Repository: KylinC/ChatFinance
Branch: main
Commit: 679b7e0536d4
Files: 41
Total size: 104.0 KB
Directory structure:
gitextract_6q7spk49/
├── .gitignore
├── LICENSE
├── README.md
├── configs/
│ ├── inference.json
│ ├── server.json
│ └── train.json
├── database_server/
│ ├── elastic_search/
│ │ ├── README
│ │ ├── clear.py
│ │ ├── db.py
│ │ └── docker-compose.yml
│ └── weaviate/
│ ├── README
│ ├── db.py
│ ├── docker-compose.yml
│ ├── scripts/
│ │ ├── QA.txt
│ │ ├── connection.py
│ │ └── query.py
│ └── utils.py
├── downloads/
│ ├── download_all.sh
│ ├── download_data.sh
│ └── download_model.sh
├── inference_6b.py
├── inference_6b.sh
├── models_server/
│ ├── chatglm2/
│ │ ├── README
│ │ ├── jina_client.py
│ │ └── jina_server.py
│ └── text2vec/
│ ├── jina_embedding.py
│ └── jina_server.py
├── prompts/
│ ├── answer_generation.py
│ ├── entity_recognition.py
│ ├── information_extraction.py
│ ├── intent_recognition.py
│ ├── open_question.py
│ └── relevance_scoring.py
├── requirements.txt
├── sft/
│ ├── chatglm2_6b_sft_adalora.py
│ ├── chatglm2_6b_sft_lora.py
│ ├── chatglm2_6b_sft_qlora.py
│ └── utils.py
├── sft_6b.sh
├── stop_all.sh
└── utils.py
================================================
FILE CONTENTS
================================================
================================================
FILE: .gitignore
================================================
# Byte-compiled / optimized / DLL files
__pycache__/
*.py[cod]
*$py.class
# C extensions
*.so
# data & models
data/
models/
# Distribution / packaging
.Python
build/
develop-eggs/
dist/
logs/
eggs/
.eggs/
lib/
lib64/
parts/
sdist/
var/
wheels/
share/python-wheels/
*.egg-info/
.installed.cfg
*.egg
MANIFEST
# PyInstaller
# Usually these files are written by a python script from a template
# before PyInstaller builds the exe, so as to inject date/other infos into it.
*.manifest
*.spec
# Installer logs
pip-log.txt
pip-delete-this-directory.txt
# Unit test / coverage reports
htmlcov/
.tox/
.nox/
.coverage
.coverage.*
.cache
nosetests.xml
coverage.xml
*.cover
*.py,cover
.hypothesis/
.pytest_cache/
cover/
# Translations
*.mo
*.pot
# Django stuff:
*.log
local_settings.py
db.sqlite3
db.sqlite3-journal
# Flask stuff:
instance/
.webassets-cache
# Scrapy stuff:
.scrapy
# Sphinx documentation
docs/_build/
# PyBuilder
.pybuilder/
target/
# Jupyter Notebook
.ipynb_checkpoints
# IPython
profile_default/
ipython_config.py
# pyenv
# For a library or package, you might want to ignore these files since the code is
# intended to run in multiple environments; otherwise, check them in:
# .python-version
# pipenv
# According to pypa/pipenv#598, it is recommended to include Pipfile.lock in version control.
# However, in case of collaboration, if having platform-specific dependencies or dependencies
# having no cross-platform support, pipenv may install dependencies that don't work, or not
# install all needed dependencies.
#Pipfile.lock
# poetry
# Similar to Pipfile.lock, it is generally recommended to include poetry.lock in version control.
# This is especially recommended for binary packages to ensure reproducibility, and is more
# commonly ignored for libraries.
# https://python-poetry.org/docs/basic-usage/#commit-your-poetrylock-file-to-version-control
#poetry.lock
# pdm
# Similar to Pipfile.lock, it is generally recommended to include pdm.lock in version control.
#pdm.lock
# pdm stores project-wide configurations in .pdm.toml, but it is recommended to not include it
# in version control.
# https://pdm.fming.dev/#use-with-ide
.pdm.toml
# PEP 582; used by e.g. github.com/David-OConnor/pyflow and github.com/pdm-project/pdm
__pypackages__/
# Celery stuff
celerybeat-schedule
celerybeat.pid
# SageMath parsed files
*.sage.py
# Environments
.env
.venv
env/
venv/
ENV/
env.bak/
venv.bak/
# Spyder project settings
.spyderproject
.spyproject
# Rope project settings
.ropeproject
# mkdocs documentation
/site
# mypy
.mypy_cache/
.dmypy.json
dmypy.json
# Pyre type checker
.pyre/
# pytype static type analyzer
.pytype/
# Cython debug symbols
cython_debug/
# PyCharm
# JetBrains specific template is maintained in a separate JetBrains.gitignore that can
# be found at https://github.com/github/gitignore/blob/main/Global/JetBrains.gitignore
# and can be added to the global gitignore or merged into this file. For a more nuclear
# option (not recommended) you can uncomment the following to ignore the entire idea folder.
#.idea/
================================================
FILE: LICENSE
================================================
GNU AFFERO GENERAL PUBLIC LICENSE
Version 3, 19 November 2007
Copyright (C) 2007 Free Software Foundation, Inc.
Everyone is permitted to copy and distribute verbatim copies
of this license document, but changing it is not allowed.
Preamble
The GNU Affero General Public License is a free, copyleft license for
software and other kinds of works, specifically designed to ensure
cooperation with the community in the case of network server software.
The licenses for most software and other practical works are designed
to take away your freedom to share and change the works. By contrast,
our General Public Licenses are intended to guarantee your freedom to
share and change all versions of a program--to make sure it remains free
software for all its users.
When we speak of free software, we are referring to freedom, not
price. Our General Public Licenses are designed to make sure that you
have the freedom to distribute copies of free software (and charge for
them if you wish), that you receive source code or can get it if you
want it, that you can change the software or use pieces of it in new
free programs, and that you know you can do these things.
Developers that use our General Public Licenses protect your rights
with two steps: (1) assert copyright on the software, and (2) offer
you this License which gives you legal permission to copy, distribute
and/or modify the software.
A secondary benefit of defending all users' freedom is that
improvements made in alternate versions of the program, if they
receive widespread use, become available for other developers to
incorporate. Many developers of free software are heartened and
encouraged by the resulting cooperation. However, in the case of
software used on network servers, this result may fail to come about.
The GNU General Public License permits making a modified version and
letting the public access it on a server without ever releasing its
source code to the public.
The GNU Affero General Public License is designed specifically to
ensure that, in such cases, the modified source code becomes available
to the community. It requires the operator of a network server to
provide the source code of the modified version running there to the
users of that server. Therefore, public use of a modified version, on
a publicly accessible server, gives the public access to the source
code of the modified version.
An older license, called the Affero General Public License and
published by Affero, was designed to accomplish similar goals. This is
a different license, not a version of the Affero GPL, but Affero has
released a new version of the Affero GPL which permits relicensing under
this license.
The precise terms and conditions for copying, distribution and
modification follow.
TERMS AND CONDITIONS
0. Definitions.
"This License" refers to version 3 of the GNU Affero General Public License.
"Copyright" also means copyright-like laws that apply to other kinds of
works, such as semiconductor masks.
"The Program" refers to any copyrightable work licensed under this
License. Each licensee is addressed as "you". "Licensees" and
"recipients" may be individuals or organizations.
To "modify" a work means to copy from or adapt all or part of the work
in a fashion requiring copyright permission, other than the making of an
exact copy. The resulting work is called a "modified version" of the
earlier work or a work "based on" the earlier work.
A "covered work" means either the unmodified Program or a work based
on the Program.
To "propagate" a work means to do anything with it that, without
permission, would make you directly or secondarily liable for
infringement under applicable copyright law, except executing it on a
computer or modifying a private copy. Propagation includes copying,
distribution (with or without modification), making available to the
public, and in some countries other activities as well.
To "convey" a work means any kind of propagation that enables other
parties to make or receive copies. Mere interaction with a user through
a computer network, with no transfer of a copy, is not conveying.
An interactive user interface displays "Appropriate Legal Notices"
to the extent that it includes a convenient and prominently visible
feature that (1) displays an appropriate copyright notice, and (2)
tells the user that there is no warranty for the work (except to the
extent that warranties are provided), that licensees may convey the
work under this License, and how to view a copy of this License. If
the interface presents a list of user commands or options, such as a
menu, a prominent item in the list meets this criterion.
1. Source Code.
The "source code" for a work means the preferred form of the work
for making modifications to it. "Object code" means any non-source
form of a work.
A "Standard Interface" means an interface that either is an official
standard defined by a recognized standards body, or, in the case of
interfaces specified for a particular programming language, one that
is widely used among developers working in that language.
The "System Libraries" of an executable work include anything, other
than the work as a whole, that (a) is included in the normal form of
packaging a Major Component, but which is not part of that Major
Component, and (b) serves only to enable use of the work with that
Major Component, or to implement a Standard Interface for which an
implementation is available to the public in source code form. A
"Major Component", in this context, means a major essential component
(kernel, window system, and so on) of the specific operating system
(if any) on which the executable work runs, or a compiler used to
produce the work, or an object code interpreter used to run it.
The "Corresponding Source" for a work in object code form means all
the source code needed to generate, install, and (for an executable
work) run the object code and to modify the work, including scripts to
control those activities. However, it does not include the work's
System Libraries, or general-purpose tools or generally available free
programs which are used unmodified in performing those activities but
which are not part of the work. For example, Corresponding Source
includes interface definition files associated with source files for
the work, and the source code for shared libraries and dynamically
linked subprograms that the work is specifically designed to require,
such as by intimate data communication or control flow between those
subprograms and other parts of the work.
The Corresponding Source need not include anything that users
can regenerate automatically from other parts of the Corresponding
Source.
The Corresponding Source for a work in source code form is that
same work.
2. Basic Permissions.
All rights granted under this License are granted for the term of
copyright on the Program, and are irrevocable provided the stated
conditions are met. This License explicitly affirms your unlimited
permission to run the unmodified Program. The output from running a
covered work is covered by this License only if the output, given its
content, constitutes a covered work. This License acknowledges your
rights of fair use or other equivalent, as provided by copyright law.
You may make, run and propagate covered works that you do not
convey, without conditions so long as your license otherwise remains
in force. You may convey covered works to others for the sole purpose
of having them make modifications exclusively for you, or provide you
with facilities for running those works, provided that you comply with
the terms of this License in conveying all material for which you do
not control copyright. Those thus making or running the covered works
for you must do so exclusively on your behalf, under your direction
and control, on terms that prohibit them from making any copies of
your copyrighted material outside their relationship with you.
Conveying under any other circumstances is permitted solely under
the conditions stated below. Sublicensing is not allowed; section 10
makes it unnecessary.
3. Protecting Users' Legal Rights From Anti-Circumvention Law.
No covered work shall be deemed part of an effective technological
measure under any applicable law fulfilling obligations under article
11 of the WIPO copyright treaty adopted on 20 December 1996, or
similar laws prohibiting or restricting circumvention of such
measures.
When you convey a covered work, you waive any legal power to forbid
circumvention of technological measures to the extent such circumvention
is effected by exercising rights under this License with respect to
the covered work, and you disclaim any intention to limit operation or
modification of the work as a means of enforcing, against the work's
users, your or third parties' legal rights to forbid circumvention of
technological measures.
4. Conveying Verbatim Copies.
You may convey verbatim copies of the Program's source code as you
receive it, in any medium, provided that you conspicuously and
appropriately publish on each copy an appropriate copyright notice;
keep intact all notices stating that this License and any
non-permissive terms added in accord with section 7 apply to the code;
keep intact all notices of the absence of any warranty; and give all
recipients a copy of this License along with the Program.
You may charge any price or no price for each copy that you convey,
and you may offer support or warranty protection for a fee.
5. Conveying Modified Source Versions.
You may convey a work based on the Program, or the modifications to
produce it from the Program, in the form of source code under the
terms of section 4, provided that you also meet all of these conditions:
a) The work must carry prominent notices stating that you modified
it, and giving a relevant date.
b) The work must carry prominent notices stating that it is
released under this License and any conditions added under section
7. This requirement modifies the requirement in section 4 to
"keep intact all notices".
c) You must license the entire work, as a whole, under this
License to anyone who comes into possession of a copy. This
License will therefore apply, along with any applicable section 7
additional terms, to the whole of the work, and all its parts,
regardless of how they are packaged. This License gives no
permission to license the work in any other way, but it does not
invalidate such permission if you have separately received it.
d) If the work has interactive user interfaces, each must display
Appropriate Legal Notices; however, if the Program has interactive
interfaces that do not display Appropriate Legal Notices, your
work need not make them do so.
A compilation of a covered work with other separate and independent
works, which are not by their nature extensions of the covered work,
and which are not combined with it such as to form a larger program,
in or on a volume of a storage or distribution medium, is called an
"aggregate" if the compilation and its resulting copyright are not
used to limit the access or legal rights of the compilation's users
beyond what the individual works permit. Inclusion of a covered work
in an aggregate does not cause this License to apply to the other
parts of the aggregate.
6. Conveying Non-Source Forms.
You may convey a covered work in object code form under the terms
of sections 4 and 5, provided that you also convey the
machine-readable Corresponding Source under the terms of this License,
in one of these ways:
a) Convey the object code in, or embodied in, a physical product
(including a physical distribution medium), accompanied by the
Corresponding Source fixed on a durable physical medium
customarily used for software interchange.
b) Convey the object code in, or embodied in, a physical product
(including a physical distribution medium), accompanied by a
written offer, valid for at least three years and valid for as
long as you offer spare parts or customer support for that product
model, to give anyone who possesses the object code either (1) a
copy of the Corresponding Source for all the software in the
product that is covered by this License, on a durable physical
medium customarily used for software interchange, for a price no
more than your reasonable cost of physically performing this
conveying of source, or (2) access to copy the
Corresponding Source from a network server at no charge.
c) Convey individual copies of the object code with a copy of the
written offer to provide the Corresponding Source. This
alternative is allowed only occasionally and noncommercially, and
only if you received the object code with such an offer, in accord
with subsection 6b.
d) Convey the object code by offering access from a designated
place (gratis or for a charge), and offer equivalent access to the
Corresponding Source in the same way through the same place at no
further charge. You need not require recipients to copy the
Corresponding Source along with the object code. If the place to
copy the object code is a network server, the Corresponding Source
may be on a different server (operated by you or a third party)
that supports equivalent copying facilities, provided you maintain
clear directions next to the object code saying where to find the
Corresponding Source. Regardless of what server hosts the
Corresponding Source, you remain obligated to ensure that it is
available for as long as needed to satisfy these requirements.
e) Convey the object code using peer-to-peer transmission, provided
you inform other peers where the object code and Corresponding
Source of the work are being offered to the general public at no
charge under subsection 6d.
A separable portion of the object code, whose source code is excluded
from the Corresponding Source as a System Library, need not be
included in conveying the object code work.
A "User Product" is either (1) a "consumer product", which means any
tangible personal property which is normally used for personal, family,
or household purposes, or (2) anything designed or sold for incorporation
into a dwelling. In determining whether a product is a consumer product,
doubtful cases shall be resolved in favor of coverage. For a particular
product received by a particular user, "normally used" refers to a
typical or common use of that class of product, regardless of the status
of the particular user or of the way in which the particular user
actually uses, or expects or is expected to use, the product. A product
is a consumer product regardless of whether the product has substantial
commercial, industrial or non-consumer uses, unless such uses represent
the only significant mode of use of the product.
"Installation Information" for a User Product means any methods,
procedures, authorization keys, or other information required to install
and execute modified versions of a covered work in that User Product from
a modified version of its Corresponding Source. The information must
suffice to ensure that the continued functioning of the modified object
code is in no case prevented or interfered with solely because
modification has been made.
If you convey an object code work under this section in, or with, or
specifically for use in, a User Product, and the conveying occurs as
part of a transaction in which the right of possession and use of the
User Product is transferred to the recipient in perpetuity or for a
fixed term (regardless of how the transaction is characterized), the
Corresponding Source conveyed under this section must be accompanied
by the Installation Information. But this requirement does not apply
if neither you nor any third party retains the ability to install
modified object code on the User Product (for example, the work has
been installed in ROM).
The requirement to provide Installation Information does not include a
requirement to continue to provide support service, warranty, or updates
for a work that has been modified or installed by the recipient, or for
the User Product in which it has been modified or installed. Access to a
network may be denied when the modification itself materially and
adversely affects the operation of the network or violates the rules and
protocols for communication across the network.
Corresponding Source conveyed, and Installation Information provided,
in accord with this section must be in a format that is publicly
documented (and with an implementation available to the public in
source code form), and must require no special password or key for
unpacking, reading or copying.
7. Additional Terms.
"Additional permissions" are terms that supplement the terms of this
License by making exceptions from one or more of its conditions.
Additional permissions that are applicable to the entire Program shall
be treated as though they were included in this License, to the extent
that they are valid under applicable law. If additional permissions
apply only to part of the Program, that part may be used separately
under those permissions, but the entire Program remains governed by
this License without regard to the additional permissions.
When you convey a copy of a covered work, you may at your option
remove any additional permissions from that copy, or from any part of
it. (Additional permissions may be written to require their own
removal in certain cases when you modify the work.) You may place
additional permissions on material, added by you to a covered work,
for which you have or can give appropriate copyright permission.
Notwithstanding any other provision of this License, for material you
add to a covered work, you may (if authorized by the copyright holders of
that material) supplement the terms of this License with terms:
a) Disclaiming warranty or limiting liability differently from the
terms of sections 15 and 16 of this License; or
b) Requiring preservation of specified reasonable legal notices or
author attributions in that material or in the Appropriate Legal
Notices displayed by works containing it; or
c) Prohibiting misrepresentation of the origin of that material, or
requiring that modified versions of such material be marked in
reasonable ways as different from the original version; or
d) Limiting the use for publicity purposes of names of licensors or
authors of the material; or
e) Declining to grant rights under trademark law for use of some
trade names, trademarks, or service marks; or
f) Requiring indemnification of licensors and authors of that
material by anyone who conveys the material (or modified versions of
it) with contractual assumptions of liability to the recipient, for
any liability that these contractual assumptions directly impose on
those licensors and authors.
All other non-permissive additional terms are considered "further
restrictions" within the meaning of section 10. If the Program as you
received it, or any part of it, contains a notice stating that it is
governed by this License along with a term that is a further
restriction, you may remove that term. If a license document contains
a further restriction but permits relicensing or conveying under this
License, you may add to a covered work material governed by the terms
of that license document, provided that the further restriction does
not survive such relicensing or conveying.
If you add terms to a covered work in accord with this section, you
must place, in the relevant source files, a statement of the
additional terms that apply to those files, or a notice indicating
where to find the applicable terms.
Additional terms, permissive or non-permissive, may be stated in the
form of a separately written license, or stated as exceptions;
the above requirements apply either way.
8. Termination.
You may not propagate or modify a covered work except as expressly
provided under this License. Any attempt otherwise to propagate or
modify it is void, and will automatically terminate your rights under
this License (including any patent licenses granted under the third
paragraph of section 11).
However, if you cease all violation of this License, then your
license from a particular copyright holder is reinstated (a)
provisionally, unless and until the copyright holder explicitly and
finally terminates your license, and (b) permanently, if the copyright
holder fails to notify you of the violation by some reasonable means
prior to 60 days after the cessation.
Moreover, your license from a particular copyright holder is
reinstated permanently if the copyright holder notifies you of the
violation by some reasonable means, this is the first time you have
received notice of violation of this License (for any work) from that
copyright holder, and you cure the violation prior to 30 days after
your receipt of the notice.
Termination of your rights under this section does not terminate the
licenses of parties who have received copies or rights from you under
this License. If your rights have been terminated and not permanently
reinstated, you do not qualify to receive new licenses for the same
material under section 10.
9. Acceptance Not Required for Having Copies.
You are not required to accept this License in order to receive or
run a copy of the Program. Ancillary propagation of a covered work
occurring solely as a consequence of using peer-to-peer transmission
to receive a copy likewise does not require acceptance. However,
nothing other than this License grants you permission to propagate or
modify any covered work. These actions infringe copyright if you do
not accept this License. Therefore, by modifying or propagating a
covered work, you indicate your acceptance of this License to do so.
10. Automatic Licensing of Downstream Recipients.
Each time you convey a covered work, the recipient automatically
receives a license from the original licensors, to run, modify and
propagate that work, subject to this License. You are not responsible
for enforcing compliance by third parties with this License.
An "entity transaction" is a transaction transferring control of an
organization, or substantially all assets of one, or subdividing an
organization, or merging organizations. If propagation of a covered
work results from an entity transaction, each party to that
transaction who receives a copy of the work also receives whatever
licenses to the work the party's predecessor in interest had or could
give under the previous paragraph, plus a right to possession of the
Corresponding Source of the work from the predecessor in interest, if
the predecessor has it or can get it with reasonable efforts.
You may not impose any further restrictions on the exercise of the
rights granted or affirmed under this License. For example, you may
not impose a license fee, royalty, or other charge for exercise of
rights granted under this License, and you may not initiate litigation
(including a cross-claim or counterclaim in a lawsuit) alleging that
any patent claim is infringed by making, using, selling, offering for
sale, or importing the Program or any portion of it.
11. Patents.
A "contributor" is a copyright holder who authorizes use under this
License of the Program or a work on which the Program is based. The
work thus licensed is called the contributor's "contributor version".
A contributor's "essential patent claims" are all patent claims
owned or controlled by the contributor, whether already acquired or
hereafter acquired, that would be infringed by some manner, permitted
by this License, of making, using, or selling its contributor version,
but do not include claims that would be infringed only as a
consequence of further modification of the contributor version. For
purposes of this definition, "control" includes the right to grant
patent sublicenses in a manner consistent with the requirements of
this License.
Each contributor grants you a non-exclusive, worldwide, royalty-free
patent license under the contributor's essential patent claims, to
make, use, sell, offer for sale, import and otherwise run, modify and
propagate the contents of its contributor version.
In the following three paragraphs, a "patent license" is any express
agreement or commitment, however denominated, not to enforce a patent
(such as an express permission to practice a patent or covenant not to
sue for patent infringement). To "grant" such a patent license to a
party means to make such an agreement or commitment not to enforce a
patent against the party.
If you convey a covered work, knowingly relying on a patent license,
and the Corresponding Source of the work is not available for anyone
to copy, free of charge and under the terms of this License, through a
publicly available network server or other readily accessible means,
then you must either (1) cause the Corresponding Source to be so
available, or (2) arrange to deprive yourself of the benefit of the
patent license for this particular work, or (3) arrange, in a manner
consistent with the requirements of this License, to extend the patent
license to downstream recipients. "Knowingly relying" means you have
actual knowledge that, but for the patent license, your conveying the
covered work in a country, or your recipient's use of the covered work
in a country, would infringe one or more identifiable patents in that
country that you have reason to believe are valid.
If, pursuant to or in connection with a single transaction or
arrangement, you convey, or propagate by procuring conveyance of, a
covered work, and grant a patent license to some of the parties
receiving the covered work authorizing them to use, propagate, modify
or convey a specific copy of the covered work, then the patent license
you grant is automatically extended to all recipients of the covered
work and works based on it.
A patent license is "discriminatory" if it does not include within
the scope of its coverage, prohibits the exercise of, or is
conditioned on the non-exercise of one or more of the rights that are
specifically granted under this License. You may not convey a covered
work if you are a party to an arrangement with a third party that is
in the business of distributing software, under which you make payment
to the third party based on the extent of your activity of conveying
the work, and under which the third party grants, to any of the
parties who would receive the covered work from you, a discriminatory
patent license (a) in connection with copies of the covered work
conveyed by you (or copies made from those copies), or (b) primarily
for and in connection with specific products or compilations that
contain the covered work, unless you entered into that arrangement,
or that patent license was granted, prior to 28 March 2007.
Nothing in this License shall be construed as excluding or limiting
any implied license or other defenses to infringement that may
otherwise be available to you under applicable patent law.
12. No Surrender of Others' Freedom.
If conditions are imposed on you (whether by court order, agreement or
otherwise) that contradict the conditions of this License, they do not
excuse you from the conditions of this License. If you cannot convey a
covered work so as to satisfy simultaneously your obligations under this
License and any other pertinent obligations, then as a consequence you may
not convey it at all. For example, if you agree to terms that obligate you
to collect a royalty for further conveying from those to whom you convey
the Program, the only way you could satisfy both those terms and this
License would be to refrain entirely from conveying the Program.
13. Remote Network Interaction; Use with the GNU General Public License.
Notwithstanding any other provision of this License, if you modify the
Program, your modified version must prominently offer all users
interacting with it remotely through a computer network (if your version
supports such interaction) an opportunity to receive the Corresponding
Source of your version by providing access to the Corresponding Source
from a network server at no charge, through some standard or customary
means of facilitating copying of software. This Corresponding Source
shall include the Corresponding Source for any work covered by version 3
of the GNU General Public License that is incorporated pursuant to the
following paragraph.
Notwithstanding any other provision of this License, you have
permission to link or combine any covered work with a work licensed
under version 3 of the GNU General Public License into a single
combined work, and to convey the resulting work. The terms of this
License will continue to apply to the part which is the covered work,
but the work with which it is combined will remain governed by version
3 of the GNU General Public License.
14. Revised Versions of this License.
The Free Software Foundation may publish revised and/or new versions of
the GNU Affero General Public License from time to time. Such new versions
will be similar in spirit to the present version, but may differ in detail to
address new problems or concerns.
Each version is given a distinguishing version number. If the
Program specifies that a certain numbered version of the GNU Affero General
Public License "or any later version" applies to it, you have the
option of following the terms and conditions either of that numbered
version or of any later version published by the Free Software
Foundation. If the Program does not specify a version number of the
GNU Affero General Public License, you may choose any version ever published
by the Free Software Foundation.
If the Program specifies that a proxy can decide which future
versions of the GNU Affero General Public License can be used, that proxy's
public statement of acceptance of a version permanently authorizes you
to choose that version for the Program.
Later license versions may give you additional or different
permissions. However, no additional obligations are imposed on any
author or copyright holder as a result of your choosing to follow a
later version.
15. Disclaimer of Warranty.
THERE IS NO WARRANTY FOR THE PROGRAM, TO THE EXTENT PERMITTED BY
APPLICABLE LAW. EXCEPT WHEN OTHERWISE STATED IN WRITING THE COPYRIGHT
HOLDERS AND/OR OTHER PARTIES PROVIDE THE PROGRAM "AS IS" WITHOUT WARRANTY
OF ANY KIND, EITHER EXPRESSED OR IMPLIED, INCLUDING, BUT NOT LIMITED TO,
THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR
PURPOSE. THE ENTIRE RISK AS TO THE QUALITY AND PERFORMANCE OF THE PROGRAM
IS WITH YOU. SHOULD THE PROGRAM PROVE DEFECTIVE, YOU ASSUME THE COST OF
ALL NECESSARY SERVICING, REPAIR OR CORRECTION.
16. Limitation of Liability.
IN NO EVENT UNLESS REQUIRED BY APPLICABLE LAW OR AGREED TO IN WRITING
WILL ANY COPYRIGHT HOLDER, OR ANY OTHER PARTY WHO MODIFIES AND/OR CONVEYS
THE PROGRAM AS PERMITTED ABOVE, BE LIABLE TO YOU FOR DAMAGES, INCLUDING ANY
GENERAL, SPECIAL, INCIDENTAL OR CONSEQUENTIAL DAMAGES ARISING OUT OF THE
USE OR INABILITY TO USE THE PROGRAM (INCLUDING BUT NOT LIMITED TO LOSS OF
DATA OR DATA BEING RENDERED INACCURATE OR LOSSES SUSTAINED BY YOU OR THIRD
PARTIES OR A FAILURE OF THE PROGRAM TO OPERATE WITH ANY OTHER PROGRAMS),
EVEN IF SUCH HOLDER OR OTHER PARTY HAS BEEN ADVISED OF THE POSSIBILITY OF
SUCH DAMAGES.
17. Interpretation of Sections 15 and 16.
If the disclaimer of warranty and limitation of liability provided
above cannot be given local legal effect according to their terms,
reviewing courts shall apply local law that most closely approximates
an absolute waiver of all civil liability in connection with the
Program, unless a warranty or assumption of liability accompanies a
copy of the Program in return for a fee.
END OF TERMS AND CONDITIONS
How to Apply These Terms to Your New Programs
If you develop a new program, and you want it to be of the greatest
possible use to the public, the best way to achieve this is to make it
free software which everyone can redistribute and change under these terms.
To do so, attach the following notices to the program. It is safest
to attach them to the start of each source file to most effectively
state the exclusion of warranty; and each file should have at least
the "copyright" line and a pointer to where the full notice is found.
Copyright (C)
This program is free software: you can redistribute it and/or modify
it under the terms of the GNU Affero General Public License as published
by the Free Software Foundation, either version 3 of the License, or
(at your option) any later version.
This program is distributed in the hope that it will be useful,
but WITHOUT ANY WARRANTY; without even the implied warranty of
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
GNU Affero General Public License for more details.
You should have received a copy of the GNU Affero General Public License
along with this program. If not, see .
Also add information on how to contact you by electronic and paper mail.
If your software can interact with users remotely through a computer
network, you should also make sure that it provides a way for users to
get its source. For example, if your program is a web application, its
interface could display a "Source" link that leads users to an archive
of the code. There are many ways you could offer source, and different
solutions will be better for different programs; see section 13 for the
specific requirements.
You should also get your employer (if you work as a programmer) or school,
if any, to sign a "copyright disclaimer" for the program, if necessary.
For more information on this, and how to apply and follow the GNU AGPL, see
.
================================================
FILE: README.md
================================================
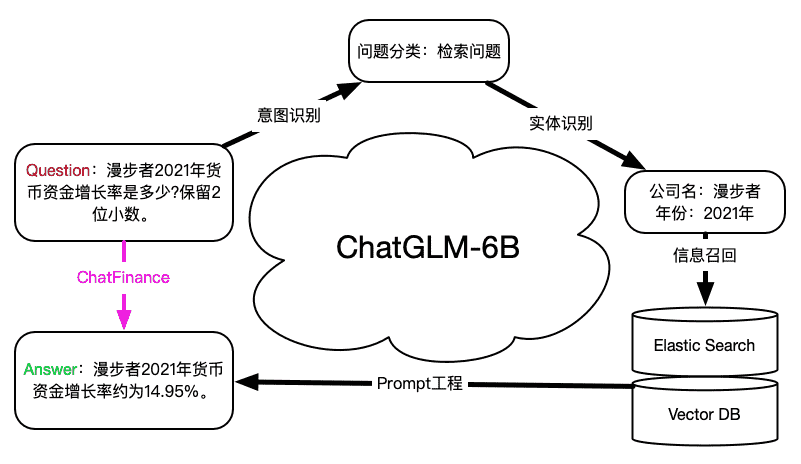
ChatFinance
金融财报问答大模型




### 框架 Framework
### 模型 Model
使用[ChatGLM2-6B](https://huggingface.co/THUDM/chatglm2-6b)模型进行微调,也可以使用base_model进行测试。
```
bash downloads/download_model.sh
```
### 数据 Dataset
原始数据为[ChatGLM评估挑战赛-金融赛道数据集](https://modelscope.cn/datasets/modelscope/chatglm_llm_fintech_raw_dataset/summary),经过OCR处理之后转化为TXT数据
保留接口:可使用公开金融数据对ElasticSearch和Weaviate数据库进行补充
```
bash downloads/download_data.sh
```
### 训练 Training
> 可以支持AMD ROCm 上的SFT
```
python sft/chatglm2_6b_sft_lora.py
```
### 推理 Inference
```
vim configs/server.json # 修改base_path和base_python
sudo bash inference_6b.sh
```
### 使用效果 Demo
```
# 文字概括
{"question": "根据2020年水发燃气的年报,请简要介绍报告期内公司行业格局和趋势的情况。", "answer": "根据2020年水发燃气的年报,公司在行业内的行业格局和趋势情况如下:\n\n1. 行业格局:在能源行业中,水发煤气在规模和市场份额方面占据领先地位。2020年,水发燃气的总资产达到1867亿元人民币,是行业内唯一一家总资产超过1000亿元人民币的公司。同时,水发煤气在煤炭、石油和天然气等领域的市场份额也位居行业前列。\n\n2. 趋势情况:随着能源转型和环保要求的提高,清洁能源已成为能源行业的发展趋势。水发煤气在年报中提到,公司正加大在清洁能源领域的投入,以适应这一趋势。此外,水发煤气还表示,将继续深化在煤炭、石油和天然气等传统领域的业务,以保持公司在能源行业的主导地位。\n\n综上所述,水发煤气在2020年的行业格局中占据了领先地位,同时也在积极应对能源转型和环保要求,加大在清洁能源领域的投入,以适应清洁能源的发展趋势。"}
# 检索
{"question": "江化微2019年研发费用和财务费用分别是多少元?", "answer": "江化微2019年研发费用为5.49亿元,财务费用为1.99亿元。"}
# 开放问题
{"question": "什么是净利润?", "answer": "净利润是指企业在扣除所有成本、税金和其他费用后,所剩余的利润。净利润通常用于衡量企业的盈利能力。"}
```
================================================
FILE: configs/inference.json
================================================
{
"train_batch_size": "auto",
"gradient_accumulation_steps": 1,
"steps_per_print": 10,
"zero_optimization": {
"stage": 2,
"allgather_partitions": true,
"reduce_scatter": true,
"allgather_bucket_size": 50000000,
"reduce_bucket_size": 50000000,
"load_from_fp32_weights": true,
"overlap_comm": true
},
"gradient_clipping": 1.0,
"fp16": {
"enabled": true,
"loss_scale": 0,
"loss_scale_window": 1000,
"hysteresis": 2,
"min_loss_scale": 1
},
"wall_clock_breakdown": true,
"zero_allow_untested_optimizer": true
}
================================================
FILE: configs/server.json
================================================
{
"base_path": "/home/kylin/workspace/ChatFinance",
"base_python": "/home/kylin/anaconda3/bin/python",
"models_path": {
"chatglm2":"models/chatglm2-6b",
"text2vec":"models/text2vec-base-chinese-paraphrase"
},
"sever_path": {
"elastic_search":"database_server/elastic_search",
"weaviate":"database_server/weaviate",
"chatglm2":"models_server/chatglm2",
"text2vec":"models_server/text2vec"
},
"port": {
"chatglm2":50002,
"text2vec":50001,
"elastic_search":50004,
"weaviate":50003
}
}
================================================
FILE: configs/train.json
================================================
================================================
FILE: database_server/elastic_search/README
================================================
# 如何做不同主机之间的数据迁移
- 在主机A上备份
docker-compose down
docker run --rm -v esdata:/data -v $(pwd):/backup ubuntu tar czvf /backup/esdata.tar.gz /data
- 拷贝
scp esdata.tar.gz
- 恢复数据
docker run --rm -v esdata:/data -v $(pwd):/backup ubuntu tar xzvf /backup/esdata.tar.gz -C /
================================================
FILE: database_server/elastic_search/clear.py
================================================
from elasticsearch import Elasticsearch
# Connect to the Elasticsearch instance
es = Elasticsearch(["http://localhost:50004"])
# Fetch all index names
all_indices = es.indices.get_alias(name="*").keys()
print(all_indices)
# Delete each index
for index in all_indices:
es.indices.delete(index=index)
================================================
FILE: database_server/elastic_search/db.py
================================================
import sys # noqa: E501
sys.path.append("/home/kylin/workspace/ChatFinance") # noqa: E501
from elasticsearch import Elasticsearch
import json
def attain_uuid(entities, uuid_dict):
for k, v in uuid_dict.items():
fg = True
for entity in entities:
if entity not in k:
fg = False
break
if fg:
print(entities, k)
return v
return None
if __name__ == "__main__":
es = Elasticsearch('http://localhost:50004')
with open("/home/kylin/workspace/ChatFinance/data/chatglm_llm_fintech_raw_dataset/uuid.json", "r") as f:
uuid_dict = json.load(f)
with open("/home/kylin/workspace/ChatFinance/data/chatglm_llm_fintech_raw_dataset/allcrawl.json", "r") as f:
crawl_dict = json.load(f)
for i, company in enumerate(crawl_dict):
for year in crawl_dict[company]:
if year not in ["2019年报", "2020年报", "2021年报"]:
continue
try:
uuid = attain_uuid(
[crawl_dict[company][year]['SECURITY_CODE'], year[:-1]], uuid_dict)
for idx, key in enumerate(crawl_dict[company][year]):
doc = {
"text": key,
}
resp = es.index(index=str(uuid), id=idx, document=doc)
except:
print(f"error {company} {year}")
if i % 99 == 0 and i > 0:
print(f"insert {3*(i+1)} file")
print(f"insert {3*len(crawl_dict)} file")
================================================
FILE: database_server/elastic_search/docker-compose.yml
================================================
version: '3.4'
services:
elasticsearch:
image: docker.elastic.co/elasticsearch/elasticsearch:8.9.0
container_name: elasticsearch
environment:
- discovery.type=single-node
- xpack.security.enabled=false
- http.max_content_length=1gb
- cluster.max_shards_per_node=50000
ports:
- "50004:9200"
networks:
- elastic
volumes:
- esdata:/usr/share/elasticsearch/data
kibana:
image: docker.elastic.co/kibana/kibana:8.9.0
container_name: kibana
ports:
- "5601:5601"
environment:
ELASTICSEARCH_URL: http://elasticsearch:9200
ELASTICSEARCH_HOSTS: http://elasticsearch:9200
networks:
- elastic
depends_on:
- elasticsearch
networks:
elastic:
driver: bridge
volumes:
esdata:
================================================
FILE: database_server/weaviate/README
================================================
# 如何做不同主机之间的数据迁移
- 在主机A上备份
docker-compose down
docker run --rm -v weaviatedata:/data -v $(pwd):/backup ubuntu tar czvf /backup/weaviatedata.tar.gz /data
- 拷贝
scp weaviatedata.tar.gz
- 恢复数据
docker run --rm -v weaviatedata:/data -v $(pwd):/backup ubuntu tar xzvf /backup/weaviatedata.tar.gz -C /
================================================
FILE: database_server/weaviate/db.py
================================================
import sys # noqa: E501
sys.path.append('/home/kylin/workspace/ChatFinance') # noqa: E501
from langchain.vectorstores import Weaviate
from utils import JinaEmbeddings
from jina import Document
import weaviate
import glob
import json
import os
client = weaviate.Client(
url="http://localhost:50003", # Replace with your endpoint
auth_client_secret=weaviate.AuthApiKey(api_key="shadowmotion-secret-key"))
embedding = JinaEmbeddings("127.0.0.1")
# print(embedding.embed_documents(read_qa_file("raw/QA.txt")))
def insert_txt(path, uuid_dict):
basename = os.path.basename(path).split('.')[0]
db = Weaviate(client=client, embedding=embedding,
index_name=f"LangChain_{uuid_dict[basename]}", text_key="text", by_text=False)
print(f"To insert -> {basename}")
print(f"index_name: {db._index_name}")
texts = []
with open(path, "r", encoding="utf-8") as f:
for i, line in enumerate(f):
if i > 0 and i % 1000 == 0:
db.add_texts(texts=texts)
print(f"文字数据已注入{i}")
texts = []
if len(line) <= 1:
continue
texts.append(line[:-1])
db.add_texts(texts=texts)
print(f"文字数据已注入{i}")
texts = []
def insert_txt_uuid(path, uuid, client, embedding):
basename = os.path.basename(path).split('.')[0]
db = Weaviate(client=client, embedding=embedding,
index_name=f"LangChain_{uuid}", text_key="text", by_text=False)
print(f"To insert -> {basename}")
print(f"index_name: {db._index_name}")
texts = []
with open(path, "r", encoding="utf-8") as f:
for i, line in enumerate(f):
if i > 0 and i % 1000 == 0:
db.add_texts(texts=texts)
# print(f"文字数据已注入{i}")
texts = []
if len(line) <= 1:
continue
texts.append(line[:-1])
db.add_texts(texts=texts)
print(f"文字数据已注入{i}")
texts = []
def insert_table(path, uuid_dict):
basename = os.path.basename(path).split('.')[0]
db = Weaviate(client=client, embedding=embedding,
index_name=f"LangChain_{uuid_dict[basename]}", text_key="text", by_text=False)
print(f"To insert -> {basename}")
print(f"index_name: {db._index_name}")
texts = []
with open(path, "r", encoding="utf-8") as f:
for i, line in enumerate(f):
if i > 0 and i % 1000 == 0:
db.add_texts(texts=texts)
print(f"表格数据已注入{i}")
texts = []
if len(line) <= 1:
continue
texts.append(line[:-1])
db.add_texts(texts=texts)
print(f"表格数据已注入{i}")
texts = []
def insert_table_uuid(path, uuid, client, embedding):
basename = os.path.basename(path).split('.')[0]
db = Weaviate(client=client, embedding=embedding,
index_name=f"LangChain_{uuid}", text_key="text", by_text=False)
print(f"To insert -> {basename}")
print(f"index_name: {db._index_name}")
texts = []
with open(path, "r", encoding="utf-8") as f:
for i, line in enumerate(f):
if i > 0 and i % 1000 == 0:
db.add_texts(texts=texts)
# print(f"表格数据已注入{i}")
texts = []
if len(line) <= 1:
continue
texts.append(line[:-1])
db.add_texts(texts=texts)
print(f"表格数据已注入{i}")
texts = []
if __name__ == "__main__":
base_tokenizer_model = '/home/kylin/workspace/ChatFinance/models/text2vec-base-chinese-paraphrase'
with open("/home/kylin/workspace/ChatFinance/data/chatglm_llm_fintech_raw_dataset/uuid.json", "r", encoding='utf-8') as f:
uuid_dict = json.load(f)
n = 30000
skip = 0
# TXT_DIRECTORY = "/home/kylin/workspace/ChatFinance/data/chatglm_llm_fintech_raw_dataset/alldata"
# file_names = glob.glob(TXT_DIRECTORY + '/*')
# for i, file_name in enumerate(file_names):
# print(f"No.{i} insert_txt")
# try:
# insert_txt(file_name, uuid_dict)
# except:
# print(f"error: {file_name}")
# if i >= n - 1:
# break
TAB_DIRECTORY = "/home/kylin/workspace/ChatFinance/data/chatglm_llm_fintech_raw_dataset/alltable"
file_names = glob.glob(TAB_DIRECTORY + '/*.cal')
print(file_names)
for i, file_name in enumerate(file_names):
if i < skip:
continue
print(f"No.{i} insert_tab")
try:
insert_table(file_name, uuid_dict)
except:
print(f"error: {file_name}")
if i >= n - 1:
break
================================================
FILE: database_server/weaviate/docker-compose.yml
================================================
version: '3.4'
services:
weaviate:
image: semitechnologies/weaviate:1.19.5
ports:
- 50003:8080
restart: on-failure:0
environment:
QUERY_DEFAULTS_LIMIT: 25
AUTHENTICATION_APIKEY_ENABLED: 'true'
AUTHENTICATION_APIKEY_ALLOWED_KEYS: 'shadowmotion-secret-key,HRSSC-secret-key'
AUTHENTICATION_APIKEY_USERS: 'shadowmotion,HRSSC'
PERSISTENCE_DATA_PATH: '/var/lib/weaviate'
DEFAULT_VECTORIZER_MODULE: 'none'
CLUSTER_HOSTNAME: 'node1'
volumes:
- weaviatedata:/var/lib/weaviate
deploy:
resources:
limits:
memory: 50g
volumes:
weaviatedata:
================================================
FILE: database_server/weaviate/scripts/QA.txt
================================================
问:能否介绍一下蓝胖子机器智能的主力产品?
答:蓝胖子机器智能的主力产品是“蓝胖智汇Doraopt”系列AI软件产品及解决方案。这是由我们的AIoT产品事业部打造的,用于提供智能供应链的整体解决方案。
问:蓝胖智汇Doraopt系列具备哪些核心技术和产品方案?
答:蓝胖智汇Doraopt系列产品拥有AI时间空间多目标优化引擎、仿真推演、智能决策及调度等模块核心技术及对应产品方案。这些技术和产品方案使我们的客户能够高效且智能地管理他们的供应链。
问:蓝胖子机器智能的团队核心技术成员有什么背景?
答:我们的团队核心技术成员都是具有丰富专业知识的人才,他们来自全球顶级院校,如卡内基梅隆大学、北京大学、澳大利亚国立大学等,专业领域涵盖AI算法、物理、数学及计算机系统等。
问:蓝胖子机器智能是什么样的公司?他们从事哪些业务?
答:蓝胖子机器智能(Dorabot)是一家成立于2015年的智能无人仓整体解决方案供应商。他们有着深厚的技术背景,运用机器人视觉、运动规划、规划和推理、自主导航、多机协作、机器学习等技术,为多个场景提供一站式解决方案。
问:蓝胖子机器智能的解决方案主要适用于哪些场景?
答:我们的一站式解决方案主要适用于物流、快递、电商仓储、海港、空港、先进制造等场景。我们为这些场景提供包含分拣、运输、码垛、入库、装载等环节的软硬件相结合的解决方案。
问:蓝胖子机器智能的解决方案包括哪些环节?
答:蓝胖子机器智能的解决方案涵盖了物流等多个环节,包括分拣、运输、码垛、入库、装载等。我们的目标是为客户提供软硬件相结合的一站式解决方案。
问:蓝胖子机器智能公司的主要产品有哪些?
答:蓝胖子机器智能公司的主要产品包括软硬件相结合的上件机器人、分拣机器人、自主移动机器人(AMR)、码垛机器人、装载机器人等。这些产品充分利用了我们在AI和机器人技术方面的技术优势。
问:在技术上,蓝胖子机器智能有哪些核心算法?
答:在技术上,蓝胖子机器智能积累了多种规划及优化算法,包括智能装箱算法、智能调度算法以及多机规划算法。这些算法使我们的产品能够在各种场景下都能有效、高效地执行任务。
问:蓝胖子机器智能的供应链解决方案是如何运作的?
答:蓝胖子机器智能的供应链解决方案针对企业供应链流通环节的完整业务流程。我们基于AI时间空间多目标优化引擎与多维度大数据洞察,对上下游多个作业环节进行全局统筹与规划。我们的目标是打通生产、装卸、运输、仓储、配送等多个场景,为客户建立业务导向型的智能运营管理平台。
问:蓝胖子机器智能的供应链解决方案能为客户带来什么样的好处?
答:蓝胖子机器智能的供应链解决方案能够全面提升客户的运营效率。我们的AI优化引擎和大数据洞察能够对上下游多个作业环节进行全局统筹与规划,从而打通生产、装卸、运输、仓储、配送等多个场景,使得客户的供应链运营更加流畅和高效。同时,我们还为客户建立了业务导向型的智能运营管理平台,帮助他们实现更高的运营效率和利润。
问:蓝胖子机器智能公司的混码算法是如何工作的?
答:蓝胖子机器智能公司的混码算法是基于AI时间空间多目标优化引擎开发的。它能根据订单中的不同货品(SKU)信息,实时生成满足不同场景业务要求的稳定垛型。同时,它还需要满足机械臂运动轨迹等约束条件。这种方法可以有效地提高装箱的效率和满载率。
问:混码算法可以带来什么样的优点?
答:利用混码算法,可以根据订单中不同的货品信息,实时生成满足各种业务需求的稳定垛型,从而提高仓库的存储和运输效率。同时,算法考虑到了机械臂的运动轨迹等约束条件,这能确保整个操作的流畅性和安全性。此外,混码算法还可以提高装箱的满载率,使得装箱更加充分。
问:我如何联系到蓝胖子机器智能公司?
答:您可以通过以下方式联系蓝胖子机器智能公司:公司网站:www.dorabot.com 或 www.doraopt.com 地址:中国深圳市南山区左炮台路2号H6 邮箱:info@dorabot.com sales@dorabot.com info.doraopt@dorabot.com 电话:+86 (755) 2165 0069
问:我能在哪里找到更多关于蓝胖子机器智能公司和他们的产品信息?
答:您可以通过访问蓝胖子机器智能公司的官方网站 www.dorabot.com 和 www.doraopt.com 来了解更多关于他们及其产品的信息。
问:蓝胖子机器智能公司有哪些主要的软件产品?
答:蓝胖子机器智能公司的主要软件产品包括名为“装满满”的智能装箱SaaS平台。它基于公司自研的AI时间空间多目标优化引擎,可以为用户提供最优的订柜策略和货物装载规划方案,从而解决物流环节中的订柜与装箱问题。
问:“装满满”是什么样的产品,它有哪些功能?
答:“装满满”是蓝胖子机器智能公司推出的一款智能装箱SaaS平台,它可以为用户提供最优的订柜策略和货物装载规划方案。其主要功能是,通过使用自研的AI时间空间多目标优化引擎,一站式解决物流环节中的订柜与装箱难题。
问:装满满的效果如何,是否已在实际业务中得到应用?
答:是的,装满满已在十多家行业龙头企业中得到应用。平均空间装载率可以达到85%到90%,每年为客户节省数千万人民币的运营成本。与传统的人工作业相比,其效率有了数倍的提升。
问:装满满的应用场景有哪些?
答:装满满已与多家合同物流方和智能制造企业合作,应用于海运、陆运以及其他多联式运输场景中。
问:装满满对于节省运营成本有哪些具体表现?
答:装满满可以大幅度提升空间装载率,平均能达到85%到90%,这可以显著降低运输成本。据统计,每年装满满可以为客户节省数千万人民币的运营成本。
问:客户在装箱过程中通常遇到哪些问题和痛点?
答:客户在装箱过程中可能会遇到多个问题和痛点。例如,由于货量大且货品SKU种类繁多,拼载规则复杂且周期性发生调整,这对人工拼柜规划提出了挑战。同时,集装箱装载率的要求高,增加了人员培育和管理的成本。此外,手工通过数据表筛选装箱效率低,易出错,增加合规管理成本。在信息协同方面也有缺陷,需要智能化工具帮助降低成本和提高效率。
问:客户在出货过程中通常遇到哪些问题和痛点?
答:客户在出货过程中,可能会因为出货量庞大,装柜要求多且各异,增加估柜及排柜难度。这可能导致难以快速准确定位货物,以便海关查验。此外,上游环节的变动可能影响估柜及排柜方案的可行性,增加订柜及订舱的成本。另一方面,打托环节依赖人工经验,缺乏作业标准,导致车柜装载率难以提升。
问:蓝胖子机器智能公司的智能装箱解决方案有哪些特点?
答:蓝胖子机器智能公司的智能装箱解决方案有多个突出的特点。首先,它可以在数分钟内完成千方货物的装柜计划,这大大提高了作业效率,达到了2-3倍的综合作业效率提升。其次,它能够每年为用户节省超过1000万人民币的海运集装箱费用。此外,其装箱方案的可靠性高,所有方案都可以成功应用于仓库实际作业。该解决方案还能缩短装箱规划时间,达到原来的7-8倍。
问:如果我有更多安装方式和定制需求,应该怎么做?
答:如果您有更多的安装方式和定制需求,可以直接与我们联系,我们的团队将竭诚为您服务。
问:蓝胖子机器智能公司的智能装箱解决方案有哪些部署方式?
答:蓝胖子机器智能公司的智能装箱解决方案有多种部署方式。这包括作为SaaS在线平台使用,或者通过API接口进行模块化集成。这些部署方式既可以满足复杂业务的灵活配置需求,也可以支持简单业务的一键求解。
问:「装满满」如何处理复杂业务?
答:针对复杂业务,「装满满」提供了自定义入口,可以自定义货物属性、装箱规则、拼装步骤等,高效求解多条件、海量货物的装箱方案。它支持批量数据多任务同时运算,快速提供计算结果,优于“线性作业”方式,经济效益更高。
问:「装满满」如何处理简单业务?
答:对于简单业务,「装满满」已配置了简便的货物数据模板。只需上传相关数据,选择装载规则,就能一键求解装箱问题。
问:「装满满」的装载方案是否安全?
答:是的,「装满满」的装载方案非常安全。它考虑了承重、结构、顺序等影响因素,旨在降低货物损失的风险。此外,它还提供了3D可视化装箱规划,并支持一键分享,有助于多方协同,提升供应链透明度。
问:DoraCLP「装满满」适用于哪些行业?
答:DoraCLP「装满满」可以广泛应用于多个行业,例如家居业和鞋服业等。
问:「装满满」有何技术优势?
答:「装满满」利用先进的持续优化学习技术和AI时间空间多目标优化引擎,可以高效处理各种装箱问题,帮助客户实现价值。
问:蓝胖子机器智能公司与哪些公司进行过合作,提供了怎样的解决方案?
答:蓝胖子机器智能公司与一些知名企业进行过合作。例如,我们与某世界知名零售巨头合作,提供「装满满」智能装箱SaaS平台,高效解决了集装箱拼载规划的各项难题。同时,我们也与某国内家电品牌合作,利用「装满满」智能装箱SaaS平台应对上游订单变动,成功缩短了预估柜、排柜时间,助力了企业降低成本,提高效率,以及实现自动化和数字化转型。
问:「装满满」智能装箱SaaS平台在装载率和计算时间方面有何优势?
答:「装满满」智能装箱SaaS平台能实现88%-90%的平均装载率,对于家电行业等领域,我们的平台能快速应对上游变化,计算时间可以节约6倍,由原先的小时级降低至分钟级。
问:「装满满」智能装箱SaaS平台如何帮助用户节省成本?
答:使用我们的「装满满」智能装箱SaaS平台,每装载10000立方米的货物,可以节省大约100万元人民币的货柜海运费。在年度规模上,这可能意味着可以节省数千万元的海运柜成本。
问:「装满满」智能装箱SaaS平台如何提高装箱作业的准确性和效率?
答:我们的「装满满」智能装箱SaaS平台内置装箱业务规则引擎,可以准确提供打托方案,实际指导估柜订柜作业。另外,我们提供3D可视化装箱方案,可以准确显示货物位置,协助快速通关。
================================================
FILE: database_server/weaviate/scripts/connection.py
================================================
# import sys # noqa: E501
# sys.path.append('/home/shadowmotion/Documents/code/demo/HRSSC') # noqa: E501
from langchain.vectorstores import Weaviate
from utils import JinaEmbeddings
from jina import Document
import weaviate
def read_qa_file(file_path):
with open(file_path, "r", encoding='utf-8') as f:
lines = f.readlines()
qa_list = []
question, answer = None, None
for line in lines:
line = line.strip() # remove leading/trailing whitespaces
if line.startswith("问:"):
# save the previous qa pair if it exists
if question and answer:
qa_list.append(f"{question} {answer}")
# start a new qa pair
question = line
answer = None
elif line.startswith("答:"):
answer = line
# don't forget the last qa pair
if question and answer:
qa_list.append(f"{question} {answer}")
return qa_list
client = weaviate.Client(
url="http://localhost:8080", # Replace with your endpoint
auth_client_secret=weaviate.AuthApiKey(api_key="shadowmotion-secret-key"))
embedding = JinaEmbeddings("127.0.0.1")
db = Weaviate(client=client, embedding=embedding,
index_name="LangChain", text_key="text", by_text=False)
# print(embedding.embed_documents(read_qa_file("raw/QA.txt")))
db.add_texts(texts=read_qa_file("./QA.txt"))
# db.add_documents(
# [Document(page_content="1", metadata={"Q": "1+1=", "A": "2"})]
# )
================================================
FILE: database_server/weaviate/scripts/query.py
================================================
import sys # noqa: E501
# sys.path.append('/home/vdb/Documents/code/demo/HRSSC') # noqa: E501
from langchain.vectorstores import Weaviate
from langchain.schema import Document
from utils import JinaEmbeddings
import weaviate
import json
import os
client = weaviate.Client(
url="http://localhost:8080", # Replace with your endpoint
auth_client_secret=weaviate.AuthApiKey(api_key="kylin-secret-key"))
embedding = JinaEmbeddings("127.0.0.1")
with open("../../data/chatglm_llm_fintech_raw_dataset/uuid.json", "r", encoding='utf-8') as f:
uuid_dict = json.load(f)
query_list = [
"公司的法定代表人是谁",
"电子邮箱是什么",
"公司的外文名称是什么",
]
index_name = "LangChain_135087231333628284559671447376917039719"
db = Weaviate(client=client, embedding=embedding,
index_name=index_name, text_key="text", by_text=False)
for query in query_list[:1]:
docs = db.similarity_search(query, k=3)
print(f" >>>>>>>>>>> {query} <<<<<<<<<<<<")
for i, e in enumerate(docs):
print(f" = = = = = = = = = = = k[{i}] = = = = = = = = = = =")
print(e.page_content)
================================================
FILE: database_server/weaviate/utils.py
================================================
import warnings # noqa: E501
warnings.filterwarnings('ignore') # noqa: E501
from langchain.embeddings.base import Embeddings
from jina import Document, DocumentArray
from jina import Client
from typing import Any, List
class JinaEmbeddings(Embeddings):
def __init__(self, host: str = "0.0.0.0", port: int = 50001, **kwargs: Any) -> None:
self.client = Client(host=host, port=port, **kwargs)
def _post(self, docs: List[Any], **kwargs: Any) -> Any:
payload = dict(inputs=docs, **kwargs)
return self.client.post(on="/", **payload)
def embed_documents(self, texts: List[str]) -> List[List[float]]:
docs = DocumentArray([Document(text=t) for t in texts])
embeddings = self._post(docs).embeddings
return [list(map(float, e)) for e in embeddings]
def embed_query(self, text: str) -> List[float]:
docs = DocumentArray([Document(text=text)])
print(docs)
embedding = self._post(docs).embeddings[0]
return list(map(float, embedding))
if __name__ == "__main__":
embedding = JinaEmbeddings("127.0.0.1")
eg = "嵌入模型(Embedding model)通常用于将词语或者短语转化为向量表示。嵌入模型通常不会有严格的输入长度限制,因为它主要关注的是如何将单个词或短语转化为向量表示。然而,在某些应用中,嵌入模型可能会在更大的上下文环境中考虑单词,这时可能会有输入长度的限制。如果你使用的是一些预训练的模型,如BERT、GPT等,它们在实际训练过程中会有一个最大序列长度限制,这是由于这些模型的结构决定的。例如,BERT模型的最大输入长度通常设定为512个词语。如果提供的输入序列长度超过这个限制,那么可能需要进行截断,或者采用其他处理策略。如果你的输入长度超过了这个限制,直接输入给模型,可能会导致出错,或者导致模型无法处理那些超出长度限制的部分,因此,通常我们在数据预处理阶段就要处理好这个问题,确保所有输入都不超过模型的长度限制。"
print(len(eg))
r = embedding.embed_query(eg)
print(len(r))
================================================
FILE: downloads/download_all.sh
================================================
#!/bin/bash
bash download_models.sh
bash download_data.sh
================================================
FILE: downloads/download_data.sh
================================================
#!/bin/bash
cd ../data || mkdir ../data
git clone http://www.modelscope.cn/datasets/modelscope/chatglm_llm_fintech_raw_dataset.git
echo "PDF data downloaded!"
================================================
FILE: downloads/download_model.sh
================================================
#!/bin/bash
cd ../models || mkdir ../models
git clone https://huggingface.co/shibing624/text2vec-base-chinese-paraphrase
echo "Embedding Model(for vector DB) downloaded!"
git clone https://huggingface.co/THUDM/chatglm2-6b
echo "ChatGML-6B Model(for vector DB) downloaded!"
================================================
FILE: inference_6b.py
================================================
from models_server.chatglm2.jina_client import encode
from prompts.intent_recognition import intent_recognition_prompt
from prompts.entity_recognition import entity_recognition_prompt
from prompts.answer_generation import answer_generation_prompt
from prompts.open_question import open_question_prompt
from models_server.text2vec.jina_embedding import JinaEmbeddings
from database_server.weaviate.db import insert_table_uuid,insert_txt_uuid
from langchain.vectorstores import Weaviate
from elasticsearch import Elasticsearch
import weaviate
import json
import os
import glob
def parse_entity_recognition(response: str):
parse_list = []
lines = response.split('\n')
for line in lines:
sep = ':' if ':' in lines[-1] else ':'
if "公司名" in line:
parse_list.append(line.split(sep)[1])
if "年份" in line:
parse_list.append(line.split(sep)[1])
return parse_list
def parse_intent_recognition(response: str):
lines = response.split('\n')
return lines[-1]
def attain_uuid(entities, uuid_dict):
for k, v in uuid_dict.items():
fg = True
for entity in entities:
if entity not in k:
fg = False
break
if fg:
print(entities, k)
return v, k
return None, None
def generate(question, uuid_dict, crawl_dict, crawl_name_dict, es, log_file):
log_file.write("= = 流程开始 = = \n")
log_file.write(f"Q:\n{question}\n\n")
# -> Intent Recognition
log_file.write("= = 意图识别 = = \n")
prompt = intent_recognition_prompt(question)
response = encode(prompt, history=[])
log_file.write(f"R:\n{response[0].text}\n\n")
if "检索问题" not in parse_intent_recognition(response[0].text):
log_file.write("开放问题直接作答\n")
prompt = open_question_prompt(question)
response = encode(prompt, history=[])
answer = response[0].text
log_file.write(f"R:\n{answer}\n\n")
return answer
# print("意图识别时间:",time.time()-initial_time)
############################ -> Entity Recognition
try_year_list = ["2021年","2022年"]
log_file.write("= = 实体提取 = = \n")
prompt = entity_recognition_prompt(question)
response = encode(prompt, history=[])
log_file.write(f"R:\n{response[0].text}\n\n")
entities = parse_entity_recognition(response[0].text)
uuid, file_name = attain_uuid(entities, uuid_dict)
log_file.write(f"R:\n{uuid}\n\n")
if not uuid and entities[0][0] == '年':
entities[0] = entities[0][1:]
uuid, file_name = attain_uuid(entities, uuid_dict)
log_file.write(f"R:\n 1)首字修复,修复公司名称: {entities[0]}\n\n")
# if not uuid:
# for try_year in try_year_list:
# old_year = entities[1]
# entities[1] = try_year
# uuid, file_name = attain_uuid(entities, uuid_dict)
# if uuid:
# log_file.write(f"R:\n 2)年份修复,{old_year} 改为 {entities[1]},uuid:{uuid}\n\n")
# break
if not uuid:
log_file.write("未知公司不予作答\n")
return ""
# print("实体提取时间:",time.time()-initial_time)
extra_information_list = []
################################ -> ElasticSearch
log_file.write("= = ElasticSearch = = \n")
# index_name = f"{uuid}"
# # index_name = "all_property"
# try:
# for word in entities:
# replaced_question = question.replace(word, '')
# search_query = {
# "query": {
# "match": {
# "text": replaced_question
# }
# }
# }
# search_resp = es.search(index=index_name, body=search_query)
# docs = search_resp["hits"]["hits"][:3]
# for i, e in enumerate(docs):
# property_name = e['_source']['text']
# company = crawl_name_dict[file_name]
# year = file_name.split("__")[4]+"报"
# property_value = crawl_dict[company][year][property_name]
# # if not property_value or property_value in ["None", "null"]:
# # continue
# log_file.write(
# f"ES: = = = = = = = = = = = k[{i}] = = = = = = = = = = =\n")
# log_file.write(e['_source']['text'])
# log_file.write("\n")
# extra_information_list.append(f"{property_name}是{property_value}")
# except:
# log_file.write("数据库暂未录入\n")
##################################### -> Embedding 尝试注入
if not extra_information_list:
# if True:
log_file.write("= = EmbeddingInsert(Table) = = \n")
Embedding_Match = False
if entities[1][-1]=="年":
target_year = entities[1][:-1]
target_name = entities[0]
log_file.write(f"尝试搜索{target_year}*{target_name}*.cal\n")
try:
target_dir = "/home/kylin/workspace/ChatFinance/data/chatglm_llm_fintech_raw_dataset/alltable"
# pattern = rf'^{target_year}.*{target_name}.*\.cal$'
pattern = os.path.join(target_dir, f"{target_year}*{target_name}*.cal")
matched_files = [os.path.abspath(path) for path in glob.glob(pattern)]
insert_table_uuid(matched_files[0],uuid,client,embedding)
log_file.write(f"搜索Table注入成功,匹配文件名字:{matched_files[0]}\n")
Embedding_Match = True
except:
log_file.write("搜索不到相关.cal文件\n")
# log_file.write("= = EmbeddingInsert(Txt) = = \n")
# log_file.write(f"尝试搜索{target_year}*{target_name}*.txt\n")
# try:
# target_dir = "/home/kylin/workspace/ChatFinance/data/chatglm_llm_fintech_raw_dataset/alldata"
# # pattern = rf'^{target_year}.*{target_name}.*\.txt$'
# pattern = os.path.join(target_dir, f"{target_year}*{target_name}*.txt")
# matched_files = [os.path.abspath(path) for path in glob.glob(pattern)]
# insert_txt_uuid(matched_files[0],uuid,client,embedding)
# log_file.write(f"搜索Txt注入成功,匹配文件名字:{matched_files[0]}\n")
# except:
# log_file.write("搜索不到相关.Txt文件\n")
##################################### -> Embedding Database
if not extra_information_list and Embedding_Match:
# if Embedding_Match:
log_file.write("= = EmbeddingDatabase = = \n")
index_name = f"LangChain_{uuid}"
try:
db = Weaviate(client=client, embedding=embedding,
index_name=index_name, text_key="text", by_text=False)
for word in entities:
replaced_question = question.replace(word, '')
docs = db.similarity_search(replaced_question, k=5)
for i, e in enumerate(docs):
log_file.write(
f"ED: = = = = = = = = = k[{i}] = = = = = = = = =\n")
log_file.write(e.page_content)
log_file.write("\n")
extra_information_list.append(e.page_content)
except:
log_file.write("数据库暂未录入\n")
# print("向量库搜索时间:",time.time()-initial_time)
log_file.write("= = AnswerGeneration = = \n")
extra_information = "\n".join(extra_information_list)
log_file.write(extra_information+'\n')
prompt = answer_generation_prompt(extra_information, question)
response = encode(prompt, history=[])
log_file.write(f"R:\n{response[0].text}\n\n")
answer=response[0].text
return answer
# import time
# initial_time = time.time()
# -> Init Embedding Database
embedding = JinaEmbeddings("127.0.0.1")
client = weaviate.Client(
url="http://localhost:50003", # Replace with your endpoint
auth_client_secret=weaviate.AuthApiKey(api_key="vdb-secret-key"))
# print("向量库时间:",time.time()-initial_time)
# -> Init Embedding Database
es = Elasticsearch('http://localhost:50004')
# print("es时间:",time.time()-initial_time)
# -> Init UUID Dict
with open("./data/chatglm_llm_fintech_raw_dataset/uuid.json", "r") as f:
uuid_dict = json.load(f)
# -> Init crawl Dict
with open("./data/chatglm_llm_fintech_raw_dataset/allcrawl.json", "r") as f:
crawl_dict = json.load(f)
with open("./data/chatglm_llm_fintech_raw_dataset/name_map_crawl.json", "r") as f:
crawl_name_dict = json.load(f)
# print("dict时间:",time.time()-initial_time)
# question = "本钢板材在2020年对联营企业和合营企业的投资收益是多少元?"
import time
from datetime import datetime
formatted_time = datetime.now().strftime('%Y-%m-%d_%H-%M-%S')
bad_ids = [0, 1, 4, 5, 10, 11, 13, 17, 21, 25, 29, 32, 37, 41, 51, 59, 61, 64, 67, 69, 71, 102, 106, 108, 115, 127, 133, 135, 141, 146, 148, 150, 152, 160, 161, 168, 170, 174, 177, 180, 183, 184, 186, 188, 194, 195, 196, 198, 210, 214, 215, 219, 222, 228, 237, 239, 240, 245, 252, 257, 259, 260, 267, 270, 271, 273, 276, 277, 278, 280, 281, 289, 295, 303, 305, 315, 332, 343, 346, 347, 361, 362, 367, 368, 370, 379, 382, 383, 393, 396, 405, 409, 416, 417, 419, 428, 429, 434, 435, 436, 438, 439, 444, 447, 448, 451, 454, 465, 470, 474, 483, 490, 495, 515, 520, 526, 530, 531, 538, 540, 541, 551, 554, 555, 556, 567, 573, 576, 581, 583, 586, 587, 590, 594, 596, 618, 619, 621, 626, 632, 634, 641, 642, 648, 653, 654, 656, 663, 667, 668, 675, 676, 683, 692, 705, 708, 714, 719, 723, 724, 726, 727, 729, 732, 733, 753, 754, 773, 776, 780, 781, 785, 793, 797, 798, 799, 801, 802, 804, 806, 811, 812, 814, 819, 822, 847, 849, 854, 856, 860, 865, 868, 870, 880, 887, 905, 906, 914, 915, 919, 924, 935, 946, 948, 951, 953, 957, 961, 970, 984, 987, 988, 989, 990, 995, 998, 1009, 1011, 1014, 1016, 1022, 1023, 1027, 1032, 1039, 1041, 1043, 1045, 1047, 1048, 1049, 1051, 1054, 1055, 1058, 1060, 1062, 1066, 1067, 1068, 1069, 1072, 1073, 1074, 1078, 1083, 1084, 1088, 1090, 1091, 1093, 1095, 1099, 1102, 1103, 1104, 1121, 1128, 1130, 1131, 1135, 1144, 1146, 1158, 1161, 1162, 1167, 1169, 1171, 1175, 1176, 1178, 1181, 1182, 1186, 1187, 1190, 1193, 1194, 1198, 1199, 1200, 1201, 1203, 1205, 1207, 1208, 1211, 1221, 1227, 1228, 1230, 1232, 1234, 1238, 1242, 1243, 1245, 1247, 1248, 1253, 1258, 1259, 1260, 1261, 1267, 1268, 1269, 1270, 1271, 1277, 1279, 1285, 1290, 1291, 1295, 1296, 1299, 1301, 1302, 1308, 1310, 1312, 1315, 1316, 1320, 1321, 1322, 1323, 1324, 1326, 1328, 1329, 1330, 1332, 1333, 1334, 1338, 1340, 1341, 1342, 1343, 1344, 1345, 1346, 1347, 1350, 1356, 1357, 1362, 1364, 1365, 1372, 1374, 1377, 1383, 1384, 1385, 1393, 1395, 1400, 1407, 1410, 1412, 1413, 1421, 1423, 1426, 1428, 1438, 1439, 1440, 1442, 1444, 1446, 1453, 1457, 1458, 1459, 1460, 1466, 1474, 1479, 1480, 1481, 1492, 1493, 1495, 1496, 1504, 1505, 1507, 1508, 1510, 1514, 1519, 1522, 1531, 1536, 1540, 1543, 1545, 1549, 1550, 1556, 1558, 1559, 1563, 1564, 1565, 1570, 1574, 1576, 1577, 1582, 1587, 1588, 1594, 1595, 1598, 1599, 1603, 1604, 1606, 1608, 1613, 1614, 1615, 1616, 1624, 1629, 1630, 1633, 1637, 1647, 1651, 1660, 1662, 1665, 1670, 1671, 1673, 1678, 1680, 1681, 1683, 1686, 1693, 1696, 1698, 1701, 1702, 1705, 1708, 1710, 1711, 1716, 1720, 1722, 1728, 1732, 1741, 1742, 1744, 1751, 1754, 1757, 1758, 1760, 1762, 1764, 1767, 1771, 1774, 1777, 1781, 1783, 1790, 1791, 1794, 1797, 1800, 1804, 1805, 1808, 1809, 1810, 1811, 1817, 1820, 1825, 1826, 1827, 1830, 1831, 1833, 1837, 1846, 1850, 1852, 1856, 1858, 1864, 1868, 1872, 1874, 1875, 1876, 1881, 1883, 1885, 1889, 1892, 1893, 1896, 1897, 1901, 1910, 1911, 1914, 1919, 1920, 1926, 1929, 1932, 1938, 1940, 1942, 1943, 1945, 1946, 1952, 1958, 1961, 1962, 1963, 1964, 1965, 1967, 1968, 1971, 1983, 1989, 1996, 1997, 1999, 2002, 2003, 2006, 2014, 2015, 2016, 2025, 2027, 2029, 2031, 2035, 2048, 2062, 2065, 2069, 2071, 2074, 2082, 2086, 2089, 2090, 2092, 2093, 2094, 2096, 2098, 2099, 2105, 2108, 2109, 2111, 2117, 2118, 2119, 2126, 2131, 2132, 2135, 2137, 2142, 2152, 2167, 2182, 2184, 2190, 2199, 2204, 2213, 2214, 2217, 2219, 2221, 2231, 2233, 2234, 2242, 2243, 2244, 2247, 2259, 2268, 2271, 2272, 2282, 2290, 2292, 2294, 2295, 2296, 2297, 2309, 2311, 2312, 2319, 2322, 2324, 2326, 2329, 2333, 2336, 2339, 2340, 2341, 2345, 2346, 2350, 2355, 2367, 2372, 2375, 2379, 2382, 2383, 2386, 2387, 2389, 2402, 2405, 2410, 2413, 2418, 2423, 2425, 2432, 2438, 2440, 2444, 2451, 2452, 2457, 2459, 2463, 2464, 2465, 2467, 2469, 2478, 2480, 2487, 2490, 2502, 2507, 2508, 2509, 2510, 2511, 2517, 2518, 2523, 2530, 2534, 2538, 2539, 2541, 2546, 2548, 2549, 2556, 2559, 2564, 2567, 2570, 2572, 2573, 2575, 2578, 2584, 2586, 2587, 2591, 2598, 2600, 2603, 2611, 2619, 2624, 2629, 2630, 2636, 2640, 2641, 2643, 2644, 2646, 2648, 2655, 2663, 2668, 2671, 2672,
2674, 2677, 2678, 2679, 2680, 2685, 2686, 2687, 2696, 2701, 2708, 2709, 2712, 2713, 2717, 2720, 2725, 2728, 2729, 2732, 2741, 2742, 2743, 2749, 2757, 2761, 2764, 2771, 2774, 2777, 2781, 2782, 2788, 2790, 2791, 2792, 2795, 2796, 2797, 2801, 2803, 2806, 2807, 2810, 2811, 2812, 2816, 2818, 2821, 2835, 2837, 2838, 2844, 2850, 2852, 2855, 2861, 2867, 2877, 2885, 2886, 2890, 2895, 2902, 2904, 2905, 2906, 2908, 2912, 2917, 2919, 2922, 2923, 2924, 2926, 2927, 2928, 2932, 2933, 2946, 2947, 2950, 2951, 2955, 2957, 2959, 2961, 2967, 2968, 2969, 2975, 2978, 2982, 2986, 2991, 2992, 2994, 2996, 2997, 2998, 3006, 3010, 3012, 3013, 3017, 3018, 3019, 3023, 3026, 3029, 3030, 3031, 3036, 3038, 3040, 3043, 3044, 3050, 3051, 3054, 3056, 3062, 3065, 3068, 3071, 3078, 3079, 3080, 3083, 3085, 3086, 3090, 3111, 3112, 3117, 3118, 3119, 3125, 3127, 3128, 3133, 3135, 3137, 3139, 3150, 3153, 3154, 3156, 3158, 3161, 3164, 3166, 3169, 3174, 3177, 3182, 3188, 3190, 3192, 3195, 3199, 3203, 3205, 3208, 3209, 3211, 3212, 3213, 3215, 3216, 3218, 3225, 3226, 3230, 3231, 3237, 3240, 3243, 3244, 3247, 3248, 3252, 3262, 3268, 3273, 3276, 3277, 3281, 3282, 3285, 3286, 3291, 3292, 3293, 3295, 3296, 3298, 3306, 3310, 3314, 3315, 3316, 3318, 3320, 3321, 3323, 3325, 3334, 3340, 3341, 3342, 3343, 3345, 3352, 3353, 3360, 3361, 3362, 3364, 3366, 3370, 3371, 3373, 3376, 3377, 3383, 3384, 3387, 3388, 3392, 3401, 3404, 3411, 3415, 3418, 3419, 3421, 3424, 3427, 3429, 3436, 3437, 3439, 3440, 3445, 3451, 3460, 3461, 3463, 3467, 3480, 3481, 3482, 3493, 3496, 3498, 3500, 3501, 3502, 3504, 3506, 3512, 3513, 3514, 3517, 3518, 3520, 3521, 3522, 3524, 3527, 3537, 3538, 3541, 3547, 3568, 3569, 3572, 3575, 3576, 3579, 3583, 3585, 3588, 3590, 3591, 3594, 3596, 3605, 3622, 3626, 3632, 3633, 3636, 3643, 3644, 3645, 3648, 3649, 3650, 3653, 3656, 3660, 3661, 3663, 3676, 3687, 3695, 3697, 3703, 3705, 3722, 3724, 3730, 3733, 3734, 3736, 3743, 3745, 3748, 3750, 3758, 3759, 3766, 3773, 3791, 3793, 3798, 3799, 3809, 3812, 3813, 3815, 3817, 3819, 3821, 3824, 3829, 3832, 3833, 3837, 3838, 3842, 3847, 3848, 3851, 3852, 3862, 3865, 3870, 3872, 3873, 3875, 3877, 3880, 3881, 3894, 3896, 3899, 3906, 3910, 3913, 3917, 3920, 3923, 3925, 3941, 3944, 3949, 3951, 3969, 3970, 3975, 3976, 3978, 3982, 3986, 3991, 3992, 3997, 3998, 4002, 4012, 4015, 4019, 4020, 4021, 4023, 4024, 4025, 4034, 4035, 4037, 4038, 4039, 4041, 4045, 4049, 4057, 4062, 4063, 4070, 4071, 4074, 4077, 4079, 4080, 4083, 4085, 4086, 4090, 4095, 4100, 4101, 4103, 4106, 4110, 4115, 4121, 4126, 4140, 4143, 4149, 4153, 4158, 4159, 4161, 4167, 4168, 4170, 4173, 4180, 4184, 4191, 4198, 4199, 4204, 4206, 4211, 4213, 4214, 4217, 4221, 4223, 4224, 4226, 4230, 4231, 4232, 4241, 4242, 4244, 4245, 4247, 4248, 4250, 4254, 4259, 4261, 4262, 4263, 4266, 4267, 4271, 4272, 4279, 4286, 4287, 4292, 4299, 4300, 4304, 4305, 4307, 4308, 4310, 4312, 4313, 4314, 4320, 4328, 4332, 4335, 4340, 4344, 4348, 4349, 4351, 4353, 4362, 4364, 4366, 4370, 4372, 4375, 4376, 4379, 4381, 4382, 4384, 4386, 4399, 4400, 4401, 4404, 4408, 4411, 4412, 4413, 4415, 4418, 4419, 4421, 4422, 4434, 4435, 4437, 4439, 4443, 4446, 4447, 4448, 4455, 4456, 4457, 4462, 4463, 4467, 4468, 4471, 4473, 4474, 4477, 4480, 4482, 4485, 4487, 4495, 4497, 4498, 4499, 4503, 4514, 4525, 4526, 4528, 4529, 4532, 4540, 4545, 4548, 4560, 4563, 4565, 4567, 4569, 4571, 4575, 4583, 4584, 4592, 4593, 4596, 4599, 4600, 4601, 4604, 4609, 4616, 4617, 4619, 4625, 4627, 4630, 4636, 4642, 4647, 4651, 4653, 4654, 4657, 4659, 4667, 4672, 4683, 4685, 4686, 4697, 4699, 4700, 4702, 4711, 4714, 4718, 4727, 4729, 4735, 4738, 4739, 4741, 4748, 4751, 4752, 4753, 4763, 4767, 4769, 4776, 4781, 4784, 4788, 4793, 4796, 4797, 4798, 4800, 4808, 4809, 4812, 4816, 4818, 4822, 4826, 4827, 4831, 4832, 4833, 4836, 4837, 4845, 4846, 4847, 4849, 4852, 4855, 4859, 4860, 4861, 4867, 4868, 4869, 4871, 4875, 4876, 4877, 4884, 4891, 4895, 4896, 4907, 4909, 4913, 4918, 4919, 4922, 4926, 4927, 4934, 4935, 4936, 4944, 4945, 4946, 4957, 4959, 4962, 4964, 4965, 4966, 4971, 4973, 4974, 4975, 4985, 4986, 4995, 4999]
with open(f"./logs/log_{formatted_time}.txt", "w") as log_file, open(f"./logs/submission_{formatted_time}.json", "w") as sm_file, open("./data/chatglm_llm_fintech_raw_dataset/test_questions.jsonl", "r") as qs_file:
question_count = 0
for question_line in qs_file:
question_count += 1
##### id 截断
# if question_count<1734:
# continue
print("question_count:",question_count)
question_dict = json.loads(question_line)
##### bad id 截断
if question_dict["id"] not in bad_ids:
continue
answer = generate(question_dict["question"], uuid_dict, crawl_dict, crawl_name_dict, es, log_file)
answer_dict = {"id":question_dict["id"],"question":question_dict["question"],"answer":answer}
sm_file.write(f"{answer_dict}\n")
time.sleep(3)
================================================
FILE: inference_6b.sh
================================================
#!/bin/bash
JSON_FILE="configs/server.json"
LOGS="logs"
BASE_PATH=$(jq -r '.base_path' $JSON_FILE)
PYTHON_PATH=$(jq -r '.base_python' $JSON_FILE)
ELASTIC_SEARCH_PATH=$(jq -r '.sever_path.elastic_search' $JSON_FILE)
WEAVIATE_PATH=$(jq -r '.sever_path.weaviate' $JSON_FILE)
LLM_SERVER=$(jq -r '.sever_path.chatglm2' $JSON_FILE)
TEXT_SERVER=$(jq -r '.sever_path.text2vec' $JSON_FILE)
# 启动 text2vec model (for WEAVIATE)
cd "$BASE_PATH/$TEXT_SERVER" && nohup $PYTHON_PATH jina_server.py > "$BASE_PATH/$LOGS/text2vec.log" 2>&1 &
echo "text2vec model start!"
# 启动 elastic search
cd "$BASE_PATH/$ELASTIC_SEARCH_PATH" && docker-compose up -d
echo "elastic DB start!"
# 启动 chatgml-6b
cd "$BASE_PATH/$LLM_SERVER" && nohup $PYTHON_PATH jina_server.py > "$BASE_PATH/$LOGS/llm.log" 2>&1 &
echo "gml-6b model start!"
# 启动 weaviate
cd "$BASE_PATH/$WEAVIATE_PATH" && docker-compose up -d
echo "weaviate DB start!"
echo "====================================="
# 启动 生成程序
cd "$BASE_PATH"
$PYTHON_PATH inference_6b.py
================================================
FILE: models_server/chatglm2/README
================================================
================================================
FILE: models_server/chatglm2/jina_client.py
================================================
# -*- coding: utf-8 -*-
from jina import Document, DocumentArray
from jina import Client
import sys
import time
sys.path.append('..')
port = 50002
c = Client(port=port)
def encode(sentence, history):
"""Get one sentence embeddings from jina server."""
r = c.post(
'/', inputs=DocumentArray([Document(text=sentence, tags={"history": history})]))
return r
if __name__ == '__main__':
# 我们创建一个会话的历史,你可以根据需要更改
history = []
# 发起一个聊天会话
sentences = ['你好', '中国人认为宇宙万法的那个源头,它是什么', '你跟我说说这宇宙万物的本源是什么?']
for sent in sentences:
# 创建请求,发送给executor
response = encode(sent, history)
# 打印返回的响应
print(f"Response: {response[0].text}")
print(f"Updated history: {response[0].tags['history']}")
# 更新会话历史
history = response[0].tags['history']
================================================
FILE: models_server/chatglm2/jina_server.py
================================================
import warnings
warnings.filterwarnings('ignore')
from jina import DocumentArray, Executor, requests, Flow
from transformers import AutoModel, AutoTokenizer
from typing import Dict, Tuple, Union, Optional
from torch.nn import Module
import logging
import torch
import pickle
import json
import os
def auto_configure_device_map(num_gpus: int) -> Dict[str, int]:
# transformer.word_embeddings 占用1层
# transformer.final_layernorm 和 lm_head 占用1层
# transformer.layers 占用 28 层
# 总共30层分配到num_gpus张卡上
num_trans_layers = 28
per_gpu_layers = 30 / num_gpus
# bugfix: 在linux中调用torch.embedding传入的weight,input不在同一device上,导致RuntimeError
# windows下 model.device 会被设置成 transformer.word_embeddings.device
# linux下 model.device 会被设置成 lm_head.device
# 在调用chat或者stream_chat时,input_ids会被放到model.device上
# 如果transformer.word_embeddings.device和model.device不同,则会导致RuntimeError
# 因此这里将transformer.word_embeddings,transformer.final_layernorm,lm_head都放到第一张卡上
# 本文件来源于https://github.com/THUDM/ChatGLM-6B/blob/main/utils.py
# 仅此处做少许修改以支持ChatGLM2
device_map = {
'transformer.embedding.word_embeddings': 0,
'transformer.encoder.final_layernorm': 0,
'transformer.output_layer': 0,
'transformer.rotary_pos_emb': 0,
'lm_head': 0
}
used = 2
gpu_target = 0
for i in range(num_trans_layers):
if used >= per_gpu_layers:
gpu_target += 1
used = 0
assert gpu_target < num_gpus
device_map[f'transformer.encoder.layers.{i}'] = gpu_target
used += 1
return device_map
def load_model_on_gpus(checkpoint_path: Union[str, os.PathLike], num_gpus: int = 2, lora_path: Optional[str] = None,
device_map: Optional[Dict[str, int]] = None, **kwargs) -> Module:
if num_gpus < 2 and device_map is None:
model = AutoModel.from_pretrained(
checkpoint_path, trust_remote_code=True, **kwargs).half().cuda()
else:
lora_path = kwargs.get('lora_path', '')
if not lora_path:
from accelerate import dispatch_model
model = AutoModel.from_pretrained(
checkpoint_path, trust_remote_code=True, **kwargs).half()
if device_map is None:
device_map = auto_configure_device_map(num_gpus)
model = dispatch_model(model, device_map=device_map)
else:
from peft import PeftModel
if device_map is None:
device_map = auto_configure_device_map(num_gpus)
model = AutoModel.from_pretrained(
checkpoint_path, trust_remote_code=True, device_map=device_map).half()
model = PeftModel.from_pretrained(model, lora_path)
logging.warn(f"Using Lora From : {lora_path}")
return model
class ChatGLM2(Executor):
def __init__(
self,
model_name: str = '',
lora_path: str = '',
device: str = None,
num_gpus: int = 0,
*args,
**kwargs,
):
super().__init__(*args, **kwargs)
self.pre_history = {}
# with open('pre_history.pickle', 'rb') as f:
# self.pre_history["pickle"] = pickle.load(f)
if device is None:
device = "cuda" if torch.cuda.is_available() else "cpu"
self.device = torch.device(device)
if device == "cuda":
self.model = load_model_on_gpus(
model_name, num_gpus=num_gpus, lora_path=lora_path)
else:
self.model = AutoModel(model_name)
self.model.to(device).eval()
self.tokenizer = AutoTokenizer.from_pretrained(
model_name, trust_remote_code=True)
@requests
def chat(self, docs: DocumentArray, pre_history: bool = False, **kwargs):
for doc in docs:
prompt = doc.text
history = doc.tags.get('history', [])
max_length = doc.tags.get('max_length', 8192)
top_p = doc.tags.get('top_p', 0.95)
temperature = doc.tags.get('temperature', 0.01)
if history:
history = json.loads(doc.tags['history'])
else:
if pre_history:
pass
else:
# history.append(self.pre_history["pickle"])
pass
# print('---------prompt----------')
# print(prompt)
response, history = self.model.chat(
self.tokenizer, prompt, history=history, max_length=max_length, top_p=top_p, temperature=temperature)
doc.text = response
doc.tags['history'] = json.dumps(history, ensure_ascii=False)
# print('--------response---------')
# print(response)
# print('----------end------------')
with open('../../configs/server.json', 'r') as file:
server_config = json.load(file)
base_path = server_config["base_path"]
model_path = os.path.join(base_path,server_config["models_path"]["chatglm2"])
# port = server_config["port"]["chatglm2"]
lora_path = ""
f = Flow(port=50002).add(
uses=ChatGLM2,
uses_with={
'model_name': model_path,
'lora_path': lora_path,
'device': 'cuda',
'num_gpus': 1,
},
gpus='device=0'
)
with f:
# start server, backend server forever
f.block()
================================================
FILE: models_server/text2vec/jina_embedding.py
================================================
import warnings # noqa: E501
warnings.filterwarnings('ignore') # noqa: E501
from langchain.embeddings.base import Embeddings
from docarray import Document, DocumentArray
from jina import Client
from typing import Any, List
class JinaEmbeddings(Embeddings):
def __init__(self, host: str = "0.0.0.0", port: int = 50001, **kwargs: Any) -> None:
self.client = Client(host=host, port=port, **kwargs)
def _post(self, docs: List[Any], **kwargs: Any) -> Any:
payload = dict(inputs=docs, **kwargs)
return self.client.post(on="/", **payload)
def embed_documents(self, texts: List[str]) -> List[List[float]]:
docs = DocumentArray([Document(text=t) for t in texts])
embeddings = self._post(docs).embeddings
return [list(map(float, e)) for e in embeddings]
def embed_query(self, text: str) -> List[float]:
docs = DocumentArray([Document(text=text)])
embedding = self._post(docs).embeddings[0]
return list(map(float, embedding))
================================================
FILE: models_server/text2vec/jina_server.py
================================================
from jina import DocumentArray, Executor, requests
from transformers import AutoModel, AutoTokenizer
from typing import Dict, Optional, Tuple
from jina import Flow
import numpy as np
import torch
import os
import json
class Text2vecEncoder(Executor):
"""The Text2vecEncoder encodes sentences into embeddings using transformers models."""
def __init__(
self,
model_name,
base_tokenizer_model: Optional[str] = None,
pooling_strategy: str = 'mean',
layer_index: int = -1,
max_length: Optional[int] = 256,
embedding_fn_name: str = '__call__',
device: str = None,
traversal_paths: str = '@r',
batch_size: int = 32,
*args,
**kwargs,
):
"""
The transformer torch encoder encodes sentences into embeddings.
:param model_name: Name of the pretrained model or path to the
model
:param base_tokenizer_model: Base tokenizer model
:param pooling_strategy: The pooling strategy to be used. The allowed values are
``'mean'``, ``'min'``, ``'max'`` and ``'cls'``.
:param layer_index: Index of the layer which contains the embeddings
:param max_length: Max length argument for the tokenizer, used for truncation. By
default the max length supported by the model will be used.
:param embedding_fn_name: Function to call on the model in order to get output
:param device: Torch device to put the model on (e.g. 'cpu', 'cuda', 'cuda:1')
:param traversal_paths: Used in the encode method an define traversal on the
received `DocumentArray`
:param batch_size: Defines the batch size for inference on the loaded
PyTorch model.
"""
super().__init__(*args, **kwargs)
self.traversal_paths = traversal_paths
self.batch_size = batch_size
base_tokenizer_model = base_tokenizer_model or model_name
self.pooling_strategy = pooling_strategy
self.layer_index = layer_index
self.max_length = max_length
if device is None:
device = "cuda" if torch.cuda.is_available() else "cpu"
self.device = torch.device(device)
self.embedding_fn_name = embedding_fn_name
self.tokenizer = AutoTokenizer.from_pretrained(base_tokenizer_model)
self.model = AutoModel.from_pretrained(
model_name, output_hidden_states=True
)
self.model.to(device).eval()
@requests
def encode(self, docs: DocumentArray, parameters: Dict = {}, **kwargs):
"""
Encode text data into a ndarray of `D` as dimension, and fill the embedding of
each Document.
:param docs: DocumentArray containing text
:param parameters: dictionary to define the `traversal_paths` and the
`batch_size`. For example,
`parameters={'traversal_paths': 'r', 'batch_size': 10}`.
:param kwargs: Additional key value arguments.
"""
docs_batch_generator = DocumentArray(
filter(
lambda x: bool(x.text),
docs[parameters.get('traversal_paths', self.traversal_paths)],
)
).batch(batch_size=parameters.get('batch_size', self.batch_size))
for batch in docs_batch_generator:
texts = batch.texts
with torch.inference_mode():
input_tokens = self._generate_input_tokens(texts)
outputs = getattr(self.model, self.embedding_fn_name)(
**input_tokens)
if isinstance(outputs, torch.Tensor):
outputs = outputs.cpu().numpy()
hidden_states = outputs.hidden_states
embeds = self._compute_embedding(hidden_states, input_tokens)
batch.embeddings = embeds
def _compute_embedding(
self, hidden_states: Tuple['torch.Tensor'], input_tokens: Dict
):
fill_vals = {'cls': 0.0, 'mean': 0.0, 'max': -np.inf, 'min': np.inf}
fill_val = torch.tensor(
fill_vals[self.pooling_strategy], device=self.device)
layer = hidden_states[self.layer_index]
attn_mask = input_tokens['attention_mask']
# Fix LongFormerModel like model which has mismatch seq_len between
# attention_mask and hidden_states
padding_len = layer.size(1) - attn_mask.size(1)
if padding_len > 0:
attn_mask = torch.nn.functional.pad(
attn_mask, (0, padding_len), value=0)
expand_attn_mask = attn_mask.unsqueeze(-1).expand_as(layer)
layer = torch.where(expand_attn_mask.bool(), layer, fill_val)
embeddings = layer.sum(dim=1) / expand_attn_mask.sum(dim=1)
return embeddings.cpu().numpy()
def _generate_input_tokens(self, texts):
if not self.tokenizer.pad_token:
self.tokenizer.add_special_tokens({'pad_token': '[PAD]'})
self.model.resize_token_embeddings(len(self.tokenizer.vocab))
input_tokens = self.tokenizer(
texts,
max_length=self.max_length,
padding='longest',
truncation=True,
return_tensors='pt',
)
input_tokens = {k: v.to(self.device) for k, v in input_tokens.items()}
return input_tokens
with open('../../configs/server.json', 'r') as file:
server_config = json.load(file)
base_path = server_config["base_path"]
model_path = os.path.join(base_path,server_config["models_path"]["text2vec"])
print(model_path)
# port = server_config["port"]["text2vec"]
lora_path = ""
f = Flow(port=50001).add(
uses=Text2vecEncoder,
uses_with={
'model_name': model_path,
'device': 'cuda',
},
gpus='device=0',
)
with f:
# start server, backend server forever
f.block()
================================================
FILE: prompts/answer_generation.py
================================================
from langchain import PromptTemplate
PROMPT = """
你需要扮演一位金融专家助手。请根据所提供的额外信息,回答下列问题。请注意,额外信息虽然都是有效的,但你只需使用与问题直接相关的部分。
要求:
1. 答案应简练、清晰、准确。
2. 仅使用与问题直接相关的额外信息进行回答。
3. 避免引入与问题无关的信息。
示例:
人类:本钢板材在2020年对联营企业和合营企业的投资收益是多少元?
额外信息:该公司的数据如下所示
其中:对联营企业和合营企业的投资收益/(损失)是374119.86
其中:对联营企业和合营企业的投资收益/(损失) 同比是-17.3366874753
营业总收入(元)是48684792685.58
营业成本是46392180562.59
AI:
本钢板材在2020年对联营企业和合营企业的投资收益是374119.86元。
现在开始:
人类:{query}
额外信息:该公司的数据如下所示
{extra_information}
AI:
"""
def answer_generation_raw_prompt():
return PromptTemplate(template=PROMPT, input_variables=["extra_information", "query"])
def answer_generation_prompt(extra_information: str, query: str):
P = PromptTemplate(template=PROMPT, input_variables=[
"extra_information", "query"])
return P.format(extra_information=extra_information, query=query)
if __name__ == "__main__":
print(answer_generation_prompt("你们公司的装箱算法可以用在服装业吗"))
================================================
FILE: prompts/entity_recognition.py
================================================
from langchain import PromptTemplate
PROMPT = """
你需要扮演一个优秀的实体提取助手。你的任务是从人类提供的问句中抽取并精确返回公司名称和年份。
示例一:
人类:抽取<请根据2020年金宇生物技术股份有限公司的年报,简述公司的社会责任工作情况。>中的公司名,年份。
公司名:金宇生物技术股份有限公司
年份:2020年
示例二:
人类:抽取<2019年安记食品股份有限公司的营业利润率是多少?结果请保留至小数点后两位。>中的公司名,年份。
公司名:安记食品股份有限公司
年份:2019年
示例三:
人类:抽取<研发费用如何影响公司的技术创新和竞争优势?>中的公司名,年份。
公司名:无
年份:无
示例四:
人类:抽取<平潭发展在2021年的投资收益增长率保留到小数点后两位是多少?>中的公司名,年份。
公司名:平潭发展
年份:2021年
示例五:
人类:抽取<请根据江化微2019年的年报,简要介绍报告期内公司主要销售客户的客户集中度情况,并结合同行业情况进行分析。>中的公司名,年份。
公司名:江化微
年份:2019年
注意:
1.你不需要做任何解释说明,并且严格按照上述示例的格式进行输出。
2.如果信息未包含对应实体,请输出"无"。
3.你不要把信息中<...>的内容当作问题回答,它是作为被实体提取的对象。
4.你的回答仅包括"公司名"和"年份"两个部分,年份请输出20xx年,请避免输出无关的信息。
现在开始:
人类:抽取<{query}>中的公司名,年份。
"""
def entity_recognition_raw_prompt():
return PromptTemplate(template=PROMPT, input_variables=["query"])
def entity_recognition_prompt(query: str):
P = PromptTemplate(template=PROMPT, input_variables=["query"])
return P.format(query=query)
if __name__ == "__main__":
print(entity_recognition_prompt("你们的装箱算法能不能用在家居业呀?主要用于是沙发的装箱。"))
================================================
FILE: prompts/information_extraction.py
================================================
from langchain import PromptTemplate
PROMPT = """
你需要扮演一个优秀的关键信息提取助手,从人类的对话中提取关键性内容(最多5个关键词),以协助其他助手更精准地回答问题。
注意:你不需要做任何解释说明,只需严格按照示例的格式输出关键词。
示例:
人类:我有一个服装厂,是否可以应用你们的装箱算法改善装载率呢?
AI: 服装厂, 装箱算法, 装载率
现在开始:
人类:{query}
AI:
"""
def information_extraction_raw_prompt():
return PromptTemplate(template=PROMPT, input_variables=["query"])
def information_extraction_prompt(query: str):
P = PromptTemplate(template=PROMPT, input_variables=["query"])
return P.format(query=query)
if __name__ == "__main__":
print(information_extraction_prompt("你们的装箱算法能不能用在家居业呀?"))
================================================
FILE: prompts/intent_recognition.py
================================================
from langchain import PromptTemplate
# 你不需要做任何解释说明,并且严格按照示例的格式进行输出,仅输出["金融常识问题","文本检索问题","数值检索问题"]。
PROMPT = """
你需要扮演一个优秀的意图识别助手,你需要写出思考过程,并判断人类的问题是属于(开放问题/检索问题)类别的一项。
示例一:
人类:判断<能否根据2020年金宇生物技术股份有限公司的年报,给我简要介绍一下报告期内公司的社会责任工作情况?>的类别。
思考:
1. 题目中出现了具体公司名称的关键词 "金宇生物技术股份有限公司"。
2. 由于题目包含具体公司名称的关键词,判断该题目属于检索问题。
答案: 检索问题
示例二:
人类:判断<2019年四方科技电子信箱是什么>的类别。
思考:
1. 题目中出现了具体公司名称的关键词 "四方科技"。
2. 由于题目包含具体公司名称的关键词,判断该题目属于检索问题。
答案: 检索问题
示例三:
人类:判断<研发费用对公司的技术创新和竞争优势有何影响?>的类别。
思考:
1. 题目中未出现任何具体公司名称的关键词。
2. 由于题目未包含具体公司名称的关键词,判断该题目属于开放问题。
答案: 开放问题
示例四:
人类:判断<请根据江化微2019年的年报,简要介绍报告期内公司主要销售客户的客户集中度情况,并结合同行业情况进行分析。>的类别。
思考:
1. 题目中出现了具体公司名称的关键词 "江化微"。
2. 由于题目包含具体公司名称的关键词,判断该题目属于检索问题。
答案: 检索问题
示例五:
人类:判断<康希诺生物股份公司在2020年的资产负债比率具体是多少,需要保留至小数点后两位?>的类别。
思考:
1. 题目中出现了具体公司名称的关键词 "康希诺生物股份公司"。
2. 由于题目包含具体公司名称的关键词,判断该题目属于检索问题。
答案: 检索问题
示例六:
人类:判断<平潭发展在2021年的投资收益增长率保留到小数点后两位是多少?>的类别。
思考:
1. 题目中出现了具体公司名称的关键词 "平潭发展"。
2. 由于题目包含具体公司名称的关键词,判断该题目属于检索问题。
答案: 检索问题
注意:
1.你不需要做任何解释说明,并且严格按照上述示例的格式进行输出, 需要包括"思考"和"答案"两部分。
2."思考"仅有"1."和"2."两个步骤,不应该有更多的思考步骤。
现在开始:
人类:判断<{query}>的类别。
"""
def intent_recognition_raw_prompt():
return PromptTemplate(template=PROMPT, input_variables=["query"])
def intent_recognition_prompt(query: str):
P = PromptTemplate(template=PROMPT, input_variables=["query"])
return P.format(query=query)
if __name__ == "__main__":
print(intent_recognition_prompt("博云新材在2020年对联营企业和合营企业的投资收益是多少元?"))
================================================
FILE: prompts/open_question.py
================================================
from langchain import PromptTemplate
PROMPT = """
你需要扮演一位金融专家助手。请根据你的专业知识,回答下列问题。
要求:
1. 答案应简练、清晰、准确。
2. 仅使用与问题直接相关的额外信息进行回答。
3. 避免引入与问题无关的信息。
示例一:
人类:什么是价值投资?
AI: 价值投资是投资策略的一种,由班杰明·葛拉汉和大卫·多德(英语:DavidDodd)所提出。和价值投资法所对应的是成长投资法。其重点是透过基本面分析中的概念,例如高股息收益率、低市盈率(P/E,股价/每股净利润)和低市净率(P/B,股价/每股净资产),去寻找并投资于一些股价被低估的股票。
示例二:
人类:什么是营业利润?
AI: 营业利润(英语:OperatingIncome、OperatingProfit)或译营业利益是营业收入减除营业成本及营业费用后之余额。其为正数,表示本期营业盈余之数;其为负数,表示本期营业亏损之数。当一间公司没有营业外收入与营业外支出,有时营业利润与息税前利润被当作同义词。
示例:
人类:什么是营业税金及附加?
AI: 营业税金及附加是指对企业或个人因经营活动所产生的收入或销售额征收的税费,以及可能与之相关的其他费用或附加费。
现在开始:
人类:{query}
AI:
"""
def open_question_prompt(query: str):
P = PromptTemplate(template=PROMPT, input_variables=["query"])
return P.format(query=query)
if __name__ == "__main__":
print(open_question_prompt("什么是营业额?"))
================================================
FILE: prompts/relevance_scoring.py
================================================
from langchain import PromptTemplate
PROMPT = """
你需要扮演一个优秀的文本相关性评估助手。你需要评估额外信息是否有助于提供更优质和简练的回答。
你不需要做任何解释说明,并且严格按照示例的格式进行输出,仅回答["是", "否"]
以下是一个示例:
人类:我有一个服装厂,是否可以应用你们的装箱算法改善装载率呢?
额外信息:问:能否介绍一下蓝胖子机器智能的主力产品? 答:蓝胖子机器智能的主力产品是“蓝胖智汇Doraopt”系列AI软件产品及解决方案。这是由我们的AIoT产品事业部打造的,用于提供智能供应链的整体解决方案。
AI:否
现在开始:
人类:{query}
额外信息:{extra_information}
AI:
"""
def relevance_scoring_raw_prompt():
return PromptTemplate(template=PROMPT, input_variables=["query", "extra_information"])
def relevance_scoring_prompt(query: str, extra_information: str):
P = PromptTemplate(template=PROMPT, input_variables=[
"query", "extra_information"])
return P.format(query=query, extra_information=extra_information)
if __name__ == "__main__":
print(relevance_scoring_prompt(
query="你们的装箱算法能不能用在家居业呀?主要用于是沙发的装箱。",
extra_information="问:DoraCLP「装满满」适用于哪些行业? 答:DoraCLP「装满满」可以广泛应用于多个行业,例如家居业和鞋服业等。"),
)
================================================
FILE: requirements.txt
================================================
accelerate==0.21.0
auto_gptq==0.3.2
camelot==13.04.13-gpl-pyqt
docarray==0.21.0
itemadapter==0.8.0
jina==3.20.0
langchain==0.0.261
numpy==1.24.1
pandas==2.0.3
peft==0.4.0
scrapy==2.10.0
torch==2.1.0.dev20230807+cu118
transformers==4.31.0
weaviate_client==3.22.1
================================================
FILE: sft/chatglm2_6b_sft_adalora.py
================================================
================================================
FILE: sft/chatglm2_6b_sft_lora.py
================================================
import pandas as pd
import numpy as np
import datasets
from tqdm import tqdm
import torch
import torch.nn as nn
import transformers
from transformers import AutoTokenizer, AutoModel, TrainingArguments, AutoConfig
from peft import get_peft_model, LoraConfig, TaskType, PeftModel
import warnings
warnings.filterwarnings("ignore")
dftrain = pd.read_parquet('/home/kylin/workspace/ChatFinance/data/sft/intent_sft_10k.parquet')
dftest = pd.read_parquet('/home/kylin/workspace/ChatFinance/data/sft/intent_sft_10k_val.parquet')
# model.chat
def build_inputs(query, history):
prompt = ""
for i, (old_query, response) in enumerate(history):
prompt += "[Round {}]\n\n问:{}\n\n答:{}\n\n".format(i + 1, old_query, response) # history中的第几轮次,问了什么,得到了什么答案
prompt += "[Round {}]\n\n问:{} -> \n\n答:".format(len(history) + 1, query) # 当前轮次,当前问话
return prompt
his = [("文本分类任务:对一段问题进行意图识别,分成开放问题或者检索问题。\n\n下面是一些范例:\n\n什么是投资比率? -> 开放问题\n快手科技2021年的营业额是多少? -> 检索问题\n利润率是指什么? -> 开放问题\n百度集团2021年的硕士生人数比例是多少 -> 检索问题\n\n请对以下问题进行分类。返回'开放问题'或者'检索问题',无需其它说明和解释。\n\n什么是股东权益? ->\n\n", 'n什么是股东权益? -> 开放问题')]
dftrain['context'] = [build_inputs(x,history=his) for x in dftrain['text']] # 定义训练集中的上文
dftrain['target'] = [x for x in dftrain['tag']] # 定义训练集中的标签
dftrain = dftrain[['context','target']]
dftest['context'] = [build_inputs(x,history=his) for x in dftest['text']]
dftest['target'] = [x for x in dftest['tag']]
dftest = dftest[['context','target']]
ds_train = datasets.Dataset.from_pandas(dftrain)
ds_val = datasets.Dataset.from_pandas(dftest)
model_name = '/home/kylin/workspace/ChatFinance/models/chatglm2-6b'
max_seq_length = 512
skip_over_length = True
tokenizer = transformers.AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
config = transformers.AutoConfig.from_pretrained(model_name, trust_remote_code=True, device_map='auto')
def preprocess(example):
context = example["context"]
target = example["target"]
context_ids = tokenizer.encode(
context,
max_length=max_seq_length,
truncation=True)
target_ids = tokenizer.encode(
target,
max_length=max_seq_length,
truncation=True,
add_special_tokens=False)
input_ids = context_ids + target_ids + [config.eos_token_id]
return {"input_ids": input_ids, "context_len": len(context_ids),'target_len':len(target_ids)}
ds_train_token = ds_train.map(preprocess).select_columns(['input_ids', 'context_len','target_len'])
if skip_over_length:
ds_train_token = ds_train_token.filter(
lambda example: example["context_len"]