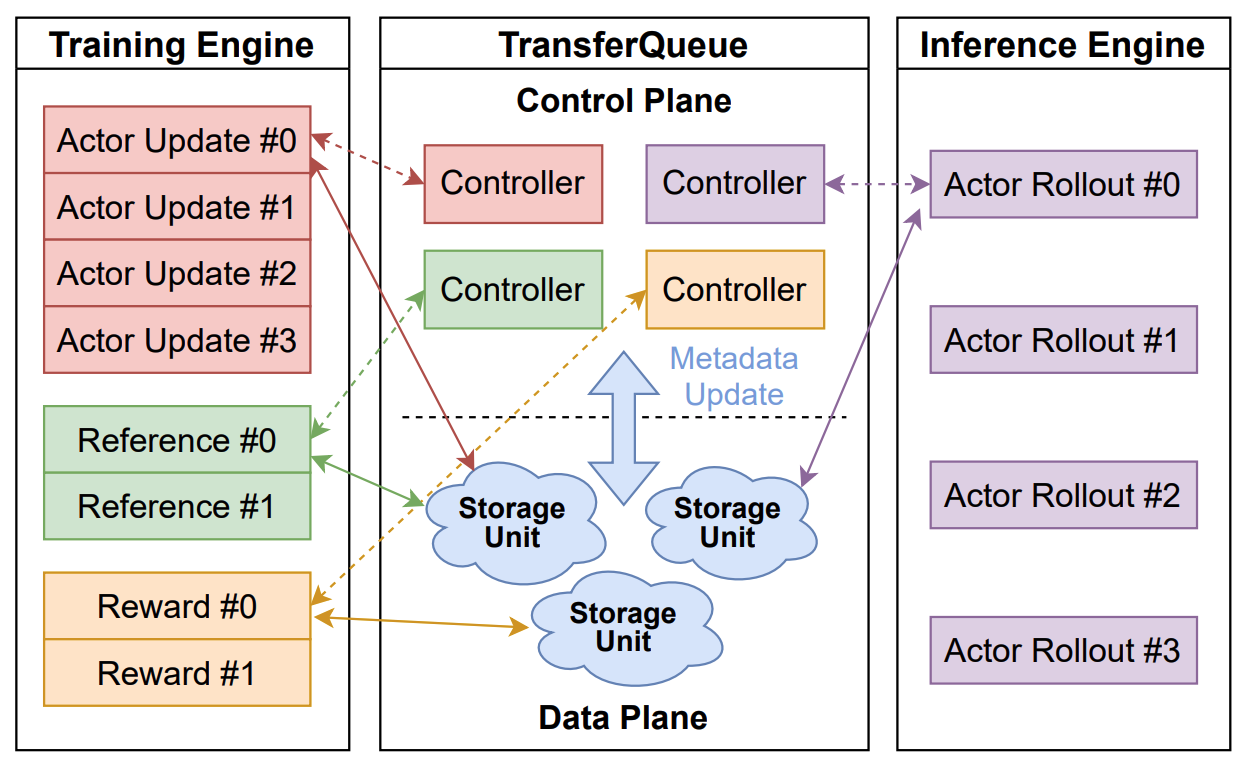
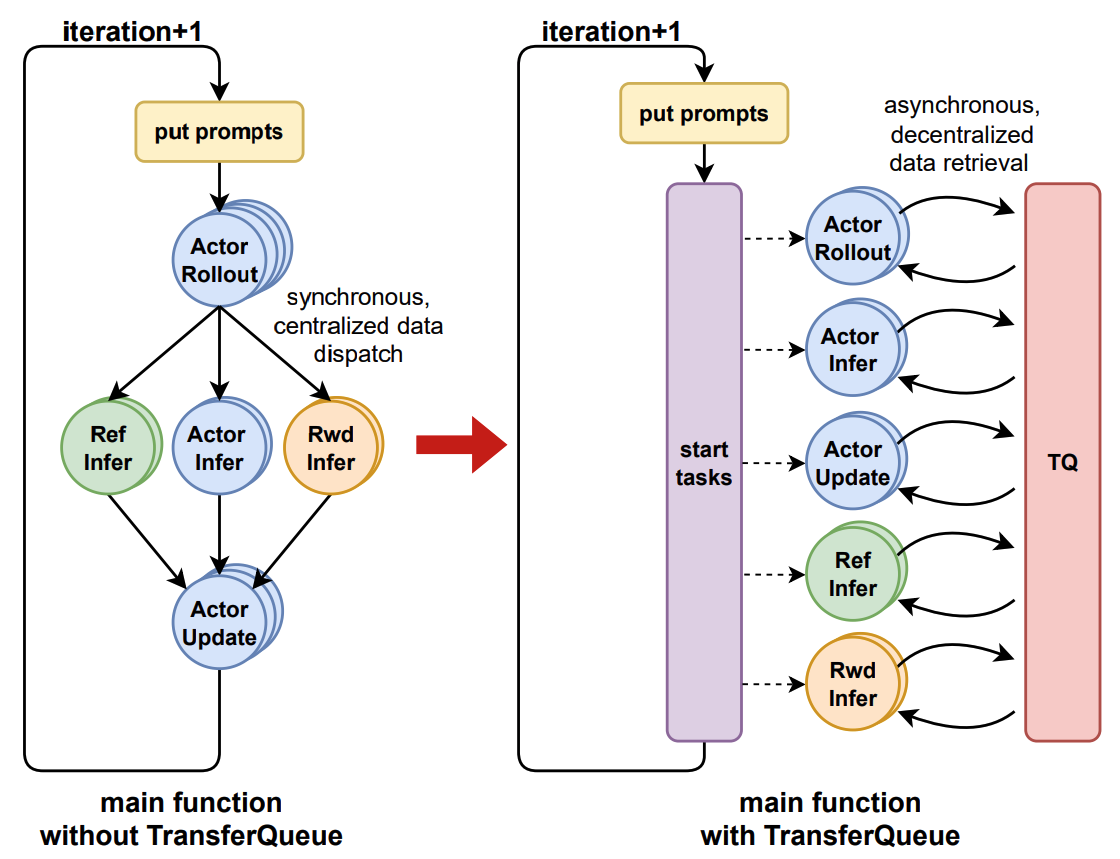
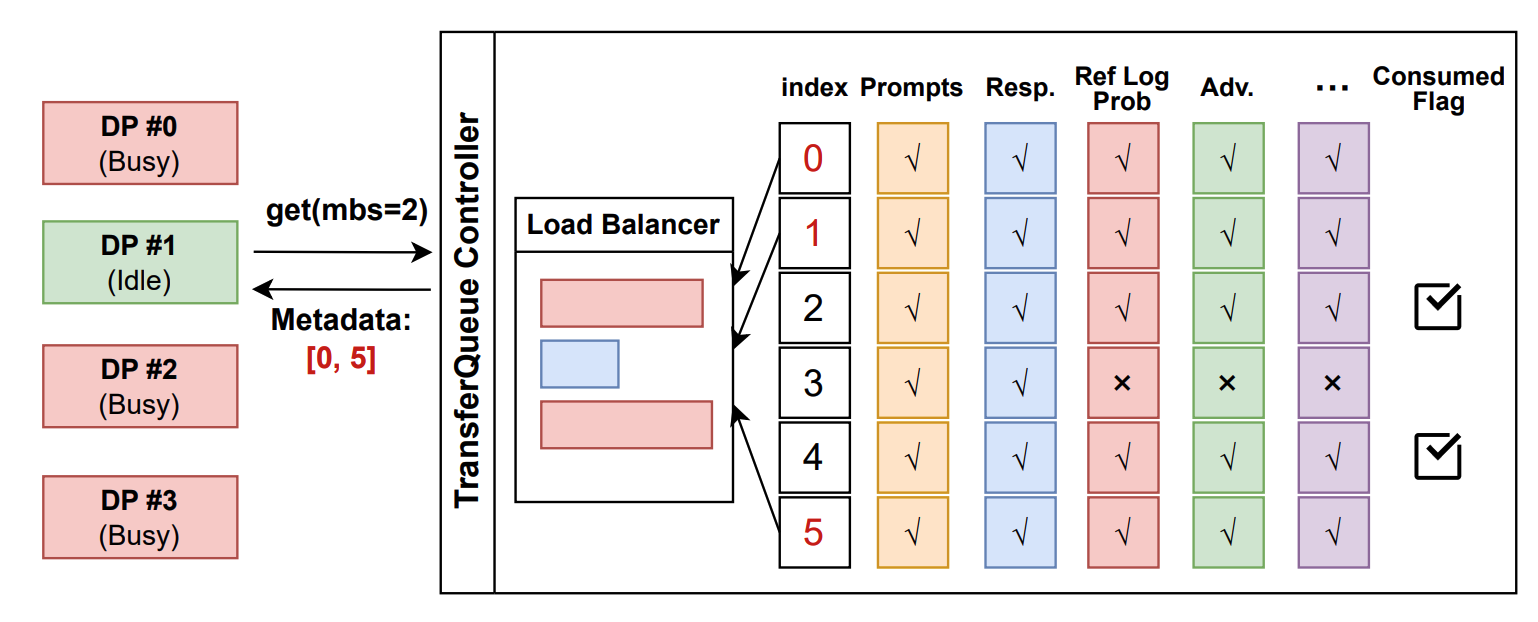
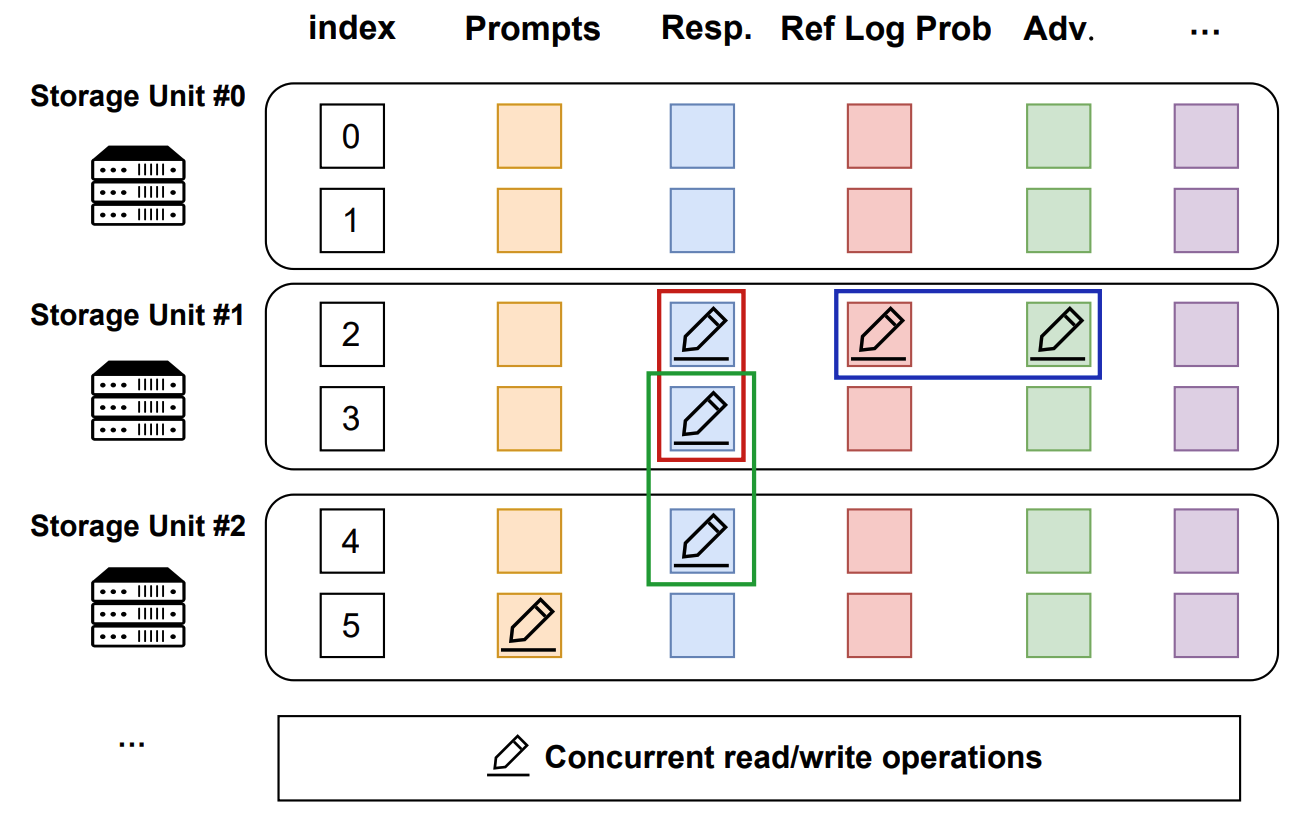
OpenOneRec
An Open Foundation Model and Benchmark to Accelerate Generative Recommendation
An Open Foundation Model and Benchmark to Accelerate Generative Recommendation


 [](https://verl.readthedocs.io/en/latest/)
[](https://verl.readthedocs.io/en/latest/)