Showing preview only (200K chars total). Download the full file or copy to clipboard to get everything.
Repository: Layout-Generation/layout-generation
Branch: master
Commit: eaa31c56f2f6
Files: 36
Total size: 58.7 MB
Directory structure:
gitextract_m9ixlycu/
├── LICENSE
├── Layout Transformer/
│ ├── Notebook/
│ │ ├── Data/
│ │ │ └── .gitkeep
│ │ ├── Layout_Transformer.ipynb
│ │ ├── Publay Weights/
│ │ │ └── .gitkeep
│ │ ├── Results/
│ │ │ └── .gitkeep
│ │ └── Rico Weights/
│ │ └── .gitkeep
│ └── readme.md
├── LayoutGAN/
│ ├── MNIST/
│ │ ├── mnist_modules.py
│ │ ├── mnist_train.py
│ │ └── mnist_utils.py
│ ├── Publaynet/
│ │ ├── modules.py
│ │ ├── train.py
│ │ └── utils.py
│ ├── README.md
│ ├── data/
│ │ └── .gitkeep
│ ├── demo/
│ │ └── .gitkeep
│ └── samples/
│ ├── MNIST_results/
│ │ └── .gitkeep
│ └── publaynet_results/
│ └── .gitkeep
├── LayoutVAE/
│ ├── Notebook/
│ │ └── LayoutVAE_Final.ipynb
│ ├── Source/
│ │ ├── bboxvae.py
│ │ ├── config.py
│ │ ├── countvae.py
│ │ ├── layoutvae.py
│ │ ├── main.py
│ │ ├── modelblocks.py
│ │ └── utils.py
│ ├── TrainedModel/
│ │ ├── bboxvae.h5
│ │ └── countvae.h5
│ └── readme.md
├── Metrics/
│ ├── Metrics_data/
│ │ ├── GAN_res.npy
│ │ ├── VAE_res.npy
│ │ ├── publaynet.npy
│ │ └── trans.npy
│ ├── README.md
│ └── metrics.ipynb
└── README.md
================================================
FILE CONTENTS
================================================
================================================
FILE: LICENSE
================================================
MIT License
Copyright (c) 2021 Layout-Generation
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE.
================================================
FILE: Layout Transformer/Notebook/Data/.gitkeep
================================================
================================================
FILE: Layout Transformer/Notebook/Layout_Transformer.ipynb
================================================
{
"cells": [
{
"cell_type": "markdown",
"metadata": {
"id": "NSLt1-42rWxE"
},
"source": [
"### **Linking Storage Drive**\n",
"---"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"colab": {
"base_uri": "https://localhost:8080/"
},
"id": "lD3wobXKqr-f",
"outputId": "fb5730a7-516a-456e-bfb4-9a6977426992"
},
"outputs": [],
"source": [
"from google.colab import drive\n",
"drive.mount('/content/drive')"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "-B6ea86VOmGK"
},
"outputs": [],
"source": [
"root = '/LayoutTransformer/'"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "_WC6MGpirp9N"
},
"source": [
"### **Imports**\n",
"---"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "-dcOiEoOrVqq"
},
"outputs": [],
"source": [
"import tensorflow as tf\n",
"from tensorflow.keras.layers import Layer\n",
"from tensorflow.keras import Model\n",
"from tensorflow.keras import backend as k\n",
"\n",
"import numpy as np\n",
"import json\n",
"import os\n",
"import gc\n",
"\n",
"import matplotlib.pyplot as plt\n",
"from matplotlib import gridspec\n",
"from matplotlib.patches import Patch"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "Jp4KLhN7J23d"
},
"source": [
"### **GPU Setup**\n",
"---"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "fcMPzjTTJ3At"
},
"outputs": [],
"source": [
"os.environ['CUDA_VISIBLE_DEVICES']='0'\n",
"config = tf.compat.v1.ConfigProto()\n",
"config.gpu_options.per_process_gpu_memory_fraction = 0.9\n",
"session = tf.compat.v1.Session(config=config)"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "nrxAk-K7sPwB"
},
"source": [
"### **Importing Data**\n",
"\n",
"Data format:\n",
" [ Number of samples x Number of Boxes x [Class,X,Y,W,H] ]\n",
"\n",
"* PublayNet\n",
"* Rico\n",
"---\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "ghN8p4iQrplX"
},
"outputs": [],
"source": [
"publaynet_data = np.load(root+'Data/publaynet.npy')\n",
"rico_data = np.load(root+'Data/rico_new.npy')"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "udEOmzv2HdGN"
},
"source": [
"### **Layers**\n",
"\n",
"---\n",
"\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "epBvDnI5HdO6"
},
"outputs": [],
"source": [
"class MMHSALayer(Layer):\n",
" '''\n",
" **Masked Multiheaded Self Attention Layer**\n",
"\n",
" heads : Specify the number of heads\n",
" '''\n",
" def __init__(self,heads=8):\n",
" super(MMHSALayer, self).__init__()\n",
" self.heads = heads\n",
"\n",
" def build(self,input_shape):\n",
" self.model_dim = input_shape[-2]\n",
" self.k = self.add_weight(shape=(self.heads,self.model_dim,self.model_dim),\n",
" initializer='random_normal',\n",
" trainable=True,\n",
" name=\"Key\")\n",
" self.q = self.add_weight(shape=(self.heads,self.model_dim,self.model_dim),\n",
" initializer='random_normal',\n",
" trainable=True,\n",
" name=\"Query\")\n",
" self.v = self.add_weight(shape=(self.heads,self.model_dim,self.model_dim),\n",
" initializer='random_normal',\n",
" trainable=True,\n",
" name=\"Value\")\n",
" self.o = self.add_weight(shape=(self.model_dim,self.model_dim*self.heads),\n",
" initializer='random_normal',\n",
" trainable=True,\n",
" name=\"Heads\")\n",
"\n",
" def call(self,inputs):\n",
" mask_shape = inputs.shape[-1] \n",
"\n",
" mask_0 = np.ones((mask_shape,mask_shape))\n",
" for i in range(mask_shape):\n",
" for j in range(mask_shape):\n",
" if (i>j):\n",
" mask_0[i][j]=0\n",
" self.mask_0 = tf.constant(mask_0,dtype=tf.float32)\n",
"\n",
" mask_inf = np.zeros((mask_shape,mask_shape))\n",
" for i in range(mask_shape):\n",
" for j in range(mask_shape):\n",
" if (i>j):\n",
" mask_inf[i][j]=-10000000000\n",
" self.mask_inf = tf.constant(mask_inf,dtype=tf.float32)\n",
"\n",
" inputs = tf.expand_dims(inputs,1)\n",
"\n",
" key=tf.matmul(self.k,inputs)\n",
" que=tf.matmul(self.q,inputs)\n",
" val=tf.matmul(self.v,inputs)\n",
"\n",
" Z=tf.matmul(tf.transpose(key,perm=[0,1,3,2]),que)*(1/np.sqrt(self.model_dim))\n",
" W=tf.multiply(Z,self.mask_0)\n",
" W=tf.add(W,self.mask_inf)\n",
" W=tf.keras.activations.softmax(W,axis=1)\n",
" W=tf.multiply(W,self.mask_0)\n",
" W=tf.matmul(val,W)\n",
"\n",
" W = tf.reshape(W,(inputs.shape[0],self.model_dim*self.heads,mask_shape))\n",
"\n",
" ans = W\n",
"\n",
" ans = tf.matmul(self.o,ans)\n",
" ans=tf.expand_dims(ans,0)\n",
"\n",
" ans = tf.squeeze(ans,axis=0)\n",
"\n",
" return ans\n",
"\n",
"class Dense2D(Layer):\n",
" '''\n",
" **2-Dimensional Dense Layer**\n",
" Applies dense layer column-wise (shared weights). Returns the column size of units.\n",
"\n",
" units : Specify the number of output units (column length)\n",
" '''\n",
" def __init__(self,units):\n",
" super(Dense2D, self).__init__()\n",
" self.units = units\n",
"\n",
" def build(self,input_shape):\n",
" input_len = input_shape[-2]\n",
"\n",
" self.w = self.add_weight(shape=(self.units,input_len),\n",
" initializer='random_normal',\n",
" trainable=True,\n",
" name=\"dense2dw\")\n",
"\n",
" def call(self,inputs,activation = None):\n",
"\n",
" ans = tf.matmul(self.w,inputs)\n",
"\n",
" return ans\n",
"\n",
"class FFLayer(Layer):\n",
" '''\n",
" **Feed Forward Layer**\n",
" Applies dense layer column-wise (shared weights), followed by a ReLU Layer, followed by another dense layer column-wise (shared weights). Returns the same column size.\n",
"\n",
" dff : Specify the number of units (column length) in the middle layer \n",
" dropout : Dropout Rate\n",
" '''\n",
" def __init__(self, dff=2048, dropout=0.1):\n",
" super(FFLayer,self).__init__()\n",
" self.dff = dff \n",
" self.dropout = dropout \n",
"\n",
" def build(self,input_shape):\n",
" self.dropout = tf.keras.layers.Dropout(self.dropout)\n",
" self.dout = input_shape[-2]\n",
"\n",
" self.w1 = self.add_weight(shape=(self.dff,self.dout),\n",
" initializer='random_normal',\n",
" trainable=True,\n",
" name=\"ffw1\")\n",
" self.w2 = self.add_weight(shape=(self.dout,self.dff),\n",
" initializer='random_normal',\n",
" trainable=True,\n",
" name=\"ffw2\")\n",
" self.b1 = self.add_weight(shape=(self.dff,1),\n",
" initializer='random_normal',\n",
" trainable=True,\n",
" name=\"ffb1\")\n",
" self.b2 = self.add_weight(shape=(self.dout,1),\n",
" initializer='random_normal',\n",
" trainable=True,\n",
" name=\"ffb2\")\n",
"\n",
" def call(self,inputs):\n",
"\n",
" ans = tf.add(tf.matmul(self.w1,inputs),self.b1)\n",
" ans = tf.keras.activations.relu(ans)\n",
" ans = tf.add(tf.matmul(self.w2,ans),self.b2)\n",
"\n",
" ans = self.dropout(ans)\n",
" \n",
" return ans\n",
"\n",
"class ANLayer(Layer):\n",
" '''\n",
" **Add and Normalize Layer**\n",
" Adds and then Normalizes column wise.\n",
" '''\n",
" def __init__(self):\n",
" super(ANLayer,self).__init__()\n",
" self.Normal = tf.keras.layers.LayerNormalization(axis=1)\n",
"\n",
" def call(self,inputs1,inputs2):\n",
" sum = tf.add(inputs1,inputs2)\n",
" ans=self.Normal(sum)\n",
" return ans"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "qJrGCXu4suIp"
},
"source": [
"### **Model**\n",
"---"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "g6cLgJ9tsuPH"
},
"outputs": [],
"source": [
"class LTModel(Model):\n",
" def __init__(self, input_shape, layers, heads, dff, model_dim, dropout):\n",
" super(LTModel, self).__init__()\n",
"\n",
" self.emb = Dense2D(model_dim)\n",
"\n",
" self.SA = []\n",
" self.AN1 = []\n",
" self.FF = []\n",
" self.AN2 = []\n",
"\n",
" for i in range(layers):\n",
" self.SA.append(MMHSALayer(heads))\n",
" self.AN1.append(ANLayer())\n",
" self.FF.append(FFLayer(dff, dropout))\n",
" self.AN2.append(ANLayer())\n",
"\n",
" self.deemb = Dense2D(input_shape)\n",
" self.sm = tf.keras.layers.Softmax(axis=1)\n",
" \n",
" def call(self, x):\n",
" x = self.emb(x)\n",
"\n",
" for i in range(len(self.SA)):\n",
" y = self.SA[i](x)\n",
" x = self.AN1[i](x,y)\n",
" y = self.FF[i](x)\n",
" x = self.AN2[i](x,y)\n",
"\n",
" x = self.deemb(x)\n",
" x = self.sm(x)\n",
"\n",
" return x"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "XkuubrSpswZ7"
},
"source": [
"### **Layout Transformer**\n",
"---"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "EEWk72cFzmwX"
},
"outputs": [],
"source": [
"class LayoutTransformer:\n",
"\n",
" def __init__(self, n_classes, class_labels=None, n_anchors=(32,32), d=512, n_layers=6, n_heads=8, dff=2048, dropout=0.1):\n",
" self.n_classes = n_classes+2\n",
" self.n_anchors = n_anchors\n",
" self.d = d\n",
" self.n_layers = n_layers\n",
" self.n_heads = n_heads\n",
" self.dff = dff\n",
" self.dropout = dropout\n",
" self.n_row = n_anchors[0]\n",
" self.n_col = n_anchors[1]\n",
" self.input_dim = 2+n_classes+2*(n_anchors[0]+n_anchors[1])\n",
" self.model = LTModel(self.input_dim, model_dim=d, layers=n_layers, heads=n_heads, dff=dff, dropout=dropout)\n",
" self.loss_his = []\n",
" self.lr_his = []\n",
" self.train_data_his = []\n",
" if class_labels == None:\n",
" self.labels = range(1,n_classes+1)\n",
" else:\n",
" self.labels = class_labels\n",
" \n",
" \n",
" def compile(self, lr=1e-5):\n",
" self.model.compile(loss=tf.keras.losses.KLDivergence(),\n",
" metrics = [tf.keras.losses.KLDivergence()],\n",
" optimizer = tf.keras.optimizers.Adam(learning_rate=lr))\n",
" \n",
" \n",
" def build(self):\n",
" self.model.build((1,self.input_dim,1))\n",
" \n",
"\n",
" def summary(self):\n",
" self.build()\n",
" print(self.model.summary())\n",
" \n",
"\n",
" def train(self, epochs, batch_size=1, train_data_index=\"All\", rlrop_factor=0.5, rlrop_patience=1000, rlrop_min_delta=0.001):\n",
" if train_data_index == \"All\":\n",
" train_data_index = range(self.data.shape[0])\n",
" rlrop = tf.keras.callbacks.ReduceLROnPlateau(factor=rlrop_factor,patience=rlrop_patience,verbose=1,min_delta=rlrop_min_delta,monitor='kl_divergence')\n",
" callbacks = [rlrop]\n",
" history = self.model.fit(x=tf.convert_to_tensor(self.x_data[train_data_index]), y=tf.convert_to_tensor(self.y_data[train_data_index]), epochs=epochs, batch_size=batch_size, callbacks=callbacks)\n",
" self.loss_his.extend(history.history['loss'])\n",
" self.lr_his.extend(history.history['lr'])\n",
" for i in range(epochs):\n",
" self.train_data_his.append(len(train_data_index))\n",
" \n",
"\n",
" def load_weights(self, folder_path, filename):\n",
" self.build()\n",
" self.model.load_weights(folder_path + '/' + str(filename) + '.h5')\n",
" his = json.loads(open(folder_path + '/' + str(filename) + '.json').read())\n",
"\n",
" self.loss_his = his['loss']\n",
" self.train_data_his = his['data']\n",
" self.lr_his = his['lr']\n",
" \n",
"\n",
" def save_weights(self, folder_path, filename):\n",
" his = json.dumps({'loss':list(np.array(self.loss_his,dtype='float')),'data':list(np.array(self.train_data_his,dtype='float')),'lr':list(np.array(self.lr_his,dtype='float'))})\n",
" open(folder_path + '/' + str(filename) + '.json','w').write(his)\n",
" self.model.save_weights(folder_path + '/' + str(filename) + '.h5')\n",
" \n",
"\n",
" def predict(self, input):\n",
" input = tf.convert_to_tensor(input, dtype='float32')\n",
" return self.model(input).numpy()\n",
" \n",
"\n",
" def load_data(self, data, rows, cols, e=0.1):\n",
" # Make number of boxes equal in eeach document\n",
" max_box = 0\n",
" for doc in data:\n",
" max_box = max(max_box,len(doc))\n",
" for doc in range(len(data)):\n",
" while (len(data[doc])<max_box):\n",
" data[doc].append([self.n_classes-1,0,0,0,0])\n",
"\n",
" self.orig_data = np.array(data,dtype='float32')\n",
" data = np.array(data,dtype='float32')\n",
"\n",
" data[:,:,1] = data[:,:,1]/cols*(self.n_col-1)\n",
" data[:,:,2] = data[:,:,2]/rows*(self.n_row-1)\n",
" data[:,:,3] = data[:,:,3]/cols*(self.n_col-1)\n",
" data[:,:,4] = data[:,:,4]/rows*(self.n_row-1)\n",
"\n",
" data = np.array(data,dtype='int')\n",
"\n",
" # Sorting\n",
" for i in range(data.shape[0]):\n",
" box_num = data[i].shape[0]\n",
"\n",
" c=0\n",
" for j in data[i]:\n",
" if j[3]==0 and j[4]==0:\n",
" break\n",
" c = c+1\n",
"\n",
" order = [*list(data[i][0:c,3].argsort()),*range(c,box_num)] # 4 Width (Col)\n",
" data[i] = np.array(data[i,order])\n",
" order = [*list(data[i][0:c,4].argsort()),*range(c,box_num)] # 3 Height (Row)\n",
" data[i] = np.array(data[i,order])\n",
" order = [*list(data[i][0:c,1].argsort()),*range(c,box_num)] # 2 X-Pos (Col)\n",
" data[i] = np.array(data[i,order])\n",
" order = [*list(data[i][0:c,2].argsort()),*range(c,box_num)] # 1 Y-Pos (Row)\n",
" data[i] = np.array(data[i,order])\n",
"\n",
" self.data = data\n",
"\n",
" # One hot encoding\n",
" onehot_data = []\n",
"\n",
" for doc in data:\n",
" cur_data = []\n",
" for box in doc:\n",
" cur_cur_data = list(np.zeros(self.input_dim))\n",
" cur_cur_data[box[0]] = 1\n",
" cur_cur_data[box[1]+self.n_classes] = 1\n",
" cur_cur_data[box[2]+self.n_classes+self.n_col] = 1\n",
" cur_cur_data[box[3]+self.n_classes+self.n_col+self.n_row] = 1\n",
" cur_cur_data[box[4]+self.n_classes+self.n_col*2+self.n_row] = 1\n",
" cur_data.append(cur_cur_data)\n",
" onehot_data.append(cur_data)\n",
"\n",
" self.onehot_data = np.array(onehot_data, dtype='int')\n",
"\n",
" # x_data with <bos> and y_data with <eos>\n",
" x_data = []\n",
" y_data = []\n",
"\n",
" for doc in onehot_data:\n",
" bos = list(np.zeros(self.input_dim))\n",
" bos[0]=1\n",
" x = [bos,*doc]\n",
" x = np.array(x).T\n",
" x_data.append(x)\n",
"\n",
" eos = list(np.zeros(self.input_dim))\n",
" eos[self.n_classes-1] = 1\n",
" y = [*doc,eos]\n",
" for box in y:\n",
" for k in range(0, self.n_classes):\n",
" box[k] = (1 - e) * box[k] + e / self.n_classes\n",
" for k in range(self.n_classes, self.n_classes+self.n_col):\n",
" box[k] = (1 - e) * box[k] + e / self.n_col\n",
" for k in range(self.n_classes+self.n_col, self.n_classes+self.n_col+self.n_row):\n",
" box[k] = (1 - e) * box[k] + e / self.n_row\n",
" for k in range(self.n_classes+self.n_col+self.n_row, self.n_classes+2*self.n_col+self.n_row):\n",
" box[k] = (1 - e) * box[k] + e / self.n_col\n",
" for k in range(self.n_classes+2*self.n_col+self.n_row, self.n_classes+2*self.n_col+2*self.n_row):\n",
" box[k] = (1 - e) * box[k] + e / self.n_row\n",
" y = np.array(y).T\n",
" y_data.append(y)\n",
"\n",
" self.x_data = np.array(x_data,dtype=\"float32\")\n",
" self.y_data = np.array(y_data,dtype=\"float32\")\n",
" \n",
"\n",
" def onehot(self,box, prob=[-1,-1,-1,-1,-1]):\n",
" p = 1\n",
" c = np.argsort(box[0:self.n_classes],axis=0)[prob[0]]\n",
" x = np.argsort(box[self.n_classes:self.n_classes+self.n_col],axis=0)[prob[1]] + self.n_classes\n",
" y = np.argsort(box[self.n_classes+self.n_col:self.n_classes+self.n_col+self.n_row],axis=0)[prob[2]] + self.n_classes+self.n_col\n",
" w = np.argsort(box[self.n_classes+self.n_col+self.n_row:self.n_classes+2*self.n_col+self.n_row],axis=0)[prob[3]] + self.n_classes+self.n_col+self.n_row\n",
" h = np.argsort(box[self.n_classes+2*self.n_col+self.n_row:self.n_classes+2*self.n_col+2*self.n_row],axis=0)[prob[4]] + self.n_classes+2*self.n_col+self.n_row\n",
" p = p*box[c][0]*box[x][0]*box[y][0]*box[w][0]*box[h][0]\n",
" res = np.zeros((self.input_dim,1))\n",
" res[c,0]=1\n",
" res[x,0]=1\n",
" res[y,0]=1\n",
" res[w,0]=1\n",
" res[h,0]=1\n",
" return (res,p)\n",
" \n",
"\n",
" def sort_prob(self,docs):\n",
" p = [int(p) for box,p in docs]\n",
" p = np.argsort(p)[::-1]\n",
" res = []\n",
" for i in p:\n",
" res.append(docs[i])\n",
" return res\n",
" \n",
"\n",
" def get_color(self,c):\n",
" color_key = [\"#00ffff\",\"#fff5ee\",\"#dc143c\",\"#ffff00\",\"#00ff00\",\"#ff00ff\",\"#1e90ff\",\n",
" \"#ff1493\",\"#8b008b\",\"#ff4500\",\"#8b4513\",\"#808000\",\"#483d8b\",\"#008000\",\n",
" \"#000080\",\"#9acd32\",\"#ffa500\",\"#ba55d3\",\"#00fa9a\",\"#dc143c\",\"#0000ff\",\n",
" \"#f08080\",\"#f0e68c\",\"#dda0dd\",\"#f2dcb3\",\"#f9cfcc\"]\n",
" return color_key[int(c)]\n",
"\n",
" def draw_layout(self,ax, doc, prob):\n",
" for spine in ax.spines.values():\n",
" spine.set_edgecolor('green')\n",
" spine.set_linewidth(1)\n",
" ax.set_xlim(0,self.n_col-1)\n",
" ax.set_ylim(0,self.n_row-1)\n",
" ax.get_xaxis().set_visible(False)\n",
" ax.get_yaxis().set_visible(False)\n",
" ax.invert_yaxis()\n",
"\n",
" for box in doc.T:\n",
" c = np.argmax(box[0:self.n_classes],axis=0)\n",
" x = np.argmax(box[self.n_classes:self.n_classes+self.n_col],axis=0)\n",
" y = np.argmax(box[self.n_classes+self.n_col:self.n_classes+self.n_col+self.n_row],axis=0)\n",
" w = np.argmax(box[self.n_classes+self.n_col+self.n_row:self.n_classes+2*self.n_col+self.n_row],axis=0)\n",
" h = np.argmax(box[self.n_classes+2*self.n_col+self.n_row:self.n_classes+2*self.n_col+2*self.n_row],axis=0)\n",
" r = plt.Rectangle((x,y),w,h, fc=self.get_color(c)+\"72\", ec=self.get_color(c),linewidth=1)\n",
" if c==self.n_classes-1:\n",
" break\n",
"\n",
" ax.add_patch(r)\n",
" \n",
"\n",
" def print_layouts(self,docs,min_boxes,beams_to_print,path=None,ratio_h_w=1.5):\n",
" plt.style.use('dark_background')\n",
" doc_num = docs[1]\n",
" docs = docs[0]\n",
" width = beams_to_print+3\n",
" height = ratio_h_w*(len(docs))+4\n",
" fig = plt.figure(figsize=(width,height),facecolor=\"#000000\",dpi=100)\n",
"\n",
" height_ratios = [0.8/(height),0.9/(height),(height-1.7)/height]\n",
" width_ratios = [(width-9)/(2*width),3/width,3/width,3/width,(width-9)/(2*width)]\n",
"\n",
" spec = gridspec.GridSpec(ncols=5, nrows=3,\n",
" width_ratios=width_ratios,\n",
" height_ratios=height_ratios,\n",
" wspace=5/width,left=0.05/width,right=(width-0.05)/width,top=0.98,bottom=0.02,hspace=0.05)\n",
" \n",
" ax = fig.add_subplot(spec[6])\n",
"\n",
" ax.plot(range(1,len(self.loss_his)+1),self.train_data_his,'-',color='red',linewidth=3)\n",
" ax.set_xlabel(\"Epochs\")\n",
" ax.set_title(\"Train Data\")\n",
" \n",
" ax = fig.add_subplot(spec[7])\n",
"\n",
" ax.plot(range(1,len(self.loss_his)+1),self.loss_his,'-',color='blue',linewidth=3)\n",
" ax.set_xlabel(\"Epochs\")\n",
" ax.set_title(\"KL Loss\")\n",
"\n",
" ax = fig.add_subplot(spec[8])\n",
"\n",
" ax.plot(range(1,len(self.loss_his)+1),self.lr_his,'-',color='green',linewidth=3)\n",
" ax.set_xlabel(\"Epochs\")\n",
" ax.set_title(\"LR\")\n",
" ax.set_yscale(\"log\")\n",
"\n",
" height_ratios = np.ones(len(docs)+2)*ratio_h_w/(height)\n",
" height_ratios[0] = 3.8/(height)\n",
" height_ratios[1] = 0.2/(height)\n",
"\n",
" spec = gridspec.GridSpec(ncols=1, nrows=len(docs)+2,\n",
" width_ratios=[1],\n",
" height_ratios=height_ratios,\n",
" wspace=0.05,left=0.02,right=0.98,top=0.98,bottom=0.02,hspace=0.05)\n",
"\n",
" ax = fig.add_subplot(spec[0])\n",
" ax.axis('off')\n",
" ax.invert_yaxis()\n",
" ax.text(0.5,0,\"Plot\",ha='center',va='bottom',fontsize=20)\n",
" doc_nums=\"\"\n",
" for i in doc_num:\n",
" doc_nums = doc_nums + \", \" + str(i)\n",
" doc_nums = doc_nums[2:]\n",
" doc_nums = \"Documents Predicted: \" + doc_nums\n",
" props = \"Classes: \" + str(self.n_classes-2) + \"; Epochs: \" + str(len(self.loss_his))\n",
" params = \"n_anchors = \" + str(self.n_anchors) + \"; d = \" + str(self.d) + \"; n_layers = \" + str(self.n_layers) + \"; n_heads = \" + str(self.n_heads) + \"; dff = \" + str(self.dff) + \"; dropout = \" + str(self.dropout)\n",
" ax.text(0.5,0.03,doc_nums+\"\\n\"+props+\"\\n\"+params,ha='center',va='top',fontsize=10)\n",
" ax.xaxis.set_visible(False)\n",
" ax.yaxis.set_visible(False)\n",
"\n",
" legend = []\n",
" legend.append(Patch(facecolor=self.get_color(0)+\"72\", label='<bos>',ec=self.get_color(0),linewidth=1))\n",
" for i in range(1,self.n_classes-1):\n",
" legend.append(Patch(facecolor=self.get_color(i)+\"72\", label=self.labels[i-1],ec=self.get_color(i),linewidth=1))\n",
" legend.append(Patch(facecolor=self.get_color(self.n_classes-1)+\"72\", label='<eos>',ec=self.get_color(self.n_classes-1),linewidth=1))\n",
" ax.legend(handles=legend,ncol=5,loc=8)\n",
"\n",
" height_ratios = np.ones(len(docs)+1)*ratio_h_w/(height)\n",
" height_ratios[0] = 4/(height)\n",
"\n",
" spec = gridspec.GridSpec(ncols=width, nrows=len(docs)+1,\n",
" width_ratios=np.ones(width),\n",
" height_ratios=height_ratios,\n",
" wspace=0.05,left=0.02,right=0.98,top=0.98,bottom=0.02,hspace=0.05)\n",
" \n",
" ax = fig.add_subplot(spec[0])\n",
" ax.axis('off')\n",
" ax.text(0.5,0,\"Ground Truth\",ha='center')\n",
"\n",
" ax = fig.add_subplot(spec[1])\n",
" ax.axis('off')\n",
" ax.text(0.5,0,\"Input\",ha='center')\n",
"\n",
" ax = fig.add_subplot(spec[2])\n",
" ax.axis('off')\n",
" ax.text(0.5,0,\"Most Probable\",ha='center')\n",
"\n",
" for i in range(1,beams_to_print+1):\n",
" ax = fig.add_subplot(spec[i+2])\n",
" ax.axis('off')\n",
" ax.text(0.5,0,\"Beam \"+str(i),ha='center')\n",
" \n",
" for input_count,doc_list in enumerate(docs):\n",
"\n",
" ax = fig.add_subplot(spec[(input_count+1)*width])\n",
" self.draw_layout(ax,doc_list[0][0],doc_list[0][1])\n",
" ax = fig.add_subplot(spec[(input_count+1)*width+1])\n",
" self.draw_layout(ax,doc_list[1][0],doc_list[1][1])\n",
" ax = fig.add_subplot(spec[(input_count+1)*width+2])\n",
" self.draw_layout(ax,doc_list[2][0],doc_list[2][1])\n",
"\n",
" doc_num=0\n",
" for doc in range(3,len(doc_list)):\n",
" if doc_num==beams_to_print:\n",
" break\n",
" if (len(doc_list[doc][0][0])>=min_boxes):\n",
" ax = fig.add_subplot(spec[(input_count+1)*width+doc])\n",
" self.draw_layout(ax,doc_list[doc][0],doc_list[doc][1])\n",
" doc_num = doc_num+1\n",
" if path!=None:\n",
" plt.savefig(path, facecolor=\"#000000\")\n",
" plt.show()\n",
" \n",
"\n",
" def layout_completion(self, initial_boxes_num=2, data_num_array=[0], beam_length=[1], max_boxes=10):\n",
" x = self.x_data[data_num_array,:,0:initial_boxes_num]\n",
" res = []\n",
"\n",
" for input_count,input in enumerate(x):\n",
" input = np.array([input])\n",
" most_prob_doc = [(input,1)]\n",
"\n",
" for step in range(max_boxes):\n",
" cur = most_prob_doc.pop(0)\n",
" pre = np.array([self.model(cur[0]).numpy()[0,:,-1]])\n",
" (box,p) = self.onehot(pre.T,[-1,-1,-1,-1,-1])\n",
" p=p*cur[1]\n",
" cur_box = np.array([box])\n",
" cur_doc = np.append(cur[0],cur_box,axis=2)\n",
"\n",
" most_prob_doc.append((cur_doc,p))\n",
"\n",
" if most_prob_doc[0][0][0,self.n_classes-1,-1]==1:\n",
" break\n",
"\n",
" docs = []\n",
" q = [(input,1)]\n",
" total_calc = 1\n",
" for step in range(max_boxes):\n",
" beam = 1\n",
" if step<len(beam_length):\n",
" beam = beam_length[step]\n",
" \n",
" for i in range(len(q)):\n",
" cur_list = []\n",
" cur = q.pop(0)\n",
" for j in ([0] if beam==1 else [0,1,2,4,8,16]):\n",
" prob = []\n",
" temp = j\n",
" for k in range(5):\n",
" prob.insert(0,-1-temp%2)\n",
" temp = int(temp/2)\n",
"\n",
" pre = np.array([self.model(cur[0]).numpy()[0,:,-1]])\n",
" (box,p) = self.onehot(pre.T,prob)\n",
"\n",
" p=p*cur[1]\n",
" cur_box = np.array([box])\n",
" cur_doc = np.append(cur[0],cur_box,axis=2)\n",
"\n",
" cur_list.append((cur_doc,p))\n",
" \n",
" cur_list = self.sort_prob(cur_list)\n",
" for j in range(beam):\n",
" if cur_list[j][0][0,self.n_classes-1,-1]==1:\n",
" docs.append(cur_list[j])\n",
" else:\n",
" q.append(cur_list[j])\n",
"\n",
" print(\"\\r\"+str(total_calc)+\" Left in Queue: \"+str(len(q))+\" ; \"+\"Current Shape: \"+str(cur[0].shape)+\" ; \"+\"Docs Prepared: \"+str(len(docs)),end=\"\")\n",
" total_calc = total_calc+1\n",
" print(\"\")\n",
"\n",
" docs = self.sort_prob(docs)\n",
"\n",
" res.append([(np.array([self.x_data[data_num_array[input_count]]]),1),(np.array([input[0]]),1),*most_prob_doc,*docs])\n",
"\n",
" return (res,data_num_array)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Publay"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "W8lGSDNFp6MU"
},
"source": [
"### **Creating Model**\n",
"---"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "wI2KUXRzPF3r"
},
"outputs": [],
"source": [
"publay_model = LayoutTransformer(n_classes=6, class_labels=['None','Text','Title','List','Table','Figure'])"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "8rXFyHPg5gq3"
},
"outputs": [],
"source": [
"publay_model.load_data(publaynet_data[0:10000],rows=1,cols=1)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### **Training Model**\n",
"---"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"model = publay_model\n",
"\n",
"epochs = 100\n",
"lrate = 1e-5\n",
"\n",
"# Reduce LR on Plateau\n",
"min_delta = 0.001\n",
"patience = 20\n",
"factor = 0.95\n",
"\n",
"count = 0\n",
"model.compile(lr=lrate)\n",
"\n",
"for i in range(epochs):\n",
" gc.collect()\n",
" k.clear_session()\n",
" try:\n",
" if model.loss_his[-2]-model.loss_his[-1]<min_delta:\n",
" count = count+1\n",
" except:\n",
" pass\n",
" \n",
" if count==patience:\n",
" count = 0\n",
" lrate = lrate*factor\n",
" model.compile(lr=lrate)\n",
" \n",
" model.train(epochs=1, batch_size=1, train_data_index='All')\n",
" model.save_weights(root+'Publay Weights','model'+str(i+1))"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### **Loading Model**\n",
"---"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"publay_model.load_weights(root+\"Publay Weights\",\"model100\")"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### **Results**\n",
"---"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"predictions = publay_model.layout_completion(data_num_array=range(10), initial_boxes_num=2, beam_length=[3,3,2], max_boxes=10)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "yGdlreZO7DmT"
},
"outputs": [],
"source": [
"publay_model.print_layouts(predictions, min_boxes=2, beams_to_print=10, path=root+'Results/publay.png' ,ratio_h_w=1.5)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Rico"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "W8lGSDNFp6MU"
},
"source": [
"### **Creating Model**\n",
"---"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "wI2KUXRzPF3r"
},
"outputs": [],
"source": [
"rico_model = LayoutTransformer(n_classes=24, class_labels=['Text','Image','Icon','Text Button','List Item','Input','Card','Web View','Radio Button','Drawer','Checkbox','Advertisement','Modal','Pager Indicator','Slider','On/Off Switch','Button Bar','Toolbar','Number Stepper','Multi-Tab','Date Picker','Map View','Video','Bottom Navigation'])"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "8rXFyHPg5gq3"
},
"outputs": [],
"source": [
"rico_model.load_data(rico_data[],rows=2560,cols=1440)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### **Training Model**\n",
"---"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"model = rico_model\n",
"\n",
"epochs = 100\n",
"lrate = 1e-5\n",
"\n",
"# Reduce LR on Plateau\n",
"min_delta = 0.001\n",
"patience = 20\n",
"factor = 0.95\n",
"\n",
"count = 0\n",
"model.compile(lr=lrate)\n",
"\n",
"for i in range(epochs):\n",
" gc.collect()\n",
" k.clear_session()\n",
" try:\n",
" if model.loss_his[-2]-model.loss_his[-1]<min_delta:\n",
" count = count+1\n",
" except:\n",
" pass\n",
" \n",
" if count==patience:\n",
" count = 0\n",
" lrate = lrate*factor\n",
" model.compile(lr=lrate)\n",
" \n",
" model.train(epochs=1, batch_size=1, train_data_index='All')\n",
" model.save_weights(root+'Rico Weights','model'+str(i+1))"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### **Loading Model**\n",
"---"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"rico_model.load_weights(root+\"Rico Weights\",\"model100\")"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### **Results**\n",
"---"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"predictions = rico_model.layout_completion(data_num_array=range(10), initial_boxes_num=2, beam_length=[3,3,2], max_boxes=10)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "yGdlreZO7DmT"
},
"outputs": [],
"source": [
"rico_model.print_layouts(predictions, min_boxes=2, beams_to_print=10, path=root+'Results/rico.png' ,ratio_h_w=1.5)"
]
}
],
"metadata": {
"accelerator": "GPU",
"colab": {
"collapsed_sections": [],
"name": "Layout Transformer.ipynb",
"provenance": []
},
"kernelspec": {
"display_name": "Python 3",
"language": "python",
"name": "python3"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.8.8"
}
},
"nbformat": 4,
"nbformat_minor": 1
}
================================================
FILE: Layout Transformer/Notebook/Publay Weights/.gitkeep
================================================
================================================
FILE: Layout Transformer/Notebook/Results/.gitkeep
================================================
================================================
FILE: Layout Transformer/Notebook/Rico Weights/.gitkeep
================================================
================================================
FILE: Layout Transformer/readme.md
================================================
# Layout Transformer Baseline Implementation
Link for the PublayNet Dataset: https://drive.google.com/file/d/1eZMp9FiSUXixYedXhVKMQldJVvTehRMz/view?usp=sharing
================================================
FILE: LayoutGAN/MNIST/mnist_modules.py
================================================
import os
import time
import math
from glob import glob
import tensorflow as tf
import numpy as np
import random
from mnist_utils import *
import matplotlib.pyplot as plt
class RelationModule(tf.keras.Model):
def __init__(self, channels=128, output_dim=128, key_dim=128, **kwargs):
super(RelationModule, self).__init__(**kwargs)
self.key_dim = key_dim
self.output_dim = output_dim
self.channels = channels
self.key = tf.keras.layers.Conv2D(
output_dim, (1, 1), strides=(1, 1), padding='valid')
self.query = tf.keras.layers.Conv2D(
key_dim, (1, 1), strides=(1, 1), padding='valid')
self.value = tf.keras.layers.Conv2D(
key_dim, (1, 1), strides=(1, 1), padding='valid')
self.projection = tf.keras.layers.Conv2D(
channels, (1, 1), strides=(1, 1), padding='valid')
def call(self, inputs):
f_k = tf.reshape(self.key(inputs), [
inputs.shape[0], inputs.shape[1]*inputs.shape[2], self.key_dim])
f_q = tf.reshape(self.query(inputs), [
inputs.shape[0], inputs.shape[1]*inputs.shape[2], self.key_dim])
f_q = tf.transpose(f_q, perm=[0, 2, 1])
f_v = tf.reshape(self.value(inputs), [
inputs.shape[0], inputs.shape[1]*inputs.shape[2], self.output_dim])
attention_weight = tf.matmul(
f_k, f_q)/math.sqrt(inputs.shape[1]*inputs.shape[2])
out = tf.matmul(tf.transpose(attention_weight, perm=[0, 2, 1]), f_v)
out = tf.reshape(
out, [inputs.shape[0], inputs.shape[1], inputs.shape[2], self.output_dim])
out = self.projection(out)
return out
class Discriminator(tf.keras.Model):
def __init__(self, n_filters=32, n_hidden=128, layout_dim=(28, 28), render=layout_point, **kwargs):
super(Discriminator, self).__init__(**kwargs)
self.layout_dim = layout_dim
self.render = render
self.act = tf.keras.layers.LeakyReLU()
self.conv1 = tf.keras.layers.Conv2D(
n_filters, (5, 5), input_shape=layout_dim, strides=(2, 2), padding='valid')
self.bn1 = tf.keras.layers.BatchNormalization()
self.conv2 = tf.keras.layers.Conv2D(
n_filters*2, (5, 5), strides=(2, 2), padding='valid')
self.bn2 = tf.keras.layers.BatchNormalization()
self.bn3 = tf.keras.layers.BatchNormalization()
self.flatten = tf.keras.layers.Flatten()
self.fc1 = tf.keras.layers.Dense(512)
self.bn4 = tf.keras.layers.BatchNormalization()
self.fc2 = tf.keras.layers.Dense(1)
def call(self, inputs):
x = self.render(inputs, self.layout_dim[0], self.layout_dim[1])
x = self.act(self.bn1(self.conv1(x)))
x = self.act(self.bn2(self.conv2(x)))
x = self.flatten(x)
x = self.act(self.bn4(self.fc1(x)))
out = self.fc2(x)
return out
class Generator(tf.keras.Model):
def __init__(self, n_filters=128, output_dim=2, n_component=128, n_class=1, include_probability=False, **kwargs):
super(Generator, self).__init__(**kwargs)
self.n_filters = n_filters
self.output_dim = output_dim
self.n_component = n_component
self.n_class = n_class
self.include_probability = include_probability
self.act = tf.keras.layers.ReLU()
self.conv1_1 = tf.keras.layers.Conv2D(n_filters, (1, 1), input_shape=(
self.n_component, self.n_class, self.output_dim), strides=(1, 1), padding='valid')
self.bn1_1 = tf.keras.layers.BatchNormalization()
self.conv1_2 = tf.keras.layers.Conv2D(
n_filters//4, (1, 1), strides=(1, 1), padding='valid')
self.bn1_2 = tf.keras.layers.BatchNormalization()
self.conv1_3 = tf.keras.layers.Conv2D(
n_filters//4, (1, 1), strides=(1, 1), padding='valid')
self.bn1_3 = tf.keras.layers.BatchNormalization()
self.conv1_4 = tf.keras.layers.Conv2D(
n_filters, (1, 1), strides=(1, 1), padding='valid')
self.bn1_4 = tf.keras.layers.BatchNormalization()
self.relation1 = RelationModule(
channels=n_class*n_filters, output_dim=n_filters, key_dim=n_filters)
self.relation2 = RelationModule(
channels=n_class*n_filters, output_dim=n_filters, key_dim=n_filters)
self.bn_x1 = tf.keras.layers.BatchNormalization()
self.bn_x2 = tf.keras.layers.BatchNormalization()
self.bn_x3 = tf.keras.layers.BatchNormalization()
self.bn_x4 = tf.keras.layers.BatchNormalization()
self.conv2_1 = tf.keras.layers.Conv2D(
n_filters, (1, 1), strides=(1, 1), padding='valid')
self.bn2_1 = tf.keras.layers.BatchNormalization()
self.conv2_2 = tf.keras.layers.Conv2D(
n_filters//4, (1, 1), strides=(1, 1), padding='valid')
self.bn2_2 = tf.keras.layers.BatchNormalization()
self.conv2_3 = tf.keras.layers.Conv2D(
n_filters//4, (1, 1), strides=(1, 1), padding='valid')
self.bn2_3 = tf.keras.layers.BatchNormalization()
self.conv2_4 = tf.keras.layers.Conv2D(
n_filters, (1, 1), strides=(1, 1), padding='valid')
self.bn2_4 = tf.keras.layers.BatchNormalization()
self.geometric_param = tf.keras.layers.Conv2D(
output_dim, (1, 1), strides=(1, 1), padding='valid')
self.class_score = tf.keras.layers.Conv2D(
n_class, (1, 1), strides=(1, 1), padding='valid')
def call(self, x):
x = tf.reshape(x, [x.shape[0], self.n_component,
self.n_class, self.output_dim])
h1_0 = self.bn1_1(self.conv1_1(x))
h1_1 = self.act(self.bn1_2(self.conv1_2(x)))
h1_2 = self.act(self.bn1_3(self.conv1_3(h1_1)))
h1_3 = self.act(self.bn1_4(self.conv1_4(h1_2)))
embedding = self.act(tf.add(h1_0, h1_3))
embedding = tf.reshape(
embedding, [x.shape[0], self.n_component, 1, -1])
context = self.act(self.bn_x2(
tf.add(embedding, self.bn_x1(self.relation1(embedding)))))
context = self.act(self.bn_x4(
tf.add(context, self.bn_x3(self.relation2(context)))))
h2_0 = self.bn2_1(self.conv2_1(context))
h2_1 = self.act(self.bn2_2(self.conv2_2(h2_0)))
h2_2 = self.act(self.bn2_3(self.conv2_3(h2_1)))
h2_3 = self.act(self.bn2_4(self.conv2_4(h2_2)))
decoded = self.act(tf.add(h2_0, h2_3))
out = self.geometric_param(decoded)
out = tf.sigmoid(tf.reshape(
out, [-1, self.n_component, self.output_dim]))
if(self.n_class > 1):
cls_score = self.class_score(decoded)
cls_prob = tf.sigmoid(tf.reshape(
cls_score, [-1, self.n_component, self.n_class]))
out = tf.concat([out, cls_prob], axis=-1)
return out
================================================
FILE: LayoutGAN/MNIST/mnist_train.py
================================================
import os
import time
import math
from glob import glob
import tensorflow as tf
import numpy as np
import random
from mnist_utils import *
from mnist_modules import *
import matplotlib.pyplot as plt
import PIL
from PIL import Image
from PIL import ImageFont, ImageDraw
from PIL import Image
os.environ['CUDA_VISIBLE_DEVICES'] = '1'
class LayoutGAN(object):
def __init__(self, geometric_dim=2, n_class=1, batch_size=64, n_component=128, layout_dim=(28, 28), d_lr=1e-5, g_lr=1.01e-5, update_ratio=2, clip_value=0.08568, dataset_name='default', dataset_path='./data/pre_data_cls.npy', checkpoint_dir=None, sample_dir=None):
self.batch_size = batch_size
self.n_component = n_component
self.n_class = n_class
self.geometric_dim = geometric_dim
self.layout_dim = layout_dim
self.dataset_name = dataset_name
self.checkpoint_dir = checkpoint_dir
self.data = np.load(dataset_path)
self.build_model(d_lr, g_lr)
self.sample_dir = sample_dir
self.update_ratio = update_ratio
self.clip_value = clip_value
epoch_step = len(self.data) // self.batch_size
dlr = tf.keras.optimizers.schedules.ExponentialDecay(
1e-5, epoch_step*20, 0.1, staircase=True, name=None)
def build_model(self, dlr, g_lr):
self.G = self.build_generator()
self.D = self.build_discriminator()
self.d_opt = tf.keras.optimizers.Adam(dlr)
self.g_opt = tf.keras.optimizers.Adam(g_lr)
def step(self, real_data, noise, training=True):
with tf.GradientTape() as disc_tape:
disc_loss = self.discriminator_loss(real_data, noise)
if(training):
gradients_of_discriminator = disc_tape.gradient(
disc_loss, self.D.trainable_variables)
self.d_opt.apply_gradients(
zip(gradients_of_discriminator, self.D.trainable_variables))
for i in range(2):
with tf.GradientTape() as gen_tape:
gen_loss = self.generator_loss(noise)
if(training):
gradients_of_generator = gen_tape.gradient(
gen_loss, self.G.trainable_variables)
self.g_opt.apply_gradients(
zip(gradients_of_generator, self.G.trainable_variables))
return gen_loss, disc_loss
def train(self):
epoch_step = len(self.data) // self.batch_size
sample = self.data[0:self.batch_size]
sample_inputs = np.array(sample).astype(np.float32)
sample_inputs = sample_inputs * 28.0 / 27.0
sample_z = np.random.normal(
0.5, 0.13, (self.batch_size, self.n_component, self.n_class, self.geometric_dim))
counter = 1
start_time = time.time()
for epoch in range(150):
np.random.shuffle(self.data)
batch_idxs = len(self.data) // self.batch_size
for idx in range(0, batch_idxs):
batch = self.data[idx*self.batch_size:(idx+1)*self.batch_size]
batch_images = np.array(batch).astype(np.float32)
batch_images = batch_images * 28.0 / 27.0
batch_z = np.random.normal(
0.5, 0.13, (self.batch_size, self.n_component, self.n_class, self.geometric_dim))
g_loss, d_loss = self.step(batch_images, batch_z)
counter += 1
if np.mod(counter, 10) == 0:
print("Epoch: [%2d] [%4d/%4d] time: %4.4f, d_loss: %.4f, g_loss: %.4f"
% (epoch, idx, batch_idxs, time.time()-start_time, d_loss, g_loss))
if np.mod(counter, 1) == 0:
samples = self.G(sample_z)
g_loss, d_loss = self.step(
sample_inputs, sample_z, training=False)
samples = np.reshape(samples, (64, 128, 2))
samples = 27.0 * samples
img_all = np.zeros(
(64, self.layout_dim[0], self.layout_dim[1], 3), dtype=np.uint8)
rendered_layout = self.D.render(
samples, self.layout_dim[0], self.layout_dim[1])
img_list = []
for img_ind in range(64):
pointset = np.rint(
samples[img_ind, :, :]).astype(np.int)
pointset = pointset[~(pointset == 0).all(1)]
img = np.zeros((28, 28), dtype=np.float32)
img[pointset[:, 0], pointset[:, 1]] = 255
img_list.append(img/255)
img = Image.fromarray(img.astype('uint8'), 'L')
img_all[img_ind, :, :, :] = np.array(
img.convert('RGB'))
img_all = np.squeeze(
merge(img_all, image_manifold_size(samples.shape[0])))
plt.imsave('{}/train_{:02d}_{:04d}.jpg'.format(self.sample_dir,
epoch, idx), np.array(img_all, dtype=np.uint8))
print("[Sample] d_loss: %.8f, g_loss: %.8f" %
(d_loss, g_loss))
def render(self):
pass
def build_discriminator(self):
return Discriminator(layout_dim=self.layout_dim, render=layout_point)
def build_generator(self):
return Generator(n_filters=512, output_dim=self.geometric_dim, n_component=self.n_component, n_class=self.n_class)
def gradient_penalty(self, real, fake):
alpha = tf.random.uniform(
shape=[real.shape[0], 1, 1], minval=0.0, maxval=1.)
interpolated = alpha * real + (1 - alpha) * fake
with tf.GradientTape() as tape_p:
tape_p.watch(interpolated)
logit = self.D(interpolated)
grad = tape_p.gradient(logit, interpolated)
grad_norm = tf.norm(tf.reshape(grad, (real.shape[0], -1)), axis=1)
return 10 * tf.reduce_mean(tf.square(grad_norm - 1.))
def generator_loss(self, z):
x = self.G(z, training=True)
fake_score = self.D(x, training=True)
g_loss = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(
logits=fake_score, labels=tf.ones_like(tf.sigmoid(fake_score))))
return g_loss
def discriminator_loss(self, x, z):
x_fake = self.G(z, training=True)
true_score = self.D(x, training=True)
fake_score = self.D(x_fake, training=True)
d_loss_real = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(
logits=true_score, labels=tf.ones_like(tf.sigmoid(true_score))))
d_loss_fake = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(
logits=fake_score, labels=tf.zeros_like(tf.sigmoid(fake_score))))
d_loss = d_loss_real + d_loss_fake
return d_loss
batch_size = 64
n_component = 128
n_class = 1
geometric_dim = 2
# give approriate path
sample_dir = "../samples/MNIST_results"
gan = LayoutGAN(batch_size=batch_size, n_component=n_component, n_class=n_class, geometric_dim=geometric_dim,
sample_dir=sample_dir, dataset_path="../data/mnist.npy")
gan.train()
================================================
FILE: LayoutGAN/MNIST/mnist_utils.py
================================================
import numpy as np
import tensorflow as tf
import math
def merge(images, size):
h, w = images.shape[1], images.shape[2]
if (images.shape[3] in (3, 4)):
c = images.shape[3] # size = 8 X 8 for 64 batch size
img = np.zeros((h * size[0], w * size[1], c))
for idx, image in enumerate(images):
i = idx % size[1]
j = idx // size[1]
img[j * h:j * h + h, i * w:i * w + w, :] = image
return img
elif images.shape[3] == 1:
img = np.zeros((h * size[0], w * size[1]))
for idx, image in enumerate(images):
i = idx % size[1]
j = idx // size[1]
img[j * h:j * h + h, i * w:i * w + w] = image[:, :, 0]
return img
def image_manifold_size(num_images):
manifold_h = int(np.floor(np.sqrt(num_images)))
manifold_w = int(np.ceil(np.sqrt(num_images)))
assert manifold_h * manifold_w == num_images
return manifold_h, manifold_w
def layout_point(final_pred, output_height, output_width):
bbox_pred = tf.reshape(final_pred, [64, 128, 2])
x_r = tf.reshape(tf.range(output_width, dtype=tf.float32),
[1, output_width, 1, 1])
x_r = tf.reshape(tf.tile(x_r, [1, 1, output_width, 1]), [
1, output_width*output_width, 1, 1])
x_r = tf.tile(x_r, [64, 1, 128, 1])
y_r = tf.reshape(tf.range(output_height, dtype=tf.float32), [
1, 1, output_height, 1])
y_r = tf.reshape(tf.tile(y_r, [1, output_height, 1, 1]), [
1, output_height*output_height, 1, 1])
y_r = tf.tile(y_r, [64, 1, 128, 1])
x_pred = tf.reshape(
tf.slice(bbox_pred, [0, 0, 0], [-1, -1, 1]), [64, 1, 128, 1])
x_pred = tf.tile(x_pred, [1, output_width*output_width, 1, 1])
x_pred = (output_width-1.0) * x_pred
y_pred = tf.reshape(
tf.slice(bbox_pred, [0, 0, 1], [-1, -1, 1]), [64, 1, 128, 1])
y_pred = tf.tile(y_pred, [1, output_height*output_height, 1, 1])
y_pred = (output_height-1.0) * y_pred
x_diff = tf.maximum(0.0, 1.0-tf.abs(x_r - x_pred))
y_diff = tf.maximum(0.0, 1.0-tf.abs(y_r - y_pred))
xy_diff = x_diff * y_diff
xy_max = tf.nn.max_pool(xy_diff, ksize=[1, 1, 128, 1], strides=[
1, 1, 1, 1], padding='VALID')
xy_max = tf.reshape(xy_max, [64, output_height, output_width, 1])
return xy_max
================================================
FILE: LayoutGAN/Publaynet/modules.py
================================================
import math
from glob import glob
import tensorflow as tf
from tensorflow.keras import initializers
import numpy as np
import random
from utils import *
class RelationModule(tf.keras.Model):
def __init__(self, channels=128, output_dim=128, key_dim=128, **kwargs):
super(RelationModule, self).__init__(**kwargs)
self.key_dim = channels
self.output_dim = channels
self.channels = channels
self.key = tf.keras.layers.Conv2D(output_dim, (1, 1), strides=(1, 1), padding='same', kernel_initializer=initializers.TruncatedNormal(
stddev=0.02, mean=0.0), bias_initializer=initializers.constant(0.0))
self.query = tf.keras.layers.Conv2D(key_dim, (1, 1), strides=(1, 1), padding='same', kernel_initializer=initializers.TruncatedNormal(
stddev=0.02, mean=0.0), bias_initializer=initializers.constant(0.0))
self.value = tf.keras.layers.Conv2D(key_dim, (1, 1), strides=(1, 1), padding='same', kernel_initializer=initializers.TruncatedNormal(
stddev=0.02, mean=0.0), bias_initializer=initializers.constant(0.0))
self.projection = tf.keras.layers.Conv2D(channels, (1, 1), strides=(1, 1), padding='same', kernel_initializer=initializers.TruncatedNormal(
stddev=0.02, mean=0.0), bias_initializer=initializers.constant(0.0))
def call(self, inputs):
f_k = tf.reshape(self.key(inputs), [
inputs.shape[0], inputs.shape[1]*inputs.shape[2], self.key_dim])
f_q = tf.reshape(self.query(inputs), [
inputs.shape[0], inputs.shape[1]*inputs.shape[2], self.key_dim])
f_q = tf.transpose(f_q, perm=[0, 2, 1])
f_v = tf.reshape(self.value(inputs), [
inputs.shape[0], inputs.shape[1]*inputs.shape[2], self.output_dim])
attention_weight = tf.matmul(
f_k, f_q)/(inputs.shape[1]*inputs.shape[2])
out = tf.matmul(tf.transpose(attention_weight, perm=[0, 2, 1]), f_v)
out = tf.reshape(
out, [inputs.shape[0], inputs.shape[1], inputs.shape[2], self.output_dim])
out = self.projection(out)
return out
class Discriminator(tf.keras.Model):
def __init__(self, n_filters=32, n_hidden=128, layout_dim=(28, 28), render=layout_bbox, **kwargs):
super(Discriminator, self).__init__(**kwargs)
self.layout_dim = layout_dim
self.render = render
self.act = tf.keras.layers.LeakyReLU(alpha=0.2)
self.conv1 = tf.keras.layers.Conv2D(32, (5, 5), input_shape=layout_dim, strides=(
2, 2), padding='valid', kernel_initializer=initializers.TruncatedNormal(stddev=0.02, mean=0.0), bias_initializer=initializers.constant(0.0))
self.bn1 = tf.keras.layers.BatchNormalization(
epsilon=1e-5, momentum=0.9)
self.conv2 = tf.keras.layers.Conv2D(32*2, (5, 5), strides=(2, 2), padding='valid', kernel_initializer=initializers.TruncatedNormal(
stddev=0.02, mean=0.0), bias_initializer=initializers.constant(0.0))
self.bn2 = tf.keras.layers.BatchNormalization(
epsilon=1e-5, momentum=0.9)
self.flatten = tf.keras.layers.Flatten()
self.fc1 = tf.keras.layers.Dense(512, kernel_initializer=initializers.RandomNormal(
stddev=0.02, mean=0.0), bias_initializer=initializers.constant(0.0))
self.bn3 = tf.keras.layers.BatchNormalization(
epsilon=1e-5, momentum=0.9)
self.fc2 = tf.keras.layers.Dense(1, kernel_initializer=initializers.RandomNormal(
stddev=0.02, mean=0.0), bias_initializer=initializers.constant(0.0))
def call(self, inputs):
x = self.render(inputs, self.layout_dim[0], self.layout_dim[1])
x = self.act(self.bn1(self.conv1(x)))
x = self.act(self.bn2(self.conv2(x)))
x = self.flatten(x)
x = self.act(self.bn3(self.fc1(x)))
out = self.fc2(x)
return out
class Generator(tf.keras.Model):
def __init__(self, n_filters=128, output_dim=2, n_component=128, n_class=1, include_probability=False, **kwargs):
super(Generator, self).__init__(**kwargs)
self.n_filters = n_filters
self.output_dim = output_dim
self.n_component = n_component
self.n_class = n_class
self.include_probability = include_probability
self.act = tf.keras.layers.ReLU()
self.conv1_1 = tf.keras.layers.Conv2D(n_filters//4, (1, 1), input_shape=(self.n_component, 1, self.n_class+self.output_dim), strides=(
1, 1), padding='same', kernel_initializer=initializers.TruncatedNormal(stddev=0.02, mean=0.0), bias_initializer=initializers.constant(0.0))
self.bn1_1 = tf.keras.layers.BatchNormalization(
epsilon=1e-5, momentum=0.9)
self.conv1_2 = tf.keras.layers.Conv2D(n_filters//16, (1, 1), strides=(1, 1), padding='same',
kernel_initializer=initializers.TruncatedNormal(stddev=0.02, mean=0.0), bias_initializer=initializers.constant(0.0))
self.bn1_2 = tf.keras.layers.BatchNormalization(
epsilon=1e-5, momentum=0.9)
self.conv1_3 = tf.keras.layers.Conv2D(n_filters//16, (1, 1), strides=(1, 1), padding='same',
kernel_initializer=initializers.TruncatedNormal(stddev=0.02, mean=0.0), bias_initializer=initializers.constant(0.0))
self.bn1_3 = tf.keras.layers.BatchNormalization(
epsilon=1e-5, momentum=0.9)
self.conv1_4 = tf.keras.layers.Conv2D(n_filters//4, (1, 1), strides=(1, 1), padding='same',
kernel_initializer=initializers.TruncatedNormal(stddev=0.02, mean=0.0), bias_initializer=initializers.constant(0.0))
self.bn1_4 = tf.keras.layers.BatchNormalization(
epsilon=1e-5, momentum=0.9)
self.relation1 = RelationModule(
channels=n_filters//4, output_dim=n_filters//4, key_dim=n_filters//4)
self.relation2 = RelationModule(
channels=n_filters//4, output_dim=n_filters//4, key_dim=n_filters//4)
self.relation3 = RelationModule(
channels=n_filters, output_dim=n_filters, key_dim=n_filters)
self.relation4 = RelationModule(
channels=n_filters, output_dim=n_filters, key_dim=n_filters)
self.bn_x1 = tf.keras.layers.BatchNormalization(
epsilon=1e-5, momentum=0.9)
self.bn_x2 = tf.keras.layers.BatchNormalization(
epsilon=1e-5, momentum=0.9)
self.bn_x3 = tf.keras.layers.BatchNormalization(
epsilon=1e-5, momentum=0.9)
self.bn_x4 = tf.keras.layers.BatchNormalization(
epsilon=1e-5, momentum=0.9)
self.bn_x5 = tf.keras.layers.BatchNormalization(
epsilon=1e-5, momentum=0.9)
self.bn_x6 = tf.keras.layers.BatchNormalization(
epsilon=1e-5, momentum=0.9)
self.bn_x7 = tf.keras.layers.BatchNormalization(
epsilon=1e-5, momentum=0.9)
self.bn_x8 = tf.keras.layers.BatchNormalization(
epsilon=1e-5, momentum=0.9)
self.conv2_1 = tf.keras.layers.Conv2D(n_filters, (1, 1), strides=(1, 1), padding='same', kernel_initializer=initializers.TruncatedNormal(
stddev=0.02, mean=0.0), bias_initializer=initializers.constant(0.0))
self.bn2_1 = tf.keras.layers.BatchNormalization(
epsilon=1e-5, momentum=0.9)
self.conv2_2 = tf.keras.layers.Conv2D(n_filters//4, (1, 1), strides=(1, 1), padding='same',
kernel_initializer=initializers.TruncatedNormal(stddev=0.02, mean=0.0), bias_initializer=initializers.constant(0.0))
self.bn2_2 = tf.keras.layers.BatchNormalization(
epsilon=1e-5, momentum=0.9)
self.conv2_3 = tf.keras.layers.Conv2D(n_filters//4, (1, 1), strides=(1, 1), padding='same',
kernel_initializer=initializers.TruncatedNormal(stddev=0.02, mean=0.0), bias_initializer=initializers.constant(0.0))
self.bn2_3 = tf.keras.layers.BatchNormalization(
epsilon=1e-5, momentum=0.9)
self.conv2_4 = tf.keras.layers.Conv2D(n_filters, (1, 1), strides=(1, 1), padding='same', kernel_initializer=initializers.TruncatedNormal(
stddev=0.02, mean=0.0), bias_initializer=initializers.constant(0.0))
self.bn2_4 = tf.keras.layers.BatchNormalization(
epsilon=1e-5, momentum=0.9)
self.geometric_param = tf.keras.layers.Conv2D(output_dim, (1, 1), strides=(
1, 1), padding='same', kernel_initializer=initializers.TruncatedNormal(stddev=0.001, mean=0.0), bias_initializer=initializers.constant(0.0))
self.class_score = tf.keras.layers.Conv2D(n_class, (1, 1), strides=(1, 1), padding='same', kernel_initializer=initializers.TruncatedNormal(
stddev=0.02, mean=0.0), bias_initializer=initializers.constant(0.0))
def call(self, x):
x = tf.reshape(x, [x.shape[0], self.n_component,
1, self.n_class+self.output_dim])
h1_0 = self.bn1_1(self.conv1_1(x))
h1_1 = self.act(self.bn1_2(self.conv1_2(x)))
h1_2 = self.act(self.bn1_3(self.conv1_3(h1_1)))
h1_3 = self.bn1_4(self.conv1_4(h1_2))
embedding = self.act(tf.add(h1_0, h1_3))
embedding = tf.reshape(
embedding, [x.shape[0], self.n_component, 1, 256])
context = self.act(self.bn_x2(
tf.add(embedding, self.bn_x1(self.relation1(embedding)))))
context = self.act(self.bn_x4(
tf.add(context, self.bn_x3(self.relation2(context)))))
h2_0 = self.bn2_1(self.conv2_1(context))
h2_1 = self.act(self.bn2_2(self.conv2_2(h2_0)))
h2_2 = self.act(self.bn2_3(self.conv2_3(h2_1)))
h2_3 = self.bn2_4(self.conv2_4(h2_2))
decoded = self.act(tf.add(h2_0, h2_3))
decoded = self.act(self.bn_x6(
tf.add(decoded, self.bn_x5(self.relation3(decoded)))))
decoded = self.act(self.bn_x8(
tf.add(decoded, self.bn_x7(self.relation4(decoded)))))
out = self.geometric_param(decoded)
out = tf.sigmoid(tf.reshape(
out, [-1, self.n_component, self.output_dim]))
cls_score = self.class_score(decoded)
cls_prob = tf.sigmoid(tf.reshape(
cls_score, [-1, self.n_component, self.n_class]))
final_pred = tf.concat([out, cls_prob], axis=-1)
return final_pred
================================================
FILE: LayoutGAN/Publaynet/train.py
================================================
import os
import time
import math
from glob import glob
import tensorflow as tf
import numpy as np
import random
from utils import *
from modules import *
import matplotlib.pyplot as plt
from tensorflow.keras import initializers
os.environ['CUDA_VISIBLE_DEVICES'] = '1'
class LayoutGAN(object):
def __init__(self, geometric_dim=2, n_class=1, batch_size=64, n_component=128, layout_dim=(28, 28), d_lr=1e-5, g_lr=1e-5, update_ratio=2, clip_value=0.1, dataset_name='default', dataset_path='./data/pre_data_cls.npy', checkpoint_dir=None, sample_dir=None):
self.batch_size = batch_size
self.n_component = n_component
self.n_class = n_class
self.geometric_dim = geometric_dim
self.layout_dim = layout_dim
self.dataset_name = dataset_name
self.checkpoint_dir = checkpoint_dir
self.data = np.load(dataset_path)
self.data = self.data[:70000]
self.build_model(d_lr, g_lr)
self.sample_dir = sample_dir
self.update_ratio = update_ratio
self.clip_value = clip_value
self.epochs = 50
def build_model(self, d_lr, g_lr):
self.G = self.build_generator()
self.D = self.build_discriminator()
epoch_step = len(self.data) // self.batch_size
dlr = tf.keras.optimizers.schedules.ExponentialDecay(
d_lr, decay_steps=20*epoch_step, decay_rate=0.1, staircase=True)
self.d_opt = tf.keras.optimizers.Adam(dlr)
self.g_opt = tf.keras.optimizers.Adam(dlr)
def step(self, real_data, noise, training=True, step=0):
with tf.GradientTape() as disc_tape:
disc_loss = self.discriminator_loss(real_data, noise)
if(training):
gradients_of_discriminator = disc_tape.gradient(
disc_loss, self.D.trainable_variables)
self.d_opt.apply_gradients(
zip(gradients_of_discriminator, self.D.trainable_variables))
for i in range(self.update_ratio):
with tf.GradientTape() as gen_tape:
gen_loss = self.generator_loss(noise)
if(training):
gradients_of_generator = gen_tape.gradient(
gen_loss, self.G.trainable_variables)
self.g_opt.apply_gradients(
zip(gradients_of_generator, self.G.trainable_variables))
return gen_loss, disc_loss
def train(self):
epoch_step = len(self.data) // self.batch_size
sample = self.data[0:self.batch_size]
sample_inputs = np.array(sample).astype(np.float32)
sample_z_bbox = np.random.normal(0.5, 0.15, (self.batch_size, 9, 4))
sample_z_cls = np.identity(
5)[np.random.randint(5, size=(self.batch_size, 9))]
sample_z = np.concatenate([sample_z_bbox, sample_z_cls], axis=-1)
counter = 1
start_time = time.time()
for epoch in range(self.epochs):
np.random.shuffle(self.data)
batch_idxs = len(self.data) // self.batch_size
for idx in range(0, batch_idxs):
batch = self.data[idx*self.batch_size:(idx+1)*self.batch_size]
batch_images = np.array(batch).astype(np.float32)
batch_z_bbox = np.random.normal(
0.5, 0.15, (self.batch_size, 9, 4))
batch_z_cls = np.identity(
5)[np.random.randint(5, size=(self.batch_size, 9))]
batch_z = np.concatenate([batch_z_bbox, batch_z_cls], axis=-1)
g_loss, d_loss = self.step(batch_images, batch_z, step=idx)
counter += 1
if np.mod(counter, 50) == 0:
current_decayed_lr = self.d_opt._decayed_lr(
tf.float32).numpy()
print("Epoch: [%2d] [%4d/%4d] time: %4.4f, lr:%.3E, d_loss: %.4f, g_loss: %.4f"
% (epoch, idx, batch_idxs, time.time()-start_time, current_decayed_lr, d_loss, g_loss))
if np.mod(counter, 500) == 0:
G_samples = self.G(sample_z, training=False)
path = '{}/train_{:02d}_{:04d}_{:2.4f}_{:2.4f}.jpg'.format(
self.sample_dir, epoch, idx, d_loss, g_loss)
change = convert_to_cxywh(np.array(G_samples))
plot_layouts(change, colors=colors,
class_names=class_names, path=path)
g_loss, d_loss = self.step(
sample_inputs, sample_z, training=False)
print("[Sample] d_loss: %.8f, g_loss: %.8f" %
(d_loss, g_loss))
def render(self):
pass
def build_discriminator(self):
return Discriminator(layout_dim=self.layout_dim, render=layout_bbox)
def build_generator(self):
return Generator(n_filters=1024, output_dim=self.geometric_dim, n_component=self.n_component, n_class=self.n_class)
def generator_loss(self, z):
x = self.G(z, training=True)
fake_score = self.D(x, training=True)
g_loss = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(
logits=fake_score, labels=tf.ones_like(tf.sigmoid(fake_score))))
return g_loss
def discriminator_loss(self, x, z):
x_fake = self.G(z, training=True)
true_score = self.D(x, training=True)
fake_score = self.D(x_fake, training=True)
d_loss_real = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(
logits=true_score, labels=tf.ones_like(tf.sigmoid(true_score))))
d_loss_fake = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(
logits=fake_score, labels=tf.zeros_like(tf.sigmoid(fake_score))))
d_loss = d_loss_real + d_loss_fake
return d_loss
if __name__ == '__main__':
batch_size = 64
n_component = 9
n_class = 5
geometric_dim = 4
gan = LayoutGAN(batch_size=batch_size, n_component=n_component,
n_class=n_class, layout_dim=(60, 40),
geometric_dim=geometric_dim,
sample_dir="./samples/publaynet_results",
dataset_path="./data/sorted_c1publay.npy")
gan.train()
================================================
FILE: LayoutGAN/Publaynet/utils.py
================================================
import numpy as np
import tensorflow as tf
import matplotlib.pyplot as plt
import matplotlib.patches as patches
from matplotlib.patches import Patch
plt.style.use('dark_background')
def convert_to_cxywh(data):
bboxes = data[..., 0:4]
labels = data[..., 4:]
mask = np.zeros_like(data[..., 3:4])
labels = np.concatenate((mask, labels), axis=2)
labels = np.argmax(labels, axis=2)
class_info = np.expand_dims(labels, axis=2)
cxywh = np.concatenate((class_info, bboxes), axis=2)
cxywh[..., 1] = cxywh[..., 1] - cxywh[..., 3]/2
cxywh[..., 2] = cxywh[..., 2] - cxywh[..., 4]/2
return cxywh
def generate_colors(class_names=None, n_class=50):
cmap = ["", "#dc143c", "#ffff00", "#00ff00", "#ff00ff", "#1e90ff", "#fff5ee",
"#00ffff", "#8b008b", "#ff4500", "#8b4513", "#808000", "#483d8b",
"#008000", "#000080", "#9acd32", "#ffa500", "#ba55d3", "#00fa9a",
"#dc143c", "#0000ff", "#f08080", "#f0e68c", "#dda0dd", "#ff1493"]
colors = dict()
if class_names == None:
class_names = []
for i in range(n_class):
class_names.append('class'+str(i+1))
for i in range(n_class):
colors[class_names[i]] = cmap[i]
return colors
class_names = ['None', 'Text', 'Title', 'List', 'Table', 'Figure']
colors = generate_colors(n_class=6, class_names=class_names)
def plot_layouts(pred, colors, class_names, path=""):
height = 15
width = 9
fig = plt.figure(figsize=(width, height), dpi=50, facecolor=(0, 0, 0))
height_ratio = [0.25, 1, 1, 1, 1, 1]
grid = plt.GridSpec(6, 4,
hspace=0.05, wspace=0.05,
height_ratios=height_ratio,
left=0.02, right=0.98, top=0.98, bottom=0.02)
index = 0
legend = []
ax = fig.add_subplot(grid[index: index+4])
index += 4
for i in range(1, 6):
legend.append(Patch(facecolor=colors[class_names[i]]+"40",
edgecolor=colors[class_names[i]],
label=class_names[i]))
ax.legend(handles=legend, ncol=3, loc=8, fontsize=25, facecolor=(0, 0, 0))
ax.axis('off')
for i in range(16):
ax = fig.add_subplot(grid[index])
index += 1
data = pred[i]
rect1 = patches.Rectangle((0, 0), 180, 240)
rect1.set_color((0, 0, 0, 1))
ax.add_patch(rect1)
for box in data:
c, x, y, w, h = box
if c == 0:
continue
x = x*180
y = y*240
w = w*180
h = h*240
rect = patches.Rectangle((x, y), w, h, linewidth=2)
rect.set_color(colors[class_names[int(c)]]+"00")
rect.set_linestyle('-')
rect.set_edgecolor(colors[class_names[int(c)]])
ax.add_patch(rect)
ax.plot()
ax.set_facecolor((0, 0, 0))
for spine in ax.spines.values():
spine.set_edgecolor('green')
spine.set_linewidth(2)
ax.invert_yaxis()
ax.set_xticks([])
ax.set_yticks([])
plt.savefig(path, facecolor=(0, 0, 0))
def layout_bbox(final_pred, output_height, output_width):
final_pred = tf.reshape(final_pred, [64, 9, 9])
bbox_reg = tf.slice(final_pred, [0, 0, 0], [-1, -1, 4])
cls_prob = tf.slice(final_pred, [0, 0, 4], [-1, -1, 5])
bbox_reg = tf.reshape(bbox_reg, [64, 9, 4])
x_c = tf.slice(bbox_reg, [0, 0, 0], [-1, -1, 1]) * output_width
y_c = tf.slice(bbox_reg, [0, 0, 1], [-1, -1, 1]) * output_height
w = tf.slice(bbox_reg, [0, 0, 2], [-1, -1, 1]) * output_width
h = tf.slice(bbox_reg, [0, 0, 3], [-1, -1, 1]) * output_height
x1 = x_c - 0.5*w
x2 = x_c + 0.5*w
y1 = y_c - 0.5*h
y2 = y_c + 0.5*h
xt = tf.reshape(tf.range(output_width, dtype=tf.float32), [1, 1, 1, -1])
xt = tf.reshape(tf.tile(xt, [64, 9, output_height, 1]), [64, 9, -1])
yt = tf.reshape(tf.range(output_height, dtype=tf.float32), [1, 1, -1, 1])
yt = tf.reshape(tf.tile(yt, [64, 9, 1, output_width]), [64, 9, -1])
x1_diff = tf.reshape(xt-x1, [64, 9, output_height, output_width, 1])
y1_diff = tf.reshape(yt-y1, [64, 9, output_height, output_width, 1])
x2_diff = tf.reshape(x2-xt, [64, 9, output_height, output_width, 1])
y2_diff = tf.reshape(y2-yt, [64, 9, output_height, output_width, 1])
x1_line = tf.nn.relu(1.0 - tf.abs(x1_diff)) * tf.minimum(
tf.nn.relu(y1_diff), 1.0) * tf.minimum(tf.nn.relu(y2_diff), 1.0)
x2_line = tf.nn.relu(1.0 - tf.abs(x2_diff)) * tf.minimum(
tf.nn.relu(y1_diff), 1.0) * tf.minimum(tf.nn.relu(y2_diff), 1.0)
y1_line = tf.nn.relu(1.0 - tf.abs(y1_diff)) * tf.minimum(
tf.nn.relu(x1_diff), 1.0) * tf.minimum(tf.nn.relu(x2_diff), 1.0)
y2_line = tf.nn.relu(1.0 - tf.abs(y2_diff)) * tf.minimum(
tf.nn.relu(x1_diff), 1.0) * tf.minimum(tf.nn.relu(x2_diff), 1.0)
xy_max = tf.reduce_max(tf.concat(
[x1_line, x2_line, y1_line, y2_line], axis=-1), axis=-1, keepdims=True)
spatial_prob = tf.multiply(
tf.tile(xy_max, [1, 1, 1, 1, 5]), tf.reshape(cls_prob, [64, 9, 1, 1, 5]))
spatial_prob_max = tf.reduce_max(spatial_prob, axis=1, keepdims=False)
return spatial_prob_max
================================================
FILE: LayoutGAN/README.md
================================================
# LayoutGAN
This repository provides implementation of "LayoutGAN: Generating Graphic Layouts with Wireframe Discriminators"
https://arxiv.org/abs/1901.06767 in Tensorflow 2.0.
## Getting Started
<a href="https://colab.research.google.com/gist/nicky7767/4330c280e8083a602c41899431fa8c28/layoutgan-final.ipynb" target="_parent"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a>
Click on the above Badge to quickstart the LayoutGAN in google colab
### Architecture

## Prerequisites
- Python 3.8
- Tensorflow 2.5.0
## MNIST Generation
1. Use [MNIST Dataset](https://drive.google.com/file/d/1qtBnEWsaKXeynOCUFHB7H9eqU6bDLJAV/view?usp=sharing). Download and put it in the data folder.
2. Dataset has dimension of (70,000, 9, 9), which consists of 70,000 samples, which contains 128 foreground pixels cordinates (N, 128, X, Y).
3. Run `python MNIST/mnist_train.py` to train a model.
4. Predictions will be saved in `samples/MNIST_results`.
### Results on MNIST

## Document Layout Generation
1. Use [PubLayNet Dataset](https://drive.google.com/file/d/1YQKyASvGDNUTJnE1x-Q2ZhhiY0VFj7oZ/view?usp=sharing). Download and put it in data folder.
2. Dataset has dimension of (72499, 9, 9), which consists of 72,499 single column layout samples extracted from PubLayNet dataset, which contains atmost 9 bounding boxes,for each bounding box first four elements are dimensions of bounding boxes (X_centre, Y_centre, Width, Height).
3. Run `python publaynet/train.py` to train a model.
4. Predictions will be saved in `samples/publaynet_results`.
### Results on single column layouts
<img src="demo/single_col_result.png" width="300" height="500">
## Related repositories
Some codes are implemented from
https://github.com/JiananLi2016/LayoutGAN-Tensorflow
================================================
FILE: LayoutGAN/data/.gitkeep
================================================
================================================
FILE: LayoutGAN/demo/.gitkeep
================================================
================================================
FILE: LayoutGAN/samples/MNIST_results/.gitkeep
================================================
================================================
FILE: LayoutGAN/samples/publaynet_results/.gitkeep
================================================
================================================
FILE: LayoutVAE/Notebook/LayoutVAE_Final.ipynb
================================================
{
"nbformat": 4,
"nbformat_minor": 0,
"metadata": {
"kernelspec": {
"language": "python",
"display_name": "Python 3",
"name": "python3"
},
"language_info": {
"name": "python",
"version": "3.7.10",
"mimetype": "text/x-python",
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"pygments_lexer": "ipython3",
"nbconvert_exporter": "python",
"file_extension": ".py"
},
"colab": {
"name": "LayoutVAE-Final.ipynb",
"provenance": [],
"collapsed_sections": []
},
"accelerator": "GPU"
},
"cells": [
{
"cell_type": "code",
"metadata": {
"id": "aoSIFtCBTLAE"
},
"source": [
"from google.colab import drive\n",
"drive.mount('/content/drive')"
],
"execution_count": null,
"outputs": []
},
{
"cell_type": "markdown",
"metadata": {
"id": "b3hWjvVkcw7G"
},
"source": [
"# Imports"
]
},
{
"cell_type": "code",
"metadata": {
"id": "Du4WO_dO0W2o",
"execution": {
"iopub.status.busy": "2021-07-22T09:46:51.330856Z",
"iopub.execute_input": "2021-07-22T09:46:51.331216Z",
"iopub.status.idle": "2021-07-22T09:46:51.719259Z",
"shell.execute_reply.started": "2021-07-22T09:46:51.331182Z",
"shell.execute_reply": "2021-07-22T09:46:51.718319Z"
},
"trusted": true
},
"source": [
"from __future__ import division\n",
"import torch as T\n",
"import torch.functional as F\n",
"import math\n",
"import PIL\n",
"import numpy as np\n",
"import pandas as pd\n",
"import matplotlib.pyplot as plt\n",
"import matplotlib.patches as patches\n",
"import matplotlib.gridspec as gridspec\n",
"from matplotlib.patches import Patch\n",
"from torch.nn import Sequential , Linear , ReLU , PoissonNLLLoss, LSTM\n",
"from torch.autograd import Variable\n",
"from torch.distributions import Normal, MultivariateNormal, Poisson, kl_divergence \n",
"from PIL import Image,ImageFont, ImageDraw\n",
"plt.style.use('dark_background')\n",
"T.set_default_tensor_type('torch.cuda.FloatTensor')"
],
"execution_count": null,
"outputs": []
},
{
"cell_type": "markdown",
"metadata": {
"id": "3599a3ADc2aR"
},
"source": [
"# Paths"
]
},
{
"cell_type": "code",
"metadata": {
"id": "2DZL1CwwetFu"
},
"source": [
"root = \"\"\n",
"DATA_PATH = root + \"\"\n",
"SAVE_MODEL_PATH = root + \"\"\n",
"SAVE_LOG_PATH = root + \"\"\n",
"SAVE_OUTPUT_PATH = root + \"\"\n",
"CVAE_PATH = root + \"\""
],
"execution_count": null,
"outputs": []
},
{
"cell_type": "markdown",
"metadata": {
"id": "c0mBZWyzc4S6"
},
"source": [
"# Model Architectures"
]
},
{
"cell_type": "code",
"metadata": {
"id": "89YDE-Eg9VBh",
"execution": {
"iopub.status.busy": "2021-07-22T12:06:02.658911Z",
"iopub.execute_input": "2021-07-22T12:06:02.659249Z",
"iopub.status.idle": "2021-07-22T12:06:02.678743Z",
"shell.execute_reply.started": "2021-07-22T12:06:02.659216Z",
"shell.execute_reply": "2021-07-22T12:06:02.677835Z"
},
"trusted": true
},
"source": [
"class fcblock(T.nn.Module):\n",
" def __init__(self, n_class):\n",
" super(fcblock, self).__init__()\n",
" self.seq = Sequential(\n",
" Linear(n_class,128),\n",
" ReLU(),\n",
" Linear(128,128),\n",
" ReLU(),\n",
" )\n",
" def forward(self,inputs):\n",
" out = self.seq(inputs)\n",
" return out\n",
"\n",
"class Embeder(T.nn.Module):\n",
" def __init__(self,n_class):\n",
" super(Embeder,self).__init__()\n",
" \n",
" self.fcb1 = fcblock(n_class)\n",
" self.fcb2 = fcblock(n_class)\n",
" self.fcb3 = fcblock(n_class)\n",
" self.fc = Linear(128*3,128)\n",
"\n",
" \n",
" def forward(self,inputs):\n",
" in1,in2,in3 = inputs\n",
" in1 = self.fcb1(in1)\n",
" in2 = self.fcb2(in2)\n",
" in3 = self.fcb3(in3)\n",
" out = T.cat((in1,in2,in3),1)\n",
" out = self.fc(out)\n",
" return out\n",
"\n",
"class Encoder(T.nn.Module):\n",
" def __init__(self, in_dim=1 ,latent_dim=32):\n",
" super(Encoder,self).__init__()\n",
" self.act = ReLU()\n",
" self.fc1 = Linear(in_dim,128)\n",
" self.fc2 = Linear(128,128)\n",
" self.fc3 = Linear(256,latent_dim)\n",
" self.fc4 = Linear(latent_dim,latent_dim)\n",
" self.fc5 = Linear(latent_dim,latent_dim)\n",
" \n",
" def forward(self,inputs):\n",
" in1,in2 = inputs\n",
" out = self.fc1(in1)\n",
" out = self.act(out)\n",
" out = self.fc2(out)\n",
" out = T.cat((out,in2),1)\n",
" out = self.fc3(out)\n",
" out = self.act(out)\n",
" mu = self.fc4(out)\n",
" logvar = self.fc5(out)\n",
" return mu,logvar\n",
"\n",
"\n",
"class Prior(T.nn.Module):\n",
" def __init__(self,latent_dim=32):\n",
" super(Prior,self).__init__()\n",
" \n",
" self.act = ReLU()\n",
" self.fc1 = Linear(128,latent_dim)\n",
" self.fc2 = Linear(latent_dim,latent_dim)\n",
" self.fc3 = Linear(latent_dim,latent_dim)\n",
" \n",
" def forward(self,inputs):\n",
" out = inputs\n",
" out = self.fc1(out)\n",
" out = self.act(out)\n",
" mu = self.fc2(out)\n",
" logvar = self.fc3(out) \n",
" return mu,logvar\n",
"\n",
"class Decoder(T.nn.Module):\n",
" def __init__(self,output_dim,latent_dim=32):\n",
" super(Decoder,self).__init__()\n",
" self.act = ReLU()\n",
" self.fc1 = Linear(128+latent_dim,128)\n",
" self.fc2 = Linear(128,64)\n",
" self.fc3 = Linear(64,output_dim)\n",
" \n",
" def forward(self,inputs):\n",
" in1,in2 = inputs\n",
" out = T.cat((in1,in2),1)\n",
" out = self.fc1(out)\n",
" out = self.act(out)\n",
" out = self.fc2(out)\n",
" out = self.act(out)\n",
" out = self.fc3(out)\n",
" return out"
],
"execution_count": null,
"outputs": []
},
{
"cell_type": "markdown",
"metadata": {
"id": "lqWGZGytlSi7"
},
"source": [
"# Loss Function for Countvae"
]
},
{
"cell_type": "code",
"metadata": {
"id": "zwTGSyrelNrV",
"execution": {
"iopub.status.busy": "2021-07-22T12:08:51.811748Z",
"iopub.execute_input": "2021-07-22T12:08:51.812140Z",
"iopub.status.idle": "2021-07-22T12:08:51.822374Z",
"shell.execute_reply.started": "2021-07-22T12:08:51.812099Z",
"shell.execute_reply": "2021-07-22T12:08:51.821128Z"
},
"trusted": true
},
"source": [
"class ELBOLoss(T.nn.Module):\n",
"\n",
" def __init__(self):\n",
" super(ELBOLoss,self).__init__()\n",
" \n",
" def forward(self,inputs):\n",
" mu1, logvar1, mu2, logvar2 , in1, in2 = inputs\n",
"\n",
" mask = (in2>0)+0.0\n",
" in2 = in2-mask\n",
"\n",
" '''KL Divergence'''\n",
" kl = 0.5 * T.sum((logvar2 - logvar1) - 1 + (logvar1.exp() + (mu2 - mu1).pow(2) )/logvar2.exp() , dim = 1).mean()\n",
" \n",
" '''Poisson Negative Log Likelihood'''\n",
" pnll = PoissonNLLLoss()(in1,in2)\n",
"\n",
" loss = kl+pnll\n",
" \n",
" return loss, pnll , kl\n",
" \n",
" \n",
"class Reparamatrize(T.nn.Module):\n",
" \n",
" def __init__(self):\n",
" super(Reparamatrize,self).__init__()\n",
" \n",
" def forward(self,inputs):\n",
" \n",
" mu , logvar = inputs\n",
" '''\n",
" mu = mean \n",
" logvar = log of diagonal elements of covariance matrix\n",
" '''\n",
" # Covarince Matrix\n",
" covar = T.diag_embed(T.exp(logvar/2), dim1=-2,dim2=-1)\n",
"\n",
" # Multivariate Normal Distribution\n",
" p = MultivariateNormal(mu,covar)\n",
" z_latent = p.rsample().float()\n",
" return z_latent\n",
"\n",
"class Sampling(T.nn.Module):\n",
"\n",
" def __init__(self,MAX_BOX):\n",
" super(Sampling,self).__init__()\n",
" self.max_box = MAX_BOX\n",
" \n",
" def forward(self,lamda):\n",
" \n",
" lamda = lamda.view(-1)\n",
" mask = T.zeros(lamda.shape[0] , self.max_box)\n",
" lamda = T.t(T.t(mask) + lamda)\n",
" mask = mask + T.arange(0,self.max_box,1)\n",
" e_lamda = T.exp(lamda)\n",
" lamda_x = lamda ** mask \n",
" fact = T.exp(T.lgamma(T.arange(0 , self.max_box)+1))\n",
" \n",
" # P = ((lambda ^ x)*e^(lamda)) / x! \n",
" probab = (lamda_x*e_lamda)/fact\n",
" sample = T.argmax(probab,dim=1)\n",
"\n",
" return sample "
],
"execution_count": null,
"outputs": []
},
{
"cell_type": "code",
"metadata": {
"id": "2xi2UNH3Tl27",
"execution": {
"iopub.status.busy": "2021-07-22T12:08:54.457132Z",
"iopub.execute_input": "2021-07-22T12:08:54.457527Z",
"iopub.status.idle": "2021-07-22T12:08:54.473628Z",
"shell.execute_reply.started": "2021-07-22T12:08:54.457492Z",
"shell.execute_reply": "2021-07-22T12:08:54.472727Z"
},
"trusted": true
},
"source": [
"class CountVAE(T.nn.Module):\n",
" \n",
" def __init__(self,n_class,max_box=9):\n",
" super(CountVAE,self).__init__()\n",
" \n",
" \n",
" self.encoder = Encoder()\n",
" self.prior = Prior()\n",
" self.decoder = Decoder(1)\n",
" self.embeder = Embeder(n_class)\n",
" self.loss = ELBOLoss() \n",
" self.rep = Reparamatrize()\n",
" self.n_class = n_class\n",
" self.pois = Sampling(max_box)\n",
" \n",
" def forward(self, inputs, isTrain = False):\n",
" \n",
" '''\n",
" isTrain(boolean) default False : defines whether data is to be treated as training data or testing\n",
" \n",
" if isTrain = True :\n",
" input must be a tuple with first value corresponding to label set and second corresponding to ground Truth\n",
" counts\n",
" else :\n",
" input must have label set\n",
" \n",
" '''\n",
" if isTrain==True:\n",
" \n",
" label_set , groundtruth_counts = inputs\n",
" Loss = 0\n",
" LL = 0\n",
" KL = 0\n",
" previous_counts = T.zeros_like(label_set)\n",
" \n",
" for i in range(self.n_class):\n",
" \n",
" current_label = T.zeros_like(previous_counts)\n",
" x_ = label_set[...,i]\n",
" current_label[...,i]= x_\n",
" z_ = groundtruth_counts[...,i].view(-1,1)\n",
" \n",
" # Generate Conditional Embedding\n",
" embedding = self.embeder([label_set, current_label, previous_counts])\n",
" \n",
" # Encoding To latet space\n",
" mu1, logvar1 = self.encoder([z_,embedding])\n",
" mu2, logvar2 = self.prior(embedding)\n",
" \n",
" # Reparamatrized Latent variable\n",
" z = self.rep([mu1,logvar1])\n",
"\n",
" # Decode from Latent space\n",
" decoded = self.decoder([embedding,z])\n",
" Closs, L_, kl_ = self.loss([mu1, logvar1, mu2, logvar2, decoded , z_])\n",
" \n",
" # Update Losses\n",
" Loss = Loss + Closs\n",
" LL = LL + L_\n",
" KL = KL + kl_\n",
" \n",
" decoded = T.exp(decoded)\n",
" \n",
" # Poisson Distributions with rate of Deoded\n",
" # q = self.pois(decoded)\n",
" q = Poisson(decoded).sample()\n",
" \n",
" # update Preivious Counts\n",
" previous_counts = previous_counts + current_label*(q.view(-1,1) + x_.view(-1,1))\n",
" \n",
" return Loss/self.n_class, KL/self.n_class, LL/self.n_class\n",
" \n",
" else:\n",
" \n",
" label_set = inputs\n",
" previous_counts = T.zeros_like(label_set)\n",
" \n",
" for i in range(self.n_class):\n",
"\n",
" current_label = T.zeros_like(previous_counts)\n",
" x_ = label_set[...,i]\n",
" current_label[...,i]= x_\n",
" \n",
" \n",
" # Generate Conditional Embedding\n",
" embedding = self.embeder([label_set, current_label, previous_counts])\n",
" \n",
" # Encoding To latet space\n",
" mu,logvar = self.prior(embedding)\n",
" \n",
" # Reparamatrized Latent variable\n",
" z = self.rep([mu,logvar])\n",
" \n",
" # Decode from Latent space\n",
" decoded = self.decoder([embedding,z])\n",
" decoded = T.exp(decoded)\n",
"\n",
" # Poisson Distributions with rate of Deoded\n",
" # q = self.pois(decoded)\n",
" q = Poisson(decoded).sample()\n",
" \n",
" # update Preivious Counts\n",
" previous_counts = previous_counts + current_label*(q.view(-1,1) + x_.view(-1,1))\n",
" \n",
" return previous_counts"
],
"execution_count": null,
"outputs": []
},
{
"cell_type": "markdown",
"metadata": {
"id": "W4LsYqsnngjh"
},
"source": [
"\n",
"# BboxVAE Model Architecture\n",
"\n",
"### Classes\n",
"1. Condtional Embedder\n",
"2. Encoder\n",
"3. Prior\n",
"4. Decoder\n",
"\n",
"### Loss\n",
"1. ELBO LOSS\n",
"\n",
"### Reparamatrize"
]
},
{
"cell_type": "code",
"metadata": {
"id": "9-3b9UJxngji",
"execution": {
"iopub.status.busy": "2021-07-22T09:47:17.692836Z",
"iopub.execute_input": "2021-07-22T09:47:17.693151Z",
"iopub.status.idle": "2021-07-22T09:47:17.701175Z",
"shell.execute_reply.started": "2021-07-22T09:47:17.693120Z",
"shell.execute_reply": "2021-07-22T09:47:17.699927Z"
},
"trusted": true
},
"source": [
"class EmbedBbox(T.nn.Module):\n",
" \n",
" def __init__(self,n_class):\n",
" super(EmbedBbox,self).__init__()\n",
" \n",
" self.fcb1 = fcblock(n_class)\n",
" self.fcb2 = fcblock(n_class)\n",
" self.seq1 = Sequential(\n",
" Linear(128,128),\n",
" ReLU()\n",
" )\n",
" \n",
" self.n_class = n_class\n",
" self.fc = Linear(128*3,128)\n",
" self.lstm = LSTM(n_class+4, hidden_size=128)\n",
"\n",
" def forward(self,inputs):\n",
" \n",
" in1,in2,in3 = inputs\n",
"\n",
" _ , (h_0 , c_0 ) = self.lstm(in3)\n",
" hn = h_0.view(-1, 128)\n",
" \n",
" in1 = self.fcb1(in1)\n",
" in2 = self.fcb2(in2)\n",
" in3 = self.seq1(hn)\n",
" \n",
" out = T.cat((in1,in2,in3),1)\n",
" out = self.fc(out)\n",
" \n",
" return out"
],
"execution_count": null,
"outputs": []
},
{
"cell_type": "markdown",
"metadata": {
"id": "FfctLBtgoCLh"
},
"source": [
"# Loss Function and Reparamatrization for BboxVAE\n",
"\n",
"## KL Divergence\n",
" Same as CountVAE\n",
"\n",
"## MSE\n",
" as reconstruction loss"
]
},
{
"cell_type": "code",
"metadata": {
"id": "g9naXD3ln_1V",
"execution": {
"iopub.status.busy": "2021-07-22T09:47:18.720808Z",
"iopub.execute_input": "2021-07-22T09:47:18.721123Z",
"iopub.status.idle": "2021-07-22T09:47:18.730454Z",
"shell.execute_reply.started": "2021-07-22T09:47:18.721091Z",
"shell.execute_reply": "2021-07-22T09:47:18.729627Z"
},
"trusted": true
},
"source": [
"class ELBOLoss_Bbox(T.nn.Module):\n",
" \n",
" def __init__(self):\n",
" super(ELBOLoss_Bbox,self).__init__()\n",
" \n",
" def forward(self,inputs):\n",
" mu1,logvar1,mu2,logvar2, xp , yp = inputs\n",
" \n",
" ''' KL Divergence '''\n",
" kl = 0.5 * T.sum((logvar2 - logvar1) - 1 + (logvar1.exp() + (mu2 - mu1).pow(2) )/logvar2.exp() , dim = -1 ).mean()\n",
" \n",
" ''' Multivariate Guassian Likelihood '''\n",
" mse = T.nn.MSELoss()(xp,yp)\n",
" loss = mse + kl\n",
" \n",
" return loss, kl,mse\n",
"\n",
"\n",
"class Reparamatrize(T.nn.Module):\n",
" \n",
" def __init__(self):\n",
" super(Reparamatrize,self).__init__()\n",
" \n",
" def forward(self,inputs):\n",
" \n",
" mu , logvar = inputs\n",
" std = T.exp(logvar/2)\n",
" eps = T.rand_like(std)\n",
"\n",
" return eps*std + mu\n",
" \n",
"\n",
"class ReparamatrizeMulti(T.nn.Module):\n",
" \n",
" def __init__(self):\n",
" super(ReparamatrizeMulti,self).__init__()\n",
" \n",
" def forward(self,inputs):\n",
" \n",
" mu = inputs\n",
" std = (T.ones_like(mu)*0.02)\n",
" eps = T.rand_like(std)\n",
" \n",
" return eps*std + mu"
],
"execution_count": null,
"outputs": []
},
{
"cell_type": "code",
"metadata": {
"id": "2F1cTxFingji",
"execution": {
"iopub.status.busy": "2021-07-22T09:47:19.239020Z",
"iopub.execute_input": "2021-07-22T09:47:19.239349Z",
"iopub.status.idle": "2021-07-22T09:47:19.257000Z",
"shell.execute_reply.started": "2021-07-22T09:47:19.239314Z",
"shell.execute_reply": "2021-07-22T09:47:19.255889Z"
},
"trusted": true
},
"source": [
"class BboxVAE(T.nn.Module):\n",
" def __init__(self,n_class,n_dim,max_box,latent_dim=32):\n",
"\n",
" super(BboxVAE,self).__init__()\n",
" \n",
" self.embeder = EmbedBbox(n_class)\n",
" self.encoder = Encoder(n_dim,latent_dim=latent_dim)\n",
" self.decoder = Decoder(n_dim,latent_dim=latent_dim)\n",
" self.prior = Prior(latent_dim=latent_dim)\n",
" self.loss = ELBOLoss_Bbox()\n",
" self.rep = Reparamatrize()\n",
" self.n_dim = n_dim\n",
" self.n_class = n_class\n",
" self.rep_mul = ReparamatrizeMulti()\n",
" self.max_box = max_box\n",
"\n",
"\n",
" def forward(self,inputs,isTrain=True):\n",
" if isTrain==True :\n",
" BoxCounts, GTBBox , BoxLabel= inputs\n",
" los = 0\n",
" kl1 = 0\n",
" ll1 = 0\n",
" for i in range(self.max_box):\n",
" if i==0:\n",
" PrevLabel = T.zeros((1 , *BoxLabel[... ,i,:].shape)) \n",
" PrevBox = T.zeros((1 , *GTBBox[...,i,:].shape))\n",
" \n",
"\n",
" GroundTruth = GTBBox[... , i ,:].view(-1,self.n_dim)\n",
" \n",
" CurrentLabel = BoxLabel[... , i ,:].view(-1,self.n_class)\n",
" \n",
" Embedding = self.embeder([BoxCounts,CurrentLabel,T.cat([PrevLabel,PrevBox] , dim = 2)])\n",
"\n",
" mu1 , logvar1 = self.encoder([GroundTruth,Embedding])\n",
" mu2 , logvar2 = self.prior(Embedding)\n",
" z1 = self.rep([mu1,logvar1])\n",
" z2 = self.rep([mu2,logvar2])\n",
" \n",
" Mu = self.decoder([Embedding,z1])\n",
" BBox = self.rep_mul(Mu)\n",
" CLoss, kl_tot , ll_tot = self.loss([mu1,logvar1,mu2,logvar2, BBox , GroundTruth])\n",
"\n",
" los = los + CLoss/self.max_box\n",
" kl1 = kl1 + kl_tot/self.max_box\n",
" ll1 = ll1 + ll_tot/self.max_box\n",
" \n",
" PrevBox = T.cat([PrevBox ,T.unsqueeze(GroundTruth,0)])\n",
" PrevLabel = T.cat([PrevLabel , T.unsqueeze(CurrentLabel,0)])\n",
"\n",
"\n",
" return los , kl1 , ll1\n",
" else:\n",
" BoxCounts, BoxLabel= inputs\n",
" BBoxes = []\n",
" for i in range(self.max_box):\n",
" if i==0:\n",
" PrevLabel = T.zeros((1 , *BoxLabel[... ,i,:].shape)) \n",
" PrevBox = T.zeros((1 , BoxLabel.shape[0] , 4))\n",
"\n",
" CurrentLabel = BoxLabel[... , i ,:].view(-1,self.n_class)\n",
" Embedding = self.embeder([BoxCounts,CurrentLabel,T.cat([PrevLabel,PrevBox] , dim = 2)])\n",
" \n",
" mu , logvar = self.prior(Embedding)\n",
" \n",
" z = self.rep([mu,logvar])\n",
" \n",
" Mu = self.decoder([Embedding,z])\n",
" \n",
" BBox = self.rep_mul(Mu)\n",
" \n",
" PrevBox = T.cat([PrevBox ,T.unsqueeze(BBox,0)])\n",
" PrevLabel = T.cat([PrevLabel , T.unsqueeze(CurrentLabel,0)])\n",
" BBoxes.append(BBox.t())\n",
" BBoxes =T.stack(BBoxes)\n",
" return BBoxes"
],
"execution_count": null,
"outputs": []
},
{
"cell_type": "markdown",
"metadata": {
"id": "ZVDs9sdm9E06"
},
"source": [
"# Layout VAE"
]
},
{
"cell_type": "code",
"metadata": {
"id": "rl17zTEq9D0S"
},
"source": [
"class LayoutVAE(T.nn.Module):\n",
"\n",
" def __init__(self, n_class = 6, max_box = 9,bboxvae_latent_dim = 32,bboxvae_lr=1e-4,countvae_lr=1e-6):\n",
" '''\n",
" ** Layout VAE **\n",
" * https://arxiv.org/abs/1907.10719\n",
" '''\n",
" super(LayoutVAE,self).__init__()\n",
"\n",
" self.max_box = max_box\n",
" self.n_class = n_class\n",
" self.lr_bvae = bboxvae_lr\n",
" self.lr_cvae = countvae_lr\n",
" self.countvae = CountVAE(n_class)\n",
" self.bboxvae = BboxVAE(n_class,4,max_box,bboxvae_latent_dim)\n",
" self.is_cvae_trained = 0\n",
" self.is_bvae_trained = 0\n",
"\n",
" def forward(self,input):\n",
" '''\n",
" Takes only Labels Set as input\n",
" Label Set : it is a vector of size n_class and contains 1 if correspinding class is present\n",
" '''\n",
" if self.is_cvae_trained == 0:\n",
" print(\"[Warning] Count VAE is Not Trained !!\")\n",
"\n",
" if self.is_bvae_trained == 0:\n",
" print(\"[Warning] Bbox VAE is Not Trained !!\")\n",
"\n",
" label_set = input\n",
" pred_class_counts = self.countvae(label_set , isTrain=False)\n",
" \n",
" # Normalize classiction between [0 , max_box]\n",
" pred_class_counts = T.floor ( self.max_box*(pred_class_counts / T.sum(pred_class_counts , dim = 1 ).view(-1,1)) )\n",
" \n",
" # Extra boxes which are not be predicted\n",
" # Their counts are set in first class\n",
" for class_count in pred_class_counts:\n",
" if(T.sum(class_count) < self.max_box):\n",
" class_count[0] = self.max_box - T.sum(class_count)\n",
"\n",
" class_labels = T.zeros(len(label_set) , self.max_box, self.n_class)\n",
"\n",
" for i in range(len(pred_class_counts)):\n",
" l = 0\n",
" for j in range(self.n_class):\n",
" for k in range(int(pred_class_counts[i][self.n_class-j-1])):\n",
" class_labels[i][l][self.n_class-j-1] = 1;\n",
" l+=1\n",
"\n",
" pred_box = self.bboxvae([ pred_class_counts, class_labels], isTrain=False)\n",
" pred_box = pred_box.permute(2,0,1)\n",
" class_info = T.unsqueeze(T.argmax(class_labels ,dim=2),dim=2)\n",
" predictions = T.cat([class_info,pred_box],dim = 2)\n",
"\n",
" for i in range(len(predictions)):\n",
" for j in range(len(predictions[i])):\n",
" if predictions[i][j][0]==0:\n",
" predictions[i][j]*=0\n",
" \n",
" self.predictions = predictions\n",
" self.pred_class_counts = pred_class_counts\n",
"\n",
" return predictions\n",
"\n",
" def load_data(self, path, frac = 0.5, train_test_split = 0.1):\n",
" '''\n",
" Loads data from npy file\n",
" path string containig path to data\n",
" frac defines the fraction of data to load\n",
"\n",
" '''\n",
" try : \n",
" Data = np.load(DATA_PATH)\n",
" # Sortind Data in proper order\n",
" order = np.argsort(Data[:,:,0])\n",
" for i in range(len(Data)):\n",
" Data[i] = Data[i][order[i][::-1]]\n",
" np.random.shuffle(Data)\n",
"\n",
" data_size = int(frac*len(Data))\n",
" test_size = int(train_test_split*data_size)\n",
" Data = T.tensor(Data[0:data_size]).float()\n",
" test_data = Data[0:test_size]\n",
" Data = Data[test_size:]\n",
"\n",
" # Prepare Data\n",
" self.class_labels = Data[...,4:]\n",
" self.class_counts = T.sum(Data[...,4:], dim = 1)\n",
" self.b_boxes = Data[...,0:4]\n",
" self.label_set = (self.class_counts !=0) + 0.0\n",
"\n",
" # Test Data\n",
" self.test_class_labels = test_data[...,4:]\n",
" self.test_class_counts = T.sum(test_data[...,4:], dim = 1)\n",
" self.test_b_boxes = test_data[...,0:4]\n",
" self.test_label_set = (self.test_class_counts !=0) + 0.0\n",
"\n",
" print(\"[Success] Data Loaded Succesfully\")\n",
"\n",
" except: \n",
" print(\"[Failed] Data Loading Failed\\n please check path\")\n",
" \n",
" def train(self, optim, train_mode = 'bboxvae', epochs = 100, bsize = 256 , validation_split = 0.1):\n",
" '''\n",
" * train_mode (str , default bboxvae) : Two optons\n",
" 1. if train_mode is bboxvae, BBoxVAE model will be trained and data \n",
" will be loaded accordingly\n",
" 2. if train_mode is countvae, CountVAE model will be trained and data \n",
" will be loaded accordingly\n",
" * epochs (int , default 100 ) : number of epochs training should run\n",
" * bsize(int default 256) : Batch Size\n",
" * validation_split(float default 0.1) : should be between between 0 and 1\n",
" 1 . it defines the size of validation data \n",
"\n",
" '''\n",
" # Create validation Split\n",
" total_examples = len(self.class_counts)\n",
" val_size = int(total_examples*validation_split)\n",
" \n",
" losses = dict()\n",
" train_data = []\n",
" if train_mode == 'countvae':\n",
" model = self.countvae\n",
" train_data = [self.label_set, self.class_counts]\n",
" else :\n",
" model = self.bboxvae\n",
" train_data = [self.class_counts, self.b_boxes, self.class_labels]\n",
"\n",
" # Validation Data \n",
" val_data = []\n",
" for x in train_data:\n",
" val_data.append(x[:val_size])\n",
"\n",
" # Train data\n",
" for i in range(len(train_data)):\n",
" train_data[i] = train_data[i][val_size:]\n",
"\n",
"\n",
" # find the number of batches\n",
" batches = len(train_data[0])//bsize\n",
" second_loss = 'mse'\n",
" if train_mode == 'countvae':\n",
" second_loss = 'poisson_nll'\n",
" \n",
" # Dictionary to keep track of model statistics\n",
" losses = {'epoch':-1, \n",
" 'batch':0,\n",
" 'lr' : 0,\n",
" 'loss':0,\n",
" 'kl_div_loss':0,\n",
" second_loss+'_loss':0,\n",
" 'val_loss':0,\n",
" 'val_kl_div_loss':0,\n",
" 'val_'+second_loss+'_loss':0\n",
" }\n",
"\n",
" history = pd.DataFrame(losses ,index = [0])\n",
" index = 1\n",
"\n",
" for ep in range(epochs):\n",
"\n",
" # if train_mode=='countvae':\n",
" # self.countvae_pred_grpah(epoch = ep,path = CVAE_PATH)\n",
"\n",
" print(f'Epoch[{ep+1}/{epochs}]')\n",
" for batch in range(batches):\n",
"\n",
" # Get Current batch\n",
" b = []\n",
" for x in train_data:\n",
" b.append(x[batch*bsize : (batch+1)*bsize])\n",
"\n",
" optim.zero_grad()\n",
"\n",
" # Train Step\n",
" loss, kl_, l_ = model(b,isTrain = True)\n",
" \n",
" # Validation Step\n",
" val_loss, val_kl_, val_l_ = model(val_data, isTrain = True)\n",
"\n",
"\n",
" # Save Statistics\n",
" losses['epoch'] = ep\n",
" losses['batch'] = batch\n",
" losses['lr'] = optim.param_groups[0]['lr']\n",
"\n",
" loss_list = [loss, kl_, l_ , val_loss , val_kl_ , val_l_]\n",
"\n",
" for i in range(6):\n",
" losses[list(losses.keys())[3+i]] = loss_list[i].cpu().clone().detach().numpy()\n",
" pass\n",
" \n",
" losses_df = pd.DataFrame(losses , index=[index])\n",
" history = pd.concat([history,losses_df])\n",
" index+=1\n",
"\n",
" # Backpropogation step and updating weights\n",
" loss.backward()\n",
" optim.step()\n",
" print('\\r Batch: {}/{} - loss : {} - val_loss : {} - val_{} : {}'.format(batch+1,batches,\n",
" losses_df['loss'][index-1],\n",
" losses_df['val_loss'][index-1],\n",
" second_loss,\n",
" losses_df['val_'+second_loss+'_loss'][index-1]),\n",
" end=\"\")\n",
" print(\"\\n\")\n",
" print('[Success] Finished Training')\n",
" return history\n",
"\n",
" def load_countvae_weights(self,path):\n",
" try :\n",
" self.countvae = T.load(path)\n",
" self.is_cvae_trained=1\n",
" print('[Success] Loaded Successfully')\n",
" except:\n",
" print('[Failed] Load Failed')\n",
"\n",
" def load_bboxvae_weights(self,path):\n",
" try :\n",
" self.bboxvae = T.load(path)\n",
" self.is_bvae_trained=1\n",
" print('[Success] Loaded Successfully')\n",
" except:\n",
" print('[Failed] Load Failed')\n",
"\n",
" def train_bboxvae(self,epochs=30, bsize=256, validation_split=0.1, optim=None): \n",
" if optim == None:\n",
" optim = T.optim.Adam(self.bboxvae.parameters(),lr=self.lr_bvae)\n",
"\n",
" # Start Training\n",
" history = self.train(optim = optim,\n",
" train_mode = 'bboxvae',\n",
" epochs = epochs,\n",
" bsize = bsize,\n",
" validation_split = validation_split\n",
" )\n",
" self.is_bvae_trained = 1\n",
" self.bvae_history = history[history.columns][1:]\n",
" return self.bvae_history\n",
"\n",
" def train_countvae(self,epochs=30, bsize=256, validation_split=0.1, optim=None):\n",
" \n",
" if optim == None:\n",
" optim = T.optim.Adam(self.countvae.parameters(),lr=self.lr_cvae)\n",
"\n",
" # Start Training\n",
" history = self.train(optim = optim,\n",
" train_mode = 'countvae',\n",
" epochs = epochs,\n",
" bsize = bsize,\n",
" validation_split = validation_split\n",
" )\n",
" self.is_cvae_trained = 1\n",
" self.cvae_history = history[history.columns][1:]\n",
" return self.cvae_history\n",
"\n",
" def pred_countvae(self,data=None):\n",
" '''\n",
" * Functions is used for for predcting from CountVAE\n",
" given label_set\n",
" * if data is None than label set from loaded data \n",
" are used for predictions.\n",
" '''\n",
"\n",
" if self.is_cvae_trained == 0:\n",
" print(\"[Warning] Count VAE is Not Trained !!\")\n",
" if data == None :\n",
" data = self.test_label_set\n",
" return self.countvae(data , isTrain=False)\n",
"\n",
" def pred_bboxvae(self,Data=None):\n",
"\n",
" '''\n",
" * Functions is used for for predcting from BboxVAE\n",
" given class_counts and class labels\n",
" * if data is None than class counts and class labels from loaded data \n",
" are used for predictions.\n",
" '''\n",
"\n",
" if self.is_bvae_trained == 0:\n",
" print(\"[Warning] Bbox VAE is Not Trained !!\")\n",
"\n",
" if Data == None :\n",
" Data = [self.test_class_counts,self.test_class_labels]\n",
"\n",
" batches = len(Data[0])//64\n",
"\n",
" for b in range(batches):\n",
"\n",
" # Get data in batch\n",
" data = [self.test_class_counts[b*64 : (b+1)*64],\n",
" self.test_class_labels[b*64 : (b+1)*64]] \n",
"\n",
" # Predict\n",
" pred = self.bboxvae(data, isTrain=False)\n",
" pred = pred.permute(2,0,1)\n",
"\n",
" # cxywh format\n",
" class_info = T.unsqueeze(T.argmax(data[1] ,dim=2),dim=2)\n",
" pred = T.cat([class_info,pred],dim = 2)\n",
"\n",
"\n",
" for i in range(len(pred)):\n",
" for j in range(len(pred[i])):\n",
" if pred[i][j][0]==0:\n",
" pred[i][j] *= 0\n",
"\n",
" if b > 0:\n",
" predictions = T.cat([predictions,pred],dim=0)\n",
" else:\n",
" predictions = pred\n",
" class_info =T.argmax(self.test_class_labels[0:64*batches] ,dim=2)\n",
" class_info = T.unsqueeze(class_info,dim=2)\n",
" gt = T.cat([class_info,self.test_b_boxes[0:64*batches]],dim = 2)\n",
" return predictions, gt\n",
" \n",
" def countvae_pred_grpah(self,path,epoch = 0):\n",
" pred_cvae = self.pred_countvae()\n",
" pred_cvae = T.sum(pred_cvae,dim=0)\n",
" pred_cvae = pred_cvae/T.sum(pred_cvae)\n",
" pred_cvae = pred_cvae.to('cpu').clone().detach().numpy()\n",
"\n",
" gt_cvae = T.sum(self.class_counts,dim=0)\n",
" gt_cvae = gt_cvae/T.sum(gt_cvae)\n",
" gt_cvae = gt_cvae.to('cpu').clone().detach().numpy()\n",
"\n",
" fig = plt.figure(figsize=(5 ,4), dpi=100 ,facecolor=(0,0,0))\n",
" ax = fig.add_subplot()\n",
" ax.plot(gt_cvae , 'red',marker = 'o', label = 'Ground Truth',linewidth=4)\n",
" ax.plot(pred_cvae,'blue',marker ='o',label = \"Predicted\" ,linewidth=4)\n",
" ax.legend()\n",
" ax.set_title('Ground Truth vs Predicted Distribution\\n Epoch = '+str(epoch))\n",
" ax.set_xlabel('Classes')\n",
" ax.set_xticks([0,1,2,3,4,5])\n",
" ax.set_xticklabels(class_names)\n",
"\n",
" plt.savefig(path+\"cvae-train-ep-\"+str(epoch)+\".png\",facecolor=(0,0,0))\n",
" plt.close()\n",
"\n",
"\n",
" def convert_to_cxywh(self,data):\n",
" \n",
" bboxes = data[...,0:4]\n",
" labels = data[...,4: ]\n",
" class_info = T.unsqueeze(T.argmax(labels ,dim=2),dim=2)\n",
" cxywh = T.cat([class_info,bboxes],dim = 2)\n",
" return cxywh\n",
"\n",
" def save_model(self,path):\n",
" \n",
" T.save(self.countvae,path+'countvae.h5')\n",
" T.save(self.bboxvae,path+'bboxvae.h5')\n",
" T.save(self,path+'selef.h5')\n",
" print('[Success] Saved Successfully')\n",
"\n",
" def save_history(self,path):\n",
"\n",
" self.cvae_history.to_csv(path+'cvae-history.csv',index=False)\n",
" self.bvae_history.to_csv(path+'bvae-history.csv',index=False)\n",
" print('[Success] Saved Successfully')\n",
"\n",
" \n"
],
"execution_count": null,
"outputs": []
},
{
"cell_type": "markdown",
"metadata": {
"id": "DpwhFKH_aFaF"
},
"source": [
"# Plotting Functions"
]
},
{
"cell_type": "code",
"metadata": {
"id": "BOjuR2gnSDvD"
},
"source": [
"def plot_history(history,title = 'Training Statistics', path =\"\"):\n",
" height = 12\n",
" width = 9\n",
" fig = plt.figure(figsize=(width,height), dpi=100 ,facecolor=(0,0,0))\n",
" height_ratio = [0.25,1,1,1]\n",
" grid = plt.GridSpec(4,2,\n",
" hspace=0.3,wspace=0.2,\n",
" height_ratios =height_ratio,\n",
" left=0.02,right=0.98,top=0.98,bottom=0.02\n",
" )\n",
" index = 0\n",
" ax = fig.add_subplot(grid[index : index+2])\n",
" index+=2\n",
" ax.text(x = 0.3 ,y = 0.5 ,s = title,fontsize=30)\n",
" ax.invert_yaxis()\n",
" ax.axis('off')\n",
" colors = ['red','blue','green']\n",
" for i in range(3):\n",
"\n",
" ax = fig.add_subplot(grid[index])\n",
" ax.plot(history[history.columns[i+3]],colors[i])\n",
" index+=1\n",
" ax.set_facecolor((0,0,0))\n",
" ax.set_title(history.columns[i+3])\n",
" ax = fig.add_subplot(grid[index])\n",
" ax.plot(history[history.columns[i+6]],colors[i])\n",
" ax.set_title(history.columns[i+6])\n",
" index+=1\n",
" ax.set_facecolor((0,0,0))\n",
" plt.savefig(path, facecolor=(0,0,0))"
],
"execution_count": null,
"outputs": []
},
{
"cell_type": "code",
"metadata": {
"id": "mBxvgs0-SUhL"
},
"source": [
"def generate_colors(class_names = None,n_class=6):\n",
" cmap = [\"\",\"#dc143c\",\"#ffff00\",\"#00ff00\",\"#ff00ff\",\"#1e90ff\",\"#fff5ee\",\n",
" \"#00ffff\",\"#8b008b\",\"#ff4500\",\"#8b4513\",\"#808000\",\"#483d8b\",\n",
" \"#008000\",\"#000080\",\"#9acd32\",\"#ffa500\",\"#ba55d3\",\"#00fa9a\",\n",
" \"#dc143c\",\"#0000ff\",\"#f08080\",\"#f0e68c\",\"#dda0dd\",\"#ff1493\"]\n",
" \n",
" colors = dict()\n",
"\n",
" if class_names == None:\n",
" class_names = []\n",
" for i in range(n_class):\n",
" class_names.append('class'+str(i+1))\n",
" \n",
" for i in range(n_class):\n",
" colors[class_names[i]] = cmap[i]\n",
"\n",
" return colors\n",
"\n",
"def plot_layouts(data,colors,class_names,title=\"Random Predictions\", path=\"\"):\n",
" '''\n",
" data in cxywh format\n",
" '''\n",
" height = 15\n",
" width = 9\n",
" fig = plt.figure(figsize=(width,height), dpi=100 ,facecolor=(0,0,0))\n",
" height_ratio = [0.5,0.25,1,1,1,1]\n",
" grid = plt.GridSpec(6,4,\n",
" hspace=0.05,wspace=0.05,\n",
" height_ratios =height_ratio,\n",
" left=0.02,right=0.98,top=0.98,bottom=0.02\n",
" )\n",
" index = 0\n",
"\n",
"\n",
" ax = fig.add_subplot(grid[index : index+4])\n",
" index+=4\n",
" ax.text(x = 0.2 ,y = 0.5 ,s = title,fontsize=30)\n",
" ax.axis('off')\n",
" legend = []\n",
" ax = fig.add_subplot(grid[index : index+4])\n",
" index += 4\n",
" \n",
" for i in range(1,6):\n",
" legend.append(Patch(facecolor=colors[class_names[i]]+\"40\",\n",
" edgecolor=colors[class_names[i]],\n",
" label= class_names[i]))\n",
" \n",
" ax.legend(handles=legend, ncol=3,loc=8, fontsize=25, facecolor=(0,0,0))\n",
" ax.axis('off')\n",
"\n",
" for i in range(16):\n",
" ax = fig.add_subplot(grid[index])\n",
" index += 1\n",
" \n",
" data = pred[i]\n",
" rect1 = patches.Rectangle((0,0),180,240)\n",
" rect1.set_color((0,0,0,1))\n",
" ax.add_patch(rect1)\n",
" for box in data:\n",
"\n",
" c,x,y,w,h = box\n",
" if c==0:\n",
" continue\n",
" x = x*180\n",
" y = y*240\n",
" w = w*180\n",
" h = h*240\n",
" rect = patches.Rectangle((x,y),w,h,linewidth=2)\n",
" rect.set_color(colors[class_names[int(c)]]+\"72\")\n",
" rect.set_linestyle('-')\n",
" rect.set_edgecolor(colors[class_names[int(c)]])\n",
" ax.add_patch(rect)\n",
" ax.plot()\n",
" ax.set_facecolor((0,0,0))\n",
" for spine in ax.spines.values():\n",
" spine.set_edgecolor('green')\n",
" spine.set_linewidth(2)\n",
" ax.invert_yaxis()\n",
" ax.set_xticks([])\n",
" ax.set_yticks([])\n",
" plt.savefig(path, facecolor=(0,0,0))\n",
" plt.show()\n",
" plt.close()"
],
"execution_count": null,
"outputs": []
},
{
"cell_type": "markdown",
"metadata": {
"id": "BRUduBg28naW"
},
"source": [
"# Training\n",
"\n"
]
},
{
"cell_type": "code",
"metadata": {
"id": "eiWxIjvZ80dH"
},
"source": [
"layoutvae = LayoutVAE()\n",
"layoutvae.load_data(DATA_PATH, frac = 0.5)"
],
"execution_count": null,
"outputs": []
},
{
"cell_type": "markdown",
"metadata": {
"id": "muczxUPh8vfp"
},
"source": [
"## Countvae"
]
},
{
"cell_type": "code",
"metadata": {
"id": "xc9TZ6DfTCrY"
},
"source": [
"# layoutvae.load_countvae_weights(path = SAVE_MODEL_PATH + \"countvae.h5\")\n",
"layoutvae.train_countvae(bsize = 512, epochs=100,validation_split=0.1)\n",
"plot_history(layoutvae.cvae_history,\n",
" title=\"CountVAE Training\",\n",
" path = SAVE_LOG_PATH+\"Cvae-train.svg\"\n",
" )\n",
"\n",
"def countvae_pred_grpah(self,path):\n",
" pred_cvae = self.pred_countvae()\n",
" pred_cvae = T.sum(pred_cvae,dim=0)\n",
" pred_cvae = pred_cvae/T.sum(pred_cvae)\n",
" pred_cvae = pred_cvae.to('cpu').clone().detach().numpy()\n",
"\n",
" gt_cvae = T.sum(self.class_counts,dim=0)\n",
" gt_cvae = gt_cvae/T.sum(gt_cvae)\n",
" gt_cvae = gt_cvae.to('cpu').clone().detach().numpy()\n",
"\n",
" fig = plt.figure(figsize=(5 ,4), dpi=100 ,facecolor=(0,0,0))\n",
" ax = fig.add_subplot()\n",
" ax.plot(gt_cvae , 'red',marker = 'o', label = 'Ground Truth',linewidth=4)\n",
" ax.plot(pred_cvae,'blue',marker ='o',label = \"Predicted\" ,linewidth=4)\n",
" ax.legend()\n",
" ax.set_title('Ground Truth vs Predicted Distribution')\n",
" ax.set_xlabel('Classes')\n",
" ax.set_xticks([0,1,2,3,4,5])\n",
" ax.set_xticklabels(class_names)\n",
"\n",
" plt.savefig(path+\"cvae-train.png\",facecolor=(0,0,0))\n",
" plt.close()"
],
"execution_count": null,
"outputs": []
},
{
"cell_type": "markdown",
"metadata": {
"id": "mYKbkK-GOn24"
},
"source": [
"## Bbox VAE"
]
},
{
"cell_type": "code",
"metadata": {
"id": "g-yqu2BBDb9A"
},
"source": [
"# layoutvae.load_bboxvae_weights(path = SAVE_MODEL_PATH + \"bboxvae.h5\")\n",
"history_df = layoutvae.train_bboxvae(bsize = 256, epochs = 150, validation_split = 0.1)\n",
"preds,gt = layoutvae.pred_bboxvae()\n",
"plot_history(layoutvae.vae_history,\n",
" title=\"BBoxVAE Training\",\n",
" path = SAVE_LOG_PATH+\"Bvae-train.svg\"\n",
" )"
],
"execution_count": null,
"outputs": []
},
{
"cell_type": "code",
"metadata": {
"id": "-9pIjabEZiTW"
},
"source": [
"class_names = ['None' , 'Text' , 'Title' , 'List' , 'Table' ,'Figure']\n",
"colors = generate_colors(n_class=6 , class_names=class_names)\n",
"\n",
"preds = layoutvae.pred_bboxvae()\n",
"for i in range(2):\n",
" plot_layouts(data = predd[i*16:(i+1)*16],\n",
" colors=colors,\n",
" class_names=class_names,\n",
" path=SAVE_OUTPUT_PATH+\"/bboxvae-preds-\"+str(i)+\".png\"\n",
" )"
],
"execution_count": null,
"outputs": []
},
{
"cell_type": "markdown",
"metadata": {
"id": "qpLk8DX9ZUoC"
},
"source": [
"# Save Model and Train History"
]
},
{
"cell_type": "code",
"metadata": {
"id": "EI4jvr7yZTrg"
},
"source": [
"layoutvae.save_model(SAVE_MODEL_PATH)\n",
"layoutvae.save_history(SAVE_LOG_PATH)"
],
"execution_count": null,
"outputs": []
},
{
"cell_type": "markdown",
"metadata": {
"id": "4wyxfkjqY3p6"
},
"source": [
"# Complete Model"
]
},
{
"cell_type": "code",
"metadata": {
"id": "zvKQB7ucLoNY"
},
"source": [
"predd = layoutvae(layoutvae.test_label_set)\n",
"for i in range(2):\n",
" plot_layouts(data = predd[i*16:(i+1)*16],\n",
" colors=colors,\n",
" class_names=class_names,\n",
" path=SAVE_OUTPUT_PATH+\"/random-preds2-\"+str(i)+\".png\"\n",
" )"
],
"execution_count": null,
"outputs": []
}
]
}
================================================
FILE: LayoutVAE/Source/bboxvae.py
================================================
# -*- coding: utf-8 -*-
"""
Created on Tue Aug 10 17:25:31 2021
@author: Tushar & Tanishk
"""
import torch as T
from modelblocks import Encoder,Prior,EmbedBbox,ELBOLoss_Bbox
from modelblocks import ReparamatrizeMulti,Reparamatrize_cvae,Decoder
class BboxVAE(T.nn.Module):
def __init__(self,n_class,n_dim,max_box,latent_dim=32):
super(BboxVAE,self).__init__()
self.embeder = EmbedBbox(n_class)
self.encoder = Encoder(n_dim,latent_dim=latent_dim)
self.decoder = Decoder(n_dim,latent_dim=latent_dim)
self.prior = Prior(latent_dim=latent_dim)
self.loss = ELBOLoss_Bbox()
self.rep = Reparamatrize_cvae()
self.n_dim = n_dim
self.n_class = n_class
self.rep_mul = ReparamatrizeMulti()
self.max_box = max_box
def forward(self,inputs,isTrain=True):
if isTrain==True :
BoxCounts, GTBBox , BoxLabel= inputs
los = 0
kl1 = 0
ll1 = 0
for i in range(self.max_box):
if i==0:
PrevLabel = T.zeros((1 , *BoxLabel[... ,i,:].shape))
PrevBox = T.zeros((1 , *GTBBox[...,i,:].shape))
GroundTruth = GTBBox[... , i ,:].view(-1,self.n_dim)
CurrentLabel = BoxLabel[... , i ,:].view(-1,self.n_class)
Embedding = self.embeder([BoxCounts,CurrentLabel,T.cat([PrevLabel,PrevBox] , dim = 2)])
mu1 , logvar1 = self.encoder([GroundTruth,Embedding])
mu2 , logvar2 = self.prior(Embedding)
z1 = self.rep([mu1,logvar1])
#z2 = self.rep([mu2,logvar2])
Mu = self.decoder([Embedding,z1])
BBox = self.rep_mul(Mu)
CLoss, kl_tot , ll_tot = self.loss([mu1,logvar1,mu2,logvar2, BBox , GroundTruth])
los = los + CLoss/self.max_box
kl1 = kl1 + kl_tot/self.max_box
ll1 = ll1 + ll_tot/self.max_box
PrevBox = T.cat([PrevBox ,T.unsqueeze(GroundTruth,0)])
PrevLabel = T.cat([PrevLabel , T.unsqueeze(CurrentLabel,0)])
return los , kl1 , ll1
else:
BoxCounts, BoxLabel= inputs
BBoxes = []
for i in range(self.max_box):
if i==0:
PrevLabel = T.zeros((1 , *BoxLabel[... ,i,:].shape))
PrevBox = T.zeros((1 , BoxLabel.shape[0] , 4))
CurrentLabel = BoxLabel[... , i ,:].view(-1,self.n_class)
Embedding = self.embeder([BoxCounts,CurrentLabel,T.cat([PrevLabel,PrevBox] , dim = 2)])
mu , logvar = self.prior(Embedding)
z = self.rep([mu,logvar])
Mu = self.decoder([Embedding,z])
BBox = self.rep_mul(Mu)
PrevBox = T.cat([PrevBox ,T.unsqueeze(BBox,0)])
PrevLabel = T.cat([PrevLabel , T.unsqueeze(CurrentLabel,0)])
BBoxes.append(BBox.t())
BBoxes =T.stack(BBoxes)
return BBoxes
================================================
FILE: LayoutVAE/Source/config.py
================================================
# -*- coding: utf-8 -*-
"""
Created on Tue Aug 10 18:24:51 2021
@author: Tushar and Tanishk
"""
# PATHS
SAVE_MODEL_PATH = ""
SAVE_LOG_PATH = ""
DATA_PATH = ""
SAVE_OUTPUT_PATH = ""
# Parameters
CVAE_LR = 1e-5
BVAE_LR = 1e-4
CVAE_EPOCHS = 1
BVAE_EPOCHS = 1
BVAE_LATENT_DIM = 32
N_CLASS = 6
MAX_BOX = 9
BVAE_BSIZE = 256
CVAE_BSIZE = 256
BVAE_VAL_SPLIT = 0.1
CVAE_VAL_SPLIT = 0.1
FRAC = 0.005
# Other
class_names = ['None' , 'Text' , 'Title' , 'List' , 'Table' ,'Figure']
================================================
FILE: LayoutVAE/Source/countvae.py
================================================
# -*- coding: utf-8 -*-
"""
Created on Tue Aug 10 17:11:05 2021
@author: Tushar & Tanishk
"""
import torch as T
from torch.distributions import Poisson
from modelblocks import Encoder, Decoder, Prior, Embeder, ELBOLoss, Reparamatrize_cvae, Sampling
class CountVAE(T.nn.Module):
def __init__(self,n_class,max_box=9):
'''
n_class = number of class (intger)
max_box = maximum number of boxes (integer)
isTrain(boolean) default False : defines whether data is to be treated as training data or testing
if isTrain = True :
input must be a tuple with first value corresponding to label set and second corresponding to ground Truth
counts
else :
input must have label set
'''
super(CountVAE,self).__init__()
self.encoder = Encoder()
self.prior = Prior()
self.decoder = Decoder(1)
self.embeder = Embeder(n_class)
self.loss = ELBOLoss()
self.rep = Reparamatrize_cvae()
self.n_class = n_class
self.pois = Sampling(max_box)
def forward(self, inputs, isTrain = False):
if isTrain==True:
label_set , groundtruth_counts = inputs
Loss = 0
LL = 0
KL = 0
previous_counts = T.zeros_like(label_set)
for i in range(self.n_class):
current_label = T.zeros_like(previous_counts)
x_ = label_set[...,i]
current_label[...,i]= x_
z_ = groundtruth_counts[...,i].view(-1,1)
# Generate Conditional Embedding
embedding = self.embeder([label_set, current_label, previous_counts])
# Encoding To latet space
mu1, logvar1 = self.encoder([z_,embedding])
mu2, logvar2 = self.prior(embedding)
# Reparamatrized Latent variable
z = self.rep([mu1,logvar1])
# Decode from Latent space
decoded = self.decoder([embedding,z])
Closs, L_, kl_ = self.loss([mu1, logvar1, mu2, logvar2, decoded , z_])
# Update Losses
Loss = Loss + Closs
LL = LL + L_
KL = KL + kl_
decoded = T.exp(decoded)
# Poisson Distributions with rate of Deoded
# q = self.pois(decoded)
q = Poisson(decoded).sample()
# update Preivious Counts
previous_counts = previous_counts + current_label*(q.view(-1,1) + x_.view(-1,1))
return Loss/self.n_class, KL/self.n_class, LL/self.n_class
else:
label_set = inputs
previous_counts = T.zeros_like(label_set)
for i in range(self.n_class):
current_label = T.zeros_like(previous_counts)
x_ = label_set[...,i]
current_label[...,i]= x_
# Generate Conditional Embedding
embedding = self.embeder([label_set, current_label, previous_counts])
# Encoding To latet space
mu,logvar = self.prior(embedding)
# Reparamatrized Latent variable
z = self.rep([mu,logvar])
# Decode from Latent space
decoded = self.decoder([embedding,z])
decoded = T.exp(decoded)
# Poisson Distributions with rate of Deoded
# q = self.pois(decoded)
q = Poisson(decoded).sample()
# update Preivious Counts
previous_counts = previous_counts + current_label*(q.view(-1,1) + x_.view(-1,1))
return previous_counts
================================================
FILE: LayoutVAE/Source/layoutvae.py
================================================
# -*- coding: utf-8 -*-
"""
Created on Tue Aug 10 17:44:46 2021
@author: Tushar & Tanishk
"""
import torch as T
from countvae import CountVAE
from bboxvae import BboxVAE
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
########################
###### LAYOUT VAE ######
########################
class LayoutVAE(T.nn.Module):
def __init__(self, n_class = 6, max_box = 9,bboxvae_latent_dim = 32,bboxvae_lr=1e-4,countvae_lr=1e-6):
'''
** Layout VAE **
* https://arxiv.org/abs/1907.10719
'''
super(LayoutVAE,self).__init__()
self.max_box = max_box
self.n_class = n_class
self.lr_bvae = bboxvae_lr
self.lr_cvae = countvae_lr
self.countvae = CountVAE(n_class)
self.bboxvae = BboxVAE(n_class,4,max_box,bboxvae_latent_dim)
self.is_cvae_trained = 0
self.is_bvae_trained = 0
def forward(self,input):
'''
Takes only Labels Set as input
Label Set : it is a vector of size n_class and contains 1 if correspinding class is present
'''
if self.is_cvae_trained == 0:
print("[Warning] Count VAE is Not Trained !!")
if self.is_bvae_trained == 0:
print("[Warning] Bbox VAE is Not Trained !!")
label_set = input
pred_class_counts = self.countvae(label_set , isTrain=False)
# Normalize classiction between [0 , max_box]
pred_class_counts = T.floor ( self.max_box*(pred_class_counts / T.sum(pred_class_counts , dim = 1 ).view(-1,1)) )
# Extra boxes which are not be predicted
# Their counts are set in first class
for class_count in pred_class_counts:
if(T.sum(class_count) < self.max_box):
class_count[0] = self.max_box - T.sum(class_count)
class_labels = T.zeros(len(label_set) , self.max_box, self.n_class)
for i in range(len(pred_class_counts)):
l = 0
for j in range(self.n_class):
for k in range(int(pred_class_counts[i][self.n_class-j-1])):
class_labels[i][l][self.n_class-j-1] = 1;
l+=1
pred_box = self.bboxvae([ pred_class_counts, class_labels], isTrain=False)
pred_box = pred_box.permute(2,0,1)
class_info = T.unsqueeze(T.argmax(class_labels ,dim=2),dim=2)
predictions = T.cat([class_info,pred_box],dim = 2)
for i in range(len(predictions)):
for j in range(len(predictions[i])):
if predictions[i][j][0]==0:
predictions[i][j]*=0
self.predictions = predictions
self.pred_class_counts = pred_class_counts
return predictions
def load_data(self, path, frac = 0.5, train_test_split = 0.1):
'''
Loads data from npy file
path string containig path to data
frac defines the fraction of data to load
'''
try :
Data = np.load(path)
# Sortind Data in proper order
np.random.shuffle(Data)
order = np.argsort(Data[:,:,0])
for i in range(len(Data)):
Data[i] = Data[i][order[i][::-1]]
data_size = int(frac*len(Data))
test_size = int(train_test_split*data_size)
Data = T.tensor(Data[0:data_size]).float()
test_data = Data[0:test_size]
Data = Data[test_size:]
# Prepare Data
self.class_labels = Data[...,4:]
self.class_counts = T.sum(Data[...,4:], dim = 1)
self.b_boxes = Data[...,0:4]
self.label_set = (self.class_counts !=0) + 0.0
# Test Data
self.test_class_labels = test_data[...,4:]
self.test_class_counts = T.sum(test_data[...,4:], dim = 1)
self.test_b_boxes = test_data[...,0:4]
self.test_label_set = (self.test_class_counts !=0) + 0.0
print("[Success] Data Loaded Succesfully")
except:
print("[Failed] Data Loading Failed\n please check path")
def train(self, optim, train_mode = 'bboxvae', epochs = 100, bsize = 256 , validation_split = 0.1):
'''
* train_mode (str , default bboxvae) : Two optons
1. if train_mode is bboxvae, BBoxVAE model will be trained and data
will be loaded accordingly
2. if train_mode is countvae, CountVAE model will be trained and data
will be loaded accordingly
* epochs (int , default 100 ) : number of epochs training should run
* bsize(int default 256) : Batch Size
* validation_split(float default 0.1) : should be between between 0 and 1
1 . it defines the size of validation data
'''
# Create validation Split
total_examples = len(self.class_counts)
val_size = int(total_examples*validation_split)
losses = dict()
train_data = []
if train_mode == 'countvae':
model = self.countvae
train_data = [self.label_set, self.class_counts]
else :
model = self.bboxvae
train_data = [self.class_counts, self.b_boxes, self.class_labels]
# Validation Data
val_data = []
for x in train_data:
val_data.append(x[:val_size])
# Train data
for i in range(len(train_data)):
train_data[i] = train_data[i][val_size:]
# find the number of batches
batches = len(train_data[0])//bsize
second_loss = 'mse'
if train_mode == 'countvae':
second_loss = 'poisson_nll'
# Dictionary to keep track of model statistics
losses = {'epoch':-1,
'batch':0,
'lr' : 0,
'loss':0,
'kl_div_loss':0,
second_loss+'_loss':0,
'val_loss':0,
'val_kl_div_loss':0,
'val_'+second_loss+'_loss':0
}
history = pd.DataFrame(losses ,index = [0])
index = 1
for ep in range(epochs):
# if train_mode=='countvae':
# self.countvae_pred_grpah(epoch = ep,path = CVAE_PATH)
print(f'Epoch[{ep+1}/{epochs}]')
for batch in range(batches):
# Get Current batch
b = []
for x in train_data:
b.append(x[batch*bsize : (batch+1)*bsize])
optim.zero_grad()
# Train Step
loss, kl_, l_ = model(b,isTrain = True)
# Validation Step
val_loss, val_kl_, val_l_ = model(val_data, isTrain = True)
# Save Statistics
losses['epoch'] = ep
losses['batch'] = batch
losses['lr'] = optim.param_groups[0]['lr']
loss_list = [loss, kl_, l_ , val_loss , val_kl_ , val_l_]
for i in range(6):
losses[list(losses.keys())[3+i]] = loss_list[i].cpu().clone().detach().numpy()
pass
losses_df = pd.DataFrame(losses , index=[index])
history = pd.concat([history,losses_df])
index+=1
# Backpropogation step and updating weights
loss.backward()
optim.step()
print('\r Batch: {}/{} - loss : {} - val_loss : {} - val_{} : {}'.format(batch+1,batches,
losses_df['loss'][index-1],
losses_df['val_loss'][index-1],
second_loss,
losses_df['val_'+second_loss+'_loss'][index-1]),
end="")
print("\n")
print('[Success] Finished Training')
return history
def load_countvae_weights(self,path):
try :
self.countvae = T.load(path)
self.is_cvae_trained=1
print('[Success] Loaded Successfully')
except:
print('[Failed] Load Failed')
def load_bboxvae_weights(self,path):
try :
self.bboxvae = T.load(path)
self.is_bvae_trained=1
print('[Success] Loaded Successfully')
except:
print('[Failed] Load Failed')
def train_bboxvae(self,epochs=30, bsize=256, validation_split=0.1, optim=None):
if optim == None:
optim = T.optim.Adam(self.bboxvae.parameters(),lr=self.lr_bvae)
# Start Training
history = self.train(optim = optim,
train_mode = 'bboxvae',
epochs = epochs,
bsize = bsize,
validation_split = validation_split
)
self.is_bvae_trained = 1
self.bvae_history = history[history.columns][1:]
return self.bvae_history
def train_countvae(self,epochs=30, bsize=256, validation_split=0.1, optim=None):
if optim == None:
optim = T.optim.Adam(self.countvae.parameters(),lr=self.lr_cvae)
# Start Training
history = self.train(optim = optim,
train_mode = 'countvae',
epochs = epochs,
bsize = bsize,
validation_split = validation_split
)
self.is_cvae_trained = 1
self.cvae_history = history[history.columns][1:]
return self.cvae_history
def pred_countvae(self,data=None):
'''
* Functions is used for for predcting from CountVAE
given label_set
* if data is None than label set from loaded data
are used for predictions.
'''
if self.is_cvae_trained == 0:
print("[Warning] Count VAE is Not Trained !!")
if data == None :
data = self.test_label_set
return self.countvae(data , isTrain=False)
def pred_bboxvae(self,Data=None):
'''
* Functions is used for for predcting from BboxVAE
given class_counts and class labels
* if data is None than class counts and class labels from loaded data
are used for predictions.
'''
if self.is_bvae_trained == 0:
print("[Warning] Bbox VAE is Not Trained !!")
if Data == None :
Data = [self.test_class_counts,self.test_class_labels]
batches = len(Data[0])//64
for b in range(batches):
# Get data in batch
data = [self.test_class_counts[b*64 : (b+1)*64],
self.test_class_labels[b*64 : (b+1)*64]]
# Predict
pred = self.bboxvae(data, isTrain=False)
pred = pred.permute(2,0,1)
# cxywh format
class_info = T.unsqueeze(T.argmax(data[1] ,dim=2),dim=2)
pred = T.cat([class_info,pred],dim = 2)
for i in range(len(pred)):
for j in range(len(pred[i])):
if pred[i][j][0]==0:
pred[i][j] *= 0
if b > 0:
predictions = T.cat([predictions,pred],dim=0)
else:
predictions = pred
class_info =T.argmax(self.test_class_labels[0:64*batches] ,dim=2)
class_info = T.unsqueeze(class_info,dim=2)
gt = T.cat([class_info,self.test_b_boxes[0:64*batches]],dim = 2)
return predictions, gt
def countvae_pred_grpah(self,path,epoch = 0):
pred_cvae = self.pred_countvae()
pred_cvae = T.sum(pred_cvae,dim=0)
pred_cvae = pred_cvae/T.sum(pred_cvae)
pred_cvae = pred_cvae.clone().detach().numpy()
gt_cvae = T.sum(self.class_counts,dim=0)
gt_cvae = gt_cvae/T.sum(gt_cvae)
gt_cvae = gt_cvae.clone().detach().numpy()
fig = plt.figure(figsize=(5 ,4), dpi=100 ,facecolor=(0,0,0))
ax = fig.add_subplot()
ax.plot(gt_cvae , 'red',marker = 'o', label = 'Ground Truth',linewidth=4)
ax.plot(pred_cvae,'blue',marker ='o',label = "Predicted" ,linewidth=4)
ax.legend()
ax.set_title('Ground Truth vs Predicted Distribution\n Epoch = '+str(epoch))
ax.set_xlabel('Classes')
ax.set_xticks([i for i in range(config.N_CLASS)])
ax.set_xticklabels(config.class_names)
plt.savefig(path+"cvae-train-ep-"+str(epoch)+".png",facecolor=(0,0,0))
plt.close()
def convert_to_cxywh(self,data):
'''
Parameters
----------
data : (torch.tensor) tensor
tensor of size (N , B , 4 + C)
N = number of examples
B = Number of boxes
C = Number of classes
Returns
-------
cxywh : (torch.tensor) tensor
tensor of size (N , B , 1 + 4)
N = number of examples
B = Number of boxes
c = class
(x,y) = upper left corner
w and h = height and width
'''
bboxes = data[...,0:4]
labels = data[...,4: ]
class_info = T.unsqueeze(T.argmax(labels ,dim=2),dim=2)
cxywh = T.cat([class_info,bboxes],dim = 2)
return cxywh
def save_model(self,path):
T.save(self.countvae,path+'countvae.h5')
T.save(self.bboxvae,path+'bboxvae.h5')
T.save(self,path+'layoutvae.h5')
print('[Success] Saved Successfully')
def save_history(self,path):
self.cvae_history.to_csv(path+'cvae-history.csv',index=False)
self.bvae_history.to_csv(path+'bvae-history.csv',index=False)
print('[Success] Saved Successfully')
================================================
FILE: LayoutVAE/Source/main.py
================================================
# -*- coding: utf-8 -*-
"""
Created on Tue Aug 10 18:26:19 2021
@author: Tushar & Tanishk
"""
from layoutvae import LayoutVAE
from utils import plot_layouts ,plot_history,generate_colors,countvae_pred_graph
import config
# Model
layoutvae = LayoutVAE(n_class=config.N_CLASS,
max_box=config.MAX_BOX,
bboxvae_latent_dim=config.BVAE_LATENT_DIM,
bboxvae_lr=config.BVAE_LR,
countvae_lr=config.CVAE_LR,
)
layoutvae.load_data(path = config.DATA_PATH,frac= config.FRAC)
history_bvae_df = layoutvae.train_bboxvae(bsize = config.BVAE_BSIZE,
epochs=config.BVAE_EPOCHS,
validation_split=config.BVAE_VAL_SPLIT)
history_cvae_df = layoutvae.train_countvae(bsize = config.CVAE_BSIZE,
epochs=config.CVAE_EPOCHS,
validation_split=config.CVAE_VAL_SPLIT)
# Save History
layoutvae.save_model(config.SAVE_MODEL_PATH)
layoutvae.save_history(config.SAVE_LOG_PATH)
# Predict Layout
colors = generate_colors(n_class=config.N_CLASS,
class_names=config.class_names)
# only using bboxvae
pred , ground_truth = layoutvae.pred_bboxvae()
for i in range(2):
plot_layouts(pred = pred[i*16:(i+1)*16],
colors=colors,
class_names=config.class_names,
path=config.SAVE_OUTPUT_PATH+"bvae-preds-"+str(i)+".png"
)
# using complete model
final_predictions = layoutvae(layoutvae.label_set)
#visualize and save predictions
plot_layouts(pred = final_predictions,
colors = colors,
title = "Random Outputs",
class_names=config.class_names,
path = config.SAVE_OUTPUT_PATH+"randout.svg")
countvae_pred_graph(layoutvae,config.SAVE_OUTPUT_PATH+"cvae-train.png")
plot_layouts(pred = pred,
colors = colors,
title = "BBoxVAE Outputs",
class_names=config.class_names,
path = config.SAVE_OUTPUT_PATH+"bboxvae-pred.svg")
# Plot and save Train History plots
plot_history(layoutvae.bvae_history , path = config.SAVE_LOG_PATH+"bvae-train.png")
plot_history(layoutvae.cvae_history , path = config.SAVE_LOG_PATH+"cvae-train.png")
# Complete Model
predd = layoutvae(layoutvae.test_label_set)
for i in range(2):
plot_layouts(pred = predd[i*16:(i+1)*16],
colors=colors,
class_names=config.class_names,
path=config.SAVE_OUTPUT_PATH+"random-preds-"+str(i)+".png"
)
================================================
FILE: LayoutVAE/Source/modelblocks.py
================================================
# -*- coding: utf-8 -*-
"""
Created on Tue Aug 10 17:14:02 2021
@author: Tushar & Tanishk
"""
from __future__ import division
import torch as T
from torch.nn import Sequential , Linear , ReLU , PoissonNLLLoss, LSTM
from torch.distributions import MultivariateNormal
class fcblock(T.nn.Module):
def __init__(self, n_class):
super(fcblock, self).__init__()
self.seq = Sequential(
Linear(n_class,128),
ReLU(),
Linear(128,128),
ReLU(),
)
def forward(self,inputs):
out = self.seq(inputs)
return out
class Embeder(T.nn.Module):
def __init__(self,n_class):
super(Embeder,self).__init__()
self.fcb1 = fcblock(n_class)
self.fcb2 = fcblock(n_class)
self.fcb3 = fcblock(n_class)
self.fc = Linear(128*3,128)
def forward(self,inputs):
in1,in2,in3 = inputs
in1 = self.fcb1(in1)
in2 = self.fcb2(in2)
in3 = self.fcb3(in3)
out = T.cat((in1,in2,in3),1)
out = self.fc(out)
return out
class Encoder(T.nn.Module):
def __init__(self, in_dim=1 ,latent_dim=32):
super(Encoder,self).__init__()
self.act = ReLU()
self.fc1 = Linear(in_dim,128)
self.fc2 = Linear(128,128)
self.fc3 = Linear(256,latent_dim)
self.fc4 = Linear(latent_dim,latent_dim)
self.fc5 = Linear(latent_dim,latent_dim)
def forward(self,inputs):
in1,in2 = inputs
out = self.fc1(in1)
out = self.act(out)
out = self.fc2(out)
out = T.cat((out,in2),1)
out = self.fc3(out)
out = self.act(out)
mu = self.fc4(out)
logvar = self.fc5(out)
return mu,logvar
class Prior(T.nn.Module):
def __init__(self,latent_dim=32):
super(Prior,self).__init__()
self.act = ReLU()
self.fc1 = Linear(128,latent_dim)
self.fc2 = Linear(latent_dim,latent_dim)
self.fc3 = Linear(latent_dim,latent_dim)
def forward(self,inputs):
out = inputs
out = self.fc1(out)
out = self.act(out)
mu = self.fc2(out)
logvar = self.fc3(out)
return mu,logvar
class Decoder(T.nn.Module):
def __init__(self,output_dim,latent_dim=32):
super(Decoder,self).__init__()
self.act = ReLU()
self.fc1 = Linear(128+latent_dim,128)
self.fc2 = Linear(128,64)
self.fc3 = Linear(64,output_dim)
def forward(self,inputs):
in1,in2 = inputs
out = T.cat((in1,in2),1)
out = self.fc1(out)
out = self.act(out)
out = self.fc2(out)
out = self.act(out)
out = self.fc3(out)
return out
"""# LOSS FUNCTION"""
class ELBOLoss(T.nn.Module):
def __init__(self):
super(ELBOLoss,self).__init__()
def forward(self,inputs):
mu1, logvar1, mu2, logvar2 , in1, in2 = inputs
mask = (in2>0)+0.0
in2 = in2-mask
'''KL Divergence'''
kl = 0.5 * T.sum((logvar2 - logvar1) - 1 + (logvar1.exp() + (mu2 - mu1).pow(2) )/logvar2.exp() , dim = 1).mean()
'''Poisson Negative Log Likelihood'''
pnll = PoissonNLLLoss()(in1,in2)
loss = kl+pnll
return loss, pnll , kl
class EmbedBbox(T.nn.Module):
def __init__(self,n_class):
super(EmbedBbox,self).__init__()
self.fcb1 = fcblock(n_class)
self.fcb2 = fcblock(n_class)
self.seq1 = Sequential(
Linear(128,128),
ReLU()
)
self.n_class = n_class
self.fc = Linear(128*3,128)
self.lstm = LSTM(n_class+4, hidden_size=128)
def forward(self,inputs):
in1,in2,in3 = inputs
_ , (h_0 , c_0 ) = self.lstm(in3)
hn = h_0.view(-1, 128)
in1 = self.fcb1(in1)
in2 = self.fcb2(in2)
in3 = self.seq1(hn)
out = T.cat((in1,in2,in3),1)
out = self.fc(out)
return out
class ELBOLoss_Bbox(T.nn.Module):
def __init__(self):
super(ELBOLoss_Bbox,self).__init__()
def forward(self,inputs):
mu1,logvar1,mu2,logvar2, xp , yp = inputs
''' KL Divergence '''
kl = 0.5 * T.sum((logvar2 - logvar1) - 1 + (logvar1.exp() + (mu2 - mu1).pow(2) )/logvar2.exp() , dim = -1 ).mean()
''' Multivariate Guassian Likelihood '''
mse = T.nn.MSELoss()(xp,yp)
loss = mse + kl
return loss, kl,mse
class Reparamatrize_bvae(T.nn.Module):
def __init__(self):
super(Reparamatrize_bvae,self).__init__()
def forward(self,inputs):
mu , logvar = inputs
std = T.exp(logvar/2)
eps = T.rand_like(std)
return eps*std + mu
class ReparamatrizeMulti(T.nn.Module):
def __init__(self):
super(ReparamatrizeMulti,self).__init__()
def forward(self,inputs):
mu = inputs
std = (T.ones_like(mu)*0.02)
eps = T.rand_like(std)
return eps*std + mu
class Reparamatrize_cvae(T.nn.Module):
def __init__(self):
super(Reparamatrize_cvae,self).__init__()
def forward(self,inputs):
mu , logvar = inputs
'''
mu = mean
logvar = log of diagonal elements of covariance matrix
'''
# Covarince Matrix
covar = T.diag_embed(T.exp(logvar/2), dim1=-2,dim2=-1)
# Multivariate Normal Distribution
p = MultivariateNormal(mu,covar)
z_latent = p.rsample().float()
return z_latent
class Sampling(T.nn.Module):
def __init__(self,MAX_BOX):
super(Sampling,self).__init__()
self.max_box = MAX_BOX
def forward(self,lamda):
lamda = lamda.view(-1)
mask = T.zeros(lamda.shape[0] , self.max_box)
lamda = T.t(T.t(mask) + lamda)
mask = mask + T.arange(0,self.max_box,1)
e_lamda = T.exp(lamda)
lamda_x = lamda ** mask
fact = T.exp(T.lgamma(T.arange(0 , self.max_box)+1))
# P = ((lambda ^ x)*e^(lamda)) / x!
probab = (lamda_x*e_lamda)/fact
sample = T.argmax(probab,dim=1)
return sample
================================================
FILE: LayoutVAE/Source/utils.py
================================================
# -*- coding: utf-8 -*-
"""
Created on Tue Aug 10 17:36:04 2021
@author: Tushar & Tanishk
"""
import torch as T
import matplotlib.pyplot as plt
import matplotlib.patches as patches
from matplotlib.patches import Patch
import config
plt.style.use('dark_background')
def plot_history(history,title = 'Training Statistics', path =""):
height = 12
width = 9
fig = plt.figure(figsize=(width,height), dpi=100 ,facecolor=(0,0,0))
height_ratio = [0.25,1,1,1]
grid = plt.GridSpec(4,2,
hspace=0.3,wspace=0.2,
height_ratios =height_ratio,
left=0.02,right=0.98,top=0.98,bottom=0.02
)
index = 0
ax = fig.add_subplot(grid[index : index+2])
index+=2
ax.text(x = 0.3 ,y = 0.5 ,s = title,fontsize=30)
ax.invert_yaxis()
ax.axis('off')
colors = ['red','blue','green']
for i in range(3):
ax = fig.add_subplot(grid[index])
ax.plot(history[history.columns[i+3]],colors[i])
index+=1
ax.set_facecolor((0,0,0))
ax.set_title(history.columns[i+3])
ax = fig.add_subplot(grid[index])
ax.plot(history[history.columns[i+6]],colors[i])
ax.set_title(history.columns[i+6])
index+=1
ax.set_facecolor((0,0,0))
ax.set_xlabel('Batches')
ax.set_ylabel('Loss')
plt.savefig(path, facecolor=(0,0,0))
def generate_colors(class_names = None,n_class=6):
'''
Parameters
----------
class_names : list, optional
List of classes in the dataset. The default is None.
n_class : integer, optional
The default is 6.
Returns
-------
colors : list of hexadecimal strings
'''
cmap = ["","#dc143c","#ffff00","#00ff00","#ff00ff","#1e90ff","#fff5ee",
"#00ffff","#8b008b","#ff4500","#8b4513","#808000","#483d8b",
"#008000","#000080","#9acd32","#ffa500","#ba55d3","#00fa9a",
"#dc143c","#0000ff","#f08080","#f0e68c","#dda0dd","#ff1493"]
colors = dict()
if class_names == None:
class_names = []
for i in range(n_class):
class_names.append('class'+str(i+1))
for i in range(n_class):
colors[class_names[i]] = cmap[i]
return colors
class_names = ['None' , 'Text' , 'Title' , 'List' , 'Table' ,'Figure']
colors = generate_colors(n_class=6 , class_names=class_names)
def plot_layouts(pred,colors,class_names,title="Predictions", path=""):
'''
data in cxywh format
'''
height = 15
width = 9
fig = plt.figure(figsize=(width,height), dpi=50 ,facecolor=(0,0,0))
height_ratio = [0.25,0.25,1,1,1,1]
grid = plt.GridSpec(6,4,
hspace=0.05,wspace=0.05,
height_ratios =height_ratio,
left=0.02,right=0.98,top=0.98,bottom=0.02
)
index = 0
ax = fig.add_subplot(grid[index : index+4])
index+=4
ax.text(x = 0.2 ,y = 0.5 ,s = title,fontsize=30)
legend = []
ax = fig.add_subplot(grid[index : index+4])
index += 4
for i in range(1,6):
legend.append(Patch(facecolor=colors[class_names[i]]+"40",
edgecolor=colors[class_names[i]],
label= class_names[i]))
ax.legend(handles=legend, ncol=3,loc=8, fontsize=25, facecolor=(0,0,0))
ax.axis('off')
for i in range(16):
ax = fig.add_subplot(grid[index])
index += 1
data = pred[i]
rect1 = patches.Rectangle((0,0),180,240)
rect1.set_color((0,0,0,1))
ax.add_patch(rect1)
for box in data:
c,x,y,w,h = box
if c==0:
continue
x = x*180
y = y*240
w = w*180
h = h*240
rect = patches.Rectangle((x,y),w,h,linewidth=2)
rect.set_color(colors[class_names[int(c)]]+"72")
rect.set_linestyle('-')
rect.set_edgecolor(colors[class_names[int(c)]])
ax.add_patch(rect)
ax.plot()
ax.set_facecolor((0,0,0))
for spine in ax.spines.values():
spine.set_edgecolor('green')
spine.set_linewidth(2)
ax.invert_yaxis()
ax.set_xticks([])
ax.set_yticks([])
plt.savefig(path , facecolor=(0,0,0))
def countvae_pred_graph(model,path=""):
pred_cvae = model.pred_countvae()
pred_cvae = T.sum(pred_cvae,dim=0)
pred_cvae = pred_cvae/T.sum(pred_cvae)
pred_cvae = pred_cvae.to('cpu').clone().detach().numpy()
gt_cvae = T.sum(model.class_counts,dim=0)
gt_cvae = gt_cvae/T.sum(gt_cvae)
gt_cvae = gt_cvae.to('cpu').clone().detach().numpy()
fig = plt.figure(figsize=(5 ,4), dpi=100 ,facecolor=(0,0,0))
ax = fig.add_subplot()
ax.plot(gt_cvae , 'red',marker = 'o', label = 'Ground Truth',linewidth=4)
ax.plot(pred_cvae,'blue',marker ='o',label = "Predicted" ,linewidth=4)
ax.legend()
ax.set_title('Ground Truth vs Predicted Distribution')
ax.set_xlabel('Classes')
ax.set_xticks([i for i in range(config.N_CLASS)])
ax.set_xticklabels(config.class_names)
plt.savefig(path,facecolor=(0,0,0))
plt.close()
================================================
FILE: LayoutVAE/readme.md
================================================
# Layout VAE
## Introduction
This repository provides PyTorch 1.9.0 implementation of Layout VAE [[1]](#1) ( Layout Variational Auto Encoder ). It is a probabilistic and autoregressive model which generates the scene layout using latent variables in lower dimensions . It is capable of generating different layouts using the same data point.
## Architecture
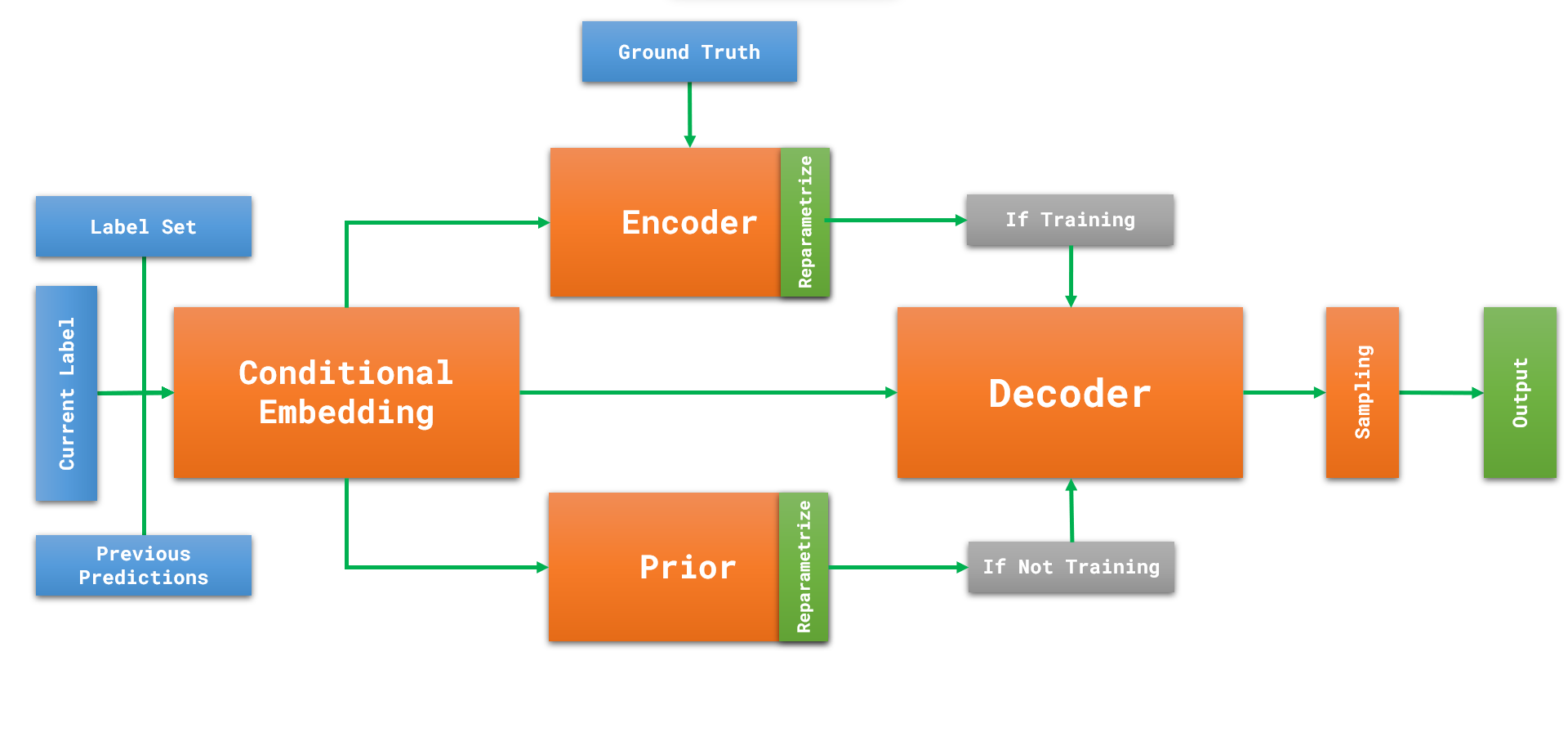
## Requirements
- PyTorch 1.9.0
- Python 3.8
## Datasets
* **PubLayNet** : It is a dataset for document layout analysis. It contains images of research papers and articles and annotations for various elements in a page such as “text”, “list”, “figure” etc in these research paper images. The dataset was obtained by automatically matching the XML representations and the content of over 1 million PDF articles that are publicly available on PubMed Central.[[2]](#2)
* We sorted the cordinates of Bounding boxes in left to right direction. and used 50% data as train data and 5% test data.
## Getting Started
<a href="https://colab.research.google.com/gist/tushar-jain01/fa99834650efb88abe3a2446c835bb9e/layoutvae-final.ipynb" target="_parent"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a>
Click on the above Badge to quickstart the LayoutVAE in google colab
## Results
### CountVAE

### BBoxVAE
<img src="https://user-images.githubusercontent.com/40228110/129759544-bf74cfe1-f1f1-4140-80e3-a117b3033b99.png" alt="Image" width="450" height="750" style="display: block; margin: 0 auto" />
## References
<a id="1">[1]</a>
LayoutVAE: Stochastic Scene Layout Generation from a Label Set.Akash Abdu Jyothi and Thibaut Durand and Jiawei He and Leonid Sigal and Greg Mori [Paper](https://arxiv.org/abs/1907.10719)
<a id="2">[2]</a>
PubLayNet : By Xu Zhong, Jianbin Tang, Antonio Jimeno Yepes [Dataset](https://developer.ibm.com/exchanges/data/all/publaynet/)
================================================
FILE: Metrics/Metrics_data/publaynet.npy
================================================
[File too large to display: 58.5 MB]
================================================
FILE: Metrics/README.md
================================================
# Metrics/Quantitative Comparison
## Intersection over Union (IoU)
The intersection over the union of boxes is calculated pairwise and are then added together. The overall IoU of the data is averaged over all the documents.
For the kth document in the data, the iou Lk is calculated as follows:

Where n is the total number of boxes in the document.
For the whole data, the loss(IoU) is calculated as follows:

Where N is the total number of documents in the data.
## Overlapping Loss
Overlapping loss is defined as the ratio of overlapping area by the box area. It is also calculated pairwise, added together and then averaged for all documents. Related expressions are given below:


## Alignment Loss
Adjacent elements (boxes) are usually in six possible alignment types: Left, X-center, Right, Top, Y-center and Bottom aligned. Denote =(xL,yT,xC,yC,xR,yB) as the top-left, center and bottom-right coordinates of the predicted bounding box, we encourage pairwise alignment among elements by introducing an alignment loss:


## Comparison
Data was normalised with respect to the original data.
| | Overlap | IOU | Alignment |
|--------------------|:-----------:|:-----------:|:---------:|
| Original Data | 1.000000 | 1.000000 | 1.000000 |
| LayoutGAN | 1172.005234 | 2745.437529 | 1.164882 |
| LayoutVAE | 119.320127 | 185.864381 | 3.493406 |
| Layout Transformer | 1.090315 | 1.422297 | 0.739862 |
================================================
FILE: Metrics/metrics.ipynb
================================================
{
"nbformat": 4,
"nbformat_minor": 2,
"metadata": {
"colab": {
"name": "metrics.ipynb",
"provenance": [],
"collapsed_sections": []
},
"kernelspec": {
"name": "python3",
"display_name": "Python 3"
},
"language_info": {
"name": "python"
}
},
"cells": [
{
"cell_type": "markdown",
"source": [
"#Imports"
],
"metadata": {
"id": "F_A3n24sMYfx"
}
},
{
"cell_type": "code",
"execution_count": 1,
"source": [
"# Drive Mounting (for Google Colab only). If not using Colab, comment the below two lines.\r\n",
"from google.colab import drive\r\n",
"drive.mount('/content/drive')"
],
"outputs": [
{
"output_type": "stream",
"name": "stdout",
"text": [
"Drive already mounted at /content/drive; to attempt to forcibly remount, call drive.mount(\"/content/drive\", force_remount=True).\n"
]
}
],
"metadata": {
"colab": {
"base_uri": "https://localhost:8080/"
},
"id": "I3oR3QRKPSfu",
"outputId": "e9e4bcd8-0436-48d4-ed38-a338a4ae3d12"
}
},
{
"cell_type": "code",
"execution_count": 2,
"source": [
"import numpy as np\r\n",
"import pandas as pd\r\n",
"from shapely.geometry import Polygon"
],
"outputs": [],
"metadata": {
"id": "yEjKDwojt5qE"
}
},
{
"cell_type": "code",
"execution_count": 3,
"source": [
"root=\"/content/drive/MyDrive/Folder_Name/\" #path of the root directory"
],
"outputs": [],
"metadata": {
"id": "X3kiwgIpsQzN"
}
},
{
"cell_type": "markdown",
"source": [
"#Data Loading"
],
"metadata": {
"id": "jdCPjnwvMgVc"
}
},
{
"cell_type": "code",
"execution_count": 4,
"source": [
"publaydata = np.load(root+\"publaynet.npy\")\r\n",
"Transformer_res=np.load(root+\"trans.npy\")\r\n",
"VAE_res = np.load(root+\"VAE_res.npy\")\r\n",
"GAN_res = np.load(root+\"GAN_res.npy\")"
],
"outputs": [],
"metadata": {
"id": "3ybVHIU8uRoW"
}
},
{
"cell_type": "markdown",
"source": [
"Reshaping and arranging data in an optimal format. Preferred format is [c x y w h]\n",
"\n",
"* c is the class of the box.\n",
"* x and y are the corrdinates for the top left corner of the box.\n",
"* w and h are the width and height respectively. \n",
"---\n",
"\n"
],
"metadata": {
"id": "Y83pq-l_NL8y"
}
},
{
"cell_type": "code",
"execution_count": 5,
"source": [
"g_data = GAN_res.reshape((1024, 9, 9))[:1000]\r\n",
"g_data = g_data[...,0:5]\r\n",
"g_data = g_data[...,[4,0,1,2,3]]\r\n",
"g_data[...,1] = g_data[...,1] - g_data[...,3]/2\r\n",
"g_data[...,2] = g_data[...,2] - g_data[...,4]/2\r\n",
"\r\n",
"g_data[0]"
],
"outputs": [
{
"output_type": "execute_result",
"data": {
"text/plain": [
"array([[0.37773186, 0.06993452, 0.19879478, 0.93849486, 0.37714368],\n",
" [0.63268024, 0.08424908, 0.09495369, 0.7752126 , 0.770834 ],\n",
" [0.31078017, 0.22171676, 0.65355074, 0.6689019 , 0.08199155],\n",
" [0.9312403 , 0.20145085, 0.0982542 , 0.66996616, 0.05629438],\n",
" [0.6019517 , 0.11892939, 0.76413304, 0.7681484 , 0.15887733],\n",
" [0.31345773, 0.22002116, 0.64820474, 0.67002124, 0.08382312],\n",
" [0.31812534, 0.22010046, 0.6488024 , 0.6710409 , 0.08644559],\n",
" [0.36010844, 0.07238191, 0.18851566, 0.9383161 , 0.40076703],\n",
" [0.93621445, 0.20135537, 0.09839028, 0.66991025, 0.05546013]],\n",
" dtype=float32)"
]
},
"metadata": {
"tags": []
},
"execution_count": 5
}
],
"metadata": {
"id": "u_RK-gO_YPYj",
"colab": {
"base_uri": "https://localhost:8080/"
},
"outputId": "a2453ea3-1302-44b8-dff5-67bfd9c979bc"
}
},
{
"cell_type": "markdown",
"source": [
"#Losses\r\n",
"Overall three losses are calculated for the comparison:\r\n",
"* Overlapping\r\n",
"* Alignment\r\n",
"* IoU\r\n",
"\r\n",
"The expressions for the calculations can be found in the Readme file shared."
],
"metadata": {
"id": "YMkdEbASNVY6"
}
},
{
"cell_type": "code",
"execution_count": 6,
"source": [
"def overlapping_loss(result):\r\n",
" losses=np.zeros(len(result))\r\n",
" idx=0\r\n",
" for i in result:\r\n",
" over=0\r\n",
" for j in range(len(i)):\r\n",
" A=float(i[j][3]*i[j][4])\r\n",
" if A==0:\r\n",
" continue\r\n",
" for k in range(len(i)):\r\n",
" if j==k:\r\n",
" continue\r\n",
" x1=i[j][1]\r\n",
" x2=i[j][1]+i[j][3]\r\n",
" y1=i[j][2]\r\n",
" y2=i[j][2]+i[j][4]\r\n",
" x3=i[k][1]\r\n",
" x4=i[k][1]+i[k][3]\r\n",
" y3=i[k][2]\r\n",
" y4=i[k][2]+i[k][4]\r\n",
" x_over=max(min(x2,x4)-max(x1,x3),0)\r\n",
" y_over=max(min(y2,y4)-max(y1,y3),0)\r\n",
" over+=x_over*y_over/A\r\n",
" losses[idx]=over\r\n",
" idx+=1\r\n",
" return np.mean(losses)*100"
],
"outputs": [],
"metadata": {
"id": "MwXRP1cqv6qT"
}
},
{
"cell_type": "code",
"execution_count": 7,
"source": [
"def alignment_loss(result):\r\n",
" xl =result[...,1] \r\n",
" yl = result[...,2]\r\n",
" \r\n",
" xr = xl+result[...,3]\r\n",
" yr = yl + result[...,4]\r\n",
"\r\n",
" xc = (xl + xr)/2\r\n",
" yc = (yl + yr)/2\r\n",
"\r\n",
" ele = [xl , yl , xc, yc, xr, yr]\r\n",
" ele1 = []\r\n",
" epsilon = 0\r\n",
" for element in ele:\r\n",
" min_xl = np.ones(shape = element.shape)\r\n",
" for i in range(len(element)):\r\n",
" for j in range(len(element[i])):\r\n",
" for k in range(len(element[i])): \r\n",
" if j != k :\r\n",
" min_xl[i][j] = min(min_xl[i][j],abs(element[i][j]-element[i][k])) \r\n",
" min_xl = -np.log(1.0-min_xl + epsilon)\r\n",
" ele1.append(min_xl)\r\n",
" ele1 = np.min(np.array(ele1), axis = 0)\r\n",
" ele1 = np.mean(np.sum(ele1 , axis = 1))\r\n",
" return ele1*100"
],
"outputs": [],
"metadata": {
"id": "vm1lD-2dHNtF"
}
},
{
"cell_type": "code",
"execution_count": 8,
"source": [
"def calculate_iou(result):\r\n",
" losses=np.zeros(len(result))\r\n",
" idx=0\r\n",
" for i in result:\r\n",
" iou=0\r\n",
" for j in range(len(i)):\r\n",
" for k in range(j+1,len(i)):\r\n",
" x1=i[j][1]\r\n",
" x2=i[j][1]+i[j][3]\r\n",
" y1=i[j][2]\r\n",
" y2=i[j][2]+i[j][4]\r\n",
" x3=i[k][1]\r\n",
" x4=i[k][1]+i[k][3]\r\n",
" y3=i[k][2]\r\n",
" y4=i[k][2]+i[k][4]\r\n",
"\r\n",
" box_1 = [[x1, y1], [x2, y1], [x2, y2], [x1, y2]]\r\n",
" box_2 = [[x3, y3], [x4, y3], [x4, y4], [x3, y4]]\r\n",
"\r\n",
" poly_1 = Polygon(box_1)\r\n",
" poly_2 = Polygon(box_2)\r\n",
"\r\n",
" if poly_1.union(poly_2).area!=0:\r\n",
" iou += poly_1.intersection(poly_2).area / poly_1.union(poly_2).area\r\n",
" losses[idx]=iou\r\n",
" idx+=1\r\n",
" return np.mean(losses)*100"
],
"outputs": [],
"metadata": {
"id": "DHPkZGI1C9sc"
}
},
{
"cell_type": "markdown",
"source": [
"#Data Comparison\n",
"Calculation of metrics for original data of 1000 documents and for all models for 1000 documents (from unseen data)."
],
"metadata": {
"id": "dxJffkgwN6jC"
}
},
{
"cell_type": "code",
"execution_count": 9,
"source": [
"overlist = [overlapping_loss(publaydata[0:1000]), overlapping_loss(g_data[0:1000]), overlapping_loss(VAE_res[0:1000]),overlapping_loss(Transformer_res)]\r\n",
"ioulist = [calculate_iou(publaydata[0:1000]), calculate_iou(g_data[0:1000]), calculate_iou(VAE_res[0:1000]),calculate_iou(Transformer_res)]\r\n",
"alignlist = [alignment_loss(publaydata[0:1000]), alignment_loss(g_data[0:1000]), alignment_loss(VAE_res[0:1000]),alignment_loss(Transformer_res)]"
],
"outputs": [],
"metadata": {
"id": "zkq1AtqOBDch"
}
},
{
"cell_type": "code",
"execution_count": 10,
"source": [
"#normalizing the lists w.r.t the original data\r\n",
"overlist/=overlist[0]\r\n",
"ioulist/=ioulist[0]\r\n",
"alignlist/=alignlist[0]\r\n",
"\r\n",
"rows = [\"Original Data\", \"LayoutGAN\", \"LayoutVAE\",\"Layout Transformer\"]\r\n",
"df=pd.DataFrame(index=rows)\r\n",
"df[\"Overlap\"]=overlist\r\n",
"df[\"IOU\"]=ioulist\r\n",
"df[\"Alignment\"]=alignlist"
],
"outputs": [],
"metadata": {
"id": "lumvx5zgC9yr"
}
},
{
"cell_type": "code",
"execution_count": 11,
"source": [
"print(\"Comparison for Publaynet Dataset\")\r\n",
"display(df)"
],
"outputs": [
{
"output_type": "stream",
"name": "stdout",
"text": [
"Comparison for Publaynet Dataset\n"
]
},
{
"output_type": "display_data",
"data": {
"text/plain": [
" Overlap IOU Alignment\n",
"Original Data 1.000000 1.000000 1.000000\n",
"LayoutGAN 1172.005234 2745.437529 1.164882\n",
"LayoutVAE 119.320127 185.864381 3.493406\n",
"Layout Transformer 1.090315 1.422297 0.739862"
],
"text/html": [
"<div>\n",
"<style scoped>\n",
" .dataframe tbody tr th:only-of-type {\n",
" vertical-align: middle;\n",
" }\n",
"\n",
" .dataframe tbody tr th {\n",
" vertical-align: top;\n",
" }\n",
"\n",
" .dataframe thead th {\n",
" text-align: right;\n",
" }\n",
"</style>\n",
"<table border=\"1\" class=\"dataframe\">\n",
" <thead>\n",
" <tr style=\"text-align: right;\">\n",
" <th></th>\n",
" <th>Overlap</th>\n",
" <th>IOU</th>\n",
" <th>Alignment</th>\n",
" </tr>\n",
" </thead>\n",
" <tbody>\n",
" <tr>\n",
" <th>Original Data</th>\n",
" <td>1.000000</td>\n",
" <td>1.000000</td>\n",
" <td>1.000000</td>\n",
" </tr>\n",
" <tr>\n",
" <th>LayoutGAN</th>\n",
" <td>1172.005234</td>\n",
" <td>2745.437529</td>\n",
" <td>1.164882</td>\n",
" </tr>\n",
" <tr>\n",
" <th>LayoutVAE</th>\n",
" <td>119.320127</td>\n",
" <td>185.864381</td>\n",
" <td>3.493406</td>\n",
" </tr>\n",
" <tr>\n",
" <th>Layout Transformer</th>\n",
" <td>1.090315</td>\n",
" <td>1.422297</td>\n",
" <td>0.739862</td>\n",
" </tr>\n",
" </tbody>\n",
"</table>\n",
"</div>"
]
},
"metadata": {
"tags": []
}
}
],
"metadata": {
"colab": {
"base_uri": "https://localhost:8080/",
"height": 190
},
"id": "GRrfRwETFmF4",
"outputId": "45f7104a-4558-43aa-d003-71b70489a259"
}
}
]
}
================================================
FILE: README.md
================================================
# Layout Generation and Baseline Implementation
## Contents
* [Layout VAE](#layout-vae)
* [Layout VAE Model](#layout-vae-model)
* [Flow Diagram of Both Count and BBox VAE](#flow-diagram)
* [Results Obtained](#results-obtained)
* [Layout Transformer](#layout-transformer)
* [Layout Transformer Model Architecture](#layout-transformer-model-architecture)
* [Results](#results)
* [LayoutGAN](#layoutgan)
* [Architecture](#architecture)
* [Results on MNIST](#results-on-mnist)
* [Results on single column layouts](#results-on-single-column-layouts)
* [Quantitative Comparison](#quantitative-comparison)
## Layout VAE
LayoutVAE is a variational autoencoder based model . It is a probabilistic and autoregressive model which generates the scene layout using latent variables in lower dimensions . It is capable of generating different layouts using the same data point.
* **CountVAE:** This is the first part of the layoutVAE model; it takes the label set as input and predicts the counts of bounding boxes for corresponding labels. The input is provided as multilabel encoding.
* **BBox VAE:** This the second part of the model was BBox VAE with LSTM based Embedding Generation. Similar to Countvae here also previous predictions along with the label set and label counts are used as conditioning info for current predictions.
### Layout VAE Model

### Flow Diagram

### Results Obtained

## Layout Transformer
Layout Transformer is a model proposed for generating structured layouts which can be used for documents, websites, apps, etc. It uses the decoder block of the Transformer Model, which is able to capture the relation of the document boxes with the previously predicted boxes (or inputs). Since it is an auto-regressive model, it can be used to generate entirely new layouts or to complete existing partial layouts.
The paper also emphasized on the fact that this model performs better than the existing models (at that time) and is better in the following aspects:
* Able to generate layouts of arbitrary lengths
* Gives better alignment due to the discretized grid
* Is able to effectively capture the relationships between boxes in a single layout, which gives meaningful layouts
### Layout Transformer Model Architecture

### Results

## LayoutGAN
LayoutGAN uses a GAN network , with the generator taking randomly sampled inputs (class probabilities and geometric parameters) as parameters, arranging them and thus producing refined geometric and class parameters.
### Architecture
<img src="LayoutGAN/demo/layoutgan.png" width="700" height="300">
### Results on MNIST

### Results on single column layouts
<img src="LayoutGAN/demo/single_col_result.png" height="787" width="473">
## Quantitative Comparison
A total of three metrics were used to compare the models.
* Overlapping Loss
* Interection over Union (IoU)
* Alignment Loss
After Calculating the losses for each model, the following comparison table was obtained:
| | Overlap | IOU | Alignment |
|--------------------|:-----------:|:-----------:|:---------:|
| Original Data | 1.000000 | 1.000000 | 1.000000 |
| LayoutGAN | 1172.005234 | 2745.437529 | 1.164882 |
| LayoutVAE | 119.320127 | 185.864381 | 3.493406 |
| Layout Transformer | 1.090315 | 1.422297 | 0.739862 |
gitextract_m9ixlycu/ ├── LICENSE ├── Layout Transformer/ │ ├── Notebook/ │ │ ├── Data/ │ │ │ └── .gitkeep │ │ ├── Layout_Transformer.ipynb │ │ ├── Publay Weights/ │ │ │ └── .gitkeep │ │ ├── Results/ │ │ │ └── .gitkeep │ │ └── Rico Weights/ │ │ └── .gitkeep │ └── readme.md ├── LayoutGAN/ │ ├── MNIST/ │ │ ├── mnist_modules.py │ │ ├── mnist_train.py │ │ └── mnist_utils.py │ ├── Publaynet/ │ │ ├── modules.py │ │ ├── train.py │ │ └── utils.py │ ├── README.md │ ├── data/ │ │ └── .gitkeep │ ├── demo/ │ │ └── .gitkeep │ └── samples/ │ ├── MNIST_results/ │ │ └── .gitkeep │ └── publaynet_results/ │ └── .gitkeep ├── LayoutVAE/ │ ├── Notebook/ │ │ └── LayoutVAE_Final.ipynb │ ├── Source/ │ │ ├── bboxvae.py │ │ ├── config.py │ │ ├── countvae.py │ │ ├── layoutvae.py │ │ ├── main.py │ │ ├── modelblocks.py │ │ └── utils.py │ ├── TrainedModel/ │ │ ├── bboxvae.h5 │ │ └── countvae.h5 │ └── readme.md ├── Metrics/ │ ├── Metrics_data/ │ │ ├── GAN_res.npy │ │ ├── VAE_res.npy │ │ ├── publaynet.npy │ │ └── trans.npy │ ├── README.md │ └── metrics.ipynb └── README.md
SYMBOL INDEX (107 symbols across 11 files)
FILE: LayoutGAN/MNIST/mnist_modules.py
class RelationModule (line 12) | class RelationModule(tf.keras.Model):
method __init__ (line 13) | def __init__(self, channels=128, output_dim=128, key_dim=128, **kwargs):
method call (line 27) | def call(self, inputs):
class Discriminator (line 45) | class Discriminator(tf.keras.Model):
method __init__ (line 46) | def __init__(self, n_filters=32, n_hidden=128, layout_dim=(28, 28), re...
method call (line 65) | def call(self, inputs):
class Generator (line 75) | class Generator(tf.keras.Model):
method __init__ (line 76) | def __init__(self, n_filters=128, output_dim=2, n_component=128, n_cla...
method call (line 124) | def call(self, x):
FILE: LayoutGAN/MNIST/mnist_train.py
class LayoutGAN (line 19) | class LayoutGAN(object):
method __init__ (line 20) | def __init__(self, geometric_dim=2, n_class=1, batch_size=64, n_compon...
method build_model (line 37) | def build_model(self, dlr, g_lr):
method step (line 43) | def step(self, real_data, noise, training=True):
method train (line 65) | def train(self):
method render (line 122) | def render(self):
method build_discriminator (line 125) | def build_discriminator(self):
method build_generator (line 128) | def build_generator(self):
method gradient_penalty (line 131) | def gradient_penalty(self, real, fake):
method generator_loss (line 144) | def generator_loss(self, z):
method discriminator_loss (line 151) | def discriminator_loss(self, x, z):
FILE: LayoutGAN/MNIST/mnist_utils.py
function merge (line 6) | def merge(images, size):
function image_manifold_size (line 25) | def image_manifold_size(num_images):
function layout_point (line 32) | def layout_point(final_pred, output_height, output_width):
FILE: LayoutGAN/Publaynet/modules.py
class RelationModule (line 10) | class RelationModule(tf.keras.Model):
method __init__ (line 11) | def __init__(self, channels=128, output_dim=128, key_dim=128, **kwargs):
method call (line 25) | def call(self, inputs):
class Discriminator (line 43) | class Discriminator(tf.keras.Model):
method __init__ (line 44) | def __init__(self, n_filters=32, n_hidden=128, layout_dim=(28, 28), re...
method call (line 67) | def call(self, inputs):
class Generator (line 77) | class Generator(tf.keras.Model):
method __init__ (line 78) | def __init__(self, n_filters=128, output_dim=2, n_component=128, n_cla...
method call (line 152) | def call(self, x):
FILE: LayoutGAN/Publaynet/train.py
class LayoutGAN (line 17) | class LayoutGAN(object):
method __init__ (line 18) | def __init__(self, geometric_dim=2, n_class=1, batch_size=64, n_compon...
method build_model (line 34) | def build_model(self, d_lr, g_lr):
method step (line 43) | def step(self, real_data, noise, training=True, step=0):
method train (line 63) | def train(self):
method render (line 109) | def render(self):
method build_discriminator (line 112) | def build_discriminator(self):
method build_generator (line 115) | def build_generator(self):
method generator_loss (line 118) | def generator_loss(self, z):
method discriminator_loss (line 125) | def discriminator_loss(self, x, z):
FILE: LayoutGAN/Publaynet/utils.py
function convert_to_cxywh (line 9) | def convert_to_cxywh(data):
function generate_colors (line 22) | def generate_colors(class_names=None, n_class=50):
function plot_layouts (line 41) | def plot_layouts(pred, colors, class_names, path=""):
function layout_bbox (line 95) | def layout_bbox(final_pred, output_height, output_width):
FILE: LayoutVAE/Source/bboxvae.py
class BboxVAE (line 11) | class BboxVAE(T.nn.Module):
method __init__ (line 12) | def __init__(self,n_class,n_dim,max_box,latent_dim=32):
method forward (line 28) | def forward(self,inputs,isTrain=True):
FILE: LayoutVAE/Source/countvae.py
class CountVAE (line 11) | class CountVAE(T.nn.Module):
method __init__ (line 13) | def __init__(self,n_class,max_box=9):
method forward (line 38) | def forward(self, inputs, isTrain = False):
FILE: LayoutVAE/Source/layoutvae.py
class LayoutVAE (line 19) | class LayoutVAE(T.nn.Module):
method __init__ (line 21) | def __init__(self, n_class = 6, max_box = 9,bboxvae_latent_dim = 32,bb...
method forward (line 37) | def forward(self,input):
method load_data (line 84) | def load_data(self, path, frac = 0.5, train_test_split = 0.1):
method train (line 122) | def train(self, optim, train_mode = 'bboxvae', epochs = 100, bsize = 2...
method load_countvae_weights (line 229) | def load_countvae_weights(self,path):
method load_bboxvae_weights (line 237) | def load_bboxvae_weights(self,path):
method train_bboxvae (line 245) | def train_bboxvae(self,epochs=30, bsize=256, validation_split=0.1, opt...
method train_countvae (line 260) | def train_countvae(self,epochs=30, bsize=256, validation_split=0.1, op...
method pred_countvae (line 276) | def pred_countvae(self,data=None):
method pred_bboxvae (line 290) | def pred_bboxvae(self,Data=None):
method countvae_pred_grpah (line 336) | def countvae_pred_grpah(self,path,epoch = 0):
method convert_to_cxywh (line 360) | def convert_to_cxywh(self,data):
method save_model (line 389) | def save_model(self,path):
method save_history (line 396) | def save_history(self,path):
FILE: LayoutVAE/Source/modelblocks.py
class fcblock (line 12) | class fcblock(T.nn.Module):
method __init__ (line 13) | def __init__(self, n_class):
method forward (line 21) | def forward(self,inputs):
class Embeder (line 25) | class Embeder(T.nn.Module):
method __init__ (line 26) | def __init__(self,n_class):
method forward (line 35) | def forward(self,inputs):
class Encoder (line 44) | class Encoder(T.nn.Module):
method __init__ (line 45) | def __init__(self, in_dim=1 ,latent_dim=32):
method forward (line 54) | def forward(self,inputs):
class Prior (line 67) | class Prior(T.nn.Module):
method __init__ (line 68) | def __init__(self,latent_dim=32):
method forward (line 76) | def forward(self,inputs):
class Decoder (line 84) | class Decoder(T.nn.Module):
method __init__ (line 85) | def __init__(self,output_dim,latent_dim=32):
method forward (line 92) | def forward(self,inputs):
class ELBOLoss (line 104) | class ELBOLoss(T.nn.Module):
method __init__ (line 106) | def __init__(self):
method forward (line 109) | def forward(self,inputs):
class EmbedBbox (line 127) | class EmbedBbox(T.nn.Module):
method __init__ (line 129) | def __init__(self,n_class):
method forward (line 143) | def forward(self,inputs):
class ELBOLoss_Bbox (line 159) | class ELBOLoss_Bbox(T.nn.Module):
method __init__ (line 161) | def __init__(self):
method forward (line 164) | def forward(self,inputs):
class Reparamatrize_bvae (line 177) | class Reparamatrize_bvae(T.nn.Module):
method __init__ (line 179) | def __init__(self):
method forward (line 182) | def forward(self,inputs):
class ReparamatrizeMulti (line 191) | class ReparamatrizeMulti(T.nn.Module):
method __init__ (line 193) | def __init__(self):
method forward (line 196) | def forward(self,inputs):
class Reparamatrize_cvae (line 204) | class Reparamatrize_cvae(T.nn.Module):
method __init__ (line 206) | def __init__(self):
method forward (line 209) | def forward(self,inputs):
class Sampling (line 224) | class Sampling(T.nn.Module):
method __init__ (line 226) | def __init__(self,MAX_BOX):
method forward (line 230) | def forward(self,lamda):
FILE: LayoutVAE/Source/utils.py
function plot_history (line 15) | def plot_history(history,title = 'Training Statistics', path =""):
function generate_colors (line 49) | def generate_colors(class_names = None,n_class=6):
function plot_layouts (line 83) | def plot_layouts(pred,colors,class_names,title="Predictions", path=""):
function countvae_pred_graph (line 147) | def countvae_pred_graph(model,path=""):
Condensed preview — 36 files, each showing path, character count, and a content snippet. Download the .json file or copy for the full structured content (209K chars).
[
{
"path": "LICENSE",
"chars": 1074,
"preview": "MIT License\n\nCopyright (c) 2021 Layout-Generation\n\nPermission is hereby granted, free of charge, to any person obtaining"
},
{
"path": "Layout Transformer/Notebook/Data/.gitkeep",
"chars": 0,
"preview": ""
},
{
"path": "Layout Transformer/Notebook/Layout_Transformer.ipynb",
"chars": 37664,
"preview": "{\n \"cells\": [\n {\n \"cell_type\": \"markdown\",\n \"metadata\": {\n \"id\": \"NSLt1-42rWxE\"\n },\n \"source\": [\n \"### **"
},
{
"path": "Layout Transformer/Notebook/Publay Weights/.gitkeep",
"chars": 0,
"preview": ""
},
{
"path": "Layout Transformer/Notebook/Results/.gitkeep",
"chars": 0,
"preview": ""
},
{
"path": "Layout Transformer/Notebook/Rico Weights/.gitkeep",
"chars": 0,
"preview": ""
},
{
"path": "Layout Transformer/readme.md",
"chars": 161,
"preview": "# Layout Transformer Baseline Implementation\n\nLink for the PublayNet Dataset: https://drive.google.com/file/d/1eZMp9FiSU"
},
{
"path": "LayoutGAN/MNIST/mnist_modules.py",
"chars": 6904,
"preview": "import os\nimport time\nimport math\nfrom glob import glob\nimport tensorflow as tf\nimport numpy as np\nimport random\nfrom mn"
},
{
"path": "LayoutGAN/MNIST/mnist_train.py",
"chars": 7207,
"preview": "import os\nimport time\nimport math\nfrom glob import glob\nimport tensorflow as tf\nimport numpy as np\nimport random\nfrom mn"
},
{
"path": "LayoutGAN/MNIST/mnist_utils.py",
"chars": 2392,
"preview": "import numpy as np\nimport tensorflow as tf\nimport math\n\n\ndef merge(images, size):\n h, w = images.shape[1], images.sha"
},
{
"path": "LayoutGAN/Publaynet/modules.py",
"chars": 10469,
"preview": "import math\nfrom glob import glob\nimport tensorflow as tf\nfrom tensorflow.keras import initializers\nimport numpy as np\ni"
},
{
"path": "LayoutGAN/Publaynet/train.py",
"chars": 6270,
"preview": "import os\nimport time\nimport math\nfrom glob import glob\nimport tensorflow as tf\nimport numpy as np\nimport random\nfrom ut"
},
{
"path": "LayoutGAN/Publaynet/utils.py",
"chars": 5245,
"preview": "import numpy as np\nimport tensorflow as tf\nimport matplotlib.pyplot as plt\nimport matplotlib.patches as patches\nfrom mat"
},
{
"path": "LayoutGAN/README.md",
"chars": 1851,
"preview": "# LayoutGAN \nThis repository provides implementation of \"LayoutGAN: Generating Graphic Layouts with Wireframe Discrimina"
},
{
"path": "LayoutGAN/data/.gitkeep",
"chars": 0,
"preview": ""
},
{
"path": "LayoutGAN/demo/.gitkeep",
"chars": 0,
"preview": ""
},
{
"path": "LayoutGAN/samples/MNIST_results/.gitkeep",
"chars": 0,
"preview": ""
},
{
"path": "LayoutGAN/samples/publaynet_results/.gitkeep",
"chars": 0,
"preview": ""
},
{
"path": "LayoutVAE/Notebook/LayoutVAE_Final.ipynb",
"chars": 55837,
"preview": "{\n \"nbformat\": 4,\n \"nbformat_minor\": 0,\n \"metadata\": {\n \"kernelspec\": {\n \"language\": \"python\",\n \"display"
},
{
"path": "LayoutVAE/Source/bboxvae.py",
"chars": 3237,
"preview": "# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Tue Aug 10 17:25:31 2021\n\n@author: Tushar & Tanishk\n\"\"\"\nimport torch as T\nfrom mo"
},
{
"path": "LayoutVAE/Source/config.py",
"chars": 579,
"preview": "# -*- coding: utf-8 -*-\r\n\"\"\"\r\nCreated on Tue Aug 10 18:24:51 2021\r\n\r\n@author: Tushar and Tanishk\r\n\"\"\"\r\n\r\n# PATHS\r\n\r\nSAVE"
},
{
"path": "LayoutVAE/Source/countvae.py",
"chars": 4264,
"preview": "# -*- coding: utf-8 -*-\r\n\"\"\"\r\nCreated on Tue Aug 10 17:11:05 2021\r\n\r\n@author: Tushar & Tanishk\r\n\"\"\"\r\nimport torch as T\r\n"
},
{
"path": "LayoutVAE/Source/layoutvae.py",
"chars": 15132,
"preview": "# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Tue Aug 10 17:44:46 2021\n\n@author: Tushar & Tanishk\n\"\"\"\nimport torch as T\nfrom co"
},
{
"path": "LayoutVAE/Source/main.py",
"chars": 2748,
"preview": "# -*- coding: utf-8 -*-\r\n\"\"\"\r\nCreated on Tue Aug 10 18:26:19 2021\r\n\r\n@author: Tushar & Tanishk\r\n\"\"\"\r\nfrom layoutvae impo"
},
{
"path": "LayoutVAE/Source/modelblocks.py",
"chars": 6373,
"preview": "# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Tue Aug 10 17:14:02 2021\n\n@author: Tushar & Tanishk\n\"\"\"\nfrom __future__ import di"
},
{
"path": "LayoutVAE/Source/utils.py",
"chars": 5425,
"preview": "# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Tue Aug 10 17:36:04 2021\n\n@author: Tushar & Tanishk\n\"\"\"\n\nimport torch as T\nimport"
},
{
"path": "LayoutVAE/readme.md",
"chars": 2034,
"preview": "# Layout VAE\n\n## Introduction\nThis repository provides PyTorch 1.9.0 implementation of Layout VAE [[1]](#1) ( Layout Var"
},
{
"path": "Metrics/README.md",
"chars": 1793,
"preview": "# Metrics/Quantitative Comparison\r\n## Intersection over Union (IoU)\r\nThe intersection over the union of boxes is calcula"
},
{
"path": "Metrics/metrics.ipynb",
"chars": 13629,
"preview": "{\n \"nbformat\": 4,\n \"nbformat_minor\": 2,\n \"metadata\": {\n \"colab\": {\n \"name\": \"metrics.ipynb\",\n \"provenanc"
},
{
"path": "README.md",
"chars": 3760,
"preview": "# Layout Generation and Baseline Implementation\n\n## Contents\n* [Layout VAE](#layout-vae)\n * [Layout VAE Model](#layout-"
}
]
// ... and 6 more files (download for full content)
About this extraction
This page contains the full source code of the Layout-Generation/layout-generation GitHub repository, extracted and formatted as plain text for AI agents and large language models (LLMs). The extraction includes 36 files (58.7 MB), approximately 54.3k tokens, and a symbol index with 107 extracted functions, classes, methods, constants, and types. Use this with OpenClaw, Claude, ChatGPT, Cursor, Windsurf, or any other AI tool that accepts text input. You can copy the full output to your clipboard or download it as a .txt file.
Extracted by GitExtract — free GitHub repo to text converter for AI. Built by Nikandr Surkov.