\n\n\n## You Only Look at Once for Real-time and Generic Multi-Task\nThis repository(Yolov8 multi-task) is the official PyTorch implementation of the paper \"You Only Look at Once for Real-time and Generic Multi-Task\". \n\n> [**You Only Look at Once for Real-time and Generic Multi-Task**](https://ieeexplore.ieee.org/document/10509552)\n>\n> by [Jiayuan Wang](https://scholar.google.ca/citations?user=1z6x5_UAAAAJ&hl=zh-CN&oi=ao), [Q. M. Jonathan Wu](https://scholar.google.com/citations?user=BJSAsE8AAAAJ&hl=zh-CN)
:email: and [Ning Zhang](https://scholar.google.ca/citations?hl=zh-CN&user=ZcYihtoAAAAJ)\n>\n> (
:email:) corresponding author.\n>\n> *[IEEE Transactions on Vehicular Technology](https://ieeexplore.ieee.org/document/10509552)*\n\n---\n\n### The Illustration of A-YOLOM\n\n\n\n### Contributions\n\n* We have developed a lightweight model capable of integrating three tasks into a single unified model. This is particularly beneficial for multi-task that demand real-time processing.\n* We have designed a novel Adaptive Concatenate Module specifically for the neck region of segmentation architectures. This module can adaptively concatenate features without manual design, further enhancing the model's generality.\n* We designed a lightweight, simple, and generic segmentation head. We have a unified loss function for the same type of task head, meaning we don't need to custom design for specific tasks. It is only built by a series of convolutional layers.\n* Extensive experiments are conducted based on publicly accessible autonomous driving datasets, which demonstrate that our model can outperform existing works, particularly in terms of inference time and visualization. Moreover, we further conducted experiments using real road datasets, which also demonstrate that our model significantly outperformed the state-of-the-art approaches.\n\n### Results\n\n#### Parameters and speed\n| Model | Parameters | FPS (bs=1) | FPS (bs=32) |\n|----------------|-------------|------------|-------------|\n| YOLOP | 7.9M | 26.0 | 134.8 |\n| HybridNet | 12.83M | 11.7 | 26.9 |\n| YOLOv8n(det) | 3.16M | 102 | 802.9 |\n| YOLOv8n(seg) | 3.26M | 82.55 | 610.49 |\n| A-YOLOM(n) | 4.43M | 39.9 | 172.2 |\n| A-YOLOM(s) | 13.61M | 39.7 | 96.2 |\n\n\n#### Traffic Object Detection Result\n\n| Model | Recall (%) | mAP50 (%) |\n|-------------|------------|------------|\n| MultiNet | 81.3 | 60.2 |\n| DLT-Net | **89.4** | 68.4 |\n| Faster R-CNN| 81.2 | 64.9 |\n| YOLOv5s | 86.8 | 77.2 |\n| YOLOv8n(det)| 82.2 | 75.1 |\n| YOLOP | 88.6 | 76.5 |\n| A-YOLOM(n) | 85.3 | 78.0 |\n| A-YOLOM(s) | 86.9 | **81.1** |\n\n#### Drivable Area Segmentation Result\n\n| Model | mIoU (%) |\n|----------------|----------|\n| MultiNet | 71.6 |\n| DLT-Net | 72.1 |\n| PSPNet | 89.6 |\n| YOLOv8n(seg) | 78.1 |\n| YOLOP | **91.6** |\n| A-YOLOM(n) | 90.5 |\n| A-YOLOM(s) | 91.0 |\n\n\n#### Lane Detection Result:\n\n| Model | Accuracy (%) | IoU (%) |\n|----------------|--------------|---------|\n| Enet | N/A | 14.64 |\n| SCNN | N/A | 15.84 |\n| ENet-SAD | N/A | 16.02 |\n| YOLOv8n(seg) | 80.5 | 22.9 |\n| YOLOP | 84.8 | 26.5 |\n| A-YOLOM(n) | 81.3 | 28.2 |\n| A-YOLOM(s) | **84.9** | **28.8** |\n\n\n#### Ablation Studies 1: Adaptive concatenation module:\n\n| Training method | Recall (%) | mAP50 (%) | mIoU (%) | Accuracy (%) | IoU (%) |\n|-----------------|------------|-----------|----------|--------------|---------|\n| YOLOM(n) | 85.2 | 77.7 | 90.6 | 80.8 | 26.7 |\n| A-YOLOM(n) | 85.3 | 78 | 90.5 | 81.3 | 28.2 |\n| YOLOM(s) | 86.9 | 81.1 | 90.9 | 83.9 | 28.2 |\n| A-YOLOM(s) | 86.9 | 81.1 | 91 | 84.9 | 28.8 |\n\n\n#### Ablation Studies 2: Results of different Multi-task model and segmentation structure:\n\n| Model | Parameters | mIoU (%) | Accuracy (%) | IoU (%) |\n|----------------|------------|----------|--------------|---------|\n| YOLOv8(segda) | 1004275 | 78.1 | - | - |\n| YOLOv8(segll) | 1004275 | - | 80.5 | 22.9 |\n| YOLOv8(multi) | 2008550 | 84.2 | 81.7 | 24.3 |\n| YOLOM(n) | 15880 | 90.6 | 80.8 | 26.7 |\n\nYOLOv8(multi) and YOLOM(n) only display two segmentation head parameters in total. They indeed have three heads, we ignore the detection head parameters because this is an ablation study for segmentation structure.\n\n \n**Notes**: \n\n- The works we has use for reference including `Multinet` ([paper](https://arxiv.org/pdf/1612.07695.pdf?utm_campaign=affiliate-ir-Optimise%20media%28%20South%20East%20Asia%29%20Pte.%20ltd._156_-99_national_R_all_ACQ_cpa_en&utm_content=&utm_source=%20388939),[code](https://github.com/MarvinTeichmann/MultiNet)),`DLT-Net` ([paper](https://ieeexplore.ieee.org/abstract/document/8937825)),`Faster R-CNN` ([paper](https://proceedings.neurips.cc/paper/2015/file/14bfa6bb14875e45bba028a21ed38046-Paper.pdf),[code](https://github.com/ShaoqingRen/faster_rcnn)),`YOLOv5s`([code](https://github.com/ultralytics/yolov5)) ,`PSPNet`([paper](https://openaccess.thecvf.com/content_cvpr_2017/papers/Zhao_Pyramid_Scene_Parsing_CVPR_2017_paper.pdf),[code](https://github.com/hszhao/PSPNet)) ,`ENet`([paper](https://arxiv.org/pdf/1606.02147.pdf),[code](https://github.com/osmr/imgclsmob)) `SCNN`([paper](https://www.aaai.org/ocs/index.php/AAAI/AAAI18/paper/download/16802/16322),[code](https://github.com/XingangPan/SCNN)) `SAD-ENet`([paper](https://openaccess.thecvf.com/content_ICCV_2019/papers/Hou_Learning_Lightweight_Lane_Detection_CNNs_by_Self_Attention_Distillation_ICCV_2019_paper.pdf),[code](https://github.com/cardwing/Codes-for-Lane-Detection)), `YOLOP`([paper](https://link.springer.com/article/10.1007/s11633-022-1339-y),[code](https://github.com/hustvl/YOLOP)), `HybridNets`([paper](https://arxiv.org/abs/2203.09035),[code](https://github.com/datvuthanh/HybridNets)), `YOLOv8`([code](https://github.com/ultralytics/ultralytics)). Thanks for their wonderful works.\n\n### Recommendation:\n- If you seek higher performance and can tolerate reduced speed and increased model complexity, we recommend our latest model, [RMT-PPAD](https://github.com/JiayuanWang-JW/RMT-PPAD). It is built on RT-DETR to implement multi-task learning and still achieves real-time performance on an RTX 4090 GPU.\n---\n\n### Visualization\n\n#### Real Road\n\n\n\n---\n\n\n### Requirement\n\nThis codebase has been developed with [**Python==3.7.16**](https://www.python.org/) with [**PyTorch==1.13.1**](https://pytorch.org/get-started/locally/).\n\nYou can use a 1080Ti GPU with 16 batch sizes. That will be fine. Only need more time to train. We recommend using a 4090 or more powerful GPU, which will be fast. \n\nWe strongly recommend you create a pure environment and follow our instructions to build yours. Otherwise, you may encounter some issues because the YOLOv8 has many mechanisms to detect your environment package automatically. Then it will change some variable values to further affect the code running. \n\n```setup\ncd YOLOv8-multi-task\npip install -e .\n```\n\n### Data preparation and Pre-trained model\n\n#### Download\n\n- Download the images from [images](https://bdd-data.berkeley.edu/).\n\n- Pre-trained model: [A-YOLOM](https://uwin365-my.sharepoint.com/:f:/g/personal/wang621_uwindsor_ca/EoUsIoFgcEhBgnO4kTjDQG4BUUSHMFXG4ami9qjvTUTofA?e=0xuAJG) # which include two version, scale \"n\" and \"s\".\n \n- Download the annotations of detection from [detection-object](https://uwin365-my.sharepoint.com/:u:/g/personal/wang621_uwindsor_ca/EeHOFLpSbp1EpN3FA1T97xABbjVEoeYefI8Kx0uKieR6xw?e=tnqHHx). \n- Download the annotations of drivable area segmentation from [seg-drivable-10](https://uwin365-my.sharepoint.com/:u:/g/personal/wang621_uwindsor_ca/EYu4C5h9qjZNg2HkNkw9nT0BImRO9HnTl2rozFFhD7zj-Q?e=gFLhpv). \n- Download the annotations of lane line segmentation from [seg-lane-11](https://uwin365-my.sharepoint.com/:u:/g/personal/wang621_uwindsor_ca/EZowlpA7sKZAuXZpphDvTBABIvAOZ6957aTYplBYGFLpeQ?e=4DNH5W). \n\nWe recommend the dataset directory structure to be the following:\n\n```\n# The id represent the correspondence relation\n├─dataset root\n│ ├─images\n│ │ ├─train2017\n│ │ ├─val2017\n│ ├─detection-object\n│ │ ├─labels\n│ │ │ ├─train2017\n│ │ │ ├─val2017\n│ ├─seg-drivable-10\n│ │ ├─labels\n│ │ │ ├─train2017\n│ │ │ ├─val2017\n│ ├─seg-lane-11\n│ │ ├─labels\n│ │ │ ├─train2017\n│ │ │ ├─val2017\n```\n\nUpdate the your dataset path in the `./ultralytics/datasets/bdd-multi.yaml`.\n\n### Training\n\nYou can set the training configuration in the `./ultralytics/yolo/cfg/default.yaml`.\n\n\n```\npython train.py\n```\nYou can change the setting in train.py\n\n```python\n# setting\n\nsys.path.insert(0, \"/home/jiayuan/ultralytics-main/ultralytics\")\n# You should change the path to your local path to \"ultralytics\" file\nmodel = YOLO('/home/jiayuan/ultralytics-main/ultralytics/models/v8/yolov8-bdd-v4-one-dropout-individual.yaml', task='multi')\n# You need to change the model path for yours.\n# The model files saved under \"./ultralytics/models/v8\" \nmodel.train(data='/home/jiayuan/ultralytics-main/ultralytics/datasets/bdd-multi-toy.yaml', batch=4, epochs=300, imgsz=(640,640), device=[4], name='v4_640', val=True, task='multi',classes=[2,3,4,9,10,11],combine_class=[2,3,4,9],single_cls=True)\n```\n- data: Please change the \"data\" path to yours. You can find it under \"./ultralytics/datasets\"\n\n- device: If you have multi-GPUs, please list your GPU numbers, such as [0,1,2,3,4,5,6,7,8]\n\n- name: Your project name, the result and trained model will save under \"./ultralytics/runs/multi/Your Project Name\"\n\n- task: If you want to use the Multi-task model, please keep \"multi\" here\n\n- classes: You can change this to control which classfication in training, 10 and 11 means drivable area and lane line segmentation. You can create or change dataset map under \"./ultralytics/datasets/bdd-multi.yaml\"\n\n- combine_class: means the model will combine \"classes\" into one class, such as our project combining the \"car\", \"bus\", \"truck\", and \"train\" into \"vehicle\".\n\n- single_cls: This will combine whole detection classes into one class, for example, you have 7 classes in your dataset, and when you use \"single_cls\", it will automatically combine them into one class. When you set single_cls=False or delete the single_cls from model.train(). Please follow the below Note to change the \"tnc\" in both dataset.yaml and model.yaml, \"nc_list\" in dataset.yaml, the output of the detection head as well. \n\n\n\n\n### Evaluation\n\nYou can set the evaluation configuration in the `./ultralytics/yolo/cfg/default.yaml`\n\n\n```\npython val.py\n```\nYou can change the setting in val.py\n\n```python\n# setting\n\nsys.path.insert(0, \"/home/jiayuan/yolom/ultralytics\")\n# The same with train, you should change the path to yours.\n\nmodel = YOLO('/home/jiayuan/ultralytics-main/ultralytics/runs/best.pt')\n# Please change this path to your well-trained model. You can use our provide the pre-train model or your model under \"./ultralytics/runs/multi/Your Project Name/weight/best.pt\"\nmetrics = model.val(data='/home/jiayuan/ultralytics-main/ultralytics/datasets/bdd-multi.yaml',device=[3],task='multi',name='val',iou=0.6,conf=0.001, imgsz=(640,640),classes=[2,3,4,9,10,11],combine_class=[2,3,4,9],single_cls=True)\n```\n- data: Please change the \"data\" path to yours. You can find it under \"./ultralytics/datasets\"\n- device: If you have multi-GPUs, please list your GPU numbers, such as [0,1,2,3,4,5,6,7,8]. We do not recommend you use multi-GPU in val because usually, one GPU is enough.\n- speed: If you want to calculate the FPS, you should set \"speed=True\". This FPS calculation method reference from `HybridNets`([code](https://github.com/datvuthanh/HybridNets))\n- single_cls: should keep the same bool value with training. \n\n### Prediction\n\n```\npython predict.py\n```\nYou can change the setting in predict.py\n\n```python\n# setting \n\nsys.path.insert(0, \"/home/jiayuan/ultralytics-main/ultralytics\")\nnumber = 3 #input how many tasks in your work, if you have 1 detection and 3 segmentation tasks, here should be 4.\nmodel = YOLO('/home/jiayuan/ultralytics-main/ultralytics/runs/best.pt') \nmodel.predict(source='/data/jiayuan/dash_camara_dataset/daytime', imgsz=(384,672), device=[3],name='v4_daytime', save=True, conf=0.25, iou=0.45, show_labels=False)\n# The predict results will save under \"runs\" folder\n```\n\nPS: If you want to use our provided pre-trained model, please make sure that your input images are (720,1280) size and keep \"imgsz=(384,672)\" to achieve the best performance, you can change the \"imgsz\" value, but the results maybe different because he is different from the training size.\n\n- source: Your input or want to predict images folder.\n- show_labels=False: close the display of the labels. Please keep in mind, when you use a pre-trained model with \"single cell=True\", labels will default to display the first class name instead.\n- boxes=False: close the bos for segmentation tasks.\n\n\n\n\n\n### Note\n- This code is easy to extend the tasks to any multi-segmentation and detection tasks, only need to modify the model yaml and dataset yaml file information and create your dataset follows our labels format, please keep in mind, you should keep \"det\" in your detection tasks name and \"seg\" in your segmentation tasks name. Then the code will be working. No need to modify the basic code, We have done the necessary work in the basic code.\n\n- Please keep in mind, when you change the detection task number of classes, please change the \"tnc\" in dataset.yaml and modle.yaml. \"tcn\" means the total number of classes, including detection and segmentation. Such as you have 7 classes for detection, 1 segmentation and another 1 segmentation. \"tnc\" should be set to 9.\n\n - \"nc_list\" also needs to update, it should match your \"labels_list\" order. Such as detection-object, seg-drivable, seg-lane in your \"labels_list\". Then \"nc_list\" should be [7,1,1]. That means you have 7 classes in detection-object, 1 class in drivable segmentation, and 1 class in lane segmentation. \n\n - You also need to change the detection head output numbers, that in model.yaml, such as \" - [[15, 18, 21], 1, Detect, [int number for detection class]] # 36 Detect(P3, P4, P5)\", please change \"int number for detection class\" to your number of classes in your detection tasks, follow above examples, here should be 7.\n\n- If you want to change some basic code to implement your idea. Please search the \"###### Jiayuan\" or \"######Jiayuan\", We have changed these parts based on `YOLOv8`([code](https://github.com/ultralytics/ultralytics)) to implement multi-task in a single model.\n\n\n\n## Citation\n\nIf you find our paper and code useful for your research, please consider giving a star :star: and citation :pencil: :\n\n```BibTeX\n@ARTICLE{wang2024you,\n author={Wang, Jiayuan and Wu, Q. M. Jonathan and Zhang, Ning},\n journal={IEEE Transactions on Vehicular Technology}, \n title={You Only Look at Once for Real-Time and Generic Multi-Task}, \n year={2024},\n pages={1-13},\n keywords={Multi-task learning;panoptic driving perception;object detection;drivable area segmentation;lane line segmentation},\n doi={10.1109/TVT.2024.3394350}}\n```\n"
},
{
"path": "bin/activate",
"content": "# This file must be used with \"source bin/activate\" *from bash*\n# you cannot run it directly\n\n\nif [ \"${BASH_SOURCE-}\" = \"$0\" ]; then\n echo \"You must source this script: \\$ source $0\" >&2\n exit 33\nfi\n\ndeactivate () {\n unset -f pydoc >/dev/null 2>&1 || true\n\n # reset old environment variables\n # ! [ -z ${VAR+_} ] returns true if VAR is declared at all\n if ! [ -z \"${_OLD_VIRTUAL_PATH:+_}\" ] ; then\n PATH=\"$_OLD_VIRTUAL_PATH\"\n export PATH\n unset _OLD_VIRTUAL_PATH\n fi\n if ! [ -z \"${_OLD_VIRTUAL_PYTHONHOME+_}\" ] ; then\n PYTHONHOME=\"$_OLD_VIRTUAL_PYTHONHOME\"\n export PYTHONHOME\n unset _OLD_VIRTUAL_PYTHONHOME\n fi\n\n # The hash command must be called to get it to forget past\n # commands. Without forgetting past commands the $PATH changes\n # we made may not be respected\n hash -r 2>/dev/null\n\n if ! [ -z \"${_OLD_VIRTUAL_PS1+_}\" ] ; then\n PS1=\"$_OLD_VIRTUAL_PS1\"\n export PS1\n unset _OLD_VIRTUAL_PS1\n fi\n\n unset VIRTUAL_ENV\n if [ ! \"${1-}\" = \"nondestructive\" ] ; then\n # Self destruct!\n unset -f deactivate\n fi\n}\n\n# unset irrelevant variables\ndeactivate nondestructive\n\nVIRTUAL_ENV='/home/jiayuan/ultralytics-main'\nif ([ \"$OSTYPE\" = \"cygwin\" ] || [ \"$OSTYPE\" = \"msys\" ]) && $(command -v cygpath &> /dev/null) ; then\n VIRTUAL_ENV=$(cygpath -u \"$VIRTUAL_ENV\")\nfi\nexport VIRTUAL_ENV\n\n_OLD_VIRTUAL_PATH=\"$PATH\"\nPATH=\"$VIRTUAL_ENV/bin:$PATH\"\nexport PATH\n\n# unset PYTHONHOME if set\nif ! [ -z \"${PYTHONHOME+_}\" ] ; then\n _OLD_VIRTUAL_PYTHONHOME=\"$PYTHONHOME\"\n unset PYTHONHOME\nfi\n\nif [ -z \"${VIRTUAL_ENV_DISABLE_PROMPT-}\" ] ; then\n _OLD_VIRTUAL_PS1=\"${PS1-}\"\n if [ \"x\" != x ] ; then\n PS1=\"() ${PS1-}\"\n else\n PS1=\"(`basename \\\"$VIRTUAL_ENV\\\"`) ${PS1-}\"\n fi\n export PS1\nfi\n\n# Make sure to unalias pydoc if it's already there\nalias pydoc 2>/dev/null >/dev/null && unalias pydoc || true\n\npydoc () {\n python -m pydoc \"$@\"\n}\n\n# The hash command must be called to get it to forget past\n# commands. Without forgetting past commands the $PATH changes\n# we made may not be respected\nhash -r 2>/dev/null\n"
},
{
"path": "bin/activate.csh",
"content": "# This file must be used with \"source bin/activate.csh\" *from csh*.\n# You cannot run it directly.\n# Created by Davide Di Blasi
.\n\nset newline='\\\n'\n\nalias deactivate 'test $?_OLD_VIRTUAL_PATH != 0 && setenv PATH \"$_OLD_VIRTUAL_PATH:q\" && unset _OLD_VIRTUAL_PATH; rehash; test $?_OLD_VIRTUAL_PROMPT != 0 && set prompt=\"$_OLD_VIRTUAL_PROMPT:q\" && unset _OLD_VIRTUAL_PROMPT; unsetenv VIRTUAL_ENV; test \"\\!:*\" != \"nondestructive\" && unalias deactivate && unalias pydoc'\n\n# Unset irrelevant variables.\ndeactivate nondestructive\n\nsetenv VIRTUAL_ENV '/home/jiayuan/ultralytics-main'\n\nset _OLD_VIRTUAL_PATH=\"$PATH:q\"\nsetenv PATH \"$VIRTUAL_ENV:q/bin:$PATH:q\"\n\n\n\nif ('' != \"\") then\n set env_name = '() '\nelse\n set env_name = '('\"$VIRTUAL_ENV:t:q\"') '\nendif\n\nif ( $?VIRTUAL_ENV_DISABLE_PROMPT ) then\n if ( $VIRTUAL_ENV_DISABLE_PROMPT == \"\" ) then\n set do_prompt = \"1\"\n else\n set do_prompt = \"0\"\n endif\nelse\n set do_prompt = \"1\"\nendif\n\nif ( $do_prompt == \"1\" ) then\n # Could be in a non-interactive environment,\n # in which case, $prompt is undefined and we wouldn't\n # care about the prompt anyway.\n if ( $?prompt ) then\n set _OLD_VIRTUAL_PROMPT=\"$prompt:q\"\n if ( \"$prompt:q\" =~ *\"$newline:q\"* ) then\n :\n else\n set prompt = \"$env_name:q$prompt:q\"\n endif\n endif\nendif\n\nunset env_name\nunset do_prompt\n\nalias pydoc python -m pydoc\n\nrehash\n"
},
{
"path": "bin/activate.fish",
"content": "# This file must be used using `source bin/activate.fish` *within a running fish ( http://fishshell.com ) session*.\n# Do not run it directly.\n\nfunction _bashify_path -d \"Converts a fish path to something bash can recognize\"\n set fishy_path $argv\n set bashy_path $fishy_path[1]\n for path_part in $fishy_path[2..-1]\n set bashy_path \"$bashy_path:$path_part\"\n end\n echo $bashy_path\nend\n\nfunction _fishify_path -d \"Converts a bash path to something fish can recognize\"\n echo $argv | tr ':' '\\n'\nend\n\nfunction deactivate -d 'Exit virtualenv mode and return to the normal environment.'\n # reset old environment variables\n if test -n \"$_OLD_VIRTUAL_PATH\"\n # https://github.com/fish-shell/fish-shell/issues/436 altered PATH handling\n if test (echo $FISH_VERSION | head -c 1) -lt 3\n set -gx PATH (_fishify_path \"$_OLD_VIRTUAL_PATH\")\n else\n set -gx PATH $_OLD_VIRTUAL_PATH\n end\n set -e _OLD_VIRTUAL_PATH\n end\n\n if test -n \"$_OLD_VIRTUAL_PYTHONHOME\"\n set -gx PYTHONHOME \"$_OLD_VIRTUAL_PYTHONHOME\"\n set -e _OLD_VIRTUAL_PYTHONHOME\n end\n\n if test -n \"$_OLD_FISH_PROMPT_OVERRIDE\"\n and functions -q _old_fish_prompt\n # Set an empty local `$fish_function_path` to allow the removal of `fish_prompt` using `functions -e`.\n set -l fish_function_path\n\n # Erase virtualenv's `fish_prompt` and restore the original.\n functions -e fish_prompt\n functions -c _old_fish_prompt fish_prompt\n functions -e _old_fish_prompt\n set -e _OLD_FISH_PROMPT_OVERRIDE\n end\n\n set -e VIRTUAL_ENV\n\n if test \"$argv[1]\" != 'nondestructive'\n # Self-destruct!\n functions -e pydoc\n functions -e deactivate\n functions -e _bashify_path\n functions -e _fishify_path\n end\nend\n\n# Unset irrelevant variables.\ndeactivate nondestructive\n\nset -gx VIRTUAL_ENV '/home/jiayuan/ultralytics-main'\n\n# https://github.com/fish-shell/fish-shell/issues/436 altered PATH handling\nif test (echo $FISH_VERSION | head -c 1) -lt 3\n set -gx _OLD_VIRTUAL_PATH (_bashify_path $PATH)\nelse\n set -gx _OLD_VIRTUAL_PATH $PATH\nend\nset -gx PATH \"$VIRTUAL_ENV\"'/bin' $PATH\n\n# Unset `$PYTHONHOME` if set.\nif set -q PYTHONHOME\n set -gx _OLD_VIRTUAL_PYTHONHOME $PYTHONHOME\n set -e PYTHONHOME\nend\n\nfunction pydoc\n python -m pydoc $argv\nend\n\nif test -z \"$VIRTUAL_ENV_DISABLE_PROMPT\"\n # Copy the current `fish_prompt` function as `_old_fish_prompt`.\n functions -c fish_prompt _old_fish_prompt\n\n function fish_prompt\n # Run the user's prompt first; it might depend on (pipe)status.\n set -l prompt (_old_fish_prompt)\n\n # Prompt override provided?\n # If not, just prepend the environment name.\n if test -n ''\n printf '(%s) ' ''\n else\n printf '(%s) ' (basename \"$VIRTUAL_ENV\")\n end\n\n string join -- \\n $prompt # handle multi-line prompts\n end\n\n set -gx _OLD_FISH_PROMPT_OVERRIDE \"$VIRTUAL_ENV\"\nend\n"
},
{
"path": "bin/activate.nu",
"content": "# This command prepares the required environment variables\ndef-env activate-virtualenv [] {\n def is-string [x] {\n ($x | describe) == 'string'\n }\n\n def has-env [name: string] {\n $name in (env).name\n }\n\n let is_windows = ((sys).host.name | str downcase) == 'windows'\n let virtual_env = '/home/jiayuan/ultralytics-main'\n let bin = 'bin'\n let path_sep = ':'\n let path_name = if $is_windows {\n if (has-env 'Path') {\n 'Path'\n } else {\n 'PATH'\n }\n } else {\n 'PATH'\n }\n\n let old_path = (\n if $is_windows {\n if (has-env 'Path') {\n $env.Path\n } else {\n $env.PATH\n }\n } else {\n $env.PATH\n } | if (is-string $in) {\n # if Path/PATH is a string, make it a list\n $in | split row $path_sep | path expand\n } else {\n $in\n }\n )\n\n let venv_path = ([$virtual_env $bin] | path join)\n let new_path = ($old_path | prepend $venv_path | str collect $path_sep)\n\n # Creating the new prompt for the session\n let virtual_prompt = if ('' == '') {\n $'(char lparen)($virtual_env | path basename)(char rparen) '\n } else {\n '() '\n }\n\n # Back up the old prompt builder\n let old_prompt_command = if (has-env 'VIRTUAL_ENV') && (has-env '_OLD_PROMPT_COMMAND') {\n $env._OLD_PROMPT_COMMAND\n } else {\n if (has-env 'PROMPT_COMMAND') {\n $env.PROMPT_COMMAND\n } else {\n ''\n }\n }\n\n # If there is no default prompt, then only the env is printed in the prompt\n let new_prompt = if (has-env 'PROMPT_COMMAND') {\n if ($old_prompt_command | describe) == 'block' {\n { $'($virtual_prompt)(do $old_prompt_command)' }\n } else {\n { $'($virtual_prompt)($old_prompt_command)' }\n }\n } else {\n { $'($virtual_prompt)' }\n }\n\n # Environment variables that will be batched loaded to the virtual env\n let new_env = {\n $path_name : $new_path\n VIRTUAL_ENV : $virtual_env\n _OLD_VIRTUAL_PATH : ($old_path | str collect $path_sep)\n _OLD_PROMPT_COMMAND : $old_prompt_command\n PROMPT_COMMAND : $new_prompt\n VIRTUAL_PROMPT : $virtual_prompt\n }\n\n # Activate the environment variables\n load-env $new_env\n}\n\n# Activate the virtualenv\nactivate-virtualenv\n\nalias pydoc = python -m pydoc\nalias deactivate = source '/home/jiayuan/ultralytics-main/bin/deactivate.nu'\n"
},
{
"path": "bin/activate.ps1",
"content": "$script:THIS_PATH = $myinvocation.mycommand.path\n$script:BASE_DIR = Split-Path (Resolve-Path \"$THIS_PATH/..\") -Parent\n\nfunction global:deactivate([switch] $NonDestructive) {\n if (Test-Path variable:_OLD_VIRTUAL_PATH) {\n $env:PATH = $variable:_OLD_VIRTUAL_PATH\n Remove-Variable \"_OLD_VIRTUAL_PATH\" -Scope global\n }\n\n if (Test-Path function:_old_virtual_prompt) {\n $function:prompt = $function:_old_virtual_prompt\n Remove-Item function:\\_old_virtual_prompt\n }\n\n if ($env:VIRTUAL_ENV) {\n Remove-Item env:VIRTUAL_ENV -ErrorAction SilentlyContinue\n }\n\n if (!$NonDestructive) {\n # Self destruct!\n Remove-Item function:deactivate\n Remove-Item function:pydoc\n }\n}\n\nfunction global:pydoc {\n python -m pydoc $args\n}\n\n# unset irrelevant variables\ndeactivate -nondestructive\n\n$VIRTUAL_ENV = $BASE_DIR\n$env:VIRTUAL_ENV = $VIRTUAL_ENV\n\nNew-Variable -Scope global -Name _OLD_VIRTUAL_PATH -Value $env:PATH\n\n$env:PATH = \"$env:VIRTUAL_ENV/bin:\" + $env:PATH\nif (!$env:VIRTUAL_ENV_DISABLE_PROMPT) {\n function global:_old_virtual_prompt {\n \"\"\n }\n $function:_old_virtual_prompt = $function:prompt\n\n if (\"\" -ne \"\") {\n function global:prompt {\n # Add the custom prefix to the existing prompt\n $previous_prompt_value = & $function:_old_virtual_prompt\n (\"() \" + $previous_prompt_value)\n }\n }\n else {\n function global:prompt {\n # Add a prefix to the current prompt, but don't discard it.\n $previous_prompt_value = & $function:_old_virtual_prompt\n $new_prompt_value = \"($( Split-Path $env:VIRTUAL_ENV -Leaf )) \"\n ($new_prompt_value + $previous_prompt_value)\n }\n }\n}\n"
},
{
"path": "bin/activate_this.py",
"content": "\"\"\"Activate virtualenv for current interpreter:\n\nUse exec(open(this_file).read(), {'__file__': this_file}).\n\nThis can be used when you must use an existing Python interpreter, not the virtualenv bin/python.\n\"\"\"\nimport os\nimport site\nimport sys\n\ntry:\n abs_file = os.path.abspath(__file__)\nexcept NameError:\n raise AssertionError(\"You must use exec(open(this_file).read(), {'__file__': this_file}))\")\n\nbin_dir = os.path.dirname(abs_file)\nbase = bin_dir[: -len(\"bin\") - 1] # strip away the bin part from the __file__, plus the path separator\n\n# prepend bin to PATH (this file is inside the bin directory)\nos.environ[\"PATH\"] = os.pathsep.join([bin_dir] + os.environ.get(\"PATH\", \"\").split(os.pathsep))\nos.environ[\"VIRTUAL_ENV\"] = base # virtual env is right above bin directory\n\n# add the virtual environments libraries to the host python import mechanism\nprev_length = len(sys.path)\nfor lib in \"../lib/python3.7/site-packages\".split(os.pathsep):\n path = os.path.realpath(os.path.join(bin_dir, lib))\n site.addsitedir(path.decode(\"utf-8\") if \"\" else path)\nsys.path[:] = sys.path[prev_length:] + sys.path[0:prev_length]\n\nsys.real_prefix = sys.prefix\nsys.prefix = base\n"
},
{
"path": "bin/deactivate.nu",
"content": "def-env deactivate-virtualenv [] {\n def has-env [name: string] {\n $name in (env).name\n }\n\n let is_windows = ((sys).host.name | str downcase) == 'windows'\n\n let path_name = if $is_windows {\n if (has-env 'Path') {\n 'Path'\n } else {\n 'PATH'\n }\n } else {\n 'PATH'\n }\n\n load-env { $path_name : $env._OLD_VIRTUAL_PATH }\n\n let-env PROMPT_COMMAND = $env._OLD_PROMPT_COMMAND\n\n # Hiding the environment variables that were created when activating the env\n hide _OLD_VIRTUAL_PATH\n hide _OLD_PROMPT_COMMAND\n hide VIRTUAL_ENV\n hide VIRTUAL_PROMPT\n}\n\ndeactivate-virtualenv\n\nhide pydoc\nhide deactivate\n"
},
{
"path": "bin/pip",
"content": "#!/home/jiayuan/ultralytics-main/bin/python\n# -*- coding: utf-8 -*-\nimport re\nimport sys\nfrom pip._internal.cli.main import main\nif __name__ == '__main__':\n sys.argv[0] = re.sub(r'(-script\\.pyw|\\.exe)?$', '', sys.argv[0])\n sys.exit(main())\n"
},
{
"path": "bin/pip-3.7",
"content": "#!/home/jiayuan/ultralytics-main/bin/python\n# -*- coding: utf-8 -*-\nimport re\nimport sys\nfrom pip._internal.cli.main import main\nif __name__ == '__main__':\n sys.argv[0] = re.sub(r'(-script\\.pyw|\\.exe)?$', '', sys.argv[0])\n sys.exit(main())\n"
},
{
"path": "bin/pip3",
"content": "#!/home/jiayuan/ultralytics-main/bin/python\n# -*- coding: utf-8 -*-\nimport re\nimport sys\nfrom pip._internal.cli.main import main\nif __name__ == '__main__':\n sys.argv[0] = re.sub(r'(-script\\.pyw|\\.exe)?$', '', sys.argv[0])\n sys.exit(main())\n"
},
{
"path": "bin/pip3.7",
"content": "#!/home/jiayuan/ultralytics-main/bin/python\n# -*- coding: utf-8 -*-\nimport re\nimport sys\nfrom pip._internal.cli.main import main\nif __name__ == '__main__':\n sys.argv[0] = re.sub(r'(-script\\.pyw|\\.exe)?$', '', sys.argv[0])\n sys.exit(main())\n"
},
{
"path": "bin/wheel",
"content": "#!/home/jiayuan/ultralytics-main/bin/python\n# -*- coding: utf-8 -*-\nimport re\nimport sys\nfrom wheel.cli import main\nif __name__ == '__main__':\n sys.argv[0] = re.sub(r'(-script\\.pyw|\\.exe)?$', '', sys.argv[0])\n sys.exit(main())\n"
},
{
"path": "bin/wheel-3.7",
"content": "#!/home/jiayuan/ultralytics-main/bin/python\n# -*- coding: utf-8 -*-\nimport re\nimport sys\nfrom wheel.cli import main\nif __name__ == '__main__':\n sys.argv[0] = re.sub(r'(-script\\.pyw|\\.exe)?$', '', sys.argv[0])\n sys.exit(main())\n"
},
{
"path": "bin/wheel3",
"content": "#!/home/jiayuan/ultralytics-main/bin/python\n# -*- coding: utf-8 -*-\nimport re\nimport sys\nfrom wheel.cli import main\nif __name__ == '__main__':\n sys.argv[0] = re.sub(r'(-script\\.pyw|\\.exe)?$', '', sys.argv[0])\n sys.exit(main())\n"
},
{
"path": "bin/wheel3.7",
"content": "#!/home/jiayuan/ultralytics-main/bin/python\n# -*- coding: utf-8 -*-\nimport re\nimport sys\nfrom wheel.cli import main\nif __name__ == '__main__':\n sys.argv[0] = re.sub(r'(-script\\.pyw|\\.exe)?$', '', sys.argv[0])\n sys.exit(main())\n"
},
{
"path": "docker/Dockerfile",
"content": "# Ultralytics YOLO 🚀, AGPL-3.0 license\n# Builds ultralytics/ultralytics:latest image on DockerHub https://hub.docker.com/r/ultralytics/ultralytics\n# Image is CUDA-optimized for YOLOv8 single/multi-GPU training and inference\n\n# Start FROM PyTorch image https://hub.docker.com/r/pytorch/pytorch or nvcr.io/nvidia/pytorch:23.03-py3\nFROM pytorch/pytorch:2.0.0-cuda11.7-cudnn8-runtime\n\n# Downloads to user config dir\nADD https://ultralytics.com/assets/Arial.ttf https://ultralytics.com/assets/Arial.Unicode.ttf /root/.config/Ultralytics/\n\n# Install linux packages\n# g++ required to build 'tflite_support' package\nRUN apt update \\\n && apt install --no-install-recommends -y gcc git zip curl htop libgl1-mesa-glx libglib2.0-0 libpython3-dev gnupg g++\n# RUN alias python=python3\n\n# Security updates\n# https://security.snyk.io/vuln/SNYK-UBUNTU1804-OPENSSL-3314796\nRUN apt upgrade --no-install-recommends -y openssl tar\n\n# Create working directory\nRUN mkdir -p /usr/src/ultralytics\nWORKDIR /usr/src/ultralytics\n\n# Copy contents\n# COPY . /usr/src/app (issues as not a .git directory)\nRUN git clone https://github.com/ultralytics/ultralytics /usr/src/ultralytics\nADD https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8n.pt /usr/src/ultralytics/\n\n# Install pip packages\nRUN python3 -m pip install --upgrade pip wheel\nRUN pip install --no-cache -e . albumentations comet tensorboard\n\n# Set environment variables\nENV OMP_NUM_THREADS=1\n\n\n# Usage Examples -------------------------------------------------------------------------------------------------------\n\n# Build and Push\n# t=ultralytics/ultralytics:latest && sudo docker build -f docker/Dockerfile -t $t . && sudo docker push $t\n\n# Pull and Run\n# t=ultralytics/ultralytics:latest && sudo docker pull $t && sudo docker run -it --ipc=host --gpus all $t\n\n# Pull and Run with local directory access\n# t=ultralytics/ultralytics:latest && sudo docker pull $t && sudo docker run -it --ipc=host --gpus all -v \"$(pwd)\"/datasets:/usr/src/datasets $t\n\n# Kill all\n# sudo docker kill $(sudo docker ps -q)\n\n# Kill all image-based\n# sudo docker kill $(sudo docker ps -qa --filter ancestor=ultralytics/ultralytics:latest)\n\n# DockerHub tag update\n# t=ultralytics/ultralytics:latest tnew=ultralytics/ultralytics:v6.2 && sudo docker pull $t && sudo docker tag $t $tnew && sudo docker push $tnew\n\n# Clean up\n# sudo docker system prune -a --volumes\n\n# Update Ubuntu drivers\n# https://www.maketecheasier.com/install-nvidia-drivers-ubuntu/\n\n# DDP test\n# python -m torch.distributed.run --nproc_per_node 2 --master_port 1 train.py --epochs 3\n\n# GCP VM from Image\n# docker.io/ultralytics/ultralytics:latest\n"
},
{
"path": "docker/Dockerfile-arm64",
"content": "# Ultralytics YOLO 🚀, AGPL-3.0 license\n# Builds ultralytics/ultralytics:latest-arm64 image on DockerHub https://hub.docker.com/r/ultralytics/ultralytics\n# Image is aarch64-compatible for Apple M1 and other ARM architectures i.e. Jetson Nano and Raspberry Pi\n\n# Start FROM Ubuntu image https://hub.docker.com/_/ubuntu\nFROM arm64v8/ubuntu:22.10\n\n# Downloads to user config dir\nADD https://ultralytics.com/assets/Arial.ttf https://ultralytics.com/assets/Arial.Unicode.ttf /root/.config/Ultralytics/\n\n# Install linux packages\nRUN apt update \\\n && apt install --no-install-recommends -y python3-pip git zip curl htop gcc libgl1-mesa-glx libglib2.0-0 libpython3-dev\n# RUN alias python=python3\n\n# Create working directory\nRUN mkdir -p /usr/src/ultralytics\nWORKDIR /usr/src/ultralytics\n\n# Copy contents\n# COPY . /usr/src/app (issues as not a .git directory)\nRUN git clone https://github.com/ultralytics/ultralytics /usr/src/ultralytics\nADD https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8n.pt /usr/src/ultralytics/\n\n# Install pip packages\nRUN python3 -m pip install --upgrade pip wheel\nRUN pip install --no-cache -e .\n\n\n# Usage Examples -------------------------------------------------------------------------------------------------------\n\n# Build and Push\n# t=ultralytics/ultralytics:latest-arm64 && sudo docker build --platform linux/arm64 -f docker/Dockerfile-arm64 -t $t . && sudo docker push $t\n\n# Pull and Run\n# t=ultralytics/ultralytics:latest-arm64 && sudo docker pull $t && sudo docker run -it --ipc=host -v \"$(pwd)\"/datasets:/usr/src/datasets $t\n"
},
{
"path": "docker/Dockerfile-cpu",
"content": "# Ultralytics YOLO 🚀, AGPL-3.0 license\n# Builds ultralytics/ultralytics:latest-cpu image on DockerHub https://hub.docker.com/r/ultralytics/ultralytics\n# Image is CPU-optimized for ONNX, OpenVINO and PyTorch YOLOv8 deployments\n\n# Start FROM Ubuntu image https://hub.docker.com/_/ubuntu\nFROM ubuntu:22.10\n\n# Downloads to user config dir\nADD https://ultralytics.com/assets/Arial.ttf https://ultralytics.com/assets/Arial.Unicode.ttf /root/.config/Ultralytics/\n\n# Install linux packages\n# g++ required to build 'tflite_support' package\nRUN apt update \\\n && apt install --no-install-recommends -y python3-pip git zip curl htop libgl1-mesa-glx libglib2.0-0 libpython3-dev gnupg g++\n# RUN alias python=python3\n\n# Create working directory\nRUN mkdir -p /usr/src/ultralytics\nWORKDIR /usr/src/ultralytics\n\n# Copy contents\n# COPY . /usr/src/app (issues as not a .git directory)\nRUN git clone https://github.com/ultralytics/ultralytics /usr/src/ultralytics\nADD https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8n.pt /usr/src/ultralytics/\n\n# Install pip packages\nRUN python3 -m pip install --upgrade pip wheel\nRUN pip install --no-cache -e . --extra-index-url https://download.pytorch.org/whl/cpu\n\n\n# Usage Examples -------------------------------------------------------------------------------------------------------\n\n# Build and Push\n# t=ultralytics/ultralytics:latest-cpu && sudo docker build -f docker/Dockerfile-cpu -t $t . && sudo docker push $t\n\n# Pull and Run\n# t=ultralytics/ultralytics:latest-cpu && sudo docker pull $t && sudo docker run -it --ipc=host -v \"$(pwd)\"/datasets:/usr/src/datasets $t\n"
},
{
"path": "docker/Dockerfile-jetson",
"content": "# Ultralytics YOLO 🚀, AGPL-3.0 license\n# Builds ultralytics/ultralytics:jetson image on DockerHub https://hub.docker.com/r/ultralytics/ultralytics\n# Supports JetPack for YOLOv8 on Jetson Nano, TX1/TX2, Xavier NX, AGX Xavier, AGX Orin, and Orin NX\n\n# Start FROM https://catalog.ngc.nvidia.com/orgs/nvidia/containers/l4t-pytorch\nFROM nvcr.io/nvidia/l4t-pytorch:r35.2.1-pth2.0-py3\n\n# Downloads to user config dir\nADD https://ultralytics.com/assets/Arial.ttf https://ultralytics.com/assets/Arial.Unicode.ttf /root/.config/Ultralytics/\n\n# Install linux packages\n# g++ required to build 'tflite_support' package\nRUN apt update \\\n && apt install --no-install-recommends -y gcc git zip curl htop libgl1-mesa-glx libglib2.0-0 libpython3-dev gnupg g++\n# RUN alias python=python3\n\n# Create working directory\nRUN mkdir -p /usr/src/ultralytics\nWORKDIR /usr/src/ultralytics\n\n# Copy contents\n# COPY . /usr/src/app (issues as not a .git directory)\nRUN git clone https://github.com/ultralytics/ultralytics /usr/src/ultralytics\nADD https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8n.pt /usr/src/ultralytics/\n\n# Install pip packages manually for TensorRT compatibility https://github.com/NVIDIA/TensorRT/issues/2567\nRUN python3 -m pip install --upgrade pip wheel\nRUN pip install --no-cache tqdm matplotlib pyyaml psutil pandas onnx \"numpy==1.23\"\nRUN pip install --no-cache -e .\n\n# Set environment variables\nENV OMP_NUM_THREADS=1\n\n\n# Usage Examples -------------------------------------------------------------------------------------------------------\n\n# Build and Push\n# t=ultralytics/ultralytics:latest-jetson && sudo docker build --platform linux/arm64 -f docker/Dockerfile-jetson -t $t . && sudo docker push $t\n\n# Pull and Run\n# t=ultralytics/ultralytics:jetson && sudo docker pull $t && sudo docker run -it --runtime=nvidia $t\n"
},
{
"path": "docs/CNAME",
"content": "docs.ultralytics.com"
},
{
"path": "docs/README.md",
"content": "---\ndescription: Learn how to install the Ultralytics package in developer mode and build/serve locally using MkDocs. Deploy your project to your host easily.\n---\n\n# Ultralytics Docs\n\nUltralytics Docs are deployed to [https://docs.ultralytics.com](https://docs.ultralytics.com).\n\n### Install Ultralytics package\n\nTo install the ultralytics package in developer mode, you will need to have Git and Python 3 installed on your system.\nThen, follow these steps:\n\n1. Clone the ultralytics repository to your local machine using Git:\n\n```bash\ngit clone https://github.com/ultralytics/ultralytics.git\n```\n\n2. Navigate to the root directory of the repository:\n\n```bash\ncd ultralytics\n```\n\n3. Install the package in developer mode using pip:\n\n```bash\npip install -e '.[dev]'\n```\n\nThis will install the ultralytics package and its dependencies in developer mode, allowing you to make changes to the\npackage code and have them reflected immediately in your Python environment.\n\nNote that you may need to use the pip3 command instead of pip if you have multiple versions of Python installed on your\nsystem.\n\n### Building and Serving Locally\n\nThe `mkdocs serve` command is used to build and serve a local version of the MkDocs documentation site. It is typically\nused during the development and testing phase of a documentation project.\n\n```bash\nmkdocs serve\n```\n\nHere is a breakdown of what this command does:\n\n- `mkdocs`: This is the command-line interface (CLI) for the MkDocs static site generator. It is used to build and serve\n MkDocs sites.\n- `serve`: This is a subcommand of the `mkdocs` CLI that tells it to build and serve the documentation site locally.\n- `-a`: This flag specifies the hostname and port number to bind the server to. The default value is `localhost:8000`.\n- `-t`: This flag specifies the theme to use for the documentation site. The default value is `mkdocs`.\n- `-s`: This flag tells the `serve` command to serve the site in silent mode, which means it will not display any log\n messages or progress updates.\n When you run the `mkdocs serve` command, it will build the documentation site using the files in the `docs/` directory\n and serve it at the specified hostname and port number. You can then view the site by going to the URL in your web\n browser.\n\nWhile the site is being served, you can make changes to the documentation files and see them reflected in the live site\nimmediately. This is useful for testing and debugging your documentation before deploying it to a live server.\n\nTo stop the serve command and terminate the local server, you can use the `CTRL+C` keyboard shortcut.\n\n### Deploying Your Documentation Site\n\nTo deploy your MkDocs documentation site, you will need to choose a hosting provider and a deployment method. Some\npopular options include GitHub Pages, GitLab Pages, and Amazon S3.\n\nBefore you can deploy your site, you will need to configure your `mkdocs.yml` file to specify the remote host and any\nother necessary deployment settings.\n\nOnce you have configured your `mkdocs.yml` file, you can use the `mkdocs deploy` command to build and deploy your site.\nThis command will build the documentation site using the files in the `docs/` directory and the specified configuration\nfile and theme, and then deploy the site to the specified remote host.\n\nFor example, to deploy your site to GitHub Pages using the gh-deploy plugin, you can use the following command:\n\n```bash\nmkdocs gh-deploy\n```\n\nIf you are using GitHub Pages, you can set a custom domain for your documentation site by going to the \"Settings\" page\nfor your repository and updating the \"Custom domain\" field in the \"GitHub Pages\" section.\n\n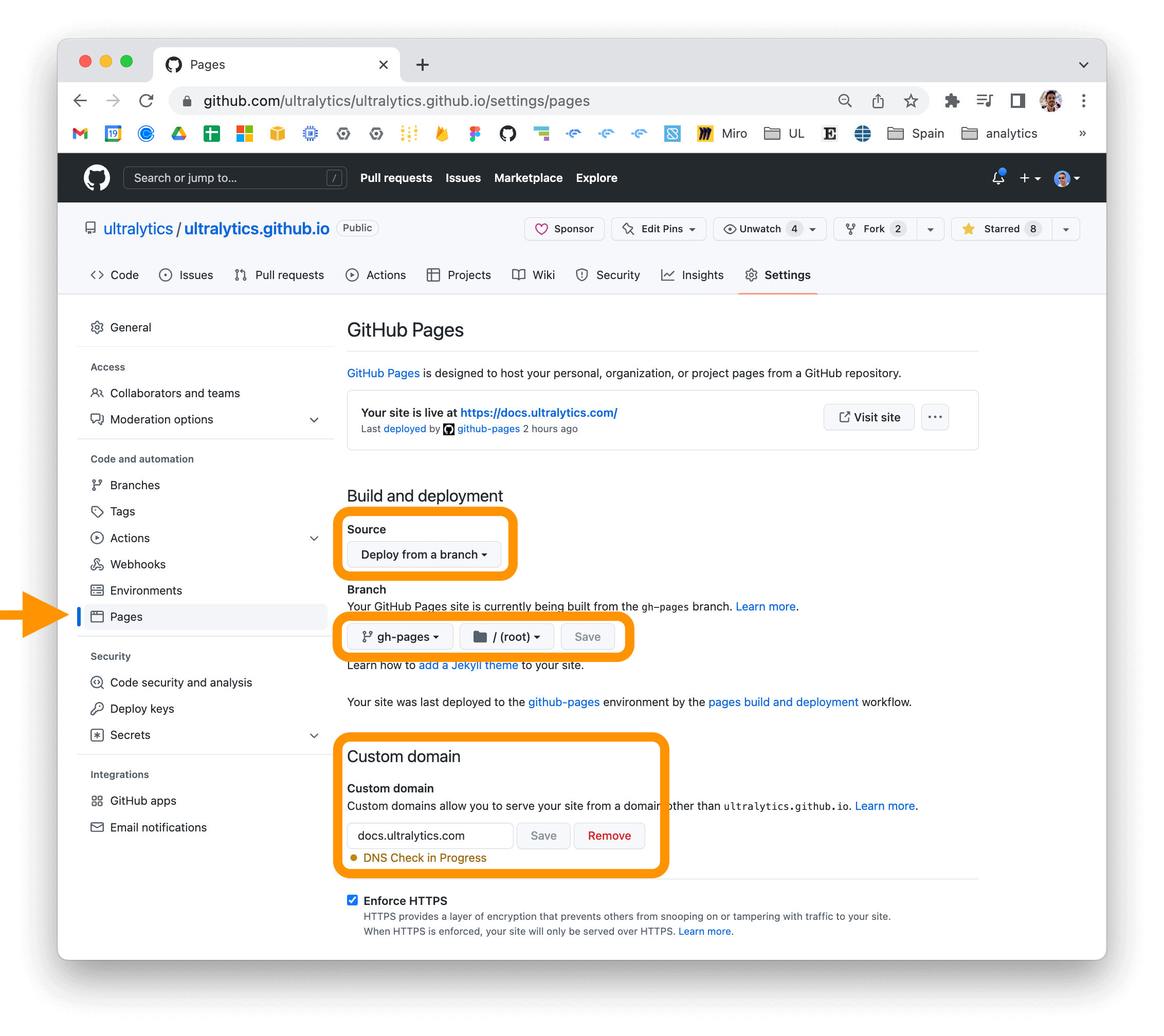\n\nFor more information on deploying your MkDocs documentation site, see\nthe [MkDocs documentation](https://www.mkdocs.org/user-guide/deploying-your-docs/)."
},
{
"path": "docs/SECURITY.md",
"content": "---\ndescription: Learn how Ultralytics prioritize security. Get insights into Snyk and GitHub CodeQL scans, and how to report security issues in YOLOv8.\n---\n\n# Security Policy\n\nAt [Ultralytics](https://ultralytics.com), the security of our users' data and systems is of utmost importance. To\nensure the safety and security of our [open-source projects](https://github.com/ultralytics), we have implemented\nseveral measures to detect and prevent security vulnerabilities.\n\n[](https://snyk.io/advisor/python/ultralytics)\n\n## Snyk Scanning\n\nWe use [Snyk](https://snyk.io/advisor/python/ultralytics) to regularly scan the YOLOv8 repository for vulnerabilities\nand security issues. Our goal is to identify and remediate any potential threats as soon as possible, to minimize any\nrisks to our users.\n\n## GitHub CodeQL Scanning\n\nIn addition to our Snyk scans, we also use\nGitHub's [CodeQL](https://docs.github.com/en/code-security/code-scanning/automatically-scanning-your-code-for-vulnerabilities-and-errors/about-code-scanning-with-codeql)\nscans to proactively identify and address security vulnerabilities.\n\n## Reporting Security Issues\n\nIf you suspect or discover a security vulnerability in the YOLOv8 repository, please let us know immediately. You can\nreach out to us directly via our [contact form](https://ultralytics.com/contact) or\nvia [security@ultralytics.com](mailto:security@ultralytics.com). Our security team will investigate and respond as soon\nas possible.\n\nWe appreciate your help in keeping the YOLOv8 repository secure and safe for everyone."
},
{
"path": "docs/build_reference.py",
"content": "# Ultralytics YOLO 🚀, AGPL-3.0 license\n\"\"\"\nHelper file to build Ultralytics Docs reference section. Recursively walks through ultralytics dir and builds an MkDocs\nreference section of *.md files composed of classes and functions, and also creates a nav menu for use in mkdocs.yaml.\n\nNote: Must be run from repository root directory. Do not run from docs directory.\n\"\"\"\n\nimport os\nimport re\nfrom collections import defaultdict\nfrom pathlib import Path\nfrom ultralytics.yolo.utils import ROOT\n\nNEW_YAML_DIR = ROOT.parent\nCODE_DIR = ROOT\nREFERENCE_DIR = ROOT.parent / 'docs/reference'\n\n\ndef extract_classes_and_functions(filepath):\n with open(filepath, 'r') as file:\n content = file.read()\n\n class_pattern = r\"(?:^|\\n)class\\s(\\w+)(?:\\(|:)\"\n func_pattern = r\"(?:^|\\n)def\\s(\\w+)\\(\"\n\n classes = re.findall(class_pattern, content)\n functions = re.findall(func_pattern, content)\n\n return classes, functions\n\n\ndef create_markdown(py_filepath, module_path, classes, functions):\n md_filepath = py_filepath.with_suffix('.md')\n\n # Read existing content and keep header content between first two ---\n header_content = \"\"\n if md_filepath.exists():\n with open(md_filepath, 'r') as file:\n existing_content = file.read()\n header_parts = existing_content.split('---', 2)\n if len(header_parts) >= 3:\n header_content = f\"{header_parts[0]}---{header_parts[1]}---\\n\\n\"\n\n md_content = [f\"# {class_name}\\n---\\n:::{module_path}.{class_name}\\n
\\n\" for class_name in classes]\n md_content.extend(f\"# {func_name}\\n---\\n:::{module_path}.{func_name}\\n
\\n\" for func_name in functions)\n md_content = header_content + \"\\n\".join(md_content)\n\n os.makedirs(os.path.dirname(md_filepath), exist_ok=True)\n with open(md_filepath, 'w') as file:\n file.write(md_content)\n\n return md_filepath.relative_to(NEW_YAML_DIR)\n\n\ndef nested_dict():\n return defaultdict(nested_dict)\n\n\ndef sort_nested_dict(d):\n return {\n key: sort_nested_dict(value) if isinstance(value, dict) else value\n for key, value in sorted(d.items())\n }\n\n\ndef create_nav_menu_yaml(nav_items):\n nav_tree = nested_dict()\n\n for item_str in nav_items:\n item = Path(item_str)\n parts = item.parts\n current_level = nav_tree['reference']\n for part in parts[2:-1]: # skip the first two parts (docs and reference) and the last part (filename)\n current_level = current_level[part]\n\n md_file_name = parts[-1].replace('.md', '')\n current_level[md_file_name] = item\n\n nav_tree_sorted = sort_nested_dict(nav_tree)\n\n def _dict_to_yaml(d, level=0):\n yaml_str = \"\"\n indent = \" \" * level\n for k, v in d.items():\n if isinstance(v, dict):\n yaml_str += f\"{indent}- {k}:\\n{_dict_to_yaml(v, level + 1)}\"\n else:\n yaml_str += f\"{indent}- {k}: {str(v).replace('docs/', '')}\\n\"\n return yaml_str\n\n with open(NEW_YAML_DIR / 'nav_menu_updated.yml', 'w') as file:\n yaml_str = _dict_to_yaml(nav_tree_sorted)\n file.write(yaml_str)\n\n\ndef main():\n nav_items = []\n for root, _, files in os.walk(CODE_DIR):\n for file in files:\n if file.endswith(\".py\") and file != \"__init__.py\":\n py_filepath = Path(root) / file\n classes, functions = extract_classes_and_functions(py_filepath)\n\n if classes or functions:\n py_filepath_rel = py_filepath.relative_to(CODE_DIR)\n md_filepath = REFERENCE_DIR / py_filepath_rel\n module_path = f\"ultralytics.{py_filepath_rel.with_suffix('').as_posix().replace('/', '.')}\"\n md_rel_filepath = create_markdown(md_filepath, module_path, classes, functions)\n nav_items.append(str(md_rel_filepath))\n\n create_nav_menu_yaml(nav_items)\n\n\nif __name__ == \"__main__\":\n main()\n"
},
{
"path": "docs/datasets/classify/caltech101.md",
"content": "---\ncomments: true\n---\n\n# 🚧 Page Under Construction ⚒\n\nThis page is currently under construction!️ 👷Please check back later for updates. 😃🔜\n"
},
{
"path": "docs/datasets/classify/caltech256.md",
"content": "---\ncomments: true\n---\n\n# 🚧 Page Under Construction ⚒\n\nThis page is currently under construction!️ 👷Please check back later for updates. 😃🔜\n"
},
{
"path": "docs/datasets/classify/cifar10.md",
"content": "---\ncomments: true\n---\n\n# 🚧 Page Under Construction ⚒\n\nThis page is currently under construction!️ 👷Please check back later for updates. 😃🔜\n"
},
{
"path": "docs/datasets/classify/cifar100.md",
"content": "---\ncomments: true\n---\n\n# 🚧 Page Under Construction ⚒\n\nThis page is currently under construction!️ 👷Please check back later for updates. 😃🔜\n"
},
{
"path": "docs/datasets/classify/fashion-mnist.md",
"content": "---\ncomments: true\n---\n\n# 🚧 Page Under Construction ⚒\n\nThis page is currently under construction!️ 👷Please check back later for updates. 😃🔜\n"
},
{
"path": "docs/datasets/classify/imagenet.md",
"content": "---\ncomments: true\n---\n\n# 🚧 Page Under Construction ⚒\n\nThis page is currently under construction!️ 👷Please check back later for updates. 😃🔜\n"
},
{
"path": "docs/datasets/classify/imagenet10.md",
"content": "---\ncomments: true\n---\n\n# 🚧 Page Under Construction ⚒\n\nThis page is currently under construction!️ 👷Please check back later for updates. 😃🔜\n"
},
{
"path": "docs/datasets/classify/imagenette.md",
"content": "---\ncomments: true\n---\n\n# 🚧 Page Under Construction ⚒\n\nThis page is currently under construction!️ 👷Please check back later for updates. 😃🔜\n"
},
{
"path": "docs/datasets/classify/imagewoof.md",
"content": "---\ncomments: true\n---\n\n# 🚧 Page Under Construction ⚒\n\nThis page is currently under construction!️ 👷Please check back later for updates. 😃🔜\n"
},
{
"path": "docs/datasets/classify/index.md",
"content": "---\ncomments: true\ndescription: Learn how torchvision organizes classification image datasets. Use this code to create and train models. CLI and Python code shown.\n---\n\n# Image Classification Datasets Overview\n\n## Dataset format\n\nThe folder structure for classification datasets in torchvision typically follows a standard format:\n\n```\nroot/\n|-- class1/\n| |-- img1.jpg\n| |-- img2.jpg\n| |-- ...\n|\n|-- class2/\n| |-- img1.jpg\n| |-- img2.jpg\n| |-- ...\n|\n|-- class3/\n| |-- img1.jpg\n| |-- img2.jpg\n| |-- ...\n|\n|-- ...\n```\n\nIn this folder structure, the `root` directory contains one subdirectory for each class in the dataset. Each subdirectory is named after the corresponding class and contains all the images for that class. Each image file is named uniquely and is typically in a common image file format such as JPEG or PNG.\n\n** Example **\n\nFor example, in the CIFAR10 dataset, the folder structure would look like this:\n\n```\ncifar-10-/\n|\n|-- train/\n| |-- airplane/\n| | |-- 10008_airplane.png\n| | |-- 10009_airplane.png\n| | |-- ...\n| |\n| |-- automobile/\n| | |-- 1000_automobile.png\n| | |-- 1001_automobile.png\n| | |-- ...\n| |\n| |-- bird/\n| | |-- 10014_bird.png\n| | |-- 10015_bird.png\n| | |-- ...\n| |\n| |-- ...\n|\n|-- test/\n| |-- airplane/\n| | |-- 10_airplane.png\n| | |-- 11_airplane.png\n| | |-- ...\n| |\n| |-- automobile/\n| | |-- 100_automobile.png\n| | |-- 101_automobile.png\n| | |-- ...\n| |\n| |-- bird/\n| | |-- 1000_bird.png\n| | |-- 1001_bird.png\n| | |-- ...\n| |\n| |-- ...\n```\n\nIn this example, the `train` directory contains subdirectories for each class in the dataset, and each class subdirectory contains all the images for that class. The `test` directory has a similar structure. The `root` directory also contains other files that are part of the CIFAR10 dataset.\n\n## Usage\n\n!!! example \"\"\n\n === \"Python\"\n \n ```python\n from ultralytics import YOLO\n \n # Load a model\n model = YOLO('yolov8n-cls.pt') # load a pretrained model (recommended for training)\n\n # Train the model\n model.train(data='path/to/dataset', epochs=100, imgsz=640)\n ```\n === \"CLI\"\n \n ```bash\n # Start training from a pretrained *.pt model\n yolo detect train data=path/to/data model=yolov8n-seg.pt epochs=100 imgsz=640\n ```\n\n## Supported Datasets\n\nTODO"
},
{
"path": "docs/datasets/classify/mnist.md",
"content": "---\ncomments: true\ndescription: Learn about the MNIST dataset, a large database of handwritten digits commonly used for training various image processing systems and machine learning models.\n---\n\n# MNIST Dataset\n\nThe [MNIST](http://yann.lecun.com/exdb/mnist/) (Modified National Institute of Standards and Technology) dataset is a large database of handwritten digits that is commonly used for training various image processing systems and machine learning models. It was created by \"re-mixing\" the samples from NIST's original datasets and has become a benchmark for evaluating the performance of image classification algorithms.\n\n## Key Features\n\n- MNIST contains 60,000 training images and 10,000 testing images of handwritten digits.\n- The dataset comprises grayscale images of size 28x28 pixels.\n- The images are normalized to fit into a 28x28 pixel bounding box and anti-aliased, introducing grayscale levels.\n- MNIST is widely used for training and testing in the field of machine learning, especially for image classification tasks.\n\n## Dataset Structure\n\nThe MNIST dataset is split into two subsets:\n\n1. **Training Set**: This subset contains 60,000 images of handwritten digits used for training machine learning models.\n2. **Testing Set**: This subset consists of 10,000 images used for testing and benchmarking the trained models.\n\n## Extended MNIST (EMNIST)\n\nExtended MNIST (EMNIST) is a newer dataset developed and released by NIST to be the successor to MNIST. While MNIST included images only of handwritten digits, EMNIST includes all the images from NIST Special Database 19, which is a large database of handwritten uppercase and lowercase letters as well as digits. The images in EMNIST were converted into the same 28x28 pixel format, by the same process, as were the MNIST images. Accordingly, tools that work with the older, smaller MNIST dataset will likely work unmodified with EMNIST.\n\n## Applications\n\nThe MNIST dataset is widely used for training and evaluating deep learning models in image classification tasks, such as Convolutional Neural Networks (CNNs), Support Vector Machines (SVMs), and various other machine learning algorithms. The dataset's simple and well-structured format makes it an essential resource for researchers and practitioners in the field of machine learning and computer vision.\n\n## Usage\n\nTo train a CNN model on the MNIST dataset for 100 epochs with an image size of 32x32, you can use the following code snippets. For a comprehensive list of available arguments, refer to the model [Training](../../modes/train.md) page.\n\n!!! example \"Train Example\"\n\n === \"Python\"\n\n ```python\n from ultralytics import YOLO\n \n # Load a model\n model = YOLO('yolov8n-cls.pt') # load a pretrained model (recommended for training)\n \n # Train the model\n model.train(data='mnist', epochs=100, imgsz=32)\n ```\n\n === \"CLI\"\n\n ```bash\n # Start training from a pretrained *.pt model\n cnn detect train data=MNIST.yaml model=cnn_mnist.pt epochs=100 imgsz=28\n ```\n\n## Sample Images and Annotations\n\nThe MNIST dataset contains grayscale images of handwritten digits, providing a well-structured dataset for image classification tasks. Here are some examples of images from the dataset:\n\n\n\nThe example showcases the variety and complexity of the handwritten digits in the MNIST dataset, highlighting the importance of a diverse dataset for training robust image classification models.\n\n## Citations and Acknowledgments\n\nIf you use the MNIST dataset in your\n\nresearch or development work, please cite the following paper:\n\n```bibtex\n@article{lecun2010mnist,\n title={MNIST handwritten digit database},\n author={LeCun, Yann and Cortes, Corinna and Burges, CJ},\n journal={ATT Labs [Online]. Available: http://yann.lecun.com/exdb/mnist},\n volume={2},\n year={2010}\n}\n```\n\nWe would like to acknowledge Yann LeCun, Corinna Cortes, and Christopher J.C. Burges for creating and maintaining the MNIST dataset as a valuable resource for the machine learning and computer vision research community. For more information about the MNIST dataset and its creators, visit the [MNIST dataset website](http://yann.lecun.com/exdb/mnist/)."
},
{
"path": "docs/datasets/detect/argoverse.md",
"content": "---\ncomments: true\ndescription: Learn about the Argoverse dataset, a rich dataset designed to support research in autonomous driving tasks such as 3D tracking, motion forecasting, and stereo depth estimation.\n---\n\n# Argoverse Dataset\n\nThe [Argoverse](https://www.argoverse.org/) dataset is a collection of data designed to support research in autonomous driving tasks, such as 3D tracking, motion forecasting, and stereo depth estimation. Developed by Argo AI, the dataset provides a wide range of high-quality sensor data, including high-resolution images, LiDAR point clouds, and map data.\n\n## Key Features\n\n- Argoverse contains over 290K labeled 3D object tracks and 5 million object instances across 1,263 distinct scenes.\n- The dataset includes high-resolution camera images, LiDAR point clouds, and richly annotated HD maps.\n- Annotations include 3D bounding boxes for objects, object tracks, and trajectory information.\n- Argoverse provides multiple subsets for different tasks, such as 3D tracking, motion forecasting, and stereo depth estimation.\n\n## Dataset Structure\n\nThe Argoverse dataset is organized into three main subsets:\n\n1. **Argoverse 3D Tracking**: This subset contains 113 scenes with over 290K labeled 3D object tracks, focusing on 3D object tracking tasks. It includes LiDAR point clouds, camera images, and sensor calibration information.\n2. **Argoverse Motion Forecasting**: This subset consists of 324K vehicle trajectories collected from 60 hours of driving data, suitable for motion forecasting tasks.\n3. **Argoverse Stereo Depth Estimation**: This subset is designed for stereo depth estimation tasks and includes over 10K stereo image pairs with corresponding LiDAR point clouds for ground truth depth estimation.\n\n## Applications\n\nThe Argoverse dataset is widely used for training and evaluating deep learning models in autonomous driving tasks such as 3D object tracking, motion forecasting, and stereo depth estimation. The dataset's diverse set of sensor data, object annotations, and map information make it a valuable resource for researchers and practitioners in the field of autonomous driving.\n\n## Dataset YAML\n\nA YAML (Yet Another Markup Language) file is used to define the dataset configuration. It contains information about the dataset's paths, classes, and other relevant information. For the case of the Argoverse dataset, the `Argoverse.yaml` file is maintained at [https://github.com/ultralytics/ultralytics/blob/main/ultralytics/datasets/Argoverse.yaml](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/datasets/Argoverse.yaml).\n\n!!! example \"ultralytics/datasets/Argoverse.yaml\"\n\n ```yaml\n --8<-- \"ultralytics/datasets/Argoverse.yaml\"\n ```\n\n## Usage\n\nTo train a YOLOv8n model on the Argoverse dataset for 100 epochs with an image size of 640, you can use the following code snippets. For a comprehensive list of available arguments, refer to the model [Training](../../modes/train.md) page.\n\n!!! example \"Train Example\"\n\n === \"Python\"\n\n ```python\n from ultralytics import YOLO\n \n # Load a model\n model = YOLO('yolov8n.pt') # load a pretrained model (recommended for training)\n \n # Train the model\n model.train(data='Argoverse.yaml', epochs=100, imgsz=640)\n ```\n\n === \"CLI\"\n\n ```bash\n # Start training from a pretrained *.pt model\n yolo detect train data=Argoverse.yaml model=yolov8n.pt epochs=100 imgsz=640\n ```\n\n## Sample Data and Annotations\n\nThe Argoverse dataset contains a diverse set of sensor data, including camera images, LiDAR point clouds, and HD map information, providing rich context for autonomous driving tasks. Here are some examples of data from the dataset, along with their corresponding annotations:\n\n\n\n- **Argoverse 3D Tracking**: This image demonstrates an example of 3D object tracking, where objects are annotated with 3D bounding boxes. The dataset provides LiDAR point clouds and camera images to facilitate the development of models for this task.\n\nThe example showcases the variety and complexity of the data in the Argoverse dataset and highlights the importance of high-quality sensor data for autonomous driving tasks.\n\n## Citations and Acknowledgments\n\nIf you use the Argoverse dataset in your research or development work, please cite the following paper:\n\n```bibtex\n@inproceedings{chang2019argoverse,\n title={Argoverse: 3D Tracking and Forecasting with Rich Maps},\n author={Chang, Ming-Fang and Lambert, John and Sangkloy, Patsorn and Singh, Jagjeet and Bak, Slawomir and Hartnett, Andrew and Wang, Dequan and Carr, Peter and Lucey, Simon and Ramanan, Deva and others},\n booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},\n pages={8748--8757},\n year={2019}\n}\n```\n\nWe would like to acknowledge Argo AI for creating and maintaining the Argoverse dataset as a valuable resource for the autonomous driving research community. For more information about the Argoverse dataset and its creators, visit the [Argoverse dataset website](https://www.argoverse.org/)."
},
{
"path": "docs/datasets/detect/coco.md",
"content": "---\ncomments: true\ndescription: Learn about the COCO dataset, designed to encourage research on object detection, segmentation, and captioning with standardized evaluation metrics.\n---\n\n# COCO Dataset\n\nThe [COCO](https://cocodataset.org/#home) (Common Objects in Context) dataset is a large-scale object detection, segmentation, and captioning dataset. It is designed to encourage research on a wide variety of object categories and is commonly used for benchmarking computer vision models. It is an essential dataset for researchers and developers working on object detection, segmentation, and pose estimation tasks.\n\n## Key Features\n\n- COCO contains 330K images, with 200K images having annotations for object detection, segmentation, and captioning tasks.\n- The dataset comprises 80 object categories, including common objects like cars, bicycles, and animals, as well as more specific categories such as umbrellas, handbags, and sports equipment.\n- Annotations include object bounding boxes, segmentation masks, and captions for each image.\n- COCO provides standardized evaluation metrics like mean Average Precision (mAP) for object detection, and mean Average Recall (mAR) for segmentation tasks, making it suitable for comparing model performance.\n\n## Dataset Structure\n\nThe COCO dataset is split into three subsets:\n\n1. **Train2017**: This subset contains 118K images for training object detection, segmentation, and captioning models.\n2. **Val2017**: This subset has 5K images used for validation purposes during model training.\n3. **Test2017**: This subset consists of 20K images used for testing and benchmarking the trained models. Ground truth annotations for this subset are not publicly available, and the results are submitted to the [COCO evaluation server](https://competitions.codalab.org/competitions/5181) for performance evaluation.\n\n## Applications\n\nThe COCO dataset is widely used for training and evaluating deep learning models in object detection (such as YOLO, Faster R-CNN, and SSD), instance segmentation (such as Mask R-CNN), and keypoint detection (such as OpenPose). The dataset's diverse set of object categories, large number of annotated images, and standardized evaluation metrics make it an essential resource for computer vision researchers and practitioners.\n\n## Dataset YAML\n\nA YAML (Yet Another Markup Language) file is used to define the dataset configuration. It contains information about the dataset's paths, classes, and other relevant information. In the case of the COCO dataset, the `coco.yaml` file is maintained at [https://github.com/ultralytics/ultralytics/blob/main/ultralytics/datasets/coco.yaml](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/datasets/coco.yaml).\n\n!!! example \"ultralytics/datasets/coco.yaml\"\n\n ```yaml\n --8<-- \"ultralytics/datasets/coco.yaml\"\n ```\n\n## Usage\n\nTo train a YOLOv8n model on the COCO dataset for 100 epochs with an image size of 640, you can use the following code snippets. For a comprehensive list of available arguments, refer to the model [Training](../../modes/train.md) page.\n\n!!! example \"Train Example\"\n\n === \"Python\"\n\n ```python\n from ultralytics import YOLO\n \n # Load a model\n model = YOLO('yolov8n.pt') # load a pretrained model (recommended for training)\n \n # Train the model\n model.train(data='coco.yaml', epochs=100, imgsz=640)\n ```\n\n === \"CLI\"\n\n ```bash\n # Start training from a pretrained *.pt model\n yolo detect train data=coco.yaml model=yolov8n.pt epochs=100 imgsz=640\n ```\n\n## Sample Images and Annotations\n\nThe COCO dataset contains a diverse set of images with various object categories and complex scenes. Here are some examples of images from the dataset, along with their corresponding annotations:\n\n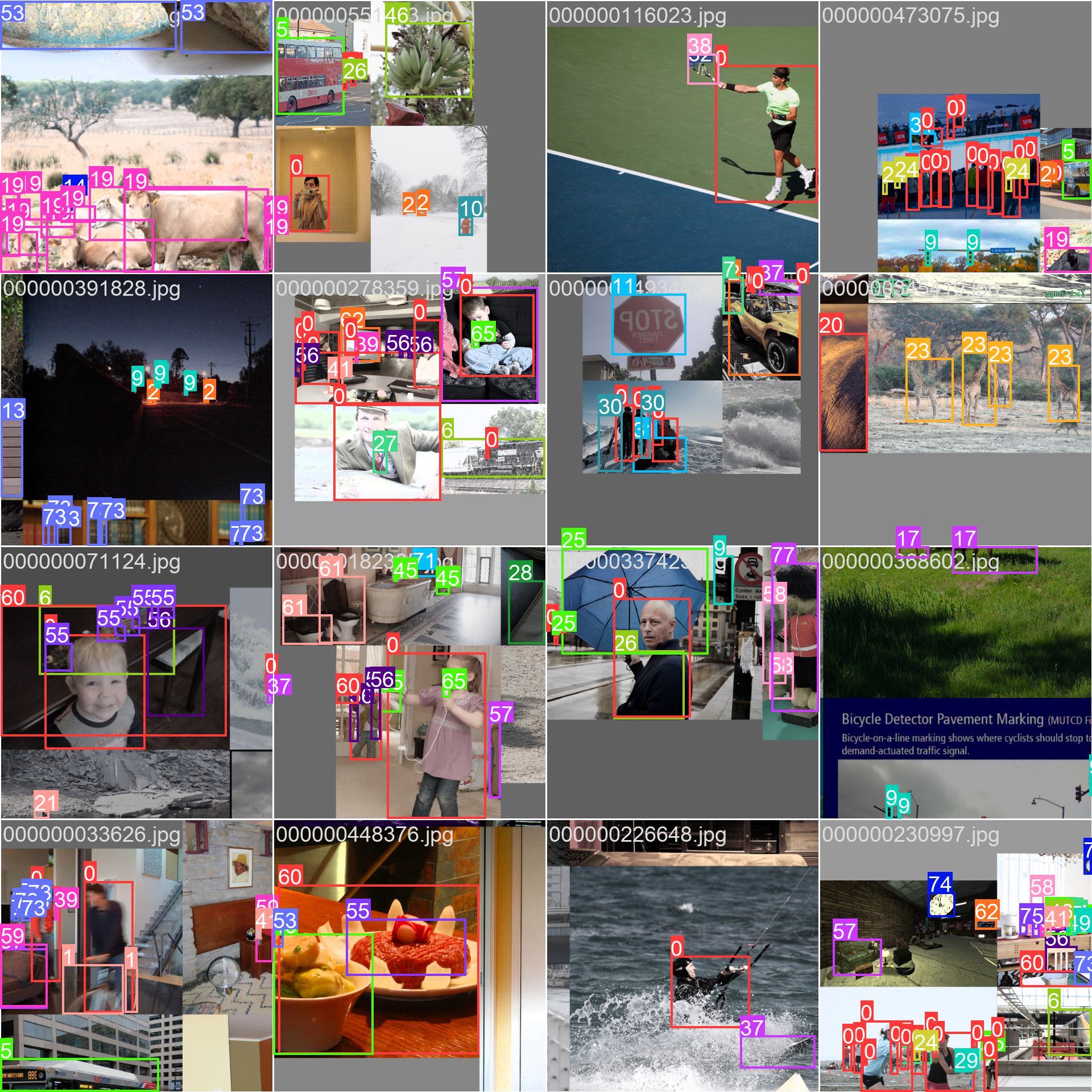\n\n- **Mosaiced Image**: This image demonstrates a training batch composed of mosaiced dataset images. Mosaicing is a technique used during training that combines multiple images into a single image to increase the variety of objects and scenes within each training batch. This helps improve the model's ability to generalize to different object sizes, aspect ratios, and contexts.\n\nThe example showcases the variety and complexity of the images in the COCO dataset and the benefits of using mosaicing during the training process.\n\n## Citations and Acknowledgments\n\nIf you use the COCO dataset in your research or development work, please cite the following paper:\n\n```bibtex\n@misc{lin2015microsoft,\n title={Microsoft COCO: Common Objects in Context}, \n author={Tsung-Yi Lin and Michael Maire and Serge Belongie and Lubomir Bourdev and Ross Girshick and James Hays and Pietro Perona and Deva Ramanan and C. Lawrence Zitnick and Piotr Dollár},\n year={2015},\n eprint={1405.0312},\n archivePrefix={arXiv},\n primaryClass={cs.CV}\n}\n```\n\nWe would like to acknowledge the COCO Consortium for creating and maintaining this valuable resource for the computer vision community. For more information about the COCO dataset and its creators, visit the [COCO dataset website](https://cocodataset.org/#home)."
},
{
"path": "docs/datasets/detect/coco8.md",
"content": "---\ncomments: true\ndescription: Get started with Ultralytics COCO8. Ideal for testing and debugging object detection models or experimenting with new detection approaches.\n---\n\n# COCO8 Dataset\n\n## Introduction\n\n[Ultralytics](https://ultralytics.com) COCO8 is a small, but versatile object detection dataset composed of the first 8\nimages of the COCO train 2017 set, 4 for training and 4 for validation. This dataset is ideal for testing and debugging\nobject detection models, or for experimenting with new detection approaches. With 8 images, it is small enough to be\neasily manageable, yet diverse enough to test training pipelines for errors and act as a sanity check before training\nlarger datasets.\n\nThis dataset is intended for use with Ultralytics [HUB](https://hub.ultralytics.com)\nand [YOLOv8](https://github.com/ultralytics/ultralytics).\n\n## Dataset YAML\n\nA YAML (Yet Another Markup Language) file is used to define the dataset configuration. It contains information about the dataset's paths, classes, and other relevant information. In the case of the COCO8 dataset, the `coco8.yaml` file is maintained at [https://github.com/ultralytics/ultralytics/blob/main/ultralytics/datasets/coco8.yaml](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/datasets/coco8.yaml).\n\n!!! example \"ultralytics/datasets/coco8.yaml\"\n\n ```yaml\n --8<-- \"ultralytics/datasets/coco8.yaml\"\n ```\n\n## Usage\n\nTo train a YOLOv8n model on the COCO8 dataset for 100 epochs with an image size of 640, you can use the following code snippets. For a comprehensive list of available arguments, refer to the model [Training](../../modes/train.md) page.\n\n!!! example \"Train Example\"\n\n === \"Python\"\n\n ```python\n from ultralytics import YOLO\n \n # Load a model\n model = YOLO('yolov8n.pt') # load a pretrained model (recommended for training)\n \n # Train the model\n model.train(data='coco8.yaml', epochs=100, imgsz=640)\n ```\n\n === \"CLI\"\n\n ```bash\n # Start training from a pretrained *.pt model\n yolo detect train data=coco8.yaml model=yolov8n.pt epochs=100 imgsz=640\n ```\n\n## Sample Images and Annotations\n\nHere are some examples of images from the COCO8 dataset, along with their corresponding annotations:\n\n \n\n- **Mosaiced Image**: This image demonstrates a training batch composed of mosaiced dataset images. Mosaicing is a technique used during training that combines multiple images into a single image to increase the variety of objects and scenes within each training batch. This helps improve the model's ability to generalize to different object sizes, aspect ratios, and contexts.\n\nThe example showcases the variety and complexity of the images in the COCO8 dataset and the benefits of using mosaicing during the training process.\n\n## Citations and Acknowledgments\n\nIf you use the COCO dataset in your research or development work, please cite the following paper:\n\n```bibtex\n@misc{lin2015microsoft,\n title={Microsoft COCO: Common Objects in Context}, \n author={Tsung-Yi Lin and Michael Maire and Serge Belongie and Lubomir Bourdev and Ross Girshick and James Hays and Pietro Perona and Deva Ramanan and C. Lawrence Zitnick and Piotr Dollár},\n year={2015},\n eprint={1405.0312},\n archivePrefix={arXiv},\n primaryClass={cs.CV}\n}\n```\n\nWe would like to acknowledge the COCO Consortium for creating and maintaining this valuable resource for the computer vision community. For more information about the COCO dataset and its creators, visit the [COCO dataset website](https://cocodataset.org/#home)."
},
{
"path": "docs/datasets/detect/globalwheat2020.md",
"content": "---\ncomments: true\ndescription: Learn about the Global Wheat Head Dataset, aimed at supporting the development of accurate wheat head models for applications in wheat phenotyping and crop management.\n---\n\n# Global Wheat Head Dataset\n\nThe [Global Wheat Head Dataset](http://www.global-wheat.com/) is a collection of images designed to support the development of accurate wheat head detection models for applications in wheat phenotyping and crop management. Wheat heads, also known as spikes, are the grain-bearing parts of the wheat plant. Accurate estimation of wheat head density and size is essential for assessing crop health, maturity, and yield potential. The dataset, created by a collaboration of nine research institutes from seven countries, covers multiple growing regions to ensure models generalize well across different environments.\n\n## Key Features\n\n- The dataset contains over 3,000 training images from Europe (France, UK, Switzerland) and North America (Canada).\n- It includes approximately 1,000 test images from Australia, Japan, and China.\n- Images are outdoor field images, capturing the natural variability in wheat head appearances.\n- Annotations include wheat head bounding boxes to support object detection tasks.\n\n## Dataset Structure\n\nThe Global Wheat Head Dataset is organized into two main subsets:\n\n1. **Training Set**: This subset contains over 3,000 images from Europe and North America. The images are labeled with wheat head bounding boxes, providing ground truth for training object detection models.\n2. **Test Set**: This subset consists of approximately 1,000 images from Australia, Japan, and China. These images are used for evaluating the performance of trained models on unseen genotypes, environments, and observational conditions.\n\n## Applications\n\nThe Global Wheat Head Dataset is widely used for training and evaluating deep learning models in wheat head detection tasks. The dataset's diverse set of images, capturing a wide range of appearances, environments, and conditions, make it a valuable resource for researchers and practitioners in the field of plant phenotyping and crop management.\n\n## Dataset YAML\n\nA YAML (Yet Another Markup Language) file is used to define the dataset configuration. It contains information about the dataset's paths, classes, and other relevant information. For the case of the Global Wheat Head Dataset, the `GlobalWheat2020.yaml` file is maintained at [https://github.com/ultralytics/ultralytics/blob/main/ultralytics/datasets/GlobalWheat2020.yaml](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/datasets/GlobalWheat2020.yaml).\n\n!!! example \"ultralytics/datasets/GlobalWheat2020.yaml\"\n\n ```yaml\n --8<-- \"ultralytics/datasets/GlobalWheat2020.yaml\"\n ```\n\n## Usage\n\nTo train a YOLOv8n model on the Global Wheat Head Dataset for 100 epochs with an image size of 640, you can use the following code snippets. For a comprehensive list of available arguments, refer to the model [Training](../../modes/train.md) page.\n\n!!! example \"Train Example\"\n\n === \"Python\"\n\n ```python\n from ultralytics import YOLO\n \n # Load a model\n model = YOLO('yolov8n.pt') # load a pretrained model (recommended for training)\n \n # Train the model\n model.train(data='GlobalWheat2020.yaml', epochs=100, imgsz=640)\n ```\n\n === \"CLI\"\n\n ```bash\n # Start training from a pretrained *.pt model\n yolo detect train data=GlobalWheat2020.yaml model=yolov8n.pt epochs=100 imgsz=640\n ```\n\n## Sample Data and Annotations\n\nThe Global Wheat Head Dataset contains a diverse set of outdoor field images, capturing the natural variability in wheat head appearances, environments, and conditions. Here are some examples of data from the dataset, along with their corresponding annotations:\n\n\n\n- **Wheat Head Detection**: This image demonstrates an example of wheat head detection, where wheat heads are annotated with bounding boxes. The dataset provides a variety of images to facilitate the development of models for this task.\n\nThe example showcases the variety and complexity of the data in the Global Wheat Head Dataset and highlights the importance of accurate wheat head detection for applications in wheat phenotyping and crop management.\n\n## Citations and Acknowledgments\n\nIf you use the Global Wheat Head Dataset in your research or development work, please cite the following paper:\n\n```bibtex\n@article{david2020global,\n title={Global Wheat Head Detection (GWHD) Dataset: A Large and Diverse Dataset of High-Resolution RGB-Labelled Images to Develop and Benchmark Wheat Head Detection Methods},\n author={David, Etienne and Madec, Simon and Sadeghi-Tehran, Pouria and Aasen, Helge and Zheng, Bangyou and Liu, Shouyang and Kirchgessner, Norbert and Ishikawa, Goro and Nagasawa, Koichi and Badhon, Minhajul and others},\n journal={arXiv preprint arXiv:2005.02162},\n year={2020}\n}\n```\n\nWe would like to acknowledge the researchers and institutions that contributed to the creation and maintenance of the Global Wheat Head Dataset as a valuable resource for the plant phenotyping and crop management research community. For more information about the dataset and its creators, visit the [Global Wheat Head Dataset website](http://www.global-wheat.com/)."
},
{
"path": "docs/datasets/detect/index.md",
"content": "---\ncomments: true\ndescription: Learn about supported dataset formats for training YOLO detection models, including Ultralytics YOLO and COCO, in this Object Detection Datasets Overview.\n---\n\n# Object Detection Datasets Overview\n\n## Supported Dataset Formats\n\n### Ultralytics YOLO format\n\n** Label Format **\n\nThe dataset format used for training YOLO detection models is as follows:\n\n1. One text file per image: Each image in the dataset has a corresponding text file with the same name as the image file and the \".txt\" extension.\n2. One row per object: Each row in the text file corresponds to one object instance in the image.\n3. Object information per row: Each row contains the following information about the object instance:\n - Object class index: An integer representing the class of the object (e.g., 0 for person, 1 for car, etc.).\n - Object center coordinates: The x and y coordinates of the center of the object, normalized to be between 0 and 1.\n - Object width and height: The width and height of the object, normalized to be between 0 and 1.\n\nThe format for a single row in the detection dataset file is as follows:\n\n```\n \n```\n\nHere is an example of the YOLO dataset format for a single image with two object instances:\n\n```\n0 0.5 0.4 0.3 0.6\n1 0.3 0.7 0.4 0.2\n```\n\nIn this example, the first object is of class 0 (person), with its center at (0.5, 0.4), width of 0.3, and height of 0.6. The second object is of class 1 (car), with its center at (0.3, 0.7), width of 0.4, and height of 0.2.\n\n** Dataset file format **\n\nThe Ultralytics framework uses a YAML file format to define the dataset and model configuration for training Detection Models. Here is an example of the YAML format used for defining a detection dataset:\n\n```\ntrain: \nval: \n\nnc: \nnames: [, , ..., ]\n\n```\n\nThe `train` and `val` fields specify the paths to the directories containing the training and validation images, respectively.\n\nThe `nc` field specifies the number of object classes in the dataset.\n\nThe `names` field is a list of the names of the object classes. The order of the names should match the order of the object class indices in the YOLO dataset files.\n\nNOTE: Either `nc` or `names` must be defined. Defining both are not mandatory\n\nAlternatively, you can directly define class names like this:\n\n```yaml\nnames:\n 0: person\n 1: bicycle\n```\n\n** Example **\n\n```yaml\ntrain: data/train/\nval: data/val/\n\nnc: 2\nnames: ['person', 'car']\n```\n\n## Usage\n\n!!! example \"\"\n\n === \"Python\"\n \n ```python\n from ultralytics import YOLO\n \n # Load a model\n model = YOLO('yolov8n.pt') # load a pretrained model (recommended for training)\n\n # Train the model\n model.train(data='coco128.yaml', epochs=100, imgsz=640)\n ```\n === \"CLI\"\n \n ```bash\n # Start training from a pretrained *.pt model\n yolo detect train data=coco128.yaml model=yolov8n.pt epochs=100 imgsz=640\n ```\n\n## Supported Datasets\n\nTODO\n\n## Port or Convert label formats\n\n### COCO dataset format to YOLO format\n\n```\nfrom ultralytics.yolo.data.converter import convert_coco\n\nconvert_coco(labels_dir='../coco/annotations/')\n```"
},
{
"path": "docs/datasets/detect/objects365.md",
"content": "---\ncomments: true\ndescription: Discover the Objects365 dataset, designed for object detection research with a focus on diverse objects, featuring 365 categories, 2 million images, and 30 million bounding boxes.\n---\n\n# Objects365 Dataset\n\nThe [Objects365](https://www.objects365.org/) dataset is a large-scale, high-quality dataset designed to foster object detection research with a focus on diverse objects in the wild. Created by a team of [Megvii](https://en.megvii.com/) researchers, the dataset offers a wide range of high-resolution images with a comprehensive set of annotated bounding boxes covering 365 object categories.\n\n## Key Features\n\n- Objects365 contains 365 object categories, with 2 million images and over 30 million bounding boxes.\n- The dataset includes diverse objects in various scenarios, providing a rich and challenging benchmark for object detection tasks.\n- Annotations include bounding boxes for objects, making it suitable for training and evaluating object detection models.\n- Objects365 pre-trained models significantly outperform ImageNet pre-trained models, leading to better generalization on various tasks.\n\n## Dataset Structure\n\nThe Objects365 dataset is organized into a single set of images with corresponding annotations:\n\n- **Images**: The dataset includes 2 million high-resolution images, each containing a variety of objects across 365 categories.\n- **Annotations**: The images are annotated with over 30 million bounding boxes, providing comprehensive ground truth information for object detection tasks.\n\n## Applications\n\nThe Objects365 dataset is widely used for training and evaluating deep learning models in object detection tasks. The dataset's diverse set of object categories and high-quality annotations make it a valuable resource for researchers and practitioners in the field of computer vision.\n\n## Dataset YAML\n\nA YAML (Yet Another Markup Language) file is used to define the dataset configuration. It contains information about the dataset's paths, classes, and other relevant information. For the case of the Objects365 Dataset, the `Objects365.yaml` file is maintained at [https://github.com/ultralytics/ultralytics/blob/main/ultralytics/datasets/Objects365.yaml](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/datasets/Objects365.yaml).\n\n!!! example \"ultralytics/datasets/Objects365.yaml\"\n\n ```yaml\n --8<-- \"ultralytics/datasets/Objects365.yaml\"\n ```\n\n## Usage\n\nTo train a YOLOv8n model on the Objects365 dataset for 100 epochs with an image size of 640, you can use the following code snippets. For a comprehensive list of available arguments, refer to the model [Training](../../modes/train.md) page.\n\n!!! example \"Train Example\"\n\n === \"Python\"\n\n ```python\n from ultralytics import YOLO\n \n # Load a model\n model = YOLO('yolov8n.pt') # load a pretrained model (recommended for training)\n \n # Train the model\n model.train(data='Objects365.yaml', epochs=100, imgsz=640)\n ```\n\n === \"CLI\"\n\n ```bash\n # Start training from a pretrained *.pt model\n yolo detect train data=Objects365.yaml model=yolov8n.pt epochs=100 imgsz=640\n ```\n\n## Sample Data and Annotations\n\nThe Objects365 dataset contains a diverse set of high-resolution images with objects from 365 categories, providing rich context for object detection tasks. Here are some examples of the images in the dataset:\n\n\n\n- **Objects365**: This image demonstrates an example of object detection, where objects are annotated with bounding boxes. The dataset provides a wide range of images to facilitate the development of models for this task.\n\nThe example showcases the variety and complexity of the data in the Objects365 dataset and highlights the importance of accurate object detection for computer vision applications.\n\n## Citations and Acknowledgments\n\nIf you use the Objects365 dataset in your research or development work, please cite the following paper:\n\n```bibtex\n@inproceedings{shao2019objects365,\n title={Objects365: A Large-scale, High-quality Dataset for Object Detection},\n author={Shao, Shuai and Li, Zeming and Zhang, Tianyuan and Peng, Chao and Yu, Gang and Li, Jing and Zhang, Xiangyu and Sun, Jian},\n booktitle={Proceedings of the IEEE/CVF International Conference on Computer Vision},\n pages={8425--8434},\n year={2019}\n}\n```\n\nWe would like to acknowledge the team of researchers who created and maintain the Objects365 dataset as a valuable resource for the computer vision research community. For more information about the Objects365 dataset and its creators, visit the [Objects365 dataset website](https://www.objects365.org/).\n"
},
{
"path": "docs/datasets/detect/sku-110k.md",
"content": "---\ncomments: true\ndescription: Explore the SKU-110k dataset, designed for object detection in densely packed retail shelf images, featuring over 110k unique SKU categories and annotations.\n---\n\n# SKU-110k Dataset\n\nThe [SKU-110k](https://github.com/eg4000/SKU110K_CVPR19) dataset is a collection of densely packed retail shelf images, designed to support research in object detection tasks. Developed by Eran Goldman et al., the dataset contains over 110,000 unique store keeping unit (SKU) categories with densely packed objects, often looking similar or even identical, positioned in close proximity.\n\n\n\n## Key Features\n\n- SKU-110k contains images of store shelves from around the world, featuring densely packed objects that pose challenges for state-of-the-art object detectors.\n- The dataset includes over 110,000 unique SKU categories, providing a diverse range of object appearances.\n- Annotations include bounding boxes for objects and SKU category labels.\n\n## Dataset Structure\n\nThe SKU-110k dataset is organized into three main subsets:\n\n1. **Training set**: This subset contains images and annotations used for training object detection models.\n2. **Validation set**: This subset consists of images and annotations used for model validation during training.\n3. **Test set**: This subset is designed for the final evaluation of trained object detection models.\n\n## Applications\n\nThe SKU-110k dataset is widely used for training and evaluating deep learning models in object detection tasks, especially in densely packed scenes such as retail shelf displays. The dataset's diverse set of SKU categories and densely packed object arrangements make it a valuable resource for researchers and practitioners in the field of computer vision.\n\n## Dataset YAML\n\nA YAML (Yet Another Markup Language) file is used to define the dataset configuration. It contains information about the dataset's paths, classes, and other relevant information. For the case of the SKU-110K dataset, the `SKU-110K.yaml` file is maintained at [https://github.com/ultralytics/ultralytics/blob/main/ultralytics/datasets/SKU-110K.yaml](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/datasets/SKU-110K.yaml).\n\n!!! example \"ultralytics/datasets/SKU-110K.yaml\"\n\n ```yaml\n --8<-- \"ultralytics/datasets/SKU-110K.yaml\"\n ```\n\n## Usage\n\nTo train a YOLOv8n model on the SKU-110K dataset for 100 epochs with an image size of 640, you can use the following code snippets. For a comprehensive list of available arguments, refer to the model [Training](../../modes/train.md) page.\n\n!!! example \"Train Example\"\n\n === \"Python\"\n\n ```python\n from ultralytics import YOLO\n \n # Load a model\n model = YOLO('yolov8n.pt') # load a pretrained model (recommended for training)\n \n # Train the model\n model.train(data='SKU-110K.yaml', epochs=100, imgsz=640)\n ```\n\n === \"CLI\"\n\n ```bash\n # Start training from a pretrained *.pt model\n yolo detect train data=SKU-110K.yaml model=yolov8n.pt epochs=100 imgsz=640\n\n## Sample Data and Annotations\n\nThe SKU-110k dataset contains a diverse set of retail shelf images with densely packed objects, providing rich context for object detection tasks. Here are some examples of data from the dataset, along with their corresponding annotations:\n\n\n\n- **Densely packed retail shelf image**: This image demonstrates an example of densely packed objects in a retail shelf setting. Objects are annotated with bounding boxes and SKU category labels.\n\nThe example showcases the variety and complexity of the data in the SKU-110k dataset and highlights the importance of high-quality data for object detection tasks.\n\n## Citations and Acknowledgments\n\nIf you use the SKU-110k dataset in your research or development work, please cite the following paper:\n\n```bibtex\n@inproceedings{goldman2019dense,\n author = {Eran Goldman and Roei Herzig and Aviv Eisenschtat and Jacob Goldberger and Tal Hassner},\n title = {Precise Detection in Densely Packed Scenes},\n booktitle = {Proc. Conf. Comput. Vision Pattern Recognition (CVPR)},\n year = {2019}\n}\n```\n\nWe would like to acknowledge Eran Goldman et al. for creating and maintaining the SKU-110k dataset as a valuable resource for the computer vision research community. For more information about the SKU-110k dataset and its creators, visit the [SKU-110k dataset GitHub repository](https://github.com/eg4000/SKU110K_CVPR19)."
},
{
"path": "docs/datasets/detect/visdrone.md",
"content": "---\ncomments: true\ndescription: Discover the VisDrone dataset, a comprehensive benchmark for drone-based computer vision tasks, including object detection, tracking, and crowd counting.\n---\n\n# VisDrone Dataset\n\nThe [VisDrone Dataset](https://github.com/VisDrone/VisDrone-Dataset) is a large-scale benchmark created by the AISKYEYE team at the Lab of Machine Learning and Data Mining, Tianjin University, China. It contains carefully annotated ground truth data for various computer vision tasks related to drone-based image and video analysis.\n\nVisDrone is composed of 288 video clips with 261,908 frames and 10,209 static images, captured by various drone-mounted cameras. The dataset covers a wide range of aspects, including location (14 different cities across China), environment (urban and rural), objects (pedestrians, vehicles, bicycles, etc.), and density (sparse and crowded scenes). The dataset was collected using various drone platforms under different scenarios and weather and lighting conditions. These frames are manually annotated with over 2.6 million bounding boxes of targets such as pedestrians, cars, bicycles, and tricycles. Attributes like scene visibility, object class, and occlusion are also provided for better data utilization.\n\n## Citation\n\nIf you use the VisDrone dataset in your research or development work, please cite the following paper:\n\n```bibtex\n@ARTICLE{9573394,\n author={Zhu, Pengfei and Wen, Longyin and Du, Dawei and Bian, Xiao and Fan, Heng and Hu, Qinghua and Ling, Haibin},\n journal={IEEE Transactions on Pattern Analysis and Machine Intelligence}, \n title={Detection and Tracking Meet Drones Challenge}, \n year={2021},\n volume={},\n number={},\n pages={1-1},\n doi={10.1109/TPAMI.2021.3119563}}\n```\n\n## Dataset Structure\n\nThe VisDrone dataset is organized into five main subsets, each focusing on a specific task:\n\n1. **Task 1**: Object detection in images\n2. **Task 2**: Object detection in videos\n3. **Task 3**: Single-object tracking\n4. **Task 4**: Multi-object tracking\n5. **Task 5**: Crowd counting\n\n## Applications\n\nThe VisDrone dataset is widely used for training and evaluating deep learning models in drone-based computer vision tasks such as object detection, object tracking, and crowd counting. The dataset's diverse set of sensor data, object annotations, and attributes make it a valuable resource for researchers and practitioners in the field of drone-based computer vision.\n\n## Dataset YAML\n\nA YAML (Yet Another Markup Language) file is used to define the dataset configuration. It contains information about the dataset's paths, classes, and other relevant information. In the case of the Visdrone dataset, the `VisDrone.yaml` file is maintained at [https://github.com/ultralytics/ultralytics/blob/main/ultralytics/datasets/VisDrone.yaml](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/datasets/VisDrone.yaml).\n\n!!! example \"ultralytics/datasets/VisDrone.yaml\"\n\n ```yaml\n --8<-- \"ultralytics/datasets/VisDrone.yaml\"\n ```\n\n## Usage\n\nTo train a YOLOv8n model on the VisDrone dataset for 100 epochs with an image size of 640, you can use the following code snippets. For a comprehensive list of available arguments, refer to the model [Training](../../modes/train.md) page.\n\n!!! example \"Train Example\"\n\n === \"Python\"\n\n ```python\n from ultralytics import YOLO\n \n # Load a model\n model = YOLO('yolov8n.pt') # load a pretrained model (recommended for training)\n \n # Train the model\n model.train(data='VisDrone.yaml', epochs=100, imgsz=640)\n ```\n\n === \"CLI\"\n\n ```bash\n # Start training from a pretrained *.pt model\n yolo detect train data=VisDrone.yaml model=yolov8n.pt epochs=100 imgsz=640\n ```\n\n## Sample Data and Annotations\n\nThe VisDrone dataset contains a diverse set of images and videos captured by drone-mounted cameras. Here are some examples of data from the dataset, along with their corresponding annotations:\n\n\n\n- **Task 1**: Object detection in images - This image demonstrates an example of object detection in images, where objects are annotated with bounding boxes. The dataset provides a wide variety of images taken from different locations, environments, and densities to facilitate the development of models for this task.\n\nThe example showcases the variety and complexity of the data in the VisDrone dataset and highlights the importance of high-quality sensor data for drone-based computer vision tasks.\n\n## Citations and Acknowledgments\n\nIf you use the VisDrone dataset in your research or development work, please cite the following paper:\n\n```bibtex\n@ARTICLE{9573394,\n author={Zhu, Pengfei and Wen, Longyin and Du, Dawei and Bian, Xiao and Fan, Heng and Hu, Qinghua and Ling, Haibin},\n journal={IEEE Transactions on Pattern Analysis and Machine Intelligence}, \n title={Detection and Tracking Meet Drones Challenge}, \n year={2021},\n volume={},\n number={},\n pages={1-1},\n doi={10.1109/TPAMI.2021.3119563}}\n```\n\nWe would like to acknowledge the AISKYEYE team at the Lab of Machine Learning and Data Mining, Tianjin University, China, for creating and maintaining the VisDrone dataset as a valuable resource for the drone-based computer vision research community. For more information about the VisDrone dataset and its creators, visit the [VisDrone Dataset GitHub repository](https://github.com/VisDrone/VisDrone-Dataset)."
},
{
"path": "docs/datasets/detect/voc.md",
"content": "---\ncomments: true\ndescription: Learn about the VOC dataset, designed to encourage research on object detection, segmentation, and classification with standardized evaluation metrics.\n---\n\n# VOC Dataset\n\nThe [PASCAL VOC](http://host.robots.ox.ac.uk/pascal/VOC/) (Visual Object Classes) dataset is a well-known object detection, segmentation, and classification dataset. It is designed to encourage research on a wide variety of object categories and is commonly used for benchmarking computer vision models. It is an essential dataset for researchers and developers working on object detection, segmentation, and classification tasks.\n\n## Key Features\n\n- VOC dataset includes two main challenges: VOC2007 and VOC2012.\n- The dataset comprises 20 object categories, including common objects like cars, bicycles, and animals, as well as more specific categories such as boats, sofas, and dining tables.\n- Annotations include object bounding boxes and class labels for object detection and classification tasks, and segmentation masks for the segmentation tasks.\n- VOC provides standardized evaluation metrics like mean Average Precision (mAP) for object detection and classification, making it suitable for comparing model performance.\n\n## Dataset Structure\n\nThe VOC dataset is split into three subsets:\n\n1. **Train**: This subset contains images for training object detection, segmentation, and classification models.\n2. **Validation**: This subset has images used for validation purposes during model training.\n3. **Test**: This subset consists of images used for testing and benchmarking the trained models. Ground truth annotations for this subset are not publicly available, and the results are submitted to the [PASCAL VOC evaluation server](http://host.robots.ox.ac.uk:8080/leaderboard/displaylb.php) for performance evaluation.\n\n## Applications\n\nThe VOC dataset is widely used for training and evaluating deep learning models in object detection (such as YOLO, Faster R-CNN, and SSD), instance segmentation (such as Mask R-CNN), and image classification. The dataset's diverse set of object categories, large number of annotated images, and standardized evaluation metrics make it an essential resource for computer vision researchers and practitioners.\n\n## Dataset YAML\n\nA YAML (Yet Another Markup Language) file is used to define the dataset configuration. It contains information about the dataset's paths, classes, and other relevant information. In the case of the VOC dataset, the `VOC.yaml` file is maintained at [https://github.com/ultralytics/ultralytics/blob/main/ultralytics/datasets/VOC.yaml](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/datasets/VOC.yaml).\n\n!!! example \"ultralytics/datasets/VOC.yaml\"\n\n ```yaml\n --8<-- \"ultralytics/datasets/VOC.yaml\"\n ```\n\n## Usage\n\nTo train a YOLOv8n model on the VOC dataset for 100 epochs with an image size of 640, you can use the following code snippets. For a comprehensive list of available arguments, refer to the model [Training](../../modes/train.md) page.\n\n!!! example \"Train Example\"\n\n === \"Python\"\n\n ```python\n from ultralytics import YOLO\n \n # Load a model\n model = YOLO('yolov8n.pt') # load a pretrained model (recommended for training)\n \n # Train the model\n model.train(data='VOC.yaml', epochs=100, imgsz=640)\n ```\n\n === \"CLI\"\n\n ```bash\n # Start training from\n a pretrained *.pt model\n yolo detect train data=VOC.yaml model=yolov8n.pt epochs=100 imgsz=640\n ```\n\n## Sample Images and Annotations\n\nThe VOC dataset contains a diverse set of images with various object categories and complex scenes. Here are some examples of images from the dataset, along with their corresponding annotations:\n\n\n\n- **Mosaiced Image**: This image demonstrates a training batch composed of mosaiced dataset images. Mosaicing is a technique used during training that combines multiple images into a single image to increase the variety of objects and scenes within each training batch. This helps improve the model's ability to generalize to different object sizes, aspect ratios, and contexts.\n\nThe example showcases the variety and complexity of the images in the VOC dataset and the benefits of using mosaicing during the training process.\n\n## Citations and Acknowledgments\n\nIf you use the VOC dataset in your research or development work, please cite the following paper:\n\n```bibtex\n@misc{everingham2010pascal,\n title={The PASCAL Visual Object Classes (VOC) Challenge}, \n author={Mark Everingham and Luc Van Gool and Christopher K. I. Williams and John Winn and Andrew Zisserman},\n year={2010},\n eprint={0909.5206},\n archivePrefix={arXiv},\n primaryClass={cs.CV}\n}\n```\n\nWe would like to acknowledge the PASCAL VOC Consortium for creating and maintaining this valuable resource for the computer vision community. For more information about the VOC dataset and its creators, visit the [PASCAL VOC dataset website](http://host.robots.ox.ac.uk/pascal/VOC/)."
},
{
"path": "docs/datasets/detect/xview.md",
"content": "---\ncomments: true\ndescription: Discover the xView Dataset, a large-scale overhead imagery dataset for object detection tasks, featuring 1M instances, 60 classes, and high-resolution images.\n---\n\n# xView Dataset\n\nThe [xView](http://xviewdataset.org/) dataset is one of the largest publicly available datasets of overhead imagery, containing images from complex scenes around the world annotated using bounding boxes. The goal of the xView dataset is to accelerate progress in four computer vision frontiers:\n\n1. Reduce minimum resolution for detection.\n2. Improve learning efficiency.\n3. Enable discovery of more object classes.\n4. Improve detection of fine-grained classes.\n\nxView builds on the success of challenges like Common Objects in Context (COCO) and aims to leverage computer vision to analyze the growing amount of available imagery from space in order to understand the visual world in new ways and address a range of important applications.\n\n## Key Features\n\n- xView contains over 1 million object instances across 60 classes.\n- The dataset has a resolution of 0.3 meters, providing higher resolution imagery than most public satellite imagery datasets.\n- xView features a diverse collection of small, rare, fine-grained, and multi-type objects with bounding box annotation.\n- Comes with a pre-trained baseline model using the TensorFlow object detection API and an example for PyTorch.\n\n## Dataset Structure\n\nThe xView dataset is composed of satellite images collected from WorldView-3 satellites at a 0.3m ground sample distance. It contains over 1 million objects across 60 classes in over 1,400 km² of imagery.\n\n## Applications\n\nThe xView dataset is widely used for training and evaluating deep learning models for object detection in overhead imagery. The dataset's diverse set of object classes and high-resolution imagery make it a valuable resource for researchers and practitioners in the field of computer vision, especially for satellite imagery analysis.\n\n## Dataset YAML\n\nA YAML (Yet Another Markup Language) file is used to define the dataset configuration. It contains information about the dataset's paths, classes, and other relevant information. In the case of the xView dataset, the `xView.yaml` file is maintained at [https://github.com/ultralytics/ultralytics/blob/main/ultralytics/datasets/xView.yaml](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/datasets/xView.yaml).\n\n!!! example \"ultralytics/datasets/xView.yaml\"\n\n ```yaml\n --8<-- \"ultralytics/datasets/xView.yaml\"\n ```\n\n## Usage\n\nTo train a model on the xView dataset for 100 epochs with an image size of 640, you can use the following code snippets. For a comprehensive list of available arguments, refer to the model [Training](../../modes/train.md) page.\n\n!!! example \"Train Example\"\n\n === \"Python\"\n\n ```python\n from ultralytics import YOLO\n \n # Load a model\n model = YOLO('yolov8n.pt') # load a pretrained model (recommended for training)\n \n # Train the model\n model.train(data='xView.yaml', epochs=100, imgsz=640)\n ```\n\n === \"CLI\"\n\n ```bash\n # Start training from a pretrained *.pt model\n yolo detect train data=xView.yaml model=yolov8n.pt epochs=100 imgsz=640\n ```\n\n## Sample Data and Annotations\n\nThe xView dataset contains high-resolution satellite images with a diverse set of objects annotated using bounding boxes. Here are some examples of data from the dataset, along with their corresponding annotations:\n\n\n\n- **Overhead Imagery**: This image demonstrates an example of object detection in overhead imagery, where objects are annotated with bounding boxes. The dataset provides high-resolution satellite images to facilitate the development of models for this task.\n\nThe example showcases the variety and complexity of the data in the xView dataset and highlights the importance of high-quality satellite imagery for object detection tasks.\n\n## Citations and Acknowledgments\n\nIf you use the xView dataset in your research or development work, please cite the following paper:\n\n```bibtex\n@misc{lam2018xview,\n title={xView: Objects in Context in Overhead Imagery}, \n author={Darius Lam and Richard Kuzma and Kevin McGee and Samuel Dooley and Michael Laielli and Matthew Klaric and Yaroslav Bulatov and Brendan McCord},\n year={2018},\n eprint={1802.07856},\n archivePrefix={arXiv},\n primaryClass={cs.CV}\n}\n```\n\nWe would like to acknowledge the [Defense Innovation Unit](https://www.diu.mil/) (DIU) and the creators of the xView dataset for their valuable contribution to the computer vision research community. For more information about the xView dataset and its creators, visit the [xView dataset website](http://xviewdataset.org/).\n"
},
{
"path": "docs/datasets/index.md",
"content": "---\ncomments: true\ndescription: Ultralytics provides support for various datasets to facilitate multiple computer vision tasks. Check out our list of main datasets and their summaries.\n---\n\n# Datasets Overview\n\nUltralytics provides support for various datasets to facilitate computer vision tasks such as detection, instance segmentation, pose estimation, classification, and multi-object tracking. Below is a list of the main Ultralytics datasets, followed by a summary of each computer vision task and the respective datasets.\n\n## [Detection Datasets](detect/index.md)\n\nBounding box object detection is a computer vision technique that involves detecting and localizing objects in an image by drawing a bounding box around each object.\n\n* [Argoverse](detect/argoverse.md): A dataset containing 3D tracking and motion forecasting data from urban environments with rich annotations.\n* [COCO](detect/coco.md): A large-scale dataset designed for object detection, segmentation, and captioning with over 200K labeled images.\n* [COCO8](detect/coco8.md): Contains the first 4 images from COCO train and COCO val, suitable for quick tests.\n* [Global Wheat 2020](detect/globalwheat2020.md): A dataset of wheat head images collected from around the world for object detection and localization tasks.\n* [Objects365](detect/objects365.md): A high-quality, large-scale dataset for object detection with 365 object categories and over 600K annotated images.\n* [SKU-110K](detect/sku-110k.md): A dataset featuring dense object detection in retail environments with over 11K images and 1.7 million bounding boxes.\n* [VisDrone](detect/visdrone.md): A dataset containing object detection and multi-object tracking data from drone-captured imagery with over 10K images and video sequences.\n* [VOC](detect/voc.md): The Pascal Visual Object Classes (VOC) dataset for object detection and segmentation with 20 object classes and over 11K images.\n* [xView](detect/xview.md): A dataset for object detection in overhead imagery with 60 object categories and over 1 million annotated objects.\n\n## [Instance Segmentation Datasets](segment/index.md)\n\nInstance segmentation is a computer vision technique that involves identifying and localizing objects in an image at the pixel level.\n\n* [COCO](segment/coco.md): A large-scale dataset designed for object detection, segmentation, and captioning tasks with over 200K labeled images.\n* [COCO8-seg](segment/coco8-seg.md): A smaller dataset for instance segmentation tasks, containing a subset of 8 COCO images with segmentation annotations.\n\n## [Pose Estimation](pose/index.md)\n\nPose estimation is a technique used to determine the pose of the object relative to the camera or the world coordinate system.\n\n* [COCO](pose/coco.md): A large-scale dataset with human pose annotations designed for pose estimation tasks.\n* [COCO8-pose](pose/coco8-pose.md): A smaller dataset for pose estimation tasks, containing a subset of 8 COCO images with human pose annotations.\n\n## [Classification](classify/index.md)\n\nImage classification is a computer vision task that involves categorizing an image into one or more predefined classes or categories based on its visual content.\n\n* [Caltech 101](classify/caltech101.md): A dataset containing images of 101 object categories for image classification tasks.\n* [Caltech 256](classify/caltech256.md): An extended version of Caltech 101 with 256 object categories and more challenging images.\n* [CIFAR-10](classify/cifar10.md): A dataset of 60K 32x32 color images in 10 classes, with 6K images per class.\n* [CIFAR-100](classify/cifar100.md): An extended version of CIFAR-10 with 100 object categories and 600 images per class.\n* [Fashion-MNIST](classify/fashion-mnist.md): A dataset consisting of 70,000 grayscale images of 10 fashion categories for image classification tasks.\n* [ImageNet](classify/imagenet.md): A large-scale dataset for object detection and image classification with over 14 million images and 20,000 categories.\n* [ImageNet-10](classify/imagenet10.md): A smaller subset of ImageNet with 10 categories for faster experimentation and testing.\n* [Imagenette](classify/imagenette.md): A smaller subset of ImageNet that contains 10 easily distinguishable classes for quicker training and testing.\n* [Imagewoof](classify/imagewoof.md): A more challenging subset of ImageNet containing 10 dog breed categories for image classification tasks.\n* [MNIST](classify/mnist.md): A dataset of 70,000 grayscale images of handwritten digits for image classification tasks.\n\n## [Multi-Object Tracking](track/index.md)\n\nMulti-object tracking is a computer vision technique that involves detecting and tracking multiple objects over time in a video sequence.\n\n* [Argoverse](detect/argoverse.md): A dataset containing 3D tracking and motion forecasting data from urban environments with rich annotations for multi-object tracking tasks.\n* [VisDrone](detect/visdrone.md): A dataset containing object detection and multi-object tracking data from drone-captured imagery with over 10K images and video sequences."
},
{
"path": "docs/datasets/pose/coco.md",
"content": "---\ncomments: true\n---\n\n# 🚧 Page Under Construction ⚒\n\nThis page is currently under construction!️ 👷Please check back later for updates. 😃🔜\n"
},
{
"path": "docs/datasets/pose/coco8-pose.md",
"content": "---\ncomments: true\ndescription: Test and debug object detection models with Ultralytics COCO8-Pose Dataset - a small, versatile pose detection dataset with 8 images.\n---\n\n# COCO8-Pose Dataset\n\n## Introduction\n\n[Ultralytics](https://ultralytics.com) COCO8-Pose is a small, but versatile pose detection dataset composed of the first\n8 images of the COCO train 2017 set, 4 for training and 4 for validation. This dataset is ideal for testing and\ndebugging object detection models, or for experimenting with new detection approaches. With 8 images, it is small enough\nto be easily manageable, yet diverse enough to test training pipelines for errors and act as a sanity check before\ntraining larger datasets.\n\nThis dataset is intended for use with Ultralytics [HUB](https://hub.ultralytics.com)\nand [YOLOv8](https://github.com/ultralytics/ultralytics).\n\n## Dataset YAML\n\nA YAML (Yet Another Markup Language) file is used to define the dataset configuration. It contains information about the dataset's paths, classes, and other relevant information. In the case of the COCO8-Pose dataset, the `coco8-pose.yaml` file is maintained at [https://github.com/ultralytics/ultralytics/blob/main/ultralytics/datasets/coco8-pose.yaml](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/datasets/coco8-pose.yaml).\n\n!!! example \"ultralytics/datasets/coco8-pose.yaml\"\n\n ```yaml\n --8<-- \"ultralytics/datasets/coco8-pose.yaml\"\n ```\n\n## Usage\n\nTo train a YOLOv8n model on the COCO8-Pose dataset for 100 epochs with an image size of 640, you can use the following code snippets. For a comprehensive list of available arguments, refer to the model [Training](../../modes/train.md) page.\n\n!!! example \"Train Example\"\n\n === \"Python\"\n\n ```python\n from ultralytics import YOLO\n \n # Load a model\n model = YOLO('yolov8n.pt') # load a pretrained model (recommended for training)\n \n # Train the model\n model.train(data='coco8-pose.yaml', epochs=100, imgsz=640)\n ```\n\n === \"CLI\"\n\n ```bash\n # Start training from a pretrained *.pt model\n yolo detect train data=coco8-pose.yaml model=yolov8n.pt epochs=100 imgsz=640\n ```\n\n## Sample Images and Annotations\n\nHere are some examples of images from the COCO8-Pose dataset, along with their corresponding annotations:\n\n
\n\n- **Mosaiced Image**: This image demonstrates a training batch composed of mosaiced dataset images. Mosaicing is a technique used during training that combines multiple images into a single image to increase the variety of objects and scenes within each training batch. This helps improve the model's ability to generalize to different object sizes, aspect ratios, and contexts.\n\nThe example showcases the variety and complexity of the images in the COCO8 dataset and the benefits of using mosaicing during the training process.\n\n## Citations and Acknowledgments\n\nIf you use the COCO dataset in your research or development work, please cite the following paper:\n\n```bibtex\n@misc{lin2015microsoft,\n title={Microsoft COCO: Common Objects in Context}, \n author={Tsung-Yi Lin and Michael Maire and Serge Belongie and Lubomir Bourdev and Ross Girshick and James Hays and Pietro Perona and Deva Ramanan and C. Lawrence Zitnick and Piotr Dollár},\n year={2015},\n eprint={1405.0312},\n archivePrefix={arXiv},\n primaryClass={cs.CV}\n}\n```\n\nWe would like to acknowledge the COCO Consortium for creating and maintaining this valuable resource for the computer vision community. For more information about the COCO dataset and its creators, visit the [COCO dataset website](https://cocodataset.org/#home)."
},
{
"path": "docs/datasets/detect/globalwheat2020.md",
"content": "---\ncomments: true\ndescription: Learn about the Global Wheat Head Dataset, aimed at supporting the development of accurate wheat head models for applications in wheat phenotyping and crop management.\n---\n\n# Global Wheat Head Dataset\n\nThe [Global Wheat Head Dataset](http://www.global-wheat.com/) is a collection of images designed to support the development of accurate wheat head detection models for applications in wheat phenotyping and crop management. Wheat heads, also known as spikes, are the grain-bearing parts of the wheat plant. Accurate estimation of wheat head density and size is essential for assessing crop health, maturity, and yield potential. The dataset, created by a collaboration of nine research institutes from seven countries, covers multiple growing regions to ensure models generalize well across different environments.\n\n## Key Features\n\n- The dataset contains over 3,000 training images from Europe (France, UK, Switzerland) and North America (Canada).\n- It includes approximately 1,000 test images from Australia, Japan, and China.\n- Images are outdoor field images, capturing the natural variability in wheat head appearances.\n- Annotations include wheat head bounding boxes to support object detection tasks.\n\n## Dataset Structure\n\nThe Global Wheat Head Dataset is organized into two main subsets:\n\n1. **Training Set**: This subset contains over 3,000 images from Europe and North America. The images are labeled with wheat head bounding boxes, providing ground truth for training object detection models.\n2. **Test Set**: This subset consists of approximately 1,000 images from Australia, Japan, and China. These images are used for evaluating the performance of trained models on unseen genotypes, environments, and observational conditions.\n\n## Applications\n\nThe Global Wheat Head Dataset is widely used for training and evaluating deep learning models in wheat head detection tasks. The dataset's diverse set of images, capturing a wide range of appearances, environments, and conditions, make it a valuable resource for researchers and practitioners in the field of plant phenotyping and crop management.\n\n## Dataset YAML\n\nA YAML (Yet Another Markup Language) file is used to define the dataset configuration. It contains information about the dataset's paths, classes, and other relevant information. For the case of the Global Wheat Head Dataset, the `GlobalWheat2020.yaml` file is maintained at [https://github.com/ultralytics/ultralytics/blob/main/ultralytics/datasets/GlobalWheat2020.yaml](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/datasets/GlobalWheat2020.yaml).\n\n!!! example \"ultralytics/datasets/GlobalWheat2020.yaml\"\n\n ```yaml\n --8<-- \"ultralytics/datasets/GlobalWheat2020.yaml\"\n ```\n\n## Usage\n\nTo train a YOLOv8n model on the Global Wheat Head Dataset for 100 epochs with an image size of 640, you can use the following code snippets. For a comprehensive list of available arguments, refer to the model [Training](../../modes/train.md) page.\n\n!!! example \"Train Example\"\n\n === \"Python\"\n\n ```python\n from ultralytics import YOLO\n \n # Load a model\n model = YOLO('yolov8n.pt') # load a pretrained model (recommended for training)\n \n # Train the model\n model.train(data='GlobalWheat2020.yaml', epochs=100, imgsz=640)\n ```\n\n === \"CLI\"\n\n ```bash\n # Start training from a pretrained *.pt model\n yolo detect train data=GlobalWheat2020.yaml model=yolov8n.pt epochs=100 imgsz=640\n ```\n\n## Sample Data and Annotations\n\nThe Global Wheat Head Dataset contains a diverse set of outdoor field images, capturing the natural variability in wheat head appearances, environments, and conditions. Here are some examples of data from the dataset, along with their corresponding annotations:\n\n\n\n- **Wheat Head Detection**: This image demonstrates an example of wheat head detection, where wheat heads are annotated with bounding boxes. The dataset provides a variety of images to facilitate the development of models for this task.\n\nThe example showcases the variety and complexity of the data in the Global Wheat Head Dataset and highlights the importance of accurate wheat head detection for applications in wheat phenotyping and crop management.\n\n## Citations and Acknowledgments\n\nIf you use the Global Wheat Head Dataset in your research or development work, please cite the following paper:\n\n```bibtex\n@article{david2020global,\n title={Global Wheat Head Detection (GWHD) Dataset: A Large and Diverse Dataset of High-Resolution RGB-Labelled Images to Develop and Benchmark Wheat Head Detection Methods},\n author={David, Etienne and Madec, Simon and Sadeghi-Tehran, Pouria and Aasen, Helge and Zheng, Bangyou and Liu, Shouyang and Kirchgessner, Norbert and Ishikawa, Goro and Nagasawa, Koichi and Badhon, Minhajul and others},\n journal={arXiv preprint arXiv:2005.02162},\n year={2020}\n}\n```\n\nWe would like to acknowledge the researchers and institutions that contributed to the creation and maintenance of the Global Wheat Head Dataset as a valuable resource for the plant phenotyping and crop management research community. For more information about the dataset and its creators, visit the [Global Wheat Head Dataset website](http://www.global-wheat.com/)."
},
{
"path": "docs/datasets/detect/index.md",
"content": "---\ncomments: true\ndescription: Learn about supported dataset formats for training YOLO detection models, including Ultralytics YOLO and COCO, in this Object Detection Datasets Overview.\n---\n\n# Object Detection Datasets Overview\n\n## Supported Dataset Formats\n\n### Ultralytics YOLO format\n\n** Label Format **\n\nThe dataset format used for training YOLO detection models is as follows:\n\n1. One text file per image: Each image in the dataset has a corresponding text file with the same name as the image file and the \".txt\" extension.\n2. One row per object: Each row in the text file corresponds to one object instance in the image.\n3. Object information per row: Each row contains the following information about the object instance:\n - Object class index: An integer representing the class of the object (e.g., 0 for person, 1 for car, etc.).\n - Object center coordinates: The x and y coordinates of the center of the object, normalized to be between 0 and 1.\n - Object width and height: The width and height of the object, normalized to be between 0 and 1.\n\nThe format for a single row in the detection dataset file is as follows:\n\n```\n \n```\n\nHere is an example of the YOLO dataset format for a single image with two object instances:\n\n```\n0 0.5 0.4 0.3 0.6\n1 0.3 0.7 0.4 0.2\n```\n\nIn this example, the first object is of class 0 (person), with its center at (0.5, 0.4), width of 0.3, and height of 0.6. The second object is of class 1 (car), with its center at (0.3, 0.7), width of 0.4, and height of 0.2.\n\n** Dataset file format **\n\nThe Ultralytics framework uses a YAML file format to define the dataset and model configuration for training Detection Models. Here is an example of the YAML format used for defining a detection dataset:\n\n```\ntrain: \nval: \n\nnc: \nnames: [, , ..., ]\n\n```\n\nThe `train` and `val` fields specify the paths to the directories containing the training and validation images, respectively.\n\nThe `nc` field specifies the number of object classes in the dataset.\n\nThe `names` field is a list of the names of the object classes. The order of the names should match the order of the object class indices in the YOLO dataset files.\n\nNOTE: Either `nc` or `names` must be defined. Defining both are not mandatory\n\nAlternatively, you can directly define class names like this:\n\n```yaml\nnames:\n 0: person\n 1: bicycle\n```\n\n** Example **\n\n```yaml\ntrain: data/train/\nval: data/val/\n\nnc: 2\nnames: ['person', 'car']\n```\n\n## Usage\n\n!!! example \"\"\n\n === \"Python\"\n \n ```python\n from ultralytics import YOLO\n \n # Load a model\n model = YOLO('yolov8n.pt') # load a pretrained model (recommended for training)\n\n # Train the model\n model.train(data='coco128.yaml', epochs=100, imgsz=640)\n ```\n === \"CLI\"\n \n ```bash\n # Start training from a pretrained *.pt model\n yolo detect train data=coco128.yaml model=yolov8n.pt epochs=100 imgsz=640\n ```\n\n## Supported Datasets\n\nTODO\n\n## Port or Convert label formats\n\n### COCO dataset format to YOLO format\n\n```\nfrom ultralytics.yolo.data.converter import convert_coco\n\nconvert_coco(labels_dir='../coco/annotations/')\n```"
},
{
"path": "docs/datasets/detect/objects365.md",
"content": "---\ncomments: true\ndescription: Discover the Objects365 dataset, designed for object detection research with a focus on diverse objects, featuring 365 categories, 2 million images, and 30 million bounding boxes.\n---\n\n# Objects365 Dataset\n\nThe [Objects365](https://www.objects365.org/) dataset is a large-scale, high-quality dataset designed to foster object detection research with a focus on diverse objects in the wild. Created by a team of [Megvii](https://en.megvii.com/) researchers, the dataset offers a wide range of high-resolution images with a comprehensive set of annotated bounding boxes covering 365 object categories.\n\n## Key Features\n\n- Objects365 contains 365 object categories, with 2 million images and over 30 million bounding boxes.\n- The dataset includes diverse objects in various scenarios, providing a rich and challenging benchmark for object detection tasks.\n- Annotations include bounding boxes for objects, making it suitable for training and evaluating object detection models.\n- Objects365 pre-trained models significantly outperform ImageNet pre-trained models, leading to better generalization on various tasks.\n\n## Dataset Structure\n\nThe Objects365 dataset is organized into a single set of images with corresponding annotations:\n\n- **Images**: The dataset includes 2 million high-resolution images, each containing a variety of objects across 365 categories.\n- **Annotations**: The images are annotated with over 30 million bounding boxes, providing comprehensive ground truth information for object detection tasks.\n\n## Applications\n\nThe Objects365 dataset is widely used for training and evaluating deep learning models in object detection tasks. The dataset's diverse set of object categories and high-quality annotations make it a valuable resource for researchers and practitioners in the field of computer vision.\n\n## Dataset YAML\n\nA YAML (Yet Another Markup Language) file is used to define the dataset configuration. It contains information about the dataset's paths, classes, and other relevant information. For the case of the Objects365 Dataset, the `Objects365.yaml` file is maintained at [https://github.com/ultralytics/ultralytics/blob/main/ultralytics/datasets/Objects365.yaml](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/datasets/Objects365.yaml).\n\n!!! example \"ultralytics/datasets/Objects365.yaml\"\n\n ```yaml\n --8<-- \"ultralytics/datasets/Objects365.yaml\"\n ```\n\n## Usage\n\nTo train a YOLOv8n model on the Objects365 dataset for 100 epochs with an image size of 640, you can use the following code snippets. For a comprehensive list of available arguments, refer to the model [Training](../../modes/train.md) page.\n\n!!! example \"Train Example\"\n\n === \"Python\"\n\n ```python\n from ultralytics import YOLO\n \n # Load a model\n model = YOLO('yolov8n.pt') # load a pretrained model (recommended for training)\n \n # Train the model\n model.train(data='Objects365.yaml', epochs=100, imgsz=640)\n ```\n\n === \"CLI\"\n\n ```bash\n # Start training from a pretrained *.pt model\n yolo detect train data=Objects365.yaml model=yolov8n.pt epochs=100 imgsz=640\n ```\n\n## Sample Data and Annotations\n\nThe Objects365 dataset contains a diverse set of high-resolution images with objects from 365 categories, providing rich context for object detection tasks. Here are some examples of the images in the dataset:\n\n\n\n- **Objects365**: This image demonstrates an example of object detection, where objects are annotated with bounding boxes. The dataset provides a wide range of images to facilitate the development of models for this task.\n\nThe example showcases the variety and complexity of the data in the Objects365 dataset and highlights the importance of accurate object detection for computer vision applications.\n\n## Citations and Acknowledgments\n\nIf you use the Objects365 dataset in your research or development work, please cite the following paper:\n\n```bibtex\n@inproceedings{shao2019objects365,\n title={Objects365: A Large-scale, High-quality Dataset for Object Detection},\n author={Shao, Shuai and Li, Zeming and Zhang, Tianyuan and Peng, Chao and Yu, Gang and Li, Jing and Zhang, Xiangyu and Sun, Jian},\n booktitle={Proceedings of the IEEE/CVF International Conference on Computer Vision},\n pages={8425--8434},\n year={2019}\n}\n```\n\nWe would like to acknowledge the team of researchers who created and maintain the Objects365 dataset as a valuable resource for the computer vision research community. For more information about the Objects365 dataset and its creators, visit the [Objects365 dataset website](https://www.objects365.org/).\n"
},
{
"path": "docs/datasets/detect/sku-110k.md",
"content": "---\ncomments: true\ndescription: Explore the SKU-110k dataset, designed for object detection in densely packed retail shelf images, featuring over 110k unique SKU categories and annotations.\n---\n\n# SKU-110k Dataset\n\nThe [SKU-110k](https://github.com/eg4000/SKU110K_CVPR19) dataset is a collection of densely packed retail shelf images, designed to support research in object detection tasks. Developed by Eran Goldman et al., the dataset contains over 110,000 unique store keeping unit (SKU) categories with densely packed objects, often looking similar or even identical, positioned in close proximity.\n\n\n\n## Key Features\n\n- SKU-110k contains images of store shelves from around the world, featuring densely packed objects that pose challenges for state-of-the-art object detectors.\n- The dataset includes over 110,000 unique SKU categories, providing a diverse range of object appearances.\n- Annotations include bounding boxes for objects and SKU category labels.\n\n## Dataset Structure\n\nThe SKU-110k dataset is organized into three main subsets:\n\n1. **Training set**: This subset contains images and annotations used for training object detection models.\n2. **Validation set**: This subset consists of images and annotations used for model validation during training.\n3. **Test set**: This subset is designed for the final evaluation of trained object detection models.\n\n## Applications\n\nThe SKU-110k dataset is widely used for training and evaluating deep learning models in object detection tasks, especially in densely packed scenes such as retail shelf displays. The dataset's diverse set of SKU categories and densely packed object arrangements make it a valuable resource for researchers and practitioners in the field of computer vision.\n\n## Dataset YAML\n\nA YAML (Yet Another Markup Language) file is used to define the dataset configuration. It contains information about the dataset's paths, classes, and other relevant information. For the case of the SKU-110K dataset, the `SKU-110K.yaml` file is maintained at [https://github.com/ultralytics/ultralytics/blob/main/ultralytics/datasets/SKU-110K.yaml](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/datasets/SKU-110K.yaml).\n\n!!! example \"ultralytics/datasets/SKU-110K.yaml\"\n\n ```yaml\n --8<-- \"ultralytics/datasets/SKU-110K.yaml\"\n ```\n\n## Usage\n\nTo train a YOLOv8n model on the SKU-110K dataset for 100 epochs with an image size of 640, you can use the following code snippets. For a comprehensive list of available arguments, refer to the model [Training](../../modes/train.md) page.\n\n!!! example \"Train Example\"\n\n === \"Python\"\n\n ```python\n from ultralytics import YOLO\n \n # Load a model\n model = YOLO('yolov8n.pt') # load a pretrained model (recommended for training)\n \n # Train the model\n model.train(data='SKU-110K.yaml', epochs=100, imgsz=640)\n ```\n\n === \"CLI\"\n\n ```bash\n # Start training from a pretrained *.pt model\n yolo detect train data=SKU-110K.yaml model=yolov8n.pt epochs=100 imgsz=640\n\n## Sample Data and Annotations\n\nThe SKU-110k dataset contains a diverse set of retail shelf images with densely packed objects, providing rich context for object detection tasks. Here are some examples of data from the dataset, along with their corresponding annotations:\n\n\n\n- **Densely packed retail shelf image**: This image demonstrates an example of densely packed objects in a retail shelf setting. Objects are annotated with bounding boxes and SKU category labels.\n\nThe example showcases the variety and complexity of the data in the SKU-110k dataset and highlights the importance of high-quality data for object detection tasks.\n\n## Citations and Acknowledgments\n\nIf you use the SKU-110k dataset in your research or development work, please cite the following paper:\n\n```bibtex\n@inproceedings{goldman2019dense,\n author = {Eran Goldman and Roei Herzig and Aviv Eisenschtat and Jacob Goldberger and Tal Hassner},\n title = {Precise Detection in Densely Packed Scenes},\n booktitle = {Proc. Conf. Comput. Vision Pattern Recognition (CVPR)},\n year = {2019}\n}\n```\n\nWe would like to acknowledge Eran Goldman et al. for creating and maintaining the SKU-110k dataset as a valuable resource for the computer vision research community. For more information about the SKU-110k dataset and its creators, visit the [SKU-110k dataset GitHub repository](https://github.com/eg4000/SKU110K_CVPR19)."
},
{
"path": "docs/datasets/detect/visdrone.md",
"content": "---\ncomments: true\ndescription: Discover the VisDrone dataset, a comprehensive benchmark for drone-based computer vision tasks, including object detection, tracking, and crowd counting.\n---\n\n# VisDrone Dataset\n\nThe [VisDrone Dataset](https://github.com/VisDrone/VisDrone-Dataset) is a large-scale benchmark created by the AISKYEYE team at the Lab of Machine Learning and Data Mining, Tianjin University, China. It contains carefully annotated ground truth data for various computer vision tasks related to drone-based image and video analysis.\n\nVisDrone is composed of 288 video clips with 261,908 frames and 10,209 static images, captured by various drone-mounted cameras. The dataset covers a wide range of aspects, including location (14 different cities across China), environment (urban and rural), objects (pedestrians, vehicles, bicycles, etc.), and density (sparse and crowded scenes). The dataset was collected using various drone platforms under different scenarios and weather and lighting conditions. These frames are manually annotated with over 2.6 million bounding boxes of targets such as pedestrians, cars, bicycles, and tricycles. Attributes like scene visibility, object class, and occlusion are also provided for better data utilization.\n\n## Citation\n\nIf you use the VisDrone dataset in your research or development work, please cite the following paper:\n\n```bibtex\n@ARTICLE{9573394,\n author={Zhu, Pengfei and Wen, Longyin and Du, Dawei and Bian, Xiao and Fan, Heng and Hu, Qinghua and Ling, Haibin},\n journal={IEEE Transactions on Pattern Analysis and Machine Intelligence}, \n title={Detection and Tracking Meet Drones Challenge}, \n year={2021},\n volume={},\n number={},\n pages={1-1},\n doi={10.1109/TPAMI.2021.3119563}}\n```\n\n## Dataset Structure\n\nThe VisDrone dataset is organized into five main subsets, each focusing on a specific task:\n\n1. **Task 1**: Object detection in images\n2. **Task 2**: Object detection in videos\n3. **Task 3**: Single-object tracking\n4. **Task 4**: Multi-object tracking\n5. **Task 5**: Crowd counting\n\n## Applications\n\nThe VisDrone dataset is widely used for training and evaluating deep learning models in drone-based computer vision tasks such as object detection, object tracking, and crowd counting. The dataset's diverse set of sensor data, object annotations, and attributes make it a valuable resource for researchers and practitioners in the field of drone-based computer vision.\n\n## Dataset YAML\n\nA YAML (Yet Another Markup Language) file is used to define the dataset configuration. It contains information about the dataset's paths, classes, and other relevant information. In the case of the Visdrone dataset, the `VisDrone.yaml` file is maintained at [https://github.com/ultralytics/ultralytics/blob/main/ultralytics/datasets/VisDrone.yaml](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/datasets/VisDrone.yaml).\n\n!!! example \"ultralytics/datasets/VisDrone.yaml\"\n\n ```yaml\n --8<-- \"ultralytics/datasets/VisDrone.yaml\"\n ```\n\n## Usage\n\nTo train a YOLOv8n model on the VisDrone dataset for 100 epochs with an image size of 640, you can use the following code snippets. For a comprehensive list of available arguments, refer to the model [Training](../../modes/train.md) page.\n\n!!! example \"Train Example\"\n\n === \"Python\"\n\n ```python\n from ultralytics import YOLO\n \n # Load a model\n model = YOLO('yolov8n.pt') # load a pretrained model (recommended for training)\n \n # Train the model\n model.train(data='VisDrone.yaml', epochs=100, imgsz=640)\n ```\n\n === \"CLI\"\n\n ```bash\n # Start training from a pretrained *.pt model\n yolo detect train data=VisDrone.yaml model=yolov8n.pt epochs=100 imgsz=640\n ```\n\n## Sample Data and Annotations\n\nThe VisDrone dataset contains a diverse set of images and videos captured by drone-mounted cameras. Here are some examples of data from the dataset, along with their corresponding annotations:\n\n\n\n- **Task 1**: Object detection in images - This image demonstrates an example of object detection in images, where objects are annotated with bounding boxes. The dataset provides a wide variety of images taken from different locations, environments, and densities to facilitate the development of models for this task.\n\nThe example showcases the variety and complexity of the data in the VisDrone dataset and highlights the importance of high-quality sensor data for drone-based computer vision tasks.\n\n## Citations and Acknowledgments\n\nIf you use the VisDrone dataset in your research or development work, please cite the following paper:\n\n```bibtex\n@ARTICLE{9573394,\n author={Zhu, Pengfei and Wen, Longyin and Du, Dawei and Bian, Xiao and Fan, Heng and Hu, Qinghua and Ling, Haibin},\n journal={IEEE Transactions on Pattern Analysis and Machine Intelligence}, \n title={Detection and Tracking Meet Drones Challenge}, \n year={2021},\n volume={},\n number={},\n pages={1-1},\n doi={10.1109/TPAMI.2021.3119563}}\n```\n\nWe would like to acknowledge the AISKYEYE team at the Lab of Machine Learning and Data Mining, Tianjin University, China, for creating and maintaining the VisDrone dataset as a valuable resource for the drone-based computer vision research community. For more information about the VisDrone dataset and its creators, visit the [VisDrone Dataset GitHub repository](https://github.com/VisDrone/VisDrone-Dataset)."
},
{
"path": "docs/datasets/detect/voc.md",
"content": "---\ncomments: true\ndescription: Learn about the VOC dataset, designed to encourage research on object detection, segmentation, and classification with standardized evaluation metrics.\n---\n\n# VOC Dataset\n\nThe [PASCAL VOC](http://host.robots.ox.ac.uk/pascal/VOC/) (Visual Object Classes) dataset is a well-known object detection, segmentation, and classification dataset. It is designed to encourage research on a wide variety of object categories and is commonly used for benchmarking computer vision models. It is an essential dataset for researchers and developers working on object detection, segmentation, and classification tasks.\n\n## Key Features\n\n- VOC dataset includes two main challenges: VOC2007 and VOC2012.\n- The dataset comprises 20 object categories, including common objects like cars, bicycles, and animals, as well as more specific categories such as boats, sofas, and dining tables.\n- Annotations include object bounding boxes and class labels for object detection and classification tasks, and segmentation masks for the segmentation tasks.\n- VOC provides standardized evaluation metrics like mean Average Precision (mAP) for object detection and classification, making it suitable for comparing model performance.\n\n## Dataset Structure\n\nThe VOC dataset is split into three subsets:\n\n1. **Train**: This subset contains images for training object detection, segmentation, and classification models.\n2. **Validation**: This subset has images used for validation purposes during model training.\n3. **Test**: This subset consists of images used for testing and benchmarking the trained models. Ground truth annotations for this subset are not publicly available, and the results are submitted to the [PASCAL VOC evaluation server](http://host.robots.ox.ac.uk:8080/leaderboard/displaylb.php) for performance evaluation.\n\n## Applications\n\nThe VOC dataset is widely used for training and evaluating deep learning models in object detection (such as YOLO, Faster R-CNN, and SSD), instance segmentation (such as Mask R-CNN), and image classification. The dataset's diverse set of object categories, large number of annotated images, and standardized evaluation metrics make it an essential resource for computer vision researchers and practitioners.\n\n## Dataset YAML\n\nA YAML (Yet Another Markup Language) file is used to define the dataset configuration. It contains information about the dataset's paths, classes, and other relevant information. In the case of the VOC dataset, the `VOC.yaml` file is maintained at [https://github.com/ultralytics/ultralytics/blob/main/ultralytics/datasets/VOC.yaml](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/datasets/VOC.yaml).\n\n!!! example \"ultralytics/datasets/VOC.yaml\"\n\n ```yaml\n --8<-- \"ultralytics/datasets/VOC.yaml\"\n ```\n\n## Usage\n\nTo train a YOLOv8n model on the VOC dataset for 100 epochs with an image size of 640, you can use the following code snippets. For a comprehensive list of available arguments, refer to the model [Training](../../modes/train.md) page.\n\n!!! example \"Train Example\"\n\n === \"Python\"\n\n ```python\n from ultralytics import YOLO\n \n # Load a model\n model = YOLO('yolov8n.pt') # load a pretrained model (recommended for training)\n \n # Train the model\n model.train(data='VOC.yaml', epochs=100, imgsz=640)\n ```\n\n === \"CLI\"\n\n ```bash\n # Start training from\n a pretrained *.pt model\n yolo detect train data=VOC.yaml model=yolov8n.pt epochs=100 imgsz=640\n ```\n\n## Sample Images and Annotations\n\nThe VOC dataset contains a diverse set of images with various object categories and complex scenes. Here are some examples of images from the dataset, along with their corresponding annotations:\n\n\n\n- **Mosaiced Image**: This image demonstrates a training batch composed of mosaiced dataset images. Mosaicing is a technique used during training that combines multiple images into a single image to increase the variety of objects and scenes within each training batch. This helps improve the model's ability to generalize to different object sizes, aspect ratios, and contexts.\n\nThe example showcases the variety and complexity of the images in the VOC dataset and the benefits of using mosaicing during the training process.\n\n## Citations and Acknowledgments\n\nIf you use the VOC dataset in your research or development work, please cite the following paper:\n\n```bibtex\n@misc{everingham2010pascal,\n title={The PASCAL Visual Object Classes (VOC) Challenge}, \n author={Mark Everingham and Luc Van Gool and Christopher K. I. Williams and John Winn and Andrew Zisserman},\n year={2010},\n eprint={0909.5206},\n archivePrefix={arXiv},\n primaryClass={cs.CV}\n}\n```\n\nWe would like to acknowledge the PASCAL VOC Consortium for creating and maintaining this valuable resource for the computer vision community. For more information about the VOC dataset and its creators, visit the [PASCAL VOC dataset website](http://host.robots.ox.ac.uk/pascal/VOC/)."
},
{
"path": "docs/datasets/detect/xview.md",
"content": "---\ncomments: true\ndescription: Discover the xView Dataset, a large-scale overhead imagery dataset for object detection tasks, featuring 1M instances, 60 classes, and high-resolution images.\n---\n\n# xView Dataset\n\nThe [xView](http://xviewdataset.org/) dataset is one of the largest publicly available datasets of overhead imagery, containing images from complex scenes around the world annotated using bounding boxes. The goal of the xView dataset is to accelerate progress in four computer vision frontiers:\n\n1. Reduce minimum resolution for detection.\n2. Improve learning efficiency.\n3. Enable discovery of more object classes.\n4. Improve detection of fine-grained classes.\n\nxView builds on the success of challenges like Common Objects in Context (COCO) and aims to leverage computer vision to analyze the growing amount of available imagery from space in order to understand the visual world in new ways and address a range of important applications.\n\n## Key Features\n\n- xView contains over 1 million object instances across 60 classes.\n- The dataset has a resolution of 0.3 meters, providing higher resolution imagery than most public satellite imagery datasets.\n- xView features a diverse collection of small, rare, fine-grained, and multi-type objects with bounding box annotation.\n- Comes with a pre-trained baseline model using the TensorFlow object detection API and an example for PyTorch.\n\n## Dataset Structure\n\nThe xView dataset is composed of satellite images collected from WorldView-3 satellites at a 0.3m ground sample distance. It contains over 1 million objects across 60 classes in over 1,400 km² of imagery.\n\n## Applications\n\nThe xView dataset is widely used for training and evaluating deep learning models for object detection in overhead imagery. The dataset's diverse set of object classes and high-resolution imagery make it a valuable resource for researchers and practitioners in the field of computer vision, especially for satellite imagery analysis.\n\n## Dataset YAML\n\nA YAML (Yet Another Markup Language) file is used to define the dataset configuration. It contains information about the dataset's paths, classes, and other relevant information. In the case of the xView dataset, the `xView.yaml` file is maintained at [https://github.com/ultralytics/ultralytics/blob/main/ultralytics/datasets/xView.yaml](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/datasets/xView.yaml).\n\n!!! example \"ultralytics/datasets/xView.yaml\"\n\n ```yaml\n --8<-- \"ultralytics/datasets/xView.yaml\"\n ```\n\n## Usage\n\nTo train a model on the xView dataset for 100 epochs with an image size of 640, you can use the following code snippets. For a comprehensive list of available arguments, refer to the model [Training](../../modes/train.md) page.\n\n!!! example \"Train Example\"\n\n === \"Python\"\n\n ```python\n from ultralytics import YOLO\n \n # Load a model\n model = YOLO('yolov8n.pt') # load a pretrained model (recommended for training)\n \n # Train the model\n model.train(data='xView.yaml', epochs=100, imgsz=640)\n ```\n\n === \"CLI\"\n\n ```bash\n # Start training from a pretrained *.pt model\n yolo detect train data=xView.yaml model=yolov8n.pt epochs=100 imgsz=640\n ```\n\n## Sample Data and Annotations\n\nThe xView dataset contains high-resolution satellite images with a diverse set of objects annotated using bounding boxes. Here are some examples of data from the dataset, along with their corresponding annotations:\n\n\n\n- **Overhead Imagery**: This image demonstrates an example of object detection in overhead imagery, where objects are annotated with bounding boxes. The dataset provides high-resolution satellite images to facilitate the development of models for this task.\n\nThe example showcases the variety and complexity of the data in the xView dataset and highlights the importance of high-quality satellite imagery for object detection tasks.\n\n## Citations and Acknowledgments\n\nIf you use the xView dataset in your research or development work, please cite the following paper:\n\n```bibtex\n@misc{lam2018xview,\n title={xView: Objects in Context in Overhead Imagery}, \n author={Darius Lam and Richard Kuzma and Kevin McGee and Samuel Dooley and Michael Laielli and Matthew Klaric and Yaroslav Bulatov and Brendan McCord},\n year={2018},\n eprint={1802.07856},\n archivePrefix={arXiv},\n primaryClass={cs.CV}\n}\n```\n\nWe would like to acknowledge the [Defense Innovation Unit](https://www.diu.mil/) (DIU) and the creators of the xView dataset for their valuable contribution to the computer vision research community. For more information about the xView dataset and its creators, visit the [xView dataset website](http://xviewdataset.org/).\n"
},
{
"path": "docs/datasets/index.md",
"content": "---\ncomments: true\ndescription: Ultralytics provides support for various datasets to facilitate multiple computer vision tasks. Check out our list of main datasets and their summaries.\n---\n\n# Datasets Overview\n\nUltralytics provides support for various datasets to facilitate computer vision tasks such as detection, instance segmentation, pose estimation, classification, and multi-object tracking. Below is a list of the main Ultralytics datasets, followed by a summary of each computer vision task and the respective datasets.\n\n## [Detection Datasets](detect/index.md)\n\nBounding box object detection is a computer vision technique that involves detecting and localizing objects in an image by drawing a bounding box around each object.\n\n* [Argoverse](detect/argoverse.md): A dataset containing 3D tracking and motion forecasting data from urban environments with rich annotations.\n* [COCO](detect/coco.md): A large-scale dataset designed for object detection, segmentation, and captioning with over 200K labeled images.\n* [COCO8](detect/coco8.md): Contains the first 4 images from COCO train and COCO val, suitable for quick tests.\n* [Global Wheat 2020](detect/globalwheat2020.md): A dataset of wheat head images collected from around the world for object detection and localization tasks.\n* [Objects365](detect/objects365.md): A high-quality, large-scale dataset for object detection with 365 object categories and over 600K annotated images.\n* [SKU-110K](detect/sku-110k.md): A dataset featuring dense object detection in retail environments with over 11K images and 1.7 million bounding boxes.\n* [VisDrone](detect/visdrone.md): A dataset containing object detection and multi-object tracking data from drone-captured imagery with over 10K images and video sequences.\n* [VOC](detect/voc.md): The Pascal Visual Object Classes (VOC) dataset for object detection and segmentation with 20 object classes and over 11K images.\n* [xView](detect/xview.md): A dataset for object detection in overhead imagery with 60 object categories and over 1 million annotated objects.\n\n## [Instance Segmentation Datasets](segment/index.md)\n\nInstance segmentation is a computer vision technique that involves identifying and localizing objects in an image at the pixel level.\n\n* [COCO](segment/coco.md): A large-scale dataset designed for object detection, segmentation, and captioning tasks with over 200K labeled images.\n* [COCO8-seg](segment/coco8-seg.md): A smaller dataset for instance segmentation tasks, containing a subset of 8 COCO images with segmentation annotations.\n\n## [Pose Estimation](pose/index.md)\n\nPose estimation is a technique used to determine the pose of the object relative to the camera or the world coordinate system.\n\n* [COCO](pose/coco.md): A large-scale dataset with human pose annotations designed for pose estimation tasks.\n* [COCO8-pose](pose/coco8-pose.md): A smaller dataset for pose estimation tasks, containing a subset of 8 COCO images with human pose annotations.\n\n## [Classification](classify/index.md)\n\nImage classification is a computer vision task that involves categorizing an image into one or more predefined classes or categories based on its visual content.\n\n* [Caltech 101](classify/caltech101.md): A dataset containing images of 101 object categories for image classification tasks.\n* [Caltech 256](classify/caltech256.md): An extended version of Caltech 101 with 256 object categories and more challenging images.\n* [CIFAR-10](classify/cifar10.md): A dataset of 60K 32x32 color images in 10 classes, with 6K images per class.\n* [CIFAR-100](classify/cifar100.md): An extended version of CIFAR-10 with 100 object categories and 600 images per class.\n* [Fashion-MNIST](classify/fashion-mnist.md): A dataset consisting of 70,000 grayscale images of 10 fashion categories for image classification tasks.\n* [ImageNet](classify/imagenet.md): A large-scale dataset for object detection and image classification with over 14 million images and 20,000 categories.\n* [ImageNet-10](classify/imagenet10.md): A smaller subset of ImageNet with 10 categories for faster experimentation and testing.\n* [Imagenette](classify/imagenette.md): A smaller subset of ImageNet that contains 10 easily distinguishable classes for quicker training and testing.\n* [Imagewoof](classify/imagewoof.md): A more challenging subset of ImageNet containing 10 dog breed categories for image classification tasks.\n* [MNIST](classify/mnist.md): A dataset of 70,000 grayscale images of handwritten digits for image classification tasks.\n\n## [Multi-Object Tracking](track/index.md)\n\nMulti-object tracking is a computer vision technique that involves detecting and tracking multiple objects over time in a video sequence.\n\n* [Argoverse](detect/argoverse.md): A dataset containing 3D tracking and motion forecasting data from urban environments with rich annotations for multi-object tracking tasks.\n* [VisDrone](detect/visdrone.md): A dataset containing object detection and multi-object tracking data from drone-captured imagery with over 10K images and video sequences."
},
{
"path": "docs/datasets/pose/coco.md",
"content": "---\ncomments: true\n---\n\n# 🚧 Page Under Construction ⚒\n\nThis page is currently under construction!️ 👷Please check back later for updates. 😃🔜\n"
},
{
"path": "docs/datasets/pose/coco8-pose.md",
"content": "---\ncomments: true\ndescription: Test and debug object detection models with Ultralytics COCO8-Pose Dataset - a small, versatile pose detection dataset with 8 images.\n---\n\n# COCO8-Pose Dataset\n\n## Introduction\n\n[Ultralytics](https://ultralytics.com) COCO8-Pose is a small, but versatile pose detection dataset composed of the first\n8 images of the COCO train 2017 set, 4 for training and 4 for validation. This dataset is ideal for testing and\ndebugging object detection models, or for experimenting with new detection approaches. With 8 images, it is small enough\nto be easily manageable, yet diverse enough to test training pipelines for errors and act as a sanity check before\ntraining larger datasets.\n\nThis dataset is intended for use with Ultralytics [HUB](https://hub.ultralytics.com)\nand [YOLOv8](https://github.com/ultralytics/ultralytics).\n\n## Dataset YAML\n\nA YAML (Yet Another Markup Language) file is used to define the dataset configuration. It contains information about the dataset's paths, classes, and other relevant information. In the case of the COCO8-Pose dataset, the `coco8-pose.yaml` file is maintained at [https://github.com/ultralytics/ultralytics/blob/main/ultralytics/datasets/coco8-pose.yaml](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/datasets/coco8-pose.yaml).\n\n!!! example \"ultralytics/datasets/coco8-pose.yaml\"\n\n ```yaml\n --8<-- \"ultralytics/datasets/coco8-pose.yaml\"\n ```\n\n## Usage\n\nTo train a YOLOv8n model on the COCO8-Pose dataset for 100 epochs with an image size of 640, you can use the following code snippets. For a comprehensive list of available arguments, refer to the model [Training](../../modes/train.md) page.\n\n!!! example \"Train Example\"\n\n === \"Python\"\n\n ```python\n from ultralytics import YOLO\n \n # Load a model\n model = YOLO('yolov8n.pt') # load a pretrained model (recommended for training)\n \n # Train the model\n model.train(data='coco8-pose.yaml', epochs=100, imgsz=640)\n ```\n\n === \"CLI\"\n\n ```bash\n # Start training from a pretrained *.pt model\n yolo detect train data=coco8-pose.yaml model=yolov8n.pt epochs=100 imgsz=640\n ```\n\n## Sample Images and Annotations\n\nHere are some examples of images from the COCO8-Pose dataset, along with their corresponding annotations:\n\n \n\n- **Mosaiced Image**: This image demonstrates a training batch composed of mosaiced dataset images. Mosaicing is a technique used during training that combines multiple images into a single image to increase the variety of objects and scenes within each training batch. This helps improve the model's ability to generalize to different object sizes, aspect ratios, and contexts.\n\nThe example showcases the variety and complexity of the images in the COCO8-Pose dataset and the benefits of using mosaicing during the training process.\n\n## Citations and Acknowledgments\n\nIf you use the COCO dataset in your research or development work, please cite the following paper:\n\n```bibtex\n@misc{lin2015microsoft,\n title={Microsoft COCO: Common Objects in Context}, \n author={Tsung-Yi Lin and Michael Maire and Serge Belongie and Lubomir Bourdev and Ross Girshick and James Hays and Pietro Perona and Deva Ramanan and C. Lawrence Zitnick and Piotr Dollár},\n year={2015},\n eprint={1405.0312},\n archivePrefix={arXiv},\n primaryClass={cs.CV}\n}\n```\n\nWe would like to acknowledge the COCO Consortium for creating and maintaining this valuable resource for the computer vision community. For more information about the COCO dataset and its creators, visit the [COCO dataset website](https://cocodataset.org/#home)."
},
{
"path": "docs/datasets/pose/index.md",
"content": "---\ncomments: true\ndescription: Learn how to format your dataset for training YOLO models with Ultralytics YOLO format using our concise tutorial and example YAML files.\n---\n\n# Pose Estimation Datasets Overview\n\n## Supported Dataset Formats\n\n### Ultralytics YOLO format\n\n** Label Format **\n\nThe dataset format used for training YOLO segmentation models is as follows:\n\n1. One text file per image: Each image in the dataset has a corresponding text file with the same name as the image file and the \".txt\" extension.\n2. One row per object: Each row in the text file corresponds to one object instance in the image.\n3. Object information per row: Each row contains the following information about the object instance:\n - Object class index: An integer representing the class of the object (e.g., 0 for person, 1 for car, etc.).\n - Object center coordinates: The x and y coordinates of the center of the object, normalized to be between 0 and 1.\n - Object width and height: The width and height of the object, normalized to be between 0 and 1.\n - Object keypoint coordinates: The keypoints of the object, normalized to be between 0 and 1.\n\nHere is an example of the label format for pose estimation task:\n\nFormat with Dim = 2\n\n```\n ... \n```\n\nFormat with Dim = 3\n\n```\n \n```\n\nIn this format, `` is the index of the class for the object,` ` are coordinates of boudning box, and ` ... ` are the pixel coordinates of the keypoints. The coordinates are separated by spaces.\n\n** Dataset file format **\n\nThe Ultralytics framework uses a YAML file format to define the dataset and model configuration for training Detection Models. Here is an example of the YAML format used for defining a detection dataset:\n\n```yaml\ntrain: \nval: \n\nnc: \nnames: [, , ..., ]\n\n# Keypoints\nkpt_shape: [num_kpts, dim] # number of keypoints, number of dims (2 for x,y or 3 for x,y,visible)\nflip_idx: [n1, n2 ... , n(num_kpts)]\n\n```\n\nThe `train` and `val` fields specify the paths to the directories containing the training and validation images, respectively.\n\nThe `nc` field specifies the number of object classes in the dataset.\n\nThe `names` field is a list of the names of the object classes. The order of the names should match the order of the object class indices in the YOLO dataset files.\n\nNOTE: Either `nc` or `names` must be defined. Defining both are not mandatory\n\nAlternatively, you can directly define class names like this:\n\n```\nnames:\n 0: person\n 1: bicycle\n```\n\n(Optional) if the points are symmetric then need flip_idx, like left-right side of human or face.\nFor example let's say there're five keypoints of facial landmark: [left eye, right eye, nose, left point of mouth, right point of mouse], and the original index is [0, 1, 2, 3, 4], then flip_idx is [1, 0, 2, 4, 3].(just exchange the left-right index, i.e 0-1 and 3-4, and do not modify others like nose in this example)\n\n** Example **\n\n```yaml\ntrain: data/train/\nval: data/val/\n\nnc: 2\nnames: ['person', 'car']\n\n# Keypoints\nkpt_shape: [17, 3] # number of keypoints, number of dims (2 for x,y or 3 for x,y,visible)\nflip_idx: [0, 2, 1, 4, 3, 6, 5, 8, 7, 10, 9, 12, 11, 14, 13, 16, 15]\n```\n\n## Usage\n\n!!! example \"\"\n\n === \"Python\"\n \n ```python\n from ultralytics import YOLO\n \n # Load a model\n model = YOLO('yolov8n-pose.pt') # load a pretrained model (recommended for training)\n\n # Train the model\n model.train(data='coco128-pose.yaml', epochs=100, imgsz=640)\n ```\n === \"CLI\"\n \n ```bash\n # Start training from a pretrained *.pt model\n yolo detect train data=coco128-pose.yaml model=yolov8n-pose.pt epochs=100 imgsz=640\n ```\n\n## Supported Datasets\n\nTODO\n\n## Port or Convert label formats\n\n### COCO dataset format to YOLO format\n\n```\nfrom ultralytics.yolo.data.converter import convert_coco\n\nconvert_coco(labels_dir='../coco/annotations/', use_keypoints=True)\n```"
},
{
"path": "docs/datasets/segment/coco.md",
"content": "---\ncomments: true\n---\n\n# 🚧 Page Under Construction ⚒\n\nThis page is currently under construction!️ 👷Please check back later for updates. 😃🔜\n"
},
{
"path": "docs/datasets/segment/coco8-seg.md",
"content": "---\ncomments: true\ndescription: Test and debug segmentation models on small, versatile COCO8-Seg instance segmentation dataset, now available for use with YOLOv8 and Ultralytics HUB.\n---\n\n# COCO8-Seg Dataset\n\n## Introduction\n\n[Ultralytics](https://ultralytics.com) COCO8-Seg is a small, but versatile instance segmentation dataset composed of the\nfirst 8 images of the COCO train 2017 set, 4 for training and 4 for validation. This dataset is ideal for testing and\ndebugging segmentation models, or for experimenting with new detection approaches. With 8 images, it is small enough to\nbe easily manageable, yet diverse enough to test training pipelines for errors and act as a sanity check before training\nlarger datasets.\n\nThis dataset is intended for use with Ultralytics [HUB](https://hub.ultralytics.com)\nand [YOLOv8](https://github.com/ultralytics/ultralytics).\n\n## Dataset YAML\n\nA YAML (Yet Another Markup Language) file is used to define the dataset configuration. It contains information about the dataset's paths, classes, and other relevant information. In the case of the COCO8-Seg dataset, the `coco8-seg.yaml` file is maintained at [https://github.com/ultralytics/ultralytics/blob/main/ultralytics/datasets/coco8-seg.yaml](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/datasets/coco8-seg.yaml).\n\n!!! example \"ultralytics/datasets/coco8-seg.yaml\"\n\n ```yaml\n --8<-- \"ultralytics/datasets/coco8-seg.yaml\"\n ```\n\n## Usage\n\nTo train a YOLOv8n model on the COCO8-Seg dataset for 100 epochs with an image size of 640, you can use the following code snippets. For a comprehensive list of available arguments, refer to the model [Training](../../modes/train.md) page.\n\n!!! example \"Train Example\"\n\n === \"Python\"\n\n ```python\n from ultralytics import YOLO\n \n # Load a model\n model = YOLO('yolov8n.pt') # load a pretrained model (recommended for training)\n \n # Train the model\n model.train(data='coco8-seg.yaml', epochs=100, imgsz=640)\n ```\n\n === \"CLI\"\n\n ```bash\n # Start training from a pretrained *.pt model\n yolo detect train data=coco8-seg.yaml model=yolov8n.pt epochs=100 imgsz=640\n ```\n\n## Sample Images and Annotations\n\nHere are some examples of images from the COCO8-Seg dataset, along with their corresponding annotations:\n\n
\n\n- **Mosaiced Image**: This image demonstrates a training batch composed of mosaiced dataset images. Mosaicing is a technique used during training that combines multiple images into a single image to increase the variety of objects and scenes within each training batch. This helps improve the model's ability to generalize to different object sizes, aspect ratios, and contexts.\n\nThe example showcases the variety and complexity of the images in the COCO8-Pose dataset and the benefits of using mosaicing during the training process.\n\n## Citations and Acknowledgments\n\nIf you use the COCO dataset in your research or development work, please cite the following paper:\n\n```bibtex\n@misc{lin2015microsoft,\n title={Microsoft COCO: Common Objects in Context}, \n author={Tsung-Yi Lin and Michael Maire and Serge Belongie and Lubomir Bourdev and Ross Girshick and James Hays and Pietro Perona and Deva Ramanan and C. Lawrence Zitnick and Piotr Dollár},\n year={2015},\n eprint={1405.0312},\n archivePrefix={arXiv},\n primaryClass={cs.CV}\n}\n```\n\nWe would like to acknowledge the COCO Consortium for creating and maintaining this valuable resource for the computer vision community. For more information about the COCO dataset and its creators, visit the [COCO dataset website](https://cocodataset.org/#home)."
},
{
"path": "docs/datasets/pose/index.md",
"content": "---\ncomments: true\ndescription: Learn how to format your dataset for training YOLO models with Ultralytics YOLO format using our concise tutorial and example YAML files.\n---\n\n# Pose Estimation Datasets Overview\n\n## Supported Dataset Formats\n\n### Ultralytics YOLO format\n\n** Label Format **\n\nThe dataset format used for training YOLO segmentation models is as follows:\n\n1. One text file per image: Each image in the dataset has a corresponding text file with the same name as the image file and the \".txt\" extension.\n2. One row per object: Each row in the text file corresponds to one object instance in the image.\n3. Object information per row: Each row contains the following information about the object instance:\n - Object class index: An integer representing the class of the object (e.g., 0 for person, 1 for car, etc.).\n - Object center coordinates: The x and y coordinates of the center of the object, normalized to be between 0 and 1.\n - Object width and height: The width and height of the object, normalized to be between 0 and 1.\n - Object keypoint coordinates: The keypoints of the object, normalized to be between 0 and 1.\n\nHere is an example of the label format for pose estimation task:\n\nFormat with Dim = 2\n\n```\n ... \n```\n\nFormat with Dim = 3\n\n```\n \n```\n\nIn this format, `` is the index of the class for the object,` ` are coordinates of boudning box, and ` ... ` are the pixel coordinates of the keypoints. The coordinates are separated by spaces.\n\n** Dataset file format **\n\nThe Ultralytics framework uses a YAML file format to define the dataset and model configuration for training Detection Models. Here is an example of the YAML format used for defining a detection dataset:\n\n```yaml\ntrain: \nval: \n\nnc: \nnames: [, , ..., ]\n\n# Keypoints\nkpt_shape: [num_kpts, dim] # number of keypoints, number of dims (2 for x,y or 3 for x,y,visible)\nflip_idx: [n1, n2 ... , n(num_kpts)]\n\n```\n\nThe `train` and `val` fields specify the paths to the directories containing the training and validation images, respectively.\n\nThe `nc` field specifies the number of object classes in the dataset.\n\nThe `names` field is a list of the names of the object classes. The order of the names should match the order of the object class indices in the YOLO dataset files.\n\nNOTE: Either `nc` or `names` must be defined. Defining both are not mandatory\n\nAlternatively, you can directly define class names like this:\n\n```\nnames:\n 0: person\n 1: bicycle\n```\n\n(Optional) if the points are symmetric then need flip_idx, like left-right side of human or face.\nFor example let's say there're five keypoints of facial landmark: [left eye, right eye, nose, left point of mouth, right point of mouse], and the original index is [0, 1, 2, 3, 4], then flip_idx is [1, 0, 2, 4, 3].(just exchange the left-right index, i.e 0-1 and 3-4, and do not modify others like nose in this example)\n\n** Example **\n\n```yaml\ntrain: data/train/\nval: data/val/\n\nnc: 2\nnames: ['person', 'car']\n\n# Keypoints\nkpt_shape: [17, 3] # number of keypoints, number of dims (2 for x,y or 3 for x,y,visible)\nflip_idx: [0, 2, 1, 4, 3, 6, 5, 8, 7, 10, 9, 12, 11, 14, 13, 16, 15]\n```\n\n## Usage\n\n!!! example \"\"\n\n === \"Python\"\n \n ```python\n from ultralytics import YOLO\n \n # Load a model\n model = YOLO('yolov8n-pose.pt') # load a pretrained model (recommended for training)\n\n # Train the model\n model.train(data='coco128-pose.yaml', epochs=100, imgsz=640)\n ```\n === \"CLI\"\n \n ```bash\n # Start training from a pretrained *.pt model\n yolo detect train data=coco128-pose.yaml model=yolov8n-pose.pt epochs=100 imgsz=640\n ```\n\n## Supported Datasets\n\nTODO\n\n## Port or Convert label formats\n\n### COCO dataset format to YOLO format\n\n```\nfrom ultralytics.yolo.data.converter import convert_coco\n\nconvert_coco(labels_dir='../coco/annotations/', use_keypoints=True)\n```"
},
{
"path": "docs/datasets/segment/coco.md",
"content": "---\ncomments: true\n---\n\n# 🚧 Page Under Construction ⚒\n\nThis page is currently under construction!️ 👷Please check back later for updates. 😃🔜\n"
},
{
"path": "docs/datasets/segment/coco8-seg.md",
"content": "---\ncomments: true\ndescription: Test and debug segmentation models on small, versatile COCO8-Seg instance segmentation dataset, now available for use with YOLOv8 and Ultralytics HUB.\n---\n\n# COCO8-Seg Dataset\n\n## Introduction\n\n[Ultralytics](https://ultralytics.com) COCO8-Seg is a small, but versatile instance segmentation dataset composed of the\nfirst 8 images of the COCO train 2017 set, 4 for training and 4 for validation. This dataset is ideal for testing and\ndebugging segmentation models, or for experimenting with new detection approaches. With 8 images, it is small enough to\nbe easily manageable, yet diverse enough to test training pipelines for errors and act as a sanity check before training\nlarger datasets.\n\nThis dataset is intended for use with Ultralytics [HUB](https://hub.ultralytics.com)\nand [YOLOv8](https://github.com/ultralytics/ultralytics).\n\n## Dataset YAML\n\nA YAML (Yet Another Markup Language) file is used to define the dataset configuration. It contains information about the dataset's paths, classes, and other relevant information. In the case of the COCO8-Seg dataset, the `coco8-seg.yaml` file is maintained at [https://github.com/ultralytics/ultralytics/blob/main/ultralytics/datasets/coco8-seg.yaml](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/datasets/coco8-seg.yaml).\n\n!!! example \"ultralytics/datasets/coco8-seg.yaml\"\n\n ```yaml\n --8<-- \"ultralytics/datasets/coco8-seg.yaml\"\n ```\n\n## Usage\n\nTo train a YOLOv8n model on the COCO8-Seg dataset for 100 epochs with an image size of 640, you can use the following code snippets. For a comprehensive list of available arguments, refer to the model [Training](../../modes/train.md) page.\n\n!!! example \"Train Example\"\n\n === \"Python\"\n\n ```python\n from ultralytics import YOLO\n \n # Load a model\n model = YOLO('yolov8n.pt') # load a pretrained model (recommended for training)\n \n # Train the model\n model.train(data='coco8-seg.yaml', epochs=100, imgsz=640)\n ```\n\n === \"CLI\"\n\n ```bash\n # Start training from a pretrained *.pt model\n yolo detect train data=coco8-seg.yaml model=yolov8n.pt epochs=100 imgsz=640\n ```\n\n## Sample Images and Annotations\n\nHere are some examples of images from the COCO8-Seg dataset, along with their corresponding annotations:\n\n \n\n- **Mosaiced Image**: This image demonstrates a training batch composed of mosaiced dataset images. Mosaicing is a technique used during training that combines multiple images into a single image to increase the variety of objects and scenes within each training batch. This helps improve the model's ability to generalize to different object sizes, aspect ratios, and contexts.\n\nThe example showcases the variety and complexity of the images in the COCO8-Seg dataset and the benefits of using mosaicing during the training process.\n\n## Citations and Acknowledgments\n\nIf you use the COCO dataset in your research or development work, please cite the following paper:\n\n```bibtex\n@misc{lin2015microsoft,\n title={Microsoft COCO: Common Objects in Context}, \n author={Tsung-Yi Lin and Michael Maire and Serge Belongie and Lubomir Bourdev and Ross Girshick and James Hays and Pietro Perona and Deva Ramanan and C. Lawrence Zitnick and Piotr Dollár},\n year={2015},\n eprint={1405.0312},\n archivePrefix={arXiv},\n primaryClass={cs.CV}\n}\n```\n\nWe would like to acknowledge the COCO Consortium for creating and maintaining this valuable resource for the computer vision community. For more information about the COCO dataset and its creators, visit the [COCO dataset website](https://cocodataset.org/#home)."
},
{
"path": "docs/datasets/segment/index.md",
"content": "---\ncomments: true\ndescription: Learn about the Ultralytics YOLO dataset format for segmentation models. Use YAML to train Detection Models. Convert COCO to YOLO format using Python.\n---\n\n# Instance Segmentation Datasets Overview\n\n## Supported Dataset Formats\n\n### Ultralytics YOLO format\n\n** Label Format **\n\nThe dataset format used for training YOLO segmentation models is as follows:\n\n1. One text file per image: Each image in the dataset has a corresponding text file with the same name as the image file and the \".txt\" extension.\n2. One row per object: Each row in the text file corresponds to one object instance in the image.\n3. Object information per row: Each row contains the following information about the object instance:\n - Object class index: An integer representing the class of the object (e.g., 0 for person, 1 for car, etc.).\n - Object bounding coordinates: The bounding coordinates around the mask area, normalized to be between 0 and 1.\n\nThe format for a single row in the segmentation dataset file is as follows:\n\n```\n ... \n```\n\nIn this format, `` is the index of the class for the object, and ` ... ` are the bounding coordinates of the object's segmentation mask. The coordinates are separated by spaces.\n\nHere is an example of the YOLO dataset format for a single image with two object instances:\n\n```\n0 0.6812 0.48541 0.67 0.4875 0.67656 0.487 0.675 0.489 0.66\n1 0.5046 0.0 0.5015 0.004 0.4984 0.00416 0.4937 0.010 0.492 0.0104\n```\n\nNote: The length of each row does not have to be equal.\n\n** Dataset file format **\n\nThe Ultralytics framework uses a YAML file format to define the dataset and model configuration for training Detection Models. Here is an example of the YAML format used for defining a detection dataset:\n\n```yaml\ntrain: \nval: \n\nnc: \nnames: [ , , ..., ]\n\n```\n\nThe `train` and `val` fields specify the paths to the directories containing the training and validation images, respectively.\n\nThe `nc` field specifies the number of object classes in the dataset.\n\nThe `names` field is a list of the names of the object classes. The order of the names should match the order of the object class indices in the YOLO dataset files.\n\nNOTE: Either `nc` or `names` must be defined. Defining both are not mandatory.\n\nAlternatively, you can directly define class names like this:\n\n```yaml\nnames:\n 0: person\n 1: bicycle\n```\n\n** Example **\n\n```yaml\ntrain: data/train/\nval: data/val/\n\nnc: 2\nnames: [ 'person', 'car' ]\n```\n\n## Usage\n\n!!! example \"\"\n\n === \"Python\"\n \n ```python\n from ultralytics import YOLO\n \n # Load a model\n model = YOLO('yolov8n-seg.pt') # load a pretrained model (recommended for training)\n\n # Train the model\n model.train(data='coco128-seg.yaml', epochs=100, imgsz=640)\n ```\n === \"CLI\"\n \n ```bash\n # Start training from a pretrained *.pt model\n yolo detect train data=coco128-seg.yaml model=yolov8n-seg.pt epochs=100 imgsz=640\n ```\n\n## Supported Datasets\n\n## Port or Convert label formats\n\n### COCO dataset format to YOLO format\n\n```\nfrom ultralytics.yolo.data.converter import convert_coco\n\nconvert_coco(labels_dir='../coco/annotations/', use_segments=True)\n```\n\n## Auto-Annotation\n\nAuto-annotation is an essential feature that allows you to generate a segmentation dataset using a pre-trained detection model. It enables you to quickly and accurately annotate a large number of images without the need for manual labeling, saving time and effort.\n\n### Generate Segmentation Dataset Using a Detection Model\n\nTo auto-annotate your dataset using the Ultralytics framework, you can use the `auto_annotate` function as shown below:\n\n```python\nfrom ultralytics.yolo.data.annotator import auto_annotate\n\nauto_annotate(data=\"path/to/images\", det_model=\"yolov8x.pt\", sam_model='sam_b.pt')\n```\n\n| Argument | Type | Description | Default |\n|------------|---------------------|---------------------------------------------------------------------------------------------------------|--------------|\n| data | str | Path to a folder containing images to be annotated. | |\n| det_model | str, optional | Pre-trained YOLO detection model. Defaults to 'yolov8x.pt'. | 'yolov8x.pt' |\n| sam_model | str, optional | Pre-trained SAM segmentation model. Defaults to 'sam_b.pt'. | 'sam_b.pt' |\n| device | str, optional | Device to run the models on. Defaults to an empty string (CPU or GPU, if available). | |\n| output_dir | str, None, optional | Directory to save the annotated results. Defaults to a 'labels' folder in the same directory as 'data'. | None |\n\nThe `auto_annotate` function takes the path to your images, along with optional arguments for specifying the pre-trained detection and [SAM segmentation models](https://docs.ultralytics.com/models/sam), the device to run the models on, and the output directory for saving the annotated results.\n\nBy leveraging the power of pre-trained models, auto-annotation can significantly reduce the time and effort required for creating high-quality segmentation datasets. This feature is particularly useful for researchers and developers working with large image collections, as it allows them to focus on model development and evaluation rather than manual annotation."
},
{
"path": "docs/datasets/track/index.md",
"content": "---\ncomments: true\ndescription: Discover the datasets compatible with Multi-Object Detector. Train your trackers and make your detections more efficient with Ultralytics' YOLO.\n---\n\n# Multi-object Tracking Datasets Overview\n\n## Dataset Format (Coming Soon)\n\nMulti-Object Detector doesn't need standalone training and directly supports pre-trained detection, segmentation or Pose models.\nSupport for training trackers alone is coming soon\n\n## Usage\n\n!!! example \"\"\n\n === \"Python\"\n \n ```python\n from ultralytics import YOLO\n\n model = YOLO('yolov8n.pt')\n results = model.track(source=\"https://youtu.be/Zgi9g1ksQHc\", conf=0.3, iou=0.5, show=True) \n ```\n === \"CLI\"\n \n ```bash\n yolo track model=yolov8n.pt source=\"https://youtu.be/Zgi9g1ksQHc\" conf=0.3, iou=0.5 show\n ```"
},
{
"path": "docs/help/CLA.md",
"content": "---\ndescription: Individual Contributor License Agreement. Settle Intellectual Property issues for Contributions made to anything open source released by Ultralytics.\n---\n\n# Ultralytics Individual Contributor License Agreement\n\nThank you for your interest in contributing to open source software projects (“Projects”) made available by Ultralytics\nSE or its affiliates (“Ultralytics”). This Individual Contributor License Agreement (“Agreement”) sets out the terms\ngoverning any source code, object code, bug fixes, configuration changes, tools, specifications, documentation, data,\nmaterials, feedback, information or other works of authorship that you submit or have submitted, in any form and in any\nmanner, to Ultralytics in respect of any of the Projects (collectively “Contributions”). If you have any questions\nrespecting this Agreement, please contact hello@ultralytics.com.\n\nYou agree that the following terms apply to all of your past, present and future Contributions. Except for the licenses\ngranted in this Agreement, you retain all of your right, title and interest in and to your Contributions.\n\n**Copyright License.** You hereby grant, and agree to grant, to Ultralytics a non-exclusive, perpetual, irrevocable,\nworldwide, fully-paid, royalty-free, transferable copyright license to reproduce, prepare derivative works of, publicly\ndisplay, publicly perform, and distribute your Contributions and such derivative works, with the right to sublicense the\nforegoing rights through multiple tiers of sublicensees.\n\n**Patent License.** You hereby grant, and agree to grant, to Ultralytics a non-exclusive, perpetual, irrevocable,\nworldwide, fully-paid, royalty-free, transferable patent license to make, have made, use, offer to sell, sell,\nimport, and otherwise transfer your Contributions, where such license applies only to those patent claims\nlicensable by you that are necessarily infringed by your Contributions alone or by combination of your\nContributions with the Project to which such Contributions were submitted, with the right to sublicense the\nforegoing rights through multiple tiers of sublicensees.\n\n**Moral Rights.** To the fullest extent permitted under applicable law, you hereby waive, and agree not to\nassert, all of your “moral rights” in or relating to your Contributions for the benefit of Ultralytics, its assigns, and\ntheir respective direct and indirect sublicensees.\n\n**Third Party Content/Rights.** If your Contribution includes or is based on any source code, object code, bug\nfixes, configuration changes, tools, specifications, documentation, data, materials, feedback, information or\nother works of authorship that were not authored by you (“Third Party Content”) or if you are aware of any\nthird party intellectual property or proprietary rights associated with your Contribution (“Third Party Rights”),\nthen you agree to include with the submission of your Contribution full details respecting such Third Party\nContent and Third Party Rights, including, without limitation, identification of which aspects of your\nContribution contain Third Party Content or are associated with Third Party Rights, the owner/author of the\nThird Party Content and Third Party Rights, where you obtained the Third Party Content, and any applicable\nthird party license terms or restrictions respecting the Third Party Content and Third Party Rights. For greater\ncertainty, the foregoing obligations respecting the identification of Third Party Content and Third Party Rights\ndo not apply to any portion of a Project that is incorporated into your Contribution to that same Project.\n\n**Representations.** You represent that, other than the Third Party Content and Third Party Rights identified by\nyou in accordance with this Agreement, you are the sole author of your Contributions and are legally entitled\nto grant the foregoing licenses and waivers in respect of your Contributions. If your Contributions were\ncreated in the course of your employment with your past or present employer(s), you represent that such\nemployer(s) has authorized you to make your Contributions on behalf of such employer(s) or such employer\n(s) has waived all of their right, title or interest in or to your Contributions.\n\n**Disclaimer.** To the fullest extent permitted under applicable law, your Contributions are provided on an \"asis\"\nbasis, without any warranties or conditions, express or implied, including, without limitation, any implied\nwarranties or conditions of non-infringement, merchantability or fitness for a particular purpose. You are not\nrequired to provide support for your Contributions, except to the extent you desire to provide support.\n\n**No Obligation.** You acknowledge that Ultralytics is under no obligation to use or incorporate your Contributions\ninto any of the Projects. The decision to use or incorporate your Contributions into any of the Projects will be\nmade at the sole discretion of Ultralytics or its authorized delegates ..\n\n**Disputes.** This Agreement shall be governed by and construed in accordance with the laws of the State of\nNew York, United States of America, without giving effect to its principles or rules regarding conflicts of laws,\nother than such principles directing application of New York law. The parties hereby submit to venue in, and\njurisdiction of the courts located in New York, New York for purposes relating to this Agreement. In the event\nthat any of the provisions of this Agreement shall be held by a court or other tribunal of competent jurisdiction\nto be unenforceable, the remaining portions hereof shall remain in full force and effect.\n\n**Assignment.** You agree that Ultralytics may assign this Agreement, and all of its rights, obligations and licenses\nhereunder."
},
{
"path": "docs/help/FAQ.md",
"content": "---\ncomments: true\ndescription: 'Get quick answers to common Ultralytics YOLO questions: Hardware requirements, fine-tuning, conversion, real-time detection, and accuracy tips.'\n---\n\n# Ultralytics YOLO Frequently Asked Questions (FAQ)\n\nThis FAQ section addresses some common questions and issues users might encounter while working with Ultralytics YOLO repositories.\n\n## 1. What are the hardware requirements for running Ultralytics YOLO?\n\nUltralytics YOLO can be run on a variety of hardware configurations, including CPUs, GPUs, and even some edge devices. However, for optimal performance and faster training and inference, we recommend using a GPU with a minimum of 8GB of memory. NVIDIA GPUs with CUDA support are ideal for this purpose.\n\n## 2. How do I fine-tune a pre-trained YOLO model on my custom dataset?\n\nTo fine-tune a pre-trained YOLO model on your custom dataset, you'll need to create a dataset configuration file (YAML) that defines the dataset's properties, such as the path to the images, the number of classes, and class names. Next, you'll need to modify the model configuration file to match the number of classes in your dataset. Finally, use the `train.py` script to start the training process with your custom dataset and the pre-trained model. You can find a detailed guide on fine-tuning YOLO in the Ultralytics documentation.\n\n## 3. How do I convert a YOLO model to ONNX or TensorFlow format?\n\nUltralytics provides built-in support for converting YOLO models to ONNX format. You can use the `export.py` script to convert a saved model to ONNX format. If you need to convert the model to TensorFlow format, you can use the ONNX model as an intermediary and then use the ONNX-TensorFlow converter to convert the ONNX model to TensorFlow format.\n\n## 4. Can I use Ultralytics YOLO for real-time object detection?\n\nYes, Ultralytics YOLO is designed to be efficient and fast, making it suitable for real-time object detection tasks. The actual performance will depend on your hardware configuration and the complexity of the model. Using a GPU and optimizing the model for your specific use case can help achieve real-time performance.\n\n## 5. How can I improve the accuracy of my YOLO model?\n\nImproving the accuracy of a YOLO model may involve several strategies, such as:\n\n- Fine-tuning the model on more annotated data\n- Data augmentation to increase the variety of training samples\n- Using a larger or more complex model architecture\n- Adjusting the learning rate, batch size, and other hyperparameters\n- Using techniques like transfer learning or knowledge distillation\n\nRemember that there's often a trade-off between accuracy and inference speed, so finding the right balance is crucial for your specific application.\n\nIf you have any more questions or need assistance, don't hesitate to consult the Ultralytics documentation or reach out to the community through GitHub Issues or the official discussion forum."
},
{
"path": "docs/help/code_of_conduct.md",
"content": "---\ncomments: true\ndescription: Read the Ultralytics Contributor Covenant Code of Conduct. Learn ways to create a welcoming community & consequences for inappropriate conduct.\n---\n\n# Ultralytics Contributor Covenant Code of Conduct\n\n## Our Pledge\n\nWe as members, contributors, and leaders pledge to make participation in our\ncommunity a harassment-free experience for everyone, regardless of age, body\nsize, visible or invisible disability, ethnicity, sex characteristics, gender\nidentity and expression, level of experience, education, socio-economic status,\nnationality, personal appearance, race, religion, or sexual identity\nand orientation.\n\nWe pledge to act and interact in ways that contribute to an open, welcoming,\ndiverse, inclusive, and healthy community.\n\n## Our Standards\n\nExamples of behavior that contributes to a positive environment for our\ncommunity include:\n\n- Demonstrating empathy and kindness toward other people\n- Being respectful of differing opinions, viewpoints, and experiences\n- Giving and gracefully accepting constructive feedback\n- Accepting responsibility and apologizing to those affected by our mistakes,\n and learning from the experience\n- Focusing on what is best not just for us as individuals, but for the\n overall community\n\nExamples of unacceptable behavior include:\n\n- The use of sexualized language or imagery, and sexual attention or\n advances of any kind\n- Trolling, insulting or derogatory comments, and personal or political attacks\n- Public or private harassment\n- Publishing others' private information, such as a physical or email\n address, without their explicit permission\n- Other conduct which could reasonably be considered inappropriate in a\n professional setting\n\n## Enforcement Responsibilities\n\nCommunity leaders are responsible for clarifying and enforcing our standards of\nacceptable behavior and will take appropriate and fair corrective action in\nresponse to any behavior that they deem inappropriate, threatening, offensive,\nor harmful.\n\nCommunity leaders have the right and responsibility to remove, edit, or reject\ncomments, commits, code, wiki edits, issues, and other contributions that are\nnot aligned to this Code of Conduct, and will communicate reasons for moderation\ndecisions when appropriate.\n\n## Scope\n\nThis Code of Conduct applies within all community spaces, and also applies when\nan individual is officially representing the community in public spaces.\nExamples of representing our community include using an official e-mail address,\nposting via an official social media account, or acting as an appointed\nrepresentative at an online or offline event.\n\n## Enforcement\n\nInstances of abusive, harassing, or otherwise unacceptable behavior may be\nreported to the community leaders responsible for enforcement at\nhello@ultralytics.com.\nAll complaints will be reviewed and investigated promptly and fairly.\n\nAll community leaders are obligated to respect the privacy and security of the\nreporter of any incident.\n\n## Enforcement Guidelines\n\nCommunity leaders will follow these Community Impact Guidelines in determining\nthe consequences for any action they deem in violation of this Code of Conduct:\n\n### 1. Correction\n\n**Community Impact**: Use of inappropriate language or other behavior deemed\nunprofessional or unwelcome in the community.\n\n**Consequence**: A private, written warning from community leaders, providing\nclarity around the nature of the violation and an explanation of why the\nbehavior was inappropriate. A public apology may be requested.\n\n### 2. Warning\n\n**Community Impact**: A violation through a single incident or series\nof actions.\n\n**Consequence**: A warning with consequences for continued behavior. No\ninteraction with the people involved, including unsolicited interaction with\nthose enforcing the Code of Conduct, for a specified period of time. This\nincludes avoiding interactions in community spaces as well as external channels\nlike social media. Violating these terms may lead to a temporary or\npermanent ban.\n\n### 3. Temporary Ban\n\n**Community Impact**: A serious violation of community standards, including\nsustained inappropriate behavior.\n\n**Consequence**: A temporary ban from any sort of interaction or public\ncommunication with the community for a specified period of time. No public or\nprivate interaction with the people involved, including unsolicited interaction\nwith those enforcing the Code of Conduct, is allowed during this period.\nViolating these terms may lead to a permanent ban.\n\n### 4. Permanent Ban\n\n**Community Impact**: Demonstrating a pattern of violation of community\nstandards, including sustained inappropriate behavior, harassment of an\nindividual, or aggression toward or disparagement of classes of individuals.\n\n**Consequence**: A permanent ban from any sort of public interaction within\nthe community.\n\n## Attribution\n\nThis Code of Conduct is adapted from the [Contributor Covenant][homepage],\nversion 2.0, available at\nhttps://www.contributor-covenant.org/version/2/0/code_of_conduct.html.\n\nCommunity Impact Guidelines were inspired by [Mozilla's code of conduct\nenforcement ladder](https://github.com/mozilla/diversity).\n\nFor answers to common questions about this code of conduct, see the FAQ at\nhttps://www.contributor-covenant.org/faq. Translations are available at\nhttps://www.contributor-covenant.org/translations.\n\n[homepage]: https://www.contributor-covenant.org"
},
{
"path": "docs/help/contributing.md",
"content": "---\ncomments: true\ndescription: Learn how to contribute to Ultralytics Open-Source YOLO Repositories with contributions guidelines, pull requests requirements, and GitHub CI tests.\n---\n\n# Contributing to Ultralytics Open-Source YOLO Repositories\n\nFirst of all, thank you for your interest in contributing to Ultralytics open-source YOLO repositories! Your contributions will help improve the project and benefit the community. This document provides guidelines and best practices for contributing to Ultralytics YOLO repositories.\n\n## Table of Contents\n\n- [Code of Conduct](#code-of-conduct)\n- [Pull Requests](#pull-requests)\n - [CLA Signing](#cla-signing)\n - [Google-Style Docstrings](#google-style-docstrings)\n - [GitHub Actions CI Tests](#github-actions-ci-tests)\n- [Bug Reports](#bug-reports)\n - [Minimum Reproducible Example](#minimum-reproducible-example)\n- [License and Copyright](#license-and-copyright)\n\n## Code of Conduct\n\nAll contributors are expected to adhere to the [Code of Conduct](code_of_conduct.md) to ensure a welcoming and inclusive environment for everyone.\n\n## Pull Requests\n\nWe welcome contributions in the form of pull requests. To make the review process smoother, please follow these guidelines:\n\n1. **Fork the repository**: Fork the Ultralytics YOLO repository to your own GitHub account.\n\n2. **Create a branch**: Create a new branch in your forked repository with a descriptive name for your changes.\n\n3. **Make your changes**: Make the changes you want to contribute. Ensure that your changes follow the coding style of the project and do not introduce new errors or warnings.\n\n4. **Test your changes**: Test your changes locally to ensure that they work as expected and do not introduce new issues.\n\n5. **Commit your changes**: Commit your changes with a descriptive commit message. Make sure to include any relevant issue numbers in your commit message.\n\n6. **Create a pull request**: Create a pull request from your forked repository to the main Ultralytics YOLO repository. In the pull request description, provide a clear explanation of your changes and how they improve the project.\n\n### CLA Signing\n\nBefore we can accept your pull request, you need to sign a [Contributor License Agreement (CLA)](CLA.md). This is a legal document stating that you agree to the terms of contributing to the Ultralytics YOLO repositories. The CLA ensures that your contributions are properly licensed and that the project can continue to be distributed under the AGPL-3.0 license.\n\nTo sign the CLA, follow the instructions provided by the CLA bot after you submit your PR.\n\n### Google-Style Docstrings\n\nWhen adding new functions or classes, please include a [Google-style docstring](https://google.github.io/styleguide/pyguide.html) to provide clear and concise documentation for other developers. This will help ensure that your contributions are easy to understand and maintain.\n\nExample Google-style docstring:\n\n```python\ndef example_function(arg1: int, arg2: str) -> bool:\n \"\"\"Example function that demonstrates Google-style docstrings.\n\n Args:\n arg1 (int): The first argument.\n arg2 (str): The second argument.\n\n Returns:\n bool: True if successful, False otherwise.\n\n Raises:\n ValueError: If `arg1` is negative or `arg2` is empty.\n \"\"\"\n if arg1 < 0 or not arg2:\n raise ValueError(\"Invalid input values\")\n return True\n```\n\n### GitHub Actions CI Tests\n\nBefore your pull request can be merged, all GitHub Actions Continuous Integration (CI) tests must pass. These tests include linting, unit tests, and other checks to ensure that your changes meet the quality standards of the project. Make sure to review the output of the GitHub Actions and fix any issues"
},
{
"path": "docs/help/index.md",
"content": "---\ncomments: true\ndescription: Get comprehensive resources for Ultralytics YOLO repositories. Find guides, FAQs, MRE creation, CLA & more. Join the supportive community now!\n---\n\nWelcome to the Ultralytics Help page! We are committed to providing you with comprehensive resources to make your experience with Ultralytics YOLO repositories as smooth and enjoyable as possible. On this page, you'll find essential links to guides and documents that will help you navigate through common tasks and address any questions you might have while using our repositories.\n\n- [Frequently Asked Questions (FAQ)](FAQ.md): Find answers to common questions and issues faced by users and contributors of Ultralytics YOLO repositories.\n- [Contributing Guide](contributing.md): Learn the best practices for submitting pull requests, reporting bugs, and contributing to the development of our repositories.\n- [Contributor License Agreement (CLA)](CLA.md): Familiarize yourself with our CLA to understand the terms and conditions for contributing to Ultralytics projects.\n- [Minimum Reproducible Example (MRE) Guide](minimum_reproducible_example.md): Understand how to create an MRE when submitting bug reports to ensure that our team can quickly and efficiently address the issue.\n- [Code of Conduct](code_of_conduct.md): Learn about our community guidelines and expectations to ensure a welcoming and inclusive environment for all participants.\n- [Security Policy](../SECURITY.md): Understand our security practices and how to report security vulnerabilities responsibly.\n\nWe highly recommend going through these guides to make the most of your collaboration with the Ultralytics community. Our goal is to maintain a welcoming and supportive environment for all users and contributors. If you need further assistance, don't hesitate to reach out to us through GitHub Issues or the official discussion forum. Happy coding!"
},
{
"path": "docs/help/minimum_reproducible_example.md",
"content": "---\ncomments: true\ndescription: Learn how to create a Minimum Reproducible Example (MRE) for Ultralytics YOLO bug reports to help maintainers and contributors understand your issue better.\n---\n\n# Creating a Minimum Reproducible Example for Bug Reports in Ultralytics YOLO Repositories\n\nWhen submitting a bug report for Ultralytics YOLO repositories, it's essential to provide a [minimum reproducible example](https://stackoverflow.com/help/minimal-reproducible-example) (MRE). An MRE is a small, self-contained piece of code that demonstrates the problem you're experiencing. Providing an MRE helps maintainers and contributors understand the issue and work on a fix more efficiently. This guide explains how to create an MRE when submitting bug reports to Ultralytics YOLO repositories.\n\n## 1. Isolate the Problem\n\nThe first step in creating an MRE is to isolate the problem. This means removing any unnecessary code or dependencies that are not directly related to the issue. Focus on the specific part of the code that is causing the problem and remove any irrelevant code.\n\n## 2. Use Public Models and Datasets\n\nWhen creating an MRE, use publicly available models and datasets to reproduce the issue. For example, use the 'yolov8n.pt' model and the 'coco8.yaml' dataset. This ensures that the maintainers and contributors can easily run your example and investigate the problem without needing access to proprietary data or custom models.\n\n## 3. Include All Necessary Dependencies\n\nMake sure to include all the necessary dependencies in your MRE. If your code relies on external libraries, specify the required packages and their versions. Ideally, provide a `requirements.txt` file or list the dependencies in your bug report.\n\n## 4. Write a Clear Description of the Issue\n\nProvide a clear and concise description of the issue you're experiencing. Explain the expected behavior and the actual behavior you're encountering. If applicable, include any relevant error messages or logs.\n\n## 5. Format Your Code Properly\n\nWhen submitting an MRE, format your code properly using code blocks in the issue description. This makes it easier for others to read and understand your code. In GitHub, you can create a code block by wrapping your code with triple backticks (\\```) and specifying the language:\n\n
\n\n- **Mosaiced Image**: This image demonstrates a training batch composed of mosaiced dataset images. Mosaicing is a technique used during training that combines multiple images into a single image to increase the variety of objects and scenes within each training batch. This helps improve the model's ability to generalize to different object sizes, aspect ratios, and contexts.\n\nThe example showcases the variety and complexity of the images in the COCO8-Seg dataset and the benefits of using mosaicing during the training process.\n\n## Citations and Acknowledgments\n\nIf you use the COCO dataset in your research or development work, please cite the following paper:\n\n```bibtex\n@misc{lin2015microsoft,\n title={Microsoft COCO: Common Objects in Context}, \n author={Tsung-Yi Lin and Michael Maire and Serge Belongie and Lubomir Bourdev and Ross Girshick and James Hays and Pietro Perona and Deva Ramanan and C. Lawrence Zitnick and Piotr Dollár},\n year={2015},\n eprint={1405.0312},\n archivePrefix={arXiv},\n primaryClass={cs.CV}\n}\n```\n\nWe would like to acknowledge the COCO Consortium for creating and maintaining this valuable resource for the computer vision community. For more information about the COCO dataset and its creators, visit the [COCO dataset website](https://cocodataset.org/#home)."
},
{
"path": "docs/datasets/segment/index.md",
"content": "---\ncomments: true\ndescription: Learn about the Ultralytics YOLO dataset format for segmentation models. Use YAML to train Detection Models. Convert COCO to YOLO format using Python.\n---\n\n# Instance Segmentation Datasets Overview\n\n## Supported Dataset Formats\n\n### Ultralytics YOLO format\n\n** Label Format **\n\nThe dataset format used for training YOLO segmentation models is as follows:\n\n1. One text file per image: Each image in the dataset has a corresponding text file with the same name as the image file and the \".txt\" extension.\n2. One row per object: Each row in the text file corresponds to one object instance in the image.\n3. Object information per row: Each row contains the following information about the object instance:\n - Object class index: An integer representing the class of the object (e.g., 0 for person, 1 for car, etc.).\n - Object bounding coordinates: The bounding coordinates around the mask area, normalized to be between 0 and 1.\n\nThe format for a single row in the segmentation dataset file is as follows:\n\n```\n ... \n```\n\nIn this format, `` is the index of the class for the object, and ` ... ` are the bounding coordinates of the object's segmentation mask. The coordinates are separated by spaces.\n\nHere is an example of the YOLO dataset format for a single image with two object instances:\n\n```\n0 0.6812 0.48541 0.67 0.4875 0.67656 0.487 0.675 0.489 0.66\n1 0.5046 0.0 0.5015 0.004 0.4984 0.00416 0.4937 0.010 0.492 0.0104\n```\n\nNote: The length of each row does not have to be equal.\n\n** Dataset file format **\n\nThe Ultralytics framework uses a YAML file format to define the dataset and model configuration for training Detection Models. Here is an example of the YAML format used for defining a detection dataset:\n\n```yaml\ntrain: \nval: \n\nnc: \nnames: [ , , ..., ]\n\n```\n\nThe `train` and `val` fields specify the paths to the directories containing the training and validation images, respectively.\n\nThe `nc` field specifies the number of object classes in the dataset.\n\nThe `names` field is a list of the names of the object classes. The order of the names should match the order of the object class indices in the YOLO dataset files.\n\nNOTE: Either `nc` or `names` must be defined. Defining both are not mandatory.\n\nAlternatively, you can directly define class names like this:\n\n```yaml\nnames:\n 0: person\n 1: bicycle\n```\n\n** Example **\n\n```yaml\ntrain: data/train/\nval: data/val/\n\nnc: 2\nnames: [ 'person', 'car' ]\n```\n\n## Usage\n\n!!! example \"\"\n\n === \"Python\"\n \n ```python\n from ultralytics import YOLO\n \n # Load a model\n model = YOLO('yolov8n-seg.pt') # load a pretrained model (recommended for training)\n\n # Train the model\n model.train(data='coco128-seg.yaml', epochs=100, imgsz=640)\n ```\n === \"CLI\"\n \n ```bash\n # Start training from a pretrained *.pt model\n yolo detect train data=coco128-seg.yaml model=yolov8n-seg.pt epochs=100 imgsz=640\n ```\n\n## Supported Datasets\n\n## Port or Convert label formats\n\n### COCO dataset format to YOLO format\n\n```\nfrom ultralytics.yolo.data.converter import convert_coco\n\nconvert_coco(labels_dir='../coco/annotations/', use_segments=True)\n```\n\n## Auto-Annotation\n\nAuto-annotation is an essential feature that allows you to generate a segmentation dataset using a pre-trained detection model. It enables you to quickly and accurately annotate a large number of images without the need for manual labeling, saving time and effort.\n\n### Generate Segmentation Dataset Using a Detection Model\n\nTo auto-annotate your dataset using the Ultralytics framework, you can use the `auto_annotate` function as shown below:\n\n```python\nfrom ultralytics.yolo.data.annotator import auto_annotate\n\nauto_annotate(data=\"path/to/images\", det_model=\"yolov8x.pt\", sam_model='sam_b.pt')\n```\n\n| Argument | Type | Description | Default |\n|------------|---------------------|---------------------------------------------------------------------------------------------------------|--------------|\n| data | str | Path to a folder containing images to be annotated. | |\n| det_model | str, optional | Pre-trained YOLO detection model. Defaults to 'yolov8x.pt'. | 'yolov8x.pt' |\n| sam_model | str, optional | Pre-trained SAM segmentation model. Defaults to 'sam_b.pt'. | 'sam_b.pt' |\n| device | str, optional | Device to run the models on. Defaults to an empty string (CPU or GPU, if available). | |\n| output_dir | str, None, optional | Directory to save the annotated results. Defaults to a 'labels' folder in the same directory as 'data'. | None |\n\nThe `auto_annotate` function takes the path to your images, along with optional arguments for specifying the pre-trained detection and [SAM segmentation models](https://docs.ultralytics.com/models/sam), the device to run the models on, and the output directory for saving the annotated results.\n\nBy leveraging the power of pre-trained models, auto-annotation can significantly reduce the time and effort required for creating high-quality segmentation datasets. This feature is particularly useful for researchers and developers working with large image collections, as it allows them to focus on model development and evaluation rather than manual annotation."
},
{
"path": "docs/datasets/track/index.md",
"content": "---\ncomments: true\ndescription: Discover the datasets compatible with Multi-Object Detector. Train your trackers and make your detections more efficient with Ultralytics' YOLO.\n---\n\n# Multi-object Tracking Datasets Overview\n\n## Dataset Format (Coming Soon)\n\nMulti-Object Detector doesn't need standalone training and directly supports pre-trained detection, segmentation or Pose models.\nSupport for training trackers alone is coming soon\n\n## Usage\n\n!!! example \"\"\n\n === \"Python\"\n \n ```python\n from ultralytics import YOLO\n\n model = YOLO('yolov8n.pt')\n results = model.track(source=\"https://youtu.be/Zgi9g1ksQHc\", conf=0.3, iou=0.5, show=True) \n ```\n === \"CLI\"\n \n ```bash\n yolo track model=yolov8n.pt source=\"https://youtu.be/Zgi9g1ksQHc\" conf=0.3, iou=0.5 show\n ```"
},
{
"path": "docs/help/CLA.md",
"content": "---\ndescription: Individual Contributor License Agreement. Settle Intellectual Property issues for Contributions made to anything open source released by Ultralytics.\n---\n\n# Ultralytics Individual Contributor License Agreement\n\nThank you for your interest in contributing to open source software projects (“Projects”) made available by Ultralytics\nSE or its affiliates (“Ultralytics”). This Individual Contributor License Agreement (“Agreement”) sets out the terms\ngoverning any source code, object code, bug fixes, configuration changes, tools, specifications, documentation, data,\nmaterials, feedback, information or other works of authorship that you submit or have submitted, in any form and in any\nmanner, to Ultralytics in respect of any of the Projects (collectively “Contributions”). If you have any questions\nrespecting this Agreement, please contact hello@ultralytics.com.\n\nYou agree that the following terms apply to all of your past, present and future Contributions. Except for the licenses\ngranted in this Agreement, you retain all of your right, title and interest in and to your Contributions.\n\n**Copyright License.** You hereby grant, and agree to grant, to Ultralytics a non-exclusive, perpetual, irrevocable,\nworldwide, fully-paid, royalty-free, transferable copyright license to reproduce, prepare derivative works of, publicly\ndisplay, publicly perform, and distribute your Contributions and such derivative works, with the right to sublicense the\nforegoing rights through multiple tiers of sublicensees.\n\n**Patent License.** You hereby grant, and agree to grant, to Ultralytics a non-exclusive, perpetual, irrevocable,\nworldwide, fully-paid, royalty-free, transferable patent license to make, have made, use, offer to sell, sell,\nimport, and otherwise transfer your Contributions, where such license applies only to those patent claims\nlicensable by you that are necessarily infringed by your Contributions alone or by combination of your\nContributions with the Project to which such Contributions were submitted, with the right to sublicense the\nforegoing rights through multiple tiers of sublicensees.\n\n**Moral Rights.** To the fullest extent permitted under applicable law, you hereby waive, and agree not to\nassert, all of your “moral rights” in or relating to your Contributions for the benefit of Ultralytics, its assigns, and\ntheir respective direct and indirect sublicensees.\n\n**Third Party Content/Rights.** If your Contribution includes or is based on any source code, object code, bug\nfixes, configuration changes, tools, specifications, documentation, data, materials, feedback, information or\nother works of authorship that were not authored by you (“Third Party Content”) or if you are aware of any\nthird party intellectual property or proprietary rights associated with your Contribution (“Third Party Rights”),\nthen you agree to include with the submission of your Contribution full details respecting such Third Party\nContent and Third Party Rights, including, without limitation, identification of which aspects of your\nContribution contain Third Party Content or are associated with Third Party Rights, the owner/author of the\nThird Party Content and Third Party Rights, where you obtained the Third Party Content, and any applicable\nthird party license terms or restrictions respecting the Third Party Content and Third Party Rights. For greater\ncertainty, the foregoing obligations respecting the identification of Third Party Content and Third Party Rights\ndo not apply to any portion of a Project that is incorporated into your Contribution to that same Project.\n\n**Representations.** You represent that, other than the Third Party Content and Third Party Rights identified by\nyou in accordance with this Agreement, you are the sole author of your Contributions and are legally entitled\nto grant the foregoing licenses and waivers in respect of your Contributions. If your Contributions were\ncreated in the course of your employment with your past or present employer(s), you represent that such\nemployer(s) has authorized you to make your Contributions on behalf of such employer(s) or such employer\n(s) has waived all of their right, title or interest in or to your Contributions.\n\n**Disclaimer.** To the fullest extent permitted under applicable law, your Contributions are provided on an \"asis\"\nbasis, without any warranties or conditions, express or implied, including, without limitation, any implied\nwarranties or conditions of non-infringement, merchantability or fitness for a particular purpose. You are not\nrequired to provide support for your Contributions, except to the extent you desire to provide support.\n\n**No Obligation.** You acknowledge that Ultralytics is under no obligation to use or incorporate your Contributions\ninto any of the Projects. The decision to use or incorporate your Contributions into any of the Projects will be\nmade at the sole discretion of Ultralytics or its authorized delegates ..\n\n**Disputes.** This Agreement shall be governed by and construed in accordance with the laws of the State of\nNew York, United States of America, without giving effect to its principles or rules regarding conflicts of laws,\nother than such principles directing application of New York law. The parties hereby submit to venue in, and\njurisdiction of the courts located in New York, New York for purposes relating to this Agreement. In the event\nthat any of the provisions of this Agreement shall be held by a court or other tribunal of competent jurisdiction\nto be unenforceable, the remaining portions hereof shall remain in full force and effect.\n\n**Assignment.** You agree that Ultralytics may assign this Agreement, and all of its rights, obligations and licenses\nhereunder."
},
{
"path": "docs/help/FAQ.md",
"content": "---\ncomments: true\ndescription: 'Get quick answers to common Ultralytics YOLO questions: Hardware requirements, fine-tuning, conversion, real-time detection, and accuracy tips.'\n---\n\n# Ultralytics YOLO Frequently Asked Questions (FAQ)\n\nThis FAQ section addresses some common questions and issues users might encounter while working with Ultralytics YOLO repositories.\n\n## 1. What are the hardware requirements for running Ultralytics YOLO?\n\nUltralytics YOLO can be run on a variety of hardware configurations, including CPUs, GPUs, and even some edge devices. However, for optimal performance and faster training and inference, we recommend using a GPU with a minimum of 8GB of memory. NVIDIA GPUs with CUDA support are ideal for this purpose.\n\n## 2. How do I fine-tune a pre-trained YOLO model on my custom dataset?\n\nTo fine-tune a pre-trained YOLO model on your custom dataset, you'll need to create a dataset configuration file (YAML) that defines the dataset's properties, such as the path to the images, the number of classes, and class names. Next, you'll need to modify the model configuration file to match the number of classes in your dataset. Finally, use the `train.py` script to start the training process with your custom dataset and the pre-trained model. You can find a detailed guide on fine-tuning YOLO in the Ultralytics documentation.\n\n## 3. How do I convert a YOLO model to ONNX or TensorFlow format?\n\nUltralytics provides built-in support for converting YOLO models to ONNX format. You can use the `export.py` script to convert a saved model to ONNX format. If you need to convert the model to TensorFlow format, you can use the ONNX model as an intermediary and then use the ONNX-TensorFlow converter to convert the ONNX model to TensorFlow format.\n\n## 4. Can I use Ultralytics YOLO for real-time object detection?\n\nYes, Ultralytics YOLO is designed to be efficient and fast, making it suitable for real-time object detection tasks. The actual performance will depend on your hardware configuration and the complexity of the model. Using a GPU and optimizing the model for your specific use case can help achieve real-time performance.\n\n## 5. How can I improve the accuracy of my YOLO model?\n\nImproving the accuracy of a YOLO model may involve several strategies, such as:\n\n- Fine-tuning the model on more annotated data\n- Data augmentation to increase the variety of training samples\n- Using a larger or more complex model architecture\n- Adjusting the learning rate, batch size, and other hyperparameters\n- Using techniques like transfer learning or knowledge distillation\n\nRemember that there's often a trade-off between accuracy and inference speed, so finding the right balance is crucial for your specific application.\n\nIf you have any more questions or need assistance, don't hesitate to consult the Ultralytics documentation or reach out to the community through GitHub Issues or the official discussion forum."
},
{
"path": "docs/help/code_of_conduct.md",
"content": "---\ncomments: true\ndescription: Read the Ultralytics Contributor Covenant Code of Conduct. Learn ways to create a welcoming community & consequences for inappropriate conduct.\n---\n\n# Ultralytics Contributor Covenant Code of Conduct\n\n## Our Pledge\n\nWe as members, contributors, and leaders pledge to make participation in our\ncommunity a harassment-free experience for everyone, regardless of age, body\nsize, visible or invisible disability, ethnicity, sex characteristics, gender\nidentity and expression, level of experience, education, socio-economic status,\nnationality, personal appearance, race, religion, or sexual identity\nand orientation.\n\nWe pledge to act and interact in ways that contribute to an open, welcoming,\ndiverse, inclusive, and healthy community.\n\n## Our Standards\n\nExamples of behavior that contributes to a positive environment for our\ncommunity include:\n\n- Demonstrating empathy and kindness toward other people\n- Being respectful of differing opinions, viewpoints, and experiences\n- Giving and gracefully accepting constructive feedback\n- Accepting responsibility and apologizing to those affected by our mistakes,\n and learning from the experience\n- Focusing on what is best not just for us as individuals, but for the\n overall community\n\nExamples of unacceptable behavior include:\n\n- The use of sexualized language or imagery, and sexual attention or\n advances of any kind\n- Trolling, insulting or derogatory comments, and personal or political attacks\n- Public or private harassment\n- Publishing others' private information, such as a physical or email\n address, without their explicit permission\n- Other conduct which could reasonably be considered inappropriate in a\n professional setting\n\n## Enforcement Responsibilities\n\nCommunity leaders are responsible for clarifying and enforcing our standards of\nacceptable behavior and will take appropriate and fair corrective action in\nresponse to any behavior that they deem inappropriate, threatening, offensive,\nor harmful.\n\nCommunity leaders have the right and responsibility to remove, edit, or reject\ncomments, commits, code, wiki edits, issues, and other contributions that are\nnot aligned to this Code of Conduct, and will communicate reasons for moderation\ndecisions when appropriate.\n\n## Scope\n\nThis Code of Conduct applies within all community spaces, and also applies when\nan individual is officially representing the community in public spaces.\nExamples of representing our community include using an official e-mail address,\nposting via an official social media account, or acting as an appointed\nrepresentative at an online or offline event.\n\n## Enforcement\n\nInstances of abusive, harassing, or otherwise unacceptable behavior may be\nreported to the community leaders responsible for enforcement at\nhello@ultralytics.com.\nAll complaints will be reviewed and investigated promptly and fairly.\n\nAll community leaders are obligated to respect the privacy and security of the\nreporter of any incident.\n\n## Enforcement Guidelines\n\nCommunity leaders will follow these Community Impact Guidelines in determining\nthe consequences for any action they deem in violation of this Code of Conduct:\n\n### 1. Correction\n\n**Community Impact**: Use of inappropriate language or other behavior deemed\nunprofessional or unwelcome in the community.\n\n**Consequence**: A private, written warning from community leaders, providing\nclarity around the nature of the violation and an explanation of why the\nbehavior was inappropriate. A public apology may be requested.\n\n### 2. Warning\n\n**Community Impact**: A violation through a single incident or series\nof actions.\n\n**Consequence**: A warning with consequences for continued behavior. No\ninteraction with the people involved, including unsolicited interaction with\nthose enforcing the Code of Conduct, for a specified period of time. This\nincludes avoiding interactions in community spaces as well as external channels\nlike social media. Violating these terms may lead to a temporary or\npermanent ban.\n\n### 3. Temporary Ban\n\n**Community Impact**: A serious violation of community standards, including\nsustained inappropriate behavior.\n\n**Consequence**: A temporary ban from any sort of interaction or public\ncommunication with the community for a specified period of time. No public or\nprivate interaction with the people involved, including unsolicited interaction\nwith those enforcing the Code of Conduct, is allowed during this period.\nViolating these terms may lead to a permanent ban.\n\n### 4. Permanent Ban\n\n**Community Impact**: Demonstrating a pattern of violation of community\nstandards, including sustained inappropriate behavior, harassment of an\nindividual, or aggression toward or disparagement of classes of individuals.\n\n**Consequence**: A permanent ban from any sort of public interaction within\nthe community.\n\n## Attribution\n\nThis Code of Conduct is adapted from the [Contributor Covenant][homepage],\nversion 2.0, available at\nhttps://www.contributor-covenant.org/version/2/0/code_of_conduct.html.\n\nCommunity Impact Guidelines were inspired by [Mozilla's code of conduct\nenforcement ladder](https://github.com/mozilla/diversity).\n\nFor answers to common questions about this code of conduct, see the FAQ at\nhttps://www.contributor-covenant.org/faq. Translations are available at\nhttps://www.contributor-covenant.org/translations.\n\n[homepage]: https://www.contributor-covenant.org"
},
{
"path": "docs/help/contributing.md",
"content": "---\ncomments: true\ndescription: Learn how to contribute to Ultralytics Open-Source YOLO Repositories with contributions guidelines, pull requests requirements, and GitHub CI tests.\n---\n\n# Contributing to Ultralytics Open-Source YOLO Repositories\n\nFirst of all, thank you for your interest in contributing to Ultralytics open-source YOLO repositories! Your contributions will help improve the project and benefit the community. This document provides guidelines and best practices for contributing to Ultralytics YOLO repositories.\n\n## Table of Contents\n\n- [Code of Conduct](#code-of-conduct)\n- [Pull Requests](#pull-requests)\n - [CLA Signing](#cla-signing)\n - [Google-Style Docstrings](#google-style-docstrings)\n - [GitHub Actions CI Tests](#github-actions-ci-tests)\n- [Bug Reports](#bug-reports)\n - [Minimum Reproducible Example](#minimum-reproducible-example)\n- [License and Copyright](#license-and-copyright)\n\n## Code of Conduct\n\nAll contributors are expected to adhere to the [Code of Conduct](code_of_conduct.md) to ensure a welcoming and inclusive environment for everyone.\n\n## Pull Requests\n\nWe welcome contributions in the form of pull requests. To make the review process smoother, please follow these guidelines:\n\n1. **Fork the repository**: Fork the Ultralytics YOLO repository to your own GitHub account.\n\n2. **Create a branch**: Create a new branch in your forked repository with a descriptive name for your changes.\n\n3. **Make your changes**: Make the changes you want to contribute. Ensure that your changes follow the coding style of the project and do not introduce new errors or warnings.\n\n4. **Test your changes**: Test your changes locally to ensure that they work as expected and do not introduce new issues.\n\n5. **Commit your changes**: Commit your changes with a descriptive commit message. Make sure to include any relevant issue numbers in your commit message.\n\n6. **Create a pull request**: Create a pull request from your forked repository to the main Ultralytics YOLO repository. In the pull request description, provide a clear explanation of your changes and how they improve the project.\n\n### CLA Signing\n\nBefore we can accept your pull request, you need to sign a [Contributor License Agreement (CLA)](CLA.md). This is a legal document stating that you agree to the terms of contributing to the Ultralytics YOLO repositories. The CLA ensures that your contributions are properly licensed and that the project can continue to be distributed under the AGPL-3.0 license.\n\nTo sign the CLA, follow the instructions provided by the CLA bot after you submit your PR.\n\n### Google-Style Docstrings\n\nWhen adding new functions or classes, please include a [Google-style docstring](https://google.github.io/styleguide/pyguide.html) to provide clear and concise documentation for other developers. This will help ensure that your contributions are easy to understand and maintain.\n\nExample Google-style docstring:\n\n```python\ndef example_function(arg1: int, arg2: str) -> bool:\n \"\"\"Example function that demonstrates Google-style docstrings.\n\n Args:\n arg1 (int): The first argument.\n arg2 (str): The second argument.\n\n Returns:\n bool: True if successful, False otherwise.\n\n Raises:\n ValueError: If `arg1` is negative or `arg2` is empty.\n \"\"\"\n if arg1 < 0 or not arg2:\n raise ValueError(\"Invalid input values\")\n return True\n```\n\n### GitHub Actions CI Tests\n\nBefore your pull request can be merged, all GitHub Actions Continuous Integration (CI) tests must pass. These tests include linting, unit tests, and other checks to ensure that your changes meet the quality standards of the project. Make sure to review the output of the GitHub Actions and fix any issues"
},
{
"path": "docs/help/index.md",
"content": "---\ncomments: true\ndescription: Get comprehensive resources for Ultralytics YOLO repositories. Find guides, FAQs, MRE creation, CLA & more. Join the supportive community now!\n---\n\nWelcome to the Ultralytics Help page! We are committed to providing you with comprehensive resources to make your experience with Ultralytics YOLO repositories as smooth and enjoyable as possible. On this page, you'll find essential links to guides and documents that will help you navigate through common tasks and address any questions you might have while using our repositories.\n\n- [Frequently Asked Questions (FAQ)](FAQ.md): Find answers to common questions and issues faced by users and contributors of Ultralytics YOLO repositories.\n- [Contributing Guide](contributing.md): Learn the best practices for submitting pull requests, reporting bugs, and contributing to the development of our repositories.\n- [Contributor License Agreement (CLA)](CLA.md): Familiarize yourself with our CLA to understand the terms and conditions for contributing to Ultralytics projects.\n- [Minimum Reproducible Example (MRE) Guide](minimum_reproducible_example.md): Understand how to create an MRE when submitting bug reports to ensure that our team can quickly and efficiently address the issue.\n- [Code of Conduct](code_of_conduct.md): Learn about our community guidelines and expectations to ensure a welcoming and inclusive environment for all participants.\n- [Security Policy](../SECURITY.md): Understand our security practices and how to report security vulnerabilities responsibly.\n\nWe highly recommend going through these guides to make the most of your collaboration with the Ultralytics community. Our goal is to maintain a welcoming and supportive environment for all users and contributors. If you need further assistance, don't hesitate to reach out to us through GitHub Issues or the official discussion forum. Happy coding!"
},
{
"path": "docs/help/minimum_reproducible_example.md",
"content": "---\ncomments: true\ndescription: Learn how to create a Minimum Reproducible Example (MRE) for Ultralytics YOLO bug reports to help maintainers and contributors understand your issue better.\n---\n\n# Creating a Minimum Reproducible Example for Bug Reports in Ultralytics YOLO Repositories\n\nWhen submitting a bug report for Ultralytics YOLO repositories, it's essential to provide a [minimum reproducible example](https://stackoverflow.com/help/minimal-reproducible-example) (MRE). An MRE is a small, self-contained piece of code that demonstrates the problem you're experiencing. Providing an MRE helps maintainers and contributors understand the issue and work on a fix more efficiently. This guide explains how to create an MRE when submitting bug reports to Ultralytics YOLO repositories.\n\n## 1. Isolate the Problem\n\nThe first step in creating an MRE is to isolate the problem. This means removing any unnecessary code or dependencies that are not directly related to the issue. Focus on the specific part of the code that is causing the problem and remove any irrelevant code.\n\n## 2. Use Public Models and Datasets\n\nWhen creating an MRE, use publicly available models and datasets to reproduce the issue. For example, use the 'yolov8n.pt' model and the 'coco8.yaml' dataset. This ensures that the maintainers and contributors can easily run your example and investigate the problem without needing access to proprietary data or custom models.\n\n## 3. Include All Necessary Dependencies\n\nMake sure to include all the necessary dependencies in your MRE. If your code relies on external libraries, specify the required packages and their versions. Ideally, provide a `requirements.txt` file or list the dependencies in your bug report.\n\n## 4. Write a Clear Description of the Issue\n\nProvide a clear and concise description of the issue you're experiencing. Explain the expected behavior and the actual behavior you're encountering. If applicable, include any relevant error messages or logs.\n\n## 5. Format Your Code Properly\n\nWhen submitting an MRE, format your code properly using code blocks in the issue description. This makes it easier for others to read and understand your code. In GitHub, you can create a code block by wrapping your code with triple backticks (\\```) and specifying the language:\n\n\n```python\n# Your Python code goes here\n```\n
\n\n## 6. Test Your MRE\n\nBefore submitting your MRE, test it to ensure that it accurately reproduces the issue. Make sure that others can run your example without any issues or modifications.\n\n## Example of an MRE\n\nHere's an example of an MRE for a hypothetical bug report:\n\n**Bug description:**\n\nWhen running the `detect.py` script on the sample image from the 'coco8.yaml' dataset, I get an error related to the dimensions of the input tensor.\n\n**MRE:**\n\n```python\nimport torch\nfrom ultralytics import YOLO\n\n# Load the model\nmodel = YOLO(\"yolov8n.pt\")\n\n# Load a 0-channel image\nimage = torch.rand(1, 0, 640, 640)\n\n# Run the model\nresults = model(image)\n```\n\n**Error message:**\n\n```\nRuntimeError: Expected input[1, 0, 640, 640] to have 3 channels, but got 0 channels instead\n```\n\n**Dependencies:**\n\n- torch==2.0.0\n- ultralytics==8.0.90\n\nIn this example, the MRE demonstrates the issue with a minimal amount of code, uses a public model ('yolov8n.pt'), includes all necessary dependencies, and provides a clear description of the problem along with the error message.\n\nBy following these guidelines, you'll help the maintainers and contributors of Ultralytics YOLO repositories to understand and resolve your issue more efficiently."
},
{
"path": "docs/hub/app/android.md",
"content": "---\ncomments: true\ndescription: Run YOLO models on your Android device for real-time object detection with Ultralytics Android App. Utilizes TensorFlow Lite and hardware delegates.\n---\n\n# Ultralytics Android App: Real-time Object Detection with YOLO Models\n\nThe Ultralytics Android App is a powerful tool that allows you to run YOLO models directly on your Android device for real-time object detection. This app utilizes TensorFlow Lite for model optimization and various hardware delegates for acceleration, enabling fast and efficient object detection.\n\n## Quantization and Acceleration\n\nTo achieve real-time performance on your Android device, YOLO models are quantized to either FP16 or INT8 precision. Quantization is a process that reduces the numerical precision of the model's weights and biases, thus reducing the model's size and the amount of computation required. This results in faster inference times without significantly affecting the model's accuracy.\n\n### FP16 Quantization\n\nFP16 (or half-precision) quantization converts the model's 32-bit floating-point numbers to 16-bit floating-point numbers. This reduces the model's size by half and speeds up the inference process, while maintaining a good balance between accuracy and performance.\n\n### INT8 Quantization\n\nINT8 (or 8-bit integer) quantization further reduces the model's size and computation requirements by converting its 32-bit floating-point numbers to 8-bit integers. This quantization method can result in a significant speedup, but it may lead to a slight reduction in mean average precision (mAP) due to the lower numerical precision.\n\n!!! tip \"mAP Reduction in INT8 Models\"\n\n The reduced numerical precision in INT8 models can lead to some loss of information during the quantization process, which may result in a slight decrease in mAP. However, this trade-off is often acceptable considering the substantial performance gains offered by INT8 quantization.\n\n## Delegates and Performance Variability\n\nDifferent delegates are available on Android devices to accelerate model inference. These delegates include CPU, [GPU](https://www.tensorflow.org/lite/android/delegates/gpu), [Hexagon](https://www.tensorflow.org/lite/android/delegates/hexagon) and [NNAPI](https://www.tensorflow.org/lite/android/delegates/nnapi). The performance of these delegates varies depending on the device's hardware vendor, product line, and specific chipsets used in the device.\n\n1. **CPU**: The default option, with reasonable performance on most devices.\n2. **GPU**: Utilizes the device's GPU for faster inference. It can provide a significant performance boost on devices with powerful GPUs.\n3. **Hexagon**: Leverages Qualcomm's Hexagon DSP for faster and more efficient processing. This option is available on devices with Qualcomm Snapdragon processors.\n4. **NNAPI**: The Android Neural Networks API (NNAPI) serves as an abstraction layer for running ML models on Android devices. NNAPI can utilize various hardware accelerators, such as CPU, GPU, and dedicated AI chips (e.g., Google's Edge TPU, or the Pixel Neural Core).\n\nHere's a table showing the primary vendors, their product lines, popular devices, and supported delegates:\n\n| Vendor | Product Lines | Popular Devices | Delegates Supported |\n|-----------------------------------------|---------------------------------------------------------------------------------------------------------------|--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|--------------------------|\n| [Qualcomm](https://www.qualcomm.com/) | [Snapdragon (e.g., 800 series)](https://www.qualcomm.com/snapdragon) | [Samsung Galaxy S21](https://www.samsung.com/global/galaxy/galaxy-s21-5g/), [OnePlus 9](https://www.oneplus.com/9), [Google Pixel 6](https://store.google.com/product/pixel_6) | CPU, GPU, Hexagon, NNAPI |\n| [Samsung](https://www.samsung.com/) | [Exynos (e.g., Exynos 2100)](https://www.samsung.com/semiconductor/minisite/exynos/) | [Samsung Galaxy S21 (Global version)](https://www.samsung.com/global/galaxy/galaxy-s21-5g/) | CPU, GPU, NNAPI |\n| [MediaTek](https://www.mediatek.com/) | [Dimensity (e.g., Dimensity 1200)](https://www.mediatek.com/products/smartphones) | [Realme GT](https://www.realme.com/global/realme-gt), [Xiaomi Redmi Note](https://www.mi.com/en/phone/redmi/note-list) | CPU, GPU, NNAPI |\n| [HiSilicon](https://www.hisilicon.com/) | [Kirin (e.g., Kirin 990)](https://www.hisilicon.com/en/products/Kirin) | [Huawei P40 Pro](https://consumer.huawei.com/en/phones/p40-pro/), [Huawei Mate 30 Pro](https://consumer.huawei.com/en/phones/mate30-pro/) | CPU, GPU, NNAPI |\n| [NVIDIA](https://www.nvidia.com/) | [Tegra (e.g., Tegra X1)](https://www.nvidia.com/en-us/autonomous-machines/embedded-systems-dev-kits-modules/) | [NVIDIA Shield TV](https://www.nvidia.com/en-us/shield/shield-tv/), [Nintendo Switch](https://www.nintendo.com/switch/) | CPU, GPU, NNAPI |\n\nPlease note that the list of devices mentioned is not exhaustive and may vary depending on the specific chipsets and device models. Always test your models on your target devices to ensure compatibility and optimal performance.\n\nKeep in mind that the choice of delegate can affect performance and model compatibility. For example, some models may not work with certain delegates, or a delegate may not be available on a specific device. As such, it's essential to test your model and the chosen delegate on your target devices for the best results.\n\n## Getting Started with the Ultralytics Android App\n\nTo get started with the Ultralytics Android App, follow these steps:\n\n1. Download the Ultralytics App from the [Google Play Store](https://play.google.com/store/apps/details?id=com.ultralytics.ultralytics_app).\n\n2. Launch the app on your Android device and sign in with your Ultralytics account. If you don't have an account yet, create one [here](https://hub.ultralytics.com/).\n\n3. Once signed in, you will see a list of your trained YOLO models. Select a model to use for object detection.\n\n4. Grant the app permission to access your device's camera.\n\n5. Point your device's camera at objects you want to detect. The app will display bounding boxes and class labels in real-time as it detects objects.\n\n6. Explore the app's settings to adjust the detection threshold, enable or disable specific object classes, and more.\n\nWith the Ultralytics Android App, you now have the power of real-time object detection using YOLO models right at your fingertips. Enjoy exploring the app's features and optimizing its settings to suit your specific use cases."
},
{
"path": "docs/hub/app/index.md",
"content": "---\ncomments: true\ndescription: Experience the power of YOLOv5 and YOLOv8 models with Ultralytics HUB app. Download from Google Play and App Store now.\n---\n\n# Ultralytics HUB App\n\n\n \n
\n
\n\n\nWelcome to the Ultralytics HUB App! We are excited to introduce this powerful mobile app that allows you to run YOLOv5 and YOLOv8 models directly on your [iOS](https://apps.apple.com/xk/app/ultralytics/id1583935240) and [Android](https://play.google.com/store/apps/details?id=com.ultralytics.ultralytics_app) devices. With the HUB App, you can utilize hardware acceleration features like Apple's Neural Engine (ANE) or Android GPU and Neural Network API (NNAPI) delegates to achieve impressive performance on your mobile device.\n\n## Features\n\n- **Run YOLOv5 and YOLOv8 models**: Experience the power of YOLO models on your mobile device for real-time object detection and image recognition tasks.\n- **Hardware Acceleration**: Benefit from Apple ANE on iOS devices or Android GPU and NNAPI delegates for optimized performance.\n- **Custom Model Training**: Train custom models with the Ultralytics HUB platform and preview them live using the HUB App.\n- **Mobile Compatibility**: The HUB App supports both iOS and Android devices, bringing the power of YOLO models to a wide range of users.\n\n## App Documentation\n\n- [**iOS**](./ios.md): Learn about YOLO CoreML models accelerated on Apple's Neural Engine for iPhones and iPads.\n- [**Android**](./android.md): Explore TFLite acceleration on Android mobile devices.\n\nGet started today by downloading the Ultralytics HUB App on your mobile device and unlock the potential of YOLOv5 and YOLOv8 models on-the-go. Don't forget to check out our comprehensive [HUB Docs](../) for more information on training, deploying, and using your custom models with the Ultralytics HUB platform."
},
{
"path": "docs/hub/app/ios.md",
"content": "---\ncomments: true\ndescription: Get started with the Ultralytics iOS app and run YOLO models in real-time for object detection on your iPhone or iPad with the Apple Neural Engine.\n---\n\n# Ultralytics iOS App: Real-time Object Detection with YOLO Models\n\nThe Ultralytics iOS App is a powerful tool that allows you to run YOLO models directly on your iPhone or iPad for real-time object detection. This app utilizes the Apple Neural Engine and Core ML for model optimization and acceleration, enabling fast and efficient object detection.\n\n## Quantization and Acceleration\n\nTo achieve real-time performance on your iOS device, YOLO models are quantized to either FP16 or INT8 precision. Quantization is a process that reduces the numerical precision of the model's weights and biases, thus reducing the model's size and the amount of computation required. This results in faster inference times without significantly affecting the model's accuracy.\n\n### FP16 Quantization\n\nFP16 (or half-precision) quantization converts the model's 32-bit floating-point numbers to 16-bit floating-point numbers. This reduces the model's size by half and speeds up the inference process, while maintaining a good balance between accuracy and performance.\n\n### INT8 Quantization\n\nINT8 (or 8-bit integer) quantization further reduces the model's size and computation requirements by converting its 32-bit floating-point numbers to 8-bit integers. This quantization method can result in a significant speedup, but it may lead to a slight reduction in accuracy.\n\n## Apple Neural Engine\n\nThe Apple Neural Engine (ANE) is a dedicated hardware component integrated into Apple's A-series and M-series chips. It's designed to accelerate machine learning tasks, particularly for neural networks, allowing for faster and more efficient execution of your YOLO models.\n\nBy combining quantized YOLO models with the Apple Neural Engine, the Ultralytics iOS App achieves real-time object detection on your iOS device without compromising on accuracy or performance.\n\n| Release Year | iPhone Name | Chipset Name | Node Size | ANE TOPs |\n|--------------|------------------------------------------------------|-------------------------------------------------------|-----------|----------|\n| 2017 | [iPhone X](https://en.wikipedia.org/wiki/IPhone_X) | [A11 Bionic](https://en.wikipedia.org/wiki/Apple_A11) | 10 nm | 0.6 |\n| 2018 | [iPhone XS](https://en.wikipedia.org/wiki/IPhone_XS) | [A12 Bionic](https://en.wikipedia.org/wiki/Apple_A12) | 7 nm | 5 |\n| 2019 | [iPhone 11](https://en.wikipedia.org/wiki/IPhone_11) | [A13 Bionic](https://en.wikipedia.org/wiki/Apple_A13) | 7 nm | 6 |\n| 2020 | [iPhone 12](https://en.wikipedia.org/wiki/IPhone_12) | [A14 Bionic](https://en.wikipedia.org/wiki/Apple_A14) | 5 nm | 11 |\n| 2021 | [iPhone 13](https://en.wikipedia.org/wiki/IPhone_13) | [A15 Bionic](https://en.wikipedia.org/wiki/Apple_A15) | 5 nm | 15.8 |\n| 2022 | [iPhone 14](https://en.wikipedia.org/wiki/IPhone_14) | [A16 Bionic](https://en.wikipedia.org/wiki/Apple_A16) | 4 nm | 17.0 |\n\nPlease note that this list only includes iPhone models from 2017 onwards, and the ANE TOPs values are approximate.\n\n## Getting Started with the Ultralytics iOS App\n\nTo get started with the Ultralytics iOS App, follow these steps:\n\n1. Download the Ultralytics App from the [App Store](https://apps.apple.com/xk/app/ultralytics/id1583935240).\n\n2. Launch the app on your iOS device and sign in with your Ultralytics account. If you don't have an account yet, create one [here](https://hub.ultralytics.com/).\n\n3. Once signed in, you will see a list of your trained YOLO models. Select a model to use for object detection.\n\n4. Grant the app permission to access your device's camera.\n\n5. Point your device's camera at objects you want to detect. The app will display bounding boxes and class labels in real-time as it detects objects.\n\n6. Explore the app's settings to adjust the detection threshold, enable or disable specific object classes, and more.\n\nWith the Ultralytics iOS App, you can now leverage the power of YOLO models for real-time object detection on your iPhone or iPad, powered by the Apple Neural Engine and optimized with FP16 or INT8 quantization."
},
{
"path": "docs/hub/datasets.md",
"content": "---\ncomments: true\ndescription: Upload custom datasets to Ultralytics HUB for YOLOv5 and YOLOv8 models. Follow YAML structure, zip and upload. Scan & train new models.\n---\n\n# HUB Datasets\n\n## 1. Upload a Dataset\n\nUltralytics HUB datasets are just like YOLOv5 and YOLOv8 🚀 datasets, they use the same structure and the same label formats to keep\neverything simple.\n\nWhen you upload a dataset to Ultralytics HUB, make sure to **place your dataset YAML inside the dataset root directory**\nas in the example shown below, and then zip for upload to [https://hub.ultralytics.com](https://hub.ultralytics.com/). Your **dataset YAML, directory\nand zip** should all share the same name. For example, if your dataset is called 'coco8' as in our\nexample [ultralytics/hub/example_datasets/coco8.zip](https://github.com/ultralytics/hub/blob/master/example_datasets/coco8.zip), then you should have a `coco8.yaml` inside your `coco8/` directory, which should zip to create `coco8.zip` for upload:\n\n```bash\nzip -r coco8.zip coco8\n```\n\nThe [example_datasets/coco8.zip](https://github.com/ultralytics/hub/blob/master/example_datasets/coco8.zip) dataset in this repository can be downloaded and unzipped to see exactly how to structure your custom dataset.\n\n\n \n
\n
\n\nThe dataset YAML is the same standard YOLOv5 and YOLOv8 YAML format. See\nthe [YOLOv5 and YOLOv8 Train Custom Data tutorial](https://docs.ultralytics.com/yolov5/tutorials/train_custom_data/) for full details.\n\n```yaml\n# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]\npath: # dataset root dir (leave empty for HUB)\ntrain: images/train # train images (relative to 'path') 8 images\nval: images/val # val images (relative to 'path') 8 images\ntest: # test images (optional)\n\n# Classes\nnames:\n 0: person\n 1: bicycle\n 2: car\n 3: motorcycle\n ...\n```\n\nAfter zipping your dataset, sign in to [Ultralytics HUB](https://bit.ly/ultralytics_hub) and click the Datasets tab.\nClick 'Upload Dataset' to upload, scan and visualize your new dataset before training new YOLOv5 or YOLOv8 models on it!\n\n "
},
{
"path": "docs/hub/index.md",
"content": "---\ncomments: true\ndescription: 'Ultralytics HUB: Train & deploy YOLO models from one spot! Use drag-and-drop interface with templates & pre-training models. Check quickstart, datasets, and more.'\n---\n\n# Ultralytics HUB\n\n\n\n
"
},
{
"path": "docs/hub/index.md",
"content": "---\ncomments: true\ndescription: 'Ultralytics HUB: Train & deploy YOLO models from one spot! Use drag-and-drop interface with templates & pre-training models. Check quickstart, datasets, and more.'\n---\n\n# Ultralytics HUB\n\n\n\n
\n
\n\n
\n\n👋 Hello from the [Ultralytics](https://ultralytics.com/) Team! We've been working hard these last few months to\nlaunch [Ultralytics HUB](https://bit.ly/ultralytics_hub), a new web tool for training and deploying all your YOLOv5 and YOLOv8 🚀\nmodels from one spot!\n\n## Introduction\n\nHUB is designed to be user-friendly and intuitive, with a drag-and-drop interface that allows users to\neasily upload their data and train new models quickly. It offers a range of pre-trained models and\ntemplates to choose from, making it easy for users to get started with training their own models. Once a model is\ntrained, it can be easily deployed and used for real-time object detection, instance segmentation and classification tasks.\n\nWe hope that the resources here will help you get the most out of HUB. Please browse the HUB Docs for details, raise an issue on GitHub for support, and join our Discord community for questions and discussions!\n\n- [**Quickstart**](./quickstart.md). Start training and deploying YOLO models with HUB in seconds.\n- [**Datasets: Preparing and Uploading**](./datasets.md). Learn how to prepare and upload your datasets to HUB in YOLO format.\n- [**Projects: Creating and Managing**](./projects.md). Group your models into projects for improved organization.\n- [**Models: Training and Exporting**](./models.md). Train YOLOv5 and YOLOv8 models on your custom datasets and export them to various formats for deployment.\n- [**Integrations: Options**](./integrations.md). Explore different integration options for your trained models, such as TensorFlow, ONNX, OpenVINO, CoreML, and PaddlePaddle.\n- [**Ultralytics HUB App**](./app/index.md). Learn about the Ultralytics App for iOS and Android, which allows you to run models directly on your mobile device.\n * [**iOS**](./app/ios.md). Learn about YOLO CoreML models accelerated on Apple's Neural Engine on iPhones and iPads.\n * [**Android**](./app/android.md). Explore TFLite acceleration on mobile devices.\n- [**Inference API**](./inference_api.md). Understand how to use the Inference API for running your trained models in the cloud to generate predictions."
},
{
"path": "docs/hub/inference_api.md",
"content": "---\ncomments: true\n---\n\n# 🚧 Page Under Construction ⚒\n\nThis page is currently under construction!️ 👷Please check back later for updates. 😃🔜\n\n# YOLO Inference API\n\nThe YOLO Inference API allows you to access the YOLOv8 object detection capabilities via a RESTful API. This enables you to run object detection on images without the need to install and set up the YOLOv8 environment locally.\n\n## API URL\n\nThe API URL is the address used to access the YOLO Inference API. In this case, the base URL is:\n\n```\nhttps://api.ultralytics.com/v1/predict\n```\n\n## Example Usage in Python\n\nTo access the YOLO Inference API with the specified model and API key using Python, you can use the following code:\n\n```python\nimport requests\n\n# API URL, use actual MODEL_ID\nurl = f\"https://api.ultralytics.com/v1/predict/MODEL_ID\"\n\n# Headers, use actual API_KEY\nheaders = {\"x-api-key\": \"API_KEY\"}\n\n# Inference arguments (optional)\ndata = {\"size\": 640, \"confidence\": 0.25, \"iou\": 0.45}\n\n# Load image and send request\nwith open(\"path/to/image.jpg\", \"rb\") as image_file:\n files = {\"image\": image_file}\n response = requests.post(url, headers=headers, files=files, data=data)\n\nprint(response.json())\n```\n\nIn this example, replace `API_KEY` with your actual API key, `MODEL_ID` with the desired model ID, and `path/to/image.jpg` with the path to the image you want to analyze.\n\n## Example Usage with CLI\n\nYou can use the YOLO Inference API with the command-line interface (CLI) by utilizing the `curl` command. Replace `API_KEY` with your actual API key, `MODEL_ID` with the desired model ID, and `image.jpg` with the path to the image you want to analyze:\n\n```bash\ncurl -X POST \"https://api.ultralytics.com/v1/predict/MODEL_ID\" \\\n\t-H \"x-api-key: API_KEY\" \\\n\t-F \"image=@/path/to/image.jpg\" \\\n\t-F \"size=640\" \\\n\t-F \"confidence=0.25\" \\\n\t-F \"iou=0.45\"\n```\n\n## Passing Arguments\n\nThis command sends a POST request to the YOLO Inference API with the specified `MODEL_ID` in the URL and the `API_KEY` in the request `headers`, along with the image file specified by `@path/to/image.jpg`.\n\nHere's an example of passing the `size`, `confidence`, and `iou` arguments via the API URL using the `requests` library in Python:\n\n```python\nimport requests\n\n# API URL, use actual MODEL_ID\nurl = f\"https://api.ultralytics.com/v1/predict/MODEL_ID\"\n\n# Headers, use actual API_KEY\nheaders = {\"x-api-key\": \"API_KEY\"}\n\n# Inference arguments (optional)\ndata = {\"size\": 640, \"confidence\": 0.25, \"iou\": 0.45}\n\n# Load image and send request\nwith open(\"path/to/image.jpg\", \"rb\") as image_file:\n files = {\"image\": image_file}\n response = requests.post(url, headers=headers, files=files, data=data)\n\nprint(response.json())\n```\n\nIn this example, the `data` dictionary contains the query arguments `size`, `confidence`, and `iou`, which tells the API to run inference at image size 640 with confidence and IoU thresholds of 0.25 and 0.45.\n\nThis will send the query parameters along with the file in the POST request. See the table below for a full list of available inference arguments.\n\n| Inference Argument | Default | Type | Notes |\n|--------------------|---------|---------|------------------------------------------------|\n| `size` | `640` | `int` | valid range is `32` - `1280` pixels |\n| `confidence` | `0.25` | `float` | valid range is `0.01` - `1.0` |\n| `iou` | `0.45` | `float` | valid range is `0.0` - `0.95` |\n| `url` | `''` | `str` | optional image URL if not image file is passed |\n| `normalize` | `False` | `bool` | |\n\n## Return JSON format\n\nThe YOLO Inference API returns a JSON list with the detection results. The format of the JSON list will be the same as the one produced locally by the `results[0].tojson()` command.\n\nThe JSON list contains information about the detected objects, their coordinates, classes, and confidence scores.\n\n### Detect Model Format\n\nYOLO detection models, such as `yolov8n.pt`, can return JSON responses from local inference, CLI API inference, and Python API inference. All of these methods produce the same JSON response format.\n\n!!! example \"Detect Model JSON Response\"\n\n === \"Local\"\n ```python\n from ultralytics import YOLO\n \n # Load model\n model = YOLO('yolov8n.pt')\n\n # Run inference\n results = model('image.jpg')\n\n # Print image.jpg results in JSON format\n print(results[0].tojson()) \n ```\n\n === \"CLI API\"\n ```bash\n curl -X POST \"https://api.ultralytics.com/v1/predict/MODEL_ID\" \\ \n -H \"x-api-key: API_KEY\" \\\n -F \"image=@/path/to/image.jpg\" \\\n -F \"size=640\" \\\n -F \"confidence=0.25\" \\\n -F \"iou=0.45\"\n ```\n\n === \"Python API\"\n ```python\n import requests\n \n # API URL, use actual MODEL_ID\n url = f\"https://api.ultralytics.com/v1/predict/MODEL_ID\"\n \n # Headers, use actual API_KEY\n headers = {\"x-api-key\": \"API_KEY\"}\n \n # Inference arguments (optional)\n data = {\"size\": 640, \"confidence\": 0.25, \"iou\": 0.45}\n \n # Load image and send request\n with open(\"path/to/image.jpg\", \"rb\") as image_file:\n files = {\"image\": image_file}\n response = requests.post(url, headers=headers, files=files, data=data)\n \n print(response.json())\n ```\n\n === \"JSON Response\"\n ```json\n {\n \"success\": True,\n \"message\": \"Inference complete.\",\n \"data\": [\n {\n \"name\": \"person\",\n \"class\": 0,\n \"confidence\": 0.8359682559967041,\n \"box\": {\n \"x1\": 0.08974208831787109,\n \"y1\": 0.27418340047200523,\n \"x2\": 0.8706787109375,\n \"y2\": 0.9887352837456598\n }\n },\n {\n \"name\": \"person\",\n \"class\": 0,\n \"confidence\": 0.8189555406570435,\n \"box\": {\n \"x1\": 0.5847355842590332,\n \"y1\": 0.05813225640190972,\n \"x2\": 0.8930277824401855,\n \"y2\": 0.9903111775716146\n }\n },\n {\n \"name\": \"tie\",\n \"class\": 27,\n \"confidence\": 0.2909725308418274,\n \"box\": {\n \"x1\": 0.3433395862579346,\n \"y1\": 0.6070465511745877,\n \"x2\": 0.40964522361755373,\n \"y2\": 0.9849439832899306\n }\n }\n ]\n }\n ```\n\n### Segment Model Format\n\nYOLO segmentation models, such as `yolov8n-seg.pt`, can return JSON responses from local inference, CLI API inference, and Python API inference. All of these methods produce the same JSON response format.\n\n!!! example \"Segment Model JSON Response\"\n\n === \"Local\"\n ```python\n from ultralytics import YOLO\n \n # Load model\n model = YOLO('yolov8n-seg.pt')\n\n # Run inference\n results = model('image.jpg')\n\n # Print image.jpg results in JSON format\n print(results[0].tojson()) \n ```\n\n === \"CLI API\"\n ```bash\n curl -X POST \"https://api.ultralytics.com/v1/predict/MODEL_ID\" \\ \n -H \"x-api-key: API_KEY\" \\\n -F \"image=@/path/to/image.jpg\" \\\n -F \"size=640\" \\\n -F \"confidence=0.25\" \\\n -F \"iou=0.45\"\n ```\n\n === \"Python API\"\n ```python\n import requests\n \n # API URL, use actual MODEL_ID\n url = f\"https://api.ultralytics.com/v1/predict/MODEL_ID\"\n \n # Headers, use actual API_KEY\n headers = {\"x-api-key\": \"API_KEY\"}\n \n # Inference arguments (optional)\n data = {\"size\": 640, \"confidence\": 0.25, \"iou\": 0.45}\n \n # Load image and send request\n with open(\"path/to/image.jpg\", \"rb\") as image_file:\n files = {\"image\": image_file}\n response = requests.post(url, headers=headers, files=files, data=data)\n \n print(response.json())\n ```\n\n === \"JSON Response\"\n Note `segments` `x` and `y` lengths may vary from one object to another. Larger or more complex objects may have more segment points.\n ```json\n {\n \"success\": True,\n \"message\": \"Inference complete.\",\n \"data\": [\n {\n \"name\": \"person\",\n \"class\": 0,\n \"confidence\": 0.856913149356842,\n \"box\": {\n \"x1\": 0.1064866065979004,\n \"y1\": 0.2798851860894097,\n \"x2\": 0.8738358497619629,\n \"y2\": 0.9894873725043403\n },\n \"segments\": {\n \"x\": [\n 0.421875,\n 0.4203124940395355,\n 0.41718751192092896\n ...\n ],\n \"y\": [\n 0.2888889014720917,\n 0.2916666567325592,\n 0.2916666567325592\n ...\n ]\n }\n },\n {\n \"name\": \"person\",\n \"class\": 0,\n \"confidence\": 0.8512625694274902,\n \"box\": {\n \"x1\": 0.5757311820983887,\n \"y1\": 0.053943040635850696,\n \"x2\": 0.8960096359252929,\n \"y2\": 0.985154045952691\n },\n \"segments\": {\n \"x\": [\n 0.7515624761581421,\n 0.75,\n 0.7437499761581421\n ...\n ],\n \"y\": [\n 0.0555555559694767,\n 0.05833333358168602,\n 0.05833333358168602\n ...\n ]\n }\n },\n {\n \"name\": \"tie\",\n \"class\": 27,\n \"confidence\": 0.6485961675643921,\n \"box\": {\n \"x1\": 0.33911995887756347,\n \"y1\": 0.6057066175672743,\n \"x2\": 0.4081430912017822,\n \"y2\": 0.9916408962673611\n },\n \"segments\": {\n \"x\": [\n 0.37187498807907104,\n 0.37031251192092896,\n 0.3687500059604645\n ...\n ],\n \"y\": [\n 0.6111111044883728,\n 0.6138888597488403,\n 0.6138888597488403\n ...\n ]\n }\n }\n ]\n }\n ```\n\n### Pose Model Format\n\nYOLO pose models, such as `yolov8n-pose.pt`, can return JSON responses from local inference, CLI API inference, and Python API inference. All of these methods produce the same JSON response format.\n\n!!! example \"Pose Model JSON Response\"\n\n === \"Local\"\n ```python\n from ultralytics import YOLO\n \n # Load model\n model = YOLO('yolov8n-seg.pt')\n\n # Run inference\n results = model('image.jpg')\n\n # Print image.jpg results in JSON format\n print(results[0].tojson()) \n ```\n\n === \"CLI API\"\n ```bash\n curl -X POST \"https://api.ultralytics.com/v1/predict/MODEL_ID\" \\ \n -H \"x-api-key: API_KEY\" \\\n -F \"image=@/path/to/image.jpg\" \\\n -F \"size=640\" \\\n -F \"confidence=0.25\" \\\n -F \"iou=0.45\"\n ```\n\n === \"Python API\"\n ```python\n import requests\n \n # API URL, use actual MODEL_ID\n url = f\"https://api.ultralytics.com/v1/predict/MODEL_ID\"\n \n # Headers, use actual API_KEY\n headers = {\"x-api-key\": \"API_KEY\"}\n \n # Inference arguments (optional)\n data = {\"size\": 640, \"confidence\": 0.25, \"iou\": 0.45}\n \n # Load image and send request\n with open(\"path/to/image.jpg\", \"rb\") as image_file:\n files = {\"image\": image_file}\n response = requests.post(url, headers=headers, files=files, data=data)\n \n print(response.json())\n ```\n\n === \"JSON Response\"\n Note COCO-keypoints pretrained models will have 17 human keypoints. The `visible` part of the keypoints indicates whether a keypoint is visible or obscured. Obscured keypoints may be outside the image or may not be visible, i.e. a person's eyes facing away from the camera.\n ```json\n {\n \"success\": True,\n \"message\": \"Inference complete.\",\n \"data\": [\n {\n \"name\": \"person\",\n \"class\": 0,\n \"confidence\": 0.8439509868621826,\n \"box\": {\n \"x1\": 0.1125,\n \"y1\": 0.28194444444444444,\n \"x2\": 0.7953125,\n \"y2\": 0.9902777777777778\n },\n \"keypoints\": {\n \"x\": [\n 0.5058594942092896,\n 0.5103894472122192,\n 0.4920862317085266\n ...\n ],\n \"y\": [\n 0.48964157700538635,\n 0.4643048942089081,\n 0.4465252459049225\n ...\n ],\n \"visible\": [\n 0.8726999163627625,\n 0.653947651386261,\n 0.9130823612213135\n ...\n ]\n }\n },\n {\n \"name\": \"person\",\n \"class\": 0,\n \"confidence\": 0.7474289536476135,\n \"box\": {\n \"x1\": 0.58125,\n \"y1\": 0.0625,\n \"x2\": 0.8859375,\n \"y2\": 0.9888888888888889\n },\n \"keypoints\": {\n \"x\": [\n 0.778544008731842,\n 0.7976160049438477,\n 0.7530890107154846\n ...\n ],\n \"y\": [\n 0.27595141530036926,\n 0.2378823608160019,\n 0.23644638061523438\n ...\n ],\n \"visible\": [\n 0.8900790810585022,\n 0.789978563785553,\n 0.8974530100822449\n ...\n ]\n }\n }\n ]\n }\n ```"
},
{
"path": "docs/hub/integrations.md",
"content": "---\ncomments: true\n---\n\n# 🚧 Page Under Construction ⚒\n\nThis page is currently under construction!️ 👷Please check back later for updates. 😃🔜\n"
},
{
"path": "docs/hub/models.md",
"content": "---\ncomments: true\ndescription: Train and Deploy your Model to 13 different formats, including TensorFlow, ONNX, OpenVINO, CoreML, Paddle or directly on Mobile.\n---\n\n# HUB Models\n\n## Train a Model\n\nConnect to the Ultralytics HUB notebook and use your model API key to begin training!\n\n\n \n\n## Deploy to Real World\n\nExport your model to 13 different formats, including TensorFlow, ONNX, OpenVINO, CoreML, Paddle and many others. Run\nmodels directly on your [iOS](https://apps.apple.com/xk/app/ultralytics/id1583935240) or\n[Android](https://play.google.com/store/apps/details?id=com.ultralytics.ultralytics_app) mobile device by downloading\nthe [Ultralytics App](https://ultralytics.com/app_install)!"
},
{
"path": "docs/hub/projects.md",
"content": "---\ncomments: true\n---\n\n# 🚧 Page Under Construction ⚒\n\nThis page is currently under construction!️ 👷Please check back later for updates. 😃🔜\n"
},
{
"path": "docs/hub/quickstart.md",
"content": "---\ncomments: true\n---\n\n# 🚧 Page Under Construction ⚒\n\nThis page is currently under construction!️ 👷Please check back later for updates. 😃🔜\n"
},
{
"path": "docs/index.md",
"content": "---\ncomments: true\ndescription: Explore Ultralytics YOLOv8, a cutting-edge real-time object detection and image segmentation model for various applications and hardware platforms.\n---\n\n
\n\n## Deploy to Real World\n\nExport your model to 13 different formats, including TensorFlow, ONNX, OpenVINO, CoreML, Paddle and many others. Run\nmodels directly on your [iOS](https://apps.apple.com/xk/app/ultralytics/id1583935240) or\n[Android](https://play.google.com/store/apps/details?id=com.ultralytics.ultralytics_app) mobile device by downloading\nthe [Ultralytics App](https://ultralytics.com/app_install)!"
},
{
"path": "docs/hub/projects.md",
"content": "---\ncomments: true\n---\n\n# 🚧 Page Under Construction ⚒\n\nThis page is currently under construction!️ 👷Please check back later for updates. 😃🔜\n"
},
{
"path": "docs/hub/quickstart.md",
"content": "---\ncomments: true\n---\n\n# 🚧 Page Under Construction ⚒\n\nThis page is currently under construction!️ 👷Please check back later for updates. 😃🔜\n"
},
{
"path": "docs/index.md",
"content": "---\ncomments: true\ndescription: Explore Ultralytics YOLOv8, a cutting-edge real-time object detection and image segmentation model for various applications and hardware platforms.\n---\n\n\n
\n \n  \n
\n
\n

\n

\n

\n
\n

\n
\n

\n
(pixels) | mAPval
50-95 | Speed
CPU ONNX
(ms) | Speed
A100 TensorRT
(ms) | params
(M) | FLOPs
(B) |\n | ---------------------------------------------------------------------------------------- | --------------------- | -------------------- | ------------------------------ | ----------------------------------- | ------------------ | ----------------- |\n | [YOLOv5nu](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov5nu.pt) | 640 | 34.3 | 73.6 | 1.06 | 2.6 | 7.7 |\n | [YOLOv5su](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov5su.pt) | 640 | 43.0 | 120.7 | 1.27 | 9.1 | 24.0 |\n | [YOLOv5mu](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov5mu.pt) | 640 | 49.0 | 233.9 | 1.86 | 25.1 | 64.2 |\n | [YOLOv5lu](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov5lu.pt) | 640 | 52.2 | 408.4 | 2.50 | 53.2 | 135.0 |\n | [YOLOv5xu](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov5xu.pt) | 640 | 53.2 | 763.2 | 3.81 | 97.2 | 246.4 |\n | | | | | | | |\n | [YOLOv5n6u](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov5n6u.pt) | 1280 | 42.1 | - | - | 4.3 | 7.8 |\n | [YOLOv5s6u](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov5s6u.pt) | 1280 | 48.6 | - | - | 15.3 | 24.6 |\n | [YOLOv5m6u](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov5m6u.pt) | 1280 | 53.6 | - | - | 41.2 | 65.7 |\n | [YOLOv5l6u](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov5l6u.pt) | 1280 | 55.7 | - | - | 86.1 | 137.4 |\n | [YOLOv5x6u](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov5x6u.pt) | 1280 | 56.8 | - | - | 155.4 | 250.7 |"
},
{
"path": "docs/models/yolov8.md",
"content": "---\ncomments: true\ndescription: Learn about YOLOv8's pre-trained weights supporting detection, instance segmentation, pose, and classification tasks. Get performance details.\n---\n\n# YOLOv8\n\n## Overview\n\nYOLOv8 is the latest iteration in the YOLO series of real-time object detectors, offering cutting-edge performance in terms of accuracy and speed. Building upon the advancements of previous YOLO versions, YOLOv8 introduces new features and optimizations that make it an ideal choice for various object detection tasks in a wide range of applications.\n\n## Key Features\n\n- **Advanced Backbone and Neck Architectures:** YOLOv8 employs state-of-the-art backbone and neck architectures, resulting in improved feature extraction and object detection performance.\n- **Anchor-free Split Ultralytics Head:** YOLOv8 adopts an anchor-free split Ultralytics head, which contributes to better accuracy and a more efficient detection process compared to anchor-based approaches.\n- **Optimized Accuracy-Speed Tradeoff:** With a focus on maintaining an optimal balance between accuracy and speed, YOLOv8 is suitable for real-time object detection tasks in diverse application areas.\n- **Variety of Pre-trained Models:** YOLOv8 offers a range of pre-trained models to cater to various tasks and performance requirements, making it easier to find the right model for your specific use case.\n\n## Supported Tasks\n\n| Model Type | Pre-trained Weights | Task |\n|-------------|------------------------------------------------------------------------------------------------------------------|-----------------------|\n| YOLOv8 | `yolov8n.pt`, `yolov8s.pt`, `yolov8m.pt`, `yolov8l.pt`, `yolov8x.pt` | Detection |\n| YOLOv8-seg | `yolov8n-seg.pt`, `yolov8s-seg.pt`, `yolov8m-seg.pt`, `yolov8l-seg.pt`, `yolov8x-seg.pt` | Instance Segmentation |\n| YOLOv8-pose | `yolov8n-pose.pt`, `yolov8s-pose.pt`, `yolov8m-pose.pt`, `yolov8l-pose.pt`, `yolov8x-pose.pt` ,`yolov8x-pose-p6` | Pose/Keypoints |\n| YOLOv8-cls | `yolov8n-cls.pt`, `yolov8s-cls.pt`, `yolov8m-cls.pt`, `yolov8l-cls.pt`, `yolov8x-cls.pt` | Classification |\n\n## Supported Modes\n\n| Mode | Supported |\n|------------|--------------------|\n| Inference | :heavy_check_mark: |\n| Validation | :heavy_check_mark: |\n| Training | :heavy_check_mark: |\n\n??? Performance\n\n === \"Detection\"\n\n | Model | size
(pixels) | mAPval
50-95 | Speed
CPU ONNX
(ms) | Speed
A100 TensorRT
(ms) | params
(M) | FLOPs
(B) |\n | ------------------------------------------------------------------------------------ | --------------------- | -------------------- | ------------------------------ | ----------------------------------- | ------------------ | ----------------- |\n | [YOLOv8n](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8n.pt) | 640 | 37.3 | 80.4 | 0.99 | 3.2 | 8.7 |\n | [YOLOv8s](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8s.pt) | 640 | 44.9 | 128.4 | 1.20 | 11.2 | 28.6 |\n | [YOLOv8m](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8m.pt) | 640 | 50.2 | 234.7 | 1.83 | 25.9 | 78.9 |\n | [YOLOv8l](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8l.pt) | 640 | 52.9 | 375.2 | 2.39 | 43.7 | 165.2 |\n | [YOLOv8x](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8x.pt) | 640 | 53.9 | 479.1 | 3.53 | 68.2 | 257.8 |\n\n === \"Segmentation\"\n\n | Model | size
(pixels) | mAPbox
50-95 | mAPmask
50-95 | Speed
CPU ONNX
(ms) | Speed
A100 TensorRT
(ms) | params
(M) | FLOPs
(B) |\n | -------------------------------------------------------------------------------------------- | --------------------- | -------------------- | --------------------- | ------------------------------ | ----------------------------------- | ------------------ | ----------------- |\n | [YOLOv8n-seg](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8n-seg.pt) | 640 | 36.7 | 30.5 | 96.1 | 1.21 | 3.4 | 12.6 |\n | [YOLOv8s-seg](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8s-seg.pt) | 640 | 44.6 | 36.8 | 155.7 | 1.47 | 11.8 | 42.6 |\n | [YOLOv8m-seg](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8m-seg.pt) | 640 | 49.9 | 40.8 | 317.0 | 2.18 | 27.3 | 110.2 |\n | [YOLOv8l-seg](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8l-seg.pt) | 640 | 52.3 | 42.6 | 572.4 | 2.79 | 46.0 | 220.5 |\n | [YOLOv8x-seg](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8x-seg.pt) | 640 | 53.4 | 43.4 | 712.1 | 4.02 | 71.8 | 344.1 |\n\n === \"Classification\"\n\n | Model | size
(pixels) | acc
top1 | acc
top5 | Speed
CPU ONNX
(ms) | Speed
A100 TensorRT
(ms) | params
(M) | FLOPs
(B) at 640 |\n | -------------------------------------------------------------------------------------------- | --------------------- | ---------------- | ---------------- | ------------------------------ | ----------------------------------- | ------------------ | ------------------------ |\n | [YOLOv8n-cls](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8n-cls.pt) | 224 | 66.6 | 87.0 | 12.9 | 0.31 | 2.7 | 4.3 |\n | [YOLOv8s-cls](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8s-cls.pt) | 224 | 72.3 | 91.1 | 23.4 | 0.35 | 6.4 | 13.5 |\n | [YOLOv8m-cls](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8m-cls.pt) | 224 | 76.4 | 93.2 | 85.4 | 0.62 | 17.0 | 42.7 |\n | [YOLOv8l-cls](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8l-cls.pt) | 224 | 78.0 | 94.1 | 163.0 | 0.87 | 37.5 | 99.7 |\n | [YOLOv8x-cls](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8x-cls.pt) | 224 | 78.4 | 94.3 | 232.0 | 1.01 | 57.4 | 154.8 |\n\n === \"Pose\"\n\n | Model | size
(pixels) | mAPpose
50-95 | mAPpose
50 | Speed
CPU ONNX
(ms) | Speed
A100 TensorRT
(ms) | params
(M) | FLOPs
(B) |\n | ---------------------------------------------------------------------------------------------------- | --------------------- | --------------------- | ------------------ | ------------------------------ | ----------------------------------- | ------------------ | ----------------- |\n | [YOLOv8n-pose](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8n-pose.pt) | 640 | 50.4 | 80.1 | 131.8 | 1.18 | 3.3 | 9.2 |\n | [YOLOv8s-pose](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8s-pose.pt) | 640 | 60.0 | 86.2 | 233.2 | 1.42 | 11.6 | 30.2 |\n | [YOLOv8m-pose](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8m-pose.pt) | 640 | 65.0 | 88.8 | 456.3 | 2.00 | 26.4 | 81.0 |\n | [YOLOv8l-pose](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8l-pose.pt) | 640 | 67.6 | 90.0 | 784.5 | 2.59 | 44.4 | 168.6 |\n | [YOLOv8x-pose](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8x-pose.pt) | 640 | 69.2 | 90.2 | 1607.1 | 3.73 | 69.4 | 263.2 |\n | [YOLOv8x-pose-p6](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8x-pose-p6.pt) | 1280 | 71.6 | 91.2 | 4088.7 | 10.04 | 99.1 | 1066.4 |"
},
{
"path": "docs/modes/benchmark.md",
"content": "---\ncomments: true\ndescription: Benchmark mode compares speed and accuracy of various YOLOv8 export formats like ONNX or OpenVINO. Optimize formats for speed or accuracy.\n---\n\n \n\n**Benchmark mode** is used to profile the speed and accuracy of various export formats for YOLOv8. The benchmarks\nprovide information on the size of the exported format, its `mAP50-95` metrics (for object detection, segmentation and pose)\nor `accuracy_top5` metrics (for classification), and the inference time in milliseconds per image across various export\nformats like ONNX, OpenVINO, TensorRT and others. This information can help users choose the optimal export format for\ntheir specific use case based on their requirements for speed and accuracy.\n\n!!! tip \"Tip\"\n\n * Export to ONNX or OpenVINO for up to 3x CPU speedup.\n * Export to TensorRT for up to 5x GPU speedup.\n\n## Usage Examples\n\nRun YOLOv8n benchmarks on all supported export formats including ONNX, TensorRT etc. See Arguments section below for a\nfull list of export arguments.\n\n!!! example \"\"\n\n === \"Python\"\n \n ```python\n from ultralytics.yolo.utils.benchmarks import benchmark\n \n # Benchmark on GPU\n benchmark(model='yolov8n.pt', imgsz=640, half=False, device=0)\n ```\n === \"CLI\"\n \n ```bash\n yolo benchmark model=yolov8n.pt imgsz=640 half=False device=0\n ```\n\n## Arguments\n\nArguments such as `model`, `imgsz`, `half`, `device`, and `hard_fail` provide users with the flexibility to fine-tune\nthe benchmarks to their specific needs and compare the performance of different export formats with ease.\n\n| Key | Value | Description |\n|-------------|---------|----------------------------------------------------------------------|\n| `model` | `None` | path to model file, i.e. yolov8n.pt, yolov8n.yaml |\n| `imgsz` | `640` | image size as scalar or (h, w) list, i.e. (640, 480) |\n| `half` | `False` | FP16 quantization |\n| `int8` | `False` | INT8 quantization |\n| `device` | `None` | device to run on, i.e. cuda device=0 or device=0,1,2,3 or device=cpu |\n| `hard_fail` | `False` | do not continue on error (bool), or val floor threshold (float) |\n\n## Export Formats\n\nBenchmarks will attempt to run automatically on all possible export formats below.\n\n| Format | `format` Argument | Model | Metadata |\n|--------------------------------------------------------------------|-------------------|---------------------------|----------|\n| [PyTorch](https://pytorch.org/) | - | `yolov8n.pt` | ✅ |\n| [TorchScript](https://pytorch.org/docs/stable/jit.html) | `torchscript` | `yolov8n.torchscript` | ✅ |\n| [ONNX](https://onnx.ai/) | `onnx` | `yolov8n.onnx` | ✅ |\n| [OpenVINO](https://docs.openvino.ai/latest/index.html) | `openvino` | `yolov8n_openvino_model/` | ✅ |\n| [TensorRT](https://developer.nvidia.com/tensorrt) | `engine` | `yolov8n.engine` | ✅ |\n| [CoreML](https://github.com/apple/coremltools) | `coreml` | `yolov8n.mlmodel` | ✅ |\n| [TF SavedModel](https://www.tensorflow.org/guide/saved_model) | `saved_model` | `yolov8n_saved_model/` | ✅ |\n| [TF GraphDef](https://www.tensorflow.org/api_docs/python/tf/Graph) | `pb` | `yolov8n.pb` | ❌ |\n| [TF Lite](https://www.tensorflow.org/lite) | `tflite` | `yolov8n.tflite` | ✅ |\n| [TF Edge TPU](https://coral.ai/docs/edgetpu/models-intro/) | `edgetpu` | `yolov8n_edgetpu.tflite` | ✅ |\n| [TF.js](https://www.tensorflow.org/js) | `tfjs` | `yolov8n_web_model/` | ✅ |\n| [PaddlePaddle](https://github.com/PaddlePaddle) | `paddle` | `yolov8n_paddle_model/` | ✅ |\n\nSee full `export` details in the [Export](https://docs.ultralytics.com/modes/export/) page."
},
{
"path": "docs/modes/export.md",
"content": "---\ncomments: true\ndescription: 'Export mode: Create a deployment-ready YOLOv8 model by converting it to various formats. Export to ONNX or OpenVINO for up to 3x CPU speedup.'\n---\n\n\n\n**Export mode** is used for exporting a YOLOv8 model to a format that can be used for deployment. In this mode, the\nmodel is converted to a format that can be used by other software applications or hardware devices. This mode is useful\nwhen deploying the model to production environments.\n\n!!! tip \"Tip\"\n\n * Export to ONNX or OpenVINO for up to 3x CPU speedup.\n * Export to TensorRT for up to 5x GPU speedup.\n\n## Usage Examples\n\nExport a YOLOv8n model to a different format like ONNX or TensorRT. See Arguments section below for a full list of\nexport arguments.\n\n!!! example \"\"\n\n === \"Python\"\n \n ```python\n from ultralytics import YOLO\n \n # Load a model\n model = YOLO('yolov8n.pt') # load an official model\n model = YOLO('path/to/best.pt') # load a custom trained\n \n # Export the model\n model.export(format='onnx')\n ```\n === \"CLI\"\n \n ```bash\n yolo export model=yolov8n.pt format=onnx # export official model\n yolo export model=path/to/best.pt format=onnx # export custom trained model\n ```\n\n## Arguments\n\nExport settings for YOLO models refer to the various configurations and options used to save or\nexport the model for use in other environments or platforms. These settings can affect the model's performance, size,\nand compatibility with different systems. Some common YOLO export settings include the format of the exported model\nfile (e.g. ONNX, TensorFlow SavedModel), the device on which the model will be run (e.g. CPU, GPU), and the presence of\nadditional features such as masks or multiple labels per box. Other factors that may affect the export process include\nthe specific task the model is being used for and the requirements or constraints of the target environment or platform.\nIt is important to carefully consider and configure these settings to ensure that the exported model is optimized for\nthe intended use case and can be used effectively in the target environment.\n\n| Key | Value | Description |\n|-------------|-----------------|------------------------------------------------------|\n| `format` | `'torchscript'` | format to export to |\n| `imgsz` | `640` | image size as scalar or (h, w) list, i.e. (640, 480) |\n| `keras` | `False` | use Keras for TF SavedModel export |\n| `optimize` | `False` | TorchScript: optimize for mobile |\n| `half` | `False` | FP16 quantization |\n| `int8` | `False` | INT8 quantization |\n| `dynamic` | `False` | ONNX/TensorRT: dynamic axes |\n| `simplify` | `False` | ONNX/TensorRT: simplify model |\n| `opset` | `None` | ONNX: opset version (optional, defaults to latest) |\n| `workspace` | `4` | TensorRT: workspace size (GB) |\n| `nms` | `False` | CoreML: add NMS |\n\n## Export Formats\n\nAvailable YOLOv8 export formats are in the table below. You can export to any format using the `format` argument,\ni.e. `format='onnx'` or `format='engine'`.\n\n| Format | `format` Argument | Model | Metadata | Arguments |\n|--------------------------------------------------------------------|-------------------|---------------------------|----------|-----------------------------------------------------|\n| [PyTorch](https://pytorch.org/) | - | `yolov8n.pt` | ✅ | - |\n| [TorchScript](https://pytorch.org/docs/stable/jit.html) | `torchscript` | `yolov8n.torchscript` | ✅ | `imgsz`, `optimize` |\n| [ONNX](https://onnx.ai/) | `onnx` | `yolov8n.onnx` | ✅ | `imgsz`, `half`, `dynamic`, `simplify`, `opset` |\n| [OpenVINO](https://docs.openvino.ai/latest/index.html) | `openvino` | `yolov8n_openvino_model/` | ✅ | `imgsz`, `half` |\n| [TensorRT](https://developer.nvidia.com/tensorrt) | `engine` | `yolov8n.engine` | ✅ | `imgsz`, `half`, `dynamic`, `simplify`, `workspace` |\n| [CoreML](https://github.com/apple/coremltools) | `coreml` | `yolov8n.mlmodel` | ✅ | `imgsz`, `half`, `int8`, `nms` |\n| [TF SavedModel](https://www.tensorflow.org/guide/saved_model) | `saved_model` | `yolov8n_saved_model/` | ✅ | `imgsz`, `keras` |\n| [TF GraphDef](https://www.tensorflow.org/api_docs/python/tf/Graph) | `pb` | `yolov8n.pb` | ❌ | `imgsz` |\n| [TF Lite](https://www.tensorflow.org/lite) | `tflite` | `yolov8n.tflite` | ✅ | `imgsz`, `half`, `int8` |\n| [TF Edge TPU](https://coral.ai/docs/edgetpu/models-intro/) | `edgetpu` | `yolov8n_edgetpu.tflite` | ✅ | `imgsz` |\n| [TF.js](https://www.tensorflow.org/js) | `tfjs` | `yolov8n_web_model/` | ✅ | `imgsz` |\n| [PaddlePaddle](https://github.com/PaddlePaddle) | `paddle` | `yolov8n_paddle_model/` | ✅ | `imgsz` |"
},
{
"path": "docs/modes/index.md",
"content": "---\ncomments: true\ndescription: Use Ultralytics YOLOv8 Modes (Train, Val, Predict, Export, Track, Benchmark) to train, validate, predict, track, export or benchmark.\n---\n\n# Ultralytics YOLOv8 Modes\n\n\n\nUltralytics YOLOv8 supports several **modes** that can be used to perform different tasks. These modes are:\n\n**Train**: For training a YOLOv8 model on a custom dataset. \n**Val**: For validating a YOLOv8 model after it has been trained. \n**Predict**: For making predictions using a trained YOLOv8 model on new images or videos. \n**Export**: For exporting a YOLOv8 model to a format that can be used for deployment. \n**Track**: For tracking objects in real-time using a YOLOv8 model. \n**Benchmark**: For benchmarking YOLOv8 exports (ONNX, TensorRT, etc.) speed and accuracy.\n\n## [Train](train.md)\n\nTrain mode is used for training a YOLOv8 model on a custom dataset. In this mode, the model is trained using the\nspecified dataset and hyperparameters. The training process involves optimizing the model's parameters so that it can\naccurately predict the classes and locations of objects in an image.\n\n[Train Examples](train.md){ .md-button .md-button--primary}\n\n## [Val](val.md)\n\nVal mode is used for validating a YOLOv8 model after it has been trained. In this mode, the model is evaluated on a\nvalidation set to measure its accuracy and generalization performance. This mode can be used to tune the hyperparameters\nof the model to improve its performance.\n\n[Val Examples](val.md){ .md-button .md-button--primary}\n\n## [Predict](predict.md)\n\nPredict mode is used for making predictions using a trained YOLOv8 model on new images or videos. In this mode, the\nmodel is loaded from a checkpoint file, and the user can provide images or videos to perform inference. The model\npredicts the classes and locations of objects in the input images or videos.\n\n[Predict Examples](predict.md){ .md-button .md-button--primary}\n\n## [Export](export.md)\n\nExport mode is used for exporting a YOLOv8 model to a format that can be used for deployment. In this mode, the model is\nconverted to a format that can be used by other software applications or hardware devices. This mode is useful when\ndeploying the model to production environments.\n\n[Export Examples](export.md){ .md-button .md-button--primary}\n\n## [Track](track.md)\n\nTrack mode is used for tracking objects in real-time using a YOLOv8 model. In this mode, the model is loaded from a\ncheckpoint file, and the user can provide a live video stream to perform real-time object tracking. This mode is useful\nfor applications such as surveillance systems or self-driving cars.\n\n[Track Examples](track.md){ .md-button .md-button--primary}\n\n## [Benchmark](benchmark.md)\n\nBenchmark mode is used to profile the speed and accuracy of various export formats for YOLOv8. The benchmarks provide\ninformation on the size of the exported format, its `mAP50-95` metrics (for object detection, segmentation and pose)\nor `accuracy_top5` metrics (for classification), and the inference time in milliseconds per image across various export\nformats like ONNX, OpenVINO, TensorRT and others. This information can help users choose the optimal export format for\ntheir specific use case based on their requirements for speed and accuracy.\n\n[Benchmark Examples](benchmark.md){ .md-button .md-button--primary}"
},
{
"path": "docs/modes/predict.md",
"content": "---\ncomments: true\ndescription: Get started with YOLOv8 Predict mode and input sources. Accepts various input sources such as images, videos, and directories.\n---\n\n\n\nYOLOv8 **predict mode** can generate predictions for various tasks, returning either a list of `Results` objects or a\nmemory-efficient generator of `Results` objects when using the streaming mode. Enable streaming mode by\npassing `stream=True` in the predictor's call method.\n\n!!! example \"Predict\"\n\n === \"Return a list with `Stream=False`\"\n ```python\n inputs = [img, img] # list of numpy arrays\n results = model(inputs) # list of Results objects\n \n for result in results:\n boxes = result.boxes # Boxes object for bbox outputs\n masks = result.masks # Masks object for segmentation masks outputs\n probs = result.probs # Class probabilities for classification outputs\n ```\n\n === \"Return a generator with `Stream=True`\"\n ```python\n inputs = [img, img] # list of numpy arrays\n results = model(inputs, stream=True) # generator of Results objects\n \n for result in results:\n boxes = result.boxes # Boxes object for bbox outputs\n masks = result.masks # Masks object for segmentation masks outputs\n probs = result.probs # Class probabilities for classification outputs\n ```\n\n!!! tip \"Tip\"\n\n Streaming mode with `stream=True` should be used for long videos or large predict sources, otherwise results will accumuate in memory and will eventually cause out-of-memory errors. \n\n## Sources\n\nYOLOv8 can accept various input sources, as shown in the table below. This includes images, URLs, PIL images, OpenCV,\nnumpy arrays, torch tensors, CSV files, videos, directories, globs, YouTube videos, and streams. The table indicates\nwhether each source can be used in streaming mode with `stream=True` ✅ and an example argument for each source.\n\n| source | model(arg) | type | notes |\n|-------------|--------------------------------------------|----------------|------------------|\n| image | `'im.jpg'` | `str`, `Path` | |\n| URL | `'https://ultralytics.com/images/bus.jpg'` | `str` | |\n| screenshot | `'screen'` | `str` | |\n| PIL | `Image.open('im.jpg')` | `PIL.Image` | HWC, RGB |\n| OpenCV | `cv2.imread('im.jpg')` | `np.ndarray` | HWC, BGR |\n| numpy | `np.zeros((640,1280,3))` | `np.ndarray` | HWC |\n| torch | `torch.zeros(16,3,320,640)` | `torch.Tensor` | BCHW, RGB |\n| CSV | `'sources.csv'` | `str`, `Path` | RTSP, RTMP, HTTP | \n| video ✅ | `'vid.mp4'` | `str`, `Path` | |\n| directory ✅ | `'path/'` | `str`, `Path` | |\n| glob ✅ | `'path/*.jpg'` | `str` | Use `*` operator |\n| YouTube ✅ | `'https://youtu.be/Zgi9g1ksQHc'` | `str` | |\n| stream ✅ | `'rtsp://example.com/media.mp4'` | `str` | RTSP, RTMP, HTTP |\n\n## Arguments\n\n`model.predict` accepts multiple arguments that control the prediction operation. These arguments can be passed directly to `model.predict`:\n!!! example\n\n ```\n model.predict(source, save=True, imgsz=320, conf=0.5)\n ```\n\nAll supported arguments:\n\n| Key | Value | Description |\n|----------------|------------------------|--------------------------------------------------------------------------------|\n| `source` | `'ultralytics/assets'` | source directory for images or videos |\n| `conf` | `0.25` | object confidence threshold for detection |\n| `iou` | `0.7` | intersection over union (IoU) threshold for NMS |\n| `half` | `False` | use half precision (FP16) |\n| `device` | `None` | device to run on, i.e. cuda device=0/1/2/3 or device=cpu |\n| `show` | `False` | show results if possible |\n| `save` | `False` | save images with results |\n| `save_txt` | `False` | save results as .txt file |\n| `save_conf` | `False` | save results with confidence scores |\n| `save_crop` | `False` | save cropped images with results |\n| `hide_labels` | `False` | hide labels |\n| `hide_conf` | `False` | hide confidence scores |\n| `max_det` | `300` | maximum number of detections per image |\n| `vid_stride` | `False` | video frame-rate stride |\n| `line_width` | `None` | The line width of the bounding boxes. If None, it is scaled to the image size. |\n| `visualize` | `False` | visualize model features |\n| `augment` | `False` | apply image augmentation to prediction sources |\n| `agnostic_nms` | `False` | class-agnostic NMS |\n| `retina_masks` | `False` | use high-resolution segmentation masks |\n| `classes` | `None` | filter results by class, i.e. class=0, or class=[0,2,3] |\n| `boxes` | `True` | Show boxes in segmentation predictions |\n\n## Image and Video Formats\n\nYOLOv8 supports various image and video formats, as specified\nin [yolo/data/utils.py](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/yolo/data/utils.py). See the\ntables below for the valid suffixes and example predict commands.\n\n### Image Suffixes\n\n| Image Suffixes | Example Predict Command | Reference |\n|----------------|----------------------------------|-------------------------------------------------------------------------------|\n| .bmp | `yolo predict source=image.bmp` | [Microsoft BMP File Format](https://en.wikipedia.org/wiki/BMP_file_format) |\n| .dng | `yolo predict source=image.dng` | [Adobe DNG](https://www.adobe.com/products/photoshop/extend.displayTab2.html) |\n| .jpeg | `yolo predict source=image.jpeg` | [JPEG](https://en.wikipedia.org/wiki/JPEG) |\n| .jpg | `yolo predict source=image.jpg` | [JPEG](https://en.wikipedia.org/wiki/JPEG) |\n| .mpo | `yolo predict source=image.mpo` | [Multi Picture Object](https://fileinfo.com/extension/mpo) |\n| .png | `yolo predict source=image.png` | [Portable Network Graphics](https://en.wikipedia.org/wiki/PNG) |\n| .tif | `yolo predict source=image.tif` | [Tag Image File Format](https://en.wikipedia.org/wiki/TIFF) |\n| .tiff | `yolo predict source=image.tiff` | [Tag Image File Format](https://en.wikipedia.org/wiki/TIFF) |\n| .webp | `yolo predict source=image.webp` | [WebP](https://en.wikipedia.org/wiki/WebP) |\n| .pfm | `yolo predict source=image.pfm` | [Portable FloatMap](https://en.wikipedia.org/wiki/Netpbm#File_formats) |\n\n### Video Suffixes\n\n| Video Suffixes | Example Predict Command | Reference |\n|----------------|----------------------------------|----------------------------------------------------------------------------------|\n| .asf | `yolo predict source=video.asf` | [Advanced Systems Format](https://en.wikipedia.org/wiki/Advanced_Systems_Format) |\n| .avi | `yolo predict source=video.avi` | [Audio Video Interleave](https://en.wikipedia.org/wiki/Audio_Video_Interleave) |\n| .gif | `yolo predict source=video.gif` | [Graphics Interchange Format](https://en.wikipedia.org/wiki/GIF) |\n| .m4v | `yolo predict source=video.m4v` | [MPEG-4 Part 14](https://en.wikipedia.org/wiki/M4V) |\n| .mkv | `yolo predict source=video.mkv` | [Matroska](https://en.wikipedia.org/wiki/Matroska) |\n| .mov | `yolo predict source=video.mov` | [QuickTime File Format](https://en.wikipedia.org/wiki/QuickTime_File_Format) |\n| .mp4 | `yolo predict source=video.mp4` | [MPEG-4 Part 14 - Wikipedia](https://en.wikipedia.org/wiki/MPEG-4_Part_14) |\n| .mpeg | `yolo predict source=video.mpeg` | [MPEG-1 Part 2](https://en.wikipedia.org/wiki/MPEG-1) |\n| .mpg | `yolo predict source=video.mpg` | [MPEG-1 Part 2](https://en.wikipedia.org/wiki/MPEG-1) |\n| .ts | `yolo predict source=video.ts` | [MPEG Transport Stream](https://en.wikipedia.org/wiki/MPEG_transport_stream) |\n| .wmv | `yolo predict source=video.wmv` | [Windows Media Video](https://en.wikipedia.org/wiki/Windows_Media_Video) |\n| .webm | `yolo predict source=video.webm` | [WebM Project](https://en.wikipedia.org/wiki/WebM) |\n\n## Working with Results\n\nThe `Results` object contains the following components:\n\n- `Results.boxes`: `Boxes` object with properties and methods for manipulating bounding boxes\n- `Results.masks`: `Masks` object for indexing masks or getting segment coordinates\n- `Results.probs`: `torch.Tensor` containing class probabilities or logits\n- `Results.orig_img`: Original image loaded in memory\n- `Results.path`: `Path` containing the path to the input image\n\nEach result is composed of a `torch.Tensor` by default, which allows for easy manipulation:\n\n!!! example \"Results\"\n\n ```python\n results = results.cuda()\n results = results.cpu()\n results = results.to('cpu')\n results = results.numpy()\n ```\n\n### Boxes\n\n`Boxes` object can be used to index, manipulate, and convert bounding boxes to different formats. Box format conversion\noperations are cached, meaning they're only calculated once per object, and those values are reused for future calls.\n\n- Indexing a `Boxes` object returns a `Boxes` object:\n\n!!! example \"Boxes\"\n\n ```python\n results = model(img)\n boxes = results[0].boxes\n box = boxes[0] # returns one box\n box.xyxy\n ```\n\n- Properties and conversions\n\n!!! example \"Boxes Properties\"\n\n ```python\n boxes.xyxy # box with xyxy format, (N, 4)\n boxes.xywh # box with xywh format, (N, 4)\n boxes.xyxyn # box with xyxy format but normalized, (N, 4)\n boxes.xywhn # box with xywh format but normalized, (N, 4)\n boxes.conf # confidence score, (N, 1)\n boxes.cls # cls, (N, 1)\n boxes.data # raw bboxes tensor, (N, 6) or boxes.boxes\n ```\n\n### Masks\n\n`Masks` object can be used index, manipulate and convert masks to segments. The segment conversion operation is cached.\n\n!!! example \"Masks\"\n\n ```python\n results = model(inputs)\n masks = results[0].masks # Masks object\n masks.xy # x, y segments (pixels), List[segment] * N\n masks.xyn # x, y segments (normalized), List[segment] * N\n masks.data # raw masks tensor, (N, H, W) or masks.masks \n ```\n\n### probs\n\n`probs` attribute of `Results` class is a `Tensor` containing class probabilities of a classification operation.\n\n!!! example \"Probs\"\n\n ```python\n results = model(inputs)\n results[0].probs # cls prob, (num_class, )\n ```\n\nClass reference documentation for `Results` module and its components can be found [here](../reference/yolo/engine/results.md)\n\n## Plotting results\n\nYou can use `plot()` function of `Result` object to plot results on in image object. It plots all components(boxes,\nmasks, classification logits, etc.) found in the results object\n\n!!! example \"Plotting\"\n\n ```python\n res = model(img)\n res_plotted = res[0].plot()\n cv2.imshow(\"result\", res_plotted)\n ```\n\n| Argument | Description |\n|-------------------------------|----------------------------------------------------------------------------------------|\n| `conf (bool)` | Whether to plot the detection confidence score. |\n| `line_width (int, optional)` | The line width of the bounding boxes. If None, it is scaled to the image size. |\n| `font_size (float, optional)` | The font size of the text. If None, it is scaled to the image size. |\n| `font (str)` | The font to use for the text. |\n| `pil (bool)` | Whether to use PIL for image plotting. |\n| `example (str)` | An example string to display. Useful for indicating the expected format of the output. |\n| `img (numpy.ndarray)` | Plot to another image. if not, plot to original image. |\n| `labels (bool)` | Whether to plot the label of bounding boxes. |\n| `boxes (bool)` | Whether to plot the bounding boxes. |\n| `masks (bool)` | Whether to plot the masks. |\n| `probs (bool)` | Whether to plot classification probability. |\n\n## Streaming Source `for`-loop\n\nHere's a Python script using OpenCV (cv2) and YOLOv8 to run inference on video frames. This script assumes you have already installed the necessary packages (opencv-python and ultralytics).\n\n!!! example \"Streaming for-loop\"\n\n ```python\n import cv2\n from ultralytics import YOLO\n \n # Load the YOLOv8 model\n model = YOLO('yolov8n.pt')\n \n # Open the video file\n video_path = \"path/to/your/video/file.mp4\"\n cap = cv2.VideoCapture(video_path)\n \n # Loop through the video frames\n while cap.isOpened():\n # Read a frame from the video\n success, frame = cap.read()\n \n if success:\n # Run YOLOv8 inference on the frame\n results = model(frame)\n \n # Visualize the results on the frame\n annotated_frame = results[0].plot()\n \n # Display the annotated frame\n cv2.imshow(\"YOLOv8 Inference\", annotated_frame)\n \n # Break the loop if 'q' is pressed\n if cv2.waitKey(1) & 0xFF == ord(\"q\"):\n break\n else:\n # Break the loop if the end of the video is reached\n break\n \n # Release the video capture object and close the display window\n cap.release()\n cv2.destroyAllWindows()\n ```\n"
},
{
"path": "docs/modes/track.md",
"content": "---\ncomments: true\ndescription: Explore YOLOv8n-based object tracking with Ultralytics' BoT-SORT and ByteTrack. Learn configuration, usage, and customization tips.\n---\n\n\n\nObject tracking is a task that involves identifying the location and class of objects, then assigning a unique ID to\nthat detection in video streams.\n\nThe output of tracker is the same as detection with an added object ID.\n\n## Available Trackers\n\nThe following tracking algorithms have been implemented and can be enabled by passing `tracker=tracker_type.yaml`\n\n* [BoT-SORT](https://github.com/NirAharon/BoT-SORT) - `botsort.yaml`\n* [ByteTrack](https://github.com/ifzhang/ByteTrack) - `bytetrack.yaml`\n\nThe default tracker is BoT-SORT.\n\n## Tracking\n\nUse a trained YOLOv8n/YOLOv8n-seg model to run tracker on video streams.\n\n!!! example \"\"\n\n === \"Python\"\n \n ```python\n from ultralytics import YOLO\n \n # Load a model\n model = YOLO('yolov8n.pt') # load an official detection model\n model = YOLO('yolov8n-seg.pt') # load an official segmentation model\n model = YOLO('path/to/best.pt') # load a custom model\n \n # Track with the model\n results = model.track(source=\"https://youtu.be/Zgi9g1ksQHc\", show=True) \n results = model.track(source=\"https://youtu.be/Zgi9g1ksQHc\", show=True, tracker=\"bytetrack.yaml\") \n ```\n === \"CLI\"\n \n ```bash\n yolo track model=yolov8n.pt source=\"https://youtu.be/Zgi9g1ksQHc\" # official detection model\n yolo track model=yolov8n-seg.pt source=... # official segmentation model\n yolo track model=path/to/best.pt source=... # custom model\n yolo track model=path/to/best.pt tracker=\"bytetrack.yaml\" # bytetrack tracker\n\n ```\n\nAs in the above usage, we support both the detection and segmentation models for tracking and the only thing you need to\ndo is loading the corresponding (detection or segmentation) model.\n\n## Configuration\n\n### Tracking\n\nTracking shares the configuration with predict, i.e `conf`, `iou`, `show`. More configurations please refer\nto [predict page](https://docs.ultralytics.com/modes/predict/).\n!!! example \"\"\n\n === \"Python\"\n \n ```python\n from ultralytics import YOLO\n \n model = YOLO('yolov8n.pt')\n results = model.track(source=\"https://youtu.be/Zgi9g1ksQHc\", conf=0.3, iou=0.5, show=True) \n ```\n === \"CLI\"\n \n ```bash\n yolo track model=yolov8n.pt source=\"https://youtu.be/Zgi9g1ksQHc\" conf=0.3, iou=0.5 show\n\n ```\n\n### Tracker\n\nWe also support using a modified tracker config file, just copy a config file i.e `custom_tracker.yaml`\nfrom [ultralytics/tracker/cfg](https://github.com/ultralytics/ultralytics/tree/main/ultralytics/tracker/cfg) and modify\nany configurations(expect the `tracker_type`) you need to.\n!!! example \"\"\n\n === \"Python\"\n \n ```python\n from ultralytics import YOLO\n \n model = YOLO('yolov8n.pt')\n results = model.track(source=\"https://youtu.be/Zgi9g1ksQHc\", tracker='custom_tracker.yaml') \n ```\n === \"CLI\"\n \n ```bash\n yolo track model=yolov8n.pt source=\"https://youtu.be/Zgi9g1ksQHc\" tracker='custom_tracker.yaml'\n ```\n\nPlease refer to [ultralytics/tracker/cfg](https://github.com/ultralytics/ultralytics/tree/main/ultralytics/tracker/cfg)\npage\n\n"
},
{
"path": "docs/modes/train.md",
"content": "---\ncomments: true\ndescription: Learn how to train custom YOLOv8 models on various datasets, configure hyperparameters, and use Ultralytics' YOLO for seamless training.\n---\n\n\n\n**Train mode** is used for training a YOLOv8 model on a custom dataset. In this mode, the model is trained using the\nspecified dataset and hyperparameters. The training process involves optimizing the model's parameters so that it can\naccurately predict the classes and locations of objects in an image.\n\n!!! tip \"Tip\"\n\n * YOLOv8 datasets like COCO, VOC, ImageNet and many others automatically download on first use, i.e. `yolo train data=coco.yaml`\n\n## Usage Examples\n\nTrain YOLOv8n on the COCO128 dataset for 100 epochs at image size 640. See Arguments section below for a full list of\ntraining arguments.\n\n!!! example \"\"\n\n === \"Python\"\n \n ```python\n from ultralytics import YOLO\n \n # Load a model\n model = YOLO('yolov8n.yaml') # build a new model from YAML\n model = YOLO('yolov8n.pt') # load a pretrained model (recommended for training)\n model = YOLO('yolov8n.yaml').load('yolov8n.pt') # build from YAML and transfer weights\n \n # Train the model\n model.train(data='coco128.yaml', epochs=100, imgsz=640)\n ```\n === \"CLI\"\n \n ```bash\n # Build a new model from YAML and start training from scratch\n yolo detect train data=coco128.yaml model=yolov8n.yaml epochs=100 imgsz=640\n\n # Start training from a pretrained *.pt model\n yolo detect train data=coco128.yaml model=yolov8n.pt epochs=100 imgsz=640\n\n # Build a new model from YAML, transfer pretrained weights to it and start training\n yolo detect train data=coco128.yaml model=yolov8n.yaml pretrained=yolov8n.pt epochs=100 imgsz=640\n ```\n\n## Arguments\n\nTraining settings for YOLO models refer to the various hyperparameters and configurations used to train the model on a\ndataset. These settings can affect the model's performance, speed, and accuracy. Some common YOLO training settings\ninclude the batch size, learning rate, momentum, and weight decay. Other factors that may affect the training process\ninclude the choice of optimizer, the choice of loss function, and the size and composition of the training dataset. It\nis important to carefully tune and experiment with these settings to achieve the best possible performance for a given\ntask.\n\n| Key | Value | Description |\n|-------------------|----------|-----------------------------------------------------------------------------|\n| `model` | `None` | path to model file, i.e. yolov8n.pt, yolov8n.yaml |\n| `data` | `None` | path to data file, i.e. coco128.yaml |\n| `epochs` | `100` | number of epochs to train for |\n| `patience` | `50` | epochs to wait for no observable improvement for early stopping of training |\n| `batch` | `16` | number of images per batch (-1 for AutoBatch) |\n| `imgsz` | `640` | size of input images as integer or w,h |\n| `save` | `True` | save train checkpoints and predict results |\n| `save_period` | `-1` | Save checkpoint every x epochs (disabled if < 1) |\n| `cache` | `False` | True/ram, disk or False. Use cache for data loading |\n| `device` | `None` | device to run on, i.e. cuda device=0 or device=0,1,2,3 or device=cpu |\n| `workers` | `8` | number of worker threads for data loading (per RANK if DDP) |\n| `project` | `None` | project name |\n| `name` | `None` | experiment name |\n| `exist_ok` | `False` | whether to overwrite existing experiment |\n| `pretrained` | `False` | whether to use a pretrained model |\n| `optimizer` | `'SGD'` | optimizer to use, choices=['SGD', 'Adam', 'AdamW', 'RMSProp'] |\n| `verbose` | `False` | whether to print verbose output |\n| `seed` | `0` | random seed for reproducibility |\n| `deterministic` | `True` | whether to enable deterministic mode |\n| `single_cls` | `False` | train multi-class data as single-class |\n| `rect` | `False` | rectangular training with each batch collated for minimum padding |\n| `cos_lr` | `False` | use cosine learning rate scheduler |\n| `close_mosaic` | `0` | (int) disable mosaic augmentation for final epochs |\n| `resume` | `False` | resume training from last checkpoint |\n| `amp` | `True` | Automatic Mixed Precision (AMP) training, choices=[True, False] |\n| `lr0` | `0.01` | initial learning rate (i.e. SGD=1E-2, Adam=1E-3) |\n| `lrf` | `0.01` | final learning rate (lr0 * lrf) |\n| `momentum` | `0.937` | SGD momentum/Adam beta1 |\n| `weight_decay` | `0.0005` | optimizer weight decay 5e-4 |\n| `warmup_epochs` | `3.0` | warmup epochs (fractions ok) |\n| `warmup_momentum` | `0.8` | warmup initial momentum |\n| `warmup_bias_lr` | `0.1` | warmup initial bias lr |\n| `box` | `7.5` | box loss gain |\n| `cls` | `0.5` | cls loss gain (scale with pixels) |\n| `dfl` | `1.5` | dfl loss gain |\n| `pose` | `12.0` | pose loss gain (pose-only) |\n| `kobj` | `2.0` | keypoint obj loss gain (pose-only) |\n| `label_smoothing` | `0.0` | label smoothing (fraction) |\n| `nbs` | `64` | nominal batch size |\n| `overlap_mask` | `True` | masks should overlap during training (segment train only) |\n| `mask_ratio` | `4` | mask downsample ratio (segment train only) |\n| `dropout` | `0.0` | use dropout regularization (classify train only) |\n| `val` | `True` | validate/test during training |\n"
},
{
"path": "docs/modes/val.md",
"content": "---\ncomments: true\ndescription: Validate and improve YOLOv8n model accuracy on COCO128 and other datasets using hyperparameter & configuration tuning, in Val mode.\n---\n\n\n\n**Val mode** is used for validating a YOLOv8 model after it has been trained. In this mode, the model is evaluated on a\nvalidation set to measure its accuracy and generalization performance. This mode can be used to tune the hyperparameters\nof the model to improve its performance.\n\n!!! tip \"Tip\"\n\n * YOLOv8 models automatically remember their training settings, so you can validate a model at the same image size and on the original dataset easily with just `yolo val model=yolov8n.pt` or `model('yolov8n.pt').val()`\n\n## Usage Examples\n\nValidate trained YOLOv8n model accuracy on the COCO128 dataset. No argument need to passed as the `model` retains it's\ntraining `data` and arguments as model attributes. See Arguments section below for a full list of export arguments.\n\n!!! example \"\"\n\n === \"Python\"\n \n ```python\n from ultralytics import YOLO\n \n # Load a model\n model = YOLO('yolov8n.pt') # load an official model\n model = YOLO('path/to/best.pt') # load a custom model\n \n # Validate the model\n metrics = model.val() # no arguments needed, dataset and settings remembered\n metrics.box.map # map50-95\n metrics.box.map50 # map50\n metrics.box.map75 # map75\n metrics.box.maps # a list contains map50-95 of each category\n ```\n === \"CLI\"\n \n ```bash\n yolo detect val model=yolov8n.pt # val official model\n yolo detect val model=path/to/best.pt # val custom model\n ```\n\n## Arguments\n\nValidation settings for YOLO models refer to the various hyperparameters and configurations used to\nevaluate the model's performance on a validation dataset. These settings can affect the model's performance, speed, and\naccuracy. Some common YOLO validation settings include the batch size, the frequency with which validation is performed\nduring training, and the metrics used to evaluate the model's performance. Other factors that may affect the validation\nprocess include the size and composition of the validation dataset and the specific task the model is being used for. It\nis important to carefully tune and experiment with these settings to ensure that the model is performing well on the\nvalidation dataset and to detect and prevent overfitting.\n\n| Key | Value | Description |\n|---------------|---------|--------------------------------------------------------------------|\n| `data` | `None` | path to data file, i.e. coco128.yaml |\n| `imgsz` | `640` | image size as scalar or (h, w) list, i.e. (640, 480) |\n| `batch` | `16` | number of images per batch (-1 for AutoBatch) |\n| `save_json` | `False` | save results to JSON file |\n| `save_hybrid` | `False` | save hybrid version of labels (labels + additional predictions) |\n| `conf` | `0.001` | object confidence threshold for detection |\n| `iou` | `0.6` | intersection over union (IoU) threshold for NMS |\n| `max_det` | `300` | maximum number of detections per image |\n| `half` | `True` | use half precision (FP16) |\n| `device` | `None` | device to run on, i.e. cuda device=0/1/2/3 or device=cpu |\n| `dnn` | `False` | use OpenCV DNN for ONNX inference |\n| `plots` | `False` | show plots during training |\n| `rect` | `False` | rectangular val with each batch collated for minimum padding |\n| `split` | `val` | dataset split to use for validation, i.e. 'val', 'test' or 'train' |\n\n## Export Formats\n\nAvailable YOLOv8 export formats are in the table below. You can export to any format using the `format` argument,\ni.e. `format='onnx'` or `format='engine'`.\n\n| Format | `format` Argument | Model | Metadata | Arguments |\n|--------------------------------------------------------------------|-------------------|---------------------------|----------|-----------------------------------------------------|\n| [PyTorch](https://pytorch.org/) | - | `yolov8n.pt` | ✅ | - |\n| [TorchScript](https://pytorch.org/docs/stable/jit.html) | `torchscript` | `yolov8n.torchscript` | ✅ | `imgsz`, `optimize` |\n| [ONNX](https://onnx.ai/) | `onnx` | `yolov8n.onnx` | ✅ | `imgsz`, `half`, `dynamic`, `simplify`, `opset` |\n| [OpenVINO](https://docs.openvino.ai/latest/index.html) | `openvino` | `yolov8n_openvino_model/` | ✅ | `imgsz`, `half` |\n| [TensorRT](https://developer.nvidia.com/tensorrt) | `engine` | `yolov8n.engine` | ✅ | `imgsz`, `half`, `dynamic`, `simplify`, `workspace` |\n| [CoreML](https://github.com/apple/coremltools) | `coreml` | `yolov8n.mlmodel` | ✅ | `imgsz`, `half`, `int8`, `nms` |\n| [TF SavedModel](https://www.tensorflow.org/guide/saved_model) | `saved_model` | `yolov8n_saved_model/` | ✅ | `imgsz`, `keras` |\n| [TF GraphDef](https://www.tensorflow.org/api_docs/python/tf/Graph) | `pb` | `yolov8n.pb` | ❌ | `imgsz` |\n| [TF Lite](https://www.tensorflow.org/lite) | `tflite` | `yolov8n.tflite` | ✅ | `imgsz`, `half`, `int8` |\n| [TF Edge TPU](https://coral.ai/docs/edgetpu/models-intro/) | `edgetpu` | `yolov8n_edgetpu.tflite` | ✅ | `imgsz` |\n| [TF.js](https://www.tensorflow.org/js) | `tfjs` | `yolov8n_web_model/` | ✅ | `imgsz` |\n| [PaddlePaddle](https://github.com/PaddlePaddle) | `paddle` | `yolov8n_paddle_model/` | ✅ | `imgsz` |"
},
{
"path": "docs/overrides/partials/comments.html",
"content": "{% if page.meta.comments %}\n\n\n\n\n\n\n\n{% endif %}\n"
},
{
"path": "docs/overrides/partials/source-file.html",
"content": "{% import \"partials/language.html\" as lang with context %}\n\n\n\n
\n\n**Benchmark mode** is used to profile the speed and accuracy of various export formats for YOLOv8. The benchmarks\nprovide information on the size of the exported format, its `mAP50-95` metrics (for object detection, segmentation and pose)\nor `accuracy_top5` metrics (for classification), and the inference time in milliseconds per image across various export\nformats like ONNX, OpenVINO, TensorRT and others. This information can help users choose the optimal export format for\ntheir specific use case based on their requirements for speed and accuracy.\n\n!!! tip \"Tip\"\n\n * Export to ONNX or OpenVINO for up to 3x CPU speedup.\n * Export to TensorRT for up to 5x GPU speedup.\n\n## Usage Examples\n\nRun YOLOv8n benchmarks on all supported export formats including ONNX, TensorRT etc. See Arguments section below for a\nfull list of export arguments.\n\n!!! example \"\"\n\n === \"Python\"\n \n ```python\n from ultralytics.yolo.utils.benchmarks import benchmark\n \n # Benchmark on GPU\n benchmark(model='yolov8n.pt', imgsz=640, half=False, device=0)\n ```\n === \"CLI\"\n \n ```bash\n yolo benchmark model=yolov8n.pt imgsz=640 half=False device=0\n ```\n\n## Arguments\n\nArguments such as `model`, `imgsz`, `half`, `device`, and `hard_fail` provide users with the flexibility to fine-tune\nthe benchmarks to their specific needs and compare the performance of different export formats with ease.\n\n| Key | Value | Description |\n|-------------|---------|----------------------------------------------------------------------|\n| `model` | `None` | path to model file, i.e. yolov8n.pt, yolov8n.yaml |\n| `imgsz` | `640` | image size as scalar or (h, w) list, i.e. (640, 480) |\n| `half` | `False` | FP16 quantization |\n| `int8` | `False` | INT8 quantization |\n| `device` | `None` | device to run on, i.e. cuda device=0 or device=0,1,2,3 or device=cpu |\n| `hard_fail` | `False` | do not continue on error (bool), or val floor threshold (float) |\n\n## Export Formats\n\nBenchmarks will attempt to run automatically on all possible export formats below.\n\n| Format | `format` Argument | Model | Metadata |\n|--------------------------------------------------------------------|-------------------|---------------------------|----------|\n| [PyTorch](https://pytorch.org/) | - | `yolov8n.pt` | ✅ |\n| [TorchScript](https://pytorch.org/docs/stable/jit.html) | `torchscript` | `yolov8n.torchscript` | ✅ |\n| [ONNX](https://onnx.ai/) | `onnx` | `yolov8n.onnx` | ✅ |\n| [OpenVINO](https://docs.openvino.ai/latest/index.html) | `openvino` | `yolov8n_openvino_model/` | ✅ |\n| [TensorRT](https://developer.nvidia.com/tensorrt) | `engine` | `yolov8n.engine` | ✅ |\n| [CoreML](https://github.com/apple/coremltools) | `coreml` | `yolov8n.mlmodel` | ✅ |\n| [TF SavedModel](https://www.tensorflow.org/guide/saved_model) | `saved_model` | `yolov8n_saved_model/` | ✅ |\n| [TF GraphDef](https://www.tensorflow.org/api_docs/python/tf/Graph) | `pb` | `yolov8n.pb` | ❌ |\n| [TF Lite](https://www.tensorflow.org/lite) | `tflite` | `yolov8n.tflite` | ✅ |\n| [TF Edge TPU](https://coral.ai/docs/edgetpu/models-intro/) | `edgetpu` | `yolov8n_edgetpu.tflite` | ✅ |\n| [TF.js](https://www.tensorflow.org/js) | `tfjs` | `yolov8n_web_model/` | ✅ |\n| [PaddlePaddle](https://github.com/PaddlePaddle) | `paddle` | `yolov8n_paddle_model/` | ✅ |\n\nSee full `export` details in the [Export](https://docs.ultralytics.com/modes/export/) page."
},
{
"path": "docs/modes/export.md",
"content": "---\ncomments: true\ndescription: 'Export mode: Create a deployment-ready YOLOv8 model by converting it to various formats. Export to ONNX or OpenVINO for up to 3x CPU speedup.'\n---\n\n\n\n**Export mode** is used for exporting a YOLOv8 model to a format that can be used for deployment. In this mode, the\nmodel is converted to a format that can be used by other software applications or hardware devices. This mode is useful\nwhen deploying the model to production environments.\n\n!!! tip \"Tip\"\n\n * Export to ONNX or OpenVINO for up to 3x CPU speedup.\n * Export to TensorRT for up to 5x GPU speedup.\n\n## Usage Examples\n\nExport a YOLOv8n model to a different format like ONNX or TensorRT. See Arguments section below for a full list of\nexport arguments.\n\n!!! example \"\"\n\n === \"Python\"\n \n ```python\n from ultralytics import YOLO\n \n # Load a model\n model = YOLO('yolov8n.pt') # load an official model\n model = YOLO('path/to/best.pt') # load a custom trained\n \n # Export the model\n model.export(format='onnx')\n ```\n === \"CLI\"\n \n ```bash\n yolo export model=yolov8n.pt format=onnx # export official model\n yolo export model=path/to/best.pt format=onnx # export custom trained model\n ```\n\n## Arguments\n\nExport settings for YOLO models refer to the various configurations and options used to save or\nexport the model for use in other environments or platforms. These settings can affect the model's performance, size,\nand compatibility with different systems. Some common YOLO export settings include the format of the exported model\nfile (e.g. ONNX, TensorFlow SavedModel), the device on which the model will be run (e.g. CPU, GPU), and the presence of\nadditional features such as masks or multiple labels per box. Other factors that may affect the export process include\nthe specific task the model is being used for and the requirements or constraints of the target environment or platform.\nIt is important to carefully consider and configure these settings to ensure that the exported model is optimized for\nthe intended use case and can be used effectively in the target environment.\n\n| Key | Value | Description |\n|-------------|-----------------|------------------------------------------------------|\n| `format` | `'torchscript'` | format to export to |\n| `imgsz` | `640` | image size as scalar or (h, w) list, i.e. (640, 480) |\n| `keras` | `False` | use Keras for TF SavedModel export |\n| `optimize` | `False` | TorchScript: optimize for mobile |\n| `half` | `False` | FP16 quantization |\n| `int8` | `False` | INT8 quantization |\n| `dynamic` | `False` | ONNX/TensorRT: dynamic axes |\n| `simplify` | `False` | ONNX/TensorRT: simplify model |\n| `opset` | `None` | ONNX: opset version (optional, defaults to latest) |\n| `workspace` | `4` | TensorRT: workspace size (GB) |\n| `nms` | `False` | CoreML: add NMS |\n\n## Export Formats\n\nAvailable YOLOv8 export formats are in the table below. You can export to any format using the `format` argument,\ni.e. `format='onnx'` or `format='engine'`.\n\n| Format | `format` Argument | Model | Metadata | Arguments |\n|--------------------------------------------------------------------|-------------------|---------------------------|----------|-----------------------------------------------------|\n| [PyTorch](https://pytorch.org/) | - | `yolov8n.pt` | ✅ | - |\n| [TorchScript](https://pytorch.org/docs/stable/jit.html) | `torchscript` | `yolov8n.torchscript` | ✅ | `imgsz`, `optimize` |\n| [ONNX](https://onnx.ai/) | `onnx` | `yolov8n.onnx` | ✅ | `imgsz`, `half`, `dynamic`, `simplify`, `opset` |\n| [OpenVINO](https://docs.openvino.ai/latest/index.html) | `openvino` | `yolov8n_openvino_model/` | ✅ | `imgsz`, `half` |\n| [TensorRT](https://developer.nvidia.com/tensorrt) | `engine` | `yolov8n.engine` | ✅ | `imgsz`, `half`, `dynamic`, `simplify`, `workspace` |\n| [CoreML](https://github.com/apple/coremltools) | `coreml` | `yolov8n.mlmodel` | ✅ | `imgsz`, `half`, `int8`, `nms` |\n| [TF SavedModel](https://www.tensorflow.org/guide/saved_model) | `saved_model` | `yolov8n_saved_model/` | ✅ | `imgsz`, `keras` |\n| [TF GraphDef](https://www.tensorflow.org/api_docs/python/tf/Graph) | `pb` | `yolov8n.pb` | ❌ | `imgsz` |\n| [TF Lite](https://www.tensorflow.org/lite) | `tflite` | `yolov8n.tflite` | ✅ | `imgsz`, `half`, `int8` |\n| [TF Edge TPU](https://coral.ai/docs/edgetpu/models-intro/) | `edgetpu` | `yolov8n_edgetpu.tflite` | ✅ | `imgsz` |\n| [TF.js](https://www.tensorflow.org/js) | `tfjs` | `yolov8n_web_model/` | ✅ | `imgsz` |\n| [PaddlePaddle](https://github.com/PaddlePaddle) | `paddle` | `yolov8n_paddle_model/` | ✅ | `imgsz` |"
},
{
"path": "docs/modes/index.md",
"content": "---\ncomments: true\ndescription: Use Ultralytics YOLOv8 Modes (Train, Val, Predict, Export, Track, Benchmark) to train, validate, predict, track, export or benchmark.\n---\n\n# Ultralytics YOLOv8 Modes\n\n\n\nUltralytics YOLOv8 supports several **modes** that can be used to perform different tasks. These modes are:\n\n**Train**: For training a YOLOv8 model on a custom dataset. \n**Val**: For validating a YOLOv8 model after it has been trained. \n**Predict**: For making predictions using a trained YOLOv8 model on new images or videos. \n**Export**: For exporting a YOLOv8 model to a format that can be used for deployment. \n**Track**: For tracking objects in real-time using a YOLOv8 model. \n**Benchmark**: For benchmarking YOLOv8 exports (ONNX, TensorRT, etc.) speed and accuracy.\n\n## [Train](train.md)\n\nTrain mode is used for training a YOLOv8 model on a custom dataset. In this mode, the model is trained using the\nspecified dataset and hyperparameters. The training process involves optimizing the model's parameters so that it can\naccurately predict the classes and locations of objects in an image.\n\n[Train Examples](train.md){ .md-button .md-button--primary}\n\n## [Val](val.md)\n\nVal mode is used for validating a YOLOv8 model after it has been trained. In this mode, the model is evaluated on a\nvalidation set to measure its accuracy and generalization performance. This mode can be used to tune the hyperparameters\nof the model to improve its performance.\n\n[Val Examples](val.md){ .md-button .md-button--primary}\n\n## [Predict](predict.md)\n\nPredict mode is used for making predictions using a trained YOLOv8 model on new images or videos. In this mode, the\nmodel is loaded from a checkpoint file, and the user can provide images or videos to perform inference. The model\npredicts the classes and locations of objects in the input images or videos.\n\n[Predict Examples](predict.md){ .md-button .md-button--primary}\n\n## [Export](export.md)\n\nExport mode is used for exporting a YOLOv8 model to a format that can be used for deployment. In this mode, the model is\nconverted to a format that can be used by other software applications or hardware devices. This mode is useful when\ndeploying the model to production environments.\n\n[Export Examples](export.md){ .md-button .md-button--primary}\n\n## [Track](track.md)\n\nTrack mode is used for tracking objects in real-time using a YOLOv8 model. In this mode, the model is loaded from a\ncheckpoint file, and the user can provide a live video stream to perform real-time object tracking. This mode is useful\nfor applications such as surveillance systems or self-driving cars.\n\n[Track Examples](track.md){ .md-button .md-button--primary}\n\n## [Benchmark](benchmark.md)\n\nBenchmark mode is used to profile the speed and accuracy of various export formats for YOLOv8. The benchmarks provide\ninformation on the size of the exported format, its `mAP50-95` metrics (for object detection, segmentation and pose)\nor `accuracy_top5` metrics (for classification), and the inference time in milliseconds per image across various export\nformats like ONNX, OpenVINO, TensorRT and others. This information can help users choose the optimal export format for\ntheir specific use case based on their requirements for speed and accuracy.\n\n[Benchmark Examples](benchmark.md){ .md-button .md-button--primary}"
},
{
"path": "docs/modes/predict.md",
"content": "---\ncomments: true\ndescription: Get started with YOLOv8 Predict mode and input sources. Accepts various input sources such as images, videos, and directories.\n---\n\n\n\nYOLOv8 **predict mode** can generate predictions for various tasks, returning either a list of `Results` objects or a\nmemory-efficient generator of `Results` objects when using the streaming mode. Enable streaming mode by\npassing `stream=True` in the predictor's call method.\n\n!!! example \"Predict\"\n\n === \"Return a list with `Stream=False`\"\n ```python\n inputs = [img, img] # list of numpy arrays\n results = model(inputs) # list of Results objects\n \n for result in results:\n boxes = result.boxes # Boxes object for bbox outputs\n masks = result.masks # Masks object for segmentation masks outputs\n probs = result.probs # Class probabilities for classification outputs\n ```\n\n === \"Return a generator with `Stream=True`\"\n ```python\n inputs = [img, img] # list of numpy arrays\n results = model(inputs, stream=True) # generator of Results objects\n \n for result in results:\n boxes = result.boxes # Boxes object for bbox outputs\n masks = result.masks # Masks object for segmentation masks outputs\n probs = result.probs # Class probabilities for classification outputs\n ```\n\n!!! tip \"Tip\"\n\n Streaming mode with `stream=True` should be used for long videos or large predict sources, otherwise results will accumuate in memory and will eventually cause out-of-memory errors. \n\n## Sources\n\nYOLOv8 can accept various input sources, as shown in the table below. This includes images, URLs, PIL images, OpenCV,\nnumpy arrays, torch tensors, CSV files, videos, directories, globs, YouTube videos, and streams. The table indicates\nwhether each source can be used in streaming mode with `stream=True` ✅ and an example argument for each source.\n\n| source | model(arg) | type | notes |\n|-------------|--------------------------------------------|----------------|------------------|\n| image | `'im.jpg'` | `str`, `Path` | |\n| URL | `'https://ultralytics.com/images/bus.jpg'` | `str` | |\n| screenshot | `'screen'` | `str` | |\n| PIL | `Image.open('im.jpg')` | `PIL.Image` | HWC, RGB |\n| OpenCV | `cv2.imread('im.jpg')` | `np.ndarray` | HWC, BGR |\n| numpy | `np.zeros((640,1280,3))` | `np.ndarray` | HWC |\n| torch | `torch.zeros(16,3,320,640)` | `torch.Tensor` | BCHW, RGB |\n| CSV | `'sources.csv'` | `str`, `Path` | RTSP, RTMP, HTTP | \n| video ✅ | `'vid.mp4'` | `str`, `Path` | |\n| directory ✅ | `'path/'` | `str`, `Path` | |\n| glob ✅ | `'path/*.jpg'` | `str` | Use `*` operator |\n| YouTube ✅ | `'https://youtu.be/Zgi9g1ksQHc'` | `str` | |\n| stream ✅ | `'rtsp://example.com/media.mp4'` | `str` | RTSP, RTMP, HTTP |\n\n## Arguments\n\n`model.predict` accepts multiple arguments that control the prediction operation. These arguments can be passed directly to `model.predict`:\n!!! example\n\n ```\n model.predict(source, save=True, imgsz=320, conf=0.5)\n ```\n\nAll supported arguments:\n\n| Key | Value | Description |\n|----------------|------------------------|--------------------------------------------------------------------------------|\n| `source` | `'ultralytics/assets'` | source directory for images or videos |\n| `conf` | `0.25` | object confidence threshold for detection |\n| `iou` | `0.7` | intersection over union (IoU) threshold for NMS |\n| `half` | `False` | use half precision (FP16) |\n| `device` | `None` | device to run on, i.e. cuda device=0/1/2/3 or device=cpu |\n| `show` | `False` | show results if possible |\n| `save` | `False` | save images with results |\n| `save_txt` | `False` | save results as .txt file |\n| `save_conf` | `False` | save results with confidence scores |\n| `save_crop` | `False` | save cropped images with results |\n| `hide_labels` | `False` | hide labels |\n| `hide_conf` | `False` | hide confidence scores |\n| `max_det` | `300` | maximum number of detections per image |\n| `vid_stride` | `False` | video frame-rate stride |\n| `line_width` | `None` | The line width of the bounding boxes. If None, it is scaled to the image size. |\n| `visualize` | `False` | visualize model features |\n| `augment` | `False` | apply image augmentation to prediction sources |\n| `agnostic_nms` | `False` | class-agnostic NMS |\n| `retina_masks` | `False` | use high-resolution segmentation masks |\n| `classes` | `None` | filter results by class, i.e. class=0, or class=[0,2,3] |\n| `boxes` | `True` | Show boxes in segmentation predictions |\n\n## Image and Video Formats\n\nYOLOv8 supports various image and video formats, as specified\nin [yolo/data/utils.py](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/yolo/data/utils.py). See the\ntables below for the valid suffixes and example predict commands.\n\n### Image Suffixes\n\n| Image Suffixes | Example Predict Command | Reference |\n|----------------|----------------------------------|-------------------------------------------------------------------------------|\n| .bmp | `yolo predict source=image.bmp` | [Microsoft BMP File Format](https://en.wikipedia.org/wiki/BMP_file_format) |\n| .dng | `yolo predict source=image.dng` | [Adobe DNG](https://www.adobe.com/products/photoshop/extend.displayTab2.html) |\n| .jpeg | `yolo predict source=image.jpeg` | [JPEG](https://en.wikipedia.org/wiki/JPEG) |\n| .jpg | `yolo predict source=image.jpg` | [JPEG](https://en.wikipedia.org/wiki/JPEG) |\n| .mpo | `yolo predict source=image.mpo` | [Multi Picture Object](https://fileinfo.com/extension/mpo) |\n| .png | `yolo predict source=image.png` | [Portable Network Graphics](https://en.wikipedia.org/wiki/PNG) |\n| .tif | `yolo predict source=image.tif` | [Tag Image File Format](https://en.wikipedia.org/wiki/TIFF) |\n| .tiff | `yolo predict source=image.tiff` | [Tag Image File Format](https://en.wikipedia.org/wiki/TIFF) |\n| .webp | `yolo predict source=image.webp` | [WebP](https://en.wikipedia.org/wiki/WebP) |\n| .pfm | `yolo predict source=image.pfm` | [Portable FloatMap](https://en.wikipedia.org/wiki/Netpbm#File_formats) |\n\n### Video Suffixes\n\n| Video Suffixes | Example Predict Command | Reference |\n|----------------|----------------------------------|----------------------------------------------------------------------------------|\n| .asf | `yolo predict source=video.asf` | [Advanced Systems Format](https://en.wikipedia.org/wiki/Advanced_Systems_Format) |\n| .avi | `yolo predict source=video.avi` | [Audio Video Interleave](https://en.wikipedia.org/wiki/Audio_Video_Interleave) |\n| .gif | `yolo predict source=video.gif` | [Graphics Interchange Format](https://en.wikipedia.org/wiki/GIF) |\n| .m4v | `yolo predict source=video.m4v` | [MPEG-4 Part 14](https://en.wikipedia.org/wiki/M4V) |\n| .mkv | `yolo predict source=video.mkv` | [Matroska](https://en.wikipedia.org/wiki/Matroska) |\n| .mov | `yolo predict source=video.mov` | [QuickTime File Format](https://en.wikipedia.org/wiki/QuickTime_File_Format) |\n| .mp4 | `yolo predict source=video.mp4` | [MPEG-4 Part 14 - Wikipedia](https://en.wikipedia.org/wiki/MPEG-4_Part_14) |\n| .mpeg | `yolo predict source=video.mpeg` | [MPEG-1 Part 2](https://en.wikipedia.org/wiki/MPEG-1) |\n| .mpg | `yolo predict source=video.mpg` | [MPEG-1 Part 2](https://en.wikipedia.org/wiki/MPEG-1) |\n| .ts | `yolo predict source=video.ts` | [MPEG Transport Stream](https://en.wikipedia.org/wiki/MPEG_transport_stream) |\n| .wmv | `yolo predict source=video.wmv` | [Windows Media Video](https://en.wikipedia.org/wiki/Windows_Media_Video) |\n| .webm | `yolo predict source=video.webm` | [WebM Project](https://en.wikipedia.org/wiki/WebM) |\n\n## Working with Results\n\nThe `Results` object contains the following components:\n\n- `Results.boxes`: `Boxes` object with properties and methods for manipulating bounding boxes\n- `Results.masks`: `Masks` object for indexing masks or getting segment coordinates\n- `Results.probs`: `torch.Tensor` containing class probabilities or logits\n- `Results.orig_img`: Original image loaded in memory\n- `Results.path`: `Path` containing the path to the input image\n\nEach result is composed of a `torch.Tensor` by default, which allows for easy manipulation:\n\n!!! example \"Results\"\n\n ```python\n results = results.cuda()\n results = results.cpu()\n results = results.to('cpu')\n results = results.numpy()\n ```\n\n### Boxes\n\n`Boxes` object can be used to index, manipulate, and convert bounding boxes to different formats. Box format conversion\noperations are cached, meaning they're only calculated once per object, and those values are reused for future calls.\n\n- Indexing a `Boxes` object returns a `Boxes` object:\n\n!!! example \"Boxes\"\n\n ```python\n results = model(img)\n boxes = results[0].boxes\n box = boxes[0] # returns one box\n box.xyxy\n ```\n\n- Properties and conversions\n\n!!! example \"Boxes Properties\"\n\n ```python\n boxes.xyxy # box with xyxy format, (N, 4)\n boxes.xywh # box with xywh format, (N, 4)\n boxes.xyxyn # box with xyxy format but normalized, (N, 4)\n boxes.xywhn # box with xywh format but normalized, (N, 4)\n boxes.conf # confidence score, (N, 1)\n boxes.cls # cls, (N, 1)\n boxes.data # raw bboxes tensor, (N, 6) or boxes.boxes\n ```\n\n### Masks\n\n`Masks` object can be used index, manipulate and convert masks to segments. The segment conversion operation is cached.\n\n!!! example \"Masks\"\n\n ```python\n results = model(inputs)\n masks = results[0].masks # Masks object\n masks.xy # x, y segments (pixels), List[segment] * N\n masks.xyn # x, y segments (normalized), List[segment] * N\n masks.data # raw masks tensor, (N, H, W) or masks.masks \n ```\n\n### probs\n\n`probs` attribute of `Results` class is a `Tensor` containing class probabilities of a classification operation.\n\n!!! example \"Probs\"\n\n ```python\n results = model(inputs)\n results[0].probs # cls prob, (num_class, )\n ```\n\nClass reference documentation for `Results` module and its components can be found [here](../reference/yolo/engine/results.md)\n\n## Plotting results\n\nYou can use `plot()` function of `Result` object to plot results on in image object. It plots all components(boxes,\nmasks, classification logits, etc.) found in the results object\n\n!!! example \"Plotting\"\n\n ```python\n res = model(img)\n res_plotted = res[0].plot()\n cv2.imshow(\"result\", res_plotted)\n ```\n\n| Argument | Description |\n|-------------------------------|----------------------------------------------------------------------------------------|\n| `conf (bool)` | Whether to plot the detection confidence score. |\n| `line_width (int, optional)` | The line width of the bounding boxes. If None, it is scaled to the image size. |\n| `font_size (float, optional)` | The font size of the text. If None, it is scaled to the image size. |\n| `font (str)` | The font to use for the text. |\n| `pil (bool)` | Whether to use PIL for image plotting. |\n| `example (str)` | An example string to display. Useful for indicating the expected format of the output. |\n| `img (numpy.ndarray)` | Plot to another image. if not, plot to original image. |\n| `labels (bool)` | Whether to plot the label of bounding boxes. |\n| `boxes (bool)` | Whether to plot the bounding boxes. |\n| `masks (bool)` | Whether to plot the masks. |\n| `probs (bool)` | Whether to plot classification probability. |\n\n## Streaming Source `for`-loop\n\nHere's a Python script using OpenCV (cv2) and YOLOv8 to run inference on video frames. This script assumes you have already installed the necessary packages (opencv-python and ultralytics).\n\n!!! example \"Streaming for-loop\"\n\n ```python\n import cv2\n from ultralytics import YOLO\n \n # Load the YOLOv8 model\n model = YOLO('yolov8n.pt')\n \n # Open the video file\n video_path = \"path/to/your/video/file.mp4\"\n cap = cv2.VideoCapture(video_path)\n \n # Loop through the video frames\n while cap.isOpened():\n # Read a frame from the video\n success, frame = cap.read()\n \n if success:\n # Run YOLOv8 inference on the frame\n results = model(frame)\n \n # Visualize the results on the frame\n annotated_frame = results[0].plot()\n \n # Display the annotated frame\n cv2.imshow(\"YOLOv8 Inference\", annotated_frame)\n \n # Break the loop if 'q' is pressed\n if cv2.waitKey(1) & 0xFF == ord(\"q\"):\n break\n else:\n # Break the loop if the end of the video is reached\n break\n \n # Release the video capture object and close the display window\n cap.release()\n cv2.destroyAllWindows()\n ```\n"
},
{
"path": "docs/modes/track.md",
"content": "---\ncomments: true\ndescription: Explore YOLOv8n-based object tracking with Ultralytics' BoT-SORT and ByteTrack. Learn configuration, usage, and customization tips.\n---\n\n\n\nObject tracking is a task that involves identifying the location and class of objects, then assigning a unique ID to\nthat detection in video streams.\n\nThe output of tracker is the same as detection with an added object ID.\n\n## Available Trackers\n\nThe following tracking algorithms have been implemented and can be enabled by passing `tracker=tracker_type.yaml`\n\n* [BoT-SORT](https://github.com/NirAharon/BoT-SORT) - `botsort.yaml`\n* [ByteTrack](https://github.com/ifzhang/ByteTrack) - `bytetrack.yaml`\n\nThe default tracker is BoT-SORT.\n\n## Tracking\n\nUse a trained YOLOv8n/YOLOv8n-seg model to run tracker on video streams.\n\n!!! example \"\"\n\n === \"Python\"\n \n ```python\n from ultralytics import YOLO\n \n # Load a model\n model = YOLO('yolov8n.pt') # load an official detection model\n model = YOLO('yolov8n-seg.pt') # load an official segmentation model\n model = YOLO('path/to/best.pt') # load a custom model\n \n # Track with the model\n results = model.track(source=\"https://youtu.be/Zgi9g1ksQHc\", show=True) \n results = model.track(source=\"https://youtu.be/Zgi9g1ksQHc\", show=True, tracker=\"bytetrack.yaml\") \n ```\n === \"CLI\"\n \n ```bash\n yolo track model=yolov8n.pt source=\"https://youtu.be/Zgi9g1ksQHc\" # official detection model\n yolo track model=yolov8n-seg.pt source=... # official segmentation model\n yolo track model=path/to/best.pt source=... # custom model\n yolo track model=path/to/best.pt tracker=\"bytetrack.yaml\" # bytetrack tracker\n\n ```\n\nAs in the above usage, we support both the detection and segmentation models for tracking and the only thing you need to\ndo is loading the corresponding (detection or segmentation) model.\n\n## Configuration\n\n### Tracking\n\nTracking shares the configuration with predict, i.e `conf`, `iou`, `show`. More configurations please refer\nto [predict page](https://docs.ultralytics.com/modes/predict/).\n!!! example \"\"\n\n === \"Python\"\n \n ```python\n from ultralytics import YOLO\n \n model = YOLO('yolov8n.pt')\n results = model.track(source=\"https://youtu.be/Zgi9g1ksQHc\", conf=0.3, iou=0.5, show=True) \n ```\n === \"CLI\"\n \n ```bash\n yolo track model=yolov8n.pt source=\"https://youtu.be/Zgi9g1ksQHc\" conf=0.3, iou=0.5 show\n\n ```\n\n### Tracker\n\nWe also support using a modified tracker config file, just copy a config file i.e `custom_tracker.yaml`\nfrom [ultralytics/tracker/cfg](https://github.com/ultralytics/ultralytics/tree/main/ultralytics/tracker/cfg) and modify\nany configurations(expect the `tracker_type`) you need to.\n!!! example \"\"\n\n === \"Python\"\n \n ```python\n from ultralytics import YOLO\n \n model = YOLO('yolov8n.pt')\n results = model.track(source=\"https://youtu.be/Zgi9g1ksQHc\", tracker='custom_tracker.yaml') \n ```\n === \"CLI\"\n \n ```bash\n yolo track model=yolov8n.pt source=\"https://youtu.be/Zgi9g1ksQHc\" tracker='custom_tracker.yaml'\n ```\n\nPlease refer to [ultralytics/tracker/cfg](https://github.com/ultralytics/ultralytics/tree/main/ultralytics/tracker/cfg)\npage\n\n"
},
{
"path": "docs/modes/train.md",
"content": "---\ncomments: true\ndescription: Learn how to train custom YOLOv8 models on various datasets, configure hyperparameters, and use Ultralytics' YOLO for seamless training.\n---\n\n\n\n**Train mode** is used for training a YOLOv8 model on a custom dataset. In this mode, the model is trained using the\nspecified dataset and hyperparameters. The training process involves optimizing the model's parameters so that it can\naccurately predict the classes and locations of objects in an image.\n\n!!! tip \"Tip\"\n\n * YOLOv8 datasets like COCO, VOC, ImageNet and many others automatically download on first use, i.e. `yolo train data=coco.yaml`\n\n## Usage Examples\n\nTrain YOLOv8n on the COCO128 dataset for 100 epochs at image size 640. See Arguments section below for a full list of\ntraining arguments.\n\n!!! example \"\"\n\n === \"Python\"\n \n ```python\n from ultralytics import YOLO\n \n # Load a model\n model = YOLO('yolov8n.yaml') # build a new model from YAML\n model = YOLO('yolov8n.pt') # load a pretrained model (recommended for training)\n model = YOLO('yolov8n.yaml').load('yolov8n.pt') # build from YAML and transfer weights\n \n # Train the model\n model.train(data='coco128.yaml', epochs=100, imgsz=640)\n ```\n === \"CLI\"\n \n ```bash\n # Build a new model from YAML and start training from scratch\n yolo detect train data=coco128.yaml model=yolov8n.yaml epochs=100 imgsz=640\n\n # Start training from a pretrained *.pt model\n yolo detect train data=coco128.yaml model=yolov8n.pt epochs=100 imgsz=640\n\n # Build a new model from YAML, transfer pretrained weights to it and start training\n yolo detect train data=coco128.yaml model=yolov8n.yaml pretrained=yolov8n.pt epochs=100 imgsz=640\n ```\n\n## Arguments\n\nTraining settings for YOLO models refer to the various hyperparameters and configurations used to train the model on a\ndataset. These settings can affect the model's performance, speed, and accuracy. Some common YOLO training settings\ninclude the batch size, learning rate, momentum, and weight decay. Other factors that may affect the training process\ninclude the choice of optimizer, the choice of loss function, and the size and composition of the training dataset. It\nis important to carefully tune and experiment with these settings to achieve the best possible performance for a given\ntask.\n\n| Key | Value | Description |\n|-------------------|----------|-----------------------------------------------------------------------------|\n| `model` | `None` | path to model file, i.e. yolov8n.pt, yolov8n.yaml |\n| `data` | `None` | path to data file, i.e. coco128.yaml |\n| `epochs` | `100` | number of epochs to train for |\n| `patience` | `50` | epochs to wait for no observable improvement for early stopping of training |\n| `batch` | `16` | number of images per batch (-1 for AutoBatch) |\n| `imgsz` | `640` | size of input images as integer or w,h |\n| `save` | `True` | save train checkpoints and predict results |\n| `save_period` | `-1` | Save checkpoint every x epochs (disabled if < 1) |\n| `cache` | `False` | True/ram, disk or False. Use cache for data loading |\n| `device` | `None` | device to run on, i.e. cuda device=0 or device=0,1,2,3 or device=cpu |\n| `workers` | `8` | number of worker threads for data loading (per RANK if DDP) |\n| `project` | `None` | project name |\n| `name` | `None` | experiment name |\n| `exist_ok` | `False` | whether to overwrite existing experiment |\n| `pretrained` | `False` | whether to use a pretrained model |\n| `optimizer` | `'SGD'` | optimizer to use, choices=['SGD', 'Adam', 'AdamW', 'RMSProp'] |\n| `verbose` | `False` | whether to print verbose output |\n| `seed` | `0` | random seed for reproducibility |\n| `deterministic` | `True` | whether to enable deterministic mode |\n| `single_cls` | `False` | train multi-class data as single-class |\n| `rect` | `False` | rectangular training with each batch collated for minimum padding |\n| `cos_lr` | `False` | use cosine learning rate scheduler |\n| `close_mosaic` | `0` | (int) disable mosaic augmentation for final epochs |\n| `resume` | `False` | resume training from last checkpoint |\n| `amp` | `True` | Automatic Mixed Precision (AMP) training, choices=[True, False] |\n| `lr0` | `0.01` | initial learning rate (i.e. SGD=1E-2, Adam=1E-3) |\n| `lrf` | `0.01` | final learning rate (lr0 * lrf) |\n| `momentum` | `0.937` | SGD momentum/Adam beta1 |\n| `weight_decay` | `0.0005` | optimizer weight decay 5e-4 |\n| `warmup_epochs` | `3.0` | warmup epochs (fractions ok) |\n| `warmup_momentum` | `0.8` | warmup initial momentum |\n| `warmup_bias_lr` | `0.1` | warmup initial bias lr |\n| `box` | `7.5` | box loss gain |\n| `cls` | `0.5` | cls loss gain (scale with pixels) |\n| `dfl` | `1.5` | dfl loss gain |\n| `pose` | `12.0` | pose loss gain (pose-only) |\n| `kobj` | `2.0` | keypoint obj loss gain (pose-only) |\n| `label_smoothing` | `0.0` | label smoothing (fraction) |\n| `nbs` | `64` | nominal batch size |\n| `overlap_mask` | `True` | masks should overlap during training (segment train only) |\n| `mask_ratio` | `4` | mask downsample ratio (segment train only) |\n| `dropout` | `0.0` | use dropout regularization (classify train only) |\n| `val` | `True` | validate/test during training |\n"
},
{
"path": "docs/modes/val.md",
"content": "---\ncomments: true\ndescription: Validate and improve YOLOv8n model accuracy on COCO128 and other datasets using hyperparameter & configuration tuning, in Val mode.\n---\n\n\n\n**Val mode** is used for validating a YOLOv8 model after it has been trained. In this mode, the model is evaluated on a\nvalidation set to measure its accuracy and generalization performance. This mode can be used to tune the hyperparameters\nof the model to improve its performance.\n\n!!! tip \"Tip\"\n\n * YOLOv8 models automatically remember their training settings, so you can validate a model at the same image size and on the original dataset easily with just `yolo val model=yolov8n.pt` or `model('yolov8n.pt').val()`\n\n## Usage Examples\n\nValidate trained YOLOv8n model accuracy on the COCO128 dataset. No argument need to passed as the `model` retains it's\ntraining `data` and arguments as model attributes. See Arguments section below for a full list of export arguments.\n\n!!! example \"\"\n\n === \"Python\"\n \n ```python\n from ultralytics import YOLO\n \n # Load a model\n model = YOLO('yolov8n.pt') # load an official model\n model = YOLO('path/to/best.pt') # load a custom model\n \n # Validate the model\n metrics = model.val() # no arguments needed, dataset and settings remembered\n metrics.box.map # map50-95\n metrics.box.map50 # map50\n metrics.box.map75 # map75\n metrics.box.maps # a list contains map50-95 of each category\n ```\n === \"CLI\"\n \n ```bash\n yolo detect val model=yolov8n.pt # val official model\n yolo detect val model=path/to/best.pt # val custom model\n ```\n\n## Arguments\n\nValidation settings for YOLO models refer to the various hyperparameters and configurations used to\nevaluate the model's performance on a validation dataset. These settings can affect the model's performance, speed, and\naccuracy. Some common YOLO validation settings include the batch size, the frequency with which validation is performed\nduring training, and the metrics used to evaluate the model's performance. Other factors that may affect the validation\nprocess include the size and composition of the validation dataset and the specific task the model is being used for. It\nis important to carefully tune and experiment with these settings to ensure that the model is performing well on the\nvalidation dataset and to detect and prevent overfitting.\n\n| Key | Value | Description |\n|---------------|---------|--------------------------------------------------------------------|\n| `data` | `None` | path to data file, i.e. coco128.yaml |\n| `imgsz` | `640` | image size as scalar or (h, w) list, i.e. (640, 480) |\n| `batch` | `16` | number of images per batch (-1 for AutoBatch) |\n| `save_json` | `False` | save results to JSON file |\n| `save_hybrid` | `False` | save hybrid version of labels (labels + additional predictions) |\n| `conf` | `0.001` | object confidence threshold for detection |\n| `iou` | `0.6` | intersection over union (IoU) threshold for NMS |\n| `max_det` | `300` | maximum number of detections per image |\n| `half` | `True` | use half precision (FP16) |\n| `device` | `None` | device to run on, i.e. cuda device=0/1/2/3 or device=cpu |\n| `dnn` | `False` | use OpenCV DNN for ONNX inference |\n| `plots` | `False` | show plots during training |\n| `rect` | `False` | rectangular val with each batch collated for minimum padding |\n| `split` | `val` | dataset split to use for validation, i.e. 'val', 'test' or 'train' |\n\n## Export Formats\n\nAvailable YOLOv8 export formats are in the table below. You can export to any format using the `format` argument,\ni.e. `format='onnx'` or `format='engine'`.\n\n| Format | `format` Argument | Model | Metadata | Arguments |\n|--------------------------------------------------------------------|-------------------|---------------------------|----------|-----------------------------------------------------|\n| [PyTorch](https://pytorch.org/) | - | `yolov8n.pt` | ✅ | - |\n| [TorchScript](https://pytorch.org/docs/stable/jit.html) | `torchscript` | `yolov8n.torchscript` | ✅ | `imgsz`, `optimize` |\n| [ONNX](https://onnx.ai/) | `onnx` | `yolov8n.onnx` | ✅ | `imgsz`, `half`, `dynamic`, `simplify`, `opset` |\n| [OpenVINO](https://docs.openvino.ai/latest/index.html) | `openvino` | `yolov8n_openvino_model/` | ✅ | `imgsz`, `half` |\n| [TensorRT](https://developer.nvidia.com/tensorrt) | `engine` | `yolov8n.engine` | ✅ | `imgsz`, `half`, `dynamic`, `simplify`, `workspace` |\n| [CoreML](https://github.com/apple/coremltools) | `coreml` | `yolov8n.mlmodel` | ✅ | `imgsz`, `half`, `int8`, `nms` |\n| [TF SavedModel](https://www.tensorflow.org/guide/saved_model) | `saved_model` | `yolov8n_saved_model/` | ✅ | `imgsz`, `keras` |\n| [TF GraphDef](https://www.tensorflow.org/api_docs/python/tf/Graph) | `pb` | `yolov8n.pb` | ❌ | `imgsz` |\n| [TF Lite](https://www.tensorflow.org/lite) | `tflite` | `yolov8n.tflite` | ✅ | `imgsz`, `half`, `int8` |\n| [TF Edge TPU](https://coral.ai/docs/edgetpu/models-intro/) | `edgetpu` | `yolov8n_edgetpu.tflite` | ✅ | `imgsz` |\n| [TF.js](https://www.tensorflow.org/js) | `tfjs` | `yolov8n_web_model/` | ✅ | `imgsz` |\n| [PaddlePaddle](https://github.com/PaddlePaddle) | `paddle` | `yolov8n_paddle_model/` | ✅ | `imgsz` |"
},
{
"path": "docs/overrides/partials/comments.html",
"content": "{% if page.meta.comments %}\n\n\n\n\n\n\n\n{% endif %}\n"
},
{
"path": "docs/overrides/partials/source-file.html",
"content": "{% import \"partials/language.html\" as lang with context %}\n\n\n\n
\n\n \n\n \n {% if page.meta.git_revision_date_localized %}\n 📅 {{ lang.t(\"source.file.date.updated\") }}:\n {{ page.meta.git_revision_date_localized }}\n {% if page.meta.git_creation_date_localized %}\n
\n 🎂 {{ lang.t(\"source.file.date.created\") }}:\n {{ page.meta.git_creation_date_localized }}\n {% endif %}\n\n \n {% elif page.meta.revision_date %}\n 📅 {{ lang.t(\"source.file.date.updated\") }}:\n {{ page.meta.revision_date }}\n {% endif %}\n \n
\n"
},
{
"path": "docs/quickstart.md",
"content": "---\ncomments: true\ndescription: Install and use YOLOv8 via CLI or Python. Run single-line commands or integrate with Python projects for object detection, segmentation, and classification.\n---\n\n## Install\n\nInstall YOLOv8 via the `ultralytics` pip package for the latest stable release or by cloning\nthe [https://github.com/ultralytics/ultralytics](https://github.com/ultralytics/ultralytics) repository for the most\nup-to-date version.\n\n!!! example \"Install\"\n\n === \"pip install (recommended)\"\n ```bash\n pip install ultralytics\n ```\n\n === \"git clone (for development)\"\n ```bash\n git clone https://github.com/ultralytics/ultralytics\n cd ultralytics\n pip install -e .\n ```\n\nSee the `ultralytics` [requirements.txt](https://github.com/ultralytics/ultralytics/blob/main/requirements.txt) file for a list of dependencies. Note that `pip` automatically installs all required dependencies.\n\n!!! tip \"Tip\"\n\n PyTorch requirements vary by operating system and CUDA requirements, so it's recommended to install PyTorch first following instructions at [https://pytorch.org/get-started/locally](https://pytorch.org/get-started/locally).\n\n \n  \n \n\n## Use with CLI\n\nThe YOLO command line interface (CLI) allows for simple single-line commands without the need for a Python environment.\nCLI requires no customization or Python code. You can simply run all tasks from the terminal with the `yolo` command. Check out the [CLI Guide](usage/cli.md) to learn more about using YOLOv8 from the command line.\n\n!!! example\n\n === \"Syntax\"\n\n Ultralytics `yolo` commands use the following syntax:\n ```bash\n yolo TASK MODE ARGS\n\n Where TASK (optional) is one of [detect, segment, classify]\n MODE (required) is one of [train, val, predict, export, track]\n ARGS (optional) are any number of custom 'arg=value' pairs like 'imgsz=320' that override defaults.\n ```\n See all ARGS in the full [Configuration Guide](usage/cfg.md) or with `yolo cfg`\n\n === \"Train\"\n\n Train a detection model for 10 epochs with an initial learning_rate of 0.01\n ```bash\n yolo train data=coco128.yaml model=yolov8n.pt epochs=10 lr0=0.01\n ```\n\n === \"Predict\"\n\n Predict a YouTube video using a pretrained segmentation model at image size 320:\n ```bash\n yolo predict model=yolov8n-seg.pt source='https://youtu.be/Zgi9g1ksQHc' imgsz=320\n ```\n\n === \"Val\"\n\n Val a pretrained detection model at batch-size 1 and image size 640:\n ```bash\n yolo val model=yolov8n.pt data=coco128.yaml batch=1 imgsz=640\n ```\n\n === \"Export\"\n\n Export a YOLOv8n classification model to ONNX format at image size 224 by 128 (no TASK required)\n ```bash\n yolo export model=yolov8n-cls.pt format=onnx imgsz=224,128\n ```\n\n === \"Special\"\n\n Run special commands to see version, view settings, run checks and more:\n ```bash\n yolo help\n yolo checks\n yolo version\n yolo settings\n yolo copy-cfg\n yolo cfg\n ```\n\n!!! warning \"Warning\"\n\n Arguments must be passed as `arg=val` pairs, split by an equals `=` sign and delimited by spaces ` ` between pairs. Do not use `--` argument prefixes or commas `,` between arguments.\n\n - `yolo predict model=yolov8n.pt imgsz=640 conf=0.25` ✅\n - `yolo predict model yolov8n.pt imgsz 640 conf 0.25` ❌\n - `yolo predict --model yolov8n.pt --imgsz 640 --conf 0.25` ❌\n\n[CLI Guide](usage/cli.md){ .md-button .md-button--primary}\n\n## Use with Python\n\nYOLOv8's Python interface allows for seamless integration into your Python projects, making it easy to load, run, and process the model's output. Designed with simplicity and ease of use in mind, the Python interface enables users to quickly implement object detection, segmentation, and classification in their projects. This makes YOLOv8's Python interface an invaluable tool for anyone looking to incorporate these functionalities into their Python projects.\n\nFor example, users can load a model, train it, evaluate its performance on a validation set, and even export it to ONNX format with just a few lines of code. Check out the [Python Guide](usage/python.md) to learn more about using YOLOv8 within your Python projects.\n\n!!! example\n\n ```python\n from ultralytics import YOLO\n \n # Create a new YOLO model from scratch\n model = YOLO('yolov8n.yaml')\n \n # Load a pretrained YOLO model (recommended for training)\n model = YOLO('yolov8n.pt')\n \n # Train the model using the 'coco128.yaml' dataset for 3 epochs\n results = model.train(data='coco128.yaml', epochs=3)\n \n # Evaluate the model's performance on the validation set\n results = model.val()\n \n # Perform object detection on an image using the model\n results = model('https://ultralytics.com/images/bus.jpg')\n \n # Export the model to ONNX format\n success = model.export(format='onnx')\n ```\n\n[Python Guide](usage/python.md){.md-button .md-button--primary}"
},
{
"path": "docs/reference/hub/auth.md",
"content": "---\ndescription: Learn how to use Ultralytics hub authentication in your projects with examples and guidelines from the Auth page on Ultralytics Docs.\n---\n\n# Auth\n---\n:::ultralytics.hub.auth.Auth\n
\n \n\n## Use with CLI\n\nThe YOLO command line interface (CLI) allows for simple single-line commands without the need for a Python environment.\nCLI requires no customization or Python code. You can simply run all tasks from the terminal with the `yolo` command. Check out the [CLI Guide](usage/cli.md) to learn more about using YOLOv8 from the command line.\n\n!!! example\n\n === \"Syntax\"\n\n Ultralytics `yolo` commands use the following syntax:\n ```bash\n yolo TASK MODE ARGS\n\n Where TASK (optional) is one of [detect, segment, classify]\n MODE (required) is one of [train, val, predict, export, track]\n ARGS (optional) are any number of custom 'arg=value' pairs like 'imgsz=320' that override defaults.\n ```\n See all ARGS in the full [Configuration Guide](usage/cfg.md) or with `yolo cfg`\n\n === \"Train\"\n\n Train a detection model for 10 epochs with an initial learning_rate of 0.01\n ```bash\n yolo train data=coco128.yaml model=yolov8n.pt epochs=10 lr0=0.01\n ```\n\n === \"Predict\"\n\n Predict a YouTube video using a pretrained segmentation model at image size 320:\n ```bash\n yolo predict model=yolov8n-seg.pt source='https://youtu.be/Zgi9g1ksQHc' imgsz=320\n ```\n\n === \"Val\"\n\n Val a pretrained detection model at batch-size 1 and image size 640:\n ```bash\n yolo val model=yolov8n.pt data=coco128.yaml batch=1 imgsz=640\n ```\n\n === \"Export\"\n\n Export a YOLOv8n classification model to ONNX format at image size 224 by 128 (no TASK required)\n ```bash\n yolo export model=yolov8n-cls.pt format=onnx imgsz=224,128\n ```\n\n === \"Special\"\n\n Run special commands to see version, view settings, run checks and more:\n ```bash\n yolo help\n yolo checks\n yolo version\n yolo settings\n yolo copy-cfg\n yolo cfg\n ```\n\n!!! warning \"Warning\"\n\n Arguments must be passed as `arg=val` pairs, split by an equals `=` sign and delimited by spaces ` ` between pairs. Do not use `--` argument prefixes or commas `,` between arguments.\n\n - `yolo predict model=yolov8n.pt imgsz=640 conf=0.25` ✅\n - `yolo predict model yolov8n.pt imgsz 640 conf 0.25` ❌\n - `yolo predict --model yolov8n.pt --imgsz 640 --conf 0.25` ❌\n\n[CLI Guide](usage/cli.md){ .md-button .md-button--primary}\n\n## Use with Python\n\nYOLOv8's Python interface allows for seamless integration into your Python projects, making it easy to load, run, and process the model's output. Designed with simplicity and ease of use in mind, the Python interface enables users to quickly implement object detection, segmentation, and classification in their projects. This makes YOLOv8's Python interface an invaluable tool for anyone looking to incorporate these functionalities into their Python projects.\n\nFor example, users can load a model, train it, evaluate its performance on a validation set, and even export it to ONNX format with just a few lines of code. Check out the [Python Guide](usage/python.md) to learn more about using YOLOv8 within your Python projects.\n\n!!! example\n\n ```python\n from ultralytics import YOLO\n \n # Create a new YOLO model from scratch\n model = YOLO('yolov8n.yaml')\n \n # Load a pretrained YOLO model (recommended for training)\n model = YOLO('yolov8n.pt')\n \n # Train the model using the 'coco128.yaml' dataset for 3 epochs\n results = model.train(data='coco128.yaml', epochs=3)\n \n # Evaluate the model's performance on the validation set\n results = model.val()\n \n # Perform object detection on an image using the model\n results = model('https://ultralytics.com/images/bus.jpg')\n \n # Export the model to ONNX format\n success = model.export(format='onnx')\n ```\n\n[Python Guide](usage/python.md){.md-button .md-button--primary}"
},
{
"path": "docs/reference/hub/auth.md",
"content": "---\ndescription: Learn how to use Ultralytics hub authentication in your projects with examples and guidelines from the Auth page on Ultralytics Docs.\n---\n\n# Auth\n---\n:::ultralytics.hub.auth.Auth\n
\n"
},
{
"path": "docs/reference/hub/session.md",
"content": "---\ndescription: Accelerate your AI development with the Ultralytics HUB Training Session. High-performance training of object detection models.\n---\n\n# HUBTrainingSession\n---\n:::ultralytics.hub.session.HUBTrainingSession\n
\n"
},
{
"path": "docs/reference/hub/utils.md",
"content": "---\ndescription: Explore Ultralytics events, including 'request_with_credentials' and 'smart_request', to improve your project's performance and efficiency.\n---\n\n# Events\n---\n:::ultralytics.hub.utils.Events\n
\n\n# request_with_credentials\n---\n:::ultralytics.hub.utils.request_with_credentials\n
\n\n# requests_with_progress\n---\n:::ultralytics.hub.utils.requests_with_progress\n
\n\n# smart_request\n---\n:::ultralytics.hub.utils.smart_request\n
\n"
},
{
"path": "docs/reference/nn/autobackend.md",
"content": "---\ndescription: Ensure class names match filenames for easy imports. Use AutoBackend to automatically rename and refactor model files.\n---\n\n# AutoBackend\n---\n:::ultralytics.nn.autobackend.AutoBackend\n
\n\n# check_class_names\n---\n:::ultralytics.nn.autobackend.check_class_names\n
\n"
},
{
"path": "docs/reference/nn/autoshape.md",
"content": "---\ndescription: Detect 80+ object categories with bounding box coordinates and class probabilities using AutoShape in Ultralytics YOLO. Explore Detections now.\n---\n\n# AutoShape\n---\n:::ultralytics.nn.autoshape.AutoShape\n
\n\n# Detections\n---\n:::ultralytics.nn.autoshape.Detections\n
\n"
},
{
"path": "docs/reference/nn/modules/block.md",
"content": "---\ndescription: Explore ultralytics.nn.modules.block to build powerful YOLO object detection models. Master DFL, HGStem, SPP, CSP components and more.\n---\n\n# DFL\n---\n:::ultralytics.nn.modules.block.DFL\n
\n\n# Proto\n---\n:::ultralytics.nn.modules.block.Proto\n
\n\n# HGStem\n---\n:::ultralytics.nn.modules.block.HGStem\n
\n\n# HGBlock\n---\n:::ultralytics.nn.modules.block.HGBlock\n
\n\n# SPP\n---\n:::ultralytics.nn.modules.block.SPP\n
\n\n# SPPF\n---\n:::ultralytics.nn.modules.block.SPPF\n
\n\n# C1\n---\n:::ultralytics.nn.modules.block.C1\n
\n\n# C2\n---\n:::ultralytics.nn.modules.block.C2\n
\n\n# C2f\n---\n:::ultralytics.nn.modules.block.C2f\n
\n\n# C3\n---\n:::ultralytics.nn.modules.block.C3\n
\n\n# C3x\n---\n:::ultralytics.nn.modules.block.C3x\n
\n\n# RepC3\n---\n:::ultralytics.nn.modules.block.RepC3\n
\n\n# C3TR\n---\n:::ultralytics.nn.modules.block.C3TR\n
\n\n# C3Ghost\n---\n:::ultralytics.nn.modules.block.C3Ghost\n
\n\n# GhostBottleneck\n---\n:::ultralytics.nn.modules.block.GhostBottleneck\n
\n\n# Bottleneck\n---\n:::ultralytics.nn.modules.block.Bottleneck\n
\n\n# BottleneckCSP\n---\n:::ultralytics.nn.modules.block.BottleneckCSP\n
\n"
},
{
"path": "docs/reference/nn/modules/conv.md",
"content": "---\ndescription: Explore convolutional neural network modules & techniques such as LightConv, DWConv, ConvTranspose, GhostConv, CBAM & autopad with Ultralytics Docs.\n---\n\n# Conv\n---\n:::ultralytics.nn.modules.conv.Conv\n
\n\n# LightConv\n---\n:::ultralytics.nn.modules.conv.LightConv\n
\n\n# DWConv\n---\n:::ultralytics.nn.modules.conv.DWConv\n
\n\n# DWConvTranspose2d\n---\n:::ultralytics.nn.modules.conv.DWConvTranspose2d\n
\n\n# ConvTranspose\n---\n:::ultralytics.nn.modules.conv.ConvTranspose\n
\n\n# Focus\n---\n:::ultralytics.nn.modules.conv.Focus\n
\n\n# GhostConv\n---\n:::ultralytics.nn.modules.conv.GhostConv\n
\n\n# RepConv\n---\n:::ultralytics.nn.modules.conv.RepConv\n
\n\n# ChannelAttention\n---\n:::ultralytics.nn.modules.conv.ChannelAttention\n
\n\n# SpatialAttention\n---\n:::ultralytics.nn.modules.conv.SpatialAttention\n
\n\n# CBAM\n---\n:::ultralytics.nn.modules.conv.CBAM\n
\n\n# Concat\n---\n:::ultralytics.nn.modules.conv.Concat\n
\n\n# autopad\n---\n:::ultralytics.nn.modules.conv.autopad\n
\n"
},
{
"path": "docs/reference/nn/modules/head.md",
"content": "---\ndescription: 'Learn about Ultralytics YOLO modules: Segment, Classify, and RTDETRDecoder. Optimize object detection and classification in your project.'\n---\n\n# Detect\n---\n:::ultralytics.nn.modules.head.Detect\n
\n\n# Segment\n---\n:::ultralytics.nn.modules.head.Segment\n
\n\n# Pose\n---\n:::ultralytics.nn.modules.head.Pose\n
\n\n# Classify\n---\n:::ultralytics.nn.modules.head.Classify\n
\n\n# RTDETRDecoder\n---\n:::ultralytics.nn.modules.head.RTDETRDecoder\n
\n"
},
{
"path": "docs/reference/nn/modules/transformer.md",
"content": "---\ndescription: Explore the Ultralytics nn modules pages on Transformer and MLP blocks, LayerNorm2d, and Deformable Transformer Decoder Layer.\n---\n\n# TransformerEncoderLayer\n---\n:::ultralytics.nn.modules.transformer.TransformerEncoderLayer\n
\n\n# AIFI\n---\n:::ultralytics.nn.modules.transformer.AIFI\n
\n\n# TransformerLayer\n---\n:::ultralytics.nn.modules.transformer.TransformerLayer\n
\n\n# TransformerBlock\n---\n:::ultralytics.nn.modules.transformer.TransformerBlock\n
\n\n# MLPBlock\n---\n:::ultralytics.nn.modules.transformer.MLPBlock\n
\n\n# MLP\n---\n:::ultralytics.nn.modules.transformer.MLP\n
\n\n# LayerNorm2d\n---\n:::ultralytics.nn.modules.transformer.LayerNorm2d\n
\n\n# MSDeformAttn\n---\n:::ultralytics.nn.modules.transformer.MSDeformAttn\n
\n\n# DeformableTransformerDecoderLayer\n---\n:::ultralytics.nn.modules.transformer.DeformableTransformerDecoderLayer\n
\n\n# DeformableTransformerDecoder\n---\n:::ultralytics.nn.modules.transformer.DeformableTransformerDecoder\n
\n"
},
{
"path": "docs/reference/nn/modules/utils.md",
"content": "---\ndescription: 'Learn about Ultralytics NN modules: get_clones, linear_init_, and multi_scale_deformable_attn_pytorch. Code examples and usage tips.'\n---\n\n# _get_clones\n---\n:::ultralytics.nn.modules.utils._get_clones\n
\n\n# bias_init_with_prob\n---\n:::ultralytics.nn.modules.utils.bias_init_with_prob\n
\n\n# linear_init_\n---\n:::ultralytics.nn.modules.utils.linear_init_\n
\n\n# inverse_sigmoid\n---\n:::ultralytics.nn.modules.utils.inverse_sigmoid\n
\n\n# multi_scale_deformable_attn_pytorch\n---\n:::ultralytics.nn.modules.utils.multi_scale_deformable_attn_pytorch\n
\n"
},
{
"path": "docs/reference/nn/tasks.md",
"content": "---\ndescription: Learn how to work with Ultralytics YOLO Detection, Segmentation & Classification Models, load weights and parse models in PyTorch.\n---\n\n# BaseModel\n---\n:::ultralytics.nn.tasks.BaseModel\n
\n\n# DetectionModel\n---\n:::ultralytics.nn.tasks.DetectionModel\n
\n\n# SegmentationModel\n---\n:::ultralytics.nn.tasks.SegmentationModel\n
\n\n# PoseModel\n---\n:::ultralytics.nn.tasks.PoseModel\n
\n\n# ClassificationModel\n---\n:::ultralytics.nn.tasks.ClassificationModel\n
\n\n# Ensemble\n---\n:::ultralytics.nn.tasks.Ensemble\n
\n\n# torch_safe_load\n---\n:::ultralytics.nn.tasks.torch_safe_load\n
\n\n# attempt_load_weights\n---\n:::ultralytics.nn.tasks.attempt_load_weights\n
\n\n# attempt_load_one_weight\n---\n:::ultralytics.nn.tasks.attempt_load_one_weight\n
\n\n# parse_model\n---\n:::ultralytics.nn.tasks.parse_model\n
\n\n# yaml_model_load\n---\n:::ultralytics.nn.tasks.yaml_model_load\n
\n\n# guess_model_scale\n---\n:::ultralytics.nn.tasks.guess_model_scale\n
\n\n# guess_model_task\n---\n:::ultralytics.nn.tasks.guess_model_task\n
\n"
},
{
"path": "docs/reference/tracker/track.md",
"content": "---\ndescription: Learn how to register custom event-tracking and track predictions with Ultralytics YOLO via on_predict_start and register_tracker methods.\n---\n\n# on_predict_start\n---\n:::ultralytics.tracker.track.on_predict_start\n
\n\n# on_predict_postprocess_end\n---\n:::ultralytics.tracker.track.on_predict_postprocess_end\n
\n\n# register_tracker\n---\n:::ultralytics.tracker.track.register_tracker\n
\n"
},
{
"path": "docs/reference/tracker/trackers/basetrack.md",
"content": "---\ndescription: 'TrackState: A comprehensive guide to Ultralytics tracker''s BaseTrack for monitoring model performance. Improve your tracking capabilities now!'\n---\n\n# TrackState\n---\n:::ultralytics.tracker.trackers.basetrack.TrackState\n
\n\n# BaseTrack\n---\n:::ultralytics.tracker.trackers.basetrack.BaseTrack\n
\n"
},
{
"path": "docs/reference/tracker/trackers/bot_sort.md",
"content": "---\ndescription: '\"Optimize tracking with Ultralytics BOTrack. Easily sort and track bots with BOTSORT. Streamline data collection for improved performance.\"'\n---\n\n# BOTrack\n---\n:::ultralytics.tracker.trackers.bot_sort.BOTrack\n
\n\n# BOTSORT\n---\n:::ultralytics.tracker.trackers.bot_sort.BOTSORT\n
\n"
},
{
"path": "docs/reference/tracker/trackers/byte_tracker.md",
"content": "---\ndescription: Learn how to track ByteAI model sizes and tips for model optimization with STrack, a byte tracking tool from Ultralytics.\n---\n\n# STrack\n---\n:::ultralytics.tracker.trackers.byte_tracker.STrack\n
\n\n# BYTETracker\n---\n:::ultralytics.tracker.trackers.byte_tracker.BYTETracker\n
\n"
},
{
"path": "docs/reference/tracker/utils/gmc.md",
"content": "---\ndescription: '\"Track Google Marketing Campaigns in GMC with Ultralytics Tracker. Learn to set up and use GMC for detailed analytics. Get started now.\"'\n---\n\n# GMC\n---\n:::ultralytics.tracker.utils.gmc.GMC\n
\n"
},
{
"path": "docs/reference/tracker/utils/kalman_filter.md",
"content": "---\ndescription: Improve object tracking with KalmanFilterXYAH in Ultralytics YOLO - an efficient and accurate algorithm for state estimation.\n---\n\n# KalmanFilterXYAH\n---\n:::ultralytics.tracker.utils.kalman_filter.KalmanFilterXYAH\n
\n\n# KalmanFilterXYWH\n---\n:::ultralytics.tracker.utils.kalman_filter.KalmanFilterXYWH\n
\n"
},
{
"path": "docs/reference/tracker/utils/matching.md",
"content": "---\ndescription: Learn how to match and fuse object detections for accurate target tracking using Ultralytics' YOLO merge_matches, iou_distance, and embedding_distance.\n---\n\n# merge_matches\n---\n:::ultralytics.tracker.utils.matching.merge_matches\n
\n\n# _indices_to_matches\n---\n:::ultralytics.tracker.utils.matching._indices_to_matches\n
\n\n# linear_assignment\n---\n:::ultralytics.tracker.utils.matching.linear_assignment\n
\n\n# ious\n---\n:::ultralytics.tracker.utils.matching.ious\n
\n\n# iou_distance\n---\n:::ultralytics.tracker.utils.matching.iou_distance\n
\n\n# v_iou_distance\n---\n:::ultralytics.tracker.utils.matching.v_iou_distance\n
\n\n# embedding_distance\n---\n:::ultralytics.tracker.utils.matching.embedding_distance\n
\n\n# gate_cost_matrix\n---\n:::ultralytics.tracker.utils.matching.gate_cost_matrix\n
\n\n# fuse_motion\n---\n:::ultralytics.tracker.utils.matching.fuse_motion\n
\n\n# fuse_iou\n---\n:::ultralytics.tracker.utils.matching.fuse_iou\n
\n\n# fuse_score\n---\n:::ultralytics.tracker.utils.matching.fuse_score\n
\n\n# bbox_ious\n---\n:::ultralytics.tracker.utils.matching.bbox_ious\n
\n"
},
{
"path": "docs/reference/yolo/data/annotator.md",
"content": "---\ndescription: Learn how to use auto_annotate in Ultralytics YOLO to generate annotations automatically for your dataset. Simplify object detection workflows.\n---\n\n# auto_annotate\n---\n:::ultralytics.yolo.data.annotator.auto_annotate\n
\n"
},
{
"path": "docs/reference/yolo/data/augment.md",
"content": "---\ndescription: Use Ultralytics YOLO Data Augmentation transforms with Base, MixUp, and Albumentations for object detection and classification.\n---\n\n# BaseTransform\n---\n:::ultralytics.yolo.data.augment.BaseTransform\n
\n\n# Compose\n---\n:::ultralytics.yolo.data.augment.Compose\n
\n\n# BaseMixTransform\n---\n:::ultralytics.yolo.data.augment.BaseMixTransform\n
\n\n# Mosaic\n---\n:::ultralytics.yolo.data.augment.Mosaic\n
\n\n# MixUp\n---\n:::ultralytics.yolo.data.augment.MixUp\n
\n\n# RandomPerspective\n---\n:::ultralytics.yolo.data.augment.RandomPerspective\n
\n\n# RandomHSV\n---\n:::ultralytics.yolo.data.augment.RandomHSV\n
\n\n# RandomFlip\n---\n:::ultralytics.yolo.data.augment.RandomFlip\n
\n\n# LetterBox\n---\n:::ultralytics.yolo.data.augment.LetterBox\n
\n\n# CopyPaste\n---\n:::ultralytics.yolo.data.augment.CopyPaste\n
\n\n# Albumentations\n---\n:::ultralytics.yolo.data.augment.Albumentations\n
\n\n# Format\n---\n:::ultralytics.yolo.data.augment.Format\n
\n\n# ClassifyLetterBox\n---\n:::ultralytics.yolo.data.augment.ClassifyLetterBox\n
\n\n# CenterCrop\n---\n:::ultralytics.yolo.data.augment.CenterCrop\n
\n\n# ToTensor\n---\n:::ultralytics.yolo.data.augment.ToTensor\n
\n\n# v8_transforms\n---\n:::ultralytics.yolo.data.augment.v8_transforms\n
\n\n# classify_transforms\n---\n:::ultralytics.yolo.data.augment.classify_transforms\n
\n\n# classify_albumentations\n---\n:::ultralytics.yolo.data.augment.classify_albumentations\n
\n"
},
{
"path": "docs/reference/yolo/data/base.md",
"content": "---\ndescription: Learn about BaseDataset in Ultralytics YOLO, a flexible dataset class for object detection. Maximize your YOLO performance with custom datasets.\n---\n\n# BaseDataset\n---\n:::ultralytics.yolo.data.base.BaseDataset\n
\n"
},
{
"path": "docs/reference/yolo/data/build.md",
"content": "---\ndescription: Maximize YOLO performance with Ultralytics' InfiniteDataLoader, seed_worker, build_dataloader, and load_inference_source functions.\n---\n\n# InfiniteDataLoader\n---\n:::ultralytics.yolo.data.build.InfiniteDataLoader\n
\n\n# _RepeatSampler\n---\n:::ultralytics.yolo.data.build._RepeatSampler\n
\n\n# seed_worker\n---\n:::ultralytics.yolo.data.build.seed_worker\n
\n\n# build_yolo_dataset\n---\n:::ultralytics.yolo.data.build.build_yolo_dataset\n
\n\n# build_dataloader\n---\n:::ultralytics.yolo.data.build.build_dataloader\n
\n\n# check_source\n---\n:::ultralytics.yolo.data.build.check_source\n
\n\n# load_inference_source\n---\n:::ultralytics.yolo.data.build.load_inference_source\n
\n"
},
{
"path": "docs/reference/yolo/data/converter.md",
"content": "---\ndescription: Convert COCO-91 to COCO-80 class, RLE to polygon, and merge multi-segment images with Ultralytics YOLO data converter. Improve your object detection.\n---\n\n# coco91_to_coco80_class\n---\n:::ultralytics.yolo.data.converter.coco91_to_coco80_class\n
\n\n# convert_coco\n---\n:::ultralytics.yolo.data.converter.convert_coco\n
\n\n# rle2polygon\n---\n:::ultralytics.yolo.data.converter.rle2polygon\n
\n\n# min_index\n---\n:::ultralytics.yolo.data.converter.min_index\n
\n\n# merge_multi_segment\n---\n:::ultralytics.yolo.data.converter.merge_multi_segment\n
\n\n# delete_dsstore\n---\n:::ultralytics.yolo.data.converter.delete_dsstore\n
\n"
},
{
"path": "docs/reference/yolo/data/dataloaders/stream_loaders.md",
"content": "---\ndescription: 'Ultralytics YOLO Docs: Learn about stream loaders for image and tensor data, as well as autocasting techniques. Check out SourceTypes and more.'\n---\n\n# SourceTypes\n---\n:::ultralytics.yolo.data.dataloaders.stream_loaders.SourceTypes\n
\n\n# LoadStreams\n---\n:::ultralytics.yolo.data.dataloaders.stream_loaders.LoadStreams\n
\n\n# LoadScreenshots\n---\n:::ultralytics.yolo.data.dataloaders.stream_loaders.LoadScreenshots\n
\n\n# LoadImages\n---\n:::ultralytics.yolo.data.dataloaders.stream_loaders.LoadImages\n
\n\n# LoadPilAndNumpy\n---\n:::ultralytics.yolo.data.dataloaders.stream_loaders.LoadPilAndNumpy\n
\n\n# LoadTensor\n---\n:::ultralytics.yolo.data.dataloaders.stream_loaders.LoadTensor\n
\n\n# autocast_list\n---\n:::ultralytics.yolo.data.dataloaders.stream_loaders.autocast_list\n
\n"
},
{
"path": "docs/reference/yolo/data/dataloaders/v5augmentations.md",
"content": "---\ndescription: Enhance image data with Albumentations CenterCrop, normalize, augment_hsv, replicate, random_perspective, cutout, & box_candidates.\n---\n\n# Albumentations\n---\n:::ultralytics.yolo.data.dataloaders.v5augmentations.Albumentations\n
\n\n# LetterBox\n---\n:::ultralytics.yolo.data.dataloaders.v5augmentations.LetterBox\n
\n\n# CenterCrop\n---\n:::ultralytics.yolo.data.dataloaders.v5augmentations.CenterCrop\n
\n\n# ToTensor\n---\n:::ultralytics.yolo.data.dataloaders.v5augmentations.ToTensor\n
\n\n# normalize\n---\n:::ultralytics.yolo.data.dataloaders.v5augmentations.normalize\n
\n\n# denormalize\n---\n:::ultralytics.yolo.data.dataloaders.v5augmentations.denormalize\n
\n\n# augment_hsv\n---\n:::ultralytics.yolo.data.dataloaders.v5augmentations.augment_hsv\n
\n\n# hist_equalize\n---\n:::ultralytics.yolo.data.dataloaders.v5augmentations.hist_equalize\n
\n\n# replicate\n---\n:::ultralytics.yolo.data.dataloaders.v5augmentations.replicate\n
\n\n# letterbox\n---\n:::ultralytics.yolo.data.dataloaders.v5augmentations.letterbox\n
\n\n# random_perspective\n---\n:::ultralytics.yolo.data.dataloaders.v5augmentations.random_perspective\n
\n\n# copy_paste\n---\n:::ultralytics.yolo.data.dataloaders.v5augmentations.copy_paste\n
\n\n# cutout\n---\n:::ultralytics.yolo.data.dataloaders.v5augmentations.cutout\n
\n\n# mixup\n---\n:::ultralytics.yolo.data.dataloaders.v5augmentations.mixup\n
\n\n# box_candidates\n---\n:::ultralytics.yolo.data.dataloaders.v5augmentations.box_candidates\n
\n\n# classify_albumentations\n---\n:::ultralytics.yolo.data.dataloaders.v5augmentations.classify_albumentations\n
\n\n# classify_transforms\n---\n:::ultralytics.yolo.data.dataloaders.v5augmentations.classify_transforms\n
\n"
},
{
"path": "docs/reference/yolo/data/dataloaders/v5loader.md",
"content": "---\ndescription: Efficiently load images and labels to models using Ultralytics YOLO's InfiniteDataLoader, LoadScreenshots, and LoadStreams.\n---\n\n# InfiniteDataLoader\n---\n:::ultralytics.yolo.data.dataloaders.v5loader.InfiniteDataLoader\n
\n\n# _RepeatSampler\n---\n:::ultralytics.yolo.data.dataloaders.v5loader._RepeatSampler\n
\n\n# LoadScreenshots\n---\n:::ultralytics.yolo.data.dataloaders.v5loader.LoadScreenshots\n
\n\n# LoadImages\n---\n:::ultralytics.yolo.data.dataloaders.v5loader.LoadImages\n
\n\n# LoadStreams\n---\n:::ultralytics.yolo.data.dataloaders.v5loader.LoadStreams\n
\n\n# LoadImagesAndLabels\n---\n:::ultralytics.yolo.data.dataloaders.v5loader.LoadImagesAndLabels\n
\n\n# ClassificationDataset\n---\n:::ultralytics.yolo.data.dataloaders.v5loader.ClassificationDataset\n
\n\n# get_hash\n---\n:::ultralytics.yolo.data.dataloaders.v5loader.get_hash\n
\n\n# exif_size\n---\n:::ultralytics.yolo.data.dataloaders.v5loader.exif_size\n
\n\n# exif_transpose\n---\n:::ultralytics.yolo.data.dataloaders.v5loader.exif_transpose\n
\n\n# seed_worker\n---\n:::ultralytics.yolo.data.dataloaders.v5loader.seed_worker\n
\n\n# create_dataloader\n---\n:::ultralytics.yolo.data.dataloaders.v5loader.create_dataloader\n
\n\n# img2label_paths\n---\n:::ultralytics.yolo.data.dataloaders.v5loader.img2label_paths\n
\n\n# flatten_recursive\n---\n:::ultralytics.yolo.data.dataloaders.v5loader.flatten_recursive\n
\n\n# extract_boxes\n---\n:::ultralytics.yolo.data.dataloaders.v5loader.extract_boxes\n
\n\n# autosplit\n---\n:::ultralytics.yolo.data.dataloaders.v5loader.autosplit\n
\n\n# verify_image_label\n---\n:::ultralytics.yolo.data.dataloaders.v5loader.verify_image_label\n
\n\n# create_classification_dataloader\n---\n:::ultralytics.yolo.data.dataloaders.v5loader.create_classification_dataloader\n
\n"
},
{
"path": "docs/reference/yolo/data/dataset.md",
"content": "---\ndescription: Create custom YOLOv5 datasets with Ultralytics YOLODataset and SemanticDataset. Streamline your object detection and segmentation projects.\n---\n\n# YOLODataset\n---\n:::ultralytics.yolo.data.dataset.YOLODataset\n
\n\n# ClassificationDataset\n---\n:::ultralytics.yolo.data.dataset.ClassificationDataset\n
\n\n# SemanticDataset\n---\n:::ultralytics.yolo.data.dataset.SemanticDataset\n
\n"
},
{
"path": "docs/reference/yolo/data/dataset_wrappers.md",
"content": "---\ndescription: Create a custom dataset of mixed and oriented rectangular objects with Ultralytics YOLO's MixAndRectDataset.\n---\n\n# MixAndRectDataset\n---\n:::ultralytics.yolo.data.dataset_wrappers.MixAndRectDataset\n
\n"
},
{
"path": "docs/reference/yolo/data/utils.md",
"content": "---\ndescription: Efficiently handle data in YOLO with Ultralytics. Utilize HUBDatasetStats and customize dataset with these data utility functions.\n---\n\n# HUBDatasetStats\n---\n:::ultralytics.yolo.data.utils.HUBDatasetStats\n
\n\n# img2label_paths\n---\n:::ultralytics.yolo.data.utils.img2label_paths\n
\n\n# get_hash\n---\n:::ultralytics.yolo.data.utils.get_hash\n
\n\n# exif_size\n---\n:::ultralytics.yolo.data.utils.exif_size\n
\n\n# verify_image_label\n---\n:::ultralytics.yolo.data.utils.verify_image_label\n
\n\n# polygon2mask\n---\n:::ultralytics.yolo.data.utils.polygon2mask\n
\n\n# polygons2masks\n---\n:::ultralytics.yolo.data.utils.polygons2masks\n
\n\n# polygons2masks_overlap\n---\n:::ultralytics.yolo.data.utils.polygons2masks_overlap\n
\n\n# check_det_dataset\n---\n:::ultralytics.yolo.data.utils.check_det_dataset\n
\n\n# check_cls_dataset\n---\n:::ultralytics.yolo.data.utils.check_cls_dataset\n
\n\n# compress_one_image\n---\n:::ultralytics.yolo.data.utils.compress_one_image\n
\n\n# delete_dsstore\n---\n:::ultralytics.yolo.data.utils.delete_dsstore\n
\n\n# zip_directory\n---\n:::ultralytics.yolo.data.utils.zip_directory\n
\n"
},
{
"path": "docs/reference/yolo/engine/exporter.md",
"content": "---\ndescription: Learn how to export your YOLO model in various formats using Ultralytics' exporter package - iOS, GDC, and more.\n---\n\n# Exporter\n---\n:::ultralytics.yolo.engine.exporter.Exporter\n
\n\n# iOSDetectModel\n---\n:::ultralytics.yolo.engine.exporter.iOSDetectModel\n
\n\n# export_formats\n---\n:::ultralytics.yolo.engine.exporter.export_formats\n
\n\n# gd_outputs\n---\n:::ultralytics.yolo.engine.exporter.gd_outputs\n
\n\n# try_export\n---\n:::ultralytics.yolo.engine.exporter.try_export\n
\n\n# export\n---\n:::ultralytics.yolo.engine.exporter.export\n
\n"
},
{
"path": "docs/reference/yolo/engine/model.md",
"content": "---\ndescription: Discover the YOLO model of Ultralytics engine to simplify your object detection tasks with state-of-the-art models.\n---\n\n# YOLO\n---\n:::ultralytics.yolo.engine.model.YOLO\n
\n"
},
{
"path": "docs/reference/yolo/engine/predictor.md",
"content": "---\ndescription: '\"The BasePredictor class in Ultralytics YOLO Engine predicts object detection in images and videos. Learn to implement YOLO with ease.\"'\n---\n\n# BasePredictor\n---\n:::ultralytics.yolo.engine.predictor.BasePredictor\n
\n"
},
{
"path": "docs/reference/yolo/engine/results.md",
"content": "---\ndescription: Learn about BaseTensor & Boxes in Ultralytics YOLO Engine. Check out Ultralytics Docs for quality tutorials and resources on object detection.\n---\n\n# BaseTensor\n---\n:::ultralytics.yolo.engine.results.BaseTensor\n
\n\n# Results\n---\n:::ultralytics.yolo.engine.results.Results\n
\n\n# Boxes\n---\n:::ultralytics.yolo.engine.results.Boxes\n
\n\n# Masks\n---\n:::ultralytics.yolo.engine.results.Masks\n
\n"
},
{
"path": "docs/reference/yolo/engine/trainer.md",
"content": "---\ndescription: Train faster with mixed precision. Learn how to use BaseTrainer with Advanced Mixed Precision to optimize YOLOv3 and YOLOv4 models.\n---\n\n# BaseTrainer\n---\n:::ultralytics.yolo.engine.trainer.BaseTrainer\n
\n\n# check_amp\n---\n:::ultralytics.yolo.engine.trainer.check_amp\n
\n"
},
{
"path": "docs/reference/yolo/engine/validator.md",
"content": "---\ndescription: Ensure YOLOv5 models meet constraints and standards with the BaseValidator class. Learn how to use it here.\n---\n\n# BaseValidator\n---\n:::ultralytics.yolo.engine.validator.BaseValidator\n
\n"
},
{
"path": "docs/reference/yolo/utils/autobatch.md",
"content": "---\ndescription: Dynamically adjusts input size to optimize GPU memory usage during training. Learn how to use check_train_batch_size with Ultralytics YOLO.\n---\n\n# check_train_batch_size\n---\n:::ultralytics.yolo.utils.autobatch.check_train_batch_size\n
\n\n# autobatch\n---\n:::ultralytics.yolo.utils.autobatch.autobatch\n
\n"
},
{
"path": "docs/reference/yolo/utils/benchmarks.md",
"content": "---\ndescription: Improve your YOLO's performance and measure its speed. Benchmark utility for YOLOv5.\n---\n\n# benchmark\n---\n:::ultralytics.yolo.utils.benchmarks.benchmark\n
\n"
},
{
"path": "docs/reference/yolo/utils/callbacks/base.md",
"content": "---\ndescription: Learn about YOLO's callback functions from on_train_start to add_integration_callbacks. See how these callbacks modify and save models.\n---\n\n# on_pretrain_routine_start\n---\n:::ultralytics.yolo.utils.callbacks.base.on_pretrain_routine_start\n
\n\n# on_pretrain_routine_end\n---\n:::ultralytics.yolo.utils.callbacks.base.on_pretrain_routine_end\n
\n\n# on_train_start\n---\n:::ultralytics.yolo.utils.callbacks.base.on_train_start\n
\n\n# on_train_epoch_start\n---\n:::ultralytics.yolo.utils.callbacks.base.on_train_epoch_start\n
\n\n# on_train_batch_start\n---\n:::ultralytics.yolo.utils.callbacks.base.on_train_batch_start\n
\n\n# optimizer_step\n---\n:::ultralytics.yolo.utils.callbacks.base.optimizer_step\n
\n\n# on_before_zero_grad\n---\n:::ultralytics.yolo.utils.callbacks.base.on_before_zero_grad\n
\n\n# on_train_batch_end\n---\n:::ultralytics.yolo.utils.callbacks.base.on_train_batch_end\n
\n\n# on_train_epoch_end\n---\n:::ultralytics.yolo.utils.callbacks.base.on_train_epoch_end\n
\n\n# on_fit_epoch_end\n---\n:::ultralytics.yolo.utils.callbacks.base.on_fit_epoch_end\n
\n\n# on_model_save\n---\n:::ultralytics.yolo.utils.callbacks.base.on_model_save\n
\n\n# on_train_end\n---\n:::ultralytics.yolo.utils.callbacks.base.on_train_end\n
\n\n# on_params_update\n---\n:::ultralytics.yolo.utils.callbacks.base.on_params_update\n
\n\n# teardown\n---\n:::ultralytics.yolo.utils.callbacks.base.teardown\n
\n\n# on_val_start\n---\n:::ultralytics.yolo.utils.callbacks.base.on_val_start\n
\n\n# on_val_batch_start\n---\n:::ultralytics.yolo.utils.callbacks.base.on_val_batch_start\n
\n\n# on_val_batch_end\n---\n:::ultralytics.yolo.utils.callbacks.base.on_val_batch_end\n
\n\n# on_val_end\n---\n:::ultralytics.yolo.utils.callbacks.base.on_val_end\n
\n\n# on_predict_start\n---\n:::ultralytics.yolo.utils.callbacks.base.on_predict_start\n
\n\n# on_predict_batch_start\n---\n:::ultralytics.yolo.utils.callbacks.base.on_predict_batch_start\n
\n\n# on_predict_batch_end\n---\n:::ultralytics.yolo.utils.callbacks.base.on_predict_batch_end\n
\n\n# on_predict_postprocess_end\n---\n:::ultralytics.yolo.utils.callbacks.base.on_predict_postprocess_end\n
\n\n# on_predict_end\n---\n:::ultralytics.yolo.utils.callbacks.base.on_predict_end\n
\n\n# on_export_start\n---\n:::ultralytics.yolo.utils.callbacks.base.on_export_start\n
\n\n# on_export_end\n---\n:::ultralytics.yolo.utils.callbacks.base.on_export_end\n
\n\n# get_default_callbacks\n---\n:::ultralytics.yolo.utils.callbacks.base.get_default_callbacks\n
\n\n# add_integration_callbacks\n---\n:::ultralytics.yolo.utils.callbacks.base.add_integration_callbacks\n
\n"
},
{
"path": "docs/reference/yolo/utils/callbacks/clearml.md",
"content": "---\ndescription: Improve your YOLOv5 model training with callbacks from ClearML. Learn about log debug samples, pre-training routines, validation and more.\n---\n\n# _log_debug_samples\n---\n:::ultralytics.yolo.utils.callbacks.clearml._log_debug_samples\n
\n\n# _log_plot\n---\n:::ultralytics.yolo.utils.callbacks.clearml._log_plot\n
\n\n# on_pretrain_routine_start\n---\n:::ultralytics.yolo.utils.callbacks.clearml.on_pretrain_routine_start\n
\n\n# on_train_epoch_end\n---\n:::ultralytics.yolo.utils.callbacks.clearml.on_train_epoch_end\n
\n\n# on_fit_epoch_end\n---\n:::ultralytics.yolo.utils.callbacks.clearml.on_fit_epoch_end\n
\n\n# on_val_end\n---\n:::ultralytics.yolo.utils.callbacks.clearml.on_val_end\n
\n\n# on_train_end\n---\n:::ultralytics.yolo.utils.callbacks.clearml.on_train_end\n
\n"
},
{
"path": "docs/reference/yolo/utils/callbacks/comet.md",
"content": "---\ndescription: Learn about YOLO callbacks using the Comet.ml platform, enhancing object detection training and testing with custom logging and visualizations.\n---\n\n# _get_comet_mode\n---\n:::ultralytics.yolo.utils.callbacks.comet._get_comet_mode\n
\n\n# _get_comet_model_name\n---\n:::ultralytics.yolo.utils.callbacks.comet._get_comet_model_name\n
\n\n# _get_eval_batch_logging_interval\n---\n:::ultralytics.yolo.utils.callbacks.comet._get_eval_batch_logging_interval\n
\n\n# _get_max_image_predictions_to_log\n---\n:::ultralytics.yolo.utils.callbacks.comet._get_max_image_predictions_to_log\n
\n\n# _scale_confidence_score\n---\n:::ultralytics.yolo.utils.callbacks.comet._scale_confidence_score\n
\n\n# _should_log_confusion_matrix\n---\n:::ultralytics.yolo.utils.callbacks.comet._should_log_confusion_matrix\n
\n\n# _should_log_image_predictions\n---\n:::ultralytics.yolo.utils.callbacks.comet._should_log_image_predictions\n
\n\n# _get_experiment_type\n---\n:::ultralytics.yolo.utils.callbacks.comet._get_experiment_type\n
\n\n# _create_experiment\n---\n:::ultralytics.yolo.utils.callbacks.comet._create_experiment\n
\n\n# _fetch_trainer_metadata\n---\n:::ultralytics.yolo.utils.callbacks.comet._fetch_trainer_metadata\n
\n\n# _scale_bounding_box_to_original_image_shape\n---\n:::ultralytics.yolo.utils.callbacks.comet._scale_bounding_box_to_original_image_shape\n
\n\n# _format_ground_truth_annotations_for_detection\n---\n:::ultralytics.yolo.utils.callbacks.comet._format_ground_truth_annotations_for_detection\n
\n\n# _format_prediction_annotations_for_detection\n---\n:::ultralytics.yolo.utils.callbacks.comet._format_prediction_annotations_for_detection\n
\n\n# _fetch_annotations\n---\n:::ultralytics.yolo.utils.callbacks.comet._fetch_annotations\n
\n\n# _create_prediction_metadata_map\n---\n:::ultralytics.yolo.utils.callbacks.comet._create_prediction_metadata_map\n
\n\n# _log_confusion_matrix\n---\n:::ultralytics.yolo.utils.callbacks.comet._log_confusion_matrix\n
\n\n# _log_images\n---\n:::ultralytics.yolo.utils.callbacks.comet._log_images\n
\n\n# _log_image_predictions\n---\n:::ultralytics.yolo.utils.callbacks.comet._log_image_predictions\n
\n\n# _log_plots\n---\n:::ultralytics.yolo.utils.callbacks.comet._log_plots\n
\n\n# _log_model\n---\n:::ultralytics.yolo.utils.callbacks.comet._log_model\n
\n\n# on_pretrain_routine_start\n---\n:::ultralytics.yolo.utils.callbacks.comet.on_pretrain_routine_start\n
\n\n# on_train_epoch_end\n---\n:::ultralytics.yolo.utils.callbacks.comet.on_train_epoch_end\n
\n\n# on_fit_epoch_end\n---\n:::ultralytics.yolo.utils.callbacks.comet.on_fit_epoch_end\n
\n\n# on_train_end\n---\n:::ultralytics.yolo.utils.callbacks.comet.on_train_end\n
\n"
},
{
"path": "docs/reference/yolo/utils/callbacks/hub.md",
"content": "---\ndescription: Improve YOLOv5 model training with Ultralytics' on-train callbacks. Boost performance on-pretrain-routine-end, model-save, train/predict start.\n---\n\n# on_pretrain_routine_end\n---\n:::ultralytics.yolo.utils.callbacks.hub.on_pretrain_routine_end\n
\n\n# on_fit_epoch_end\n---\n:::ultralytics.yolo.utils.callbacks.hub.on_fit_epoch_end\n
\n\n# on_model_save\n---\n:::ultralytics.yolo.utils.callbacks.hub.on_model_save\n
\n\n# on_train_end\n---\n:::ultralytics.yolo.utils.callbacks.hub.on_train_end\n
\n\n# on_train_start\n---\n:::ultralytics.yolo.utils.callbacks.hub.on_train_start\n
\n\n# on_val_start\n---\n:::ultralytics.yolo.utils.callbacks.hub.on_val_start\n
\n\n# on_predict_start\n---\n:::ultralytics.yolo.utils.callbacks.hub.on_predict_start\n
\n\n# on_export_start\n---\n:::ultralytics.yolo.utils.callbacks.hub.on_export_start\n
\n"
},
{
"path": "docs/reference/yolo/utils/callbacks/mlflow.md",
"content": "---\ndescription: Track model performance and metrics with MLflow in YOLOv5. Use callbacks like on_pretrain_routine_end or on_train_end to log information.\n---\n\n# on_pretrain_routine_end\n---\n:::ultralytics.yolo.utils.callbacks.mlflow.on_pretrain_routine_end\n
\n\n# on_fit_epoch_end\n---\n:::ultralytics.yolo.utils.callbacks.mlflow.on_fit_epoch_end\n
\n\n# on_train_end\n---\n:::ultralytics.yolo.utils.callbacks.mlflow.on_train_end\n
\n"
},
{
"path": "docs/reference/yolo/utils/callbacks/neptune.md",
"content": "---\ndescription: Improve YOLOv5 training with Neptune, a powerful logging tool. Track metrics like images, plots, and epochs for better model performance.\n---\n\n# _log_scalars\n---\n:::ultralytics.yolo.utils.callbacks.neptune._log_scalars\n
\n\n# _log_images\n---\n:::ultralytics.yolo.utils.callbacks.neptune._log_images\n
\n\n# _log_plot\n---\n:::ultralytics.yolo.utils.callbacks.neptune._log_plot\n
\n\n# on_pretrain_routine_start\n---\n:::ultralytics.yolo.utils.callbacks.neptune.on_pretrain_routine_start\n
\n\n# on_train_epoch_end\n---\n:::ultralytics.yolo.utils.callbacks.neptune.on_train_epoch_end\n
\n\n# on_fit_epoch_end\n---\n:::ultralytics.yolo.utils.callbacks.neptune.on_fit_epoch_end\n
\n\n# on_val_end\n---\n:::ultralytics.yolo.utils.callbacks.neptune.on_val_end\n
\n\n# on_train_end\n---\n:::ultralytics.yolo.utils.callbacks.neptune.on_train_end\n
\n"
},
{
"path": "docs/reference/yolo/utils/callbacks/raytune.md",
"content": "---\ndescription: '\"Improve YOLO model performance with on_fit_epoch_end callback. Learn to integrate with Ray Tune for hyperparameter tuning. Ultralytics YOLO docs.\"'\n---\n\n# on_fit_epoch_end\n---\n:::ultralytics.yolo.utils.callbacks.raytune.on_fit_epoch_end\n
\n"
},
{
"path": "docs/reference/yolo/utils/callbacks/tensorboard.md",
"content": "---\ndescription: Learn how to monitor the training process with Tensorboard using Ultralytics YOLO's \"_log_scalars\" and \"on_batch_end\" methods.\n---\n\n# _log_scalars\n---\n:::ultralytics.yolo.utils.callbacks.tensorboard._log_scalars\n
\n\n# on_pretrain_routine_start\n---\n:::ultralytics.yolo.utils.callbacks.tensorboard.on_pretrain_routine_start\n
\n\n# on_batch_end\n---\n:::ultralytics.yolo.utils.callbacks.tensorboard.on_batch_end\n
\n\n# on_fit_epoch_end\n---\n:::ultralytics.yolo.utils.callbacks.tensorboard.on_fit_epoch_end\n
\n"
},
{
"path": "docs/reference/yolo/utils/callbacks/wb.md",
"content": "---\ndescription: Learn how to use Ultralytics YOLO's built-in callbacks `on_pretrain_routine_start` and `on_train_epoch_end` for improved training performance.\n---\n\n# on_pretrain_routine_start\n---\n:::ultralytics.yolo.utils.callbacks.wb.on_pretrain_routine_start\n
\n\n# on_fit_epoch_end\n---\n:::ultralytics.yolo.utils.callbacks.wb.on_fit_epoch_end\n
\n\n# on_train_epoch_end\n---\n:::ultralytics.yolo.utils.callbacks.wb.on_train_epoch_end\n
\n\n# on_train_end\n---\n:::ultralytics.yolo.utils.callbacks.wb.on_train_end\n
\n"
},
{
"path": "docs/reference/yolo/utils/checks.md",
"content": "---\ndescription: 'Check functions for YOLO utils: image size, version, font, requirements, filename suffix, YAML file, YOLO, and Git version.'\n---\n\n# is_ascii\n---\n:::ultralytics.yolo.utils.checks.is_ascii\n
\n\n# check_imgsz\n---\n:::ultralytics.yolo.utils.checks.check_imgsz\n
\n\n# check_version\n---\n:::ultralytics.yolo.utils.checks.check_version\n
\n\n# check_latest_pypi_version\n---\n:::ultralytics.yolo.utils.checks.check_latest_pypi_version\n
\n\n# check_pip_update_available\n---\n:::ultralytics.yolo.utils.checks.check_pip_update_available\n
\n\n# check_font\n---\n:::ultralytics.yolo.utils.checks.check_font\n
\n\n# check_python\n---\n:::ultralytics.yolo.utils.checks.check_python\n
\n\n# check_requirements\n---\n:::ultralytics.yolo.utils.checks.check_requirements\n
\n\n# check_suffix\n---\n:::ultralytics.yolo.utils.checks.check_suffix\n
\n\n# check_yolov5u_filename\n---\n:::ultralytics.yolo.utils.checks.check_yolov5u_filename\n
\n\n# check_file\n---\n:::ultralytics.yolo.utils.checks.check_file\n
\n\n# check_yaml\n---\n:::ultralytics.yolo.utils.checks.check_yaml\n
\n\n# check_imshow\n---\n:::ultralytics.yolo.utils.checks.check_imshow\n
\n\n# check_yolo\n---\n:::ultralytics.yolo.utils.checks.check_yolo\n
\n\n# git_describe\n---\n:::ultralytics.yolo.utils.checks.git_describe\n
\n\n# print_args\n---\n:::ultralytics.yolo.utils.checks.print_args\n
\n"
},
{
"path": "docs/reference/yolo/utils/dist.md",
"content": "---\ndescription: Learn how to find free network port and generate DDP (Distributed Data Parallel) command in Ultralytics YOLO with easy examples.\n---\n\n# find_free_network_port\n---\n:::ultralytics.yolo.utils.dist.find_free_network_port\n
\n\n# generate_ddp_file\n---\n:::ultralytics.yolo.utils.dist.generate_ddp_file\n
\n\n# generate_ddp_command\n---\n:::ultralytics.yolo.utils.dist.generate_ddp_command\n
\n\n# ddp_cleanup\n---\n:::ultralytics.yolo.utils.dist.ddp_cleanup\n
\n"
},
{
"path": "docs/reference/yolo/utils/downloads.md",
"content": "---\ndescription: Download and unzip YOLO pretrained models. Ultralytics YOLO docs utils.downloads.unzip_file, checks disk space, downloads and attempts assets.\n---\n\n# is_url\n---\n:::ultralytics.yolo.utils.downloads.is_url\n
\n\n# unzip_file\n---\n:::ultralytics.yolo.utils.downloads.unzip_file\n
\n\n# check_disk_space\n---\n:::ultralytics.yolo.utils.downloads.check_disk_space\n
\n\n# safe_download\n---\n:::ultralytics.yolo.utils.downloads.safe_download\n
\n\n# attempt_download_asset\n---\n:::ultralytics.yolo.utils.downloads.attempt_download_asset\n
\n\n# download\n---\n:::ultralytics.yolo.utils.downloads.download\n
\n"
},
{
"path": "docs/reference/yolo/utils/errors.md",
"content": "---\ndescription: Learn about HUBModelError in Ultralytics YOLO Docs. Resolve the error and get the most out of your YOLO model.\n---\n\n# HUBModelError\n---\n:::ultralytics.yolo.utils.errors.HUBModelError\n
\n"
},
{
"path": "docs/reference/yolo/utils/files.md",
"content": "---\ndescription: 'Learn about Ultralytics YOLO files and directory utilities: WorkingDirectory, file_age, file_size, and make_dirs.'\n---\n\n# WorkingDirectory\n---\n:::ultralytics.yolo.utils.files.WorkingDirectory\n
\n\n# increment_path\n---\n:::ultralytics.yolo.utils.files.increment_path\n
\n\n# file_age\n---\n:::ultralytics.yolo.utils.files.file_age\n
\n\n# file_date\n---\n:::ultralytics.yolo.utils.files.file_date\n
\n\n# file_size\n---\n:::ultralytics.yolo.utils.files.file_size\n
\n\n# get_latest_run\n---\n:::ultralytics.yolo.utils.files.get_latest_run\n
\n\n# make_dirs\n---\n:::ultralytics.yolo.utils.files.make_dirs\n
\n"
},
{
"path": "docs/reference/yolo/utils/instance.md",
"content": "---\ndescription: Learn about Bounding Boxes (Bboxes) and _ntuple in Ultralytics YOLO for object detection. Improve accuracy and speed with these powerful tools.\n---\n\n# Bboxes\n---\n:::ultralytics.yolo.utils.instance.Bboxes\n
\n\n# Instances\n---\n:::ultralytics.yolo.utils.instance.Instances\n
\n\n# _ntuple\n---\n:::ultralytics.yolo.utils.instance._ntuple\n
\n"
},
{
"path": "docs/reference/yolo/utils/loss.md",
"content": "---\ndescription: Learn about Varifocal Loss and Keypoint Loss in Ultralytics YOLO for advanced bounding box and pose estimation. Visit our docs for more.\n---\n\n# VarifocalLoss\n---\n:::ultralytics.yolo.utils.loss.VarifocalLoss\n
\n\n# BboxLoss\n---\n:::ultralytics.yolo.utils.loss.BboxLoss\n
\n\n# KeypointLoss\n---\n:::ultralytics.yolo.utils.loss.KeypointLoss\n
\n"
},
{
"path": "docs/reference/yolo/utils/metrics.md",
"content": "---\ndescription: Explore Ultralytics YOLO's FocalLoss, DetMetrics, PoseMetrics, ClassifyMetrics, and more with Ultralytics Metrics documentation.\n---\n\n# FocalLoss\n---\n:::ultralytics.yolo.utils.metrics.FocalLoss\n
\n\n# ConfusionMatrix\n---\n:::ultralytics.yolo.utils.metrics.ConfusionMatrix\n
\n\n# Metric\n---\n:::ultralytics.yolo.utils.metrics.Metric\n
\n\n# DetMetrics\n---\n:::ultralytics.yolo.utils.metrics.DetMetrics\n
\n\n# SegmentMetrics\n---\n:::ultralytics.yolo.utils.metrics.SegmentMetrics\n
\n\n# PoseMetrics\n---\n:::ultralytics.yolo.utils.metrics.PoseMetrics\n
\n\n# ClassifyMetrics\n---\n:::ultralytics.yolo.utils.metrics.ClassifyMetrics\n
\n\n# box_area\n---\n:::ultralytics.yolo.utils.metrics.box_area\n
\n\n# bbox_ioa\n---\n:::ultralytics.yolo.utils.metrics.bbox_ioa\n
\n\n# box_iou\n---\n:::ultralytics.yolo.utils.metrics.box_iou\n
\n\n# bbox_iou\n---\n:::ultralytics.yolo.utils.metrics.bbox_iou\n
\n\n# mask_iou\n---\n:::ultralytics.yolo.utils.metrics.mask_iou\n
\n\n# kpt_iou\n---\n:::ultralytics.yolo.utils.metrics.kpt_iou\n
\n\n# smooth_BCE\n---\n:::ultralytics.yolo.utils.metrics.smooth_BCE\n
\n\n# smooth\n---\n:::ultralytics.yolo.utils.metrics.smooth\n
\n\n# plot_pr_curve\n---\n:::ultralytics.yolo.utils.metrics.plot_pr_curve\n
\n\n# plot_mc_curve\n---\n:::ultralytics.yolo.utils.metrics.plot_mc_curve\n
\n\n# compute_ap\n---\n:::ultralytics.yolo.utils.metrics.compute_ap\n
\n\n# ap_per_class\n---\n:::ultralytics.yolo.utils.metrics.ap_per_class\n
\n"
},
{
"path": "docs/reference/yolo/utils/ops.md",
"content": "---\ndescription: Learn about various utility functions in Ultralytics YOLO, including x, y, width, height conversions, non-max suppression, and more.\n---\n\n# Profile\n---\n:::ultralytics.yolo.utils.ops.Profile\n
\n\n# coco80_to_coco91_class\n---\n:::ultralytics.yolo.utils.ops.coco80_to_coco91_class\n
\n\n# segment2box\n---\n:::ultralytics.yolo.utils.ops.segment2box\n
\n\n# scale_boxes\n---\n:::ultralytics.yolo.utils.ops.scale_boxes\n
\n\n# make_divisible\n---\n:::ultralytics.yolo.utils.ops.make_divisible\n
\n\n# non_max_suppression\n---\n:::ultralytics.yolo.utils.ops.non_max_suppression\n
\n\n# clip_boxes\n---\n:::ultralytics.yolo.utils.ops.clip_boxes\n
\n\n# clip_coords\n---\n:::ultralytics.yolo.utils.ops.clip_coords\n
\n\n# scale_image\n---\n:::ultralytics.yolo.utils.ops.scale_image\n
\n\n# xyxy2xywh\n---\n:::ultralytics.yolo.utils.ops.xyxy2xywh\n
\n\n# xywh2xyxy\n---\n:::ultralytics.yolo.utils.ops.xywh2xyxy\n
\n\n# xywhn2xyxy\n---\n:::ultralytics.yolo.utils.ops.xywhn2xyxy\n
\n\n# xyxy2xywhn\n---\n:::ultralytics.yolo.utils.ops.xyxy2xywhn\n
\n\n# xyn2xy\n---\n:::ultralytics.yolo.utils.ops.xyn2xy\n
\n\n# xywh2ltwh\n---\n:::ultralytics.yolo.utils.ops.xywh2ltwh\n
\n\n# xyxy2ltwh\n---\n:::ultralytics.yolo.utils.ops.xyxy2ltwh\n
\n\n# ltwh2xywh\n---\n:::ultralytics.yolo.utils.ops.ltwh2xywh\n
\n\n# ltwh2xyxy\n---\n:::ultralytics.yolo.utils.ops.ltwh2xyxy\n
\n\n# segments2boxes\n---\n:::ultralytics.yolo.utils.ops.segments2boxes\n
\n\n# resample_segments\n---\n:::ultralytics.yolo.utils.ops.resample_segments\n
\n\n# crop_mask\n---\n:::ultralytics.yolo.utils.ops.crop_mask\n
\n\n# process_mask_upsample\n---\n:::ultralytics.yolo.utils.ops.process_mask_upsample\n
\n\n# process_mask\n---\n:::ultralytics.yolo.utils.ops.process_mask\n
\n\n# process_mask_native\n---\n:::ultralytics.yolo.utils.ops.process_mask_native\n
\n\n# scale_coords\n---\n:::ultralytics.yolo.utils.ops.scale_coords\n
\n\n# masks2segments\n---\n:::ultralytics.yolo.utils.ops.masks2segments\n
\n\n# clean_str\n---\n:::ultralytics.yolo.utils.ops.clean_str\n
\n"
},
{
"path": "docs/reference/yolo/utils/plotting.md",
"content": "---\ndescription: 'Discover the power of YOLO''s plotting functions: Colors, Labels and Images. Code examples to output targets and visualize features. Check it now.'\n---\n\n# Colors\n---\n:::ultralytics.yolo.utils.plotting.Colors\n
\n\n# Annotator\n---\n:::ultralytics.yolo.utils.plotting.Annotator\n
\n\n# plot_labels\n---\n:::ultralytics.yolo.utils.plotting.plot_labels\n
\n\n# save_one_box\n---\n:::ultralytics.yolo.utils.plotting.save_one_box\n
\n\n# plot_images\n---\n:::ultralytics.yolo.utils.plotting.plot_images\n
\n\n# plot_results\n---\n:::ultralytics.yolo.utils.plotting.plot_results\n
\n\n# output_to_target\n---\n:::ultralytics.yolo.utils.plotting.output_to_target\n
\n\n# feature_visualization\n---\n:::ultralytics.yolo.utils.plotting.feature_visualization\n
\n"
},
{
"path": "docs/reference/yolo/utils/tal.md",
"content": "---\ndescription: Improve your YOLO models with Ultralytics' TaskAlignedAssigner, select_highest_overlaps, and dist2bbox utilities. Streamline your workflow today.\n---\n\n# TaskAlignedAssigner\n---\n:::ultralytics.yolo.utils.tal.TaskAlignedAssigner\n
\n\n# select_candidates_in_gts\n---\n:::ultralytics.yolo.utils.tal.select_candidates_in_gts\n
\n\n# select_highest_overlaps\n---\n:::ultralytics.yolo.utils.tal.select_highest_overlaps\n
\n\n# make_anchors\n---\n:::ultralytics.yolo.utils.tal.make_anchors\n
\n\n# dist2bbox\n---\n:::ultralytics.yolo.utils.tal.dist2bbox\n
\n\n# bbox2dist\n---\n:::ultralytics.yolo.utils.tal.bbox2dist\n
\n"
},
{
"path": "docs/reference/yolo/utils/torch_utils.md",
"content": "---\ndescription: Optimize your PyTorch models with Ultralytics YOLO's torch_utils functions such as ModelEMA, select_device, and is_parallel.\n---\n\n# ModelEMA\n---\n:::ultralytics.yolo.utils.torch_utils.ModelEMA\n
\n\n# EarlyStopping\n---\n:::ultralytics.yolo.utils.torch_utils.EarlyStopping\n
\n\n# torch_distributed_zero_first\n---\n:::ultralytics.yolo.utils.torch_utils.torch_distributed_zero_first\n
\n\n# smart_inference_mode\n---\n:::ultralytics.yolo.utils.torch_utils.smart_inference_mode\n
\n\n# select_device\n---\n:::ultralytics.yolo.utils.torch_utils.select_device\n
\n\n# time_sync\n---\n:::ultralytics.yolo.utils.torch_utils.time_sync\n
\n\n# fuse_conv_and_bn\n---\n:::ultralytics.yolo.utils.torch_utils.fuse_conv_and_bn\n
\n\n# fuse_deconv_and_bn\n---\n:::ultralytics.yolo.utils.torch_utils.fuse_deconv_and_bn\n
\n\n# model_info\n---\n:::ultralytics.yolo.utils.torch_utils.model_info\n
\n\n# get_num_params\n---\n:::ultralytics.yolo.utils.torch_utils.get_num_params\n
\n\n# get_num_gradients\n---\n:::ultralytics.yolo.utils.torch_utils.get_num_gradients\n
\n\n# get_flops\n---\n:::ultralytics.yolo.utils.torch_utils.get_flops\n
\n\n# initialize_weights\n---\n:::ultralytics.yolo.utils.torch_utils.initialize_weights\n
\n\n# scale_img\n---\n:::ultralytics.yolo.utils.torch_utils.scale_img\n
\n\n# make_divisible\n---\n:::ultralytics.yolo.utils.torch_utils.make_divisible\n
\n\n# copy_attr\n---\n:::ultralytics.yolo.utils.torch_utils.copy_attr\n
\n\n# get_latest_opset\n---\n:::ultralytics.yolo.utils.torch_utils.get_latest_opset\n
\n\n# intersect_dicts\n---\n:::ultralytics.yolo.utils.torch_utils.intersect_dicts\n
\n\n# is_parallel\n---\n:::ultralytics.yolo.utils.torch_utils.is_parallel\n
\n\n# de_parallel\n---\n:::ultralytics.yolo.utils.torch_utils.de_parallel\n
\n\n# one_cycle\n---\n:::ultralytics.yolo.utils.torch_utils.one_cycle\n
\n\n# init_seeds\n---\n:::ultralytics.yolo.utils.torch_utils.init_seeds\n
\n\n# strip_optimizer\n---\n:::ultralytics.yolo.utils.torch_utils.strip_optimizer\n
\n\n# profile\n---\n:::ultralytics.yolo.utils.torch_utils.profile\n
\n"
},
{
"path": "docs/reference/yolo/v8/classify/predict.md",
"content": "---\ndescription: Learn how to use ClassificationPredictor in Ultralytics YOLOv8 for object classification tasks in a simple and efficient way.\n---\n\n# ClassificationPredictor\n---\n:::ultralytics.yolo.v8.classify.predict.ClassificationPredictor\n
\n\n# predict\n---\n:::ultralytics.yolo.v8.classify.predict.predict\n
\n"
},
{
"path": "docs/reference/yolo/v8/classify/train.md",
"content": "---\ndescription: Train a custom image classification model using Ultralytics YOLOv8 with ClassificationTrainer. Boost accuracy and efficiency today.\n---\n\n# ClassificationTrainer\n---\n:::ultralytics.yolo.v8.classify.train.ClassificationTrainer\n
\n\n# train\n---\n:::ultralytics.yolo.v8.classify.train.train\n
\n"
},
{
"path": "docs/reference/yolo/v8/classify/val.md",
"content": "---\ndescription: Ensure model classification accuracy with Ultralytics YOLO's ClassificationValidator. Validate and improve your model with ease.\n---\n\n# ClassificationValidator\n---\n:::ultralytics.yolo.v8.classify.val.ClassificationValidator\n
\n\n# val\n---\n:::ultralytics.yolo.v8.classify.val.val\n
\n"
},
{
"path": "docs/reference/yolo/v8/detect/predict.md",
"content": "---\ndescription: Detect and predict objects in images and videos using the Ultralytics YOLO v8 model with DetectionPredictor.\n---\n\n# DetectionPredictor\n---\n:::ultralytics.yolo.v8.detect.predict.DetectionPredictor\n
\n\n# predict\n---\n:::ultralytics.yolo.v8.detect.predict.predict\n
\n"
},
{
"path": "docs/reference/yolo/v8/detect/train.md",
"content": "---\ndescription: Train and optimize custom object detection models with Ultralytics DetectionTrainer and train functions. Get started with YOLO v8 today.\n---\n\n# DetectionTrainer\n---\n:::ultralytics.yolo.v8.detect.train.DetectionTrainer\n
\n\n# Loss\n---\n:::ultralytics.yolo.v8.detect.train.Loss\n
\n\n# train\n---\n:::ultralytics.yolo.v8.detect.train.train\n
\n"
},
{
"path": "docs/reference/yolo/v8/detect/val.md",
"content": "---\ndescription: Validate YOLOv5 detections using this PyTorch module. Ensure model accuracy with NMS IOU threshold tuning and label mapping.\n---\n\n# DetectionValidator\n---\n:::ultralytics.yolo.v8.detect.val.DetectionValidator\n
\n\n# val\n---\n:::ultralytics.yolo.v8.detect.val.val\n
\n"
},
{
"path": "docs/reference/yolo/v8/pose/predict.md",
"content": "---\ndescription: Predict human pose coordinates and confidence scores using YOLOv5. Use on real-time video streams or static images.\n---\n\n# PosePredictor\n---\n:::ultralytics.yolo.v8.pose.predict.PosePredictor\n
\n\n# predict\n---\n:::ultralytics.yolo.v8.pose.predict.predict\n
\n"
},
{
"path": "docs/reference/yolo/v8/pose/train.md",
"content": "---\ndescription: Boost posture detection using PoseTrainer and train models using train() API. Learn PoseLoss for ultra-fast and accurate pose detection with Ultralytics YOLO.\n---\n\n# PoseTrainer\n---\n:::ultralytics.yolo.v8.pose.train.PoseTrainer\n
\n\n# PoseLoss\n---\n:::ultralytics.yolo.v8.pose.train.PoseLoss\n
\n\n# train\n---\n:::ultralytics.yolo.v8.pose.train.train\n
\n"
},
{
"path": "docs/reference/yolo/v8/pose/val.md",
"content": "---\ndescription: Ensure proper human poses in images with YOLOv8 Pose Validation, part of the Ultralytics YOLO v8 suite.\n---\n\n# PoseValidator\n---\n:::ultralytics.yolo.v8.pose.val.PoseValidator\n
\n\n# val\n---\n:::ultralytics.yolo.v8.pose.val.val\n
\n"
},
{
"path": "docs/reference/yolo/v8/segment/predict.md",
"content": "---\ndescription: '\"Use SegmentationPredictor in YOLOv8 for efficient object detection and segmentation. Explore Ultralytics YOLO Docs for more information.\"'\n---\n\n# SegmentationPredictor\n---\n:::ultralytics.yolo.v8.segment.predict.SegmentationPredictor\n
\n\n# predict\n---\n:::ultralytics.yolo.v8.segment.predict.predict\n
\n"
},
{
"path": "docs/reference/yolo/v8/segment/train.md",
"content": "---\ndescription: Learn about SegmentationTrainer and Train in Ultralytics YOLO v8 for efficient object detection models. Improve your training with Ultralytics Docs.\n---\n\n# SegmentationTrainer\n---\n:::ultralytics.yolo.v8.segment.train.SegmentationTrainer\n
\n\n# SegLoss\n---\n:::ultralytics.yolo.v8.segment.train.SegLoss\n
\n\n# train\n---\n:::ultralytics.yolo.v8.segment.train.train\n
\n"
},
{
"path": "docs/reference/yolo/v8/segment/val.md",
"content": "---\ndescription: Ensure segmentation quality on large datasets with SegmentationValidator. Review and visualize results with ease. Learn more at Ultralytics Docs.\n---\n\n# SegmentationValidator\n---\n:::ultralytics.yolo.v8.segment.val.SegmentationValidator\n
\n\n# val\n---\n:::ultralytics.yolo.v8.segment.val.val\n
\n"
},
{
"path": "docs/robots.txt",
"content": "User-agent: *\n"
},
{
"path": "docs/stylesheets/style.css",
"content": "/* Table format like GitHub ----------------------------------------------------------------------------------------- */\nth, td {\n border: 1px solid var(--md-typeset-table-color);\n border-spacing: 0;\n border-bottom: none;\n border-left: none;\n border-top: none;\n}\n\n.md-typeset__table {\n line-height: 1;\n}\n\n.md-typeset__table table:not([class]) {\n font-size: .74rem;\n border-right: none;\n}\n\n.md-typeset__table table:not([class]) td,\n.md-typeset__table table:not([class]) th {\n padding: 9px;\n}\n\n/* light mode alternating table bg colors */\n.md-typeset__table tr:nth-child(2n) {\n background-color: #f8f8f8;\n}\n\n/* dark mode alternating table bg colors */\n[data-md-color-scheme=\"slate\"] .md-typeset__table tr:nth-child(2n) {\n background-color: hsla(var(--md-hue),25%,25%,1)\n}\n/* Table format like GitHub ----------------------------------------------------------------------------------------- */\n\n/* Code block vertical scroll */\n.md-typeset pre > code {\n max-height: 20rem;\n}"
},
{
"path": "docs/tasks/classify.md",
"content": "---\ncomments: true\ndescription: Check YOLO class label with only one class for the whole image, using image classification. Get strategies for training and validation models.\n---\n\nImage classification is the simplest of the three tasks and involves classifying an entire image into one of a set of\npredefined classes.\n\n \n\nThe output of an image classifier is a single class label and a confidence score. Image\nclassification is useful when you need to know only what class an image belongs to and don't need to know where objects\nof that class are located or what their exact shape is.\n\n!!! tip \"Tip\"\n\n YOLOv8 Classify models use the `-cls` suffix, i.e. `yolov8n-cls.pt` and are pretrained on [ImageNet](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/datasets/ImageNet.yaml).\n\n## [Models](https://github.com/ultralytics/ultralytics/tree/main/ultralytics/models/v8)\n\nYOLOv8 pretrained Classify models are shown here. Detect, Segment and Pose models are pretrained on\nthe [COCO](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/datasets/coco.yaml) dataset, while Classify\nmodels are pretrained on\nthe [ImageNet](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/datasets/ImageNet.yaml) dataset.\n\n[Models](https://github.com/ultralytics/ultralytics/tree/main/ultralytics/models) download automatically from the latest\nUltralytics [release](https://github.com/ultralytics/assets/releases) on first use.\n\n| Model | size
\n\nThe output of an image classifier is a single class label and a confidence score. Image\nclassification is useful when you need to know only what class an image belongs to and don't need to know where objects\nof that class are located or what their exact shape is.\n\n!!! tip \"Tip\"\n\n YOLOv8 Classify models use the `-cls` suffix, i.e. `yolov8n-cls.pt` and are pretrained on [ImageNet](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/datasets/ImageNet.yaml).\n\n## [Models](https://github.com/ultralytics/ultralytics/tree/main/ultralytics/models/v8)\n\nYOLOv8 pretrained Classify models are shown here. Detect, Segment and Pose models are pretrained on\nthe [COCO](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/datasets/coco.yaml) dataset, while Classify\nmodels are pretrained on\nthe [ImageNet](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/datasets/ImageNet.yaml) dataset.\n\n[Models](https://github.com/ultralytics/ultralytics/tree/main/ultralytics/models) download automatically from the latest\nUltralytics [release](https://github.com/ultralytics/assets/releases) on first use.\n\n| Model | size
(pixels) | acc
top1 | acc
top5 | Speed
CPU ONNX
(ms) | Speed
A100 TensorRT
(ms) | params
(M) | FLOPs
(B) at 640 |\n|----------------------------------------------------------------------------------------------|-----------------------|------------------|------------------|--------------------------------|-------------------------------------|--------------------|--------------------------|\n| [YOLOv8n-cls](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8n-cls.pt) | 224 | 66.6 | 87.0 | 12.9 | 0.31 | 2.7 | 4.3 |\n| [YOLOv8s-cls](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8s-cls.pt) | 224 | 72.3 | 91.1 | 23.4 | 0.35 | 6.4 | 13.5 |\n| [YOLOv8m-cls](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8m-cls.pt) | 224 | 76.4 | 93.2 | 85.4 | 0.62 | 17.0 | 42.7 |\n| [YOLOv8l-cls](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8l-cls.pt) | 224 | 78.0 | 94.1 | 163.0 | 0.87 | 37.5 | 99.7 |\n| [YOLOv8x-cls](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8x-cls.pt) | 224 | 78.4 | 94.3 | 232.0 | 1.01 | 57.4 | 154.8 |\n\n- **acc** values are model accuracies on the [ImageNet](https://www.image-net.org/) dataset validation set.\n
Reproduce by `yolo val classify data=path/to/ImageNet device=0`\n- **Speed** averaged over ImageNet val images using an [Amazon EC2 P4d](https://aws.amazon.com/ec2/instance-types/p4/)\n instance.\n
Reproduce by `yolo val classify data=path/to/ImageNet batch=1 device=0|cpu`\n\n## Train\n\nTrain YOLOv8n-cls on the MNIST160 dataset for 100 epochs at image size 64. For a full list of available arguments\nsee the [Configuration](../usage/cfg.md) page.\n\n!!! example \"\"\n\n === \"Python\"\n \n ```python\n from ultralytics import YOLO\n \n # Load a model\n model = YOLO('yolov8n-cls.yaml') # build a new model from YAML\n model = YOLO('yolov8n-cls.pt') # load a pretrained model (recommended for training)\n model = YOLO('yolov8n-cls.yaml').load('yolov8n-cls.pt') # build from YAML and transfer weights\n \n # Train the model\n model.train(data='mnist160', epochs=100, imgsz=64)\n ```\n\n === \"CLI\"\n\n ```bash\n # Build a new model from YAML and start training from scratch\n yolo classify train data=mnist160 model=yolov8n-cls.yaml epochs=100 imgsz=64\n\n # Start training from a pretrained *.pt model\n yolo classify train data=mnist160 model=yolov8n-cls.pt epochs=100 imgsz=64\n\n # Build a new model from YAML, transfer pretrained weights to it and start training\n yolo classify train data=mnist160 model=yolov8n-cls.yaml pretrained=yolov8n-cls.pt epochs=100 imgsz=64\n ```\n\n### Dataset format\n\nThe YOLO classification dataset format is same as the torchvision format. Each class of images has its own folder and you have to simply pass the path of the dataset folder, i.e, `yolo classify train data=\"path/to/dataset\"`\n\n```\ndataset/\n├── train/\n├──── class1/\n├──── class2/\n├──── class3/\n├──── ...\n├── val/\n├──── class1/\n├──── class2/\n├──── class3/\n├──── ...\n```\n\n## Val\n\nValidate trained YOLOv8n-cls model accuracy on the MNIST160 dataset. No argument need to passed as the `model` retains\nit's training `data` and arguments as model attributes.\n\n!!! example \"\"\n\n === \"Python\"\n \n ```python\n from ultralytics import YOLO\n \n # Load a model\n model = YOLO('yolov8n-cls.pt') # load an official model\n model = YOLO('path/to/best.pt') # load a custom model\n \n # Validate the model\n metrics = model.val() # no arguments needed, dataset and settings remembered\n metrics.top1 # top1 accuracy\n metrics.top5 # top5 accuracy\n ```\n === \"CLI\"\n \n ```bash\n yolo classify val model=yolov8n-cls.pt # val official model\n yolo classify val model=path/to/best.pt # val custom model\n ```\n\n## Predict\n\nUse a trained YOLOv8n-cls model to run predictions on images.\n\n!!! example \"\"\n\n === \"Python\"\n \n ```python\n from ultralytics import YOLO\n \n # Load a model\n model = YOLO('yolov8n-cls.pt') # load an official model\n model = YOLO('path/to/best.pt') # load a custom model\n \n # Predict with the model\n results = model('https://ultralytics.com/images/bus.jpg') # predict on an image\n ```\n === \"CLI\"\n \n ```bash\n yolo classify predict model=yolov8n-cls.pt source='https://ultralytics.com/images/bus.jpg' # predict with official model\n yolo classify predict model=path/to/best.pt source='https://ultralytics.com/images/bus.jpg' # predict with custom model\n ```\n\nSee full `predict` mode details in the [Predict](https://docs.ultralytics.com/modes/predict/) page.\n\n## Export\n\nExport a YOLOv8n-cls model to a different format like ONNX, CoreML, etc.\n\n!!! example \"\"\n\n === \"Python\"\n \n ```python\n from ultralytics import YOLO\n \n # Load a model\n model = YOLO('yolov8n-cls.pt') # load an official model\n model = YOLO('path/to/best.pt') # load a custom trained\n \n # Export the model\n model.export(format='onnx')\n ```\n === \"CLI\"\n \n ```bash\n yolo export model=yolov8n-cls.pt format=onnx # export official model\n yolo export model=path/to/best.pt format=onnx # export custom trained model\n ```\n\nAvailable YOLOv8-cls export formats are in the table below. You can predict or validate directly on exported models,\ni.e. `yolo predict model=yolov8n-cls.onnx`. Usage examples are shown for your model after export completes.\n\n| Format | `format` Argument | Model | Metadata | Arguments |\n|--------------------------------------------------------------------|-------------------|-------------------------------|----------|-----------------------------------------------------|\n| [PyTorch](https://pytorch.org/) | - | `yolov8n-cls.pt` | ✅ | - |\n| [TorchScript](https://pytorch.org/docs/stable/jit.html) | `torchscript` | `yolov8n-cls.torchscript` | ✅ | `imgsz`, `optimize` |\n| [ONNX](https://onnx.ai/) | `onnx` | `yolov8n-cls.onnx` | ✅ | `imgsz`, `half`, `dynamic`, `simplify`, `opset` |\n| [OpenVINO](https://docs.openvino.ai/latest/index.html) | `openvino` | `yolov8n-cls_openvino_model/` | ✅ | `imgsz`, `half` |\n| [TensorRT](https://developer.nvidia.com/tensorrt) | `engine` | `yolov8n-cls.engine` | ✅ | `imgsz`, `half`, `dynamic`, `simplify`, `workspace` |\n| [CoreML](https://github.com/apple/coremltools) | `coreml` | `yolov8n-cls.mlmodel` | ✅ | `imgsz`, `half`, `int8`, `nms` |\n| [TF SavedModel](https://www.tensorflow.org/guide/saved_model) | `saved_model` | `yolov8n-cls_saved_model/` | ✅ | `imgsz`, `keras` |\n| [TF GraphDef](https://www.tensorflow.org/api_docs/python/tf/Graph) | `pb` | `yolov8n-cls.pb` | ❌ | `imgsz` |\n| [TF Lite](https://www.tensorflow.org/lite) | `tflite` | `yolov8n-cls.tflite` | ✅ | `imgsz`, `half`, `int8` |\n| [TF Edge TPU](https://coral.ai/docs/edgetpu/models-intro/) | `edgetpu` | `yolov8n-cls_edgetpu.tflite` | ✅ | `imgsz` |\n| [TF.js](https://www.tensorflow.org/js) | `tfjs` | `yolov8n-cls_web_model/` | ✅ | `imgsz` |\n| [PaddlePaddle](https://github.com/PaddlePaddle) | `paddle` | `yolov8n-cls_paddle_model/` | ✅ | `imgsz` |\n\nSee full `export` details in the [Export](https://docs.ultralytics.com/modes/export/) page."
},
{
"path": "docs/tasks/detect.md",
"content": "---\ncomments: true\ndescription: Learn how to use YOLOv8, an object detection model pre-trained with COCO and about the different YOLOv8 models and how to train and export them.\n---\n\nObject detection is a task that involves identifying the location and class of objects in an image or video stream.\n\n\n\nThe output of an object detector is a set of bounding boxes that enclose the objects in the image, along with class labels and confidence scores for each box. Object detection is a good choice when you need to identify objects of interest in a scene, but don't need to know exactly where the object is or its exact shape.\n\n!!! tip \"Tip\"\n\n YOLOv8 Detect models are the default YOLOv8 models, i.e. `yolov8n.pt` and are pretrained on [COCO](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/datasets/coco.yaml).\n\n## [Models](https://github.com/ultralytics/ultralytics/tree/main/ultralytics/models/v8)\n\nYOLOv8 pretrained Detect models are shown here. Detect, Segment and Pose models are pretrained on the [COCO](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/datasets/coco.yaml) dataset, while Classify models are pretrained on the [ImageNet](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/datasets/ImageNet.yaml) dataset.\n\n[Models](https://github.com/ultralytics/ultralytics/tree/main/ultralytics/models) download automatically from the latest Ultralytics [release](https://github.com/ultralytics/assets/releases) on first use.\n\n| Model | size
(pixels) | mAPval
50-95 | Speed
CPU ONNX
(ms) | Speed
A100 TensorRT
(ms) | params
(M) | FLOPs
(B) |\n|--------------------------------------------------------------------------------------|-----------------------|----------------------|--------------------------------|-------------------------------------|--------------------|-------------------|\n| [YOLOv8n](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8n.pt) | 640 | 37.3 | 80.4 | 0.99 | 3.2 | 8.7 |\n| [YOLOv8s](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8s.pt) | 640 | 44.9 | 128.4 | 1.20 | 11.2 | 28.6 |\n| [YOLOv8m](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8m.pt) | 640 | 50.2 | 234.7 | 1.83 | 25.9 | 78.9 |\n| [YOLOv8l](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8l.pt) | 640 | 52.9 | 375.2 | 2.39 | 43.7 | 165.2 |\n| [YOLOv8x](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8x.pt) | 640 | 53.9 | 479.1 | 3.53 | 68.2 | 257.8 |\n\n- **mAPval** values are for single-model single-scale on [COCO val2017](http://cocodataset.org) dataset.\n
Reproduce by `yolo val detect data=coco.yaml device=0`\n- **Speed** averaged over COCO val images using an [Amazon EC2 P4d](https://aws.amazon.com/ec2/instance-types/p4/)\n instance.\n
Reproduce by `yolo val detect data=coco128.yaml batch=1 device=0|cpu`\n\n## Train\n\nTrain YOLOv8n on the COCO128 dataset for 100 epochs at image size 640. For a full list of available arguments see the [Configuration](../usage/cfg.md) page.\n\n!!! example \"\"\n\n === \"Python\"\n \n ```python\n from ultralytics import YOLO\n \n # Load a model\n model = YOLO('yolov8n.yaml') # build a new model from YAML\n model = YOLO('yolov8n.pt') # load a pretrained model (recommended for training)\n model = YOLO('yolov8n.yaml').load('yolov8n.pt') # build from YAML and transfer weights\n \n # Train the model\n model.train(data='coco128.yaml', epochs=100, imgsz=640)\n ```\n === \"CLI\"\n \n ```bash\n # Build a new model from YAML and start training from scratch\n yolo detect train data=coco128.yaml model=yolov8n.yaml epochs=100 imgsz=640\n\n # Start training from a pretrained *.pt model\n yolo detect train data=coco128.yaml model=yolov8n.pt epochs=100 imgsz=640\n\n # Build a new model from YAML, transfer pretrained weights to it and start training\n yolo detect train data=coco128.yaml model=yolov8n.yaml pretrained=yolov8n.pt epochs=100 imgsz=640\n ```\n\n### Dataset format\n\nYOLO detection dataset format can be found in detail in the [Dataset Guide](../yolov5/tutorials/train_custom_data.md). To convert your existing dataset from other formats( like COCO, VOC etc.) to YOLO format, please use [json2yolo tool](https://github.com/ultralytics/JSON2YOLO) by Ultralytics.\n\n## Val\n\nValidate trained YOLOv8n model accuracy on the COCO128 dataset. No argument need to passed as the `model` retains it's training `data` and arguments as model attributes.\n\n!!! example \"\"\n\n === \"Python\"\n \n ```python\n from ultralytics import YOLO\n \n # Load a model\n model = YOLO('yolov8n.pt') # load an official model\n model = YOLO('path/to/best.pt') # load a custom model\n \n # Validate the model\n metrics = model.val() # no arguments needed, dataset and settings remembered\n metrics.box.map # map50-95\n metrics.box.map50 # map50\n metrics.box.map75 # map75\n metrics.box.maps # a list contains map50-95 of each category\n ```\n === \"CLI\"\n \n ```bash\n yolo detect val model=yolov8n.pt # val official model\n yolo detect val model=path/to/best.pt # val custom model\n ```\n\n## Predict\n\nUse a trained YOLOv8n model to run predictions on images.\n\n!!! example \"\"\n\n === \"Python\"\n \n ```python\n from ultralytics import YOLO\n \n # Load a model\n model = YOLO('yolov8n.pt') # load an official model\n model = YOLO('path/to/best.pt') # load a custom model\n \n # Predict with the model\n results = model('https://ultralytics.com/images/bus.jpg') # predict on an image\n ```\n === \"CLI\"\n \n ```bash\n yolo detect predict model=yolov8n.pt source='https://ultralytics.com/images/bus.jpg' # predict with official model\n yolo detect predict model=path/to/best.pt source='https://ultralytics.com/images/bus.jpg' # predict with custom model\n ```\n\nSee full `predict` mode details in the [Predict](https://docs.ultralytics.com/modes/predict/) page.\n\n## Export\n\nExport a YOLOv8n model to a different format like ONNX, CoreML, etc.\n\n!!! example \"\"\n\n === \"Python\"\n \n ```python\n from ultralytics import YOLO\n \n # Load a model\n model = YOLO('yolov8n.pt') # load an official model\n model = YOLO('path/to/best.pt') # load a custom trained\n \n # Export the model\n model.export(format='onnx')\n ```\n === \"CLI\"\n \n ```bash\n yolo export model=yolov8n.pt format=onnx # export official model\n yolo export model=path/to/best.pt format=onnx # export custom trained model\n ```\n\nAvailable YOLOv8 export formats are in the table below. You can predict or validate directly on exported models, i.e. `yolo predict model=yolov8n.onnx`. Usage examples are shown for your model after export completes.\n\n| Format | `format` Argument | Model | Metadata | Arguments |\n|--------------------------------------------------------------------|-------------------|---------------------------|----------|-----------------------------------------------------|\n| [PyTorch](https://pytorch.org/) | - | `yolov8n.pt` | ✅ | - |\n| [TorchScript](https://pytorch.org/docs/stable/jit.html) | `torchscript` | `yolov8n.torchscript` | ✅ | `imgsz`, `optimize` |\n| [ONNX](https://onnx.ai/) | `onnx` | `yolov8n.onnx` | ✅ | `imgsz`, `half`, `dynamic`, `simplify`, `opset` |\n| [OpenVINO](https://docs.openvino.ai/latest/index.html) | `openvino` | `yolov8n_openvino_model/` | ✅ | `imgsz`, `half` |\n| [TensorRT](https://developer.nvidia.com/tensorrt) | `engine` | `yolov8n.engine` | ✅ | `imgsz`, `half`, `dynamic`, `simplify`, `workspace` |\n| [CoreML](https://github.com/apple/coremltools) | `coreml` | `yolov8n.mlmodel` | ✅ | `imgsz`, `half`, `int8`, `nms` |\n| [TF SavedModel](https://www.tensorflow.org/guide/saved_model) | `saved_model` | `yolov8n_saved_model/` | ✅ | `imgsz`, `keras` |\n| [TF GraphDef](https://www.tensorflow.org/api_docs/python/tf/Graph) | `pb` | `yolov8n.pb` | ❌ | `imgsz` |\n| [TF Lite](https://www.tensorflow.org/lite) | `tflite` | `yolov8n.tflite` | ✅ | `imgsz`, `half`, `int8` |\n| [TF Edge TPU](https://coral.ai/docs/edgetpu/models-intro/) | `edgetpu` | `yolov8n_edgetpu.tflite` | ✅ | `imgsz` |\n| [TF.js](https://www.tensorflow.org/js) | `tfjs` | `yolov8n_web_model/` | ✅ | `imgsz` |\n| [PaddlePaddle](https://github.com/PaddlePaddle) | `paddle` | `yolov8n_paddle_model/` | ✅ | `imgsz` |\n\nSee full `export` details in the [Export](https://docs.ultralytics.com/modes/export/) page."
},
{
"path": "docs/tasks/index.md",
"content": "---\ncomments: true\ndescription: Learn how Ultralytics YOLOv8 AI framework supports detection, segmentation, classification, and pose/keypoint estimation tasks.\n---\n\n# Ultralytics YOLOv8 Tasks\n\nYOLOv8 is an AI framework that supports multiple computer vision **tasks**. The framework can be used to\nperform [detection](detect.md), [segmentation](segment.md), [classification](classify.md),\nand [pose](pose.md) estimation. Each of these tasks has a different objective and use case.\n\n\n\n## [Detection](detect.md)\n\nDetection is the primary task supported by YOLOv8. It involves detecting objects in an image or video frame and drawing\nbounding boxes around them. The detected objects are classified into different categories based on their features.\nYOLOv8 can detect multiple objects in a single image or video frame with high accuracy and speed.\n\n[Detection Examples](detect.md){ .md-button .md-button--primary}\n\n## [Segmentation](segment.md)\n\nSegmentation is a task that involves segmenting an image into different regions based on the content of the image. Each\nregion is assigned a label based on its content. This task is useful in applications such as image segmentation and\nmedical imaging. YOLOv8 uses a variant of the U-Net architecture to perform segmentation.\n\n[Segmentation Examples](segment.md){ .md-button .md-button--primary}\n\n## [Classification](classify.md)\n\nClassification is a task that involves classifying an image into different categories. YOLOv8 can be used to classify\nimages based on their content. It uses a variant of the EfficientNet architecture to perform classification.\n\n[Classification Examples](classify.md){ .md-button .md-button--primary}\n\n## [Pose](pose.md)\n\nPose/keypoint detection is a task that involves detecting specific points in an image or video frame. These points are\nreferred to as keypoints and are used to track movement or pose estimation. YOLOv8 can detect keypoints in an image or\nvideo frame with high accuracy and speed.\n\n[Pose Examples](pose.md){ .md-button .md-button--primary}\n\n## Conclusion\n\nYOLOv8 supports multiple tasks, including detection, segmentation, classification, and keypoints detection. Each of\nthese tasks has different objectives and use cases. By understanding the differences between these tasks, you can choose\nthe appropriate task for your computer vision application."
},
{
"path": "docs/tasks/pose.md",
"content": "---\ncomments: true\ndescription: Learn how to use YOLOv8 pose estimation models to identify the position of keypoints on objects in an image, and how to train, validate, predict, and export these models for use with various formats such as ONNX or CoreML.\n---\n\nPose estimation is a task that involves identifying the location of specific points in an image, usually referred\nto as keypoints. The keypoints can represent various parts of the object such as joints, landmarks, or other distinctive\nfeatures. The locations of the keypoints are usually represented as a set of 2D `[x, y]` or 3D `[x, y, visible]`\ncoordinates.\n\n\n\nThe output of a pose estimation model is a set of points that represent the keypoints on an object in the image, usually\nalong with the confidence scores for each point. Pose estimation is a good choice when you need to identify specific\nparts of an object in a scene, and their location in relation to each other.\n\n!!! tip \"Tip\"\n\n YOLOv8 _pose_ models use the `-pose` suffix, i.e. `yolov8n-pose.pt`. These models are trained on the [COCO keypoints](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/datasets/coco-pose.yaml) dataset and are suitable for a variety of pose estimation tasks.\n\n## [Models](https://github.com/ultralytics/ultralytics/tree/main/ultralytics/models/v8)\n\nYOLOv8 pretrained Pose models are shown here. Detect, Segment and Pose models are pretrained on\nthe [COCO](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/datasets/coco.yaml) dataset, while Classify\nmodels are pretrained on\nthe [ImageNet](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/datasets/ImageNet.yaml) dataset.\n\n[Models](https://github.com/ultralytics/ultralytics/tree/main/ultralytics/models) download automatically from the latest\nUltralytics [release](https://github.com/ultralytics/assets/releases) on first use.\n\n| Model | size
(pixels) | mAPpose
50-95 | mAPpose
50 | Speed
CPU ONNX
(ms) | Speed
A100 TensorRT
(ms) | params
(M) | FLOPs
(B) |\n|------------------------------------------------------------------------------------------------------|-----------------------|-----------------------|--------------------|--------------------------------|-------------------------------------|--------------------|-------------------|\n| [YOLOv8n-pose](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8n-pose.pt) | 640 | 50.4 | 80.1 | 131.8 | 1.18 | 3.3 | 9.2 |\n| [YOLOv8s-pose](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8s-pose.pt) | 640 | 60.0 | 86.2 | 233.2 | 1.42 | 11.6 | 30.2 |\n| [YOLOv8m-pose](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8m-pose.pt) | 640 | 65.0 | 88.8 | 456.3 | 2.00 | 26.4 | 81.0 |\n| [YOLOv8l-pose](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8l-pose.pt) | 640 | 67.6 | 90.0 | 784.5 | 2.59 | 44.4 | 168.6 |\n| [YOLOv8x-pose](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8x-pose.pt) | 640 | 69.2 | 90.2 | 1607.1 | 3.73 | 69.4 | 263.2 |\n| [YOLOv8x-pose-p6](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8x-pose-p6.pt) | 1280 | 71.6 | 91.2 | 4088.7 | 10.04 | 99.1 | 1066.4 |\n\n- **mAPval** values are for single-model single-scale on [COCO Keypoints val2017](http://cocodataset.org)\n dataset.\n
Reproduce by `yolo val pose data=coco-pose.yaml device=0`\n- **Speed** averaged over COCO val images using an [Amazon EC2 P4d](https://aws.amazon.com/ec2/instance-types/p4/)\n instance.\n
Reproduce by `yolo val pose data=coco8-pose.yaml batch=1 device=0|cpu`\n\n## Train\n\nTrain a YOLOv8-pose model on the COCO128-pose dataset.\n\n!!! example \"\"\n\n === \"Python\"\n \n ```python\n from ultralytics import YOLO\n \n # Load a model\n model = YOLO('yolov8n-pose.yaml') # build a new model from YAML\n model = YOLO('yolov8n-pose.pt') # load a pretrained model (recommended for training)\n model = YOLO('yolov8n-pose.yaml').load('yolov8n-pose.pt') # build from YAML and transfer weights\n \n # Train the model\n model.train(data='coco8-pose.yaml', epochs=100, imgsz=640)\n ```\n === \"CLI\"\n \n ```bash\n # Build a new model from YAML and start training from scratch\n yolo pose train data=coco8-pose.yaml model=yolov8n-pose.yaml epochs=100 imgsz=640\n\n # Start training from a pretrained *.pt model\n yolo pose train data=coco8-pose.yaml model=yolov8n-pose.pt epochs=100 imgsz=640\n\n # Build a new model from YAML, transfer pretrained weights to it and start training\n yolo pose train data=coco8-pose.yaml model=yolov8n-pose.yaml pretrained=yolov8n-pose.pt epochs=100 imgsz=640\n ```\n\n## Val\n\nValidate trained YOLOv8n-pose model accuracy on the COCO128-pose dataset. No argument need to passed as the `model`\nretains it's\ntraining `data` and arguments as model attributes.\n\n!!! example \"\"\n\n === \"Python\"\n \n ```python\n from ultralytics import YOLO\n \n # Load a model\n model = YOLO('yolov8n-pose.pt') # load an official model\n model = YOLO('path/to/best.pt') # load a custom model\n \n # Validate the model\n metrics = model.val() # no arguments needed, dataset and settings remembered\n metrics.box.map # map50-95\n metrics.box.map50 # map50\n metrics.box.map75 # map75\n metrics.box.maps # a list contains map50-95 of each category\n ```\n === \"CLI\"\n \n ```bash\n yolo pose val model=yolov8n-pose.pt # val official model\n yolo pose val model=path/to/best.pt # val custom model\n ```\n\n## Predict\n\nUse a trained YOLOv8n-pose model to run predictions on images.\n\n!!! example \"\"\n\n === \"Python\"\n \n ```python\n from ultralytics import YOLO\n \n # Load a model\n model = YOLO('yolov8n-pose.pt') # load an official model\n model = YOLO('path/to/best.pt') # load a custom model\n \n # Predict with the model\n results = model('https://ultralytics.com/images/bus.jpg') # predict on an image\n ```\n === \"CLI\"\n \n ```bash\n yolo pose predict model=yolov8n-pose.pt source='https://ultralytics.com/images/bus.jpg' # predict with official model\n yolo pose predict model=path/to/best.pt source='https://ultralytics.com/images/bus.jpg' # predict with custom model\n ```\n\nSee full `predict` mode details in the [Predict](https://docs.ultralytics.com/modes/predict/) page.\n\n## Export\n\nExport a YOLOv8n Pose model to a different format like ONNX, CoreML, etc.\n\n!!! example \"\"\n\n === \"Python\"\n \n ```python\n from ultralytics import YOLO\n \n # Load a model\n model = YOLO('yolov8n-pose.pt') # load an official model\n model = YOLO('path/to/best.pt') # load a custom trained\n \n # Export the model\n model.export(format='onnx')\n ```\n === \"CLI\"\n \n ```bash\n yolo export model=yolov8n-pose.pt format=onnx # export official model\n yolo export model=path/to/best.pt format=onnx # export custom trained model\n ```\n\nAvailable YOLOv8-pose export formats are in the table below. You can predict or validate directly on exported models,\ni.e. `yolo predict model=yolov8n-pose.onnx`. Usage examples are shown for your model after export completes.\n\n| Format | `format` Argument | Model | Metadata | Arguments |\n|--------------------------------------------------------------------|-------------------|--------------------------------|----------|-----------------------------------------------------|\n| [PyTorch](https://pytorch.org/) | - | `yolov8n-pose.pt` | ✅ | - |\n| [TorchScript](https://pytorch.org/docs/stable/jit.html) | `torchscript` | `yolov8n-pose.torchscript` | ✅ | `imgsz`, `optimize` |\n| [ONNX](https://onnx.ai/) | `onnx` | `yolov8n-pose.onnx` | ✅ | `imgsz`, `half`, `dynamic`, `simplify`, `opset` |\n| [OpenVINO](https://docs.openvino.ai/latest/index.html) | `openvino` | `yolov8n-pose_openvino_model/` | ✅ | `imgsz`, `half` |\n| [TensorRT](https://developer.nvidia.com/tensorrt) | `engine` | `yolov8n-pose.engine` | ✅ | `imgsz`, `half`, `dynamic`, `simplify`, `workspace` |\n| [CoreML](https://github.com/apple/coremltools) | `coreml` | `yolov8n-pose.mlmodel` | ✅ | `imgsz`, `half`, `int8`, `nms` |\n| [TF SavedModel](https://www.tensorflow.org/guide/saved_model) | `saved_model` | `yolov8n-pose_saved_model/` | ✅ | `imgsz`, `keras` |\n| [TF GraphDef](https://www.tensorflow.org/api_docs/python/tf/Graph) | `pb` | `yolov8n-pose.pb` | ❌ | `imgsz` |\n| [TF Lite](https://www.tensorflow.org/lite) | `tflite` | `yolov8n-pose.tflite` | ✅ | `imgsz`, `half`, `int8` |\n| [TF Edge TPU](https://coral.ai/docs/edgetpu/models-intro/) | `edgetpu` | `yolov8n-pose_edgetpu.tflite` | ✅ | `imgsz` |\n| [TF.js](https://www.tensorflow.org/js) | `tfjs` | `yolov8n-pose_web_model/` | ✅ | `imgsz` |\n| [PaddlePaddle](https://github.com/PaddlePaddle) | `paddle` | `yolov8n-pose_paddle_model/` | ✅ | `imgsz` |\n\nSee full `export` details in the [Export](https://docs.ultralytics.com/modes/export/) page."
},
{
"path": "docs/tasks/segment.md",
"content": "---\ncomments: true\ndescription: Learn what Instance segmentation is. Get pretrained YOLOv8 segment models, and how to train and export them to segments masks. Check the preformance metrics!\n---\n\nInstance segmentation goes a step further than object detection and involves identifying individual objects in an image\nand segmenting them from the rest of the image.\n\n\n\nThe output of an instance segmentation model is a set of masks or\ncontours that outline each object in the image, along with class labels and confidence scores for each object. Instance\nsegmentation is useful when you need to know not only where objects are in an image, but also what their exact shape is.\n\n!!! tip \"Tip\"\n\n YOLOv8 Segment models use the `-seg` suffix, i.e. `yolov8n-seg.pt` and are pretrained on [COCO](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/datasets/coco.yaml).\n\n## [Models](https://github.com/ultralytics/ultralytics/tree/main/ultralytics/models/v8)\n\nYOLOv8 pretrained Segment models are shown here. Detect, Segment and Pose models are pretrained on\nthe [COCO](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/datasets/coco.yaml) dataset, while Classify\nmodels are pretrained on\nthe [ImageNet](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/datasets/ImageNet.yaml) dataset.\n\n[Models](https://github.com/ultralytics/ultralytics/tree/main/ultralytics/models) download automatically from the latest\nUltralytics [release](https://github.com/ultralytics/assets/releases) on first use.\n\n| Model | size
(pixels) | mAPbox
50-95 | mAPmask
50-95 | Speed
CPU ONNX
(ms) | Speed
A100 TensorRT
(ms) | params
(M) | FLOPs
(B) |\n|----------------------------------------------------------------------------------------------|-----------------------|----------------------|-----------------------|--------------------------------|-------------------------------------|--------------------|-------------------|\n| [YOLOv8n-seg](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8n-seg.pt) | 640 | 36.7 | 30.5 | 96.1 | 1.21 | 3.4 | 12.6 |\n| [YOLOv8s-seg](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8s-seg.pt) | 640 | 44.6 | 36.8 | 155.7 | 1.47 | 11.8 | 42.6 |\n| [YOLOv8m-seg](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8m-seg.pt) | 640 | 49.9 | 40.8 | 317.0 | 2.18 | 27.3 | 110.2 |\n| [YOLOv8l-seg](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8l-seg.pt) | 640 | 52.3 | 42.6 | 572.4 | 2.79 | 46.0 | 220.5 |\n| [YOLOv8x-seg](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8x-seg.pt) | 640 | 53.4 | 43.4 | 712.1 | 4.02 | 71.8 | 344.1 |\n\n- **mAPval** values are for single-model single-scale on [COCO val2017](http://cocodataset.org) dataset.\n
Reproduce by `yolo val segment data=coco.yaml device=0`\n- **Speed** averaged over COCO val images using an [Amazon EC2 P4d](https://aws.amazon.com/ec2/instance-types/p4/)\n instance.\n
Reproduce by `yolo val segment data=coco128-seg.yaml batch=1 device=0|cpu`\n\n## Train\n\nTrain YOLOv8n-seg on the COCO128-seg dataset for 100 epochs at image size 640. For a full list of available\narguments see the [Configuration](../usage/cfg.md) page.\n\n!!! example \"\"\n\n === \"Python\"\n \n ```python\n from ultralytics import YOLO\n \n # Load a model\n model = YOLO('yolov8n-seg.yaml') # build a new model from YAML\n model = YOLO('yolov8n-seg.pt') # load a pretrained model (recommended for training)\n model = YOLO('yolov8n-seg.yaml').load('yolov8n.pt') # build from YAML and transfer weights\n \n # Train the model\n model.train(data='coco128-seg.yaml', epochs=100, imgsz=640)\n ```\n === \"CLI\"\n \n ```bash\n # Build a new model from YAML and start training from scratch\n yolo segment train data=coco128-seg.yaml model=yolov8n-seg.yaml epochs=100 imgsz=640\n\n # Start training from a pretrained *.pt model\n yolo segment train data=coco128-seg.yaml model=yolov8n-seg.pt epochs=100 imgsz=640\n\n # Build a new model from YAML, transfer pretrained weights to it and start training\n yolo segment train data=coco128-seg.yaml model=yolov8n-seg.yaml pretrained=yolov8n-seg.pt epochs=100 imgsz=640\n ```\n\n### Dataset format\n\nYOLO segmentation dataset label format extends detection format with segment points.\n\n`cls x1 y1 x2 y2 p1 p2 ... pn`\n\nTo convert your existing dataset from other formats( like COCO, VOC etc.) to YOLO format, please use [json2yolo tool](https://github.com/ultralytics/JSON2YOLO) by Ultralytics.\n\n## Val\n\nValidate trained YOLOv8n-seg model accuracy on the COCO128-seg dataset. No argument need to passed as the `model`\nretains it's training `data` and arguments as model attributes.\n\n!!! example \"\"\n\n === \"Python\"\n \n ```python\n from ultralytics import YOLO\n \n # Load a model\n model = YOLO('yolov8n-seg.pt') # load an official model\n model = YOLO('path/to/best.pt') # load a custom model\n \n # Validate the model\n metrics = model.val() # no arguments needed, dataset and settings remembered\n metrics.box.map # map50-95(B)\n metrics.box.map50 # map50(B)\n metrics.box.map75 # map75(B)\n metrics.box.maps # a list contains map50-95(B) of each category\n metrics.seg.map # map50-95(M)\n metrics.seg.map50 # map50(M)\n metrics.seg.map75 # map75(M)\n metrics.seg.maps # a list contains map50-95(M) of each category\n ```\n === \"CLI\"\n \n ```bash\n yolo segment val model=yolov8n-seg.pt # val official model\n yolo segment val model=path/to/best.pt # val custom model\n ```\n\n## Predict\n\nUse a trained YOLOv8n-seg model to run predictions on images.\n\n!!! example \"\"\n\n === \"Python\"\n \n ```python\n from ultralytics import YOLO\n \n # Load a model\n model = YOLO('yolov8n-seg.pt') # load an official model\n model = YOLO('path/to/best.pt') # load a custom model\n \n # Predict with the model\n results = model('https://ultralytics.com/images/bus.jpg') # predict on an image\n ```\n === \"CLI\"\n \n ```bash\n yolo segment predict model=yolov8n-seg.pt source='https://ultralytics.com/images/bus.jpg' # predict with official model\n yolo segment predict model=path/to/best.pt source='https://ultralytics.com/images/bus.jpg' # predict with custom model\n ```\n\nSee full `predict` mode details in the [Predict](https://docs.ultralytics.com/modes/predict/) page.\n\n## Export\n\nExport a YOLOv8n-seg model to a different format like ONNX, CoreML, etc.\n\n!!! example \"\"\n\n === \"Python\"\n \n ```python\n from ultralytics import YOLO\n \n # Load a model\n model = YOLO('yolov8n-seg.pt') # load an official model\n model = YOLO('path/to/best.pt') # load a custom trained\n \n # Export the model\n model.export(format='onnx')\n ```\n === \"CLI\"\n \n ```bash\n yolo export model=yolov8n-seg.pt format=onnx # export official model\n yolo export model=path/to/best.pt format=onnx # export custom trained model\n ```\n\nAvailable YOLOv8-seg export formats are in the table below. You can predict or validate directly on exported models,\ni.e. `yolo predict model=yolov8n-seg.onnx`. Usage examples are shown for your model after export completes.\n\n| Format | `format` Argument | Model | Metadata | Arguments |\n|--------------------------------------------------------------------|-------------------|-------------------------------|----------|-----------------------------------------------------|\n| [PyTorch](https://pytorch.org/) | - | `yolov8n-seg.pt` | ✅ | - |\n| [TorchScript](https://pytorch.org/docs/stable/jit.html) | `torchscript` | `yolov8n-seg.torchscript` | ✅ | `imgsz`, `optimize` |\n| [ONNX](https://onnx.ai/) | `onnx` | `yolov8n-seg.onnx` | ✅ | `imgsz`, `half`, `dynamic`, `simplify`, `opset` |\n| [OpenVINO](https://docs.openvino.ai/latest/index.html) | `openvino` | `yolov8n-seg_openvino_model/` | ✅ | `imgsz`, `half` |\n| [TensorRT](https://developer.nvidia.com/tensorrt) | `engine` | `yolov8n-seg.engine` | ✅ | `imgsz`, `half`, `dynamic`, `simplify`, `workspace` |\n| [CoreML](https://github.com/apple/coremltools) | `coreml` | `yolov8n-seg.mlmodel` | ✅ | `imgsz`, `half`, `int8`, `nms` |\n| [TF SavedModel](https://www.tensorflow.org/guide/saved_model) | `saved_model` | `yolov8n-seg_saved_model/` | ✅ | `imgsz`, `keras` |\n| [TF GraphDef](https://www.tensorflow.org/api_docs/python/tf/Graph) | `pb` | `yolov8n-seg.pb` | ❌ | `imgsz` |\n| [TF Lite](https://www.tensorflow.org/lite) | `tflite` | `yolov8n-seg.tflite` | ✅ | `imgsz`, `half`, `int8` |\n| [TF Edge TPU](https://coral.ai/docs/edgetpu/models-intro/) | `edgetpu` | `yolov8n-seg_edgetpu.tflite` | ✅ | `imgsz` |\n| [TF.js](https://www.tensorflow.org/js) | `tfjs` | `yolov8n-seg_web_model/` | ✅ | `imgsz` |\n| [PaddlePaddle](https://github.com/PaddlePaddle) | `paddle` | `yolov8n-seg_paddle_model/` | ✅ | `imgsz` |\n\nSee full `export` details in the [Export](https://docs.ultralytics.com/modes/export/) page."
},
{
"path": "docs/usage/callbacks.md",
"content": "---\ncomments: true\ndescription: Learn how to leverage callbacks in Ultralytics YOLO framework to perform custom tasks in trainer, validator, predictor and exporter modes.\n---\n\n## Callbacks\n\nUltralytics framework supports callbacks as entry points in strategic stages of train, val, export, and predict modes.\nEach callback accepts a `Trainer`, `Validator`, or `Predictor` object depending on the operation type. All properties of\nthese objects can be found in Reference section of the docs.\n\n## Examples\n\n### Returning additional information with Prediction\n\nIn this example, we want to return the original frame with each result object. Here's how we can do that\n\n```python\ndef on_predict_batch_end(predictor):\n # Retrieve the batch data\n _, im0s, _, _ = predictor.batch\n \n # Ensure that im0s is a list\n im0s = im0s if isinstance(im0s, list) else [im0s]\n \n # Combine the prediction results with the corresponding frames\n predictor.results = zip(predictor.results, im0s)\n\n# Create a YOLO model instance\nmodel = YOLO(f'yolov8n.pt')\n\n# Add the custom callback to the model\nmodel.add_callback(\"on_predict_batch_end\", on_predict_batch_end)\n\n# Iterate through the results and frames\nfor (result, frame) in model.track/predict():\n pass\n```\n\n## All callbacks\n\nHere are all supported callbacks. See callbacks [source code](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/yolo/utils/callbacks/base.py) for additional details.\n\n### Trainer Callbacks\n\n| Callback | Description |\n|-----------------------------|---------------------------------------------------------|\n| `on_pretrain_routine_start` | Triggered at the beginning of pre-training routine |\n| `on_pretrain_routine_end` | Triggered at the end of pre-training routine |\n| `on_train_start` | Triggered when the training starts |\n| `on_train_epoch_start` | Triggered at the start of each training epoch |\n| `on_train_batch_start` | Triggered at the start of each training batch |\n| `optimizer_step` | Triggered during the optimizer step |\n| `on_before_zero_grad` | Triggered before gradients are zeroed |\n| `on_train_batch_end` | Triggered at the end of each training batch |\n| `on_train_epoch_end` | Triggered at the end of each training epoch |\n| `on_fit_epoch_end` | Triggered at the end of each fit epoch |\n| `on_model_save` | Triggered when the model is saved |\n| `on_train_end` | Triggered when the training process ends |\n| `on_params_update` | Triggered when model parameters are updated |\n| `teardown` | Triggered when the training process is being cleaned up |\n\n### Validator Callbacks\n\n| Callback | Description |\n|----------------------|-------------------------------------------------|\n| `on_val_start` | Triggered when the validation starts |\n| `on_val_batch_start` | Triggered at the start of each validation batch |\n| `on_val_batch_end` | Triggered at the end of each validation batch |\n| `on_val_end` | Triggered when the validation ends |\n\n### Predictor Callbacks\n\n| Callback | Description |\n|------------------------------|---------------------------------------------------|\n| `on_predict_start` | Triggered when the prediction process starts |\n| `on_predict_batch_start` | Triggered at the start of each prediction batch |\n| `on_predict_postprocess_end` | Triggered at the end of prediction postprocessing |\n| `on_predict_batch_end` | Triggered at the end of each prediction batch |\n| `on_predict_end` | Triggered when the prediction process ends |\n\n### Exporter Callbacks\n\n| Callback | Description |\n|-------------------|------------------------------------------|\n| `on_export_start` | Triggered when the export process starts |\n| `on_export_end` | Triggered when the export process ends |"
},
{
"path": "docs/usage/cfg.md",
"content": "---\ncomments: true\ndescription: 'Learn about YOLO settings and modes for different tasks like detection, segmentation etc. Train and predict with custom argparse commands.'\n---\n\nYOLO settings and hyperparameters play a critical role in the model's performance, speed, and accuracy. These settings\nand hyperparameters can affect the model's behavior at various stages of the model development process, including\ntraining, validation, and prediction.\n\nYOLOv8 'yolo' CLI commands use the following syntax:\n\n!!! example \"\"\n\n === \"CLI\"\n \n ```bash\n yolo TASK MODE ARGS\n ```\n\n === \"Python\"\n \n ```python\n from ultralytics import YOLO\n \n # Load a YOLOv8 model from a pre-trained weights file\n model = YOLO('yolov8n.pt')\n \n # Run MODE mode using the custom arguments ARGS (guess TASK)\n model.MODE(ARGS)\n ```\n\nWhere:\n\n- `TASK` (optional) is one of `[detect, segment, classify, pose]`. If it is not passed explicitly YOLOv8 will try to\n guess\n the `TASK` from the model type.\n- `MODE` (required) is one of `[train, val, predict, export, track, benchmark]`\n- `ARGS` (optional) are any number of custom `arg=value` pairs like `imgsz=320` that override defaults.\n For a full list of available `ARGS` see the [Configuration](cfg.md) page and `defaults.yaml`\n GitHub [source](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/yolo/cfg/default.yaml).\n\n#### Tasks\n\nYOLO models can be used for a variety of tasks, including detection, segmentation, classification and pose. These tasks\ndiffer in the type of output they produce and the specific problem they are designed to solve.\n\n**Detect**: For identifying and localizing objects or regions of interest in an image or video. \n**Segment**: For dividing an image or video into regions or pixels that correspond to different objects or classes. \n**Classify**: For predicting the class label of an input image. \n**Pose**: For identifying objects and estimating their keypoints in an image or video.\n\n| Key | Value | Description |\n|--------|------------|-------------------------------------------------|\n| `task` | `'detect'` | YOLO task, i.e. detect, segment, classify, pose |\n\n[Tasks Guide](../tasks/index.md){ .md-button .md-button--primary}\n\n#### Modes\n\nYOLO models can be used in different modes depending on the specific problem you are trying to solve. These modes\ninclude:\n\n**Train**: For training a YOLOv8 model on a custom dataset. \n**Val**: For validating a YOLOv8 model after it has been trained. \n**Predict**: For making predictions using a trained YOLOv8 model on new images or videos. \n**Export**: For exporting a YOLOv8 model to a format that can be used for deployment. \n**Track**: For tracking objects in real-time using a YOLOv8 model. \n**Benchmark**: For benchmarking YOLOv8 exports (ONNX, TensorRT, etc.) speed and accuracy.\n\n| Key | Value | Description |\n|--------|-----------|---------------------------------------------------------------|\n| `mode` | `'train'` | YOLO mode, i.e. train, val, predict, export, track, benchmark |\n\n[Modes Guide](../modes/index.md){ .md-button .md-button--primary}\n\n## Train\n\nThe training settings for YOLO models encompass various hyperparameters and configurations used during the training process. These settings influence the model's performance, speed, and accuracy. Key training settings include batch size, learning rate, momentum, and weight decay. Additionally, the choice of optimizer, loss function, and training dataset composition can impact the training process. Careful tuning and experimentation with these settings are crucial for optimizing performance.\n\n| Key | Value | Description |\n|-------------------|----------|-----------------------------------------------------------------------------|\n| `model` | `None` | path to model file, i.e. yolov8n.pt, yolov8n.yaml |\n| `data` | `None` | path to data file, i.e. coco128.yaml |\n| `epochs` | `100` | number of epochs to train for |\n| `patience` | `50` | epochs to wait for no observable improvement for early stopping of training |\n| `batch` | `16` | number of images per batch (-1 for AutoBatch) |\n| `imgsz` | `640` | size of input images as integer or w,h |\n| `save` | `True` | save train checkpoints and predict results |\n| `save_period` | `-1` | Save checkpoint every x epochs (disabled if < 1) |\n| `cache` | `False` | True/ram, disk or False. Use cache for data loading |\n| `device` | `None` | device to run on, i.e. cuda device=0 or device=0,1,2,3 or device=cpu |\n| `workers` | `8` | number of worker threads for data loading (per RANK if DDP) |\n| `project` | `None` | project name |\n| `name` | `None` | experiment name |\n| `exist_ok` | `False` | whether to overwrite existing experiment |\n| `pretrained` | `False` | whether to use a pretrained model |\n| `optimizer` | `'SGD'` | optimizer to use, choices=['SGD', 'Adam', 'AdamW', 'RMSProp'] |\n| `verbose` | `False` | whether to print verbose output |\n| `seed` | `0` | random seed for reproducibility |\n| `deterministic` | `True` | whether to enable deterministic mode |\n| `single_cls` | `False` | train multi-class data as single-class |\n| `rect` | `False` | rectangular training with each batch collated for minimum padding |\n| `cos_lr` | `False` | use cosine learning rate scheduler |\n| `close_mosaic` | `0` | (int) disable mosaic augmentation for final epochs |\n| `resume` | `False` | resume training from last checkpoint |\n| `amp` | `True` | Automatic Mixed Precision (AMP) training, choices=[True, False] |\n| `lr0` | `0.01` | initial learning rate (i.e. SGD=1E-2, Adam=1E-3) |\n| `lrf` | `0.01` | final learning rate (lr0 * lrf) |\n| `momentum` | `0.937` | SGD momentum/Adam beta1 |\n| `weight_decay` | `0.0005` | optimizer weight decay 5e-4 |\n| `warmup_epochs` | `3.0` | warmup epochs (fractions ok) |\n| `warmup_momentum` | `0.8` | warmup initial momentum |\n| `warmup_bias_lr` | `0.1` | warmup initial bias lr |\n| `box` | `7.5` | box loss gain |\n| `cls` | `0.5` | cls loss gain (scale with pixels) |\n| `dfl` | `1.5` | dfl loss gain |\n| `pose` | `12.0` | pose loss gain (pose-only) |\n| `kobj` | `2.0` | keypoint obj loss gain (pose-only) |\n| `label_smoothing` | `0.0` | label smoothing (fraction) |\n| `nbs` | `64` | nominal batch size |\n| `overlap_mask` | `True` | masks should overlap during training (segment train only) |\n| `mask_ratio` | `4` | mask downsample ratio (segment train only) |\n| `dropout` | `0.0` | use dropout regularization (classify train only) |\n| `val` | `True` | validate/test during training |\n\n[Train Guide](../modes/train.md){ .md-button .md-button--primary}\n\n## Predict\n\nThe prediction settings for YOLO models encompass a range of hyperparameters and configurations that influence the model's performance, speed, and accuracy during inference on new data. Careful tuning and experimentation with these settings are essential to achieve optimal performance for a specific task. Key settings include the confidence threshold, Non-Maximum Suppression (NMS) threshold, and the number of classes considered. Additional factors affecting the prediction process are input data size and format, the presence of supplementary features such as masks or multiple labels per box, and the particular task the model is employed for.\n\n| Key | Value | Description |\n|----------------|------------------------|--------------------------------------------------------------------------------|\n| `source` | `'ultralytics/assets'` | source directory for images or videos |\n| `conf` | `0.25` | object confidence threshold for detection |\n| `iou` | `0.7` | intersection over union (IoU) threshold for NMS |\n| `half` | `False` | use half precision (FP16) |\n| `device` | `None` | device to run on, i.e. cuda device=0/1/2/3 or device=cpu |\n| `show` | `False` | show results if possible |\n| `save` | `False` | save images with results |\n| `save_txt` | `False` | save results as .txt file |\n| `save_conf` | `False` | save results with confidence scores |\n| `save_crop` | `False` | save cropped images with results |\n| `show_labels` | `True` | show object labels in plots |\n| `show_conf` | `True` | show object confidence scores in plots |\n| `max_det` | `300` | maximum number of detections per image |\n| `vid_stride` | `False` | video frame-rate stride |\n| `line_width` | `None` | The line width of the bounding boxes. If None, it is scaled to the image size. |\n| `visualize` | `False` | visualize model features |\n| `augment` | `False` | apply image augmentation to prediction sources |\n| `agnostic_nms` | `False` | class-agnostic NMS |\n| `retina_masks` | `False` | use high-resolution segmentation masks |\n| `classes` | `None` | filter results by class, i.e. class=0, or class=[0,2,3] |\n| `boxes` | `True` | Show boxes in segmentation predictions |\n\n[Predict Guide](../modes/predict.md){ .md-button .md-button--primary}\n\n## Val\n\nThe val (validation) settings for YOLO models involve various hyperparameters and configurations used to evaluate the model's performance on a validation dataset. These settings influence the model's performance, speed, and accuracy. Common YOLO validation settings include batch size, validation frequency during training, and performance evaluation metrics. Other factors affecting the validation process include the validation dataset's size and composition, as well as the specific task the model is employed for. Careful tuning and experimentation with these settings are crucial to ensure optimal performance on the validation dataset and detect and prevent overfitting.\n\n| Key | Value | Description |\n|---------------|---------|--------------------------------------------------------------------|\n| `save_json` | `False` | save results to JSON file |\n| `save_hybrid` | `False` | save hybrid version of labels (labels + additional predictions) |\n| `conf` | `0.001` | object confidence threshold for detection |\n| `iou` | `0.6` | intersection over union (IoU) threshold for NMS |\n| `max_det` | `300` | maximum number of detections per image |\n| `half` | `True` | use half precision (FP16) |\n| `device` | `None` | device to run on, i.e. cuda device=0/1/2/3 or device=cpu |\n| `dnn` | `False` | use OpenCV DNN for ONNX inference |\n| `plots` | `False` | show plots during training |\n| `rect` | `False` | rectangular val with each batch collated for minimum padding |\n| `split` | `val` | dataset split to use for validation, i.e. 'val', 'test' or 'train' |\n\n[Val Guide](../modes/val.md){ .md-button .md-button--primary}\n\n## Export\n\nExport settings for YOLO models encompass configurations and options related to saving or exporting the model for use in different environments or platforms. These settings can impact the model's performance, size, and compatibility with various systems. Key export settings include the exported model file format (e.g., ONNX, TensorFlow SavedModel), the target device (e.g., CPU, GPU), and additional features such as masks or multiple labels per box. The export process may also be affected by the model's specific task and the requirements or constraints of the destination environment or platform. It is crucial to thoughtfully configure these settings to ensure the exported model is optimized for the intended use case and functions effectively in the target environment.\n\n| Key | Value | Description |\n|-------------|-----------------|------------------------------------------------------|\n| `format` | `'torchscript'` | format to export to |\n| `imgsz` | `640` | image size as scalar or (h, w) list, i.e. (640, 480) |\n| `keras` | `False` | use Keras for TF SavedModel export |\n| `optimize` | `False` | TorchScript: optimize for mobile |\n| `half` | `False` | FP16 quantization |\n| `int8` | `False` | INT8 quantization |\n| `dynamic` | `False` | ONNX/TF/TensorRT: dynamic axes |\n| `simplify` | `False` | ONNX: simplify model |\n| `opset` | `None` | ONNX: opset version (optional, defaults to latest) |\n| `workspace` | `4` | TensorRT: workspace size (GB) |\n| `nms` | `False` | CoreML: add NMS |\n\n[Export Guide](../modes/export.md){ .md-button .md-button--primary}\n\n## Augmentation\n\nAugmentation settings for YOLO models refer to the various transformations and modifications\napplied to the training data to increase the diversity and size of the dataset. These settings can affect the model's\nperformance, speed, and accuracy. Some common YOLO augmentation settings include the type and intensity of the\ntransformations applied (e.g. random flips, rotations, cropping, color changes), the probability with which each\ntransformation is applied, and the presence of additional features such as masks or multiple labels per box. Other\nfactors that may affect the augmentation process include the size and composition of the original dataset and the\nspecific task the model is being used for. It is important to carefully tune and experiment with these settings to\nensure that the augmented dataset is diverse and representative enough to train a high-performing model.\n\n| Key | Value | Description |\n|---------------|-------|-------------------------------------------------|\n| `hsv_h` | 0.015 | image HSV-Hue augmentation (fraction) |\n| `hsv_s` | 0.7 | image HSV-Saturation augmentation (fraction) |\n| `hsv_v` | 0.4 | image HSV-Value augmentation (fraction) |\n| `degrees` | 0.0 | image rotation (+/- deg) |\n| `translate` | 0.1 | image translation (+/- fraction) |\n| `scale` | 0.5 | image scale (+/- gain) |\n| `shear` | 0.0 | image shear (+/- deg) |\n| `perspective` | 0.0 | image perspective (+/- fraction), range 0-0.001 |\n| `flipud` | 0.0 | image flip up-down (probability) |\n| `fliplr` | 0.5 | image flip left-right (probability) |\n| `mosaic` | 1.0 | image mosaic (probability) |\n| `mixup` | 0.0 | image mixup (probability) |\n| `copy_paste` | 0.0 | segment copy-paste (probability) |\n\n## Logging, checkpoints, plotting and file management\n\nLogging, checkpoints, plotting, and file management are important considerations when training a YOLO model.\n\n- Logging: It is often helpful to log various metrics and statistics during training to track the model's progress and\n diagnose any issues that may arise. This can be done using a logging library such as TensorBoard or by writing log\n messages to a file.\n- Checkpoints: It is a good practice to save checkpoints of the model at regular intervals during training. This allows\n you to resume training from a previous point if the training process is interrupted or if you want to experiment with\n different training configurations.\n- Plotting: Visualizing the model's performance and training progress can be helpful for understanding how the model is\n behaving and identifying potential issues. This can be done using a plotting library such as matplotlib or by\n generating plots using a logging library such as TensorBoard.\n- File management: Managing the various files generated during the training process, such as model checkpoints, log\n files, and plots, can be challenging. It is important to have a clear and organized file structure to keep track of\n these files and make it easy to access and analyze them as needed.\n\nEffective logging, checkpointing, plotting, and file management can help you keep track of the model's progress and make\nit easier to debug and optimize the training process.\n\n| Key | Value | Description |\n|------------|----------|------------------------------------------------------------------------------------------------|\n| `project` | `'runs'` | project name |\n| `name` | `'exp'` | experiment name. `exp` gets automatically incremented if not specified, i.e, `exp`, `exp2` ... |\n| `exist_ok` | `False` | whether to overwrite existing experiment |\n| `plots` | `False` | save plots during train/val |\n| `save` | `False` | save train checkpoints and predict results |"
},
{
"path": "docs/usage/cli.md",
"content": "---\ncomments: true\ndescription: Learn how to use YOLOv8 from the Command Line Interface (CLI) through simple, single-line commands with `yolo` without Python code.\n---\n\n# Command Line Interface Usage\n\nThe YOLO command line interface (CLI) allows for simple single-line commands without the need for a Python environment.\nCLI requires no customization or Python code. You can simply run all tasks from the terminal with the `yolo` command.\n\n!!! example\n\n === \"Syntax\"\n\n Ultralytics `yolo` commands use the following syntax:\n ```bash\n yolo TASK MODE ARGS\n\n Where TASK (optional) is one of [detect, segment, classify]\n MODE (required) is one of [train, val, predict, export, track]\n ARGS (optional) are any number of custom 'arg=value' pairs like 'imgsz=320' that override defaults.\n ```\n See all ARGS in the full [Configuration Guide](./cfg.md) or with `yolo cfg`\n\n === \"Train\"\n\n Train a detection model for 10 epochs with an initial learning_rate of 0.01\n ```bash\n yolo train data=coco128.yaml model=yolov8n.pt epochs=10 lr0=0.01\n ```\n\n === \"Predict\"\n\n Predict a YouTube video using a pretrained segmentation model at image size 320:\n ```bash\n yolo predict model=yolov8n-seg.pt source='https://youtu.be/Zgi9g1ksQHc' imgsz=320\n ```\n\n === \"Val\"\n\n Val a pretrained detection model at batch-size 1 and image size 640:\n ```bash\n yolo val model=yolov8n.pt data=coco128.yaml batch=1 imgsz=640\n ```\n\n === \"Export\"\n\n Export a YOLOv8n classification model to ONNX format at image size 224 by 128 (no TASK required)\n ```bash\n yolo export model=yolov8n-cls.pt format=onnx imgsz=224,128\n ```\n\n === \"Special\"\n\n Run special commands to see version, view settings, run checks and more:\n ```bash\n yolo help\n yolo checks\n yolo version\n yolo settings\n yolo copy-cfg\n yolo cfg\n ```\n\nWhere:\n\n- `TASK` (optional) is one of `[detect, segment, classify]`. If it is not passed explicitly YOLOv8 will try to guess\n the `TASK` from the model type.\n- `MODE` (required) is one of `[train, val, predict, export, track]`\n- `ARGS` (optional) are any number of custom `arg=value` pairs like `imgsz=320` that override defaults.\n For a full list of available `ARGS` see the [Configuration](cfg.md) page and `defaults.yaml`\n GitHub [source](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/yolo/cfg/default.yaml).\n\n!!! warning \"Warning\"\n\n Arguments must be passed as `arg=val` pairs, split by an equals `=` sign and delimited by spaces ` ` between pairs. Do not use `--` argument prefixes or commas `,` beteen arguments.\n\n - `yolo predict model=yolov8n.pt imgsz=640 conf=0.25` ✅\n - `yolo predict model yolov8n.pt imgsz 640 conf 0.25` ❌\n - `yolo predict --model yolov8n.pt --imgsz 640 --conf 0.25` ❌\n\n## Train\n\nTrain YOLOv8n on the COCO128 dataset for 100 epochs at image size 640. For a full list of available arguments see\nthe [Configuration](cfg.md) page.\n\n!!! example \"Example\"\n\n === \"Train\"\n \n Start training YOLOv8n on COCO128 for 100 epochs at image-size 640.\n ```bash\n yolo detect train data=coco128.yaml model=yolov8n.pt epochs=100 imgsz=640\n ```\n\n === \"Resume\"\n\n Resume an interrupted training.\n ```bash\n yolo detect train resume model=last.pt\n ```\n\n## Val\n\nValidate trained YOLOv8n model accuracy on the COCO128 dataset. No argument need to passed as the `model` retains it's\ntraining `data` and arguments as model attributes.\n\n!!! example \"Example\"\n\n === \"Official\"\n\n Validate an official YOLOv8n model.\n ```bash\n yolo detect val model=yolov8n.pt\n ```\n\n === \"Custom\"\n\n Validate a custom-trained model.\n ```bash\n yolo detect val model=path/to/best.pt\n ```\n\n## Predict\n\nUse a trained YOLOv8n model to run predictions on images.\n\n!!! example \"Example\"\n\n === \"Official\"\n\n Predict with an official YOLOv8n model.\n ```bash\n yolo detect predict model=yolov8n.pt source='https://ultralytics.com/images/bus.jpg'\n ```\n\n === \"Custom\"\n\n Predict with a custom model.\n ```bash\n yolo detect predict model=path/to/best.pt source='https://ultralytics.com/images/bus.jpg'\n ```\n\n## Export\n\nExport a YOLOv8n model to a different format like ONNX, CoreML, etc.\n\n!!! example \"Example\"\n\n === \"Official\"\n\n Export an official YOLOv8n model to ONNX format.\n ```bash\n yolo export model=yolov8n.pt format=onnx\n ```\n\n === \"Custom\"\n\n Export a custom-trained model to ONNX format.\n ```bash\n yolo export model=path/to/best.pt format=onnx\n ```\n\nAvailable YOLOv8 export formats are in the table below. You can export to any format using the `format` argument,\ni.e. `format='onnx'` or `format='engine'`.\n\n| Format | `format` Argument | Model | Metadata |\n|--------------------------------------------------------------------|-------------------|---------------------------|----------|\n| [PyTorch](https://pytorch.org/) | - | `yolov8n.pt` | ✅ |\n| [TorchScript](https://pytorch.org/docs/stable/jit.html) | `torchscript` | `yolov8n.torchscript` | ✅ |\n| [ONNX](https://onnx.ai/) | `onnx` | `yolov8n.onnx` | ✅ |\n| [OpenVINO](https://docs.openvino.ai/latest/index.html) | `openvino` | `yolov8n_openvino_model/` | ✅ |\n| [TensorRT](https://developer.nvidia.com/tensorrt) | `engine` | `yolov8n.engine` | ✅ |\n| [CoreML](https://github.com/apple/coremltools) | `coreml` | `yolov8n.mlmodel` | ✅ |\n| [TF SavedModel](https://www.tensorflow.org/guide/saved_model) | `saved_model` | `yolov8n_saved_model/` | ✅ |\n| [TF GraphDef](https://www.tensorflow.org/api_docs/python/tf/Graph) | `pb` | `yolov8n.pb` | ❌ |\n| [TF Lite](https://www.tensorflow.org/lite) | `tflite` | `yolov8n.tflite` | ✅ |\n| [TF Edge TPU](https://coral.ai/docs/edgetpu/models-intro/) | `edgetpu` | `yolov8n_edgetpu.tflite` | ✅ |\n| [TF.js](https://www.tensorflow.org/js) | `tfjs` | `yolov8n_web_model/` | ✅ |\n| [PaddlePaddle](https://github.com/PaddlePaddle) | `paddle` | `yolov8n_paddle_model/` | ✅ |\n\n---\n\n## Overriding default arguments\n\nDefault arguments can be overridden by simply passing them as arguments in the CLI in `arg=value` pairs.\n\n!!! tip \"\"\n\n === \"Train\"\n Train a detection model for `10 epochs` with `learning_rate` of `0.01`\n ```bash\n yolo detect train data=coco128.yaml model=yolov8n.pt epochs=10 lr0=0.01\n ```\n\n === \"Predict\"\n Predict a YouTube video using a pretrained segmentation model at image size 320:\n ```bash\n yolo segment predict model=yolov8n-seg.pt source='https://youtu.be/Zgi9g1ksQHc' imgsz=320\n ```\n\n === \"Val\"\n Validate a pretrained detection model at batch-size 1 and image size 640:\n ```bash\n yolo detect val model=yolov8n.pt data=coco128.yaml batch=1 imgsz=640\n ```\n\n---\n\n## Overriding default config file\n\nYou can override the `default.yaml` config file entirely by passing a new file with the `cfg` arguments,\ni.e. `cfg=custom.yaml`.\n\nTo do this first create a copy of `default.yaml` in your current working dir with the `yolo copy-cfg` command.\n\nThis will create `default_copy.yaml`, which you can then pass as `cfg=default_copy.yaml` along with any additional args,\nlike `imgsz=320` in this example:\n\n!!! example \"\"\n\n === \"CLI\"\n ```bash\n yolo copy-cfg\n yolo cfg=default_copy.yaml imgsz=320\n ```"
},
{
"path": "docs/usage/engine.md",
"content": "---\ncomments: true\ndescription: Learn how to train and customize your models fast with the Ultralytics YOLO 'DetectionTrainer' and 'CustomTrainer'. Read more here!\n---\n\nBoth the Ultralytics YOLO command-line and python interfaces are simply a high-level abstraction on the base engine\nexecutors. Let's take a look at the Trainer engine.\n\n## BaseTrainer\n\nBaseTrainer contains the generic boilerplate training routine. It can be customized for any task based over overriding\nthe required functions or operations as long the as correct formats are followed. For example, you can support your own\ncustom model and dataloader by just overriding these functions:\n\n* `get_model(cfg, weights)` - The function that builds the model to be trained\n* `get_dataloder()` - The function that builds the dataloader\n More details and source code can be found in [`BaseTrainer` Reference](../reference/yolo/engine/trainer.md)\n\n## DetectionTrainer\n\nHere's how you can use the YOLOv8 `DetectionTrainer` and customize it.\n\n```python\nfrom ultralytics.yolo.v8.detect import DetectionTrainer\n\ntrainer = DetectionTrainer(overrides={...})\ntrainer.train()\ntrained_model = trainer.best # get best model\n```\n\n### Customizing the DetectionTrainer\n\nLet's customize the trainer **to train a custom detection model** that is not supported directly. You can do this by\nsimply overloading the existing the `get_model` functionality:\n\n```python\nfrom ultralytics.yolo.v8.detect import DetectionTrainer\n\n\nclass CustomTrainer(DetectionTrainer):\n def get_model(self, cfg, weights):\n ...\n\n\ntrainer = CustomTrainer(overrides={...})\ntrainer.train()\n```\n\nYou now realize that you need to customize the trainer further to:\n\n* Customize the `loss function`.\n* Add `callback` that uploads model to your Google Drive after every 10 `epochs`\n Here's how you can do it:\n\n```python\nfrom ultralytics.yolo.v8.detect import DetectionTrainer\n\n\nclass CustomTrainer(DetectionTrainer):\n def get_model(self, cfg, weights):\n ...\n\n def criterion(self, preds, batch):\n # get ground truth\n imgs = batch[\"imgs\"]\n bboxes = batch[\"bboxes\"]\n ...\n return loss, loss_items # see Reference-> Trainer for details on the expected format\n\n\n# callback to upload model weights\ndef log_model(trainer):\n last_weight_path = trainer.last\n ...\n\n\ntrainer = CustomTrainer(overrides={...})\ntrainer.add_callback(\"on_train_epoch_end\", log_model) # Adds to existing callback\ntrainer.train()\n```\n\nTo know more about Callback triggering events and entry point, checkout our [Callbacks Guide](callbacks.md)\n\n## Other engine components\n\nThere are other components that can be customized similarly like `Validators` and `Predictors`\nSee Reference section for more information on these."
},
{
"path": "docs/usage/hyperparameter_tuning.md",
"content": "---\ncomments: true\ndescription: Discover how to integrate hyperparameter tuning with Ray Tune and Ultralytics YOLOv8. Speed up the tuning process and optimize your model's performance.\n---\n\n# Hyperparameter Tuning with Ray Tune and YOLOv8\n\nHyperparameter tuning (or hyperparameter optimization) is the process of determining the right combination of hyperparameters that maximizes model performance. It works by running multiple trials in a single training process, evaluating the performance of each trial, and selecting the best hyperparameter values based on the evaluation results.\n\n## Ultralytics YOLOv8 and Ray Tune Integration\n\n[Ultralytics](https://ultralytics.com) YOLOv8 integrates hyperparameter tuning with Ray Tune, allowing you to easily optimize your YOLOv8 model's hyperparameters. By using Ray Tune, you can leverage advanced search algorithms, parallelism, and early stopping to speed up the tuning process and achieve better model performance.\n\n### Ray Tune\n\n\n\n[Ray Tune](https://docs.ray.io/en/latest/tune/index.html) is a powerful and flexible hyperparameter tuning library for machine learning models. It provides an efficient way to optimize hyperparameters by supporting various search algorithms, parallelism, and early stopping strategies. Ray Tune's flexible architecture enables seamless integration with popular machine learning frameworks, including Ultralytics YOLOv8.\n\n### Weights & Biases\n\nYOLOv8 also supports optional integration with [Weights & Biases](https://wandb.ai/site) (wandb) for tracking the tuning progress.\n\n## Installation\n\nTo install the required packages, run:\n\n!!! tip \"Installation\"\n\n ```bash\n pip install -U ultralytics \"ray[tune]\" # install and/or update\n pip install wandb # optional\n ```\n\n## Usage\n\n!!! example \"Usage\"\n\n ```python\n from ultralytics import YOLO\n\n model = YOLO(\"yolov8n.pt\")\n results = model.tune(data=\"coco128.yaml\")\n ```\n\n## `tune()` Method Parameters\n\nThe `tune()` method in YOLOv8 provides an easy-to-use interface for hyperparameter tuning with Ray Tune. It accepts several arguments that allow you to customize the tuning process. Below is a detailed explanation of each parameter:\n\n| Parameter | Type | Description | Default Value |\n|-----------------|----------------|-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|---------------|\n| `data` | str | The dataset configuration file (in YAML format) to run the tuner on. This file should specify the training and validation data paths, as well as other dataset-specific settings. | |\n| `space` | dict, optional | A dictionary defining the hyperparameter search space for Ray Tune. Each key corresponds to a hyperparameter name, and the value specifies the range of values to explore during tuning. If not provided, YOLOv8 uses a default search space with various hyperparameters. | |\n| `grace_period` | int, optional | The grace period in epochs for the [ASHA scheduler](https://docs.ray.io/en/latest/tune/api_docs/schedulers.html#asha-tune-schedulers-asha) in Ray Tune. The scheduler will not terminate any trial before this number of epochs, allowing the model to have some minimum training before making a decision on early stopping. | 10 |\n| `gpu_per_trial` | int, optional | The number of GPUs to allocate per trial during tuning. This helps manage GPU usage, particularly in multi-GPU environments. If not provided, the tuner will use all available GPUs. | None |\n| `max_samples` | int, optional | The maximum number of trials to run during tuning. This parameter helps control the total number of hyperparameter combinations tested, ensuring the tuning process does not run indefinitely. | 10 |\n| `train_args` | dict, optional | A dictionary of additional arguments to pass to the `train()` method during tuning. These arguments can include settings like the number of training epochs, batch size, and other training-specific configurations. | {} |\n\nBy customizing these parameters, you can fine-tune the hyperparameter optimization process to suit your specific needs and available computational resources.\n\n## Default Search Space Description\n\nThe following table lists the default search space parameters for hyperparameter tuning in YOLOv8 with Ray Tune. Each parameter has a specific value range defined by `tune.uniform()`.\n\n| Parameter | Value Range | Description |\n|-----------------|----------------------------|------------------------------------------|\n| lr0 | `tune.uniform(1e-5, 1e-1)` | Initial learning rate |\n| lrf | `tune.uniform(0.01, 1.0)` | Final learning rate factor |\n| momentum | `tune.uniform(0.6, 0.98)` | Momentum |\n| weight_decay | `tune.uniform(0.0, 0.001)` | Weight decay |\n| warmup_epochs | `tune.uniform(0.0, 5.0)` | Warmup epochs |\n| warmup_momentum | `tune.uniform(0.0, 0.95)` | Warmup momentum |\n| box | `tune.uniform(0.02, 0.2)` | Box loss weight |\n| cls | `tune.uniform(0.2, 4.0)` | Class loss weight |\n| hsv_h | `tune.uniform(0.0, 0.1)` | Hue augmentation range |\n| hsv_s | `tune.uniform(0.0, 0.9)` | Saturation augmentation range |\n| hsv_v | `tune.uniform(0.0, 0.9)` | Value (brightness) augmentation range |\n| degrees | `tune.uniform(0.0, 45.0)` | Rotation augmentation range (degrees) |\n| translate | `tune.uniform(0.0, 0.9)` | Translation augmentation range |\n| scale | `tune.uniform(0.0, 0.9)` | Scaling augmentation range |\n| shear | `tune.uniform(0.0, 10.0)` | Shear augmentation range (degrees) |\n| perspective | `tune.uniform(0.0, 0.001)` | Perspective augmentation range |\n| flipud | `tune.uniform(0.0, 1.0)` | Vertical flip augmentation probability |\n| fliplr | `tune.uniform(0.0, 1.0)` | Horizontal flip augmentation probability |\n| mosaic | `tune.uniform(0.0, 1.0)` | Mosaic augmentation probability |\n| mixup | `tune.uniform(0.0, 1.0)` | Mixup augmentation probability |\n| copy_paste | `tune.uniform(0.0, 1.0)` | Copy-paste augmentation probability |\n\n## Custom Search Space Example\n\nIn this example, we demonstrate how to use a custom search space for hyperparameter tuning with Ray Tune and YOLOv8. By providing a custom search space, you can focus the tuning process on specific hyperparameters of interest.\n\n!!! example \"Usage\"\n\n ```python\n from ultralytics import YOLO\n from ray import tune\n \n model = YOLO(\"yolov8n.pt\")\n result = model.tune(\n data=\"coco128.yaml\",\n space={\"lr0\": tune.uniform(1e-5, 1e-1)},\n train_args={\"epochs\": 50}\n )\n ```\n\nIn the code snippet above, we create a YOLO model with the \"yolov8n.pt\" pretrained weights. Then, we call the `tune()` method, specifying the dataset configuration with \"coco128.yaml\". We provide a custom search space for the initial learning rate `lr0` using a dictionary with the key \"lr0\" and the value `tune.uniform(1e-5, 1e-1)`. Finally, we pass additional training arguments, such as the number of epochs, using the `train_args` parameter."
},
{
"path": "docs/usage/python.md",
"content": "---\ncomments: true\ndescription: Integrate YOLOv8 in Python. Load, use pretrained models, train, and infer images. Export to ONNX. Track objects in videos.\n---\n\n# Python Usage\n\nWelcome to the YOLOv8 Python Usage documentation! This guide is designed to help you seamlessly integrate YOLOv8 into\nyour Python projects for object detection, segmentation, and classification. Here, you'll learn how to load and use\npretrained models, train new models, and perform predictions on images. The easy-to-use Python interface is a valuable\nresource for anyone looking to incorporate YOLOv8 into their Python projects, allowing you to quickly implement advanced\nobject detection capabilities. Let's get started!\n\nFor example, users can load a model, train it, evaluate its performance on a validation set, and even export it to ONNX\nformat with just a few lines of code.\n\n!!! example \"Python\"\n\n ```python\n from ultralytics import YOLO\n \n # Create a new YOLO model from scratch\n model = YOLO('yolov8n.yaml')\n \n # Load a pretrained YOLO model (recommended for training)\n model = YOLO('yolov8n.pt')\n \n # Train the model using the 'coco128.yaml' dataset for 3 epochs\n results = model.train(data='coco128.yaml', epochs=3)\n \n # Evaluate the model's performance on the validation set\n results = model.val()\n \n # Perform object detection on an image using the model\n results = model('https://ultralytics.com/images/bus.jpg')\n \n # Export the model to ONNX format\n success = model.export(format='onnx')\n ```\n\n## [Train](../modes/train.md)\n\nTrain mode is used for training a YOLOv8 model on a custom dataset. In this mode, the model is trained using the\nspecified dataset and hyperparameters. The training process involves optimizing the model's parameters so that it can\naccurately predict the classes and locations of objects in an image.\n\n!!! example \"Train\"\n\n === \"From pretrained(recommended)\"\n ```python\n from ultralytics import YOLO\n\n model = YOLO('yolov8n.pt') # pass any model type\n model.train(epochs=5)\n ```\n\n === \"From scratch\"\n ```python\n from ultralytics import YOLO\n\n model = YOLO('yolov8n.yaml')\n model.train(data='coco128.yaml', epochs=5)\n ```\n\n === \"Resume\"\n ```python\n model = YOLO(\"last.pt\")\n model.train(resume=True)\n ```\n\n[Train Examples](../modes/train.md){ .md-button .md-button--primary}\n\n## [Val](../modes/val.md)\n\nVal mode is used for validating a YOLOv8 model after it has been trained. In this mode, the model is evaluated on a\nvalidation set to measure its accuracy and generalization performance. This mode can be used to tune the hyperparameters\nof the model to improve its performance.\n\n!!! example \"Val\"\n\n === \"Val after training\"\n ```python\n from ultralytics import YOLO\n\n model = YOLO('yolov8n.yaml')\n model.train(data='coco128.yaml', epochs=5)\n model.val() # It'll automatically evaluate the data you trained.\n ```\n\n === \"Val independently\"\n ```python\n from ultralytics import YOLO\n\n model = YOLO(\"model.pt\")\n # It'll use the data yaml file in model.pt if you don't set data.\n model.val()\n # or you can set the data you want to val\n model.val(data='coco128.yaml')\n ```\n\n[Val Examples](../modes/val.md){ .md-button .md-button--primary}\n\n## [Predict](../modes/predict.md)\n\nPredict mode is used for making predictions using a trained YOLOv8 model on new images or videos. In this mode, the\nmodel is loaded from a checkpoint file, and the user can provide images or videos to perform inference. The model\npredicts the classes and locations of objects in the input images or videos.\n\n!!! example \"Predict\"\n\n === \"From source\"\n ```python\n from ultralytics import YOLO\n from PIL import Image\n import cv2\n\n model = YOLO(\"model.pt\")\n # accepts all formats - image/dir/Path/URL/video/PIL/ndarray. 0 for webcam\n results = model.predict(source=\"0\")\n results = model.predict(source=\"folder\", show=True) # Display preds. Accepts all YOLO predict arguments\n\n # from PIL\n im1 = Image.open(\"bus.jpg\")\n results = model.predict(source=im1, save=True) # save plotted images\n\n # from ndarray\n im2 = cv2.imread(\"bus.jpg\")\n results = model.predict(source=im2, save=True, save_txt=True) # save predictions as labels\n\n # from list of PIL/ndarray\n results = model.predict(source=[im1, im2])\n ```\n\n === \"Results usage\"\n ```python\n # results would be a list of Results object including all the predictions by default\n # but be careful as it could occupy a lot memory when there're many images, \n # especially the task is segmentation.\n # 1. return as a list\n results = model.predict(source=\"folder\")\n\n # results would be a generator which is more friendly to memory by setting stream=True\n # 2. return as a generator\n results = model.predict(source=0, stream=True)\n\n for result in results:\n # Detection\n result.boxes.xyxy # box with xyxy format, (N, 4)\n result.boxes.xywh # box with xywh format, (N, 4)\n result.boxes.xyxyn # box with xyxy format but normalized, (N, 4)\n result.boxes.xywhn # box with xywh format but normalized, (N, 4)\n result.boxes.conf # confidence score, (N, 1)\n result.boxes.cls # cls, (N, 1)\n\n # Segmentation\n result.masks.data # masks, (N, H, W)\n result.masks.xy # x,y segments (pixels), List[segment] * N\n result.masks.xyn # x,y segments (normalized), List[segment] * N\n\n # Classification\n result.probs # cls prob, (num_class, )\n\n # Each result is composed of torch.Tensor by default, \n # in which you can easily use following functionality:\n result = result.cuda()\n result = result.cpu()\n result = result.to(\"cpu\")\n result = result.numpy()\n ```\n\n[Predict Examples](../modes/predict.md){ .md-button .md-button--primary}\n\n## [Export](../modes/export.md)\n\nExport mode is used for exporting a YOLOv8 model to a format that can be used for deployment. In this mode, the model is\nconverted to a format that can be used by other software applications or hardware devices. This mode is useful when\ndeploying the model to production environments.\n\n!!! example \"Export\"\n\n === \"Export to ONNX\"\n\n Export an official YOLOv8n model to ONNX with dynamic batch-size and image-size.\n ```python\n from ultralytics import YOLO\n\n model = YOLO('yolov8n.pt')\n model.export(format='onnx', dynamic=True)\n ```\n\n === \"Export to TensorRT\"\n\n Export an official YOLOv8n model to TensorRT on `device=0` for acceleration on CUDA devices.\n ```python\n from ultralytics import YOLO\n\n model = YOLO('yolov8n.pt')\n model.export(format='onnx', device=0)\n ```\n\n[Export Examples](../modes/export.md){ .md-button .md-button--primary}\n\n## [Track](../modes/track.md)\n\nTrack mode is used for tracking objects in real-time using a YOLOv8 model. In this mode, the model is loaded from a\ncheckpoint file, and the user can provide a live video stream to perform real-time object tracking. This mode is useful\nfor applications such as surveillance systems or self-driving cars.\n\n!!! example \"Track\"\n\n === \"Python\"\n \n ```python\n from ultralytics import YOLO\n \n # Load a model\n model = YOLO('yolov8n.pt') # load an official detection model\n model = YOLO('yolov8n-seg.pt') # load an official segmentation model\n model = YOLO('path/to/best.pt') # load a custom model\n \n # Track with the model\n results = model.track(source=\"https://youtu.be/Zgi9g1ksQHc\", show=True) \n results = model.track(source=\"https://youtu.be/Zgi9g1ksQHc\", show=True, tracker=\"bytetrack.yaml\") \n ```\n\n[Track Examples](../modes/track.md){ .md-button .md-button--primary}\n\n## [Benchmark](../modes/benchmark.md)\n\nBenchmark mode is used to profile the speed and accuracy of various export formats for YOLOv8. The benchmarks provide\ninformation on the size of the exported format, its `mAP50-95` metrics (for object detection and segmentation)\nor `accuracy_top5` metrics (for classification), and the inference time in milliseconds per image across various export\nformats like ONNX, OpenVINO, TensorRT and others. This information can help users choose the optimal export format for\ntheir specific use case based on their requirements for speed and accuracy.\n\n!!! example \"Benchmark\"\n\n === \"Python\"\n \n Benchmark an official YOLOv8n model across all export formats.\n ```python\n from ultralytics.yolo.utils.benchmarks import benchmark\n \n # Benchmark\n benchmark(model='yolov8n.pt', imgsz=640, half=False, device=0)\n ```\n\n[Benchmark Examples](../modes/benchmark.md){ .md-button .md-button--primary}\n\n## Using Trainers\n\n`YOLO` model class is a high-level wrapper on the Trainer classes. Each YOLO task has its own trainer that inherits\nfrom `BaseTrainer`.\n\n!!! tip \"Detection Trainer Example\"\n\n ```python\n from ultralytics.yolo import v8 import DetectionTrainer, DetectionValidator, DetectionPredictor\n\n # trainer\n trainer = DetectionTrainer(overrides={})\n trainer.train()\n trained_model = trainer.best\n\n # Validator\n val = DetectionValidator(args=...)\n val(model=trained_model)\n\n # predictor\n pred = DetectionPredictor(overrides={})\n pred(source=SOURCE, model=trained_model)\n\n # resume from last weight\n overrides[\"resume\"] = trainer.last\n trainer = detect.DetectionTrainer(overrides=overrides)\n ```\n\nYou can easily customize Trainers to support custom tasks or explore R&D ideas.\nLearn more about Customizing `Trainers`, `Validators` and `Predictors` to suit your project needs in the Customization\nSection.\n\n[Customization tutorials](engine.md){ .md-button .md-button--primary}"
},
{
"path": "docs/yolov5/environments/aws_quickstart_tutorial.md",
"content": "---\ncomments: true\ndescription: Get started with YOLOv5 on AWS. Our comprehensive guide provides everything you need to know to run YOLOv5 on an Amazon Deep Learning instance.\n---\n\n# YOLOv5 🚀 on AWS Deep Learning Instance: A Comprehensive Guide\n\nThis guide will help new users run YOLOv5 on an Amazon Web Services (AWS) Deep Learning instance. AWS offers a [Free Tier](https://aws.amazon.com/free/) and a [credit program](https://aws.amazon.com/activate/) for a quick and affordable start.\n\nOther quickstart options for YOLOv5 include our [Colab Notebook](https://colab.research.google.com/github/ultralytics/yolov5/blob/master/tutorial.ipynb) , [GCP Deep Learning VM](https://docs.ultralytics.com/yolov5/environments/google_cloud_quickstart_tutorial), and our Docker image at [Docker Hub](https://hub.docker.com/r/ultralytics/yolov5)  . *Updated: 21 April 2023*.\n\n## 1. AWS Console Sign-in\n\nCreate an account or sign in to the AWS console at [https://aws.amazon.com/console/](https://aws.amazon.com/console/) and select the **EC2** service.\n\n\n\n## 2. Launch Instance\n\nIn the EC2 section of the AWS console, click the **Launch instance** button.\n\n\n\n### Choose an Amazon Machine Image (AMI)\n\nEnter 'Deep Learning' in the search field and select the most recent Ubuntu Deep Learning AMI (recommended), or an alternative Deep Learning AMI. For more information on selecting an AMI, see [Choosing Your DLAMI](https://docs.aws.amazon.com/dlami/latest/devguide/options.html).\n\n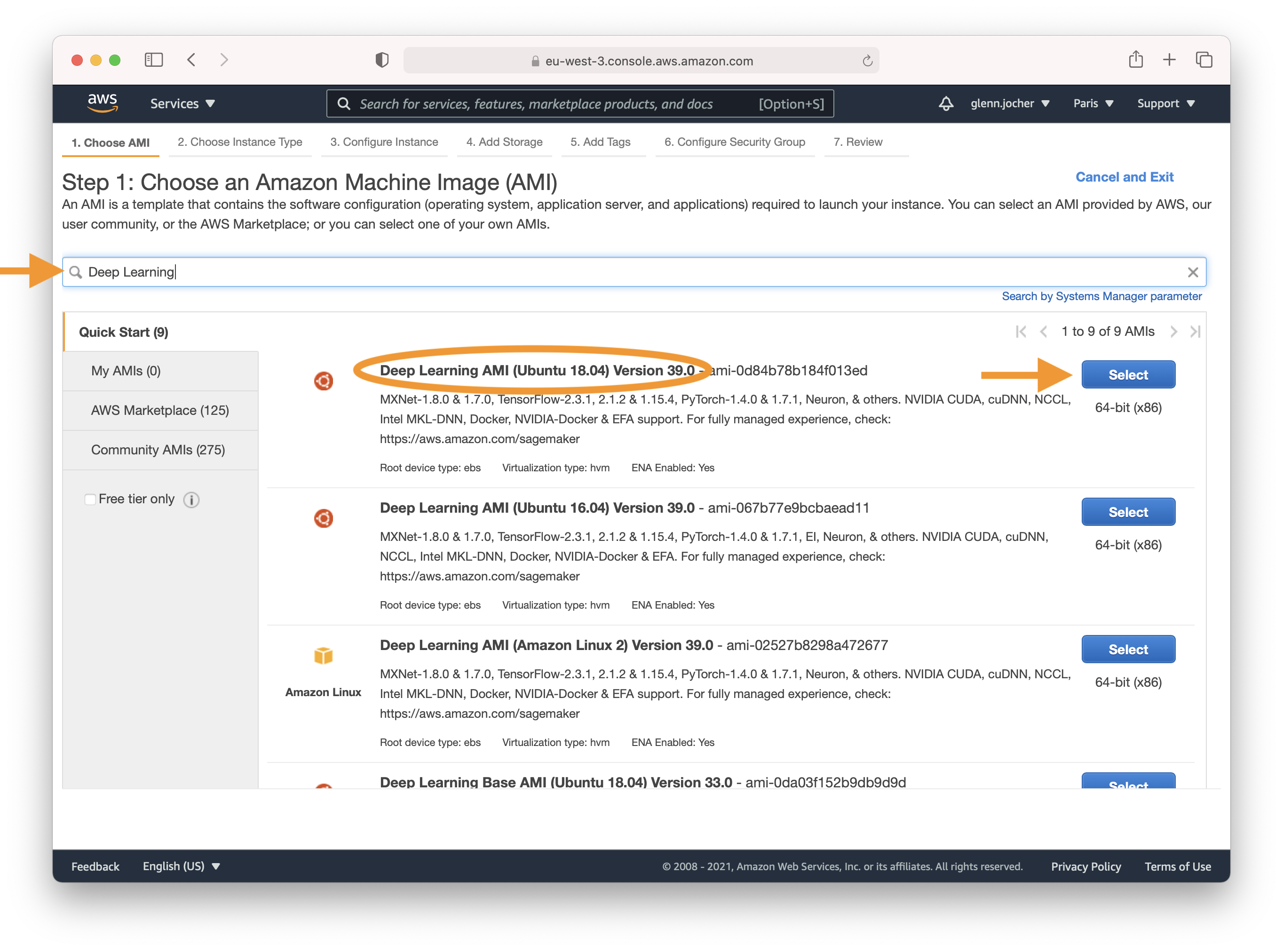\n\n### Select an Instance Type\n\nA GPU instance is recommended for most deep learning purposes. Training new models will be faster on a GPU instance than a CPU instance. Multi-GPU instances or distributed training across multiple instances with GPUs can offer sub-linear scaling. To set up distributed training, see [Distributed Training](https://docs.aws.amazon.com/dlami/latest/devguide/distributed-training.html).\n\n**Note:** The size of your model should be a factor in selecting an instance. If your model exceeds an instance's available RAM, select a different instance type with enough memory for your application.\n\nRefer to [EC2 Instance Types](https://aws.amazon.com/ec2/instance-types/) and choose Accelerated Computing to see the different GPU instance options.\n\n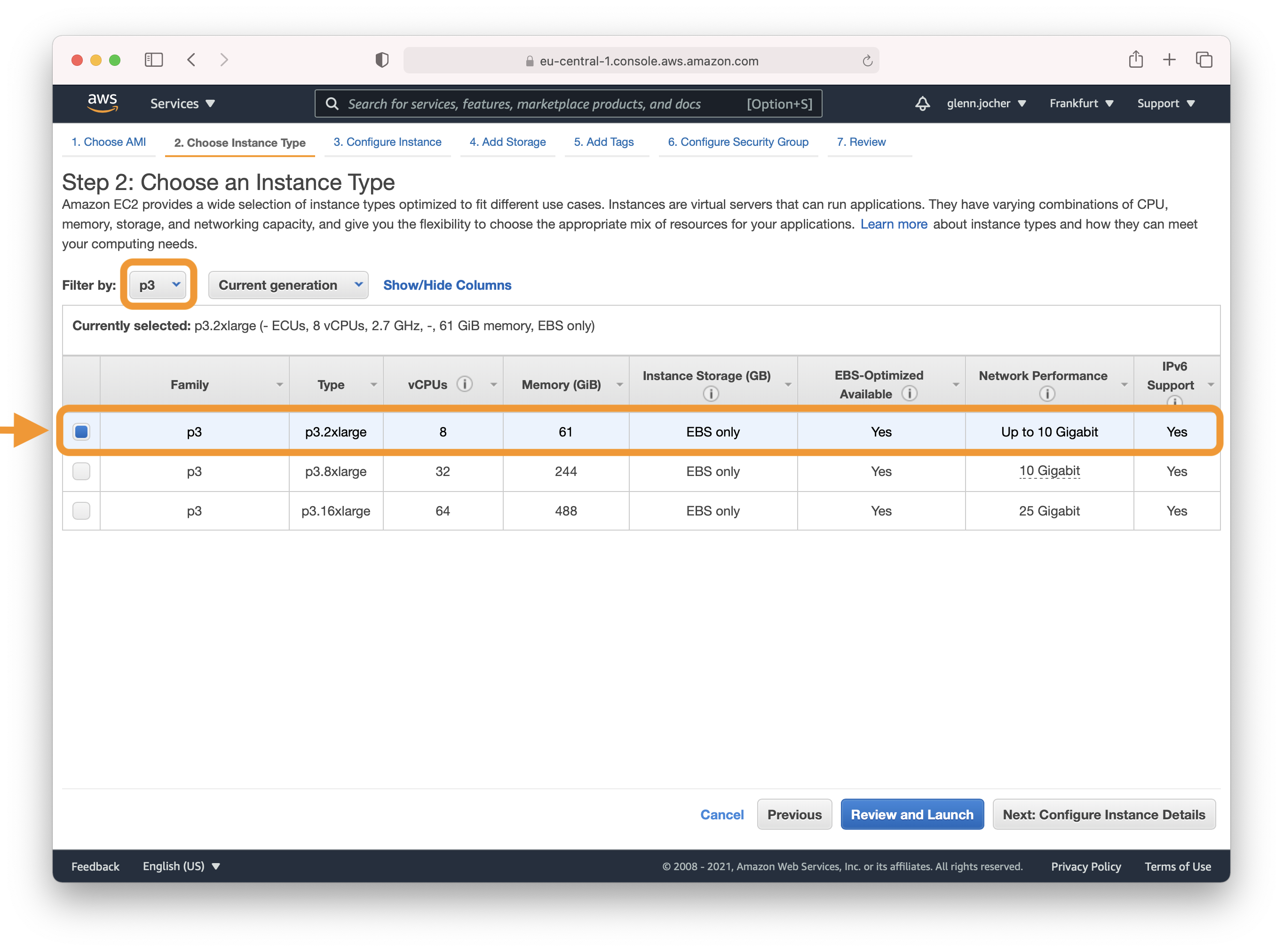\n\nFor more information on GPU monitoring and optimization, see [GPU Monitoring and Optimization](https://docs.aws.amazon.com/dlami/latest/devguide/tutorial-gpu.html). For pricing, see [On-Demand Pricing](https://aws.amazon.com/ec2/pricing/on-demand/) and [Spot Pricing](https://aws.amazon.com/ec2/spot/pricing/).\n\n### Configure Instance Details\n\nAmazon EC2 Spot Instances let you take advantage of unused EC2 capacity in the AWS cloud. Spot Instances are available at up to a 70% discount compared to On-Demand prices. We recommend a persistent spot instance, which will save your data and restart automatically when spot instance availability returns after spot instance termination. For full-price On-Demand instances, leave these settings at their default values.\n\n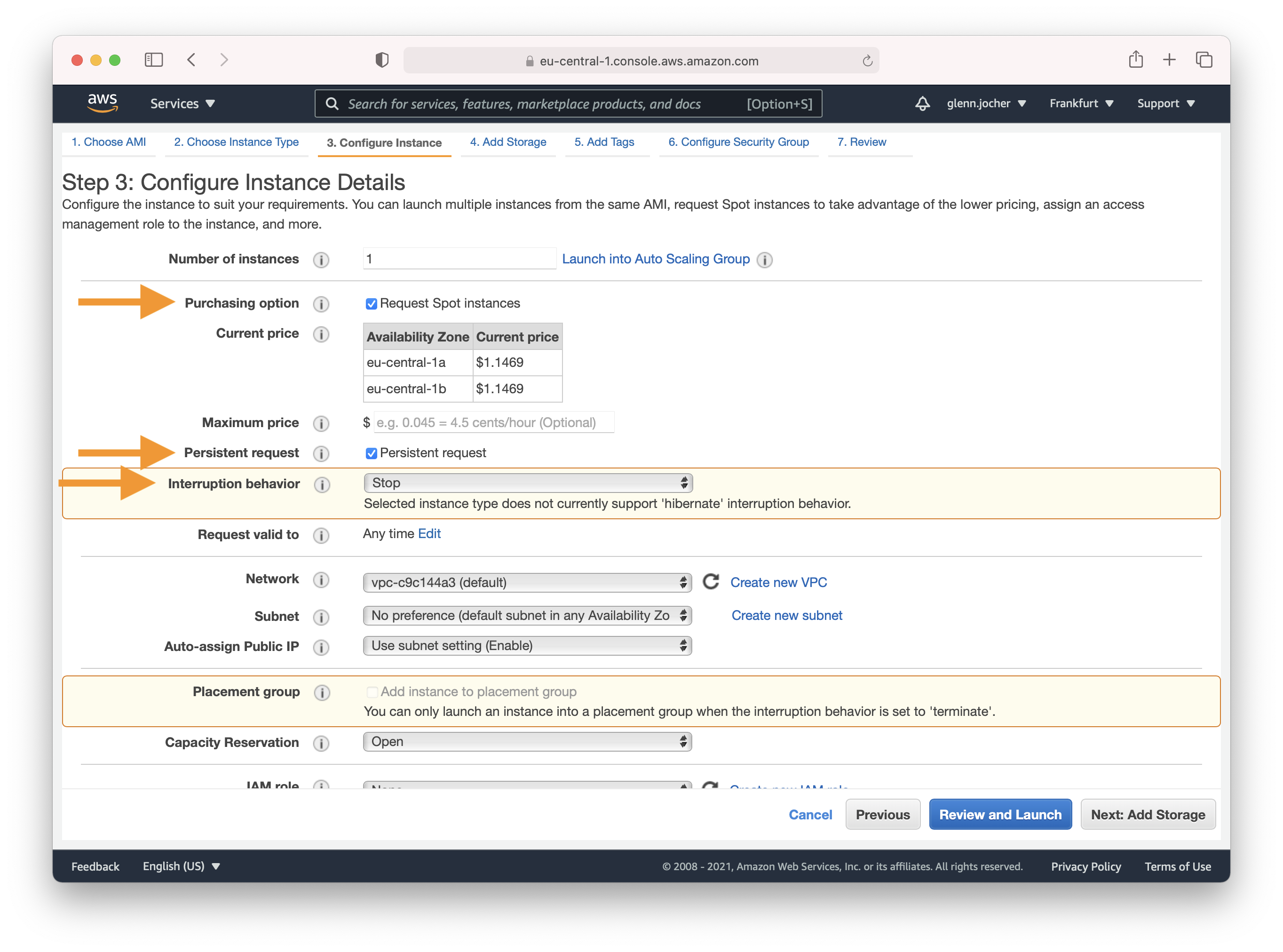\n\nComplete Steps 4-7 to finalize your instance hardware and security settings, and then launch the instance.\n\n## 3. Connect to Instance\n\nSelect the checkbox next to your running instance, and then click Connect. Copy and paste the SSH terminal command into a terminal of your choice to connect to your instance.\n\n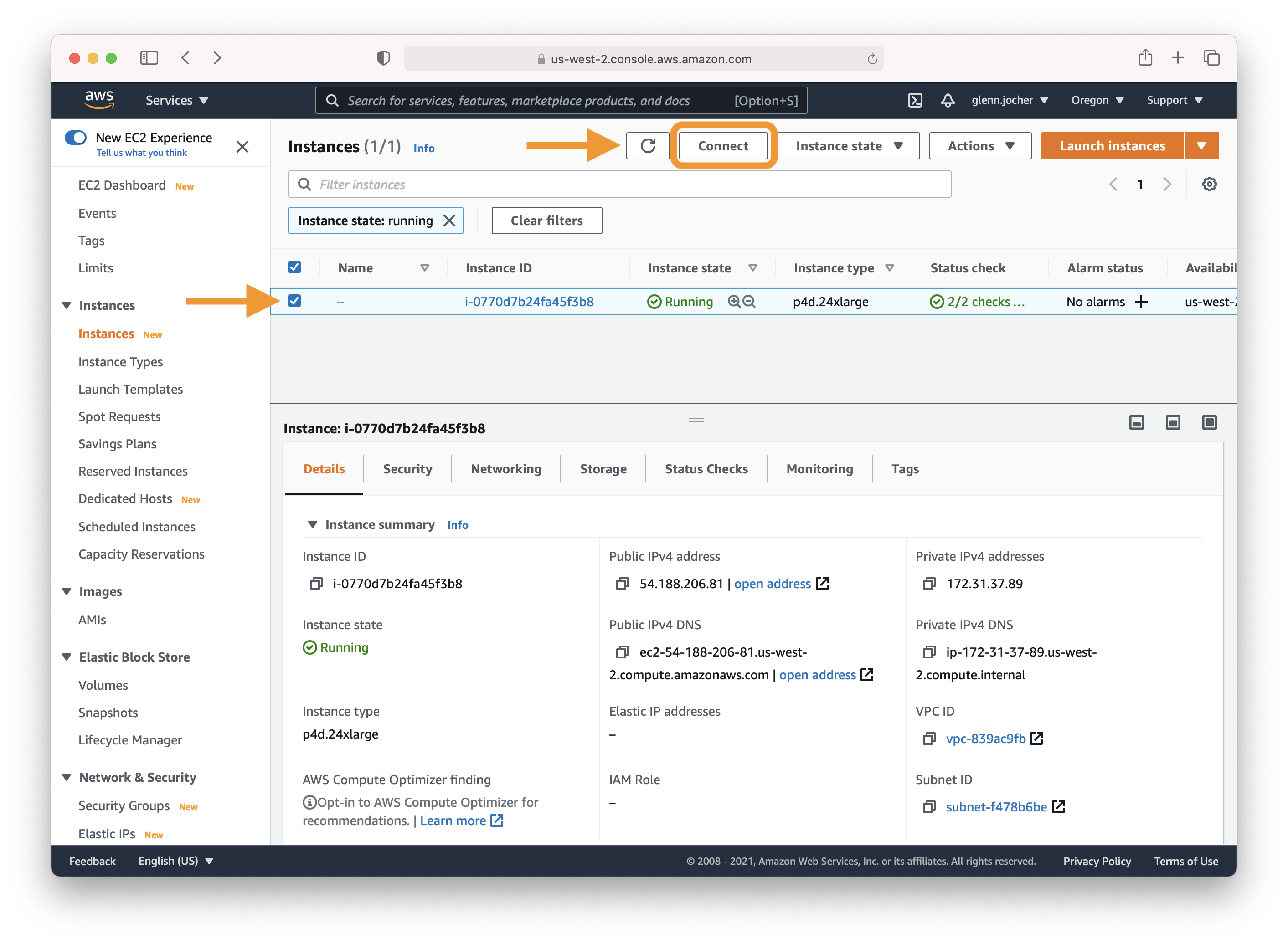\n\n## 4. Run YOLOv5\n\nOnce you have logged in to your instance, clone the repository and install the dependencies in a [**Python>=3.7.0**](https://www.python.org/) environment, including [**PyTorch>=1.7**](https://pytorch.org/get-started/locally/). [Models](https://github.com/ultralytics/yolov5/tree/master/models) and [datasets](https://github.com/ultralytics/yolov5/tree/master/data) download automatically from the latest YOLOv5 [release](https://github.com/ultralytics/yolov5/releases).\n\n```bash\ngit clone https://github.com/ultralytics/yolov5 # clone\ncd yolov5\npip install -r requirements.txt # install\n```\n\nThen, start training, testing, detecting, and exporting YOLOv5 models:\n\n```bash\npython train.py # train a model\npython val.py --weights yolov5s.pt # validate a model for Precision, Recall, and mAP\npython detect.py --weights yolov5s.pt --source path/to/images # run inference on images and videos\npython export.py --weights yolov5s.pt --include onnx coreml tflite # export models to other formats\n```\n\n## Optional Extras\n\nAdd 64GB of swap memory (to `--cache` large datasets):\n\n```bash\nsudo fallocate -l 64G /swapfile\nsudo chmod 600 /swapfile\nsudo mkswap /swapfile\nsudo swapon /swapfile\nfree -h # check memory\n```\n\nNow you have successfully set up and run YOLOv5 on an AWS Deep Learning instance. Enjoy training, testing, and deploying your object detection models!"
},
{
"path": "docs/yolov5/environments/docker_image_quickstart_tutorial.md",
"content": "---\ncomments: true\ndescription: Get started with YOLOv5 in a Docker container. Learn to set up and run YOLOv5 models and explore other quickstart options. 🚀\n---\n\n# Get Started with YOLOv5 🚀 in Docker\n\nThis tutorial will guide you through the process of setting up and running YOLOv5 in a Docker container.\n\nYou can also explore other quickstart options for YOLOv5, such as our [Colab Notebook](https://colab.research.google.com/github/ultralytics/yolov5/blob/master/tutorial.ipynb) , [GCP Deep Learning VM](https://docs.ultralytics.com/yolov5/environments/google_cloud_quickstart_tutorial), and [Amazon AWS](https://docs.ultralytics.com/yolov5/environments/aws_quickstart_tutorial). *Updated: 21 April 2023*.\n\n## Prerequisites\n\n1. **Nvidia Driver**: Version 455.23 or higher. Download from [Nvidia's website](https://www.nvidia.com/Download/index.aspx).\n2. **Nvidia-Docker**: Allows Docker to interact with your local GPU. Installation instructions are available on the [Nvidia-Docker GitHub repository](https://github.com/NVIDIA/nvidia-docker).\n3. **Docker Engine - CE**: Version 19.03 or higher. Download and installation instructions can be found on the [Docker website](https://docs.docker.com/install/).\n\n## Step 1: Pull the YOLOv5 Docker Image\n\nThe Ultralytics YOLOv5 DockerHub repository is available at [https://hub.docker.com/r/ultralytics/yolov5](https://hub.docker.com/r/ultralytics/yolov5). Docker Autobuild ensures that the `ultralytics/yolov5:latest` image is always in sync with the most recent repository commit. To pull the latest image, run the following command:\n\n```bash\nsudo docker pull ultralytics/yolov5:latest\n```\n\n## Step 2: Run the Docker Container\n\n### Basic container:\n\nRun an interactive instance of the YOLOv5 Docker image (called a \"container\") using the `-it` flag:\n\n```bash\nsudo docker run --ipc=host -it ultralytics/yolov5:latest\n```\n\n### Container with local file access:\n\nTo run a container with access to local files (e.g., COCO training data in `/datasets`), use the `-v` flag:\n\n```bash\nsudo docker run --ipc=host -it -v \"$(pwd)\"/datasets:/usr/src/datasets ultralytics/yolov5:latest\n```\n\n### Container with GPU access:\n\nTo run a container with GPU access, use the `--gpus all` flag:\n\n```bash\nsudo docker run --ipc=host -it --gpus all ultralytics/yolov5:latest\n```\n\n## Step 3: Use YOLOv5 🚀 within the Docker Container\n\nNow you can train, test, detect, and export YOLOv5 models within the running Docker container:\n\n```bash\npython train.py # train a model\npython val.py --weights yolov5s.pt # validate a model for Precision, Recall, and mAP\npython detect.py --weights yolov5s.pt --source path/to/images # run inference on images and videos\npython export.py --weights yolov5s.pt --include onnx coreml tflite # export models to other formats\n```\n\n
. *Updated: 21 April 2023*.\n\n## 1. AWS Console Sign-in\n\nCreate an account or sign in to the AWS console at [https://aws.amazon.com/console/](https://aws.amazon.com/console/) and select the **EC2** service.\n\n\n\n## 2. Launch Instance\n\nIn the EC2 section of the AWS console, click the **Launch instance** button.\n\n\n\n### Choose an Amazon Machine Image (AMI)\n\nEnter 'Deep Learning' in the search field and select the most recent Ubuntu Deep Learning AMI (recommended), or an alternative Deep Learning AMI. For more information on selecting an AMI, see [Choosing Your DLAMI](https://docs.aws.amazon.com/dlami/latest/devguide/options.html).\n\n\n\n### Select an Instance Type\n\nA GPU instance is recommended for most deep learning purposes. Training new models will be faster on a GPU instance than a CPU instance. Multi-GPU instances or distributed training across multiple instances with GPUs can offer sub-linear scaling. To set up distributed training, see [Distributed Training](https://docs.aws.amazon.com/dlami/latest/devguide/distributed-training.html).\n\n**Note:** The size of your model should be a factor in selecting an instance. If your model exceeds an instance's available RAM, select a different instance type with enough memory for your application.\n\nRefer to [EC2 Instance Types](https://aws.amazon.com/ec2/instance-types/) and choose Accelerated Computing to see the different GPU instance options.\n\n\n\nFor more information on GPU monitoring and optimization, see [GPU Monitoring and Optimization](https://docs.aws.amazon.com/dlami/latest/devguide/tutorial-gpu.html). For pricing, see [On-Demand Pricing](https://aws.amazon.com/ec2/pricing/on-demand/) and [Spot Pricing](https://aws.amazon.com/ec2/spot/pricing/).\n\n### Configure Instance Details\n\nAmazon EC2 Spot Instances let you take advantage of unused EC2 capacity in the AWS cloud. Spot Instances are available at up to a 70% discount compared to On-Demand prices. We recommend a persistent spot instance, which will save your data and restart automatically when spot instance availability returns after spot instance termination. For full-price On-Demand instances, leave these settings at their default values.\n\n\n\nComplete Steps 4-7 to finalize your instance hardware and security settings, and then launch the instance.\n\n## 3. Connect to Instance\n\nSelect the checkbox next to your running instance, and then click Connect. Copy and paste the SSH terminal command into a terminal of your choice to connect to your instance.\n\n\n\n## 4. Run YOLOv5\n\nOnce you have logged in to your instance, clone the repository and install the dependencies in a [**Python>=3.7.0**](https://www.python.org/) environment, including [**PyTorch>=1.7**](https://pytorch.org/get-started/locally/). [Models](https://github.com/ultralytics/yolov5/tree/master/models) and [datasets](https://github.com/ultralytics/yolov5/tree/master/data) download automatically from the latest YOLOv5 [release](https://github.com/ultralytics/yolov5/releases).\n\n```bash\ngit clone https://github.com/ultralytics/yolov5 # clone\ncd yolov5\npip install -r requirements.txt # install\n```\n\nThen, start training, testing, detecting, and exporting YOLOv5 models:\n\n```bash\npython train.py # train a model\npython val.py --weights yolov5s.pt # validate a model for Precision, Recall, and mAP\npython detect.py --weights yolov5s.pt --source path/to/images # run inference on images and videos\npython export.py --weights yolov5s.pt --include onnx coreml tflite # export models to other formats\n```\n\n## Optional Extras\n\nAdd 64GB of swap memory (to `--cache` large datasets):\n\n```bash\nsudo fallocate -l 64G /swapfile\nsudo chmod 600 /swapfile\nsudo mkswap /swapfile\nsudo swapon /swapfile\nfree -h # check memory\n```\n\nNow you have successfully set up and run YOLOv5 on an AWS Deep Learning instance. Enjoy training, testing, and deploying your object detection models!"
},
{
"path": "docs/yolov5/environments/docker_image_quickstart_tutorial.md",
"content": "---\ncomments: true\ndescription: Get started with YOLOv5 in a Docker container. Learn to set up and run YOLOv5 models and explore other quickstart options. 🚀\n---\n\n# Get Started with YOLOv5 🚀 in Docker\n\nThis tutorial will guide you through the process of setting up and running YOLOv5 in a Docker container.\n\nYou can also explore other quickstart options for YOLOv5, such as our [Colab Notebook](https://colab.research.google.com/github/ultralytics/yolov5/blob/master/tutorial.ipynb) , [GCP Deep Learning VM](https://docs.ultralytics.com/yolov5/environments/google_cloud_quickstart_tutorial), and [Amazon AWS](https://docs.ultralytics.com/yolov5/environments/aws_quickstart_tutorial). *Updated: 21 April 2023*.\n\n## Prerequisites\n\n1. **Nvidia Driver**: Version 455.23 or higher. Download from [Nvidia's website](https://www.nvidia.com/Download/index.aspx).\n2. **Nvidia-Docker**: Allows Docker to interact with your local GPU. Installation instructions are available on the [Nvidia-Docker GitHub repository](https://github.com/NVIDIA/nvidia-docker).\n3. **Docker Engine - CE**: Version 19.03 or higher. Download and installation instructions can be found on the [Docker website](https://docs.docker.com/install/).\n\n## Step 1: Pull the YOLOv5 Docker Image\n\nThe Ultralytics YOLOv5 DockerHub repository is available at [https://hub.docker.com/r/ultralytics/yolov5](https://hub.docker.com/r/ultralytics/yolov5). Docker Autobuild ensures that the `ultralytics/yolov5:latest` image is always in sync with the most recent repository commit. To pull the latest image, run the following command:\n\n```bash\nsudo docker pull ultralytics/yolov5:latest\n```\n\n## Step 2: Run the Docker Container\n\n### Basic container:\n\nRun an interactive instance of the YOLOv5 Docker image (called a \"container\") using the `-it` flag:\n\n```bash\nsudo docker run --ipc=host -it ultralytics/yolov5:latest\n```\n\n### Container with local file access:\n\nTo run a container with access to local files (e.g., COCO training data in `/datasets`), use the `-v` flag:\n\n```bash\nsudo docker run --ipc=host -it -v \"$(pwd)\"/datasets:/usr/src/datasets ultralytics/yolov5:latest\n```\n\n### Container with GPU access:\n\nTo run a container with GPU access, use the `--gpus all` flag:\n\n```bash\nsudo docker run --ipc=host -it --gpus all ultralytics/yolov5:latest\n```\n\n## Step 3: Use YOLOv5 🚀 within the Docker Container\n\nNow you can train, test, detect, and export YOLOv5 models within the running Docker container:\n\n```bash\npython train.py # train a model\npython val.py --weights yolov5s.pt # validate a model for Precision, Recall, and mAP\npython detect.py --weights yolov5s.pt --source path/to/images # run inference on images and videos\npython export.py --weights yolov5s.pt --include onnx coreml tflite # export models to other formats\n```\n\n
"
},
{
"path": "docs/yolov5/environments/google_cloud_quickstart_tutorial.md",
"content": "---\ncomments: true\ndescription: Set up YOLOv5 on a Google Cloud Platform (GCP) Deep Learning VM. Train, test, detect, and export YOLOv5 models. Tutorial updated April 2023.\n---\n\n# Run YOLOv5 🚀 on Google Cloud Platform (GCP) Deep Learning Virtual Machine (VM) ⭐\n\nThis tutorial will guide you through the process of setting up and running YOLOv5 on a GCP Deep Learning VM. New GCP users are eligible for a [$300 free credit offer](https://cloud.google.com/free/docs/gcp-free-tier#free-trial).\n\nYou can also explore other quickstart options for YOLOv5, such as our [Colab Notebook](https://colab.research.google.com/github/ultralytics/yolov5/blob/master/tutorial.ipynb) , [Amazon AWS](https://docs.ultralytics.com/yolov5/environments/aws_quickstart_tutorial) and our Docker image at [Docker Hub](https://hub.docker.com/r/ultralytics/yolov5) . *Updated: 21 April 2023*.\n\n**Last Updated**: 6 May 2022\n\n## Step 1: Create a Deep Learning VM\n\n1. Go to the [GCP marketplace](https://console.cloud.google.com/marketplace/details/click-to-deploy-images/deeplearning) and select a **Deep Learning VM**.\n2. Choose an **n1-standard-8** instance (with 8 vCPUs and 30 GB memory).\n3. Add a GPU of your choice.\n4. Check 'Install NVIDIA GPU driver automatically on first startup?'\n5. Select a 300 GB SSD Persistent Disk for sufficient I/O speed.\n6. Click 'Deploy'.\n\nThe preinstalled [Anaconda](https://docs.anaconda.com/anaconda/packages/pkg-docs/) Python environment includes all dependencies.\n\n \n\n## Step 2: Set Up the VM\n\nClone the YOLOv5 repository and install the [requirements.txt](https://github.com/ultralytics/yolov5/blob/master/requirements.txt) in a [**Python>=3.7.0**](https://www.python.org/) environment, including [**PyTorch>=1.7**](https://pytorch.org/get-started/locally/). [Models](https://github.com/ultralytics/yolov5/tree/master/models) and [datasets](https://github.com/ultralytics/yolov5/tree/master/data) will be downloaded automatically from the latest YOLOv5 [release](https://github.com/ultralytics/yolov5/releases).\n\n```bash\ngit clone https://github.com/ultralytics/yolov5 # clone\ncd yolov5\npip install -r requirements.txt # install\n```\n\n## Step 3: Run YOLOv5 🚀 on the VM\n\nYou can now train, test, detect, and export YOLOv5 models on your VM:\n\n```bash\npython train.py # train a model\npython val.py --weights yolov5s.pt # validate a model for Precision, Recall, and mAP\npython detect.py --weights yolov5s.pt --source path/to/images # run inference on images and videos\npython export.py --weights yolov5s.pt --include onnx coreml tflite # export models to other formats\n```\n\n
\n\n## Step 2: Set Up the VM\n\nClone the YOLOv5 repository and install the [requirements.txt](https://github.com/ultralytics/yolov5/blob/master/requirements.txt) in a [**Python>=3.7.0**](https://www.python.org/) environment, including [**PyTorch>=1.7**](https://pytorch.org/get-started/locally/). [Models](https://github.com/ultralytics/yolov5/tree/master/models) and [datasets](https://github.com/ultralytics/yolov5/tree/master/data) will be downloaded automatically from the latest YOLOv5 [release](https://github.com/ultralytics/yolov5/releases).\n\n```bash\ngit clone https://github.com/ultralytics/yolov5 # clone\ncd yolov5\npip install -r requirements.txt # install\n```\n\n## Step 3: Run YOLOv5 🚀 on the VM\n\nYou can now train, test, detect, and export YOLOv5 models on your VM:\n\n```bash\npython train.py # train a model\npython val.py --weights yolov5s.pt # validate a model for Precision, Recall, and mAP\npython detect.py --weights yolov5s.pt --source path/to/images # run inference on images and videos\npython export.py --weights yolov5s.pt --include onnx coreml tflite # export models to other formats\n```\n\n "
},
{
"path": "docs/yolov5/index.md",
"content": "---\ncomments: true\ndescription: Discover the YOLOv5 object detection model designed to deliver fast and accurate real-time results. Let's dive into this documentation to harness its full potential!\n---\n\n# Ultralytics YOLOv5\n\n
"
},
{
"path": "docs/yolov5/index.md",
"content": "---\ncomments: true\ndescription: Discover the YOLOv5 object detection model designed to deliver fast and accurate real-time results. Let's dive into this documentation to harness its full potential!\n---\n\n# Ultralytics YOLOv5\n\n\n
\n \n  \n
\n
\n\n

\n
\n
\n
\n
\n
\n
\n
\n
\n\nWelcome to the Ultralytics YOLOv5 🚀 Docs! YOLOv5, or You Only Look Once version 5, is an Ultralytics object detection model designed to deliver fast and accurate real-time results.\n
\nThis powerful deep learning framework is built on the PyTorch platform and has gained immense popularity due to its ease of use, high performance, and versatility. In this documentation, we will guide you through the installation process, explain the model's architecture, showcase various use-cases, and provide detailed tutorials to help you harness the full potential of YOLOv5 for your computer vision projects. Let's dive in!\n\n
\n"
},
{
"path": "docs/yolov5/quickstart_tutorial.md",
"content": "---\ncomments: true\ndescription: Learn how to quickly start using YOLOv5 including installation, inference, and training on this Ultralytics Docs page.\n---\n\n# YOLOv5 Quickstart\n\nSee below for quickstart examples.\n\n## Install\n\nClone repo and install [requirements.txt](https://github.com/ultralytics/yolov5/blob/master/requirements.txt) in a\n[**Python>=3.7.0**](https://www.python.org/) environment, including\n[**PyTorch>=1.7**](https://pytorch.org/get-started/locally/).\n\n```bash\ngit clone https://github.com/ultralytics/yolov5 # clone\ncd yolov5\npip install -r requirements.txt # install\n```\n\n## Inference\n\nYOLOv5 [PyTorch Hub](https://docs.ultralytics.com/yolov5/tutorials/pytorch_hub_model_loading) inference. [Models](https://github.com/ultralytics/yolov5/tree/master/models) download automatically from the latest\nYOLOv5 [release](https://github.com/ultralytics/yolov5/releases).\n\n```python\nimport torch\n\n# Model\nmodel = torch.hub.load(\"ultralytics/yolov5\", \"yolov5s\") # or yolov5n - yolov5x6, custom\n\n# Images\nimg = \"https://ultralytics.com/images/zidane.jpg\" # or file, Path, PIL, OpenCV, numpy, list\n\n# Inference\nresults = model(img)\n\n# Results\nresults.print() # or .show(), .save(), .crop(), .pandas(), etc.\n```\n\n## Inference with detect.py\n\n`detect.py` runs inference on a variety of sources, downloading [models](https://github.com/ultralytics/yolov5/tree/master/models) automatically from\nthe latest YOLOv5 [release](https://github.com/ultralytics/yolov5/releases) and saving results to `runs/detect`.\n\n```bash\npython detect.py --weights yolov5s.pt --source 0 # webcam\n img.jpg # image\n vid.mp4 # video\n screen # screenshot\n path/ # directory\n list.txt # list of images\n list.streams # list of streams\n 'path/*.jpg' # glob\n 'https://youtu.be/Zgi9g1ksQHc' # YouTube\n 'rtsp://example.com/media.mp4' # RTSP, RTMP, HTTP stream\n```\n\n## Training\n\nThe commands below reproduce YOLOv5 [COCO](https://github.com/ultralytics/yolov5/blob/master/data/scripts/get_coco.sh)\nresults. [Models](https://github.com/ultralytics/yolov5/tree/master/models)\nand [datasets](https://github.com/ultralytics/yolov5/tree/master/data) download automatically from the latest\nYOLOv5 [release](https://github.com/ultralytics/yolov5/releases). Training times for YOLOv5n/s/m/l/x are\n1/2/4/6/8 days on a V100 GPU ([Multi-GPU](https://docs.ultralytics.com/yolov5/tutorials/multi_gpu_training) times faster). Use the\nlargest `--batch-size` possible, or pass `--batch-size -1` for\nYOLOv5 [AutoBatch](https://github.com/ultralytics/yolov5/pull/5092). Batch sizes shown for V100-16GB.\n\n```bash\npython train.py --data coco.yaml --epochs 300 --weights '' --cfg yolov5n.yaml --batch-size 128\n yolov5s 64\n yolov5m 40\n yolov5l 24\n yolov5x 16\n```\n\n "
},
{
"path": "docs/yolov5/tutorials/architecture_description.md",
"content": "---\ncomments: true\ndescription: 'Ultralytics YOLOv5 Docs: Learn model structure, data augmentation & training strategies. Build targets and the losses of object detection.'\n---\n\n## 1. Model Structure\n\nYOLOv5 (v6.0/6.1) consists of:\n\n- **Backbone**: `New CSP-Darknet53`\n- **Neck**: `SPPF`, `New CSP-PAN`\n- **Head**: `YOLOv3 Head`\n\nModel structure (`yolov5l.yaml`):\n\n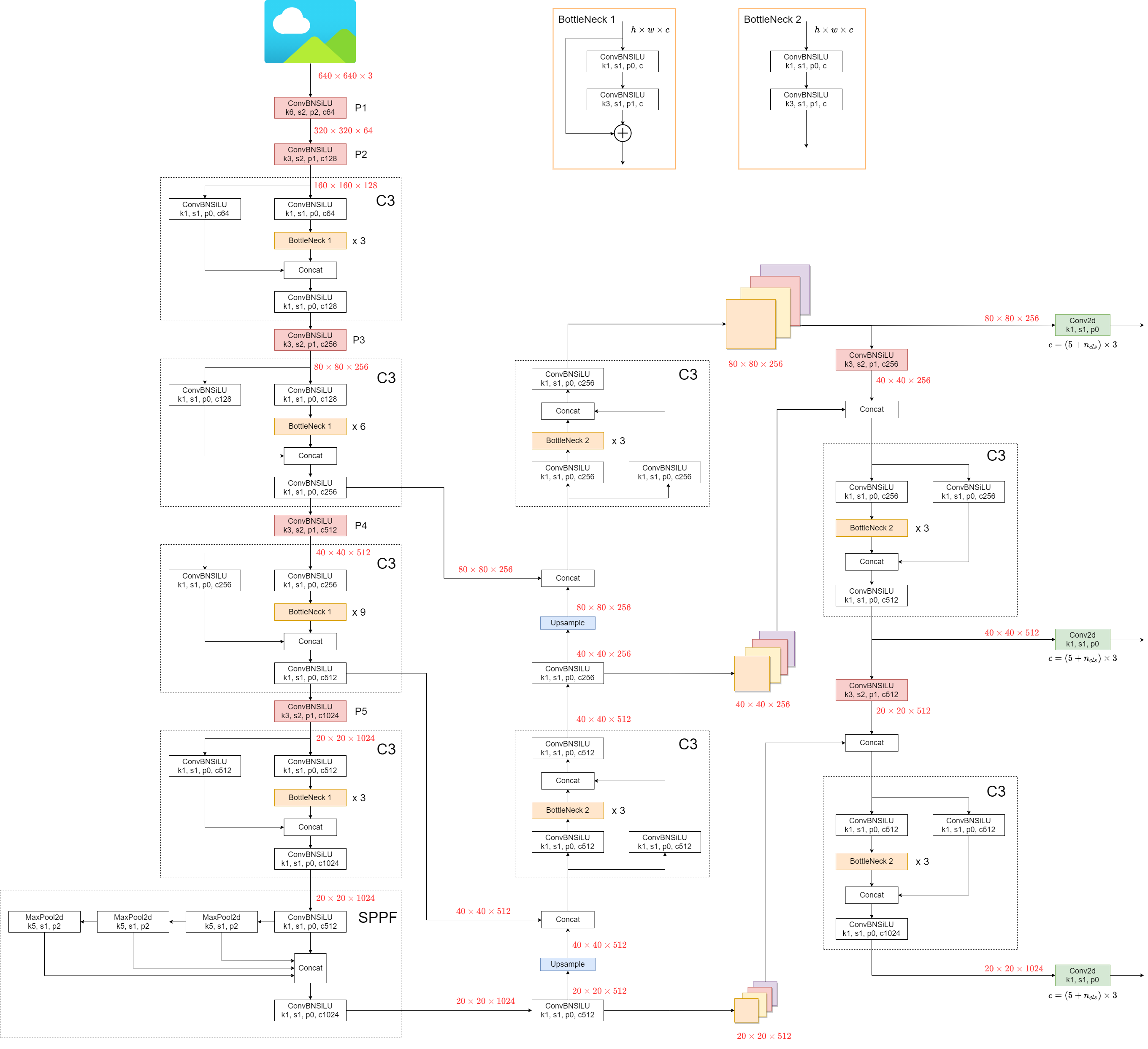\n\nSome minor changes compared to previous versions:\n\n1. Replace the `Focus` structure with `6x6 Conv2d`(more efficient, refer #4825)\n2. Replace the `SPP` structure with `SPPF`(more than double the speed)\n\n
"
},
{
"path": "docs/yolov5/tutorials/architecture_description.md",
"content": "---\ncomments: true\ndescription: 'Ultralytics YOLOv5 Docs: Learn model structure, data augmentation & training strategies. Build targets and the losses of object detection.'\n---\n\n## 1. Model Structure\n\nYOLOv5 (v6.0/6.1) consists of:\n\n- **Backbone**: `New CSP-Darknet53`\n- **Neck**: `SPPF`, `New CSP-PAN`\n- **Head**: `YOLOv3 Head`\n\nModel structure (`yolov5l.yaml`):\n\n\n\nSome minor changes compared to previous versions:\n\n1. Replace the `Focus` structure with `6x6 Conv2d`(more efficient, refer #4825)\n2. Replace the `SPP` structure with `SPPF`(more than double the speed)\n\n\ntest code
\n\n```python\nimport time\nimport torch\nimport torch.nn as nn\n\n\nclass SPP(nn.Module):\n def __init__(self):\n super().__init__()\n self.maxpool1 = nn.MaxPool2d(5, 1, padding=2)\n self.maxpool2 = nn.MaxPool2d(9, 1, padding=4)\n self.maxpool3 = nn.MaxPool2d(13, 1, padding=6)\n\n def forward(self, x):\n o1 = self.maxpool1(x)\n o2 = self.maxpool2(x)\n o3 = self.maxpool3(x)\n return torch.cat([x, o1, o2, o3], dim=1)\n\n\nclass SPPF(nn.Module):\n def __init__(self):\n super().__init__()\n self.maxpool = nn.MaxPool2d(5, 1, padding=2)\n\n def forward(self, x):\n o1 = self.maxpool(x)\n o2 = self.maxpool(o1)\n o3 = self.maxpool(o2)\n return torch.cat([x, o1, o2, o3], dim=1)\n\n\ndef main():\n input_tensor = torch.rand(8, 32, 16, 16)\n spp = SPP()\n sppf = SPPF()\n output1 = spp(input_tensor)\n output2 = sppf(input_tensor)\n\n print(torch.equal(output1, output2))\n\n t_start = time.time()\n for _ in range(100):\n spp(input_tensor)\n print(f\"spp time: {time.time() - t_start}\")\n\n t_start = time.time()\n for _ in range(100):\n sppf(input_tensor)\n print(f\"sppf time: {time.time() - t_start}\")\n\n\nif __name__ == '__main__':\n main()\n```\n\nresult:\n\n```\nTrue\nspp time: 0.5373051166534424\nsppf time: 0.20780706405639648\n```\n\n \n\n## 2. Data Augmentation\n\n- Mosaic\n  \n\n- Copy paste\n
\n\n- Copy paste\n  \n\n- Random affine(Rotation, Scale, Translation and Shear)\n
\n\n- Random affine(Rotation, Scale, Translation and Shear)\n  \n\n- MixUp\n
\n\n- MixUp\n  \n\n- Albumentations\n- Augment HSV(Hue, Saturation, Value)\n
\n\n- Albumentations\n- Augment HSV(Hue, Saturation, Value)\n  \n\n- Random horizontal flip\n
\n\n- Random horizontal flip\n  \n\n## 3. Training Strategies\n\n- Multi-scale training(0.5~1.5x)\n- AutoAnchor(For training custom data)\n- Warmup and Cosine LR scheduler\n- EMA(Exponential Moving Average)\n- Mixed precision\n- Evolve hyper-parameters\n\n## 4. Others\n\n### 4.1 Compute Losses\n\nThe YOLOv5 loss consists of three parts:\n\n- Classes loss(BCE loss)\n- Objectness loss(BCE loss)\n- Location loss(CIoU loss)\n\n\n\n### 4.2 Balance Losses\n\nThe objectness losses of the three prediction layers(`P3`, `P4`, `P5`) are weighted differently. The balance weights are `[4.0, 1.0, 0.4]` respectively.\n\n\n\n### 4.3 Eliminate Grid Sensitivity\n\nIn YOLOv2 and YOLOv3, the formula for calculating the predicted target information is:\n\n+c_x) \n+c_y) \n \n\n\n
\n\n## 3. Training Strategies\n\n- Multi-scale training(0.5~1.5x)\n- AutoAnchor(For training custom data)\n- Warmup and Cosine LR scheduler\n- EMA(Exponential Moving Average)\n- Mixed precision\n- Evolve hyper-parameters\n\n## 4. Others\n\n### 4.1 Compute Losses\n\nThe YOLOv5 loss consists of three parts:\n\n- Classes loss(BCE loss)\n- Objectness loss(BCE loss)\n- Location loss(CIoU loss)\n\n\n\n### 4.2 Balance Losses\n\nThe objectness losses of the three prediction layers(`P3`, `P4`, `P5`) are weighted differently. The balance weights are `[4.0, 1.0, 0.4]` respectively.\n\n\n\n### 4.3 Eliminate Grid Sensitivity\n\nIn YOLOv2 and YOLOv3, the formula for calculating the predicted target information is:\n\n+c_x) \n+c_y) \n \n\n\n \n\n\n\nIn YOLOv5, the formula is:\n\n-0.5)+c_x) \n-0.5)+c_y) \n)^2) \n)^2)\n\nCompare the center point offset before and after scaling. The center point offset range is adjusted from (0, 1) to (-0.5, 1.5).\nTherefore, offset can easily get 0 or 1.\n\n
\n\n\n\nIn YOLOv5, the formula is:\n\n-0.5)+c_x) \n-0.5)+c_y) \n)^2) \n)^2)\n\nCompare the center point offset before and after scaling. The center point offset range is adjusted from (0, 1) to (-0.5, 1.5).\nTherefore, offset can easily get 0 or 1.\n\n \n\nCompare the height and width scaling ratio(relative to anchor) before and after adjustment. The original yolo/darknet box equations have a serious flaw. Width and Height are completely unbounded as they are simply out=exp(in), which is dangerous, as it can lead to runaway gradients, instabilities, NaN losses and ultimately a complete loss of training. [refer this issue](https://github.com/ultralytics/yolov5/issues/471#issuecomment-662009779)\n\n
\n\nCompare the height and width scaling ratio(relative to anchor) before and after adjustment. The original yolo/darknet box equations have a serious flaw. Width and Height are completely unbounded as they are simply out=exp(in), which is dangerous, as it can lead to runaway gradients, instabilities, NaN losses and ultimately a complete loss of training. [refer this issue](https://github.com/ultralytics/yolov5/issues/471#issuecomment-662009779)\n\n \n\n### 4.4 Build Targets\n\nMatch positive samples:\n\n- Calculate the aspect ratio of GT and Anchor Templates\n\n\n\n\n\n)\n\n)\n\n)\n\n\n\n
\n\n### 4.4 Build Targets\n\nMatch positive samples:\n\n- Calculate the aspect ratio of GT and Anchor Templates\n\n\n\n\n\n)\n\n)\n\n)\n\n\n\n \n\n- Assign the successfully matched Anchor Templates to the corresponding cells\n\n
\n\n- Assign the successfully matched Anchor Templates to the corresponding cells\n\n \n\n- Because the center point offset range is adjusted from (0, 1) to (-0.5, 1.5). GT Box can be assigned to more anchors.\n\n
\n\n- Because the center point offset range is adjusted from (0, 1) to (-0.5, 1.5). GT Box can be assigned to more anchors.\n\n "
},
{
"path": "docs/yolov5/tutorials/clearml_logging_integration.md",
"content": "---\ncomments: true\ndescription: Integrate ClearML with YOLOv5 to track experiments and manage data versions. Optimize hyperparameters and remotely monitor your runs.\n---\n\n# ClearML Integration\n\n
"
},
{
"path": "docs/yolov5/tutorials/clearml_logging_integration.md",
"content": "---\ncomments: true\ndescription: Integrate ClearML with YOLOv5 to track experiments and manage data versions. Optimize hyperparameters and remotely monitor your runs.\n---\n\n# ClearML Integration\n\n
 \n\n## About ClearML\n\n[ClearML](https://cutt.ly/yolov5-tutorial-clearml) is an [open-source](https://github.com/allegroai/clearml) toolbox designed to save you time ⏱️.\n\n🔨 Track every YOLOv5 training run in the experiment manager\n\n🔧 Version and easily access your custom training data with the integrated ClearML Data Versioning Tool\n\n🔦 Remotely train and monitor your YOLOv5 training runs using ClearML Agent\n\n🔬 Get the very best mAP using ClearML Hyperparameter Optimization\n\n🔭 Turn your newly trained YOLOv5 model into an API with just a few commands using ClearML Serving\n\n
\n\n## About ClearML\n\n[ClearML](https://cutt.ly/yolov5-tutorial-clearml) is an [open-source](https://github.com/allegroai/clearml) toolbox designed to save you time ⏱️.\n\n🔨 Track every YOLOv5 training run in the experiment manager\n\n🔧 Version and easily access your custom training data with the integrated ClearML Data Versioning Tool\n\n🔦 Remotely train and monitor your YOLOv5 training runs using ClearML Agent\n\n🔬 Get the very best mAP using ClearML Hyperparameter Optimization\n\n🔭 Turn your newly trained YOLOv5 model into an API with just a few commands using ClearML Serving\n\n
\nAnd so much more. It's up to you how many of these tools you want to use, you can stick to the experiment manager, or chain them all together into an impressive pipeline!\n
\n
\n\n\n\n
\n
\n\n## 🦾 Setting Things Up\n\nTo keep track of your experiments and/or data, ClearML needs to communicate to a server. You have 2 options to get one:\n\nEither sign up for free to the [ClearML Hosted Service](https://cutt.ly/yolov5-tutorial-clearml) or you can set up your own server, see [here](https://clear.ml/docs/latest/docs/deploying_clearml/clearml_server). Even the server is open-source, so even if you're dealing with sensitive data, you should be good to go!\n\n1. Install the `clearml` python package:\n\n ```bash\n pip install clearml\n ```\n\n2. Connect the ClearML SDK to the server by [creating credentials](https://app.clear.ml/settings/workspace-configuration) (go right top to Settings -> Workspace -> Create new credentials), then execute the command below and follow the instructions:\n\n ```bash\n clearml-init\n ```\n\nThat's it! You're done 😎\n\n
\n\n## 🚀 Training YOLOv5 With ClearML\n\nTo enable ClearML experiment tracking, simply install the ClearML pip package.\n\n```bash\npip install clearml>=1.2.0\n```\n\nThis will enable integration with the YOLOv5 training script. Every training run from now on, will be captured and stored by the ClearML experiment manager.\n\nIf you want to change the `project_name` or `task_name`, use the `--project` and `--name` arguments of the `train.py` script, by default the project will be called `YOLOv5` and the task `Training`.\nPLEASE NOTE: ClearML uses `/` as a delimiter for subprojects, so be careful when using `/` in your project name!\n\n```bash\npython train.py --img 640 --batch 16 --epochs 3 --data coco128.yaml --weights yolov5s.pt --cache\n```\n\nor with custom project and task name:\n\n```bash\npython train.py --project my_project --name my_training --img 640 --batch 16 --epochs 3 --data coco128.yaml --weights yolov5s.pt --cache\n```\n\nThis will capture:\n\n- Source code + uncommitted changes\n- Installed packages\n- (Hyper)parameters\n- Model files (use `--save-period n` to save a checkpoint every n epochs)\n- Console output\n- Scalars (mAP_0.5, mAP_0.5:0.95, precision, recall, losses, learning rates, ...)\n- General info such as machine details, runtime, creation date etc.\n- All produced plots such as label correlogram and confusion matrix\n- Images with bounding boxes per epoch\n- Mosaic per epoch\n- Validation images per epoch\n- ...\n\nThat's a lot right? 🤯\nNow, we can visualize all of this information in the ClearML UI to get an overview of our training progress. Add custom columns to the table view (such as e.g. mAP_0.5) so you can easily sort on the best performing model. Or select multiple experiments and directly compare them!\n\nThere even more we can do with all of this information, like hyperparameter optimization and remote execution, so keep reading if you want to see how that works!\n\n
\n\n## 🔗 Dataset Version Management\n\nVersioning your data separately from your code is generally a good idea and makes it easy to acquire the latest version too. This repository supports supplying a dataset version ID, and it will make sure to get the data if it's not there yet. Next to that, this workflow also saves the used dataset ID as part of the task parameters, so you will always know for sure which data was used in which experiment!\n\n\n\n### Prepare Your Dataset\n\nThe YOLOv5 repository supports a number of different datasets by using yaml files containing their information. By default datasets are downloaded to the `../datasets` folder in relation to the repository root folder. So if you downloaded the `coco128` dataset using the link in the yaml or with the scripts provided by yolov5, you get this folder structure:\n\n```\n..\n|_ yolov5\n|_ datasets\n |_ coco128\n |_ images\n |_ labels\n |_ LICENSE\n |_ README.txt\n```\n\nBut this can be any dataset you wish. Feel free to use your own, as long as you keep to this folder structure.\n\nNext, ⚠️**copy the corresponding yaml file to the root of the dataset folder**⚠️. This yaml files contains the information ClearML will need to properly use the dataset. You can make this yourself too, of course, just follow the structure of the example yamls.\n\nBasically we need the following keys: `path`, `train`, `test`, `val`, `nc`, `names`.\n\n```\n..\n|_ yolov5\n|_ datasets\n |_ coco128\n |_ images\n |_ labels\n |_ coco128.yaml # <---- HERE!\n |_ LICENSE\n |_ README.txt\n```\n\n### Upload Your Dataset\n\nTo get this dataset into ClearML as a versioned dataset, go to the dataset root folder and run the following command:\n\n```bash\ncd coco128\nclearml-data sync --project YOLOv5 --name coco128 --folder .\n```\n\nThe command `clearml-data sync` is actually a shorthand command. You could also run these commands one after the other:\n\n```bash\n# Optionally add --parent if you want to base\n# this version on another dataset version, so no duplicate files are uploaded!\nclearml-data create --name coco128 --project YOLOv5\nclearml-data add --files .\nclearml-data close\n```\n\n### Run Training Using A ClearML Dataset\n\nNow that you have a ClearML dataset, you can very simply use it to train custom YOLOv5 🚀 models!\n\n```bash\npython train.py --img 640 --batch 16 --epochs 3 --data clearml:// --weights yolov5s.pt --cache\n```\n\n
\n\n## 👀 Hyperparameter Optimization\n\nNow that we have our experiments and data versioned, it's time to take a look at what we can build on top!\n\nUsing the code information, installed packages and environment details, the experiment itself is now **completely reproducible**. In fact, ClearML allows you to clone an experiment and even change its parameters. We can then just rerun it with these new parameters automatically, this is basically what HPO does!\n\nTo **run hyperparameter optimization locally**, we've included a pre-made script for you. Just make sure a training task has been run at least once, so it is in the ClearML experiment manager, we will essentially clone it and change its hyperparameters.\n\nYou'll need to fill in the ID of this `template task` in the script found at `utils/loggers/clearml/hpo.py` and then just run it :) You can change `task.execute_locally()` to `task.execute()` to put it in a ClearML queue and have a remote agent work on it instead.\n\n```bash\n# To use optuna, install it first, otherwise you can change the optimizer to just be RandomSearch\npip install optuna\npython utils/loggers/clearml/hpo.py\n```\n\n\n\n## 🤯 Remote Execution (advanced)\n\nRunning HPO locally is really handy, but what if we want to run our experiments on a remote machine instead? Maybe you have access to a very powerful GPU machine on-site, or you have some budget to use cloud GPUs.\nThis is where the ClearML Agent comes into play. Check out what the agent can do here:\n\n- [YouTube video](https://youtu.be/MX3BrXnaULs)\n- [Documentation](https://clear.ml/docs/latest/docs/clearml_agent)\n\nIn short: every experiment tracked by the experiment manager contains enough information to reproduce it on a different machine (installed packages, uncommitted changes etc.). So a ClearML agent does just that: it listens to a queue for incoming tasks and when it finds one, it recreates the environment and runs it while still reporting scalars, plots etc. to the experiment manager.\n\nYou can turn any machine (a cloud VM, a local GPU machine, your own laptop ... ) into a ClearML agent by simply running:\n\n```bash\nclearml-agent daemon --queue [--docker]\n```\n\n### Cloning, Editing And Enqueuing\n\nWith our agent running, we can give it some work. Remember from the HPO section that we can clone a task and edit the hyperparameters? We can do that from the interface too!\n\n🪄 Clone the experiment by right-clicking it\n\n🎯 Edit the hyperparameters to what you wish them to be\n\n⏳ Enqueue the task to any of the queues by right-clicking it\n\n\n\n### Executing A Task Remotely\n\nNow you can clone a task like we explained above, or simply mark your current script by adding `task.execute_remotely()` and on execution it will be put into a queue, for the agent to start working on!\n\nTo run the YOLOv5 training script remotely, all you have to do is add this line to the training.py script after the clearml logger has been instantiated:\n\n```python\n# ...\n# Loggers\ndata_dict = None\nif RANK in {-1, 0}:\n loggers = Loggers(save_dir, weights, opt, hyp, LOGGER) # loggers instance\n if loggers.clearml:\n loggers.clearml.task.execute_remotely(queue=\"my_queue\") # <------ ADD THIS LINE\n # Data_dict is either None is user did not choose for ClearML dataset or is filled in by ClearML\n data_dict = loggers.clearml.data_dict\n# ...\n```\n\nWhen running the training script after this change, python will run the script up until that line, after which it will package the code and send it to the queue instead!\n\n### Autoscaling workers\n\nClearML comes with autoscalers too! This tool will automatically spin up new remote machines in the cloud of your choice (AWS, GCP, Azure) and turn them into ClearML agents for you whenever there are experiments detected in the queue. Once the tasks are processed, the autoscaler will automatically shut down the remote machines, and you stop paying!\n\nCheck out the autoscalers getting started video below.\n\n[](https://youtu.be/j4XVMAaUt3E)"
},
{
"path": "docs/yolov5/tutorials/comet_logging_integration.md",
"content": "---\ncomments: true\ndescription: Learn how to use YOLOv5 with Comet, a tool for logging and visualizing machine learning model metrics in real-time. Install, log and analyze seamlessly.\n---\n\n \n\n# YOLOv5 with Comet\n\nThis guide will cover how to use YOLOv5 with [Comet](https://bit.ly/yolov5-readme-comet2)\n\n# About Comet\n\nComet builds tools that help data scientists, engineers, and team leaders accelerate and optimize machine learning and deep learning models.\n\nTrack and visualize model metrics in real time, save your hyperparameters, datasets, and model checkpoints, and visualize your model predictions with [Comet Custom Panels](https://www.comet.com/docs/v2/guides/comet-dashboard/code-panels/about-panels/?utm_source=yolov5&utm_medium=partner&utm_campaign=partner_yolov5_2022&utm_content=github)!\nComet makes sure you never lose track of your work and makes it easy to share results and collaborate across teams of all sizes!\n\n# Getting Started\n\n## Install Comet\n\n```shell\npip install comet_ml\n```\n\n## Configure Comet Credentials\n\nThere are two ways to configure Comet with YOLOv5.\n\nYou can either set your credentials through environment variables\n\n**Environment Variables**\n\n```shell\nexport COMET_API_KEY=\nexport COMET_PROJECT_NAME= # This will default to 'yolov5'\n```\n\nOr create a `.comet.config` file in your working directory and set your credentials there.\n\n**Comet Configuration File**\n\n```\n[comet]\napi_key=\nproject_name= # This will default to 'yolov5'\n```\n\n## Run the Training Script\n\n```shell\n# Train YOLOv5s on COCO128 for 5 epochs\npython train.py --img 640 --batch 16 --epochs 5 --data coco128.yaml --weights yolov5s.pt\n```\n\nThat's it! Comet will automatically log your hyperparameters, command line arguments, training and validation metrics. You can visualize and analyze your runs in the Comet UI\n\n
\n\n# YOLOv5 with Comet\n\nThis guide will cover how to use YOLOv5 with [Comet](https://bit.ly/yolov5-readme-comet2)\n\n# About Comet\n\nComet builds tools that help data scientists, engineers, and team leaders accelerate and optimize machine learning and deep learning models.\n\nTrack and visualize model metrics in real time, save your hyperparameters, datasets, and model checkpoints, and visualize your model predictions with [Comet Custom Panels](https://www.comet.com/docs/v2/guides/comet-dashboard/code-panels/about-panels/?utm_source=yolov5&utm_medium=partner&utm_campaign=partner_yolov5_2022&utm_content=github)!\nComet makes sure you never lose track of your work and makes it easy to share results and collaborate across teams of all sizes!\n\n# Getting Started\n\n## Install Comet\n\n```shell\npip install comet_ml\n```\n\n## Configure Comet Credentials\n\nThere are two ways to configure Comet with YOLOv5.\n\nYou can either set your credentials through environment variables\n\n**Environment Variables**\n\n```shell\nexport COMET_API_KEY=\nexport COMET_PROJECT_NAME= # This will default to 'yolov5'\n```\n\nOr create a `.comet.config` file in your working directory and set your credentials there.\n\n**Comet Configuration File**\n\n```\n[comet]\napi_key=\nproject_name= # This will default to 'yolov5'\n```\n\n## Run the Training Script\n\n```shell\n# Train YOLOv5s on COCO128 for 5 epochs\npython train.py --img 640 --batch 16 --epochs 5 --data coco128.yaml --weights yolov5s.pt\n```\n\nThat's it! Comet will automatically log your hyperparameters, command line arguments, training and validation metrics. You can visualize and analyze your runs in the Comet UI\n\n \n\n# Try out an Example!\n\nCheck out an example of a [completed run here](https://www.comet.com/examples/comet-example-yolov5/a0e29e0e9b984e4a822db2a62d0cb357?experiment-tab=chart&showOutliers=true&smoothing=0&transformY=smoothing&xAxis=step&utm_source=yolov5&utm_medium=partner&utm_campaign=partner_yolov5_2022&utm_content=github)\n\nOr better yet, try it out yourself in this Colab Notebook\n\n[](https://colab.research.google.com/drive/1RG0WOQyxlDlo5Km8GogJpIEJlg_5lyYO?usp=sharing)\n\n# Log automatically\n\nBy default, Comet will log the following items\n\n## Metrics\n\n- Box Loss, Object Loss, Classification Loss for the training and validation data\n- mAP_0.5, mAP_0.5:0.95 metrics for the validation data.\n- Precision and Recall for the validation data\n\n## Parameters\n\n- Model Hyperparameters\n- All parameters passed through the command line options\n\n## Visualizations\n\n- Confusion Matrix of the model predictions on the validation data\n- Plots for the PR and F1 curves across all classes\n- Correlogram of the Class Labels\n\n# Configure Comet Logging\n\nComet can be configured to log additional data either through command line flags passed to the training script\nor through environment variables.\n\n```shell\nexport COMET_MODE=online # Set whether to run Comet in 'online' or 'offline' mode. Defaults to online\nexport COMET_MODEL_NAME= #Set the name for the saved model. Defaults to yolov5\nexport COMET_LOG_CONFUSION_MATRIX=false # Set to disable logging a Comet Confusion Matrix. Defaults to true\nexport COMET_MAX_IMAGE_UPLOADS= # Controls how many total image predictions to log to Comet. Defaults to 100.\nexport COMET_LOG_PER_CLASS_METRICS=true # Set to log evaluation metrics for each detected class at the end of training. Defaults to false\nexport COMET_DEFAULT_CHECKPOINT_FILENAME= # Set this if you would like to resume training from a different checkpoint. Defaults to 'last.pt'\nexport COMET_LOG_BATCH_LEVEL_METRICS=true # Set this if you would like to log training metrics at the batch level. Defaults to false.\nexport COMET_LOG_PREDICTIONS=true # Set this to false to disable logging model predictions\n```\n\n## Logging Checkpoints with Comet\n\nLogging Models to Comet is disabled by default. To enable it, pass the `save-period` argument to the training script. This will save the\nlogged checkpoints to Comet based on the interval value provided by `save-period`\n\n```shell\npython train.py \\\n--img 640 \\\n--batch 16 \\\n--epochs 5 \\\n--data coco128.yaml \\\n--weights yolov5s.pt \\\n--save-period 1\n```\n\n## Logging Model Predictions\n\nBy default, model predictions (images, ground truth labels and bounding boxes) will be logged to Comet.\n\nYou can control the frequency of logged predictions and the associated images by passing the `bbox_interval` command line argument. Predictions can be visualized using Comet's Object Detection Custom Panel. This frequency corresponds to every Nth batch of data per epoch. In the example below, we are logging every 2nd batch of data for each epoch.\n\n**Note:** The YOLOv5 validation dataloader will default to a batch size of 32, so you will have to set the logging frequency accordingly.\n\nHere is an [example project using the Panel](https://www.comet.com/examples/comet-example-yolov5?shareable=YcwMiJaZSXfcEXpGOHDD12vA1&utm_source=yolov5&utm_medium=partner&utm_campaign=partner_yolov5_2022&utm_content=github)\n\n```shell\npython train.py \\\n--img 640 \\\n--batch 16 \\\n--epochs 5 \\\n--data coco128.yaml \\\n--weights yolov5s.pt \\\n--bbox_interval 2\n```\n\n### Controlling the number of Prediction Images logged to Comet\n\nWhen logging predictions from YOLOv5, Comet will log the images associated with each set of predictions. By default a maximum of 100 validation images are logged. You can increase or decrease this number using the `COMET_MAX_IMAGE_UPLOADS` environment variable.\n\n```shell\nenv COMET_MAX_IMAGE_UPLOADS=200 python train.py \\\n--img 640 \\\n--batch 16 \\\n--epochs 5 \\\n--data coco128.yaml \\\n--weights yolov5s.pt \\\n--bbox_interval 1\n```\n\n### Logging Class Level Metrics\n\nUse the `COMET_LOG_PER_CLASS_METRICS` environment variable to log mAP, precision, recall, f1 for each class.\n\n```shell\nenv COMET_LOG_PER_CLASS_METRICS=true python train.py \\\n--img 640 \\\n--batch 16 \\\n--epochs 5 \\\n--data coco128.yaml \\\n--weights yolov5s.pt\n```\n\n## Uploading a Dataset to Comet Artifacts\n\nIf you would like to store your data using [Comet Artifacts](https://www.comet.com/docs/v2/guides/data-management/using-artifacts/#learn-more?utm_source=yolov5&utm_medium=partner&utm_campaign=partner_yolov5_2022&utm_content=github), you can do so using the `upload_dataset` flag.\n\nThe dataset be organized in the way described in the [YOLOv5 documentation](train_custom_data.md). The dataset config `yaml` file must follow the same format as that of the `coco128.yaml` file.\n\n```shell\npython train.py \\\n--img 640 \\\n--batch 16 \\\n--epochs 5 \\\n--data coco128.yaml \\\n--weights yolov5s.pt \\\n--upload_dataset\n```\n\nYou can find the uploaded dataset in the Artifacts tab in your Comet Workspace\n
\n\n# Try out an Example!\n\nCheck out an example of a [completed run here](https://www.comet.com/examples/comet-example-yolov5/a0e29e0e9b984e4a822db2a62d0cb357?experiment-tab=chart&showOutliers=true&smoothing=0&transformY=smoothing&xAxis=step&utm_source=yolov5&utm_medium=partner&utm_campaign=partner_yolov5_2022&utm_content=github)\n\nOr better yet, try it out yourself in this Colab Notebook\n\n[](https://colab.research.google.com/drive/1RG0WOQyxlDlo5Km8GogJpIEJlg_5lyYO?usp=sharing)\n\n# Log automatically\n\nBy default, Comet will log the following items\n\n## Metrics\n\n- Box Loss, Object Loss, Classification Loss for the training and validation data\n- mAP_0.5, mAP_0.5:0.95 metrics for the validation data.\n- Precision and Recall for the validation data\n\n## Parameters\n\n- Model Hyperparameters\n- All parameters passed through the command line options\n\n## Visualizations\n\n- Confusion Matrix of the model predictions on the validation data\n- Plots for the PR and F1 curves across all classes\n- Correlogram of the Class Labels\n\n# Configure Comet Logging\n\nComet can be configured to log additional data either through command line flags passed to the training script\nor through environment variables.\n\n```shell\nexport COMET_MODE=online # Set whether to run Comet in 'online' or 'offline' mode. Defaults to online\nexport COMET_MODEL_NAME= #Set the name for the saved model. Defaults to yolov5\nexport COMET_LOG_CONFUSION_MATRIX=false # Set to disable logging a Comet Confusion Matrix. Defaults to true\nexport COMET_MAX_IMAGE_UPLOADS= # Controls how many total image predictions to log to Comet. Defaults to 100.\nexport COMET_LOG_PER_CLASS_METRICS=true # Set to log evaluation metrics for each detected class at the end of training. Defaults to false\nexport COMET_DEFAULT_CHECKPOINT_FILENAME= # Set this if you would like to resume training from a different checkpoint. Defaults to 'last.pt'\nexport COMET_LOG_BATCH_LEVEL_METRICS=true # Set this if you would like to log training metrics at the batch level. Defaults to false.\nexport COMET_LOG_PREDICTIONS=true # Set this to false to disable logging model predictions\n```\n\n## Logging Checkpoints with Comet\n\nLogging Models to Comet is disabled by default. To enable it, pass the `save-period` argument to the training script. This will save the\nlogged checkpoints to Comet based on the interval value provided by `save-period`\n\n```shell\npython train.py \\\n--img 640 \\\n--batch 16 \\\n--epochs 5 \\\n--data coco128.yaml \\\n--weights yolov5s.pt \\\n--save-period 1\n```\n\n## Logging Model Predictions\n\nBy default, model predictions (images, ground truth labels and bounding boxes) will be logged to Comet.\n\nYou can control the frequency of logged predictions and the associated images by passing the `bbox_interval` command line argument. Predictions can be visualized using Comet's Object Detection Custom Panel. This frequency corresponds to every Nth batch of data per epoch. In the example below, we are logging every 2nd batch of data for each epoch.\n\n**Note:** The YOLOv5 validation dataloader will default to a batch size of 32, so you will have to set the logging frequency accordingly.\n\nHere is an [example project using the Panel](https://www.comet.com/examples/comet-example-yolov5?shareable=YcwMiJaZSXfcEXpGOHDD12vA1&utm_source=yolov5&utm_medium=partner&utm_campaign=partner_yolov5_2022&utm_content=github)\n\n```shell\npython train.py \\\n--img 640 \\\n--batch 16 \\\n--epochs 5 \\\n--data coco128.yaml \\\n--weights yolov5s.pt \\\n--bbox_interval 2\n```\n\n### Controlling the number of Prediction Images logged to Comet\n\nWhen logging predictions from YOLOv5, Comet will log the images associated with each set of predictions. By default a maximum of 100 validation images are logged. You can increase or decrease this number using the `COMET_MAX_IMAGE_UPLOADS` environment variable.\n\n```shell\nenv COMET_MAX_IMAGE_UPLOADS=200 python train.py \\\n--img 640 \\\n--batch 16 \\\n--epochs 5 \\\n--data coco128.yaml \\\n--weights yolov5s.pt \\\n--bbox_interval 1\n```\n\n### Logging Class Level Metrics\n\nUse the `COMET_LOG_PER_CLASS_METRICS` environment variable to log mAP, precision, recall, f1 for each class.\n\n```shell\nenv COMET_LOG_PER_CLASS_METRICS=true python train.py \\\n--img 640 \\\n--batch 16 \\\n--epochs 5 \\\n--data coco128.yaml \\\n--weights yolov5s.pt\n```\n\n## Uploading a Dataset to Comet Artifacts\n\nIf you would like to store your data using [Comet Artifacts](https://www.comet.com/docs/v2/guides/data-management/using-artifacts/#learn-more?utm_source=yolov5&utm_medium=partner&utm_campaign=partner_yolov5_2022&utm_content=github), you can do so using the `upload_dataset` flag.\n\nThe dataset be organized in the way described in the [YOLOv5 documentation](train_custom_data.md). The dataset config `yaml` file must follow the same format as that of the `coco128.yaml` file.\n\n```shell\npython train.py \\\n--img 640 \\\n--batch 16 \\\n--epochs 5 \\\n--data coco128.yaml \\\n--weights yolov5s.pt \\\n--upload_dataset\n```\n\nYou can find the uploaded dataset in the Artifacts tab in your Comet Workspace\n \n\nYou can preview the data directly in the Comet UI.\n
\n\nYou can preview the data directly in the Comet UI.\n \n\nArtifacts are versioned and also support adding metadata about the dataset. Comet will automatically log the metadata from your dataset `yaml` file\n
\n\nArtifacts are versioned and also support adding metadata about the dataset. Comet will automatically log the metadata from your dataset `yaml` file\n \n\n### Using a saved Artifact\n\nIf you would like to use a dataset from Comet Artifacts, set the `path` variable in your dataset `yaml` file to point to the following Artifact resource URL.\n\n```\n# contents of artifact.yaml file\npath: \"comet:///:\"\n```\n\nThen pass this file to your training script in the following way\n\n```shell\npython train.py \\\n--img 640 \\\n--batch 16 \\\n--epochs 5 \\\n--data artifact.yaml \\\n--weights yolov5s.pt\n```\n\nArtifacts also allow you to track the lineage of data as it flows through your Experimentation workflow. Here you can see a graph that shows you all the experiments that have used your uploaded dataset.\n
\n\n### Using a saved Artifact\n\nIf you would like to use a dataset from Comet Artifacts, set the `path` variable in your dataset `yaml` file to point to the following Artifact resource URL.\n\n```\n# contents of artifact.yaml file\npath: \"comet:///:\"\n```\n\nThen pass this file to your training script in the following way\n\n```shell\npython train.py \\\n--img 640 \\\n--batch 16 \\\n--epochs 5 \\\n--data artifact.yaml \\\n--weights yolov5s.pt\n```\n\nArtifacts also allow you to track the lineage of data as it flows through your Experimentation workflow. Here you can see a graph that shows you all the experiments that have used your uploaded dataset.\n \n\n## Resuming a Training Run\n\nIf your training run is interrupted for any reason, e.g. disrupted internet connection, you can resume the run using the `resume` flag and the Comet Run Path.\n\nThe Run Path has the following format `comet:////`.\n\nThis will restore the run to its state before the interruption, which includes restoring the model from a checkpoint, restoring all hyperparameters and training arguments and downloading Comet dataset Artifacts if they were used in the original run. The resumed run will continue logging to the existing Experiment in the Comet UI\n\n```shell\npython train.py \\\n--resume \"comet://\"\n```\n\n## Hyperparameter Search with the Comet Optimizer\n\nYOLOv5 is also integrated with Comet's Optimizer, making is simple to visualize hyperparameter sweeps in the Comet UI.\n\n### Configuring an Optimizer Sweep\n\nTo configure the Comet Optimizer, you will have to create a JSON file with the information about the sweep. An example file has been provided in `utils/loggers/comet/optimizer_config.json`\n\n```shell\npython utils/loggers/comet/hpo.py \\\n --comet_optimizer_config \"utils/loggers/comet/optimizer_config.json\"\n```\n\nThe `hpo.py` script accepts the same arguments as `train.py`. If you wish to pass additional arguments to your sweep simply add them after\nthe script.\n\n```shell\npython utils/loggers/comet/hpo.py \\\n --comet_optimizer_config \"utils/loggers/comet/optimizer_config.json\" \\\n --save-period 1 \\\n --bbox_interval 1\n```\n\n### Running a Sweep in Parallel\n\n```shell\ncomet optimizer -j utils/loggers/comet/hpo.py \\\n utils/loggers/comet/optimizer_config.json\"\n```\n\n### Visualizing Results\n\nComet provides a number of ways to visualize the results of your sweep. Take a look at a [project with a completed sweep here](https://www.comet.com/examples/comet-example-yolov5/view/PrlArHGuuhDTKC1UuBmTtOSXD/panels?utm_source=yolov5&utm_medium=partner&utm_campaign=partner_yolov5_2022&utm_content=github)\n\n
\n\n## Resuming a Training Run\n\nIf your training run is interrupted for any reason, e.g. disrupted internet connection, you can resume the run using the `resume` flag and the Comet Run Path.\n\nThe Run Path has the following format `comet:////`.\n\nThis will restore the run to its state before the interruption, which includes restoring the model from a checkpoint, restoring all hyperparameters and training arguments and downloading Comet dataset Artifacts if they were used in the original run. The resumed run will continue logging to the existing Experiment in the Comet UI\n\n```shell\npython train.py \\\n--resume \"comet://\"\n```\n\n## Hyperparameter Search with the Comet Optimizer\n\nYOLOv5 is also integrated with Comet's Optimizer, making is simple to visualize hyperparameter sweeps in the Comet UI.\n\n### Configuring an Optimizer Sweep\n\nTo configure the Comet Optimizer, you will have to create a JSON file with the information about the sweep. An example file has been provided in `utils/loggers/comet/optimizer_config.json`\n\n```shell\npython utils/loggers/comet/hpo.py \\\n --comet_optimizer_config \"utils/loggers/comet/optimizer_config.json\"\n```\n\nThe `hpo.py` script accepts the same arguments as `train.py`. If you wish to pass additional arguments to your sweep simply add them after\nthe script.\n\n```shell\npython utils/loggers/comet/hpo.py \\\n --comet_optimizer_config \"utils/loggers/comet/optimizer_config.json\" \\\n --save-period 1 \\\n --bbox_interval 1\n```\n\n### Running a Sweep in Parallel\n\n```shell\ncomet optimizer -j utils/loggers/comet/hpo.py \\\n utils/loggers/comet/optimizer_config.json\"\n```\n\n### Visualizing Results\n\nComet provides a number of ways to visualize the results of your sweep. Take a look at a [project with a completed sweep here](https://www.comet.com/examples/comet-example-yolov5/view/PrlArHGuuhDTKC1UuBmTtOSXD/panels?utm_source=yolov5&utm_medium=partner&utm_campaign=partner_yolov5_2022&utm_content=github)\n\n "
},
{
"path": "docs/yolov5/tutorials/hyperparameter_evolution.md",
"content": "---\ncomments: true\ndescription: Learn to find optimum YOLOv5 hyperparameters via **evolution**. A guide to learn hyperparameter tuning with Genetic Algorithms.\n---\n\n📚 This guide explains **hyperparameter evolution** for YOLOv5 🚀. Hyperparameter evolution is a method of [Hyperparameter Optimization](https://en.wikipedia.org/wiki/Hyperparameter_optimization) using a [Genetic Algorithm](https://en.wikipedia.org/wiki/Genetic_algorithm) (GA) for optimization. UPDATED 25 September 2022.\n\nHyperparameters in ML control various aspects of training, and finding optimal values for them can be a challenge. Traditional methods like grid searches can quickly become intractable due to 1) the high dimensional search space 2) unknown correlations among the dimensions, and 3) expensive nature of evaluating the fitness at each point, making GA a suitable candidate for hyperparameter searches.\n\n## Before You Start\n\nClone repo and install [requirements.txt](https://github.com/ultralytics/yolov5/blob/master/requirements.txt) in a [**Python>=3.7.0**](https://www.python.org/) environment, including [**PyTorch>=1.7**](https://pytorch.org/get-started/locally/). [Models](https://github.com/ultralytics/yolov5/tree/master/models) and [datasets](https://github.com/ultralytics/yolov5/tree/master/data) download automatically from the latest YOLOv5 [release](https://github.com/ultralytics/yolov5/releases).\n\n```bash\ngit clone https://github.com/ultralytics/yolov5 # clone\ncd yolov5\npip install -r requirements.txt # install\n```\n\n## 1. Initialize Hyperparameters\n\nYOLOv5 has about 30 hyperparameters used for various training settings. These are defined in `*.yaml` files in the `/data/hyps` directory. Better initial guesses will produce better final results, so it is important to initialize these values properly before evolving. If in doubt, simply use the default values, which are optimized for YOLOv5 COCO training from scratch.\n\n```yaml\n# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license\n# Hyperparameters for low-augmentation COCO training from scratch\n# python train.py --batch 64 --cfg yolov5n6.yaml --weights '' --data coco.yaml --img 640 --epochs 300 --linear\n# See tutorials for hyperparameter evolution https://github.com/ultralytics/yolov5#tutorials\n\nlr0: 0.01 # initial learning rate (SGD=1E-2, Adam=1E-3)\nlrf: 0.01 # final OneCycleLR learning rate (lr0 * lrf)\nmomentum: 0.937 # SGD momentum/Adam beta1\nweight_decay: 0.0005 # optimizer weight decay 5e-4\nwarmup_epochs: 3.0 # warmup epochs (fractions ok)\nwarmup_momentum: 0.8 # warmup initial momentum\nwarmup_bias_lr: 0.1 # warmup initial bias lr\nbox: 0.05 # box loss gain\ncls: 0.5 # cls loss gain\ncls_pw: 1.0 # cls BCELoss positive_weight\nobj: 1.0 # obj loss gain (scale with pixels)\nobj_pw: 1.0 # obj BCELoss positive_weight\niou_t: 0.20 # IoU training threshold\nanchor_t: 4.0 # anchor-multiple threshold\n# anchors: 3 # anchors per output layer (0 to ignore)\nfl_gamma: 0.0 # focal loss gamma (efficientDet default gamma=1.5)\nhsv_h: 0.015 # image HSV-Hue augmentation (fraction)\nhsv_s: 0.7 # image HSV-Saturation augmentation (fraction)\nhsv_v: 0.4 # image HSV-Value augmentation (fraction)\ndegrees: 0.0 # image rotation (+/- deg)\ntranslate: 0.1 # image translation (+/- fraction)\nscale: 0.5 # image scale (+/- gain)\nshear: 0.0 # image shear (+/- deg)\nperspective: 0.0 # image perspective (+/- fraction), range 0-0.001\nflipud: 0.0 # image flip up-down (probability)\nfliplr: 0.5 # image flip left-right (probability)\nmosaic: 1.0 # image mosaic (probability)\nmixup: 0.0 # image mixup (probability)\ncopy_paste: 0.0 # segment copy-paste (probability)\n```\n\n## 2. Define Fitness\n\nFitness is the value we seek to maximize. In YOLOv5 we define a default fitness function as a weighted combination of metrics: `mAP@0.5` contributes 10% of the weight and `mAP@0.5:0.95` contributes the remaining 90%, with [Precision `P` and Recall `R`](https://en.wikipedia.org/wiki/Precision_and_recall) absent. You may adjust these as you see fit or use the default fitness definition in utils/metrics.py (recommended).\n\n```python\ndef fitness(x): \n # Model fitness as a weighted combination of metrics \n w = [0.0, 0.0, 0.1, 0.9] # weights for [P, R, mAP@0.5, mAP@0.5:0.95] \n return (x[:, :4] * w).sum(1) \n```\n\n## 3. Evolve\n\nEvolution is performed about a base scenario which we seek to improve upon. The base scenario in this example is finetuning COCO128 for 10 epochs using pretrained YOLOv5s. The base scenario training command is:\n\n```bash\npython train.py --epochs 10 --data coco128.yaml --weights yolov5s.pt --cache\n```\n\nTo evolve hyperparameters **specific to this scenario**, starting from our initial values defined in **Section 1.**, and maximizing the fitness defined in **Section 2.**, append `--evolve`:\n\n```bash\n# Single-GPU\npython train.py --epochs 10 --data coco128.yaml --weights yolov5s.pt --cache --evolve\n\n# Multi-GPU\nfor i in 0 1 2 3 4 5 6 7; do\n sleep $(expr 30 \\* $i) && # 30-second delay (optional)\n echo 'Starting GPU '$i'...' &&\n nohup python train.py --epochs 10 --data coco128.yaml --weights yolov5s.pt --cache --device $i --evolve > evolve_gpu_$i.log &\ndone\n\n# Multi-GPU bash-while (not recommended)\nfor i in 0 1 2 3 4 5 6 7; do\n sleep $(expr 30 \\* $i) && # 30-second delay (optional)\n echo 'Starting GPU '$i'...' &&\n \"$(while true; do nohup python train.py... --device $i --evolve 1 > evolve_gpu_$i.log; done)\" &\ndone\n```\n\nThe default evolution settings will run the base scenario 300 times, i.e. for 300 generations. You can modify generations via the `--evolve` argument, i.e. `python train.py --evolve 1000`.\nhttps://github.com/ultralytics/yolov5/blob/6a3ee7cf03efb17fbffde0e68b1a854e80fe3213/train.py#L608\n\nThe main genetic operators are **crossover** and **mutation**. In this work mutation is used, with an 80% probability and a 0.04 variance to create new offspring based on a combination of the best parents from all previous generations. Results are logged to `runs/evolve/exp/evolve.csv`, and the highest fitness offspring is saved every generation as `runs/evolve/hyp_evolved.yaml`:\n\n```yaml\n# YOLOv5 Hyperparameter Evolution Results\n# Best generation: 287\n# Last generation: 300\n# metrics/precision, metrics/recall, metrics/mAP_0.5, metrics/mAP_0.5:0.95, val/box_loss, val/obj_loss, val/cls_loss\n# 0.54634, 0.55625, 0.58201, 0.33665, 0.056451, 0.042892, 0.013441\n\nlr0: 0.01 # initial learning rate (SGD=1E-2, Adam=1E-3)\nlrf: 0.2 # final OneCycleLR learning rate (lr0 * lrf)\nmomentum: 0.937 # SGD momentum/Adam beta1\nweight_decay: 0.0005 # optimizer weight decay 5e-4\nwarmup_epochs: 3.0 # warmup epochs (fractions ok)\nwarmup_momentum: 0.8 # warmup initial momentum\nwarmup_bias_lr: 0.1 # warmup initial bias lr\nbox: 0.05 # box loss gain\ncls: 0.5 # cls loss gain\ncls_pw: 1.0 # cls BCELoss positive_weight\nobj: 1.0 # obj loss gain (scale with pixels)\nobj_pw: 1.0 # obj BCELoss positive_weight\niou_t: 0.20 # IoU training threshold\nanchor_t: 4.0 # anchor-multiple threshold\n# anchors: 3 # anchors per output layer (0 to ignore)\nfl_gamma: 0.0 # focal loss gamma (efficientDet default gamma=1.5)\nhsv_h: 0.015 # image HSV-Hue augmentation (fraction)\nhsv_s: 0.7 # image HSV-Saturation augmentation (fraction)\nhsv_v: 0.4 # image HSV-Value augmentation (fraction)\ndegrees: 0.0 # image rotation (+/- deg)\ntranslate: 0.1 # image translation (+/- fraction)\nscale: 0.5 # image scale (+/- gain)\nshear: 0.0 # image shear (+/- deg)\nperspective: 0.0 # image perspective (+/- fraction), range 0-0.001\nflipud: 0.0 # image flip up-down (probability)\nfliplr: 0.5 # image flip left-right (probability)\nmosaic: 1.0 # image mosaic (probability)\nmixup: 0.0 # image mixup (probability)\ncopy_paste: 0.0 # segment copy-paste (probability)\n```\n\nWe recommend a minimum of 300 generations of evolution for best results. Note that **evolution is generally expensive and time-consuming**, as the base scenario is trained hundreds of times, possibly requiring hundreds or thousands of GPU hours.\n\n## 4. Visualize\n\n`evolve.csv` is plotted as `evolve.png` by `utils.plots.plot_evolve()` after evolution finishes with one subplot per hyperparameter showing fitness (y-axis) vs hyperparameter values (x-axis). Yellow indicates higher concentrations. Vertical distributions indicate that a parameter has been disabled and does not mutate. This is user selectable in the `meta` dictionary in train.py, and is useful for fixing parameters and preventing them from evolving.\n\n\n\n## Environments\n\nYOLOv5 may be run in any of the following up-to-date verified environments (with all dependencies including [CUDA](https://developer.nvidia.com/cuda)/[CUDNN](https://developer.nvidia.com/cudnn), [Python](https://www.python.org/) and [PyTorch](https://pytorch.org/) preinstalled):\n\n- **Notebooks** with free GPU: \n- **Google Cloud** Deep Learning VM. See [GCP Quickstart Guide](https://docs.ultralytics.com/yolov5/environments/google_cloud_quickstart_tutorial/)\n- **Amazon** Deep Learning AMI. See [AWS Quickstart Guide](https://docs.ultralytics.com/yolov5/environments/aws_quickstart_tutorial/)\n- **Docker Image**. See [Docker Quickstart Guide](https://docs.ultralytics.com/yolov5/environments/docker_image_quickstart_tutorial/) \n\n## Status\n\n\n\nIf this badge is green, all [YOLOv5 GitHub Actions](https://github.com/ultralytics/yolov5/actions) Continuous Integration (CI) tests are currently passing. CI tests verify correct operation of YOLOv5 [training](https://github.com/ultralytics/yolov5/blob/master/train.py), [validation](https://github.com/ultralytics/yolov5/blob/master/val.py), [inference](https://github.com/ultralytics/yolov5/blob/master/detect.py), [export](https://github.com/ultralytics/yolov5/blob/master/export.py) and [benchmarks](https://github.com/ultralytics/yolov5/blob/master/benchmarks.py) on macOS, Windows, and Ubuntu every 24 hours and on every commit."
},
{
"path": "docs/yolov5/tutorials/model_ensembling.md",
"content": "---\ncomments: true\ndescription: Learn how to ensemble YOLOv5 models for improved mAP and Recall! Clone the repo, install requirements, and start testing and inference.\n---\n\n📚 This guide explains how to use YOLOv5 🚀 **model ensembling** during testing and inference for improved mAP and Recall. \nUPDATED 25 September 2022.\n\nFrom [https://en.wikipedia.org/wiki/Ensemble_learning](https://en.wikipedia.org/wiki/Ensemble_learning):\n> Ensemble modeling is a process where multiple diverse models are created to predict an outcome, either by using many different modeling algorithms or using different training data sets. The ensemble model then aggregates the prediction of each base model and results in once final prediction for the unseen data. The motivation for using ensemble models is to reduce the generalization error of the prediction. As long as the base models are diverse and independent, the prediction error of the model decreases when the ensemble approach is used. The approach seeks the wisdom of crowds in making a prediction. Even though the ensemble model has multiple base models within the model, it acts and performs as a single model.\n\n## Before You Start\n\nClone repo and install [requirements.txt](https://github.com/ultralytics/yolov5/blob/master/requirements.txt) in a [**Python>=3.7.0**](https://www.python.org/) environment, including [**PyTorch>=1.7**](https://pytorch.org/get-started/locally/). [Models](https://github.com/ultralytics/yolov5/tree/master/models) and [datasets](https://github.com/ultralytics/yolov5/tree/master/data) download automatically from the latest YOLOv5 [release](https://github.com/ultralytics/yolov5/releases).\n\n```bash\ngit clone https://github.com/ultralytics/yolov5 # clone\ncd yolov5\npip install -r requirements.txt # install\n```\n\n## Test Normally\n\nBefore ensembling we want to establish the baseline performance of a single model. This command tests YOLOv5x on COCO val2017 at image size 640 pixels. `yolov5x.pt` is the largest and most accurate model available. Other options are `yolov5s.pt`, `yolov5m.pt` and `yolov5l.pt`, or you own checkpoint from training a custom dataset `./weights/best.pt`. For details on all available models please see our README [table](https://github.com/ultralytics/yolov5#pretrained-checkpoints).\n\n```bash\npython val.py --weights yolov5x.pt --data coco.yaml --img 640 --half\n```\n\nOutput:\n\n```shell\nval: data=./data/coco.yaml, weights=['yolov5x.pt'], batch_size=32, imgsz=640, conf_thres=0.001, iou_thres=0.65, task=val, device=, single_cls=False, augment=False, verbose=False, save_txt=False, save_hybrid=False, save_conf=False, save_json=True, project=runs/val, name=exp, exist_ok=False, half=True\nYOLOv5 🚀 v5.0-267-g6a3ee7c torch 1.9.0+cu102 CUDA:0 (Tesla P100-PCIE-16GB, 16280.875MB)\n\nFusing layers... \nModel Summary: 476 layers, 87730285 parameters, 0 gradients\n\nval: Scanning '../datasets/coco/val2017' images and labels...4952 found, 48 missing, 0 empty, 0 corrupted: 100% 5000/5000 [00:01<00:00, 2846.03it/s]\nval: New cache created: ../datasets/coco/val2017.cache\n Class Images Labels P R mAP@.5 mAP@.5:.95: 100% 157/157 [02:30<00:00, 1.05it/s]\n all 5000 36335 0.746 0.626 0.68 0.49\nSpeed: 0.1ms pre-process, 22.4ms inference, 1.4ms NMS per image at shape (32, 3, 640, 640) # <--- baseline speed\n\nEvaluating pycocotools mAP... saving runs/val/exp/yolov5x_predictions.json...\n...\n Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.504 # <--- baseline mAP\n Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.688\n Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.546\n Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.351\n Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.551\n Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.644\n Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.382\n Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.628\n Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.681 # <--- baseline mAR\n Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.524\n Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.735\n Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.826\n```\n\n## Ensemble Test\n\nMultiple pretrained models may be ensembled together at test and inference time by simply appending extra models to the `--weights` argument in any existing val.py or detect.py command. This example tests an ensemble of 2 models together:\n\n- YOLOv5x\n- YOLOv5l6\n\n```bash\npython val.py --weights yolov5x.pt yolov5l6.pt --data coco.yaml --img 640 --half\n```\n\nOutput:\n\n```shell\nval: data=./data/coco.yaml, weights=['yolov5x.pt', 'yolov5l6.pt'], batch_size=32, imgsz=640, conf_thres=0.001, iou_thres=0.6, task=val, device=, single_cls=False, augment=False, verbose=False, save_txt=False, save_hybrid=False, save_conf=False, save_json=True, project=runs/val, name=exp, exist_ok=False, half=True\nYOLOv5 🚀 v5.0-267-g6a3ee7c torch 1.9.0+cu102 CUDA:0 (Tesla P100-PCIE-16GB, 16280.875MB)\n\nFusing layers... \nModel Summary: 476 layers, 87730285 parameters, 0 gradients # Model 1\nFusing layers... \nModel Summary: 501 layers, 77218620 parameters, 0 gradients # Model 2\nEnsemble created with ['yolov5x.pt', 'yolov5l6.pt'] # Ensemble notice\n\nval: Scanning '../datasets/coco/val2017.cache' images and labels... 4952 found, 48 missing, 0 empty, 0 corrupted: 100% 5000/5000 [00:00<00:00, 49695545.02it/s]\n Class Images Labels P R mAP@.5 mAP@.5:.95: 100% 157/157 [03:58<00:00, 1.52s/it]\n all 5000 36335 0.747 0.637 0.692 0.502\nSpeed: 0.1ms pre-process, 39.5ms inference, 2.0ms NMS per image at shape (32, 3, 640, 640) # <--- ensemble speed\n\nEvaluating pycocotools mAP... saving runs/val/exp3/yolov5x_predictions.json...\n...\n Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.515 # <--- ensemble mAP\n Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.699\n Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.557\n Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.356\n Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.563\n Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.668\n Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.387\n Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.638\n Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.689 # <--- ensemble mAR\n Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.526\n Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.743\n Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.844\n```\n\n## Ensemble Inference\n\nAppend extra models to the `--weights` argument to run ensemble inference:\n\n```bash\npython detect.py --weights yolov5x.pt yolov5l6.pt --img 640 --source data/images\n```\n\nOutput:\n\n```bash\ndetect: weights=['yolov5x.pt', 'yolov5l6.pt'], source=data/images, imgsz=640, conf_thres=0.25, iou_thres=0.45, max_det=1000, device=, view_img=False, save_txt=False, save_conf=False, save_crop=False, nosave=False, classes=None, agnostic_nms=False, augment=False, update=False, project=runs/detect, name=exp, exist_ok=False, line_width=3, hide_labels=False, hide_conf=False, half=False\nYOLOv5 🚀 v5.0-267-g6a3ee7c torch 1.9.0+cu102 CUDA:0 (Tesla P100-PCIE-16GB, 16280.875MB)\n\nFusing layers... \nModel Summary: 476 layers, 87730285 parameters, 0 gradients\nFusing layers... \nModel Summary: 501 layers, 77218620 parameters, 0 gradients\nEnsemble created with ['yolov5x.pt', 'yolov5l6.pt']\n\nimage 1/2 /content/yolov5/data/images/bus.jpg: 640x512 4 persons, 1 bus, 1 tie, Done. (0.063s)\nimage 2/2 /content/yolov5/data/images/zidane.jpg: 384x640 3 persons, 2 ties, Done. (0.056s)\nResults saved to runs/detect/exp2\nDone. (0.223s)\n```\n\n
"
},
{
"path": "docs/yolov5/tutorials/hyperparameter_evolution.md",
"content": "---\ncomments: true\ndescription: Learn to find optimum YOLOv5 hyperparameters via **evolution**. A guide to learn hyperparameter tuning with Genetic Algorithms.\n---\n\n📚 This guide explains **hyperparameter evolution** for YOLOv5 🚀. Hyperparameter evolution is a method of [Hyperparameter Optimization](https://en.wikipedia.org/wiki/Hyperparameter_optimization) using a [Genetic Algorithm](https://en.wikipedia.org/wiki/Genetic_algorithm) (GA) for optimization. UPDATED 25 September 2022.\n\nHyperparameters in ML control various aspects of training, and finding optimal values for them can be a challenge. Traditional methods like grid searches can quickly become intractable due to 1) the high dimensional search space 2) unknown correlations among the dimensions, and 3) expensive nature of evaluating the fitness at each point, making GA a suitable candidate for hyperparameter searches.\n\n## Before You Start\n\nClone repo and install [requirements.txt](https://github.com/ultralytics/yolov5/blob/master/requirements.txt) in a [**Python>=3.7.0**](https://www.python.org/) environment, including [**PyTorch>=1.7**](https://pytorch.org/get-started/locally/). [Models](https://github.com/ultralytics/yolov5/tree/master/models) and [datasets](https://github.com/ultralytics/yolov5/tree/master/data) download automatically from the latest YOLOv5 [release](https://github.com/ultralytics/yolov5/releases).\n\n```bash\ngit clone https://github.com/ultralytics/yolov5 # clone\ncd yolov5\npip install -r requirements.txt # install\n```\n\n## 1. Initialize Hyperparameters\n\nYOLOv5 has about 30 hyperparameters used for various training settings. These are defined in `*.yaml` files in the `/data/hyps` directory. Better initial guesses will produce better final results, so it is important to initialize these values properly before evolving. If in doubt, simply use the default values, which are optimized for YOLOv5 COCO training from scratch.\n\n```yaml\n# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license\n# Hyperparameters for low-augmentation COCO training from scratch\n# python train.py --batch 64 --cfg yolov5n6.yaml --weights '' --data coco.yaml --img 640 --epochs 300 --linear\n# See tutorials for hyperparameter evolution https://github.com/ultralytics/yolov5#tutorials\n\nlr0: 0.01 # initial learning rate (SGD=1E-2, Adam=1E-3)\nlrf: 0.01 # final OneCycleLR learning rate (lr0 * lrf)\nmomentum: 0.937 # SGD momentum/Adam beta1\nweight_decay: 0.0005 # optimizer weight decay 5e-4\nwarmup_epochs: 3.0 # warmup epochs (fractions ok)\nwarmup_momentum: 0.8 # warmup initial momentum\nwarmup_bias_lr: 0.1 # warmup initial bias lr\nbox: 0.05 # box loss gain\ncls: 0.5 # cls loss gain\ncls_pw: 1.0 # cls BCELoss positive_weight\nobj: 1.0 # obj loss gain (scale with pixels)\nobj_pw: 1.0 # obj BCELoss positive_weight\niou_t: 0.20 # IoU training threshold\nanchor_t: 4.0 # anchor-multiple threshold\n# anchors: 3 # anchors per output layer (0 to ignore)\nfl_gamma: 0.0 # focal loss gamma (efficientDet default gamma=1.5)\nhsv_h: 0.015 # image HSV-Hue augmentation (fraction)\nhsv_s: 0.7 # image HSV-Saturation augmentation (fraction)\nhsv_v: 0.4 # image HSV-Value augmentation (fraction)\ndegrees: 0.0 # image rotation (+/- deg)\ntranslate: 0.1 # image translation (+/- fraction)\nscale: 0.5 # image scale (+/- gain)\nshear: 0.0 # image shear (+/- deg)\nperspective: 0.0 # image perspective (+/- fraction), range 0-0.001\nflipud: 0.0 # image flip up-down (probability)\nfliplr: 0.5 # image flip left-right (probability)\nmosaic: 1.0 # image mosaic (probability)\nmixup: 0.0 # image mixup (probability)\ncopy_paste: 0.0 # segment copy-paste (probability)\n```\n\n## 2. Define Fitness\n\nFitness is the value we seek to maximize. In YOLOv5 we define a default fitness function as a weighted combination of metrics: `mAP@0.5` contributes 10% of the weight and `mAP@0.5:0.95` contributes the remaining 90%, with [Precision `P` and Recall `R`](https://en.wikipedia.org/wiki/Precision_and_recall) absent. You may adjust these as you see fit or use the default fitness definition in utils/metrics.py (recommended).\n\n```python\ndef fitness(x): \n # Model fitness as a weighted combination of metrics \n w = [0.0, 0.0, 0.1, 0.9] # weights for [P, R, mAP@0.5, mAP@0.5:0.95] \n return (x[:, :4] * w).sum(1) \n```\n\n## 3. Evolve\n\nEvolution is performed about a base scenario which we seek to improve upon. The base scenario in this example is finetuning COCO128 for 10 epochs using pretrained YOLOv5s. The base scenario training command is:\n\n```bash\npython train.py --epochs 10 --data coco128.yaml --weights yolov5s.pt --cache\n```\n\nTo evolve hyperparameters **specific to this scenario**, starting from our initial values defined in **Section 1.**, and maximizing the fitness defined in **Section 2.**, append `--evolve`:\n\n```bash\n# Single-GPU\npython train.py --epochs 10 --data coco128.yaml --weights yolov5s.pt --cache --evolve\n\n# Multi-GPU\nfor i in 0 1 2 3 4 5 6 7; do\n sleep $(expr 30 \\* $i) && # 30-second delay (optional)\n echo 'Starting GPU '$i'...' &&\n nohup python train.py --epochs 10 --data coco128.yaml --weights yolov5s.pt --cache --device $i --evolve > evolve_gpu_$i.log &\ndone\n\n# Multi-GPU bash-while (not recommended)\nfor i in 0 1 2 3 4 5 6 7; do\n sleep $(expr 30 \\* $i) && # 30-second delay (optional)\n echo 'Starting GPU '$i'...' &&\n \"$(while true; do nohup python train.py... --device $i --evolve 1 > evolve_gpu_$i.log; done)\" &\ndone\n```\n\nThe default evolution settings will run the base scenario 300 times, i.e. for 300 generations. You can modify generations via the `--evolve` argument, i.e. `python train.py --evolve 1000`.\nhttps://github.com/ultralytics/yolov5/blob/6a3ee7cf03efb17fbffde0e68b1a854e80fe3213/train.py#L608\n\nThe main genetic operators are **crossover** and **mutation**. In this work mutation is used, with an 80% probability and a 0.04 variance to create new offspring based on a combination of the best parents from all previous generations. Results are logged to `runs/evolve/exp/evolve.csv`, and the highest fitness offspring is saved every generation as `runs/evolve/hyp_evolved.yaml`:\n\n```yaml\n# YOLOv5 Hyperparameter Evolution Results\n# Best generation: 287\n# Last generation: 300\n# metrics/precision, metrics/recall, metrics/mAP_0.5, metrics/mAP_0.5:0.95, val/box_loss, val/obj_loss, val/cls_loss\n# 0.54634, 0.55625, 0.58201, 0.33665, 0.056451, 0.042892, 0.013441\n\nlr0: 0.01 # initial learning rate (SGD=1E-2, Adam=1E-3)\nlrf: 0.2 # final OneCycleLR learning rate (lr0 * lrf)\nmomentum: 0.937 # SGD momentum/Adam beta1\nweight_decay: 0.0005 # optimizer weight decay 5e-4\nwarmup_epochs: 3.0 # warmup epochs (fractions ok)\nwarmup_momentum: 0.8 # warmup initial momentum\nwarmup_bias_lr: 0.1 # warmup initial bias lr\nbox: 0.05 # box loss gain\ncls: 0.5 # cls loss gain\ncls_pw: 1.0 # cls BCELoss positive_weight\nobj: 1.0 # obj loss gain (scale with pixels)\nobj_pw: 1.0 # obj BCELoss positive_weight\niou_t: 0.20 # IoU training threshold\nanchor_t: 4.0 # anchor-multiple threshold\n# anchors: 3 # anchors per output layer (0 to ignore)\nfl_gamma: 0.0 # focal loss gamma (efficientDet default gamma=1.5)\nhsv_h: 0.015 # image HSV-Hue augmentation (fraction)\nhsv_s: 0.7 # image HSV-Saturation augmentation (fraction)\nhsv_v: 0.4 # image HSV-Value augmentation (fraction)\ndegrees: 0.0 # image rotation (+/- deg)\ntranslate: 0.1 # image translation (+/- fraction)\nscale: 0.5 # image scale (+/- gain)\nshear: 0.0 # image shear (+/- deg)\nperspective: 0.0 # image perspective (+/- fraction), range 0-0.001\nflipud: 0.0 # image flip up-down (probability)\nfliplr: 0.5 # image flip left-right (probability)\nmosaic: 1.0 # image mosaic (probability)\nmixup: 0.0 # image mixup (probability)\ncopy_paste: 0.0 # segment copy-paste (probability)\n```\n\nWe recommend a minimum of 300 generations of evolution for best results. Note that **evolution is generally expensive and time-consuming**, as the base scenario is trained hundreds of times, possibly requiring hundreds or thousands of GPU hours.\n\n## 4. Visualize\n\n`evolve.csv` is plotted as `evolve.png` by `utils.plots.plot_evolve()` after evolution finishes with one subplot per hyperparameter showing fitness (y-axis) vs hyperparameter values (x-axis). Yellow indicates higher concentrations. Vertical distributions indicate that a parameter has been disabled and does not mutate. This is user selectable in the `meta` dictionary in train.py, and is useful for fixing parameters and preventing them from evolving.\n\n\n\n## Environments\n\nYOLOv5 may be run in any of the following up-to-date verified environments (with all dependencies including [CUDA](https://developer.nvidia.com/cuda)/[CUDNN](https://developer.nvidia.com/cudnn), [Python](https://www.python.org/) and [PyTorch](https://pytorch.org/) preinstalled):\n\n- **Notebooks** with free GPU: \n- **Google Cloud** Deep Learning VM. See [GCP Quickstart Guide](https://docs.ultralytics.com/yolov5/environments/google_cloud_quickstart_tutorial/)\n- **Amazon** Deep Learning AMI. See [AWS Quickstart Guide](https://docs.ultralytics.com/yolov5/environments/aws_quickstart_tutorial/)\n- **Docker Image**. See [Docker Quickstart Guide](https://docs.ultralytics.com/yolov5/environments/docker_image_quickstart_tutorial/) \n\n## Status\n\n\n\nIf this badge is green, all [YOLOv5 GitHub Actions](https://github.com/ultralytics/yolov5/actions) Continuous Integration (CI) tests are currently passing. CI tests verify correct operation of YOLOv5 [training](https://github.com/ultralytics/yolov5/blob/master/train.py), [validation](https://github.com/ultralytics/yolov5/blob/master/val.py), [inference](https://github.com/ultralytics/yolov5/blob/master/detect.py), [export](https://github.com/ultralytics/yolov5/blob/master/export.py) and [benchmarks](https://github.com/ultralytics/yolov5/blob/master/benchmarks.py) on macOS, Windows, and Ubuntu every 24 hours and on every commit."
},
{
"path": "docs/yolov5/tutorials/model_ensembling.md",
"content": "---\ncomments: true\ndescription: Learn how to ensemble YOLOv5 models for improved mAP and Recall! Clone the repo, install requirements, and start testing and inference.\n---\n\n📚 This guide explains how to use YOLOv5 🚀 **model ensembling** during testing and inference for improved mAP and Recall. \nUPDATED 25 September 2022.\n\nFrom [https://en.wikipedia.org/wiki/Ensemble_learning](https://en.wikipedia.org/wiki/Ensemble_learning):\n> Ensemble modeling is a process where multiple diverse models are created to predict an outcome, either by using many different modeling algorithms or using different training data sets. The ensemble model then aggregates the prediction of each base model and results in once final prediction for the unseen data. The motivation for using ensemble models is to reduce the generalization error of the prediction. As long as the base models are diverse and independent, the prediction error of the model decreases when the ensemble approach is used. The approach seeks the wisdom of crowds in making a prediction. Even though the ensemble model has multiple base models within the model, it acts and performs as a single model.\n\n## Before You Start\n\nClone repo and install [requirements.txt](https://github.com/ultralytics/yolov5/blob/master/requirements.txt) in a [**Python>=3.7.0**](https://www.python.org/) environment, including [**PyTorch>=1.7**](https://pytorch.org/get-started/locally/). [Models](https://github.com/ultralytics/yolov5/tree/master/models) and [datasets](https://github.com/ultralytics/yolov5/tree/master/data) download automatically from the latest YOLOv5 [release](https://github.com/ultralytics/yolov5/releases).\n\n```bash\ngit clone https://github.com/ultralytics/yolov5 # clone\ncd yolov5\npip install -r requirements.txt # install\n```\n\n## Test Normally\n\nBefore ensembling we want to establish the baseline performance of a single model. This command tests YOLOv5x on COCO val2017 at image size 640 pixels. `yolov5x.pt` is the largest and most accurate model available. Other options are `yolov5s.pt`, `yolov5m.pt` and `yolov5l.pt`, or you own checkpoint from training a custom dataset `./weights/best.pt`. For details on all available models please see our README [table](https://github.com/ultralytics/yolov5#pretrained-checkpoints).\n\n```bash\npython val.py --weights yolov5x.pt --data coco.yaml --img 640 --half\n```\n\nOutput:\n\n```shell\nval: data=./data/coco.yaml, weights=['yolov5x.pt'], batch_size=32, imgsz=640, conf_thres=0.001, iou_thres=0.65, task=val, device=, single_cls=False, augment=False, verbose=False, save_txt=False, save_hybrid=False, save_conf=False, save_json=True, project=runs/val, name=exp, exist_ok=False, half=True\nYOLOv5 🚀 v5.0-267-g6a3ee7c torch 1.9.0+cu102 CUDA:0 (Tesla P100-PCIE-16GB, 16280.875MB)\n\nFusing layers... \nModel Summary: 476 layers, 87730285 parameters, 0 gradients\n\nval: Scanning '../datasets/coco/val2017' images and labels...4952 found, 48 missing, 0 empty, 0 corrupted: 100% 5000/5000 [00:01<00:00, 2846.03it/s]\nval: New cache created: ../datasets/coco/val2017.cache\n Class Images Labels P R mAP@.5 mAP@.5:.95: 100% 157/157 [02:30<00:00, 1.05it/s]\n all 5000 36335 0.746 0.626 0.68 0.49\nSpeed: 0.1ms pre-process, 22.4ms inference, 1.4ms NMS per image at shape (32, 3, 640, 640) # <--- baseline speed\n\nEvaluating pycocotools mAP... saving runs/val/exp/yolov5x_predictions.json...\n...\n Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.504 # <--- baseline mAP\n Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.688\n Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.546\n Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.351\n Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.551\n Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.644\n Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.382\n Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.628\n Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.681 # <--- baseline mAR\n Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.524\n Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.735\n Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.826\n```\n\n## Ensemble Test\n\nMultiple pretrained models may be ensembled together at test and inference time by simply appending extra models to the `--weights` argument in any existing val.py or detect.py command. This example tests an ensemble of 2 models together:\n\n- YOLOv5x\n- YOLOv5l6\n\n```bash\npython val.py --weights yolov5x.pt yolov5l6.pt --data coco.yaml --img 640 --half\n```\n\nOutput:\n\n```shell\nval: data=./data/coco.yaml, weights=['yolov5x.pt', 'yolov5l6.pt'], batch_size=32, imgsz=640, conf_thres=0.001, iou_thres=0.6, task=val, device=, single_cls=False, augment=False, verbose=False, save_txt=False, save_hybrid=False, save_conf=False, save_json=True, project=runs/val, name=exp, exist_ok=False, half=True\nYOLOv5 🚀 v5.0-267-g6a3ee7c torch 1.9.0+cu102 CUDA:0 (Tesla P100-PCIE-16GB, 16280.875MB)\n\nFusing layers... \nModel Summary: 476 layers, 87730285 parameters, 0 gradients # Model 1\nFusing layers... \nModel Summary: 501 layers, 77218620 parameters, 0 gradients # Model 2\nEnsemble created with ['yolov5x.pt', 'yolov5l6.pt'] # Ensemble notice\n\nval: Scanning '../datasets/coco/val2017.cache' images and labels... 4952 found, 48 missing, 0 empty, 0 corrupted: 100% 5000/5000 [00:00<00:00, 49695545.02it/s]\n Class Images Labels P R mAP@.5 mAP@.5:.95: 100% 157/157 [03:58<00:00, 1.52s/it]\n all 5000 36335 0.747 0.637 0.692 0.502\nSpeed: 0.1ms pre-process, 39.5ms inference, 2.0ms NMS per image at shape (32, 3, 640, 640) # <--- ensemble speed\n\nEvaluating pycocotools mAP... saving runs/val/exp3/yolov5x_predictions.json...\n...\n Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.515 # <--- ensemble mAP\n Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.699\n Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.557\n Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.356\n Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.563\n Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.668\n Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.387\n Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.638\n Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.689 # <--- ensemble mAR\n Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.526\n Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.743\n Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.844\n```\n\n## Ensemble Inference\n\nAppend extra models to the `--weights` argument to run ensemble inference:\n\n```bash\npython detect.py --weights yolov5x.pt yolov5l6.pt --img 640 --source data/images\n```\n\nOutput:\n\n```bash\ndetect: weights=['yolov5x.pt', 'yolov5l6.pt'], source=data/images, imgsz=640, conf_thres=0.25, iou_thres=0.45, max_det=1000, device=, view_img=False, save_txt=False, save_conf=False, save_crop=False, nosave=False, classes=None, agnostic_nms=False, augment=False, update=False, project=runs/detect, name=exp, exist_ok=False, line_width=3, hide_labels=False, hide_conf=False, half=False\nYOLOv5 🚀 v5.0-267-g6a3ee7c torch 1.9.0+cu102 CUDA:0 (Tesla P100-PCIE-16GB, 16280.875MB)\n\nFusing layers... \nModel Summary: 476 layers, 87730285 parameters, 0 gradients\nFusing layers... \nModel Summary: 501 layers, 77218620 parameters, 0 gradients\nEnsemble created with ['yolov5x.pt', 'yolov5l6.pt']\n\nimage 1/2 /content/yolov5/data/images/bus.jpg: 640x512 4 persons, 1 bus, 1 tie, Done. (0.063s)\nimage 2/2 /content/yolov5/data/images/zidane.jpg: 384x640 3 persons, 2 ties, Done. (0.056s)\nResults saved to runs/detect/exp2\nDone. (0.223s)\n```\n\n \n\n## Environments\n\nYOLOv5 may be run in any of the following up-to-date verified environments (with all dependencies including [CUDA](https://developer.nvidia.com/cuda)/[CUDNN](https://developer.nvidia.com/cudnn), [Python](https://www.python.org/) and [PyTorch](https://pytorch.org/) preinstalled):\n\n- **Notebooks** with free GPU: \n- **Google Cloud** Deep Learning VM. See [GCP Quickstart Guide](https://docs.ultralytics.com/yolov5/environments/google_cloud_quickstart_tutorial/)\n- **Amazon** Deep Learning AMI. See [AWS Quickstart Guide](https://docs.ultralytics.com/yolov5/environments/aws_quickstart_tutorial/)\n- **Docker Image**. See [Docker Quickstart Guide](https://docs.ultralytics.com/yolov5/environments/docker_image_quickstart_tutorial/) \n\n## Status\n\n\n\nIf this badge is green, all [YOLOv5 GitHub Actions](https://github.com/ultralytics/yolov5/actions) Continuous Integration (CI) tests are currently passing. CI tests verify correct operation of YOLOv5 [training](https://github.com/ultralytics/yolov5/blob/master/train.py), [validation](https://github.com/ultralytics/yolov5/blob/master/val.py), [inference](https://github.com/ultralytics/yolov5/blob/master/detect.py), [export](https://github.com/ultralytics/yolov5/blob/master/export.py) and [benchmarks](https://github.com/ultralytics/yolov5/blob/master/benchmarks.py) on macOS, Windows, and Ubuntu every 24 hours and on every commit."
},
{
"path": "docs/yolov5/tutorials/model_export.md",
"content": "---\ncomments: true\ndescription: Export YOLOv5 models to TFLite, ONNX, CoreML, and TensorRT formats. Achieve up to 5x GPU speedup using TensorRT. Benchmarks included.\n---\n\n# TFLite, ONNX, CoreML, TensorRT Export\n\n📚 This guide explains how to export a trained YOLOv5 🚀 model from PyTorch to ONNX and TorchScript formats. \nUPDATED 8 December 2022.\n\n## Before You Start\n\nClone repo and install [requirements.txt](https://github.com/ultralytics/yolov5/blob/master/requirements.txt) in a [**Python>=3.7.0**](https://www.python.org/) environment, including [**PyTorch>=1.7**](https://pytorch.org/get-started/locally/). [Models](https://github.com/ultralytics/yolov5/tree/master/models) and [datasets](https://github.com/ultralytics/yolov5/tree/master/data) download automatically from the latest YOLOv5 [release](https://github.com/ultralytics/yolov5/releases).\n\n```bash\ngit clone https://github.com/ultralytics/yolov5 # clone\ncd yolov5\npip install -r requirements.txt # install\n```\n\nFor [TensorRT](https://developer.nvidia.com/tensorrt) export example (requires GPU) see our Colab [notebook](https://colab.research.google.com/github/ultralytics/yolov5/blob/master/tutorial.ipynb#scrollTo=VTRwsvA9u7ln&line=2&uniqifier=1) appendix section. \n\n## Formats\n\nYOLOv5 inference is officially supported in 11 formats:\n\n💡 ProTip: Export to ONNX or OpenVINO for up to 3x CPU speedup. See [CPU Benchmarks](https://github.com/ultralytics/yolov5/pull/6613).\n💡 ProTip: Export to TensorRT for up to 5x GPU speedup. See [GPU Benchmarks](https://github.com/ultralytics/yolov5/pull/6963).\n\n| Format | `export.py --include` | Model |\n|:---------------------------------------------------------------------------|:----------------------|:--------------------------|\n| [PyTorch](https://pytorch.org/) | - | `yolov5s.pt` |\n| [TorchScript](https://pytorch.org/docs/stable/jit.html) | `torchscript` | `yolov5s.torchscript` |\n| [ONNX](https://onnx.ai/) | `onnx` | `yolov5s.onnx` |\n| [OpenVINO](https://docs.openvino.ai/latest/index.html) | `openvino` | `yolov5s_openvino_model/` |\n| [TensorRT](https://developer.nvidia.com/tensorrt) | `engine` | `yolov5s.engine` |\n| [CoreML](https://github.com/apple/coremltools) | `coreml` | `yolov5s.mlmodel` |\n| [TensorFlow SavedModel](https://www.tensorflow.org/guide/saved_model) | `saved_model` | `yolov5s_saved_model/` |\n| [TensorFlow GraphDef](https://www.tensorflow.org/api_docs/python/tf/Graph) | `pb` | `yolov5s.pb` |\n| [TensorFlow Lite](https://www.tensorflow.org/lite) | `tflite` | `yolov5s.tflite` |\n| [TensorFlow Edge TPU](https://coral.ai/docs/edgetpu/models-intro/) | `edgetpu` | `yolov5s_edgetpu.tflite` |\n| [TensorFlow.js](https://www.tensorflow.org/js) | `tfjs` | `yolov5s_web_model/` |\n| [PaddlePaddle](https://github.com/PaddlePaddle) | `paddle` | `yolov5s_paddle_model/` |\n\n## Benchmarks\n\nBenchmarks below run on a Colab Pro with the YOLOv5 tutorial notebook . To reproduce:\n\n```bash\npython benchmarks.py --weights yolov5s.pt --imgsz 640 --device 0\n```\n\n### Colab Pro V100 GPU\n\n```\nbenchmarks: weights=/content/yolov5/yolov5s.pt, imgsz=640, batch_size=1, data=/content/yolov5/data/coco128.yaml, device=0, half=False, test=False\nChecking setup...\nYOLOv5 🚀 v6.1-135-g7926afc torch 1.10.0+cu111 CUDA:0 (Tesla V100-SXM2-16GB, 16160MiB)\nSetup complete ✅ (8 CPUs, 51.0 GB RAM, 46.7/166.8 GB disk)\n\nBenchmarks complete (458.07s)\n Format mAP@0.5:0.95 Inference time (ms)\n0 PyTorch 0.4623 10.19\n1 TorchScript 0.4623 6.85\n2 ONNX 0.4623 14.63\n3 OpenVINO NaN NaN\n4 TensorRT 0.4617 1.89\n5 CoreML NaN NaN\n6 TensorFlow SavedModel 0.4623 21.28\n7 TensorFlow GraphDef 0.4623 21.22\n8 TensorFlow Lite NaN NaN\n9 TensorFlow Edge TPU NaN NaN\n10 TensorFlow.js NaN NaN\n```\n\n### Colab Pro CPU\n\n```\nbenchmarks: weights=/content/yolov5/yolov5s.pt, imgsz=640, batch_size=1, data=/content/yolov5/data/coco128.yaml, device=cpu, half=False, test=False\nChecking setup...\nYOLOv5 🚀 v6.1-135-g7926afc torch 1.10.0+cu111 CPU\nSetup complete ✅ (8 CPUs, 51.0 GB RAM, 41.5/166.8 GB disk)\n\nBenchmarks complete (241.20s)\n Format mAP@0.5:0.95 Inference time (ms)\n0 PyTorch 0.4623 127.61\n1 TorchScript 0.4623 131.23\n2 ONNX 0.4623 69.34\n3 OpenVINO 0.4623 66.52\n4 TensorRT NaN NaN\n5 CoreML NaN NaN\n6 TensorFlow SavedModel 0.4623 123.79\n7 TensorFlow GraphDef 0.4623 121.57\n8 TensorFlow Lite 0.4623 316.61\n9 TensorFlow Edge TPU NaN NaN\n10 TensorFlow.js NaN NaN\n```\n\n## Export a Trained YOLOv5 Model\n\nThis command exports a pretrained YOLOv5s model to TorchScript and ONNX formats. `yolov5s.pt` is the 'small' model, the second-smallest model available. Other options are `yolov5n.pt`, `yolov5m.pt`, `yolov5l.pt` and `yolov5x.pt`, along with their P6 counterparts i.e. `yolov5s6.pt` or you own custom training checkpoint i.e. `runs/exp/weights/best.pt`. For details on all available models please see our README [table](https://github.com/ultralytics/yolov5#pretrained-checkpoints).\n\n```bash\npython export.py --weights yolov5s.pt --include torchscript onnx\n```\n\n💡 ProTip: Add `--half` to export models at FP16 half precision for smaller file sizes\n\nOutput:\n\n```bash\nexport: data=data/coco128.yaml, weights=['yolov5s.pt'], imgsz=[640, 640], batch_size=1, device=cpu, half=False, inplace=False, train=False, keras=False, optimize=False, int8=False, dynamic=False, simplify=False, opset=12, verbose=False, workspace=4, nms=False, agnostic_nms=False, topk_per_class=100, topk_all=100, iou_thres=0.45, conf_thres=0.25, include=['torchscript', 'onnx']\nYOLOv5 🚀 v6.2-104-ge3e5122 Python-3.7.13 torch-1.12.1+cu113 CPU\n\nDownloading https://github.com/ultralytics/yolov5/releases/download/v6.2/yolov5s.pt to yolov5s.pt...\n100% 14.1M/14.1M [00:00<00:00, 274MB/s]\n\nFusing layers... \nYOLOv5s summary: 213 layers, 7225885 parameters, 0 gradients\n\nPyTorch: starting from yolov5s.pt with output shape (1, 25200, 85) (14.1 MB)\n\nTorchScript: starting export with torch 1.12.1+cu113...\nTorchScript: export success ✅ 1.7s, saved as yolov5s.torchscript (28.1 MB)\n\nONNX: starting export with onnx 1.12.0...\nONNX: export success ✅ 2.3s, saved as yolov5s.onnx (28.0 MB)\n\nExport complete (5.5s)\nResults saved to /content/yolov5\nDetect: python detect.py --weights yolov5s.onnx \nValidate: python val.py --weights yolov5s.onnx \nPyTorch Hub: model = torch.hub.load('ultralytics/yolov5', 'custom', 'yolov5s.onnx')\nVisualize: https://netron.app/\n```\n\nThe 3 exported models will be saved alongside the original PyTorch model:\n
\n\n## Environments\n\nYOLOv5 may be run in any of the following up-to-date verified environments (with all dependencies including [CUDA](https://developer.nvidia.com/cuda)/[CUDNN](https://developer.nvidia.com/cudnn), [Python](https://www.python.org/) and [PyTorch](https://pytorch.org/) preinstalled):\n\n- **Notebooks** with free GPU: \n- **Google Cloud** Deep Learning VM. See [GCP Quickstart Guide](https://docs.ultralytics.com/yolov5/environments/google_cloud_quickstart_tutorial/)\n- **Amazon** Deep Learning AMI. See [AWS Quickstart Guide](https://docs.ultralytics.com/yolov5/environments/aws_quickstart_tutorial/)\n- **Docker Image**. See [Docker Quickstart Guide](https://docs.ultralytics.com/yolov5/environments/docker_image_quickstart_tutorial/) \n\n## Status\n\n\n\nIf this badge is green, all [YOLOv5 GitHub Actions](https://github.com/ultralytics/yolov5/actions) Continuous Integration (CI) tests are currently passing. CI tests verify correct operation of YOLOv5 [training](https://github.com/ultralytics/yolov5/blob/master/train.py), [validation](https://github.com/ultralytics/yolov5/blob/master/val.py), [inference](https://github.com/ultralytics/yolov5/blob/master/detect.py), [export](https://github.com/ultralytics/yolov5/blob/master/export.py) and [benchmarks](https://github.com/ultralytics/yolov5/blob/master/benchmarks.py) on macOS, Windows, and Ubuntu every 24 hours and on every commit."
},
{
"path": "docs/yolov5/tutorials/model_export.md",
"content": "---\ncomments: true\ndescription: Export YOLOv5 models to TFLite, ONNX, CoreML, and TensorRT formats. Achieve up to 5x GPU speedup using TensorRT. Benchmarks included.\n---\n\n# TFLite, ONNX, CoreML, TensorRT Export\n\n📚 This guide explains how to export a trained YOLOv5 🚀 model from PyTorch to ONNX and TorchScript formats. \nUPDATED 8 December 2022.\n\n## Before You Start\n\nClone repo and install [requirements.txt](https://github.com/ultralytics/yolov5/blob/master/requirements.txt) in a [**Python>=3.7.0**](https://www.python.org/) environment, including [**PyTorch>=1.7**](https://pytorch.org/get-started/locally/). [Models](https://github.com/ultralytics/yolov5/tree/master/models) and [datasets](https://github.com/ultralytics/yolov5/tree/master/data) download automatically from the latest YOLOv5 [release](https://github.com/ultralytics/yolov5/releases).\n\n```bash\ngit clone https://github.com/ultralytics/yolov5 # clone\ncd yolov5\npip install -r requirements.txt # install\n```\n\nFor [TensorRT](https://developer.nvidia.com/tensorrt) export example (requires GPU) see our Colab [notebook](https://colab.research.google.com/github/ultralytics/yolov5/blob/master/tutorial.ipynb#scrollTo=VTRwsvA9u7ln&line=2&uniqifier=1) appendix section. \n\n## Formats\n\nYOLOv5 inference is officially supported in 11 formats:\n\n💡 ProTip: Export to ONNX or OpenVINO for up to 3x CPU speedup. See [CPU Benchmarks](https://github.com/ultralytics/yolov5/pull/6613).\n💡 ProTip: Export to TensorRT for up to 5x GPU speedup. See [GPU Benchmarks](https://github.com/ultralytics/yolov5/pull/6963).\n\n| Format | `export.py --include` | Model |\n|:---------------------------------------------------------------------------|:----------------------|:--------------------------|\n| [PyTorch](https://pytorch.org/) | - | `yolov5s.pt` |\n| [TorchScript](https://pytorch.org/docs/stable/jit.html) | `torchscript` | `yolov5s.torchscript` |\n| [ONNX](https://onnx.ai/) | `onnx` | `yolov5s.onnx` |\n| [OpenVINO](https://docs.openvino.ai/latest/index.html) | `openvino` | `yolov5s_openvino_model/` |\n| [TensorRT](https://developer.nvidia.com/tensorrt) | `engine` | `yolov5s.engine` |\n| [CoreML](https://github.com/apple/coremltools) | `coreml` | `yolov5s.mlmodel` |\n| [TensorFlow SavedModel](https://www.tensorflow.org/guide/saved_model) | `saved_model` | `yolov5s_saved_model/` |\n| [TensorFlow GraphDef](https://www.tensorflow.org/api_docs/python/tf/Graph) | `pb` | `yolov5s.pb` |\n| [TensorFlow Lite](https://www.tensorflow.org/lite) | `tflite` | `yolov5s.tflite` |\n| [TensorFlow Edge TPU](https://coral.ai/docs/edgetpu/models-intro/) | `edgetpu` | `yolov5s_edgetpu.tflite` |\n| [TensorFlow.js](https://www.tensorflow.org/js) | `tfjs` | `yolov5s_web_model/` |\n| [PaddlePaddle](https://github.com/PaddlePaddle) | `paddle` | `yolov5s_paddle_model/` |\n\n## Benchmarks\n\nBenchmarks below run on a Colab Pro with the YOLOv5 tutorial notebook . To reproduce:\n\n```bash\npython benchmarks.py --weights yolov5s.pt --imgsz 640 --device 0\n```\n\n### Colab Pro V100 GPU\n\n```\nbenchmarks: weights=/content/yolov5/yolov5s.pt, imgsz=640, batch_size=1, data=/content/yolov5/data/coco128.yaml, device=0, half=False, test=False\nChecking setup...\nYOLOv5 🚀 v6.1-135-g7926afc torch 1.10.0+cu111 CUDA:0 (Tesla V100-SXM2-16GB, 16160MiB)\nSetup complete ✅ (8 CPUs, 51.0 GB RAM, 46.7/166.8 GB disk)\n\nBenchmarks complete (458.07s)\n Format mAP@0.5:0.95 Inference time (ms)\n0 PyTorch 0.4623 10.19\n1 TorchScript 0.4623 6.85\n2 ONNX 0.4623 14.63\n3 OpenVINO NaN NaN\n4 TensorRT 0.4617 1.89\n5 CoreML NaN NaN\n6 TensorFlow SavedModel 0.4623 21.28\n7 TensorFlow GraphDef 0.4623 21.22\n8 TensorFlow Lite NaN NaN\n9 TensorFlow Edge TPU NaN NaN\n10 TensorFlow.js NaN NaN\n```\n\n### Colab Pro CPU\n\n```\nbenchmarks: weights=/content/yolov5/yolov5s.pt, imgsz=640, batch_size=1, data=/content/yolov5/data/coco128.yaml, device=cpu, half=False, test=False\nChecking setup...\nYOLOv5 🚀 v6.1-135-g7926afc torch 1.10.0+cu111 CPU\nSetup complete ✅ (8 CPUs, 51.0 GB RAM, 41.5/166.8 GB disk)\n\nBenchmarks complete (241.20s)\n Format mAP@0.5:0.95 Inference time (ms)\n0 PyTorch 0.4623 127.61\n1 TorchScript 0.4623 131.23\n2 ONNX 0.4623 69.34\n3 OpenVINO 0.4623 66.52\n4 TensorRT NaN NaN\n5 CoreML NaN NaN\n6 TensorFlow SavedModel 0.4623 123.79\n7 TensorFlow GraphDef 0.4623 121.57\n8 TensorFlow Lite 0.4623 316.61\n9 TensorFlow Edge TPU NaN NaN\n10 TensorFlow.js NaN NaN\n```\n\n## Export a Trained YOLOv5 Model\n\nThis command exports a pretrained YOLOv5s model to TorchScript and ONNX formats. `yolov5s.pt` is the 'small' model, the second-smallest model available. Other options are `yolov5n.pt`, `yolov5m.pt`, `yolov5l.pt` and `yolov5x.pt`, along with their P6 counterparts i.e. `yolov5s6.pt` or you own custom training checkpoint i.e. `runs/exp/weights/best.pt`. For details on all available models please see our README [table](https://github.com/ultralytics/yolov5#pretrained-checkpoints).\n\n```bash\npython export.py --weights yolov5s.pt --include torchscript onnx\n```\n\n💡 ProTip: Add `--half` to export models at FP16 half precision for smaller file sizes\n\nOutput:\n\n```bash\nexport: data=data/coco128.yaml, weights=['yolov5s.pt'], imgsz=[640, 640], batch_size=1, device=cpu, half=False, inplace=False, train=False, keras=False, optimize=False, int8=False, dynamic=False, simplify=False, opset=12, verbose=False, workspace=4, nms=False, agnostic_nms=False, topk_per_class=100, topk_all=100, iou_thres=0.45, conf_thres=0.25, include=['torchscript', 'onnx']\nYOLOv5 🚀 v6.2-104-ge3e5122 Python-3.7.13 torch-1.12.1+cu113 CPU\n\nDownloading https://github.com/ultralytics/yolov5/releases/download/v6.2/yolov5s.pt to yolov5s.pt...\n100% 14.1M/14.1M [00:00<00:00, 274MB/s]\n\nFusing layers... \nYOLOv5s summary: 213 layers, 7225885 parameters, 0 gradients\n\nPyTorch: starting from yolov5s.pt with output shape (1, 25200, 85) (14.1 MB)\n\nTorchScript: starting export with torch 1.12.1+cu113...\nTorchScript: export success ✅ 1.7s, saved as yolov5s.torchscript (28.1 MB)\n\nONNX: starting export with onnx 1.12.0...\nONNX: export success ✅ 2.3s, saved as yolov5s.onnx (28.0 MB)\n\nExport complete (5.5s)\nResults saved to /content/yolov5\nDetect: python detect.py --weights yolov5s.onnx \nValidate: python val.py --weights yolov5s.onnx \nPyTorch Hub: model = torch.hub.load('ultralytics/yolov5', 'custom', 'yolov5s.onnx')\nVisualize: https://netron.app/\n```\n\nThe 3 exported models will be saved alongside the original PyTorch model:\n
\n\n[Netron Viewer](https://github.com/lutzroeder/netron) is recommended for visualizing exported models:\n
\n\n## Exported Model Usage Examples\n\n`detect.py` runs inference on exported models:\n\n```bash\npython detect.py --weights yolov5s.pt # PyTorch\n yolov5s.torchscript # TorchScript\n yolov5s.onnx # ONNX Runtime or OpenCV DNN with --dnn\n yolov5s_openvino_model # OpenVINO\n yolov5s.engine # TensorRT\n yolov5s.mlmodel # CoreML (macOS only)\n yolov5s_saved_model # TensorFlow SavedModel\n yolov5s.pb # TensorFlow GraphDef\n yolov5s.tflite # TensorFlow Lite\n yolov5s_edgetpu.tflite # TensorFlow Edge TPU\n yolov5s_paddle_model # PaddlePaddle\n```\n\n`val.py` runs validation on exported models:\n\n```bash\npython val.py --weights yolov5s.pt # PyTorch\n yolov5s.torchscript # TorchScript\n yolov5s.onnx # ONNX Runtime or OpenCV DNN with --dnn\n yolov5s_openvino_model # OpenVINO\n yolov5s.engine # TensorRT\n yolov5s.mlmodel # CoreML (macOS Only)\n yolov5s_saved_model # TensorFlow SavedModel\n yolov5s.pb # TensorFlow GraphDef\n yolov5s.tflite # TensorFlow Lite\n yolov5s_edgetpu.tflite # TensorFlow Edge TPU\n yolov5s_paddle_model # PaddlePaddle\n```\n\nUse PyTorch Hub with exported YOLOv5 models:\n\n``` python\nimport torch\n\n# Model\nmodel = torch.hub.load('ultralytics/yolov5', 'custom', 'yolov5s.pt')\n 'yolov5s.torchscript ') # TorchScript\n 'yolov5s.onnx') # ONNX Runtime\n 'yolov5s_openvino_model') # OpenVINO\n 'yolov5s.engine') # TensorRT\n 'yolov5s.mlmodel') # CoreML (macOS Only)\n 'yolov5s_saved_model') # TensorFlow SavedModel\n 'yolov5s.pb') # TensorFlow GraphDef\n 'yolov5s.tflite') # TensorFlow Lite\n 'yolov5s_edgetpu.tflite') # TensorFlow Edge TPU\n 'yolov5s_paddle_model') # PaddlePaddle\n\n# Images\nimg = 'https://ultralytics.com/images/zidane.jpg' # or file, Path, PIL, OpenCV, numpy, list\n\n# Inference\nresults = model(img)\n\n# Results\nresults.print() # or .show(), .save(), .crop(), .pandas(), etc.\n```\n\n## OpenCV DNN inference\n\nOpenCV inference with ONNX models:\n\n```bash\npython export.py --weights yolov5s.pt --include onnx\n\npython detect.py --weights yolov5s.onnx --dnn # detect\npython val.py --weights yolov5s.onnx --dnn # validate\n```\n\n## C++ Inference\n\nYOLOv5 OpenCV DNN C++ inference on exported ONNX model examples:\n\n- [https://github.com/Hexmagic/ONNX-yolov5/blob/master/src/test.cpp](https://github.com/Hexmagic/ONNX-yolov5/blob/master/src/test.cpp)\n- [https://github.com/doleron/yolov5-opencv-cpp-python](https://github.com/doleron/yolov5-opencv-cpp-python)\n\nYOLOv5 OpenVINO C++ inference examples:\n\n- [https://github.com/dacquaviva/yolov5-openvino-cpp-python](https://github.com/dacquaviva/yolov5-openvino-cpp-python)\n- [https://github.com/UNeedCryDear/yolov5-seg-opencv-dnn-cpp](https://github.com/UNeedCryDear/yolov5-seg-opencv-dnn-cpp)\n\n## TensorFlow.js Web Browser Inference\n\n- [https://aukerul-shuvo.github.io/YOLOv5_TensorFlow-JS/](https://aukerul-shuvo.github.io/YOLOv5_TensorFlow-JS/)\n\n## Environments\n\nYOLOv5 may be run in any of the following up-to-date verified environments (with all dependencies including [CUDA](https://developer.nvidia.com/cuda)/[CUDNN](https://developer.nvidia.com/cudnn), [Python](https://www.python.org/) and [PyTorch](https://pytorch.org/) preinstalled):\n\n- **Notebooks** with free GPU: \n- **Google Cloud** Deep Learning VM. See [GCP Quickstart Guide](https://docs.ultralytics.com/yolov5/environments/google_cloud_quickstart_tutorial/)\n- **Amazon** Deep Learning AMI. See [AWS Quickstart Guide](https://docs.ultralytics.com/yolov5/environments/aws_quickstart_tutorial/)\n- **Docker Image**. See [Docker Quickstart Guide](https://docs.ultralytics.com/yolov5/environments/docker_image_quickstart_tutorial/) \n\n## Status\n\n\n\nIf this badge is green, all [YOLOv5 GitHub Actions](https://github.com/ultralytics/yolov5/actions) Continuous Integration (CI) tests are currently passing. CI tests verify correct operation of YOLOv5 [training](https://github.com/ultralytics/yolov5/blob/master/train.py), [validation](https://github.com/ultralytics/yolov5/blob/master/val.py), [inference](https://github.com/ultralytics/yolov5/blob/master/detect.py), [export](https://github.com/ultralytics/yolov5/blob/master/export.py) and [benchmarks](https://github.com/ultralytics/yolov5/blob/master/benchmarks.py) on macOS, Windows, and Ubuntu every 24 hours and on every commit."
},
{
"path": "docs/yolov5/tutorials/model_pruning_and_sparsity.md",
"content": "---\ncomments: true\ndescription: Learn how to apply pruning to your YOLOv5 models. See the before and after performance with an explanation of sparsity and more.\n---\n\n📚 This guide explains how to apply **pruning** to YOLOv5 🚀 models. \nUPDATED 25 September 2022.\n\n## Before You Start\n\nClone repo and install [requirements.txt](https://github.com/ultralytics/yolov5/blob/master/requirements.txt) in a [**Python>=3.7.0**](https://www.python.org/) environment, including [**PyTorch>=1.7**](https://pytorch.org/get-started/locally/). [Models](https://github.com/ultralytics/yolov5/tree/master/models) and [datasets](https://github.com/ultralytics/yolov5/tree/master/data) download automatically from the latest YOLOv5 [release](https://github.com/ultralytics/yolov5/releases).\n\n```bash\ngit clone https://github.com/ultralytics/yolov5 # clone\ncd yolov5\npip install -r requirements.txt # install\n```\n\n## Test Normally\n\nBefore pruning we want to establish a baseline performance to compare to. This command tests YOLOv5x on COCO val2017 at image size 640 pixels. `yolov5x.pt` is the largest and most accurate model available. Other options are `yolov5s.pt`, `yolov5m.pt` and `yolov5l.pt`, or you own checkpoint from training a custom dataset `./weights/best.pt`. For details on all available models please see our README [table](https://github.com/ultralytics/yolov5#pretrained-checkpoints).\n\n```bash\npython val.py --weights yolov5x.pt --data coco.yaml --img 640 --half\n```\n\nOutput:\n\n```shell\nval: data=/content/yolov5/data/coco.yaml, weights=['yolov5x.pt'], batch_size=32, imgsz=640, conf_thres=0.001, iou_thres=0.65, task=val, device=, workers=8, single_cls=False, augment=False, verbose=False, save_txt=False, save_hybrid=False, save_conf=False, save_json=True, project=runs/val, name=exp, exist_ok=False, half=True, dnn=False\nYOLOv5 🚀 v6.0-224-g4c40933 torch 1.10.0+cu111 CUDA:0 (Tesla V100-SXM2-16GB, 16160MiB)\n\nFusing layers... \nModel Summary: 444 layers, 86705005 parameters, 0 gradients\nval: Scanning '/content/datasets/coco/val2017.cache' images and labels... 4952 found, 48 missing, 0 empty, 0 corrupt: 100% 5000/5000 [00:00\n\n30% pruned output:\n\n```bash\nval: data=/content/yolov5/data/coco.yaml, weights=['yolov5x.pt'], batch_size=32, imgsz=640, conf_thres=0.001, iou_thres=0.65, task=val, device=, workers=8, single_cls=False, augment=False, verbose=False, save_txt=False, save_hybrid=False, save_conf=False, save_json=True, project=runs/val, name=exp, exist_ok=False, half=True, dnn=False\nYOLOv5 🚀 v6.0-224-g4c40933 torch 1.10.0+cu111 CUDA:0 (Tesla V100-SXM2-16GB, 16160MiB)\n\nFusing layers... \nModel Summary: 444 layers, 86705005 parameters, 0 gradients\nPruning model... 0.3 global sparsity\nval: Scanning '/content/datasets/coco/val2017.cache' images and labels... 4952 found, 48 missing, 0 empty, 0 corrupt: 100% 5000/5000 [00:00 \n- **Google Cloud** Deep Learning VM. See [GCP Quickstart Guide](https://docs.ultralytics.com/yolov5/environments/google_cloud_quickstart_tutorial/)\n- **Amazon** Deep Learning AMI. See [AWS Quickstart Guide](https://docs.ultralytics.com/yolov5/environments/aws_quickstart_tutorial/)\n- **Docker Image**. See [Docker Quickstart Guide](https://docs.ultralytics.com/yolov5/environments/docker_image_quickstart_tutorial/) \n\n## Status\n\n\n\nIf this badge is green, all [YOLOv5 GitHub Actions](https://github.com/ultralytics/yolov5/actions) Continuous Integration (CI) tests are currently passing. CI tests verify correct operation of YOLOv5 [training](https://github.com/ultralytics/yolov5/blob/master/train.py), [validation](https://github.com/ultralytics/yolov5/blob/master/val.py), [inference](https://github.com/ultralytics/yolov5/blob/master/detect.py), [export](https://github.com/ultralytics/yolov5/blob/master/export.py) and [benchmarks](https://github.com/ultralytics/yolov5/blob/master/benchmarks.py) on macOS, Windows, and Ubuntu every 24 hours and on every commit."
},
{
"path": "docs/yolov5/tutorials/multi_gpu_training.md",
"content": "---\ncomments: true\ndescription: Learn how to train your dataset on single or multiple machines using YOLOv5 on multiple GPUs. Use simple commands with DDP mode for faster performance.\n---\n\n📚 This guide explains how to properly use **multiple** GPUs to train a dataset with YOLOv5 🚀 on single or multiple machine(s). \nUPDATED 25 December 2022.\n\n## Before You Start\n\nClone repo and install [requirements.txt](https://github.com/ultralytics/yolov5/blob/master/requirements.txt) in a [**Python>=3.7.0**](https://www.python.org/) environment, including [**PyTorch>=1.7**](https://pytorch.org/get-started/locally/). [Models](https://github.com/ultralytics/yolov5/tree/master/models) and [datasets](https://github.com/ultralytics/yolov5/tree/master/data) download automatically from the latest YOLOv5 [release](https://github.com/ultralytics/yolov5/releases).\n\n```bash\ngit clone https://github.com/ultralytics/yolov5 # clone\ncd yolov5\npip install -r requirements.txt # install\n```\n\n💡 ProTip! **Docker Image** is recommended for all Multi-GPU trainings. See [Docker Quickstart Guide](https://docs.ultralytics.com/yolov5/environments/docker_image_quickstart_tutorial/) \n\n💡 ProTip! `torch.distributed.run` replaces `torch.distributed.launch` in **PyTorch>=1.9**. See [docs](https://pytorch.org/docs/stable/distributed.html) for details.\n\n## Training\n\nSelect a pretrained model to start training from. Here we select [YOLOv5s](https://github.com/ultralytics/yolov5/blob/master/models/yolov5s.yaml), the smallest and fastest model available. See our README [table](https://github.com/ultralytics/yolov5#pretrained-checkpoints) for a full comparison of all models. We will train this model with Multi-GPU on the [COCO](https://github.com/ultralytics/yolov5/blob/master/data/scripts/get_coco.sh) dataset.\n\n
\n\n### Single GPU\n\n```bash\npython train.py --batch 64 --data coco.yaml --weights yolov5s.pt --device 0\n```\n\n### Multi-GPU [DataParallel](https://pytorch.org/docs/stable/nn.html#torch.nn.DataParallel) Mode (⚠️ not recommended)\n\nYou can increase the `device` to use Multiple GPUs in DataParallel mode.\n\n```bash\npython train.py --batch 64 --data coco.yaml --weights yolov5s.pt --device 0,1\n```\n\nThis method is slow and barely speeds up training compared to using just 1 GPU.\n\n### Multi-GPU [DistributedDataParallel](https://pytorch.org/docs/stable/nn.html#torch.nn.parallel.DistributedDataParallel) Mode (✅ recommended)\n\nYou will have to pass `python -m torch.distributed.run --nproc_per_node`, followed by the usual arguments.\n\n```bash\npython -m torch.distributed.run --nproc_per_node 2 train.py --batch 64 --data coco.yaml --weights yolov5s.pt --device 0,1\n```\n\n`--nproc_per_node` specifies how many GPUs you would like to use. In the example above, it is 2.\n`--batch ` is the total batch-size. It will be divided evenly to each GPU. In the example above, it is 64/2=32 per GPU.\n\nThe code above will use GPUs `0... (N-1)`.\n\n\n Use specific GPUs (click to expand)
\n\nYou can do so by simply passing `--device` followed by your specific GPUs. For example, in the code below, we will use GPUs `2,3`.\n\n```bash\npython -m torch.distributed.run --nproc_per_node 2 train.py --batch 64 --data coco.yaml --cfg yolov5s.yaml --weights '' --device 2,3\n```\n\n \n\n\n Use SyncBatchNorm (click to expand)
\n\n[SyncBatchNorm](https://pytorch.org/docs/master/generated/torch.nn.SyncBatchNorm.html) could increase accuracy for multiple gpu training, however, it will slow down training by a significant factor. It is **only** available for Multiple GPU DistributedDataParallel training.\n\nIt is best used when the batch-size on **each** GPU is small (<= 8).\n\nTo use SyncBatchNorm, simple pass `--sync-bn` to the command like below,\n\n```bash\npython -m torch.distributed.run --nproc_per_node 2 train.py --batch 64 --data coco.yaml --cfg yolov5s.yaml --weights '' --sync-bn\n```\n\n \n\n\n Use Multiple machines (click to expand)
\n\nThis is **only** available for Multiple GPU DistributedDataParallel training.\n\nBefore we continue, make sure the files on all machines are the same, dataset, codebase, etc. Afterwards, make sure the machines can communicate to each other.\n\nYou will have to choose a master machine(the machine that the others will talk to). Note down its address(`master_addr`) and choose a port(`master_port`). I will use `master_addr = 192.168.1.1` and `master_port = 1234` for the example below.\n\nTo use it, you can do as the following,\n\n```bash\n# On master machine 0\npython -m torch.distributed.run --nproc_per_node G --nnodes N --node_rank 0 --master_addr \"192.168.1.1\" --master_port 1234 train.py --batch 64 --data coco.yaml --cfg yolov5s.yaml --weights ''\n```\n\n```bash\n# On machine R\npython -m torch.distributed.run --nproc_per_node G --nnodes N --node_rank R --master_addr \"192.168.1.1\" --master_port 1234 train.py --batch 64 --data coco.yaml --cfg yolov5s.yaml --weights ''\n```\n\nwhere `G` is number of GPU per machine, `N` is the number of machines, and `R` is the machine number from `0...(N-1)`.\nLet's say I have two machines with two GPUs each, it would be `G = 2` , `N = 2`, and `R = 1` for the above.\n\nTraining will not start until all `N` machines are connected. Output will only be shown on master machine!\n\n \n\n### Notes\n\n- Windows support is untested, Linux is recommended.\n- `--batch ` must be a multiple of the number of GPUs.\n- GPU 0 will take slightly more memory than the other GPUs as it maintains EMA and is responsible for checkpointing etc.\n- If you get `RuntimeError: Address already in use`, it could be because you are running multiple trainings at a time. To fix this, simply use a different port number by adding `--master_port` like below,\n\n```bash\npython -m torch.distributed.run --master_port 1234 --nproc_per_node 2 ...\n```\n\n## Results\n\nDDP profiling results on an [AWS EC2 P4d instance](https://docs.ultralytics.com/yolov5/environments/aws_quickstart_tutorial/) with 8x A100 SXM4-40GB for YOLOv5l for 1 COCO epoch.\n\n\n Profiling code
\n\n```bash\n# prepare\nt=ultralytics/yolov5:latest && sudo docker pull $t && sudo docker run -it --ipc=host --gpus all -v \"$(pwd)\"/coco:/usr/src/coco $t\npip3 install torch==1.9.0+cu111 torchvision==0.10.0+cu111 -f https://download.pytorch.org/whl/torch_stable.html\ncd .. && rm -rf app && git clone https://github.com/ultralytics/yolov5 -b master app && cd app\ncp data/coco.yaml data/coco_profile.yaml\n\n# profile\npython train.py --batch-size 16 --data coco_profile.yaml --weights yolov5l.pt --epochs 1 --device 0 \npython -m torch.distributed.run --nproc_per_node 2 train.py --batch-size 32 --data coco_profile.yaml --weights yolov5l.pt --epochs 1 --device 0,1 \npython -m torch.distributed.run --nproc_per_node 4 train.py --batch-size 64 --data coco_profile.yaml --weights yolov5l.pt --epochs 1 --device 0,1,2,3 \npython -m torch.distributed.run --nproc_per_node 8 train.py --batch-size 128 --data coco_profile.yaml --weights yolov5l.pt --epochs 1 --device 0,1,2,3,4,5,6,7\n```\n\n \n\n| GPUs
A100 | batch-size | CUDA_mem
device0 (G) | COCO
train | COCO
val |\n|--------------|------------|------------------------------|--------------------|------------------|\n| 1x | 16 | 26GB | 20:39 | 0:55 |\n| 2x | 32 | 26GB | 11:43 | 0:57 |\n| 4x | 64 | 26GB | 5:57 | 0:55 |\n| 8x | 128 | 26GB | 3:09 | 0:57 |\n\n## FAQ\n\nIf an error occurs, please read the checklist below first! (It could save your time)\n\n\n Checklist (click to expand)
\n\n\n - Have you properly read this post?
\n - Have you tried to reclone the codebase? The code changes daily.
\n - Have you tried to search for your error? Someone may have already encountered it in this repo or in another and have the solution.
\n - Have you installed all the requirements listed on top (including the correct Python and Pytorch versions)?
\n - Have you tried in other environments listed in the \"Environments\" section below?
\n - Have you tried with another dataset like coco128 or coco2017? It will make it easier to find the root cause.
\n
\n\nIf you went through all the above, feel free to raise an Issue by giving as much detail as possible following the template.\n\n \n\n## Environments\n\nYOLOv5 may be run in any of the following up-to-date verified environments (with all dependencies including [CUDA](https://developer.nvidia.com/cuda)/[CUDNN](https://developer.nvidia.com/cudnn), [Python](https://www.python.org/) and [PyTorch](https://pytorch.org/) preinstalled):\n\n- **Notebooks** with free GPU: \n- **Google Cloud** Deep Learning VM. See [GCP Quickstart Guide](https://docs.ultralytics.com/yolov5/environments/google_cloud_quickstart_tutorial/)\n- **Amazon** Deep Learning AMI. See [AWS Quickstart Guide](https://docs.ultralytics.com/yolov5/environments/aws_quickstart_tutorial/)\n- **Docker Image**. See [Docker Quickstart Guide](https://docs.ultralytics.com/yolov5/environments/docker_image_quickstart_tutorial/) \n\n## Status\n\n\n\nIf this badge is green, all [YOLOv5 GitHub Actions](https://github.com/ultralytics/yolov5/actions) Continuous Integration (CI) tests are currently passing. CI tests verify correct operation of YOLOv5 [training](https://github.com/ultralytics/yolov5/blob/master/train.py), [validation](https://github.com/ultralytics/yolov5/blob/master/val.py), [inference](https://github.com/ultralytics/yolov5/blob/master/detect.py), [export](https://github.com/ultralytics/yolov5/blob/master/export.py) and [benchmarks](https://github.com/ultralytics/yolov5/blob/master/benchmarks.py) on macOS, Windows, and Ubuntu every 24 hours and on every commit.\n\n## Credits\n\nI would like to thank @MagicFrogSJTU, who did all the heavy lifting, and @glenn-jocher for guiding us along the way."
},
{
"path": "docs/yolov5/tutorials/neural_magic_pruning_quantization.md",
"content": "---\ncomments: true\ndescription: Learn how to deploy YOLOv5 with DeepSparse to achieve exceptional CPU performance close to GPUs, using pruning, and quantization.
\n---\n\n\n\nWelcome to software-delivered AI.\n\nThis guide explains how to deploy YOLOv5 with Neural Magic's DeepSparse.\n\nDeepSparse is an inference runtime with exceptional performance on CPUs. For instance, compared to the ONNX Runtime baseline, DeepSparse offers a 5.8x speed-up for YOLOv5s, running on the same machine!\n\n\n  \n
\n
\n\nFor the first time, your deep learning workloads can meet the performance demands of production without the complexity and costs of hardware accelerators.\nPut simply, DeepSparse gives you the performance of GPUs and the simplicity of software:\n\n- **Flexible Deployments**: Run consistently across cloud, data center, and edge with any hardware provider from Intel to AMD to ARM\n- **Infinite Scalability**: Scale vertically to 100s of cores, out with standard Kubernetes, or fully-abstracted with Serverless\n- **Easy Integration**: Clean APIs for integrating your model into an application and monitoring it in production\n\n### How Does DeepSparse Achieve GPU-Class Performance?\n\nDeepSparse takes advantage of model sparsity to gain its performance speedup.\n\nSparsification through pruning and quantization is a broadly studied technique, allowing order-of-magnitude reductions in the size and compute needed to\nexecute a network, while maintaining high accuracy. DeepSparse is sparsity-aware, meaning it skips the zeroed out parameters, shrinking amount of compute\nin a forward pass. Since the sparse computation is now memory bound, DeepSparse executes the network depth-wise, breaking the problem into Tensor Columns,\nvertical stripes of computation that fit in cache.\n\n\n  \n
\n
\n\nSparse networks with compressed computation, executed depth-wise in cache, allows DeepSparse to deliver GPU-class performance on CPUs!\n\n### How Do I Create A Sparse Version of YOLOv5 Trained on My Data?\n\nNeural Magic's open-source model repository, SparseZoo, contains pre-sparsified checkpoints of each YOLOv5 model. Using SparseML, which is integrated with Ultralytics, you can fine-tune a sparse checkpoint onto your data with a single CLI command.\n\n[Checkout Neural Magic's YOLOv5 documentation for more details](https://docs.neuralmagic.com/use-cases/object-detection/sparsifying).\n\n## DeepSparse Usage\n\nWe will walk through an example benchmarking and deploying a sparse version of YOLOv5s with DeepSparse.\n\n### Install DeepSparse\n\nRun the following to install DeepSparse. We recommend you use a virtual environment with Python.\n\n```bash\npip install deepsparse[server,yolo,onnxruntime]\n```\n\n### Collect an ONNX File\n\nDeepSparse accepts a model in the ONNX format, passed either as:\n\n- A SparseZoo stub which identifies an ONNX file in the SparseZoo\n- A local path to an ONNX model in a filesystem\n\nThe examples below use the standard dense and pruned-quantized YOLOv5s checkpoints, identified by the following SparseZoo stubs:\n\n```bash\nzoo:cv/detection/yolov5-s/pytorch/ultralytics/coco/base-none\nzoo:cv/detection/yolov5-s/pytorch/ultralytics/coco/pruned65_quant-none\n```\n\n### Deploy a Model\n\nDeepSparse offers convenient APIs for integrating your model into an application.\n\nTo try the deployment examples below, pull down a sample image and save it as `basilica.jpg` with the following:\n\n```bash\nwget -O basilica.jpg https://raw.githubusercontent.com/neuralmagic/deepsparse/main/src/deepsparse/yolo/sample_images/basilica.jpg\n```\n\n#### Python API\n\n`Pipelines` wrap pre-processing and output post-processing around the runtime, providing a clean interface for adding DeepSparse to an application.\nThe DeepSparse-Ultralytics integration includes an out-of-the-box `Pipeline` that accepts raw images and outputs the bounding boxes.\n\nCreate a `Pipeline` and run inference:\n\n```python\nfrom deepsparse import Pipeline\n\n# list of images in local filesystem\nimages = [\"basilica.jpg\"]\n\n# create Pipeline\nmodel_stub = \"zoo:cv/detection/yolov5-s/pytorch/ultralytics/coco/pruned65_quant-none\"\nyolo_pipeline = Pipeline.create(\n task=\"yolo\",\n model_path=model_stub,\n)\n\n# run inference on images, receive bounding boxes + classes\npipeline_outputs = yolo_pipeline(images=images, iou_thres=0.6, conf_thres=0.001)\nprint(pipeline_outputs)\n```\n\nIf you are running in the cloud, you may get an error that open-cv cannot find `libGL.so.1`. Running the following on Ubuntu installs it:\n\n```\napt-get install libgl1-mesa-glx\n```\n\n#### HTTP Server\n\nDeepSparse Server runs on top of the popular FastAPI web framework and Uvicorn web server. With just a single CLI command, you can easily setup a model\nservice endpoint with DeepSparse. The Server supports any Pipeline from DeepSparse, including object detection with YOLOv5, enabling you to send raw\nimages to the endpoint and receive the bounding boxes.\n\nSpin up the Server with the pruned-quantized YOLOv5s:\n\n```bash\ndeepsparse.server \\\n --task yolo \\\n --model_path zoo:cv/detection/yolov5-s/pytorch/ultralytics/coco/pruned65_quant-none\n```\n\nAn example request, using Python's `requests` package:\n\n```python\nimport requests, json\n\n# list of images for inference (local files on client side)\npath = ['basilica.jpg'] \nfiles = [('request', open(img, 'rb')) for img in path]\n\n# send request over HTTP to /predict/from_files endpoint\nurl = 'http://0.0.0.0:5543/predict/from_files'\nresp = requests.post(url=url, files=files)\n\n# response is returned in JSON\nannotations = json.loads(resp.text) # dictionary of annotation results\nbounding_boxes = annotations[\"boxes\"]\nlabels = annotations[\"labels\"]\n```\n\n#### Annotate CLI\n\nYou can also use the annotate command to have the engine save an annotated photo on disk. Try --source 0 to annotate your live webcam feed!\n\n```bash\ndeepsparse.object_detection.annotate --model_filepath zoo:cv/detection/yolov5-s/pytorch/ultralytics/coco/pruned65_quant-none --source basilica.jpg\n```\n\nRunning the above command will create an `annotation-results` folder and save the annotated image inside.\n\n\n \n
\n
\n\n## Benchmarking Performance\n\nWe will compare DeepSparse's throughput to ONNX Runtime's throughput on YOLOv5s, using DeepSparse's benchmarking script.\n\nThe benchmarks were run on an AWS `c6i.8xlarge` instance (16 cores).\n\n### Batch 32 Performance Comparison\n\n#### ONNX Runtime Baseline\n\nAt batch 32, ONNX Runtime achieves 42 images/sec with the standard dense YOLOv5s:\n\n```bash\ndeepsparse.benchmark zoo:cv/detection/yolov5-s/pytorch/ultralytics/coco/base-none -s sync -b 32 -nstreams 1 -e onnxruntime\n\n> Original Model Path: zoo:cv/detection/yolov5-s/pytorch/ultralytics/coco/base-none\n> Batch Size: 32\n> Scenario: sync\n> Throughput (items/sec): 41.9025\n```\n\n#### DeepSparse Dense Performance\n\nWhile DeepSparse offers its best performance with optimized sparse models, it also performs well with the standard dense YOLOv5s.\n\nAt batch 32, DeepSparse achieves 70 images/sec with the standard dense YOLOv5s, a **1.7x performance improvement over ORT**!\n\n```bash\ndeepsparse.benchmark zoo:cv/detection/yolov5-s/pytorch/ultralytics/coco/base-none -s sync -b 32 -nstreams 1\n\n> Original Model Path: zoo:cv/detection/yolov5-s/pytorch/ultralytics/coco/base-none\n> Batch Size: 32\n> Scenario: sync\n> Throughput (items/sec): 69.5546\n```\n\n#### DeepSparse Sparse Performance\n\nWhen sparsity is applied to the model, DeepSparse's performance gains over ONNX Runtime is even stronger.\n\nAt batch 32, DeepSparse achieves 241 images/sec with the pruned-quantized YOLOv5s, a **5.8x performance improvement over ORT**!\n\n```bash\ndeepsparse.benchmark zoo:cv/detection/yolov5-s/pytorch/ultralytics/coco/pruned65_quant-none -s sync -b 32 -nstreams 1\n\n> Original Model Path: zoo:cv/detection/yolov5-s/pytorch/ultralytics/coco/pruned65_quant-none\n> Batch Size: 32\n> Scenario: sync\n> Throughput (items/sec): 241.2452\n```\n\n### Batch 1 Performance Comparison\n\nDeepSparse is also able to gain a speed-up over ONNX Runtime for the latency-sensitive, batch 1 scenario.\n\n#### ONNX Runtime Baseline\n\nAt batch 1, ONNX Runtime achieves 48 images/sec with the standard, dense YOLOv5s.\n\n```bash\ndeepsparse.benchmark zoo:cv/detection/yolov5-s/pytorch/ultralytics/coco/base-none -s sync -b 1 -nstreams 1 -e onnxruntime\n\n> Original Model Path: zoo:cv/detection/yolov5-s/pytorch/ultralytics/coco/base-none\n> Batch Size: 1\n> Scenario: sync\n> Throughput (items/sec): 48.0921\n```\n\n#### DeepSparse Sparse Performance\n\nAt batch 1, DeepSparse achieves 135 items/sec with a pruned-quantized YOLOv5s, **a 2.8x performance gain over ONNX Runtime!**\n\n```bash\ndeepsparse.benchmark zoo:cv/detection/yolov5-s/pytorch/ultralytics/coco/pruned65_quant-none -s sync -b 1 -nstreams 1\n\n> Original Model Path: zoo:cv/detection/yolov5-s/pytorch/ultralytics/coco/pruned65_quant-none\n> Batch Size: 1\n> Scenario: sync\n> Throughput (items/sec): 134.9468\n```\n\nSince `c6i.8xlarge` instances have VNNI instructions, DeepSparse's throughput can be pushed further if weights are pruned in blocks of 4.\n\nAt batch 1, DeepSparse achieves 180 items/sec with a 4-block pruned-quantized YOLOv5s, a **3.7x performance gain over ONNX Runtime!**\n\n```bash\ndeepsparse.benchmark zoo:cv/detection/yolov5-s/pytorch/ultralytics/coco/pruned35_quant-none-vnni -s sync -b 1 -nstreams 1\n\n> Original Model Path: zoo:cv/detection/yolov5-s/pytorch/ultralytics/coco/pruned35_quant-none-vnni\n> Batch Size: 1\n> Scenario: sync\n> Throughput (items/sec): 179.7375\n```\n\n## Get Started With DeepSparse\n\n**Research or Testing?** DeepSparse Community is free for research and testing. Get started with our [Documentation](https://docs.neuralmagic.com/)."
},
{
"path": "docs/yolov5/tutorials/pytorch_hub_model_loading.md",
"content": "---\ncomments: true\ndescription: Learn how to load YOLOv5🚀 from PyTorch Hub at https://pytorch.org/hub/ultralytics_yolov5 and perform image inference. UPDATED 26 March 2023.\n---\n\n📚 This guide explains how to load YOLOv5 🚀 from PyTorch Hub at [https://pytorch.org/hub/ultralytics_yolov5](https://pytorch.org/hub/ultralytics_yolov5). \nUPDATED 26 March 2023.\n\n## Before You Start\n\nInstall [requirements.txt](https://github.com/ultralytics/yolov5/blob/master/requirements.txt) in a [**Python>=3.7.0**](https://www.python.org/) environment, including [**PyTorch>=1.7**](https://pytorch.org/get-started/locally/). [Models](https://github.com/ultralytics/yolov5/tree/master/models) and [datasets](https://github.com/ultralytics/yolov5/tree/master/data) download automatically from the latest YOLOv5 [release](https://github.com/ultralytics/yolov5/releases).\n\n```bash\npip install -r https://raw.githubusercontent.com/ultralytics/yolov5/master/requirements.txt\n```\n\n💡 ProTip: Cloning [https://github.com/ultralytics/yolov5](https://github.com/ultralytics/yolov5) is **not** required 😃\n\n## Load YOLOv5 with PyTorch Hub\n\n### Simple Example\n\nThis example loads a pretrained YOLOv5s model from PyTorch Hub as `model` and passes an image for inference. `'yolov5s'` is the lightest and fastest YOLOv5 model. For details on all available models please see the [README](https://github.com/ultralytics/yolov5#pretrained-checkpoints).\n\n```python\nimport torch\n\n# Model\nmodel = torch.hub.load('ultralytics/yolov5', 'yolov5s')\n\n# Image\nim = 'https://ultralytics.com/images/zidane.jpg'\n\n# Inference\nresults = model(im)\n\nresults.pandas().xyxy[0]\n# xmin ymin xmax ymax confidence class name\n# 0 749.50 43.50 1148.0 704.5 0.874023 0 person\n# 1 433.50 433.50 517.5 714.5 0.687988 27 tie\n# 2 114.75 195.75 1095.0 708.0 0.624512 0 person\n# 3 986.00 304.00 1028.0 420.0 0.286865 27 tie\n```\n\n### Detailed Example\n\nThis example shows **batched inference** with **PIL** and **OpenCV** image sources. `results` can be **printed** to console, **saved** to `runs/hub`, **showed** to screen on supported environments, and returned as **tensors** or **pandas** dataframes.\n\n```python\nimport cv2\nimport torch\nfrom PIL import Image\n\n# Model\nmodel = torch.hub.load('ultralytics/yolov5', 'yolov5s')\n\n# Images\nfor f in 'zidane.jpg', 'bus.jpg':\n torch.hub.download_url_to_file('https://ultralytics.com/images/' + f, f) # download 2 images\nim1 = Image.open('zidane.jpg') # PIL image\nim2 = cv2.imread('bus.jpg')[..., ::-1] # OpenCV image (BGR to RGB)\n\n# Inference\nresults = model([im1, im2], size=640) # batch of images\n\n# Results\nresults.print() \nresults.save() # or .show()\n\nresults.xyxy[0] # im1 predictions (tensor)\nresults.pandas().xyxy[0] # im1 predictions (pandas)\n# xmin ymin xmax ymax confidence class name\n# 0 749.50 43.50 1148.0 704.5 0.874023 0 person\n# 1 433.50 433.50 517.5 714.5 0.687988 27 tie\n# 2 114.75 195.75 1095.0 708.0 0.624512 0 person\n# 3 986.00 304.00 1028.0 420.0 0.286865 27 tie\n```\n\n
 \n\nFor all inference options see YOLOv5 `AutoShape()` forward [method](https://github.com/ultralytics/yolov5/blob/30e4c4f09297b67afedf8b2bcd851833ddc9dead/models/common.py#L243-L252).\n\n### Inference Settings\n\nYOLOv5 models contain various inference attributes such as **confidence threshold**, **IoU threshold**, etc. which can be set by:\n\n```python\nmodel.conf = 0.25 # NMS confidence threshold\n iou = 0.45 # NMS IoU threshold\n agnostic = False # NMS class-agnostic\n multi_label = False # NMS multiple labels per box\n classes = None # (optional list) filter by class, i.e. = [0, 15, 16] for COCO persons, cats and dogs\n max_det = 1000 # maximum number of detections per image\n amp = False # Automatic Mixed Precision (AMP) inference\n\nresults = model(im, size=320) # custom inference size\n```\n\n### Device\n\nModels can be transferred to any device after creation:\n\n```python\nmodel.cpu() # CPU\nmodel.cuda() # GPU\nmodel.to(device) # i.e. device=torch.device(0)\n```\n\nModels can also be created directly on any `device`:\n\n```python\nmodel = torch.hub.load('ultralytics/yolov5', 'yolov5s', device='cpu') # load on CPU\n```\n\n💡 ProTip: Input images are automatically transferred to the correct model device before inference.\n\n### Silence Outputs\n\nModels can be loaded silently with `_verbose=False`:\n\n```python\nmodel = torch.hub.load('ultralytics/yolov5', 'yolov5s', _verbose=False) # load silently\n```\n\n### Input Channels\n\nTo load a pretrained YOLOv5s model with 4 input channels rather than the default 3:\n\n```python\nmodel = torch.hub.load('ultralytics/yolov5', 'yolov5s', channels=4)\n```\n\nIn this case the model will be composed of pretrained weights **except for** the very first input layer, which is no longer the same shape as the pretrained input layer. The input layer will remain initialized by random weights.\n\n### Number of Classes\n\nTo load a pretrained YOLOv5s model with 10 output classes rather than the default 80:\n\n```python\nmodel = torch.hub.load('ultralytics/yolov5', 'yolov5s', classes=10)\n```\n\nIn this case the model will be composed of pretrained weights **except for** the output layers, which are no longer the same shape as the pretrained output layers. The output layers will remain initialized by random weights.\n\n### Force Reload\n\nIf you run into problems with the above steps, setting `force_reload=True` may help by discarding the existing cache and force a fresh download of the latest YOLOv5 version from PyTorch Hub.\n\n```python\nmodel = torch.hub.load('ultralytics/yolov5', 'yolov5s', force_reload=True) # force reload\n```\n\n### Screenshot Inference\n\nTo run inference on your desktop screen:\n\n```python\nimport torch\nfrom PIL import ImageGrab\n\n# Model\nmodel = torch.hub.load('ultralytics/yolov5', 'yolov5s')\n\n# Image\nim = ImageGrab.grab() # take a screenshot\n\n# Inference\nresults = model(im)\n```\n\n### Multi-GPU Inference\n\nYOLOv5 models can be loaded to multiple GPUs in parallel with threaded inference:\n\n```python\nimport torch\nimport threading\n\ndef run(model, im):\n results = model(im)\n results.save()\n\n# Models\nmodel0 = torch.hub.load('ultralytics/yolov5', 'yolov5s', device=0)\nmodel1 = torch.hub.load('ultralytics/yolov5', 'yolov5s', device=1)\n\n# Inference\nthreading.Thread(target=run, args=[model0, 'https://ultralytics.com/images/zidane.jpg'], daemon=True).start()\nthreading.Thread(target=run, args=[model1, 'https://ultralytics.com/images/bus.jpg'], daemon=True).start()\n```\n\n### Training\n\nTo load a YOLOv5 model for training rather than inference, set `autoshape=False`. To load a model with randomly initialized weights (to train from scratch) use `pretrained=False`. You must provide your own training script in this case. Alternatively see our YOLOv5 [Train Custom Data Tutorial](https://docs.ultralytics.com/yolov5/tutorials/train_custom_data) for model training.\n\n```python\nmodel = torch.hub.load('ultralytics/yolov5', 'yolov5s', autoshape=False) # load pretrained\nmodel = torch.hub.load('ultralytics/yolov5', 'yolov5s', autoshape=False, pretrained=False) # load scratch\n```\n\n### Base64 Results\n\nFor use with API services. See https://github.com/ultralytics/yolov5/pull/2291 and [Flask REST API](https://github.com/ultralytics/yolov5/tree/master/utils/flask_rest_api) example for details.\n\n```python\nresults = model(im) # inference\n\nresults.ims # array of original images (as np array) passed to model for inference\nresults.render() # updates results.ims with boxes and labels\nfor im in results.ims:\n buffered = BytesIO()\n im_base64 = Image.fromarray(im)\n im_base64.save(buffered, format=\"JPEG\")\n print(base64.b64encode(buffered.getvalue()).decode('utf-8')) # base64 encoded image with results\n```\n\n### Cropped Results\n\nResults can be returned and saved as detection crops:\n\n```python\nresults = model(im) # inference\ncrops = results.crop(save=True) # cropped detections dictionary\n```\n\n### Pandas Results\n\nResults can be returned as [Pandas DataFrames](https://pandas.pydata.org/):\n\n```python\nresults = model(im) # inference\nresults.pandas().xyxy[0] # Pandas DataFrame\n```\n\n
\n\nFor all inference options see YOLOv5 `AutoShape()` forward [method](https://github.com/ultralytics/yolov5/blob/30e4c4f09297b67afedf8b2bcd851833ddc9dead/models/common.py#L243-L252).\n\n### Inference Settings\n\nYOLOv5 models contain various inference attributes such as **confidence threshold**, **IoU threshold**, etc. which can be set by:\n\n```python\nmodel.conf = 0.25 # NMS confidence threshold\n iou = 0.45 # NMS IoU threshold\n agnostic = False # NMS class-agnostic\n multi_label = False # NMS multiple labels per box\n classes = None # (optional list) filter by class, i.e. = [0, 15, 16] for COCO persons, cats and dogs\n max_det = 1000 # maximum number of detections per image\n amp = False # Automatic Mixed Precision (AMP) inference\n\nresults = model(im, size=320) # custom inference size\n```\n\n### Device\n\nModels can be transferred to any device after creation:\n\n```python\nmodel.cpu() # CPU\nmodel.cuda() # GPU\nmodel.to(device) # i.e. device=torch.device(0)\n```\n\nModels can also be created directly on any `device`:\n\n```python\nmodel = torch.hub.load('ultralytics/yolov5', 'yolov5s', device='cpu') # load on CPU\n```\n\n💡 ProTip: Input images are automatically transferred to the correct model device before inference.\n\n### Silence Outputs\n\nModels can be loaded silently with `_verbose=False`:\n\n```python\nmodel = torch.hub.load('ultralytics/yolov5', 'yolov5s', _verbose=False) # load silently\n```\n\n### Input Channels\n\nTo load a pretrained YOLOv5s model with 4 input channels rather than the default 3:\n\n```python\nmodel = torch.hub.load('ultralytics/yolov5', 'yolov5s', channels=4)\n```\n\nIn this case the model will be composed of pretrained weights **except for** the very first input layer, which is no longer the same shape as the pretrained input layer. The input layer will remain initialized by random weights.\n\n### Number of Classes\n\nTo load a pretrained YOLOv5s model with 10 output classes rather than the default 80:\n\n```python\nmodel = torch.hub.load('ultralytics/yolov5', 'yolov5s', classes=10)\n```\n\nIn this case the model will be composed of pretrained weights **except for** the output layers, which are no longer the same shape as the pretrained output layers. The output layers will remain initialized by random weights.\n\n### Force Reload\n\nIf you run into problems with the above steps, setting `force_reload=True` may help by discarding the existing cache and force a fresh download of the latest YOLOv5 version from PyTorch Hub.\n\n```python\nmodel = torch.hub.load('ultralytics/yolov5', 'yolov5s', force_reload=True) # force reload\n```\n\n### Screenshot Inference\n\nTo run inference on your desktop screen:\n\n```python\nimport torch\nfrom PIL import ImageGrab\n\n# Model\nmodel = torch.hub.load('ultralytics/yolov5', 'yolov5s')\n\n# Image\nim = ImageGrab.grab() # take a screenshot\n\n# Inference\nresults = model(im)\n```\n\n### Multi-GPU Inference\n\nYOLOv5 models can be loaded to multiple GPUs in parallel with threaded inference:\n\n```python\nimport torch\nimport threading\n\ndef run(model, im):\n results = model(im)\n results.save()\n\n# Models\nmodel0 = torch.hub.load('ultralytics/yolov5', 'yolov5s', device=0)\nmodel1 = torch.hub.load('ultralytics/yolov5', 'yolov5s', device=1)\n\n# Inference\nthreading.Thread(target=run, args=[model0, 'https://ultralytics.com/images/zidane.jpg'], daemon=True).start()\nthreading.Thread(target=run, args=[model1, 'https://ultralytics.com/images/bus.jpg'], daemon=True).start()\n```\n\n### Training\n\nTo load a YOLOv5 model for training rather than inference, set `autoshape=False`. To load a model with randomly initialized weights (to train from scratch) use `pretrained=False`. You must provide your own training script in this case. Alternatively see our YOLOv5 [Train Custom Data Tutorial](https://docs.ultralytics.com/yolov5/tutorials/train_custom_data) for model training.\n\n```python\nmodel = torch.hub.load('ultralytics/yolov5', 'yolov5s', autoshape=False) # load pretrained\nmodel = torch.hub.load('ultralytics/yolov5', 'yolov5s', autoshape=False, pretrained=False) # load scratch\n```\n\n### Base64 Results\n\nFor use with API services. See https://github.com/ultralytics/yolov5/pull/2291 and [Flask REST API](https://github.com/ultralytics/yolov5/tree/master/utils/flask_rest_api) example for details.\n\n```python\nresults = model(im) # inference\n\nresults.ims # array of original images (as np array) passed to model for inference\nresults.render() # updates results.ims with boxes and labels\nfor im in results.ims:\n buffered = BytesIO()\n im_base64 = Image.fromarray(im)\n im_base64.save(buffered, format=\"JPEG\")\n print(base64.b64encode(buffered.getvalue()).decode('utf-8')) # base64 encoded image with results\n```\n\n### Cropped Results\n\nResults can be returned and saved as detection crops:\n\n```python\nresults = model(im) # inference\ncrops = results.crop(save=True) # cropped detections dictionary\n```\n\n### Pandas Results\n\nResults can be returned as [Pandas DataFrames](https://pandas.pydata.org/):\n\n```python\nresults = model(im) # inference\nresults.pandas().xyxy[0] # Pandas DataFrame\n```\n\n\n Pandas Output (click to expand)
\n\n```python\nprint(results.pandas().xyxy[0])\n# xmin ymin xmax ymax confidence class name\n# 0 749.50 43.50 1148.0 704.5 0.874023 0 person\n# 1 433.50 433.50 517.5 714.5 0.687988 27 tie\n# 2 114.75 195.75 1095.0 708.0 0.624512 0 person\n# 3 986.00 304.00 1028.0 420.0 0.286865 27 tie\n```\n\n \n\n### Sorted Results\n\nResults can be sorted by column, i.e. to sort license plate digit detection left-to-right (x-axis):\n\n```python\nresults = model(im) # inference\nresults.pandas().xyxy[0].sort_values('xmin') # sorted left-right\n```\n\n### Box-Cropped Results\n\nResults can be returned and saved as detection crops:\n\n```python\nresults = model(im) # inference\ncrops = results.crop(save=True) # cropped detections dictionary\n```\n\n### JSON Results\n\nResults can be returned in JSON format once converted to `.pandas()` dataframes using the `.to_json()` method. The JSON format can be modified using the `orient` argument. See pandas `.to_json()` [documentation](https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.to_json.html) for details.\n\n```python\nresults = model(ims) # inference\nresults.pandas().xyxy[0].to_json(orient=\"records\") # JSON img1 predictions\n```\n\n\n JSON Output (click to expand)
\n\n```json\n[\n{\"xmin\":749.5,\"ymin\":43.5,\"xmax\":1148.0,\"ymax\":704.5,\"confidence\":0.8740234375,\"class\":0,\"name\":\"person\"},\n{\"xmin\":433.5,\"ymin\":433.5,\"xmax\":517.5,\"ymax\":714.5,\"confidence\":0.6879882812,\"class\":27,\"name\":\"tie\"},\n{\"xmin\":115.25,\"ymin\":195.75,\"xmax\":1096.0,\"ymax\":708.0,\"confidence\":0.6254882812,\"class\":0,\"name\":\"person\"},\n{\"xmin\":986.0,\"ymin\":304.0,\"xmax\":1028.0,\"ymax\":420.0,\"confidence\":0.2873535156,\"class\":27,\"name\":\"tie\"}\n]\n```\n\n \n\n## Custom Models\n\nThis example loads a custom 20-class [VOC](https://github.com/ultralytics/yolov5/blob/master/data/VOC.yaml)-trained YOLOv5s model `'best.pt'` with PyTorch Hub.\n\n```python\nmodel = torch.hub.load('ultralytics/yolov5', 'custom', path='path/to/best.pt') # local model\nmodel = torch.hub.load('path/to/yolov5', 'custom', path='path/to/best.pt', source='local') # local repo\n```\n\n## TensorRT, ONNX and OpenVINO Models\n\nPyTorch Hub supports inference on most YOLOv5 export formats, including custom trained models. See [TFLite, ONNX, CoreML, TensorRT Export tutorial](https://docs.ultralytics.com/yolov5/tutorials/model_export) for details on exporting models.\n\n💡 ProTip: **TensorRT** may be up to 2-5X faster than PyTorch on [**GPU benchmarks**](https://github.com/ultralytics/yolov5/pull/6963) \n💡 ProTip: **ONNX** and **OpenVINO** may be up to 2-3X faster than PyTorch on [**CPU benchmarks**](https://github.com/ultralytics/yolov5/pull/6613)\n\n```python\nmodel = torch.hub.load('ultralytics/yolov5', 'custom', path='yolov5s.pt') # PyTorch\n 'yolov5s.torchscript') # TorchScript\n 'yolov5s.onnx') # ONNX\n 'yolov5s_openvino_model/') # OpenVINO\n 'yolov5s.engine') # TensorRT\n 'yolov5s.mlmodel') # CoreML (macOS-only)\n 'yolov5s.tflite') # TFLite\n 'yolov5s_paddle_model/') # PaddlePaddle\n```\n\n## Environments\n\nYOLOv5 may be run in any of the following up-to-date verified environments (with all dependencies including [CUDA](https://developer.nvidia.com/cuda)/[CUDNN](https://developer.nvidia.com/cudnn), [Python](https://www.python.org/) and [PyTorch](https://pytorch.org/) preinstalled):\n\n- **Notebooks** with free GPU: \n- **Google Cloud** Deep Learning VM. See [GCP Quickstart Guide](https://docs.ultralytics.com/yolov5/environments/google_cloud_quickstart_tutorial/)\n- **Amazon** Deep Learning AMI. See [AWS Quickstart Guide](https://docs.ultralytics.com/yolov5/environments/aws_quickstart_tutorial/)\n- **Docker Image**. See [Docker Quickstart Guide](https://docs.ultralytics.com/yolov5/environments/docker_image_quickstart_tutorial/) \n\n## Status\n\n\n\nIf this badge is green, all [YOLOv5 GitHub Actions](https://github.com/ultralytics/yolov5/actions) Continuous Integration (CI) tests are currently passing. CI tests verify correct operation of YOLOv5 [training](https://github.com/ultralytics/yolov5/blob/master/train.py), [validation](https://github.com/ultralytics/yolov5/blob/master/val.py), [inference](https://github.com/ultralytics/yolov5/blob/master/detect.py), [export](https://github.com/ultralytics/yolov5/blob/master/export.py) and [benchmarks](https://github.com/ultralytics/yolov5/blob/master/benchmarks.py) on macOS, Windows, and Ubuntu every 24 hours and on every commit."
},
{
"path": "docs/yolov5/tutorials/roboflow_datasets_integration.md",
"content": "---\ncomments: true\ndescription: Use Roboflow to organize, label, prepare, version & host datasets for training YOLOv5 models. Upload via UI, API, or Python, making versions with custom preprocessing and offline augmentation. Export in YOLOv5 format and access custom training tutorials. Use active learning to improve model deployments.\n---\n\n# Roboflow Datasets\n\nYou can now use Roboflow to organize, label, prepare, version, and host your datasets for training YOLOv5 🚀 models. Roboflow is free to use with YOLOv5 if you make your workspace public. \nUPDATED 30 September 2021.\n\n## Upload\n\nYou can upload your data to Roboflow via [web UI](https://docs.roboflow.com/adding-data), [rest API](https://docs.roboflow.com/adding-data/upload-api), or [python](https://docs.roboflow.com/python).\n\n## Labeling\n\nAfter uploading data to Roboflow, you can label your data and review previous labels.\n\n[](https://roboflow.com/annotate)\n\n## Versioning\n\nYou can make versions of your dataset with different preprocessing and offline augmentation options. YOLOv5 does online augmentations natively, so be intentional when layering Roboflow's offline augs on top.\n\n\n\n## Exporting Data\n\nYou can download your data in YOLOv5 format to quickly begin training.\n\n```\nfrom roboflow import Roboflow\nrf = Roboflow(api_key=\"YOUR API KEY HERE\")\nproject = rf.workspace().project(\"YOUR PROJECT\")\ndataset = project.version(\"YOUR VERSION\").download(\"yolov5\")\n```\n\n## Custom Training\n\nWe have released a custom training tutorial demonstrating all of the above capabilities. You can access the code here:\n\n[](https://colab.research.google.com/github/roboflow-ai/yolov5-custom-training-tutorial/blob/main/yolov5-custom-training.ipynb)\n\n## Active Learning\n\nThe real world is messy and your model will invariably encounter situations your dataset didn't anticipate. Using [active learning](https://blog.roboflow.com/what-is-active-learning/) is an important strategy to iteratively improve your dataset and model. With the Roboflow and YOLOv5 integration, you can quickly make improvements on your model deployments by using a battle tested machine learning pipeline.\n\n
"
},
{
"path": "docs/yolov5/tutorials/running_on_jetson_nano.md",
"content": "---\ncomments: true\ndescription: Deploy YOLOv5 on NVIDIA Jetson using TensorRT and DeepStream SDK for high performance inference. Step-by-step guide with code snippets.\n---\n\n# Deploy on NVIDIA Jetson using TensorRT and DeepStream SDK\n\n📚 This guide explains how to deploy a trained model into NVIDIA Jetson Platform and perform inference using TensorRT and DeepStream SDK. Here we use TensorRT to maximize the inference performance on the Jetson platform. \nUPDATED 18 November 2022.\n\n## Hardware Verification\n\nWe have tested and verified this guide on the following Jetson devices\n\n- [Seeed reComputer J1010 built with Jetson Nano module](https://www.seeedstudio.com/Jetson-10-1-A0-p-5336.html)\n- [Seeed reComputer J2021 built with Jetson Xavier NX module](https://www.seeedstudio.com/reComputer-J2021-p-5438.html)\n\n## Before You Start\n\nMake sure you have properly installed **JetPack SDK** with all the **SDK Components** and **DeepStream SDK** on the Jetson device as this includes CUDA, TensorRT and DeepStream SDK which are needed for this guide.\n\nJetPack SDK provides a full development environment for hardware-accelerated AI-at-the-edge development. All Jetson modules and developer kits are supported by JetPack SDK.\n\nThere are two major installation methods including,\n\n1. SD Card Image Method\n2. NVIDIA SDK Manager Method\n\nYou can find a very detailed installation guide from NVIDIA [official website](https://developer.nvidia.com/jetpack-sdk-461). You can also find guides corresponding to the above-mentioned [reComputer J1010](https://wiki.seeedstudio.com/reComputer_J1010_J101_Flash_Jetpack) and [reComputer J2021](https://wiki.seeedstudio.com/reComputer_J2021_J202_Flash_Jetpack).\n\n## Install Necessary Packages\n\n- **Step 1.** Access the terminal of Jetson device, install pip and upgrade it\n\n```sh\nsudo apt update\nsudo apt install -y python3-pip\npip3 install --upgrade pip\n```\n\n- **Step 2.** Clone the following repo\n\n```sh\ngit clone https://github.com/ultralytics/yolov5\n```\n\n- **Step 3.** Open **requirements.txt**\n\n```sh\ncd yolov5\nvi requirements.txt\n```\n\n- **Step 5.** Edit the following lines. Here you need to press **i** first to enter editing mode. Press **ESC**, then type **:wq** to save and quit\n\n```sh\n# torch>=1.7.0\n# torchvision>=0.8.1\n```\n\n**Note:** torch and torchvision are excluded for now because they will be installed later.\n\n- **Step 6.** install the below dependency\n\n```sh\nsudo apt install -y libfreetype6-dev\n```\n\n- **Step 7.** Install the necessary packages\n\n```sh\npip3 install -r requirements.txt\n```\n\n## Install PyTorch and Torchvision\n\nWe cannot install PyTorch and Torchvision from pip because they are not compatible to run on Jetson platform which is based on **ARM aarch64 architecture**. Therefore, we need to manually install pre-built PyTorch pip wheel and compile/ install Torchvision from source.\n\nVisit [this page](https://forums.developer.nvidia.com/t/pytorch-for-jetson) to access all the PyTorch and Torchvision links.\n\nHere are some of the versions supported by JetPack 4.6 and above.\n\n**PyTorch v1.10.0**\n\nSupported by JetPack 4.4 (L4T R32.4.3) / JetPack 4.4.1 (L4T R32.4.4) / JetPack 4.5 (L4T R32.5.0) / JetPack 4.5.1 (L4T R32.5.1) / JetPack 4.6 (L4T R32.6.1) with Python 3.6\n\n**file_name:** torch-1.10.0-cp36-cp36m-linux_aarch64.whl\n**URL:** [https://nvidia.box.com/shared/static/fjtbno0vpo676a25cgvuqc1wty0fkkg6.whl](https://nvidia.box.com/shared/static/fjtbno0vpo676a25cgvuqc1wty0fkkg6.whl)\n\n**PyTorch v1.12.0**\n\nSupported by JetPack 5.0 (L4T R34.1.0) / JetPack 5.0.1 (L4T R34.1.1) / JetPack 5.0.2 (L4T R35.1.0) with Python 3.8\n\n**file_name:** torch-1.12.0a0+2c916ef.nv22.3-cp38-cp38-linux_aarch64.whl\n**URL:** [https://developer.download.nvidia.com/compute/redist/jp/v50/pytorch/torch-1.12.0a0+2c916ef.nv22.3-cp38-cp38-linux_aarch64.whl](https://developer.download.nvidia.com/compute/redist/jp/v50/pytorch/torch-1.12.0a0+2c916ef.nv22.3-cp38-cp38-linux_aarch64.whl)\n\n- **Step 1.** Install torch according to your JetPack version in the following format\n\n```sh\nwget -O \npip3 install \n```\n\nFor example, here we are running **JP4.6.1**, and therefore we choose **PyTorch v1.10.0**\n\n```sh\ncd ~\nsudo apt-get install -y libopenblas-base libopenmpi-dev\nwget https://nvidia.box.com/shared/static/fjtbno0vpo676a25cgvuqc1wty0fkkg6.whl -O torch-1.10.0-cp36-cp36m-linux_aarch64.whl\npip3 install torch-1.10.0-cp36-cp36m-linux_aarch64.whl\n```\n\n- **Step 2.** Install torchvision depending on the version of PyTorch that you have installed. For example, we chose **PyTorch v1.10.0**, which means, we need to choose **Torchvision v0.11.1**\n\n```sh\nsudo apt install -y libjpeg-dev zlib1g-dev\ngit clone --branch v0.11.1 https://github.com/pytorch/vision torchvision\ncd torchvision\nsudo python3 setup.py install \n```\n\nHere a list of the corresponding torchvision version that you need to install according to the PyTorch version:\n\n- PyTorch v1.10 - torchvision v0.11.1\n- PyTorch v1.12 - torchvision v0.13.0\n\n## DeepStream Configuration for YOLOv5\n\n- **Step 1.** Clone the following repo\n\n```sh\ncd ~\ngit clone https://github.com/marcoslucianops/DeepStream-Yolo\n```\n\n- **Step 2.** Copy **gen_wts_yoloV5.py** from **DeepStream-Yolo/utils** into **yolov5** directory\n\n```sh\ncp DeepStream-Yolo/utils/gen_wts_yoloV5.py yolov5\n```\n\n- **Step 3.** Inside the yolov5 repo, download **pt file** from YOLOv5 releases (example for YOLOv5s 6.1)\n\n```sh\ncd yolov5\nwget https://github.com/ultralytics/yolov5/releases/download/v6.1/yolov5s.pt\n```\n\n- **Step 4.** Generate the **cfg** and **wts** files\n\n```sh\npython3 gen_wts_yoloV5.py -w yolov5s.pt\n```\n\n**Note**: To change the inference size (default: 640)\n\n```sh\n-s SIZE\n--size SIZE\n-s HEIGHT WIDTH\n--size HEIGHT WIDTH\n\nExample for 1280:\n\n-s 1280\nor\n-s 1280 1280\n```\n\n- **Step 5.** Copy the generated **cfg** and **wts** files into the **DeepStream-Yolo** folder\n\n```sh\ncp yolov5s.cfg ~/DeepStream-Yolo\ncp yolov5s.wts ~/DeepStream-Yolo\n```\n\n- **Step 6.** Open the **DeepStream-Yolo** folder and compile the library\n\n```sh\ncd ~/DeepStream-Yolo\nCUDA_VER=11.4 make -C nvdsinfer_custom_impl_Yolo # for DeepStream 6.1\nCUDA_VER=10.2 make -C nvdsinfer_custom_impl_Yolo # for DeepStream 6.0.1 / 6.0\n```\n\n- **Step 7.** Edit the **config_infer_primary_yoloV5.txt** file according to your model\n\n```sh\n[property]\n...\ncustom-network-config=yolov5s.cfg\nmodel-file=yolov5s.wts\n...\n```\n\n- **Step 8.** Edit the **deepstream_app_config** file\n\n```sh\n...\n[primary-gie]\n...\nconfig-file=config_infer_primary_yoloV5.txt\n```\n\n- **Step 9.** Change the video source in **deepstream_app_config** file. Here a default video file is loaded as you can see below\n\n```sh\n...\n[source0]\n...\nuri=file:///opt/nvidia/deepstream/deepstream/samples/streams/sample_1080p_h264.mp4\n```\n\n## Run the Inference\n\n```sh\ndeepstream-app -c deepstream_app_config.txt\n```\n\n\n\nThe above result is running on **Jetson Xavier NX** with **FP32** and **YOLOv5s 640x640**. We can see that the **FPS** is around **30**.\n\n## INT8 Calibration\n\nIf you want to use INT8 precision for inference, you need to follow the steps below\n\n- **Step 1.** Install OpenCV\n\n```sh\nsudo apt-get install libopencv-dev\n```\n\n- **Step 2.** Compile/recompile the **nvdsinfer_custom_impl_Yolo** library with OpenCV support\n\n```sh\ncd ~/DeepStream-Yolo\nCUDA_VER=11.4 OPENCV=1 make -C nvdsinfer_custom_impl_Yolo # for DeepStream 6.1\nCUDA_VER=10.2 OPENCV=1 make -C nvdsinfer_custom_impl_Yolo # for DeepStream 6.0.1 / 6.0\n```\n\n- **Step 3.** For COCO dataset, download the [val2017](https://drive.google.com/file/d/1gbvfn7mcsGDRZ_luJwtITL-ru2kK99aK/view?usp=sharing), extract, and move to **DeepStream-Yolo** folder\n\n- **Step 4.** Make a new directory for calibration images\n\n```sh\nmkdir calibration\n```\n\n- **Step 5.** Run the following to select 1000 random images from COCO dataset to run calibration\n\n```sh\nfor jpg in $(ls -1 val2017/*.jpg | sort -R | head -1000); do \\\n cp ${jpg} calibration/; \\\ndone\n```\n\n**Note:** NVIDIA recommends at least 500 images to get a good accuracy. On this example, 1000 images are chosen to get better accuracy (more images = more accuracy). Higher INT8_CALIB_BATCH_SIZE values will result in more accuracy and faster calibration speed. Set it according to you GPU memory. You can set it from **head -1000**. For example, for 2000 images, **head -2000**. This process can take a long time.\n\n- **Step 6.** Create the **calibration.txt** file with all selected images\n\n```sh\nrealpath calibration/*jpg > calibration.txt\n```\n\n- **Step 7.** Set environment variables\n\n```sh\nexport INT8_CALIB_IMG_PATH=calibration.txt\nexport INT8_CALIB_BATCH_SIZE=1\n```\n\n- **Step 8.** Update the **config_infer_primary_yoloV5.txt** file\n\nFrom\n\n```sh\n...\nmodel-engine-file=model_b1_gpu0_fp32.engine\n#int8-calib-file=calib.table\n...\nnetwork-mode=0\n...\n```\n\nTo\n\n```sh\n...\nmodel-engine-file=model_b1_gpu0_int8.engine\nint8-calib-file=calib.table\n...\nnetwork-mode=1\n...\n```\n\n- **Step 9.** Run the inference\n\n```sh\ndeepstream-app -c deepstream_app_config.txt\n```\n\n\n\nThe above result is running on **Jetson Xavier NX** with **INT8** and **YOLOv5s 640x640**. We can see that the **FPS** is around **60**.\n\n## Benchmark results\n\nThe following table summarizes how different models perform on **Jetson Xavier NX**.\n\n| Model Name | Precision | Inference Size | Inference Time (ms) | FPS |\n|------------|-----------|----------------|---------------------|-----|\n| YOLOv5s | FP32 | 320x320 | 16.66 | 60 | \n| | FP32 | 640x640 | 33.33 | 30 | \n| | INT8 | 640x640 | 16.66 | 60 | \n| YOLOv5n | FP32 | 640x640 | 16.66 | 60 | \n\n### Additional\n\nThis tutorial is written by our friends at seeed @lakshanthad and Elaine"
},
{
"path": "docs/yolov5/tutorials/test_time_augmentation.md",
"content": "---\ncomments: true\ndescription: Learn how to use Test Time Augmentation (TTA) with YOLOv5 to improve mAP and Recall during testing and inference. Code examples included.\n---\n\n# Test-Time Augmentation (TTA)\n\n📚 This guide explains how to use Test Time Augmentation (TTA) during testing and inference for improved mAP and Recall with YOLOv5 🚀. \nUPDATED 25 September 2022.\n\n## Before You Start\n\nClone repo and install [requirements.txt](https://github.com/ultralytics/yolov5/blob/master/requirements.txt) in a [**Python>=3.7.0**](https://www.python.org/) environment, including [**PyTorch>=1.7**](https://pytorch.org/get-started/locally/). [Models](https://github.com/ultralytics/yolov5/tree/master/models) and [datasets](https://github.com/ultralytics/yolov5/tree/master/data) download automatically from the latest YOLOv5 [release](https://github.com/ultralytics/yolov5/releases).\n\n```bash\ngit clone https://github.com/ultralytics/yolov5 # clone\ncd yolov5\npip install -r requirements.txt # install\n```\n\n## Test Normally\n\nBefore trying TTA we want to establish a baseline performance to compare to. This command tests YOLOv5x on COCO val2017 at image size 640 pixels. `yolov5x.pt` is the largest and most accurate model available. Other options are `yolov5s.pt`, `yolov5m.pt` and `yolov5l.pt`, or you own checkpoint from training a custom dataset `./weights/best.pt`. For details on all available models please see our README [table](https://github.com/ultralytics/yolov5#pretrained-checkpoints).\n\n```bash\npython val.py --weights yolov5x.pt --data coco.yaml --img 640 --half\n```\n\nOutput:\n\n```shell\nval: data=./data/coco.yaml, weights=['yolov5x.pt'], batch_size=32, imgsz=640, conf_thres=0.001, iou_thres=0.65, task=val, device=, single_cls=False, augment=False, verbose=False, save_txt=False, save_hybrid=False, save_conf=False, save_json=True, project=runs/val, name=exp, exist_ok=False, half=True\nYOLOv5 🚀 v5.0-267-g6a3ee7c torch 1.9.0+cu102 CUDA:0 (Tesla P100-PCIE-16GB, 16280.875MB)\n\nFusing layers... \nModel Summary: 476 layers, 87730285 parameters, 0 gradients\n\nval: Scanning '../datasets/coco/val2017' images and labels...4952 found, 48 missing, 0 empty, 0 corrupted: 100% 5000/5000 [00:01<00:00, 2846.03it/s]\nval: New cache created: ../datasets/coco/val2017.cache\n Class Images Labels P R mAP@.5 mAP@.5:.95: 100% 157/157 [02:30<00:00, 1.05it/s]\n all 5000 36335 0.746 0.626 0.68 0.49\nSpeed: 0.1ms pre-process, 22.4ms inference, 1.4ms NMS per image at shape (32, 3, 640, 640) # <--- baseline speed\n\nEvaluating pycocotools mAP... saving runs/val/exp/yolov5x_predictions.json...\n...\n Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.504 # <--- baseline mAP\n Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.688\n Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.546\n Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.351\n Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.551\n Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.644\n Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.382\n Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.628\n Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.681 # <--- baseline mAR\n Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.524\n Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.735\n Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.826\n```\n\n## Test with TTA\n\nAppend `--augment` to any existing `val.py` command to enable TTA, and increase the image size by about 30% for improved results. Note that inference with TTA enabled will typically take about 2-3X the time of normal inference as the images are being left-right flipped and processed at 3 different resolutions, with the outputs merged before NMS. Part of the speed decrease is simply due to larger image sizes (832 vs 640), while part is due to the actual TTA operations.\n\n```bash\npython val.py --weights yolov5x.pt --data coco.yaml --img 832 --augment --half\n```\n\nOutput:\n\n```shell\nval: data=./data/coco.yaml, weights=['yolov5x.pt'], batch_size=32, imgsz=832, conf_thres=0.001, iou_thres=0.6, task=val, device=, single_cls=False, augment=True, verbose=False, save_txt=False, save_hybrid=False, save_conf=False, save_json=True, project=runs/val, name=exp, exist_ok=False, half=True\nYOLOv5 🚀 v5.0-267-g6a3ee7c torch 1.9.0+cu102 CUDA:0 (Tesla P100-PCIE-16GB, 16280.875MB)\n\nFusing layers... \n/usr/local/lib/python3.7/dist-packages/torch/nn/functional.py:718: UserWarning: Named tensors and all their associated APIs are an experimental feature and subject to change. Please do not use them for anything important until they are released as stable. (Triggered internally at /pytorch/c10/core/TensorImpl.h:1156.)\n return torch.max_pool2d(input, kernel_size, stride, padding, dilation, ceil_mode)\nModel Summary: 476 layers, 87730285 parameters, 0 gradients\nval: Scanning '../datasets/coco/val2017' images and labels...4952 found, 48 missing, 0 empty, 0 corrupted: 100% 5000/5000 [00:01<00:00, 2885.61it/s]\nval: New cache created: ../datasets/coco/val2017.cache\n Class Images Labels P R mAP@.5 mAP@.5:.95: 100% 157/157 [07:29<00:00, 2.86s/it]\n all 5000 36335 0.718 0.656 0.695 0.503\nSpeed: 0.2ms pre-process, 80.6ms inference, 2.7ms NMS per image at shape (32, 3, 832, 832) # <--- TTA speed\n\nEvaluating pycocotools mAP... saving runs/val/exp2/yolov5x_predictions.json...\n...\n Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.516 # <--- TTA mAP\n Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.701\n Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.562\n Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.361\n Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.564\n Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.656\n Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.388\n Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.640\n Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.696 # <--- TTA mAR\n Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.553\n Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.744\n Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.833\n```\n\n## Inference with TTA\n\n`detect.py` TTA inference operates identically to `val.py` TTA: simply append `--augment` to any existing `detect.py` command:\n\n```bash\npython detect.py --weights yolov5s.pt --img 832 --source data/images --augment\n```\n\nOutput:\n\n```bash\ndetect: weights=['yolov5s.pt'], source=data/images, imgsz=832, conf_thres=0.25, iou_thres=0.45, max_det=1000, device=, view_img=False, save_txt=False, save_conf=False, save_crop=False, nosave=False, classes=None, agnostic_nms=False, augment=True, update=False, project=runs/detect, name=exp, exist_ok=False, line_width=3, hide_labels=False, hide_conf=False, half=False\nYOLOv5 🚀 v5.0-267-g6a3ee7c torch 1.9.0+cu102 CUDA:0 (Tesla P100-PCIE-16GB, 16280.875MB)\n\nDownloading https://github.com/ultralytics/yolov5/releases/download/v5.0/yolov5s.pt to yolov5s.pt...\n100% 14.1M/14.1M [00:00<00:00, 81.9MB/s]\n\nFusing layers... \nModel Summary: 224 layers, 7266973 parameters, 0 gradients\nimage 1/2 /content/yolov5/data/images/bus.jpg: 832x640 4 persons, 1 bus, 1 fire hydrant, Done. (0.029s)\nimage 2/2 /content/yolov5/data/images/zidane.jpg: 480x832 3 persons, 3 ties, Done. (0.024s)\nResults saved to runs/detect/exp\nDone. (0.156s)\n```\n\n \n\n### PyTorch Hub TTA\n\nTTA is automatically integrated into all [YOLOv5 PyTorch Hub](https://pytorch.org/hub/ultralytics_yolov5) models, and can be accessed by passing `augment=True` at inference time.\n\n```python\nimport torch\n\n# Model\nmodel = torch.hub.load('ultralytics/yolov5', 'yolov5s') # or yolov5m, yolov5x, custom\n\n# Images\nimg = 'https://ultralytics.com/images/zidane.jpg' # or file, PIL, OpenCV, numpy, multiple\n\n# Inference\nresults = model(img, augment=True) # <--- TTA inference\n\n# Results\nresults.print() # or .show(), .save(), .crop(), .pandas(), etc.\n```\n\n### Customize\n\nYou can customize the TTA ops applied in the YOLOv5 `forward_augment()` method [here](https://github.com/ultralytics/yolov5/blob/8c6f9e15bfc0000d18b976a95b9d7c17d407ec91/models/yolo.py#L125-L137).\n\n## Environments\n\nYOLOv5 may be run in any of the following up-to-date verified environments (with all dependencies including [CUDA](https://developer.nvidia.com/cuda)/[CUDNN](https://developer.nvidia.com/cudnn), [Python](https://www.python.org/) and [PyTorch](https://pytorch.org/) preinstalled):\n\n- **Notebooks** with free GPU: \n- **Google Cloud** Deep Learning VM. See [GCP Quickstart Guide](https://docs.ultralytics.com/yolov5/environments/google_cloud_quickstart_tutorial/)\n- **Amazon** Deep Learning AMI. See [AWS Quickstart Guide](https://docs.ultralytics.com/yolov5/environments/aws_quickstart_tutorial/)\n- **Docker Image**. See [Docker Quickstart Guide](https://docs.ultralytics.com/yolov5/environments/docker_image_quickstart_tutorial/) \n\n## Status\n\n\n\nIf this badge is green, all [YOLOv5 GitHub Actions](https://github.com/ultralytics/yolov5/actions) Continuous Integration (CI) tests are currently passing. CI tests verify correct operation of YOLOv5 [training](https://github.com/ultralytics/yolov5/blob/master/train.py), [validation](https://github.com/ultralytics/yolov5/blob/master/val.py), [inference](https://github.com/ultralytics/yolov5/blob/master/detect.py), [export](https://github.com/ultralytics/yolov5/blob/master/export.py) and [benchmarks](https://github.com/ultralytics/yolov5/blob/master/benchmarks.py) on macOS, Windows, and Ubuntu every 24 hours and on every commit."
},
{
"path": "docs/yolov5/tutorials/tips_for_best_training_results.md",
"content": "---\ncomments: true\ndescription: Get the most out of YOLOv5 with this guide; producing best results, checking dataset, hypertuning & more. Updated May 2022.\n---\n\n📚 This guide explains how to produce the best mAP and training results with YOLOv5 🚀. \nUPDATED 25 May 2022.\n\nMost of the time good results can be obtained with no changes to the models or training settings, **provided your dataset is sufficiently large and well labelled**. If at first you don't get good results, there are steps you might be able to take to improve, but we always recommend users **first train with all default settings** before considering any changes. This helps establish a performance baseline and spot areas for improvement.\n\nIf you have questions about your training results **we recommend you provide the maximum amount of information possible** if you expect a helpful response, including results plots (train losses, val losses, P, R, mAP), PR curve, confusion matrix, training mosaics, test results and dataset statistics images such as labels.png. All of these are located in your `project/name` directory, typically `yolov5/runs/train/exp`.\n\nWe've put together a full guide for users looking to get the best results on their YOLOv5 trainings below.\n\n## Dataset\n\n- **Images per class.** ≥ 1500 images per class recommended\n- **Instances per class.** ≥ 10000 instances (labeled objects) per class recommended\n- **Image variety.** Must be representative of deployed environment. For real-world use cases we recommend images from different times of day, different seasons, different weather, different lighting, different angles, different sources (scraped online, collected locally, different cameras) etc.\n- **Label consistency.** All instances of all classes in all images must be labelled. Partial labelling will not work.\n- **Label accuracy.** Labels must closely enclose each object. No space should exist between an object and it's bounding box. No objects should be missing a label.\n- **Label verification.** View `train_batch*.jpg` on train start to verify your labels appear correct, i.e. see [example](https://docs.ultralytics.com/yolov5/tutorials/train_custom_data#local-logging) mosaic.\n- **Background images.** Background images are images with no objects that are added to a dataset to reduce False Positives (FP). We recommend about 0-10% background images to help reduce FPs (COCO has 1000 background images for reference, 1% of the total). No labels are required for background images.\n\n
\n\n### PyTorch Hub TTA\n\nTTA is automatically integrated into all [YOLOv5 PyTorch Hub](https://pytorch.org/hub/ultralytics_yolov5) models, and can be accessed by passing `augment=True` at inference time.\n\n```python\nimport torch\n\n# Model\nmodel = torch.hub.load('ultralytics/yolov5', 'yolov5s') # or yolov5m, yolov5x, custom\n\n# Images\nimg = 'https://ultralytics.com/images/zidane.jpg' # or file, PIL, OpenCV, numpy, multiple\n\n# Inference\nresults = model(img, augment=True) # <--- TTA inference\n\n# Results\nresults.print() # or .show(), .save(), .crop(), .pandas(), etc.\n```\n\n### Customize\n\nYou can customize the TTA ops applied in the YOLOv5 `forward_augment()` method [here](https://github.com/ultralytics/yolov5/blob/8c6f9e15bfc0000d18b976a95b9d7c17d407ec91/models/yolo.py#L125-L137).\n\n## Environments\n\nYOLOv5 may be run in any of the following up-to-date verified environments (with all dependencies including [CUDA](https://developer.nvidia.com/cuda)/[CUDNN](https://developer.nvidia.com/cudnn), [Python](https://www.python.org/) and [PyTorch](https://pytorch.org/) preinstalled):\n\n- **Notebooks** with free GPU: \n- **Google Cloud** Deep Learning VM. See [GCP Quickstart Guide](https://docs.ultralytics.com/yolov5/environments/google_cloud_quickstart_tutorial/)\n- **Amazon** Deep Learning AMI. See [AWS Quickstart Guide](https://docs.ultralytics.com/yolov5/environments/aws_quickstart_tutorial/)\n- **Docker Image**. See [Docker Quickstart Guide](https://docs.ultralytics.com/yolov5/environments/docker_image_quickstart_tutorial/) \n\n## Status\n\n\n\nIf this badge is green, all [YOLOv5 GitHub Actions](https://github.com/ultralytics/yolov5/actions) Continuous Integration (CI) tests are currently passing. CI tests verify correct operation of YOLOv5 [training](https://github.com/ultralytics/yolov5/blob/master/train.py), [validation](https://github.com/ultralytics/yolov5/blob/master/val.py), [inference](https://github.com/ultralytics/yolov5/blob/master/detect.py), [export](https://github.com/ultralytics/yolov5/blob/master/export.py) and [benchmarks](https://github.com/ultralytics/yolov5/blob/master/benchmarks.py) on macOS, Windows, and Ubuntu every 24 hours and on every commit."
},
{
"path": "docs/yolov5/tutorials/tips_for_best_training_results.md",
"content": "---\ncomments: true\ndescription: Get the most out of YOLOv5 with this guide; producing best results, checking dataset, hypertuning & more. Updated May 2022.\n---\n\n📚 This guide explains how to produce the best mAP and training results with YOLOv5 🚀. \nUPDATED 25 May 2022.\n\nMost of the time good results can be obtained with no changes to the models or training settings, **provided your dataset is sufficiently large and well labelled**. If at first you don't get good results, there are steps you might be able to take to improve, but we always recommend users **first train with all default settings** before considering any changes. This helps establish a performance baseline and spot areas for improvement.\n\nIf you have questions about your training results **we recommend you provide the maximum amount of information possible** if you expect a helpful response, including results plots (train losses, val losses, P, R, mAP), PR curve, confusion matrix, training mosaics, test results and dataset statistics images such as labels.png. All of these are located in your `project/name` directory, typically `yolov5/runs/train/exp`.\n\nWe've put together a full guide for users looking to get the best results on their YOLOv5 trainings below.\n\n## Dataset\n\n- **Images per class.** ≥ 1500 images per class recommended\n- **Instances per class.** ≥ 10000 instances (labeled objects) per class recommended\n- **Image variety.** Must be representative of deployed environment. For real-world use cases we recommend images from different times of day, different seasons, different weather, different lighting, different angles, different sources (scraped online, collected locally, different cameras) etc.\n- **Label consistency.** All instances of all classes in all images must be labelled. Partial labelling will not work.\n- **Label accuracy.** Labels must closely enclose each object. No space should exist between an object and it's bounding box. No objects should be missing a label.\n- **Label verification.** View `train_batch*.jpg` on train start to verify your labels appear correct, i.e. see [example](https://docs.ultralytics.com/yolov5/tutorials/train_custom_data#local-logging) mosaic.\n- **Background images.** Background images are images with no objects that are added to a dataset to reduce False Positives (FP). We recommend about 0-10% background images to help reduce FPs (COCO has 1000 background images for reference, 1% of the total). No labels are required for background images.\n\n \n\n## Model Selection\n\nLarger models like YOLOv5x and [YOLOv5x6](https://github.com/ultralytics/yolov5/releases/tag/v5.0) will produce better results in nearly all cases, but have more parameters, require more CUDA memory to train, and are slower to run. For **mobile** deployments we recommend YOLOv5s/m, for **cloud** deployments we recommend YOLOv5l/x. See our README [table](https://github.com/ultralytics/yolov5#pretrained-checkpoints) for a full comparison of all models.\n\n
\n\n## Model Selection\n\nLarger models like YOLOv5x and [YOLOv5x6](https://github.com/ultralytics/yolov5/releases/tag/v5.0) will produce better results in nearly all cases, but have more parameters, require more CUDA memory to train, and are slower to run. For **mobile** deployments we recommend YOLOv5s/m, for **cloud** deployments we recommend YOLOv5l/x. See our README [table](https://github.com/ultralytics/yolov5#pretrained-checkpoints) for a full comparison of all models.\n\n
\n\n- **Start from Pretrained weights.** Recommended for small to medium-sized datasets (i.e. [VOC](https://github.com/ultralytics/yolov5/blob/master/data/VOC.yaml), [VisDrone](https://github.com/ultralytics/yolov5/blob/master/data/VisDrone.yaml), [GlobalWheat](https://github.com/ultralytics/yolov5/blob/master/data/GlobalWheat2020.yaml)). Pass the name of the model to the `--weights` argument. Models download automatically from the [latest YOLOv5 release](https://github.com/ultralytics/yolov5/releases).\n\n```shell\npython train.py --data custom.yaml --weights yolov5s.pt\n yolov5m.pt\n yolov5l.pt\n yolov5x.pt\n custom_pretrained.pt\n```\n\n- **Start from Scratch.** Recommended for large datasets (i.e. [COCO](https://github.com/ultralytics/yolov5/blob/master/data/coco.yaml), [Objects365](https://github.com/ultralytics/yolov5/blob/master/data/Objects365.yaml), [OIv6](https://storage.googleapis.com/openimages/web/index.html)). Pass the model architecture yaml you are interested in, along with an empty `--weights ''` argument:\n\n```bash\npython train.py --data custom.yaml --weights '' --cfg yolov5s.yaml\n yolov5m.yaml\n yolov5l.yaml\n yolov5x.yaml\n```\n\n## Training Settings\n\nBefore modifying anything, **first train with default settings to establish a performance baseline**. A full list of train.py settings can be found in the [train.py](https://github.com/ultralytics/yolov5/blob/master/train.py) argparser.\n\n- **Epochs.** Start with 300 epochs. If this overfits early then you can reduce epochs. If overfitting does not occur after 300 epochs, train longer, i.e. 600, 1200 etc epochs.\n- **Image size.** COCO trains at native resolution of `--img 640`, though due to the high amount of small objects in the dataset it can benefit from training at higher resolutions such as `--img 1280`. If there are many small objects then custom datasets will benefit from training at native or higher resolution. Best inference results are obtained at the same `--img` as the training was run at, i.e. if you train at `--img 1280` you should also test and detect at `--img 1280`.\n- **Batch size.** Use the largest `--batch-size` that your hardware allows for. Small batch sizes produce poor batchnorm statistics and should be avoided.\n- **Hyperparameters.** Default hyperparameters are in [hyp.scratch-low.yaml](https://github.com/ultralytics/yolov5/blob/master/data/hyps/hyp.scratch-low.yaml). We recommend you train with default hyperparameters first before thinking of modifying any. In general, increasing augmentation hyperparameters will reduce and delay overfitting, allowing for longer trainings and higher final mAP. Reduction in loss component gain hyperparameters like `hyp['obj']` will help reduce overfitting in those specific loss components. For an automated method of optimizing these hyperparameters, see our [Hyperparameter Evolution Tutorial](https://docs.ultralytics.com/yolov5/tutorials/hyperparameter_evolution).\n\n## Further Reading\n\nIf you'd like to know more, a good place to start is Karpathy's 'Recipe for Training Neural Networks', which has great ideas for training that apply broadly across all ML domains: [http://karpathy.github.io/2019/04/25/recipe/](http://karpathy.github.io/2019/04/25/recipe/)\n\nGood luck 🍀 and let us know if you have any other questions!"
},
{
"path": "docs/yolov5/tutorials/train_custom_data.md",
"content": "---\ncomments: true\ndescription: Train your custom dataset with YOLOv5. Learn to collect, label and annotate images, and train and deploy models. Get started now.\n---\n\n📚 This guide explains how to train your own **custom dataset** with [YOLOv5](https://github.com/ultralytics/yolov5) 🚀. \nUPDATED 26 March 2023.\n\n## Before You Start\n\nClone repo and install [requirements.txt](https://github.com/ultralytics/yolov5/blob/master/requirements.txt) in a [**Python>=3.7.0**](https://www.python.org/) environment, including [**PyTorch>=1.7**](https://pytorch.org/get-started/locally/). [Models](https://github.com/ultralytics/yolov5/tree/master/models) and [datasets](https://github.com/ultralytics/yolov5/tree/master/data) download automatically from the latest YOLOv5 [release](https://github.com/ultralytics/yolov5/releases).\n\n```bash\ngit clone https://github.com/ultralytics/yolov5 # clone\ncd yolov5\npip install -r requirements.txt # install\n```\n\n## Train On Custom Data\n\n\n \n
\n
\n
\n\nCreating a custom model to detect your objects is an iterative process of collecting and organizing images, labeling your objects of interest, training a model, deploying it into the wild to make predictions, and then using that deployed model to collect examples of edge cases to repeat and improve.\n\n### 1. Create Dataset\n\nYOLOv5 models must be trained on labelled data in order to learn classes of objects in that data. There are two options for creating your dataset before you start training:\n\n\nUse Roboflow to create your dataset in YOLO format
\n\n### 1.1 Collect Images\n\nYour model will learn by example. Training on images similar to the ones it will see in the wild is of the utmost importance. Ideally, you will collect a wide variety of images from the same configuration (camera, angle, lighting, etc.) as you will ultimately deploy your project.\n\nIf this is not possible, you can start from [a public dataset](https://universe.roboflow.com/?ref=ultralytics) to train your initial model and then [sample images from the wild during inference](https://blog.roboflow.com/computer-vision-active-learning-tips/?ref=ultralytics) to improve your dataset and model iteratively.\n\n### 1.2 Create Labels\n\nOnce you have collected images, you will need to annotate the objects of interest to create a ground truth for your model to learn from.\n\n
\n\n[Roboflow Annotate](https://roboflow.com/annotate?ref=ultralytics) is a simple\nweb-based tool for managing and labeling your images with your team and exporting\nthem in [YOLOv5's annotation format](https://roboflow.com/formats/yolov5-pytorch-txt?ref=ultralytics).\n\n### 1.3 Prepare Dataset for YOLOv5\n\nWhether you [label your images with Roboflow](https://roboflow.com/annotate?ref=ultralytics) or not, you can use it to convert your dataset into YOLO format, create a YOLOv5 YAML configuration file, and host it for importing into your training script.\n\n[Create a free Roboflow account](https://app.roboflow.com/?model=yolov5&ref=ultralytics)\nand upload your dataset to a `Public` workspace, label any unannotated images,\nthen generate and export a version of your dataset in `YOLOv5 Pytorch` format.\n\nNote: YOLOv5 does online augmentation during training, so we do not recommend\napplying any augmentation steps in Roboflow for training with YOLOv5. But we\nrecommend applying the following preprocessing steps:\n\n
\n\n* **Auto-Orient** - to strip EXIF orientation from your images.\n* **Resize (Stretch)** - to the square input size of your model (640x640 is the YOLOv5 default).\n\nGenerating a version will give you a point in time snapshot of your dataset so\nyou can always go back and compare your future model training runs against it,\neven if you add more images or change its configuration later.\n\n
\n\nExport in `YOLOv5 Pytorch` format, then copy the snippet into your training\nscript or notebook to download your dataset.\n\n
\n\nNow continue with `2. Select a Model`.\n \n\n\nOr manually prepare your dataset
\n\n### 1.1 Create dataset.yaml\n\n[COCO128](https://www.kaggle.com/ultralytics/coco128) is an example small tutorial dataset composed of the first 128 images in [COCO](http://cocodataset.org/#home) train2017. These same 128 images are used for both training and validation to verify our training pipeline is capable of overfitting. [data/coco128.yaml](https://github.com/ultralytics/yolov5/blob/master/data/coco128.yaml), shown below, is the dataset config file that defines 1) the dataset root directory `path` and relative paths to `train` / `val` / `test` image directories (or *.txt files with image paths) and 2) a class `names` dictionary:\n\n```yaml\n# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]\npath: ../datasets/coco128 # dataset root dir\ntrain: images/train2017 # train images (relative to 'path') 128 images\nval: images/train2017 # val images (relative to 'path') 128 images\ntest: # test images (optional)\n\n# Classes (80 COCO classes)\nnames:\n 0: person\n 1: bicycle\n 2: car\n ...\n 77: teddy bear\n 78: hair drier\n 79: toothbrush\n```\n\n### 1.2 Create Labels\n\nAfter using an annotation tool to label your images, export your labels to **YOLO format**, with one `*.txt` file per image (if no objects in image, no `*.txt` file is required). The `*.txt` file specifications are:\n\n- One row per object\n- Each row is `class x_center y_center width height` format.\n- Box coordinates must be in **normalized xywh** format (from 0 - 1). If your boxes are in pixels, divide `x_center` and `width` by image width, and `y_center` and `height` by image height.\n- Class numbers are zero-indexed (start from 0).\n\n
\n\nThe label file corresponding to the above image contains 2 persons (class `0`) and a tie (class `27`):\n\n
\n\n### 1.3 Organize Directories\n\nOrganize your train and val images and labels according to the example below. YOLOv5 assumes `/coco128` is inside a `/datasets` directory **next to** the `/yolov5` directory. **YOLOv5 locates labels automatically for each image** by replacing the last instance of `/images/` in each image path with `/labels/`. For example:\n\n```bash\n../datasets/coco128/images/im0.jpg # image\n../datasets/coco128/labels/im0.txt # label\n```\n\n
\n \n\n### 2. Select a Model\n\nSelect a pretrained model to start training from. Here we select [YOLOv5s](https://github.com/ultralytics/yolov5/blob/master/models/yolov5s.yaml), the second-smallest and fastest model available. See our README [table](https://github.com/ultralytics/yolov5#pretrained-checkpoints) for a full comparison of all models.\n\n
\n\n### 3. Train\n\nTrain a YOLOv5s model on COCO128 by specifying dataset, batch-size, image size and either pretrained `--weights yolov5s.pt` (recommended), or randomly initialized `--weights '' --cfg yolov5s.yaml` (not recommended). Pretrained weights are auto-downloaded from the [latest YOLOv5 release](https://github.com/ultralytics/yolov5/releases).\n\n```bash\npython train.py --img 640 --epochs 3 --data coco128.yaml --weights yolov5s.pt\n```\n\n!!! tip \"Tip\"\n\n 💡 Add `--cache ram` or `--cache disk` to speed up training (requires significant RAM/disk resources). \n\n!!! tip \"Tip\"\n\n 💡 Always train from a local dataset. Mounted or network drives like Google Drive will be very slow. \n\nAll training results are saved to `runs/train/` with incrementing run directories, i.e. `runs/train/exp2`, `runs/train/exp3` etc. For more details see the Training section of our tutorial notebook. \n\n### 4. Visualize\n\n#### Comet Logging and Visualization 🌟 NEW\n\n[Comet](https://bit.ly/yolov5-readme-comet) is now fully integrated with YOLOv5. Track and visualize model metrics in real time, save your hyperparameters, datasets, and model checkpoints, and visualize your model predictions with [Comet Custom Panels](https://bit.ly/yolov5-colab-comet-panels)! Comet makes sure you never lose track of your work and makes it easy to share results and collaborate across teams of all sizes!\n\nGetting started is easy:\n\n```shell\npip install comet_ml # 1. install\nexport COMET_API_KEY= # 2. paste API key\npython train.py --img 640 --epochs 3 --data coco128.yaml --weights yolov5s.pt # 3. train\n```\n\nTo learn more about all the supported Comet features for this integration, check out the [Comet Tutorial](https://docs.ultralytics.com/yolov5/tutorials/comet_logging_integration). If you'd like to learn more about Comet, head over to our [documentation](https://bit.ly/yolov5-colab-comet-docs). Get started by trying out the Comet Colab Notebook:\n[](https://colab.research.google.com/drive/1RG0WOQyxlDlo5Km8GogJpIEJlg_5lyYO?usp=sharing)\n\n\n\n#### ClearML Logging and Automation 🌟 NEW\n\n[ClearML](https://cutt.ly/yolov5-notebook-clearml) is completely integrated into YOLOv5 to track your experimentation, manage dataset versions and even remotely execute training runs. To enable ClearML:\n\n- `pip install clearml`\n- run `clearml-init` to connect to a ClearML server (**deploy your own open-source server [here](https://github.com/allegroai/clearml-server)**, or use our free hosted server [here](https://cutt.ly/yolov5-notebook-clearml))\n\nYou'll get all the great expected features from an experiment manager: live updates, model upload, experiment comparison etc. but ClearML also tracks uncommitted changes and installed packages for example. Thanks to that ClearML Tasks (which is what we call experiments) are also reproducible on different machines! With only 1 extra line, we can schedule a YOLOv5 training task on a queue to be executed by any number of ClearML Agents (workers).\n\nYou can use ClearML Data to version your dataset and then pass it to YOLOv5 simply using its unique ID. This will help you keep track of your data without adding extra hassle. Explore the [ClearML Tutorial](https://docs.ultralytics.com/yolov5/tutorials/clearml_logging_integration) for details!\n\n\n \n\n#### Local Logging\n\nTraining results are automatically logged with [Tensorboard](https://www.tensorflow.org/tensorboard) and [CSV](https://github.com/ultralytics/yolov5/pull/4148) loggers to `runs/train`, with a new experiment directory created for each new training as `runs/train/exp2`, `runs/train/exp3`, etc.\n\nThis directory contains train and val statistics, mosaics, labels, predictions and augmented mosaics, as well as metrics and charts including precision-recall (PR) curves and confusion matrices.\n\n
\n\n#### Local Logging\n\nTraining results are automatically logged with [Tensorboard](https://www.tensorflow.org/tensorboard) and [CSV](https://github.com/ultralytics/yolov5/pull/4148) loggers to `runs/train`, with a new experiment directory created for each new training as `runs/train/exp2`, `runs/train/exp3`, etc.\n\nThis directory contains train and val statistics, mosaics, labels, predictions and augmented mosaics, as well as metrics and charts including precision-recall (PR) curves and confusion matrices.\n\n \n\nResults file `results.csv` is updated after each epoch, and then plotted as `results.png` (below) after training completes. You can also plot any `results.csv` file manually:\n\n```python\nfrom utils.plots import plot_results\nplot_results('path/to/results.csv') # plot 'results.csv' as 'results.png'\n```\n\n
\n\nResults file `results.csv` is updated after each epoch, and then plotted as `results.png` (below) after training completes. You can also plot any `results.csv` file manually:\n\n```python\nfrom utils.plots import plot_results\nplot_results('path/to/results.csv') # plot 'results.csv' as 'results.png'\n```\n\n
\n\n## Next Steps\n\nOnce your model is trained you can use your best checkpoint `best.pt` to:\n\n* Run [CLI](https://github.com/ultralytics/yolov5#quick-start-examples) or [Python](https://docs.ultralytics.com/yolov5/tutorials/pytorch_hub_model_loading) inference on new images and videos\n* [Validate](https://github.com/ultralytics/yolov5/blob/master/val.py) accuracy on train, val and test splits\n* [Export](https://docs.ultralytics.com/yolov5/tutorials/model_export) to TensorFlow, Keras, ONNX, TFlite, TF.js, CoreML and TensorRT formats\n* [Evolve](https://docs.ultralytics.com/yolov5/tutorials/hyperparameter_evolution) hyperparameters to improve performance\n* [Improve](https://docs.roboflow.com/adding-data/upload-api?ref=ultralytics) your model by sampling real-world images and adding them to your dataset\n\n## Environments\n\nYOLOv5 may be run in any of the following up-to-date verified environments (with all dependencies including [CUDA](https://developer.nvidia.com/cuda)/[CUDNN](https://developer.nvidia.com/cudnn), [Python](https://www.python.org/) and [PyTorch](https://pytorch.org/) preinstalled):\n\n- **Notebooks** with free GPU: \n- **Google Cloud** Deep Learning VM. See [GCP Quickstart Guide](https://docs.ultralytics.com/yolov5/environments/google_cloud_quickstart_tutorial/)\n- **Amazon** Deep Learning AMI. See [AWS Quickstart Guide](https://docs.ultralytics.com/yolov5/environments/aws_quickstart_tutorial/)\n- **Docker Image**. See [Docker Quickstart Guide](https://docs.ultralytics.com/yolov5/environments/docker_image_quickstart_tutorial/) \n\n## Status\n\n\n\nIf this badge is green, all [YOLOv5 GitHub Actions](https://github.com/ultralytics/yolov5/actions) Continuous Integration (CI) tests are currently passing. CI tests verify correct operation of YOLOv5 [training](https://github.com/ultralytics/yolov5/blob/master/train.py), [validation](https://github.com/ultralytics/yolov5/blob/master/val.py), [inference](https://github.com/ultralytics/yolov5/blob/master/detect.py), [export](https://github.com/ultralytics/yolov5/blob/master/export.py) and [benchmarks](https://github.com/ultralytics/yolov5/blob/master/benchmarks.py) on macOS, Windows, and Ubuntu every 24 hours and on every commit."
},
{
"path": "docs/yolov5/tutorials/transfer_learning_with_frozen_layers.md",
"content": "---\ncomments: true\ndescription: Learn how to freeze YOLOv5 when transfer learning. Retrain a pre-trained model on new data faster and with fewer resources.\n---\n\n📚 This guide explains how to **freeze** YOLOv5 🚀 layers when **transfer learning**. Transfer learning is a useful way to quickly retrain a model on new data without having to retrain the entire network. Instead, part of the initial weights are frozen in place, and the rest of the weights are used to compute loss and are updated by the optimizer. This requires less resources than normal training and allows for faster training times, though it may also result in reductions to final trained accuracy. \nUPDATED 25 September 2022.\n\n## Before You Start\n\nClone repo and install [requirements.txt](https://github.com/ultralytics/yolov5/blob/master/requirements.txt) in a [**Python>=3.7.0**](https://www.python.org/) environment, including [**PyTorch>=1.7**](https://pytorch.org/get-started/locally/). [Models](https://github.com/ultralytics/yolov5/tree/master/models) and [datasets](https://github.com/ultralytics/yolov5/tree/master/data) download automatically from the latest YOLOv5 [release](https://github.com/ultralytics/yolov5/releases).\n\n```bash\ngit clone https://github.com/ultralytics/yolov5 # clone\ncd yolov5\npip install -r requirements.txt # install\n```\n\n## Freeze Backbone\n\nAll layers that match the train.py `freeze` list in train.py will be frozen by setting their gradients to zero before training starts.\n\n```python\n # Freeze \n freeze = [f'model.{x}.' for x in range(freeze)] # layers to freeze \n for k, v in model.named_parameters(): \n v.requires_grad = True # train all layers \n if any(x in k for x in freeze): \n print(f'freezing {k}') \n v.requires_grad = False \n```\n\nTo see a list of module names:\n\n```python\nfor k, v in model.named_parameters():\n print(k)\n\n# Output\nmodel.0.conv.conv.weight\nmodel.0.conv.bn.weight\nmodel.0.conv.bn.bias\nmodel.1.conv.weight\nmodel.1.bn.weight\nmodel.1.bn.bias\nmodel.2.cv1.conv.weight\nmodel.2.cv1.bn.weight\n...\nmodel.23.m.0.cv2.bn.weight\nmodel.23.m.0.cv2.bn.bias\nmodel.24.m.0.weight\nmodel.24.m.0.bias\nmodel.24.m.1.weight\nmodel.24.m.1.bias\nmodel.24.m.2.weight\nmodel.24.m.2.bias\n```\n\nLooking at the model architecture we can see that the model backbone is layers 0-9:\n\n```yaml\n# YOLOv5 backbone \n backbone: \n # [from, number, module, args] \n [[-1, 1, Focus, [64, 3]], # 0-P1/2 \n [-1, 1, Conv, [128, 3, 2]], # 1-P2/4 \n [-1, 3, BottleneckCSP, [128]], \n [-1, 1, Conv, [256, 3, 2]], # 3-P3/8 \n [-1, 9, BottleneckCSP, [256]], \n [-1, 1, Conv, [512, 3, 2]], # 5-P4/16 \n [-1, 9, BottleneckCSP, [512]], \n [-1, 1, Conv, [1024, 3, 2]], # 7-P5/32 \n [-1, 1, SPP, [1024, [5, 9, 13]]], \n [-1, 3, BottleneckCSP, [1024, False]], # 9 \n ] \n \n # YOLOv5 head \n head: \n [[-1, 1, Conv, [512, 1, 1]], \n [-1, 1, nn.Upsample, [None, 2, 'nearest']], \n [[-1, 6], 1, Concat, [1]], # cat backbone P4 \n [-1, 3, BottleneckCSP, [512, False]], # 13 \n \n [-1, 1, Conv, [256, 1, 1]], \n [-1, 1, nn.Upsample, [None, 2, 'nearest']], \n [[-1, 4], 1, Concat, [1]], # cat backbone P3 \n [-1, 3, BottleneckCSP, [256, False]], # 17 (P3/8-small) \n \n [-1, 1, Conv, [256, 3, 2]], \n [[-1, 14], 1, Concat, [1]], # cat head P4 \n [-1, 3, BottleneckCSP, [512, False]], # 20 (P4/16-medium) \n \n [-1, 1, Conv, [512, 3, 2]], \n [[-1, 10], 1, Concat, [1]], # cat head P5 \n [-1, 3, BottleneckCSP, [1024, False]], # 23 (P5/32-large) \n \n [[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5) \n ] \n```\n\nso we can define the freeze list to contain all modules with 'model.0.' - 'model.9.' in their names:\n\n```bash\npython train.py --freeze 10\n```\n\n## Freeze All Layers\n\nTo freeze the full model except for the final output convolution layers in Detect(), we set freeze list to contain all modules with 'model.0.' - 'model.23.' in their names:\n\n```bash\npython train.py --freeze 24\n```\n\n## Results\n\nWe train YOLOv5m on VOC on both of the above scenarios, along with a default model (no freezing), starting from the official COCO pretrained `--weights yolov5m.pt`:\n\n```python\ntrain.py --batch 48 --weights yolov5m.pt --data voc.yaml --epochs 50 --cache --img 512 --hyp hyp.finetune.yaml\n```\n\n### Accuracy Comparison\n\nThe results show that freezing speeds up training, but reduces final accuracy slightly.\n\n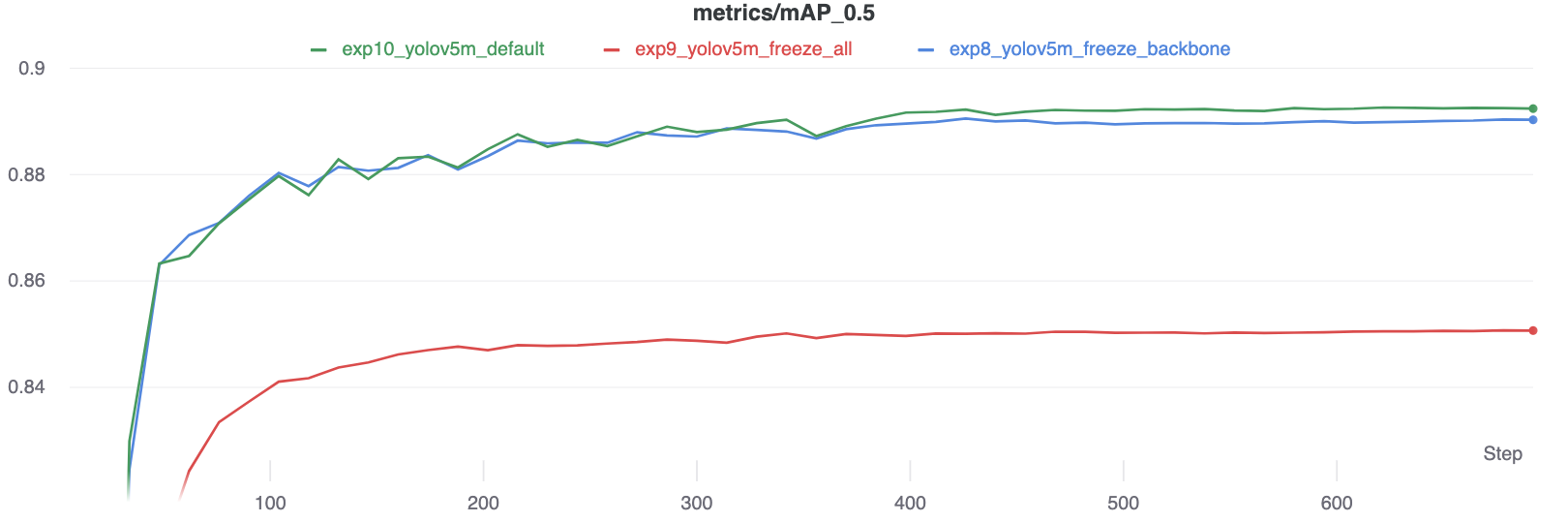\n\n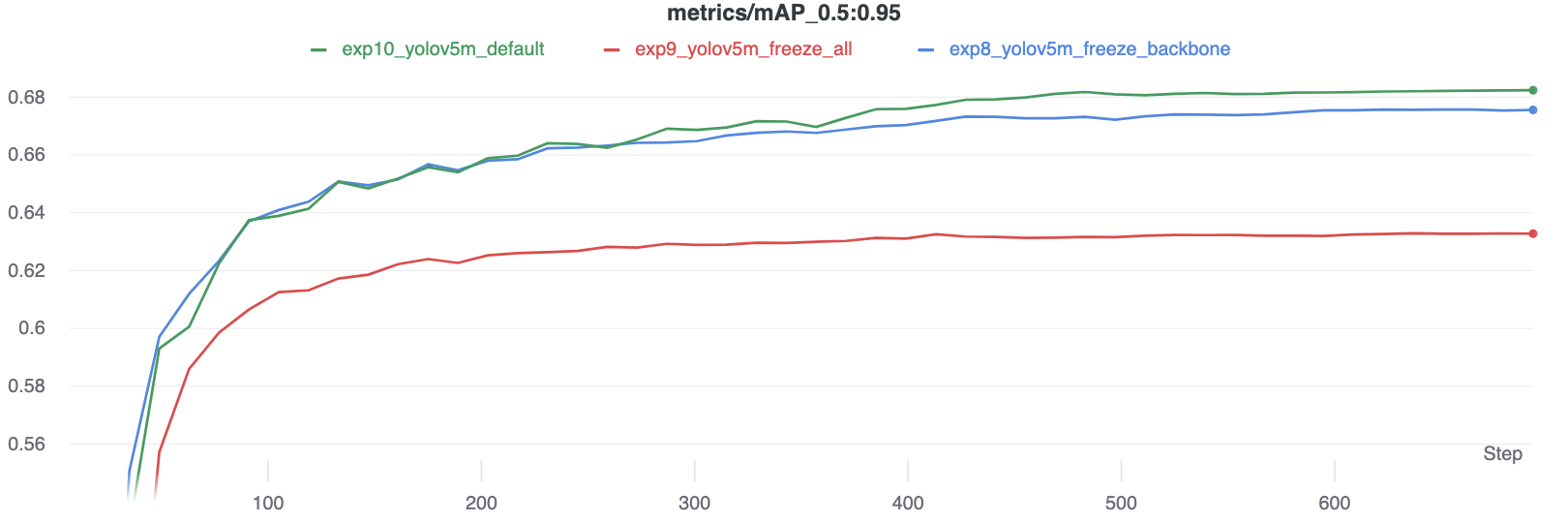\n\n \n\n### GPU Utilization Comparison\n\nInterestingly, the more modules are frozen the less GPU memory is required to train, and the lower GPU utilization. This indicates that larger models, or models trained at larger --image-size may benefit from freezing in order to train faster.\n\n\n\n\n\n## Environments\n\nYOLOv5 may be run in any of the following up-to-date verified environments (with all dependencies including [CUDA](https://developer.nvidia.com/cuda)/[CUDNN](https://developer.nvidia.com/cudnn), [Python](https://www.python.org/) and [PyTorch](https://pytorch.org/) preinstalled):\n\n- **Notebooks** with free GPU: \n- **Google Cloud** Deep Learning VM. See [GCP Quickstart Guide](https://docs.ultralytics.com/yolov5/environments/google_cloud_quickstart_tutorial/)\n- **Amazon** Deep Learning AMI. See [AWS Quickstart Guide](https://docs.ultralytics.com/yolov5/environments/aws_quickstart_tutorial/)\n- **Docker Image**. See [Docker Quickstart Guide](https://docs.ultralytics.com/yolov5/environments/docker_image_quickstart_tutorial/) \n\n## Status\n\n\n\nIf this badge is green, all [YOLOv5 GitHub Actions](https://github.com/ultralytics/yolov5/actions) Continuous Integration (CI) tests are currently passing. CI tests verify correct operation of YOLOv5 [training](https://github.com/ultralytics/yolov5/blob/master/train.py), [validation](https://github.com/ultralytics/yolov5/blob/master/val.py), [inference](https://github.com/ultralytics/yolov5/blob/master/detect.py), [export](https://github.com/ultralytics/yolov5/blob/master/export.py) and [benchmarks](https://github.com/ultralytics/yolov5/blob/master/benchmarks.py) on macOS, Windows, and Ubuntu every 24 hours and on every commit."
},
{
"path": "examples/README.md",
"content": "## Ultralytics YOLOv8 Example Applications\n\nThis repository features a collection of real-world applications and walkthroughs, provided as either Python files or notebooks. Explore the examples below to see how YOLOv8 can be integrated into various applications.\n\n### Ultralytics YOLO Example Applications\n\n| Title | Format | Contributor |\n| -------------------------------------------------------------------------------------------------------------- | ------------------ | --------------------------------------------------- |\n| [YOLO ONNX Detection Inference with C++](./YOLOv8-CPP-Inference) | C++/ONNX | [Justas Bartnykas](https://github.com/JustasBart) |\n| [YOLO OpenCV ONNX Detection Python](./YOLOv8-OpenCV-ONNX-Python) | OpenCV/Python/ONNX | [Farid Inawan](https://github.com/frdteknikelektro) |\n| [YOLO .Net ONNX Detection C#](https://www.nuget.org/packages/Yolov8.Net) | C# .Net | [Samuel Stainback](https://github.com/sstainba) |\n| [YOLOv8 on NVIDIA Jetson(TensorRT and DeepStream)](https://wiki.seeedstudio.com/YOLOv8-DeepStream-TRT-Jetson/) | Python | [Lakshantha](https://github.com/lakshanthad) |\n\n### How to Contribute\n\nWe welcome contributions from the community in the form of examples, applications, and guides. To contribute, please follow these steps:\n\n1. Create a pull request (PR) with the `[Example]` prefix in the title, adding your project folder to the `examples/` directory in the repository.\n1. Ensure that your project meets the following criteria:\n - Utilizes the `ultralytics` package.\n - Includes a `README.md` file with instructions on how to run the project.\n - Avoids adding large assets or dependencies unless absolutely necessary.\n - The contributor is expected to provide support for issues related to their examples.\n\nIf you have any questions or concerns about these requirements, please submit a PR, and we will be more than happy to guide you.\n"
},
{
"path": "examples/YOLOv8-CPP-Inference/CMakeLists.txt",
"content": "cmake_minimum_required(VERSION 3.5)\n\nproject(Yolov8CPPInference VERSION 0.1)\n\nset(CMAKE_INCLUDE_CURRENT_DIR ON)\n\n# CUDA\nset(CUDA_TOOLKIT_ROOT_DIR \"/usr/local/cuda\")\nfind_package(CUDA 11 REQUIRED)\n\nset(CMAKE_CUDA_STANDARD 11)\nset(CMAKE_CUDA_STANDARD_REQUIRED ON)\n# !CUDA\n\n# OpenCV\nfind_package(OpenCV REQUIRED)\ninclude_directories(${OpenCV_INCLUDE_DIRS})\n# !OpenCV\n\nset(PROJECT_SOURCES\n main.cpp\n\n inference.h\n inference.cpp\n)\n\nadd_executable(Yolov8CPPInference ${PROJECT_SOURCES})\ntarget_link_libraries(Yolov8CPPInference ${OpenCV_LIBS})\n"
},
{
"path": "examples/YOLOv8-CPP-Inference/README.md",
"content": "# YOLOv8/YOLOv5 Inference C++\n\nThis example demonstrates how to perform inference using YOLOv8 and YOLOv5 models in C++ with OpenCV's DNN API.\n\n## Usage\n\n```bash\ngit clone ultralytics\ncd ultralytics\npip install .\ncd examples/cpp_\n\n# Add a **yolov8\\_.onnx** and/or **yolov5\\_.onnx** model(s) to the ultralytics folder.\n# Edit the **main.cpp** to change the **projectBasePath** to match your user.\n\n# Note that by default the CMake file will try and import the CUDA library to be used with the OpenCVs dnn (cuDNN) GPU Inference.\n# If your OpenCV build does not use CUDA/cuDNN you can remove that import call and run the example on CPU.\n\nmkdir build\ncd build\ncmake ..\nmake\n./Yolov8CPPInference\n```\n\n## Exporting YOLOv8 and YOLOv5 Models\n\nTo export YOLOv8 models:\n\n```commandline\nyolo export model=yolov8s.pt imgsz=480,640 format=onnx opset=12\n```\n\nTo export YOLOv5 models:\n\n```commandline\npython3 export.py --weights yolov5s.pt --img 480 640 --include onnx --opset 12\n```\n\nyolov8s.onnx:\n\n\n\nyolov5s.onnx:\n\n\n\nThis repository utilizes OpenCV's DNN API to run ONNX exported models of YOLOv5 and YOLOv8. In theory, it should work for YOLOv6 and YOLOv7 as well, but they have not been tested. Note that the example networks are exported with rectangular (640x480) resolutions, but any exported resolution will work. You may want to use the letterbox approach for square images, depending on your use case.\n\nThe **main** branch version uses Qt as a GUI wrapper. The primary focus here is the **Inference** class file, which demonstrates how to transpose YOLOv8 models to work as YOLOv5 models.\n"
},
{
"path": "examples/YOLOv8-CPP-Inference/inference.cpp",
"content": "#include \"inference.h\"\n\nInference::Inference(const std::string &onnxModelPath, const cv::Size &modelInputShape, const std::string &classesTxtFile, const bool &runWithCuda)\n{\n modelPath = onnxModelPath;\n modelShape = modelInputShape;\n classesPath = classesTxtFile;\n cudaEnabled = runWithCuda;\n\n loadOnnxNetwork();\n // loadClassesFromFile(); The classes are hard-coded for this example\n}\n\nstd::vector Inference::runInference(const cv::Mat &input)\n{\n cv::Mat modelInput = input;\n if (letterBoxForSquare && modelShape.width == modelShape.height)\n modelInput = formatToSquare(modelInput);\n\n cv::Mat blob;\n cv::dnn::blobFromImage(modelInput, blob, 1.0/255.0, modelShape, cv::Scalar(), true, false);\n net.setInput(blob);\n\n std::vector outputs;\n net.forward(outputs, net.getUnconnectedOutLayersNames());\n\n int rows = outputs[0].size[1];\n int dimensions = outputs[0].size[2];\n\n bool yolov8 = false;\n // yolov5 has an output of shape (batchSize, 25200, 85) (Num classes + box[x,y,w,h] + confidence[c])\n // yolov8 has an output of shape (batchSize, 84, 8400) (Num classes + box[x,y,w,h])\n if (dimensions > rows) // Check if the shape[2] is more than shape[1] (yolov8)\n {\n yolov8 = true;\n rows = outputs[0].size[2];\n dimensions = outputs[0].size[1];\n\n outputs[0] = outputs[0].reshape(1, dimensions);\n cv::transpose(outputs[0], outputs[0]);\n }\n float *data = (float *)outputs[0].data;\n\n float x_factor = modelInput.cols / modelShape.width;\n float y_factor = modelInput.rows / modelShape.height;\n\n std::vector class_ids;\n std::vector confidences;\n std::vector boxes;\n\n for (int i = 0; i < rows; ++i)\n {\n if (yolov8)\n {\n float *classes_scores = data+4;\n\n cv::Mat scores(1, classes.size(), CV_32FC1, classes_scores);\n cv::Point class_id;\n double maxClassScore;\n\n minMaxLoc(scores, 0, &maxClassScore, 0, &class_id);\n\n if (maxClassScore > modelScoreThreshold)\n {\n confidences.push_back(maxClassScore);\n class_ids.push_back(class_id.x);\n\n float x = data[0];\n float y = data[1];\n float w = data[2];\n float h = data[3];\n\n int left = int((x - 0.5 * w) * x_factor);\n int top = int((y - 0.5 * h) * y_factor);\n\n int width = int(w * x_factor);\n int height = int(h * y_factor);\n\n boxes.push_back(cv::Rect(left, top, width, height));\n }\n }\n else // yolov5\n {\n float confidence = data[4];\n\n if (confidence >= modelConfidenceThreshold)\n {\n float *classes_scores = data+5;\n\n cv::Mat scores(1, classes.size(), CV_32FC1, classes_scores);\n cv::Point class_id;\n double max_class_score;\n\n minMaxLoc(scores, 0, &max_class_score, 0, &class_id);\n\n if (max_class_score > modelScoreThreshold)\n {\n confidences.push_back(confidence);\n class_ids.push_back(class_id.x);\n\n float x = data[0];\n float y = data[1];\n float w = data[2];\n float h = data[3];\n\n int left = int((x - 0.5 * w) * x_factor);\n int top = int((y - 0.5 * h) * y_factor);\n\n int width = int(w * x_factor);\n int height = int(h * y_factor);\n\n boxes.push_back(cv::Rect(left, top, width, height));\n }\n }\n }\n\n data += dimensions;\n }\n\n std::vector nms_result;\n cv::dnn::NMSBoxes(boxes, confidences, modelScoreThreshold, modelNMSThreshold, nms_result);\n\n std::vector detections{};\n for (unsigned long i = 0; i < nms_result.size(); ++i)\n {\n int idx = nms_result[i];\n\n Detection result;\n result.class_id = class_ids[idx];\n result.confidence = confidences[idx];\n\n std::random_device rd;\n std::mt19937 gen(rd());\n std::uniform_int_distribution dis(100, 255);\n result.color = cv::Scalar(dis(gen),\n dis(gen),\n dis(gen));\n\n result.className = classes[result.class_id];\n result.box = boxes[idx];\n\n detections.push_back(result);\n }\n\n return detections;\n}\n\nvoid Inference::loadClassesFromFile()\n{\n std::ifstream inputFile(classesPath);\n if (inputFile.is_open())\n {\n std::string classLine;\n while (std::getline(inputFile, classLine))\n classes.push_back(classLine);\n inputFile.close();\n }\n}\n\nvoid Inference::loadOnnxNetwork()\n{\n net = cv::dnn::readNetFromONNX(modelPath);\n if (cudaEnabled)\n {\n std::cout << \"\\nRunning on CUDA\" << std::endl;\n net.setPreferableBackend(cv::dnn::DNN_BACKEND_CUDA);\n net.setPreferableTarget(cv::dnn::DNN_TARGET_CUDA);\n }\n else\n {\n std::cout << \"\\nRunning on CPU\" << std::endl;\n net.setPreferableBackend(cv::dnn::DNN_BACKEND_OPENCV);\n net.setPreferableTarget(cv::dnn::DNN_TARGET_CPU);\n }\n}\n\ncv::Mat Inference::formatToSquare(const cv::Mat &source)\n{\n int col = source.cols;\n int row = source.rows;\n int _max = MAX(col, row);\n cv::Mat result = cv::Mat::zeros(_max, _max, CV_8UC3);\n source.copyTo(result(cv::Rect(0, 0, col, row)));\n return result;\n}\n"
},
{
"path": "examples/YOLOv8-CPP-Inference/inference.h",
"content": "#ifndef INFERENCE_H\n#define INFERENCE_H\n\n// Cpp native\n#include \n#include \n#include \n#include \n\n// OpenCV / DNN / Inference\n#include \n#include \n#include \n\nstruct Detection\n{\n int class_id{0};\n std::string className{};\n float confidence{0.0};\n cv::Scalar color{};\n cv::Rect box{};\n};\n\nclass Inference\n{\npublic:\n Inference(const std::string &onnxModelPath, const cv::Size &modelInputShape = {640, 640}, const std::string &classesTxtFile = \"\", const bool &runWithCuda = true);\n std::vector runInference(const cv::Mat &input);\n\nprivate:\n void loadClassesFromFile();\n void loadOnnxNetwork();\n cv::Mat formatToSquare(const cv::Mat &source);\n\n std::string modelPath{};\n std::string classesPath{};\n bool cudaEnabled{};\n\n std::vector classes{\"person\", \"bicycle\", \"car\", \"motorcycle\", \"airplane\", \"bus\", \"train\", \"truck\", \"boat\", \"traffic light\", \"fire hydrant\", \"stop sign\", \"parking meter\", \"bench\", \"bird\", \"cat\", \"dog\", \"horse\", \"sheep\", \"cow\", \"elephant\", \"bear\", \"zebra\", \"giraffe\", \"backpack\", \"umbrella\", \"handbag\", \"tie\", \"suitcase\", \"frisbee\", \"skis\", \"snowboard\", \"sports ball\", \"kite\", \"baseball bat\", \"baseball glove\", \"skateboard\", \"surfboard\", \"tennis racket\", \"bottle\", \"wine glass\", \"cup\", \"fork\", \"knife\", \"spoon\", \"bowl\", \"banana\", \"apple\", \"sandwich\", \"orange\", \"broccoli\", \"carrot\", \"hot dog\", \"pizza\", \"donut\", \"cake\", \"chair\", \"couch\", \"potted plant\", \"bed\", \"dining table\", \"toilet\", \"tv\", \"laptop\", \"mouse\", \"remote\", \"keyboard\", \"cell phone\", \"microwave\", \"oven\", \"toaster\", \"sink\", \"refrigerator\", \"book\", \"clock\", \"vase\", \"scissors\", \"teddy bear\", \"hair drier\", \"toothbrush\"};\n\n cv::Size2f modelShape{};\n\n float modelConfidenceThreshold {0.25};\n float modelScoreThreshold {0.45};\n float modelNMSThreshold {0.50};\n\n bool letterBoxForSquare = true;\n\n cv::dnn::Net net;\n};\n\n#endif // INFERENCE_H\n"
},
{
"path": "examples/YOLOv8-CPP-Inference/main.cpp",
"content": "#include \n#include \n#include \n\n#include \n\n#include \"inference.h\"\n\nusing namespace std;\nusing namespace cv;\n\nint main(int argc, char **argv)\n{\n std::string projectBasePath = \"/home/user/ultralytics\"; // Set your ultralytics base path\n\n bool runOnGPU = true;\n\n //\n // Pass in either:\n //\n // \"yolov8s.onnx\" or \"yolov5s.onnx\"\n //\n // To run Inference with yolov8/yolov5 (ONNX)\n //\n\n // Note that in this example the classes are hard-coded and 'classes.txt' is a place holder.\n Inference inf(projectBasePath + \"/yolov8s.onnx\", cv::Size(640, 480), \"classes.txt\", runOnGPU);\n\n std::vector imageNames;\n imageNames.push_back(projectBasePath + \"/ultralytics/assets/bus.jpg\");\n imageNames.push_back(projectBasePath + \"/ultralytics/assets/zidane.jpg\");\n\n for (int i = 0; i < imageNames.size(); ++i)\n {\n cv::Mat frame = cv::imread(imageNames[i]);\n\n // Inference starts here...\n std::vector output = inf.runInference(frame);\n\n int detections = output.size();\n std::cout << \"Number of detections:\" << detections << std::endl;\n\n for (int i = 0; i < detections; ++i)\n {\n Detection detection = output[i];\n\n cv::Rect box = detection.box;\n cv::Scalar color = detection.color;\n\n // Detection box\n cv::rectangle(frame, box, color, 2);\n\n // Detection box text\n std::string classString = detection.className + ' ' + std::to_string(detection.confidence).substr(0, 4);\n cv::Size textSize = cv::getTextSize(classString, cv::FONT_HERSHEY_DUPLEX, 1, 2, 0);\n cv::Rect textBox(box.x, box.y - 40, textSize.width + 10, textSize.height + 20);\n\n cv::rectangle(frame, textBox, color, cv::FILLED);\n cv::putText(frame, classString, cv::Point(box.x + 5, box.y - 10), cv::FONT_HERSHEY_DUPLEX, 1, cv::Scalar(0, 0, 0), 2, 0);\n }\n // Inference ends here...\n\n // This is only for preview purposes\n float scale = 0.8;\n cv::resize(frame, frame, cv::Size(frame.cols*scale, frame.rows*scale));\n cv::imshow(\"Inference\", frame);\n\n cv::waitKey(-1);\n }\n}\n"
},
{
"path": "examples/YOLOv8-OpenCV-ONNX-Python/README.md",
"content": "# YOLOv8 - OpenCV\n\nImplementation YOLOv8 on OpenCV using ONNX Format.\n\nJust simply clone and run\n\n```bash\npip install -r requirements.txt\npython main.py --model yolov8n.onnx --img image.jpg\n```\n\nIf you start from scratch:\n\n```bash\npip install ultralytics\nyolo export model=yolov8n.pt imgsz=640 format=onnx opset=12\n```\n\n_\\*Make sure to include \"opset=12\"_\n"
},
{
"path": "examples/YOLOv8-OpenCV-ONNX-Python/main.py",
"content": "import argparse\n\nimport cv2.dnn\nimport numpy as np\n\nfrom ultralytics.yolo.utils import ROOT, yaml_load\nfrom ultralytics.yolo.utils.checks import check_yaml\n\nCLASSES = yaml_load(check_yaml('coco128.yaml'))['names']\n\ncolors = np.random.uniform(0, 255, size=(len(CLASSES), 3))\n\n\ndef draw_bounding_box(img, class_id, confidence, x, y, x_plus_w, y_plus_h):\n label = f'{CLASSES[class_id]} ({confidence:.2f})'\n color = colors[class_id]\n cv2.rectangle(img, (x, y), (x_plus_w, y_plus_h), color, 2)\n cv2.putText(img, label, (x - 10, y - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.5, color, 2)\n\n\ndef main(onnx_model, input_image):\n model: cv2.dnn.Net = cv2.dnn.readNetFromONNX(onnx_model)\n original_image: np.ndarray = cv2.imread(input_image)\n [height, width, _] = original_image.shape\n length = max((height, width))\n image = np.zeros((length, length, 3), np.uint8)\n image[0:height, 0:width] = original_image\n scale = length / 640\n\n blob = cv2.dnn.blobFromImage(image, scalefactor=1 / 255, size=(640, 640), swapRB=True)\n model.setInput(blob)\n outputs = model.forward()\n\n outputs = np.array([cv2.transpose(outputs[0])])\n rows = outputs.shape[1]\n\n boxes = []\n scores = []\n class_ids = []\n\n for i in range(rows):\n classes_scores = outputs[0][i][4:]\n (minScore, maxScore, minClassLoc, (x, maxClassIndex)) = cv2.minMaxLoc(classes_scores)\n if maxScore >= 0.25:\n box = [\n outputs[0][i][0] - (0.5 * outputs[0][i][2]), outputs[0][i][1] - (0.5 * outputs[0][i][3]),\n outputs[0][i][2], outputs[0][i][3]]\n boxes.append(box)\n scores.append(maxScore)\n class_ids.append(maxClassIndex)\n\n result_boxes = cv2.dnn.NMSBoxes(boxes, scores, 0.25, 0.45, 0.5)\n\n detections = []\n for i in range(len(result_boxes)):\n index = result_boxes[i]\n box = boxes[index]\n detection = {\n 'class_id': class_ids[index],\n 'class_name': CLASSES[class_ids[index]],\n 'confidence': scores[index],\n 'box': box,\n 'scale': scale}\n detections.append(detection)\n draw_bounding_box(original_image, class_ids[index], scores[index], round(box[0] * scale), round(box[1] * scale),\n round((box[0] + box[2]) * scale), round((box[1] + box[3]) * scale))\n\n cv2.imshow('image', original_image)\n cv2.waitKey(0)\n cv2.destroyAllWindows()\n\n return detections\n\n\nif __name__ == '__main__':\n parser = argparse.ArgumentParser()\n parser.add_argument('--model', default='yolov8n.onnx', help='Input your onnx model.')\n parser.add_argument('--img', default=str(ROOT / 'assets/bus.jpg'), help='Path to input image.')\n args = parser.parse_args()\n main(args.model, args.img)\n"
},
{
"path": "examples/hub.ipynb",
"content": "{\n \"nbformat\": 4,\n \"nbformat_minor\": 0,\n \"metadata\": {\n \"colab\": {\n \"name\": \"Ultralytics HUB\",\n \"provenance\": []\n },\n \"kernelspec\": {\n \"name\": \"python3\",\n \"display_name\": \"Python 3\"\n },\n \"language_info\": {\n \"name\": \"python\"\n },\n \"accelerator\": \"GPU\"\n },\n \"cells\": [\n {\n \"cell_type\": \"markdown\",\n \"metadata\": {\n \"id\": \"FIzICjaph_Wy\"\n },\n \"source\": [\n \"\\n\",\n \"
\n\n### GPU Utilization Comparison\n\nInterestingly, the more modules are frozen the less GPU memory is required to train, and the lower GPU utilization. This indicates that larger models, or models trained at larger --image-size may benefit from freezing in order to train faster.\n\n\n\n\n\n## Environments\n\nYOLOv5 may be run in any of the following up-to-date verified environments (with all dependencies including [CUDA](https://developer.nvidia.com/cuda)/[CUDNN](https://developer.nvidia.com/cudnn), [Python](https://www.python.org/) and [PyTorch](https://pytorch.org/) preinstalled):\n\n- **Notebooks** with free GPU: \n- **Google Cloud** Deep Learning VM. See [GCP Quickstart Guide](https://docs.ultralytics.com/yolov5/environments/google_cloud_quickstart_tutorial/)\n- **Amazon** Deep Learning AMI. See [AWS Quickstart Guide](https://docs.ultralytics.com/yolov5/environments/aws_quickstart_tutorial/)\n- **Docker Image**. See [Docker Quickstart Guide](https://docs.ultralytics.com/yolov5/environments/docker_image_quickstart_tutorial/) \n\n## Status\n\n\n\nIf this badge is green, all [YOLOv5 GitHub Actions](https://github.com/ultralytics/yolov5/actions) Continuous Integration (CI) tests are currently passing. CI tests verify correct operation of YOLOv5 [training](https://github.com/ultralytics/yolov5/blob/master/train.py), [validation](https://github.com/ultralytics/yolov5/blob/master/val.py), [inference](https://github.com/ultralytics/yolov5/blob/master/detect.py), [export](https://github.com/ultralytics/yolov5/blob/master/export.py) and [benchmarks](https://github.com/ultralytics/yolov5/blob/master/benchmarks.py) on macOS, Windows, and Ubuntu every 24 hours and on every commit."
},
{
"path": "examples/README.md",
"content": "## Ultralytics YOLOv8 Example Applications\n\nThis repository features a collection of real-world applications and walkthroughs, provided as either Python files or notebooks. Explore the examples below to see how YOLOv8 can be integrated into various applications.\n\n### Ultralytics YOLO Example Applications\n\n| Title | Format | Contributor |\n| -------------------------------------------------------------------------------------------------------------- | ------------------ | --------------------------------------------------- |\n| [YOLO ONNX Detection Inference with C++](./YOLOv8-CPP-Inference) | C++/ONNX | [Justas Bartnykas](https://github.com/JustasBart) |\n| [YOLO OpenCV ONNX Detection Python](./YOLOv8-OpenCV-ONNX-Python) | OpenCV/Python/ONNX | [Farid Inawan](https://github.com/frdteknikelektro) |\n| [YOLO .Net ONNX Detection C#](https://www.nuget.org/packages/Yolov8.Net) | C# .Net | [Samuel Stainback](https://github.com/sstainba) |\n| [YOLOv8 on NVIDIA Jetson(TensorRT and DeepStream)](https://wiki.seeedstudio.com/YOLOv8-DeepStream-TRT-Jetson/) | Python | [Lakshantha](https://github.com/lakshanthad) |\n\n### How to Contribute\n\nWe welcome contributions from the community in the form of examples, applications, and guides. To contribute, please follow these steps:\n\n1. Create a pull request (PR) with the `[Example]` prefix in the title, adding your project folder to the `examples/` directory in the repository.\n1. Ensure that your project meets the following criteria:\n - Utilizes the `ultralytics` package.\n - Includes a `README.md` file with instructions on how to run the project.\n - Avoids adding large assets or dependencies unless absolutely necessary.\n - The contributor is expected to provide support for issues related to their examples.\n\nIf you have any questions or concerns about these requirements, please submit a PR, and we will be more than happy to guide you.\n"
},
{
"path": "examples/YOLOv8-CPP-Inference/CMakeLists.txt",
"content": "cmake_minimum_required(VERSION 3.5)\n\nproject(Yolov8CPPInference VERSION 0.1)\n\nset(CMAKE_INCLUDE_CURRENT_DIR ON)\n\n# CUDA\nset(CUDA_TOOLKIT_ROOT_DIR \"/usr/local/cuda\")\nfind_package(CUDA 11 REQUIRED)\n\nset(CMAKE_CUDA_STANDARD 11)\nset(CMAKE_CUDA_STANDARD_REQUIRED ON)\n# !CUDA\n\n# OpenCV\nfind_package(OpenCV REQUIRED)\ninclude_directories(${OpenCV_INCLUDE_DIRS})\n# !OpenCV\n\nset(PROJECT_SOURCES\n main.cpp\n\n inference.h\n inference.cpp\n)\n\nadd_executable(Yolov8CPPInference ${PROJECT_SOURCES})\ntarget_link_libraries(Yolov8CPPInference ${OpenCV_LIBS})\n"
},
{
"path": "examples/YOLOv8-CPP-Inference/README.md",
"content": "# YOLOv8/YOLOv5 Inference C++\n\nThis example demonstrates how to perform inference using YOLOv8 and YOLOv5 models in C++ with OpenCV's DNN API.\n\n## Usage\n\n```bash\ngit clone ultralytics\ncd ultralytics\npip install .\ncd examples/cpp_\n\n# Add a **yolov8\\_.onnx** and/or **yolov5\\_.onnx** model(s) to the ultralytics folder.\n# Edit the **main.cpp** to change the **projectBasePath** to match your user.\n\n# Note that by default the CMake file will try and import the CUDA library to be used with the OpenCVs dnn (cuDNN) GPU Inference.\n# If your OpenCV build does not use CUDA/cuDNN you can remove that import call and run the example on CPU.\n\nmkdir build\ncd build\ncmake ..\nmake\n./Yolov8CPPInference\n```\n\n## Exporting YOLOv8 and YOLOv5 Models\n\nTo export YOLOv8 models:\n\n```commandline\nyolo export model=yolov8s.pt imgsz=480,640 format=onnx opset=12\n```\n\nTo export YOLOv5 models:\n\n```commandline\npython3 export.py --weights yolov5s.pt --img 480 640 --include onnx --opset 12\n```\n\nyolov8s.onnx:\n\n\n\nyolov5s.onnx:\n\n\n\nThis repository utilizes OpenCV's DNN API to run ONNX exported models of YOLOv5 and YOLOv8. In theory, it should work for YOLOv6 and YOLOv7 as well, but they have not been tested. Note that the example networks are exported with rectangular (640x480) resolutions, but any exported resolution will work. You may want to use the letterbox approach for square images, depending on your use case.\n\nThe **main** branch version uses Qt as a GUI wrapper. The primary focus here is the **Inference** class file, which demonstrates how to transpose YOLOv8 models to work as YOLOv5 models.\n"
},
{
"path": "examples/YOLOv8-CPP-Inference/inference.cpp",
"content": "#include \"inference.h\"\n\nInference::Inference(const std::string &onnxModelPath, const cv::Size &modelInputShape, const std::string &classesTxtFile, const bool &runWithCuda)\n{\n modelPath = onnxModelPath;\n modelShape = modelInputShape;\n classesPath = classesTxtFile;\n cudaEnabled = runWithCuda;\n\n loadOnnxNetwork();\n // loadClassesFromFile(); The classes are hard-coded for this example\n}\n\nstd::vector Inference::runInference(const cv::Mat &input)\n{\n cv::Mat modelInput = input;\n if (letterBoxForSquare && modelShape.width == modelShape.height)\n modelInput = formatToSquare(modelInput);\n\n cv::Mat blob;\n cv::dnn::blobFromImage(modelInput, blob, 1.0/255.0, modelShape, cv::Scalar(), true, false);\n net.setInput(blob);\n\n std::vector outputs;\n net.forward(outputs, net.getUnconnectedOutLayersNames());\n\n int rows = outputs[0].size[1];\n int dimensions = outputs[0].size[2];\n\n bool yolov8 = false;\n // yolov5 has an output of shape (batchSize, 25200, 85) (Num classes + box[x,y,w,h] + confidence[c])\n // yolov8 has an output of shape (batchSize, 84, 8400) (Num classes + box[x,y,w,h])\n if (dimensions > rows) // Check if the shape[2] is more than shape[1] (yolov8)\n {\n yolov8 = true;\n rows = outputs[0].size[2];\n dimensions = outputs[0].size[1];\n\n outputs[0] = outputs[0].reshape(1, dimensions);\n cv::transpose(outputs[0], outputs[0]);\n }\n float *data = (float *)outputs[0].data;\n\n float x_factor = modelInput.cols / modelShape.width;\n float y_factor = modelInput.rows / modelShape.height;\n\n std::vector class_ids;\n std::vector confidences;\n std::vector boxes;\n\n for (int i = 0; i < rows; ++i)\n {\n if (yolov8)\n {\n float *classes_scores = data+4;\n\n cv::Mat scores(1, classes.size(), CV_32FC1, classes_scores);\n cv::Point class_id;\n double maxClassScore;\n\n minMaxLoc(scores, 0, &maxClassScore, 0, &class_id);\n\n if (maxClassScore > modelScoreThreshold)\n {\n confidences.push_back(maxClassScore);\n class_ids.push_back(class_id.x);\n\n float x = data[0];\n float y = data[1];\n float w = data[2];\n float h = data[3];\n\n int left = int((x - 0.5 * w) * x_factor);\n int top = int((y - 0.5 * h) * y_factor);\n\n int width = int(w * x_factor);\n int height = int(h * y_factor);\n\n boxes.push_back(cv::Rect(left, top, width, height));\n }\n }\n else // yolov5\n {\n float confidence = data[4];\n\n if (confidence >= modelConfidenceThreshold)\n {\n float *classes_scores = data+5;\n\n cv::Mat scores(1, classes.size(), CV_32FC1, classes_scores);\n cv::Point class_id;\n double max_class_score;\n\n minMaxLoc(scores, 0, &max_class_score, 0, &class_id);\n\n if (max_class_score > modelScoreThreshold)\n {\n confidences.push_back(confidence);\n class_ids.push_back(class_id.x);\n\n float x = data[0];\n float y = data[1];\n float w = data[2];\n float h = data[3];\n\n int left = int((x - 0.5 * w) * x_factor);\n int top = int((y - 0.5 * h) * y_factor);\n\n int width = int(w * x_factor);\n int height = int(h * y_factor);\n\n boxes.push_back(cv::Rect(left, top, width, height));\n }\n }\n }\n\n data += dimensions;\n }\n\n std::vector nms_result;\n cv::dnn::NMSBoxes(boxes, confidences, modelScoreThreshold, modelNMSThreshold, nms_result);\n\n std::vector detections{};\n for (unsigned long i = 0; i < nms_result.size(); ++i)\n {\n int idx = nms_result[i];\n\n Detection result;\n result.class_id = class_ids[idx];\n result.confidence = confidences[idx];\n\n std::random_device rd;\n std::mt19937 gen(rd());\n std::uniform_int_distribution dis(100, 255);\n result.color = cv::Scalar(dis(gen),\n dis(gen),\n dis(gen));\n\n result.className = classes[result.class_id];\n result.box = boxes[idx];\n\n detections.push_back(result);\n }\n\n return detections;\n}\n\nvoid Inference::loadClassesFromFile()\n{\n std::ifstream inputFile(classesPath);\n if (inputFile.is_open())\n {\n std::string classLine;\n while (std::getline(inputFile, classLine))\n classes.push_back(classLine);\n inputFile.close();\n }\n}\n\nvoid Inference::loadOnnxNetwork()\n{\n net = cv::dnn::readNetFromONNX(modelPath);\n if (cudaEnabled)\n {\n std::cout << \"\\nRunning on CUDA\" << std::endl;\n net.setPreferableBackend(cv::dnn::DNN_BACKEND_CUDA);\n net.setPreferableTarget(cv::dnn::DNN_TARGET_CUDA);\n }\n else\n {\n std::cout << \"\\nRunning on CPU\" << std::endl;\n net.setPreferableBackend(cv::dnn::DNN_BACKEND_OPENCV);\n net.setPreferableTarget(cv::dnn::DNN_TARGET_CPU);\n }\n}\n\ncv::Mat Inference::formatToSquare(const cv::Mat &source)\n{\n int col = source.cols;\n int row = source.rows;\n int _max = MAX(col, row);\n cv::Mat result = cv::Mat::zeros(_max, _max, CV_8UC3);\n source.copyTo(result(cv::Rect(0, 0, col, row)));\n return result;\n}\n"
},
{
"path": "examples/YOLOv8-CPP-Inference/inference.h",
"content": "#ifndef INFERENCE_H\n#define INFERENCE_H\n\n// Cpp native\n#include \n#include \n#include \n#include \n\n// OpenCV / DNN / Inference\n#include \n#include \n#include \n\nstruct Detection\n{\n int class_id{0};\n std::string className{};\n float confidence{0.0};\n cv::Scalar color{};\n cv::Rect box{};\n};\n\nclass Inference\n{\npublic:\n Inference(const std::string &onnxModelPath, const cv::Size &modelInputShape = {640, 640}, const std::string &classesTxtFile = \"\", const bool &runWithCuda = true);\n std::vector runInference(const cv::Mat &input);\n\nprivate:\n void loadClassesFromFile();\n void loadOnnxNetwork();\n cv::Mat formatToSquare(const cv::Mat &source);\n\n std::string modelPath{};\n std::string classesPath{};\n bool cudaEnabled{};\n\n std::vector classes{\"person\", \"bicycle\", \"car\", \"motorcycle\", \"airplane\", \"bus\", \"train\", \"truck\", \"boat\", \"traffic light\", \"fire hydrant\", \"stop sign\", \"parking meter\", \"bench\", \"bird\", \"cat\", \"dog\", \"horse\", \"sheep\", \"cow\", \"elephant\", \"bear\", \"zebra\", \"giraffe\", \"backpack\", \"umbrella\", \"handbag\", \"tie\", \"suitcase\", \"frisbee\", \"skis\", \"snowboard\", \"sports ball\", \"kite\", \"baseball bat\", \"baseball glove\", \"skateboard\", \"surfboard\", \"tennis racket\", \"bottle\", \"wine glass\", \"cup\", \"fork\", \"knife\", \"spoon\", \"bowl\", \"banana\", \"apple\", \"sandwich\", \"orange\", \"broccoli\", \"carrot\", \"hot dog\", \"pizza\", \"donut\", \"cake\", \"chair\", \"couch\", \"potted plant\", \"bed\", \"dining table\", \"toilet\", \"tv\", \"laptop\", \"mouse\", \"remote\", \"keyboard\", \"cell phone\", \"microwave\", \"oven\", \"toaster\", \"sink\", \"refrigerator\", \"book\", \"clock\", \"vase\", \"scissors\", \"teddy bear\", \"hair drier\", \"toothbrush\"};\n\n cv::Size2f modelShape{};\n\n float modelConfidenceThreshold {0.25};\n float modelScoreThreshold {0.45};\n float modelNMSThreshold {0.50};\n\n bool letterBoxForSquare = true;\n\n cv::dnn::Net net;\n};\n\n#endif // INFERENCE_H\n"
},
{
"path": "examples/YOLOv8-CPP-Inference/main.cpp",
"content": "#include \n#include \n#include \n\n#include \n\n#include \"inference.h\"\n\nusing namespace std;\nusing namespace cv;\n\nint main(int argc, char **argv)\n{\n std::string projectBasePath = \"/home/user/ultralytics\"; // Set your ultralytics base path\n\n bool runOnGPU = true;\n\n //\n // Pass in either:\n //\n // \"yolov8s.onnx\" or \"yolov5s.onnx\"\n //\n // To run Inference with yolov8/yolov5 (ONNX)\n //\n\n // Note that in this example the classes are hard-coded and 'classes.txt' is a place holder.\n Inference inf(projectBasePath + \"/yolov8s.onnx\", cv::Size(640, 480), \"classes.txt\", runOnGPU);\n\n std::vector imageNames;\n imageNames.push_back(projectBasePath + \"/ultralytics/assets/bus.jpg\");\n imageNames.push_back(projectBasePath + \"/ultralytics/assets/zidane.jpg\");\n\n for (int i = 0; i < imageNames.size(); ++i)\n {\n cv::Mat frame = cv::imread(imageNames[i]);\n\n // Inference starts here...\n std::vector output = inf.runInference(frame);\n\n int detections = output.size();\n std::cout << \"Number of detections:\" << detections << std::endl;\n\n for (int i = 0; i < detections; ++i)\n {\n Detection detection = output[i];\n\n cv::Rect box = detection.box;\n cv::Scalar color = detection.color;\n\n // Detection box\n cv::rectangle(frame, box, color, 2);\n\n // Detection box text\n std::string classString = detection.className + ' ' + std::to_string(detection.confidence).substr(0, 4);\n cv::Size textSize = cv::getTextSize(classString, cv::FONT_HERSHEY_DUPLEX, 1, 2, 0);\n cv::Rect textBox(box.x, box.y - 40, textSize.width + 10, textSize.height + 20);\n\n cv::rectangle(frame, textBox, color, cv::FILLED);\n cv::putText(frame, classString, cv::Point(box.x + 5, box.y - 10), cv::FONT_HERSHEY_DUPLEX, 1, cv::Scalar(0, 0, 0), 2, 0);\n }\n // Inference ends here...\n\n // This is only for preview purposes\n float scale = 0.8;\n cv::resize(frame, frame, cv::Size(frame.cols*scale, frame.rows*scale));\n cv::imshow(\"Inference\", frame);\n\n cv::waitKey(-1);\n }\n}\n"
},
{
"path": "examples/YOLOv8-OpenCV-ONNX-Python/README.md",
"content": "# YOLOv8 - OpenCV\n\nImplementation YOLOv8 on OpenCV using ONNX Format.\n\nJust simply clone and run\n\n```bash\npip install -r requirements.txt\npython main.py --model yolov8n.onnx --img image.jpg\n```\n\nIf you start from scratch:\n\n```bash\npip install ultralytics\nyolo export model=yolov8n.pt imgsz=640 format=onnx opset=12\n```\n\n_\\*Make sure to include \"opset=12\"_\n"
},
{
"path": "examples/YOLOv8-OpenCV-ONNX-Python/main.py",
"content": "import argparse\n\nimport cv2.dnn\nimport numpy as np\n\nfrom ultralytics.yolo.utils import ROOT, yaml_load\nfrom ultralytics.yolo.utils.checks import check_yaml\n\nCLASSES = yaml_load(check_yaml('coco128.yaml'))['names']\n\ncolors = np.random.uniform(0, 255, size=(len(CLASSES), 3))\n\n\ndef draw_bounding_box(img, class_id, confidence, x, y, x_plus_w, y_plus_h):\n label = f'{CLASSES[class_id]} ({confidence:.2f})'\n color = colors[class_id]\n cv2.rectangle(img, (x, y), (x_plus_w, y_plus_h), color, 2)\n cv2.putText(img, label, (x - 10, y - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.5, color, 2)\n\n\ndef main(onnx_model, input_image):\n model: cv2.dnn.Net = cv2.dnn.readNetFromONNX(onnx_model)\n original_image: np.ndarray = cv2.imread(input_image)\n [height, width, _] = original_image.shape\n length = max((height, width))\n image = np.zeros((length, length, 3), np.uint8)\n image[0:height, 0:width] = original_image\n scale = length / 640\n\n blob = cv2.dnn.blobFromImage(image, scalefactor=1 / 255, size=(640, 640), swapRB=True)\n model.setInput(blob)\n outputs = model.forward()\n\n outputs = np.array([cv2.transpose(outputs[0])])\n rows = outputs.shape[1]\n\n boxes = []\n scores = []\n class_ids = []\n\n for i in range(rows):\n classes_scores = outputs[0][i][4:]\n (minScore, maxScore, minClassLoc, (x, maxClassIndex)) = cv2.minMaxLoc(classes_scores)\n if maxScore >= 0.25:\n box = [\n outputs[0][i][0] - (0.5 * outputs[0][i][2]), outputs[0][i][1] - (0.5 * outputs[0][i][3]),\n outputs[0][i][2], outputs[0][i][3]]\n boxes.append(box)\n scores.append(maxScore)\n class_ids.append(maxClassIndex)\n\n result_boxes = cv2.dnn.NMSBoxes(boxes, scores, 0.25, 0.45, 0.5)\n\n detections = []\n for i in range(len(result_boxes)):\n index = result_boxes[i]\n box = boxes[index]\n detection = {\n 'class_id': class_ids[index],\n 'class_name': CLASSES[class_ids[index]],\n 'confidence': scores[index],\n 'box': box,\n 'scale': scale}\n detections.append(detection)\n draw_bounding_box(original_image, class_ids[index], scores[index], round(box[0] * scale), round(box[1] * scale),\n round((box[0] + box[2]) * scale), round((box[1] + box[3]) * scale))\n\n cv2.imshow('image', original_image)\n cv2.waitKey(0)\n cv2.destroyAllWindows()\n\n return detections\n\n\nif __name__ == '__main__':\n parser = argparse.ArgumentParser()\n parser.add_argument('--model', default='yolov8n.onnx', help='Input your onnx model.')\n parser.add_argument('--img', default=str(ROOT / 'assets/bus.jpg'), help='Path to input image.')\n args = parser.parse_args()\n main(args.model, args.img)\n"
},
{
"path": "examples/hub.ipynb",
"content": "{\n \"nbformat\": 4,\n \"nbformat_minor\": 0,\n \"metadata\": {\n \"colab\": {\n \"name\": \"Ultralytics HUB\",\n \"provenance\": []\n },\n \"kernelspec\": {\n \"name\": \"python3\",\n \"display_name\": \"Python 3\"\n },\n \"language_info\": {\n \"name\": \"python\"\n },\n \"accelerator\": \"GPU\"\n },\n \"cells\": [\n {\n \"cell_type\": \"markdown\",\n \"metadata\": {\n \"id\": \"FIzICjaph_Wy\"\n },\n \"source\": [\n \"\\n\",\n \" \\n\",\n \"\\n\",\n \"
\\n\",\n \"\\n\",\n \"\\n\",\n \"
\\n\",\n \" 
\\n\",\n \"
\\n\",\n \" 
\\n\",\n \"\\n\",\n \"Welcome to the [Ultralytics](https://ultralytics.com/) HUB notebook! \\n\",\n \"\\n\",\n \"This notebook allows you to train [YOLOv5](https://github.com/ultralytics/yolov5) and [YOLOv8](https://github.com/ultralytics/ultralytics) 🚀 models using [HUB](https://hub.ultralytics.com/). Please browse the YOLOv8
Docs for details, raise an issue on
GitHub for support, and join our
Discord community for questions and discussions!\\n\",\n \"
\\n\",\n \"\\n\",\n \"
\\n\",\n \" 
\\n\",\n \"\\n\",\n \"\\n\",\n \"
\\n\",\n \"

\\n\",\n \"
\\n\",\n \"

\\n\",\n \"
\\n\",\n \"\\n\",\n \"Welcome to the Ultralytics YOLOv8 🚀 notebook!
YOLOv8 is the latest version of the YOLO (You Only Look Once) AI models developed by
Ultralytics. This notebook serves as the starting point for exploring the various resources available to help you get started with YOLOv8 and understand its features and capabilities.\\n\",\n \"\\n\",\n \"YOLOv8 models are fast, accurate, and easy to use, making them ideal for various object detection and image segmentation tasks. They can be trained on large datasets and run on diverse hardware platforms, from CPUs to GPUs.\\n\",\n \"\\n\",\n \"We hope that the resources in this notebook will help you get the most out of YOLOv8. Please browse the YOLOv8
Docs for details, raise an issue on
GitHub for support, and join our
Discord community for questions and discussions!\\n\",\n \"\\n\",\n \"
 \"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"metadata\": {\n \"id\": \"0eq1SMWl6Sfn\"\n },\n \"source\": [\n \"# 2. Val\\n\",\n \"Validate a model's accuracy on the [COCO](https://cocodataset.org/#home) dataset's `val` or `test` splits. The latest YOLOv8 [models](https://github.com/ultralytics/ultralytics#models) are downloaded automatically the first time they are used. See [YOLOv8 Val Docs](https://docs.ultralytics.com/modes/val/) for more information.\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"metadata\": {\n \"id\": \"WQPtK1QYVaD_\"\n },\n \"source\": [\n \"# Download COCO val\\n\",\n \"import torch\\n\",\n \"torch.hub.download_url_to_file('https://ultralytics.com/assets/coco2017val.zip', 'tmp.zip') # download (780M - 5000 images)\\n\",\n \"!unzip -q tmp.zip -d datasets && rm tmp.zip # unzip\"\n ],\n \"execution_count\": null,\n \"outputs\": []\n },\n {\n \"cell_type\": \"code\",\n \"metadata\": {\n \"id\": \"X58w8JLpMnjH\",\n \"outputId\": \"3e5a9c48-8eba-45eb-d92f-8456cf94b60e\",\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n }\n },\n \"source\": [\n \"# Validate YOLOv8n on COCO128 val\\n\",\n \"!yolo val model=yolov8n.pt data=coco128.yaml\"\n ],\n \"execution_count\": 3,\n \"outputs\": [\n {\n \"output_type\": \"stream\",\n \"name\": \"stdout\",\n \"text\": [\n \"Ultralytics YOLOv8.0.71 🚀 Python-3.9.16 torch-2.0.0+cu118 CUDA:0 (Tesla T4, 15102MiB)\\n\",\n \"YOLOv8n summary (fused): 168 layers, 3151904 parameters, 0 gradients, 8.7 GFLOPs\\n\",\n \"\\n\",\n \"Dataset 'coco128.yaml' images not found ⚠️, missing paths ['/content/datasets/coco128/images/train2017']\\n\",\n \"Downloading https://ultralytics.com/assets/coco128.zip to /content/datasets/coco128.zip...\\n\",\n \"100% 6.66M/6.66M [00:01<00:00, 6.80MB/s]\\n\",\n \"Unzipping /content/datasets/coco128.zip to /content/datasets...\\n\",\n \"Dataset download success ✅ (2.2s), saved to \\u001b[1m/content/datasets\\u001b[0m\\n\",\n \"\\n\",\n \"Downloading https://ultralytics.com/assets/Arial.ttf to /root/.config/Ultralytics/Arial.ttf...\\n\",\n \"100% 755k/755k [00:00<00:00, 107MB/s]\\n\",\n \"\\u001b[34m\\u001b[1mval: \\u001b[0mScanning /content/datasets/coco128/labels/train2017... 126 images, 2 backgrounds, 80 corrupt: 100% 128/128 [00:00<00:00, 1183.28it/s]\\n\",\n \"\\u001b[34m\\u001b[1mval: \\u001b[0mNew cache created: /content/datasets/coco128/labels/train2017.cache\\n\",\n \" Class Images Instances Box(P R mAP50 mAP50-95): 100% 8/8 [00:12<00:00, 1.54s/it]\\n\",\n \" all 128 929 0.64 0.537 0.605 0.446\\n\",\n \" person 128 254 0.797 0.677 0.764 0.538\\n\",\n \" bicycle 128 6 0.514 0.333 0.315 0.264\\n\",\n \" car 128 46 0.813 0.217 0.273 0.168\\n\",\n \" motorcycle 128 5 0.687 0.887 0.898 0.685\\n\",\n \" airplane 128 6 0.82 0.833 0.927 0.675\\n\",\n \" bus 128 7 0.491 0.714 0.728 0.671\\n\",\n \" train 128 3 0.534 0.667 0.706 0.604\\n\",\n \" truck 128 12 1 0.332 0.473 0.297\\n\",\n \" boat 128 6 0.226 0.167 0.316 0.134\\n\",\n \" traffic light 128 14 0.734 0.2 0.202 0.139\\n\",\n \" stop sign 128 2 1 0.992 0.995 0.701\\n\",\n \" bench 128 9 0.839 0.582 0.62 0.365\\n\",\n \" bird 128 16 0.921 0.728 0.864 0.51\\n\",\n \" cat 128 4 0.875 1 0.995 0.791\\n\",\n \" dog 128 9 0.603 0.889 0.785 0.585\\n\",\n \" horse 128 2 0.597 1 0.995 0.518\\n\",\n \" elephant 128 17 0.849 0.765 0.9 0.679\\n\",\n \" bear 128 1 0.593 1 0.995 0.995\\n\",\n \" zebra 128 4 0.848 1 0.995 0.965\\n\",\n \" giraffe 128 9 0.72 1 0.951 0.722\\n\",\n \" backpack 128 6 0.589 0.333 0.376 0.232\\n\",\n \" umbrella 128 18 0.804 0.5 0.643 0.414\\n\",\n \" handbag 128 19 0.424 0.0526 0.165 0.0889\\n\",\n \" tie 128 7 0.804 0.714 0.674 0.476\\n\",\n \" suitcase 128 4 0.635 0.883 0.745 0.534\\n\",\n \" frisbee 128 5 0.675 0.8 0.759 0.688\\n\",\n \" skis 128 1 0.567 1 0.995 0.497\\n\",\n \" snowboard 128 7 0.742 0.714 0.747 0.5\\n\",\n \" sports ball 128 6 0.716 0.433 0.485 0.278\\n\",\n \" kite 128 10 0.817 0.45 0.569 0.184\\n\",\n \" baseball bat 128 4 0.551 0.25 0.353 0.175\\n\",\n \" baseball glove 128 7 0.624 0.429 0.429 0.293\\n\",\n \" skateboard 128 5 0.846 0.6 0.6 0.41\\n\",\n \" tennis racket 128 7 0.726 0.387 0.487 0.33\\n\",\n \" bottle 128 18 0.448 0.389 0.376 0.208\\n\",\n \" wine glass 128 16 0.743 0.362 0.584 0.333\\n\",\n \" cup 128 36 0.58 0.278 0.404 0.29\\n\",\n \" fork 128 6 0.527 0.167 0.246 0.184\\n\",\n \" knife 128 16 0.564 0.5 0.59 0.36\\n\",\n \" spoon 128 22 0.597 0.182 0.328 0.19\\n\",\n \" bowl 128 28 0.648 0.643 0.618 0.491\\n\",\n \" banana 128 1 0 0 0.124 0.0379\\n\",\n \" sandwich 128 2 0.249 0.5 0.308 0.308\\n\",\n \" orange 128 4 1 0.31 0.995 0.623\\n\",\n \" broccoli 128 11 0.374 0.182 0.249 0.203\\n\",\n \" carrot 128 24 0.648 0.458 0.572 0.362\\n\",\n \" hot dog 128 2 0.351 0.553 0.745 0.721\\n\",\n \" pizza 128 5 0.644 1 0.995 0.843\\n\",\n \" donut 128 14 0.657 1 0.94 0.864\\n\",\n \" cake 128 4 0.618 1 0.945 0.845\\n\",\n \" chair 128 35 0.506 0.514 0.442 0.239\\n\",\n \" couch 128 6 0.463 0.5 0.706 0.555\\n\",\n \" potted plant 128 14 0.65 0.643 0.711 0.472\\n\",\n \" bed 128 3 0.698 0.667 0.789 0.625\\n\",\n \" dining table 128 13 0.432 0.615 0.485 0.366\\n\",\n \" toilet 128 2 0.615 0.5 0.695 0.676\\n\",\n \" tv 128 2 0.373 0.62 0.745 0.696\\n\",\n \" laptop 128 3 1 0 0.451 0.361\\n\",\n \" mouse 128 2 1 0 0.0625 0.00625\\n\",\n \" remote 128 8 0.843 0.5 0.605 0.529\\n\",\n \" cell phone 128 8 0 0 0.0549 0.0393\\n\",\n \" microwave 128 3 0.435 0.667 0.806 0.718\\n\",\n \" oven 128 5 0.412 0.4 0.339 0.27\\n\",\n \" sink 128 6 0.35 0.167 0.182 0.129\\n\",\n \" refrigerator 128 5 0.589 0.4 0.604 0.452\\n\",\n \" book 128 29 0.629 0.103 0.346 0.178\\n\",\n \" clock 128 9 0.788 0.83 0.875 0.74\\n\",\n \" vase 128 2 0.376 1 0.828 0.795\\n\",\n \" scissors 128 1 1 0 0.249 0.0746\\n\",\n \" teddy bear 128 21 0.877 0.333 0.591 0.394\\n\",\n \" toothbrush 128 5 0.743 0.6 0.638 0.374\\n\",\n \"Speed: 5.3ms preprocess, 20.1ms inference, 0.0ms loss, 11.7ms postprocess per image\\n\",\n \"Results saved to \\u001b[1mruns/detect/val\\u001b[0m\\n\"\n ]\n }\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"metadata\": {\n \"id\": \"ZY2VXXXu74w5\"\n },\n \"source\": [\n \"# 3. Train\\n\",\n \"\\n\",\n \"
\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"metadata\": {\n \"id\": \"0eq1SMWl6Sfn\"\n },\n \"source\": [\n \"# 2. Val\\n\",\n \"Validate a model's accuracy on the [COCO](https://cocodataset.org/#home) dataset's `val` or `test` splits. The latest YOLOv8 [models](https://github.com/ultralytics/ultralytics#models) are downloaded automatically the first time they are used. See [YOLOv8 Val Docs](https://docs.ultralytics.com/modes/val/) for more information.\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"metadata\": {\n \"id\": \"WQPtK1QYVaD_\"\n },\n \"source\": [\n \"# Download COCO val\\n\",\n \"import torch\\n\",\n \"torch.hub.download_url_to_file('https://ultralytics.com/assets/coco2017val.zip', 'tmp.zip') # download (780M - 5000 images)\\n\",\n \"!unzip -q tmp.zip -d datasets && rm tmp.zip # unzip\"\n ],\n \"execution_count\": null,\n \"outputs\": []\n },\n {\n \"cell_type\": \"code\",\n \"metadata\": {\n \"id\": \"X58w8JLpMnjH\",\n \"outputId\": \"3e5a9c48-8eba-45eb-d92f-8456cf94b60e\",\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n }\n },\n \"source\": [\n \"# Validate YOLOv8n on COCO128 val\\n\",\n \"!yolo val model=yolov8n.pt data=coco128.yaml\"\n ],\n \"execution_count\": 3,\n \"outputs\": [\n {\n \"output_type\": \"stream\",\n \"name\": \"stdout\",\n \"text\": [\n \"Ultralytics YOLOv8.0.71 🚀 Python-3.9.16 torch-2.0.0+cu118 CUDA:0 (Tesla T4, 15102MiB)\\n\",\n \"YOLOv8n summary (fused): 168 layers, 3151904 parameters, 0 gradients, 8.7 GFLOPs\\n\",\n \"\\n\",\n \"Dataset 'coco128.yaml' images not found ⚠️, missing paths ['/content/datasets/coco128/images/train2017']\\n\",\n \"Downloading https://ultralytics.com/assets/coco128.zip to /content/datasets/coco128.zip...\\n\",\n \"100% 6.66M/6.66M [00:01<00:00, 6.80MB/s]\\n\",\n \"Unzipping /content/datasets/coco128.zip to /content/datasets...\\n\",\n \"Dataset download success ✅ (2.2s), saved to \\u001b[1m/content/datasets\\u001b[0m\\n\",\n \"\\n\",\n \"Downloading https://ultralytics.com/assets/Arial.ttf to /root/.config/Ultralytics/Arial.ttf...\\n\",\n \"100% 755k/755k [00:00<00:00, 107MB/s]\\n\",\n \"\\u001b[34m\\u001b[1mval: \\u001b[0mScanning /content/datasets/coco128/labels/train2017... 126 images, 2 backgrounds, 80 corrupt: 100% 128/128 [00:00<00:00, 1183.28it/s]\\n\",\n \"\\u001b[34m\\u001b[1mval: \\u001b[0mNew cache created: /content/datasets/coco128/labels/train2017.cache\\n\",\n \" Class Images Instances Box(P R mAP50 mAP50-95): 100% 8/8 [00:12<00:00, 1.54s/it]\\n\",\n \" all 128 929 0.64 0.537 0.605 0.446\\n\",\n \" person 128 254 0.797 0.677 0.764 0.538\\n\",\n \" bicycle 128 6 0.514 0.333 0.315 0.264\\n\",\n \" car 128 46 0.813 0.217 0.273 0.168\\n\",\n \" motorcycle 128 5 0.687 0.887 0.898 0.685\\n\",\n \" airplane 128 6 0.82 0.833 0.927 0.675\\n\",\n \" bus 128 7 0.491 0.714 0.728 0.671\\n\",\n \" train 128 3 0.534 0.667 0.706 0.604\\n\",\n \" truck 128 12 1 0.332 0.473 0.297\\n\",\n \" boat 128 6 0.226 0.167 0.316 0.134\\n\",\n \" traffic light 128 14 0.734 0.2 0.202 0.139\\n\",\n \" stop sign 128 2 1 0.992 0.995 0.701\\n\",\n \" bench 128 9 0.839 0.582 0.62 0.365\\n\",\n \" bird 128 16 0.921 0.728 0.864 0.51\\n\",\n \" cat 128 4 0.875 1 0.995 0.791\\n\",\n \" dog 128 9 0.603 0.889 0.785 0.585\\n\",\n \" horse 128 2 0.597 1 0.995 0.518\\n\",\n \" elephant 128 17 0.849 0.765 0.9 0.679\\n\",\n \" bear 128 1 0.593 1 0.995 0.995\\n\",\n \" zebra 128 4 0.848 1 0.995 0.965\\n\",\n \" giraffe 128 9 0.72 1 0.951 0.722\\n\",\n \" backpack 128 6 0.589 0.333 0.376 0.232\\n\",\n \" umbrella 128 18 0.804 0.5 0.643 0.414\\n\",\n \" handbag 128 19 0.424 0.0526 0.165 0.0889\\n\",\n \" tie 128 7 0.804 0.714 0.674 0.476\\n\",\n \" suitcase 128 4 0.635 0.883 0.745 0.534\\n\",\n \" frisbee 128 5 0.675 0.8 0.759 0.688\\n\",\n \" skis 128 1 0.567 1 0.995 0.497\\n\",\n \" snowboard 128 7 0.742 0.714 0.747 0.5\\n\",\n \" sports ball 128 6 0.716 0.433 0.485 0.278\\n\",\n \" kite 128 10 0.817 0.45 0.569 0.184\\n\",\n \" baseball bat 128 4 0.551 0.25 0.353 0.175\\n\",\n \" baseball glove 128 7 0.624 0.429 0.429 0.293\\n\",\n \" skateboard 128 5 0.846 0.6 0.6 0.41\\n\",\n \" tennis racket 128 7 0.726 0.387 0.487 0.33\\n\",\n \" bottle 128 18 0.448 0.389 0.376 0.208\\n\",\n \" wine glass 128 16 0.743 0.362 0.584 0.333\\n\",\n \" cup 128 36 0.58 0.278 0.404 0.29\\n\",\n \" fork 128 6 0.527 0.167 0.246 0.184\\n\",\n \" knife 128 16 0.564 0.5 0.59 0.36\\n\",\n \" spoon 128 22 0.597 0.182 0.328 0.19\\n\",\n \" bowl 128 28 0.648 0.643 0.618 0.491\\n\",\n \" banana 128 1 0 0 0.124 0.0379\\n\",\n \" sandwich 128 2 0.249 0.5 0.308 0.308\\n\",\n \" orange 128 4 1 0.31 0.995 0.623\\n\",\n \" broccoli 128 11 0.374 0.182 0.249 0.203\\n\",\n \" carrot 128 24 0.648 0.458 0.572 0.362\\n\",\n \" hot dog 128 2 0.351 0.553 0.745 0.721\\n\",\n \" pizza 128 5 0.644 1 0.995 0.843\\n\",\n \" donut 128 14 0.657 1 0.94 0.864\\n\",\n \" cake 128 4 0.618 1 0.945 0.845\\n\",\n \" chair 128 35 0.506 0.514 0.442 0.239\\n\",\n \" couch 128 6 0.463 0.5 0.706 0.555\\n\",\n \" potted plant 128 14 0.65 0.643 0.711 0.472\\n\",\n \" bed 128 3 0.698 0.667 0.789 0.625\\n\",\n \" dining table 128 13 0.432 0.615 0.485 0.366\\n\",\n \" toilet 128 2 0.615 0.5 0.695 0.676\\n\",\n \" tv 128 2 0.373 0.62 0.745 0.696\\n\",\n \" laptop 128 3 1 0 0.451 0.361\\n\",\n \" mouse 128 2 1 0 0.0625 0.00625\\n\",\n \" remote 128 8 0.843 0.5 0.605 0.529\\n\",\n \" cell phone 128 8 0 0 0.0549 0.0393\\n\",\n \" microwave 128 3 0.435 0.667 0.806 0.718\\n\",\n \" oven 128 5 0.412 0.4 0.339 0.27\\n\",\n \" sink 128 6 0.35 0.167 0.182 0.129\\n\",\n \" refrigerator 128 5 0.589 0.4 0.604 0.452\\n\",\n \" book 128 29 0.629 0.103 0.346 0.178\\n\",\n \" clock 128 9 0.788 0.83 0.875 0.74\\n\",\n \" vase 128 2 0.376 1 0.828 0.795\\n\",\n \" scissors 128 1 1 0 0.249 0.0746\\n\",\n \" teddy bear 128 21 0.877 0.333 0.591 0.394\\n\",\n \" toothbrush 128 5 0.743 0.6 0.638 0.374\\n\",\n \"Speed: 5.3ms preprocess, 20.1ms inference, 0.0ms loss, 11.7ms postprocess per image\\n\",\n \"Results saved to \\u001b[1mruns/detect/val\\u001b[0m\\n\"\n ]\n }\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"metadata\": {\n \"id\": \"ZY2VXXXu74w5\"\n },\n \"source\": [\n \"# 3. Train\\n\",\n \"\\n\",\n \"
\\n\",\n \"\\n\",\n \"Train YOLOv8 on [Detect](https://docs.ultralytics.com/tasks/detect/), [Segment](https://docs.ultralytics.com/tasks/segment/), [Classify](https://docs.ultralytics.com/tasks/classify/) and [Pose](https://docs.ultralytics.com/tasks/pose/) datasets. See [YOLOv8 Train Docs](https://docs.ultralytics.com/modes/train/) for more information.\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"metadata\": {\n \"id\": \"1NcFxRcFdJ_O\",\n \"outputId\": \"b60a1f74-8035-4f9e-b4b0-604f9cf76231\",\n \"colab\": {\n \"base_uri\": \"https://localhost:8080/\"\n }\n },\n \"source\": [\n \"# Train YOLOv8n on COCO128 for 3 epochs\\n\",\n \"!yolo train model=yolov8n.pt data=coco128.yaml epochs=3 imgsz=640\"\n ],\n \"execution_count\": 4,\n \"outputs\": [\n {\n \"output_type\": \"stream\",\n \"name\": \"stdout\",\n \"text\": [\n \"Ultralytics YOLOv8.0.71 🚀 Python-3.9.16 torch-2.0.0+cu118 CUDA:0 (Tesla T4, 15102MiB)\\n\",\n \"\\u001b[34m\\u001b[1myolo/engine/trainer: \\u001b[0mtask=detect, mode=train, model=yolov8n.pt, data=coco128.yaml, epochs=3, patience=50, batch=16, imgsz=640, save=True, save_period=-1, cache=False, device=None, workers=8, project=None, name=None, exist_ok=False, pretrained=False, optimizer=SGD, verbose=True, seed=0, deterministic=True, single_cls=False, image_weights=False, rect=False, cos_lr=False, close_mosaic=0, resume=False, amp=True, overlap_mask=True, mask_ratio=4, dropout=0.0, val=True, split=val, save_json=False, save_hybrid=False, conf=None, iou=0.7, max_det=300, half=False, dnn=False, plots=True, source=None, show=False, save_txt=False, save_conf=False, save_crop=False, show_labels=True, show_conf=True, vid_stride=1, line_width=3, visualize=False, augment=False, agnostic_nms=False, classes=None, retina_masks=False, boxes=True, format=torchscript, keras=False, optimize=False, int8=False, dynamic=False, simplify=False, opset=None, workspace=4, nms=False, lr0=0.01, lrf=0.01, momentum=0.937, weight_decay=0.0005, warmup_epochs=3.0, warmup_momentum=0.8, warmup_bias_lr=0.1, box=7.5, cls=0.5, dfl=1.5, pose=12.0, kobj=1.0, label_smoothing=0.0, nbs=64, hsv_h=0.015, hsv_s=0.7, hsv_v=0.4, degrees=0.0, translate=0.1, scale=0.5, shear=0.0, perspective=0.0, flipud=0.0, fliplr=0.5, mosaic=1.0, mixup=0.0, copy_paste=0.0, cfg=None, v5loader=False, tracker=botsort.yaml, save_dir=runs/detect/train\\n\",\n \"\\n\",\n \" from n params module arguments \\n\",\n \" 0 -1 1 464 ultralytics.nn.modules.Conv [3, 16, 3, 2] \\n\",\n \" 1 -1 1 4672 ultralytics.nn.modules.Conv [16, 32, 3, 2] \\n\",\n \" 2 -1 1 7360 ultralytics.nn.modules.C2f [32, 32, 1, True] \\n\",\n \" 3 -1 1 18560 ultralytics.nn.modules.Conv [32, 64, 3, 2] \\n\",\n \" 4 -1 2 49664 ultralytics.nn.modules.C2f [64, 64, 2, True] \\n\",\n \" 5 -1 1 73984 ultralytics.nn.modules.Conv [64, 128, 3, 2] \\n\",\n \" 6 -1 2 197632 ultralytics.nn.modules.C2f [128, 128, 2, True] \\n\",\n \" 7 -1 1 295424 ultralytics.nn.modules.Conv [128, 256, 3, 2] \\n\",\n \" 8 -1 1 460288 ultralytics.nn.modules.C2f [256, 256, 1, True] \\n\",\n \" 9 -1 1 164608 ultralytics.nn.modules.SPPF [256, 256, 5] \\n\",\n \" 10 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest'] \\n\",\n \" 11 [-1, 6] 1 0 ultralytics.nn.modules.Concat [1] \\n\",\n \" 12 -1 1 148224 ultralytics.nn.modules.C2f [384, 128, 1] \\n\",\n \" 13 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest'] \\n\",\n \" 14 [-1, 4] 1 0 ultralytics.nn.modules.Concat [1] \\n\",\n \" 15 -1 1 37248 ultralytics.nn.modules.C2f [192, 64, 1] \\n\",\n \" 16 -1 1 36992 ultralytics.nn.modules.Conv [64, 64, 3, 2] \\n\",\n \" 17 [-1, 12] 1 0 ultralytics.nn.modules.Concat [1] \\n\",\n \" 18 -1 1 123648 ultralytics.nn.modules.C2f [192, 128, 1] \\n\",\n \" 19 -1 1 147712 ultralytics.nn.modules.Conv [128, 128, 3, 2] \\n\",\n \" 20 [-1, 9] 1 0 ultralytics.nn.modules.Concat [1] \\n\",\n \" 21 -1 1 493056 ultralytics.nn.modules.C2f [384, 256, 1] \\n\",\n \" 22 [15, 18, 21] 1 897664 ultralytics.nn.modules.Detect [80, [64, 128, 256]] \\n\",\n \"Model summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPs\\n\",\n \"\\n\",\n \"Transferred 355/355 items from pretrained weights\\n\",\n \"\\u001b[34m\\u001b[1mTensorBoard: \\u001b[0mStart with 'tensorboard --logdir runs/detect/train', view at http://localhost:6006/\\n\",\n \"\\u001b[34m\\u001b[1mAMP: \\u001b[0mrunning Automatic Mixed Precision (AMP) checks with YOLOv8n...\\n\",\n \"\\u001b[34m\\u001b[1mAMP: \\u001b[0mchecks passed ✅\\n\",\n \"\\u001b[34m\\u001b[1moptimizer:\\u001b[0m SGD(lr=0.01) with parameter groups 57 weight(decay=0.0), 64 weight(decay=0.0005), 63 bias\\n\",\n \"\\u001b[34m\\u001b[1mtrain: \\u001b[0mScanning /content/datasets/coco128/labels/train2017.cache... 126 images, 2 backgrounds, 80 corrupt: 100% 128/128 [00:00\\n\"\n ],\n \"metadata\": {\n \"id\": \"Phm9ccmOKye5\"\n }\n },\n {\n \"cell_type\": \"markdown\",\n \"source\": [\n \"## 1. Detection\\n\",\n \"\\n\",\n \"YOLOv8 _detection_ models have no suffix and are the default YOLOv8 models, i.e. `yolov8n.pt` and are pretrained on COCO. See [Detection Docs](https://docs.ultralytics.com/tasks/detect/) for full details.\\n\"\n ],\n \"metadata\": {\n \"id\": \"yq26lwpYK1lq\"\n }\n },\n {\n \"cell_type\": \"code\",\n \"source\": [\n \"# Load YOLOv8n, train it on COCO128 for 3 epochs and predict an image with it\\n\",\n \"from ultralytics import YOLO\\n\",\n \"\\n\",\n \"model = YOLO('yolov8n.pt') # load a pretrained YOLOv8n detection model\\n\",\n \"model.train(data='coco128.yaml', epochs=3) # train the model\\n\",\n \"model('https://ultralytics.com/images/bus.jpg') # predict on an image\"\n ],\n \"metadata\": {\n \"id\": \"8Go5qqS9LbC5\"\n },\n \"execution_count\": null,\n \"outputs\": []\n },\n {\n \"cell_type\": \"markdown\",\n \"source\": [\n \"## 2. Segmentation\\n\",\n \"\\n\",\n \"YOLOv8 _segmentation_ models use the `-seg` suffix, i.e. `yolov8n-seg.pt` and are pretrained on COCO. See [Segmentation Docs](https://docs.ultralytics.com/tasks/segment/) for full details.\\n\"\n ],\n \"metadata\": {\n \"id\": \"7ZW58jUzK66B\"\n }\n },\n {\n \"cell_type\": \"code\",\n \"source\": [\n \"# Load YOLOv8n-seg, train it on COCO128-seg for 3 epochs and predict an image with it\\n\",\n \"from ultralytics import YOLO\\n\",\n \"\\n\",\n \"model = YOLO('yolov8n-seg.pt') # load a pretrained YOLOv8n segmentation model\\n\",\n \"model.train(data='coco128-seg.yaml', epochs=3) # train the model\\n\",\n \"model('https://ultralytics.com/images/bus.jpg') # predict on an image\"\n ],\n \"metadata\": {\n \"id\": \"WFPJIQl_L5HT\"\n },\n \"execution_count\": null,\n \"outputs\": []\n },\n {\n \"cell_type\": \"markdown\",\n \"source\": [\n \"## 3. Classification\\n\",\n \"\\n\",\n \"YOLOv8 _classification_ models use the `-cls` suffix, i.e. `yolov8n-cls.pt` and are pretrained on ImageNet. See [Classification Docs](https://docs.ultralytics.com/tasks/classify/) for full details.\\n\"\n ],\n \"metadata\": {\n \"id\": \"ax3p94VNK9zR\"\n }\n },\n {\n \"cell_type\": \"code\",\n \"source\": [\n \"# Load YOLOv8n-cls, train it on mnist160 for 3 epochs and predict an image with it\\n\",\n \"from ultralytics import YOLO\\n\",\n \"\\n\",\n \"model = YOLO('yolov8n-cls.pt') # load a pretrained YOLOv8n classification model\\n\",\n \"model.train(data='mnist160', epochs=3) # train the model\\n\",\n \"model('https://ultralytics.com/images/bus.jpg') # predict on an image\"\n ],\n \"metadata\": {\n \"id\": \"5q9Zu6zlL5rS\"\n },\n \"execution_count\": null,\n \"outputs\": []\n },\n {\n \"cell_type\": \"markdown\",\n \"source\": [\n \"## 4. Pose\\n\",\n \"\\n\",\n \"YOLOv8 _pose_ models use the `-pose` suffix, i.e. `yolov8n-pose.pt` and are pretrained on COCO Keypoints. See [Pose Docs](https://docs.ultralytics.com/tasks/pose/) for full details.\"\n ],\n \"metadata\": {\n \"id\": \"SpIaFLiO11TG\"\n }\n },\n {\n \"cell_type\": \"code\",\n \"source\": [\n \"# Load YOLOv8n-pose, train it on COCO8-pose for 3 epochs and predict an image with it\\n\",\n \"from ultralytics import YOLO\\n\",\n \"\\n\",\n \"model = YOLO('yolov8n-pose.pt') # load a pretrained YOLOv8n classification model\\n\",\n \"model.train(data='coco8-pose.yaml', epochs=3) # train the model\\n\",\n \"model('https://ultralytics.com/images/bus.jpg') # predict on an image\"\n ],\n \"metadata\": {\n \"id\": \"si4aKFNg19vX\"\n },\n \"execution_count\": null,\n \"outputs\": []\n },\n {\n \"cell_type\": \"markdown\",\n \"metadata\": {\n \"id\": \"IEijrePND_2I\"\n },\n \"source\": [\n \"# Appendix\\n\",\n \"\\n\",\n \"Additional content below.\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"source\": [\n \"# Git clone and run tests on updates branch\\n\",\n \"!git clone https://github.com/ultralytics/ultralytics -b updates\\n\",\n \"%pip install -qe ultralytics\\n\",\n \"!pytest ultralytics/tests\"\n ],\n \"metadata\": {\n \"id\": \"uRKlwxSJdhd1\"\n },\n \"execution_count\": null,\n \"outputs\": []\n },\n {\n \"cell_type\": \"code\",\n \"source\": [\n \"# Validate multiple models\\n\",\n \"for x in 'nsmlx':\\n\",\n \" !yolo val model=yolov8{x}.pt data=coco.yaml\"\n ],\n \"metadata\": {\n \"id\": \"Wdc6t_bfzDDk\"\n },\n \"execution_count\": null,\n \"outputs\": []\n }\n ]\n}\n"
},
{
"path": "lib/python3.7/site-packages/_distutils_hack/__init__.py",
"content": "# don't import any costly modules\nimport sys\nimport os\n\n\nis_pypy = '__pypy__' in sys.builtin_module_names\n\n\ndef warn_distutils_present():\n if 'distutils' not in sys.modules:\n return\n if is_pypy and sys.version_info < (3, 7):\n # PyPy for 3.6 unconditionally imports distutils, so bypass the warning\n # https://foss.heptapod.net/pypy/pypy/-/blob/be829135bc0d758997b3566062999ee8b23872b4/lib-python/3/site.py#L250\n return\n import warnings\n\n warnings.warn(\n \"Distutils was imported before Setuptools, but importing Setuptools \"\n \"also replaces the `distutils` module in `sys.modules`. This may lead \"\n \"to undesirable behaviors or errors. To avoid these issues, avoid \"\n \"using distutils directly, ensure that setuptools is installed in the \"\n \"traditional way (e.g. not an editable install), and/or make sure \"\n \"that setuptools is always imported before distutils.\"\n )\n\n\ndef clear_distutils():\n if 'distutils' not in sys.modules:\n return\n import warnings\n\n warnings.warn(\"Setuptools is replacing distutils.\")\n mods = [\n name\n for name in sys.modules\n if name == \"distutils\" or name.startswith(\"distutils.\")\n ]\n for name in mods:\n del sys.modules[name]\n\n\ndef enabled():\n \"\"\"\n Allow selection of distutils by environment variable.\n \"\"\"\n which = os.environ.get('SETUPTOOLS_USE_DISTUTILS', 'local')\n return which == 'local'\n\n\ndef ensure_local_distutils():\n import importlib\n\n clear_distutils()\n\n # With the DistutilsMetaFinder in place,\n # perform an import to cause distutils to be\n # loaded from setuptools._distutils. Ref #2906.\n with shim():\n importlib.import_module('distutils')\n\n # check that submodules load as expected\n core = importlib.import_module('distutils.core')\n assert '_distutils' in core.__file__, core.__file__\n assert 'setuptools._distutils.log' not in sys.modules\n\n\ndef do_override():\n \"\"\"\n Ensure that the local copy of distutils is preferred over stdlib.\n\n See https://github.com/pypa/setuptools/issues/417#issuecomment-392298401\n for more motivation.\n \"\"\"\n if enabled():\n warn_distutils_present()\n ensure_local_distutils()\n\n\nclass _TrivialRe:\n def __init__(self, *patterns):\n self._patterns = patterns\n\n def match(self, string):\n return all(pat in string for pat in self._patterns)\n\n\nclass DistutilsMetaFinder:\n def find_spec(self, fullname, path, target=None):\n # optimization: only consider top level modules and those\n # found in the CPython test suite.\n if path is not None and not fullname.startswith('test.'):\n return\n\n method_name = 'spec_for_{fullname}'.format(**locals())\n method = getattr(self, method_name, lambda: None)\n return method()\n\n def spec_for_distutils(self):\n if self.is_cpython():\n return\n\n import importlib\n import importlib.abc\n import importlib.util\n\n try:\n mod = importlib.import_module('setuptools._distutils')\n except Exception:\n # There are a couple of cases where setuptools._distutils\n # may not be present:\n # - An older Setuptools without a local distutils is\n # taking precedence. Ref #2957.\n # - Path manipulation during sitecustomize removes\n # setuptools from the path but only after the hook\n # has been loaded. Ref #2980.\n # In either case, fall back to stdlib behavior.\n return\n\n class DistutilsLoader(importlib.abc.Loader):\n def create_module(self, spec):\n mod.__name__ = 'distutils'\n return mod\n\n def exec_module(self, module):\n pass\n\n return importlib.util.spec_from_loader(\n 'distutils', DistutilsLoader(), origin=mod.__file__\n )\n\n @staticmethod\n def is_cpython():\n \"\"\"\n Suppress supplying distutils for CPython (build and tests).\n Ref #2965 and #3007.\n \"\"\"\n return os.path.isfile('pybuilddir.txt')\n\n def spec_for_pip(self):\n \"\"\"\n Ensure stdlib distutils when running under pip.\n See pypa/pip#8761 for rationale.\n \"\"\"\n if self.pip_imported_during_build():\n return\n clear_distutils()\n self.spec_for_distutils = lambda: None\n\n @classmethod\n def pip_imported_during_build(cls):\n \"\"\"\n Detect if pip is being imported in a build script. Ref #2355.\n \"\"\"\n import traceback\n\n return any(\n cls.frame_file_is_setup(frame) for frame, line in traceback.walk_stack(None)\n )\n\n @staticmethod\n def frame_file_is_setup(frame):\n \"\"\"\n Return True if the indicated frame suggests a setup.py file.\n \"\"\"\n # some frames may not have __file__ (#2940)\n return frame.f_globals.get('__file__', '').endswith('setup.py')\n\n def spec_for_sensitive_tests(self):\n \"\"\"\n Ensure stdlib distutils when running select tests under CPython.\n\n python/cpython#91169\n \"\"\"\n clear_distutils()\n self.spec_for_distutils = lambda: None\n\n sensitive_tests = (\n [\n 'test.test_distutils',\n 'test.test_peg_generator',\n 'test.test_importlib',\n ]\n if sys.version_info < (3, 10)\n else [\n 'test.test_distutils',\n ]\n )\n\n\nfor name in DistutilsMetaFinder.sensitive_tests:\n setattr(\n DistutilsMetaFinder,\n f'spec_for_{name}',\n DistutilsMetaFinder.spec_for_sensitive_tests,\n )\n\n\nDISTUTILS_FINDER = DistutilsMetaFinder()\n\n\ndef add_shim():\n DISTUTILS_FINDER in sys.meta_path or insert_shim()\n\n\nclass shim:\n def __enter__(self):\n insert_shim()\n\n def __exit__(self, exc, value, tb):\n remove_shim()\n\n\ndef insert_shim():\n sys.meta_path.insert(0, DISTUTILS_FINDER)\n\n\ndef remove_shim():\n try:\n sys.meta_path.remove(DISTUTILS_FINDER)\n except ValueError:\n pass\n"
},
{
"path": "lib/python3.7/site-packages/_distutils_hack/override.py",
"content": "__import__('_distutils_hack').do_override()\n"
},
{
"path": "lib/python3.7/site-packages/_virtualenv.pth",
"content": "import _virtualenv"
},
{
"path": "lib/python3.7/site-packages/_virtualenv.py",
"content": "\"\"\"Patches that are applied at runtime to the virtual environment\"\"\"\n# -*- coding: utf-8 -*-\n\nimport os\nimport sys\n\nVIRTUALENV_PATCH_FILE = os.path.join(__file__)\n\n\ndef patch_dist(dist):\n \"\"\"\n Distutils allows user to configure some arguments via a configuration file:\n https://docs.python.org/3/install/index.html#distutils-configuration-files\n\n Some of this arguments though don't make sense in context of the virtual environment files, let's fix them up.\n \"\"\"\n # we cannot allow some install config as that would get packages installed outside of the virtual environment\n old_parse_config_files = dist.Distribution.parse_config_files\n\n def parse_config_files(self, *args, **kwargs):\n result = old_parse_config_files(self, *args, **kwargs)\n install = self.get_option_dict(\"install\")\n\n if \"prefix\" in install: # the prefix governs where to install the libraries\n install[\"prefix\"] = VIRTUALENV_PATCH_FILE, os.path.abspath(sys.prefix)\n for base in (\"purelib\", \"platlib\", \"headers\", \"scripts\", \"data\"):\n key = \"install_{}\".format(base)\n if key in install: # do not allow global configs to hijack venv paths\n install.pop(key, None)\n return result\n\n dist.Distribution.parse_config_files = parse_config_files\n\n\n# Import hook that patches some modules to ignore configuration values that break package installation in case\n# of virtual environments.\n_DISTUTILS_PATCH = \"distutils.dist\", \"setuptools.dist\"\nif sys.version_info > (3, 4):\n # https://docs.python.org/3/library/importlib.html#setting-up-an-importer\n\n class _Finder:\n \"\"\"A meta path finder that allows patching the imported distutils modules\"\"\"\n\n fullname = None\n\n # lock[0] is threading.Lock(), but initialized lazily to avoid importing threading very early at startup,\n # because there are gevent-based applications that need to be first to import threading by themselves.\n # See https://github.com/pypa/virtualenv/issues/1895 for details.\n lock = []\n\n def find_spec(self, fullname, path, target=None): # noqa: U100\n if fullname in _DISTUTILS_PATCH and self.fullname is None:\n # initialize lock[0] lazily\n if len(self.lock) == 0:\n import threading\n\n lock = threading.Lock()\n # there is possibility that two threads T1 and T2 are simultaneously running into find_spec,\n # observing .lock as empty, and further going into hereby initialization. However due to the GIL,\n # list.append() operation is atomic and this way only one of the threads will \"win\" to put the lock\n # - that every thread will use - into .lock[0].\n # https://docs.python.org/3/faq/library.html#what-kinds-of-global-value-mutation-are-thread-safe\n self.lock.append(lock)\n\n from functools import partial\n from importlib.util import find_spec\n\n with self.lock[0]:\n self.fullname = fullname\n try:\n spec = find_spec(fullname, path)\n if spec is not None:\n # https://www.python.org/dev/peps/pep-0451/#how-loading-will-work\n is_new_api = hasattr(spec.loader, \"exec_module\")\n func_name = \"exec_module\" if is_new_api else \"load_module\"\n old = getattr(spec.loader, func_name)\n func = self.exec_module if is_new_api else self.load_module\n if old is not func:\n try:\n setattr(spec.loader, func_name, partial(func, old))\n except AttributeError:\n pass # C-Extension loaders are r/o such as zipimporter with int:\n \"\"\"This is an internal API only meant for use by pip's own console scripts.\n\n For additional details, see https://github.com/pypa/pip/issues/7498.\n \"\"\"\n from pip._internal.utils.entrypoints import _wrapper\n\n return _wrapper(args)\n"
},
{
"path": "lib/python3.7/site-packages/pip/__main__.py",
"content": "import os\nimport sys\nimport warnings\n\n# Remove '' and current working directory from the first entry\n# of sys.path, if present to avoid using current directory\n# in pip commands check, freeze, install, list and show,\n# when invoked as python -m pip \nif sys.path[0] in (\"\", os.getcwd()):\n sys.path.pop(0)\n\n# If we are running from a wheel, add the wheel to sys.path\n# This allows the usage python pip-*.whl/pip install pip-*.whl\nif __package__ == \"\":\n # __file__ is pip-*.whl/pip/__main__.py\n # first dirname call strips of '/__main__.py', second strips off '/pip'\n # Resulting path is the name of the wheel itself\n # Add that to sys.path so we can import pip\n path = os.path.dirname(os.path.dirname(__file__))\n sys.path.insert(0, path)\n\nif __name__ == \"__main__\":\n # Work around the error reported in #9540, pending a proper fix.\n # Note: It is essential the warning filter is set *before* importing\n # pip, as the deprecation happens at import time, not runtime.\n warnings.filterwarnings(\n \"ignore\", category=DeprecationWarning, module=\".*packaging\\\\.version\"\n )\n from pip._internal.cli.main import main as _main\n\n sys.exit(_main())\n"
},
{
"path": "lib/python3.7/site-packages/pip/__pip-runner__.py",
"content": "\"\"\"Execute exactly this copy of pip, within a different environment.\n\nThis file is named as it is, to ensure that this module can't be imported via\nan import statement.\n\"\"\"\n\n# /!\\ This version compatibility check section must be Python 2 compatible. /!\\\n\nimport sys\n\n# Copied from setup.py\nPYTHON_REQUIRES = (3, 7)\n\n\ndef version_str(version): # type: ignore\n return \".\".join(str(v) for v in version)\n\n\nif sys.version_info[:2] < PYTHON_REQUIRES:\n raise SystemExit(\n \"This version of pip does not support python {} (requires >={}).\".format(\n version_str(sys.version_info[:2]), version_str(PYTHON_REQUIRES)\n )\n )\n\n# From here on, we can use Python 3 features, but the syntax must remain\n# Python 2 compatible.\n\nimport runpy # noqa: E402\nfrom importlib.machinery import PathFinder # noqa: E402\nfrom os.path import dirname # noqa: E402\n\nPIP_SOURCES_ROOT = dirname(dirname(__file__))\n\n\nclass PipImportRedirectingFinder:\n @classmethod\n def find_spec(self, fullname, path=None, target=None): # type: ignore\n if fullname != \"pip\":\n return None\n\n spec = PathFinder.find_spec(fullname, [PIP_SOURCES_ROOT], target)\n assert spec, (PIP_SOURCES_ROOT, fullname)\n return spec\n\n\nsys.meta_path.insert(0, PipImportRedirectingFinder())\n\nassert __name__ == \"__main__\", \"Cannot run __pip-runner__.py as a non-main module\"\nrunpy.run_module(\"pip\", run_name=\"__main__\", alter_sys=True)\n"
},
{
"path": "lib/python3.7/site-packages/pip/_internal/__init__.py",
"content": "from typing import List, Optional\n\nimport pip._internal.utils.inject_securetransport # noqa\nfrom pip._internal.utils import _log\n\n# init_logging() must be called before any call to logging.getLogger()\n# which happens at import of most modules.\n_log.init_logging()\n\n\ndef main(args: (Optional[List[str]]) = None) -> int:\n \"\"\"This is preserved for old console scripts that may still be referencing\n it.\n\n For additional details, see https://github.com/pypa/pip/issues/7498.\n \"\"\"\n from pip._internal.utils.entrypoints import _wrapper\n\n return _wrapper(args)\n"
},
{
"path": "lib/python3.7/site-packages/pip/_internal/build_env.py",
"content": "\"\"\"Build Environment used for isolation during sdist building\n\"\"\"\n\nimport logging\nimport os\nimport pathlib\nimport site\nimport sys\nimport textwrap\nfrom collections import OrderedDict\nfrom sysconfig import get_paths\nfrom types import TracebackType\nfrom typing import TYPE_CHECKING, Iterable, List, Optional, Set, Tuple, Type\n\nfrom pip._vendor.certifi import where\nfrom pip._vendor.packaging.requirements import Requirement\nfrom pip._vendor.packaging.version import Version\n\nfrom pip import __file__ as pip_location\nfrom pip._internal.cli.spinners import open_spinner\nfrom pip._internal.locations import get_platlib, get_prefixed_libs, get_purelib\nfrom pip._internal.metadata import get_default_environment, get_environment\nfrom pip._internal.utils.subprocess import call_subprocess\nfrom pip._internal.utils.temp_dir import TempDirectory, tempdir_kinds\n\nif TYPE_CHECKING:\n from pip._internal.index.package_finder import PackageFinder\n\nlogger = logging.getLogger(__name__)\n\n\nclass _Prefix:\n def __init__(self, path: str) -> None:\n self.path = path\n self.setup = False\n self.bin_dir = get_paths(\n \"nt\" if os.name == \"nt\" else \"posix_prefix\",\n vars={\"base\": path, \"platbase\": path},\n )[\"scripts\"]\n self.lib_dirs = get_prefixed_libs(path)\n\n\ndef get_runnable_pip() -> str:\n \"\"\"Get a file to pass to a Python executable, to run the currently-running pip.\n\n This is used to run a pip subprocess, for installing requirements into the build\n environment.\n \"\"\"\n source = pathlib.Path(pip_location).resolve().parent\n\n if not source.is_dir():\n # This would happen if someone is using pip from inside a zip file. In that\n # case, we can use that directly.\n return str(source)\n\n return os.fsdecode(source / \"__pip-runner__.py\")\n\n\ndef _get_system_sitepackages() -> Set[str]:\n \"\"\"Get system site packages\n\n Usually from site.getsitepackages,\n but fallback on `get_purelib()/get_platlib()` if unavailable\n (e.g. in a virtualenv created by virtualenv<20)\n\n Returns normalized set of strings.\n \"\"\"\n if hasattr(site, \"getsitepackages\"):\n system_sites = site.getsitepackages()\n else:\n # virtualenv < 20 overwrites site.py without getsitepackages\n # fallback on get_purelib/get_platlib.\n # this is known to miss things, but shouldn't in the cases\n # where getsitepackages() has been removed (inside a virtualenv)\n system_sites = [get_purelib(), get_platlib()]\n return {os.path.normcase(path) for path in system_sites}\n\n\nclass BuildEnvironment:\n \"\"\"Creates and manages an isolated environment to install build deps\"\"\"\n\n def __init__(self) -> None:\n temp_dir = TempDirectory(kind=tempdir_kinds.BUILD_ENV, globally_managed=True)\n\n self._prefixes = OrderedDict(\n (name, _Prefix(os.path.join(temp_dir.path, name)))\n for name in (\"normal\", \"overlay\")\n )\n\n self._bin_dirs: List[str] = []\n self._lib_dirs: List[str] = []\n for prefix in reversed(list(self._prefixes.values())):\n self._bin_dirs.append(prefix.bin_dir)\n self._lib_dirs.extend(prefix.lib_dirs)\n\n # Customize site to:\n # - ensure .pth files are honored\n # - prevent access to system site packages\n system_sites = _get_system_sitepackages()\n\n self._site_dir = os.path.join(temp_dir.path, \"site\")\n if not os.path.exists(self._site_dir):\n os.mkdir(self._site_dir)\n with open(\n os.path.join(self._site_dir, \"sitecustomize.py\"), \"w\", encoding=\"utf-8\"\n ) as fp:\n fp.write(\n textwrap.dedent(\n \"\"\"\n import os, site, sys\n\n # First, drop system-sites related paths.\n original_sys_path = sys.path[:]\n known_paths = set()\n for path in {system_sites!r}:\n site.addsitedir(path, known_paths=known_paths)\n system_paths = set(\n os.path.normcase(path)\n for path in sys.path[len(original_sys_path):]\n )\n original_sys_path = [\n path for path in original_sys_path\n if os.path.normcase(path) not in system_paths\n ]\n sys.path = original_sys_path\n\n # Second, add lib directories.\n # ensuring .pth file are processed.\n for path in {lib_dirs!r}:\n assert not path in sys.path\n site.addsitedir(path)\n \"\"\"\n ).format(system_sites=system_sites, lib_dirs=self._lib_dirs)\n )\n\n def __enter__(self) -> None:\n self._save_env = {\n name: os.environ.get(name, None)\n for name in (\"PATH\", \"PYTHONNOUSERSITE\", \"PYTHONPATH\")\n }\n\n path = self._bin_dirs[:]\n old_path = self._save_env[\"PATH\"]\n if old_path:\n path.extend(old_path.split(os.pathsep))\n\n pythonpath = [self._site_dir]\n\n os.environ.update(\n {\n \"PATH\": os.pathsep.join(path),\n \"PYTHONNOUSERSITE\": \"1\",\n \"PYTHONPATH\": os.pathsep.join(pythonpath),\n }\n )\n\n def __exit__(\n self,\n exc_type: Optional[Type[BaseException]],\n exc_val: Optional[BaseException],\n exc_tb: Optional[TracebackType],\n ) -> None:\n for varname, old_value in self._save_env.items():\n if old_value is None:\n os.environ.pop(varname, None)\n else:\n os.environ[varname] = old_value\n\n def check_requirements(\n self, reqs: Iterable[str]\n ) -> Tuple[Set[Tuple[str, str]], Set[str]]:\n \"\"\"Return 2 sets:\n - conflicting requirements: set of (installed, wanted) reqs tuples\n - missing requirements: set of reqs\n \"\"\"\n missing = set()\n conflicting = set()\n if reqs:\n env = (\n get_environment(self._lib_dirs)\n if hasattr(self, \"_lib_dirs\")\n else get_default_environment()\n )\n for req_str in reqs:\n req = Requirement(req_str)\n # We're explicitly evaluating with an empty extra value, since build\n # environments are not provided any mechanism to select specific extras.\n if req.marker is not None and not req.marker.evaluate({\"extra\": \"\"}):\n continue\n dist = env.get_distribution(req.name)\n if not dist:\n missing.add(req_str)\n continue\n if isinstance(dist.version, Version):\n installed_req_str = f\"{req.name}=={dist.version}\"\n else:\n installed_req_str = f\"{req.name}==={dist.version}\"\n if not req.specifier.contains(dist.version, prereleases=True):\n conflicting.add((installed_req_str, req_str))\n # FIXME: Consider direct URL?\n return conflicting, missing\n\n def install_requirements(\n self,\n finder: \"PackageFinder\",\n requirements: Iterable[str],\n prefix_as_string: str,\n *,\n kind: str,\n ) -> None:\n prefix = self._prefixes[prefix_as_string]\n assert not prefix.setup\n prefix.setup = True\n if not requirements:\n return\n self._install_requirements(\n get_runnable_pip(),\n finder,\n requirements,\n prefix,\n kind=kind,\n )\n\n @staticmethod\n def _install_requirements(\n pip_runnable: str,\n finder: \"PackageFinder\",\n requirements: Iterable[str],\n prefix: _Prefix,\n *,\n kind: str,\n ) -> None:\n args: List[str] = [\n sys.executable,\n pip_runnable,\n \"install\",\n \"--ignore-installed\",\n \"--no-user\",\n \"--prefix\",\n prefix.path,\n \"--no-warn-script-location\",\n ]\n if logger.getEffectiveLevel() <= logging.DEBUG:\n args.append(\"-v\")\n for format_control in (\"no_binary\", \"only_binary\"):\n formats = getattr(finder.format_control, format_control)\n args.extend(\n (\n \"--\" + format_control.replace(\"_\", \"-\"),\n \",\".join(sorted(formats or {\":none:\"})),\n )\n )\n\n index_urls = finder.index_urls\n if index_urls:\n args.extend([\"-i\", index_urls[0]])\n for extra_index in index_urls[1:]:\n args.extend([\"--extra-index-url\", extra_index])\n else:\n args.append(\"--no-index\")\n for link in finder.find_links:\n args.extend([\"--find-links\", link])\n\n for host in finder.trusted_hosts:\n args.extend([\"--trusted-host\", host])\n if finder.allow_all_prereleases:\n args.append(\"--pre\")\n if finder.prefer_binary:\n args.append(\"--prefer-binary\")\n args.append(\"--\")\n args.extend(requirements)\n extra_environ = {\"_PIP_STANDALONE_CERT\": where()}\n with open_spinner(f\"Installing {kind}\") as spinner:\n call_subprocess(\n args,\n command_desc=f\"pip subprocess to install {kind}\",\n spinner=spinner,\n extra_environ=extra_environ,\n )\n\n\nclass NoOpBuildEnvironment(BuildEnvironment):\n \"\"\"A no-op drop-in replacement for BuildEnvironment\"\"\"\n\n def __init__(self) -> None:\n pass\n\n def __enter__(self) -> None:\n pass\n\n def __exit__(\n self,\n exc_type: Optional[Type[BaseException]],\n exc_val: Optional[BaseException],\n exc_tb: Optional[TracebackType],\n ) -> None:\n pass\n\n def cleanup(self) -> None:\n pass\n\n def install_requirements(\n self,\n finder: \"PackageFinder\",\n requirements: Iterable[str],\n prefix_as_string: str,\n *,\n kind: str,\n ) -> None:\n raise NotImplementedError()\n"
},
{
"path": "lib/python3.7/site-packages/pip/_internal/cache.py",
"content": "\"\"\"Cache Management\n\"\"\"\n\nimport hashlib\nimport json\nimport logging\nimport os\nfrom pathlib import Path\nfrom typing import Any, Dict, List, Optional, Set\n\nfrom pip._vendor.packaging.tags import Tag, interpreter_name, interpreter_version\nfrom pip._vendor.packaging.utils import canonicalize_name\n\nfrom pip._internal.exceptions import InvalidWheelFilename\nfrom pip._internal.models.direct_url import DirectUrl\nfrom pip._internal.models.format_control import FormatControl\nfrom pip._internal.models.link import Link\nfrom pip._internal.models.wheel import Wheel\nfrom pip._internal.utils.temp_dir import TempDirectory, tempdir_kinds\nfrom pip._internal.utils.urls import path_to_url\n\nlogger = logging.getLogger(__name__)\n\nORIGIN_JSON_NAME = \"origin.json\"\n\n\ndef _hash_dict(d: Dict[str, str]) -> str:\n \"\"\"Return a stable sha224 of a dictionary.\"\"\"\n s = json.dumps(d, sort_keys=True, separators=(\",\", \":\"), ensure_ascii=True)\n return hashlib.sha224(s.encode(\"ascii\")).hexdigest()\n\n\nclass Cache:\n \"\"\"An abstract class - provides cache directories for data from links\n\n\n :param cache_dir: The root of the cache.\n :param format_control: An object of FormatControl class to limit\n binaries being read from the cache.\n :param allowed_formats: which formats of files the cache should store.\n ('binary' and 'source' are the only allowed values)\n \"\"\"\n\n def __init__(\n self, cache_dir: str, format_control: FormatControl, allowed_formats: Set[str]\n ) -> None:\n super().__init__()\n assert not cache_dir or os.path.isabs(cache_dir)\n self.cache_dir = cache_dir or None\n self.format_control = format_control\n self.allowed_formats = allowed_formats\n\n _valid_formats = {\"source\", \"binary\"}\n assert self.allowed_formats.union(_valid_formats) == _valid_formats\n\n def _get_cache_path_parts(self, link: Link) -> List[str]:\n \"\"\"Get parts of part that must be os.path.joined with cache_dir\"\"\"\n\n # We want to generate an url to use as our cache key, we don't want to\n # just re-use the URL because it might have other items in the fragment\n # and we don't care about those.\n key_parts = {\"url\": link.url_without_fragment}\n if link.hash_name is not None and link.hash is not None:\n key_parts[link.hash_name] = link.hash\n if link.subdirectory_fragment:\n key_parts[\"subdirectory\"] = link.subdirectory_fragment\n\n # Include interpreter name, major and minor version in cache key\n # to cope with ill-behaved sdists that build a different wheel\n # depending on the python version their setup.py is being run on,\n # and don't encode the difference in compatibility tags.\n # https://github.com/pypa/pip/issues/7296\n key_parts[\"interpreter_name\"] = interpreter_name()\n key_parts[\"interpreter_version\"] = interpreter_version()\n\n # Encode our key url with sha224, we'll use this because it has similar\n # security properties to sha256, but with a shorter total output (and\n # thus less secure). However the differences don't make a lot of\n # difference for our use case here.\n hashed = _hash_dict(key_parts)\n\n # We want to nest the directories some to prevent having a ton of top\n # level directories where we might run out of sub directories on some\n # FS.\n parts = [hashed[:2], hashed[2:4], hashed[4:6], hashed[6:]]\n\n return parts\n\n def _get_candidates(self, link: Link, canonical_package_name: str) -> List[Any]:\n can_not_cache = not self.cache_dir or not canonical_package_name or not link\n if can_not_cache:\n return []\n\n formats = self.format_control.get_allowed_formats(canonical_package_name)\n if not self.allowed_formats.intersection(formats):\n return []\n\n candidates = []\n path = self.get_path_for_link(link)\n if os.path.isdir(path):\n for candidate in os.listdir(path):\n candidates.append((candidate, path))\n return candidates\n\n def get_path_for_link(self, link: Link) -> str:\n \"\"\"Return a directory to store cached items in for link.\"\"\"\n raise NotImplementedError()\n\n def get(\n self,\n link: Link,\n package_name: Optional[str],\n supported_tags: List[Tag],\n ) -> Link:\n \"\"\"Returns a link to a cached item if it exists, otherwise returns the\n passed link.\n \"\"\"\n raise NotImplementedError()\n\n\nclass SimpleWheelCache(Cache):\n \"\"\"A cache of wheels for future installs.\"\"\"\n\n def __init__(self, cache_dir: str, format_control: FormatControl) -> None:\n super().__init__(cache_dir, format_control, {\"binary\"})\n\n def get_path_for_link(self, link: Link) -> str:\n \"\"\"Return a directory to store cached wheels for link\n\n Because there are M wheels for any one sdist, we provide a directory\n to cache them in, and then consult that directory when looking up\n cache hits.\n\n We only insert things into the cache if they have plausible version\n numbers, so that we don't contaminate the cache with things that were\n not unique. E.g. ./package might have dozens of installs done for it\n and build a version of 0.0...and if we built and cached a wheel, we'd\n end up using the same wheel even if the source has been edited.\n\n :param link: The link of the sdist for which this will cache wheels.\n \"\"\"\n parts = self._get_cache_path_parts(link)\n assert self.cache_dir\n # Store wheels within the root cache_dir\n return os.path.join(self.cache_dir, \"wheels\", *parts)\n\n def get(\n self,\n link: Link,\n package_name: Optional[str],\n supported_tags: List[Tag],\n ) -> Link:\n candidates = []\n\n if not package_name:\n return link\n\n canonical_package_name = canonicalize_name(package_name)\n for wheel_name, wheel_dir in self._get_candidates(link, canonical_package_name):\n try:\n wheel = Wheel(wheel_name)\n except InvalidWheelFilename:\n continue\n if canonicalize_name(wheel.name) != canonical_package_name:\n logger.debug(\n \"Ignoring cached wheel %s for %s as it \"\n \"does not match the expected distribution name %s.\",\n wheel_name,\n link,\n package_name,\n )\n continue\n if not wheel.supported(supported_tags):\n # Built for a different python/arch/etc\n continue\n candidates.append(\n (\n wheel.support_index_min(supported_tags),\n wheel_name,\n wheel_dir,\n )\n )\n\n if not candidates:\n return link\n\n _, wheel_name, wheel_dir = min(candidates)\n return Link(path_to_url(os.path.join(wheel_dir, wheel_name)))\n\n\nclass EphemWheelCache(SimpleWheelCache):\n \"\"\"A SimpleWheelCache that creates it's own temporary cache directory\"\"\"\n\n def __init__(self, format_control: FormatControl) -> None:\n self._temp_dir = TempDirectory(\n kind=tempdir_kinds.EPHEM_WHEEL_CACHE,\n globally_managed=True,\n )\n\n super().__init__(self._temp_dir.path, format_control)\n\n\nclass CacheEntry:\n def __init__(\n self,\n link: Link,\n persistent: bool,\n ):\n self.link = link\n self.persistent = persistent\n self.origin: Optional[DirectUrl] = None\n origin_direct_url_path = Path(self.link.file_path).parent / ORIGIN_JSON_NAME\n if origin_direct_url_path.exists():\n self.origin = DirectUrl.from_json(origin_direct_url_path.read_text())\n\n\nclass WheelCache(Cache):\n \"\"\"Wraps EphemWheelCache and SimpleWheelCache into a single Cache\n\n This Cache allows for gracefully degradation, using the ephem wheel cache\n when a certain link is not found in the simple wheel cache first.\n \"\"\"\n\n def __init__(\n self, cache_dir: str, format_control: Optional[FormatControl] = None\n ) -> None:\n if format_control is None:\n format_control = FormatControl()\n super().__init__(cache_dir, format_control, {\"binary\"})\n self._wheel_cache = SimpleWheelCache(cache_dir, format_control)\n self._ephem_cache = EphemWheelCache(format_control)\n\n def get_path_for_link(self, link: Link) -> str:\n return self._wheel_cache.get_path_for_link(link)\n\n def get_ephem_path_for_link(self, link: Link) -> str:\n return self._ephem_cache.get_path_for_link(link)\n\n def get(\n self,\n link: Link,\n package_name: Optional[str],\n supported_tags: List[Tag],\n ) -> Link:\n cache_entry = self.get_cache_entry(link, package_name, supported_tags)\n if cache_entry is None:\n return link\n return cache_entry.link\n\n def get_cache_entry(\n self,\n link: Link,\n package_name: Optional[str],\n supported_tags: List[Tag],\n ) -> Optional[CacheEntry]:\n \"\"\"Returns a CacheEntry with a link to a cached item if it exists or\n None. The cache entry indicates if the item was found in the persistent\n or ephemeral cache.\n \"\"\"\n retval = self._wheel_cache.get(\n link=link,\n package_name=package_name,\n supported_tags=supported_tags,\n )\n if retval is not link:\n return CacheEntry(retval, persistent=True)\n\n retval = self._ephem_cache.get(\n link=link,\n package_name=package_name,\n supported_tags=supported_tags,\n )\n if retval is not link:\n return CacheEntry(retval, persistent=False)\n\n return None\n\n @staticmethod\n def record_download_origin(cache_dir: str, download_info: DirectUrl) -> None:\n origin_path = Path(cache_dir) / ORIGIN_JSON_NAME\n if origin_path.is_file():\n origin = DirectUrl.from_json(origin_path.read_text())\n # TODO: use DirectUrl.equivalent when https://github.com/pypa/pip/pull/10564\n # is merged.\n if origin.url != download_info.url:\n logger.warning(\n \"Origin URL %s in cache entry %s does not match download URL %s. \"\n \"This is likely a pip bug or a cache corruption issue.\",\n origin.url,\n cache_dir,\n download_info.url,\n )\n origin_path.write_text(download_info.to_json(), encoding=\"utf-8\")\n"
},
{
"path": "lib/python3.7/site-packages/pip/_internal/cli/__init__.py",
"content": "\"\"\"Subpackage containing all of pip's command line interface related code\n\"\"\"\n\n# This file intentionally does not import submodules\n"
},
{
"path": "lib/python3.7/site-packages/pip/_internal/cli/autocompletion.py",
"content": "\"\"\"Logic that powers autocompletion installed by ``pip completion``.\n\"\"\"\n\nimport optparse\nimport os\nimport sys\nfrom itertools import chain\nfrom typing import Any, Iterable, List, Optional\n\nfrom pip._internal.cli.main_parser import create_main_parser\nfrom pip._internal.commands import commands_dict, create_command\nfrom pip._internal.metadata import get_default_environment\n\n\ndef autocomplete() -> None:\n \"\"\"Entry Point for completion of main and subcommand options.\"\"\"\n # Don't complete if user hasn't sourced bash_completion file.\n if \"PIP_AUTO_COMPLETE\" not in os.environ:\n return\n cwords = os.environ[\"COMP_WORDS\"].split()[1:]\n cword = int(os.environ[\"COMP_CWORD\"])\n try:\n current = cwords[cword - 1]\n except IndexError:\n current = \"\"\n\n parser = create_main_parser()\n subcommands = list(commands_dict)\n options = []\n\n # subcommand\n subcommand_name: Optional[str] = None\n for word in cwords:\n if word in subcommands:\n subcommand_name = word\n break\n # subcommand options\n if subcommand_name is not None:\n # special case: 'help' subcommand has no options\n if subcommand_name == \"help\":\n sys.exit(1)\n # special case: list locally installed dists for show and uninstall\n should_list_installed = not current.startswith(\"-\") and subcommand_name in [\n \"show\",\n \"uninstall\",\n ]\n if should_list_installed:\n env = get_default_environment()\n lc = current.lower()\n installed = [\n dist.canonical_name\n for dist in env.iter_installed_distributions(local_only=True)\n if dist.canonical_name.startswith(lc)\n and dist.canonical_name not in cwords[1:]\n ]\n # if there are no dists installed, fall back to option completion\n if installed:\n for dist in installed:\n print(dist)\n sys.exit(1)\n\n should_list_installables = (\n not current.startswith(\"-\") and subcommand_name == \"install\"\n )\n if should_list_installables:\n for path in auto_complete_paths(current, \"path\"):\n print(path)\n sys.exit(1)\n\n subcommand = create_command(subcommand_name)\n\n for opt in subcommand.parser.option_list_all:\n if opt.help != optparse.SUPPRESS_HELP:\n for opt_str in opt._long_opts + opt._short_opts:\n options.append((opt_str, opt.nargs))\n\n # filter out previously specified options from available options\n prev_opts = [x.split(\"=\")[0] for x in cwords[1 : cword - 1]]\n options = [(x, v) for (x, v) in options if x not in prev_opts]\n # filter options by current input\n options = [(k, v) for k, v in options if k.startswith(current)]\n # get completion type given cwords and available subcommand options\n completion_type = get_path_completion_type(\n cwords,\n cword,\n subcommand.parser.option_list_all,\n )\n # get completion files and directories if ``completion_type`` is\n # ````, ```` or ````\n if completion_type:\n paths = auto_complete_paths(current, completion_type)\n options = [(path, 0) for path in paths]\n for option in options:\n opt_label = option[0]\n # append '=' to options which require args\n if option[1] and option[0][:2] == \"--\":\n opt_label += \"=\"\n print(opt_label)\n else:\n # show main parser options only when necessary\n\n opts = [i.option_list for i in parser.option_groups]\n opts.append(parser.option_list)\n flattened_opts = chain.from_iterable(opts)\n if current.startswith(\"-\"):\n for opt in flattened_opts:\n if opt.help != optparse.SUPPRESS_HELP:\n subcommands += opt._long_opts + opt._short_opts\n else:\n # get completion type given cwords and all available options\n completion_type = get_path_completion_type(cwords, cword, flattened_opts)\n if completion_type:\n subcommands = list(auto_complete_paths(current, completion_type))\n\n print(\" \".join([x for x in subcommands if x.startswith(current)]))\n sys.exit(1)\n\n\ndef get_path_completion_type(\n cwords: List[str], cword: int, opts: Iterable[Any]\n) -> Optional[str]:\n \"\"\"Get the type of path completion (``file``, ``dir``, ``path`` or None)\n\n :param cwords: same as the environmental variable ``COMP_WORDS``\n :param cword: same as the environmental variable ``COMP_CWORD``\n :param opts: The available options to check\n :return: path completion type (``file``, ``dir``, ``path`` or None)\n \"\"\"\n if cword < 2 or not cwords[cword - 2].startswith(\"-\"):\n return None\n for opt in opts:\n if opt.help == optparse.SUPPRESS_HELP:\n continue\n for o in str(opt).split(\"/\"):\n if cwords[cword - 2].split(\"=\")[0] == o:\n if not opt.metavar or any(\n x in (\"path\", \"file\", \"dir\") for x in opt.metavar.split(\"/\")\n ):\n return opt.metavar\n return None\n\n\ndef auto_complete_paths(current: str, completion_type: str) -> Iterable[str]:\n \"\"\"If ``completion_type`` is ``file`` or ``path``, list all regular files\n and directories starting with ``current``; otherwise only list directories\n starting with ``current``.\n\n :param current: The word to be completed\n :param completion_type: path completion type(``file``, ``path`` or ``dir``)\n :return: A generator of regular files and/or directories\n \"\"\"\n directory, filename = os.path.split(current)\n current_path = os.path.abspath(directory)\n # Don't complete paths if they can't be accessed\n if not os.access(current_path, os.R_OK):\n return\n filename = os.path.normcase(filename)\n # list all files that start with ``filename``\n file_list = (\n x for x in os.listdir(current_path) if os.path.normcase(x).startswith(filename)\n )\n for f in file_list:\n opt = os.path.join(current_path, f)\n comp_file = os.path.normcase(os.path.join(directory, f))\n # complete regular files when there is not ```` after option\n # complete directories when there is ````, ```` or\n # ````after option\n if completion_type != \"dir\" and os.path.isfile(opt):\n yield comp_file\n elif os.path.isdir(opt):\n yield os.path.join(comp_file, \"\")\n"
},
{
"path": "lib/python3.7/site-packages/pip/_internal/cli/base_command.py",
"content": "\"\"\"Base Command class, and related routines\"\"\"\n\nimport functools\nimport logging\nimport logging.config\nimport optparse\nimport os\nimport sys\nimport traceback\nfrom optparse import Values\nfrom typing import Any, Callable, List, Optional, Tuple\n\nfrom pip._vendor.rich import traceback as rich_traceback\n\nfrom pip._internal.cli import cmdoptions\nfrom pip._internal.cli.command_context import CommandContextMixIn\nfrom pip._internal.cli.parser import ConfigOptionParser, UpdatingDefaultsHelpFormatter\nfrom pip._internal.cli.status_codes import (\n ERROR,\n PREVIOUS_BUILD_DIR_ERROR,\n UNKNOWN_ERROR,\n VIRTUALENV_NOT_FOUND,\n)\nfrom pip._internal.exceptions import (\n BadCommand,\n CommandError,\n DiagnosticPipError,\n InstallationError,\n NetworkConnectionError,\n PreviousBuildDirError,\n UninstallationError,\n)\nfrom pip._internal.utils.filesystem import check_path_owner\nfrom pip._internal.utils.logging import BrokenStdoutLoggingError, setup_logging\nfrom pip._internal.utils.misc import get_prog, normalize_path\nfrom pip._internal.utils.temp_dir import TempDirectoryTypeRegistry as TempDirRegistry\nfrom pip._internal.utils.temp_dir import global_tempdir_manager, tempdir_registry\nfrom pip._internal.utils.virtualenv import running_under_virtualenv\n\n__all__ = [\"Command\"]\n\nlogger = logging.getLogger(__name__)\n\n\nclass Command(CommandContextMixIn):\n usage: str = \"\"\n ignore_require_venv: bool = False\n\n def __init__(self, name: str, summary: str, isolated: bool = False) -> None:\n super().__init__()\n\n self.name = name\n self.summary = summary\n self.parser = ConfigOptionParser(\n usage=self.usage,\n prog=f\"{get_prog()} {name}\",\n formatter=UpdatingDefaultsHelpFormatter(),\n add_help_option=False,\n name=name,\n description=self.__doc__,\n isolated=isolated,\n )\n\n self.tempdir_registry: Optional[TempDirRegistry] = None\n\n # Commands should add options to this option group\n optgroup_name = f\"{self.name.capitalize()} Options\"\n self.cmd_opts = optparse.OptionGroup(self.parser, optgroup_name)\n\n # Add the general options\n gen_opts = cmdoptions.make_option_group(\n cmdoptions.general_group,\n self.parser,\n )\n self.parser.add_option_group(gen_opts)\n\n self.add_options()\n\n def add_options(self) -> None:\n pass\n\n def handle_pip_version_check(self, options: Values) -> None:\n \"\"\"\n This is a no-op so that commands by default do not do the pip version\n check.\n \"\"\"\n # Make sure we do the pip version check if the index_group options\n # are present.\n assert not hasattr(options, \"no_index\")\n\n def run(self, options: Values, args: List[str]) -> int:\n raise NotImplementedError\n\n def parse_args(self, args: List[str]) -> Tuple[Values, List[str]]:\n # factored out for testability\n return self.parser.parse_args(args)\n\n def main(self, args: List[str]) -> int:\n try:\n with self.main_context():\n return self._main(args)\n finally:\n logging.shutdown()\n\n def _main(self, args: List[str]) -> int:\n # We must initialize this before the tempdir manager, otherwise the\n # configuration would not be accessible by the time we clean up the\n # tempdir manager.\n self.tempdir_registry = self.enter_context(tempdir_registry())\n # Intentionally set as early as possible so globally-managed temporary\n # directories are available to the rest of the code.\n self.enter_context(global_tempdir_manager())\n\n options, args = self.parse_args(args)\n\n # Set verbosity so that it can be used elsewhere.\n self.verbosity = options.verbose - options.quiet\n\n level_number = setup_logging(\n verbosity=self.verbosity,\n no_color=options.no_color,\n user_log_file=options.log,\n )\n\n # TODO: Try to get these passing down from the command?\n # without resorting to os.environ to hold these.\n # This also affects isolated builds and it should.\n\n if options.no_input:\n os.environ[\"PIP_NO_INPUT\"] = \"1\"\n\n if options.exists_action:\n os.environ[\"PIP_EXISTS_ACTION\"] = \" \".join(options.exists_action)\n\n if options.require_venv and not self.ignore_require_venv:\n # If a venv is required check if it can really be found\n if not running_under_virtualenv():\n logger.critical(\"Could not find an activated virtualenv (required).\")\n sys.exit(VIRTUALENV_NOT_FOUND)\n\n if options.cache_dir:\n options.cache_dir = normalize_path(options.cache_dir)\n if not check_path_owner(options.cache_dir):\n logger.warning(\n \"The directory '%s' or its parent directory is not owned \"\n \"or is not writable by the current user. The cache \"\n \"has been disabled. Check the permissions and owner of \"\n \"that directory. If executing pip with sudo, you should \"\n \"use sudo's -H flag.\",\n options.cache_dir,\n )\n options.cache_dir = None\n\n def intercepts_unhandled_exc(\n run_func: Callable[..., int]\n ) -> Callable[..., int]:\n @functools.wraps(run_func)\n def exc_logging_wrapper(*args: Any) -> int:\n try:\n status = run_func(*args)\n assert isinstance(status, int)\n return status\n except DiagnosticPipError as exc:\n logger.error(\"[present-rich] %s\", exc)\n logger.debug(\"Exception information:\", exc_info=True)\n\n return ERROR\n except PreviousBuildDirError as exc:\n logger.critical(str(exc))\n logger.debug(\"Exception information:\", exc_info=True)\n\n return PREVIOUS_BUILD_DIR_ERROR\n except (\n InstallationError,\n UninstallationError,\n BadCommand,\n NetworkConnectionError,\n ) as exc:\n logger.critical(str(exc))\n logger.debug(\"Exception information:\", exc_info=True)\n\n return ERROR\n except CommandError as exc:\n logger.critical(\"%s\", exc)\n logger.debug(\"Exception information:\", exc_info=True)\n\n return ERROR\n except BrokenStdoutLoggingError:\n # Bypass our logger and write any remaining messages to\n # stderr because stdout no longer works.\n print(\"ERROR: Pipe to stdout was broken\", file=sys.stderr)\n if level_number <= logging.DEBUG:\n traceback.print_exc(file=sys.stderr)\n\n return ERROR\n except KeyboardInterrupt:\n logger.critical(\"Operation cancelled by user\")\n logger.debug(\"Exception information:\", exc_info=True)\n\n return ERROR\n except BaseException:\n logger.critical(\"Exception:\", exc_info=True)\n\n return UNKNOWN_ERROR\n\n return exc_logging_wrapper\n\n try:\n if not options.debug_mode:\n run = intercepts_unhandled_exc(self.run)\n else:\n run = self.run\n rich_traceback.install(show_locals=True)\n return run(options, args)\n finally:\n self.handle_pip_version_check(options)\n"
},
{
"path": "lib/python3.7/site-packages/pip/_internal/cli/cmdoptions.py",
"content": "\"\"\"\nshared options and groups\n\nThe principle here is to define options once, but *not* instantiate them\nglobally. One reason being that options with action='append' can carry state\nbetween parses. pip parses general options twice internally, and shouldn't\npass on state. To be consistent, all options will follow this design.\n\"\"\"\n\n# The following comment should be removed at some point in the future.\n# mypy: strict-optional=False\n\nimport importlib.util\nimport logging\nimport os\nimport textwrap\nfrom functools import partial\nfrom optparse import SUPPRESS_HELP, Option, OptionGroup, OptionParser, Values\nfrom textwrap import dedent\nfrom typing import Any, Callable, Dict, Optional, Tuple\n\nfrom pip._vendor.packaging.utils import canonicalize_name\n\nfrom pip._internal.cli.parser import ConfigOptionParser\nfrom pip._internal.exceptions import CommandError\nfrom pip._internal.locations import USER_CACHE_DIR, get_src_prefix\nfrom pip._internal.models.format_control import FormatControl\nfrom pip._internal.models.index import PyPI\nfrom pip._internal.models.target_python import TargetPython\nfrom pip._internal.utils.hashes import STRONG_HASHES\nfrom pip._internal.utils.misc import strtobool\n\nlogger = logging.getLogger(__name__)\n\n\ndef raise_option_error(parser: OptionParser, option: Option, msg: str) -> None:\n \"\"\"\n Raise an option parsing error using parser.error().\n\n Args:\n parser: an OptionParser instance.\n option: an Option instance.\n msg: the error text.\n \"\"\"\n msg = f\"{option} error: {msg}\"\n msg = textwrap.fill(\" \".join(msg.split()))\n parser.error(msg)\n\n\ndef make_option_group(group: Dict[str, Any], parser: ConfigOptionParser) -> OptionGroup:\n \"\"\"\n Return an OptionGroup object\n group -- assumed to be dict with 'name' and 'options' keys\n parser -- an optparse Parser\n \"\"\"\n option_group = OptionGroup(parser, group[\"name\"])\n for option in group[\"options\"]:\n option_group.add_option(option())\n return option_group\n\n\ndef check_dist_restriction(options: Values, check_target: bool = False) -> None:\n \"\"\"Function for determining if custom platform options are allowed.\n\n :param options: The OptionParser options.\n :param check_target: Whether or not to check if --target is being used.\n \"\"\"\n dist_restriction_set = any(\n [\n options.python_version,\n options.platforms,\n options.abis,\n options.implementation,\n ]\n )\n\n binary_only = FormatControl(set(), {\":all:\"})\n sdist_dependencies_allowed = (\n options.format_control != binary_only and not options.ignore_dependencies\n )\n\n # Installations or downloads using dist restrictions must not combine\n # source distributions and dist-specific wheels, as they are not\n # guaranteed to be locally compatible.\n if dist_restriction_set and sdist_dependencies_allowed:\n raise CommandError(\n \"When restricting platform and interpreter constraints using \"\n \"--python-version, --platform, --abi, or --implementation, \"\n \"either --no-deps must be set, or --only-binary=:all: must be \"\n \"set and --no-binary must not be set (or must be set to \"\n \":none:).\"\n )\n\n if check_target:\n if dist_restriction_set and not options.target_dir:\n raise CommandError(\n \"Can not use any platform or abi specific options unless \"\n \"installing via '--target'\"\n )\n\n\ndef _path_option_check(option: Option, opt: str, value: str) -> str:\n return os.path.expanduser(value)\n\n\ndef _package_name_option_check(option: Option, opt: str, value: str) -> str:\n return canonicalize_name(value)\n\n\nclass PipOption(Option):\n TYPES = Option.TYPES + (\"path\", \"package_name\")\n TYPE_CHECKER = Option.TYPE_CHECKER.copy()\n TYPE_CHECKER[\"package_name\"] = _package_name_option_check\n TYPE_CHECKER[\"path\"] = _path_option_check\n\n\n###########\n# options #\n###########\n\nhelp_: Callable[..., Option] = partial(\n Option,\n \"-h\",\n \"--help\",\n dest=\"help\",\n action=\"help\",\n help=\"Show help.\",\n)\n\ndebug_mode: Callable[..., Option] = partial(\n Option,\n \"--debug\",\n dest=\"debug_mode\",\n action=\"store_true\",\n default=False,\n help=(\n \"Let unhandled exceptions propagate outside the main subroutine, \"\n \"instead of logging them to stderr.\"\n ),\n)\n\nisolated_mode: Callable[..., Option] = partial(\n Option,\n \"--isolated\",\n dest=\"isolated_mode\",\n action=\"store_true\",\n default=False,\n help=(\n \"Run pip in an isolated mode, ignoring environment variables and user \"\n \"configuration.\"\n ),\n)\n\nrequire_virtualenv: Callable[..., Option] = partial(\n Option,\n \"--require-virtualenv\",\n \"--require-venv\",\n dest=\"require_venv\",\n action=\"store_true\",\n default=False,\n help=(\n \"Allow pip to only run in a virtual environment; \"\n \"exit with an error otherwise.\"\n ),\n)\n\npython: Callable[..., Option] = partial(\n Option,\n \"--python\",\n dest=\"python\",\n help=\"Run pip with the specified Python interpreter.\",\n)\n\nverbose: Callable[..., Option] = partial(\n Option,\n \"-v\",\n \"--verbose\",\n dest=\"verbose\",\n action=\"count\",\n default=0,\n help=\"Give more output. Option is additive, and can be used up to 3 times.\",\n)\n\nno_color: Callable[..., Option] = partial(\n Option,\n \"--no-color\",\n dest=\"no_color\",\n action=\"store_true\",\n default=False,\n help=\"Suppress colored output.\",\n)\n\nversion: Callable[..., Option] = partial(\n Option,\n \"-V\",\n \"--version\",\n dest=\"version\",\n action=\"store_true\",\n help=\"Show version and exit.\",\n)\n\nquiet: Callable[..., Option] = partial(\n Option,\n \"-q\",\n \"--quiet\",\n dest=\"quiet\",\n action=\"count\",\n default=0,\n help=(\n \"Give less output. Option is additive, and can be used up to 3\"\n \" times (corresponding to WARNING, ERROR, and CRITICAL logging\"\n \" levels).\"\n ),\n)\n\nprogress_bar: Callable[..., Option] = partial(\n Option,\n \"--progress-bar\",\n dest=\"progress_bar\",\n type=\"choice\",\n choices=[\"on\", \"off\"],\n default=\"on\",\n help=\"Specify whether the progress bar should be used [on, off] (default: on)\",\n)\n\nlog: Callable[..., Option] = partial(\n PipOption,\n \"--log\",\n \"--log-file\",\n \"--local-log\",\n dest=\"log\",\n metavar=\"path\",\n type=\"path\",\n help=\"Path to a verbose appending log.\",\n)\n\nno_input: Callable[..., Option] = partial(\n Option,\n # Don't ask for input\n \"--no-input\",\n dest=\"no_input\",\n action=\"store_true\",\n default=False,\n help=\"Disable prompting for input.\",\n)\n\nproxy: Callable[..., Option] = partial(\n Option,\n \"--proxy\",\n dest=\"proxy\",\n type=\"str\",\n default=\"\",\n help=\"Specify a proxy in the form scheme://[user:passwd@]proxy.server:port.\",\n)\n\nretries: Callable[..., Option] = partial(\n Option,\n \"--retries\",\n dest=\"retries\",\n type=\"int\",\n default=5,\n help=\"Maximum number of retries each connection should attempt \"\n \"(default %default times).\",\n)\n\ntimeout: Callable[..., Option] = partial(\n Option,\n \"--timeout\",\n \"--default-timeout\",\n metavar=\"sec\",\n dest=\"timeout\",\n type=\"float\",\n default=15,\n help=\"Set the socket timeout (default %default seconds).\",\n)\n\n\ndef exists_action() -> Option:\n return Option(\n # Option when path already exist\n \"--exists-action\",\n dest=\"exists_action\",\n type=\"choice\",\n choices=[\"s\", \"i\", \"w\", \"b\", \"a\"],\n default=[],\n action=\"append\",\n metavar=\"action\",\n help=\"Default action when a path already exists: \"\n \"(s)witch, (i)gnore, (w)ipe, (b)ackup, (a)bort.\",\n )\n\n\ncert: Callable[..., Option] = partial(\n PipOption,\n \"--cert\",\n dest=\"cert\",\n type=\"path\",\n metavar=\"path\",\n help=(\n \"Path to PEM-encoded CA certificate bundle. \"\n \"If provided, overrides the default. \"\n \"See 'SSL Certificate Verification' in pip documentation \"\n \"for more information.\"\n ),\n)\n\nclient_cert: Callable[..., Option] = partial(\n PipOption,\n \"--client-cert\",\n dest=\"client_cert\",\n type=\"path\",\n default=None,\n metavar=\"path\",\n help=\"Path to SSL client certificate, a single file containing the \"\n \"private key and the certificate in PEM format.\",\n)\n\nindex_url: Callable[..., Option] = partial(\n Option,\n \"-i\",\n \"--index-url\",\n \"--pypi-url\",\n dest=\"index_url\",\n metavar=\"URL\",\n default=PyPI.simple_url,\n help=\"Base URL of the Python Package Index (default %default). \"\n \"This should point to a repository compliant with PEP 503 \"\n \"(the simple repository API) or a local directory laid out \"\n \"in the same format.\",\n)\n\n\ndef extra_index_url() -> Option:\n return Option(\n \"--extra-index-url\",\n dest=\"extra_index_urls\",\n metavar=\"URL\",\n action=\"append\",\n default=[],\n help=\"Extra URLs of package indexes to use in addition to \"\n \"--index-url. Should follow the same rules as \"\n \"--index-url.\",\n )\n\n\nno_index: Callable[..., Option] = partial(\n Option,\n \"--no-index\",\n dest=\"no_index\",\n action=\"store_true\",\n default=False,\n help=\"Ignore package index (only looking at --find-links URLs instead).\",\n)\n\n\ndef find_links() -> Option:\n return Option(\n \"-f\",\n \"--find-links\",\n dest=\"find_links\",\n action=\"append\",\n default=[],\n metavar=\"url\",\n help=\"If a URL or path to an html file, then parse for links to \"\n \"archives such as sdist (.tar.gz) or wheel (.whl) files. \"\n \"If a local path or file:// URL that's a directory, \"\n \"then look for archives in the directory listing. \"\n \"Links to VCS project URLs are not supported.\",\n )\n\n\ndef trusted_host() -> Option:\n return Option(\n \"--trusted-host\",\n dest=\"trusted_hosts\",\n action=\"append\",\n metavar=\"HOSTNAME\",\n default=[],\n help=\"Mark this host or host:port pair as trusted, even though it \"\n \"does not have valid or any HTTPS.\",\n )\n\n\ndef constraints() -> Option:\n return Option(\n \"-c\",\n \"--constraint\",\n dest=\"constraints\",\n action=\"append\",\n default=[],\n metavar=\"file\",\n help=\"Constrain versions using the given constraints file. \"\n \"This option can be used multiple times.\",\n )\n\n\ndef requirements() -> Option:\n return Option(\n \"-r\",\n \"--requirement\",\n dest=\"requirements\",\n action=\"append\",\n default=[],\n metavar=\"file\",\n help=\"Install from the given requirements file. \"\n \"This option can be used multiple times.\",\n )\n\n\ndef editable() -> Option:\n return Option(\n \"-e\",\n \"--editable\",\n dest=\"editables\",\n action=\"append\",\n default=[],\n metavar=\"path/url\",\n help=(\n \"Install a project in editable mode (i.e. setuptools \"\n '\"develop mode\") from a local project path or a VCS url.'\n ),\n )\n\n\ndef _handle_src(option: Option, opt_str: str, value: str, parser: OptionParser) -> None:\n value = os.path.abspath(value)\n setattr(parser.values, option.dest, value)\n\n\nsrc: Callable[..., Option] = partial(\n PipOption,\n \"--src\",\n \"--source\",\n \"--source-dir\",\n \"--source-directory\",\n dest=\"src_dir\",\n type=\"path\",\n metavar=\"dir\",\n default=get_src_prefix(),\n action=\"callback\",\n callback=_handle_src,\n help=\"Directory to check out editable projects into. \"\n 'The default in a virtualenv is \"/src\". '\n 'The default for global installs is \"/src\".',\n)\n\n\ndef _get_format_control(values: Values, option: Option) -> Any:\n \"\"\"Get a format_control object.\"\"\"\n return getattr(values, option.dest)\n\n\ndef _handle_no_binary(\n option: Option, opt_str: str, value: str, parser: OptionParser\n) -> None:\n existing = _get_format_control(parser.values, option)\n FormatControl.handle_mutual_excludes(\n value,\n existing.no_binary,\n existing.only_binary,\n )\n\n\ndef _handle_only_binary(\n option: Option, opt_str: str, value: str, parser: OptionParser\n) -> None:\n existing = _get_format_control(parser.values, option)\n FormatControl.handle_mutual_excludes(\n value,\n existing.only_binary,\n existing.no_binary,\n )\n\n\ndef no_binary() -> Option:\n format_control = FormatControl(set(), set())\n return Option(\n \"--no-binary\",\n dest=\"format_control\",\n action=\"callback\",\n callback=_handle_no_binary,\n type=\"str\",\n default=format_control,\n help=\"Do not use binary packages. Can be supplied multiple times, and \"\n 'each time adds to the existing value. Accepts either \":all:\" to '\n 'disable all binary packages, \":none:\" to empty the set (notice '\n \"the colons), or one or more package names with commas between \"\n \"them (no colons). Note that some packages are tricky to compile \"\n \"and may fail to install when this option is used on them.\",\n )\n\n\ndef only_binary() -> Option:\n format_control = FormatControl(set(), set())\n return Option(\n \"--only-binary\",\n dest=\"format_control\",\n action=\"callback\",\n callback=_handle_only_binary,\n type=\"str\",\n default=format_control,\n help=\"Do not use source packages. Can be supplied multiple times, and \"\n 'each time adds to the existing value. Accepts either \":all:\" to '\n 'disable all source packages, \":none:\" to empty the set, or one '\n \"or more package names with commas between them. Packages \"\n \"without binary distributions will fail to install when this \"\n \"option is used on them.\",\n )\n\n\nplatforms: Callable[..., Option] = partial(\n Option,\n \"--platform\",\n dest=\"platforms\",\n metavar=\"platform\",\n action=\"append\",\n default=None,\n help=(\n \"Only use wheels compatible with . Defaults to the \"\n \"platform of the running system. Use this option multiple times to \"\n \"specify multiple platforms supported by the target interpreter.\"\n ),\n)\n\n\n# This was made a separate function for unit-testing purposes.\ndef _convert_python_version(value: str) -> Tuple[Tuple[int, ...], Optional[str]]:\n \"\"\"\n Convert a version string like \"3\", \"37\", or \"3.7.3\" into a tuple of ints.\n\n :return: A 2-tuple (version_info, error_msg), where `error_msg` is\n non-None if and only if there was a parsing error.\n \"\"\"\n if not value:\n # The empty string is the same as not providing a value.\n return (None, None)\n\n parts = value.split(\".\")\n if len(parts) > 3:\n return ((), \"at most three version parts are allowed\")\n\n if len(parts) == 1:\n # Then we are in the case of \"3\" or \"37\".\n value = parts[0]\n if len(value) > 1:\n parts = [value[0], value[1:]]\n\n try:\n version_info = tuple(int(part) for part in parts)\n except ValueError:\n return ((), \"each version part must be an integer\")\n\n return (version_info, None)\n\n\ndef _handle_python_version(\n option: Option, opt_str: str, value: str, parser: OptionParser\n) -> None:\n \"\"\"\n Handle a provided --python-version value.\n \"\"\"\n version_info, error_msg = _convert_python_version(value)\n if error_msg is not None:\n msg = \"invalid --python-version value: {!r}: {}\".format(\n value,\n error_msg,\n )\n raise_option_error(parser, option=option, msg=msg)\n\n parser.values.python_version = version_info\n\n\npython_version: Callable[..., Option] = partial(\n Option,\n \"--python-version\",\n dest=\"python_version\",\n metavar=\"python_version\",\n action=\"callback\",\n callback=_handle_python_version,\n type=\"str\",\n default=None,\n help=dedent(\n \"\"\"\\\n The Python interpreter version to use for wheel and \"Requires-Python\"\n compatibility checks. Defaults to a version derived from the running\n interpreter. The version can be specified using up to three dot-separated\n integers (e.g. \"3\" for 3.0.0, \"3.7\" for 3.7.0, or \"3.7.3\"). A major-minor\n version can also be given as a string without dots (e.g. \"37\" for 3.7.0).\n \"\"\"\n ),\n)\n\n\nimplementation: Callable[..., Option] = partial(\n Option,\n \"--implementation\",\n dest=\"implementation\",\n metavar=\"implementation\",\n default=None,\n help=(\n \"Only use wheels compatible with Python \"\n \"implementation , e.g. 'pp', 'jy', 'cp', \"\n \" or 'ip'. If not specified, then the current \"\n \"interpreter implementation is used. Use 'py' to force \"\n \"implementation-agnostic wheels.\"\n ),\n)\n\n\nabis: Callable[..., Option] = partial(\n Option,\n \"--abi\",\n dest=\"abis\",\n metavar=\"abi\",\n action=\"append\",\n default=None,\n help=(\n \"Only use wheels compatible with Python abi , e.g. 'pypy_41'. \"\n \"If not specified, then the current interpreter abi tag is used. \"\n \"Use this option multiple times to specify multiple abis supported \"\n \"by the target interpreter. Generally you will need to specify \"\n \"--implementation, --platform, and --python-version when using this \"\n \"option.\"\n ),\n)\n\n\ndef add_target_python_options(cmd_opts: OptionGroup) -> None:\n cmd_opts.add_option(platforms())\n cmd_opts.add_option(python_version())\n cmd_opts.add_option(implementation())\n cmd_opts.add_option(abis())\n\n\ndef make_target_python(options: Values) -> TargetPython:\n target_python = TargetPython(\n platforms=options.platforms,\n py_version_info=options.python_version,\n abis=options.abis,\n implementation=options.implementation,\n )\n\n return target_python\n\n\ndef prefer_binary() -> Option:\n return Option(\n \"--prefer-binary\",\n dest=\"prefer_binary\",\n action=\"store_true\",\n default=False,\n help=\"Prefer older binary packages over newer source packages.\",\n )\n\n\ncache_dir: Callable[..., Option] = partial(\n PipOption,\n \"--cache-dir\",\n dest=\"cache_dir\",\n default=USER_CACHE_DIR,\n metavar=\"dir\",\n type=\"path\",\n help=\"Store the cache data in .\",\n)\n\n\ndef _handle_no_cache_dir(\n option: Option, opt: str, value: str, parser: OptionParser\n) -> None:\n \"\"\"\n Process a value provided for the --no-cache-dir option.\n\n This is an optparse.Option callback for the --no-cache-dir option.\n \"\"\"\n # The value argument will be None if --no-cache-dir is passed via the\n # command-line, since the option doesn't accept arguments. However,\n # the value can be non-None if the option is triggered e.g. by an\n # environment variable, like PIP_NO_CACHE_DIR=true.\n if value is not None:\n # Then parse the string value to get argument error-checking.\n try:\n strtobool(value)\n except ValueError as exc:\n raise_option_error(parser, option=option, msg=str(exc))\n\n # Originally, setting PIP_NO_CACHE_DIR to a value that strtobool()\n # converted to 0 (like \"false\" or \"no\") caused cache_dir to be disabled\n # rather than enabled (logic would say the latter). Thus, we disable\n # the cache directory not just on values that parse to True, but (for\n # backwards compatibility reasons) also on values that parse to False.\n # In other words, always set it to False if the option is provided in\n # some (valid) form.\n parser.values.cache_dir = False\n\n\nno_cache: Callable[..., Option] = partial(\n Option,\n \"--no-cache-dir\",\n dest=\"cache_dir\",\n action=\"callback\",\n callback=_handle_no_cache_dir,\n help=\"Disable the cache.\",\n)\n\nno_deps: Callable[..., Option] = partial(\n Option,\n \"--no-deps\",\n \"--no-dependencies\",\n dest=\"ignore_dependencies\",\n action=\"store_true\",\n default=False,\n help=\"Don't install package dependencies.\",\n)\n\nignore_requires_python: Callable[..., Option] = partial(\n Option,\n \"--ignore-requires-python\",\n dest=\"ignore_requires_python\",\n action=\"store_true\",\n help=\"Ignore the Requires-Python information.\",\n)\n\nno_build_isolation: Callable[..., Option] = partial(\n Option,\n \"--no-build-isolation\",\n dest=\"build_isolation\",\n action=\"store_false\",\n default=True,\n help=\"Disable isolation when building a modern source distribution. \"\n \"Build dependencies specified by PEP 518 must be already installed \"\n \"if this option is used.\",\n)\n\ncheck_build_deps: Callable[..., Option] = partial(\n Option,\n \"--check-build-dependencies\",\n dest=\"check_build_deps\",\n action=\"store_true\",\n default=False,\n help=\"Check the build dependencies when PEP517 is used.\",\n)\n\n\ndef _handle_no_use_pep517(\n option: Option, opt: str, value: str, parser: OptionParser\n) -> None:\n \"\"\"\n Process a value provided for the --no-use-pep517 option.\n\n This is an optparse.Option callback for the no_use_pep517 option.\n \"\"\"\n # Since --no-use-pep517 doesn't accept arguments, the value argument\n # will be None if --no-use-pep517 is passed via the command-line.\n # However, the value can be non-None if the option is triggered e.g.\n # by an environment variable, for example \"PIP_NO_USE_PEP517=true\".\n if value is not None:\n msg = \"\"\"A value was passed for --no-use-pep517,\n probably using either the PIP_NO_USE_PEP517 environment variable\n or the \"no-use-pep517\" config file option. Use an appropriate value\n of the PIP_USE_PEP517 environment variable or the \"use-pep517\"\n config file option instead.\n \"\"\"\n raise_option_error(parser, option=option, msg=msg)\n\n # If user doesn't wish to use pep517, we check if setuptools is installed\n # and raise error if it is not.\n if not importlib.util.find_spec(\"setuptools\"):\n msg = \"It is not possible to use --no-use-pep517 without setuptools installed.\"\n raise_option_error(parser, option=option, msg=msg)\n\n # Otherwise, --no-use-pep517 was passed via the command-line.\n parser.values.use_pep517 = False\n\n\nuse_pep517: Any = partial(\n Option,\n \"--use-pep517\",\n dest=\"use_pep517\",\n action=\"store_true\",\n default=None,\n help=\"Use PEP 517 for building source distributions \"\n \"(use --no-use-pep517 to force legacy behaviour).\",\n)\n\nno_use_pep517: Any = partial(\n Option,\n \"--no-use-pep517\",\n dest=\"use_pep517\",\n action=\"callback\",\n callback=_handle_no_use_pep517,\n default=None,\n help=SUPPRESS_HELP,\n)\n\n\ndef _handle_config_settings(\n option: Option, opt_str: str, value: str, parser: OptionParser\n) -> None:\n key, sep, val = value.partition(\"=\")\n if sep != \"=\":\n parser.error(f\"Arguments to {opt_str} must be of the form KEY=VAL\") # noqa\n dest = getattr(parser.values, option.dest)\n if dest is None:\n dest = {}\n setattr(parser.values, option.dest, dest)\n dest[key] = val\n\n\nconfig_settings: Callable[..., Option] = partial(\n Option,\n \"--config-settings\",\n dest=\"config_settings\",\n type=str,\n action=\"callback\",\n callback=_handle_config_settings,\n metavar=\"settings\",\n help=\"Configuration settings to be passed to the PEP 517 build backend. \"\n \"Settings take the form KEY=VALUE. Use multiple --config-settings options \"\n \"to pass multiple keys to the backend.\",\n)\n\ninstall_options: Callable[..., Option] = partial(\n Option,\n \"--install-option\",\n dest=\"install_options\",\n action=\"append\",\n metavar=\"options\",\n help=\"Extra arguments to be supplied to the setup.py install \"\n 'command (use like --install-option=\"--install-scripts=/usr/local/'\n 'bin\"). Use multiple --install-option options to pass multiple '\n \"options to setup.py install. If you are using an option with a \"\n \"directory path, be sure to use absolute path.\",\n)\n\nbuild_options: Callable[..., Option] = partial(\n Option,\n \"--build-option\",\n dest=\"build_options\",\n metavar=\"options\",\n action=\"append\",\n help=\"Extra arguments to be supplied to 'setup.py bdist_wheel'.\",\n)\n\nglobal_options: Callable[..., Option] = partial(\n Option,\n \"--global-option\",\n dest=\"global_options\",\n action=\"append\",\n metavar=\"options\",\n help=\"Extra global options to be supplied to the setup.py \"\n \"call before the install or bdist_wheel command.\",\n)\n\nno_clean: Callable[..., Option] = partial(\n Option,\n \"--no-clean\",\n action=\"store_true\",\n default=False,\n help=\"Don't clean up build directories.\",\n)\n\npre: Callable[..., Option] = partial(\n Option,\n \"--pre\",\n action=\"store_true\",\n default=False,\n help=\"Include pre-release and development versions. By default, \"\n \"pip only finds stable versions.\",\n)\n\ndisable_pip_version_check: Callable[..., Option] = partial(\n Option,\n \"--disable-pip-version-check\",\n dest=\"disable_pip_version_check\",\n action=\"store_true\",\n default=False,\n help=\"Don't periodically check PyPI to determine whether a new version \"\n \"of pip is available for download. Implied with --no-index.\",\n)\n\nroot_user_action: Callable[..., Option] = partial(\n Option,\n \"--root-user-action\",\n dest=\"root_user_action\",\n default=\"warn\",\n choices=[\"warn\", \"ignore\"],\n help=\"Action if pip is run as a root user. By default, a warning message is shown.\",\n)\n\n\ndef _handle_merge_hash(\n option: Option, opt_str: str, value: str, parser: OptionParser\n) -> None:\n \"\"\"Given a value spelled \"algo:digest\", append the digest to a list\n pointed to in a dict by the algo name.\"\"\"\n if not parser.values.hashes:\n parser.values.hashes = {}\n try:\n algo, digest = value.split(\":\", 1)\n except ValueError:\n parser.error(\n \"Arguments to {} must be a hash name \" # noqa\n \"followed by a value, like --hash=sha256:\"\n \"abcde...\".format(opt_str)\n )\n if algo not in STRONG_HASHES:\n parser.error(\n \"Allowed hash algorithms for {} are {}.\".format( # noqa\n opt_str, \", \".join(STRONG_HASHES)\n )\n )\n parser.values.hashes.setdefault(algo, []).append(digest)\n\n\nhash: Callable[..., Option] = partial(\n Option,\n \"--hash\",\n # Hash values eventually end up in InstallRequirement.hashes due to\n # __dict__ copying in process_line().\n dest=\"hashes\",\n action=\"callback\",\n callback=_handle_merge_hash,\n type=\"string\",\n help=\"Verify that the package's archive matches this \"\n \"hash before installing. Example: --hash=sha256:abcdef...\",\n)\n\n\nrequire_hashes: Callable[..., Option] = partial(\n Option,\n \"--require-hashes\",\n dest=\"require_hashes\",\n action=\"store_true\",\n default=False,\n help=\"Require a hash to check each requirement against, for \"\n \"repeatable installs. This option is implied when any package in a \"\n \"requirements file has a --hash option.\",\n)\n\n\nlist_path: Callable[..., Option] = partial(\n PipOption,\n \"--path\",\n dest=\"path\",\n type=\"path\",\n action=\"append\",\n help=\"Restrict to the specified installation path for listing \"\n \"packages (can be used multiple times).\",\n)\n\n\ndef check_list_path_option(options: Values) -> None:\n if options.path and (options.user or options.local):\n raise CommandError(\"Cannot combine '--path' with '--user' or '--local'\")\n\n\nlist_exclude: Callable[..., Option] = partial(\n PipOption,\n \"--exclude\",\n dest=\"excludes\",\n action=\"append\",\n metavar=\"package\",\n type=\"package_name\",\n help=\"Exclude specified package from the output\",\n)\n\n\nno_python_version_warning: Callable[..., Option] = partial(\n Option,\n \"--no-python-version-warning\",\n dest=\"no_python_version_warning\",\n action=\"store_true\",\n default=False,\n help=\"Silence deprecation warnings for upcoming unsupported Pythons.\",\n)\n\n\nuse_new_feature: Callable[..., Option] = partial(\n Option,\n \"--use-feature\",\n dest=\"features_enabled\",\n metavar=\"feature\",\n action=\"append\",\n default=[],\n choices=[\n \"fast-deps\",\n \"truststore\",\n \"no-binary-enable-wheel-cache\",\n ],\n help=\"Enable new functionality, that may be backward incompatible.\",\n)\n\nuse_deprecated_feature: Callable[..., Option] = partial(\n Option,\n \"--use-deprecated\",\n dest=\"deprecated_features_enabled\",\n metavar=\"feature\",\n action=\"append\",\n default=[],\n choices=[\n \"legacy-resolver\",\n ],\n help=(\"Enable deprecated functionality, that will be removed in the future.\"),\n)\n\n\n##########\n# groups #\n##########\n\ngeneral_group: Dict[str, Any] = {\n \"name\": \"General Options\",\n \"options\": [\n help_,\n debug_mode,\n isolated_mode,\n require_virtualenv,\n python,\n verbose,\n version,\n quiet,\n log,\n no_input,\n proxy,\n retries,\n timeout,\n exists_action,\n trusted_host,\n cert,\n client_cert,\n cache_dir,\n no_cache,\n disable_pip_version_check,\n no_color,\n no_python_version_warning,\n use_new_feature,\n use_deprecated_feature,\n ],\n}\n\nindex_group: Dict[str, Any] = {\n \"name\": \"Package Index Options\",\n \"options\": [\n index_url,\n extra_index_url,\n no_index,\n find_links,\n ],\n}\n"
},
{
"path": "lib/python3.7/site-packages/pip/_internal/cli/command_context.py",
"content": "from contextlib import ExitStack, contextmanager\nfrom typing import ContextManager, Generator, TypeVar\n\n_T = TypeVar(\"_T\", covariant=True)\n\n\nclass CommandContextMixIn:\n def __init__(self) -> None:\n super().__init__()\n self._in_main_context = False\n self._main_context = ExitStack()\n\n @contextmanager\n def main_context(self) -> Generator[None, None, None]:\n assert not self._in_main_context\n\n self._in_main_context = True\n try:\n with self._main_context:\n yield\n finally:\n self._in_main_context = False\n\n def enter_context(self, context_provider: ContextManager[_T]) -> _T:\n assert self._in_main_context\n\n return self._main_context.enter_context(context_provider)\n"
},
{
"path": "lib/python3.7/site-packages/pip/_internal/cli/main.py",
"content": "\"\"\"Primary application entrypoint.\n\"\"\"\nimport locale\nimport logging\nimport os\nimport sys\nfrom typing import List, Optional\n\nfrom pip._internal.cli.autocompletion import autocomplete\nfrom pip._internal.cli.main_parser import parse_command\nfrom pip._internal.commands import create_command\nfrom pip._internal.exceptions import PipError\nfrom pip._internal.utils import deprecation\n\nlogger = logging.getLogger(__name__)\n\n\n# Do not import and use main() directly! Using it directly is actively\n# discouraged by pip's maintainers. The name, location and behavior of\n# this function is subject to change, so calling it directly is not\n# portable across different pip versions.\n\n# In addition, running pip in-process is unsupported and unsafe. This is\n# elaborated in detail at\n# https://pip.pypa.io/en/stable/user_guide/#using-pip-from-your-program.\n# That document also provides suggestions that should work for nearly\n# all users that are considering importing and using main() directly.\n\n# However, we know that certain users will still want to invoke pip\n# in-process. If you understand and accept the implications of using pip\n# in an unsupported manner, the best approach is to use runpy to avoid\n# depending on the exact location of this entry point.\n\n# The following example shows how to use runpy to invoke pip in that\n# case:\n#\n# sys.argv = [\"pip\", your, args, here]\n# runpy.run_module(\"pip\", run_name=\"__main__\")\n#\n# Note that this will exit the process after running, unlike a direct\n# call to main. As it is not safe to do any processing after calling\n# main, this should not be an issue in practice.\n\n\ndef main(args: Optional[List[str]] = None) -> int:\n if args is None:\n args = sys.argv[1:]\n\n # Configure our deprecation warnings to be sent through loggers\n deprecation.install_warning_logger()\n\n autocomplete()\n\n try:\n cmd_name, cmd_args = parse_command(args)\n except PipError as exc:\n sys.stderr.write(f\"ERROR: {exc}\")\n sys.stderr.write(os.linesep)\n sys.exit(1)\n\n # Needed for locale.getpreferredencoding(False) to work\n # in pip._internal.utils.encoding.auto_decode\n try:\n locale.setlocale(locale.LC_ALL, \"\")\n except locale.Error as e:\n # setlocale can apparently crash if locale are uninitialized\n logger.debug(\"Ignoring error %s when setting locale\", e)\n command = create_command(cmd_name, isolated=(\"--isolated\" in cmd_args))\n\n return command.main(cmd_args)\n"
},
{
"path": "lib/python3.7/site-packages/pip/_internal/cli/main_parser.py",
"content": "\"\"\"A single place for constructing and exposing the main parser\n\"\"\"\n\nimport os\nimport subprocess\nimport sys\nfrom typing import List, Optional, Tuple\n\nfrom pip._internal.build_env import get_runnable_pip\nfrom pip._internal.cli import cmdoptions\nfrom pip._internal.cli.parser import ConfigOptionParser, UpdatingDefaultsHelpFormatter\nfrom pip._internal.commands import commands_dict, get_similar_commands\nfrom pip._internal.exceptions import CommandError\nfrom pip._internal.utils.misc import get_pip_version, get_prog\n\n__all__ = [\"create_main_parser\", \"parse_command\"]\n\n\ndef create_main_parser() -> ConfigOptionParser:\n \"\"\"Creates and returns the main parser for pip's CLI\"\"\"\n\n parser = ConfigOptionParser(\n usage=\"\\n%prog [options]\",\n add_help_option=False,\n formatter=UpdatingDefaultsHelpFormatter(),\n name=\"global\",\n prog=get_prog(),\n )\n parser.disable_interspersed_args()\n\n parser.version = get_pip_version()\n\n # add the general options\n gen_opts = cmdoptions.make_option_group(cmdoptions.general_group, parser)\n parser.add_option_group(gen_opts)\n\n # so the help formatter knows\n parser.main = True # type: ignore\n\n # create command listing for description\n description = [\"\"] + [\n f\"{name:27} {command_info.summary}\"\n for name, command_info in commands_dict.items()\n ]\n parser.description = \"\\n\".join(description)\n\n return parser\n\n\ndef identify_python_interpreter(python: str) -> Optional[str]:\n # If the named file exists, use it.\n # If it's a directory, assume it's a virtual environment and\n # look for the environment's Python executable.\n if os.path.exists(python):\n if os.path.isdir(python):\n # bin/python for Unix, Scripts/python.exe for Windows\n # Try both in case of odd cases like cygwin.\n for exe in (\"bin/python\", \"Scripts/python.exe\"):\n py = os.path.join(python, exe)\n if os.path.exists(py):\n return py\n else:\n return python\n\n # Could not find the interpreter specified\n return None\n\n\ndef parse_command(args: List[str]) -> Tuple[str, List[str]]:\n parser = create_main_parser()\n\n # Note: parser calls disable_interspersed_args(), so the result of this\n # call is to split the initial args into the general options before the\n # subcommand and everything else.\n # For example:\n # args: ['--timeout=5', 'install', '--user', 'INITools']\n # general_options: ['--timeout==5']\n # args_else: ['install', '--user', 'INITools']\n general_options, args_else = parser.parse_args(args)\n\n # --python\n if general_options.python and \"_PIP_RUNNING_IN_SUBPROCESS\" not in os.environ:\n # Re-invoke pip using the specified Python interpreter\n interpreter = identify_python_interpreter(general_options.python)\n if interpreter is None:\n raise CommandError(\n f\"Could not locate Python interpreter {general_options.python}\"\n )\n\n pip_cmd = [\n interpreter,\n get_runnable_pip(),\n ]\n pip_cmd.extend(args)\n\n # Set a flag so the child doesn't re-invoke itself, causing\n # an infinite loop.\n os.environ[\"_PIP_RUNNING_IN_SUBPROCESS\"] = \"1\"\n returncode = 0\n try:\n proc = subprocess.run(pip_cmd)\n returncode = proc.returncode\n except (subprocess.SubprocessError, OSError) as exc:\n raise CommandError(f\"Failed to run pip under {interpreter}: {exc}\")\n sys.exit(returncode)\n\n # --version\n if general_options.version:\n sys.stdout.write(parser.version)\n sys.stdout.write(os.linesep)\n sys.exit()\n\n # pip || pip help -> print_help()\n if not args_else or (args_else[0] == \"help\" and len(args_else) == 1):\n parser.print_help()\n sys.exit()\n\n # the subcommand name\n cmd_name = args_else[0]\n\n if cmd_name not in commands_dict:\n guess = get_similar_commands(cmd_name)\n\n msg = [f'unknown command \"{cmd_name}\"']\n if guess:\n msg.append(f'maybe you meant \"{guess}\"')\n\n raise CommandError(\" - \".join(msg))\n\n # all the args without the subcommand\n cmd_args = args[:]\n cmd_args.remove(cmd_name)\n\n return cmd_name, cmd_args\n"
},
{
"path": "lib/python3.7/site-packages/pip/_internal/cli/parser.py",
"content": "\"\"\"Base option parser setup\"\"\"\n\nimport logging\nimport optparse\nimport shutil\nimport sys\nimport textwrap\nfrom contextlib import suppress\nfrom typing import Any, Dict, Generator, List, Tuple\n\nfrom pip._internal.cli.status_codes import UNKNOWN_ERROR\nfrom pip._internal.configuration import Configuration, ConfigurationError\nfrom pip._internal.utils.misc import redact_auth_from_url, strtobool\n\nlogger = logging.getLogger(__name__)\n\n\nclass PrettyHelpFormatter(optparse.IndentedHelpFormatter):\n \"\"\"A prettier/less verbose help formatter for optparse.\"\"\"\n\n def __init__(self, *args: Any, **kwargs: Any) -> None:\n # help position must be aligned with __init__.parseopts.description\n kwargs[\"max_help_position\"] = 30\n kwargs[\"indent_increment\"] = 1\n kwargs[\"width\"] = shutil.get_terminal_size()[0] - 2\n super().__init__(*args, **kwargs)\n\n def format_option_strings(self, option: optparse.Option) -> str:\n return self._format_option_strings(option)\n\n def _format_option_strings(\n self, option: optparse.Option, mvarfmt: str = \" <{}>\", optsep: str = \", \"\n ) -> str:\n \"\"\"\n Return a comma-separated list of option strings and metavars.\n\n :param option: tuple of (short opt, long opt), e.g: ('-f', '--format')\n :param mvarfmt: metavar format string\n :param optsep: separator\n \"\"\"\n opts = []\n\n if option._short_opts:\n opts.append(option._short_opts[0])\n if option._long_opts:\n opts.append(option._long_opts[0])\n if len(opts) > 1:\n opts.insert(1, optsep)\n\n if option.takes_value():\n assert option.dest is not None\n metavar = option.metavar or option.dest.lower()\n opts.append(mvarfmt.format(metavar.lower()))\n\n return \"\".join(opts)\n\n def format_heading(self, heading: str) -> str:\n if heading == \"Options\":\n return \"\"\n return heading + \":\\n\"\n\n def format_usage(self, usage: str) -> str:\n \"\"\"\n Ensure there is only one newline between usage and the first heading\n if there is no description.\n \"\"\"\n msg = \"\\nUsage: {}\\n\".format(self.indent_lines(textwrap.dedent(usage), \" \"))\n return msg\n\n def format_description(self, description: str) -> str:\n # leave full control over description to us\n if description:\n if hasattr(self.parser, \"main\"):\n label = \"Commands\"\n else:\n label = \"Description\"\n # some doc strings have initial newlines, some don't\n description = description.lstrip(\"\\n\")\n # some doc strings have final newlines and spaces, some don't\n description = description.rstrip()\n # dedent, then reindent\n description = self.indent_lines(textwrap.dedent(description), \" \")\n description = f\"{label}:\\n{description}\\n\"\n return description\n else:\n return \"\"\n\n def format_epilog(self, epilog: str) -> str:\n # leave full control over epilog to us\n if epilog:\n return epilog\n else:\n return \"\"\n\n def indent_lines(self, text: str, indent: str) -> str:\n new_lines = [indent + line for line in text.split(\"\\n\")]\n return \"\\n\".join(new_lines)\n\n\nclass UpdatingDefaultsHelpFormatter(PrettyHelpFormatter):\n \"\"\"Custom help formatter for use in ConfigOptionParser.\n\n This is updates the defaults before expanding them, allowing\n them to show up correctly in the help listing.\n\n Also redact auth from url type options\n \"\"\"\n\n def expand_default(self, option: optparse.Option) -> str:\n default_values = None\n if self.parser is not None:\n assert isinstance(self.parser, ConfigOptionParser)\n self.parser._update_defaults(self.parser.defaults)\n assert option.dest is not None\n default_values = self.parser.defaults.get(option.dest)\n help_text = super().expand_default(option)\n\n if default_values and option.metavar == \"URL\":\n if isinstance(default_values, str):\n default_values = [default_values]\n\n # If its not a list, we should abort and just return the help text\n if not isinstance(default_values, list):\n default_values = []\n\n for val in default_values:\n help_text = help_text.replace(val, redact_auth_from_url(val))\n\n return help_text\n\n\nclass CustomOptionParser(optparse.OptionParser):\n def insert_option_group(\n self, idx: int, *args: Any, **kwargs: Any\n ) -> optparse.OptionGroup:\n \"\"\"Insert an OptionGroup at a given position.\"\"\"\n group = self.add_option_group(*args, **kwargs)\n\n self.option_groups.pop()\n self.option_groups.insert(idx, group)\n\n return group\n\n @property\n def option_list_all(self) -> List[optparse.Option]:\n \"\"\"Get a list of all options, including those in option groups.\"\"\"\n res = self.option_list[:]\n for i in self.option_groups:\n res.extend(i.option_list)\n\n return res\n\n\nclass ConfigOptionParser(CustomOptionParser):\n \"\"\"Custom option parser which updates its defaults by checking the\n configuration files and environmental variables\"\"\"\n\n def __init__(\n self,\n *args: Any,\n name: str,\n isolated: bool = False,\n **kwargs: Any,\n ) -> None:\n self.name = name\n self.config = Configuration(isolated)\n\n assert self.name\n super().__init__(*args, **kwargs)\n\n def check_default(self, option: optparse.Option, key: str, val: Any) -> Any:\n try:\n return option.check_value(key, val)\n except optparse.OptionValueError as exc:\n print(f\"An error occurred during configuration: {exc}\")\n sys.exit(3)\n\n def _get_ordered_configuration_items(\n self,\n ) -> Generator[Tuple[str, Any], None, None]:\n # Configuration gives keys in an unordered manner. Order them.\n override_order = [\"global\", self.name, \":env:\"]\n\n # Pool the options into different groups\n section_items: Dict[str, List[Tuple[str, Any]]] = {\n name: [] for name in override_order\n }\n for section_key, val in self.config.items():\n # ignore empty values\n if not val:\n logger.debug(\n \"Ignoring configuration key '%s' as it's value is empty.\",\n section_key,\n )\n continue\n\n section, key = section_key.split(\".\", 1)\n if section in override_order:\n section_items[section].append((key, val))\n\n # Yield each group in their override order\n for section in override_order:\n for key, val in section_items[section]:\n yield key, val\n\n def _update_defaults(self, defaults: Dict[str, Any]) -> Dict[str, Any]:\n \"\"\"Updates the given defaults with values from the config files and\n the environ. Does a little special handling for certain types of\n options (lists).\"\"\"\n\n # Accumulate complex default state.\n self.values = optparse.Values(self.defaults)\n late_eval = set()\n # Then set the options with those values\n for key, val in self._get_ordered_configuration_items():\n # '--' because configuration supports only long names\n option = self.get_option(\"--\" + key)\n\n # Ignore options not present in this parser. E.g. non-globals put\n # in [global] by users that want them to apply to all applicable\n # commands.\n if option is None:\n continue\n\n assert option.dest is not None\n\n if option.action in (\"store_true\", \"store_false\"):\n try:\n val = strtobool(val)\n except ValueError:\n self.error(\n \"{} is not a valid value for {} option, \" # noqa\n \"please specify a boolean value like yes/no, \"\n \"true/false or 1/0 instead.\".format(val, key)\n )\n elif option.action == \"count\":\n with suppress(ValueError):\n val = strtobool(val)\n with suppress(ValueError):\n val = int(val)\n if not isinstance(val, int) or val < 0:\n self.error(\n \"{} is not a valid value for {} option, \" # noqa\n \"please instead specify either a non-negative integer \"\n \"or a boolean value like yes/no or false/true \"\n \"which is equivalent to 1/0.\".format(val, key)\n )\n elif option.action == \"append\":\n val = val.split()\n val = [self.check_default(option, key, v) for v in val]\n elif option.action == \"callback\":\n assert option.callback is not None\n late_eval.add(option.dest)\n opt_str = option.get_opt_string()\n val = option.convert_value(opt_str, val)\n # From take_action\n args = option.callback_args or ()\n kwargs = option.callback_kwargs or {}\n option.callback(option, opt_str, val, self, *args, **kwargs)\n else:\n val = self.check_default(option, key, val)\n\n defaults[option.dest] = val\n\n for key in late_eval:\n defaults[key] = getattr(self.values, key)\n self.values = None\n return defaults\n\n def get_default_values(self) -> optparse.Values:\n \"\"\"Overriding to make updating the defaults after instantiation of\n the option parser possible, _update_defaults() does the dirty work.\"\"\"\n if not self.process_default_values:\n # Old, pre-Optik 1.5 behaviour.\n return optparse.Values(self.defaults)\n\n # Load the configuration, or error out in case of an error\n try:\n self.config.load()\n except ConfigurationError as err:\n self.exit(UNKNOWN_ERROR, str(err))\n\n defaults = self._update_defaults(self.defaults.copy()) # ours\n for option in self._get_all_options():\n assert option.dest is not None\n default = defaults.get(option.dest)\n if isinstance(default, str):\n opt_str = option.get_opt_string()\n defaults[option.dest] = option.check_value(opt_str, default)\n return optparse.Values(defaults)\n\n def error(self, msg: str) -> None:\n self.print_usage(sys.stderr)\n self.exit(UNKNOWN_ERROR, f\"{msg}\\n\")\n"
},
{
"path": "lib/python3.7/site-packages/pip/_internal/cli/progress_bars.py",
"content": "import functools\nfrom typing import Callable, Generator, Iterable, Iterator, Optional, Tuple\n\nfrom pip._vendor.rich.progress import (\n BarColumn,\n DownloadColumn,\n FileSizeColumn,\n Progress,\n ProgressColumn,\n SpinnerColumn,\n TextColumn,\n TimeElapsedColumn,\n TimeRemainingColumn,\n TransferSpeedColumn,\n)\n\nfrom pip._internal.utils.logging import get_indentation\n\nDownloadProgressRenderer = Callable[[Iterable[bytes]], Iterator[bytes]]\n\n\ndef _rich_progress_bar(\n iterable: Iterable[bytes],\n *,\n bar_type: str,\n size: int,\n) -> Generator[bytes, None, None]:\n assert bar_type == \"on\", \"This should only be used in the default mode.\"\n\n if not size:\n total = float(\"inf\")\n columns: Tuple[ProgressColumn, ...] = (\n TextColumn(\"[progress.description]{task.description}\"),\n SpinnerColumn(\"line\", speed=1.5),\n FileSizeColumn(),\n TransferSpeedColumn(),\n TimeElapsedColumn(),\n )\n else:\n total = size\n columns = (\n TextColumn(\"[progress.description]{task.description}\"),\n BarColumn(),\n DownloadColumn(),\n TransferSpeedColumn(),\n TextColumn(\"eta\"),\n TimeRemainingColumn(),\n )\n\n progress = Progress(*columns, refresh_per_second=30)\n task_id = progress.add_task(\" \" * (get_indentation() + 2), total=total)\n with progress:\n for chunk in iterable:\n yield chunk\n progress.update(task_id, advance=len(chunk))\n\n\ndef get_download_progress_renderer(\n *, bar_type: str, size: Optional[int] = None\n) -> DownloadProgressRenderer:\n \"\"\"Get an object that can be used to render the download progress.\n\n Returns a callable, that takes an iterable to \"wrap\".\n \"\"\"\n if bar_type == \"on\":\n return functools.partial(_rich_progress_bar, bar_type=bar_type, size=size)\n else:\n return iter # no-op, when passed an iterator\n"
},
{
"path": "lib/python3.7/site-packages/pip/_internal/cli/req_command.py",
"content": "\"\"\"Contains the Command base classes that depend on PipSession.\n\nThe classes in this module are in a separate module so the commands not\nneeding download / PackageFinder capability don't unnecessarily import the\nPackageFinder machinery and all its vendored dependencies, etc.\n\"\"\"\n\nimport logging\nimport os\nimport sys\nfrom functools import partial\nfrom optparse import Values\nfrom typing import TYPE_CHECKING, Any, List, Optional, Tuple\n\nfrom pip._internal.cache import WheelCache\nfrom pip._internal.cli import cmdoptions\nfrom pip._internal.cli.base_command import Command\nfrom pip._internal.cli.command_context import CommandContextMixIn\nfrom pip._internal.exceptions import CommandError, PreviousBuildDirError\nfrom pip._internal.index.collector import LinkCollector\nfrom pip._internal.index.package_finder import PackageFinder\nfrom pip._internal.models.selection_prefs import SelectionPreferences\nfrom pip._internal.models.target_python import TargetPython\nfrom pip._internal.network.session import PipSession\nfrom pip._internal.operations.build.build_tracker import BuildTracker\nfrom pip._internal.operations.prepare import RequirementPreparer\nfrom pip._internal.req.constructors import (\n install_req_from_editable,\n install_req_from_line,\n install_req_from_parsed_requirement,\n install_req_from_req_string,\n)\nfrom pip._internal.req.req_file import parse_requirements\nfrom pip._internal.req.req_install import InstallRequirement\nfrom pip._internal.resolution.base import BaseResolver\nfrom pip._internal.self_outdated_check import pip_self_version_check\nfrom pip._internal.utils.temp_dir import (\n TempDirectory,\n TempDirectoryTypeRegistry,\n tempdir_kinds,\n)\nfrom pip._internal.utils.virtualenv import running_under_virtualenv\n\nif TYPE_CHECKING:\n from ssl import SSLContext\n\nlogger = logging.getLogger(__name__)\n\n\ndef _create_truststore_ssl_context() -> Optional[\"SSLContext\"]:\n if sys.version_info < (3, 10):\n raise CommandError(\"The truststore feature is only available for Python 3.10+\")\n\n try:\n import ssl\n except ImportError:\n logger.warning(\"Disabling truststore since ssl support is missing\")\n return None\n\n try:\n import truststore\n except ImportError:\n raise CommandError(\n \"To use the truststore feature, 'truststore' must be installed into \"\n \"pip's current environment.\"\n )\n\n return truststore.SSLContext(ssl.PROTOCOL_TLS_CLIENT)\n\n\nclass SessionCommandMixin(CommandContextMixIn):\n\n \"\"\"\n A class mixin for command classes needing _build_session().\n \"\"\"\n\n def __init__(self) -> None:\n super().__init__()\n self._session: Optional[PipSession] = None\n\n @classmethod\n def _get_index_urls(cls, options: Values) -> Optional[List[str]]:\n \"\"\"Return a list of index urls from user-provided options.\"\"\"\n index_urls = []\n if not getattr(options, \"no_index\", False):\n url = getattr(options, \"index_url\", None)\n if url:\n index_urls.append(url)\n urls = getattr(options, \"extra_index_urls\", None)\n if urls:\n index_urls.extend(urls)\n # Return None rather than an empty list\n return index_urls or None\n\n def get_default_session(self, options: Values) -> PipSession:\n \"\"\"Get a default-managed session.\"\"\"\n if self._session is None:\n self._session = self.enter_context(self._build_session(options))\n # there's no type annotation on requests.Session, so it's\n # automatically ContextManager[Any] and self._session becomes Any,\n # then https://github.com/python/mypy/issues/7696 kicks in\n assert self._session is not None\n return self._session\n\n def _build_session(\n self,\n options: Values,\n retries: Optional[int] = None,\n timeout: Optional[int] = None,\n fallback_to_certifi: bool = False,\n ) -> PipSession:\n cache_dir = options.cache_dir\n assert not cache_dir or os.path.isabs(cache_dir)\n\n if \"truststore\" in options.features_enabled:\n try:\n ssl_context = _create_truststore_ssl_context()\n except Exception:\n if not fallback_to_certifi:\n raise\n ssl_context = None\n else:\n ssl_context = None\n\n session = PipSession(\n cache=os.path.join(cache_dir, \"http\") if cache_dir else None,\n retries=retries if retries is not None else options.retries,\n trusted_hosts=options.trusted_hosts,\n index_urls=self._get_index_urls(options),\n ssl_context=ssl_context,\n )\n\n # Handle custom ca-bundles from the user\n if options.cert:\n session.verify = options.cert\n\n # Handle SSL client certificate\n if options.client_cert:\n session.cert = options.client_cert\n\n # Handle timeouts\n if options.timeout or timeout:\n session.timeout = timeout if timeout is not None else options.timeout\n\n # Handle configured proxies\n if options.proxy:\n session.proxies = {\n \"http\": options.proxy,\n \"https\": options.proxy,\n }\n\n # Determine if we can prompt the user for authentication or not\n session.auth.prompting = not options.no_input\n\n return session\n\n\nclass IndexGroupCommand(Command, SessionCommandMixin):\n\n \"\"\"\n Abstract base class for commands with the index_group options.\n\n This also corresponds to the commands that permit the pip version check.\n \"\"\"\n\n def handle_pip_version_check(self, options: Values) -> None:\n \"\"\"\n Do the pip version check if not disabled.\n\n This overrides the default behavior of not doing the check.\n \"\"\"\n # Make sure the index_group options are present.\n assert hasattr(options, \"no_index\")\n\n if options.disable_pip_version_check or options.no_index:\n return\n\n # Otherwise, check if we're using the latest version of pip available.\n session = self._build_session(\n options,\n retries=0,\n timeout=min(5, options.timeout),\n # This is set to ensure the function does not fail when truststore is\n # specified in use-feature but cannot be loaded. This usually raises a\n # CommandError and shows a nice user-facing error, but this function is not\n # called in that try-except block.\n fallback_to_certifi=True,\n )\n with session:\n pip_self_version_check(session, options)\n\n\nKEEPABLE_TEMPDIR_TYPES = [\n tempdir_kinds.BUILD_ENV,\n tempdir_kinds.EPHEM_WHEEL_CACHE,\n tempdir_kinds.REQ_BUILD,\n]\n\n\ndef warn_if_run_as_root() -> None:\n \"\"\"Output a warning for sudo users on Unix.\n\n In a virtual environment, sudo pip still writes to virtualenv.\n On Windows, users may run pip as Administrator without issues.\n This warning only applies to Unix root users outside of virtualenv.\n \"\"\"\n if running_under_virtualenv():\n return\n if not hasattr(os, \"getuid\"):\n return\n # On Windows, there are no \"system managed\" Python packages. Installing as\n # Administrator via pip is the correct way of updating system environments.\n #\n # We choose sys.platform over utils.compat.WINDOWS here to enable Mypy platform\n # checks: https://mypy.readthedocs.io/en/stable/common_issues.html\n if sys.platform == \"win32\" or sys.platform == \"cygwin\":\n return\n\n if os.getuid() != 0:\n return\n\n logger.warning(\n \"Running pip as the 'root' user can result in broken permissions and \"\n \"conflicting behaviour with the system package manager. \"\n \"It is recommended to use a virtual environment instead: \"\n \"https://pip.pypa.io/warnings/venv\"\n )\n\n\ndef with_cleanup(func: Any) -> Any:\n \"\"\"Decorator for common logic related to managing temporary\n directories.\n \"\"\"\n\n def configure_tempdir_registry(registry: TempDirectoryTypeRegistry) -> None:\n for t in KEEPABLE_TEMPDIR_TYPES:\n registry.set_delete(t, False)\n\n def wrapper(\n self: RequirementCommand, options: Values, args: List[Any]\n ) -> Optional[int]:\n assert self.tempdir_registry is not None\n if options.no_clean:\n configure_tempdir_registry(self.tempdir_registry)\n\n try:\n return func(self, options, args)\n except PreviousBuildDirError:\n # This kind of conflict can occur when the user passes an explicit\n # build directory with a pre-existing folder. In that case we do\n # not want to accidentally remove it.\n configure_tempdir_registry(self.tempdir_registry)\n raise\n\n return wrapper\n\n\nclass RequirementCommand(IndexGroupCommand):\n def __init__(self, *args: Any, **kw: Any) -> None:\n super().__init__(*args, **kw)\n\n self.cmd_opts.add_option(cmdoptions.no_clean())\n\n @staticmethod\n def determine_resolver_variant(options: Values) -> str:\n \"\"\"Determines which resolver should be used, based on the given options.\"\"\"\n if \"legacy-resolver\" in options.deprecated_features_enabled:\n return \"legacy\"\n\n return \"2020-resolver\"\n\n @classmethod\n def make_requirement_preparer(\n cls,\n temp_build_dir: TempDirectory,\n options: Values,\n build_tracker: BuildTracker,\n session: PipSession,\n finder: PackageFinder,\n use_user_site: bool,\n download_dir: Optional[str] = None,\n verbosity: int = 0,\n ) -> RequirementPreparer:\n \"\"\"\n Create a RequirementPreparer instance for the given parameters.\n \"\"\"\n temp_build_dir_path = temp_build_dir.path\n assert temp_build_dir_path is not None\n\n resolver_variant = cls.determine_resolver_variant(options)\n if resolver_variant == \"2020-resolver\":\n lazy_wheel = \"fast-deps\" in options.features_enabled\n if lazy_wheel:\n logger.warning(\n \"pip is using lazily downloaded wheels using HTTP \"\n \"range requests to obtain dependency information. \"\n \"This experimental feature is enabled through \"\n \"--use-feature=fast-deps and it is not ready for \"\n \"production.\"\n )\n else:\n lazy_wheel = False\n if \"fast-deps\" in options.features_enabled:\n logger.warning(\n \"fast-deps has no effect when used with the legacy resolver.\"\n )\n\n return RequirementPreparer(\n build_dir=temp_build_dir_path,\n src_dir=options.src_dir,\n download_dir=download_dir,\n build_isolation=options.build_isolation,\n check_build_deps=options.check_build_deps,\n build_tracker=build_tracker,\n session=session,\n progress_bar=options.progress_bar,\n finder=finder,\n require_hashes=options.require_hashes,\n use_user_site=use_user_site,\n lazy_wheel=lazy_wheel,\n verbosity=verbosity,\n )\n\n @classmethod\n def make_resolver(\n cls,\n preparer: RequirementPreparer,\n finder: PackageFinder,\n options: Values,\n wheel_cache: Optional[WheelCache] = None,\n use_user_site: bool = False,\n ignore_installed: bool = True,\n ignore_requires_python: bool = False,\n force_reinstall: bool = False,\n upgrade_strategy: str = \"to-satisfy-only\",\n use_pep517: Optional[bool] = None,\n py_version_info: Optional[Tuple[int, ...]] = None,\n ) -> BaseResolver:\n \"\"\"\n Create a Resolver instance for the given parameters.\n \"\"\"\n make_install_req = partial(\n install_req_from_req_string,\n isolated=options.isolated_mode,\n use_pep517=use_pep517,\n config_settings=getattr(options, \"config_settings\", None),\n )\n resolver_variant = cls.determine_resolver_variant(options)\n # The long import name and duplicated invocation is needed to convince\n # Mypy into correctly typechecking. Otherwise it would complain the\n # \"Resolver\" class being redefined.\n if resolver_variant == \"2020-resolver\":\n import pip._internal.resolution.resolvelib.resolver\n\n return pip._internal.resolution.resolvelib.resolver.Resolver(\n preparer=preparer,\n finder=finder,\n wheel_cache=wheel_cache,\n make_install_req=make_install_req,\n use_user_site=use_user_site,\n ignore_dependencies=options.ignore_dependencies,\n ignore_installed=ignore_installed,\n ignore_requires_python=ignore_requires_python,\n force_reinstall=force_reinstall,\n upgrade_strategy=upgrade_strategy,\n py_version_info=py_version_info,\n )\n import pip._internal.resolution.legacy.resolver\n\n return pip._internal.resolution.legacy.resolver.Resolver(\n preparer=preparer,\n finder=finder,\n wheel_cache=wheel_cache,\n make_install_req=make_install_req,\n use_user_site=use_user_site,\n ignore_dependencies=options.ignore_dependencies,\n ignore_installed=ignore_installed,\n ignore_requires_python=ignore_requires_python,\n force_reinstall=force_reinstall,\n upgrade_strategy=upgrade_strategy,\n py_version_info=py_version_info,\n )\n\n def get_requirements(\n self,\n args: List[str],\n options: Values,\n finder: PackageFinder,\n session: PipSession,\n ) -> List[InstallRequirement]:\n \"\"\"\n Parse command-line arguments into the corresponding requirements.\n \"\"\"\n requirements: List[InstallRequirement] = []\n for filename in options.constraints:\n for parsed_req in parse_requirements(\n filename,\n constraint=True,\n finder=finder,\n options=options,\n session=session,\n ):\n req_to_add = install_req_from_parsed_requirement(\n parsed_req,\n isolated=options.isolated_mode,\n user_supplied=False,\n )\n requirements.append(req_to_add)\n\n for req in args:\n req_to_add = install_req_from_line(\n req,\n None,\n isolated=options.isolated_mode,\n use_pep517=options.use_pep517,\n user_supplied=True,\n config_settings=getattr(options, \"config_settings\", None),\n )\n requirements.append(req_to_add)\n\n for req in options.editables:\n req_to_add = install_req_from_editable(\n req,\n user_supplied=True,\n isolated=options.isolated_mode,\n use_pep517=options.use_pep517,\n config_settings=getattr(options, \"config_settings\", None),\n )\n requirements.append(req_to_add)\n\n # NOTE: options.require_hashes may be set if --require-hashes is True\n for filename in options.requirements:\n for parsed_req in parse_requirements(\n filename, finder=finder, options=options, session=session\n ):\n req_to_add = install_req_from_parsed_requirement(\n parsed_req,\n isolated=options.isolated_mode,\n use_pep517=options.use_pep517,\n user_supplied=True,\n )\n requirements.append(req_to_add)\n\n # If any requirement has hash options, enable hash checking.\n if any(req.has_hash_options for req in requirements):\n options.require_hashes = True\n\n if not (args or options.editables or options.requirements):\n opts = {\"name\": self.name}\n if options.find_links:\n raise CommandError(\n \"You must give at least one requirement to {name} \"\n '(maybe you meant \"pip {name} {links}\"?)'.format(\n **dict(opts, links=\" \".join(options.find_links))\n )\n )\n else:\n raise CommandError(\n \"You must give at least one requirement to {name} \"\n '(see \"pip help {name}\")'.format(**opts)\n )\n\n return requirements\n\n @staticmethod\n def trace_basic_info(finder: PackageFinder) -> None:\n \"\"\"\n Trace basic information about the provided objects.\n \"\"\"\n # Display where finder is looking for packages\n search_scope = finder.search_scope\n locations = search_scope.get_formatted_locations()\n if locations:\n logger.info(locations)\n\n def _build_package_finder(\n self,\n options: Values,\n session: PipSession,\n target_python: Optional[TargetPython] = None,\n ignore_requires_python: Optional[bool] = None,\n ) -> PackageFinder:\n \"\"\"\n Create a package finder appropriate to this requirement command.\n\n :param ignore_requires_python: Whether to ignore incompatible\n \"Requires-Python\" values in links. Defaults to False.\n \"\"\"\n link_collector = LinkCollector.create(session, options=options)\n selection_prefs = SelectionPreferences(\n allow_yanked=True,\n format_control=options.format_control,\n allow_all_prereleases=options.pre,\n prefer_binary=options.prefer_binary,\n ignore_requires_python=ignore_requires_python,\n )\n\n return PackageFinder.create(\n link_collector=link_collector,\n selection_prefs=selection_prefs,\n target_python=target_python,\n )\n"
},
{
"path": "lib/python3.7/site-packages/pip/_internal/cli/spinners.py",
"content": "import contextlib\nimport itertools\nimport logging\nimport sys\nimport time\nfrom typing import IO, Generator, Optional\n\nfrom pip._internal.utils.compat import WINDOWS\nfrom pip._internal.utils.logging import get_indentation\n\nlogger = logging.getLogger(__name__)\n\n\nclass SpinnerInterface:\n def spin(self) -> None:\n raise NotImplementedError()\n\n def finish(self, final_status: str) -> None:\n raise NotImplementedError()\n\n\nclass InteractiveSpinner(SpinnerInterface):\n def __init__(\n self,\n message: str,\n file: Optional[IO[str]] = None,\n spin_chars: str = \"-\\\\|/\",\n # Empirically, 8 updates/second looks nice\n min_update_interval_seconds: float = 0.125,\n ):\n self._message = message\n if file is None:\n file = sys.stdout\n self._file = file\n self._rate_limiter = RateLimiter(min_update_interval_seconds)\n self._finished = False\n\n self._spin_cycle = itertools.cycle(spin_chars)\n\n self._file.write(\" \" * get_indentation() + self._message + \" ... \")\n self._width = 0\n\n def _write(self, status: str) -> None:\n assert not self._finished\n # Erase what we wrote before by backspacing to the beginning, writing\n # spaces to overwrite the old text, and then backspacing again\n backup = \"\\b\" * self._width\n self._file.write(backup + \" \" * self._width + backup)\n # Now we have a blank slate to add our status\n self._file.write(status)\n self._width = len(status)\n self._file.flush()\n self._rate_limiter.reset()\n\n def spin(self) -> None:\n if self._finished:\n return\n if not self._rate_limiter.ready():\n return\n self._write(next(self._spin_cycle))\n\n def finish(self, final_status: str) -> None:\n if self._finished:\n return\n self._write(final_status)\n self._file.write(\"\\n\")\n self._file.flush()\n self._finished = True\n\n\n# Used for dumb terminals, non-interactive installs (no tty), etc.\n# We still print updates occasionally (once every 60 seconds by default) to\n# act as a keep-alive for systems like Travis-CI that take lack-of-output as\n# an indication that a task has frozen.\nclass NonInteractiveSpinner(SpinnerInterface):\n def __init__(self, message: str, min_update_interval_seconds: float = 60.0) -> None:\n self._message = message\n self._finished = False\n self._rate_limiter = RateLimiter(min_update_interval_seconds)\n self._update(\"started\")\n\n def _update(self, status: str) -> None:\n assert not self._finished\n self._rate_limiter.reset()\n logger.info(\"%s: %s\", self._message, status)\n\n def spin(self) -> None:\n if self._finished:\n return\n if not self._rate_limiter.ready():\n return\n self._update(\"still running...\")\n\n def finish(self, final_status: str) -> None:\n if self._finished:\n return\n self._update(f\"finished with status '{final_status}'\")\n self._finished = True\n\n\nclass RateLimiter:\n def __init__(self, min_update_interval_seconds: float) -> None:\n self._min_update_interval_seconds = min_update_interval_seconds\n self._last_update: float = 0\n\n def ready(self) -> bool:\n now = time.time()\n delta = now - self._last_update\n return delta >= self._min_update_interval_seconds\n\n def reset(self) -> None:\n self._last_update = time.time()\n\n\n@contextlib.contextmanager\ndef open_spinner(message: str) -> Generator[SpinnerInterface, None, None]:\n # Interactive spinner goes directly to sys.stdout rather than being routed\n # through the logging system, but it acts like it has level INFO,\n # i.e. it's only displayed if we're at level INFO or better.\n # Non-interactive spinner goes through the logging system, so it is always\n # in sync with logging configuration.\n if sys.stdout.isatty() and logger.getEffectiveLevel() <= logging.INFO:\n spinner: SpinnerInterface = InteractiveSpinner(message)\n else:\n spinner = NonInteractiveSpinner(message)\n try:\n with hidden_cursor(sys.stdout):\n yield spinner\n except KeyboardInterrupt:\n spinner.finish(\"canceled\")\n raise\n except Exception:\n spinner.finish(\"error\")\n raise\n else:\n spinner.finish(\"done\")\n\n\nHIDE_CURSOR = \"\\x1b[?25l\"\nSHOW_CURSOR = \"\\x1b[?25h\"\n\n\n@contextlib.contextmanager\ndef hidden_cursor(file: IO[str]) -> Generator[None, None, None]:\n # The Windows terminal does not support the hide/show cursor ANSI codes,\n # even via colorama. So don't even try.\n if WINDOWS:\n yield\n # We don't want to clutter the output with control characters if we're\n # writing to a file, or if the user is running with --quiet.\n # See https://github.com/pypa/pip/issues/3418\n elif not file.isatty() or logger.getEffectiveLevel() > logging.INFO:\n yield\n else:\n file.write(HIDE_CURSOR)\n try:\n yield\n finally:\n file.write(SHOW_CURSOR)\n"
},
{
"path": "lib/python3.7/site-packages/pip/_internal/cli/status_codes.py",
"content": "SUCCESS = 0\nERROR = 1\nUNKNOWN_ERROR = 2\nVIRTUALENV_NOT_FOUND = 3\nPREVIOUS_BUILD_DIR_ERROR = 4\nNO_MATCHES_FOUND = 23\n"
},
{
"path": "lib/python3.7/site-packages/pip/_internal/commands/__init__.py",
"content": "\"\"\"\nPackage containing all pip commands\n\"\"\"\n\nimport importlib\nfrom collections import namedtuple\nfrom typing import Any, Dict, Optional\n\nfrom pip._internal.cli.base_command import Command\n\nCommandInfo = namedtuple(\"CommandInfo\", \"module_path, class_name, summary\")\n\n# This dictionary does a bunch of heavy lifting for help output:\n# - Enables avoiding additional (costly) imports for presenting `--help`.\n# - The ordering matters for help display.\n#\n# Even though the module path starts with the same \"pip._internal.commands\"\n# prefix, the full path makes testing easier (specifically when modifying\n# `commands_dict` in test setup / teardown).\ncommands_dict: Dict[str, CommandInfo] = {\n \"install\": CommandInfo(\n \"pip._internal.commands.install\",\n \"InstallCommand\",\n \"Install packages.\",\n ),\n \"download\": CommandInfo(\n \"pip._internal.commands.download\",\n \"DownloadCommand\",\n \"Download packages.\",\n ),\n \"uninstall\": CommandInfo(\n \"pip._internal.commands.uninstall\",\n \"UninstallCommand\",\n \"Uninstall packages.\",\n ),\n \"freeze\": CommandInfo(\n \"pip._internal.commands.freeze\",\n \"FreezeCommand\",\n \"Output installed packages in requirements format.\",\n ),\n \"inspect\": CommandInfo(\n \"pip._internal.commands.inspect\",\n \"InspectCommand\",\n \"Inspect the python environment.\",\n ),\n \"list\": CommandInfo(\n \"pip._internal.commands.list\",\n \"ListCommand\",\n \"List installed packages.\",\n ),\n \"show\": CommandInfo(\n \"pip._internal.commands.show\",\n \"ShowCommand\",\n \"Show information about installed packages.\",\n ),\n \"check\": CommandInfo(\n \"pip._internal.commands.check\",\n \"CheckCommand\",\n \"Verify installed packages have compatible dependencies.\",\n ),\n \"config\": CommandInfo(\n \"pip._internal.commands.configuration\",\n \"ConfigurationCommand\",\n \"Manage local and global configuration.\",\n ),\n \"search\": CommandInfo(\n \"pip._internal.commands.search\",\n \"SearchCommand\",\n \"Search PyPI for packages.\",\n ),\n \"cache\": CommandInfo(\n \"pip._internal.commands.cache\",\n \"CacheCommand\",\n \"Inspect and manage pip's wheel cache.\",\n ),\n \"index\": CommandInfo(\n \"pip._internal.commands.index\",\n \"IndexCommand\",\n \"Inspect information available from package indexes.\",\n ),\n \"wheel\": CommandInfo(\n \"pip._internal.commands.wheel\",\n \"WheelCommand\",\n \"Build wheels from your requirements.\",\n ),\n \"hash\": CommandInfo(\n \"pip._internal.commands.hash\",\n \"HashCommand\",\n \"Compute hashes of package archives.\",\n ),\n \"completion\": CommandInfo(\n \"pip._internal.commands.completion\",\n \"CompletionCommand\",\n \"A helper command used for command completion.\",\n ),\n \"debug\": CommandInfo(\n \"pip._internal.commands.debug\",\n \"DebugCommand\",\n \"Show information useful for debugging.\",\n ),\n \"help\": CommandInfo(\n \"pip._internal.commands.help\",\n \"HelpCommand\",\n \"Show help for commands.\",\n ),\n}\n\n\ndef create_command(name: str, **kwargs: Any) -> Command:\n \"\"\"\n Create an instance of the Command class with the given name.\n \"\"\"\n module_path, class_name, summary = commands_dict[name]\n module = importlib.import_module(module_path)\n command_class = getattr(module, class_name)\n command = command_class(name=name, summary=summary, **kwargs)\n\n return command\n\n\ndef get_similar_commands(name: str) -> Optional[str]:\n \"\"\"Command name auto-correct.\"\"\"\n from difflib import get_close_matches\n\n name = name.lower()\n\n close_commands = get_close_matches(name, commands_dict.keys())\n\n if close_commands:\n return close_commands[0]\n else:\n return None\n"
},
{
"path": "lib/python3.7/site-packages/pip/_internal/commands/cache.py",
"content": "import os\nimport textwrap\nfrom optparse import Values\nfrom typing import Any, List\n\nimport pip._internal.utils.filesystem as filesystem\nfrom pip._internal.cli.base_command import Command\nfrom pip._internal.cli.status_codes import ERROR, SUCCESS\nfrom pip._internal.exceptions import CommandError, PipError\nfrom pip._internal.utils.logging import getLogger\n\nlogger = getLogger(__name__)\n\n\nclass CacheCommand(Command):\n \"\"\"\n Inspect and manage pip's wheel cache.\n\n Subcommands:\n\n - dir: Show the cache directory.\n - info: Show information about the cache.\n - list: List filenames of packages stored in the cache.\n - remove: Remove one or more package from the cache.\n - purge: Remove all items from the cache.\n\n ```` can be a glob expression or a package name.\n \"\"\"\n\n ignore_require_venv = True\n usage = \"\"\"\n %prog dir\n %prog info\n %prog list [] [--format=[human, abspath]]\n %prog remove \n %prog purge\n \"\"\"\n\n def add_options(self) -> None:\n\n self.cmd_opts.add_option(\n \"--format\",\n action=\"store\",\n dest=\"list_format\",\n default=\"human\",\n choices=(\"human\", \"abspath\"),\n help=\"Select the output format among: human (default) or abspath\",\n )\n\n self.parser.insert_option_group(0, self.cmd_opts)\n\n def run(self, options: Values, args: List[str]) -> int:\n handlers = {\n \"dir\": self.get_cache_dir,\n \"info\": self.get_cache_info,\n \"list\": self.list_cache_items,\n \"remove\": self.remove_cache_items,\n \"purge\": self.purge_cache,\n }\n\n if not options.cache_dir:\n logger.error(\"pip cache commands can not function since cache is disabled.\")\n return ERROR\n\n # Determine action\n if not args or args[0] not in handlers:\n logger.error(\n \"Need an action (%s) to perform.\",\n \", \".join(sorted(handlers)),\n )\n return ERROR\n\n action = args[0]\n\n # Error handling happens here, not in the action-handlers.\n try:\n handlers[action](options, args[1:])\n except PipError as e:\n logger.error(e.args[0])\n return ERROR\n\n return SUCCESS\n\n def get_cache_dir(self, options: Values, args: List[Any]) -> None:\n if args:\n raise CommandError(\"Too many arguments\")\n\n logger.info(options.cache_dir)\n\n def get_cache_info(self, options: Values, args: List[Any]) -> None:\n if args:\n raise CommandError(\"Too many arguments\")\n\n num_http_files = len(self._find_http_files(options))\n num_packages = len(self._find_wheels(options, \"*\"))\n\n http_cache_location = self._cache_dir(options, \"http\")\n wheels_cache_location = self._cache_dir(options, \"wheels\")\n http_cache_size = filesystem.format_directory_size(http_cache_location)\n wheels_cache_size = filesystem.format_directory_size(wheels_cache_location)\n\n message = (\n textwrap.dedent(\n \"\"\"\n Package index page cache location: {http_cache_location}\n Package index page cache size: {http_cache_size}\n Number of HTTP files: {num_http_files}\n Locally built wheels location: {wheels_cache_location}\n Locally built wheels size: {wheels_cache_size}\n Number of locally built wheels: {package_count}\n \"\"\"\n )\n .format(\n http_cache_location=http_cache_location,\n http_cache_size=http_cache_size,\n num_http_files=num_http_files,\n wheels_cache_location=wheels_cache_location,\n package_count=num_packages,\n wheels_cache_size=wheels_cache_size,\n )\n .strip()\n )\n\n logger.info(message)\n\n def list_cache_items(self, options: Values, args: List[Any]) -> None:\n if len(args) > 1:\n raise CommandError(\"Too many arguments\")\n\n if args:\n pattern = args[0]\n else:\n pattern = \"*\"\n\n files = self._find_wheels(options, pattern)\n if options.list_format == \"human\":\n self.format_for_human(files)\n else:\n self.format_for_abspath(files)\n\n def format_for_human(self, files: List[str]) -> None:\n if not files:\n logger.info(\"No locally built wheels cached.\")\n return\n\n results = []\n for filename in files:\n wheel = os.path.basename(filename)\n size = filesystem.format_file_size(filename)\n results.append(f\" - {wheel} ({size})\")\n logger.info(\"Cache contents:\\n\")\n logger.info(\"\\n\".join(sorted(results)))\n\n def format_for_abspath(self, files: List[str]) -> None:\n if not files:\n return\n\n results = []\n for filename in files:\n results.append(filename)\n\n logger.info(\"\\n\".join(sorted(results)))\n\n def remove_cache_items(self, options: Values, args: List[Any]) -> None:\n if len(args) > 1:\n raise CommandError(\"Too many arguments\")\n\n if not args:\n raise CommandError(\"Please provide a pattern\")\n\n files = self._find_wheels(options, args[0])\n\n no_matching_msg = \"No matching packages\"\n if args[0] == \"*\":\n # Only fetch http files if no specific pattern given\n files += self._find_http_files(options)\n else:\n # Add the pattern to the log message\n no_matching_msg += ' for pattern \"{}\"'.format(args[0])\n\n if not files:\n logger.warning(no_matching_msg)\n\n for filename in files:\n os.unlink(filename)\n logger.verbose(\"Removed %s\", filename)\n logger.info(\"Files removed: %s\", len(files))\n\n def purge_cache(self, options: Values, args: List[Any]) -> None:\n if args:\n raise CommandError(\"Too many arguments\")\n\n return self.remove_cache_items(options, [\"*\"])\n\n def _cache_dir(self, options: Values, subdir: str) -> str:\n return os.path.join(options.cache_dir, subdir)\n\n def _find_http_files(self, options: Values) -> List[str]:\n http_dir = self._cache_dir(options, \"http\")\n return filesystem.find_files(http_dir, \"*\")\n\n def _find_wheels(self, options: Values, pattern: str) -> List[str]:\n wheel_dir = self._cache_dir(options, \"wheels\")\n\n # The wheel filename format, as specified in PEP 427, is:\n # {distribution}-{version}(-{build})?-{python}-{abi}-{platform}.whl\n #\n # Additionally, non-alphanumeric values in the distribution are\n # normalized to underscores (_), meaning hyphens can never occur\n # before `-{version}`.\n #\n # Given that information:\n # - If the pattern we're given contains a hyphen (-), the user is\n # providing at least the version. Thus, we can just append `*.whl`\n # to match the rest of it.\n # - If the pattern we're given doesn't contain a hyphen (-), the\n # user is only providing the name. Thus, we append `-*.whl` to\n # match the hyphen before the version, followed by anything else.\n #\n # PEP 427: https://www.python.org/dev/peps/pep-0427/\n pattern = pattern + (\"*.whl\" if \"-\" in pattern else \"-*.whl\")\n\n return filesystem.find_files(wheel_dir, pattern)\n"
},
{
"path": "lib/python3.7/site-packages/pip/_internal/commands/check.py",
"content": "import logging\nfrom optparse import Values\nfrom typing import List\n\nfrom pip._internal.cli.base_command import Command\nfrom pip._internal.cli.status_codes import ERROR, SUCCESS\nfrom pip._internal.operations.check import (\n check_package_set,\n create_package_set_from_installed,\n)\nfrom pip._internal.utils.misc import write_output\n\nlogger = logging.getLogger(__name__)\n\n\nclass CheckCommand(Command):\n \"\"\"Verify installed packages have compatible dependencies.\"\"\"\n\n usage = \"\"\"\n %prog [options]\"\"\"\n\n def run(self, options: Values, args: List[str]) -> int:\n\n package_set, parsing_probs = create_package_set_from_installed()\n missing, conflicting = check_package_set(package_set)\n\n for project_name in missing:\n version = package_set[project_name].version\n for dependency in missing[project_name]:\n write_output(\n \"%s %s requires %s, which is not installed.\",\n project_name,\n version,\n dependency[0],\n )\n\n for project_name in conflicting:\n version = package_set[project_name].version\n for dep_name, dep_version, req in conflicting[project_name]:\n write_output(\n \"%s %s has requirement %s, but you have %s %s.\",\n project_name,\n version,\n req,\n dep_name,\n dep_version,\n )\n\n if missing or conflicting or parsing_probs:\n return ERROR\n else:\n write_output(\"No broken requirements found.\")\n return SUCCESS\n"
},
{
"path": "lib/python3.7/site-packages/pip/_internal/commands/completion.py",
"content": "import sys\nimport textwrap\nfrom optparse import Values\nfrom typing import List\n\nfrom pip._internal.cli.base_command import Command\nfrom pip._internal.cli.status_codes import SUCCESS\nfrom pip._internal.utils.misc import get_prog\n\nBASE_COMPLETION = \"\"\"\n# pip {shell} completion start{script}# pip {shell} completion end\n\"\"\"\n\nCOMPLETION_SCRIPTS = {\n \"bash\": \"\"\"\n _pip_completion()\n {{\n COMPREPLY=( $( COMP_WORDS=\"${{COMP_WORDS[*]}}\" \\\\\n COMP_CWORD=$COMP_CWORD \\\\\n PIP_AUTO_COMPLETE=1 $1 2>/dev/null ) )\n }}\n complete -o default -F _pip_completion {prog}\n \"\"\",\n \"zsh\": \"\"\"\n function _pip_completion {{\n local words cword\n read -Ac words\n read -cn cword\n reply=( $( COMP_WORDS=\"$words[*]\" \\\\\n COMP_CWORD=$(( cword-1 )) \\\\\n PIP_AUTO_COMPLETE=1 $words[1] 2>/dev/null ))\n }}\n compctl -K _pip_completion {prog}\n \"\"\",\n \"fish\": \"\"\"\n function __fish_complete_pip\n set -lx COMP_WORDS (commandline -o) \"\"\n set -lx COMP_CWORD ( \\\\\n math (contains -i -- (commandline -t) $COMP_WORDS)-1 \\\\\n )\n set -lx PIP_AUTO_COMPLETE 1\n string split \\\\ -- (eval $COMP_WORDS[1])\n end\n complete -fa \"(__fish_complete_pip)\" -c {prog}\n \"\"\",\n \"powershell\": \"\"\"\n if ((Test-Path Function:\\\\TabExpansion) -and -not `\n (Test-Path Function:\\\\_pip_completeBackup)) {{\n Rename-Item Function:\\\\TabExpansion _pip_completeBackup\n }}\n function TabExpansion($line, $lastWord) {{\n $lastBlock = [regex]::Split($line, '[|;]')[-1].TrimStart()\n if ($lastBlock.StartsWith(\"{prog} \")) {{\n $Env:COMP_WORDS=$lastBlock\n $Env:COMP_CWORD=$lastBlock.Split().Length - 1\n $Env:PIP_AUTO_COMPLETE=1\n (& {prog}).Split()\n Remove-Item Env:COMP_WORDS\n Remove-Item Env:COMP_CWORD\n Remove-Item Env:PIP_AUTO_COMPLETE\n }}\n elseif (Test-Path Function:\\\\_pip_completeBackup) {{\n # Fall back on existing tab expansion\n _pip_completeBackup $line $lastWord\n }}\n }}\n \"\"\",\n}\n\n\nclass CompletionCommand(Command):\n \"\"\"A helper command to be used for command completion.\"\"\"\n\n ignore_require_venv = True\n\n def add_options(self) -> None:\n self.cmd_opts.add_option(\n \"--bash\",\n \"-b\",\n action=\"store_const\",\n const=\"bash\",\n dest=\"shell\",\n help=\"Emit completion code for bash\",\n )\n self.cmd_opts.add_option(\n \"--zsh\",\n \"-z\",\n action=\"store_const\",\n const=\"zsh\",\n dest=\"shell\",\n help=\"Emit completion code for zsh\",\n )\n self.cmd_opts.add_option(\n \"--fish\",\n \"-f\",\n action=\"store_const\",\n const=\"fish\",\n dest=\"shell\",\n help=\"Emit completion code for fish\",\n )\n self.cmd_opts.add_option(\n \"--powershell\",\n \"-p\",\n action=\"store_const\",\n const=\"powershell\",\n dest=\"shell\",\n help=\"Emit completion code for powershell\",\n )\n\n self.parser.insert_option_group(0, self.cmd_opts)\n\n def run(self, options: Values, args: List[str]) -> int:\n \"\"\"Prints the completion code of the given shell\"\"\"\n shells = COMPLETION_SCRIPTS.keys()\n shell_options = [\"--\" + shell for shell in sorted(shells)]\n if options.shell in shells:\n script = textwrap.dedent(\n COMPLETION_SCRIPTS.get(options.shell, \"\").format(prog=get_prog())\n )\n print(BASE_COMPLETION.format(script=script, shell=options.shell))\n return SUCCESS\n else:\n sys.stderr.write(\n \"ERROR: You must pass {}\\n\".format(\" or \".join(shell_options))\n )\n return SUCCESS\n"
},
{
"path": "lib/python3.7/site-packages/pip/_internal/commands/configuration.py",
"content": "import logging\nimport os\nimport subprocess\nfrom optparse import Values\nfrom typing import Any, List, Optional\n\nfrom pip._internal.cli.base_command import Command\nfrom pip._internal.cli.status_codes import ERROR, SUCCESS\nfrom pip._internal.configuration import (\n Configuration,\n Kind,\n get_configuration_files,\n kinds,\n)\nfrom pip._internal.exceptions import PipError\nfrom pip._internal.utils.logging import indent_log\nfrom pip._internal.utils.misc import get_prog, write_output\n\nlogger = logging.getLogger(__name__)\n\n\nclass ConfigurationCommand(Command):\n \"\"\"\n Manage local and global configuration.\n\n Subcommands:\n\n - list: List the active configuration (or from the file specified)\n - edit: Edit the configuration file in an editor\n - get: Get the value associated with command.option\n - set: Set the command.option=value\n - unset: Unset the value associated with command.option\n - debug: List the configuration files and values defined under them\n\n Configuration keys should be dot separated command and option name,\n with the special prefix \"global\" affecting any command. For example,\n \"pip config set global.index-url https://example.org/\" would configure\n the index url for all commands, but \"pip config set download.timeout 10\"\n would configure a 10 second timeout only for \"pip download\" commands.\n\n If none of --user, --global and --site are passed, a virtual\n environment configuration file is used if one is active and the file\n exists. Otherwise, all modifications happen to the user file by\n default.\n \"\"\"\n\n ignore_require_venv = True\n usage = \"\"\"\n %prog [] list\n %prog [] [--editor ] edit\n\n %prog [] get command.option\n %prog [] set command.option value\n %prog [] unset command.option\n %prog [] debug\n \"\"\"\n\n def add_options(self) -> None:\n self.cmd_opts.add_option(\n \"--editor\",\n dest=\"editor\",\n action=\"store\",\n default=None,\n help=(\n \"Editor to use to edit the file. Uses VISUAL or EDITOR \"\n \"environment variables if not provided.\"\n ),\n )\n\n self.cmd_opts.add_option(\n \"--global\",\n dest=\"global_file\",\n action=\"store_true\",\n default=False,\n help=\"Use the system-wide configuration file only\",\n )\n\n self.cmd_opts.add_option(\n \"--user\",\n dest=\"user_file\",\n action=\"store_true\",\n default=False,\n help=\"Use the user configuration file only\",\n )\n\n self.cmd_opts.add_option(\n \"--site\",\n dest=\"site_file\",\n action=\"store_true\",\n default=False,\n help=\"Use the current environment configuration file only\",\n )\n\n self.parser.insert_option_group(0, self.cmd_opts)\n\n def run(self, options: Values, args: List[str]) -> int:\n handlers = {\n \"list\": self.list_values,\n \"edit\": self.open_in_editor,\n \"get\": self.get_name,\n \"set\": self.set_name_value,\n \"unset\": self.unset_name,\n \"debug\": self.list_config_values,\n }\n\n # Determine action\n if not args or args[0] not in handlers:\n logger.error(\n \"Need an action (%s) to perform.\",\n \", \".join(sorted(handlers)),\n )\n return ERROR\n\n action = args[0]\n\n # Determine which configuration files are to be loaded\n # Depends on whether the command is modifying.\n try:\n load_only = self._determine_file(\n options, need_value=(action in [\"get\", \"set\", \"unset\", \"edit\"])\n )\n except PipError as e:\n logger.error(e.args[0])\n return ERROR\n\n # Load a new configuration\n self.configuration = Configuration(\n isolated=options.isolated_mode, load_only=load_only\n )\n self.configuration.load()\n\n # Error handling happens here, not in the action-handlers.\n try:\n handlers[action](options, args[1:])\n except PipError as e:\n logger.error(e.args[0])\n return ERROR\n\n return SUCCESS\n\n def _determine_file(self, options: Values, need_value: bool) -> Optional[Kind]:\n file_options = [\n key\n for key, value in (\n (kinds.USER, options.user_file),\n (kinds.GLOBAL, options.global_file),\n (kinds.SITE, options.site_file),\n )\n if value\n ]\n\n if not file_options:\n if not need_value:\n return None\n # Default to user, unless there's a site file.\n elif any(\n os.path.exists(site_config_file)\n for site_config_file in get_configuration_files()[kinds.SITE]\n ):\n return kinds.SITE\n else:\n return kinds.USER\n elif len(file_options) == 1:\n return file_options[0]\n\n raise PipError(\n \"Need exactly one file to operate upon \"\n \"(--user, --site, --global) to perform.\"\n )\n\n def list_values(self, options: Values, args: List[str]) -> None:\n self._get_n_args(args, \"list\", n=0)\n\n for key, value in sorted(self.configuration.items()):\n write_output(\"%s=%r\", key, value)\n\n def get_name(self, options: Values, args: List[str]) -> None:\n key = self._get_n_args(args, \"get [name]\", n=1)\n value = self.configuration.get_value(key)\n\n write_output(\"%s\", value)\n\n def set_name_value(self, options: Values, args: List[str]) -> None:\n key, value = self._get_n_args(args, \"set [name] [value]\", n=2)\n self.configuration.set_value(key, value)\n\n self._save_configuration()\n\n def unset_name(self, options: Values, args: List[str]) -> None:\n key = self._get_n_args(args, \"unset [name]\", n=1)\n self.configuration.unset_value(key)\n\n self._save_configuration()\n\n def list_config_values(self, options: Values, args: List[str]) -> None:\n \"\"\"List config key-value pairs across different config files\"\"\"\n self._get_n_args(args, \"debug\", n=0)\n\n self.print_env_var_values()\n # Iterate over config files and print if they exist, and the\n # key-value pairs present in them if they do\n for variant, files in sorted(self.configuration.iter_config_files()):\n write_output(\"%s:\", variant)\n for fname in files:\n with indent_log():\n file_exists = os.path.exists(fname)\n write_output(\"%s, exists: %r\", fname, file_exists)\n if file_exists:\n self.print_config_file_values(variant)\n\n def print_config_file_values(self, variant: Kind) -> None:\n \"\"\"Get key-value pairs from the file of a variant\"\"\"\n for name, value in self.configuration.get_values_in_config(variant).items():\n with indent_log():\n write_output(\"%s: %s\", name, value)\n\n def print_env_var_values(self) -> None:\n \"\"\"Get key-values pairs present as environment variables\"\"\"\n write_output(\"%s:\", \"env_var\")\n with indent_log():\n for key, value in sorted(self.configuration.get_environ_vars()):\n env_var = f\"PIP_{key.upper()}\"\n write_output(\"%s=%r\", env_var, value)\n\n def open_in_editor(self, options: Values, args: List[str]) -> None:\n editor = self._determine_editor(options)\n\n fname = self.configuration.get_file_to_edit()\n if fname is None:\n raise PipError(\"Could not determine appropriate file.\")\n elif '\"' in fname:\n # This shouldn't happen, unless we see a username like that.\n # If that happens, we'd appreciate a pull request fixing this.\n raise PipError(\n f'Can not open an editor for a file name containing \"\\n{fname}'\n )\n\n try:\n subprocess.check_call(f'{editor} \"{fname}\"', shell=True)\n except FileNotFoundError as e:\n if not e.filename:\n e.filename = editor\n raise\n except subprocess.CalledProcessError as e:\n raise PipError(\n \"Editor Subprocess exited with exit code {}\".format(e.returncode)\n )\n\n def _get_n_args(self, args: List[str], example: str, n: int) -> Any:\n \"\"\"Helper to make sure the command got the right number of arguments\"\"\"\n if len(args) != n:\n msg = (\n \"Got unexpected number of arguments, expected {}. \"\n '(example: \"{} config {}\")'\n ).format(n, get_prog(), example)\n raise PipError(msg)\n\n if n == 1:\n return args[0]\n else:\n return args\n\n def _save_configuration(self) -> None:\n # We successfully ran a modifying command. Need to save the\n # configuration.\n try:\n self.configuration.save()\n except Exception:\n logger.exception(\n \"Unable to save configuration. Please report this as a bug.\"\n )\n raise PipError(\"Internal Error.\")\n\n def _determine_editor(self, options: Values) -> str:\n if options.editor is not None:\n return options.editor\n elif \"VISUAL\" in os.environ:\n return os.environ[\"VISUAL\"]\n elif \"EDITOR\" in os.environ:\n return os.environ[\"EDITOR\"]\n else:\n raise PipError(\"Could not determine editor to use.\")\n"
},
{
"path": "lib/python3.7/site-packages/pip/_internal/commands/debug.py",
"content": "import importlib.resources\nimport locale\nimport logging\nimport os\nimport sys\nfrom optparse import Values\nfrom types import ModuleType\nfrom typing import Any, Dict, List, Optional\n\nimport pip._vendor\nfrom pip._vendor.certifi import where\nfrom pip._vendor.packaging.version import parse as parse_version\n\nfrom pip._internal.cli import cmdoptions\nfrom pip._internal.cli.base_command import Command\nfrom pip._internal.cli.cmdoptions import make_target_python\nfrom pip._internal.cli.status_codes import SUCCESS\nfrom pip._internal.configuration import Configuration\nfrom pip._internal.metadata import get_environment\nfrom pip._internal.utils.logging import indent_log\nfrom pip._internal.utils.misc import get_pip_version\n\nlogger = logging.getLogger(__name__)\n\n\ndef show_value(name: str, value: Any) -> None:\n logger.info(\"%s: %s\", name, value)\n\n\ndef show_sys_implementation() -> None:\n logger.info(\"sys.implementation:\")\n implementation_name = sys.implementation.name\n with indent_log():\n show_value(\"name\", implementation_name)\n\n\ndef create_vendor_txt_map() -> Dict[str, str]:\n with importlib.resources.open_text(\"pip._vendor\", \"vendor.txt\") as f:\n # Purge non version specifying lines.\n # Also, remove any space prefix or suffixes (including comments).\n lines = [\n line.strip().split(\" \", 1)[0] for line in f.readlines() if \"==\" in line\n ]\n\n # Transform into \"module\" -> version dict.\n return dict(line.split(\"==\", 1) for line in lines)\n\n\ndef get_module_from_module_name(module_name: str) -> ModuleType:\n # Module name can be uppercase in vendor.txt for some reason...\n module_name = module_name.lower()\n # PATCH: setuptools is actually only pkg_resources.\n if module_name == \"setuptools\":\n module_name = \"pkg_resources\"\n\n __import__(f\"pip._vendor.{module_name}\", globals(), locals(), level=0)\n return getattr(pip._vendor, module_name)\n\n\ndef get_vendor_version_from_module(module_name: str) -> Optional[str]:\n module = get_module_from_module_name(module_name)\n version = getattr(module, \"__version__\", None)\n\n if not version:\n # Try to find version in debundled module info.\n assert module.__file__ is not None\n env = get_environment([os.path.dirname(module.__file__)])\n dist = env.get_distribution(module_name)\n if dist:\n version = str(dist.version)\n\n return version\n\n\ndef show_actual_vendor_versions(vendor_txt_versions: Dict[str, str]) -> None:\n \"\"\"Log the actual version and print extra info if there is\n a conflict or if the actual version could not be imported.\n \"\"\"\n for module_name, expected_version in vendor_txt_versions.items():\n extra_message = \"\"\n actual_version = get_vendor_version_from_module(module_name)\n if not actual_version:\n extra_message = (\n \" (Unable to locate actual module version, using\"\n \" vendor.txt specified version)\"\n )\n actual_version = expected_version\n elif parse_version(actual_version) != parse_version(expected_version):\n extra_message = (\n \" (CONFLICT: vendor.txt suggests version should\"\n \" be {})\".format(expected_version)\n )\n logger.info(\"%s==%s%s\", module_name, actual_version, extra_message)\n\n\ndef show_vendor_versions() -> None:\n logger.info(\"vendored library versions:\")\n\n vendor_txt_versions = create_vendor_txt_map()\n with indent_log():\n show_actual_vendor_versions(vendor_txt_versions)\n\n\ndef show_tags(options: Values) -> None:\n tag_limit = 10\n\n target_python = make_target_python(options)\n tags = target_python.get_tags()\n\n # Display the target options that were explicitly provided.\n formatted_target = target_python.format_given()\n suffix = \"\"\n if formatted_target:\n suffix = f\" (target: {formatted_target})\"\n\n msg = \"Compatible tags: {}{}\".format(len(tags), suffix)\n logger.info(msg)\n\n if options.verbose < 1 and len(tags) > tag_limit:\n tags_limited = True\n tags = tags[:tag_limit]\n else:\n tags_limited = False\n\n with indent_log():\n for tag in tags:\n logger.info(str(tag))\n\n if tags_limited:\n msg = (\n \"...\\n[First {tag_limit} tags shown. Pass --verbose to show all.]\"\n ).format(tag_limit=tag_limit)\n logger.info(msg)\n\n\ndef ca_bundle_info(config: Configuration) -> str:\n levels = set()\n for key, _ in config.items():\n levels.add(key.split(\".\")[0])\n\n if not levels:\n return \"Not specified\"\n\n levels_that_override_global = [\"install\", \"wheel\", \"download\"]\n global_overriding_level = [\n level for level in levels if level in levels_that_override_global\n ]\n if not global_overriding_level:\n return \"global\"\n\n if \"global\" in levels:\n levels.remove(\"global\")\n return \", \".join(levels)\n\n\nclass DebugCommand(Command):\n \"\"\"\n Display debug information.\n \"\"\"\n\n usage = \"\"\"\n %prog \"\"\"\n ignore_require_venv = True\n\n def add_options(self) -> None:\n cmdoptions.add_target_python_options(self.cmd_opts)\n self.parser.insert_option_group(0, self.cmd_opts)\n self.parser.config.load()\n\n def run(self, options: Values, args: List[str]) -> int:\n logger.warning(\n \"This command is only meant for debugging. \"\n \"Do not use this with automation for parsing and getting these \"\n \"details, since the output and options of this command may \"\n \"change without notice.\"\n )\n show_value(\"pip version\", get_pip_version())\n show_value(\"sys.version\", sys.version)\n show_value(\"sys.executable\", sys.executable)\n show_value(\"sys.getdefaultencoding\", sys.getdefaultencoding())\n show_value(\"sys.getfilesystemencoding\", sys.getfilesystemencoding())\n show_value(\n \"locale.getpreferredencoding\",\n locale.getpreferredencoding(),\n )\n show_value(\"sys.platform\", sys.platform)\n show_sys_implementation()\n\n show_value(\"'cert' config value\", ca_bundle_info(self.parser.config))\n show_value(\"REQUESTS_CA_BUNDLE\", os.environ.get(\"REQUESTS_CA_BUNDLE\"))\n show_value(\"CURL_CA_BUNDLE\", os.environ.get(\"CURL_CA_BUNDLE\"))\n show_value(\"pip._vendor.certifi.where()\", where())\n show_value(\"pip._vendor.DEBUNDLED\", pip._vendor.DEBUNDLED)\n\n show_vendor_versions()\n\n show_tags(options)\n\n return SUCCESS\n"
},
{
"path": "lib/python3.7/site-packages/pip/_internal/commands/download.py",
"content": "import logging\nimport os\nfrom optparse import Values\nfrom typing import List\n\nfrom pip._internal.cli import cmdoptions\nfrom pip._internal.cli.cmdoptions import make_target_python\nfrom pip._internal.cli.req_command import RequirementCommand, with_cleanup\nfrom pip._internal.cli.status_codes import SUCCESS\nfrom pip._internal.operations.build.build_tracker import get_build_tracker\nfrom pip._internal.req.req_install import (\n LegacySetupPyOptionsCheckMode,\n check_legacy_setup_py_options,\n)\nfrom pip._internal.utils.misc import ensure_dir, normalize_path, write_output\nfrom pip._internal.utils.temp_dir import TempDirectory\n\nlogger = logging.getLogger(__name__)\n\n\nclass DownloadCommand(RequirementCommand):\n \"\"\"\n Download packages from:\n\n - PyPI (and other indexes) using requirement specifiers.\n - VCS project urls.\n - Local project directories.\n - Local or remote source archives.\n\n pip also supports downloading from \"requirements files\", which provide\n an easy way to specify a whole environment to be downloaded.\n \"\"\"\n\n usage = \"\"\"\n %prog [options] [package-index-options] ...\n %prog [options] -r [package-index-options] ...\n %prog [options] ...\n %prog [options] ...\n %prog [options] ...\"\"\"\n\n def add_options(self) -> None:\n self.cmd_opts.add_option(cmdoptions.constraints())\n self.cmd_opts.add_option(cmdoptions.requirements())\n self.cmd_opts.add_option(cmdoptions.no_deps())\n self.cmd_opts.add_option(cmdoptions.global_options())\n self.cmd_opts.add_option(cmdoptions.no_binary())\n self.cmd_opts.add_option(cmdoptions.only_binary())\n self.cmd_opts.add_option(cmdoptions.prefer_binary())\n self.cmd_opts.add_option(cmdoptions.src())\n self.cmd_opts.add_option(cmdoptions.pre())\n self.cmd_opts.add_option(cmdoptions.require_hashes())\n self.cmd_opts.add_option(cmdoptions.progress_bar())\n self.cmd_opts.add_option(cmdoptions.no_build_isolation())\n self.cmd_opts.add_option(cmdoptions.use_pep517())\n self.cmd_opts.add_option(cmdoptions.no_use_pep517())\n self.cmd_opts.add_option(cmdoptions.check_build_deps())\n self.cmd_opts.add_option(cmdoptions.ignore_requires_python())\n\n self.cmd_opts.add_option(\n \"-d\",\n \"--dest\",\n \"--destination-dir\",\n \"--destination-directory\",\n dest=\"download_dir\",\n metavar=\"dir\",\n default=os.curdir,\n help=\"Download packages into .\",\n )\n\n cmdoptions.add_target_python_options(self.cmd_opts)\n\n index_opts = cmdoptions.make_option_group(\n cmdoptions.index_group,\n self.parser,\n )\n\n self.parser.insert_option_group(0, index_opts)\n self.parser.insert_option_group(0, self.cmd_opts)\n\n @with_cleanup\n def run(self, options: Values, args: List[str]) -> int:\n\n options.ignore_installed = True\n # editable doesn't really make sense for `pip download`, but the bowels\n # of the RequirementSet code require that property.\n options.editables = []\n\n cmdoptions.check_dist_restriction(options)\n\n options.download_dir = normalize_path(options.download_dir)\n ensure_dir(options.download_dir)\n\n session = self.get_default_session(options)\n\n target_python = make_target_python(options)\n finder = self._build_package_finder(\n options=options,\n session=session,\n target_python=target_python,\n ignore_requires_python=options.ignore_requires_python,\n )\n\n build_tracker = self.enter_context(get_build_tracker())\n\n directory = TempDirectory(\n delete=not options.no_clean,\n kind=\"download\",\n globally_managed=True,\n )\n\n reqs = self.get_requirements(args, options, finder, session)\n check_legacy_setup_py_options(\n options, reqs, LegacySetupPyOptionsCheckMode.DOWNLOAD\n )\n\n preparer = self.make_requirement_preparer(\n temp_build_dir=directory,\n options=options,\n build_tracker=build_tracker,\n session=session,\n finder=finder,\n download_dir=options.download_dir,\n use_user_site=False,\n verbosity=self.verbosity,\n )\n\n resolver = self.make_resolver(\n preparer=preparer,\n finder=finder,\n options=options,\n ignore_requires_python=options.ignore_requires_python,\n use_pep517=options.use_pep517,\n py_version_info=options.python_version,\n )\n\n self.trace_basic_info(finder)\n\n requirement_set = resolver.resolve(reqs, check_supported_wheels=True)\n\n downloaded: List[str] = []\n for req in requirement_set.requirements.values():\n if req.satisfied_by is None:\n assert req.name is not None\n preparer.save_linked_requirement(req)\n downloaded.append(req.name)\n if downloaded:\n write_output(\"Successfully downloaded %s\", \" \".join(downloaded))\n\n return SUCCESS\n"
},
{
"path": "lib/python3.7/site-packages/pip/_internal/commands/freeze.py",
"content": "import sys\nfrom optparse import Values\nfrom typing import List\n\nfrom pip._internal.cli import cmdoptions\nfrom pip._internal.cli.base_command import Command\nfrom pip._internal.cli.status_codes import SUCCESS\nfrom pip._internal.operations.freeze import freeze\nfrom pip._internal.utils.compat import stdlib_pkgs\n\nDEV_PKGS = {\"pip\", \"setuptools\", \"distribute\", \"wheel\"}\n\n\nclass FreezeCommand(Command):\n \"\"\"\n Output installed packages in requirements format.\n\n packages are listed in a case-insensitive sorted order.\n \"\"\"\n\n usage = \"\"\"\n %prog [options]\"\"\"\n log_streams = (\"ext://sys.stderr\", \"ext://sys.stderr\")\n\n def add_options(self) -> None:\n self.cmd_opts.add_option(\n \"-r\",\n \"--requirement\",\n dest=\"requirements\",\n action=\"append\",\n default=[],\n metavar=\"file\",\n help=(\n \"Use the order in the given requirements file and its \"\n \"comments when generating output. This option can be \"\n \"used multiple times.\"\n ),\n )\n self.cmd_opts.add_option(\n \"-l\",\n \"--local\",\n dest=\"local\",\n action=\"store_true\",\n default=False,\n help=(\n \"If in a virtualenv that has global access, do not output \"\n \"globally-installed packages.\"\n ),\n )\n self.cmd_opts.add_option(\n \"--user\",\n dest=\"user\",\n action=\"store_true\",\n default=False,\n help=\"Only output packages installed in user-site.\",\n )\n self.cmd_opts.add_option(cmdoptions.list_path())\n self.cmd_opts.add_option(\n \"--all\",\n dest=\"freeze_all\",\n action=\"store_true\",\n help=(\n \"Do not skip these packages in the output:\"\n \" {}\".format(\", \".join(DEV_PKGS))\n ),\n )\n self.cmd_opts.add_option(\n \"--exclude-editable\",\n dest=\"exclude_editable\",\n action=\"store_true\",\n help=\"Exclude editable package from output.\",\n )\n self.cmd_opts.add_option(cmdoptions.list_exclude())\n\n self.parser.insert_option_group(0, self.cmd_opts)\n\n def run(self, options: Values, args: List[str]) -> int:\n skip = set(stdlib_pkgs)\n if not options.freeze_all:\n skip.update(DEV_PKGS)\n\n if options.excludes:\n skip.update(options.excludes)\n\n cmdoptions.check_list_path_option(options)\n\n for line in freeze(\n requirement=options.requirements,\n local_only=options.local,\n user_only=options.user,\n paths=options.path,\n isolated=options.isolated_mode,\n skip=skip,\n exclude_editable=options.exclude_editable,\n ):\n sys.stdout.write(line + \"\\n\")\n return SUCCESS\n"
},
{
"path": "lib/python3.7/site-packages/pip/_internal/commands/hash.py",
"content": "import hashlib\nimport logging\nimport sys\nfrom optparse import Values\nfrom typing import List\n\nfrom pip._internal.cli.base_command import Command\nfrom pip._internal.cli.status_codes import ERROR, SUCCESS\nfrom pip._internal.utils.hashes import FAVORITE_HASH, STRONG_HASHES\nfrom pip._internal.utils.misc import read_chunks, write_output\n\nlogger = logging.getLogger(__name__)\n\n\nclass HashCommand(Command):\n \"\"\"\n Compute a hash of a local package archive.\n\n These can be used with --hash in a requirements file to do repeatable\n installs.\n \"\"\"\n\n usage = \"%prog [options] ...\"\n ignore_require_venv = True\n\n def add_options(self) -> None:\n self.cmd_opts.add_option(\n \"-a\",\n \"--algorithm\",\n dest=\"algorithm\",\n choices=STRONG_HASHES,\n action=\"store\",\n default=FAVORITE_HASH,\n help=\"The hash algorithm to use: one of {}\".format(\n \", \".join(STRONG_HASHES)\n ),\n )\n self.parser.insert_option_group(0, self.cmd_opts)\n\n def run(self, options: Values, args: List[str]) -> int:\n if not args:\n self.parser.print_usage(sys.stderr)\n return ERROR\n\n algorithm = options.algorithm\n for path in args:\n write_output(\n \"%s:\\n--hash=%s:%s\", path, algorithm, _hash_of_file(path, algorithm)\n )\n return SUCCESS\n\n\ndef _hash_of_file(path: str, algorithm: str) -> str:\n \"\"\"Return the hash digest of a file.\"\"\"\n with open(path, \"rb\") as archive:\n hash = hashlib.new(algorithm)\n for chunk in read_chunks(archive):\n hash.update(chunk)\n return hash.hexdigest()\n"
},
{
"path": "lib/python3.7/site-packages/pip/_internal/commands/help.py",
"content": "from optparse import Values\nfrom typing import List\n\nfrom pip._internal.cli.base_command import Command\nfrom pip._internal.cli.status_codes import SUCCESS\nfrom pip._internal.exceptions import CommandError\n\n\nclass HelpCommand(Command):\n \"\"\"Show help for commands\"\"\"\n\n usage = \"\"\"\n %prog \"\"\"\n ignore_require_venv = True\n\n def run(self, options: Values, args: List[str]) -> int:\n from pip._internal.commands import (\n commands_dict,\n create_command,\n get_similar_commands,\n )\n\n try:\n # 'pip help' with no args is handled by pip.__init__.parseopt()\n cmd_name = args[0] # the command we need help for\n except IndexError:\n return SUCCESS\n\n if cmd_name not in commands_dict:\n guess = get_similar_commands(cmd_name)\n\n msg = [f'unknown command \"{cmd_name}\"']\n if guess:\n msg.append(f'maybe you meant \"{guess}\"')\n\n raise CommandError(\" - \".join(msg))\n\n command = create_command(cmd_name)\n command.parser.print_help()\n\n return SUCCESS\n"
},
{
"path": "lib/python3.7/site-packages/pip/_internal/commands/index.py",
"content": "import logging\nfrom optparse import Values\nfrom typing import Any, Iterable, List, Optional, Union\n\nfrom pip._vendor.packaging.version import LegacyVersion, Version\n\nfrom pip._internal.cli import cmdoptions\nfrom pip._internal.cli.req_command import IndexGroupCommand\nfrom pip._internal.cli.status_codes import ERROR, SUCCESS\nfrom pip._internal.commands.search import print_dist_installation_info\nfrom pip._internal.exceptions import CommandError, DistributionNotFound, PipError\nfrom pip._internal.index.collector import LinkCollector\nfrom pip._internal.index.package_finder import PackageFinder\nfrom pip._internal.models.selection_prefs import SelectionPreferences\nfrom pip._internal.models.target_python import TargetPython\nfrom pip._internal.network.session import PipSession\nfrom pip._internal.utils.misc import write_output\n\nlogger = logging.getLogger(__name__)\n\n\nclass IndexCommand(IndexGroupCommand):\n \"\"\"\n Inspect information available from package indexes.\n \"\"\"\n\n usage = \"\"\"\n %prog versions \n \"\"\"\n\n def add_options(self) -> None:\n cmdoptions.add_target_python_options(self.cmd_opts)\n\n self.cmd_opts.add_option(cmdoptions.ignore_requires_python())\n self.cmd_opts.add_option(cmdoptions.pre())\n self.cmd_opts.add_option(cmdoptions.no_binary())\n self.cmd_opts.add_option(cmdoptions.only_binary())\n\n index_opts = cmdoptions.make_option_group(\n cmdoptions.index_group,\n self.parser,\n )\n\n self.parser.insert_option_group(0, index_opts)\n self.parser.insert_option_group(0, self.cmd_opts)\n\n def run(self, options: Values, args: List[str]) -> int:\n handlers = {\n \"versions\": self.get_available_package_versions,\n }\n\n logger.warning(\n \"pip index is currently an experimental command. \"\n \"It may be removed/changed in a future release \"\n \"without prior warning.\"\n )\n\n # Determine action\n if not args or args[0] not in handlers:\n logger.error(\n \"Need an action (%s) to perform.\",\n \", \".join(sorted(handlers)),\n )\n return ERROR\n\n action = args[0]\n\n # Error handling happens here, not in the action-handlers.\n try:\n handlers[action](options, args[1:])\n except PipError as e:\n logger.error(e.args[0])\n return ERROR\n\n return SUCCESS\n\n def _build_package_finder(\n self,\n options: Values,\n session: PipSession,\n target_python: Optional[TargetPython] = None,\n ignore_requires_python: Optional[bool] = None,\n ) -> PackageFinder:\n \"\"\"\n Create a package finder appropriate to the index command.\n \"\"\"\n link_collector = LinkCollector.create(session, options=options)\n\n # Pass allow_yanked=False to ignore yanked versions.\n selection_prefs = SelectionPreferences(\n allow_yanked=False,\n allow_all_prereleases=options.pre,\n ignore_requires_python=ignore_requires_python,\n )\n\n return PackageFinder.create(\n link_collector=link_collector,\n selection_prefs=selection_prefs,\n target_python=target_python,\n )\n\n def get_available_package_versions(self, options: Values, args: List[Any]) -> None:\n if len(args) != 1:\n raise CommandError(\"You need to specify exactly one argument\")\n\n target_python = cmdoptions.make_target_python(options)\n query = args[0]\n\n with self._build_session(options) as session:\n finder = self._build_package_finder(\n options=options,\n session=session,\n target_python=target_python,\n ignore_requires_python=options.ignore_requires_python,\n )\n\n versions: Iterable[Union[LegacyVersion, Version]] = (\n candidate.version for candidate in finder.find_all_candidates(query)\n )\n\n if not options.pre:\n # Remove prereleases\n versions = (\n version for version in versions if not version.is_prerelease\n )\n versions = set(versions)\n\n if not versions:\n raise DistributionNotFound(\n \"No matching distribution found for {}\".format(query)\n )\n\n formatted_versions = [str(ver) for ver in sorted(versions, reverse=True)]\n latest = formatted_versions[0]\n\n write_output(\"{} ({})\".format(query, latest))\n write_output(\"Available versions: {}\".format(\", \".join(formatted_versions)))\n print_dist_installation_info(query, latest)\n"
},
{
"path": "lib/python3.7/site-packages/pip/_internal/commands/inspect.py",
"content": "import logging\nfrom optparse import Values\nfrom typing import Any, Dict, List\n\nfrom pip._vendor.packaging.markers import default_environment\nfrom pip._vendor.rich import print_json\n\nfrom pip import __version__\nfrom pip._internal.cli import cmdoptions\nfrom pip._internal.cli.req_command import Command\nfrom pip._internal.cli.status_codes import SUCCESS\nfrom pip._internal.metadata import BaseDistribution, get_environment\nfrom pip._internal.utils.compat import stdlib_pkgs\nfrom pip._internal.utils.urls import path_to_url\n\nlogger = logging.getLogger(__name__)\n\n\nclass InspectCommand(Command):\n \"\"\"\n Inspect the content of a Python environment and produce a report in JSON format.\n \"\"\"\n\n ignore_require_venv = True\n usage = \"\"\"\n %prog [options]\"\"\"\n\n def add_options(self) -> None:\n self.cmd_opts.add_option(\n \"--local\",\n action=\"store_true\",\n default=False,\n help=(\n \"If in a virtualenv that has global access, do not list \"\n \"globally-installed packages.\"\n ),\n )\n self.cmd_opts.add_option(\n \"--user\",\n dest=\"user\",\n action=\"store_true\",\n default=False,\n help=\"Only output packages installed in user-site.\",\n )\n self.cmd_opts.add_option(cmdoptions.list_path())\n self.parser.insert_option_group(0, self.cmd_opts)\n\n def run(self, options: Values, args: List[str]) -> int:\n logger.warning(\n \"pip inspect is currently an experimental command. \"\n \"The output format may change in a future release without prior warning.\"\n )\n\n cmdoptions.check_list_path_option(options)\n dists = get_environment(options.path).iter_installed_distributions(\n local_only=options.local,\n user_only=options.user,\n skip=set(stdlib_pkgs),\n )\n output = {\n \"version\": \"0\",\n \"pip_version\": __version__,\n \"installed\": [self._dist_to_dict(dist) for dist in dists],\n \"environment\": default_environment(),\n # TODO tags? scheme?\n }\n print_json(data=output)\n return SUCCESS\n\n def _dist_to_dict(self, dist: BaseDistribution) -> Dict[str, Any]:\n res: Dict[str, Any] = {\n \"metadata\": dist.metadata_dict,\n \"metadata_location\": dist.info_location,\n }\n # direct_url. Note that we don't have download_info (as in the installation\n # report) since it is not recorded in installed metadata.\n direct_url = dist.direct_url\n if direct_url is not None:\n res[\"direct_url\"] = direct_url.to_dict()\n else:\n # Emulate direct_url for legacy editable installs.\n editable_project_location = dist.editable_project_location\n if editable_project_location is not None:\n res[\"direct_url\"] = {\n \"url\": path_to_url(editable_project_location),\n \"dir_info\": {\n \"editable\": True,\n },\n }\n # installer\n installer = dist.installer\n if dist.installer:\n res[\"installer\"] = installer\n # requested\n if dist.installed_with_dist_info:\n res[\"requested\"] = dist.requested\n return res\n"
},
{
"path": "lib/python3.7/site-packages/pip/_internal/commands/install.py",
"content": "import errno\nimport json\nimport operator\nimport os\nimport shutil\nimport site\nfrom optparse import SUPPRESS_HELP, Values\nfrom typing import Iterable, List, Optional\n\nfrom pip._vendor.packaging.utils import canonicalize_name\nfrom pip._vendor.rich import print_json\n\nfrom pip._internal.cache import WheelCache\nfrom pip._internal.cli import cmdoptions\nfrom pip._internal.cli.cmdoptions import make_target_python\nfrom pip._internal.cli.req_command import (\n RequirementCommand,\n warn_if_run_as_root,\n with_cleanup,\n)\nfrom pip._internal.cli.status_codes import ERROR, SUCCESS\nfrom pip._internal.exceptions import CommandError, InstallationError\nfrom pip._internal.locations import get_scheme\nfrom pip._internal.metadata import get_environment\nfrom pip._internal.models.format_control import FormatControl\nfrom pip._internal.models.installation_report import InstallationReport\nfrom pip._internal.operations.build.build_tracker import get_build_tracker\nfrom pip._internal.operations.check import ConflictDetails, check_install_conflicts\nfrom pip._internal.req import install_given_reqs\nfrom pip._internal.req.req_install import (\n InstallRequirement,\n LegacySetupPyOptionsCheckMode,\n check_legacy_setup_py_options,\n)\nfrom pip._internal.utils.compat import WINDOWS\nfrom pip._internal.utils.deprecation import (\n LegacyInstallReasonFailedBdistWheel,\n deprecated,\n)\nfrom pip._internal.utils.distutils_args import parse_distutils_args\nfrom pip._internal.utils.filesystem import test_writable_dir\nfrom pip._internal.utils.logging import getLogger\nfrom pip._internal.utils.misc import (\n ensure_dir,\n get_pip_version,\n protect_pip_from_modification_on_windows,\n write_output,\n)\nfrom pip._internal.utils.temp_dir import TempDirectory\nfrom pip._internal.utils.virtualenv import (\n running_under_virtualenv,\n virtualenv_no_global,\n)\nfrom pip._internal.wheel_builder import (\n BdistWheelAllowedPredicate,\n build,\n should_build_for_install_command,\n)\n\nlogger = getLogger(__name__)\n\n\ndef get_check_bdist_wheel_allowed(\n format_control: FormatControl,\n) -> BdistWheelAllowedPredicate:\n def check_binary_allowed(req: InstallRequirement) -> bool:\n canonical_name = canonicalize_name(req.name or \"\")\n allowed_formats = format_control.get_allowed_formats(canonical_name)\n return \"binary\" in allowed_formats\n\n return check_binary_allowed\n\n\nclass InstallCommand(RequirementCommand):\n \"\"\"\n Install packages from:\n\n - PyPI (and other indexes) using requirement specifiers.\n - VCS project urls.\n - Local project directories.\n - Local or remote source archives.\n\n pip also supports installing from \"requirements files\", which provide\n an easy way to specify a whole environment to be installed.\n \"\"\"\n\n usage = \"\"\"\n %prog [options] [package-index-options] ...\n %prog [options] -r [package-index-options] ...\n %prog [options] [-e] ...\n %prog [options] [-e] ...\n %prog [options] ...\"\"\"\n\n def add_options(self) -> None:\n self.cmd_opts.add_option(cmdoptions.requirements())\n self.cmd_opts.add_option(cmdoptions.constraints())\n self.cmd_opts.add_option(cmdoptions.no_deps())\n self.cmd_opts.add_option(cmdoptions.pre())\n\n self.cmd_opts.add_option(cmdoptions.editable())\n self.cmd_opts.add_option(\n \"--dry-run\",\n action=\"store_true\",\n dest=\"dry_run\",\n default=False,\n help=(\n \"Don't actually install anything, just print what would be. \"\n \"Can be used in combination with --ignore-installed \"\n \"to 'resolve' the requirements.\"\n ),\n )\n self.cmd_opts.add_option(\n \"-t\",\n \"--target\",\n dest=\"target_dir\",\n metavar=\"dir\",\n default=None,\n help=(\n \"Install packages into . \"\n \"By default this will not replace existing files/folders in \"\n \". Use --upgrade to replace existing packages in \"\n \"with new versions.\"\n ),\n )\n cmdoptions.add_target_python_options(self.cmd_opts)\n\n self.cmd_opts.add_option(\n \"--user\",\n dest=\"use_user_site\",\n action=\"store_true\",\n help=(\n \"Install to the Python user install directory for your \"\n \"platform. Typically ~/.local/, or %APPDATA%\\\\Python on \"\n \"Windows. (See the Python documentation for site.USER_BASE \"\n \"for full details.)\"\n ),\n )\n self.cmd_opts.add_option(\n \"--no-user\",\n dest=\"use_user_site\",\n action=\"store_false\",\n help=SUPPRESS_HELP,\n )\n self.cmd_opts.add_option(\n \"--root\",\n dest=\"root_path\",\n metavar=\"dir\",\n default=None,\n help=\"Install everything relative to this alternate root directory.\",\n )\n self.cmd_opts.add_option(\n \"--prefix\",\n dest=\"prefix_path\",\n metavar=\"dir\",\n default=None,\n help=(\n \"Installation prefix where lib, bin and other top-level \"\n \"folders are placed\"\n ),\n )\n\n self.cmd_opts.add_option(cmdoptions.src())\n\n self.cmd_opts.add_option(\n \"-U\",\n \"--upgrade\",\n dest=\"upgrade\",\n action=\"store_true\",\n help=(\n \"Upgrade all specified packages to the newest available \"\n \"version. The handling of dependencies depends on the \"\n \"upgrade-strategy used.\"\n ),\n )\n\n self.cmd_opts.add_option(\n \"--upgrade-strategy\",\n dest=\"upgrade_strategy\",\n default=\"only-if-needed\",\n choices=[\"only-if-needed\", \"eager\"],\n help=(\n \"Determines how dependency upgrading should be handled \"\n \"[default: %default]. \"\n '\"eager\" - dependencies are upgraded regardless of '\n \"whether the currently installed version satisfies the \"\n \"requirements of the upgraded package(s). \"\n '\"only-if-needed\" - are upgraded only when they do not '\n \"satisfy the requirements of the upgraded package(s).\"\n ),\n )\n\n self.cmd_opts.add_option(\n \"--force-reinstall\",\n dest=\"force_reinstall\",\n action=\"store_true\",\n help=\"Reinstall all packages even if they are already up-to-date.\",\n )\n\n self.cmd_opts.add_option(\n \"-I\",\n \"--ignore-installed\",\n dest=\"ignore_installed\",\n action=\"store_true\",\n help=(\n \"Ignore the installed packages, overwriting them. \"\n \"This can break your system if the existing package \"\n \"is of a different version or was installed \"\n \"with a different package manager!\"\n ),\n )\n\n self.cmd_opts.add_option(cmdoptions.ignore_requires_python())\n self.cmd_opts.add_option(cmdoptions.no_build_isolation())\n self.cmd_opts.add_option(cmdoptions.use_pep517())\n self.cmd_opts.add_option(cmdoptions.no_use_pep517())\n self.cmd_opts.add_option(cmdoptions.check_build_deps())\n\n self.cmd_opts.add_option(cmdoptions.config_settings())\n self.cmd_opts.add_option(cmdoptions.install_options())\n self.cmd_opts.add_option(cmdoptions.global_options())\n\n self.cmd_opts.add_option(\n \"--compile\",\n action=\"store_true\",\n dest=\"compile\",\n default=True,\n help=\"Compile Python source files to bytecode\",\n )\n\n self.cmd_opts.add_option(\n \"--no-compile\",\n action=\"store_false\",\n dest=\"compile\",\n help=\"Do not compile Python source files to bytecode\",\n )\n\n self.cmd_opts.add_option(\n \"--no-warn-script-location\",\n action=\"store_false\",\n dest=\"warn_script_location\",\n default=True,\n help=\"Do not warn when installing scripts outside PATH\",\n )\n self.cmd_opts.add_option(\n \"--no-warn-conflicts\",\n action=\"store_false\",\n dest=\"warn_about_conflicts\",\n default=True,\n help=\"Do not warn about broken dependencies\",\n )\n self.cmd_opts.add_option(cmdoptions.no_binary())\n self.cmd_opts.add_option(cmdoptions.only_binary())\n self.cmd_opts.add_option(cmdoptions.prefer_binary())\n self.cmd_opts.add_option(cmdoptions.require_hashes())\n self.cmd_opts.add_option(cmdoptions.progress_bar())\n self.cmd_opts.add_option(cmdoptions.root_user_action())\n\n index_opts = cmdoptions.make_option_group(\n cmdoptions.index_group,\n self.parser,\n )\n\n self.parser.insert_option_group(0, index_opts)\n self.parser.insert_option_group(0, self.cmd_opts)\n\n self.cmd_opts.add_option(\n \"--report\",\n dest=\"json_report_file\",\n metavar=\"file\",\n default=None,\n help=(\n \"Generate a JSON file describing what pip did to install \"\n \"the provided requirements. \"\n \"Can be used in combination with --dry-run and --ignore-installed \"\n \"to 'resolve' the requirements. \"\n \"When - is used as file name it writes to stdout. \"\n \"When writing to stdout, please combine with the --quiet option \"\n \"to avoid mixing pip logging output with JSON output.\"\n ),\n )\n\n @with_cleanup\n def run(self, options: Values, args: List[str]) -> int:\n if options.use_user_site and options.target_dir is not None:\n raise CommandError(\"Can not combine '--user' and '--target'\")\n\n upgrade_strategy = \"to-satisfy-only\"\n if options.upgrade:\n upgrade_strategy = options.upgrade_strategy\n\n cmdoptions.check_dist_restriction(options, check_target=True)\n\n install_options = options.install_options or []\n\n logger.verbose(\"Using %s\", get_pip_version())\n options.use_user_site = decide_user_install(\n options.use_user_site,\n prefix_path=options.prefix_path,\n target_dir=options.target_dir,\n root_path=options.root_path,\n isolated_mode=options.isolated_mode,\n )\n\n target_temp_dir: Optional[TempDirectory] = None\n target_temp_dir_path: Optional[str] = None\n if options.target_dir:\n options.ignore_installed = True\n options.target_dir = os.path.abspath(options.target_dir)\n if (\n # fmt: off\n os.path.exists(options.target_dir) and\n not os.path.isdir(options.target_dir)\n # fmt: on\n ):\n raise CommandError(\n \"Target path exists but is not a directory, will not continue.\"\n )\n\n # Create a target directory for using with the target option\n target_temp_dir = TempDirectory(kind=\"target\")\n target_temp_dir_path = target_temp_dir.path\n self.enter_context(target_temp_dir)\n\n global_options = options.global_options or []\n\n session = self.get_default_session(options)\n\n target_python = make_target_python(options)\n finder = self._build_package_finder(\n options=options,\n session=session,\n target_python=target_python,\n ignore_requires_python=options.ignore_requires_python,\n )\n build_tracker = self.enter_context(get_build_tracker())\n\n directory = TempDirectory(\n delete=not options.no_clean,\n kind=\"install\",\n globally_managed=True,\n )\n\n try:\n reqs = self.get_requirements(args, options, finder, session)\n check_legacy_setup_py_options(\n options, reqs, LegacySetupPyOptionsCheckMode.INSTALL\n )\n\n if \"no-binary-enable-wheel-cache\" in options.features_enabled:\n # TODO: remove format_control from WheelCache when the deprecation cycle\n # is over\n wheel_cache = WheelCache(options.cache_dir)\n else:\n if options.format_control.no_binary:\n deprecated(\n reason=(\n \"--no-binary currently disables reading from \"\n \"the cache of locally built wheels. In the future \"\n \"--no-binary will not influence the wheel cache.\"\n ),\n replacement=\"to use the --no-cache-dir option\",\n feature_flag=\"no-binary-enable-wheel-cache\",\n issue=11453,\n gone_in=\"23.1\",\n )\n wheel_cache = WheelCache(options.cache_dir, options.format_control)\n\n # Only when installing is it permitted to use PEP 660.\n # In other circumstances (pip wheel, pip download) we generate\n # regular (i.e. non editable) metadata and wheels.\n for req in reqs:\n req.permit_editable_wheels = True\n\n reject_location_related_install_options(reqs, options.install_options)\n\n preparer = self.make_requirement_preparer(\n temp_build_dir=directory,\n options=options,\n build_tracker=build_tracker,\n session=session,\n finder=finder,\n use_user_site=options.use_user_site,\n verbosity=self.verbosity,\n )\n resolver = self.make_resolver(\n preparer=preparer,\n finder=finder,\n options=options,\n wheel_cache=wheel_cache,\n use_user_site=options.use_user_site,\n ignore_installed=options.ignore_installed,\n ignore_requires_python=options.ignore_requires_python,\n force_reinstall=options.force_reinstall,\n upgrade_strategy=upgrade_strategy,\n use_pep517=options.use_pep517,\n )\n\n self.trace_basic_info(finder)\n\n requirement_set = resolver.resolve(\n reqs, check_supported_wheels=not options.target_dir\n )\n\n if options.json_report_file:\n logger.warning(\n \"--report is currently an experimental option. \"\n \"The output format may change in a future release \"\n \"without prior warning.\"\n )\n\n report = InstallationReport(requirement_set.requirements_to_install)\n if options.json_report_file == \"-\":\n print_json(data=report.to_dict())\n else:\n with open(options.json_report_file, \"w\", encoding=\"utf-8\") as f:\n json.dump(report.to_dict(), f, indent=2, ensure_ascii=False)\n\n if options.dry_run:\n would_install_items = sorted(\n (r.metadata[\"name\"], r.metadata[\"version\"])\n for r in requirement_set.requirements_to_install\n )\n if would_install_items:\n write_output(\n \"Would install %s\",\n \" \".join(\"-\".join(item) for item in would_install_items),\n )\n return SUCCESS\n\n try:\n pip_req = requirement_set.get_requirement(\"pip\")\n except KeyError:\n modifying_pip = False\n else:\n # If we're not replacing an already installed pip,\n # we're not modifying it.\n modifying_pip = pip_req.satisfied_by is None\n protect_pip_from_modification_on_windows(modifying_pip=modifying_pip)\n\n check_bdist_wheel_allowed = get_check_bdist_wheel_allowed(\n finder.format_control\n )\n\n reqs_to_build = [\n r\n for r in requirement_set.requirements.values()\n if should_build_for_install_command(r, check_bdist_wheel_allowed)\n ]\n\n _, build_failures = build(\n reqs_to_build,\n wheel_cache=wheel_cache,\n verify=True,\n build_options=[],\n global_options=global_options,\n )\n\n # If we're using PEP 517, we cannot do a legacy setup.py install\n # so we fail here.\n pep517_build_failure_names: List[str] = [\n r.name for r in build_failures if r.use_pep517 # type: ignore\n ]\n if pep517_build_failure_names:\n raise InstallationError(\n \"Could not build wheels for {}, which is required to \"\n \"install pyproject.toml-based projects\".format(\n \", \".join(pep517_build_failure_names)\n )\n )\n\n # For now, we just warn about failures building legacy\n # requirements, as we'll fall through to a setup.py install for\n # those.\n for r in build_failures:\n if not r.use_pep517:\n r.legacy_install_reason = LegacyInstallReasonFailedBdistWheel\n\n to_install = resolver.get_installation_order(requirement_set)\n\n # Check for conflicts in the package set we're installing.\n conflicts: Optional[ConflictDetails] = None\n should_warn_about_conflicts = (\n not options.ignore_dependencies and options.warn_about_conflicts\n )\n if should_warn_about_conflicts:\n conflicts = self._determine_conflicts(to_install)\n\n # Don't warn about script install locations if\n # --target or --prefix has been specified\n warn_script_location = options.warn_script_location\n if options.target_dir or options.prefix_path:\n warn_script_location = False\n\n installed = install_given_reqs(\n to_install,\n install_options,\n global_options,\n root=options.root_path,\n home=target_temp_dir_path,\n prefix=options.prefix_path,\n warn_script_location=warn_script_location,\n use_user_site=options.use_user_site,\n pycompile=options.compile,\n )\n\n lib_locations = get_lib_location_guesses(\n user=options.use_user_site,\n home=target_temp_dir_path,\n root=options.root_path,\n prefix=options.prefix_path,\n isolated=options.isolated_mode,\n )\n env = get_environment(lib_locations)\n\n installed.sort(key=operator.attrgetter(\"name\"))\n items = []\n for result in installed:\n item = result.name\n try:\n installed_dist = env.get_distribution(item)\n if installed_dist is not None:\n item = f\"{item}-{installed_dist.version}\"\n except Exception:\n pass\n items.append(item)\n\n if conflicts is not None:\n self._warn_about_conflicts(\n conflicts,\n resolver_variant=self.determine_resolver_variant(options),\n )\n\n installed_desc = \" \".join(items)\n if installed_desc:\n write_output(\n \"Successfully installed %s\",\n installed_desc,\n )\n except OSError as error:\n show_traceback = self.verbosity >= 1\n\n message = create_os_error_message(\n error,\n show_traceback,\n options.use_user_site,\n )\n logger.error(message, exc_info=show_traceback) # noqa\n\n return ERROR\n\n if options.target_dir:\n assert target_temp_dir\n self._handle_target_dir(\n options.target_dir, target_temp_dir, options.upgrade\n )\n if options.root_user_action == \"warn\":\n warn_if_run_as_root()\n return SUCCESS\n\n def _handle_target_dir(\n self, target_dir: str, target_temp_dir: TempDirectory, upgrade: bool\n ) -> None:\n ensure_dir(target_dir)\n\n # Checking both purelib and platlib directories for installed\n # packages to be moved to target directory\n lib_dir_list = []\n\n # Checking both purelib and platlib directories for installed\n # packages to be moved to target directory\n scheme = get_scheme(\"\", home=target_temp_dir.path)\n purelib_dir = scheme.purelib\n platlib_dir = scheme.platlib\n data_dir = scheme.data\n\n if os.path.exists(purelib_dir):\n lib_dir_list.append(purelib_dir)\n if os.path.exists(platlib_dir) and platlib_dir != purelib_dir:\n lib_dir_list.append(platlib_dir)\n if os.path.exists(data_dir):\n lib_dir_list.append(data_dir)\n\n for lib_dir in lib_dir_list:\n for item in os.listdir(lib_dir):\n if lib_dir == data_dir:\n ddir = os.path.join(data_dir, item)\n if any(s.startswith(ddir) for s in lib_dir_list[:-1]):\n continue\n target_item_dir = os.path.join(target_dir, item)\n if os.path.exists(target_item_dir):\n if not upgrade:\n logger.warning(\n \"Target directory %s already exists. Specify \"\n \"--upgrade to force replacement.\",\n target_item_dir,\n )\n continue\n if os.path.islink(target_item_dir):\n logger.warning(\n \"Target directory %s already exists and is \"\n \"a link. pip will not automatically replace \"\n \"links, please remove if replacement is \"\n \"desired.\",\n target_item_dir,\n )\n continue\n if os.path.isdir(target_item_dir):\n shutil.rmtree(target_item_dir)\n else:\n os.remove(target_item_dir)\n\n shutil.move(os.path.join(lib_dir, item), target_item_dir)\n\n def _determine_conflicts(\n self, to_install: List[InstallRequirement]\n ) -> Optional[ConflictDetails]:\n try:\n return check_install_conflicts(to_install)\n except Exception:\n logger.exception(\n \"Error while checking for conflicts. Please file an issue on \"\n \"pip's issue tracker: https://github.com/pypa/pip/issues/new\"\n )\n return None\n\n def _warn_about_conflicts(\n self, conflict_details: ConflictDetails, resolver_variant: str\n ) -> None:\n package_set, (missing, conflicting) = conflict_details\n if not missing and not conflicting:\n return\n\n parts: List[str] = []\n if resolver_variant == \"legacy\":\n parts.append(\n \"pip's legacy dependency resolver does not consider dependency \"\n \"conflicts when selecting packages. This behaviour is the \"\n \"source of the following dependency conflicts.\"\n )\n else:\n assert resolver_variant == \"2020-resolver\"\n parts.append(\n \"pip's dependency resolver does not currently take into account \"\n \"all the packages that are installed. This behaviour is the \"\n \"source of the following dependency conflicts.\"\n )\n\n # NOTE: There is some duplication here, with commands/check.py\n for project_name in missing:\n version = package_set[project_name][0]\n for dependency in missing[project_name]:\n message = (\n \"{name} {version} requires {requirement}, \"\n \"which is not installed.\"\n ).format(\n name=project_name,\n version=version,\n requirement=dependency[1],\n )\n parts.append(message)\n\n for project_name in conflicting:\n version = package_set[project_name][0]\n for dep_name, dep_version, req in conflicting[project_name]:\n message = (\n \"{name} {version} requires {requirement}, but {you} have \"\n \"{dep_name} {dep_version} which is incompatible.\"\n ).format(\n name=project_name,\n version=version,\n requirement=req,\n dep_name=dep_name,\n dep_version=dep_version,\n you=(\"you\" if resolver_variant == \"2020-resolver\" else \"you'll\"),\n )\n parts.append(message)\n\n logger.critical(\"\\n\".join(parts))\n\n\ndef get_lib_location_guesses(\n user: bool = False,\n home: Optional[str] = None,\n root: Optional[str] = None,\n isolated: bool = False,\n prefix: Optional[str] = None,\n) -> List[str]:\n scheme = get_scheme(\n \"\",\n user=user,\n home=home,\n root=root,\n isolated=isolated,\n prefix=prefix,\n )\n return [scheme.purelib, scheme.platlib]\n\n\ndef site_packages_writable(root: Optional[str], isolated: bool) -> bool:\n return all(\n test_writable_dir(d)\n for d in set(get_lib_location_guesses(root=root, isolated=isolated))\n )\n\n\ndef decide_user_install(\n use_user_site: Optional[bool],\n prefix_path: Optional[str] = None,\n target_dir: Optional[str] = None,\n root_path: Optional[str] = None,\n isolated_mode: bool = False,\n) -> bool:\n \"\"\"Determine whether to do a user install based on the input options.\n\n If use_user_site is False, no additional checks are done.\n If use_user_site is True, it is checked for compatibility with other\n options.\n If use_user_site is None, the default behaviour depends on the environment,\n which is provided by the other arguments.\n \"\"\"\n # In some cases (config from tox), use_user_site can be set to an integer\n # rather than a bool, which 'use_user_site is False' wouldn't catch.\n if (use_user_site is not None) and (not use_user_site):\n logger.debug(\"Non-user install by explicit request\")\n return False\n\n if use_user_site:\n if prefix_path:\n raise CommandError(\n \"Can not combine '--user' and '--prefix' as they imply \"\n \"different installation locations\"\n )\n if virtualenv_no_global():\n raise InstallationError(\n \"Can not perform a '--user' install. User site-packages \"\n \"are not visible in this virtualenv.\"\n )\n logger.debug(\"User install by explicit request\")\n return True\n\n # If we are here, user installs have not been explicitly requested/avoided\n assert use_user_site is None\n\n # user install incompatible with --prefix/--target\n if prefix_path or target_dir:\n logger.debug(\"Non-user install due to --prefix or --target option\")\n return False\n\n # If user installs are not enabled, choose a non-user install\n if not site.ENABLE_USER_SITE:\n logger.debug(\"Non-user install because user site-packages disabled\")\n return False\n\n # If we have permission for a non-user install, do that,\n # otherwise do a user install.\n if site_packages_writable(root=root_path, isolated=isolated_mode):\n logger.debug(\"Non-user install because site-packages writeable\")\n return False\n\n logger.info(\n \"Defaulting to user installation because normal site-packages \"\n \"is not writeable\"\n )\n return True\n\n\ndef reject_location_related_install_options(\n requirements: List[InstallRequirement], options: Optional[List[str]]\n) -> None:\n \"\"\"If any location-changing --install-option arguments were passed for\n requirements or on the command-line, then show a deprecation warning.\n \"\"\"\n\n def format_options(option_names: Iterable[str]) -> List[str]:\n return [\"--{}\".format(name.replace(\"_\", \"-\")) for name in option_names]\n\n offenders = []\n\n for requirement in requirements:\n install_options = requirement.install_options\n location_options = parse_distutils_args(install_options)\n if location_options:\n offenders.append(\n \"{!r} from {}\".format(\n format_options(location_options.keys()), requirement\n )\n )\n\n if options:\n location_options = parse_distutils_args(options)\n if location_options:\n offenders.append(\n \"{!r} from command line\".format(format_options(location_options.keys()))\n )\n\n if not offenders:\n return\n\n raise CommandError(\n \"Location-changing options found in --install-option: {}.\"\n \" This is unsupported, use pip-level options like --user,\"\n \" --prefix, --root, and --target instead.\".format(\"; \".join(offenders))\n )\n\n\ndef create_os_error_message(\n error: OSError, show_traceback: bool, using_user_site: bool\n) -> str:\n \"\"\"Format an error message for an OSError\n\n It may occur anytime during the execution of the install command.\n \"\"\"\n parts = []\n\n # Mention the error if we are not going to show a traceback\n parts.append(\"Could not install packages due to an OSError\")\n if not show_traceback:\n parts.append(\": \")\n parts.append(str(error))\n else:\n parts.append(\".\")\n\n # Spilt the error indication from a helper message (if any)\n parts[-1] += \"\\n\"\n\n # Suggest useful actions to the user:\n # (1) using user site-packages or (2) verifying the permissions\n if error.errno == errno.EACCES:\n user_option_part = \"Consider using the `--user` option\"\n permissions_part = \"Check the permissions\"\n\n if not running_under_virtualenv() and not using_user_site:\n parts.extend(\n [\n user_option_part,\n \" or \",\n permissions_part.lower(),\n ]\n )\n else:\n parts.append(permissions_part)\n parts.append(\".\\n\")\n\n # Suggest the user to enable Long Paths if path length is\n # more than 260\n if (\n WINDOWS\n and error.errno == errno.ENOENT\n and error.filename\n and len(error.filename) > 260\n ):\n parts.append(\n \"HINT: This error might have occurred since \"\n \"this system does not have Windows Long Path \"\n \"support enabled. You can find information on \"\n \"how to enable this at \"\n \"https://pip.pypa.io/warnings/enable-long-paths\\n\"\n )\n\n return \"\".join(parts).strip() + \"\\n\"\n"
},
{
"path": "lib/python3.7/site-packages/pip/_internal/commands/list.py",
"content": "import json\nimport logging\nfrom optparse import Values\nfrom typing import TYPE_CHECKING, Generator, List, Optional, Sequence, Tuple, cast\n\nfrom pip._vendor.packaging.utils import canonicalize_name\n\nfrom pip._internal.cli import cmdoptions\nfrom pip._internal.cli.req_command import IndexGroupCommand\nfrom pip._internal.cli.status_codes import SUCCESS\nfrom pip._internal.exceptions import CommandError\nfrom pip._internal.index.collector import LinkCollector\nfrom pip._internal.index.package_finder import PackageFinder\nfrom pip._internal.metadata import BaseDistribution, get_environment\nfrom pip._internal.models.selection_prefs import SelectionPreferences\nfrom pip._internal.network.session import PipSession\nfrom pip._internal.utils.compat import stdlib_pkgs\nfrom pip._internal.utils.misc import tabulate, write_output\n\nif TYPE_CHECKING:\n from pip._internal.metadata.base import DistributionVersion\n\n class _DistWithLatestInfo(BaseDistribution):\n \"\"\"Give the distribution object a couple of extra fields.\n\n These will be populated during ``get_outdated()``. This is dirty but\n makes the rest of the code much cleaner.\n \"\"\"\n\n latest_version: DistributionVersion\n latest_filetype: str\n\n _ProcessedDists = Sequence[_DistWithLatestInfo]\n\n\nlogger = logging.getLogger(__name__)\n\n\nclass ListCommand(IndexGroupCommand):\n \"\"\"\n List installed packages, including editables.\n\n Packages are listed in a case-insensitive sorted order.\n \"\"\"\n\n ignore_require_venv = True\n usage = \"\"\"\n %prog [options]\"\"\"\n\n def add_options(self) -> None:\n self.cmd_opts.add_option(\n \"-o\",\n \"--outdated\",\n action=\"store_true\",\n default=False,\n help=\"List outdated packages\",\n )\n self.cmd_opts.add_option(\n \"-u\",\n \"--uptodate\",\n action=\"store_true\",\n default=False,\n help=\"List uptodate packages\",\n )\n self.cmd_opts.add_option(\n \"-e\",\n \"--editable\",\n action=\"store_true\",\n default=False,\n help=\"List editable projects.\",\n )\n self.cmd_opts.add_option(\n \"-l\",\n \"--local\",\n action=\"store_true\",\n default=False,\n help=(\n \"If in a virtualenv that has global access, do not list \"\n \"globally-installed packages.\"\n ),\n )\n self.cmd_opts.add_option(\n \"--user\",\n dest=\"user\",\n action=\"store_true\",\n default=False,\n help=\"Only output packages installed in user-site.\",\n )\n self.cmd_opts.add_option(cmdoptions.list_path())\n self.cmd_opts.add_option(\n \"--pre\",\n action=\"store_true\",\n default=False,\n help=(\n \"Include pre-release and development versions. By default, \"\n \"pip only finds stable versions.\"\n ),\n )\n\n self.cmd_opts.add_option(\n \"--format\",\n action=\"store\",\n dest=\"list_format\",\n default=\"columns\",\n choices=(\"columns\", \"freeze\", \"json\"),\n help=\"Select the output format among: columns (default), freeze, or json\",\n )\n\n self.cmd_opts.add_option(\n \"--not-required\",\n action=\"store_true\",\n dest=\"not_required\",\n help=\"List packages that are not dependencies of installed packages.\",\n )\n\n self.cmd_opts.add_option(\n \"--exclude-editable\",\n action=\"store_false\",\n dest=\"include_editable\",\n help=\"Exclude editable package from output.\",\n )\n self.cmd_opts.add_option(\n \"--include-editable\",\n action=\"store_true\",\n dest=\"include_editable\",\n help=\"Include editable package from output.\",\n default=True,\n )\n self.cmd_opts.add_option(cmdoptions.list_exclude())\n index_opts = cmdoptions.make_option_group(cmdoptions.index_group, self.parser)\n\n self.parser.insert_option_group(0, index_opts)\n self.parser.insert_option_group(0, self.cmd_opts)\n\n def _build_package_finder(\n self, options: Values, session: PipSession\n ) -> PackageFinder:\n \"\"\"\n Create a package finder appropriate to this list command.\n \"\"\"\n link_collector = LinkCollector.create(session, options=options)\n\n # Pass allow_yanked=False to ignore yanked versions.\n selection_prefs = SelectionPreferences(\n allow_yanked=False,\n allow_all_prereleases=options.pre,\n )\n\n return PackageFinder.create(\n link_collector=link_collector,\n selection_prefs=selection_prefs,\n )\n\n def run(self, options: Values, args: List[str]) -> int:\n if options.outdated and options.uptodate:\n raise CommandError(\"Options --outdated and --uptodate cannot be combined.\")\n\n if options.outdated and options.list_format == \"freeze\":\n raise CommandError(\n \"List format 'freeze' can not be used with the --outdated option.\"\n )\n\n cmdoptions.check_list_path_option(options)\n\n skip = set(stdlib_pkgs)\n if options.excludes:\n skip.update(canonicalize_name(n) for n in options.excludes)\n\n packages: \"_ProcessedDists\" = [\n cast(\"_DistWithLatestInfo\", d)\n for d in get_environment(options.path).iter_installed_distributions(\n local_only=options.local,\n user_only=options.user,\n editables_only=options.editable,\n include_editables=options.include_editable,\n skip=skip,\n )\n ]\n\n # get_not_required must be called firstly in order to find and\n # filter out all dependencies correctly. Otherwise a package\n # can't be identified as requirement because some parent packages\n # could be filtered out before.\n if options.not_required:\n packages = self.get_not_required(packages, options)\n\n if options.outdated:\n packages = self.get_outdated(packages, options)\n elif options.uptodate:\n packages = self.get_uptodate(packages, options)\n\n self.output_package_listing(packages, options)\n return SUCCESS\n\n def get_outdated(\n self, packages: \"_ProcessedDists\", options: Values\n ) -> \"_ProcessedDists\":\n return [\n dist\n for dist in self.iter_packages_latest_infos(packages, options)\n if dist.latest_version > dist.version\n ]\n\n def get_uptodate(\n self, packages: \"_ProcessedDists\", options: Values\n ) -> \"_ProcessedDists\":\n return [\n dist\n for dist in self.iter_packages_latest_infos(packages, options)\n if dist.latest_version == dist.version\n ]\n\n def get_not_required(\n self, packages: \"_ProcessedDists\", options: Values\n ) -> \"_ProcessedDists\":\n dep_keys = {\n canonicalize_name(dep.name)\n for dist in packages\n for dep in (dist.iter_dependencies() or ())\n }\n\n # Create a set to remove duplicate packages, and cast it to a list\n # to keep the return type consistent with get_outdated and\n # get_uptodate\n return list({pkg for pkg in packages if pkg.canonical_name not in dep_keys})\n\n def iter_packages_latest_infos(\n self, packages: \"_ProcessedDists\", options: Values\n ) -> Generator[\"_DistWithLatestInfo\", None, None]:\n with self._build_session(options) as session:\n finder = self._build_package_finder(options, session)\n\n def latest_info(\n dist: \"_DistWithLatestInfo\",\n ) -> Optional[\"_DistWithLatestInfo\"]:\n all_candidates = finder.find_all_candidates(dist.canonical_name)\n if not options.pre:\n # Remove prereleases\n all_candidates = [\n candidate\n for candidate in all_candidates\n if not candidate.version.is_prerelease\n ]\n\n evaluator = finder.make_candidate_evaluator(\n project_name=dist.canonical_name,\n )\n best_candidate = evaluator.sort_best_candidate(all_candidates)\n if best_candidate is None:\n return None\n\n remote_version = best_candidate.version\n if best_candidate.link.is_wheel:\n typ = \"wheel\"\n else:\n typ = \"sdist\"\n dist.latest_version = remote_version\n dist.latest_filetype = typ\n return dist\n\n for dist in map(latest_info, packages):\n if dist is not None:\n yield dist\n\n def output_package_listing(\n self, packages: \"_ProcessedDists\", options: Values\n ) -> None:\n packages = sorted(\n packages,\n key=lambda dist: dist.canonical_name,\n )\n if options.list_format == \"columns\" and packages:\n data, header = format_for_columns(packages, options)\n self.output_package_listing_columns(data, header)\n elif options.list_format == \"freeze\":\n for dist in packages:\n if options.verbose >= 1:\n write_output(\n \"%s==%s (%s)\", dist.raw_name, dist.version, dist.location\n )\n else:\n write_output(\"%s==%s\", dist.raw_name, dist.version)\n elif options.list_format == \"json\":\n write_output(format_for_json(packages, options))\n\n def output_package_listing_columns(\n self, data: List[List[str]], header: List[str]\n ) -> None:\n # insert the header first: we need to know the size of column names\n if len(data) > 0:\n data.insert(0, header)\n\n pkg_strings, sizes = tabulate(data)\n\n # Create and add a separator.\n if len(data) > 0:\n pkg_strings.insert(1, \" \".join(map(lambda x: \"-\" * x, sizes)))\n\n for val in pkg_strings:\n write_output(val)\n\n\ndef format_for_columns(\n pkgs: \"_ProcessedDists\", options: Values\n) -> Tuple[List[List[str]], List[str]]:\n \"\"\"\n Convert the package data into something usable\n by output_package_listing_columns.\n \"\"\"\n header = [\"Package\", \"Version\"]\n\n running_outdated = options.outdated\n if running_outdated:\n header.extend([\"Latest\", \"Type\"])\n\n has_editables = any(x.editable for x in pkgs)\n if has_editables:\n header.append(\"Editable project location\")\n\n if options.verbose >= 1:\n header.append(\"Location\")\n if options.verbose >= 1:\n header.append(\"Installer\")\n\n data = []\n for proj in pkgs:\n # if we're working on the 'outdated' list, separate out the\n # latest_version and type\n row = [proj.raw_name, str(proj.version)]\n\n if running_outdated:\n row.append(str(proj.latest_version))\n row.append(proj.latest_filetype)\n\n if has_editables:\n row.append(proj.editable_project_location or \"\")\n\n if options.verbose >= 1:\n row.append(proj.location or \"\")\n if options.verbose >= 1:\n row.append(proj.installer)\n\n data.append(row)\n\n return data, header\n\n\ndef format_for_json(packages: \"_ProcessedDists\", options: Values) -> str:\n data = []\n for dist in packages:\n info = {\n \"name\": dist.raw_name,\n \"version\": str(dist.version),\n }\n if options.verbose >= 1:\n info[\"location\"] = dist.location or \"\"\n info[\"installer\"] = dist.installer\n if options.outdated:\n info[\"latest_version\"] = str(dist.latest_version)\n info[\"latest_filetype\"] = dist.latest_filetype\n editable_project_location = dist.editable_project_location\n if editable_project_location:\n info[\"editable_project_location\"] = editable_project_location\n data.append(info)\n return json.dumps(data)\n"
},
{
"path": "lib/python3.7/site-packages/pip/_internal/commands/search.py",
"content": "import logging\nimport shutil\nimport sys\nimport textwrap\nimport xmlrpc.client\nfrom collections import OrderedDict\nfrom optparse import Values\nfrom typing import TYPE_CHECKING, Dict, List, Optional\n\nfrom pip._vendor.packaging.version import parse as parse_version\n\nfrom pip._internal.cli.base_command import Command\nfrom pip._internal.cli.req_command import SessionCommandMixin\nfrom pip._internal.cli.status_codes import NO_MATCHES_FOUND, SUCCESS\nfrom pip._internal.exceptions import CommandError\nfrom pip._internal.metadata import get_default_environment\nfrom pip._internal.models.index import PyPI\nfrom pip._internal.network.xmlrpc import PipXmlrpcTransport\nfrom pip._internal.utils.logging import indent_log\nfrom pip._internal.utils.misc import write_output\n\nif TYPE_CHECKING:\n from typing import TypedDict\n\n class TransformedHit(TypedDict):\n name: str\n summary: str\n versions: List[str]\n\n\nlogger = logging.getLogger(__name__)\n\n\nclass SearchCommand(Command, SessionCommandMixin):\n \"\"\"Search for PyPI packages whose name or summary contains .\"\"\"\n\n usage = \"\"\"\n %prog [options] \"\"\"\n ignore_require_venv = True\n\n def add_options(self) -> None:\n self.cmd_opts.add_option(\n \"-i\",\n \"--index\",\n dest=\"index\",\n metavar=\"URL\",\n default=PyPI.pypi_url,\n help=\"Base URL of Python Package Index (default %default)\",\n )\n\n self.parser.insert_option_group(0, self.cmd_opts)\n\n def run(self, options: Values, args: List[str]) -> int:\n if not args:\n raise CommandError(\"Missing required argument (search query).\")\n query = args\n pypi_hits = self.search(query, options)\n hits = transform_hits(pypi_hits)\n\n terminal_width = None\n if sys.stdout.isatty():\n terminal_width = shutil.get_terminal_size()[0]\n\n print_results(hits, terminal_width=terminal_width)\n if pypi_hits:\n return SUCCESS\n return NO_MATCHES_FOUND\n\n def search(self, query: List[str], options: Values) -> List[Dict[str, str]]:\n index_url = options.index\n\n session = self.get_default_session(options)\n\n transport = PipXmlrpcTransport(index_url, session)\n pypi = xmlrpc.client.ServerProxy(index_url, transport)\n try:\n hits = pypi.search({\"name\": query, \"summary\": query}, \"or\")\n except xmlrpc.client.Fault as fault:\n message = \"XMLRPC request failed [code: {code}]\\n{string}\".format(\n code=fault.faultCode,\n string=fault.faultString,\n )\n raise CommandError(message)\n assert isinstance(hits, list)\n return hits\n\n\ndef transform_hits(hits: List[Dict[str, str]]) -> List[\"TransformedHit\"]:\n \"\"\"\n The list from pypi is really a list of versions. We want a list of\n packages with the list of versions stored inline. This converts the\n list from pypi into one we can use.\n \"\"\"\n packages: Dict[str, \"TransformedHit\"] = OrderedDict()\n for hit in hits:\n name = hit[\"name\"]\n summary = hit[\"summary\"]\n version = hit[\"version\"]\n\n if name not in packages.keys():\n packages[name] = {\n \"name\": name,\n \"summary\": summary,\n \"versions\": [version],\n }\n else:\n packages[name][\"versions\"].append(version)\n\n # if this is the highest version, replace summary and score\n if version == highest_version(packages[name][\"versions\"]):\n packages[name][\"summary\"] = summary\n\n return list(packages.values())\n\n\ndef print_dist_installation_info(name: str, latest: str) -> None:\n env = get_default_environment()\n dist = env.get_distribution(name)\n if dist is not None:\n with indent_log():\n if dist.version == latest:\n write_output(\"INSTALLED: %s (latest)\", dist.version)\n else:\n write_output(\"INSTALLED: %s\", dist.version)\n if parse_version(latest).pre:\n write_output(\n \"LATEST: %s (pre-release; install\"\n \" with `pip install --pre`)\",\n latest,\n )\n else:\n write_output(\"LATEST: %s\", latest)\n\n\ndef print_results(\n hits: List[\"TransformedHit\"],\n name_column_width: Optional[int] = None,\n terminal_width: Optional[int] = None,\n) -> None:\n if not hits:\n return\n if name_column_width is None:\n name_column_width = (\n max(\n [\n len(hit[\"name\"]) + len(highest_version(hit.get(\"versions\", [\"-\"])))\n for hit in hits\n ]\n )\n + 4\n )\n\n for hit in hits:\n name = hit[\"name\"]\n summary = hit[\"summary\"] or \"\"\n latest = highest_version(hit.get(\"versions\", [\"-\"]))\n if terminal_width is not None:\n target_width = terminal_width - name_column_width - 5\n if target_width > 10:\n # wrap and indent summary to fit terminal\n summary_lines = textwrap.wrap(summary, target_width)\n summary = (\"\\n\" + \" \" * (name_column_width + 3)).join(summary_lines)\n\n name_latest = f\"{name} ({latest})\"\n line = f\"{name_latest:{name_column_width}} - {summary}\"\n try:\n write_output(line)\n print_dist_installation_info(name, latest)\n except UnicodeEncodeError:\n pass\n\n\ndef highest_version(versions: List[str]) -> str:\n return max(versions, key=parse_version)\n"
},
{
"path": "lib/python3.7/site-packages/pip/_internal/commands/show.py",
"content": "import logging\nfrom optparse import Values\nfrom typing import Generator, Iterable, Iterator, List, NamedTuple, Optional\n\nfrom pip._vendor.packaging.utils import canonicalize_name\n\nfrom pip._internal.cli.base_command import Command\nfrom pip._internal.cli.status_codes import ERROR, SUCCESS\nfrom pip._internal.metadata import BaseDistribution, get_default_environment\nfrom pip._internal.utils.misc import write_output\n\nlogger = logging.getLogger(__name__)\n\n\nclass ShowCommand(Command):\n \"\"\"\n Show information about one or more installed packages.\n\n The output is in RFC-compliant mail header format.\n \"\"\"\n\n usage = \"\"\"\n %prog [options] ...\"\"\"\n ignore_require_venv = True\n\n def add_options(self) -> None:\n self.cmd_opts.add_option(\n \"-f\",\n \"--files\",\n dest=\"files\",\n action=\"store_true\",\n default=False,\n help=\"Show the full list of installed files for each package.\",\n )\n\n self.parser.insert_option_group(0, self.cmd_opts)\n\n def run(self, options: Values, args: List[str]) -> int:\n if not args:\n logger.warning(\"ERROR: Please provide a package name or names.\")\n return ERROR\n query = args\n\n results = search_packages_info(query)\n if not print_results(\n results, list_files=options.files, verbose=options.verbose\n ):\n return ERROR\n return SUCCESS\n\n\nclass _PackageInfo(NamedTuple):\n name: str\n version: str\n location: str\n requires: List[str]\n required_by: List[str]\n installer: str\n metadata_version: str\n classifiers: List[str]\n summary: str\n homepage: str\n project_urls: List[str]\n author: str\n author_email: str\n license: str\n entry_points: List[str]\n files: Optional[List[str]]\n\n\ndef search_packages_info(query: List[str]) -> Generator[_PackageInfo, None, None]:\n \"\"\"\n Gather details from installed distributions. Print distribution name,\n version, location, and installed files. Installed files requires a\n pip generated 'installed-files.txt' in the distributions '.egg-info'\n directory.\n \"\"\"\n env = get_default_environment()\n\n installed = {dist.canonical_name: dist for dist in env.iter_all_distributions()}\n query_names = [canonicalize_name(name) for name in query]\n missing = sorted(\n [name for name, pkg in zip(query, query_names) if pkg not in installed]\n )\n if missing:\n logger.warning(\"Package(s) not found: %s\", \", \".join(missing))\n\n def _get_requiring_packages(current_dist: BaseDistribution) -> Iterator[str]:\n return (\n dist.metadata[\"Name\"] or \"UNKNOWN\"\n for dist in installed.values()\n if current_dist.canonical_name\n in {canonicalize_name(d.name) for d in dist.iter_dependencies()}\n )\n\n for query_name in query_names:\n try:\n dist = installed[query_name]\n except KeyError:\n continue\n\n requires = sorted((req.name for req in dist.iter_dependencies()), key=str.lower)\n required_by = sorted(_get_requiring_packages(dist), key=str.lower)\n\n try:\n entry_points_text = dist.read_text(\"entry_points.txt\")\n entry_points = entry_points_text.splitlines(keepends=False)\n except FileNotFoundError:\n entry_points = []\n\n files_iter = dist.iter_declared_entries()\n if files_iter is None:\n files: Optional[List[str]] = None\n else:\n files = sorted(files_iter)\n\n metadata = dist.metadata\n\n yield _PackageInfo(\n name=dist.raw_name,\n version=str(dist.version),\n location=dist.location or \"\",\n requires=requires,\n required_by=required_by,\n installer=dist.installer,\n metadata_version=dist.metadata_version or \"\",\n classifiers=metadata.get_all(\"Classifier\", []),\n summary=metadata.get(\"Summary\", \"\"),\n homepage=metadata.get(\"Home-page\", \"\"),\n project_urls=metadata.get_all(\"Project-URL\", []),\n author=metadata.get(\"Author\", \"\"),\n author_email=metadata.get(\"Author-email\", \"\"),\n license=metadata.get(\"License\", \"\"),\n entry_points=entry_points,\n files=files,\n )\n\n\ndef print_results(\n distributions: Iterable[_PackageInfo],\n list_files: bool,\n verbose: bool,\n) -> bool:\n \"\"\"\n Print the information from installed distributions found.\n \"\"\"\n results_printed = False\n for i, dist in enumerate(distributions):\n results_printed = True\n if i > 0:\n write_output(\"---\")\n\n write_output(\"Name: %s\", dist.name)\n write_output(\"Version: %s\", dist.version)\n write_output(\"Summary: %s\", dist.summary)\n write_output(\"Home-page: %s\", dist.homepage)\n write_output(\"Author: %s\", dist.author)\n write_output(\"Author-email: %s\", dist.author_email)\n write_output(\"License: %s\", dist.license)\n write_output(\"Location: %s\", dist.location)\n write_output(\"Requires: %s\", \", \".join(dist.requires))\n write_output(\"Required-by: %s\", \", \".join(dist.required_by))\n\n if verbose:\n write_output(\"Metadata-Version: %s\", dist.metadata_version)\n write_output(\"Installer: %s\", dist.installer)\n write_output(\"Classifiers:\")\n for classifier in dist.classifiers:\n write_output(\" %s\", classifier)\n write_output(\"Entry-points:\")\n for entry in dist.entry_points:\n write_output(\" %s\", entry.strip())\n write_output(\"Project-URLs:\")\n for project_url in dist.project_urls:\n write_output(\" %s\", project_url)\n if list_files:\n write_output(\"Files:\")\n if dist.files is None:\n write_output(\"Cannot locate RECORD or installed-files.txt\")\n else:\n for line in dist.files:\n write_output(\" %s\", line.strip())\n return results_printed\n"
},
{
"path": "lib/python3.7/site-packages/pip/_internal/commands/uninstall.py",
"content": "import logging\nfrom optparse import Values\nfrom typing import List\n\nfrom pip._vendor.packaging.utils import canonicalize_name\n\nfrom pip._internal.cli import cmdoptions\nfrom pip._internal.cli.base_command import Command\nfrom pip._internal.cli.req_command import SessionCommandMixin, warn_if_run_as_root\nfrom pip._internal.cli.status_codes import SUCCESS\nfrom pip._internal.exceptions import InstallationError\nfrom pip._internal.req import parse_requirements\nfrom pip._internal.req.constructors import (\n install_req_from_line,\n install_req_from_parsed_requirement,\n)\nfrom pip._internal.utils.misc import protect_pip_from_modification_on_windows\n\nlogger = logging.getLogger(__name__)\n\n\nclass UninstallCommand(Command, SessionCommandMixin):\n \"\"\"\n Uninstall packages.\n\n pip is able to uninstall most installed packages. Known exceptions are:\n\n - Pure distutils packages installed with ``python setup.py install``, which\n leave behind no metadata to determine what files were installed.\n - Script wrappers installed by ``python setup.py develop``.\n \"\"\"\n\n usage = \"\"\"\n %prog [options] ...\n %prog [options] -r ...\"\"\"\n\n def add_options(self) -> None:\n self.cmd_opts.add_option(\n \"-r\",\n \"--requirement\",\n dest=\"requirements\",\n action=\"append\",\n default=[],\n metavar=\"file\",\n help=(\n \"Uninstall all the packages listed in the given requirements \"\n \"file. This option can be used multiple times.\"\n ),\n )\n self.cmd_opts.add_option(\n \"-y\",\n \"--yes\",\n dest=\"yes\",\n action=\"store_true\",\n help=\"Don't ask for confirmation of uninstall deletions.\",\n )\n self.cmd_opts.add_option(cmdoptions.root_user_action())\n self.parser.insert_option_group(0, self.cmd_opts)\n\n def run(self, options: Values, args: List[str]) -> int:\n session = self.get_default_session(options)\n\n reqs_to_uninstall = {}\n for name in args:\n req = install_req_from_line(\n name,\n isolated=options.isolated_mode,\n )\n if req.name:\n reqs_to_uninstall[canonicalize_name(req.name)] = req\n else:\n logger.warning(\n \"Invalid requirement: %r ignored -\"\n \" the uninstall command expects named\"\n \" requirements.\",\n name,\n )\n for filename in options.requirements:\n for parsed_req in parse_requirements(\n filename, options=options, session=session\n ):\n req = install_req_from_parsed_requirement(\n parsed_req, isolated=options.isolated_mode\n )\n if req.name:\n reqs_to_uninstall[canonicalize_name(req.name)] = req\n if not reqs_to_uninstall:\n raise InstallationError(\n f\"You must give at least one requirement to {self.name} (see \"\n f'\"pip help {self.name}\")'\n )\n\n protect_pip_from_modification_on_windows(\n modifying_pip=\"pip\" in reqs_to_uninstall\n )\n\n for req in reqs_to_uninstall.values():\n uninstall_pathset = req.uninstall(\n auto_confirm=options.yes,\n verbose=self.verbosity > 0,\n )\n if uninstall_pathset:\n uninstall_pathset.commit()\n if options.root_user_action == \"warn\":\n warn_if_run_as_root()\n return SUCCESS\n"
},
{
"path": "lib/python3.7/site-packages/pip/_internal/commands/wheel.py",
"content": "import logging\nimport os\nimport shutil\nfrom optparse import Values\nfrom typing import List\n\nfrom pip._internal.cache import WheelCache\nfrom pip._internal.cli import cmdoptions\nfrom pip._internal.cli.req_command import RequirementCommand, with_cleanup\nfrom pip._internal.cli.status_codes import SUCCESS\nfrom pip._internal.exceptions import CommandError\nfrom pip._internal.operations.build.build_tracker import get_build_tracker\nfrom pip._internal.req.req_install import (\n InstallRequirement,\n LegacySetupPyOptionsCheckMode,\n check_legacy_setup_py_options,\n)\nfrom pip._internal.utils.deprecation import deprecated\nfrom pip._internal.utils.misc import ensure_dir, normalize_path\nfrom pip._internal.utils.temp_dir import TempDirectory\nfrom pip._internal.wheel_builder import build, should_build_for_wheel_command\n\nlogger = logging.getLogger(__name__)\n\n\nclass WheelCommand(RequirementCommand):\n \"\"\"\n Build Wheel archives for your requirements and dependencies.\n\n Wheel is a built-package format, and offers the advantage of not\n recompiling your software during every install. For more details, see the\n wheel docs: https://wheel.readthedocs.io/en/latest/\n\n 'pip wheel' uses the build system interface as described here:\n https://pip.pypa.io/en/stable/reference/build-system/\n\n \"\"\"\n\n usage = \"\"\"\n %prog [options] ...\n %prog [options] -r ...\n %prog [options] [-e] ...\n %prog [options] [-e] ...\n %prog [options] ...\"\"\"\n\n def add_options(self) -> None:\n\n self.cmd_opts.add_option(\n \"-w\",\n \"--wheel-dir\",\n dest=\"wheel_dir\",\n metavar=\"dir\",\n default=os.curdir,\n help=(\n \"Build wheels into , where the default is the \"\n \"current working directory.\"\n ),\n )\n self.cmd_opts.add_option(cmdoptions.no_binary())\n self.cmd_opts.add_option(cmdoptions.only_binary())\n self.cmd_opts.add_option(cmdoptions.prefer_binary())\n self.cmd_opts.add_option(cmdoptions.no_build_isolation())\n self.cmd_opts.add_option(cmdoptions.use_pep517())\n self.cmd_opts.add_option(cmdoptions.no_use_pep517())\n self.cmd_opts.add_option(cmdoptions.check_build_deps())\n self.cmd_opts.add_option(cmdoptions.constraints())\n self.cmd_opts.add_option(cmdoptions.editable())\n self.cmd_opts.add_option(cmdoptions.requirements())\n self.cmd_opts.add_option(cmdoptions.src())\n self.cmd_opts.add_option(cmdoptions.ignore_requires_python())\n self.cmd_opts.add_option(cmdoptions.no_deps())\n self.cmd_opts.add_option(cmdoptions.progress_bar())\n\n self.cmd_opts.add_option(\n \"--no-verify\",\n dest=\"no_verify\",\n action=\"store_true\",\n default=False,\n help=\"Don't verify if built wheel is valid.\",\n )\n\n self.cmd_opts.add_option(cmdoptions.config_settings())\n self.cmd_opts.add_option(cmdoptions.build_options())\n self.cmd_opts.add_option(cmdoptions.global_options())\n\n self.cmd_opts.add_option(\n \"--pre\",\n action=\"store_true\",\n default=False,\n help=(\n \"Include pre-release and development versions. By default, \"\n \"pip only finds stable versions.\"\n ),\n )\n\n self.cmd_opts.add_option(cmdoptions.require_hashes())\n\n index_opts = cmdoptions.make_option_group(\n cmdoptions.index_group,\n self.parser,\n )\n\n self.parser.insert_option_group(0, index_opts)\n self.parser.insert_option_group(0, self.cmd_opts)\n\n @with_cleanup\n def run(self, options: Values, args: List[str]) -> int:\n session = self.get_default_session(options)\n\n finder = self._build_package_finder(options, session)\n wheel_cache = WheelCache(options.cache_dir, options.format_control)\n\n options.wheel_dir = normalize_path(options.wheel_dir)\n ensure_dir(options.wheel_dir)\n\n build_tracker = self.enter_context(get_build_tracker())\n\n directory = TempDirectory(\n delete=not options.no_clean,\n kind=\"wheel\",\n globally_managed=True,\n )\n\n reqs = self.get_requirements(args, options, finder, session)\n check_legacy_setup_py_options(\n options, reqs, LegacySetupPyOptionsCheckMode.WHEEL\n )\n\n if \"no-binary-enable-wheel-cache\" in options.features_enabled:\n # TODO: remove format_control from WheelCache when the deprecation cycle\n # is over\n wheel_cache = WheelCache(options.cache_dir)\n else:\n if options.format_control.no_binary:\n deprecated(\n reason=(\n \"--no-binary currently disables reading from \"\n \"the cache of locally built wheels. In the future \"\n \"--no-binary will not influence the wheel cache.\"\n ),\n replacement=\"to use the --no-cache-dir option\",\n feature_flag=\"no-binary-enable-wheel-cache\",\n issue=11453,\n gone_in=\"23.1\",\n )\n wheel_cache = WheelCache(options.cache_dir, options.format_control)\n\n preparer = self.make_requirement_preparer(\n temp_build_dir=directory,\n options=options,\n build_tracker=build_tracker,\n session=session,\n finder=finder,\n download_dir=options.wheel_dir,\n use_user_site=False,\n verbosity=self.verbosity,\n )\n\n resolver = self.make_resolver(\n preparer=preparer,\n finder=finder,\n options=options,\n wheel_cache=wheel_cache,\n ignore_requires_python=options.ignore_requires_python,\n use_pep517=options.use_pep517,\n )\n\n self.trace_basic_info(finder)\n\n requirement_set = resolver.resolve(reqs, check_supported_wheels=True)\n\n reqs_to_build: List[InstallRequirement] = []\n for req in requirement_set.requirements.values():\n if req.is_wheel:\n preparer.save_linked_requirement(req)\n elif should_build_for_wheel_command(req):\n reqs_to_build.append(req)\n\n # build wheels\n build_successes, build_failures = build(\n reqs_to_build,\n wheel_cache=wheel_cache,\n verify=(not options.no_verify),\n build_options=options.build_options or [],\n global_options=options.global_options or [],\n )\n for req in build_successes:\n assert req.link and req.link.is_wheel\n assert req.local_file_path\n # copy from cache to target directory\n try:\n shutil.copy(req.local_file_path, options.wheel_dir)\n except OSError as e:\n logger.warning(\n \"Building wheel for %s failed: %s\",\n req.name,\n e,\n )\n build_failures.append(req)\n if len(build_failures) != 0:\n raise CommandError(\"Failed to build one or more wheels\")\n\n return SUCCESS\n"
},
{
"path": "lib/python3.7/site-packages/pip/_internal/configuration.py",
"content": "\"\"\"Configuration management setup\n\nSome terminology:\n- name\n As written in config files.\n- value\n Value associated with a name\n- key\n Name combined with it's section (section.name)\n- variant\n A single word describing where the configuration key-value pair came from\n\"\"\"\n\nimport configparser\nimport locale\nimport os\nimport sys\nfrom typing import Any, Dict, Iterable, List, NewType, Optional, Tuple\n\nfrom pip._internal.exceptions import (\n ConfigurationError,\n ConfigurationFileCouldNotBeLoaded,\n)\nfrom pip._internal.utils import appdirs\nfrom pip._internal.utils.compat import WINDOWS\nfrom pip._internal.utils.logging import getLogger\nfrom pip._internal.utils.misc import ensure_dir, enum\n\nRawConfigParser = configparser.RawConfigParser # Shorthand\nKind = NewType(\"Kind\", str)\n\nCONFIG_BASENAME = \"pip.ini\" if WINDOWS else \"pip.conf\"\nENV_NAMES_IGNORED = \"version\", \"help\"\n\n# The kinds of configurations there are.\nkinds = enum(\n USER=\"user\", # User Specific\n GLOBAL=\"global\", # System Wide\n SITE=\"site\", # [Virtual] Environment Specific\n ENV=\"env\", # from PIP_CONFIG_FILE\n ENV_VAR=\"env-var\", # from Environment Variables\n)\nOVERRIDE_ORDER = kinds.GLOBAL, kinds.USER, kinds.SITE, kinds.ENV, kinds.ENV_VAR\nVALID_LOAD_ONLY = kinds.USER, kinds.GLOBAL, kinds.SITE\n\nlogger = getLogger(__name__)\n\n\n# NOTE: Maybe use the optionx attribute to normalize keynames.\ndef _normalize_name(name: str) -> str:\n \"\"\"Make a name consistent regardless of source (environment or file)\"\"\"\n name = name.lower().replace(\"_\", \"-\")\n if name.startswith(\"--\"):\n name = name[2:] # only prefer long opts\n return name\n\n\ndef _disassemble_key(name: str) -> List[str]:\n if \".\" not in name:\n error_message = (\n \"Key does not contain dot separated section and key. \"\n \"Perhaps you wanted to use 'global.{}' instead?\"\n ).format(name)\n raise ConfigurationError(error_message)\n return name.split(\".\", 1)\n\n\ndef get_configuration_files() -> Dict[Kind, List[str]]:\n global_config_files = [\n os.path.join(path, CONFIG_BASENAME) for path in appdirs.site_config_dirs(\"pip\")\n ]\n\n site_config_file = os.path.join(sys.prefix, CONFIG_BASENAME)\n legacy_config_file = os.path.join(\n os.path.expanduser(\"~\"),\n \"pip\" if WINDOWS else \".pip\",\n CONFIG_BASENAME,\n )\n new_config_file = os.path.join(appdirs.user_config_dir(\"pip\"), CONFIG_BASENAME)\n return {\n kinds.GLOBAL: global_config_files,\n kinds.SITE: [site_config_file],\n kinds.USER: [legacy_config_file, new_config_file],\n }\n\n\nclass Configuration:\n \"\"\"Handles management of configuration.\n\n Provides an interface to accessing and managing configuration files.\n\n This class converts provides an API that takes \"section.key-name\" style\n keys and stores the value associated with it as \"key-name\" under the\n section \"section\".\n\n This allows for a clean interface wherein the both the section and the\n key-name are preserved in an easy to manage form in the configuration files\n and the data stored is also nice.\n \"\"\"\n\n def __init__(self, isolated: bool, load_only: Optional[Kind] = None) -> None:\n super().__init__()\n\n if load_only is not None and load_only not in VALID_LOAD_ONLY:\n raise ConfigurationError(\n \"Got invalid value for load_only - should be one of {}\".format(\n \", \".join(map(repr, VALID_LOAD_ONLY))\n )\n )\n self.isolated = isolated\n self.load_only = load_only\n\n # Because we keep track of where we got the data from\n self._parsers: Dict[Kind, List[Tuple[str, RawConfigParser]]] = {\n variant: [] for variant in OVERRIDE_ORDER\n }\n self._config: Dict[Kind, Dict[str, Any]] = {\n variant: {} for variant in OVERRIDE_ORDER\n }\n self._modified_parsers: List[Tuple[str, RawConfigParser]] = []\n\n def load(self) -> None:\n \"\"\"Loads configuration from configuration files and environment\"\"\"\n self._load_config_files()\n if not self.isolated:\n self._load_environment_vars()\n\n def get_file_to_edit(self) -> Optional[str]:\n \"\"\"Returns the file with highest priority in configuration\"\"\"\n assert self.load_only is not None, \"Need to be specified a file to be editing\"\n\n try:\n return self._get_parser_to_modify()[0]\n except IndexError:\n return None\n\n def items(self) -> Iterable[Tuple[str, Any]]:\n \"\"\"Returns key-value pairs like dict.items() representing the loaded\n configuration\n \"\"\"\n return self._dictionary.items()\n\n def get_value(self, key: str) -> Any:\n \"\"\"Get a value from the configuration.\"\"\"\n orig_key = key\n key = _normalize_name(key)\n try:\n return self._dictionary[key]\n except KeyError:\n # disassembling triggers a more useful error message than simply\n # \"No such key\" in the case that the key isn't in the form command.option\n _disassemble_key(key)\n raise ConfigurationError(f\"No such key - {orig_key}\")\n\n def set_value(self, key: str, value: Any) -> None:\n \"\"\"Modify a value in the configuration.\"\"\"\n key = _normalize_name(key)\n self._ensure_have_load_only()\n\n assert self.load_only\n fname, parser = self._get_parser_to_modify()\n\n if parser is not None:\n section, name = _disassemble_key(key)\n\n # Modify the parser and the configuration\n if not parser.has_section(section):\n parser.add_section(section)\n parser.set(section, name, value)\n\n self._config[self.load_only][key] = value\n self._mark_as_modified(fname, parser)\n\n def unset_value(self, key: str) -> None:\n \"\"\"Unset a value in the configuration.\"\"\"\n orig_key = key\n key = _normalize_name(key)\n self._ensure_have_load_only()\n\n assert self.load_only\n if key not in self._config[self.load_only]:\n raise ConfigurationError(f\"No such key - {orig_key}\")\n\n fname, parser = self._get_parser_to_modify()\n\n if parser is not None:\n section, name = _disassemble_key(key)\n if not (\n parser.has_section(section) and parser.remove_option(section, name)\n ):\n # The option was not removed.\n raise ConfigurationError(\n \"Fatal Internal error [id=1]. Please report as a bug.\"\n )\n\n # The section may be empty after the option was removed.\n if not parser.items(section):\n parser.remove_section(section)\n self._mark_as_modified(fname, parser)\n\n del self._config[self.load_only][key]\n\n def save(self) -> None:\n \"\"\"Save the current in-memory state.\"\"\"\n self._ensure_have_load_only()\n\n for fname, parser in self._modified_parsers:\n logger.info(\"Writing to %s\", fname)\n\n # Ensure directory exists.\n ensure_dir(os.path.dirname(fname))\n\n with open(fname, \"w\") as f:\n parser.write(f)\n\n #\n # Private routines\n #\n\n def _ensure_have_load_only(self) -> None:\n if self.load_only is None:\n raise ConfigurationError(\"Needed a specific file to be modifying.\")\n logger.debug(\"Will be working with %s variant only\", self.load_only)\n\n @property\n def _dictionary(self) -> Dict[str, Any]:\n \"\"\"A dictionary representing the loaded configuration.\"\"\"\n # NOTE: Dictionaries are not populated if not loaded. So, conditionals\n # are not needed here.\n retval = {}\n\n for variant in OVERRIDE_ORDER:\n retval.update(self._config[variant])\n\n return retval\n\n def _load_config_files(self) -> None:\n \"\"\"Loads configuration from configuration files\"\"\"\n config_files = dict(self.iter_config_files())\n if config_files[kinds.ENV][0:1] == [os.devnull]:\n logger.debug(\n \"Skipping loading configuration files due to \"\n \"environment's PIP_CONFIG_FILE being os.devnull\"\n )\n return\n\n for variant, files in config_files.items():\n for fname in files:\n # If there's specific variant set in `load_only`, load only\n # that variant, not the others.\n if self.load_only is not None and variant != self.load_only:\n logger.debug(\"Skipping file '%s' (variant: %s)\", fname, variant)\n continue\n\n parser = self._load_file(variant, fname)\n\n # Keeping track of the parsers used\n self._parsers[variant].append((fname, parser))\n\n def _load_file(self, variant: Kind, fname: str) -> RawConfigParser:\n logger.verbose(\"For variant '%s', will try loading '%s'\", variant, fname)\n parser = self._construct_parser(fname)\n\n for section in parser.sections():\n items = parser.items(section)\n self._config[variant].update(self._normalized_keys(section, items))\n\n return parser\n\n def _construct_parser(self, fname: str) -> RawConfigParser:\n parser = configparser.RawConfigParser()\n # If there is no such file, don't bother reading it but create the\n # parser anyway, to hold the data.\n # Doing this is useful when modifying and saving files, where we don't\n # need to construct a parser.\n if os.path.exists(fname):\n locale_encoding = locale.getpreferredencoding(False)\n try:\n parser.read(fname, encoding=locale_encoding)\n except UnicodeDecodeError:\n # See https://github.com/pypa/pip/issues/4963\n raise ConfigurationFileCouldNotBeLoaded(\n reason=f\"contains invalid {locale_encoding} characters\",\n fname=fname,\n )\n except configparser.Error as error:\n # See https://github.com/pypa/pip/issues/4893\n raise ConfigurationFileCouldNotBeLoaded(error=error)\n return parser\n\n def _load_environment_vars(self) -> None:\n \"\"\"Loads configuration from environment variables\"\"\"\n self._config[kinds.ENV_VAR].update(\n self._normalized_keys(\":env:\", self.get_environ_vars())\n )\n\n def _normalized_keys(\n self, section: str, items: Iterable[Tuple[str, Any]]\n ) -> Dict[str, Any]:\n \"\"\"Normalizes items to construct a dictionary with normalized keys.\n\n This routine is where the names become keys and are made the same\n regardless of source - configuration files or environment.\n \"\"\"\n normalized = {}\n for name, val in items:\n key = section + \".\" + _normalize_name(name)\n normalized[key] = val\n return normalized\n\n def get_environ_vars(self) -> Iterable[Tuple[str, str]]:\n \"\"\"Returns a generator with all environmental vars with prefix PIP_\"\"\"\n for key, val in os.environ.items():\n if key.startswith(\"PIP_\"):\n name = key[4:].lower()\n if name not in ENV_NAMES_IGNORED:\n yield name, val\n\n # XXX: This is patched in the tests.\n def iter_config_files(self) -> Iterable[Tuple[Kind, List[str]]]:\n \"\"\"Yields variant and configuration files associated with it.\n\n This should be treated like items of a dictionary.\n \"\"\"\n # SMELL: Move the conditions out of this function\n\n # environment variables have the lowest priority\n config_file = os.environ.get(\"PIP_CONFIG_FILE\", None)\n if config_file is not None:\n yield kinds.ENV, [config_file]\n else:\n yield kinds.ENV, []\n\n config_files = get_configuration_files()\n\n # at the base we have any global configuration\n yield kinds.GLOBAL, config_files[kinds.GLOBAL]\n\n # per-user configuration next\n should_load_user_config = not self.isolated and not (\n config_file and os.path.exists(config_file)\n )\n if should_load_user_config:\n # The legacy config file is overridden by the new config file\n yield kinds.USER, config_files[kinds.USER]\n\n # finally virtualenv configuration first trumping others\n yield kinds.SITE, config_files[kinds.SITE]\n\n def get_values_in_config(self, variant: Kind) -> Dict[str, Any]:\n \"\"\"Get values present in a config file\"\"\"\n return self._config[variant]\n\n def _get_parser_to_modify(self) -> Tuple[str, RawConfigParser]:\n # Determine which parser to modify\n assert self.load_only\n parsers = self._parsers[self.load_only]\n if not parsers:\n # This should not happen if everything works correctly.\n raise ConfigurationError(\n \"Fatal Internal error [id=2]. Please report as a bug.\"\n )\n\n # Use the highest priority parser.\n return parsers[-1]\n\n # XXX: This is patched in the tests.\n def _mark_as_modified(self, fname: str, parser: RawConfigParser) -> None:\n file_parser_tuple = (fname, parser)\n if file_parser_tuple not in self._modified_parsers:\n self._modified_parsers.append(file_parser_tuple)\n\n def __repr__(self) -> str:\n return f\"{self.__class__.__name__}({self._dictionary!r})\"\n"
},
{
"path": "lib/python3.7/site-packages/pip/_internal/distributions/__init__.py",
"content": "from pip._internal.distributions.base import AbstractDistribution\nfrom pip._internal.distributions.sdist import SourceDistribution\nfrom pip._internal.distributions.wheel import WheelDistribution\nfrom pip._internal.req.req_install import InstallRequirement\n\n\ndef make_distribution_for_install_requirement(\n install_req: InstallRequirement,\n) -> AbstractDistribution:\n \"\"\"Returns a Distribution for the given InstallRequirement\"\"\"\n # Editable requirements will always be source distributions. They use the\n # legacy logic until we create a modern standard for them.\n if install_req.editable:\n return SourceDistribution(install_req)\n\n # If it's a wheel, it's a WheelDistribution\n if install_req.is_wheel:\n return WheelDistribution(install_req)\n\n # Otherwise, a SourceDistribution\n return SourceDistribution(install_req)\n"
},
{
"path": "lib/python3.7/site-packages/pip/_internal/distributions/base.py",
"content": "import abc\n\nfrom pip._internal.index.package_finder import PackageFinder\nfrom pip._internal.metadata.base import BaseDistribution\nfrom pip._internal.req import InstallRequirement\n\n\nclass AbstractDistribution(metaclass=abc.ABCMeta):\n \"\"\"A base class for handling installable artifacts.\n\n The requirements for anything installable are as follows:\n\n - we must be able to determine the requirement name\n (or we can't correctly handle the non-upgrade case).\n\n - for packages with setup requirements, we must also be able\n to determine their requirements without installing additional\n packages (for the same reason as run-time dependencies)\n\n - we must be able to create a Distribution object exposing the\n above metadata.\n \"\"\"\n\n def __init__(self, req: InstallRequirement) -> None:\n super().__init__()\n self.req = req\n\n @abc.abstractmethod\n def get_metadata_distribution(self) -> BaseDistribution:\n raise NotImplementedError()\n\n @abc.abstractmethod\n def prepare_distribution_metadata(\n self,\n finder: PackageFinder,\n build_isolation: bool,\n check_build_deps: bool,\n ) -> None:\n raise NotImplementedError()\n"
},
{
"path": "lib/python3.7/site-packages/pip/_internal/distributions/installed.py",
"content": "from pip._internal.distributions.base import AbstractDistribution\nfrom pip._internal.index.package_finder import PackageFinder\nfrom pip._internal.metadata import BaseDistribution\n\n\nclass InstalledDistribution(AbstractDistribution):\n \"\"\"Represents an installed package.\n\n This does not need any preparation as the required information has already\n been computed.\n \"\"\"\n\n def get_metadata_distribution(self) -> BaseDistribution:\n assert self.req.satisfied_by is not None, \"not actually installed\"\n return self.req.satisfied_by\n\n def prepare_distribution_metadata(\n self,\n finder: PackageFinder,\n build_isolation: bool,\n check_build_deps: bool,\n ) -> None:\n pass\n"
},
{
"path": "lib/python3.7/site-packages/pip/_internal/distributions/sdist.py",
"content": "import logging\nfrom typing import Iterable, Set, Tuple\n\nfrom pip._internal.build_env import BuildEnvironment\nfrom pip._internal.distributions.base import AbstractDistribution\nfrom pip._internal.exceptions import InstallationError\nfrom pip._internal.index.package_finder import PackageFinder\nfrom pip._internal.metadata import BaseDistribution\nfrom pip._internal.utils.subprocess import runner_with_spinner_message\n\nlogger = logging.getLogger(__name__)\n\n\nclass SourceDistribution(AbstractDistribution):\n \"\"\"Represents a source distribution.\n\n The preparation step for these needs metadata for the packages to be\n generated, either using PEP 517 or using the legacy `setup.py egg_info`.\n \"\"\"\n\n def get_metadata_distribution(self) -> BaseDistribution:\n return self.req.get_dist()\n\n def prepare_distribution_metadata(\n self,\n finder: PackageFinder,\n build_isolation: bool,\n check_build_deps: bool,\n ) -> None:\n # Load pyproject.toml, to determine whether PEP 517 is to be used\n self.req.load_pyproject_toml()\n\n # Set up the build isolation, if this requirement should be isolated\n should_isolate = self.req.use_pep517 and build_isolation\n if should_isolate:\n # Setup an isolated environment and install the build backend static\n # requirements in it.\n self._prepare_build_backend(finder)\n # Check that if the requirement is editable, it either supports PEP 660 or\n # has a setup.py or a setup.cfg. This cannot be done earlier because we need\n # to setup the build backend to verify it supports build_editable, nor can\n # it be done later, because we want to avoid installing build requirements\n # needlessly. Doing it here also works around setuptools generating\n # UNKNOWN.egg-info when running get_requires_for_build_wheel on a directory\n # without setup.py nor setup.cfg.\n self.req.isolated_editable_sanity_check()\n # Install the dynamic build requirements.\n self._install_build_reqs(finder)\n # Check if the current environment provides build dependencies\n should_check_deps = self.req.use_pep517 and check_build_deps\n if should_check_deps:\n pyproject_requires = self.req.pyproject_requires\n assert pyproject_requires is not None\n conflicting, missing = self.req.build_env.check_requirements(\n pyproject_requires\n )\n if conflicting:\n self._raise_conflicts(\"the backend dependencies\", conflicting)\n if missing:\n self._raise_missing_reqs(missing)\n self.req.prepare_metadata()\n\n def _prepare_build_backend(self, finder: PackageFinder) -> None:\n # Isolate in a BuildEnvironment and install the build-time\n # requirements.\n pyproject_requires = self.req.pyproject_requires\n assert pyproject_requires is not None\n\n self.req.build_env = BuildEnvironment()\n self.req.build_env.install_requirements(\n finder, pyproject_requires, \"overlay\", kind=\"build dependencies\"\n )\n conflicting, missing = self.req.build_env.check_requirements(\n self.req.requirements_to_check\n )\n if conflicting:\n self._raise_conflicts(\"PEP 517/518 supported requirements\", conflicting)\n if missing:\n logger.warning(\n \"Missing build requirements in pyproject.toml for %s.\",\n self.req,\n )\n logger.warning(\n \"The project does not specify a build backend, and \"\n \"pip cannot fall back to setuptools without %s.\",\n \" and \".join(map(repr, sorted(missing))),\n )\n\n def _get_build_requires_wheel(self) -> Iterable[str]:\n with self.req.build_env:\n runner = runner_with_spinner_message(\"Getting requirements to build wheel\")\n backend = self.req.pep517_backend\n assert backend is not None\n with backend.subprocess_runner(runner):\n return backend.get_requires_for_build_wheel()\n\n def _get_build_requires_editable(self) -> Iterable[str]:\n with self.req.build_env:\n runner = runner_with_spinner_message(\n \"Getting requirements to build editable\"\n )\n backend = self.req.pep517_backend\n assert backend is not None\n with backend.subprocess_runner(runner):\n return backend.get_requires_for_build_editable()\n\n def _install_build_reqs(self, finder: PackageFinder) -> None:\n # Install any extra build dependencies that the backend requests.\n # This must be done in a second pass, as the pyproject.toml\n # dependencies must be installed before we can call the backend.\n if (\n self.req.editable\n and self.req.permit_editable_wheels\n and self.req.supports_pyproject_editable()\n ):\n build_reqs = self._get_build_requires_editable()\n else:\n build_reqs = self._get_build_requires_wheel()\n conflicting, missing = self.req.build_env.check_requirements(build_reqs)\n if conflicting:\n self._raise_conflicts(\"the backend dependencies\", conflicting)\n self.req.build_env.install_requirements(\n finder, missing, \"normal\", kind=\"backend dependencies\"\n )\n\n def _raise_conflicts(\n self, conflicting_with: str, conflicting_reqs: Set[Tuple[str, str]]\n ) -> None:\n format_string = (\n \"Some build dependencies for {requirement} \"\n \"conflict with {conflicting_with}: {description}.\"\n )\n error_message = format_string.format(\n requirement=self.req,\n conflicting_with=conflicting_with,\n description=\", \".join(\n f\"{installed} is incompatible with {wanted}\"\n for installed, wanted in sorted(conflicting_reqs)\n ),\n )\n raise InstallationError(error_message)\n\n def _raise_missing_reqs(self, missing: Set[str]) -> None:\n format_string = (\n \"Some build dependencies for {requirement} are missing: {missing}.\"\n )\n error_message = format_string.format(\n requirement=self.req, missing=\", \".join(map(repr, sorted(missing)))\n )\n raise InstallationError(error_message)\n"
},
{
"path": "lib/python3.7/site-packages/pip/_internal/distributions/wheel.py",
"content": "from pip._vendor.packaging.utils import canonicalize_name\n\nfrom pip._internal.distributions.base import AbstractDistribution\nfrom pip._internal.index.package_finder import PackageFinder\nfrom pip._internal.metadata import (\n BaseDistribution,\n FilesystemWheel,\n get_wheel_distribution,\n)\n\n\nclass WheelDistribution(AbstractDistribution):\n \"\"\"Represents a wheel distribution.\n\n This does not need any preparation as wheels can be directly unpacked.\n \"\"\"\n\n def get_metadata_distribution(self) -> BaseDistribution:\n \"\"\"Loads the metadata from the wheel file into memory and returns a\n Distribution that uses it, not relying on the wheel file or\n requirement.\n \"\"\"\n assert self.req.local_file_path, \"Set as part of preparation during download\"\n assert self.req.name, \"Wheels are never unnamed\"\n wheel = FilesystemWheel(self.req.local_file_path)\n return get_wheel_distribution(wheel, canonicalize_name(self.req.name))\n\n def prepare_distribution_metadata(\n self,\n finder: PackageFinder,\n build_isolation: bool,\n check_build_deps: bool,\n ) -> None:\n pass\n"
},
{
"path": "lib/python3.7/site-packages/pip/_internal/exceptions.py",
"content": "\"\"\"Exceptions used throughout package.\n\nThis module MUST NOT try to import from anything within `pip._internal` to\noperate. This is expected to be importable from any/all files within the\nsubpackage and, thus, should not depend on them.\n\"\"\"\n\nimport configparser\nimport re\nfrom itertools import chain, groupby, repeat\nfrom typing import TYPE_CHECKING, Dict, List, Optional, Union\n\nfrom pip._vendor.requests.models import Request, Response\nfrom pip._vendor.rich.console import Console, ConsoleOptions, RenderResult\nfrom pip._vendor.rich.markup import escape\nfrom pip._vendor.rich.text import Text\n\nif TYPE_CHECKING:\n from hashlib import _Hash\n from typing import Literal\n\n from pip._internal.metadata import BaseDistribution\n from pip._internal.req.req_install import InstallRequirement\n\n\n#\n# Scaffolding\n#\ndef _is_kebab_case(s: str) -> bool:\n return re.match(r\"^[a-z]+(-[a-z]+)*$\", s) is not None\n\n\ndef _prefix_with_indent(\n s: Union[Text, str],\n console: Console,\n *,\n prefix: str,\n indent: str,\n) -> Text:\n if isinstance(s, Text):\n text = s\n else:\n text = console.render_str(s)\n\n return console.render_str(prefix, overflow=\"ignore\") + console.render_str(\n f\"\\n{indent}\", overflow=\"ignore\"\n ).join(text.split(allow_blank=True))\n\n\nclass PipError(Exception):\n \"\"\"The base pip error.\"\"\"\n\n\nclass DiagnosticPipError(PipError):\n \"\"\"An error, that presents diagnostic information to the user.\n\n This contains a bunch of logic, to enable pretty presentation of our error\n messages. Each error gets a unique reference. Each error can also include\n additional context, a hint and/or a note -- which are presented with the\n main error message in a consistent style.\n\n This is adapted from the error output styling in `sphinx-theme-builder`.\n \"\"\"\n\n reference: str\n\n def __init__(\n self,\n *,\n kind: 'Literal[\"error\", \"warning\"]' = \"error\",\n reference: Optional[str] = None,\n message: Union[str, Text],\n context: Optional[Union[str, Text]],\n hint_stmt: Optional[Union[str, Text]],\n note_stmt: Optional[Union[str, Text]] = None,\n link: Optional[str] = None,\n ) -> None:\n # Ensure a proper reference is provided.\n if reference is None:\n assert hasattr(self, \"reference\"), \"error reference not provided!\"\n reference = self.reference\n assert _is_kebab_case(reference), \"error reference must be kebab-case!\"\n\n self.kind = kind\n self.reference = reference\n\n self.message = message\n self.context = context\n\n self.note_stmt = note_stmt\n self.hint_stmt = hint_stmt\n\n self.link = link\n\n super().__init__(f\"<{self.__class__.__name__}: {self.reference}>\")\n\n def __repr__(self) -> str:\n return (\n f\"<{self.__class__.__name__}(\"\n f\"reference={self.reference!r}, \"\n f\"message={self.message!r}, \"\n f\"context={self.context!r}, \"\n f\"note_stmt={self.note_stmt!r}, \"\n f\"hint_stmt={self.hint_stmt!r}\"\n \")>\"\n )\n\n def __rich_console__(\n self,\n console: Console,\n options: ConsoleOptions,\n ) -> RenderResult:\n colour = \"red\" if self.kind == \"error\" else \"yellow\"\n\n yield f\"[{colour} bold]{self.kind}[/]: [bold]{self.reference}[/]\"\n yield \"\"\n\n if not options.ascii_only:\n # Present the main message, with relevant context indented.\n if self.context is not None:\n yield _prefix_with_indent(\n self.message,\n console,\n prefix=f\"[{colour}]×[/] \",\n indent=f\"[{colour}]│[/] \",\n )\n yield _prefix_with_indent(\n self.context,\n console,\n prefix=f\"[{colour}]╰─>[/] \",\n indent=f\"[{colour}] [/] \",\n )\n else:\n yield _prefix_with_indent(\n self.message,\n console,\n prefix=\"[red]×[/] \",\n indent=\" \",\n )\n else:\n yield self.message\n if self.context is not None:\n yield \"\"\n yield self.context\n\n if self.note_stmt is not None or self.hint_stmt is not None:\n yield \"\"\n\n if self.note_stmt is not None:\n yield _prefix_with_indent(\n self.note_stmt,\n console,\n prefix=\"[magenta bold]note[/]: \",\n indent=\" \",\n )\n if self.hint_stmt is not None:\n yield _prefix_with_indent(\n self.hint_stmt,\n console,\n prefix=\"[cyan bold]hint[/]: \",\n indent=\" \",\n )\n\n if self.link is not None:\n yield \"\"\n yield f\"Link: {self.link}\"\n\n\n#\n# Actual Errors\n#\nclass ConfigurationError(PipError):\n \"\"\"General exception in configuration\"\"\"\n\n\nclass InstallationError(PipError):\n \"\"\"General exception during installation\"\"\"\n\n\nclass UninstallationError(PipError):\n \"\"\"General exception during uninstallation\"\"\"\n\n\nclass MissingPyProjectBuildRequires(DiagnosticPipError):\n \"\"\"Raised when pyproject.toml has `build-system`, but no `build-system.requires`.\"\"\"\n\n reference = \"missing-pyproject-build-system-requires\"\n\n def __init__(self, *, package: str) -> None:\n super().__init__(\n message=f\"Can not process {escape(package)}\",\n context=Text(\n \"This package has an invalid pyproject.toml file.\\n\"\n \"The [build-system] table is missing the mandatory `requires` key.\"\n ),\n note_stmt=\"This is an issue with the package mentioned above, not pip.\",\n hint_stmt=Text(\"See PEP 518 for the detailed specification.\"),\n )\n\n\nclass InvalidPyProjectBuildRequires(DiagnosticPipError):\n \"\"\"Raised when pyproject.toml an invalid `build-system.requires`.\"\"\"\n\n reference = \"invalid-pyproject-build-system-requires\"\n\n def __init__(self, *, package: str, reason: str) -> None:\n super().__init__(\n message=f\"Can not process {escape(package)}\",\n context=Text(\n \"This package has an invalid `build-system.requires` key in \"\n f\"pyproject.toml.\\n{reason}\"\n ),\n note_stmt=\"This is an issue with the package mentioned above, not pip.\",\n hint_stmt=Text(\"See PEP 518 for the detailed specification.\"),\n )\n\n\nclass NoneMetadataError(PipError):\n \"\"\"Raised when accessing a Distribution's \"METADATA\" or \"PKG-INFO\".\n\n This signifies an inconsistency, when the Distribution claims to have\n the metadata file (if not, raise ``FileNotFoundError`` instead), but is\n not actually able to produce its content. This may be due to permission\n errors.\n \"\"\"\n\n def __init__(\n self,\n dist: \"BaseDistribution\",\n metadata_name: str,\n ) -> None:\n \"\"\"\n :param dist: A Distribution object.\n :param metadata_name: The name of the metadata being accessed\n (can be \"METADATA\" or \"PKG-INFO\").\n \"\"\"\n self.dist = dist\n self.metadata_name = metadata_name\n\n def __str__(self) -> str:\n # Use `dist` in the error message because its stringification\n # includes more information, like the version and location.\n return \"None {} metadata found for distribution: {}\".format(\n self.metadata_name,\n self.dist,\n )\n\n\nclass UserInstallationInvalid(InstallationError):\n \"\"\"A --user install is requested on an environment without user site.\"\"\"\n\n def __str__(self) -> str:\n return \"User base directory is not specified\"\n\n\nclass InvalidSchemeCombination(InstallationError):\n def __str__(self) -> str:\n before = \", \".join(str(a) for a in self.args[:-1])\n return f\"Cannot set {before} and {self.args[-1]} together\"\n\n\nclass DistributionNotFound(InstallationError):\n \"\"\"Raised when a distribution cannot be found to satisfy a requirement\"\"\"\n\n\nclass RequirementsFileParseError(InstallationError):\n \"\"\"Raised when a general error occurs parsing a requirements file line.\"\"\"\n\n\nclass BestVersionAlreadyInstalled(PipError):\n \"\"\"Raised when the most up-to-date version of a package is already\n installed.\"\"\"\n\n\nclass BadCommand(PipError):\n \"\"\"Raised when virtualenv or a command is not found\"\"\"\n\n\nclass CommandError(PipError):\n \"\"\"Raised when there is an error in command-line arguments\"\"\"\n\n\nclass PreviousBuildDirError(PipError):\n \"\"\"Raised when there's a previous conflicting build directory\"\"\"\n\n\nclass NetworkConnectionError(PipError):\n \"\"\"HTTP connection error\"\"\"\n\n def __init__(\n self,\n error_msg: str,\n response: Optional[Response] = None,\n request: Optional[Request] = None,\n ) -> None:\n \"\"\"\n Initialize NetworkConnectionError with `request` and `response`\n objects.\n \"\"\"\n self.response = response\n self.request = request\n self.error_msg = error_msg\n if (\n self.response is not None\n and not self.request\n and hasattr(response, \"request\")\n ):\n self.request = self.response.request\n super().__init__(error_msg, response, request)\n\n def __str__(self) -> str:\n return str(self.error_msg)\n\n\nclass InvalidWheelFilename(InstallationError):\n \"\"\"Invalid wheel filename.\"\"\"\n\n\nclass UnsupportedWheel(InstallationError):\n \"\"\"Unsupported wheel.\"\"\"\n\n\nclass InvalidWheel(InstallationError):\n \"\"\"Invalid (e.g. corrupt) wheel.\"\"\"\n\n def __init__(self, location: str, name: str):\n self.location = location\n self.name = name\n\n def __str__(self) -> str:\n return f\"Wheel '{self.name}' located at {self.location} is invalid.\"\n\n\nclass MetadataInconsistent(InstallationError):\n \"\"\"Built metadata contains inconsistent information.\n\n This is raised when the metadata contains values (e.g. name and version)\n that do not match the information previously obtained from sdist filename,\n user-supplied ``#egg=`` value, or an install requirement name.\n \"\"\"\n\n def __init__(\n self, ireq: \"InstallRequirement\", field: str, f_val: str, m_val: str\n ) -> None:\n self.ireq = ireq\n self.field = field\n self.f_val = f_val\n self.m_val = m_val\n\n def __str__(self) -> str:\n return (\n f\"Requested {self.ireq} has inconsistent {self.field}: \"\n f\"expected {self.f_val!r}, but metadata has {self.m_val!r}\"\n )\n\n\nclass LegacyInstallFailure(DiagnosticPipError):\n \"\"\"Error occurred while executing `setup.py install`\"\"\"\n\n reference = \"legacy-install-failure\"\n\n def __init__(self, package_details: str) -> None:\n super().__init__(\n message=\"Encountered error while trying to install package.\",\n context=package_details,\n hint_stmt=\"See above for output from the failure.\",\n note_stmt=\"This is an issue with the package mentioned above, not pip.\",\n )\n\n\nclass InstallationSubprocessError(DiagnosticPipError, InstallationError):\n \"\"\"A subprocess call failed.\"\"\"\n\n reference = \"subprocess-exited-with-error\"\n\n def __init__(\n self,\n *,\n command_description: str,\n exit_code: int,\n output_lines: Optional[List[str]],\n ) -> None:\n if output_lines is None:\n output_prompt = Text(\"See above for output.\")\n else:\n output_prompt = (\n Text.from_markup(f\"[red][{len(output_lines)} lines of output][/]\\n\")\n + Text(\"\".join(output_lines))\n + Text.from_markup(R\"[red]\\[end of output][/]\")\n )\n\n super().__init__(\n message=(\n f\"[green]{escape(command_description)}[/] did not run successfully.\\n\"\n f\"exit code: {exit_code}\"\n ),\n context=output_prompt,\n hint_stmt=None,\n note_stmt=(\n \"This error originates from a subprocess, and is likely not a \"\n \"problem with pip.\"\n ),\n )\n\n self.command_description = command_description\n self.exit_code = exit_code\n\n def __str__(self) -> str:\n return f\"{self.command_description} exited with {self.exit_code}\"\n\n\nclass MetadataGenerationFailed(InstallationSubprocessError, InstallationError):\n reference = \"metadata-generation-failed\"\n\n def __init__(\n self,\n *,\n package_details: str,\n ) -> None:\n super(InstallationSubprocessError, self).__init__(\n message=\"Encountered error while generating package metadata.\",\n context=escape(package_details),\n hint_stmt=\"See above for details.\",\n note_stmt=\"This is an issue with the package mentioned above, not pip.\",\n )\n\n def __str__(self) -> str:\n return \"metadata generation failed\"\n\n\nclass HashErrors(InstallationError):\n \"\"\"Multiple HashError instances rolled into one for reporting\"\"\"\n\n def __init__(self) -> None:\n self.errors: List[\"HashError\"] = []\n\n def append(self, error: \"HashError\") -> None:\n self.errors.append(error)\n\n def __str__(self) -> str:\n lines = []\n self.errors.sort(key=lambda e: e.order)\n for cls, errors_of_cls in groupby(self.errors, lambda e: e.__class__):\n lines.append(cls.head)\n lines.extend(e.body() for e in errors_of_cls)\n if lines:\n return \"\\n\".join(lines)\n return \"\"\n\n def __bool__(self) -> bool:\n return bool(self.errors)\n\n\nclass HashError(InstallationError):\n \"\"\"\n A failure to verify a package against known-good hashes\n\n :cvar order: An int sorting hash exception classes by difficulty of\n recovery (lower being harder), so the user doesn't bother fretting\n about unpinned packages when he has deeper issues, like VCS\n dependencies, to deal with. Also keeps error reports in a\n deterministic order.\n :cvar head: A section heading for display above potentially many\n exceptions of this kind\n :ivar req: The InstallRequirement that triggered this error. This is\n pasted on after the exception is instantiated, because it's not\n typically available earlier.\n\n \"\"\"\n\n req: Optional[\"InstallRequirement\"] = None\n head = \"\"\n order: int = -1\n\n def body(self) -> str:\n \"\"\"Return a summary of me for display under the heading.\n\n This default implementation simply prints a description of the\n triggering requirement.\n\n :param req: The InstallRequirement that provoked this error, with\n its link already populated by the resolver's _populate_link().\n\n \"\"\"\n return f\" {self._requirement_name()}\"\n\n def __str__(self) -> str:\n return f\"{self.head}\\n{self.body()}\"\n\n def _requirement_name(self) -> str:\n \"\"\"Return a description of the requirement that triggered me.\n\n This default implementation returns long description of the req, with\n line numbers\n\n \"\"\"\n return str(self.req) if self.req else \"unknown package\"\n\n\nclass VcsHashUnsupported(HashError):\n \"\"\"A hash was provided for a version-control-system-based requirement, but\n we don't have a method for hashing those.\"\"\"\n\n order = 0\n head = (\n \"Can't verify hashes for these requirements because we don't \"\n \"have a way to hash version control repositories:\"\n )\n\n\nclass DirectoryUrlHashUnsupported(HashError):\n \"\"\"A hash was provided for a version-control-system-based requirement, but\n we don't have a method for hashing those.\"\"\"\n\n order = 1\n head = (\n \"Can't verify hashes for these file:// requirements because they \"\n \"point to directories:\"\n )\n\n\nclass HashMissing(HashError):\n \"\"\"A hash was needed for a requirement but is absent.\"\"\"\n\n order = 2\n head = (\n \"Hashes are required in --require-hashes mode, but they are \"\n \"missing from some requirements. Here is a list of those \"\n \"requirements along with the hashes their downloaded archives \"\n \"actually had. Add lines like these to your requirements files to \"\n \"prevent tampering. (If you did not enable --require-hashes \"\n \"manually, note that it turns on automatically when any package \"\n \"has a hash.)\"\n )\n\n def __init__(self, gotten_hash: str) -> None:\n \"\"\"\n :param gotten_hash: The hash of the (possibly malicious) archive we\n just downloaded\n \"\"\"\n self.gotten_hash = gotten_hash\n\n def body(self) -> str:\n # Dodge circular import.\n from pip._internal.utils.hashes import FAVORITE_HASH\n\n package = None\n if self.req:\n # In the case of URL-based requirements, display the original URL\n # seen in the requirements file rather than the package name,\n # so the output can be directly copied into the requirements file.\n package = (\n self.req.original_link\n if self.req.original_link\n # In case someone feeds something downright stupid\n # to InstallRequirement's constructor.\n else getattr(self.req, \"req\", None)\n )\n return \" {} --hash={}:{}\".format(\n package or \"unknown package\", FAVORITE_HASH, self.gotten_hash\n )\n\n\nclass HashUnpinned(HashError):\n \"\"\"A requirement had a hash specified but was not pinned to a specific\n version.\"\"\"\n\n order = 3\n head = (\n \"In --require-hashes mode, all requirements must have their \"\n \"versions pinned with ==. These do not:\"\n )\n\n\nclass HashMismatch(HashError):\n \"\"\"\n Distribution file hash values don't match.\n\n :ivar package_name: The name of the package that triggered the hash\n mismatch. Feel free to write to this after the exception is raise to\n improve its error message.\n\n \"\"\"\n\n order = 4\n head = (\n \"THESE PACKAGES DO NOT MATCH THE HASHES FROM THE REQUIREMENTS \"\n \"FILE. If you have updated the package versions, please update \"\n \"the hashes. Otherwise, examine the package contents carefully; \"\n \"someone may have tampered with them.\"\n )\n\n def __init__(self, allowed: Dict[str, List[str]], gots: Dict[str, \"_Hash\"]) -> None:\n \"\"\"\n :param allowed: A dict of algorithm names pointing to lists of allowed\n hex digests\n :param gots: A dict of algorithm names pointing to hashes we\n actually got from the files under suspicion\n \"\"\"\n self.allowed = allowed\n self.gots = gots\n\n def body(self) -> str:\n return \" {}:\\n{}\".format(self._requirement_name(), self._hash_comparison())\n\n def _hash_comparison(self) -> str:\n \"\"\"\n Return a comparison of actual and expected hash values.\n\n Example::\n\n Expected sha256 abcdeabcdeabcdeabcdeabcdeabcdeabcdeabcdeabcde\n or 123451234512345123451234512345123451234512345\n Got bcdefbcdefbcdefbcdefbcdefbcdefbcdefbcdefbcdef\n\n \"\"\"\n\n def hash_then_or(hash_name: str) -> \"chain[str]\":\n # For now, all the decent hashes have 6-char names, so we can get\n # away with hard-coding space literals.\n return chain([hash_name], repeat(\" or\"))\n\n lines: List[str] = []\n for hash_name, expecteds in self.allowed.items():\n prefix = hash_then_or(hash_name)\n lines.extend(\n (\" Expected {} {}\".format(next(prefix), e)) for e in expecteds\n )\n lines.append(\n \" Got {}\\n\".format(self.gots[hash_name].hexdigest())\n )\n return \"\\n\".join(lines)\n\n\nclass UnsupportedPythonVersion(InstallationError):\n \"\"\"Unsupported python version according to Requires-Python package\n metadata.\"\"\"\n\n\nclass ConfigurationFileCouldNotBeLoaded(ConfigurationError):\n \"\"\"When there are errors while loading a configuration file\"\"\"\n\n def __init__(\n self,\n reason: str = \"could not be loaded\",\n fname: Optional[str] = None,\n error: Optional[configparser.Error] = None,\n ) -> None:\n super().__init__(error)\n self.reason = reason\n self.fname = fname\n self.error = error\n\n def __str__(self) -> str:\n if self.fname is not None:\n message_part = f\" in {self.fname}.\"\n else:\n assert self.error is not None\n message_part = f\".\\n{self.error}\\n\"\n return f\"Configuration file {self.reason}{message_part}\"\n"
},
{
"path": "lib/python3.7/site-packages/pip/_internal/index/__init__.py",
"content": "\"\"\"Index interaction code\n\"\"\"\n"
},
{
"path": "lib/python3.7/site-packages/pip/_internal/index/collector.py",
"content": "\"\"\"\nThe main purpose of this module is to expose LinkCollector.collect_sources().\n\"\"\"\n\nimport collections\nimport email.message\nimport functools\nimport itertools\nimport json\nimport logging\nimport os\nimport urllib.parse\nimport urllib.request\nfrom html.parser import HTMLParser\nfrom optparse import Values\nfrom typing import (\n TYPE_CHECKING,\n Callable,\n Dict,\n Iterable,\n List,\n MutableMapping,\n NamedTuple,\n Optional,\n Sequence,\n Tuple,\n Union,\n)\n\nfrom pip._vendor import requests\nfrom pip._vendor.requests import Response\nfrom pip._vendor.requests.exceptions import RetryError, SSLError\n\nfrom pip._internal.exceptions import NetworkConnectionError\nfrom pip._internal.models.link import Link\nfrom pip._internal.models.search_scope import SearchScope\nfrom pip._internal.network.session import PipSession\nfrom pip._internal.network.utils import raise_for_status\nfrom pip._internal.utils.filetypes import is_archive_file\nfrom pip._internal.utils.misc import redact_auth_from_url\nfrom pip._internal.vcs import vcs\n\nfrom .sources import CandidatesFromPage, LinkSource, build_source\n\nif TYPE_CHECKING:\n from typing import Protocol\nelse:\n Protocol = object\n\nlogger = logging.getLogger(__name__)\n\nResponseHeaders = MutableMapping[str, str]\n\n\ndef _match_vcs_scheme(url: str) -> Optional[str]:\n \"\"\"Look for VCS schemes in the URL.\n\n Returns the matched VCS scheme, or None if there's no match.\n \"\"\"\n for scheme in vcs.schemes:\n if url.lower().startswith(scheme) and url[len(scheme)] in \"+:\":\n return scheme\n return None\n\n\nclass _NotAPIContent(Exception):\n def __init__(self, content_type: str, request_desc: str) -> None:\n super().__init__(content_type, request_desc)\n self.content_type = content_type\n self.request_desc = request_desc\n\n\ndef _ensure_api_header(response: Response) -> None:\n \"\"\"\n Check the Content-Type header to ensure the response contains a Simple\n API Response.\n\n Raises `_NotAPIContent` if the content type is not a valid content-type.\n \"\"\"\n content_type = response.headers.get(\"Content-Type\", \"Unknown\")\n\n content_type_l = content_type.lower()\n if content_type_l.startswith(\n (\n \"text/html\",\n \"application/vnd.pypi.simple.v1+html\",\n \"application/vnd.pypi.simple.v1+json\",\n )\n ):\n return\n\n raise _NotAPIContent(content_type, response.request.method)\n\n\nclass _NotHTTP(Exception):\n pass\n\n\ndef _ensure_api_response(url: str, session: PipSession) -> None:\n \"\"\"\n Send a HEAD request to the URL, and ensure the response contains a simple\n API Response.\n\n Raises `_NotHTTP` if the URL is not available for a HEAD request, or\n `_NotAPIContent` if the content type is not a valid content type.\n \"\"\"\n scheme, netloc, path, query, fragment = urllib.parse.urlsplit(url)\n if scheme not in {\"http\", \"https\"}:\n raise _NotHTTP()\n\n resp = session.head(url, allow_redirects=True)\n raise_for_status(resp)\n\n _ensure_api_header(resp)\n\n\ndef _get_simple_response(url: str, session: PipSession) -> Response:\n \"\"\"Access an Simple API response with GET, and return the response.\n\n This consists of three parts:\n\n 1. If the URL looks suspiciously like an archive, send a HEAD first to\n check the Content-Type is HTML or Simple API, to avoid downloading a\n large file. Raise `_NotHTTP` if the content type cannot be determined, or\n `_NotAPIContent` if it is not HTML or a Simple API.\n 2. Actually perform the request. Raise HTTP exceptions on network failures.\n 3. Check the Content-Type header to make sure we got a Simple API response,\n and raise `_NotAPIContent` otherwise.\n \"\"\"\n if is_archive_file(Link(url).filename):\n _ensure_api_response(url, session=session)\n\n logger.debug(\"Getting page %s\", redact_auth_from_url(url))\n\n resp = session.get(\n url,\n headers={\n \"Accept\": \", \".join(\n [\n \"application/vnd.pypi.simple.v1+json\",\n \"application/vnd.pypi.simple.v1+html; q=0.1\",\n \"text/html; q=0.01\",\n ]\n ),\n # We don't want to blindly returned cached data for\n # /simple/, because authors generally expecting that\n # twine upload && pip install will function, but if\n # they've done a pip install in the last ~10 minutes\n # it won't. Thus by setting this to zero we will not\n # blindly use any cached data, however the benefit of\n # using max-age=0 instead of no-cache, is that we will\n # still support conditional requests, so we will still\n # minimize traffic sent in cases where the page hasn't\n # changed at all, we will just always incur the round\n # trip for the conditional GET now instead of only\n # once per 10 minutes.\n # For more information, please see pypa/pip#5670.\n \"Cache-Control\": \"max-age=0\",\n },\n )\n raise_for_status(resp)\n\n # The check for archives above only works if the url ends with\n # something that looks like an archive. However that is not a\n # requirement of an url. Unless we issue a HEAD request on every\n # url we cannot know ahead of time for sure if something is a\n # Simple API response or not. However we can check after we've\n # downloaded it.\n _ensure_api_header(resp)\n\n logger.debug(\n \"Fetched page %s as %s\",\n redact_auth_from_url(url),\n resp.headers.get(\"Content-Type\", \"Unknown\"),\n )\n\n return resp\n\n\ndef _get_encoding_from_headers(headers: ResponseHeaders) -> Optional[str]:\n \"\"\"Determine if we have any encoding information in our headers.\"\"\"\n if headers and \"Content-Type\" in headers:\n m = email.message.Message()\n m[\"content-type\"] = headers[\"Content-Type\"]\n charset = m.get_param(\"charset\")\n if charset:\n return str(charset)\n return None\n\n\nclass CacheablePageContent:\n def __init__(self, page: \"IndexContent\") -> None:\n assert page.cache_link_parsing\n self.page = page\n\n def __eq__(self, other: object) -> bool:\n return isinstance(other, type(self)) and self.page.url == other.page.url\n\n def __hash__(self) -> int:\n return hash(self.page.url)\n\n\nclass ParseLinks(Protocol):\n def __call__(self, page: \"IndexContent\") -> Iterable[Link]:\n ...\n\n\ndef with_cached_index_content(fn: ParseLinks) -> ParseLinks:\n \"\"\"\n Given a function that parses an Iterable[Link] from an IndexContent, cache the\n function's result (keyed by CacheablePageContent), unless the IndexContent\n `page` has `page.cache_link_parsing == False`.\n \"\"\"\n\n @functools.lru_cache(maxsize=None)\n def wrapper(cacheable_page: CacheablePageContent) -> List[Link]:\n return list(fn(cacheable_page.page))\n\n @functools.wraps(fn)\n def wrapper_wrapper(page: \"IndexContent\") -> List[Link]:\n if page.cache_link_parsing:\n return wrapper(CacheablePageContent(page))\n return list(fn(page))\n\n return wrapper_wrapper\n\n\n@with_cached_index_content\ndef parse_links(page: \"IndexContent\") -> Iterable[Link]:\n \"\"\"\n Parse a Simple API's Index Content, and yield its anchor elements as Link objects.\n \"\"\"\n\n content_type_l = page.content_type.lower()\n if content_type_l.startswith(\"application/vnd.pypi.simple.v1+json\"):\n data = json.loads(page.content)\n for file in data.get(\"files\", []):\n link = Link.from_json(file, page.url)\n if link is None:\n continue\n yield link\n return\n\n parser = HTMLLinkParser(page.url)\n encoding = page.encoding or \"utf-8\"\n parser.feed(page.content.decode(encoding))\n\n url = page.url\n base_url = parser.base_url or url\n for anchor in parser.anchors:\n link = Link.from_element(anchor, page_url=url, base_url=base_url)\n if link is None:\n continue\n yield link\n\n\nclass IndexContent:\n \"\"\"Represents one response (or page), along with its URL\"\"\"\n\n def __init__(\n self,\n content: bytes,\n content_type: str,\n encoding: Optional[str],\n url: str,\n cache_link_parsing: bool = True,\n ) -> None:\n \"\"\"\n :param encoding: the encoding to decode the given content.\n :param url: the URL from which the HTML was downloaded.\n :param cache_link_parsing: whether links parsed from this page's url\n should be cached. PyPI index urls should\n have this set to False, for example.\n \"\"\"\n self.content = content\n self.content_type = content_type\n self.encoding = encoding\n self.url = url\n self.cache_link_parsing = cache_link_parsing\n\n def __str__(self) -> str:\n return redact_auth_from_url(self.url)\n\n\nclass HTMLLinkParser(HTMLParser):\n \"\"\"\n HTMLParser that keeps the first base HREF and a list of all anchor\n elements' attributes.\n \"\"\"\n\n def __init__(self, url: str) -> None:\n super().__init__(convert_charrefs=True)\n\n self.url: str = url\n self.base_url: Optional[str] = None\n self.anchors: List[Dict[str, Optional[str]]] = []\n\n def handle_starttag(self, tag: str, attrs: List[Tuple[str, Optional[str]]]) -> None:\n if tag == \"base\" and self.base_url is None:\n href = self.get_href(attrs)\n if href is not None:\n self.base_url = href\n elif tag == \"a\":\n self.anchors.append(dict(attrs))\n\n def get_href(self, attrs: List[Tuple[str, Optional[str]]]) -> Optional[str]:\n for name, value in attrs:\n if name == \"href\":\n return value\n return None\n\n\ndef _handle_get_simple_fail(\n link: Link,\n reason: Union[str, Exception],\n meth: Optional[Callable[..., None]] = None,\n) -> None:\n if meth is None:\n meth = logger.debug\n meth(\"Could not fetch URL %s: %s - skipping\", link, reason)\n\n\ndef _make_index_content(\n response: Response, cache_link_parsing: bool = True\n) -> IndexContent:\n encoding = _get_encoding_from_headers(response.headers)\n return IndexContent(\n response.content,\n response.headers[\"Content-Type\"],\n encoding=encoding,\n url=response.url,\n cache_link_parsing=cache_link_parsing,\n )\n\n\ndef _get_index_content(link: Link, *, session: PipSession) -> Optional[\"IndexContent\"]:\n url = link.url.split(\"#\", 1)[0]\n\n # Check for VCS schemes that do not support lookup as web pages.\n vcs_scheme = _match_vcs_scheme(url)\n if vcs_scheme:\n logger.warning(\n \"Cannot look at %s URL %s because it does not support lookup as web pages.\",\n vcs_scheme,\n link,\n )\n return None\n\n # Tack index.html onto file:// URLs that point to directories\n scheme, _, path, _, _, _ = urllib.parse.urlparse(url)\n if scheme == \"file\" and os.path.isdir(urllib.request.url2pathname(path)):\n # add trailing slash if not present so urljoin doesn't trim\n # final segment\n if not url.endswith(\"/\"):\n url += \"/\"\n # TODO: In the future, it would be nice if pip supported PEP 691\n # style respones in the file:// URLs, however there's no\n # standard file extension for application/vnd.pypi.simple.v1+json\n # so we'll need to come up with something on our own.\n url = urllib.parse.urljoin(url, \"index.html\")\n logger.debug(\" file: URL is directory, getting %s\", url)\n\n try:\n resp = _get_simple_response(url, session=session)\n except _NotHTTP:\n logger.warning(\n \"Skipping page %s because it looks like an archive, and cannot \"\n \"be checked by a HTTP HEAD request.\",\n link,\n )\n except _NotAPIContent as exc:\n logger.warning(\n \"Skipping page %s because the %s request got Content-Type: %s. \"\n \"The only supported Content-Types are application/vnd.pypi.simple.v1+json, \"\n \"application/vnd.pypi.simple.v1+html, and text/html\",\n link,\n exc.request_desc,\n exc.content_type,\n )\n except NetworkConnectionError as exc:\n _handle_get_simple_fail(link, exc)\n except RetryError as exc:\n _handle_get_simple_fail(link, exc)\n except SSLError as exc:\n reason = \"There was a problem confirming the ssl certificate: \"\n reason += str(exc)\n _handle_get_simple_fail(link, reason, meth=logger.info)\n except requests.ConnectionError as exc:\n _handle_get_simple_fail(link, f\"connection error: {exc}\")\n except requests.Timeout:\n _handle_get_simple_fail(link, \"timed out\")\n else:\n return _make_index_content(resp, cache_link_parsing=link.cache_link_parsing)\n return None\n\n\nclass CollectedSources(NamedTuple):\n find_links: Sequence[Optional[LinkSource]]\n index_urls: Sequence[Optional[LinkSource]]\n\n\nclass LinkCollector:\n\n \"\"\"\n Responsible for collecting Link objects from all configured locations,\n making network requests as needed.\n\n The class's main method is its collect_sources() method.\n \"\"\"\n\n def __init__(\n self,\n session: PipSession,\n search_scope: SearchScope,\n ) -> None:\n self.search_scope = search_scope\n self.session = session\n\n @classmethod\n def create(\n cls,\n session: PipSession,\n options: Values,\n suppress_no_index: bool = False,\n ) -> \"LinkCollector\":\n \"\"\"\n :param session: The Session to use to make requests.\n :param suppress_no_index: Whether to ignore the --no-index option\n when constructing the SearchScope object.\n \"\"\"\n index_urls = [options.index_url] + options.extra_index_urls\n if options.no_index and not suppress_no_index:\n logger.debug(\n \"Ignoring indexes: %s\",\n \",\".join(redact_auth_from_url(url) for url in index_urls),\n )\n index_urls = []\n\n # Make sure find_links is a list before passing to create().\n find_links = options.find_links or []\n\n search_scope = SearchScope.create(\n find_links=find_links,\n index_urls=index_urls,\n no_index=options.no_index,\n )\n link_collector = LinkCollector(\n session=session,\n search_scope=search_scope,\n )\n return link_collector\n\n @property\n def find_links(self) -> List[str]:\n return self.search_scope.find_links\n\n def fetch_response(self, location: Link) -> Optional[IndexContent]:\n \"\"\"\n Fetch an HTML page containing package links.\n \"\"\"\n return _get_index_content(location, session=self.session)\n\n def collect_sources(\n self,\n project_name: str,\n candidates_from_page: CandidatesFromPage,\n ) -> CollectedSources:\n # The OrderedDict calls deduplicate sources by URL.\n index_url_sources = collections.OrderedDict(\n build_source(\n loc,\n candidates_from_page=candidates_from_page,\n page_validator=self.session.is_secure_origin,\n expand_dir=False,\n cache_link_parsing=False,\n )\n for loc in self.search_scope.get_index_urls_locations(project_name)\n ).values()\n find_links_sources = collections.OrderedDict(\n build_source(\n loc,\n candidates_from_page=candidates_from_page,\n page_validator=self.session.is_secure_origin,\n expand_dir=True,\n cache_link_parsing=True,\n )\n for loc in self.find_links\n ).values()\n\n if logger.isEnabledFor(logging.DEBUG):\n lines = [\n f\"* {s.link}\"\n for s in itertools.chain(find_links_sources, index_url_sources)\n if s is not None and s.link is not None\n ]\n lines = [\n f\"{len(lines)} location(s) to search \"\n f\"for versions of {project_name}:\"\n ] + lines\n logger.debug(\"\\n\".join(lines))\n\n return CollectedSources(\n find_links=list(find_links_sources),\n index_urls=list(index_url_sources),\n )\n"
},
{
"path": "lib/python3.7/site-packages/pip/_internal/index/package_finder.py",
"content": "\"\"\"Routines related to PyPI, indexes\"\"\"\n\n# The following comment should be removed at some point in the future.\n# mypy: strict-optional=False\n\nimport enum\nimport functools\nimport itertools\nimport logging\nimport re\nfrom typing import FrozenSet, Iterable, List, Optional, Set, Tuple, Union\n\nfrom pip._vendor.packaging import specifiers\nfrom pip._vendor.packaging.tags import Tag\nfrom pip._vendor.packaging.utils import canonicalize_name\nfrom pip._vendor.packaging.version import _BaseVersion\nfrom pip._vendor.packaging.version import parse as parse_version\n\nfrom pip._internal.exceptions import (\n BestVersionAlreadyInstalled,\n DistributionNotFound,\n InvalidWheelFilename,\n UnsupportedWheel,\n)\nfrom pip._internal.index.collector import LinkCollector, parse_links\nfrom pip._internal.models.candidate import InstallationCandidate\nfrom pip._internal.models.format_control import FormatControl\nfrom pip._internal.models.link import Link\nfrom pip._internal.models.search_scope import SearchScope\nfrom pip._internal.models.selection_prefs import SelectionPreferences\nfrom pip._internal.models.target_python import TargetPython\nfrom pip._internal.models.wheel import Wheel\nfrom pip._internal.req import InstallRequirement\nfrom pip._internal.utils._log import getLogger\nfrom pip._internal.utils.filetypes import WHEEL_EXTENSION\nfrom pip._internal.utils.hashes import Hashes\nfrom pip._internal.utils.logging import indent_log\nfrom pip._internal.utils.misc import build_netloc\nfrom pip._internal.utils.packaging import check_requires_python\nfrom pip._internal.utils.unpacking import SUPPORTED_EXTENSIONS\n\n__all__ = [\"FormatControl\", \"BestCandidateResult\", \"PackageFinder\"]\n\n\nlogger = getLogger(__name__)\n\nBuildTag = Union[Tuple[()], Tuple[int, str]]\nCandidateSortingKey = Tuple[int, int, int, _BaseVersion, Optional[int], BuildTag]\n\n\ndef _check_link_requires_python(\n link: Link,\n version_info: Tuple[int, int, int],\n ignore_requires_python: bool = False,\n) -> bool:\n \"\"\"\n Return whether the given Python version is compatible with a link's\n \"Requires-Python\" value.\n\n :param version_info: A 3-tuple of ints representing the Python\n major-minor-micro version to check.\n :param ignore_requires_python: Whether to ignore the \"Requires-Python\"\n value if the given Python version isn't compatible.\n \"\"\"\n try:\n is_compatible = check_requires_python(\n link.requires_python,\n version_info=version_info,\n )\n except specifiers.InvalidSpecifier:\n logger.debug(\n \"Ignoring invalid Requires-Python (%r) for link: %s\",\n link.requires_python,\n link,\n )\n else:\n if not is_compatible:\n version = \".\".join(map(str, version_info))\n if not ignore_requires_python:\n logger.verbose(\n \"Link requires a different Python (%s not in: %r): %s\",\n version,\n link.requires_python,\n link,\n )\n return False\n\n logger.debug(\n \"Ignoring failed Requires-Python check (%s not in: %r) for link: %s\",\n version,\n link.requires_python,\n link,\n )\n\n return True\n\n\nclass LinkType(enum.Enum):\n candidate = enum.auto()\n different_project = enum.auto()\n yanked = enum.auto()\n format_unsupported = enum.auto()\n format_invalid = enum.auto()\n platform_mismatch = enum.auto()\n requires_python_mismatch = enum.auto()\n\n\nclass LinkEvaluator:\n\n \"\"\"\n Responsible for evaluating links for a particular project.\n \"\"\"\n\n _py_version_re = re.compile(r\"-py([123]\\.?[0-9]?)$\")\n\n # Don't include an allow_yanked default value to make sure each call\n # site considers whether yanked releases are allowed. This also causes\n # that decision to be made explicit in the calling code, which helps\n # people when reading the code.\n def __init__(\n self,\n project_name: str,\n canonical_name: str,\n formats: FrozenSet[str],\n target_python: TargetPython,\n allow_yanked: bool,\n ignore_requires_python: Optional[bool] = None,\n ) -> None:\n \"\"\"\n :param project_name: The user supplied package name.\n :param canonical_name: The canonical package name.\n :param formats: The formats allowed for this package. Should be a set\n with 'binary' or 'source' or both in it.\n :param target_python: The target Python interpreter to use when\n evaluating link compatibility. This is used, for example, to\n check wheel compatibility, as well as when checking the Python\n version, e.g. the Python version embedded in a link filename\n (or egg fragment) and against an HTML link's optional PEP 503\n \"data-requires-python\" attribute.\n :param allow_yanked: Whether files marked as yanked (in the sense\n of PEP 592) are permitted to be candidates for install.\n :param ignore_requires_python: Whether to ignore incompatible\n PEP 503 \"data-requires-python\" values in HTML links. Defaults\n to False.\n \"\"\"\n if ignore_requires_python is None:\n ignore_requires_python = False\n\n self._allow_yanked = allow_yanked\n self._canonical_name = canonical_name\n self._ignore_requires_python = ignore_requires_python\n self._formats = formats\n self._target_python = target_python\n\n self.project_name = project_name\n\n def evaluate_link(self, link: Link) -> Tuple[LinkType, str]:\n \"\"\"\n Determine whether a link is a candidate for installation.\n\n :return: A tuple (result, detail), where *result* is an enum\n representing whether the evaluation found a candidate, or the reason\n why one is not found. If a candidate is found, *detail* will be the\n candidate's version string; if one is not found, it contains the\n reason the link fails to qualify.\n \"\"\"\n version = None\n if link.is_yanked and not self._allow_yanked:\n reason = link.yanked_reason or \"\"\n return (LinkType.yanked, f\"yanked for reason: {reason}\")\n\n if link.egg_fragment:\n egg_info = link.egg_fragment\n ext = link.ext\n else:\n egg_info, ext = link.splitext()\n if not ext:\n return (LinkType.format_unsupported, \"not a file\")\n if ext not in SUPPORTED_EXTENSIONS:\n return (\n LinkType.format_unsupported,\n f\"unsupported archive format: {ext}\",\n )\n if \"binary\" not in self._formats and ext == WHEEL_EXTENSION:\n reason = f\"No binaries permitted for {self.project_name}\"\n return (LinkType.format_unsupported, reason)\n if \"macosx10\" in link.path and ext == \".zip\":\n return (LinkType.format_unsupported, \"macosx10 one\")\n if ext == WHEEL_EXTENSION:\n try:\n wheel = Wheel(link.filename)\n except InvalidWheelFilename:\n return (\n LinkType.format_invalid,\n \"invalid wheel filename\",\n )\n if canonicalize_name(wheel.name) != self._canonical_name:\n reason = f\"wrong project name (not {self.project_name})\"\n return (LinkType.different_project, reason)\n\n supported_tags = self._target_python.get_tags()\n if not wheel.supported(supported_tags):\n # Include the wheel's tags in the reason string to\n # simplify troubleshooting compatibility issues.\n file_tags = \", \".join(wheel.get_formatted_file_tags())\n reason = (\n f\"none of the wheel's tags ({file_tags}) are compatible \"\n f\"(run pip debug --verbose to show compatible tags)\"\n )\n return (LinkType.platform_mismatch, reason)\n\n version = wheel.version\n\n # This should be up by the self.ok_binary check, but see issue 2700.\n if \"source\" not in self._formats and ext != WHEEL_EXTENSION:\n reason = f\"No sources permitted for {self.project_name}\"\n return (LinkType.format_unsupported, reason)\n\n if not version:\n version = _extract_version_from_fragment(\n egg_info,\n self._canonical_name,\n )\n if not version:\n reason = f\"Missing project version for {self.project_name}\"\n return (LinkType.format_invalid, reason)\n\n match = self._py_version_re.search(version)\n if match:\n version = version[: match.start()]\n py_version = match.group(1)\n if py_version != self._target_python.py_version:\n return (\n LinkType.platform_mismatch,\n \"Python version is incorrect\",\n )\n\n supports_python = _check_link_requires_python(\n link,\n version_info=self._target_python.py_version_info,\n ignore_requires_python=self._ignore_requires_python,\n )\n if not supports_python:\n reason = f\"{version} Requires-Python {link.requires_python}\"\n return (LinkType.requires_python_mismatch, reason)\n\n logger.debug(\"Found link %s, version: %s\", link, version)\n\n return (LinkType.candidate, version)\n\n\ndef filter_unallowed_hashes(\n candidates: List[InstallationCandidate],\n hashes: Hashes,\n project_name: str,\n) -> List[InstallationCandidate]:\n \"\"\"\n Filter out candidates whose hashes aren't allowed, and return a new\n list of candidates.\n\n If at least one candidate has an allowed hash, then all candidates with\n either an allowed hash or no hash specified are returned. Otherwise,\n the given candidates are returned.\n\n Including the candidates with no hash specified when there is a match\n allows a warning to be logged if there is a more preferred candidate\n with no hash specified. Returning all candidates in the case of no\n matches lets pip report the hash of the candidate that would otherwise\n have been installed (e.g. permitting the user to more easily update\n their requirements file with the desired hash).\n \"\"\"\n if not hashes:\n logger.debug(\n \"Given no hashes to check %s links for project %r: \"\n \"discarding no candidates\",\n len(candidates),\n project_name,\n )\n # Make sure we're not returning back the given value.\n return list(candidates)\n\n matches_or_no_digest = []\n # Collect the non-matches for logging purposes.\n non_matches = []\n match_count = 0\n for candidate in candidates:\n link = candidate.link\n if not link.has_hash:\n pass\n elif link.is_hash_allowed(hashes=hashes):\n match_count += 1\n else:\n non_matches.append(candidate)\n continue\n\n matches_or_no_digest.append(candidate)\n\n if match_count:\n filtered = matches_or_no_digest\n else:\n # Make sure we're not returning back the given value.\n filtered = list(candidates)\n\n if len(filtered) == len(candidates):\n discard_message = \"discarding no candidates\"\n else:\n discard_message = \"discarding {} non-matches:\\n {}\".format(\n len(non_matches),\n \"\\n \".join(str(candidate.link) for candidate in non_matches),\n )\n\n logger.debug(\n \"Checked %s links for project %r against %s hashes \"\n \"(%s matches, %s no digest): %s\",\n len(candidates),\n project_name,\n hashes.digest_count,\n match_count,\n len(matches_or_no_digest) - match_count,\n discard_message,\n )\n\n return filtered\n\n\nclass CandidatePreferences:\n\n \"\"\"\n Encapsulates some of the preferences for filtering and sorting\n InstallationCandidate objects.\n \"\"\"\n\n def __init__(\n self,\n prefer_binary: bool = False,\n allow_all_prereleases: bool = False,\n ) -> None:\n \"\"\"\n :param allow_all_prereleases: Whether to allow all pre-releases.\n \"\"\"\n self.allow_all_prereleases = allow_all_prereleases\n self.prefer_binary = prefer_binary\n\n\nclass BestCandidateResult:\n \"\"\"A collection of candidates, returned by `PackageFinder.find_best_candidate`.\n\n This class is only intended to be instantiated by CandidateEvaluator's\n `compute_best_candidate()` method.\n \"\"\"\n\n def __init__(\n self,\n candidates: List[InstallationCandidate],\n applicable_candidates: List[InstallationCandidate],\n best_candidate: Optional[InstallationCandidate],\n ) -> None:\n \"\"\"\n :param candidates: A sequence of all available candidates found.\n :param applicable_candidates: The applicable candidates.\n :param best_candidate: The most preferred candidate found, or None\n if no applicable candidates were found.\n \"\"\"\n assert set(applicable_candidates) <= set(candidates)\n\n if best_candidate is None:\n assert not applicable_candidates\n else:\n assert best_candidate in applicable_candidates\n\n self._applicable_candidates = applicable_candidates\n self._candidates = candidates\n\n self.best_candidate = best_candidate\n\n def iter_all(self) -> Iterable[InstallationCandidate]:\n \"\"\"Iterate through all candidates.\"\"\"\n return iter(self._candidates)\n\n def iter_applicable(self) -> Iterable[InstallationCandidate]:\n \"\"\"Iterate through the applicable candidates.\"\"\"\n return iter(self._applicable_candidates)\n\n\nclass CandidateEvaluator:\n\n \"\"\"\n Responsible for filtering and sorting candidates for installation based\n on what tags are valid.\n \"\"\"\n\n @classmethod\n def create(\n cls,\n project_name: str,\n target_python: Optional[TargetPython] = None,\n prefer_binary: bool = False,\n allow_all_prereleases: bool = False,\n specifier: Optional[specifiers.BaseSpecifier] = None,\n hashes: Optional[Hashes] = None,\n ) -> \"CandidateEvaluator\":\n \"\"\"Create a CandidateEvaluator object.\n\n :param target_python: The target Python interpreter to use when\n checking compatibility. If None (the default), a TargetPython\n object will be constructed from the running Python.\n :param specifier: An optional object implementing `filter`\n (e.g. `packaging.specifiers.SpecifierSet`) to filter applicable\n versions.\n :param hashes: An optional collection of allowed hashes.\n \"\"\"\n if target_python is None:\n target_python = TargetPython()\n if specifier is None:\n specifier = specifiers.SpecifierSet()\n\n supported_tags = target_python.get_tags()\n\n return cls(\n project_name=project_name,\n supported_tags=supported_tags,\n specifier=specifier,\n prefer_binary=prefer_binary,\n allow_all_prereleases=allow_all_prereleases,\n hashes=hashes,\n )\n\n def __init__(\n self,\n project_name: str,\n supported_tags: List[Tag],\n specifier: specifiers.BaseSpecifier,\n prefer_binary: bool = False,\n allow_all_prereleases: bool = False,\n hashes: Optional[Hashes] = None,\n ) -> None:\n \"\"\"\n :param supported_tags: The PEP 425 tags supported by the target\n Python in order of preference (most preferred first).\n \"\"\"\n self._allow_all_prereleases = allow_all_prereleases\n self._hashes = hashes\n self._prefer_binary = prefer_binary\n self._project_name = project_name\n self._specifier = specifier\n self._supported_tags = supported_tags\n # Since the index of the tag in the _supported_tags list is used\n # as a priority, precompute a map from tag to index/priority to be\n # used in wheel.find_most_preferred_tag.\n self._wheel_tag_preferences = {\n tag: idx for idx, tag in enumerate(supported_tags)\n }\n\n def get_applicable_candidates(\n self,\n candidates: List[InstallationCandidate],\n ) -> List[InstallationCandidate]:\n \"\"\"\n Return the applicable candidates from a list of candidates.\n \"\"\"\n # Using None infers from the specifier instead.\n allow_prereleases = self._allow_all_prereleases or None\n specifier = self._specifier\n versions = {\n str(v)\n for v in specifier.filter(\n # We turn the version object into a str here because otherwise\n # when we're debundled but setuptools isn't, Python will see\n # packaging.version.Version and\n # pkg_resources._vendor.packaging.version.Version as different\n # types. This way we'll use a str as a common data interchange\n # format. If we stop using the pkg_resources provided specifier\n # and start using our own, we can drop the cast to str().\n (str(c.version) for c in candidates),\n prereleases=allow_prereleases,\n )\n }\n\n # Again, converting version to str to deal with debundling.\n applicable_candidates = [c for c in candidates if str(c.version) in versions]\n\n filtered_applicable_candidates = filter_unallowed_hashes(\n candidates=applicable_candidates,\n hashes=self._hashes,\n project_name=self._project_name,\n )\n\n return sorted(filtered_applicable_candidates, key=self._sort_key)\n\n def _sort_key(self, candidate: InstallationCandidate) -> CandidateSortingKey:\n \"\"\"\n Function to pass as the `key` argument to a call to sorted() to sort\n InstallationCandidates by preference.\n\n Returns a tuple such that tuples sorting as greater using Python's\n default comparison operator are more preferred.\n\n The preference is as follows:\n\n First and foremost, candidates with allowed (matching) hashes are\n always preferred over candidates without matching hashes. This is\n because e.g. if the only candidate with an allowed hash is yanked,\n we still want to use that candidate.\n\n Second, excepting hash considerations, candidates that have been\n yanked (in the sense of PEP 592) are always less preferred than\n candidates that haven't been yanked. Then:\n\n If not finding wheels, they are sorted by version only.\n If finding wheels, then the sort order is by version, then:\n 1. existing installs\n 2. wheels ordered via Wheel.support_index_min(self._supported_tags)\n 3. source archives\n If prefer_binary was set, then all wheels are sorted above sources.\n\n Note: it was considered to embed this logic into the Link\n comparison operators, but then different sdist links\n with the same version, would have to be considered equal\n \"\"\"\n valid_tags = self._supported_tags\n support_num = len(valid_tags)\n build_tag: BuildTag = ()\n binary_preference = 0\n link = candidate.link\n if link.is_wheel:\n # can raise InvalidWheelFilename\n wheel = Wheel(link.filename)\n try:\n pri = -(\n wheel.find_most_preferred_tag(\n valid_tags, self._wheel_tag_preferences\n )\n )\n except ValueError:\n raise UnsupportedWheel(\n \"{} is not a supported wheel for this platform. It \"\n \"can't be sorted.\".format(wheel.filename)\n )\n if self._prefer_binary:\n binary_preference = 1\n if wheel.build_tag is not None:\n match = re.match(r\"^(\\d+)(.*)$\", wheel.build_tag)\n build_tag_groups = match.groups()\n build_tag = (int(build_tag_groups[0]), build_tag_groups[1])\n else: # sdist\n pri = -(support_num)\n has_allowed_hash = int(link.is_hash_allowed(self._hashes))\n yank_value = -1 * int(link.is_yanked) # -1 for yanked.\n return (\n has_allowed_hash,\n yank_value,\n binary_preference,\n candidate.version,\n pri,\n build_tag,\n )\n\n def sort_best_candidate(\n self,\n candidates: List[InstallationCandidate],\n ) -> Optional[InstallationCandidate]:\n \"\"\"\n Return the best candidate per the instance's sort order, or None if\n no candidate is acceptable.\n \"\"\"\n if not candidates:\n return None\n best_candidate = max(candidates, key=self._sort_key)\n return best_candidate\n\n def compute_best_candidate(\n self,\n candidates: List[InstallationCandidate],\n ) -> BestCandidateResult:\n \"\"\"\n Compute and return a `BestCandidateResult` instance.\n \"\"\"\n applicable_candidates = self.get_applicable_candidates(candidates)\n\n best_candidate = self.sort_best_candidate(applicable_candidates)\n\n return BestCandidateResult(\n candidates,\n applicable_candidates=applicable_candidates,\n best_candidate=best_candidate,\n )\n\n\nclass PackageFinder:\n \"\"\"This finds packages.\n\n This is meant to match easy_install's technique for looking for\n packages, by reading pages and looking for appropriate links.\n \"\"\"\n\n def __init__(\n self,\n link_collector: LinkCollector,\n target_python: TargetPython,\n allow_yanked: bool,\n format_control: Optional[FormatControl] = None,\n candidate_prefs: Optional[CandidatePreferences] = None,\n ignore_requires_python: Optional[bool] = None,\n ) -> None:\n \"\"\"\n This constructor is primarily meant to be used by the create() class\n method and from tests.\n\n :param format_control: A FormatControl object, used to control\n the selection of source packages / binary packages when consulting\n the index and links.\n :param candidate_prefs: Options to use when creating a\n CandidateEvaluator object.\n \"\"\"\n if candidate_prefs is None:\n candidate_prefs = CandidatePreferences()\n\n format_control = format_control or FormatControl(set(), set())\n\n self._allow_yanked = allow_yanked\n self._candidate_prefs = candidate_prefs\n self._ignore_requires_python = ignore_requires_python\n self._link_collector = link_collector\n self._target_python = target_python\n\n self.format_control = format_control\n\n # These are boring links that have already been logged somehow.\n self._logged_links: Set[Tuple[Link, LinkType, str]] = set()\n\n # Don't include an allow_yanked default value to make sure each call\n # site considers whether yanked releases are allowed. This also causes\n # that decision to be made explicit in the calling code, which helps\n # people when reading the code.\n @classmethod\n def create(\n cls,\n link_collector: LinkCollector,\n selection_prefs: SelectionPreferences,\n target_python: Optional[TargetPython] = None,\n ) -> \"PackageFinder\":\n \"\"\"Create a PackageFinder.\n\n :param selection_prefs: The candidate selection preferences, as a\n SelectionPreferences object.\n :param target_python: The target Python interpreter to use when\n checking compatibility. If None (the default), a TargetPython\n object will be constructed from the running Python.\n \"\"\"\n if target_python is None:\n target_python = TargetPython()\n\n candidate_prefs = CandidatePreferences(\n prefer_binary=selection_prefs.prefer_binary,\n allow_all_prereleases=selection_prefs.allow_all_prereleases,\n )\n\n return cls(\n candidate_prefs=candidate_prefs,\n link_collector=link_collector,\n target_python=target_python,\n allow_yanked=selection_prefs.allow_yanked,\n format_control=selection_prefs.format_control,\n ignore_requires_python=selection_prefs.ignore_requires_python,\n )\n\n @property\n def target_python(self) -> TargetPython:\n return self._target_python\n\n @property\n def search_scope(self) -> SearchScope:\n return self._link_collector.search_scope\n\n @search_scope.setter\n def search_scope(self, search_scope: SearchScope) -> None:\n self._link_collector.search_scope = search_scope\n\n @property\n def find_links(self) -> List[str]:\n return self._link_collector.find_links\n\n @property\n def index_urls(self) -> List[str]:\n return self.search_scope.index_urls\n\n @property\n def trusted_hosts(self) -> Iterable[str]:\n for host_port in self._link_collector.session.pip_trusted_origins:\n yield build_netloc(*host_port)\n\n @property\n def allow_all_prereleases(self) -> bool:\n return self._candidate_prefs.allow_all_prereleases\n\n def set_allow_all_prereleases(self) -> None:\n self._candidate_prefs.allow_all_prereleases = True\n\n @property\n def prefer_binary(self) -> bool:\n return self._candidate_prefs.prefer_binary\n\n def set_prefer_binary(self) -> None:\n self._candidate_prefs.prefer_binary = True\n\n def requires_python_skipped_reasons(self) -> List[str]:\n reasons = {\n detail\n for _, result, detail in self._logged_links\n if result == LinkType.requires_python_mismatch\n }\n return sorted(reasons)\n\n def make_link_evaluator(self, project_name: str) -> LinkEvaluator:\n canonical_name = canonicalize_name(project_name)\n formats = self.format_control.get_allowed_formats(canonical_name)\n\n return LinkEvaluator(\n project_name=project_name,\n canonical_name=canonical_name,\n formats=formats,\n target_python=self._target_python,\n allow_yanked=self._allow_yanked,\n ignore_requires_python=self._ignore_requires_python,\n )\n\n def _sort_links(self, links: Iterable[Link]) -> List[Link]:\n \"\"\"\n Returns elements of links in order, non-egg links first, egg links\n second, while eliminating duplicates\n \"\"\"\n eggs, no_eggs = [], []\n seen: Set[Link] = set()\n for link in links:\n if link not in seen:\n seen.add(link)\n if link.egg_fragment:\n eggs.append(link)\n else:\n no_eggs.append(link)\n return no_eggs + eggs\n\n def _log_skipped_link(self, link: Link, result: LinkType, detail: str) -> None:\n entry = (link, result, detail)\n if entry not in self._logged_links:\n # Put the link at the end so the reason is more visible and because\n # the link string is usually very long.\n logger.debug(\"Skipping link: %s: %s\", detail, link)\n self._logged_links.add(entry)\n\n def get_install_candidate(\n self, link_evaluator: LinkEvaluator, link: Link\n ) -> Optional[InstallationCandidate]:\n \"\"\"\n If the link is a candidate for install, convert it to an\n InstallationCandidate and return it. Otherwise, return None.\n \"\"\"\n result, detail = link_evaluator.evaluate_link(link)\n if result != LinkType.candidate:\n self._log_skipped_link(link, result, detail)\n return None\n\n return InstallationCandidate(\n name=link_evaluator.project_name,\n link=link,\n version=detail,\n )\n\n def evaluate_links(\n self, link_evaluator: LinkEvaluator, links: Iterable[Link]\n ) -> List[InstallationCandidate]:\n \"\"\"\n Convert links that are candidates to InstallationCandidate objects.\n \"\"\"\n candidates = []\n for link in self._sort_links(links):\n candidate = self.get_install_candidate(link_evaluator, link)\n if candidate is not None:\n candidates.append(candidate)\n\n return candidates\n\n def process_project_url(\n self, project_url: Link, link_evaluator: LinkEvaluator\n ) -> List[InstallationCandidate]:\n logger.debug(\n \"Fetching project page and analyzing links: %s\",\n project_url,\n )\n index_response = self._link_collector.fetch_response(project_url)\n if index_response is None:\n return []\n\n page_links = list(parse_links(index_response))\n\n with indent_log():\n package_links = self.evaluate_links(\n link_evaluator,\n links=page_links,\n )\n\n return package_links\n\n @functools.lru_cache(maxsize=None)\n def find_all_candidates(self, project_name: str) -> List[InstallationCandidate]:\n \"\"\"Find all available InstallationCandidate for project_name\n\n This checks index_urls and find_links.\n All versions found are returned as an InstallationCandidate list.\n\n See LinkEvaluator.evaluate_link() for details on which files\n are accepted.\n \"\"\"\n link_evaluator = self.make_link_evaluator(project_name)\n\n collected_sources = self._link_collector.collect_sources(\n project_name=project_name,\n candidates_from_page=functools.partial(\n self.process_project_url,\n link_evaluator=link_evaluator,\n ),\n )\n\n page_candidates_it = itertools.chain.from_iterable(\n source.page_candidates()\n for sources in collected_sources\n for source in sources\n if source is not None\n )\n page_candidates = list(page_candidates_it)\n\n file_links_it = itertools.chain.from_iterable(\n source.file_links()\n for sources in collected_sources\n for source in sources\n if source is not None\n )\n file_candidates = self.evaluate_links(\n link_evaluator,\n sorted(file_links_it, reverse=True),\n )\n\n if logger.isEnabledFor(logging.DEBUG) and file_candidates:\n paths = []\n for candidate in file_candidates:\n assert candidate.link.url # we need to have a URL\n try:\n paths.append(candidate.link.file_path)\n except Exception:\n paths.append(candidate.link.url) # it's not a local file\n\n logger.debug(\"Local files found: %s\", \", \".join(paths))\n\n # This is an intentional priority ordering\n return file_candidates + page_candidates\n\n def make_candidate_evaluator(\n self,\n project_name: str,\n specifier: Optional[specifiers.BaseSpecifier] = None,\n hashes: Optional[Hashes] = None,\n ) -> CandidateEvaluator:\n \"\"\"Create a CandidateEvaluator object to use.\"\"\"\n candidate_prefs = self._candidate_prefs\n return CandidateEvaluator.create(\n project_name=project_name,\n target_python=self._target_python,\n prefer_binary=candidate_prefs.prefer_binary,\n allow_all_prereleases=candidate_prefs.allow_all_prereleases,\n specifier=specifier,\n hashes=hashes,\n )\n\n @functools.lru_cache(maxsize=None)\n def find_best_candidate(\n self,\n project_name: str,\n specifier: Optional[specifiers.BaseSpecifier] = None,\n hashes: Optional[Hashes] = None,\n ) -> BestCandidateResult:\n \"\"\"Find matches for the given project and specifier.\n\n :param specifier: An optional object implementing `filter`\n (e.g. `packaging.specifiers.SpecifierSet`) to filter applicable\n versions.\n\n :return: A `BestCandidateResult` instance.\n \"\"\"\n candidates = self.find_all_candidates(project_name)\n candidate_evaluator = self.make_candidate_evaluator(\n project_name=project_name,\n specifier=specifier,\n hashes=hashes,\n )\n return candidate_evaluator.compute_best_candidate(candidates)\n\n def find_requirement(\n self, req: InstallRequirement, upgrade: bool\n ) -> Optional[InstallationCandidate]:\n \"\"\"Try to find a Link matching req\n\n Expects req, an InstallRequirement and upgrade, a boolean\n Returns a InstallationCandidate if found,\n Raises DistributionNotFound or BestVersionAlreadyInstalled otherwise\n \"\"\"\n hashes = req.hashes(trust_internet=False)\n best_candidate_result = self.find_best_candidate(\n req.name,\n specifier=req.specifier,\n hashes=hashes,\n )\n best_candidate = best_candidate_result.best_candidate\n\n installed_version: Optional[_BaseVersion] = None\n if req.satisfied_by is not None:\n installed_version = req.satisfied_by.version\n\n def _format_versions(cand_iter: Iterable[InstallationCandidate]) -> str:\n # This repeated parse_version and str() conversion is needed to\n # handle different vendoring sources from pip and pkg_resources.\n # If we stop using the pkg_resources provided specifier and start\n # using our own, we can drop the cast to str().\n return (\n \", \".join(\n sorted(\n {str(c.version) for c in cand_iter},\n key=parse_version,\n )\n )\n or \"none\"\n )\n\n if installed_version is None and best_candidate is None:\n logger.critical(\n \"Could not find a version that satisfies the requirement %s \"\n \"(from versions: %s)\",\n req,\n _format_versions(best_candidate_result.iter_all()),\n )\n\n raise DistributionNotFound(\n \"No matching distribution found for {}\".format(req)\n )\n\n best_installed = False\n if installed_version and (\n best_candidate is None or best_candidate.version <= installed_version\n ):\n best_installed = True\n\n if not upgrade and installed_version is not None:\n if best_installed:\n logger.debug(\n \"Existing installed version (%s) is most up-to-date and \"\n \"satisfies requirement\",\n installed_version,\n )\n else:\n logger.debug(\n \"Existing installed version (%s) satisfies requirement \"\n \"(most up-to-date version is %s)\",\n installed_version,\n best_candidate.version,\n )\n return None\n\n if best_installed:\n # We have an existing version, and its the best version\n logger.debug(\n \"Installed version (%s) is most up-to-date (past versions: %s)\",\n installed_version,\n _format_versions(best_candidate_result.iter_applicable()),\n )\n raise BestVersionAlreadyInstalled\n\n logger.debug(\n \"Using version %s (newest of versions: %s)\",\n best_candidate.version,\n _format_versions(best_candidate_result.iter_applicable()),\n )\n return best_candidate\n\n\ndef _find_name_version_sep(fragment: str, canonical_name: str) -> int:\n \"\"\"Find the separator's index based on the package's canonical name.\n\n :param fragment: A + filename \"fragment\" (stem) or\n egg fragment.\n :param canonical_name: The package's canonical name.\n\n This function is needed since the canonicalized name does not necessarily\n have the same length as the egg info's name part. An example::\n\n >>> fragment = 'foo__bar-1.0'\n >>> canonical_name = 'foo-bar'\n >>> _find_name_version_sep(fragment, canonical_name)\n 8\n \"\"\"\n # Project name and version must be separated by one single dash. Find all\n # occurrences of dashes; if the string in front of it matches the canonical\n # name, this is the one separating the name and version parts.\n for i, c in enumerate(fragment):\n if c != \"-\":\n continue\n if canonicalize_name(fragment[:i]) == canonical_name:\n return i\n raise ValueError(f\"{fragment} does not match {canonical_name}\")\n\n\ndef _extract_version_from_fragment(fragment: str, canonical_name: str) -> Optional[str]:\n \"\"\"Parse the version string from a + filename\n \"fragment\" (stem) or egg fragment.\n\n :param fragment: The string to parse. E.g. foo-2.1\n :param canonical_name: The canonicalized name of the package this\n belongs to.\n \"\"\"\n try:\n version_start = _find_name_version_sep(fragment, canonical_name) + 1\n except ValueError:\n return None\n version = fragment[version_start:]\n if not version:\n return None\n return version\n"
},
{
"path": "lib/python3.7/site-packages/pip/_internal/index/sources.py",
"content": "import logging\nimport mimetypes\nimport os\nimport pathlib\nfrom typing import Callable, Iterable, Optional, Tuple\n\nfrom pip._internal.models.candidate import InstallationCandidate\nfrom pip._internal.models.link import Link\nfrom pip._internal.utils.urls import path_to_url, url_to_path\nfrom pip._internal.vcs import is_url\n\nlogger = logging.getLogger(__name__)\n\nFoundCandidates = Iterable[InstallationCandidate]\nFoundLinks = Iterable[Link]\nCandidatesFromPage = Callable[[Link], Iterable[InstallationCandidate]]\nPageValidator = Callable[[Link], bool]\n\n\nclass LinkSource:\n @property\n def link(self) -> Optional[Link]:\n \"\"\"Returns the underlying link, if there's one.\"\"\"\n raise NotImplementedError()\n\n def page_candidates(self) -> FoundCandidates:\n \"\"\"Candidates found by parsing an archive listing HTML file.\"\"\"\n raise NotImplementedError()\n\n def file_links(self) -> FoundLinks:\n \"\"\"Links found by specifying archives directly.\"\"\"\n raise NotImplementedError()\n\n\ndef _is_html_file(file_url: str) -> bool:\n return mimetypes.guess_type(file_url, strict=False)[0] == \"text/html\"\n\n\nclass _FlatDirectorySource(LinkSource):\n \"\"\"Link source specified by ``--find-links=``.\n\n This looks the content of the directory, and returns:\n\n * ``page_candidates``: Links listed on each HTML file in the directory.\n * ``file_candidates``: Archives in the directory.\n \"\"\"\n\n def __init__(\n self,\n candidates_from_page: CandidatesFromPage,\n path: str,\n ) -> None:\n self._candidates_from_page = candidates_from_page\n self._path = pathlib.Path(os.path.realpath(path))\n\n @property\n def link(self) -> Optional[Link]:\n return None\n\n def page_candidates(self) -> FoundCandidates:\n for path in self._path.iterdir():\n url = path_to_url(str(path))\n if not _is_html_file(url):\n continue\n yield from self._candidates_from_page(Link(url))\n\n def file_links(self) -> FoundLinks:\n for path in self._path.iterdir():\n url = path_to_url(str(path))\n if _is_html_file(url):\n continue\n yield Link(url)\n\n\nclass _LocalFileSource(LinkSource):\n \"\"\"``--find-links=`` or ``--[extra-]index-url=``.\n\n If a URL is supplied, it must be a ``file:`` URL. If a path is supplied to\n the option, it is converted to a URL first. This returns:\n\n * ``page_candidates``: Links listed on an HTML file.\n * ``file_candidates``: The non-HTML file.\n \"\"\"\n\n def __init__(\n self,\n candidates_from_page: CandidatesFromPage,\n link: Link,\n ) -> None:\n self._candidates_from_page = candidates_from_page\n self._link = link\n\n @property\n def link(self) -> Optional[Link]:\n return self._link\n\n def page_candidates(self) -> FoundCandidates:\n if not _is_html_file(self._link.url):\n return\n yield from self._candidates_from_page(self._link)\n\n def file_links(self) -> FoundLinks:\n if _is_html_file(self._link.url):\n return\n yield self._link\n\n\nclass _RemoteFileSource(LinkSource):\n \"\"\"``--find-links=`` or ``--[extra-]index-url=``.\n\n This returns:\n\n * ``page_candidates``: Links listed on an HTML file.\n * ``file_candidates``: The non-HTML file.\n \"\"\"\n\n def __init__(\n self,\n candidates_from_page: CandidatesFromPage,\n page_validator: PageValidator,\n link: Link,\n ) -> None:\n self._candidates_from_page = candidates_from_page\n self._page_validator = page_validator\n self._link = link\n\n @property\n def link(self) -> Optional[Link]:\n return self._link\n\n def page_candidates(self) -> FoundCandidates:\n if not self._page_validator(self._link):\n return\n yield from self._candidates_from_page(self._link)\n\n def file_links(self) -> FoundLinks:\n yield self._link\n\n\nclass _IndexDirectorySource(LinkSource):\n \"\"\"``--[extra-]index-url=``.\n\n This is treated like a remote URL; ``candidates_from_page`` contains logic\n for this by appending ``index.html`` to the link.\n \"\"\"\n\n def __init__(\n self,\n candidates_from_page: CandidatesFromPage,\n link: Link,\n ) -> None:\n self._candidates_from_page = candidates_from_page\n self._link = link\n\n @property\n def link(self) -> Optional[Link]:\n return self._link\n\n def page_candidates(self) -> FoundCandidates:\n yield from self._candidates_from_page(self._link)\n\n def file_links(self) -> FoundLinks:\n return ()\n\n\ndef build_source(\n location: str,\n *,\n candidates_from_page: CandidatesFromPage,\n page_validator: PageValidator,\n expand_dir: bool,\n cache_link_parsing: bool,\n) -> Tuple[Optional[str], Optional[LinkSource]]:\n\n path: Optional[str] = None\n url: Optional[str] = None\n if os.path.exists(location): # Is a local path.\n url = path_to_url(location)\n path = location\n elif location.startswith(\"file:\"): # A file: URL.\n url = location\n path = url_to_path(location)\n elif is_url(location):\n url = location\n\n if url is None:\n msg = (\n \"Location '%s' is ignored: \"\n \"it is either a non-existing path or lacks a specific scheme.\"\n )\n logger.warning(msg, location)\n return (None, None)\n\n if path is None:\n source: LinkSource = _RemoteFileSource(\n candidates_from_page=candidates_from_page,\n page_validator=page_validator,\n link=Link(url, cache_link_parsing=cache_link_parsing),\n )\n return (url, source)\n\n if os.path.isdir(path):\n if expand_dir:\n source = _FlatDirectorySource(\n candidates_from_page=candidates_from_page,\n path=path,\n )\n else:\n source = _IndexDirectorySource(\n candidates_from_page=candidates_from_page,\n link=Link(url, cache_link_parsing=cache_link_parsing),\n )\n return (url, source)\n elif os.path.isfile(path):\n source = _LocalFileSource(\n candidates_from_page=candidates_from_page,\n link=Link(url, cache_link_parsing=cache_link_parsing),\n )\n return (url, source)\n logger.warning(\n \"Location '%s' is ignored: it is neither a file nor a directory.\",\n location,\n )\n return (url, None)\n"
},
{
"path": "lib/python3.7/site-packages/pip/_internal/locations/__init__.py",
"content": "import functools\nimport logging\nimport os\nimport pathlib\nimport sys\nimport sysconfig\nfrom typing import Any, Dict, Generator, List, Optional, Tuple\n\nfrom pip._internal.models.scheme import SCHEME_KEYS, Scheme\nfrom pip._internal.utils.compat import WINDOWS\nfrom pip._internal.utils.deprecation import deprecated\nfrom pip._internal.utils.virtualenv import running_under_virtualenv\n\nfrom . import _sysconfig\nfrom .base import (\n USER_CACHE_DIR,\n get_major_minor_version,\n get_src_prefix,\n is_osx_framework,\n site_packages,\n user_site,\n)\n\n__all__ = [\n \"USER_CACHE_DIR\",\n \"get_bin_prefix\",\n \"get_bin_user\",\n \"get_major_minor_version\",\n \"get_platlib\",\n \"get_prefixed_libs\",\n \"get_purelib\",\n \"get_scheme\",\n \"get_src_prefix\",\n \"site_packages\",\n \"user_site\",\n]\n\n\nlogger = logging.getLogger(__name__)\n\n\n_PLATLIBDIR: str = getattr(sys, \"platlibdir\", \"lib\")\n\n_USE_SYSCONFIG_DEFAULT = sys.version_info >= (3, 10)\n\n\ndef _should_use_sysconfig() -> bool:\n \"\"\"This function determines the value of _USE_SYSCONFIG.\n\n By default, pip uses sysconfig on Python 3.10+.\n But Python distributors can override this decision by setting:\n sysconfig._PIP_USE_SYSCONFIG = True / False\n Rationale in https://github.com/pypa/pip/issues/10647\n\n This is a function for testability, but should be constant during any one\n run.\n \"\"\"\n return bool(getattr(sysconfig, \"_PIP_USE_SYSCONFIG\", _USE_SYSCONFIG_DEFAULT))\n\n\n_USE_SYSCONFIG = _should_use_sysconfig()\n\nif not _USE_SYSCONFIG:\n # Import distutils lazily to avoid deprecation warnings,\n # but import it soon enough that it is in memory and available during\n # a pip reinstall.\n from . import _distutils\n\n# Be noisy about incompatibilities if this platforms \"should\" be using\n# sysconfig, but is explicitly opting out and using distutils instead.\nif _USE_SYSCONFIG_DEFAULT and not _USE_SYSCONFIG:\n _MISMATCH_LEVEL = logging.WARNING\nelse:\n _MISMATCH_LEVEL = logging.DEBUG\n\n\ndef _looks_like_bpo_44860() -> bool:\n \"\"\"The resolution to bpo-44860 will change this incorrect platlib.\n\n See .\n \"\"\"\n from distutils.command.install import INSTALL_SCHEMES\n\n try:\n unix_user_platlib = INSTALL_SCHEMES[\"unix_user\"][\"platlib\"]\n except KeyError:\n return False\n return unix_user_platlib == \"$usersite\"\n\n\ndef _looks_like_red_hat_patched_platlib_purelib(scheme: Dict[str, str]) -> bool:\n platlib = scheme[\"platlib\"]\n if \"/$platlibdir/\" in platlib:\n platlib = platlib.replace(\"/$platlibdir/\", f\"/{_PLATLIBDIR}/\")\n if \"/lib64/\" not in platlib:\n return False\n unpatched = platlib.replace(\"/lib64/\", \"/lib/\")\n return unpatched.replace(\"$platbase/\", \"$base/\") == scheme[\"purelib\"]\n\n\n@functools.lru_cache(maxsize=None)\ndef _looks_like_red_hat_lib() -> bool:\n \"\"\"Red Hat patches platlib in unix_prefix and unix_home, but not purelib.\n\n This is the only way I can see to tell a Red Hat-patched Python.\n \"\"\"\n from distutils.command.install import INSTALL_SCHEMES\n\n return all(\n k in INSTALL_SCHEMES\n and _looks_like_red_hat_patched_platlib_purelib(INSTALL_SCHEMES[k])\n for k in (\"unix_prefix\", \"unix_home\")\n )\n\n\n@functools.lru_cache(maxsize=None)\ndef _looks_like_debian_scheme() -> bool:\n \"\"\"Debian adds two additional schemes.\"\"\"\n from distutils.command.install import INSTALL_SCHEMES\n\n return \"deb_system\" in INSTALL_SCHEMES and \"unix_local\" in INSTALL_SCHEMES\n\n\n@functools.lru_cache(maxsize=None)\ndef _looks_like_red_hat_scheme() -> bool:\n \"\"\"Red Hat patches ``sys.prefix`` and ``sys.exec_prefix``.\n\n Red Hat's ``00251-change-user-install-location.patch`` changes the install\n command's ``prefix`` and ``exec_prefix`` to append ``\"/local\"``. This is\n (fortunately?) done quite unconditionally, so we create a default command\n object without any configuration to detect this.\n \"\"\"\n from distutils.command.install import install\n from distutils.dist import Distribution\n\n cmd: Any = install(Distribution())\n cmd.finalize_options()\n return (\n cmd.exec_prefix == f\"{os.path.normpath(sys.exec_prefix)}/local\"\n and cmd.prefix == f\"{os.path.normpath(sys.prefix)}/local\"\n )\n\n\n@functools.lru_cache(maxsize=None)\ndef _looks_like_slackware_scheme() -> bool:\n \"\"\"Slackware patches sysconfig but fails to patch distutils and site.\n\n Slackware changes sysconfig's user scheme to use ``\"lib64\"`` for the lib\n path, but does not do the same to the site module.\n \"\"\"\n if user_site is None: # User-site not available.\n return False\n try:\n paths = sysconfig.get_paths(scheme=\"posix_user\", expand=False)\n except KeyError: # User-site not available.\n return False\n return \"/lib64/\" in paths[\"purelib\"] and \"/lib64/\" not in user_site\n\n\n@functools.lru_cache(maxsize=None)\ndef _looks_like_msys2_mingw_scheme() -> bool:\n \"\"\"MSYS2 patches distutils and sysconfig to use a UNIX-like scheme.\n\n However, MSYS2 incorrectly patches sysconfig ``nt`` scheme. The fix is\n likely going to be included in their 3.10 release, so we ignore the warning.\n See msys2/MINGW-packages#9319.\n\n MSYS2 MINGW's patch uses lowercase ``\"lib\"`` instead of the usual uppercase,\n and is missing the final ``\"site-packages\"``.\n \"\"\"\n paths = sysconfig.get_paths(\"nt\", expand=False)\n return all(\n \"Lib\" not in p and \"lib\" in p and not p.endswith(\"site-packages\")\n for p in (paths[key] for key in (\"platlib\", \"purelib\"))\n )\n\n\ndef _fix_abiflags(parts: Tuple[str]) -> Generator[str, None, None]:\n ldversion = sysconfig.get_config_var(\"LDVERSION\")\n abiflags = getattr(sys, \"abiflags\", None)\n\n # LDVERSION does not end with sys.abiflags. Just return the path unchanged.\n if not ldversion or not abiflags or not ldversion.endswith(abiflags):\n yield from parts\n return\n\n # Strip sys.abiflags from LDVERSION-based path components.\n for part in parts:\n if part.endswith(ldversion):\n part = part[: (0 - len(abiflags))]\n yield part\n\n\n@functools.lru_cache(maxsize=None)\ndef _warn_mismatched(old: pathlib.Path, new: pathlib.Path, *, key: str) -> None:\n issue_url = \"https://github.com/pypa/pip/issues/10151\"\n message = (\n \"Value for %s does not match. Please report this to <%s>\"\n \"\\ndistutils: %s\"\n \"\\nsysconfig: %s\"\n )\n logger.log(_MISMATCH_LEVEL, message, key, issue_url, old, new)\n\n\ndef _warn_if_mismatch(old: pathlib.Path, new: pathlib.Path, *, key: str) -> bool:\n if old == new:\n return False\n _warn_mismatched(old, new, key=key)\n return True\n\n\n@functools.lru_cache(maxsize=None)\ndef _log_context(\n *,\n user: bool = False,\n home: Optional[str] = None,\n root: Optional[str] = None,\n prefix: Optional[str] = None,\n) -> None:\n parts = [\n \"Additional context:\",\n \"user = %r\",\n \"home = %r\",\n \"root = %r\",\n \"prefix = %r\",\n ]\n\n logger.log(_MISMATCH_LEVEL, \"\\n\".join(parts), user, home, root, prefix)\n\n\ndef get_scheme(\n dist_name: str,\n user: bool = False,\n home: Optional[str] = None,\n root: Optional[str] = None,\n isolated: bool = False,\n prefix: Optional[str] = None,\n) -> Scheme:\n new = _sysconfig.get_scheme(\n dist_name,\n user=user,\n home=home,\n root=root,\n isolated=isolated,\n prefix=prefix,\n )\n if _USE_SYSCONFIG:\n return new\n\n old = _distutils.get_scheme(\n dist_name,\n user=user,\n home=home,\n root=root,\n isolated=isolated,\n prefix=prefix,\n )\n\n warning_contexts = []\n for k in SCHEME_KEYS:\n old_v = pathlib.Path(getattr(old, k))\n new_v = pathlib.Path(getattr(new, k))\n\n if old_v == new_v:\n continue\n\n # distutils incorrectly put PyPy packages under ``site-packages/python``\n # in the ``posix_home`` scheme, but PyPy devs said they expect the\n # directory name to be ``pypy`` instead. So we treat this as a bug fix\n # and not warn about it. See bpo-43307 and python/cpython#24628.\n skip_pypy_special_case = (\n sys.implementation.name == \"pypy\"\n and home is not None\n and k in (\"platlib\", \"purelib\")\n and old_v.parent == new_v.parent\n and old_v.name.startswith(\"python\")\n and new_v.name.startswith(\"pypy\")\n )\n if skip_pypy_special_case:\n continue\n\n # sysconfig's ``osx_framework_user`` does not include ``pythonX.Y`` in\n # the ``include`` value, but distutils's ``headers`` does. We'll let\n # CPython decide whether this is a bug or feature. See bpo-43948.\n skip_osx_framework_user_special_case = (\n user\n and is_osx_framework()\n and k == \"headers\"\n and old_v.parent.parent == new_v.parent\n and old_v.parent.name.startswith(\"python\")\n )\n if skip_osx_framework_user_special_case:\n continue\n\n # On Red Hat and derived Linux distributions, distutils is patched to\n # use \"lib64\" instead of \"lib\" for platlib.\n if k == \"platlib\" and _looks_like_red_hat_lib():\n continue\n\n # On Python 3.9+, sysconfig's posix_user scheme sets platlib against\n # sys.platlibdir, but distutils's unix_user incorrectly coninutes\n # using the same $usersite for both platlib and purelib. This creates a\n # mismatch when sys.platlibdir is not \"lib\".\n skip_bpo_44860 = (\n user\n and k == \"platlib\"\n and not WINDOWS\n and sys.version_info >= (3, 9)\n and _PLATLIBDIR != \"lib\"\n and _looks_like_bpo_44860()\n )\n if skip_bpo_44860:\n continue\n\n # Slackware incorrectly patches posix_user to use lib64 instead of lib,\n # but not usersite to match the location.\n skip_slackware_user_scheme = (\n user\n and k in (\"platlib\", \"purelib\")\n and not WINDOWS\n and _looks_like_slackware_scheme()\n )\n if skip_slackware_user_scheme:\n continue\n\n # Both Debian and Red Hat patch Python to place the system site under\n # /usr/local instead of /usr. Debian also places lib in dist-packages\n # instead of site-packages, but the /usr/local check should cover it.\n skip_linux_system_special_case = (\n not (user or home or prefix or running_under_virtualenv())\n and old_v.parts[1:3] == (\"usr\", \"local\")\n and len(new_v.parts) > 1\n and new_v.parts[1] == \"usr\"\n and (len(new_v.parts) < 3 or new_v.parts[2] != \"local\")\n and (_looks_like_red_hat_scheme() or _looks_like_debian_scheme())\n )\n if skip_linux_system_special_case:\n continue\n\n # On Python 3.7 and earlier, sysconfig does not include sys.abiflags in\n # the \"pythonX.Y\" part of the path, but distutils does.\n skip_sysconfig_abiflag_bug = (\n sys.version_info < (3, 8)\n and not WINDOWS\n and k in (\"headers\", \"platlib\", \"purelib\")\n and tuple(_fix_abiflags(old_v.parts)) == new_v.parts\n )\n if skip_sysconfig_abiflag_bug:\n continue\n\n # MSYS2 MINGW's sysconfig patch does not include the \"site-packages\"\n # part of the path. This is incorrect and will be fixed in MSYS.\n skip_msys2_mingw_bug = (\n WINDOWS and k in (\"platlib\", \"purelib\") and _looks_like_msys2_mingw_scheme()\n )\n if skip_msys2_mingw_bug:\n continue\n\n # CPython's POSIX install script invokes pip (via ensurepip) against the\n # interpreter located in the source tree, not the install site. This\n # triggers special logic in sysconfig that's not present in distutils.\n # https://github.com/python/cpython/blob/8c21941ddaf/Lib/sysconfig.py#L178-L194\n skip_cpython_build = (\n sysconfig.is_python_build(check_home=True)\n and not WINDOWS\n and k in (\"headers\", \"include\", \"platinclude\")\n )\n if skip_cpython_build:\n continue\n\n warning_contexts.append((old_v, new_v, f\"scheme.{k}\"))\n\n if not warning_contexts:\n return old\n\n # Check if this path mismatch is caused by distutils config files. Those\n # files will no longer work once we switch to sysconfig, so this raises a\n # deprecation message for them.\n default_old = _distutils.distutils_scheme(\n dist_name,\n user,\n home,\n root,\n isolated,\n prefix,\n ignore_config_files=True,\n )\n if any(default_old[k] != getattr(old, k) for k in SCHEME_KEYS):\n deprecated(\n reason=(\n \"Configuring installation scheme with distutils config files \"\n \"is deprecated and will no longer work in the near future. If you \"\n \"are using a Homebrew or Linuxbrew Python, please see discussion \"\n \"at https://github.com/Homebrew/homebrew-core/issues/76621\"\n ),\n replacement=None,\n gone_in=None,\n )\n return old\n\n # Post warnings about this mismatch so user can report them back.\n for old_v, new_v, key in warning_contexts:\n _warn_mismatched(old_v, new_v, key=key)\n _log_context(user=user, home=home, root=root, prefix=prefix)\n\n return old\n\n\ndef get_bin_prefix() -> str:\n new = _sysconfig.get_bin_prefix()\n if _USE_SYSCONFIG:\n return new\n\n old = _distutils.get_bin_prefix()\n if _warn_if_mismatch(pathlib.Path(old), pathlib.Path(new), key=\"bin_prefix\"):\n _log_context()\n return old\n\n\ndef get_bin_user() -> str:\n return _sysconfig.get_scheme(\"\", user=True).scripts\n\n\ndef _looks_like_deb_system_dist_packages(value: str) -> bool:\n \"\"\"Check if the value is Debian's APT-controlled dist-packages.\n\n Debian's ``distutils.sysconfig.get_python_lib()`` implementation returns the\n default package path controlled by APT, but does not patch ``sysconfig`` to\n do the same. This is similar to the bug worked around in ``get_scheme()``,\n but here the default is ``deb_system`` instead of ``unix_local``. Ultimately\n we can't do anything about this Debian bug, and this detection allows us to\n skip the warning when needed.\n \"\"\"\n if not _looks_like_debian_scheme():\n return False\n if value == \"/usr/lib/python3/dist-packages\":\n return True\n return False\n\n\ndef get_purelib() -> str:\n \"\"\"Return the default pure-Python lib location.\"\"\"\n new = _sysconfig.get_purelib()\n if _USE_SYSCONFIG:\n return new\n\n old = _distutils.get_purelib()\n if _looks_like_deb_system_dist_packages(old):\n return old\n if _warn_if_mismatch(pathlib.Path(old), pathlib.Path(new), key=\"purelib\"):\n _log_context()\n return old\n\n\ndef get_platlib() -> str:\n \"\"\"Return the default platform-shared lib location.\"\"\"\n new = _sysconfig.get_platlib()\n if _USE_SYSCONFIG:\n return new\n\n from . import _distutils\n\n old = _distutils.get_platlib()\n if _looks_like_deb_system_dist_packages(old):\n return old\n if _warn_if_mismatch(pathlib.Path(old), pathlib.Path(new), key=\"platlib\"):\n _log_context()\n return old\n\n\ndef _deduplicated(v1: str, v2: str) -> List[str]:\n \"\"\"Deduplicate values from a list.\"\"\"\n if v1 == v2:\n return [v1]\n return [v1, v2]\n\n\ndef _looks_like_apple_library(path: str) -> bool:\n \"\"\"Apple patches sysconfig to *always* look under */Library/Python*.\"\"\"\n if sys.platform[:6] != \"darwin\":\n return False\n return path == f\"/Library/Python/{get_major_minor_version()}/site-packages\"\n\n\ndef get_prefixed_libs(prefix: str) -> List[str]:\n \"\"\"Return the lib locations under ``prefix``.\"\"\"\n new_pure, new_plat = _sysconfig.get_prefixed_libs(prefix)\n if _USE_SYSCONFIG:\n return _deduplicated(new_pure, new_plat)\n\n old_pure, old_plat = _distutils.get_prefixed_libs(prefix)\n old_lib_paths = _deduplicated(old_pure, old_plat)\n\n # Apple's Python (shipped with Xcode and Command Line Tools) hard-code\n # platlib and purelib to '/Library/Python/X.Y/site-packages'. This will\n # cause serious build isolation bugs when Apple starts shipping 3.10 because\n # pip will install build backends to the wrong location. This tells users\n # who is at fault so Apple may notice it and fix the issue in time.\n if all(_looks_like_apple_library(p) for p in old_lib_paths):\n deprecated(\n reason=(\n \"Python distributed by Apple's Command Line Tools incorrectly \"\n \"patches sysconfig to always point to '/Library/Python'. This \"\n \"will cause build isolation to operate incorrectly on Python \"\n \"3.10 or later. Please help report this to Apple so they can \"\n \"fix this. https://developer.apple.com/bug-reporting/\"\n ),\n replacement=None,\n gone_in=None,\n )\n return old_lib_paths\n\n warned = [\n _warn_if_mismatch(\n pathlib.Path(old_pure),\n pathlib.Path(new_pure),\n key=\"prefixed-purelib\",\n ),\n _warn_if_mismatch(\n pathlib.Path(old_plat),\n pathlib.Path(new_plat),\n key=\"prefixed-platlib\",\n ),\n ]\n if any(warned):\n _log_context(prefix=prefix)\n\n return old_lib_paths\n"
},
{
"path": "lib/python3.7/site-packages/pip/_internal/locations/_distutils.py",
"content": "\"\"\"Locations where we look for configs, install stuff, etc\"\"\"\n\n# The following comment should be removed at some point in the future.\n# mypy: strict-optional=False\n\n# If pip's going to use distutils, it should not be using the copy that setuptools\n# might have injected into the environment. This is done by removing the injected\n# shim, if it's injected.\n#\n# See https://github.com/pypa/pip/issues/8761 for the original discussion and\n# rationale for why this is done within pip.\ntry:\n __import__(\"_distutils_hack\").remove_shim()\nexcept (ImportError, AttributeError):\n pass\n\nimport logging\nimport os\nimport sys\nfrom distutils.cmd import Command as DistutilsCommand\nfrom distutils.command.install import SCHEME_KEYS\nfrom distutils.command.install import install as distutils_install_command\nfrom distutils.sysconfig import get_python_lib\nfrom typing import Dict, List, Optional, Tuple, Union, cast\n\nfrom pip._internal.models.scheme import Scheme\nfrom pip._internal.utils.compat import WINDOWS\nfrom pip._internal.utils.virtualenv import running_under_virtualenv\n\nfrom .base import get_major_minor_version\n\nlogger = logging.getLogger(__name__)\n\n\ndef distutils_scheme(\n dist_name: str,\n user: bool = False,\n home: Optional[str] = None,\n root: Optional[str] = None,\n isolated: bool = False,\n prefix: Optional[str] = None,\n *,\n ignore_config_files: bool = False,\n) -> Dict[str, str]:\n \"\"\"\n Return a distutils install scheme\n \"\"\"\n from distutils.dist import Distribution\n\n dist_args: Dict[str, Union[str, List[str]]] = {\"name\": dist_name}\n if isolated:\n dist_args[\"script_args\"] = [\"--no-user-cfg\"]\n\n d = Distribution(dist_args)\n if not ignore_config_files:\n try:\n d.parse_config_files()\n except UnicodeDecodeError:\n # Typeshed does not include find_config_files() for some reason.\n paths = d.find_config_files() # type: ignore\n logger.warning(\n \"Ignore distutils configs in %s due to encoding errors.\",\n \", \".join(os.path.basename(p) for p in paths),\n )\n obj: Optional[DistutilsCommand] = None\n obj = d.get_command_obj(\"install\", create=True)\n assert obj is not None\n i = cast(distutils_install_command, obj)\n # NOTE: setting user or home has the side-effect of creating the home dir\n # or user base for installations during finalize_options()\n # ideally, we'd prefer a scheme class that has no side-effects.\n assert not (user and prefix), f\"user={user} prefix={prefix}\"\n assert not (home and prefix), f\"home={home} prefix={prefix}\"\n i.user = user or i.user\n if user or home:\n i.prefix = \"\"\n i.prefix = prefix or i.prefix\n i.home = home or i.home\n i.root = root or i.root\n i.finalize_options()\n\n scheme = {}\n for key in SCHEME_KEYS:\n scheme[key] = getattr(i, \"install_\" + key)\n\n # install_lib specified in setup.cfg should install *everything*\n # into there (i.e. it takes precedence over both purelib and\n # platlib). Note, i.install_lib is *always* set after\n # finalize_options(); we only want to override here if the user\n # has explicitly requested it hence going back to the config\n if \"install_lib\" in d.get_option_dict(\"install\"):\n scheme.update(dict(purelib=i.install_lib, platlib=i.install_lib))\n\n if running_under_virtualenv():\n if home:\n prefix = home\n elif user:\n prefix = i.install_userbase\n else:\n prefix = i.prefix\n scheme[\"headers\"] = os.path.join(\n prefix,\n \"include\",\n \"site\",\n f\"python{get_major_minor_version()}\",\n dist_name,\n )\n\n if root is not None:\n path_no_drive = os.path.splitdrive(os.path.abspath(scheme[\"headers\"]))[1]\n scheme[\"headers\"] = os.path.join(root, path_no_drive[1:])\n\n return scheme\n\n\ndef get_scheme(\n dist_name: str,\n user: bool = False,\n home: Optional[str] = None,\n root: Optional[str] = None,\n isolated: bool = False,\n prefix: Optional[str] = None,\n) -> Scheme:\n \"\"\"\n Get the \"scheme\" corresponding to the input parameters. The distutils\n documentation provides the context for the available schemes:\n https://docs.python.org/3/install/index.html#alternate-installation\n\n :param dist_name: the name of the package to retrieve the scheme for, used\n in the headers scheme path\n :param user: indicates to use the \"user\" scheme\n :param home: indicates to use the \"home\" scheme and provides the base\n directory for the same\n :param root: root under which other directories are re-based\n :param isolated: equivalent to --no-user-cfg, i.e. do not consider\n ~/.pydistutils.cfg (posix) or ~/pydistutils.cfg (non-posix) for\n scheme paths\n :param prefix: indicates to use the \"prefix\" scheme and provides the\n base directory for the same\n \"\"\"\n scheme = distutils_scheme(dist_name, user, home, root, isolated, prefix)\n return Scheme(\n platlib=scheme[\"platlib\"],\n purelib=scheme[\"purelib\"],\n headers=scheme[\"headers\"],\n scripts=scheme[\"scripts\"],\n data=scheme[\"data\"],\n )\n\n\ndef get_bin_prefix() -> str:\n # XXX: In old virtualenv versions, sys.prefix can contain '..' components,\n # so we need to call normpath to eliminate them.\n prefix = os.path.normpath(sys.prefix)\n if WINDOWS:\n bin_py = os.path.join(prefix, \"Scripts\")\n # buildout uses 'bin' on Windows too?\n if not os.path.exists(bin_py):\n bin_py = os.path.join(prefix, \"bin\")\n return bin_py\n # Forcing to use /usr/local/bin for standard macOS framework installs\n # Also log to ~/Library/Logs/ for use with the Console.app log viewer\n if sys.platform[:6] == \"darwin\" and prefix[:16] == \"/System/Library/\":\n return \"/usr/local/bin\"\n return os.path.join(prefix, \"bin\")\n\n\ndef get_purelib() -> str:\n return get_python_lib(plat_specific=False)\n\n\ndef get_platlib() -> str:\n return get_python_lib(plat_specific=True)\n\n\ndef get_prefixed_libs(prefix: str) -> Tuple[str, str]:\n return (\n get_python_lib(plat_specific=False, prefix=prefix),\n get_python_lib(plat_specific=True, prefix=prefix),\n )\n"
},
{
"path": "lib/python3.7/site-packages/pip/_internal/locations/_sysconfig.py",
"content": "import logging\nimport os\nimport sys\nimport sysconfig\nimport typing\n\nfrom pip._internal.exceptions import InvalidSchemeCombination, UserInstallationInvalid\nfrom pip._internal.models.scheme import SCHEME_KEYS, Scheme\nfrom pip._internal.utils.virtualenv import running_under_virtualenv\n\nfrom .base import change_root, get_major_minor_version, is_osx_framework\n\nlogger = logging.getLogger(__name__)\n\n\n# Notes on _infer_* functions.\n# Unfortunately ``get_default_scheme()`` didn't exist before 3.10, so there's no\n# way to ask things like \"what is the '_prefix' scheme on this platform\". These\n# functions try to answer that with some heuristics while accounting for ad-hoc\n# platforms not covered by CPython's default sysconfig implementation. If the\n# ad-hoc implementation does not fully implement sysconfig, we'll fall back to\n# a POSIX scheme.\n\n_AVAILABLE_SCHEMES = set(sysconfig.get_scheme_names())\n\n_PREFERRED_SCHEME_API = getattr(sysconfig, \"get_preferred_scheme\", None)\n\n\ndef _should_use_osx_framework_prefix() -> bool:\n \"\"\"Check for Apple's ``osx_framework_library`` scheme.\n\n Python distributed by Apple's Command Line Tools has this special scheme\n that's used when:\n\n * This is a framework build.\n * We are installing into the system prefix.\n\n This does not account for ``pip install --prefix`` (also means we're not\n installing to the system prefix), which should use ``posix_prefix``, but\n logic here means ``_infer_prefix()`` outputs ``osx_framework_library``. But\n since ``prefix`` is not available for ``sysconfig.get_default_scheme()``,\n which is the stdlib replacement for ``_infer_prefix()``, presumably Apple\n wouldn't be able to magically switch between ``osx_framework_library`` and\n ``posix_prefix``. ``_infer_prefix()`` returning ``osx_framework_library``\n means its behavior is consistent whether we use the stdlib implementation\n or our own, and we deal with this special case in ``get_scheme()`` instead.\n \"\"\"\n return (\n \"osx_framework_library\" in _AVAILABLE_SCHEMES\n and not running_under_virtualenv()\n and is_osx_framework()\n )\n\n\ndef _infer_prefix() -> str:\n \"\"\"Try to find a prefix scheme for the current platform.\n\n This tries:\n\n * A special ``osx_framework_library`` for Python distributed by Apple's\n Command Line Tools, when not running in a virtual environment.\n * Implementation + OS, used by PyPy on Windows (``pypy_nt``).\n * Implementation without OS, used by PyPy on POSIX (``pypy``).\n * OS + \"prefix\", used by CPython on POSIX (``posix_prefix``).\n * Just the OS name, used by CPython on Windows (``nt``).\n\n If none of the above works, fall back to ``posix_prefix``.\n \"\"\"\n if _PREFERRED_SCHEME_API:\n return _PREFERRED_SCHEME_API(\"prefix\")\n if _should_use_osx_framework_prefix():\n return \"osx_framework_library\"\n implementation_suffixed = f\"{sys.implementation.name}_{os.name}\"\n if implementation_suffixed in _AVAILABLE_SCHEMES:\n return implementation_suffixed\n if sys.implementation.name in _AVAILABLE_SCHEMES:\n return sys.implementation.name\n suffixed = f\"{os.name}_prefix\"\n if suffixed in _AVAILABLE_SCHEMES:\n return suffixed\n if os.name in _AVAILABLE_SCHEMES: # On Windows, prefx is just called \"nt\".\n return os.name\n return \"posix_prefix\"\n\n\ndef _infer_user() -> str:\n \"\"\"Try to find a user scheme for the current platform.\"\"\"\n if _PREFERRED_SCHEME_API:\n return _PREFERRED_SCHEME_API(\"user\")\n if is_osx_framework() and not running_under_virtualenv():\n suffixed = \"osx_framework_user\"\n else:\n suffixed = f\"{os.name}_user\"\n if suffixed in _AVAILABLE_SCHEMES:\n return suffixed\n if \"posix_user\" not in _AVAILABLE_SCHEMES: # User scheme unavailable.\n raise UserInstallationInvalid()\n return \"posix_user\"\n\n\ndef _infer_home() -> str:\n \"\"\"Try to find a home for the current platform.\"\"\"\n if _PREFERRED_SCHEME_API:\n return _PREFERRED_SCHEME_API(\"home\")\n suffixed = f\"{os.name}_home\"\n if suffixed in _AVAILABLE_SCHEMES:\n return suffixed\n return \"posix_home\"\n\n\n# Update these keys if the user sets a custom home.\n_HOME_KEYS = [\n \"installed_base\",\n \"base\",\n \"installed_platbase\",\n \"platbase\",\n \"prefix\",\n \"exec_prefix\",\n]\nif sysconfig.get_config_var(\"userbase\") is not None:\n _HOME_KEYS.append(\"userbase\")\n\n\ndef get_scheme(\n dist_name: str,\n user: bool = False,\n home: typing.Optional[str] = None,\n root: typing.Optional[str] = None,\n isolated: bool = False,\n prefix: typing.Optional[str] = None,\n) -> Scheme:\n \"\"\"\n Get the \"scheme\" corresponding to the input parameters.\n\n :param dist_name: the name of the package to retrieve the scheme for, used\n in the headers scheme path\n :param user: indicates to use the \"user\" scheme\n :param home: indicates to use the \"home\" scheme\n :param root: root under which other directories are re-based\n :param isolated: ignored, but kept for distutils compatibility (where\n this controls whether the user-site pydistutils.cfg is honored)\n :param prefix: indicates to use the \"prefix\" scheme and provides the\n base directory for the same\n \"\"\"\n if user and prefix:\n raise InvalidSchemeCombination(\"--user\", \"--prefix\")\n if home and prefix:\n raise InvalidSchemeCombination(\"--home\", \"--prefix\")\n\n if home is not None:\n scheme_name = _infer_home()\n elif user:\n scheme_name = _infer_user()\n else:\n scheme_name = _infer_prefix()\n\n # Special case: When installing into a custom prefix, use posix_prefix\n # instead of osx_framework_library. See _should_use_osx_framework_prefix()\n # docstring for details.\n if prefix is not None and scheme_name == \"osx_framework_library\":\n scheme_name = \"posix_prefix\"\n\n if home is not None:\n variables = {k: home for k in _HOME_KEYS}\n elif prefix is not None:\n variables = {k: prefix for k in _HOME_KEYS}\n else:\n variables = {}\n\n paths = sysconfig.get_paths(scheme=scheme_name, vars=variables)\n\n # Logic here is very arbitrary, we're doing it for compatibility, don't ask.\n # 1. Pip historically uses a special header path in virtual environments.\n # 2. If the distribution name is not known, distutils uses 'UNKNOWN'. We\n # only do the same when not running in a virtual environment because\n # pip's historical header path logic (see point 1) did not do this.\n if running_under_virtualenv():\n if user:\n base = variables.get(\"userbase\", sys.prefix)\n else:\n base = variables.get(\"base\", sys.prefix)\n python_xy = f\"python{get_major_minor_version()}\"\n paths[\"include\"] = os.path.join(base, \"include\", \"site\", python_xy)\n elif not dist_name:\n dist_name = \"UNKNOWN\"\n\n scheme = Scheme(\n platlib=paths[\"platlib\"],\n purelib=paths[\"purelib\"],\n headers=os.path.join(paths[\"include\"], dist_name),\n scripts=paths[\"scripts\"],\n data=paths[\"data\"],\n )\n if root is not None:\n for key in SCHEME_KEYS:\n value = change_root(root, getattr(scheme, key))\n setattr(scheme, key, value)\n return scheme\n\n\ndef get_bin_prefix() -> str:\n # Forcing to use /usr/local/bin for standard macOS framework installs.\n if sys.platform[:6] == \"darwin\" and sys.prefix[:16] == \"/System/Library/\":\n return \"/usr/local/bin\"\n return sysconfig.get_paths()[\"scripts\"]\n\n\ndef get_purelib() -> str:\n return sysconfig.get_paths()[\"purelib\"]\n\n\ndef get_platlib() -> str:\n return sysconfig.get_paths()[\"platlib\"]\n\n\ndef get_prefixed_libs(prefix: str) -> typing.Tuple[str, str]:\n paths = sysconfig.get_paths(vars={\"base\": prefix, \"platbase\": prefix})\n return (paths[\"purelib\"], paths[\"platlib\"])\n"
},
{
"path": "lib/python3.7/site-packages/pip/_internal/locations/base.py",
"content": "import functools\nimport os\nimport site\nimport sys\nimport sysconfig\nimport typing\n\nfrom pip._internal.exceptions import InstallationError\nfrom pip._internal.utils import appdirs\nfrom pip._internal.utils.virtualenv import running_under_virtualenv\n\n# Application Directories\nUSER_CACHE_DIR = appdirs.user_cache_dir(\"pip\")\n\n# FIXME doesn't account for venv linked to global site-packages\nsite_packages: typing.Optional[str] = sysconfig.get_path(\"purelib\")\n\n\ndef get_major_minor_version() -> str:\n \"\"\"\n Return the major-minor version of the current Python as a string, e.g.\n \"3.7\" or \"3.10\".\n \"\"\"\n return \"{}.{}\".format(*sys.version_info)\n\n\ndef change_root(new_root: str, pathname: str) -> str:\n \"\"\"Return 'pathname' with 'new_root' prepended.\n\n If 'pathname' is relative, this is equivalent to os.path.join(new_root, pathname).\n Otherwise, it requires making 'pathname' relative and then joining the\n two, which is tricky on DOS/Windows and Mac OS.\n\n This is borrowed from Python's standard library's distutils module.\n \"\"\"\n if os.name == \"posix\":\n if not os.path.isabs(pathname):\n return os.path.join(new_root, pathname)\n else:\n return os.path.join(new_root, pathname[1:])\n\n elif os.name == \"nt\":\n (drive, path) = os.path.splitdrive(pathname)\n if path[0] == \"\\\\\":\n path = path[1:]\n return os.path.join(new_root, path)\n\n else:\n raise InstallationError(\n f\"Unknown platform: {os.name}\\n\"\n \"Can not change root path prefix on unknown platform.\"\n )\n\n\ndef get_src_prefix() -> str:\n if running_under_virtualenv():\n src_prefix = os.path.join(sys.prefix, \"src\")\n else:\n # FIXME: keep src in cwd for now (it is not a temporary folder)\n try:\n src_prefix = os.path.join(os.getcwd(), \"src\")\n except OSError:\n # In case the current working directory has been renamed or deleted\n sys.exit(\"The folder you are executing pip from can no longer be found.\")\n\n # under macOS + virtualenv sys.prefix is not properly resolved\n # it is something like /path/to/python/bin/..\n return os.path.abspath(src_prefix)\n\n\ntry:\n # Use getusersitepackages if this is present, as it ensures that the\n # value is initialised properly.\n user_site: typing.Optional[str] = site.getusersitepackages()\nexcept AttributeError:\n user_site = site.USER_SITE\n\n\n@functools.lru_cache(maxsize=None)\ndef is_osx_framework() -> bool:\n return bool(sysconfig.get_config_var(\"PYTHONFRAMEWORK\"))\n"
},
{
"path": "lib/python3.7/site-packages/pip/_internal/main.py",
"content": "from typing import List, Optional\n\n\ndef main(args: Optional[List[str]] = None) -> int:\n \"\"\"This is preserved for old console scripts that may still be referencing\n it.\n\n For additional details, see https://github.com/pypa/pip/issues/7498.\n \"\"\"\n from pip._internal.utils.entrypoints import _wrapper\n\n return _wrapper(args)\n"
},
{
"path": "lib/python3.7/site-packages/pip/_internal/metadata/__init__.py",
"content": "import contextlib\nimport functools\nimport os\nimport sys\nfrom typing import TYPE_CHECKING, List, Optional, Type, cast\n\nfrom pip._internal.utils.misc import strtobool\n\nfrom .base import BaseDistribution, BaseEnvironment, FilesystemWheel, MemoryWheel, Wheel\n\nif TYPE_CHECKING:\n from typing import Protocol\nelse:\n Protocol = object\n\n__all__ = [\n \"BaseDistribution\",\n \"BaseEnvironment\",\n \"FilesystemWheel\",\n \"MemoryWheel\",\n \"Wheel\",\n \"get_default_environment\",\n \"get_environment\",\n \"get_wheel_distribution\",\n \"select_backend\",\n]\n\n\ndef _should_use_importlib_metadata() -> bool:\n \"\"\"Whether to use the ``importlib.metadata`` or ``pkg_resources`` backend.\n\n By default, pip uses ``importlib.metadata`` on Python 3.11+, and\n ``pkg_resourcess`` otherwise. This can be overridden by a couple of ways:\n\n * If environment variable ``_PIP_USE_IMPORTLIB_METADATA`` is set, it\n dictates whether ``importlib.metadata`` is used, regardless of Python\n version.\n * On Python 3.11+, Python distributors can patch ``importlib.metadata``\n to add a global constant ``_PIP_USE_IMPORTLIB_METADATA = False``. This\n makes pip use ``pkg_resources`` (unless the user set the aforementioned\n environment variable to *True*).\n \"\"\"\n with contextlib.suppress(KeyError, ValueError):\n return bool(strtobool(os.environ[\"_PIP_USE_IMPORTLIB_METADATA\"]))\n if sys.version_info < (3, 11):\n return False\n import importlib.metadata\n\n return bool(getattr(importlib.metadata, \"_PIP_USE_IMPORTLIB_METADATA\", True))\n\n\nclass Backend(Protocol):\n Distribution: Type[BaseDistribution]\n Environment: Type[BaseEnvironment]\n\n\n@functools.lru_cache(maxsize=None)\ndef select_backend() -> Backend:\n if _should_use_importlib_metadata():\n from . import importlib\n\n return cast(Backend, importlib)\n from . import pkg_resources\n\n return cast(Backend, pkg_resources)\n\n\ndef get_default_environment() -> BaseEnvironment:\n \"\"\"Get the default representation for the current environment.\n\n This returns an Environment instance from the chosen backend. The default\n Environment instance should be built from ``sys.path`` and may use caching\n to share instance state accorss calls.\n \"\"\"\n return select_backend().Environment.default()\n\n\ndef get_environment(paths: Optional[List[str]]) -> BaseEnvironment:\n \"\"\"Get a representation of the environment specified by ``paths``.\n\n This returns an Environment instance from the chosen backend based on the\n given import paths. The backend must build a fresh instance representing\n the state of installed distributions when this function is called.\n \"\"\"\n return select_backend().Environment.from_paths(paths)\n\n\ndef get_directory_distribution(directory: str) -> BaseDistribution:\n \"\"\"Get the distribution metadata representation in the specified directory.\n\n This returns a Distribution instance from the chosen backend based on\n the given on-disk ``.dist-info`` directory.\n \"\"\"\n return select_backend().Distribution.from_directory(directory)\n\n\ndef get_wheel_distribution(wheel: Wheel, canonical_name: str) -> BaseDistribution:\n \"\"\"Get the representation of the specified wheel's distribution metadata.\n\n This returns a Distribution instance from the chosen backend based on\n the given wheel's ``.dist-info`` directory.\n\n :param canonical_name: Normalized project name of the given wheel.\n \"\"\"\n return select_backend().Distribution.from_wheel(wheel, canonical_name)\n\n\ndef get_metadata_distribution(\n metadata_contents: bytes,\n filename: str,\n canonical_name: str,\n) -> BaseDistribution:\n \"\"\"Get the dist representation of the specified METADATA file contents.\n\n This returns a Distribution instance from the chosen backend sourced from the data\n in `metadata_contents`.\n\n :param metadata_contents: Contents of a METADATA file within a dist, or one served\n via PEP 658.\n :param filename: Filename for the dist this metadata represents.\n :param canonical_name: Normalized project name of the given dist.\n \"\"\"\n return select_backend().Distribution.from_metadata_file_contents(\n metadata_contents,\n filename,\n canonical_name,\n )\n"
},
{
"path": "lib/python3.7/site-packages/pip/_internal/metadata/_json.py",
"content": "# Extracted from https://github.com/pfmoore/pkg_metadata\n\nfrom email.header import Header, decode_header, make_header\nfrom email.message import Message\nfrom typing import Any, Dict, List, Union\n\nMETADATA_FIELDS = [\n # Name, Multiple-Use\n (\"Metadata-Version\", False),\n (\"Name\", False),\n (\"Version\", False),\n (\"Dynamic\", True),\n (\"Platform\", True),\n (\"Supported-Platform\", True),\n (\"Summary\", False),\n (\"Description\", False),\n (\"Description-Content-Type\", False),\n (\"Keywords\", False),\n (\"Home-page\", False),\n (\"Download-URL\", False),\n (\"Author\", False),\n (\"Author-email\", False),\n (\"Maintainer\", False),\n (\"Maintainer-email\", False),\n (\"License\", False),\n (\"Classifier\", True),\n (\"Requires-Dist\", True),\n (\"Requires-Python\", False),\n (\"Requires-External\", True),\n (\"Project-URL\", True),\n (\"Provides-Extra\", True),\n (\"Provides-Dist\", True),\n (\"Obsoletes-Dist\", True),\n]\n\n\ndef json_name(field: str) -> str:\n return field.lower().replace(\"-\", \"_\")\n\n\ndef msg_to_json(msg: Message) -> Dict[str, Any]:\n \"\"\"Convert a Message object into a JSON-compatible dictionary.\"\"\"\n\n def sanitise_header(h: Union[Header, str]) -> str:\n if isinstance(h, Header):\n chunks = []\n for bytes, encoding in decode_header(h):\n if encoding == \"unknown-8bit\":\n try:\n # See if UTF-8 works\n bytes.decode(\"utf-8\")\n encoding = \"utf-8\"\n except UnicodeDecodeError:\n # If not, latin1 at least won't fail\n encoding = \"latin1\"\n chunks.append((bytes, encoding))\n return str(make_header(chunks))\n return str(h)\n\n result = {}\n for field, multi in METADATA_FIELDS:\n if field not in msg:\n continue\n key = json_name(field)\n if multi:\n value: Union[str, List[str]] = [\n sanitise_header(v) for v in msg.get_all(field)\n ]\n else:\n value = sanitise_header(msg.get(field))\n if key == \"keywords\":\n # Accept both comma-separated and space-separated\n # forms, for better compatibility with old data.\n if \",\" in value:\n value = [v.strip() for v in value.split(\",\")]\n else:\n value = value.split()\n result[key] = value\n\n payload = msg.get_payload()\n if payload:\n result[\"description\"] = payload\n\n return result\n"
},
{
"path": "lib/python3.7/site-packages/pip/_internal/metadata/base.py",
"content": "import csv\nimport email.message\nimport functools\nimport json\nimport logging\nimport pathlib\nimport re\nimport zipfile\nfrom typing import (\n IO,\n TYPE_CHECKING,\n Any,\n Collection,\n Container,\n Dict,\n Iterable,\n Iterator,\n List,\n NamedTuple,\n Optional,\n Tuple,\n Union,\n)\n\nfrom pip._vendor.packaging.requirements import Requirement\nfrom pip._vendor.packaging.specifiers import InvalidSpecifier, SpecifierSet\nfrom pip._vendor.packaging.utils import NormalizedName\nfrom pip._vendor.packaging.version import LegacyVersion, Version\n\nfrom pip._internal.exceptions import NoneMetadataError\nfrom pip._internal.locations import site_packages, user_site\nfrom pip._internal.models.direct_url import (\n DIRECT_URL_METADATA_NAME,\n DirectUrl,\n DirectUrlValidationError,\n)\nfrom pip._internal.utils.compat import stdlib_pkgs # TODO: Move definition here.\nfrom pip._internal.utils.egg_link import egg_link_path_from_sys_path\nfrom pip._internal.utils.misc import is_local, normalize_path\nfrom pip._internal.utils.packaging import safe_extra\nfrom pip._internal.utils.urls import url_to_path\n\nfrom ._json import msg_to_json\n\nif TYPE_CHECKING:\n from typing import Protocol\nelse:\n Protocol = object\n\nDistributionVersion = Union[LegacyVersion, Version]\n\nInfoPath = Union[str, pathlib.PurePath]\n\nlogger = logging.getLogger(__name__)\n\n\nclass BaseEntryPoint(Protocol):\n @property\n def name(self) -> str:\n raise NotImplementedError()\n\n @property\n def value(self) -> str:\n raise NotImplementedError()\n\n @property\n def group(self) -> str:\n raise NotImplementedError()\n\n\ndef _convert_installed_files_path(\n entry: Tuple[str, ...],\n info: Tuple[str, ...],\n) -> str:\n \"\"\"Convert a legacy installed-files.txt path into modern RECORD path.\n\n The legacy format stores paths relative to the info directory, while the\n modern format stores paths relative to the package root, e.g. the\n site-packages directory.\n\n :param entry: Path parts of the installed-files.txt entry.\n :param info: Path parts of the egg-info directory relative to package root.\n :returns: The converted entry.\n\n For best compatibility with symlinks, this does not use ``abspath()`` or\n ``Path.resolve()``, but tries to work with path parts:\n\n 1. While ``entry`` starts with ``..``, remove the equal amounts of parts\n from ``info``; if ``info`` is empty, start appending ``..`` instead.\n 2. Join the two directly.\n \"\"\"\n while entry and entry[0] == \"..\":\n if not info or info[-1] == \"..\":\n info += (\"..\",)\n else:\n info = info[:-1]\n entry = entry[1:]\n return str(pathlib.Path(*info, *entry))\n\n\nclass RequiresEntry(NamedTuple):\n requirement: str\n extra: str\n marker: str\n\n\nclass BaseDistribution(Protocol):\n @classmethod\n def from_directory(cls, directory: str) -> \"BaseDistribution\":\n \"\"\"Load the distribution from a metadata directory.\n\n :param directory: Path to a metadata directory, e.g. ``.dist-info``.\n \"\"\"\n raise NotImplementedError()\n\n @classmethod\n def from_metadata_file_contents(\n cls,\n metadata_contents: bytes,\n filename: str,\n project_name: str,\n ) -> \"BaseDistribution\":\n \"\"\"Load the distribution from the contents of a METADATA file.\n\n This is used to implement PEP 658 by generating a \"shallow\" dist object that can\n be used for resolution without downloading or building the actual dist yet.\n\n :param metadata_contents: The contents of a METADATA file.\n :param filename: File name for the dist with this metadata.\n :param project_name: Name of the project this dist represents.\n \"\"\"\n raise NotImplementedError()\n\n @classmethod\n def from_wheel(cls, wheel: \"Wheel\", name: str) -> \"BaseDistribution\":\n \"\"\"Load the distribution from a given wheel.\n\n :param wheel: A concrete wheel definition.\n :param name: File name of the wheel.\n\n :raises InvalidWheel: Whenever loading of the wheel causes a\n :py:exc:`zipfile.BadZipFile` exception to be thrown.\n :raises UnsupportedWheel: If the wheel is a valid zip, but malformed\n internally.\n \"\"\"\n raise NotImplementedError()\n\n def __repr__(self) -> str:\n return f\"{self.raw_name} {self.version} ({self.location})\"\n\n def __str__(self) -> str:\n return f\"{self.raw_name} {self.version}\"\n\n @property\n def location(self) -> Optional[str]:\n \"\"\"Where the distribution is loaded from.\n\n A string value is not necessarily a filesystem path, since distributions\n can be loaded from other sources, e.g. arbitrary zip archives. ``None``\n means the distribution is created in-memory.\n\n Do not canonicalize this value with e.g. ``pathlib.Path.resolve()``. If\n this is a symbolic link, we want to preserve the relative path between\n it and files in the distribution.\n \"\"\"\n raise NotImplementedError()\n\n @property\n def editable_project_location(self) -> Optional[str]:\n \"\"\"The project location for editable distributions.\n\n This is the directory where pyproject.toml or setup.py is located.\n None if the distribution is not installed in editable mode.\n \"\"\"\n # TODO: this property is relatively costly to compute, memoize it ?\n direct_url = self.direct_url\n if direct_url:\n if direct_url.is_local_editable():\n return url_to_path(direct_url.url)\n else:\n # Search for an .egg-link file by walking sys.path, as it was\n # done before by dist_is_editable().\n egg_link_path = egg_link_path_from_sys_path(self.raw_name)\n if egg_link_path:\n # TODO: get project location from second line of egg_link file\n # (https://github.com/pypa/pip/issues/10243)\n return self.location\n return None\n\n @property\n def installed_location(self) -> Optional[str]:\n \"\"\"The distribution's \"installed\" location.\n\n This should generally be a ``site-packages`` directory. This is\n usually ``dist.location``, except for legacy develop-installed packages,\n where ``dist.location`` is the source code location, and this is where\n the ``.egg-link`` file is.\n\n The returned location is normalized (in particular, with symlinks removed).\n \"\"\"\n raise NotImplementedError()\n\n @property\n def info_location(self) -> Optional[str]:\n \"\"\"Location of the .[egg|dist]-info directory or file.\n\n Similarly to ``location``, a string value is not necessarily a\n filesystem path. ``None`` means the distribution is created in-memory.\n\n For a modern .dist-info installation on disk, this should be something\n like ``{location}/{raw_name}-{version}.dist-info``.\n\n Do not canonicalize this value with e.g. ``pathlib.Path.resolve()``. If\n this is a symbolic link, we want to preserve the relative path between\n it and other files in the distribution.\n \"\"\"\n raise NotImplementedError()\n\n @property\n def installed_by_distutils(self) -> bool:\n \"\"\"Whether this distribution is installed with legacy distutils format.\n\n A distribution installed with \"raw\" distutils not patched by setuptools\n uses one single file at ``info_location`` to store metadata. We need to\n treat this specially on uninstallation.\n \"\"\"\n info_location = self.info_location\n if not info_location:\n return False\n return pathlib.Path(info_location).is_file()\n\n @property\n def installed_as_egg(self) -> bool:\n \"\"\"Whether this distribution is installed as an egg.\n\n This usually indicates the distribution was installed by (older versions\n of) easy_install.\n \"\"\"\n location = self.location\n if not location:\n return False\n return location.endswith(\".egg\")\n\n @property\n def installed_with_setuptools_egg_info(self) -> bool:\n \"\"\"Whether this distribution is installed with the ``.egg-info`` format.\n\n This usually indicates the distribution was installed with setuptools\n with an old pip version or with ``single-version-externally-managed``.\n\n Note that this ensure the metadata store is a directory. distutils can\n also installs an ``.egg-info``, but as a file, not a directory. This\n property is *False* for that case. Also see ``installed_by_distutils``.\n \"\"\"\n info_location = self.info_location\n if not info_location:\n return False\n if not info_location.endswith(\".egg-info\"):\n return False\n return pathlib.Path(info_location).is_dir()\n\n @property\n def installed_with_dist_info(self) -> bool:\n \"\"\"Whether this distribution is installed with the \"modern format\".\n\n This indicates a \"modern\" installation, e.g. storing metadata in the\n ``.dist-info`` directory. This applies to installations made by\n setuptools (but through pip, not directly), or anything using the\n standardized build backend interface (PEP 517).\n \"\"\"\n info_location = self.info_location\n if not info_location:\n return False\n if not info_location.endswith(\".dist-info\"):\n return False\n return pathlib.Path(info_location).is_dir()\n\n @property\n def canonical_name(self) -> NormalizedName:\n raise NotImplementedError()\n\n @property\n def version(self) -> DistributionVersion:\n raise NotImplementedError()\n\n @property\n def setuptools_filename(self) -> str:\n \"\"\"Convert a project name to its setuptools-compatible filename.\n\n This is a copy of ``pkg_resources.to_filename()`` for compatibility.\n \"\"\"\n return self.raw_name.replace(\"-\", \"_\")\n\n @property\n def direct_url(self) -> Optional[DirectUrl]:\n \"\"\"Obtain a DirectUrl from this distribution.\n\n Returns None if the distribution has no `direct_url.json` metadata,\n or if `direct_url.json` is invalid.\n \"\"\"\n try:\n content = self.read_text(DIRECT_URL_METADATA_NAME)\n except FileNotFoundError:\n return None\n try:\n return DirectUrl.from_json(content)\n except (\n UnicodeDecodeError,\n json.JSONDecodeError,\n DirectUrlValidationError,\n ) as e:\n logger.warning(\n \"Error parsing %s for %s: %s\",\n DIRECT_URL_METADATA_NAME,\n self.canonical_name,\n e,\n )\n return None\n\n @property\n def installer(self) -> str:\n try:\n installer_text = self.read_text(\"INSTALLER\")\n except (OSError, ValueError, NoneMetadataError):\n return \"\" # Fail silently if the installer file cannot be read.\n for line in installer_text.splitlines():\n cleaned_line = line.strip()\n if cleaned_line:\n return cleaned_line\n return \"\"\n\n @property\n def requested(self) -> bool:\n return self.is_file(\"REQUESTED\")\n\n @property\n def editable(self) -> bool:\n return bool(self.editable_project_location)\n\n @property\n def local(self) -> bool:\n \"\"\"If distribution is installed in the current virtual environment.\n\n Always True if we're not in a virtualenv.\n \"\"\"\n if self.installed_location is None:\n return False\n return is_local(self.installed_location)\n\n @property\n def in_usersite(self) -> bool:\n if self.installed_location is None or user_site is None:\n return False\n return self.installed_location.startswith(normalize_path(user_site))\n\n @property\n def in_site_packages(self) -> bool:\n if self.installed_location is None or site_packages is None:\n return False\n return self.installed_location.startswith(normalize_path(site_packages))\n\n def is_file(self, path: InfoPath) -> bool:\n \"\"\"Check whether an entry in the info directory is a file.\"\"\"\n raise NotImplementedError()\n\n def iter_distutils_script_names(self) -> Iterator[str]:\n \"\"\"Find distutils 'scripts' entries metadata.\n\n If 'scripts' is supplied in ``setup.py``, distutils records those in the\n installed distribution's ``scripts`` directory, a file for each script.\n \"\"\"\n raise NotImplementedError()\n\n def read_text(self, path: InfoPath) -> str:\n \"\"\"Read a file in the info directory.\n\n :raise FileNotFoundError: If ``path`` does not exist in the directory.\n :raise NoneMetadataError: If ``path`` exists in the info directory, but\n cannot be read.\n \"\"\"\n raise NotImplementedError()\n\n def iter_entry_points(self) -> Iterable[BaseEntryPoint]:\n raise NotImplementedError()\n\n def _metadata_impl(self) -> email.message.Message:\n raise NotImplementedError()\n\n @functools.lru_cache(maxsize=1)\n def _metadata_cached(self) -> email.message.Message:\n # When we drop python 3.7 support, move this to the metadata property and use\n # functools.cached_property instead of lru_cache.\n metadata = self._metadata_impl()\n self._add_egg_info_requires(metadata)\n return metadata\n\n @property\n def metadata(self) -> email.message.Message:\n \"\"\"Metadata of distribution parsed from e.g. METADATA or PKG-INFO.\n\n This should return an empty message if the metadata file is unavailable.\n\n :raises NoneMetadataError: If the metadata file is available, but does\n not contain valid metadata.\n \"\"\"\n return self._metadata_cached()\n\n @property\n def metadata_dict(self) -> Dict[str, Any]:\n \"\"\"PEP 566 compliant JSON-serializable representation of METADATA or PKG-INFO.\n\n This should return an empty dict if the metadata file is unavailable.\n\n :raises NoneMetadataError: If the metadata file is available, but does\n not contain valid metadata.\n \"\"\"\n return msg_to_json(self.metadata)\n\n @property\n def metadata_version(self) -> Optional[str]:\n \"\"\"Value of \"Metadata-Version:\" in distribution metadata, if available.\"\"\"\n return self.metadata.get(\"Metadata-Version\")\n\n @property\n def raw_name(self) -> str:\n \"\"\"Value of \"Name:\" in distribution metadata.\"\"\"\n # The metadata should NEVER be missing the Name: key, but if it somehow\n # does, fall back to the known canonical name.\n return self.metadata.get(\"Name\", self.canonical_name)\n\n @property\n def requires_python(self) -> SpecifierSet:\n \"\"\"Value of \"Requires-Python:\" in distribution metadata.\n\n If the key does not exist or contains an invalid value, an empty\n SpecifierSet should be returned.\n \"\"\"\n value = self.metadata.get(\"Requires-Python\")\n if value is None:\n return SpecifierSet()\n try:\n # Convert to str to satisfy the type checker; this can be a Header object.\n spec = SpecifierSet(str(value))\n except InvalidSpecifier as e:\n message = \"Package %r has an invalid Requires-Python: %s\"\n logger.warning(message, self.raw_name, e)\n return SpecifierSet()\n return spec\n\n def iter_dependencies(self, extras: Collection[str] = ()) -> Iterable[Requirement]:\n \"\"\"Dependencies of this distribution.\n\n For modern .dist-info distributions, this is the collection of\n \"Requires-Dist:\" entries in distribution metadata.\n \"\"\"\n raise NotImplementedError()\n\n def iter_provided_extras(self) -> Iterable[str]:\n \"\"\"Extras provided by this distribution.\n\n For modern .dist-info distributions, this is the collection of\n \"Provides-Extra:\" entries in distribution metadata.\n \"\"\"\n raise NotImplementedError()\n\n def _iter_declared_entries_from_record(self) -> Optional[Iterator[str]]:\n try:\n text = self.read_text(\"RECORD\")\n except FileNotFoundError:\n return None\n # This extra Path-str cast normalizes entries.\n return (str(pathlib.Path(row[0])) for row in csv.reader(text.splitlines()))\n\n def _iter_declared_entries_from_legacy(self) -> Optional[Iterator[str]]:\n try:\n text = self.read_text(\"installed-files.txt\")\n except FileNotFoundError:\n return None\n paths = (p for p in text.splitlines(keepends=False) if p)\n root = self.location\n info = self.info_location\n if root is None or info is None:\n return paths\n try:\n info_rel = pathlib.Path(info).relative_to(root)\n except ValueError: # info is not relative to root.\n return paths\n if not info_rel.parts: # info *is* root.\n return paths\n return (\n _convert_installed_files_path(pathlib.Path(p).parts, info_rel.parts)\n for p in paths\n )\n\n def iter_declared_entries(self) -> Optional[Iterator[str]]:\n \"\"\"Iterate through file entries declared in this distribution.\n\n For modern .dist-info distributions, this is the files listed in the\n ``RECORD`` metadata file. For legacy setuptools distributions, this\n comes from ``installed-files.txt``, with entries normalized to be\n compatible with the format used by ``RECORD``.\n\n :return: An iterator for listed entries, or None if the distribution\n contains neither ``RECORD`` nor ``installed-files.txt``.\n \"\"\"\n return (\n self._iter_declared_entries_from_record()\n or self._iter_declared_entries_from_legacy()\n )\n\n def _iter_requires_txt_entries(self) -> Iterator[RequiresEntry]:\n \"\"\"Parse a ``requires.txt`` in an egg-info directory.\n\n This is an INI-ish format where an egg-info stores dependencies. A\n section name describes extra other environment markers, while each entry\n is an arbitrary string (not a key-value pair) representing a dependency\n as a requirement string (no markers).\n\n There is a construct in ``importlib.metadata`` called ``Sectioned`` that\n does mostly the same, but the format is currently considered private.\n \"\"\"\n try:\n content = self.read_text(\"requires.txt\")\n except FileNotFoundError:\n return\n extra = marker = \"\" # Section-less entries don't have markers.\n for line in content.splitlines():\n line = line.strip()\n if not line or line.startswith(\"#\"): # Comment; ignored.\n continue\n if line.startswith(\"[\") and line.endswith(\"]\"): # A section header.\n extra, _, marker = line.strip(\"[]\").partition(\":\")\n continue\n yield RequiresEntry(requirement=line, extra=extra, marker=marker)\n\n def _iter_egg_info_extras(self) -> Iterable[str]:\n \"\"\"Get extras from the egg-info directory.\"\"\"\n known_extras = {\"\"}\n for entry in self._iter_requires_txt_entries():\n if entry.extra in known_extras:\n continue\n known_extras.add(entry.extra)\n yield entry.extra\n\n def _iter_egg_info_dependencies(self) -> Iterable[str]:\n \"\"\"Get distribution dependencies from the egg-info directory.\n\n To ease parsing, this converts a legacy dependency entry into a PEP 508\n requirement string. Like ``_iter_requires_txt_entries()``, there is code\n in ``importlib.metadata`` that does mostly the same, but not do exactly\n what we need.\n\n Namely, ``importlib.metadata`` does not normalize the extra name before\n putting it into the requirement string, which causes marker comparison\n to fail because the dist-info format do normalize. This is consistent in\n all currently available PEP 517 backends, although not standardized.\n \"\"\"\n for entry in self._iter_requires_txt_entries():\n if entry.extra and entry.marker:\n marker = f'({entry.marker}) and extra == \"{safe_extra(entry.extra)}\"'\n elif entry.extra:\n marker = f'extra == \"{safe_extra(entry.extra)}\"'\n elif entry.marker:\n marker = entry.marker\n else:\n marker = \"\"\n if marker:\n yield f\"{entry.requirement} ; {marker}\"\n else:\n yield entry.requirement\n\n def _add_egg_info_requires(self, metadata: email.message.Message) -> None:\n \"\"\"Add egg-info requires.txt information to the metadata.\"\"\"\n if not metadata.get_all(\"Requires-Dist\"):\n for dep in self._iter_egg_info_dependencies():\n metadata[\"Requires-Dist\"] = dep\n if not metadata.get_all(\"Provides-Extra\"):\n for extra in self._iter_egg_info_extras():\n metadata[\"Provides-Extra\"] = extra\n\n\nclass BaseEnvironment:\n \"\"\"An environment containing distributions to introspect.\"\"\"\n\n @classmethod\n def default(cls) -> \"BaseEnvironment\":\n raise NotImplementedError()\n\n @classmethod\n def from_paths(cls, paths: Optional[List[str]]) -> \"BaseEnvironment\":\n raise NotImplementedError()\n\n def get_distribution(self, name: str) -> Optional[\"BaseDistribution\"]:\n \"\"\"Given a requirement name, return the installed distributions.\n\n The name may not be normalized. The implementation must canonicalize\n it for lookup.\n \"\"\"\n raise NotImplementedError()\n\n def _iter_distributions(self) -> Iterator[\"BaseDistribution\"]:\n \"\"\"Iterate through installed distributions.\n\n This function should be implemented by subclass, but never called\n directly. Use the public ``iter_distribution()`` instead, which\n implements additional logic to make sure the distributions are valid.\n \"\"\"\n raise NotImplementedError()\n\n def iter_all_distributions(self) -> Iterator[BaseDistribution]:\n \"\"\"Iterate through all installed distributions without any filtering.\"\"\"\n for dist in self._iter_distributions():\n # Make sure the distribution actually comes from a valid Python\n # packaging distribution. Pip's AdjacentTempDirectory leaves folders\n # e.g. ``~atplotlib.dist-info`` if cleanup was interrupted. The\n # valid project name pattern is taken from PEP 508.\n project_name_valid = re.match(\n r\"^([A-Z0-9]|[A-Z0-9][A-Z0-9._-]*[A-Z0-9])$\",\n dist.canonical_name,\n flags=re.IGNORECASE,\n )\n if not project_name_valid:\n logger.warning(\n \"Ignoring invalid distribution %s (%s)\",\n dist.canonical_name,\n dist.location,\n )\n continue\n yield dist\n\n def iter_installed_distributions(\n self,\n local_only: bool = True,\n skip: Container[str] = stdlib_pkgs,\n include_editables: bool = True,\n editables_only: bool = False,\n user_only: bool = False,\n ) -> Iterator[BaseDistribution]:\n \"\"\"Return a list of installed distributions.\n\n This is based on ``iter_all_distributions()`` with additional filtering\n options. Note that ``iter_installed_distributions()`` without arguments\n is *not* equal to ``iter_all_distributions()``, since some of the\n configurations exclude packages by default.\n\n :param local_only: If True (default), only return installations\n local to the current virtualenv, if in a virtualenv.\n :param skip: An iterable of canonicalized project names to ignore;\n defaults to ``stdlib_pkgs``.\n :param include_editables: If False, don't report editables.\n :param editables_only: If True, only report editables.\n :param user_only: If True, only report installations in the user\n site directory.\n \"\"\"\n it = self.iter_all_distributions()\n if local_only:\n it = (d for d in it if d.local)\n if not include_editables:\n it = (d for d in it if not d.editable)\n if editables_only:\n it = (d for d in it if d.editable)\n if user_only:\n it = (d for d in it if d.in_usersite)\n return (d for d in it if d.canonical_name not in skip)\n\n\nclass Wheel(Protocol):\n location: str\n\n def as_zipfile(self) -> zipfile.ZipFile:\n raise NotImplementedError()\n\n\nclass FilesystemWheel(Wheel):\n def __init__(self, location: str) -> None:\n self.location = location\n\n def as_zipfile(self) -> zipfile.ZipFile:\n return zipfile.ZipFile(self.location, allowZip64=True)\n\n\nclass MemoryWheel(Wheel):\n def __init__(self, location: str, stream: IO[bytes]) -> None:\n self.location = location\n self.stream = stream\n\n def as_zipfile(self) -> zipfile.ZipFile:\n return zipfile.ZipFile(self.stream, allowZip64=True)\n"
},
{
"path": "lib/python3.7/site-packages/pip/_internal/metadata/importlib/__init__.py",
"content": "from ._dists import Distribution\nfrom ._envs import Environment\n\n__all__ = [\"Distribution\", \"Environment\"]\n"
},
{
"path": "lib/python3.7/site-packages/pip/_internal/metadata/importlib/_compat.py",
"content": "import importlib.metadata\nfrom typing import Any, Optional, Protocol, cast\n\n\nclass BadMetadata(ValueError):\n def __init__(self, dist: importlib.metadata.Distribution, *, reason: str) -> None:\n self.dist = dist\n self.reason = reason\n\n def __str__(self) -> str:\n return f\"Bad metadata in {self.dist} ({self.reason})\"\n\n\nclass BasePath(Protocol):\n \"\"\"A protocol that various path objects conform.\n\n This exists because importlib.metadata uses both ``pathlib.Path`` and\n ``zipfile.Path``, and we need a common base for type hints (Union does not\n work well since ``zipfile.Path`` is too new for our linter setup).\n\n This does not mean to be exhaustive, but only contains things that present\n in both classes *that we need*.\n \"\"\"\n\n @property\n def name(self) -> str:\n raise NotImplementedError()\n\n @property\n def parent(self) -> \"BasePath\":\n raise NotImplementedError()\n\n\ndef get_info_location(d: importlib.metadata.Distribution) -> Optional[BasePath]:\n \"\"\"Find the path to the distribution's metadata directory.\n\n HACK: This relies on importlib.metadata's private ``_path`` attribute. Not\n all distributions exist on disk, so importlib.metadata is correct to not\n expose the attribute as public. But pip's code base is old and not as clean,\n so we do this to avoid having to rewrite too many things. Hopefully we can\n eliminate this some day.\n \"\"\"\n return getattr(d, \"_path\", None)\n\n\ndef get_dist_name(dist: importlib.metadata.Distribution) -> str:\n \"\"\"Get the distribution's project name.\n\n The ``name`` attribute is only available in Python 3.10 or later. We are\n targeting exactly that, but Mypy does not know this.\n \"\"\"\n name = cast(Any, dist).name\n if not isinstance(name, str):\n raise BadMetadata(dist, reason=\"invalid metadata entry 'name'\")\n return name\n"
},
{
"path": "lib/python3.7/site-packages/pip/_internal/metadata/importlib/_dists.py",
"content": "import email.message\nimport importlib.metadata\nimport os\nimport pathlib\nimport zipfile\nfrom typing import (\n Collection,\n Dict,\n Iterable,\n Iterator,\n Mapping,\n Optional,\n Sequence,\n cast,\n)\n\nfrom pip._vendor.packaging.requirements import Requirement\nfrom pip._vendor.packaging.utils import NormalizedName, canonicalize_name\nfrom pip._vendor.packaging.version import parse as parse_version\n\nfrom pip._internal.exceptions import InvalidWheel, UnsupportedWheel\nfrom pip._internal.metadata.base import (\n BaseDistribution,\n BaseEntryPoint,\n DistributionVersion,\n InfoPath,\n Wheel,\n)\nfrom pip._internal.utils.misc import normalize_path\nfrom pip._internal.utils.packaging import safe_extra\nfrom pip._internal.utils.temp_dir import TempDirectory\nfrom pip._internal.utils.wheel import parse_wheel, read_wheel_metadata_file\n\nfrom ._compat import BasePath, get_dist_name\n\n\nclass WheelDistribution(importlib.metadata.Distribution):\n \"\"\"An ``importlib.metadata.Distribution`` read from a wheel.\n\n Although ``importlib.metadata.PathDistribution`` accepts ``zipfile.Path``,\n its implementation is too \"lazy\" for pip's needs (we can't keep the ZipFile\n handle open for the entire lifetime of the distribution object).\n\n This implementation eagerly reads the entire metadata directory into the\n memory instead, and operates from that.\n \"\"\"\n\n def __init__(\n self,\n files: Mapping[pathlib.PurePosixPath, bytes],\n info_location: pathlib.PurePosixPath,\n ) -> None:\n self._files = files\n self.info_location = info_location\n\n @classmethod\n def from_zipfile(\n cls,\n zf: zipfile.ZipFile,\n name: str,\n location: str,\n ) -> \"WheelDistribution\":\n info_dir, _ = parse_wheel(zf, name)\n paths = (\n (name, pathlib.PurePosixPath(name.split(\"/\", 1)[-1]))\n for name in zf.namelist()\n if name.startswith(f\"{info_dir}/\")\n )\n files = {\n relpath: read_wheel_metadata_file(zf, fullpath)\n for fullpath, relpath in paths\n }\n info_location = pathlib.PurePosixPath(location, info_dir)\n return cls(files, info_location)\n\n def iterdir(self, path: InfoPath) -> Iterator[pathlib.PurePosixPath]:\n # Only allow iterating through the metadata directory.\n if pathlib.PurePosixPath(str(path)) in self._files:\n return iter(self._files)\n raise FileNotFoundError(path)\n\n def read_text(self, filename: str) -> Optional[str]:\n try:\n data = self._files[pathlib.PurePosixPath(filename)]\n except KeyError:\n return None\n try:\n text = data.decode(\"utf-8\")\n except UnicodeDecodeError as e:\n wheel = self.info_location.parent\n error = f\"Error decoding metadata for {wheel}: {e} in {filename} file\"\n raise UnsupportedWheel(error)\n return text\n\n\nclass Distribution(BaseDistribution):\n def __init__(\n self,\n dist: importlib.metadata.Distribution,\n info_location: Optional[BasePath],\n installed_location: Optional[BasePath],\n ) -> None:\n self._dist = dist\n self._info_location = info_location\n self._installed_location = installed_location\n\n @classmethod\n def from_directory(cls, directory: str) -> BaseDistribution:\n info_location = pathlib.Path(directory)\n dist = importlib.metadata.Distribution.at(info_location)\n return cls(dist, info_location, info_location.parent)\n\n @classmethod\n def from_metadata_file_contents(\n cls,\n metadata_contents: bytes,\n filename: str,\n project_name: str,\n ) -> BaseDistribution:\n # Generate temp dir to contain the metadata file, and write the file contents.\n temp_dir = pathlib.Path(\n TempDirectory(kind=\"metadata\", globally_managed=True).path\n )\n metadata_path = temp_dir / \"METADATA\"\n metadata_path.write_bytes(metadata_contents)\n # Construct dist pointing to the newly created directory.\n dist = importlib.metadata.Distribution.at(metadata_path.parent)\n return cls(dist, metadata_path.parent, None)\n\n @classmethod\n def from_wheel(cls, wheel: Wheel, name: str) -> BaseDistribution:\n try:\n with wheel.as_zipfile() as zf:\n dist = WheelDistribution.from_zipfile(zf, name, wheel.location)\n except zipfile.BadZipFile as e:\n raise InvalidWheel(wheel.location, name) from e\n except UnsupportedWheel as e:\n raise UnsupportedWheel(f\"{name} has an invalid wheel, {e}\")\n return cls(dist, dist.info_location, pathlib.PurePosixPath(wheel.location))\n\n @property\n def location(self) -> Optional[str]:\n if self._info_location is None:\n return None\n return str(self._info_location.parent)\n\n @property\n def info_location(self) -> Optional[str]:\n if self._info_location is None:\n return None\n return str(self._info_location)\n\n @property\n def installed_location(self) -> Optional[str]:\n if self._installed_location is None:\n return None\n return normalize_path(str(self._installed_location))\n\n def _get_dist_name_from_location(self) -> Optional[str]:\n \"\"\"Try to get the name from the metadata directory name.\n\n This is much faster than reading metadata.\n \"\"\"\n if self._info_location is None:\n return None\n stem, suffix = os.path.splitext(self._info_location.name)\n if suffix not in (\".dist-info\", \".egg-info\"):\n return None\n return stem.split(\"-\", 1)[0]\n\n @property\n def canonical_name(self) -> NormalizedName:\n name = self._get_dist_name_from_location() or get_dist_name(self._dist)\n return canonicalize_name(name)\n\n @property\n def version(self) -> DistributionVersion:\n return parse_version(self._dist.version)\n\n def is_file(self, path: InfoPath) -> bool:\n return self._dist.read_text(str(path)) is not None\n\n def iter_distutils_script_names(self) -> Iterator[str]:\n # A distutils installation is always \"flat\" (not in e.g. egg form), so\n # if this distribution's info location is NOT a pathlib.Path (but e.g.\n # zipfile.Path), it can never contain any distutils scripts.\n if not isinstance(self._info_location, pathlib.Path):\n return\n for child in self._info_location.joinpath(\"scripts\").iterdir():\n yield child.name\n\n def read_text(self, path: InfoPath) -> str:\n content = self._dist.read_text(str(path))\n if content is None:\n raise FileNotFoundError(path)\n return content\n\n def iter_entry_points(self) -> Iterable[BaseEntryPoint]:\n # importlib.metadata's EntryPoint structure sasitfies BaseEntryPoint.\n return self._dist.entry_points\n\n def _metadata_impl(self) -> email.message.Message:\n # From Python 3.10+, importlib.metadata declares PackageMetadata as the\n # return type. This protocol is unfortunately a disaster now and misses\n # a ton of fields that we need, including get() and get_payload(). We\n # rely on the implementation that the object is actually a Message now,\n # until upstream can improve the protocol. (python/cpython#94952)\n return cast(email.message.Message, self._dist.metadata)\n\n def iter_provided_extras(self) -> Iterable[str]:\n return (\n safe_extra(extra) for extra in self.metadata.get_all(\"Provides-Extra\", [])\n )\n\n def iter_dependencies(self, extras: Collection[str] = ()) -> Iterable[Requirement]:\n contexts: Sequence[Dict[str, str]] = [{\"extra\": safe_extra(e)} for e in extras]\n for req_string in self.metadata.get_all(\"Requires-Dist\", []):\n req = Requirement(req_string)\n if not req.marker:\n yield req\n elif not extras and req.marker.evaluate({\"extra\": \"\"}):\n yield req\n elif any(req.marker.evaluate(context) for context in contexts):\n yield req\n"
},
{
"path": "lib/python3.7/site-packages/pip/_internal/metadata/importlib/_envs.py",
"content": "import functools\nimport importlib.metadata\nimport logging\nimport os\nimport pathlib\nimport sys\nimport zipfile\nimport zipimport\nfrom typing import Iterator, List, Optional, Sequence, Set, Tuple\n\nfrom pip._vendor.packaging.utils import NormalizedName, canonicalize_name\n\nfrom pip._internal.metadata.base import BaseDistribution, BaseEnvironment\nfrom pip._internal.models.wheel import Wheel\nfrom pip._internal.utils.deprecation import deprecated\nfrom pip._internal.utils.filetypes import WHEEL_EXTENSION\n\nfrom ._compat import BadMetadata, BasePath, get_dist_name, get_info_location\nfrom ._dists import Distribution\n\nlogger = logging.getLogger(__name__)\n\n\ndef _looks_like_wheel(location: str) -> bool:\n if not location.endswith(WHEEL_EXTENSION):\n return False\n if not os.path.isfile(location):\n return False\n if not Wheel.wheel_file_re.match(os.path.basename(location)):\n return False\n return zipfile.is_zipfile(location)\n\n\nclass _DistributionFinder:\n \"\"\"Finder to locate distributions.\n\n The main purpose of this class is to memoize found distributions' names, so\n only one distribution is returned for each package name. At lot of pip code\n assumes this (because it is setuptools's behavior), and not doing the same\n can potentially cause a distribution in lower precedence path to override a\n higher precedence one if the caller is not careful.\n\n Eventually we probably want to make it possible to see lower precedence\n installations as well. It's useful feature, after all.\n \"\"\"\n\n FoundResult = Tuple[importlib.metadata.Distribution, Optional[BasePath]]\n\n def __init__(self) -> None:\n self._found_names: Set[NormalizedName] = set()\n\n def _find_impl(self, location: str) -> Iterator[FoundResult]:\n \"\"\"Find distributions in a location.\"\"\"\n # Skip looking inside a wheel. Since a package inside a wheel is not\n # always valid (due to .data directories etc.), its .dist-info entry\n # should not be considered an installed distribution.\n if _looks_like_wheel(location):\n return\n # To know exactly where we find a distribution, we have to feed in the\n # paths one by one, instead of dumping the list to importlib.metadata.\n for dist in importlib.metadata.distributions(path=[location]):\n info_location = get_info_location(dist)\n try:\n raw_name = get_dist_name(dist)\n except BadMetadata as e:\n logger.warning(\"Skipping %s due to %s\", info_location, e.reason)\n continue\n normalized_name = canonicalize_name(raw_name)\n if normalized_name in self._found_names:\n continue\n self._found_names.add(normalized_name)\n yield dist, info_location\n\n def find(self, location: str) -> Iterator[BaseDistribution]:\n \"\"\"Find distributions in a location.\n\n The path can be either a directory, or a ZIP archive.\n \"\"\"\n for dist, info_location in self._find_impl(location):\n if info_location is None:\n installed_location: Optional[BasePath] = None\n else:\n installed_location = info_location.parent\n yield Distribution(dist, info_location, installed_location)\n\n def find_linked(self, location: str) -> Iterator[BaseDistribution]:\n \"\"\"Read location in egg-link files and return distributions in there.\n\n The path should be a directory; otherwise this returns nothing. This\n follows how setuptools does this for compatibility. The first non-empty\n line in the egg-link is read as a path (resolved against the egg-link's\n containing directory if relative). Distributions found at that linked\n location are returned.\n \"\"\"\n path = pathlib.Path(location)\n if not path.is_dir():\n return\n for child in path.iterdir():\n if child.suffix != \".egg-link\":\n continue\n with child.open() as f:\n lines = (line.strip() for line in f)\n target_rel = next((line for line in lines if line), \"\")\n if not target_rel:\n continue\n target_location = str(path.joinpath(target_rel))\n for dist, info_location in self._find_impl(target_location):\n yield Distribution(dist, info_location, path)\n\n def _find_eggs_in_dir(self, location: str) -> Iterator[BaseDistribution]:\n from pip._vendor.pkg_resources import find_distributions\n\n from pip._internal.metadata import pkg_resources as legacy\n\n with os.scandir(location) as it:\n for entry in it:\n if not entry.name.endswith(\".egg\"):\n continue\n for dist in find_distributions(entry.path):\n yield legacy.Distribution(dist)\n\n def _find_eggs_in_zip(self, location: str) -> Iterator[BaseDistribution]:\n from pip._vendor.pkg_resources import find_eggs_in_zip\n\n from pip._internal.metadata import pkg_resources as legacy\n\n try:\n importer = zipimport.zipimporter(location)\n except zipimport.ZipImportError:\n return\n for dist in find_eggs_in_zip(importer, location):\n yield legacy.Distribution(dist)\n\n def find_eggs(self, location: str) -> Iterator[BaseDistribution]:\n \"\"\"Find eggs in a location.\n\n This actually uses the old *pkg_resources* backend. We likely want to\n deprecate this so we can eventually remove the *pkg_resources*\n dependency entirely. Before that, this should first emit a deprecation\n warning for some versions when using the fallback since importing\n *pkg_resources* is slow for those who don't need it.\n \"\"\"\n if os.path.isdir(location):\n yield from self._find_eggs_in_dir(location)\n if zipfile.is_zipfile(location):\n yield from self._find_eggs_in_zip(location)\n\n\n@functools.lru_cache(maxsize=None) # Warn a distribution exactly once.\ndef _emit_egg_deprecation(location: Optional[str]) -> None:\n deprecated(\n reason=f\"Loading egg at {location} is deprecated.\",\n replacement=\"to use pip for package installation.\",\n gone_in=None,\n )\n\n\nclass Environment(BaseEnvironment):\n def __init__(self, paths: Sequence[str]) -> None:\n self._paths = paths\n\n @classmethod\n def default(cls) -> BaseEnvironment:\n return cls(sys.path)\n\n @classmethod\n def from_paths(cls, paths: Optional[List[str]]) -> BaseEnvironment:\n if paths is None:\n return cls(sys.path)\n return cls(paths)\n\n def _iter_distributions(self) -> Iterator[BaseDistribution]:\n finder = _DistributionFinder()\n for location in self._paths:\n yield from finder.find(location)\n for dist in finder.find_eggs(location):\n # _emit_egg_deprecation(dist.location) # TODO: Enable this.\n yield dist\n # This must go last because that's how pkg_resources tie-breaks.\n yield from finder.find_linked(location)\n\n def get_distribution(self, name: str) -> Optional[BaseDistribution]:\n matches = (\n distribution\n for distribution in self.iter_all_distributions()\n if distribution.canonical_name == canonicalize_name(name)\n )\n return next(matches, None)\n"
},
{
"path": "lib/python3.7/site-packages/pip/_internal/metadata/pkg_resources.py",
"content": "import email.message\nimport email.parser\nimport logging\nimport os\nimport zipfile\nfrom typing import Collection, Iterable, Iterator, List, Mapping, NamedTuple, Optional\n\nfrom pip._vendor import pkg_resources\nfrom pip._vendor.packaging.requirements import Requirement\nfrom pip._vendor.packaging.utils import NormalizedName, canonicalize_name\nfrom pip._vendor.packaging.version import parse as parse_version\n\nfrom pip._internal.exceptions import InvalidWheel, NoneMetadataError, UnsupportedWheel\nfrom pip._internal.utils.egg_link import egg_link_path_from_location\nfrom pip._internal.utils.misc import display_path, normalize_path\nfrom pip._internal.utils.wheel import parse_wheel, read_wheel_metadata_file\n\nfrom .base import (\n BaseDistribution,\n BaseEntryPoint,\n BaseEnvironment,\n DistributionVersion,\n InfoPath,\n Wheel,\n)\n\nlogger = logging.getLogger(__name__)\n\n\nclass EntryPoint(NamedTuple):\n name: str\n value: str\n group: str\n\n\nclass InMemoryMetadata:\n \"\"\"IMetadataProvider that reads metadata files from a dictionary.\n\n This also maps metadata decoding exceptions to our internal exception type.\n \"\"\"\n\n def __init__(self, metadata: Mapping[str, bytes], wheel_name: str) -> None:\n self._metadata = metadata\n self._wheel_name = wheel_name\n\n def has_metadata(self, name: str) -> bool:\n return name in self._metadata\n\n def get_metadata(self, name: str) -> str:\n try:\n return self._metadata[name].decode()\n except UnicodeDecodeError as e:\n # Augment the default error with the origin of the file.\n raise UnsupportedWheel(\n f\"Error decoding metadata for {self._wheel_name}: {e} in {name} file\"\n )\n\n def get_metadata_lines(self, name: str) -> Iterable[str]:\n return pkg_resources.yield_lines(self.get_metadata(name))\n\n def metadata_isdir(self, name: str) -> bool:\n return False\n\n def metadata_listdir(self, name: str) -> List[str]:\n return []\n\n def run_script(self, script_name: str, namespace: str) -> None:\n pass\n\n\nclass Distribution(BaseDistribution):\n def __init__(self, dist: pkg_resources.Distribution) -> None:\n self._dist = dist\n\n @classmethod\n def from_directory(cls, directory: str) -> BaseDistribution:\n dist_dir = directory.rstrip(os.sep)\n\n # Build a PathMetadata object, from path to metadata. :wink:\n base_dir, dist_dir_name = os.path.split(dist_dir)\n metadata = pkg_resources.PathMetadata(base_dir, dist_dir)\n\n # Determine the correct Distribution object type.\n if dist_dir.endswith(\".egg-info\"):\n dist_cls = pkg_resources.Distribution\n dist_name = os.path.splitext(dist_dir_name)[0]\n else:\n assert dist_dir.endswith(\".dist-info\")\n dist_cls = pkg_resources.DistInfoDistribution\n dist_name = os.path.splitext(dist_dir_name)[0].split(\"-\")[0]\n\n dist = dist_cls(base_dir, project_name=dist_name, metadata=metadata)\n return cls(dist)\n\n @classmethod\n def from_metadata_file_contents(\n cls,\n metadata_contents: bytes,\n filename: str,\n project_name: str,\n ) -> BaseDistribution:\n metadata_dict = {\n \"METADATA\": metadata_contents,\n }\n dist = pkg_resources.DistInfoDistribution(\n location=filename,\n metadata=InMemoryMetadata(metadata_dict, filename),\n project_name=project_name,\n )\n return cls(dist)\n\n @classmethod\n def from_wheel(cls, wheel: Wheel, name: str) -> BaseDistribution:\n try:\n with wheel.as_zipfile() as zf:\n info_dir, _ = parse_wheel(zf, name)\n metadata_dict = {\n path.split(\"/\", 1)[-1]: read_wheel_metadata_file(zf, path)\n for path in zf.namelist()\n if path.startswith(f\"{info_dir}/\")\n }\n except zipfile.BadZipFile as e:\n raise InvalidWheel(wheel.location, name) from e\n except UnsupportedWheel as e:\n raise UnsupportedWheel(f\"{name} has an invalid wheel, {e}\")\n dist = pkg_resources.DistInfoDistribution(\n location=wheel.location,\n metadata=InMemoryMetadata(metadata_dict, wheel.location),\n project_name=name,\n )\n return cls(dist)\n\n @property\n def location(self) -> Optional[str]:\n return self._dist.location\n\n @property\n def installed_location(self) -> Optional[str]:\n egg_link = egg_link_path_from_location(self.raw_name)\n if egg_link:\n location = egg_link\n elif self.location:\n location = self.location\n else:\n return None\n return normalize_path(location)\n\n @property\n def info_location(self) -> Optional[str]:\n return self._dist.egg_info\n\n @property\n def installed_by_distutils(self) -> bool:\n # A distutils-installed distribution is provided by FileMetadata. This\n # provider has a \"path\" attribute not present anywhere else. Not the\n # best introspection logic, but pip has been doing this for a long time.\n try:\n return bool(self._dist._provider.path)\n except AttributeError:\n return False\n\n @property\n def canonical_name(self) -> NormalizedName:\n return canonicalize_name(self._dist.project_name)\n\n @property\n def version(self) -> DistributionVersion:\n return parse_version(self._dist.version)\n\n def is_file(self, path: InfoPath) -> bool:\n return self._dist.has_metadata(str(path))\n\n def iter_distutils_script_names(self) -> Iterator[str]:\n yield from self._dist.metadata_listdir(\"scripts\")\n\n def read_text(self, path: InfoPath) -> str:\n name = str(path)\n if not self._dist.has_metadata(name):\n raise FileNotFoundError(name)\n content = self._dist.get_metadata(name)\n if content is None:\n raise NoneMetadataError(self, name)\n return content\n\n def iter_entry_points(self) -> Iterable[BaseEntryPoint]:\n for group, entries in self._dist.get_entry_map().items():\n for name, entry_point in entries.items():\n name, _, value = str(entry_point).partition(\"=\")\n yield EntryPoint(name=name.strip(), value=value.strip(), group=group)\n\n def _metadata_impl(self) -> email.message.Message:\n \"\"\"\n :raises NoneMetadataError: if the distribution reports `has_metadata()`\n True but `get_metadata()` returns None.\n \"\"\"\n if isinstance(self._dist, pkg_resources.DistInfoDistribution):\n metadata_name = \"METADATA\"\n else:\n metadata_name = \"PKG-INFO\"\n try:\n metadata = self.read_text(metadata_name)\n except FileNotFoundError:\n if self.location:\n displaying_path = display_path(self.location)\n else:\n displaying_path = repr(self.location)\n logger.warning(\"No metadata found in %s\", displaying_path)\n metadata = \"\"\n feed_parser = email.parser.FeedParser()\n feed_parser.feed(metadata)\n return feed_parser.close()\n\n def iter_dependencies(self, extras: Collection[str] = ()) -> Iterable[Requirement]:\n if extras: # pkg_resources raises on invalid extras, so we sanitize.\n extras = frozenset(extras).intersection(self._dist.extras)\n return self._dist.requires(extras)\n\n def iter_provided_extras(self) -> Iterable[str]:\n return self._dist.extras\n\n\nclass Environment(BaseEnvironment):\n def __init__(self, ws: pkg_resources.WorkingSet) -> None:\n self._ws = ws\n\n @classmethod\n def default(cls) -> BaseEnvironment:\n return cls(pkg_resources.working_set)\n\n @classmethod\n def from_paths(cls, paths: Optional[List[str]]) -> BaseEnvironment:\n return cls(pkg_resources.WorkingSet(paths))\n\n def _iter_distributions(self) -> Iterator[BaseDistribution]:\n for dist in self._ws:\n yield Distribution(dist)\n\n def _search_distribution(self, name: str) -> Optional[BaseDistribution]:\n \"\"\"Find a distribution matching the ``name`` in the environment.\n\n This searches from *all* distributions available in the environment, to\n match the behavior of ``pkg_resources.get_distribution()``.\n \"\"\"\n canonical_name = canonicalize_name(name)\n for dist in self.iter_all_distributions():\n if dist.canonical_name == canonical_name:\n return dist\n return None\n\n def get_distribution(self, name: str) -> Optional[BaseDistribution]:\n # Search the distribution by looking through the working set.\n dist = self._search_distribution(name)\n if dist:\n return dist\n\n # If distribution could not be found, call working_set.require to\n # update the working set, and try to find the distribution again.\n # This might happen for e.g. when you install a package twice, once\n # using setup.py develop and again using setup.py install. Now when\n # running pip uninstall twice, the package gets removed from the\n # working set in the first uninstall, so we have to populate the\n # working set again so that pip knows about it and the packages gets\n # picked up and is successfully uninstalled the second time too.\n try:\n # We didn't pass in any version specifiers, so this can never\n # raise pkg_resources.VersionConflict.\n self._ws.require(name)\n except pkg_resources.DistributionNotFound:\n return None\n return self._search_distribution(name)\n"
},
{
"path": "lib/python3.7/site-packages/pip/_internal/models/__init__.py",
"content": "\"\"\"A package that contains models that represent entities.\n\"\"\"\n"
},
{
"path": "lib/python3.7/site-packages/pip/_internal/models/candidate.py",
"content": "from pip._vendor.packaging.version import parse as parse_version\n\nfrom pip._internal.models.link import Link\nfrom pip._internal.utils.models import KeyBasedCompareMixin\n\n\nclass InstallationCandidate(KeyBasedCompareMixin):\n \"\"\"Represents a potential \"candidate\" for installation.\"\"\"\n\n __slots__ = [\"name\", \"version\", \"link\"]\n\n def __init__(self, name: str, version: str, link: Link) -> None:\n self.name = name\n self.version = parse_version(version)\n self.link = link\n\n super().__init__(\n key=(self.name, self.version, self.link),\n defining_class=InstallationCandidate,\n )\n\n def __repr__(self) -> str:\n return \"\".format(\n self.name,\n self.version,\n self.link,\n )\n\n def __str__(self) -> str:\n return \"{!r} candidate (version {} at {})\".format(\n self.name,\n self.version,\n self.link,\n )\n"
},
{
"path": "lib/python3.7/site-packages/pip/_internal/models/direct_url.py",
"content": "\"\"\" PEP 610 \"\"\"\nimport json\nimport re\nimport urllib.parse\nfrom typing import Any, Dict, Iterable, Optional, Type, TypeVar, Union\n\n__all__ = [\n \"DirectUrl\",\n \"DirectUrlValidationError\",\n \"DirInfo\",\n \"ArchiveInfo\",\n \"VcsInfo\",\n]\n\nT = TypeVar(\"T\")\n\nDIRECT_URL_METADATA_NAME = \"direct_url.json\"\nENV_VAR_RE = re.compile(r\"^\\$\\{[A-Za-z0-9-_]+\\}(:\\$\\{[A-Za-z0-9-_]+\\})?$\")\n\n\nclass DirectUrlValidationError(Exception):\n pass\n\n\ndef _get(\n d: Dict[str, Any], expected_type: Type[T], key: str, default: Optional[T] = None\n) -> Optional[T]:\n \"\"\"Get value from dictionary and verify expected type.\"\"\"\n if key not in d:\n return default\n value = d[key]\n if not isinstance(value, expected_type):\n raise DirectUrlValidationError(\n \"{!r} has unexpected type for {} (expected {})\".format(\n value, key, expected_type\n )\n )\n return value\n\n\ndef _get_required(\n d: Dict[str, Any], expected_type: Type[T], key: str, default: Optional[T] = None\n) -> T:\n value = _get(d, expected_type, key, default)\n if value is None:\n raise DirectUrlValidationError(f\"{key} must have a value\")\n return value\n\n\ndef _exactly_one_of(infos: Iterable[Optional[\"InfoType\"]]) -> \"InfoType\":\n infos = [info for info in infos if info is not None]\n if not infos:\n raise DirectUrlValidationError(\n \"missing one of archive_info, dir_info, vcs_info\"\n )\n if len(infos) > 1:\n raise DirectUrlValidationError(\n \"more than one of archive_info, dir_info, vcs_info\"\n )\n assert infos[0] is not None\n return infos[0]\n\n\ndef _filter_none(**kwargs: Any) -> Dict[str, Any]:\n \"\"\"Make dict excluding None values.\"\"\"\n return {k: v for k, v in kwargs.items() if v is not None}\n\n\nclass VcsInfo:\n name = \"vcs_info\"\n\n def __init__(\n self,\n vcs: str,\n commit_id: str,\n requested_revision: Optional[str] = None,\n ) -> None:\n self.vcs = vcs\n self.requested_revision = requested_revision\n self.commit_id = commit_id\n\n @classmethod\n def _from_dict(cls, d: Optional[Dict[str, Any]]) -> Optional[\"VcsInfo\"]:\n if d is None:\n return None\n return cls(\n vcs=_get_required(d, str, \"vcs\"),\n commit_id=_get_required(d, str, \"commit_id\"),\n requested_revision=_get(d, str, \"requested_revision\"),\n )\n\n def _to_dict(self) -> Dict[str, Any]:\n return _filter_none(\n vcs=self.vcs,\n requested_revision=self.requested_revision,\n commit_id=self.commit_id,\n )\n\n\nclass ArchiveInfo:\n name = \"archive_info\"\n\n def __init__(\n self,\n hash: Optional[str] = None,\n ) -> None:\n self.hash = hash\n\n @classmethod\n def _from_dict(cls, d: Optional[Dict[str, Any]]) -> Optional[\"ArchiveInfo\"]:\n if d is None:\n return None\n return cls(hash=_get(d, str, \"hash\"))\n\n def _to_dict(self) -> Dict[str, Any]:\n return _filter_none(hash=self.hash)\n\n\nclass DirInfo:\n name = \"dir_info\"\n\n def __init__(\n self,\n editable: bool = False,\n ) -> None:\n self.editable = editable\n\n @classmethod\n def _from_dict(cls, d: Optional[Dict[str, Any]]) -> Optional[\"DirInfo\"]:\n if d is None:\n return None\n return cls(editable=_get_required(d, bool, \"editable\", default=False))\n\n def _to_dict(self) -> Dict[str, Any]:\n return _filter_none(editable=self.editable or None)\n\n\nInfoType = Union[ArchiveInfo, DirInfo, VcsInfo]\n\n\nclass DirectUrl:\n def __init__(\n self,\n url: str,\n info: InfoType,\n subdirectory: Optional[str] = None,\n ) -> None:\n self.url = url\n self.info = info\n self.subdirectory = subdirectory\n\n def _remove_auth_from_netloc(self, netloc: str) -> str:\n if \"@\" not in netloc:\n return netloc\n user_pass, netloc_no_user_pass = netloc.split(\"@\", 1)\n if (\n isinstance(self.info, VcsInfo)\n and self.info.vcs == \"git\"\n and user_pass == \"git\"\n ):\n return netloc\n if ENV_VAR_RE.match(user_pass):\n return netloc\n return netloc_no_user_pass\n\n @property\n def redacted_url(self) -> str:\n \"\"\"url with user:password part removed unless it is formed with\n environment variables as specified in PEP 610, or it is ``git``\n in the case of a git URL.\n \"\"\"\n purl = urllib.parse.urlsplit(self.url)\n netloc = self._remove_auth_from_netloc(purl.netloc)\n surl = urllib.parse.urlunsplit(\n (purl.scheme, netloc, purl.path, purl.query, purl.fragment)\n )\n return surl\n\n def validate(self) -> None:\n self.from_dict(self.to_dict())\n\n @classmethod\n def from_dict(cls, d: Dict[str, Any]) -> \"DirectUrl\":\n return DirectUrl(\n url=_get_required(d, str, \"url\"),\n subdirectory=_get(d, str, \"subdirectory\"),\n info=_exactly_one_of(\n [\n ArchiveInfo._from_dict(_get(d, dict, \"archive_info\")),\n DirInfo._from_dict(_get(d, dict, \"dir_info\")),\n VcsInfo._from_dict(_get(d, dict, \"vcs_info\")),\n ]\n ),\n )\n\n def to_dict(self) -> Dict[str, Any]:\n res = _filter_none(\n url=self.redacted_url,\n subdirectory=self.subdirectory,\n )\n res[self.info.name] = self.info._to_dict()\n return res\n\n @classmethod\n def from_json(cls, s: str) -> \"DirectUrl\":\n return cls.from_dict(json.loads(s))\n\n def to_json(self) -> str:\n return json.dumps(self.to_dict(), sort_keys=True)\n\n def is_local_editable(self) -> bool:\n return isinstance(self.info, DirInfo) and self.info.editable\n"
},
{
"path": "lib/python3.7/site-packages/pip/_internal/models/format_control.py",
"content": "from typing import FrozenSet, Optional, Set\n\nfrom pip._vendor.packaging.utils import canonicalize_name\n\nfrom pip._internal.exceptions import CommandError\n\n\nclass FormatControl:\n \"\"\"Helper for managing formats from which a package can be installed.\"\"\"\n\n __slots__ = [\"no_binary\", \"only_binary\"]\n\n def __init__(\n self,\n no_binary: Optional[Set[str]] = None,\n only_binary: Optional[Set[str]] = None,\n ) -> None:\n if no_binary is None:\n no_binary = set()\n if only_binary is None:\n only_binary = set()\n\n self.no_binary = no_binary\n self.only_binary = only_binary\n\n def __eq__(self, other: object) -> bool:\n if not isinstance(other, self.__class__):\n return NotImplemented\n\n if self.__slots__ != other.__slots__:\n return False\n\n return all(getattr(self, k) == getattr(other, k) for k in self.__slots__)\n\n def __repr__(self) -> str:\n return \"{}({}, {})\".format(\n self.__class__.__name__, self.no_binary, self.only_binary\n )\n\n @staticmethod\n def handle_mutual_excludes(value: str, target: Set[str], other: Set[str]) -> None:\n if value.startswith(\"-\"):\n raise CommandError(\n \"--no-binary / --only-binary option requires 1 argument.\"\n )\n new = value.split(\",\")\n while \":all:\" in new:\n other.clear()\n target.clear()\n target.add(\":all:\")\n del new[: new.index(\":all:\") + 1]\n # Without a none, we want to discard everything as :all: covers it\n if \":none:\" not in new:\n return\n for name in new:\n if name == \":none:\":\n target.clear()\n continue\n name = canonicalize_name(name)\n other.discard(name)\n target.add(name)\n\n def get_allowed_formats(self, canonical_name: str) -> FrozenSet[str]:\n result = {\"binary\", \"source\"}\n if canonical_name in self.only_binary:\n result.discard(\"source\")\n elif canonical_name in self.no_binary:\n result.discard(\"binary\")\n elif \":all:\" in self.only_binary:\n result.discard(\"source\")\n elif \":all:\" in self.no_binary:\n result.discard(\"binary\")\n return frozenset(result)\n\n def disallow_binaries(self) -> None:\n self.handle_mutual_excludes(\n \":all:\",\n self.no_binary,\n self.only_binary,\n )\n"
},
{
"path": "lib/python3.7/site-packages/pip/_internal/models/index.py",
"content": "import urllib.parse\n\n\nclass PackageIndex:\n \"\"\"Represents a Package Index and provides easier access to endpoints\"\"\"\n\n __slots__ = [\"url\", \"netloc\", \"simple_url\", \"pypi_url\", \"file_storage_domain\"]\n\n def __init__(self, url: str, file_storage_domain: str) -> None:\n super().__init__()\n self.url = url\n self.netloc = urllib.parse.urlsplit(url).netloc\n self.simple_url = self._url_for_path(\"simple\")\n self.pypi_url = self._url_for_path(\"pypi\")\n\n # This is part of a temporary hack used to block installs of PyPI\n # packages which depend on external urls only necessary until PyPI can\n # block such packages themselves\n self.file_storage_domain = file_storage_domain\n\n def _url_for_path(self, path: str) -> str:\n return urllib.parse.urljoin(self.url, path)\n\n\nPyPI = PackageIndex(\"https://pypi.org/\", file_storage_domain=\"files.pythonhosted.org\")\nTestPyPI = PackageIndex(\n \"https://test.pypi.org/\", file_storage_domain=\"test-files.pythonhosted.org\"\n)\n"
},
{
"path": "lib/python3.7/site-packages/pip/_internal/models/installation_report.py",
"content": "from typing import Any, Dict, Sequence\n\nfrom pip._vendor.packaging.markers import default_environment\n\nfrom pip import __version__\nfrom pip._internal.req.req_install import InstallRequirement\n\n\nclass InstallationReport:\n def __init__(self, install_requirements: Sequence[InstallRequirement]):\n self._install_requirements = install_requirements\n\n @classmethod\n def _install_req_to_dict(cls, ireq: InstallRequirement) -> Dict[str, Any]:\n assert ireq.download_info, f\"No download_info for {ireq}\"\n res = {\n # PEP 610 json for the download URL. download_info.archive_info.hash may\n # be absent when the requirement was installed from the wheel cache\n # and the cache entry was populated by an older pip version that did not\n # record origin.json.\n \"download_info\": ireq.download_info.to_dict(),\n # is_direct is true if the requirement was a direct URL reference (which\n # includes editable requirements), and false if the requirement was\n # downloaded from a PEP 503 index or --find-links.\n \"is_direct\": bool(ireq.original_link),\n # requested is true if the requirement was specified by the user (aka\n # top level requirement), and false if it was installed as a dependency of a\n # requirement. https://peps.python.org/pep-0376/#requested\n \"requested\": ireq.user_supplied,\n # PEP 566 json encoding for metadata\n # https://www.python.org/dev/peps/pep-0566/#json-compatible-metadata\n \"metadata\": ireq.get_dist().metadata_dict,\n }\n if ireq.user_supplied and ireq.extras:\n # For top level requirements, the list of requested extras, if any.\n res[\"requested_extras\"] = list(sorted(ireq.extras))\n return res\n\n def to_dict(self) -> Dict[str, Any]:\n return {\n \"version\": \"0\",\n \"pip_version\": __version__,\n \"install\": [\n self._install_req_to_dict(ireq) for ireq in self._install_requirements\n ],\n # https://peps.python.org/pep-0508/#environment-markers\n # TODO: currently, the resolver uses the default environment to evaluate\n # environment markers, so that is what we report here. In the future, it\n # should also take into account options such as --python-version or\n # --platform, perhaps under the form of an environment_override field?\n # https://github.com/pypa/pip/issues/11198\n \"environment\": default_environment(),\n }\n"
},
{
"path": "lib/python3.7/site-packages/pip/_internal/models/link.py",
"content": "import functools\nimport itertools\nimport logging\nimport os\nimport posixpath\nimport re\nimport urllib.parse\nfrom dataclasses import dataclass\nfrom typing import (\n TYPE_CHECKING,\n Any,\n Dict,\n List,\n Mapping,\n NamedTuple,\n Optional,\n Tuple,\n Union,\n)\n\nfrom pip._internal.utils.filetypes import WHEEL_EXTENSION\nfrom pip._internal.utils.hashes import Hashes\nfrom pip._internal.utils.misc import (\n pairwise,\n redact_auth_from_url,\n split_auth_from_netloc,\n splitext,\n)\nfrom pip._internal.utils.models import KeyBasedCompareMixin\nfrom pip._internal.utils.urls import path_to_url, url_to_path\n\nif TYPE_CHECKING:\n from pip._internal.index.collector import IndexContent\n\nlogger = logging.getLogger(__name__)\n\n\n# Order matters, earlier hashes have a precedence over later hashes for what\n# we will pick to use.\n_SUPPORTED_HASHES = (\"sha512\", \"sha384\", \"sha256\", \"sha224\", \"sha1\", \"md5\")\n\n\n@dataclass(frozen=True)\nclass LinkHash:\n \"\"\"Links to content may have embedded hash values. This class parses those.\n\n `name` must be any member of `_SUPPORTED_HASHES`.\n\n This class can be converted to and from `ArchiveInfo`. While ArchiveInfo intends to\n be JSON-serializable to conform to PEP 610, this class contains the logic for\n parsing a hash name and value for correctness, and then checking whether that hash\n conforms to a schema with `.is_hash_allowed()`.\"\"\"\n\n name: str\n value: str\n\n _hash_re = re.compile(\n # NB: we do not validate that the second group (.*) is a valid hex\n # digest. Instead, we simply keep that string in this class, and then check it\n # against Hashes when hash-checking is needed. This is easier to debug than\n # proactively discarding an invalid hex digest, as we handle incorrect hashes\n # and malformed hashes in the same place.\n r\"({choices})=(.*)\".format(\n choices=\"|\".join(re.escape(hash_name) for hash_name in _SUPPORTED_HASHES)\n ),\n )\n\n def __post_init__(self) -> None:\n assert self._hash_re.match(f\"{self.name}={self.value}\")\n\n @classmethod\n @functools.lru_cache(maxsize=None)\n def split_hash_name_and_value(cls, url: str) -> Optional[\"LinkHash\"]:\n \"\"\"Search a string for a checksum algorithm name and encoded output value.\"\"\"\n match = cls._hash_re.search(url)\n if match is None:\n return None\n name, value = match.groups()\n return cls(name=name, value=value)\n\n def as_hashes(self) -> Hashes:\n \"\"\"Return a Hashes instance which checks only for the current hash.\"\"\"\n return Hashes({self.name: [self.value]})\n\n def is_hash_allowed(self, hashes: Optional[Hashes]) -> bool:\n \"\"\"\n Return True if the current hash is allowed by `hashes`.\n \"\"\"\n if hashes is None:\n return False\n return hashes.is_hash_allowed(self.name, hex_digest=self.value)\n\n\ndef _clean_url_path_part(part: str) -> str:\n \"\"\"\n Clean a \"part\" of a URL path (i.e. after splitting on \"@\" characters).\n \"\"\"\n # We unquote prior to quoting to make sure nothing is double quoted.\n return urllib.parse.quote(urllib.parse.unquote(part))\n\n\ndef _clean_file_url_path(part: str) -> str:\n \"\"\"\n Clean the first part of a URL path that corresponds to a local\n filesystem path (i.e. the first part after splitting on \"@\" characters).\n \"\"\"\n # We unquote prior to quoting to make sure nothing is double quoted.\n # Also, on Windows the path part might contain a drive letter which\n # should not be quoted. On Linux where drive letters do not\n # exist, the colon should be quoted. We rely on urllib.request\n # to do the right thing here.\n return urllib.request.pathname2url(urllib.request.url2pathname(part))\n\n\n# percent-encoded: /\n_reserved_chars_re = re.compile(\"(@|%2F)\", re.IGNORECASE)\n\n\ndef _clean_url_path(path: str, is_local_path: bool) -> str:\n \"\"\"\n Clean the path portion of a URL.\n \"\"\"\n if is_local_path:\n clean_func = _clean_file_url_path\n else:\n clean_func = _clean_url_path_part\n\n # Split on the reserved characters prior to cleaning so that\n # revision strings in VCS URLs are properly preserved.\n parts = _reserved_chars_re.split(path)\n\n cleaned_parts = []\n for to_clean, reserved in pairwise(itertools.chain(parts, [\"\"])):\n cleaned_parts.append(clean_func(to_clean))\n # Normalize %xx escapes (e.g. %2f -> %2F)\n cleaned_parts.append(reserved.upper())\n\n return \"\".join(cleaned_parts)\n\n\ndef _ensure_quoted_url(url: str) -> str:\n \"\"\"\n Make sure a link is fully quoted.\n For example, if ' ' occurs in the URL, it will be replaced with \"%20\",\n and without double-quoting other characters.\n \"\"\"\n # Split the URL into parts according to the general structure\n # `scheme://netloc/path;parameters?query#fragment`.\n result = urllib.parse.urlparse(url)\n # If the netloc is empty, then the URL refers to a local filesystem path.\n is_local_path = not result.netloc\n path = _clean_url_path(result.path, is_local_path=is_local_path)\n return urllib.parse.urlunparse(result._replace(path=path))\n\n\nclass Link(KeyBasedCompareMixin):\n \"\"\"Represents a parsed link from a Package Index's simple URL\"\"\"\n\n __slots__ = [\n \"_parsed_url\",\n \"_url\",\n \"_hashes\",\n \"comes_from\",\n \"requires_python\",\n \"yanked_reason\",\n \"dist_info_metadata\",\n \"link_hash\",\n \"cache_link_parsing\",\n ]\n\n def __init__(\n self,\n url: str,\n comes_from: Optional[Union[str, \"IndexContent\"]] = None,\n requires_python: Optional[str] = None,\n yanked_reason: Optional[str] = None,\n dist_info_metadata: Optional[str] = None,\n link_hash: Optional[LinkHash] = None,\n cache_link_parsing: bool = True,\n hashes: Optional[Mapping[str, str]] = None,\n ) -> None:\n \"\"\"\n :param url: url of the resource pointed to (href of the link)\n :param comes_from: instance of IndexContent where the link was found,\n or string.\n :param requires_python: String containing the `Requires-Python`\n metadata field, specified in PEP 345. This may be specified by\n a data-requires-python attribute in the HTML link tag, as\n described in PEP 503.\n :param yanked_reason: the reason the file has been yanked, if the\n file has been yanked, or None if the file hasn't been yanked.\n This is the value of the \"data-yanked\" attribute, if present, in\n a simple repository HTML link. If the file has been yanked but\n no reason was provided, this should be the empty string. See\n PEP 592 for more information and the specification.\n :param dist_info_metadata: the metadata attached to the file, or None if no such\n metadata is provided. This is the value of the \"data-dist-info-metadata\"\n attribute, if present, in a simple repository HTML link. This may be parsed\n into its own `Link` by `self.metadata_link()`. See PEP 658 for more\n information and the specification.\n :param link_hash: a checksum for the content the link points to. If not\n provided, this will be extracted from the link URL, if the URL has\n any checksum.\n :param cache_link_parsing: A flag that is used elsewhere to determine\n whether resources retrieved from this link\n should be cached. PyPI index urls should\n generally have this set to False, for\n example.\n :param hashes: A mapping of hash names to digests to allow us to\n determine the validity of a download.\n \"\"\"\n\n # url can be a UNC windows share\n if url.startswith(\"\\\\\\\\\"):\n url = path_to_url(url)\n\n self._parsed_url = urllib.parse.urlsplit(url)\n # Store the url as a private attribute to prevent accidentally\n # trying to set a new value.\n self._url = url\n self._hashes = hashes if hashes is not None else {}\n\n self.comes_from = comes_from\n self.requires_python = requires_python if requires_python else None\n self.yanked_reason = yanked_reason\n self.dist_info_metadata = dist_info_metadata\n self.link_hash = link_hash or LinkHash.split_hash_name_and_value(self._url)\n\n super().__init__(key=url, defining_class=Link)\n\n self.cache_link_parsing = cache_link_parsing\n\n @classmethod\n def from_json(\n cls,\n file_data: Dict[str, Any],\n page_url: str,\n ) -> Optional[\"Link\"]:\n \"\"\"\n Convert an pypi json document from a simple repository page into a Link.\n \"\"\"\n file_url = file_data.get(\"url\")\n if file_url is None:\n return None\n\n url = _ensure_quoted_url(urllib.parse.urljoin(page_url, file_url))\n pyrequire = file_data.get(\"requires-python\")\n yanked_reason = file_data.get(\"yanked\")\n dist_info_metadata = file_data.get(\"dist-info-metadata\")\n hashes = file_data.get(\"hashes\", {})\n\n # The Link.yanked_reason expects an empty string instead of a boolean.\n if yanked_reason and not isinstance(yanked_reason, str):\n yanked_reason = \"\"\n # The Link.yanked_reason expects None instead of False.\n elif not yanked_reason:\n yanked_reason = None\n\n return cls(\n url,\n comes_from=page_url,\n requires_python=pyrequire,\n yanked_reason=yanked_reason,\n hashes=hashes,\n dist_info_metadata=dist_info_metadata,\n )\n\n @classmethod\n def from_element(\n cls,\n anchor_attribs: Dict[str, Optional[str]],\n page_url: str,\n base_url: str,\n ) -> Optional[\"Link\"]:\n \"\"\"\n Convert an anchor element's attributes in a simple repository page to a Link.\n \"\"\"\n href = anchor_attribs.get(\"href\")\n if not href:\n return None\n\n url = _ensure_quoted_url(urllib.parse.urljoin(base_url, href))\n pyrequire = anchor_attribs.get(\"data-requires-python\")\n yanked_reason = anchor_attribs.get(\"data-yanked\")\n dist_info_metadata = anchor_attribs.get(\"data-dist-info-metadata\")\n\n return cls(\n url,\n comes_from=page_url,\n requires_python=pyrequire,\n yanked_reason=yanked_reason,\n dist_info_metadata=dist_info_metadata,\n )\n\n def __str__(self) -> str:\n if self.requires_python:\n rp = f\" (requires-python:{self.requires_python})\"\n else:\n rp = \"\"\n if self.comes_from:\n return \"{} (from {}){}\".format(\n redact_auth_from_url(self._url), self.comes_from, rp\n )\n else:\n return redact_auth_from_url(str(self._url))\n\n def __repr__(self) -> str:\n return f\"





 \n
\n


