format(int(time.time()*1000))\n\n\t# 获取答案并解析问题\n\tdef get_question(self):\n\t\tto = True\n\t\twhile to:\n\t\t\tlist_dir = os.listdir('./')\n\t\t\tif 'question.txt' not in list_dir:\n\t\t\t\tfw = open('question.txt', 'w')\n\t\t\t\tfw.write('百万英雄尚未出题请稍后!')\n\t\t\t\tfw.close()\t\t\n\t\t\tgo = True\n\t\t\twhile go:\n\t\t\t\treq = requests.get(self.api, verify=False)\n\t\t\t\treq.encoding = 'utf-8'\n\t\t\t\thtml = req.text\n\n\t\t\t\tprint(html)\n\t\t\t\tif '*' in html:\n\t\t\t\t\tquestion_start = html.index('*')\n\t\t\t\t\ttry:\n\t\t\t\t\t\t\n\t\t\t\t\t\tquestion_end = html.index('?')\n\t\t\t\t\texcept:\n\t\t\t\t\t\tquestion_end = html.index('?')\n\t\t\t\t\tquestion = html[question_start:question_end][2:]\n\t\t\t\t\tif question != None:\n\t\t\t\t\t\tfr = open('question.txt', 'r')\n\t\t\t\t\t\ttext = fr.readline()\n\t\t\t\t\t\tfr.close()\n\t\t\t\t\t\tif text != question:\n\t\t\t\t\t\t\tprint(question)\n\t\t\t\t\t\t\tgo = False\n\t\t\t\t\t\t\twith open('question.txt', 'w') as f:\n\t\t\t\t\t\t\t\tf.write(question)\n\t\t\t\t\t\telse:\n\t\t\t\t\t\t\ttime.sleep(1)\n\t\t\t\t\telse:\n\t\t\t\t\t\tto = False\n\t\t\t\telse:\n\t\t\t\t\tto = False\n\n\t\t\ttemp = re.findall(r'[\\u4e00-\\u9fa5a-zA-Z0-9\\+\\-\\*/]', html[question_end+1:])\n\t\t\tb_index = []\n\t\t\tprint(temp)\n\n\t\t\tfor index, each in enumerate(temp):\n\t\t\t\tif each == 'B':\n\t\t\t\t\tb_index.append(index)\n\t\t\t\telif each == 'P' and (len(temp) - index) <= 3 :\n\t\t\t\t\tb_index.append(index)\n\t\t\t\t\tbreak\n\n\t\t\tif len(b_index) == 4:\n\t\t\t\ta = ''.join(temp[b_index[0] + 1:b_index[1]])\n\t\t\t\tb = ''.join(temp[b_index[1] + 1:b_index[2]])\n\t\t\t\tc = ''.join(temp[b_index[2] + 1:b_index[3]])\n\t\t\t\talternative_answers = [a,b,c]\n\n\t\t\t\tif '下列' in question:\n\t\t\t\t\tquestion = a + ' ' + b + ' ' + c + ' ' + question.replace('下列', '')\n\t\t\t\telif '以下' in question:\n\t\t\t\t\tquestion = a + ' ' + b + ' ' + c + ' ' + question.replace('以下', '')\n\t\t\telse:\n\t\t\t\talternative_answers = []\n\t\t\t# 根据问题和备选答案搜索答案\n\t\t\tself.search(question, alternative_answers)\n\t\t\ttime.sleep(1)\n\n\tdef search(self, question, alternative_answers):\n\t\tprint(question)\n\t\tprint(alternative_answers)\n\t\tinfos = {\"word\":question}\n\t\t# 调用百度接口\n\t\turl = self.baidu + 'lm=0&rn=10&pn=0&fr=search&ie=gbk&' + urllib.parse.urlencode(infos, encoding='GB2312')\n\t\tprint(url)\n\t\theaders = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.86 Safari/537.36',\n\t\t}\n\t\tsess = requests.Session()\n\t\treq = sess.get(url = url, headers=headers, verify=False)\n\t\treq.encoding = 'gbk'\n\t\t# print(req.text)\n\t\tbf = BeautifulSoup(req.text, 'lxml')\n\t\tanswers = bf.find_all('dd',class_='dd answer')\n\t\tfor answer in answers:\n\t\t\tprint(answer.text)\n\n\t\t# 推荐答案\n\t\trecommend = ''\n\t\tif alternative_answers != []:\n\t\t\tbest = []\n\t\t\tprint('\\n')\n\t\t\tfor answer in answers:\n\t\t\t\t# print(answer.text)\n\t\t\t\tfor each_answer in alternative_answers:\n\t\t\t\t\tif each_answer in answer.text:\n\t\t\t\t\t\tbest.append(each_answer)\n\t\t\t\t\t\tprint(each_answer,end=' ')\n\t\t\t\t\t\t# print(answer.text)\n\t\t\t\t\t\tprint('\\n')\n\t\t\t\t\t\tbreak\n\t\t\tstatistics = {}\n\t\t\tfor each in best:\n\t\t\t\tif each not in statistics.keys():\n\t\t\t\t\tstatistics[each] = 1\n\t\t\t\telse:\n\t\t\t\t\tstatistics[each] += 1\n\t\t\terrors = ['没有', '不是', '不对', '不正确','错误','不包括','不包含','不在','错']\n\t\t\terror_list = list(map(lambda x: x in question, errors))\n\t\t\tprint(error_list)\n\t\t\tif sum(error_list) >= 1:\n\t\t\t\tfor each_answer in alternative_answers:\n\t\t\t\t\tif each_answer not in statistics.items():\n\t\t\t\t\t\trecommend = each_answer\n\t\t\t\t\t\tprint('推荐答案:', recommend)\n\t\t\t\t\t\tbreak\n\t\t\telif statistics != {}:\n\t\t\t\trecommend = sorted(statistics.items(), key=lambda e:e[1], reverse=True)[0][0]\n\t\t\t\tprint('推荐答案:', recommend)\n\n\t\t# 写入文件\n\t\twith open('file.txt', 'w') as f:\n\t\t\tf.write('问题:' + question)\n\t\t\tf.write('\\n')\n\t\t\tf.write('*' * 50)\n\t\t\tf.write('\\n')\n\t\t\tif alternative_answers != []:\n\t\t\t\tf.write('选项:')\n\t\t\t\tfor i in range(len(alternative_answers)):\n\t\t\t\t\tf.write(alternative_answers[i])\n\t\t\t\t\tf.write(' ')\n\t\t\tf.write('\\n')\n\t\t\tf.write('*' * 50)\n\t\t\tf.write('\\n')\n\t\t\tf.write('参考答案:\\n')\n\t\t\tfor answer in answers:\n\t\t\t\tf.write(answer.text)\n\t\t\t\tf.write('\\n')\n\t\t\tf.write('*' * 50)\n\t\t\tf.write('\\n')\n\t\t\tif recommend != '':\n\t\t\t\tf.write('最终答案请自行斟酌!\\t')\n\t\t\t\tf.write('推荐答案:' + sorted(statistics.items(), key=lambda e:e[1], reverse=True)[0][0])\n\n\nif __name__ == '__main__':\n\tbw = BaiWan()\n\tbw.get_question()"
},
{
"path": "baiwan/file.txt",
"content": "⣺Ǽ¼\n**************************************************\nѡ723 81 101 \n**************************************************\nο𰸣\n\nƼ\n81 ÿİһйžգҲСһڡ August 1, anniversary of the founding of the Chinese People's Liberation Army֪Ⱦ뵽http://baike.baidu.com/view/23211.htm\n[ϸ]\n\nãйžĽÿİһգưһڣİһպ\n𣺽81գ71ա ÿ81йžգ׳ơһڡ192781գй챱ˣܶ Ҷͦ е쵼£ڽϲװ壬췴Թ...\n730\n𣺰һǽڣǰһ첻731ô\n192781һϲ,йװɵĵһǹ,־йй쵼װʱ,־й͵ӵĵÿİһйž\nԴйʱй쵼ϲ塣192781յϲ壬йװɵĵһǹ־йй쵼װʱڣ־й͵ӵĵ 19337£...\nԪ1181101\n𣺰һŽ\n 201581 ũ ʮ 201681 ũ إ ÿİһйžգҲСһڡ1933711գлάʱίԱ630յĽ飬81...\n**************************************************\nմã\tƼ𰸣81"
},
{
"path": "baiwan/index.html",
"content": "\n\n \n \n \n Jack Cui答题辅助系统\n \n \n 百万英雄答题辅助系统
\n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n \n\n \n\n"
},
{
"path": "baiwan/question.txt",
"content": "Ǽ¼"
},
{
"path": "bilibili/README.md",
"content": "## 功能\n\n下载B站视频和弹幕,将xml原生弹幕转换为ass弹幕文件,支持plotplayer等播放器的弹幕播放。\n\n## 作者\n\n* Website: [http://cuijiahua.com](http://cuijiahua.com \"悬停显示\")\n* Author: Jack Cui\n* Date: 2018.6.12\n\n## 更新\n\n* 2018.09.12:添加FFmpeg分段视频合并\n\n## 使用说明\n\nFFmpeg下载,并配置环境变量。http://ffmpeg.org/\n\n\tpython bilibili.py -d 猫 -k 猫 -p 10\n\n\t三个参数:\n\t-d\t保存视频的文件夹名\n\t-k\tB站搜索的关键字\n\t-p\t下载搜索结果前多少页\n"
},
{
"path": "bilibili/bilibili.py",
"content": "# -*-coding:utf-8 -*-\n# Website: http://cuijiahua.com\n# Author: Jack Cui\n# Date: 2018.6.9\n\nimport requests, json, re, sys, os, urllib, argparse, time\nfrom urllib.request import urlretrieve\nfrom contextlib import closing\nfrom urllib import parse\nimport xml2ass\n\nclass BiliBili:\n\tdef __init__(self, dirname, keyword):\n\t\tself.dn_headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.167 Safari/537.36',\n\t\t\t'Accept': '*/*',\n\t\t\t'Accept-Encoding': 'gzip, deflate, br',\n\t\t\t'Accept-Language': 'zh-CN,zh;q=0.9',\n\t\t\t'Referer': 'https://search.bilibili.com/all?keyword=%s' % parse.quote(keyword)}\n\n\t\tself.search_headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.167 Safari/537.36',\n\t\t\t'Accept-Language': 'zh-CN,zh;q=0.9',\n\t\t\t'Accept-Encoding': 'gzip, deflate, br',\n\t\t\t'Accept': 'application/json, text/plain, */*'}\n\n\t\tself.video_headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.167 Safari/537.36',\n\t\t\t'Accept-Language': 'zh-CN,zh;q=0.9',\n\t\t\t'Accept-Encoding': 'gzip, deflate, br',\n\t\t\t'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8'}\n\n\t\tself.danmu_header = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.167 Safari/537.36',\n\t\t\t'Accept': '*/*',\n\t\t\t'Accept-Encoding': 'gzip, deflate, br',\n\t\t\t'Accept-Language': 'zh-CN,zh;q=0.9'}\n\n\t\tself.sess = requests.Session()\n\n\t\tself.dir = dirname\n\n\tdef video_downloader(self, video_url, video_name):\n\t\t\"\"\"\n\t\t视频下载\n\t\tParameters:\n\t\t\tvideo_url: 带水印的视频地址\n\t\t\tvideo_name: 视频名\n\t\tReturns:\n\t\t\t无\n\t\t\"\"\"\n\t\tsize = 0\n\t\twith closing(self.sess.get(video_url, headers=self.dn_headers, stream=True, verify=False)) as response:\n\t\t\tchunk_size = 1024\n\t\t\tcontent_size = int(response.headers['content-length'])\n\t\t\tif response.status_code == 200:\n\t\t\t\tsys.stdout.write(' [文件大小]:%0.2f MB\\n' % (content_size / chunk_size / 1024))\n\t\t\t\tvideo_name = os.path.join(self.dir, video_name)\n\t\t\t\twith open(video_name, 'wb') as file:\n\t\t\t\t\tfor data in response.iter_content(chunk_size = chunk_size):\n\t\t\t\t\t\tfile.write(data)\n\t\t\t\t\t\tsize += len(data)\n\t\t\t\t\t\tfile.flush()\n\n\t\t\t\t\t\tsys.stdout.write(' [下载进度]:%.2f%%' % float(size / content_size * 100) + '\\r')\n\t\t\t\t\t\t# sys.stdout.flush()\n\t\t\t\t\t\tif size / content_size == 1:\n\t\t\t\t\t\t\tprint('\\n')\n\t\t\telse:\n\t\t\t\tprint('链接异常')\n\n\tdef search_video(self, search_url):\n\t\t\"\"\"\n\t\t搜索接口\n\t\tParameters:\n\t\t\tsearch_url: 带水印的视频地址\n\t\tReturns:\n\t\t\ttitles:视频名列表\n\t\t\tarcurls: 视频播放地址列表\n\t\t\"\"\"\n\t\treq = self.sess.get(url=search_url, headers=self.search_headers, verify=False)\n\t\thtml = json.loads(req.text)\n\t\tvideos = html[\"data\"]['result']\n\t\ttitles = []\n\t\tarcurls = []\n\t\tfor video in videos:\n\t\t\ttitles.append(video['title'].replace('','').replace('',''))\n\t\t\tarcurls.append(video['arcurl'])\n\t\treturn titles, arcurls\n\n\tdef get_download_url(self, arcurl):\n\t\t\"\"\"\n\t\t获取视频下载地址\n\t\tParameters:\n\t\t\tarcurl: 视频播放地址\n\t\t\toid:弹幕地址参数\n\t\tReturns:\n\t\t\tdownload_url:视频下载地址\n\t\t\"\"\"\n\t\treq = self.sess.get(url=arcurl, headers=self.video_headers, verify=False)\n\t\tpattern = '.__playinfo__=(.*)\")\n\t\ttac = _tac_re.search(share_user.text).group(1)\n\t\t_dytk_re = re.compile(r\"dytk\\s*:\\s*'(.+)'\")\n\t\tdytk = _dytk_re.search(share_user.text).group(1)\n\t\t_nickname_re = re.compile(r'(.+?)<\\/p>')\n\t\tnickname = _nickname_re.search(share_user.text).group(1)\n\t\tdata = {\n\t\t\t'tac': tac.split('|')[0],\n\t\t\t'user_id': user_id,\n\t\t}\n\t\treq = requests.post(sign_api, data=data)\n\t\twhile req.status_code != 200:\n\t\t\treq = requests.post(sign_api, data=data)\n\t\tsign = req.json().get('signature')\n\t\tuser_url_prefix = 'https://www.iesdouyin.com/web/api/v2/aweme/like' if type_flag == 'f' else 'https://www.iesdouyin.com/web/api/v2/aweme/post'\n\t\tprint('解析视频链接中')\n\t\twhile has_more != 0:\n\t\t\tuser_url = user_url_prefix + '/?user_id=%s&sec_uid=&count=21&max_cursor=%s&aid=1128&_signature=%s&dytk=%s' % (user_id, max_cursor, sign, dytk)\n\t\t\treq = requests.get(user_url, headers=self.headers)\n\t\t\twhile req.status_code != 200:\n\t\t\t\treq = requests.get(user_url, headers=self.headers)\n\t\t\thtml = json.loads(req.text)\n\t\t\tfor each in html['aweme_list']:\n\t\t\t\ttry:\n\t\t\t\t\turl = 'https://aweme.snssdk.com/aweme/v1/play/?video_id=%s&line=0&ratio=720p&media_type=4&vr_type=0&improve_bitrate=0&is_play_url=1&is_support_h265=0&source=PackSourceEnum_PUBLISH'\n\t\t\t\t\tvid = each['video']['vid']\n\t\t\t\t\tvideo_url = url % vid\n\t\t\t\texcept:\n\t\t\t\t\tcontinue\n\t\t\t\tshare_desc = each['desc']\n\t\t\t\tif os.name == 'nt':\n\t\t\t\t\tfor c in r'\\/:*?\"<>|':\n\t\t\t\t\t\tnickname = nickname.replace(c, '').strip().strip('\\.')\n\t\t\t\t\t\tshare_desc = share_desc.replace(c, '').strip()\n\t\t\t\tshare_id = each['aweme_id']\n\t\t\t\tif share_desc in ['抖音-原创音乐短视频社区', 'TikTok', '']:\n\t\t\t\t\tvideo_names.append(share_id + '.mp4')\n\t\t\t\telse:\n\t\t\t\t\tvideo_names.append(share_id + '-' + share_desc + '.mp4')\n\t\t\t\tshare_url = 'https://www.iesdouyin.com/share/video/%s' % share_id\n\t\t\t\tshare_urls.append(share_url)\n\t\t\t\tvideo_urls.append(video_url)\n\t\t\tmax_cursor = html['max_cursor']\n\t\t\thas_more = html['has_more']\n\n\t\treturn video_names, video_urls, share_urls, nickname\n\n\tdef get_download_url(self, video_url, watermark_flag):\n\t\t\"\"\"\n\t\t获得带水印的视频播放地址\n\t\tParameters:\n\t\t\tvideo_url:带水印的视频播放地址\n\t\tReturns:\n\t\t\tdownload_url: 带水印的视频下载地址\n\t\t\"\"\"\n\t\t# 带水印视频\n\t\tif watermark_flag == True:\n\t\t\tdownload_url = video_url.replace('/play/', '/playwm/')\n\t\t# 无水印视频\n\t\telse:\n\t\t\tdownload_url = video_url.replace('/playwm/', '/play/')\n\n\t\treturn download_url\n\n\tdef video_downloader(self, video_url, video_name, watermark_flag=False):\n\t\t\"\"\"\n\t\t视频下载\n\t\tParameters:\n\t\t\tvideo_url: 带水印的视频地址\n\t\t\tvideo_name: 视频名\n\t\t\twatermark_flag: 是否下载带水印的视频\n\t\tReturns:\n\t\t\t无\n\t\t\"\"\"\n\t\tsize = 0\n\t\tvideo_url = self.get_download_url(video_url, watermark_flag=watermark_flag)\n\t\twith closing(requests.get(video_url, headers=self.headers1, stream=True)) as response:\n\t\t\tchunk_size = 1024\n\t\t\tcontent_size = int(response.headers['content-length'])\n\t\t\tif response.status_code == 200:\n\t\t\t\tsys.stdout.write(' [文件大小]:%0.2f MB\\n' % (content_size / chunk_size / 1024))\n\n\t\t\t\twith open(video_name, 'wb') as file:\n\t\t\t\t\tfor data in response.iter_content(chunk_size = chunk_size):\n\t\t\t\t\t\tfile.write(data)\n\t\t\t\t\t\tsize += len(data)\n\t\t\t\t\t\tfile.flush()\n\n\t\t\t\t\t\tsys.stdout.write(' [下载进度]:%.2f%%' % float(size / content_size * 100) + '\\r')\n\t\t\t\t\t\tsys.stdout.flush()\n\n\tdef run(self):\n\t\t\"\"\"\n\t\t运行函数\n\t\tParameters:\n\t\t\tNone\n\t\tReturns:\n\t\t\tNone\n\t\t\"\"\"\n\t\tself.hello()\n\t\tprint('UID取得方式:\\n分享用户页面,用浏览器打开短链接,原始链接中/share/user/后的数字即是UID')\n\t\tuser_id = input('请输入UID (例如60388937600):')\n\t\tuser_id = user_id if user_id else '60388937600'\n\t\twatermark_flag = input('是否下载带水印的视频 (0-否(默认), 1-是):')\n\t\twatermark_flag = watermark_flag if watermark_flag!='' else '0'\n\t\twatermark_flag = bool(int(watermark_flag))\n\t\ttype_flag = input('f-收藏的(默认), p-上传的:')\n\t\ttype_flag = type_flag if type_flag!='' else 'f'\n\t\tsave_dir = input('保存路径 (例如\"E:/Download/\", 默认\"./Download/\"):')\n\t\tsave_dir = save_dir if save_dir else \"./Download/\"\n\t\tvideo_names, video_urls, share_urls, nickname = self.get_video_urls(user_id, type_flag)\n\t\tnickname_dir = os.path.join(save_dir, nickname)\n\t\tif not os.path.exists(save_dir):\n\t\t\tos.makedirs(save_dir)\n\t\tif nickname not in os.listdir(save_dir):\n\t\t\tos.mkdir(nickname_dir)\n\t\tif type_flag == 'f':\n\t\t\tif 'favorite' not in os.listdir(nickname_dir):\n\t\t\t\tos.mkdir(os.path.join(nickname_dir, 'favorite'))\n\t\tprint('视频下载中:共有%d个作品!\\n' % len(video_urls))\n\t\tfor num in range(len(video_urls)):\n\t\t\tprint(' 解析第%d个视频链接 [%s] 中,请稍后!\\n' % (num + 1, share_urls[num]))\n\t\t\tif '\\\\' in video_names[num]:\n\t\t\t\tvideo_name = video_names[num].replace('\\\\', '')\n\t\t\telif '/' in video_names[num]:\n\t\t\t\tvideo_name = video_names[num].replace('/', '')\n\t\t\telse:\n\t\t\t\tvideo_name = video_names[num]\n\t\t\tvideo_path = os.path.join(nickname_dir, video_name) if type_flag!='f' else os.path.join(nickname_dir, 'favorite', video_name)\n\t\t\tif os.path.isfile(video_path):\n\t\t\t\tprint('视频已存在')\n\t\t\telse:\n\t\t\t\tself.video_downloader(video_urls[num], video_path, watermark_flag)\n\t\t\tprint('\\n')\n\t\tprint('下载完成!')\n\n\tdef hello(self):\n\t\t\"\"\"\n\t\t打印欢迎界面\n\t\tParameters:\n\t\t\tNone\n\t\tReturns:\n\t\t\tNone\n\t\t\"\"\"\n\t\tprint('*' * 100)\n\t\tprint('\\t\\t\\t\\t抖音App视频下载小助手')\n\t\tprint('\\t\\t作者:Jack Cui、steven7851')\n\t\tprint('*' * 100)\n\n\nif __name__ == '__main__':\n\tdouyin = DouYin()\n\tdouyin.run()\n"
},
{
"path": "douyin/fuck-byted-acrawler.js",
"content": "// Referer:https://raw.githubusercontent.com/loadchange/amemv-crawler/master/fuck-byted-acrawler.js\nfunction generateSignature(userId) {\n this.navigator = {\n userAgent: \"Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 like Mac OS X) AppleWebKit/604.1.38 (KHTML, like Gecko) Version/11.0 Mobile/15A372 Safari/604.1\"\n }\n var e = {}\n\n var r = (function () {\n function e(e, a, r) {\n return (b[e] || (b[e] = t(\"x,y\", \"return x \" + e + \" y\")))(r, a)\n }\n\n function a(e, a, r) {\n return (k[r] || (k[r] = t(\"x,y\", \"return new x[y](\" + Array(r + 1).join(\",x[++y]\").substr(1) + \")\")))(e, a)\n }\n\n function r(e, a, r) {\n var n, t, s = {}, b = s.d = r ? r.d + 1 : 0;\n for (s[\"$\" + b] = s, t = 0; t < b; t++) s[n = \"$\" + t] = r[n];\n for (t = 0, b = s.length = a.length; t < b; t++) s[t] = a[t];\n return c(e, 0, s)\n }\n\n function c(t, b, k) {\n function u(e) {\n v[x++] = e\n }\n\n function f() {\n return g = t.charCodeAt(b++) - 32, t.substring(b, b += g)\n }\n\n function l() {\n try {\n y = c(t, b, k)\n } catch (e) {\n h = e, y = l\n }\n }\n\n for (var h, y, d, g, v = [], x = 0; ;) switch (g = t.charCodeAt(b++) - 32) {\n case 1:\n u(!v[--x]);\n break;\n case 4:\n v[x++] = f();\n break;\n case 5:\n u(function (e) {\n var a = 0, r = e.length;\n return function () {\n var c = a < r;\n return c && u(e[a++]), c\n }\n }(v[--x]));\n break;\n case 6:\n y = v[--x], u(v[--x](y));\n break;\n case 8:\n if (g = t.charCodeAt(b++) - 32, l(), b += g, g = t.charCodeAt(b++) - 32, y === c) b += g; else if (y !== l) return y;\n break;\n case 9:\n v[x++] = c;\n break;\n case 10:\n u(s(v[--x]));\n break;\n case 11:\n y = v[--x], u(v[--x] + y);\n break;\n case 12:\n for (y = f(), d = [], g = 0; g < y.length; g++) d[g] = y.charCodeAt(g) ^ g + y.length;\n u(String.fromCharCode.apply(null, d));\n break;\n case 13:\n y = v[--x], h = delete v[--x][y];\n break;\n case 14:\n v[x++] = t.charCodeAt(b++) - 32;\n break;\n case 59:\n u((g = t.charCodeAt(b++) - 32) ? (y = x, v.slice(x -= g, y)) : []);\n break;\n case 61:\n u(v[--x][t.charCodeAt(b++) - 32]);\n break;\n case 62:\n g = v[--x], k[0] = 65599 * k[0] + k[1].charCodeAt(g) >>> 0;\n break;\n case 65:\n h = v[--x], y = v[--x], v[--x][y] = h;\n break;\n case 66:\n u(e(t[b++], v[--x], v[--x]));\n break;\n case 67:\n y = v[--x], d = v[--x], u((g = v[--x]).x === c ? r(g.y, y, k) : g.apply(d, y));\n break;\n case 68:\n u(e((g = t[b++]) < \"<\" ? (b--, f()) : g + g, v[--x], v[--x]));\n break;\n case 70:\n u(!1);\n break;\n case 71:\n v[x++] = n;\n break;\n case 72:\n v[x++] = +f();\n break;\n case 73:\n u(parseInt(f(), 36));\n break;\n case 75:\n if (v[--x]) {\n b++;\n break\n }\n case 74:\n g = t.charCodeAt(b++) - 32 << 16 >> 16, b += g;\n break;\n case 76:\n u(k[t.charCodeAt(b++) - 32]);\n break;\n case 77:\n y = v[--x], u(v[--x][y]);\n break;\n case 78:\n g = t.charCodeAt(b++) - 32, u(a(v, x -= g + 1, g));\n break;\n case 79:\n g = t.charCodeAt(b++) - 32, u(k[\"$\" + g]);\n break;\n case 81:\n h = v[--x], v[--x][f()] = h;\n break;\n case 82:\n u(v[--x][f()]);\n break;\n case 83:\n h = v[--x], k[t.charCodeAt(b++) - 32] = h;\n break;\n case 84:\n v[x++] = !0;\n break;\n case 85:\n v[x++] = void 0;\n break;\n case 86:\n u(v[x - 1]);\n break;\n case 88:\n h = v[--x], y = v[--x], v[x++] = h, v[x++] = y;\n break;\n case 89:\n u(function () {\n function e() {\n return r(e.y, arguments, k)\n }\n\n return e.y = f(), e.x = c, e\n }());\n break;\n case 90:\n v[x++] = null;\n break;\n case 91:\n v[x++] = h;\n break;\n case 93:\n h = v[--x];\n break;\n case 0:\n return v[--x];\n default:\n u((g << 16 >> 16) - 16)\n }\n }\n\n var n = this, t = n.Function, s = Object.keys || function (e) {\n var a = {}, r = 0;\n for (var c in e) a[r++] = c;\n return a.length = r, a\n }, b = {}, k = {};\n return r\n })()\n ('gr$Daten Иb/s!l y͒yĹg,(lfi~ah`{mv,-n|jqewVxp{rvmmx,&effkx[!cs\"l\".Pq%widthl\"@q&heightl\"vr*getContextx$\"2d[!cs#l#,*;?|u.|uc{uq$fontl#vr(fillTextx$$龘ฑภ경2<[#c}l#2q*shadowBlurl#1q-shadowOffsetXl#$$limeq+shadowColorl#vr#arcx88802[%c}l#vr&strokex[ c}l\"v,)}eOmyoZB]mx[ cs!0s$l$Pb>>s!0s%yA0s\"l\"l!r&lengthb&l!l Bd>&+l!l &+l!l 6d>&+l!l &+ s,y=o!o!]/q\"13o!l q\"10o!],l 2d>& s.{s-yMo!o!]0q\"13o!]*Ld>>b|s!o!l q\"10o!],l!& s/yIo!o!].q\"13o!],o!]*Jd>>b|&o!]+l &+ s0l-l!&l-l!i\\'1z141z4b/@d= self.total: \n end_str = '\\n' \n self.status = status or self.fin_status \n print(self.__get_info(), end=end_str, ) \n\n\nif __name__ == '__main__':\n\t#url = 'http://www.demongan.com/source/game/二十四点.zip'\n\t#filename = '二十四点.zip'\n\tprint('*' * 100)\n\tprint('\\t\\t\\t\\t欢迎使用文件下载小助手')\n\tprint('作者:Jack-Cui\\n博客:http://blog.csdn.net/c406495762')\n\tprint('*' * 100)\n\turl = input('请输入需要下载的文件链接:\\n')\n\tfilename = url.split('/')[-1]\n\twith closing(requests.get(url, stream=True)) as response: \n\t\tchunk_size = 1024 \n\t\tcontent_size = int(response.headers['content-length']) \n\t\tif response.status_code == 200:\n\t\t\tprint('文件大小:%0.2f KB' % (content_size / chunk_size))\n\t\t\tprogress = ProgressBar(\"%s下载进度\" % filename\n\t\t\t , total = content_size \n\t\t\t , unit = \"KB\" \n\t\t\t , chunk_size = chunk_size \n\t\t\t , run_status = \"正在下载\" \n\t\t\t , fin_status = \"下载完成\") \n\n\t\t\twith open(filename, \"wb\") as file: \n\t\t\t for data in response.iter_content(chunk_size=chunk_size): \n\t\t\t file.write(data) \n\t\t\t progress.refresh(count=len(data)) \n\t\telse:\n\t\t\tprint('链接异常')"
},
{
"path": "financical.py",
"content": "#-*- coding:UTF-8 -*-\nimport sys\nimport pymysql\nimport requests\nimport json\nimport re\nfrom bs4 import BeautifulSoup\n\n\"\"\"\n类说明:获取财务数据\n\nAuthor:\n\tJack Cui\nBlog:\n\thttp://blog.csdn.net/c406495762\nZhihu:\n\thttps://www.zhihu.com/people/Jack--Cui/\nModify:\n\t2017-08-31\n\"\"\"\nclass FinancialData():\n\n\tdef __init__(self):\n\t\t#服务器域名\n\t\tself.server = 'http://quotes.money.163.com/'\n\t\tself.cwnb = 'http://quotes.money.163.com/hkstock/cwsj_'\n\t\t#主要财务指标\n\t\tself.cwzb_dict = {'EPS':'基本每股收益','EPS_DILUTED':'摊薄每股收益','GROSS_MARGIN':'毛利率',\n\t\t'CAPITAL_ADEQUACY':'资本充足率','LOANS_DEPOSITS':'贷款回报率','ROTA':'总资产收益率',\n\t\t'ROEQUITY':'净资产收益率','CURRENT_RATIO':'流动比率','QUICK_RATIO':'速动比率',\n\t\t'ROLOANS':'存贷比','INVENTORY_TURNOVER':'存货周转率','GENERAL_ADMIN_RATIO':'管理费用比率',\n\t\t'TOTAL_ASSET2TURNOVER':'资产周转率','FINCOSTS_GROSSPROFIT':'财务费用比率','TURNOVER_CASH':'销售现金比率','YEAREND_DATE':'报表日期'}\n\t\t#利润表\n\t\tself.lrb_dict = {'TURNOVER':'总营收','OPER_PROFIT':'经营利润','PBT':'除税前利润',\n\t\t'NET_PROF':'净利润','EPS':'每股基本盈利','DPS':'每股派息',\n\t\t'INCOME_INTEREST':'利息收益','INCOME_NETTRADING':'交易收益','INCOME_NETFEE':'费用收益','YEAREND_DATE':'报表日期'}\n\t\t#资产负债表\n\t\tself.fzb_dict = {\n\t\t\t'FIX_ASS':'固定资产','CURR_ASS':'流动资产','CURR_LIAB':'流动负债',\n\t\t\t'INVENTORY':'存款','CASH':'现金及银行存结','OTHER_ASS':'其他资产',\n\t\t\t'TOTAL_ASS':'总资产','TOTAL_LIAB':'总负债','EQUITY':'股东权益',\n\t\t\t'CASH_SHORTTERMFUND':'库存现金及短期资金','DEPOSITS_FROM_CUSTOMER':'客户存款',\n\t\t\t'FINANCIALASSET_SALE':'可供出售之证券','LOAN_TO_BANK':'银行同业存款及贷款',\n\t\t\t'DERIVATIVES_LIABILITIES':'金融负债','DERIVATIVES_ASSET':'金融资产','YEAREND_DATE':'报表日期'}\n\t\t#现金流表\n\t\tself.llb_dict = {\n\t\t\t'CF_NCF_OPERACT':'经营活动产生的现金流','CF_INT_REC':'已收利息','CF_INT_PAID':'已付利息',\n\t\t\t'CF_INT_REC':'已收股息','CF_DIV_PAID':'已派股息','CF_INV':'投资活动产生现金流',\n\t\t\t'CF_FIN_ACT':'融资活动产生现金流','CF_BEG':'期初现金及现金等价物','CF_CHANGE_CSH':'现金及现金等价物净增加额',\n\t\t\t'CF_END':'期末现金及现金等价物','CF_EXCH':'汇率变动影响','YEAREND_DATE':'报表日期'}\n\t\t#总表\n\t\tself.table_dict = {'cwzb':self.cwzb_dict,'lrb':self.lrb_dict,'fzb':self.fzb_dict,'llb':self.llb_dict}\n\t\t#请求头\n\t\tself.headers = {'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',\n\t\t\t'Accept-Encoding': 'gzip, deflate',\n\t\t\t'Accept-Language': 'zh-CN,zh;q=0.8',\n\t\t\t'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.109 Safari/537.36'}\n\t\n\t\"\"\"\n\t函数说明:获取股票页面信息\n\n\tAuthor:\n\t\tJack Cui\n\tParameters:\n\t url - 股票财务数据界面地址\n\tReturns:\n\t name - 股票名\n\t table_name_list - 财务报表名称\n\t table_date_list - 财务报表年限\n\t url_list - 财务报表查询连接\n\tBlog:\n\t\thttp://blog.csdn.net/c406495762\n\tZhihu:\n\t\thttps://www.zhihu.com/people/Jack--Cui/\n\tModify:\n\t\t2017-08-31\n\t\"\"\"\n\tdef get_informations(self, url):\n\t\treq = requests.get(url = url, headers = self.headers)\n\t\treq.encoding = 'utf-8'\n\t\thtml = req.text\n\t\tpage_bf = BeautifulSoup(html, 'lxml')\n\t\t#股票名称,股票代码\n\t\tname = page_bf.find_all('span', class_ = 'name')[0].string\n\t\t# code = page_bf.find_all('span', class_ = 'code')[0].string\n\t\t# code = re.findall('\\d+',code)[0]\n\n\t\t#存储各个表名的列表\n\t\ttable_name_list = []\n\t\ttable_date_list = []\n\t\teach_date_list = []\n\t\turl_list = []\n\t\t#表名和表时间\n\t\ttable_name = page_bf.find_all('div', class_ = 'titlebar3')\n\t\tfor each_table_name in table_name:\n\t\t\t#表名\n\t\t\ttable_name_list.append(each_table_name.span.string)\n\t\t\t#表时间\n\t\t\tfor each_table_date in each_table_name.div.find_all('select', id = re.compile('.+1$')):\n\t\t\t\turl_list.append(re.findall('(\\w+)1',each_table_date.get('id'))[0])\n\t\t\t\tfor each_date in each_table_date.find_all('option'):\n\t\t\t\t\teach_date_list.append(each_date.string)\n\t\t\t\ttable_date_list.append(each_date_list)\n\t\t\t\teach_date_list = []\n\t\treturn name,table_name_list,table_date_list,url_list\n\n\t\"\"\"\n\t函数说明:财务报表入库\n\n\tAuthor:\n\t\tJack Cui\n\tParameters:\n\t name - 股票名\n\t table_name_list - 财务报表名称\n\t table_date_list - 财务报表年限\n\t url_list - 财务报表查询连接\n\tReturns:\n\t\t无\n\tBlog:\n\t\thttp://blog.csdn.net/c406495762\n\tZhihu:\n\t\thttps://www.zhihu.com/people/Jack--Cui/\n\tModify:\n\t\t2017-08-31\n\t\"\"\"\n\tdef insert_tables(self, name, table_name_list,table_date_list, url_list):\n\t\t#打开数据库连接:host-连接主机地址,port-端口号,user-用户名,passwd-用户密码,db-数据库名,charset-编码\n\t\tconn = pymysql.connect(host='127.0.0.1', port=3306, user='root', passwd='yourpasswd',db='financialdata',charset='utf8')\n\t\t#使用cursor()方法获取操作游标\n\t\tcursor = conn.cursor() \n\t\t#插入信息\n\t\tfor i in range(len(table_name_list)):\n\t\t\tsys.stdout.write(' [正在下载 ] %s' % table_name_list[i] + '\\r')\n\t\t\t#获取数据地址\n\t\t\turl = self.server + 'hk/service/cwsj_service.php?symbol={}&start={}&end={}&type={}&unit=yuan'.format(code,table_date_list[i][-1],table_date_list[i][0],url_list[i])\n\t\t\treq_table = requests.get(url = url, headers = self.headers)\n\t\t\ttable = req_table.json()\n\t\t\tnums = len(table)\n\t\t\tvalue_dict = {}\n\t\t\tfor num in range(nums):\n\t\t\t\tsys.stdout.write(' [正在下载 %.2f%%] ' % (((num+1) / nums)*100) + '\\r')\n\t\t\t\tsys.stdout.flush()\n\t\t\t\tvalue_dict['股票名'] = name\n\t\t\t\tvalue_dict['股票代码'] = code\n\t\t\t\tfor key, value in table[i].items():\n\t\t\t\t\tif key in self.table_dict[url_list[i]]:\n\t\t\t\t\t\tvalue_dict[self.table_dict[url_list[i]][key]] = value\n\n\t\t\t\tsql1 = \"\"\"\n\t\t\t\tINSERT INTO %s (`股票名`,`股票代码`,`报表日期`) VALUES ('%s','%s','%s')\"\"\" % (url_list[i],value_dict['股票名'],value_dict['股票代码'],value_dict['报表日期'])\n\t\t\t\ttry:\n\t\t\t\t\tcursor.execute(sql1)\n\t\t\t\t\t# 执行sql语句\n\t\t\t\t\tconn.commit()\n\t\t\t\texcept:\n\t\t\t\t\t# 发生错误时回滚\n\t\t\t\t\tconn.rollback()\n\n\t\t\t\tfor key, value in value_dict.items():\n\t\t\t\t\tif key not in ['股票名','股票代码','报表日期']:\n\t\t\t\t\t\tsql2 = \"\"\"\n\t\t\t\t\t\tUPDATE %s SET %s='%s' WHERE `股票名`='%s' AND `报表日期`='%s'\"\"\" % (url_list[i],key,value,value_dict['股票名'],value_dict['报表日期'])\n\t\t\t\t\t\ttry:\n\t\t\t\t\t\t\tcursor.execute(sql2)\n\t\t\t\t\t\t\t# 执行sql语句\n\t\t\t\t\t\t\tconn.commit()\n\t\t\t\t\t\texcept:\n\t\t\t\t\t\t\t# 发生错误时回滚\n\t\t\t\t\t\t\tconn.rollback()\n\t\t\t\tvalue_dict = {}\n\t\t\tprint(' [下载完成 ')\n\n\t\t# 关闭数据库连接\n\t\tcursor.close() \n\t\tconn.close()\n\nif __name__ == '__main__':\n\tprint('*' * 100)\n\tprint('\\t\\t\\t\\t\\t财务数据下载助手\\n')\n\tprint('作者:Jack-Cui\\n')\n\tprint('About Me:\\n')\n\tprint(' 知乎:https://www.zhihu.com/people/Jack--Cui')\n\tprint(' Blog:http://blog.csdn.net/c406495762')\n\tprint(' Gihub:https://github.com/Jack-Cherish\\n')\n\tprint('*' * 100)\n\tfd = FinancialData()\n\t#上市股票地址\n\tcode = input('请输入股票代码:')\n\n\tname,table_name_list,table_date_list,url_list = fd.get_informations(fd.cwnb + code + '.html')\n\tprint('\\n %s:(%s)财务数据下载中!\\n' % (name,code))\n\tfd.insert_tables(name,table_name_list,table_date_list,url_list)\n\tprint('\\n %s:(%s)财务数据下载完成!' % (name,code))"
},
{
"path": "geetest.py",
"content": "# -*-coding:utf-8 -*-\nimport random\nimport re\nimport time\n# 图片转换\nimport base64\nfrom urllib.request import urlretrieve\n\nfrom bs4 import BeautifulSoup\n\nimport PIL.Image as image\nfrom selenium import webdriver\nfrom selenium.webdriver import ActionChains\nfrom selenium.webdriver.common.by import By\nfrom selenium.webdriver.support import expected_conditions as EC\nfrom selenium.webdriver.support.ui import WebDriverWait\n\ndef save_base64img(data_str, save_name):\n \"\"\"\n 将 base64 数据转化为图片保存到指定位置\n :param data_str: base64 数据,不包含类型\n :param save_name: 保存的全路径\n \"\"\"\n img_data = base64.b64decode(data_str)\n file = open(save_name, 'wb')\n file.write(img_data)\n file.close()\n\n\ndef get_base64_by_canvas(driver, class_name, contain_type):\n \"\"\"\n 将 canvas 标签内容转换为 base64 数据\n :param driver: webdriver 对象\n :param class_name: canvas 标签的类名\n :param contain_type: 返回的数据是否包含类型\n :return: base64 数据\n \"\"\"\n # 防止图片未加载完就下载一张空图\n bg_img = ''\n while len(bg_img) < 5000:\n getImgJS = 'return document.getElementsByClassName(\"' + class_name + '\")[0].toDataURL(\"image/png\");'\n bg_img = driver.execute_script(getImgJS)\n time.sleep(0.5)\n # print(bg_img)\n if contain_type:\n return bg_img\n else:\n return bg_img[bg_img.find(',') + 1:]\n\n\ndef save_bg(driver, bg_path=\"bg.png\", bg_class=\"geetest_canvas_bg geetest_absolute\"):\n \"\"\"\n 保存包含缺口的背景图\n :param driver: webdriver 对象\n :param bg_path: 保存路径\n :param bg_class: 背景图的 class 属性\n :return: 保存路径\n \"\"\"\n bg_img_data = get_base64_by_canvas(driver, bg_class, False)\n save_base64img(bg_img_data, bg_path)\n return bg_path\n\n\ndef save_full_bg(driver, full_bg_path=\"fbg.png\", full_bg_class=\"geetest_canvas_fullbg geetest_fade geetest_absolute\"):\n \"\"\"\n 保存完整的的背景图\n :param driver: webdriver 对象\n :param full_bg_path: 保存路径\n :param full_bg_class: 完整背景图的 class 属性\n :return: 保存路径\n \"\"\"\n bg_img_data = get_base64_by_canvas(driver, full_bg_class, False)\n save_base64img(bg_img_data, full_bg_path)\n return full_bg_path\n\nclass Crack():\n\tdef __init__(self,keyword):\n\t\tself.url = '*'\n\t\tself.browser = webdriver.Chrome('D:\\\\chromedriver.exe')\n\t\tself.wait = WebDriverWait(self.browser, 100)\n\t\tself.keyword = keyword\n\t\tself.BORDER = 6\n\n\tdef open(self):\n\t\t\"\"\"\n\t\t打开浏览器,并输入查询内容\n\t\t\"\"\"\n\t\tself.browser.get(self.url)\n\t\tkeyword = self.wait.until(EC.presence_of_element_located((By.ID, 'keyword_qycx')))\n\t\tbowton = self.wait.until(EC.presence_of_element_located((By.CLASS_NAME, 'btn')))\n\t\tkeyword.send_keys(self.keyword)\n\t\tbowton.click()\n\n\tdef get_images(self, bg_filename = 'bg.jpg', fullbg_filename = 'fullbg.jpg'):\n\t\t\"\"\"\n\t\t获取验证码图片\n\t\t:return: 图片的location信息\n\t\t\"\"\"\n\t\tbg = []\n\t\tfullgb = []\n\t\twhile bg == [] and fullgb == []:\n\t\t\tbf = BeautifulSoup(self.browser.page_source, 'lxml')\n\t\t\tbg = bf.find_all('div', class_ = 'gt_cut_bg_slice')\n\t\t\tfullgb = bf.find_all('div', class_ = 'gt_cut_fullbg_slice')\n\t\tbg_url = re.findall('url\\(\\\"(.*)\\\"\\);', bg[0].get('style'))[0].replace('webp', 'jpg')\n\t\tfullgb_url = re.findall('url\\(\\\"(.*)\\\"\\);', fullgb[0].get('style'))[0].replace('webp', 'jpg')\n\t\tbg_location_list = []\n\t\tfullbg_location_list = []\n\t\tfor each_bg in bg:\n\t\t\tlocation = {}\n\t\t\tlocation['x'] = int(re.findall('background-position: (.*)px (.*)px;',each_bg.get('style'))[0][0])\n\t\t\tlocation['y'] = int(re.findall('background-position: (.*)px (.*)px;',each_bg.get('style'))[0][1])\n\t\t\tbg_location_list.append(location)\n\t\tfor each_fullgb in fullgb:\n\t\t\tlocation = {}\n\t\t\tlocation['x'] = int(re.findall('background-position: (.*)px (.*)px;',each_fullgb.get('style'))[0][0])\n\t\t\tlocation['y'] = int(re.findall('background-position: (.*)px (.*)px;',each_fullgb.get('style'))[0][1])\n\t\t\tfullbg_location_list.append(location)\n\n\t\turlretrieve(url = bg_url, filename = bg_filename)\n\t\tprint('缺口图片下载完成')\n\t\turlretrieve(url = fullgb_url, filename = fullbg_filename)\n\t\tprint('背景图片下载完成')\n\t\treturn bg_location_list, fullbg_location_list\n\n\tdef get_merge_image(self, filename, location_list):\n\t\t\"\"\"\n\t\t根据位置对图片进行合并还原\n\t\t:filename:图片\n\t\t:location_list:图片位置\n\t\t\"\"\"\n\t\tim = image.open(filename)\n\t\tnew_im = image.new('RGB', (260,116))\n\t\tim_list_upper=[]\n\t\tim_list_down=[]\n\n\t\tfor location in location_list:\n\t\t\tif location['y'] == -58:\n\t\t\t\tim_list_upper.append(im.crop((abs(location['x']),58,abs(location['x']) + 10, 166)))\n\t\t\tif location['y'] == 0:\n\t\t\t\tim_list_down.append(im.crop((abs(location['x']),0,abs(location['x']) + 10, 58)))\n\n\t\tnew_im = image.new('RGB', (260,116))\n\n\t\tx_offset = 0\n\t\tfor im in im_list_upper:\n\t\t\tnew_im.paste(im, (x_offset,0))\n\t\t\tx_offset += im.size[0]\n\n\t\tx_offset = 0\n\t\tfor im in im_list_down:\n\t\t\tnew_im.paste(im, (x_offset,58))\n\t\t\tx_offset += im.size[0]\n\n\t\tnew_im.save(filename)\n\n\t\treturn new_im\n\n\tdef get_merge_image(self, filename, location_list):\n\t\t\"\"\"\n\t\t根据位置对图片进行合并还原\n\t\t:filename:图片\n\t\t:location_list:图片位置\n\t\t\"\"\"\n\t\tim = image.open(filename)\n\t\tnew_im = image.new('RGB', (260,116))\n\t\tim_list_upper=[]\n\t\tim_list_down=[]\n\n\t\tfor location in location_list:\n\t\t\tif location['y']==-58:\n\t\t\t\tim_list_upper.append(im.crop((abs(location['x']),58,abs(location['x'])+10,166)))\n\t\t\tif location['y']==0:\n\t\t\t\tim_list_down.append(im.crop((abs(location['x']),0,abs(location['x'])+10,58)))\n\n\t\tnew_im = image.new('RGB', (260,116))\n\n\t\tx_offset = 0\n\t\tfor im in im_list_upper:\n\t\t\tnew_im.paste(im, (x_offset,0))\n\t\t\tx_offset += im.size[0]\n\n\t\tx_offset = 0\n\t\tfor im in im_list_down:\n\t\t\tnew_im.paste(im, (x_offset,58))\n\t\t\tx_offset += im.size[0]\n\n\t\tnew_im.save(filename)\n\n\t\treturn new_im\n\n\tdef is_pixel_equal(self, img1, img2, x, y):\n\t\t\"\"\"\n\t\t判断两个像素是否相同\n\t\t:param image1: 图片1\n\t\t:param image2: 图片2\n\t\t:param x: 位置x\n\t\t:param y: 位置y\n\t\t:return: 像素是否相同\n\t\t\"\"\"\n\t\t# 取两个图片的像素点\n\t\tpix1 = img1.load()[x, y]\n\t\tpix2 = img2.load()[x, y]\n\t\tthreshold = 60\n\t\tif (abs(pix1[0] - pix2[0] < threshold) and abs(pix1[1] - pix2[1] < threshold) and abs(pix1[2] - pix2[2] < threshold)):\n\t\t\treturn True\n\t\telse:\n\t\t\treturn False\n\n\tdef get_gap(self, img1, img2):\n\t\t\"\"\"\n\t\t获取缺口偏移量\n\t\t:param img1: 不带缺口图片\n\t\t:param img2: 带缺口图片\n\t\t:return:\n\t\t\"\"\"\n\t\tleft = 43\n\t\tfor i in range(left, img1.size[0]):\n\t\t\tfor j in range(img1.size[1]):\n\t\t\t\tif not self.is_pixel_equal(img1, img2, i, j):\n\t\t\t\t\tleft = i\n\t\t\t\t\treturn left\n\t\treturn left\t\n\n\tdef get_track(self, distance):\n\t\t\"\"\"\n\t\t根据偏移量获取移动轨迹\n\t\t:param distance: 偏移量\n\t\t:return: 移动轨迹\n\t\t\"\"\"\n\t\t# 移动轨迹\n\t\ttrack = []\n\t\t# 当前位移\n\t\tcurrent = 0\n\t\t# 减速阈值\n\t\tmid = distance * 4 / 5\n\t\t# 计算间隔\n\t\tt = 0.2\n\t\t# 初速度\n\t\tv = 0\n \n\t\twhile current < distance:\n\t\t\tif current < mid:\n\t\t\t\t# 加速度为正2\n\t\t\t\ta = 2\n\t\t\telse:\t\n\t\t\t\t# 加速度为负3\n\t\t\t\ta = -3\n\t\t\t# 初速度v0\n\t\t\tv0 = v\n\t\t\t# 当前速度v = v0 + at\n\t\t\tv = v0 + a * t\n\t\t\t# 移动距离x = v0t + 1/2 * a * t^2\n\t\t\tmove = v0 * t + 1 / 2 * a * t * t\n\t\t\t# 当前位移\n\t\t\tcurrent += move\n\t\t\t# 加入轨迹\n\t\t\ttrack.append(round(move))\n\t\treturn track\n\n\tdef get_slider(self):\n\t\t\"\"\"\n\t\t获取滑块\n\t\t:return: 滑块对象\n\t\t\"\"\"\n\t\twhile True:\n\t\t\ttry:\n\t\t\t\tslider = self.browser.find_element_by_xpath(\"//div[@class='gt_slider_knob gt_show']\")\n\t\t\t\tbreak\n\t\t\texcept:\n\t\t\t\ttime.sleep(0.5)\n\t\treturn slider\n\n\tdef move_to_gap(self, slider, track):\n\t\t\"\"\"\n\t\t拖动滑块到缺口处\n\t\t:param slider: 滑块\n\t\t:param track: 轨迹\n\t\t:return:\n\t\t\"\"\"\n\t\tActionChains(self.browser).click_and_hold(slider).perform()\n\t\twhile track:\n\t\t\tx = random.choice(track)\n\t\t\tActionChains(self.browser).move_by_offset(xoffset=x, yoffset=0).perform()\n\t\t\ttrack.remove(x)\n\t\ttime.sleep(0.5)\n\t\tActionChains(self.browser).release().perform()\n\n\tdef crack(self):\n\t\t# 打开浏览器\n\t\tself.open()\n\n\t\t# 保存的图片名字\n\t\tbg_filename = 'bg.jpg'\n\t\tfullbg_filename = 'fullbg.jpg'\n\n\t\t# 获取图片\n\t\tbg_location_list, fullbg_location_list = self.get_images(bg_filename, fullbg_filename)\n\n\t\t# 根据位置对图片进行合并还原\n\t\t# 方法1\n\t\t# bg_img = self.get_merge_image(bg_filename, bg_location_list)\n\t\t# fullbg_img = self.get_merge_image(fullbg_filename, fullbg_location_list)\n\t\t# 方法2\n\t\tbg_img = save_bg(self.browser)\n\t\tfull_bg_img = save_full_bg(self.browser)\n\n\t\t# 获取缺口位置\n\t\t# 方法1\n\t\t# gap = self.get_gap(fullbg_img, bg_img)\n\t\t# 方法2\n\t\tgap = self.get_gap(image.open(full_bg_img), image.open(bg_img))\n\t\tprint('缺口位置', gap)\n\n\t\ttrack = self.get_track(gap-self.BORDER)\n\t\tprint('滑动滑块')\n\t\tprint(track)\n\n\t\t# # 点按呼出缺口\n\t\t# slider = self.get_slider()\n\t\t# # 拖动滑块到缺口处\n\t\t# self.move_to_gap(slider, track)\n\nif __name__ == '__main__':\n\tprint('开始验证')\n\tcrack = Crack(u'中国移动')\n\tcrack.crack()\n\tprint('验证成功')\n"
},
{
"path": "hero.py",
"content": "#-*- coding: UTF-8 -*-\nfrom urllib.request import urlretrieve\nimport requests\nimport os\n\n\"\"\"\n函数说明:下载《英雄联盟盒子》中的英雄图片\n\nParameters:\n url - GET请求地址,通过Fiddler抓包获取\n header - headers信息\nReturns:\n 无\nAuthor:\n Jack Cui\nBlog:\n http://blog.csdn.net/c406495762\nModify:\n 2017-08-07\n\"\"\"\ndef hero_imgs_download(url, header):\n req = requests.get(url = url, headers = header).json()\n hero_num = len(req['list'])\n print('一共有%d个英雄' % hero_num)\n hero_images_path = 'hero_images'\n for each_hero in req['list']:\n hero_photo_url = each_hero['cover']\n hero_name = each_hero['name'] + '.jpg'\n filename = hero_images_path + '/' + hero_name\n if hero_images_path not in os.listdir():\n os.makedirs(hero_images_path)\n urlretrieve(url = hero_photo_url, filename = filename)\n\n\"\"\"\n函数说明:打印所有英雄的名字和ID\n\nParameters:\n url - GET请求地址,通过Fiddler抓包获取\n header - headers信息\nReturns:\n 无\nAuthor:\n Jack Cui\nBlog:\n http://blog.csdn.net/c406495762\nModify:\n 2017-08-07\n\"\"\"\ndef hero_list(url, header):\n\tprint('*' * 100)\n\tprint('\\t\\t\\t\\t欢迎使用《王者荣耀》出装下助手!')\n\tprint('*' * 100)\n\treq = requests.get(url = url, headers = header).json()\n\tflag = 0\n\tfor each_hero in req['list']:\n\t\tflag += 1\n\t\tprint('%s的ID为:%-7s' % (each_hero['name'], each_hero['hero_id']), end = '\\t\\t')\n\t\tif flag == 3:\n\t\t\tprint('\\n', end = '')\n\t\t\tflag = 0\n\n\"\"\"\n函数说明:根据equip_id查询武器名字和价格\n\nParameters:\n equip_id - 武器的ID\n weapon_info - 存储所有武器的字典\nReturns:\n weapon_name - 武器的名字\n weapon_price - 武器的价格\nAuthor:\n Jack Cui\nBlog:\n http://blog.csdn.net/c406495762\nModify:\n 2017-08-07\n\"\"\"\ndef seek_weapon(equip_id, weapon_info):\n\tfor each_weapon in weapon_info:\n\t\tif each_weapon['equip_id'] == str(equip_id):\n\t\t\tweapon_name = each_weapon['name']\n\t\t\tweapon_price = each_weapon['price']\n\t\t\treturn weapon_name, weapon_price\n\n\n\"\"\"\n函数说明:获取并打印出装信息\n\nParameters:\n url - GET请求地址,通过Fiddler抓包获取\n header - headers信息\n weapon_info - 存储所有武器的字典\nReturns:\n\t无\nAuthor:\n Jack Cui\nBlog:\n http://blog.csdn.net/c406495762\nModify:\n 2017-08-07\n\"\"\"\ndef hero_info(url, header, weapon_info):\n\treq = requests.get(url = url, headers = header).json()\n\tprint('\\n历史上的%s:\\n %s' % (req['info']['name'], req['info']['history_intro']))\n\tfor each_equip_choice in req['info']['equip_choice']:\n\t\tprint('\\n%s:\\n %s' % (each_equip_choice['title'], each_equip_choice['description']))\n\t\ttotal_price = 0\n\t\tflag = 0\n\t\tfor each_weapon in each_equip_choice['list']:\n\t\t\tflag += 1\n\t\t\tweapon_name, weapon_price = seek_weapon(each_weapon['equip_id'], weapon_info)\n\t\t\tprint('%s:%s' % (weapon_name, weapon_price), end = '\\t')\n\t\t\tif flag == 3:\n\t\t\t\tprint('\\n', end = '')\n\t\t\t\tflag = 0\n\t\t\ttotal_price += int(weapon_price)\n\t\tprint('神装套件价格共计:%d' % total_price)\n\n\n\"\"\"\n函数说明:获取武器信息\n\nParameters:\n url - GET请求地址,通过Fiddler抓包获取\n header - headers信息\nReturns:\n weapon_info_dict - 武器信息\nAuthor:\n Jack Cui\nBlog:\n http://blog.csdn.net/c406495762\nModify:\n 2017-08-07\n\"\"\"\ndef hero_weapon(url, header):\n req = requests.get(url = url, headers = header).json()\n weapon_info_dict = req['list']\n return weapon_info_dict\n\n\nif __name__ == '__main__':\n headers = {'Accept-Charset': 'UTF-8',\n 'Accept-Encoding': 'gzip,deflate',\n 'User-Agent': 'Dalvik/2.1.0 (Linux; U; Android 6.0.1; MI 5 MIUI/V8.1.6.0.MAACNDI)',\n 'X-Requested-With': 'XMLHttpRequest',\n 'Content-type': 'application/x-www-form-urlencoded',\n 'Connection': 'Keep-Alive',\n 'Host': 'gamehelper.gm825.com'}\n weapon_url = \"http://gamehelper.gm825.com/wzry/equip/list?channel_id=90009a&app_id=h9044j&game_id=7622&game_name=%E7%8E%8B%E8%80%85%E8%8D%A3%E8%80%80&vcode=12.0.3&version_code=1203&cuid=2654CC14D2D3894DBF5808264AE2DAD7&ovr=6.0.1&device=Xiaomi_MI+5&net_type=1&client_id=1Yfyt44QSqu7PcVdDduBYQ%3D%3D&info_ms=fBzJ%2BCu4ZDAtl4CyHuZ%2FJQ%3D%3D&info_ma=XshbgIgi0V1HxXTqixI%2BKbgXtNtOP0%2Fn1WZtMWRWj5o%3D&mno=0&info_la=9AChHTMC3uW%2BfY8%2BCFhcFw%3D%3D&info_ci=9AChHTMC3uW%2BfY8%2BCFhcFw%3D%3D&mcc=0&clientversion=&bssid=VY%2BeiuZRJ%2FwaXmoLLVUrMODX1ZTf%2F2dzsWn2AOEM0I4%3D&os_level=23&os_id=dc451556fc0eeadb&resolution=1080_1920&dpi=480&client_ip=192.168.0.198&pdunid=a83d20d8\"\n heros_url = \"http://gamehelper.gm825.com/wzry/hero/list?channel_id=90009a&app_id=h9044j&game_id=7622&game_name=%E7%8E%8B%E8%80%85%E8%8D%A3%E8%80%80&vcode=12.0.3&version_code=1203&cuid=2654CC14D2D3894DBF5808264AE2DAD7&ovr=6.0.1&device=Xiaomi_MI+5&net_type=1&client_id=1Yfyt44QSqu7PcVdDduBYQ%3D%3D&info_ms=fBzJ%2BCu4ZDAtl4CyHuZ%2FJQ%3D%3D&info_ma=XshbgIgi0V1HxXTqixI%2BKbgXtNtOP0%2Fn1WZtMWRWj5o%3D&mno=0&info_la=9AChHTMC3uW%2BfY8%2BCFhcFw%3D%3D&info_ci=9AChHTMC3uW%2BfY8%2BCFhcFw%3D%3D&mcc=0&clientversion=&bssid=VY%2BeiuZRJ%2FwaXmoLLVUrMODX1ZTf%2F2dzsWn2AOEM0I4%3D&os_level=23&os_id=dc451556fc0eeadb&resolution=1080_1920&dpi=480&client_ip=192.168.0.198&pdunid=a83d20d8\"\n hero_list(heros_url, headers)\n hero_id = input(\"请输入要查询的英雄ID:\")\n hero_url = \"http://gamehelper.gm825.com/wzry/hero/detail?hero_id={}&channel_id=90009a&app_id=h9044j&game_id=7622&game_name=%E7%8E%8B%E8%80%85%E8%8D%A3%E8%80%80&vcode=12.0.3&version_code=1203&cuid=2654CC14D2D3894DBF5808264AE2DAD7&ovr=6.0.1&device=Xiaomi_MI+5&net_type=1&client_id=1Yfyt44QSqu7PcVdDduBYQ%3D%3D&info_ms=fBzJ%2BCu4ZDAtl4CyHuZ%2FJQ%3D%3D&info_ma=XshbgIgi0V1HxXTqixI%2BKbgXtNtOP0%2Fn1WZtMWRWj5o%3D&mno=0&info_la=9AChHTMC3uW%2BfY8%2BCFhcFw%3D%3D&info_ci=9AChHTMC3uW%2BfY8%2BCFhcFw%3D%3D&mcc=0&clientversion=&bssid=VY%2BeiuZRJ%2FwaXmoLLVUrMODX1ZTf%2F2dzsWn2AOEM0I4%3D&os_level=23&os_id=dc451556fc0eeadb&resolution=1080_1920&dpi=480&client_ip=192.168.0.198&pdunid=a83d20d8\".format(hero_id)\n weapon_info_dict = hero_weapon(weapon_url, headers)\n hero_info(hero_url, headers, weapon_info_dict)"
},
{
"path": "one_hour_spider/biquge20180731.py",
"content": "# -*- coding:utf-8 -*-\nimport requests\nfrom bs4 import BeautifulSoup\nimport os\n\n\"\"\"\n从www.biqubao.com笔趣阁爬取小说,楼主教程中的网址我当时没打开,\n就参照楼主教程,爬取了笔趣阁小说网的内容。\n 2018-07-31\n\"\"\"\n\nif __name__=='__main__':\n #所要爬取的小说主页,每次使用时,修改该网址即可,同时保证本地保存根路径存在即可\n target=\"https://www.biqubao.com/book/17570/\"\n # 本地保存爬取的文本根路径\n save_path = 'G:/pythonlearn'\n #笔趣阁网站根路径\n index_path='https://www.biqubao.com'\n\n req=requests.get(url=target)\n #查看request默认的编码,发现与网站response不符,改为网站使用的gdk\n print(req.encoding)\n req.encoding = 'gbk'\n #解析html\n soup=BeautifulSoup(req.text,\"html.parser\")\n list_tag=soup.div(id=\"list\")\n print('list_tag:',list_tag)\n #获取小说名称\n story_title=list_tag[0].dl.dt.string\n # 根据小说名称创建一个文件夹,如果不存在就新建\n dir_path=save_path+'/'+story_title\n if not os.path.exists(dir_path):\n os.path.join(save_path,story_title)\n os.mkdir(dir_path)\n #开始循环每一个章节,获取章节名称,与章节对应的网址\n for dd_tag in list_tag[0].dl.find_all('dd'):\n #章节名称\n chapter_name=dd_tag.string\n #章节网址\n chapter_url=index_path+dd_tag.a.get('href')\n #访问该章节详情网址,爬取该章节正文\n chapter_req = requests.get(url=chapter_url)\n chapter_req.encoding = 'gbk'\n chapter_soup = BeautifulSoup(chapter_req.text, \"html.parser\")\n #解析出来正文所在的标签\n content_tag = chapter_soup.div.find(id=\"content\")\n #获取正文文本,并将空格替换为换行符\n content_text = str(content_tag.text.replace('\\xa0','\\n'))\n #将当前章节,写入以章节名字命名的txt文件\n with open(dir_path+'/'+chapter_name+'.txt', 'w') as f:\n f.write('本文网址:'+chapter_url)\n f.write(content_text)"
},
{
"path": "one_hour_spider/biqukan.py",
"content": "# -*- coding:UTF-8 -*-\nfrom bs4 import BeautifulSoup\nimport requests, sys\n\n\"\"\"\n类说明:下载《笔趣看》网小说《一念永恒》\nParameters:\n\t无\nReturns:\n\t无\nModify:\n\t2017-09-13\n\"\"\"\nclass downloader(object):\n\n\tdef __init__(self):\n\t\tself.server = 'http://www.biqukan.com/'\n\t\tself.target = 'http://www.biqukan.com/1_1094/'\n\t\tself.names = []\t\t\t#存放章节名\n\t\tself.urls = []\t\t\t#存放章节链接\n\t\tself.nums = 0\t\t\t#章节数\n\n\t\"\"\"\n\t函数说明:获取下载链接\n\tParameters:\n\t\t无\n\tReturns:\n\t\t无\n\tModify:\n\t\t2017-09-13\n\t\"\"\"\n\tdef get_download_url(self):\n\t req = requests.get(url = self.target)\n\t html = req.text\n\t div_bf = BeautifulSoup(html)\n\t div = div_bf.find_all('div', class_ = 'listmain')\n\t a_bf = BeautifulSoup(str(div[0]))\n\t a = a_bf.find_all('a')\n\t self.nums = len(a[15:])\t\t\t\t\t\t\t\t#剔除不必要的章节,并统计章节数\n\t for each in a[15:]:\n\t \tself.names.append(each.string)\n\t \tself.urls.append(self.server + each.get('href'))\n\n\t\"\"\"\n\t函数说明:获取章节内容\n\tParameters:\n\t\ttarget - 下载连接(string)\n\tReturns:\n\t\ttexts - 章节内容(string)\n\tModify:\n\t\t2017-09-13\n\t\"\"\"\n\tdef get_contents(self, target):\n\t\treq = requests.get(url = target)\n\t\thtml = req.text\n\t\tbf = BeautifulSoup(html)\n\t\ttexts = bf.find_all('div', class_ = 'showtxt')\n\t\ttexts = texts[0].text.replace('\\xa0'*8,'\\n\\n')\n\t\treturn texts\n\n\t\"\"\"\n\t函数说明:将爬取的文章内容写入文件\n\tParameters:\n\t\tname - 章节名称(string)\n\t\tpath - 当前路径下,小说保存名称(string)\n\t\ttext - 章节内容(string)\n\tReturns:\n\t\t无\n\tModify:\n\t\t2017-09-13\n\t\"\"\"\n\tdef writer(self, name, path, text):\n\t\twrite_flag = True\n\t\twith open(path, 'a', encoding='utf-8') as f:\n\t\t\tf.write(name + '\\n')\n\t\t\tf.writelines(text)\n\t\t\tf.write('\\n\\n')\n\nif __name__ == \"__main__\":\n\tdl = downloader()\n\tdl.get_download_url()\n\tprint('《一年永恒》开始下载:')\n\tfor i in range(dl.nums):\n\t\tdl.writer(dl.names[i], '一念永恒.txt', dl.get_contents(dl.urls[i]))\n\t\tsys.stdout.write(\" 已下载:%.3f%%\" % float(i/dl.nums*100) + '\\r')\n\t\tsys.stdout.flush()\n\tprint('《一年永恒》下载完成')\n"
},
{
"path": "one_hour_spider/unsplash.py",
"content": "# -*- coding:UTF-8 -*-\nimport requests, json, time, sys\nfrom contextlib import closing\n\nclass get_photos(object):\n\n\tdef __init__(self):\n\t\tself.photos_id = []\n\t\tself.download_server = 'https://unsplash.com/photos/xxx/download?force=trues'\n\t\tself.target = 'http://unsplash.com/napi/feeds/home'\n\t\tself.headers = {'authorization':'Client-ID c94869b36aa272dd62dfaeefed769d4115fb3189a9d1ec88ed457207747be626'}\n\n\t\"\"\"\n\t函数说明:获取图片ID\n\tParameters:\n\t\t无\n\tReturns:\n\t\t无\n\tModify:\n\t\t2017-09-13\n\t\"\"\"\t\n\tdef get_ids(self):\n\t\treq = requests.get(url=self.target, headers=self.headers, verify=False)\n\t\thtml = json.loads(req.text)\n\t\tnext_page = html['next_page']\n\t\tfor each in html['photos']:\n\t\t\tself.photos_id.append(each['id'])\n\t\ttime.sleep(1)\n\t\tfor i in range(5):\n\t\t\treq = requests.get(url=next_page, headers=self.headers, verify=False)\n\t\t\thtml = json.loads(req.text)\n\t\t\tnext_page = html['next_page']\n\t\t\tfor each in html['photos']:\n\t\t\t\tself.photos_id.append(each['id'])\n\t\t\ttime.sleep(1)\n\n\n\t\"\"\"\n\t函数说明:图片下载\n\tParameters:\n\t\t无\n\tReturns:\n\t\t无\n\tModify:\n\t\t2017-09-13\n\t\"\"\"\t\n\tdef download(self, photo_id, filename):\n\t\theaders = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.79 Safari/537.36'}\n\t\ttarget = self.download_server.replace('xxx', photo_id)\n\t\twith closing(requests.get(url=target, stream=True, verify = False, headers = self.headers)) as r:\n\t\t\twith open('%d.jpg' % filename, 'ab+') as f:\n\t\t\t\tfor chunk in r.iter_content(chunk_size = 1024):\n\t\t\t\t\tif chunk:\n\t\t\t\t\t\tf.write(chunk)\n\t\t\t\t\t\tf.flush()\n\nif __name__ == '__main__':\n\tgp = get_photos()\n\tprint('获取图片连接中:')\n\tgp.get_ids()\n\tprint('图片下载中:')\n\tfor i in range(len(gp.photos_id)):\n\t\tprint(' 正在下载第%d张图片' % (i+1))\n\t\tgp.download(gp.photos_id[i], (i+1))"
},
{
"path": "one_hour_spider/unsplash20180731.py",
"content": "# -*- coding:utf-8 -*-\nimport requests\nimport json\nimport os\nfrom contextlib import closing\n\n\"\"\"\n从https://unsplash.com/爬取壁纸代码,使用时我是开启了代理软件\n国内网速貌似有些限制,很慢\n 2018-07-31\n\"\"\"\n\n# 本地保存图片根路径(请确保根路径存在)\nsave_path = 'G:/pythonlearn'\ndir_path=save_path+'/'+'unsplash-image'\nif not os.path.exists(dir_path):\n os.path.join(save_path, 'unsplash-image')\n os.mkdir(dir_path)\nn=10\n#n建议从第2页开始,因为第一页的per_page可能是1,不是12\nwhile n>2:\n print('当前爬取第'+str(n)+'次加载图片(本次共12张)')\n url='https://unsplash.com/napi/photos?page='+str(n)+'&per_page=12&order_by=latest'\n req=requests.get(url=url)\n html=json.loads(req.text)\n for each in html:\n downloadurl=each['links'][\"download\"]\n jpgrep=requests.get(url=downloadurl)\n with closing(requests.get(url=downloadurl, stream=True)) as r:\n with open(dir_path+'/'+each['id']+'.jpg', 'ab+') as f:\n for chunk in r.iter_content(chunk_size=1024):\n if chunk:\n f.write(chunk)\n f.flush()\n n=n-1"
},
{
"path": "one_hour_spider/vidoe_downloader.py",
"content": "#-*- coding:UTF-8 -*-\nimport requests,re, json, sys\nfrom bs4 import BeautifulSoup\nfrom urllib import request\n\nclass video_downloader():\n\tdef __init__(self, url):\n\t\tself.server = 'http://api.xfsub.com'\n\t\tself.api = 'http://api.xfsub.com/xfsub_api/?url='\n\t\tself.get_url_api = 'http://api.xfsub.com/xfsub_api/url.php'\n\t\tself.url = url.split('#')[0]\n\t\tself.headers = {'Referer': 'http://api.xfsub.com/xfsub_api/?url=%s?qqdrsign=055a4' % self.url}\n\t\tself.target = self.api + self.url\n\t\tself.s = requests.session()\n\n\t\"\"\"\n\t函数说明:获取key、time、url等参数\n\tParameters:\n\t\t无\n\tReturns:\n\t\t无\n\tModify:\n\t\t2017-09-18\n\t\"\"\"\n\tdef get_key(self):\n\t\treq = self.s.get(url=self.target)\n\t\treq.encoding = 'utf-8'\n\t\tself.info = json.loads(re.findall('\"url.php\",\\ (.+),', req.text)[0])\t#使用正则表达式匹配结果,将匹配的结果存入info变量中\n\n\t\"\"\"\n\t函数说明:获取视频地址\n\tParameters:\n\t\t无\n\tReturns:\n\t\tvideo_url - 视频存放地址\n\tModify:\n\t\t2017-09-18\n\t\"\"\"\n\tdef get_url(self):\n\t\tdata = {'time':self.info['time'],\n\t\t\t'key':self.info['key'],\n\t\t\t'url':self.info['url'],\n\t\t\t'type':''}\n\t\treq = self.s.post(url=self.get_url_api,data=data, headers=self.headers)\n\t\turl = self.server + json.loads(req.text)['url']\n\t\treq = self.s.get(url=url, headers=self.headers)\n\t\tbf = BeautifulSoup(req.text,'xml')\t\t\t\t\t\t\t\t\t\t#因为文件是xml格式的,所以要进行xml解析。\n\t\tvideo_url = bf.find('file').string\t\t\t\t\t\t\t\t\t\t#匹配到视频地址\n\t\treturn video_url\n\n\t\"\"\"\n\t函数说明:回调函数,打印下载进度\n\tParameters:\n\t\ta b c - 返回信息\n\tReturns:\n\t\t无\n\tModify:\n\t\t2017-09-18\n\t\"\"\"\n\tdef Schedule(self, a, b, c):\n\t\tper = 100.0*a*b/c\n\t\tif per > 100 :\n\t\t\tper = 1\n\t\tsys.stdout.write(\" \" + \"%.2f%% 已经下载的大小:%ld 文件大小:%ld\" % (per,a*b,c) + '\\r')\n\t\tsys.stdout.flush()\n\n\t\"\"\"\n\t函数说明:视频下载\n\tParameters:\n\t\turl - 视频地址\n\t\tfilename - 视频名字\n\tReturns:\n\t\t无\n\tModify:\n\t\t2017-09-18\n\t\"\"\"\n\tdef video_download(self, url, filename):\n\t\trequest.urlretrieve(url=url,filename=filename,reporthook=self.Schedule)\n\n\nif __name__ == '__main__':\n\turl = 'http://www.iqiyi.com/v_19rr7qhfg0.html#vfrm=19-9-0-1'\n\tvd = video_downloader(url)\n\tfilename = '加勒比海盗5'\n\tprint('%s下载中:' % filename)\n\tvd.get_key()\n\tvideo_url = vd.get_url()\n\tprint(' 获取地址成功:%s' % video_url)\n\tvd.video_download(video_url, filename+'.mp4')\n\tprint('\\n下载完成!')\n"
},
{
"path": "shuaia.py",
"content": "# -*- coding:UTF-8 -*-\nfrom bs4 import BeautifulSoup\nfrom urllib.request import urlretrieve\nimport requests\nimport os\nimport time\n\nif __name__ == '__main__':\n\tlist_url = []\n\tfor num in range(1,3):\n\t\tif num == 1:\n\t\t\turl = 'http://www.shuaia.net/index.html'\n\t\telse:\n\t\t\turl = 'http://www.shuaia.net/index_%d.html' % num\n\t\theaders = {\n\t\t\t\t\"User-Agent\":\"Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36\"\n\t\t}\n\t\treq = requests.get(url = url,headers = headers)\n\t\treq.encoding = 'utf-8'\n\t\thtml = req.text\n\t\tbf = BeautifulSoup(html, 'lxml')\n\t\ttargets_url = bf.find_all(class_='item-img')\n\t\t\n\t\tfor each in targets_url:\n\t\t\tlist_url.append(each.img.get('alt') + '=' + each.get('href'))\n\n\tprint('连接采集完成')\n\n\tfor each_img in list_url:\n\t\timg_info = each_img.split('=')\n\t\ttarget_url = img_info[1]\n\t\tfilename = img_info[0] + '.jpg'\n\t\tprint('下载:' + filename)\n\t\theaders = {\n\t\t\t\"User-Agent\":\"Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36\"\n\t\t}\n\t\timg_req = requests.get(url = target_url,headers = headers)\n\t\timg_req.encoding = 'utf-8'\n\t\timg_html = img_req.text\n\t\timg_bf_1 = BeautifulSoup(img_html, 'lxml')\n\t\timg_url = img_bf_1.find_all('div', class_='wr-single-content-list')\n\t\timg_bf_2 = BeautifulSoup(str(img_url), 'lxml')\n\t\timg_url = 'http://www.shuaia.net' + img_bf_2.div.img.get('src')\n\t\tif 'images' not in os.listdir():\n\t\t\tos.makedirs('images')\n\t\turlretrieve(url = img_url,filename = 'images/' + filename)\n\t\ttime.sleep(1)\n\n\tprint('下载完成!')"
},
{
"path": "video_downloader/MyQR/__init__.py",
"content": ""
},
{
"path": "video_downloader/MyQR/mylibs/ECC.py",
"content": "# -*- coding: utf-8 -*-\n\nfrom MyQR.mylibs.constant import GP_list, ecc_num_per_block, lindex, po2, log\n \n#ecc: Error Correction Codewords\ndef encode(ver, ecl, data_codewords):\n en = ecc_num_per_block[ver-1][lindex[ecl]]\n ecc = []\n for dc in data_codewords:\n ecc.append(get_ecc(dc, en))\n return ecc\n\ndef get_ecc(dc, ecc_num):\n gp = GP_list[ecc_num]\n remainder = dc\n for i in range(len(dc)):\n remainder = divide(remainder, *gp)\n return remainder\n \ndef divide(MP, *GP):\n if MP[0]:\n GP = list(GP)\n for i in range(len(GP)):\n GP[i] += log[MP[0]]\n if GP[i] > 255:\n GP[i] %= 255\n GP[i] = po2[GP[i]]\n return XOR(GP, *MP)\n else:\n return XOR([0]*len(GP), *MP)\n \n \ndef XOR(GP, *MP):\n MP = list(MP)\n a = len(MP) - len(GP)\n if a < 0:\n MP += [0] * (-a)\n elif a > 0:\n GP += [0] * a\n \n remainder = []\n for i in range(1, len(MP)):\n remainder.append(MP[i]^GP[i])\n return remainder"
},
{
"path": "video_downloader/MyQR/mylibs/__init__.py",
"content": "# -*- coding: utf-8 -*-\n"
},
{
"path": "video_downloader/MyQR/mylibs/constant.py",
"content": "# -*- coding: utf-8 -*-\n\"\"\"\n***** for data.py *******\n\"\"\"\n# character capacities\n# {level1: [version1(mode1,mode2,mode3,mode4), version2(..,..,..,..), ...],\n# level2: [version1(mode1,mode2,mode3,mode4), version2(..,..,..,..),...],\n# ...}\nchar_cap = {\n 'L': [(41, 25, 17, 10), (77, 47, 32, 20), (127, 77, 53, 32), (187, 114, 78, 48), (255, 154, 106, 65), (322, 195, 134, 82), (370, 224, 154, 95), (461, 279, 192, 118), (552, 335, 230, 141), (652, 395, 271, 167), (772, 468, 321, 198), (883, 535, 367, 226), (1022, 619, 425, 262), (1101, 667, 458, 282), (1250, 758, 520, 320), (1408, 854, 586, 361), (1548, 938, 644, 397), (1725, 1046, 718, 442), (1903, 1153, 792, 488), (2061, 1249, 858, 528), (2232, 1352, 929, 572), (2409, 1460, 1003, 618), (2620, 1588, 1091, 672), (2812, 1704, 1171, 721), (3057, 1853, 1273, 784), (3283, 1990, 1367, 842), (3517, 2132, 1465, 902), (3669, 2223, 1528, 940), (3909, 2369, 1628, 1002), (4158, 2520, 1732, 1066), (4417, 2677, 1840, 1132), (4686, 2840, 1952, 1201), (4965, 3009, 2068, 1273), (5253, 3183, 2188, 1347), (5529, 3351, 2303, 1417), (5836, 3537, 2431, 1496), (6153, 3729, 2563, 1577), (6479, 3927, 2699, 1661), (6743, 4087, 2809, 1729), (7089, 4296, 2953, 1817)],\n 'M': [(34, 20, 14, 8), (63, 38, 26, 16), (101, 61, 42, 26), (149, 90, 62, 38), (202, 122, 84, 52), (255, 154, 106, 65), (293, 178, 122, 75), (365, 221, 152, 93), (432, 262, 180, 111), (513, 311, 213, 131), (604, 366, 251, 155), (691, 419, 287, 177), (796, 483, 331, 204), (871, 528, 362, 223), (991, 600, 412, 254), (1082, 656, 450, 277), (1212, 734, 504, 310), (1346, 816, 560, 345), (1500, 909, 624, 384), (1600, 970, 666, 410), (1708, 1035, 711, 438), (1872, 1134, 779, 480), (2059, 1248, 857, 528), (2188, 1326, 911, 561), (2395, 1451, 997, 614), (2544, 1542, 1059, 652), (2701, 1637, 1125, 692), (2857, 1732, 1190, 732), (3035, 1839, 1264, 778), (3289, 1994, 1370, 843), (3486, 2113, 1452, 894), (3693, 2238, 1538, 947), (3909, 2369, 1628, 1002), (4134, 2506, 1722, 1060), (4343, 2632, 1809, 1113), (4588, 2780, 1911, 1176), (4775, 2894, 1989, 1224), (5039, 3054, 2099, 1292), (5313, 3220, 2213, 1362), (5596, 3391, 2331, 1435)],\n 'Q': [(27, 16, 11, 7), (48, 29, 20, 12), (77, 47, 32, 20), (111, 67, 46, 28), (144, 87, 60, 37), (178, 108, 74, 45), (207, 125, 86, 53), (259, 157, 108, 66), (312, 189, 130, 80), (364, 221, 151, 93), (427, 259, 177, 109), (489, 296, 203, 125), (580, 352, 241, 149), (621, 376, 258, 159), (703, 426, 292, 180), (775, 470, 322, 198), (876, 531, 364, 224), (948, 574, 394, 243), (1063, 644, 442, 272), (1159, 702, 482, 297), (1224, 742, 509, 314), (1358, 823, 565, 348), (1468, 890, 611, 376), (1588, 963, 661, 407), (1718, 1041, 715, 440), (1804, 1094, 751, 462), (1933, 1172, 805, 496), (2085, 1263, 868, 534), (2181, 1322, 908, 559), (2358, 1429, 982, 604), (2473, 1499, 1030, 634), (2670, 1618, 1112, 684), (2805, 1700, 1168, 719), (2949, 1787, 1228, 756), (3081, 1867, 1283, 790), (3244, 1966, 1351, 832), (3417, 2071, 1423, 876), (3599, 2181, 1499, 923), (3791, 2298, 1579, 972), (3993, 2420, 1663, 1024)],\n 'H': [(17, 10, 7, 4), (34, 20, 14, 8), (58, 35, 24, 15), (82, 50, 34, 21), (106, 64, 44, 27), (139, 84, 58, 36), (154, 93, 64, 39), (202, 122, 84, 52), (235, 143, 98, 60), (288, 174, 119, 74), (331, 200, 137, 85), (374, 227, 155, 96), (427, 259, 177, 109), (468, 283, 194, 120), (530, 321, 220, 136), (602, 365, 250, 154), (674, 408, 280, 173), (746, 452, 310, 191), (813, 493, 338, 208), (919, 557, 382, 235), (969, 587, 403, 248), (1056, 640, 439, 270), (1108, 672, 461, 284), (1228, 744, 511, 315), (1286, 779, 535, 330), (1425, 864, 593, 365), (1501, 910, 625, 385), (1581, 958, 658, 405), (1677, 1016, 698, 430), (1782, 1080, 742, 457), (1897, 1150, 790, 486), (2022, 1226, 842, 518), (2157, 1307, 898, 553), (2301, 1394, 958, 590), (2361, 1431, 983, 605), (2524, 1530, 1051, 647), (2625, 1591, 1093, 673), (2735, 1658, 1139, 701), (2927, 1774, 1219, 750), (3057, 1852, 1273, 784)]\n }\n\nmindex = {'numeric':0, 'alphanumeric':1, 'byte':2, 'kanji':3}\n\n# [\n# version1[level1,level2,level3,level4], \n# version2[..,..,..,..],\n# ...\n# ]\nrequired_bytes = [\n [19, 16, 13, 9], [34, 28, 22, 16], [55, 44, 34, 26], [80, 64, 48, 36], [108, 86, 62, 46], [136, 108, 76, 60], [156, 124, 88, 66], [194, 154, 110, 86], [232, 182, 132, 100], [274, 216, 154, 122], [324, 254, 180, 140], [370, 290, 206, 158], [428, 334, 244, 180], [461, 365, 261, 197], [523, 415, 295, 223], [589, 453, 325, 253], [647, 507, 367, 283], [721, 563, 397, 313], [795, 627, 445, 341], [861, 669, 485, 385], [932, 714, 512, 406], [1006, 782, 568, 442], [1094, 860, 614, 464], [1174, 914, 664, 514], [1276, 1000, 718, 538], [1370, 1062, 754, 596], [1468, 1128, 808, 628], [1531, 1193, 871, 661], [1631, 1267, 911, 701], [1735, 1373, 985, 745], [1843, 1455, 1033, 793], [1955, 1541, 1115, 845], [2071, 1631, 1171, 901], [2191, 1725, 1231, 961], [2306, 1812, 1286, 986], [2434, 1914, 1354, 1054], [2566, 1992, 1426, 1096], [2702, 2102, 1502, 1142], [2812, 2216, 1582, 1222], [2956, 2334, 1666, 1276]\n ]\n\nnum_list = '0123456789'\nalphanum_list = '0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ $%*+-./:'\n\n# [\n# version1[\n# level1(num_of_group_1_blocks, DC_per_group_1_block, num_of_group_2_blocks, DC_per_group_2_block),\n# level2(..,..,..,..),\n# level3(..,..,..,..),\n# level4(..,..,..,..)\n# ], \n# version2[level1(..), level2(..), level3(..), level4(..)],\n# ...\n# ]\ngrouping_list = [\n [(1, 19, 0, 0), (1, 16, 0, 0), (1, 13, 0, 0), (1, 9, 0, 0)], [(1, 34, 0, 0), (1, 28, 0, 0), (1, 22, 0, 0), (1, 16, 0, 0)], [(1, 55, 0, 0), (1, 44, 0, 0), (2, 17, 0, 0), (2, 13, 0, 0)], [(1, 80, 0, 0), (2, 32, 0, 0), (2, 24, 0, 0), (4, 9, 0, 0)], [(1, 108, 0, 0), (2, 43, 0, 0), (2, 15, 2, 16), (2, 11, 2, 12)], [(2, 68, 0, 0), (4, 27, 0, 0), (4, 19, 0, 0), (4, 15, 0, 0)], [(2, 78, 0, 0), (4, 31, 0, 0), (2, 14, 4, 15), (4, 13, 1, 14)], [(2, 97, 0, 0), (2, 38, 2, 39), (4, 18, 2, 19), (4, 14, 2, 15)], [(2, 116, 0, 0), (3, 36, 2, 37), (4, 16, 4, 17), (4, 12, 4, 13)], [(2, 68, 2, 69), (4, 43, 1, 44), (6, 19, 2, 20), (6, 15, 2, 16)], [(4, 81, 0, 0), (1, 50, 4, 51), (4, 22, 4, 23), (3, 12, 8, 13)], [(2, 92, 2, 93), (6, 36, 2, 37), (4, 20, 6, 21), (7, 14, 4, 15)], [(4, 107, 0, 0), (8, 37, 1, 38), (8, 20, 4, 21), (12, 11, 4, 12)], [(3, 115, 1, 116), (4, 40, 5, 41), (11, 16, 5, 17), (11, 12, 5, 13)], [(5, 87, 1, 88), (5, 41, 5, 42), (5, 24, 7, 25), (11, 12, 7, 13)], [(5, 98, 1, 99), (7, 45, 3, 46), (15, 19, 2, 20), (3, 15, 13, 16)], [(1, 107, 5, 108), (10, 46, 1, 47), (1, 22, 15, 23), (2, 14, 17, 15)], [(5, 120, 1, 121), (9, 43, 4, 44), (17, 22, 1, 23), (2, 14, 19, 15)], [(3, 113, 4, 114), (3, 44, 11, 45), (17, 21, 4, 22), (9, 13, 16, 14)], [(3, 107, 5, 108), (3, 41, 13, 42), (15, 24, 5, 25), (15, 15, 10, 16)], [(4, 116, 4, 117), (17, 42, 0, 0), (17, 22, 6, 23), (19, 16, 6, 17)], [(2, 111, 7, 112), (17, 46, 0, 0), (7, 24, 16, 25), (34, 13, 0, 0)], [(4, 121, 5, 122), (4, 47, 14, 48), (11, 24, 14, 25), (16, 15, 14, 16)], [(6, 117, 4, 118), (6, 45, 14, 46), (11, 24, 16, 25), (30, 16, 2, 17)], [(8, 106, 4, 107), (8, 47, 13, 48), (7, 24, 22, 25), (22, 15, 13, 16)], [(10, 114, 2, 115), (19, 46, 4, 47), (28, 22, 6, 23), (33, 16, 4, 17)], [(8, 122, 4, 123), (22, 45, 3, 46), (8, 23, 26, 24), (12, 15, 28, 16)], [(3, 117, 10, 118), (3, 45, 23, 46), (4, 24, 31, 25), (11, 15, 31, 16)], [(7, 116, 7, 117), (21, 45, 7, 46), (1, 23, 37, 24), (19, 15, 26, 16)], [(5, 115, 10, 116), (19, 47, 10, 48), (15, 24, 25, 25), (23, 15, 25, 16)], [(13, 115, 3, 116), (2, 46, 29, 47), (42, 24, 1, 25), (23, 15, 28, 16)], [(17, 115, 0, 0), (10, 46, 23, 47), (10, 24, 35, 25), (19, 15, 35, 16)], [(17, 115, 1, 116), (14, 46, 21, 47), (29, 24, 19, 25), (11, 15, 46, 16)], [(13, 115, 6, 116), (14, 46, 23, 47), (44, 24, 7, 25), (59, 16, 1, 17)], [(12, 121, 7, 122), (12, 47, 26, 48), (39, 24, 14, 25), (22, 15, 41, 16)], [(6, 121, 14, 122), (6, 47, 34, 48), (46, 24, 10, 25), (2, 15, 64, 16)], [(17, 122, 4, 123), (29, 46, 14, 47), (49, 24, 10, 25), (24, 15, 46, 16)], [(4, 122, 18, 123), (13, 46, 32, 47), (48, 24, 14, 25), (42, 15, 32, 16)], [(20, 117, 4, 118), (40, 47, 7, 48), (43, 24, 22, 25), (10, 15, 67, 16)], [(19, 118, 6, 119), (18, 47, 31, 48), (34, 24, 34, 25), (20, 15, 61, 16)]\n ]\n\nmode_indicator = {'numeric': '0001', 'alphanumeric': '0010', 'byte': '0100', 'kanji': '1000'}\n\n\n\n\"\"\"\n****** for ECC.py *******\n\"\"\"\n#GP: Generator Polynomial, MP: Message Polynomial\nGP_list = {\n 7: [0, 87, 229, 146, 149, 238, 102, 21],\n 10: [0, 251, 67, 46, 61, 118, 70, 64, 94, 32, 45],\n 13: [0, 74, 152, 176, 100, 86, 100, 106, 104, 130, 218, 206, 140, 78],\n 15: [0, 8, 183, 61, 91, 202, 37, 51, 58, 58, 237, 140, 124, 5, 99, 105],\n 16: [0, 120, 104, 107, 109, 102, 161, 76, 3, 91, 191, 147, 169, 182, 194, 225, 120],\n 17: [0, 43, 139, 206, 78, 43, 239, 123, 206, 214, 147, 24, 99, 150, 39, 243, 163, 136],\n 18: [0, 215, 234, 158, 94, 184, 97, 118, 170, 79, 187, 152, 148, 252, 179, 5, 98, 96, 153],\n 20: [0, 17, 60, 79, 50, 61, 163, 26, 187, 202, 180, 221, 225, 83, 239, 156, 164, 212, 212, 188, 190],\n 22: [0, 210, 171, 247, 242, 93, 230, 14, 109, 221, 53, 200, 74, 8, 172, 98, 80, 219, 134, 160, 105, 165, 231],\n 24: [0, 229, 121, 135, 48, 211, 117, 251, 126, 159, 180, 169, 152, 192, 226, 228, 218, 111, 0, 117, 232, 87, 96, 227, 21],\n 26: [0, 173, 125, 158, 2, 103, 182, 118, 17, 145, 201, 111, 28, 165, 53, 161, 21, 245, 142, 13, 102, 48, 227, 153, 145, 218, 70],\n 28: [0, 168, 223, 200, 104, 224, 234, 108, 180, 110, 190, 195, 147, 205, 27, 232, 201, 21, 43, 245, 87, 42, 195, 212, 119, 242, 37, 9, 123],\n 30: [0, 41, 173, 145, 152, 216, 31, 179, 182, 50, 48, 110, 86, 239, 96, 222, 125, 42, 173, 226, 193, 224, 130, 156, 37, 251, 216, 238, 40, 192, 180]\n }\n\n# Error Correction Codewords per block\n# [version1(level1,level2,level3,level4),\n# version2(..,..,..,..),\n# ....]\necc_num_per_block = [\n (7, 10, 13, 17), (10, 16, 22, 28), (15, 26, 18, 22), (20, 18, 26, 16), (26, 24, 18, 22), (18, 16, 24, 28), (20, 18, 18, 26), (24, 22, 22, 26), (30, 22, 20, 24), (18, 26, 24, 28), (20, 30, 28, 24), (24, 22, 26, 28), (26, 22, 24, 22), (30, 24, 20, 24), (22, 24, 30, 24), (24, 28, 24, 30), (28, 28, 28, 28), (30, 26, 28, 28), (28, 26, 26, 26), (28, 26, 30, 28), (28, 26, 28, 30), (28, 28, 30, 24), (30, 28, 30, 30), (30, 28, 30, 30), (26, 28, 30, 30), (28, 28, 28, 30), (30, 28, 30, 30), (30, 28, 30, 30), (30, 28, 30, 30), (30, 28, 30, 30), (30, 28, 30, 30), (30, 28, 30, 30), (30, 28, 30, 30), (30, 28, 30, 30), (30, 28, 30, 30), (30, 28, 30, 30), (30, 28, 30, 30), (30, 28, 30, 30), (30, 28, 30, 30), (30, 28, 30, 30)\n ]\n \n\n# powers of 2 list \npo2 = [\n 1, 2, 4, 8, 16, 32, 64, 128, 29, 58, 116, 232, 205, 135, 19, 38, 76, 152, 45, 90, 180, 117, 234, 201, 143, 3, 6, 12, 24, 48, 96, 192, 157, 39, 78, 156, 37, 74, 148, 53, 106, 212, 181, 119, 238, 193, 159, 35, 70, 140, 5, 10, 20, 40, 80, 160, 93, 186, 105, 210, 185, 111, 222, 161, 95, 190, 97, 194, 153, 47, 94, 188, 101, 202, 137, 15, 30, 60, 120, 240, 253, 231, 211, 187, 107, 214, 177, 127, 254, 225, 223, 163, 91, 182, 113, 226, 217, 175, 67, 134, 17, 34, 68, 136, 13, 26, 52, 104, 208, 189, 103, 206, 129, 31, 62, 124, 248, 237, 199, 147, 59, 118, 236, 197, 151, 51, 102, 204, 133, 23, 46, 92, 184, 109, 218, 169, 79, 158, 33, 66, 132, 21, 42, 84, 168, 77, 154, 41, 82, 164, 85, 170, 73, 146, 57, 114, 228, 213, 183, 115, 230, 209, 191, 99, 198, 145, 63, 126, 252, 229, 215, 179, 123, 246, 241, 255, 227, 219, 171, 75, 150, 49, 98, 196, 149, 55, 110, 220, 165, 87, 174, 65, 130, 25, 50, 100, 200, 141, 7, 14, 28, 56, 112, 224, 221, 167, 83, 166, 81, 162, 89, 178, 121, 242, 249, 239, 195, 155, 43, 86, 172, 69, 138, 9, 18, 36, 72, 144, 61, 122, 244, 245, 247, 243, 251, 235, 203, 139, 11, 22, 44, 88, 176, 125, 250, 233, 207, 131, 27, 54, 108, 216, 173, 71, 142, 1\n ]\n \n# log list\nlog = [\n None, 0, 1, 25, 2, 50, 26, 198, 3, 223, 51, 238, 27, 104, 199, 75, 4, 100, 224, 14, 52, 141, 239, 129, 28, 193, 105, 248, 200, 8, 76, 113, 5, 138, 101, 47, 225, 36, 15, 33, 53, 147, 142, 218, 240, 18, 130, 69, 29, 181, 194, 125, 106, 39, 249, 185, 201, 154, 9, 120, 77, 228, 114, 166, 6, 191, 139, 98, 102, 221, 48, 253, 226, 152, 37, 179, 16, 145, 34, 136, 54, 208, 148, 206, 143, 150, 219, 189, 241, 210, 19, 92, 131, 56, 70, 64, 30, 66, 182, 163, 195, 72, 126, 110, 107, 58, 40, 84, 250, 133, 186, 61, 202, 94, 155, 159, 10, 21, 121, 43, 78, 212, 229, 172, 115, 243, 167, 87, 7, 112, 192, 247, 140, 128, 99, 13, 103, 74, 222, 237, 49, 197, 254, 24, 227, 165, 153, 119, 38, 184, 180, 124, 17, 68, 146, 217, 35, 32, 137, 46, 55, 63, 209, 91, 149, 188, 207, 205, 144, 135, 151, 178, 220, 252, 190, 97, 242, 86, 211, 171, 20, 42, 93, 158, 132, 60, 57, 83, 71, 109, 65, 162, 31, 45, 67, 216, 183, 123, 164, 118, 196, 23, 73, 236, 127, 12, 111, 246, 108, 161, 59, 82, 41, 157, 85, 170, 251, 96, 134, 177, 187, 204, 62, 90, 203, 89, 95, 176, 156, 169, 160, 81, 11, 245, 22, 235, 122, 117, 44, 215, 79, 174, 213, 233, 230, 231, 173, 232, 116, 214, 244, 234, 168, 80, 88, 175\n ]\n\n\"\"\"\n****** for data.py + ECC.py + structure.py + matrix.py *******\n\"\"\"\nlindex = {'L':0, 'M':1, 'Q':2, 'H':3}\n \n\"\"\"\n****** for structure.py *******\n\"\"\" \nrequired_remainder_bits = (0,7,7,7,7,7,0,0,0,0,0,0,0,3,3,3,3,3,3,3,4,4,4,4,4,4,4,3,3,3,3,3,3,3,0,0,0,0,0,0)\n\n# [\n# version1[\n# level1(num_of_group_1_blocks, DC_per_group_1_block, num_of_group_2_blocks, DC_per_group_2_block),\n# level2(..,..,..,..),\n# level3(..,..,..,..),\n# level4(..,..,..,..)\n# ], \n# version2[level1(..), level2(..), level3(..), level4(..)],\n# ...\n# ]\ngrouping_list = [\n [(1, 19, 0, 0), (1, 16, 0, 0), (1, 13, 0, 0), (1, 9, 0, 0)], [(1, 34, 0, 0), (1, 28, 0, 0), (1, 22, 0, 0), (1, 16, 0, 0)], [(1, 55, 0, 0), (1, 44, 0, 0), (2, 17, 0, 0), (2, 13, 0, 0)], [(1, 80, 0, 0), (2, 32, 0, 0), (2, 24, 0, 0), (4, 9, 0, 0)], [(1, 108, 0, 0), (2, 43, 0, 0), (2, 15, 2, 16), (2, 11, 2, 12)], [(2, 68, 0, 0), (4, 27, 0, 0), (4, 19, 0, 0), (4, 15, 0, 0)], [(2, 78, 0, 0), (4, 31, 0, 0), (2, 14, 4, 15), (4, 13, 1, 14)], [(2, 97, 0, 0), (2, 38, 2, 39), (4, 18, 2, 19), (4, 14, 2, 15)], [(2, 116, 0, 0), (3, 36, 2, 37), (4, 16, 4, 17), (4, 12, 4, 13)], [(2, 68, 2, 69), (4, 43, 1, 44), (6, 19, 2, 20), (6, 15, 2, 16)], [(4, 81, 0, 0), (1, 50, 4, 51), (4, 22, 4, 23), (3, 12, 8, 13)], [(2, 92, 2, 93), (6, 36, 2, 37), (4, 20, 6, 21), (7, 14, 4, 15)], [(4, 107, 0, 0), (8, 37, 1, 38), (8, 20, 4, 21), (12, 11, 4, 12)], [(3, 115, 1, 116), (4, 40, 5, 41), (11, 16, 5, 17), (11, 12, 5, 13)], [(5, 87, 1, 88), (5, 41, 5, 42), (5, 24, 7, 25), (11, 12, 7, 13)], [(5, 98, 1, 99), (7, 45, 3, 46), (15, 19, 2, 20), (3, 15, 13, 16)], [(1, 107, 5, 108), (10, 46, 1, 47), (1, 22, 15, 23), (2, 14, 17, 15)], [(5, 120, 1, 121), (9, 43, 4, 44), (17, 22, 1, 23), (2, 14, 19, 15)], [(3, 113, 4, 114), (3, 44, 11, 45), (17, 21, 4, 22), (9, 13, 16, 14)], [(3, 107, 5, 108), (3, 41, 13, 42), (15, 24, 5, 25), (15, 15, 10, 16)], [(4, 116, 4, 117), (17, 42, 0, 0), (17, 22, 6, 23), (19, 16, 6, 17)], [(2, 111, 7, 112), (17, 46, 0, 0), (7, 24, 16, 25), (34, 13, 0, 0)], [(4, 121, 5, 122), (4, 47, 14, 48), (11, 24, 14, 25), (16, 15, 14, 16)], [(6, 117, 4, 118), (6, 45, 14, 46), (11, 24, 16, 25), (30, 16, 2, 17)], [(8, 106, 4, 107), (8, 47, 13, 48), (7, 24, 22, 25), (22, 15, 13, 16)], [(10, 114, 2, 115), (19, 46, 4, 47), (28, 22, 6, 23), (33, 16, 4, 17)], [(8, 122, 4, 123), (22, 45, 3, 46), (8, 23, 26, 24), (12, 15, 28, 16)], [(3, 117, 10, 118), (3, 45, 23, 46), (4, 24, 31, 25), (11, 15, 31, 16)], [(7, 116, 7, 117), (21, 45, 7, 46), (1, 23, 37, 24), (19, 15, 26, 16)], [(5, 115, 10, 116), (19, 47, 10, 48), (15, 24, 25, 25), (23, 15, 25, 16)], [(13, 115, 3, 116), (2, 46, 29, 47), (42, 24, 1, 25), (23, 15, 28, 16)], [(17, 115, 0, 0), (10, 46, 23, 47), (10, 24, 35, 25), (19, 15, 35, 16)], [(17, 115, 1, 116), (14, 46, 21, 47), (29, 24, 19, 25), (11, 15, 46, 16)], [(13, 115, 6, 116), (14, 46, 23, 47), (44, 24, 7, 25), (59, 16, 1, 17)], [(12, 121, 7, 122), (12, 47, 26, 48), (39, 24, 14, 25), (22, 15, 41, 16)], [(6, 121, 14, 122), (6, 47, 34, 48), (46, 24, 10, 25), (2, 15, 64, 16)], [(17, 122, 4, 123), (29, 46, 14, 47), (49, 24, 10, 25), (24, 15, 46, 16)], [(4, 122, 18, 123), (13, 46, 32, 47), (48, 24, 14, 25), (42, 15, 32, 16)], [(20, 117, 4, 118), (40, 47, 7, 48), (43, 24, 22, 25), (10, 15, 67, 16)], [(19, 118, 6, 119), (18, 47, 31, 48), (34, 24, 34, 25), (20, 15, 61, 16)]\n ]\n\n\n\n\"\"\"\n****** for matrix.py *******\n\"\"\"\n# Alignment Pattern Locations\nalig_location = [\n (6, 18), (6, 22), (6, 26), (6, 30), (6, 34), (6, 22, 38), (6, 24, 42), (6, 26, 46), (6, 28, 50), (6, 30, 54), (6, 32, 58), (6, 34, 62), (6, 26, 46, 66), (6, 26, 48, 70), (6, 26, 50, 74), (6, 30, 54, 78), (6, 30, 56, 82), (6, 30, 58, 86), (6, 34, 62, 90), (6, 28, 50, 72, 94), (6, 26, 50, 74, 98), (6, 30, 54, 78, 102), (6, 28, 54, 80, 106), (6, 32, 58, 84, 110), (6, 30, 58, 86, 114), (6, 34, 62, 90, 118), (6, 26, 50, 74, 98, 122), (6, 30, 54, 78, 102, 126), (6, 26, 52, 78, 104, 130), (6, 30, 56, 82, 108, 134), (6, 34, 60, 86, 112, 138), (6, 30, 58, 86, 114, 142), (6, 34, 62, 90, 118, 146), (6, 30, 54, 78, 102, 126, 150), (6, 24, 50, 76, 102, 128, 154), (6, 28, 54, 80, 106, 132, 158), (6, 32, 58, 84, 110, 136, 162), (6, 26, 54, 82, 110, 138, 166), (6, 30, 58, 86, 114, 142, 170)\n ]\n\n# List of all Format Information Strings\n# [\n# level1[mask_pattern0, mask_pattern1, mask_...3,...], \n# level2[...], \n# level3[...], \n# level4[...]\n# ] \nformat_info_str = [\n ['111011111000100', '111001011110011', '111110110101010', '111100010011101', '110011000101111', '110001100011000', '110110001000001', '110100101110110'], ['101010000010010', '101000100100101', '101111001111100', '101101101001011', '100010111111001', '100000011001110', '100111110010111', '100101010100000'], ['011010101011111', '011000001101000', '011111100110001', '011101000000110', '010010010110100', '010000110000011', '010111011011010', '010101111101101'], ['001011010001001', '001001110111110', '001110011100111', '001100111010000', '000011101100010', '000001001010101', '000110100001100', '000100000111011']\n ]\n\n# Version Information Strings\nversion_info_str = [\n '000111110010010100', '001000010110111100', '001001101010011001', '001010010011010011', '001011101111110110', '001100011101100010', '001101100001000111', '001110011000001101', '001111100100101000', '010000101101111000', '010001010001011101', '010010101000010111', '010011010100110010', '010100100110100110', '010101011010000011', '010110100011001001', '010111011111101100', '011000111011000100', '011001000111100001', '011010111110101011', '011011000010001110', '011100110000011010', '011101001100111111', '011110110101110101', '011111001001010000', '100000100111010101', '100001011011110000', '100010100010111010', '100011011110011111', '100100101100001011', '100101010000101110', '100110101001100100', '100111010101000001', '101000110001101001'\n ]\n"
},
{
"path": "video_downloader/MyQR/mylibs/data.py",
"content": "# -*- coding: utf-8 -*-\n\nfrom MyQR.mylibs.constant import char_cap, required_bytes, mindex, lindex, num_list, alphanum_list, grouping_list, mode_indicator\n \n# ecl: Error Correction Level(L,M,Q,H)\ndef encode(ver, ecl, str):\n mode_encoding = {\n 'numeric': numeric_encoding,\n 'alphanumeric': alphanumeric_encoding,\n 'byte': byte_encoding,\n 'kanji': kanji_encoding\n }\n \n ver, mode = analyse(ver, ecl, str)\n \n # print('line 16: mode:', mode)\n \n code = mode_indicator[mode] + get_cci(ver, mode, str) + mode_encoding[mode](str)\n \n # Add a Terminator\n rqbits = 8 * required_bytes[ver-1][lindex[ecl]]\n b = rqbits - len(code)\n code += '0000' if b >= 4 else '0' * b\n \n # Make the Length a Multiple of 8\n while len(code) % 8 != 0:\n code += '0'\n \n # Add Pad Bytes if the String is Still too Short\n while len(code) < rqbits: \n code += '1110110000010001' if rqbits - len(code) >= 16 else '11101100'\n \n data_code = [code[i:i+8] for i in range(len(code)) if i%8 == 0]\n data_code = [int(i,2) for i in data_code]\n\n g = grouping_list[ver-1][lindex[ecl]]\n data_codewords, i = [], 0\n for n in range(g[0]):\n data_codewords.append(data_code[i:i+g[1]])\n i += g[1]\n for n in range(g[2]):\n data_codewords.append(data_code[i:i+g[3]])\n i += g[3]\n \n return ver, data_codewords\n \ndef analyse(ver, ecl, str):\n if all(i in num_list for i in str):\n mode = 'numeric'\n elif all(i in alphanum_list for i in str):\n mode = 'alphanumeric'\n else:\n mode = 'byte'\n \n m = mindex[mode]\n l = len(str)\n for i in range(40):\n if char_cap[ecl][i][m] > l:\n ver = i + 1 if i+1 > ver else ver\n break\n \n return ver, mode\n\ndef numeric_encoding(str): \n str_list = [str[i:i+3] for i in range(0,len(str),3)]\n code = ''\n for i in str_list:\n rqbin_len = 10\n if len(i) == 1: \n rqbin_len = 4\n elif len(i) == 2:\n rqbin_len = 7\n code_temp = bin(int(i))[2:]\n code += ('0'*(rqbin_len - len(code_temp)) + code_temp)\n return code\n \ndef alphanumeric_encoding(str):\n code_list = [alphanum_list.index(i) for i in str]\n code = ''\n for i in range(1, len(code_list), 2):\n c = bin(code_list[i-1] * 45 + code_list[i])[2:]\n c = '0'*(11-len(c)) + c\n code += c\n if i != len(code_list) - 1:\n c = bin(code_list[-1])[2:]\n c = '0'*(6-len(c)) + c\n code += c\n \n return code\n \ndef byte_encoding(str):\n code = ''\n for i in str:\n c = bin(ord(i.encode('iso-8859-1')))[2:]\n c = '0'*(8-len(c)) + c\n code += c\n return code\n \ndef kanji_encoding(str):\n pass\n \n# cci: character count indicator \ndef get_cci(ver, mode, str):\n if 1 <= ver <= 9:\n cci_len = (10, 9, 8, 8)[mindex[mode]]\n elif 10 <= ver <= 26:\n cci_len = (12, 11, 16, 10)[mindex[mode]]\n else:\n cci_len = (14, 13, 16, 12)[mindex[mode]]\n \n cci = bin(len(str))[2:]\n cci = '0' * (cci_len - len(cci)) + cci\n return cci\n \nif __name__ == '__main__':\n s = '123456789'\n v, datacode = encode(1, 'H', s)\n print(v, datacode)"
},
{
"path": "video_downloader/MyQR/mylibs/draw.py",
"content": "# -*- coding: utf-8 -*-\n\nfrom PIL import Image\nimport os\n\ndef draw_qrcode(abspath, qrmatrix):\n unit_len = 3\n x = y = 4*unit_len\n pic = Image.new('1', [(len(qrmatrix)+8)*unit_len]*2, 'white')\n \n for line in qrmatrix:\n for module in line:\n if module:\n draw_a_black_unit(pic, x, y, unit_len)\n x += unit_len\n x, y = 4*unit_len, y+unit_len\n\n saving = os.path.join(abspath, 'qrcode.png')\n pic.save(saving)\n return saving\n \ndef draw_a_black_unit(p, x, y, ul):\n for i in range(ul):\n for j in range(ul):\n p.putpixel((x+i, y+j), 0)"
},
{
"path": "video_downloader/MyQR/mylibs/matrix.py",
"content": "# -*- coding: utf-8 -*-\n \nfrom MyQR.mylibs.constant import alig_location, format_info_str, version_info_str, lindex\n \ndef get_qrmatrix(ver, ecl, bits):\n num = (ver - 1) * 4 + 21\n qrmatrix = [[None] * num for i in range(num)]\n # [([None] * num * num)[i:i+num] for i in range(num * num) if i % num == 0] \n\n # Add the Finder Patterns & Add the Separators\n add_finder_and_separator(qrmatrix)\n \n # Add the Alignment Patterns\n add_alignment(ver, qrmatrix)\n \n # Add the Timing Patterns\n add_timing(qrmatrix)\n \n # Add the Dark Module and Reserved Areas\n add_dark_and_reserving(ver, qrmatrix)\n \n maskmatrix = [i[:] for i in qrmatrix]\n \n # Place the Data Bits\n place_bits(bits, qrmatrix)\n \n # Data Masking\n mask_num, qrmatrix = mask(maskmatrix, qrmatrix)\n \n # Format Information\n add_format_and_version_string(ver, ecl, mask_num, qrmatrix)\n\n return qrmatrix\n\ndef add_finder_and_separator(m): \n for i in range(8):\n for j in range(8):\n if i in (0, 6):\n m[i][j] = m[-i-1][j] = m[i][-j-1] = 0 if j == 7 else 1\n elif i in (1, 5):\n m[i][j] = m[-i-1][j] = m[i][-j-1] = 1 if j in (0, 6) else 0 \n elif i == 7:\n m[i][j] = m[-i-1][j] = m[i][-j-1] = 0\n else:\n m[i][j] = m[-i-1][j] = m[i][-j-1] = 0 if j in (1, 5, 7) else 1\n \ndef add_alignment(ver, m):\n if ver > 1:\n coordinates = alig_location[ver-2]\n for i in coordinates:\n for j in coordinates:\n if m[i][j] is None:\n add_an_alignment(i, j, m)\n \ndef add_an_alignment(row, column, m):\n for i in range(row-2, row+3):\n for j in range(column-2, column+3):\n m[i][j] = 1 if i in (row-2, row+2) or j in (column-2, column+2) else 0\n m[row][column] = 1\n \ndef add_timing(m):\n for i in range(8, len(m)-8):\n m[i][6] = m[6][i] = 1 if i % 2 ==0 else 0\n \ndef add_dark_and_reserving(ver, m):\n for j in range(8):\n m[8][j] = m[8][-j-1] = m[j][8] = m[-j-1][8] = 0\n m[8][8] = 0\n m[8][6] = m[6][8] = m[-8][8] = 1\n \n if ver > 6:\n for i in range(6):\n for j in (-9, -10, -11):\n m[i][j] = m[j][i] = 0\n \ndef place_bits(bits, m):\n bit = (int(i) for i in bits)\n\n up = True\n for a in range(len(m)-1, 0, -2):\n a = a-1 if a <= 6 else a\n irange = range(len(m)-1, -1, -1) if up else range(len(m))\n for i in irange:\n for j in (a, a-1):\n if m[i][j] is None:\n m[i][j] = next(bit)\n up = not up\n \ndef mask(mm, m):\n mps = get_mask_patterns(mm)\n scores = []\n for mp in mps:\n for i in range(len(mp)):\n for j in range(len(mp)):\n mp[i][j] = mp[i][j] ^ m[i][j]\n scores.append(compute_score(mp))\n best = scores.index(min(scores))\n return best, mps[best]\n \ndef get_mask_patterns(mm):\n def formula(i, row, column):\n if i == 0:\n return (row + column) % 2 == 0\n elif i == 1:\n return row % 2 == 0\n elif i == 2:\n return column % 3 == 0\n elif i == 3:\n return (row + column) % 3 == 0\n elif i == 4:\n return (row // 2 + column // 3) % 2 == 0\n elif i == 5:\n return ((row * column) % 2) + ((row * column) % 3) == 0\n elif i == 6:\n return (((row * column) % 2) + ((row * column) % 3)) % 2 == 0\n elif i == 7:\n return \t(((row + column) % 2) + ((row * column) % 3)) % 2 == 0\n\n mm[-8][8] = None\n for i in range(len(mm)):\n for j in range(len(mm)):\n mm[i][j] = 0 if mm[i][j] is not None else mm[i][j]\n mps = []\n for i in range(8):\n mp = [ii[:] for ii in mm]\n for row in range(len(mp)):\n for column in range(len(mp)):\n mp[row][column] = 1 if mp[row][column] is None and formula(i, row, column) else 0\n mps.append(mp)\n \n return mps\n \ndef compute_score(m):\n def evaluation1(m):\n def ev1(ma):\n sc = 0\n for mi in ma:\n j = 0\n while j < len(mi)-4:\n n = 4\n while mi[j:j+n+1] in [[1]*(n+1), [0]*(n+1)]:\n n += 1\n (sc, j) = (sc+n-2, j+n) if n > 4 else (sc, j+1)\n return sc\n return ev1(m) + ev1(list(map(list, zip(*m))))\n \n def evaluation2(m):\n sc = 0\n for i in range(len(m)-1):\n for j in range(len(m)-1):\n sc += 3 if m[i][j] == m[i+1][j] == m[i][j+1] == m[i+1][j+1] else 0\n return sc\n \n def evaluation3(m):\n def ev3(ma):\n sc = 0\n for mi in ma:\n j = 0\n while j < len(mi)-10:\n if mi[j:j+11] == [1,0,1,1,1,0,1,0,0,0,0]:\n sc += 40\n j += 7\n elif mi[j:j+11] == [0,0,0,0,1,0,1,1,1,0,1]:\n sc += 40\n j += 4\n else:\n j += 1\n return sc\n return ev3(m) + ev3(list(map(list, zip(*m))))\n \n def evaluation4(m):\n darknum = 0\n for i in m:\n darknum += sum(i)\n percent = darknum / (len(m)**2) * 100\n s = int((50 - percent) / 5) * 5\n return 2*s if s >=0 else -2*s\n\n score = evaluation1(m) + evaluation2(m)+ evaluation3(m) + evaluation4(m)\n return score\n \ndef add_format_and_version_string(ver, ecl, mask_num, m):\n fs = [int(i) for i in format_info_str[lindex[ecl]][mask_num]]\n for j in range(6):\n m[8][j] = m[-j-1][8] = fs[j]\n m[8][-j-1] = m[j][8] = fs[-j-1]\n m[8][7] = m[-7][8] = fs[6]\n m[8][8] = m[8][-8] = fs[7]\n m[7][8] = m[8][-7] = fs[8]\n \n if ver > 6:\n vs = (int(i) for i in version_info_str[ver-7])\n for j in range(5, -1, -1):\n for i in (-9, -10, -11):\n m[i][j] = m[j][i] = next(vs)"
},
{
"path": "video_downloader/MyQR/mylibs/structure.py",
"content": "# -*- coding: utf-8 -*-\n\nfrom MyQR.mylibs.constant import required_remainder_bits, lindex, grouping_list\n\ndef structure_final_bits(ver, ecl, data_codewords, ecc):\n final_message = interleave_dc(ver, ecl, data_codewords) + interleave_ecc(ecc)\n \n # convert to binary & Add Remainder Bits if Necessary\n final_bits = ''.join(['0'*(8-len(i))+i for i in [bin(i)[2:] for i in final_message]]) + '0' * required_remainder_bits[ver-1]\n \n return final_bits\n\ndef interleave_dc(ver, ecl, data_codewords):\n id = []\n for t in zip(*data_codewords):\n id += list(t)\n g = grouping_list[ver-1][lindex[ecl]]\n if g[3]:\n for i in range(g[2]):\n id.append(data_codewords[i-g[2]][-1])\n return id\n \ndef interleave_ecc(ecc):\n ie = []\n for t in zip(*ecc):\n ie += list(t)\n return ie"
},
{
"path": "video_downloader/MyQR/mylibs/theqrmodule.py",
"content": "# -*- coding: utf-8 -*-\n\nfrom MyQR.mylibs import data, ECC, structure, matrix, draw\n\n# ver: Version from 1 to 40\n# ecl: Error Correction Level (L,M,Q,H)\n# get a qrcode picture of 3*3 pixels per module\ndef get_qrcode(ver, ecl, str, save_place):\n # Data Coding\n ver, data_codewords = data.encode(ver, ecl, str)\n\n # Error Correction Coding\n ecc = ECC.encode(ver, ecl, data_codewords)\n \n # Structure final bits\n final_bits = structure.structure_final_bits(ver, ecl, data_codewords, ecc)\n \n # Get the QR Matrix\n qrmatrix = matrix.get_qrmatrix(ver, ecl, final_bits)\n \n # Draw the picture and Save it, then return the real ver and the absolute name\n return ver, draw.draw_qrcode(save_place, qrmatrix)\n"
},
{
"path": "video_downloader/MyQR/myqr.py",
"content": "#!/usr/bin/env python3\n# -*- coding: utf-8 -*-\n\nimport os\nfrom MyQR.mylibs import theqrmodule\nfrom PIL import Image\n \n# Positional parameters\n# words: str\n#\n# Optional parameters\n# version: int, from 1 to 40\n# level: str, just one of ('L','M','Q','H')\n# picutre: str, a filename of a image\n# colorized: bool\n# constrast: float\n# brightness: float\n# save_name: str, the output filename like 'example.png'\n# save_dir: str, the output directory\n#\n# See [https://github.com/sylnsfar/qrcode] for more details!\ndef run(words, version=1, level='H', picture=None, colorized=False, contrast=1.0, brightness=1.0, save_name=None, save_dir=os.getcwd()):\n\n supported_chars = r\"0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz ··,.:;+-*/\\~!@#$%^&`'=<>[]()?_{}|\"\n\n\n # check every parameter\n if not isinstance(words, str) or any(i not in supported_chars for i in words):\n raise ValueError('Wrong words! Make sure the characters are supported!')\n if not isinstance(version, int) or version not in range(1, 41):\n raise ValueError('Wrong version! Please choose a int-type value from 1 to 40!')\n if not isinstance(level, str) or len(level)>1 or level not in 'LMQH':\n raise ValueError(\"Wrong level! Please choose a str-type level from {'L','M','Q','H'}!\")\n if picture:\n if not isinstance(picture, str) or not os.path.isfile(picture) or picture[-4:] not in ('.jpg','.png','.bmp','.gif'):\n raise ValueError(\"Wrong picture! Input a filename that exists and be tailed with one of {'.jpg', '.png', '.bmp', '.gif'}!\")\n if picture[-4:] == '.gif' and save_name and save_name[-4:] != '.gif':\n raise ValueError('Wrong save_name! If the picuter is .gif format, the output filename should be .gif format, too!')\n if not isinstance(colorized, bool):\n raise ValueError('Wrong colorized! Input a bool-type value!')\n if not isinstance(contrast, float):\n raise ValueError('Wrong contrast! Input a float-type value!')\n if not isinstance(brightness, float):\n raise ValueError('Wrong brightness! Input a float-type value!')\n if save_name and (not isinstance(save_name, str) or save_name[-4:] not in ('.jpg','.png','.bmp','.gif')):\n raise ValueError(\"Wrong save_name! Input a filename tailed with one of {'.jpg', '.png', '.bmp', '.gif'}!\")\n if not os.path.isdir(save_dir):\n raise ValueError('Wrong save_dir! Input a existing-directory!')\n \n \n def combine(ver, qr_name, bg_name, colorized, contrast, brightness, save_dir, save_name=None):\n from MyQR.mylibs.constant import alig_location\n from PIL import ImageEnhance, ImageFilter\n \n qr = Image.open(qr_name)\n qr = qr.convert('RGBA') if colorized else qr\n \n bg0 = Image.open(bg_name).convert('RGBA')\n bg0 = ImageEnhance.Contrast(bg0).enhance(contrast)\n bg0 = ImageEnhance.Brightness(bg0).enhance(brightness)\n\n if bg0.size[0] < bg0.size[1]:\n bg0 = bg0.resize((qr.size[0]-24, (qr.size[0]-24)*int(bg0.size[1]/bg0.size[0])))\n else:\n bg0 = bg0.resize(((qr.size[1]-24)*int(bg0.size[0]/bg0.size[1]), qr.size[1]-24)) \n \n bg = bg0 if colorized else bg0.convert('1')\n \n aligs = []\n if ver > 1:\n aloc = alig_location[ver-2]\n for a in range(len(aloc)):\n for b in range(len(aloc)):\n if not ((a==b==0) or (a==len(aloc)-1 and b==0) or (a==0 and b==len(aloc)-1)):\n for i in range(3*(aloc[a]-2), 3*(aloc[a]+3)):\n for j in range(3*(aloc[b]-2), 3*(aloc[b]+3)):\n aligs.append((i,j))\n\n for i in range(qr.size[0]-24):\n for j in range(qr.size[1]-24):\n if not ((i in (18,19,20)) or (j in (18,19,20)) or (i<24 and j<24) or (i<24 and j>qr.size[1]-49) or (i>qr.size[0]-49 and j<24) or ((i,j) in aligs) or (i%3==1 and j%3==1) or (bg0.getpixel((i,j))[3]==0)):\n qr.putpixel((i+12,j+12), bg.getpixel((i,j)))\n \n qr_name = os.path.join(save_dir, os.path.splitext(os.path.basename(bg_name))[0] + '_qrcode.png') if not save_name else os.path.join(save_dir, save_name)\n qr.resize((qr.size[0]*3, qr.size[1]*3)).save(qr_name)\n return qr_name\n\n tempdir = os.path.join(os.path.expanduser('~'), '.myqr')\n \n try:\n if not os.path.exists(tempdir):\n os.makedirs(tempdir)\n\n ver, qr_name = theqrmodule.get_qrcode(version, level, words, tempdir)\n\n if picture and picture[-4:]=='.gif':\n import imageio\n \n im = Image.open(picture)\n duration = im.info.get('duration', 0)\n im.save(os.path.join(tempdir, '0.png'))\n while True:\n try:\n seq = im.tell()\n im.seek(seq + 1)\n im.save(os.path.join(tempdir, '%s.png' %(seq+1)))\n except EOFError:\n break\n \n imsname = []\n for s in range(seq+1):\n bg_name = os.path.join(tempdir, '%s.png' % s)\n imsname.append(combine(ver, qr_name, bg_name, colorized, contrast, brightness, tempdir))\n \n ims = [imageio.imread(pic) for pic in imsname]\n qr_name = os.path.join(save_dir, os.path.splitext(os.path.basename(picture))[0] + '_qrcode.gif') if not save_name else os.path.join(save_dir, save_name)\n imageio.mimwrite(qr_name, ims, '.gif', **{ 'duration': duration/1000 })\n elif picture:\n qr_name = combine(ver, qr_name, picture, colorized, contrast, brightness, save_dir, save_name)\n elif qr_name:\n qr = Image.open(qr_name)\n qr_name = os.path.join(save_dir, os.path.basename(qr_name)) if not save_name else os.path.join(save_dir, save_name)\n qr.resize((qr.size[0]*3, qr.size[1]*3)).save(qr_name)\n \n return ver, level, qr_name\n \n except:\n raise\n finally:\n import shutil\n if os.path.exists(tempdir):\n shutil.rmtree(tempdir) "
},
{
"path": "video_downloader/MyQR/terminal.py",
"content": "#!/usr/bin/env python3\n# -*- coding: utf-8 -*-\n\nfrom MyQR.myqr import run\nimport os\n\ndef main():\n import argparse\n argparser = argparse.ArgumentParser()\n argparser.add_argument('Words', help = 'The words to produce you QR-code picture, like a URL or a sentence. Please read the README file for the supported characters.')\n argparser.add_argument('-v', '--version', type = int, choices = range(1,41), default = 1, help = 'The version means the length of a side of the QR-Code picture. From little size to large is 1 to 40.')\n argparser.add_argument('-l', '--level', choices = list('LMQH'), default = 'H', help = 'Use this argument to choose an Error-Correction-Level: L(Low), M(Medium) or Q(Quartile), H(High). Otherwise, just use the default one: H')\n argparser.add_argument('-p', '--picture', help = 'the picture e.g. example.jpg')\n argparser.add_argument('-c', '--colorized', action = 'store_true', help = \"Produce a colorized QR-Code with your picture. Just works when there is a correct '-p' or '--picture'.\")\n argparser.add_argument('-con', '--contrast', type = float, default = 1.0, help = 'A floating point value controlling the enhancement of contrast. Factor 1.0 always returns a copy of the original image, lower factors mean less color (brightness, contrast, etc), and higher values more. There are no restrictions on this value. Default: 1.0')\n argparser.add_argument('-bri', '--brightness', type = float, default = 1.0, help = 'A floating point value controlling the enhancement of brightness. Factor 1.0 always returns a copy of the original image, lower factors mean less color (brightness, contrast, etc), and higher values more. There are no restrictions on this value. Default: 1.0')\n argparser.add_argument('-n', '--name', help = \"The filename of output tailed with one of {'.jpg', '.png', '.bmp', '.gif'}. eg. exampl.png\")\n argparser.add_argument('-d', '--directory', default = os.getcwd(), help = 'The directory of output.')\n args = argparser.parse_args()\n \n if args.picture and args.picture[-4:]=='.gif':\n print('It may take a while, please wait for minutes...')\n \n try:\n ver, ecl, qr_name = run(\n args.Words,\n args.version,\n args.level,\n args.picture,\n args.colorized,\n args.contrast,\n args.brightness,\n args.name,\n args.directory\n ) \n print('Succeed! \\nCheck out your', str(ver) + '-' + str(ecl), 'QR-code:', qr_name)\n except:\n raise"
},
{
"path": "video_downloader/requirements.txt",
"content": "imageio\nnumpy\nPillow\nbeautifulsoup4\n"
},
{
"path": "video_downloader/video_downloader.py",
"content": "# -*- coding:utf-8 -*-\nfrom tkinter.filedialog import askdirectory\nfrom MyQR.myqr import run\nfrom urllib import request, parse\nfrom bs4 import BeautifulSoup\n\nimport tkinter.messagebox as msgbox\nimport tkinter as tk\nimport webbrowser\nimport re\nimport json\nimport os\nimport types\nimport requests\nimport time\n\n\n\"\"\"\n类说明:爱奇艺、优酷等实现在线观看以及视频下载的类\n\nParameters:\n\twidth - tkinter主界面宽\n\theight - tkinter主界面高\n\nReturns:\n\t无\n\nModify:\n\t2017-05-09\n\"\"\"\nclass APP:\n\tdef __init__(self, width = 500, height = 300):\n\t\tself.w = width\n\t\tself.h = height\n\t\tself.title = ' VIP视频破解助手'\n\t\tself.root = tk.Tk(className=self.title)\n\t\tself.url = tk.StringVar()\n\t\tself.v = tk.IntVar()\n\t\tself.v.set(1)\n\n\n\t\t#Frame空间\n\t\tframe_1 = tk.Frame(self.root)\n\t\tframe_2 = tk.Frame(self.root)\n\t\tframe_3 = tk.Frame(self.root)\n\t\t\n\t\t#Menu菜单\n\t\tmenu = tk.Menu(self.root)\n\t\tself.root.config(menu = menu)\n\t\tfilemenu = tk.Menu(menu,tearoff=0)\n\t\tmoviemenu = tk.Menu(menu,tearoff = 0)\n\t\tmenu.add_cascade(label = '菜单', menu = filemenu)\n\t\tmenu.add_cascade(label = '友情链接', menu = moviemenu)\n\t\tfilemenu.add_command(label = '使用说明',command = lambda :webbrowser.open('http://blog.csdn.net/c406495762/article/details/71334633'))\n\t\tfilemenu.add_command(label = '关于作者',command = lambda :webbrowser.open('http://blog.csdn.net/c406495762'))\n\t\tfilemenu.add_command(label = '退出',command = self.root.quit)\n\n\t\t#各个网站链接\n\t\tmoviemenu.add_command(label = '网易公开课',command = lambda :webbrowser.open('http://open.163.com/'))\n\t\tmoviemenu.add_command(label = '腾讯视频',command = lambda :webbrowser.open('http://v.qq.com/'))\n\t\tmoviemenu.add_command(label = '搜狐视频',command = lambda :webbrowser.open('http://tv.sohu.com/'))\n\t\tmoviemenu.add_command(label = '芒果TV',command = lambda :webbrowser.open('http://www.mgtv.com/'))\n\t\tmoviemenu.add_command(label = '爱奇艺',command = lambda :webbrowser.open('http://www.iqiyi.com/'))\n\t\tmoviemenu.add_command(label = 'PPTV',command = lambda :webbrowser.open('http://www.bilibili.com/'))\n\t\tmoviemenu.add_command(label = '优酷',command = lambda :webbrowser.open('http://www.youku.com/'))\n\t\tmoviemenu.add_command(label = '乐视',command = lambda :webbrowser.open('http://www.le.com/'))\n\t\tmoviemenu.add_command(label = '土豆',command = lambda :webbrowser.open('http://www.tudou.com/'))\n\t\tmoviemenu.add_command(label = 'A站',command = lambda :webbrowser.open('http://www.acfun.tv/'))\n\t\tmoviemenu.add_command(label = 'B站',command = lambda :webbrowser.open('http://www.bilibili.com/'))\n\n\t\t#控件内容设置\n\t\tgroup = tk.Label(frame_1,text = '请选择一个视频播放通道:', padx = 10, pady = 10)\n\t\ttb1 = tk.Radiobutton(frame_1,text = '通道一', variable = self.v, value = 1, width = 10, height = 3)\n\t\ttb2 = tk.Radiobutton(frame_1,text = '通道二', variable = self.v, value = 2, width = 10, height = 3)\n\t\tlabel1 = tk.Label(frame_2, text = \"请输入视频链接:\")\n\t\tentry = tk.Entry(frame_2, textvariable = self.url, highlightcolor = 'Fuchsia', highlightthickness = 1,width = 35)\n\t\tlabel2 = tk.Label(frame_2, text = \" \")\n\t\tplay = tk.Button(frame_2, text = \"播放\", font = ('楷体',12), fg = 'Purple', width = 2, height = 1, command = self.video_play)\n\t\tlabel3 = tk.Label(frame_2, text = \" \")\n\t\t# download = tk.Button(frame_2, text = \"下载\", font = ('楷体',12), fg = 'Purple', width = 2, height = 1, command = self.download_wmxz)\n\t\tQR_Code = tk.Button(frame_3, text = \"手机观看\", font = ('楷体',12), fg = 'Purple', width = 10, height = 2, command = self.QR_Code)\n\t\tlabel_explain = tk.Label(frame_3, fg = 'red', font = ('楷体',12), text = '\\n注意:支持大部分主流视频网站的视频播放!\\n此软件仅用于交流学习,请勿用于任何商业用途!')\n\t\tlabel_warning = tk.Label(frame_3, fg = 'blue', font = ('楷体',12),text = '\\n建议:将Chrome内核浏览器设置为默认浏览器\\n作者:Jack_Cui')\n\n\n\n\t\t#控件布局\n\t\tframe_1.pack()\n\t\tframe_2.pack()\n\t\tframe_3.pack()\n\t\tgroup.grid(row = 0, column = 0)\n\t\ttb1.grid(row = 0, column = 1)\n\t\ttb2.grid(row = 0, column = 2)\n\t\tlabel1.grid(row = 0, column = 0)\n\t\tentry.grid(row = 0, column = 1)\n\t\tlabel2.grid(row = 0, column = 2)\n\t\tplay.grid(row = 0, column = 3,ipadx = 10, ipady = 10)\n\t\tlabel3.grid(row = 0, column = 4)\n\t\t# download.grid(row = 0, column = 5,ipadx = 10, ipady = 10)\n\t\tQR_Code.grid(row = 0, column = 0)\n\t\tlabel_explain.grid(row = 1, column = 0)\n\t\tlabel_warning.grid(row = 2, column = 0)\n\n\t\"\"\"\n\t函数说明:jsonp解析\n\n\tParameters:\n\t\t_jsonp - jsonp字符串\n\n\tReturns:\n\t\t_json - json格式数据\n\n\tModify:\n\t\t2017-05-11\n\t\"\"\"\n\tdef loads_jsonp(self, _jsonp):\n\t\ttry:\n\t\t\t_json = json.loads(re.match(\".*?({.*}).*\",_jsonp,re.S).group(1))\n\t\t\treturn _json\n\t\texcept:\n\t\t\traise ValueError('Invalid Input')\n\n\t\"\"\"\n\t函数说明:视频播放\n\n\tParameters:\n\t\tself\n\n\tReturns:\n\t\t无\n\n\tModify:\n\t\t2017-05-09\n\t\"\"\"\n\tdef video_play(self):\n\t\t#视频解析网站地址\n\t\tport_1 = 'http://www.wmxz.wang/video.php?url='\n\t\tport_2 = 'http://www.vipjiexi.com/tong.php?url='\n\n\t\t#正则表达是判定是否为合法链接\n\t\tif re.match(r'^https?:/{2}\\w.+$', self.url.get()):\n\t\t\tif self.v.get() == 1:\n\t\t\t\t#视频链接获取\n\t\t\t\tip = self.url.get()\n\t\t\t\t#视频链接加密\n\t\t\t\tip = parse.quote_plus(ip)\n\t\t\t\t#浏览器打开\n\t\t\t\twebbrowser.open(port_1 + self.url.get())\n\t\t\telif self.v.get() == 2:\n\t\t\t\t#链接获取\n\t\t\t\tip = self.url.get()\n\t\t\t\t#链接加密\n\t\t\t\tip = parse.quote_plus(ip)\n\n\t\t\t\t#获取time、key、url\n\t\t\t\tget_url = 'http://www.vipjiexi.com/x2/tong.php?url=%s' % ip \n\t\t\t\t# get_url_head = {\n\t\t\t\t# \t'User-Agent':'Mozilla/5.0 (Linux; Android 4.1.1; Nexus 7 Build/JRO03D) AppleWebKit/535.19 (KHTML, like Gecko) Chrome/18.0.1025.166 Safari/535.19',\n\t\t\t\t# \t'Referer':'http://www.vipjiexi.com/',\n\t\t\t\t# }\n\t\t\t\t# get_url_req = request.Request(url = get_url, headers = get_url_head)\n\t\t\t\t# get_url_response = request.urlopen(get_url_req)\n\t\t\t\t# get_url_html = get_url_response.read().decode('utf-8')\n\t\t\t\t# bf = BeautifulSoup(get_url_html, 'lxml')\n\t\t\t\t# a = str(bf.find_all('script'))\n\t\t\t\t# pattern = re.compile('\"api.php\", {\"time\":\"(\\d+)\", \"key\": \"(.+)\", \"url\": \"(.+)\",\"type\"', re.IGNORECASE)\n\t\t\t\t# string = pattern.findall(a)\n\t\t\t\t# now_time = string[0][0]\n\t\t\t\t# now_key = string[0][1]\n\t\t\t\t# now_url = string[0][2] \n\n\t\t\t\t# #请求播放,获取Success = 1\n\t\t\t\t# get_movie_url = 'http://www.vipjiexi.com/x2/api.php'\n\t\t\t\t# get_movie_data = {\n\t\t\t\t# \t'key':'%s' % now_key,\n\t\t\t\t# \t'time':'%s' % now_time,\n\t\t\t\t# \t'type':'',\n\t\t\t\t# \t'url':'%s' % now_url\n\t\t\t\t# }\n\t\t\t\t# get_movie_head = {\n\t\t\t\t# \t'User-Agent':'Mozilla/5.0 (Linux; Android 4.1.1; Nexus 7 Build/JRO03D) AppleWebKit/535.19 (KHTML, like Gecko) Chrome/18.0.1025.166 Safari/535.19',\n\t\t\t\t# \t'Referer':'http://www.vipjiexi.com/x2/tong.php?',\n\t\t\t\t# \t'url':'%s' % ip,\n\t\t\t\t# }\n\t\t\t\t# get_movie_req = request.Request(url = get_movie_url, headers = get_movie_head)\n\t\t\t\t# get_movie_data = parse.urlencode(get_movie_data).encode('utf-8')\n\t\t\t\t# get_movie_response = request.urlopen(get_movie_req, get_movie_data)\n\t\t\t\t#请求之后立刻打开\n\t\t\t\twebbrowser.open(get_url)\n\n\t\telse:\n\t\t\tmsgbox.showerror(title='错误',message='视频链接地址无效,请重新输入!')\n\n\t\"\"\"\n\t函数说明:视频下载,通过无名小站抓包(已经无法使用)\n\n\tParameters:\n\t\tself\n\n\tReturns:\n\t\t无\n\n\tModify:\n\t\t2017-06-15\n\t\"\"\"\n\tdef download_wmxz(self):\t\n\t\tif re.match(r'^https?:/{2}\\w.+$', self.url.get()):\n\t\t\t#视频链接获取\n\t\t\tip = self.url.get()\n\t\t\t#视频链接加密\n\t\t\tip = parse.quote_plus(ip)\n\n\t\t\t#获取保存视频的url\n\t\t\tget_url = 'http://www.sfsft.com/index.php?url=%s' % ip \n\t\t\thead = {\n\t\t\t\t'User-Agent':'Mozilla/5.0 (Linux; Android 4.1.1; Nexus 7 Build/JRO03D) AppleWebKit/535.19 (KHTML, like Gecko) Chrome/18.0.1025.166 Safari/535.19',\n\t\t\t\t'Referer':'http://www.sfsft.com/index.php?url=%s' % ip\n\t\t\t}\n\t\t\tget_url_req = request.Request(url = get_url, headers = head)\n\t\t\tget_url_response = request.urlopen(get_url_req)\n\t\t\tget_url_html = get_url_response.read().decode('utf-8')\n\t\t\tbf = BeautifulSoup(get_url_html, 'lxml')\n\t\t\ta = str(bf.find_all('script'))\n\t\t\tpattern = re.compile(\"url : '(.+)',\", re.IGNORECASE)\n\t\t\turl = pattern.findall(a)[0]\n\n\t\t\t#获取视频地址\n\t\t\tget_movie_url = 'http://www.sfsft.com/api.php'\n\t\t\tget_movie_data = {\n\t\t\t\t'up':'0',\n\t\t\t\t'url':'%s' % url,\n\t\t\t}\n\t\t\tget_movie_req = request.Request(url = get_movie_url, headers = head)\n\t\t\tget_movie_data = parse.urlencode(get_movie_data).encode('utf-8')\n\t\t\tget_movie_response = request.urlopen(get_movie_req, get_movie_data)\n\t\t\tget_movie_html = get_movie_response.read().decode('utf-8')\n\t\t\tget_movie_data = json.loads(get_movie_html)\n\t\t\twebbrowser.open(get_movie_data['url'])\n\t\telse:\n\t\t\tmsgbox.showerror(title='错误',message='视频链接地址无效,请重新输入!')\n\n\n\t\"\"\"\n\t函数说明:生成二维码,手机观看\n\n\tParameters:\n\t\tself\n\n\tReturns:\n\t\t无\n\n\tModify:\n\t\t2017-05-12\n\t\"\"\"\n\tdef QR_Code(self):\t\n\t\tif re.match(r'^https?:/{2}\\w.+$', self.url.get()):\n\t\t\t#视频链接获取\n\t\t\tip = self.url.get()\n\t\t\t#视频链接加密\n\t\t\tip = parse.quote_plus(ip)\n\n\t\t\turl = 'http://www.wmxz.wang/video.php?url=%s' % ip\n\t\t\twords = url\n\t\t\timages_pwd = os.getcwd() + '\\Images\\\\'\n\t\t\tpng_path = images_pwd + 'bg.png'\n\t\t\tqr_name = 'qrcode.png'\n\t\t\tqr_path = images_pwd + 'qrcode.png'\n\n\t\t\trun(words = words, picture = png_path, save_name = qr_name, save_dir = images_pwd)\n\n\t\t\ttop = tk.Toplevel(self.root)\n\t\t\timg = tk.PhotoImage(file = qr_path)\n\t\t\ttext_label = tk.Label(top, fg = 'red', font = ('楷体',15), text = \"手机浏览器扫描二维码,在线观看视频!\")\n\t\t\timg_label = tk.Label(top, image = img)\n\t\t\ttext_label.pack()\n\t\t\timg_label.pack()\n\t\t\ttop.mainloop()\n\n\t\telse:\n\t\t\tmsgbox.showerror(title='错误',message='视频链接地址无效,请重新输入!')\n\n\t\"\"\"\n\t函数说明:tkinter窗口居中\n\n\tParameters:\n\t\tself\n\n\tReturns:\n\t\t无\n\n\tModify:\n\t\t2017-05-09\n\t\"\"\"\n\tdef center(self):\n\t\tws = self.root.winfo_screenwidth()\n\t\ths = self.root.winfo_screenheight()\n\t\tx = int( (ws/2) - (self.w/2) )\n\t\ty = int( (hs/2) - (self.h/2) )\n\t\tself.root.geometry('{}x{}+{}+{}'.format(self.w, self.h, x, y))\n\n\t\"\"\"\n\t函数说明:loop等待用户事件\n\n\tParameters:\n\t\tself\n\n\tReturns:\n\t\t无\n\n\tModify:\n\t\t2017-05-09\n\t\"\"\"\n\tdef loop(self):\n\t\tself.root.resizable(False, False)\t#禁止修改窗口大小\n\t\tself.center()\t\t\t\t\t\t#窗口居中\n\t\tself.root.mainloop()\n\nif __name__ == '__main__':\n\tapp = APP()\t\t\t#实例化APP对象\n\tapp.loop()\t\t\t#loop等待用户事件\n\n\n\n\n"
},
{
"path": "zhengfang_system_spider/README.md",
"content": "# ZhengFang_System_Spider\n对正方教务管理系统的个人课表,个人学生成绩,绩点等简单爬取\n\n## 依赖环境\npython 3.6\n### python库\nhttp请求:requests,urllib \n数据提取:re,lxml,bs4 \n存储相关:os,sys \n验证码处理:PIL \n\n## 下载安装\n在终端输入如下命令:\n```bash\ngit clone git@github.com:Jack-Cherish/python-spider.git\n```\n\n## 使用方法\n\n### 安装依赖包\n```bash\npip install -r requirements.txt\n```\n\n### 运行\n在当前目录下输入:\n```\ncd zhengfang_system_spider\npython spider.py\n```\n运行爬虫,按提示输入学校教务网,学号,密码,输入验证码 \n\n\n\n稍等几秒钟,当前ZhengFang_System_Spider文件夹下就会生成zhengfang.txt \n个人课表,成绩绩点均已保存到该文本文件中\n\n\n"
},
{
"path": "zhengfang_system_spider/requirements.txt",
"content": "lxml==4.6.3\nrequests==2.20.0\nPillow>=6.2.2\nbeautifulsoup4==4.6.0\n"
},
{
"path": "zhengfang_system_spider/spider.py",
"content": "#!/usr/bin/env python\n#-*- coding: utf-8 -*-\n\n__author__ = 'ZYSzys'\n\nimport requests\nimport re\nimport os\nimport sys\nimport urllib\nimport getpass\nfrom lxml import etree\nfrom PIL import Image\nfrom imp import reload\nfrom bs4 import BeautifulSoup\n\n\nclass Who:\n def __init__(self, user, pswd):\n self.user = user\n self.pswd = pswd\n\n\nclass Tool:\n rma = re.compile('|')\n rmtb = re.compile('
||
')\n rmtr = re.compile('| | ||
||
')\n rmtime1 = re.compile('| .*? | ')\n rmtime2 = re.compile('.*? | ')\n\n def replace(self, x):\n x = re.sub(self.rma, ' ', x)\n x = re.sub(self.rmtb, '---', x)\n x = re.sub(self.rmtr, ' ', x)\n x = re.sub(self.rmtime1, '\\n', x)\n x = re.sub(self.rmtime2, '', x)\n return x.strip()\n\n\ndef Getgrade(response):\n html = response.content\n soup = BeautifulSoup(html, 'lxml')\n trs = soup.find(id=\"Datagrid1\").findAll(\"tr\")\n Grades = []\n keys = []\n tds = trs[0].findAll(\"td\")\n tds = tds[:2] + tds[3:5] + tds[6:9]\n for td in tds:\n keys.append(td.string)\n for tr in trs[1:]:\n tds = tr.findAll(\"td\")\n tds = tds[:2] + tds[3:5] + tds[6:9]\n values = []\n for td in tds:\n values.append(td.string)\n one = dict((key, value) for key, value in zip(keys, values))\n Grades.append(one)\n return Grades\n\n\ndef Getgradetestresults(trs):\n results = []\n k = []\n for td in trs[0].xpath('.//td/text()'):\n k.append(td)\n trs = trs[1:]\n for tr in trs:\n tds = tr.xpath('.//td/text()')\n v = []\n for td in tds:\n v.append(td)\n one = dict((i, j) for i, j in zip(k, v))\n results.append(one)\n return results\n\n\nclass University:\n def __init__(self, student, baseurl):\n reload(sys)\n self.student = student\n self.baseurl = baseurl\n self.session = requests.session()\n self.session.headers['User-Agent'] = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.115 Safari/537.36'\n\n def Login(self):\n url = self.baseurl+'/default2.aspx'\n res = self.session.get(url)\n cont = res.content\n selector = etree.HTML(cont)\n __VIEWSTATE = selector.xpath('//*[@id=\"form1\"]/input/@value')[0]\n imgurl = self.baseurl + '/CheckCode.aspx'\n imgres = self.session.get(imgurl, stream=True)\n img = imgres.content\n with open('code.jpg', 'wb') as f:\n f.write(img)\n jpg = Image.open('{}/code.jpg'.format(os.getcwd()))\n jpg.show()\n jpg.close\n code = input('输入验证码:')\n RadioButtonList1 = u\"学生\"\n data = {\n \"__VIEWSTATE\": __VIEWSTATE,\n \"txtUserName\": self.student.user,\n \"TextBox1\": self.student.pswd,\n \"TextBox2\": self.student.pswd,\n \"txtSecretCode\": code,\n \"RadioButtonList1\": RadioButtonList1,\n \"Button1\": \"\",\n \"lbLanguage\": \"\"\n }\n loginres = self.session.post(url, data=data)\n logcont = loginres.text\n pattern = re.compile(\n '
 \n
\n  ◦\\/:*?\"<>| ':\n filename = filename.replace(c, '')\n save_video_name = filename + '.mp4'\n all_video[xunlei_video_name] = save_video_name\n\n addTasktoXunlei(download_url)\n # 弹幕下载\n danmu_name = filename + '.xml'\n danmu_ass = filename + '.ass'\n oid = download_url.split('/')[6]\n danmu_url = 'https://api.bilibili.com/x/v1/dm/list.so?oid={}'.format(oid)\n danmu_header = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.167 Safari/537.36',\n 'Accept': '*/*',\n 'Accept-Encoding': 'gzip, deflate, br',\n 'Accept-Language': 'zh-CN,zh;q=0.9'}\n with closing(sess.get(danmu_url, headers=danmu_header, stream=True, verify=False)) as response: \n if response.status_code == 200:\n with open(danmu_name, 'wb') as file:\n for data in response.iter_content():\n file.write(data)\n file.flush()\n else:\n print('链接异常')\n time.sleep(0.5)\n xml2ass.Danmaku2ASS(danmu_name, danmu_ass, 1280, 720)\n# 视频重命名\nfor key, item in all_video.items():\n while key not in os.listdir('./'):\n time.sleep(1)\n os.rename(key, item)\n"
},
{
"path": "2020/bilibili/xml2ass.py",
"content": "# The original author of this program, Danmaku2ASS, is StarBrilliant.\n# This file is released under General Public License version 3.\n# You should have received a copy of General Public License text alongside with\n# this program. If not, you can obtain it at http://gnu.org/copyleft/gpl.html .\n# This program comes with no warranty, the author will not be resopnsible for\n# any damage or problems caused by this program.\n\nimport argparse\nimport calendar\nimport gettext\nimport io\nimport json\nimport logging\nimport math\nimport os\nimport random\nimport re\nimport sys\nimport time\nimport xml.dom.minidom\n\n\nif sys.version_info < (3,):\n raise RuntimeError('at least Python 3.0 is required')\n\ngettext.install('danmaku2ass', os.path.join(os.path.dirname(os.path.abspath(os.path.realpath(sys.argv[0] or 'locale'))), 'locale'))\n\ndef SeekZero(function):\n def decorated_function(file_):\n file_.seek(0)\n try:\n return function(file_)\n finally:\n file_.seek(0)\n return decorated_function\n\n\ndef EOFAsNone(function):\n def decorated_function(*args, **kwargs):\n try:\n return function(*args, **kwargs)\n except EOFError:\n return None\n return decorated_function\n\n\n@SeekZero\n@EOFAsNone\ndef ProbeCommentFormat(f):\n tmp = f.read(1)\n if tmp == '[':\n return 'Acfun'\n # It is unwise to wrap a JSON object in an array!\n # See this: http://haacked.com/archive/2008/11/20/anatomy-of-a-subtle-json-vulnerability.aspx/\n # Do never follow what Acfun developers did!\n elif tmp == '{':\n tmp = f.read(14)\n if tmp == '\"status_code\":':\n return 'Tudou'\n elif tmp == '\"root\":{\"total':\n return 'sH5V'\n elif tmp == '<':\n tmp = f.read(1)\n if tmp == '?':\n tmp = f.read(38)\n if tmp == 'xml version=\"1.0\" encoding=\"UTF-8\"?>
◦\\/:*?\"<>| ':\n filename = filename.replace(c, '')\n save_video_name = filename + '.mp4'\n all_video[xunlei_video_name] = save_video_name\n\n addTasktoXunlei(download_url)\n # 弹幕下载\n danmu_name = filename + '.xml'\n danmu_ass = filename + '.ass'\n oid = download_url.split('/')[6]\n danmu_url = 'https://api.bilibili.com/x/v1/dm/list.so?oid={}'.format(oid)\n danmu_header = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.167 Safari/537.36',\n 'Accept': '*/*',\n 'Accept-Encoding': 'gzip, deflate, br',\n 'Accept-Language': 'zh-CN,zh;q=0.9'}\n with closing(sess.get(danmu_url, headers=danmu_header, stream=True, verify=False)) as response: \n if response.status_code == 200:\n with open(danmu_name, 'wb') as file:\n for data in response.iter_content():\n file.write(data)\n file.flush()\n else:\n print('链接异常')\n time.sleep(0.5)\n xml2ass.Danmaku2ASS(danmu_name, danmu_ass, 1280, 720)\n# 视频重命名\nfor key, item in all_video.items():\n while key not in os.listdir('./'):\n time.sleep(1)\n os.rename(key, item)\n"
},
{
"path": "2020/bilibili/xml2ass.py",
"content": "# The original author of this program, Danmaku2ASS, is StarBrilliant.\n# This file is released under General Public License version 3.\n# You should have received a copy of General Public License text alongside with\n# this program. If not, you can obtain it at http://gnu.org/copyleft/gpl.html .\n# This program comes with no warranty, the author will not be resopnsible for\n# any damage or problems caused by this program.\n\nimport argparse\nimport calendar\nimport gettext\nimport io\nimport json\nimport logging\nimport math\nimport os\nimport random\nimport re\nimport sys\nimport time\nimport xml.dom.minidom\n\n\nif sys.version_info < (3,):\n raise RuntimeError('at least Python 3.0 is required')\n\ngettext.install('danmaku2ass', os.path.join(os.path.dirname(os.path.abspath(os.path.realpath(sys.argv[0] or 'locale'))), 'locale'))\n\ndef SeekZero(function):\n def decorated_function(file_):\n file_.seek(0)\n try:\n return function(file_)\n finally:\n file_.seek(0)\n return decorated_function\n\n\ndef EOFAsNone(function):\n def decorated_function(*args, **kwargs):\n try:\n return function(*args, **kwargs)\n except EOFError:\n return None\n return decorated_function\n\n\n@SeekZero\n@EOFAsNone\ndef ProbeCommentFormat(f):\n tmp = f.read(1)\n if tmp == '[':\n return 'Acfun'\n # It is unwise to wrap a JSON object in an array!\n # See this: http://haacked.com/archive/2008/11/20/anatomy-of-a-subtle-json-vulnerability.aspx/\n # Do never follow what Acfun developers did!\n elif tmp == '{':\n tmp = f.read(14)\n if tmp == '\"status_code\":':\n return 'Tudou'\n elif tmp == '\"root\":{\"total':\n return 'sH5V'\n elif tmp == '<':\n tmp = f.read(1)\n if tmp == '?':\n tmp = f.read(38)\n if tmp == 'xml version=\"1.0\" encoding=\"UTF-8\"?>