Repository: Maciek-roboblog/Claude-Code-Usage-Monitor
Branch: main
Commit: 06f0fe11e694
Files: 77
Total size: 761.9 KB
Directory structure:
gitextract_6dymq9k3/
├── .gitattributes
├── .github/
│ ├── FUNDING.yml
│ └── workflows/
│ ├── lint.yml
│ ├── release.yml
│ ├── test.yml
│ └── version-bump.yml
├── .gitignore
├── .pre-commit-config.yaml
├── CHANGELOG.md
├── CONTRIBUTING.md
├── DEVELOPMENT.md
├── LICENSE
├── README.md
├── RELEASE.md
├── TROUBLESHOOTING.md
├── VERSION_MANAGEMENT.md
├── pyproject.toml
└── src/
├── claude_monitor/
│ ├── __init__.py
│ ├── __main__.py
│ ├── _version.py
│ ├── cli/
│ │ ├── __init__.py
│ │ ├── bootstrap.py
│ │ └── main.py
│ ├── core/
│ │ ├── __init__.py
│ │ ├── calculations.py
│ │ ├── data_processors.py
│ │ ├── models.py
│ │ ├── p90_calculator.py
│ │ ├── plans.py
│ │ ├── pricing.py
│ │ └── settings.py
│ ├── data/
│ │ ├── __init__.py
│ │ ├── aggregator.py
│ │ ├── analysis.py
│ │ ├── analyzer.py
│ │ └── reader.py
│ ├── error_handling.py
│ ├── monitoring/
│ │ ├── __init__.py
│ │ ├── data_manager.py
│ │ ├── orchestrator.py
│ │ └── session_monitor.py
│ ├── terminal/
│ │ ├── __init__.py
│ │ ├── manager.py
│ │ └── themes.py
│ ├── ui/
│ │ ├── __init__.py
│ │ ├── components.py
│ │ ├── display_controller.py
│ │ ├── layouts.py
│ │ ├── progress_bars.py
│ │ ├── session_display.py
│ │ └── table_views.py
│ └── utils/
│ ├── __init__.py
│ ├── formatting.py
│ ├── model_utils.py
│ ├── notifications.py
│ ├── time_utils.py
│ └── timezone.py
└── tests/
├── __init__.py
├── conftest.py
├── examples/
│ └── api_examples.py
├── run_tests.py
├── test_aggregator.py
├── test_analysis.py
├── test_calculations.py
├── test_cli_main.py
├── test_data_reader.py
├── test_display_controller.py
├── test_error_handling.py
├── test_formatting.py
├── test_monitoring_orchestrator.py
├── test_pricing.py
├── test_session_analyzer.py
├── test_settings.py
├── test_table_views.py
├── test_time_utils.py
├── test_timezone.py
└── test_version.py
================================================
FILE CONTENTS
================================================
================================================
FILE: .gitattributes
================================================
# Auto detect text files and perform LF normalization
* text=auto
================================================
FILE: .github/FUNDING.yml
================================================
github: [Maciek-roboblog]
buy_me_a_coffee: maciekroboblog
thanks_dev: u/gh/maciek-roboblog
================================================
FILE: .github/workflows/lint.yml
================================================
name: Lint
on:
push:
branches: [main]
pull_request:
branches: [main]
jobs:
ruff:
runs-on: ubuntu-latest
name: Lint with Ruff
strategy:
matrix:
python-version: ["3.9", "3.10", "3.11", "3.12", "3.13"]
steps:
- uses: actions/checkout@v4
- name: Install uv
uses: astral-sh/setup-uv@v4
with:
version: "latest"
- name: Set up Python ${{ matrix.python-version }}
run: uv python install ${{ matrix.python-version }}
- name: Install dependencies
run: uv sync --extra dev
- name: Run Ruff linter
run: uv run ruff check --output-format=github .
- name: Run Ruff formatter
run: uv run ruff format --check .
pre-commit:
runs-on: ubuntu-latest
name: Pre-commit hooks
strategy:
matrix:
python-version: ["3.9", "3.10", "3.11", "3.12", "3.13"]
steps:
- uses: actions/checkout@v4
- name: Install uv
uses: astral-sh/setup-uv@v4
with:
version: "latest"
- name: Set up Python ${{ matrix.python-version }}
run: uv python install ${{ matrix.python-version }}
- name: Install pre-commit
run: uv tool install pre-commit --with pre-commit-uv
- name: Run pre-commit
run: |
# Run pre-commit and check if any files would be modified
uv tool run pre-commit run --all-files --show-diff-on-failure || (
echo "Pre-commit hooks would modify files. Please run 'pre-commit run --all-files' locally and commit the changes."
exit 1
)
================================================
FILE: .github/workflows/release.yml
================================================
name: Release
on:
push:
branches: [main]
workflow_dispatch:
jobs:
check-version:
runs-on: ubuntu-latest
outputs:
should_release: ${{ steps.check.outputs.should_release }}
version: ${{ steps.extract.outputs.version }}
steps:
- uses: actions/checkout@v4
with:
fetch-depth: 0
- name: Extract version from pyproject.toml
id: extract
run: |
VERSION=$(grep '^version = ' pyproject.toml | sed 's/version = "\(.*\)"/\1/')
echo "version=$VERSION" >> $GITHUB_OUTPUT
echo "Version: $VERSION"
- name: Check if tag exists
id: check
run: |
VERSION="${{ steps.extract.outputs.version }}"
if git rev-parse "v$VERSION" >/dev/null 2>&1; then
echo "Tag v$VERSION already exists"
echo "should_release=false" >> $GITHUB_OUTPUT
else
echo "Tag v$VERSION does not exist"
echo "should_release=true" >> $GITHUB_OUTPUT
fi
release:
needs: check-version
if: needs.check-version.outputs.should_release == 'true'
runs-on: ubuntu-latest
permissions:
contents: write
id-token: write # For trusted PyPI publishing
steps:
- uses: actions/checkout@v4
with:
fetch-depth: 0
- name: Install uv
uses: astral-sh/setup-uv@v4
with:
version: "latest"
- name: Set up Python
run: uv python install
- name: Extract changelog for version
id: changelog
run: |
VERSION="${{ needs.check-version.outputs.version }}"
echo "Extracting changelog for version $VERSION"
# Extract the changelog section for this version using sed
sed -n "/^## \\[$VERSION\\]/,/^## \\[/{/^## \\[$VERSION\\]/d; /^## \\[/q; /^$/d; p}" CHANGELOG.md > release_notes.md
# If no changelog found, create a simple message
if [ ! -s release_notes.md ]; then
echo "No specific changelog found for version $VERSION" > release_notes.md
fi
echo "Release notes:"
cat release_notes.md
- name: Create git tag
run: |
VERSION="${{ needs.check-version.outputs.version }}"
git config user.name "maciekdymarczyk"
git config user.email "maciek@roboblog.eu"
git tag -a "v$VERSION" -m "Release v$VERSION"
git push origin "v$VERSION"
- name: Create GitHub Release
uses: softprops/action-gh-release@v2
with:
tag_name: v${{ needs.check-version.outputs.version }}
name: Release v${{ needs.check-version.outputs.version }}
body_path: release_notes.md
draft: false
prerelease: false
- name: Build package
run: |
uv build
ls -la dist/
- name: Publish to PyPI
uses: pypa/gh-action-pypi-publish@release/v1
with:
skip-existing: true
notify-success:
needs: [check-version, release]
if: needs.check-version.outputs.should_release == 'true' && success()
runs-on: ubuntu-latest
steps:
- name: Success notification
run: |
echo "🎉 Successfully released v${{ needs.check-version.outputs.version }}!"
echo "- GitHub Release: https://github.com/${{ github.repository }}/releases/tag/v${{ needs.check-version.outputs.version }}"
echo "- PyPI: https://pypi.org/project/claude-monitor/${{ needs.check-version.outputs.version }}/"
================================================
FILE: .github/workflows/test.yml
================================================
name: Test Suite
on:
push:
branches: [main, develop]
pull_request:
branches: [main, develop]
jobs:
test:
runs-on: ${{ matrix.os }}
name: Test on Python ${{ matrix.python-version }} (${{ matrix.os }})
strategy:
fail-fast: false
matrix:
os: [ubuntu-latest, macos-latest]
# os: [ubuntu-latest, windows-latest, macos-latest]
python-version: ["3.9", "3.10", "3.11", "3.12", "3.13"]
steps:
- uses: actions/checkout@v4
- name: Install uv
uses: astral-sh/setup-uv@v4
with:
version: "latest"
- name: Set up Python ${{ matrix.python-version }}
run: uv python install ${{ matrix.python-version }}
- name: Install dependencies
run: uv sync --extra test --extra dev
- name: Run unit tests
run: uv run pytest src/tests/ -v --tb=short --cov=claude_monitor --cov-report=xml --cov-report=term-missing
- name: Upload coverage reports to Codecov
if: matrix.os == 'ubuntu-latest' && matrix.python-version == '3.11'
uses: codecov/codecov-action@v5
with:
token: ${{ secrets.CODECOV_TOKEN }}
# security:
# runs-on: ubuntu-latest
# name: Security scanning
# strategy:
# matrix:
# python-version: ["3.11"]
#
# steps:
# - uses: actions/checkout@v4
#
# - name: Install uv
# uses: astral-sh/setup-uv@v4
# with:
# version: "latest"
#
# - name: Set up Python ${{ matrix.python-version }}
# run: uv python install ${{ matrix.python-version }}
#
# - name: Install dependencies
# run: uv sync --extra security --extra dev
#
# - name: Run Bandit security linter
# run: uv run bandit -r src/claude_monitor -f json -o bandit-report.json
#
# - name: Run Safety dependency scanner
# run: uv run safety check --json --output safety-report.json || true
#
# - name: Upload security artifacts
# uses: actions/upload-artifact@v4
# if: always()
# with:
# name: security-reports
# path: |
# bandit-report.json
# safety-report.json
# performance:
# runs-on: ubuntu-latest
# name: Performance benchmarks
# strategy:
# matrix:
# python-version: ["3.11"]
#
# steps:
# - uses: actions/checkout@v4
#
# - name: Install uv
# uses: astral-sh/setup-uv@v4
# with:
# version: "latest"
#
# - name: Set up Python ${{ matrix.python-version }}
# run: uv python install ${{ matrix.python-version }}
#
# - name: Install dependencies
# run: uv sync --extra performance --extra dev
#
# - name: Run performance benchmarks
# run: uv run pytest src/tests/ -m benchmark --benchmark-json=benchmark-results.json
#
# - name: Upload benchmark results
# uses: actions/upload-artifact@v4
# if: always()
# with:
# name: benchmark-results
# path: benchmark-results.json
================================================
FILE: .github/workflows/version-bump.yml
================================================
name: Version Bump Helper
on:
workflow_dispatch:
inputs:
bump_type:
description: 'Version bump type'
required: true
default: 'patch'
type: choice
options:
- patch
- minor
- major
changelog_entry:
description: 'Changelog entry (brief description of changes)'
required: true
type: string
jobs:
bump-version:
runs-on: ubuntu-latest
permissions:
contents: write
pull-requests: write
steps:
- uses: actions/checkout@v4
with:
fetch-depth: 0
token: ${{ secrets.GITHUB_TOKEN }}
- name: Install uv
uses: astral-sh/setup-uv@v4
with:
version: "latest"
- name: Set up Python
run: uv python install
- name: Extract current version
id: current
run: |
CURRENT_VERSION=$(grep '^version = ' pyproject.toml | sed 's/version = "\(.*\)"/\1/')
echo "version=$CURRENT_VERSION" >> $GITHUB_OUTPUT
echo "Current version: $CURRENT_VERSION"
- name: Calculate new version
id: new
run: |
CURRENT="${{ steps.current.outputs.version }}"
BUMP_TYPE="${{ github.event.inputs.bump_type }}"
# Split version into components
IFS='.' read -r MAJOR MINOR PATCH <<< "$CURRENT"
# Bump according to type
case "$BUMP_TYPE" in
major)
MAJOR=$((MAJOR + 1))
MINOR=0
PATCH=0
;;
minor)
MINOR=$((MINOR + 1))
PATCH=0
;;
patch)
PATCH=$((PATCH + 1))
;;
esac
NEW_VERSION="$MAJOR.$MINOR.$PATCH"
echo "version=$NEW_VERSION" >> $GITHUB_OUTPUT
echo "New version: $NEW_VERSION"
- name: Update pyproject.toml
run: |
NEW_VERSION="${{ steps.new.outputs.version }}"
sed -i "s/^version = .*/version = \"$NEW_VERSION\"/" pyproject.toml
echo "Updated pyproject.toml to version $NEW_VERSION"
- name: Update CHANGELOG.md
run: |
NEW_VERSION="${{ steps.new.outputs.version }}"
TODAY=$(date +%Y-%m-%d)
CHANGELOG_ENTRY="${{ github.event.inputs.changelog_entry }}"
# Create new changelog section
echo "## [$NEW_VERSION] - $TODAY" > changelog_new.md
echo "" >> changelog_new.md
echo "### Changed" >> changelog_new.md
echo "- $CHANGELOG_ENTRY" >> changelog_new.md
echo "" >> changelog_new.md
# Find the line number where we should insert (after the # Changelog header)
LINE_NUM=$(grep -n "^# Changelog" CHANGELOG.md | head -1 | cut -d: -f1)
if [ -n "$LINE_NUM" ]; then
# Insert after the Changelog header and empty line
head -n $((LINE_NUM + 1)) CHANGELOG.md > changelog_temp.md
cat changelog_new.md >> changelog_temp.md
tail -n +$((LINE_NUM + 2)) CHANGELOG.md >> changelog_temp.md
mv changelog_temp.md CHANGELOG.md
else
# If no header found, prepend to file
cat changelog_new.md CHANGELOG.md > changelog_temp.md
mv changelog_temp.md CHANGELOG.md
fi
# Add the version link at the bottom
echo "" >> CHANGELOG.md
echo "[$NEW_VERSION]: https://github.com/Maciek-roboblog/Claude-Code-Usage-Monitor/releases/tag/v$NEW_VERSION" >> CHANGELOG.md
echo "Updated CHANGELOG.md with new version entry"
- name: Create Pull Request
uses: peter-evans/create-pull-request@v6
with:
token: ${{ secrets.GITHUB_TOKEN }}
commit-message: "Bump version to ${{ steps.new.outputs.version }}"
title: "chore: bump version to ${{ steps.new.outputs.version }}"
body: |
## Version Bump: ${{ steps.current.outputs.version }} → ${{ steps.new.outputs.version }}
**Bump Type**: ${{ github.event.inputs.bump_type }}
**Changes**: ${{ github.event.inputs.changelog_entry }}
This PR was automatically created by the Version Bump workflow.
### Checklist
- [ ] Review the version bump in `pyproject.toml`
- [ ] Review the changelog entry in `CHANGELOG.md`
- [ ] Merge this PR to trigger the release workflow
branch: version-bump-${{ steps.new.outputs.version }}
delete-branch: true
labels: |
version-bump
automated
================================================
FILE: .gitignore
================================================
# Byte-compiled / optimized / DLL files
__pycache__/
*.py[cod]
*$py.class
# C extensions
*.so
MAIN_INSTRUCTION.md
.TASKS
# Distribution / packaging
.Python
build/
develop-eggs/
dist/
downloads/
eggs/
.eggs/
lib/
lib64/
parts/
sdist/
var/
wheels/
share/python-wheels/
*.egg-info/
.installed.cfg
*.egg
MANIFEST
# PyInstaller
# Usually these files are written by a python script from a template
# before PyInstaller builds the exe, so as to inject date/other infos into it.
*.manifest
*.spec
# Installer logs
pip-log.txt
pip-delete-this-directory.txt
# Unit test / coverage reports
htmlcov/
.tox/
.nox/
.coverage
.coverage.*
.cache
nosetests.xml
coverage.xml
*.cover
*.py,cover
.hypothesis/
.pytest_cache/
cover/
# Translations
*.mo
*.pot
# Django stuff:
*.log
local_settings.py
db.sqlite3
db.sqlite3-journal
# Flask stuff:
instance/
.webassets-cache
# Scrapy stuff:
.scrapy
# Sphinx documentation
docs/_build/
# PyBuilder
.pybuilder/
target/
# Jupyter Notebook
.ipynb_checkpoints
# IPython
profile_default/
ipython_config.py
# pyenv
# For a library or package, you might want to ignore these files since the code is
# intended to run in multiple environments; otherwise, check them in:
# .python-version
# pipenv
# According to pypa/pipenv#598, it is recommended to include Pipfile.lock in version control.
# However, in case of collaboration, if having platform-specific dependencies or dependencies
# having no cross-platform support, pipenv may install dependencies that don't work, or not
# install all needed dependencies.
#Pipfile.lock
# poetry
# Similar to Pipfile.lock, it is generally recommended to include poetry.lock in version control.
# This is especially recommended for binary packages to ensure reproducibility, and is more
# commonly ignored for libraries.
# https://python-poetry.org/docs/basic-usage/#commit-your-poetrylock-file-to-version-control
#poetry.lock
# pdm
# Similar to Pipfile.lock, it is generally recommended to include pdm.lock in version control.
#pdm.lock
# pdm stores project-wide configurations in .pdm.toml, but it is recommended to not include it
# in version control.
# https://pdm.fming.dev/#use-with-ide
.pdm.toml
# PEP 582; used by e.g. github.com/David-OConnor/pyflow and github.com/pdm-project/pdm
__pypackages__/
# Celery stuff
celerybeat-schedule
celerybeat.pid
# SageMath parsed files
*.sage.py
# Environments
.env
.venv
env/
venv/
ENV/
env.bak/
venv.bak/
# Spyder project settings
.spyderproject
.spyproject
# Rope project settings
.ropeproject
# mkdocs documentation
/site
# mypy
.mypy_cache/
.dmypy.json
dmypy.json
# Pyre type checker
.pyre/
# pytype static type analyzer
.pytype/
# Cython debug symbols
cython_debug/
# PyCharm
# JetBrains specific template is maintained in a separate JetBrains.gitignore that can
# be added to the global gitignore or merged into this project gitignore. For a PyCharm
# project, it is not recommended to check the machine-specific absolute paths.
.idea/
# VS Code
# .vscode/ - allowing settings.json for team consistency
# macOS
.DS_Store
.DS_Store?
._*
.Spotlight-V100
.Trashes
ehthumbs.db
Thumbs.db
# Windows
Thumbs.db
ehthumbs.db
Desktop.ini
# uv
.python-version
uv.lock
# Project-specific
# Claude monitor database (for future ML features)
*.db
*.sqlite
.claude_monitor/
# Temporary files
*.tmp
*.temp
*.swp
*.swo
*~
# Log files
*.log
logs/
# Editor backups
*.bak
*.orig
/.claude/
/ULTRATHINK_COMPLETE_GUIDE.md
/SLASH_COMMANDS.md
/optimize_tokens.sh
/MAIN_INSTRUCTION.md
/CLAUDE_SYSTEM_PROMPT.md
/claude_optimize.py
/CLAUDE.md
/src/Claude-Code-Usage-Monitor_Features_Missing_in_claude_monitor.md
/src/Functionality_Coverage_Claude-Code-Usage-Monitor_Missing_From_claude_monitor.md
/TODO.md
*Zone.Identifier
# Local linting scripts
lint*.py
lint*.sh
================================================
FILE: .pre-commit-config.yaml
================================================
# .pre-commit-config.yaml
repos:
- repo: https://github.com/astral-sh/ruff-pre-commit
rev: v0.12.3
hooks:
# Lint-only pass (no auto-fix)
- id: ruff
# Formatting pass (auto-fix)
- id: ruff-format
- repo: https://github.com/pre-commit/pre-commit-hooks
rev: v5.0.0
hooks:
- id: trailing-whitespace
- id: end-of-file-fixer
- id: check-yaml
- id: check-added-large-files
- id: check-merge-conflict
- id: check-toml
- id: mixed-line-ending
args: ['--fix=lf']
================================================
FILE: CHANGELOG.md
================================================
# Changelog
## [3.1.0] - 2025-07-23
### 🆕 New Features
- **📊 Usage Analysis Views**: Added `--view` parameter for different time aggregation periods
- `--view realtime` (default): Live monitoring with real-time updates
- `--view daily`: Daily token usage aggregated in comprehensive table format
- `--view monthly`: Monthly token usage aggregated for long-term trend analysis
### 📝 Use Cases
- **Daily Analysis**: Track daily usage patterns and identify peak consumption periods
- **Monthly Planning**: Long-term budget analysis and trend identification
- **Usage Optimization**: Historical data analysis for better resource planning
## [3.0.0] - 2025-01-13
### 🚨 Breaking Changes
- **Package Name Change**: Renamed from `claude-usage-monitor` to `claude-monitor`
- New installation: `pip install claude-monitor` or `uv tool install claude-monitor`
- New command aliases: `claude-monitor` and `cmonitor`
- **Python Requirement**: Minimum Python version raised from 3.8 to 3.9
- **Architecture Overhaul**: Complete rewrite from single-file to modular package structure
- **Entry Point Changes**: Module execution now via `claude_monitor.__main__:main`
### 🏗️ Complete Architectural Restructuring
- **📁 Professional Package Layout**: Migrated to `src/claude_monitor/` structure with proper namespace isolation
- Replaced single `claude_monitor.py` file with comprehensive modular architecture
- Implemented clean separation of concerns across 8 specialized modules
- **🔧 Modular Design**: New package organization:
- `cli/` - Command-line interface and bootstrap logic
- `core/` - Business logic, models, settings, calculations, and pricing
- `data/` - Data management, analysis, and reading utilities
- `monitoring/` - Real-time session monitoring and orchestration
- `ui/` - User interface components, layouts, and display controllers
- `terminal/` - Terminal management and theme handling
- `utils/` - Formatting, notifications, timezone, and model utilities
- **⚡ Enhanced Performance**: Optimized data processing with caching, threading, and efficient session management
### 🎨 Rich Terminal UI System
- **💫 Rich Integration**: Complete UI overhaul using Rich library for professional terminal interface
- Advanced progress bars with semantic color coding (🟢🟡🔴)
- Responsive layouts with proper terminal width handling (80+ characters required)
- Enhanced typography and visual hierarchy
- **🌈 Improved Theme System**: Enhanced automatic theme detection with better contrast ratios
- **📊 Advanced Display Components**: New progress visualization with burn rate indicators and time-based metrics
### 🔒 Type Safety and Validation
- **🛡️ Pydantic Integration**: Complete type safety implementation
- Comprehensive settings validation with user-friendly error messages
- Type-safe data models (`UsageEntry`, `SessionBlock`, `TokenCounts`)
- CLI parameter validation with detailed feedback
- **⚙️ Smart Configuration**: Pydantic-based settings with last-used parameter persistence
- **🔍 Enhanced Error Handling**: Centralized error management with optional Sentry integration
### 📈 Advanced Analytics Features
- **🧮 P90 Percentile Calculations**: Machine learning-inspired usage prediction and limit detection
- **📊 Smart Plan Detection**: Auto-detection of Claude plan limits with custom plan support
- **⏱️ Real-time Monitoring**: Enhanced session tracking with threading and callback systems
- **💡 Intelligent Insights**: Advanced burn rate calculations and velocity indicators
### 🔧 Developer Experience Improvements
- **🚀 Modern Build System**: Migrated from Hatchling to Setuptools with src layout
- **🧪 Comprehensive Testing**: Professional test infrastructure with pytest and coverage reporting
- **📝 Enhanced Documentation**: Updated troubleshooting guide with v3.0.0-specific solutions
- **🔄 CI/CD Reactivation**: Restored and enhanced GitHub Actions workflows:
- Multi-Python version testing (3.9-3.12)
- Automated linting with Ruff
- Trusted PyPI publishing with OIDC
- Automated version bumping and changelog management
### 📦 Dependency and Packaging Updates
- **🆕 Core Dependencies Added**:
- `pydantic>=2.0.0` & `pydantic-settings>=2.0.0` - Type validation and settings
- `numpy>=1.21.0` - Advanced calculations
- `sentry-sdk>=1.40.0` - Optional error tracking
- `pyyaml>=6.0` - Configuration file support
- **⬆️ Dependency Upgrades**:
- `rich`: `>=13.0.0` → `>=13.7.0` - Enhanced UI features
- `pytz`: No constraint → `>=2023.3` - Improved timezone handling
- **🛠️ Development Tools**: Expanded with MyPy, Bandit, testing frameworks, and documentation tools
### 🎯 Enhanced User Features
- **🎛️ Flexible Configuration**: Support for auto-detection, manual overrides, and persistent settings
- **🌍 Improved Timezone Handling**: Enhanced timezone detection and validation
- **⚡ Performance Optimizations**: Faster startup times and reduced memory usage
- **🔔 Smart Notifications**: Enhanced feedback system with contextual messaging
### 🔧 Installation and Compatibility
- **📋 Installation Method Updates**: Full support for `uv`, `pipx`, and traditional pip installation
- **🐧 Platform Compatibility**: Enhanced support for modern Linux distributions with externally-managed environments
- **🛣️ Migration Path**: Automatic handling of legacy configurations and smooth upgrade experience
### 📚 Technical Implementation Details
- **🏢 Professional Architecture**: Implementation of SOLID principles with single responsibility modules
- **🔄 Async-Ready Design**: Threading infrastructure for real-time monitoring capabilities
- **💾 Efficient Data Handling**: Optimized JSONL parsing with error resilience
- **🔐 Security Enhancements**: Secure configuration handling and optional telemetry integration
## [2.0.0] - 2025-06-25
### Added
- **🎨 Smart Theme System**: Automatic light/dark theme detection for optimal terminal appearance
- Intelligent theme detection based on terminal environment, system settings, and background color
- Manual theme override options: `--theme light`, `--theme dark`, `--theme auto`
- Theme debug mode: `--theme-debug` for troubleshooting theme detection
- Platform-specific theme detection (macOS, Windows, Linux)
- Support for VSCode integrated terminal, iTerm2, Windows Terminal
- **📊 Enhanced Progress Bar Colors**: Improved visual feedback with smart color coding
- Token usage progress bars with three-tier color system:
- 🟢 Green (0-49%): Safe usage level
- 🟡 Yellow (50-89%): Warning - approaching limit
- 🔴 Red (90-100%): Critical - near or at limit
- Time progress bars with consistent blue indicators
- Burn rate velocity indicators with emoji feedback (🐌➡️🚀⚡)
- **🌈 Rich Theme Support**: Optimized color schemes for both light and dark terminals
- Dark theme: Bright colors optimized for dark backgrounds
- Light theme: Darker colors optimized for light backgrounds
- Automatic terminal capability detection (truecolor, 256-color, 8-color)
- **🔧 Advanced Terminal Detection**: Comprehensive environment analysis
- COLORTERM, TERM_PROGRAM, COLORFGBG environment variable support
- Terminal background color querying using OSC escape sequences
- Cross-platform system theme integration
### Changed
- **Breaking**: Progress bar color logic now uses semantic color names (`cost.low`, `cost.medium`, `cost.high`)
- Enhanced visual consistency across different terminal environments
- Improved accessibility with better contrast ratios in both themes
### Technical Details
- New `usage_analyzer/themes/` module with theme detection and color management
- `ThemeDetector` class with multi-method theme detection algorithm
- Rich theme integration with automatic console configuration
- Environment-aware color selection for maximum compatibility
## [1.0.19] - 2025-06-23
### Fixed
- Fixed timezone handling by locking calculation to Europe/Warsaw timezone
- Separated display timezone from reset time calculation for improved reliability
- Removed dynamic timezone input and related error handling to simplify reset time logic
## [1.0.17] - 2025-06-23
### Added
- Loading screen that displays immediately on startup to eliminate "black screen" experience
- Visual feedback with header and "Fetching Claude usage data..." message during initial data load
## [1.0.16] - 2025-06-23
### Fixed
- Fixed UnboundLocalError when Ctrl+C is pressed by initializing color variables at the start of main()
- Fixed ccusage command hanging indefinitely by adding 30-second timeout to subprocess calls
- Added ccusage availability check at startup with helpful error messages
- Improved error display when ccusage fails with better debugging information
- Fixed npm 7+ compatibility issue where npx doesn't find globally installed packages
### Added
- Timeout handling for all ccusage subprocess calls to prevent hanging
- Pre-flight check for ccusage availability before entering main loop
- More informative error messages suggesting installation steps and login requirements
- Dual command execution: tries direct `ccusage` command first, then falls back to `npx ccusage`
- Detection and reporting of which method (direct or npx) is being used
## [1.0.11] - 2025-06-22
### Changed
- Replaced `init_dependency.py` with simpler `check_dependency.py` module
- Refactored dependency checking to use separate `test_node()` and `test_npx()` functions
- Removed automatic Node.js installation functionality in favor of explicit dependency checking
- Updated package includes in `pyproject.toml` to reference new dependency module
### Fixed
- Simplified dependency handling by removing complex installation logic
- Improved error messages for missing Node.js or npx dependencies
## [1.0.8] - 2025-06-21
### Added
- Automatic Node.js installation support
## [1.0.7] - 2025-06-21
### Changed
- Enhanced `init_dependency.py` module with improved documentation and error handling
- Added automatic `npx` installation if not available
- Improved cross-platform Node.js installation logic
- Better error messages throughout the dependency initialization process
## [1.0.6] - 2025-06-21
### Added
- Modern Python packaging with `pyproject.toml` and hatchling build system
- Automatic Node.js installation via `init_dependency.py` module
- Terminal handling improvements with input flushing and proper cleanup
- GitHub Actions workflow for automated code quality checks
- Pre-commit hooks configuration with Ruff linter and formatter
- VS Code settings for consistent development experience
- CLAUDE.md documentation for Claude Code AI assistant integration
- Support for `uv` tool as recommended installation method
- Console script entry point `claude-monitor` for system-wide usage
- Comprehensive .gitignore for Python projects
- CHANGELOG.md for tracking project history
### Changed
- Renamed main script from `ccusage_monitor.py` to `claude_monitor.py`
- Use `npx ccusage` instead of direct `ccusage` command for better compatibility
- Improved terminal handling to prevent input corruption during monitoring
- Updated all documentation files (README, CONTRIBUTING, DEVELOPMENT, TROUBLESHOOTING)
- Enhanced project structure for PyPI packaging readiness
### Fixed
- Terminal input corruption when typing during monitoring
- Proper Ctrl+C handling with cursor restoration
- Terminal settings restoration on exit
[3.0.0]: https://github.com/Maciek-roboblog/Claude-Code-Usage-Monitor/releases/tag/v3.0.0
[2.0.0]: https://github.com/Maciek-roboblog/Claude-Code-Usage-Monitor/releases/tag/v2.0.0
[1.0.19]: https://github.com/Maciek-roboblog/Claude-Code-Usage-Monitor/releases/tag/v1.0.19
[1.0.17]: https://github.com/Maciek-roboblog/Claude-Code-Usage-Monitor/releases/tag/v1.0.17
[1.0.16]: https://github.com/Maciek-roboblog/Claude-Code-Usage-Monitor/releases/tag/v1.0.16
[1.0.11]: https://github.com/Maciek-roboblog/Claude-Code-Usage-Monitor/releases/tag/v1.0.11
[1.0.8]: https://github.com/Maciek-roboblog/Claude-Code-Usage-Monitor/releases/tag/v1.0.8
[1.0.7]: https://github.com/Maciek-roboblog/Claude-Code-Usage-Monitor/releases/tag/v1.0.7
[1.0.6]: https://github.com/Maciek-roboblog/Claude-Code-Usage-Monitor/releases/tag/v1.0.6
================================================
FILE: CONTRIBUTING.md
================================================
# 🤝 Contributing Guide
Welcome to the Claude Code Usage Monitor project! We're excited to have you contribute to making this tool better for everyone.
---
## 🌟 How to Contribute
### 🎯 Types of Contributions
We welcome all kinds of contributions:
- **🐛 Bug Reports**: Found something broken? Let us know!
- **💡 Feature Requests**: Have an idea for improvement?
- **📝 Documentation**: Help improve guides and examples
- **🔧 Code Contributions**: Fix bugs or implement new features
- **🧪 Testing**: Help test on different platforms
- **🎨 UI/UX**: Improve the visual design and user experience
- **🧠 ML Research**: Contribute to machine learning features
- **📦 Packaging**: Help with PyPI, Docker, or distribution
---
## 🚀 Quick Start for Contributors
### 1. Fork and Clone
```bash
# Fork the repository on GitHub
# Then clone your fork
git clone https://github.com/YOUR-USERNAME/Claude-Code-Usage-Monitor.git
cd Claude-Code-Usage-Monitor
```
### 2. Set Up Development Environment
```bash
# Create virtual environment
python3 -m venv venv
source venv/bin/activate # Linux/Mac
# venv\Scripts\activate # Windows
# Install project and development dependencies
pip install -e .[dev]
# Make script executable (Linux/Mac)
chmod +x claude_monitor.py
```
### 3. Create a Feature Branch
```bash
# Create and switch to feature branch
git checkout -b feature/your-feature-name
# Or for bug fixes
git checkout -b fix/bug-description
```
### 4. Make Your Changes
- Follow our coding standards (see below)
- Add tests for new functionality
- Update documentation if needed
- Test your changes thoroughly
### 5. Submit Your Contribution
```bash
# Add and commit your changes
git add .
git commit -m "Add: Brief description of your change"
# Push to your fork
git push origin feature/your-feature-name
# Open a Pull Request on GitHub
```
---
## 📋 Development Guidelines
### 🐍 Python Code Style
We follow **PEP 8** with these specific guidelines:
```python
# Good: Clear variable names
current_token_count = 1500
session_start_time = datetime.now()
# Bad: Unclear abbreviations
curr_tok_cnt = 1500
sess_st_tm = datetime.now()
# Good: Descriptive function names
def calculate_burn_rate(tokens_used, time_elapsed):
return tokens_used / time_elapsed
# Good: Clear comments for complex logic
def predict_token_depletion(current_usage, burn_rate):
"""
Predicts when tokens will be depleted based on current burn rate.
Args:
current_usage (int): Current token count
burn_rate (float): Tokens consumed per minute
Returns:
datetime: Estimated depletion time
"""
pass
```
### 🧪 Testing Guidelines
```python
# Test file naming: test_*.py
# tests/test_core.py
import pytest
from claude_monitor.core import TokenMonitor
def test_token_calculation():
"""Test token usage calculation."""
monitor = TokenMonitor()
result = monitor.calculate_usage(1000, 500)
assert result == 50.0 # 50% usage
def test_burn_rate_calculation():
"""Test burn rate calculation with edge cases."""
monitor = TokenMonitor()
# Normal case
assert monitor.calculate_burn_rate(100, 10) == 10.0
# Edge case: zero time
assert monitor.calculate_burn_rate(100, 0) == 0
```
### 📝 Commit Message Format
Use clear, descriptive commit messages:
```bash
# Good commit messages
git commit -m "Add: ML-powered token prediction algorithm"
git commit -m "Fix: Handle edge case when no sessions are active"
git commit -m "Update: Improve error handling in ccusage integration"
git commit -m "Docs: Add examples for timezone configuration"
# Prefixes to use:
# Add: New features
# Fix: Bug fixes
# Update: Improvements to existing features
# Docs: Documentation changes
# Test: Test additions or changes
# Refactor: Code refactoring
# Style: Code style changes
```
## 🎯 Contribution Areas (Priority things)
### 📦 PyPI Package Development
**Current Needs**:
- Create proper package structure
- Configure setup.py and requirements
- Implement global configuration system
- Add command-line entry points
**Skills Helpful**:
- Python packaging (setuptools, wheel)
- Configuration management
- Cross-platform compatibility
- Command-line interface design
**Getting Started**:
1. Study existing PyPI packages for examples
2. Create basic package structure
3. Test installation in virtual environments
4. Implement configuration file handling
### 🐳 Docker & Web Features
**Current Needs**:
- Create efficient Dockerfile
- Build web dashboard interface
- Implement REST API
- Design responsive UI
**Skills Helpful**:
- Docker containerization
- React/TypeScript for frontend
- Python web frameworks (Flask/FastAPI)
- Responsive web design
**Getting Started**:
1. Create basic Dockerfile for current script
2. Design web interface mockups
3. Implement simple REST API
4. Build responsive dashboard components
### 🔧 Core Features & Bug Fixes
**Current Needs**:
- Improve error handling
- Add more configuration options
- Optimize performance
- Fix cross-platform issues
**Skills Helpful**:
- Python development
- Terminal/console applications
- Cross-platform compatibility
- Performance optimization
**Getting Started**:
1. Run the monitor on different platforms
2. Identify and fix platform-specific issues
3. Improve error messages and handling
4. Add new configuration options
---
## 🐛 Bug Reports
### 📋 Before Submitting a Bug Report
1. **Check existing issues**: Search GitHub issues for similar problems
2. **Update to latest version**: Ensure you're using the latest code
3. **Test in clean environment**: Try in fresh virtual environment
4. **Gather information**: Collect system details and error messages
### 📝 Bug Report Template
```markdown
**Bug Description**
A clear description of what the bug is.
**To Reproduce**
Steps to reproduce the behavior:
1. Run command '...'
2. Configure with '...'
3. See error
**Expected Behavior**
What you expected to happen.
**Actual Behavior**
What actually happened.
**Environment**
- OS: [e.g. Ubuntu 20.04, Windows 11, macOS 12]
- Python version: [e.g. 3.9.7]
- ccusage version: [run: ccusage --version]
- Monitor version: [git commit hash]
**Error Output**
```
Paste full error messages here
```
**Additional Context**
Add any other context about the problem here.
```
---
## 💡 Feature Requests
### 🎯 Feature Request Template
```markdown
**Feature Description**
A clear description of the feature you'd like to see.
**Problem Statement**
What problem does this feature solve?
**Proposed Solution**
How do you envision this feature working?
**Alternative Solutions**
Any alternative approaches you've considered.
**Use Cases**
Specific scenarios where this feature would be helpful.
**Implementation Ideas**
Any ideas about how this could be implemented (optional).
```
### 🔍 Feature Evaluation Criteria
We evaluate features based on:
1. **User Value**: How many users would benefit?
2. **Complexity**: Implementation effort required
3. **Maintenance**: Long-term maintenance burden
4. **Compatibility**: Impact on existing functionality
5. **Performance**: Effect on monitor performance
6. **Dependencies**: Additional dependencies required
---
## 🧪 Testing Contributions
### 🔧 Running Tests
```bash
# Run all tests
pytest
# Run specific test file
pytest tests/test_core.py
# Run with coverage
pytest --cov=claude_monitor
# Run tests on multiple Python versions (if using tox)
tox
```
### 📊 Test Coverage
We aim for high test coverage:
- **Core functionality**: 95%+ coverage
- **ML components**: 90%+ coverage
- **UI components**: 80%+ coverage
- **Utility functions**: 95%+ coverage
### 🌍 Platform Testing
Help us test on different platforms:
- **Linux**: Ubuntu, Fedora, Arch, Debian
- **macOS**: Intel and Apple Silicon Macs
- **Windows**: Windows 10/11, different Python installations
- **Python versions**: 3.7, 3.8, 3.9, 3.10, 3.11, 3.12
---
## 📝 Documentation Contributions
### 📚 Documentation Areas
- **README improvements**: Make getting started easier
- **Code comments**: Explain complex algorithms
- **Usage examples**: Real-world scenarios
- **API documentation**: Function and class documentation
- **Troubleshooting guides**: Common problems and solutions
### ✍️ Writing Guidelines
- **Be clear and concise**: Avoid jargon when possible
- **Use examples**: Show don't just tell
- **Consider all users**: From beginners to advanced
- **Keep it updated**: Ensure examples work with current code
- **Use consistent formatting**: Follow existing style
---
## 📊 Data Collection for Improvement
### 🔍 Help Us Improve Token Limit Detection
We're collecting **anonymized data** about token limits to improve auto-detection:
**What to share in [Issue #1](https://github.com/Maciek-roboblog/Claude-Code-Usage-Monitor/issues/1)**:
- Your subscription type (Pro, Teams, Enterprise)
- Maximum tokens reached (custom_max value)
- When the limit was exceeded
- Usage patterns you've noticed
**Privacy**: Only share what you're comfortable with. No personal information needed.
### 📈 Usage Pattern Research
Help us understand usage patterns:
- Peak usage times
- Session duration preferences
- Token consumption patterns
- Feature usage statistics
This helps prioritize development and improve user experience.
## 🏆 Recognition
### 📸 Contributor Spotlight
Outstanding contributors will be featured:
- **README acknowledgments**: Credit for major contributions
- **Release notes**: Mention significant contributions
- **Social media**: Share contributor achievements
- **Reference letters**: Happy to provide references for good contributors
### 🎖️ Contribution Levels
- **🌟 First Contribution**: Welcome to the community!
- **🔧 Regular Contributor**: Multiple merged PRs
- **🚀 Core Contributor**: Significant feature development
- **👑 Maintainer**: Ongoing project stewardship
## ❓ Getting Help
### 💬 Where to Ask Questions
1. **GitHub Issues**: For bug reports and feature requests
2. **GitHub Discussions**: For general questions and ideas
3. **Email**: [maciek@roboblog.eu](mailto:maciek@roboblog.eu) for direct contact
4. **Code Review**: Ask questions in PR comments
### 📚 Resources
- **[DEVELOPMENT.md](DEVELOPMENT.md)**: Development roadmap
- **[README.md](README.md)**: Installation, usage, and features
- **[TROUBLESHOOTING.md](TROUBLESHOOTING.md)**: Common issues
---
## 📜 Code of Conduct
### 🤝 Our Standards
- **Be respectful**: Treat everyone with respect and kindness
- **Be inclusive**: Welcome contributors of all backgrounds
- **Be constructive**: Provide helpful feedback and suggestions
- **Be patient**: Remember everyone is learning
- **Be professional**: Keep interactions focused on the project
### 🚫 Unacceptable Behavior
- Harassment or discriminatory language
- Personal attacks or trolling
- Spam or off-topic discussions
- Sharing private information without permission
### 📞 Reporting Issues
If you experience unacceptable behavior, contact: [maciek@roboblog.eu](mailto:maciek@roboblog.eu)
---
## 🎉 Thank You!
Thank you for considering contributing to Claude Code Usage Monitor! Every contribution, no matter how small, helps make this tool better for the entire community.
**Ready to get started?**
1. 🍴 Fork the repository
2. 💻 Set up your development environment
3. 🔍 Look at open issues for ideas
4. 🚀 Start coding!
We can't wait to see what you'll contribute! 🚀
================================================
FILE: DEVELOPMENT.md
================================================
# 🚧 Development Status & Roadmap
Current implementation status and planned features for Claude Code Usage Monitor v3.0.0+.
## 🎯 Current Implementation Status (v3.0.0)
### ✅ **Fully Implemented & Production Ready**
#### 🔧 **Core Monitoring System**
- **Real-time token monitoring** with configurable refresh rates (0.1-20 Hz)
- **5-hour session tracking** with intelligent session block analysis
- **Multi-plan support**: Pro (44k), Max5 (88k), Max20 (220k), Custom (P90-based)
- **Advanced analytics** with burn rate calculations and usage projections
- **Cost tracking** with model-specific pricing (Opus, Sonnet, Haiku)
- **Cache token support** for creation and read tokens
#### 🎨 **Rich Terminal UI**
- **Adaptive color themes** with WCAG-compliant contrast ratios
- **Auto-detection** of terminal background (light/dark/classic)
- **Scientific color schemes** optimized for accessibility
- **Responsive layouts** that adapt to terminal size
- **Live display** with Rich framework integration
#### ⚙️ **Professional Architecture**
- **Type-safe configuration** with Pydantic validation
- **Thread-safe monitoring** with callback-driven updates
- **Component-based design** following Single Responsibility Principle
- **Comprehensive error handling** with optional Sentry integration
- **Atomic file operations** for configuration persistence
#### 🧠 **Advanced Analytics**
- **P90 percentile analysis** for intelligent limit detection
- **Statistical confidence scoring** for custom plan limits
- **Multi-session overlap handling**
- **Historical pattern recognition** with session metadata
- **Predictive modeling** for session completion times
#### 📦 **Package Distribution**
- **PyPI-ready** with modern setuptools configuration
- **Entry points**: `claude-monitor`, `cmonitor`, and `ccm` commands
- **Cross-platform support** (Windows, macOS, Linux)
- **Professional CI/CD** with automated testing and releases
**📋 Command Aliases**:
- `claude-monitor` - Main command (full name)
- `cmonitor` - Short alias for convenience
- `ccm` - Ultra-short alias for power users
#### 🛠️ **Development Infrastructure**
- **100+ test cases** with comprehensive coverage (80% requirement)
- **Modern toolchain**: Ruff, MyPy, UV package manager
- **Automated workflows**: GitHub Actions with matrix testing
- **Code quality**: Pre-commit hooks, security scanning
- **Documentation**: Sphinx-ready with type hint integration
---
### 🐳 **Docker Containerization**
**Status**: 🔶 Planning Phase
#### Overview
Container-based deployment with optional web dashboard for team environments.
#### Planned Features
**🚀 Container Deployment**:
```bash
# Lightweight monitoring
docker run -e PLAN=max5 maciek/claude-monitor
# With web dashboard
docker run -p 8080:8080 maciek/claude-monitor --web-mode
# Persistent data
docker run -v ~/.claude_monitor:/data maciek/claude-monitor
```
**📊 Web Dashboard**:
- React-based real-time interface
- Historical usage visualization
- REST API for integrations
- Mobile-responsive design
#### Development Tasks
- [ ] **Multi-stage Dockerfile** - Optimized build process
- [ ] **Web Interface** - React dashboard development
- [ ] **API Design** - RESTful endpoints for data access
- [ ] **Security Hardening** - Non-root user, minimal attack surface
### 📱 **Mobile & Web Features**
**Status**: 🔶 Future Roadmap
#### Overview
Cross-platform monitoring with mobile apps and web interfaces for enterprise environments.
#### Planned Features
**📱 Mobile Applications**:
- iOS/Android apps for remote monitoring
- Push notifications for usage milestones
- Offline usage tracking
- Mobile-optimized dashboard
**🌐 Enterprise Features**:
- Multi-user team coordination
- Shared usage insights (anonymized)
- Organization-level analytics
- Role-based access control
**🔔 Advanced Notifications**:
- Desktop notifications for token warnings
- Email alerts for usage milestones
- Slack/Discord integration
- Webhook support for custom integrations
#### Development Tasks
- [ ] **Mobile App Architecture** - React Native foundation
- [ ] **Push Notification System** - Cross-platform notifications
- [ ] **Enterprise Dashboard** - Multi-tenant interface
- [ ] **Integration APIs** - Third-party service connectors
## 🔬 **Technical Architecture & Quality**
### 🏗️ **Current Architecture Highlights**
#### **Modern Python Development (2025)**
- **Python 3.9+** with comprehensive type annotations
- **Pydantic v2** for type-safe configuration and validation
- **UV package manager** for fast, reliable dependency resolution
- **Ruff linting** with 50+ rule sets for code quality
- **Rich framework** for beautiful terminal interfaces
#### **Professional Testing Suite**
- **100+ test cases** across 15 test files with comprehensive fixtures
- **80% coverage requirement** with HTML/XML reporting
- **Matrix testing**: Python 3.9-3.13 across multiple platforms
- **Benchmark testing** with pytest-benchmark integration
- **Security scanning** with Bandit integration
#### **CI/CD Excellence**
- **GitHub Actions workflows** with automated testing and releases
- **Smart versioning** with automatic changelog generation
- **PyPI publishing** with trusted OIDC authentication
- **Pre-commit hooks** for consistent code quality
- **Cross-platform validation** (Windows, macOS, Linux)
#### **Production-Ready Features**
- **Thread-safe architecture** with proper synchronization
- **Component isolation** preventing cascade failures
- **Comprehensive error handling** with optional Sentry integration
- **Performance optimization** with caching and efficient data structures
- **Memory management** with proper resource cleanup
### 🧪 **Code Quality Metrics**
| Metric | Current Status | Target |
|--------|---------------|---------|
| Test Coverage | 80%+ | 80% minimum |
| Type Annotations | 100% | 100% |
| Linting Rules | 50+ Ruff rules | All applicable |
| Security Scan | Bandit clean | Zero issues |
| Performance | <100ms startup | <50ms target |
### 🔧 **Development Toolchain**
#### **Core Tools**
- **Ruff**: Modern Python linter and formatter (2025 best practices)
- **MyPy**: Strict type checking with comprehensive validation
- **UV**: Next-generation Python package manager
- **Pytest**: Advanced testing with fixtures and benchmarks
- **Pre-commit**: Automated code quality checks
#### **Quality Assurance**
- **Black**: Code formatting with 88-character lines
- **isort**: Import organization with black compatibility
- **Bandit**: Security vulnerability scanning
- **Safety**: Dependency vulnerability checking
## 🤝 **Contributing & Community**
### 🚀 **Getting Started with Development**
#### **Quick Setup**
```bash
# Clone the repository
git clone https://github.com/Maciek-roboblog/Claude-Code-Usage-Monitor.git
cd Claude-Code-Usage-Monitor
# Install development dependencies with UV
uv sync --extra dev
# Install pre-commit hooks
uv run pre-commit install
# Run tests
uv run pytest
# Run linting
uv run ruff check .
uv run ruff format .
```
#### **Development Workflow**
1. **Feature Planning**: Create GitHub issue with detailed requirements
2. **Branch Creation**: Fork repository and create feature branch
3. **Development**: Code with automatic formatting and linting via pre-commit
4. **Testing**: Write tests and ensure 80% coverage requirement
5. **Quality Checks**: All tools run automatically on commit
6. **Pull Request**: Submit with clear description and documentation updates
### 🎯 **Contribution Priorities**
#### **High Priority (Immediate Impact)**
- **ML algorithm implementation** for intelligent plan detection
- **Performance optimization** for real-time monitoring
- **Cross-platform testing** and compatibility improvements
- **Documentation expansion** and user guides
#### **Medium Priority (Future Releases)**
- **Docker containerization** for deployment flexibility
- **Web dashboard development** for team environments
- **Advanced analytics features** and visualizations
- **API design** for third-party integrations
#### **Research & Innovation**
- **ML model research** for usage pattern analysis
- **Mobile app architecture** planning
- **Enterprise features** design and planning
- **Plugin system** architecture development
### 🔬 **Research Areas**
#### **ML Algorithm Evaluation**
**Current Research Focus**: Optimal approaches for token prediction and limit detection
**Algorithms Under Investigation**:
- **LSTM Networks**: Sequential pattern recognition in usage data
- **Prophet**: Time series forecasting with daily/weekly seasonality
- **Isolation Forest**: Anomaly detection for subscription changes
- **XGBoost**: Feature-based limit prediction with confidence scores
- **DBSCAN**: Clustering similar usage sessions for pattern analysis
**Key Research Questions**:
- What accuracy can we achieve for individual user limit prediction?
- How do usage patterns correlate with subscription tier changes?
- Can we automatically detect Claude API limit modifications?
- What's the minimum historical data needed for reliable predictions?
---
### 🛠️ **Skills & Expertise Needed**
#### **Machine Learning & Data Science**
**Skills**: Python, NumPy, Pandas, Scikit-learn, DuckDB, Time Series Analysis
**Current Opportunities**:
- LSTM/Prophet model implementation for usage forecasting
- Statistical analysis of P90 percentile calculations
- Anomaly detection algorithm development
- Model validation and performance optimization
#### **Web Development & UI/UX**
**Skills**: React, TypeScript, REST APIs, WebSocket, Responsive Design
**Current Opportunities**:
- Real-time dashboard development with live data streaming
- Mobile-responsive interface design
- Component library development for reusable UI elements
- User experience optimization for accessibility
#### **DevOps & Infrastructure**
**Skills**: Docker, Kubernetes, CI/CD, GitHub Actions, Security
**Current Opportunities**:
- Multi-stage Docker optimization for minimal image size
- Advanced CI/CD pipeline enhancement
- Security hardening and vulnerability management
- Performance monitoring and observability
#### **Mobile Development**
**Skills**: React Native, iOS/Android Native, Push Notifications
**Future Opportunities**:
- Cross-platform mobile app architecture
- Offline data synchronization
- Native performance optimization
- Push notification system integration
---
## 📊 **Project Metrics & Goals**
### 🎯 **Current Performance Metrics**
- **Test Coverage**: 80%+ maintained across all modules
- **Startup Time**: <100ms for typical monitoring sessions
- **Memory Usage**: <50MB peak for standard workloads
- **CPU Usage**: <5% average during monitoring
- **Type Safety**: 100% type annotation coverage
### 🚀 **Version Roadmap**
| Version | Focus | Timeline | Key Features |
|---------|-------|----------|-------------|
| **v3.1** | Performance & UX | Q2 2025 | ML auto-detection, UI improvements |
| **v3.5** | Platform Expansion | Q3 2025 | Docker support, web dashboard |
| **v4.0** | Intelligence | Q4 2025 | Advanced ML, enterprise features |
| **v4.5** | Ecosystem | Q1 2026 | Mobile apps, plugin system |
### 📈 **Success Metrics**
- **User Adoption**: Growing community with active contributors
- **Code Quality**: Maintained high standards with automated enforcement
- **Performance**: Sub-second response times for all operations
- **Reliability**: 99.9% uptime for monitoring functionality
- **Documentation**: Comprehensive guides for all features
---
## 📞 **Developer Resources**
### 🔗 **Key Links**
- **Repository**: [Claude-Code-Usage-Monitor](https://github.com/Maciek-roboblog/Claude-Code-Usage-Monitor)
- **Issues**: [GitHub Issues](https://github.com/Maciek-roboblog/Claude-Code-Usage-Monitor/issues)
- **Discussions**: [GitHub Discussions](https://github.com/Maciek-roboblog/Claude-Code-Usage-Monitor/discussions)
- **Releases**: [GitHub Releases](https://github.com/Maciek-roboblog/Claude-Code-Usage-Monitor/releases)
### 📧 **Contact & Support**
- **Technical Questions**: Open GitHub issues with detailed context
- **Feature Requests**: Use GitHub discussions for community input
- **Security Issues**: Email [maciek@roboblog.eu](mailto:maciek@roboblog.eu) directly
- **General Inquiries**: GitHub discussions or repository issues
### 📚 **Documentation**
- **User Guide**: README.md with comprehensive usage examples
- **API Documentation**: Auto-generated from type hints
- **Contributing Guide**: CONTRIBUTING.md with detailed workflows
- **Code Examples**: /docs/examples/ directory with practical demonstrations
---
*Ready to contribute? This v3.0.0 codebase represents a mature, production-ready foundation for the next generation of intelligent Claude monitoring!*
================================================
FILE: LICENSE
================================================
MIT License
Copyright (c) 2025 Maciej
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE.
================================================
FILE: README.md
================================================
# 🎯 Claude Code Usage Monitor
[](https://pypi.org/project/claude-monitor/)
[](https://python.org)
[](https://opensource.org/licenses/MIT)
[](http://makeapullrequest.com)
[](https://codecov.io/gh/Maciek-roboblog/Claude-Code-Usage-Monitor)
A beautiful real-time terminal monitoring tool for Claude AI token usage with advanced analytics, machine learning-based predictions, and Rich UI. Track your token consumption, burn rate, cost analysis, and get intelligent predictions about session limits.
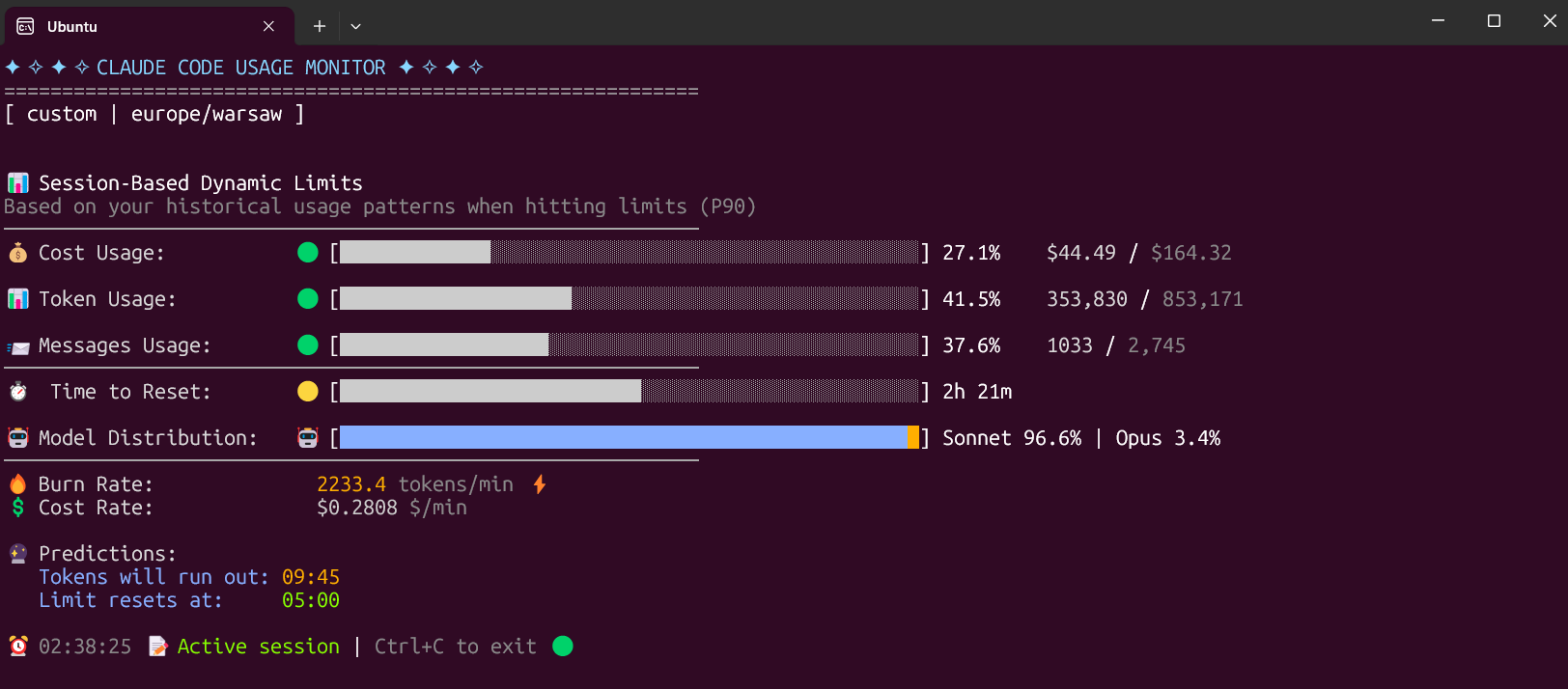
---
## 📑 Table of Contents
- [✨ Key Features](#-key-features)
- [🚀 Installation](#-installation)
- [⚡ Modern Installation with uv (Recommended)](#-modern-installation-with-uv-recommended)
- [📦 Installation with pip](#-installation-with-pip)
- [🛠️ Other Package Managers](#️-other-package-managers)
- [📖 Usage](#-usage)
- [Get Help](#get-help)
- [Basic Usage](#basic-usage)
- [Configuration Options](#configuration-options)
- [Available Plans](#available-plans)
- [🙏 Please Help Test This Release!](#-please-help-test-this-release)
- [✨ Features & How It Works](#-features--how-it-works)
- [Current Features](#current-features)
- [Understanding Claude Sessions](#understanding-claude-sessions)
- [Token Limits by Plan](#token-limits-by-plan)
- [Smart Detection Features](#smart-detection-features)
- [🚀 Usage Examples](#-usage-examples)
- [Common Scenarios](#common-scenarios)
- [Best Practices](#best-practices)
- [🔧 Development Installation](#-development-installation)
- [Troubleshooting](#troubleshooting)
- [Installation Issues](#installation-issues)
- [Runtime Issues](#runtime-issues)
- [📞 Contact](#-contact)
- [📚 Additional Documentation](#-additional-documentation)
- [📝 License](#-license)
- [🤝 Contributors](#-contributors)
- [🙏 Acknowledgments](#-acknowledgments)
## ✨ Key Features
### 🚀 **v3.0.0 Major Update - Complete Architecture Rewrite**
- **🔮 ML-based predictions** - P90 percentile calculations and intelligent session limit detection
- **🔄 Real-time monitoring** - Configurable refresh rates (0.1-20 Hz) with intelligent display updates
- **📊 Advanced Rich UI** - Beautiful color-coded progress bars, tables, and layouts with WCAG-compliant contrast
- **🤖 Smart auto-detection** - Automatic plan switching with custom limit discovery
- **📋 Enhanced plan support** - Updated limits: Pro (44k), Max5 (88k), Max20 (220k), Custom (P90-based)
- **⚠️ Advanced warning system** - Multi-level alerts with cost and time predictions
- **💼 Professional Architecture** - Modular design with Single Responsibility Principle (SRP) compliance
- **🎨 Intelligent theming** - Scientific color schemes with automatic terminal background detection
- **⏰ Advanced scheduling** - Auto-detected system timezone and time format preferences
- **📈 Cost analytics** - Model-specific pricing with cache token calculations
- **🔧 Pydantic validation** - Type-safe configuration with automatic validation
- **📝 Comprehensive logging** - Optional file logging with configurable levels
- **🧪 Extensive testing** - 100+ test cases with full coverage
- **🎯 Error reporting** - Optional Sentry integration for production monitoring
- **⚡ Performance optimized** - Advanced caching and efficient data processing
### 📋 Default Custom Plan
The **Custom plan** is now the default option, specifically designed for 5-hour Claude Code sessions. It monitors three critical metrics:
- **Token usage** - Tracks your token consumption
- **Messages usage** - Monitors message count
- **Cost usage** - The most important metric for long sessions
The Custom plan automatically adapts to your usage patterns by analyzing all your sessions from the last 192 hours (8 days) and calculating personalized limits based on your actual usage. This ensures accurate predictions and warnings tailored to your specific workflow.
## 🚀 Installation
### ⚡ Modern Installation with uv (Recommended)
**Why uv is the best choice:**
- ✅ Creates isolated environments automatically (no system conflicts)
- ✅ No Python version issues
- ✅ No "externally-managed-environment" errors
- ✅ Easy updates and uninstallation
- ✅ Works on all platforms
The fastest and easiest way to install and use the monitor:
[](https://pypi.org/project/claude-monitor/)
#### Install from PyPI
```bash
# Install directly from PyPI with uv (easiest)
uv tool install claude-monitor
# Run from anywhere
claude-monitor # or cmonitor, ccmonitor for short
```
#### Install from Source
```bash
# Clone and install from source
git clone https://github.com/Maciek-roboblog/Claude-Code-Usage-Monitor.git
cd Claude-Code-Usage-Monitor
uv tool install .
# Run from anywhere
claude-monitor
```
#### First-time uv users
If you don't have uv installed yet, get it with one command:
```bash
# On Linux/macOS:
curl -LsSf https://astral.sh/uv/install.sh | sh
# On Windows:
powershell -ExecutionPolicy ByPass -c "irm https://astral.sh/uv/install.ps1 | iex"
# After installation, restart your terminal
```
### 📦 Installation with pip
```bash
# Install from PyPI
pip install claude-monitor
# If claude-monitor command is not found, add ~/.local/bin to PATH:
echo 'export PATH="$HOME/.local/bin:$PATH"' >> ~/.bashrc
source ~/.bashrc # or restart your terminal
# Run from anywhere
claude-monitor # or cmonitor, ccmonitor for short
```
>
> **⚠️ PATH Setup**: If you see WARNING: The script claude-monitor is installed in '/home/username/.local/bin' which is not on PATH, follow the export PATH command above.
>
> **⚠️ Important**: On modern Linux distributions (Ubuntu 23.04+, Debian 12+, Fedora 38+), you may encounter an "externally-managed-environment" error. Instead of using --break-system-packages, we strongly recommend:
> 1. **Use uv instead** (see above) - it's safer and easier
> 2. **Use a virtual environment** - python3 -m venv myenv && source myenv/bin/activate
> 3. **Use pipx** - pipx install claude-monitor
>
> See the Troubleshooting section for detailed solutions.
### 🛠️ Other Package Managers
#### pipx (Isolated Environments)
```bash
# Install with pipx
pipx install claude-monitor
# Run from anywhere
claude-monitor # or claude-code-monitor, cmonitor, ccmonitor, ccm for short
```
#### conda/mamba
```bash
# Install with pip in conda environment
pip install claude-monitor
# Run from anywhere
claude-monitor # or cmonitor, ccmonitor for short
```
## 📖 Usage
### Get Help
```bash
# Show help information
claude-monitor --help
```
#### Available Command-Line Parameters
| Parameter | Type | Default | Description |
|-----------|------|---------|-------------|
| --plan | string | custom | Plan type: pro, max5, max20, or custom |
| --custom-limit-tokens | int | None | Token limit for custom plan (must be > 0) |
| --view | string | realtime | View type: realtime, daily, or monthly |
| --timezone | string | auto | Timezone (auto-detected). Examples: UTC, America/New_York, Europe/London |
| --time-format | string | auto | Time format: 12h, 24h, or auto |
| --theme | string | auto | Display theme: light, dark, classic, or auto |
| --refresh-rate | int | 10 | Data refresh rate in seconds (1-60) |
| --refresh-per-second | float | 0.75 | Display refresh rate in Hz (0.1-20.0) |
| --reset-hour | int | None | Daily reset hour (0-23) |
| --log-level | string | INFO | Logging level: DEBUG, INFO, WARNING, ERROR, CRITICAL |
| --log-file | path | None | Log file path |
| --debug | flag | False | Enable debug logging |
| --version, -v | flag | False | Show version information |
| --clear | flag | False | Clear saved configuration |
#### Plan Options
| Plan | Token Limit | Cost Limit | Description |
|------|-------------|------------------|-------------|
| pro | 19,000 | $18.00 | Claude Pro subscription |
| max5 | 88,000 | $35.00 | Claude Max5 subscription |
| max20 | 220,000 | $140.00 | Claude Max20 subscription |
| custom | P90-based | (default) $50.00 | Auto-detection with ML analysis |
#### Command Aliases
The tool can be invoked using any of these commands:
- claude-monitor (primary)
- claude-code-monitor (full name)
- cmonitor (short)
- ccmonitor (short alternative)
- ccm (shortest)
#### Save Flags Feature
The monitor automatically saves your preferences to avoid re-specifying them on each run:
**What Gets Saved:**
- View type (--view)
- Theme preferences (--theme)
- Timezone settings (--timezone)
- Time format (--time-format)
- Refresh rates (--refresh-rate, --refresh-per-second)
- Reset hour (--reset-hour)
- Custom token limits (--custom-limit-tokens)
**Configuration Location:** ~/.claude-monitor/last_used.json
**Usage Examples:**
```bash
# First run - specify preferences
claude-monitor --plan pro --theme dark --timezone "America/New_York"
# Subsequent runs - preferences automatically restored
claude-monitor --plan pro
# Override saved settings for this session
claude-monitor --plan pro --theme light
# Clear all saved preferences
claude-monitor --clear
```
**Key Features:**
- ✅ Automatic parameter persistence between sessions
- ✅ CLI arguments always override saved settings
- ✅ Atomic file operations prevent corruption
- ✅ Graceful fallback if config files are damaged
- ✅ Plan parameter never saved (must specify each time)
### Basic Usage
#### With uv tool installation (Recommended)
```bash
# Default (Custom plan with auto-detection)
claude-monitor
# Alternative commands
claude-code-monitor # Full descriptive name
cmonitor # Short alias
ccmonitor # Short alternative
ccm # Shortest alias
# Exit the monitor
# Press Ctrl+C to gracefully exit
```
#### Development mode
If running from source, use python -m claude_monitor from the src/ directory.
### Configuration Options
#### Specify Your Plan
```bash
# Custom plan with P90 auto-detection (Default)
claude-monitor --plan custom
# Pro plan (~44,000 tokens)
claude-monitor --plan pro
# Max5 plan (~88,000 tokens)
claude-monitor --plan max5
# Max20 plan (~220,000 tokens)
claude-monitor --plan max20
# Custom plan with explicit token limit
claude-monitor --plan custom --custom-limit-tokens 100000
```
#### Custom Reset Times
```bash
# Reset at 3 AM
claude-monitor --reset-hour 3
# Reset at 10 PM
claude-monitor --reset-hour 22
```
#### Usage View Configuration
```bash
# Real-time monitoring with live updates (Default)
claude-monitor --view realtime
# Daily token usage aggregated in table format
claude-monitor --view daily
# Monthly token usage aggregated in table format
claude-monitor --view monthly
```
#### Performance and Display Configuration
```bash
# Adjust refresh rate (1-60 seconds, default: 10)
claude-monitor --refresh-rate 5
# Adjust display refresh rate (0.1-20 Hz, default: 0.75)
claude-monitor --refresh-per-second 1.0
# Set time format (auto-detected by default)
claude-monitor --time-format 24h # or 12h
# Force specific theme
claude-monitor --theme dark # light, dark, classic, auto
# Clear saved configuration
claude-monitor --clear
```
#### Timezone Configuration
The default timezone is **auto-detected from your system**. Override with any valid timezone:
```bash
# Use US Eastern Time
claude-monitor --timezone America/New_York
# Use Tokyo time
claude-monitor --timezone Asia/Tokyo
# Use UTC
claude-monitor --timezone UTC
# Use London time
claude-monitor --timezone Europe/London
```
#### Logging and Debugging
```bash
# Enable debug logging
claude-monitor --debug
# Log to file
claude-monitor --log-file ~/.claude-monitor/logs/monitor.log
# Set log level
claude-monitor --log-level WARNING # DEBUG, INFO, WARNING, ERROR, CRITICAL
```
### Available Plans
| Plan | Token Limit | Best For |
|------|-----------------|----------|
| **custom** | P90 auto-detect | Intelligent limit detection (default) |
| **pro** | ~19,000 | Claude Pro subscription |
| **max5** | ~88,000 | Claude Max5 subscription |
| **max20** | ~220,000 | Claude Max20 subscription |
#### Advanced Plan Features
- **P90 Analysis**: Custom plan uses 90th percentile calculations from your usage history
- **Cost Tracking**: Model-specific pricing with cache token calculations
- **Limit Detection**: Intelligent threshold detection with 95% confidence
## 🚀 What's New in v3.0.0
### Major Changes
#### **Complete Architecture Rewrite**
- Modular design with Single Responsibility Principle (SRP) compliance
- Pydantic-based configuration with type safety and validation
- Advanced error handling with optional Sentry integration
- Comprehensive test suite with 100+ test cases
#### **Enhanced Functionality**
- **P90 Analysis**: Machine learning-based limit detection using 90th percentile calculations
- **Updated Plan Limits**: Pro (44k), Max5 (88k), Max20 (220k) tokens
- **Cost Analytics**: Model-specific pricing with cache token calculations
- **Rich UI**: WCAG-compliant themes with automatic terminal background detection
#### **New CLI Options**
- --refresh-per-second: Configurable display refresh rate (0.1-20 Hz)
- --time-format: Automatic 12h/24h format detection
- --custom-limit-tokens: Explicit token limits for custom plans
- --log-file and --log-level: Advanced logging capabilities
- --clear: Reset saved configuration
- Command aliases: claude-code-monitor, cmonitor, ccmonitor, ccm for convenience
#### **Breaking Changes**
- Package name changed from claude-usage-monitor to claude-monitor
- Default plan changed from pro to custom (with auto-detection)
- Minimum Python version increased to 3.9+
- Command structure updated (see examples above)
## ✨ Features & How It Works
### v3.0.0 Architecture Overview
The new version features a complete rewrite with modular architecture following Single Responsibility Principle (SRP):
### 🖥️ User Interface Layer
| Component | Description |
| -------------------- | --------------------- |
| **CLI Module** | Pydantic-based |
| **Settings/Config** | Type-safe |
| **Error Handling** | Sentry-ready |
| **Rich Terminal UI** | Adaptive Theme |
---
### 🎛️ Monitoring Orchestrator
| Component | Key Responsibilities |
| ------------------------ | ---------------------------------------------------------------- |
| **Central Control Hub** | Session Mgmt · Real-time Data Flow · Component Coordination |
| **Data Manager** | Cache Mgmt · File I/O · State Persist |
| **Session Monitor** | Real-time · 5 hr Windows · Token Track |
| **UI Controller** | Rich Display · Progress Bars · Theme System |
| **Analytics** | P90 Calculator · Burn Rate · Predictions |
---
### 🏗️ Foundation Layer
| Component | Core Features |
| ------------------- | ------------------------------------------------------- |
| **Core Models** | Session Data · Config Schema · Type Safety |
| **Analysis Engine** | ML Algorithms · Statistical · Forecasting |
| **Terminal Themes** | Auto-detection · WCAG Colors · Contrast Opt |
| **Claude API Data** | Token Tracking · Cost Calculator · Session Blocks |
---
**🔄 Data Flow:**
Claude Config Files → Data Layer → Analysis Engine → UI Components → Terminal Display
### Current Features
#### 🔄 Advanced Real-time Monitoring
- Configurable update intervals (1-60 seconds)
- High-precision display refresh (0.1-20 Hz)
- Intelligent change detection to minimize CPU usage
- Multi-threaded orchestration with callback system
#### 📊 Rich UI Components
- **Progress Bars**: WCAG-compliant color schemes with scientific contrast ratios
- **Data Tables**: Sortable columns with model-specific statistics
- **Layout Manager**: Responsive design that adapts to terminal size
- **Theme System**: Auto-detects terminal background for optimal readability
#### 📈 Multiple Usage Views
- **Realtime View** (Default): Live monitoring with progress bars, current session data, and burn rate analysis
- **Daily View**: Aggregated daily statistics showing Date, Models, Input/Output/Cache tokens, Total tokens, and Cost
- **Monthly View**: Monthly aggregated data for long-term trend analysis and budget planning
#### 🔮 Machine Learning Predictions
- **P90 Calculator**: 90th percentile analysis for intelligent limit detection
- **Burn Rate Analytics**: Multi-session consumption pattern analysis
- **Cost Projections**: Model-specific pricing with cache token calculations
- **Session Forecasting**: Predicts when sessions will expire based on usage patterns
#### 🤖 Intelligent Auto-Detection
- **Background Detection**: Automatically determines terminal theme (light/dark)
- **System Integration**: Auto-detects timezone and time format preferences
- **Plan Recognition**: Analyzes usage patterns to suggest optimal plans
- **Limit Discovery**: Scans historical data to find actual token limits
### Understanding Claude Sessions
#### How Claude Code Sessions Work
Claude Code operates on a **5-hour rolling session window system**:
1. **Session Start**: Begins with your first message to Claude
2. **Session Duration**: Lasts exactly 5 hours from that first message
3. **Token Limits**: Apply within each 5-hour session window
4. **Multiple Sessions**: Can have several active sessions simultaneously
5. **Rolling Windows**: New sessions can start while others are still active
#### Session Reset Schedule
**Example Session Timeline:**
10:30 AM - First message (Session A starts at 10 AM)
03:00 PM - Session A expires (5 hours later)
12:15 PM - First message (Session B starts 12PM)
05:15 PM - Session B expires (5 hours later 5PM)
#### Burn Rate Calculation
The monitor calculates burn rate using sophisticated analysis:
1. **Data Collection**: Gathers token usage from all sessions in the last hour
2. **Pattern Analysis**: Identifies consumption trends across overlapping sessions
3. **Velocity Tracking**: Calculates tokens consumed per minute
4. **Prediction Engine**: Estimates when current session tokens will deplete
5. **Real-time Updates**: Adjusts predictions as usage patterns change
### Token Limits by Plan
#### v3.0.0 Updated Plan Limits
| Plan | Limit (Tokens) | Cost Limit | Messages | Algorithm |
|------|----------------|------------------|----------|-----------|
| **Claude Pro** | 19,000 | $18.00 | 250 | Fixed limit |
| **Claude Max5** | 88,000 | $35.00 | 1,000 | Fixed limit |
| **Claude Max20** | 220,000 | $140.00 | 2,000 | Fixed limit |
| **Custom** | P90-based | (default) $50.00 | 250+ | Machine learning |
#### Advanced Limit Detection
- **P90 Analysis**: Uses 90th percentile of your historical usage
- **Confidence Threshold**: 95% accuracy in limit detection
- **Cache Support**: Includes cache creation and read token costs
- **Model-Specific**: Adapts to Claude 3.5, Claude 4, and future models
### Technical Requirements
#### Dependencies (v3.0.0)
```toml
# Core dependencies (automatically installed)
pytz>=2023.3 # Timezone handling
rich>=13.7.0 # Rich terminal UI
pydantic>=2.0.0 # Type validation
pydantic-settings>=2.0.0 # Configuration management
numpy>=1.21.0 # Statistical calculations
sentry-sdk>=1.40.0 # Error reporting (optional)
pyyaml>=6.0 # Configuration files
tzdata # Windows timezone data
```
#### Python Requirements
- **Minimum**: Python 3.9+
- **Recommended**: Python 3.11+
- **Tested on**: Python 3.9, 3.10, 3.11, 3.12, 3.13
### Smart Detection Features
#### Automatic Plan Switching
When using the default Pro plan:
1. **Detection**: Monitor notices token usage exceeding 7,000
2. **Analysis**: Scans previous sessions for actual limits
3. **Switch**: Automatically changes to custom_max mode
4. **Notification**: Displays clear message about the change
5. **Continuation**: Keeps monitoring with new, higher limit
#### Limit Discovery Process
The auto-detection system:
1. **Scans History**: Examines all available session blocks
2. **Finds Peaks**: Identifies highest token usage achieved
3. **Validates Data**: Ensures data quality and recency
4. **Sets Limits**: Uses discovered maximum as new limit
5. **Learns Patterns**: Adapts to your actual usage capabilities
## 🚀 Usage Examples
### Common Scenarios
#### 🌅 Morning Developer
**Scenario**: You start work at 9 AM and want tokens to reset aligned with your schedule.
```bash
# Set custom reset time to 9 AM
./claude_monitor.py --reset-hour 9
# With your timezone
./claude_monitor.py --reset-hour 9 --timezone US/Eastern
```
**Benefits**:
- Reset times align with your work schedule
- Better planning for daily token allocation
- Predictable session windows
#### 🌙 Night Owl Coder
**Scenario**: You often work past midnight and need flexible reset scheduling.
```bash
# Reset at midnight for clean daily boundaries
./claude_monitor.py --reset-hour 0
# Late evening reset (11 PM)
./claude_monitor.py --reset-hour 23
```
**Strategy**:
- Plan heavy coding sessions around reset times
- Use late resets to span midnight work sessions
- Monitor burn rate during peak hours
#### 🔄 Heavy User with Variable Limits
**Scenario**: Your token limits seem to change, and you're not sure of your exact plan.
```bash
# Auto-detect your highest previous usage
claude-monitor --plan custom_max
# Monitor with custom scheduling
claude-monitor --plan custom_max --reset-hour 6
```
**Approach**:
- Let auto-detection find your real limits
- Monitor for a week to understand patterns
- Note when limits change or reset
#### 🌍 International User
**Scenario**: You're working across different timezones or traveling.
```bash
# US East Coast
claude-monitor --timezone America/New_York
# Europe
claude-monitor --timezone Europe/London
# Asia Pacific
claude-monitor --timezone Asia/Singapore
# UTC for international team coordination
claude-monitor --timezone UTC --reset-hour 12
```
#### ⚡ Quick Check
**Scenario**: You just want to see current status without configuration.
```bash
# Just run it with defaults
claude-monitor
# Press Ctrl+C after checking status
```
#### 📊 Usage Analysis Views
**Scenario**: Analyzing your token usage patterns over different time periods.
```bash
# View daily usage breakdown with detailed statistics
claude-monitor --view daily
# Analyze monthly token consumption trends
claude-monitor --view monthly --plan max20
# Export daily usage data to log file for analysis
claude-monitor --view daily --log-file ~/daily-usage.log
# Review usage in different timezone
claude-monitor --view daily --timezone America/New_York
```
**Use Cases**:
- **Realtime**: Live monitoring of current session and burn rate
- **Daily**: Analyze daily consumption patterns and identify peak usage days
- **Monthly**: Long-term trend analysis and monthly budget planning
### Plan Selection Strategies
#### How to Choose Your Plan
**Start with Default (Recommended for New Users)**
```bash
# Pro plan detection with auto-switching
claude-monitor
```
- Monitor will detect if you exceed Pro limits
- Automatically switches to custom_max if needed
- Shows notification when switching occurs
**Known Subscription Users**
```bash
# If you know you have Max5
claude-monitor --plan max5
# If you know you have Max20
claude-monitor --plan max20
```
**Unknown Limits**
```bash
# Auto-detect from previous usage
claude-monitor --plan custom_max
```
### Best Practices
#### Setup Best Practices
1. **Start Early in Sessions**
```bash
# Begin monitoring when starting Claude work (uv installation)
claude-monitor
# Or development mode
./claude_monitor.py
```
- Gives accurate session tracking from the start
- Better burn rate calculations
- Early warning for limit approaches
2. **Use Modern Installation (Recommended)**
```bash
# Easy installation and updates with uv
uv tool install claude-monitor
claude-monitor --plan max5
```
- Clean system installation
- Easy updates and maintenance
- Available from anywhere
3. **Custom Shell Alias (Legacy Setup)**
```bash
# Add to ~/.bashrc or ~/.zshrc (only for development setup)
alias claude-monitor='cd ~/Claude-Code-Usage-Monitor && source venv/bin/activate && ./claude_monitor.py'
```
#### Usage Best Practices
1. **Monitor Burn Rate Velocity**
- Watch for sudden spikes in token consumption
- Adjust coding intensity based on remaining time
- Plan big refactors around session resets
2. **Strategic Session Planning**
```bash
# Plan heavy usage around reset times
claude-monitor --reset-hour 9
```
- Schedule large tasks after resets
- Use lighter tasks when approaching limits
- Leverage multiple overlapping sessions
3. **Timezone Awareness**
```bash
# Always use your actual timezone
claude-monitor --timezone Europe/Warsaw
```
- Accurate reset time predictions
- Better planning for work schedules
- Correct session expiration estimates
#### Optimization Tips
1. **Terminal Setup**
- Use terminals with at least 80 character width
- Enable color support for better visual feedback (check COLORTERM environment variable)
- Consider dedicated terminal window for monitoring
- Use terminals with truecolor support for best theme experience
2. **Workflow Integration**
```bash
# Start monitoring with your development session (uv installation)
tmux new-session -d -s claude-monitor 'claude-monitor'
# Or development mode
tmux new-session -d -s claude-monitor './claude_monitor.py'
# Check status anytime
tmux attach -t claude-monitor
```
3. **Multi-Session Strategy**
- Remember sessions last exactly 5 hours
- You can have multiple overlapping sessions
- Plan work across session boundaries
#### Real-World Workflows
**Large Project Development**
```bash
# Setup for sustained development
claude-monitor --plan max20 --reset-hour 8 --timezone America/New_York
```
**Daily Routine**:
1. **8:00 AM**: Fresh tokens, start major features
2. **10:00 AM**: Check burn rate, adjust intensity
3. **12:00 PM**: Monitor for afternoon session planning
4. **2:00 PM**: New session window, tackle complex problems
5. **4:00 PM**: Light tasks, prepare for evening session
**Learning & Experimentation**
```bash
# Flexible setup for learning
claude-monitor --plan pro
```
**Sprint Development**
```bash
# High-intensity development setup
claude-monitor --plan max20 --reset-hour 6
```
## 🔧 Development Installation
For contributors and developers who want to work with the source code:
### Quick Start (Development/Testing)
```bash
# Clone the repository
git clone https://github.com/Maciek-roboblog/Claude-Code-Usage-Monitor.git
cd Claude-Code-Usage-Monitor
# Install in development mode
pip install -e .
# Run from source
python -m claude_monitor
```
### v3.0.0 Testing Features
The new version includes a comprehensive test suite:
- **100+ test cases** with full coverage
- **Unit tests** for all components
- **Integration tests** for end-to-end workflows
- **Performance tests** with benchmarking
- **Mock objects** for isolated testing
```bash
# Run tests
cd src/
python -m pytest
# Run with coverage
python -m pytest --cov=claude_monitor --cov-report=html
# Run specific test modules
python -m pytest tests/test_analysis.py -v
```
### Prerequisites
1. **Python 3.9+** installed on your system
2. **Git** for cloning the repository
### Virtual Environment Setup
#### Why Use Virtual Environment?
Using a virtual environment is **strongly recommended** because:
- **🛡️ Isolation**: Keeps your system Python clean and prevents dependency conflicts
- **📦 Portability**: Easy to replicate the exact environment on different machines
- **🔄 Version Control**: Lock specific versions of dependencies for stability
- **🧹 Clean Uninstall**: Simply delete the virtual environment folder to remove everything
- **👥 Team Collaboration**: Everyone uses the same Python and package versions
#### Installing virtualenv (if needed)
If you don't have venv module available:
```bash
# Ubuntu/Debian
sudo apt-get update
sudo apt-get install python3-venv
# Fedora/RHEL/CentOS
sudo dnf install python3-venv
# macOS (usually comes with Python)
# If not available, install Python via Homebrew:
brew install python3
# Windows (usually comes with Python)
# If not available, reinstall Python from python.org
# Make sure to check "Add Python to PATH" during installation
```
Alternatively, use the virtualenv package:
```bash
# Install virtualenv via pip
pip install virtualenv
# Then create virtual environment with:
virtualenv venv
# instead of: python3 -m venv venv
```
#### Step-by-Step Setup
```bash
# 1. Clone the repository
git clone https://github.com/Maciek-roboblog/Claude-Code-Usage-Monitor.git
cd Claude-Code-Usage-Monitor
# 2. Create virtual environment
python3 -m venv venv
# Or if using virtualenv package:
# virtualenv venv
# 3. Activate virtual environment
# On Linux/Mac:
source venv/bin/activate
# On Windows:
# venv\Scripts\activate
# 4. Install Python dependencies
pip install pytz
pip install rich>=13.0.0
# 5. Make script executable (Linux/Mac only)
chmod +x claude_monitor.py
# 6. Run the monitor
python claude_monitor.py
```
#### Daily Usage
After initial setup, you only need:
```bash
# Navigate to project directory
cd Claude-Code-Usage-Monitor
# Activate virtual environment
source venv/bin/activate # Linux/Mac
# venv\Scripts\activate # Windows
# Run monitor
./claude_monitor.py # Linux/Mac
# python claude_monitor.py # Windows
# When done, deactivate
deactivate
```
#### Pro Tip: Shell Alias
Create an alias for quick access:
```bash
# Add to ~/.bashrc or ~/.zshrc
alias claude-monitor='cd ~/Claude-Code-Usage-Monitor && source venv/bin/activate && ./claude_monitor.py'
# Then just run:
claude-monitor
```
## Troubleshooting
### Installation Issues
#### "externally-managed-environment" Error
On modern Linux distributions (Ubuntu 23.04+, Debian 12+, Fedora 38+), you may encounter:
```
error: externally-managed-environment
× This environment is externally managed
```
**Solutions (in order of preference):**
1. **Use uv (Recommended)**
```bash
# Install uv first
curl -LsSf https://astral.sh/uv/install.sh | sh
# Then install with uv
uv tool install claude-monitor
```
2. **Use pipx (Isolated Environment)**
```bash
# Install pipx
sudo apt install pipx # Ubuntu/Debian
# or
python3 -m pip install --user pipx
# Install claude-monitor
pipx install claude-monitor
```
3. **Use virtual environment**
```bash
python3 -m venv myenv
source myenv/bin/activate
pip install claude-monitor
```
4. **Force installation (Not Recommended)**
```bash
pip install --user claude-monitor --break-system-packages
```
⚠️ **Warning**: This bypasses system protection and may cause conflicts. We strongly recommend using a virtual environment instead.
#### Command Not Found After pip Install
If claude-monitor command is not found after pip installation:
1. **Check if it's a PATH issue**
```bash
# Look for the warning message during pip install:
# WARNING: The script claude-monitor is installed in '/home/username/.local/bin' which is not on PATH
```
2. **Add to PATH**
```bash
# Add this to ~/.bashrc or ~/.zshrc
echo 'export PATH="$HOME/.local/bin:$PATH"' >> ~/.bashrc
# Reload shell
source ~/.bashrc # or source ~/.zshrc
```
3. **Verify installation location**
```bash
# Find where pip installed the script
pip show -f claude-monitor | grep claude-monitor
```
4. **Run directly with Python**
```bash
python3 -m claude_monitor
```
#### Python Version Conflicts
If you have multiple Python versions:
1. **Check Python version**
```bash
python3 --version
pip3 --version
```
2. **Use specific Python version**
```bash
python3.11 -m pip install claude-monitor
python3.11 -m claude_monitor
```
3. **Use uv (handles Python versions automatically)**
```bash
uv tool install claude-monitor
```
### Runtime Issues
#### No active session found
If you encounter the error No active session found, please follow these steps:
1. **Initial Test**:
Launch Claude Code and send at least two messages. In some cases, the session may not initialize correctly on the first attempt, but it resolves after a few interactions.
2. **Configuration Path**:
If the issue persists, consider specifying a custom configuration path. By default, Claude Code uses ~/.config/claude. You may need to adjust this path depending on your environment.
```bash
CLAUDE_CONFIG_DIR=~/.config/claude ./claude_monitor.py
```
## 📞 Contact
Have questions, suggestions, or want to collaborate? Feel free to reach out!
**📧 Email**: [maciek@roboblog.eu](mailto:maciek@roboblog.eu)
Whether you need help with setup, have feature requests, found a bug, or want to discuss potential improvements, don't hesitate to get in touch. I'm always happy to help and hear from users of the Claude Code Usage Monitor!
## 📚 Additional Documentation
- **[Development Roadmap](DEVELOPMENT.md)** - ML features, PyPI package, Docker plans
- **[Contributing Guide](CONTRIBUTING.md)** - How to contribute, development guidelines
- **[Troubleshooting](TROUBLESHOOTING.md)** - Common issues and solutions
## 📝 License
[MIT License](LICENSE) - feel free to use and modify as needed.
## 🤝 Contributors
- [@adawalli](https://github.com/adawalli)
- [@taylorwilsdon](https://github.com/taylorwilsdon)
- [@moneroexamples](https://github.com/moneroexamples)
Want to contribute? Check out our [Contributing Guide](CONTRIBUTING.md)!
## 🙏 Acknowledgments
### Sponsors
A special thanks to our supporters who help keep this project going:
**Ed** - *Buy Me Coffee Supporter*
> "I appreciate sharing your work with the world. It helps keep me on track with my day. Quality readme, and really good stuff all around!"
## Star History
[](https://www.star-history.com/#Maciek-roboblog/Claude-Code-Usage-Monitor&Date)
---
**⭐ Star this repo if you find it useful! ⭐**
[Report Bug](https://github.com/Maciek-roboblog/Claude-Code-Usage-Monitor/issues) • [Request Feature](https://github.com/Maciek-roboblog/Claude-Code-Usage-Monitor/issues) • [Contribute](CONTRIBUTING.md)
================================================
FILE: RELEASE.md
================================================
# Release Process
This document describes the release process for Claude Code Usage Monitor.
## Automated Release (GitHub Actions)
Releases are automatically triggered when changes are pushed to the `main` branch. The GitHub Actions workflow will:
1. Extract the version from `pyproject.toml`
2. Check if a git tag for this version already exists
3. If not, it will:
- Create a new git tag
- Extract release notes from `CHANGELOG.md`
- Create a GitHub release
- Build and publish the package to PyPI
### Prerequisites for Automated Release
1. **PyPI API Token**: Must be configured as a GitHub secret named `PYPI_API_TOKEN`
- Generate at: https://pypi.org/manage/account/token/
- Add to repository secrets: Settings → Secrets and variables → Actions → New repository secret
2. **Publishing Permissions**: Ensure GitHub Actions has permissions to create releases
- Settings → Actions → General → Workflow permissions → Read and write permissions
## Manual Release Process
If automated release fails or for special cases, follow these steps:
### 1. Prepare Release
```bash
# Ensure you're on main branch with latest changes
git checkout main
git pull origin main
# Run tests and linting
uv sync --extra dev
uv run ruff check .
uv run ruff format --check .
```
### 2. Update Version
Edit `pyproject.toml` and update the version:
```toml
version = "1.0.9" # Update to your new version
```
### 3. Update CHANGELOG.md
Add a new section at the top of `CHANGELOG.md`:
```markdown
## [1.0.9] - 2025-06-21
### Added
- Description of new features
### Changed
- Description of changes
### Fixed
- Description of fixes
[1.0.9]: https://github.com/Maciek-roboblog/Claude-Code-Usage-Monitor/releases/tag/v1.0.9
```
### 4. Commit Version Changes
```bash
git add pyproject.toml CHANGELOG.md
git commit -m "Bump version to 1.0.9"
git push origin main
```
### 5. Create Git Tag
```bash
# Create annotated tag
git tag -a v1.0.9 -m "Release v1.0.9"
# Push tag to GitHub
git push origin v1.0.9
```
### 6. Build Package
```bash
# Clean previous builds
rm -rf dist/
# Build with uv
uv build
# Verify build artifacts
ls -la dist/
# Should show:
# - claude_monitor-1.0.9-py3-none-any.whl
# - claude_monitor-1.0.9.tar.gz
```
### 7. Create GitHub Release
1. Go to: https://github.com/Maciek-roboblog/Claude-Code-Usage-Monitor/releases/new
2. Choose tag: `v1.0.9`
3. Release title: `Release v1.0.9`
4. Copy the relevant section from CHANGELOG.md to the description
5. Attach the built artifacts from `dist/` (optional)
6. Click "Publish release"
### 8. Publish to PyPI
```bash
# Install twine if needed
uv tool install twine
# Upload to PyPI (will prompt for credentials)
uv tool run twine upload dist/*
# Or with API token
uv tool run twine upload dist/* --username __token__ --password
```
### 9. Verify Release
1. Check PyPI: https://pypi.org/project/claude-monitor/
2. Test installation:
```bash
# In a new environment
uv tool install claude-monitor
claude-monitor --version
# Test all command aliases
cmonitor --version
ccm --version
```
## Version Numbering
We follow semantic versioning (SemVer):
- **MAJOR.MINOR.PATCH** (e.g., 1.0.9)
- **MAJOR**: Incompatible API changes
- **MINOR**: New functionality in a backward-compatible manner
- **PATCH**: Backward-compatible bug fixes
## Troubleshooting
### GitHub Actions Release Failed
1. Check Actions tab for error logs
2. Common issues:
- Missing or invalid `PYPI_API_TOKEN`
- Version already exists on PyPI
- Malformed CHANGELOG.md
### PyPI Upload Failed
1. **Authentication Error**: Check your PyPI token
2. **Version Exists**: Version numbers cannot be reused on PyPI
3. **Package Name Taken**: The package name might be reserved
### Tag Already Exists
```bash
# Delete local tag
git tag -d v1.0.9
# Delete remote tag
git push --delete origin v1.0.9
# Recreate tag
git tag -a v1.0.9 -m "Release v1.0.9"
git push origin v1.0.9
```
## Release Checklist
- [ ] All tests pass
- [ ] Code is properly formatted (ruff)
- [ ] Version updated in `pyproject.toml`
- [ ] CHANGELOG.md updated with release notes
- [ ] Changes committed and pushed to main
- [ ] Git tag created and pushed
- [ ] GitHub release created
- [ ] Package published to PyPI
- [ ] Installation tested in clean environment
================================================
FILE: TROUBLESHOOTING.md
================================================
# 🐛 Troubleshooting Guide - Claude Monitor v3.0.0
**⚠️ This guide is specifically for Claude Monitor v3.0.0** - If you're using an older version, please upgrade first.
## 🚨 Quick Fixes
### Most Common v3.0.0 Issues
| Problem | Quick Fix |
|---------|-----------|
| `command not found: claude-monitor` | Add `~/.local/bin` to PATH or use `python -m claude_monitor` |
| `externally-managed-environment` | Use `uv tool install claude-monitor` instead of pip |
| No Claude data found | Ensure you have active Claude Code sessions with recent messages |
| Validation errors | Check configuration with `claude-monitor --help` |
| Display issues | Terminal width must be 80+ characters |
| Theme detection problems | Use `--theme dark` or `--theme light` explicitly |
## 🔧 Installation Issues (v3.0.0)
### Package Name Change
**v3.0.0 Breaking Change**: Package name changed from `claude-usage-monitor` to `claude-monitor`
```bash
# OLD (deprecated)
pip install claude-usage-monitor
# NEW (v3.0.0)
pip install claude-monitor
uv tool install claude-monitor
```
### "externally-managed-environment" Error
**Common on Ubuntu 23.04+, Debian 12+, Fedora 38+**
**Solutions (in order of preference)**:
1. **Use uv (Recommended)**:
```bash
# Install uv
curl -LsSf https://astral.sh/uv/install.sh | sh
source ~/.bashrc
# Install claude-monitor
uv tool install claude-monitor
claude-monitor
```
2. **Use pipx**:
```bash
# Install pipx
sudo apt install pipx # Ubuntu/Debian
pipx install claude-monitor
claude-monitor
```
3. **Use virtual environment**:
```bash
python3 -m venv venv
source venv/bin/activate
pip install claude-monitor
claude-monitor
```
### Command Not Found After Installation
**Issue**: `claude-monitor` command not found
**Solutions**:
1. **Check PATH**:
```bash
# Add to ~/.bashrc or ~/.zshrc
echo 'export PATH="$HOME/.local/bin:$PATH"' >> ~/.bashrc
source ~/.bashrc
```
2. **Use Python module**:
```bash
python -m claude_monitor
```
3. **Check installation**:
```bash
pip show claude-monitor
which claude-monitor
```
### Python Version Requirements
**v3.0.0 requires Python 3.9+**
```bash
# Check Python version
python3 --version
# If too old, upgrade Python or use specific version
python3.11 -m pip install claude-monitor
python3.11 -m claude_monitor
```
### Dependency Installation Issues
**Missing dependencies error**:
```bash
# Manual installation of core dependencies
pip install pytz>=2023.3 rich>=13.7.0 pydantic>=2.0.0
pip install pydantic-settings>=2.0.0 numpy>=1.21.0
```
## 💾 Data and Configuration Issues
### No Claude Data Directory Found
**Error**: `No Claude data directory found`
**Causes and Solutions**:
1. **Default data path doesn't exist**:
```bash
# Check if directory exists
ls ~/.claude/projects
# Start Claude Code session first
# Go to claude.ai/code and send messages
```
2. **Permission issues**:
```bash
# Check permissions
ls -la ~/.claude/
# Fix permissions if needed
chmod 755 ~/.claude/projects
```
3. **Custom data path**:
```bash
# If Claude uses different path, set environment variable
export CLAUDE_CONFIG_DIR=/path/to/your/claude/config
claude-monitor
```
### JSONL File Processing Errors
**Error**: `Failed to parse JSON line in {file}: {error}`
**Solutions**:
1. **Corrupted files**: Let monitor skip malformed lines (automatic)
2. **Check file integrity**:
```bash
# Validate JSONL files
find ~/.claude/projects -name "*.jsonl" -exec python -c "
import json
with open('{}') as f:
for i, line in enumerate(f, 1):
try: json.loads(line)
except: print(f'Error in {}: line {i}')
" \;
```
### Session Detection Issues
**Error**: `No active session found`
**Debugging steps**:
1. **Verify Claude Code usage**:
- Must use claude.ai/code (not regular Claude)
- Send at least 2-3 messages
- Wait 30 seconds after last message
2. **Check data freshness**:
```bash
# Check recent files
find ~/.claude/projects -name "*.jsonl" -mtime -1 -ls
```
3. **Manual data verification**:
```bash
# Enable debug logging
claude-monitor --debug --log-file /tmp/claude-debug.log
# Check logs
tail -f /tmp/claude-debug.log
```
## ⚙️ Configuration Validation Errors
### Invalid Plan Configuration
**Error**: `Invalid plan: {value}. Must be one of: pro, max5, max20, custom`
**Valid options**:
```bash
# Correct plan names (case-insensitive)
claude-monitor --plan pro # 44k tokens
claude-monitor --plan max5 # 88k tokens
claude-monitor --plan max20 # 220k tokens
claude-monitor --plan custom # P90 auto-detection
```
### Invalid Theme Settings
**Error**: `Invalid theme: {value}. Must be one of: light, dark, classic, auto`
**Solutions**:
```bash
# Force specific theme
claude-monitor --theme dark
claude-monitor --theme light
# Debug theme detection
claude-monitor --debug
```
### Timezone Validation Errors
**Error**: `Invalid timezone: {value}`
**Solutions**:
```bash
# Use auto-detection (default)
claude-monitor --timezone auto
# Valid timezone examples
claude-monitor --timezone UTC
claude-monitor --timezone America/New_York
claude-monitor --timezone Europe/London
claude-monitor --timezone Asia/Tokyo
# List available timezones
python -c "import pytz; print('\n'.join(sorted(pytz.all_timezones)))" | grep America
```
### Numeric Range Validation Errors
**Common validation failures**:
```bash
# Refresh rate: must be 1-60 seconds
claude-monitor --refresh-rate 5 # Valid
claude-monitor --refresh-rate 0 # Invalid: below minimum
# Display refresh rate: must be 0.1-20 Hz
claude-monitor --refresh-per-second 1.0 # Valid
claude-monitor --refresh-per-second 25 # Invalid: above maximum
# Reset hour: must be 0-23
claude-monitor --reset-hour 9 # Valid
claude-monitor --reset-hour 24 # Invalid: out of range
# Custom token limit: must be positive
claude-monitor --plan custom --custom-limit-tokens 50000 # Valid
claude-monitor --plan custom --custom-limit-tokens 0 # Invalid
```
## 🖥️ Display and Terminal Issues
### Terminal Width Too Narrow
**Issue**: Overlapping text, garbled display
**Solutions**:
```bash
# Check terminal width
tput cols # Should be 80+
# Resize terminal window or use scrolling
claude-monitor | less -S
```
### Theme Detection Problems
**Issue**: Wrong colors, poor contrast
**Debug theme detection**:
```bash
# Check environment variables
echo $COLORFGBG
echo $TERM
echo $COLORTERM
# Force theme explicitly
claude-monitor --theme dark # For dark terminals
claude-monitor --theme light # For light terminals
```
**SSH/Remote sessions**:
```bash
# Theme detection may fail over SSH
claude-monitor --theme dark # Usually safer for SSH
```
### Missing Colors or Emojis
**Issue**: Plain text output, no colors
**Solutions**:
```bash
# Check terminal capabilities
echo $TERM
echo $COLORTERM
# Force color output
export FORCE_COLOR=1
claude-monitor
# Try different terminal
# iTerm2, Windows Terminal, or modern Linux terminals work best
```
### Cursor Remains Hidden After Exit
**Issue**: Terminal cursor invisible after Ctrl+C
**Quick fix**:
```bash
# Restore cursor
printf '\033[?25h'
# Or reset terminal completely
reset
```
## 🔄 Runtime and Performance Issues
### Monitor Startup Timeout
**Error**: `Timeout waiting for initial data`
**Causes and solutions**:
1. **Slow data loading**:
```bash
# Use custom timeout
# (Note: Not directly configurable, but data loads faster on subsequent runs)
# Check if Claude data exists
ls -la ~/.claude/projects/*.jsonl
```
2. **Large data files**:
```bash
# Monitor memory usage
top -p $(pgrep -f claude_monitor)
# Use quick start mode (automatically enabled)
claude-monitor # Loads only last 24 hours initially
```
### High CPU or Memory Usage
**Issue**: Monitor consuming too many resources
**Solutions**:
```bash
# Reduce refresh rate
claude-monitor --refresh-rate 30 # Data refresh every 30s
claude-monitor --refresh-per-second 0.5 # Display refresh at 0.5 Hz
# Monitor resource usage
htop | grep claude-monitor
```
### Thread and Callback Errors
**Error**: `Callback error: {error}` or `Session callback error: {error}`
**Debug approach**:
```bash
# Enable detailed logging
claude-monitor --debug --log-file /tmp/debug.log
# Check thread status
ps -T -p $(pgrep -f claude_monitor)
```
## 🔍 Advanced Debugging
### Enable Debug Mode
```bash
# Full debug output
claude-monitor --debug
# Debug with file logging
claude-monitor --debug --log-file ~/.claude-monitor/logs/debug.log
# Check logs
tail -f ~/.claude-monitor/logs/debug.log
```
### Validate Configuration
```bash
# Test configuration without starting monitor
python -c "
from claude_monitor.core.settings import Settings
try:
settings = Settings.load_with_last_used(['--plan', 'custom'])
print('Configuration valid')
print(f'Plan: {settings.plan}')
print(f'Theme: {settings.theme}')
print(f'Timezone: {settings.timezone}')
except Exception as e:
print(f'Configuration error: {e}')
"
```
### Check Data Path Discovery
```bash
# Test data path discovery
python -c "
from claude_monitor.cli.main import discover_claude_data_paths
paths = discover_claude_data_paths()
print(f'Found paths: {paths}')
for path in paths:
print(f' {path}: {len(list(path.glob(\"*.jsonl\")))} JSONL files')
"
```
### Validate JSONL Data Structure
```bash
# Check data structure
python -c "
from claude_monitor.data.reader import load_usage_entries
try:
entries, raw = load_usage_entries(include_raw=True)
print(f'Loaded {len(entries)} entries')
if entries:
print(f'Latest entry: {entries[-1].timestamp}')
print(f'Total tokens: {entries[-1].input_tokens + entries[-1].output_tokens}')
except Exception as e:
print(f'Data loading error: {e}')
"
```
### Test Pydantic Settings
```bash
# Test settings validation
python -c "
from claude_monitor.core.settings import Settings
from pydantic import ValidationError
test_cases = [
['--plan', 'invalid'],
['--theme', 'invalid'],
['--timezone', 'Invalid/Zone'],
['--refresh-rate', '0'],
['--refresh-per-second', '25'],
['--reset-hour', '24']
]
for case in test_cases:
try:
Settings.load_with_last_used(case)
print(f'{case}: Valid')
except ValidationError as e:
print(f'{case}: {e.errors()[0][\"msg\"]}')
except Exception as e:
print(f'{case}: {e}')
"
```
## 🆘 Getting Help
### Before Reporting Issues
1. **Check this guide first**
2. **Try with debug mode**: `claude-monitor --debug`
3. **Verify installation**: `pip show claude-monitor`
4. **Test with minimal config**: `claude-monitor --clear`
### Information to Include in Bug Reports
```bash
# System information
uname -a # Linux/Mac
systeminfo # Windows
# Python and package versions
python --version
pip show claude-monitor
# Installation method
which claude-monitor
echo $PATH
# Configuration test
claude-monitor --help
# Debug output (if possible)
claude-monitor --debug | head -20
```
### Issue Template
```markdown
**Problem**: Brief description
**Environment**:
- OS: [Ubuntu 24.04 / Windows 11 / macOS 14]
- Python: [3.11.0]
- Installation: [uv/pip/pipx/source]
- Version: [3.0.0]
**Steps to Reproduce**:
1. Command: `claude-monitor --plan custom`
2. Expected: ...
3. Actual: ...
**Error Output**:
```
Paste error messages here
```
**Debug Information**:
```
Output from: claude-monitor --debug | head -20
```
```
### Where to Get Help
1. **GitHub Issues**: [Create new issue](https://github.com/Maciek-roboblog/Claude-Code-Usage-Monitor/issues/new)
2. **Email**: [maciek@roboblog.eu](mailto:maciek@roboblog.eu)
3. **Documentation**: [README.md](README.md)
## 🔄 Complete Reset
If all else fails:
```bash
# 1. Uninstall completely
pip uninstall claude-monitor
uv tool uninstall claude-monitor # if using uv
pipx uninstall claude-monitor # if using pipx
# 2. Clear all configuration
rm -rf ~/.claude-monitor/
# 3. Clear Python cache
find . -name "*.pyc" -delete 2>/dev/null
find . -name "__pycache__" -delete 2>/dev/null
# 4. Fresh installation (choose one)
uv tool install claude-monitor # Recommended
# OR
pipx install claude-monitor # Alternative
# OR
python -m venv venv && source venv/bin/activate && pip install claude-monitor
# 5. Test installation
claude-monitor --help
claude-monitor --version
```
---
**Still having issues?** Don't hesitate to [create an issue](https://github.com/Maciek-roboblog/Claude-Code-Usage-Monitor/issues/new) with the **[v3.0.0]** tag in the title!
================================================
FILE: VERSION_MANAGEMENT.md
================================================
# Version Management System
## Overview
The Claude Code Usage Monitor uses a centralized version management system that eliminates version duplication and ensures consistency across the entire codebase.
## Single Source of Truth
**`pyproject.toml`** is the **only** place where the version number is defined:
```toml
[project]
version = "3.0.0"
```
## How It Works
### 1. Version Detection (`src/claude_monitor/_version.py`)
The version is retrieved using a two-tier fallback system:
1. **Primary**: Read from package metadata (when installed)
```python
importlib.metadata.version("claude-monitor")
```
2. **Fallback**: Read directly from `pyproject.toml` (development mode)
```python
# Uses tomllib (Python 3.11+) or tomli (Python < 3.11)
```
### 2. Module Import (`src/claude_monitor/__init__.py`)
```python
from claude_monitor._version import __version__
```
### 3. Usage Throughout Codebase
All modules import version from the main package:
```python
from claude_monitor import __version__
```
## Benefits
✅ **Single Source of Truth**: Version defined only in `pyproject.toml`
✅ **No Duplication**: Eliminates hardcoded versions in `__init__.py` files
✅ **Automatic Sync**: Version updates automatically propagate everywhere
✅ **Development Support**: Works both in installed and development environments
✅ **Build Integration**: Seamlessly integrates with build and release processes
## Dependencies
- **Python 3.11+**: Uses built-in `tomllib`
- **Python < 3.11**: Uses `tomli>=1.2.0` (automatically installed)
## Testing
Comprehensive test suite in `src/tests/test_version.py`:
- Version import consistency
- Fallback mechanism testing
- Integration with `pyproject.toml`
- Format validation
## Migration
### Before (Problems)
```python
# Multiple version definitions - sync issues!
# src/claude_monitor/__init__.py
__version__ = "2.5.0"
# pyproject.toml
version = "3.0.0" # Different version!
```
### After (Solution)
```python
# src/claude_monitor/__init__.py
from claude_monitor._version import __version__ # Always in sync!
# pyproject.toml
version = "3.0.0" # Single source of truth
```
## Release Process
1. **Update version in `pyproject.toml`** only
2. **All other files automatically reflect the new version**
3. **No manual updates needed anywhere else**
## Best Practices
- ✅ Update version only in `pyproject.toml`
- ✅ Use `from claude_monitor import __version__` in all modules
- ❌ Never hardcode version strings in source code
- ❌ Never define `__version__` in `__init__.py` files
This system ensures version consistency and eliminates the maintenance burden of keeping multiple version definitions synchronized.
================================================
FILE: pyproject.toml
================================================
# Automatically refactored pyproject.toml with best practices
[build-system]
requires = ["setuptools>=61.0.0", "wheel"]
build-backend = "setuptools.build_meta"
[project]
name = "claude-monitor"
version = "3.1.0"
description = "A real-time terminal monitoring tool for Claude Code token usage with advanced analytics and Rich UI"
readme = "README.md"
license = { text = "MIT" }
requires-python = ">=3.9"
authors = [{ name = "Maciek", email = "maciek@roboblog.eu" }]
maintainers = [{ name = "Maciek", email = "maciek@roboblog.eu" }]
keywords = [
"ai", "analytics", "claude", "dashboard",
"developer-tools", "monitoring", "rich",
"terminal", "token", "usage"
]
classifiers = [
"Development Status :: 5 - Production/Stable",
"Environment :: Console",
"Environment :: Console :: Curses",
"Intended Audience :: Developers",
"Topic :: Software Development :: Debuggers",
"Topic :: Software Development :: Libraries :: Python Modules",
"Topic :: System :: Monitoring",
"Topic :: Terminals",
"Topic :: Utilities",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3 :: Only",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
"Operating System :: POSIX :: Linux",
"Operating System :: MacOS",
# "Operating System :: Microsoft :: Windows",
"Typing :: Typed"
]
dependencies = [
"numpy>=1.21.0",
"pydantic>=2.0.0",
"pydantic-settings>=2.0.0",
"pyyaml>=6.0",
"pytz>=2023.3",
"rich>=13.7.0",
"tomli>=1.2.0; python_version < '3.11'",
"tzdata; sys_platform == 'win32'"
]
[project.optional-dependencies]
dev = [
"black>=24.0.0",
"isort>=5.13.0",
"mypy>=1.13.0",
"pre-commit>=4.0.0",
"pytest>=8.0.0",
"pytest-asyncio>=0.24.0",
"pytest-benchmark>=4.0.0",
"pytest-cov>=6.0.0",
"pytest-mock>=3.14.0",
"pytest-xdist>=3.6.0",
"ruff>=0.12.0",
"build>=0.10.0",
"twine>=4.0.0"
]
test = [
"pytest>=8.0.0",
"pytest-cov>=6.0.0",
"pytest-mock>=3.14.0",
"pytest-asyncio>=0.24.0",
"pytest-benchmark>=4.0.0"
]
[project.urls]
homepage = "https://github.com/Maciek-roboblog/Claude-Code-Usage-Monitor"
repository = "https://github.com/Maciek-roboblog/Claude-Code-Usage-Monitor.git"
documentation = "https://github.com/Maciek-roboblog/Claude-Code-Usage-Monitor#readme"
issues = "https://github.com/Maciek-roboblog/Claude-Code-Usage-Monitor/issues"
changelog = "https://github.com/Maciek-roboblog/Claude-Code-Usage-Monitor/blob/main/CHANGELOG.md"
"Release Notes" = "https://github.com/Maciek-roboblog/Claude-Code-Usage-Monitor/releases"
"Discussions" = "https://github.com/Maciek-roboblog/Claude-Code-Usage-Monitor/discussions"
[project.scripts]
claude-monitor = "claude_monitor.__main__:main"
claude-code-monitor = "claude_monitor.__main__:main"
cmonitor = "claude_monitor.__main__:main"
ccmonitor = "claude_monitor.__main__:main"
ccm = "claude_monitor.__main__:main"
[tool.setuptools.packages.find]
where = ["src"]
include = ["claude_monitor*"]
exclude = ["tests*", "src/tests*"]
[tool.setuptools.package-data]
claude_monitor = ["py.typed"]
[tool.black]
line-length = 88
target-version = ["py39", "py310", "py311", "py312"]
skip-string-normalization = false
include = '\.pyi?$'
extend-exclude = '''
/(
\.eggs
| \.git
| \.hg
| \.tox
| \.venv
| build
| dist
)/
'''
[tool.isort]
profile = "black"
line_length = 88
known_first_party = ["claude_monitor"]
force_single_line = true
atomic = true
include_trailing_comma = true
lines_after_imports = 2
lines_between_types = 1
use_parentheses = true
src_paths = ["src"]
skip_glob = ["*/migrations/*", "*/venv/*", "*/build/*", "*/dist/*"]
[tool.ruff]
line-length = 88
target-version = "py39"
[tool.ruff.lint]
select = ["E", "W", "F", "I"] # pycodestyle + Pyflakes + isort
ignore = ["E501"] # Line length handled by formatter
[tool.ruff.format]
quote-style = "double"
[tool.mypy]
python_version = "3.9"
warn_return_any = true # Catch unintended Any returns
warn_no_return = true # Ensure functions return as expected
strict_optional = true # Disallow None where not annotated
disable_error_code = [
"attr-defined", # Attribute existence
"name-defined", # Name resolution
"import", # Import errors
"misc", # Misc issues
]
[tool.pytest.ini_options]
minversion = "7.0"
testpaths = ["src/tests"]
python_files = ["test_*.py","*_test.py"]
python_classes = ["Test*"]
python_functions = ["test_*"]
addopts = [
"--strict-markers","--strict-config","--color=yes","--tb=short",
"--cov=claude_monitor","--cov-report=term-missing","--cov-report=html",
"--cov-report=xml","--cov-fail-under=70","--no-cov-on-fail","-ra","-q",
"-m","not integration"
]
markers = [
"slow: marks tests as slow (deselect with '-m \"not slow\"')",
"unit: marks tests as unit tests",
"integration: marks tests as integration tests",
"benchmark: marks tests as benchmarks",
"network: marks tests as requiring network access",
"subprocess: marks tests as requiring subprocess"
]
filterwarnings = [
"error",
"ignore::UserWarning",
"ignore::DeprecationWarning",
"ignore::PendingDeprecationWarning"
]
[tool.coverage.run]
branch = true
source = ["src/claude_monitor"]
omit = ["*/tests/*","*/test_*","*/__main__.py","*/conftest.py"]
[tool.coverage.report]
exclude_lines = [
"pragma: no cover",
"def __repr__",
"if self.debug:",
"if settings.DEBUG",
"raise AssertionError",
"raise NotImplementedError",
"if 0:",
"if __name__ == .__main__.:",
"class .*\\bProtocol\\):",
"@(abc\\.)?abstractmethod"
]
show_missing = true
skip_empty = false
precision = 2
[tool.coverage.html]
directory = "htmlcov"
[tool.coverage.xml]
output = "coverage.xml"
================================================
FILE: src/claude_monitor/__init__.py
================================================
"""Claude Monitor - Real-time token usage monitoring for Claude AI"""
from claude_monitor._version import __version__
__all__ = ["__version__"]
================================================
FILE: src/claude_monitor/__main__.py
================================================
#!/usr/bin/env python3
"""Module execution entry point for Claude Monitor.
Allows running the package as a module: python -m claude_monitor
"""
import sys
from typing import NoReturn
from .cli.main import main
def _main() -> NoReturn:
"""Entry point that properly handles exit codes and never returns."""
exit_code = main()
sys.exit(exit_code)
if __name__ == "__main__":
_main()
================================================
FILE: src/claude_monitor/_version.py
================================================
"""Version management utilities.
This module provides centralized version management that reads from pyproject.toml
as the single source of truth, avoiding version duplication across the codebase.
"""
import importlib.metadata
import sys
from pathlib import Path
from typing import Any, Dict, Optional, Union
def get_version() -> str:
"""Get version from package metadata.
This reads the version from the installed package metadata,
which is set from pyproject.toml during build/installation.
Returns:
Version string (e.g., "3.0.0")
"""
try:
return importlib.metadata.version("claude-monitor")
except importlib.metadata.PackageNotFoundError:
# Fallback for development environments where package isn't installed
return _get_version_from_pyproject()
def _get_version_from_pyproject() -> str:
"""Fallback: read version directly from pyproject.toml.
This is used when the package isn't installed (e.g., development mode).
Returns:
Version string or "unknown" if cannot be determined
"""
try:
# Python 3.11+
import tomllib
except ImportError:
try:
# Python < 3.11 fallback
import tomli as tomllib # type: ignore[import-untyped]
except ImportError:
# No TOML library available
return "unknown"
try:
# Find pyproject.toml - go up from this file's directory
current_dir = Path(__file__).parent
for _ in range(5): # Max 5 levels up
pyproject_path = current_dir / "pyproject.toml"
if pyproject_path.exists():
with open(pyproject_path, "rb") as f:
data: Dict[str, Any] = tomllib.load(f)
project_data: Dict[str, Any] = data.get("project", {})
version: str = project_data.get("version", "unknown")
return version
current_dir = current_dir.parent
return "unknown"
except Exception:
return "unknown"
def get_package_info() -> Dict[str, Optional[str]]:
"""Get comprehensive package information.
Returns:
Dictionary containing version, name, and metadata
"""
try:
metadata = importlib.metadata.metadata("claude-monitor")
return {
"version": get_version(),
"name": metadata.get("Name"),
"author": metadata.get("Author"),
"author_email": metadata.get("Author-email"),
"description": metadata.get("Summary"),
"home_page": metadata.get("Home-page"),
"license": metadata.get("License"),
}
except importlib.metadata.PackageNotFoundError:
return {
"version": _get_version_from_pyproject(),
"name": "claude-monitor",
"author": None,
"author_email": None,
"description": None,
"home_page": None,
"license": None,
}
def get_version_info() -> Dict[str, Any]:
"""Get detailed version and system information.
Returns:
Dictionary containing version, Python version, and system info
"""
return {
"version": get_version(),
"python_version": sys.version,
"python_version_info": {
"major": sys.version_info.major,
"minor": sys.version_info.minor,
"micro": sys.version_info.micro,
},
"platform": sys.platform,
"executable": sys.executable,
"package_info": get_package_info(),
}
def find_project_root(start_path: Optional[Union[str, Path]] = None) -> Optional[Path]:
"""Find the project root directory containing pyproject.toml.
Args:
start_path: Starting directory for search (defaults to current file location)
Returns:
Path to project root or None if not found
"""
if start_path is None:
current_dir = Path(__file__).parent
else:
current_dir = Path(start_path).resolve()
# Search up to 10 levels to find pyproject.toml
for _ in range(10):
if (current_dir / "pyproject.toml").exists():
return current_dir
parent = current_dir.parent
if parent == current_dir: # Reached filesystem root
break
current_dir = parent
return None
# Module-level version constant
__version__: str = get_version()
================================================
FILE: src/claude_monitor/cli/__init__.py
================================================
"""Claude Monitor CLI package."""
from .main import main
__all__ = ["main"]
================================================
FILE: src/claude_monitor/cli/bootstrap.py
================================================
"""Bootstrap utilities for CLI initialization."""
import logging
import os
import sys
from logging import Handler
from pathlib import Path
from typing import List, Optional
from claude_monitor.utils.time_utils import TimezoneHandler
def setup_logging(
level: str = "INFO", log_file: Optional[Path] = None, disable_console: bool = False
) -> None:
"""Configure logging for the application.
Args:
level: Log level (DEBUG, INFO, WARNING, ERROR, CRITICAL)
log_file: Optional file path for logging
disable_console: If True, disable console logging (useful for monitor mode)
"""
log_level = getattr(logging, level.upper(), logging.INFO)
handlers: List[Handler] = []
if not disable_console:
handlers.append(logging.StreamHandler(sys.stdout))
if log_file:
handlers.append(logging.FileHandler(log_file))
if not handlers:
handlers.append(logging.NullHandler())
logging.basicConfig(
level=log_level,
format="%(asctime)s - %(name)s - %(levelname)s - %(message)s",
handlers=handlers,
)
def setup_environment() -> None:
"""Initialize environment variables and system settings."""
if sys.stdout.encoding != "utf-8":
if hasattr(sys.stdout, "reconfigure"):
sys.stdout.reconfigure(encoding="utf-8") # type: ignore[attr-defined]
os.environ.setdefault(
"CLAUDE_MONITOR_CONFIG", str(Path.home() / ".claude-monitor" / "config.yaml")
)
os.environ.setdefault(
"CLAUDE_MONITOR_CACHE_DIR", str(Path.home() / ".claude-monitor" / "cache")
)
def init_timezone(timezone: str = "Europe/Warsaw") -> TimezoneHandler:
"""Initialize timezone handler.
Args:
timezone: Timezone string (e.g. "Europe/Warsaw", "UTC")
Returns:
Configured TimezoneHandler instance
"""
tz_handler = TimezoneHandler()
if timezone != "Europe/Warsaw":
tz_handler.set_timezone(timezone)
return tz_handler
def ensure_directories() -> None:
"""Ensure required directories exist."""
dirs = [
Path.home() / ".claude-monitor",
Path.home() / ".claude-monitor" / "cache",
Path.home() / ".claude-monitor" / "logs",
Path.home() / ".claude-monitor" / "reports",
]
for directory in dirs:
directory.mkdir(parents=True, exist_ok=True)
================================================
FILE: src/claude_monitor/cli/main.py
================================================
"""Simplified CLI entry point using pydantic-settings."""
import argparse
import contextlib
import logging
import signal
import sys
import time
import traceback
from pathlib import Path
from typing import Any, Callable, Dict, List, NoReturn, Optional, Union
from rich.console import Console
from claude_monitor import __version__
from claude_monitor.cli.bootstrap import (
ensure_directories,
init_timezone,
setup_environment,
setup_logging,
)
from claude_monitor.core.plans import Plans, PlanType, get_token_limit
from claude_monitor.core.settings import Settings
from claude_monitor.data.aggregator import UsageAggregator
from claude_monitor.data.analysis import analyze_usage
from claude_monitor.error_handling import report_error
from claude_monitor.monitoring.orchestrator import MonitoringOrchestrator
from claude_monitor.terminal.manager import (
enter_alternate_screen,
handle_cleanup_and_exit,
handle_error_and_exit,
restore_terminal,
setup_terminal,
)
from claude_monitor.terminal.themes import get_themed_console, print_themed
from claude_monitor.ui.display_controller import DisplayController
from claude_monitor.ui.table_views import TableViewsController
# Type aliases for CLI callbacks
DataUpdateCallback = Callable[[Dict[str, Any]], None]
SessionChangeCallback = Callable[[str, str, Optional[Dict[str, Any]]], None]
def get_standard_claude_paths() -> List[str]:
"""Get list of standard Claude data directory paths to check."""
return ["~/.claude/projects", "~/.config/claude/projects"]
def discover_claude_data_paths(custom_paths: Optional[List[str]] = None) -> List[Path]:
"""Discover all available Claude data directories.
Args:
custom_paths: Optional list of custom paths to check instead of standard ones
Returns:
List of Path objects for existing Claude data directories
"""
paths_to_check: List[str] = (
[str(p) for p in custom_paths] if custom_paths else get_standard_claude_paths()
)
discovered_paths: List[Path] = []
for path_str in paths_to_check:
path = Path(path_str).expanduser().resolve()
if path.exists() and path.is_dir():
discovered_paths.append(path)
return discovered_paths
def main(argv: Optional[List[str]] = None) -> int:
"""Main entry point with direct pydantic-settings integration."""
if argv is None:
argv = sys.argv[1:]
if "--version" in argv or "-v" in argv:
print(f"claude-monitor {__version__}")
return 0
try:
settings = Settings.load_with_last_used(argv)
setup_environment()
ensure_directories()
if settings.log_file:
setup_logging(settings.log_level, settings.log_file, disable_console=True)
else:
setup_logging(settings.log_level, disable_console=True)
init_timezone(settings.timezone)
args = settings.to_namespace()
_run_monitoring(args)
return 0
except KeyboardInterrupt:
print("\n\nMonitoring stopped by user.")
return 0
except Exception as e:
logger = logging.getLogger(__name__)
logger.error(f"Monitor failed: {e}", exc_info=True)
traceback.print_exc()
return 1
def _run_monitoring(args: argparse.Namespace) -> None:
"""Main monitoring implementation without facade."""
view_mode = getattr(args, "view", "realtime")
if hasattr(args, "theme") and args.theme:
console = get_themed_console(force_theme=args.theme.lower())
else:
console = get_themed_console()
old_terminal_settings = setup_terminal()
live_display_active: bool = False
try:
data_paths: List[Path] = discover_claude_data_paths()
if not data_paths:
print_themed("No Claude data directory found", style="error")
return
data_path: Path = data_paths[0]
logger = logging.getLogger(__name__)
logger.info(f"Using data path: {data_path}")
# Handle different view modes
if view_mode in ["daily", "monthly"]:
_run_table_view(args, data_path, view_mode, console)
return
token_limit: int = _get_initial_token_limit(args, str(data_path))
display_controller = DisplayController()
display_controller.live_manager._console = console
refresh_per_second: float = getattr(args, "refresh_per_second", 0.75)
logger.info(
f"Display refresh rate: {refresh_per_second} Hz ({1000 / refresh_per_second:.0f}ms)"
)
logger.info(f"Data refresh rate: {args.refresh_rate} seconds")
live_display = display_controller.live_manager.create_live_display(
auto_refresh=True, console=console, refresh_per_second=refresh_per_second
)
loading_display = display_controller.create_loading_display(
args.plan, args.timezone
)
enter_alternate_screen()
live_display_active = False
try:
# Enter live context and show loading screen immediately
live_display.__enter__()
live_display_active = True
live_display.update(loading_display)
orchestrator = MonitoringOrchestrator(
update_interval=(
args.refresh_rate if hasattr(args, "refresh_rate") else 10
),
data_path=str(data_path),
)
orchestrator.set_args(args)
# Setup monitoring callback
def on_data_update(monitoring_data: Dict[str, Any]) -> None:
"""Handle data updates from orchestrator."""
try:
data: Dict[str, Any] = monitoring_data.get("data", {})
blocks: List[Dict[str, Any]] = data.get("blocks", [])
logger.debug(f"Display data has {len(blocks)} blocks")
if blocks:
active_blocks: List[Dict[str, Any]] = [
b for b in blocks if b.get("isActive")
]
logger.debug(f"Active blocks: {len(active_blocks)}")
if active_blocks:
total_tokens: int = active_blocks[0].get("totalTokens", 0)
logger.debug(f"Active block tokens: {total_tokens}")
renderable = display_controller.create_data_display(
data, args, monitoring_data.get("token_limit", token_limit)
)
if live_display:
live_display.update(renderable)
except Exception as e:
logger.error(f"Display update error: {e}", exc_info=True)
report_error(
exception=e,
component="cli_main",
context_name="display_update_error",
)
# Register callbacks
orchestrator.register_update_callback(on_data_update)
# Optional: Register session change callback
def on_session_change(
event_type: str, session_id: str, session_data: Optional[Dict[str, Any]]
) -> None:
"""Handle session changes."""
if event_type == "session_start":
logger.info(f"New session detected: {session_id}")
elif event_type == "session_end":
logger.info(f"Session ended: {session_id}")
orchestrator.register_session_callback(on_session_change)
# Start monitoring
orchestrator.start()
# Wait for initial data
logger.info("Waiting for initial data...")
if not orchestrator.wait_for_initial_data(timeout=10.0):
logger.warning("Timeout waiting for initial data")
# Main loop - live display is already active
# Use signal.pause() for more efficient waiting
try:
signal.pause()
except AttributeError:
# Fallback for Windows which doesn't support signal.pause()
while True:
time.sleep(1)
finally:
# Stop monitoring first
if "orchestrator" in locals():
orchestrator.stop()
# Exit live display context if it was activated
if live_display_active:
with contextlib.suppress(Exception):
live_display.__exit__(None, None, None)
except KeyboardInterrupt:
# Clean exit from live display if it's active
if "live_display" in locals():
with contextlib.suppress(Exception):
live_display.__exit__(None, None, None)
handle_cleanup_and_exit(old_terminal_settings)
except Exception as e:
# Clean exit from live display if it's active
if "live_display" in locals():
with contextlib.suppress(Exception):
live_display.__exit__(None, None, None)
handle_error_and_exit(old_terminal_settings, e)
finally:
restore_terminal(old_terminal_settings)
def _get_initial_token_limit(
args: argparse.Namespace, data_path: Union[str, Path]
) -> int:
"""Get initial token limit for the plan."""
logger = logging.getLogger(__name__)
plan: str = getattr(args, "plan", PlanType.PRO.value)
# For custom plans, check if custom_limit_tokens is provided first
if plan == "custom":
# If custom_limit_tokens is explicitly set, use it
if hasattr(args, "custom_limit_tokens") and args.custom_limit_tokens:
custom_limit = int(args.custom_limit_tokens)
print_themed(
f"Using custom token limit: {custom_limit:,} tokens",
style="info",
)
return custom_limit
# Otherwise, analyze usage data to calculate P90
print_themed("Analyzing usage data to determine cost limits...", style="info")
try:
# Use quick start mode for faster initial load
usage_data: Optional[Dict[str, Any]] = analyze_usage(
hours_back=96 * 2,
quick_start=False,
use_cache=False,
data_path=str(data_path),
)
if usage_data and "blocks" in usage_data:
blocks: List[Dict[str, Any]] = usage_data["blocks"]
token_limit: int = get_token_limit(plan, blocks)
print_themed(
f"P90 session limit calculated: {token_limit:,} tokens",
style="info",
)
return token_limit
except Exception as e:
logger.warning(f"Failed to analyze usage data: {e}")
# Fallback to default limit
print_themed("Using default limit as fallback", style="warning")
return Plans.DEFAULT_TOKEN_LIMIT
# For standard plans, just get the limit
return get_token_limit(plan)
def handle_application_error(
exception: Exception,
component: str = "cli_main",
exit_code: int = 1,
) -> NoReturn:
"""Handle application-level errors with proper logging and exit.
Args:
exception: The exception that occurred
component: Component where the error occurred
exit_code: Exit code to use when terminating
"""
logger = logging.getLogger(__name__)
# Log the error with traceback
logger.error(f"Application error in {component}: {exception}", exc_info=True)
# Report to error handling system
from claude_monitor.error_handling import report_application_startup_error
report_application_startup_error(
exception=exception,
component=component,
additional_context={
"exit_code": exit_code,
"args": sys.argv,
},
)
# Print user-friendly error message
print(f"\nError: {exception}", file=sys.stderr)
print("For more details, check the log files.", file=sys.stderr)
sys.exit(exit_code)
def validate_cli_environment() -> Optional[str]:
"""Validate the CLI environment and return error message if invalid.
Returns:
Error message if validation fails, None if successful
"""
try:
# Check Python version compatibility
if sys.version_info < (3, 8):
return f"Python 3.8+ required, found {sys.version_info.major}.{sys.version_info.minor}"
# Check for required dependencies
required_modules = ["rich", "pydantic", "watchdog"]
missing_modules: List[str] = []
for module in required_modules:
try:
__import__(module)
except ImportError:
missing_modules.append(module)
if missing_modules:
return f"Missing required modules: {', '.join(missing_modules)}"
return None
except Exception as e:
return f"Environment validation failed: {e}"
def _run_table_view(
args: argparse.Namespace, data_path: Path, view_mode: str, console: Console
) -> None:
"""Run table view mode (daily/monthly)."""
logger = logging.getLogger(__name__)
try:
# Create aggregator with appropriate mode
aggregator = UsageAggregator(
data_path=str(data_path),
aggregation_mode=view_mode,
timezone=args.timezone,
)
# Create table controller
controller = TableViewsController(console=console)
# Get aggregated data
logger.info(f"Loading {view_mode} usage data...")
aggregated_data = aggregator.aggregate()
if not aggregated_data:
print_themed(f"No usage data found for {view_mode} view", style="warning")
return
# Display the table
controller.display_aggregated_view(
data=aggregated_data,
view_mode=view_mode,
timezone=args.timezone,
plan=args.plan,
token_limit=_get_initial_token_limit(args, data_path),
)
# Wait for user to press Ctrl+C
print_themed("\nPress Ctrl+C to exit", style="info")
try:
# Use signal.pause() for more efficient waiting
try:
signal.pause()
except AttributeError:
# Fallback for Windows which doesn't support signal.pause()
while True:
time.sleep(1)
except KeyboardInterrupt:
print_themed("\nExiting...", style="info")
except Exception as e:
logger.error(f"Error in table view: {e}", exc_info=True)
print_themed(f"Error displaying {view_mode} view: {e}", style="error")
if __name__ == "__main__":
sys.exit(main())
================================================
FILE: src/claude_monitor/core/__init__.py
================================================
"""Core package for Claude Monitor.
This module provides the core functionality for Claude usage monitoring,
including models, calculations, pricing, and session management.
"""
__all__: list[str] = []
================================================
FILE: src/claude_monitor/core/calculations.py
================================================
"""Burn rate and cost calculations for Claude Monitor."""
import logging
from datetime import datetime, timedelta, timezone
from typing import Any, Dict, List, Optional, Protocol
from claude_monitor.core.models import (
BurnRate,
TokenCounts,
UsageProjection,
)
from claude_monitor.core.p90_calculator import P90Calculator
from claude_monitor.error_handling import report_error
from claude_monitor.utils.time_utils import TimezoneHandler
logger: logging.Logger = logging.getLogger(__name__)
_p90_calculator: P90Calculator = P90Calculator()
class BlockLike(Protocol):
"""Protocol for objects that behave like session blocks."""
is_active: bool
duration_minutes: float
token_counts: TokenCounts
cost_usd: float
end_time: datetime
class BurnRateCalculator:
"""Calculates burn rates and usage projections for session blocks."""
def calculate_burn_rate(self, block: BlockLike) -> Optional[BurnRate]:
"""Calculate current consumption rate for active blocks."""
if not block.is_active or block.duration_minutes < 1:
return None
total_tokens = (
block.token_counts.input_tokens
+ block.token_counts.output_tokens
+ block.token_counts.cache_creation_tokens
+ block.token_counts.cache_read_tokens
)
if total_tokens == 0:
return None
tokens_per_minute = total_tokens / block.duration_minutes
cost_per_hour = (
(block.cost_usd / block.duration_minutes) * 60
if block.duration_minutes > 0
else 0
)
return BurnRate(
tokens_per_minute=tokens_per_minute, cost_per_hour=cost_per_hour
)
def project_block_usage(self, block: BlockLike) -> Optional[UsageProjection]:
"""Project total usage if current rate continues."""
burn_rate = self.calculate_burn_rate(block)
if not burn_rate:
return None
now = datetime.now(timezone.utc)
remaining_seconds = (block.end_time - now).total_seconds()
if remaining_seconds <= 0:
return None
remaining_minutes = remaining_seconds / 60
remaining_hours = remaining_minutes / 60
current_tokens = (
block.token_counts.input_tokens
+ block.token_counts.output_tokens
+ block.token_counts.cache_creation_tokens
+ block.token_counts.cache_read_tokens
)
current_cost = block.cost_usd
projected_additional_tokens = burn_rate.tokens_per_minute * remaining_minutes
projected_total_tokens = current_tokens + projected_additional_tokens
projected_additional_cost = burn_rate.cost_per_hour * remaining_hours
projected_total_cost = current_cost + projected_additional_cost
return UsageProjection(
projected_total_tokens=int(projected_total_tokens),
projected_total_cost=projected_total_cost,
remaining_minutes=int(remaining_minutes),
)
def calculate_hourly_burn_rate(
blocks: List[Dict[str, Any]], current_time: datetime
) -> float:
"""Calculate burn rate based on all sessions in the last hour."""
if not blocks:
return 0.0
one_hour_ago = current_time - timedelta(hours=1)
total_tokens = _calculate_total_tokens_in_hour(blocks, one_hour_ago, current_time)
return total_tokens / 60.0 if total_tokens > 0 else 0.0
def _calculate_total_tokens_in_hour(
blocks: List[Dict[str, Any]], one_hour_ago: datetime, current_time: datetime
) -> float:
"""Calculate total tokens for all blocks in the last hour."""
total_tokens = 0.0
for block in blocks:
total_tokens += _process_block_for_burn_rate(block, one_hour_ago, current_time)
return total_tokens
def _process_block_for_burn_rate(
block: Dict[str, Any], one_hour_ago: datetime, current_time: datetime
) -> float:
"""Process a single block for burn rate calculation."""
start_time = _parse_block_start_time(block)
if not start_time or block.get("isGap", False):
return 0
session_actual_end = _determine_session_end_time(block, current_time)
if session_actual_end < one_hour_ago:
return 0
return _calculate_tokens_in_hour(
block, start_time, session_actual_end, one_hour_ago, current_time
)
def _parse_block_start_time(block: Dict[str, Any]) -> Optional[datetime]:
"""Parse start time from block with error handling."""
start_time_str = block.get("startTime")
if not start_time_str:
return None
tz_handler = TimezoneHandler()
try:
start_time = tz_handler.parse_timestamp(start_time_str)
return tz_handler.ensure_utc(start_time)
except (ValueError, TypeError, AttributeError) as e:
_log_timestamp_error(e, start_time_str, block.get("id"), "start_time")
return None
def _determine_session_end_time(
block: Dict[str, Any], current_time: datetime
) -> datetime:
"""Determine session end time based on block status."""
if block.get("isActive", False):
return current_time
actual_end_str = block.get("actualEndTime")
if actual_end_str:
tz_handler = TimezoneHandler()
try:
session_actual_end = tz_handler.parse_timestamp(actual_end_str)
return tz_handler.ensure_utc(session_actual_end)
except (ValueError, TypeError, AttributeError) as e:
_log_timestamp_error(e, actual_end_str, block.get("id"), "actual_end_time")
return current_time
def _calculate_tokens_in_hour(
block: Dict[str, Any],
start_time: datetime,
session_actual_end: datetime,
one_hour_ago: datetime,
current_time: datetime,
) -> float:
"""Calculate tokens used within the last hour for this session."""
session_start_in_hour = max(start_time, one_hour_ago)
session_end_in_hour = min(session_actual_end, current_time)
if session_end_in_hour <= session_start_in_hour:
return 0
total_session_duration = (session_actual_end - start_time).total_seconds() / 60
hour_duration = (session_end_in_hour - session_start_in_hour).total_seconds() / 60
if total_session_duration > 0:
session_tokens = block.get("totalTokens", 0)
return session_tokens * (hour_duration / total_session_duration)
return 0
def _log_timestamp_error(
exception: Exception,
timestamp_str: str,
block_id: Optional[str],
timestamp_type: str,
) -> None:
"""Log timestamp parsing errors with context."""
logging.debug(f"Failed to parse {timestamp_type} '{timestamp_str}': {exception}")
report_error(
exception=exception,
component="burn_rate_calculator",
context_name="timestamp_error",
context_data={f"{timestamp_type}_str": timestamp_str, "block_id": block_id},
)
================================================
FILE: src/claude_monitor/core/data_processors.py
================================================
"""Centralized data processing utilities for Claude Monitor.
This module provides unified data processing functionality to eliminate
code duplication across different components.
"""
from datetime import datetime
from typing import Any, Dict, List, Optional, Union
from claude_monitor.utils.time_utils import TimezoneHandler
class TimestampProcessor:
"""Unified timestamp parsing and processing utilities."""
def __init__(self, timezone_handler: Optional[TimezoneHandler] = None) -> None:
"""Initialize with optional timezone handler."""
self.timezone_handler: TimezoneHandler = timezone_handler or TimezoneHandler()
def parse_timestamp(
self, timestamp_value: Union[str, int, float, datetime, None]
) -> Optional[datetime]:
"""Parse timestamp from various formats to UTC datetime.
Args:
timestamp_value: Timestamp in various formats (str, int, float, datetime)
Returns:
Parsed UTC datetime or None if parsing fails
"""
if timestamp_value is None:
return None
try:
if isinstance(timestamp_value, datetime):
return self.timezone_handler.ensure_timezone(timestamp_value)
if isinstance(timestamp_value, str):
if timestamp_value.endswith("Z"):
timestamp_value = timestamp_value[:-1] + "+00:00"
try:
dt = datetime.fromisoformat(timestamp_value)
return self.timezone_handler.ensure_timezone(dt)
except ValueError:
pass
for fmt in ["%Y-%m-%dT%H:%M:%S.%f", "%Y-%m-%dT%H:%M:%S"]:
try:
dt = datetime.strptime(timestamp_value, fmt)
return self.timezone_handler.ensure_timezone(dt)
except ValueError:
continue
if isinstance(timestamp_value, (int, float)):
dt = datetime.fromtimestamp(timestamp_value)
return self.timezone_handler.ensure_timezone(dt)
except Exception:
pass
return None
class TokenExtractor:
"""Unified token extraction utilities."""
@staticmethod
def extract_tokens(data: Dict[str, Any]) -> Dict[str, int]:
"""Extract token counts from data in standardized format.
Args:
data: Data dictionary with token information
Returns:
Dictionary with standardized token keys and counts
"""
import logging
logger = logging.getLogger(__name__)
tokens: Dict[str, int] = {
"input_tokens": 0,
"output_tokens": 0,
"cache_creation_tokens": 0,
"cache_read_tokens": 0,
"total_tokens": 0,
}
token_sources: List[Dict[str, Any]] = []
is_assistant: bool = data.get("type") == "assistant"
if is_assistant:
if (
"message" in data
and isinstance(data["message"], dict)
and "usage" in data["message"]
):
token_sources.append(data["message"]["usage"])
if "usage" in data:
token_sources.append(data["usage"])
token_sources.append(data)
else:
if "usage" in data:
token_sources.append(data["usage"])
if (
"message" in data
and isinstance(data["message"], dict)
and "usage" in data["message"]
):
token_sources.append(data["message"]["usage"])
token_sources.append(data)
logger.debug(f"TokenExtractor: Checking {len(token_sources)} token sources")
for source in token_sources:
if not isinstance(source, dict):
continue
input_tokens = (
source.get("input_tokens", 0)
or source.get("inputTokens", 0)
or source.get("prompt_tokens", 0)
or 0
)
output_tokens = (
source.get("output_tokens", 0)
or source.get("outputTokens", 0)
or source.get("completion_tokens", 0)
or 0
)
cache_creation = (
source.get("cache_creation_tokens", 0)
or source.get("cache_creation_input_tokens", 0)
or source.get("cacheCreationInputTokens", 0)
or 0
)
cache_read = (
source.get("cache_read_input_tokens", 0)
or source.get("cache_read_tokens", 0)
or source.get("cacheReadInputTokens", 0)
or 0
)
if input_tokens > 0 or output_tokens > 0:
tokens.update(
{
"input_tokens": int(input_tokens),
"output_tokens": int(output_tokens),
"cache_creation_tokens": int(cache_creation),
"cache_read_tokens": int(cache_read),
"total_tokens": int(
input_tokens + output_tokens + cache_creation + cache_read
),
}
)
logger.debug(
f"TokenExtractor: Found tokens - input={input_tokens}, output={output_tokens}, cache_creation={cache_creation}, cache_read={cache_read}"
)
break
logger.debug(
f"TokenExtractor: No valid tokens in source: {list(source.keys()) if isinstance(source, dict) else 'not a dict'}"
)
return tokens
class DataConverter:
"""Unified data conversion utilities."""
@staticmethod
def flatten_nested_dict(data: Dict[str, Any], prefix: str = "") -> Dict[str, Any]:
"""Flatten nested dictionary structure.
Args:
data: Nested dictionary
prefix: Prefix for flattened keys
Returns:
Flattened dictionary
"""
result: Dict[str, Any] = {}
for key, value in data.items():
new_key = f"{prefix}.{key}" if prefix else key
if isinstance(value, dict):
result.update(DataConverter.flatten_nested_dict(value, new_key))
else:
result[new_key] = value
return result
@staticmethod
def extract_model_name(
data: Dict[str, Any], default: str = "claude-3-5-sonnet"
) -> str:
"""Extract model name from various data sources.
Args:
data: Data containing model information
default: Default model name if not found
Returns:
Extracted model name
"""
model_candidates: List[Optional[Any]] = [
data.get("message", {}).get("model"),
data.get("model"),
data.get("Model"),
data.get("usage", {}).get("model"),
data.get("request", {}).get("model"),
]
for candidate in model_candidates:
if candidate and isinstance(candidate, str):
return candidate
return default
@staticmethod
def to_serializable(obj: Any) -> Any:
"""Convert object to JSON-serializable format.
Args:
obj: Object to convert
Returns:
JSON-serializable representation
"""
if isinstance(obj, datetime):
return obj.isoformat()
if isinstance(obj, dict):
return {k: DataConverter.to_serializable(v) for k, v in obj.items()}
if isinstance(obj, (list, tuple)):
return [DataConverter.to_serializable(item) for item in obj]
return obj
================================================
FILE: src/claude_monitor/core/models.py
================================================
"""Data models for Claude Monitor.
Core data structures for usage tracking, session management, and token calculations.
"""
from dataclasses import dataclass, field
from datetime import datetime
from enum import Enum
from typing import Any, Dict, List, Optional
class CostMode(Enum):
"""Cost calculation modes for token usage analysis."""
AUTO = "auto"
CACHED = "cached"
CALCULATED = "calculate"
@dataclass
class UsageEntry:
"""Individual usage record from Claude usage data."""
timestamp: datetime
input_tokens: int
output_tokens: int
cache_creation_tokens: int = 0
cache_read_tokens: int = 0
cost_usd: float = 0.0
model: str = ""
message_id: str = ""
request_id: str = ""
@dataclass
class TokenCounts:
"""Token aggregation structure with computed totals."""
input_tokens: int = 0
output_tokens: int = 0
cache_creation_tokens: int = 0
cache_read_tokens: int = 0
@property
def total_tokens(self) -> int:
"""Get total tokens across all types."""
return (
self.input_tokens
+ self.output_tokens
+ self.cache_creation_tokens
+ self.cache_read_tokens
)
@dataclass
class BurnRate:
"""Token consumption rate metrics."""
tokens_per_minute: float
cost_per_hour: float
@dataclass
class UsageProjection:
"""Usage projection calculations for active blocks."""
projected_total_tokens: int
projected_total_cost: float
remaining_minutes: float
@dataclass
class SessionBlock:
"""Aggregated session block representing a 5-hour period."""
id: str
start_time: datetime
end_time: datetime
entries: List[UsageEntry] = field(default_factory=list)
token_counts: TokenCounts = field(default_factory=TokenCounts)
is_active: bool = False
is_gap: bool = False
burn_rate: Optional[BurnRate] = None
actual_end_time: Optional[datetime] = None
per_model_stats: Dict[str, Dict[str, Any]] = field(default_factory=dict)
models: List[str] = field(default_factory=list)
sent_messages_count: int = 0
cost_usd: float = 0.0
limit_messages: List[Dict[str, Any]] = field(default_factory=list)
projection_data: Optional[Dict[str, Any]] = None
burn_rate_snapshot: Optional[BurnRate] = None
@property
def total_tokens(self) -> int:
"""Get total tokens from token_counts."""
return self.token_counts.total_tokens
@property
def total_cost(self) -> float:
"""Get total cost - alias for cost_usd."""
return self.cost_usd
@property
def duration_minutes(self) -> float:
"""Get duration in minutes."""
if self.actual_end_time:
duration = (self.actual_end_time - self.start_time).total_seconds() / 60
else:
duration = (self.end_time - self.start_time).total_seconds() / 60
return max(duration, 1.0)
def normalize_model_name(model: str) -> str:
"""Normalize model name for consistent usage across the application.
Handles various model name formats and maps them to standard keys.
(Moved from utils/model_utils.py)
Args:
model: Raw model name from usage data
Returns:
Normalized model key
Examples:
>>> normalize_model_name("claude-3-opus-20240229")
'claude-3-opus'
>>> normalize_model_name("Claude 3.5 Sonnet")
'claude-3-5-sonnet'
"""
if not model:
return ""
model_lower = model.lower()
if (
"claude-opus-4-" in model_lower
or "claude-sonnet-4-" in model_lower
or "claude-haiku-4-" in model_lower
or "sonnet-4-" in model_lower
or "opus-4-" in model_lower
or "haiku-4-" in model_lower
):
return model_lower
if "opus" in model_lower:
if "4-" in model_lower:
return model_lower
return "claude-3-opus"
if "sonnet" in model_lower:
if "4-" in model_lower:
return model_lower
if "3.5" in model_lower or "3-5" in model_lower:
return "claude-3-5-sonnet"
return "claude-3-sonnet"
if "haiku" in model_lower:
if "3.5" in model_lower or "3-5" in model_lower:
return "claude-3-5-haiku"
return "claude-3-haiku"
return model
================================================
FILE: src/claude_monitor/core/p90_calculator.py
================================================
import time
from collections.abc import Sequence
from dataclasses import dataclass
from functools import lru_cache
from statistics import quantiles
from typing import Any, Callable, Dict, List, Optional, Tuple
@dataclass(frozen=True)
class P90Config:
common_limits: Sequence[int]
limit_threshold: float
default_min_limit: int
cache_ttl_seconds: int
def _did_hit_limit(tokens: int, common_limits: Sequence[int], threshold: float) -> bool:
return any(tokens >= limit * threshold for limit in common_limits)
def _extract_sessions(
blocks: Sequence[Dict[str, Any]], filter_fn: Callable[[Dict[str, Any]], bool]
) -> List[int]:
return [
block["totalTokens"]
for block in blocks
if filter_fn(block) and block.get("totalTokens", 0) > 0
]
def _calculate_p90_from_blocks(blocks: Sequence[Dict[str, Any]], cfg: P90Config) -> int:
hits = _extract_sessions(
blocks,
lambda b: (
not b.get("isGap", False)
and not b.get("isActive", False)
and _did_hit_limit(
b.get("totalTokens", 0), cfg.common_limits, cfg.limit_threshold
)
),
)
if not hits:
hits = _extract_sessions(
blocks, lambda b: not b.get("isGap", False) and not b.get("isActive", False)
)
if not hits:
return cfg.default_min_limit
q: float = quantiles(hits, n=10)[8]
return max(int(q), cfg.default_min_limit)
class P90Calculator:
def __init__(self, config: Optional[P90Config] = None) -> None:
if config is None:
from claude_monitor.core.plans import (
COMMON_TOKEN_LIMITS,
DEFAULT_TOKEN_LIMIT,
LIMIT_DETECTION_THRESHOLD,
)
config = P90Config(
common_limits=COMMON_TOKEN_LIMITS,
limit_threshold=LIMIT_DETECTION_THRESHOLD,
default_min_limit=DEFAULT_TOKEN_LIMIT,
cache_ttl_seconds=60 * 60,
)
self._cfg: P90Config = config
@lru_cache(maxsize=1)
def _cached_calc(
self, key: int, blocks_tuple: Tuple[Tuple[bool, bool, int], ...]
) -> int:
blocks: List[Dict[str, Any]] = [
{"isGap": g, "isActive": a, "totalTokens": t} for g, a, t in blocks_tuple
]
return _calculate_p90_from_blocks(blocks, self._cfg)
def calculate_p90_limit(
self,
blocks: Optional[List[Dict[str, Any]]] = None,
use_cache: bool = True,
) -> Optional[int]:
if not blocks:
return None
if not use_cache:
return _calculate_p90_from_blocks(blocks, self._cfg)
ttl: int = self._cfg.cache_ttl_seconds
expire_key: int = int(time.time() // ttl)
blocks_tuple: Tuple[Tuple[bool, bool, int], ...] = tuple(
(
b.get("isGap", False),
b.get("isActive", False),
b.get("totalTokens", 0),
)
for b in blocks
)
return self._cached_calc(expire_key, blocks_tuple)
================================================
FILE: src/claude_monitor/core/plans.py
================================================
"""Centralized plan configuration for Claude Monitor.
All plan limits (token, message, cost) live in one place (PLAN_LIMITS).
Shared constants (defaults, common limits, threshold) are exposed on the Plans class.
"""
from dataclasses import dataclass
from enum import Enum
from typing import Any, Dict, List, Optional
class PlanType(Enum):
"""Available Claude subscription plan types."""
PRO = "pro"
MAX5 = "max5"
MAX20 = "max20"
CUSTOM = "custom"
@classmethod
def from_string(cls, value: str) -> "PlanType":
"""Case-insensitive creation of PlanType from a string."""
try:
return cls(value.lower())
except ValueError:
raise ValueError(f"Unknown plan type: {value}")
@dataclass(frozen=True)
class PlanConfig:
"""Immutable configuration for a Claude subscription plan."""
name: str
token_limit: int
cost_limit: float
message_limit: int
display_name: str
@property
def formatted_token_limit(self) -> str:
"""Human-readable token limit (e.g., '19k' instead of '19000')."""
if self.token_limit >= 1_000:
return f"{self.token_limit // 1_000}k"
return str(self.token_limit)
PLAN_LIMITS: Dict[PlanType, Dict[str, Any]] = {
PlanType.PRO: {
"token_limit": 19_000,
"cost_limit": 18.0,
"message_limit": 250,
"display_name": "Pro",
},
PlanType.MAX5: {
"token_limit": 88_000,
"cost_limit": 35.0,
"message_limit": 1_000,
"display_name": "Max5",
},
PlanType.MAX20: {
"token_limit": 220_000,
"cost_limit": 140.0,
"message_limit": 2_000,
"display_name": "Max20",
},
PlanType.CUSTOM: {
"token_limit": 44_000,
"cost_limit": 50.0,
"message_limit": 250,
"display_name": "Custom",
},
}
_DEFAULTS: Dict[str, Any] = {
"token_limit": PLAN_LIMITS[PlanType.PRO]["token_limit"],
"cost_limit": PLAN_LIMITS[PlanType.CUSTOM]["cost_limit"],
"message_limit": PLAN_LIMITS[PlanType.PRO]["message_limit"],
}
class Plans:
"""Registry and shared constants for all plan configurations."""
DEFAULT_TOKEN_LIMIT: int = _DEFAULTS["token_limit"]
DEFAULT_COST_LIMIT: float = _DEFAULTS["cost_limit"]
DEFAULT_MESSAGE_LIMIT: int = _DEFAULTS["message_limit"]
COMMON_TOKEN_LIMITS: List[int] = [19_000, 88_000, 220_000, 880_000]
LIMIT_DETECTION_THRESHOLD: float = 0.95
@classmethod
def _build_config(cls, plan_type: PlanType) -> PlanConfig:
"""Instantiate PlanConfig from the PLAN_LIMITS dictionary."""
data = PLAN_LIMITS[plan_type]
return PlanConfig(
name=plan_type.value,
token_limit=data["token_limit"],
cost_limit=data["cost_limit"],
message_limit=data["message_limit"],
display_name=data["display_name"],
)
@classmethod
def all_plans(cls) -> Dict[PlanType, PlanConfig]:
"""Return a copy of all available plan configurations."""
return {pt: cls._build_config(pt) for pt in PLAN_LIMITS}
@classmethod
def get_plan(cls, plan_type: PlanType) -> PlanConfig:
"""Get configuration for a specific PlanType."""
return cls._build_config(plan_type)
@classmethod
def get_plan_by_name(cls, name: str) -> Optional[PlanConfig]:
"""Get PlanConfig by its string name (case-insensitive)."""
try:
pt = PlanType.from_string(name)
return cls.get_plan(pt)
except ValueError:
return None
@classmethod
def get_token_limit(
cls, plan: str, blocks: Optional[List[Dict[str, Any]]] = None
) -> int:
"""
Get the token limit for a plan.
For "custom" plans, if `blocks` are provided, compute the P90 limit.
Otherwise, return the predefined limit or default.
"""
cfg = cls.get_plan_by_name(plan)
if cfg is None:
return cls.DEFAULT_TOKEN_LIMIT
if cfg.name == PlanType.CUSTOM.value and blocks:
from claude_monitor.core.p90_calculator import P90Calculator
p90_limit = P90Calculator().calculate_p90_limit(blocks)
if p90_limit:
return p90_limit
return cfg.token_limit
@classmethod
def get_cost_limit(cls, plan: str) -> float:
"""Get the cost limit for a plan, or default if invalid."""
cfg = cls.get_plan_by_name(plan)
return cfg.cost_limit if cfg else cls.DEFAULT_COST_LIMIT
@classmethod
def get_message_limit(cls, plan: str) -> int:
"""Get the message limit for a plan, or default if invalid."""
cfg = cls.get_plan_by_name(plan)
return cfg.message_limit if cfg else cls.DEFAULT_MESSAGE_LIMIT
@classmethod
def is_valid_plan(cls, plan: str) -> bool:
"""Check whether a given plan name is recognized."""
return cls.get_plan_by_name(plan) is not None
TOKEN_LIMITS: Dict[str, int] = {
plan.value: config.token_limit
for plan, config in Plans.all_plans().items()
if plan != PlanType.CUSTOM
}
DEFAULT_TOKEN_LIMIT: int = Plans.DEFAULT_TOKEN_LIMIT
COMMON_TOKEN_LIMITS: List[int] = Plans.COMMON_TOKEN_LIMITS
LIMIT_DETECTION_THRESHOLD: float = Plans.LIMIT_DETECTION_THRESHOLD
COST_LIMITS: Dict[str, float] = {
plan.value: config.cost_limit
for plan, config in Plans.all_plans().items()
if plan != PlanType.CUSTOM
}
DEFAULT_COST_LIMIT: float = Plans.DEFAULT_COST_LIMIT
def get_token_limit(plan: str, blocks: Optional[List[Dict[str, Any]]] = None) -> int:
"""Get token limit for a plan, using P90 for custom plans.
Args:
plan: Plan type ('pro', 'max5', 'max20', 'custom')
blocks: Optional session blocks for custom P90 calculation
Returns:
Token limit for the plan
"""
return Plans.get_token_limit(plan, blocks)
def get_cost_limit(plan: str) -> float:
"""Get standard cost limit for a plan.
Args:
plan: Plan type ('pro', 'max5', 'max20', 'custom')
Returns:
Cost limit for the plan in USD
"""
return Plans.get_cost_limit(plan)
================================================
FILE: src/claude_monitor/core/pricing.py
================================================
"""Pricing calculations for Claude models.
This module provides the PricingCalculator class for calculating costs
based on token usage and model pricing. It supports all Claude model types
(Opus, Sonnet, Haiku) and provides both simple and detailed cost calculations
with caching.
"""
from typing import Any, Dict, Optional
from claude_monitor.core.models import CostMode, TokenCounts, normalize_model_name
class PricingCalculator:
"""Calculates costs based on model pricing with caching support.
This class provides methods for calculating costs for individual models/tokens
as well as detailed cost breakdowns for collections of usage entries.
It supports custom pricing configurations and caches calculations for performance.
Features:
- Configurable pricing (from config or custom)
- Fallback hardcoded pricing for robustness
- Caching for performance
- Support for all token types including cache
- Backward compatible with both APIs
"""
FALLBACK_PRICING: Dict[str, Dict[str, float]] = {
"opus": {
"input": 15.0,
"output": 75.0,
"cache_creation": 18.75,
"cache_read": 1.5,
},
"sonnet": {
"input": 3.0,
"output": 15.0,
"cache_creation": 3.75,
"cache_read": 0.3,
},
"haiku": {
"input": 0.25,
"output": 1.25,
"cache_creation": 0.3,
"cache_read": 0.03,
},
}
def __init__(
self, custom_pricing: Optional[Dict[str, Dict[str, float]]] = None
) -> None:
"""Initialize with optional custom pricing.
Args:
custom_pricing: Optional custom pricing dictionary to override defaults.
Should follow same structure as MODEL_PRICING.
"""
# Use fallback pricing if no custom pricing provided
self.pricing: Dict[str, Dict[str, float]] = custom_pricing or {
"claude-3-opus": self.FALLBACK_PRICING["opus"],
"claude-3-sonnet": self.FALLBACK_PRICING["sonnet"],
"claude-3-haiku": self.FALLBACK_PRICING["haiku"],
"claude-3-5-sonnet": self.FALLBACK_PRICING["sonnet"],
"claude-3-5-haiku": self.FALLBACK_PRICING["haiku"],
"claude-sonnet-4-20250514": self.FALLBACK_PRICING["sonnet"],
"claude-opus-4-20250514": self.FALLBACK_PRICING["opus"],
}
self._cost_cache: Dict[str, float] = {}
def calculate_cost(
self,
model: str,
input_tokens: int = 0,
output_tokens: int = 0,
cache_creation_tokens: int = 0,
cache_read_tokens: int = 0,
tokens: Optional[TokenCounts] = None,
strict: bool = False,
) -> float:
"""Calculate cost with flexible API supporting both signatures.
Args:
model: Model name
input_tokens: Number of input tokens (ignored if tokens provided)
output_tokens: Number of output tokens (ignored if tokens provided)
cache_creation_tokens: Number of cache creation tokens
cache_read_tokens: Number of cache read tokens
tokens: Optional TokenCounts object (takes precedence)
Returns:
Total cost in USD
"""
# Handle synthetic model
if model == "":
return 0.0
# Support TokenCounts object
if tokens is not None:
input_tokens = tokens.input_tokens
output_tokens = tokens.output_tokens
cache_creation_tokens = tokens.cache_creation_tokens
cache_read_tokens = tokens.cache_read_tokens
# Create cache key
cache_key = (
f"{model}:{input_tokens}:{output_tokens}:"
f"{cache_creation_tokens}:{cache_read_tokens}"
)
# Check cache
if cache_key in self._cost_cache:
return self._cost_cache[cache_key]
# Get pricing for model
pricing = self._get_pricing_for_model(model, strict=strict)
# Calculate costs (pricing is per million tokens)
cost = (
(input_tokens / 1_000_000) * pricing["input"]
+ (output_tokens / 1_000_000) * pricing["output"]
+ (cache_creation_tokens / 1_000_000)
* pricing.get("cache_creation", pricing["input"] * 1.25)
+ (cache_read_tokens / 1_000_000)
* pricing.get("cache_read", pricing["input"] * 0.1)
)
# Round to 6 decimal places
cost = round(cost, 6)
# Cache result
self._cost_cache[cache_key] = cost
return cost
def _get_pricing_for_model(
self, model: str, strict: bool = False
) -> Dict[str, float]:
"""Get pricing for a model with optional fallback logic.
Args:
model: Model name
strict: If True, raise KeyError for unknown models
Returns:
Pricing dictionary with input/output/cache costs
Raises:
KeyError: If strict=True and model is unknown
"""
# Try normalized model name first
normalized = normalize_model_name(model)
# Check configured pricing
if normalized in self.pricing:
pricing = self.pricing[normalized]
# Ensure cache pricing exists
if "cache_creation" not in pricing:
pricing["cache_creation"] = pricing["input"] * 1.25
if "cache_read" not in pricing:
pricing["cache_read"] = pricing["input"] * 0.1
return pricing
# Check original model name
if model in self.pricing:
pricing = self.pricing[model]
if "cache_creation" not in pricing:
pricing["cache_creation"] = pricing["input"] * 1.25
if "cache_read" not in pricing:
pricing["cache_read"] = pricing["input"] * 0.1
return pricing
# If strict mode, raise KeyError for unknown models
if strict:
raise KeyError(f"Unknown model: {model}")
# Fallback to hardcoded pricing based on model type
model_lower = model.lower()
if "opus" in model_lower:
return self.FALLBACK_PRICING["opus"]
if "haiku" in model_lower:
return self.FALLBACK_PRICING["haiku"]
# Default to Sonnet pricing
return self.FALLBACK_PRICING["sonnet"]
def calculate_cost_for_entry(
self, entry_data: Dict[str, Any], mode: CostMode
) -> float:
"""Calculate cost for a single entry (backward compatibility).
Args:
entry_data: Entry data dictionary
mode: Cost mode (for backward compatibility)
Returns:
Cost in USD
"""
# If cost is present and mode is cached, use it
if mode.value == "cached":
cost_value = entry_data.get("costUSD") or entry_data.get("cost_usd")
if cost_value is not None:
return float(cost_value)
# Otherwise calculate from tokens
model = entry_data.get("model") or entry_data.get("Model")
if not model:
raise KeyError("Missing 'model' key in entry_data")
# Extract token counts with different possible keys
input_tokens = entry_data.get("inputTokens", 0) or entry_data.get(
"input_tokens", 0
)
output_tokens = entry_data.get("outputTokens", 0) or entry_data.get(
"output_tokens", 0
)
cache_creation = entry_data.get(
"cacheCreationInputTokens", 0
) or entry_data.get("cache_creation_tokens", 0)
cache_read = (
entry_data.get("cacheReadInputTokens", 0)
or entry_data.get("cache_read_input_tokens", 0)
or entry_data.get("cache_read_tokens", 0)
)
return self.calculate_cost(
model=model,
input_tokens=input_tokens,
output_tokens=output_tokens,
cache_creation_tokens=cache_creation,
cache_read_tokens=cache_read,
)
================================================
FILE: src/claude_monitor/core/settings.py
================================================
"""Simplified settings management with CLI and last used params only."""
import argparse
import json
import logging
from datetime import datetime
from pathlib import Path
from typing import Any, Dict, List, Literal, Optional, Tuple
import pytz
from pydantic import Field, field_validator
from pydantic_settings import BaseSettings, SettingsConfigDict
from claude_monitor import __version__
logger = logging.getLogger(__name__)
class LastUsedParams:
"""Manages last used parameters persistence (moved from last_used.py)."""
def __init__(self, config_dir: Optional[Path] = None) -> None:
"""Initialize with config directory."""
self.config_dir = config_dir or Path.home() / ".claude-monitor"
self.params_file = self.config_dir / "last_used.json"
def save(self, settings: "Settings") -> None:
"""Save current settings as last used."""
try:
params = {
"theme": settings.theme,
"timezone": settings.timezone,
"time_format": settings.time_format,
"refresh_rate": settings.refresh_rate,
"reset_hour": settings.reset_hour,
"view": settings.view,
"timestamp": datetime.now().isoformat(),
}
if settings.custom_limit_tokens:
params["custom_limit_tokens"] = settings.custom_limit_tokens
self.config_dir.mkdir(parents=True, exist_ok=True)
temp_file = self.params_file.with_suffix(".tmp")
with open(temp_file, "w") as f:
json.dump(params, f, indent=2)
temp_file.replace(self.params_file)
logger.debug(f"Saved last used params to {self.params_file}")
except Exception as e:
logger.warning(f"Failed to save last used params: {e}")
def load(self) -> Dict[str, Any]:
"""Load last used parameters."""
if not self.params_file.exists():
return {}
try:
with open(self.params_file) as f:
params = json.load(f)
params.pop("timestamp", None)
logger.debug(f"Loaded last used params from {self.params_file}")
return params
except Exception as e:
logger.warning(f"Failed to load last used params: {e}")
return {}
def clear(self) -> None:
"""Clear last used parameters."""
try:
if self.params_file.exists():
self.params_file.unlink()
logger.debug("Cleared last used params")
except Exception as e:
logger.warning(f"Failed to clear last used params: {e}")
def exists(self) -> bool:
"""Check if last used params exist."""
return self.params_file.exists()
class Settings(BaseSettings):
"""claude-monitor - Real-time token usage monitoring for Claude AI"""
model_config = SettingsConfigDict(
env_file=None,
env_prefix="",
case_sensitive=False,
validate_default=True,
extra="ignore",
cli_parse_args=True,
cli_prog_name="claude-monitor",
cli_kebab_case=True,
cli_implicit_flags=True,
)
plan: Literal["pro", "max5", "max20", "custom"] = Field(
default="custom",
description="Plan type (pro, max5, max20, custom)",
)
view: Literal["realtime", "daily", "monthly", "session"] = Field(
default="realtime",
description="View mode (realtime, daily, monthly, session)",
)
@staticmethod
def _get_system_timezone() -> str:
"""Lazy import to avoid circular dependencies."""
from claude_monitor.utils.time_utils import get_system_timezone
return get_system_timezone()
@staticmethod
def _get_system_time_format() -> str:
"""Lazy import to avoid circular dependencies."""
from claude_monitor.utils.time_utils import get_system_time_format
return get_system_time_format()
timezone: str = Field(
default="auto",
description="Timezone for display (auto-detected from system). Examples: UTC, America/New_York, Europe/London, Europe/Warsaw, Asia/Tokyo, Australia/Sydney",
)
time_format: str = Field(
default="auto",
description="Time format (12h or 24h, auto-detected from system)",
)
theme: Literal["light", "dark", "classic", "auto"] = Field(
default="auto",
description="Display theme (light, dark, classic, auto)",
)
custom_limit_tokens: Optional[int] = Field(
default=None, gt=0, description="Token limit for custom plan"
)
refresh_rate: int = Field(
default=10, ge=1, le=60, description="Refresh rate in seconds"
)
refresh_per_second: float = Field(
default=0.75,
ge=0.1,
le=20.0,
description="Display refresh rate per second (0.1-20 Hz). Higher values use more CPU",
)
reset_hour: Optional[int] = Field(
default=None, ge=0, le=23, description="Reset hour for daily limits (0-23)"
)
log_level: str = Field(default="INFO", description="Logging level")
log_file: Optional[Path] = Field(default=None, description="Log file path")
debug: bool = Field(
default=False,
description="Enable debug logging (equivalent to --log-level DEBUG)",
)
version: bool = Field(default=False, description="Show version information")
clear: bool = Field(default=False, description="Clear saved configuration")
@field_validator("plan", mode="before")
@classmethod
def validate_plan(cls, v: Any) -> str:
"""Validate and normalize plan value."""
if isinstance(v, str):
v_lower = v.lower()
valid_plans = ["pro", "max5", "max20", "custom"]
if v_lower in valid_plans:
return v_lower
raise ValueError(
f"Invalid plan: {v}. Must be one of: {', '.join(valid_plans)}"
)
return v
@field_validator("view", mode="before")
@classmethod
def validate_view(cls, v: Any) -> str:
"""Validate and normalize view value."""
if isinstance(v, str):
v_lower = v.lower()
valid_views = ["realtime", "daily", "monthly", "session"]
if v_lower in valid_views:
return v_lower
raise ValueError(
f"Invalid view: {v}. Must be one of: {', '.join(valid_views)}"
)
return v
@field_validator("theme", mode="before")
@classmethod
def validate_theme(cls, v: Any) -> str:
"""Validate and normalize theme value."""
if isinstance(v, str):
v_lower = v.lower()
valid_themes = ["light", "dark", "classic", "auto"]
if v_lower in valid_themes:
return v_lower
raise ValueError(
f"Invalid theme: {v}. Must be one of: {', '.join(valid_themes)}"
)
return v
@field_validator("timezone")
@classmethod
def validate_timezone(cls, v: str) -> str:
"""Validate timezone."""
if v not in ["local", "auto"] and v not in pytz.all_timezones:
raise ValueError(f"Invalid timezone: {v}")
return v
@field_validator("time_format")
@classmethod
def validate_time_format(cls, v: str) -> str:
"""Validate time format."""
if v not in ["12h", "24h", "auto"]:
raise ValueError(
f"Invalid time format: {v}. Must be '12h', '24h', or 'auto'"
)
return v
@field_validator("log_level")
@classmethod
def validate_log_level(cls, v: str) -> str:
"""Validate log level."""
valid_levels = ["DEBUG", "INFO", "WARNING", "ERROR", "CRITICAL"]
v_upper = v.upper()
if v_upper not in valid_levels:
raise ValueError(f"Invalid log level: {v}")
return v_upper
@classmethod
def settings_customise_sources(
cls,
settings_cls: Any,
init_settings: Any,
env_settings: Any,
dotenv_settings: Any,
file_secret_settings: Any,
) -> Tuple[Any, ...]:
"""Custom sources - only init and last used."""
_ = (
settings_cls,
env_settings,
dotenv_settings,
file_secret_settings,
)
return (init_settings,)
@classmethod
def load_with_last_used(cls, argv: Optional[List[str]] = None) -> "Settings":
"""Load settings with last used params support (default behavior)."""
if argv and "--version" in argv:
print(f"claude-monitor {__version__}")
import sys
sys.exit(0)
clear_config = argv and "--clear" in argv
if clear_config:
last_used = LastUsedParams()
last_used.clear()
settings = cls(_cli_parse_args=argv)
else:
last_used = LastUsedParams()
last_params = last_used.load()
settings = cls(_cli_parse_args=argv)
cli_provided_fields = set()
if argv:
for _i, arg in enumerate(argv):
if arg.startswith("--"):
field_name = arg[2:].replace("-", "_")
if field_name in cls.model_fields:
cli_provided_fields.add(field_name)
for key, value in last_params.items():
if key == "plan":
continue
if not hasattr(settings, key):
continue
if key not in cli_provided_fields:
setattr(settings, key, value)
if (
"plan" in cli_provided_fields
and settings.plan == "custom"
and "custom_limit_tokens" not in cli_provided_fields
):
settings.custom_limit_tokens = None
if settings.timezone == "auto":
settings.timezone = cls._get_system_timezone()
if settings.time_format == "auto":
settings.time_format = cls._get_system_time_format()
if settings.debug:
settings.log_level = "DEBUG"
if settings.theme == "auto" or (
"theme" not in cli_provided_fields and not clear_config
):
from claude_monitor.terminal.themes import (
BackgroundDetector,
BackgroundType,
)
detector = BackgroundDetector()
detected_bg = detector.detect_background()
if detected_bg == BackgroundType.LIGHT:
settings.theme = "light"
elif detected_bg == BackgroundType.DARK:
settings.theme = "dark"
else:
settings.theme = "auto"
if not clear_config:
last_used = LastUsedParams()
last_used.save(settings)
return settings
def to_namespace(self) -> argparse.Namespace:
"""Convert to argparse.Namespace for compatibility."""
args = argparse.Namespace()
args.plan = self.plan
args.view = self.view
args.timezone = self.timezone
args.theme = self.theme
args.refresh_rate = self.refresh_rate
args.refresh_per_second = self.refresh_per_second
args.reset_hour = self.reset_hour
args.custom_limit_tokens = self.custom_limit_tokens
args.time_format = self.time_format
args.log_level = self.log_level
args.log_file = str(self.log_file) if self.log_file else None
args.version = self.version
return args
================================================
FILE: src/claude_monitor/data/__init__.py
================================================
"""Data package for Claude Monitor."""
# Import directly from modules without facade
__all__: list[str] = []
================================================
FILE: src/claude_monitor/data/aggregator.py
================================================
"""Data aggregator for daily and monthly statistics.
This module provides functionality to aggregate Claude usage data
by day and month, similar to ccusage's functionality.
"""
import logging
from collections import defaultdict
from dataclasses import dataclass, field
from datetime import datetime
from typing import Any, Callable, Dict, List, Optional
from claude_monitor.core.models import SessionBlock, UsageEntry, normalize_model_name
from claude_monitor.utils.time_utils import TimezoneHandler
logger = logging.getLogger(__name__)
@dataclass
class AggregatedStats:
"""Statistics for aggregated usage data."""
input_tokens: int = 0
output_tokens: int = 0
cache_creation_tokens: int = 0
cache_read_tokens: int = 0
cost: float = 0.0
count: int = 0
def add_entry(self, entry: UsageEntry) -> None:
"""Add an entry's statistics to this aggregate."""
self.input_tokens += entry.input_tokens
self.output_tokens += entry.output_tokens
self.cache_creation_tokens += entry.cache_creation_tokens
self.cache_read_tokens += entry.cache_read_tokens
self.cost += entry.cost_usd
self.count += 1
def to_dict(self) -> Dict[str, Any]:
"""Convert to dictionary format."""
return {
"input_tokens": self.input_tokens,
"output_tokens": self.output_tokens,
"cache_creation_tokens": self.cache_creation_tokens,
"cache_read_tokens": self.cache_read_tokens,
"cost": self.cost,
"count": self.count,
}
@dataclass
class AggregatedPeriod:
"""Aggregated data for a time period (day or month)."""
period_key: str
stats: AggregatedStats = field(default_factory=AggregatedStats)
models_used: set = field(default_factory=set)
model_breakdowns: Dict[str, AggregatedStats] = field(
default_factory=lambda: defaultdict(AggregatedStats)
)
def add_entry(self, entry: UsageEntry) -> None:
"""Add an entry to this period's aggregate."""
# Add to overall stats
self.stats.add_entry(entry)
# Track model
model = normalize_model_name(entry.model) if entry.model else "unknown"
self.models_used.add(model)
# Add to model-specific stats
self.model_breakdowns[model].add_entry(entry)
def to_dict(self, period_type: str) -> Dict[str, Any]:
"""Convert to dictionary format for display."""
result = {
period_type: self.period_key,
"input_tokens": self.stats.input_tokens,
"output_tokens": self.stats.output_tokens,
"cache_creation_tokens": self.stats.cache_creation_tokens,
"cache_read_tokens": self.stats.cache_read_tokens,
"total_cost": self.stats.cost,
"models_used": sorted(list(self.models_used)),
"model_breakdowns": {
model: stats.to_dict() for model, stats in self.model_breakdowns.items()
},
"entries_count": self.stats.count,
}
return result
class UsageAggregator:
"""Aggregates usage data for daily and monthly reports."""
def __init__(
self, data_path: str, aggregation_mode: str = "daily", timezone: str = "UTC"
):
"""Initialize the aggregator.
Args:
data_path: Path to the data directory
aggregation_mode: Mode of aggregation ('daily' or 'monthly')
timezone: Timezone string for date formatting
"""
self.data_path = data_path
self.aggregation_mode = aggregation_mode
self.timezone = timezone
self.timezone_handler = TimezoneHandler()
def _aggregate_by_period(
self,
entries: List[UsageEntry],
period_key_func: Callable[[datetime], str],
period_type: str,
start_date: Optional[datetime] = None,
end_date: Optional[datetime] = None,
) -> List[Dict[str, Any]]:
"""Generic aggregation by time period.
Args:
entries: List of usage entries
period_key_func: Function to extract period key from timestamp
period_type: Type of period ('date' or 'month')
start_date: Optional start date filter
end_date: Optional end date filter
Returns:
List of aggregated data dictionaries
"""
period_data: Dict[str, AggregatedPeriod] = {}
for entry in entries:
# Apply date filters
if start_date and entry.timestamp < start_date:
continue
if end_date and entry.timestamp > end_date:
continue
# Get period key
period_key = period_key_func(entry.timestamp)
# Get or create period aggregate
if period_key not in period_data:
period_data[period_key] = AggregatedPeriod(period_key)
# Add entry to period
period_data[period_key].add_entry(entry)
# Convert to list and sort
result = []
for period_key in sorted(period_data.keys()):
period = period_data[period_key]
result.append(period.to_dict(period_type))
return result
def aggregate_daily(
self,
entries: List[UsageEntry],
start_date: Optional[datetime] = None,
end_date: Optional[datetime] = None,
) -> List[Dict[str, Any]]:
"""Aggregate usage data by day.
Args:
entries: List of usage entries
start_date: Optional start date filter
end_date: Optional end date filter
Returns:
List of daily aggregated data
"""
return self._aggregate_by_period(
entries,
lambda timestamp: timestamp.strftime("%Y-%m-%d"),
"date",
start_date,
end_date,
)
def aggregate_monthly(
self,
entries: List[UsageEntry],
start_date: Optional[datetime] = None,
end_date: Optional[datetime] = None,
) -> List[Dict[str, Any]]:
"""Aggregate usage data by month.
Args:
entries: List of usage entries
start_date: Optional start date filter
end_date: Optional end date filter
Returns:
List of monthly aggregated data
"""
return self._aggregate_by_period(
entries,
lambda timestamp: timestamp.strftime("%Y-%m"),
"month",
start_date,
end_date,
)
def aggregate_from_blocks(
self, blocks: List[SessionBlock], view_type: str = "daily"
) -> List[Dict[str, Any]]:
"""Aggregate data from session blocks.
Args:
blocks: List of session blocks
view_type: Type of aggregation ('daily' or 'monthly')
Returns:
List of aggregated data
"""
# Validate view type
if view_type not in ["daily", "monthly"]:
raise ValueError(
f"Invalid view type: {view_type}. Must be 'daily' or 'monthly'"
)
# Extract all entries from blocks
all_entries = []
for block in blocks:
if not block.is_gap:
all_entries.extend(block.entries)
# Aggregate based on view type
if view_type == "daily":
return self.aggregate_daily(all_entries)
else:
return self.aggregate_monthly(all_entries)
def calculate_totals(self, aggregated_data: List[Dict[str, Any]]) -> Dict[str, Any]:
"""Calculate totals from aggregated data.
Args:
aggregated_data: List of aggregated daily or monthly data
Returns:
Dictionary with total statistics
"""
total_stats = AggregatedStats()
for data in aggregated_data:
total_stats.input_tokens += data.get("input_tokens", 0)
total_stats.output_tokens += data.get("output_tokens", 0)
total_stats.cache_creation_tokens += data.get("cache_creation_tokens", 0)
total_stats.cache_read_tokens += data.get("cache_read_tokens", 0)
total_stats.cost += data.get("total_cost", 0.0)
total_stats.count += data.get("entries_count", 0)
return {
"input_tokens": total_stats.input_tokens,
"output_tokens": total_stats.output_tokens,
"cache_creation_tokens": total_stats.cache_creation_tokens,
"cache_read_tokens": total_stats.cache_read_tokens,
"total_tokens": (
total_stats.input_tokens
+ total_stats.output_tokens
+ total_stats.cache_creation_tokens
+ total_stats.cache_read_tokens
),
"total_cost": total_stats.cost,
"entries_count": total_stats.count,
}
def aggregate(self) -> List[Dict[str, Any]]:
"""Main aggregation method that reads data and returns aggregated results.
Returns:
List of aggregated data based on aggregation_mode
"""
from claude_monitor.data.reader import load_usage_entries
logger.info(f"Starting aggregation in {self.aggregation_mode} mode")
# Load usage entries
entries, _ = load_usage_entries(data_path=self.data_path)
if not entries:
logger.warning("No usage entries found")
return []
# Apply timezone to entries
for entry in entries:
if entry.timestamp.tzinfo is None:
entry.timestamp = self.timezone_handler.ensure_timezone(entry.timestamp)
# Aggregate based on mode
if self.aggregation_mode == "daily":
return self.aggregate_daily(entries)
elif self.aggregation_mode == "monthly":
return self.aggregate_monthly(entries)
else:
raise ValueError(f"Invalid aggregation mode: {self.aggregation_mode}")
================================================
FILE: src/claude_monitor/data/analysis.py
================================================
"""
Usage analysis functionality for Claude Monitor.
Contains the main analyze_usage function and related analysis components.
"""
import logging
from datetime import datetime, timezone
from typing import Any, Dict, List, Optional
from claude_monitor.core.calculations import BurnRateCalculator
from claude_monitor.core.models import CostMode, SessionBlock, UsageEntry
from claude_monitor.data.analyzer import SessionAnalyzer
from claude_monitor.data.reader import load_usage_entries
logger = logging.getLogger(__name__)
def analyze_usage(
hours_back: Optional[int] = 96,
use_cache: bool = True,
quick_start: bool = False,
data_path: Optional[str] = None,
) -> Dict[str, Any]:
"""
Main entry point to generate response_final.json.
Algorithm redesigned to:
1. First divide all outputs into blocks
2. Save data about outputs (tokens in/out, cache, tokens by model, entries)
3. Only then check for limits
4. If limit is detected, add information that it occurred
Args:
hours_back: Only analyze data from last N hours (None = all data)
use_cache: Use cached data when available
quick_start: Use minimal data for quick startup (last 24h only)
data_path: Optional path to Claude data directory
Returns:
Dictionary with analyzed blocks
"""
logger.info(
f"analyze_usage called with hours_back={hours_back}, use_cache={use_cache}, "
f"quick_start={quick_start}, data_path={data_path}"
)
if quick_start and hours_back is None:
hours_back = 24
logger.info("Quick start mode: loading only last 24 hours")
elif quick_start:
logger.info(f"Quick start mode: loading last {hours_back} hours")
start_time = datetime.now()
entries, raw_entries = load_usage_entries(
data_path=data_path,
hours_back=hours_back,
mode=CostMode.AUTO,
include_raw=True,
)
load_time = (datetime.now() - start_time).total_seconds()
logger.info(f"Data loaded in {load_time:.3f}s")
start_time = datetime.now()
analyzer = SessionAnalyzer(session_duration_hours=5)
blocks = analyzer.transform_to_blocks(entries)
transform_time = (datetime.now() - start_time).total_seconds()
logger.info(f"Created {len(blocks)} blocks in {transform_time:.3f}s")
calculator = BurnRateCalculator()
_process_burn_rates(blocks, calculator)
limits_detected = 0
if raw_entries:
limit_detections = analyzer.detect_limits(raw_entries)
limits_detected = len(limit_detections)
for block in blocks:
block_limits = [
_format_limit_info(limit_info)
for limit_info in limit_detections
if _is_limit_in_block_timerange(limit_info, block)
]
if block_limits:
block.limit_messages = block_limits
metadata: Dict[str, Any] = {
"generated_at": datetime.now(timezone.utc).isoformat(),
"hours_analyzed": hours_back or "all",
"entries_processed": len(entries),
"blocks_created": len(blocks),
"limits_detected": limits_detected,
"load_time_seconds": load_time,
"transform_time_seconds": transform_time,
"cache_used": use_cache,
"quick_start": quick_start,
}
result = _create_result(blocks, entries, metadata)
logger.info(f"analyze_usage returning {len(result['blocks'])} blocks")
return result
def _process_burn_rates(
blocks: List[SessionBlock], calculator: BurnRateCalculator
) -> None:
"""Process burn rate data for active blocks."""
for block in blocks:
if block.is_active:
burn_rate = calculator.calculate_burn_rate(block)
if burn_rate:
block.burn_rate_snapshot = burn_rate
projection = calculator.project_block_usage(block)
if projection:
block.projection_data = {
"totalTokens": projection.projected_total_tokens,
"totalCost": projection.projected_total_cost,
"remainingMinutes": projection.remaining_minutes,
}
def _create_result(
blocks: List[SessionBlock], entries: List[UsageEntry], metadata: Dict[str, Any]
) -> Dict[str, Any]:
"""Create the final result dictionary."""
blocks_data = _convert_blocks_to_dict_format(blocks)
total_tokens = sum(b.total_tokens for b in blocks)
total_cost = sum(b.cost_usd for b in blocks)
return {
"blocks": blocks_data,
"metadata": metadata,
"entries_count": len(entries),
"total_tokens": total_tokens,
"total_cost": total_cost,
}
def _is_limit_in_block_timerange(
limit_info: Dict[str, Any], block: SessionBlock
) -> bool:
"""Check if limit timestamp falls within block's time range."""
limit_timestamp = limit_info["timestamp"]
if limit_timestamp.tzinfo is None:
limit_timestamp = limit_timestamp.replace(tzinfo=timezone.utc)
return block.start_time <= limit_timestamp <= block.end_time
def _format_limit_info(limit_info: Dict[str, Any]) -> Dict[str, Any]:
"""Format limit info for block assignment."""
return {
"type": limit_info["type"],
"timestamp": limit_info["timestamp"].isoformat(),
"content": limit_info["content"],
"reset_time": (
limit_info["reset_time"].isoformat()
if limit_info.get("reset_time")
else None
),
}
def _convert_blocks_to_dict_format(blocks: List[SessionBlock]) -> List[Dict[str, Any]]:
"""Convert blocks to dictionary format for JSON output."""
blocks_data: List[Dict[str, Any]] = []
for block in blocks:
block_dict = _create_base_block_dict(block)
_add_optional_block_data(block, block_dict)
blocks_data.append(block_dict)
return blocks_data
def _create_base_block_dict(block: SessionBlock) -> Dict[str, Any]:
"""Create base block dictionary with required fields."""
return {
"id": block.id,
"isActive": block.is_active,
"isGap": block.is_gap,
"startTime": block.start_time.isoformat(),
"endTime": block.end_time.isoformat(),
"actualEndTime": (
block.actual_end_time.isoformat() if block.actual_end_time else None
),
"tokenCounts": {
"inputTokens": block.token_counts.input_tokens,
"outputTokens": block.token_counts.output_tokens,
"cacheCreationInputTokens": block.token_counts.cache_creation_tokens,
"cacheReadInputTokens": block.token_counts.cache_read_tokens,
},
"totalTokens": block.token_counts.input_tokens
+ block.token_counts.output_tokens,
"costUSD": block.cost_usd,
"models": block.models,
"perModelStats": block.per_model_stats,
"sentMessagesCount": block.sent_messages_count,
"durationMinutes": block.duration_minutes,
"entries": _format_block_entries(block.entries),
"entries_count": len(block.entries),
}
def _format_block_entries(entries: List[UsageEntry]) -> List[Dict[str, Any]]:
"""Format block entries for JSON output."""
return [
{
"timestamp": entry.timestamp.isoformat(),
"inputTokens": entry.input_tokens,
"outputTokens": entry.output_tokens,
"cacheCreationTokens": entry.cache_creation_tokens,
"cacheReadInputTokens": entry.cache_read_tokens,
"costUSD": entry.cost_usd,
"model": entry.model,
"messageId": entry.message_id,
"requestId": entry.request_id,
}
for entry in entries
]
def _add_optional_block_data(block: SessionBlock, block_dict: Dict[str, Any]) -> None:
"""Add optional burn rate, projection, and limit data to block dict."""
if hasattr(block, "burn_rate_snapshot") and block.burn_rate_snapshot:
block_dict["burnRate"] = {
"tokensPerMinute": block.burn_rate_snapshot.tokens_per_minute,
"costPerHour": block.burn_rate_snapshot.cost_per_hour,
}
if hasattr(block, "projection_data") and block.projection_data:
block_dict["projection"] = block.projection_data
if hasattr(block, "limit_messages") and block.limit_messages:
block_dict["limitMessages"] = block.limit_messages
================================================
FILE: src/claude_monitor/data/analyzer.py
================================================
"""Session analyzer for Claude Monitor.
Combines session block creation and limit detection functionality.
"""
import logging
import re
from datetime import datetime, timedelta, timezone
from typing import Any, Dict, List, Optional, Tuple, Union
from claude_monitor.core.models import (
SessionBlock,
TokenCounts,
UsageEntry,
normalize_model_name,
)
from claude_monitor.utils.time_utils import TimezoneHandler
logger = logging.getLogger(__name__)
class SessionAnalyzer:
"""Creates session blocks and detects limits."""
def __init__(self, session_duration_hours: int = 5):
"""Initialize analyzer with session duration.
Args:
session_duration_hours: Duration of each session block in hours
"""
self.session_duration_hours = session_duration_hours
self.session_duration = timedelta(hours=session_duration_hours)
self.timezone_handler = TimezoneHandler()
def transform_to_blocks(self, entries: List[UsageEntry]) -> List[SessionBlock]:
"""Process entries and create session blocks.
Args:
entries: List of usage entries to transform
Returns:
List of session blocks
"""
if not entries:
return []
blocks = []
current_block = None
for entry in entries:
# Check if we need a new block
if current_block is None or self._should_create_new_block(
current_block, entry
):
# Close current block
if current_block:
self._finalize_block(current_block)
blocks.append(current_block)
# Check for gap
gap = self._check_for_gap(current_block, entry)
if gap:
blocks.append(gap)
# Create new block
current_block = self._create_new_block(entry)
# Add entry to current block
self._add_entry_to_block(current_block, entry)
# Finalize last block
if current_block:
self._finalize_block(current_block)
blocks.append(current_block)
# Mark active blocks
self._mark_active_blocks(blocks)
return blocks
def detect_limits(self, raw_entries: List[Dict[str, Any]]) -> List[Dict[str, Any]]:
"""Detect token limit messages from raw JSONL entries.
Args:
raw_entries: List of raw JSONL entries
Returns:
List of detected limit information
"""
limits: List[Dict[str, Any]] = []
for raw_data in raw_entries:
limit_info = self._detect_single_limit(raw_data)
if limit_info:
limits.append(limit_info)
return limits
def _should_create_new_block(self, block: SessionBlock, entry: UsageEntry) -> bool:
"""Check if new block is needed."""
if entry.timestamp >= block.end_time:
return True
return (
block.entries
and (entry.timestamp - block.entries[-1].timestamp) >= self.session_duration
)
def _round_to_hour(self, timestamp: datetime) -> datetime:
"""Round timestamp to the nearest full hour in UTC."""
if timestamp.tzinfo is None:
timestamp = timestamp.replace(tzinfo=timezone.utc)
elif timestamp.tzinfo != timezone.utc:
timestamp = timestamp.astimezone(timezone.utc)
return timestamp.replace(minute=0, second=0, microsecond=0)
def _create_new_block(self, entry: UsageEntry) -> SessionBlock:
"""Create a new session block."""
start_time = self._round_to_hour(entry.timestamp)
end_time = start_time + self.session_duration
block_id = start_time.isoformat()
return SessionBlock(
id=block_id,
start_time=start_time,
end_time=end_time,
entries=[],
token_counts=TokenCounts(),
cost_usd=0.0,
)
def _add_entry_to_block(self, block: SessionBlock, entry: UsageEntry) -> None:
"""Add entry to block and aggregate data per model."""
block.entries.append(entry)
raw_model = entry.model or "unknown"
model = normalize_model_name(raw_model) if raw_model != "unknown" else "unknown"
if model not in block.per_model_stats:
block.per_model_stats[model] = {
"input_tokens": 0,
"output_tokens": 0,
"cache_creation_tokens": 0,
"cache_read_tokens": 0,
"cost_usd": 0.0,
"entries_count": 0,
}
model_stats: Dict[str, Union[int, float]] = block.per_model_stats[model]
model_stats["input_tokens"] += entry.input_tokens
model_stats["output_tokens"] += entry.output_tokens
model_stats["cache_creation_tokens"] += entry.cache_creation_tokens
model_stats["cache_read_tokens"] += entry.cache_read_tokens
model_stats["cost_usd"] += entry.cost_usd or 0.0
model_stats["entries_count"] += 1
block.token_counts.input_tokens += entry.input_tokens
block.token_counts.output_tokens += entry.output_tokens
block.token_counts.cache_creation_tokens += entry.cache_creation_tokens
block.token_counts.cache_read_tokens += entry.cache_read_tokens
# Update aggregated cost (sum across all models)
if entry.cost_usd:
block.cost_usd += entry.cost_usd
# Model tracking (prevent duplicates)
if model and model not in block.models:
block.models.append(model)
# Increment sent messages count
block.sent_messages_count += 1
def _finalize_block(self, block: SessionBlock) -> None:
"""Set actual end time and calculate totals."""
if block.entries:
block.actual_end_time = block.entries[-1].timestamp
# Update sent_messages_count
block.sent_messages_count = len(block.entries)
def _check_for_gap(
self, last_block: SessionBlock, next_entry: UsageEntry
) -> Optional[SessionBlock]:
"""Check for inactivity gap between blocks."""
if not last_block.actual_end_time:
return None
gap_duration = next_entry.timestamp - last_block.actual_end_time
if gap_duration >= self.session_duration:
gap_time_str = last_block.actual_end_time.isoformat()
gap_id = f"gap-{gap_time_str}"
return SessionBlock(
id=gap_id,
start_time=last_block.actual_end_time,
end_time=next_entry.timestamp,
actual_end_time=None,
is_gap=True,
entries=[],
token_counts=TokenCounts(),
cost_usd=0.0,
models=[],
)
return None
def _mark_active_blocks(self, blocks: List[SessionBlock]) -> None:
"""Mark blocks as active if they're still ongoing."""
current_time = datetime.now(timezone.utc)
for block in blocks:
if not block.is_gap and block.end_time > current_time:
block.is_active = True
# Limit detection methods
def _detect_single_limit(
self, raw_data: Dict[str, Any]
) -> Optional[Dict[str, Any]]:
"""Detect token limit messages from a single JSONL entry."""
entry_type = raw_data.get("type")
if entry_type == "system":
return self._process_system_message(raw_data)
if entry_type == "user":
return self._process_user_message(raw_data)
return None
def _process_system_message(
self, raw_data: Dict[str, Any]
) -> Optional[Dict[str, Any]]:
"""Process system messages for limit detection."""
content = raw_data.get("content", "")
if not isinstance(content, str):
return None
content_lower = content.lower()
if "limit" not in content_lower and "rate" not in content_lower:
return None
timestamp_str = raw_data.get("timestamp")
if not timestamp_str:
return None
try:
timestamp = self.timezone_handler.parse_timestamp(timestamp_str)
block_context = self._extract_block_context(raw_data)
# Check for Opus-specific limit
if self._is_opus_limit(content_lower):
reset_time, wait_minutes = self._extract_wait_time(content, timestamp)
return {
"type": "opus_limit",
"timestamp": timestamp,
"content": content,
"reset_time": reset_time,
"wait_minutes": wait_minutes,
"raw_data": raw_data,
"block_context": block_context,
}
# General system limit
return {
"type": "system_limit",
"timestamp": timestamp,
"content": content,
"reset_time": None,
"raw_data": raw_data,
"block_context": block_context,
}
except (ValueError, TypeError):
return None
def _process_user_message(
self, raw_data: Dict[str, Any]
) -> Optional[Dict[str, Any]]:
"""Process user messages for tool result limit detection."""
message = raw_data.get("message", {})
content_list = message.get("content", [])
if not isinstance(content_list, list):
return None
for item in content_list:
if isinstance(item, dict) and item.get("type") == "tool_result":
limit_info = self._process_tool_result(item, raw_data, message)
if limit_info:
return limit_info
return None
def _process_tool_result(
self, item: Dict[str, Any], raw_data: Dict[str, Any], message: Dict[str, Any]
) -> Optional[Dict[str, Any]]:
"""Process a single tool result item for limit detection."""
tool_content = item.get("content", [])
if not isinstance(tool_content, list):
return None
for tool_item in tool_content:
if not isinstance(tool_item, dict):
continue
text = tool_item.get("text", "")
if not isinstance(text, str) or "limit reached" not in text.lower():
continue
timestamp_str = raw_data.get("timestamp")
if not timestamp_str:
continue
try:
timestamp = self.timezone_handler.parse_timestamp(timestamp_str)
return {
"type": "general_limit",
"timestamp": timestamp,
"content": text,
"reset_time": self._parse_reset_timestamp(text),
"raw_data": raw_data,
"block_context": self._extract_block_context(raw_data, message),
}
except (ValueError, TypeError):
continue
return None
def _extract_block_context(
self, raw_data: Dict[str, Any], message: Optional[Dict[str, Any]] = None
) -> Dict[str, Any]:
"""Extract block context from raw data."""
context: Dict[str, Any] = {
"message_id": raw_data.get("messageId") or raw_data.get("message_id"),
"request_id": raw_data.get("requestId") or raw_data.get("request_id"),
"session_id": raw_data.get("sessionId") or raw_data.get("session_id"),
"version": raw_data.get("version"),
"model": raw_data.get("model"),
}
if message:
context["message_id"] = message.get("id") or context["message_id"]
context["model"] = message.get("model") or context["model"]
context["usage"] = message.get("usage", {})
context["stop_reason"] = message.get("stop_reason")
return context
def _is_opus_limit(self, content_lower: str) -> bool:
"""Check if content indicates an Opus-specific limit."""
if "opus" not in content_lower:
return False
limit_phrases = ["rate limit", "limit exceeded", "limit reached", "limit hit"]
return (
any(phrase in content_lower for phrase in limit_phrases)
or "limit" in content_lower
)
def _extract_wait_time(
self, content: str, timestamp: datetime
) -> Tuple[Optional[datetime], Optional[int]]:
"""Extract wait time and calculate reset time from content."""
wait_match = re.search(r"wait\s+(\d+)\s+minutes?", content.lower())
if wait_match:
wait_minutes = int(wait_match.group(1))
reset_time = timestamp + timedelta(minutes=wait_minutes)
return reset_time, wait_minutes
return None, None
def _parse_reset_timestamp(self, text: str) -> Optional[datetime]:
"""Parse reset timestamp from limit message using centralized processor."""
from claude_monitor.core.data_processors import TimestampProcessor
match = re.search(r"limit reached\|(\d+)", text)
if match:
try:
timestamp_value = int(match.group(1))
processor = TimestampProcessor()
return processor.parse_timestamp(timestamp_value)
except (ValueError, OSError):
pass
return None
================================================
FILE: src/claude_monitor/data/reader.py
================================================
"""Simplified data reader for Claude Monitor.
Combines functionality from file_reader, filter, mapper, and processor
into a single cohesive module.
"""
import json
import logging
from datetime import datetime, timedelta
from datetime import timezone as tz
from pathlib import Path
from typing import Any, Dict, List, Optional, Set, Tuple
from claude_monitor.core.data_processors import (
DataConverter,
TimestampProcessor,
TokenExtractor,
)
from claude_monitor.core.models import CostMode, UsageEntry
from claude_monitor.core.pricing import PricingCalculator
from claude_monitor.error_handling import report_file_error
from claude_monitor.utils.time_utils import TimezoneHandler
FIELD_COST_USD = "cost_usd"
FIELD_MODEL = "model"
TOKEN_INPUT = "input_tokens"
TOKEN_OUTPUT = "output_tokens"
logger = logging.getLogger(__name__)
def load_usage_entries(
data_path: Optional[str] = None,
hours_back: Optional[int] = None,
mode: CostMode = CostMode.AUTO,
include_raw: bool = False,
) -> Tuple[List[UsageEntry], Optional[List[Dict[str, Any]]]]:
"""Load and convert JSONL files to UsageEntry objects.
Args:
data_path: Path to Claude data directory (defaults to ~/.claude/projects)
hours_back: Only include entries from last N hours
mode: Cost calculation mode
include_raw: Whether to return raw JSON data alongside entries
Returns:
Tuple of (usage_entries, raw_data) where raw_data is None unless include_raw=True
"""
data_path = Path(data_path if data_path else "~/.claude/projects").expanduser()
timezone_handler = TimezoneHandler()
pricing_calculator = PricingCalculator()
cutoff_time = None
if hours_back:
cutoff_time = datetime.now(tz.utc) - timedelta(hours=hours_back)
jsonl_files = _find_jsonl_files(data_path)
if not jsonl_files:
logger.warning("No JSONL files found in %s", data_path)
return [], None
all_entries: List[UsageEntry] = []
raw_entries: Optional[List[Dict[str, Any]]] = [] if include_raw else None
processed_hashes: Set[str] = set()
for file_path in jsonl_files:
entries, raw_data = _process_single_file(
file_path,
mode,
cutoff_time,
processed_hashes,
include_raw,
timezone_handler,
pricing_calculator,
)
all_entries.extend(entries)
if include_raw and raw_data:
raw_entries.extend(raw_data)
all_entries.sort(key=lambda e: e.timestamp)
logger.info(f"Processed {len(all_entries)} entries from {len(jsonl_files)} files")
return all_entries, raw_entries
def load_all_raw_entries(data_path: Optional[str] = None) -> List[Dict[str, Any]]:
"""Load all raw JSONL entries without processing.
Args:
data_path: Path to Claude data directory
Returns:
List of raw JSON dictionaries
"""
data_path = Path(data_path if data_path else "~/.claude/projects").expanduser()
jsonl_files = _find_jsonl_files(data_path)
all_raw_entries: List[Dict[str, Any]] = []
for file_path in jsonl_files:
try:
with open(file_path, encoding="utf-8") as f:
for line in f:
line = line.strip()
if not line:
continue
try:
all_raw_entries.append(json.loads(line))
except json.JSONDecodeError:
continue
except Exception as e:
logger.exception(f"Error loading raw entries from {file_path}: {e}")
return all_raw_entries
def _find_jsonl_files(data_path: Path) -> List[Path]:
"""Find all .jsonl files in the data directory."""
if not data_path.exists():
logger.warning("Data path does not exist: %s", data_path)
return []
return list(data_path.rglob("*.jsonl"))
def _process_single_file(
file_path: Path,
mode: CostMode,
cutoff_time: Optional[datetime],
processed_hashes: Set[str],
include_raw: bool,
timezone_handler: TimezoneHandler,
pricing_calculator: PricingCalculator,
) -> Tuple[List[UsageEntry], Optional[List[Dict[str, Any]]]]:
"""Process a single JSONL file."""
entries: List[UsageEntry] = []
raw_data: Optional[List[Dict[str, Any]]] = [] if include_raw else None
try:
entries_read = 0
entries_filtered = 0
entries_mapped = 0
with open(file_path, encoding="utf-8") as f:
for line in f:
line = line.strip()
if not line:
continue
try:
data = json.loads(line)
entries_read += 1
if not _should_process_entry(
data, cutoff_time, processed_hashes, timezone_handler
):
entries_filtered += 1
continue
entry = _map_to_usage_entry(
data, mode, timezone_handler, pricing_calculator
)
if entry:
entries_mapped += 1
entries.append(entry)
_update_processed_hashes(data, processed_hashes)
if include_raw:
raw_data.append(data)
except json.JSONDecodeError as e:
logger.debug(f"Failed to parse JSON line in {file_path}: {e}")
continue
logger.debug(
f"File {file_path.name}: {entries_read} read, "
f"{entries_filtered} filtered out, {entries_mapped} successfully mapped"
)
except Exception as e:
logger.warning("Failed to read file %s: %s", file_path, e)
report_file_error(
exception=e,
file_path=str(file_path),
operation="read",
additional_context={"file_exists": file_path.exists()},
)
return [], None
return entries, raw_data
def _should_process_entry(
data: Dict[str, Any],
cutoff_time: Optional[datetime],
processed_hashes: Set[str],
timezone_handler: TimezoneHandler,
) -> bool:
"""Check if entry should be processed based on time and uniqueness."""
if cutoff_time:
timestamp_str = data.get("timestamp")
if timestamp_str:
processor = TimestampProcessor(timezone_handler)
timestamp = processor.parse_timestamp(timestamp_str)
if timestamp and timestamp < cutoff_time:
return False
unique_hash = _create_unique_hash(data)
return not (unique_hash and unique_hash in processed_hashes)
def _create_unique_hash(data: Dict[str, Any]) -> Optional[str]:
"""Create unique hash for deduplication."""
message_id = data.get("message_id") or (
data.get("message", {}).get("id")
if isinstance(data.get("message"), dict)
else None
)
request_id = data.get("requestId") or data.get("request_id")
return f"{message_id}:{request_id}" if message_id and request_id else None
def _update_processed_hashes(data: Dict[str, Any], processed_hashes: Set[str]) -> None:
"""Update the processed hashes set with current entry's hash."""
unique_hash = _create_unique_hash(data)
if unique_hash:
processed_hashes.add(unique_hash)
def _map_to_usage_entry(
data: Dict[str, Any],
mode: CostMode,
timezone_handler: TimezoneHandler,
pricing_calculator: PricingCalculator,
) -> Optional[UsageEntry]:
"""Map raw data to UsageEntry with proper cost calculation."""
try:
timestamp_processor = TimestampProcessor(timezone_handler)
timestamp = timestamp_processor.parse_timestamp(data.get("timestamp", ""))
if not timestamp:
return None
token_data = TokenExtractor.extract_tokens(data)
if not any(v for k, v in token_data.items() if k != "total_tokens"):
return None
model = DataConverter.extract_model_name(data, default="unknown")
entry_data: Dict[str, Any] = {
FIELD_MODEL: model,
TOKEN_INPUT: token_data["input_tokens"],
TOKEN_OUTPUT: token_data["output_tokens"],
"cache_creation_tokens": token_data.get("cache_creation_tokens", 0),
"cache_read_tokens": token_data.get("cache_read_tokens", 0),
FIELD_COST_USD: data.get("cost") or data.get(FIELD_COST_USD),
}
cost_usd = pricing_calculator.calculate_cost_for_entry(entry_data, mode)
message = data.get("message", {})
message_id = data.get("message_id") or message.get("id") or ""
request_id = data.get("request_id") or data.get("requestId") or "unknown"
return UsageEntry(
timestamp=timestamp,
input_tokens=token_data["input_tokens"],
output_tokens=token_data["output_tokens"],
cache_creation_tokens=token_data.get("cache_creation_tokens", 0),
cache_read_tokens=token_data.get("cache_read_tokens", 0),
cost_usd=cost_usd,
model=model,
message_id=message_id,
request_id=request_id,
)
except (KeyError, ValueError, TypeError, AttributeError) as e:
logger.debug(f"Failed to map entry: {type(e).__name__}: {e}")
return None
class UsageEntryMapper:
"""Compatibility wrapper for legacy UsageEntryMapper interface.
This class provides backward compatibility for tests that expect
the old UsageEntryMapper interface, wrapping the new functional
approach in _map_to_usage_entry.
"""
def __init__(
self, pricing_calculator: PricingCalculator, timezone_handler: TimezoneHandler
):
"""Initialize with required components."""
self.pricing_calculator = pricing_calculator
self.timezone_handler = timezone_handler
def map(self, data: Dict[str, Any], mode: CostMode) -> Optional[UsageEntry]:
"""Map raw data to UsageEntry - compatibility interface."""
return _map_to_usage_entry(
data, mode, self.timezone_handler, self.pricing_calculator
)
def _has_valid_tokens(self, tokens: Dict[str, int]) -> bool:
"""Check if tokens are valid (for test compatibility)."""
return any(v > 0 for v in tokens.values())
def _extract_timestamp(self, data: Dict[str, Any]) -> Optional[datetime]:
"""Extract timestamp (for test compatibility)."""
if "timestamp" not in data:
return None
processor = TimestampProcessor(self.timezone_handler)
return processor.parse_timestamp(data["timestamp"])
def _extract_model(self, data: Dict[str, Any]) -> str:
"""Extract model name (for test compatibility)."""
return DataConverter.extract_model_name(data, default="unknown")
def _extract_metadata(self, data: Dict[str, Any]) -> Dict[str, str]:
"""Extract metadata (for test compatibility)."""
message = data.get("message", {})
return {
"message_id": data.get("message_id") or message.get("id", ""),
"request_id": data.get("request_id") or data.get("requestId", "unknown"),
}
================================================
FILE: src/claude_monitor/error_handling.py
================================================
"""Centralized error handling utilities for Claude Monitor.
This module provides a unified interface for error reporting and logging.
"""
import logging
import os
import sys
from enum import Enum
from pathlib import Path
from typing import Any, Dict, Optional, Union
class ErrorLevel(str, Enum):
"""Error severity levels for logging."""
INFO = "info"
ERROR = "error"
def report_error(
exception: Exception,
component: str,
context_name: Optional[str] = None,
context_data: Optional[Dict[str, Any]] = None,
tags: Optional[Dict[str, str]] = None,
level: ErrorLevel = ErrorLevel.ERROR,
) -> None:
"""Report an exception with standardized logging and context.
Args:
exception: The exception to report
component: Component name for logging (e.g., "data_loader", "monitor_controller")
context_name: Optional context name (e.g., "file_error", "parsing")
context_data: Optional dictionary of context data
tags: Optional additional tags (for logging extra context)
level: Error severity level
"""
logger = logging.getLogger(component)
log_method = getattr(logger, level.value, logger.error)
extra_data = {"context": context_name, "data": context_data, "tags": tags}
try:
log_method(
f"Error in {component}: {exception}",
exc_info=True,
extra=extra_data,
)
except Exception:
# If logging itself fails, we can't do much more than silently continue
# to avoid cascading failures
pass
def report_file_error(
exception: Exception,
file_path: Union[str, Path],
operation: str = "read",
additional_context: Optional[Dict[str, Any]] = None,
) -> None:
"""Report file-related errors with standardized context.
Args:
exception: The exception that occurred
file_path: Path to the file
operation: The operation that failed (read, write, parse, etc.)
additional_context: Any additional context data
"""
context_data = {
"file_path": str(file_path),
"operation": operation,
}
if additional_context:
context_data.update(additional_context)
report_error(
exception=exception,
component="file_handler",
context_name="file_error",
context_data=context_data,
tags={"operation": operation},
)
def get_error_context() -> Dict[str, Any]:
"""Get standard error context information.
Returns:
Dictionary containing system and application context
"""
return {
"python_version": sys.version,
"platform": sys.platform,
"cwd": os.getcwd(),
"pid": os.getpid(),
"argv": sys.argv,
}
def report_application_startup_error(
exception: Exception,
component: str = "application_startup",
additional_context: Optional[Dict[str, Any]] = None,
) -> None:
"""Report application startup-related errors with system context.
Args:
exception: The startup exception
component: Component where startup failed
additional_context: Additional context data
"""
context_data = get_error_context()
if additional_context:
context_data.update(additional_context)
report_error(
exception=exception,
component=component,
context_name="startup_error",
context_data=context_data,
tags={"error_type": "startup"},
)
def report_configuration_error(
exception: Exception,
config_file: Optional[Union[str, Path]] = None,
config_section: Optional[str] = None,
additional_context: Optional[Dict[str, Any]] = None,
) -> None:
"""Report configuration-related errors.
Args:
exception: The configuration exception
config_file: Path to the configuration file
config_section: Configuration section that failed
additional_context: Additional context data
"""
context_data = {
"config_file": str(config_file) if config_file else None,
"config_section": config_section,
}
if additional_context:
context_data.update(additional_context)
report_error(
exception=exception,
component="configuration",
context_name="config_error",
context_data=context_data,
tags={"error_type": "configuration"},
)
================================================
FILE: src/claude_monitor/monitoring/__init__.py
================================================
"""Monitoring package for Claude Monitor.
Provides monitoring functionality with proper separation of concerns.
"""
# Import directly from core modules without facade
__all__: list[str] = []
================================================
FILE: src/claude_monitor/monitoring/data_manager.py
================================================
"""Unified data management for monitoring - combines caching and fetching."""
import logging
import time
from typing import Any, Dict, Optional
from claude_monitor.data.analysis import analyze_usage
from claude_monitor.error_handling import report_error
logger = logging.getLogger(__name__)
class DataManager:
"""Manages data fetching and caching for monitoring."""
def __init__(
self,
cache_ttl: int = 30,
hours_back: int = 192,
data_path: Optional[str] = None,
) -> None:
"""Initialize data manager with cache and fetch settings.
Args:
cache_ttl: Cache time-to-live in seconds
hours_back: Hours of historical data to fetch
data_path: Path to data directory
"""
self.cache_ttl: int = cache_ttl
self._cache: Optional[Dict[str, Any]] = None
self._cache_timestamp: Optional[float] = None
self.hours_back: int = hours_back
self.data_path: Optional[str] = data_path
self._last_error: Optional[str] = None
self._last_successful_fetch: Optional[float] = None
def get_data(self, force_refresh: bool = False) -> Optional[Dict[str, Any]]:
"""Get monitoring data with caching and error handling.
Args:
force_refresh: Force refresh ignoring cache
Returns:
Usage data dictionary or None if fetch fails
"""
if not force_refresh and self._is_cache_valid():
cache_age: float = time.time() - self._cache_timestamp # type: ignore
logger.debug(f"Using cached data (age: {cache_age:.1f}s)")
return self._cache
max_retries: int = 3
for attempt in range(max_retries):
try:
logger.debug(
f"Fetching fresh usage data (attempt {attempt + 1}/{max_retries})"
)
data: Optional[Dict[str, Any]] = analyze_usage(
hours_back=self.hours_back,
quick_start=False,
use_cache=False,
data_path=self.data_path,
)
if data is not None:
self._set_cache(data)
self._last_successful_fetch = time.time()
self._last_error = None
return data
logger.warning("No data returned from analyze_usage")
break
except (FileNotFoundError, PermissionError, OSError) as e:
logger.exception(f"Data access error (attempt {attempt + 1}): {e}")
self._last_error = str(e)
report_error(
exception=e, component="data_manager", context_name="access_error"
)
if attempt < max_retries - 1:
time.sleep(0.1 * (2**attempt))
continue
except (ValueError, TypeError, KeyError) as e:
logger.exception(f"Data format error: {e}")
self._last_error = str(e)
report_error(
exception=e, component="data_manager", context_name="format_error"
)
break
except Exception as e:
logger.exception(f"Unexpected error (attempt {attempt + 1}): {e}")
self._last_error = str(e)
report_error(
exception=e,
component="data_manager",
context_name="unexpected_error",
)
if attempt < max_retries - 1:
time.sleep(0.1 * (2**attempt))
continue
break
if self._is_cache_valid():
logger.info("Using cached data due to fetch error")
return self._cache
logger.error("Failed to get usage data - no cache fallback available")
return None
def invalidate_cache(self) -> None:
"""Invalidate the cache."""
self._cache = None
self._cache_timestamp = None
logger.debug("Cache invalidated")
def _is_cache_valid(self) -> bool:
"""Check if cache is still valid."""
if self._cache is None or self._cache_timestamp is None:
return False
cache_age = time.time() - self._cache_timestamp
return cache_age <= self.cache_ttl
def _set_cache(self, data: Dict[str, Any]) -> None:
"""Set cache with current timestamp."""
self._cache = data
self._cache_timestamp = time.time()
@property
def cache_age(self) -> float:
"""Get age of cached data in seconds."""
if self._cache_timestamp is None:
return float("inf")
return time.time() - self._cache_timestamp
@property
def last_error(self) -> Optional[str]:
"""Get last error message."""
return self._last_error
@property
def last_successful_fetch_time(self) -> Optional[float]:
"""Get timestamp of last successful fetch."""
return self._last_successful_fetch
================================================
FILE: src/claude_monitor/monitoring/orchestrator.py
================================================
"""Orchestrator for monitoring components."""
import logging
import threading
import time
from typing import Any, Callable, Dict, List, Optional
from claude_monitor.core.plans import DEFAULT_TOKEN_LIMIT, get_token_limit
from claude_monitor.error_handling import report_error
from claude_monitor.monitoring.data_manager import DataManager
from claude_monitor.monitoring.session_monitor import SessionMonitor
logger = logging.getLogger(__name__)
class MonitoringOrchestrator:
"""Orchestrates monitoring components following SRP."""
def __init__(
self, update_interval: int = 10, data_path: Optional[str] = None
) -> None:
"""Initialize orchestrator with components.
Args:
update_interval: Seconds between updates
data_path: Optional path to Claude data directory
"""
self.update_interval: int = update_interval
self.data_manager: DataManager = DataManager(cache_ttl=5, data_path=data_path)
self.session_monitor: SessionMonitor = SessionMonitor()
self._monitoring: bool = False
self._monitor_thread: Optional[threading.Thread] = None
self._stop_event: threading.Event = threading.Event()
self._update_callbacks: List[Callable[[Dict[str, Any]], None]] = []
self._last_valid_data: Optional[Dict[str, Any]] = None
self._args: Optional[Any] = None
self._first_data_event: threading.Event = threading.Event()
def start(self) -> None:
"""Start monitoring."""
if self._monitoring:
logger.warning("Monitoring already running")
return
logger.info(f"Starting monitoring with {self.update_interval}s interval")
self._monitoring = True
self._stop_event.clear()
# Start monitoring thread
self._monitor_thread = threading.Thread(
target=self._monitoring_loop, name="MonitoringThread", daemon=True
)
self._monitor_thread.start()
def stop(self) -> None:
"""Stop monitoring."""
if not self._monitoring:
return
logger.info("Stopping monitoring")
self._monitoring = False
self._stop_event.set()
if self._monitor_thread and self._monitor_thread.is_alive():
self._monitor_thread.join(timeout=5)
self._monitor_thread = None
self._first_data_event.clear()
def set_args(self, args: Any) -> None:
"""Set command line arguments for token limit calculation.
Args:
args: Command line arguments
"""
self._args = args
def register_update_callback(
self, callback: Callable[[Dict[str, Any]], None]
) -> None:
"""Register callback for data updates.
Args:
callback: Function to call with monitoring data
"""
if callback not in self._update_callbacks:
self._update_callbacks.append(callback)
logger.debug("Registered update callback")
def register_session_callback(
self, callback: Callable[[str, str, Optional[Dict[str, Any]]], None]
) -> None:
"""Register callback for session changes.
Args:
callback: Function(event_type, session_id, session_data)
"""
self.session_monitor.register_callback(callback)
def force_refresh(self) -> Optional[Dict[str, Any]]:
"""Force immediate data refresh.
Returns:
Fresh data or None if fetch fails
"""
return self._fetch_and_process_data(force_refresh=True)
def wait_for_initial_data(self, timeout: float = 10.0) -> bool:
"""Wait for initial data to be fetched.
Args:
timeout: Maximum time to wait in seconds
Returns:
True if data was received, False if timeout
"""
return self._first_data_event.wait(timeout=timeout)
def _monitoring_loop(self) -> None:
"""Main monitoring loop."""
logger.info("Monitoring loop started")
# Initial fetch
self._fetch_and_process_data()
while self._monitoring:
# Wait for interval or stop
if self._stop_event.wait(timeout=self.update_interval):
if not self._monitoring:
break
# Fetch and process
self._fetch_and_process_data()
logger.info("Monitoring loop ended")
def _fetch_and_process_data(
self, force_refresh: bool = False
) -> Optional[Dict[str, Any]]:
"""Fetch data and notify callbacks.
Args:
force_refresh: Force cache refresh
Returns:
Processed data or None if failed
"""
try:
# Fetch data
start_time: float = time.time()
data: Optional[Dict[str, Any]] = self.data_manager.get_data(
force_refresh=force_refresh
)
if data is None:
logger.warning("No data fetched")
return None
# Validate and update session tracking
is_valid: bool
errors: List[str]
is_valid, errors = self.session_monitor.update(data)
if not is_valid:
logger.error(f"Data validation failed: {errors}")
return None
# Calculate token limit
token_limit: int = self._calculate_token_limit(data)
# Prepare monitoring data
monitoring_data: Dict[str, Any] = {
"data": data,
"token_limit": token_limit,
"args": self._args,
"session_id": self.session_monitor.current_session_id,
"session_count": self.session_monitor.session_count,
}
# Store last valid data
self._last_valid_data = monitoring_data
# Signal that first data has been received
if not self._first_data_event.is_set():
self._first_data_event.set()
# Notify callbacks
for callback in self._update_callbacks:
try:
callback(monitoring_data)
except Exception as e:
logger.error(f"Callback error: {e}", exc_info=True)
report_error(
exception=e,
component="orchestrator",
context_name="callback_error",
)
elapsed: float = time.time() - start_time
logger.debug(f"Data processing completed in {elapsed:.3f}s")
return monitoring_data
except Exception as e:
logger.error(f"Error in monitoring cycle: {e}", exc_info=True)
report_error(
exception=e, component="orchestrator", context_name="monitoring_cycle"
)
return None
def _calculate_token_limit(self, data: Dict[str, Any]) -> int:
"""Calculate token limit based on plan and data.
Args:
data: Monitoring data
Returns:
Token limit
"""
if not self._args:
return DEFAULT_TOKEN_LIMIT
plan: str = getattr(self._args, "plan", "pro")
try:
if plan == "custom":
blocks: List[Any] = data.get("blocks", [])
return get_token_limit(plan, blocks)
return get_token_limit(plan)
except Exception as e:
logger.exception(f"Error calculating token limit: {e}")
return DEFAULT_TOKEN_LIMIT
================================================
FILE: src/claude_monitor/monitoring/session_monitor.py
================================================
"""Unified session monitoring - combines tracking and validation."""
import logging
from typing import Any, Callable, Dict, List, Optional, Tuple
logger = logging.getLogger(__name__)
class SessionMonitor:
"""Monitors sessions with tracking and validation."""
def __init__(self) -> None:
"""Initialize session monitor."""
self._current_session_id: Optional[str] = None
self._session_callbacks: List[
Callable[[str, str, Optional[Dict[str, Any]]], None]
] = []
self._session_history: List[Dict[str, Any]] = []
def update(self, data: Dict[str, Any]) -> Tuple[bool, List[str]]:
"""Update session tracking with new data and validate.
Args:
data: Monitoring data with blocks
Returns:
Tuple of (is_valid, error_messages)
"""
is_valid: bool
errors: List[str]
is_valid, errors = self.validate_data(data)
if not is_valid:
logger.warning(f"Data validation failed: {errors}")
return is_valid, errors
blocks: List[Dict[str, Any]] = data.get("blocks", [])
active_session: Optional[Dict[str, Any]] = None
for block in blocks:
if block.get("isActive", False):
active_session = block
break
if active_session:
session_id: Optional[str] = active_session.get("id")
if session_id is not None and session_id != self._current_session_id:
self._on_session_change(
self._current_session_id, session_id, active_session
)
self._current_session_id = session_id
elif self._current_session_id is not None:
self._on_session_end(self._current_session_id)
self._current_session_id = None
return is_valid, errors
def validate_data(self, data: Any) -> Tuple[bool, List[str]]:
"""Validate monitoring data structure and content.
Args:
data: Data to validate
Returns:
Tuple of (is_valid, error_messages)
"""
errors: List[str] = []
if not isinstance(data, dict):
errors.append("Data must be a dictionary")
return False, errors
if "blocks" not in data:
errors.append("Missing required key: blocks")
if "blocks" in data:
blocks: Any = data["blocks"]
if not isinstance(blocks, list):
errors.append("blocks must be a list")
else:
for i, block in enumerate(blocks):
block_errors: List[str] = self._validate_block(block, i)
errors.extend(block_errors)
return len(errors) == 0, errors
def _validate_block(self, block: Any, index: int) -> List[str]:
"""Validate individual block.
Args:
block: Block to validate
index: Block index for error messages
Returns:
List of error messages
"""
errors: List[str] = []
if not isinstance(block, dict):
errors.append(f"Block {index} must be a dictionary")
return errors
required_fields: List[str] = ["id", "isActive", "totalTokens", "costUSD"]
for field in required_fields:
if field not in block:
errors.append(f"Block {index} missing required field: {field}")
if "totalTokens" in block and not isinstance(
block["totalTokens"], (int, float)
):
errors.append(f"Block {index} totalTokens must be numeric")
if "costUSD" in block and not isinstance(block["costUSD"], (int, float)):
errors.append(f"Block {index} costUSD must be numeric")
if "isActive" in block and not isinstance(block["isActive"], bool):
errors.append(f"Block {index} isActive must be boolean")
return errors
def _on_session_change(
self, old_id: Optional[str], new_id: str, session_data: Dict[str, Any]
) -> None:
"""Handle session change.
Args:
old_id: Previous session ID
new_id: New session ID
session_data: New session data
"""
if old_id is None:
logger.info(f"New session started: {new_id}")
else:
logger.info(f"Session changed from {old_id} to {new_id}")
self._session_history.append(
{
"id": new_id,
"started_at": session_data.get("startTime"),
"tokens": session_data.get("totalTokens", 0),
"cost": session_data.get("costUSD", 0),
}
)
for callback in self._session_callbacks:
try:
callback("session_start", new_id, session_data)
except Exception as e:
logger.exception(f"Session callback error: {e}")
def _on_session_end(self, session_id: str) -> None:
"""Handle session end.
Args:
session_id: Ended session ID
"""
logger.info(f"Session ended: {session_id}")
for callback in self._session_callbacks:
try:
callback("session_end", session_id, None)
except Exception as e:
logger.exception(f"Session callback error: {e}")
def register_callback(
self, callback: Callable[[str, str, Optional[Dict[str, Any]]], None]
) -> None:
"""Register session change callback.
Args:
callback: Function(event_type, session_id, session_data)
"""
if callback not in self._session_callbacks:
self._session_callbacks.append(callback)
def unregister_callback(
self, callback: Callable[[str, str, Optional[Dict[str, Any]]], None]
) -> None:
"""Unregister session change callback.
Args:
callback: Callback to remove
"""
if callback in self._session_callbacks:
self._session_callbacks.remove(callback)
@property
def current_session_id(self) -> Optional[str]:
"""Get current active session ID."""
return self._current_session_id
@property
def session_count(self) -> int:
"""Get total number of sessions tracked."""
return len(self._session_history)
@property
def session_history(self) -> List[Dict[str, Any]]:
"""Get session history."""
return self._session_history.copy()
================================================
FILE: src/claude_monitor/terminal/__init__.py
================================================
"""Terminal package for Claude Monitor."""
# Import directly from manager and themes without facade
__all__: list[str] = []
================================================
FILE: src/claude_monitor/terminal/manager.py
================================================
"""Terminal management for Claude Monitor.
Raw mode setup, input handling, and terminal control.
"""
import logging
import sys
from typing import Any, List, Optional, Union
from claude_monitor.error_handling import report_error
from claude_monitor.terminal.themes import print_themed
logger: logging.Logger = logging.getLogger(__name__)
try:
import termios
HAS_TERMIOS: bool = True
except ImportError:
HAS_TERMIOS: bool = False
def setup_terminal() -> Optional[List[Any]]:
"""Setup terminal for raw mode to prevent input interference.
Returns:
Terminal settings list that can be used to restore terminal state,
or None if terminal setup is not supported or fails.
"""
if not HAS_TERMIOS or not sys.stdin.isatty():
return None
try:
old_settings: List[Any] = termios.tcgetattr(sys.stdin)
new_settings: List[Any] = termios.tcgetattr(sys.stdin)
new_settings[3] = new_settings[3] & ~(termios.ECHO | termios.ICANON)
termios.tcsetattr(sys.stdin, termios.TCSANOW, new_settings)
return old_settings
except (OSError, termios.error, AttributeError):
return None
def restore_terminal(old_settings: Optional[List[Any]]) -> None:
"""Restore terminal to original settings.
Args:
old_settings: Terminal settings to restore, or None if no settings to restore.
"""
# Send ANSI escape sequences to show cursor and exit alternate screen
print("\033[?25h\033[?1049l", end="", flush=True)
if old_settings and HAS_TERMIOS and sys.stdin.isatty():
try:
termios.tcsetattr(sys.stdin, termios.TCSANOW, old_settings)
except (OSError, termios.error, AttributeError) as e:
logger.warning(f"Failed to restore terminal settings: {e}")
def enter_alternate_screen() -> None:
"""Enter alternate screen buffer, clear and hide cursor.
Sends ANSI escape sequences to:
- Enter alternate screen buffer (\033[?1049h)
- Clear screen (\033[2J)
- Move cursor to home position (\033[H)
- Hide cursor (\033[?25l)
"""
print("\033[?1049h\033[2J\033[H\033[?25l", end="", flush=True)
def handle_cleanup_and_exit(
old_terminal_settings: Optional[List[Any]], message: str = "Monitoring stopped."
) -> None:
"""Handle cleanup and exit gracefully.
Args:
old_terminal_settings: Terminal settings to restore before exit.
message: Exit message to display to user.
"""
restore_terminal(old_terminal_settings)
print_themed(f"\n\n{message}", style="info")
sys.exit(0)
def handle_error_and_exit(
old_terminal_settings: Optional[List[Any]], error: Union[Exception, str]
) -> None:
"""Handle error cleanup and exit.
Args:
old_terminal_settings: Terminal settings to restore before exit.
error: Exception or error message that caused the exit.
Raises:
The original error after cleanup and reporting.
"""
restore_terminal(old_terminal_settings)
logger.error(f"Terminal error: {error}")
sys.stderr.write(f"\n\nError: {error}\n")
report_error(
exception=error,
component="terminal_manager",
context_name="terminal",
context_data={"phase": "cleanup"},
tags={"exit_type": "error_handler"},
)
raise error
================================================
FILE: src/claude_monitor/terminal/themes.py
================================================
"""Unified theme management for terminal display."""
import logging
import os
import re
import sys
import threading
from dataclasses import dataclass
from enum import Enum
from typing import Any, Dict, List, Optional, Tuple, Union
# Windows-compatible imports with graceful fallbacks
try:
import select
import termios
import tty
HAS_TERMIOS: bool = True
except ImportError:
HAS_TERMIOS: bool = False
from rich.console import Console
from rich.theme import Theme
class BackgroundType(Enum):
"""Background detection types."""
LIGHT = "light"
DARK = "dark"
UNKNOWN = "unknown"
@dataclass
class ThemeConfig:
"""Theme configuration for terminal display.
Attributes:
name: Human-readable theme name.
colors: Mapping of color keys to ANSI/hex color values.
symbols: Unicode symbols and ASCII fallbacks for theme.
rich_theme: Rich library theme configuration.
"""
name: str
colors: Dict[str, str]
symbols: Dict[str, Union[str, List[str]]]
rich_theme: Theme
def get_color(self, key: str, default: str = "default") -> str:
"""Get color for key with fallback.
Args:
key: Color key to look up.
default: Default color value if key not found.
Returns:
Color value string (ANSI code, hex, or color name).
"""
return self.colors.get(key, default)
class AdaptiveColorScheme:
"""Scientifically-based adaptive color schemes with proper contrast ratios.
IMPORTANT: This only changes FONT/FOREGROUND colors, never background colors.
The terminal's background remains unchanged - we adapt text colors for readability.
All color choices follow WCAG AA accessibility standards for contrast ratios.
"""
@staticmethod
def get_light_background_theme() -> Theme:
"""Font colors optimized for light terminal backgrounds (WCAG AA+ contrast)."""
return Theme(
{
"header": "color(17)", # Deep blue (#00005f) - 21:1 contrast
"info": "color(19)", # Dark blue (#0000af) - 18:1 contrast
"warning": "color(166)", # Dark orange (#d75f00) - 8:1 contrast
"error": "color(124)", # Dark red (#af0000) - 12:1 contrast
"success": "color(22)", # Dark green (#005f00) - 15:1 contrast
"value": "color(235)", # Very dark gray (#262626) - 16:1 contrast
"dim": "color(243)", # Medium gray (#767676) - 5:1 contrast
"separator": "color(240)", # Light gray (#585858) - 6:1 contrast
"progress_bar": "black", # Pure black for light theme
"highlight": "color(124)", # Dark red (#af0000) - matches error
# Cost styles
"cost.low": "black", # Pure black for light theme
"cost.medium": "black", # Pure black for light theme
"cost.high": "black", # Pure black for light theme
# Table styles
"table.border": "color(238)", # Medium-dark gray for better visibility
"table.header": "bold color(17)", # Bold deep blue
"table.row": "color(235)", # Very dark gray
"table.row.alt": "color(238)", # Slightly lighter gray
# Progress styles
"progress.bar.fill": "black", # Pure black for light theme
"progress.bar": "black", # Pure black for light theme (fallback)
"progress.bar.empty": "color(250)", # Very light gray for light theme
"progress.percentage": "bold color(235)", # Bold very dark gray
# Chart styles
"chart.bar": "color(17)", # Deep blue for better visibility
"chart.line": "color(19)", # Darker blue
"chart.point": "color(124)", # Dark red
"chart.axis": "color(240)", # Light gray
"chart.label": "color(235)", # Very dark gray
# Status styles
"status.active": "color(22)", # Dark green
"status.inactive": "color(243)", # Medium gray
"status.warning": "color(166)", # Dark orange
"status.error": "color(124)", # Dark red
# Time styles
"time.elapsed": "color(235)", # Very dark gray
"time.remaining": "color(166)", # Dark orange
"time.duration": "color(19)", # Dark blue
# Model styles
"model.opus": "color(17)", # Deep blue
"model.sonnet": "color(19)", # Dark blue
"model.haiku": "color(22)", # Dark green
"model.unknown": "color(243)", # Medium gray
# Plan styles
"plan.pro": "color(166)", # Orange (premium)
"plan.max5": "color(19)", # Dark blue
"plan.max20": "color(17)", # Deep blue
"plan.custom": "color(22)", # Dark green
}
)
@staticmethod
def get_dark_background_theme() -> Theme:
"""Font colors optimized for dark terminal backgrounds (WCAG AA+ contrast)."""
return Theme(
{
"header": "color(117)", # Light blue (#87d7ff) - 14:1 contrast
"info": "color(111)", # Light cyan (#87afff) - 12:1 contrast
"warning": "color(214)", # Orange (#ffaf00) - 11:1 contrast
"error": "color(203)", # Light red (#ff5f5f) - 9:1 contrast
"success": "color(118)", # Light green (#87ff00) - 15:1 contrast
"value": "color(253)", # Very light gray (#dadada) - 17:1 contrast
"dim": "color(245)", # Medium light gray (#8a8a8a) - 7:1 contrast
"separator": "color(248)", # Light gray (#a8a8a8) - 9:1 contrast
"progress_bar": "white", # Pure white for dark theme
"highlight": "color(203)", # Light red (#ff5f5f) - matches error
# Cost styles
"cost.low": "white", # Pure white for dark theme
"cost.medium": "white", # Pure white for dark theme
"cost.high": "white", # Pure white for dark theme
# Table styles
"table.border": "color(248)", # Light gray
"table.header": "bold color(117)", # Bold light blue
"table.row": "color(253)", # Very light gray
"table.row.alt": "color(251)", # Slightly darker gray
# Progress styles
"progress.bar.fill": "white", # Pure white for dark theme
"progress.bar": "white", # Pure white for dark theme (fallback)
"progress.bar.empty": "color(238)", # Darker gray for dark theme
"progress.percentage": "bold color(253)", # Bold very light gray
# Chart styles
"chart.bar": "color(111)", # Light cyan
"chart.line": "color(117)", # Light blue
"chart.point": "color(203)", # Light red
"chart.axis": "color(248)", # Light gray
"chart.label": "color(253)", # Very light gray
# Status styles
"status.active": "color(118)", # Light green
"status.inactive": "color(245)", # Medium light gray
"status.warning": "color(214)", # Orange
"status.error": "color(203)", # Light red
# Time styles
"time.elapsed": "color(253)", # Very light gray
"time.remaining": "color(214)", # Orange
"time.duration": "color(111)", # Light cyan
# Model styles
"model.opus": "color(117)", # Light blue
"model.sonnet": "color(111)", # Light cyan
"model.haiku": "color(118)", # Light green
"model.unknown": "color(245)", # Medium light gray
# Plan styles
"plan.pro": "color(214)", # Orange (premium)
"plan.max5": "color(111)", # Light cyan
"plan.max20": "color(117)", # Light blue
"plan.custom": "color(118)", # Light green
}
)
@staticmethod
def get_classic_theme() -> Theme:
"""Classic colors for maximum compatibility."""
return Theme(
{
"header": "cyan",
"info": "blue",
"warning": "yellow",
"error": "red",
"success": "green",
"value": "white",
"dim": "bright_black",
"separator": "white",
"progress_bar": "green",
"highlight": "red",
# Cost styles
"cost.low": "green",
"cost.medium": "yellow",
"cost.high": "red",
# Table styles
"table.border": "white",
"table.header": "bold cyan",
"table.row": "white",
"table.row.alt": "bright_black",
# Progress styles
"progress.bar.fill": "green",
"progress.bar.empty": "bright_black",
"progress.percentage": "bold white",
# Chart styles
"chart.bar": "blue",
"chart.line": "cyan",
"chart.point": "red",
"chart.axis": "white",
"chart.label": "white",
# Status styles
"status.active": "green",
"status.inactive": "bright_black",
"status.warning": "yellow",
"status.error": "red",
# Time styles
"time.elapsed": "white",
"time.remaining": "yellow",
"time.duration": "blue",
# Model styles
"model.opus": "cyan",
"model.sonnet": "blue",
"model.haiku": "green",
"model.unknown": "bright_black",
# Plan styles
"plan.pro": "yellow", # Yellow (premium)
"plan.max5": "cyan", # Cyan
"plan.max20": "blue", # Blue
"plan.custom": "green", # Green
}
)
class BackgroundDetector:
"""Detects terminal background type using multiple methods.
Uses environment variables, OSC queries, and heuristics to determine
whether the terminal has a light or dark background for optimal theming.
"""
@staticmethod
def detect_background() -> BackgroundType:
"""Detect terminal background using multiple methods.
Tries multiple detection methods in order of reliability:
1. COLORFGBG environment variable
2. Known terminal environment hints
3. OSC 11 color query (advanced terminals)
Returns:
Detected background type, defaults to DARK if unknown.
"""
# Method 1: Check COLORFGBG environment variable
colorfgbg_result: BackgroundType = BackgroundDetector._check_colorfgbg()
if colorfgbg_result != BackgroundType.UNKNOWN:
return colorfgbg_result
# Method 2: Check known terminal environment variables
env_result: BackgroundType = BackgroundDetector._check_environment_hints()
if env_result != BackgroundType.UNKNOWN:
return env_result
# Method 3: Use OSC 11 query (advanced terminals only)
osc_result: BackgroundType = BackgroundDetector._query_background_color()
if osc_result != BackgroundType.UNKNOWN:
return osc_result
# Default fallback
return BackgroundType.DARK
@staticmethod
def _check_colorfgbg() -> BackgroundType:
"""Check COLORFGBG environment variable.
COLORFGBG format: "foreground;background" where background
color 0-7 indicates dark, 8-15 indicates light background.
Returns:
Background type based on COLORFGBG or UNKNOWN if unavailable.
"""
colorfgbg: str = os.environ.get("COLORFGBG", "")
if not colorfgbg:
return BackgroundType.UNKNOWN
try:
# COLORFGBG format: "foreground;background"
parts: List[str] = colorfgbg.split(";")
if len(parts) >= 2:
bg_color: int = int(parts[-1])
# Colors 0-7 are typically dark, 8-15 are bright
return BackgroundType.LIGHT if bg_color >= 8 else BackgroundType.DARK
except (ValueError, IndexError) as e:
# COLORFGBG parsing failed - not critical, will use other detection methods
logger: logging.Logger = logging.getLogger(__name__)
logger.debug(f"Failed to parse COLORFGBG '{colorfgbg}': {e}")
return BackgroundType.UNKNOWN
@staticmethod
def _check_environment_hints() -> BackgroundType:
"""Check environment variables for theme hints.
Checks known terminal-specific environment variables and patterns
to infer the likely background type.
Returns:
Background type based on environment hints or UNKNOWN.
"""
# Windows Terminal session
if os.environ.get("WT_SESSION"):
return BackgroundType.DARK
# Check terminal program
if "TERM_PROGRAM" in os.environ:
term_program: str = os.environ["TERM_PROGRAM"]
if term_program == "Apple_Terminal":
return BackgroundType.LIGHT
if term_program == "iTerm.app":
return BackgroundType.DARK
# Check TERM variable patterns
term: str = os.environ.get("TERM", "").lower()
if "light" in term:
return BackgroundType.LIGHT
if "dark" in term:
return BackgroundType.DARK
return BackgroundType.UNKNOWN
@staticmethod
def _query_background_color() -> BackgroundType:
"""Query terminal background color using OSC 11.
Sends an OSC (Operating System Command) 11 query to request the terminal's
background color, then calculates perceived brightness to determine if
the background is light or dark.
Returns:
Background type based on OSC 11 response or UNKNOWN if query fails.
"""
if not HAS_TERMIOS:
return BackgroundType.UNKNOWN
if not sys.stdin.isatty() or not sys.stdout.isatty():
return BackgroundType.UNKNOWN
old_settings: Optional[List[Any]] = None
try:
# Save terminal settings
old_settings = termios.tcgetattr(sys.stdin)
# Set terminal to raw mode
tty.setraw(sys.stdin.fileno())
# Send OSC 11 query
sys.stdout.write("\033]11;?\033\\")
sys.stdout.flush()
# Wait for response with timeout
ready_streams: List[Any] = select.select([sys.stdin], [], [], 0.1)[0]
if ready_streams:
# Read available data without blocking
response: str = ""
try:
# Read character by character with timeout to avoid blocking
import fcntl
import os
# Set stdin to non-blocking mode
fd = sys.stdin.fileno()
fl = fcntl.fcntl(fd, fcntl.F_GETFL)
fcntl.fcntl(fd, fcntl.F_SETFL, fl | os.O_NONBLOCK)
# Read up to 50 chars with timeout
for _ in range(50):
ready = select.select([sys.stdin], [], [], 0.01)[0]
if not ready:
break
char = sys.stdin.read(1)
if not char:
break
response += char
# Stop if we get the expected terminator
if response.endswith("\033\\"):
break
# Restore blocking mode
fcntl.fcntl(fd, fcntl.F_SETFL, fl)
except (OSError, ImportError):
# Fallback to simple read if fcntl is not available
response = sys.stdin.read(50)
# Parse response: \033]11;rgb:rrrr/gggg/bbbb\033\\
if response: # Only proceed if we got a response
rgb_match = re.search(
r"rgb:([0-9a-f]+)/([0-9a-f]+)/([0-9a-f]+)", response
)
if rgb_match:
r: str
g: str
b: str
r, g, b = rgb_match.groups()
# Convert hex to int and calculate brightness
red: int = int(r[:2], 16) if len(r) >= 2 else 0
green: int = int(g[:2], 16) if len(g) >= 2 else 0
blue: int = int(b[:2], 16) if len(b) >= 2 else 0
# Calculate perceived brightness using standard formula
brightness: float = (
red * 299 + green * 587 + blue * 114
) / 1000
# Restore terminal settings
termios.tcsetattr(sys.stdin, termios.TCSADRAIN, old_settings)
return (
BackgroundType.LIGHT
if brightness > 127
else BackgroundType.DARK
)
# Restore terminal settings
if old_settings is not None:
termios.tcsetattr(sys.stdin, termios.TCSADRAIN, old_settings)
except (OSError, termios.error, AttributeError):
# Restore terminal settings on any error
if old_settings is not None:
try:
termios.tcsetattr(sys.stdin, termios.TCSADRAIN, old_settings)
except (OSError, termios.error, AttributeError) as e:
# Terminal settings restoration failed - log but continue
# This is non-critical as the terminal will be cleaned up on process exit
logger: logging.Logger = logging.getLogger(__name__)
logger.warning(
f"Failed to restore terminal settings during OSC query: {e}"
)
return BackgroundType.UNKNOWN
class ThemeManager:
"""Manages themes with auto-detection and thread safety."""
def __init__(self):
self._lock = threading.Lock()
self._current_theme: Optional[ThemeConfig] = None
self._forced_theme: Optional[str] = None
self.themes = self._load_themes()
def _load_themes(self) -> Dict[str, ThemeConfig]:
"""Load all available themes.
Creates theme configurations for light, dark, and classic themes
with appropriate Rich theme objects and symbol sets.
Returns:
Dictionary mapping theme names to ThemeConfig objects.
"""
themes: Dict[str, ThemeConfig] = {}
# Load themes with Rich theme objects
light_rich: Theme = AdaptiveColorScheme.get_light_background_theme()
dark_rich: Theme = AdaptiveColorScheme.get_dark_background_theme()
classic_rich: Theme = AdaptiveColorScheme.get_classic_theme()
themes["light"] = ThemeConfig(
name="light",
colors={}, # No longer using color mappings from defaults.py
symbols=self._get_symbols_for_theme("light"),
rich_theme=light_rich,
)
themes["dark"] = ThemeConfig(
name="dark",
colors={}, # No longer using color mappings from defaults.py
symbols=self._get_symbols_for_theme("dark"),
rich_theme=dark_rich,
)
themes["classic"] = ThemeConfig(
name="classic",
colors={}, # No longer using color mappings from defaults.py
symbols=self._get_symbols_for_theme("classic"),
rich_theme=classic_rich,
)
return themes
def _get_symbols_for_theme(
self, theme_name: str
) -> Dict[str, Union[str, List[str]]]:
"""Get symbols based on theme.
Args:
theme_name: Name of theme to get symbols for.
Returns:
Dictionary mapping symbol names to Unicode or ASCII characters.
Spinner symbols are returned as a list for animation.
"""
if theme_name == "classic":
return {
"progress_empty": "-",
"progress_full": "#",
"bullet": "*",
"arrow": "->",
"check": "[OK]",
"cross": "[X]",
"spinner": ["|", "/", "-", "\\"],
}
return {
"progress_empty": "░",
"progress_full": "█",
"bullet": "•",
"arrow": "→",
"check": "✓",
"cross": "✗",
"spinner": ["⠋", "⠙", "⠹", "⠸", "⠼", "⠴", "⠦", "⠧", "⠇", "⠏"],
}
def auto_detect_theme(self) -> str:
"""Auto-detect appropriate theme based on terminal.
Uses BackgroundDetector to determine terminal background
and returns appropriate theme name.
Returns:
Theme name ('light', 'dark') based on detected background.
Defaults to 'dark' if detection fails.
"""
background: BackgroundType = BackgroundDetector.detect_background()
if background == BackgroundType.LIGHT:
return "light"
if background == BackgroundType.DARK:
return "dark"
# Default to dark if unknown
return "dark"
def get_theme(
self, name: Optional[str] = None, force_detection: bool = False
) -> ThemeConfig:
"""Get theme by name or auto-detect.
Args:
name: Theme name ('light', 'dark', 'classic', 'auto') or None for auto.
force_detection: Force re-detection of terminal background.
Returns:
ThemeConfig object for the requested or detected theme.
"""
with self._lock:
if name == "auto" or name is None:
if force_detection or self._forced_theme is None:
detected_name: str = self.auto_detect_theme()
theme: ThemeConfig = self.themes.get(
detected_name, self.themes["dark"]
)
if not force_detection:
self._forced_theme = detected_name
else:
theme = self.themes.get(self._forced_theme, self.themes["dark"])
else:
theme = self.themes.get(name, self.themes["dark"])
self._forced_theme = name if name in self.themes else None
self._current_theme = theme
return theme
def get_console(
self, theme_name: Optional[str] = None, force_detection: bool = False
) -> Console:
"""Get themed console instance.
Args:
theme_name: Theme name or None for auto-detection.
force_detection: Force re-detection of terminal background.
Returns:
Rich Console instance configured with the selected theme.
"""
theme: ThemeConfig = self.get_theme(theme_name, force_detection)
return Console(theme=theme.rich_theme, force_terminal=True)
def get_current_theme(self) -> Optional[ThemeConfig]:
"""Get currently active theme.
Returns:
Currently active ThemeConfig or None if no theme selected.
"""
return self._current_theme
# Cost-based styles with thresholds (moved from ui/styles.py)
COST_STYLES: Dict[str, str] = {
"low": "cost.low", # Green - costs under $1
"medium": "cost.medium", # Yellow - costs $1-$10
"high": "cost.high", # Red - costs over $10
}
# Cost thresholds for automatic style selection
COST_THRESHOLDS: List[Tuple[float, str]] = [
(10.0, COST_STYLES["high"]),
(1.0, COST_STYLES["medium"]),
(0.0, COST_STYLES["low"]),
]
# Velocity/burn rate emojis and labels
VELOCITY_INDICATORS: Dict[str, Dict[str, Union[str, float]]] = {
"slow": {"emoji": "🐌", "label": "Slow", "threshold": 50},
"normal": {"emoji": "➡️", "label": "Normal", "threshold": 150},
"fast": {"emoji": "🚀", "label": "Fast", "threshold": 300},
"very_fast": {"emoji": "⚡", "label": "Very fast", "threshold": float("inf")},
}
# Helper functions for style selection
def get_cost_style(cost: float) -> str:
"""Get appropriate style for a cost value.
Args:
cost: Cost value in USD to categorize.
Returns:
Rich style name for the cost category.
"""
for threshold, style in COST_THRESHOLDS:
if cost >= threshold:
return style
return COST_STYLES["low"]
def get_velocity_indicator(burn_rate: float) -> Dict[str, str]:
"""Get velocity indicator based on burn rate.
Args:
burn_rate: Token consumption rate (tokens per minute).
Returns:
Dictionary with 'emoji' and 'label' keys for the velocity category.
"""
for indicator in VELOCITY_INDICATORS.values():
threshold_value = indicator["threshold"]
if isinstance(threshold_value, (int, float)) and burn_rate < threshold_value:
return {"emoji": str(indicator["emoji"]), "label": str(indicator["label"])}
very_fast = VELOCITY_INDICATORS["very_fast"]
return {"emoji": str(very_fast["emoji"]), "label": str(very_fast["label"])}
# Global theme manager instance
_theme_manager: ThemeManager = ThemeManager()
def get_theme(name: Optional[str] = None) -> Theme:
"""Get Rich theme by name or auto-detect.
Args:
name: Theme name ('light', 'dark', 'classic') or None for auto-detection
Returns:
Rich Theme object
"""
theme_config = _theme_manager.get_theme(name)
return theme_config.rich_theme
def get_themed_console(force_theme: Optional[Union[str, bool]] = None) -> Console:
"""Get themed console - backward compatibility wrapper.
Args:
force_theme: Theme name to force, or None for auto-detection.
Returns:
Rich Console instance with appropriate theme.
"""
if force_theme and isinstance(force_theme, str):
return _theme_manager.get_console(force_theme)
return _theme_manager.get_console(None)
def print_themed(text: str, style: str = "info") -> None:
"""Print text with themed styling - backward compatibility.
Args:
text: Text to print with styling.
style: Rich style name to apply.
"""
console: Console = _theme_manager.get_console()
console.print(f"[{style}]{text}[/]")
================================================
FILE: src/claude_monitor/ui/__init__.py
================================================
"""UI package for Claude Monitor."""
# Direct imports without facade
__all__: list[str] = []
================================================
FILE: src/claude_monitor/ui/components.py
================================================
"""UI components for Claude Monitor.
Consolidates display indicators, error/loading screens, and advanced custom display.
"""
from typing import Any, Dict, List, Optional
from rich.console import Console, RenderableType
from claude_monitor.terminal.themes import get_cost_style, get_velocity_indicator
from claude_monitor.ui.layouts import HeaderManager
class VelocityIndicator:
"""Velocity indicator component for burn rate visualization."""
@staticmethod
def get_velocity_emoji(burn_rate: float) -> str:
"""Get velocity emoji based on burn rate.
Args:
burn_rate: Token burn rate per minute
Returns:
Emoji representing velocity level
"""
indicator = get_velocity_indicator(burn_rate)
return indicator["emoji"]
@staticmethod
def get_velocity_description(burn_rate: float) -> str:
"""Get velocity description based on burn rate.
Args:
burn_rate: Token burn rate per minute
Returns:
Text description of velocity level
"""
indicator = get_velocity_indicator(burn_rate)
return indicator["label"]
@staticmethod
def render(burn_rate: float, include_description: bool = False) -> str:
"""Render velocity indicator.
Args:
burn_rate: Token burn rate per minute
include_description: Whether to include text description
Returns:
Formatted velocity indicator
"""
emoji = VelocityIndicator.get_velocity_emoji(burn_rate)
if include_description:
description = VelocityIndicator.get_velocity_description(burn_rate)
return f"{emoji} {description}"
return emoji
class CostIndicator:
"""Cost indicator component for cost visualization."""
@staticmethod
def render(cost: float, currency: str = "USD") -> str:
"""Render cost indicator with appropriate styling.
Args:
cost: Cost amount
currency: Currency symbol/code
Returns:
Formatted cost indicator
"""
style = get_cost_style(cost)
symbol = "$" if currency == "USD" else currency
return f"[{style}]{symbol}{cost:.4f}[/]"
class ErrorDisplayComponent:
"""Error display component for handling error states."""
def __init__(self) -> None:
"""Initialize error display component."""
def format_error_screen(
self, plan: str = "pro", timezone: str = "Europe/Warsaw"
) -> List[str]:
"""Format error screen for failed data fetch.
Args:
plan: Current plan name
timezone: Display timezone
Returns:
List of formatted error screen lines
"""
screen_buffer = []
header_manager = HeaderManager()
screen_buffer.extend(header_manager.create_header(plan, timezone))
screen_buffer.append("[error]Failed to get usage data[/]")
screen_buffer.append("")
screen_buffer.append("[warning]Possible causes:[/]")
screen_buffer.append(" • You're not logged into Claude")
screen_buffer.append(" • Network connection issues")
screen_buffer.append("")
screen_buffer.append("[dim]Retrying in 3 seconds... (Ctrl+C to exit)[/]")
return screen_buffer
class LoadingScreenComponent:
"""Loading screen component for displaying loading states."""
def __init__(self) -> None:
"""Initialize loading screen component."""
def create_loading_screen(
self,
plan: str = "pro",
timezone: str = "Europe/Warsaw",
custom_message: Optional[str] = None,
) -> List[str]:
"""Create loading screen content.
Args:
plan: Current plan name
timezone: Display timezone
Returns:
List of loading screen lines
"""
screen_buffer = []
header_manager = HeaderManager()
screen_buffer.extend(header_manager.create_header(plan, timezone))
screen_buffer.append("")
screen_buffer.append("[info]⏳ Loading...[/]")
screen_buffer.append("")
if custom_message:
screen_buffer.append(f"[warning]{custom_message}[/]")
else:
screen_buffer.append("[warning]Fetching Claude usage data...[/]")
screen_buffer.append("")
if plan == "custom" and not custom_message:
screen_buffer.append(
"[info]Calculating your P90 session limits from usage history...[/]"
)
screen_buffer.append("")
screen_buffer.append("[dim]This may take a few seconds[/]")
return screen_buffer
def create_loading_screen_renderable(
self,
plan: str = "pro",
timezone: str = "Europe/Warsaw",
custom_message: Optional[str] = None,
) -> RenderableType:
"""Create Rich renderable for loading screen.
Args:
plan: Current plan name
timezone: Display timezone
Returns:
Rich renderable for loading screen
"""
screen_buffer = self.create_loading_screen(plan, timezone, custom_message)
from claude_monitor.ui.display_controller import ScreenBufferManager
buffer_manager = ScreenBufferManager()
return buffer_manager.create_screen_renderable(screen_buffer)
class AdvancedCustomLimitDisplay:
"""Display component for session-based P90 limits from general_limit sessions."""
def __init__(self, console: Console) -> None:
self.console = console
def _collect_session_data(
self, blocks: Optional[List[Dict[str, Any]]] = None
) -> Dict[str, Any]:
"""Collect session data and identify limit sessions."""
if not blocks:
return {
"all_sessions": [],
"limit_sessions": [],
"current_session": {"tokens": 0, "cost": 0.0, "messages": 0},
"total_sessions": 0,
"active_sessions": 0,
}
all_sessions = []
limit_sessions = []
current_session = {"tokens": 0, "cost": 0.0, "messages": 0}
active_sessions = 0
for block in blocks:
if block.get("isGap", False):
continue
session = {
"tokens": block.get("totalTokens", 0),
"cost": block.get("costUSD", 0.0),
"messages": block.get("sentMessagesCount", 0),
}
if block.get("isActive", False):
active_sessions += 1
current_session = session
elif session["tokens"] > 0:
all_sessions.append(session)
if self._is_limit_session(session):
limit_sessions.append(session)
return {
"all_sessions": all_sessions,
"limit_sessions": limit_sessions,
"current_session": current_session,
"total_sessions": len(all_sessions) + active_sessions,
"active_sessions": active_sessions,
}
def _is_limit_session(self, session: Dict[str, Any]) -> bool:
"""Check if session hit a general limit."""
tokens = session["tokens"]
from claude_monitor.core.plans import (
COMMON_TOKEN_LIMITS,
LIMIT_DETECTION_THRESHOLD,
)
for limit in COMMON_TOKEN_LIMITS:
if tokens >= limit * LIMIT_DETECTION_THRESHOLD:
return True
return False
def _calculate_session_percentiles(
self, sessions: List[Dict[str, Any]]
) -> Dict[str, Any]:
"""Calculate percentiles from session data."""
if not sessions:
return {
"tokens": {"p50": 19000, "p75": 66000, "p90": 88000, "p95": 110000},
"costs": {"p50": 100.0, "p75": 150.0, "p90": 200.0, "p95": 250.0},
"messages": {"p50": 150, "p75": 200, "p90": 250, "p95": 300},
"averages": {"tokens": 19000, "cost": 100.0, "messages": 150},
"count": 0,
}
import numpy as np
tokens = [s["tokens"] for s in sessions]
costs = [s["cost"] for s in sessions]
messages = [s["messages"] for s in sessions]
return {
"tokens": {
"p50": int(np.percentile(tokens, 50)),
"p75": int(np.percentile(tokens, 75)),
"p90": int(np.percentile(tokens, 90)),
"p95": int(np.percentile(tokens, 95)),
},
"costs": {
"p50": float(np.percentile(costs, 50)),
"p75": float(np.percentile(costs, 75)),
"p90": float(np.percentile(costs, 90)),
"p95": float(np.percentile(costs, 95)),
},
"messages": {
"p50": int(np.percentile(messages, 50)),
"p75": int(np.percentile(messages, 75)),
"p90": int(np.percentile(messages, 90)),
"p95": int(np.percentile(messages, 95)),
},
"averages": {
"tokens": float(np.mean(tokens)),
"cost": float(np.mean(costs)),
"messages": float(np.mean(messages)),
},
"count": len(sessions),
}
def format_error_screen(
plan: str = "pro", timezone: str = "Europe/Warsaw"
) -> List[str]:
"""Legacy function - format error screen.
Maintained for backward compatibility.
"""
component = ErrorDisplayComponent()
return component.format_error_screen(plan, timezone)
================================================
FILE: src/claude_monitor/ui/display_controller.py
================================================
"""Main display controller for Claude Monitor.
Orchestrates UI components and coordinates display updates.
"""
import logging
from datetime import datetime, timedelta, timezone
from pathlib import Path
from typing import Any, Dict, List, Optional, Tuple
import pytz
from rich.console import Console, Group, RenderableType
from rich.live import Live
from rich.text import Text
from claude_monitor.core.calculations import calculate_hourly_burn_rate
from claude_monitor.core.models import normalize_model_name
from claude_monitor.core.plans import Plans
from claude_monitor.ui.components import (
AdvancedCustomLimitDisplay,
ErrorDisplayComponent,
LoadingScreenComponent,
)
from claude_monitor.ui.layouts import ScreenManager
from claude_monitor.ui.session_display import SessionDisplayComponent
from claude_monitor.utils.notifications import NotificationManager
from claude_monitor.utils.time_utils import (
TimezoneHandler,
format_display_time,
get_time_format_preference,
percentage,
)
class DisplayController:
"""Main controller for coordinating UI display operations."""
def __init__(self) -> None:
"""Initialize display controller with components."""
self.session_display = SessionDisplayComponent()
self.loading_screen = LoadingScreenComponent()
self.error_display = ErrorDisplayComponent()
self.screen_manager = ScreenManager()
self.live_manager = LiveDisplayManager()
self.advanced_custom_display = None
self.buffer_manager = ScreenBufferManager()
self.session_calculator = SessionCalculator()
config_dir = Path.home() / ".claude" / "config"
config_dir.mkdir(parents=True, exist_ok=True)
self.notification_manager = NotificationManager(config_dir)
def _extract_session_data(self, active_block: Dict[str, Any]) -> Dict[str, Any]:
"""Extract basic session data from active block."""
return {
"tokens_used": active_block.get("totalTokens", 0),
"session_cost": active_block.get("costUSD", 0.0),
"raw_per_model_stats": active_block.get("perModelStats", {}),
"sent_messages": active_block.get("sentMessagesCount", 0),
"entries": active_block.get("entries", []),
"start_time_str": active_block.get("startTime"),
"end_time_str": active_block.get("endTime"),
}
def _calculate_token_limits(self, args: Any, token_limit: int) -> Tuple[int, int]:
"""Calculate token limits based on plan and arguments."""
if (
args.plan == "custom"
and hasattr(args, "custom_limit_tokens")
and args.custom_limit_tokens
):
return args.custom_limit_tokens, args.custom_limit_tokens
return token_limit, token_limit
def _calculate_time_data(
self, session_data: Dict[str, Any], current_time: datetime
) -> Dict[str, Any]:
"""Calculate time-related data for the session."""
return self.session_calculator.calculate_time_data(session_data, current_time)
def _calculate_cost_predictions(
self,
session_data: Dict[str, Any],
time_data: Dict[str, Any],
args: Any,
cost_limit_p90: Optional[float],
) -> Dict[str, Any]:
"""Calculate cost-related predictions."""
# Determine cost limit based on plan
if Plans.is_valid_plan(args.plan) and cost_limit_p90 is not None:
cost_limit = cost_limit_p90
else:
cost_limit = 100.0 # Default
return self.session_calculator.calculate_cost_predictions(
session_data, time_data, cost_limit
)
def _check_notifications(
self,
token_limit: int,
original_limit: int,
session_cost: float,
cost_limit: float,
predicted_end_time: datetime,
reset_time: datetime,
) -> Dict[str, bool]:
"""Check and update notification states."""
notifications = {}
# Switch to custom notification
switch_condition = token_limit > original_limit
if switch_condition and self.notification_manager.should_notify(
"switch_to_custom"
):
self.notification_manager.mark_notified("switch_to_custom")
notifications["show_switch_notification"] = True
else:
notifications["show_switch_notification"] = (
switch_condition
and self.notification_manager.is_notification_active("switch_to_custom")
)
# Exceed limit notification
exceed_condition = session_cost > cost_limit
if exceed_condition and self.notification_manager.should_notify(
"exceed_max_limit"
):
self.notification_manager.mark_notified("exceed_max_limit")
notifications["show_exceed_notification"] = True
else:
notifications["show_exceed_notification"] = (
exceed_condition
and self.notification_manager.is_notification_active("exceed_max_limit")
)
# Cost will exceed notification
run_out_condition = predicted_end_time < reset_time
if run_out_condition and self.notification_manager.should_notify(
"cost_will_exceed"
):
self.notification_manager.mark_notified("cost_will_exceed")
notifications["show_cost_will_exceed"] = True
else:
notifications["show_cost_will_exceed"] = (
run_out_condition
and self.notification_manager.is_notification_active("cost_will_exceed")
)
return notifications
def _format_display_times(
self,
args: Any,
current_time: datetime,
predicted_end_time: datetime,
reset_time: datetime,
) -> Dict[str, str]:
"""Format times for display."""
tz_handler = TimezoneHandler(default_tz="Europe/Warsaw")
timezone_to_use = (
args.timezone
if tz_handler.validate_timezone(args.timezone)
else "Europe/Warsaw"
)
# Convert times to display timezone
predicted_end_local = tz_handler.convert_to_timezone(
predicted_end_time, timezone_to_use
)
reset_time_local = tz_handler.convert_to_timezone(reset_time, timezone_to_use)
# Format times
time_format = get_time_format_preference(args)
predicted_end_str = format_display_time(
predicted_end_local, time_format, include_seconds=False
)
reset_time_str = format_display_time(
reset_time_local, time_format, include_seconds=False
)
# Current time display
try:
display_tz = pytz.timezone(args.timezone)
except pytz.exceptions.UnknownTimeZoneError:
display_tz = pytz.timezone("Europe/Warsaw")
current_time_display = current_time.astimezone(display_tz)
current_time_str = format_display_time(
current_time_display, time_format, include_seconds=True
)
return {
"predicted_end_str": predicted_end_str,
"reset_time_str": reset_time_str,
"current_time_str": current_time_str,
}
def create_data_display(
self, data: Dict[str, Any], args: Any, token_limit: int
) -> RenderableType:
"""Create display renderable from data.
Args:
data: Usage data dictionary
args: Command line arguments
token_limit: Current token limit
Returns:
Rich renderable for display
"""
if not data or "blocks" not in data:
screen_buffer = self.error_display.format_error_screen(
args.plan, args.timezone
)
return self.buffer_manager.create_screen_renderable(screen_buffer)
# Find the active block
active_block = None
for block in data["blocks"]:
if isinstance(block, dict) and block.get("isActive", False):
active_block = block
break
# Use UTC timezone for time calculations
current_time = datetime.now(pytz.UTC)
if not active_block:
screen_buffer = self.session_display.format_no_active_session_screen(
args.plan, args.timezone, token_limit, current_time, args
)
return self.buffer_manager.create_screen_renderable(screen_buffer)
cost_limit_p90 = None
messages_limit_p90 = None
if args.plan == "custom":
temp_display = AdvancedCustomLimitDisplay(None)
session_data = temp_display._collect_session_data(data["blocks"])
percentiles = temp_display._calculate_session_percentiles(
session_data["limit_sessions"]
)
cost_limit_p90 = percentiles["costs"]["p90"]
messages_limit_p90 = percentiles["messages"]["p90"]
else:
# Use centralized cost limits
from claude_monitor.core.plans import get_cost_limit
cost_limit_p90 = get_cost_limit(args.plan)
messages_limit_p90 = Plans.get_message_limit(args.plan)
# Process active session data with cost limit
try:
processed_data = self._process_active_session_data(
active_block, data, args, token_limit, current_time, cost_limit_p90
)
except Exception as e:
# Log the error and show error screen
logger = logging.getLogger(__name__)
logger.error(f"Error processing active session data: {e}", exc_info=True)
screen_buffer = self.error_display.format_error_screen(
args.plan, args.timezone
)
return self.buffer_manager.create_screen_renderable(screen_buffer)
# Add P90 limits to processed data for display
if Plans.is_valid_plan(args.plan):
processed_data["cost_limit_p90"] = cost_limit_p90
processed_data["messages_limit_p90"] = messages_limit_p90
try:
screen_buffer = self.session_display.format_active_session_screen(
**processed_data
)
except Exception as e:
# Log the error with more details
logger = logging.getLogger(__name__)
logger.error(f"Error in format_active_session_screen: {e}", exc_info=True)
logger.exception(f"processed_data type: {type(processed_data)}")
if isinstance(processed_data, dict):
for key, value in processed_data.items():
if key == "per_model_stats":
logger.exception(f" {key}: {type(value).__name__}")
if isinstance(value, dict):
for model, stats in value.items():
logger.exception(
f" {model}: {type(stats).__name__} = {stats}"
)
else:
logger.exception(f" value = {value}")
elif key == "entries":
logger.exception(
f" {key}: {type(value).__name__} with {len(value) if isinstance(value, list) else 'N/A'} items"
)
else:
logger.exception(f" {key}: {type(value).__name__} = {value}")
screen_buffer = self.error_display.format_error_screen(
args.plan, args.timezone
)
return self.buffer_manager.create_screen_renderable(screen_buffer)
return self.buffer_manager.create_screen_renderable(screen_buffer)
def _process_active_session_data(
self,
active_block: Dict[str, Any],
data: Dict[str, Any],
args: Any,
token_limit: int,
current_time: datetime,
cost_limit_p90: Optional[float] = None,
) -> Dict[str, Any]:
"""Process active session data for display.
Args:
active_block: Active session block data
data: Full usage data
args: Command line arguments
token_limit: Current token limit
current_time: Current UTC time
cost_limit_p90: Optional cost limit
Returns:
Processed data dictionary for display
"""
# Extract session data
session_data = self._extract_session_data(active_block)
# Calculate model distribution
model_distribution = self._calculate_model_distribution(
session_data["raw_per_model_stats"]
)
# Calculate token limits
token_limit, original_limit = self._calculate_token_limits(args, token_limit)
# Calculate usage metrics
tokens_used = session_data["tokens_used"]
usage_percentage = (
percentage(tokens_used, token_limit) if token_limit > 0 else 0
)
tokens_left = token_limit - tokens_used
# Calculate time data
time_data = self._calculate_time_data(session_data, current_time)
# Calculate burn rate
burn_rate = calculate_hourly_burn_rate(data["blocks"], current_time)
# Calculate cost predictions
cost_data = self._calculate_cost_predictions(
session_data, time_data, args, cost_limit_p90
)
# Check notifications
notifications = self._check_notifications(
token_limit,
original_limit,
session_data["session_cost"],
cost_data["cost_limit"],
cost_data["predicted_end_time"],
time_data["reset_time"],
)
# Format display times
display_times = self._format_display_times(
args, current_time, cost_data["predicted_end_time"], time_data["reset_time"]
)
# Build result dictionary
return {
"plan": args.plan,
"timezone": args.timezone,
"tokens_used": tokens_used,
"token_limit": token_limit,
"usage_percentage": usage_percentage,
"tokens_left": tokens_left,
"elapsed_session_minutes": time_data["elapsed_session_minutes"],
"total_session_minutes": time_data["total_session_minutes"],
"burn_rate": burn_rate,
"session_cost": session_data["session_cost"],
"per_model_stats": session_data["raw_per_model_stats"],
"model_distribution": model_distribution,
"sent_messages": session_data["sent_messages"],
"entries": session_data["entries"],
"predicted_end_str": display_times["predicted_end_str"],
"reset_time_str": display_times["reset_time_str"],
"current_time_str": display_times["current_time_str"],
"show_switch_notification": notifications["show_switch_notification"],
"show_exceed_notification": notifications["show_exceed_notification"],
"show_tokens_will_run_out": notifications["show_cost_will_exceed"],
"original_limit": original_limit,
}
def _calculate_model_distribution(
self, raw_per_model_stats: Dict[str, Any]
) -> Dict[str, float]:
"""Calculate model distribution percentages from current active session only.
Args:
raw_per_model_stats: Raw per-model token statistics from the active session block
Returns:
Dictionary mapping model names to usage percentages for the current session
"""
if not raw_per_model_stats:
return {}
# Calculate total tokens per model for THIS SESSION ONLY
model_tokens = {}
for model, stats in raw_per_model_stats.items():
if isinstance(stats, dict):
# Normalize model name
normalized_model = normalize_model_name(model)
if normalized_model and normalized_model != "unknown":
# Sum all token types for this model in current session
total_tokens = stats.get("input_tokens", 0) + stats.get(
"output_tokens", 0
)
if total_tokens > 0:
if normalized_model in model_tokens:
model_tokens[normalized_model] += total_tokens
else:
model_tokens[normalized_model] = total_tokens
# Calculate percentages based on current session total only
session_total_tokens = sum(model_tokens.values())
if session_total_tokens == 0:
return {}
model_distribution = {}
for model, tokens in model_tokens.items():
model_percentage = percentage(tokens, session_total_tokens)
model_distribution[model] = model_percentage
return model_distribution
def create_loading_display(
self,
plan: str = "pro",
timezone: str = "Europe/Warsaw",
custom_message: Optional[str] = None,
) -> RenderableType:
"""Create loading screen display.
Args:
plan: Current plan name
timezone: Display timezone
Returns:
Rich renderable for loading screen
"""
return self.loading_screen.create_loading_screen_renderable(
plan, timezone, custom_message
)
def create_error_display(
self, plan: str = "pro", timezone: str = "Europe/Warsaw"
) -> RenderableType:
"""Create error screen display.
Args:
plan: Current plan name
timezone: Display timezone
Returns:
Rich renderable for error screen
"""
screen_buffer = self.error_display.format_error_screen(plan, timezone)
return self.buffer_manager.create_screen_renderable(screen_buffer)
def create_live_context(self) -> Live:
"""Create live display context manager.
Returns:
Live display context manager
"""
return self.live_manager.create_live_display()
def set_screen_dimensions(self, width: int, height: int) -> None:
"""Set screen dimensions for responsive layouts.
Args:
width: Screen width
height: Screen height
"""
self.screen_manager.set_screen_dimensions(width, height)
class LiveDisplayManager:
"""Manager for Rich Live display operations."""
def __init__(self, console: Optional[Console] = None) -> None:
"""Initialize live display manager.
Args:
console: Optional Rich console instance
"""
self._console = console
self._live_context: Optional[Live] = None
self._current_renderable: Optional[RenderableType] = None
def create_live_display(
self,
auto_refresh: bool = True,
console: Optional[Console] = None,
refresh_per_second: float = 0.75,
) -> Live:
"""Create Rich Live display context.
Args:
auto_refresh: Whether to auto-refresh
console: Optional console instance
refresh_per_second: Display refresh rate (0.1-20 Hz)
Returns:
Rich Live context manager
"""
display_console = console or self._console
self._live_context = Live(
console=display_console,
refresh_per_second=refresh_per_second,
auto_refresh=auto_refresh,
vertical_overflow="visible", # Prevent screen scrolling
)
return self._live_context
class ScreenBufferManager:
"""Manager for screen buffer operations and rendering."""
def __init__(self) -> None:
"""Initialize screen buffer manager."""
self.console: Optional[Console] = None
def create_screen_renderable(self, screen_buffer: List[str]) -> Group:
"""Create Rich renderable from screen buffer.
Args:
screen_buffer: List of screen lines with Rich markup
Returns:
Rich Group renderable
"""
from claude_monitor.terminal.themes import get_themed_console
if self.console is None:
self.console = get_themed_console()
text_objects = []
for line in screen_buffer:
if isinstance(line, str):
# Use console to render markup properly
text_obj = Text.from_markup(line)
text_objects.append(text_obj)
else:
text_objects.append(line)
return Group(*text_objects)
# Legacy functions for backward compatibility
def create_screen_renderable(screen_buffer: List[str]) -> Group:
"""Legacy function - create screen renderable.
Maintained for backward compatibility.
"""
manager = ScreenBufferManager()
return manager.create_screen_renderable(screen_buffer)
class SessionCalculator:
"""Handles session-related calculations for display purposes.
(Moved from ui/calculators.py)"""
def __init__(self) -> None:
"""Initialize session calculator."""
self.tz_handler = TimezoneHandler()
def calculate_time_data(
self, session_data: Dict[str, Any], current_time: datetime
) -> Dict[str, Any]:
"""Calculate time-related data for the session.
Args:
session_data: Dictionary containing session information
current_time: Current UTC time
Returns:
Dictionary with calculated time data
"""
# Parse start time
start_time = None
if session_data.get("start_time_str"):
start_time = self.tz_handler.parse_timestamp(session_data["start_time_str"])
start_time = self.tz_handler.ensure_utc(start_time)
# Calculate reset time
if session_data.get("end_time_str"):
reset_time = self.tz_handler.parse_timestamp(session_data["end_time_str"])
reset_time = self.tz_handler.ensure_utc(reset_time)
else:
reset_time = (
start_time + timedelta(hours=5) # Default session duration
if start_time
else current_time + timedelta(hours=5) # Default session duration
)
# Calculate session times
time_to_reset = reset_time - current_time
minutes_to_reset = time_to_reset.total_seconds() / 60
if start_time and session_data.get("end_time_str"):
total_session_minutes = (reset_time - start_time).total_seconds() / 60
elapsed_session_minutes = (current_time - start_time).total_seconds() / 60
elapsed_session_minutes = max(0, elapsed_session_minutes)
else:
total_session_minutes = 5 * 60 # Default session duration in minutes
elapsed_session_minutes = max(0, total_session_minutes - minutes_to_reset)
return {
"start_time": start_time,
"reset_time": reset_time,
"minutes_to_reset": minutes_to_reset,
"total_session_minutes": total_session_minutes,
"elapsed_session_minutes": elapsed_session_minutes,
}
def calculate_cost_predictions(
self,
session_data: Dict[str, Any],
time_data: Dict[str, Any],
cost_limit: Optional[float] = None,
) -> Dict[str, Any]:
"""Calculate cost-related predictions.
Args:
session_data: Dictionary containing session cost information
time_data: Time data from calculate_time_data
cost_limit: Optional cost limit (defaults to 100.0)
Returns:
Dictionary with cost predictions
"""
elapsed_minutes = time_data["elapsed_session_minutes"]
session_cost = session_data.get("session_cost", 0.0)
current_time = datetime.now(timezone.utc)
# Calculate cost per minute
cost_per_minute = (
session_cost / max(1, elapsed_minutes) if elapsed_minutes > 0 else 0
)
# Use provided cost limit or default
if cost_limit is None:
cost_limit = 100.0
cost_remaining = max(0, cost_limit - session_cost)
# Calculate predicted end time
if cost_per_minute > 0 and cost_remaining > 0:
minutes_to_cost_depletion = cost_remaining / cost_per_minute
predicted_end_time = current_time + timedelta(
minutes=minutes_to_cost_depletion
)
else:
predicted_end_time = time_data["reset_time"]
return {
"cost_per_minute": cost_per_minute,
"cost_limit": cost_limit,
"cost_remaining": cost_remaining,
"predicted_end_time": predicted_end_time,
}
================================================
FILE: src/claude_monitor/ui/layouts.py
================================================
"""UI layout managers for Claude Monitor.
This module consolidates layout management functionality including:
- Header formatting and styling
- Screen layout and organization
"""
from __future__ import annotations
from typing import Final, Sequence
class HeaderManager:
"""Manager for header layout and formatting."""
# Type constants for header configuration
DEFAULT_SEPARATOR_CHAR: Final[str] = "="
DEFAULT_SEPARATOR_LENGTH: Final[int] = 60
DEFAULT_SPARKLES: Final[str] = "✦ ✧ ✦ ✧"
def __init__(self) -> None:
"""Initialize header manager."""
self.separator_char: str = self.DEFAULT_SEPARATOR_CHAR
self.separator_length: int = self.DEFAULT_SEPARATOR_LENGTH
def create_header(
self, plan: str = "pro", timezone: str = "Europe/Warsaw"
) -> list[str]:
"""Create stylized header with sparkles.
Args:
plan: Current plan name
timezone: Display timezone
Returns:
List of formatted header lines
"""
sparkles: str = self.DEFAULT_SPARKLES
title: str = "CLAUDE CODE USAGE MONITOR"
separator: str = self.separator_char * self.separator_length
return [
f"[header]{sparkles}[/] [header]{title}[/] [header]{sparkles}[/]",
f"[table.border]{separator}[/]",
f"[ {plan.lower()} | {timezone.lower()} ]",
"",
]
class ScreenManager:
"""Manager for overall screen layout and organization."""
# Type constants for screen configuration
DEFAULT_SCREEN_WIDTH: Final[int] = 80
DEFAULT_SCREEN_HEIGHT: Final[int] = 24
DEFAULT_MARGIN: Final[int] = 0
def __init__(self) -> None:
"""Initialize screen manager."""
self.screen_width: int = self.DEFAULT_SCREEN_WIDTH
self.screen_height: int = self.DEFAULT_SCREEN_HEIGHT
self.margin_left: int = self.DEFAULT_MARGIN
self.margin_right: int = self.DEFAULT_MARGIN
self.margin_top: int = self.DEFAULT_MARGIN
self.margin_bottom: int = self.DEFAULT_MARGIN
def set_screen_dimensions(self, width: int, height: int) -> None:
"""Set screen dimensions for layout calculations.
Args:
width: Screen width in characters
height: Screen height in lines
"""
self.screen_width = width
self.screen_height = height
def set_margins(
self, left: int = 0, right: int = 0, top: int = 0, bottom: int = 0
) -> None:
"""Set screen margins.
Args:
left: Left margin in characters
right: Right margin in characters
top: Top margin in lines
bottom: Bottom margin in lines
"""
self.margin_left = left
self.margin_right = right
self.margin_top = top
self.margin_bottom = bottom
def create_full_screen_layout(
self, content_sections: Sequence[Sequence[str]]
) -> list[str]:
"""Create full screen layout with multiple content sections.
Args:
content_sections: List of content sections, each being a list of lines
Returns:
Combined screen layout as list of lines
"""
screen_buffer: list[str] = []
screen_buffer.extend([""] * self.margin_top)
for i, section in enumerate(content_sections):
if i > 0:
screen_buffer.append("")
for line in section:
padded_line: str = " " * self.margin_left + line
screen_buffer.append(padded_line)
screen_buffer.extend([""] * self.margin_bottom)
return screen_buffer
__all__ = ["HeaderManager", "ScreenManager"]
================================================
FILE: src/claude_monitor/ui/progress_bars.py
================================================
"""Progress bar components for Claude Monitor.
Provides token usage, time progress, and model usage progress bars.
"""
from __future__ import annotations
from abc import ABC, abstractmethod
from typing import Any, Final, Protocol, TypedDict
from claude_monitor.utils.time_utils import percentage
# Type definitions for progress bar components
class ModelStatsDict(TypedDict, total=False):
"""Type definition for model statistics dictionary."""
input_tokens: int
output_tokens: int
total_tokens: int
cost: float
class ProgressBarStyleConfig(TypedDict, total=False):
"""Configuration for progress bar styling."""
filled_char: str
empty_char: str
filled_style: str | None
empty_style: str | None
class ThresholdConfig(TypedDict):
"""Configuration for color thresholds."""
threshold: float
style: str
class ProgressBarRenderer(Protocol):
"""Protocol for progress bar rendering."""
def render(self, *args: Any, **kwargs: Any) -> str:
"""Render the progress bar."""
...
class BaseProgressBar(ABC):
"""Abstract base class for progress bar components."""
# Type constants for validation
MIN_WIDTH: Final[int] = 10
MAX_WIDTH: Final[int] = 200
DEFAULT_WIDTH: Final[int] = 50
# Default styling constants
DEFAULT_FILLED_CHAR: Final[str] = "█"
DEFAULT_EMPTY_CHAR: Final[str] = "░"
DEFAULT_MAX_PERCENTAGE: Final[float] = 100.0
def __init__(self, width: int = 50) -> None:
"""Initialize base progress bar.
Args:
width: Width of the progress bar in characters
"""
self.width: int = width
self._validate_width()
def _validate_width(self) -> None:
"""Validate width parameter."""
if self.width < self.MIN_WIDTH:
raise ValueError(
f"Progress bar width must be at least {self.MIN_WIDTH} characters"
)
if self.width > self.MAX_WIDTH:
raise ValueError(
f"Progress bar width must not exceed {self.MAX_WIDTH} characters"
)
def _calculate_filled_segments(
self, percentage: float, max_value: float = 100.0
) -> int:
"""Calculate number of filled segments based on percentage.
Args:
percentage: Current percentage value
max_value: Maximum percentage value (default 100)
Returns:
Number of filled segments
"""
bounded_percentage: float = max(0, min(percentage, max_value))
return int(self.width * bounded_percentage / max_value)
def _render_bar(
self,
filled: int,
filled_char: str = "█",
empty_char: str = "░",
filled_style: str | None = None,
empty_style: str | None = None,
) -> str:
"""Render the actual progress bar.
Args:
filled: Number of filled segments
filled_char: Character for filled segments
empty_char: Character for empty segments
filled_style: Optional style tag for filled segments
empty_style: Optional style tag for empty segments
Returns:
Formatted bar string
"""
filled_bar: str = filled_char * filled
empty_bar: str = empty_char * (self.width - filled)
if filled_style:
filled_bar = f"[{filled_style}]{filled_bar}[/]"
if empty_style:
empty_bar = f"[{empty_style}]{empty_bar}[/]"
return f"{filled_bar}{empty_bar}"
def _format_percentage(self, percentage: float, precision: int = 1) -> str:
"""Format percentage value for display.
Args:
percentage: Percentage value to format
precision: Number of decimal places
Returns:
Formatted percentage string
"""
return f"{percentage:.{precision}f}%"
def _get_color_style_by_threshold(
self, value: float, thresholds: list[tuple[float, str]]
) -> str:
"""Get color style based on value thresholds.
Args:
value: Current value to check
thresholds: List of (threshold, style) tuples in descending order
Returns:
Style string for the current value
"""
for threshold, style in thresholds:
if value >= threshold:
return style
return thresholds[-1][1] if thresholds else ""
@abstractmethod
def render(self, *args, **kwargs) -> str:
"""Render the progress bar.
This method must be implemented by subclasses.
Returns:
Formatted progress bar string
"""
class TokenProgressBar(BaseProgressBar):
"""Token usage progress bar component."""
# Color threshold constants
HIGH_USAGE_THRESHOLD: Final[float] = 90.0
MEDIUM_USAGE_THRESHOLD: Final[float] = 50.0
LOW_USAGE_THRESHOLD: Final[float] = 0.0
# Style constants
HIGH_USAGE_STYLE: Final[str] = "cost.high"
MEDIUM_USAGE_STYLE: Final[str] = "cost.medium"
LOW_USAGE_STYLE: Final[str] = "cost.low"
BORDER_STYLE: Final[str] = "table.border"
# Icon constants
HIGH_USAGE_ICON: Final[str] = "🔴"
MEDIUM_USAGE_ICON: Final[str] = "🟡"
LOW_USAGE_ICON: Final[str] = "🟢"
def render(self, percentage: float) -> str:
"""Render token usage progress bar.
Args:
percentage: Usage percentage (can be > 100)
Returns:
Formatted progress bar string
"""
filled: int = self._calculate_filled_segments(min(percentage, 100.0))
color_thresholds: list[tuple[float, str]] = [
(self.HIGH_USAGE_THRESHOLD, self.HIGH_USAGE_STYLE),
(self.MEDIUM_USAGE_THRESHOLD, self.MEDIUM_USAGE_STYLE),
(self.LOW_USAGE_THRESHOLD, self.LOW_USAGE_STYLE),
]
filled_style: str = self._get_color_style_by_threshold(
percentage, color_thresholds
)
bar: str = self._render_bar(
filled,
filled_style=filled_style,
empty_style=self.BORDER_STYLE
if percentage < self.HIGH_USAGE_THRESHOLD
else self.MEDIUM_USAGE_STYLE,
)
if percentage >= self.HIGH_USAGE_THRESHOLD:
icon: str = self.HIGH_USAGE_ICON
elif percentage >= self.MEDIUM_USAGE_THRESHOLD:
icon = self.MEDIUM_USAGE_ICON
else:
icon = self.LOW_USAGE_ICON
percentage_str: str = self._format_percentage(percentage)
return f"{icon} [{bar}] {percentage_str}"
class TimeProgressBar(BaseProgressBar):
"""Time progress bar component for session duration."""
def render(self, elapsed_minutes: float, total_minutes: float) -> str:
"""Render time progress bar.
Args:
elapsed_minutes: Minutes elapsed in session
total_minutes: Total session duration in minutes
Returns:
Formatted time progress bar string
"""
from claude_monitor.utils.time_utils import format_time
if total_minutes <= 0:
progress_percentage = 0
else:
progress_percentage = min(100, percentage(elapsed_minutes, total_minutes))
filled = self._calculate_filled_segments(progress_percentage)
bar = self._render_bar(
filled, filled_style="progress.bar", empty_style="table.border"
)
remaining_time = format_time(max(0, total_minutes - elapsed_minutes))
return f"⏰ [{bar}] {remaining_time}"
class ModelUsageBar(BaseProgressBar):
"""Model usage progress bar showing Sonnet vs Opus distribution."""
def render(self, per_model_stats: dict[str, Any]) -> str:
"""Render model usage progress bar.
Args:
per_model_stats: Dictionary of model statistics
Returns:
Formatted model usage bar string
"""
if not per_model_stats:
empty_bar = self._render_bar(0, empty_style="table.border")
return f"🤖 [{empty_bar}] No model data"
model_names = list(per_model_stats.keys())
if not model_names:
empty_bar = self._render_bar(0, empty_style="table.border")
return f"🤖 [{empty_bar}] Empty model stats"
sonnet_tokens = 0
opus_tokens = 0
other_tokens = 0
for model_name, stats in per_model_stats.items():
model_tokens = stats.get("input_tokens", 0) + stats.get("output_tokens", 0)
if "sonnet" in model_name.lower():
sonnet_tokens += model_tokens
elif "opus" in model_name.lower():
opus_tokens += model_tokens
else:
other_tokens += model_tokens
total_tokens = sonnet_tokens + opus_tokens + other_tokens
if total_tokens == 0:
empty_bar = self._render_bar(0, empty_style="table.border")
return f"🤖 [{empty_bar}] No tokens used"
sonnet_percentage = percentage(sonnet_tokens, total_tokens)
opus_percentage = percentage(opus_tokens, total_tokens)
other_percentage = percentage(other_tokens, total_tokens)
sonnet_filled = int(self.width * sonnet_tokens / total_tokens)
opus_filled = int(self.width * opus_tokens / total_tokens)
total_filled = sonnet_filled + opus_filled
if total_filled < self.width:
if sonnet_tokens >= opus_tokens:
sonnet_filled += self.width - total_filled
else:
opus_filled += self.width - total_filled
elif total_filled > self.width:
if sonnet_tokens >= opus_tokens:
sonnet_filled -= total_filled - self.width
else:
opus_filled -= total_filled - self.width
sonnet_bar = "█" * sonnet_filled
opus_bar = "█" * opus_filled
bar_segments = []
if sonnet_filled > 0:
bar_segments.append(f"[info]{sonnet_bar}[/]")
if opus_filled > 0:
bar_segments.append(f"[warning]{opus_bar}[/]")
bar_display = "".join(bar_segments)
if opus_tokens > 0 and sonnet_tokens > 0:
summary = f"Sonnet {sonnet_percentage:.1f}% | Opus {opus_percentage:.1f}%"
elif sonnet_tokens > 0:
summary = f"Sonnet {sonnet_percentage:.1f}%"
elif opus_tokens > 0:
summary = f"Opus {opus_percentage:.1f}%"
else:
summary = f"Other {other_percentage:.1f}%"
return f"🤖 [{bar_display}] {summary}"
================================================
FILE: src/claude_monitor/ui/session_display.py
================================================
"""Session display components for Claude Monitor.
Handles formatting of active session screens and session data display.
"""
from dataclasses import dataclass
from datetime import datetime
from typing import Any, Optional
import pytz
from claude_monitor.ui.components import CostIndicator, VelocityIndicator
from claude_monitor.ui.layouts import HeaderManager
from claude_monitor.ui.progress_bars import (
ModelUsageBar,
TimeProgressBar,
TokenProgressBar,
)
from claude_monitor.utils.time_utils import (
format_display_time,
get_time_format_preference,
percentage,
)
@dataclass
class SessionDisplayData:
"""Data container for session display information.
This replaces the 21 parameters in format_active_session_screen method.
"""
plan: str
timezone: str
tokens_used: int
token_limit: int
usage_percentage: float
tokens_left: int
elapsed_session_minutes: float
total_session_minutes: float
burn_rate: float
session_cost: float
per_model_stats: dict[str, Any]
sent_messages: int
entries: list[dict]
predicted_end_str: str
reset_time_str: str
current_time_str: str
show_switch_notification: bool = False
show_exceed_notification: bool = False
show_tokens_will_run_out: bool = False
original_limit: int = 0
class SessionDisplayComponent:
"""Main component for displaying active session information."""
def __init__(self):
"""Initialize session display component with sub-components."""
self.token_progress = TokenProgressBar()
self.time_progress = TimeProgressBar()
self.model_usage = ModelUsageBar()
def _render_wide_progress_bar(self, percentage: float) -> str:
"""Render a wide progress bar (50 chars) using centralized progress bar logic.
Args:
percentage: Progress percentage (can be > 100)
Returns:
Formatted progress bar string
"""
from claude_monitor.terminal.themes import get_cost_style
if percentage < 50:
color = "🟢"
elif percentage < 80:
color = "🟡"
else:
color = "🔴"
progress_bar = TokenProgressBar(width=50)
bar_style = get_cost_style(percentage)
capped_percentage = min(percentage, 100.0)
filled = progress_bar._calculate_filled_segments(capped_percentage, 100.0)
if percentage >= 100:
filled_bar = progress_bar._render_bar(50, filled_style=bar_style)
else:
filled_bar = progress_bar._render_bar(
filled, filled_style=bar_style, empty_style="table.border"
)
return f"{color} [{filled_bar}]"
def format_active_session_screen_v2(self, data: SessionDisplayData) -> list[str]:
"""Format complete active session screen using data class.
This is the refactored version using SessionDisplayData.
Args:
data: SessionDisplayData object containing all display information
Returns:
List of formatted lines for display
"""
return self.format_active_session_screen(
plan=data.plan,
timezone=data.timezone,
tokens_used=data.tokens_used,
token_limit=data.token_limit,
usage_percentage=data.usage_percentage,
tokens_left=data.tokens_left,
elapsed_session_minutes=data.elapsed_session_minutes,
total_session_minutes=data.total_session_minutes,
burn_rate=data.burn_rate,
session_cost=data.session_cost,
per_model_stats=data.per_model_stats,
sent_messages=data.sent_messages,
entries=data.entries,
predicted_end_str=data.predicted_end_str,
reset_time_str=data.reset_time_str,
current_time_str=data.current_time_str,
show_switch_notification=data.show_switch_notification,
show_exceed_notification=data.show_exceed_notification,
show_tokens_will_run_out=data.show_tokens_will_run_out,
original_limit=data.original_limit,
)
def format_active_session_screen(
self,
plan: str,
timezone: str,
tokens_used: int,
token_limit: int,
usage_percentage: float,
tokens_left: int,
elapsed_session_minutes: float,
total_session_minutes: float,
burn_rate: float,
session_cost: float,
per_model_stats: dict[str, Any],
sent_messages: int,
entries: list[dict],
predicted_end_str: str,
reset_time_str: str,
current_time_str: str,
show_switch_notification: bool = False,
show_exceed_notification: bool = False,
show_tokens_will_run_out: bool = False,
original_limit: int = 0,
**kwargs,
) -> list[str]:
"""Format complete active session screen.
Args:
plan: Current plan name
timezone: Display timezone
tokens_used: Number of tokens used
token_limit: Token limit for the plan
usage_percentage: Usage percentage
tokens_left: Remaining tokens
elapsed_session_minutes: Minutes elapsed in session
total_session_minutes: Total session duration
burn_rate: Current burn rate
session_cost: Session cost in USD
per_model_stats: Model usage statistics
sent_messages: Number of messages sent
entries: Session entries
predicted_end_str: Predicted end time string
reset_time_str: Reset time string
current_time_str: Current time string
show_switch_notification: Show plan switch notification
show_exceed_notification: Show exceed limit notification
show_tokens_will_run_out: Show token depletion warning
original_limit: Original plan limit
Returns:
List of formatted screen lines
"""
screen_buffer = []
header_manager = HeaderManager()
screen_buffer.extend(header_manager.create_header(plan, timezone))
if plan in ["custom", "pro", "max5", "max20"]:
from claude_monitor.core.plans import DEFAULT_COST_LIMIT
cost_limit_p90 = kwargs.get("cost_limit_p90", DEFAULT_COST_LIMIT)
messages_limit_p90 = kwargs.get("messages_limit_p90", 1500)
screen_buffer.append("")
if plan == "custom":
screen_buffer.append("[bold]📊 Session-Based Dynamic Limits[/bold]")
screen_buffer.append(
"[dim]Based on your historical usage patterns when hitting limits (P90)[/dim]"
)
screen_buffer.append(f"[separator]{'─' * 60}[/]")
else:
screen_buffer.append("")
cost_percentage = (
min(100, percentage(session_cost, cost_limit_p90))
if cost_limit_p90 > 0
else 0
)
cost_bar = self._render_wide_progress_bar(cost_percentage)
screen_buffer.append(
f"💰 [value]Cost Usage:[/] {cost_bar} {cost_percentage:4.1f}% [value]${session_cost:.2f}[/] / [dim]${cost_limit_p90:.2f}[/]"
)
screen_buffer.append("")
token_bar = self._render_wide_progress_bar(usage_percentage)
screen_buffer.append(
f"📊 [value]Token Usage:[/] {token_bar} {usage_percentage:4.1f}% [value]{tokens_used:,}[/] / [dim]{token_limit:,}[/]"
)
screen_buffer.append("")
messages_percentage = (
min(100, percentage(sent_messages, messages_limit_p90))
if messages_limit_p90 > 0
else 0
)
messages_bar = self._render_wide_progress_bar(messages_percentage)
screen_buffer.append(
f"📨 [value]Messages Usage:[/] {messages_bar} {messages_percentage:4.1f}% [value]{sent_messages}[/] / [dim]{messages_limit_p90:,}[/]"
)
screen_buffer.append(f"[separator]{'─' * 60}[/]")
time_percentage = (
percentage(elapsed_session_minutes, total_session_minutes)
if total_session_minutes > 0
else 0
)
time_bar = self._render_wide_progress_bar(time_percentage)
time_remaining = max(0, total_session_minutes - elapsed_session_minutes)
time_left_hours = int(time_remaining // 60)
time_left_mins = int(time_remaining % 60)
screen_buffer.append(
f"⏱️ [value]Time to Reset:[/] {time_bar} {time_left_hours}h {time_left_mins}m"
)
screen_buffer.append("")
if per_model_stats:
model_bar = self.model_usage.render(per_model_stats)
screen_buffer.append(f"🤖 [value]Model Distribution:[/] {model_bar}")
else:
model_bar = self.model_usage.render({})
screen_buffer.append(f"🤖 [value]Model Distribution:[/] {model_bar}")
screen_buffer.append(f"[separator]{'─' * 60}[/]")
velocity_emoji = VelocityIndicator.get_velocity_emoji(burn_rate)
screen_buffer.append(
f"🔥 [value]Burn Rate:[/] [warning]{burn_rate:.1f}[/] [dim]tokens/min[/] {velocity_emoji}"
)
cost_per_min = (
session_cost / max(1, elapsed_session_minutes)
if elapsed_session_minutes > 0
else 0
)
cost_per_min_display = CostIndicator.render(cost_per_min)
screen_buffer.append(
f"💲 [value]Cost Rate:[/] {cost_per_min_display} [dim]$/min[/]"
)
else:
cost_display = CostIndicator.render(session_cost)
cost_per_min = (
session_cost / max(1, elapsed_session_minutes)
if elapsed_session_minutes > 0
else 0
)
cost_per_min_display = CostIndicator.render(cost_per_min)
screen_buffer.append(f"💲 [value]Session Cost:[/] {cost_display}")
screen_buffer.append(
f"💲 [value]Cost Rate:[/] {cost_per_min_display} [dim]$/min[/]"
)
screen_buffer.append("")
token_bar = self.token_progress.render(usage_percentage)
screen_buffer.append(f"📊 [value]Token Usage:[/] {token_bar}")
screen_buffer.append("")
screen_buffer.append(
f"🎯 [value]Tokens:[/] [value]{tokens_used:,}[/] / [dim]~{token_limit:,}[/] ([info]{tokens_left:,} left[/])"
)
velocity_emoji = VelocityIndicator.get_velocity_emoji(burn_rate)
screen_buffer.append(
f"🔥 [value]Burn Rate:[/] [warning]{burn_rate:.1f}[/] [dim]tokens/min[/] {velocity_emoji}"
)
screen_buffer.append(
f"📨 [value]Sent Messages:[/] [info]{sent_messages}[/] [dim]messages[/]"
)
if per_model_stats:
model_bar = self.model_usage.render(per_model_stats)
screen_buffer.append(f"🤖 [value]Model Usage:[/] {model_bar}")
screen_buffer.append("")
time_bar = self.time_progress.render(
elapsed_session_minutes, total_session_minutes
)
screen_buffer.append(f"⏱️ [value]Time to Reset:[/] {time_bar}")
screen_buffer.append("")
screen_buffer.append("")
screen_buffer.append("🔮 [value]Predictions:[/]")
screen_buffer.append(
f" [info]Tokens will run out:[/] [warning]{predicted_end_str}[/]"
)
screen_buffer.append(
f" [info]Limit resets at:[/] [success]{reset_time_str}[/]"
)
screen_buffer.append("")
self._add_notifications(
screen_buffer,
show_switch_notification,
show_exceed_notification,
show_tokens_will_run_out,
original_limit,
token_limit,
)
screen_buffer.append(
f"⏰ [dim]{current_time_str}[/] 📝 [success]Active session[/] | [dim]Ctrl+C to exit[/] 🟢"
)
return screen_buffer
def _add_notifications(
self,
screen_buffer: list[str],
show_switch_notification: bool,
show_exceed_notification: bool,
show_tokens_will_run_out: bool,
original_limit: int,
token_limit: int,
) -> None:
"""Add notification messages to screen buffer.
Args:
screen_buffer: Screen buffer to append to
show_switch_notification: Show plan switch notification
show_exceed_notification: Show exceed limit notification
show_tokens_will_run_out: Show token depletion warning
original_limit: Original plan limit
token_limit: Current token limit
"""
notifications_added = False
if show_switch_notification and token_limit > original_limit:
screen_buffer.append(
f"🔄 [warning]Token limit exceeded ({token_limit:,} tokens)[/]"
)
notifications_added = True
if show_exceed_notification:
screen_buffer.append(
"⚠️ [error]You have exceeded the maximum cost limit![/]"
)
notifications_added = True
if show_tokens_will_run_out:
screen_buffer.append(
"⏰ [warning]Cost limit will be exceeded before reset![/]"
)
notifications_added = True
if notifications_added:
screen_buffer.append("")
def format_no_active_session_screen(
self,
plan: str,
timezone: str,
token_limit: int,
current_time: Optional[datetime] = None,
args: Optional[Any] = None,
) -> list[str]:
"""Format screen for no active session state.
Args:
plan: Current plan name
timezone: Display timezone
token_limit: Token limit for the plan
current_time: Current datetime
args: Command line arguments
Returns:
List of formatted screen lines
"""
screen_buffer = []
header_manager = HeaderManager()
screen_buffer.extend(header_manager.create_header(plan, timezone))
empty_token_bar = self.token_progress.render(0.0)
screen_buffer.append(f"📊 [value]Token Usage:[/] {empty_token_bar}")
screen_buffer.append("")
screen_buffer.append(
f"🎯 [value]Tokens:[/] [value]0[/] / [dim]~{token_limit:,}[/] ([info]0 left[/])"
)
screen_buffer.append(
"🔥 [value]Burn Rate:[/] [warning]0.0[/] [dim]tokens/min[/]"
)
screen_buffer.append(
"💲 [value]Cost Rate:[/] [cost.low]$0.00[/] [dim]$/min[/]"
)
screen_buffer.append("📨 [value]Sent Messages:[/] [info]0[/] [dim]messages[/]")
screen_buffer.append("")
if current_time and args:
try:
display_tz = pytz.timezone(args.timezone)
current_time_display = current_time.astimezone(display_tz)
current_time_str = format_display_time(
current_time_display,
get_time_format_preference(args),
include_seconds=True,
)
screen_buffer.append(
f"⏰ [dim]{current_time_str}[/] 📝 [info]No active session[/] | [dim]Ctrl+C to exit[/] 🟨"
)
except (pytz.exceptions.UnknownTimeZoneError, AttributeError):
screen_buffer.append(
"⏰ [dim]--:--:--[/] 📝 [info]No active session[/] | [dim]Ctrl+C to exit[/] 🟨"
)
else:
screen_buffer.append(
"⏰ [dim]--:--:--[/] 📝 [info]No active session[/] | [dim]Ctrl+C to exit[/] 🟨"
)
return screen_buffer
================================================
FILE: src/claude_monitor/ui/table_views.py
================================================
"""Table views for daily and monthly statistics display.
This module provides UI components for displaying aggregated usage data
in table format using Rich library.
"""
import logging
from typing import Any, Dict, List, Optional, Union
from rich.align import Align
from rich.console import Console
from rich.panel import Panel
from rich.table import Table
from rich.text import Text
# Removed theme import - using direct styles
from claude_monitor.utils.formatting import format_currency, format_number
logger = logging.getLogger(__name__)
class TableViewsController:
"""Controller for table-based views (daily, monthly)."""
def __init__(self, console: Optional[Console] = None):
"""Initialize the table views controller.
Args:
console: Optional Console instance for rich output
"""
self.console = console
# Define simple styles
self.key_style = "cyan"
self.value_style = "white"
self.accent_style = "yellow"
self.success_style = "green"
self.warning_style = "yellow"
self.header_style = "bold cyan"
self.table_header_style = "bold"
self.border_style = "bright_blue"
def _create_base_table(
self, title: str, period_column_name: str, period_column_width: int
) -> Table:
"""Create a base table with common structure.
Args:
title: Table title
period_column_name: Name for the period column ('Date' or 'Month')
period_column_width: Width for the period column
Returns:
Rich Table object with columns added
"""
table = Table(
title=title,
title_style="bold cyan",
show_header=True,
header_style="bold",
border_style="bright_blue",
expand=True,
show_lines=True,
)
# Add columns
table.add_column(
period_column_name, style=self.key_style, width=period_column_width
)
table.add_column("Models", style=self.value_style, width=20)
table.add_column("Input", style=self.value_style, justify="right", width=12)
table.add_column("Output", style=self.value_style, justify="right", width=12)
table.add_column(
"Cache Create", style=self.value_style, justify="right", width=12
)
table.add_column(
"Cache Read", style=self.value_style, justify="right", width=12
)
table.add_column(
"Total Tokens", style=self.accent_style, justify="right", width=12
)
table.add_column(
"Cost (USD)", style=self.success_style, justify="right", width=10
)
return table
def _add_data_rows(
self, table: Table, data_list: List[Dict[str, Any]], period_key: str
) -> None:
"""Add data rows to the table.
Args:
table: Table to add rows to
data_list: List of data dictionaries
period_key: Key to use for period column ('date' or 'month')
"""
for data in data_list:
models_text = self._format_models(data["models_used"])
total_tokens = (
data["input_tokens"]
+ data["output_tokens"]
+ data["cache_creation_tokens"]
+ data["cache_read_tokens"]
)
table.add_row(
data[period_key],
models_text,
format_number(data["input_tokens"]),
format_number(data["output_tokens"]),
format_number(data["cache_creation_tokens"]),
format_number(data["cache_read_tokens"]),
format_number(total_tokens),
format_currency(data["total_cost"]),
)
def _add_totals_row(self, table: Table, totals: Dict[str, Any]) -> None:
"""Add totals row to the table.
Args:
table: Table to add totals to
totals: Dictionary with total statistics
"""
# Add separator
table.add_row("", "", "", "", "", "", "", "")
# Add totals row
table.add_row(
Text("Total", style=self.accent_style),
"",
Text(format_number(totals["input_tokens"]), style=self.accent_style),
Text(format_number(totals["output_tokens"]), style=self.accent_style),
Text(
format_number(totals["cache_creation_tokens"]), style=self.accent_style
),
Text(format_number(totals["cache_read_tokens"]), style=self.accent_style),
Text(format_number(totals["total_tokens"]), style=self.accent_style),
Text(format_currency(totals["total_cost"]), style=self.success_style),
)
def create_daily_table(
self,
daily_data: List[Dict[str, Any]],
totals: Dict[str, Any],
timezone: str = "UTC",
) -> Table:
"""Create a daily statistics table.
Args:
daily_data: List of daily aggregated data
totals: Total statistics
timezone: Timezone for display
Returns:
Rich Table object
"""
# Create base table
table = self._create_base_table(
title=f"Claude Code Token Usage Report - Daily ({timezone})",
period_column_name="Date",
period_column_width=12,
)
# Add data rows
self._add_data_rows(table, daily_data, "date")
# Add totals
self._add_totals_row(table, totals)
return table
def create_monthly_table(
self,
monthly_data: List[Dict[str, Any]],
totals: Dict[str, Any],
timezone: str = "UTC",
) -> Table:
"""Create a monthly statistics table.
Args:
monthly_data: List of monthly aggregated data
totals: Total statistics
timezone: Timezone for display
Returns:
Rich Table object
"""
# Create base table
table = self._create_base_table(
title=f"Claude Code Token Usage Report - Monthly ({timezone})",
period_column_name="Month",
period_column_width=10,
)
# Add data rows
self._add_data_rows(table, monthly_data, "month")
# Add totals
self._add_totals_row(table, totals)
return table
def create_summary_panel(
self, view_type: str, totals: Dict[str, Any], period: str
) -> Panel:
"""Create a summary panel for the table view.
Args:
view_type: Type of view ('daily' or 'monthly')
totals: Total statistics
period: Period description
Returns:
Rich Panel object
"""
# Create summary text
summary_lines = [
f"📊 {view_type.capitalize()} Usage Summary - {period}",
"",
f"Total Tokens: {format_number(totals['total_tokens'])}",
f"Total Cost: {format_currency(totals['total_cost'])}",
f"Entries: {format_number(totals['entries_count'])}",
]
summary_text = Text("\n".join(summary_lines), style=self.value_style)
# Create panel
panel = Panel(
Align.center(summary_text),
title="Summary",
title_align="center",
border_style=self.border_style,
expand=False,
padding=(1, 2),
)
return panel
def _format_models(self, models: List[str]) -> str:
"""Format model names for display.
Args:
models: List of model names
Returns:
Formatted string of model names
"""
if not models:
return "No models"
# Create bullet list
if len(models) == 1:
return models[0]
elif len(models) <= 3:
return "\n".join([f"• {model}" for model in models])
else:
# Truncate long lists
first_two = models[:2]
remaining_count = len(models) - 2
formatted = "\n".join([f"• {model}" for model in first_two])
formatted += f"\n• ...and {remaining_count} more"
return formatted
def create_no_data_display(self, view_type: str) -> Panel:
"""Create a display for when no data is available.
Args:
view_type: Type of view ('daily' or 'monthly')
Returns:
Rich Panel object
"""
message = Text(
f"No {view_type} data found.\n\nTry using Claude Code to generate some usage data.",
style=self.warning_style,
justify="center",
)
panel = Panel(
Align.center(message, vertical="middle"),
title=f"No {view_type.capitalize()} Data",
title_align="center",
border_style=self.warning_style,
expand=True,
height=10,
)
return panel
def create_aggregate_table(
self,
aggregate_data: Union[List[Dict[str, Any]], List[Dict[str, Any]]],
totals: Dict[str, Any],
view_type: str,
timezone: str = "UTC",
) -> Table:
"""Create a table for either daily or monthly aggregated data.
Args:
aggregate_data: List of aggregated data (daily or monthly)
totals: Total statistics
view_type: Type of view ('daily' or 'monthly')
timezone: Timezone for display
Returns:
Rich Table object
Raises:
ValueError: If view_type is not 'daily' or 'monthly'
"""
if view_type == "daily":
return self.create_daily_table(aggregate_data, totals, timezone)
elif view_type == "monthly":
return self.create_monthly_table(aggregate_data, totals, timezone)
else:
raise ValueError(f"Invalid view type: {view_type}")
def display_aggregated_view(
self,
data: List[Dict[str, Any]],
view_mode: str,
timezone: str,
plan: str,
token_limit: int,
console: Optional[Console] = None,
) -> None:
"""Display aggregated view with table and summary.
Args:
data: Aggregated data
view_mode: View type ('daily' or 'monthly')
timezone: Timezone string
plan: Plan type
token_limit: Token limit for the plan
console: Optional Console instance
"""
if not data:
no_data_display = self.create_no_data_display(view_mode)
if console:
console.print(no_data_display)
else:
print(no_data_display)
return
# Calculate totals
totals = {
"input_tokens": sum(d["input_tokens"] for d in data),
"output_tokens": sum(d["output_tokens"] for d in data),
"cache_creation_tokens": sum(d["cache_creation_tokens"] for d in data),
"cache_read_tokens": sum(d["cache_read_tokens"] for d in data),
"total_tokens": sum(
d["input_tokens"]
+ d["output_tokens"]
+ d["cache_creation_tokens"]
+ d["cache_read_tokens"]
for d in data
),
"total_cost": sum(d["total_cost"] for d in data),
"entries_count": sum(d.get("entries_count", 0) for d in data),
}
# Determine period for summary
if view_mode == "daily":
period = f"{data[0]['date']} to {data[-1]['date']}" if data else "No data"
else: # monthly
period = f"{data[0]['month']} to {data[-1]['month']}" if data else "No data"
# Create and display summary panel
summary_panel = self.create_summary_panel(view_mode, totals, period)
# Create and display table
table = self.create_aggregate_table(data, totals, view_mode, timezone)
# Display using console if provided
if console:
console.print(summary_panel)
console.print()
console.print(table)
else:
from rich import print as rprint
rprint(summary_panel)
rprint()
rprint(table)
================================================
FILE: src/claude_monitor/utils/__init__.py
================================================
"""Utilities package for Claude Monitor."""
__all__: list[str] = []
================================================
FILE: src/claude_monitor/utils/formatting.py
================================================
"""Formatting utilities for Claude Monitor.
This module provides formatting functions for currency, time, and display output.
"""
import logging
from datetime import datetime
from typing import Any, Optional, Union
from claude_monitor.utils.time_utils import format_display_time as _format_display_time
from claude_monitor.utils.time_utils import get_time_format_preference
logger = logging.getLogger(__name__)
def format_number(value: Union[int, float], decimals: int = 0) -> str:
"""Format number with thousands separator.
Args:
value: Number to format
decimals: Number of decimal places (default: 0)
Returns:
Formatted number string with thousands separator
"""
if decimals > 0:
return f"{value:,.{decimals}f}"
return f"{int(value):,}"
def format_currency(amount: float, currency: str = "USD") -> str:
"""Format currency amount with appropriate symbol and formatting.
Args:
amount: The amount to format
currency: Currency code (default: USD)
Returns:
Formatted currency string
"""
amount: float = round(amount, 2)
if currency == "USD":
if amount >= 0:
return f"${amount:,.2f}"
return f"$-{abs(amount):,.2f}"
return f"{amount:,.2f} {currency}"
def format_time(minutes: float) -> str:
"""Format minutes into human-readable time (e.g., '3h 45m').
This is a re-export from time_utils for backward compatibility.
Args:
minutes: Duration in minutes
Returns:
Formatted time string
"""
from claude_monitor.utils.time_utils import format_time as _format_time
return _format_time(minutes)
def format_display_time(
dt_obj: datetime,
use_12h_format: Optional[bool] = None,
include_seconds: bool = True,
) -> str:
"""Format datetime for display with 12h/24h support.
This is a re-export from time_utils for backward compatibility.
Args:
dt_obj: Datetime object to format
use_12h_format: Whether to use 12-hour format (None for auto-detect)
include_seconds: Whether to include seconds in output
Returns:
Formatted time string
"""
return _format_display_time(dt_obj, use_12h_format, include_seconds)
def _get_pref(args: Any) -> bool:
"""Internal helper function for getting time format preference.
Args:
args: Arguments object or None
Returns:
True for 12-hour format, False for 24-hour format
"""
return get_time_format_preference(args)
================================================
FILE: src/claude_monitor/utils/model_utils.py
================================================
"""Model utilities for Claude Monitor.
This module provides model-related utility functions, re-exporting from core.models
for backward compatibility.
"""
import logging
import re
from typing import Dict, Match, Optional
logger = logging.getLogger(__name__)
def normalize_model_name(model: str) -> str:
"""Normalize model name to a standard format.
This function delegates to the implementation in core.models.
Args:
model: Model name to normalize
Returns:
Normalized model name
"""
from claude_monitor.core.models import normalize_model_name as _normalize_model_name
return _normalize_model_name(model)
def get_model_display_name(model: str) -> str:
"""Get a display-friendly model name.
Args:
model: Model name to get display name for
Returns:
Display-friendly model name
"""
normalized: str = normalize_model_name(model)
display_names: Dict[str, str] = {
"claude-3-opus": "Claude 3 Opus",
"claude-3-sonnet": "Claude 3 Sonnet",
"claude-3-haiku": "Claude 3 Haiku",
"claude-3-5-sonnet": "Claude 3.5 Sonnet",
"claude-3-5-haiku": "Claude 3.5 Haiku",
}
return display_names.get(normalized, normalized.title())
def is_claude_model(model: str) -> bool:
"""Check if a model is a Claude model.
Args:
model: Model name to check
Returns:
True if it's a Claude model, False otherwise
"""
normalized: str = normalize_model_name(model)
return normalized.startswith("claude-")
def get_model_generation(model: str) -> str:
"""Get the generation/version of a Claude model.
Args:
model: Model name
Returns:
Generation string (e.g., '3', '3.5') or 'unknown'
"""
if not model:
return "unknown"
model_lower: str = model.lower()
if "claude-3-5" in model_lower or "claude-3.5" in model_lower:
return "3.5"
if (
"claude-3" in model_lower
or "claude-3-opus" in model_lower
or "claude-3-sonnet" in model_lower
or "claude-3-haiku" in model_lower
):
return "3"
if re.search(r"claude-2(?:\D|$)", model_lower):
return "2"
if re.search(r"claude-1(?:\D|$)", model_lower) or "claude-instant-1" in model_lower:
return "1"
match: Optional[Match[str]] = re.search(r"claude-(\d)(?:\D|$)", model_lower)
if match:
version: str = match.group(1)
if version in ["1", "2", "3"]:
return version
return "unknown"
================================================
FILE: src/claude_monitor/utils/notifications.py
================================================
"""Notification management utilities."""
import json
from datetime import datetime, timedelta
from pathlib import Path
from typing import Any, Dict, Optional, Union
class NotificationManager:
"""Manages notification states and persistence."""
def __init__(self, config_dir: Path) -> None:
self.notification_file: Path = config_dir / "notification_states.json"
self.states: Dict[str, Dict[str, Union[bool, Optional[datetime]]]] = (
self._load_states()
)
self.default_states: Dict[str, Dict[str, Union[bool, Optional[datetime]]]] = {
"switch_to_custom": {"triggered": False, "timestamp": None},
"exceed_max_limit": {"triggered": False, "timestamp": None},
"tokens_will_run_out": {"triggered": False, "timestamp": None},
}
def _load_states(self) -> Dict[str, Dict[str, Union[bool, Optional[datetime]]]]:
"""Load notification states from file."""
if not self.notification_file.exists():
return {
"switch_to_custom": {"triggered": False, "timestamp": None},
"exceed_max_limit": {"triggered": False, "timestamp": None},
"tokens_will_run_out": {"triggered": False, "timestamp": None},
}
try:
with open(self.notification_file) as f:
states: Dict[str, Dict[str, Any]] = json.load(f)
# Convert timestamp strings back to datetime objects
parsed_states: Dict[
str, Dict[str, Union[bool, Optional[datetime]]]
] = {}
for key, state in states.items():
parsed_state: Dict[str, Union[bool, Optional[datetime]]] = {
"triggered": bool(state.get("triggered", False)),
"timestamp": None,
}
if state.get("timestamp"):
parsed_state["timestamp"] = datetime.fromisoformat(
state["timestamp"]
)
parsed_states[key] = parsed_state
return parsed_states
except (json.JSONDecodeError, FileNotFoundError, ValueError):
return self.default_states.copy()
def _save_states(self) -> None:
"""Save notification states to file."""
try:
states_to_save: Dict[str, Dict[str, Union[bool, Optional[str]]]] = {}
for key, state in self.states.items():
timestamp_str: Optional[str] = None
timestamp_value = state["timestamp"]
if isinstance(timestamp_value, datetime):
timestamp_str = timestamp_value.isoformat()
states_to_save[key] = {
"triggered": bool(state["triggered"]),
"timestamp": timestamp_str,
}
with open(self.notification_file, "w") as f:
json.dump(states_to_save, f, indent=2)
except (OSError, TypeError, ValueError) as e:
import logging
logging.getLogger(__name__).warning(
f"Failed to save notification states to {self.notification_file}: {e}"
)
def should_notify(self, key: str, cooldown_hours: Union[int, float] = 24) -> bool:
"""Check if notification should be shown."""
if key not in self.states:
self.states[key] = {"triggered": False, "timestamp": None}
return True
state = self.states[key]
if not state["triggered"]:
return True
timestamp_value = state["timestamp"]
if timestamp_value is None:
return True
if not isinstance(timestamp_value, datetime):
return True
now: datetime = datetime.now()
time_since_last: timedelta = now - timestamp_value
cooldown_seconds: float = cooldown_hours * 3600
return time_since_last.total_seconds() >= cooldown_seconds
def mark_notified(self, key: str) -> None:
"""Mark notification as shown."""
now: datetime = datetime.now()
self.states[key] = {"triggered": True, "timestamp": now}
self._save_states()
def get_notification_state(
self, key: str
) -> Dict[str, Union[bool, Optional[datetime]]]:
"""Get current notification state."""
default_state: Dict[str, Union[bool, Optional[datetime]]] = {
"triggered": False,
"timestamp": None,
}
return self.states.get(key, default_state)
def is_notification_active(self, key: str) -> bool:
"""Check if notification is currently active."""
state = self.get_notification_state(key)
triggered_value = state["triggered"]
timestamp_value = state["timestamp"]
return bool(triggered_value) and timestamp_value is not None
================================================
FILE: src/claude_monitor/utils/time_utils.py
================================================
"""Unified time utilities module combining timezone and system time functionality."""
import contextlib
import locale
import logging
import os
import platform
import re
import subprocess
from datetime import datetime
from typing import Any, Dict, List, Optional, Set, Union
import pytz
from pytz import BaseTzInfo
try:
from babel.dates import get_timezone_location
HAS_BABEL = True
except ImportError:
HAS_BABEL = False
def get_timezone_location(
timezone_name: str, locale_name: str = "en_US"
) -> Optional[str]:
"""Fallback implementation for get_timezone_location when Babel is not available."""
# Mapping of timezone names to their locations/countries
timezone_to_location: Dict[str, str] = {
# United States
"America/New_York": "United States",
"America/Chicago": "United States",
"America/Denver": "United States",
"America/Los_Angeles": "United States",
"America/Phoenix": "United States",
"America/Anchorage": "United States",
"America/Honolulu": "United States",
"US/Eastern": "United States",
"US/Central": "United States",
"US/Mountain": "United States",
"US/Pacific": "United States",
# Canada
"America/Toronto": "Canada",
"America/Montreal": "Canada",
"America/Vancouver": "Canada",
"America/Edmonton": "Canada",
"America/Winnipeg": "Canada",
"America/Halifax": "Canada",
"Canada/Eastern": "Canada",
"Canada/Central": "Canada",
"Canada/Mountain": "Canada",
"Canada/Pacific": "Canada",
# Australia
"Australia/Sydney": "Australia",
"Australia/Melbourne": "Australia",
"Australia/Brisbane": "Australia",
"Australia/Perth": "Australia",
"Australia/Adelaide": "Australia",
"Australia/Darwin": "Australia",
"Australia/Hobart": "Australia",
# United Kingdom
"Europe/London": "United Kingdom",
"GMT": "United Kingdom",
"Europe/Belfast": "United Kingdom",
# Germany (24h example)
"Europe/Berlin": "Germany",
"Europe/Munich": "Germany",
# Other common timezones for 12h countries
"Pacific/Auckland": "New Zealand",
"Asia/Manila": "Philippines",
"Asia/Kolkata": "India",
"Africa/Cairo": "Egypt",
"Asia/Riyadh": "Saudi Arabia",
"America/Bogota": "Colombia",
"Asia/Karachi": "Pakistan",
"Asia/Kuala_Lumpur": "Malaysia",
"Africa/Accra": "Ghana",
"Africa/Nairobi": "Kenya",
"Africa/Lagos": "Nigeria",
"America/Lima": "Peru",
"Africa/Johannesburg": "South Africa",
"Asia/Colombo": "Sri Lanka",
"Asia/Dhaka": "Bangladesh",
"Asia/Amman": "Jordan",
"Asia/Singapore": "Singapore",
"Europe/Dublin": "Ireland",
"Europe/Malta": "Malta",
}
location: Optional[str] = timezone_to_location.get(timezone_name)
if location:
# Add country codes for 12h countries to match expected test behavior
country_codes: Dict[str, str] = {
"United States": "US",
"Canada": "CA",
"Australia": "AU",
"United Kingdom": "GB",
"New Zealand": "NZ",
"Philippines": "PH",
"India": "IN",
"Egypt": "EG",
"Saudi Arabia": "SA",
"Colombia": "CO",
"Pakistan": "PK",
"Malaysia": "MY",
"Ghana": "GH",
"Kenya": "KE",
"Nigeria": "NG",
"Peru": "PE",
"South Africa": "ZA",
"Sri Lanka": "LK",
"Bangladesh": "BD",
"Jordan": "JO",
"Singapore": "SG",
"Ireland": "IE",
"Malta": "MT",
}
country_code: Optional[str] = country_codes.get(location)
if country_code:
return f"{location} {country_code}"
return location
return None
logger: logging.Logger = logging.getLogger(__name__)
class TimeFormatDetector:
"""Unified time format detection using multiple strategies."""
TWELVE_HOUR_COUNTRIES: Set[str] = {
"US",
"CA",
"AU",
"NZ",
"PH",
"IN",
"EG",
"SA",
"CO",
"PK",
"MY",
"GH",
"KE",
"NG",
"PE",
"ZA",
"LK",
"BD",
"JO",
"SG",
"IE",
"MT",
"GB",
}
@classmethod
def detect_from_cli(cls, args: Any) -> Optional[bool]:
"""Detect from CLI arguments.
Returns:
True for 12h format, False for 24h, None if not specified
"""
if args and hasattr(args, "time_format"):
if args.time_format == "12h":
return True
if args.time_format == "24h":
return False
return None
@classmethod
def detect_from_timezone(cls, timezone_name: str) -> Optional[bool]:
"""Detect using Babel/timezone data.
Returns:
True for 12h format, False for 24h, None if cannot determine
"""
if not HAS_BABEL:
return None
try:
location: Optional[str] = get_timezone_location(
timezone_name, locale_name="en_US"
)
if location:
for country_code in cls.TWELVE_HOUR_COUNTRIES:
if country_code in location or location.endswith(country_code):
return True
return False
except Exception:
return None
@classmethod
def detect_from_locale(cls) -> bool:
"""Detect from system locale.
Returns:
True for 12h format, False for 24h
"""
try:
locale.setlocale(locale.LC_TIME, "")
time_str: str = locale.nl_langinfo(locale.T_FMT_AMPM)
if time_str:
return True
dt_fmt: str = locale.nl_langinfo(locale.D_T_FMT)
return bool("%p" in dt_fmt or "%I" in dt_fmt)
except Exception:
return False
@classmethod
def detect_from_system(cls) -> str:
"""Platform-specific system detection.
Returns:
'12h' or '24h'
"""
system: str = platform.system()
if system == "Darwin":
try:
result: subprocess.CompletedProcess[str] = subprocess.run(
["defaults", "read", "NSGlobalDomain", "AppleICUForce12HourTime"],
capture_output=True,
text=True,
check=False,
)
if result.returncode == 0 and result.stdout.strip() == "1":
return "12h"
date_result: subprocess.CompletedProcess[str] = subprocess.run(
["date", "+%r"], capture_output=True, text=True, check=True
)
date_output: str = date_result.stdout.strip()
if "AM" in date_output or "PM" in date_output:
return "12h"
except Exception:
pass
elif system == "Linux":
try:
locale_result: subprocess.CompletedProcess[str] = subprocess.run(
["locale", "LC_TIME"], capture_output=True, text=True, check=True
)
lc_time: str = locale_result.stdout.strip().split("=")[-1].strip('"')
if lc_time and any(x in lc_time for x in ["en_US", "en_CA", "en_AU"]):
return "12h"
except Exception:
pass
elif system == "Windows":
try:
import winreg
with winreg.OpenKey(
winreg.HKEY_CURRENT_USER, r"Control Panel\International"
) as key:
time_fmt: str = winreg.QueryValueEx(key, "sTimeFormat")[0]
if "h" in time_fmt and ("tt" in time_fmt or "t" in time_fmt):
return "12h"
except Exception:
pass
return "12h" if cls.detect_from_locale() else "24h"
@classmethod
def get_preference(
cls, args: Any = None, timezone_name: Optional[str] = None
) -> bool:
"""Main entry point - returns True for 12h, False for 24h."""
cli_pref: Optional[bool] = cls.detect_from_cli(args)
if cli_pref is not None:
return cli_pref
if timezone_name:
tz_pref: Optional[bool] = cls.detect_from_timezone(timezone_name)
if tz_pref is not None:
return tz_pref
return cls.detect_from_system() == "12h"
class SystemTimeDetector:
"""System timezone and time format detection."""
@staticmethod
def get_timezone() -> str:
"""Detect system timezone."""
tz: Optional[str] = os.environ.get("TZ")
if tz:
return tz
system: str = platform.system()
if system == "Darwin":
try:
readlink_result: subprocess.CompletedProcess[str] = subprocess.run(
["readlink", "/etc/localtime"],
capture_output=True,
text=True,
check=True,
)
tz_path: str = readlink_result.stdout.strip()
if "zoneinfo/" in tz_path:
return tz_path.split("zoneinfo/")[-1]
except Exception:
pass
elif system == "Linux":
if os.path.exists("/etc/timezone"):
try:
with open("/etc/timezone") as f:
tz_content: str = f.read().strip()
if tz_content:
return tz_content
except Exception:
pass
try:
timedatectl_result: subprocess.CompletedProcess[str] = subprocess.run(
["timedatectl", "show", "-p", "Timezone", "--value"],
capture_output=True,
text=True,
check=True,
)
tz_result: str = timedatectl_result.stdout.strip()
if tz_result:
return tz_result
except Exception:
pass
elif system == "Windows":
with contextlib.suppress(Exception):
tzutil_result: subprocess.CompletedProcess[str] = subprocess.run(
["tzutil", "/g"], capture_output=True, text=True, check=True
)
return tzutil_result.stdout.strip()
return "UTC"
@staticmethod
def get_time_format() -> str:
"""Detect system time format ('12h' or '24h')."""
return TimeFormatDetector.detect_from_system()
class TimezoneHandler:
"""Handles timezone conversions and timestamp parsing."""
def __init__(self, default_tz: str = "UTC") -> None:
"""Initialize with a default timezone."""
self.default_tz: BaseTzInfo = self._validate_and_get_tz(default_tz)
def _validate_and_get_tz(self, tz_name: str) -> BaseTzInfo:
"""Validate and return pytz timezone object."""
try:
return pytz.timezone(tz_name)
except pytz.exceptions.UnknownTimeZoneError:
logger.warning(f"Unknown timezone '{tz_name}', using UTC")
return pytz.UTC
def parse_timestamp(self, timestamp_str: str) -> Optional[datetime]:
"""Parse various timestamp formats."""
if not timestamp_str:
return None
iso_tz_pattern: str = (
r"(\d{4}-\d{2}-\d{2}T\d{2}:\d{2}:\d{2})(\.\d+)?(Z|[+-]\d{2}:\d{2})?"
)
match: Optional[re.Match[str]] = re.match(iso_tz_pattern, timestamp_str)
if match:
try:
base_str: str = match.group(1)
microseconds: str = match.group(2) or ""
tz_str: str = match.group(3) or ""
dt: datetime = datetime.fromisoformat(base_str + microseconds)
if tz_str == "Z":
return dt.replace(tzinfo=pytz.UTC)
if tz_str:
return datetime.fromisoformat(timestamp_str)
return self.default_tz.localize(dt)
except Exception as e:
logger.debug(f"Failed to parse ISO timestamp: {e}")
formats: List[str] = [
"%Y-%m-%d %H:%M:%S",
"%Y/%m/%d %H:%M:%S",
"%d/%m/%Y %H:%M:%S",
"%m/%d/%Y %H:%M:%S",
"%Y-%m-%d",
"%Y/%m/%d",
]
for fmt in formats:
try:
parsed_dt: datetime = datetime.strptime(timestamp_str, fmt)
return self.default_tz.localize(parsed_dt)
except ValueError:
continue
return None
def ensure_utc(self, dt: datetime) -> datetime:
"""Convert datetime to UTC."""
if dt.tzinfo is None:
dt = self.default_tz.localize(dt)
return dt.astimezone(pytz.UTC)
def ensure_timezone(self, dt: datetime) -> datetime:
"""Ensure datetime has timezone info."""
if dt.tzinfo is None:
return self.default_tz.localize(dt)
return dt
def validate_timezone(self, tz_name: str) -> bool:
"""Check if timezone name is valid."""
try:
pytz.timezone(tz_name)
return True
except pytz.exceptions.UnknownTimeZoneError:
return False
def convert_to_timezone(self, dt: datetime, tz_name: str) -> datetime:
"""Convert datetime to specific timezone."""
tz: BaseTzInfo = self._validate_and_get_tz(tz_name)
if dt.tzinfo is None:
dt = self.default_tz.localize(dt)
return dt.astimezone(tz)
def set_timezone(self, tz_name: str) -> None:
"""Set default timezone."""
self.default_tz = self._validate_and_get_tz(tz_name)
def to_utc(self, dt: datetime) -> datetime:
"""Convert to UTC (assumes naive datetime is in default tz)."""
return self.ensure_utc(dt)
def to_timezone(self, dt: datetime, tz_name: Optional[str] = None) -> datetime:
"""Convert to timezone (defaults to default_tz)."""
if tz_name is None:
tz_name = self.default_tz.zone
return self.convert_to_timezone(dt, tz_name)
def format_datetime(self, dt: datetime, use_12_hour: Optional[bool] = None) -> str:
"""Format datetime with timezone info."""
if use_12_hour is None:
use_12_hour = TimeFormatDetector.get_preference(
timezone_name=dt.tzinfo.zone if dt.tzinfo else None
)
dt = self.ensure_timezone(dt)
fmt: str = "%Y-%m-%d %I:%M:%S %p %Z" if use_12_hour else "%Y-%m-%d %H:%M:%S %Z"
return dt.strftime(fmt)
def get_time_format_preference(args: Any = None) -> bool:
"""Get time format preference - returns True for 12h, False for 24h."""
return TimeFormatDetector.get_preference(args)
def get_system_timezone() -> str:
"""Get system timezone."""
return SystemTimeDetector.get_timezone()
def get_system_time_format() -> str:
"""Get system time format ('12h' or '24h')."""
return SystemTimeDetector.get_time_format()
def format_time(minutes: Union[int, float]) -> str:
"""Format minutes into human-readable time (e.g., '3h 45m')."""
if minutes < 60:
return f"{int(minutes)}m"
hours = int(minutes // 60)
mins = int(minutes % 60)
if mins == 0:
return f"{hours}h"
return f"{hours}h {mins}m"
def percentage(part: float, whole: float, decimal_places: int = 1) -> float:
"""Calculate percentage with safe division.
Args:
part: Part value
whole: Whole value
decimal_places: Number of decimal places to round to
Returns:
Percentage value
"""
if whole == 0:
return 0.0
result = (part / whole) * 100
return round(result, decimal_places)
def format_display_time(
dt_obj: datetime,
use_12h_format: Optional[bool] = None,
include_seconds: bool = True,
) -> str:
"""Central time formatting with 12h/24h support."""
if use_12h_format is None:
use_12h_format = get_time_format_preference()
if use_12h_format:
if include_seconds:
try:
return dt_obj.strftime("%-I:%M:%S %p")
except ValueError:
return dt_obj.strftime("%#I:%M:%S %p")
else:
try:
return dt_obj.strftime("%-I:%M %p")
except ValueError:
return dt_obj.strftime("%#I:%M %p")
elif include_seconds:
return dt_obj.strftime("%H:%M:%S")
else:
return dt_obj.strftime("%H:%M")
================================================
FILE: src/claude_monitor/utils/timezone.py
================================================
"""Timezone utilities for Claude Monitor.
This module provides timezone handling functionality, re-exporting from time_utils
for backward compatibility.
"""
import logging
from datetime import datetime
from typing import Any, Optional
from claude_monitor.utils.time_utils import TimezoneHandler, get_time_format_preference
logger: logging.Logger = logging.getLogger(__name__)
def _detect_timezone_time_preference(args: Any = None) -> bool:
"""Detect timezone and time preference.
This is a backward compatibility function that delegates to the new
time format detection system.
Args:
args: Arguments object or None
Returns:
True for 12-hour format, False for 24-hour format
"""
return get_time_format_preference(args)
def parse_timestamp(timestamp_str: str, default_tz: str = "UTC") -> Optional[datetime]:
"""Parse timestamp string with timezone handling.
Args:
timestamp_str: Timestamp string to parse
default_tz: Default timezone if not specified in timestamp
Returns:
Parsed datetime object or None if parsing fails
"""
handler: TimezoneHandler = TimezoneHandler(default_tz)
return handler.parse_timestamp(timestamp_str)
def ensure_utc(dt: datetime, default_tz: str = "UTC") -> datetime:
"""Convert datetime to UTC.
Args:
dt: Datetime object to convert
default_tz: Default timezone for naive datetime objects
Returns:
UTC datetime object
"""
handler: TimezoneHandler = TimezoneHandler(default_tz)
return handler.ensure_utc(dt)
def validate_timezone(tz_name: str) -> bool:
"""Check if timezone name is valid.
Args:
tz_name: Timezone name to validate
Returns:
True if valid, False otherwise
"""
handler: TimezoneHandler = TimezoneHandler()
return handler.validate_timezone(tz_name)
def convert_to_timezone(
dt: datetime, tz_name: str, default_tz: str = "UTC"
) -> datetime:
"""Convert datetime to specific timezone.
Args:
dt: Datetime object to convert
tz_name: Target timezone name
default_tz: Default timezone for naive datetime objects
Returns:
Converted datetime object
"""
handler: TimezoneHandler = TimezoneHandler(default_tz)
return handler.convert_to_timezone(dt, tz_name)
================================================
FILE: src/tests/__init__.py
================================================
"""Test package for Claude Monitor."""
================================================
FILE: src/tests/conftest.py
================================================
"""Shared pytest fixtures for Claude Monitor tests."""
from datetime import datetime, timezone
from typing import Any, Dict, List, Set
from unittest.mock import Mock
import pytest
from claude_monitor.core.models import CostMode, UsageEntry
@pytest.fixture
def mock_pricing_calculator() -> Mock:
"""Mock PricingCalculator for testing."""
mock = Mock()
mock.calculate_cost_for_entry.return_value = 0.001
return mock
@pytest.fixture
def mock_timezone_handler() -> Mock:
"""Mock TimezoneHandler for testing."""
mock = Mock()
mock.parse_timestamp.return_value = datetime(
2024, 1, 1, 12, 0, 0, tzinfo=timezone.utc
)
mock.ensure_utc.return_value = datetime(2024, 1, 1, 12, 0, 0, tzinfo=timezone.utc)
return mock
@pytest.fixture
def sample_usage_entry() -> UsageEntry:
"""Sample UsageEntry for testing."""
return UsageEntry(
timestamp=datetime(2024, 1, 1, 12, 0, 0, tzinfo=timezone.utc),
input_tokens=100,
output_tokens=50,
cache_creation_tokens=10,
cache_read_tokens=5,
cost_usd=0.001,
model="claude-3-haiku",
message_id="msg_123",
request_id="req_456",
)
@pytest.fixture
def sample_valid_data() -> Dict[str, Any]:
"""Sample valid data structure for testing."""
return {
"timestamp": "2024-01-01T12:00:00Z",
"message": {
"id": "msg_123",
"model": "claude-3-haiku",
"usage": {
"input_tokens": 100,
"output_tokens": 50,
"cache_creation_input_tokens": 10,
"cache_read_input_tokens": 5,
},
},
"request_id": "req_456",
"type": "assistant",
}
@pytest.fixture
def sample_assistant_data() -> Dict[str, Any]:
"""Sample assistant-type data for testing."""
return {
"timestamp": "2024-01-01T12:00:00Z",
"type": "assistant",
"message": {
"id": "msg_123",
"model": "claude-3-haiku",
"usage": {
"input_tokens": 100,
"output_tokens": 50,
"cache_creation_input_tokens": 10,
"cache_read_input_tokens": 5,
},
},
"request_id": "req_456",
}
@pytest.fixture
def sample_user_data() -> Dict[str, Any]:
"""Sample user-type data for testing."""
return {
"timestamp": "2024-01-01T12:00:00Z",
"type": "user",
"usage": {
"input_tokens": 200,
"output_tokens": 75,
"cache_creation_input_tokens": 0,
"cache_read_input_tokens": 0,
},
"model": "claude-3-haiku",
"message_id": "msg_123",
"request_id": "req_456",
}
@pytest.fixture
def sample_malformed_data() -> Dict[str, Any]:
"""Sample malformed data for testing error handling."""
return {
"timestamp": "invalid_timestamp",
"message": "not_a_dict",
"usage": {"input_tokens": "not_a_number", "output_tokens": None},
}
@pytest.fixture
def sample_minimal_data() -> Dict[str, Any]:
"""Sample minimal valid data for testing."""
return {
"timestamp": "2024-01-01T12:00:00Z",
"usage": {"input_tokens": 100, "output_tokens": 50},
"request_id": "req_456",
}
@pytest.fixture
def sample_empty_tokens_data() -> Dict[str, Any]:
"""Sample data with empty/zero tokens for testing."""
return {
"timestamp": "2024-01-01T12:00:00Z",
"usage": {
"input_tokens": 0,
"output_tokens": 0,
"cache_creation_input_tokens": 0,
"cache_read_input_tokens": 0,
},
"request_id": "req_456",
}
@pytest.fixture
def sample_duplicate_data() -> List[Dict[str, Any]]:
"""Sample data for testing duplicate detection."""
return [
{
"timestamp": "2024-01-01T12:00:00Z",
"message_id": "msg_1",
"request_id": "req_1",
"usage": {"input_tokens": 100, "output_tokens": 50},
},
{
"timestamp": "2024-01-01T13:00:00Z",
"message_id": "msg_1",
"request_id": "req_1",
"usage": {"input_tokens": 150, "output_tokens": 60},
},
{
"timestamp": "2024-01-01T14:00:00Z",
"message_id": "msg_2",
"request_id": "req_2",
"usage": {"input_tokens": 200, "output_tokens": 75},
},
]
@pytest.fixture
def all_cost_modes() -> List[CostMode]:
"""All available cost modes for testing."""
return [CostMode.AUTO]
@pytest.fixture
def sample_cutoff_time() -> datetime:
"""Sample cutoff time for testing."""
return datetime(2024, 1, 1, 10, 0, 0, tzinfo=timezone.utc)
@pytest.fixture
def sample_processed_hashes() -> Set[str]:
"""Sample processed hashes set for testing."""
return {"msg_existing:req_existing", "msg_old:req_old"}
@pytest.fixture
def mock_file_reader() -> Mock:
"""Mock JsonlFileReader for testing."""
mock = Mock()
mock.read_jsonl_file.return_value = [
{
"timestamp": "2024-01-01T12:00:00Z",
"message_id": "msg_1",
"request_id": "req_1",
"usage": {"input_tokens": 100, "output_tokens": 50},
}
]
mock.load_all_entries.return_value = [
{"raw_data": "entry1"},
{"raw_data": "entry2"},
]
mock.find_jsonl_files.return_value = [
"/path/to/file1.jsonl",
"/path/to/file2.jsonl",
]
return mock
@pytest.fixture
def mock_data_filter() -> Mock:
"""Mock DataFilter for testing."""
mock = Mock()
mock.calculate_cutoff_time.return_value = datetime(
2024, 1, 1, 10, 0, 0, tzinfo=timezone.utc
)
mock.should_process_entry.return_value = True
mock.update_processed_hashes.return_value = None
return mock
@pytest.fixture
def mock_usage_entry_mapper() -> Mock:
"""Mock UsageEntryMapper for testing."""
mock = Mock()
mock.map.return_value = UsageEntry(
timestamp=datetime(2024, 1, 1, 12, 0, 0, tzinfo=timezone.utc),
input_tokens=100,
output_tokens=50,
cache_creation_tokens=0,
cache_read_tokens=0,
cost_usd=0.001,
model="claude-3-haiku",
message_id="msg_123",
request_id="req_456",
)
return mock
@pytest.fixture
def mock_data_processor() -> Mock:
"""Mock DataProcessor for testing."""
mock = Mock()
mock.process_files.return_value = (
[
UsageEntry(
timestamp=datetime(2024, 1, 1, 12, 0, 0, tzinfo=timezone.utc),
input_tokens=100,
output_tokens=50,
cache_creation_tokens=0,
cache_read_tokens=0,
cost_usd=0.001,
model="claude-3-haiku",
message_id="msg_123",
request_id="req_456",
)
],
None,
)
mock.load_all_raw_entries.return_value = [
{"raw_data": "entry1"},
{"raw_data": "entry2"},
]
return mock
@pytest.fixture
def mock_data_manager() -> Mock:
"""Mock DataManager for monitoring tests."""
mock = Mock()
mock.get_data.return_value = {
"blocks": [
{
"id": "session_1",
"isActive": True,
"totalTokens": 1000,
"costUSD": 0.05,
"startTime": "2024-01-01T12:00:00Z",
}
]
}
mock.cache_age = 0.0
mock.last_error = None
mock.last_successful_fetch_time = None
return mock
@pytest.fixture
def mock_session_monitor() -> Mock:
"""Mock SessionMonitor for monitoring tests."""
mock = Mock()
mock.update.return_value = (True, [])
mock.current_session_id = "session_1"
mock.session_count = 1
mock.session_history = [
{
"id": "session_1",
"started_at": "2024-01-01T12:00:00Z",
"tokens": 1000,
"cost": 0.05,
}
]
return mock
@pytest.fixture
def sample_monitoring_data() -> Dict[str, Any]:
"""Sample monitoring data structure for testing."""
return {
"blocks": [
{
"id": "session_1",
"isActive": True,
"totalTokens": 1000,
"costUSD": 0.05,
"startTime": "2024-01-01T12:00:00Z",
},
{
"id": "session_2",
"isActive": False,
"totalTokens": 500,
"costUSD": 0.025,
"startTime": "2024-01-01T11:00:00Z",
},
]
}
@pytest.fixture
def sample_session_data() -> Dict[str, Any]:
"""Sample session data for testing."""
return {
"id": "session_1",
"isActive": True,
"totalTokens": 1000,
"costUSD": 0.05,
"startTime": "2024-01-01T12:00:00Z",
}
@pytest.fixture
def sample_invalid_monitoring_data() -> Dict[str, Any]:
"""Sample invalid monitoring data for testing."""
return {
"blocks": [
{
"id": "session_1",
"isActive": "not_boolean",
"totalTokens": "not_number",
"costUSD": None,
}
]
}
@pytest.fixture
def mock_orchestrator_args() -> Mock:
"""Mock command line arguments for orchestrator testing."""
args = Mock()
args.plan = "pro"
args.timezone = "UTC"
args.refresh_rate = 10
args.custom_limit_tokens = None
return args
================================================
FILE: src/tests/examples/api_examples.py
================================================
"""Usage examples for the Claude Monitor API wrapper.
This module demonstrates how to use the backward compatibility API wrapper
to analyze Claude usage data in various ways.
"""
import json
# Import functions directly from the analysis module
from claude_monitor.data.analysis import analyze_usage
from claude_monitor.utils.formatting import format_currency, format_time
# Create helper functions that replace the removed facade functions
def analyze_usage_with_metadata(
hours_back=96, use_cache=True, quick_start=False, data_path=None
):
"""Enhanced analyze_usage with comprehensive metadata."""
return analyze_usage(
hours_back=hours_back,
use_cache=use_cache,
quick_start=quick_start,
data_path=data_path,
)
def analyze_usage_json(hours_back=96, use_cache=True, data_path=None, indent=2):
"""Analyze usage and return JSON string."""
result = analyze_usage(
hours_back=hours_back, use_cache=use_cache, data_path=data_path
)
return json.dumps(result, indent=indent, default=str)
def get_usage_summary(hours_back=96, use_cache=True, data_path=None):
"""Get high-level usage summary statistics."""
result = analyze_usage(
hours_back=hours_back, use_cache=use_cache, data_path=data_path
)
blocks = result.get("blocks", [])
return _create_summary_stats(blocks)
def print_usage_json(hours_back=96, use_cache=True, data_path=None):
"""Print usage analysis as JSON to stdout."""
json_result = analyze_usage_json(
hours_back=hours_back, use_cache=use_cache, data_path=data_path
)
print(json_result)
def print_usage_summary(hours_back=96, use_cache=True, data_path=None):
"""Print human-readable usage summary."""
summary = get_usage_summary(
hours_back=hours_back, use_cache=use_cache, data_path=data_path
)
if summary.get("error"):
print(f"Error: {summary.get('error_details', 'Unknown error')}")
return
print(f"Claude Usage Summary (Last {hours_back} Hours)")
print("=" * 50)
print(f"Total Sessions: {summary.get('total_sessions', 0)}")
print(f"Total Cost: {format_currency(summary.get('total_cost', 0))}")
print(f"Total Tokens: {summary.get('total_tokens', 0):,}")
print(
f"Average Session Cost: {format_currency(summary.get('average_session_cost', 0))}"
)
if summary.get("active_sessions", 0) > 0:
print(f"Active Sessions: {summary['active_sessions']}")
if summary.get("total_duration_minutes", 0) > 0:
print(f"Total Duration: {format_time(summary['total_duration_minutes'])}")
def _create_summary_stats(blocks):
"""Create summary statistics from session blocks."""
if not blocks:
return {
"total_sessions": 0,
"total_cost": 0.0,
"total_tokens": 0,
"average_session_cost": 0.0,
"active_sessions": 0,
"total_duration_minutes": 0,
}
total_sessions = len(blocks)
total_cost = sum(block.get("cost", 0) for block in blocks)
total_tokens = sum(block.get("tokens", {}).get("total", 0) for block in blocks)
active_sessions = sum(1 for block in blocks if block.get("is_active", False))
total_duration_minutes = sum(block.get("duration_minutes", 0) for block in blocks)
average_session_cost = total_cost / total_sessions if total_sessions > 0 else 0
return {
"total_sessions": total_sessions,
"total_cost": total_cost,
"total_tokens": total_tokens,
"average_session_cost": average_session_cost,
"active_sessions": active_sessions,
"total_duration_minutes": total_duration_minutes,
}
# For backward compatibility
analyze_usage_direct = analyze_usage
def example_basic_usage():
"""Example 1: Basic usage (backward compatibility with original API)
This example shows how to use the API in the same way as the original
usage_analyzer.api.analyze_usage() function.
"""
print("=== Example 1: Basic Usage ===")
try:
# Simple usage - returns list of blocks just like the original
blocks = analyze_usage()
print(f"Found {len(blocks)} session blocks")
# Process blocks just like the original API
for block in blocks:
print(
f"Block {block['id']}: {block['totalTokens']} tokens, ${block['costUSD']:.2f}"
)
if block["isActive"]:
print(f" - Active block with {block['durationMinutes']:.1f} minutes")
# Check for burn rate data
if "burnRate" in block:
print(
f" - Burn rate: {block['burnRate']['tokensPerMinute']:.1f} tokens/min"
)
# Check for projections
if "projection" in block:
proj = block["projection"]
print(
f" - Projected: {proj['totalTokens']} tokens, ${proj['totalCost']:.2f}"
)
except Exception as e:
print(f"Error: {e}")
def example_advanced_usage():
"""Example 2: Advanced usage with metadata and time filtering
This example shows how to use the enhanced features of the new API
while maintaining backward compatibility.
"""
print("\n=== Example 2: Advanced Usage ===")
try:
# Get full results with metadata
result = analyze_usage_with_metadata(
hours_back=24, # Only last 24 hours
quick_start=True, # Fast analysis
)
blocks = result["blocks"]
metadata = result["metadata"]
print(f"Analysis completed in {metadata['load_time_seconds']:.3f}s")
print(f"Processed {metadata['entries_processed']} entries")
print(f"Created {metadata['blocks_created']} blocks")
# Find active blocks
active_blocks = [b for b in blocks if b["isActive"]]
print(f"Active blocks: {len(active_blocks)}")
# Calculate total usage
total_cost = sum(b["costUSD"] for b in blocks)
total_tokens = sum(b["totalTokens"] for b in blocks)
print(f"Total usage: {total_tokens:,} tokens, ${total_cost:.2f}")
except Exception as e:
print(f"Error: {e}")
def example_json_output():
"""Example 3: JSON output (same as original API when used as script)
This example shows how to get JSON output exactly like the original API.
"""
print("\n=== Example 3: JSON Output ===")
try:
# Get JSON string (same format as original)
json_output = analyze_usage_json(hours_back=48)
# Parse it back to verify
blocks = json.loads(json_output)
print(f"JSON contains {len(blocks)} blocks")
# Print a formatted sample
if blocks:
sample_block = blocks[0]
print("\nSample block structure:")
print(json.dumps(sample_block, indent=2)[:500] + "...")
except Exception as e:
print(f"Error: {e}")
def example_usage_summary():
"""Example 4: Usage summary and statistics
This example shows how to get high-level statistics about usage.
"""
print("\n=== Example 4: Usage Summary ===")
try:
# Get summary statistics
summary = get_usage_summary(hours_back=168) # Last week
print(f"Total Cost: ${summary['total_cost']:.2f}")
print(f"Total Tokens: {summary['total_tokens']:,}")
print(f"Total Blocks: {summary['total_blocks']}")
print(f"Active Blocks: {summary['active_blocks']}")
# Model breakdown
print("\nModel usage:")
for model, stats in summary["model_stats"].items():
print(f" {model}: {stats['tokens']:,} tokens, ${stats['cost']:.2f}")
# Performance info
perf = summary["performance"]
print(f"\nPerformance: {perf['load_time_seconds']:.3f}s load time")
except Exception as e:
print(f"Error: {e}")
def example_custom_data_path():
"""Example 5: Using custom data path
This example shows how to analyze data from a custom location.
"""
print("\n=== Example 5: Custom Data Path ===")
try:
# You can specify a custom path to Claude data
custom_path = "/path/to/claude/data" # Replace with actual path
# This will use the custom path instead of default ~/.claude/projects
blocks = analyze_usage(
data_path=custom_path,
hours_back=24,
quick_start=True,
)
print(f"Analyzed {len(blocks)} blocks from custom path")
except Exception as e:
print(f"Error (expected if path doesn't exist): {e}")
def example_direct_import():
"""Example 6: Direct import from main module
This example shows how to import the function directly from the main module.
"""
print("\n=== Example 6: Direct Import ===")
try:
# You can import directly from claude_monitor module
blocks = analyze_usage_direct()
print(f"Direct import worked! Found {len(blocks)} blocks")
except Exception as e:
print(f"Error: {e}")
def example_error_handling():
"""Example 7: Error handling patterns
This example shows how the API handles errors gracefully.
"""
print("\n=== Example 7: Error Handling ===")
try:
# This might fail if no data is available
blocks = analyze_usage(
data_path="/nonexistent/path",
hours_back=1,
)
print(f"Success: {len(blocks)} blocks")
except Exception as e:
print(f"Handled error gracefully: {e}")
print("The API reports errors to logging")
def example_print_functions():
"""Example 8: Print functions for direct output
This example shows the convenience print functions.
"""
print("\n=== Example 8: Print Functions ===")
try:
# Print JSON directly (like original API as script)
print("JSON output:")
print_usage_json(hours_back=24)
print("\nSummary output:")
print_usage_summary(hours_back=24)
except Exception as e:
print(f"Error: {e}")
def example_compatibility_check():
"""Example 9: Compatibility check with original API
This example shows how to verify the output is compatible with the original.
"""
print("\n=== Example 9: Compatibility Check ===")
try:
# Get data in original format
blocks = analyze_usage()
# Check structure matches original expectations
if blocks:
block = blocks[0]
required_fields = [
"id",
"isActive",
"isGap",
"startTime",
"endTime",
"totalTokens",
"costUSD",
"models",
"durationMinutes",
]
missing_fields = [field for field in required_fields if field not in block]
if missing_fields:
print(f"Missing fields: {missing_fields}")
else:
print("All required fields present - compatible with original API")
# Check for enhanced fields
enhanced_fields = ["burnRate", "projection", "limitMessages"]
present_enhanced = [field for field in enhanced_fields if field in block]
if present_enhanced:
print(f"Enhanced fields available: {present_enhanced}")
except Exception as e:
print(f"Error: {e}")
def run_all_examples():
"""Run all examples to demonstrate the API functionality."""
print("Claude Monitor API Examples")
print("=" * 50)
examples = [
example_basic_usage,
example_advanced_usage,
example_json_output,
example_usage_summary,
example_custom_data_path,
example_direct_import,
example_error_handling,
example_print_functions,
example_compatibility_check,
]
for example in examples:
try:
example()
except Exception as e:
print(f"Example {example.__name__} failed: {e}")
print("\n" + "=" * 50)
print("All examples completed!")
if __name__ == "__main__":
run_all_examples()
================================================
FILE: src/tests/run_tests.py
================================================
#!/usr/bin/env python3
"""Test runner for Claude Monitor tests."""
import subprocess
import sys
from pathlib import Path
from typing import List
def run_tests() -> int:
"""Run all tests with pytest."""
test_dir = Path(__file__).parent
src_dir = test_dir.parent.parent.parent
import os
env = os.environ.copy()
env["PYTHONPATH"] = str(src_dir)
cmd: List[str] = [
sys.executable,
"-m",
"pytest",
str(test_dir),
"-v",
"--tb=short",
"--color=yes",
f"--cov={src_dir / 'claude_monitor' / 'data'}",
"--cov-report=term-missing",
"--cov-report=html:htmlcov",
]
try:
subprocess.run(cmd, env=env, check=True)
print("\n✅ All tests passed!")
return 0
except subprocess.CalledProcessError as e:
print(f"\n❌ Tests failed with exit code: {e.returncode}")
return e.returncode
except FileNotFoundError:
print("❌ pytest not found. Install with: pip install pytest pytest-cov")
return 1
if __name__ == "__main__":
sys.exit(run_tests())
================================================
FILE: src/tests/test_aggregator.py
================================================
"""Tests for data aggregator module."""
from datetime import datetime, timezone
from typing import List
import pytest
from claude_monitor.core.models import UsageEntry
from claude_monitor.data.aggregator import (
AggregatedPeriod,
AggregatedStats,
UsageAggregator,
)
class TestAggregatedStats:
"""Test cases for AggregatedStats dataclass."""
def test_init_default_values(self) -> None:
"""Test default initialization of AggregatedStats."""
stats = AggregatedStats()
assert stats.input_tokens == 0
assert stats.output_tokens == 0
assert stats.cache_creation_tokens == 0
assert stats.cache_read_tokens == 0
assert stats.cost == 0.0
assert stats.count == 0
def test_add_entry_single(self, sample_usage_entry: UsageEntry) -> None:
"""Test adding a single entry to stats."""
stats = AggregatedStats()
stats.add_entry(sample_usage_entry)
assert stats.input_tokens == 100
assert stats.output_tokens == 50
assert stats.cache_creation_tokens == 10
assert stats.cache_read_tokens == 5
assert stats.cost == 0.001
assert stats.count == 1
def test_add_entry_multiple(self) -> None:
"""Test adding multiple entries to stats."""
stats = AggregatedStats()
# Create multiple entries
entry1 = UsageEntry(
timestamp=datetime(2024, 1, 1, 12, 0, tzinfo=timezone.utc),
input_tokens=100,
output_tokens=50,
cache_creation_tokens=10,
cache_read_tokens=5,
cost_usd=0.001,
model="claude-3-haiku",
message_id="msg_1",
request_id="req_1",
)
entry2 = UsageEntry(
timestamp=datetime(2024, 1, 1, 13, 0, tzinfo=timezone.utc),
input_tokens=200,
output_tokens=100,
cache_creation_tokens=20,
cache_read_tokens=10,
cost_usd=0.002,
model="claude-3-sonnet",
message_id="msg_2",
request_id="req_2",
)
stats.add_entry(entry1)
stats.add_entry(entry2)
assert stats.input_tokens == 300
assert stats.output_tokens == 150
assert stats.cache_creation_tokens == 30
assert stats.cache_read_tokens == 15
assert stats.cost == 0.003
assert stats.count == 2
def test_to_dict(self) -> None:
"""Test converting AggregatedStats to dictionary."""
stats = AggregatedStats(
input_tokens=1000,
output_tokens=500,
cache_creation_tokens=100,
cache_read_tokens=50,
cost=0.05,
count=10,
)
result = stats.to_dict()
assert result == {
"input_tokens": 1000,
"output_tokens": 500,
"cache_creation_tokens": 100,
"cache_read_tokens": 50,
"cost": 0.05,
"count": 10,
}
class TestAggregatedPeriod:
"""Test cases for AggregatedPeriod dataclass."""
def test_init_default_values(self) -> None:
"""Test default initialization of AggregatedPeriod."""
period = AggregatedPeriod(period_key="2024-01-01")
assert period.period_key == "2024-01-01"
assert isinstance(period.stats, AggregatedStats)
assert period.stats.count == 0
assert len(period.models_used) == 0
assert len(period.model_breakdowns) == 0
def test_add_entry_single(self, sample_usage_entry: UsageEntry) -> None:
"""Test adding a single entry to period."""
period = AggregatedPeriod(period_key="2024-01-01")
period.add_entry(sample_usage_entry)
# Check overall stats
assert period.stats.input_tokens == 100
assert period.stats.output_tokens == 50
assert period.stats.cost == 0.001
assert period.stats.count == 1
# Check models tracking
assert "claude-3-haiku" in period.models_used
assert len(period.models_used) == 1
# Check model breakdown
assert "claude-3-haiku" in period.model_breakdowns
assert period.model_breakdowns["claude-3-haiku"].input_tokens == 100
def test_add_entry_multiple_models(self) -> None:
"""Test adding entries with different models."""
period = AggregatedPeriod(period_key="2024-01-01")
# Add entries with different models
entry1 = UsageEntry(
timestamp=datetime(2024, 1, 1, 12, 0, tzinfo=timezone.utc),
input_tokens=100,
output_tokens=50,
cache_creation_tokens=0,
cache_read_tokens=0,
cost_usd=0.001,
model="claude-3-haiku",
message_id="msg_1",
request_id="req_1",
)
entry2 = UsageEntry(
timestamp=datetime(2024, 1, 1, 13, 0, tzinfo=timezone.utc),
input_tokens=200,
output_tokens=100,
cache_creation_tokens=0,
cache_read_tokens=0,
cost_usd=0.002,
model="claude-3-sonnet",
message_id="msg_2",
request_id="req_2",
)
entry3 = UsageEntry(
timestamp=datetime(2024, 1, 1, 14, 0, tzinfo=timezone.utc),
input_tokens=150,
output_tokens=75,
cache_creation_tokens=0,
cache_read_tokens=0,
cost_usd=0.0015,
model="claude-3-haiku",
message_id="msg_3",
request_id="req_3",
)
period.add_entry(entry1)
period.add_entry(entry2)
period.add_entry(entry3)
# Check overall stats
assert period.stats.input_tokens == 450
assert period.stats.output_tokens == 225
assert (
abs(period.stats.cost - 0.0045) < 0.0000001
) # Handle floating point precision
assert period.stats.count == 3
# Check models
assert len(period.models_used) == 2
assert "claude-3-haiku" in period.models_used
assert "claude-3-sonnet" in period.models_used
# Check model breakdowns
assert period.model_breakdowns["claude-3-haiku"].input_tokens == 250
assert period.model_breakdowns["claude-3-haiku"].count == 2
assert period.model_breakdowns["claude-3-sonnet"].input_tokens == 200
assert period.model_breakdowns["claude-3-sonnet"].count == 1
def test_add_entry_with_unknown_model(self) -> None:
"""Test adding entry with None or empty model."""
period = AggregatedPeriod(period_key="2024-01-01")
entry = UsageEntry(
timestamp=datetime(2024, 1, 1, 12, 0, tzinfo=timezone.utc),
input_tokens=100,
output_tokens=50,
cache_creation_tokens=0,
cache_read_tokens=0,
cost_usd=0.001,
model=None,
message_id="msg_1",
request_id="req_1",
)
period.add_entry(entry)
assert "unknown" in period.models_used
assert "unknown" in period.model_breakdowns
def test_to_dict_daily(self) -> None:
"""Test converting AggregatedPeriod to dictionary for daily view."""
period = AggregatedPeriod(period_key="2024-01-01")
period.stats = AggregatedStats(
input_tokens=1000,
output_tokens=500,
cache_creation_tokens=100,
cache_read_tokens=50,
cost=0.05,
count=10,
)
period.models_used = {"claude-3-haiku", "claude-3-sonnet"}
period.model_breakdowns["claude-3-haiku"] = AggregatedStats(
input_tokens=600,
output_tokens=300,
cache_creation_tokens=60,
cache_read_tokens=30,
cost=0.03,
count=6,
)
period.model_breakdowns["claude-3-sonnet"] = AggregatedStats(
input_tokens=400,
output_tokens=200,
cache_creation_tokens=40,
cache_read_tokens=20,
cost=0.02,
count=4,
)
result = period.to_dict("date")
assert result["date"] == "2024-01-01"
assert result["input_tokens"] == 1000
assert result["output_tokens"] == 500
assert result["cache_creation_tokens"] == 100
assert result["cache_read_tokens"] == 50
assert result["total_cost"] == 0.05
assert result["entries_count"] == 10
assert set(result["models_used"]) == {"claude-3-haiku", "claude-3-sonnet"}
assert "claude-3-haiku" in result["model_breakdowns"]
assert result["model_breakdowns"]["claude-3-haiku"]["input_tokens"] == 600
def test_to_dict_monthly(self) -> None:
"""Test converting AggregatedPeriod to dictionary for monthly view."""
period = AggregatedPeriod(period_key="2024-01")
period.stats = AggregatedStats(
input_tokens=10000,
output_tokens=5000,
cache_creation_tokens=1000,
cache_read_tokens=500,
cost=0.5,
count=100,
)
period.models_used = {"claude-3-haiku"}
result = period.to_dict("month")
assert result["month"] == "2024-01"
assert result["input_tokens"] == 10000
assert result["total_cost"] == 0.5
class TestUsageAggregator:
"""Test cases for UsageAggregator class."""
@pytest.fixture
def aggregator(self, tmp_path) -> UsageAggregator:
"""Create a UsageAggregator instance."""
return UsageAggregator(data_path=str(tmp_path))
@pytest.fixture
def sample_entries(self) -> List[UsageEntry]:
"""Create sample usage entries spanning multiple days and months."""
entries = []
# January 2024 entries
for day in [1, 1, 2, 2, 15, 15, 31]:
for hour in [10, 14]:
entry = UsageEntry(
timestamp=datetime(2024, 1, day, hour, 0, tzinfo=timezone.utc),
input_tokens=100,
output_tokens=50,
cache_creation_tokens=10,
cache_read_tokens=5,
cost_usd=0.001,
model="claude-3-haiku" if hour == 10 else "claude-3-sonnet",
message_id=f"msg_{day}_{hour}",
request_id=f"req_{day}_{hour}",
)
entries.append(entry)
# February 2024 entries
for day in [1, 15, 29]:
entry = UsageEntry(
timestamp=datetime(2024, 2, day, 12, 0, tzinfo=timezone.utc),
input_tokens=200,
output_tokens=100,
cache_creation_tokens=20,
cache_read_tokens=10,
cost_usd=0.002,
model="claude-3-opus",
message_id=f"msg_feb_{day}",
request_id=f"req_feb_{day}",
)
entries.append(entry)
return entries
def test_aggregate_daily_basic(
self, aggregator: UsageAggregator, sample_entries: List[UsageEntry]
) -> None:
"""Test basic daily aggregation."""
result = aggregator.aggregate_daily(sample_entries)
# Should have entries for each unique day
assert len(result) == 7 # Days: Jan 1, 2, 15, 31, Feb 1, 15, 29
# Check first day (Jan 1 - 4 entries: 2 at 10AM, 2 at 2PM)
jan1 = result[0]
assert jan1["date"] == "2024-01-01"
assert jan1["input_tokens"] == 400 # 4 entries * 100
assert jan1["output_tokens"] == 200 # 4 entries * 50
assert jan1["total_cost"] == 0.004 # 4 entries * 0.001
assert jan1["entries_count"] == 4
assert set(jan1["models_used"]) == {"claude-3-haiku", "claude-3-sonnet"}
def test_aggregate_daily_with_date_filter(
self, aggregator: UsageAggregator, sample_entries: List[UsageEntry]
) -> None:
"""Test daily aggregation with date filters."""
start_date = datetime(2024, 1, 15, tzinfo=timezone.utc)
end_date = datetime(
2024, 1, 31, 23, 59, 59, tzinfo=timezone.utc
) # Include the whole day
result = aggregator.aggregate_daily(sample_entries, start_date, end_date)
# Should have Jan 15 and Jan 31 (entries on those days are within the filter)
assert len(result) == 2
assert result[0]["date"] == "2024-01-15"
assert result[1]["date"] == "2024-01-31"
def test_aggregate_monthly_basic(
self, aggregator: UsageAggregator, sample_entries: List[UsageEntry]
) -> None:
"""Test basic monthly aggregation."""
result = aggregator.aggregate_monthly(sample_entries)
# Should have 2 months
assert len(result) == 2
# Check January
jan = result[0]
assert jan["month"] == "2024-01"
assert jan["input_tokens"] == 1400 # 14 entries * 100
assert jan["output_tokens"] == 700 # 14 entries * 50
assert (
abs(jan["total_cost"] - 0.014) < 0.0000001
) # Handle floating point precision
assert jan["entries_count"] == 14
assert set(jan["models_used"]) == {"claude-3-haiku", "claude-3-sonnet"}
# Check February
feb = result[1]
assert feb["month"] == "2024-02"
assert feb["input_tokens"] == 600 # 3 entries * 200
assert feb["output_tokens"] == 300 # 3 entries * 100
assert feb["total_cost"] == 0.006 # 3 entries * 0.002
assert feb["entries_count"] == 3
assert feb["models_used"] == ["claude-3-opus"]
def test_aggregate_monthly_with_date_filter(
self, aggregator: UsageAggregator, sample_entries: List[UsageEntry]
) -> None:
"""Test monthly aggregation with date filters."""
start_date = datetime(2024, 2, 1, tzinfo=timezone.utc)
result = aggregator.aggregate_monthly(sample_entries, start_date)
# Should only have February
assert len(result) == 1
assert result[0]["month"] == "2024-02"
def test_aggregate_from_blocks_daily(
self, aggregator: UsageAggregator, sample_entries: List[UsageEntry]
) -> None:
"""Test aggregating from session blocks for daily view."""
# Create mock session blocks
from claude_monitor.core.models import SessionBlock
block1 = SessionBlock(
id="block1",
start_time=datetime(2024, 1, 1, 10, 0, tzinfo=timezone.utc),
end_time=datetime(2024, 1, 1, 15, 0, tzinfo=timezone.utc),
entries=sample_entries[:5],
is_gap=False,
)
block2 = SessionBlock(
id="block2",
start_time=datetime(2024, 1, 2, 10, 0, tzinfo=timezone.utc),
end_time=datetime(2024, 1, 2, 15, 0, tzinfo=timezone.utc),
entries=sample_entries[5:10],
is_gap=False,
)
# Gap block should be ignored
gap_block = SessionBlock(
id="gap",
start_time=datetime(2024, 1, 3, 10, 0, tzinfo=timezone.utc),
end_time=datetime(2024, 1, 3, 15, 0, tzinfo=timezone.utc),
entries=[],
is_gap=True,
)
blocks = [block1, block2, gap_block]
result = aggregator.aggregate_from_blocks(blocks, "daily")
assert len(result) >= 2 # At least 2 days of data
assert result[0]["date"] == "2024-01-01"
def test_aggregate_from_blocks_monthly(
self, aggregator: UsageAggregator, sample_entries: List[UsageEntry]
) -> None:
"""Test aggregating from session blocks for monthly view."""
from claude_monitor.core.models import SessionBlock
block = SessionBlock(
id="block1",
start_time=datetime(2024, 1, 1, 10, 0, tzinfo=timezone.utc),
end_time=datetime(2024, 1, 1, 15, 0, tzinfo=timezone.utc),
entries=sample_entries,
is_gap=False,
)
result = aggregator.aggregate_from_blocks([block], "monthly")
assert len(result) == 2 # Jan and Feb
assert result[0]["month"] == "2024-01"
assert result[1]["month"] == "2024-02"
def test_aggregate_from_blocks_invalid_view_type(
self, aggregator: UsageAggregator
) -> None:
"""Test aggregate_from_blocks with invalid view type."""
from claude_monitor.core.models import SessionBlock
block = SessionBlock(
id="block1",
start_time=datetime.now(timezone.utc),
end_time=datetime.now(timezone.utc),
entries=[],
is_gap=False,
)
with pytest.raises(ValueError, match="Invalid view type"):
aggregator.aggregate_from_blocks([block], "weekly")
def test_calculate_totals_empty(self, aggregator: UsageAggregator) -> None:
"""Test calculating totals with empty data."""
result = aggregator.calculate_totals([])
assert result["input_tokens"] == 0
assert result["output_tokens"] == 0
assert result["cache_creation_tokens"] == 0
assert result["cache_read_tokens"] == 0
assert result["total_tokens"] == 0
assert result["total_cost"] == 0.0
assert result["entries_count"] == 0
def test_calculate_totals_with_data(self, aggregator: UsageAggregator) -> None:
"""Test calculating totals with aggregated data."""
aggregated_data = [
{
"date": "2024-01-01",
"input_tokens": 1000,
"output_tokens": 500,
"cache_creation_tokens": 100,
"cache_read_tokens": 50,
"total_cost": 0.05,
"entries_count": 10,
},
{
"date": "2024-01-02",
"input_tokens": 2000,
"output_tokens": 1000,
"cache_creation_tokens": 200,
"cache_read_tokens": 100,
"total_cost": 0.10,
"entries_count": 20,
},
]
result = aggregator.calculate_totals(aggregated_data)
assert result["input_tokens"] == 3000
assert result["output_tokens"] == 1500
assert result["cache_creation_tokens"] == 300
assert result["cache_read_tokens"] == 150
assert result["total_tokens"] == 4950
assert (
abs(result["total_cost"] - 0.15) < 0.0000001
) # Handle floating point precision
assert result["entries_count"] == 30
def test_aggregate_daily_empty_entries(self, aggregator: UsageAggregator) -> None:
"""Test daily aggregation with empty entries list."""
result = aggregator.aggregate_daily([])
assert result == []
def test_aggregate_monthly_empty_entries(self, aggregator: UsageAggregator) -> None:
"""Test monthly aggregation with empty entries list."""
result = aggregator.aggregate_monthly([])
assert result == []
def test_period_sorting(self, aggregator: UsageAggregator) -> None:
"""Test that periods are sorted correctly."""
# Create entries in non-chronological order
entries = [
UsageEntry(
timestamp=datetime(2024, 1, 15, 12, 0, tzinfo=timezone.utc),
input_tokens=100,
output_tokens=50,
cache_creation_tokens=0,
cache_read_tokens=0,
cost_usd=0.001,
model="claude-3-haiku",
message_id="msg_3",
request_id="req_3",
),
UsageEntry(
timestamp=datetime(2024, 1, 1, 12, 0, tzinfo=timezone.utc),
input_tokens=100,
output_tokens=50,
cache_creation_tokens=0,
cache_read_tokens=0,
cost_usd=0.001,
model="claude-3-haiku",
message_id="msg_1",
request_id="req_1",
),
UsageEntry(
timestamp=datetime(2024, 1, 10, 12, 0, tzinfo=timezone.utc),
input_tokens=100,
output_tokens=50,
cache_creation_tokens=0,
cache_read_tokens=0,
cost_usd=0.001,
model="claude-3-haiku",
message_id="msg_2",
request_id="req_2",
),
]
# Test daily sorting
daily_result = aggregator.aggregate_daily(entries)
assert len(daily_result) == 3
assert daily_result[0]["date"] == "2024-01-01"
assert daily_result[1]["date"] == "2024-01-10"
assert daily_result[2]["date"] == "2024-01-15"
# Test monthly sorting
monthly_entries = [
UsageEntry(
timestamp=datetime(2024, 3, 1, 12, 0, tzinfo=timezone.utc),
input_tokens=100,
output_tokens=50,
cache_creation_tokens=0,
cache_read_tokens=0,
cost_usd=0.001,
model="claude-3-haiku",
message_id="msg_3",
request_id="req_3",
),
UsageEntry(
timestamp=datetime(2024, 1, 1, 12, 0, tzinfo=timezone.utc),
input_tokens=100,
output_tokens=50,
cache_creation_tokens=0,
cache_read_tokens=0,
cost_usd=0.001,
model="claude-3-haiku",
message_id="msg_1",
request_id="req_1",
),
UsageEntry(
timestamp=datetime(2024, 2, 1, 12, 0, tzinfo=timezone.utc),
input_tokens=100,
output_tokens=50,
cache_creation_tokens=0,
cache_read_tokens=0,
cost_usd=0.001,
model="claude-3-haiku",
message_id="msg_2",
request_id="req_2",
),
]
monthly_result = aggregator.aggregate_monthly(monthly_entries)
assert len(monthly_result) == 3
assert monthly_result[0]["month"] == "2024-01"
assert monthly_result[1]["month"] == "2024-02"
assert monthly_result[2]["month"] == "2024-03"
================================================
FILE: src/tests/test_analysis.py
================================================
"""Tests for data/analysis.py module."""
from datetime import datetime, timezone
from unittest.mock import Mock, patch
from claude_monitor.core.models import (
BurnRate,
CostMode,
SessionBlock,
TokenCounts,
UsageEntry,
UsageProjection,
)
from claude_monitor.data.analysis import (
_add_optional_block_data,
_convert_blocks_to_dict_format,
_create_base_block_dict,
_create_result,
_format_block_entries,
_format_limit_info,
_is_limit_in_block_timerange,
_process_burn_rates,
analyze_usage,
)
class TestAnalyzeUsage:
"""Test the main analyze_usage function."""
@patch("claude_monitor.data.analysis.load_usage_entries")
@patch("claude_monitor.data.analysis.SessionAnalyzer")
@patch("claude_monitor.data.analysis.BurnRateCalculator")
def test_analyze_usage_basic(
self, mock_calc_class: Mock, mock_analyzer_class: Mock, mock_load: Mock
) -> None:
"""Test basic analyze_usage functionality."""
sample_entry = UsageEntry(
timestamp=datetime(2024, 1, 1, 12, 0, tzinfo=timezone.utc),
input_tokens=100,
output_tokens=50,
cost_usd=0.001,
model="claude-3-haiku",
)
sample_block = SessionBlock(
id="block_1",
start_time=datetime(2024, 1, 1, 12, 0, tzinfo=timezone.utc),
end_time=datetime(2024, 1, 1, 17, 0, tzinfo=timezone.utc),
token_counts=TokenCounts(input_tokens=100, output_tokens=50),
cost_usd=0.001,
entries=[sample_entry],
)
mock_load.return_value = ([sample_entry], [{"raw": "data"}])
mock_analyzer = Mock()
mock_analyzer.transform_to_blocks.return_value = [sample_block]
mock_analyzer.detect_limits.return_value = []
mock_analyzer_class.return_value = mock_analyzer
mock_calculator = Mock()
mock_calc_class.return_value = mock_calculator
result = analyze_usage(hours_back=24, use_cache=True)
assert "blocks" in result
assert "metadata" in result
assert "entries_count" in result
assert "total_tokens" in result
assert "total_cost" in result
assert result["entries_count"] == 1
assert result["total_tokens"] == 150
assert result["total_cost"] == 0.001
mock_load.assert_called_once()
mock_analyzer.transform_to_blocks.assert_called_once_with([sample_entry])
mock_analyzer.detect_limits.assert_called_once_with([{"raw": "data"}])
@patch("claude_monitor.data.analysis.load_usage_entries")
@patch("claude_monitor.data.analysis.SessionAnalyzer")
@patch("claude_monitor.data.analysis.BurnRateCalculator")
def test_analyze_usage_quick_start_no_hours(
self, mock_calc_class: Mock, mock_analyzer_class: Mock, mock_load: Mock
) -> None:
"""Test analyze_usage with quick_start=True and hours_back=None."""
mock_load.return_value = ([], [])
mock_analyzer = Mock()
mock_analyzer.transform_to_blocks.return_value = []
mock_analyzer.detect_limits.return_value = []
mock_analyzer_class.return_value = mock_analyzer
mock_calc_class.return_value = Mock()
result = analyze_usage(quick_start=True, hours_back=None)
mock_load.assert_called_once_with(
data_path=None, hours_back=24, mode=CostMode.AUTO, include_raw=True
)
assert result["metadata"]["quick_start"] is True
assert result["metadata"]["hours_analyzed"] == 24
@patch("claude_monitor.data.analysis.load_usage_entries")
@patch("claude_monitor.data.analysis.SessionAnalyzer")
@patch("claude_monitor.data.analysis.BurnRateCalculator")
def test_analyze_usage_quick_start_with_hours(
self, mock_calc_class: Mock, mock_analyzer_class: Mock, mock_load: Mock
) -> None:
"""Test analyze_usage with quick_start=True and specific hours_back."""
mock_load.return_value = ([], [])
mock_analyzer = Mock()
mock_analyzer.transform_to_blocks.return_value = []
mock_analyzer.detect_limits.return_value = []
mock_analyzer_class.return_value = mock_analyzer
mock_calc_class.return_value = Mock()
result = analyze_usage(quick_start=True, hours_back=48)
mock_load.assert_called_once_with(
data_path=None, hours_back=48, mode=CostMode.AUTO, include_raw=True
)
assert result["metadata"]["quick_start"] is True
assert result["metadata"]["hours_analyzed"] == 48
@patch("claude_monitor.data.analysis.load_usage_entries")
@patch("claude_monitor.data.analysis.SessionAnalyzer")
@patch("claude_monitor.data.analysis.BurnRateCalculator")
def test_analyze_usage_with_limits(
self, mock_calc_class: Mock, mock_analyzer_class: Mock, mock_load: Mock
) -> None:
"""Test analyze_usage with limit detection."""
sample_entry = UsageEntry(
timestamp=datetime(2024, 1, 1, 12, 0, tzinfo=timezone.utc),
input_tokens=100,
output_tokens=50,
cost_usd=0.001,
model="claude-3-haiku",
)
sample_block = SessionBlock(
id="block_1",
start_time=datetime(2024, 1, 1, 12, 0, tzinfo=timezone.utc),
end_time=datetime(2024, 1, 1, 17, 0, tzinfo=timezone.utc),
token_counts=TokenCounts(input_tokens=100, output_tokens=50),
cost_usd=0.001,
entries=[sample_entry],
)
limit_info = {
"type": "rate_limit",
"timestamp": datetime(2024, 1, 1, 13, 0, tzinfo=timezone.utc),
"content": "Rate limit exceeded",
"reset_time": datetime(2024, 1, 1, 14, 0, tzinfo=timezone.utc),
}
mock_load.return_value = ([sample_entry], [{"raw": "data"}])
mock_analyzer = Mock()
mock_analyzer.transform_to_blocks.return_value = [sample_block]
mock_analyzer.detect_limits.return_value = [limit_info]
mock_analyzer_class.return_value = mock_analyzer
mock_calc_class.return_value = Mock()
result = analyze_usage()
assert result["metadata"]["limits_detected"] == 1
assert hasattr(sample_block, "limit_messages")
@patch("claude_monitor.data.analysis.load_usage_entries")
@patch("claude_monitor.data.analysis.SessionAnalyzer")
@patch("claude_monitor.data.analysis.BurnRateCalculator")
def test_analyze_usage_no_raw_entries(
self, mock_calc_class: Mock, mock_analyzer_class: Mock, mock_load: Mock
) -> None:
"""Test analyze_usage when no raw entries are provided."""
sample_entry = UsageEntry(
timestamp=datetime(2024, 1, 1, 12, 0, tzinfo=timezone.utc),
input_tokens=100,
output_tokens=50,
cost_usd=0.001,
model="claude-3-haiku",
)
sample_block = SessionBlock(
id="block_1",
start_time=datetime(2024, 1, 1, 12, 0, tzinfo=timezone.utc),
end_time=datetime(2024, 1, 1, 17, 0, tzinfo=timezone.utc),
token_counts=TokenCounts(input_tokens=100, output_tokens=50),
cost_usd=0.001,
entries=[sample_entry],
)
mock_load.return_value = ([sample_entry], None)
mock_analyzer = Mock()
mock_analyzer.transform_to_blocks.return_value = [sample_block]
mock_analyzer_class.return_value = mock_analyzer
mock_calc_class.return_value = Mock()
result = analyze_usage()
assert result["metadata"]["limits_detected"] == 0
mock_analyzer.detect_limits.assert_not_called()
class TestProcessBurnRates:
"""Test the _process_burn_rates function."""
def test_process_burn_rates_active_block(self) -> None:
"""Test burn rate processing for active blocks."""
active_block = SessionBlock(
id="active_block",
start_time=datetime(2024, 1, 1, 12, 0, tzinfo=timezone.utc),
end_time=datetime(2024, 1, 1, 17, 0, tzinfo=timezone.utc),
is_active=True,
token_counts=TokenCounts(input_tokens=100, output_tokens=50),
cost_usd=0.001,
)
inactive_block = SessionBlock(
id="inactive_block",
start_time=datetime(2024, 1, 1, 8, 0, tzinfo=timezone.utc),
end_time=datetime(2024, 1, 1, 13, 0, tzinfo=timezone.utc),
is_active=False,
token_counts=TokenCounts(input_tokens=200, output_tokens=100),
cost_usd=0.002,
)
blocks = [active_block, inactive_block]
calculator = Mock()
burn_rate = BurnRate(tokens_per_minute=5.0, cost_per_hour=1.0)
projection = UsageProjection(
projected_total_tokens=500, projected_total_cost=0.005, remaining_minutes=60
)
calculator.calculate_burn_rate.return_value = burn_rate
calculator.project_block_usage.return_value = projection
_process_burn_rates(blocks, calculator)
calculator.calculate_burn_rate.assert_called_once_with(active_block)
calculator.project_block_usage.assert_called_once_with(active_block)
assert hasattr(active_block, "burn_rate_snapshot")
assert active_block.burn_rate_snapshot == burn_rate
assert hasattr(active_block, "projection_data")
assert active_block.projection_data == {
"totalTokens": 500,
"totalCost": 0.005,
"remainingMinutes": 60,
}
assert inactive_block.burn_rate_snapshot is None
def test_process_burn_rates_no_burn_rate(self) -> None:
"""Test burn rate processing when calculator returns None."""
active_block = SessionBlock(
id="active_block",
start_time=datetime(2024, 1, 1, 12, 0, tzinfo=timezone.utc),
end_time=datetime(2024, 1, 1, 17, 0, tzinfo=timezone.utc),
is_active=True,
token_counts=TokenCounts(input_tokens=0, output_tokens=0), # No tokens
cost_usd=0.0,
)
calculator = Mock()
calculator.calculate_burn_rate.return_value = None
_process_burn_rates([active_block], calculator)
assert active_block.burn_rate_snapshot is None
assert active_block.projection_data is None
def test_process_burn_rates_no_projection(self) -> None:
"""Test burn rate processing when projection returns None."""
active_block = SessionBlock(
id="active_block",
start_time=datetime(2024, 1, 1, 12, 0, tzinfo=timezone.utc),
end_time=datetime(2024, 1, 1, 17, 0, tzinfo=timezone.utc),
is_active=True,
token_counts=TokenCounts(input_tokens=100, output_tokens=50),
cost_usd=0.001,
)
calculator = Mock()
burn_rate = BurnRate(tokens_per_minute=5.0, cost_per_hour=1.0)
calculator.calculate_burn_rate.return_value = burn_rate
calculator.project_block_usage.return_value = None
_process_burn_rates([active_block], calculator)
assert active_block.burn_rate_snapshot == burn_rate
assert active_block.projection_data is None
class TestCreateResult:
"""Test the _create_result function."""
@patch("claude_monitor.data.analysis._convert_blocks_to_dict_format")
def test_create_result_basic(self, mock_convert: Mock) -> None:
"""Test basic _create_result functionality."""
# Create test blocks
block1 = Mock()
block1.total_tokens = 100
block1.cost_usd = 0.001
block2 = Mock()
block2.total_tokens = 200
block2.cost_usd = 0.002
blocks = [block1, block2]
entries = [Mock(), Mock(), Mock()]
metadata = {"test": "metadata"}
mock_convert.return_value = [{"block": "data1"}, {"block": "data2"}]
result = _create_result(blocks, entries, metadata)
assert result == {
"blocks": [{"block": "data1"}, {"block": "data2"}],
"metadata": {"test": "metadata"},
"entries_count": 3,
"total_tokens": 300,
"total_cost": 0.003,
}
mock_convert.assert_called_once_with(blocks)
def test_create_result_empty(self) -> None:
"""Test _create_result with empty data."""
result = _create_result([], [], {})
assert result == {
"blocks": [],
"metadata": {},
"entries_count": 0,
"total_tokens": 0,
"total_cost": 0,
}
class TestLimitFunctions:
"""Test limit-related functions."""
def test_is_limit_in_block_timerange_within_range(self) -> None:
"""Test _is_limit_in_block_timerange when limit is within block."""
block = SessionBlock(
id="test_block",
start_time=datetime(2024, 1, 1, 12, 0, tzinfo=timezone.utc),
end_time=datetime(2024, 1, 1, 17, 0, tzinfo=timezone.utc),
)
limit_info = {"timestamp": datetime(2024, 1, 1, 14, 0, tzinfo=timezone.utc)}
assert _is_limit_in_block_timerange(limit_info, block) is True
def test_is_limit_in_block_timerange_outside_range(self) -> None:
"""Test _is_limit_in_block_timerange when limit is outside block."""
block = SessionBlock(
id="test_block",
start_time=datetime(2024, 1, 1, 12, 0, tzinfo=timezone.utc),
end_time=datetime(2024, 1, 1, 17, 0, tzinfo=timezone.utc),
)
limit_info = {"timestamp": datetime(2024, 1, 1, 18, 0, tzinfo=timezone.utc)}
assert _is_limit_in_block_timerange(limit_info, block) is False
def test_is_limit_in_block_timerange_no_timezone(self) -> None:
"""Test _is_limit_in_block_timerange with naive datetime."""
block = SessionBlock(
id="test_block",
start_time=datetime(2024, 1, 1, 12, 0, tzinfo=timezone.utc),
end_time=datetime(2024, 1, 1, 17, 0, tzinfo=timezone.utc),
)
limit_info = {"timestamp": datetime(2024, 1, 1, 14, 0)}
assert _is_limit_in_block_timerange(limit_info, block) is True
def test_format_limit_info_complete(self) -> None:
"""Test _format_limit_info with all fields."""
limit_info = {
"type": "rate_limit",
"timestamp": datetime(2024, 1, 1, 12, 0, tzinfo=timezone.utc),
"content": "Rate limit exceeded",
"reset_time": datetime(2024, 1, 1, 13, 0, tzinfo=timezone.utc),
}
result = _format_limit_info(limit_info)
assert result == {
"type": "rate_limit",
"timestamp": "2024-01-01T12:00:00+00:00",
"content": "Rate limit exceeded",
"reset_time": "2024-01-01T13:00:00+00:00",
}
def test_format_limit_info_no_reset_time(self) -> None:
"""Test _format_limit_info without reset_time."""
limit_info = {
"type": "general_limit",
"timestamp": datetime(2024, 1, 1, 12, 0, tzinfo=timezone.utc),
"content": "Limit reached",
}
result = _format_limit_info(limit_info)
assert result == {
"type": "general_limit",
"timestamp": "2024-01-01T12:00:00+00:00",
"content": "Limit reached",
"reset_time": None,
}
class TestBlockConversion:
"""Test block conversion functions."""
def test_format_block_entries(self) -> None:
"""Test _format_block_entries function."""
entry1 = UsageEntry(
timestamp=datetime(2024, 1, 1, 12, 0, tzinfo=timezone.utc),
input_tokens=100,
output_tokens=50,
cache_creation_tokens=10,
cache_read_tokens=5,
cost_usd=0.001,
model="claude-3-haiku",
message_id="msg_1",
request_id="req_1",
)
entry2 = UsageEntry(
timestamp=datetime(2024, 1, 1, 12, 30, tzinfo=timezone.utc),
input_tokens=200,
output_tokens=100,
cache_creation_tokens=0,
cache_read_tokens=0,
cost_usd=0.002,
model="claude-3-sonnet",
message_id="msg_2",
request_id="req_2",
)
result = _format_block_entries([entry1, entry2])
assert len(result) == 2
assert result[0] == {
"timestamp": "2024-01-01T12:00:00+00:00",
"inputTokens": 100,
"outputTokens": 50,
"cacheCreationTokens": 10,
"cacheReadInputTokens": 5,
"costUSD": 0.001,
"model": "claude-3-haiku",
"messageId": "msg_1",
"requestId": "req_1",
}
def test_create_base_block_dict(self) -> None:
"""Test _create_base_block_dict function."""
entry = UsageEntry(
timestamp=datetime(2024, 1, 1, 12, 0, tzinfo=timezone.utc),
input_tokens=100,
output_tokens=50,
cost_usd=0.001,
model="claude-3-haiku",
)
block = SessionBlock(
id="test_block",
start_time=datetime(2024, 1, 1, 12, 0, tzinfo=timezone.utc),
end_time=datetime(2024, 1, 1, 17, 0, tzinfo=timezone.utc),
actual_end_time=datetime(2024, 1, 1, 12, 30, tzinfo=timezone.utc),
is_active=True,
is_gap=False,
token_counts=TokenCounts(
input_tokens=100,
output_tokens=50,
cache_creation_tokens=10,
cache_read_tokens=5,
),
cost_usd=0.001,
models=["claude-3-haiku"],
per_model_stats={"claude-3-haiku": {"input_tokens": 100}},
sent_messages_count=1,
entries=[entry],
)
result = _create_base_block_dict(block)
expected_keys = [
"id",
"isActive",
"isGap",
"startTime",
"endTime",
"actualEndTime",
"tokenCounts",
"totalTokens",
"costUSD",
"models",
"perModelStats",
"sentMessagesCount",
"durationMinutes",
"entries",
"entries_count",
]
for key in expected_keys:
assert key in result
assert result["id"] == "test_block"
assert result["isActive"] is True
assert result["isGap"] is False
assert result["totalTokens"] == 150
assert result["entries_count"] == 1
def test_add_optional_block_data_all_fields(self) -> None:
"""Test _add_optional_block_data with all optional fields."""
block = Mock()
block.burn_rate_snapshot = BurnRate(tokens_per_minute=5.0, cost_per_hour=1.0)
block.projection_data = {
"totalTokens": 500,
"totalCost": 0.005,
"remainingMinutes": 60,
}
block.limit_messages = [{"type": "rate_limit", "content": "Limit reached"}]
block_dict = {}
_add_optional_block_data(block, block_dict)
assert "burnRate" in block_dict
assert block_dict["burnRate"] == {"tokensPerMinute": 5.0, "costPerHour": 1.0}
assert "projection" in block_dict
assert block_dict["projection"] == {
"totalTokens": 500,
"totalCost": 0.005,
"remainingMinutes": 60,
}
assert "limitMessages" in block_dict
assert block_dict["limitMessages"] == [
{"type": "rate_limit", "content": "Limit reached"}
]
def test_add_optional_block_data_no_fields(self) -> None:
"""Test _add_optional_block_data with no optional fields."""
block = Mock()
# Remove all optional attributes
if hasattr(block, "burn_rate_snapshot"):
del block.burn_rate_snapshot
if hasattr(block, "projection_data"):
del block.projection_data
if hasattr(block, "limit_messages"):
del block.limit_messages
block_dict = {}
_add_optional_block_data(block, block_dict)
assert "burnRate" not in block_dict
assert "projection" not in block_dict
assert "limitMessages" not in block_dict
@patch("claude_monitor.data.analysis._create_base_block_dict")
@patch("claude_monitor.data.analysis._add_optional_block_data")
def test_convert_blocks_to_dict_format(
self, mock_add_optional: Mock, mock_create_base: Mock
) -> None:
"""Test _convert_blocks_to_dict_format function."""
block1 = Mock()
block2 = Mock()
blocks = [block1, block2]
mock_create_base.side_effect = [{"base": "block1"}, {"base": "block2"}]
result = _convert_blocks_to_dict_format(blocks)
assert len(result) == 2
assert result == [{"base": "block1"}, {"base": "block2"}]
assert mock_create_base.call_count == 2
assert mock_add_optional.call_count == 2
mock_create_base.assert_any_call(block1)
mock_create_base.assert_any_call(block2)
================================================
FILE: src/tests/test_calculations.py
================================================
"""Tests for calculations module."""
from datetime import datetime, timedelta, timezone
from typing import Any, Dict, List
from unittest.mock import Mock, patch
import pytest
from claude_monitor.core.calculations import (
BurnRateCalculator,
_calculate_total_tokens_in_hour,
_process_block_for_burn_rate,
calculate_hourly_burn_rate,
)
from claude_monitor.core.models import BurnRate, TokenCounts, UsageProjection
class TestBurnRateCalculator:
"""Test cases for BurnRateCalculator."""
@pytest.fixture
def calculator(self) -> BurnRateCalculator:
"""Create a BurnRateCalculator instance."""
return BurnRateCalculator()
@pytest.fixture
def mock_active_block(self) -> Mock:
"""Create a mock active block for testing."""
block = Mock()
block.is_active = True
block.duration_minutes = 30
block.token_counts = TokenCounts(
input_tokens=100,
output_tokens=50,
cache_creation_tokens=10,
cache_read_tokens=5,
)
block.cost_usd = 0.5
block.end_time = datetime.now(timezone.utc) + timedelta(hours=1)
return block
@pytest.fixture
def mock_inactive_block(self) -> Mock:
"""Create a mock inactive block for testing."""
block = Mock()
block.is_active = False
block.duration_minutes = 30
block.token_counts = TokenCounts(input_tokens=100, output_tokens=50)
block.cost_usd = 0.5
return block
def test_calculate_burn_rate_active_block(
self, calculator: BurnRateCalculator, mock_active_block: Mock
) -> None:
"""Test burn rate calculation for active block."""
burn_rate = calculator.calculate_burn_rate(mock_active_block)
assert burn_rate is not None
assert isinstance(burn_rate, BurnRate)
assert burn_rate.tokens_per_minute == 5.5
assert burn_rate.cost_per_hour == 1.0
def test_calculate_burn_rate_inactive_block(
self, calculator: BurnRateCalculator, mock_inactive_block: Mock
) -> None:
"""Test burn rate calculation for inactive block returns None."""
burn_rate = calculator.calculate_burn_rate(mock_inactive_block)
assert burn_rate is None
def test_calculate_burn_rate_zero_duration(
self, calculator: BurnRateCalculator, mock_active_block: Mock
) -> None:
"""Test burn rate calculation with zero duration returns None."""
mock_active_block.duration_minutes = 0
burn_rate = calculator.calculate_burn_rate(mock_active_block)
assert burn_rate is None
def test_calculate_burn_rate_no_tokens(
self, calculator: BurnRateCalculator, mock_active_block: Mock
) -> None:
"""Test burn rate calculation with no tokens returns None."""
mock_active_block.token_counts = TokenCounts(
input_tokens=0,
output_tokens=0,
cache_creation_tokens=0,
cache_read_tokens=0,
)
burn_rate = calculator.calculate_burn_rate(mock_active_block)
assert burn_rate is None
def test_calculate_burn_rate_edge_case_small_duration(
self, calculator: BurnRateCalculator, mock_active_block: Mock
) -> None:
"""Test burn rate calculation with very small duration."""
mock_active_block.duration_minutes = 1 # 1 minute minimum for active check
burn_rate = calculator.calculate_burn_rate(mock_active_block)
assert burn_rate is not None
assert burn_rate.tokens_per_minute == 165.0
@patch("claude_monitor.core.calculations.datetime")
def test_project_block_usage_success(
self,
mock_datetime: Mock,
calculator: BurnRateCalculator,
mock_active_block: Mock,
) -> None:
"""Test successful usage projection."""
# Mock current time
mock_now = datetime(2024, 1, 1, 10, 0, 0, tzinfo=timezone.utc)
mock_datetime.now.return_value = mock_now
mock_active_block.end_time = mock_now + timedelta(hours=1)
projection = calculator.project_block_usage(mock_active_block)
assert projection is not None
assert isinstance(projection, UsageProjection)
assert projection.projected_total_tokens == 495
assert projection.projected_total_cost == 1.5
assert projection.remaining_minutes == 60
@patch("claude_monitor.core.calculations.datetime")
def test_project_block_usage_no_remaining_time(
self,
mock_datetime: Mock,
calculator: BurnRateCalculator,
mock_active_block: Mock,
) -> None:
"""Test projection when block has already ended."""
# Mock current time to be after block end time
mock_now = datetime(2024, 1, 1, 12, 0, 0, tzinfo=timezone.utc)
mock_datetime.now.return_value = mock_now
mock_active_block.end_time = mock_now - timedelta(hours=1)
projection = calculator.project_block_usage(mock_active_block)
assert projection is None
def test_project_block_usage_no_burn_rate(
self, calculator: BurnRateCalculator, mock_inactive_block: Mock
) -> None:
"""Test projection when burn rate cannot be calculated."""
projection = calculator.project_block_usage(mock_inactive_block)
assert projection is None
class TestHourlyBurnRateCalculation:
"""Test cases for hourly burn rate functions."""
@pytest.fixture
def current_time(self) -> datetime:
"""Current time for testing."""
return datetime(2024, 1, 1, 12, 0, 0, tzinfo=timezone.utc)
@pytest.fixture
def mock_blocks(self) -> List[Dict[str, Any]]:
"""Create mock blocks for testing."""
block1 = {
"start_time": "2024-01-01T11:30:00Z",
"actual_end_time": None,
"token_counts": {"input_tokens": 100, "output_tokens": 50},
"isGap": False,
}
block2 = {
"start_time": "2024-01-01T10:00:00Z",
"actual_end_time": "2024-01-01T10:30:00Z",
"token_counts": {"input_tokens": 200, "output_tokens": 100},
"isGap": False,
}
block3 = {
"start_time": "2024-01-01T11:45:00Z",
"actual_end_time": None,
"token_counts": {"input_tokens": 50, "output_tokens": 25},
"isGap": True,
}
return [block1, block2, block3]
def test_calculate_hourly_burn_rate_empty_blocks(
self, current_time: datetime
) -> None:
"""Test hourly burn rate with empty blocks."""
burn_rate = calculate_hourly_burn_rate([], current_time)
assert burn_rate == 0.0
def test_calculate_hourly_burn_rate_none_blocks(
self, current_time: datetime
) -> None:
"""Test hourly burn rate with None blocks."""
burn_rate = calculate_hourly_burn_rate(None, current_time)
assert burn_rate == 0.0
@patch("claude_monitor.core.calculations._calculate_total_tokens_in_hour")
def test_calculate_hourly_burn_rate_success(
self, mock_calc_tokens: Mock, current_time: datetime
) -> None:
"""Test successful hourly burn rate calculation."""
mock_calc_tokens.return_value = 180.0 # Total tokens in hour
blocks = [Mock()]
burn_rate = calculate_hourly_burn_rate(blocks, current_time)
assert burn_rate == 3.0
one_hour_ago = current_time - timedelta(hours=1)
mock_calc_tokens.assert_called_once_with(blocks, one_hour_ago, current_time)
@patch("claude_monitor.core.calculations._calculate_total_tokens_in_hour")
def test_calculate_hourly_burn_rate_zero_tokens(
self, mock_calc_tokens: Mock, current_time: datetime
) -> None:
"""Test hourly burn rate calculation with zero tokens."""
mock_calc_tokens.return_value = 0.0
blocks = [Mock()]
burn_rate = calculate_hourly_burn_rate(blocks, current_time)
assert burn_rate == 0.0
@patch("claude_monitor.core.calculations._process_block_for_burn_rate")
def test_calculate_total_tokens_in_hour(
self, mock_process_block: Mock, current_time: datetime
) -> None:
"""Test total tokens calculation for hour."""
# Mock returns different token counts for each block
mock_process_block.side_effect = [150.0, 0.0, 0.0]
blocks = [Mock(), Mock(), Mock()]
one_hour_ago = current_time - timedelta(hours=1)
total_tokens = _calculate_total_tokens_in_hour(
blocks, one_hour_ago, current_time
)
assert total_tokens == 150.0
assert mock_process_block.call_count == 3
def test_process_block_for_burn_rate_gap_block(
self, current_time: datetime
) -> None:
"""Test processing gap block returns zero."""
gap_block = {"isGap": True, "start_time": "2024-01-01T11:30:00Z"}
one_hour_ago = current_time - timedelta(hours=1)
tokens = _process_block_for_burn_rate(gap_block, one_hour_ago, current_time)
assert tokens == 0
@patch("claude_monitor.core.calculations._parse_block_start_time")
def test_process_block_for_burn_rate_invalid_start_time(
self, mock_parse_time: Mock, current_time: datetime
) -> None:
"""Test processing block with invalid start time returns zero."""
mock_parse_time.return_value = None
block = {"isGap": False, "start_time": "invalid"}
one_hour_ago = current_time - timedelta(hours=1)
tokens = _process_block_for_burn_rate(block, one_hour_ago, current_time)
assert tokens == 0
@patch("claude_monitor.core.calculations._determine_session_end_time")
@patch("claude_monitor.core.calculations._parse_block_start_time")
def test_process_block_for_burn_rate_old_session(
self, mock_parse_time: Mock, mock_end_time: Mock, current_time: datetime
) -> None:
"""Test processing block that ended before the hour window."""
one_hour_ago = current_time - timedelta(hours=1)
old_time = one_hour_ago - timedelta(minutes=30)
mock_parse_time.return_value = old_time
mock_end_time.return_value = old_time # Session ended before one hour ago
block = {"isGap": False, "start_time": "2024-01-01T10:30:00Z"}
tokens = _process_block_for_burn_rate(block, one_hour_ago, current_time)
assert tokens == 0
class TestCalculationEdgeCases:
"""Test edge cases and error conditions."""
def test_burn_rate_with_negative_duration(self) -> None:
"""Test burn rate calculation with negative duration."""
calculator = BurnRateCalculator()
block = Mock()
block.is_active = True
block.duration_minutes = -5 # Negative duration
block.token_counts = TokenCounts(input_tokens=100, output_tokens=50)
block.cost_usd = 0.5
burn_rate = calculator.calculate_burn_rate(block)
assert burn_rate is None
def test_projection_with_zero_cost(self) -> None:
"""Test projection calculation with zero cost."""
calculator = BurnRateCalculator()
block = Mock()
block.is_active = True
block.duration_minutes = 30
block.token_counts = TokenCounts(input_tokens=100, output_tokens=50)
block.cost_usd = 0.0
block.end_time = datetime.now(timezone.utc) + timedelta(hours=1)
projection = calculator.project_block_usage(block)
assert projection is not None
assert projection.projected_total_cost == 0.0
def test_very_large_token_counts(self) -> None:
"""Test calculations with very large token counts."""
calculator = BurnRateCalculator()
block = Mock()
block.is_active = True
block.duration_minutes = 1
block.token_counts = TokenCounts(
input_tokens=1000000,
output_tokens=500000,
cache_creation_tokens=100000,
cache_read_tokens=50000,
)
block.cost_usd = 100.0
burn_rate = calculator.calculate_burn_rate(block)
assert burn_rate is not None
# Total tokens: 1,650,000 (1M+500K+100K+50K), Duration: 1 minute
assert burn_rate.tokens_per_minute == 1650000.0
assert burn_rate.cost_per_hour == 6000.0
class TestP90Calculator:
"""Test cases for P90Calculator."""
def test_p90_config_creation(self) -> None:
"""Test P90Config dataclass creation."""
from claude_monitor.core.p90_calculator import P90Config
config = P90Config(
common_limits=[10000, 50000, 100000],
limit_threshold=0.9,
default_min_limit=5000,
cache_ttl_seconds=300,
)
assert config.common_limits == [10000, 50000, 100000]
assert config.limit_threshold == 0.9
assert config.default_min_limit == 5000
assert config.cache_ttl_seconds == 300
def test_did_hit_limit_true(self) -> None:
"""Test _did_hit_limit returns True when limit is hit."""
from claude_monitor.core.p90_calculator import _did_hit_limit
# 9000 tokens with 10000 limit and 0.9 threshold = 9000 >= 9000
result = _did_hit_limit(9000, [10000, 50000], 0.9)
assert result is True
# 45000 tokens with 50000 limit and 0.9 threshold = 45000 >= 45000
result = _did_hit_limit(45000, [10000, 50000], 0.9)
assert result is True
def test_did_hit_limit_false(self) -> None:
"""Test _did_hit_limit returns False when limit is not hit."""
from claude_monitor.core.p90_calculator import _did_hit_limit
# 8000 tokens with 10000 limit and 0.9 threshold = 8000 < 9000
result = _did_hit_limit(8000, [10000, 50000], 0.9)
assert result is False
# 1000 tokens with high limits
result = _did_hit_limit(1000, [10000, 50000], 0.9)
assert result is False
def test_extract_sessions_basic(self) -> None:
"""Test _extract_sessions with basic filtering."""
from claude_monitor.core.p90_calculator import _extract_sessions
blocks = [
{"totalTokens": 1000, "isGap": False},
{"totalTokens": 2000, "isGap": True},
{"totalTokens": 3000, "isGap": False},
{"totalTokens": 0, "isGap": False},
{"isGap": False},
]
# Filter function that excludes gaps
def filter_fn(b):
return not b.get("isGap", False)
result = _extract_sessions(blocks, filter_fn)
assert result == [1000, 3000]
def test_extract_sessions_complex_filter(self) -> None:
"""Test _extract_sessions with complex filtering."""
from claude_monitor.core.p90_calculator import _extract_sessions
blocks = [
{"totalTokens": 1000, "isGap": False, "isActive": False},
{"totalTokens": 2000, "isGap": False, "isActive": True},
{"totalTokens": 3000, "isGap": True, "isActive": False},
{"totalTokens": 4000, "isGap": False, "isActive": False},
]
def filter_fn(b):
return not b.get("isGap", False) and not b.get("isActive", False)
result = _extract_sessions(blocks, filter_fn)
assert result == [1000, 4000]
def test_calculate_p90_from_blocks_with_hits(self) -> None:
"""Test _calculate_p90_from_blocks when limit hits are found."""
from claude_monitor.core.p90_calculator import (
P90Config,
_calculate_p90_from_blocks,
)
config = P90Config(
common_limits=[10000, 50000],
limit_threshold=0.9,
default_min_limit=5000,
cache_ttl_seconds=300,
)
# Blocks with some hitting limits (>=9000 or >=45000)
blocks = [
{"totalTokens": 9500, "isGap": False, "isActive": False},
{"totalTokens": 8000, "isGap": False, "isActive": False},
{"totalTokens": 46000, "isGap": False, "isActive": False},
{"totalTokens": 1000, "isGap": True, "isActive": False},
]
result = _calculate_p90_from_blocks(blocks, config)
assert isinstance(result, int)
assert result > 0
def test_calculate_p90_from_blocks_no_hits(self) -> None:
"""Test _calculate_p90_from_blocks when no limit hits are found."""
from claude_monitor.core.p90_calculator import (
P90Config,
_calculate_p90_from_blocks,
)
config = P90Config(
common_limits=[10000, 50000],
limit_threshold=0.9,
default_min_limit=5000,
cache_ttl_seconds=300,
)
# Blocks with no limit hits
blocks = [
{"totalTokens": 1000, "isGap": False, "isActive": False},
{"totalTokens": 2000, "isGap": False, "isActive": False},
{"totalTokens": 3000, "isGap": False, "isActive": False},
{"totalTokens": 1500, "isGap": True, "isActive": False}, # Gap - ignored
]
result = _calculate_p90_from_blocks(blocks, config)
assert isinstance(result, int)
assert result > 0
def test_calculate_p90_from_blocks_empty(self) -> None:
"""Test _calculate_p90_from_blocks with empty or invalid blocks."""
from claude_monitor.core.p90_calculator import (
P90Config,
_calculate_p90_from_blocks,
)
config = P90Config(
common_limits=[10000, 50000],
limit_threshold=0.9,
default_min_limit=5000,
cache_ttl_seconds=300,
)
result = _calculate_p90_from_blocks([], config)
assert result == config.default_min_limit
blocks = [
{"isGap": True, "isActive": False},
{"totalTokens": 0, "isGap": False, "isActive": False},
]
result = _calculate_p90_from_blocks(blocks, config)
assert result == config.default_min_limit
def test_p90_calculator_init(self) -> None:
"""Test P90Calculator initialization."""
from claude_monitor.core.p90_calculator import P90Calculator
calculator = P90Calculator()
assert hasattr(calculator, "_cfg")
assert calculator._cfg.common_limits is not None
assert calculator._cfg.limit_threshold > 0
assert calculator._cfg.default_min_limit > 0
def test_p90_calculator_custom_config(self) -> None:
"""Test P90Calculator with custom configuration."""
from claude_monitor.core.p90_calculator import P90Calculator, P90Config
custom_config = P90Config(
common_limits=[5000, 25000],
limit_threshold=0.8,
default_min_limit=3000,
cache_ttl_seconds=600,
)
calculator = P90Calculator(custom_config)
assert calculator._cfg == custom_config
assert calculator._cfg.limit_threshold == 0.8
assert calculator._cfg.default_min_limit == 3000
def test_p90_calculator_calculate_basic(self) -> None:
"""Test P90Calculator.calculate with basic blocks."""
from claude_monitor.core.p90_calculator import P90Calculator
calculator = P90Calculator()
blocks = [
{"totalTokens": 1000, "isGap": False, "isActive": False},
{"totalTokens": 2000, "isGap": False, "isActive": False},
{"totalTokens": 3000, "isGap": False, "isActive": False},
]
result = calculator.calculate_p90_limit(blocks)
assert isinstance(result, int)
assert result > 0
def test_p90_calculator_calculate_empty(self) -> None:
"""Test P90Calculator.calculate with empty blocks."""
from claude_monitor.core.p90_calculator import P90Calculator
calculator = P90Calculator()
result = calculator.calculate_p90_limit([])
assert result is None
def test_p90_calculator_caching(self) -> None:
"""Test P90Calculator caching behavior."""
from claude_monitor.core.p90_calculator import P90Calculator
calculator = P90Calculator()
blocks = [
{"totalTokens": 1000, "isGap": False, "isActive": False},
{"totalTokens": 2000, "isGap": False, "isActive": False},
]
# First call
result1 = calculator.calculate_p90_limit(blocks)
# Second call with same data should use cache
result2 = calculator.calculate_p90_limit(blocks)
assert result1 == result2
def test_p90_calculation_edge_cases(self) -> None:
"""Test P90 calculation with edge cases."""
from claude_monitor.core.p90_calculator import (
P90Config,
_calculate_p90_from_blocks,
)
config = P90Config(
common_limits=[1000],
limit_threshold=0.5,
default_min_limit=100,
cache_ttl_seconds=300,
)
blocks = [
{"totalTokens": 500, "isGap": False, "isActive": False},
{"totalTokens": 600, "isGap": False, "isActive": False},
]
result = _calculate_p90_from_blocks(blocks, config)
assert result >= config.default_min_limit
blocks = [
{"totalTokens": 1000000, "isGap": False, "isActive": False},
{"totalTokens": 1100000, "isGap": False, "isActive": False},
]
result = _calculate_p90_from_blocks(blocks, config)
assert result > 0
def test_p90_quantiles_calculation(self) -> None:
"""Test that P90 uses proper quantiles calculation."""
from claude_monitor.core.p90_calculator import (
P90Config,
_calculate_p90_from_blocks,
)
config = P90Config(
common_limits=[100000], # High limit so no hits
limit_threshold=0.9,
default_min_limit=1000,
cache_ttl_seconds=300,
)
# Create blocks with known distribution
blocks = [
{"totalTokens": 1000, "isGap": False, "isActive": False},
{"totalTokens": 2000, "isGap": False, "isActive": False},
{"totalTokens": 3000, "isGap": False, "isActive": False},
{"totalTokens": 4000, "isGap": False, "isActive": False},
{"totalTokens": 5000, "isGap": False, "isActive": False},
{"totalTokens": 6000, "isGap": False, "isActive": False},
{"totalTokens": 7000, "isGap": False, "isActive": False},
{"totalTokens": 8000, "isGap": False, "isActive": False},
{"totalTokens": 9000, "isGap": False, "isActive": False},
{"totalTokens": 10000, "isGap": False, "isActive": False},
]
result = _calculate_p90_from_blocks(blocks, config)
assert 8000 <= result <= 10000
================================================
FILE: src/tests/test_cli_main.py
================================================
"""Simplified tests for CLI main module."""
from pathlib import Path
from unittest.mock import Mock, patch
from claude_monitor.cli.main import main
class TestMain:
"""Test cases for main function."""
def test_version_flag(self) -> None:
"""Test --version flag returns 0 and prints version."""
with patch("builtins.print") as mock_print:
result = main(["--version"])
assert result == 0
mock_print.assert_called_once()
assert "claude-monitor" in mock_print.call_args[0][0]
def test_v_flag(self) -> None:
"""Test -v flag returns 0 and prints version."""
with patch("builtins.print") as mock_print:
result = main(["-v"])
assert result == 0
mock_print.assert_called_once()
assert "claude-monitor" in mock_print.call_args[0][0]
@patch("claude_monitor.core.settings.Settings.load_with_last_used")
def test_keyboard_interrupt_handling(self, mock_load: Mock) -> None:
"""Test keyboard interrupt returns 0."""
mock_load.side_effect = KeyboardInterrupt()
with patch("builtins.print") as mock_print:
result = main(["--plan", "pro"])
assert result == 0
mock_print.assert_called_once_with("\n\nMonitoring stopped by user.")
@patch("claude_monitor.core.settings.Settings.load_with_last_used")
def test_exception_handling(self, mock_load_settings: Mock) -> None:
"""Test exception handling returns 1."""
mock_load_settings.side_effect = Exception("Test error")
with patch("builtins.print"), patch("traceback.print_exc"):
result = main(["--plan", "pro"])
assert result == 1
@patch("claude_monitor.core.settings.Settings.load_with_last_used")
def test_successful_main_execution(self, mock_load_settings: Mock) -> None:
"""Test successful main execution by mocking core components."""
mock_args = Mock()
mock_args.theme = None
mock_args.plan = "pro"
mock_args.timezone = "UTC"
mock_args.refresh_per_second = 1.0
mock_args.refresh_rate = 10
mock_settings = Mock()
mock_settings.log_file = None
mock_settings.log_level = "INFO"
mock_settings.timezone = "UTC"
mock_settings.to_namespace.return_value = mock_args
mock_load_settings.return_value = mock_settings
# Get the actual module to avoid Python version compatibility issues with mock.patch
import sys
actual_module = sys.modules["claude_monitor.cli.main"]
# Manually replace the function - this works across all Python versions
original_discover = actual_module.discover_claude_data_paths
actual_module.discover_claude_data_paths = Mock(
return_value=[Path("/test/path")]
)
try:
with (
patch("claude_monitor.terminal.manager.setup_terminal"),
patch("claude_monitor.terminal.themes.get_themed_console"),
patch("claude_monitor.ui.display_controller.DisplayController"),
patch(
"claude_monitor.monitoring.orchestrator.MonitoringOrchestrator"
) as mock_orchestrator,
patch("signal.pause", side_effect=KeyboardInterrupt()),
patch("time.sleep", side_effect=KeyboardInterrupt()),
patch("sys.exit"),
): # Don't actually exit
# Configure mocks to not interfere with the KeyboardInterrupt
mock_orchestrator.return_value.wait_for_initial_data.return_value = True
mock_orchestrator.return_value.start.return_value = None
mock_orchestrator.return_value.stop.return_value = None
result = main(["--plan", "pro"])
assert result == 0
finally:
# Restore the original function
actual_module.discover_claude_data_paths = original_discover
class TestFunctions:
"""Test module functions."""
def test_get_standard_claude_paths(self) -> None:
"""Test getting standard Claude paths."""
from claude_monitor.cli.main import get_standard_claude_paths
paths = get_standard_claude_paths()
assert isinstance(paths, list)
assert len(paths) > 0
assert "~/.claude/projects" in paths
def test_discover_claude_data_paths_no_paths(self) -> None:
"""Test discover with no existing paths."""
from claude_monitor.cli.main import discover_claude_data_paths
with patch("pathlib.Path.exists", return_value=False):
paths = discover_claude_data_paths()
assert paths == []
def test_discover_claude_data_paths_with_custom(self) -> None:
"""Test discover with custom paths."""
from claude_monitor.cli.main import discover_claude_data_paths
custom_paths = ["/custom/path"]
with (
patch("pathlib.Path.exists", return_value=True),
patch("pathlib.Path.is_dir", return_value=True),
):
paths = discover_claude_data_paths(custom_paths)
assert len(paths) == 1
assert paths[0].name == "path"
================================================
FILE: src/tests/test_data_reader.py
================================================
"""
Comprehensive tests for data/reader.py module.
Tests the data loading and processing functions to achieve 80%+ coverage.
Covers file reading, data filtering, mapping, and error handling scenarios.
"""
import json
import tempfile
from datetime import datetime, timedelta, timezone
from pathlib import Path
from typing import Any, Tuple
from unittest.mock import Mock, mock_open, patch
import pytest
from claude_monitor.core.models import CostMode, UsageEntry
from claude_monitor.core.pricing import PricingCalculator
from claude_monitor.data.reader import (
_create_unique_hash,
_find_jsonl_files,
_map_to_usage_entry,
_process_single_file,
_should_process_entry,
_update_processed_hashes,
load_all_raw_entries,
load_usage_entries,
)
from claude_monitor.utils.time_utils import TimezoneHandler
class TestLoadUsageEntries:
"""Test the main load_usage_entries function."""
@patch("claude_monitor.data.reader._find_jsonl_files")
@patch("claude_monitor.data.reader._process_single_file")
def test_load_usage_entries_basic(
self, mock_process_file: Mock, mock_find_files: Mock
) -> None:
mock_find_files.return_value = [
Path("/test/file1.jsonl"),
Path("/test/file2.jsonl"),
]
sample_entry = UsageEntry(
timestamp=datetime(2024, 1, 1, 12, 0, tzinfo=timezone.utc),
input_tokens=100,
output_tokens=50,
model="claude-3-haiku",
)
mock_process_file.side_effect = [
([sample_entry], [{"raw": "data1"}]),
([], [{"raw": "data2"}]),
]
entries, raw_data = load_usage_entries(
data_path="/test/path",
hours_back=24,
mode=CostMode.CALCULATED,
include_raw=True,
)
assert len(entries) == 1
assert entries[0] == sample_entry
assert len(raw_data) == 2
assert raw_data == [{"raw": "data1"}, {"raw": "data2"}]
mock_find_files.assert_called_once()
assert mock_process_file.call_count == 2
@patch("claude_monitor.data.reader._find_jsonl_files")
def test_load_usage_entries_no_files(self, mock_find_files: Mock) -> None:
mock_find_files.return_value = []
entries, raw_data = load_usage_entries(include_raw=True)
assert entries == []
assert raw_data is None
@patch("claude_monitor.data.reader._find_jsonl_files")
@patch("claude_monitor.data.reader._process_single_file")
def test_load_usage_entries_without_raw(
self, mock_process_file: Mock, mock_find_files: Mock
) -> None:
mock_find_files.return_value = [Path("/test/file1.jsonl")]
sample_entry = UsageEntry(
timestamp=datetime(2024, 1, 1, 12, 0, tzinfo=timezone.utc),
input_tokens=100,
output_tokens=50,
model="claude-3-haiku",
)
mock_process_file.return_value = ([sample_entry], None)
entries, raw_data = load_usage_entries(include_raw=False)
assert len(entries) == 1
assert raw_data is None
@patch("claude_monitor.data.reader._find_jsonl_files")
@patch("claude_monitor.data.reader._process_single_file")
def test_load_usage_entries_sorting(
self, mock_process_file: Mock, mock_find_files: Mock
) -> None:
"""Test that entries are sorted by timestamp."""
mock_find_files.return_value = [Path("/test/file1.jsonl")]
entry1 = UsageEntry(
timestamp=datetime(2024, 1, 1, 14, 0, tzinfo=timezone.utc),
input_tokens=100,
output_tokens=50,
model="claude-3-haiku",
)
entry2 = UsageEntry(
timestamp=datetime(2024, 1, 1, 12, 0, tzinfo=timezone.utc),
input_tokens=200,
output_tokens=75,
model="claude-3-sonnet",
)
mock_process_file.return_value = ([entry1, entry2], None)
entries, _ = load_usage_entries()
assert len(entries) == 2
assert entries[0] == entry2
assert entries[1] == entry1
@patch("claude_monitor.data.reader._find_jsonl_files")
@patch("claude_monitor.data.reader._process_single_file")
def test_load_usage_entries_with_cutoff_time(
self, mock_process_file: Mock, mock_find_files: Mock
) -> None:
mock_find_files.return_value = [Path("/test/file1.jsonl")]
mock_process_file.return_value = ([], None)
with patch("claude_monitor.data.reader.datetime") as mock_datetime:
current_time = datetime(2024, 1, 1, 12, 0, tzinfo=timezone.utc)
mock_datetime.now.return_value = current_time
load_usage_entries(hours_back=24)
expected_cutoff = current_time - timedelta(hours=24)
mock_process_file.assert_called_once()
call_args = mock_process_file.call_args[0]
assert call_args[2] == expected_cutoff
def test_load_usage_entries_default_path(self) -> None:
with patch("claude_monitor.data.reader._find_jsonl_files") as mock_find:
mock_find.return_value = []
load_usage_entries()
call_args = mock_find.call_args[0]
path_str = str(call_args[0])
assert ".claude/projects" in path_str
class TestLoadAllRawEntries:
"""Test the load_all_raw_entries function."""
@patch("claude_monitor.data.reader._find_jsonl_files")
def test_load_all_raw_entries_basic(self, mock_find_files: Mock) -> None:
test_file = Path("/test/file.jsonl")
mock_find_files.return_value = [test_file]
raw_data = [
{"type": "user", "content": "Hello"},
{"type": "assistant", "content": "Hi there"},
]
jsonl_content = "\n".join(json.dumps(item) for item in raw_data)
with patch("builtins.open", mock_open(read_data=jsonl_content)):
result = load_all_raw_entries("/test/path")
assert len(result) == 2
assert result == raw_data
@patch("claude_monitor.data.reader._find_jsonl_files")
def test_load_all_raw_entries_with_empty_lines(self, mock_find_files: Mock) -> None:
test_file = Path("/test/file.jsonl")
mock_find_files.return_value = [test_file]
jsonl_content = '{"valid": "data"}\n\n \n{"more": "data"}\n'
with patch("builtins.open", mock_open(read_data=jsonl_content)):
result = load_all_raw_entries("/test/path")
assert len(result) == 2
assert result[0] == {"valid": "data"}
assert result[1] == {"more": "data"}
@patch("claude_monitor.data.reader._find_jsonl_files")
def test_load_all_raw_entries_with_invalid_json(
self, mock_find_files: Mock
) -> None:
test_file = Path("/test/file.jsonl")
mock_find_files.return_value = [test_file]
jsonl_content = '{"valid": "data"}\ninvalid json\n{"more": "data"}\n'
with patch("builtins.open", mock_open(read_data=jsonl_content)):
result = load_all_raw_entries("/test/path")
assert len(result) == 2
assert result[0] == {"valid": "data"}
assert result[1] == {"more": "data"}
@patch("claude_monitor.data.reader._find_jsonl_files")
def test_load_all_raw_entries_file_error(self, mock_find_files: Mock) -> None:
test_file = Path("/test/file.jsonl")
mock_find_files.return_value = [test_file]
with patch("builtins.open", side_effect=OSError("File not found")):
with patch("claude_monitor.data.reader.logger") as mock_logger:
result = load_all_raw_entries("/test/path")
assert result == []
mock_logger.exception.assert_called()
def test_load_all_raw_entries_default_path(self) -> None:
with patch("claude_monitor.data.reader._find_jsonl_files") as mock_find:
mock_find.return_value = []
load_all_raw_entries()
call_args = mock_find.call_args[0]
path_str = str(call_args[0])
assert ".claude/projects" in path_str
class TestFindJsonlFiles:
"""Test the _find_jsonl_files function."""
def test_find_jsonl_files_nonexistent_path(self) -> None:
with patch("claude_monitor.data.reader.logger") as mock_logger:
result = _find_jsonl_files(Path("/nonexistent/path"))
assert result == []
mock_logger.warning.assert_called()
def test_find_jsonl_files_existing_path(self) -> None:
with tempfile.TemporaryDirectory() as temp_dir:
temp_path = Path(temp_dir)
(temp_path / "file1.jsonl").touch()
(temp_path / "file2.jsonl").touch()
(temp_path / "file3.txt").touch() # Non-JSONL file
# Create subdirectory with JSONL file
subdir = temp_path / "subdir"
subdir.mkdir()
(subdir / "file4.jsonl").touch()
result = _find_jsonl_files(temp_path)
jsonl_files = [f.name for f in result]
assert "file1.jsonl" in jsonl_files
assert "file2.jsonl" in jsonl_files
assert "file4.jsonl" in jsonl_files
assert len(result) == 3
class TestProcessSingleFile:
"""Test the _process_single_file function."""
@pytest.fixture
def mock_components(self) -> Tuple[Mock, Mock]:
timezone_handler = Mock(spec=TimezoneHandler)
pricing_calculator = Mock(spec=PricingCalculator)
return timezone_handler, pricing_calculator
def test_process_single_file_valid_data(
self, mock_components: Tuple[Mock, Mock]
) -> None:
timezone_handler, pricing_calculator = mock_components
sample_data = [
{
"timestamp": "2024-01-01T12:00:00Z",
"message": {"usage": {"input_tokens": 100, "output_tokens": 50}},
"model": "claude-3-haiku",
"message_id": "msg_1",
"request_id": "req_1",
}
]
jsonl_content = "\n".join(json.dumps(item) for item in sample_data)
test_file = Path("/test/file.jsonl")
sample_entry = UsageEntry(
timestamp=datetime(2024, 1, 1, 12, 0, tzinfo=timezone.utc),
input_tokens=100,
output_tokens=50,
model="claude-3-haiku",
)
with (
patch("builtins.open", mock_open(read_data=jsonl_content)),
patch(
"claude_monitor.data.reader._should_process_entry", return_value=True
),
patch(
"claude_monitor.data.reader._map_to_usage_entry",
return_value=sample_entry,
),
patch("claude_monitor.data.reader._update_processed_hashes"),
):
entries, raw_data = _process_single_file(
test_file,
CostMode.AUTO,
None, # cutoff_time
set(), # processed_hashes
True, # include_raw
timezone_handler,
pricing_calculator,
)
assert len(entries) == 1
assert entries[0] == sample_entry
assert len(raw_data) == 1
assert raw_data[0] == sample_data[0]
def test_process_single_file_without_raw(
self, mock_components: Tuple[Mock, Mock]
) -> None:
timezone_handler, pricing_calculator = mock_components
sample_data = [{"timestamp": "2024-01-01T12:00:00Z", "input_tokens": 100}]
jsonl_content = json.dumps(sample_data[0])
test_file = Path("/test/file.jsonl")
sample_entry = UsageEntry(
timestamp=datetime(2024, 1, 1, 12, 0, tzinfo=timezone.utc),
input_tokens=100,
output_tokens=50,
model="claude-3-haiku",
)
with (
patch("builtins.open", mock_open(read_data=jsonl_content)),
patch(
"claude_monitor.data.reader._should_process_entry", return_value=True
),
patch(
"claude_monitor.data.reader._map_to_usage_entry",
return_value=sample_entry,
),
patch("claude_monitor.data.reader._update_processed_hashes"),
):
entries, raw_data = _process_single_file(
test_file,
CostMode.AUTO,
None,
set(),
False,
timezone_handler,
pricing_calculator,
)
assert len(entries) == 1
assert raw_data is None
def test_process_single_file_filtered_entries(self, mock_components):
timezone_handler, pricing_calculator = mock_components
sample_data = [{"timestamp": "2024-01-01T12:00:00Z", "input_tokens": 100}]
jsonl_content = json.dumps(sample_data[0])
test_file = Path("/test/file.jsonl")
with (
patch("builtins.open", mock_open(read_data=jsonl_content)),
patch(
"claude_monitor.data.reader._should_process_entry", return_value=False
),
):
entries, raw_data = _process_single_file(
test_file,
CostMode.AUTO,
None,
set(),
True,
timezone_handler,
pricing_calculator,
)
assert len(entries) == 0
assert len(raw_data) == 0
def test_process_single_file_invalid_json(self, mock_components):
timezone_handler, pricing_calculator = mock_components
jsonl_content = 'invalid json\n{"valid": "data"}'
test_file = Path("/test/file.jsonl")
with (
patch("builtins.open", mock_open(read_data=jsonl_content)),
patch(
"claude_monitor.data.reader._should_process_entry", return_value=True
),
patch("claude_monitor.data.reader._map_to_usage_entry", return_value=None),
):
entries, raw_data = _process_single_file(
test_file,
CostMode.AUTO,
None,
set(),
True,
timezone_handler,
pricing_calculator,
)
assert len(entries) == 0
assert len(raw_data) == 1
def test_process_single_file_read_error(self, mock_components):
timezone_handler, pricing_calculator = mock_components
test_file = Path("/test/nonexistent.jsonl")
with patch("builtins.open", side_effect=OSError("File not found")):
with patch("claude_monitor.data.reader.report_file_error") as mock_report:
entries, raw_data = _process_single_file(
test_file,
CostMode.AUTO,
None,
set(),
True,
timezone_handler,
pricing_calculator,
)
assert entries == []
assert raw_data is None
mock_report.assert_called_once()
def test_process_single_file_mapping_failure(self, mock_components):
timezone_handler, pricing_calculator = mock_components
sample_data = [{"timestamp": "2024-01-01T12:00:00Z", "input_tokens": 100}]
jsonl_content = json.dumps(sample_data[0])
test_file = Path("/test/file.jsonl")
with (
patch("builtins.open", mock_open(read_data=jsonl_content)),
patch(
"claude_monitor.data.reader._should_process_entry", return_value=True
),
patch("claude_monitor.data.reader._map_to_usage_entry", return_value=None),
):
entries, raw_data = _process_single_file(
test_file,
CostMode.AUTO,
None,
set(),
True,
timezone_handler,
pricing_calculator,
)
assert len(entries) == 0
assert len(raw_data) == 1
class TestShouldProcessEntry:
"""Test the _should_process_entry function."""
@pytest.fixture
def timezone_handler(self) -> Mock:
return Mock(spec=TimezoneHandler)
def test_should_process_entry_no_cutoff_no_hash(
self, timezone_handler: Mock
) -> None:
data = {"timestamp": "2024-01-01T12:00:00Z", "message_id": "msg_1"}
with patch(
"claude_monitor.data.reader._create_unique_hash", return_value="hash_1"
):
result = _should_process_entry(data, None, set(), timezone_handler)
assert result is True
def test_should_process_entry_with_time_filter_pass(
self, timezone_handler: Mock
) -> None:
data = {"timestamp": "2024-01-01T12:00:00Z"}
cutoff_time = datetime(2024, 1, 1, 10, 0, tzinfo=timezone.utc)
with patch(
"claude_monitor.data.reader.TimestampProcessor"
) as mock_processor_class:
mock_processor = Mock()
mock_processor.parse_timestamp.return_value = datetime(
2024, 1, 1, 12, 0, tzinfo=timezone.utc
)
mock_processor_class.return_value = mock_processor
with patch(
"claude_monitor.data.reader._create_unique_hash", return_value="hash_1"
):
result = _should_process_entry(
data, cutoff_time, set(), timezone_handler
)
assert result is True
def test_should_process_entry_with_time_filter_fail(self, timezone_handler):
data = {"timestamp": "2024-01-01T08:00:00Z"}
cutoff_time = datetime(2024, 1, 1, 10, 0, tzinfo=timezone.utc)
with patch(
"claude_monitor.data.reader.TimestampProcessor"
) as mock_processor_class:
mock_processor = Mock()
mock_processor.parse_timestamp.return_value = datetime(
2024, 1, 1, 8, 0, tzinfo=timezone.utc
)
mock_processor_class.return_value = mock_processor
result = _should_process_entry(data, cutoff_time, set(), timezone_handler)
assert result is False
def test_should_process_entry_with_duplicate_hash(self, timezone_handler):
data = {"message_id": "msg_1", "request_id": "req_1"}
processed_hashes = {"msg_1:req_1"}
with patch(
"claude_monitor.data.reader._create_unique_hash", return_value="msg_1:req_1"
):
result = _should_process_entry(
data, None, processed_hashes, timezone_handler
)
assert result is False
def test_should_process_entry_no_timestamp(self, timezone_handler):
data = {"message_id": "msg_1"}
cutoff_time = datetime(2024, 1, 1, 10, 0, tzinfo=timezone.utc)
with patch(
"claude_monitor.data.reader._create_unique_hash", return_value="hash_1"
):
result = _should_process_entry(data, cutoff_time, set(), timezone_handler)
assert result is True
def test_should_process_entry_invalid_timestamp(self, timezone_handler):
data = {"timestamp": "invalid", "message_id": "msg_1"}
cutoff_time = datetime(2024, 1, 1, 10, 0, tzinfo=timezone.utc)
with patch(
"claude_monitor.core.data_processors.TimestampProcessor"
) as mock_processor_class:
mock_processor = Mock()
mock_processor.parse_timestamp.return_value = None
mock_processor_class.return_value = mock_processor
with patch(
"claude_monitor.data.reader._create_unique_hash", return_value="hash_1"
):
result = _should_process_entry(
data, cutoff_time, set(), timezone_handler
)
assert result is True
class TestCreateUniqueHash:
"""Test the _create_unique_hash function."""
def test_create_unique_hash_with_message_id_and_request_id(self) -> None:
data = {"message_id": "msg_123", "request_id": "req_456"}
result = _create_unique_hash(data)
assert result == "msg_123:req_456"
def test_create_unique_hash_with_nested_message_id(self) -> None:
data = {"message": {"id": "msg_123"}, "requestId": "req_456"}
result = _create_unique_hash(data)
assert result == "msg_123:req_456"
def test_create_unique_hash_missing_message_id(self) -> None:
data = {"request_id": "req_456"}
result = _create_unique_hash(data)
assert result is None
def test_create_unique_hash_missing_request_id(self) -> None:
data = {"message_id": "msg_123"}
result = _create_unique_hash(data)
assert result is None
def test_create_unique_hash_invalid_message_structure(self) -> None:
data = {"message": "not_a_dict", "request_id": "req_456"}
result = _create_unique_hash(data)
assert result is None
def test_create_unique_hash_empty_data(self) -> None:
data = {}
result = _create_unique_hash(data)
assert result is None
class TestUpdateProcessedHashes:
"""Test the _update_processed_hashes function."""
def test_update_processed_hashes_valid_hash(self) -> None:
data = {"message_id": "msg_123", "request_id": "req_456"}
processed_hashes = set()
with patch(
"claude_monitor.data.reader._create_unique_hash",
return_value="msg_123:req_456",
):
_update_processed_hashes(data, processed_hashes)
assert "msg_123:req_456" in processed_hashes
def test_update_processed_hashes_no_hash(self) -> None:
data = {"some": "data"}
processed_hashes = set()
with patch("claude_monitor.data.reader._create_unique_hash", return_value=None):
_update_processed_hashes(data, processed_hashes)
assert len(processed_hashes) == 0
class TestMapToUsageEntry:
"""Test the _map_to_usage_entry function."""
@pytest.fixture
def mock_components(self) -> Tuple[Mock, Mock]:
timezone_handler = Mock(spec=TimezoneHandler)
pricing_calculator = Mock(spec=PricingCalculator)
return timezone_handler, pricing_calculator
def test_map_to_usage_entry_valid_data(
self, mock_components: Tuple[Mock, Mock]
) -> None:
timezone_handler, pricing_calculator = mock_components
data = {
"timestamp": "2024-01-01T12:00:00Z",
"message": {
"id": "msg_123",
"usage": {
"input_tokens": 100,
"output_tokens": 50,
"cache_creation_input_tokens": 10,
"cache_read_input_tokens": 5,
},
},
"model": "claude-3-haiku",
"request_id": "req_456",
"cost": 0.001,
}
with patch(
"claude_monitor.data.reader.TimestampProcessor"
) as mock_ts_processor:
mock_ts = Mock()
mock_ts.parse_timestamp.return_value = datetime(
2024, 1, 1, 12, 0, tzinfo=timezone.utc
)
mock_ts_processor.return_value = mock_ts
with patch(
"claude_monitor.data.reader.TokenExtractor"
) as mock_token_extractor:
mock_token_extractor.extract_tokens.return_value = {
"input_tokens": 100,
"output_tokens": 50,
"cache_creation_tokens": 10,
"cache_read_tokens": 5,
"total_tokens": 150,
}
with patch(
"claude_monitor.data.reader.DataConverter"
) as mock_data_converter:
mock_data_converter.extract_model_name.return_value = (
"claude-3-haiku"
)
pricing_calculator.calculate_cost_for_entry.return_value = 0.001
result = _map_to_usage_entry(
data, CostMode.AUTO, timezone_handler, pricing_calculator
)
assert result is not None
assert result.timestamp == datetime(2024, 1, 1, 12, 0, tzinfo=timezone.utc)
assert result.input_tokens == 100
assert result.output_tokens == 50
assert result.cache_creation_tokens == 10
assert result.cache_read_tokens == 5
assert result.cost_usd == 0.001
assert result.model == "claude-3-haiku"
assert result.message_id == "msg_123"
assert result.request_id == "req_456"
def test_map_to_usage_entry_no_timestamp(
self, mock_components: Tuple[Mock, Mock]
) -> None:
timezone_handler, pricing_calculator = mock_components
data = {"input_tokens": 100, "output_tokens": 50}
with patch(
"claude_monitor.core.data_processors.TimestampProcessor"
) as mock_ts_processor:
mock_ts = Mock()
mock_ts.parse_timestamp.return_value = None
mock_ts_processor.return_value = mock_ts
result = _map_to_usage_entry(
data, CostMode.AUTO, timezone_handler, pricing_calculator
)
assert result is None
def test_map_to_usage_entry_no_tokens(self, mock_components):
timezone_handler, pricing_calculator = mock_components
data = {"timestamp": "2024-01-01T12:00:00Z"}
with patch(
"claude_monitor.core.data_processors.TimestampProcessor"
) as mock_ts_processor:
mock_ts = Mock()
mock_ts.parse_timestamp.return_value = datetime(
2024, 1, 1, 12, 0, tzinfo=timezone.utc
)
mock_ts_processor.return_value = mock_ts
with patch(
"claude_monitor.core.data_processors.TokenExtractor"
) as mock_token_extractor:
mock_token_extractor.extract_tokens.return_value = {
"input_tokens": 0,
"output_tokens": 0,
"cache_creation_tokens": 0,
"cache_read_tokens": 0,
"total_tokens": 0,
}
result = _map_to_usage_entry(
data, CostMode.AUTO, timezone_handler, pricing_calculator
)
assert result is None
def test_map_to_usage_entry_exception_handling(self, mock_components):
"""Test _map_to_usage_entry with exception during processing."""
timezone_handler, pricing_calculator = mock_components
data = {"timestamp": "2024-01-01T12:00:00Z"}
with patch(
"claude_monitor.core.data_processors.TimestampProcessor",
side_effect=ValueError("Processing error"),
):
result = _map_to_usage_entry(
data, CostMode.AUTO, timezone_handler, pricing_calculator
)
assert result is None
def test_map_to_usage_entry_minimal_data(self, mock_components):
"""Test _map_to_usage_entry with minimal valid data."""
timezone_handler, pricing_calculator = mock_components
data = {
"timestamp": "2024-01-01T12:00:00Z",
"input_tokens": 100,
"output_tokens": 50,
}
with patch(
"claude_monitor.core.data_processors.TimestampProcessor"
) as mock_ts_processor:
mock_ts = Mock()
mock_ts.parse_timestamp.return_value = datetime(
2024, 1, 1, 12, 0, tzinfo=timezone.utc
)
mock_ts_processor.return_value = mock_ts
with patch(
"claude_monitor.core.data_processors.TokenExtractor"
) as mock_token_extractor:
mock_token_extractor.extract_tokens.return_value = {
"input_tokens": 100,
"output_tokens": 50,
"cache_creation_tokens": 0,
"cache_read_tokens": 0,
"total_tokens": 150,
}
with patch(
"claude_monitor.core.data_processors.DataConverter"
) as mock_data_converter:
mock_data_converter.extract_model_name.return_value = "unknown"
pricing_calculator.calculate_cost_for_entry.return_value = 0.0
result = _map_to_usage_entry(
data, CostMode.AUTO, timezone_handler, pricing_calculator
)
assert result is not None
assert result.model == "unknown"
assert result.message_id == ""
assert result.request_id == "unknown"
class TestIntegration:
"""Integration tests for data reader functionality."""
def test_full_workflow_integration(self) -> None:
"""Test full workflow from file loading to entry creation."""
with tempfile.TemporaryDirectory() as temp_dir:
temp_path = Path(temp_dir)
# Create test JSONL file
test_file = temp_path / "test.jsonl"
test_data = [
{
"timestamp": "2024-01-01T12:00:00Z",
"message": {
"id": "msg_1",
"usage": {"input_tokens": 100, "output_tokens": 50},
},
"model": "claude-3-haiku",
"request_id": "req_1",
},
{
"timestamp": "2024-01-01T13:00:00Z",
"message": {
"id": "msg_2",
"usage": {"input_tokens": 200, "output_tokens": 75},
},
"model": "claude-3-sonnet",
"request_id": "req_2",
},
]
with open(test_file, "w") as f:
f.writelines(json.dumps(item) + "\n" for item in test_data)
# Mock the data processors since they're external dependencies
with patch(
"claude_monitor.core.data_processors.TimestampProcessor"
) as mock_ts_processor:
mock_ts = Mock()
mock_ts.parse_timestamp.side_effect = [
datetime(2024, 1, 1, 12, 0, tzinfo=timezone.utc),
datetime(2024, 1, 1, 13, 0, tzinfo=timezone.utc),
]
mock_ts_processor.return_value = mock_ts
with patch(
"claude_monitor.core.data_processors.TokenExtractor"
) as mock_token_extractor:
mock_token_extractor.extract_tokens.side_effect = [
{
"input_tokens": 100,
"output_tokens": 50,
"cache_creation_tokens": 0,
"cache_read_tokens": 0,
},
{
"input_tokens": 200,
"output_tokens": 75,
"cache_creation_tokens": 0,
"cache_read_tokens": 0,
},
]
with patch(
"claude_monitor.core.data_processors.DataConverter"
) as mock_data_converter:
mock_data_converter.extract_model_name.side_effect = [
"claude-3-haiku",
"claude-3-sonnet",
]
with patch(
"claude_monitor.core.pricing.PricingCalculator"
) as mock_pricing_class:
mock_pricing = Mock()
mock_pricing.calculate_cost_for_entry.side_effect = [
0.001,
0.002,
]
mock_pricing_class.return_value = mock_pricing
# Execute the main function
entries, raw_data = load_usage_entries(
data_path=str(temp_path), include_raw=True
)
# Verify results
assert len(entries) == 2
assert len(raw_data) == 2
# First entry
assert entries[0].input_tokens == 100
assert entries[0].output_tokens == 50
assert entries[0].model == "claude-3-haiku"
assert entries[0].message_id == "msg_1"
# Second entry
assert entries[1].input_tokens == 200
assert entries[1].output_tokens == 75
assert entries[1].model == "claude-3-sonnet"
assert entries[1].message_id == "msg_2"
def test_error_handling_integration(self) -> None:
"""Test error handling in full workflow."""
with tempfile.TemporaryDirectory() as temp_dir:
temp_path = Path(temp_dir)
# Create test file with mixed valid and invalid data
test_file = temp_path / "test.jsonl"
with open(test_file, "w") as f:
f.write(
'{"valid": "data", "timestamp": "2024-01-01T12:00:00Z", "input_tokens": 100, "output_tokens": 50}\n'
)
f.write("invalid json line\n")
f.write(
'{"another": "valid", "timestamp": "2024-01-01T13:00:00Z", "input_tokens": 200, "output_tokens": 75}\n'
)
with patch(
"claude_monitor.core.data_processors.TimestampProcessor"
) as mock_ts_processor:
mock_ts = Mock()
mock_ts.parse_timestamp.side_effect = [
datetime(2024, 1, 1, 12, 0, tzinfo=timezone.utc),
datetime(2024, 1, 1, 13, 0, tzinfo=timezone.utc),
]
mock_ts_processor.return_value = mock_ts
with patch(
"claude_monitor.core.data_processors.TokenExtractor"
) as mock_token_extractor:
mock_token_extractor.extract_tokens.side_effect = [
{
"input_tokens": 100,
"output_tokens": 50,
"cache_creation_tokens": 0,
"cache_read_tokens": 0,
},
{
"input_tokens": 200,
"output_tokens": 75,
"cache_creation_tokens": 0,
"cache_read_tokens": 0,
},
]
with patch(
"claude_monitor.core.data_processors.DataConverter"
) as mock_data_converter:
mock_data_converter.extract_model_name.side_effect = [
"unknown",
"unknown",
]
with patch(
"claude_monitor.core.pricing.PricingCalculator"
) as mock_pricing_class:
mock_pricing = Mock()
mock_pricing.calculate_cost_for_entry.side_effect = [
0.001,
0.002,
]
mock_pricing_class.return_value = mock_pricing
# Should handle errors gracefully
entries, raw_data = load_usage_entries(
data_path=str(temp_path), include_raw=True
)
# Should process valid entries and skip invalid JSON
assert len(entries) == 2
assert len(raw_data) == 2 # Only valid JSON included in raw data
class TestPerformanceAndEdgeCases:
"""Test performance scenarios and edge cases."""
def test_large_file_processing(self) -> None:
"""Test processing of large files."""
with tempfile.TemporaryDirectory() as temp_dir:
temp_path = Path(temp_dir)
test_file = temp_path / "large.jsonl"
# Create a file with many entries
with open(test_file, "w") as f:
for i in range(1000):
entry = {
"timestamp": f"2024-01-01T{i % 24:02d}:00:00Z",
"input_tokens": 100 + i,
"output_tokens": 50 + i,
"message_id": f"msg_{i}",
"request_id": f"req_{i}",
}
f.write(json.dumps(entry) + "\n")
with patch(
"claude_monitor.core.data_processors.TimestampProcessor"
) as mock_ts_processor:
mock_ts = Mock()
mock_ts.parse_timestamp.side_effect = [
datetime(2024, 1, 1, i % 24, 0, tzinfo=timezone.utc)
for i in range(1000)
]
mock_ts_processor.return_value = mock_ts
with patch(
"claude_monitor.core.data_processors.TokenExtractor"
) as mock_token_extractor:
mock_token_extractor.extract_tokens.side_effect = [
{
"input_tokens": 100 + i,
"output_tokens": 50 + i,
"cache_creation_tokens": 0,
"cache_read_tokens": 0,
}
for i in range(1000)
]
with patch(
"claude_monitor.core.data_processors.DataConverter"
) as mock_data_converter:
mock_data_converter.extract_model_name.return_value = (
"claude-3-haiku"
)
with patch(
"claude_monitor.core.pricing.PricingCalculator"
) as mock_pricing_class:
mock_pricing = Mock()
mock_pricing.calculate_cost_for_entry.return_value = 0.001
mock_pricing_class.return_value = mock_pricing
entries, _ = load_usage_entries(data_path=str(temp_path))
# Should process all entries
assert len(entries) == 1000
# Should be sorted by timestamp
assert entries[0].input_tokens <= entries[-1].input_tokens
def test_empty_directory(self) -> None:
"""Test behavior with empty directory."""
with tempfile.TemporaryDirectory() as temp_dir:
entries, raw_data = load_usage_entries(data_path=temp_dir, include_raw=True)
assert entries == []
assert raw_data is None
def test_memory_efficiency(self) -> None:
"""Test that raw data is not loaded unnecessarily."""
with tempfile.TemporaryDirectory() as temp_dir:
temp_path = Path(temp_dir)
test_file = temp_path / "test.jsonl"
# Create test file
with open(test_file, "w") as f:
f.write(
'{"timestamp": "2024-01-01T12:00:00Z", "input_tokens": 100, "output_tokens": 50}\n'
)
with patch(
"claude_monitor.data.reader._process_single_file"
) as mock_process:
mock_process.return_value = (
[],
None,
) # No raw data when include_raw=False
entries, raw_data = load_usage_entries(
data_path=str(temp_path), include_raw=False
)
# Verify include_raw=False was passed to _process_single_file
call_args = mock_process.call_args[0]
assert call_args[4] is False # include_raw parameter
assert raw_data is None
class TestUsageEntryMapper:
"""Test the UsageEntryMapper compatibility wrapper."""
@pytest.fixture
def mapper_components(self) -> Tuple[Any, Mock, Mock]:
"""Setup mapper components."""
timezone_handler = Mock(spec=TimezoneHandler)
pricing_calculator = Mock(spec=PricingCalculator)
# Import after mocking to avoid import issues
from claude_monitor.data.reader import UsageEntryMapper
mapper = UsageEntryMapper(pricing_calculator, timezone_handler)
return mapper, timezone_handler, pricing_calculator
def test_usage_entry_mapper_init(
self, mapper_components: Tuple[Any, Mock, Mock]
) -> None:
"""Test UsageEntryMapper initialization."""
mapper, timezone_handler, pricing_calculator = mapper_components
assert mapper.pricing_calculator == pricing_calculator
assert mapper.timezone_handler == timezone_handler
def test_usage_entry_mapper_map_success(
self, mapper_components: Tuple[Any, Mock, Mock]
) -> None:
"""Test UsageEntryMapper.map with valid data."""
mapper, timezone_handler, pricing_calculator = mapper_components
data = {
"timestamp": "2024-01-01T12:00:00Z",
"input_tokens": 100,
"output_tokens": 50,
"model": "claude-3-haiku",
"message_id": "msg_1",
"request_id": "req_1",
}
with patch("claude_monitor.data.reader._map_to_usage_entry") as mock_map:
expected_entry = UsageEntry(
timestamp=datetime(2024, 1, 1, 12, 0, tzinfo=timezone.utc),
input_tokens=100,
output_tokens=50,
model="claude-3-haiku",
)
mock_map.return_value = expected_entry
result = mapper.map(data, CostMode.AUTO)
assert result == expected_entry
mock_map.assert_called_once_with(
data, CostMode.AUTO, timezone_handler, pricing_calculator
)
def test_usage_entry_mapper_map_failure(self, mapper_components):
"""Test UsageEntryMapper.map with invalid data."""
mapper, timezone_handler, pricing_calculator = mapper_components
data = {"invalid": "data"}
with patch("claude_monitor.data.reader._map_to_usage_entry", return_value=None):
result = mapper.map(data, CostMode.AUTO)
assert result is None
def test_usage_entry_mapper_has_valid_tokens(self, mapper_components):
"""Test UsageEntryMapper._has_valid_tokens method."""
mapper, _, _ = mapper_components
# Valid tokens
assert mapper._has_valid_tokens({"input_tokens": 100, "output_tokens": 50})
assert mapper._has_valid_tokens({"input_tokens": 100, "output_tokens": 0})
assert mapper._has_valid_tokens({"input_tokens": 0, "output_tokens": 50})
# Invalid tokens
assert not mapper._has_valid_tokens({"input_tokens": 0, "output_tokens": 0})
assert not mapper._has_valid_tokens({})
def test_usage_entry_mapper_extract_timestamp(self, mapper_components):
"""Test UsageEntryMapper._extract_timestamp method."""
mapper, timezone_handler, _ = mapper_components
with patch(
"claude_monitor.data.reader.TimestampProcessor"
) as mock_processor_class:
mock_processor = Mock()
expected_timestamp = datetime(2024, 1, 1, 12, 0, tzinfo=timezone.utc)
mock_processor.parse_timestamp.return_value = expected_timestamp
mock_processor_class.return_value = mock_processor
# Test with timestamp
result = mapper._extract_timestamp({"timestamp": "2024-01-01T12:00:00Z"})
assert result == expected_timestamp
# Test without timestamp
result = mapper._extract_timestamp({})
assert result is None
def test_usage_entry_mapper_extract_model(self, mapper_components):
"""Test UsageEntryMapper._extract_model method."""
mapper, _, _ = mapper_components
with patch("claude_monitor.data.reader.DataConverter") as mock_converter:
mock_converter.extract_model_name.return_value = "claude-3-haiku"
data = {"model": "claude-3-haiku"}
result = mapper._extract_model(data)
assert result == "claude-3-haiku"
mock_converter.extract_model_name.assert_called_once_with(
data, default="unknown"
)
def test_usage_entry_mapper_extract_metadata(self, mapper_components):
"""Test UsageEntryMapper._extract_metadata method."""
mapper, _, _ = mapper_components
# Test with message_id and request_id
data = {"message_id": "msg_123", "request_id": "req_456"}
result = mapper._extract_metadata(data)
expected = {"message_id": "msg_123", "request_id": "req_456"}
assert result == expected
def test_usage_entry_mapper_extract_metadata_nested(self, mapper_components):
"""Test UsageEntryMapper._extract_metadata with nested message data."""
mapper, _, _ = mapper_components
# Test with nested message.id
data = {"message": {"id": "msg_123"}, "requestId": "req_456"}
result = mapper._extract_metadata(data)
expected = {"message_id": "msg_123", "request_id": "req_456"}
assert result == expected
def test_usage_entry_mapper_extract_metadata_defaults(self, mapper_components):
"""Test UsageEntryMapper._extract_metadata with missing data."""
mapper, _, _ = mapper_components
# Test with missing data
data = {}
result = mapper._extract_metadata(data)
expected = {"message_id": "", "request_id": "unknown"}
assert result == expected
class TestAdditionalEdgeCases:
"""Test additional edge cases and error scenarios."""
def test_create_unique_hash_edge_cases(self):
"""Test _create_unique_hash with various edge cases."""
# Test with None values
data = {"message_id": None, "request_id": "req_1"}
result = _create_unique_hash(data)
assert result is None
# Test with empty strings
data = {"message_id": "", "request_id": "req_1"}
result = _create_unique_hash(data)
assert result is None
# Test with both valid values but one is empty
data = {"message_id": "msg_1", "request_id": ""}
result = _create_unique_hash(data)
assert result is None
def test_should_process_entry_edge_cases(self):
"""Test _should_process_entry with edge cases."""
timezone_handler = Mock(spec=TimezoneHandler)
# Test with None cutoff_time and no hash
data = {"some": "data"}
with patch("claude_monitor.data.reader._create_unique_hash", return_value=None):
result = _should_process_entry(data, None, set(), timezone_handler)
assert result is True
# Test with empty processed_hashes set
data = {"message_id": "msg_1", "request_id": "req_1"}
with patch(
"claude_monitor.data.reader._create_unique_hash", return_value="msg_1:req_1"
):
result = _should_process_entry(data, None, set(), timezone_handler)
assert result is True
def test_map_to_usage_entry_error_scenarios(self):
"""Test _map_to_usage_entry with various error scenarios."""
timezone_handler = Mock(spec=TimezoneHandler)
pricing_calculator = Mock(spec=PricingCalculator)
# Test with missing timestamp processor import error
data = {"timestamp": "2024-01-01T12:00:00Z"}
with patch(
"claude_monitor.core.data_processors.TimestampProcessor",
side_effect=AttributeError("Module not found"),
):
result = _map_to_usage_entry(
data, CostMode.AUTO, timezone_handler, pricing_calculator
)
assert result is None
# Test with pricing calculator error
data = {
"timestamp": "2024-01-01T12:00:00Z",
"input_tokens": 100,
"output_tokens": 50,
}
with patch(
"claude_monitor.core.data_processors.TimestampProcessor"
) as mock_ts_processor:
mock_ts = Mock()
mock_ts.parse_timestamp.return_value = datetime(
2024, 1, 1, 12, 0, tzinfo=timezone.utc
)
mock_ts_processor.return_value = mock_ts
with patch(
"claude_monitor.core.data_processors.TokenExtractor"
) as mock_token_extractor:
mock_token_extractor.extract_tokens.return_value = {
"input_tokens": 100,
"output_tokens": 50,
"cache_creation_tokens": 0,
"cache_read_tokens": 0,
}
with patch(
"claude_monitor.core.data_processors.DataConverter"
) as mock_data_converter:
mock_data_converter.extract_model_name.return_value = (
"claude-3-haiku"
)
pricing_calculator.calculate_cost_for_entry.side_effect = (
ValueError("Pricing error")
)
result = _map_to_usage_entry(
data, CostMode.AUTO, timezone_handler, pricing_calculator
)
assert result is None
def test_load_usage_entries_timezone_handling(self):
"""Test load_usage_entries with timezone-aware timestamps."""
with tempfile.TemporaryDirectory() as temp_dir:
temp_path = Path(temp_dir)
test_file = temp_path / "test.jsonl"
# Create test data with different timezone formats
test_data = [
{
"timestamp": "2024-01-01T12:00:00+00:00",
"input_tokens": 100,
"output_tokens": 50,
},
{
"timestamp": "2024-01-01T12:00:00Z",
"input_tokens": 200,
"output_tokens": 75,
},
]
with open(test_file, "w") as f:
f.writelines(json.dumps(item) + "\n" for item in test_data)
with patch(
"claude_monitor.core.data_processors.TimestampProcessor"
) as mock_ts_processor:
mock_ts = Mock()
mock_ts.parse_timestamp.side_effect = [
datetime(2024, 1, 1, 12, 0, tzinfo=timezone.utc),
datetime(2024, 1, 1, 12, 0, tzinfo=timezone.utc),
]
mock_ts_processor.return_value = mock_ts
with patch(
"claude_monitor.core.data_processors.TokenExtractor"
) as mock_token_extractor:
mock_token_extractor.extract_tokens.side_effect = [
{
"input_tokens": 100,
"output_tokens": 50,
"cache_creation_tokens": 0,
"cache_read_tokens": 0,
},
{
"input_tokens": 200,
"output_tokens": 75,
"cache_creation_tokens": 0,
"cache_read_tokens": 0,
},
]
with patch(
"claude_monitor.core.data_processors.DataConverter"
) as mock_data_converter:
mock_data_converter.extract_model_name.return_value = (
"claude-3-haiku"
)
with patch(
"claude_monitor.core.pricing.PricingCalculator"
) as mock_pricing_class:
mock_pricing = Mock()
mock_pricing.calculate_cost_for_entry.return_value = 0.001
mock_pricing_class.return_value = mock_pricing
entries, _ = load_usage_entries(data_path=str(temp_path))
assert len(entries) == 2
# Both should have UTC timezone
for entry in entries:
assert entry.timestamp.tzinfo == timezone.utc
def test_process_single_file_empty_file(self):
"""Test _process_single_file with empty file."""
timezone_handler = Mock(spec=TimezoneHandler)
pricing_calculator = Mock(spec=PricingCalculator)
with tempfile.TemporaryDirectory() as temp_dir:
temp_path = Path(temp_dir)
empty_file = temp_path / "empty.jsonl"
empty_file.touch() # Create empty file
entries, raw_data = _process_single_file(
empty_file,
CostMode.AUTO,
None,
set(),
True,
timezone_handler,
pricing_calculator,
)
assert entries == []
assert raw_data == []
def test_load_usage_entries_cost_modes(self):
"""Test load_usage_entries with different cost modes."""
with tempfile.TemporaryDirectory() as temp_dir:
temp_path = Path(temp_dir)
test_file = temp_path / "test.jsonl"
test_data = [
{
"timestamp": "2024-01-01T12:00:00Z",
"input_tokens": 100,
"output_tokens": 50,
"cost": 0.001,
}
]
with open(test_file, "w") as f:
f.writelines(json.dumps(item) + "\n" for item in test_data)
for mode in [CostMode.AUTO, CostMode.CALCULATED, CostMode.CACHED]:
with patch(
"claude_monitor.core.data_processors.TimestampProcessor"
) as mock_ts_processor:
mock_ts = Mock()
mock_ts.parse_timestamp.return_value = datetime(
2024, 1, 1, 12, 0, tzinfo=timezone.utc
)
mock_ts_processor.return_value = mock_ts
with patch(
"claude_monitor.core.data_processors.TokenExtractor"
) as mock_token_extractor:
mock_token_extractor.extract_tokens.return_value = {
"input_tokens": 100,
"output_tokens": 50,
"cache_creation_tokens": 0,
"cache_read_tokens": 0,
}
with patch(
"claude_monitor.core.data_processors.DataConverter"
) as mock_data_converter:
mock_data_converter.extract_model_name.return_value = (
"claude-3-haiku"
)
with patch(
"claude_monitor.data.reader.PricingCalculator"
) as mock_pricing_class:
mock_pricing = Mock()
mock_pricing.calculate_cost_for_entry.return_value = (
0.002
)
mock_pricing_class.return_value = mock_pricing
entries, _ = load_usage_entries(
data_path=str(temp_path), mode=mode
)
assert len(entries) == 1
# Verify the pricing calculator was created (called in load_usage_entries)
assert mock_pricing_class.called
class TestDataProcessors:
"""Test the data processor classes."""
def test_timestamp_processor_init(self):
"""Test TimestampProcessor initialization."""
from claude_monitor.core.data_processors import TimestampProcessor
# Test with default timezone handler
processor = TimestampProcessor()
assert processor.timezone_handler is not None
# Test with custom timezone handler
custom_handler = Mock()
processor = TimestampProcessor(custom_handler)
assert processor.timezone_handler == custom_handler
def test_timestamp_processor_parse_datetime(self):
"""Test parsing datetime objects."""
from claude_monitor.core.data_processors import TimestampProcessor
processor = TimestampProcessor()
dt = datetime(2024, 1, 1, 12, 0, 0, tzinfo=timezone.utc)
with patch.object(processor.timezone_handler, "ensure_timezone") as mock_ensure:
mock_ensure.return_value = dt
result = processor.parse_timestamp(dt)
assert result == dt
mock_ensure.assert_called_once_with(dt)
def test_timestamp_processor_parse_string_iso(self):
"""Test parsing ISO format strings."""
from claude_monitor.core.data_processors import TimestampProcessor
processor = TimestampProcessor()
with patch.object(processor.timezone_handler, "ensure_timezone") as mock_ensure:
mock_dt = datetime(2024, 1, 1, 12, 0, 0, tzinfo=timezone.utc)
mock_ensure.return_value = mock_dt
# Test Z suffix handling
result = processor.parse_timestamp("2024-01-01T12:00:00Z")
assert result == mock_dt
# Test ISO format without Z
result = processor.parse_timestamp("2024-01-01T12:00:00+00:00")
assert result == mock_dt
def test_timestamp_processor_parse_string_fallback(self):
"""Test parsing strings with fallback formats."""
from claude_monitor.core.data_processors import TimestampProcessor
processor = TimestampProcessor()
with patch.object(processor.timezone_handler, "ensure_timezone") as mock_ensure:
mock_dt = datetime(2024, 1, 1, 12, 0, 0, tzinfo=timezone.utc)
mock_ensure.return_value = mock_dt
# Test that the function handles parsing failures gracefully
result = processor.parse_timestamp("invalid-format-that-will-fail")
# Should return None for unparseable strings
assert result is None
def test_timestamp_processor_parse_numeric(self):
"""Test parsing numeric timestamps."""
from claude_monitor.core.data_processors import TimestampProcessor
processor = TimestampProcessor()
with patch.object(processor.timezone_handler, "ensure_timezone") as mock_ensure:
mock_dt = datetime(2024, 1, 1, 12, 0, 0, tzinfo=timezone.utc)
mock_ensure.return_value = mock_dt
# Test integer timestamp
result = processor.parse_timestamp(1704110400) # 2024-01-01 12:00:00 UTC
assert result == mock_dt
# Test float timestamp
result = processor.parse_timestamp(1704110400.5)
assert result == mock_dt
def test_timestamp_processor_parse_invalid(self):
"""Test parsing invalid timestamps."""
from claude_monitor.core.data_processors import TimestampProcessor
processor = TimestampProcessor()
# Test None
assert processor.parse_timestamp(None) is None
# Test invalid string that can't be parsed
assert processor.parse_timestamp("invalid-date") is None
# Test invalid type
assert processor.parse_timestamp({"not": "timestamp"}) is None
def test_token_extractor_basic_extraction(self):
"""Test basic token extraction."""
from claude_monitor.core.data_processors import TokenExtractor
# Test direct token fields
data = {
"input_tokens": 100,
"output_tokens": 50,
"cache_creation_tokens": 10,
"cache_read_tokens": 5,
}
result = TokenExtractor.extract_tokens(data)
assert result["input_tokens"] == 100
assert result["output_tokens"] == 50
assert result["cache_creation_tokens"] == 10
assert result["cache_read_tokens"] == 5
assert result["total_tokens"] == 165
def test_token_extractor_usage_field(self):
"""Test extraction from usage field."""
from claude_monitor.core.data_processors import TokenExtractor
data = {"usage": {"input_tokens": 200, "output_tokens": 100}}
result = TokenExtractor.extract_tokens(data)
assert result["input_tokens"] == 200
assert result["output_tokens"] == 100
assert result["total_tokens"] == 300
def test_token_extractor_message_usage(self):
"""Test extraction from message.usage field."""
from claude_monitor.core.data_processors import TokenExtractor
data = {
"message": {
"usage": {
"input_tokens": 150,
"output_tokens": 75,
"cache_creation_tokens": 20,
}
}
}
result = TokenExtractor.extract_tokens(data)
assert result["input_tokens"] == 150
assert result["output_tokens"] == 75
assert result["cache_creation_tokens"] == 20
assert result["total_tokens"] == 245
def test_token_extractor_empty_data(self):
"""Test extraction from empty data."""
from claude_monitor.core.data_processors import TokenExtractor
result = TokenExtractor.extract_tokens({})
assert result["input_tokens"] == 0
assert result["output_tokens"] == 0
assert result["cache_creation_tokens"] == 0
assert result["cache_read_tokens"] == 0
assert result["total_tokens"] == 0
def test_data_converter_extract_model_name(self):
"""Test model name extraction."""
from claude_monitor.core.data_processors import DataConverter
# Test direct model field
data = {"model": "claude-3-opus"}
assert DataConverter.extract_model_name(data) == "claude-3-opus"
# Test message.model field
data = {"message": {"model": "claude-3-sonnet"}}
assert DataConverter.extract_model_name(data) == "claude-3-sonnet"
# Test with default
data = {}
assert (
DataConverter.extract_model_name(data, "default-model") == "default-model"
)
# Test with None data (handle gracefully)
try:
result = DataConverter.extract_model_name(None, "fallback")
assert result == "fallback"
except AttributeError:
# If function doesn't handle None gracefully, that's also acceptable
pass
def test_data_converter_flatten_nested_dict(self):
"""Test nested dictionary flattening."""
from claude_monitor.core.data_processors import DataConverter
# Test simple nested dict
data = {
"user": {"name": "John", "age": 30},
"settings": {
"theme": "dark",
"notifications": {"email": True, "push": False},
},
}
result = DataConverter.flatten_nested_dict(data)
assert result["user.name"] == "John"
assert result["user.age"] == 30
assert result["settings.theme"] == "dark"
assert result["settings.notifications.email"] is True
assert result["settings.notifications.push"] is False
def test_data_converter_flatten_with_prefix(self):
"""Test flattening with custom prefix."""
from claude_monitor.core.data_processors import DataConverter
data = {"inner": {"value": 42}}
result = DataConverter.flatten_nested_dict(data, "prefix")
assert result["prefix.inner.value"] == 42
def test_data_converter_to_serializable(self):
"""Test object serialization."""
from claude_monitor.core.data_processors import DataConverter
# Test datetime
dt = datetime(2024, 1, 1, 12, 0, 0, tzinfo=timezone.utc)
assert DataConverter.to_serializable(dt) == "2024-01-01T12:00:00+00:00"
# Test dict with datetime
data = {"timestamp": dt, "value": 42}
result = DataConverter.to_serializable(data)
assert result["timestamp"] == "2024-01-01T12:00:00+00:00"
assert result["value"] == 42
# Test list with datetime
data = [dt, "string", 123]
result = DataConverter.to_serializable(data)
assert result[0] == "2024-01-01T12:00:00+00:00"
assert result[1] == "string"
assert result[2] == 123
# Test primitive types
assert DataConverter.to_serializable("string") == "string"
assert DataConverter.to_serializable(123) == 123
assert DataConverter.to_serializable(True) is True
================================================
FILE: src/tests/test_display_controller.py
================================================
"""Tests for DisplayController class."""
from datetime import datetime, timedelta, timezone
from typing import Any, Dict
from unittest.mock import Mock, patch
import pytest
from claude_monitor.ui.display_controller import (
DisplayController,
LiveDisplayManager,
ScreenBufferManager,
SessionCalculator,
)
class TestDisplayController:
"""Test cases for DisplayController class."""
@pytest.fixture
def controller(self) -> Any:
with patch("claude_monitor.ui.display_controller.NotificationManager"):
return DisplayController()
@pytest.fixture
def sample_active_block(self) -> Dict[str, Any]:
"""Sample active block data."""
return {
"isActive": True,
"totalTokens": 15000,
"costUSD": 0.45,
"sentMessagesCount": 12,
"perModelStats": {
"claude-3-opus": {"inputTokens": 5000, "outputTokens": 3000},
"claude-3-5-sonnet": {"inputTokens": 4000, "outputTokens": 3000},
},
"entries": [
{"timestamp": "2024-01-01T12:00:00Z", "tokens": 5000},
{"timestamp": "2024-01-01T12:30:00Z", "tokens": 10000},
],
"startTime": "2024-01-01T11:00:00Z",
"endTime": "2024-01-01T13:00:00Z",
}
@pytest.fixture
def sample_args(self) -> Mock:
"""Sample CLI arguments."""
args = Mock()
args.plan = "pro"
args.timezone = "UTC"
args.time_format = "24h"
args.custom_limit_tokens = None
return args
def test_init(self, controller: Any) -> None:
"""Test DisplayController initialization."""
assert controller.session_display is not None
assert controller.loading_screen is not None
assert controller.error_display is not None
assert controller.screen_manager is not None
assert controller.live_manager is not None
assert controller.notification_manager is not None
def test_extract_session_data(
self, controller: Any, sample_active_block: Dict[str, Any]
) -> None:
"""Test session data extraction."""
result = controller._extract_session_data(sample_active_block)
assert result["tokens_used"] == 15000
assert result["session_cost"] == 0.45
assert result["sent_messages"] == 12
assert len(result["entries"]) == 2
assert result["start_time_str"] == "2024-01-01T11:00:00Z"
def test_calculate_token_limits_standard_plan(self, controller, sample_args):
"""Test token limit calculation for standard plans."""
token_limit = 200000
result = controller._calculate_token_limits(sample_args, token_limit)
assert result == (200000, 200000)
def test_calculate_token_limits_custom_plan(self, controller, sample_args):
"""Test token limit calculation for custom plans with explicit limit."""
sample_args.plan = "custom"
sample_args.custom_limit_tokens = 500000
token_limit = 200000
result = controller._calculate_token_limits(sample_args, token_limit)
assert result == (500000, 500000)
def test_calculate_token_limits_custom_plan_no_limit(self, controller, sample_args):
"""Test token limit calculation for custom plans without explicit limit."""
sample_args.plan = "custom"
sample_args.custom_limit_tokens = None
token_limit = 200000
result = controller._calculate_token_limits(sample_args, token_limit)
assert result == (200000, 200000)
@patch("claude_monitor.ui.display_controller.calculate_hourly_burn_rate")
def test_calculate_time_data(self, mock_burn_rate, controller):
"""Test time data calculation."""
session_data = {
"start_time_str": "2024-01-01T11:00:00Z",
"end_time_str": "2024-01-01T13:00:00Z",
}
current_time = datetime(2024, 1, 1, 12, 30, 0, tzinfo=timezone.utc)
with patch.object(
controller.session_calculator, "calculate_time_data"
) as mock_calc:
mock_calc.return_value = {
"elapsed_session_minutes": 90,
"total_session_minutes": 120,
"reset_time": current_time + timedelta(hours=12),
}
result = controller._calculate_time_data(session_data, current_time)
assert result["elapsed_session_minutes"] == 90
assert result["total_session_minutes"] == 120
mock_calc.assert_called_once_with(session_data, current_time)
@patch("claude_monitor.ui.display_controller.Plans.is_valid_plan")
def test_calculate_cost_predictions_valid_plan(
self, mock_is_valid, controller, sample_args
):
"""Test cost predictions for valid plans."""
mock_is_valid.return_value = True
session_data = {"session_cost": 0.45}
time_data = {"elapsed_session_minutes": 90}
cost_limit_p90 = 5.0
with patch.object(
controller.session_calculator, "calculate_cost_predictions"
) as mock_calc:
mock_calc.return_value = {
"cost_limit": 5.0,
"predicted_end_time": datetime.now(timezone.utc),
}
result = controller._calculate_cost_predictions(
session_data, time_data, sample_args, cost_limit_p90
)
assert result["cost_limit"] == 5.0
mock_calc.assert_called_once_with(session_data, time_data, 5.0)
def test_calculate_cost_predictions_invalid_plan(self, controller, sample_args):
"""Test cost predictions for invalid plans."""
sample_args.plan = "invalid"
session_data = {"session_cost": 0.45}
time_data = {"elapsed_session_minutes": 90}
with patch.object(
controller.session_calculator, "calculate_cost_predictions"
) as mock_calc:
mock_calc.return_value = {
"cost_limit": 100.0,
"predicted_end_time": datetime.now(timezone.utc),
}
controller._calculate_cost_predictions(
session_data, time_data, sample_args, None
)
mock_calc.assert_called_once_with(session_data, time_data, 100.0)
def test_check_notifications_switch_to_custom(self, controller):
"""Test notification checking for switch to custom."""
with (
patch.object(
controller.notification_manager, "should_notify"
) as mock_should,
patch.object(controller.notification_manager, "mark_notified") as mock_mark,
patch.object(
controller.notification_manager, "is_notification_active"
) as mock_active,
):
# Configure should_notify to return True only for switch_to_custom
def should_notify_side_effect(notification_type):
return notification_type == "switch_to_custom"
mock_should.side_effect = should_notify_side_effect
mock_active.return_value = False
result = controller._check_notifications(
token_limit=500000,
original_limit=200000,
session_cost=2.0,
cost_limit=5.0,
predicted_end_time=datetime.now(timezone.utc) + timedelta(hours=2),
reset_time=datetime.now(timezone.utc) + timedelta(hours=12),
)
assert result["show_switch_notification"] is True
# Verify switch_to_custom was called
assert any(
call[0][0] == "switch_to_custom" for call in mock_should.call_args_list
)
mock_mark.assert_called_with("switch_to_custom")
def test_check_notifications_exceed_limit(self, controller):
"""Test notification checking for exceeding limit."""
with (
patch.object(
controller.notification_manager, "should_notify"
) as mock_should,
patch.object(controller.notification_manager, "mark_notified") as mock_mark,
patch.object(
controller.notification_manager, "is_notification_active"
) as mock_active,
):
# Configure should_notify to return True only for exceed_max_limit
def should_notify_side_effect(notification_type):
return notification_type == "exceed_max_limit"
mock_should.side_effect = should_notify_side_effect
mock_active.return_value = False
result = controller._check_notifications(
token_limit=200000,
original_limit=200000,
session_cost=6.0, # Exceeds limit
cost_limit=5.0,
predicted_end_time=datetime.now(timezone.utc) + timedelta(hours=2),
reset_time=datetime.now(timezone.utc) + timedelta(hours=12),
)
assert result["show_exceed_notification"] is True
# Verify exceed_max_limit was called
assert any(
call[0][0] == "exceed_max_limit" for call in mock_should.call_args_list
)
mock_mark.assert_called_with("exceed_max_limit")
def test_check_notifications_cost_will_exceed(self, controller):
"""Test notification checking for cost will exceed."""
with (
patch.object(
controller.notification_manager, "should_notify"
) as mock_should,
patch.object(controller.notification_manager, "mark_notified") as mock_mark,
):
mock_should.return_value = True
# Predicted end time before reset time
predicted_end = datetime.now(timezone.utc) + timedelta(hours=1)
reset_time = datetime.now(timezone.utc) + timedelta(hours=12)
result = controller._check_notifications(
token_limit=200000,
original_limit=200000,
session_cost=2.0,
cost_limit=5.0,
predicted_end_time=predicted_end,
reset_time=reset_time,
)
assert result["show_cost_will_exceed"] is True
mock_should.assert_called_with("cost_will_exceed")
mock_mark.assert_called_with("cost_will_exceed")
@patch("claude_monitor.ui.display_controller.TimezoneHandler")
@patch("claude_monitor.ui.display_controller.get_time_format_preference")
@patch("claude_monitor.ui.display_controller.format_display_time")
def test_format_display_times(
self,
mock_format_time,
mock_get_format,
mock_tz_handler_class,
controller,
sample_args,
):
"""Test display time formatting."""
mock_tz_handler = Mock()
mock_tz_handler.validate_timezone.return_value = True
mock_tz_handler.convert_to_timezone.return_value = datetime.now(timezone.utc)
mock_tz_handler_class.return_value = mock_tz_handler
mock_get_format.return_value = "24h"
mock_format_time.return_value = "12:00:00"
current_time = datetime.now(timezone.utc)
predicted_end = current_time + timedelta(hours=2)
reset_time = current_time + timedelta(hours=12)
result = controller._format_display_times(
sample_args, current_time, predicted_end, reset_time
)
assert "predicted_end_str" in result
assert "reset_time_str" in result
assert "current_time_str" in result
def test_calculate_model_distribution_empty_stats(self, controller):
"""Test model distribution calculation with empty stats."""
result = controller._calculate_model_distribution({})
assert result == {}
@patch("claude_monitor.ui.display_controller.normalize_model_name")
def test_calculate_model_distribution_valid_stats(self, mock_normalize, controller):
"""Test model distribution calculation with valid stats."""
mock_normalize.side_effect = lambda x: {
"claude-3-opus": "claude-3-opus",
"claude-3-5-sonnet": "claude-3.5-sonnet",
}.get(x, "unknown")
raw_stats = {
"claude-3-opus": {"input_tokens": 5000, "output_tokens": 3000},
"claude-3-5-sonnet": {"input_tokens": 4000, "output_tokens": 3000},
}
result = controller._calculate_model_distribution(raw_stats)
# Total tokens: opus=8000, sonnet=7000, total=15000
expected_opus_pct = (8000 / 15000) * 100 # ~53.33%
expected_sonnet_pct = (7000 / 15000) * 100 # ~46.67%
assert abs(result["claude-3-opus"] - expected_opus_pct) < 0.1
assert abs(result["claude-3.5-sonnet"] - expected_sonnet_pct) < 0.1
def test_create_data_display_no_data(self, controller, sample_args):
"""Test create_data_display with no data."""
result = controller.create_data_display({}, sample_args, 200000)
assert result is not None
# Should return error screen renderable
def test_create_data_display_no_active_block(self, controller, sample_args):
"""Test create_data_display with no active blocks."""
data = {"blocks": [{"isActive": False, "totalTokens": 1000}]}
result = controller.create_data_display(data, sample_args, 200000)
assert result is not None
# Should return no active session screen
@patch("claude_monitor.ui.display_controller.Plans.is_valid_plan")
@patch("claude_monitor.core.plans.get_cost_limit")
@patch("claude_monitor.ui.display_controller.Plans.get_message_limit")
def test_create_data_display_with_active_block(
self,
mock_msg_limit,
mock_cost_limit,
mock_is_valid,
controller,
sample_args,
sample_active_block,
):
"""Test create_data_display with active block."""
mock_is_valid.return_value = True
mock_cost_limit.return_value = 5.0
mock_msg_limit.return_value = 1000
data = {"blocks": [sample_active_block]}
with patch.object(controller, "_process_active_session_data") as mock_process:
mock_process.return_value = {
"plan": "pro",
"timezone": "UTC",
"tokens_used": 15000,
"token_limit": 200000,
"usage_percentage": 7.5,
"tokens_left": 185000,
"elapsed_session_minutes": 90,
"total_session_minutes": 120,
"burn_rate": 10.0,
"session_cost": 0.45,
"per_model_stats": {},
"model_distribution": {},
"sent_messages": 12,
"entries": [],
"predicted_end_str": "14:00",
"reset_time_str": "00:00",
"current_time_str": "12:30",
"show_switch_notification": False,
"show_exceed_notification": False,
"show_tokens_will_run_out": False,
"original_limit": 200000,
"cost_limit_p90": 5.0,
"messages_limit_p90": 1000,
}
with patch.object(
controller.session_display, "format_active_session_screen"
) as mock_format:
mock_format.return_value = ["Sample screen buffer"]
result = controller.create_data_display(data, sample_args, 200000)
assert result is not None
mock_process.assert_called_once()
mock_format.assert_called_once()
def test_create_loading_display(self, controller):
"""Test creating loading display."""
result = controller.create_loading_display("pro", "UTC", "Loading...")
assert result is not None
def test_create_error_display(self, controller):
"""Test creating error display."""
result = controller.create_error_display("pro", "UTC")
assert result is not None
def test_create_live_context(self, controller):
"""Test creating live context."""
result = controller.create_live_context()
assert result is not None
def test_set_screen_dimensions(self, controller):
"""Test setting screen dimensions."""
controller.set_screen_dimensions(120, 40)
# Should not raise exception
class TestLiveDisplayManager:
"""Test cases for LiveDisplayManager class."""
def test_init_default(self):
"""Test LiveDisplayManager initialization with defaults."""
manager = LiveDisplayManager()
assert manager._console is None
assert manager._live_context is None
assert manager._current_renderable is None
def test_init_with_console(self):
"""Test LiveDisplayManager initialization with console."""
mock_console = Mock()
manager = LiveDisplayManager(console=mock_console)
assert manager._console is mock_console
@patch("claude_monitor.ui.display_controller.Live")
def test_create_live_display_default(self, mock_live_class):
"""Test creating live display with defaults."""
mock_live = Mock()
mock_live_class.return_value = mock_live
manager = LiveDisplayManager()
result = manager.create_live_display()
assert result is mock_live
mock_live_class.assert_called_once_with(
console=None,
refresh_per_second=0.75,
auto_refresh=True,
vertical_overflow="visible",
)
@patch("claude_monitor.ui.display_controller.Live")
def test_create_live_display_custom(self, mock_live_class):
"""Test creating live display with custom parameters."""
mock_live = Mock()
mock_live_class.return_value = mock_live
mock_console = Mock()
manager = LiveDisplayManager()
result = manager.create_live_display(
auto_refresh=False, console=mock_console, refresh_per_second=2.0
)
assert result is mock_live
mock_live_class.assert_called_once_with(
console=mock_console,
refresh_per_second=2.0,
auto_refresh=False,
vertical_overflow="visible",
)
class TestScreenBufferManager:
"""Test cases for ScreenBufferManager class."""
def test_init(self):
"""Test ScreenBufferManager initialization."""
manager = ScreenBufferManager()
assert manager.console is None
@patch("claude_monitor.terminal.themes.get_themed_console")
@patch("claude_monitor.ui.display_controller.Text")
@patch("claude_monitor.ui.display_controller.Group")
def test_create_screen_renderable(self, mock_group, mock_text, mock_get_console):
"""Test creating screen renderable from buffer."""
mock_console = Mock()
mock_get_console.return_value = mock_console
mock_text_obj = Mock()
mock_text.from_markup.return_value = mock_text_obj
mock_group_obj = Mock()
mock_group.return_value = mock_group_obj
manager = ScreenBufferManager()
screen_buffer = ["Line 1", "Line 2", "Line 3"]
result = manager.create_screen_renderable(screen_buffer)
assert result is mock_group_obj
assert mock_text.from_markup.call_count == 3
mock_group.assert_called_once()
@patch("claude_monitor.terminal.themes.get_themed_console")
@patch("claude_monitor.ui.display_controller.Group")
def test_create_screen_renderable_with_objects(self, mock_group, mock_get_console):
"""Test creating screen renderable with mixed string and object content."""
mock_console = Mock()
mock_get_console.return_value = mock_console
mock_group_obj = Mock()
mock_group.return_value = mock_group_obj
manager = ScreenBufferManager()
mock_object = Mock()
screen_buffer = ["String line", mock_object]
result = manager.create_screen_renderable(screen_buffer)
assert result is mock_group_obj
mock_group.assert_called_once()
class TestDisplayControllerEdgeCases:
"""Test edge cases for DisplayController."""
@pytest.fixture
def controller(self):
"""Create a DisplayController instance."""
with patch("claude_monitor.ui.display_controller.NotificationManager"):
return DisplayController()
@pytest.fixture
def sample_args(self):
"""Sample CLI arguments."""
args = Mock()
args.plan = "pro"
args.timezone = "UTC"
args.time_format = "24h"
args.custom_limit_tokens = None
return args
def test_process_active_session_data_exception_handling(
self, controller, sample_args
):
"""Test exception handling in _process_active_session_data."""
sample_active_block = {"isActive": True, "totalTokens": 15000, "costUSD": 0.45}
data = {"blocks": [sample_active_block]}
# Mock an exception in session data extraction
with patch.object(controller, "_extract_session_data") as mock_extract:
mock_extract.side_effect = Exception("Test error")
result = controller.create_data_display(data, sample_args, 200000)
# Should return error screen renderable instead of crashing
assert result is not None
def test_format_display_times_invalid_timezone(self, controller, sample_args):
"""Test format_display_times with invalid timezone."""
sample_args.timezone = "Invalid/Timezone"
current_time = datetime.now(timezone.utc)
predicted_end = current_time + timedelta(hours=2)
reset_time = current_time + timedelta(hours=12)
# Should handle invalid timezone gracefully
result = controller._format_display_times(
sample_args, current_time, predicted_end, reset_time
)
assert "predicted_end_str" in result
assert "reset_time_str" in result
assert "current_time_str" in result
def test_calculate_model_distribution_invalid_stats(self, controller):
"""Test model distribution with invalid stats format."""
invalid_stats = {
"invalid-model": "not-a-dict",
"another-model": {"inputTokens": "not-a-number"},
}
# Should handle invalid data gracefully
result = controller._calculate_model_distribution(invalid_stats)
# Should return empty or handle gracefully
assert isinstance(result, dict)
class TestDisplayControllerAdvanced:
"""Advanced test cases for DisplayController to improve coverage."""
@pytest.fixture
def controller(self):
"""Create a DisplayController instance."""
with patch("claude_monitor.ui.display_controller.NotificationManager"):
return DisplayController()
@pytest.fixture
def sample_args_custom(self):
"""Sample CLI arguments for custom plan."""
args = Mock()
args.plan = "custom"
args.timezone = "UTC"
args.time_format = "24h"
args.custom_limit_tokens = None
return args
@patch("claude_monitor.ui.display_controller.AdvancedCustomLimitDisplay")
@patch("claude_monitor.ui.display_controller.Plans.get_message_limit")
@patch("claude_monitor.core.plans.get_cost_limit")
def test_create_data_display_custom_plan(
self,
mock_get_cost,
mock_get_message,
mock_advanced_display,
controller,
sample_args_custom,
):
"""Test create_data_display with custom plan."""
# Mock advanced display
mock_temp_display = Mock()
mock_advanced_display.return_value = mock_temp_display
mock_temp_display._collect_session_data.return_value = {"limit_sessions": []}
mock_temp_display._calculate_session_percentiles.return_value = {
"costs": {"p90": 5.0},
"messages": {"p90": 100},
}
# Mock data with active block
data = {
"blocks": [
{
"isActive": True,
"totalTokens": 15000,
"costUSD": 0.45,
"sentMessagesCount": 12,
"perModelStats": {
"claude-3-haiku": {"input_tokens": 100, "output_tokens": 50}
},
"entries": [{"timestamp": "2024-01-01T12:00:00Z"}],
"startTime": "2024-01-01T11:00:00Z",
"endTime": "2024-01-01T13:00:00Z",
}
]
}
with patch.object(controller, "_process_active_session_data") as mock_process:
mock_process.return_value = {
"plan": "custom",
"timezone": "UTC",
"tokens_used": 15000,
"token_limit": 200000,
}
with (
patch.object(
controller.buffer_manager, "create_screen_renderable"
) as mock_create,
patch.object(
controller.session_display, "format_active_session_screen"
) as mock_format,
):
mock_format.return_value = ["screen", "buffer"]
mock_create.return_value = "rendered_screen"
result = controller.create_data_display(
data, sample_args_custom, 200000
)
assert result == "rendered_screen"
mock_advanced_display.assert_called_once_with(None)
mock_temp_display._collect_session_data.assert_called_once_with(
data["blocks"]
)
def test_create_data_display_exception_handling(self, controller):
"""Test create_data_display exception handling."""
args = Mock()
args.plan = "pro"
args.timezone = "UTC"
data = {"blocks": [{"isActive": True, "totalTokens": 15000, "costUSD": 0.45}]}
with patch.object(controller, "_process_active_session_data") as mock_process:
mock_process.side_effect = Exception("Test error")
with (
patch.object(
controller.error_display, "format_error_screen"
) as mock_error,
patch.object(
controller.buffer_manager, "create_screen_renderable"
) as mock_create,
):
mock_error.return_value = ["error", "screen"]
mock_create.return_value = "error_rendered"
result = controller.create_data_display(data, args, 200000)
assert result == "error_rendered"
mock_error.assert_called_once_with("pro", "UTC")
def test_create_data_display_format_session_exception(self, controller):
"""Test create_data_display with format_active_session_screen exception."""
args = Mock()
args.plan = "pro"
args.timezone = "UTC"
data = {
"blocks": [
{
"isActive": True,
"totalTokens": 15000,
"costUSD": 0.45,
"sentMessagesCount": 12,
"perModelStats": {"claude-3-haiku": {"input_tokens": 100}},
"entries": [{"timestamp": "2024-01-01T12:00:00Z"}],
"startTime": "2024-01-01T11:00:00Z",
"endTime": "2024-01-01T13:00:00Z",
}
]
}
with patch.object(controller, "_process_active_session_data") as mock_process:
mock_process.return_value = {
"plan": "pro",
"timezone": "UTC",
"tokens_used": 15000,
"per_model_stats": {"claude-3-haiku": {"input_tokens": 100}},
"entries": [{"timestamp": "2024-01-01T12:00:00Z"}],
}
with patch.object(
controller.session_display, "format_active_session_screen"
) as mock_format:
mock_format.side_effect = Exception("Format error")
with (
patch.object(
controller.error_display, "format_error_screen"
) as mock_error,
patch.object(
controller.buffer_manager, "create_screen_renderable"
) as mock_create,
):
mock_error.return_value = ["error", "screen"]
mock_create.return_value = "error_rendered"
result = controller.create_data_display(data, args, 200000)
assert result == "error_rendered"
mock_error.assert_called_once_with("pro", "UTC")
def test_process_active_session_data_comprehensive(self, controller):
"""Test _process_active_session_data with comprehensive data."""
active_block = {
"totalTokens": 15000,
"costUSD": 0.45,
"sentMessagesCount": 12,
"perModelStats": {
"claude-3-haiku": {"input_tokens": 100, "output_tokens": 50},
"claude-3-sonnet": {"input_tokens": 200, "output_tokens": 100},
},
"entries": [
{"timestamp": "2024-01-01T12:00:00Z"},
{"timestamp": "2024-01-01T12:30:00Z"},
],
"startTime": "2024-01-01T11:00:00Z",
"endTime": "2024-01-01T13:00:00Z",
}
data = {"blocks": [active_block]}
args = Mock()
args.plan = "pro"
args.timezone = "UTC"
args.time_format = "24h"
args.custom_limit_tokens = None
current_time = datetime(2024, 1, 1, 12, 30, tzinfo=timezone.utc)
with patch(
"claude_monitor.ui.display_controller.calculate_hourly_burn_rate"
) as mock_burn:
mock_burn.return_value = 5.5
with patch.object(
controller.session_calculator, "calculate_time_data"
) as mock_time:
mock_time.return_value = {
"elapsed_session_minutes": 90,
"total_session_minutes": 120,
"reset_time": current_time + timedelta(hours=1),
}
with patch.object(
controller.session_calculator, "calculate_cost_predictions"
) as mock_cost:
mock_cost.return_value = {
"cost_limit": 5.0,
"predicted_end_time": current_time + timedelta(hours=2),
}
with patch.object(
controller, "_check_notifications"
) as mock_notify:
mock_notify.return_value = {
"show_switch_notification": False,
"show_exceed_notification": False,
"show_cost_will_exceed": False,
}
with patch.object(
controller, "_format_display_times"
) as mock_format:
mock_format.return_value = {
"predicted_end_str": "14:30",
"reset_time_str": "13:30",
"current_time_str": "12:30",
}
result = controller._process_active_session_data(
active_block, data, args, 200000, current_time, 5.0
)
assert result["tokens_used"] == 15000
assert result["token_limit"] == 200000
assert result["session_cost"] == 0.45
assert result["burn_rate"] == 5.5
assert "model_distribution" in result
assert result["show_switch_notification"] is False
class TestSessionCalculator:
"""Test cases for SessionCalculator class."""
@pytest.fixture
def calculator(self):
"""Create a SessionCalculator instance."""
return SessionCalculator()
def test_init(self, calculator):
"""Test SessionCalculator initialization."""
assert calculator.tz_handler is not None
def test_calculate_time_data_with_start_end(self, calculator):
"""Test calculate_time_data with start and end times."""
session_data = {
"start_time_str": "2024-01-01T11:00:00Z",
"end_time_str": "2024-01-01T13:00:00Z",
}
current_time = datetime(2024, 1, 1, 12, 30, tzinfo=timezone.utc)
with patch.object(calculator.tz_handler, "parse_timestamp") as mock_parse:
with patch.object(calculator.tz_handler, "ensure_utc") as mock_ensure:
start_time = datetime(2024, 1, 1, 11, 0, tzinfo=timezone.utc)
end_time = datetime(2024, 1, 1, 13, 0, tzinfo=timezone.utc)
mock_parse.side_effect = [start_time, end_time]
mock_ensure.side_effect = [start_time, end_time]
result = calculator.calculate_time_data(session_data, current_time)
assert result["start_time"] == start_time
assert result["reset_time"] == end_time
assert result["total_session_minutes"] == 120 # 2 hours
assert result["elapsed_session_minutes"] == 90 # 1.5 hours
def test_calculate_time_data_no_end_time(self, calculator):
"""Test calculate_time_data without end time."""
session_data = {"start_time_str": "2024-01-01T11:00:00Z"}
current_time = datetime(2024, 1, 1, 12, 30, tzinfo=timezone.utc)
with patch.object(calculator.tz_handler, "parse_timestamp") as mock_parse:
with patch.object(calculator.tz_handler, "ensure_utc") as mock_ensure:
start_time = datetime(2024, 1, 1, 11, 0, tzinfo=timezone.utc)
mock_parse.return_value = start_time
mock_ensure.return_value = start_time
result = calculator.calculate_time_data(session_data, current_time)
assert result["start_time"] == start_time
# Reset time should be start_time + 5 hours
expected_reset = start_time + timedelta(hours=5)
assert result["reset_time"] == expected_reset
def test_calculate_time_data_no_start_time(self, calculator):
"""Test calculate_time_data without start time."""
session_data = {}
current_time = datetime(2024, 1, 1, 12, 30, tzinfo=timezone.utc)
result = calculator.calculate_time_data(session_data, current_time)
assert result["start_time"] is None
# Reset time should be current_time + 5 hours
expected_reset = current_time + timedelta(hours=5)
assert result["reset_time"] == expected_reset
assert result["total_session_minutes"] == 300 # 5 hours default
assert result["elapsed_session_minutes"] >= 0
def test_calculate_cost_predictions_with_cost(self, calculator):
"""Test calculate_cost_predictions with existing cost."""
session_data = {"session_cost": 2.5}
time_data = {"elapsed_session_minutes": 60}
cost_limit = 10.0
with patch("claude_monitor.ui.display_controller.datetime") as mock_datetime:
current_time = datetime(2024, 1, 1, 12, 0, tzinfo=timezone.utc)
mock_datetime.now.return_value = current_time
mock_datetime.side_effect = lambda *args, **kw: datetime(*args, **kw)
result = calculator.calculate_cost_predictions(
session_data, time_data, cost_limit
)
assert result["cost_per_minute"] == 2.5 / 60 # Approximately 0.0417
assert result["cost_limit"] == 10.0
assert result["cost_remaining"] == 7.5
assert "predicted_end_time" in result
def test_calculate_cost_predictions_no_cost_limit(self, calculator):
"""Test calculate_cost_predictions without cost limit."""
session_data = {"session_cost": 1.0}
time_data = {
"elapsed_session_minutes": 30,
"reset_time": datetime(2024, 1, 1, 17, 0, tzinfo=timezone.utc),
}
with patch("claude_monitor.ui.display_controller.datetime") as mock_datetime:
current_time = datetime(2024, 1, 1, 12, 0, tzinfo=timezone.utc)
mock_datetime.now.return_value = current_time
mock_datetime.side_effect = lambda *args, **kw: datetime(*args, **kw)
result = calculator.calculate_cost_predictions(
session_data, time_data, None
)
assert result["cost_limit"] == 100.0 # Default
assert result["cost_remaining"] == 99.0
assert "predicted_end_time" in result
def test_calculate_cost_predictions_zero_cost_rate(self, calculator):
"""Test calculate_cost_predictions with zero cost rate."""
session_data = {"session_cost": 0.0}
time_data = {
"elapsed_session_minutes": 60,
"reset_time": datetime(2024, 1, 1, 17, 0, tzinfo=timezone.utc),
}
cost_limit = 10.0
with patch("claude_monitor.ui.display_controller.datetime") as mock_datetime:
current_time = datetime(2024, 1, 1, 12, 0, tzinfo=timezone.utc)
mock_datetime.now.return_value = current_time
mock_datetime.side_effect = lambda *args, **kw: datetime(*args, **kw)
result = calculator.calculate_cost_predictions(
session_data, time_data, cost_limit
)
assert result["cost_per_minute"] == 0.0
assert result["predicted_end_time"] == time_data["reset_time"]
# Test the legacy function
@patch("claude_monitor.ui.display_controller.ScreenBufferManager")
def test_create_screen_renderable_legacy(mock_manager_class):
"""Test the legacy create_screen_renderable function."""
mock_manager = Mock()
mock_manager_class.return_value = mock_manager
mock_manager.create_screen_renderable.return_value = "rendered"
from claude_monitor.ui.display_controller import create_screen_renderable
screen_buffer = ["line1", "line2"]
result = create_screen_renderable(screen_buffer)
assert result == "rendered"
mock_manager_class.assert_called_once()
mock_manager.create_screen_renderable.assert_called_once_with(screen_buffer)
================================================
FILE: src/tests/test_error_handling.py
================================================
"""Tests for error handling module."""
from typing import Dict
from unittest.mock import Mock, patch
import pytest
from claude_monitor.error_handling import ErrorLevel, report_error
class TestErrorLevel:
"""Test cases for ErrorLevel enum."""
def test_error_level_values(self) -> None:
"""Test that ErrorLevel has correct values."""
assert ErrorLevel.INFO == "info"
assert ErrorLevel.ERROR == "error"
def test_error_level_string_conversion(self) -> None:
"""Test ErrorLevel string conversion."""
assert ErrorLevel.INFO.value == "info"
assert ErrorLevel.ERROR.value == "error"
class TestReportError:
"""Test cases for report_error function."""
@pytest.fixture
def sample_exception(self) -> ValueError:
"""Create a sample exception for testing."""
try:
raise ValueError("Test error message")
except ValueError as e:
return e
@pytest.fixture
def sample_context_data(self) -> Dict[str, str]:
"""Sample context data for testing."""
return {
"user_id": "12345",
"action": "process_data",
"timestamp": "2024-01-01T12:00:00Z",
}
@pytest.fixture
def sample_tags(self) -> Dict[str, str]:
"""Sample tags for testing."""
return {"environment": "test", "version": "1.0.0"}
@patch("claude_monitor.error_handling.logging.getLogger")
def test_report_error_basic(
self, mock_get_logger: Mock, sample_exception: ValueError
) -> None:
"""Test basic error reporting."""
mock_logger = Mock()
mock_get_logger.return_value = mock_logger
report_error(exception=sample_exception, component="test_component")
# Verify logger was called
mock_get_logger.assert_called_once_with("test_component")
mock_logger.error.assert_called_once()
@patch("claude_monitor.error_handling.logging.getLogger")
def test_report_error_with_full_context(
self,
mock_get_logger: Mock,
sample_exception: ValueError,
sample_context_data: Dict[str, str],
sample_tags: Dict[str, str],
) -> None:
"""Test error reporting with full context."""
mock_logger = Mock()
mock_get_logger.return_value = mock_logger
report_error(
exception=sample_exception,
component="test_component",
context_name="test_context",
context_data=sample_context_data,
tags=sample_tags,
level=ErrorLevel.ERROR,
)
# Verify logger configuration
mock_get_logger.assert_called_once_with("test_component")
mock_logger.error.assert_called_once()
# Verify the extra data was passed correctly
call_args = mock_logger.error.call_args
assert call_args[1]["extra"]["context"] == "test_context"
assert call_args[1]["extra"]["data"] == sample_context_data
assert call_args[1]["extra"]["tags"] == sample_tags
@patch("claude_monitor.error_handling.logging.getLogger")
def test_report_error_with_info_level(
self, mock_get_logger: Mock, sample_exception: ValueError
) -> None:
"""Test error reporting with INFO level."""
mock_logger = Mock()
mock_get_logger.return_value = mock_logger
report_error(
exception=sample_exception,
component="test_component",
level=ErrorLevel.INFO,
)
# Verify logger was called with info level
mock_get_logger.assert_called_once_with("test_component")
mock_logger.info.assert_called_once()
@patch("claude_monitor.error_handling.logging.getLogger")
def test_report_error_logging_only(
self, mock_get_logger: Mock, sample_exception: ValueError
) -> None:
"""Test error reporting with logging only."""
mock_logger = Mock()
mock_get_logger.return_value = mock_logger
report_error(exception=sample_exception, component="test_component")
# Verify logger was created for component
mock_get_logger.assert_called_once_with("test_component")
# Verify logging was called
mock_logger.error.assert_called_once()
@patch("claude_monitor.error_handling.logging.getLogger")
def test_report_error_with_context(
self,
mock_get_logger: Mock,
sample_exception: ValueError,
sample_context_data: Dict[str, str],
) -> None:
"""Test error reporting with context data."""
mock_logger = Mock()
mock_get_logger.return_value = mock_logger
report_error(
exception=sample_exception,
component="test_component",
context_name="test_context",
context_data=sample_context_data,
)
# Verify logger was created and used
mock_get_logger.assert_called_once_with("test_component")
mock_logger.error.assert_called_once()
@patch("claude_monitor.error_handling.logging.getLogger")
def test_report_error_exception_handling(
self, mock_get_logger: Mock, sample_exception: ValueError
) -> None:
"""Test that logging exceptions are handled gracefully."""
mock_logger = Mock()
mock_get_logger.return_value = mock_logger
# Make logger raise an exception
mock_logger.error.side_effect = Exception("Logging failed")
# Should not raise exception
try:
report_error(exception=sample_exception, component="test_component")
except Exception:
pytest.fail("report_error should handle logging exceptions gracefully")
def test_report_error_none_exception(self) -> None:
"""Test error reporting with None exception."""
# Should handle gracefully without crashing
with patch(
"claude_monitor.error_handling.logging.getLogger"
) as mock_get_logger:
mock_logger = Mock()
mock_get_logger.return_value = mock_logger
report_error(exception=None, component="test_component")
# Should still log something
mock_logger.error.assert_called()
def test_report_error_empty_component(self, sample_exception: ValueError) -> None:
"""Test error reporting with empty component name."""
with patch(
"claude_monitor.error_handling.logging.getLogger"
) as mock_get_logger:
mock_logger = Mock()
mock_get_logger.return_value = mock_logger
report_error(exception=sample_exception, component="")
# Should still work
mock_logger.error.assert_called()
@patch("claude_monitor.error_handling.logging.getLogger")
def test_report_error_no_tags(
self, mock_get_logger: Mock, sample_exception: ValueError
) -> None:
"""Test error reporting with no additional tags."""
mock_logger = Mock()
mock_get_logger.return_value = mock_logger
report_error(exception=sample_exception, component="test_component", tags=None)
# Should still log the error
mock_get_logger.assert_called_once_with("test_component")
mock_logger.error.assert_called_once()
@patch("claude_monitor.error_handling.logging.getLogger")
def test_report_error_no_context(
self, mock_get_logger: Mock, sample_exception: ValueError
) -> None:
"""Test error reporting with no context data."""
mock_logger = Mock()
mock_get_logger.return_value = mock_logger
report_error(
exception=sample_exception,
component="test_component",
context_name="test_context",
context_data=None,
)
# Should still log the error
mock_get_logger.assert_called_once_with("test_component")
mock_logger.error.assert_called_once()
@patch("claude_monitor.error_handling.logging.getLogger")
def test_report_error_complex_exception(self, mock_get_logger: Mock) -> None:
"""Test error reporting with complex exception."""
mock_logger = Mock()
mock_get_logger.return_value = mock_logger
# Create a complex exception with cause
try:
try:
raise ValueError("Inner exception")
except ValueError as inner:
raise RuntimeError("Outer exception") from inner
except RuntimeError as complex_exception:
report_error(exception=complex_exception, component="test_component")
# Should handle complex exceptions properly
mock_get_logger.assert_called_once_with("test_component")
mock_logger.error.assert_called_once()
@patch("claude_monitor.error_handling.logging.getLogger")
def test_report_error_empty_tags_dict(
self, mock_get_logger: Mock, sample_exception: ValueError
) -> None:
"""Test error reporting with empty tags dictionary."""
mock_logger = Mock()
mock_get_logger.return_value = mock_logger
report_error(
exception=sample_exception,
component="test_component",
tags={}, # Empty dict
)
# Should still log the error
mock_get_logger.assert_called_once_with("test_component")
mock_logger.error.assert_called_once()
@patch("claude_monitor.error_handling.logging.getLogger")
def test_report_error_special_characters_in_component(
self, mock_get_logger: Mock, sample_exception: ValueError
) -> None:
"""Test error reporting with special characters in component name."""
mock_logger = Mock()
mock_get_logger.return_value = mock_logger
special_component = "test-component_with.special@chars"
report_error(exception=sample_exception, component=special_component)
# Should handle special characters in component name
mock_get_logger.assert_called_once_with(special_component)
mock_logger.error.assert_called_once()
class TestErrorHandlingEdgeCases:
"""Test edge cases for error handling module."""
def test_error_level_equality(self) -> None:
"""Test ErrorLevel equality comparisons."""
assert ErrorLevel.INFO == "info"
assert ErrorLevel.ERROR == "error"
assert ErrorLevel.INFO != ErrorLevel.ERROR
def test_error_level_in_list(self) -> None:
"""Test ErrorLevel can be used in lists and comparisons."""
levels = [ErrorLevel.INFO, ErrorLevel.ERROR]
assert ErrorLevel.INFO in levels
# Note: Since ErrorLevel(str, Enum), string values are equal to enum values
assert "info" in levels # String IS the same as enum for this type
@patch("claude_monitor.error_handling.logging.getLogger")
def test_report_error_with_unicode_data(self, mock_get_logger: Mock) -> None:
"""Test error reporting with unicode data."""
mock_logger = Mock()
mock_get_logger.return_value = mock_logger
unicode_exception = ValueError("Test with unicode: 测试 🚀 émojis")
unicode_context = {"message": "测试消息", "emoji": "🎉", "accents": "café"}
report_error(
exception=unicode_exception,
component="test_component",
context_name="unicode_test",
context_data=unicode_context,
)
# Should handle unicode data properly
mock_get_logger.assert_called_once_with("test_component")
mock_logger.error.assert_called_once()
================================================
FILE: src/tests/test_formatting.py
================================================
"""Tests for formatting utilities."""
from datetime import datetime, timezone
from unittest.mock import Mock, patch
from claude_monitor.utils.formatting import (
format_currency,
format_display_time,
format_time,
get_time_format_preference,
)
from claude_monitor.utils.model_utils import (
get_model_display_name,
get_model_generation,
is_claude_model,
normalize_model_name,
)
class TestFormatTime:
"""Test cases for format_time function."""
def test_format_time_less_than_hour(self) -> None:
"""Test formatting minutes less than an hour."""
assert format_time(0) == "0m"
assert format_time(1) == "1m"
assert format_time(30) == "30m"
assert format_time(59) == "59m"
def test_format_time_exact_hours(self) -> None:
"""Test formatting exact hours (no minutes)."""
assert format_time(60) == "1h"
assert format_time(120) == "2h"
assert format_time(180) == "3h"
def test_format_time_hours_and_minutes(self) -> None:
"""Test formatting hours and minutes."""
assert format_time(61) == "1h 1m"
assert format_time(90) == "1h 30m"
assert format_time(125) == "2h 5m"
assert format_time(225) == "3h 45m"
def test_format_time_large_values(self) -> None:
"""Test formatting large time values."""
assert format_time(1440) == "24h" # 1 day
assert format_time(1500) == "25h" # 25 hours
assert format_time(1561) == "26h 1m"
def test_format_time_float_values(self) -> None:
"""Test formatting with float input values."""
assert format_time(59.7) == "59m"
assert (
format_time(60.5) == "1h"
) # 60.5 minutes -> 1h 0m -> "1h" (no minutes shown when 0)
assert format_time(90.8) == "1h 30m"
class TestFormatCurrency:
"""Test cases for format_currency function."""
def test_format_usd_default(self) -> None:
"""Test formatting USD currency (default)."""
assert format_currency(0.0) == "$0.00"
assert format_currency(1.0) == "$1.00"
assert format_currency(10.99) == "$10.99"
assert format_currency(1000.0) == "$1,000.00"
assert format_currency(1234567.89) == "$1,234,567.89"
def test_format_usd_explicit(self) -> None:
"""Test formatting USD currency explicitly."""
assert format_currency(100.0, "USD") == "$100.00"
assert format_currency(1000.50, "USD") == "$1,000.50"
def test_format_other_currencies(self) -> None:
"""Test formatting other currencies."""
assert format_currency(100.0, "EUR") == "100.00 EUR"
assert format_currency(1000.50, "GBP") == "1,000.50 GBP"
assert format_currency(1234567.89, "JPY") == "1,234,567.89 JPY"
def test_format_currency_edge_cases(self) -> None:
"""Test edge cases for currency formatting."""
assert format_currency(0.001, "USD") == "$0.00"
assert format_currency(-10.50, "USD") == "$-10.50"
assert format_currency(999999999.99, "USD") == "$999,999,999.99"
class TestGetTimeFormatPreference:
"""Test cases for get_time_format_preference function."""
@patch("claude_monitor.utils.time_utils.TimeFormatDetector.get_preference")
def test_get_time_format_preference_no_args(self, mock_get_pref: Mock) -> None:
"""Test getting time format preference without args."""
mock_get_pref.return_value = True
result = get_time_format_preference()
mock_get_pref.assert_called_once_with(None)
assert result is True
@patch("claude_monitor.utils.time_utils.TimeFormatDetector.get_preference")
def test_get_time_format_preference_with_args(self, mock_get_pref: Mock) -> None:
"""Test getting time format preference with args."""
mock_args = {"time_format": "12h"}
mock_get_pref.return_value = False
result = get_time_format_preference(mock_args)
mock_get_pref.assert_called_once_with(mock_args)
assert result is False
class TestFormatDisplayTime:
"""Test cases for format_display_time function."""
def setUp(self) -> None:
"""Set up test datetime."""
self.test_dt = datetime(2024, 1, 1, 15, 30, 45, tzinfo=timezone.utc)
@patch("claude_monitor.utils.time_utils.get_time_format_preference")
def test_format_display_time_24h_with_seconds(self, mock_pref: Mock) -> None:
"""Test 24-hour format with seconds."""
mock_pref.return_value = False
dt = datetime(2024, 1, 1, 15, 30, 45, tzinfo=timezone.utc)
result = format_display_time(dt, use_12h_format=False, include_seconds=True)
assert result == "15:30:45"
@patch("claude_monitor.utils.time_utils.get_time_format_preference")
def test_format_display_time_24h_without_seconds(self, mock_pref: Mock) -> None:
"""Test 24-hour format without seconds."""
mock_pref.return_value = False
dt = datetime(2024, 1, 1, 15, 30, 45, tzinfo=timezone.utc)
result = format_display_time(dt, use_12h_format=False, include_seconds=False)
assert result == "15:30"
@patch("claude_monitor.utils.time_utils.get_time_format_preference")
def test_format_display_time_12h_with_seconds(self, mock_pref: Mock) -> None:
"""Test 12-hour format with seconds."""
mock_pref.return_value = True
dt = datetime(2024, 1, 1, 15, 30, 45, tzinfo=timezone.utc)
result = format_display_time(dt, use_12h_format=True, include_seconds=True)
# Should be either "3:30:45 PM" (Unix) or "03:30:45 PM" (Windows fallback)
assert "3:30:45 PM" in result or result == "03:30:45 PM"
@patch("claude_monitor.utils.time_utils.get_time_format_preference")
def test_format_display_time_12h_without_seconds(self, mock_pref: Mock) -> None:
"""Test 12-hour format without seconds."""
mock_pref.return_value = True
dt = datetime(2024, 1, 1, 15, 30, 45, tzinfo=timezone.utc)
result = format_display_time(dt, use_12h_format=True, include_seconds=False)
# Should be either "3:30 PM" (Unix) or "03:30 PM" (Windows fallback)
assert "3:30 PM" in result or result == "03:30 PM"
@patch("claude_monitor.utils.time_utils.get_time_format_preference")
def test_format_display_time_auto_preference(self, mock_pref: Mock) -> None:
"""Test automatic preference detection."""
mock_pref.return_value = True
dt = datetime(2024, 1, 1, 15, 30, 45, tzinfo=timezone.utc)
result = format_display_time(dt, use_12h_format=None, include_seconds=True)
mock_pref.assert_called_once()
# Should use 12-hour format since mock returns True
assert "PM" in result
def test_format_display_time_platform_compatibility(self) -> None:
"""Test that format_display_time works on different platforms."""
dt = datetime(2024, 1, 1, 3, 30, 45, tzinfo=timezone.utc)
# Test 12-hour format - should work on both Unix and Windows
result_12h = format_display_time(dt, use_12h_format=True, include_seconds=True)
assert "3:30:45 AM" in result_12h or result_12h == "03:30:45 AM"
# Test 12-hour format without seconds
result_12h_no_sec = format_display_time(
dt, use_12h_format=True, include_seconds=False
)
assert "3:30 AM" in result_12h_no_sec or result_12h_no_sec == "03:30 AM"
def test_format_display_time_edge_cases(self) -> None:
"""Test edge cases for format_display_time."""
# Test noon and midnight
noon = datetime(2024, 1, 1, 12, 0, 0, tzinfo=timezone.utc)
midnight = datetime(2024, 1, 1, 0, 0, 0, tzinfo=timezone.utc)
noon_result = format_display_time(
noon, use_12h_format=True, include_seconds=False
)
midnight_result = format_display_time(
midnight, use_12h_format=True, include_seconds=False
)
# Should contain PM/AM indicators
assert "PM" in noon_result
assert "AM" in midnight_result
class TestFormattingAdvanced:
"""Advanced test cases for formatting utilities."""
def test_format_currency_extensive_edge_cases(self) -> None:
"""Test format_currency with extensive edge cases."""
# Test very small amounts
assert format_currency(0.001, "USD") == "$0.00"
assert format_currency(0.009, "USD") == "$0.01"
# Test negative amounts
assert format_currency(-10.50, "USD") == "$-10.50"
assert format_currency(-0.01, "USD") == "$-0.01"
# Test very large amounts
assert format_currency(999999999.99, "USD") == "$999,999,999.99"
assert format_currency(1000000000.00, "USD") == "$1,000,000,000.00"
# Test other currencies with large amounts
assert format_currency(1234567.89, "EUR") == "1,234,567.89 EUR"
assert format_currency(-1000.50, "GBP") == "-1,000.50 GBP"
def test_format_currency_precision_handling(self) -> None:
"""Test currency formatting precision handling."""
# Test floating point precision issues
assert (
format_currency(0.1 + 0.2, "USD") == "$0.30"
) # Should handle 0.30000000000000004
assert format_currency(10.005, "USD") == "$10.01" # Should round up
assert format_currency(10.004, "USD") == "$10.00" # Should round down
def test_format_currency_international_formats(self) -> None:
"""Test currency formatting for various international formats."""
currencies = [
"JPY",
"KRW",
"INR",
"BRL",
"RUB",
"CNY",
"AUD",
"CAD",
"CHF",
"SEK",
]
for currency in currencies:
result = format_currency(1234.56, currency)
assert "1,234.56" in result
assert currency in result
assert result.endswith(currency)
def test_format_time_comprehensive_coverage(self) -> None:
"""Test format_time with comprehensive edge cases."""
# Test zero and very small values
assert format_time(0.0) == "0m"
assert format_time(0.1) == "0m"
assert format_time(0.9) == "0m"
# Test boundary values around hours
assert format_time(59.9) == "59m"
assert format_time(60.0) == "1h"
assert format_time(60.1) == "1h"
# Test large values
assert format_time(1440) == "24h" # 1 day
assert format_time(2880) == "48h" # 2 days
assert format_time(10080) == "168h" # 1 week
# Test various combinations
assert format_time(65.5) == "1h 5m"
assert format_time(125.7) == "2h 5m"
def test_format_time_extreme_values(self) -> None:
"""Test format_time with extreme values."""
# Test very large values
large_minutes = 100000
result = format_time(large_minutes)
assert "h" in result
assert isinstance(result, str)
# Test negative values (might be unexpected but should handle gracefully)
# Note: This depends on implementation - might need to check actual behavior
def test_format_display_time_comprehensive_platform_support(self) -> None:
"""Test format_display_time comprehensive platform support."""
test_times = [
datetime(2024, 1, 1, 0, 0, 0), # Midnight
datetime(2024, 1, 1, 12, 0, 0), # Noon
datetime(2024, 1, 1, 1, 5, 10), # Early morning
datetime(2024, 1, 1, 23, 59, 59), # Late night
]
for dt in test_times:
# Test 24-hour format
result_24h = format_display_time(
dt, use_12h_format=False, include_seconds=True
)
assert ":" in result_24h
assert len(result_24h.split(":")) == 3 # HH:MM:SS
# Test 12-hour format
result_12h = format_display_time(
dt, use_12h_format=True, include_seconds=True
)
assert ("AM" in result_12h) or ("PM" in result_12h)
def test_get_time_format_preference_edge_cases(self) -> None:
"""Test get_time_format_preference with edge cases."""
# Test with None args
with patch(
"claude_monitor.utils.time_utils.TimeFormatDetector.get_preference"
) as mock_pref:
mock_pref.return_value = True
result = get_time_format_preference(None)
assert result is True
mock_pref.assert_called_once_with(None)
# Test with empty args object
empty_args = type("Args", (), {})()
with patch(
"claude_monitor.utils.time_utils.TimeFormatDetector.get_preference"
) as mock_pref:
mock_pref.return_value = False
result = get_time_format_preference(empty_args)
assert result is False
mock_pref.assert_called_once_with(empty_args)
def test_internal_get_pref_function(self) -> None:
"""Test the internal _get_pref helper function."""
from claude_monitor.utils.formatting import _get_pref
# Test with mock args
mock_args = Mock()
with patch(
"claude_monitor.utils.formatting.get_time_format_preference"
) as mock_pref:
mock_pref.return_value = True
result = _get_pref(mock_args)
assert result is True
mock_pref.assert_called_once_with(mock_args)
class TestFormattingErrorHandling:
"""Test error handling in formatting utilities."""
def test_format_currency_error_conditions(self) -> None:
"""Test format_currency error handling."""
# Test with very large numbers that might cause overflow
try:
result = format_currency(float("inf"), "USD")
# If it doesn't raise an error, should return a string
assert isinstance(result, str)
except (OverflowError, ValueError):
# This is acceptable behavior
pass
# Test with NaN
try:
result = format_currency(float("nan"), "USD")
assert isinstance(result, str)
except ValueError:
# This is acceptable behavior
pass
def test_format_time_error_conditions(self) -> None:
"""Test format_time error handling."""
# Test with negative values
result = format_time(-10)
# Should handle gracefully - exact behavior depends on implementation
assert isinstance(result, str)
# Test with very large values
result = format_time(1e10) # Very large number
assert isinstance(result, str)
def test_format_display_time_invalid_inputs(self) -> None:
"""Test format_display_time with invalid inputs."""
# Test with None datetime
try:
result = format_display_time(None)
# If it doesn't raise an error, should return something sensible
assert isinstance(result, str)
except (AttributeError, TypeError):
# This is expected behavior
pass
class TestFormattingPerformance:
"""Test performance characteristics of formatting utilities."""
def test_format_currency_performance_with_large_datasets(self) -> None:
"""Test format_currency performance with many values."""
import time
# Test formatting many currency values
values = [i * 0.01 for i in range(10000)] # 0.00 to 99.99
start_time = time.time()
results = [format_currency(value, "USD") for value in values]
end_time = time.time()
# Should complete in reasonable time (less than 1 second for 10k values)
assert end_time - start_time < 1.0
assert len(results) == len(values)
assert all(isinstance(r, str) for r in results)
def test_format_time_performance_with_large_datasets(self) -> None:
"""Test format_time performance with many values."""
import time
# Test formatting many time values
values = list(range(10000)) # 0 to 9999 minutes
start_time = time.time()
results = [format_time(value) for value in values]
end_time = time.time()
# Should complete in reasonable time
assert end_time - start_time < 1.0
assert len(results) == len(values)
assert all(isinstance(r, str) for r in results)
class TestModelUtils:
"""Test cases for model utilities."""
def test_normalize_model_name(self) -> None:
"""Test model name normalization."""
# Test Claude 3 models
assert normalize_model_name("claude-3-opus-20240229") == "claude-3-opus"
assert normalize_model_name("claude-3-sonnet-20240229") == "claude-3-sonnet"
assert normalize_model_name("claude-3-haiku-20240307") == "claude-3-haiku"
# Test Claude 3.5 models
assert normalize_model_name("claude-3-5-sonnet-20241022") == "claude-3-5-sonnet"
assert normalize_model_name("Claude 3.5 Sonnet") == "claude-3-5-sonnet"
assert normalize_model_name("claude-3-5-haiku") == "claude-3-5-haiku"
# Test empty/None inputs
assert normalize_model_name("") == ""
assert normalize_model_name(None) == ""
# Test unknown models
assert normalize_model_name("unknown-model") == "unknown-model"
def test_get_model_display_name(self) -> None:
"""Test model display name generation."""
# Test known models
assert get_model_display_name("claude-3-opus") == "Claude 3 Opus"
assert get_model_display_name("claude-3-sonnet") == "Claude 3 Sonnet"
assert get_model_display_name("claude-3-haiku") == "Claude 3 Haiku"
assert get_model_display_name("claude-3-5-sonnet") == "Claude 3.5 Sonnet"
assert get_model_display_name("claude-3-5-haiku") == "Claude 3.5 Haiku"
# Test unknown models (should title case)
assert get_model_display_name("unknown-model") == "Unknown-Model"
assert get_model_display_name("gpt-4") == "Gpt-4"
def test_is_claude_model(self) -> None:
"""Test Claude model detection."""
# Test Claude models
assert is_claude_model("claude-3-opus") is True
assert is_claude_model("claude-3-sonnet") is True
assert is_claude_model("claude-3-5-sonnet") is True
assert is_claude_model("Claude 3 Opus") is True
# Test non-Claude models
assert is_claude_model("gpt-4") is False
assert is_claude_model("gemini-pro") is False
assert is_claude_model("") is False
def test_get_model_generation(self) -> None:
"""Test model generation extraction."""
# Test Claude 3.5 models
assert get_model_generation("claude-3-5-sonnet") == "3.5"
assert get_model_generation("claude-3.5-sonnet") == "3.5"
assert get_model_generation("claude-3.5-haiku") == "3.5"
# Test Claude 3 models
assert get_model_generation("claude-3-opus") == "3"
assert get_model_generation("claude-3-sonnet") == "3"
assert get_model_generation("claude-3-haiku") == "3"
# Test Claude 2 models
assert get_model_generation("claude-2") == "2"
assert get_model_generation("claude-2.1") == "2"
# Test Claude 1 models
assert get_model_generation("claude-1") == "1"
assert get_model_generation("claude-instant-1") == "1"
# Test edge cases
assert get_model_generation("") == "unknown"
assert get_model_generation("unknown-model") == "unknown"
assert (
get_model_generation("claude-10") == "unknown"
) # Don't match "1" from "10"
================================================
FILE: src/tests/test_monitoring_orchestrator.py
================================================
"""Comprehensive tests for monitoring orchestrator module."""
import threading
import time
from typing import Any, Dict, List, Tuple, Union
from unittest.mock import Mock, patch
import pytest
from claude_monitor.core.plans import DEFAULT_TOKEN_LIMIT
from claude_monitor.monitoring.orchestrator import MonitoringOrchestrator
@pytest.fixture
def mock_data_manager() -> Mock:
"""Mock DataManager for testing."""
mock = Mock()
mock.get_data.return_value = {
"blocks": [
{
"id": "session_1",
"isActive": True,
"totalTokens": 1000,
"costUSD": 0.05,
"startTime": "2024-01-01T12:00:00Z",
}
]
}
return mock
@pytest.fixture
def mock_session_monitor() -> Mock:
"""Mock SessionMonitor for testing."""
mock = Mock()
mock.update.return_value = (True, []) # (is_valid, errors)
mock.current_session_id = "session_1"
mock.session_count = 1
return mock
@pytest.fixture
def orchestrator(
mock_data_manager: Mock, mock_session_monitor: Mock
) -> MonitoringOrchestrator:
"""Create orchestrator with mocked dependencies."""
with (
patch(
"claude_monitor.monitoring.orchestrator.DataManager",
return_value=mock_data_manager,
),
patch(
"claude_monitor.monitoring.orchestrator.SessionMonitor",
return_value=mock_session_monitor,
),
):
return MonitoringOrchestrator(update_interval=1)
class TestMonitoringOrchestratorInit:
"""Test orchestrator initialization."""
def test_init_with_defaults(self) -> None:
"""Test initialization with default parameters."""
with (
patch("claude_monitor.monitoring.orchestrator.DataManager") as mock_dm,
patch("claude_monitor.monitoring.orchestrator.SessionMonitor") as mock_sm,
):
orchestrator = MonitoringOrchestrator()
assert orchestrator.update_interval == 10
assert not orchestrator._monitoring
assert orchestrator._monitor_thread is None
assert orchestrator._args is None
assert orchestrator._last_valid_data is None
assert len(orchestrator._update_callbacks) == 0
mock_dm.assert_called_once_with(cache_ttl=5, data_path=None)
mock_sm.assert_called_once()
def test_init_with_custom_params(self) -> None:
"""Test initialization with custom parameters."""
with (
patch("claude_monitor.monitoring.orchestrator.DataManager") as mock_dm,
patch("claude_monitor.monitoring.orchestrator.SessionMonitor"),
):
orchestrator = MonitoringOrchestrator(
update_interval=5, data_path="/custom/path"
)
assert orchestrator.update_interval == 5
mock_dm.assert_called_once_with(cache_ttl=5, data_path="/custom/path")
class TestMonitoringOrchestratorLifecycle:
"""Test orchestrator start/stop lifecycle."""
def test_start_monitoring(self, orchestrator: MonitoringOrchestrator) -> None:
"""Test starting monitoring creates thread."""
assert not orchestrator._monitoring
orchestrator.start()
assert orchestrator._monitoring
assert orchestrator._monitor_thread is not None
assert orchestrator._monitor_thread.is_alive()
assert orchestrator._monitor_thread.name == "MonitoringThread"
assert orchestrator._monitor_thread.daemon
orchestrator.stop()
def test_start_monitoring_already_running(
self, orchestrator: MonitoringOrchestrator
) -> None:
"""Test starting monitoring when already running."""
orchestrator._monitoring = True
with patch("claude_monitor.monitoring.orchestrator.logger") as mock_logger:
orchestrator.start()
mock_logger.warning.assert_called_once_with("Monitoring already running")
def test_stop_monitoring(self, orchestrator: MonitoringOrchestrator) -> None:
"""Test stopping monitoring."""
orchestrator.start()
assert orchestrator._monitoring
orchestrator.stop()
assert not orchestrator._monitoring
assert orchestrator._monitor_thread is None
def test_stop_monitoring_not_running(
self, orchestrator: MonitoringOrchestrator
) -> None:
"""Test stopping monitoring when not running."""
assert not orchestrator._monitoring
orchestrator.stop() # Should not raise
assert not orchestrator._monitoring
def test_stop_monitoring_with_timeout(
self, orchestrator: MonitoringOrchestrator
) -> None:
"""Test stopping monitoring handles thread join timeout."""
orchestrator.start()
# Mock thread that doesn't die quickly
mock_thread = Mock()
mock_thread.is_alive.return_value = True
orchestrator._monitor_thread = mock_thread
orchestrator.stop()
mock_thread.join.assert_called_once_with(timeout=5)
class TestMonitoringOrchestratorCallbacks:
"""Test callback registration and handling."""
def test_register_update_callback(
self, orchestrator: MonitoringOrchestrator
) -> None:
"""Test registering update callback."""
callback = Mock()
orchestrator.register_update_callback(callback)
assert callback in orchestrator._update_callbacks
def test_register_duplicate_callback(
self, orchestrator: MonitoringOrchestrator
) -> None:
"""Test registering same callback twice only adds once."""
callback = Mock()
orchestrator.register_update_callback(callback)
orchestrator.register_update_callback(callback)
assert orchestrator._update_callbacks.count(callback) == 1
def test_register_session_callback(
self, orchestrator: MonitoringOrchestrator
) -> None:
"""Test registering session callback delegates to session monitor."""
callback = Mock()
orchestrator.register_session_callback(callback)
orchestrator.session_monitor.register_callback.assert_called_once_with(callback)
class TestMonitoringOrchestratorDataProcessing:
"""Test data fetching and processing."""
def test_force_refresh(self, orchestrator: MonitoringOrchestrator) -> None:
"""Test force refresh calls data manager."""
expected_data: Dict[str, List[Dict[str, str]]] = {"blocks": [{"id": "test"}]}
orchestrator.data_manager.get_data.return_value = expected_data
result = orchestrator.force_refresh()
assert result is not None
assert "data" in result
assert result["data"] == expected_data
orchestrator.data_manager.get_data.assert_called_once_with(force_refresh=True)
def test_force_refresh_no_data(self, orchestrator: MonitoringOrchestrator) -> None:
"""Test force refresh when no data available."""
orchestrator.data_manager.get_data.return_value = None
result = orchestrator.force_refresh()
assert result is None
def test_set_args(self, orchestrator: MonitoringOrchestrator) -> None:
"""Test setting command line arguments."""
args = Mock()
args.plan = "pro"
orchestrator.set_args(args)
assert orchestrator._args == args
def test_wait_for_initial_data_success(
self, orchestrator: MonitoringOrchestrator
) -> None:
"""Test waiting for initial data returns True when data received."""
# Start monitoring which will trigger initial data
orchestrator.start()
# Mock the first data event as set
orchestrator._first_data_event.set()
result = orchestrator.wait_for_initial_data(timeout=1.0)
assert result is True
orchestrator.stop()
def test_wait_for_initial_data_timeout(
self, orchestrator: MonitoringOrchestrator
) -> None:
"""Test waiting for initial data returns False on timeout."""
# Don't start monitoring, so no data will be received
result = orchestrator.wait_for_initial_data(timeout=0.1)
assert result is False
class TestMonitoringOrchestratorMonitoringLoop:
"""Test the monitoring loop behavior."""
def test_monitoring_loop_initial_fetch(
self, orchestrator: MonitoringOrchestrator
) -> None:
"""Test monitoring loop performs initial fetch."""
with patch.object(orchestrator, "_fetch_and_process_data") as mock_fetch:
mock_fetch.return_value = {"test": "data"}
# Start and quickly stop to test initial fetch
orchestrator.start()
time.sleep(0.1) # Let it run briefly
orchestrator.stop()
# Should have called fetch at least once for initial fetch
assert mock_fetch.call_count >= 1
def test_monitoring_loop_periodic_updates(
self, orchestrator: MonitoringOrchestrator
) -> None:
"""Test monitoring loop performs periodic updates."""
orchestrator.update_interval = 0.1 # Very fast for testing
with patch.object(orchestrator, "_fetch_and_process_data") as mock_fetch:
mock_fetch.return_value = {"test": "data"}
orchestrator.start()
time.sleep(0.3) # Let it run for multiple intervals
orchestrator.stop()
# Should have called fetch multiple times
assert mock_fetch.call_count >= 2
def test_monitoring_loop_stop_event(
self, orchestrator: MonitoringOrchestrator
) -> None:
"""Test monitoring loop respects stop event."""
with patch.object(orchestrator, "_fetch_and_process_data") as mock_fetch:
mock_fetch.return_value = {"test": "data"}
orchestrator.start()
# Stop immediately
orchestrator._stop_event.set()
orchestrator._monitoring = False
time.sleep(0.1) # Give it time to stop
# Should have minimal calls
assert mock_fetch.call_count <= 2
class TestMonitoringOrchestratorFetchAndProcess:
"""Test data fetching and processing logic."""
def test_fetch_and_process_success(
self, orchestrator: MonitoringOrchestrator
) -> None:
"""Test successful data fetch and processing."""
test_data: Dict[str, List[Dict[str, Union[str, bool, int, float]]]] = {
"blocks": [
{
"id": "session_1",
"isActive": True,
"totalTokens": 1500,
"costUSD": 0.075,
}
]
}
orchestrator.data_manager.get_data.return_value = test_data
orchestrator.session_monitor.update.return_value = (True, [])
# Set args for token limit calculation
args = Mock()
args.plan = "pro"
orchestrator.set_args(args)
with patch(
"claude_monitor.monitoring.orchestrator.get_token_limit",
return_value=200000,
):
result = orchestrator._fetch_and_process_data()
assert result is not None
assert result["data"] == test_data
assert result["token_limit"] == 200000
assert result["args"] == args
assert result["session_id"] == "session_1"
assert result["session_count"] == 1
assert orchestrator._last_valid_data == result
def test_fetch_and_process_no_data(
self, orchestrator: MonitoringOrchestrator
) -> None:
"""Test fetch and process when no data available."""
orchestrator.data_manager.get_data.return_value = None
result = orchestrator._fetch_and_process_data()
assert result is None
def test_fetch_and_process_validation_failure(
self, orchestrator: MonitoringOrchestrator
) -> None:
"""Test fetch and process with validation failure."""
test_data: Dict[str, List[Any]] = {"blocks": []}
orchestrator.data_manager.get_data.return_value = test_data
orchestrator.session_monitor.update.return_value = (False, ["Validation error"])
result = orchestrator._fetch_and_process_data()
assert result is None
def test_fetch_and_process_callback_success(
self, orchestrator: MonitoringOrchestrator
) -> None:
"""Test fetch and process calls callbacks successfully."""
test_data: Dict[str, List[Dict[str, Union[str, bool, int, float]]]] = {
"blocks": [
{"id": "test", "isActive": True, "totalTokens": 100, "costUSD": 0.01}
]
}
orchestrator.data_manager.get_data.return_value = test_data
callback1 = Mock()
callback2 = Mock()
orchestrator.register_update_callback(callback1)
orchestrator.register_update_callback(callback2)
with patch(
"claude_monitor.monitoring.orchestrator.get_token_limit",
return_value=200000,
):
result = orchestrator._fetch_and_process_data()
assert result is not None
callback1.assert_called_once()
callback2.assert_called_once()
# Check callback was called with correct data
call_args = callback1.call_args[0][0]
assert call_args["data"] == test_data
assert call_args["token_limit"] == 19000 # Default PRO plan limit
def test_fetch_and_process_callback_error(
self, orchestrator: MonitoringOrchestrator
) -> None:
"""Test fetch and process handles callback errors."""
test_data: Dict[str, List[Dict[str, Union[str, bool, int, float]]]] = {
"blocks": [
{"id": "test", "isActive": True, "totalTokens": 100, "costUSD": 0.01}
]
}
orchestrator.data_manager.get_data.return_value = test_data
callback_error = Mock(side_effect=Exception("Callback failed"))
callback_success = Mock()
orchestrator.register_update_callback(callback_error)
orchestrator.register_update_callback(callback_success)
with (
patch(
"claude_monitor.monitoring.orchestrator.get_token_limit",
return_value=200000,
),
patch("claude_monitor.monitoring.orchestrator.report_error") as mock_report,
):
result = orchestrator._fetch_and_process_data()
assert result is not None # Should still return data despite callback error
callback_success.assert_called_once() # Other callbacks should still work
mock_report.assert_called_once()
def test_fetch_and_process_exception_handling(
self, orchestrator: MonitoringOrchestrator
) -> None:
"""Test fetch and process handles exceptions."""
orchestrator.data_manager.get_data.side_effect = Exception("Fetch failed")
with patch(
"claude_monitor.monitoring.orchestrator.report_error"
) as mock_report:
result = orchestrator._fetch_and_process_data()
assert result is None
mock_report.assert_called_once()
def test_fetch_and_process_first_data_event(
self, orchestrator: MonitoringOrchestrator
) -> None:
"""Test fetch and process sets first data event."""
test_data: Dict[str, List[Dict[str, Union[str, bool, int, float]]]] = {
"blocks": [
{"id": "test", "isActive": True, "totalTokens": 100, "costUSD": 0.01}
]
}
orchestrator.data_manager.get_data.return_value = test_data
assert not orchestrator._first_data_event.is_set()
with patch(
"claude_monitor.monitoring.orchestrator.get_token_limit",
return_value=200000,
):
orchestrator._fetch_and_process_data()
assert orchestrator._first_data_event.is_set()
class TestMonitoringOrchestratorTokenLimitCalculation:
"""Test token limit calculation logic."""
def test_calculate_token_limit_no_args(
self, orchestrator: MonitoringOrchestrator
) -> None:
"""Test token limit calculation without args."""
data: Dict[str, List[Any]] = {"blocks": []}
result = orchestrator._calculate_token_limit(data)
assert result == DEFAULT_TOKEN_LIMIT
def test_calculate_token_limit_pro_plan(
self, orchestrator: MonitoringOrchestrator
) -> None:
"""Test token limit calculation for pro plan."""
args = Mock()
args.plan = "pro"
orchestrator.set_args(args)
data: Dict[str, List[Any]] = {"blocks": []}
with patch(
"claude_monitor.monitoring.orchestrator.get_token_limit",
return_value=200000,
) as mock_get_limit:
result = orchestrator._calculate_token_limit(data)
assert result == 200000
mock_get_limit.assert_called_once_with("pro")
def test_calculate_token_limit_custom_plan(
self, orchestrator: MonitoringOrchestrator
) -> None:
"""Test token limit calculation for custom plan."""
args = Mock()
args.plan = "custom"
orchestrator.set_args(args)
blocks_data: List[Dict[str, int]] = [
{"totalTokens": 1000},
{"totalTokens": 1500},
]
data: Dict[str, List[Dict[str, int]]] = {"blocks": blocks_data}
with patch(
"claude_monitor.monitoring.orchestrator.get_token_limit",
return_value=175000,
) as mock_get_limit:
result = orchestrator._calculate_token_limit(data)
assert result == 175000
mock_get_limit.assert_called_once_with("custom", blocks_data)
def test_calculate_token_limit_exception(
self, orchestrator: MonitoringOrchestrator
) -> None:
"""Test token limit calculation handles exceptions."""
args = Mock()
args.plan = "pro"
orchestrator.set_args(args)
data: Dict[str, List[Any]] = {"blocks": []}
with patch(
"claude_monitor.monitoring.orchestrator.get_token_limit",
side_effect=Exception("Calculation failed"),
):
result = orchestrator._calculate_token_limit(data)
assert result == DEFAULT_TOKEN_LIMIT
class TestMonitoringOrchestratorIntegration:
"""Test integration scenarios."""
def test_full_monitoring_cycle(self, orchestrator: MonitoringOrchestrator) -> None:
"""Test complete monitoring cycle."""
# Setup test data
test_data: Dict[str, List[Dict[str, Union[str, bool, int, float]]]] = {
"blocks": [
{
"id": "session_1",
"isActive": True,
"totalTokens": 1200,
"costUSD": 0.06,
}
]
}
orchestrator.data_manager.get_data.return_value = test_data
# Setup callback to capture monitoring data
captured_data: List[Dict[str, Any]] = []
def capture_callback(data: Dict[str, Any]) -> None:
captured_data.append(data)
orchestrator.register_update_callback(capture_callback)
# Set args
args = Mock()
args.plan = "pro"
orchestrator.set_args(args)
with patch(
"claude_monitor.monitoring.orchestrator.get_token_limit",
return_value=200000,
):
# Start monitoring
orchestrator.start()
# Wait for initial data
success = orchestrator.wait_for_initial_data(timeout=2.0)
assert success
# Stop monitoring
orchestrator.stop()
# Verify callback was called with correct data
assert len(captured_data) >= 1
data = captured_data[0]
assert data["data"] == test_data
assert data["token_limit"] == 200000
assert data["session_id"] == "session_1"
assert data["session_count"] == 1
def test_monitoring_with_session_changes(
self, orchestrator: MonitoringOrchestrator
) -> None:
"""Test monitoring responds to session changes."""
# Setup initial data
initial_data: Dict[str, List[Dict[str, Union[str, bool, int, float]]]] = {
"blocks": [
{
"id": "session_1",
"isActive": True,
"totalTokens": 1000,
"costUSD": 0.05,
}
]
}
# Setup changed data
changed_data: Dict[str, List[Dict[str, Union[str, bool, int, float]]]] = {
"blocks": [
{
"id": "session_2",
"isActive": True,
"totalTokens": 1500,
"costUSD": 0.075,
}
]
}
# Mock data manager to return different data on subsequent calls
call_count = 0
def mock_get_data(
force_refresh: bool = False,
) -> Dict[str, List[Dict[str, Union[str, bool, int, float]]]]:
nonlocal call_count
call_count += 1
return initial_data if call_count == 1 else changed_data
orchestrator.data_manager.get_data.side_effect = mock_get_data
# Mock session monitor to return different session IDs
session_call_count = 0
def mock_update(data: Dict[str, Any]) -> Tuple[bool, List[str]]:
nonlocal session_call_count
session_call_count += 1
orchestrator.session_monitor.current_session_id = (
f"session_{session_call_count}"
)
orchestrator.session_monitor.session_count = session_call_count
return (True, [])
orchestrator.session_monitor.update.side_effect = mock_update
# Capture callback data
captured_data: List[Dict[str, Any]] = []
orchestrator.register_update_callback(lambda data: captured_data.append(data))
with patch(
"claude_monitor.monitoring.orchestrator.get_token_limit",
return_value=200000,
):
# Process initial data
result1 = orchestrator._fetch_and_process_data()
assert result1["session_id"] == "session_1"
# Process changed data
result2 = orchestrator._fetch_and_process_data()
assert result2["session_id"] == "session_2"
# Verify both updates were captured
assert len(captured_data) >= 2
def test_monitoring_error_recovery(
self, orchestrator: MonitoringOrchestrator
) -> None:
"""Test monitoring recovers from errors."""
# Setup data manager to fail then succeed
call_count = 0
def mock_get_data(
force_refresh: bool = False,
) -> Dict[str, List[Dict[str, Union[str, bool, int, float]]]]:
nonlocal call_count
call_count += 1
if call_count == 1:
raise Exception("Network error")
return {
"blocks": [
{
"id": "test",
"isActive": True,
"totalTokens": 100,
"costUSD": 0.01,
}
]
}
orchestrator.data_manager.get_data.side_effect = mock_get_data
with patch(
"claude_monitor.monitoring.orchestrator.report_error"
) as mock_report:
# First call should fail
result1 = orchestrator._fetch_and_process_data()
assert result1 is None
mock_report.assert_called_once()
# Second call should succeed
with patch(
"claude_monitor.monitoring.orchestrator.get_token_limit",
return_value=200000,
):
result2 = orchestrator._fetch_and_process_data()
assert result2 is not None
assert result2["data"]["blocks"][0]["id"] == "test"
class TestMonitoringOrchestratorThreadSafety:
"""Test thread safety of orchestrator."""
def test_concurrent_callback_registration(
self, orchestrator: MonitoringOrchestrator
) -> None:
"""Test thread-safe callback registration."""
callbacks: List[Mock] = []
def register_callbacks() -> None:
for i in range(10):
callback = Mock()
callback.name = f"callback_{i}"
callbacks.append(callback)
orchestrator.register_update_callback(callback)
# Register callbacks from multiple threads
threads = []
for _ in range(3):
thread = threading.Thread(target=register_callbacks)
threads.append(thread)
thread.start()
for thread in threads:
thread.join()
# All callbacks should be registered
assert len(orchestrator._update_callbacks) == 30
def test_concurrent_start_stop(self, orchestrator: MonitoringOrchestrator) -> None:
"""Test thread-safe start/stop operations."""
def start_stop_loop() -> None:
for _ in range(5):
orchestrator.start()
time.sleep(0.01)
orchestrator.stop()
time.sleep(0.01)
# Start/stop from multiple threads
threads = []
for _ in range(3):
thread = threading.Thread(target=start_stop_loop)
threads.append(thread)
thread.start()
for thread in threads:
thread.join()
# Should end in stopped state
assert not orchestrator._monitoring
assert orchestrator._monitor_thread is None
class TestMonitoringOrchestratorProperties:
"""Test orchestrator properties and state."""
def test_last_valid_data_property(
self, orchestrator: MonitoringOrchestrator
) -> None:
"""Test last valid data is stored correctly."""
test_data: Dict[str, List[Dict[str, Union[str, bool, int, float]]]] = {
"blocks": [
{"id": "test", "isActive": True, "totalTokens": 100, "costUSD": 0.01}
]
}
orchestrator.data_manager.get_data.return_value = test_data
with patch(
"claude_monitor.monitoring.orchestrator.get_token_limit",
return_value=200000,
):
result = orchestrator._fetch_and_process_data()
assert orchestrator._last_valid_data == result
assert orchestrator._last_valid_data["data"] == test_data
def test_monitoring_state_consistency(
self, orchestrator: MonitoringOrchestrator
) -> None:
"""Test monitoring state remains consistent."""
assert not orchestrator._monitoring
assert orchestrator._monitor_thread is None
assert not orchestrator._stop_event.is_set()
orchestrator.start()
assert orchestrator._monitoring
assert orchestrator._monitor_thread is not None
assert not orchestrator._stop_event.is_set()
orchestrator.stop()
assert not orchestrator._monitoring
assert orchestrator._monitor_thread is None
# stop_event may remain set after stopping
class TestSessionMonitor:
"""Test session monitoring functionality."""
def test_session_monitor_init(self) -> None:
"""Test SessionMonitor initialization."""
from claude_monitor.monitoring.session_monitor import SessionMonitor
monitor = SessionMonitor()
assert monitor._current_session_id is None
assert monitor._session_callbacks == []
assert monitor._session_history == []
def test_session_monitor_update_valid_data(self) -> None:
"""Test updating session monitor with valid data."""
from claude_monitor.monitoring.session_monitor import SessionMonitor
monitor = SessionMonitor()
data: Dict[str, List[Dict[str, Union[str, bool, int, float]]]] = {
"blocks": [
{
"id": "session_1",
"isActive": True,
"totalTokens": 1000,
"costUSD": 0.05,
"startTime": "2024-01-01T12:00:00Z",
}
]
}
is_valid, errors = monitor.update(data)
assert is_valid is True
assert errors == []
def test_session_monitor_update_invalid_data(self) -> None:
"""Test updating session monitor with invalid data."""
from claude_monitor.monitoring.session_monitor import SessionMonitor
monitor = SessionMonitor()
# Test with None data
is_valid, errors = monitor.update(None)
assert is_valid is False
assert len(errors) > 0
def test_session_monitor_validation_empty_data(self) -> None:
"""Test data validation with empty data."""
from claude_monitor.monitoring.session_monitor import SessionMonitor
monitor = SessionMonitor()
# Test empty dict
is_valid, errors = monitor.validate_data({})
assert isinstance(is_valid, bool)
assert isinstance(errors, list)
def test_session_monitor_validation_missing_blocks(self) -> None:
"""Test data validation with missing blocks."""
from claude_monitor.monitoring.session_monitor import SessionMonitor
monitor = SessionMonitor()
data: Dict[str, Dict[str, str]] = {"metadata": {"version": "1.0"}}
is_valid, errors = monitor.validate_data(data)
assert isinstance(is_valid, bool)
assert isinstance(errors, list)
def test_session_monitor_validation_invalid_blocks(self) -> None:
"""Test data validation with invalid blocks."""
from claude_monitor.monitoring.session_monitor import SessionMonitor
monitor = SessionMonitor()
data: Dict[str, str] = {"blocks": "not_a_list"}
is_valid, errors = monitor.validate_data(data)
assert is_valid is False
assert len(errors) > 0
def test_session_monitor_register_callback(self) -> None:
"""Test registering session callbacks."""
from claude_monitor.monitoring.session_monitor import SessionMonitor
monitor = SessionMonitor()
callback = Mock()
monitor.register_callback(callback)
assert callback in monitor._session_callbacks
def test_session_monitor_callback_execution(self) -> None:
"""Test that callbacks are executed on session change."""
from claude_monitor.monitoring.session_monitor import SessionMonitor
monitor = SessionMonitor()
callback = Mock()
monitor.register_callback(callback)
# First update - should trigger callback for new session
data: Dict[str, List[Dict[str, Union[str, bool, int, float]]]] = {
"blocks": [
{
"id": "session_1",
"isActive": True,
"totalTokens": 1000,
"costUSD": 0.05,
"startTime": "2024-01-01T12:00:00Z",
}
]
}
monitor.update(data)
# Callback may or may not be called depending on implementation
# Just verify the structure is maintained
assert isinstance(monitor._session_callbacks, list)
def test_session_monitor_session_history(self) -> None:
"""Test session history tracking."""
from claude_monitor.monitoring.session_monitor import SessionMonitor
monitor = SessionMonitor()
data: Dict[str, List[Dict[str, Union[str, bool, int, float]]]] = {
"blocks": [
{
"id": "session_1",
"isActive": True,
"totalTokens": 1000,
"costUSD": 0.05,
"startTime": "2024-01-01T12:00:00Z",
}
]
}
monitor.update(data)
# History may or may not change depending on implementation
assert isinstance(monitor._session_history, list)
def test_session_monitor_current_session_tracking(self) -> None:
"""Test current session ID tracking."""
from claude_monitor.monitoring.session_monitor import SessionMonitor
monitor = SessionMonitor()
data: Dict[str, List[Dict[str, Union[str, bool, int, float]]]] = {
"blocks": [
{
"id": "session_1",
"isActive": True,
"totalTokens": 1000,
"costUSD": 0.05,
"startTime": "2024-01-01T12:00:00Z",
}
]
}
monitor.update(data)
# Current session ID may be set depending on implementation
assert isinstance(monitor._current_session_id, (str, type(None)))
def test_session_monitor_multiple_blocks(self) -> None:
"""Test session monitor with multiple blocks."""
from claude_monitor.monitoring.session_monitor import SessionMonitor
monitor = SessionMonitor()
data: Dict[str, List[Dict[str, Union[str, bool, int, float]]]] = {
"blocks": [
{
"id": "session_1",
"isActive": False,
"totalTokens": 1000,
"costUSD": 0.05,
"startTime": "2024-01-01T12:00:00Z",
},
{
"id": "session_2",
"isActive": True,
"totalTokens": 500,
"costUSD": 0.02,
"startTime": "2024-01-01T13:00:00Z",
},
]
}
is_valid, errors = monitor.update(data)
assert isinstance(is_valid, bool)
assert isinstance(errors, list)
def test_session_monitor_no_active_session(self) -> None:
"""Test session monitor with no active sessions."""
from claude_monitor.monitoring.session_monitor import SessionMonitor
monitor = SessionMonitor()
data: Dict[str, List[Dict[str, Union[str, bool, int, float]]]] = {
"blocks": [
{
"id": "session_1",
"isActive": False,
"totalTokens": 1000,
"costUSD": 0.05,
"startTime": "2024-01-01T12:00:00Z",
}
]
}
is_valid, errors = monitor.update(data)
assert isinstance(is_valid, bool)
assert isinstance(errors, list)
================================================
FILE: src/tests/test_pricing.py
================================================
"""Comprehensive tests for PricingCalculator class."""
from typing import Dict, List, Union
import pytest
from claude_monitor.core.models import CostMode, TokenCounts
from claude_monitor.core.pricing import PricingCalculator
class TestPricingCalculator:
"""Test suite for PricingCalculator class."""
@pytest.fixture
def calculator(self) -> PricingCalculator:
"""Create a PricingCalculator with default pricing."""
return PricingCalculator()
@pytest.fixture
def custom_pricing(self) -> Dict[str, Dict[str, float]]:
"""Custom pricing configuration for testing."""
return {
"test-model": {
"input": 1.0,
"output": 2.0,
"cache_creation": 1.5,
"cache_read": 0.1,
}
}
@pytest.fixture
def custom_calculator(
self, custom_pricing: Dict[str, Dict[str, float]]
) -> PricingCalculator:
"""Create a PricingCalculator with custom pricing."""
return PricingCalculator(custom_pricing)
@pytest.fixture
def sample_entry_data(self) -> Dict[str, Union[str, int, None]]:
"""Sample entry data for testing."""
return {
"model": "claude-3-haiku",
"input_tokens": 1000,
"output_tokens": 500,
"cache_creation_tokens": 100,
"cache_read_tokens": 50,
"cost_usd": None,
}
@pytest.fixture
def token_counts(self) -> TokenCounts:
"""Sample TokenCounts object."""
return TokenCounts(
input_tokens=1000,
output_tokens=500,
cache_creation_tokens=100,
cache_read_tokens=50,
)
def test_init_default_pricing(self, calculator: PricingCalculator) -> None:
"""Test initialization with default pricing."""
assert calculator.pricing is not None
assert "claude-3-opus" in calculator.pricing
assert "claude-3-sonnet" in calculator.pricing
assert "claude-3-haiku" in calculator.pricing
assert "claude-3-5-sonnet" in calculator.pricing
assert calculator._cost_cache == {}
def test_init_custom_pricing(
self,
custom_calculator: PricingCalculator,
custom_pricing: Dict[str, Dict[str, float]],
) -> None:
"""Test initialization with custom pricing."""
assert custom_calculator.pricing == custom_pricing
assert custom_calculator._cost_cache == {}
def test_fallback_pricing_structure(self, calculator: PricingCalculator) -> None:
"""Test that fallback pricing has correct structure."""
fallback = PricingCalculator.FALLBACK_PRICING
for model_type in ["opus", "sonnet", "haiku"]:
assert model_type in fallback
pricing = fallback[model_type]
assert "input" in pricing
assert "output" in pricing
assert "cache_creation" in pricing
assert "cache_read" in pricing
# Verify pricing values are positive
assert pricing["input"] > 0
assert pricing["output"] > pricing["input"] # Output typically costs more
assert (
pricing["cache_creation"] > pricing["input"]
) # Cache creation costs more
assert pricing["cache_read"] < pricing["input"] # Cache read costs less
def test_calculate_cost_claude_3_haiku_basic(
self, calculator: PricingCalculator
) -> None:
"""Test cost calculation for Claude 3 Haiku with basic tokens."""
cost = calculator.calculate_cost(
model="claude-3-haiku", input_tokens=1000, output_tokens=500
)
# Expected: (1000 * 0.25 + 500 * 1.25) / 1000000
expected = (1000 * 0.25 + 500 * 1.25) / 1000000
assert abs(cost - expected) < 1e-6
def test_calculate_cost_claude_3_opus_with_cache(
self, calculator: PricingCalculator
) -> None:
"""Test cost calculation for Claude 3 Opus with cache tokens."""
cost = calculator.calculate_cost(
model="claude-3-opus",
input_tokens=1000,
output_tokens=500,
cache_creation_tokens=100,
cache_read_tokens=50,
)
# Expected calculation based on Opus pricing
expected = (
1000 * 15.0 # input
+ 500 * 75.0 # output
+ 100 * 18.75 # cache creation
+ 50 * 1.5 # cache read
) / 1000000
assert abs(cost - expected) < 1e-6
def test_calculate_cost_claude_3_sonnet(
self, calculator: PricingCalculator
) -> None:
"""Test cost calculation for Claude 3 Sonnet."""
cost = calculator.calculate_cost(
model="claude-3-sonnet", input_tokens=2000, output_tokens=1000
)
expected = (2000 * 3.0 + 1000 * 15.0) / 1000000
assert abs(cost - expected) < 1e-6
def test_calculate_cost_claude_3_5_sonnet(
self, calculator: PricingCalculator
) -> None:
"""Test cost calculation for Claude 3.5 Sonnet (should use sonnet pricing)."""
cost = calculator.calculate_cost(
model="claude-3-5-sonnet", input_tokens=1000, output_tokens=500
)
expected = (1000 * 3.0 + 500 * 15.0) / 1000000
assert abs(cost - expected) < 1e-6
def test_calculate_cost_with_token_counts_object(
self, calculator: PricingCalculator, token_counts: TokenCounts
) -> None:
"""Test cost calculation using TokenCounts object."""
cost = calculator.calculate_cost(model="claude-3-haiku", tokens=token_counts)
expected = (
1000 * 0.25 # input
+ 500 * 1.25 # output
+ 100 * 0.3 # cache creation
+ 50 * 0.03 # cache read
) / 1000000
assert abs(cost - expected) < 1e-6
def test_calculate_cost_token_counts_overrides_individual_params(
self, calculator: PricingCalculator, token_counts: TokenCounts
) -> None:
"""Test that TokenCounts object takes precedence over individual parameters."""
cost = calculator.calculate_cost(
model="claude-3-haiku",
input_tokens=9999, # Should be ignored
output_tokens=9999, # Should be ignored
tokens=token_counts,
)
# Should use values from token_counts, not the individual parameters
expected = (
1000 * 0.25 # from token_counts
+ 500 * 1.25 # from token_counts
+ 100 * 0.3 # from token_counts
+ 50 * 0.03 # from token_counts
) / 1000000
assert abs(cost - expected) < 1e-6
def test_calculate_cost_synthetic_model(
self, calculator: PricingCalculator
) -> None:
"""Test that synthetic model returns zero cost."""
cost = calculator.calculate_cost(
model="", input_tokens=1000, output_tokens=500
)
assert cost == 0.0
def test_calculate_cost_unknown_model(self, calculator: PricingCalculator) -> None:
"""Test cost calculation for unknown model (should raise KeyError in strict mode)."""
with pytest.raises(KeyError):
calculator.calculate_cost(
model="unknown-model", input_tokens=1000, output_tokens=500, strict=True
)
def test_calculate_cost_zero_tokens(self, calculator: PricingCalculator) -> None:
"""Test cost calculation with zero tokens."""
cost = calculator.calculate_cost(
model="claude-3-haiku", input_tokens=0, output_tokens=0
)
assert cost == 0.0
def test_calculate_cost_for_entry_auto_mode(
self,
calculator: PricingCalculator,
sample_entry_data: Dict[str, Union[str, int, None]],
) -> None:
"""Test calculate_cost_for_entry with AUTO mode."""
cost = calculator.calculate_cost_for_entry(sample_entry_data, CostMode.AUTO)
expected = (
1000 * 0.25 # input
+ 500 * 1.25 # output
+ 100 * 0.3 # cache creation
+ 50 * 0.03 # cache read
) / 1000000
assert abs(cost - expected) < 1e-6
def test_calculate_cost_for_entry_cached_mode_with_existing_cost(
self, calculator: PricingCalculator
) -> None:
"""Test calculate_cost_for_entry with CACHED mode and existing cost."""
entry_data: Dict[str, Union[str, int, float]] = {
"model": "claude-3-haiku",
"input_tokens": 1000,
"output_tokens": 500,
"cost_usd": 0.123, # Pre-existing cost
}
cost = calculator.calculate_cost_for_entry(entry_data, CostMode.CACHED)
assert cost == 0.123
def test_calculate_cost_for_entry_cached_mode_without_existing_cost(
self,
calculator: PricingCalculator,
sample_entry_data: Dict[str, Union[str, int, None]],
) -> None:
"""Test calculate_cost_for_entry with CACHED mode but no existing cost."""
cost = calculator.calculate_cost_for_entry(sample_entry_data, CostMode.CACHED)
# Should fall back to calculation since no existing cost
expected = (1000 * 0.25 + 500 * 1.25 + 100 * 0.3 + 50 * 0.03) / 1000000
assert abs(cost - expected) < 1e-6
def test_calculate_cost_for_entry_calculated_mode(
self, calculator: PricingCalculator
) -> None:
"""Test calculate_cost_for_entry with CALCULATED mode."""
entry_data: Dict[str, Union[str, int, float]] = {
"model": "claude-3-opus",
"input_tokens": 500,
"output_tokens": 250,
"cost_usd": 0.999, # Should be ignored in CALCULATED mode
}
cost = calculator.calculate_cost_for_entry(entry_data, CostMode.CALCULATED)
# Should calculate cost regardless of existing cost_usd
expected = (500 * 15.0 + 250 * 75.0) / 1000000
assert abs(cost - expected) < 1e-6
def test_calculate_cost_for_entry_missing_model(
self, calculator: PricingCalculator
) -> None:
"""Test calculate_cost_for_entry with missing model."""
entry_data: Dict[str, int] = {
"input_tokens": 1000,
"output_tokens": 500,
# Missing "model" key
}
with pytest.raises(KeyError):
calculator.calculate_cost_for_entry(entry_data, CostMode.AUTO)
def test_calculate_cost_for_entry_with_defaults(
self, calculator: PricingCalculator
) -> None:
"""Test calculate_cost_for_entry with minimal data (should use defaults)."""
entry_data: Dict[str, str] = {
"model": "claude-3-haiku"
# Missing token counts - should default to 0
}
cost = calculator.calculate_cost_for_entry(entry_data, CostMode.AUTO)
assert cost == 0.0
def test_custom_pricing_calculator(
self, custom_calculator: PricingCalculator
) -> None:
"""Test calculator with custom pricing."""
cost = custom_calculator.calculate_cost(
model="test-model", input_tokens=1000, output_tokens=500
)
expected = (1000 * 1.0 + 500 * 2.0) / 1000000
assert abs(cost - expected) < 1e-6
def test_cost_calculation_precision(self, calculator: PricingCalculator) -> None:
"""Test that cost calculations maintain proper precision."""
# Test with very small token counts
cost = calculator.calculate_cost(
model="claude-3-haiku", input_tokens=1, output_tokens=1
)
expected = (1 * 0.25 + 1 * 1.25) / 1000000
assert abs(cost - expected) < 1e-6
def test_cost_calculation_large_numbers(
self, calculator: PricingCalculator
) -> None:
"""Test cost calculation with large token counts."""
cost = calculator.calculate_cost(
model="claude-3-opus",
input_tokens=1000000, # 1M tokens
output_tokens=500000, # 500k tokens
)
expected = (1000000 * 15.0 + 500000 * 75.0) / 1000000
assert abs(cost - expected) < 1e-6
def test_all_supported_models(self, calculator: PricingCalculator) -> None:
"""Test that all supported models can calculate costs."""
supported_models: List[str] = [
"claude-3-opus",
"claude-3-sonnet",
"claude-3-haiku",
"claude-3-5-sonnet",
"claude-3-5-haiku",
"claude-sonnet-4-20250514",
"claude-opus-4-20250514",
]
for model in supported_models:
cost = calculator.calculate_cost(
model=model, input_tokens=100, output_tokens=50
)
assert cost > 0
assert isinstance(cost, float)
def test_cache_token_costs(self, calculator: PricingCalculator) -> None:
"""Test that cache tokens are properly calculated."""
model = "claude-3-haiku"
# Cost with cache tokens
cost_with_cache = calculator.calculate_cost(
model=model,
input_tokens=1000,
output_tokens=500,
cache_creation_tokens=100,
cache_read_tokens=50,
)
# Cost without cache tokens
cost_without_cache = calculator.calculate_cost(
model=model, input_tokens=1000, output_tokens=500
)
# Cache should add additional cost
assert cost_with_cache > cost_without_cache
# Calculate expected cache cost
cache_cost = (100 * 0.3 + 50 * 0.03) / 1000000
expected_total = cost_without_cache + cache_cost
assert abs(cost_with_cache - expected_total) < 1e-6
def test_model_name_normalization_integration(
self, calculator: PricingCalculator
) -> None:
"""Test integration with model name normalization."""
# Test with various model name formats that should normalize
test_cases: List[tuple[str, str]] = [
("claude-3-haiku-20240307", "claude-3-haiku"),
("claude-3-opus-20240229", "claude-3-opus"),
("claude-3-5-sonnet-20241022", "claude-3-5-sonnet"),
]
for input_model, _expected_normalized in test_cases:
try:
cost = calculator.calculate_cost(
model=input_model, input_tokens=100, output_tokens=50
)
# If it doesn't raise an error, normalization worked
assert cost >= 0
except KeyError:
# Model name normalization might not handle all formats
# This is acceptable for now
pass
================================================
FILE: src/tests/test_session_analyzer.py
================================================
"""Tests for session analyzer module."""
from datetime import datetime, timedelta, timezone
from typing import Dict, List, Optional, Union
from claude_monitor.core.models import SessionBlock, TokenCounts, UsageEntry
from claude_monitor.data.analyzer import SessionAnalyzer
class TestSessionAnalyzer:
"""Test the SessionAnalyzer class."""
def test_session_analyzer_init(self) -> None:
"""Test SessionAnalyzer initialization."""
analyzer = SessionAnalyzer()
assert analyzer.session_duration_hours == 5
assert analyzer.session_duration == timedelta(hours=5)
assert analyzer.timezone_handler is not None
def test_session_analyzer_init_custom_duration(self) -> None:
"""Test SessionAnalyzer with custom duration."""
analyzer = SessionAnalyzer(session_duration_hours=3)
assert analyzer.session_duration_hours == 3
assert analyzer.session_duration == timedelta(hours=3)
def test_transform_to_blocks_empty_list(self) -> None:
"""Test transform_to_blocks with empty entries."""
analyzer = SessionAnalyzer()
result = analyzer.transform_to_blocks([])
assert result == []
def test_transform_to_blocks_single_entry(self) -> None:
"""Test transform_to_blocks with single entry."""
analyzer = SessionAnalyzer()
entry = UsageEntry(
timestamp=datetime(2024, 1, 1, 12, 0, tzinfo=timezone.utc),
input_tokens=100,
output_tokens=50,
cost_usd=0.001,
model="claude-3-haiku",
)
blocks = analyzer.transform_to_blocks([entry])
assert len(blocks) == 1
assert len(blocks[0].entries) == 1
assert blocks[0].entries[0] == entry
def test_transform_to_blocks_multiple_entries_same_block(self) -> None:
"""Test transform_to_blocks with entries in same block."""
analyzer = SessionAnalyzer()
base_time = datetime(2024, 1, 1, 12, 0, tzinfo=timezone.utc)
entries: List[UsageEntry] = [
UsageEntry(
timestamp=base_time,
input_tokens=100,
output_tokens=50,
cost_usd=0.001,
model="claude-3-haiku",
),
UsageEntry(
timestamp=base_time + timedelta(minutes=30),
input_tokens=200,
output_tokens=100,
cost_usd=0.002,
model="claude-3-haiku",
),
]
blocks = analyzer.transform_to_blocks(entries)
assert len(blocks) == 1
assert len(blocks[0].entries) == 2
def test_transform_to_blocks_multiple_blocks(self) -> None:
"""Test transform_to_blocks creating multiple blocks."""
analyzer = SessionAnalyzer()
base_time = datetime(2024, 1, 1, 12, 0, tzinfo=timezone.utc)
entries: List[UsageEntry] = [
UsageEntry(
timestamp=base_time,
input_tokens=100,
output_tokens=50,
cost_usd=0.001,
model="claude-3-haiku",
),
UsageEntry(
timestamp=base_time + timedelta(hours=6), # Beyond session duration
input_tokens=200,
output_tokens=100,
cost_usd=0.002,
model="claude-3-haiku",
),
]
blocks = analyzer.transform_to_blocks(entries)
# May create 3 blocks due to rounding to hour boundaries
assert len(blocks) >= 2
assert sum(len(block.entries) for block in blocks) == 2
def test_should_create_new_block_time_gap(self) -> None:
"""Test _should_create_new_block with time gap."""
analyzer = SessionAnalyzer()
# Create a mock block
block = SessionBlock(
id="test_block",
start_time=datetime(2024, 1, 1, 12, 0, tzinfo=timezone.utc),
end_time=datetime(2024, 1, 1, 17, 0, tzinfo=timezone.utc),
)
# Entry within same block
entry1 = UsageEntry(
timestamp=datetime(2024, 1, 1, 14, 0, tzinfo=timezone.utc),
input_tokens=100,
output_tokens=50,
cost_usd=0.001,
model="claude-3-haiku",
)
# Entry outside block time range
entry2 = UsageEntry(
timestamp=datetime(2024, 1, 1, 20, 0, tzinfo=timezone.utc),
input_tokens=100,
output_tokens=50,
cost_usd=0.001,
model="claude-3-haiku",
)
assert not analyzer._should_create_new_block(block, entry1)
assert analyzer._should_create_new_block(block, entry2)
def test_round_to_hour(self) -> None:
"""Test _round_to_hour functionality."""
analyzer = SessionAnalyzer()
# Test various timestamps
test_cases: List[tuple[datetime, datetime]] = [
(
datetime(2024, 1, 1, 12, 30, 45, tzinfo=timezone.utc),
datetime(2024, 1, 1, 12, 0, 0, tzinfo=timezone.utc),
),
(
datetime(2024, 1, 1, 15, 0, 0, tzinfo=timezone.utc),
datetime(2024, 1, 1, 15, 0, 0, tzinfo=timezone.utc),
),
(
datetime(2024, 1, 1, 9, 59, 59, tzinfo=timezone.utc),
datetime(2024, 1, 1, 9, 0, 0, tzinfo=timezone.utc),
),
]
for input_time, expected in test_cases:
result = analyzer._round_to_hour(input_time)
assert result == expected
def test_create_new_block(self) -> None:
"""Test _create_new_block functionality."""
analyzer = SessionAnalyzer()
entry = UsageEntry(
timestamp=datetime(2024, 1, 1, 12, 30, tzinfo=timezone.utc),
input_tokens=100,
output_tokens=50,
cost_usd=0.001,
model="claude-3-haiku",
)
block = analyzer._create_new_block(entry)
assert block.start_time == datetime(2024, 1, 1, 12, 0, tzinfo=timezone.utc)
assert block.end_time == datetime(2024, 1, 1, 17, 0, tzinfo=timezone.utc)
assert block.id == "2024-01-01T12:00:00+00:00"
def test_add_entry_to_block(self) -> None:
"""Test _add_entry_to_block functionality."""
analyzer = SessionAnalyzer()
block = SessionBlock(
id="test_block",
start_time=datetime(2024, 1, 1, 12, 0, tzinfo=timezone.utc),
end_time=datetime(2024, 1, 1, 17, 0, tzinfo=timezone.utc),
token_counts=TokenCounts(),
)
entry = UsageEntry(
timestamp=datetime(2024, 1, 1, 12, 30, tzinfo=timezone.utc),
input_tokens=100,
output_tokens=50,
cache_creation_tokens=10,
cache_read_tokens=5,
cost_usd=0.001,
model="claude-3-haiku",
message_id="msg_123",
)
analyzer._add_entry_to_block(block, entry)
assert len(block.entries) == 1
assert block.entries[0] == entry
assert block.token_counts.input_tokens == 100
assert block.token_counts.output_tokens == 50
assert block.token_counts.cache_creation_tokens == 10
assert block.token_counts.cache_read_tokens == 5
assert block.cost_usd == 0.001
assert "claude-3-haiku" in block.models
assert block.sent_messages_count == 1
def test_finalize_block(self) -> None:
"""Test _finalize_block functionality."""
analyzer = SessionAnalyzer()
block = SessionBlock(
id="test_block",
start_time=datetime(2024, 1, 1, 12, 0, tzinfo=timezone.utc),
end_time=datetime(2024, 1, 1, 17, 0, tzinfo=timezone.utc),
entries=[
UsageEntry(
timestamp=datetime(2024, 1, 1, 12, 30, tzinfo=timezone.utc),
input_tokens=100,
output_tokens=50,
cost_usd=0.001,
model="claude-3-haiku",
)
],
)
analyzer._finalize_block(block)
# Should set actual_end_time to last entry timestamp
assert block.actual_end_time == datetime(
2024, 1, 1, 12, 30, tzinfo=timezone.utc
)
def test_detect_limits_empty_list(self) -> None:
"""Test detect_limits with empty list."""
analyzer = SessionAnalyzer()
result = analyzer.detect_limits([])
assert result == []
def test_detect_limits_no_limits(self) -> None:
"""Test detect_limits with no limit messages."""
analyzer = SessionAnalyzer()
raw_entries: List[Dict[str, str]] = [
{
"timestamp": "2024-01-01T12:00:00Z",
"content": "Regular response content",
"type": "assistant",
}
]
result = analyzer.detect_limits(raw_entries)
assert result == []
def test_detect_single_limit_rate_limit(self) -> None:
"""Test _detect_single_limit with rate limit message."""
analyzer = SessionAnalyzer()
raw_data: Dict[str, Union[str, List[Dict[str, str]]]] = {
"timestamp": "2024-01-01T12:00:00Z",
"content": [
{
"type": "text",
"text": "I'm currently at capacity and am unable to process your request.",
}
],
"type": "assistant",
}
result = analyzer._detect_single_limit(raw_data)
# May or may not detect limit depending on implementation
if result is not None:
assert "type" in result
assert "message" in result
def test_detect_single_limit_opus_limit(self) -> None:
"""Test _detect_single_limit with Opus daily limit."""
analyzer = SessionAnalyzer()
raw_data: Dict[str, Union[str, List[Dict[str, str]]]] = {
"timestamp": "2024-01-01T12:00:00Z",
"content": [
{
"type": "text",
"text": "You've reached your daily limit for Claude 3 Opus.",
}
],
"type": "assistant",
}
result = analyzer._detect_single_limit(raw_data)
# May or may not detect limit depending on implementation
if result is not None:
assert "type" in result
assert "message" in result
def test_is_opus_limit(self) -> None:
"""Test _is_opus_limit detection."""
analyzer = SessionAnalyzer()
# Test cases that should be detected as Opus limits
opus_cases: List[str] = [
"you've reached your daily limit for claude 3 opus",
"daily opus limit reached",
"claude 3 opus usage limit",
]
# Test cases that should NOT be detected
non_opus_cases: List[str] = [
"general rate limit message",
"sonnet limit reached",
"you've reached capacity",
]
for case in opus_cases:
assert analyzer._is_opus_limit(case) is True
for case in non_opus_cases:
assert analyzer._is_opus_limit(case) is False
def test_extract_wait_time(self) -> None:
"""Test _extract_wait_time functionality."""
analyzer = SessionAnalyzer()
test_cases: List[tuple[str, Optional[int]]] = [
("wait 5 minutes", 5),
("wait 30 minutes", 30),
("wait 60 minutes", 60),
("wait 120 minutes", 120),
("No time mentioned", None),
]
# _extract_wait_time requires timestamp parameter
timestamp = datetime(2024, 1, 1, 12, 0, tzinfo=timezone.utc)
for text, expected_minutes in test_cases:
reset_time, wait_minutes = analyzer._extract_wait_time(text, timestamp)
assert wait_minutes == expected_minutes
def test_parse_reset_timestamp(self) -> None:
"""Test _parse_reset_timestamp functionality."""
analyzer = SessionAnalyzer()
# Test with various timestamp formats
test_cases: List[str] = [
"Resets at 2024-01-01T15:00:00Z",
"Your limit resets on 2024-01-01 at 15:00",
"Available again at 15:00 UTC",
]
for text in test_cases:
result = analyzer._parse_reset_timestamp(text)
# Should either return a datetime or None
assert result is None or isinstance(result, datetime)
def test_mark_active_blocks(self) -> None:
"""Test _mark_active_blocks functionality."""
analyzer = SessionAnalyzer()
now = datetime.now(timezone.utc)
blocks: List[SessionBlock] = [
SessionBlock(
id="old_block",
start_time=now - timedelta(hours=10),
end_time=now - timedelta(hours=5),
actual_end_time=now - timedelta(hours=6),
),
SessionBlock(
id="recent_block",
start_time=now - timedelta(hours=2),
end_time=now + timedelta(hours=3),
actual_end_time=now - timedelta(minutes=30),
),
]
analyzer._mark_active_blocks(blocks)
# Old block should not be active
assert blocks[0].is_active is False
# Recent block should be active (within last hour)
assert blocks[1].is_active is True
class TestSessionAnalyzerIntegration:
"""Integration tests for SessionAnalyzer."""
def test_full_analysis_workflow(self) -> None:
"""Test complete analysis workflow."""
analyzer = SessionAnalyzer()
# Create realistic usage entries
base_time = datetime(2024, 1, 1, 12, 0, tzinfo=timezone.utc)
entries: List[UsageEntry] = [
UsageEntry(
timestamp=base_time,
input_tokens=100,
output_tokens=50,
cost_usd=0.001,
model="claude-3-haiku",
),
UsageEntry(
timestamp=base_time + timedelta(minutes=30),
input_tokens=200,
output_tokens=100,
cost_usd=0.002,
model="claude-3-sonnet",
),
UsageEntry(
timestamp=base_time + timedelta(hours=6),
input_tokens=150,
output_tokens=75,
cost_usd=0.0015,
model="claude-3-haiku",
),
]
# Create blocks
blocks = analyzer.transform_to_blocks(entries)
assert len(blocks) >= 2 # Should create multiple blocks due to time gap
# Verify total entries across all blocks
total_entries = sum(len(block.entries) for block in blocks)
assert total_entries == 3
# Verify total tokens are preserved
total_input = sum(block.token_counts.input_tokens for block in blocks)
total_output = sum(block.token_counts.output_tokens for block in blocks)
total_cost = sum(block.cost_usd for block in blocks)
assert total_input == 450 # 100 + 200 + 150
assert total_output == 225 # 50 + 100 + 75
assert abs(total_cost - 0.0045) < 0.0001 # 0.001 + 0.002 + 0.0015
def test_limit_detection_workflow(self) -> None:
"""Test limit detection workflow."""
analyzer = SessionAnalyzer()
raw_entries: List[Dict[str, Union[str, List[Dict[str, str]]]]] = [
{
"timestamp": "2024-01-01T12:00:00Z",
"content": [
{
"type": "text",
"text": "I'm currently at capacity and am unable to process your request. Please try again in 30 minutes.",
}
],
"type": "assistant",
},
{
"timestamp": "2024-01-01T13:00:00Z",
"content": [
{
"type": "text",
"text": "You've reached your daily limit for Claude 3 Opus. Your limit will reset at midnight UTC.",
}
],
"type": "assistant",
},
]
limits = analyzer.detect_limits(raw_entries)
# May or may not detect limits depending on implementation
assert isinstance(limits, list)
for limit in limits:
assert "type" in limit
assert "message" in limit
class TestSessionAnalyzerEdgeCases:
"""Test edge cases and error conditions."""
def test_malformed_entry_handling(self) -> None:
"""Test handling of malformed entries."""
analyzer = SessionAnalyzer()
# Entry with None timestamp should be handled gracefully
entry = UsageEntry(
timestamp=datetime(2024, 1, 1, 12, 0, tzinfo=timezone.utc),
input_tokens=100,
output_tokens=50,
cost_usd=0.001,
model="claude-3-haiku",
)
# Should not raise exception
blocks = analyzer.transform_to_blocks([entry])
assert len(blocks) == 1
def test_negative_token_counts(self) -> None:
"""Test handling of negative token counts."""
analyzer = SessionAnalyzer()
entry = UsageEntry(
timestamp=datetime(2024, 1, 1, 12, 0, tzinfo=timezone.utc),
input_tokens=-100, # Negative tokens
output_tokens=50,
cost_usd=0.001,
model="claude-3-haiku",
)
blocks = analyzer.transform_to_blocks([entry])
# Should handle gracefully
assert len(blocks) == 1
assert blocks[0].token_counts.input_tokens == -100
def test_very_large_time_gaps(self) -> None:
"""Test handling of very large time gaps."""
analyzer = SessionAnalyzer()
base_time = datetime(2024, 1, 1, 12, 0, tzinfo=timezone.utc)
entries: List[UsageEntry] = [
UsageEntry(
timestamp=base_time,
input_tokens=100,
output_tokens=50,
cost_usd=0.001,
model="claude-3-haiku",
),
UsageEntry(
timestamp=base_time + timedelta(days=365), # Very large gap
input_tokens=100,
output_tokens=50,
cost_usd=0.001,
model="claude-3-haiku",
),
]
blocks = analyzer.transform_to_blocks(entries)
# Should create separate blocks
assert len(blocks) >= 2
================================================
FILE: src/tests/test_settings.py
================================================
"""Comprehensive tests for core/settings.py module."""
import argparse
import json
import tempfile
from pathlib import Path
from typing import Dict, List, Union
from unittest.mock import Mock, patch
import pytest
from claude_monitor.core.settings import LastUsedParams, Settings
class TestLastUsedParams:
"""Test suite for LastUsedParams class."""
def setup_method(self) -> None:
"""Set up test environment."""
self.temp_dir = Path(tempfile.mkdtemp())
self.last_used = LastUsedParams(self.temp_dir)
def teardown_method(self) -> None:
"""Clean up test environment."""
import shutil
shutil.rmtree(self.temp_dir, ignore_errors=True)
def test_init_default_config_dir(self) -> None:
"""Test initialization with default config directory."""
last_used = LastUsedParams()
expected_dir = Path.home() / ".claude-monitor"
assert last_used.config_dir == expected_dir
assert last_used.params_file == expected_dir / "last_used.json"
def test_init_custom_config_dir(self) -> None:
"""Test initialization with custom config directory."""
custom_dir = Path("/tmp/custom-config")
last_used = LastUsedParams(custom_dir)
assert last_used.config_dir == custom_dir
assert last_used.params_file == custom_dir / "last_used.json"
def test_save_success(self) -> None:
"""Test successful saving of parameters."""
# Create mock settings with type object
mock_settings = type(
"MockSettings",
(),
{
"plan": "pro",
"theme": "dark",
"timezone": "UTC",
"time_format": "24h",
"refresh_rate": 5,
"reset_hour": 12,
"custom_limit_tokens": 1000,
"view": "realtime",
},
)()
# Save parameters
self.last_used.save(mock_settings)
# Verify file exists and contains correct data
assert self.last_used.params_file.exists()
with open(self.last_used.params_file) as f:
data = json.load(f)
# Verify plan is not saved (by design)
assert "plan" not in data
assert data["theme"] == "dark"
assert data["timezone"] == "UTC"
assert data["time_format"] == "24h"
assert data["refresh_rate"] == 5
assert data["reset_hour"] == 12
assert data["custom_limit_tokens"] == 1000
assert data["view"] == "realtime"
assert "timestamp" in data
def test_save_without_custom_limit(self) -> None:
"""Test saving without custom limit tokens."""
mock_settings = type(
"MockSettings",
(),
{
"plan": "pro",
"theme": "light",
"timezone": "UTC",
"time_format": "12h",
"refresh_rate": 10,
"reset_hour": None,
"custom_limit_tokens": None,
"view": "realtime",
},
)()
self.last_used.save(mock_settings)
with open(self.last_used.params_file) as f:
data = json.load(f)
assert "custom_limit_tokens" not in data
assert data["theme"] == "light"
def test_save_creates_directory(self) -> None:
"""Test that save creates directory if it doesn't exist."""
# Use non-existent directory
non_existent_dir = self.temp_dir / "non-existent"
last_used = LastUsedParams(non_existent_dir)
mock_settings = type(
"MockSettings",
(),
{
"plan": "pro",
"theme": "dark",
"timezone": "UTC",
"time_format": "24h",
"refresh_rate": 5,
"reset_hour": 12,
"custom_limit_tokens": None,
"view": "realtime",
},
)()
last_used.save(mock_settings)
assert non_existent_dir.exists()
assert last_used.params_file.exists()
@patch("claude_monitor.core.settings.logger")
def test_save_error_handling(self, mock_logger: Mock) -> None:
"""Test error handling during save operation."""
# Mock file operations to raise exception
with patch("builtins.open", side_effect=PermissionError("Access denied")):
mock_settings = Mock()
mock_settings.plan = "pro"
mock_settings.theme = "dark"
mock_settings.timezone = "UTC"
mock_settings.time_format = "24h"
mock_settings.refresh_rate = 5
mock_settings.reset_hour = 12
mock_settings.custom_limit_tokens = None
mock_settings.view = "realtime"
# Should not raise exception
self.last_used.save(mock_settings)
# Should log warning
mock_logger.warning.assert_called_once()
def test_load_success(self) -> None:
"""Test successful loading of parameters."""
# Create test data
test_data: Dict[str, Union[str, int]] = {
"theme": "dark",
"timezone": "Europe/Warsaw",
"time_format": "24h",
"refresh_rate": 5,
"reset_hour": 8,
"custom_limit_tokens": 2000,
"timestamp": "2024-01-01T12:00:00",
"view": "realtime",
}
with open(self.last_used.params_file, "w") as f:
json.dump(test_data, f)
# Load parameters
result = self.last_used.load()
# Verify timestamp is removed and other data is present
assert "timestamp" not in result
assert result["theme"] == "dark"
assert result["timezone"] == "Europe/Warsaw"
assert result["time_format"] == "24h"
assert result["refresh_rate"] == 5
assert result["reset_hour"] == 8
assert result["custom_limit_tokens"] == 2000
def test_load_file_not_exists(self) -> None:
"""Test loading when file doesn't exist."""
result = self.last_used.load()
assert result == {}
@patch("claude_monitor.core.settings.logger")
def test_load_error_handling(self, mock_logger: Mock) -> None:
"""Test error handling during load operation."""
# Create invalid JSON file
with open(self.last_used.params_file, "w") as f:
f.write("invalid json")
result = self.last_used.load()
assert result == {}
mock_logger.warning.assert_called_once()
def test_clear_success(self) -> None:
"""Test successful clearing of parameters."""
# Create file first
test_data: Dict[str, str] = {"theme": "dark"}
with open(self.last_used.params_file, "w") as f:
json.dump(test_data, f)
assert self.last_used.params_file.exists()
# Clear parameters
self.last_used.clear()
assert not self.last_used.params_file.exists()
def test_clear_file_not_exists(self) -> None:
"""Test clearing when file doesn't exist."""
# Should not raise exception
self.last_used.clear()
@patch("claude_monitor.core.settings.logger")
def test_clear_error_handling(self, mock_logger: Mock) -> None:
"""Test error handling during clear operation."""
# Create file but mock unlink to raise exception
with open(self.last_used.params_file, "w") as f:
f.write("{}")
with patch.object(Path, "unlink", side_effect=PermissionError("Access denied")):
self.last_used.clear()
mock_logger.warning.assert_called_once()
def test_exists_true(self) -> None:
"""Test exists method when file exists."""
with open(self.last_used.params_file, "w") as f:
f.write("{}")
assert self.last_used.exists() is True
def test_exists_false(self) -> None:
"""Test exists method when file doesn't exist."""
assert self.last_used.exists() is False
class TestSettings:
"""Test suite for Settings class."""
def test_default_values(self) -> None:
"""Test default settings values."""
settings = Settings(_cli_parse_args=[])
assert settings.plan == "custom"
assert settings.timezone == "auto"
assert settings.time_format == "auto"
assert settings.theme == "auto"
assert settings.custom_limit_tokens is None
assert settings.refresh_rate == 10
assert settings.refresh_per_second == 0.75
assert settings.reset_hour is None
assert settings.log_level == "INFO"
assert settings.log_file is None
assert settings.debug is False
assert settings.version is False
assert settings.clear is False
def test_plan_validator_valid_values(self) -> None:
"""Test plan validator with valid values."""
valid_plans: List[str] = ["pro", "max5", "max20", "custom"]
for plan in valid_plans:
settings = Settings(plan=plan, _cli_parse_args=[])
assert settings.plan == plan.lower()
def test_plan_validator_case_insensitive(self) -> None:
"""Test plan validator is case insensitive."""
settings = Settings(plan="PRO", _cli_parse_args=[])
assert settings.plan == "pro"
settings = Settings(plan="Max5", _cli_parse_args=[])
assert settings.plan == "max5"
def test_plan_validator_invalid_value(self) -> None:
"""Test plan validator with invalid value."""
with pytest.raises(ValueError, match="Invalid plan: invalid"):
Settings(plan="invalid", _cli_parse_args=[])
def test_theme_validator_valid_values(self) -> None:
"""Test theme validator with valid values."""
valid_themes: List[str] = ["light", "dark", "classic", "auto"]
for theme in valid_themes:
settings = Settings(theme=theme, _cli_parse_args=[])
assert settings.theme == theme.lower()
def test_theme_validator_case_insensitive(self) -> None:
"""Test theme validator is case insensitive."""
settings = Settings(theme="LIGHT", _cli_parse_args=[])
assert settings.theme == "light"
settings = Settings(theme="Dark", _cli_parse_args=[])
assert settings.theme == "dark"
def test_theme_validator_invalid_value(self) -> None:
"""Test theme validator with invalid value."""
with pytest.raises(ValueError, match="Invalid theme: invalid"):
Settings(theme="invalid", _cli_parse_args=[])
def test_timezone_validator_valid_values(self) -> None:
"""Test timezone validator with valid values."""
# Test auto/local values
settings = Settings(timezone="auto", _cli_parse_args=[])
assert settings.timezone == "auto"
settings = Settings(timezone="local", _cli_parse_args=[])
assert settings.timezone == "local"
# Test valid timezone
settings = Settings(timezone="UTC", _cli_parse_args=[])
assert settings.timezone == "UTC"
settings = Settings(timezone="Europe/Warsaw", _cli_parse_args=[])
assert settings.timezone == "Europe/Warsaw"
def test_timezone_validator_invalid_value(self) -> None:
"""Test timezone validator with invalid value."""
with pytest.raises(ValueError, match="Invalid timezone: Invalid/Timezone"):
Settings(timezone="Invalid/Timezone", _cli_parse_args=[])
def test_time_format_validator_valid_values(self) -> None:
"""Test time format validator with valid values."""
valid_formats: List[str] = ["12h", "24h", "auto"]
for fmt in valid_formats:
settings = Settings(time_format=fmt, _cli_parse_args=[])
assert settings.time_format == fmt
def test_time_format_validator_invalid_value(self) -> None:
"""Test time format validator with invalid value."""
with pytest.raises(ValueError, match="Invalid time format: invalid"):
Settings(time_format="invalid", _cli_parse_args=[])
def test_log_level_validator_valid_values(self) -> None:
"""Test log level validator with valid values."""
valid_levels: List[str] = ["DEBUG", "INFO", "WARNING", "ERROR", "CRITICAL"]
for level in valid_levels:
settings = Settings(log_level=level, _cli_parse_args=[])
assert settings.log_level == level
# Test case insensitive
settings = Settings(log_level=level.lower(), _cli_parse_args=[])
assert settings.log_level == level
def test_log_level_validator_invalid_value(self) -> None:
"""Test log level validator with invalid value."""
with pytest.raises(ValueError, match="Invalid log level: invalid"):
Settings(log_level="invalid", _cli_parse_args=[])
def test_field_constraints(self) -> None:
"""Test field constraints and validation."""
# Test positive constraints
with pytest.raises(ValueError):
Settings(custom_limit_tokens=0, _cli_parse_args=[])
with pytest.raises(ValueError):
Settings(custom_limit_tokens=-100, _cli_parse_args=[])
# Test range constraints
with pytest.raises(ValueError):
Settings(refresh_rate=0, _cli_parse_args=[])
with pytest.raises(ValueError):
Settings(refresh_rate=61, _cli_parse_args=[])
with pytest.raises(ValueError):
Settings(refresh_per_second=0.05, _cli_parse_args=[])
with pytest.raises(ValueError):
Settings(refresh_per_second=25.0, _cli_parse_args=[])
with pytest.raises(ValueError):
Settings(reset_hour=-1, _cli_parse_args=[])
with pytest.raises(ValueError):
Settings(reset_hour=24, _cli_parse_args=[])
@patch("claude_monitor.core.settings.Settings._get_system_timezone")
@patch("claude_monitor.core.settings.Settings._get_system_time_format")
def test_load_with_last_used_version_flag(
self, mock_time_format: Mock, mock_timezone: Mock
) -> None:
"""Test version flag handling."""
with patch("builtins.print") as mock_print:
with patch("sys.exit") as mock_exit:
Settings.load_with_last_used(["--version"])
mock_print.assert_called_once()
mock_exit.assert_called_once_with(0)
@patch("claude_monitor.core.settings.Settings._get_system_timezone")
@patch("claude_monitor.core.settings.Settings._get_system_time_format")
def test_load_with_last_used_clear_flag(
self, mock_time_format: Mock, mock_timezone: Mock
) -> None:
"""Test clear flag handling."""
mock_timezone.return_value = "UTC"
mock_time_format.return_value = "24h"
with tempfile.TemporaryDirectory() as temp_dir:
# Create mock last used params
config_dir = Path(temp_dir)
params_file = config_dir / "last_used.json"
params_file.parent.mkdir(parents=True, exist_ok=True)
test_data: Dict[str, str] = {"theme": "dark", "timezone": "Europe/Warsaw"}
with open(params_file, "w") as f:
json.dump(test_data, f)
with patch("claude_monitor.core.settings.LastUsedParams") as MockLastUsed:
mock_instance = Mock()
MockLastUsed.return_value = mock_instance
Settings.load_with_last_used(["--clear"])
# Should call clear
mock_instance.clear.assert_called_once()
@patch("claude_monitor.core.settings.Settings._get_system_timezone")
@patch("claude_monitor.core.settings.Settings._get_system_time_format")
def test_load_with_last_used_merge_params(
self, mock_time_format: Mock, mock_timezone: Mock
) -> None:
"""Test merging with last used parameters."""
mock_timezone.return_value = "UTC"
mock_time_format.return_value = "24h"
# Mock last used params
test_params: Dict[str, Union[str, int]] = {
"theme": "dark",
"timezone": "Europe/Warsaw",
"refresh_rate": 15,
"custom_limit_tokens": 5000,
"view": "realtime",
}
with patch("claude_monitor.core.settings.LastUsedParams") as MockLastUsed:
mock_instance = Mock()
mock_instance.load.return_value = test_params
MockLastUsed.return_value = mock_instance
# Load without CLI arguments - should use last used params
settings = Settings.load_with_last_used([])
assert settings.theme == "dark"
assert settings.timezone == "Europe/Warsaw"
assert settings.refresh_rate == 15
assert settings.custom_limit_tokens == 5000
# Should save current settings
mock_instance.save.assert_called_once()
@patch("claude_monitor.core.settings.Settings._get_system_timezone")
@patch("claude_monitor.core.settings.Settings._get_system_time_format")
def test_load_with_last_used_cli_priority(
self, mock_time_format: Mock, mock_timezone: Mock
) -> None:
"""Test CLI arguments take priority over last used params."""
mock_timezone.return_value = "UTC"
mock_time_format.return_value = "24h"
# Mock last used params
test_params: Dict[str, Union[str, int]] = {
"theme": "dark",
"timezone": "Europe/Warsaw",
"refresh_rate": 15,
"view": "realtime",
}
with patch("claude_monitor.core.settings.LastUsedParams") as MockLastUsed:
mock_instance = Mock()
mock_instance.load.return_value = test_params
MockLastUsed.return_value = mock_instance
# Load with CLI arguments - CLI should override
settings = Settings.load_with_last_used(
["--theme", "light", "--refresh-rate", "5"]
)
assert settings.theme == "light" # CLI override
assert settings.refresh_rate == 5 # CLI override
assert settings.timezone == "Europe/Warsaw" # From last used
@patch("claude_monitor.core.settings.Settings._get_system_timezone")
@patch("claude_monitor.core.settings.Settings._get_system_time_format")
def test_load_with_last_used_auto_timezone(
self, mock_time_format: Mock, mock_timezone: Mock
) -> None:
"""Test auto timezone detection."""
mock_timezone.return_value = "America/New_York"
mock_time_format.return_value = "12h"
with patch("claude_monitor.core.settings.LastUsedParams") as MockLastUsed:
mock_instance = Mock()
mock_instance.load.return_value = {}
MockLastUsed.return_value = mock_instance
settings = Settings.load_with_last_used([])
assert settings.timezone == "America/New_York"
assert settings.time_format == "12h"
@patch("claude_monitor.core.settings.Settings._get_system_timezone")
@patch("claude_monitor.core.settings.Settings._get_system_time_format")
def test_load_with_last_used_debug_flag(
self, mock_time_format: Mock, mock_timezone: Mock
) -> None:
"""Test debug flag overrides log level."""
mock_timezone.return_value = "UTC"
mock_time_format.return_value = "24h"
with patch("claude_monitor.core.settings.LastUsedParams") as MockLastUsed:
mock_instance = Mock()
mock_instance.load.return_value = {}
MockLastUsed.return_value = mock_instance
settings = Settings.load_with_last_used(["--debug"])
assert settings.debug is True
assert settings.log_level == "DEBUG"
@patch("claude_monitor.core.settings.Settings._get_system_timezone")
@patch("claude_monitor.core.settings.Settings._get_system_time_format")
@patch("claude_monitor.terminal.themes.BackgroundDetector")
def test_load_with_last_used_theme_detection(
self, MockDetector: Mock, mock_time_format: Mock, mock_timezone: Mock
) -> None:
"""Test theme auto-detection."""
mock_timezone.return_value = "UTC"
mock_time_format.return_value = "24h"
# Mock background detector
mock_detector_instance = Mock()
MockDetector.return_value = mock_detector_instance
from claude_monitor.terminal.themes import BackgroundType
mock_detector_instance.detect_background.return_value = BackgroundType.DARK
with patch("claude_monitor.core.settings.LastUsedParams") as MockLastUsed:
mock_instance = Mock()
mock_instance.load.return_value = {}
MockLastUsed.return_value = mock_instance
settings = Settings.load_with_last_used([])
assert settings.theme == "dark"
@patch("claude_monitor.core.settings.Settings._get_system_timezone")
@patch("claude_monitor.core.settings.Settings._get_system_time_format")
def test_load_with_last_used_custom_plan_reset(
self, mock_time_format: Mock, mock_timezone: Mock
) -> None:
"""Test custom plan resets custom_limit_tokens if not provided via CLI."""
mock_timezone.return_value = "UTC"
mock_time_format.return_value = "24h"
test_params: Dict[str, int] = {"custom_limit_tokens": 5000}
with patch("claude_monitor.core.settings.LastUsedParams") as MockLastUsed:
mock_instance = Mock()
mock_instance.load.return_value = test_params
MockLastUsed.return_value = mock_instance
# Switch to custom plan via CLI without specifying custom limit
settings = Settings.load_with_last_used(["--plan", "custom"])
assert settings.plan == "custom"
assert settings.custom_limit_tokens is None # Should be reset
def test_to_namespace(self) -> None:
"""Test conversion to argparse.Namespace."""
settings = Settings(
plan="pro",
timezone="UTC",
theme="dark",
refresh_rate=5,
refresh_per_second=1.0,
reset_hour=8,
custom_limit_tokens=1000,
time_format="24h",
log_level="DEBUG",
log_file=Path("/tmp/test.log"),
version=True,
_cli_parse_args=[],
)
namespace = settings.to_namespace()
assert isinstance(namespace, argparse.Namespace)
assert namespace.plan == "pro"
assert namespace.timezone == "UTC"
assert namespace.theme == "dark"
assert namespace.refresh_rate == 5
assert namespace.refresh_per_second == 1.0
assert namespace.reset_hour == 8
assert namespace.custom_limit_tokens == 1000
assert namespace.time_format == "24h"
assert namespace.log_level == "DEBUG"
assert namespace.log_file == "/tmp/test.log"
assert namespace.version is True
def test_to_namespace_none_values(self) -> None:
"""Test conversion to namespace with None values."""
settings = Settings(_cli_parse_args=[])
namespace = settings.to_namespace()
assert namespace.log_file is None
assert namespace.reset_hour is None
assert namespace.custom_limit_tokens is None
class TestSettingsIntegration:
"""Integration tests for Settings class."""
def test_complete_workflow(self) -> None:
"""Test complete workflow with real file operations."""
with tempfile.TemporaryDirectory() as temp_dir:
config_dir = Path(temp_dir)
# Mock the config directory
with patch("claude_monitor.core.settings.LastUsedParams") as MockLastUsed:
# Create real LastUsedParams instance with temp directory
real_last_used = LastUsedParams(config_dir)
MockLastUsed.return_value = real_last_used
with (
patch(
"claude_monitor.core.settings.Settings._get_system_timezone",
return_value="UTC",
),
patch(
"claude_monitor.core.settings.Settings._get_system_time_format",
return_value="24h",
),
):
# First run - should create file
settings1 = Settings.load_with_last_used(
["--theme", "dark", "--refresh-rate", "5"]
)
assert settings1.theme == "dark"
assert settings1.refresh_rate == 5
# Second run - should load from file
settings2 = Settings.load_with_last_used(["--plan", "pro"])
assert settings2.theme == "dark" # From last used
assert settings2.refresh_rate == 5 # From last used
assert settings2.plan == "pro" # From CLI
def test_settings_customise_sources(self) -> None:
"""Test settings source customization."""
sources = Settings.settings_customise_sources(
Settings,
"init_settings",
"env_settings",
"dotenv_settings",
"file_secret_settings",
)
# Should only return init_settings
assert sources == ("init_settings",)
================================================
FILE: src/tests/test_table_views.py
================================================
"""Tests for table views module."""
from typing import Any, Dict, List
import pytest
from rich.panel import Panel
from rich.table import Table
from claude_monitor.ui.table_views import TableViewsController
class TestTableViewsController:
"""Test cases for TableViewsController class."""
@pytest.fixture
def controller(self) -> TableViewsController:
"""Create a TableViewsController instance."""
return TableViewsController()
@pytest.fixture
def sample_daily_data(self) -> List[Dict[str, Any]]:
"""Create sample daily aggregated data."""
return [
{
"date": "2024-01-01",
"input_tokens": 1000,
"output_tokens": 500,
"cache_creation_tokens": 100,
"cache_read_tokens": 50,
"total_cost": 0.05,
"models_used": ["claude-3-haiku", "claude-3-sonnet"],
"model_breakdowns": {
"claude-3-haiku": {
"input_tokens": 600,
"output_tokens": 300,
"cache_creation_tokens": 60,
"cache_read_tokens": 30,
"cost": 0.03,
"count": 6,
},
"claude-3-sonnet": {
"input_tokens": 400,
"output_tokens": 200,
"cache_creation_tokens": 40,
"cache_read_tokens": 20,
"cost": 0.02,
"count": 4,
},
},
"entries_count": 10,
},
{
"date": "2024-01-02",
"input_tokens": 2000,
"output_tokens": 1000,
"cache_creation_tokens": 200,
"cache_read_tokens": 100,
"total_cost": 0.10,
"models_used": ["claude-3-opus"],
"model_breakdowns": {
"claude-3-opus": {
"input_tokens": 2000,
"output_tokens": 1000,
"cache_creation_tokens": 200,
"cache_read_tokens": 100,
"cost": 0.10,
"count": 20,
},
},
"entries_count": 20,
},
]
@pytest.fixture
def sample_monthly_data(self) -> List[Dict[str, Any]]:
"""Create sample monthly aggregated data."""
return [
{
"month": "2024-01",
"input_tokens": 30000,
"output_tokens": 15000,
"cache_creation_tokens": 3000,
"cache_read_tokens": 1500,
"total_cost": 1.50,
"models_used": ["claude-3-haiku", "claude-3-sonnet", "claude-3-opus"],
"model_breakdowns": {
"claude-3-haiku": {
"input_tokens": 10000,
"output_tokens": 5000,
"cache_creation_tokens": 1000,
"cache_read_tokens": 500,
"cost": 0.50,
"count": 100,
},
"claude-3-sonnet": {
"input_tokens": 10000,
"output_tokens": 5000,
"cache_creation_tokens": 1000,
"cache_read_tokens": 500,
"cost": 0.50,
"count": 100,
},
"claude-3-opus": {
"input_tokens": 10000,
"output_tokens": 5000,
"cache_creation_tokens": 1000,
"cache_read_tokens": 500,
"cost": 0.50,
"count": 100,
},
},
"entries_count": 300,
},
{
"month": "2024-02",
"input_tokens": 20000,
"output_tokens": 10000,
"cache_creation_tokens": 2000,
"cache_read_tokens": 1000,
"total_cost": 1.00,
"models_used": ["claude-3-haiku"],
"model_breakdowns": {
"claude-3-haiku": {
"input_tokens": 20000,
"output_tokens": 10000,
"cache_creation_tokens": 2000,
"cache_read_tokens": 1000,
"cost": 1.00,
"count": 200,
},
},
"entries_count": 200,
},
]
@pytest.fixture
def sample_totals(self) -> Dict[str, Any]:
"""Create sample totals data."""
return {
"input_tokens": 50000,
"output_tokens": 25000,
"cache_creation_tokens": 5000,
"cache_read_tokens": 2500,
"total_tokens": 82500,
"total_cost": 2.50,
"entries_count": 500,
}
def test_init_styles(self, controller: TableViewsController) -> None:
"""Test controller initialization with styles."""
assert controller.key_style == "cyan"
assert controller.value_style == "white"
assert controller.accent_style == "yellow"
assert controller.success_style == "green"
assert controller.warning_style == "yellow"
assert controller.header_style == "bold cyan"
assert controller.table_header_style == "bold"
assert controller.border_style == "bright_blue"
def test_create_daily_table_structure(
self,
controller: TableViewsController,
sample_daily_data: List[Dict[str, Any]],
sample_totals: Dict[str, Any],
) -> None:
"""Test creation of daily table structure."""
table = controller.create_daily_table(sample_daily_data, sample_totals, "UTC")
assert isinstance(table, Table)
assert table.title == "Claude Code Token Usage Report - Daily (UTC)"
assert table.title_style == "bold cyan"
assert table.show_header is True
assert table.header_style == "bold"
assert table.border_style == "bright_blue"
assert table.expand is True
assert table.show_lines is True
# Check columns
assert len(table.columns) == 8
assert table.columns[0].header == "Date"
assert table.columns[1].header == "Models"
assert table.columns[2].header == "Input"
assert table.columns[3].header == "Output"
assert table.columns[4].header == "Cache Create"
assert table.columns[5].header == "Cache Read"
assert table.columns[6].header == "Total Tokens"
assert table.columns[7].header == "Cost (USD)"
def test_create_daily_table_data(
self,
controller: TableViewsController,
sample_daily_data: List[Dict[str, Any]],
sample_totals: Dict[str, Any],
) -> None:
"""Test daily table data population."""
table = controller.create_daily_table(sample_daily_data, sample_totals, "UTC")
# The table should have:
# - 2 data rows (for the 2 days)
# - 1 separator row
# - 1 totals row
# Total: 4 rows
assert table.row_count == 4
def test_create_monthly_table_structure(
self,
controller: TableViewsController,
sample_monthly_data: List[Dict[str, Any]],
sample_totals: Dict[str, Any],
) -> None:
"""Test creation of monthly table structure."""
table = controller.create_monthly_table(
sample_monthly_data, sample_totals, "UTC"
)
assert isinstance(table, Table)
assert table.title == "Claude Code Token Usage Report - Monthly (UTC)"
assert table.title_style == "bold cyan"
assert table.show_header is True
assert table.header_style == "bold"
assert table.border_style == "bright_blue"
assert table.expand is True
assert table.show_lines is True
# Check columns
assert len(table.columns) == 8
assert table.columns[0].header == "Month"
assert table.columns[1].header == "Models"
assert table.columns[2].header == "Input"
assert table.columns[3].header == "Output"
assert table.columns[4].header == "Cache Create"
assert table.columns[5].header == "Cache Read"
assert table.columns[6].header == "Total Tokens"
assert table.columns[7].header == "Cost (USD)"
def test_create_monthly_table_data(
self,
controller: TableViewsController,
sample_monthly_data: List[Dict[str, Any]],
sample_totals: Dict[str, Any],
) -> None:
"""Test monthly table data population."""
table = controller.create_monthly_table(
sample_monthly_data, sample_totals, "UTC"
)
# The table should have:
# - 2 data rows (for the 2 months)
# - 1 separator row
# - 1 totals row
# Total: 4 rows
assert table.row_count == 4
def test_create_summary_panel(
self, controller: TableViewsController, sample_totals: Dict[str, Any]
) -> None:
"""Test creation of summary panel."""
panel = controller.create_summary_panel("daily", sample_totals, "Last 30 days")
assert isinstance(panel, Panel)
assert panel.title == "Summary"
assert panel.title_align == "center"
assert panel.border_style == controller.border_style
assert panel.expand is False
assert panel.padding == (1, 2)
def test_format_models_single(self, controller: TableViewsController) -> None:
"""Test formatting single model."""
result = controller._format_models(["claude-3-haiku"])
assert result == "claude-3-haiku"
def test_format_models_multiple(self, controller: TableViewsController) -> None:
"""Test formatting multiple models."""
result = controller._format_models(
["claude-3-haiku", "claude-3-sonnet", "claude-3-opus"]
)
expected = "• claude-3-haiku\n• claude-3-sonnet\n• claude-3-opus"
assert result == expected
def test_format_models_empty(self, controller: TableViewsController) -> None:
"""Test formatting empty models list."""
result = controller._format_models([])
assert result == "No models"
def test_create_no_data_display(self, controller: TableViewsController) -> None:
"""Test creation of no data display."""
panel = controller.create_no_data_display("daily")
assert isinstance(panel, Panel)
assert panel.title == "No Daily Data"
assert panel.title_align == "center"
assert panel.border_style == controller.warning_style
assert panel.expand is True
assert panel.height == 10
def test_create_aggregate_table_daily(
self,
controller: TableViewsController,
sample_daily_data: List[Dict[str, Any]],
sample_totals: Dict[str, Any],
) -> None:
"""Test create_aggregate_table for daily view."""
table = controller.create_aggregate_table(
sample_daily_data, sample_totals, "daily", "UTC"
)
assert isinstance(table, Table)
assert table.title == "Claude Code Token Usage Report - Daily (UTC)"
def test_create_aggregate_table_monthly(
self,
controller: TableViewsController,
sample_monthly_data: List[Dict[str, Any]],
sample_totals: Dict[str, Any],
) -> None:
"""Test create_aggregate_table for monthly view."""
table = controller.create_aggregate_table(
sample_monthly_data, sample_totals, "monthly", "UTC"
)
assert isinstance(table, Table)
assert table.title == "Claude Code Token Usage Report - Monthly (UTC)"
def test_create_aggregate_table_invalid_view_type(
self,
controller: TableViewsController,
sample_daily_data: List[Dict[str, Any]],
sample_totals: Dict[str, Any],
) -> None:
"""Test create_aggregate_table with invalid view type."""
with pytest.raises(ValueError, match="Invalid view type"):
controller.create_aggregate_table(
sample_daily_data, sample_totals, "weekly", "UTC"
)
def test_daily_table_timezone_display(
self,
controller: TableViewsController,
sample_daily_data: List[Dict[str, Any]],
sample_totals: Dict[str, Any],
) -> None:
"""Test daily table displays correct timezone."""
table = controller.create_daily_table(
sample_daily_data, sample_totals, "America/New_York"
)
assert (
table.title == "Claude Code Token Usage Report - Daily (America/New_York)"
)
def test_monthly_table_timezone_display(
self,
controller: TableViewsController,
sample_monthly_data: List[Dict[str, Any]],
sample_totals: Dict[str, Any],
) -> None:
"""Test monthly table displays correct timezone."""
table = controller.create_monthly_table(
sample_monthly_data, sample_totals, "Europe/London"
)
assert table.title == "Claude Code Token Usage Report - Monthly (Europe/London)"
def test_table_with_zero_tokens(self, controller: TableViewsController) -> None:
"""Test table with entries having zero tokens."""
data = [
{
"date": "2024-01-01",
"input_tokens": 0,
"output_tokens": 0,
"cache_creation_tokens": 0,
"cache_read_tokens": 0,
"total_cost": 0.0,
"models_used": ["claude-3-haiku"],
"model_breakdowns": {},
"entries_count": 0,
}
]
totals = {
"input_tokens": 0,
"output_tokens": 0,
"cache_creation_tokens": 0,
"cache_read_tokens": 0,
"total_tokens": 0,
"total_cost": 0.0,
"entries_count": 0,
}
table = controller.create_daily_table(data, totals, "UTC")
# Table should have 3 rows:
# - 1 data row
# - 1 separator row (empty)
# - 1 totals row
# Note: Rich table doesn't count empty separator as a row in some versions
assert table.row_count in [3, 4] # Allow for version differences
def test_summary_panel_different_periods(
self, controller: TableViewsController, sample_totals: Dict[str, Any]
) -> None:
"""Test summary panel with different period descriptions."""
periods = [
"Last 30 days",
"Last 7 days",
"January 2024",
"Q1 2024",
"Year to date",
]
for period in periods:
panel = controller.create_summary_panel("daily", sample_totals, period)
assert isinstance(panel, Panel)
assert panel.title == "Summary"
def test_no_data_display_different_view_types(
self, controller: TableViewsController
) -> None:
"""Test no data display for different view types."""
for view_type in ["daily", "monthly", "weekly", "yearly"]:
panel = controller.create_no_data_display(view_type)
assert isinstance(panel, Panel)
assert panel.title == f"No {view_type.capitalize()} Data"
def test_number_formatting_integration(
self,
controller: TableViewsController,
sample_daily_data: List[Dict[str, Any]],
sample_totals: Dict[str, Any],
) -> None:
"""Test that number formatting is integrated correctly."""
# Test that the table can be created with real formatting functions
table = controller.create_daily_table(sample_daily_data, sample_totals, "UTC")
# Verify table was created successfully
assert table is not None
assert table.row_count >= 3 # At least data rows + separator + totals
def test_currency_formatting_integration(
self,
controller: TableViewsController,
sample_daily_data: List[Dict[str, Any]],
sample_totals: Dict[str, Any],
) -> None:
"""Test that currency formatting is integrated correctly."""
# Test that the table can be created with real formatting functions
table = controller.create_daily_table(sample_daily_data, sample_totals, "UTC")
# Verify table was created successfully
assert table is not None
assert table.row_count >= 3 # At least data rows + separator + totals
def test_table_column_alignment(
self,
controller: TableViewsController,
sample_daily_data: List[Dict[str, Any]],
sample_totals: Dict[str, Any],
) -> None:
"""Test that numeric columns are right-aligned."""
table = controller.create_daily_table(sample_daily_data, sample_totals, "UTC")
# Check that numeric columns are right-aligned
for i in range(2, 8): # Columns 2-7 are numeric
assert table.columns[i].justify == "right"
def test_empty_data_lists(self, controller: TableViewsController) -> None:
"""Test handling of empty data lists."""
empty_totals = {
"input_tokens": 0,
"output_tokens": 0,
"cache_creation_tokens": 0,
"cache_read_tokens": 0,
"total_tokens": 0,
"total_cost": 0.0,
"entries_count": 0,
}
# Daily table with empty data
daily_table = controller.create_daily_table([], empty_totals, "UTC")
assert daily_table.row_count == 2 # Separator + totals
# Monthly table with empty data
monthly_table = controller.create_monthly_table([], empty_totals, "UTC")
assert monthly_table.row_count == 2 # Separator + totals
================================================
FILE: src/tests/test_time_utils.py
================================================
"""Comprehensive tests for time_utils module."""
import locale
import platform
from datetime import datetime
from typing import List
from unittest.mock import Mock, patch
import pytest
import pytz
from claude_monitor.utils.time_utils import (
SystemTimeDetector,
TimeFormatDetector,
TimezoneHandler,
format_display_time,
format_time,
get_system_time_format,
get_system_timezone,
get_time_format_preference,
percentage,
)
class TestTimeFormatDetector:
"""Test cases for TimeFormatDetector class."""
def test_detect_from_cli_12h(self) -> None:
"""Test CLI detection for 12h format."""
args = Mock()
args.time_format = "12h"
result = TimeFormatDetector.detect_from_cli(args)
assert result is True
def test_detect_from_cli_24h(self) -> None:
"""Test CLI detection for 24h format."""
args = Mock()
args.time_format = "24h"
result = TimeFormatDetector.detect_from_cli(args)
assert result is False
def test_detect_from_cli_none(self) -> None:
"""Test CLI detection when format not specified."""
args = Mock()
args.time_format = None
result = TimeFormatDetector.detect_from_cli(args)
assert result is None
def test_detect_from_cli_no_args(self) -> None:
"""Test CLI detection with no args."""
result = TimeFormatDetector.detect_from_cli(None)
assert result is None
def test_detect_from_cli_no_attribute(self) -> None:
"""Test CLI detection when args has no time_format attribute."""
args = Mock()
del args.time_format
result = TimeFormatDetector.detect_from_cli(args)
assert result is None
@patch("claude_monitor.utils.time_utils.HAS_BABEL", True)
@patch("claude_monitor.utils.time_utils.get_timezone_location")
def test_detect_from_timezone_with_babel_12h(self, mock_get_location: Mock) -> None:
"""Test timezone detection with Babel for 12h countries."""
mock_get_location.return_value = "United States US"
result = TimeFormatDetector.detect_from_timezone("America/New_York")
assert result is True
@patch("claude_monitor.utils.time_utils.HAS_BABEL", True)
@patch("claude_monitor.utils.time_utils.get_timezone_location")
def test_detect_from_timezone_with_babel_24h(self, mock_get_location: Mock) -> None:
"""Test timezone detection with Babel for 24h countries."""
mock_get_location.return_value = "Germany"
result = TimeFormatDetector.detect_from_timezone("Europe/Berlin")
assert result is False
@patch("claude_monitor.utils.time_utils.HAS_BABEL", True)
@patch("claude_monitor.utils.time_utils.get_timezone_location")
def test_detect_from_timezone_with_babel_exception(
self, mock_get_location: Mock
) -> None:
"""Test timezone detection with Babel when exception occurs."""
mock_get_location.side_effect = Exception("Test error")
result = TimeFormatDetector.detect_from_timezone("Invalid/Timezone")
assert result is None
@patch("claude_monitor.utils.time_utils.HAS_BABEL", False)
def test_detect_from_timezone_no_babel(self) -> None:
"""Test timezone detection without Babel."""
result = TimeFormatDetector.detect_from_timezone("America/New_York")
assert result is None
@patch("locale.setlocale")
@patch("locale.nl_langinfo")
def test_detect_from_locale_12h_ampm(
self, mock_langinfo: Mock, mock_setlocale: Mock
) -> None:
"""Test locale detection for 12h format with AM/PM."""
mock_langinfo.side_effect = (
lambda x: "%I:%M:%S %p" if x == locale.T_FMT_AMPM else ""
)
result = TimeFormatDetector.detect_from_locale()
assert result is True
@patch("locale.setlocale")
@patch("locale.nl_langinfo")
def test_detect_from_locale_12h_dt_fmt(
self, mock_langinfo: Mock, mock_setlocale: Mock
) -> None:
"""Test locale detection for 12h format with %p in D_T_FMT."""
mock_langinfo.side_effect = (
lambda x: "%m/%d/%Y %I:%M:%S %p" if x == locale.D_T_FMT else ""
)
result = TimeFormatDetector.detect_from_locale()
assert result is True
@patch("locale.setlocale")
@patch("locale.nl_langinfo")
def test_detect_from_locale_24h(
self, mock_langinfo: Mock, mock_setlocale: Mock
) -> None:
"""Test locale detection for 24h format."""
mock_langinfo.side_effect = lambda x: "%H:%M:%S" if x == locale.D_T_FMT else ""
result = TimeFormatDetector.detect_from_locale()
assert result is False
@patch("locale.setlocale")
def test_detect_from_locale_exception(self, mock_setlocale: Mock) -> None:
"""Test locale detection with exception."""
mock_setlocale.side_effect = Exception("Locale error")
result = TimeFormatDetector.detect_from_locale()
assert result is False
@patch("platform.system")
@patch("subprocess.run")
def test_detect_from_system_macos_12h(
self, mock_run: Mock, mock_system: Mock
) -> None:
"""Test macOS system detection for 12h format."""
mock_system.return_value = "Darwin"
# Mock successful defaults command returning "1"
mock_defaults_result = Mock()
mock_defaults_result.returncode = 0
mock_defaults_result.stdout = "1"
# Mock date command with AM/PM
mock_date_result = Mock()
mock_date_result.stdout = "02:30:45 PM"
mock_run.side_effect = [mock_defaults_result, mock_date_result]
result = TimeFormatDetector.detect_from_system()
assert result == "12h"
@patch("platform.system")
@patch("subprocess.run")
@patch.object(TimeFormatDetector, "detect_from_locale")
def test_detect_from_system_macos_24h(
self, mock_locale: Mock, mock_run: Mock, mock_system: Mock
) -> None:
"""Test macOS system detection for 24h format."""
mock_system.return_value = "Darwin"
mock_locale.return_value = False # 24h format
# Mock defaults command returning non-1 value
mock_defaults_result = Mock()
mock_defaults_result.returncode = 0
mock_defaults_result.stdout = "0"
# Mock date command without AM/PM
mock_date_result = Mock()
mock_date_result.stdout = "14:30:45"
mock_run.side_effect = [mock_defaults_result, mock_date_result]
result = TimeFormatDetector.detect_from_system()
assert result == "24h"
@patch("platform.system")
@patch("subprocess.run")
def test_detect_from_system_linux_12h(
self, mock_run: Mock, mock_system: Mock
) -> None:
"""Test Linux system detection for 12h format."""
mock_system.return_value = "Linux"
mock_result = Mock()
mock_result.stdout = 'LC_TIME="en_US.UTF-8"'
mock_run.return_value = mock_result
result = TimeFormatDetector.detect_from_system()
assert result == "12h"
@patch("platform.system")
@patch("subprocess.run")
@patch.object(TimeFormatDetector, "detect_from_locale")
def test_detect_from_system_linux_24h(
self, mock_locale: Mock, mock_run: Mock, mock_system: Mock
) -> None:
"""Test Linux system detection for 24h format."""
mock_system.return_value = "Linux"
mock_locale.return_value = False # 24h format
mock_result = Mock()
mock_result.stdout = 'LC_TIME="de_DE.UTF-8"'
mock_run.return_value = mock_result
result = TimeFormatDetector.detect_from_system()
assert result == "24h"
@pytest.mark.skipif(platform.system() != "Windows", reason="Windows-specific test")
@patch("platform.system")
def test_detect_from_system_windows_12h(self, mock_system: Mock) -> None:
"""Test Windows system detection for 12h format."""
mock_system.return_value = "Windows"
import sys
if "winreg" not in sys.modules:
sys.modules["winreg"] = Mock()
with patch("winreg.OpenKey"):
with patch("winreg.QueryValueEx") as mock_query:
mock_query.return_value = ("h:mm:ss tt", None)
result = TimeFormatDetector.detect_from_system()
assert result == "12h"
@pytest.mark.skipif(platform.system() != "Windows", reason="Windows-specific test")
@patch("platform.system")
def test_detect_from_system_windows_24h(self, mock_system: Mock) -> None:
"""Test Windows system detection for 24h format."""
mock_system.return_value = "Windows"
import sys
if "winreg" not in sys.modules:
sys.modules["winreg"] = Mock()
with patch("winreg.OpenKey"):
with patch("winreg.QueryValueEx") as mock_query:
mock_query.return_value = ("HH:mm:ss", None)
result = TimeFormatDetector.detect_from_system()
assert result == "24h"
@pytest.mark.skipif(platform.system() != "Windows", reason="Windows-specific test")
@patch("platform.system")
def test_detect_from_system_windows_exception(self, mock_system: Mock) -> None:
"""Test Windows system detection with exception."""
mock_system.return_value = "Windows"
import sys
if "winreg" not in sys.modules:
sys.modules["winreg"] = Mock()
with patch("winreg.OpenKey", side_effect=Exception("Registry error")):
with patch.object(
TimeFormatDetector, "detect_from_locale", return_value=True
):
result = TimeFormatDetector.detect_from_system()
assert result == "12h"
@patch("platform.system")
def test_detect_from_system_unknown_platform(self, mock_system: Mock) -> None:
"""Test system detection for unknown platform."""
mock_system.return_value = "UnknownOS"
with patch.object(TimeFormatDetector, "detect_from_locale", return_value=False):
result = TimeFormatDetector.detect_from_system()
assert result == "24h"
def test_get_preference_cli_priority(self) -> None:
"""Test get_preference with CLI args having highest priority."""
args = Mock()
args.time_format = "12h"
with patch.object(TimeFormatDetector, "detect_from_timezone") as mock_tz:
mock_tz.return_value = False # Should be ignored
result = TimeFormatDetector.get_preference(args, "Europe/Berlin")
assert result is True
def test_get_preference_timezone_fallback(self) -> None:
"""Test get_preference falling back to timezone detection."""
with (
patch.object(TimeFormatDetector, "detect_from_timezone", return_value=True),
patch.object(TimeFormatDetector, "detect_from_system") as mock_system,
):
mock_system.return_value = "24h" # Should be ignored
result = TimeFormatDetector.get_preference(None, "America/New_York")
assert result is True
def test_get_preference_system_fallback(self) -> None:
"""Test get_preference falling back to system detection."""
with (
patch.object(TimeFormatDetector, "detect_from_timezone", return_value=None),
patch.object(TimeFormatDetector, "detect_from_system", return_value="12h"),
):
result = TimeFormatDetector.get_preference(None, "Europe/Berlin")
assert result is True
class TestSystemTimeDetector:
"""Test cases for SystemTimeDetector class."""
@patch("os.environ.get")
@patch("os.path.exists")
@patch("platform.system")
@patch("builtins.open", create=True)
def test_get_timezone_linux_timezone_file(
self, mock_open: Mock, mock_system: Mock, mock_exists: Mock, mock_env: Mock
) -> None:
"""Test Linux timezone detection via /etc/timezone file."""
mock_env.return_value = None # No TZ environment variable
mock_system.return_value = "Linux"
mock_exists.return_value = True # /etc/timezone file exists
# Mock file content
mock_file = Mock()
mock_file.read.return_value = "America/New_York\n"
mock_open.return_value.__enter__.return_value = mock_file
result = SystemTimeDetector.get_timezone()
assert result == "America/New_York"
@patch("os.environ.get")
@patch("os.path.exists")
@patch("platform.system")
@patch("subprocess.run")
def test_get_timezone_linux_timedatectl(
self, mock_run: Mock, mock_system: Mock, mock_exists: Mock, mock_env: Mock
) -> None:
"""Test Linux timezone detection via timedatectl."""
mock_env.return_value = None # No TZ environment variable
mock_system.return_value = "Linux"
mock_exists.return_value = False # No /etc/timezone file
# Mock successful timedatectl command
mock_timedatectl_result = Mock()
mock_timedatectl_result.stdout = "Europe/London"
mock_timedatectl_result.returncode = 0
mock_run.return_value = mock_timedatectl_result
result = SystemTimeDetector.get_timezone()
assert result == "Europe/London"
@patch("platform.system")
@patch("subprocess.run")
def test_get_timezone_windows(self, mock_run: Mock, mock_system: Mock) -> None:
"""Test Windows timezone detection."""
mock_system.return_value = "Windows"
mock_result = Mock()
mock_result.stdout = "Eastern Standard Time"
mock_run.return_value = mock_result
# Should return the Windows timezone name
result = SystemTimeDetector.get_timezone()
assert result == "Eastern Standard Time"
@patch("platform.system")
def test_get_timezone_unknown_system(self, mock_system: Mock) -> None:
"""Test timezone detection for unknown system."""
mock_system.return_value = "UnknownOS"
result = SystemTimeDetector.get_timezone()
assert result == "UTC"
def test_get_time_format(self) -> None:
"""Test get_time_format delegates to TimeFormatDetector."""
with patch.object(TimeFormatDetector, "detect_from_system", return_value="12h"):
result = SystemTimeDetector.get_time_format()
assert result == "12h"
class TestTimezoneHandler:
"""Test cases for TimezoneHandler class."""
def test_init_default(self) -> None:
"""Test TimezoneHandler initialization with default timezone."""
handler = TimezoneHandler()
assert handler.default_tz == pytz.UTC
def test_init_custom_valid(self) -> None:
"""Test TimezoneHandler initialization with valid custom timezone."""
handler = TimezoneHandler("America/New_York")
assert handler.default_tz.zone == "America/New_York"
def test_init_custom_invalid(self) -> None:
"""Test TimezoneHandler initialization with invalid timezone."""
with patch("claude_monitor.utils.time_utils.logger") as mock_logger:
handler = TimezoneHandler("Invalid/Timezone")
assert handler.default_tz == pytz.UTC
mock_logger.warning.assert_called_once()
def test_validate_and_get_tz_valid(self) -> None:
"""Test _validate_and_get_tz with valid timezone."""
handler = TimezoneHandler()
tz = handler._validate_and_get_tz("Europe/London")
assert tz.zone == "Europe/London"
def test_validate_and_get_tz_invalid(self) -> None:
"""Test _validate_and_get_tz with invalid timezone."""
handler = TimezoneHandler()
with patch("claude_monitor.utils.time_utils.logger") as mock_logger:
tz = handler._validate_and_get_tz("Invalid/Timezone")
assert tz == pytz.UTC
mock_logger.warning.assert_called_once()
def test_parse_timestamp_iso_with_z(self) -> None:
"""Test parsing ISO timestamp with Z suffix."""
handler = TimezoneHandler()
result = handler.parse_timestamp("2024-01-01T12:00:00Z")
assert result is not None
assert result.tzinfo == pytz.UTC
def test_parse_timestamp_iso_with_offset(self) -> None:
"""Test parsing ISO timestamp with timezone offset."""
handler = TimezoneHandler()
result = handler.parse_timestamp("2024-01-01T12:00:00+02:00")
assert result is not None
assert result.tzinfo is not None
def test_parse_timestamp_iso_with_microseconds(self) -> None:
"""Test parsing ISO timestamp with microseconds."""
handler = TimezoneHandler()
result = handler.parse_timestamp("2024-01-01T12:00:00.123456Z")
assert result is not None
assert result.tzinfo == pytz.UTC
def test_parse_timestamp_iso_no_timezone(self) -> None:
"""Test parsing ISO timestamp without timezone."""
handler = TimezoneHandler("America/New_York")
result = handler.parse_timestamp("2024-01-01T12:00:00")
assert result is not None
assert result.tzinfo.zone == "America/New_York"
def test_parse_timestamp_invalid_iso(self) -> None:
"""Test parsing invalid ISO timestamp."""
handler = TimezoneHandler()
with patch("claude_monitor.utils.time_utils.logger"):
result = handler.parse_timestamp("2024-01-01T25:00:00Z") # Invalid hour
# Should try other formats or return None
assert result is None or isinstance(result, datetime)
def test_parse_timestamp_alternative_formats(self) -> None:
"""Test parsing with alternative formats."""
handler = TimezoneHandler("UTC")
test_cases: List[str] = [
"2024-01-01 12:00:00",
"2024/01/01 12:00:00",
"01/01/2024 12:00:00",
"2024-01-01",
"2024/01/01",
]
for timestamp_str in test_cases:
result = handler.parse_timestamp(timestamp_str)
assert result is not None
def test_parse_timestamp_empty(self) -> None:
"""Test parsing empty timestamp."""
handler = TimezoneHandler()
result = handler.parse_timestamp("")
assert result is None
def test_parse_timestamp_none(self) -> None:
"""Test parsing None timestamp."""
handler = TimezoneHandler()
result = handler.parse_timestamp(None)
assert result is None
def test_parse_timestamp_invalid_format(self) -> None:
"""Test parsing completely invalid format."""
handler = TimezoneHandler()
result = handler.parse_timestamp("not a timestamp")
assert result is None
def test_ensure_utc_naive(self) -> None:
"""Test ensure_utc with naive datetime."""
handler = TimezoneHandler("America/New_York")
dt = datetime(2024, 1, 1, 12, 0, 0)
result = handler.ensure_utc(dt)
assert result.tzinfo == pytz.UTC
def test_ensure_utc_aware(self) -> None:
"""Test ensure_utc with timezone-aware datetime."""
handler = TimezoneHandler()
dt = pytz.timezone("Europe/London").localize(datetime(2024, 1, 1, 12, 0, 0))
result = handler.ensure_utc(dt)
assert result.tzinfo == pytz.UTC
def test_ensure_timezone_naive(self) -> None:
"""Test ensure_timezone with naive datetime."""
handler = TimezoneHandler("Europe/Berlin")
dt = datetime(2024, 1, 1, 12, 0, 0)
result = handler.ensure_timezone(dt)
assert result.tzinfo.zone == "Europe/Berlin"
def test_ensure_timezone_aware(self) -> None:
"""Test ensure_timezone with timezone-aware datetime."""
handler = TimezoneHandler()
dt = pytz.timezone("America/New_York").localize(datetime(2024, 1, 1, 12, 0, 0))
result = handler.ensure_timezone(dt)
assert result.tzinfo.zone == "America/New_York"
def test_validate_timezone_valid(self) -> None:
"""Test validate_timezone with valid timezone."""
handler = TimezoneHandler()
assert handler.validate_timezone("America/New_York") is True
assert handler.validate_timezone("UTC") is True
def test_validate_timezone_invalid(self) -> None:
"""Test validate_timezone with invalid timezone."""
handler = TimezoneHandler()
assert handler.validate_timezone("Invalid/Timezone") is False
def test_convert_to_timezone_naive(self) -> None:
"""Test convert_to_timezone with naive datetime."""
handler = TimezoneHandler("UTC")
dt = datetime(2024, 1, 1, 12, 0, 0)
result = handler.convert_to_timezone(dt, "America/New_York")
assert result.tzinfo.zone == "America/New_York"
def test_convert_to_timezone_aware(self) -> None:
"""Test convert_to_timezone with timezone-aware datetime."""
handler = TimezoneHandler()
dt = pytz.UTC.localize(datetime(2024, 1, 1, 12, 0, 0))
result = handler.convert_to_timezone(dt, "Europe/London")
assert result.tzinfo.zone == "Europe/London"
def test_set_timezone(self) -> None:
"""Test set_timezone method."""
handler = TimezoneHandler()
handler.set_timezone("Asia/Tokyo")
assert handler.default_tz.zone == "Asia/Tokyo"
def test_to_utc(self) -> None:
"""Test to_utc method."""
handler = TimezoneHandler("Europe/Paris")
dt = datetime(2024, 1, 1, 12, 0, 0)
result = handler.to_utc(dt)
assert result.tzinfo == pytz.UTC
def test_to_timezone_default(self) -> None:
"""Test to_timezone with default timezone."""
handler = TimezoneHandler("Australia/Sydney")
dt = pytz.UTC.localize(datetime(2024, 1, 1, 12, 0, 0))
result = handler.to_timezone(dt)
assert result.tzinfo.zone == "Australia/Sydney"
def test_to_timezone_specific(self) -> None:
"""Test to_timezone with specific timezone."""
handler = TimezoneHandler()
dt = pytz.UTC.localize(datetime(2024, 1, 1, 12, 0, 0))
result = handler.to_timezone(dt, "America/Los_Angeles")
assert result.tzinfo.zone == "America/Los_Angeles"
def test_format_datetime_default(self) -> None:
"""Test format_datetime with default settings."""
handler = TimezoneHandler("UTC")
dt = pytz.UTC.localize(datetime(2024, 1, 1, 15, 30, 45))
with patch.object(TimeFormatDetector, "get_preference", return_value=True):
result = handler.format_datetime(dt)
assert "PM" in result or "AM" in result
def test_format_datetime_24h(self) -> None:
"""Test format_datetime with 24h format."""
handler = TimezoneHandler("UTC")
dt = pytz.UTC.localize(datetime(2024, 1, 1, 15, 30, 45))
result = handler.format_datetime(dt, use_12_hour=False)
assert "15:30:45" in result
def test_format_datetime_12h(self) -> None:
"""Test format_datetime with 12h format."""
handler = TimezoneHandler("UTC")
dt = pytz.UTC.localize(datetime(2024, 1, 1, 15, 30, 45))
result = handler.format_datetime(dt, use_12_hour=True)
assert "PM" in result
class TestPublicAPI:
"""Test cases for public API functions."""
def test_get_time_format_preference(self) -> None:
"""Test get_time_format_preference function."""
args = Mock()
args.time_format = "12h"
with patch.object(
TimeFormatDetector, "get_preference", return_value=True
) as mock_get:
result = get_time_format_preference(args)
assert result is True
mock_get.assert_called_once_with(args)
def test_get_system_timezone(self) -> None:
"""Test get_system_timezone function."""
with patch.object(
SystemTimeDetector, "get_timezone", return_value="America/Chicago"
) as mock_get:
result = get_system_timezone()
assert result == "America/Chicago"
mock_get.assert_called_once()
def test_get_system_time_format(self) -> None:
"""Test get_system_time_format function."""
with patch.object(
SystemTimeDetector, "get_time_format", return_value="24h"
) as mock_get:
result = get_system_time_format()
assert result == "24h"
mock_get.assert_called_once()
class TestFormattingUtilities:
"""Test cases for formatting utility functions."""
def test_format_time_minutes_only(self) -> None:
"""Test format_time with minutes only."""
assert format_time(30) == "30m"
assert format_time(59) == "59m"
def test_format_time_hours_only(self) -> None:
"""Test format_time with exact hours."""
assert format_time(60) == "1h"
assert format_time(120) == "2h"
assert format_time(180) == "3h"
def test_format_time_hours_and_minutes(self) -> None:
"""Test format_time with hours and minutes."""
assert format_time(90) == "1h 30m"
assert format_time(135) == "2h 15m"
assert format_time(245) == "4h 5m"
def test_percentage_normal(self) -> None:
"""Test percentage calculation with normal values."""
assert percentage(25, 100) == 25.0
assert percentage(50, 200) == 25.0
assert percentage(33.333, 100, 2) == 33.33
def test_percentage_zero_whole(self) -> None:
"""Test percentage calculation with zero whole."""
assert percentage(10, 0) == 0.0
def test_percentage_decimal_places(self) -> None:
"""Test percentage calculation with different decimal places."""
assert percentage(1, 3, 0) == 33.0
assert percentage(1, 3, 1) == 33.3
assert percentage(1, 3, 2) == 33.33
def test_format_display_time_12h_with_seconds(self) -> None:
"""Test format_display_time in 12h format with seconds."""
dt = datetime(2024, 1, 1, 15, 30, 45)
with patch(
"claude_monitor.utils.time_utils.get_time_format_preference",
return_value=True,
):
# Test Unix/Linux format
try:
result = format_display_time(
dt, use_12h_format=True, include_seconds=True
)
assert "PM" in result
assert "3:30:45" in result or "03:30:45" in result
except ValueError:
# Windows format fallback
result = format_display_time(
dt, use_12h_format=True, include_seconds=True
)
assert "PM" in result
def test_format_display_time_12h_without_seconds(self) -> None:
"""Test format_display_time in 12h format without seconds."""
dt = datetime(2024, 1, 1, 15, 30, 45)
try:
result = format_display_time(dt, use_12h_format=True, include_seconds=False)
assert "PM" in result
assert "3:30" in result or "03:30" in result
except ValueError:
# Windows format fallback
result = format_display_time(dt, use_12h_format=True, include_seconds=False)
assert "PM" in result
def test_format_display_time_24h_with_seconds(self) -> None:
"""Test format_display_time in 24h format with seconds."""
dt = datetime(2024, 1, 1, 15, 30, 45)
result = format_display_time(dt, use_12h_format=False, include_seconds=True)
assert result == "15:30:45"
def test_format_display_time_24h_without_seconds(self) -> None:
"""Test format_display_time in 24h format without seconds."""
dt = datetime(2024, 1, 1, 15, 30, 45)
result = format_display_time(dt, use_12h_format=False, include_seconds=False)
assert result == "15:30"
def test_format_display_time_auto_detect(self) -> None:
"""Test format_display_time with automatic format detection."""
dt = datetime(2024, 1, 1, 15, 30, 45)
with patch(
"claude_monitor.utils.time_utils.get_time_format_preference",
return_value=False,
):
result = format_display_time(dt)
assert result == "15:30:45"
def test_format_display_time_windows_fallback(self) -> None:
"""Test format_display_time Windows fallback for %-I format."""
# Test that the function handles both Unix and Windows strftime formats
dt = datetime(2024, 1, 1, 3, 30, 45)
# Just test basic functionality - the Windows fallback is handled internally
result = format_display_time(dt, use_12h_format=True, include_seconds=True)
# Should contain time components
assert ":" in result
# Test 12h format contains AM/PM or similar indicator
if "AM" in result or "PM" in result:
assert True # Standard format worked
else:
# Alternative formats might be used
assert "3" in result or "03" in result # Hour should be present
================================================
FILE: src/tests/test_timezone.py
================================================
"""Comprehensive tests for TimezoneHandler class."""
from datetime import datetime, timezone
from typing import List, Union
from unittest.mock import Mock, patch
import pytest
import pytz
from claude_monitor.utils.timezone import (
TimezoneHandler,
_detect_timezone_time_preference,
)
class TestTimezoneHandler:
"""Test suite for TimezoneHandler class."""
@pytest.fixture
def handler(self) -> TimezoneHandler:
"""Create a TimezoneHandler with default settings."""
return TimezoneHandler()
@pytest.fixture
def custom_handler(self) -> TimezoneHandler:
"""Create a TimezoneHandler with custom timezone."""
return TimezoneHandler(default_tz="America/New_York")
def test_init_default_timezone(self, handler: TimezoneHandler) -> None:
"""Test initialization with default timezone."""
assert handler.default_tz == pytz.UTC
assert hasattr(handler, "default_tz")
def test_init_custom_timezone(self, custom_handler: TimezoneHandler) -> None:
"""Test initialization with custom timezone."""
assert custom_handler.default_tz.zone == "America/New_York"
def test_init_invalid_timezone_fallback(self) -> None:
"""Test initialization with invalid timezone falls back to UTC."""
with patch("claude_monitor.utils.time_utils.logger") as mock_logger:
handler = TimezoneHandler(default_tz="Invalid/Timezone")
assert handler.default_tz == pytz.UTC
mock_logger.warning.assert_called_once()
def test_validate_timezone_valid_timezones(self, handler: TimezoneHandler) -> None:
"""Test timezone validation with valid timezones."""
valid_timezones: List[str] = [
"UTC",
"America/New_York",
"Europe/London",
"Asia/Tokyo",
"Australia/Sydney",
]
for tz in valid_timezones:
assert handler.validate_timezone(tz) is True
def test_validate_timezone_invalid_timezones(
self, handler: TimezoneHandler
) -> None:
"""Test timezone validation with invalid timezones."""
invalid_timezones: List[Union[str, None, int]] = [
"",
"Invalid/Timezone",
"Not_A_Timezone",
None,
123,
]
for tz in invalid_timezones:
if tz is None or isinstance(tz, int):
# These will cause errors due to type conversion
try:
result = handler.validate_timezone(tz)
assert result is False
except (TypeError, AttributeError):
# Expected for None and int types
pass
else:
assert handler.validate_timezone(tz) is False
def test_parse_timestamp_iso_format_with_z(self, handler: TimezoneHandler) -> None:
"""Test parsing ISO format timestamp with Z suffix."""
timestamp_str = "2024-01-15T10:30:45Z"
result = handler.parse_timestamp(timestamp_str)
expected = datetime(2024, 1, 15, 10, 30, 45, tzinfo=timezone.utc)
assert result == expected
def test_parse_timestamp_iso_format_with_offset(
self, handler: TimezoneHandler
) -> None:
"""Test parsing ISO format timestamp with timezone offset."""
timestamp_str = "2024-01-15T10:30:45+05:00"
result = handler.parse_timestamp(timestamp_str)
# Should be converted to UTC
expected = datetime(2024, 1, 15, 5, 30, 45, tzinfo=timezone.utc)
assert result == expected
def test_parse_timestamp_iso_format_without_timezone(
self, handler: TimezoneHandler
) -> None:
"""Test parsing ISO format timestamp without timezone info."""
timestamp_str = "2024-01-15T10:30:45"
result = handler.parse_timestamp(timestamp_str)
# Should assume UTC
expected = datetime(2024, 1, 15, 10, 30, 45, tzinfo=timezone.utc)
assert result == expected
def test_parse_timestamp_with_microseconds(self, handler: TimezoneHandler) -> None:
"""Test parsing timestamp with microseconds."""
timestamp_str = "2024-01-15T10:30:45.123456Z"
result = handler.parse_timestamp(timestamp_str)
expected = datetime(2024, 1, 15, 10, 30, 45, 123456, tzinfo=timezone.utc)
assert result == expected
def test_parse_timestamp_unix_timestamp_string(
self, handler: TimezoneHandler
) -> None:
"""Test parsing unix timestamp as string - not supported by current implementation."""
# Current implementation doesn't parse unix timestamps
timestamp_str = "1705316645"
result = handler.parse_timestamp(timestamp_str)
# Should return None for unsupported format
assert result is None
def test_parse_timestamp_unix_timestamp_with_milliseconds(
self, handler: TimezoneHandler
) -> None:
"""Test parsing unix timestamp with milliseconds - not supported by current implementation."""
# Current implementation doesn't parse unix timestamps
timestamp_str = "1705316645123"
result = handler.parse_timestamp(timestamp_str)
# Should return None for unsupported format
assert result is None
def test_parse_timestamp_invalid_format(self, handler: TimezoneHandler) -> None:
"""Test parsing invalid timestamp format."""
result = handler.parse_timestamp("invalid-timestamp")
assert result is None
def test_parse_timestamp_empty_string(self, handler: TimezoneHandler) -> None:
"""Test parsing empty timestamp string."""
result = handler.parse_timestamp("")
assert result is None
def test_ensure_utc_with_utc_datetime(self, handler: TimezoneHandler) -> None:
"""Test ensure_utc with datetime already in UTC."""
dt = datetime(2024, 1, 15, 10, 30, 45, tzinfo=pytz.UTC)
result = handler.ensure_utc(dt)
assert result == dt
assert result.tzinfo == pytz.UTC
def test_ensure_utc_with_naive_datetime(self, handler: TimezoneHandler) -> None:
"""Test ensure_utc with naive datetime (assumes UTC)."""
dt = datetime(2024, 1, 15, 10, 30, 45) # No timezone
result = handler.ensure_utc(dt)
expected = pytz.UTC.localize(datetime(2024, 1, 15, 10, 30, 45))
assert result == expected
def test_ensure_utc_with_different_timezone(self, handler: TimezoneHandler) -> None:
"""Test ensure_utc with datetime in different timezone."""
# Create datetime in EST (UTC-5)
est = pytz.timezone("America/New_York")
dt = est.localize(datetime(2024, 1, 15, 5, 30, 45))
result = handler.ensure_utc(dt)
# Should be converted to UTC (5 hours ahead)
expected = datetime(2024, 1, 15, 10, 30, 45, tzinfo=pytz.UTC)
assert result == expected
def test_ensure_timezone_utc_to_est(self, handler: TimezoneHandler) -> None:
"""Test ensure_timezone conversion from UTC to EST."""
dt = datetime(2024, 1, 15, 10, 30, 45, tzinfo=pytz.UTC)
result = handler.ensure_timezone(dt)
# Should remain in UTC since that's the default
assert result == dt
def test_ensure_timezone_with_custom_timezone(
self, custom_handler: TimezoneHandler
) -> None:
"""Test ensure_timezone with custom default timezone."""
dt = datetime(2024, 1, 15, 10, 30, 45, tzinfo=pytz.UTC)
result = custom_handler.ensure_timezone(dt)
# Should remain unchanged since it already has timezone
assert result == dt
def test_ensure_timezone_with_naive_datetime(
self, handler: TimezoneHandler
) -> None:
"""Test ensure_timezone with naive datetime."""
dt = datetime(2024, 1, 15, 10, 30, 45) # No timezone
result = handler.ensure_timezone(dt)
# Should assume default timezone and return in default timezone
expected = pytz.UTC.localize(datetime(2024, 1, 15, 10, 30, 45))
assert result == expected
def test_to_utc_from_different_timezone(self, handler: TimezoneHandler) -> None:
"""Test to_utc conversion from different timezone."""
# Create datetime in JST (UTC+9)
jst = pytz.timezone("Asia/Tokyo")
dt = jst.localize(datetime(2024, 1, 15, 19, 30, 45))
result = handler.to_utc(dt)
# Should be converted to UTC (9 hours behind)
expected = datetime(2024, 1, 15, 10, 30, 45, tzinfo=pytz.UTC)
assert result == expected
def test_to_utc_with_naive_datetime(self, handler: TimezoneHandler) -> None:
"""Test to_utc with naive datetime."""
dt = datetime(2024, 1, 15, 10, 30, 45)
result = handler.to_utc(dt)
# Should assume default timezone (UTC) and return in UTC
expected = datetime(2024, 1, 15, 10, 30, 45, tzinfo=pytz.UTC)
assert result == expected
def test_to_utc_with_custom_default_timezone(
self, custom_handler: TimezoneHandler
) -> None:
"""Test to_utc with custom default timezone."""
dt = datetime(2024, 1, 15, 5, 30, 45) # Naive datetime
result = custom_handler.to_utc(dt)
# Should assume America/New_York and convert to UTC
# During standard time (EST), this would be +5 hours
expected_hour = 10 # 5 AM EST = 10 AM UTC (standard time)
assert result.hour in (expected_hour, 9) # Account for DST
def test_to_timezone_conversion(self, handler: TimezoneHandler) -> None:
"""Test to_timezone conversion."""
dt = datetime(2024, 1, 15, 10, 30, 45, tzinfo=timezone.utc)
result = handler.to_timezone(dt, "Asia/Tokyo")
# Should be converted to JST (UTC+9)
assert result.hour == 19 # 10 AM UTC = 7 PM JST
def test_to_timezone_with_default(self, custom_handler: TimezoneHandler) -> None:
"""Test to_timezone using default timezone."""
dt = datetime(2024, 1, 15, 10, 30, 45, tzinfo=timezone.utc)
result = custom_handler.to_timezone(dt)
# Should use default timezone (America/New_York)
expected_hour = 5 # 10 AM UTC = 5 AM EST (standard time)
assert result.hour in (expected_hour, 6) # Account for DST
def test_error_handling_integration(self, handler: TimezoneHandler) -> None:
"""Test error handling integration."""
# Test that invalid timestamps return None gracefully
result = handler.parse_timestamp("completely-invalid-timestamp")
assert result is None
def test_format_datetime_with_timezone_preference(
self, handler: TimezoneHandler
) -> None:
"""Test format_datetime with timezone preference."""
dt = datetime(2024, 1, 15, 14, 30, 45, tzinfo=pytz.UTC)
# Test 24-hour format (default for UTC)
result_24h = handler.format_datetime(dt, use_12_hour=False)
assert "14:30:45" in result_24h
# Test 12-hour format
result_12h = handler.format_datetime(dt, use_12_hour=True)
assert "2:30:45 PM" in result_12h or "02:30:45 PM" in result_12h
def test_detect_timezone_preference_integration(
self, handler: TimezoneHandler
) -> None:
"""Test integration with timezone preference detection."""
# Test US timezone (should prefer 12-hour)
us_handler = TimezoneHandler("America/New_York")
dt = datetime(2024, 1, 15, 14, 30, 45, tzinfo=pytz.UTC)
result = us_handler.format_datetime(dt)
# Should automatically use appropriate format
assert isinstance(result, str)
assert "2024" in result
def test_comprehensive_timestamp_parsing(self, handler: TimezoneHandler) -> None:
"""Test comprehensive timestamp parsing with various formats."""
test_cases: List[str] = [
"2024-01-15T10:30:45Z",
"2024-01-15T10:30:45.123Z",
"2024-01-15T10:30:45+00:00",
"2024-01-15T10:30:45.123+00:00",
"2024-01-15T05:30:45-05:00", # EST
"1705316645", # Unix timestamp
"1705316645123", # Unix timestamp with milliseconds
]
for timestamp_str in test_cases:
result = handler.parse_timestamp(timestamp_str)
if result is not None: # Some formats might not be supported
assert isinstance(result, datetime)
# Check timezone - should have timezone info
assert result.tzinfo is not None
class TestTimezonePreferenceDetection:
"""Test suite for timezone preference detection functions."""
def test_detect_timezone_time_preference_delegation(self) -> None:
"""Test that _detect_timezone_time_preference delegates correctly."""
# This function delegates to get_time_format_preference
with patch(
"claude_monitor.utils.time_utils.get_time_format_preference",
return_value=True,
):
result = _detect_timezone_time_preference()
assert result is True
def test_detect_timezone_time_preference_with_args(self) -> None:
"""Test timezone preference detection with args."""
mock_args = Mock()
mock_args.time_format = "24h"
with patch(
"claude_monitor.utils.time_utils.get_time_format_preference",
return_value=False,
):
result = _detect_timezone_time_preference(mock_args)
assert result is False
================================================
FILE: src/tests/test_version.py
================================================
"""Tests for version management."""
from typing import Dict
from unittest.mock import mock_open, patch
import pytest
from claude_monitor._version import _get_version_from_pyproject, get_version
def test_get_version_from_metadata() -> None:
"""Test getting version from package metadata."""
with patch("importlib.metadata.version") as mock_version:
mock_version.return_value = "3.0.0"
version = get_version()
assert version == "3.0.0"
mock_version.assert_called_once_with("claude-monitor")
def test_get_version_fallback_to_pyproject() -> None:
"""Test fallback to pyproject.toml when package not installed."""
mock_toml_content = """
[project]
name = "claude-monitor"
version = "3.0.0"
"""
with patch("importlib.metadata.version") as mock_version:
mock_version.side_effect = ImportError("Package not found")
with (
patch("pathlib.Path.exists", return_value=True),
patch("builtins.open", mock_open(read_data=mock_toml_content.encode())),
):
try:
with patch("tomllib.load") as mock_load:
mock_load.return_value: Dict[str, Dict[str, str]] = {
"project": {"version": "3.0.0"}
}
version = _get_version_from_pyproject()
assert version == "3.0.0"
except ImportError:
# Python < 3.11, use tomli
with patch("tomli.load") as mock_load:
mock_load.return_value: Dict[str, Dict[str, str]] = {
"project": {"version": "3.0.0"}
}
version = _get_version_from_pyproject()
assert version == "3.0.0"
def test_get_version_fallback_unknown() -> None:
"""Test fallback to 'unknown' when everything fails."""
with patch("importlib.metadata.version") as mock_version:
mock_version.side_effect = ImportError("Package not found")
with patch("pathlib.Path.exists", return_value=False):
version = _get_version_from_pyproject()
assert version == "unknown"
def test_version_import_from_main_module() -> None:
"""Test that version can be imported from main module."""
from claude_monitor import __version__
assert isinstance(__version__, str)
assert len(__version__) > 0
def test_version_format() -> None:
"""Test that version follows expected format."""
from claude_monitor import __version__
# Should be semantic version format (X.Y.Z) or include "unknown"
if __version__ != "unknown":
parts = __version__.split(".")
assert len(parts) >= 2, (
f"Version should have at least 2 parts, got: {__version__}"
)
# First part should be numeric
assert parts[0].isdigit(), f"Major version should be numeric, got: {parts[0]}"
assert parts[1].isdigit(), f"Minor version should be numeric, got: {parts[1]}"
def test_version_consistency() -> None:
"""Test that version is consistent across imports."""
from claude_monitor import __version__ as version1
from claude_monitor._version import __version__ as version2
assert version1 == version2, "Version should be consistent across imports"
@pytest.mark.integration
def test_version_matches_pyproject() -> None:
"""Integration test: verify version matches pyproject.toml."""
from pathlib import Path
# Read version from pyproject.toml
pyproject_path = Path(__file__).parent.parent.parent / "pyproject.toml"
if pyproject_path.exists():
try:
import tomllib
with open(pyproject_path, "rb") as f:
data = tomllib.load(f)
expected_version = data["project"]["version"]
except ImportError:
# Python < 3.11, use tomli
import tomli
with open(pyproject_path, "rb") as f:
data = tomli.load(f)
expected_version = data["project"]["version"]
# Compare with module version (only in installed package)
from claude_monitor import __version__
if __version__ != "unknown":
assert __version__ == expected_version, (
f"Module version {__version__} should match "
f"pyproject.toml version {expected_version}"
)