 \n\n##### 시간 복잡도\n\n- 인접 행렬 : O(V^2)\n- 인접 리스트 : O(V+E)\n\n> V는 접점, E는 간선을 뜻한다\n\n
\n\n##### 시간 복잡도\n\n- 인접 행렬 : O(V^2)\n- 인접 리스트 : O(V+E)\n\n> V는 접점, E는 간선을 뜻한다\n\n\n\n
\n\n### BFS\n\n> 루트 노드 또는 임의 노드에서 **인접한 노드부터 먼저 탐색**하는 방법\n\n**큐**를 통해 구현한다. (해당 노드의 주변부터 탐색해야하기 때문)\n\n
\n\n- 최소 비용(즉, 모든 곳을 탐색하는 것보다 최소 비용이 우선일 때)에 적합\n\n
 \n\n##### 시간 복잡도\n\n- 인접 행렬 : O(V^2)\n- 인접 리스트 : O(V+E)\n\n##### Code\n\n```c\n#include
\n\n##### 시간 복잡도\n\n- 인접 행렬 : O(V^2)\n- 인접 리스트 : O(V+E)\n\n##### Code\n\n```c\n#include \n\n**연습문제** : [[BOJ] DFS와 BFS](https://www.acmicpc.net/problem/1260)\n\n
\n\n##### [참고 자료]\n\n- [링크](https://developer-mac.tistory.com/64)" }, { "path": "Algorithm/Hash Table 구현하기.md", "content": "# Hash Table 구현하기\n\n> 알고리즘 문제를 풀기위해 필수적으로 알아야 할 개념\n\n브루트 포스(완전 탐색)으로는 시간초과에 빠지게 되는 문제에서는 해시를 적용시켜야 한다.\n\n
\n\n[연습 문제 링크](
\n\nN(1~100000)의 값만큼 문자열이 입력된다.\n\n처음 입력되는 문자열은 \"OK\", 들어온 적이 있던 문자열은 \"문자열+index\"로 출력하면 된다.\n\nex)\n\n##### Input\n\n```\n5\nabcd\nabc\nabcd\nabcd\nab\n```\n\n##### Output\n\n```\nOK\nOK\nabcd1\nabcd2\nOK\n```\n\n
\n\n문제를 이해하는 건 쉽다. 똑같은 문자열이 들어왔는지 체크해보고, 들어온 문자열은 인덱스 번호를 부여해서 출력해주면 된다.\n\n
\n\n하지만, 현재 N값은 최대 10만이다. 브루트 포스로 접근하면 N^2이 되므로 100억번의 연산이 필요해서 시간초과에 빠질 것이다. 따라서 **'해시 테이블'**을 이용해 해결해야 한다. \n\n
\n\n입력된 문자열 값을 해시 키로 변환시켜 저장하면서 최대한 시간을 줄여나가도록 구현해야 한다.\n\n이 문제는 해시 테이블을 알고리즘에서 적용시켜보기 위해 연습하기에 아주 좋은 문제 같다. 특히 삼성 상시 SW역량테스트 B형을 준비하는 사람들에게 추천하고 싶은 문제다. 해시 테이블 구현을 연습하기 딱 좋다.\n\n
\n\n
\n\n#### **해시 테이블 구현**\n\n해시 테이블은 탐색을 최대한 줄여주기 위해, input에 대한 key 값을 얻어내서 관리하는 방식이다.\n\n현재 최대 N 값은 10만이다. 이차원 배열로 1000/100으로 나누어 관리하면, 더 효율적일 것이다.\n\n충돌 값이 들어오는 것을 감안해 최대한 고려해서, 나는 두번째 배열 값에 4를 곱해서 선언한다.\n\n
\n\n```\n\nkey 값을 얻어서 저장할 때, 서로다른 문자열이라도 같은 key 값으로 들어올 수 있다. \n(이것이 해시에 대한 이론을 배울 때 나오는 충돌 현상이다.)\n\n충돌이 일어나는 것을 최대한 피해야하지만, 무조건 피할 수 있다는 보장은 없다. 그래서 두번째 배열 값을 조금 넉넉히 선언해두는 것이다.\n\n```\n\n이를 고려해 final 값으로 선언한 해시 값은 아래와 같다.\n\n```java\nstatic final int HASH_SIZE = 1000;\nstatic final int HASH_LEN = 400;\nstatic final int HASH_VAL = 17; // 소수로 할 것\n```\n\nHASH_VAL 값은 우리가 input 값을 받았을 때 해당하는 key 값을 얻을 때 활용한다.\n\n최대한 input 값들마다 key 값이 겹치지 않기 위해 하기 위해서는 소수로 선언해야한다. (그래서 보통 17, 19, 23으로 선언하는 것 같다.)\n\n
\n\nkey 값을 얻는 메소드 구현 방법은 아래와 같다. ( 각자 사람마다 다르므로 꼭 이게 정답은 아니다 )\n\n```java\npublic static int getHashKey(String str) {\n \n int key = 0;\n \n for (int i = 0; i < str.length(); i++) {\n key = (key * HASH_VAL) + str.charAt(i);\n }\n \n if(key < 0) key = -key; // 만약 key 값이 음수면 양수로 바꿔주기\n \n return key % HASH_SIZE;\n \n}\n```\n\ninput 값을 매개변수로 받는다. 만약 string 값으로 들어온다고 가정해보자.\n\nstring 값의 한글자(character)마다 int형 값을 얻어낼 수 있다. 이를 활용해 string 값의 length만큼 반복문을 돌면서, 그 문자열만의 key 값을 만들어내는 것이 가능하다.\n\n우리는 이 key 값을 배열 인덱스로 활용할 것이기 때문에 음수면 안된다. 만약 key 값의 결과가 음수면 양수로 바꿔주는 조건문이 필요하다.\n\n
\n\n마지막으로 return 값으로 key를 우리가 선언한 HASH_SIZE로 나눈 나머지 값을 얻도록 한다.\n\n현재 계산된 key 값은 매우 크기 때문에 HASH_SIZE로 나눈 나머지 값으로 key를 활용할 것이다. (이 때문에 데이터가 많으면 많을수록 충돌되는 key값이 존재할 수 밖에 없다. - 우리는 최대한 충돌을 줄이면서 최적화시키기 위한 것..!)\n\n
\n\n이제 우리는 input으로 받은 string 값의 key 값을 얻었다.\n\n해당 key 값의 배열에서 이 값이 들어온 적이 있는지 확인하는 과정이 필요하다.\n\n
\n\n이제 우리는 모든 곳을 탐색할 필요없이, 이 key에 해당하는 배열에서만 확인하면 되므로 시간이 엄~~청 절약된다.\n\n
\n\n```java\nstatic int[][] data = new int[HASH_SIZE][HASH_LEN];\n\nstring str = \"apple\";\n\nint key = getHashKey(str); // apple에 대한 key 값 얻음\n\ndata[key][index]; // 이곳에 apple을 저장해서 관리하면 찾는 시간을 줄일 수 있는 것\n```\n\n여기서 HASH_SIZE가 1000이었고, 우리가 key 값을 리턴할 때 1000으로 나눈 나머지로 저장했으므로 이 안에서만 key 값이 들어오게 된다는 것을 이해할 수 있다.\n\n
\n\nArrayList로 2차원배열을 관리하면, 그냥 계속 추가해주면 되므로 구현이 간편하다.\n\n하지만 삼성 sw 역량테스트 B형처럼 라이브러리를 사용하지 못하는 경우에는, 배열로 선언해서 추가해나가야 한다. 또한 ArrayList 활용보다 배열이 훨씬 시간을 줄일 수 있기 때문에 되도록이면 배열을 이용하도록 하자\n\n
\n\n여기서 끝은 아니다. 이제 우리는 단순히 key 값만 받아온 것 뿐이다.\n\n해당 key 배열에서, apple이 들어온적이 있는지 없는지 체크해야한다. (문제에서 들어온적 있는건 숫자를 붙여서 출력해야 했기 때문이다.)\n\n
\n\n데이터의 수가 많으면 key 배열 안에서 다른 문자열이라도 같은 key로 저장되는 값들이 존재할 것이기 때문에 해당 key 배열을 돌면서 apple과 일치하는 문자열이 있는지 확인하는 과정이 필요하다.\n\n
\n\n따라서 key 값을 매개변수로 넣고 문자열이 들어왔던 적이 있는지 체크하는 함수를 구현하자\n\n```java\npublic static int checking(int key) {\n \n int len = length[key]; // 현재 key에 담긴 수 (같은 key 값으로 들어오는 문자열이 있을 수 있다)\n \n if(len != 0) { // 이미 들어온 적 있음\n \n for (int i = 0; i < len; i++) { // 이미 들어온 문자열이 해당 key 배열에 있는지 확인\n if(str.equals(s_data[key][i])) {\n data[key][i]++;\n return data[key][i];\n }\n }\n \n }\n \n // 들어온 적이 없었으면 해당 key배열에서 문자열을 저장하고 길이 1 늘리기\n s_data[key][length[key]++] = str;\n\n return -1; // 처음으로 들어가는 경우 -1 리턴\n}\n```\n\nlength[] 배열은 HASH_SIZE만큼 선언된 것으로, key 값을 얻은 후, 처음 들어온 문자열일 때마다 숫자를 1씩 늘려서 해당 key 배열에 몇개의 데이터가 저장되어있는지 확인하는 공간이다.\n\n
\n\n**우리가 출력해야하는 조건은 처음 들어온건 \"OK\" 다시 또 들어온건 \"data + 들어온 수\"였다.**\n\n
\n\n- \"OK\"로 출력해야 하는 조건\n\n > 해당 key의 배열 length가 0일 때는 무조건 처음 들어오는 데이터다.\n >\n > 또한 1이상일 때, 그 key 배열 안에서 만약 apple을 찾지 못했다면 이 또한 처음 들어오는 데이터다.\n\n
\n\n- \"data + 들어온 수\"로 출력해야 하는 조건\n\n > 만약 1이상일 때 key 배열에서 apple 값을 찾았다면 이제 'apple+들어온 수'를 출력하도록 구현해야한다.\n\n
\n\n그래서 나는 3개의 배열을 선언해서 활용했다.\n\n```java\nstatic int[][] data = new int[HASH_SIZE][HASH_LEN];\nstatic int[] length = new int[HASH_SIZE];\nstatic String[][] s_data = new String[HASH_SIZE][HASH_LEN];\n```\n\ndata[][] 배열 : input으로 받는 문자열이 들어온 수를 저장하는 곳\n\nlength[] 배열 : key 값마다 들어온 수를 저장하는 곳\n\ns_data[][] 배열 : input으로 받은 문자열을 저장하는 곳 \n\n
\n\n진행 과정을 설명하면 아래와 같다. (apple - banana - abc - abc 순으로 입력되고, apple과 abc의 key값은 5로 같다고 가정하겠다.)\n\n
\n\n```\n1. apple이 들어옴. key 값을 얻으니 5가 나옴. length[5]는 0이므로 처음 들어온 데이터임. length[5]++하고 \"OK\"출력\n\n2. banana가 들어옴. key 값을 얻으니 3이 나옴. length[3]은 0이므로 처음 들어온 데이터임. length[3]++하고 \"OK\"출력\n\n<< 중요 >>\n3. abc가 들어옴. key 값을 얻으니 5가 나옴. length[5]는 0이 아님. 해당 key 값에 누가 들어온적이 있음. \nlength[5]만큼 반복문을 돌면서 s_data[key]의 배열과 abc가 일치하는 값이 있는지 확인함. 현재 length[5]는 1이고, s_data[key][0] = \"apple\"이므로 일치하는 값이 없기 때문에 length[5]를 1 증가시키고 s_data[key][length[5]]에 abc를 넣고 \"OK\"출력\n\n<< 중요 >>\n4. abc가 들어옴. key 값을 얻으니 5가 나옴. length[5] = 2임.\ns_data[key]를 2만큼 반복문을 돌면서 abc가 있는지 찾음. 1번째 인덱스 값에는 apple이 저장되어 있고 2번째 인덱스 값에서 abc가 일치함을 찾았음!!\n따라서 해당 data[key][index] 값을 1 증가시키고 이 값을 return 해주면서 메소드를 끝냄\n→ 메인함수에서 input으로 들어온 abc 값과 리턴값으로 나온 1을 붙여서 출력해주면 됨 (abc1)\n```\n\n
\n\n진행과정을 통해 어떤 방식으로 구현되는지 충분히 이해할 수 있을 것이다.\n\n
\n\n#### 전체 소스코드\n\n```java\npackage CodeForces;\n\nimport java.io.BufferedReader;\nimport java.io.InputStreamReader;\n\npublic class Solution {\n\t\n\tstatic final int HASH_SIZE = 1000;\n\tstatic final int HASH_LEN = 400;\n\tstatic final int HASH_VAL = 17; // 소수로 할 것\n\t\n\tstatic int[][] data = new int[HASH_SIZE][HASH_LEN];\n\tstatic int[] length = new int[HASH_SIZE];\n\tstatic String[][] s_data = new String[HASH_SIZE][HASH_LEN];\n\tstatic String str;\n\tstatic int N;\n\n\tpublic static void main(String[] args) throws Exception {\n\t\t\n\t\tBufferedReader br = new BufferedReader(new InputStreamReader(System.in));\n\t\tStringBuilder sb = new StringBuilder();\n\t\t\n\t\tN = Integer.parseInt(br.readLine()); // 입력 수 (1~100000)\n\t\t\n\t\tfor (int i = 0; i < N; i++) {\n\t\t\t\n\t\t\tstr = br.readLine();\n\t\t\t\n\t\t\tint key = getHashKey(str);\n\t\t\tint cnt = checking(key);\n\t\t\t\n\t\t\tif(cnt != -1) { // 이미 들어왔던 문자열\n\t\t\t\tsb.append(str).append(cnt).append(\"\\n\");\n\t\t\t}\n\t\t\telse sb.append(\"OK\").append(\"\\n\");\n\t\t}\n\t\t\n\t\tSystem.out.println(sb.toString());\n\t}\n\t\n\tpublic static int getHashKey(String str) {\n\t\t\n\t\tint key = 0;\n\t\t\n\t\tfor (int i = 0; i < str.length(); i++) {\n\t\t\tkey = (key * HASH_VAL) + str.charAt(i) + HASH_VAL;\n\t\t}\n\t\t\n\t\tif(key < 0) key = -key; // 만약 key 값이 음수면 양수로 바꿔주기\n\t\t\n\t\treturn key % HASH_SIZE;\n\t\t\n\t}\n\t\n\tpublic static int checking(int key) {\n\t\t\n\t\tint len = length[key]; // 현재 key에 담긴 수 (같은 key 값으로 들어오는 문자열이 있을 수 있다)\n\t\t\n\t\tif(len != 0) { // 이미 들어온 적 있음\n\t\t\t\n\t\t\tfor (int i = 0; i < len; i++) { // 이미 들어온 문자열이 해당 key 배열에 있는지 확인\n\t\t\t\tif(str.equals(s_data[key][i])) {\n\t\t\t\t\tdata[key][i]++;\n\t\t\t\t\treturn data[key][i];\n\t\t\t\t}\n\t\t\t}\n\t\t\t\n\t\t}\n\t\t\n\t\t// 들어온 적이 없었으면 해당 key배열에서 문자열을 저장하고 길이 1 늘리기\n\t\ts_data[key][length[key]++] = str;\n\n\t\treturn -1; // 처음으로 들어가는 경우 -1 리턴\n\t}\n\n}\n```\n\n" }, { "path": "Algorithm/HeapSort.md", "content": "#### 힙 소트(Heap Sort)\n\n---\n\n\n\n완전 이진 트리를 기본으로 하는 힙(Heap) 자료구조를 기반으로한 정렬 방식\n\n***완전 이진 트리란?***\n\n> 삽입할 때 왼쪽부터 차례대로 추가하는 이진 트리\n\n\n\n힙 소트는 `불안정 정렬`에 속함\n\n\n\n**시간복잡도**\n\n| 평균 | 최선 | 최악 |\n| :------: | :------: | :------: |\n| Θ(nlogn) | Ω(nlogn) | O(nlogn) |\n\n\n\n##### 과정\n\n1. 최대 힙을 구성\n2. 현재 힙 루트는 가장 큰 값이 존재함. 루트의 값을 마지막 요소와 바꾼 후, 힙의 사이즈 하나 줄임\n3. 힙의 사이즈가 1보다 크면 위 과정 반복\n\n\n\n
 \n\n루트를 마지막 노드로 대체 (11 → 4), 다시 최대 힙 구성\n\n
\n\n루트를 마지막 노드로 대체 (11 → 4), 다시 최대 힙 구성\n\n \n\n\n\n이와 같은 방식으로 최대 값을 하나씩 뽑아내면서 정렬하는 것이 힙 소트\n\n\n\n```java\npublic void heapSort(int[] array) {\n int n = array.length;\n \n // max heap 초기화\n for (int i = n/2-1; i>=0; i--){\n heapify(array, n, i); // 1\n }\n \n // extract 연산\n for (int i = n-1; i>0; i--) {\n swap(array, 0, i); \n heapify(array, i, 0); // 2\n }\n}\n```\n\n\n\n##### 1번째 heapify\n\n> 일반 배열을 힙으로 구성하는 역할\n>\n> 자식노드로부터 부모노드 비교\n>\n> \n>\n> - *n/2-1부터 0까지 인덱스가 도는 이유는?*\n>\n> 부모 노드의 인덱스를 기준으로 왼쪽 자식노드 (i*2 + 1), 오른쪽 자식 노드(i*2 + 2)이기 때문\n\n\n\n##### 2번째 heapify\n\n> 요소가 하나 제거된 이후에 다시 최대 힙을 구성하기 위함\n>\n> 루트를 기준으로 진행(extract 연산 처리를 위해)\n\n\n\n```java\npublic void heapify(int array[], int n, int i) {\n int p = i;\n int l = i*2 + 1;\n int r = i*2 + 2;\n \n //왼쪽 자식노드\n if (l < n && array[p] < array[l]) {\n p = l;\n }\n //오른쪽 자식노드\n if (r < n && array[p] < array[r]) {\n p = r;\n }\n \n //부모노드 < 자식노드\n if(i != p) {\n swap(array, p, i);\n heapify(array, n, p);\n }\n}\n```\n\n**다시 최대 힙을 구성할 때까지** 부모 노드와 자식 노드를 swap하며 재귀 진행\n\n\n\n퀵정렬과 합병정렬의 성능이 좋기 때문에 힙 정렬의 사용빈도가 높지는 않음.\n\n하지만 힙 자료구조가 많이 활용되고 있으며, 이때 함께 따라오는 개념이 `힙 소트`\n\n\n\n##### 힙 소트가 유용할 때\n\n- 가장 크거나 가장 작은 값을 구할 때\n\n > 최소 힙 or 최대 힙의 루트 값이기 때문에 한번의 힙 구성을 통해 구하는 것이 가능\n\n- 최대 k 만큼 떨어진 요소들을 정렬할 때\n\n > 삽입정렬보다 더욱 개선된 결과를 얻어낼 수 있음\n\n\n\n##### 전체 소스 코드\n\n```java\nprivate void solve() {\n int[] array = { 230, 10, 60, 550, 40, 220, 20 };\n \n heapSort(array);\n \n for (int v : array) {\n System.out.println(v);\n }\n}\n \npublic static void heapify(int array[], int n, int i) {\n int p = i;\n int l = i * 2 + 1;\n int r = i * 2 + 2;\n \n if (l < n && array[p] < array[l]) {\n p = l;\n }\n \n if (r < n && array[p] < array[r]) {\n p = r;\n }\n \n if (i != p) {\n swap(array, p, i);\n heapify(array, n, p);\n }\n}\n \npublic static void heapSort(int[] array) {\n int n = array.length;\n \n // init, max heap\n for (int i = n / 2 - 1; i >= 0; i--) {\n heapify(array, n, i);\n }\n \n // for extract max element from heap\n for (int i = n - 1; i > 0; i--) {\n swap(array, 0, i);\n heapify(array, i, 0);\n }\n}\n \npublic static void swap(int[] array, int a, int b) {\n int temp = array[a];\n array[a] = array[b];\n array[b] = temp;\n}\n```\n\n"
},
{
"path": "Algorithm/LCA(Lowest Common Ancestor).md",
"content": "## LCA(Lowest Common Ancestor) 알고리즘\n\n> 최소 공통 조상 찾는 알고리즘\n>\n> → 두 정점이 만나는 최초 부모 정점을 찾는 것!\n\n트리 형식이 아래와 같이 주어졌다고 하자\n\n
\n\n\n\n이와 같은 방식으로 최대 값을 하나씩 뽑아내면서 정렬하는 것이 힙 소트\n\n\n\n```java\npublic void heapSort(int[] array) {\n int n = array.length;\n \n // max heap 초기화\n for (int i = n/2-1; i>=0; i--){\n heapify(array, n, i); // 1\n }\n \n // extract 연산\n for (int i = n-1; i>0; i--) {\n swap(array, 0, i); \n heapify(array, i, 0); // 2\n }\n}\n```\n\n\n\n##### 1번째 heapify\n\n> 일반 배열을 힙으로 구성하는 역할\n>\n> 자식노드로부터 부모노드 비교\n>\n> \n>\n> - *n/2-1부터 0까지 인덱스가 도는 이유는?*\n>\n> 부모 노드의 인덱스를 기준으로 왼쪽 자식노드 (i*2 + 1), 오른쪽 자식 노드(i*2 + 2)이기 때문\n\n\n\n##### 2번째 heapify\n\n> 요소가 하나 제거된 이후에 다시 최대 힙을 구성하기 위함\n>\n> 루트를 기준으로 진행(extract 연산 처리를 위해)\n\n\n\n```java\npublic void heapify(int array[], int n, int i) {\n int p = i;\n int l = i*2 + 1;\n int r = i*2 + 2;\n \n //왼쪽 자식노드\n if (l < n && array[p] < array[l]) {\n p = l;\n }\n //오른쪽 자식노드\n if (r < n && array[p] < array[r]) {\n p = r;\n }\n \n //부모노드 < 자식노드\n if(i != p) {\n swap(array, p, i);\n heapify(array, n, p);\n }\n}\n```\n\n**다시 최대 힙을 구성할 때까지** 부모 노드와 자식 노드를 swap하며 재귀 진행\n\n\n\n퀵정렬과 합병정렬의 성능이 좋기 때문에 힙 정렬의 사용빈도가 높지는 않음.\n\n하지만 힙 자료구조가 많이 활용되고 있으며, 이때 함께 따라오는 개념이 `힙 소트`\n\n\n\n##### 힙 소트가 유용할 때\n\n- 가장 크거나 가장 작은 값을 구할 때\n\n > 최소 힙 or 최대 힙의 루트 값이기 때문에 한번의 힙 구성을 통해 구하는 것이 가능\n\n- 최대 k 만큼 떨어진 요소들을 정렬할 때\n\n > 삽입정렬보다 더욱 개선된 결과를 얻어낼 수 있음\n\n\n\n##### 전체 소스 코드\n\n```java\nprivate void solve() {\n int[] array = { 230, 10, 60, 550, 40, 220, 20 };\n \n heapSort(array);\n \n for (int v : array) {\n System.out.println(v);\n }\n}\n \npublic static void heapify(int array[], int n, int i) {\n int p = i;\n int l = i * 2 + 1;\n int r = i * 2 + 2;\n \n if (l < n && array[p] < array[l]) {\n p = l;\n }\n \n if (r < n && array[p] < array[r]) {\n p = r;\n }\n \n if (i != p) {\n swap(array, p, i);\n heapify(array, n, p);\n }\n}\n \npublic static void heapSort(int[] array) {\n int n = array.length;\n \n // init, max heap\n for (int i = n / 2 - 1; i >= 0; i--) {\n heapify(array, n, i);\n }\n \n // for extract max element from heap\n for (int i = n - 1; i > 0; i--) {\n swap(array, 0, i);\n heapify(array, i, 0);\n }\n}\n \npublic static void swap(int[] array, int a, int b) {\n int temp = array[a];\n array[a] = array[b];\n array[b] = temp;\n}\n```\n\n"
},
{
"path": "Algorithm/LCA(Lowest Common Ancestor).md",
"content": "## LCA(Lowest Common Ancestor) 알고리즘\n\n> 최소 공통 조상 찾는 알고리즘\n>\n> → 두 정점이 만나는 최초 부모 정점을 찾는 것!\n\n트리 형식이 아래와 같이 주어졌다고 하자\n\n \n\n4와 5의 LCA는? → 4와 5의 첫 부모 정점은 '2'\n\n4와 6의 LCA는? → 첫 부모 정점은 root인 '1'\n\n***어떻게 찾죠?***\n\n해당 정점의 depth와 parent를 저장해두는 방식이다. 현재 그림에서의 depth는 아래와 같을 것이다.\n\n```\n[depth : 정점]\n0 → 1(root 정점)\n1 → 2, 3\n2 → 4, 5, 6, 7\n```\n\n
\n\n4와 5의 LCA는? → 4와 5의 첫 부모 정점은 '2'\n\n4와 6의 LCA는? → 첫 부모 정점은 root인 '1'\n\n***어떻게 찾죠?***\n\n해당 정점의 depth와 parent를 저장해두는 방식이다. 현재 그림에서의 depth는 아래와 같을 것이다.\n\n```\n[depth : 정점]\n0 → 1(root 정점)\n1 → 2, 3\n2 → 4, 5, 6, 7\n```\n\n\n\nparent는 정점마다 가지는 부모 정점을 저장해둔다. 위의 예시에서 저장된 parent 배열은 아래와 같다.\n\n```java\n// 1 ~ 7번 정점 (root는 부모가 없기 때문에 0)\nint parent[] = {0, 1, 1, 2, 2, 3, 3}\n```\n\n이제\n\n이 두 배열을 활용해서 두 정점이 주어졌을 때 LCA를 찾을 수 있다. 과정은 아래와 같다.\n\n```java\n// 두 정점의 depth 확인하기\nwhile(true){\n\tif(depth가 일치)\n\t\tif(두 정점의 parent 일치?) LCA 찾음(종료)\n else 두 정점을 자신의 parent 정점 값으로 변경\n else // depth 불일치\n 더 depth가 깊은 정점을 해당 정점의 parent 정점으로 변경(depth가 감소됨)\n}\n```\n\n
\n\n트리 문제에서 공통 조상을 찾아야하는 문제나, 정점과 정점 사이의 이동거리 또는 방문경로를 저장해야 할 경우 사용하면 된다. " }, { "path": "Algorithm/LIS (Longest Increasing Sequence).md", "content": "## LIS (Longest Increasing Sequence)\n\n> 최장 증가 수열 : 가장 긴 증가하는 부분 수열\n\n[ 7, **2**, **3**, 8, **4**, **5** ] → 해당 배열에서는 [2,3,4,5]가 LIS로 답은 4\n\n
\n\n##### 구현 방법 (시간복잡도)\n\n1. DP : O(N^2)\n2. Lower Bound : O(NlogN)\n\n
\n\n##### DP 활용 코드\n\n```java\nint arr[] = {7, 2, 3, 8, 4, 5};\nint dp[] = new int[arr.length]; // LIS 저장 배열\n\n\nfor(int i = 1; i < dp.length; i++) {\n for(int j = i-1; j>=0; j--) {\n if(arr[i] > arr[j]) {\n dp[i] = (dp[i] < dp[j]+1) ? dp[j]+1 : dp[i];\n }\n }\n}\n\nfor (int i = 0; i < dp.length; i++) {\n\tif(max < dp[i]) max = dp[i];\n}\n\n// 저장된 dp 배열 값 : [0, 0, 1, 2, 2, 3]\n// LIS : dp배열에 저장된 값 중 최대 값 + 1\n```\n\n
\n\n하지만, N^2으로 해결할 수 없는 문제라면? (ex. 배열의 길이가 최대 10만일 때..)\n\n이때는 Lower Bound를 활용한 LIS 구현을 진행해야한다.\n\n" }, { "path": "Algorithm/MergeSort.md", "content": "#### 머지 소트(Merge Sort)\n\n---\n\n\n\n합병 정렬이라고도 부르며, 분할 정복 방법을 통해 구현\n\n***분할 정복이란?***\n\n> 큰 문제를 작은 문제 단위로 쪼개면서 해결해나가는 방식\n\n\n\n빠른 정렬로 분류되며, 퀵소트와 함께 많이 언급되는 정렬 방식이다.\n\n\n\n퀵소트와는 반대로 `안정 정렬`에 속함\n\n**시간복잡도**\n\n| 평균 | 최선 | 최악 |\n| :------: | :------: | :------: |\n| Θ(nlogn) | Ω(nlogn) | O(nlogn) |\n\n요소를 쪼갠 후, 다시 합병시키면서 정렬해나가는 방식으로, 쪼개는 방식은 퀵정렬과 유사\n\n\n\n- mergeSort\n\n```java\npublic void mergeSort(int[] array, int left, int right) {\n \n if(left < right) {\n int mid = (left + right) / 2;\n \n mergeSort(array, left, mid);\n mergeSort(array, mid+1, right);\n merge(array, left, mid, right);\n }\n \n}\n```\n\n정렬 로직에 있어서 merge() 메소드가 핵심\n\n\n\n*퀵소트와의 차이점*\n\n> 퀵정렬 : 우선 피벗을 통해 정렬(partition) → 영역을 쪼갬(quickSort)\n>\n> 합병정렬 : 영역을 쪼갤 수 있을 만큼 쪼갬(mergeSort) → 정렬(merge)\n\n\n\n- merge()\n\n```java\npublic static void merge(int[] array, int left, int mid, int right) {\n int[] L = Arrays.copyOfRange(array, left, mid + 1);\n int[] R = Arrays.copyOfRange(array, mid + 1, right + 1);\n \n int i = 0, j = 0, k = left;\n int ll = L.length, rl = R.length;\n \n while(i < ll && j < rl) {\n if(L[i] <= R[j]) {\n array[k] = L[i++];\n }\n else {\n array[k] = R[j++];\n }\n k++;\n }\n \n // remain\n while(i < ll) {\n array[k++] = L[i++];\n }\n while(j < rl) {\n array[k++] = R[j++];\n }\n}\n```\n\n이미 **합병의 대상이 되는 두 영역이 각 영역에 대해서 정렬이 되어있기 때문**에 단순히 두 배열을 **순차적으로 비교하면서 정렬할 수가 있다.**\n\n\n\n\n\n**★★★합병정렬은 순차적**인 비교로 정렬을 진행하므로, **LinkedList의 정렬이 필요할 때 사용하면 효율적**이다.★★★\n\n\n\n*LinkedList를 퀵정렬을 사용해 정렬하면?*\n\n> 성능이 좋지 않음\n>\n> 퀵정렬은, 순차 접근이 아닌 **임의 접근이기 때문**\n\n\n\n**LinkedList는 삽입, 삭제 연산에서 유용**하지만 **접근 연산에서는 비효율적**임\n\n따라서 임의로 접근하는 퀵소트를 활용하면 오버헤드 발생이 증가하게 됨\n\n> 배열은 인덱스를 이용해서 접근이 가능하지만, LinkedList는 Head부터 탐색해야 함\n>\n> 배열[O(1)] vs LinkedList[O(n)] \n\n\n\n\n\n```java\nprivate void solve() {\n int[] array = { 230, 10, 60, 550, 40, 220, 20 };\n \n mergeSort(array, 0, array.length - 1);\n \n for (int v : array) {\n System.out.println(v);\n }\n}\n \npublic static void mergeSort(int[] array, int left, int right) {\n if (left < right) {\n int mid = (left + right) / 2;\n \n mergeSort(array, left, mid);\n mergeSort(array, mid + 1, right);\n merge(array, left, mid, right);\n }\n}\n \npublic static void merge(int[] array, int left, int mid, int right) {\n int[] L = Arrays.copyOfRange(array, left, mid + 1);\n int[] R = Arrays.copyOfRange(array, mid + 1, right + 1);\n \n int i = 0, j = 0, k = left;\n int ll = L.length, rl = R.length;\n \n while (i < ll && j < rl) {\n if (L[i] <= R[j]) {\n array[k] = L[i++];\n } else {\n array[k] = R[j++];\n }\n k++;\n }\n \n while (i < ll) {\n array[k++] = L[i++];\n }\n \n while (j < rl) {\n array[k++] = R[j++];\n }\n}\n```\n\n" }, { "path": "Algorithm/QuickSort.md", "content": "안전 정렬 : 동일한 값에 기존 순서가 유지 (버블, 삽입)\n\n불안정 정렬 : 동일한 값에 기존 순서가 유지X (선택,퀵)\n\n\n\n#### 퀵소트\n\n---\n\n퀵소트는 최악의 경우 O(n^2), 평균적으로 Θ(nlogn)을 가짐\n\n\n\n```java\npublic void quickSort(int[] array, int left, int right) {\n \n if(left >= right) return;\n \n int pi = partition(array, left, right);\n \n quickSort(array, left, pi-1);\n quickSort(array, pi+1, right);\n \n}\n```\n\n\n\n피벗 선택 방식 : 첫번째, 중간, 마지막, 랜덤\n\n(선택 방식에 따라 속도가 달라지므로 중요함)\n\n\n\n```java\npublic int partition(int[] array, int left, int right) {\n int pivot = array[left];\n int i = left, j = right;\n \n while(i < j) {\n while(pivot < array[j]) {\n j--;\n }\n while(i
\n\n#### Data Structure\n\n1. **배열** : 임의의 사이즈를 선언 (Heap, Queue, Binary Tree, Hashing 사용)\n2. **스택** : 행 특정조건에 따라 push, pop 적용\n3. **큐** : BFS를 통해 순서대로 접근할 때 적용\n4. **연결리스트** : 배열 구현, 포인터 구현 2가지 방법 - 삽입,삭제가 많이 일어날 때 활용하기\n5. **그래프** : 경우의 수, 연결 관계가 있을 때 적용\n6. **해싱** : 데이터 수만큼 메모리에 생성할 수 없는 상황에 적용\n7. **트리** : Heap과 BST(이진탐색)\n\n
\n\n#### Algorithm\n\n1. **★재귀(Recursion)** : 가장 많이 활용. 중요한 건 호출 횟수를 줄여야 함 (반복 조건, 종료 조건 체크)\n2. **★BFS, DFS** : 2차원 배열에서 확장 시, 경우의 수를 탐색할 때 구조체(class)와 visited 체크를 사용함\n3. **★정렬** : 퀵소트나 머지소트가 대표적이지만, 보통 퀵소트를 사용함\n4. **★메모이제이션(memoization)** : 이전 결과가 또 사용될 때, 반복 작업을 안하도록 저장\n5. **★이분탐색(Binary Search)** : logN으로 시간복잡도를 줄일 수 있는 간단하면서 핵심적인 알고리즘\n6. **최소신장트리(MST)** : 사이클이 포함되지 않고 모든 정점이 연결된 트리에 사용 (크루스칼, 프림)\n7. **최소공통조상(LCA)** : 경우의 수에서 조건이 겹치는 경우. 최단 경로 탐색시 공통인 경우가 많을 때 적용\n8. **Disjoint-Set** : 서로소 집합. 인접한 집함의 모임으로 Tree의 일종이며 시간복잡도가 낮음\n9. **분할 정복** : 머지 소트에 사용되며 범위를 나누어 확인할 때 사용\n10. **트라이(Trie)** : 모든 String을 저장해나가며 비교하는 방법\n11. **비트마스킹** : `|는 OR, &는 AND, ^는 XOR` <<를 통해 메모리를 절약할 수 있음\n\n
\n\n- Sort 시간복잡도\n\n
 \n\n"
},
{
"path": "Algorithm/SAMSUNG Software PRO등급 준비.md",
"content": "## SAMSUNG Software PRO등급 준비\n\n작성 : 2020.08.10.\n\n
\n\n"
},
{
"path": "Algorithm/SAMSUNG Software PRO등급 준비.md",
"content": "## SAMSUNG Software PRO등급 준비\n\n작성 : 2020.08.10.\n\n\n\n#### 역량 테스트 단계\n\n---\n\n- *Advanced*\n\n- #### *Professional*\n\n- *Expert*\n\n
\n\n**시험 시간 및 문제 수** : 4시간 1문제\n\nProfessional 단계부터는 라이브러리를 사용할 수 없다.\n\n> C/Cpp 경우, 동적할당 라이브러리인 `malloc.h`까지만 허용\n\n
\n\n또한 전체적인 로직은 구현이 되어있는 상태이며, 사용자가 필수적으로 구현해야 할 메소드 부분이 빈칸으로 제공된다. (`main.cpp`와 `user.cpp`가 주어지며, 우리는 `user.cpp`를 구현하면 된다)\n\n
\n\n크게 두 가지 유형으로 출제되고 있다.\n\n1. **실행 시간을 최대한 감소**시켜 문제를 해결하라\n2. **쿼리 함수를 최소한 실행**시켜 문제를 해결하라\n\n결국, 최대한 **효율적인 코드를 작성하여 시간, 메모리를 절약하는 것**이 Professinal 등급의 핵심이다.\n\n
\n\nProfessional 등급 문제를 해결하기 위해 필수적으로 알아야 할 것(직접 구현할 수 있어야하는) 들\n\n##### [박트리님 블로그 참고 - '역량테스트 B형 공부법'](https://baactree.tistory.com/53)\n\n- 큐, 스택\n- 정렬\n- 힙\n- 해싱\n- 연결리스트\n- 트리\n- 메모이제이션\n- 비트마스킹\n- 이분탐색\n- 분할정복\n\n추가 : 트라이, LCA, BST, 세그먼트 트리 등 \n\n
\n\n## 문제 풀기 연습\n\n> 60분 - 설계\n>\n> 120분 - 구현\n>\n> 60분 - 디버깅 및 최적화 \n\n
\n\n### 설계\n\n---\n\n1. #### 문제 빠르게 이해하기\n\n 시험 문제는 상세한 예제를 통해 충분히 이해할 수 있도록 제공된다. 따라서 우선 읽으면서 전체적으로 어떤 문제인지 **전체적인 틀을 파악**하자\n\n
\n\n2. #### 구현해야 할 함수 확인하기\n\n 문제에 사용자가 구현해야 할 함수가 제공된다. 특히 필요한 파라미터와 리턴 타입을 알려주므로, 어떤 방식으로 인풋과 아웃풋이 이뤄질 지 함수를 통해 파악하자\n\n
\n\n3. #### 제약 조건 확인하기\n\n 문제의 전체적인 곳에서, 범위 값이 작성되어 있을 것이다. 또한 문제의 마지막에는 제약 조건이 있다. 이 조건들은 문제를 풀 때 핵심이 되는 부분이다. 반드시 체크를 해두고, 설계 시 하나라도 빼먹지 않도록 주의하자\n\n
\n\n4. #### 해결 방법 고민하기\n\n 문제 이해와 구현 함수 파악이 끝났다면, 어떤 방식으로 해결할 것인지 작성해보자.\n\n 전체적인 프로세스를 전개하고, 이때 필요한 자료구조, 구조체 등 설계의 큰 틀부터 그려나간다.\n\n 최대값으로 문제에 주어졌을 때 필요한 사이즈가 얼마인 지, 어떤 타입의 변수들을 갖추고 있어야 하는 지부터 해시나 연결리스트를 사용할 자료구조에 대해 미리 파악 후 작성해두도록 한다.\n\n
\n\n5. #### 수도 코드 작성하기\n\n 각 프로세스 별로, 필요한 로직에 대해 간단히 수도 코드를 작성해두자. 특히 제약 조건이나 놓치기 쉬운 것들은 미리 체크해두고, 작성해두면 구현으로 옮길 때 실수를 줄일 수 있다.\n\n
\n\n##### *만약 설계 중 도저히 흐름이 이해가 안간다면?*\n\n> 높은 확률로 main.cpp에서 답을 찾을 수 있다. 문제 이해가 잘 되지 않을 때는, main.cpp와 user.cpp 사이에 어떻게 연결되는 지 main.cpp 코드를 뜯어보고 이해해보자.\n\n
\n\n### 구현\n\n---\n\n1. #### 설계한 프로세스를 주석으로 옮기기\n\n 내가 해결할 방향에 대해 먼저 코드 안에 주석으로 핵심만 담아둔다. 이 주석을 보고 필요한 부분을 구현해나가면 설계를 완벽히 옮기는 데 큰 도움이 된다.\n\n
\n\n2. #### 먼저 전역에 필요한 부분 작성하기\n\n 소스 코드 내 전체적으로 활용될 구조체 및 전역 변수들에 대한 부분부터 구현을 시작한다. 이때 `#define`와 같은 전처리기를 적극 활용하여 선언에 필요한 값들을 미리 지정해두자\n\n
\n\n3. #### Check 함수들의 동작 여부 확인하기\n\n 문자열 복사, 비교 등 모두 직접 구현해야 하므로, 혹시 실수를 대비하여 함수를 만들었을 때 제대로 동작하는 지 체크하자. 이때 실수한 걸 넘어가면, 디버깅 때 찾기 위해서 엄청난 고생을 할 수도 있다.\n\n
\n\n4. #### 다시 한번 제약조건 확인하기\n\n 결국 디버깅에서 문제가 되는 건 제약 조건을 제대로 지키지 않았을 경우가 다반사다. 코드 내에서 제약 조건을 모두 체크하여 잘 구현했는 지 확인해보자\n\n
\n\n### 디버깅 및 최적화\n\n---\n\n1. #### input 데이터 활용하기\n\n input 데이터가 text 파일로 주어진다. 물론 방대한 데이터의 양이라 디버깅을 하려면 매우 까다롭다. 보통 1~2번 테스트케이스는 작은 데이터 값이므로, 이 값들을 활용해 문제점을 찾아낼 수도 있다.\n\n
\n\n2. #### main.cpp를 디버깅에 활용하기\n\n 문제가 발생했을 때, main.cpp를 활용하여 디버깅을 할 수도 있다. 문제가 될만한 부분에 출력값을 찍어보면서 도움이 될만한 부분을 찾아보자. 문제에 따라 다르겠지만, 생각보다 main.cpp 안의 코드에서 중요한 정보들을 깨달을 수도 있다.\n\n
\n\n3. #### init 함수 고민하기\n\n 어쩌면 가장 중요한 함수이기도 하다. 이 초기화 함수를 얼마나 효율적으로 구현하느냐에 따라 합격 유무가 달라진다. 최대한 매 테스트케이스마다 초기화하는 변수들이나 공간을 줄여야 실행 시간을 줄일 수 있다. 따라서 인덱스를 잘 관리하여 init 함수를 잘 짜보는 연습을 해보자\n\n
\n\n4. #### 실행 시간 감소 고민하기\n\n 이 밖에도 실행 시간을 줄이기 위한 고민을 끝까지 해야하는 것이 중요하다. 문제를 accept 했다고 해서 합격을 하는 시험이 아니다. 다른 지원자들보다 효율적이고 빠른 시간으로 문제를 풀어야 pass할 수 있다. 내가 작성한 자료구조보다 더 빠른 해결 방법이 생각났다면, 수정 과정을 거쳐보기도 하고, 많이 활용되는 변수에는 register를 적용하는 등 최대한 실행 시간을 감소시킬 수 있는 방안을 생각하여 적용하는 시도를 해야한다.\n\n
\n\n
\n\n## 시험 대비\n\n1. #### 비슷한 문제 풀어보기\n\n 임직원들만 이용할 수 있는 사내 SWEA 사이트에서 기출과 유사한 유형의 문제들을 제공해준다. 특히 시험 환경과 똑같이 이뤄지기 때문에 연습해보기 좋다. 많은 문제들을 풀어보면서 유형에 익숙해지는 것이 가장 중요할 것 같다.\n\n
\n\n2. #### 다른 사람 코드로 배우기\n\n 이게 개인적으로 핵심인 것 같다. 1번에서 말한 사이트에서 기출 유형 문제들을 해결한 사람들의 코드를 볼 수 있도록 제공되어 있다. 특히 해결된 코드의 실행 시간이나 사용 메모리도 볼 수 있다는 점이 좋다. 따라서 문제 해결에 어려움이 있거나, 더 나은 코드를 배우기 위해 적극적으로 활용해야 한다.\n\n
\n\n
\n\n올해 안에 꼭 합격하자!\n(2021.05 합격)\n" }, { "path": "Algorithm/Sort_Counting.md", "content": "#### Comparison Sort\n\n------\n\n> N개 원소의 배열이 있을 때, 이를 모두 정렬하는 가짓수는 N!임\n>\n> 따라서, Comparison Sort를 통해 생기는 트리의 말단 노드가 N! 이상의 노드 갯수를 갖기 위해서는, 2^h >= N! 를 만족하는 h를 가져야 하고, 이 식을 h > O(nlgn)을 가져야 한다. (h는 트리의 높이,,, 즉 Comparison sort의 시간 복잡도임)\n\n이런 O(nlgn)을 줄일 수 있는 방법은 Comparison을 하지 않는 것\n\n\n\n#### Counting Sort 과정\n\n----\n\n시간 복잡도 : O(n + k) -> k는 배열에서 등장하는 최대값\n\n공간 복잡도 : O(k) -> k만큼의 배열을 만들어야 함.\n\nCounting이 필요 : 각 숫자가 몇 번 등장했는지 센다.\n\n```c\nint arr[5]; \t\t// [5, 4, 3, 2, 1]\nint sorted_arr[5];\n// 과정 1 - counting 배열의 사이즈를 최대값 5가 담기도록 크게 잡기\nint counting[6];\t// 단점 : counting 배열의 사이즈의 범위를 가능한 값의 범위만큼 크게 잡아야 하므로, 비효율적이 됨.\n\n// 과정 2 - counting 배열의 값을 증가해주기.\nfor (int i = 0; i < arr.length; i++) {\n counting[arr[i]]++;\n}\n// 과정 3 - counting 배열을 누적합으로 만들어주기.\nfor (int i = 1; i < counting.length; i++) {\n counting[i] += counting[i - 1];\n}\n// 과정 4 - 뒤에서부터 배열을 돌면서, 해당하는 값의 인덱스에 값을 넣어주기.\nfor (int i = arr.length - 1; i >= 0; i--) {\n sorted_arr[counting[arr[i]] - 1] = arr[i];\n counting[arr[i]]--;\n}\n```\n\n* 사용 : 정렬하는 숫자가 특정한 범위 내에 있을 때 사용\n\n (Suffix Array 를 얻을 때, 시간복잡도 O(nlgn)으로 얻을 수 있음.)\n\n* 장점 : O(n) 의 시간복잡도\n\n* 단점 : 배열 사이즈 N 만큼 돌 때, 증가시켜주는 Counting 배열의 크기가 큼.\n\n (메모리 낭비가 심함)" }, { "path": "Algorithm/Sort_Radix.md", "content": "#### Comparison Sort\n\n---\n\n> N개 원소의 배열이 있을 때, 이를 모두 정렬하는 가짓수는 N!임\n>\n> 따라서, Comparison Sort를 통해 생기는 트리의 말단 노드가 N! 이상의 노드 갯수를 갖기 위해서는, 2^h >= N! 를 만족하는 h를 가져야 하고, 이 식을 h > O(nlgn)을 가져야 한다. (h는 트리의 높이,,, 즉 Comparison sort의 시간 복잡도임)\n\n이런 O(nlgn)을 줄일 수 있는 방법은 Comparison을 하지 않는 것\n\n\n\n#### Radix sort\n\n----\n\n데이터를 구성하는 기본 요소 (Radix) 를 이용하여 정렬을 진행하는 방식\n\n> 입력 데이터의 최대값에 따라서 Counting Sort의 비효율성을 개선하기 위해서, Radix Sort를 사용할 수 있음.\n>\n> 자릿수의 값 별로 (예) 둘째 자리, 첫째 자리) 정렬을 하므로, 나올 수 있는 값의 최대 사이즈는 9임 (범위 : 0 ~ 9)\n\n* 시간 복잡도 : O(d * (n + b)) \n\n -> d는 정렬할 숫자의 자릿수, b는 10 (k와 같으나 10으로 고정되어 있다.)\n\n ( Counting Sort의 경우 : O(n + k) 로 배열의 최댓값 k에 영향을 받음 )\n\n* 장점 : 문자열, 정수 정렬 가능\n\n* 단점 : 자릿수가 없는 것은 정렬할 수 없음. (부동 소숫점)\n\n 중간 결과를 저장할 bucket 공간이 필요함.\n\n#### 소스 코드\n\n```c\nvoid countSort(int arr[], int n, int exp) {\n\tint buffer[n];\n int i, count[10] = {0};\n \n // exp의 자릿수에 해당하는 count 증가\n for (i = 0; i < n; i++){\n count[(arr[i] / exp) % 10]++;\n }\n // 누적합 구하기\n for (i = 1; i < 10; i++) {\n count[i] += count[i - 1];\n }\n // 일반적인 Counting sort 과정\n for (i = n - 1; i >= 0; i--) {\n buffer[count[(arr[i]/exp) % 10] - 1] = arr[i];\n count[(arr[i] / exp) % 10]--;\n }\n for (i = 0; i < n; i++){\n arr[i] = buffer[i];\n }\n}\n\nvoid radixsort(int arr[], int n) {\n // 최댓값 자리만큼 돌기\n int m = getMax(arr, n);\n \n // 최댓값을 나눴을 때, 0이 나오면 모든 숫자가 exp의 아래\n for (int exp = 1; m / exp > 0; exp *= 10) {\n countSort(arr, n, exp);\n }\n}\nint main() {\n int arr[] = {170, 45, 75, 90, 802, 24, 2, 66};\n int n = sizeof(arr) / sizeof(arr[0]);\t\t\t// 좋은 습관\n radixsort(arr, n);\n \n for (int i = 0; i < n; i++){\n cout << arr[i] << \" \";\n }\n return 0;\n}\n```\n\n\n\n#### 질문\n\n---\n\nQ1) 왜 낮은 자리수부터 정렬을 합니까?\n\nMSD (Most-Significant-Digit) 과 LSD (Least-Significant-Digit)을 비교하라는 질문\n\nMSD는 가장 큰 자리수부터 Counting sort 하는 것을 의미하고, LSD는 가장 낮은 자리수부터 Counting sort 하는 것을 의미함. (즉, 둘 다 할 수 있음)\n\n* LSD의 경우 1600000 과 1을 비교할 때, Digit의 갯수만큼 따져야하는 단점이 있음.\n 그에 반해 MSD는 마지막 자리수까지 확인해 볼 필요가 없음.\n* LSD는 중간에 정렬 결과를 알 수 없음. (예) 10004와 70002의 비교)\n 반면, MSD는 중간에 중요한 숫자를 알 수 있음. 따라서 시간을 줄일 수 있음. 그러나, 정렬이 되었는지 확인하는 과정이 필요하고, 이 때문에 메모리를 더 사용\n* LSD는 알고리즘이 일관됨 (Branch Free algorithm)\n 그러나 MSD는 일관되지 못함. --> 따라서 Radix sort는 주로 LSD를 언급함.\n* LSD는 자릿수가 정해진 경우 좀 더 빠를 수 있음." }, { "path": "Algorithm/code/Heap.java", "content": "public class Heap {\n\t\n\tstatic int N, heapSize;\n\tstatic int[] arr;\n\t\n\tstatic void init(int n) {\n\t\tN = n;\n\t\tarr = new int[N+1];\n\t\theapSize = 0;\n\t}\n\t\n\tstatic void add(int n) {\n\t\tarr[++heapSize] = n;\n\t\t\n\t\tfor (int i = heapSize; i > 1; i/=2) {\n\t\t\tif(arr[i] < arr[i/2]) {\n\t\t\t\tswap(i/2, i);\n\t\t\t}\n\t\t\telse break;\n\t\t}\n\t}\n\tstatic int remove(int[] arr) {\n\t\tif(heapSize == 0) return 0;\n\t\t\n\t\tint rm = arr[1];\n\t\tarr[1] = arr[heapSize];\n\t\tarr[heapSize--] = 0;\n\t\t\n\t\tfor (int i = 1; i*2 <= heapSize;) {\n\t\t\t\n\t\t\tif(i*2+1 <= heapSize) {\n\t\t\t\n\t\t\t\tif(arr[i] < arr[i*2] && arr[i] < arr[i*2+1]) break;\n\t\t\t\t\n\t\t\t\telse if(arr[i*2] < arr[i*2+1]) {\n\t\t\t\t\tswap(i, i*2);\n\t\t\t\t\ti = i*2;\n\t\t\t\t}\n\t\t\t\telse {\n\t\t\t\t\tswap(i, i*2+1);\n\t\t\t\t\ti = i*2+1;\n\t\t\t\t}\n\t\t\t}\n\t\t\telse {\n\t\t\t\tif(arr[i] > arr[i*2]) {\n\t\t\t\t\tswap(i, i*2);\n\t\t\t\t\ti = i*2;\n\t\t\t\t}\n\t\t\t\telse\n\t\t\t\t\tbreak;\n\t\t\t}\n\t\t}\n\t\t\n\t\treturn rm;\n\t}\n\t\n\tstatic void swap(int a, int b) {\n\t\tint temp = arr[a];\n\t\tarr[a] = arr[b];\n\t\tarr[b] = temp;\n\t}\n}\n" }, { "path": "Algorithm/code/InsertionSort.java", "content": "public class InsertionSort {\n \n static int[] arr = {10, 2, 6, 4, 3, 7, 5};\n \n public static void insertionSort(int[] arr) {\n for(int i = 1; i < arr.length; i++) {\n int num = arr[i]; // 기준\n int aux = i - 1; // 비교대상\n \n while(aux >= 0 && num < arr[aux]) {\n arr[aux+1] = arr[aux];\n aux--;\n }\n arr[aux+1] = num;\n }\n }\n \n public static void main(String[] args) {\n \n insertionSort(arr);\n System.out.println(Arrays.toString(arr));\n }\n \n}\n" }, { "path": "Algorithm/code/QuickSort.java", "content": "import java.util.Arrays;\n\npublic class QuickSort {\n\t\n\tstatic int[] arr = {5, 1, 1, 2, 1, 4, 4, 4, 5, 5};\n\t\n\tpublic static void main(String[] args) throws Exception {\n\t\t\n\t\tquickSort(arr, 0, arr.length-1);\n\t\t\n\t\tSystem.out.println(Arrays.toString(arr));\n\t\t\n\t}\n\t\n\tpublic static void quickSort(int[] arr, int start, int end) {\n\t\t\n\t\tif(start >= end) return;\n\t\t\n\t\tif(start < end) {\n\t\t\t\n\t\t\tint i = start-1;\n\t\t\tint j = end+1;\n\t\t\tint pivot = arr[(start+end)/2];\n\t\t\t\n\t\t\twhile(i < j) {\n\t\t\t\t\n\t\t\t\twhile(arr[++i] < pivot) {}\n\t\t\t\twhile(arr[--j] > pivot) {}\n\t\t\t\t\n\t\t\t\tif (i >= j) break;\n\t\t\t\t\n\t\t\t\tint temp = arr[i];\n\t\t\t\tarr[i] = arr[j];\n\t\t\t\tarr[j] = temp;\n\t\t\t}\n\t\t\t\n\t\t\tquickSort(arr, start, i-1);\n\t\t\tquickSort(arr, j+1, end);\n\t\t}\n\t\t\n\t}\n}\n" }, { "path": "Algorithm/code/bubbleSort.java", "content": "void bubbleSort(int[] arr) {\n int temp = 0;\n\tfor(int i = 0; i < arr.length; i++) {\n\t\tfor(int j= 1 ; j < arr.length-i; j++) {\n\t\t\tif(arr[j-1] > arr[j]) {\n\t\t\t\ttemp = arr[j-1];\n\t\t\t\tarr[j-1] = arr[j];\n\t\t\t\tarr[j] = temp;\n\t\t\t}\n\t\t}\n\t}\n\tSystem.out.println(Arrays.toString(arr));\n}\n" }, { "path": "Algorithm/code/mergeSort.java", "content": "import java.util.Arrays;\nimport java.util.Random;\n\npublic class mergeSort {\n\t// SIZE 십 만\n\tstatic int MAX_LEN = 100_000;\n\n\tpublic static void main(String[] args) {\n\n\t\tRandom r = new Random(100);\n\t\tint merge_idx, collections_idx;\n\t\tint arr_merge[], arr_collections[];\n\n\t\tmerge_idx = 0;\n\t\tcollections_idx = 0;\n\t\tarr_merge = new int[MAX_LEN];\n\t\tarr_collections = new int[MAX_LEN];\n\n\t\t// 랜덤으로 배열을 생성하는 부분\n\t\tfor (int i = 0; i < MAX_LEN; i++) {\n\t\t\tint temp = (r.nextInt() % 10000);\n\t\t\tarr_merge[merge_idx++] = temp;\n\t\t\tarr_collections[collections_idx++] = temp;\n\t\t}\n\n\t\tArrays.sort(arr_collections);\n\t\tmergeSort(arr_merge, 0, MAX_LEN - 1);\n\n\t\t// 정렬이 제대로 되었는지 확인하는 부분.\n\t\tfor (int i = 0; i < MAX_LEN; i++) {\n\t\t\tif (arr_collections[i] != arr_merge[i]) {\n\t\t\t\tSystem.out.println(\"MergeSort 실패!\");\n\t\t\t\treturn;\n\t\t\t}\n\t\t}\n\t\tSystem.out.println(\"MergeSort 성공\");\n\t\treturn;\n\t}\n\n\tprivate static void mergeSort(int[] arr, int left, int right) {\n\n\t\t// (1) 재귀 호출을 통해 더이상 쪼개지지 않을 때까지 쪼개야 된다.\n\t\tif (left >= right)\n\t\t\treturn;\n\n\t\tint mid = (left + right) / 2;\n\t\tint i = left;\n\t\tint j = mid+1;\n\n\t\tmergeSort(arr, left, mid);\n\t\tmergeSort(arr, mid+1, right);\n\n\t\t// (2) 배열을 인덱스를 통해서 절반으로 쪼개고, 한쪽이 다 쓸 때까지 반복문을 돌린다.\n\t\tint[] buffer = new int[right - left + 1];\n\t\tint bidx = 0;\n\t\t\n\t\t// 왼쪽이랑 오른쪽 각각 비교\n\t\twhile (true) {\n\t\t\tif(arr[i] <= arr[j]) { // stable\n\t\t\t\tbuffer[bidx++] = arr[i];\n\t\t\t\ti++;\n\t\t\t} else {\n\t\t\t\tbuffer[bidx++] = arr[j];\n\t\t\t\tj++;\n\t\t\t}\n\t\t\t\n\t\t\tif(i > mid || j > right) \n\t\t\t\tbreak;\n\t\t}\n\n\t\t// (3) 남은 것(오른쪽 or 왼쪽)을 전부 buffer에 넣어야 한다.\n\t\t// 왼쪽 전부 써버리기\n\t\twhile(i <= mid) {\n\t\t\tbuffer[bidx++] = arr[i++];\n\t\t}\n\t\t//오른쪽 전부 써버리기\n\t\twhile(j <= right) {\n\t\t\tbuffer[bidx++] = arr[j++];\n\t\t}\n\n\t\t// (4) buffer에 있는 것을 기존 배열의 인덱스 위에 덮어준다.\n\t\tfor (int k = 0; k < bidx; k++) {\n\t\t\tarr[left+k] = buffer[k];\n\t\t}\n\t}\n}\n" }, { "path": "Algorithm/professional/프로 준비법.md", "content": "# 프로 준비법\n\n
\n\n#### Professional 시험 주요 특징\n\n- 4시간동안 1문제를 푼다.\n- 언어는 `c, cpp, java`로 가능하다.\n- 라이브러리를 사용할 수 없으며, 직접 자료구조를 구현해야한다. (`malloc.h`만 가능)\n- 전체적인 로직은 구현이 되어있는 상태이며, 사용자가 구현해야 할 메소드 부분이 빈칸으로 제공된다. (`main.cpp`와 `user.cpp`가 주어지며, 우리는 `user.cpp`를 구현하면 된다)\n- 시험 유형 2가지\n - 1) 내부 테스트케이스를 제한 메모리, 시간 내에 해결해야한다. (50개 3초, 메모리 256MB 이내)\n - 2) 주어진 쿼리 함수를 최소한으로 호출하여 문제를 해결해야 한다.\n- 주로 샘플 테스트케이스는 5개가 주어지며, 이를 활용해 디버깅을 해볼 수 있다.\n- 시험장에서는 Reference Code가 주어지며 사용할 수 있다. (자료구조, 알고리즘)\n\n
\n\n#### 핵심 자료구조\n\n- Queue, Stack\n- Sort\n- Linked List\n- Hash\n- Heap\n- Binary Search\n\n
\n\n### 학습 시작\n\n---\n\n#### 1) Visual Studio 설정하기\n\n1. Visual C++ 빈 프로젝트 생성\n\n2. `user.cpp`와 `main.cpp` 생성\n\n3. 프로젝트명 오른쪽 마우스 클릭 → 속성\n\n4. `C/C++`에서 SDL 검사 아니요로 변경\n\n > 디버깅할 때 scanf나 printf를 사용하기 위함\n\n5. `링커/시스템`에서 맨위 `하위 시스템`이 공란이면 `콘솔(/SUBSYSTEM:CONSOLE)`로 설정\n\n > 공란이면 run할 때 콘솔창이 켜있는 상태로 유지가 되지 않음 (반드시 설정)\n\n
\n\n#### 2) cpp로 프로 문제 풀 때 알아야 할 것\n\n- printf로 출력 확인해보기 위한 라이브러리 : `#include
\n\n```\nDP를 활용한 최단 경로 탐색 알고리즘\n```\n\n
\n\n\n\n
 \n\n
\n\n\n\n다익스트라 알고리즘은 특정한 정점에서 다른 모든 정점으로 가는 최단 경로를 기록한다.\n\n여기서 DP가 적용되는 이유는, 굳이 한 번 최단 거리를 구한 곳은 다시 구할 필요가 없기 때문이다. 이를 활용해 정점에서 정점까지 간선을 따라 이동할 때 최단 거리를 효율적으로 구할 수 있다.\n\n
\n\n다익스트라를 구현하기 위해 두 가지를 저장해야 한다.\n\n- 해당 정점까지의 최단 거리를 저장\n\n- 정점을 방문했는 지 저장\n\n시작 정점으로부터 정점들의 최단 거리를 저장하는 배열과, 방문 여부를 저장하는 것이다.\n\n
\n\n다익스트라의 알고리즘 순서는 아래와 같다.\n\n1. ##### 최단 거리 값은 무한대 값으로 초기화한다.\n\n ```java\n for(int i = 1; i <= n; i++){\n distance[i] = Integer.MAX_VALUE;\n }\n ```\n\n2. ##### 시작 정점의 최단 거리는 0이다. 그리고 시작 정점을 방문 처리한다.\n\n ```java\n distance[start] = 0;\n visited[start] = true;\n ```\n\n3. ##### 시작 정점과 연결된 정점들의 최단 거리 값을 갱신한다.\n\n ```java\n for(int i = 1; i <= n; i++){\n if(!visited[i] && map[start][i] != 0) {\n \tdistance[i] = map[start][i];\n }\n }\n ```\n\n4. ##### 방문하지 않은 정점 중 최단 거리가 최소인 정점을 찾는다.\n\n ```java\n int min = Integer.MAX_VALUE;\n int midx = -1;\n \n for(int i = 1; i <= n; i++){\n if(!visited[i] && distance[i] != Integer.MAX_VALUE) {\n \tif(distance[i] < min) {\n min = distance[i];\n midx = i;\n }\n }\n }\n ```\n\n5. ##### 찾은 정점을 방문 체크로 변경 후, 해당 정점과 연결된 방문하지 않은 정점의 최단 거리 값을 갱신한다.\n\n ```java\n visited[midx] = true;\n for(int i = 1; i <= n; i++){\n if(!visited[i] && map[midx][i] != 0) {\n \tif(distance[i] > distance[midx] + map[midx][i]) {\n distance[i] = distance[midx] + map[midx][i];\n }\n }\n }\n ```\n\n6. ##### 모든 정점을 방문할 때까지 4~5번을 반복한다.\n\n
\n\n#### 다익스트라 적용 시 알아야할 점\n\n- 인접 행렬로 구현하면 시간 복잡도는 O(N^2)이다.\n\n- 인접 리스트로 구현하면 시간 복잡도는 O(N*logN)이다.\n\n > 선형 탐색으로 시간 초과가 나는 문제는 인접 리스트로 접근해야한다. (우선순위 큐)\n\n- 간선의 값이 양수일 때만 가능하다.\n\n
\n\n
\n\n#### [참고사항]\n\n- [링크](https://ko.wikipedia.org/wiki/%EB%8D%B0%EC%9D%B4%ED%81%AC%EC%8A%A4%ED%8A%B8%EB%9D%BC_%EC%95%8C%EA%B3%A0%EB%A6%AC%EC%A6%98)\n- [링크](https://bumbums.tistory.com/4)" }, { "path": "Algorithm/동적 계획법 (Dynamic Programming).md", "content": "## 동적 계획법 (Dynamic Programming)\n\n> 복잡한 문제를 간단한 여러 개의 문제로 나누어 푸는 방법\n\n
\n\n흔히 말하는 DP가 바로 '동적 계획법'\n\n**한 가지 문제**에 대해서, **단 한 번만 풀도록** 만들어주는 알고리즘이다.\n\n즉, 똑같은 연산을 반복하지 않도록 만들어준다. 실행 시간을 줄이기 위해 많이 이용되는 수학적 접근 방식의 알고리즘이라고 할 수 있다.\n\n
\n\n동적 계획법은 **Optimal Substructure**에서 효과를 발휘한다.\n\n*Optimal Substructure* : 답을 구하기 위해 이미 했던 똑같은 계산을 계속 반복하는 문제 구조\n\n
\n\n#### 접근 방식\n\n커다란 문제를 쉽게 해결하기 위해 작게 쪼개서 해결하는 방법인 분할 정복과 매우 유사하다. 하지만 간단한 문제로 만드는 과정에서 중복 여부에 대한 차이점이 존재한다.\n\n즉, 동적 계획법은 간단한 작은 문제들 속에서 '계속 반복되는 연산'을 활용하여 빠르게 풀 수 있는 것이 핵심이다.\n\n
\n\n#### 조건\n\n- 작은 문제에서 반복이 일어남\n- 같은 문제는 항상 정답이 같음\n\n이 두 가지 조건이 충족한다면, 동적 계획법을 이용하여 문제를 풀 수 있다.\n\n같은 문제가 항상 정답이 같고, 반복적으로 일어난다는 점을 활용해 메모이제이션(Memoization)으로 큰 문제를 해결해나가는 것이다.\n\n
\n\n*메모이제이션(Memoization)* : 한 번 계산한 문제는 다시 계산하지 않도록 저장해두고 활용하는 방식\n\n> 피보나치 수열에서 재귀를 활용하여 풀 경우, 같은 연산을 계속 반복함을 알 수 있다.\n>\n> 이때, 메모이제이션을 통해 같은 작업을 되풀이 하지 않도록 구현하면 효율적이다.\n\n```\nfibonacci(5) = fibonacci(4) + fibonacci(3)\nfibonacci(4) = fibonacci(3) + fibonacci(2)\nfibonacci(3) = fibonacci(2) + fibonacci(1)\n\n이처럼 같은 연산이 계속 반복적으로 이용될 때, 메모이제이션을 활용하여 값을 미리 저장해두면 효율적\n```\n\n피보나치 구현에 재귀를 활용했다면 시간복잡도는 O(2^n)이지만, 동적 계획법을 활용하면 O(N)으로 해결할 수 있다.\n\n
\n\n#### 구현 방식\n\n- Bottom-up : 작은 문제부터 차근차근 구하는 방법\n- Top-down : 큰 문제를 풀다가 풀리지 않은 작은 문제가 있다면 그때 해결하는 방법 (재귀 방식)\n\n> Bottom-up은 해결이 용이하지만, 가독성이 떨어짐\n>\n> Top-down은 가독성이 좋지만, 코드 작성이 힘듬\n\n
\n\n동적 계획법으로 문제를 풀 때는, 우선 작은 문제부터 해결해나가보는 것이 좋다.\n\n작은 문제들을 풀어나가다보면 이전에 구해둔 더 작은 문제들이 활용되는 것을 확인하게 된다. 이에 대한 규칙을 찾았을 때 **점화식**을 도출해내어 동적 계획법을 적용시키자\n\n
\n\n
\n\n##### [참고 자료]\n\n- [링크](https://namu.wiki/w/%EB%8F%99%EC%A0%81%20%EA%B3%84%ED%9A%8D%EB%B2%95)" }, { "path": "Algorithm/비트마스크(BitMask).md", "content": "## 비트마스크(BitMask)\n\n> 집합의 요소들의 구성 여부를 표현할 때 유용한 테크닉\n\n
\n\n##### *왜 비트마스크를 사용하는가?*\n\n- DP나 순열 등, 배열 활용만으로 해결할 수 없는 문제\n- 작은 메모리와 빠른 수행시간으로 해결이 가능 (But, 원소의 수가 많지 않아야 함)\n- 집합을 배열의 인덱스로 표현할 수 있음\n\n- 코드가 간결해짐\n\n
\n\n##### *비트(Bit)란?*\n\n> 컴퓨터에서 사용되는 데이터의 최소 단위 (0과 1)\n>\n> 2진법을 생각하면 편하다.\n\n
\n\n우리가 흔히 사용하는 10진수를 2진수로 바꾸면?\n\n`9(10진수) → 1001(2진수)`\n\n
\n\n#### 비트마스킹 활용해보기\n\n> 0과 1로, flag 활용하기\n\n[1, 2, 3, 4 ,5] 라는 집합이 있다고 가정해보자.\n\n여기서 임의로 몇 개를 골라 뽑아서 확인을 해야하는 상황이 주어졌다. (즉, 부분집합을 의미)\n\n```\n{1}, {2} , ... , {1,2} , ... , {1,2,5} , ... , {1,2,3,4,5}\n```\n\n물론, 간단히 for문 돌려가며 배열에 저장하며 경우의 수를 구할 순 있다.\n\n하지만 비트마스킹을 하면, 각 요소를 인덱스처럼 표현하여 효율적인 접근이 가능하다.\n\n```\n[1,2,3,4,5] → 11111\n[2,3,4,5] → 11110\n[1,2,5] → 10011\n[2] → 00010\n```\n\n집합의 i번째 요소가 존재하면 `1`, 그렇지 않으면 `0`을 의미하는 것이다.\n\n이러한 2진수는 다시 10진수로 변환도 가능하다.\n\n`11111`은 10진수로 31이므로, 부분집합을 **정수를 통해 나타내는 것**이 가능하다는 것을 알 수 있다.\n\n> 31은 [1,2,3,4,5] 전체에 해당하는 부분집합에 해당한다는 의미!\n\n이로써, 해당 부분집합에 i를 추가하고 싶을때 i번째 비트를 1로만 바꿔주면 표현이 가능해졌다.\n\n이런 행위는 **비트 연산**을 통해 제어가 가능하다.\n\n
\n\n#### 비트 연산\n\n> AND, OR, XOR, NOT, SHIFT\n\n- AND(&) : 대응하는 두 비트가 모두 1일 때, 1 반환\n\n- OR(|) : 대응하는 두 비트 중 모두 1이거나 하나라도 1일때, 1 반환\n\n- XOR(^) : 대응하는 두 비트가 서로 다를 때, 1 반환\n\n- NOT(~) : 비트 값 반전하여 반환\n\n- SHIFT(>>, <<) : 왼쪽 혹은 오른쪽으로 비트 옮겨 반환\n\n - 왼쪽 시프트 : `A * 2^B`\n - 오른쪽 시프트 : `A / 2^B`\n\n ```\n [왼 쪽] 0001 → 0010 → 0100 → 1000 : 1 → 2 → 4 → 8\n [오른쪽] 1000 → 0100 → 0010 → 0001 : 8 → 4 → 2 → 1\n ```\n\n
\n\n비트연산 연습문제 : [백준 12813](https://www.acmicpc.net/problem/12813)\n\n##### 구현 코드(C)\n\n```C\n#include
\n\n연습이 되었다면, 다시 비트마스크로 돌아와 비트연산을 활용해보자\n\n크게 삽입, 삭제, 조회로 나누어 진다.\n\n
\n\n#### 1.삽입\n\n현재 이진수로 `10101`로 표현되고 있을 때, i번째 비트 값을 1로 변경하려고 한다.\n\ni = 3일 때 변경 후에는 `11101`이 나와야 한다. 이때는 **OR연산을 활용**한다.\n\n```\n10101 | 1 << 3\n```\n\n`1 << 3`은 `1000`이므로 `10101 | 01000`이 되어 `11101`을 만들 수 있다.\n\n
\n\n#### 2.삭제\n\n반대로 0으로 변경하려면, **AND연산과 NOT 연산을 활용**한다.\n\n```\n11101 & ~1 << 3\n```\n\n`~1 << 3`은 `10111`이므로, `11101 & 10111`이 되어 `10101`을 만들 수 있다.\n\n
\n\n#### 3.조회\n\ni번째 비트가 무슨 값인지 알려면, **AND연산을 활용**한다.\n\n```\n10101 & 1 << i\n\n3번째 비트 값 : 10101 & (1 << 3) = 10101 & 01000 → 0\n4번째 비트 값 : 10101 & (1 << 4) = 10101 & 10000 → 10000\n```\n\n이처럼 결과값이 0이 나왔을 때는 i번째 비트 값이 0인 것을 파악할 수 있다. (반대로 0이 아니면 무조건 1인 것)\n\n이러한 방법을 활용하여 문제를 해결하는 것이 비트마스크다.\n\n
\n\n비트마스크 연습문제 : [백준 2098](https://www.acmicpc.net/problem/2098)\n\n
\n\n해당 문제는 모든 도시를 한 번만 방문하면서 다시 시작점으로 돌아오는 최소 거리 비용을 구해야한다.\n\n완전탐색으로 답을 구할 수는 있지만, N이 최대 16이기 때문에 16!으로 시간초과에 빠지게 된다.\n\n따라서 DP를 활용해야 하며, 방문 여부를 배열로 관리하기 힘드므로 비트마스크를 활용하면 좋은 문제다.\n\n
\n\n
\n\n##### [참고자료]\n\n- [링크](https://mygumi.tistory.com/361)\n\n" }, { "path": "Algorithm/순열 & 조합.md", "content": "# 순열 & 조합\n\n
\n\n### Java 코드\n\n```java\nimport java.util.ArrayList;\nimport java.util.Arrays;\n\npublic class 순열조합 {\n\tstatic char[] arr = { 'a', 'b', 'c', 'd' };\n\tstatic int r = 2;\n\n\t//arr배열에서 r개를 선택한다.\n\t//선택된 요소들은 set배열에 저장.\n\tpublic static void main(String[] args) {\n\n\t\tset = new char[r];\n\t\t\n\t\tSystem.out.println(\"==조합==\");\n\t\tcomb(0,0);\n\n\t\tSystem.out.println(\"==중복조합==\");\n\t\trcomb(0, 0);\n\t\t\n\t\tvisit = new boolean[arr.length];\n\t\tSystem.out.println(\"==순열==\");\n\t\tperm(0);\n\n\t\tSystem.out.println(\"==중복순열==\");\n\t\trperm(0);\n\t\t\n\t\tSystem.out.println(\"==부분집합==\");\n\t\tsetList = new ArrayList<>();\n\t\tsubset(0,0);\n\t}\n\n\tstatic char[] set;\n\n\tpublic static void comb(int len, int k) { // 조합\n\t\tif (len == r) {\n\t\t\tSystem.out.println(Arrays.toString(set));\n\t\t\treturn;\n\t\t}\n\t\tif (k == arr.length)\n\t\t\treturn;\n\n\t\tset[len] = arr[k];\n\n\t\tcomb(len + 1, k + 1);\n\t\tcomb(len, k + 1);\n\n\t}\n\n\tpublic static void rcomb(int len, int k) { // 중복조합\n\t\tif (len == r) {\n\t\t\tSystem.out.println(Arrays.toString(set));\n\t\t\treturn;\n\t\t}\n\t\tif (k == arr.length)\n\t\t\treturn;\n\n\t\tset[len] = arr[k];\n\n\t\trcomb(len + 1, k);\n\t\trcomb(len, k + 1);\n\n\t}\n\n\tstatic boolean[] visit;\n\n\tpublic static void perm(int len) {// 순열\n\t\tif (len == r) {\n\t\t\tSystem.out.println(Arrays.toString(set));\n\t\t\treturn;\n\t\t}\n\n\t\tfor (int i = 0; i < arr.length; i++) {\n\t\t\tif (!visit[i]) {\n\t\t\t\tset[len] = arr[i];\n\t\t\t\tvisit[i] = true;\n\t\t\t\tperm(len + 1);\n\t\t\t\tvisit[i] = false;\n\t\t\t}\n\t\t}\n\t}\n\n\tpublic static void rperm(int len) {// 중복순열\n\t\tif (len == r) {\n\t\t\tSystem.out.println(Arrays.toString(set));\n\t\t\treturn;\n\t\t}\n\n\t\tfor (int i = 0; i < arr.length; i++) {\n\t\t\tset[len] = arr[i];\n\t\t\trperm(len + 1);\n\t\t}\n\t}\n\n\tstatic ArrayList
\n\n*프로세서란?*\n\n> 메모리에 저장된 명령어들을 실행하는 유한 상태 오토마톤\n\n
\n\n##### ARM : Advanced RISC Machine\n\n즉, `진보된 RISC 기기`의 약자로 ARM의 핵심은 RISC이다.\n\nRISC : Reduced Instruction Set Computing (감소된 명령 집합 컴퓨팅)\n\n`단순한 명령 집합을 가진 프로세서`가 `복잡한 명령 집합을 가진 프로세서`보다 훨씬 더 효율적이지 않을까?로 탄생함\n\n
\n\n
\n\n#### ARM 구조\n\n---\n\n
 \n\n
\n\n\n\nARM은 칩의 기본 설계 구조만 만들고, 실제 기능 추가와 최적화 부분은 개별 반도체 제조사의 영역으로 맡긴다. 따라서 물리적 설계는 같아도, 명령 집합이 모두 다르기 때문에 서로 다른 칩이 되기도 하는 것이 ARM.\n\n소비자에게는 칩이 논리적 구조인 명령 집합으로 구성되면서, 이런 특성 때문에 물리적 설계 베이스는 같지만 용도에 따라 다양한 제품군을 만날 수 있는 특징이 있다.\n\n아무래도 아키텍처는 논리적인 명령 집합을 물리적으로 표현한 것이므로, 명령어가 많고 복잡해질수록 실제 물리적인 칩 구조도 크고 복잡해진다.\n\n하지만, ARM은 RISC 설계 기반으로 '단순한 명령집합을 가진 프로세서가 복잡한 것보다 효율적'임을 기반하기 때문에 명령 집합과 구조 자체가 단순하다. 따라서 ARM 기반 프로세서가 더 작고, 효율적이며 상대적으로 느린 것이다.\n\n
\n\n단순한 명령 집합은, 적은 수의 트랜지스터만 필요하므로 간결한 설계와 더 작은 크기를 가능케 한다. 반도체 기본 부품인 트랜지스터는 전원을 소비해 다이의 크기를 증가시키기 때문에 스마트폰이나 태블릿PC를 위한 프로세서에는 가능한 적은 트랜지스터를 가진 것이 이상적이다.\n\n따라서, 명령 집합의 수가 적기 때문에 트랜지스터 수가 적고 이를 통해 크기가 작고 전원 소모가 낮은 ARM CPU가 스마트폰, 태블릿PC와 같은 모바일 기기에 많이 사용되고 있다.\n\n
\n\n
\n\n#### ARM의 장점은?\n\n---\n\n
 \n\n
\n\n\n\n소비자에 있어 ARM은 '생태계'의 하나라고 생각할 수 있다. ARM을 위해 개발된 프로그램은 오직 ARM 프로세서가 탑재된 기기에서만 실행할 수 있다. (즉, x86 CPU 프로세서 기반 프로그램에서는 ARM 기반 기기에서 실행할 수 없음)\n\n따라서 ARM에서 실행되던 프로그램을 x86 프로세서에서 실행되도록 하려면 (혹은 그 반대로) 프로그램에 수정이 가해져야만 한다.\n\n
\n\n하지만, 하나의 ARM 기기에 동작하는 OS는 다른 ARM 기반 기기에서도 잘 동작한다. 이러한 장점 덕분에 수많은 버전의 안드로이드가 탄생하고 있으며 또한 HP나 블랙베리의 태블릿에도 안드로이드가 탑재될 수 있는 가능성이 생기게 된 것이다.\n\n(하지만 애플사는 iOS 소스코드를 공개하지 않고 있기 때문에 애플 기기는 불가능하다)\n\nARM을 만드는 기업들은 전력 소모를 줄이고 성능을 높이기 위해 설계를 개선하며 노력하고 있다.\n\n
\n\n
\n\n
\n\n##### [참고 자료]\n\n- [링크](https://sergeswin.com/611)\n" }, { "path": "Computer Science/Computer Architecture/고정 소수점 & 부동 소수점.md", "content": "## 고정 소수점 & 부동 소수점\n\n
\n\n컴퓨터에서 실수를 표현하는 방법은 `고정 소수점`과 `부동 소수점` 두가지 방식이 존재한다.\n\n
\n\n1. #### 고정 소수점(Fixed Point)\n\n > 소수점이 찍힐 위치를 미리 정해놓고 소수를 표현하는 방식 (정수 + 소수)\n >\n > ```\n > -3.141592는 부호(-)와 정수부(3), 소수부(0.141592) 3가지 요소 필요함\n > ```\n\n 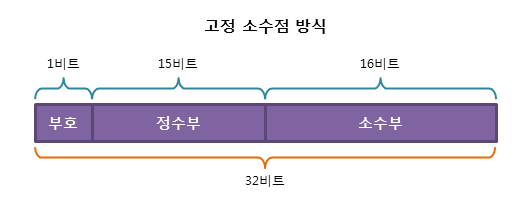\n\n **장점** : 실수를 정수부와 소수부로 표현하여 단순하다.\n\n **단점** : 표현의 범위가 너무 적어서 활용하기 힘들다. (정수부는 15bit, 소수부는 16bit)\n\n
\n\n
\n\n2. #### 부동 소수점(Floating Point)\n\n > 실수를 가수부 + 지수부로 표현한다.\n >\n > - 가수 : 실수의 실제값 표현\n > - 지수 : 크기를 표현함. 가수의 어디쯤에 소수점이 있는지 나타냄\n\n **지수의 값에 따라 소수점이 움직이는 방식**을 활용한 실수 표현 방법이다.\n\n 즉, 소수점의 위치가 고정되어 있지 않는다.\n\n 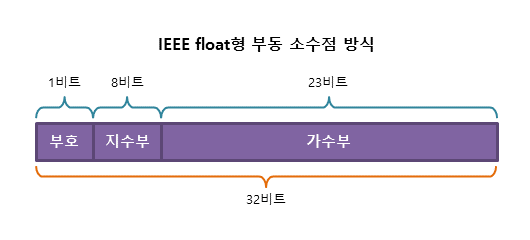\n\n **장점** : 표현할 수 있는 수의 범위가 넓어진다. (현재 대부분 시스템에서 활용 중)\n\n **단점** : 오차가 발생할 수 있다. (부동소수점으로 표현할 수 있는 방법이 매우 다양함)\n \n
\n\n
\n \n3. #### 고정 소수점과 부동 소수점의 일반적인 사용 사례.\n\n**고정 소수점 사용 상황.**\n1. 임베디드 시스켐과 마이크로컨트롤러\n - 메모리와 처리 능력이 제한된 환경에서 고정 소수점 연산이 일반적입니다. 이는 부동 소수점 연산을 지원하는 하드웨어가 없거나, 그러한 연산이 배터리 수명이나 다른 자원을 과도하게 소모할 수 있기 때문입니다.\n\n2. 실시간 시스템\n - 예측 가능한 실행 시간이 중요한 실시간 응용 프로그램에서는 고정 소수점 연산이 선호됩니다. 이는 부동 소수점 연산이 가변적인 실행 시간을 가질 수 있기 때문입니다.\n\n3. 비용 민감형 하드웨어\n - 부동 소수점 연산자를 지원하는 비용이 더 들 수 있어, 가격을 낮추기 위해 고정 소수점 연산을 사용하는 경우가 있습니다.\n\n4. 디지털 신호 처리(DSP)\n - 일부 디지털 신호 처리 알고리즘은 정확하게 정의된 범위 내의 값을 사용하기 때문에 고정 소수점 연산으로 충분한 경우가 많습니다.\n\n**부동 소수점 사용 상황.**\n1. 과학적 계산\n - 넓은 범위의 값과 높은 정밀도가 요구되는 과학적 및 엔지니어링 계산에는 부동 소수점이 사용됩니다.\n\n2. 3D 그래픽스\n - 3D 모델링과 같은 그래픽 작업에서는 부동 소수점 연산이 광범위하게 사용되며, 높은 정밀도와 다양한 크기의 값을 처리할 수 있어야 합니다.\n\n3. 금융 분석\n - 복잡한 금융 모델링과 위험 평가에서는 높은 수준의 정밀도가 필요할 수 있으며, 부동 소수점 연산이 적합할 수 있습니다.\n\n4. 컴퓨터 시뮬레이션\n - 물리적 시스템의 시뮬레이션은 넓은 범위의 값과 높은 정밀도를 요구하기 때문에, 부동 소수점 연산이 필수적입니다.\n\n**결론.**\n- 고정 소수점은 주로 리소스가 제한적이고 높은 정밀도가 필요하지 않은 환경에서 사용됩니다.\n- 부동 소수점은 더 넓은 범위와 높은 정밀도를 필요로 하는 복잡한 계산에 적합합니다.\n- 현대 프로세서의 경우, 부동 소수점 연산의 속도도 매우 빨라져서 예전만큼 고정 소수점과 부동 소수점 사이의 성능 차이가 크지 않을 수 있습니다.\n" }, { "path": "Computer Science/Computer Architecture/명령어 Cycle.md", "content": "## 명령어 Cycle\n\n- PC : 다음 실행할 명령어의 주소를 저장\n- MAR : 다음에 읽거나 쓸 기억장소의 주소를 지정\n- MBR : 기억장치에 저장될 데이터 혹은 기억장치로부터 읽은 데이터를 임시 저장\n- IR : 현재 수행 중인 명령어 저장\n- ALU : 산술연산과 논리연산 수행\n\n
\n\n#### Fetch Cycle\n\n---\n\n> 명령어를 주기억장치에서 CPU 명령어 레지스터로 가져와 해독하는 단계\n\n1) PC에 있는 명령어 주소를 MAR로 가져옴 (그 이후 PC는 +1)\n\n2) MAR에 저장된 주소에 해당하는 값을 메모리에서 가져와서 MBR에 저장\n\n(이때 가져온 값은 Data 또는 Opcode(명령어))\n\n3) 만약 Opcode를 가져왔다면, IR에서 Decode하는 단계 거침 (명령어를 해석하여 Data로 만들어야 함)\n\n4) 1~2과정에서 가져온 데이터를 ALU에서 수행 (Excute Cycle). 연산 결과는 MBR을 거쳐 메모리로 다시 저장" }, { "path": "Computer Science/Computer Architecture/중앙처리장치(CPU) 작동 원리.md", "content": "## 중앙처리장치(CPU) 작동 원리\n\n\n\nCPU는 컴퓨터에서 가장 핵심적인 역할을 수행하는 부분. '인간의 두뇌'에 해당\n\n크게 연산장치, 제어장치, 레지스터 3가지로 구성됨\n\n\n\n- ##### 연산 장치\n\n > 산술연산과 논리연산 수행 (따라서 산술논리연산장치라고도 불림)\n >\n > 연산에 필요한 데이터를 레지스터에서 가져오고, 연산 결과를 다시 레지스터로 보냄\n\n- ##### 제어 장치\n\n > 명령어를 순서대로 실행할 수 있도록 제어하는 장치\n >\n > 주기억장치에서 프로그램 명령어를 꺼내 해독하고, 그 결과에 따라 명령어 실행에 필요한 제어 신호를 기억장치, 연산장치, 입출력장치로 보냄\n >\n > 또한 이들 장치가 보낸 신호를 받아, 다음에 수행할 동작을 결정함\n\n- ##### 레지스터\n\n > 고속 기억장치임\n >\n > 명령어 주소, 코드, 연산에 필요한 데이터, 연산 결과 등을 임시로 저장\n >\n > 용도에 따라 범용 레지스터와 특수목적 레지스터로 구분됨\n >\n > 중앙처리장치 종류에 따라 사용할 수 있는 레지스터 개수와 크기가 다름\n >\n > - 범용 레지스터 : 연산에 필요한 데이터나 연산 결과를 임시로 저장\n > - 특수목적 레지스터 : 특별한 용도로 사용하는 레지스터\n\n\n\n#### 특수 목적 레지스터 중 중요한 것들\n\n- MAR(메모리 주소 레지스터) : 읽기와 쓰기 연산을 수행할 주기억장치 주소 저장\n- PC(프로그램 카운터) : 다음에 수행할 명령어 주소 저장\n- IR(명령어 레지스터) : 현재 실행 중인 명령어 저장\n- MBR(메모리 버퍼 레지스터) : 주기억장치에서 읽어온 데이터 or 저장할 데이터 임시 저장\n- AC(누산기) : 연산 결과 임시 저장\n\n\n\n#### CPU의 동작 과정\n\n1. 주기억장치는 입력장치에서 입력받은 데이터 또는 보조기억장치에 저장된 프로그램 읽어옴\n2. CPU는 프로그램을 실행하기 위해 주기억장치에 저장된 프로그램 명령어와 데이터를 읽어와 처리하고 결과를 다시 주기억장치에 저장\n3. 주기억장치는 처리 결과를 보조기억장치에 저장하거나 출력장치로 보냄\n4. 제어장치는 1~3 과정에서 명령어가 순서대로 실행되도록 각 장치를 제어\n\n\n\n##### 명령어 세트란?\n\nCPU가 실행할 명령어의 집합\n\n> 연산 코드(Operation Code) + 피연산자(Operand)로 이루어짐\n>\n> 연산 코드 : 실행할 연산\n>\n> 피연산자 : 필요한 데이터 or 저장 위치\n\n\n\n연산 코드는 연산, 제어, 데이터 전달, 입출력 기능을 가짐\n\n피연산자는 주소, 숫자/문자, 논리 데이터 등을 저장\n\n\n\nCPU는 프로그램 실행하기 위해 주기억장치에서 명령어를 순차적으로 인출하여 해독하고 실행하는 과정을 반복함\n\nCPU가 주기억장치에서 한번에 하나의 명령어를 인출하여 실행하는데 필요한 일련의 활동을 '명령어 사이클'이라고 말함\n\n명령어 사이클은 인출/실행/간접/인터럽트 사이클로 나누어짐\n\n주기억장치의 지정된 주소에서 하나의 명령어를 가져오고, 실행 사이클에서는 명령어를 실행함. 하나의 명령어 실행이 완료되면 그 다음 명령어에 대한 인출 사이클 시작\n\n\n\n##### 인출 사이클과 실행 사이클에 의한 명령어 처리 과정\n\n> 인출 사이클에서 가장 중요한 부분은 PC(프로그램 카운터) 값 증가\n\n- PC에 저장된 주소를 MAR로 전달\n\n- 저장된 내용을 토대로 주기억장치의 해당 주소에서 명령어 인출\n- 인출한 명령어를 MBR에 저장\n- 다음 명령어를 인출하기 위해 PC 값 증가시킴\n- 메모리 버퍼 레지스터(MBR)에 저장된 내용을 명령어 레지스터(IR)에 전달\n\n```\nT0 : MAR ← PC\nT1 : MBR ← M[MAR], PC ← PC+1\nT2 : IR ← MBR\n```\n\n여기까지는 인출하기까지의 과정\n\n\n\n##### 인출한 이후, 명령어를 실행하는 과정\n\n> ADD addr 명령어 연산\n\n```\nT0 : MAR ← IR(Addr)\nT1 : MBR ← M[MAR]\nT2 : AC ← AC + MBR\n```\n\n이미 인출이 진행되고 명령어만 실행하면 되기 때문에 PC를 증가할 필요x\n\nIR에 MBR의 값이 이미 저장된 상태를 의미함\n\n따라서 AC에 MBR을 더해주기만 하면 됨\n\n> LOAD addr 명령어 연산\n\n```\nT0 : MAR ← IR(Addr)\nT1 : MBR ← M[MAR]\nT2 : AC ← MBR\n```\n\n기억장치에 있는 데이터를 AC로 이동하는 명령어\n\n> STA addr 명령어 연산\n\n```\nT0 : MAR ← IR(Addr)\nT1 : MBR ← AC\nT2 : M[MAR] ← MBR\n```\n\nAC에 있는 데이터를 기억장치로 저장하는 명령어\n\n> JUMP addr 명령어 연산\n\n```\nT0 : PC ← IR(Addr)\n```\n\nPC값을 IR의 주소값으로 변경하는 분기 명령어\n\n\n" }, { "path": "Computer Science/Computer Architecture/캐시 메모리(Cache Memory).md", "content": "## 캐시 메모리(Cache Memory)\n\n속도가 빠른 장치와 느린 장치에서 속도 차이에 따른 병목 현상을 줄이기 위한 메모리를 말한다.\n\n
\n\n```\nex1) CPU 코어와 메모리 사이의 병목 현상 완화\nex2) 웹 브라우저 캐시 파일은, 하드디스크와 웹페이지 사이의 병목 현상을 완화\n```\n\n
\n\nCPU가 주기억장치에서 저장된 데이터를 읽어올 때, 자주 사용하는 데이터를 캐시 메모리에 저장한 뒤, 다음에 이용할 때 주기억장치가 아닌 캐시 메모리에서 먼저 가져오면서 속도를 향상시킨다.\n\n속도라는 장점을 얻지만, 용량이 적기도 하고 비용이 비싼 점이 있다.\n\n
\n\nCPU에는 이러한 캐시 메모리가 2~3개 정도 사용된다. (L1, L2, L3 캐시 메모리라고 부른다)\n\n속도와 크기에 따라 분류한 것으로, 일반적으로 L1 캐시부터 먼저 사용된다. (CPU에서 가장 빠르게 접근하고, 여기서 데이터를 찾지 못하면 L2로 감)\n\n
\n\n***듀얼 코어 프로세서의 캐시 메모리*** : 각 코어마다 독립된 L1 캐시 메모리를 가지고, 두 코어가 공유하는 L2 캐시 메모리가 내장됨\n\n만약 L1 캐시가 128kb면, 64/64로 나누어 64kb에 명령어를 처리하기 직전의 명령어를 임시 저장하고, 나머지 64kb에는 실행 후 명령어를 임시저장한다. (명령어 세트로 구성, I-Cache - D-Cache)\n\n- L1 : CPU 내부에 존재\n- L2 : CPU와 RAM 사이에 존재\n- L3 : 보통 메인보드에 존재한다고 함\n\n> 캐시 메모리 크기가 작은 이유는, SRAM 가격이 매우 비쌈\n\n
\n\n***디스크 캐시*** : 주기억장치(RAM)와 보조기억장치(하드디스크) 사이에 존재하는 캐시\n\n
\n\n#### 캐시 메모리 작동 원리\n\n- ##### 시간 지역성\n\n for나 while 같은 반복문에 사용하는 조건 변수처럼 한번 참조된 데이터는 잠시후 또 참조될 가능성이 높음\n\n- ##### 공간 지역성\n\n A[0], A[1]과 같은 연속 접근 시, 참조된 데이터 근처에 있는 데이터가 잠시후 또 사용될 가능성이 높음\n\n> 이처럼 참조 지역성의 원리가 존재한다.\n\n
\n\n캐시에 데이터를 저장할 때는, 이러한 참조 지역성(공간)을 최대한 활용하기 위해 해당 데이터뿐만 아니라, 옆 주소의 데이터도 같이 가져와 미래에 쓰일 것을 대비한다.\n\nCPU가 요청한 데이터가 캐시에 있으면 'Cache Hit', 없어서 DRAM에서 가져오면 'Cache Miss'\n\n
\n\n#### 캐시 미스 경우 3가지\n\n1. ##### Cold miss\n\n 해당 메모리 주소를 처음 불러서 나는 미스\n\n2. ##### Conflict miss\n\n 캐시 메모리에 A와 B 데이터를 저장해야 하는데, A와 B가 같은 캐시 메모리 주소에 할당되어 있어서 나는 미스 (direct mapped cache에서 많이 발생)\n\n ```\n 항상 핸드폰과 열쇠를 오른쪽 주머니에 넣고 다니는데, 잠깐 친구가 준 물건을 받느라 손에 들고 있던 핸드폰을 가방에 넣었음. 그 이후 핸드폰을 찾으려 오른쪽 주머니에서 찾는데 없는 상황\n ```\n\n3. ##### Capacity miss\n\n 캐시 메모리의 공간이 부족해서 나는 미스 (Conflict는 주소 할당 문제, Capacity는 공간 문제)\n\n
\n\n캐시 **크기를 키워서 문제를 해결하려하면, 캐시 접근속도가 느려지고 파워를 많이 먹는 단점**이 생김\n\n
\n\n#### 구조 및 작동 방식\n\n- ##### Direct Mapped Cache\n\n
\n\n- ##### Fully Associative Cache \n\n 비어있는 캐시 메모리가 있으면, 마음대로 주소를 저장하는 방식\n\n 저장할 때는 매우 간단하지만, 찾을 때가 문제\n\n 조건이나 규칙이 없어서 특정 캐시 Set 안에 있는 모든 블럭을 한번에 찾아 원하는 데이터가 있는지 검색해야 한다. CAM이라는 특수한 메모리 구조를 사용해야하지만 가격이 매우 비싸다.\n\n
\n\n- ##### Set Associative Cache\n\n Direct + Fully 방식이다. 특정 행을 지정하고, 그 행안의 어떤 열이든 비어있을 때 저장하는 방식이다. Direct에 비해 검색 속도는 느리지만, 저장이 빠르고 Fully에 비해 저장이 느린 대신 검색이 빠른 중간형이다.\n\n > 실제로 위 두가지보다 나중에 나온 방식\n\n
\n\n
\n\n##### [참고 자료]\n\n- [링크](https://it.donga.com/215/ )\n\n- [링크](https://namu.moe/w/%EC%BA%90%EC%8B%9C%20%EB%A9%94%EB%AA%A8%EB%A6%AC)\n" }, { "path": "Computer Science/Computer Architecture/컴퓨터의 구성.md", "content": "## 컴퓨터의 구성\n\n컴퓨터가 가지는 구성에 대해 알아보자\n\n
\n\n컴퓨터 시스템은 크게 하드웨어와 소프트웨어로 나누어진다.\n\n**하드웨어** : 컴퓨터를 구성하는 기계적 장치\n\n**소프트웨어** : 하드웨어의 동작을 지시하고 제어하는 명령어 집합\n\n
\n\n#### 하드웨어\n\n---\n\n- 중앙처리장치(CPU)\n- 기억장치 : RAM, HDD\n- 입출력 장치 : 마우스, 프린터\n\n#### 소프트웨어\n\n---\n\n- 시스템 소프트웨어 : 운영체제, 컴파일러\n- 응용 소프트웨어 : 워드프로세서, 스프레드시트\n\n
\n\n먼저 하드웨어부터 살펴보자\n\n
\n\n##### 중앙처리장치(CPU)\n\n인간으로 따지면 두뇌에 해당하는 부분\n\n주기억장치에서 프로그램 명령어와 데이터를 읽어와 처리하고 명령어의 수행 순서를 제어함\n중앙처리장치는 비교와 연산을 담당하는 산술논리연산장치(ALU)와 명령어의 해석과 실행을 담당하는 **제어장치**, 속도가 빠른 데이터 기억장소인 **레지스터**로 구성되어있음\n\n개인용 컴퓨터와 같은 소형 컴퓨터에서는 CPU를 마이크로프로세서라고도 부름\n\n
\n\n##### 기억장치\n\n프로그램, 데이터, 연산의 중간 결과를 저장하는 장치\n\n주기억장치와 보조기억장치로 나누어지며, RAM과 ROM도 이곳에 해당함. 실행중인 프로그램과 같은 프로그램에 필요한 데이터를 일시적으로 저장한다.\n\n보조기억장치는 하드디스크 등을 말하며, 주기억장치에 비해 속도는 느리지만 많은 자료를 영구적으로 보관할 수 있는 장점이 있다.\n\n
\n\n##### 입출력장치\n\n입력과 출력 장치로 나누어짐. \n\n입력 장치는 컴퓨터 내부로 자료를 입력하는 장치 (키보드, 마우스 등)\n\n출력 장치는 컴퓨터에서 외부로 표현하는 장치 (프린터, 모니터, 스피커 등)\n\n
\n\n
\n\n#### 시스템 버스\n\n> 하드웨어 구성 요소를 물리적으로 연결하는 선\n\n각 구성요소가 다른 구성요소로 데이터를 보낼 수 있도록 통로가 되어줌\n\n용도에 따라 데이터 버스, 주소 버스, 제어 버스로 나누어짐\n\n
\n\n##### 데이터 버스\n\n중앙처리장치와 기타 장치 사이에서 데이터를 전달하는 통로\n\n기억장치와 입출력장치의 명령어와 데이터를 중앙처리장치로 보내거나, 중앙처리장치의 연산 결과를 기억장치와 입출력장치로 보내는 '양방향' 버스임\n\n##### 주소 버스\n\n데이터를 정확히 실어나르기 위해서는 기억장치 '주소'를 정해주어야 함.\n\n주소버스는 중앙처리장치가 주기억장치나 입출력장치로 기억장치 주소를 전달하는 통로이기 때문에 '단방향' 버스임\n\n##### 제어 버스\n\n주소 버스와 데이터 버스는 모든 장치에 공유되기 때문에 이를 제어할 수단이 필요함\n\n제어 버스는 중앙처리장치가 기억장치나 입출력장치에 제어 신호를 전달하는 통로임\n\n제어 신호 종류 : 기억장치 읽기 및 쓰기, 버스 요청 및 승인, 인터럽트 요청 및 승인, 클락, 리셋 등\n\n제어 버스는 읽기 동작과 쓰기 동작을 모두 수행하기 때문에 '양방향' 버스임\n\n
\n\n컴퓨터는 기본적으로 **읽고 처리한 뒤 저장**하는 과정으로 이루어짐\n\n(READ → PROCESS → WRITE)\n\n이 과정을 진행하면서 끊임없이 주기억장치(RAM)과 소통한다. 이때 운영체제가 64bit라면, CPU는 RAM으로부터 데이터를 한번에 64비트씩 읽어온다.\n\n
" }, { "path": "Computer Science/Computer Architecture/패리티 비트 & 해밍 코드.md", "content": "## 패리티 비트 & 해밍 코드\n\n
\n\n### 패리티 비트\n\n> 정보 전달 과정에서 오류가 생겼는 지 검사하기 위해 추가하는 비트를 말한다.\n>\n> 전송하고자 하는 데이터의 각 문자에 1비트를 더하여 전송한다.\n\n
\n\n**종류** : 짝수, 홀수\n\n전체 비트에서 (짝수, 홀수)에 맞도록 비트를 정하는 것\n\n
\n\n***짝수 패리티일 때 7비트 데이터가 1010001라면?***\n\n> 1이 총 3개이므로, 짝수로 맞춰주기 위해 1을 더해야 함\n>\n> 답 : 11010001 (맨앞이 패리티비트)\n\n
\n\n
\n\n### 해밍 코드\n\n> 데이터 전송 시 1비트의 에러를 정정할 수 있는 자기 오류정정 코드를 말한다.\n>\n> 패리티비트를 보고, 1비트에 대한 오류를 정정할 곳을 찾아 수정할 수 있다.\n> (패리티 비트는 오류를 검출하기만 할 뿐 수정하지는 않기 때문에 해밍 코드를 활용)\n\n
\n\n##### 방법\n\n2의 n승 번째 자리인 1,2,4번째 자릿수가 패리티 비트라는 것으로 부터 시작한다. 이 숫자로부터 시작하는 세개의 패리티 비트가 짝수인지, 홀수인지 기준으로 판별한다.\n\n
\n\n***짝수 패리티의 해밍 코드가 0011011일때 오류가 수정된 코드는?***\n\n1) 1, 3, 5, 7번째 비트 확인 : 0101로 짝수이므로 '0'\n\n2) 2, 3, 6, 7번째 비트 확인 : 0111로 홀수이므로 '1'\n\n3) 4, 5, 6, 7번째 비트 확인 : 1011로 홀수이므로 '1'\n\n
\n\n역순으로 패리티비트 '110'을 도출했다. 10진법으로 바꾸면 '6'으로, 6번째 비트를 수정하면 된다.\n\n따라서 **정답은 00110'0'1**이다." }, { "path": "Computer Science/Data Structure/Array vs ArrayList vs LinkedList.md", "content": "## Array vs ArrayList vs LinkedList\n\n
\n\n세 자료구조를 한 문장으로 정의하면 아래와 같이 말할 수 있다.\n\n\n\n
 \n\n
\n\n \n\n
\n\n\n\n- **Array**는 index로 빠르게 값을 찾는 것이 가능함\n- **LinkedList**는 데이터의 삽입 및 삭제가 빠름\n- **ArrayList**는 데이터를 찾는데 빠르지만, 삽입 및 삭제가 느림\n\n
\n\n좀 더 자세히 비교하면?\n\n
\n\n우선 배열(Array)는 **선언할 때 크기와 데이터 타입을 지정**해야 한다.\n\n```java\nint arr[10];\nString arr[5];\n```\n\n이처럼, **array**은 메모리 공간에 할당할 사이즈를 미리 정해놓고 사용하는 자료구조다.\n\n따라서 계속 데이터가 늘어날 때, 최대 사이즈를 알 수 없을 때는 사용하기에 부적합하다.\n\n또한 중간에 데이터를 삽입하거나 삭제할 때도 매우 비효율적이다.\n\n4번째 index 값에 새로운 값을 넣어야 한다면? 원래값을 뒤로 밀어내고 해당 index에 덮어씌워야 한다. 기본적으로 사이즈를 정해놓은 배열에서는 해결하기엔 부적합한 점이 많다.\n\n대신, 배열을 사용하면 index가 존재하기 때문에 위치를 바로 알 수 있어 검색에 편한 장점이 있다.\n\n
\n\n이를 해결하기 위해 나온 것이 **List**다.\n\nList는 array처럼 **크기를 정해주지 않아도 된다**. 대신 array에서 index가 중요했다면, List에서는 순서가 중요하다.\n\n크기가 정해져있지 않기 때문에, 중간에 데이터를 추가하거나 삭제하더라도 array에서 갖고 있던 문제점을 해결 가능하다. index를 가지고 있으므로 검색도 빠르다.\n\n하지만, 중간에 데이터를 추가 및 삭제할 때 시간이 오래걸리는 단점이 존재한다. (더하거나 뺄때마다 줄줄이 당겨지거나 밀려날 때 진행되는 연산이 추가, 메모리도 낭비..)\n\n
\n\n그렇다면 **LinkedList**는?\n\n연결리스트에는 단일, 다중 등 여러가지가 존재한다.\n\n종류가 무엇이든, **한 노드에 연결될 노드의 포인터 위치를 가리키는 방식**으로 되어있다.\n\n> 단일은 뒤에 노드만 가리키고, 다중은 앞뒤 노드를 모두 가리키는 차이\n\n
\n\n이런 방식을 활용하면서, 데이터의 중간에 삽입 및 삭제를 하더라도 전체를 돌지 않아도 이전 값과 다음값이 가르켰던 주소값만 수정하여 연결시켜주면 되기 때문에 빠르게 진행할 수 있다.\n\n이렇게만 보면 가장 좋은 방법 같아보이지만, `List의 k번째 값을 찾아라`에서는 비효율적이다.\n\n
\n\narray나 arrayList에서 index를 갖고 있기 때문에 검색이 빠르지만, LinkedList는 처음부터 살펴봐야하므로(순차) 검색에 있어서는 시간이 더 걸린다는 단점이 존재한다. \n\n
\n\n따라서 상황에 맞게 자료구조를 잘 선택해서 사용하는 것이 중요하다." }, { "path": "Computer Science/Data Structure/Array.md", "content": "### 배열 (Array)\n\n---\n\n- C++에서 사이즈 구하기 \n\n```\nint arr[] = { 1, 2, 3, 4, 5, 6, 7 }; \nint n = sizeof(arr) / sizeof(arr[0]); // 7\n```\n\n
\n\n
\n\n1. #### 배열 회전 프로그램\n\n\n\n\n\n\n\n*전체 코드는 각 하이퍼링크를 눌러주시면 이동됩니다.*\n\n
\n\n- [기본적인 회전 알고리즘 구현](https://github.com/gyoogle/tech-interview-for-developer/blob/master/Computer%20Science/Data%20Structure/code/rotate_array.cpp)\n\n > temp를 활용해서 첫번째 인덱스 값을 저장 후\n > arr[0]~arr[n-1]을 각각 arr[1]~arr[n]의 값을 주고, arr[n]에 temp를 넣어준다.\n >\n > ```\n > void leftRotatebyOne(int arr[], int n){\n > int temp = arr[0], i;\n > for(i = 0; i < n-1; i++){\n > arr[i] = arr[i+1];\n > }\n > arr[i] = temp;\n > }\n > ```\n >\n > 이 함수를 활용해 원하는 회전 수 만큼 for문을 돌려 구현이 가능\n\n
\n\n- [저글링 알고리즘 구현](https://github.com/gyoogle/tech-interview-for-developer/blob/master/Computer%20Science/Data%20Structure/code/juggling_array.cpp)\n\n > \n >\n > 최대공약수 gcd를 이용해 집합을 나누어 여러 요소를 한꺼번에 이동시키는 것\n >\n > 위 그림처럼 배열이 아래와 같다면\n >\n > arr[] = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12}\n >\n > 1,2,3을 뒤로 옮길 때, 인덱스를 3개씩 묶고 회전시키는 방법이다.\n >\n > a) arr [] -> { **4** 2 3 **7** 5 6 **10** 8 9 **1** 11 12}\n >\n > b) arr [] -> {4 **5** 3 7 **8** 6 10 **11** 9 1 **2** 12}\n >\n > c) arr [] -> {4 5 **6** 7 8 **9** 10 11 **12** 1 2 **3** }\n\n
\n\n- [역전 알고리즘 구현](https://github.com/gyoogle/tech-interview-for-developer/blob/master/Computer%20Science/Data%20Structure/code/reversal_array.cpp)\n\n > 회전시키는 수에 대해 구간을 나누어 reverse로 구현하는 방법\n >\n > d = 2이면\n >\n > 1,2 / 3,4,5,6,7로 구간을 나눈다.\n >\n > 첫번째 구간 reverse -> 2,1\n >\n > 두번째 구간 reverse -> 7,6,5,4,3\n >\n > 합치기 -> 2,1,7,6,5,4,3\n >\n > 합친 배열을 reverse -> **3,4,5,6,7,1,2**\n >\n >\n >\n > - swap을 통한 reverse\n >\n > ```\n > void reverseArr(int arr[], int start, int end){\n > \n > while (start < end){\n > int temp = arr[start];\n > arr[start] = arr[end];\n > arr[end] = temp;\n > \n > start++;\n > end--;\n > }\n > }\n > ```\n >\n >\n >\n > - 구간을 d로 나누었을 때 역전 알고리즘 구현\n >\n > ```\n > void rotateLeft(int arr[], int d, int n){\n > reverseArr(arr, 0, d-1);\n > reverseArr(arr, d, n-1);\n > reverseArr(arr, 0, n-1);\n > }\n > ```\n\n
\n\n
\n\n2. #### 배열의 특정 최대 합 구하기\n\n\n\n**예시)** arr[i]가 있을 때, i*arr[i]의 Sum이 가장 클 때 그 값을 출력하기 \n\n(회전하면서 최대값을 찾아야한다.)\n\n```\nInput: arr[] = {1, 20, 2, 10}\nOutput: 72\n\n2번 회전했을 때 아래와 같이 최대값이 나오게 된다.\n{2, 10, 1, 20}\n20*3 + 1*2 + 10*1 + 2*0 = 72\n\nInput: arr[] = {10, 1, 2, 3, 4, 5, 6, 7, 8, 9};\nOutput: 330\n\n9번 회전했을 때 아래와 같이 최대값이 나오게 된다.\n{1, 2, 3, 4, 5, 6, 7, 8, 9, 10};\n0*1 + 1*2 + 2*3 ... 9*10 = 330\n```\n\n
\n\n##### 접근 방법\n\narr[i]의 전체 합과 i*arr[i]의 전체 합을 저장할 변수 선언\n\n최종 가장 큰 sum 값을 저장할 변수 선언\n\n배열을 회전시키면서 i*arr[i]의 합의 값을 저장하고, 가장 큰 값을 저장해서 출력하면 된다.\n\n
\n\n##### 해결법\n\n```\n회전 없이 i*arr[i]의 sum을 저장한 값\nR0 = 0*arr[0] + 1*arr[1] +...+ (n-1)*arr[n-1]\n\n\n1번 회전하고 i*arr[i]의 sum을 저장한 값\nR1 = 0*arr[n-1] + 1*arr[0] +...+ (n-1)*arr[n-2]\n\n이 두개를 빼면?\nR1 - R0 = arr[0] + arr[1] + ... + arr[n-2] - (n-1)*arr[n-1]\n\n2번 회전하고 i*arr[i]의 sum을 저장한 값\nR2 = 0*arr[n-2] + 1*arr[n-1] +...+ (n-1)*arr[n-3]\n\n1번 회전한 값과 빼면?\nR2 - R1 = arr[0] + arr[1] + ... + arr[n-3] - (n-1)*arr[n-2] + arr[n-1]\n\n\n여기서 규칙을 찾을 수 있음.\n\nRj - Rj-1 = arrSum - n * arr[n-j]\n\n이를 활용해서 몇번 회전했을 때 최대값이 나오는 지 구할 수 있다.\n```\n\n[구현 소스 코드 링크](https://github.com/gyoogle/tech-interview-for-developer/blob/master/Computer%20Science/Data%20Structure/code/maxvalue_array.cpp)\n\n
\n\n
\n\n3. #### 특정 배열을 arr[i] = i로 재배열 하기\n\n**예시)** 주어진 배열에서 arr[i] = i이 가능한 것만 재배열 시키기\n\n```\nInput : arr = {-1, -1, 6, 1, 9, 3, 2, -1, 4, -1}\nOutput : [-1, 1, 2, 3, 4, -1, 6, -1, -1, 9]\n\nInput : arr = {19, 7, 0, 3, 18, 15, 12, 6, 1, 8,\n 11, 10, 9, 5, 13, 16, 2, 14, 17, 4}\nOutput : [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, \n 11, 12, 13, 14, 15, 16, 17, 18, 19]\n```\n\narr[i] = i가 없으면 -1로 채운다.\n\n\n\n##### 접근 방법\n\narr[i]가 -1이 아니고, arr[i]이 i가 아닐 때가 우선 조건\n\n해당 arr[i] 값을 저장(x)해두고, 이 값이 x일 때 arr[x]를 탐색\n\narr[x] 값을 저장(y)해두고, arr[x]가 -1이 아니면서 arr[x]가 x가 아닌 동안을 탐색\n\narr[x]를 x값으로 저장해주고, 기존의 x를 y로 수정\n\n```\nint fix(int A[], int len){\n \n for(int i = 0; i < len; i++) {\n \n \n if (A[i] != -1 && A[i] != i){ // A[i]가 -1이 아니고, i도 아닐 때\n \n int x = A[i]; // 해당 값을 x에 저장\n \n while(A[x] != -1 && A[x] != x){ // A[x]가 -1이 아니고, x도 아닐 때\n \n int y = A[x]; // 해당 값을 y에 저장\n A[x] = x; \n \n x = y;\n }\n \n A[x] = x;\n \n if (A[i] != i){\n A[i] = -1;\n }\n }\n }\n \n}\n```\n\n[구현 소스 코드 링크](https://github.com/gyoogle/tech-interview-for-developer/blob/master/Computer%20Science/Data%20Structure/code/rearrange_array.cpp)\n\n
\n\n
\n" }, { "path": "Computer Science/Data Structure/B Tree & B+ Tree.md", "content": "## B Tree & B+ Tree\n\n
\n\n> **이진 트리**는 하나의 부모가 두 개의 자식밖에 가지질 못하고, 균형이 맞지 않으면 검색 효율이 선형검색 급으로 떨어진다. 하지만 이진 트리 구조의 간결함과 균형만 맞다면 검색, 삽입, 삭제 모두 O(logN)의 성능을 보이는 장점이 있기 때문에 계속 개선시키기 위한 노력이 이루어지고 있다.\n\n
\n\n#### B Tree\n\n---\n\n데이터베이스, 파일 시스템에서 널리 사용되는 트리 자료구조의 일종이다.\n\n이진 트리를 확장해서, 더 많은 수의 자식을 가질 수 있게 일반화 시킨 것이 B-Tree\n\n
\n\n자식 수에 대한 일반화를 진행하면서, 하나의 레벨에 더 저장되는 것 뿐만 아니라 트리의 균형을 자동으로 맞춰주는 로직까지 갖추었다. 단순하고 효율적이며, 레벨로만 따지면 완전히 균형을 맞춘 트리다.\n\n```\n대량의 데이터를 처리해야 할 때, 검색 구조의 경우 하나의 노드에 많은 데이터를 가질 수 있다는 점은 상당히 큰 장점이다.\n\n대량의 데이터는 메모리보다 블럭 단위로 입출력하는 하드디스크 or SSD에 저장해야하기 때문!\n\nex) 한 블럭이 1024 바이트면, 2바이트를 읽으나 1024바이트를 읽으나 똑같은 입출력 비용 발생. 따라서 하나의 노드를 모두 1024바이트로 꽉 채워서 조절할 수 있으면 입출력에 있어서 효율적인 구성을 갖출 수 있다.\n\n→ B-Tree는 이러한 장점을 토대로 많은 데이터베이스 시스템의 인덱스 저장 방법으로 애용하고 있음\n```\n\n
\n\n##### 규칙\n\n- 노드의 자료수가 N이면, 자식 수는 N+1이어야 함\n- 각 노드의 자료는 정렬된 상태여야함\n- 루트 노드는 적어도 2개 이상의 자식을 가져야함\n- 루트 노드를 제외한 모든 노드는 적어도 M/2개의 자료를 가지고 있어야함\n- 외부 노드로 가는 경로의 길이는 모두 같음.\n- 입력 자료는 중복 될 수 없음\n\n
\n\n
\n\n#### B+ Tree\n\n---\n\n데이터의 빠른 접근을 위한 인덱스 역할만 하는 비단말 노드(not Leaf)가 추가로 있음\n\n(기존의 B-Tree와 데이터의 연결리스트로 구현된 색인구조)\n\n
\n\nB-Tree의 변형 구조로, index 부분과 leaf 노드로 구성된 순차 데이터 부분으로 이루어진다. 인덱스 부분의 key 값은 leaf에 있는 key 값을 직접 찾아가는데 사용함.\n\n
\n\n##### 장점\n\n> 블럭 사이즈를 더 많이 이용할 수 있음 (key 값에 대한 하드디스크 액세스 주소가 없기 때문)\n>\n> leaf 노드끼리 연결 리스트로 연결되어 있어서 범위 탐색에 매우 유리함\n\n##### 단점\n\n> B-tree의 경우 최상 케이스에서는 루트에서 끝날 수 있지만, B+tree는 무조건 leaf 노드까지 내려가봐야 함\n\n
\n\n
\n\n
\n\n##### B-Tree & B+ Tree\n\n> B-tree는 각 노드에 데이터가 저장됨\n>\n> B+tree는 index 노드와 leaf 노드로 분리되어 저장됨\n>\n> (또한, leaf 노드는 서로 연결되어 있어서 임의접근이나 순차접근 모두 성능이 우수함)\n\n
\n\nB-tree는 각 노드에서 key와 data 모두 들어갈 수 있고, data는 disk block으로 포인터가 될 수 있음\n\nB+tree는 각 노드에서 key만 들어감. 따라서 data는 모두 leaf 노드에만 존재\n\nB+tree는 add와 delete가 모두 leaf 노드에서만 이루어짐\n\n
\n\n**참고자료** : [링크](
\n\n***이진탐색트리의 목적은?***\n\n> 이진탐색 + 연결리스트\n\n이진탐색 : **탐색에 소요되는 시간복잡도는 O(logN)**, but 삽입,삭제가 불가능\n\n연결리스트 : **삽입, 삭제의 시간복잡도는 O(1)**, but 탐색하는 시간복잡도가 O(N)\n\n이 두가지를 합하여 장점을 모두 얻는 것이 **'이진탐색트리'**\n\n즉, 효율적인 탐색 능력을 가지고, 자료의 삽입 삭제도 가능하게 만들자\n\n
\n\n
 \n\n
\n\n\n\n#### 특징\n\n- 각 노드의 자식이 2개 이하\n- 각 노드의 왼쪽 자식은 부모보다 작고, 오른쪽 자식은 부모보다 큼\n- 중복된 노드가 없어야 함\n\n***중복이 없어야 하는 이유는?***\n\n검색 목적 자료구조인데, 굳이 중복이 많은 경우에 트리를 사용하여 검색 속도를 느리게 할 필요가 없음. (트리에 삽입하는 것보다, 노드에 count 값을 가지게 하여 처리하는 것이 훨씬 효율적)\n\n
\n\n이진탐색트리의 순회는 **'중위순회(inorder)' 방식 (왼쪽 - 루트 - 오른쪽)**\n\n중위 순회로 **정렬된 순서**를 읽을 수 있음\n\n
\n\n#### BST 핵심연산\n\n- 검색\n- 삽입\n- 삭제\n- 트리 생성\n- 트리 삭제\n\n
\n\n#### 시간 복잡도\n\n- 균등 트리 : 노드 개수가 N개일 때 O(logN)\n- 편향 트리 : 노드 개수가 N개일 때 O(N)\n\n> 삽입, 검색, 삭제 시간복잡도는 **트리의 Depth**에 비례\n\n
\n\n#### 삭제의 3가지 Case\n\n1) 자식이 없는 leaf 노드일 때 → 그냥 삭제\n\n2) 자식이 1개인 노드일 때 → 지워진 노드에 자식을 올리기\n\n3) 자식이 2개인 노드일 때 → 오른쪽 자식 노드에서 가장 작은 값 or 왼쪽 자식 노드에서 가장 큰 값 올리기\n\n
\n\n편향된 트리(정렬된 상태 값을 트리로 만들면 한쪽으로만 뻗음)는 시간복잡도가 O(N)이므로 트리를 사용할 이유가 사라짐 → 이를 바로 잡도록 도와주는 개선된 트리가 AVL Tree, RedBlack Tree\n\n
\n\n[소스 코드(java)](
\n\n```\nLee → 해싱함수 → 5\nKim → 해싱함수 → 3\nPark → 해싱함수 → 2\n...\nChun → 해싱함수 → 5 // Lee와 해싱값 충돌\n```\n\n결국 데이터가 많아지면, 다른 데이터가 같은 해시 값으로 충돌나는 현상이 발생함 **'collision' 현상**\n\n**_그래도 해시 테이블을 쓰는 이유는?_**\n\n> 적은 자원으로 많은 데이터를 효율적으로 관리하기 위해\n>\n> 하드디스크나, 클라우드에 존재하는 무한한 데이터들을 유한한 개수의 해시값으로 매핑하면 작은 메모리로도 프로세스 관리가 가능해짐!\n\n- 언제나 동일한 해시값 리턴, index를 알면 빠른 데이터 검색이 가능해짐\n- 해시테이블의 시간복잡도 O(1) - (이진탐색트리는 O(logN))\n\n
\n\n##### 충돌 문제 해결\n\n1. **체이닝** : 연결리스트로 노드를 계속 추가해나가는 방식\n (제한 없이 계속 연결 가능, but 메모리 문제)\n\n2. **Open Addressing** : 해시 함수로 얻은 주소가 아닌 다른 주소에 데이터를 저장할 수 있도록 허용 (해당 키 값에 저장되어있으면 다음 주소에 저장)\n\n3. **선형 탐사** : 정해진 고정 폭으로 옮겨 해시값의 중복을 피함\n4. **제곱 탐사** : 정해진 고정 폭을 제곱수로 옮겨 해시값의 중복을 피함\n\n
\n\n## 해시 버킷 동적 확장\n\n해시 버킷의 크기가 충분히 크다면 해시 충돌 빈도를 낮출 수 있다\n\n하지만 메모리는 한정된 자원이기 때문에 무작정 큰 공간을 할당해 줄 수 없다\n\n때문에 `load factor`가 일정 수준 이상 이라면 (보편적으로는 0.7 ~ 0.8) 해시 버킷의 크기를 확장하는 동적 확장 방식을 사용한다\n\n- **load factor** : 할당된 키의 개수 / 해시 버킷의 크기\n\n해시 버킷이 동적 확장 될 때 `리해싱` 과정을 거치게 된다\n\n- **리해싱(Rehashing)** : 기존 저장되어 있는 값들을 다시 해싱하여 새로운 키를 부여하는 것을 말한다\n\n
\n\n
\n\n참고자료 : [링크](https://ratsgo.github.io/data%20structure&algorithm/2017/10/25/hash/)\n" }, { "path": "Computer Science/Data Structure/Heap.md", "content": "## [자료구조] 힙(Heap)\n\n
\n\n##### 알아야할 것\n\n> 1.힙의 개념\n>\n> 2.힙의 삽입 및 삭제\n\n
\n\n힙은, 우선순위 큐를 위해 만들어진 자료구조다.\n\n먼저 **우선순위 큐**에 대해서 간략히 알아보자 \n\n
\n\n**우선순위 큐** : 우선순위의 개념을 큐에 도입한 자료구조\n\n> 데이터들이 우선순위를 가지고 있음. 우선순위가 높은 데이터가 먼저 나감\n\n스택은 LIFO, 큐는 FIFO\n\n
\n\n##### 언제 사용?\n\n> 시뮬레이션 시스템, 작업 스케줄링, 수치해석 계산\n\n우선순위 큐는 배열, 연결리스트, 힙으로 구현 (힙으로 구현이 가장 효율적!)\n\n힙 → 삽입 : O(logn) , 삭제 : O(logn)\n\n
\n\n
\n\n### 힙(Heap)\n\n---\n\n완전 이진 트리의 일종\n\n> 여러 값 중, 최대값과 최소값을 빠르게 찾아내도록 만들어진 자료구조\n\n반정렬 상태\n\n힙 트리는 중복된 값 허용 (이진 탐색 트리는 중복값 허용X)\n\n
\n\n#### 힙 종류\n\n###### 최대 힙(max heap)\n\n 부모 노드의 키 값이 자식 노드의 키 값보다 크거나 같은 완전 이진 트리\n\n###### 최소 힙(min heap)\n\n 부모 노드의 키 값이 자식 노드의 키 값보다 작거나 같은 완전 이진 트리\n\n
 \n\n
\n\n\n\n#### 구현\n\n---\n\n힙을 저장하는 표준적인 자료구조는 `배열`\n\n구현을 쉽게 하기 위해 배열의 첫번째 인덱스인 0은 사용되지 않음\n\n특정 위치의 노드 번호는 새로운 노드가 추가되어도 변하지 않음\n\n(ex. 루트 노드(1)의 오른쪽 노드 번호는 항상 3)\n\n
\n\n##### 부모 노드와 자식 노드 관계\n\n```\n왼쪽 자식 index = (부모 index) * 2\n\n오른쪽 자식 index = (부모 index) * 2 + 1\n\n부모 index = (자식 index) / 2\n```\n\n
\n\n#### 힙의 삽입\n\n1.힙에 새로운 요소가 들어오면, 일단 새로운 노드를 힙의 마지막 노드에 삽입\n\n2.새로운 노드를 부모 노드들과 교환\n\n
\n\n###### 최대 힙 삽입 구현\n\n```java\nvoid insert_max_heap(int x) {\n \n maxHeap[++heapSize] = x; \n // 힙 크기를 하나 증가하고, 마지막 노드에 x를 넣음\n \n for( int i = heapSize; i > 1; i /= 2) {\n \n // 마지막 노드가 자신의 부모 노드보다 크면 swap\n if(maxHeap[i/2] < maxHeap[i]) {\n swap(i/2, i);\n } else {\n break;\n }\n \n }\n}\n```\n\n부모 노드는 자신의 인덱스의 /2 이므로, 비교하고 자신이 더 크면 swap하는 방식\n\n
\n\n#### 힙의 삭제\n\n1.최대 힙에서 최대값은 루트 노드이므로 루트 노드가 삭제됨\n(최대 힙에서 삭제 연산은 최대값 요소를 삭제하는 것)\n\n2.삭제된 루트 노드에는 힙의 마지막 노드를 가져옴\n\n3.힙을 재구성\n\n
\n\n###### 최대 힙 삭제 구현\n\n```java\nint delete_max_heap() {\n \n if(heapSize == 0) // 배열이 비어있으면 리턴\n return 0;\n \n int item = maxHeap[1]; // 루트 노드의 값을 저장\n maxHeap[1] = maxHeap[heapSize]; // 마지막 노드 값을 루트로 이동\n maxHeap[heapSize--] = 0; // 힙 크기를 하나 줄이고 마지막 노드 0 초기화\n \n for(int i = 1; i*2 <= heapSize;) {\n \n // 마지막 노드가 왼쪽 노드와 오른쪽 노드보다 크면 끝\n if(maxHeap[i] > maxHeap[i*2] && maxHeap[i] > maxHeap[i*2+1]) {\n break;\n }\n \n // 왼쪽 노드가 더 큰 경우, swap\n else if (maxHeap[i*2] > maxHeap[i*2+1]) {\n swap(i, i*2);\n i = i*2;\n }\n \n // 오른쪽 노드가 더 큰 경우\n else {\n swap(i, i*2+1);\n i = i*2+1;\n }\n }\n \n return item;\n \n}\n```\n\n
\n\n
\n\n**[참고 자료]** [링크](
\n\n**왜 Linked List를 사용하나?**\n\n> 배열은 비슷한 유형의 선형 데이터를 저장하는데 사용할 수 있지만 제한 사항이 있음\n>\n> 1) 배열의 크기가 고정되어 있어 미리 요소의 수에 대해 할당을 받아야 함\n>\n> 2) 새로운 요소를 삽입하는 것은 비용이 많이 듬 (공간을 만들고, 기존 요소 전부 이동)\n\n**장점**\n\n> 1) 동적 크기\n>\n> 2) 삽입/삭제 용이\n\n**단점**\n\n> 1) 임의로 액세스를 허용할 수 없음. 즉, 첫 번째 노드부터 순차적으로 요소에 액세스 해야함 (이진 검색 수행 불가능)\n>\n> 2) 포인터의 여분의 메모리 공간이 목록의 각 요소에 필요\n\n\n\n노드 구현은 아래와 같이 데이터와 다음 노드에 대한 참조로 나타낼 수 있다\n\n```\n// A linked list node \nstruct Node \n{ \n int data; \n struct Node *next; \n}; \n```\n\n\n\n**Single Linked List**\n\n노드 3개를 잇는 코드를 만들어보자\n\n```\n head second third \n | | | \n | | | \n +---+---+ +---+---+ +----+----+ \n | 1 | o----->| 2 | o-----> | 3 | # | \n +---+---+ +---+---+ +----+----+\n```\n\n[소스 코드]()\n\n\n\n
\n\n
\n\n**노드 추가**\n\n- 앞쪽에 노드 추가\n\n```\nvoid push(struct Node** head_ref, int new_data){\n struct Node* new_node = (struct Node*) malloc(sizeof(struct Node));\n\n new_node->data = new_data;\n\n new_node->next = (*head_ref);\n\n (*head_ref) = new_node;\n}\n```\n\n\n\n- 특정 노드 다음에 추가\n\n```\nvoid insertAfter(struct Node* prev_node, int new_data){\n if (prev_node == NULL){\n printf(\"이전 노드가 NULL이 아니어야 합니다.\");\n return;\n }\n\n struct Node* new_node = (struct Node*) malloc(sizeof(struct Node));\n\n new_node->data = new_data;\n new_node->next = prev_node->next;\n\n prev_node->next = new_node;\n \n}\n```\n\n\n\n- 끝쪽에 노드 추가\n\n```\nvoid append(struct Node** head_ref, int new_data){\n struct Node* new_node = (struct Node*)malloc(sizeof(struct Node));\n\n struct Node *last = *head_ref;\n\n new_node->data = new_data;\n\n new_node->next = NULL;\n\n if (*head_ref == NULL){\n *head_ref = new_node;\n return;\n }\n\n while(last->next != NULL){\n last = last->next;\n }\n\n last->next = new_node;\n return;\n\n}\n```\n\n" }, { "path": "Computer Science/Data Structure/README.md", "content": "## 자료구조\n\n
\n\n#### 배열(Array)\n\n---\n\n정적으로 필요한만큼만 원소를 저장할 수 있는 공간이 할당\n\n이때 각 원소의 주소는 연속적으로 할당됨\n\nindex를 통해 O(1)에 접근이 가능함\n\n삽입 및 삭제는 O(N)\n\n지정된 개수가 초과되면? → **배열 크기를 재할당한 후 복사**해야함\n\n
\n\n#### 리스트(List)\n\n---\n\n노드(Node)들의 연결로 이루어짐\n\n크기 제한이 없음 ( heap 용량만 충분하면! )\n\n다음 노드에 대한 **참조를 통해 접근** ( O(N) )\n\n삽입과 삭제가 편함 O(1)\n\n
\n\n#### ArrayList\n\n---\n\n동적으로 크기가 조정되는 배열\n\n배열이 가득 차면? → 알아서 그 크기를 2배로 할당하고 복사 수행\n\n재할당에 걸리는 시간은 O(N)이지만, 자주 일어나는 일이 아니므로 접근시간은 O(1)\n\n
\n\n#### 스택(Stack)\n\n---\n\nLIFO 방식 (나중에 들어온게 먼저 나감)\n\n원소의 삽입 및 삭제가 한쪽 끝에서만 이루어짐 (이 부분을 top이라고 칭함)\n\n함수 호출 시 지역변수, 매개변수 정보를 저장하기 위한 공간을 스택으로 사용함\n\n
\n\n#### 큐(Queue)\n\n---\n\nFIFO 방식 (먼저 들어온게 먼저 나감)\n\n원소의 삽입 및 삭제가 양쪽 끝에서 일어남 (front, rear)\n\nFIFO 운영체제, 은행 대기열 등에 해당\n\n
\n\n#### 우선순위 큐(Priority Queue)\n\n---\n\nFIFO 방식이 아닌 데이터를 근거로 한 우선순위를 판단하고, 우선순위가 높은 것부터 나감\n\n구현 방법 3가지 (배열, 연결리스트, 힙)\n\n##### 1.배열\n\n간단하게 구현이 가능\n\n데이터 삽입 및 삭제 과정을 진행 시, O(N)으로 비효율 발생 (**한 칸씩 당기거나 밀어야하기 때문**)\n\n삽입 위치를 찾기 위해 배열의 모든 데이터를 탐색해야 함 (우선순위가 가장 낮을 경우)\n\n##### 2.연결리스트\n\n삽입 및 삭제 O(1)\n\n하지만 삽입 위치를 찾을 때는 배열과 마찬가지로 비효율 발생\n\n##### 3.힙\n\n힙은 위 2가지를 모두 효율적으로 처리가 가능함 (따라서 우선순위 큐는 대부분 힙으로 구현)\n\n힙은 **완전이진트리의 성질을 만족하므로, 1차원 배열로 표현이 가능**함 ( O(1)에 접근이 가능 )\n\nroot index에 따라 child index를 계산할 수 있음\n\n```\nroot index = 0\n\nleft index = index * 2 + 1\nright index = index * 2 + 2\n```\n\n**데이터의 삽입**은 트리의 leaf node(자식이 없는 노드)부터 시작\n\n삽입 후, heapify 과정을 통해 힙의 모든 부모-자식 노드의 우선순위에 맞게 설정됨\n(이때, 부모의 우선순위는 자식의 우선순위보다 커야 함)\n\n**데이터의 삭제**는 root node를 삭제함 (우선순위가 가장 큰 것)\n\n삭제 후, 마지막 leaf node를 root node로 옮긴 뒤 heapify 과정 수행\n\n
\n\n#### 트리(Tree)\n\n---\n\n사이클이 없는 무방향 그래프\n\n완전이진트리 기준 높이는 logN\n\n트리를 순회하는 방법은 여러가지가 있음\n\n1.**중위 순회** : left-root-right\n\n2.**전위 순회** : root-left-right\n\n3.**후위 순회** : left-right-root\n\n4.**레벨 순서 순회** : 노드를 레벨 순서로 방문 (BFS와 동일해 큐로 구현 가능)\n\n
\n\n#### 이진탐색트리(BST)\n\n---\n\n노드의 왼쪽은 노드의 값보다 작은 값들, 오른쪽은 노드의 값보다 큰 값으로 구성\n\n삽입 및 삭제, 탐색까지 이상적일 때는 모두 O(logN) 가능\n\n만약 편향된 트리면 O(N)으로 최악의 경우가 발생\n\n
\n\n#### 해시 테이블(Hash Table)\n\n---\n\n효율적 탐색을 위한 자료구조\n\nkey - value 쌍으로 이루어짐\n\n해시 함수를 통해 입력받은 key를 정수값(index)로 대응시킴\n\n충돌(collision)에 대한 고려 필요\n\n
\n\n##### 충돌(collision) 해결방안\n\n해시 테이블에서 중복된 값에 대한 충돌 가능성이 있기 때문에 해결방안을 세워야 함\n\n##### 1.선형 조사법(linear probing)\n\n충돌이 일어난 항목을 해시 테이블의 다른 위치에 저장\n\n```\n예시)\nht[k], ht[k+1], ht[k+2] ...\n\n※ 삽입 상황\n충돌이 ht[k]에서 일어났다면, ht[k+1]이 비어있는지 조사함. 차있으면 ht[k+2] 조사 ...\n테이블 끝까지 도달하면 다시 처음으로 돌아옴. 시작 위치로 돌아온 경우는 테이블이 모두 가득 찬 경우임\n\n※ 검색 상황\nht[k]에 있는 키가 다른 값이면, ht[k+1]에 같은 키가 있는지 조사함. \n비어있는 공간이 나오거나, 검색을 시작한 위치로 돌아오면 찾는 키가 없는 경우\n```\n\n##### 2.이차 조사법\n\n선형 조사법에서 발생하는 **집적화 문제를 완화**시켜 줌\n\n```\nh(k), h(k)+1, h(k)+4, h(k)+9 ...\n```\n\n##### 3.이중 해시법\n\n재해싱(rehasing)이라고도 함\n\n충돌로 인해 비어있는 버킷을 찾을 때 추가적인 해시 함수 h'()를 사용하는 방식\n\n```\nh'(k) = C - (k mod C)\n\n조사 위치\nh(k), h(k)+h'(k), h(k) + 2h'(k) ...\n```\n\n##### 4.체이닝\n\n각 버킷을 고정된 개수의 슬롯 대신, 유동적 크기를 갖는 **연결리스트로 구성**하는 방식\n\n충돌 뿐만 아니라 오버플로우 문제도 해결 가능\n\n버킷 내에서 항목을 찾을 때는 연결리스트 순차 탐색 활용\n\n##### 5.해싱 성능 분석\n\n```\na = n / M\n\na = 적재 비율\nn = 저장되는 항목 개수\nM = 해시테이블 크기\n```\n\n
\n\n##### 맵(map)과 해시맵(hashMap)의 차이는?\n\nmap 컨테이너는 이진탐색트리(BST)를 사용하다가 최근에 레드블랙트리를 사용하는 중\n\nkey 값을 이용해 트리를 탐색하는 방식임 → 따라서 데이터 접근, 삽입, 삭제는 O( logN )\n\n반면 해시맵은 해시함수를 활용해 O(1)에 접근 가능\n\n하지만 C++에서는 해시맵을 STL로 지원해주지 않는데, 충돌 해결에 있어서 안정적인 방법이 아니기 때문 (해시 함수는 collision 정책에 따라 성능차이가 큼) " }, { "path": "Computer Science/Data Structure/Stack & Queue.md", "content": "## 스택(Stack)\n\n입력과 출력이 한 곳(방향)으로 제한\n\n##### LIFO (Last In First Out, 후입선출) : 가장 나중에 들어온 것이 가장 먼저 나옴\n\n
\n\n***언제 사용?***\n\n함수의 콜스택, 문자열 역순 출력, 연산자 후위표기법\n\n
\n\n데이터 넣음 : push() \n\n데이터 최상위 값 뺌 : pop()\n\n비어있는 지 확인 : isEmpty()\n\n꽉차있는 지 확인 : isFull()\n\n+SP\n\n
\n\npush와 pop할 때는 해당 위치를 알고 있어야 하므로 기억하고 있는 '스택 포인터(SP)'가 필요함\n\n스택 포인터는 다음 값이 들어갈 위치를 가리키고 있음 (처음 기본값은 -1)\n\n```java\nprivate int sp = -1;\n```\n\n
\n\n##### push\n\n```java\npublic void push(Object o) {\n if(isFull(o)) {\n return;\n }\n \n stack[++sp] = o;\n}\n```\n\n스택 포인터가 최대 크기와 같으면 return\n\n아니면 스택의 최상위 위치에 값을 넣음\n\n
\n\n##### pop\n\n```java\npublic Object pop() {\n \n if(isEmpty(sp)) {\n return null;\n }\n \n Object o = stack[sp--];\n return o;\n \n}\n```\n\n스택 포인터가 0이 되면 null로 return;\n\n아니면 스택의 최상위 위치 값을 꺼내옴\n\n
\n\n##### isEmpty\n\n```java\nprivate boolean isEmpty(int cnt) {\n return sp == -1 ? true : false;\n}\n```\n\n입력 값이 최초 값과 같다면 true, 아니면 false\n\n
\n\n##### isFull\n\n```java\nprivate boolean isFull(int cnt) {\n return sp + 1 == MAX_SIZE ? true : false;\n}\n```\n\n스택 포인터 값+1이 MAX_SIZE와 같으면 true, 아니면 false\n\n
\n\n
\n\n#### 동적 배열 스택\n\n위처럼 구현하면 스택에는 MAX_SIZE라는 최대 크기가 존재해야 한다\n\n(스택 포인터와 MAX_SIZE를 비교해서 isFull 메소드로 비교해야되기 때문!)\n\n
\n\n최대 크기가 없는 스택을 만드려면?\n\n> arraycopy를 활용한 동적배열 사용\n\n
\n\n```java\npublic void push(Object o) {\n \n if(isFull(sp)) {\n \n Object[] arr = new Object[MAX_SIZE * 2];\n System.arraycopy(stack, 0, arr, 0, MAX_SIZE);\n stack = arr;\n MAX_SIZE *= 2; // 2배로 증가\n }\n \n stack[sp++] = o;\n}\n```\n\n기존 스택의 2배 크기만큼 임시 배열(arr)을 만들고\n\narraycopy를 통해 stack의 인덱스 0부터 MAX_SIZE만큼을 arr 배열의 0번째부터 복사한다\n\n복사 후에 arr의 참조값을 stack에 덮어씌운다\n\n마지막으로 MAX_SIZE의 값을 2배로 증가시켜주면 된다.\n\n
\n\n이러면, 스택이 가득찼을 때 자동으로 확장되는 스택을 구현할 수 있음\n\n
\n\n#### 스택을 연결리스트로 구현해도 해결 가능\n\n```java\npublic class Node {\n\n public int data;\n public Node next;\n\n public Node() {\n }\n\n public Node(int data) {\n this.data = data;\n this.next = null;\n }\n}\n```\n\n```java\npublic class Stack {\n private Node head;\n private Node top;\n\n public Stack() {\n head = top = null;\n }\n\n private Node createNode(int data) {\n return new Node(data);\n }\n\n private boolean isEmpty() {\n return top == null ? true : false;\n }\n\n public void push(int data) {\n if (isEmpty()) { // 스택이 비어있다면\n head = createNode(data);\n top = head;\n }\n else { //스택이 비어있지 않다면 마지막 위치를 찾아 새 노드를 연결시킨다.\n Node pointer = head;\n\n while (pointer.next != null)\n pointer = pointer.next;\n\n pointer.next = createNode(data);\n top = pointer.next;\n }\n }\n\n public int pop() {\n int popData;\n if (!isEmpty()) { // 스택이 비어있지 않다면!! => 데이터가 있다면!!\n popData = top.data; // pop될 데이터를 미리 받아놓는다.\n Node pointer = head; // 현재 위치를 확인할 임시 노드 포인터\n\n if (head == top) // 데이터가 하나라면\n head = top = null;\n else { // 데이터가 2개 이상이라면\n while (pointer.next != top) // top을 가리키는 노드를 찾는다.\n pointer = pointer.next;\n\n pointer.next = null; // 마지막 노드의 연결을 끊는다.\n top = pointer; // top을 이동시킨다.\n }\n return popData;\n }\n return -1; // -1은 데이터가 없다는 의미로 지정해둠.\n\n }\n\n}\n```\n\n
\n\n
\n\n
\n\n## 큐(Queue)\n\n입력과 출력을 한 쪽 끝(front, rear)으로 제한\n\n##### FIFO (First In First Out, 선입선출) : 가장 먼저 들어온 것이 가장 먼저 나옴\n\n
\n\n***언제 사용?***\n\n버퍼, 마구 입력된 것을 처리하지 못하고 있는 상황, BFS\n\n
\n\n큐의 가장 첫 원소를 front, 끝 원소를 rear라고 부름\n\n큐는 **들어올 때 rear로 들어오지만, 나올 때는 front부터 빠지는 특성**을 가짐\n\n접근방법은 가장 첫 원소와 끝 원소로만 가능\n\n
\n\n데이터 넣음 : enQueue()\n\n데이터 뺌 : deQueue()\n\n비어있는 지 확인 : isEmpty()\n\n꽉차있는 지 확인 : isFull()\n\n
\n\n데이터를 넣고 뺄 때 해당 값의 위치를 기억해야 함. (스택에서 스택 포인터와 같은 역할)\n\n이 위치를 기억하고 있는 게 front와 rear\n\nfront : deQueue 할 위치 기억\n\nrear : enQueue 할 위치 기억\n\n
\n\n##### 기본값\n\n```java\nprivate int size = 0; \nprivate int rear = -1; \nprivate int front = -1;\n\nQueue(int size) { \n this.size = size;\n this.queue = new Object[size];\n}\n```\n\n
\n\n
\n\n##### enQueue\n\n```java\npublic void enQueue(Object o) {\n \n if(isFull()) {\n return;\n }\n \n queue[++rear] = o;\n}\n```\n\nenQueue 시, 가득 찼다면 꽉 차 있는 상태에서 enQueue를 했기 때문에 overflow\n\n아니면 rear에 값 넣고 1 증가\n\n
\n\n
\n\n##### deQueue\n\n```java\npublic Object deQueue(Object o) {\n \n if(isEmpty()) { \n return null;\n }\n \n Object o = queue[front];\n queue[front++] = null;\n return o;\n}\n```\n\ndeQueue를 할 때 공백이면 underflow\n\nfront에 위치한 값을 object에 꺼낸 후, 꺼낸 위치는 null로 채워줌\n\n
\n\n##### isEmpty\n\n```java\npublic boolean isEmpty() {\n return front == rear;\n}\n```\n\nfront와 rear가 같아지면 비어진 것\n\n
\n\n##### isFull\n\n```java\npublic boolean isFull() {\n return (rear == queueSize-1);\n}\n```\n\nrear가 사이즈-1과 같아지면 가득찬 것\n\n
\n\n---\n\n일반 큐의 단점 : 큐에 빈 메모리가 남아 있어도, 꽉 차있는것으로 판단할 수도 있음\n\n(rear가 끝에 도달했을 때)\n\n
\n\n이를 개선한 것이 **'원형 큐'**\n\n논리적으로 배열의 처음과 끝이 연결되어 있는 것으로 간주함!\n\n
\n\n원형 큐는 초기 공백 상태일 때 front와 rear가 0\n\n공백, 포화 상태를 쉽게 구분하기 위해 **자리 하나를 항상 비워둠**\n\n```\n(index + 1) % size로 순환시킨다\n```\n\n
\n\n##### 기본값\n\n```java\nprivate int size = 0; \nprivate int rear = 0; \nprivate int front = 0;\n\nQueue(int size) { \n this.size = size;\n this.queue = new Object[size];\n}\n```\n\n
\n\n##### enQueue\n\n```java\npublic void enQueue(Object o) {\n \n if(isFull()) {\n return;\n }\n \n rear = (++rear) % size;\n queue[rear] = o;\n}\n```\n\nenQueue 시, 가득 찼다면 꽉 차 있는 상태에서 enQueue를 했기 때문에 overflow\n\n
\n\n
\n\n##### deQueue\n\n```java\npublic Object deQueue(Object o) {\n \n if(isEmpty()) { \n return null;\n }\n \n front = (++front) % size;\n Object o = queue[front];\n return o;\n}\n```\n\ndeQueue를 할 때 공백이면 underflow\n\n
\n\n##### isEmpty\n\n```java\npublic boolean isEmpty() {\n return front == rear;\n}\n```\n\nfront와 rear가 같아지면 비어진 것\n\n
\n\n##### isFull\n\n```java\npublic boolean isFull() {\n return ((rear+1) % size == front);\n}\n```\n\nrear+1%size가 front와 같으면 가득찬 것\n\n
\n\n원형 큐의 단점 : 메모리 공간은 잘 활용하지만, 배열로 구현되어 있기 때문에 큐의 크기가 제한\n\n
\n\n
\n\n이를 개선한 것이 '연결리스트 큐'\n\n##### 연결리스트 큐는 크기가 제한이 없고 삽입, 삭제가 편리\n\n
\n\n##### enqueue 구현\n\n```java\npublic void enqueue(E item) {\n Node oldlast = tail; // 기존의 tail 임시 저장\n tail = new Node; // 새로운 tail 생성\n tail.item = item;\n tail.next = null;\n if(isEmpty()) head = tail; // 큐가 비어있으면 head와 tail 모두 같은 노드 가리킴\n else oldlast.next = tail; // 비어있지 않으면 기존 tail의 next = 새로운 tail로 설정\n}\n```\n\n> - 데이터 추가는 끝 부분인 tail에 한다.\n>\n> - 기존의 tail는 보관하고, 새로운 tail 생성\n>\n> - 큐가 비었으면 head = tail를 통해 둘이 같은 노드를 가리키도록 한다.\n> - 큐가 비어있지 않으면, 기존 tail의 next에 새로만든 tail를 설정해준다.\n\n
\n\n##### dequeue 구현\n\n```java\npublic T dequeue() {\n // 비어있으면\n if(isEmpty()) {\n tail = head;\n return null;\n }\n // 비어있지 않으면\n else {\n T item = head.item; // 빼낼 현재 front 값 저장\n head = head.next; // front를 다음 노드로 설정\n return item;\n }\n}\n```\n\n> - 데이터는 head로부터 꺼낸다. (가장 먼저 들어온 것부터 빼야하므로)\n> - head의 데이터를 미리 저장해둔다.\n> - 기존의 head를 그 다음 노드의 head로 설정한다.\n> - 저장해둔 데이터를 return 해서 값을 빼온다.\n\n
\n\n이처럼 삽입은 tail, 제거는 head로 하면서 삽입/삭제를 스택처럼 O(1)에 가능하도록 구현이 가능하다.\n" }, { "path": "Computer Science/Data Structure/Tree.md", "content": "# Tree\n\n
\n\n```\nNode와 Edge로 이루어진 자료구조\nTree의 특성을 이해하자\n```\n\n
\n\n
 \n\n
\n\n\n\n트리는 값을 가진 `노드(Node)`와 이 노드들을 연결해주는 `간선(Edge)`으로 이루어져있다.\n\n그림 상 데이터 1을 가진 노드가 `루트(Root) 노드`다.\n\n모든 노드들은 0개 이상의 자식(Child) 노드를 갖고 있으며 보통 부모-자식 관계로 부른다.\n\n
\n\n아래처럼 가족 관계도를 그릴 때 트리 형식으로 나타내는 경우도 많이 봤을 것이다. 자료구조의 트리도 이 방식을 그대로 구현한 것이다.\n\n
 \n\n
\n\n\n\n트리는 몇 가지 특징이 있다.\n\n- 트리에는 사이클이 존재할 수 없다. (만약 사이클이 만들어진다면, 그것은 트리가 아니고 그래프다)\n- 모든 노드는 자료형으로 표현이 가능하다.\n- 루트에서 한 노드로 가는 경로는 유일한 경로 뿐이다.\n- 노드의 개수가 N개면, 간선은 N-1개를 가진다.\n\n
\n\n가장 중요한 것은, `그래프`와 `트리`의 차이가 무엇인가인데, 이는 사이클의 유무로 설명할 수 있다.\n\n사이클이 존재하지 않는 `그래프`라 하여 무조건 `트리`인 것은 아니다 사이클이 존재하지 않는 그래프는 `Forest`라 지칭하며 트리의 경우 싸이클이 존재하지 않고 모든 노드가 간선으로 이어져 있어야 한다\n\n
\n\n### 트리 순회 방식\n\n트리를 순회하는 방식은 총 4가지가 있다. 위의 그림을 예시로 진행해보자\n\n
\n\n
\n\n\n\n1. #### 전위 순회(pre-order)\n\n 각 부모 노드를 순차적으로 먼저 방문하는 방식이다.\n\n (부모 → 왼쪽 자식 → 오른쪽 자식)\n\n > 1 → 2 → 4 → 8 → 9 → 5 → 10 → 11 → 3 → 6 → 13 → 7 → 14\n\n
\n\n2. #### 중위 순회(in-order)\n\n 왼쪽 하위 트리를 방문 후 부모 노드를 방문하는 방식이다.\n\n (왼쪽 자식 → 부모 → 오른쪽 자식)\n\n > 8 → 4 → 9 → 2 → 10 → 5 → 11 → 1 → 6 → 13 → 3 →14 → 7\n\n
\n\n3. #### 후위 순회(post-order)\n\n 왼쪽 하위 트리부터 하위를 모두 방문 후 부모 노드를 방문하는 방식이다.\n\n (왼쪽 자식 → 오른쪽 자식 → 부모)\n\n > 8 → 9 → 4 → 10 → 11 → 5 → 2 → 13 → 6 → 14 → 7 → 3 → 1\n\n
\n\n4. #### 레벨 순회(level-order)\n\n 부모 노드부터 계층 별로 방문하는 방식이다.\n\n > 1 → 2 → 3 → 4 → 5 → 6 → 7 → 8 → 9 → 10 → 11 → 13 → 14\n\n
\n\n
\n\n### Code\n\n```java\npublic class Tree
\n\n
\n\n#### [참고 자료]\n\n- [링크](https://www.geeksforgeeks.org/binary-tree-data-structure/)\n" }, { "path": "Computer Science/Data Structure/Trie.md", "content": "## 트라이(Trie)\n\n> 문자열에서 검색을 빠르게 도와주는 자료구조\n\n```\n정수형에서 이진탐색트리를 이용하면 시간복잡도 O(logN)\n하지만 문자열에서 적용했을 때, 문자열 최대 길이가 M이면 O(M*logN)이 된다.\n\n트라이를 활용하면? → O(M)으로 문자열 검색이 가능함!\n```\n\n
\n\n
 \n\n> 예시 그림에서 주어지는 배열의 총 문자열 개수는 8개인데, 트라이를 활용한 트리에서도 마지막 끝나는 노드마다 '네모' 모양으로 구성된 것을 확인하면 총 8개다.\n\n
\n\n> 예시 그림에서 주어지는 배열의 총 문자열 개수는 8개인데, 트라이를 활용한 트리에서도 마지막 끝나는 노드마다 '네모' 모양으로 구성된 것을 확인하면 총 8개다.\n\n\n\n해당 자료구조를 풀어보기 위해 좋은 문제 : [백준 5052(전화번호 목록)](
\n\n#### 공격 방법\n\n##### 1) 인증 우회\n\n보통 로그인을 할 때, 아이디와 비밀번호를 input 창에 입력하게 된다. 쉽게 이해하기 위해 가벼운 예를 들어보자. 아이디가 abc, 비밀번호가 만약 1234일 때 쿼리는 아래와 같은 방식으로 전송될 것이다.\n\n```\nSELECT * FROM USER WHERE ID = \"abc\" AND PASSWORD = \"1234\";\n```\n\nSQL Injection으로 공격할 때, input 창에 비밀번호를 입력함과 동시에 다른 쿼리문을 함께 입력하는 것이다.\n\n```\n1234; DELETE * USER FROM ID = \"1\";\n```\n\n보안이 완벽하지 않은 경우, 이처럼 비밀번호가 아이디와 일치해서 True가 되고 뒤에 작성한 DELETE 문도 데이터베이스에 영향을 줄 수도 있게 되는 치명적인 상황이다.\n\n이 밖에도 기본 쿼리문의 WHERE 절에 OR문을 추가하여 `'1' = '1'`과 같은 true문을 작성하여 무조건 적용되도록 수정한 뒤 DB를 마음대로 조작할 수도 있다. \n\n
\n\n##### 2) 데이터 노출\n\n시스템에서 발생하는 에러 메시지를 이용해 공격하는 방법이다. 보통 에러는 개발자가 버그를 수정하는 면에서 도움을 받을 수 있는 존재다. 해커들은 이를 역이용해 악의적인 구문을 삽입하여 에러를 유발시킨다.\n\n즉 예를 들면, 해커는 **GET 방식으로 동작하는 URL 쿼리 스트링을 추가하여 에러를 발생**시킨다. 이에 해당하는 오류가 발생하면, 이를 통해 해당 웹앱의 데이터베이스 구조를 유추할 수 있고 해킹에 활용한다.\n\n
\n\n
\n\n#### 방어 방법\n\n##### 1) input 값을 받을 때, 특수문자 여부 검사하기\n\n> 로그인 전, 검증 로직을 추가하여 미리 설정한 특수문자들이 들어왔을 때 요청을 막아낸다.\n\n##### 2) SQL 서버 오류 발생 시, 해당하는 에러 메시지 감추기\n\n> view를 활용하여 원본 데이터베이스 테이블에는 접근 권한을 높인다. 일반 사용자는 view로만 접근하여 에러를 볼 수 없도록 만든다.\n\n##### 3) preparestatement 사용하기\n\n> preparestatement를 사용하면, 특수문자를 자동으로 escaping 해준다. (statement와는 다르게 쿼리문에서 전달인자 값을 `?`로 받는 것) 이를 활용해 서버 측에서 필터링 과정을 통해서 공격을 방어한다.\n\n" }, { "path": "Computer Science/Database/SQL과 NOSQL의 차이.md", "content": "## SQL과 NOSQL의 차이\n\n
\n\n웹 앱을 개발할 때, 데이터베이스를 선택할 때 고민하게 된다.\n\n
\n\n```\nMySQL과 같은 SQL을 사용할까? 아니면 MongoDB와 같은 NoSQL을 사용할까?\n```\n\n
\n\n보통 Spring에서 개발할 때는 MySQL을, Node.js에서는 MongoDB를 주로 사용했을 것이다.\n\n하지만 그냥 단순히 프레임워크에 따라 결정하는 것이 아니다. 프로젝트를 진행하기에 앞서 적합한 데이터베이스를 택해야 한다. 차이점을 알아보자\n\n
\n\n#### SQL (관계형 DB)\n\n---\n\n SQL을 사용하면 RDBMS에서 데이터를 저장, 수정, 삭제 및 검색 할 수 있음\n\n관계형 데이터베이스에는 핵심적인 두 가지 특징이 있다.\n\n- 데이터는 **정해진 데이터 스키마에 따라 테이블에 저장**된다.\n- 데이터는 **관계를 통해 여러 테이블에 분산**된다.\n\n
\n\n데이터는 테이블에 레코드로 저장되는데, 각 테이블마다 명확하게 정의된 구조가 있다.\n해당 구조는 필드의 이름과 데이터 유형으로 정의된다.\n\n따라서 **스키마를 준수하지 않은 레코드는 테이블에 추가할 수 없다.** 즉, 스키마를 수정하지 않는 이상은 정해진 구조에 맞는 레코드만 추가가 가능한 것이 관계형 데이터베이스의 특징 중 하나다.\n\n
\n\n또한, 데이터의 중복을 피하기 위해 '관계'를 이용한다.\n\n
 \n\n하나의 테이블에서 중복 없이 하나의 데이터만을 관리하기 때문에 다른 테이블에서 부정확한 데이터를 다룰 위험이 없어지는 장점이 있다.\n\n
\n\n하나의 테이블에서 중복 없이 하나의 데이터만을 관리하기 때문에 다른 테이블에서 부정확한 데이터를 다룰 위험이 없어지는 장점이 있다.\n\n\n\n
\n\n#### NoSQL (비관계형 DB)\n\n---\n\n말그대로 관계형 DB의 반대다.\n\n**스키마도 없고, 관계도 없다!**\n\n
\n\nNoSQL에서는 레코드를 문서(documents)라고 부른다.\n\n여기서 SQL과 핵심적인 차이가 있는데, SQL은 정해진 스키마를 따르지 않으면 데이터 추가가 불가능했다. 하지만 NoSQL에서는 다른 구조의 데이터를 같은 컬렉션에 추가가 가능하다.\n\n
\n\n문서(documents)는 Json과 비슷한 형태로 가지고 있다. 관계형 데이터베이스처럼 여러 테이블에 나누어담지 않고, 관련 데이터를 동일한 '컬렉션'에 넣는다.\n\n따라서 위 사진에 SQL에서 진행한 Orders, Users, Products 테이블로 나눈 것을 NoSQL에서는 Orders에 한꺼번에 포함해서 저장하게 된다.\n\n따라서 여러 테이블에 조인할 필요없이 이미 필요한 모든 것을 갖춘 문서를 작성하는 것이 NoSQL이다. (NoSQL에는 조인이라는 개념이 존재하지 않음)\n\n
\n\n그러면 조인하고 싶을 때 NoSQL은 어떻게 할까? \n\n> 컬렉션을 통해 데이터를 복제하여 각 컬렉션 일부분에 속하는 데이터를 정확하게 산출하도록 한다.\n\n하지만 이러면 데이터가 중복되어 서로 영향을 줄 위험이 있다. 따라서 조인을 잘 사용하지 않고 자주 변경되지 않는 데이터일 때 NoSQL을 쓰면 상당히 효율적이다.\n\n
\n\n
\n\n#### 확장 개념\n\n두 데이터베이스를 비교할 때 중요한 Scaling 개념도 존재한다.\n\n데이터베이스 서버의 확장성은 '수직적' 확장과 '수평적' 확장으로 나누어진다.\n\n- 수직적 확장 : 단순히 데이터베이스 서버의 성능을 향상시키는 것 (ex. CPU 업그레이드)\n- 수평적 확장 : 더 많은 서버가 추가되고 데이터베이스가 전체적으로 분산됨을 의미 (하나의 데이터베이스에서 작동하지만 여러 호스트에서 작동)\n\n
\n\n데이터 저장 방식으로 인해 SQL 데이터베이스는 일반적으로 수직적 확장만 지원함\n\n> 수평적 확장은 NoSQL 데이터베이스에서만 가능\n\n
\n\n
\n\n#### 그럼 둘 중에 뭘 선택?\n\n정답은 없다. 둘다 훌륭한 솔루션이고 어떤 데이터를 다루느냐에 따라 선택을 고려해야한다.\n\n
\n\n##### SQL 장점\n\n- 명확하게 정의된 스키마, 데이터 무결성 보장\n- 관계는 각 데이터를 중복없이 한번만 저장\n\n##### SQL 단점\n\n- 덜 유연함. 데이터 스키마를 사전에 계획하고 알려야 함. (나중에 수정하기 힘듬)\n- 관계를 맺고 있어서 조인문이 많은 복잡한 쿼리가 만들어질 수 있음\n- 대체로 수직적 확장만 가능함\n\n
\n\n##### NoSQL 장점\n\n- 스키마가 없어서 유연함. 언제든지 저장된 데이터를 조정하고 새로운 필드 추가 가능\n- 데이터는 애플리케이션이 필요로 하는 형식으로 저장됨. 데이터 읽어오는 속도 빨라짐\n- 수직 및 수평 확장이 가능해서 애플리케이션이 발생시키는 모든 읽기/쓰기 요청 처리 가능\n\n##### NoSQL 단점\n\n- 유연성으로 인해 데이터 구조 결정을 미루게 될 수 있음\n- 데이터 중복을 계속 업데이트 해야 함\n- 데이터가 여러 컬렉션에 중복되어 있기 때문에 수정 시 모든 컬렉션에서 수행해야 함\n (SQL에서는 중복 데이터가 없으므로 한번만 수행이 가능)\n\n
\n\n
\n\n#### SQL 데이터베이스 사용이 더 좋을 때\n\n- 관계를 맺고 있는 데이터가 자주 변경되는 애플리케이션의 경우\n\n > NoSQL에서는 여러 컬렉션을 모두 수정해야 하기 때문에 비효율적\n\n- 변경될 여지가 없고, 명확한 스키마가 사용자와 데이터에게 중요한 경우\n\n
\n\n#### NoSQL 데이터베이스 사용이 더 좋을 때\n\n- 정확한 데이터 구조를 알 수 없거나 변경/확장 될 수 있는 경우\n- 읽기를 자주 하지만, 데이터 변경은 자주 없는 경우\n- 데이터베이스를 수평으로 확장해야 하는 경우 (막대한 양의 데이터를 다뤄야 하는 경우)\n\n
\n\n
\n\n하나의 제시 방법이지 완전한 정답이 정해져 있는 것은 아니다.\n\nSQL을 선택해서 복잡한 JOIN문을 만들지 않도록 설계하여 단점을 없앨 수도 있고\n\nNoSQL을 선택해서 중복 데이터를 줄이는 방법으로 설계해서 단점을 없앨 수도 있다.\n\n" }, { "path": "Computer Science/Database/Transaction Isolation Level.md", "content": "## 트랜잭션 격리 수준(Transaction Isolation Level)\n\n
\n\n#### **Isolation level** \n\n---\n\n트랜잭션에서 일관성 없는 데이터를 허용하도록 하는 수준\n\n
\n\n#### Isolation level의 필요성\n\n----\n\n데이터베이스는 ACID 특징과 같이 트랜잭션이 독립적인 수행을 하도록 한다.\n\n따라서 Locking을 통해, 트랜잭션이 DB를 다루는 동안 다른 트랜잭션이 관여하지 못하도록 막는 것이 필요하다.\n\n하지만 무조건 Locking으로 동시에 수행되는 수많은 트랜잭션들을 순서대로 처리하는 방식으로 구현하게 되면 데이터베이스의 성능은 떨어지게 될 것이다.\n\n그렇다고 해서, 성능을 높이기 위해 Locking의 범위를 줄인다면, 잘못된 값이 처리될 문제가 발생하게 된다.\n\n- 따라서 최대한 효율적인 Locking 방법이 필요함!\n\n
\n\n#### Isolation level 종류\n\n----\n\n1. ##### Read Uncommitted (레벨 0)\n\n > SELECT 문장이 수행되는 동안 해당 데이터에 Shared Lock이 걸리지 않는 계층\n\n 트랜잭션에 처리중이거나, 아직 Commit되지 않은 데이터를 다른 트랜잭션이 읽는 것을 허용함\n\n ```\n 사용자1이 A라는 데이터를 B라는 데이터로 변경하는 동안 사용자2는 아직 완료되지 않은(Uncommitted) 트랜잭션이지만 데이터B를 읽을 수 있다\n ```\n\n 데이터베이스의 일관성을 유지하는 것이 불가능함\n\n
\n\n2. ##### Read Committed (레벨 1)\n\n > SELECT 문장이 수행되는 동안 해당 데이터에 Shared Lock이 걸리는 계층\n\n 트랜잭션이 수행되는 동안 다른 트랜잭션이 접근할 수 없어 대기하게 됨\n\n Commit이 이루어진 트랜잭션만 조회 가능\n\n 대부분의 SQL 서버가 Default로 사용하는 Isolation Level임\n\n ```\n 사용자1이 A라는 데이터를 B라는 데이터로 변경하는 동안 사용자2는 해당 데이터에 접근이 불가능함\n ```\n\n
\n\n3. ##### Repeatable Read (레벨 2)\n\n > 트랜잭션이 완료될 때까지 SELECT 문장이 사용하는 모든 데이터에 Shared Lock이 걸리는 계층\n\n 트랜잭션이 범위 내에서 조회한 데이터 내용이 항상 동일함을 보장함\n\n 다른 사용자는 트랜잭션 영역에 해당되는 데이터에 대한 수정 불가능\n \n MySQL에서 Default로 사용하는 Isolation Level\n\n
\n\n4. ##### Serializable (레벨 3)\n\n > 트랜잭션이 완료될 때까지 SELECT 문장이 사용하는 모든 데이터에 Shared Lock이 걸리는 계층\n\n 완벽한 읽기 일관성 모드를 제공함\n\n 다른 사용자는 트랜잭션 영역에 해당되는 데이터에 대한 수정 및 입력 불가능\n\n
\n\n
\n\n***선택 시 고려사항***\n\nIsolation Level에 대한 조정은, 동시성과 데이터 무결성에 연관되어 있음\n\n동시성을 증가시키면 데이터 무결성에 문제가 발생하고, 데이터 무결성을 유지하면 동시성이 떨어지게 됨\n\n레벨을 높게 조정할 수록 발생하는 비용이 증가함\n\n
\n\n##### 낮은 단계 Isolation Level을 활용할 때 발생하는 현상들\n\n- Dirty Read\n\n > 커밋되지 않은 수정중인 데이터를 다른 트랜잭션에서 읽을 수 있도록 허용할 때 발생하는 현상\n >\n > 어떤 트랜잭션에서 아직 실행이 끝나지 않은 다른 트랜잭션에 의한 변경사항을 보게되는 경우 \n - 발생 Level: Read Uncommitted\n\n- Non-Repeatable Read\n\n > 한 트랜잭션에서 같은 쿼리를 두 번 수행할 때 그 사이에 다른 트랜잭션 값을 수정 또는 삭제하면서 두 쿼리의 결과가 상이하게 나타나는 일관성이 깨진 현상\n - 발생 Level: Read Committed, Read Uncommitted\n\n- Phantom Read\n\n > 한 트랜잭션 안에서 일정 범위의 레코드를 두 번 이상 읽었을 때, 첫번째 쿼리에서 없던 레코드가 두번째 쿼리에서 나타나는 현상\n >\n > 트랜잭션 도중 새로운 레코드 삽입을 허용하기 때문에 나타나는 현상임\n - 발생 Level: Repeatable Read, Read Committed, Read Uncommitted\n\n\n\n" }, { "path": "Computer Science/Database/Transaction.md", "content": "# DB 트랜잭션(Transaction)\n\n
\n\n#### 트렌잭션이란?\n\n> 데이터베이스의 상태를 변화시키기 위해 수행하는 작업 단위\n\n
\n\n상태를 변화시킨다는 것 → **SQL 질의어를 통해 DB에 접근하는 것**\n\n```\n- SELECT\n- INSERT\n- DELETE\n- UPDATE\n```\n\n
\n\n작업 단위 → **많은 SQL 명령문들을 사람이 정하는 기준에 따라 정하는 것**\n\n```\n예시) 사용자 A가 사용자 B에게 만원을 송금한다.\n\n* 이때 DB 작업\n- 1. 사용자 A의 계좌에서 만원을 차감한다 : UPDATE 문을 사용해 사용자 A의 잔고를 변경\n- 2. 사용자 B의 계좌에 만원을 추가한다 : UPDATE 문을 사용해 사용자 B의 잔고를 변경\n\n현재 작업 단위 : 출금 UPDATE문 + 입금 UPDATE문\n→ 이를 통틀어 하나의 트랜잭션이라고 한다.\n- 위 두 쿼리문 모두 성공적으로 완료되어야만 \"하나의 작업(트랜잭션)\"이 완료되는 것이다. `Commit`\n- 작업 단위에 속하는 쿼리 중 하나라도 실패하면 모든 쿼리문을 취소하고 이전 상태로 돌려놓아야한다. `Rollback`\n\n```\n\n
\n\n**즉, 하나의 트랜잭션 설계를 잘 만드는 것이 데이터를 다룰 때 많은 이점을 가져다준다.**\n\n
\n\n#### 트랜잭션 특징\n\n---\n\n- 원자성(Atomicity)\n\n > 트랜잭션이 DB에 모두 반영되거나, 혹은 전혀 반영되지 않아야 된다.\n\n- 일관성(Consistency)\n\n > 트랜잭션의 작업 처리 결과는 항상 일관성 있어야 한다.\n\n- 독립성(Isolation)\n\n > 둘 이상의 트랜잭션이 동시에 병행 실행되고 있을 때, 어떤 트랜잭션도 다른 트랜잭션 연산에 끼어들 수 없다.\n\n- 지속성(Durability)\n\n > 트랜잭션이 성공적으로 완료되었으면, 결과는 영구적으로 반영되어야 한다.\n\n
\n\n##### Commit\n\n하나의 트랜잭션이 성공적으로 끝났고, DB가 일관성있는 상태일 때 이를 알려주기 위해 사용하는 연산\n\n
\n\n##### Rollback\n\n하나의 트랜잭션 처리가 비정상적으로 종료되어 트랜잭션 원자성이 깨진 경우\n\ntransaction이 정상적으로 종료되지 않았을 때, last consistent state (예) Transaction의 시작 상태) 로 roll back 할 수 있음. \n\n
\n\n*상황이 주어지면 DB 측면에서 어떻게 해결할 수 있을지 대답할 수 있어야 함*\n\n
\n\n---\n\n
\n\n#### Transaction 관리를 위한 DBMS의 전략\n\n이해를 위한 2가지 개념 : DBMS의 구조 / Buffer 관리 정책\n\n
\n\n1) DBMS의 구조\n\n> 크게 2가지 : Query Processor (질의 처리기), Storage System (저장 시스템)\n>\n> 입출력 단위 : 고정 길이의 page 단위로 disk에 읽거나 쓴다.\n>\n> 저장 공간 : 비휘발성 저장 장치인 disk에 저장, 일부분을 Main Memory에 저장\n\n
 \n\n
\n\n\n\n2) Page Buffer Manager or Buffer Manager\n\nDBMS의 Storage System에 속하는 모듈 중 하나로, Main Memory에 유지하는 페이지를 관리하는 모듈\n\n> Buffer 관리 정책에 따라, UNDO 복구와 REDO 복구가 요구되거나 그렇지 않게 되므로, transaction 관리에 매우 중요한 결정을 가져온다.\n\n
\n\n3) UNDO\n\n필요한 이유 : 수정된 Page들이 **Buffer 교체 알고리즘에 따라서 디스크에 출력**될 수 있음. Buffer 교체는 **transaction과는 무관하게 buffer의 상태에 따라서, 결정됨**. 이로 인해, 정상적으로 종료되지 않은 transaction이 변경한 page들은 원상 복구 되어야 하는데, 이 복구를 undo라고 함.\n\n- 2개의 정책 (수정된 페이지를 디스크에 쓰는 시점으로 분류)\n\n steal : 수정된 페이지를 언제든지 디스크에 쓸 수 있는 정책\n\n - 대부분의 DBMS가 채택하는 Buffer 관리 정책\n - UNDO logging과 복구를 필요로 함.\n\n
\n\n ¬steal : 수정된 페이지들을 EOT (End Of Transaction)까지는 버퍼에 유지하는 정책\n\n - UNDO 작업이 필요하지 않지만, 매우 큰 메모리 버퍼가 필요함.\n\n
\n\n4) REDO\n\n이미 commit한 transaction의 수정을 재반영하는 복구 작업\n\nBuffer 관리 정책에 영향을 받음\n\n- Transaction이 종료되는 시점에 해당 transaction이 수정한 page를 디스크에 쓸 것인가 아닌가로 기준.\n\n
\n\n FORCE : 수정했던 모든 페이지를 Transaction commit 시점에 disk에 반영\n\n transaction이 commit 되었을 때 수정된 페이지들이 disk 상에 반영되므로 redo 필요 없음.\n\n
\n\n ¬FORCE : commit 시점에 반영하지 않는 정책\n\n transaction이 disk 상의 db에 반영되지 않을 수 있기에 redo 복구가 필요. (대부분의 DBMS 정책)\n\n
\n \n
\n\n#### [참고사항]\n\n- [링크](https://d2.naver.com/helloworld/407507)" }, { "path": "Computer Science/Database/[DB] Anomaly.md", "content": "#### [DB] Anomaly\n\n---\n\n> 정규화를 해야하는 이유는 잘못된 테이블 설계로 인해 Anomaly (이상 현상)가 나타나기 때문이다.\n>\n> 이 페이지에서는 Anomaly가 무엇인지 살펴본다.\n\n예) {Student ID, Course ID, Department, Course ID, Grade}\n\n1. 삽입 이상 (Insertion Anomaly)\n\n 기본키가 {Student ID, Course ID} 인 경우 -> Course를 수강하지 않은 학생은 Course ID가 없는 현상이 발생함. 결국 Course ID를 Null로 할 수밖에 없는데, 기본키는 Null이 될 수 없으므로, Table에 추가될 수 없음.\n\n 굳이 삽입하기 위해서는 '미수강'과 같은 Course ID를 만들어야 함.\n\n > 불필요한 데이터를 추가해야지, 삽입할 수 있는 상황 = Insertion Anomaly\n\n \n\n2. 갱신 이상 (Update Anomaly)\n\n 만약 어떤 학생의 전공 (Department) 이 \"컴퓨터에서 음악\"으로 바뀌는 경우.\n\n 모든 Department를 \"음악\"으로 바꾸어야 함. 그러나 일부를 깜빡하고 바꾸지 못하는 경우, 제대로 파악 못함.\n\n > 일부만 변경하여, 데이터가 불일치 하는 모순의 문제 = Update Anomaly\n\n \n\n3. 삭제 이상 (Deletion Anomaly)\n\n 만약 어떤 학생이 수강을 철회하는 경우, {Student ID, Department, Course ID, Grade}의 정보 중\n\n Student ID, Department 와 같은 학생에 대한 정보도 함께 삭제됨.\n\n > 튜플 삭제로 인해 꼭 필요한 데이터까지 함께 삭제되는 문제 = Deletion Anomaly\n\n\n\n" }, { "path": "Computer Science/Database/[DB] Index.md", "content": "# Index(인덱스)\n\n
\n\n#### 목적\n\n```\n추가적인 쓰기 작업과 저장 공간을 활용하여 데이터베이스 테이블의 검색 속도를 향상시키기 위한 자료구조\n```\n\n테이블의 칼럼을 색인화한다.\n\n> 마치, 두꺼운 책의 목차와 같다고 생각하면 편하다.\n\n데이터베이스 안의 레코드를 처음부터 풀스캔하지 않고, B+ Tree로 구성된 구조에서 Index 파일 검색으로 속도를 향상시키는 기술이다.\n\n
\n\n
\n\n#### 파일 구성\n\n테이블 생성 시, 3가지 파일이 생성된다.\n\n- FRM : 테이블 구조 저장 파일\n- MYD : 실제 데이터 파일\n- MYI : Index 정보 파일 (Index 사용 시 생성)\n\n
\n\n사용자가 쿼리를 통해 Index를 사용하는 칼럼을 검색하게 되면, 이때 MYI 파일의 내용을 활용한다.\n\n
\n\n#### 단점\n\n- Index 생성시, .mdb 파일 크기가 증가한다.\n- **한 페이지를 동시에 수정할 수 있는 병행성**이 줄어든다.\n- 인덱스 된 Field에서 Data를 업데이트하거나, **Record를 추가 또는 삭제시 성능이 떨어진다.**\n- 데이터 변경 작업이 자주 일어나는 경우, **Index를 재작성**해야 하므로 성능에 영향을 미친다.\n\n
\n\n#### 상황 분석\n\n- ##### 사용하면 좋은 경우\n\n (1) Where 절에서 자주 사용되는 Column\n\n (2) 외래키가 사용되는 Column\n\n (3) Join에 자주 사용되는 Column\n\n
\n\n- ##### Index 사용을 피해야 하는 경우\n\n (1) Data 중복도가 높은 Column\n\n (2) DML이 자주 일어나는 Column\n\n
\n\n#### DML이 일어났을 때의 상황\n\n- ##### INSERT\n\n 기존 Block에 여유가 없을 때, 새로운 Data가 입력된다.\n\n → 새로운 Block을 할당 받은 후, Key를 옮기는 작업을 수행한다.\n\n → Index split 작업 동안, 해당 Block의 Key 값에 대해서 DML이 블로킹 된다. (대기 이벤트 발생)\n\n → 이때 Block의 논리적인 순서와 물리적인 순서가 달라질 수 있다. (인덱스 조각화)\n\n- ##### DELETE\n\n
\n\n
\n\n#### 인덱스 관리 방식\n\n- ##### B-Tree 자료구조\n\n 이진 탐색트리와 유사한 자료구조\n\n 자식 노드를 둘이상 가질 수 있고 Balanced Tree 라는 특징이 있다 → 즉 탐색 연산에 있어 O(log N)의 시간복잡도를 갖는다.\n\n 모든 노드들에 대해 값을 저장하고 있으며 포인터 역할을 동반한다.\n\n- ##### B+Tree 자료구조\n\n B-Tree를 개선한 형태의 자료구조\n\n 값을 리프노드에만 저장하며 리프노드들 끼리는 링크드 리스트로 연결되어 있다 → 때문에 부등호문 연산에 대해 효과적이다.\n\n 리프 노드를 제외한 노드들은 포인터의 역할만을 수행한다.\n\n- ##### HashTable 자료구조\n\n 해시 함수를 이용해서 값을 인덱스로 변경 하여 관리하는 자료구조\n\n 일반적인 경우 탐색, 삽입, 삭제 연산에 대해 O(1)의 시간 복잡도를 갖는다.\n\n 다른 관리 방식에 비해 빠른 성능을 갖는다.\n\n 최악의 경우 해시 충돌이 발생하는 것으로 탐색, 삽입, 삭제 연산에 대해 O(N)의 시간복잡도를 갖는다.\n\n 값 자체를 변경하기 때문에 부등호문, 포함문등의 연산에 사용할 수 없다.\n\n##### [참고사항]\n\n- [링크](https://lalwr.blogspot.com/2016/02/db-index.html)\n" }, { "path": "Computer Science/Database/[DB] Key.md", "content": "### [DB] Key\n\n---\n\n> Key란? : 검색, 정렬시 Tuple을 구분할 수 있는 기준이 되는 Attribute.\n\n
\n\n#### 1. Candidate Key (후보키)\n\n> Tuple을 유일하게 식별하기 위해 사용하는 속성들의 부분 집합. (기본키로 사용할 수 있는 속성들)\n\n2가지 조건 만족\n\n* 유일성 : Key로 하나의 Tuple을 유일하게 식별할 수 있음\n* 최소성 : 꼭 필요한 속성으로만 구성\n\n
\n\n#### 2. Primary Key (기본키)\n\n> 후보키 중 선택한 Main Key\n\n특징 \n\n* Null 값을 가질 수 없음\n* 동일한 값이 중복될 수 없음\n\n
\n\n#### 3. Alternate Key (대체키)\n\n> 후보키 중 기본키를 제외한 나머지 키 = 보조키\n\n
\n\n#### 4. Super Key (슈퍼키)\n\n> 유일성은 만족하지만, 최소성은 만족하지 못하는 키\n\n
\n\n#### 5. Foreign Key (외래키)\n\n> 다른 릴레이션의 기본키를 그대로 참조하는 속성의 집합\n\n
\n" }, { "path": "Computer Science/Database/[Database SQL] JOIN.md", "content": "## [Database SQL] JOIN\n\n##### 조인이란?\n\n> 두 개 이상의 테이블이나 데이터베이스를 연결하여 데이터를 검색하는 방법\n\n테이블을 연결하려면, 적어도 하나의 칼럼을 서로 공유하고 있어야 하므로 이를 이용하여 데이터 검색에 활용한다.\n\n
\n\n#### JOIN 종류\n\n---\n\n- INNER JOIN\n- LEFT OUTER JOIN\n- RIGHT OUTER JOIN\n- FULL OUTER JOIN\n- CROSS JOIN\n- SELF JOIN\n\n
\n\n
\n\n- #### INNER JOIN\n\n
 \n\n 교집합으로, 기준 테이블과 join 테이블의 중복된 값을 보여준다.\n\n ```sql\n SELECT\n A.NAME, B.AGE\n FROM EX_TABLE A\n INNER JOIN JOIN_TABLE B ON A.NO_EMP = B.NO_EMP\n ```\n\n
\n\n 교집합으로, 기준 테이블과 join 테이블의 중복된 값을 보여준다.\n\n ```sql\n SELECT\n A.NAME, B.AGE\n FROM EX_TABLE A\n INNER JOIN JOIN_TABLE B ON A.NO_EMP = B.NO_EMP\n ```\n\n \n\n- #### LEFT OUTER JOIN\n\n
 \n\n 기준테이블값과 조인테이블과 중복된 값을 보여준다.\n\n 왼쪽테이블 기준으로 JOIN을 한다고 생각하면 편하다.\n\n ```SQL\n SELECT\n A.NAME, B.AGE\n FROM EX_TABLE A\n LEFT OUTER JOIN JOIN_TABLE B ON A.NO_EMP = B.NO_EMP\n ```\n\n
\n\n 기준테이블값과 조인테이블과 중복된 값을 보여준다.\n\n 왼쪽테이블 기준으로 JOIN을 한다고 생각하면 편하다.\n\n ```SQL\n SELECT\n A.NAME, B.AGE\n FROM EX_TABLE A\n LEFT OUTER JOIN JOIN_TABLE B ON A.NO_EMP = B.NO_EMP\n ```\n\n \n\n- #### RIGHT OUTER JOIN\n\n
 \n\n LEFT OUTER JOIN과는 반대로 오른쪽 테이블 기준으로 JOIN하는 것이다.\n\n ```SQL\n SELECT\n A.NAME, B.AGE\n FROM EX_TABLE A\n RIGHT OUTER JOIN JOIN_TABLE B ON A.NO_EMP = B.NO_EMP\n ```\n\n
\n\n LEFT OUTER JOIN과는 반대로 오른쪽 테이블 기준으로 JOIN하는 것이다.\n\n ```SQL\n SELECT\n A.NAME, B.AGE\n FROM EX_TABLE A\n RIGHT OUTER JOIN JOIN_TABLE B ON A.NO_EMP = B.NO_EMP\n ```\n\n \n\n- #### FULL OUTER JOIN\n\n
 \n\n 합집합을 말한다. A와 B 테이블의 모든 데이터가 검색된다.\n\n ```sql\n SELECT\n A.NAME, B.AGE\n FROM EX_TABLE A\n FULL OUTER JOIN JOIN_TABLE B ON A.NO_EMP = B.NO_EMP\n ```\n\n
\n\n 합집합을 말한다. A와 B 테이블의 모든 데이터가 검색된다.\n\n ```sql\n SELECT\n A.NAME, B.AGE\n FROM EX_TABLE A\n FULL OUTER JOIN JOIN_TABLE B ON A.NO_EMP = B.NO_EMP\n ```\n\n \n\n- #### CROSS JOIN\n\n
 \n\n 모든 경우의 수를 전부 표현해주는 방식이다.\n\n A가 3개, B가 4개면 총 3*4 = 12개의 데이터가 검색된다.\n\n ```sql\n SELECT\n A.NAME, B.AGE\n FROM EX_TABLE A\n CROSS JOIN JOIN_TABLE B\n ```\n\n
\n\n 모든 경우의 수를 전부 표현해주는 방식이다.\n\n A가 3개, B가 4개면 총 3*4 = 12개의 데이터가 검색된다.\n\n ```sql\n SELECT\n A.NAME, B.AGE\n FROM EX_TABLE A\n CROSS JOIN JOIN_TABLE B\n ```\n\n \n\n- #### SELF JOIN\n\n
 \n\n 자기자신과 자기자신을 조인하는 것이다.\n\n 하나의 테이블을 여러번 복사해서 조인한다고 생각하면 편하다.\n\n 자신이 갖고 있는 칼럼을 다양하게 변형시켜 활용할 때 자주 사용한다.\n\n ``` sql\n SELECT\n A.NAME, B.AGE\n FROM EX_TABLE A, EX_TABLE B\n ```\n\n \n\n
\n\n 자기자신과 자기자신을 조인하는 것이다.\n\n 하나의 테이블을 여러번 복사해서 조인한다고 생각하면 편하다.\n\n 자신이 갖고 있는 칼럼을 다양하게 변형시켜 활용할 때 자주 사용한다.\n\n ``` sql\n SELECT\n A.NAME, B.AGE\n FROM EX_TABLE A, EX_TABLE B\n ```\n\n \n\n\n\n
\n\n##### [참고]\n\n[링크](
\n\n```\n일련의 쿼리를 마치 하나의 함수처럼 실행하기 위한 쿼리의 집합\n```\n\n
\n\n데이터베이스에서 SQL을 통해 작업을 하다 보면, 하나의 쿼리문으로 원하는 결과를 얻을 수 없을 때가 생긴다. 원하는 결과물을 얻기 위해 사용할 여러줄의 쿼리문을 한 번의 요청으로 실행하면 좋지 않을까? 또한, 인자 값만 상황에 따라 바뀌고 동일한 로직의 복잡한 쿼리문을 필요할 때마다 작성한다면 비효율적이지 않을까?\n\n이럴 때 사용할 수 있는 것이 바로 프로시저다.\n\n
\n\n\n\n
 \n\n
\n\n\n\n프로시저를 만들어두면, 애플리케이션에서 여러 상황에 따라 해당 쿼리문이 필요할 때 인자 값만 전달하여 쉽게 원하는 결과물을 받아낼 수 있다.\n\n
\n\n#### 프로시저 생성 및 호출\n\n```plsql\nCREATE OR REPLACE PROCEDURE 프로시저명(변수명1 IN 데이터타입, 변수명2 OUT 데이터타입) -- 인자 값은 필수 아님\nIS\n[\n변수명1 데이터타입;\n변수명2 데이터타입;\n..\n]\nBEGIN\n 필요한 기능; -- 인자값 활용 가능\nEND;\n\nEXEC 프로시저명; -- 호출\n```\n\n
\n\n#### 예시1 (IN)\n\n```plsql\nCREATE OR REPLACE PROCEDURE test( name IN VARCHAR2 ) \nIS\n\tmsg VARCHAR2(5) := '내 이름은';\nBEGIN \n\tdbms_output.put_line(msg||' '||name); \nEND;\n\nEXEC test('규글');\n```\n\n```\n내 이름은 규글\n```\n\n
\n\n#### 예시2 (OUT)\n\n```plsql\nCREATE OR REPLACE PROCEDURE test( name OUT VARCHAR2 ) \nIS\nBEGIN \n\tname := 'Gyoogle'\nEND;\n\nDECLARE\nout_name VARCHAR2(100);\n\nBEGIN\ntest(out_name);\ndbms_output.put_line('내 이름은 '||out_name);\nEND;\n```\n\n```\n내 이름은 Gyoogle\n```\n\n
\n\n
\n\n### 프로시저 장점\n\n---\n\n1. #### 최적화 & 캐시\n\n 프로시저의 최초 실행 시 최적화 상태로 컴파일이 되며, 그 이후 프로시저 캐시에 저장된다.\n\n 만약 해당 프로세스가 여러번 사용될 때, 다시 컴파일 작업을 거치지 않고 캐시에서 가져오게 된다.\n\n2. #### 유지 보수\n\n 작업이 변경될 때, 다른 작업은 건드리지 않고 프로시저 내부에서 수정만 하면 된다.\n (But, 장점이 단점이 될 수도 있는 부분이기도.. )\n\n3. #### 트래픽 감소\n\n 클라이언트가 직접 SQL문을 작성하지 않고, 프로시저명에 매개변수만 담아 전달하면 된다. 즉, SQL문이 서버에 이미 저장되어 있기 때문에 클라이언트와 서버 간 네트워크 상 트래픽이 감소된다.\n\n4. #### 보안\n\n 프로시저 내에서 참조 중인 테이블의 접근을 막을 수 있다.\n\n
\n\n### 프로시저 단점\n\n---\n\n1. #### 호환성\n\n 구문 규칙이 SQL / PSM 표준과의 호환성이 낮기 때문에 코드 자산으로의 재사용성이 나쁘다.\n\n2. #### 성능\n\n 문자 또는 숫자 연산에서 프로그래밍 언어인 C나 Java보다 성능이 느리다.\n\n3. #### 디버깅\n\n 에러가 발생했을 때, 어디서 잘못됐는지 디버깅하는 것이 힘들 수 있다.\n\n
\n\n
\n\n#### [참고 자료]\n\n- [링크](https://ko.wikipedia.org/wiki/%EC%A0%80%EC%9E%A5_%ED%94%84%EB%A1%9C%EC%8B%9C%EC%A0%80)\n- [링크](https://itability.tistory.com/51)" }, { "path": "Computer Science/Database/정규화(Normalization).md", "content": "# 정규화(Normalization)\n\n
\n\n```\n데이터의 중복을 줄이고, 무결성을 향상시킬 수 있는 정규화에 대해 알아보자\n```\n\n
\n\n### Normalization\n\n가장 큰 목표는 테이블 간 **중복된 데이터를 허용하지 않는 것**이다.\n\n중복된 데이터를 만들지 않으면, 무결성을 유지할 수 있고, DB 저장 용량 또한 효율적으로 관리할 수 있다.\n\n
\n\n### 목적\n\n- 데이터의 중복을 없애면서 불필요한 데이터를 최소화시킨다.\n- 무결성을 지키고, 이상 현상을 방지한다.\n- 테이블 구성을 논리적이고 직관적으로 할 수 있다.\n- 데이터베이스 구조 확장이 용이해진다.\n\n
\n\n정규화에는 여러가지 단계가 있지만, 대체적으로 1~3단계 정규화까지의 과정을 거친다.\n\n
\n\n### 제 1정규화(1NF)\n\n테이블 컬럼이 원자값(하나의 값)을 갖도록 테이블을 분리시키는 것을 말한다.\n\n만족해야 할 조건은 아래와 같다.\n\n- 어떤 릴레이션에 속한 모든 도메인이 원자값만으로 되어 있어야한다.\n- 모든 속성에 반복되는 그룹이 나타나지 않는다.\n- 기본키를 사용하여 관련 데이터의 각 집합을 고유하게 식별할 수 있어야 한다.\n\n
\n\n
 \n\n
\n\n\n\n현재 테이블은 전화번호를 여러개 가지고 있어 원자값이 아니다. 따라서 1NF에 맞추기 위해서는 아래와 같이 분리할 수 있다.\n\n
\n\n
 \n\n
\n\n\n\n
\n\n### 제 2정규화(2NF)\n\n테이블의 모든 컬럼이 완전 함수적 종속을 만족해야 한다.\n\n조금 쉽게 말하면, 테이블에서 기본키가 복합키(키1, 키2)로 묶여있을 때, 두 키 중 하나의 키만으로 다른 컬럼을 결정지을 수 있으면 안된다.\n\n> 기본키의 부분집합 키가 결정자가 되어선 안된다는 것\n\n
\n\n
 \n\n
\n\n\n\n`Manufacture`과 `Model`이 키가 되어 `Model Full Name`을 알 수 있다.\n\n`Manufacturer Country`는 `Manufacturer`로 인해 결정된다. (부분 함수 종속)\n\n따라서, `Model`과 `Manufacturer Country`는 아무런 연관관계가 없는 상황이다.\n\n
\n\n결국 완전 함수적 종속을 충족시키지 못하고 있는 테이블이다. 부분 함수 종속을 해결하기 위해 테이블을 아래와 같이 나눠서 2NF를 만족할 수 있다.\n\n
\n\n
 \n\n
\n\n\n\n
\n\n### 제 3정규화(3NF)\n\n2NF가 진행된 테이블에서 이행적 종속을 없애기 위해 테이블을 분리하는 것이다.\n\n> 이행적 종속 : A → B, B → C면 A → C가 성립된다\n\n아래 두가지 조건을 만족시켜야 한다.\n\n- 릴레이션이 2NF에 만족한다.\n- 기본키가 아닌 속성들은 기본키에 의존한다.\n\n
\n\n
 \n\n
\n\n\n\n현재 테이블에서는 `Tournament`와 `Year`이 기본키다.\n\n`Winner`는 이 두 복합키를 통해 결정된다.\n\n하지만 `Winner Date of Birth`는 기본키가 아닌 `Winner`에 의해 결정되고 있다. \n\n따라서 이는 3NF를 위반하고 있으므로 아래와 같이 분리해야 한다.\n\n
\n\n
 \n\n
\n\n\n\n
\n\n#### [참고 사항]\n\n- [링크](https://wkdtjsgur100.github.io/database-normalization/)\n" }, { "path": "Computer Science/Network/DNS.md", "content": "# DNS (Domain Name Server)\n\n모든 통신은 IP를 기반으로 연결된다. 하지만 사용자에게 일일히 IP 주소를 입력하기란 UX적으로 좋지 않다\n\n때문에 DNS 가 등장 했으며 DNS 는 IP 주소와 도메인 주소를 매핑하는 역할을 수행한다\n\n## 도메인 주소가 IP로 변환되는 과정\n\n1. 디바이스는 hosts 파일을 열어 봅니다\n - hosts 파일에는 로컬에서 직접 설정한 호스트 이름과 IP 주소를 매핑 하고 있습니다\n2. DNS는 캐시를 확인 합니다\n - 기존에 접속했던 사이트의 경우 캐시에 남아 있을 수 있습니다\n - DNS는 브라우저 캐시, 로컬 캐시(OS 캐시), 라우터 캐시, ISP(Internet Service Provider)캐시 순으로 확인 합니다\n3. DNS는 Root DNS에 요청을 보냅니다\n - 모든 DNS에는 Root DNS의 주소가 포함 되어 있습니다\n - 이를 통해 Root DNS에게 질의를 보내게 됩니다\n - Root DNS는 도메인 주소의 최상위 계층을 확인하여 TLD(Top Level DNS)의 주소를 반환 합니다\n4. DNS는 TLD에 요청을 보냅니다\n - Root DNS로 부터 반환받은 주소를 통해 요청을 보냅니다\n - TLD는 도메인에 권한이 있는 Authoritative DNS의 주소를 반환 합니다\n5. DNS는 Authoritative DNS에 요청을 보냅니다\n - 도메인 이름에 대한 IP 주소를 반환 합니다\n\n- 이때 요청을 보내는 DNS의 경우 재귀적으로 요청을 보내기 때문에 `DNS 리쿼서`라 지칭 하고 요청을 받는 DNS를 `네임서버`라 지칭 합니다\n" }, { "path": "Computer Science/Network/HTTP & HTTPS.md", "content": "## HTTP & HTTPS\n\n
\n\n- ##### HTTP(HyperText Transfer Protocol)\n\n 인터넷 상에서 클라이언트와 서버가 자원을 주고 받을 때 쓰는 통신 규약\n\n
\n\nHTTP는 텍스트 교환이므로, 누군가 네트워크에서 신호를 가로채면 내용이 노출되는 보안 이슈가 존재한다.\n\n이런 보안 문제를 해결해주는 프로토콜이 **'HTTPS'**\n\n
\n\n#### HTTP의 보안 취약점\n\n1. **도청이 가능하다**\n\n- 평문으로 통신하기 때문에 도청이 가능하다\n- 이를 해결하기 위해서 통신자체를암호화(HTTPS)하거나 데이터를 암호화 하는 방법등이 있다\n- 데이터를 암호화 하는 경우 수신측에서는 보호화 과정이 필요하다\n\n2. **위장이 가능하다**\n\n- 통신 상대를 확인하지 않기 깨문에 위장된 상대와 통신할 수 있다\n- HTTPS는 CA 인증서를 통해 인증된 상대와 통신이 가능하다\n\n3. **변조가 가능하다**\n\n- 완전성을 보장하지 않기 때문에 변조가 가능하다\n- HTTPS는 메세지 인증 코드(MAC), 전자 서명등을 통해 변조를 방지 한다\n\n
\n\n- ##### HTTPS(HyperText Transfer Protocol Secure)\n\n 인터넷 상에서 정보를 암호화하는 SSL 프로토콜을 사용해 클라이언트와 서버가 자원을 주고 받을 때 쓰는 통신 규약\n\nHTTPS는 텍스트를 암호화한다. (공개키 암호화 방식으로!) : [공개키 설명](https://github.com/kim6394/tech-interview-for-developer/blob/master/Computer%20Science/Network/%EB%8C%80%EC%B9%AD%ED%82%A4%20%26%20%EA%B3%B5%EA%B0%9C%ED%82%A4.md)\n\n
\n\n
\n\n#### HTTPS 통신 흐름\n\n1. 애플리케이션 서버(A)를 만드는 기업은 HTTPS를 적용하기 위해 공개키와 개인키를 만든다.\n\n2. 신뢰할 수 있는 CA 기업을 선택하고, 그 기업에게 내 공개키 관리를 부탁하며 계약을 한다.\n\n**_CA란?_** : Certificate Authority로, 공개키를 저장해주는 신뢰성이 검증된 민간기업\n\n3. 계약 완료된 CA 기업은 해당 기업의 이름, A서버 공개키, 공개키 암호화 방법을 담은 인증서를 만들고, 해당 인증서를 CA 기업의 개인키로 암호화해서 A서버에게 제공한다.\n\n4. A서버는 암호화된 인증서를 갖게 되었다. 이제 A서버는 A서버의 공개키로 암호화된 HTTPS 요청이 아닌 요청이 오면, 이 암호화된 인증서를 클라이언트에게 건내준다.\n\n5. 클라이언트가 `main.html` 파일을 달라고 A서버에 요청했다고 가정하자. HTTPS 요청이 아니기 때문에 CA기업이 A서버의 정보를 CA 기업의 개인키로 암호화한 인증서를 받게 된다.\n\nCA 기업의 공개키는 브라우저가 이미 알고있다. (세계적으로 신뢰할 수 있는 기업으로 등록되어 있기 때문에, 브라우저가 인증서를 탐색하여 해독이 가능한 것)\n\n6. 브라우저는 해독한 뒤 A서버의 공개키를 얻게 되었다.\n\n7. 클라이언트가 A서버와 HandShaking 과정에서 주고받은 난수를 조합하여 pre-master-secret-key 를 생성한 뒤, A서버의 공개키로 해당 대칭키를 암호화하여 서버로 보냅니다.\n\n8. A서버는 암호화된 대칭키를 자신의 개인키로 복호화 하여 클라이언트와 동일한 대칭키를 획득합니다.\n\n9. 클라이언트, 서버는 각각 pre-master-secret-key를 master-secret-key으로 만듭니다.\n\n10. master-secret-key 를 통해 session-key를 생성하고 이를 이용하여 대칭키 방식으로 통신합니다.\n\n11. 각 통신이 종료될 때마다 session-key를 파기합니다.\n\n
\n\nHTTPS도 무조건 안전한 것은 아니다. (신뢰받는 CA 기업이 아닌 자체 인증서 발급한 경우 등)\n\n이때는 HTTPS지만 브라우저에서 `주의 요함`, `안전하지 않은 사이트`와 같은 알림으로 주의 받게 된다.\n\n
\n\n##### [참고사항]\n\n[링크](https://jeong-pro.tistory.com/89)\n" }, { "path": "Computer Science/Network/OSI 7 계층.md", "content": "## OSI 7 계층\n\n
\n\n
 \n\n
\n\n\n\n#### 7계층은 왜 나눌까?\n\n통신이 일어나는 과정을 단계별로 알 수 있고, 특정한 곳에 이상이 생기면 그 단계만 수정할 수 있기 때문이다.\n\n
\n\n##### 1) 물리(Physical)\n\n> 리피터, 케이블, 허브 등\n\n단지 데이터를 전기적인 신호로 변환해서 주고받는 기능을 진행하는 공간\n\n즉, 데이터를 전송하는 역할만 진행한다.\n\n
\n\n##### 2) 데이터 링크(Data Link)\n\n> 브릿지, 스위치 등\n\n물리 계층으로 송수신되는 정보를 관리하여 안전하게 전달되도록 도와주는 역할\n\nMac 주소를 통해 통신한다. 프레임에 Mac 주소를 부여하고 에러검출, 재전송, 흐름제어를 진행한다.\n\n
\n\n##### 3) 네트워크(Network)\n\n> 라우터, IP\n\n데이터를 목적지까지 가장 안전하고 빠르게 전달하는 기능을 담당한다.\n\n라우터를 통해 이동할 경로를 선택하여 IP 주소를 지정하고, 해당 경로에 따라 패킷을 전달해준다.\n\n라우팅, 흐름 제어, 오류 제어, 세그먼테이션 등을 수행한다.\n\n
\n\n##### 4) 전송(Transport)\n\n> TCP, UDP\n\nTCP와 UDP 프로토콜을 통해 통신을 활성화한다. 포트를 열어두고, 프로그램들이 전송을 할 수 있도록 제공해준다.\n\n- TCP : 신뢰성, 연결지향적\n\n- UDP : 비신뢰성, 비연결성, 실시간\n\n
\n\n##### 5) 세션(Session)\n\n> API, Socket\n\n데이터가 통신하기 위한 논리적 연결을 담당한다. TCP/IP 세션을 만들고 없애는 책임을 지니고 있다.\n\n
\n\n##### 6) 표현(Presentation)\n\n> JPEG, MPEG 등\n\n데이터 표현에 대한 독립성을 제공하고 암호화하는 역할을 담당한다.\n\n파일 인코딩, 명령어를 포장, 압축, 암호화한다.\n\n
\n\n##### 7) 응용(Application)\n\n> HTTP, FTP, DNS 등\n\n최종 목적지로, 응용 프로세스와 직접 관계하여 일반적인 응용 서비스를 수행한다.\n\n사용자 인터페이스, 전자우편, 데이터베이스 관리 등의 서비스를 제공한다.\n" }, { "path": "Computer Science/Network/TCP (흐름제어혼잡제어).md", "content": "\n\n\n\n### TCP (흐름제어/혼잡제어)\n\n---\n\n#### 들어가기 전\n\n- TCP 통신이란?\n - 네트워크 통신에서 신뢰적인 연결방식\n - TCP는 기본적으로 unreliable network에서, reliable network를 보장할 수 있도록 하는 프로토콜\n - TCP는 network congestion avoidance algorithm을 사용\n- reliable network를 보장한다는 것은 4가지 문제점 존재\n - 손실 : packet이 손실될 수 있는 문제\n - 순서 바뀜 : packet의 순서가 바뀌는 문제\n - Congestion : 네트워크가 혼잡한 문제\n - Overload : receiver가 overload 되는 문제\n- 흐름제어/혼잡제어란?\n - 흐름제어 (endsystem 대 endsystem)\n - 송신측과 수신측의 데이터 처리 속도 차이를 해결하기 위한 기법\n - Flow Control은 receiver가 packet을 지나치게 많이 받지 않도록 조절하는 것\n - 기본 개념은 receiver가 sender에게 현재 자신의 상태를 feedback 한다는 점\n - 혼잡제어 : 송신측의 데이터 전달과 네트워크의 데이터 처리 속도 차이를 해결하기 위한 기법\n- 전송의 전체 과정\n - 응용 계층(Application Layer)에서 데이터를 전송할 때, 보내는 쪽(sender)의 애플리케이션(Application)은 소켓(Socket)에 데이터를 쓰게 됩니다. \n - 이 데이터는 전송 계층(Transport Layer)으로 전달되어 세그먼트(Segment)라는 작은 단위로 나누어집니다. \n - 전송 계층은 이 세그먼트를 네트워크 계층(Network Layer)에 넘겨줍니다.\n - 전송된 데이터는 수신자(receiver) 쪽으로 전달되어, 수신자 쪽에서는 수신 버퍼(Receive Buffer)에 저장됩니다. \n - 이때, 수신자 쪽에서는 수신 버퍼의 용량을 넘치게 하지 않도록 조절해야 합니다. \n - 수신자 쪽에서는 자신의 수신 버퍼의 남은 용량을 상대방(sender)에게 알려주는데, 이를 \"수신 윈도우(Receive Window)\"라고 합니다.\n - 송신자(sender)는 수신자의 수신 윈도우를 확인하여 수신자의 수신 버퍼 용량을 초과하지 않도록 데이터를 전송합니다. \n - 이를 통해 데이터 전송 중에 수신 버퍼가 넘치는 현상을 방지하면서, 안정적인 데이터 전송을 보장합니다. 이를 \"플로우 컨트롤(Flow Control)\"이라고 합니다.\n\n따라서, 플로우 컨트롤은 전송 중에 발생하는 수신 버퍼의 오버플로우를 방지하면서, 안정적인 데이터 전송을 위해 중요한 기술입니다.\n\n#### 1. 흐름제어 (Flow Control)\n\n- 수신측이 송신측보다 데이터 처리 속도가 빠르면 문제없지만, 송신측의 속도가 빠를 경우 문제가 생긴다.\n\n- 수신측에서 제한된 저장 용량을 초과한 이후에 도착하는 데이터는 손실 될 수 있으며, 만약 손실 된다면 불필요하게 응답과 데이터 전송이 송/수신 측 간에 빈번히 발생한다.\n\n- 이러한 위험을 줄이기 위해 송신 측의 데이터 전송량을 수신측에 따라 조절해야한다.\n\n- 해결방법\n\n - Stop and Wait : 매번 전송한 패킷에 대해 확인 응답을 받아야만 그 다음 패킷을 전송하는 방법\n\n -
 \n\n - Sliding Window (Go Back N ARQ) \n\n - 수신측에서 설정한 윈도우 크기만큼 송신측에서 확인응답없이 세그먼트를 전송할 수 있게 하여 데이터 흐름을 동적으로 조절하는 제어기법\n\n - 목적 : 전송은 되었지만, acked를 받지 못한 byte의 숫자를 파악하기 위해 사용하는 protocol\n\n LastByteSent - LastByteAcked <= ReceivecWindowAdvertised\n\n (마지막에 보내진 바이트 - 마지막에 확인된 바이트 <= 남아있는 공간) ==\n\n (현재 공중에 떠있는 패킷 수 <= sliding window)\n\n - 동작방식 : 먼저 윈도우에 포함되는 모든 패킷을 전송하고, 그 패킷들의 전달이 확인되는대로 이 윈도우를 옆으로 옮김으로써 그 다음 패킷들을 전송\n\n -
\n\n - Sliding Window (Go Back N ARQ) \n\n - 수신측에서 설정한 윈도우 크기만큼 송신측에서 확인응답없이 세그먼트를 전송할 수 있게 하여 데이터 흐름을 동적으로 조절하는 제어기법\n\n - 목적 : 전송은 되었지만, acked를 받지 못한 byte의 숫자를 파악하기 위해 사용하는 protocol\n\n LastByteSent - LastByteAcked <= ReceivecWindowAdvertised\n\n (마지막에 보내진 바이트 - 마지막에 확인된 바이트 <= 남아있는 공간) ==\n\n (현재 공중에 떠있는 패킷 수 <= sliding window)\n\n - 동작방식 : 먼저 윈도우에 포함되는 모든 패킷을 전송하고, 그 패킷들의 전달이 확인되는대로 이 윈도우를 옆으로 옮김으로써 그 다음 패킷들을 전송\n\n -  \n\n - Window : TCP/IP를 사용하는 모든 호스트들은 송신하기 위한 것과 수신하기 위한 2개의 Window를 가지고 있다. 호스트들은 실제 데이터를 보내기 전에 '3 way handshaking'을 통해 수신 호스트의 receive window size에 자신의 send window size를 맞추게 된다.\n\n - 세부구조\n\n 1. 송신 버퍼\n -
\n\n - Window : TCP/IP를 사용하는 모든 호스트들은 송신하기 위한 것과 수신하기 위한 2개의 Window를 가지고 있다. 호스트들은 실제 데이터를 보내기 전에 '3 way handshaking'을 통해 수신 호스트의 receive window size에 자신의 send window size를 맞추게 된다.\n\n - 세부구조\n\n 1. 송신 버퍼\n -  - \n - 200 이전의 바이트는 이미 전송되었고, 확인응답을 받은 상태\n - 200 ~ 202 바이트는 전송되었으나 확인응답을 받지 못한 상태\n - 203 ~ 211 바이트는 아직 전송이 되지 않은 상태\n 2. 수신 윈도우\n -
- \n - 200 이전의 바이트는 이미 전송되었고, 확인응답을 받은 상태\n - 200 ~ 202 바이트는 전송되었으나 확인응답을 받지 못한 상태\n - 203 ~ 211 바이트는 아직 전송이 되지 않은 상태\n 2. 수신 윈도우\n -  \n 3. 송신 윈도우\n -
\n 3. 송신 윈도우\n -  \n - 수신 윈도우보다 작거나 같은 크기로 송신 윈도우를 지정하게되면 흐름제어가 가능하다.\n 4. 송신 윈도우 이동\n -
\n - 수신 윈도우보다 작거나 같은 크기로 송신 윈도우를 지정하게되면 흐름제어가 가능하다.\n 4. 송신 윈도우 이동\n -  \n - Before : 203 ~ 204를 전송하면 수신측에서는 확인 응답 203을 보내고, 송신측은 이를 받아 after 상태와 같이 수신 윈도우를 203 ~ 209 범위로 이동\n - after : 205 ~ 209가 전송 가능한 상태\n 5. Selected Repeat\n\n
\n - Before : 203 ~ 204를 전송하면 수신측에서는 확인 응답 203을 보내고, 송신측은 이를 받아 after 상태와 같이 수신 윈도우를 203 ~ 209 범위로 이동\n - after : 205 ~ 209가 전송 가능한 상태\n 5. Selected Repeat\n\n\n\n#### 2. 혼잡제어 (Congestion Control)\n\n- 송신측의 데이터는 지역망이나 인터넷으로 연결된 대형 네트워크를 통해 전달된다. 만약 한 라우터에 데이터가 몰릴 경우, 자신에게 온 데이터를 모두 처리할 수 없게 된다. 이런 경우 호스트들은 또 다시 재전송을 하게되고 결국 혼잡만 가중시켜 오버플로우나 데이터 손실을 발생시키게 된다. 따라서 이러한 네트워크의 혼잡을 피하기 위해 송신측에서 보내는 데이터의 전송속도를 강제로 줄이게 되는데, 이러한 작업을 혼잡제어라고 한다.\n- 또한 네트워크 내에 패킷의 수가 과도하게 증가하는 현상을 혼잡이라 하며, 혼잡 현상을 방지하거나 제거하는 기능을 혼잡제어라고 한다.\n- 흐름제어가 송신측과 수신측 사이의 전송속도를 다루는데 반해, 혼잡제어는 호스트와 라우터를 포함한 보다 넓은 관점에서 전송 문제를 다루게 된다.\n- 해결 방법\n -
 \n - AIMD(Additive Increase / Multiplicative Decrease)\n - 처음에 패킷을 하나씩 보내고 이것이 문제없이 도착하면 window 크기(단위 시간 내에 보내는 패킷의 수)를 1씩 증가시켜가며 전송하는 방법\n - 패킷 전송에 실패하거나 일정 시간을 넘으면 패킷의 보내는 속도를 절반으로 줄인다.\n - 공평한 방식으로, 여러 호스트가 한 네트워크를 공유하고 있으면 나중에 진입하는 쪽이 처음에는 불리하지만, 시간이 흐르면 평형상태로 수렴하게 되는 특징이 있다.\n - 문제점은 초기에 네트워크의 높은 대역폭을 사용하지 못하여 오랜 시간이 걸리게 되고, 네트워크가 혼잡해지는 상황을 미리 감지하지 못한다. 즉, 네트워크가 혼잡해지고 나서야 대역폭을 줄이는 방식이다.\n - Slow Start (느린 시작)\n - AIMD 방식이 네트워크의 수용량 주변에서는 효율적으로 작동하지만, 처음에 전송 속도를 올리는데 시간이 오래 걸리는 단점이 존재했다.\n - Slow Start 방식은 AIMD와 마찬가지로 패킷을 하나씩 보내면서 시작하고, 패킷이 문제없이 도착하면 각각의 ACK 패킷마다 window size를 1씩 늘려준다. 즉, 한 주기가 지나면 window size가 2배로 된다. \n - 전송속도는 AIMD에 반해 지수 함수 꼴로 증가한다. 대신에 혼잡 현상이 발생하면 window size를 1로 떨어뜨리게 된다.\n - 처음에는 네트워크의 수용량을 예상할 수 있는 정보가 없지만, 한번 혼잡 현상이 발생하고 나면 네트워크의 수용량을 어느 정도 예상할 수 있다. \n - 그러므로 혼잡 현상이 발생하였던 window size의 절반까지는 이전처럼 지수 함수 꼴로 창 크기를 증가시키고 그 이후부터는 완만하게 1씩 증가시킨다.\n - Fast Retransmit (빠른 재전송)\n - 빠른 재전송은 TCP의 혼잡 조절에 추가된 정책이다. \n - 패킷을 받는 쪽에서 먼저 도착해야할 패킷이 도착하지 않고 다음 패킷이 도착한 경우에도 ACK 패킷을 보내게 된다. \n - 단, 순서대로 잘 도착한 마지막 패킷의 다음 패킷의 순번을 ACK 패킷에 실어서 보내게 되므로, 중간에 하나가 손실되게 되면 송신 측에서는 순번이 중복된 ACK 패킷을 받게 된다. 이것을 감지하는 순간 문제가 되는 순번의 패킷을 재전송 해줄 수 있다.\n - 중복된 순번의 패킷을 3개 받으면 재전송을 하게 된다. 약간 혼잡한 상황이 일어난 것이므로 혼잡을 감지하고 window size를 줄이게 된다.\n - Fast Recovery (빠른 회복)\n - 혼잡한 상태가 되면 window size를 1로 줄이지 않고 반으로 줄이고 선형증가시키는 방법이다. 이 정책까지 적용하면 혼잡 상황을 한번 겪고 나서부터는 순수한 AIMD 방식으로 동작하게 된다.\n\n
\n - AIMD(Additive Increase / Multiplicative Decrease)\n - 처음에 패킷을 하나씩 보내고 이것이 문제없이 도착하면 window 크기(단위 시간 내에 보내는 패킷의 수)를 1씩 증가시켜가며 전송하는 방법\n - 패킷 전송에 실패하거나 일정 시간을 넘으면 패킷의 보내는 속도를 절반으로 줄인다.\n - 공평한 방식으로, 여러 호스트가 한 네트워크를 공유하고 있으면 나중에 진입하는 쪽이 처음에는 불리하지만, 시간이 흐르면 평형상태로 수렴하게 되는 특징이 있다.\n - 문제점은 초기에 네트워크의 높은 대역폭을 사용하지 못하여 오랜 시간이 걸리게 되고, 네트워크가 혼잡해지는 상황을 미리 감지하지 못한다. 즉, 네트워크가 혼잡해지고 나서야 대역폭을 줄이는 방식이다.\n - Slow Start (느린 시작)\n - AIMD 방식이 네트워크의 수용량 주변에서는 효율적으로 작동하지만, 처음에 전송 속도를 올리는데 시간이 오래 걸리는 단점이 존재했다.\n - Slow Start 방식은 AIMD와 마찬가지로 패킷을 하나씩 보내면서 시작하고, 패킷이 문제없이 도착하면 각각의 ACK 패킷마다 window size를 1씩 늘려준다. 즉, 한 주기가 지나면 window size가 2배로 된다. \n - 전송속도는 AIMD에 반해 지수 함수 꼴로 증가한다. 대신에 혼잡 현상이 발생하면 window size를 1로 떨어뜨리게 된다.\n - 처음에는 네트워크의 수용량을 예상할 수 있는 정보가 없지만, 한번 혼잡 현상이 발생하고 나면 네트워크의 수용량을 어느 정도 예상할 수 있다. \n - 그러므로 혼잡 현상이 발생하였던 window size의 절반까지는 이전처럼 지수 함수 꼴로 창 크기를 증가시키고 그 이후부터는 완만하게 1씩 증가시킨다.\n - Fast Retransmit (빠른 재전송)\n - 빠른 재전송은 TCP의 혼잡 조절에 추가된 정책이다. \n - 패킷을 받는 쪽에서 먼저 도착해야할 패킷이 도착하지 않고 다음 패킷이 도착한 경우에도 ACK 패킷을 보내게 된다. \n - 단, 순서대로 잘 도착한 마지막 패킷의 다음 패킷의 순번을 ACK 패킷에 실어서 보내게 되므로, 중간에 하나가 손실되게 되면 송신 측에서는 순번이 중복된 ACK 패킷을 받게 된다. 이것을 감지하는 순간 문제가 되는 순번의 패킷을 재전송 해줄 수 있다.\n - 중복된 순번의 패킷을 3개 받으면 재전송을 하게 된다. 약간 혼잡한 상황이 일어난 것이므로 혼잡을 감지하고 window size를 줄이게 된다.\n - Fast Recovery (빠른 회복)\n - 혼잡한 상태가 되면 window size를 1로 줄이지 않고 반으로 줄이고 선형증가시키는 방법이다. 이 정책까지 적용하면 혼잡 상황을 한번 겪고 나서부터는 순수한 AIMD 방식으로 동작하게 된다.\n\n\n\n[ref]
\n\n-
\n\n### 3 way handshake - 연결 성립\n\nTCP는 정확한 전송을 보장해야 한다. 따라서 통신하기에 앞서, 논리적인 접속을 성립하기 위해 3 way handshake 과정을 진행한다.\n\n
 \n\n1) 클라이언트가 서버에게 SYN 패킷을 보냄 (sequence : x)\n\n2) 서버가 SYN(x)을 받고, 클라이언트로 받았다는 신호인 ACK와 SYN 패킷을 보냄 (sequence : y, ACK : x + 1)\n\n3) 클라이언트는 서버의 응답은 ACK(x+1)와 SYN(y) 패킷을 받고, ACK(y+1)를 서버로 보냄\n\n
\n\n1) 클라이언트가 서버에게 SYN 패킷을 보냄 (sequence : x)\n\n2) 서버가 SYN(x)을 받고, 클라이언트로 받았다는 신호인 ACK와 SYN 패킷을 보냄 (sequence : y, ACK : x + 1)\n\n3) 클라이언트는 서버의 응답은 ACK(x+1)와 SYN(y) 패킷을 받고, ACK(y+1)를 서버로 보냄\n\n\n\n이렇게 3번의 통신이 완료되면 연결이 성립된다. (3번이라 3 way handshake인 것)\n\n
\n\n
\n\n### 4 way handshake - 연결 해제\n\n연결 성립 후, 모든 통신이 끝났다면 해제해야 한다.\n\n
 \n\n1) 클라이언트는 서버에게 연결을 종료한다는 FIN 플래그를 보낸다.\n\n2) 서버는 FIN을 받고, 확인했다는 ACK를 클라이언트에게 보낸다. (이때 모든 데이터를 보내기 위해 CLOSE_WAIT 상태가 된다)\n\n3) 데이터를 모두 보냈다면, 연결이 종료되었다는 FIN 플래그를 클라이언트에게 보낸다.\n\n4) 클라이언트는 FIN을 받고, 확인했다는 ACK를 서버에게 보낸다. (아직 서버로부터 받지 못한 데이터가 있을 수 있으므로 TIME_WAIT을 통해 기다린다.)\n\n- 서버는 ACK를 받은 이후 소켓을 닫는다 (Closed)\n\n- TIME_WAIT 시간이 끝나면 클라이언트도 닫는다 (Closed)\n\n
\n\n1) 클라이언트는 서버에게 연결을 종료한다는 FIN 플래그를 보낸다.\n\n2) 서버는 FIN을 받고, 확인했다는 ACK를 클라이언트에게 보낸다. (이때 모든 데이터를 보내기 위해 CLOSE_WAIT 상태가 된다)\n\n3) 데이터를 모두 보냈다면, 연결이 종료되었다는 FIN 플래그를 클라이언트에게 보낸다.\n\n4) 클라이언트는 FIN을 받고, 확인했다는 ACK를 서버에게 보낸다. (아직 서버로부터 받지 못한 데이터가 있을 수 있으므로 TIME_WAIT을 통해 기다린다.)\n\n- 서버는 ACK를 받은 이후 소켓을 닫는다 (Closed)\n\n- TIME_WAIT 시간이 끝나면 클라이언트도 닫는다 (Closed)\n\n\n\n이렇게 4번의 통신이 완료되면 연결이 해제된다.\n\n
\n\n
\n\n##### [참고 자료]\n\n[링크](
\n\n```\nHTTPS에서 클라이언트와 서버간 통신 전\nSSL 인증서로 신뢰성 여부를 판단하기 위해 연결하는 방식\n```\n\n
\n\n\n\n
\n\n### 진행 순서\n\n1. 클라이언트는 서버에게 `client hello` 메시지를 담아 서버로 보낸다.\n 이때 암호화된 정보를 함께 담는데, `버전`, `암호 알고리즘`, `압축 방식` 등을 담는다.\n\n
\n\n2. 서버는 클라이언트가 보낸 암호 알고리즘과 압축 방식을 받고, `세션 ID`와 `CA 공개 인증서`를 `server hello` 메시지와 함께 담아 응답한다. 이 CA 인증서에는 앞으로 통신 이후 사용할 대칭키가 생성되기 전, 클라이언트에서 handshake 과정 속 암호화에 사용할 공개키를 담고 있다.\n\n
\n\n3. 클라이언트 측은 서버에서 보낸 CA 인증서에 대해 유효한 지 CA 목록에서 확인하는 과정을 진행한다.\n\n
\n\n4. CA 인증서에 대한 신뢰성이 확보되었다면, 클라이언트는 난수 바이트를 생성하여 서버의 공개키로 암호화한다. 이 난수 바이트는 대칭키를 정하는데 사용이 되고, 앞으로 서로 메시지를 통신할 때 암호화하는데 사용된다.\n\n
\n\n5. 만약 2번 단계에서 서버가 클라이언트 인증서를 함께 요구했다면, 클라이언트의 인증서와 클라이언트의 개인키로 암호화된 임의의 바이트 문자열을 함께 보내준다.\n\n
\n\n6. 서버는 클라이언트의 인증서를 확인 후, 난수 바이트를 자신의 개인키로 복호화 후 대칭 마스터 키 생성에 활용한다.\n\n
\n\n7. 클라이언트는 handshake 과정이 완료되었다는 `finished` 메시지를 서버에 보내면서, 지금까지 보낸 교환 내역들을 해싱 후 그 값을 대칭키로 암호화하여 같이 담아 보내준다.\n\n
\n\n8. 서버도 동일하게 교환 내용들을 해싱한 뒤 클라이언트에서 보내준 값과 일치하는 지 확인한다. 일치하면 서버도 마찬가지로 `finished` 메시지를 이번에 만든 대칭키로 암호화하여 보낸다.\n\n
\n\n9. 클라이언트는 해당 메시지를 대칭키로 복호화하여 서로 통신이 가능한 신뢰받은 사용자란 걸 인지하고, 앞으로 클라이언트와 서버는 해당 대칭키로 데이터를 주고받을 수 있게 된다.\n\n
\n\n
\n\n#### [참고 자료]\n\n- [링크](https://wangin9.tistory.com/entry/%EB%B8%8C%EB%9D%BC%EC%9A%B0%EC%A0%80%EC%97%90-URL-%EC%9E%85%EB%A0%A5-%ED%9B%84-%EC%9D%BC%EC%96%B4%EB%82%98%EB%8A%94-%EC%9D%BC%EB%93%A4-5TLSSSL-Handshake)" }, { "path": "Computer Science/Network/UDP.md", "content": "### 2019.08.26.(월) [BYM] UDP란? \n\n---\n\n#### 들어가기 전\n\n- UDP 통신이란?\n\n - User Datagram Protocol의 약자로 데이터를 데이터그램 단위로 처리하는 프로토콜이다. \n - 비연결형, 신뢰성 없는 전송 프로토콜이다.\n - 데이터그램 단위로 쪼개면서 전송을 해야하기 때문에 전송 계층이다.\n - Transport layer에서 사용하는 프로토콜.\n\n- TCP와 UDP는 왜 나오게 됐는가?\n\n 1. IP의 역할은 Host to Host (장치 to 장치)만을 지원한다. 장치에서 장치로 이동은 IP로 해결되지만, 하나의 장비안에서 수많은 프로그램들이 통신을 할 경우에는 IP만으로는 한계가 있다.\n\n 2. 또한, IP에서 오류가 발생한다면 ICMP에서 알려준다. 하지만 ICMP는 알려주기만 할 뿐 대처를 못하기 때문에 IP보다 위에서 처리를 해줘야 한다.\n\n - 1번을 해결하기 위하여 포트 번호가 나오게 됐고, 2번을 해결하기 위해 상위 프로토콜인 TCP와 UDP가 나오게 되었다.\n\n * *ICMP : 인터넷 제어 메시지 프로토콜로 네트워크 컴퓨터 위에서 돌아가는 운영체제에서 오류 메시지를 전송받는데 주로 쓰임\n\n- 그렇다면 TCP와 UDP가 어떻게 오류를 해결하는가?\n\n - TCP : 데이터의 분실, 중복, 순서가 뒤바뀜 등을 자동으로 보정해줘서 송수신 데이터의 정확한 전달을 할 수 있도록 해준다.\n - UDP : IP가 제공하는 정도의 수준만을 제공하는 간단한 IP 상위 계층의 프로토콜이다. TCP와는 다르게 에러가 날 수도 있고, 재전송이나 순서가 뒤바뀔 수도 있어서 이 경우, 어플리케이션에서 처리하는 번거로움이 존재한다.\n\n- UDP는 왜 사용할까?\n\n - UDP의 결정적인 장점은 데이터의 신속성이다. 데이터의 처리가 TCP보다 빠르다.\n - 주로 실시간 방송과 온라인 게임에서 사용된다. 네트워크 환경이 안 좋을때, 끊기는 현상을 생각하면 된다.\n\n- DNS(Domain Name System)에서 UDP를 사용하는 이유\n\n - Request의 양이 작음 -> UDP Request에 담길 수 있다.\n - 3 way handshaking으로 연결을 유지할 필요가 없다. (오버헤드 발생)\n - Request에 대한 손실은 Application Layer에서 제어가 가능하다.\n - DNS : port 53번\n - But, TCP를 사용할 때가 있다! 크기가 512(UDP 제한)이 넘을 때, TCP를 사용해야한다. \n\n
\n\n#### 1. UDP Header\n\n-
 \n - Source port : 시작 포트\n - Destination port : 도착지 포트\n - Length : 길이\n - _Checksum_ : 오류 검출\n - 중복 검사의 한 형태로, 오류 정정을 통해 공간이나 시간 속에서 송신된 자료의 무결성을 보호하는 단순한 방법이다.\n\n
\n - Source port : 시작 포트\n - Destination port : 도착지 포트\n - Length : 길이\n - _Checksum_ : 오류 검출\n - 중복 검사의 한 형태로, 오류 정정을 통해 공간이나 시간 속에서 송신된 자료의 무결성을 보호하는 단순한 방법이다.\n\n\n\n- 이렇게 간단하므로, TCP 보다 용량이 가볍고 송신 속도가 빠르게 작동됨. \n\n- 그러나 확인 응답을 못하므로, TCP보다 신뢰도가 떨어짐. \n- UDP는 비연결성, TCP는 연결성으로 정의할 수 있음.\n\n
\n\n#### DNS과 UDP 통신 프로토콜을 사용함.\n\nDNS는 데이터를 교환하는 경우임\n\n이때, TCP를 사용하게 되면, 데이터를 송신할 때까지 세션 확립을 위한 처리를 하고, 송신한 데이터가 수신되었는지 점검하는 과정이 필요하므로, Protocol overhead가 UDP에 비해서 큼.\n\n------\n\nDNS는 Application layer protocol임.\n\n모든 Application layer protocol은 TCP, UDP 중 하나의 Transport layer protocol을 사용해야 함.\n\n(TCP는 reliable, UDP는 not reliable임) / DNS는 reliable해야할 것 같은데 왜 UDP를 사용할까?\n\n\n\n사용하는 이유 \n\n1. TCP가 3-way handshake를 사용하는 반면, UDP는 connection 을 유지할 필요가 없음.\n\n2. DNS request는 UDP segment에 꼭 들어갈 정도로 작음.\n\n DNS query는 single UDP request와 server로부터의 single UDP reply로 구성되어 있음.\n\n3. UDP는 not reliable이나, reliability는 application layer에 추가될 수 있음.\n (Timeout 추가나, resend 작업을 통해)\n\nDNS는 UDP를 53번 port에서 사용함.\n\n------\n\n그러나 TCP를 사용하는 경우가 있음.\n\nZone transfer 을 사용해야하는 경우에는 TCP를 사용해야 함.\n\n(Zone Transfer : DNS 서버 간의 요청을 주고 받을 떄 사용하는 transfer)\n\n만약에 데이터가 512 bytes를 넘거나, 응답을 못받은 경우 TCP로 함.\n\n
\n\n[ref]
\n\n-
\n\n1. #### Blocking I/O\n\n I/O Blocking 형태의 작업은 \n\n (1) Process(Thread)가 Kernel에게 I/O를 요청하는 함수를 호출\n\n (2) Kernel이 작업을 완료하면 작업 결과를 반환 받음.\n\n \n\n * 특징\n * I/O 작업이 진행되는 동안 user Process(Thread) 는 자신의 작업을 중단한 채 대기\n * Resource 낭비가 심함
(I/O 작업이 CPU 자원을 거의 쓰지 않으므로)\n\n
\n\n `여러 Client 가 접속하는 서버를 Blocking 방식으로 구현하는 경우` -> I/O 작업을 진행하는 작업을 중지 -> 다른 Client가 진행중인 작업을 중지하면 안되므로, client 별로 별도의 Thread를 생성해야 함 -> 접속자 수가 매우 많아짐\n\n 이로 인해, 많아진 Threads 로 *컨텍스트 스위칭 횟수가 증가함,,, 비효율적인 동작 방식*\n\n
\n\n2. #### Non-Blocking I/O\n\n I/O 작업이 진행되는 동안 User Process의 작업을 중단하지 않음. \n\n * 진행 순서\n\n 1. User Process가 recvfrom 함수 호출 (커널에게 해당 Socket으로부터 data를 받고 싶다고 요청함)\n\n 2. Kernel은 이 요청에 대해서, 곧바로 recvBuffer를 채워서 보내지 못하므로, \"EWOULDBLOCK\"을 return함.\n\n 3. Blocking 방식과 달리, User Process는 다른 작업을 진행할 수 있음.\n\n 4. recvBuffer에 user가 받을 수 있는 데이터가 있는 경우, Buffer로부터 데이터를 복사하여 받아옴.\n\n > 이때, recvBuffer는 Kernel이 가지고 있는 메모리에 적재되어 있으므로, Memory간 복사로 인해, I/O보다 훨씬 빠른 속도로 data를 받아올 수 있음.\n\n 5. recvfrom 함수는 빠른 속도로 data를 복사한 후, 복사한 data의 길이와 함께 반환함.\n\n\n\n\n\n" }, { "path": "Computer Science/Network/[Network] Blocking,Non-blocking & Synchronous,Asynchronous.md", "content": "# [Network] Blocking/Non-blocking & Synchronous/Asynchronous\n\n
\n\n```\n동기/비동기는 우리가 일상 생활에서 많이 들을 수 있는 말이다.\n\nBlocking과 Synchronous, 그리고 Non-blocking과 Asysnchronous를\n서로 같은 개념이라고 착각하기 쉽다.\n\n각자 어떤 의미를 가지는지 간단하게 살펴보자\n```\n\n
\n\n
 \n\n
\n\n\n\n[homoefficio](http://homoefficio.github.io/2017/02/19/Blocking-NonBlocking-Synchronous-Asynchronous/)님 블로그에 나온 2대2 매트릭스로 잘 정리된 사진이다. 이 사진만 보고 모두 이해가 된다면, 차이점에 대해 잘 알고 있는 것이다.\n\n
\n\n## Blocking/Non-blocking\n\n블럭/논블럭은 간단히 말해서 `호출된 함수`가 `호출한 함수`에게 제어권을 건네주는 유무의 차이라고 볼 수 있다.\n\n함수 A, B가 있고, A 안에서 B를 호출했다고 가정해보자. 이때 호출한 함수는 A고, 호출된 함수는 B가 된다. 현재 B가 호출되면서 B는 자신의 일을 진행해야 한다. (제어권이 B에게 주어진 상황)\n\n- **Blocking** : 함수 B는 내 할 일을 다 마칠 때까지 제어권을 가지고 있는다. A는 B가 다 마칠 때까지 기다려야 한다.\n- **Non-blocking** : 함수 B는 할 일을 마치지 않았어도 A에게 제어권을 바로 넘겨준다. A는 B를 기다리면서도 다른 일을 진행할 수 있다.\n\n즉, 호출된 함수에서 일을 시작할 때 바로 제어권을 리턴해주느냐, 할 일을 마치고 리턴해주느냐에 따라 블럭과 논블럭으로 나누어진다고 볼 수 있다.\n\n
\n\n## Synchronous/Asynchronous\n\n동기/비동기는 일을 수행 중인 `동시성`에 주목하자\n\n아까처럼 함수 A와 B라고 똑같이 생각했을 때, B의 수행 결과나 종료 상태를 A가 신경쓰고 있는 유무의 차이라고 생각하면 된다.\n\n- **Synchronous** : 함수 A는 함수 B가 일을 하는 중에 기다리면서, 현재 상태가 어떤지 계속 체크한다. \n- **Asynchronous** : 함수 B의 수행 상태를 B 혼자 직접 신경쓰면서 처리한다. (Callback)\n\n즉, 호출된 함수(B)를 호출한 함수(A)가 신경쓰는지, 호출된 함수(B) 스스로 신경쓰는지를 동기/비동기라고 생각하면 된다.\n\n비동기는 호출시 Callback을 전달하여 작업의 완료 여부를 호출한 함수에게 답하게 된다. (Callback이 오기 전까지 호출한 함수는 신경쓰지 않고 다른 일을 할 수 있음)\n\n
\n\n
\n\n위 그림처럼 총 4가지의 경우가 나올 수 있다. 이걸 좀 더 이해하기 쉽게 Case 별로 예시를 통해 보면서 이해하고 넘어가보자\n\n
\n\n```\n상황 : 치킨집에 직접 치킨을 사러감\n```\n\n
\n\n### 1) Blocking & Synchronous\n\n```\n나 : 사장님 치킨 한마리만 포장해주세요\n사장님 : 네 금방되니까 잠시만요!\n나 : 넹\n-- 사장님 치킨 튀기는 중--\n나 : (아 언제 되지?..궁금한데 그냥 멀뚱히 서서 치킨 튀기는거 보면서 기다림)\n```\n\n
\n\n### 2) Blocking & Asynchronous\n\n```\n나 : 사장님 치킨 한마리만 포장해주세요\n사장님 : 네 금방되니까 잠시만요!\n나 : 앗 넹\n-- 사장님 치킨 튀기는 중--\n나 : (언제 되는지 안 궁금함, 잠시만이래서 다 될때까지 서서 붙잡힌 상황)\n```\n\n
\n\n### 3) Non-blocking & Synchronous\n\n```\n나 : 사장님 치킨 한마리만 포장해주세요\n사장님 : 네~ 주문 밀려서 시간 좀 걸리니까 볼일 보시다 오세요\n나 : 넹\n-- 사장님 치킨 튀기는 중--\n(5분뒤) 나 : 제꺼 나왔나요?\n사장님 : 아직이요\n(10분뒤) 나 : 제꺼 나왔나요?\n사장님 : 아직이요ㅠ\n(15분뒤) 나 : 제꺼 나왔나요?\n사장님 : 아직이요ㅠㅠ\n```\n\n
\n\n### 4) Non-blocking & Asynchronous\n\n```\n나 : 사장님 치킨 한마리만 포장해주세요\n사장님 : 네~ 주문 밀려서 시간 좀 걸리니까 볼일 보시다 오세요\n나 : 넹\n-- 사장님 치킨 튀기는 중--\n나 : (앉아서 다른 일 하는 중)\n...\n사장님 : 치킨 나왔습니다\n나 : 잘먹겠습니다~\n```\n\n
\n\n#### [참고 사항]\n\n- [링크](http://homoefficio.github.io/2017/02/19/Blocking-NonBlocking-Synchronous-Asynchronous/)\n- [링크](https://musma.github.io/2019/04/17/blocking-and-synchronous.html)\n\n" }, { "path": "Computer Science/Network/대칭키 & 공개키.md", "content": "## 대칭키 & 공개키\n\n
\n\n#### 대칭키(Symmetric Key)\n\n> 암호화와 복호화에 같은 암호키(대칭키)를 사용하는 알고리즘\n\n동일한 키를 주고받기 때문에, 매우 빠르다는 장점이 있음\n\nbut, 대칭키 전달과정에서 해킹 위험에 노출\n\n
\n\n#### 공개키(Public Key)/비대칭키(Asymmetric Key)\n\n> 암호화와 복호화에 사용하는 암호키를 분리한 알고리즘\n\n대칭키의 키 분배 문제를 해결하기 위해 고안됨.(대칭키일 때는 송수신자 간만 키를 알아야하기 때문에 분배가 복잡하고 어렵지만 공개키와 비밀키로 분리할 경우, 남들이 알아도 되는 공개키만 공개하면 되므로)\n\n자신이 가지고 있는 고유한 암호키(비밀키)로만 복호화할 수 있는 암호키(공개키)를 대중에 공개함\n\n
\n\n##### 공개키 암호화 방식 진행 과정\n\n1) A가 웹 상에 공개된 'B의 공개키'를 이용해 평문을 암호화하여 B에게 보냄\n2) B는 자신의 비밀키로 복호화한 평문을 확인, A의 공개키로 응답을 암호화하여 A에개 보냄\n3) A는 자신의 비밀키로 암호화된 응답문을 복호화함\n\n하지만 이 방식은 Confidentiallity만 보장해줄 뿐, Integrity나 Authenticity는 보장해주지 못함\n\n-> 이는 MAC(Message Authentication Code)나 전자 서명(Digital Signature)으로 해결\n(MAC은 공개키 방식이 아니라 대칭키 방식임을 유의! T=MAC(K,M) 형식)\n\n대칭키에 비해 암호화 복호화가 매우 복잡함\n\n(암호화하는 키가 복호화하는 키가 서로 다르기 때문)\n\n
\n\n
\n\n##### 대칭키와 공개키 암호화 방식을 적절히 혼합해보면? (하이브리드 방식)\n\n> SSL 탄생의 시초가 됨\n\n```\n1. A가 B의 공개키로 암호화 통신에 사용할 대칭키를 암호화하고 B에게 보냄\n2. B는 암호문을 받고, 자신의 비밀키로 복호화함\n3. B는 A로부터 얻은 대칭키로 A에게 보낼 평문을 암호화하여 A에게 보냄\n4. A는 자신의 대칭키로 암호문을 복호화함\n5. 앞으로 이 대칭키로 암호화를 통신함\n```\n\n즉, 대칭키를 주고받을 때만 공개키 암호화 방식을 사용하고 이후에는 계속 대칭키 암호화 방식으로 통신하는 것!\n\n
\n" }, { "path": "Computer Science/Network/로드 밸런싱(Load Balancing).md", "content": "## 로드 밸런싱(Load Balancing)\n\n> 둘 이상의 CPU or 저장장치와 같은 컴퓨터 자원들에게 작업을 나누는 것\n\n
\n\n
 \n\n요즘 시대에는 웹사이트에 접속하는 인원이 급격히 늘어나게 되었다.\n\n따라서 이 사람들에 대해 모든 트래픽을 감당하기엔 1대의 서버로는 부족하다. 대응 방안으로 하드웨어의 성능을 올리거나(Scale-up) 여러대의 서버가 나눠서 일하도록 만드는 것(Scale-out)이 있다. 하드웨어 향상 비용이 더욱 비싸기도 하고, 서버가 여러대면 무중단 서비스를 제공하는 환경 구성이 용이하므로 Scale-out이 효과적이다. 이때 여러 서버에게 균등하게 트래픽을 분산시켜주는 것이 바로 **로드 밸런싱**이다.\n\n
\n\n요즘 시대에는 웹사이트에 접속하는 인원이 급격히 늘어나게 되었다.\n\n따라서 이 사람들에 대해 모든 트래픽을 감당하기엔 1대의 서버로는 부족하다. 대응 방안으로 하드웨어의 성능을 올리거나(Scale-up) 여러대의 서버가 나눠서 일하도록 만드는 것(Scale-out)이 있다. 하드웨어 향상 비용이 더욱 비싸기도 하고, 서버가 여러대면 무중단 서비스를 제공하는 환경 구성이 용이하므로 Scale-out이 효과적이다. 이때 여러 서버에게 균등하게 트래픽을 분산시켜주는 것이 바로 **로드 밸런싱**이다.\n\n\n\n**로드 밸런싱**은 분산식 웹 서비스로, 여러 서버에 부하(Load)를 나누어주는 역할을 한다. Load Balancer를 클라이언트와 서버 사이에 두고, 부하가 일어나지 않도록 여러 서버에 분산시켜주는 방식이다. 서비스를 운영하는 사이트의 규모에 따라 웹 서버를 추가로 증설하면서 로드 밸런서로 관리해주면 웹 서버의 부하를 해결할 수 있다.\n\n
\n\n#### 로드 밸런서가 서버를 선택하는 방식\n\n- 라운드 로빈(Round Robin) : CPU 스케줄링의 라운드 로빈 방식 활용\n- Least Connections : 연결 개수가 가장 적은 서버 선택 (트래픽으로 인해 세션이 길어지는 경우 권장)\n- Source : 사용자 IP를 해싱하여 분배 (특정 사용자가 항상 같은 서버로 연결되는 것 보장)\n\n
\n\n#### 로드 밸런서 장애 대비\n\n서버를 분배하는 로드 밸런서에 문제가 생길 수 있기 때문에 로드 밸런서를 이중화하여 대비한다.\n\n> Active 상태와 Passive 상태\n\n
\n\n##### [참고자료]\n\n- [링크](
\n\n### 1. 스케줄링\n\n> CPU 를 잘 사용하기 위해 프로세스를 잘 배정하기\n\n- 조건 : 오버헤드 ↓ / 사용률 ↑ / 기아 현상 ↓\n- 목표\n 1. `Batch System`: 가능하면 많은 일을 수행. 시간(time) 보단 처리량(throughout)이 중요\n 2. `Interactive System`: 빠른 응답 시간. 적은 대기 시간.\n 3. `Real-time System`: 기한(deadline) 맞추기.\n\n### 2. 선점 / 비선점 스케줄링\n\n- 선점 (preemptive) : OS가 CPU의 사용권을 선점할 수 있는 경우, 강제 회수하는 경우 (처리시간 예측 어려움)\n- 비선점 (nonpreemptive) : 프로세스 종료 or I/O 등의 이벤트가 있을 때까지 실행 보장 (처리시간 예측 용이함)\n\n### 3. 프로세스 상태\n\n\n- 선점 스케줄링 : `Interrupt`, `I/O or Event Completion`, `I/O or Event Wait`, `Exit`\n- 비선점 스케줄링 : `I/O or Event Wait`, `Exit`\n\n---\n\n**프로세스의 상태 전이**\n\n✓ **승인 (Admitted)** : 프로세스 생성이 가능하여 승인됨.\n\n✓ **스케줄러 디스패치 (Scheduler Dispatch)** : 준비 상태에 있는 프로세스 중 하나를 선택하여 실행시키는 것.\n\n✓ **인터럽트 (Interrupt)** : 예외, 입출력, 이벤트 등이 발생하여 현재 실행 중인 프로세스를 준비 상태로 바꾸고, 해당 작업을 먼저 처리하는 것.\n\n✓ **입출력 또는 이벤트 대기 (I/O or Event wait)** : 실행 중인 프로세스가 입출력이나 이벤트를 처리해야 하는 경우, 입출력/이벤트가 모두 끝날 때까지 대기 상태로 만드는 것.\n\n✓ **입출력 또는 이벤트 완료 (I/O or Event Completion)** : 입출력/이벤트가 끝난 프로세스를 준비 상태로 전환하여 스케줄러에 의해 선택될 수 있도록 만드는 것.\n\n### 4. CPU 스케줄링의 종류\n\n- 비선점 스케줄링\n 1. FCFS (First Come First Served)\n - 큐에 도착한 순서대로 CPU 할당\n - 실행 시간이 짧은 게 뒤로 가면 평균 대기 시간이 길어짐\n 2. SJF (Shortest Job First)\n - 수행시간이 가장 짧다고 판단되는 작업을 먼저 수행\n - FCFS 보다 평균 대기 시간 감소, 짧은 작업에 유리\n 3. HRN (Hightest Response-ratio Next)\n - 우선순위를 계산하여 점유 불평등을 보완한 방법(SJF의 단점 보완)\n - 우선순위 = (대기시간 + 실행시간) / (실행시간)\n\n- 선점 스케줄링\n 1. Priority Scheduling\n - 정적/동적으로 우선순위를 부여하여 우선순위가 높은 순서대로 처리\n - 우선 순위가 낮은 프로세스가 무한정 기다리는 Starvation 이 생길 수 있음\n - Aging 방법으로 Starvation 문제 해결 가능\n 2. Round Robin\n - FCFS에 의해 프로세스들이 보내지면 각 프로세스는 동일한 시간의 `Time Quantum` 만큼 CPU를 할당 받음\n - `Time Quantum` or `Time Slice` : 실행의 최소 단위 시간\n - 할당 시간(`Time Quantum`)이 크면 FCFS와 같게 되고, 작으면 문맥 교환 (Context Switching) 잦아져서 오버헤드 증가\n 3. Multilevel-Queue (다단계 큐)\n \n \n - 작업들을 여러 종류의 그룹으로 나누어 여러 개의 큐를 이용하는 기법\n \n\n - 우선순위가 낮은 큐들이 실행 못하는 걸 방지하고자 각 큐마다 다른 `Time Quantum`을 설정 해주는 방식 사용\n - 우선순위가 높은 큐는 작은 `Time Quantum` 할당. 우선순위가 낮은 큐는 큰 `Time Quantum` 할당.\n 4. Multilevel-Feedback-Queue (다단계 피드백 큐)\n\n \n\n - 다단계 큐에서 자신의 `Time Quantum`을 다 채운 프로세스는 밑으로 내려가고 자신의 `Time Quantum`을 다 채우지 못한 프로세스는 원래 큐 그대로\n - Time Quantum을 다 채운 프로세스는 CPU burst 프로세스로 판단하기 때문\n - 짧은 작업에 유리, 입출력 위주(Interrupt가 잦은) 작업에 우선권을 줌\n - 처리 시간이 짧은 프로세스를 먼저 처리하기 때문에 Turnaround 평균 시간을 줄여줌\n\n### 5. CPU 스케줄링 척도\n\n1. Response Time\n - 작업이 처음 실행되기까지 걸린 시간\n2. Turnaround Time\n - 실행 시간과 대기 시간을 모두 합한 시간으로 작업이 완료될 때 까지 걸린 시간\n\n---\n\n### 출처\n\n- 스케줄링 목표 : [링크](https://jhnyang.tistory.com/29?category=815411)\n- 프로세스 전이도 그림 출처 : [링크](https://rebas.kr/852)\n- CPU 스케줄링 종류 및 정의 참고 : [링크](https://m.blog.naver.com/PostView.nhn?blogId=so_fragrant&logNo=80056608452&proxyReferer=https:%2F%2Fwww.google.com%2F)\n- 다단계큐 참고 : [링크](https://jhnyang.tistory.com/28)\n- 다단계 피드백 큐 참고 : [링크](https://jhnyang.tistory.com/156)\n" }, { "path": "Computer Science/Operating System/DeadLock.md", "content": "## 데드락 (DeadLock, 교착 상태)\n\n> 두 개 이상의 프로세스나 스레드가 서로 자원을 얻지 못해서 다음 처리를 하지 못하는 상태\n>\n> 무한히 다음 자원을 기다리게 되는 상태를 말한다.\n>\n> 시스템적으로 한정된 자원을 여러 곳에서 사용하려고 할 때 발생한다.\n\n> _(마치, 외나무 다리의 양 끝에서 서로가 비켜주기를 기다리고만 있는 것과 같다.)_\n\n
\n\n- 데드락이 일어나는 경우\n\n
 \n\n프로세스1과 2가 자원1, 2를 모두 얻어야 한다고 가정해보자\n\nt1 : 프로세스1이 자원1을 얻음 / 프로세스2가 자원2를 얻음\n\nt2 : 프로세스1은 자원2를 기다림 / 프로세스2는 자원1을 기다림\n\n
\n\n프로세스1과 2가 자원1, 2를 모두 얻어야 한다고 가정해보자\n\nt1 : 프로세스1이 자원1을 얻음 / 프로세스2가 자원2를 얻음\n\nt2 : 프로세스1은 자원2를 기다림 / 프로세스2는 자원1을 기다림\n\n\n\n현재 서로 원하는 자원이 상대방에 할당되어 있어서 두 프로세스는 무한정 wait 상태에 빠짐\n\n→ 이것이 바로 **DeadLock**!!!!!!\n\n
\n\n(주로 발생하는 경우)\n\n> 멀티 프로그래밍 환경에서 한정된 자원을 얻기 위해 서로 경쟁하는 상황 발생\n>\n> 한 프로세스가 자원을 요청했을 때, 동시에 그 자원을 사용할 수 없는 상황이 발생할 수 있음. 이때 프로세스는 대기 상태로 들어감\n>\n> 대기 상태로 들어간 프로세스들이 실행 상태로 변경될 수 없을 때 '교착 상태' 발생\n\n
\n\n##### _데드락(DeadLock) 발생 조건_\n\n> 4가지 모두 성립해야 데드락 발생\n>\n> (하나라도 성립하지 않으면 데드락 문제 해결 가능)\n\n1. ##### 상호 배제(Mutual exclusion)\n\n > 자원은 한번에 한 프로세스만 사용할 수 있음\n\n2. ##### 점유 대기(Hold and wait)\n\n > 최소한 하나의 자원을 점유하고 있으면서 다른 프로세스에 할당되어 사용하고 있는 자원을 추가로 점유하기 위해 대기하는 프로세스가 존재해야 함\n\n3. ##### 비선점(No preemption)\n\n > 다른 프로세스에 할당된 자원은 사용이 끝날 때까지 강제로 빼앗을 수 없음\n\n4. ##### 순환 대기(Circular wait)\n\n > 프로세스의 집합에서 순환 형태로 자원을 대기하고 있어야 함\n\n
\n\n##### _데드락(DeadLock) 처리_\n\n---\n\n##### 교착 상태를 예방 & 회피\n\n1. ##### 예방(prevention)\n\n 교착 상태 발생 조건 중 하나를 제거하면서 해결한다 (자원 낭비 엄청 심함)\n\n > - 상호배제 부정 : 여러 프로세스가 공유 자원 사용\n > - 점유대기 부정 : 프로세스 실행전 모든 자원을 할당\n > - 비선점 부정 : 자원 점유 중인 프로세스가 다른 자원을 요구할 때 가진 자원 반납\n > - 순환대기 부정 : 자원에 고유번호 할당 후 순서대로 자원 요구\n\n2. ##### 회피(avoidance)\n\n 교착 상태 발생 시 피해나가는 방법\n\n > 은행원 알고리즘(Banker's Algorithm)\n >\n > - 은행에서 모든 고객의 요구가 충족되도록 현금을 할당하는데서 유래함\n > - 프로세스가 자원을 요구할 때, 시스템은 자원을 할당한 후에도 안정 상태로 남아있게 되는지 사전에 검사하여 교착 상태 회피\n > - 안정 상태면 자원 할당, 아니면 다른 프로세스들이 자원 해지까지 대기\n\n > 자원 할당 그래프 알고리즘(Resource-Allocation Graph Algorithm)\n >\n > - 자원과 프로세스에 대해 요청 간선과 할당 간선을 적용하여 교착 상태를 회피하는 알고리즘\n > - 프로세스가 자원을 요구 시 요청 간선을 할당 간선으로 변경 했을 시 사이클이 생성 되는지 확인한다\n > - 사이클이 생성된다 하여 무조건 교착상태인 것은 아니다\n > > - 자원에 하나의 인스턴스만 존재 시 **교착 상태**로 판별한다\n > > - 자원에 여러 인스턴스가 존재 시 **교착 상태 가능성**으로 판별한다\n > - 사이클을 생성하지 않으면 자원을 할당한다\n\n##### 교착 상태를 탐지 & 회복\n\n교착 상태가 되도록 허용한 다음 회복시키는 방법\n\n1. ##### 탐지(Detection)\n\n 자원 할당 그래프를 통해 교착 상태를 탐지함\n\n 자원 요청 시, 탐지 알고리즘을 실행시켜 그에 대한 오버헤드 발생함\n\n2. ##### 회복(Recovery)\n\n 교착 상태 일으킨 프로세스를 종료하거나, 할당된 자원을 해제시켜 회복시키는 방법\n\n > ##### 프로세스 종료 방법\n >\n > - 교착 상태의 프로세스를 모두 중지\n > - 교착 상태가 제거될 때까지 하나씩 프로세스 중지\n >\n > ##### 자원 선점 방법\n >\n > - 교착 상태의 프로세스가 점유하고 있는 자원을 선점해 다른 프로세스에게 할당 (해당 프로세스 일시정지 시킴)\n > - 우선 순위가 낮은 프로세스나 수행 횟수 적은 프로세스 위주로 프로세스 자원 선점\n\n#### 주요 질문\n\n1. 데드락(교착 상태)가 뭔가요? 발생 조건에 대해 말해보세요.\n\n2. 회피 기법인 은행원 알고리즘이 뭔지 설명해보세요.\n\n3. 기아상태를 설명하는 식사하는 철학자 문제에 대해 설명해보세요.\n\n > 교착 상태 해결책\n >\n > 1. n명이 앉을 수 있는 테이블에서 철학자를 n-1명만 앉힘\n > 2. 한 철학자가 젓가락 두개를 모두 집을 수 있는 상황에서만 젓가락 집도록 허용\n > 3. 누군가는 왼쪽 젓가락을 먼저 집지 않고 오른쪽 젓가락을 먼저 집도록 허용\n" }, { "path": "Computer Science/Operating System/File System.md", "content": "## 파일 시스템(File System)\n\n
\n\n컴퓨터에서 파일이나 자료를 쉽게 발견할 수 있도록, 유지 및 관리하는 방법이다.\n\n저장매체에는 수많은 파일이 있기 때문에, 이런 파일들을 관리하는 방법을 말한다.\n\n#####
\n\n##### 특징\n\n- 커널 영역에서 동작\n- 파일 CRUD 기능을 원활히 수행하기 위한 목적\n\n- 계층적 디렉터리 구조를 가짐\n- 디스크 파티션 별로 하나씩 둘 수 있음\n\n##### 역할\n\n- 파일 관리\n- 보조 저장소 관리\n- 파일 무결성 메커니즘\n- 접근 방법 제공\n\n##### 개발 목적\n\n- 하드디스크와 메인 메모리 속도차를 줄이기 위함\n- 파일 관리\n- 하드디스크 용량 효율적 이용\n\n##### 구조\n\n- 메타 영역 : 데이터 영역에 기록된 파일의 이름, 위치, 크기, 시간정보, 삭제유무 등의 파일 정보\n- 데이터 영역 : 파일의 데이터\n\n
\n\n
\n\n#### 접근 방법\n\n1. ##### 순차 접근(Sequential Access)\n\n > 가장 간단한 접근 방법으로, 대부분 연산은 read와 write\n\n
 \n\n 현재 위치를 가리키는 포인터에서 시스템 콜이 발생할 경우 포인터를 앞으로 보내면서 read와 write를 진행. 뒤로 돌아갈 땐 지정한 offset만큼 되감기를 해야 한다. (테이프 모델 기반)\n\n2. ##### 직접 접근(Direct Access)\n\n > 특별한 순서없이, 빠르게 레코드를 read, write 가능\n\n
\n\n 현재 위치를 가리키는 포인터에서 시스템 콜이 발생할 경우 포인터를 앞으로 보내면서 read와 write를 진행. 뒤로 돌아갈 땐 지정한 offset만큼 되감기를 해야 한다. (테이프 모델 기반)\n\n2. ##### 직접 접근(Direct Access)\n\n > 특별한 순서없이, 빠르게 레코드를 read, write 가능\n\n  \n\n 현재 위치를 가리키는 cp 변수만 유지하면 직접 접근 파일을 가지고 순차 파일 기능을 쉽게 구현이 가능하다.\n\n 무작위 파일 블록에 대한 임의 접근을 허용한다. 따라서 순서의 제약이 없음\n\n 대규모 정보를 접근할 때 유용하기 때문에 '데이터베이스'에 활용된다.\n\n3. 기타 접근\n\n > 직접 접근 파일에 기반하여 색인 구축\n\n
\n\n 현재 위치를 가리키는 cp 변수만 유지하면 직접 접근 파일을 가지고 순차 파일 기능을 쉽게 구현이 가능하다.\n\n 무작위 파일 블록에 대한 임의 접근을 허용한다. 따라서 순서의 제약이 없음\n\n 대규모 정보를 접근할 때 유용하기 때문에 '데이터베이스'에 활용된다.\n\n3. 기타 접근\n\n > 직접 접근 파일에 기반하여 색인 구축\n\n  \n\n 크기가 큰 파일을 입출력 탐색할 수 있게 도와주는 방법임\n\n
\n\n 크기가 큰 파일을 입출력 탐색할 수 있게 도와주는 방법임\n\n\n\n
\n\n### 디렉터리와 디스크 구조\n\n---\n\n- ##### 1단계 디렉터리\n\n > 가장 간단한 구조\n\n 파일들은 서로 유일한 이름을 가짐. 서로 다른 사용자라도 같은 이름 사용 불가\n\n
 \n\n- ##### 2단계 디렉터리\n\n > 사용자에게 개별적인 디렉터리 만들어줌\n\n - UFD : 자신만의 사용자 파일 디렉터리\n - MFD : 사용자의 이름과 계정번호로 색인되어 있는 디렉터리\n\n
\n\n- ##### 2단계 디렉터리\n\n > 사용자에게 개별적인 디렉터리 만들어줌\n\n - UFD : 자신만의 사용자 파일 디렉터리\n - MFD : 사용자의 이름과 계정번호로 색인되어 있는 디렉터리\n\n  \n\n- ##### 트리 구조 디렉터리\n\n > 2단계 구조 확장된 다단계 트리 구조\n\n 한 비트를 활용하여, 일반 파일(0)인지 디렉터리 파일(1) 구분\n\n
\n\n- ##### 트리 구조 디렉터리\n\n > 2단계 구조 확장된 다단계 트리 구조\n\n 한 비트를 활용하여, 일반 파일(0)인지 디렉터리 파일(1) 구분\n\n  \n\n- 그래프 구조 디렉터리\n\n > 순환이 발생하지 않도록 하위 디렉터리가 아닌 파일에 대한 링크만 허용하거나, 가비지 컬렉션을 이용해 전체 파일 시스템을 순회하고 접근 가능한 모든 것을 표시\n\n 링크가 있으면 우회하여 순환을 피할 수 있음\n\n
\n\n- 그래프 구조 디렉터리\n\n > 순환이 발생하지 않도록 하위 디렉터리가 아닌 파일에 대한 링크만 허용하거나, 가비지 컬렉션을 이용해 전체 파일 시스템을 순회하고 접근 가능한 모든 것을 표시\n\n 링크가 있으면 우회하여 순환을 피할 수 있음\n\n  \n\n\n\n\n\n\n\n\n\n\n\n\n\n##### [참고 자료]\n\n- [링크]( https://noep.github.io/2016/02/23/10th-filesystem/ )"
},
{
"path": "Computer Science/Operating System/IPC(Inter Process Communication).md",
"content": "### IPC(Inter Process Communication)\n\n---\n\n
\n\n\n\n\n\n\n\n\n\n\n\n\n\n##### [참고 자료]\n\n- [링크]( https://noep.github.io/2016/02/23/10th-filesystem/ )"
},
{
"path": "Computer Science/Operating System/IPC(Inter Process Communication).md",
"content": "### IPC(Inter Process Communication)\n\n---\n\n \n\n
\n\n\n\n프로세스는 독립적으로 실행된다. 즉, 독립 되어있다는 것은 다른 프로세스에게 영향을 받지 않는다고 말할 수 있다. (스레드는 프로세스 안에서 자원을 공유하므로 영향을 받는다)\n\n이런 독립적 구조를 가진 **프로세스 간의 통신**을 해야 하는 상황이 있을 것이다. 이를 가능하도록 해주는 것이 바로 IPC 통신이다.\n\n
\n\n프로세스는 커널이 제공하는 IPC 설비를 이용해 프로세스간 통신을 할 수 있게 된다.\n\n***커널이란?***\n\n> 운영체제의 핵심적인 부분으로, 다른 모든 부분에 여러 기본적인 서비스를 제공해줌\n\n
\n\nIPC 설비 종류도 여러가지가 있다. 필요에 따라 IPC 설비를 선택해서 사용해야 한다.\n\n
\n\n#### IPC 종류\n\n1. ##### 익명 PIPE\n\n > 파이프는 두 개의 프로세스를 연결하는데 하나의 프로세스는 데이터를 쓰기만 하고, 다른 하나는 데이터를 읽기만 할 수 있다.\n >\n > **한쪽 방향으로만 통신이 가능한 반이중 통신**이라고도 부른다.\n >\n > 따라서 양쪽으로 모두 송/수신을 하고 싶으면 2개의 파이프를 만들어야 한다.\n >\n > \n >\n >\n > 매우 간단하게 사용할 수 있는 장점이 있고, 단순한 데이터 흐름을 가질 땐 파이프를 사용하는 것이 효율적이다. 단점으로는 전이중 통신을 위해 2개를 만들어야 할 때는 구현이 복잡해지게 된다.\n\n
\n\n2. ##### Named PIPE(FIFO)\n\n > 익명 파이프는 통신할 프로세스를 명확히 알 수 있는 경우에 사용한다. (부모-자식 프로세스 간 통신처럼)\n >\n > Named 파이프는 전혀 모르는 상태의 프로세스들 사이 통신에 사용한다.\n >\n > 즉, 익명 파이프의 확장된 상태로 **부모 프로세스와 무관한 다른 프로세스도 통신이 가능한 것** (통신을 위해 이름있는 파일을 사용)\n >\n > \n >\n >\n > 하지만, Named 파이프 역시 읽기/쓰기 동시에 불가능함. 따라서 전이중 통신을 위해서는 익명 파이프처럼 2개를 만들어야 가능\n\n
\n\n3. ##### Message Queue\n\n > 입출력 방식은 Named 파이프와 동일함\n >\n > 다른점은 메시지 큐는 파이프처럼 데이터의 흐름이 아니라 메모리 공간이다.\n >\n > \n >\n >\n > 사용할 데이터에 번호를 붙이면서 여러 프로세스가 동시에 데이터를 쉽게 다룰 수 있다.\n\n
\n\n4. ##### 공유 메모리\n\n > 파이프, 메시지 큐가 통신을 이용한 설비라면, **공유 메모리는 데이터 자체를 공유하도록 지원하는 설비**다.\n > \n >\n > 프로세스의 메모리 영역은 독립적으로 가지며 다른 프로세스가 접근하지 못하도록 반드시 보호돼야한다. 하지만 다른 프로세스가 데이터를 사용하도록 해야하는 상황도 필요할 것이다. 파이프를 이용해 통신을 통해 데이터 전달도 가능하지만, 스레드처럼 메모리를 공유하도록 해준다면 더욱 편할 것이다.\n > \n >\n > 공유 메모리는 **프로세스간 메모리 영역을 공유해서 사용할 수 있도록 허용**해준다.\n >\n > 프로세스가 공유 메모리 할당을 커널에 요청하면, 커널은 해당 프로세스에 메모리 공간을 할당해주고 이후 모든 프로세스는 해당 메모리 영역에 접근할 수 있게 된다.\n >\n > - **중개자 없이 곧바로 메모리에 접근할 수 있어서 IPC 중에 가장 빠르게 작동함**\n\n
\n\n5. ##### 메모리 맵\n\n > 공유 메모리처럼 메모리를 공유해준다. 메모리 맵은 **열린 파일을 메모리에 맵핑시켜서 공유**하는 방식이다. (즉 공유 매개체가 파일+메모리)\n >\n > 주로 파일로 대용량 데이터를 공유해야 할 때 사용한다.\n\n
\n\n6. ##### 소켓\n\n > 네트워크 소켓 통신을 통해 데이터를 공유한다.\n >\n > 클라이언트와 서버가 소켓을 통해서 통신하는 구조로, 원격에서 프로세스 간 데이터를 공유할 때 사용한다.\n >\n > 서버(bind, listen, accept), 클라이언트(connect)\n\n
\n\n\n\n
\n\n이러한 IPC 통신에서 프로세스 간 데이터를 동기화하고 보호하기 위해 세마포어와 뮤텍스를 사용한다. (공유된 자원에 한번에 하나의 프로세스만 접근시킬 때)\n" }, { "path": "Computer Science/Operating System/Interrupt.md", "content": "## 인터럽트(Interrupt)\n\n##### 정의\n\n프로그램을 실행하는 도중에 예기치 않은 상황이 발생할 경우 현재 실행 중인 작업을 즉시 중단하고, 발생된 상황에 대한 우선 처리가 필요함을 CPU에게 알리는 것\n
\n\n지금 수행 중인 일보다 더 중요한 일(ex. 입출력, 우선 순위 연산 등)이 발생하면 그 일을 먼저 처리하고 나서 하던 일을 계속해야한다.\n\n
\n\n외부/내부 인터럽트는 `CPU의 하드웨어 신호에 의해 발생`\n\n소프트웨어 인터럽트는 `명령어의 수행에 의해 발생`\n\n- ##### 외부 인터럽트\n\n 입출력 장치, 타이밍 장치, 전원 등 외부적인 요인으로 발생\n\n `전원 이상, 기계 착오, 외부 신호, 입출력`\n\n
\n\n- ##### 내부 인터럽트\n\n Trap이라고 부르며, 잘못된 명령이나 데이터를 사용할 때 발생\n\n > 0으로 나누기가 발생, 오버플로우, 명령어를 잘못 사용한 경우 (Exception)\n\n- ##### 소프트웨어 인터럽트\n\n 프로그램 처리 중 명령의 요청에 의해 발생한 것 (SVC 인터럽트)\n\n > 사용자가 프로그램을 실행시킬 때 발생\n >\n > 소프트웨어 이용 중에 다른 프로세스를 실행시키면 시분할 처리를 위해 자원 할당 동작이 수행된다.\n\n
\n\n#### 인터럽트 발생 처리 과정\n\n
\n\n즉, 컨트롤러가 입력을 받아들이는 방법(우선순위 판별방법)에는 두가지가 있다.\n\n- ##### 폴링 방식\n\n 사용자가 명령어를 사용해 입력 핀의 값을 계속 읽어 변화를 알아내는 방식\n\n 인터럽트 요청 플래그를 차례로 비교하여 우선순위가 가장 높은 인터럽트 자원을 찾아 이에 맞는 인터럽트 서비스 루틴을 수행한다. (하드웨어에 비해 속도 느림)\n\n- ##### 인터럽트 방식\n\n MCU 자체가 하드웨어적으로 변화를 체크하여 변화 시에만 일정한 동작을 하는 방식\n\n - Daisy Chain\n - 병렬 우선순위 부여 \n\n
\n\n인터럽트 방식은 하드웨어로 지원을 받아야 하는 제약이 있지만, 폴링에 비해 신속하게 대응하는 것이 가능하다. 따라서 **'실시간 대응'**이 필요할 때는 필수적인 기능이다.\n\n
\n\n즉, 인터럽트는 **발생시기를 예측하기 힘든 경우에 컨트롤러가 가장 빠르게 대응할 수 있는 방법**이다.\n\n" }, { "path": "Computer Science/Operating System/Memory.md", "content": "#### 메인 메모리(main memory)\n\n> 메인 메모리는 CPU가 직접 접근할 수 있는 기억 장치\n>\n> 프로세스가 실행되려면 프로그램이 메모리에 올라와야 함\n\n주소가 할당된 일련의 바이트들로 구성되어 있음\n\n
\n\nCPU는 레지스터가 지시하는대로 메모리에 접근하여 다음에 수행할 명령어를 가져옴\n\n명령어 수행 시 메모리에 필요한 데이터가 없으면 해당 데이터를 우선 가져와야 함\n\n이 역할을 하는 것이 바로 **MMU**.\n\n
\n\n#### MMU (Memory Management Unit, 메모리 관리 장치)\n\n- 논리 주소를 물리 주소로 변환해 준다.\n\n- 메모리 보호나 캐시 관리 등 CPU가 메모리에 접근하는 것을 총 관리해 주는 하드웨어임\n\n
\n\n메모리의 공간이 한정적이기 때문에, 사용자에게 더 많은 메모리를 제공하기 위해 '가상 주소'라는 개념이 등장 (가상 주소는 프로그램 상에서 사용자가 보는 주소 공간이라고 보면 됨)\n\n이 가상 주소에서 실제 데이터가 담겨 있는 곳에 접근하기 위해선 빠른 주소 변환이 필요한데, 이를 MMU가 도와주는 것\n\n즉, MMU의 역할은 다음과 같다고 말할 수 있다.\n\n> MMU가 지원되지 않으면, physical address를 직접 접근해야 하기 때문에 부담이 있다.\n>\n> MMU는 사용자가 기억장소를 일일이 할당해야 하는 불편을 없애준다.\n>\n> 프로세스의 크기가 실제 메모리의 용량을 초과해도 실행될 수 있게 해준다.\n\n
\n\n또한 메인 메모리의 직접 접근은 비효율적이므로, CPU와 메인 메모리 속도를 맞추기 위해 캐시가 존재함\n\n
\n\n##### MMU의 메모리 보호\n\n프로세스는 독립적인 메모리 공간을 가져야 되고, 자신의 공간만 접근해야 함\n\n따라서 한 프로세스에게 합법적인 주소 영역을 설정하고, 잘못된 접근이 오면 trap을 발생시키며 보호함\n\n
 \n\nbase와 limit 레지스터를 활용한 메모리 보호 기법\n\nbase 레지스터는 메모리상의 프로세스 시작주소를 물리 주소로 저장\nlimit 레지스터는 프로세스의 사이즈를 저장\n\n이로써 프로세스의 접근 가능한 합법적인 메모리 영역(x)은\n\n```\nbase <= x < base+limit\n```\n\n이 영역 밖에서 접근을 요구하면 trap을 발생시키는 것\n\n
\n\nbase와 limit 레지스터를 활용한 메모리 보호 기법\n\nbase 레지스터는 메모리상의 프로세스 시작주소를 물리 주소로 저장\nlimit 레지스터는 프로세스의 사이즈를 저장\n\n이로써 프로세스의 접근 가능한 합법적인 메모리 영역(x)은\n\n```\nbase <= x < base+limit\n```\n\n이 영역 밖에서 접근을 요구하면 trap을 발생시키는 것\n\n\n\n안전성을 위해 base와 limit 레지스터는 커널 모드에서만 수정 가능하도록 설계 (사용자 모드에서는 직접 변경할 수 없도록)\n\n
\n\n
\n\n##### 메모리 과할당(over allocating)\n\n> 실제 메모리의 사이즈보다 더 큰 사이즈의 메모리를 프로세스에 할당한 상황\n\n
\n\n페이지 기법과 같은 메모리 관리 기법은 사용자가 눈치채지 못하도록 눈속임을 통해 메모리를 할당해 줌 (가상 메모리를 이용해서)\n\n
\n\n과할당 상황에 대해서 사용자를 속인 것을 들킬만한 상황이 존재함\n\n1. 프로세스 실행 도중 페이지 폴트 발생\n2. 페이지 폴트를 발생시킨 페이지 위치를 디스크에서 찾음\n3. 메모리의 빈 프레임에 페이지를 올려야 하는데, 모든 메모리가 사용 중이라 빈 프레임이 없음\n\n
\n\n이러한 과할당을 해결하기 위해선, 빈 프레임을 확보할 수 있어야 함\n\n1. 메모리에 올라와 있는 한 프로세스를 종료시켜 빈 프레임을 얻음\n\n2. 프로세스 하나를 swap out하고, 이 공간을 빈 프레임으로 활용\n\n
\n\nswapping 기법을 통해 공간을 바꿔치기하는 2번 방법과는 달리 1번은 사용자에게 페이징 시스템을 들킬 가능성이 매우 높아서 하면 안 됨\n\n(페이징 기법은 사용자 모르게 시스템 능률을 높이기 위해 선택한 일이므로 들키지 않게 처리해야 한다)\n\n
\n\n따라서, 2번과 같은 해결책을 통해 페이지 교체가 이루어져야 함\n\n
\n\n
\n\n##### 페이지 교체\n\n> 메모리 과할당이 발생했을 때, 프로세스 하나를 swap out해서 빈 프레임을 확보하는 것\n\n
\n\n1. 프로세스 실행 도중 페이지 부재 발생\n\n2. 페이지 폴트를 발생시킨 페이지 위치를 디스크에서 찾음\n\n3. 메모리에 빈 프레임이 있는지 확인\n\n > 빈 프레임이 있으면 해당 프레임을 사용\n >\n > 빈 프레임이 없으면, victim 프레임을 선정해 디스크에 기록하고 페이지 테이블을 업데이트함\n\n4. 빈 프레임에 페이지 폴트가 발생한 페이지를 올리고, 페이지 테이블 업데이트\n\n
\n\n페이지 교체가 이루어지면 아무 일이 없던 것 처럼 프로세스를 계속 수행시켜주면서 사용자가 알지 못하도록 해야 함\n\n이때, 아무 일도 일어나지 않은 것처럼 하려면, 페이지 교체 당시 오버헤드를 최대한 줄여야 함\n\n
\n\n##### 오버헤드를 감소시키는 해결법\n\n이처럼 빈 프레임이 없는 상황에서 victim 프레임을 비울 때와 원하는 페이지를 프레임으로 올릴 때 두 번의 디스크 접근이 이루어짐\n\n페이지 교체가 많이 이루어지면, 이처럼 입출력 연산이 많이 발생하게 되면서 오버헤드 문제가 발생함\n\n
\n\n##### 방법1\n\n변경비트를 모든 페이지마다 둬서, victim 페이지가 정해지면 해당 페이지의 비트를 확인\n\n해당 비트가 set 상태면? → 해당 페이지 내용이 디스크 상의 페이지 내용과 달라졌다는 뜻\n(즉, 페이지가 메모리 올라온 이후 한 번이라도 수정이 일어났던 것. 따라서 이건 디스크에 기록해야 함)\n\nbit가 clear 상태라면? → 디스크 상의 페이지 내용과 메모리 상의 페이지가 정확히 일치하는 상황\n(즉, 디스크와 내용이 같아서 기록할 필요가 없음)\n\n비트를 활용해 디스크에 기록하는 횟수를 줄이면서 오버헤드에 대한 수를 최대 절반으로 감소시키는 방법임\n\n
\n\n##### 방법2\n\n페이지 교체 알고리즘을 상황에 따라 잘 선택해야 함\n\n현재 상황에서 페이지 폴트를 발생할 확률을 최대한 줄여줄 수 있는 교체 알고리즘을 사용\n\nFIFO\n\nOPT\n\nLRU\n\n
\n\n
\n\n#### 캐시 메모리\n\n> 주기억장치에 저장된 내용의 일부를 임시로 저장해두는 기억장치\n>\n> CPU와 주기억장치의 속도 차이로 성능 저하를 방지하기 위한 방법\n\nCPU가 이미 봤던걸 다시 재접근할 때, 메모리 참조 및 인출 과정에 대한 비용을 줄이기 위해 캐시에 저장해둔 데이터를 활용한다\n\n캐시는 플리플롭 소자로 구성되어 SRAM으로 되어있어서 DRAM보다 빠른 장점을 지님\n\n
\n\n##### CPU와 기억장치의 상호작용\n\nCPU에서 주소를 전달 → 캐시 기억장치에 명령이 존재하는지 확인\n\n(존재) Hit\n\n해당 명령어를 CPU로 전송 → 완료\n\n(비존재) Miss\n\n명령어를 갖고 주기억장치로 접근 → 해당 명령어를 가진 데이터 인출 → 해당 명령어 데이터를 캐시에 저장 → 해당 명령어를 CPU로 전송 → 완료\n\n
\n\n이처럼 캐시를 잘 활용한다면 비용을 많이 줄일 수 있음\n\n따라서 CPU가 어떤 데이터를 원할지 어느 정도 예측할 수 있어야 함\n\n(캐시에 많이 활용되는 쓸모 있는 정보가 들어있어야 성능이 높아짐)\n\n
\n\n적중률을 극대화시키기 위해 사용되는 것이 바로 `지역성의 원리`\n\n##### 지역성\n\n> 기억 장치 내의 정보를 균일하게 액세스 하는 것이 아니라 한 순간에 특정부분을 집중적으로 참조하는 특성\n\n
\n\n지역성의 종류는 시간과 공간으로 나누어짐\n\n**시간 지역성** : 최근에 참조된 주소의 내용은 곧 다음에도 참조되는 특성\n\n**공간 지역성** : 실제 프로그램이 참조된 주소와 인접한 주소의 내용이 다시 참조되는 특성\n\n
\n\n
\n\n#### 캐싱 라인\n\n빈번하게 사용되는 데이터들을 캐시에 저장했더라도, 내가 필요한 데이터를 캐시에서 찾을 때 모든 데이터를 순회하는 것은 시간 낭비다.\n\n즉, 캐시에 목적 데이터가 저장되어 있을 때 바로 접근하여 출력할 수 있어야 캐시 활용이 의미 있어짐\n\n따라서 캐시에 데이터를 저장할 시, 자료구조를 활용해 묶어서 저장하는데 이를 `캐싱 라인`이라고 부른다.\n\n즉, 캐시에 저장하는 데이터에 데이터의 메모리 주소를 함께 저장하면서 빠르게 원하는 정보를 찾을 수 있음 (set이나 map 등을 활용)\n" }, { "path": "Computer Science/Operating System/Operation System.md", "content": "## 운영 체제란 무엇인가?\n\n> **운영 체제(OS, Operating System)**\n>\n> : 하드웨어를 관리하고, 컴퓨터 시스템의 자원들을 효율적으로 관리하며, 응용 프로그램과 하드웨어 간의 인터페이스로써 다른 응용 프로그램이 유용한 작업을 할 수 있도록 환경을 제공해준다.\n>\n> 즉, 운영 체제는 **사용자가 컴퓨터를 편리하고 효과적으로 사용할 수 있도록 환경을 제공하는 시스템 소프트웨어**라고 할 수 있다.\n>\n> (*종류로는 Windows, Linux, UNIX, MS-DOS 등이 있으며, 시스템의 역할 구분에 따라 각각 용이점이 있다.*)\n\n
\n\n---\n\n### [ 운영체제의 역할 ]\n\n
\n\n##### 1. 프로세스 관리\n\n- 프로세스, 스레드\n- 스케줄링\n- 동기화\n- IPC 통신\n\n##### 2. 저장장치 관리\n\n- 메모리 관리\n- 가상 메모리\n- 파일 시스템\n\n##### 3. 네트워킹\n\n- TCP/IP\n- 기타 프로토콜\n\n##### 4. 사용자 관리\n\n- 계정 관리\n- 접근권한 관리\n\n##### 5. 디바이스 드라이버\n\n- 순차접근 장치\n- 임의접근 장치\n- 네트워크 장치\n\n
\n\n---\n\n### [ 각 역할에 대한 자세한 설명 ]\n\n
\n\n### 1. 프로세스 관리\n\n운영체제에서 작동하는 응용 프로그램을 관리하는 기능이다.\n\n어떤 의미에서는 프로세서(CPU) 관리하는 것이라고 볼 수도 있다. 현재 CPU를 점유해야 할 프로세스를 결정하고, 실제로 CPU를 프로세스에 할당하며, 이 프로세스 간 공유 자원 접근과 통신 등을 관리하게 된다.\n\n
\n\n### 2. 저장장치 관리\n\n1차 저장장치에 해당하는 메인 메모리와 2차 저장장치에 해당하는 하드디스크, NAND 등을 관리하는 기능이다.\n\n- 1차 저장장치(Main Memory)\n - 프로세스에 할당하는 메모리 영역의 할당과 해제\n - 각 메모리 영역 간의 침범 방지\n - 메인 메모리의 효율적 활용을 위한 가상 메모리 기능\n- 2차 저장장치(HDD, NAND Flash Memory 등)\n - 파일 형식의 데이터 저장\n - 이런 파일 데이터 관리를 위한 파일 시스템을 OS에서 관리\n - `FAT, NTFS, EXT2, JFS, XFS` 등 많은 파일 시스템들이 개발되어 사용 중\n
\n### 3. 네트워킹\n\n네트워킹은 컴퓨터 활용의 핵심과도 같아졌다.\n\nTCP/IP 기반의 인터넷에 연결하거나, 응용 프로그램이 네트워크를 사용하려면 **운영체제에서 네트워크 프로토콜을 지원**해야 한다. 현재 상용 OS들은 다양하고 많은 네트워크 프로토콜을 지원한다.\n\n이처럼 운영체제는 사용자와 컴퓨터 하드웨어 사이에 위치해서, 하드웨어를 운영 및 관리하고 명령어를 제어하여 응용 프로그램 및 하드웨어를 소프트웨어적으로 제어 및 관리를 해야한다.\n
\n### 4. 사용자 관리\n\n우리가 사용하는 PC는 오직 한 사람만의 것일까? 아니다.\n\n하나의 PC로도 여러 사람이 사용하는 경우가 많다. 그래서 운영체제는 한 컴퓨터를 여러 사람이 사용하는 환경도 지원해야 한다. 가족들이 각자의 계정을 만들어 PC를 사용한다면, 이는 하나의 컴퓨터를 여러 명이 사용한다고 말할 수 있다.\n\n따라서, 운영체제는 각 계정을 관리할 수 있는 기능이 필요하다. 사용자 별로 프라이버시와 보안을 위해 개인 파일에 대해선 다른 사용자가 접근할 수 없도록 해야 한다. 이 밖에도 파일이나 시스템 자원에 접근 권한을 지정할 수 있도록 지원하는 것이 사용자 관리 기능이다.\n
\n### 5. 디바이스 드라이버\n\n운영체제는 시스템의 자원, 하드웨어를 관리한다. 시스템에는 여러 하드웨어가 붙어있는데, 이들을 운영체제에서 인식하고 관리하게 만들어 응용 프로그램이 하드웨어를 사용할 수 있게 만들어야 한다.\n\n따라서, 운영체제 안에 하드웨어를 추상화 해주는 계층이 필요하다. 이 계층이 바로 디바이스 드라이버라고 불린다. 하드웨어의 종류가 많은 만큼, 운영체제 내부의 디바이스 드라이버도 많이 존재한다.\n\n이러한 수많은 디바이스 드라이버들을 관리하는 기능 또한 운영체제가 맡고 있다.\n\n---\n\n
\n\n##### [참고 자료 및 주제와 관련하여 참고하면 좋은 곳 링크]\n\n- 도서 - '도전 임베디드 OS 만들기' *( 이만우 저, 인사이트 출판 )*\n- 글 - '운영체제란 무엇인가?' *( https://coding-factory.tistory.com/300 )*" }, { "path": "Computer Science/Operating System/PCB & Context Switcing.md", "content": "## PCB & Context Switching\n\n
\n\n#### Process Management\n\n> CPU가 프로세스가 여러개일 때, CPU 스케줄링을 통해 관리하는 것을 말함\n\n이때, CPU는 각 프로세스들이 누군지 알아야 관리가 가능함\n\n프로세스들의 특징을 갖고있는 것이 바로 `Process Metadata`\n\n- Process Metadata\n - Process ID\n - Process State\n - Process Priority\n - CPU Registers\n - Owner\n - CPU Usage\n - Memeory Usage\n\n이 메타데이터는 프로세스가 생성되면 `PCB(Process Control Block)`이라는 곳에 저장됨\n\n
\n\n#### PCB(Process Control Block)\n\n> 프로세스 메타데이터들을 저장해 놓는 곳, 한 PCB 안에는 한 프로세스의 정보가 담김\n\n
 \n\n##### 다시 정리해보면?\n\n```\n프로그램 실행 → 프로세스 생성 → 프로세스 주소 공간에 (코드, 데이터, 스택) 생성 \n→ 이 프로세스의 메타데이터들이 PCB에 저장\n```\n\n
\n\n##### 다시 정리해보면?\n\n```\n프로그램 실행 → 프로세스 생성 → 프로세스 주소 공간에 (코드, 데이터, 스택) 생성 \n→ 이 프로세스의 메타데이터들이 PCB에 저장\n```\n\n\n\n##### PCB가 왜 필요한가요?\n\n> CPU에서는 프로세스의 상태에 따라 교체작업이 이루어진다. (interrupt가 발생해서 할당받은 프로세스가 waiting 상태가 되고 다른 프로세스를 running으로 바꿔 올릴 때)\n>\n> 이때, **앞으로 다시 수행할 대기 중인 프로세스에 관한 저장 값을 PCB에 저장해두는 것**이다.\n\n##### PCB는 어떻게 관리되나요?\n\n> Linked List 방식으로 관리함\n>\n> PCB List Head에 PCB들이 생성될 때마다 붙게 된다. 주소값으로 연결이 이루어져 있는 연결리스트이기 때문에 삽입 삭제가 용이함.\n>\n> 즉, 프로세스가 생성되면 해당 PCB가 생성되고 프로세스 완료시 제거됨\n\n
\n\n
\n\n이렇게 수행 중인 프로세스를 변경할 때, CPU의 레지스터 정보가 변경되는 것을 `Context Switching`이라고 한다.\n\n#### Context Switching\n\n> CPU가 이전의 프로세스 상태를 PCB에 보관하고, 또 다른 프로세스의 정보를 PCB에 읽어 레지스터에 적재하는 과정\n\n보통 인터럽트가 발생하거나, 실행 중인 CPU 사용 허가시간을 모두 소모하거나, 입출력을 위해 대기해야 하는 경우에 Context Switching이 발생\n\n`즉, 프로세스가 Ready → Running, Running → Ready, Running → Waiting처럼 상태 변경 시 발생!` \n\n
\n\n##### Context Switching의 OverHead란?\n\noverhead는 과부하라는 뜻으로 보통 안좋은 말로 많이 쓰인다.\n\n하지만 프로세스 작업 중에는 OverHead를 감수해야 하는 상황이 있다.\n\n```\n프로세스를 수행하다가 입출력 이벤트가 발생해서 대기 상태로 전환시킴\n이때, CPU를 그냥 놀게 놔두는 것보다 다른 프로세스를 수행시키는 것이 효율적\n```\n\n즉, CPU에 계속 프로세스를 수행시키도록 하기 위해서 다른 프로세스를 실행시키고 Context Switching 하는 것\n\nCPU가 놀지 않도록 만들고, 사용자에게 빠르게 일처리를 제공해주기 위한 것이다.\n" }, { "path": "Computer Science/Operating System/Page Replacement Algorithm.md", "content": "### 페이지 교체 알고리즘\n\n---\n\n> 페이지 부재 발생 → 새로운 페이지를 할당해야 함 → 현재 할당된 페이지 중 어떤 것 교체할 지 결정하는 방법\n\n
\n\n- 좀 더 자세하게 생각해보면?\n\n가상 메모리는 `요구 페이지 기법`을 통해 필요한 페이지만 메모리에 적재하고 사용하지 않는 부분은 그대로 둠\n\n하지만 필요한 페이지만 올려도 메모리는 결국 가득 차게 되고, 올라와있던 페이지가 사용이 다 된 후에도 자리만 차지하고 있을 수 있음\n\n따라서 메모리가 가득 차면, 추가로 페이지를 가져오기 위해서 안쓰는 페이지는 out하고, 해당 공간에 현재 필요한 페이지를 in 시켜야 함\n\n여기서 어떤 페이지를 out 시켜야할 지 정해야 함. (이때 out 되는 페이지를 victim page라고 부름) \n\n기왕이면 수정이 되지 않는 페이지를 선택해야 좋음\n(Why? : 만약 수정되면 메인 메모리에서 내보낼 때, 하드디스크에서 또 수정을 진행해야 하므로 시간이 오래 걸림)\n\n> 이와 같은 상황에서 상황에 맞는 페이지 교체를 진행하기 위해 페이지 교체 알고리즘이 존재하는 것!\n\n
\n\n##### Page Reference String\n\n> CPU는 논리 주소를 통해 특정 주소를 요구함\n>\n> 메인 메모리에 올라와 있는 주소들은 페이지의 단위로 가져오기 때문에 페이지 번호가 연속되어 나타나게 되면 페이지 결함 발생 X\n>\n> 따라서 CPU의 주소 요구에 따라 페이지 결함이 일어나지 않는 부분은 생략하여 표시하는 방법이 바로 `Page Reference String`\n\n
\n\n1. ##### FIFO 알고리즘\n\n > First-in First-out, 메모리에 먼저 올라온 페이지를 먼저 내보내는 알고리즘\n\n victim page : out 되는 페이지는, 가장 먼저 메모리에 올라온 페이지\n\n 가장 간단한 방법으로, 특히 초기화 코드에서 적절한 방법임\n\n `초기화 코드` : 처음 프로세스 실행될 때 최초 초기화를 시키는 역할만 진행하고 다른 역할은 수행하지 않으므로, 메인 메모리에서 빼도 괜찮음\n\n 하지만 처음 프로세스 실행시에는 무조건 필요한 코드이므로, FIFO 알고리즘을 사용하면 초기화를 시켜준 후 가장 먼저 내보내는 것이 가능함\n\n \n\n
 \n\n
\n\n\n\n
\n\n2. ##### OPT 알고리즘\n\n > Optimal Page Replacement 알고리즘, 앞으로 가장 사용하지 않을 페이지를 가장 우선적으로 내보냄\n\n FIFO에 비해 페이지 결함의 횟수를 많이 감소시킬 수 있음\n\n 하지만, 실질적으로 페이지가 앞으로 잘 사용되지 않을 것이라는 보장이 없기 때문에 수행하기 어려운 알고리즘임\n\n
 \n\n
\n\n\n\n3. ##### LRU 알고리즘\n\n > Least-Recently-Used, 최근에 사용하지 않은 페이지를 가장 먼저 내려보내는 알고리즘\n\n 최근에 사용하지 않았으면, 나중에도 사용되지 않을 것이라는 아이디어에서 나옴\n\n OPT의 경우 미래 예측이지만, LRU의 경우는 과거를 보고 판단하므로 실질적으로 사용이 가능한 알고리즘\n\n (실제로도 최근에 사용하지 않은 페이지는 앞으로도 사용하지 않을 확률이 높다)\n\n OPT보다는 페이지 결함이 더 일어날 수 있지만, **실제로 사용할 수 있는 페이지 교체 알고리즘에서는 가장 좋은 방법 중 하나임**\n\n
 \n\n\n\n##### 교체 방식\n\n- Global 교체\n\n > 메모리 상의 모든 프로세스 페이지에 대해 교체하는 방식\n\n- Local 교체\n\n > 메모리 상의 자기 프로세스 페이지에서만 교체하는 방식\n\n\n\n다중 프로그래밍의 경우, 메인 메모리에 다양한 프로세스가 동시에 올라올 수 있음\n\n따라서, 다양한 프로세스의 페이지가 메모리에 존재함\n\n페이지 교체 시, 다양한 페이지 교체 알고리즘을 활용해 victim page를 선정하는데, 선정 기준을 Global로 하느냐, Local로 하느냐에 대한 차이\n\n→ 실제로는 전체를 기준으로 페이지를 교체하는 것이 더 효율적이라고 함. 자기 프로세스 페이지에서만 교체를 하면, 교체를 해야할 때 각각 모두 교체를 진행해야 하므로 비효율적\n"
},
{
"path": "Computer Science/Operating System/Paging and Segmentation.md",
"content": "### 페이징과 세그먼테이션\n\n---\n\n##### 기법을 쓰는 이유\n\n> 다중 프로그래밍 시스템에 여러 프로세스를 수용하기 위해 주기억장치를 동적 분할하는 메모리 관리 작업이 필요해서\n\n
\n\n\n\n##### 교체 방식\n\n- Global 교체\n\n > 메모리 상의 모든 프로세스 페이지에 대해 교체하는 방식\n\n- Local 교체\n\n > 메모리 상의 자기 프로세스 페이지에서만 교체하는 방식\n\n\n\n다중 프로그래밍의 경우, 메인 메모리에 다양한 프로세스가 동시에 올라올 수 있음\n\n따라서, 다양한 프로세스의 페이지가 메모리에 존재함\n\n페이지 교체 시, 다양한 페이지 교체 알고리즘을 활용해 victim page를 선정하는데, 선정 기준을 Global로 하느냐, Local로 하느냐에 대한 차이\n\n→ 실제로는 전체를 기준으로 페이지를 교체하는 것이 더 효율적이라고 함. 자기 프로세스 페이지에서만 교체를 하면, 교체를 해야할 때 각각 모두 교체를 진행해야 하므로 비효율적\n"
},
{
"path": "Computer Science/Operating System/Paging and Segmentation.md",
"content": "### 페이징과 세그먼테이션\n\n---\n\n##### 기법을 쓰는 이유\n\n> 다중 프로그래밍 시스템에 여러 프로세스를 수용하기 위해 주기억장치를 동적 분할하는 메모리 관리 작업이 필요해서\n\n\n\n#### 메모리 관리 기법\n\n1. 연속 메모리 관리\n\n > 프로그램 전체가 하나의 커다란 공간에 연속적으로 할당되어야 함\n\n - 고정 분할 기법 : 주기억장치가 고정된 파티션으로 분할 (**내부 단편화 발생**)\n - 동적 분할 기법 : 파티션들이 동적 생성되며 자신의 크기와 같은 파티션에 적재 (**외부 단편화 발생**)\n\n
\n\n2. 불연속 메모리 관리\n\n > 프로그램의 일부가 서로 다른 주소 공간에 할당될 수 있는 기법\n\n 페이지 : 고정 사이즈의 작은 프로세스 조각\n\n 프레임 : 페이지 크기와 같은 주기억장치 메모리 조각\n\n 단편화 : 기억 장치의 빈 공간 or 자료가 여러 조각으로 나뉘는 현상\n\n 세그먼트 : 서로 다른 크기를 가진 논리적 블록이 연속적 공간에 배치되는 것\n
\n\n **고정 크기** : 페이징(Paging)\n\n **가변 크기** : 세그먼테이션(Segmentation)\n
\n\n - 단순 페이징\n\n > 각 프로세스는 프레임들과 같은 길이를 가진 균등 페이지로 나뉨\n >\n > 외부 단편화 X\n >\n > 소량의 내부 단편화 존재\n\n - 단순 세그먼테이션\n\n > 각 프로세스는 여러 세그먼트들로 나뉨\n >\n > 내부 단편화 X, 메모리 사용 효율 개선, 동적 분할을 통한 오버헤드 감소\n >\n > 외부 단편화 존재\n\n - 가상 메모리 페이징\n\n > 단순 페이징과 비교해 프로세스 페이지 전부를 로드시킬 필요X\n >\n > 필요한 페이지가 있으면 나중에 자동으로 불러들어짐\n >\n > 외부 단편화 X\n >\n > 복잡한 메모리 관리로 오버헤드 발생\n\n - 가상 메모리 세그먼테이션\n\n > 필요하지 않은 세그먼트들은 로드되지 않음\n >\n > 필요한 세그먼트 있을때 나중에 자동으로 불러들어짐\n >\n > 내부 단편화X\n >\n > 복잡한 메모리 관리로 오버헤드 발생\n\n" }, { "path": "Computer Science/Operating System/Process Address Space.md", "content": "## 프로세스의 주소 공간\n\n> 프로그램이 CPU에 의해 실행됨 → 프로세스가 생성되고 메모리에 '**프로세스 주소 공간**'이 할당됨\n\n프로세스 주소 공간에는 코드, 데이터, 스택으로 이루어져 있다.\n\n- **코드 Segment** : 프로그램 소스 코드 저장\n- **데이터 Segment** : 전역 변수 저장\n- **스택 Segment** : 함수, 지역 변수 저장\n\n
\n\n***왜 이렇게 구역을 나눈건가요?***\n\n최대한 데이터를 공유하여 메모리 사용량을 줄여야 합니다. \n\nCode는 같은 프로그램 자체에서는 모두 같은 내용이기 때문에 따로 관리하여 공유함\n\nStack과 데이터를 나눈 이유는, 스택 구조의 특성과 전역 변수의 활용성을 위한 것!\n\n
\n\n
 \n\n```\n프로그램의 함수와 지역 변수는, LIFO(가장 나중에 들어간게 먼저 나옴)특성을 가진 스택에서 실행된다. \n따라서 이 함수들 안에서 공통으로 사용하는 '전역 변수'는 따로 지정해주면 메모리를 아낄 수 있다.\n```\n"
},
{
"path": "Computer Science/Operating System/Process Management & PCB.md",
"content": "## PCB & Context Switching\n\n
\n\n```\n프로그램의 함수와 지역 변수는, LIFO(가장 나중에 들어간게 먼저 나옴)특성을 가진 스택에서 실행된다. \n따라서 이 함수들 안에서 공통으로 사용하는 '전역 변수'는 따로 지정해주면 메모리를 아낄 수 있다.\n```\n"
},
{
"path": "Computer Science/Operating System/Process Management & PCB.md",
"content": "## PCB & Context Switching\n\n\n\n#### Process Management\n\n> CPU가 프로세스가 여러개일 때, CPU 스케줄링을 통해 관리하는 것을 말함\n\n이때, CPU는 각 프로세스들이 누군지 알아야 관리가 가능함\n\n프로세스들의 특징을 갖고있는 것이 바로 `Process Metadata`\n\n- Process Metadata\n - Process ID\n - Process State\n - Process Priority\n - CPU Registers\n - Owner\n - CPU Usage\n - Memeory Usage\n\n이 메타데이터는 프로세스가 생성되면 `PCB(Process Control Block)`이라는 곳에 저장됨\n\n
\n\n#### PCB(Process Control Block)\n\n> 프로세스 메타데이터들을 저장해 놓는 곳, 한 PCB 안에는 한 프로세스의 정보가 담김\n\n
\n\n##### 다시 정리해보면?\n\n```\n프로그램 실행 → 프로세스 생성 → 프로세스 주소 공간에 (코드, 데이터, 스택) 생성 \n→ 이 프로세스의 메타데이터들이 PCB에 저장\n```\n\n\n\n##### PCB가 왜 필요한가요?\n\n> CPU에서는 프로세스의 상태에 따라 교체작업이 이루어진다. (interrupt가 발생해서 할당받은 프로세스가 wating 상태가 되고 다른 프로세스를 running으로 바꿔 올릴 때)\n>\n> 이때, **앞으로 다시 수행할 대기 중인 프로세스에 관한 저장 값을 PCB에 저장해두는 것**이다.\n\n##### PCB는 어떻게 관리되나요?\n\n> Linked List 방식으로 관리함\n>\n> PCB List Head에 PCB들이 생성될 때마다 붙게 된다. 주소값으로 연결이 이루어져 있는 연결리스트이기 때문에 삽입 삭제가 용이함.\n>\n> 즉, 프로세스가 생성되면 해당 PCB가 생성되고 프로세스 완료시 제거됨\n\n
\n\n
\n\n이렇게 수행 중인 프로세스를 변경할 때, CPU의 레지스터 정보가 변경되는 것을 `Context Switching`이라고 한다.\n\n#### Context Switching\n\n> CPU가 이전의 프로세스 상태를 PCB에 보관하고, 또 다른 프로세스의 정보를 PCB에 읽어 레지스터에 적재하는 과정\n\n보통 인터럽트가 발생하거나, 실행 중인 CPU 사용 허가시간을 모두 소모하거나, 입출랙을 위해 대기해야 하는 경우에 Context Switching이 발생\n\n`즉, 프로세스가 Ready → Running, Running → Ready, Running → Waiting처럼 상태 변경 시 발생!` \n\n
\n\n##### Context Switching의 OverHead란?\n\noverhead는 과부하라는 뜻으로 보통 안좋은 말로 많이 쓰인다.\n\n하지만 프로세스 작업 중에는 OverHead를 감수해야 하는 상황이 있다.\n\n```\n프로세스를 수행하다가 입출력 이벤트가 발생해서 대기 상태로 전환시킴\n이때, CPU를 그냥 놀게 놔두는 것보다 다른 프로세스를 수행시키는 것이 효율적\n```\n\n즉, CPU에 계속 프로세스를 수행시키도록 하기 위해서 다른 프로세스를 실행시키고 Context Switching 하는 것\n\nCPU가 놀지 않도록 만들고, 사용자에게 빠르게 일처리를 제공해주기 위한 것이다." }, { "path": "Computer Science/Operating System/Process vs Thread.md", "content": "# 프로세스 & 스레드\n\n
\n\n> **프로세스** : 프로그램을 메모리 상에서 실행중인 작업\n>\n> **스레드** : 프로세스 안에서 실행되는 여러 흐름 단위\n\n
\n\n기본적으로 프로세스마다 최소 1개의 스레드 소유 (메인 스레드 포함)\n\n
\n\n\n\n프로세스는 각각 별도의 주소공간 할당 (독립적)\n\n- Code : 코드 자체를 구성하는 메모리 영역(프로그램 명령)\n\n- Data : 전역변수, 정적변수, 배열 등\n - 초기화 된 데이터는 data 영역에 저장\n - 초기화 되지 않은 데이터는 bss 영역에 저장\n- Heap : 동적 할당 시 사용 (new(), malloc() 등)\n\n- Stack : 지역변수, 매개변수, 리턴 값 (임시 메모리 영역)\n\n
\n\n스레드는 Stack만 따로 할당 받고 나머지 영역은 서로 공유\n\n- Stack 영역만 따로 할당 받는 이유\n - 쓰레드는 독립적인 동작을 수행하기 위해 존재 한다\n - 즉 독립적으로 함수를 호출 할 수 있어야 한다\n - 때문에 함수의 매개변수, 지역변수등을 저장하는 스택 메모리 영역은 독립적으로 할당 받아야 한다\n\n
\n\n하나의 프로세스가 생성될 때, 기본적으로 하나의 스레드 같이 생성\n\n
\n\n**프로세스는 자신만의 고유 공간과 자원을 할당받아 사용**하는데 반해, **스레드는 다른 스레드와 공간, 자원을 공유하면서 사용**하는 차이가 존재함\n\n
\n\n
\n\n##### 멀티프로세스\n\n> 하나의 프로그램을 여러개의 프로세스로 구성하여 각 프로세스가 병렬적으로 작업을 수행하는 것\n\n**장점** : 안전성 (메모리 침범 문제를 OS 차원에서 해결)\n\n**단점** : 각각 독립된 메모리 영역을 갖고 있어, 작업량 많을 수록 오버헤드 발생. Context Switching으로 인한 성능 저하\n\n
\n\n***Context Switching*이란?**\n\n> 프로세스의 상태 정보를 저장하고 복원하는 일련의 과정\n>\n> 즉, 동작 중인 프로세스가 대기하면서 해당 프로세스의 상태를 보관하고, 대기하고 있던 다음 순번의 프로세스가 동작하면서 이전에 보관했던 프로세스 상태를 복구하는 과정을 말함\n>\n> → 프로세스는 각 독립된 메모리 영역을 할당받아 사용되므로, 캐시 메모리 초기화와 같은 무거운 작업이 진행되었을 때 오버헤드가 발생할 문제가 존재함\n\n
\n\n
\n\n##### 멀티 스레드\n\n> 하나의 응용 프로그램에서 여러 스레드를 구성해 각 스레드가 하나의 작업을 처리하는 것\n\n스레드들이 공유 메모리를 통해 다수의 작업을 동시에 처리하도록 해줌\n\n
\n\n**장점** : 독립적인 프로세스에 비해 공유 메모리만큼의 시간, 자원 손실이 감소\n전역 변수와 정적 변수에 대한 자료 공유 가능\n\n**단점** : 안전성 문제. 하나의 스레드가 데이터 공간 망가뜨리면, 모든 스레드가 작동 불능 상태 (공유 메모리를 갖기 때문)\n\n- 멀티스레드의 안전성에 대한 단점은 Critical Section 기법을 통해 대비함\n\n > 하나의 스레드가 공유 데이터 값을 변경하는 시점에 다른 스레드가 그 값을 읽으려할 때 발생하는 문제를 해결하기 위한 동기화 과정\n >\n > ```\n > 상호 배제, 진행, 한정된 대기를 충족해야함\n > ```\n" }, { "path": "Computer Science/Operating System/Race Condition.md", "content": "## [OS] Race Condition\n\n공유 자원에 대해 여러 프로세스가 동시에 접근할 때, 결과값에 영향을 줄 수 있는 상태\n\n> 동시 접근 시 자료의 일관성을 해치는 결과가 나타남\n\n
\n\n#### Race Condition이 발생하는 경우\n\n1. ##### 커널 작업을 수행하는 중에 인터럽트 발생\n\n - 문제점 : 커널모드에서 데이터를 로드하여 작업을 수행하다가 인터럽트가 발생하여 같은 데이터를 조작하는 경우\n - 해결법 : 커널모드에서 작업을 수행하는 동안, 인터럽트를 disable 시켜 CPU 제어권을 가져가지 못하도록 한다.\n\n2. ##### 프로세스가 'System Call'을 하여 커널 모드로 진입하여 작업을 수행하는 도중 문맥 교환이 발생할 때\n\n - 문제점 : 프로세스1이 커널모드에서 데이터를 조작하는 도중, 시간이 초과되어 CPU 제어권이 프로세스2로 넘어가 같은 데이터를 조작하는 경우 ( 프로세스2가 작업에 반영되지 않음 )\n - 해결법 : 프로세스가 커널모드에서 작업을 하는 경우 시간이 초과되어도 CPU 제어권이 다른 프로세스에게 넘어가지 않도록 함\n\n3. ##### 멀티 프로세서 환경에서 공유 메모리 내의 커널 데이터에 접근할 때\n\n - 문제점 : 멀티 프로세서 환경에서 2개의 CPU가 동시에 커널 내부의 공유 데이터에 접근하여 조작하는 경우\n - 해결법 : 커널 내부에 있는 각 공유 데이터에 접근할 때마다, 그 데이터에 대한 lock/unlock을 하는 방법\n\n \n\n" }, { "path": "Computer Science/Operating System/Semaphore & Mutex.md", "content": "## 세마포어(Semaphore) & 뮤텍스(Mutex)\n\n
\n\n공유된 자원에 여러 프로세스가 동시에 접근하면서 문제가 발생할 수 있다. 이때 공유된 자원의 데이터는 한 번에 하나의 프로세스만 접근할 수 있도록 제한을 둬야 한다.\n\n이를 위해 나온 것이 바로 **'세마포어'**\n\n**세마포어** : 멀티프로그래밍 환경에서 공유 자원에 대한 접근을 제한하는 방법\n\n
\n\n##### 임계 구역(Critical Section)\n\n> 여러 프로세스가 데이터를 공유하며 수행될 때, **각 프로세스에서 공유 데이터를 접근하는 프로그램 코드 부분**\n\n공유 데이터를 여러 프로세스가 동시에 접근할 때 잘못된 결과를 만들 수 있기 때문에, 한 프로세스가 임계 구역을 수행할 때는 다른 프로세스가 접근하지 못하도록 해야 한다.\n\n
\n\n#### 세마포어 P, V 연산\n\nP : 임계 구역 들어가기 전에 수행 ( 프로세스 진입 여부를 자원의 개수(S)를 통해 결정)\n\nV : 임계 구역에서 나올 때 수행 ( 자원 반납 알림, 대기 중인 프로세스를 깨우는 신호 )\n\n
\n\n##### 구현 방법\n\n```sql\nP(S);\n\n// --- 임계 구역 ---\n\nV(S);\n```\n\n
\n\n```sql\nprocedure P(S) --> 최초 S값은 1임\n while S=0 do wait --> S가 0면 1이 될때까지 기다려야 함\n S := S-1 --> S를 0로 만들어 다른 프로세스가 들어 오지 못하도록 함\nend P\n\n--- 임계 구역 ---\n\nprocedure V(S) --> 현재상태는 S가 0임\n S := S+1 --> S를 1로 원위치시켜 해제하는 과정\nend V\n```\n\n이를 통해, 한 프로세스가 P 혹은 V를 수행하고 있는 동안 프로세스가 인터럽트 당하지 않게 된다. P와 V를 사용하여 임계 구역에 대한 상호배제 구현이 가능하게 되었다.\n\n***예시***\n\n> 최초 S 값은 1이고, 현재 해당 구역을 수행할 프로세스 A, B가 있다고 가정하자\n\n1. 먼저 도착한 A가 P(S)를 실행하여 S를 0으로 만들고 임계구역에 들어감\n2. 그 뒤에 도착한 B가 P(S)를 실행하지만 S가 0이므로 대기 상태\n3. A가 임계구역 수행을 마치고 V(S)를 실행하면 S는 다시 1이 됨\n4. B는 이제 P(S)에서 while문을 빠져나올 수 있고, 임계구역으로 들어가 수행함\n\n
\n\n
\n\n**뮤텍스** : 임계 구역을 가진 스레드들의 실행시간이 서로 겹치지 않고 각각 단독으로 실행되게 하는 기술\n\n> 상호 배제(**Mut**ual **Ex**clusion)의 약자임\n\n해당 접근을 조율하기 위해 lock과 unlock을 사용한다.\n\n- lock : 현재 임계 구역에 들어갈 권한을 얻어옴 ( 만약 다른 프로세스/스레드가 임계 구역 수행 중이면 종료할 때까지 대기 )\n- unlock : 현재 임계 구역을 모두 사용했음을 알림. ( 대기 중인 다른 프로세스/스레드가 임계 구역에 진입할 수 있음 )\n\n
\n\n뮤텍스는 상태가 0, 1로 **이진 세마포어**로 부르기도 함\n\n
\n\n#### **뮤텍스 알고리즘**\n\n1. ##### 데커(Dekker) 알고리즘\n\n flag와 turn 변수를 통해 임계 구역에 들어갈 프로세스/스레드를 결정하는 방식\n\n - flag : 프로세스 중 누가 임계영역에 진입할 것인지 나타내는 변수\n - turn : 누가 임계구역에 들어갈 차례인지 나타내는 변수\n\n ```java\n while(true) {\n flag[i] = true; // 프로세스 i가 임계 구역 진입 시도\n while(flag[j]) { // 프로세스 j가 현재 임계 구역에 있는지 확인\n if(turn == j) { // j가 임계 구역 사용 중이면\n flag[i] = false; // 프로세스 i 진입 취소\n while(turn == j); // turn이 j에서 변경될 때까지 대기\n flag[i] = true; // j turn이 끝나면 다시 진입 시도\n }\n }\n }\n \n // ------- 임계 구역 ---------\n \n turn = j; // 임계 구역 사용 끝나면 turn을 넘김\n flag[i] = false; // flag 값을 false로 바꿔 임계 구역 사용 완료를 알림\n ```\n\n
\n\n2. ##### 피터슨(Peterson) 알고리즘\n\n 데커와 유사하지만, 상대방 프로세스/스레드에게 진입 기회를 양보하는 것에 차이가 있음\n\n ```java\n while(true) {\n flag[i] = true; // 프로세스 i가 임계 구역 진입 시도\n turn = j; // 다른 프로세스에게 진입 기회 양보\n while(flag[j] && turn == j) { // 다른 프로세스가 진입 시도하면 대기\n }\n }\n \n // ------- 임계 구역 ---------\n \n flag[i] = false; // flag 값을 false로 바꿔 임계 구역 사용 완료를 알림\n ```\n\n
\n\n3. ##### 제과점(Bakery) 알고리즘\n\n 여러 프로세스/스레드에 대한 처리가 가능한 알고리즘. 가장 작은 수의 번호표를 가지고 있는 프로세스가 임계 구역에 진입한다.\n\n ```java\n while(true) {\n \n isReady[i] = true; // 번호표 받을 준비\n number[i] = max(number[0~n-1]) + 1; // 현재 실행 중인 프로세스 중에 가장 큰 번호 배정 \n isReady[i] = false; // 번호표 수령 완료\n \n for(j = 0; j < n; j++) { // 모든 프로세스 번호표 비교\n while(isReady[j]); // 비교 프로세스가 번호표 받을 때까지 대기\n while(number[j] && number[j] < number[i] && j < i);\n \n // 프로세스 j가 번호표 가지고 있어야 함\n // 프로세스 j의 번호표 < 프로세스 i의 번호표\n }\n \n // ------- 임계 구역 ---------\n \n number[i] = 0; // 임계 구역 사용 종료\n }\n ```\n\n \n" }, { "path": "Computer Science/Operating System/[OS] System Call (Fork Wait Exec).md", "content": "#### [Operating System] System Call\n\n---\n\nfork( ), exec( ), wait( )와 같은 것들은 Process 생성과 제어를 위한 System call임.\n\n- fork, exec는 새로운 Process 생성과 관련이 되어 있다.\n- wait는 Process (Parent)가 만든 다른 Process(child) 가 끝날 때까지 기다리는 명령어임.\n\n---\n\n##### Fork\n\n> 새로운 Process를 생성할 때 사용.\n>\n> 그러나, 이상한 방식임.\n\n```c\n#include
\n\n클린코드와 리팩토링은 의미만 보면 비슷하다고 느껴진다. 어떤 차이점이 있을지 생각해보자\n\n
\n\n#### 클린코드\n\n클린코드란, 가독성이 높은 코드를 말한다.\n\n가독성을 높이려면 다음과 같이 구현해야 한다.\n\n- 네이밍이 잘 되어야 함\n- 오류가 없어야 함\n- 중복이 없어야 함\n- 의존성을 최대한 줄여야 함\n- 클래스 혹은 메소드가 한가지 일만 처리해야 함\n\n
\n\n얼마나 **코드가 잘 읽히는 지, 코드가 지저분하지 않고 정리된 코드인지**를 나타내는 것이 바로 '클린 코드'\n\n```java\npublic int AAA(int a, int b){\n return a+b;\n}\npublic int BBB(int a, int b){\n return a-b;\n}\n```\n\n
\n\n두 가지 문제점이 있다.\n\n
\n\n```java\npublic int sum(int a, int b){\n return a+b;\n}\n\npublic int sub(int a, int b){\n return a-b;\n}\n```\n\n첫째는 **함수 네이밍**이다. 다른 사람들이 봐도 무슨 역할을 하는 함수인 지 알 수 있는 이름을 사용해야 한다.\n\n둘째는 **함수와 함수 사이의 간격**이다. 여러 함수가 존재할 때 간격을 나누지 않으면 시작과 끝을 구분하는 것이 매우 힘들다.\n\n
\n\n
\n\n#### 리팩토링\n\n프로그램의 외부 동작은 그대로 둔 채, 내부의 코드를 정리하면서 개선하는 것을 말함\n\n```\n이미 공사가 끝난 집이지만, 더 튼튼하고 멋진 집을 만들기 위해 내부 구조를 개선하는 리모델링 작업\n```\n\n
\n\n프로젝트가 끝나면, 지저분한 코드를 볼 때 가독성이 떨어지는 부분이 존재한다. 이 부분을 개선시키기 위해 필요한 것이 바로 '리팩토링 기법'\n\n리팩토링 작업은 코드의 가독성을 높이고, 향후 이루어질 유지보수에 큰 도움이 된다.\n\n
\n\n##### 리팩토링이 필요한 코드는?\n\n- 중복 코드\n- 긴 메소드\n- 거대한 클래스\n- Switch 문\n- 절차지향으로 구현한 코드\n\n
\n\n리팩토링의 목적은, 소프트웨어를 더 이해하기 쉽고 수정하기 쉽게 만드는 것\n\n```\n리팩토링은 성능을 최적화시키는 것이 아니다.\n코드를 신속하게 개발할 수 있게 만들어주고, 코드 품질을 좋게 만들어준다.\n```\n\n이해하기 쉽고, 수정하기 쉬우면? → 개발 속도가 증가!\n\n
\n\n##### 리팩토링이 필요한 상황\n\n> 소프트웨어에 새로운 기능을 추가해야 할 때\n\n```\n명심해야할 것은, 우선 코드가 제대로 돌아가야 한다는 것. 리팩토링은 우선적으로 해야 할 일이 아님을 명심하자\n```\n\n
\n\n객체지향 특징을 살리려면, switch-case 문을 적게 사용해야 함\n\n(switch문은 오버라이드로 다 바꿔버리자)\n\n
\n\n\n\n\n\n\n\n\n\n\n\n##### 리팩토링 예제\n\n
\n\n1번\n\n```java\n// 수정 전\npublic int getFoodPrice(int arg1, int arg2) {\n return arg1 * arg2;\n}\n```\n\n함수명 직관적 수정, 변수명을 의미에 맞게 수정\n\n```java\n// 수정 후\npublic int getTotalFoodPrice(int price, int quantity) {\n return price * quantity;\n}\n```\n\n
\n\n2번\n\n```java\n// 수정 전\npublic int getTotalPrice(int price, int quantity, double discount) {\n return (int) ((price * quantity) * (price * quantity) * (discount /100));\n}\n```\n\n`price * quantity`가 중복된다. 따로 변수로 추출하자\n\n할인율을 계산하는 부분을 메소드로 따로 추출하자\n\n할인율 함수 같은 경우는 항상 일정하므로 외부에서 건드리지 못하도록 private 선언\n\n```java\n// 수정 후\npublic int getTotalFoodPrice(int price, int quantity, double discount) {\n int totalPriceQuantity = price * quantity;\n return (int) (totalPriceQuantity - getDiscountPrice(discount, totalPriceQuantity))\n}\n\nprivate double getDiscountPrice(double discount, int totalPriceQuantity) {\n return totalPriceQuantity * (discount / 100);\n}\n```\n\n
\n\n이 코드를 한번 더 리팩토링 해보면?\n\n
\n\n\n\n\n\n3번\n\n```java\n// 수정 전\npublic int getTotalFoodPrice(int price, int quantity, double discount) {\n\t\n int totalPriceQuantity = price * quantity;\n return (int) (totalPriceQuantity - getDiscountPrice(discount, totalPriceQuantity))\n}\n\nprivate double getDiscountPrice(double discount, int totalPriceQuantity) {\n return totalPriceQuantity * (discount / 100);\n}\n```\n\n
\n\ntotalPriceQuantity를 getter 메소드로 추출이 가능하다.\n\n지불한다는 의미를 주기 위해 메소드 명을 수정해주자\n\n
\n\n```java\n// 수정 후\npublic int getFoodPriceToPay(int price, int quantity, double discount) {\n \n int totalPriceQuantity = getTotalPriceQuantity(price, quantity);\n return (int) (totalPriceQuantity - getDiscountPrice(discount, totalPriceQuantity));\n}\n\nprivate double getDiscountPrice(double discount, int totalPriceQuantity) {\n return totalPriceQuantity * (discount / 100);\n}\n\nprivate int getTotalPriceQuantity(int price, int quantity) {\n return price * quantity;\n}\n```\n\n
\n\n
\n\n##### 클린코드와 리팩토링의 차이?\n\n리팩토링이 더 큰 의미를 가진 것 같다. 클린 코드는 단순히 가독성을 높이기 위한 작업으로 이루어져 있다면, 리팩토링은 클린 코드를 포함한 유지보수를 위한 코드 개선이 이루어진다.\n\n클린코드와 같은 부분은 설계부터 잘 이루어져 있는 것이 중요하고, 리팩토링은 결과물이 나온 이후 수정이나 추가 작업이 진행될 때 개선해나가는 것이 올바른 방향이다.\n\n" }, { "path": "Computer Science/Software Engineering/Fuctional Programming.md", "content": "## 함수형 프로그래밍\n\n> 순수 함수를 조합하고 공유 상태, 변경 가능한 데이터 및 부작용을 **피해** 소프트웨어를 만드는 프로세스\n\n
\n\n
 \n\n
\n\n\n\n'선언형' 프로그래밍으로, 애플리케이션의 상태는 순수 함수를 통해 전달된다.\n\n애플리케이션의 상태가 일반적으로 공유되고 객체의 메서드와 함께 배치되는 OOP와는 대조되는 프로그래밍 방식\n\n
\n\n- ##### 명령형 프로그래밍(절차지향, 객체지향)\n\n > 상태와 상태를 변경시키는 관점에서 연산을 설명하는 방식 \n >\n > 알고리즘을 명시하고, 목표는 명시하지 않음\n\n- ##### 선언형 프로그래밍\n\n > How보다는 What을 설명하는 방식 (어떻게보단 무엇을)\n >\n > 알고리즘을 명시하지 않고 목표만 명시함\n\n
\n\n```\n명령형 프로그래밍은 어떻게 할지 표현하고, 선언형 프로그래밍은 무엇을 할 건지 표현한다.\n```\n\n
\n\n함수형 코드는 명령형 프로그래밍이나 OOP 코드보다 더 간결하고 예측가능하여 테스트하는 것이 쉽다.\n\n(하지만 익숙치 않으면 더 복잡해보이고 이해하기 어려움)\n\n
\n\n함수형 프로그래밍은 프로그래밍 언어나 방식을 배우는 것이 아닌, 함수로 프로그래밍하는 사고를 배우는 것이다.\n\n`기존의 사고방식을 전환하여 프로그래밍을 더 유연하게 문제해결 하도록 접근하는 것`\n\n
\n\n#### 함수형 프로그래밍의 의미를 파악하기 전 꼭 알아야 할 것들\n\n- 순수 함수 (Pure functions)\n\n > 입출력이 순수해야함 : 반드시 하나 이상의 인자를 받고, 받은 인자를 처리해 반드시 결과물을 돌려줘야 함. 인자 외 다른 변수 사용 금지\n\n- 합성 함수 (Function composition)\n\n- 공유상태 피하기 (Avoid shared state)\n\n- 상태변화 피하기 (Avoid mutating state)\n\n- 부작용 피하기 (Avoid side effects)\n\n > 프로그래머가 바꾸고자 하는 변수 외에는 변경되면 안됨. 원본 데이터는 절대 불변!\n\n
\n\n대표적인 자바스크립트 함수형 프로그래밍 함수 : map, filter, reduce\n\n
\n\n##### 함수형 프로그래밍 예시\n\n```javascript\nvar arr = [1, 2, 3, 4, 5];\nvar map = arr.map(function(x) {\n return x * 2;\n}); // [2, 4, 6, 8, 10]\n```\n\narr을 넣어서 map을 얻었음. arr을 사용했지만 값은 변하지 않았고 map이라는 결과를 내고 어떠한 부작용도 낳지 않음\n\n이런 것이 바로 함수형 프로그래밍의 순수함수라고 말한다.\n\n
\n\n```javascript\nvar arr = [1, 2, 3, 4, 5];\nvar condition = function(x) { return x % 2 === 0; }\nvar ex = function(array) {\n return array.filter(condition);\n};\nex(arr); // [2, 4]\n```\n\n이는 순수함수가 아니다. 이유는 ex 메소드에서 인자가 아닌 condition을 사용했기 때문.\n\n순수함수로 고치면 아래와 같다.\n\n```javascript\nvar ex = function(array, cond) {\n return array.filter(cond);\n};\nex(arr, condition);\n```\n\n순수함수로 만들면, 에러를 추적하는 것이 쉬워진다. 인자에 문제가 있거나 함수 내부에 문제가 있거나 둘 중 하나일 수 밖에 없기 때문이다.\n\n
\n\n
\n\n### Java에서의 함수형 프로그래밍\n\n---\n\nJava 8이 릴리즈되면서, Java에서도 함수형 프로그래밍이 가능해졌다.\n\n```\n함수형 프로그래밍 : 부수효과를 없애고 순수 함수를 만들어 모듈화 수준을 높이는 프로그래밍 패러다임\n```\n\n부수효과 : 주어진 값 이외의 외부 변수 및 프로그래밍 실행에 영향을 끼치지 않아야 된다는 의미\n\n최대한 순수함수를 지향하고, 숨겨진 입출력을 최대한 제거하여 코드를 순수한 입출력 관계로 사용하는 것이 함수형 프로그래밍의 목적이다.\n\n\n\nJava의 객체 지향은 명령형 프로그래밍이고, 함수형은 선언형 프로그래밍이다.\n\n둘의 차이는 `문제해결의 관점`\n\n여태까지 우리는 Java에서 객체지향 프로그래밍을 할 때 '데이터를 어떻게 처리할 지에 대해 명령을 통해 해결'했다.\n\n함수형 프로그래밍은 선언적 함수를 통해 '무엇을 풀어나가야할지 결정'하는 것이다.\n\n\n\n##### Java에서 활용할 수 있는 함수형 프로그래밍\n\n- 람다식\n- stream api\n- 함수형 인터페이스\n\n\n\nJava 8에는 Stream API가 추가되었다.\n\n```java\nimport java.util.Arrays;\nimport java.util.List;\n\npublic class stream {\n\n\tpublic static void main(String[] args) {\n\t\tList
\n\n보통 OOP라고 많이 부른다. 객체지향은 수 없이 많이 들어왔지만, 이게 뭔지 설명해달라고 하면 어디서부터 해야할 지 막막해진다.. 개념을 잡아보자\n\n
\n\n객체지향 패러다임이 나오기 이전의 패러다임들부터 간단하게 살펴보자. \n\n패러다임의 발전 과정을 보면 점점 개발자들이 **편하게 개발할 수 있도록 개선되는 방식**으로 나아가고 있는 걸 확인할 수 있다.\n\n
\n\n가장 먼저 **순차적, 비구조적 프로그래밍**이 있다. 말 그대로 순차적으로 코딩해나가는 것!\n\n필요한 게 있으면 계속 순서대로 추가해가며 구현하는 방식이다. 직관적일 것처럼 생각되지만, 점점 규모가 커지게 되면 어떻게 될까?\n\n이런 비구조적 프로그래밍에서는 **goto문을 활용**한다. 만약 이전에 작성했던 코드가 다시 필요하면 그 곳으로 이동하기 위한 것이다. 점점 규모가 커지면 goto문을 무분별하게 사용하게 되고, 마치 실뜨기를 하는 것처럼 베베 꼬이게 된다. (코드 안에서 위로 갔다가 아래로 갔다가..뒤죽박죽) 나중에 코드가 어떻게 연결되어 있는지 확인조차 하지 못하게 될 문제점이 존재한다.\n\n> 이러면, 코딩보다 흐름을 이해하는 데 시간을 다 소비할 가능성이 크다\n\n오늘날 수업을 듣거나 공부하면서 `goto문은 사용하지 않는게 좋다!`라는 말을 분명 들어봤을 것이다. goto문은 장기적으로 봤을 때 크게 도움이 되지 않는 구현 방식이기 때문에 그런 것이었다. \n\n
\n\n이런 문제점을 해결하기 위해 탄생한 것이 바로 **절차적, 구조적 프로그래밍**이다. 이건 대부분 많이 들어본 패러다임일 것이다. \n\n**반복될 가능성이 있는 것들을 재사용이 가능한 함수(프로시저)로 만들어 사용**하는 프로그래밍 방식이다. \n\n여기서 보통 절차라는 의미는 함수(프로시저)를 뜻하고, 구조는 모듈을 뜻한다. 모듈이 함수보다 더 작은 의미이긴 하지만, 요즘은 큰 틀로 같은 의미로 쓰이고 있다. \n\n
\n\n##### *프로시저는 뭔가요?*\n\n> 반환값(리턴)이 따로 존재하지 않는 함수를 뜻한다. 예를 들면, printf와 같은 함수는 반환값을 얻기 위한 것보단, 화면에 출력하는 용도로 쓰이는 함수다. 이와 같은 함수를 프로시저로 부른다.\n>\n> (정확히 말하면 printf는 int형을 리턴해주기는 함. 하지만 목적 자체는 프로시저에 가까움)\n\n
\n\n하지만 이런 패러다임도 문제점이 존재한다. 바로 `너무 추상적`이라는 것..\n\n실제로 사용되는 프로그램들은 추상적이지만은 않다. 함수는 논리적 단위로 표현되지만, 실제 데이터에 해당하는 변수나 상수 값들은 물리적 요소로 되어있기 때문이다.\n\n
\n\n도서관리 프로그램이 있다고 가정해보자.\n\n책에 해당하는 자료형(필드)를 구현해야 한다. 또한 책과 관련된 함수를 구현해야 한다. 구조적인 프로그래밍에서는 이들을 따로 만들어야 한다. 결국 많은 데이터를 만들어야 할 때, 구분하기 힘들고 비효율적으로 코딩할 가능성이 높아진다. \n\n> 책에 대한 자료형, 책에 대한 함수가 물리적으론 같이 있을 수 있지만 (같은 위치에 기록)\n>\n> 논리적으로는 함께할 수 없는 구조가 바로 `구조적 프로그래밍`\n\n
\n\n따라서, 이를 한번에 묶기 위한 패러다임이 탄생한다.\n\n
\n\n바로 **객체지향 프로그래밍**이다.\n\n우리가 vo를 만들 때와 같은 형태다. 클래스마다 필요한 필드를 선언하고, getter와 setter로 구성된 모습으로 해결한다. 바로 **특정한 개념의 함수와 자료형을 함께 묶어서 관리하기 위해 탄생**한 것!\n\n
\n\n가장 중요한 점은, **객체 내부에 자료형(필드)와 함수(메소드)가 같이 존재하는 것**이다.\n\n이제 도서관리 프로그램을 만들 때, 해당하는 책의 제목, 저자, 페이지와 같은 자료형과 읽기, 예약하기 등 메소드를 '책'이라는 객체에 한번에 묶어서 저장하는 것이 가능해졌다.\n\n이처럼 가능한 모든 물리적, 논리적 요소를 객체로 만드려는 것이 `객체지향 프로그래밍`이라고 말할 수 있다.\n\n
\n\n객체지향으로 구현하게 되면, 객체 간의 독립성이 생기고 중복코드의 양이 줄어드는 장점이 있다. 또한 독립성이 확립되면 유지보수에도 도움이 될 것이다.\n\n
\n\n#### 특징\n\n객체지향의 패러다임이 생겨나면서 크게 4가지 특징을 갖추게 되었다.\n\n이 4가지 특성을 잘 이해하고 구현해야 객체를 통한 효율적인 구현이 가능해진다.\n\n
\n\n1. ##### 추상화(Abstraction)\n\n > 필요로 하는 속성이나 행동을 추출하는 작업\n\n 추상적인 개념에 의존하여 설계해야 유연함을 갖출 수 있다.\n\n 즉, 세부적인 사물들의 공통적인 특징을 파악한 후 하나의 집합으로 만들어내는 것이 추상화다\n\n ```\n ex. 아우디, BMW, 벤츠는 모두 '자동차'라는 공통점이 있다.\n \n 자동차라는 추상화 집합을 만들어두고, 자동차들이 가진 공통적인 특징들을 만들어 활용한다.\n ```\n\n ***'왜 필요하죠?'***\n\n 예를 들면, '현대'와 같은 다른 자동차 브랜드가 추가될 수도 있다. 이때 추상화로 구현해두면 다른 곳의 코드는 수정할 필요 없이 추가로 만들 부분만 새로 생성해주면 된다.\n
\n\n2. ##### 캡슐화(Encapsulation)\n\n > 낮은 결합도를 유지할 수 있도록 설계하는 것\n\n 쉽게 말하면, **한 곳에서 변화가 일어나도 다른 곳에 미치는 영향을 최소화 시키는 것**을 말한다.\n\n (객체가 내부적으로 기능을 어떻게 구현하는지 감추는 것!)\n\n 결합도가 낮도록 만들어야 하는 이유가 무엇일까? **결합도(coupling)란, 어떤 기능을 실행할 때 다른 클래스나 모듈에 얼마나 의존적인가를 나타내는 말**이다.\n\n 즉, 독립적으로 만들어진 객체들 간의 의존도가 최대한 낮게 만드는 것이 중요하다. 객체들 간의 의존도가 높아지면 굳이 객체 지향으로 설계하는 의미가 없어진다.\n\n 우리는 소프트웨어 공학에서 **객체 안의 모듈 간의 요소가 밀접한 관련이 있는 것으로 구성하여 응집도를 높이고 결합도를 줄여야 요구사항 변경에 대처하는 좋은 설계 방법**이라고 배운다.\n\n 이것이 바로 `캡슐화`와 크게 연관된 부분이라고 할 수 있다.\n\n
\n\n\n 그렇다면, 캡슐화는 어떻게 높은 응집도와 낮은 결합도를 갖게 할까?\n\n 바로 **정보 은닉**을 활용한다.\n\n 외부에서 접근할 필요가 없는 것들은 private으로 접근하지 못하도록 제한을 두는 것이다.\n\n (객체안의 필드를 선언할 때 private으로 선언하라는 말이 바로 이 때문!!)\n\n
\n\n3. ##### 상속\n\n > 일반화 관계(Generalization)라고도 하며, 여러 개체들이 지닌 공통된 특성을 부각시켜 하나의 개념이나 법칙으로 성립하는 과정\n\n 일반화(상속)은 또 다른 캡슐화다.\n\n **자식 클래스를 외부로부터 은닉하는 캡슐화의 일종**이라고 말할 수 있다.\n\n
\n\n 아까 자동차를 통해 예를 들어 추상화를 설명했었다. 여기에 추가로 대리 운전을 하는 사람 클래스가 있다고 생각해보자. 이때, 자동차의 자식 클래스에 해당하는 벤츠, BMW, 아우디 등은 캡슐화를 통해 은닉해둔 상태다.\n
\n\n 사람 클래스의 관점으로는, 구체적인 자동차의 종류가 숨겨져 있는 상태다. 대리 운전자 입장에서는 자동차의 종류가 어떤 것인지는 운전하는데 크게 중요하지 않다.\n\n 새로운 자동차들이 추가된다고 해도, 사람 클래스는 영향을 받지 않는 것이 중요하다. 그러므로 캡슐화를 통해 사람 클래스 입장에서는 확인할 수 없도록 구현하는 것이다.\n\n
\n\n 이처럼, 상속 관계에서는 단순히 하나의 클래스 안에서 속성 및 연산들의 캡슐화에 한정되지 않는다. 즉, 자식 클래스 자체를 캡슐화하여 '사람 클래스'와 같은 외부에 은닉하는 것으로 확장되는 것이다.\n\n 이처럼 자식 클래스를 캡슐화해두면, 외부에선 이러한 클래스들에 영향을 받지 않고 개발을 이어갈 수 있는 장점이 있다.\n\n
\n\n ##### 상속 재사용의 단점\n\n 상속을 통한 재사용을 할 때 나타나는 단점도 존재한다.\n\n 1) 상위 클래스(부모 클래스)의 변경이 어려워진다.\n\n > 부모 클래스에 의존하는 자식 클래스가 많을 때, 부모 클래스의 변경이 필요하다면?\n >\n > 이를 의존하는 자식 클래스들이 영향을 받게 된다.\n\n 2) 불필요한 클래스가 증가할 수 있다.\n\n > 유사기능 확장시, 필요 이상의 불필요한 클래스를 만들어야 하는 상황이 발생할 수 있다.\n\n 3) 상속이 잘못 사용될 수 있다.\n\n > 같은 종류가 아닌 클래스의 구현을 재사용하기 위해 상속을 받게 되면, 문제가 발생할 수 있다. 상속 받는 클래스가 부모 클래스와 IS-A 관계가 아닐 때 이에 해당한다.\n\n
\n\n ***해결책은?***\n\n 객체 조립(Composition), 컴포지션이라고 부르기도 한다.\n\n 객체 조립은, **필드에서 다른 객체를 참조하는 방식으로 구현**된다.\n\n 상속에 비해 비교적 런타임 구조가 복잡해지고, 구현이 어려운 단점이 존재하지만 변경 시 유연함을 확보하는데 장점이 매우 크다. \n\n 따라서 같은 종류가 아닌 클래스를 상속하고 싶을 때는 객체 조립을 우선적으로 적용하는 것이 좋다.\n\n
\n\n ***그럼 상속은 언제 사용?***\n\n - IS-A 관계가 성립할 때\n - 재사용 관점이 아닌, 기능의 확장 관점일 때\n\n
\n\n4. ##### 다형성(Polymorphism)\n\n > 서로 다른 클래스의 객체가 같은 메시지를 받았을 때 각자의 방식으로 동작하는 능력\n\n 객체 지향의 핵심과도 같은 부분이다.\n\n 다형성은, 상속과 함께 활용할 때 큰 힘을 발휘한다. 이와 같은 구현은 코드를 간결하게 해주고, 유연함을 갖추게 해준다.\n\n
\n\n\n 즉, **부모 클래스의 메소드를 자식 클래스가 오버라이딩해서 자신의 역할에 맞게 활용하는 것이 다형성**이다.\n\n 이처럼 다형성을 사용하면, 구체적으로 현재 어떤 클래스 객체가 참조되는 지는 무관하게 프로그래밍하는 것이 가능하다.\n\n 상속 관계에 있으면, 새로운 자식 클래스가 추가되어도 부모 클래스의 함수를 참조해오면 되기 때문에 다른 클래스는 영향을 받지 않게 된다.\n\n
\n\n
\n\n#### 객체 지향 설계 과정\n\n- 제공해야 할 기능을 찾고 세분화한다. 그리고 그 기능을 알맞은 객체에 할당한다.\n- 기능을 구현하는데 필요한 데이터를 객체에 추가한다.\n- 그 데이터를 이용하는 기능을 넣는다.\n- 기능은 최대한 캡슐화하여 구현한다.\n- 객체 간에 어떻게 메소드 요청을 주고받을 지 결정한다.\n\n
\n\n#### 객체 지향 설계 원칙\n\nSOLID라고 부르는 5가지 설계 원칙이 존재한다.\n\n1. ##### SRP(Single Responsibility) - 단일 책임 원칙\n\n 클래스는 단 한 개의 책임을 가져야 한다.\n\n 클래스를 변경하는 이유는 단 한개여야 한다.\n\n 이를 지키지 않으면, 한 책임의 변경에 의해 다른 책임과 관련된 코드에 영향이 갈 수 있다.\n\n
\n\n2. ##### OCP(Open-Closed) - 개방-폐쇄 원칙\n\n 확장에는 열려 있어야 하고, 변경에는 닫혀 있어야 한다.\n\n 기능을 변경하거나 확장할 수 있으면서, 그 기능을 사용하는 코드는 수정하지 않는다.\n\n 이를 지키지 않으면, instanceof와 같은 연산자를 사용하거나 다운 캐스팅이 일어난다.\n\n
\n\n3. ##### LSP(Liskov Substitution) - 리스코프 치환 원칙\n\n 상위 타입의 객체를 하위 타입의 객체로 치환해도, 상위 타입을 사용하는 프로그램은 정상적으로 동작해야 한다.\n\n 상속 관계가 아닌 클래스들을 상속 관계로 설정하면, 이 원칙이 위배된다.\n\n
\n\n4. ##### ISP(Interface Segregation) - 인터페이스 분리 원칙\n\n 인터페이스는 그 인터페이스를 사용하는 클라이언트를 기준으로 분리해야 한다.\n\n 각 클라이언트가 필요로 하는 인터페이스들을 분리함으로써, 각 클라이언트가 사용하지 않는 인터페이스에 변경이 발생하더라도 영향을 받지 않도록 만들어야 한다.\n\n
\n\n5. ##### DIP(Dependency Inversion) - 의존 역전 원칙\n\n 고수준 모듈은 저수준 모듈의 구현에 의존해서는 안된다.\n\n 저수준 모듈이 고수준 모듈에서 정의한 추상 타입에 의존해야 한다.\n\n 즉, 저수준 모듈이 변경돼도 고수준 모듈은 변경할 필요가 없는 것이다.\n\n" }, { "path": "Computer Science/Software Engineering/TDD(Test Driven Development).md", "content": "## TDD(Test Driven Development)\n\n\n##### TDD : 테스트 주도 개발\n\n'테스트가 개발을 이끌어 나간다.'\n\n
\n
\n우리는 보통 개발할 때, 설계(디자인)를 한 이후 코드 개발과 테스트 과정을 거치게 된다.\n
\n\n\n\n\n\n
\n하지만 TDD는 기존 방법과는 다르게, 테스트케이스를 먼저 작성한 이후에 실제 코드를 개발하는 리팩토링 절차를 밟는다.\n
\n\n\n\n
\n```\n작가가 책을 쓰는 과정에 대해서 생각해보자.\n\n책을 쓰기 전, 목차를 먼저 구성한다.\n이후 목차에 맞는 내용을 먼저 구상한 뒤, 초안을 작성하고 고쳐쓰기를 반복한다.\n\n목차 구성 : 테스트 코드 작성\n초안 작성 : 코드 개발\n고쳐 쓰기 : 코드 수정(리팩토링)\n```\n
\n\n\n반복적인 '검토'와 '고쳐쓰기'를 통해 좋은 글이 완성된다. 이런 방법을 소프트웨어에 적용한 것이 TDD!\n\n> 소프트웨어 또한 반복적인 테스트와 수정을 통해 고품질의 소프트웨어를 탄생시킬 수 있다.\n\n\n##### 장점\n\n작업과 동시에 테스트를 진행하면서 실시간으로 오류 파악이 가능함 ( 시스템 결함 방지 )\n\n짧은 개발 주기를 통해 고객의 요구사항 빠르게 수용 가능. 피드백이 가능하고 진행 상황 파악이 쉬움\n\n자동화 도구를 이용한 TDD 테스트케이스를 단위 테스트로 사용이 가능함\n\n(자바는 JUnit, C와 C++은 CppUnit 등)\n\n개발자가 기대하는 앱의 동작에 관한 문서를 테스트가 제공해줌
\n`또한 이 테스트 케이스는 코드와 함께 업데이트 되므로 문서 작성과 거리가 먼 개발자에게 매우 좋음`\n\n##### 단점\n\n기존 개발 프로세스에 테스트케이스 설계가 추가되므로 생산 비용 증가\n\n테스트의 방향성, 프로젝트 성격에 따른 테스트 프레임워크 선택 등 추가로 고려할 부분의 증가\n\n
\n
\n
\n\n#### 점수 계산 프로그램을 통한 TDD 예제 진행\n\n---\n\n중간고사, 기말고사, 과제 점수를 통한 성적을 내는 간단한 프로그램을 만들어보자\n\n점수 총합 90점 이상은 A, 80점 이상은 B, 70점 이상은 C, 60점 이상은 D, 나머지는 F다.\n\n
\n\nTDD 테스트케이스를 먼저 작성한다.\n\n35 + 25 + 25 = 85점이므로 등급이 B가 나와야 한다.\n\n따라서 assertEquals의 인자값을 \"B\"로 주고, 테스트 결과가 일치하는지 확인하는 과정을 진행해보자\n
\n```java\npublic class GradeTest {\n \n @Test\n public void scoreResult() {\n \n Score score = new Score(35, 25, 25); // Score 클래스 생성\n SimpleScoreStrategy scores = new SimpleScoreStrategy();\n \n String resultGrade = scores.computeGrade(score); // 점수 계산\n \n assertEquals(\"B\", resultGrade); // 확인\n }\n \n}\n```\n
\n
\n\n현재는 **Score 클래스와 computeGrade() 메소드가 구현되지 않은 상태**다. (테스트 코드로만 존재)\n\n테스트 코드에 맞춰서 코드 개발을 진행하자\n
\n
\n\n우선 점수를 저장할 Score 클래스를 생성한다\n
\n````java\npublic class Score {\n \n private int middleScore = 0;\n private int finalScore = 0;\n private int homeworkScore = 0;\n \n public Score(int middleScore, int finalScore, int homeworkScore) {\n this.middleScore = middleScore;\n this.finalScore = finalScore;\n this.homeworkScore = homeworkScore;\n }\n \n public int getMiddleScore(){\n return middleScore;\n }\n \n public int getFinalScore(){\n return finalScore;\n }\n \n public int getHomeworkScore(){\n return homeworkScore;\n }\n \n}\n````\n
\n
\n\n이제 점수 계산을 통해 성적을 뿌려줄 computeGrade() 메소드를 가진 클래스를 만든다.\n\n
\n\n우선 인터페이스를 구현하자\n
\n```java\npublic interface ScoreStrategy {\n \n public String computeGrade(Score score);\n \n}\n```\n\n
\n\n인터페이스를 가져와 오버라이딩한 클래스를 구현한다\n
\n```java\npublic class SimpleScoreStrategy implements ScoreStrategy {\n \n public String computeGrade(Score score) {\n \n int totalScore = score.getMiddleScore() + score.getFinalScore() + score.getHomeworkScore(); // 점수 총합\n \n String gradeResult = null; // 학점 저장할 String 변수\n \n if(totalScore >= 90) {\n gradeResult = \"A\";\n } else if(totalScore >= 80) {\n gradeResult = \"B\";\n } else if(totalScore >= 70) {\n gradeResult = \"C\";\n } else if(totalScore >= 60) {\n gradeResult = \"D\";\n } else {\n gradeResult = \"F\";\n }\n \n return gradeResult;\n }\n \n}\n```\n
\n
\n\n이제 테스트 코드로 돌아가서, 실제로 통과할 정보를 입력해본 뒤 결과를 확인해보자\n\n이때 예외 처리, 중복 제거, 추가 기능을 통한 리팩토링 작업을 통해 완성도 높은 프로젝트를 구현할 수 있도록 노력하자!\n\n
\n\n통과가 가능한 정보를 넣고 실행하면, 아래와 같이 에러 없이 제대로 실행되는 모습을 볼 수 있다.\n
\n
\n\n\n\n
\n
\n\n\n***굳이 필요하나요?***\n\n딱봐도 귀찮아 보인다. 저렇게 확인 안해도 결과물을 알 수 있지 않냐고 반문할 수도 있다.\n\n하지만 예시는 간단하게 보였을 뿐, 실제 실무 프로젝트에서는 다양한 출력 결과물이 필요하고, 원하는 테스트 결과가 나오는 지 확인하는 과정은 필수적인 부분이다.\n\n\n\nTDD를 활용하면, 처음 시작하는 단계에서 테스트케이스를 설계하기 위한 초기 비용이 확실히 더 들게 된다. 하지만 개발 과정에 있어서 '초기 비용'보다 '유지보수 비용'이 더 클 수 있다는 것을 명심하자\n\n또한 안전성이 필요한 소프트웨어 프로젝트에서는 개발 초기 단계부터 확실하게 다져놓고 가는 것이 중요하다. \n\n유지보수 비용이 더 크거나 비행기, 기차에 필요한 소프트웨어 등 안전성이 중요한 프로젝트의 경우 현재 실무에서도 TDD를 활용한 개발을 통해 이루어지고 있다.\n\n\n\n" }, { "path": "Computer Science/Software Engineering/데브옵스(DevOps).md", "content": "## 데브옵스(DevOps)\n\n
\n\n> Development + Operations의 합성어\n\n소프트웨어 개발자와 정보기술 전문가 간의 소통, 협업 및 통합을 강조하는 개발 환경이나 문화를 의미한다.\n\n
\n\n**목적** : 소프트웨어 제품과 서비스를 빠른 시간에 개발 및 배포하는 것\n\n
\n\n결국, 소프트웨어 제품이나 서비스를 알맞은 시기에 출시하기 위해 개발과 운영이 상호 의존적으로 대응해야 한다는 의미로 많이 사용하고 있다.\n\n
\n\n
\n\n데브옵스의 개념은 애자일 기법과 지속적 통합의 개념과도 관련이 있다.\n\n- ##### 애자일 기법\n\n 실질적인 코딩을 기반으로 일정한 주기에 따라 지속적으로 프로토타입을 형성하고, 필요한 요구사항을 파악하며 이에 따라 즉시 수정사항을 적용하여 결과적으로 하나의 큰 소프트웨어를 개발하는 적응형 개발 방법\n\n- ##### 지속적 통합\n\n 통합 작업을 초기부터 계속 수행해서 지속적으로 소프트웨어의 품질 제어를 적용하는 것\n\n
\n\n
\n\n##### [참고 자료]\n\n- [링크](https://post.naver.com/viewer/postView.nhn?volumeNo=16319612&memberNo=202219)" }, { "path": "Computer Science/Software Engineering/마이크로서비스 아키텍처(MSA).md", "content": "# 마이크로서비스 아키텍처(MSA)\n\n
\n\n```\nMSA는 소프트웨어 개발 기법 중 하나로, 어플리케이션 단위를 '목적'으로 나누는 것이 핵심\n```\n\n
\n\n## Monolithic vs MSA \n\nMSA가 도입되기 전, Monolithic 아키텍처 방식으로 개발이 이루어졌다. Monolithic의 사전적 정의에 맞게 '한 덩어리'에 해당하는 구조로 이루어져 있다. 모든 기능을 하나의 어플리케이션에서 비즈니스 로직을 구성해 운영한다. 따라서 개발을 하거나 환경설정에 있어서 간단한 장점이 있어 작은 사이즈의 프로젝트에서는 유리하지만, 시스템이 점점 확장되거나 큰 프로젝트에서는 단점들이 존재한다.\n\n- 빌드/테스트 시간의 증가 : 하나를 수정해도 시스템 전체를 빌드해야 함. 즉, 유지보수가 힘들다\n- 작은 문제가 시스템 전체에 문제를 일으킴 : 만약 하나의 서비스 부분에 트래픽 문제로 서버가 다운되면, 모든 서비스 이용이 불가능할 것이다.\n- 확장성에 불리 : 서비스 마다 이용률이 다를 수 있다. 하나의 서비스를 확장하기 위해 전체 프로젝트를 확장해야 한다.\n\n
\n\nMSA는 좀 더 세분화 시킨 아키텍처라고 말할 수 있다. 한꺼번에 비즈니스 로직을 구성하던 Monolithic 방식과는 다르게 기능(목적)별로 컴포넌트를 나누고 조합할 수 있도록 구축한다.\n\n
 \n\n
\n\n \n\n
\n\n\n\nMSA에서 각 컴포넌트는 API를 통해 다른 서비스와 통신을 하는데, 모든 서비스는 각각 독립된 서버로 운영하고 배포하기 때문에 서로 의존성이 없다. 하나의 서비스에 문제가 생겨도 다른 서비스에는 영향을 끼치지 않으며, 서비스 별로 부분적인 확장이 가능한 장점이 있다.\n\n
 \n\n즉, 서비스 별로 개발팀이 꾸려지면 다른 팀과 의존없이 팀 내에서 피드백을 빠르게 할 수 있고, 비교적 유연하게 운영이 가능할 것이다.\n\n좋은 점만 있지는 않다. MSA는 서비스 별로 호출할 때 API로 통신하므로 속도가 느리다. 그리고 서비스 별로 통신에 맞는 데이터로 맞추는 과정이 필요하기도 하다. Monolithic 방식은 하나의 프로세스 내에서 진행되기 때문에 속도 면에서는 MSA보다 훨씬 빠를 것이다. 또한, MSA는 DB 또한 개별적으로 운영되기 때문에 트랜잭션으로 묶기 힘든 점도 있다. \n\n
\n\n즉, 서비스 별로 개발팀이 꾸려지면 다른 팀과 의존없이 팀 내에서 피드백을 빠르게 할 수 있고, 비교적 유연하게 운영이 가능할 것이다.\n\n좋은 점만 있지는 않다. MSA는 서비스 별로 호출할 때 API로 통신하므로 속도가 느리다. 그리고 서비스 별로 통신에 맞는 데이터로 맞추는 과정이 필요하기도 하다. Monolithic 방식은 하나의 프로세스 내에서 진행되기 때문에 속도 면에서는 MSA보다 훨씬 빠를 것이다. 또한, MSA는 DB 또한 개별적으로 운영되기 때문에 트랜잭션으로 묶기 힘든 점도 있다. \n\n\n\n따라서, 서비스별로 분리를 하면서 얻을 수 있는 장점도 있지만, 그만큼 체계적으로 준비돼 있지 않으면 MSA로 인해 오히려 프로젝트 성능이 떨어질 수도 있다는 점을 알고있어야 한다. 정답이 정해져 있는 것이 아니라, 프로젝트 목적, 현재 상황에 맞는 아키텍처 방식이 무엇인지 설계할 때부터 잘 고민해서 선택하자.\n\n
\n\n
\n\n#### [참고 자료]\n\n- [링크](https://medium.com/@shaul1991/%EC%B4%88%EB%B3%B4%EA%B0%9C%EB%B0%9C%EC%9E%90-%EC%9D%BC%EC%A7%80-%EB%8C%80%EC%84%B8-msa-%EB%84%88-%EB%AD%90%EB%8B%88-efba5cfafdeb)\n- [링크](http://clipsoft.co.kr/wp/blog/%EB%A7%88%EC%9D%B4%ED%81%AC%EB%A1%9C%EC%84%9C%EB%B9%84%EC%8A%A4-%EC%95%84%ED%82%A4%ED%85%8D%EC%B2%98msa-%EA%B0%9C%EB%85%90/)" }, { "path": "Computer Science/Software Engineering/써드파티(3rd party)란.md", "content": "## 써드 파티(3rd party)란?\n\n
\n\n간혹 써드 파티라는 말을 종종 볼 수 있다. 경제 용어가 IT에서 쓰이는 부분이다.\n\n##### *3rd party*\n\n> 하드웨어 생산자와 소프트웨어 개발자의 관계를 나타낼 때 사용한다.\n>\n> 그 중에서 **서드파티**는, 프로그래밍을 도와주는 라이브러리를 만드는 외부 생산자를 뜻한다.\n>\n> ```\n> ex) 게임제조사와 소비자를 연결해주는 게임회사(퍼플리싱)\n> 스마일게이트와 같은 회사\n> ```\n\n
\n\n##### *개발자 측면으로 보면?*\n\n- 하드웨어 생산자가 '직접' 소프트웨어를 개발하는 경우 : 퍼스트 파티 개발자\n- 하드웨어 생산자인 기업과 자사간의 관계(또는 하청업체)에 속한 소프트웨어 개발자 : **세컨드 파티 개발자**\n- 아무 관련없는 제3자 소프트웨어 개발자 : 서드 파티 개발자\n\n
\n\n주로 편한 개발을 위해 `플러그인`이나 `라이브러리` 혹은 `프레임워크`를 사용하는데, 이처럼 제 3자로 중간다리 역할로 도움을 주는 것이 **서드 파티**로 볼 수 있고, 이런 것을 만드는 개발자가 **서드 파티 개발자**다.\n\n
\n\n
\n\n##### [참고 사항]\n\n- [링크](https://ko.wikipedia.org/wiki/%EC%84%9C%EB%93%9C_%ED%8C%8C%ED%8B%B0_%EA%B0%9C%EB%B0%9C%EC%9E%90)" }, { "path": "Computer Science/Software Engineering/애자일(Agile).md", "content": "## 애자일(Agile)\n\n
\n\n소프트웨어 개발 기법으로 많이 들어본 단어다. 특히 소프트웨어 공학 수업을 들을 때 분명 배웠다. (근데 기억이 안남..)\n\n폭포수 모델, 애자일 기법 등등.. 무엇인지 알아보자\n\n
\n\n#### 등장배경\n\n초기 소프트웨어 개발 방법은 **계획 중심의 프로세스**였다.\n\n마치 도시 계획으로 건축에서 사용하는 방법과 유사하며, 당시에는 이런 프로세스를 활용하는 프로젝트가 대부분이었다.\n\n
\n\n##### 하지만 지금은?\n\n90년대 이후, 소프트웨어 분야가 넓어지면서 소프트웨어 사용자들이 '일반 대중들'로 바뀌기 시작했다. 이제 모든 사람들이 소프트웨어 사용의 대상이 되면서 트렌드가 급격하게 빨리 변화하는 시대가 도래했다.\n\n이로써 비즈니스 사이클(제품 수명)이 짧아졌고, SW 개발의 불확실성이 높아지게 되었다.\n\n
\n\n##### 새로운 개발 방법 등장\n\n개발의 불확실성이 높아지면서, 옛날의 전통적 개발 방법 적용이 어려워졌고 사람들은 새로운 자신만의 SW 개발 방법을 구축해 사용하게 된다.\n\n- 창의성이나 혁신은 계획에서 나오는 것이 아니라고 생각했기 때문!\n\n
\n\n그래서 **경량 방법론 주의자**들은 일단 해보고 고쳐나가자는 방식으로 개발하게 되었다.\n\n> 규칙을 적게 만들고, 가볍게 대응을 잘하는 방법을 적용하는 것\n\n아주 잘하는 단계에 이르게 되면, 겉으로 보기엔 미리 큰 그림을 만들어 놓고 하는 것처럼 보이게 됨\n\n```\nex)\n즉흥연기를 잘하게 되면, 겉에서 봤을 때 사람들이 '저거 대본아니야?'라는 생각을 할 수도 있음\n```\n\n이런 경량 방법론 주의자들이 모여 자신들이 사용하는 개발 방법론을 공유하고, 공통점을 추려서 애자일이라는 용어에 의미가 담기게 된 것이다.\n\n
\n\n#### 애자일이란?\n\n---\n\n
 \n\n**'협력'과 '피드백'**을 더 자주하고, 일찍하고, 잘하는 것!\n\n
\n\n**'협력'과 '피드백'**을 더 자주하고, 일찍하고, 잘하는 것!\n\n\n\n애자일의 핵심은 바로 '협력'과 '피드백'이다.\n\n
\n\n#### 1.협력\n\n> 소프트웨어를 개발한 사람들 안에서의 협력을 말함(직무 역할을 넘어선 협력)\n\n스스로 느낀 좋은 통찰은 협력을 통해 다른 사람에게도 전해줄 수 있음\n\n예상치 못한 팀의 기대 효과를 가져옴\n\n```\nex) 좋은 일은 x2가 된다.\n\n어떤 사람이 2배의 속도로 개발할 수 있는 방법을 발견함\n\n협력이 약하면? → 혼자만 좋은 보상과 칭찬을 받음. 하지만 그 사람 코드와 다른 사람의 코드의 이질감이 생겨서 시스템 문제 발생 가능성\n\n협력이 강하면? → 다른 사람과 공유해서 모두 같이 빠르게 개발하고 더 나은 발전점을 찾기에 용이함. 팀 전체 개선이 일어나는 긍정적 효과 발생\n```\n\n```\nex) 안 좋은 일은 /2가 된다.\n\n문제가 발생하는 부분을 찾기 쉬워짐\n예상치 못한 문제를 협력으로 막을 수 있음\n\n실수를 했는데 어딘지 찾기 힘들거나, 개선점이 생각나지 않을 때 서로 다른 사람들과 협력하면 새로운 방안이 탄생할 수도 있음\n```\n\n
\n\n#### 2.피드백\n\n학습의 가장 큰 전제조건이 '피드백'. 내가 어떻게 했는지 확인하면서 학습을 진행해야 함\n\n소프트웨어의 불확실성이 높을 수록 학습의 중요도는 올라간다.\n**(모르는 게 많으면 더 빨리 배워나가야 하기 때문!!)**\n\n
\n\n일을 잘하는 사람은 이처럼 피드백을 찾는 능력 뛰어남. 더 많은 사람들에게 피드백을 구하고 발전시켜 나간다.\n\n
\n\n##### 피드백 진행 방법\n\n```\n내부적으로는 내가 만든 것이 어떻게 됐는지 확인하고, 외부적으로는 내가 만든 것을 고객이나 다른 부서가 사용해보고 나온 산출물을 통해 또 다른 것을 배워나가는 것!\n```\n\n
\n\n
\n\n#### 불확실성\n\n애자일에서는 소프트웨어 개발의 불확실성이 중요함\n\n불확실성이 높으면, `우리가 생각한거랑 다르다..`라는 상황에 직면한다.\n\n이때 전통적인 방법론과 애자일의 방법론의 차이는 아래와 같다.\n\n```\n전통적 방법론 \n: '그때 계획 세울 때 좀 더 잘 세워둘껄.. \n이런 리스크도 생각했어야 했는데ㅠ 일단 계속 진행하자'\n\n애자일 방법론\n: '이건 생각 못했네. 어쩔 수 없지. 다시 빨리 수정해보자'\n```\n\n
\n\n전통적 방법에 속하는 '폭포수 모델'은 요구분석단계에서 한번에 모든 요구사항을 정확하게 전달하는 것이 원칙이다. 하지만 요즘같이 변화가 많은 프로젝트에서는 현실적으로 불가능에 가깝다.\n\n
\n\n이런 한계점을 극복해주는 애자일은, **개발 과정에 있어서 시스템 변경사항을 유연하게 or 기민하게 대응할 수 있도록 방법론을 제공**해준다.\n\n
\n\n
\n\n#### 진행 방법\n\n1. 개발자와 고객 사이의 지속적 커뮤니케이션을 통해 변화하는 요구사항을 수용한다.\n2. 고객이 결정한 사항을 가장 우선으로 시행하고, 개발자 개인의 가치보다 팀의 목표를 우선으로 한다.\n3. 팀원들과 주기적인 미팅을 통해 프로젝트를 점검한다.\n4. 주기적으로 제품 시현을 하고 고객으로부터 피드백을 받는다.\n5. 프로그램 품질 향상에 신경쓰며 간단한 내부 구조 형성을 통한 비용절감을 목표로 한다.\n\n
\n\n애자일을 통한 가장 많이 사용하는 개발 방법론이 **'스크럼'**\n\n> 럭비 경기에서 사용되던 용어인데, 반칙으로 인해 경기가 중단됐을 때 쓰는 대형을 말함\n\n즉, 소프트웨어 측면에서 `팀이라는 단어가 주는 의미를 적용시키고, 효율적인 성과를 얻기 위한 것`\n\n
\n\n
 \n\n
\n\n\n\n1. #### 제품 기능 목록 작성\n\n > 개발할 제품에 대한 요구사항 목록 작성\n >\n > 우선순위가 매겨진, 사용자의 요구사항 목록이라고 말할 수 있음\n >\n > 개발 중에 수정이 가능하기는 하지만, **일반적으로 한 주기가 끝날 때까지는 제품 기능 목록을 수정하지 않는 것이 원칙**\n\n2. #### 스프린트 Backlog\n\n > 스프린트 각각의 목표에 도달하기 위해 필요한 작업 목록\n >\n > - 세부적으로 어떤 것을 구현해야 하는지\n > - 작업자\n > - 예상 작업 시간\n >\n > 최종적으로 개발이 어떻게 진행되고 있는지 상황 파악 가능\n\n3. #### 스프린트\n\n > `작은 단위의 개발 업무를 단기간 내에 전력질주하여 개발한다`\n >\n > 한달동안의 큰 계획을 **3~5일 단위로 반복 주기**를 정했다면 이것이 스크럼에서 스프린트에 해당함\n >\n > - 주기가 회의를 통해 결정되면 (보통 2주 ~ 4주) 목표와 내용이 개발 도중에 바뀌지 않아야 하고, 팀원들 동의 없이 바꿀 수 없는 것이 원칙\n\n4. #### 일일 스크럼 회의\n\n > 몇가지 규칙이 있다.\n >\n > 모든 팀원이 참석하여 매일하고, 짧게(15분)하고, 진행 상황 점검한다.\n >\n > 한사람씩 어제 한 일, 오늘 할 일, 문제점 및 어려운 점을 이야기함\n >\n > 완료된 세부 작업 항목을 스프린트 현황판에서 업데이트 시킴\n\n5. #### 제품완성 및 스프린트 검토 회의\n\n > 모든 스프린트 주기가 끝나면, 제품 기능 목록에서 작성한 제품이 완성된다.\n >\n > 최종 제품이 나오면 고객들 앞에서 시연을 통한 스프린트 검토 회의 진행\n >\n > - 고객의 요구사항에 얼마나 부합했는가?\n > - 개선점 및 피드백\n\n6. #### 스프린트 회고\n\n > 스프린트에서 수행한 활동과 개발한 것을 되돌아보며 개선점이나 규칙 및 표준을 잘 준수했는지 검토\n >\n > `팀의 단점보다는 강점과 장점을 찾아 더 극대화하는데 초점을 둔다`\n\n
\n\n#### 스크럼 장점\n\n---\n\n- 스프린트마다 생산되는 실행 가능한 제품을 통해 사용자와 의견을 나눌 수 있음\n- 회의를 통해 팀원들간 신속한 협조와 조율이 가능\n- 자신의 일정을 직접 발표함으로써 업무 집중 환경 조성\n- 프로젝트 진행 현황을 통해 신속하게 목표와 결과 추정이 가능하며 변화 시도가 용이함\n\n
\n\n#### 스크럼 단점\n\n---\n\n- 추가 작업 시간이 필요함 (스프린트마다 테스트 제품을 만들어야하기 때문)\n- 15분이라는 회의 시간을 지키기 힘듬 ( 시간이 초과되면 그만큼 작업 시간이 줄어듬)\n- 스크럼은 프로젝트 관리에 무게중심을 두기 때문에 프로세스 품질 평가에는 미약함\n\n
\n\n
\n\n#### 요약\n\n---\n\n스크럼 모델은 애자일 개발 방법론 중 하나\n\n회의를 통해 `스프린트` 개발 주기를 정한 뒤, 이 주기마다 회의 때 정했던 계획들을 구현해나감\n\n하나의 스프린트가 끝날 때마다 검토 회의를 통해, 생산되는 프로토타입으로 사용자들의 피드백을 받으며 더 나은 결과물을 구현해낼 수 있음\n\n\n\n
\n\n**[참고 자료]** : [링크1](
\n\n#### 전문가들이 표현한 '클린코드'\n\n>`한 가지를 제대로 한다.`\n>\n>`단순하고 직접적이다.`\n>\n>`특정 목적을 달성하는 방법은 하나만 제공한다.`\n>\n>`중복 줄이기, 표현력 높이기, 초반부터 간단한 추상화 고려하기 이 세가지가 비결`\n>\n>`코드를 읽으면서 짐작했던 기능을 각 루틴이 그대로 수행하는 것`\n\n
\n\n#### 클린코드란?\n\n코드를 작성하는 의도와 목적이 명확하며, 다른 사람이 쉽게 읽을 수 있어야 함\n\n> 즉, 가독성이 좋아야 한다.\n\n
\n\n##### 가독성을 높인다는 것은?\n\n다른 사람이 코드를 봐도, 자유롭게 수정이 가능하고 버그를 찾고 변경된 내용이 어떻게 상호작용하는지 이해하는 시간을 최소화 시키는 것...\n\n
\n\n클린코드를 만들기 위한 규칙이 있다.\n\n
\n\n#### 1.네이밍(Naming)\n\n> 변수, 클래스, 메소드에 의도가 분명한 이름을 사용한다.\n\n```java\nint elapsedTimeInDays;\nint daysSinceCreation;\nint fileAgeInDays;\n```\n\n잘못된 정보를 전달할 수 있는 이름을 사용하지 않는다.\n\n범용적으로 사용되는 단어 사용X (aix, hp 등)\n\n연속된 숫자나 불용어를 덧붙이는 방식은 피해야함\n\n
\n\n#### 2.주석달기(Comment)\n\n> 코드를 읽는 사람이 코드를 작성한 사람만큼 잘 이해할 수 있도록 도와야 함\n\n주석은 반드시 달아야 할 이유가 있는 경우에만 작성하도록 한다.\n\n즉, 코드를 빠르게 유추할 수 있는 내용에는 주석을 사용하지 않는 것이 좋다.\n\n설명을 위한 설명은 달지 않는다.\n\n```c\n// 주어진 'name'으로 노드를 찾거나 아니면 null을 반환한다.\n// 만약 depth <= 0이면 'subtree'만 검색한다.\n// 만약 depth == N 이면 N 레벨과 그 아래만 검색한다.\nNode* FindNodeInSubtree(Node* subtree, string name, int depth);\n```\n\n
\n\n#### 3.꾸미기(Aesthetics)\n\n> 보기좋게 배치하고 꾸민다. 보기 좋은 코드가 읽기도 좋다.\n\n규칙적인 들여쓰기와 줄바꿈으로 가독성을 향상시키자\n\n일관성있고 간결한 패턴을 적용해 줄바꿈한다.\n\n메소드를 이용해 불규칙한 중복 코드를 제거한다.\n\n
\n\n클래스 전체를 하나의 그룹이라고 생각하지 말고, 그 안에서도 여러 그룹으로 나누는 것이 읽기에 좋다.\n\n
\n\n#### 4.흐름제어 만들기(Making control flow easy to read)\n\n- 왼쪽에는 변수를, 오른쪽에는 상수를 두고 비교\n\n ```java\n if(length >= 10)\n \n while(bytes_received < bytest_expected)\n ```\n\n
\n\n- 부정이 아닌 긍정을 다루자\n\n ```java\n if( a == b ) { // a!=b는 부정\n \t// same\n } else {\n \t// different\n }\n ```\n\n
\n\n- if/else를 사용하며, 삼항 연산자는 매우 간단한 경우만 사용\n\n- do/while 루프는 피하자\n\n
\n\n#### 5.착한 함수(Function)\n\n> 함수는 가급적 작게, 한번에 하나의 작업만 수행하도록 작성\n\n
\n\n온라인 투표로 예를 들어보자\n\n사용자가 추천을 하거나, 이미 선택한 추천을 변경하기 위해 버튼을 누르면 vote_change(old_vote, new_vote) 함수를 호출한다고 가정해보자\n\n```javascript\nvar vote_changed = function (old_vote, new_vote) {\n \n\tvar score = get_score();\n \n\tif (new_vote !== old_vote) {\n\t\tif (new_vote == 'Up') {\n\t\t\tscore += (old_vote === 'Down' ? 2 : 1);\n\t\t} else if (new_vote == 'Down') {\n\t\t\tscore -= (old_vote === 'Up' ? 2 : 1);\n\t\t} else if (new_vote == '') {\n\t\t\tscore += (old_vote === 'Up' ? -1 : 1);\n\t\t}\n\t}\n\tset_score(score);\n \n};\n```\n\n총점을 변경해주는 한 가지 역할을 하는 함수같지만, 두가지 일을 하고 있다.\n\n- old_vote와 new_vote의 상태에 따른 score 계산\n- 총점을 계산\n\n
\n\n별도로 함수로 분리하여 가독성을 향상시키자\n\n```javascript\nvar vote_value = function (vote) {\n \n if(vote === 'Up') {\n return +1;\n }\n if(vote === 'Down') {\n return -1;\n }\n return 0;\n \n};\n\nvar vote_changed = function (old_vote, new_vote) {\n \n var score = get_score();\n \n score -= vote_value(old_vote); // 이전 값 제거\n score += vote_value(new_vote); // 새로운 값 더함\n set_score(score);\n};\n```\n\n훨씬 깔끔한 코드가 되었다!\n\n
\n\n
\n\n#### 코드리뷰 & 리팩토링\n\n> 레거시 코드(테스트가 불가능하거나 어려운 코드)를 클린 코드로 만드는 방법\n\n
\n\n**코드리뷰를 통해 냄새나는 코드를 발견**하면, **리팩토링을 통해 점진적으로 개선**해나간다.\n\n
\n\n##### 코드 인스펙션(code inspection)\n\n> 작성한 개발 소스 코드를 분석하여 개발 표준에 위배되었거나 잘못 작성된 부분을 수정하는 작업\n\n
\n\n##### 절차 과정\n\n1. Planning : 계획 수립\n2. Overview : 교육과 역할 정의\n3. Preparation : 인스펙션을 위한 인터뷰, 산출물, 도구 준비\n4. Meeting : 검토 회의로 각자 역할을 맡아 임무 수행\n5. Rework : 발견한 결함을 수정하고 재검토 필요한지 여부 결정\n6. Follow-up : 보고된 결함 및 이슈가 수정되었는지 확인하고 시정조치 이행\n\n
\n\n#### 리팩토링\n\n> 냄새나는 코드를 점진적으로 반복 수행되는 과정을 통해 코드를 조금씩 개선해나가는 것\n\n
\n\n##### 리팩토링 대상\n\n- 메소드 정리 : 그룹으로 묶을 수 있는 코드, 수식을 메소드로 변경함\n- 객체 간의 기능 이동 : 메소드 기능에 따른 위치 변경, 클래스 기능을 명확히 구분\n- 데이터 구성 : 캡슐화 기법을 적용해 데이터 접근 관리\n- 조건문 단순화 : 조건 논리를 단순하고 명확하게 작성\n- 메소드 호출 단순화 : 메소드 이름이나 목적이 맞지 않을 때 변경\n- 클래스 및 메소드 일반화 : 동일 기능 메소드가 여러개 있으면 수퍼클래스로 이동\n\n
\n\n##### 리팩토링 진행 방법\n\n아키텍처 관점 시작 → 디자인 패턴 적용 → 단계적으로 하위 기능에 대한 변경으로 진행\n\n의도하지 않은 기능 변경이나 버그 발생 대비해 회귀테스트 진행\n\n이클립스와 같은 IDE 도구로 이용\n\n
\n\n\n\n### 시큐어 코딩\n\n> 안전한 소프트웨어를 개발하기 위해, 소스코드 등에 존재할 수 있는 잠재적인 보안약점을 제거하는 것\n\n
\n\n##### 보안 약점을 노려 발생하는 사고사례들\n\n- SQL 인젝션 취약점으로 개인유출 사고 발생\n- URL 파라미터 조작 개인정보 노출\n- 무작위 대입공격 기프트카드 정보 유출\n\n
\n\n##### SQL 인젝션 예시\n\n- 안전하지 않은 코드\n\n```\nString query \"SELECT * FROM users WHERE userid = '\" + userid + \"'\" + \"AND password = '\" + password + \"'\";\n\nStatement stmt = connection.createStatement();\nResultSet rs = stmt.executeQuery(query);\n```\n\n
\n\n- 안전한 코드\n\n```\nString query = \"SELECT * FROM users WHERE userid = ? AND password = ?\";\n\nPrepareStatement stmt = connection.prepareStatement(query);\nstmt.setString(1, userid);\nstmt.setString(2, password);\nResultSet rs = stmt.executeQuery();\n```\n\n적절한 검증 작업이 수행되어야 안전함\n\n
\n\n입력받는 값의 변수를 `$` 대신 `#`을 사용하면서 바인딩 처리로 시큐어 코딩이 가능하다.\n\n
\n" }, { "path": "Design Pattern/Adapter Pattern.md", "content": "### 어댑터 패턴\n\n---\n\n> - 용도 : 클래스를 바로 사용할 수 없는 경우가 있음 (다른 곳에서 개발했다거나, 수정할 수 없을 때)\n> 중간에서 변환 역할을 해주는 클래스가 필요 → 어댑터 패턴\n>\n> - 사용 방법 : 상속\n> - 호환되지 않은 인터페이스를 사용하는 클라이언트 그대로 활용 가능\n>\n> - 향후 인터페이스가 바뀌더라도, 변경 내역은 어댑터에 캡슐화 되므로 클라이언트 바뀔 필요X\n\n\n\n
\n\n##### 클래스 다이어그램\n\n\n\n\n\n아이폰의 이어폰을 생각해보자\n\n가장 흔한 이어폰 잭을 아이폰에 사용하려면, 잭 자체가 맞지 않는다.\n\n따라서 우리는 어댑터를 따로 구매해서 연결해야 이런 이어폰들을 사용할 수 있다\n\n\n\n이처럼 **어댑터는 필요로 하는 인터페이스로 바꿔주는 역할**을 한다\n\n\n\n\n\n\n\n이처럼 업체에서 제공한 클래스가 기존 시스템에 맞지 않으면?\n\n> 기존 시스템을 수정할 것이 아니라, 어댑터를 활용해 유연하게 해결하자\n\n\n\n
\n\n##### 코드로 어댑터 패턴 이해하기\n\n> 오리와 칠면조 인터페이스 생성\n>\n> 만약 오리 객체가 부족해서 칠면조 객체를 대신 사용해야 한다면?\n>\n> 두 객체는 인터페이스가 다르므로, 바로 칠면조 객체를 사용하는 것은 불가능함\n>\n> 따라서 칠면조 어댑터를 생성해서 활용해야 한다\n\n\n\n- Duck.java\n\n```java\npackage AdapterPattern;\n\npublic interface Duck {\n\tpublic void quack();\n\tpublic void fly();\n}\n```\n\n\n\n- Turkey.java\n\n```java\npackage AdapterPattern;\n\npublic interface Turkey {\n\tpublic void gobble();\n\tpublic void fly();\n}\n```\n\n\n\n- WildTurkey.java\n\n```java\npackage AdapterPattern;\n\npublic class WildTurkey implements Turkey {\n\n\t@Override\n\tpublic void gobble() {\n\t\tSystem.out.println(\"Gobble gobble\");\n\t}\n\n\t@Override\n\tpublic void fly() {\n\t\tSystem.out.println(\"I'm flying a short distance\");\n\t}\n}\n```\n\n- TurkeyAdapter.java\n\n```java\npackage AdapterPattern;\n\npublic class TurkeyAdapter implements Duck {\n\n\tTurkey turkey;\n\n\tpublic TurkeyAdapter(Turkey turkey) {\n\t\tthis.turkey = turkey;\n\t}\n\n\t@Override\n\tpublic void quack() {\n\t\tturkey.gobble();\n\t}\n\n\t@Override\n\tpublic void fly() {\n\t\tturkey.fly();\n\t}\n\n}\n```\n\n- DuckTest.java\n\n```java\npackage AdapterPattern;\n\npublic class DuckTest {\n\n\tpublic static void main(String[] args) {\n\n\t\tMallardDuck duck = new MallardDuck();\n\t\tWildTurkey turkey = new WildTurkey();\n\t\tDuck turkeyAdapter = new TurkeyAdapter(turkey);\n\n\t\tSystem.out.println(\"The turkey says...\");\n\t\tturkey.gobble();\n\t\tturkey.fly();\n\n\t\tSystem.out.println(\"The Duck says...\");\n\t\ttestDuck(duck);\n\n\t\tSystem.out.println(\"The TurkeyAdapter says...\");\n\t\ttestDuck(turkeyAdapter);\n\n\t}\n\n\tpublic static void testDuck(Duck duck) {\n\n\t\tduck.quack();\n\t\tduck.fly();\n\n\t}\n}\n```\n아까 확인한 클래스 다이어그램에서 Target은 오리에 해당하며, Adapter는 칠면조라고 생각하면 된다.\n\n" }, { "path": "Design Pattern/Composite Pattern.md", "content": "# Composite Pattern\n\n### 목적\ncompositie pattern의 사용 목적은 object의 **hierarchies**를 표현하고 각각의 object를 독립적으로 동일한 인터페이스를 통해 처리할 수 있게한다.\n\n아래 Composite pattern의 class diagram을 보자\n\n\n\n위의 그림의 Leaf 클래스와 Composite 클래스를 같은 interface로 제어하기 위해서 Component abstract 클래스를 생성하였다.\n\n위의 그림을 코드로 표현 하였다.\n\n**Component 클래스**\n```java\npublic class Component {\n public void operation() {\n throw new UnsupportedOperationException();\n }\n public void add(Component component) {\n throw new UnsupportedOperationException();\n }\n\n public void remove(Component component) {\n throw new UnsupportedOperationException();\n }\n\n public Component getChild(int i) {\n throw new UnsupportedOperationException();\n }\n}\n```\nLeaf 클래스와 Compositie 클래스가 상속하는 Component 클래스로 Leaf 클래스에서 사용하지 않는 메소드 호출 시 exception을 발생시키게 구현하였다.\n\n**Leaf 클래스**\n```java\npublic class Leaf extends Component {\n String name;\n public Leaf(String name) {\n ...\n }\n\n public void operation() {\n .. something ...\n }\n}\n```\n\n**Composite class**\n```java\npublic class Composite extends Component {\n ArrayList components = new ArrayList();\n String name;\n\n public Composite(String name) {\n ....\n }\n\n public void operation() {\n Iterator iter = components.iterator();\n while (iter.hasNext()) {\n Component component = (Component)iter.next();\n component.operation();\n }\n }\n public void add(Component component) {\n components.add(component);\n }\n\n public void remove(Component component) {\n components.remove(component);\n }\n\n public Component getChild(int i) {\n return (Component)components.get(i);\n }\n}\n```\n\n## 구현 시 고려해야할 사항\n- 위의 코드는 parent만이 child를 참조할 수 있다. 구현 이전에 child가 parent를 참조해야 하는지 고려해야 한다.\n- 어떤 클래스가 children을 관리할 것인가?\n\n## Children 관리를 위한 2가지 Composite pattern\n\n\n위의 예제로 Component 클래스에 add, removem getChild 같은 method가 선언이 되어있으며 Transparency를 제공한다.\n\n장점 : Leaf 클래스와 Composite 클래스를 구분할 필요없이 Component Class로 생각할 수 있다.\n\n단점 : Leaf 클래스가 chidren 관리 함수 호출 시 run time에 exception이 발생한다.\n\n\n\n이전 예제에서 children을 관리하는 함수를 Composite 클래스에 선언 되어있으며 Safety를 제공한다.\n\n장점 : Leaf 클래스가 chidren 관리 함수 호출 시 compile time에 문제를 확인할 수 있다.\n\n단점 : Leaf 클래스와 Composite 클래스를 구분하여야 한다.\n\n## 관련 패턴\n### Decorator\n공통점 : composition이 재귀적으로 발생한다.\n\n차이점 : decorator 패턴은 responsibilites를 추가하는 것이 목표이지만 composite 패턴은 hierarchy를 표현하기 위해서 사용된다.\n\n### Iterator\n공통점 : aggregate object을 순차적으로 접근한다." }, { "path": "Design Pattern/Design Pattern_Adapter.md", "content": "#### Design Pattern - Adapter Pattern\n\n---\n\n[어댑터 패턴]\n\n국가별 사용하는 전압이 달라서 220v를 110v형으로 바꿔서 끼우는 경우를 생각해보기.\n\n- 실행 부분 (Main.java)\n\n ```java\n public class Main {\n public static void main (String[] args) {\n MediaPlayer player = new MP3();\n player.play(\"file.mp3\");\n \n // MediaPlayer로 실행 못하는 MP4가 있음.\n // 이것을 mp3처럼 실행시키기 위해서,\n // Adapter를 생성하기.\n player = new FormatAdapter(new MP4());\n player.play(\"file.mp4\");\n }\n }\n ```\n\n- 변환 장치 부분 (FormatAdapter.java)\n\n ```java\n // MediaPlayer의 기능을 활용하기 위해 FormatAdapter라는 새로운 클래스를 생성\n // 그리고 그 클래스 내부에 (MP4, MKV와 같은) 클래스를 정리하려고 함.\n public class FormatAdapter implements MediaPlayer {\n private MediaPackage media;\n public FormatAdapter(MediaPackage m) {\n media = m;\n }\n // 그리고 반드시 사용해야하는 클래스의 함수를 선언해 둠\n @Override\n public void play(String filename) {\n System.out.print(\"Using Adapter\");\n media.playFile(filename);\n }\n }\n ```\n\n" }, { "path": "Design Pattern/Design Pattern_Factory Method.md", "content": "#### Design Pattern - Factory Method Pattern\n\n---\n\n한 줄 설명 : 객체를 만드는 부분을 Sub class에 맡기는 패턴.\n\n> Robot (추상 클래스)\n>\n> \tㄴ SuperRobot\n>\n> \tㄴ PowerRobot\n>\n> RobotFactory (추상 클래스)\n>\n> \tㄴ SuperRobotFactory\n>\n> \tㄴ ModifiedSuperRobotFactory\n\n즉 Robot이라는 클래스를 RobotFactory에서 생성함.\n\n- RobotFactory 클래스 생성\n\n```java\npublic abstract class RobotFactory {\n\tabstract Robot createRobot(String name);\n}\n```\n\n* SuperRobotFactory 클래스 생성\n\n```java\npublic class SuperRobotFactory extends RobotFactory {\n\t@Override\n\tRobot createRobot(String name) {\n\t\tswitch(name) {\n\t\tcase \"super\" :\n\t\t\treturn new SuperRobot();\n\t\tcase \"power\" :\n\t\t\treturn new PowerRobot();\n\t\t}\n\t\treturn null;\n\t}\n}\n```\n\n생성하는 클래스를 따로 만듬...\n\n그 클래스는 factory 클래스를 상속하고 있기 때문에, 반드시 createRobot을 선언해야 함.\n\nname으로 건너오는 값에 따라서, 생성되는 Robot이 다르게 설계됨.\n\n---\n\n정리하면, 생성하는 객체를 별도로 둔다. 그리고, 그 객체에 넘어오는 값에 따라서, 다른 로봇 (피자)를 만들어 낸다.\n\n" }, { "path": "Design Pattern/Design Pattern_Template Method.md", "content": "#### 디자인 패턴 _ Template Method Pattern\n\n---\n\n[디자인 패턴 예]\n\n1. 템플릿 메서드 패턴\n\n 특정 환경 or 상황에 맞게 확장, 변경할 때 유용한 패턴\n\n **추상 클래스, 구현 클래스** 둘로 구분. \n\n 추상클래스 (Abstract Class) : 메인이 되는 로직 부분은 일반 메소드로 선언해 둠.\n\n 구현클래스 (Concrete Class) : 메소드를 선언 후 호출하는 방식.\n\n - 장점\n - 구현 클래스에서는 추상 클래스에 선언된 메소드만 사용하므로, **핵심 로직 관리가 용이**\n - 객체 추가 및 확장 가능\n - 단점\n - 추상 메소드가 많아지면, 클래스 관리가 복잡함.\n\n * 설명\n\n 1) HouseTemplate.java\n\n > Template 추상 클래스를 하나 생성. (예, HouseTemplate)\n >\n > 이 HouseTemplate을 사용할 때는,\n >\n > \"HouseTemplate houseType = new WoodenHouse()\" 이런 식으로 넣음.\n >\n > HouseTemplate 내부에 **buildHouse**라는 변해서는 안되는 핵심 로직을 만들어 놓음. (장점 1)\n >\n > Template 클래스 내부의 **핵심 로직 내부의 함수**를 상속하는 클래스가 직접 구현하도록, abstract를 지정해 둠.\n\n ```java\n public abstract class HouseTemplate {\n \n // 이런 식으로 buildHouse라는 함수 (핵심 로직)을 선언해 둠.\n public final void buildHouse() {\n buildFoundation();\t// (1)\n buildPillars();\t\t// (2)\n buildWalls();\t\t// (3)\n buildWindows();\t\t// (4)\n System.out.println(\"House is built.\");\n }\n \n // buildFoundation(); 정의 부분 (1)\n // buildWalls(); 정의 부분\t\t(2)\n \n // 위의 두 함수와는 다르게 이 클래스를 상속받는 클래스가 별도로 구현했으면 하는 메소드들은 abstract로 선언하여, 정의하도록 함\n public abstract void buildWalls();\t// (3)\n public abstract void buildPillars();// (4)\n \n }\n \n ```\n\n \n\n 2) WoodenHouse.java (GlassHouse.java도 가능)\n\n > HouseTemplate을 상속받는 클래스.\n >\n > Wooden이나, Glass에 따라서 buildHouse 내부의 핵심 로직이 바뀔 수 있으므로,\n >\n > 이 부분을 반드시 선언하도록 지정해둠.\n\n ```java\n public class WoodenHouse extends HouseTemplate {\n @Override\n public void buildWalls() {\n System.out.println(\"Building Wooden Walls\");\n }\n @Override\n public void buildPillars() {\n System.out.println(\"Building Pillars with Wood coating\");\n }\n }\n ```\n\n " }, { "path": "Design Pattern/Observer pattern.md", "content": "## 옵저버 패턴(Observer pattern)\n\n> 상태를 가지고 있는 주체 객체 & 상태의 변경을 알아야 하는 관찰 객체\n\n(1 대 1 or 1 대 N 관계)\n\n서로의 정보를 주고받는 과정에서 정보의 단위가 클수록, 객체들의 규모가 클수록 복잡성이 증가하게 된다. 이때 가이드라인을 제시해줄 수 있는 것이 '옵저버 패턴'\n\n
\n\n##### 주체 객체와 관찰 객체의 예는?\n\n```\n잡지사 : 구독자\n우유배달업체 : 고객\n```\n\n구독자, 고객들은 정보를 얻거나 받아야 하는 주체와 관계를 형성하게 된다. 관계가 지속되다가 정보를 원하지 않으면 해제할 수도 있다. (잡지 구독을 취소하거나 우유 배달을 중지하는 것처럼)\n\n> 이때, 객체와의 관계를 맺고 끊는 상태 변경 정보를 Observer에 알려줘서 관리하는 것을 말한다.\n\n
\n\n
 \n\n- ##### Publisher 인터페이스\n\n > Observer들을 관리하는 메소드를 가지고 있음\n >\n > 옵저버 등록(add), 제외(delete), 옵저버들에게 정보를 알려줌(notifyObserver)\n\n ```java\n public interface Publisher { \n public void add(Observer observer); \n public void delete(Observer observer); \n public void notifyObserver(); \n }\n ```\n\n
\n\n- ##### Publisher 인터페이스\n\n > Observer들을 관리하는 메소드를 가지고 있음\n >\n > 옵저버 등록(add), 제외(delete), 옵저버들에게 정보를 알려줌(notifyObserver)\n\n ```java\n public interface Publisher { \n public void add(Observer observer); \n public void delete(Observer observer); \n public void notifyObserver(); \n }\n ```\n\n \n\n- ##### Observer 인터페이스\n\n > 정보를 업데이트(update)\n\n ```java\n public interface Observer { \n public void update(String title, String news); }\n ```\n\n
\n\n- ##### NewsMachine 클래스\n\n > Publisher를 구현한 클래스로, 정보를 제공해주는 퍼블리셔가 됨\n\n ```java\n public class NewsMachine implements Publisher {\n private ArrayList
\n\n- ##### AnnualSubscriber, EventSubscriber 클래스\n\n > Observer를 구현한 클래스들로, notifyObserver()를 호출하면서 알려줄 때마다 Update가 호출됨\n\n ```java\n public class EventSubscriber implements Observer {\n \n private String newsString;\n private Publisher publisher;\n \n public EventSubscriber(Publisher publisher) {\n this.publisher = publisher;\n publisher.add(this);\n }\n \n @Override\n public void update(String title, String news) {\n newsString = title + \" \" + news;\n display();\n }\n \n public void withdraw() {\n publisher.delete(this);\n }\n \n public void display() {\n System.out.println(\"이벤트 유저\");\n System.out.println(newsString);\n }\n \n }\n ```\n\n
\n\n
\n\nJava에는 옵저버 패턴을 적용한 것들을 기본적으로 제공해줌\n\n> Observer 인터페이스, Observable 클래스\n\n하지만 Observable은 클래스로 구현되어 있기 때문에 사용하려면 상속을 해야 함. 따라서 다른 상속을 함께 이용할 수 없는 단점 존재\n\n
\n\n
\n\n#### 정리\n\n> 옵저버 패턴은, 한 객체의 상태가 바뀌면 그 객체에 의존하는 다른 객체들에게 연락이 가고, 자동으로 정보가 갱신되는 1:N 관계(혹은 1대1)를 정의한다.\n>\n> 인터페이스를 통해 연결하여 느슨한 결합성을 유지하며, Publisher와 Observer 인터페이스를 적용한다.\n>\n> 안드로이드 개발시, OnClickListener와 같은 것들이 옵저버 패턴이 적용된 것 (버튼(Publisher)을 클릭했을 때 상태 변화를 옵저버인 OnClickListener로 알려주로독 함)\n\n
\n\n##### [참고]\n\n[링크](
\n\n즉, 싱글톤 패턴은 '하나'의 인스턴스만 생성하여 사용하는 디자인 패턴이다.\n\n> 인스턴스가 필요할 때, 똑같은 인스턴스를 만들지 않고 기존의 인스턴스를 활용하는 것!\n\n
\n\n생성자가 여러번 호출되도, 실제로 생성되는 객체는 하나이며 최초로 생성된 이후에 호출된 생성자는 이미 생성한 객체를 반환시키도록 만드는 것이다\n\n(java에서는 생성자를 private으로 선언해 다른 곳에서 생성하지 못하도록 만들고, getInstance() 메소드를 통해 받아서 사용하도록 구현한다)\n\n
\n\n##### *왜 쓰나요?*\n\n먼저, 객체를 생성할 때마다 메모리 영역을 할당받아야 한다. 하지만 한번의 new를 통해 객체를 생성한다면 메모리 낭비를 방지할 수 있다.\n\n또한 싱글톤으로 구현한 인스턴스는 '전역'이므로, 다른 클래스의 인스턴스들이 데이터를 공유하는 것이 가능한 장점이 있다.\n\n
\n\n##### *많이 사용하는 경우가 언제인가요?*\n\n주로 공통된 객체를 여러개 생성해서 사용해야하는 상황\n\n```\n데이터베이스에서 커넥션풀, 스레드풀, 캐시, 로그 기록 객체 등\n```\n\n안드로이드 앱 : 각 액티비티 들이나, 클래스마다 주요 클래스들을 하나하나 전달하는게 번거롭기 때문에 싱글톤 클래스를 만들어 어디서든 접근하도록 설계\n\n또한 인스턴스가 절대적으로 한 개만 존재하는 것을 보증하고 싶을 때 사용함\n\n
\n\n##### *단점도 있나요?*\n\n객체 지향 설계 원칙 중에 `개방-폐쇄 원칙`이란 것이 존재한다.\n\n만약 싱글톤 인스턴스가 혼자 너무 많은 일을 하거나, 많은 데이터를 공유시키면 다른 클래스들 간의 결합도가 높아지게 되는데, 이때 개방-폐쇄 원칙이 위배된다.\n\n결합도가 높아지게 되면, 유지보수가 힘들고 테스트도 원활하게 진행할 수 없는 문제점이 발생한다.\n\n
\n\n또한, 멀티 스레드 환경에서 동기화 처리를 하지 않았을 때, 인스턴스가 2개가 생성되는 문제도 발생할 수 있다.\n\n
\n\n따라서, 반드시 싱글톤이 필요한 상황이 아니면 지양하는 것이 좋다고 한다. (설계 자체에서 싱글톤 활용을 원활하게 할 자신이 있으면 괜찮음)\n\n
\n\n
\n\n#### 멀티스레드 환경에서 안전한 싱글톤 만드는 법\n\n---\n\n1. ##### Lazy Initialization (초기화 지연)\n\n ```java\n public class ThreadSafe_Lazy_Initialization{\n \n private static ThreadSafe_Lazy_Initialization instance;\n \n private ThreadSafe_Lazy_Initialization(){}\n \n public static synchronized ThreadSafe_Lazy_Initialization getInstance(){\n if(instance == null){\n instance = new ThreadSafe_Lazy_Initialization();\n }\n return instance;\n }\n \n }\n ```\n\n private static으로 인스턴스 변수 만듬\n\n private으로 생성자를 만들어 외부에서의 생성을 막음\n\n synchronized 동기화를 활용해 스레드를 안전하게 만듬\n\n > 하지만, synchronized는 큰 성능저하를 발생시키므로 권장하지 않는 방법\n\n
\n\n2. ##### Lazy Initialization + Double-checked Locking\n\n > 1번의 성능저하를 완화시키는 방법\n\n ```java\n public class ThreadSafe_Lazy_Initialization{\n private volatile static ThreadSafe_Lazy_Initialization instance;\n \n private ThreadSafe_Lazy_Initialization(){}\n \n public static ThreadSafe_Lazy_Initialization getInstance(){\n \tif(instance == null) {\n \tsynchronized (ThreadSafe_Lazy_Initialization.class){\n if(instance == null){\n instance = new ThreadSafe_Lazy_Initialization();\n }\n }\n }\n return instance;\n }\n }\n ```\n\n 1번과는 달리, 먼저 조건문으로 인스턴스의 존재 여부를 확인한 다음 두번째 조건문에서 synchronized를 통해 동기화를 시켜 인스턴스를 생성하는 방법\n\n 스레드를 안전하게 만들면서, 처음 생성 이후에는 synchronized를 실행하지 않기 때문에 성능저하 완화가 가능함\n\n > 하지만 완전히 완벽한 방법은 아님\n\n
\n\n3. ##### Initialization on demand holder idiom (holder에 의한 초기화)\n\n 클래스 안에 클래스(holder)를 두어 JVM의 클래스 로더 매커니즘과 클래스가 로드되는 시점을 이용한 방법\n\n ```java\n public class Something {\n private Something() {\n }\n \n private static class LazyHolder {\n public static final Something INSTANCE = new Something();\n }\n \n public static Something getInstance() {\n return LazyHolder.INSTANCE;\n }\n }\n ```\n\n 2번처럼 동기화를 사용하지 않는 방법을 안하는 이유는, 개발자가 직접 동기화 문제에 대한 코드를 작성하면서 회피하려고 하면 프로그램 구조가 그만큼 복잡해지고 비용 문제가 발생할 수 있음. 또한 코드 자체가 정확하지 못할 때도 많음\n\n
\n\n\n 이 때문에, 3번과 같은 방식으로 JVM의 클래스 초기화 과정에서 보장되는 `원자적 특성`을 이용해 싱글톤의 초기화 문제에 대한 책임을 JVM에게 떠넘기는 걸 활용함\n\n
\n\n 클래스 안에 선언한 클래스인 holder에서 선언된 인스턴스는 static이기 때문에 클래스 로딩시점에서 한번만 호출된다. 또한 final을 사용해서 다시 값이 할당되지 않도록 만드는 방식을 사용한 것\n\n > 실제로 가장 많이 사용되는 일반적인 싱글톤 클래스 사용 방법이 3번이다.\n" }, { "path": "Design Pattern/Strategy Pattern.md", "content": "## 스트레티지 패턴(Strategy Pattern)\n\n> 어떤 동작을 하는 로직을 정의하고, 이것들을 하나로 묶어(캡슐화) 관리하는 패턴\n\n새로운 로직을 추가하거나 변경할 때, 한번에 효율적으로 변경이 가능하다.\n\n
\n\n```\n[ 슈팅 게임을 설계하시오 ]\n유닛 종류 : 전투기, 헬리콥터\n유닛들은 미사일을 발사할 수 있다.\n전투기는 직선 미사일을, 헬리콥터는 유도 미사일을 발사한다.\n필살기로는 폭탄이 있는데, 전투기에는 있고 헬리콥터에는 없다.\n```\n\n
\n\nStrategy pattern을 적용한 설계는 아래와 같다.\n\n
 \n\n> 상속은 무분별한 소스 중복이 일어날 수 있으므로, 컴포지션을 활용한다. (인터페이스와 로직의 클래스와의 관계를 컴포지션하고, 유닛에서 상황에 맞는 로직을 쓰게끔 유도하는 것)\n\n
\n\n> 상속은 무분별한 소스 중복이 일어날 수 있으므로, 컴포지션을 활용한다. (인터페이스와 로직의 클래스와의 관계를 컴포지션하고, 유닛에서 상황에 맞는 로직을 쓰게끔 유도하는 것)\n\n\n\n- ##### 미사일을 쏘는 것과 폭탄을 사용하는 것을 캡슐화하자\n\n ShootAction과 BombAction으로 인터페이스를 선언하고, 각자 필요한 로직을 클래스로 만들어 implement한다.\n\n- ##### 전투기와 헬리콥터를 묶을 Unit 추상 클래스를 만들자\n\n Unit에는 공통적으로 사용되는 메서드들이 들어있고, 미사일과 폭탄을 선언하기 위해 variable로 인터페이스들을 선언한다.\n\n
\n\n전투기와 헬리콥터는 Unit 클래스를 상속받고, 생성자에 맞는 로직을 정의해주면 끝난다.\n\n##### 전투기 예시\n\n```java\nclass Fighter extends Unit {\n private ShootAction shootAction;\n private BombAction bombAction;\n \n public Fighter() {\n shootAction = new OneWayMissle();\n bombAction = new SpreadBomb();\n }\n}\n```\n\n`Fighter.doAttack()`을 호출하면, OneWayMissle의 attack()이 호출될 것이다.\n\n
\n\n#### 정리\n\n이처럼 Strategy Pattern을 활용하면 로직을 독립적으로 관리하는 것이 편해진다. 로직에 들어가는 '행동'을 클래스로 선언하고, 인터페이스와 연결하는 방식으로 구성하는 것!\n\n
\n\n
\n\n##### [참고]\n\n[링크](
\n\n#### 조건\n\n- 클래스는 추상(abstract)로 만든다.\n- 단계를 진행하는 메소드는 수정이 불가능하도록 final 키워드를 추가한다.\n- 각 단계들은 외부는 막고, 자식들만 활용할 수 있도록 protected로 선언한다.\n\n
\n\n예를 들어보자. 피자를 만들 때는 크게 `반죽 → 토핑 → 굽기` 로 3단계로 이루어져있다.\n\n이 단계는 항상 유지되며, 순서가 바뀔 일은 없다. 물론 실제로는 도우에 따라 반죽이 달라질 수 있겠지만, 일단 모든 피자의 반죽과 굽기는 동일하다고 가정하자. 그러면 피자 종류에 따라 토핑만 바꾸면 된다.\n\n```java\nabstract class Pizza {\n \n protected void 반죽() { System.out.println(\"반죽!\"); }\n abstract void 토핑() {}\n protected void 굽기() { System.out.println(\"굽기!\"); }\n \n final void makePizza() { // 상속 받은 클래스에서 수정 불가\n this.반죽();\n this.토핑();\n this.굽기();\n }\n \n}\n```\n\n```java\nclass PotatoPizza extends Pizza {\n \n @Override\n void 토핑() {\n System.out.println(\"고구마 넣기!\");\n }\n \n}\n\nclass TomatoPizza extends Pizza {\n \n @Override\n void 토핑() {\n System.out.println(\"토마토 넣기!\");\n }\n \n}\n```\n\nabstract 키워드를 통해 자식 클래스에서는 선택적으로 메소드를 오버라이드 할 수 있게 된다.\n\n
\n\n
\n\n#### abstract와 Interface의 차이는?\n\n- abstract : 부모의 기능을 자식에서 확장시켜나가고 싶을 때\n- interface : 해당 클래스가 가진 함수의 기능을 활용하고 싶을 때\n\n> abstract는 다중 상속이 안된다. 상황에 맞게 활용하자!\n\n\n\n" }, { "path": "Design Pattern/[Design Pattern] Overview.md", "content": "### [Design Pattern] 개요\n\n---\n\n> 일종의 설계 기법이며, 설계 방법이다.\n\n\n\n* #### 목적\n\n SW **재사용성, 호환성, 유지 보수성**을 보장.\n\n
\n\n* #### 특징\n\n **디자인 패턴은 아이디어**임, 특정한 구현이 아님.\n\n 프로젝트에 항상 적용해야 하는 것은 아니지만, 추후 재사용, 호환, 유지 보수시 발생하는 **문제 해결을 예방하기 위해 패턴을 만들어 둔 것**임.\n\n
\n\n* #### 원칙\n\n ##### SOLID (객체지향 설계 원칙)\n\n (간략한 설명)\n\n 1. ##### Single Responsibility Principle\n\n > 하나의 클래스는 하나의 역할만 해야 함.\n\n 2. ##### Open - Close Principle\n\n > 확장 (상속)에는 열려있고, 수정에는 닫혀 있어야 함.\n\n 3. ##### Liskov Substitution Principle\n\n > 자식이 부모의 자리에 항상 교체될 수 있어야 함.\n\n 4. ##### Interface Segregation Principle\n\n > 인터페이스가 잘 분리되어서, 클래스가 꼭 필요한 인터페이스만 구현하도록 해야함.\n\n 5. ##### Dependency Inversion Property\n\n > 상위 모듈이 하위 모듈에 의존하면 안됨.\n >\n > 둘 다 추상화에 의존하며, 추상화는 세부 사항에 의존하면 안됨.\n\n
\n\n* #### 분류 (중요)\n\n`3가지 패턴의 목적을 이해하기!`\n\n1. 생성 패턴 (Creational) : 객체의 **생성 방식** 결정\n\n Class-creational patterns, Object-creational patterns.\n\n ```text\n 예) DBConnection을 관리하는 Instance를 하나만 만들 수 있도록 제한하여, 불필요한 연결을 막음.\n ```\n\n
\n\n2. 구조 패턴 (Structural) : 객체간의 **관계**를 조직\n\n ```text\n 예) 2개의 인터페이스가 서로 호환이 되지 않을 때, 둘을 연결해주기 위해서 새로운 클래스를 만들어서 연결시킬 수 있도록 함.\n ```\n\n
\n\n3. 행위 패턴 (Behavioral): 객체의 **행위**를 조직, 관리, 연합\n\n ```text\n 예) 하위 클래스에서 구현해야 하는 함수 및 알고리즘들을 미리 선언하여, 상속시 이를 필수로 구현하도록 함.\n ```\n\n
\n\n" }, { "path": "ETC/Collaborate with Git on Javascript and Node.js.md", "content": "## Javascript와 Node.js로 Git을 통해 협업하기\n\n
\n\n협업 프로젝트를 하기 위해서는 Git을 잘 써야한다. \n\n하나의 프로젝트를 같이 작업하면서 자신에게 주어진 파트에 대한 영역을 pull과 push 할 때 다른 팀원과 꼬이지 않도록 branch를 나누어 pull request 하는 등등..\n\n협업 과정을 연습해보자\n\n
\n\n
\n\n### Prerequisites\n\n| Required | Description |\n| ------------------------------------------------------------ | ------------------------------------------------------------ |\n| [Git](https://git-scm.com/) | We follow the [GitHub Flow](https://guides.github.com/introduction/flow/) |\n| [Node.js](https://github.com/stunstunstun/awesome-javascript/blob/master/nodejs.org) | 10.15.0 LTS |\n| [Yarn](https://yarnpkg.com/lang/en/) | 1.12.3 or above |\n\n
\n\n#### Git과 GitHub을 활용한 협업 개발\n\nGit : 프로젝트를 진행할 때 소스 코드의 버전 관리를 효율적으로 처리할 수 있게 설계된 도구\n\nGitHub : Git의 원격 저장소를 생성하고 관리할 수 있는 기능 제공함. 이슈와 pull request를 중심으로 요구사항을 관리\n\n
\n\nGit 저장소 생성\n\n```\n$ mkdir awesome-javascript\n$ cd awesome-javascript\n$ git init\n```\n\n
\n\nGitHub 계정에 같은 이름의 저장소를 생성한 후, `git remote` 명령어를 통해 원격 저장소 추가\n\n```\n$ git remote add origin 'Github 주소'\n```\n\n
\n\n#### GitHub에 이슈 등록하기\n\n------\n\n***이슈는 왜 등록하는거죠?***\n\n코드 작성하기에 앞서, 요구사항이나 해결할 문제를 명확하게 정의하는 것이 중요\n\nGitHub의 이슈 관리 기능을 활용하면 협업하는 동료와 쉽게 공유가 가능함\n\n
\n\nGitHub 저장소의 `Issues 탭에서 New issue를 클릭`해서 이슈를 작성할 수 있음\n\n
\n\n이슈와 pull request 요청에 작성하는 글의 형식을 템플릿으로 관리할 수 있음\n\n(템플릿은 마크다운 형식)\n\n
\n\n##### 숨긴 폴더인 .github 폴더에서 이슈 템플릿과 pull request 템플릿을 관리하는 방법\n\n> devops/github-templates 브랜치에 템플릿 파일을 생성하고 github에 푸시하자\n\n```\n$ git checkout -b devops/github-templates\n$ mkdir .github\n$ touch .github/ISSUE_TEMPLATE.md # Create issue template\n$ touch .github/PULL_REQUEST_TEMPLATE.md # Create pull request template\n$ git add .\n$ git commit -m ':memo: Add GitHub Templates'\n$ git push -u origin devops/github-templates\n```\n\n
\n\n
\n\n#### Node.js와 Yarn으로 개발 환경 설정하기\n\n------\n\n오늘날 javascript는 애플리케이션 개발에 많이 사용되고 있다.\n\n이때 git을 활용한 협업 환경뿐만 아니라 코드 검증, 테스트, 빌드, 배포 등의 과정에서 만나는 문제를 해결할 수 있는 개발 환경도 설정해야 한다.\n\n> 이때 많이 사용하는 것이 Node.js와 npm, yarn\n\n
\n\n**Node.js와 npm** : JavaScript가 거대한 오픈소스 생태계를 확보하는 데 결정적인 역할을 함\n\n
\n\n**Node.js**는 Google이 V8 엔진으로 만든 Javascript 런타임 환경으로 오늘날 상당히 많이 쓰이는 중!\n\n**npm**은 Node.js를 설치할 때 포함되는데, 패키지를 프로젝트에 추가할 수 있도록 다양한 명령을 제공하는 패키지 관리 도구라고 보면 된다.\n\n**yarn**은 페이스북이 개발한 패키지 매니저로, 규모가 커지는 프로젝트에서 npm을 사용하다가 보안, 빌드 성능 문제를 겪는 문제를 해결하기 위해 탄생함\n\n
\n\nNode.js 설치 후, yarn을 npm 명령어를 통해 전역으로 설치하자\n\n```\n$ npm install yarn -g\n```\n\n
\n\n#### 프로젝트 생성\n\n------\n\n`yarn init` 명령어 실행\n\n프로젝트 기본 정보를 입력하면 새로운 프로젝트가 생성됨\n\n
\n\npakage.json 파일이 생성된 것을 확인할 수 있다.\n\n```json\n{\n \"name\": \"awesome-javascript\",\n \"version\": \"1.0.0\",\n \"main\": \"index.js\",\n \"repository\": \"https://github.com/kim6394/awesome-javascript.git\",\n \"author\": \"gyuseok
\n\n***추가로 생성된 yarn.lock 파일은 뭔가요?***\n\n앱을 개발하는 도중 혹은 배포할 때 프로젝트에서 사용하는 패키지가 업데이트 되는 경우가 있다. 또한 협업하는 동료들마다 다른 버전의 패키지가 설치될 수도 있다.\n\nyarn은 모든 시스템에서 패키지 버전을 일관되게 관리하기 위해 `yarn.lock` 파일을 프로젝트 최상위 폴더에 자동으로 생성함.\n\n(사용자는 이 파일을 직접 수정하면 안됨. 오로지 cli 명령어를 사용해 관리해야한다!)\n\n
\n\n#### 프로젝트 공유\n\n현재 프로젝트는 Git의 원격 저장소에 반영해요 협업하는 동료와 공유가 가능하다.\n\n프로젝트에 생성된 `pakage.json`과 `yarn.lock` 파일도 원격 저장소에서 관리해야 협업하는 동료들과 애플리케이션을 안정적으로 운영하는 것이 가능해짐\n\n
\n\n원격 저장소에 공유 시, 모듈이 설치되는 `node-_modules` 폴더는 제외시켜야 한다. 폴더의 용량도 크고, 어차피 **yarn.lock 파일을 통해 동기화 되기 때문**에 따로 git 저장소에서 관리할 필요가 없음\n\n따라서, 해당 폴더를 .gitignore 파일에 추가해 git 관리 대상에서 제외시키자\n\n```\n$ echo \"node_modules/\" > .gitignore\n```\n\n
\n\n
\n\n##### 이슈 해결 관련 브랜치 생성 & 프로젝트 push\n\n> 이번엔 이슈 해결과 관련된 브랜치를 생성하고, 프로젝트를 github에 푸시해보자\n\n```\n$ git add .\n$ git checkout -b issue/1\n$ git commit -m 'Create project with Yarn'\n$ git push -u origin issue/1\n```\n\n
\n\n푸시가 완려되면, GitHub 저장소에 `pull request`가 생성된 것을 확인할 수 있다.\n\npull request는 **작성한 코드를 master 브랜치에 병합하기 위해 협업하는 동료들에게 코드 리뷰를 요청하는 작업**임\n\nPull requests 탭에서 New pull request 버튼을 클릭해 pull request를 생성할 수 있다\n\n
\n\n##### pull request시 주의할 점\n\n리뷰를 하는 사람에게 충분한 정보를 제공해야 함\n\n새로운 기능을 추가했으면, 기능을 사용하기 위한 재현 시나리오와 테스트 시나리오를 추가하는 것이 좋음.\n\n개발 환경이 변경되었다면 변경 내역도 반드시 포함하자\n\n
\n\n#### Jest로 테스트 환경 설정\n\n실제로 프로젝트를 진행하면, 활용되는 Javascript 구현 코드가 만들어질 것이고 이를 검증하는 테스트 환경이 필요하게 된다.\n\nJavascript 테스트 도구로는 jest를 많이 사용한다.\n\n
\n\nGitHub의 REST API v3을 활용해 특정 GitHub 사용자 정보를 가져오는 코드를 작성해보고, 테스트 환경 설정 방법에 대해 알아보자\n\n
\n\n##### 테스트 코드 작성\n\n구현 코드 작성 이전, 구현하려는 기능의 의도를 테스트 코드로 표현해보자\n\n테스트 코드 저장 폴더 : `__test__`\n\n구현 코드 저장 폴더 : `lib`\n\n테스트 코드 : `github.test.js`\n\n
\n\n```\n$ mkdir __tests__ lib\n$ touch __tests__/github.test.js\n```\n\n
\n\ngithub.test.js에 테스트 코드를 작성해보자\n\n내 GitHub `kim6394` 계정의 사용자 정보를 가져왔는지 확인하는 코드다. \n\n```javascript\nconst GitHub = require('../lib/github')\n\ndescribe('Integration with GitHub API', () => {\n let github\n\n beforeAll ( () => {\n github = new GitHub({\n accessToken: process.env.ACCESS_TOKEN,\n baseURL: 'https://api.github.com',\n })\n })\n\n test('Get a user', async () => {\n const res = await github.getUser('kim6394')\n expect(res).toEqual (\n expect.objectContaining({\n login: 'kim6394',\n })\n )\n })\n})\n```\n\n
\n\n##### Jest 설치\n\nyarn에서 테스트 코드를 실행할 때는 `yarn test`\n\n먼저 설치를 진행하자\n\n```\n$ yarn add jest --dev\n```\n\n******\n\n***`--dev` 속성은 뭔가요?***\n\n> 설치할 때 이처럼 작성하면, `devDependencies` 속성에 패키지를 추가시킨다. 이 옵션으로 설치된 패키지는, 앱이 실행되는 런타임 환경에는 영향을 미치지 않는다.\n\n
\n\n테스트 명령을 위한 script 속성을 pakage.json에 설정하자\n\n```json\n \"scripts\": {\n \"test\": \"jest\"\n },\n \"dependencies\": {\n \"axios\": \"^0.19.0\",\n \"node-fetch\": \"^2.6.0\"\n },\n \"devDependencies\": {\n \"jest\": \"^24.8.0\"\n }\n```\n\n
\n\n##### 구현 코드 작성\n\n아직 구현 코드를 작성하지 않았기 때문에 테스트 실행이 되지 않을 것이다.\n\nlib 폴더에 구현 코드를 작성해보자\n\n`lib/github.js`\n\n```javascript\nconst fetch = require('node-fetch')\n\nclass GitHub {\n constructor({ accessToken, baseURL }) {\n this.accessToken = accessToken\n this.baseURL = baseURL\n }\n\n async getUser(username) {\n if(!this.accessToken) {\n throw new Error('accessToken is required.')\n }\n\n return fetch(`${this.baseURL}/users/${username}`, {\n method: 'GET',\n headers: {\n Authorization: `token ${this.accessToken}`,\n 'Content-Type' : 'application/json',\n },\n }).then(res => res.json())\n }\n}\n\nmodule.exports = GitHub\n```\n\n
\n\n이제 GitHub 홈페이지에서 access token을 생성해서 테스트해보자\n\n토큰은 사용자마다 다르므로 자신이 생성한 토큰 값으로 입력한다\n\n```\n$ ACCESS_TOKEN=29ed3249e4aebc0d5cfc39e84a2081ad6b24a57c yarn test\n```\n\n아래와 같이 테스트가 정상적으로 작동되어 출력되는 것을 확인할 수 있을 것이다!\n\n```\nyarn run v1.10.1\n$ jest\n PASS __tests__/github.test.js\n Integration with GitHub API\n √ Get a user (947ms)\n\nTest Suites: 1 passed, 1 total\nTests: 1 passed, 1 total\nSnapshots: 0 total\nTime: 3.758s\nRan all test suites.\nDone in 5.30s.\n```\n\n
\n\n
\n\n#### Travis CI를 활용한 리뷰 환경 개선\n\n---\n\n동료와 협업하여 애플리케이션을 개발하는 과정은, pull request를 생성하고 공유한 코드를 리뷰, 함께 개선하는 과정이라고 말할 수 있다.\n\n지금까지 진행한 과정을 확인한 리뷰어가 다음과 같이 답을 보내왔다.\n\n
\n\n>README.md를 참고해 테스트 명령을 실행했지만 실패했습니다..\n\n
\n\n무슨 문제일까? 내 로컬 환경에서는 분명 테스트 케이스를 통해 테스트 성공을 확인할 수 있었다. 리뷰어가 보낸 문제는, 다른 환경에서 테스트 실패로 인한 문제다.\n\n이처럼 테스트케이스에 정의된 테스트를 실행하는 일은 개발과정에서 반복되는 작업이다. 따라서 리뷰어가 테스트를 매번 실행하게 하는 건 매우 비효율적이다. \n\nCI 도구가 자동으로 실행하도록 프로젝트 리뷰 방법을 개선시켜보자\n\n
\n\n##### Travis CI로 테스트 자동화\n\n저장소의 Settings 탭에서 Branches를 클릭한 후, Branch protection rules에서 CI 연동기능을 사용해보자\n\n(CI 도구 빌드 프로세스에 정의한 작업이 성공해야만 master 브랜치에 소스코드가 병합되도록 제약 조건을 주는 것)\n\n
\n\n대표적인 CI 도구는 Jenkins이지만, CI 서버 구축 운영에 비용이 든다.\n\n
\n\nTravis CI는 아래와 같은 작업을 위임한다\n\n- ESLint를 통한 코드 컨벤션 검증\n- Jest를 통한 테스트 자동화\n\n
\n\nTravis CI의 연동과 설정이 완료되면, pull request를 요청한 소스코드가 Travis CI를 거치도록 GitHub 저장소의 Branch protection rules 항목을 설정한다.\n\n이를 설정해두면, 작성해둔 구현 코드와 테스트 코드로 pull request를 요청했을 때 Travis CI 서버에서 자동으로 테스트를 실행할 수 있게 된다.\n\n
\n\n##### GitHub-Travis CI 연동\n\nhttps://travis-ci.org/에서 GitHub Login\n\nhttps://travis-ci.org/account/repositories에서 연결할 repository 허용\n\n프로젝트에 .travis.yml 설정 파일 추가\n\n
\n\n`.travis.yml`\n\n```yml\n---\nlanguage: node_js\nnode_js:\n - 10.15.0\ncache:\n yarn: true\n directories:\n - node_modules\n\nenv:\n global:\n - PATH=$HOME/.yarn/bin:$PATH\n\nservices:\n - mongodb\n\nbefore_install:\n - curl -o- -L https://yarnpkg.com/install.sh | bash\n\nscript:\n - yarn install\n - yarn test\n```\n\n
\n\n\n다시 돌아와서, 리뷰어가 테스트를 실패한 이유는 access token 값이 전달되지 못했기 때문이다.\n\n환경 변수를 관리하기 위해선 Git 저장소에서 설정 정보를 관리하고, 값의 유효성을 검증하는 것이 좋다.\n\n(보안 문제가 있을 때는 다른 방법 강구)\n\n
\n\n`dotenv과 joi 모듈`을 사용하면, .env 할 일에 원하는 값을 등록하고 유효성 검증을 할 수 있다.\n\n프로젝트에 .env 파일을 생성하고, access token 값을 등록해두자\n\n
\n\n이제 yarn으로 두 모듈을 설치한다.\n\n```\n$ yarn add dotenv joi\n$ git add .\n$ git commit -m 'Integration with dotenv and joi to manage config properties'\n$ git push\n```\n\n이제 Travis CI로 자동 테스트 결과를 확인할 수 있다.\n\n
\n\n
\n\n#### Node.js 버전 유지시키기\n\n---\n\n개발자들간의 Node.js 버전이 달라서 문제가 발생할 수도 있다.\n\n애플리케이션의 서비스를 안정적으로 관리하기 위해서는 개발자의 로컬 시스템, CI 서버, 빌드 서버의 Node.js 버전을 일관적으로 유지하는 것이 중요하다.\n\n
\n\n`package.json`에서 engines 속성, nvm을 활용해 버전을 일관되게 유지해보자\n\n```\n\"engines\": {\n \"node\": \">=10.15.3\",\n },\n```\n\n
\n\n.nvmrc 파일 추가 후, nvm use 명령어를 실행하면 engines 속성에 설정한 Node.js의 버전을 사용한다.\n\n
\n\n```\n$ echo \"10.15.3\" > .nvmrc\n$ git add .\n$ nvm use\nFound '/Users/user/github/awesome-javascript/.nvmrc' with version <10.15.3> \nNow using node v10.15.3 (npm v6.4.1) \n...\n$ git commit -m 'Add .nvmrc to maintain the same Node.js LTS version'\n```\n\n
\n\n
\n\n
\n\n\n\n지금까지 알아본 점\n\n- Git과 GitHub을 활용해 협업 공간을 구성\n- Node.js 기반 개발 환경과 테스트 환경 설정\n- 개발 환경을 GitHub에 공유하고 리뷰하면서 발생 문제를 해결시켜나감\n\n
\n\n지속적인 코드 리뷰를 하기 위해 자동화를 시키자. 이에 사용하기 좋은 것들\n\n- ESLint로 코드 컨벤션 검증\n- Jest로 테스트 자동화\n- Codecov로 코드 커버리지 점검\n- GitHub의 webhook api로 코드 리뷰 요청\n\n
\n\n자동화를 시켜놓으면, 개발자들은 코드 의도를 알 수 있는 commit message, commit range만 신경 쓰면 된다.\n\n
\n\n협업하며 개발하는 과정에는 코드 작성 후 pull request를 생성하여 병합까지 많은 검증이 필요하다. \n\n테스트 코드는 이 과정에서 예상치 못한 문제가 발생할 확률을 줄여주며, 구현 코드 의도를 효과적으로 전달할 수 있다.\n\n또한 리뷰 시, 코드 컨벤션 검증뿐만 아니라 비즈니스 로직의 발생 문제도 고민이 가능하다.\n\n
\n\n
\n\n**[참고 사항]** \n\n- [링크](
\n\nGit은 컴퓨터 파일의 변경사항을 추적하고 여러 명의 사용자들 간에 해당 파일들의 작업을 조율하기 위한 분산 버전 관리 시스템이다. 따라서, 커밋 메시지를 작성할 때 사용자 간 원활한 소통을 위해 일관된 형식을 사용하면 많은 도움이 된다.\n\n기업마다 다양한 컨벤션이 존재하므로, 소속된 곳의 규칙에 따르면 되며 아래 예시는 'Udacity'의 커밋 메시지 스타일로 작성되었다.\n\n
\n\n### 커밋 메시지 형식\n\n```bash\ntype: Subject\n\nbody\n\nfooter\n```\n\n기본적으로 3가지 영역(제목, 본문, 꼬리말)으로 나누어졌다.\n\n메시지 type은 아래와 같이 분류된다. 아래와 같이 소문자로 작성한다.\n\n- `feat` : 새로운 기능 추가\n- `fix` : 버그 수정\n- `docs` : 문서 내용 변경\n- `style` : 포맷팅, 세미콜론 누락, 코드 변경이 없는 경우 등\n- `refactor` : 코드 리팩토링\n- `test` : 테스트 코드 작성\n- `chore` : 빌드 수정, 패키지 매니저 설정, 운영 코드 변경이 없는 경우 등\n\n
\n\n#### Subject (제목)\n\n`Subject(제목)`은 최대 50글자가 넘지 않고, 마침표와 특수기호는 사용하지 않는다.\n\n영문 표기 시, 첫글자는 대문자로 표기하며 과거시제를 사용하지 않는다. 그리고 간결하고 요점만 서술해야 한다.\n\n> Added (X) → Add (O)\n\n
\n\n#### Body (본문)\n\n`Body (본문)`은 최대한 상세히 적고, `무엇`을 `왜` 진행했는 지 설명해야 한다. 만약 한 줄이 72자가 넘어가면 다음 문단으로 나눠 작성하도록 한다.\n\n
\n\n#### Footer (꼬리말)\n\n`Footer (꼬리말)`은 이슈 트래커의 ID를 작성한다.\n\n어떤 이슈와 관련된 커밋인지(Resolves), 그 외 참고할 사항이 있는지(See also)로 작성하면 좋다.\n\n
\n\n### 커밋 메시지 예시\n\n위 내용을 작성한 커밋 메시지 예시다.\n\n```markdown\nfeat: Summarize changes in around 50 characters or less\n\nMore detailed explanatory text, if necessary. Wrap it to about 72\ncharacters or so. In some contexts, the first line is treated as the\nsubject of the commit and the rest of the text as the body. The\nblank line separating the summary from the body is critical (unless\nyou omit the body entirely); various tools like `log`, `shortlog`\nand `rebase` can get confused if you run the two together.\n\nExplain the problem that this commit is solving. Focus on why you\nare making this change as opposed to how (the code explains that).\nAre there side effects or other unintuitive consequences of this\nchange? Here's the place to explain them.\n\nFurther paragraphs come after blank lines.\n\n - Bullet points are okay, too\n\n - Typically a hyphen or asterisk is used for the bullet, preceded\n by a single space, with blank lines in between, but conventions\n vary here\n\nIf you use an issue tracker, put references to them at the bottom,\nlike this:\n\nResolves: #123\nSee also: #456, #789\n```\n\n
\n\n
\n\n#### [참고 자료]\n\n- [링크](https://udacity.github.io/git-styleguide/)" }, { "path": "ETC/Git vs GitHub vs GitLab Flow.md", "content": "# Git vs GitHub vs GitLab Flow\n\n
\n\n```\ngit-flow의 종류는 크게 3가지로 분리된다.\n어떤 차이점이 있는지 간단히 알아보자\n```\n\n
\n\n## 1. Git Flow\n\n가장 최초로 제안된 Workflow 방식이며, 대규모 프로젝트 관리에 적합한 방식으로 평가받는다.\n\n기본 브랜치는 5가지다.\n\n- feature → develop → release → hotfix → master\n\n
\n\n
 \n\n
\n\n\n\n### Master\n\n> 릴리즈 시 사용하는 최종 단계 메인 브랜치\n\nTag를 통해 버전 관리를 한다.\n\n
\n\n### Develop\n\n> 다음 릴리즈 버전 개발을 진행하는 브랜치\n\n추가 기능 구현이 필요해지면, 해당 브랜치에서 다시 브랜치(Feature)를 내어 개발을 진행하고, 완료된 기능은 다시 Develop 브랜치로 Merge한다.\n\n
\n\n### Feature\n\n> Develop 브랜치에서 기능 구현을 할 때 만드는 브랜치\n\n한 기능 단위마다 Feature 브랜치를 생성하는게 원칙이다.\n\n
\n\n### Release\n\n> Develop에서 파생된 브랜치\n\nMaster 브랜치로 현재 코드가 Merge 될 수 있는지 테스트하고, 이 과정에서 발생한 버그를 고치는 공간이다. 확인 결과 이상이 없다면, 해당 브랜치는 Master와 Merge한다.\n\n
\n\n### Hotfix\n\n> Mater브랜치의 버그를 수정하는 브랜치\n\n검수를 해도 릴리즈된 Master 브랜치에서 버그가 발견되는 경우가 존재한다. 이때 Hotfix 브랜치를 내어 버그 수정을 진행한다. 디버그가 완료되면 Master, Develop 브랜치에 Merge해주고 브랜치를 닫는다.\n\n
\n\n `git-flow`에서 가장 중심이 되는 브랜치는 `master`와 `develop`이다. (무조건 필요)\n\n> 이름을 변경할 수는 있지만, 통상적으로 사용하는 이름이므로 그대로 사용하도록 하자\n\n진행 과정 중에 Merge된 `feature`, `release`, `hotfix` 브랜치는 닫아서 삭제하도록 한다.\n\n이처럼 계획적인 릴리즈를 가지고 스케줄이 짜여진 대규모 프로젝트에는 git-flow가 적합하다. 하지만 대부분 일반적인 프로젝트에서는 불필요한 절차들이 많아 생산성을 떨어뜨린다는 의견도 많은 방식이다.\n\n
\n\n## 2. GitHub Flow\n\n> git-flow를 개선하기 위해 나온 하나의 방식\n\n흐름이 단순한 만큼, 역할도 단순하다. git flow의 `hotfix`나 `feature` 브랜치를 구분하지 않고, pull request를 권장한다.\n\n
\n\n
 \n\n
\n\n\n\nMaster 브랜치가 릴리즈에 있어 절대적 역할을 한다. \n\nMaster 브랜치는 항상 최신으로 유지하며, Stable한 상태로 product에 배포되는 브랜치다.\n\n따라서 Merge 전에 충분한 테스트 과정을 거쳐야 한다. (브랜치를 push하고 Jenkins로 테스트)\n\n
\n\n새로운 브랜치는 항상 `Master` 브랜치에서 만들며, 새로운 기능 추가나 버그 해결을 위한 브랜치는 해당 역할에 대한 이름을 명확하게 지어주고, 커밋 메시지 또한 알기 쉽도록 작성해야 한다.\n\n그리고 Merge 전에는 `pull request`를 통해 공유하여 코드 리뷰를 진행한다. 이를 통해 피드백을 받고, Merge 준비가 완료되면 Master 브랜치로 요청하게 된다.\n\n> 이 Merge는 바로 product에 반영되므로 충분한 논의가 필요하며 **CI**도 필수적이다.\n\nMerge가 완료되면, push를 진행하고 자동으로 배포가 완료된다. (GitHub-flow의 핵심적인 부분)\n\n
\n\n#### CI (Continuous Integration)\n\n- 형상관리 항목에 대한 선정과 형상관리 구성 방식 결정\n\n- 빌드/배포 자동화 방식\n\n- 단위테스트/통합테스트 방식\n\n> 이 세가지를 모두 고려한 자동화된 프로세스를 구성하는 것\n\n
\n\n
\n\n## 3. GitLab Flow\n\n> github flow의 간단한 배포 이슈를 보완하기 위해 관련 내용을 추가로 덧붙인 flow 방식\n\n
\n\n
 \n\n
\n\n\n\nProduction 브랜치가 존재하여 커밋 내용을 일방적으로 Deploy 하는 형태를 갖추고 있다.\n\nMaster 브랜치와 Production 브랜치 사이에 `pre-production` 브랜치를 두어 개발 내용을 바로 반영하지 않고, 시간을 두고 반영한다. 이를 통한 이점은, Production 브랜치에서 릴리즈된 코드가 항상 프로젝트의 최신 버전 상태를 유지할 필요가 없는 것이다.\n\n즉, github-flow의 단점인 안정성과 배포 시기 조절에 대한 부분을 production이라는 추가 브랜치를 두어 보강하는 전력이라고 볼 수 있다.\n\n
\n\n
\n\n## 정리\n\n3가지 방법 중 무엇이 가장 나은 방식이라고 선택할 수 없다. 프로젝트, 개발자, 릴리즈 계획 등 상황에 따라 적합한 방법을 택해야 한다.\n\n배달의 민족인 '우아한 형제들'이 github-flow에서 git-flow로 워크플로우를 변경한 것 처럼 ([해당 기사 링크](https://woowabros.github.io/experience/2017/10/30/baemin-mobile-git-branch-strategy.html)) 브랜칭과 배포에 대한 전략 상황에 따라 변경이 가능한 부분이다.\n\n따라서 각자 팀의 상황에 맞게 적절한 워크플로우를 선택하여 생산성을 높이는 것이 중요할 것이다.\n\n
\n\n
\n\n#### [참고 자료]\n\n- [링크](https://ujuc.github.io/2015/12/16/git-flow-github-flow-gitlab-flow/)\n- [링크](https://medium.com/extales/git을-다루는-workflow-gitflow-github-flow-gitlab-flow-849d4e4104d9)\n- [링크](https://allroundplaying.tistory.com/49)\n\n
\n\n
\n" }, { "path": "ETC/GitHub Fork로 협업하기.md", "content": "### GitHub Fork로 협업하기 \n\n---\n\n1. Fork한 자신의 원격 저장소 확인 (최초에는 존재하지 않음)\n\n ```bash\n git remote -v\n ```\n\n2. Fork한 자신의 로컬 저장소에 Fork한 원격 저장소 등록\n\n ```bash\n git remote add upstream {원격저장소의 Git 주소}\n ```\n\n3. 등록된 원격 저장소 확인\n\n ```bash\n git remote -v\n ```\n\n4. 원격 저장소의 최신 내용을 Fork한 자신의 저장소에 업데이트 \n\n ```bash\n git fetch upstream\n git checkout master\n git merge upstream/master\n ```\n\n - pull : fetch + merge\n\n
\n\n- [ref] \n - https://help.github.com/articles/configuring-a-remote-for-a-fork/\n - https://help.github.com/articles/syncing-a-fork/\n\n" }, { "path": "ETC/GitHub 저장소(repository) 미러링.md", "content": "### GitHub 저장소(repository) 미러링\n\n---\n\n- ##### 미러링 : commit log를 유지하며 clone\n\n#####
\n\n1. #### 저장소 미러링\n\n 1. 복사하고자 하는 저장소의 bare clone 생성\n\n ```bach\n git clone --bare {복사하고자하는저장소의 git 주소}\n ```\n\n 2. 새로운 저장소로 mirror-push\n\n ```bash\n cd {복사하고자하는저장소의git 주소}\n git push --mirror {붙여놓을저장소의git주소}\n ```\n\n 3. 1번에서 생성된 저장소 삭제\n\n
\n\n1. #### 100MB를 넘어가는 파일을 가진 저장소 미러링\n\n 1. [git lfs](https://git-lfs.github.com/)와 [BFG Repo Cleaner](https://rtyley.github.io/bfg-repo-cleaner/) 설치\n\n 2. 복사하고자 하는 저장소의 bare clone 생성\n\n ```bach\n git clone --mirror {복사하고자하는저장소의 git 주소}\n ```\n\n 3. commit history에서 large file을 찾아 트랙킹\n\n ```bash\n git filter-branch --tree-filter 'git lfs track \"*.{zip,jar}\"' -- --all\n ```\n\n 4. BFG를 이용하여 해당 파일들을 git lfs로 변경\n\n ```bash\n java -jar ~/usr/bfg-repo-cleaner/bfg-1.13.0.jar --convert-to-git-lfs '*.zip'\n java -jar ~/usr/bfg-repo-cleaner/bfg-1.13.0.jar --convert-to-git-lfs '*.jar'\n ```\n\n 5. 새로운 저장소로 mirror-push\n\n ```bash\n cd {복사하고자하는저장소의git 주소}\n git push --mirror {붙여놓을저장소의git주소}\n ```\n\n 6. 1번에서 생성된 저장소 삭제\n\n
\n\n- ref\n - [GitHub Help](https://help.github.com/articles/duplicating-a-repository/)\n - [stack overflow](https://stackoverflow.com/questions/37986291/how-to-import-git-repositories-with-large-files)\n\n" }, { "path": "ETC/OPIC.md", "content": "## OPIC\n\n> 인터뷰 형식의 영어 스피킹 시험\n\n
\n\n정형화된 비즈니스 영어에 가까운 토익스피킹과는 다르게 자유로운 실전 영어 스타일\n\n문법, 단어의 완성도가 떨어져도 괜찮음. '나의 이야기'를 전달하고 내가 관심있는 소재에 대한 답변을 하는 스피킹 시험\n\n
\n\n### 출제 유형\n\n---\n\n1. #### 묘사하기\n\n ```\n 'Describe your favourite celebrity.'\n 당신이 가장 좋아하는 연예인을 묘사해보세요\n ```\n\n
\n\n2. #### 설명하기\n\n ```\n 'Can you describe your typical day?'\n 당신의 일상을 말해줄 수 있나요?\n ```\n\n
\n\n3. #### 가정하기\n\n ```\n 'Your credit card stopped working. Ask a question to your card company.'\n 당신의 신용카드가 정지되었습니다. 카드 회사에 문의하세요.\n ```\n\n
\n\n4. #### 콤보 (같은 주제에 대한 2~3문제)\n\n ```\n 'What is your favorite food?'\n 'Can you tell me the steps to make your favorite food?'\n 'You are in restarurant. Can you order your favorite food?'\n ```\n\n
\n\n
\n\n### 참고사항\n\n---\n\n- Survey에서 선택한 항목들이 나옴\n- 외운 답변은 감점한다는 항목이 있음\n\n- 40분간 15개에 대한 질문을 답변하는 형식\n\n- 오픽은 한 문제당 정해진 답변시간이 없음\n- 15문제를 다 못 끝내도 점수에는 영향이 없음\n\n
\n\n단어를 또박또박 발음하도록 연습하고, 이해가 되는 수준의 단어와 문법을 지키자\n\n이야기를 할 때 논리적으로 말하자\n\n```\nFirst ~, Second ~\nIn the morning ~, In the afternoon ~\n```\n\n" }, { "path": "ETC/[인적성] 명제 추리 풀이법.md", "content": "## [인적성] 명제 추리 풀이법\n\n
\n\n모든, 어떤이 들어간 문장에 대한 명제 추리는 항상 까다롭다. 이를 대우로 바꾸며 옳은 문장을 찾기 위한 문제는 인적성에서 꼭 나온다.\n\n실제로 정확한 답을 유추하기 위해 벤다이어그램을 그리는 등 다양한 해결책을 제시하지만 실제 문제 풀이는 **1분안에 풀어야하므로 비효율적**이다. 약간 암기형으로 접근하자.\n\n
\n\n문장을 수식 기호로 간단히 바꾸기\n\n```\n모든 = →\n어떤 = &\n부정 = ~\n```\n\n
\n\n#### ex) 모든 남자는 사람이다.\n\n`남자 → 사람`\n\n**모든**은 포함의 개념이므로 **대우도 가능** `~사람 → ~남자`\n\n
\n\n#### ex) 어떤 여자는 사람이 아니다.\n\n`여자 & ~사람`\n\n**어떤**은 일부의 개념이므로 **대우X**\n\n
\n\n#### 유형 1\n\n```\n전제1 : 모든 취업준비생은 열심히 공부를 하는 사람이다.\n전제2 : _______________________________________\n\n결론 : 어떤 열심히 공부하는 사람은 독서를 좋아하지 않는다.\n```\n\n**전제1,2에 모든으로 시작하는 문장과 어떤으로 시작하는 문장으로 구성되고, 결론에는 어떤으로 시작하는 문장으로 구성된 상황**\n\n결론의 두 부분은 전제1의 **모든**으로 시작하는 뒷 부분, 전제2의 **어떤**으로 시작하는 문장 앞뒤 중 한개가 포함\n\nor\n\n전제2의 **어떤** 중 나머지 한개는 전제1을 성립시키기위한 **모든**으로 시작하는 앞부분이 되야 함\n\n```\n취업준비생 → 공부하는 사람\n______________________ : 취업준비생 & ~독서를 좋아하는 사람\n공부하는 사람 & ~독서를 좋아하는 사람\n```\n\n
\n\n#### 유형 2\n\n```\n전제1 : 모든 기술개발은 미래를 예측해야 한다.\n전제2 : _________________________________\n\n결론 : 어떤 기술개발은 기업을 성공시킨다.\n```\n\n유형 1의 전제2와 결론의 위치가 바뀐 상황 (즉, 전제1의 앞의 조건으로 전제2가 나오지 않고 결론으로 간 상황)\n
\n\n```\n기술개발 → 미래예측\n__________________ : 미래예측 → 기업성공\n기술개발 & 기업성공\n```\n\n
\n\n
\n\n확실히 이해가 안되면 그냥 외워서 맞추자. 여기에 시간낭비할 필요가 없으므로 빠르게 풀고 지나가야 함" }, { "path": "ETC/반도체 개념정리.md", "content": "### 반도체(Semiconductor)\n\n> 도체와 부도체의 중간정도 되는 물질\n\n
\n\n빛이나 열을 가하거나, 특정 불순물을 첨가해 도체처럼 전기가 흐르게 함\n\n즉, **전기전도성을 조절할 수 있는 것**이 반도체\n\n
\n\n반도체 기술은 보통 집적회로(IC) 기술을 말한다.\n\n***집적회로(IC)*** : 다이오드, 트랜지스터 등을 초소형화, 고집적화시켜 전기적으로 동작하도록 한 것 → ***작은 반도체 속에 하나의 전자회로로 구성해 집어넣어 성능을 높인다!***\n\n
\n\n
\n\n### 메모리 반도체(Memory Semiconductor)\n\n> 정보(Data)를 저장하는 용도로 사용되는 반도체\n\n
\n\n#### 메모리 반도체 종류\n\n- ##### 램(Random Access Memory)\n\n 정보를 기록하고, 기록해 둔 정보를 읽거나 수정할 수 있음 (휘발성 - 전원이 꺼지면 정보 날아감)\n\n > **DRAM** : 일정 시간마다 자료 유지를 위해 리프레시가 필요 (트랜지스터 1개 & 커패시터 1개)\n >\n > **SRAM** : 전원이 공급되는 한 기억정보가 유지\n\n- ##### 롬(Read Only Memory)\n\n 기록된 정보만 읽을 수 있고, 수정할 수는 없음 (비휘발성 - 전원이 꺼져도 정보 유지)\n\n > **Flash Memory** : 전력소모가 적고 고속 프로그래밍 가능(트랜지스터 1개)\n\n
\n\n메모리 반도체는 기억장치로, **얼마나 많은 양을 기억하고 얼마나 빨리 동작하는가**가 중요\n\n(대용량 & 고성능)\n\n모바일 기기의 사용이 많아지면서 **초박형 & 저전력성**도 중요해짐\n\n
 \n\n
\n\n\n\n### 시스템 반도체(System Semiconductor)\n\n> 논리와 연산, 제어 기능 등을 수행하는 반도체\n\n
\n\n메모리 반도체와 달리, 디지털화된 전기적 정보(Data)를 **연산하거나 처리**(제어, 변환, 가공 등)하는 반도체\n\n
\n\n#### 시스템 반도체 종류\n\n- ##### 마이크로컴포넌츠\n\n 전자 제품의 두뇌 역할을 하는 시스템 반도체 (마이컴이라고도 부름)\n\n > **MPU**\n >\n > **MCU(Micro Controller Unit)** : 단순 기능부터 특수 기능까지 제품의 다양한 특성을 컨트롤\n >\n > **DSP(Digital Signal Processor)** : 빠른 속도로 디지털 신호를 처리해 영상, 음성, 데이터를 사용하는 전자제품에 많이 사용\n\n- ##### 아날로그 IC\n\n 음악과 같은 각종 아날로그 신호를 컴퓨터가 인식할 수 있는 디지털 신호로 바꿔주는 반도체\n\n- ##### 로직 IC\n\n 논리회로(AND, OR, NOT 등)로 구성되며, 제품 특정 부분을 제어하는 반도체\n\n- ##### 광학 반도체\n\n 빛 → 전기신호, 전기신호 → 빛으로 변환해주는 반도체\n\n
\n\n
 \n\n
\n\n\n\n#### SoC(System on Chip)\n\n> 전체 시스템을 칩 하나에 담은 기술집약적 반도체\n\n
\n\n여러 기능을 가진 기기들로 구성된 시스템을 하나의 칩으로 만드는 기술\n\n연산소자(CPU) + 메모리 소자(DRAM, 플래시 등) + 디지털신호처리소자(DSP) 등 주요 반도체 소자를 하나의 칩에 구현해서 하나의 시스템을 만드는 것\n\n
\n\n이를 통해 여러 기능을 가진 반도체가 하나의 칩으로 통합되면서 **제품 소형화가 가능하고, 제조비용을 감소할 수 있는 효과**를 가져온다.\n\n
\n\n
\n\n#### 모바일 AP(Mobile Applicaton Processor)\n\n> 스마트폰, 태플릿PC 등 전자기기에 탑재되어 명령해석, 연산, 제어 등의 두뇌 역할을 하는 시스템 반도체\n\n
\n\n일반적으로 PC는 CPU와 메모리, 그래픽카드, 하드디스크 등 연결을 제어하는 칩셋으로 구성됨.\n\n모바일 AP는 CPU 기능과 다른 장치를 제어하는 칩셋의 기능을 모두 포함함. **필요한 OS와 앱을 구동시키며 여러 시스템 장치/인터페이스를 컨트롤하는 기능을 하나의 칩에 모두 포함하는 것**\n\n
\n\n**주요 기능** : OS 실행, 웹 브라우징, 멀티 터치 스크린 입력 실행 등 스마트 기기 핵심기능 담당하는 CPU & 그래픽 영상 데이터를 처리해 화면에 표시해주는 GPU\n\n이 밖에도 비디오 녹화, 카메라, 모바일 게임 등 여러 시스템 구동을 담당하는 서브 프로세서들이 존재함\n\n
\n\n
\n\n#### 임베디드 플래시 로직 공정\n\n> 시스템 반도체 회로 안에 플래시메모리 회로를 구현한 것\n\n**시스템 반도체 칩** : 데이터를 제어 및 처리\n\n**플래시 메모리 칩** : 데이터를 기억\n\n
\n\n집적도와 전력 효율을 높일 수 있어 `가전, 모바일, 자동차 등` 다양한 애플리케이션 제품에 적용함\n\n
\n\n
\n\n#### 반도체 분류\n\n- **표준형 반도체(Standard)** : 규격이 정해져 있어 일정 요건 맞추면 어떤 전자제품에서도 사용 가능\n- **주문형 반도체(ASIC)** : 특정한 제품을 위해 사용되는 맞춤형 반도체\n\n
\n\n
\n\n#### 플래시 메모리(Flash Memory)\n\n> 전원이 끊겨도 데이터를 보존하는 특성을 가진 반도체\n\n**ROM과 RAM의 장점을 동시에 지님** (전원이 꺼져도 데이터 보존 + 정보의 입출력이 자유로움)\n\n따라서 휴대전화, USB 드라이브, 디지털 카메라 등 휴대용 기기의 대용량 정보 저장 용도로 사용\n\n
\n\n##### 플래시 메모리 종류\n\n> 반도체 칩 내부의 전자회로 형태에 따라 구분됨\n\n- **NAND(데이터 저장)** - 소형화, 대용량화\n\n 직렬 형태, 셀을 수직으로 배열하는 구조라 좁은 면적에 많이 만들 수 있어 **용량을 늘리기 쉬움**\n\n 데이터를 순차적으로 찾아 읽기 때문에, 별도 셀의 주소를 기억할 필요가 없어 **쓰기 속도가 빠름**\n\n- **NOR(코드 저장)** - 안전성, 빠른 검색\n\n 병렬 형태, 데이터를 빨리 찾을 수 있어서 **읽기 속도가 빠르고 안전성이 우수함**\n\n 셀의 주소를 기억해야돼서 회로가 복잡하고 대용량화가 어려움\n\n
\n\n
\n\n#### SSD(Solid State Drive)\n\n> 메모리 반도체를 저장매체로 사용하는 차세대 대용량 저장장치\n\n
\n\nHDD를 대체한 컴퓨터의 OS와 데이터를 저장하는 보조기억장치임 (반도체 칩에 정보가 저장되어 SSD라고 불림)\n\nNAND 플래시 메모리에 정보를 저장하여 전력소모가 적고, 소형 및 경량화가 가능함\n\n
\n\n##### SSD 구성\n\n- **NAND Flash** : 데이터 저장용 메모리\n- **Controller** : 인터페이스와 메모리 사이 데이터 교환 작업 제어\n- **DRAM** : 외부 장치와 캐시메모리 역할\n\n
\n\n보급형 SSD가 출시되면서 노트북 & 데스크탑 PC에 많이 사용되며, 빅데이터 시대에 급증하는 데이터를 관리하기 위해 데이터센터의 핵심 저장 장치로 이용되고 있음\n\n
\n\n
\n\n### 반도체 업체 종류\n\n---\n\n- ##### 종합 반도체 업체(IDM)\n\n 제품 설계부터 완제품 생산까지 모든 분야를 자체 운영 - 대규모 반도체 업체임\n\n- ##### 파운드리 업체(Foundry)\n\n 반도체 제조과정만 전담 - 반도체 생산설비를 갖추고 있으며 위탁 업체의 제품을 대신 생산하여 이익을 얻음\n\n- ##### 반도체 설계(팹리스) 업체(Fabless)\n\n 설계 기술만 가짐 - 보통 하나의 생산라인 건설에 엄청난 비용이 들기 때문에, 설계 전문 업체(Fabless)들은 파운드리 업체에 위탁하여 생산함\n\n
\n\n
\n\n#### 수율(Yield)\n\n> 결함이 없는 합격품의 비율\n\n웨이퍼 한 장에 설계된 최대 칩의 개수 대비 실제 생상된 정상 칩의 개수를 백분율로 나타낸 것 (불량률의 반대말)\n\n수율이 높을수록 생산성이 향상됨을 의미함. 따라서 수율을 높이는 것이 중요\n\n***수율을 높이려면?*** : 공정장비의 정확도와 클린룸의 청정도가 높아야 함\n\n
\n\n
\n\n#### NFC(Near Field Communication)\n\n> 10cm 이내의 근거리에서 데이터를 교환할 수 있는 무선통신기술\n\n통신거리가 짧아 상대적 보안이 우수하고, 가격이 저렴함\n\n교통카드 or 전자결제에서 대표적으로 사용되며 IT기기 및 생활 가전제품으로 확대되고 있음\n\n
\n\n
\n\n#### 패키징(Packaging)\n\n> 반도체 칩을 탑재될 전자기기에 적합한 형태로 만드는 공정\n\n칩을 외부 환경으로부터 보호하고, 단자 간 연결을 위해 전기적으로 포장하는 공정이다.\n\n패키지 테스트를 통해 다양한 조건에서 특성을 측정해 불량 유무를 구별함\n\n
\n\n
\n\n#### 이미지 센서(Image Sensor)\n\n> 피사체 정보를 읽어 전기적인 영상신호로 변화해주는 소자\n\n카메라 렌즈를 통해 들어온 빛을 전기적 디지털 신호로 변환해주는 역할\n\n**영상신호를 저장 및 전송해 디스플레이 장치로 촬영 사진을 볼수 있도록 만들어주는 반도체** (필름 카메라의 필름과 유사)\n\n- CCD : 전하결합소자\n- CMOS : 상보성 금속산화 반도체\n\n디지털 영상기기에 많이 활용된다. (스마트폰, 태블릿PC, 고해상도 디지털 카메라 등)\n\n
 \n\n\n\n
\n\n\n\n\n\n
\n\n##### [참고 자료]\n\n[삼성메모리반도체](
\n\n- ##### 디노미네이션\n\n 화폐의 액면 단위를 100분의 1 혹은 10분의 1 등으로 낮추는 화폐개혁\n\n
\n\n- ##### 카니발라이제이션\n\n 파격적인 후속 제품이 시장에 출시되어 기존 제품 점유율, 수익성, 판매 등에 영향을 미치는 것\n\n
\n\n- ##### 선강퉁\n\n 선전주식시장 - 홍콩주식시장의 교차투자를 허용하는 것\n\n
\n\n- ##### 후강퉁\n\n 상하이주식시장 - 홍콩주식시장의 교차투자를 허용하는 것\n\n
\n\n- 미국발 금융위기 이후 세계 각국에서 취한 금융개혁 조치\n\n - 스트레스 테스트 실시\n - 볼커 룰 시행\n - 바젤3의 도입\n\n
\n\n- ##### 회색코뿔소\n\n 지속적인 경고로 충분히 예상할 수 있지만 쉽게 간과하는 위험 요인\n\n
\n\n- ##### 블랙스완\n\n 도저히 일어날 것 같지 않지만 만약 발생할 경우 시장에 엄청난 충격을 몰고 오는 사건\n\n
\n\n- ##### 화이트스완\n\n 역사적으로 되풀이된 금융위기를 가리킴\n\n
\n\n- ##### 네온스완\n\n 절대 불가능한 상황 (스스로 빛을 내는 백조)\n\n
\n\n- ##### 그린메일\n\n 경영권을 넘볼 수 있는 수준의 주식을 확보한 특정 집단이 기업의 경영자로 하여금 보유한 주식을 프리미엄 가격에 되사줄 것을 요구하는 행위\n\n
\n\n- ##### 차등의결권제도\n\n 1주 1의결권원칙의 예외를 인정하여 1주당 의결권이 서로 상이한 2종류 이상의 주식을 발행하는 것\n\n
\n\n- ##### 엥겔지수\n\n 가계의 소비지출 중에서 식료품비가 차지하는 비중을 뜻함\n\n
\n\n- ##### 빅맥지수\n\n 각 국가의 물가 수준을 비교하는 구매력평가지수의 일종\n\n
\n\n- ##### 지니계수\n\n 소득불평등을 측정하는 지표\n\n
\n\n- ##### 슈바베지수\n\n 가계의 소비지출 중에서 전월세 비용이나 주택 관련 대출 상환금 등 주거비가 차지하는 비율\n\n
\n\n- ##### 젠트리피케이션\n\n 낙후된 지역에 인구가 몰리면서 원주민이 외부로 내몰리는 현상\n\n
\n\n- ##### 브렉시트\n\n 영국의 EU 탈퇴\n\n
\n\n- ##### 게리맨더링\n\n 선거에 유리하도록 기형적으로 선거구를 확정하는 일\n\n
\n\n- ##### 리쇼어링\n\n 비용 등의 문제로 해외에 진출했던 자국 기업들에게 일정한 혜택을 부여하여 본국으로 회귀시키는 일련의 정책\n\n
\n\n- ##### 다보스포럼\n\n 스위스 제네바에서 매년 1~2월경 기업인, 경제학과, 언론인, 정치인들이 모여 세계 경제 개선에 대한 토론을 하는 회의\n\n
\n\n- ##### AIIB\n\n 아시아 태평양 지역의 기반시설 구축 지원 목적으로 중국이 주도하는 아시아지역 인프라 투자 은행\n\n
\n\n- ##### OECD\n\n 회원 상호간 관심분야에 대한 정책을 토의하고 조정하는 36개국의 임의기구\n\n
\n\n- ##### ECB\n\n 유럽연합(EU)의 통합정책을 수행하는 중앙은행\n\n
\n\n- ##### 비트코인\n\n 한국은행 등과 같이 발권과 관련된 기관의 통제 없이 네트워크상에서 거래 가능한 가상화폐\n\n
\n\n- ##### 블록체인\n\n 거래 당사자의 거래 내역을 금융기관 시스템에 저장하는 것이 아니라 거래자별로 모든 내용을 공유하는 형태의 거래 방식 ('분산원장'이라고 표현)\n\n
\n\n- ##### 로보어드바이저\n\n AI 알고리즘, 빅데이터를 활용한 투자자의 투자성향, 리스크선호도, 목표수익률 등을 분석하고 그 결과를 바탕으로 온라인 자산관리서비스를 제공하는 것\n\n
\n\n- ##### 사이드카\n\n 선물가격에 대한 변동이 지속되어 프로그램매매 효력을 5분간 정지하는 제도\n\n
\n\n- ##### 서킷브레이커\n\n 코스피, 코스닥 지수 급등, 급락 변동이 1분간 지속될 경우 단계를 발동하여 20분씩 당일 거래를 중단하는 제도" }, { "path": "ETC/임베디드 시스템.md", "content": "## 임베디드 시스템\n\n
\n\n특정한 목적을 수행하도록 만든 컴퓨터로, 사람의 개입 없이 작동 가능한 하드웨어와 소프트웨어의 결합체\n\n임베디드 시스템의 하드웨어는 특정 목적을 위해 설계됨\n\n
\n\n#### 임베디드 시스템의 특징\n\n- 특정 기능 수행\n- 실시간 처리\n- 대량 생산\n- 안정성\n- 배터리로 동작\n\n
\n\n#### 임베디드 구성 요소\n\n- 하드웨어\n- 소프트웨어\n\n
\n\n#### 임베디드 하드웨어의 구성요소\n\n- 입출력 장치\n- Flash Memory\n- CPU\n- RAM\n- 통신장치\n- 회로기판\n\n
\n\n#### 임베디드 소프트웨어 분류\n\n- 시스템 소프트웨어 : 시스템 전체 운영 담당\n- 응용 소프트웨어 : 입출력 장치 포함 특수 용도 작업 담당 (사용자와 대면)\n\n
\n\n#### 펌웨어 기반 소프트웨어\n\n- 운영체제없이 하드웨어 시스템을 구동하기 위한 응용 프로그램\n- 간단한 임베디드 시스템의 소프트웨어\n\n
\n\n#### 운영체제 기반 소프트웨어\n\n- 소프트웨어가 복잡해지면서 펌웨어 형태로는 한계 도달\n- 운영체제는 하드웨어에 의존적인 부분, 여러 프로그램이 공통으로 이용할 수 있는 부분을 별도로 분리하는 프로그램\n\n
\n\n
\n\n##### [참고사항]\n\n- [링크](https://myeonguni.tistory.com/1739)\n\n\n\n" }, { "path": "Interview/Interview List.md", "content": "# Interview List\n\n간단히 개념들을 정리해보며 머리 속에 넣자~\n\n
\n\n- [언어(Java, C++ ... )](
\n\n
\n\n### 언어(C++ 등..)\n\n---\n\n#### Vector와 ArrayList의 차이는?\n\n> Vector : 동기식. 한 스레드가 벡터 작업 중이면 다른 스레드가 벡터 보유 불가능\n>\n> ArrayList : 비동기식. 여러 스레드가 arraylist에서 동시 작업이 가능\n\n
\n\n#### Serialization이란?\n\n> 직렬화. 객체의 상태 혹은 데이터 구조를 기록할 수 있는 포맷으로 변환해줌\n>\n> 나중에 재구성 할 수 있게 자바 객체를 JSON으로 변환해주거나 JSON을 자바 객체로 변환해주는 라이브러리\n\n
\n\n#### Hash란?\n\n> 데이터 삽입 및 삭제 시, 기존 데이터를 밀어내거나 채우지 않고 데이터와 연관된 고유한 숫자를 생성해 인덱스로 사용하는 방법\n>\n> 검색 속도가 매우 빠르다\n\n
\n\n#### Call by Value vs Call by Reference\n\n> 값에 의한 호출 : 값을 복사해서 새로운 함수로 넘기는 호출 방식. 원본 값 변경X\n>\n> 참조에 의한 호출 : 주소 값을 인자로 전달하는 호출 방식. 원본 값 변경O\n\n
\n\n#### 배열과 연결리스트 차이는?\n\n> 배열은 인덱스를 가짐. 원하는 데이터를 한번에 접근하기 때문에 접근 속도 빠름.\n>\n> 크기 변경이 불가능하며, 데이터 삽입 및 삭제 시 그 위치의 다음 위치부터 모든 데이터 위치를 변경해야 되는 단점 존재\n>\n> 연결리스트는 인덱스 대신에 현재 위치의 이전/다음 위치를 기억함.\n>\n> 크기는 가변적. 인덱스 접근이 아니기 때문에 연결되어 있는 링크를 쭉 따라가야 접근이 가능함. (따라서 배열보다 속도 느림)\n>\n> 데이터 삽입 및 삭제는 논리적 주소만 바꿔주면 되기 때문에 매우 용이함\n>\n> - 데이터의 양이 많고 삽입/삭제가 없음. 데이터 검색을 많이 해야할 때 → Array\n> - 데이터의 양이 적고 삽입/삭제 빈번함 → LinkedList\n\n
\n\n#### 스레드는 어떤 방식으로 생성하나요? 장단점도 말해주세요\n\n> 생성방법 : Runnable(인터페이스)로 선언되어 있는 클래스 or Thread 클래스를 상속받아서 run() 메소드를 구현해주면 됨\n>\n> 장점 : 빠른 프로세스 생성, 메모리를 적게 사용 가능, 정보 공유가 쉬움\n>\n> 단점 : 데드락에 빠질 위험이 존재\n\n
\n\n#### C++ 실행 과정\n\n> 전처리 : #define, #include 지시자 해석\n>\n> 컴파일 : 고급 언어 소스 프로그램 입력 받고, 어셈블리 파일 만듬\n>\n> 어셈블 : 어셈블리 파일을 오브젝트 파일로 만듬\n>\n> 링크 : 오브젝트 파일을 엮어 실행파일을 만들고 라이브러리 함수 연결\n>\n> 실행\n\n
\n\n#### 메모리, 성능을 개선하기 위해 생각나는 방법은?\n\n> static을 사용해 선언한다.\n>\n> 인스턴스 변수에 접근할 일이 없으면, static 메소드를 선언하여 호출하자\n>\n> 모든 객체가 서로 공유할 수 있기 때문에 메모리가 절약되고 연속적으로 그 값의 흐름을 이어갈 수 있는 장점이 존재\n\n
\n\n#### 클래스와 구조체의 차이는?\n\n> 구조체는 하나의 구조로 묶일 수 있는 변수들의 집합이다.\n>\n> 클래스는 변수뿐만 아니라, 메소드도 포함시킬 수 있음\n>\n> (물론 함수 포인터를 이용해 구조체도 클래스처럼 만들어 낼 수도 있다.)\n\n
\n\n#### 포인터를 이해하기 쉽도록 설명해주세요\n\n> 포인터는 메모리 주소를 저장하는 변수임\n>\n> 주소를 지칭하고 있는 곳인데, 예를 들면 엘리베이터에서 포인터는 해당 층을 표시하는 버튼이라고 할 수 있음. 10층을 누르면 10층으로 이동하듯, 해당 위치를 가리키고 있는 변수!\n>\n> 포인터를 사용할 때 주의할 점은, 어떤 주소를 가리키고 있어야만 사용이 가능함\n\n
\n\n
\n\n
\n\n### 운영체제\n\n---\n\n#### 프로세스와 스레드 차이\n\n> 프로세스는 메모리 상에서 실행중인 프로그램을 말하며, 스레드는 이 프로세스 안에서 실행되는 흐름 단위를 말한다.\n>\n> 프로세스마다 최소 하나의 스레드를 보유하고 있으며, 각각 별도의 주소공간을 독립적으로 할당받는다. (code, data, heap, stack)\n>\n> 스레드는 이중에 stack만 따로 할당받고 나머지 영역은 스레드끼리 서로 공유한다.\n>\n> ##### 요약\n>\n> **프로세스** : 자신만의 고유 공간과 자원을 할당받아 사용\n>\n> **스레드** : 다른 스레드와 공간과 자원을 공유하면서 사용\n\n
\n\n#### 멀티 프로세스로 처리 가능한 걸 굳이 멀티 스레드로 하는 이유는?\n\n> 프로세스를 생성하여 자원을 할당하는 시스템 콜이 감소함으로써 자원의 효율적 관리가 가능함\n>\n> 프로세스 간의 통신(IPC)보다 스레드 간의 통신 비용이 적어 작업들 간 부담이 감소함\n>\n> 대신, 멀티 스레드를 사용할 때는 공유 자원으로 인한 문제 해결을 위해 '동기화'에 신경써야 한다.\n\n
\n\n#### 교착상태(DeadLock)가 무엇이며, 4가지 조건은?\n\n> 프로세스가 자원을 얻지 못해 다음 처리를 하지 못하는 상태를 말한다.\n>\n> 시스템적으로 한정된 자원을 여러 곳에서 사용하려고 할 때 발생하는 문제임\n>\n> 교착상태의 4가지 조건은 아래와 같다.\n>\n> - 상호배제 : 프로세스들이 필요로 하는 자원에 대해 배타적 통제권을 요구함\n> - 점유대기 : 프로세스가 할당된 자원을 가진 상태에서 다른 자원 기다림\n> - 비선점 : 프로세스가 어떤 자원의 사용을 끝날 때까지 그 자원을 뺏을 수 없음\n> - 순환대기 : 각 프로세스는 순환적으로 다음 프로세스가 요구하는 자원을 갖고 있음\n>\n> 이 4가지 조건 중 하나라도 만족하지 않으면 교착상태는 발생하지 않음\n>\n> (순환대기는 점유대기와 비선점을 모두 만족해야만 성립합. 따라서 4가지가 서로 독립적이진 않음)\n\n
\n\n#### 교착상태 해결 방법 4가지\n\n> - 예방\n> - 회피\n> - 무시\n> - 발견\n\n
\n\n#### 메모리 계층 (상-하층 순)\n\n> | 레지스터 |\n> | :--------: |\n> | 캐시 |\n> | 메모리 |\n> | 하드디스크 |\n\n
\n\n#### 메모리 할당 알고리즘 First fit, Next fit, Best fit 결과\n\n> - First fit : 메모리의 처음부터 검사해서 크기가 충분한 첫번째 메모리에 할당\n> - Next fit : 마지막으로 참조한 메모리 공간에서부터 탐색을 시작해 공간을 찾음\n> - Best fit : 모든 메모리 공간을 검사해서 내부 단편화를 최소화하는 공간에 할당\n\n
\n\n#### 페이지 교체 알고리즘에 따른 페이지 폴트 방식\n\n> OPT : 최적 교체. 앞으로 가장 오랫동안 사용하지 않을 페이지 교체 (실현 가능성 희박)\n>\n> FIFO : 메모리가 할당된 순서대로 페이지를 교체\n>\n> LRU : 최근에 가장 오랫동안 사용하지 않은 페이지를 교체\n>\n> LFU : 사용 빈도가 가장 적은 페이지를 교체\n>\n> NUR : 최근에 사용하지 않은 페이지를 교체\n\n
\n\n#### 외부 단편화와 내부 단편화란?\n\n> 외부 단편화 : 작업보다 많은 공간이 있더라도 실제로 그 작업을 받아들일 수 없는 경우 (메모리 배치에 따라 발생하는 문제)\n>\n> 내부 단편화 : 작업에 필요한 공간보다 많은 공간을 할당받음으로써 발생하는 내부의 사용 불가능한 공간\n\n
\n\n#### 가상 메모리란?\n\n> 메모리에 로드된, 실행중인 프로세스가 메모리가 아닌 가상의 공간을 참조해 마치 커다란 물리 메모리를 갖는 것처럼 사용할 수 있게 해주는 기법\n\n
\n\n#### 페이징과 세그먼테이션이란?\n\n> ##### 페이징\n>\n> 페이지 단위의 논리-물리 주소 관리 기법.\n> 논리 주소 공간이 하나의 연속적인 물리 메모리 공간에 들어가야하는 제약을 해결하기 위한 기법\n> 논리 주소 공간과 물리 주소 공간을 분리해야함(주소의 동적 재배치 허용), 변환을 위한 MMU 필요\n>\n> 특징 : 외부 단편화를 없앨 수 있음. 페이지가 클수록 내부 단편화도 커짐\n>\n> ##### 세그먼테이션\n>\n> 사용자/프로그래머 관점의 메모리 관리 기법. 페이징 기법은 같은 크기의 페이지를 갖는 것 과는 다르게 논리적 단위(세그먼트)로 나누므로 미리 분할하는 것이 아니고 메모리 사용할 시점에 할당됨\n\n
\n\n#### 뮤텍스, 세마포어가 뭔지, 차이점은?\n\n> ##### 세마포어\n>\n> 운영체제에서 공유 자원에 대한 접속을 제어하기 위해 사용되는 신호\n> 공유자원에 접근할 수 있는 최대 허용치만큼만 동시에 사용자 접근 가능\n> 스레드들은 리소스 접근 요청을 할 수 있고, 세마포어는 카운트가 하나씩 줄어들게 되며 리소스가 모두 사용중인 경우(카운트=0) 다음 작업은 대기를 하게 된다\n>\n> ##### 뮤텍스\n>\n> 상호배제, 제어되는 섹션에 하나의 스레드만 허용하기 때문에, 해당 섹션에 접근하려는 다른 스레드들을 강제적으로 막음으로써 첫 번째 스레드가 해당 섹션을 빠져나올 때까지 기다리는 것\n> (대기열(큐) 구조라고 생각하면 됨)\n>\n> ##### 차이점\n>\n> - 세마포어는 뮤텍스가 될 수 있지만, 뮤텍스는 세마포어가 될 수 없음\n> - 세마포어는 소유 불가능하지만, 뮤택스는 소유가 가능함\n> - 동기화의 개수가 다름\n\n
\n\n#### Context Switching이란?\n\n> 하나의 프로세스가 CPU를 사용 중인 상태에서 다른 프로세스가 CPU를 사용하도록 하기 위해, 이전의 프로세스 상태를 보관하고 새로운 프로세스의 상태를 적재하는 작업\n>\n> 한 프로세스의 문맥은 그 프로세스의 PCB에 기록됨\n\n
\n\n#### 사용자 수준 스레드 vs 커널 수준 스레드 차이는?\n\n> ##### 사용자 수준 스레드\n>\n> 장점 : context switching이 없어서 커널 스레드보다 오버헤드가 적음 (스레드 전환 시 커널 스케줄러 호출할 필요가 없기 때문)\n>\n> 단점 : 프로세스 내의 한 스레드가 커널로 진입하는 순간, 나머지 스레드들도 전부 정지됨 (커널이 스레드의 존재를 알지 못하기 때문에)\n>\n> ##### 커널 수준 스레드\n>\n> 장점 : 사용자 수준 스레드보다 효율적임. 커널 스레드를 쓰면 멀티프로세서를 활용할 수 있기 때문이다. 사용자 스레드는 CPU가 아무리 많아도 커널 모드의 스케줄이 되지 않으므로, 각 CPU에 효율적으로 스레드 배당할 수가 없음\n>\n> 단점 : context switching이 발생함. 이 과정에서 프로세서 모드가 사용자 모드와 커널 모드 사이를 움직이기 때문에 많이 돌아다닐 수록 성능이 떨어지게 된다.\n\n
\n\n#### 가상메모리란?\n\n> 프로세스에서 사용하는 메모리 주소와 실제 물리적 메모리 주소는 다를 수 있음\n>\n> 따라서 메모리 = 실제 + 가상 메모리라고 생각하면 안됨\n>\n> 메모리가 부족해서 가상메모리를 사용하는 건 맞지만, 가상메모리를 쓴다고 실제 메모리처럼 사용하는 것은 아님\n>\n> 실제 메모리 안에 공간이 부족하면, **현재 사용하고 있지 않은 데이터를 빼내어 가상 메모리에 저장해두고, 실제 메모리에선 처리만 하게 하는 것이 가상 메모리의 역할**이다.\n>\n> 즉, 실제 메모리에 놀고 있는 공간이 없게 계속 일을 시키는 것. 이를 도와주는 것이 '가상 메모리'\n\n
\n\n#### fork()와 vfork()의 차이점은?\n\n> fork()는 부모 프로세스의 메모리를 복사해서 사용\n>\n> vfork()는 부모 프로세스와의 메모리를 공유함. 복사하지 않기 때문에 fork()보다 생성 속도 빠름.\n> 하지만 자원을 공유하기 때문에 자원에 대한 race condition이 발생하지 않도록 하기 위해 부모 프로세스는 자식 프로세스가 exit하거나 execute가 호출되기 전까지 block된다\n\n
\n\n#### Race Condition이란?\n\n> 두 개 이상의 프로세스가 공통 자원을 병행적으로 읽거나 쓸 때, 공용 데이터에 대한 접근이 순서에 따라 실행 결과가 달라지는 상황\n>\n> Race Condition이 발생하게 되면, 모든 프로세스에 원하는 결과가 발생하는 것을 보장할 수 없음. 따라서 이러한 상황은 피해야 하며 상호배제나 임계구역으로 해결이 가능하다.\n\n
\n\n#### 리눅스에서 시스템 콜과 서브루틴의 차이는?\n\n> 우선 커널을 확인하자\n>\n>
 \n>\n> 커널은 하드웨어를 둘러싸고 있음\n>\n> 즉, 커널은 하드웨어를 제어하기 위한 일종의 API와 같음\n>\n> 서브루틴(SubRoutine)은 우리가 프로그래밍할 때 사용하는 대부분의 API를 얘기하는 것\n>\n> ```\n> stdio.h에 있는 printf나 scanf\n> string.h에 있는 strcmp나 strcpy\n> ```\n>\n> ##### 서브루틴과 시스템 콜의 차이는?\n>\n> 서브루틴이 시스템 콜을 호출하고, 시스템 콜이 수행한 결과를 서브루틴에 보냄\n>\n> 시스템 콜 호출 시, 커널이 호출되고 커널이 수행한 임의의 결과 데이터를 다시 시스템 콜로 보냄\n>\n> 즉, 진행 방식은 아래와 같다.\n>\n> ```\n> 서브루틴이 시스템 콜 호출 → 시스템 콜은 커널 호출 → 커널은 자신의 역할을 수행하고 (하드웨어를 제어함) 나온 결과 데이터를 시스템 콜에게 보냄 → 시스템 콜이 다시 서브루틴에게 보냄\n> ```\n>\n> 실무로 사용할 때 둘의 큰 차이는 없음(api를 호출해서 사용하는 것은 동일)\n\n
\n>\n> 커널은 하드웨어를 둘러싸고 있음\n>\n> 즉, 커널은 하드웨어를 제어하기 위한 일종의 API와 같음\n>\n> 서브루틴(SubRoutine)은 우리가 프로그래밍할 때 사용하는 대부분의 API를 얘기하는 것\n>\n> ```\n> stdio.h에 있는 printf나 scanf\n> string.h에 있는 strcmp나 strcpy\n> ```\n>\n> ##### 서브루틴과 시스템 콜의 차이는?\n>\n> 서브루틴이 시스템 콜을 호출하고, 시스템 콜이 수행한 결과를 서브루틴에 보냄\n>\n> 시스템 콜 호출 시, 커널이 호출되고 커널이 수행한 임의의 결과 데이터를 다시 시스템 콜로 보냄\n>\n> 즉, 진행 방식은 아래와 같다.\n>\n> ```\n> 서브루틴이 시스템 콜 호출 → 시스템 콜은 커널 호출 → 커널은 자신의 역할을 수행하고 (하드웨어를 제어함) 나온 결과 데이터를 시스템 콜에게 보냄 → 시스템 콜이 다시 서브루틴에게 보냄\n> ```\n>\n> 실무로 사용할 때 둘의 큰 차이는 없음(api를 호출해서 사용하는 것은 동일)\n\n\n\n
\n\n
\n\n### 데이터베이스\n\n------\n\n#### 오라클 시퀀스(Oracle Sequence)\n\n> UNIQUE한 값을 생성해주는 오라클 객체\n>\n> 시퀀스를 생성하면 PK와 같이 순차적으로 증가하는 컬럼을 자동 생성할수 있다.\n>\n> ```\n> CREATE SEQUENCE 시퀀스이름\n> \tSTART WITH n\n> \tINCREMENT BY n ...\n> ```\n\n
\n\n#### DBMS란?\n\n> 데이터베이스 관리 시스템\n>\n> 다수의 사용자가 데이터베이스 내의 데이터를 접근할 수 있도록 설계된 시스템\n\n
\n\n#### DBMS의 기능은?\n\n> - 정의 기능(DDL: Data Definition Language)\n >\n\n- 데이터베이스가 어떤 용도이며 어떤 식으로 이용될것이라는 것에 대한 정의가 필요함\n\n> - CREATE, ALTER, DROP, RENAME\n>\n> - 조작 기능(DML: Data Manipulation Language)\n >\n\n- 데이터베이스를 만들었을 때 그 정보를 수정하거나 삭제 추가 검색 할 수 있어야함\n\n> - SELECT, INSERT, UPDATE, DELETE\n>\n> - 제어 기능(DCL: Data Control Language)\n >\n\n- 데이터베이스에 접근하고 객체들을 사용하도록 권한을 주고 회수하는 명령\n\n> - GRANT REVOKE\n\n
\n\n#### UML이란?\n\n> 프로그램 설계를 표현하기 위해 사용하는 그림으로 된 표기법\n>\n> 이해하기 힘든 복잡한 시스템을 의사소통하기 위해 만듬\n\n
\n\n#### DB에서 View는 무엇인가? 가상 테이블이란?\n\n> 허용된 데이터를 제한적으로 보여주기 위한 것\n>\n> 하나 이상의 테이블에서 유도된 가상 테이블이다.\n>\n> - 사용자가 view에 접근했을 때 해당하는 데이터를 원본에서 가져온다.\n>\n> view에 나타나지 않은 데이터를 간편히 보호할 수 있는 장점 존재\n\n
\n\n#### 정규화란?\n\n> 중복을 최대한 줄여 데이터를 구조화하고, 불필요한 데이터를 제거해 데이터를 논리적으로 저장하는 것\n>\n> 이상현상이 일어나지 않도록 정규화 시킨다!\n\n
\n\n#### 이상현상이란?\n\n> 릴레이션에서 일부 속성들의 종속으로 인해 데이터 중복이 발생하는 것 (insert, update, delete)\n\n
\n\n#### 데이터베이스를 설계할 때 가장 중요한 것이 무엇이라고 생각하나요?\n\n> 무결성을 보장해야 합니다.\n>\n> ##### 무결성 보장 방법은?\n>\n> 데이터를 조작하는 프로그램 내에서 데이터 생성, 수정, 삭제 시 무결성 조건을 검증한다.\n>\n> 트리거 이벤트 시 저장 SQL을 실행하고 무결성 조건을 실행한다.\n>\n> DB제약조건 기능을 선언한다.\n\n
\n\n#### 데이터베이스 무결성이란?\n\n> 테이블에 있는 모든 행들이 유일한 식별자를 가질 것을 요구함 (같은 값 X)\n>\n> 외래키 값은 NULL이거나 참조 테이블의 PK값이어야 함\n>\n> 한 컬럼에 대해 NULL 허용 여부와 자료형, 규칙으로 타당한 데이터 값 지정\n\n
\n\n#### 트리거란?\n\n> 자동으로 실행되도록 정의된 저장 프로시저\n>\n> (insert, update, delete문에 대한 응답을 자동으로 호출한다.)\n>\n> ##### 사용하는 이유는?\n>\n> 업무 규칙 보장, 업무 처리 자동화, 데이터 무결성 강화\n\n
\n\n#### 오라클과 MySQL의 차이는?\n\n> 일단 Oracle이 MySQL보다 훨~씬 좋음\n>\n> 오라클 : 대규모 트랜잭션 로드를 처리하고, 성능 최적화를 위해 여러 서버에 대용량 DB를 분산함\n>\n> MySQL : 단일 데이터베이스로 제한되어있고, 대용량 데이터베이스로는 부적합. 작은 프로젝트에서 적용시키기 용이하며 이전 상태를 복원하는데 commit과 rollback만 존재\n\n
\n\n#### Commit과 Rollback이란?\n\n> Commit : 하나의 논리적 단위(트랜잭션)에 대한 작업이 성공적으로 끝났을 때, 이 트랜잭션이 행한 갱신 연산이 완료된 것을 트랜잭션 관리자에게 알려주는 연산\n>\n> Rollback : 하나의 트랜잭션 처리가 비정상적으로 종료되어 DB의 일관성을 깨뜨렸을 때, 모든 연산을 취소시키는 연산\n\n
\n\n#### JDBC와 ODBC의 차이는?\n\n> - JDBC\n > 자바에서 DB에 접근하여 데이터를 조회, 삽입, 수정, 삭제 가능\n > DBMS 종류에 따라 맞는 jdbc를 설치해야함\n> - ODBC\n > 응용 프로그램에서 DB 접근을 위한 표준 개방형 응용 프로그램 인터페이스\n > MS사에서 만들었으며, Excel/Text 등 여러 종류의 데이터에 접근할 수 있음\n\n
\n\n#### 데이터 베이스에서 인덱스(색인)이란 무엇인가요\n\n> - 책으로 비유하자면 목차로 비유할 수 있다.\n> - DBMS에서 저장 성능을 희생하여 데이터 읽기 속도를 높이는 기능\n> - 데이터가 정렬되어 들어간다\n> - 양이 많은 테이블에서 일부 데이터만 불러 왔을 때, 이를 풀 스캔 시 처리 성능 떨어짐\n> - 종류\n >\n\n- B+-Tree 인덱스 : 원래의 값을 이용하여 인덱싱\n\n> - Hash 인덱스 : 칼럼 값으로 해시 값 게산하여 인덱싱, 메모리 기반 DB에서 많이 사용\n> - B>Hash\n> - 생성시 고려해야 할 점\n >\n\n- 테이블 전체 로우 수 15%이하 데이터 조회시 생성\n\n> - 테이블 건수가 적으면 인덱스 생성 하지 않음, 풀 스캔이 빠름\n> - 자주 쓰는 컬럼을 앞으로 지정\n> - DML시 인덱스에도 수정 작업이 동시에 발생하므로 DML이 많은 테이블은 인덱스 생성 하지 않음\n\n\n
\n\n
\n\n## 네트워크\n\n
\n\n#### OSI 7계층을 설명하시오\n\n> OSI 7계층이란, 통신 접속에서 완료까지의 과정을 7단계로 정의한 국제 통신 표준 규약\n>\n> **물리** : 전송하는데 필요한 기능을 제공 ( 통신 케이블, 허브 )\n>\n> **데이터링크** : 송/수신 확인. MAC 주소를 가지고 통신함 ( 브릿지, 스위치 )\n>\n> **네트워크** : 패킷을 네트워크 간의 IP를 통해 데이터 전달 ( 라우팅 )\n>\n> **전송** : 두 host 시스템으로부터 발생하는 데이터 흐름 제공\n>\n> **세션** : 통신 시스템 사용자간의 연결을 유지 및 설정함\n>\n> **표현** : 세션 계층 간의 주고받는 인터페이스를 일관성있게 제공\n>\n> **응용** : 사용자가 네트워크에 접근할 수 있도록 서비스 제공\n\n
\n\n#### TCP/IP 프로토콜을 스택 4계층으로 짓고 설명하시오\n\n> - ##### LINK 계층\n\n >\n > > 물리적인 영역의 표준화에 대한 결과\n > >\n > > 가장 기본이 되는 영역으로 LAN, WAN과 같은 네트워크 표준과 관련된 프로토콜을 정의하는 영역이다\n\n>\n> - ##### IP 계층\n\n >\n > > 경로 검색을 해주는 계층임\n > >\n > > IP 자체는 비연결지향적이며, 신뢰할 수 없는 프로토콜이다\n > >\n > > 데이터를 전송할 때마다 거쳐야할 경로를 선택해주지만, 경로가 일정하지 않음. 또한 데이터 전송 중에 경로상 문제가 발생할 때 데이터가 손실되거나 오류가 발생하는 문제가 발생할 수 있음. 따라서 IP 계층은 오류 발생에 대한 대비가 되어있지 않은 프로토콜임\n\n>\n> - ##### TCP/UDP (전송) 계층\n\n >\n > > 데이터의 실제 송수신을 담당함\n > >\n > > UDP는 TCP에 비해 상대적으로 간단하고, TCP는 신뢰성잇는 데이터 전송을 담당함\n > >\n > > TCP는 데이터 전송 시, IP 프로토콜이 기반임 (IP는 문제 해결에 문제가 있는데 TCP가 신뢰라고?)\n > >\n > > → IP의 문제를 해결해주는 것이 TCP인 것. 데이터의 순서가 올바르게 전송 갔는지 확인해주며 대화를 주고받는 방식임. 이처럼 확인 절차를 걸치며 신뢰성 없는 IP에 신뢰성을 부여한 프로토콜이 TCP이다\n\n>\n> - ##### 애플리케이션 계층\n\n >\n > > 서버와 클라이언트를 만드는 과정에서 프로그램 성격에 따라 데이터 송수신에 대한 약속들이 정해지는데, 이것이 바로 애플리케이션 계층이다\n\n
\n\n#### TCP란?\n\n> 서버와 클라이언트의 함수 호출 순서가 중요하다\n>\n> **서버** : socket() 생성 → bind() 소켓 주소할당 → listen() 연결요청 대기상태 → accept() 연결허용 → read/write() 데이터 송수신 → close() 연결종료\n>\n> **클라이언트** : socket() 생성 → connect() 연결요청 → read/write() 데이터 송수신 → close() 연결종료\n>\n> ##### 둘의 차이는?\n>\n> 클라이언트 소켓을 생성한 후, 서버로 연결을 요청하는 과정에서 차이가 존재한다.\n>\n> 서버는 listen() 호출 이후부터 연결요청 대기 큐를 만들어 놓고, 그 이후에 클라이언트가 연결 요청을 할 수 있다. 이때 서버가 바로 accept()를 호출할 수 있는데, 연결되기 전까지 호출된 위치에서 블로킹 상태에 놓이게 된다.\n>\n> 이처럼 연결지향적인 TCP는 신뢰성 있는 데이터 전송이 가능함 (3-way handshaking)\n>\n> 흐름제어와 혼잡제어를 지원해서 데이터 순서를 보장해줌\n>\n> - 흐름제어 : 송신 측과 수신 측의 데이터 처리 속도 차이를 조절해주는 것\n>\n> - 혼잡 제어 : 네트워크 내의 패킷 수가 넘치게 증가하지 않도록 방지하는 것\n>\n> 정확성 높은 전송을 하기 위해 속도가 느린 단점이 있고, 주로 웹 HTTP 통신, 이메일, 파일 전송에 사용됨\n\n
\n\n#### 3-way handshaking이란?\n\n> TCP 소켓은 연결 설정과정 중에 총 3번의 대화를 주고 받는다.\n>\n> (SYN : 연결 요청 플래그 / ACK : 응답)\n>\n> - 클라이언트는 서버에 접속 요청하는 SYN(M) 패킷을 보냄\n> - 서버는 클라이언트 요청인 SYN(M)을 받고, 클라이언트에게 요청을 수락한다는 ACK(M+1)와 SYN(N)이 설정된 패킷을 발송함\n> - 클라이언트는 서버의 수락 응답인 ACK(M+1)와 SYN(N) 패킷을 받고, ACK(N+1)를 서버로 보내면 연결이 성립됨\n> - 클라이언트가 연결 종료하겠다는 FIN 플래그를 전송함\n> - 서버는 클라이언트의 요청(FIN)을 받고, 알겠다는 확인 메시지로 ACK를 보냄. 그 이후 데이터를 모두 보낼 때까지 잠깐 TIME_OUT이 됨\n> - 데이터를 모두 보내고 통신이 끝났으면 연결이 종료되었다고 클라이언트에게 FIN플래그를 전송함\n> - 클라이언트는 FIN 메시지를 확인했다는 ACK를 보냄\n> - 클라이언트의 ACK 메시지를 받은 서버는 소켓 연결을 close함\n> - 클라이언트는 아직 서버로부터 받지 못한 데이터가 있을 것을 대비해서, 일정 시간동안 세션을 남겨놓고 잉여 패킷을 기다리는 과정을 거침 ( TIME_WAIT )\n\n
\n\n#### UDP란?\n\n> TCP의 대안으로, IP와 같이 쓰일 땐 UDP/IP라고도 부름\n>\n> TCP와 마찬가지로, 실제 데이터 단위를 받기 위해 IP를 사용함. 그러나 TCP와는 달리 메시지를 패킷으로 나누고, 반대편에서 재조립하는 등의 서비스를 제공하지 않음\n> 즉, 여러 컴퓨터를 거치지 않고 데이터를 주고 받을 컴퓨터끼리 직접 연결할 때 UDP를 사용한다.\n>\n> UDP를 사용해 목적지(IP)로 메시지를 보낼 수 있으며, 컴퓨터를 거쳐 목적지까지 도달할 수도 있음\n> (도착하지 않을 가능성도 존재함)\n>\n> 정보를 받는 컴퓨터는 포트를 열어두고, 패킷이 올 때까지 기다리며 데이터가 오면 모두 다 받아들인다. 패킷이 도착했을 때 출발지에 대한 정보(IP와 PORT)를 알 수 있음\n>\n> UDP는 이런 특성 때문에 비신뢰적이고, 안정적이지 않은 프로토콜임. 하지만 TCP보다 속도가 매우 빠르고 편해서 데이터 유실이 일어나도 큰 상관이 없는 스트리밍이나 화면 전송에 사용됨\n\n
\n\n#### HTTP와 HTTPS의 차이는?\n\n> HTTP 동작 순서 : TCP → HTTP\n>\n> HTTPS 동작 순서 : TCP → SSL → HTTP\n>\n> SSL(Secure Socket Layer)을 쓰냐 안쓰냐의 차이다. SSL 프로토콜은 정보를 암호화시키고 이때 공개키와 개인키 두가지를 이용한다.\n>\n> HTTPS는 인터넷 상에서 정보를 암호화하기 위해 SSL 프로토콜을 이용해 데이터를 전송하고 있다는 것을 말한다. 즉, 문서 전송시 암호화 처리 유무에 따라 HTTP와 HTTPS로 나누어지는 것\n>\n> 모든 사이트가 HTTPS로 하지 않는 이유는, 암호화 과정으로 인한 속도 저하가 발생하기 때문이다.\n\n
\n\n#### GET과 POST의 차이는?\n\n> 둘다 HTTP 프로토콜을 이용해 서버에 무언가 요청할 때 사용하는 방식이다.\n>\n> GET 방식은, URL을 통해 모든 파라미터를 전달하기 때문에 주소창에 전달 값이 노출됨. URL 길이가 제한이 있기 때문에 전송 데이터 양이 한정되어 있고, 형식에 맞지 않으면 인코딩해서 전달해야 함\n>\n> POST 방식은 HTTP BODY에 데이터를 포함해서 전달함. 웹 브라우저 사용자의 눈에는 직접적으로 파라미터가 노출되지 않고 길이 제한도 없음.\n>\n> 보통 GET은 가져올 때, POST는 수행하는 역할에 활용한다.\n>\n> GET은 SELECT 성향이 있어서 서버에서 어떤 데이터를 가져와서 보여주는 용도로 활용\n>\n> POST는 서버의 값이나 상태를 바꾸기 위해 활용\n\n
\n\n#### IOCP를 설명하시오\n\n> IOCP는 어떤 I/O 핸들에 대해, 블록 되지 않게 비동기 작업을 하면서 프로그램 대기시간을 줄이는 목적으로 사용된다.\n>\n> 동기화 Object 세마포어의 특성과, 큐를 가진 커널 Object다. 대부분 멀티 스레드 상에서 사용되고, 큐는 자체적으로 운영하는 특징 때문에 스레드 풀링에 적합함\n>\n> 동기화와 동시에 큐를 통한 데이터 전달 IOCP는, 스레드 풀링을 위한 것이라고 할 수 있음\n>\n> ##### POOLING이란?\n>\n> 여러 스레드를 생성하여 대기시키고, 필요할 때 가져다가 사용한 뒤에 다시 반납하는 과정\n> (스레드의 생성과 파괴는 상당히 큰 오버헤드가 존재하기 때문에 이 과정을 이용한다)\n>\n> IOCP의 장점은 사용자가 설정한 버퍼만 사용하기 때문에 더 효율적으로 작동시킬 수 있음.\n> (기존에는 OS버퍼, 사용자 버퍼로 따로 분리해서 운영했음)\n>\n> 커널 레벨에서는 모든 I/O를 비동기로 처리하기 때문에 효율적인 순서에 따라 접근할 수 있음\n\n
\n\n#### 라우터와 스위치의 차이는?\n\n> 라우터는 3계층 장비로, 수신한 패킷의 정보를 보고 경로를 설정해 패킷을 전송하는 역할을 수행하는 장비\n>\n> 스위치는 주로 내부 네트워크에 위치하며 MAC 주소 테이블을 이용해 해당 프레임을 전송하는 2계층 장비\n\n
\n\n
\n\n## 스프링\n\n
\n\n#### Dispatcher-Servlet\n\n> 서블릿 컨테이너에서 HTTP 프로토콜을 통해 들어오는 모든 요청을 제일 앞에서 처리해주는 프론트 컨트롤러를 말함\n>\n> 따라서 서버가 받기 전에, 공통처리 작업을 디스패처 서블릿이 처리해주고 적절한 세부 컨트롤러로 작업을 위임해줍니다.\n>\n> 디스패처 서블릿이 처리하는 url 패턴을 지정해줘야 하는데, 일반적으로는 .mvc와 같은 패턴으로 처리하라고 미리 지정해줍니다.\n>\n>\n> 디스패처 서블릿으로 인해 web.xml이 가진 역할이 상당히 축소되었습니다. 기존에는 모든 서블릿을 url 매핑 활용을 위해 모두 web.xml에 등록해 주었지만, 디스패처 서블릿은 그 전에 모든 요청을 핸들링해주면서 작업을 편리하게 할 수 있도록 도와줍니다. 또한 이 서블릿을 통해 MVC를 사용할 수 있기 때문에 웹 개발 시 큰 장점을 가져다 줍니다.\n\n
\n\n#### DI(Dependency Injection)\n\n> 스프링 컨테이너가 지원하는 핵심 개념 중 하나로, 설정 파일을 통해 객체간의 의존관계를 설정하는 역할을 합니다.\n>\n> 각 클래스 사이에 필요로 하는 의존관계를 Bean 설정 정보 바탕으로 컨테이너가 자동으로 연결합니다.\n>\n> 객체는 직접 의존하고 있는 객체를 생성하거나 검색할 필요가 없으므로 코드 관리가 쉬워지는 장점이 있습니다.\n\n
\n\n#### AOP(Aspect Oriented Programming)\n\n> 공통의 관심 사항을 적용해서 발생하는 의존 관계의 복잡성과 코드 중복을 해소해줍니다.\n>\n> 각 클래스에서 공통 관심 사항을 구현한 모듈에 대한 의존관계를 갖기 보단, Aspect를 이용해 핵심 로직을 구현한 각 클래스에 공통 기능을 적용합니다.\n>\n> 간단한 설정만으로도 공통 기능을 여러 클래스에 적용할 수 있는 장점이 있으며 핵심 로직 코드를 수정하지 않고도 웹 애플리케이션의 보안, 로깅, 트랜잭션과 같은 공통 관심 사항을 AOP를 이용해 간단하게 적용할 수 있습니다.\n\n
\n\n#### AOP 용어\n\n> Advice : 언제 공통 관심기능을 핵심 로직에 적용할지 정의\n>\n> Joinpoint : Advice를 적용이 가능한 지점을 의미 (before, after 등등)\n>\n> Pointcut : Joinpoint의 부분집합으로, 실제로 Advice가 적용되는 Joinpoint를 나타냄\n>\n> Weaving : Advice를 핵심 로직코드에 적용하는 것\n>\n> Aspect : 여러 객체에 공통으로 적용되는 공통 관심 사항을 말함. 트랜잭션이나 보안 등이 Aspect의 좋은 예\n\n
\n\n#### DAO(Data Access Object)\n\n> DB에 데이터를 조회하거나 조작하는 기능들을 전담합니다.\n>\n> Mybatis를 이용할 때는, mapper.xml에 쿼리문을 작성하고 이를 mapper 클래스에서 받아와 DAO에게 넘겨주는 식으로 구현합니다.\n\n
\n\n#### Annotation\n\n> 소스코드에 @어노테이션의 형태로 표현하며 클래스, 필드, 메소드의 선언부에 적용할 수 있는 특정기능이 부여된 표현법을 말합니다.\n>\n> 애플리케이션 규모가 커질수록, xml 환경설정이 매우 복잡해지는데 이러한 어려움을 개선시키기 위해 자바 파일에 어노테이션을 적용해서 개발자가 설정 파일 작업을 할 때 발생시키는 오류를 최소화해주는 역할을 합니다.\n>\n> 어노테이션 사용으로 소스 코드에 메타데이터를 보관할 수 있고, 컴파일 타임의 체크뿐 아니라 어노테이션 API를 사용해 코드 가독성도 높여줍니다.\n\n- @Controller : dispatcher-servlet.xml에서 bean 태그로 정의하는 것과 같음.\n- @RequestMapping : 특정 메소드에서 요청되는 URL과 매칭시키는 어노테이션\n- @Autowired : 자동으로 의존성 주입하기 위한 어노테이션\n- @Service : 비즈니스 로직 처리하는 서비스 클래스에 등록\n- @Repository : DAO에 등록\n\n
\n\n#### Spring JDBC\n\n> 데이터베이스 테이블과, 자바 객체 사이의 단순한 매핑을 간단한 설정을 통해 처리하는 것\n>\n> 기존의 JDBC에서는 구현하고 싶은 로직마다 필요한 SQL문이 모두 달랐고, 이에 필요한 Connection, PrepareStatement, ResultSet 등을 생성하고 Exception 처리도 모두 해야하는 번거러움이 존재했습니다.\n>\n> Spring에서는 JDBC와 ORM 프레임워크를 직접 지원하기 때문에 따로 작성하지 않아도 모두 다 처리해주는 장점이 있습니다.\n\n
\n\n#### MyBatis\n\n> 객체, 데이터베이스, Mapper 자체를 독립적으로 작성하고, DTO에 해당하는 부분과 SQL 실행결과를 매핑해서 사용할 수 있도록 지원함\n>\n> 기존에는 DAO에 모두 SQL문이 자바 소스상에 위치했으나, MyBatis를 통해 SQL은 XML 설정 파일로 관리합니다.\n>\n> 설정파일로 분리하면, 수정할 때 설정파일만 건드리면 되므로 유지보수에 매우 좋습니다. 또한 매개변수나 리턴 타입으로 매핑되는 모든 DTO에 관련된 부분도 모두 설정파일에서 작업할 수 있는 장점이 있습니다.\n\n
\n\n
\n\n
\n" }, { "path": "Interview/Mock Test/2019년 #기업 2차 필기테스트 유형.md", "content": "1. 데드락\n2. IP 프로토콜\n3. 서브넷 마스크(브로드캐스팅)\n4. Isolation Level\n5. 이진 탐색 트리\n6. 버블 정렬\n7. Round Robin 스케줄링\n8. 페이징 번호\n9. DB JOIN\n10. C언어 Struct variable byte size\n11. LRU 캐싱\n12. Max Heap\n13. 다익스트라\n14. 부동소수점\n\n\n\n" }, { "path": "Interview/Mock Test/2019년 #기업 필기테스트.md", "content": "1. ##### 일치하는 자료구조 작성하기\n\n > 1) 문자열이 주어지고 빠른 검색 ~~ : 해시\n >\n > 2) 운영체제 라운드 로빈에서 사용 ~~ : 연결리스트 \n >\n > 3) 우선순위로 뽑고 ~~~ : 힙\n >\n > 4) 후위연산하는 ~~ : 스택\n\n2. ##### FCFS 스케줄링 평균반환시간, 평균대기시간 구하기\n\n3. ##### 고객 - 주문 - 주문서의 (일대일, 일대다, 다대일, 다대다) 관계 구하기\n\n4. ##### Binary Tree 수도코드\n\n > Tree node size 구하기 : left + right + 1\n >\n > Tree node depth 구하기 : max(left, right) + 1\n\n5. ##### 배열 x와 배열 y의 일치값 찾는 시간복잡도의 최악과 최선은?\n\n ```java\n boolean chk = false;\n for(int i = 0; i < arr1.length i++) {\n for(int j = 0; j < arr2.length; j++) {\n if(arr1[i] == arr[j]) {\n chk = true;\n return;\n }\n }\n }\n ```\n\n6. ##### BFS 수도코드\n\n ```\n 1) queue 생성\n 2) enqueue()\n while() {\n 3) dequeue()\n \n if() {\n 4) enqueue()\n }\n }\n ```\n\n6. ##### Binary Search 수도코드\n\n > start와 end를 어떻게 바꿔가야하는 지 작성\n >\n > ```\n > if(arr[mid] < value) {\n > 1) start = mid + 1;\n > }\n > else(arr[mid] > value) {\n > 2) end = mid - 1;\n > }\n > ```\n\n7. ##### 데드락 교착 상태 4가지 \n\n8. ##### 제 2정규화 만들기\n\n > 1) 판매번호, 판매일자, 판매처 코드, 판매처명\n >\n > 2) 판매번호, 상품번호, 상품명, 단가, 수량\n >\n > 이 두개를 제2정규화 써서 다시 나누기\n\n" }, { "path": "Interview/Mock Test/2019년 면접질문.md", "content": "1. 퀵소트 구현하고 시간복잡도 설명\n2. 최악으로 바꾸고 진행\n3. 공간복잡도\n4. 디자인패턴이 뭐로 나눠지는지\n5. 아는거 다말하고 뭔지설명하면서 어디 영역에 해당하는지\n6. PWA랑 SPA 차이점\n7. Vue 라이프사이클\n8. vue router를 어떻게 활용했는지\n9. CPU 스케줄링 알고리즘이 뭐고 있는거 설명\n10. 더블링크드리스트 구현\n11. 페이지 교체 알고리즘 종류\n12. 자바 빈 태그 그냥말고 커스터마이징해서 활용한 경험\n\n\n\n- Java와 Javascript의 차이\n- 객체 지향이란?\n- 캐시에 대해 설명해보면?\n- 스택에 대해 설명해보면?\n- UI와 UX의 차이\n- 네이티브 앱, 웹 앱, 하이브리드 앱의 차이는?\n- 애플리케이션 개발 경험이 있는지?\n- 가장 관심있는 신기술 트렌드는?\n- PWA가 뭔가?\n- 데브옵스가 뭔지 아는지?\n- 마이크로 서비스 애플리케이션(MSA)에 대해 아는가?\n- REST API란?" }, { "path": "Interview/Mock Test/GML Test (2019-10-03).md", "content": "### GML Test (2019-10-03)\n\n---\n\n1. OOP 특징에 대해 잘못 설명한 것은?\n\n > 1. OOP는 유지 보수성, 재사용성, 확장성이라는 장점이 있다.\n > 2. 캡슐화는 정보 은닉을 통해 높은 결합도와 낮은 응집도를 갖도록 한다.\n > 3. 캡슐화는 만일의 상황(타인이 외부에서 조작)을 대비해서 외부에서 특정 속성이나 메서드를 시용자가 사용할 수 없도록 숨겨놓은 것이다.\n > 4. 다형성은 부모클레스에서 물려받은 가상 함수를 자식 클래스 내에서 오버라이딩 되어 사용되는 것이다.\n > 5. 객체는 소프트웨어 세계에 구현할 대상이고, 이를 구현하기 위한 설계도가 클래스이며, 이 설계도에 따라 소프트웨어 세계에 구현된 실체가 인스턴스다.\n\n2. 라이브러리와 프레임워크에 대해 잘못 설명하고 있는 것은?\n\n > 1. 택환브이 : 프레임워크는 전체적인 흐름을 스스로가 쥐고 있으며 사용자는 그 안에서 필요한 코드를 짜 넣는 것이야!\n > 2. 규렐로 : 프레임워크에는 분명한 제어의 역전 개념이 적용되어 있어야돼!\n > 3. 이기문지기 : 객체를 프레임워크에 주입하는 것을 Dependency Injection이라고 해!\n > 4. 규석기시대 : 라이브러리는 톱, 망치, 삽 같은 연장이라고 생각할 수 있어!\n > 5. 라이언 : 프레임워크는 프로그래밍할 규칙 없이 사용자가 정의한대로 개발할 수 있는 장점이 있어!\n\n3. 운영체제의 운영 기법 중 동시에 프로그램을 수행할 수 있는 CPU를 두 개 이상 두고 각각 그 업무를 분담하여 처리할 수 있는 방식을 의미하는 것은?\n\n > 1. Multi-Processing System\n > 2. Time-Sharing System \n > 3. Real-Time System\n > 4. Multi-Programming System\n > 5. Batch Prcessing System\n\n4. http에 대한 설명으로 틀린 것은?\n\n > 1. http는 웹상에서 클라이언트와 웹서버간 통신을 위한 프로토콜 중 하나이다.\n > 2. http/1.1은 동시 전송이 가능하지만, 요청과 응답이 순차적으로 이루어진다.\n > 3. http/2.0은 헤더 압축으로 http/1.1보다 빠르다\n > 4. http/2.0은 한 커넥션으로 동시에 여러 메시지를 주고 받을 수 있다.\n > 5. http/1.1은 기본적으로 Connection 당 하나의 요청을 처리하도록 설계되어있다.\n\n5. 쿠키와 세션에 대해 잘못 설명한 것은?\n\n > 1. 쿠키는 사용자가 따로 요청하지 않아도 브라우저가 Request시에 Request Header를 넣어서 자동으로 서버에 전송한다.\n > 2. 세션은 쿠키를 사용한다.\n > 3. 동접자 수가 많은 웹 사이트인 경우 세션을 사용하면 성능 향상에 큰 도움이 된다.\n >\n > 4. 보안 면에서는 쿠키보다 세션이 더 우수하며, 요청 속도를 쿠키가 세션보다 빠르다.\n > 5. 세션은 쿠키와 달리 서버 측에서 관리한다.\n\n6. RISC와 CISC에 대해 잘못 설명한 것은?\n\n > 1. CPU에서 수행하는 동작 대부분이 몇개의 명령어 만으로 가능하다는 사실에 기반하여 구현한 것으로 고정된 길이의 명령어를 사용하는 것은 RISC이다.\n > 2. 두 방식 중 소프트웨어의 비중이 더 큰 것을 RISC이다.\n > 3. RISC는 프로그램을 구성할 때 상대적으로 많은 명령어가 필요하다.\n > 4. 모든 고급언어 문장들에 대해 각각 기계 명령어가 대응 되도록 하는 것은 CISC이다.\n > 5. 두 방식 중 전력소모가 크고, 가격이 비싼 것은 RISC이다.\n\n7. Database에서 Join에 대해 잘못 설명한 것은?\n\n > 1. A와 B테이블을 INNER Join하면 두 테이블이 모두 가지고 있는 데이터만 검색된다.\n > 2. A와 B테이블이 서로 겹치지 않는 데이터가 4개 있을때, LEFT OUTER Join을 하면 결과값에 NULL은 4개 존재한다.\n > 3. A LEFT JOIN B 와 B RIGHT JOIN A는 완전히 같은 식이다. \n > 4. A 테이블의 개수가 6개, B 테이블의 개수가 4개일때, Cross Join을 하면, 결과의 개수는 24개이다.\n > 5. 셀프 조인은 조인 연산 보다 중첩 질의가 더욱 빠르기 때문에 잘 사용하지 않는다.\n\n8. 멀티프로세스 환경에서 CPU가 어떤 하나의 프로세스를 실행하고 있는 상태에서 인터럽트 요청에 의해 다음 우선 순위의 프로세스가 실행되어야 할 때, 기존의 프로세스의 상태 또는 레지스터 값을 저장하고 CPU가 다음 프로세스를 수행하도록 새로운 프로세스의 상태 또는 레지스터 값을 교체하는 작업을 무엇이라고 할까? ( )\n\n9. Database의 INDEX에 대해 잘못 설명한 것은?\n\n > 1. 키 값을 기초로 하여 테이블에서 검색과 정렬 속도를 향상시킨다.\n > 2. 여러 필드로 이루어진 인덱스를 사용한다고해서 첫 필드 값이 같은 레코드를 구분할 수 있진 않다.\n > 3. 테이블의 기본키는 자동으로 인덱스가 된다.\n > 4. 필드 중에는 데이터 형식 때문에 인덱스 될 수 없는 필드가 존재할 수 있다.\n > 5. 인덱스 된 필드에서 데이터를 업데이트하거나, 레코드를 추가 또는 삭제할 때 성능이 떨어진다.\n\n10. 커널 레벨 스레드에 대해 잘못 설명한 것은?\n\n > 1. 프로세스의 스레드들을 몇몇 프로세서에 한꺼번에 디스패치 할 수 있기 때문에 멀티프로세서 환경에서 매우 빠르게 동작한다.\n > 2. 다른 스레드가 입출력 작업이 다 끝날 때까지 다른 스레드를 사용해 다른 작업을 진행할 수 없다.\n > 3. 커널이 각 스레드를 개별적으로 관리할 수 있다.\n > 4. 커널이 직접 스레드를 제공해주기 때문에 안정성과 다양한 기능이 제공된다.\n > 5. 프로그래머 요청에 따라 스레드를 생성하고 스케줄링하는 주체가 커널이면 커널 레벨 스레드라고 한다.\n\n* 정답은 맨 밑에 있습니다.\n\n
\n\n
\n\n
\n\n
\n\n
\n\n
\n\n
\n\n
\n\n
\n\n1. 2\n2. 5\n3. 1\n4. 2\n5. 3\n6. 5\n7. 5\n8. Context Switching\n9. 2\n10. 2\n\n\n\n" }, { "path": "Interview/README.md", "content": "### 기술 면접 준비하기\n\n------\n\n- #### 시작하기\n\n *기술면접을 준비할 때는 절대 문제와 답을 읽는 식으로 하지 말고, 문제를 직접 푸는 훈련을 해야합니다.*\n\n 1. ##### 직접 문제를 풀수 있도록 노력하자\n\n - 포기하지말고, 최대한 힌트를 보지말고 답을 찾자\n\n 2. ##### 코드를 종이에 적자\n\n - 컴퓨터를 이용하면 코드 문법 강조나, 자동완성 기능으로 도움 받을 수 있기 때문에 손으로 먼저 적는 연습하자\n\n 3. ##### 코드를 테스트하자\n\n - 기본 조건, 오류 발생 조건 등을 테스트 하자. \n\n 4. ##### 종이에 적은 코드를 그대로 컴퓨터로 옮기고 실행해보자\n\n - 종이로 적었을 때 실수를 많이 했을 것이다. 컴퓨터로 옮기면서 실수 목록을 적고 다음부터 저지르지 않도록 유의하자\n\n
\n\n- #### 기술면접에서 필수로 알아야 하는 것\n\n 1. ##### 자료구조\n\n - 연결리스트(Linked Lists)\n - 트리, 트라이(Tries), 그래프\n - 스택 & 큐\n - 힙(Heaps)\n - Vector / ArrayList\n - 해시테이블\n\n 2. ##### 알고리즘\n\n - BFS (너비 우선 탐색)\n - DFS (깊이 우선 탐색)\n - 이진 탐색\n - 병합 정렬(Merge Sort)\n - 퀵 정렬\n\n 3. ##### 개념\n\n - 비트 조작(Bit Manipulation)\n - 메모리 (스택 vs 힙)\n - 재귀\n - DP (다이나믹 프로그래밍)\n - big-O (시간과 공간 개념)\n\n
\n\n- #### 면접에서 문제가 주어지면 해야할 순서\n\n *면접관은 우리가 문제를 어떻게 풀었는 지, 과정을 알고 싶어하기 때문에 끊임없이 설명해야합니다!*\n\n 1. ##### 듣기\n\n - 문제 설명 관련 정보는 집중해서 듣자. 중요한 부분이 있을 수 있습니다.\n\n 2. ##### 예제\n\n - 직접 예제를 만들어서 디버깅하고 확인하기\n\n 3. ##### 무식하게 풀기\n\n - 처음에는 최적의 알고리즘을 생각하지말고 무식하게 풀어보기\n\n 4. ##### 최적화\n\n - BUD (병목현상, 불필요 작업, 중복 작업)을 최적화 시키며 개선하기\n\n 5. ##### 검토하기\n\n - 다시 처음부터 실수가 없는지 검토하기\n\n 6. ##### 구현하기\n\n - 모듈화된 코드 사용하기\n - 에러를 검증하기\n - 필요시, 다른 클래스나 구조체 사용하기\n - 좋은 변수명 사용하기\n\n 7. ##### 테스트\n\n - 개념적 테스트 - 코드 리뷰\n - 특이한 코드들 확인\n - 산술연산이나 NULL 노드 부분 실수 없나 확인\n - 작은 크기의 테스트들 확인\n\n
\n\n- #### 오답 대처법\n\n *또한 면접은 '상대평가'입니다. 즉, 문제가 어렵다면 다른 사람도 마찬가지이므로 너무 두려워하지 말아야합니다.*\n\n - 면접관들은 답을 평가할 때 맞춤, 틀림으로 평가하지 않기 때문에, 면접에서 모든 문제의 정답을 맞춰야 할 필요는 없습니다.\n - 중요하게 여기는 부분\n - 얼마나 최종 답안이 최적 해법에 근접한가\n - 최종 답안을 내는데 시간이 얼마나 걸렸나\n - 얼마나 힌트를 필요로 했는가\n - 얼마나 코드가 깔끔한가\n\n
" }, { "path": "Interview/[Java] Interview List.md", "content": "# [Java ]Interview List\n\n> - 간단히 개념들을 정리해보며 머리 속에 넣자~\n> - 질문 자체에 없는 질문 의도가 있는 경우 추가 했습니다.\n> - 완전한 설명보다는 면접 답변에 초점을 두며, 추가로 답변하면 좋은 키워드를 기록했습니다.\n\n- [언어(Java, C++ ... )](https://github.com/kim6394/Dev_BasicKnowledge/blob/master/Interview/README.md#언어)\n- [운영체제](https://github.com/kim6394/Dev_BasicKnowledge/blob/master/Interview/README.md#운영체제)\n- [데이터베이스](https://github.com/kim6394/Dev_BasicKnowledge/blob/master/Interview/README.md#데이터베이스)\n- [네트워크](https://github.com/kim6394/Dev_BasicKnowledge/blob/master/Interview/README.md#네트워크)\n- [스프링](https://github.com/kim6394/Dev_BasicKnowledge/blob/master/Interview/README.md#스프링)\n\n### 가비지 컬렉션이란?\n\n> 배경 & 질문 의도\n\n- JVM 의 구조, 특히 Heap Area 에 대한 이해\n\n> 답변\n\n- 자바가 실행되는 JVM 에서 사용되는 객체, 즉 Heap 영역의 객체를 관리해 주는 기능을 말합니다.\n- 이 과정에서 stop the world 가 일어나게 되며, 이 일련 과정을 효율적으로 하기 위해서는 가비지 컬렉터 변경 또는 세부 값 조정이 필요합니다.\n\n> 키워드 & 꼬리 질문\n\n- 가비지 컬렉션 과정, 가비지 컬렉터 종류에 대한 이해\n\n### StringBuilder와 StringBuffer의 차이는?\n\n> 배경 & 질문 의도\n\n- mutation(가변), immutation(불변) 이해\n- 불변 객체인 String 의 연산에서 오는 퍼포먼스 이슈 이해\n- String\n - immutation\n - String 문자열을 연산하는 과정에서 불변 객체의 반복 생성으로 퍼포먼스가 낮아짐.\n\n> 답변\n\n- 같은점\n - mutation\n - append() 등의 api 지원\n- 차이점\n - StringBuilder 는 동기화를 지원하지 않아 싱글 스레드에서 속도가 빠릅니다.\n - StringBuffer 는 멀티 스레드 환경에서의 동기화를 지원하지만 이런 구현은 로직을 의심해야 합니다.\n\n> 키워드 & 꼬리 질문\n\n- [실무에서의 String 연산](https://hyune-c.tistory.com/entry/String-%EC%9D%84-%EC%9E%98-%EC%8D%A8%EB%B3%B4%EC%9E%90)\n\n### Java의 메모리 영역은?\n\n> 배경 & 질문 의도\n\n- JVM 구조의 이해\n\n> 답변\n\n- 메소드, 힙, 스택, pc 레지스터, 네이티브 영역으로 구분됩니다.\n - 메소드 영역은 클래스가 로딩될 때 생성되며 주로 static 변수가 저장됩니다.\n - 힙 영역은 런타임시 할당되며 주로 객체가 저장됩니다.\n - 스택 영역은 컴파일시 할당되며 메소드 호출시 지역변수가 저장됩니다.\n - pc 레지스터는 스레드가 생성될 때마다 생성되는 영역으로 다음 명령어의 주소를 알고 있습니다.\n - 네이티브 영역은 자바 외 언어로 작성된 코드를 위한 영역입니다.\n- 힙과 스택은 같은 메모리 공간을 동적으로 공유하며, 과도하게 사용하는 경우 OOM 이 발생할 수 있습니다.\n- 힙 영역은 GC 를 통해 정리됩니다.\n\n> 키워드 & 꼬리 질문\n\n- Method Area (Class Area)\n - 클래스가 로딩될 때 생성됩니다.\n - 클래스, 변수, 메소드 정보\n - static 변수\n - Constant pool - 문자 상수, 타입, 필드, 객체참조가 저장됨\n- Stack Area\n - 컴파일 타임시 할당됩니다.\n - 메소드를 호출할 때 개별적으로 스택이 생성되며 종료시 해제 됩니다.\n - 지역 변수 등 임시 값이 생성되는 영역\n - Heap 영역에 생성되는 객체의 주소 값을 가지고 있습니다.\n- Heap Area\n - 런타임시 할당 됩니다.\n - new 키워드로 생성되는 객체와 배열이 저장되는 영역\n - 참조하는 변수가 없어도 바로 지워지지 않습니다. -> GC 를 통해 제거됨.\n- Java : GC, 컴파일/런타임 차이\n- CS : 프로세스/단일 스레드/멀티 스레드 차이\n\n### 오버로딩과 오버라이딩 차이는?\n\n> 배경 & 질문 의도\n\n> 답변\n\n- 오버로딩\n - 반환타입 관계 없음, 메소드명 같음, 매개변수 다름 (자료형 또는 순서)\n- 오버라이딩\n - 반환타입, 메소드명, 매개변수 모두 같음\n - 부모 클래스로부터 상속받은 메소드를 재정의하는 것.\n\n> 키워드 & 꼬리 질문\n\n- 오버로딩은 생성자가 여러개 필요한 경우 유용합니다.\n- 결합도를 낮추기 위한 방법 중 하나로 interface 사용이 있으며, 이 과정에서 오버라이딩이 적극 사용됩니다.\n\n### 추상 클래스와 인터페이스 차이는?\n\n> 배경 & 질문 의도\n\n> 답변\n\n- abstract class 추상 클래스\n - 단일 상속을 지원합니다.\n - 변수를 가질 수 있습니다.\n - 하나 이상의 abstract 메소드가 존재해야 합니다.\n - 자식 클래스에서 상속을 통해 abstract 메소드를 구현합니다. (extends)\n - abstract 메소드가 아닌 구현된 메소드를 상속 받을 수 있습니다.\n- interface 인터페이스\n - 다중 상속을 지원합니다.\n - 변수를 가질 수 없습니다. 상수는 가능합니다.\n - 모든 메소드는 선언부만 존재합니다.\n - 구현 클래스는 선언된 모든 메소드를 overriding 합니다.\n\n> 키워드 & 꼬리 질문\n\n- java 버전이 올라갈수록 abstract 의 기능을 interface 가 흡수하고 있습니다.\n - java 8: interface 에서 default method 사용 가능\n - java 9: interface 에서 private method 사용 가능\n\n### 제네릭이란?\n\n- 클래스에서 사용할 타입을 클래스 외부에서 설정하도록 만드는 것\n- 제네릭으로 선언한 클래스는, 내가 원하는 타입으로 만들어 사용이 가능함\n- <안에는 참조자료형(클래스, 인터페이스, 배열)만 가능함 (기본자료형을 이용하기 위해선 wrapper 클래스를 활용해야 함)\n- 참고\n - Autoboxing, Unboxing\n\n### 접근 제어자란? (Access Modifier)\n\n> 배경 & 질문 의도\n\n> 답변\n\n- public: 모든 접근 허용\n- protected: 상속받은 클래스 or 같은 패키지만 접근 허용\n- default: 기본 제한자. 자신 클래스 내부 or 같은 패키지만 접근 허용\n- private: 외부 접근 불가능. 같은 클래스 내에서만 가능\n\n> 키워드 & 꼬리 질문\n\n- 참고\n - 보통 명시적인 표현을 선호하여 default 는 잘 쓰이지 않습니다.\n\n### Java 컴파일 과정\n\n> 배경 & 질문 의도\n\n- CS 에 가까운 질문\n\n> 답변\n\n1. 컴파일러가 변환: 소스코드 -> 자바 바이트 코드(.class)\n2. JVM이 변환: 바이트코드 -> 기계어\n3. 인터프리터 방식으로 애플리케이션 실행\n\n> 키워드 & 꼬리 질문\n\n- JIT 컴파일러\n" }, { "path": "LICENSE", "content": "MIT License\n\nCopyright (c) 2019 Gyuseok Kim\n\nPermission is hereby granted, free of charge, to any person obtaining a copy\nof this software and associated documentation files (the \"Software\"), to deal\nin the Software without restriction, including without limitation the rights\nto use, copy, modify, merge, publish, distribute, sublicense, and/or sell\ncopies of the Software, and to permit persons to whom the Software is\nfurnished to do so, subject to the following conditions:\n\nThe above copyright notice and this permission notice shall be included in all\ncopies or substantial portions of the Software.\n\nTHE SOFTWARE IS PROVIDED \"AS IS\", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR\nIMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,\nFITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE\nAUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER\nLIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,\nOUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE\nSOFTWARE.\n" }, { "path": "Language/[C++] Vector Container.md", "content": "# [C++] Vector Container\n\n
\n\n```cpp\n#include
\n\n## 생성\n\n- `vector<\"Type\"> v;`\n- `vector<\"Type\"> v2(v); ` : v2에 v 복사\n\n### Function\n\n- `v.assign(5, 2);` : 2 값으로 5개 원소 할당\n- `v.at(index);` : index번째 원소 참조 (범위 점검 o)\n- `v[index];` : index번째 원소 참조 (범위 점검 x)\n- `v.front(); v.back();` : 첫번째와 마지막 원소 참조\n- `v.clear();` : 모든 원소 제거 (메모리는 유지)\n- `v.push_back(data); v.pop_back(data);` : 마지막 원소 뒤에 data 삽입, 마지막 원소 제거\n- `v.begin(); v.end();` : 첫번째 원소, 마지막의 다음을 가리킴 (iterator 필요)\n- `v.resize(n);` : n으로 크기 변경\n- `v.size();` : vector 원소 개수 리턴\n- `v.capacity();` : 할당된 공간 크기 리턴\n- `v.empty();` : 비어있는 지 여부 확인 (true, false)\n\n```\ncapacity : 할당된 메모리 크기\nsize : 할당된 메모리 원소 개수\n```\n\n
\n\n```cpp\n#include
\n\n
\n\n#### [참고 자료]\n\n- [링크](https://blockdmask.tistory.com/70)" }, { "path": "Language/[C++] 가상 함수(virtual function).md", "content": "### 가상 함수(virtual function)\n\n---\n\n> C++에서 자식 클래스에서 재정의(오버라이딩)할 것으로 기대하는 멤버 함수를 의미함\n>\n> 멤버 함수 앞에 `virtual` 키워드를 사용하여 선언함 → 실행시간에 함수의 다형성을 구현할 때 사용\n\n
\n\n##### 선언 규칙\n\n- 클래스의 public 영역에 선언해야 한다.\n- 가상 함수는 static일 수 없다.\n- 실행시간 다형성을 얻기 위해, 기본 클래스의 포인터 또는 참조를 통해 접근해야 한다.\n- 가상 함수는 반환형과 매개변수가 자식 클래스에서도 일치해야 한다.\n\n```c++\nclass parent {\npublic :\n virtual void v_print() {\n cout << \"parent\" << \"\\n\";\n }\n void print() {\n cout << \"parent\" << \"\\n\";\n }\n};\n \nclass child : public parent {\npublic :\n void v_print() {\n cout << \"child\" << \"\\n\";\n }\n void print() {\n cout << \"child\" << \"\\n\";\n }\n};\n \nint main() {\n parent* p;\n child c;\n p = &c;\n \n p->v_print();\n p->print();\n \n return 0;\n}\n// 출력 결과\n// child\n// parent\n```\n\nparent 클래스를 가리키는 포인터 p를 선언하고 child 클래스의 객체 c를 선언한 상태\n\n포인터 p가 c 객체를 가리키고 있음 (몸체는 parent 클래스지만, 현재 실제 객체는 child 클래스)\n\n포인터 p를 활용해 `virtual`을 활용한 가상 함수인 `v_print()`와 오버라이딩된 함수 `print()`의 출력은 다르게 나오는 것을 확인할 수 있다.\n\n> 가상 함수는 실행시간에 값이 결정됨 (후기 바인딩)\n\nprint()는 컴파일 시간에 이미 결정되어 parent가 호출되는 것으로 결정이 끝남" }, { "path": "Language/[C++] 입출력 실행속도 줄이는 법.md", "content": "## [C++] 입출력 실행속도 줄이는 법\n\n
\n\nC++로 알고리즘 문제를 풀 때, `cin, cout`은 실행속도가 느리다. 하지만 최적화 방법을 이용하면 실행속도 단축에 효율적이다.\n\n만약 `cin, cout`을 문제풀이에 사용하고 싶다면, 시간을 단축하고 싶다면 사용하자\n\n```\n최적화 시 거의 절반의 시간이 단축된다.\n```\n\n
\n\n```c++\nint main(void)\n{\n ios_base :: sync_with_stdio(false);\n cin.tie(NULL);\n cout.tie(NULL);\n}\n```\n\n`ios_base`는 c++에서 사용하는 iostream의 cin, cout 등을 함축한다.\n\n`sync_with_stdio(false)`는 c언어의 stdio.h와 동기화하지만, 그 안에서 활용하는 printf, scanf, getchar, fgets, puts, putchar 등은 false로 동기화하지 않음을 뜻한다.\n\n
\n\n***주의***\n\n```\n따라서, cin/scanf와 cout/printf를 같이 쓰면 문제가 발생하므로 조심하자\n```\n\n또한, 이는 싱글 스레드 환경에서만 효율적일뿐(즉, 알고리즘 문제 풀이할 때) 실무에선 사용하지 말자\n\n그리고 크게 차이 안나므로 그냥 `printf/scanf` 써도 된다!" }, { "path": "Language/[C] 구조체 메모리 크기 계산.md", "content": "## [C] 구조체 메모리 크기 (Struct Memory Size)\n\ntypedef struct 선언 시, 변수 선언에 대한 메모리 공간 크기에 대해 알아보자\n\n> 기업 필기 테스트에서 자주 나오는 유형이기도 함\n\n
\n\n- char : 1바이트\n- int : 4바이트\n- double : 8바이트\n\n`sizeof` 메소드를 통해 해당 변수의 사이즈를 알 수 있음\n\n
\n\n#### 크기 계산\n\n---\n\n```c\ntypedef struct student {\n char a;\n int b;\n}S;\n\nvoid main() {\n printf(\"메모리 크기 = %d/n\", sizeof(S)); // 8\n}\n```\n\nchar는 1바이트고, int는 4바이트라서 5바이트가 필요하다.\n\n하지만 메모리 공간은 5가 아닌 **8이 찍힐 것이다**.\n\n***Why?***\n\n구조체가 메모리 공간을 잡는 원리에는 크게 두가지 규칙이 있다.\n\n1. 각각의 멤버를 저장하기 위해서는 **기본 4바이트 단위로 구성**된다. (4의 배수 단위)\n 즉, char 데이터 1개를 저장할 때 이 1개의 데이터를 읽어오기 위해서 1바이트를 읽어오는 것이 아니라 이 데이터가 포함된 '4바이트'를 읽는다.\n2. 구조체 각 멤버 중에서 가장 큰 멤버의 크기에 영향을 받는다.\n\n
\n\n이 규칙이 적용된 메모리 공간은 아래와 같을 것이다.\n\na는 char형이지만, 기본 4바이트 단위 구성으로 인해 3바이트의 여유공간이 생긴다.\n\n
 \n\n
\n\n\n\n그렇다면 이와 같을 때는 어떨까?\n\n```c\ntypedef struct student {\n char a;\n char b;\n int c;\n}S;\n```\n\n
 \n\n똑같이 8바이트가 필요하며, char형으로 선언된 a,b가 4바이트 안에 함께 들어가고 2바이트의 여유 공간이 생긴다.\n\n
\n\n똑같이 8바이트가 필요하며, char형으로 선언된 a,b가 4바이트 안에 함께 들어가고 2바이트의 여유 공간이 생긴다.\n\n\n\n이제부터 헷갈리는 경우다.\n\n```c\ntypedef struct student {\n char a;\n int c;\n char b;\n}S;\n```\n\n구성은 같지만, 순서가 다르다.\n\n자료타입은 일치하지만, 선언된 순서에 따라 할당되는 메모리 공간이 아래와 같이 달라진다.\n\n
 \n\n이 경우에는 총 12바이트가 필요하게 된다.\n\n
\n\n이 경우에는 총 12바이트가 필요하게 된다.\n\n\n\n```c\ntypedef struct student {\n char a;\n int c;\n double b;\n}S;\n```\n\n두 규칙이 모두 적용되는 상황이다. b가 double로 8바이트이므로 기본 공간이 8바이트로 설정된다. 하지만 a와 c는 8바이트로 해결이 가능하기 때문에 16바이트로 해결이 가능하다.\n\n
 \n\n
\n\n\n\n
\n\n##### [참고자료]\n\n[링크](
\n\n##### *동적할당이란?*\n\n> 프로그램 실행 중에 동적으로 메모리를 할당하는 것\n>\n> Heap 영역에 할당한다\n\n
\n\n- `
\n\n#### 중요\n\n할당한 메모리는 반드시 해제하자 (해제안하면 메모리 릭, 누수 발생)\n\n
\n\n```c\n#include
\n\n
\n\n##### [참고 자료]\n\n- [링크](https://blockdmask.tistory.com/290)\n\n" }, { "path": "Language/[C] 포인터(Pointer).md", "content": "## [C] 포인터(Pointer)\n\n
\n\n***포인터*** : 특정 변수를 가리키는 역할을 하는 변수\n\n
\n\nmain에서 한번 만들어둔 변수 값을 다른 함수에서 그대로 사용하거나, 변경하고 싶은 경우가 있다.\n\n같은 지역에 있는 변수라면 사용 및 변경이 간단하지만, 다른 지역인 경우에는 해당 값을 임시 변수로 받아 반환하는 식으로 처리한다.\n\n이때 효율적으로 처리할 수 있도록 **포인터**를 사용하는 것!\n\n포인터는 **메모리를 할당받고 해당 공간을 기억하는 것이 가능**하다.\n\n
\n\n아래와 같은 코드가 있을 때를 확인해보자\n\n```c\n#include
\n\n`int* p;` : int형 포인터로 p라는 이름의 변수를 선언\n\n`p = #` : p의 값에 num 변수의 주소값 대입\n\n`printf(\"%d\", *p);` : p에 *를 붙이면 p에 가리키는 주소에 있는 값을 나타냄\n\n`printf(\"%d\", p);` : p가 가리키고 있는 주소를 나타냄\n\n
\n\n```c\n#include
\n\n
\n\n#### 이중 포인터\n\n포인터의 포인터, 즉 포인터의 메모리 주소를 저장하는 것을 말한다.\n\n```c\n#include
 \n\n
\n\n\n\n
\n\n##### [참고사항]\n\n[링크](
\n\n> shallow copy와 deep copy가 어떻게 다른지 알아보자\n\n
\n\n### 얕은 복사(shallow copy)\n\n한 객체의 모든 멤버 변수의 값을 다른 객체로 복사\n\n
\n\n### 깊은 복사(deep copy)\n\n모든 멤버 변수의 값뿐만 아니라, 포인터 변수가 가리키는 모든 객체에 대해서도 복사\n\n
\n\n
\n\n```cpp\nstruct Test {\n char *ptr;\n};\n\nvoid shallow_copy(Test &src, Test &dest) {\n dest.ptr = src.ptr;\n}\n\nvoid deep_copy(Test &src, Test &dest) {\n dest.ptr = (char*)malloc(strlen(src.ptr) + 1);\n strcpy(dest.ptr, src.ptr);\n}\n```\n\n
\n\n`shallow_copy`를 사용하면, 객체 생성과 삭제에 관련된 많은 프로그래밍 오류가 프로그램 실행 시간에 발생할 수 있다.\n\n```\n즉, 얕은 복사는 프로그래머가 스스로 무엇을 하는 지\n잘 이해하고 있는 상황에서 주의하여 사용해야 한다\n```\n\n대부분, 얕은 복사는 실제 데이터를 복제하지 않고서, 복잡한 자료구조에 관한 정보를 전달할 때 사용한다. 얕은 복사로 만들어진 객체를 삭제할 때는 조심해야 한다.\n\n
\n\n실제로 얕은 복사는 실무에서 거의 사용되지 않는다. 대부분 깊은 복사를 사용해야 하는데, 복사되는 자료구조의 크기가 작으면 더욱 깊은 복사가 필요하다.\n\n
\n\n
\n\n#### [참고 자료]\n\n- 코딩 인터뷰 완전분석" }, { "path": "Language/[Java] Auto Boxing & Unboxing.md", "content": "# [Java] 오토 박싱 & 오토 언박싱\n\n
\n\n자바에는 기본 타입과 Wrapper 클래스가 존재한다.\n\n- 기본 타입 : `int, long, float, double, boolean` 등\n- Wrapper 클래스 : `Integer, Long, Float, Double, Boolean ` 등\n\n
\n\n박싱과 언박싱에 대한 개념을 먼저 살펴보자\n\n> 박싱 : 기본 타입 데이터에 대응하는 Wrapper 클래스로 만드는 동작\n>\n> 언박싱 : Wrapper 클래스에서 기본 타입으로 변환\n\n```JAVA\n// 박싱\nint i = 10;\nInteger num = new Integer(i);\n\n// 언박싱\nInteger num = new Integer(10);\nint i = num.intValue();\n```\n\n
\n\n
 \n\n
\n\n\n\n#### 오토 박싱 & 오토 언박싱\n\nJDK 1.5부터는 자바 컴파일러가 박싱과 언박싱이 필요한 상황에 자동으로 처리를 해준다.\n\n```JAVA\n// 오토 박싱\nint i = 10;\nInteger num = i;\n\n// 오토 언박싱\nInteger num = new Integer(10);\nint i = num;\n```\n\n
\n\n### 성능\n\n편의성을 위해 오토 박싱과 언박싱이 제공되고 있지만, 내부적으로 추가 연산 작업이 거치게 된다.\n\n따라서, 오토 박싱&언박싱이 일어나지 않도록 동일한 타입 연산이 이루어지도록 구현하자.\n\n#### 오토 박싱 연산\n\n```java\npublic static void main(String[] args) {\n long t = System.currentTimeMillis();\n Long sum = 0L;\n for (long i = 0; i < 1000000; i++) {\n sum += i;\n }\n System.out.println(\"실행 시간: \" + (System.currentTimeMillis() - t) + \" ms\");\n}\n\n// 실행 시간 : 19 ms\n```\n\n#### 동일 타입 연산\n\n```java\npublic static void main(String[] args) {\n long t = System.currentTimeMillis();\n long sum = 0L;\n for (long i = 0; i < 1000000; i++) {\n sum += i;\n }\n System.out.println(\"실행 시간: \" + (System.currentTimeMillis() - t) + \" ms\") ;\n}\n\n// 실행 시간 : 4 ms\n```\n\n
\n\n100만건 기준으로 약 5배의 성능 차이가 난다. 따라서 서비스를 개발하면서 불필요한 오토 캐스팅이 일어나는 지 확인하는 습관을 가지자.\n\n
\n\n
\n\n#### [참고 사항]\n\n- [링크](http://tcpschool.com/java/java_api_wrapper)\n- [링크](https://sas-study.tistory.com/407)\n\n" }, { "path": "Language/[Java] Interned String in JAVA.md", "content": "# Interned String in Java\n자바(Java)의 문자열(String)은 불변(immutable)하다. \nString의 함수를 호출을 하면 해당 객체를 직접 수정하는 것이 아니라, 함수의 결과로 해당 객체가 아닌 다른 객체를 반환한다.\n그러나 항상 그런 것은 아니다. 아래 예를 보자.\n```java\npublic void func() {\n String haribo1st = new String(\"HARIBO\");\n String copiedHaribo1st = haribo1st.toUpperCase();\n\n System.out.println(haribo1st == copiedHaribo1st); \n}\n```\n`\"HARIBO\"`라는 문자열을 선언한 후, `toUpperCase()`를 호출하고 있다.\n앞서 말대로 불변 객체이기 때문에 `toUpperCase()`를 호출하면 기존 객체와 다른 객체가 나와야 한다.\n그러나 `==`으로 비교를 해보면 `true`로 서로 같은 값이다.\n그 이유는 `toUpperCase()` 함수의 로직 때문이다. 해당 함수는 lower case의 문자가 발견되지 않으면 기존의 객체를 반환한다.\n\n그렇다면 생성자(`new String(\"HARIBO\")`)를 이용해서 문자열을 생성하면 `\"HARIBO\"`으로 선언한 객체와 같은 객체일까?\n아니다. 생성자를 통해 선언하게 되면 같은 문자열을 가진 새로운 객체가 생성된다. 즉, 힙(heap)에 새로운 메모리를 할당하는 것이다.\n\n```java\npublic void func() {\n String haribo1st = new String(\"HARIBO\");\n String haribo3rd = \"HARIBO\";\n\n System.out.println(haribo1st == haribo3rd);\n System.out.println(haribo1st.equals(haribo3rd));\n}\n```\n위의 예제를 보면 `==` 비교의 결과는 `false`이지만 `equals()`의 결과는 `true`이다.\n두 개의 문자열은 같은 값을 가지지만 실제로는 다른 객체이다.\n두 객체의 hash 값을 비교해보면 확실하게 알 수 있다.\n\n```java\npublic void func() {\n String haribo3rd = \"HARIBO\";\n String haribo4th = String.valueOf(\"HARIBO\");\n \n System.out.println(haribo3rd == haribo4th);\n System.out.println(haribo3rd.equals(haribo4th));\n}\n```\n이번에는 리터럴(literal)로 선언한 객체와 `String.valueOf()`로 가져온 객체를 한번 살펴보자.\n`valueOf()`함수를 들어가보면 알겠지만, 주어진 매개 변수가 null인지 확인한 후 null이 아니면 매개 변수의 `toString()`을 호출한다.\n여기서 `String.toString()`은 `this`를 반환한다. 즉, 두 구문 모두 `\"HARIBO\"`처럼 리터럴 선언이다. \n그렇다면 리터럴로 선언한 객체는 왜 같은 객체일까?\n\n바로 JVM에서 constant pool을 통해 문자열을 관리하고 있기 때문이다.\n리터럴로 선언한 문자열이 constant pool에 있으면 해당 객체를 바로 가져온다.\n만약 pool에 없다면 새로 객체를 생성한 후, pool에 등록하고 가져온다.\n이러한 플로우를 거치기 때문에 `\"HARIBO\"`로 선언한 문자열은 같은 객체로 나오는 것이다.\n`String.intern()` 함수를 참고해보자. \n\n### References\n- https://www.latera.kr/blog/2019-02-09-java-string-intern/\n- https://blog.naver.com/adamdoha/222817943149" }, { "path": "Language/[Java] Intrinsic Lock.md", "content": "### Java 고유 락 (Intrinsic Lock)\n\n---\n\n#### Intrinsic Lock / Synchronized Block / Reentrancy\n\nIntrinsic Lock (= monitor lock = monitor) : Java의 모든 객체는 lock을 갖고 있음.\n\n*Synchronized 블록은 Intrinsic Lock을 이용해서, Thread의 접근을 제어함.*\n\n```java\npublic class Counter {\n private int count;\n \n public int increase() {\n return ++count;\t\t// Thread-safe 하지 않은 연산\n }\n}\n```\n\n
\n\nQ) ++count 문이 atomic 연산인가?\n\nA) read (count 값을 읽음) -> modify (count 값 수정) -> write (count 값 저장)의 과정에서, 여러 Thread가 **공유 자원(count)으로 접근할 수 있으므로, 동시성 문제가 발생**함.\n\n
\n\n#### Synchronized 블록을 사용한 Thread-safe Case\n\n```java\npublic class Counter{\n private Object lock = new Object(); // 모든 객체가 가능 (Lock이 있음)\n private int count;\n \n public int increase() {\n // 단계 (1)\n synchronized(lock){\t// lock을 이용하여, count 변수에의 접근을 막음\n return ++count;\n }\n \n /* \n 단계 (2)\n synchronized(this) { // this도 객체이므로 lock으로 사용 가능\n \treturn ++count;\n }\n */\n }\n /*\n 단계 (3)\n public synchronized int increase() {\n \treturn ++count;\n }\n */\n}\n```\n\n단계 3과 같이 *lock 생성 없이 synchronized 블록 구현 가능*\n\n
\n\n\n\n#### Reentrancy\n\n재진입 : Lock을 획득한 Thread가 같은 Lock을 얻기 위해 대기할 필요가 없는 것\n\n(Lock의 획득이 '**호출 단위**'가 아닌 **Thread 단위**로 일어나는 것)\n\n```java\npublic class Reentrancy {\n // b가 Synchronized로 선언되어 있더라도, a 진입시 lock을 획득하였음.\n // b를 호출할 수 있게 됨.\n public synchronized void a() {\n System.out.println(\"a\");\n b();\n }\n \n public synchronized void b() {\n System.out.println(\"b\");\n }\n \n public static void main (String[] args) {\n new Reentrancy().a();\n }\n}\n```\n\n
\n\n#### Structured Lock vs Reentrant Lock\n\n**Structured Lock (구조적 Lock) : 고유 lock을 이용한 동기화**\n\n(Synchronized 블록 단위로 lock의 획득 / 해제가 일어나므로)\n\n\n\n따라서,\n\nA획득 -> B획득 -> B해제 -> A해제는 가능하지만,\n\nA획득 -> B획득 -> A해제 -> B해제는 불가능함.\n\n이것을 가능하게 하기 위해서는 **Reentrant Lock (명시적 Lock) 을 사용**해야 함.\n\n
\n\n#### Visibility\n\n* 가시성 : 여러 Thread가 동시에 작동하였을 때, 한 Thread가 쓴 값을 다른 Thread가 볼 수 있는지, 없는지 여부\n\n* 문제 : 하나의 Thread가 쓴 값을 다른 Thread가 볼 수 있느냐 없느냐. (볼 수 없으면 문제가 됨)\n\n* Lock : Structure Lock과 Reentrant Lock은 Visibility를 보장.\n\n* 원인 :\n\n1. 최적화를 위해 Compiler나 CPU에서 발생하는 코드 재배열로 인해서.\n2. CPU core의 cache 값이 Memory에 제때 쓰이지 않아 발생하는 문제.\n\n
\n\n" }, { "path": "Language/[Java] Java 8 정리.md", "content": "# [Java] Java 8 정리\n\n
\n\n```\nJava 8은 가장 큰 변화가 있던 버전이다.\n자바로 구현하기 힘들었던 병렬 프로세싱을 활용할 수 있게 된 버전이기 때문\n```\n\n
\n\n시대가 발전하면서 이제 PC에서 멀티 코어 이상은 대중화되었다. 이제 수많은 데이터를 효율적으로 처리하기 위해서 '병렬' 처리는 필수적이다.\n\n자바 프로그래밍은 다른 언어에 비해 병렬 처리가 쉽지 않다. 물론, 스레드를 사용하면 놀고 있는 유휴 코어를 활용할 수 있다. (대표적으로 스레드 풀) 하지만 개발자가 관리하기 어렵고, 사용하면서 많은 에러가 발생할 수 있는 단점이 존재한다.\n\n이를 해결하기 위해 8버전에서는 좀 더 개발자들이 병렬 처리를 쉽고 간편하게 할 수 있도록 기능들이 추가되었다.\n\n
\n\n크게 3가지 기능이 8버전에서 추가되었다.\n\n- Stream API\n- Method Reference & Lamda\n- Default Method\n\n
\n\nStream API는 병렬 연산을 지원하는 API다. 이제 기존에 병렬 처리를 위해 사용하던 `synchronized`를 사용하지 않아도 된다. synchronized는 에러를 유발할 가능성과 비용 측면에서 문제점이 많은 단점이 있었다.\n\nStream API는 주어진 항목들을 연속으로 제공하는 기능이다. 파이프라인을 구축하여, 진행되는 순서는 정해져있지만 동시에 작업을 처리하는 것이 가능하다. \n\n스트림 파이프라인이 작업을 처리할 때 여러 CPU 코어에 할당 작업을 진행한다. 이를 통해서 하나의 큰 항목을 처리할 때 효율적으로 작업할 수 있는 것이다. 즉, 스레드를 사용하지 않아도 병렬 처리를 간편히 할 수 있게 되었다.\n\n
\n\n또한, 메소드 레퍼런스와 람다를 자바에서도 활용할 수 있게 되면서, 동작 파라미터를 구현할 수 있게 되었다. 기존에도 익명 클래스로 구현은 가능했지만, 코드가 복잡해지고 재사용이 힘든 단점을 해결할 수 있게 되었다.\n\n\n\n
\n\n
\n\n#### [참고 자료]\n\n- [링크](http://friday.fun25.co.kr/blog/?p=266)" }, { "path": "Language/[Java] wait notify notifyAll.md", "content": "#### Object 클래스 wait, notify, notifyAll\n\n----\n\nJava의 최상위 클래스 = Object 클래스\n\nObject Class 가 갖고 있는 메서드\n\n* toString()\n\n* hashCode()\n\n* wait()\n\n 갖고 있던 **고유 lock 해제, Thread를 잠들게 함**\n\n* notify()\n\n **잠들던 Thread** 중 임의의 **하나를 깨움**.\n\n* notifyAll()\n\n 잠들어 있던 Thread 를 **모두 깨움**.\n\n \n\n \n\n*wait, notify, notifyAll : 호출하는 스레드가 반드시 고유 락을 갖고 있어야 함.*\n\n=> Synchronized 블록 내에서 실행되어야 함.\n\n=> 그 블록 안에서 호출하는 경우 IllegalMonitorStateException 발생.\n\n\n\n" }, { "path": "Language/[Java] 직렬화(Serialization).md", "content": "# [Java] 직렬화(Serialization)\n\n
\n\n```\n자바 시스템 내부에서 사용되는 객체 또는 데이터를 외부의 자바 시스템에서도 사용할 수 있도록 바이트(byte) 형태로 데이터 변환하는 기술\n```\n\n
\n\n각자 PC의 OS마다 서로 다른 가상 메모리 주소 공간을 갖기 때문에, Reference Type의 데이터들은 인스턴스를 전달 할 수 없다.\n\n따라서, 이런 문제를 해결하기 위해선 주소값이 아닌 Byte 형태로 직렬화된 객체 데이터를 전달해야 한다.\n\n직렬화된 데이터들은 모두 Primitive Type(기본형)이 되고, 이는 파일 저장이나 네트워크 전송 시 파싱이 가능한 유의미한 데이터가 된다. 따라서, 전송 및 저장이 가능한 데이터로 만들어주는 것이 바로 **'직렬화(Serialization)'**이라고 말할 수 있다.\n\n
\n\n
 \n\n
\n\n\n\n### 직렬화 조건\n\n----\n\n자바에서는 간단히 `java.io.Serializable` 인터페이스 구현으로 직렬화/역직렬화가 가능하다.\n\n> 역직렬화는 직렬화된 데이터를 받는쪽에서 다시 객체 데이터로 변환하기 위한 작업을 말한다.\n\n**직렬화 대상** : 인터페이스 상속 받은 객체, Primitive 타입의 데이터\n\nPrimitive 타입이 아닌 Reference 타입처럼 주소값을 지닌 객체들은 바이트로 변환하기 위해 Serializable 인터페이스를 구현해야 한다.\n\n
\n\n### 직렬화 상황\n\n----\n\n- JVM에 상주하는 객체 데이터를 영속화할 때 사용\n- Servlet Session\n- Cache\n- Java RMI(Remote Method Invocation)\n\n
\n\n### 직렬화 구현\n\n---\n\n```java\n@Entity\n@AllArgsConstructor\n@toString\npublic class Post implements Serializable {\nprivate static final long serialVersionUID = 1L;\n \nprivate String title;\nprivate String content;\n```\n\n`serialVersionUID`를 만들어준다.\n\n```java\nPost post = new Post(\"제목\", \"내용\");\nbyte[] serializedPost;\ntry (ByteArrayOutputStream baos = new ByteArrayOutputStream()) {\n try (ObjectOutputStream oos = new ObjectOutputStream(baos)) {\n oos.writeObject(post);\n\n serializedPost = baos.toByteArray();\n }\n}\n```\n\n`ObjectOutputStream`으로 직렬화를 진행한다. Byte로 변환된 값을 저장하면 된다.\n\n
\n\n### 역직렬화 예시\n\n```java\ntry (ByteArrayInputStream bais = new ByteArrayInputStream(serializedPost)) {\n try (ObjectInputStream ois = new ObjectInputStream(bais)) {\n\n Object objectPost = ois.readObject();\n Post post = (Post) objectPost;\n }\n}\n```\n\n`ObjectInputStream`로 역직렬화를 진행한다. Byte의 값을 다시 객체로 저장하는 과정이다.\n\n
\n\n### 직렬화 serialVersionUID\n\n위의 코드에서 `serialVersionUID`를 직접 설정했었다. 사실 선언하지 않아도, 자동으로 해시값이 할당된다.\n\n직접 설정한 이유는 기존의 클래스 멤버 변수가 변경되면 `serialVersionUID`가 달라지는데, 역직렬화 시 달라진 넘버로 Exception이 발생될 수 있다.\n\n따라서 직접 `serialVersionUID`을 관리해야 클래스의 변수가 변경되어도 직렬화에 문제가 발생하지 않게 된다.\n\n> `serialVersionUID`을 관리하더라도, 멤버 변수의 타입이 다르거나, 제거 혹은 변수명을 바꾸게 되면 Exception은 발생하지 않지만 데이터가 누락될 수 있다.\n\n
\n\n### 요약\n\n- 데이터를 통신 상에서 전송 및 저장하기 위해 직렬화/역직렬화를 사용한다.\n\n- `serialVersionUID`는 개발자가 직접 관리한다.\n\n- 클래스 변경을 개발자가 예측할 수 없을 때는 직렬화 사용을 지양한다.\n\n- 개발자가 직접 컨트롤 할 수 없는 클래스(라이브러리 등)는 직렬화 사용을 지양한다.\n\n- 자주 변경되는 클래스는 직렬화 사용을 지양한다.\n\n- 역직렬화에 실패하는 상황에 대한 예외처리는 필수로 구현한다.\n\n- 직렬화 데이터는 타입, 클래스 메타정보를 포함하므로 사이즈가 크다. 트래픽에 따라 비용 증가 문제가 발생할 수 있기 때문에 JSON 포맷으로 변경하는 것이 좋다.\n\n > JSON 포맷이 직렬화 데이터 포맷보다 2~10배 더 효율적\n\n
\n\n
\n\n#### [참고자료]\n\n- [링크](https://techvidvan.com/tutorials/serialization-in-java/)\n- [링크](https://techblog.woowahan.com/2550/)\n- [링크](https://ryan-han.com/post/java/serialization/)" }, { "path": "Language/[Java] 컴포지션(Composition).md", "content": "# [Java] 컴포지션(Composition)\n\n
\n\n```\n컴포지션 : 기존 클래스가 새로운 클래스의 구성요소가 되는 것\n상속(Inheritance)의 단점을 커버할 수 있는 컴포지션에 대해 알아보자\n```\n\n
\n\n우선 상속(Inheritance)이란, 하위 클래스가 상위 클래스의 특성을 재정의 한 것을 말한다. 부모 클래스의 메서드를 오버라이딩하여 자식에 맞게 재사용하는 등, 상당히 많이 쓰이는 개념이면서 활용도도 높다. \n\n하지만 장점만 존재하는 것은 아니다. 상속을 제대로 사용하지 않으면 유연성을 해칠 수 있다.\n\n
\n\n#### 구현 상속(클래스→클래스)의 단점\n\n1) 캡슐화를 위반\n\n2) 유연하지 못한 설계\n\n3) 다중상속 불가능\n\n
\n\n#### 오류의 예시\n\n다음은, HashSet에 요소를 몇 번 삽입했는지 count 변수로 체크하여 출력하는 예제다.\n\n```java\npublic class CustomHashSet
\n\n```java\npublic class Main {\n public static void main(String[] args) {\n CustomHashSet
\n\n```java\n// AbstractCollection의 addAll 메서드\npublic boolean addAll(Collection c) {\n boolean modified = false;\n for (E e : c)\n if (add(e))\n modified = true;\n return modified;\n}\n```\n\n해당 메서드를 보면, `add(e)`가 사용되는 것을 볼 수 있다. 여기서 왜 6이 나온지 이해가 되었을 것이다.\n\n우리는 CustomHashSet에서 `add()` 와 `addAll()`를 모두 오버라이딩하여 count 변수를 각각 증가시켜줬다. 결국 두 메서드가 모두 실행되면서 총 6번의 count가 저장되는 것이다.\n\n따라서 이를 해결하기 위해선 두 메소드 중에 하나의 count를 증가하는 곳을 지워야한다. 하지만 이러면 눈으로 봤을 때 코드의 논리가 깨질 뿐만 아니라, 추후에 HashSet 클래스에 변경이 생기기라도 한다면 큰 오류를 범할 수도 있게 된다.\n\n결과론적으로, 위와 같이 상속을 사용했을 때 유연하지 못함과 캡슐화에 위배될 수 있다는 문제점을 볼 수 있다.\n\n
\n\n
\n\n### 그렇다면 컴포지션은?\n\n상속처럼 기존의 클래스를 확장(extend)하는 것이 아닌, **새로운 클래스를 생성하여 private 필드로 기존 클래스의 인스턴스를 참조하는 방식**이 바로 컴포지션이다.\n\n> forwarding이라고도 부른다.\n\n새로운 클래스이기 때문에, 여기서 어떠한 생성 작업이 일어나더라도 기존의 클래스는 전혀 영향을 받지 않는다는 점이 핵심이다.\n\n위의 예제를 개선하여, 컴포지션 방식으로 만들어보자\n\n
\n\n```java\npublic class CustomHashSet
\n\n상속을 쓰지말라는 이야기는 아니다. 상속을 사용하는 상황은 LSP 원칙에 따라 IS-A 관계가 반드시 성립할 때만 사용해야 한다. 하지만 현실적으로 추후의 변화가 이루어질 수 있는 방향성을 고려해봤을 때 이렇게 명확한 IS-A 관계를 성립한다고 보장할 수 없는 경우가 대부분이다.\n\n결국 이런 문제를 피하기 위해선, 컴포지션 기법을 사용하는 것이 객체 지향적인 설계를 할 때 유연함을 갖추고 나아갈 수 있을 것이다.\n\n
\n\n
\n\n#### [참고 자료]\n\n- [링크](https://github.com/jbloch/effective-java-3e-source-code/tree/master/src/effectivejava/chapter4/item18)\n- [링크](https://dev-cool.tistory.com/22)\n\n" }, { "path": "Language/[Javascript] Closure.md", "content": "# [Javascript] Closure\n\nclosure는 주변 state(lexical environment를 의미)에 대한 참조와 함께 묶인 함수의 조합이다. 다시말해서, closure는 inner function이 outer function의 scope를 접근할 수 있게 해준다. JavaScript에서 closure는 함수 생성 시간에 함수가 생성될 때마다 만들어진다.\n\n## Lexical scoping\n아래 예제를 보자\n```js\nfunction init() {\n var name = 'Mozilla'; // name is a local variable created by init\n function displayName() { // displayName() is the inner function, a closure\n alert(name); // use variable declared in the parent function\n }\n displayName();\n}\ninit();\n```\nclosure는 inner function이 outer function의 scope에 접근할 수 있기 때문에 위의 예제에서 inner function인 displayName()이 outer function인 init()의 local 변수 name을 참조하고 있다.\n\nlexical scoping은 nested 함수에서 변수 이름이 확인되는 방식을 정의한다. inner function은 parent function이 return 되었더라고 parent function의 scope를 가지고 있다. 아래 예제를 보자\n```js\n/* lexical scope (also called static scope)*/\nfunction func() {\n var x = 5;\n function func2() {\n console.log(x);\n }\n func2();\n}\n\nfunc() // print 5\n```\n```js\n/* dynamic scope */\nfunction func() {\n console.log(x)\n}\n\nfunction dummy1() {\n x = 5;\n func();\n}\n\nfunction dummy2() {\n x = 10;\n func();\n}\n\ndummy1() // print 5\ndummy2() // print 10\n```\n첫 번째 예제는 compile-time에 추론할 수 있기 때문에 static이며 두 번째 예제는 outer scope가 dynamic 하고 function의 chain call에 의존하기 때문에 dynamic이라고 불린다.\n\n## Closure\n```js\nfunction makeFunc() {\n var name = 'Mozilla';\n function displayName() {\n alert(name);\n }\n return displayName;\n}\n\nvar myFunc = makeFunc();\nmyFunc();\n```\n위의 예제는 처음의 init() 함수와 같은 효과를 가진다. 차이점은 inner function인 displayName()이 outer function이 실행되기 이전에 return 되었다는 것이다.\n\n다른 programming language에서는 함수의 local variable은 함수가 실행되는 동안에서만 존재한다. makeFunc()가 호출되고 끝난다음에 더 이상 name 변수에 접근하지 못해야 할 것 같지만 JavaScript에서는 그렇지 않다.\n\n그 이유는 JavaScript의 함수가 closure를 형성하기 때문이다. closure란 함수와 lexical environment의 조합이다. 이 environment는 closure가 생설 될 때 scope 내에 있던 모든 local 변수로 구성된다. 위의 경우에, myFunc는 makeFunc가 실행될 때 만들어진 displayName의 instance를 참조한다. displayName의 instance는 name 변수를 가진 lexical environment를 참조하는 것을 유지한다. 이러현 이유로 myFunc가 실행 될 때, name 변수는 사용가능한 상태로 남아있다.\n\nclosure는 매우 유용하다. 왜냐하면 data와 함수를 연결 시켜주기 때문이다. 이것은 data와 하나 또는 여러개의 method와 연결 되어있는 OOP(object-oriented programming)과 똑같다.\n\n결국 closure를 이용하여 OOP의 object로 이용할 수 있다.\n\n## Emulating private methods with closures\nJava와 다르게 JavaScript은 private를 구현하기 위한 native 방법을 제공하지 않는다. 그러나 closure를 통해서 private를 구현할 수 있다.\n\n아래 예제는 [Module Design Pattern](https://www.google.com/search?q=javascript+module+pattern)을 따른다.\n```js\nvar counter = (function() {\n var privateCounter = 0;\n\n function changeBy(val) {\n privateCounter += val;\n }\n\n return {\n increment: function() {\n changeBy(1);\n },\n\n decrement: function() {\n changeBy(-1);\n },\n\n value: function() {\n return privateCounter;\n }\n };\n})();\n\nconsole.log(counter.value()); // 0.\n\ncounter.increment();\ncounter.increment();\nconsole.log(counter.value()); // 2.\n\ncounter.decrement();\nconsole.log(counter.value()); // 1.\n```\n위의 예제에서 counter.increment 와 counter.decrement, counter.value는 같은 lexical environment를 공유하고 있다. \n\n공유된 lexical environment는 선언가 동시에 실행되는 anonymous function([IIFE](https://developer.mozilla.org/en-US/docs/Glossary/IIFE))의 body에 생성되어 있다. lexical environment는 private 변수와 함수를 가지고 있어 anonymous function의 외부에서 접근할 수 없다.\n\n아래는 anonymous function이 아닌 function을 사용한 예제이다\n```js\nvar makeCounter = function() {\n var privateCounter = 0;\n function changeBy(val) {\n privateCounter += val;\n }\n return {\n increment: function() {\n changeBy(1);\n },\n\n decrement: function() {\n changeBy(-1);\n },\n\n value: function() {\n return privateCounter;\n }\n }\n};\n\nvar counter1 = makeCounter();\nvar counter2 = makeCounter();\n\nalert(counter1.value()); // 0.\n\ncounter1.increment();\ncounter1.increment();\nalert(counter1.value()); // 2.\n\ncounter1.decrement();\nalert(counter1.value()); // 1.\nalert(counter2.value()); // 0.\n```\n위의 예제는 closure 보다는 object를 사용하는 것을 추천한다. 위에서 makeCounter() 가 호출될 때마다 increment, decrement, value 함수들이 새로 assign되어 오버헤드가 발생한다. 즉, object의 prototype에 함수들을 선언하고 object를 운용하는 것이 더 효율적이다.\n\n```js\nfunction makeCounter() {\n this.publicCounter = 0;\n}\n\nmakeCounter.prototype = {\n changeBy : function(val) {\n this.publicCounter += val;\n },\n increment : function() {\n this.changeBy(1);\n },\n decrement : function() {\n this.changeBy(-1);\n },\n value : function() {\n return this.publicCounter;\n }\n}\nvar counter1 = new makeCounter();\nvar counter2 = new makeCounter();\n\nalert(counter1.value()); // 0.\n\ncounter1.increment();\ncounter1.increment();\nalert(counter1.value()); // 2.\n\ncounter1.decrement();\nalert(counter1.value()); // 1.\nalert(counter2.value()); // 0.\n```\n\n## Closure Scope Chain\n모든 closure는 3가지 scope를 가지고 있다.\n- Local Scope(Own scope)\n- Outer Functions Scope\n- Global Scope\n\n```js\n// global scope\nvar e = 10;\nfunction sum(a){\n return function(b){\n return function(c){\n // outer functions scope\n return function(d){\n // local scope\n return a + b + c + d + e;\n }\n }\n }\n}\n\nconsole.log(sum(1)(2)(3)(4)); // log 20\n\n// You can also write without anonymous functions:\n\n// global scope\nvar e = 10;\nfunction sum(a){\n return function sum2(b){\n return function sum3(c){\n // outer functions scope\n return function sum4(d){\n // local scope\n return a + b + c + d + e;\n }\n }\n }\n}\n\nvar s = sum(1);\nvar s1 = s(2);\nvar s2 = s1(3);\nvar s3 = s2(4);\nconsole.log(s3) //log 20\n```\n위의 예제를 통해서 closure는 모든 outer function scope를 가진다는 것을 알 수 있다.\n\n## Creating closures in loops: A common mistake\n아래 예제를 보자\n```html\n
Helpful notes will appear here
\nE-mail:
\nName:
\nAge:
\n```\n\n```js\nfunction showHelp(help) {\n document.getElementById('help').textContent = help;\n}\n\nfunction setupHelp() {\n var helpText = [\n {'id': 'email', 'help': 'Your e-mail address'},\n {'id': 'name', 'help': 'Your full name'},\n {'id': 'age', 'help': 'Your age (you must be over 16)'}\n ];\n\n for (var i = 0; i < helpText.length; i++) {\n var item = helpText[i];\n document.getElementById(item.id).onfocus = function() {\n showHelp(item.help);\n }\n }\n}\n\nsetupHelp();\n```\n위의 코드는 정상적으로 동작하지 않는다. 모든 element에서 age의 help text가 보일 것이다. 그 이유는 onfocus가 closure이기 때문이다. closure는 function 선언과 setupHelp의 fucntion scope를 가지고 있다. 3개의 closure를 loop에 의해서 만들어지며 같은 lexical environment를 공유하고 있다. 하지만 item은 var로 선언이 되어있어 hoisting이 일어난다. item.help는 onfocus 함수가 실행될 때 결정되므로 항상 age의 help text가 전달이 된다.\n아래는 해결방법이다.\n\n```js\nfunction showHelp(help) {\n document.getElementById('help').textContent = help;\n}\n\nfunction makeHelpCallback(help) {\n return function() {\n showHelp(help);\n };\n}\n\nfunction setupHelp() {\n var helpText = [\n {'id': 'email', 'help': 'Your e-mail address'},\n {'id': 'name', 'help': 'Your full name'},\n {'id': 'age', 'help': 'Your age (you must be over 16)'}\n ];\n\n for (var i = 0; i < helpText.length; i++) {\n var item = helpText[i];\n document.getElementById(item.id).onfocus = makeHelpCallback(item.help);\n }\n}\n\nsetupHelp();\n```\n하나의 lexical environment를 공유하는 대신 makeHekpCallback 함수가 새로운 lexical environment를 만들었다.\n\n다른 방법으로는 anonymous closure(IIFE)를 이용한다.\n\n```js\nfunction showHelp(help) {\n document.getElementById('help').textContent = help;\n}\n\nfunction setupHelp() {\n var helpText = [\n {'id': 'email', 'help': 'Your e-mail address'},\n {'id': 'name', 'help': 'Your full name'},\n {'id': 'age', 'help': 'Your age (you must be over 16)'}\n ];\n\n for (var i = 0; i < helpText.length; i++) {\n (function() {\n var item = helpText[i];\n document.getElementById(item.id).onfocus = function() {\n showHelp(item.help);\n }\n })(); // Immediate event listener attachment with the current value of item (preserved until iteration).\n }\n}\n\nsetupHelp();\n```\n\nlet keyword를 사용해서 해결할 수 있다.\n```js\nfunction showHelp(help) {\n document.getElementById('help').textContent = help;\n}\n\nfunction setupHelp() {\n var helpText = [\n {'id': 'email', 'help': 'Your e-mail address'},\n {'id': 'name', 'help': 'Your full name'},\n {'id': 'age', 'help': 'Your age (you must be over 16)'}\n ];\n\n for (let i = 0; i < helpText.length; i++) {\n let item = helpText[i];\n document.getElementById(item.id).onfocus = function() {\n showHelp(item.help);\n }\n }\n}\n\nsetupHelp();\n```\n\n## Performane consideration\nclosure가 필요하지 않을 때 closure를 만드는 것은 메모리와 속도에 악영향을 끼친다.\n\n예를들어, 새로운 object/class를 만들 때, method는 object의 생성자 대신에 object의 prototype에 있는 것이 좋다. 왜냐하면 생성자가 호출될 때마다, method는 reassign 되기 때문이다.\n```js\nfunction MyObject(name, message) {\n this.name = name.toString();\n this.message = message.toString();\n this.getName = function() {\n return this.name;\n };\n\n this.getMessage = function() {\n return this.message;\n };\n}\n```\n위의 예제에서 getName과 getMessage는 생성자가 호출될 때마다 reaasign된다.\n```js\nfunction MyObject(name, message) {\n this.name = name.toString();\n this.message = message.toString();\n}\nMyObject.prototype = {\n getName: function() {\n return this.name;\n },\n getMessage: function() {\n return this.message;\n }\n};\n```\nprototype 전부를 다시 재선언하는 것은 추천하지 않는다.\n```js\nfunction MyObject(name, message) {\n this.name = name.toString();\n this.message = message.toString();\n}\nMyObject.prototype.getName = function() {\n return this.name;\n};\nMyObject.prototype.getMessage = function() {\n return this.message;\n};\n```\n" }, { "path": "Language/[Javascript] ES2015+ 요약 정리.md", "content": "# [Javascript] ES2015+ 요약 정리\n\n\n\n
\n\n### ES2015+의 등장\n\n기존의 자바스크립트 문법에 다른 언어의 장점들을 더한 편리한 기능들이 많이 추가되었다. 이 중에 활용도가 높은 부분에 대해서 알아보자.\n\n
\n\n### 1. const, let\n\n---\n\n자바스크립트에서 변수를 선언할 때 var를 이용해왔다. 하지만 이제 var는 `const`와 `let`으로 대체할 것이다.\n\nconst와 let은 함수 스코프를 가지는 var와는 달리 **블록 스코프**를 갖는다.\n\n블록 스코프는 `if, while, for, function` 등에서 사용하는 중괄호에 속하는 범위를 뜻한다. 따라서 const와 let을 이 중괄호 안에서 사용하게 된다면, 그 스코프 범위 안에서만 접근이 가능하다. 이를 통해 호이스팅에 관련된 문제는 자연스럽게 해결할 수 있다.\n\n
\n\n#### *그렇다면 const와 let은 무슨 차이일까?*\n\n간단히 말해서 let은 대입한 값을 계속 수정할 수 있지만, const는 한번 대입하면 다른 값 대입을 할 수 없고 초기화 시 값이 필요다.\n\n\n```javascript\nconst a = 0;\na = 1; // error\n\n\nlet b = 0;\nb = 1; // 1\n\nconst c; // error \n```\n\n
\n\n
\n\n### 2. 템플릿 문자열\n\n---\n\n백틱(`)을 이용해 새로운 문자열을 만들 수 있다.\n\n> 백틱은 키보드에서 `tab키` 위에 있다\n\n
\n\n백틱을 활용해서 문자열 안에 변수도 넣을 수 있게 되었다. 기존에는 변수가 등장할 때마다 따옴표를 닫고 +를 통해 연결했는데 이제 백틱을 활용하면 변수가 포함된 문자열을 한번에 모두 작성이 가능해졌다.\n\n
\n\n```javascript\nvar string = num1 + ' + ' + num2 + ' = ' + result;\n\nconst string = `${num1} + ${num2} = ${result}`;\n```\n\n
\n\n아래가 훨씬 가독성이 좋아졌다. 또한, 백틱 안에 따옴표를 함께 작성하는 것도 가능하다.\n\n
\n\n
\n\n### 3. 객체 리터럴\n\n---\n\n다음 코드는 oldObject 객체에 동적으로 속성을 추가하는 상황이다.\n\n- #### 기존 코드\n\n```javascript\nvar sayNode = function() {\n console.log('Node');\n};\n \nvar es = 'ES';\nvar oldObject = {\n sayJS: function(){\n console.log('JS');\n },\n sayNode: sayNode,\n};\n \noldObject[es + 6] = 'Fantastic';\n \noldObject.sayNode();\noldObject.sayJS();\nconsole.log(oldObject.ES6);\n```\n\n
\n\n이제 위와 같은 코드를 아래처럼 수정할 수 있다.\n\n```javascript\nvar sayNode = function() {\n console.log('Node');\n};\n \nvar es = 'ES';\n \nconst newObject = {\n sayJS() {\n console.log('JS');\n },\n sayNode,\n [es+6]: 'Fantastic',\n};\n \nnewObject.sayNode();\nnewObject.sayJS();\nconsole.log(newObject.ES6);\n```\n\n
\n\noldObject와 newObject를 비교해보자.\n\n객체의 메서드에 함수를 연결할 때 이제 `:`와 같은 콜론과 function을 붙이지 않아도 가능해졌다.\n\n또한 `sayNode : sayNode`와 같이 중복되는 이름의 변수는 그냥 간단히 sayNode 하나만 작성하면 된다.\n\n또한 객체의 속성명을 동적으로 생성이 가능하다. 이전에는 객체 리터럴 바깥에서 [es+6]으로 만들었지만, 이제 객체 리터럴 안에서 만들 수 있는 모습을 확인할 수 있다.\n\n> 코드의 양을 줄이고, 편리하니 익숙해지면 좋다.\n\n
\n\n
\n\n### 4. 화살표 함수\n\n---\n\n기존의 `function {}`도 이전처럼 사용이 가능하지만, ES2015 이후로 화살표 함수가 생기면서 많이 사용되고 있다.\n\n```javascript\nfunction add1(x, y) {\n\treturn x+y;\n}\n\nconst add2 = (x, y) => x + y;\n```\n\n
\n\n두 가지 모두 똑같은 기능을 하는 함수다. 하지만 화살표 함수에서는 function 대신 `=>` 기호로 선언한다. 이는 **return문을 줄일 수 있는 장점**이 있다. 또한 화살표 함수는 **function과 this 바인드 방식에서 차이점**이 존재한다.\n\n
\n\n- #### 기존 코드\n\n```javascript\nvar relationship1 = {\n name: 'kim',\n friends: ['a', 'b', 'c'],\n logFriends: function() {\n var that = this; // relationship1을 가리키는 this를 that에 저장\n \n this.friends.forEach(function(friend){\n console.log(that.name, friend);\n });\n },\n};\nrelationship1.logFriends();\n```\n\n
\n\n`relationship1.logFriends()`에서 forEach문 안에 function 선언문을 사용했다. \n\n이로써 각자 다른 함수 스코프 this를 가지게 되므로 friends 값을 가져오기 위해서 `that`이라는 변수를 만들어 이에 this 값을 미리 저장해놓는 모습이다.\n\n
\n\n```javascript\nconst relationship2 = {\n name: 'kim',\n friends: ['a', 'b', 'c'],\n logFriends() {\n this.friends.forEach(friend => {\n console.log(this.name, friend);\n });\n },\n};\nrelationship2.logFriends();\n```\n\n
\n\n이번에는 forEach문에서 function을 선언하지 않고 화살표 함수를 사용했다. \n\n따라서 바로 바깥 스코프인 `logFriends()`의 **this를 그대로 사용이 가능한 상황**입니다. 이런 상황에서는 function 대신 화살표 함수를 사용하면서 따로 바깥 스코프의 this를 저장해놓고 불러오지 않아도 돼서 편리하다.\n\n
\n\n
\n\n### 5. 비구조화 할당\n\n---\n\n객체나 배열에서 속성 혹은 요소를 꺼내올때 사용한다.\n\n
\n\n- #### 기존 코드\n\n```javascript\nvar candyMachine = {\n status: {\n name: 'node',\n count: 5,\n },\n getCandy: function(){\n return \"Hi\";\n }\n};\n \nvar getCandy = candyMachine.getCandy;\nvar count = candyMachine.status.count;\n```\n\n기존에는 객체에서 속성을 가져올 때 이처럼 작성했다.\n\n
\n\n```javascript\nconst candyMachine1 = {\n status: {\n name: 'node',\n count: 5,\n },\n getCandy1() {\n return \"Hi\";\n }\n};\n \nconst { getCandy1, status: { count } } = candyMachine1;\n\nconsole.log(getCandy1()) // Hi\nconsole.log(count) // 5\n```\n\n하지만 이처럼 간단하게 한 줄로 나타내는 것이 가능해졌다. 여러 단계 안의 속성도 count1을 가져오는 것처럼 작성이 가능하다.\n\n
\n\n이 뿐만 아니라, 배열에서도 마찬가지로 적용이 가능하다.\n\n```javascript\nvar array = ['nodejs', {}, 10, true];\nvar node = array[0];\nvar obj = array[1];\nvar bool = array[array.length - 1];\n```\n\n
\n\narray라는 배열 안에 4가지 요소를 넣고 가져오는 모습을 확인할 수 있다.\n\n
\n\n```javascript\nconst array1 = ['nodejs', {}, 10, true];\nconst [node, obj, , bool] = array1;\n```\n\n
\n\nbool은 true를 가져오기 위해 배열의 마지막 부분에 작성한 걸 볼 수 있다. 이처럼 작성하면 맨 끝이라고 자동으로 인식해주니 상당히 편한 장점이 있다.\n\n
\n\n이처럼 **비구조화 할당**을 이용하면, 배열이 위치마다 변수를 넣어 똑같은 역할을 하도록 만들 수 있다. 코드 줄도 상당히 줄일 수 있고, 특히 `Node.js`에서는 모듈을 사용하기 때문에 이런 방식이 많이 사용된다고 한다.\n\n
\n\n
\n\n### 6. 프로미스(promise)\n\n---\n\n자바스크립트와 Node는 **비동기 프로그래밍으로 이벤트 주도 방식을 활용**하면서 콜백 함수를 많이 사용하게 된다. 콜백 함수 자체가 복잡한 것도 있고, 이해하기 어려운 자바스크립트 내용 중 하나이기도 하다.\n\n
\n\n이에 ES2015부터는 콜백 대신 API들이 프로미스 기반으로 재구성되고 있다. 따라서 프로미스에 대해 잘 이해하고 사용하게 된다면, 복잡한 콜백 함수의 지옥에서 벗어날 수 있으니 확실히 알고 있어야 한다.\n\n
\n\npromise 객체 구조는 아래와 같다.\n\n```javascript\nconst condition = true;\n \nconst promise = new Promise((resolve, reject) => {\n if (condition){\n resolve('성공');\n } else {\n reject('실패');\n }\n});\n \npromise\n .then((message) => {\n console.log(message);\n })\n .catch((error) => {\n console.log(error);\n });\n```\n\n
\n\n`new Promise`로 프로미스를 생성할 수 있다. 그리고 안에 `resolve와 reject`를 매개변수로 갖는 콜백 함수를 넣는 방식이다.\n\n이제 선언한 promise 변수에 `then과 catch` 메서드를 붙이는 것이 가능하다. \n\n```\nresolve가 호출되면 then이 실행되고, reject가 호출되면 catch가 실행된다.\n```\n\n이제 resolve와 reject에 넣어준 인자는 각각 then과 catch의 매개변수에서 받을 수 있게 되었다. \n\n즉, condition이 true가 되면 resolve('성공')이 호출되어 message에 '성공'이 들어가 log로 출력된다. 반대로 false면 reject('실패')가 호출되어 catch문이 실행되고 error에 '실패'가 되어 출력될 것이다.\n\n
\n\n이제 이러한 방식을 활용해 콜백을 프로미스로 바꿔보자.\n\n```javascript\nfunction findAndSaveUser(Users) {\n Users.findOne({}, (err, user) => { // 첫번째 콜백\n if(err) {\n return console.error(err);\n }\n user.name = 'kim';\n user.save((err) => { // 두번째 콜백\n if(err) {\n return console.error(err);\n }\n Users.findOne({gender: 'm'}, (err, user) => { // 세번째 콜백\n // 생략\n });\n });\n });\n}\n```\n\n
\n\n보통 콜백 함수를 사용하는 패턴은 이와 같이 작성할 것이다. **현재 콜백 함수가 세 번 중첩**된 모습을 볼 수 있다.\n\n즉, 콜백 함수가 나올때 마다 코드가 깊어지고 각 콜백 함수마다 에러도 따로 처리해주고 있다.\n\n
\n\n프로미스를 활용하면 아래와 같이 작성이 가능하다.\n\n```javascript\nfunction findAndSaveUser1(Users) {\n Users.findOne({})\n .then((user) => {\n user.name = 'kim';\n return user.save();\n })\n .then((user) => {\n return Users.findOne({gender: 'm'});\n })\n .then((user) => {\n // 생략\n })\n .catch(err => {\n console.error(err);\n });\n}\n```\n\n
\n\n`then`을 활용해 코드가 깊어지지 않도록 만들었다. 이때, then 메서드들은 순차적으로 실행된다. \n\n에러는 마지막 catch를 통해 한번에 처리가 가능하다. 하지만 모든 콜백 함수를 이처럼 고칠 수 있는 건 아니고, `find와 save` 메서드가 프로미스 방식을 지원하기 때문에 가능한 상황이다.\n\n> 지원하지 않는 콜백 함수는 `util.promisify`를 통해 가능하다.\n\n
\n\n프로미스 여러개를 한꺼번에 실행할 수 있는 방법은 `Promise.all`을 활용하면 된다.\n\n```javascript\nconst promise1 = Promise.resolve('성공1');\nconst promise2 = Promise.resolve('성공2');\n \nPromise.all([promise1, promise2])\n .then((result) => {\n console.log(result);\n })\n .catch((error) => {\n console.error(err);\n });\n```\n\n
\n\n`promise.all`에 해당하는 모든 프로미스가 resolve 상태여야 then으로 넘어간다. 만약 하나라도 reject가 있다면, catch문으로 넘어간다.\n\n기존의 콜백을 활용했다면, 여러번 중첩해서 구현했어야하지만 프로미스를 사용하면 이처럼 깔끔하게 만들 수 있다.\n\n
\n\n
\n\n### 7. async/await\n\n---\n\nES2017에 추가된 최신 기능이며, Node에서는 7,6버전부터 지원하는 기능이다. Node처럼 **비동기 프로그래밍을 할 때 유용하게 사용**되고, 콜백의 복잡성을 해결하기 위한 **프로미스를 조금 더 깔끔하게 만들어주는 도움**을 준다.\n\n
\n\n이전에 학습한 프로미스 코드를 가져와보자.\n\n```javascript\nfunction findAndSaveUser1(Users) {\n Users.findOne({})\n .then((user) => {\n user.name = 'kim';\n return user.save();\n })\n .then((user) => {\n return Users.findOne({gender: 'm'});\n })\n .then((user) => {\n // 생략\n })\n .catch(err => {\n console.error(err);\n });\n}\n```\n\n
\n\n콜백의 깊이 문제를 해결하기는 했지만, 여전히 코드가 길긴 하다. 여기에 `async/await` 문법을 사용하면 아래와 같이 바꿀 수 있다.\n\n
\n\n```javascript\nasync function findAndSaveUser(Users) {\n try{\n let user = await Users.findOne({});\n user.name = 'kim';\n user = await user.save();\n user = await Users.findOne({gender: 'm'});\n // 생략\n \n } catch(err) {\n console.error(err);\n } \n}\n```\n\n
\n\n상당히 짧아진 모습을 볼 수 있다.\n\nfunction 앞에 `async`을 붙여주고, 프로미스 앞에 `await`을 붙여주면 된다. await을 붙인 프로미스가 resolve될 때까지 기다린 후 다음 로직으로 넘어가는 방식이다.\n\n
\n\n앞에서 배운 화살표 함수로 나타냈을 때 `async/await`을 사용하면 아래와 같다.\n\n```javascript\nconst findAndSaveUser = async (Users) => {\n try{\n let user = await Users.findOne({});\n user.name = 'kim';\n user = await user.save();\n user = await user.findOne({gender: 'm'});\n } catch(err){\n console.error(err);\n }\n}\n```\n\n
\n\n화살표 함수를 사용하면서도 `async/await`으로 비교적 간단히 코드를 작성할 수 있다. \n\n예전에는 중첩된 콜백함수를 활용한 구현이 당연시 되었지만, 이제 그런 상황에 `async/await`을 적극 활용해 작성하는 연습을 해보면 좋을 것이다.\n\n
\n\n
\n\n#### [참고 자료]\n\n- [링크 - Node.js 도서](http://www.yes24.com/Product/Goods/62597864)\n" }, { "path": "Language/[Javascript] 데이터 타입.md", "content": "\n# 데이터 타입\n\n자바스크립트의 데이터 타입은 크게 Primitive type, Structural Type, Structural Root Primitive 로 나눌 수 있다.\n\n- Primitive type\n - undefined : typeof instance === 'undefined'\n - Boolean : typeof instance === 'boolean'\n - Number : typeof instance === 'number'\n - String : typeof instance === 'string'\n - BitInt : typeof instance === 'bigint'\n - Symbol : typeof instance === 'symbol'\n- Structural Types\n - Object : typeof instance === 'object'\n - Fuction : typeof instance === 'fuction'\n- Structural Root Primitive\n - null : typeof instance === 'obejct'\n\n기본적인 것은 설명하지 않으며, 놓칠 수 있는 부분만 설명하겠다.\n\n### Number Type\n\nECMAScript Specification을 참조하면 number type은 double-precision 64-bit binary 형식을 따른다. \n\n아래 예제를 보자\n\n```jsx\nconsole.log(1 === 1.0); // true\n```\n\n즉 number type은 모두 실수로 처리된다.\n\n### BigInt Type\n\nBigInt type은 number type의 범위를 넘어가는 숫자를 안전하게 저장하고 실행할 수 있게 해준다. BitInt는 n을 붙여 할당할 수 있다.\n\n```jsx\nconst x = 2n ** 53n;\n9007199254740992n\n```\n\n### Symbol Type\n\nSymbol Type은 **unique**하고 **immutable** 하다. 이렇나 특성 때문에 주로 이름이 충돌할 위험이 없는 obejct의 유일한 property key를 만들기 위해서 사용된다.\n\n```jsx\nvar key = Symbol('key');\n\nvar obj = {};\n\nobj[key] = 'test';\n```\n\n## 데이터 타입의 필요성\n\n```jsx\nvar score = 100;\n```\n\n위 코드가 실행되면 자바스크립트 엔진은 아래와 같이 동작한다.\n\n1. score는 특정 주소 addr1를 가르키며 그 값은 undefined 이다.\n2. 자바스크립트 엔진은 100이 number type 인 것을 해석하여 addr1와는 다른 주소 addr2에 8바이트의 메모리 공간을 확보하고 값 100을 저장하며 score는 addr2를 가르킨다. (할당)\n\n만약 값을 참조할려고 할 떄에도 한 번에 읽어야 할 메모리 공간의 크기(바이트 수)를 알아야 한다. 자바스크립트 엔진은 number type의 값이 할당 되어있는 것을 알기 때무네 8바이트 만큼 읽게 된다.\n\n정리하면 데이터 타입이 필요한 이유는 다음과 같다.\n\n- 값을 저장할 때 확보해야 하는 메모리 공간의 크기를 결정하기 위해\n- 값을 참조할 때 한 번에 읽어 들여야 할 메모리 공간의 크기를 결정하기 위해\n- 메모리에서 읽어 들인 2진수를 어떻게 해석할지 결정하기 위해" }, { "path": "Language/[Javasript] Object Prototype.md", "content": "# Object Prototype\nPrototype은 JavaScript object가 다른 object에서 상속하는 매커니즘이다. \n\n## A prototype-based language?\nJavaScript는 종종 prototype-based language로 설명된다. prototype-based language는 상속을 지원하고 object는 prototype object를 갖는다. prototype object는 method와 property를 상속하는 template object 같은 것이다.\n\nobject의 prototype object 또한 prototype object를 가지고 있으며 이것을 **prototype chain** 이라고 부른다.\n\nJavaScript에서 연결은 object instance와 prototype(\\__proto__ 속성 또는 constructor의 prototype 속성) 사이에 만들어진다\n\n## Understanding prototype objects\n아래 예제를 보자.\n```js\nfunction Person(first, last, age, gender, interests) {\n\n // property and method definitions\n this.name = {\n 'first': first,\n 'last' : last\n };\n this.age = age;\n this.gender = gender;\n //...see link in summary above for full definition\n}\n```\n우리는 object instance를 아래와 같이 만들 수 있다.\n```js\nlet person1 = new Person('Bob', 'Smith', 32, 'male', ['music', 'skiing']);\n```\n\nperson1에 있는 method를 부른다면 어떤일이 발생할 것인가?\n```js\nperson1.valueOf()\n```\nvalueOf()를 호출하면\n- 브라우저는 person1 object가 valueOf() method를 가졌는지 확인한다. 즉, 생성자인 Person()에 정의되어 있는지 확인한다.\n- 그렇지 않다면 person1의 prototype object를 확인한다. prototype object에 method가 없다면 prototype object의 prototype object를 확인하며 prototype object가 null이 될 때까지 탐색한다.\n" }, { "path": "Language/[Python] 매크로 라이브러리.md", "content": "# 파이썬 매크로\n\n
\n\n### 설치\n\n```\npip install pyautogui\n\nimport pyautogui as pag\n```\n\n
\n\n### 마우스 명령\n\n마우스 커서 위치 좌표 추출\n\n```python\nx, y = pag.position()\nprint(x, y)\n\npos = pag.position()\nprint(pos) # Point(x=?, y=?)\n```\n\n
\n\n마우스 위치 이동 (좌측 상단 0,0 기준)\n\n```\npag.moveTo(0,0)\n```\n\n현재 마우스 커서 위치 기준 이동\n\n```python\npag.moveRel(1,0) # x방향으로 1픽셀만큼 움직임\n```\n\n
\n\n마우스 클릭\n\n```python\npag.click((100,100))\npag.click(x=100,y=100) # (100,100) 클릭\n\npag.rightClick() # 우클릭\npag.doubleClick() # 더블클릭\n```\n\n
\n\n마우스 드래그\n\n```python\npag.dragTo(x=100, y=100, duration=2) \n# 현재 커서 위치에서 좌표(100,100)까지 2초간 드래그하겠다\n```\n\n> duration 값이 없으면 드래그가 잘 안되는 경우도 있으므로 설정하기\n\n
\n\n### 키보드 명령\n\n글자 타이핑\n\n```python\npag.typewrite(\"ABC\", interval=1)\n# interval은 천천히 글자를 입력할때 사용하기\n```\n\n
\n\n글자 아닌 다른 키보드 누르기\n\n```python\npag.press('enter') # 엔터키\n```\n\n> press 키 네임 모음 : [링크](https://pyautogui.readthedocs.io/en/latest/keyboard.html)\n\n
\n\n보조키 누른 상태 유지 & 떼기\n\n```python\npag.keyDown('shift') # shift 누른 상태 유지\npag.keyUp('shift') # 누르고 있는 shift 떼기\n```\n\n
\n\n많이 쓰는 명령어 함수 사용\n\n```python\npag.hotkey('ctrl', 'c') # ctrl+c\n```\n\n
\n\n
\n\n#### [참고 자료]\n\n- [링크](https://m.blog.naver.com/jsk6824/221765884364)" }, { "path": "Language/[c] C언어 컴파일 과정.md", "content": "### C언어 컴파일 과정\n\n---\n\ngcc를 통해 C언어로 작성된 코드가 컴파일되는 과정을 알아보자\n\n
\n\n
 \n\n이러한 과정을 거치면서, 결과물은 컴퓨터가 이해할 수 있는 바이너리 파일로 만들어진다. 이 파일을 실행하면 주기억장치(RAM)로 적재되어 시스템에서 동작하게 되는 것이다.\n\n
\n\n이러한 과정을 거치면서, 결과물은 컴퓨터가 이해할 수 있는 바이너리 파일로 만들어진다. 이 파일을 실행하면 주기억장치(RAM)로 적재되어 시스템에서 동작하게 되는 것이다.\n\n\n\n1. #### 전처리 과정\n\n - 헤더파일 삽입 (#include 구문을 만나면 헤더파일을 찾아 그 내용을 순차적으로 삽입)\n - 매크로 치환 및 적용 (#define, #ifdef와 같은 전처리기 매크로 치환 및 처리)\n\n
\n\n2. #### 컴파일 과정 (전단부 - 중단부 - 후단부)\n\n - **전단부** (언어 종속적인 부분 처리 - 어휘, 구문, 의미 분석)\n - **중단부** (SSA 기반으로 최적화 수행 - 프로그램 수행 속도 향상으로 성능 높이기 위함)\n - **후단부** (RTS로 아키텍처 최적화 수행 - 더 효율적인 명령어로 대체해서 성능 높이기 위함)\n\n
\n\n3. #### 어셈블 과정\n\n > 컴파일이 끝나면 어셈블리 코드가 됨. 이 코드는 어셈블러에 의해 기계어가 된다.\n\n - 어셈블러로 생성되는 파일은 명령어와 데이터가 들어있는 ELF 바이너리 포맷 구조를 가짐\n (링커가 여러 바이너리 파일을 하나의 실행 파일로 효과적으로 묶기 위해 `명령어와 데이터 범위`를 일정한 규칙을 갖고 형식화 해놓음)\n\n
\n\n4. #### 링킹 과정\n\n > 오브젝트 파일들과 프로그램에서 사용된 C 라이브러리를 링크함\n >\n > 해당 링킹 과정을 거치면 실행파일이 드디어 만들어짐\n\n
\n\n" }, { "path": "Language/[java] Call by value와 Call by reference.md", "content": "## Call by value와 Call by reference\n\n
\n\n상당히 기본적인 질문이지만, 헷갈리기 쉬운 주제다.\n\n
\n\n#### call by value\n\n> 값에 의한 호출\n\n함수가 호출될 때, 메모리 공간 안에서는 함수를 위한 별도의 임시공간이 생성됨\n(종료 시 해당 공간 사라짐)\n\ncall by value 호출 방식은 함수 호출 시 전달되는 변수 값을 복사해서 함수 인자로 전달함\n\n이때 복사된 인자는 함수 안에서 지역적으로 사용되기 때문에 local value 속성을 가짐\n\n```\n따라서, 함수 안에서 인자 값이 변경되더라도, 외부 변수 값은 변경안됨\n```\n\n
\n\n##### 예시\n\n```c++\nvoid func(int n) {\n n = 20;\n}\n\nvoid main() {\n int n = 10;\n func(n);\n printf(\"%d\", n);\n}\n```\n\n> printf로 출력되는 값은 그대로 10이 출력된다.\n\n
\n\n#### call by reference\n\n> 참조에 의한 호출\n\ncall by reference 호출 방식은 함수 호출 시 인자로 전달되는 변수의 레퍼런스를 전달함\n\n따라서 함수 안에서 인자 값이 변경되면, 아규먼트로 전달된 객체의 값도 변경됨\n\n```c++\nvoid func(int *n) {\n *n = 20;\n}\n\nvoid main() {\n int n = 10;\n func(&n);\n printf(\"%d\", n);\n}\n```\n\n> printf로 출력되는 값은 20이 된다.\n\n
\n\n
\n\n#### Java 함수 호출 방식\n\n
\n\n#### 정리\n\nCall by value의 경우, 데이터 값을 복사해서 함수로 전달하기 때문에 원본의 데이터가 변경될 가능성이 없다. 하지만 인자를 넘겨줄 때마다 메모리 공간을 할당해야해서 메모리 공간을 더 잡아먹는다.\n\nCall by reference의 경우 메모리 공간 할당 문제는 해결했지만, 원본 값이 변경될 수 있다는 위험이 존재한다.\n" }, { "path": "Language/[java] Casting(업캐스팅 & 다운캐스팅).md", "content": "## Casting(업캐스팅 & 다운캐스팅)\n\n#### 캐스팅이란?\n\n> 변수가 원하는 정보를 다 갖고 있는 것\n\n```java\nint a = 0.1; // (1) 에러 발생 X\nint b = (int) true; // (2) 에러 발생 O, boolean은 int로 캐스트 불가\n```\n\n(1)은 0.1이 double형이지만, int로 될 정보 또한 가지고 있음\n\n(2)는 true는 int형이 될 정보를 가지고 있지 않음\n\n
\n\n##### 캐스팅이 필요한 이유는?\n\n1. **다형성** : 오버라이딩된 함수를 분리해서 활용할 수 있다.\n2. **상속** : 캐스팅을 통해 범용적인 프로그래밍이 가능하다.\n\n
\n\n##### 형변환의 종류\n\n1. **묵시적 형변환** : 캐스팅이 자동으로 발생 (업캐스팅)\n\n ```java\n Parent p = new Child(); // (Parent) new Child()할 필요가 없음\n ```\n\n > Parent를 상속받은 Child는 Parent의 속성을 포함하고 있기 때문\n\n
\n\n2. **명시적 형변환** : 캐스팅할 내용을 적어줘야 하는 경우 (다운캐스팅)\n\n ```java\n Parent p = new Child();\n Child c = (Child) p;\n ```\n\n > 다운캐스팅은 업캐스팅이 발생한 이후에 작용한다.\n\n
\n\n##### 예시 문제\n\n```java\nclass Parent {\n\tint age;\n\n\tParent() {}\n\n\tParent(int age) {\n\t\tthis.age = age;\n\t}\n\n\tvoid printInfo() {\n\t\tSystem.out.println(\"Parent Call!!!!\");\n\t}\n}\n\nclass Child extends Parent {\n\tString name;\n\n\tChild() {}\n\n\tChild(int age, String name) {\n\t\tsuper(age);\n\t\tthis.name = name;\n\t}\n\n\t@Override \n\tvoid printInfo() {\n\t\tSystem.out.println(\"Child Call!!!!\");\n\t}\n\n}\n\npublic class test {\n public static void main(String[] args) {\n Parent p = new Child();\n \n p.printInfo(); // 문제1 : 출력 결과는?\n Child c = (Child) new Parent(); //문제2 : 에러 종류는?\n }\n}\n```\n\n문제1 : `Child Call!!!!`\n\n> 자바에서는 오버라이딩된 함수를 동적 바인딩하기 때문에, Parent에 담겼어도 Child의 printInfo() 함수를 불러오게 된다.\n\n문제2 : `Runtime Error`\n\n> 컴파일 과정에서는 데이터형의 일치만 따진다. 프로그래머가 따로 (Child)로 형변환을 해줬기 때문에 컴파일러는 문법이 맞다고 생각해서 넘어간다. 하지만 런타임 과정에서 Child 클래스에 Parent 클래스를 넣을 수 없다는 것을 알게 되고, 런타임 에러가 나오게 되는것!\n\n" }, { "path": "Language/[java] Java major feature changes.md", "content": "> Java 버전별 변화 중 중요한 부분만 기록했습니다. 더 자세한건 참고의 링크를 봐주세요.\n\n## Java 8\n\n1. 함수형 프로그래밍 패러다임 적용\n 1. Lambda expression\n 2. Stream\n 3. Functional interface\n 4. Optional\n2. interface 에서 default method 사용 가능\n3. 새로운 Date and Time API\n4. JVM 개선\n 1. JVM 에 의해 크기가 결정되던 Permanent Heap 삭제\n 2. OS 가 자동 조정하는 Native 메모리 영역인 Metaspace 추가\n 3. `Default GC` Serial GC -> Parallel GC (멀티 스레드 방식)\n\n## Java 9\n\n1. module\n2. interface 에서 private method 사용 가능\n3. Collection, Stream, Optional API 사용법 개선\n 1. ex) Immutable collection, Stream.ofNullable(), Optional.orElseGet()\n4. `Default GC` Parallel GC -> G1GC (멀티 프로세서 환경에 적합)\n\n## Java 10\n\n1. var (지역 변수 타입 추론)\n\n## Java 11\n\n1. HTTP Client API\n 1. HTTP/2 지원\n 2. RestTemplate 의 상위 호환\n2. String API 사용법 개선\n3. OracleJDK 독점 기능이 OpenJDK 에 포함\n\n## 참고\n\n- [Java Latest Versions and Features](https://howtodoinjava.com/java-version-wise-features-history/)\n- [JDK 8에서 Perm 영역은 왜 삭제됐을까](https://johngrib.github.io/wiki/java8-why-permgen-removed/)\n- [Java 11 String API Additions](https://www.baeldung.com/java-11-string-api)\n" }, { "path": "Language/[java] Java에서의 Thread.md", "content": "## Java에서의 Thread\n\n
\n\n요즘 OS는 모두 멀티태스킹을 지원한다.\n\n***멀티태스킹이란?***\n\n> 예를 들면, 컴퓨터로 음악을 들으면서 웹서핑도 하는 것\n>\n> 쉽게 말해서 두 가지 이상의 작업을 동시에 하는 것을 말한다.\n\n
\n\n실제로 동시에 처리될 수 있는 프로세스의 개수는 CPU 코어의 개수와 동일한데, 이보다 많은 개수의 프로세스가 존재하기 때문에 모두 함께 동시에 처리할 수는 없다.\n\n각 코어들은 아주 짧은 시간동안 여러 프로세스를 번갈아가며 처리하는 방식을 통해 동시에 동작하는 것처럼 보이게 할 뿐이다.\n\n이와 마찬가지로, 멀티스레딩이란 하나의 프로세스 안에 여러개의 스레드가 동시에 작업을 수행하는 것을 말한다. 스레드는 하나의 작업단위라고 생각하면 편하다.\n\n
\n\n#### 스레드 구현\n\n---\n\n자바에서 스레드 구현 방법은 2가지가 있다.\n\n1. Runnable 인터페이스 구현\n2. Thread 클래스 상속\n\n둘다 run() 메소드를 오버라이딩 하는 방식이다.\n\n
\n\n```java\npublic class MyThread implements Runnable {\n @Override\n public void run() {\n // 수행 코드\n }\n}\n```\n\n
\n\n```java\npublic class MyThread extends Thread {\n @Override\n public void run() {\n // 수행 코드\n }\n}\n```\n\n
\n\n#### 스레드 생성\n\n---\n\n하지만 두가지 방법은 인스턴스 생성 방법에 차이가 있다.\n\nRunnable 인터페이스를 구현한 경우는, 해당 클래스를 인스턴스화해서 Thread 생성자에 argument로 넘겨줘야 한다.\n\n그리고 run()을 호출하면 Runnable 인터페이스에서 구현한 run()이 호출되므로 따로 오버라이딩하지 않아도 되는 장점이 있다.\n\n```java\npublic static void main(String[] args) {\n Runnable r = new MyThread();\n Thread t = new Thread(r, \"mythread\");\n}\n```\n\n
\n\nThread 클래스를 상속받은 경우는, 상속받은 클래스 자체를 스레드로 사용할 수 있다.\n\n또, Thread 클래스를 상속받으면 스레드 클래스의 메소드(getName())를 바로 사용할 수 있지만, Runnable 구현의 경우 Thread 클래스의 static 메소드인 currentThread()를 호출하여 현재 스레드에 대한 참조를 얻어와야만 호출이 가능하다.\n\n```java\npublic class ThreadTest implements Runnable {\n public ThreadTest() {}\n \n public ThreadTest(String name){\n Thread t = new Thread(this, name);\n t.start();\n }\n \n @Override\n public void run() {\n for(int i = 0; i <= 50; i++) {\n System.out.print(i + \":\" + Thread.currentThread().getName() + \" \");\n try {\n Thread.sleep(100);\n } catch (InterruptedException e) {\n e.printStackTrace();\n }\n }\n }\n}\n```\n\n
\n\n#### 스레드 실행\n\n> 스레드의 실행은 run() 호출이 아닌 start() 호출로 해야한다.\n\n***Why?***\n\n우리는 분명 run() 메소드를 정의했는데, 실제 스레드 작업을 시키려면 start()로 작업해야 한다고 한다.\n\nrun()으로 작업 지시를 하면 스레드가 일을 안할까? 그렇지 않다. 두 메소드 모두 같은 작업을 한다. **하지만 run() 메소드를 사용한다면, 이건 스레드를 사용하는 것이 아니다.**\n\n
\n\nJava에는 콜 스택(call stack)이 있다. 이 영역이 실질적인 명령어들을 담고 있는 메모리로, 하나씩 꺼내서 실행시키는 역할을 한다.\n\n만약 동시에 두 가지 작업을 한다면, 두 개 이상의 콜 스택이 필요하게 된다.\n\n**스레드를 이용한다는 건, JVM이 다수의 콜 스택을 번갈아가며 일처리**를 하고 사용자는 동시에 작업하는 것처럼 보여준다.\n\n즉, run() 메소드를 이용한다는 것은 main()의 콜 스택 하나만 이용하는 것으로 스레드 활용이 아니다. (그냥 스레드 객체의 run이라는 메소드를 호출하는 것 뿐이게 되는 것..)\n\nstart() 메소드를 호출하면, JVM은 알아서 스레드를 위한 콜 스택을 새로 만들어주고 context switching을 통해 스레드답게 동작하도록 해준다.\n\n우리는 새로운 콜 스택을 만들어 작업을 해야 스레드 일처리가 되는 것이기 때문에 start() 메소드를 써야하는 것이다!\n\n```\nstart()는 스레드가 작업을 실행하는데 필요한 콜 스택을 생성한 다음 run()을 호출해서 그 스택 안에 run()을 저장할 수 있도록 해준다.\n```\n\n
\n\n#### 스레드의 실행제어\n\n> 스레드의 상태는 5가지가 있다\n\n- NEW : 스레드가 생성되고 아직 start()가 호출되지 않은 상태\n- RUNNABLE : 실행 중 또는 실행 가능 상태\n- BLOCKED : 동기화 블럭에 의해 일시정지된 상태(lock이 풀릴 때까지 기다림)\n- WAITING, TIME_WAITING : 실행가능하지 않은 일시정지 상태\n- TERMINATED : 스레드 작업이 종료된 상태\n\n
\n\n스레드로 구현하는 것이 어려운 이유는 바로 동기화와 스케줄링 때문이다.\n\n스케줄링과 관련된 메소드는 sleep(), join(), yield(), interrupt()와 같은 것들이 있다.\n\nstart() 이후에 join()을 해주면 main 스레드가 모두 종료될 때까지 기다려주는 일도 해준다.\n\n
\n\n
\n\n#### 동기화\n\n멀티스레드로 구현을 하다보면, 동기화는 필수적이다. \n\n동기화가 필요한 이유는, **여러 스레드가 같은 프로세스 내의 자원을 공유하면서 작업할 때 서로의 작업이 다른 작업에 영향을 주기 때문**이다.\n\n스레드의 동기화를 위해선, 임계 영역(critical section)과 잠금(lock)을 활용한다.\n\n임계영역을 지정하고, 임계영역을 가지고 있는 lock을 단 하나의 스레드에게만 빌려주는 개념으로 이루어져있다.\n\n따라서 임계구역 안에서 수행할 코드가 완료되면, lock을 반납해줘야 한다.\n\n
\n\n#### 스레드 동기화 방법\n\n- 임계 영역(critical section) : 공유 자원에 단 하나의 스레드만 접근하도록(하나의 프로세스에 속한 스레드만 가능)\n- 뮤텍스(mutex) : 공유 자원에 단 하나의 스레드만 접근하도록(서로 다른 프로세스에 속한 스레드도 가능)\n- 이벤트(event) : 특정한 사건 발생을 다른 스레드에게 알림\n- 세마포어(semaphore) : 한정된 개수의 자원을 여러 스레드가 사용하려고 할 때 접근 제한\n- 대기 가능 타이머(waitable timer) : 특정 시간이 되면 대기 중이던 스레드 깨움\n\n
\n\n#### synchronized 활용\n\n> synchronized를 활용해 임계영역을 설정할 수 있다.\n\n서로 다른 두 객체가 동기화를 하지 않은 메소드를 같이 오버라이딩해서 이용하면, 두 스레드가 동시에 진행되므로 원하는 출력 값을 얻지 못한다.\n\n이때 오버라이딩되는 부모 클래스의 메소드에 synchronized 키워드로 임계영역을 설정해주면 해결할 수 있다.\n\n```java\n//synchronized : 스레드의 동기화. 공유 자원에 lock\npublic synchronized void saveMoney(int save){ // 입금\n int m = money;\n try{\n Thread.sleep(2000); // 지연시간 2초\n } catch (Exception e){\n\n }\n money = m + save;\n System.out.println(\"입금 처리\");\n\n}\n\npublic synchronized void minusMoney(int minus){ // 출금\n int m = money;\n try{\n Thread.sleep(3000); // 지연시간 3초\n } catch (Exception e){\n\n }\n money = m - minus;\n System.out.println(\"출금 완료\");\n}\n```\n\n
\n\n#### wait()과 notify() 활용 \n\n> 스레드가 서로 협력관계일 경우에는 무작정 대기시키는 것으로 올바르게 실행되지 않기 때문에 사용한다.\n\n- wait() : 스레드가 lock을 가지고 있으면, lock 권한을 반납하고 대기하게 만듬\n\n- notify() : 대기 상태인 스레드에게 다시 lock 권한을 부여하고 수행하게 만듬\n\n이 두 메소드는 동기화 된 영역(임계 영역)내에서 사용되어야 한다.\n\n동기화 처리한 메소드들이 반복문에서 활용된다면, 의도한대로 결과가 나오지 않는다. 이때 wait()과 notify()를 try-catch 문에서 적절히 활용해 해결할 수 있다.\n\n```java\n/**\n* 스레드 동기화 중 협력관계 처리작업 : wait() notify()\n* 스레드 간 협력 작업 강화\n*/\n\npublic synchronized void makeBread(){\n if (breadCount >= 10){\n try {\n System.out.println(\"빵 생산 초과\");\n wait(); // Thread를 Not Runnable 상태로 전환\n } catch (Exception e) {\n\n }\n }\n breadCount++; // 빵 생산\n System.out.println(\"빵을 만듦. 총 \" + breadCount + \"개\");\n notify(); // Thread를 Runnable 상태로 전환\n}\n\npublic synchronized void eatBread(){\n if (breadCount < 1){\n try {\n System.out.println(\"빵이 없어 기다림\");\n wait();\n } catch (Exception e) {\n\n }\n }\n breadCount--;\n System.out.println(\"빵을 먹음. 총 \" + breadCount + \"개\");\n notify();\n}\n```\n\n조건 만족 안할 시 wait(), 만족 시 notify()를 받아 수행한다." }, { "path": "Language/[java] Record.md", "content": "# [Java] Record\n\n
\n\n
 \n\n
\n\n\n\n```\nJava 14에서 프리뷰로 도입된 클래스 타입\n순수히 데이터를 보유하기 위한 클래스\n```\n\n
\n\nJava 14버전부터 도입되고 16부터 정식 스펙에 포함된 Record는 class처럼 타입으로 사용이 가능하다.\n\n객체를 생성할 때 보통 아래와 같이 개발자가 만들어야한다.\n\n
\n\n```java\npublic class Person {\n private final String name;\n private final int age;\n \n public Person(String name, int age) {\n this.name = name;\n this.age = age;\n }\n \n public String getName() {\n return name;\n }\n \n public int getAge() {\n return age;\n }\n}\n```\n\n- 클래스 `Person` 을 만든다. \n- 필드 `name`, `age`를 생성한다.\n- 생성자를 만든다.\n- getter를 구현한다.\n\n
\n\n보통 `Entity`나 `DTO` 구현에 있어서 많이 사용하는 형식이다.\n\n이를 Record 타입의 클래스로 만들면 상당히 단순해진다.\n\n
\n\n```java\npublic record Person(\n\tString name,\n int age\n) {}\n```\n\n
\n\n자동으로 필드를 `private final` 로 선언하여 만들어주고, `생성자`와 `getter`까지 암묵적으로 생성된다. 또한 `equals`, `hashCode`, `toString` 도 자동으로 생성된다고 하니 매우 편리하다.\n\n대신 `getter` 메소드의 경우 구현시 `getXXX()`로 명칭을 짓지만, 자동으로 만들어주는 메소드는 `name()`, `age()`와 같이 필드명으로 생성된다.\n\n
\n\n
\n\n#### [참고 자료]\n\n- [링크](https://coding-start.tistory.com/355)" }, { "path": "Language/[java] Stream.md", "content": "# JAVA Stream\n\n> Java 8버전 이상부터는 Stream API를 지원한다\n\n
\n\n자바에서도 8버전 이상부터 람다를 사용한 함수형 프로그래밍이 가능해졌다.\n\n기존에 존재하던 Collection과 Stream은 무슨 차이가 있을까? 바로 **'데이터 계산 시점'**이다.\n\n##### Collection\n\n- 모든 값을 메모리에 저장하는 자료구조다. 따라서 Collection에 추가하기 전에 미리 계산이 완료되어있어야 한다.\n- 외부 반복을 통해 사용자가 직접 반복 작업을 거쳐 요소를 가져올 수 있다(for-each)\n\n##### Stream\n\n- 요청할 때만 요소를 계산한다. 내부 반복을 사용하므로, 추출 요소만 선언해주면 알아서 반복 처리를 진행한다.\n- 스트림에 요소를 따로 추가 혹은 제거하는 작업은 불가능하다.\n\n> Collection은 핸드폰에 음악 파일을 미리 저장하여 재생하는 플레이어라면, Stream은 필요할 때 검색해서 듣는 멜론과 같은 음악 어플이라고 생각하면 된다.\n\n
\n\n#### 외부 반복 & 내부 반복\n\nCollection은 외부 반복, Stream은 내부 반복이라고 했다. 두 차이를 알아보자.\n\n**성능 면에서는 '내부 반복'**이 비교적 좋다. 내부 반복은 작업을 병렬 처리하면서 최적화된 순서로 처리해준다. 하지만 외부 반복은 명시적으로 컬렉션 항목을 하나씩 가져와서 처리해야하기 때문에 최적화에 불리하다.\n\n즉, Collection에서 병렬성을 이용하려면 직접 `synchronized`를 통해 관리해야만 한다.\n\n
\n\n
 \n\n
\n\n\n\n#### Stream 연산\n\n스트림은 연산 과정이 '중간'과 '최종'으로 나누어진다.\n\n`filter, map, limit` 등 파이프라이닝이 가능한 연산을 중간 연산, `count, collect` 등 스트림을 닫는 연산을 최종 연산이라고 한다.\n\n둘로 나누는 이유는, 중간 연산들은 스트림을 반환해야 하는데, 모두 한꺼번에 병합하여 연산을 처리한 다음 최종 연산에서 한꺼번에 처리하게 된다.\n\nex) Item 중에 가격이 1000 이상인 이름을 5개 선택한다.\n\n```java\nList
\n\n#### Stream 중간 연산\n\n- filter(Predicate) : Predicate를 인자로 받아 true인 요소를 포함한 스트림 반환\n- distinct() : 중복 필터링\n- limit(n) : 주어진 사이즈 이하 크기를 갖는 스트림 반환\n- skip(n) : 처음 요소 n개 제외한 스트림 반환\n- map(Function) : 매핑 함수의 result로 구성된 스트림 반환\n- flatMap() : 스트림의 콘텐츠로 매핑함. map과 달리 평면화된 스트림 반환\n\n> 중간 연산은 모두 스트림을 반환한다.\n\n#### Stream 최종 연산\n\n- (boolean) allMatch(Predicate) : 모든 스트림 요소가 Predicate와 일치하는지 검사\n- (boolean) anyMatch(Predicate) : 하나라도 일치하는 요소가 있는지 검사\n- (boolean) noneMatch(Predicate) : 매치되는 요소가 없는지 검사\n- (Optional) findAny() : 현재 스트림에서 임의의 요소 반환\n- (Optional) findFirst() : 스트림의 첫번째 요소\n- reduce() : 모든 스트림 요소를 처리해 값을 도출. 두 개의 인자를 가짐\n- collect() : 스트림을 reduce하여 list, map, 정수 형식 컬렉션을 만듬 \n- (void) forEach() : 스트림 각 요소를 소비하며 람다 적용\n- (Long) count : 스트림 요소 개수 반환\n\n
\n\n#### Optional 클래스\n\n값의 존재나 여부를 표현하는 컨테이너 Class\n\n- null로 인한 버그를 막을 수 있는 장점이 있다.\n- isPresent() : Optional이 값을 포함할 때 True 반환\n\n
\n\n### Stream 활용 예제\n\n1. map()\n\n ```java\n List
\n\n
\n\n#### [참고자료]\n\n- [링크](https://velog.io/@adam2/JAVA8%EC%9D%98-%EC%8A%A4%ED%8A%B8%EB%A6%BC-%EC%95%8C%EC%95%84%EB%B3%B4%EA%B8%B0)\n- [링크](https://sehoonoverflow.tistory.com/26)" }, { "path": "Language/[java] String StringBuilder StringBuffer 차이.md", "content": "### String, StringBuffer, StringBuilder\n\n----\n\n| 분류 | String | StringBuffer | StringBuilder |\n| ------ | --------- | ------------------------------- | -------------------- |\n| 변경 | Immutable | Mutable | Mutable |\n| 동기화 | | Synchronized 가능 (Thread-safe) | Synchronized 불가능. |\n\n---\n\n#### 1. String 특징\n\n* new 연산을 통해 생성된 인스턴스의 메모리 공간은 변하지 않음 (Immutable)\n* Garbage Collector로 제거되어야 함.\n* 문자열 연산시 새로 객체를 만드는 Overhead 발생\n* 객체가 불변하므로, Multithread에서 동기화를 신경 쓸 필요가 없음. (조회 연산에 매우 큰 장점)\n\n*String 클래스 : 문자열 연산이 적고, 조회가 많은 멀티쓰레드 환경에서 좋음*\n\n
\n\n#### 2. StringBuffer, StringBuilder 특징\n\n- 공통점\n - new 연산으로 클래스를 한 번만 만듬 (Mutable)\n - 문자열 연산시 새로 객체를 만들지 않고, 크기를 변경시킴\n - StringBuffer와 StringBuilder 클래스의 메서드가 동일함.\n- 차이점\n - StringBuffer는 Thread-Safe함 / StringBuilder는 Thread-safe하지 않음 (불가능)\n \n
\n\n*StringBuffer 클래스 : 문자열 연산이 많은 Multi-Thread 환경*\n\n*StringBuilder 클래스 : 문자열 연산이 많은 Single-Thread 또는 Thread 신경 안쓰는 환경*\n" }, { "path": "Language/[java] 자바 가상 머신(Java Virtual Machine).md", "content": "## 자바 가상 머신(Java Virtual Machine)\n\n시스템 메모리를 관리하면서, 자바 기반 애플리케이션을 위해 이식 가능한 실행 환경을 제공함\n\n
\n\n
.jpg\") \n\n
\n\n\n\nJVM은, 다른 프로그램을 실행시키는 것이 목적이다.\n\n갖춘 기능으로는 크게 2가지로 말할 수 있다.\n\n
\n\n1. 자바 프로그램이 어느 기기나 운영체제 상에서도 실행될 수 있도록 하는 것\n2. 프로그램 메모리를 관리하고 최적화하는 것\n\n
\n\n```\nJVM은 코드를 실행하고, 해당 코드에 대해 런타임 환경을 제공하는 프로그램에 대한 사양임\n```\n\n
\n\n개발자들이 말하는 JVM은 보통 `어떤 기기상에서 실행되고 있는 프로세스, 특히 자바 앱에 대한 리소스를 대표하고 통제하는 서버`를 지칭한다.\n\n자바 애플리케이션을 클래스 로더를 통해 읽어들이고, 자바 API와 함께 실행하는 역할. JAVA와 OS 사이에서 중개자 역할을 수행하여 OS에 구애받지 않고 재사용을 가능하게 해준다.\n\n
\n\n#### JVM에서의 메모리 관리\n\n---\n\nJVM 실행에 있어서 가장 일반적인 상호작용은, 힙과 스택의 메모리 사용을 확인하는 것\n\n
\n\n##### 실행 과정\n\n1. 프로그램이 실행되면, JVM은 OS로부터 이 프로그램이 필요로하는 메모리를 할당받음. JVM은 이 메모리를 용도에 따라 여러 영역으로 나누어 관리함\n2. 자바 컴파일러(JAVAC)가 자바 소스코드를 읽고, 자바 바이트코드(.class)로 변환시킴\n3. 변경된 class 파일들을 클래스 로더를 통해 JVM 메모리 영역으로 로딩함\n4. 로딩된 class파일들은 Execution engine을 통해 해석됨\n5. 해석된 바이트 코드는 메모리 영역에 배치되어 실질적인 수행이 이루어짐. 이러한 실행 과정 속 JVM은 필요에 따라 스레드 동기화나 가비지 컬렉션 같은 메모리 관리 작업을 수행함\n\n
\n\n
 \n\n
\n\n\n\n##### 자바 컴파일러\n\n자바 소스코드(.java)를 바이트 코드(.class)로 변환시켜줌\n\n
\n\n##### 클래스 로더\n\nJVM은 런타임시에 처음으로 클래스를 참조할 때 해당 클래스를 로드하고 메모리 영역에 배치시킴. 이 동적 로드를 담당하는 부분이 바로 클래스 로더\n\n
\n\n##### Runtime Data Areas\n\nJVM이 운영체제 위에서 실행되면서 할당받는 메모리 영역임\n\n총 5가지 영역으로 나누어짐 : PC 레지스터, JVM 스택, 네이티브 메서드 스택, 힙, 메서드 영역\n\n(이 중에 힙과 메서드 영역은 모든 스레드가 공유해서 사용함)\n\n**PC 레지스터** : 스레드가 어떤 명령어로 실행되어야 할지 기록하는 부분(JVM 명령의 주소를 가짐)\n\n**스택 Area** : 지역변수, 매개변수, 메서드 정보, 임시 데이터 등을 저장\n\n**네이티브 메서드 스택** : 실제 실행할 수 있는 기계어로 작성된 프로그램을 실행시키는 영역\n\n**힙** : 런타임에 동적으로 할당되는 데이터가 저장되는 영역. 객체나 배열 생성이 여기에 해당함\n\n(또한 힙에 할당된 데이터들은 가비지컬렉터의 대상이 됨. JVM 성능 이슈에서 가장 많이 언급되는 공간임)\n\n**메서드 영역** : JVM이 시작될 때 생성되고, JVM이 읽은 각각의 클래스와 인터페이스에 대한 런타임 상수 풀, 필드 및 메서드 코드, 정적 변수, 메서드의 바이트 코드 등을 보관함\n\n
\n\n
\n\n##### 가비지 컬렉션(Garbage Collection)\n\n자바 이전에는 프로그래머가 모든 프로그램 메모리를 관리했음\n하지만, 자바에서는 `JVM`이 프로그램 메모리를 관리함!\n\nJVM은 가비지 컬렉션이라는 프로세스를 통해 메모리를 관리함. 가비지 컬렉션은 자바 프로그램에서 사용되지 않는 메모리를 지속적으로 찾아내서 제거하는 역할을 함.\n\n**실행순서** : 참조되지 않은 객체들을 탐색 후 삭제 → 삭제된 객체의 메모리 반환 → 힙 메모리 재사용\n\n
" }, { "path": "Language/[java] 자바 컴파일 과정.md", "content": "### 자바 컴파일과정\n\n---\n\n#### 들어가기전\n\n> 자바는 OS에 독립적인 특징을 가지고 있습니다. 그게 가능한 이유는 JVM(Java Vitual Machine) 덕분인데요. 그렇다면 JVM(Java Vitual Machine)의 어떠한 기능 때문에, OS에 독립적으로 실행시킬 수 있는지 자바 컴파일 과정을 통해 알아보도록 하겠습니다.\n\n
 \n\n
\n\n \n\n---\n\n#### 자바 컴파일 순서\n\n1. 개발자가 자바 소스코드(.java)를 작성합니다. \n2. 자바 컴파일러(Java Compiler)가 자바 소스파일을 컴파일합니다. 이때 나오는 파일은 자바 바이트 코드(.class)파일로 아직 컴퓨터가 읽을 수 없는 자바 가상 머신이 이해할 수 있는 코드입니다. 바이트 코드의 각 명령어는 1바이트 크기의 Opcode와 추가 피연산자로 이루어져 있습니다. \n3. 컴파일된 바이트 코드를 JVM의 클래스로더(Class Loader)에게 전달합니다.\n4. 클래스 로더는 동적로딩(Dynamic Loading)을 통해 필요한 클래스들을 로딩 및 링크하여 런타임 데이터 영역(Runtime Data area), 즉 JVM의 메모리에 올립니다.\n - 클래스 로더 세부 동작\n 1. 로드 : 클래스 파일을 가져와서 JVM의 메모리에 로드합니다.\n 2. 검증 : 자바 언어 명세(Java Language Specification) 및 JVM 명세에 명시된 대로 구성되어 있는지 검사합니다.\n 3. 준비 : 클래스가 필요로 하는 메모리를 할당합니다. (필드, 메서드, 인터페이스 등등)\n 4. 분석 : 클래스의 상수 풀 내 모든 심볼릭 레퍼런스를 다이렉트 레퍼런스로 변경합니다.\n 5. 초기화 : 클래스 변수들을 적절한 값으로 초기화합니다. (static 필드)\n5. 실행엔진(Execution Engine)은 JVM 메모리에 올라온 바이트 코드들을 명령어 단위로 하나씩 가져와서 실행합니다. 이때, 실행 엔진은 두가지 방식으로 변경합니다.\n 1. 인터프리터 : 바이트 코드 명령어를 하나씩 읽어서 해석하고 실행합니다. 하나하나의 실행은 빠르나, 전체적인 실행 속도가 느리다는 단점을 가집니다. \n 2. JIT 컴파일러(Just-In-Time Compiler) : 인터프리터의 단점을 보완하기 위해 도입된 방식으로 바이트 코드 전체를 컴파일하여 바이너리 코드로 변경하고 이후에는 해당 메서드를 더이상 인터프리팅 하지 않고, 바이너리 코드로 직접 실행하는 방식입니다. 하나씩 인터프리팅하여 실행하는 것이 아니라 바이트 코드 전체가 컴파일된 바이너리 코드를 실행하는 것이기 때문에 전체적인 실행속도는 인터프리팅 방식보다 빠릅니다.\n\n---\n\nReference (추가로 읽어보면 좋은 자료)\n\n[1] https://steady-snail.tistory.com/67\n\n[2] https://aljjabaegi.tistory.com/387\n\n"
},
{
"path": "Linux/Linux Basic Command.md",
"content": "## 리눅스 기본 명령어\n\n> 실무에서 자주 사용하는 명령어들\n\n
\n\n---\n\n#### 자바 컴파일 순서\n\n1. 개발자가 자바 소스코드(.java)를 작성합니다. \n2. 자바 컴파일러(Java Compiler)가 자바 소스파일을 컴파일합니다. 이때 나오는 파일은 자바 바이트 코드(.class)파일로 아직 컴퓨터가 읽을 수 없는 자바 가상 머신이 이해할 수 있는 코드입니다. 바이트 코드의 각 명령어는 1바이트 크기의 Opcode와 추가 피연산자로 이루어져 있습니다. \n3. 컴파일된 바이트 코드를 JVM의 클래스로더(Class Loader)에게 전달합니다.\n4. 클래스 로더는 동적로딩(Dynamic Loading)을 통해 필요한 클래스들을 로딩 및 링크하여 런타임 데이터 영역(Runtime Data area), 즉 JVM의 메모리에 올립니다.\n - 클래스 로더 세부 동작\n 1. 로드 : 클래스 파일을 가져와서 JVM의 메모리에 로드합니다.\n 2. 검증 : 자바 언어 명세(Java Language Specification) 및 JVM 명세에 명시된 대로 구성되어 있는지 검사합니다.\n 3. 준비 : 클래스가 필요로 하는 메모리를 할당합니다. (필드, 메서드, 인터페이스 등등)\n 4. 분석 : 클래스의 상수 풀 내 모든 심볼릭 레퍼런스를 다이렉트 레퍼런스로 변경합니다.\n 5. 초기화 : 클래스 변수들을 적절한 값으로 초기화합니다. (static 필드)\n5. 실행엔진(Execution Engine)은 JVM 메모리에 올라온 바이트 코드들을 명령어 단위로 하나씩 가져와서 실행합니다. 이때, 실행 엔진은 두가지 방식으로 변경합니다.\n 1. 인터프리터 : 바이트 코드 명령어를 하나씩 읽어서 해석하고 실행합니다. 하나하나의 실행은 빠르나, 전체적인 실행 속도가 느리다는 단점을 가집니다. \n 2. JIT 컴파일러(Just-In-Time Compiler) : 인터프리터의 단점을 보완하기 위해 도입된 방식으로 바이트 코드 전체를 컴파일하여 바이너리 코드로 변경하고 이후에는 해당 메서드를 더이상 인터프리팅 하지 않고, 바이너리 코드로 직접 실행하는 방식입니다. 하나씩 인터프리팅하여 실행하는 것이 아니라 바이트 코드 전체가 컴파일된 바이너리 코드를 실행하는 것이기 때문에 전체적인 실행속도는 인터프리팅 방식보다 빠릅니다.\n\n---\n\nReference (추가로 읽어보면 좋은 자료)\n\n[1] https://steady-snail.tistory.com/67\n\n[2] https://aljjabaegi.tistory.com/387\n\n"
},
{
"path": "Linux/Linux Basic Command.md",
"content": "## 리눅스 기본 명령어\n\n> 실무에서 자주 사용하는 명령어들\n\n\n\n`shutdown`, `halt`, `init 0`, `poweroff` : 시스템 종료 \n\n`reboot`, `init 6`, `shutdown -r now` : 시스템 재부팅 \n\n
\n\n`sudo` : 다른 사용자가 super user권한으로 실행\n\n`su` : 사용자의 권한을 root로 변경\n\n`pwd` : 현재 자신이 위치한 디렉토리\n\n`cd` : 디렉토리 이동 \n\n`ls` : 현재 자신이 속해있는 폴더 내의 파일, 폴더 표시 \n\n`mkdir` : 디렉토리 생성 \n\n`rmdir` : 디렉토리 삭제 \n\n`touch` : 파일 생성 (크기 0) \n\n`cp` : 파일 복사 (디렉토리 내부까지 복사 시, `cp - R`)\n\n`mv` : 파일 이동\n\n`rm` : 파일 삭제 (디렉토리 삭제 시에는 보통 `rm -R`을 많이 사용)\n\n`cat` : 파일의 내용을 화면에 출력 \n\n`more` : 화면 단위로 보기 쉽게 내용 출력 \n\n`less` : more보다 조금 더 보기 편함 \n\n`find` : 특정한 파일을 찾는 명령어\n\n`grep` : 특정 패턴으로 파일을 찾는 명령어 \n\n`>>` : 리다이렉션 (파일 끼워넣기 등)\n\n`file` : 파일 종류 확인 \n\n`which` : 특정 명령어의 위치 찾음 \n\n\n
\n\n`ping` : 네트워크 상태 점검 및 도메인 IP 확인\n\n`ifconfig` : 리눅스 IP 확인 및 설정\n\n`netstat` : 네트워크의 상태\n\n`nbstat` : IP 충돌 시, 충돌된 컴퓨터를 찾기 위함\n\n`traceroute` : 알고 싶은 목적지까지 경로를 찾아줌\n\n`route` : 라우팅 테이블 구성 상태 \n\n`clock` : 시간 조절 명령어\n\n`date` : 시간, 날짜 출력 및 시간과 날짜 변경 \n\n
\n\n`rpm` : rpm 패키지 설치, 삭제 및 관리 \n\n`yum` : rpm보다 더 유용함 (다른 필요한 rpm 패키기지까지 알아서 다운로드)\n\n`free` : 시스템 메모리의 정보 출력 \n\n`ps` : 현재 실행되고 있는 프로세스 목록 출력\n\n`pstree` : 트리 형식으로 출력 \n\n`top` : 리눅스 시스템의 운용 상황을 실시간으로 모니터링 가능\n\n`kill` : 특정 프로세스에 특정 signal을 보냄 \n\n`killall` : 특정 프로세스 모두 종료\n\n`killall5` : 모든 프로세스 종료 (사용X)\n\n
\n\n`tar`, `gzip` 등 : 압축 파일 묶거나 품\n\n`chmod` : 파일 or 디렉토리 권한 수정 \n\n`chown` : 파일 or 디렉토리 소유자, 소유 그룹 수정 \n\n`chgrp` : 파일 or 디렉토리 소유 그룹 수정 \n\n`umask` : 파일 생성시의 권한 값을 변경\n\n`at` : 정해진 시간에 하나의 작업만 수행 \n\n`crontab` : 반복적인 작업을 수행 (디스크 최적화를 위한 반복적 로그 파일 삭제 등에 활용) \n\n
\n\n`useradd` : 새로운 사용자 계정 생성 \n\n`password` : 사용자 계정의 비밀번호 설정\n\n`userdel` : 사용자 계정 삭제 \n\n`usermod` : 사용자 계정 수정 \n\n`groupadd` : 그룹 생성\n\n`groupdel` : 그룹 삭제 \n\n`groups` : 그룹 확인 \n\n`newgrp` : 자신이 속한 그룹 변경 \n\n`mesg` : 메시지 응답 가능 및 불가 설정 \n\n`talk` : 로그인한 사용자끼리 대화 \n\n`wall` : 시스템 로그인한 모든 사용자에게 메시지 전송\n\n`write` : 로그인한 사용자에게 메시지 전달\n\n`dd` : 블럭 단위로 파일을 복사하거나 변환\n\n
\n\n
\n\n
\n\n##### [참고 자료]\n\n- [링크](https://vaert.tistory.com/103)\n\n " }, { "path": "Linux/Permission.md", "content": "## 퍼미션(Permisson) 활용\n\n
\n\n리눅스의 모든 파일과 디렉토리는 퍼미션들의 집합으로 구성되어있다.\n\n이러한 Permission은 시스템에 대한 읽기, 쓰기, 실행에 대한 접근 여부를 결정한다. (`ls -l`로 확인 가능)\n\n퍼미션은, 다중 사용자 환경을 제공하는 리눅스에서는 가장 기초적인 보안 방법이다.\n\n
\n\n1. #### 접근 통제 기법\n\n - ##### DAC (Discretionary Access Control)\n\n 객체에 대한 접근을 사용자 개인 or 그룹의 식별자를 기반으로 제어하는 방법\n\n > 운영체제 (윈도우, 리눅스)\n\n - ##### MAC (Mandotory Access Control)\n\n 모든 접근 제어를 관리자가 설정한대로 제어되는 방법\n\n > 관리자에 의한 강제적 접근 제어\n\n - ##### RBAC (Role Based Access Control)\n\n 관리자가 사용자에게는 특정한 역할을 부여하고, 각 역할마다 권리와 권한을 설정\n\n > 역할 기반 접근 제어\n\n
\n\n2. #### 퍼미션 카테고리\n\n
 \n\n > r : 읽기 / w : 쓰기 / x : 실행 / - : 권한 없음\n\n ex) `-rwxrw-r--. 1 root root 2104 1월 20 06:30 passwd`\n\n - `-rwx` : 소유자\n - `rw-` : 관리 그룹\n - `r--.` : 나머지\n - `1` : 링크 수\n - `root` : 소유자\n - `root` : 관리 그룹\n - `2104` : 파일크기\n - `1월 20 06:30` : 마지막 변경 날짜/시간\n - `passwd` : 파일 이름\n\n
\n\n > r : 읽기 / w : 쓰기 / x : 실행 / - : 권한 없음\n\n ex) `-rwxrw-r--. 1 root root 2104 1월 20 06:30 passwd`\n\n - `-rwx` : 소유자\n - `rw-` : 관리 그룹\n - `r--.` : 나머지\n - `1` : 링크 수\n - `root` : 소유자\n - `root` : 관리 그룹\n - `2104` : 파일크기\n - `1월 20 06:30` : 마지막 변경 날짜/시간\n - `passwd` : 파일 이름\n\n \n\n3. #### 퍼미션 모드\n\n ##### 1) 심볼릭 모드\n\n
 \n\n
\n\n  \n\n 명령어 : `chmod [권한] [파일 이름]`\n\n > 그룹(g)에게 실행 권한(x)를 더할 경우\n >\n > `chmod g+x`\n\n
\n\n 명령어 : `chmod [권한] [파일 이름]`\n\n > 그룹(g)에게 실행 권한(x)를 더할 경우\n >\n > `chmod g+x`\n\n \n\n ##### 2) 8진수 모드\n\n chmod 숫자 표기법은, 0~7까지의 8진수 조합을 사용자(u), 그룹(g), 기타(o)에 맞춰 숫자로 표기하는 것이다.\n\n > r = 4 / w = 2 / x = 1 / - = 0\n\n
 \n\n
\n\n \n \n
\n \n ##### [참고 자료]\n \n - [링크](http://cocotp10.blogspot.com/2018/01/linux-centos7.html)\n\n" }, { "path": "Linux/Von Neumann Architecture.md", "content": "## 폰 노이만 구조\n\n> 존 폰 노이만이 고안한 내장 메모리 순차처리 방식\n\n
\n\n프로그램과 데이터를 하나의 메모리에 저장하여 사용하는 방식\n\n데이터는 메모리에 읽거나 쓰는 것이 가능하지만, 명령어는 메모리에서 읽기만 가능하다.\n\n
\n\n
 \n\n
\n\n\n\n즉, CPU와 하나의 메모리를 사용해 처리하는 현대 범용 컴퓨터들이 사용하는 구조 모델이다.\n\n
\n\n##### 장점\n\n하드웨어를 재배치할 필요없이 프로그램(소프트웨어)만 교체하면 된다. (범용성 향상)\n\n##### 단점\n\n메모리와 CPU를 연결하는 버스는 하나이므로, 폰 노이만 구조는 순차적으로 정보를 처리하기 때문에 '고속 병렬처리'에는 부적합하다.\n\n> 이를 폰 노이만 병목현상이라고 함\n\n
\n\n폰 노이만 구조는 순차적 처리이기 때문에 CPU가 명령어를 읽음과 동시에 데이터를 읽지는 못하는 문제가 있는 것이다.\n\n이를 해결하기 위해 대안으로 하버드 구조가 있다고 한다." }, { "path": "New Technology/AI/Linear regression 실습.md", "content": "### [딥러닝] Tensorflow로 간단한 Linear regression 알고리즘 구현\n\n
\n\n시험 점수를 예상해야 할 때 (0~100) > regression을 사용\n\nregression을 사용하는 예제를 살펴보자\n\n
\n\n
\n\n여러 x와 y 값을 가지고 그래프를 그리며 가장 근접하는 선형(Linear)을 찾아야 한다.\n\n이 선형을 통해서 앞으로 사용자가 입력하는 x 값에 해당하는 가장 근접한 y 값을 출력해낼 수 있는 것이다.\n\n
 \n\n
\n\n\n\n현재 파란 선이 가설 H(x)에 해당한다.\n\n실제 입력 값들 (1,1) (2,2) (3,3)과 선의 거리를 비교해서 근접할수록 좋은 가설을 했다고 말할 수 있다.\n\n
\n\n
\n\n이를 찾기 위해서 Hypothesis(가설)을 세워 cost(비용)을 구해 W와 b의 값을 도출해야 한다.\n\n
\n\n#### **Linear regression 알고리즘의 최종 목적 : cost 값을 최소화하는 W와 b를 찾자**\n\n
\n\n
 \n\n- H(x) : 가설\n\n- cost(W,b) : 비용\n\n- W : weight\n\n- b : bias\n\n- m : 데이터 개수\n\n- H(x^(i)) : 예측 값\n\n- y^(i) : 실제 값\n\n
\n\n- H(x) : 가설\n\n- cost(W,b) : 비용\n\n- W : weight\n\n- b : bias\n\n- m : 데이터 개수\n\n- H(x^(i)) : 예측 값\n\n- y^(i) : 실제 값\n\n\n\n**(예측값 - 실제값)의 제곱을 하는 이유는?**\n\n> 양수가 나올 수도 있고, 음수가 나올 수도 있다. 또한 제곱을 하면, 거리가 더 먼 결과일 수록 값은 더욱 커지게 되어 패널티를 더 줄 수 있는 장점이 있다.\n\n
\n\n
 \n\n이제 실제로, 파이썬을 이용해서 Linear regression을 구현해보자\n\n
\n\n이제 실제로, 파이썬을 이용해서 Linear regression을 구현해보자\n\n\n\n
\n\n#### **미리 x와 y 값을 주었을 때**\n\n```python\nimport tensorflow as tf\n \n# X and Y data\nx_train = [1, 2, 3]\ny_train = [1, 2, 3]\n \nW = tf.Variable(tf.random_normal([1]), name='weight')\nb = tf.Variable(tf.random_normal([1]), name='bias')\n \n# Our hypothesis XW+b\nhypothesis = x_train * W + b // 가설 정의\n \n# cost/loss function\ncost = tf.reduce_mean(tf.square(hypothesis - y_train))\n \n#Minimize\noptimizer = tf.train.GradientDescentOptimizer(learning_rate=0.01)\ntrain = optimizer.minimize(cost)\n \n# Launch the graph in a session.\nsess = tf.Session()\n \n# Initializes global variables in the graph.\nsess.run(tf.global_variables_initializer())\n \n# Fit the line\nfor step in range(2001):\n sess.run(train)\n if step % 20 == 0:\n print(step, sess.run(cost), sess.run(W), sess.run(b))\n```\n\n
\n\n
 \n\n```\nx_train = [1, 2, 3]\ny_train = [1, 2, 3]\n```\n\n
\n\n```\nx_train = [1, 2, 3]\ny_train = [1, 2, 3]\n```\n\n\n\n2000번 돌린 결과, [W = 1, b = 0]으로 수렴해가고 있는 것을 알 수 있다.\n\n따라서, `H(x) = (1)x + 0`로 표현이 가능하다.\n\n
\n\n
\n\n```\noptimizer = tf.train.GradientDescentOptimizer(learning_rate=0.01)\n```\n\n
\n\n**최소화 과정에서 나오는 learning_rate는 무엇인가?**\n\nGradientDescent는 Cost function이 최소값이 되는 최적의 해를 찾는 과정을 나타낸다.\n\n이때 다음 point를 어느 정도로 옮길 지 결정하는 것을 learning_rate라고 한다.\n\n
\n\n**learning rate를 너무 크게 잡으면?**\n\n- 최적의 값으로 수렴하지 않고 발산해버리는 경우가 발생(Overshooting)\n\n
\n\n**learning rate를 너무 작게 잡으면?**\n\n- 수렴하는 속도가 너무 느리고, local minimum에 빠질 확률 증가\n\n
\n\n> 보통 learning_rate는 0.01에서 0.5를 사용하는 것 같아보인다.\n\n
\n\n
\n\n#### placeholder를 이용해서 실행되는 값을 나중에 던져줄 때\n\n```python\nimport tensorflow as tf\n \nW = tf.Variable(tf.random_normal([1]), name='weight')\nb = tf.Variable(tf.random_normal([1]), name='bias')\n \nX = tf.placeholder(tf.float32, shape=[None])\nY = tf.placeholder(tf.float32, shape=[None])\n \n# Our hypothesis XW+b\nhypothesis = X * W + b\n# cost/loss function\ncost = tf.reduce_mean(tf.square(hypothesis - Y))\n#Minimize\noptimizer = tf.train.GradientDescentOptimizer(learning_rate=0.01)\ntrain = optimizer.minimize(cost)\n \n# Launch the graph in a session.\nsess = tf.Session()\n# Initializes global variables in the graph.\nsess.run(tf.global_variables_initializer())\n \n# Fit the line\nfor step in range(2001):\n cost_val, W_val, b_val, _ = sess.run([cost, W, b, train],\n feed_dict = {X: [1, 2, 3, 4, 5],\n Y: [2.1, 3.1, 4.1, 5.1, 6.1]})\n if step % 20 == 0:\n print(step, cost_val, W_val, b_val)\n```\n\n
\n\n
 \n\n```\nfeed_dict = {X: [1, 2, 3, 4, 5],\n Y: [2.1, 3.1, 4.1, 5.1, 6.1]})\n```\n\n2000번 돌린 결과, [W = 1, b = 1.1]로 수렴해가고 있는 것을 알 수 있다.\n\n즉, `H(x) = (1)x + 1.1`로 표현이 가능하다.\n\n
\n\n```\nfeed_dict = {X: [1, 2, 3, 4, 5],\n Y: [2.1, 3.1, 4.1, 5.1, 6.1]})\n```\n\n2000번 돌린 결과, [W = 1, b = 1.1]로 수렴해가고 있는 것을 알 수 있다.\n\n즉, `H(x) = (1)x + 1.1`로 표현이 가능하다.\n\n\n\n
\n\n이 구현된 모델을 통해 x값을 입력해서 도출되는 y값을 아래와 같이 알아볼 수 있다.\n\n
 "
},
{
"path": "New Technology/AI/README.md",
"content": "### **AI/ML 용어 정리**\n\n---\n\n- **머신러닝:** 인공 지능의 한 분야로, 컴퓨터가 학습할 수 있도록 하는 알고리즘과 기술을 개발하는 분야입니다.\n- **데이터 마이닝:** 정형화된 데이터를 중심으로 분석하고 이해하고 예측하는 분야입니다.\n- **지도학습 (Supervised learning):** 정답을 주고 학습시키는 머신러닝의 방법론. 대표적으로 regression과 classification이 있습니다.\n- **비지도학습 (Unsupervised learning):** 정답이 없는 데이터가 어떻게 구성되었는지를 알아내는 머신러닝의 학습 방법론. 지도 학습 혹은 강화 학습과는 달리 입력값에 대한 목표치가 주어지지 않습니다.\n- **강화학습 (Reinforcement Learning):** 설정된 환경속에 보상을 주며 학습하는 머신러닝의 학습 방법론입니다.\n- **Representation Learning:** 부분적인 특징을 찾는 것이 아닌 하나의 뉴럴 넷 모델로 전체의 특징을 학습하는 것을 의미합니다.\n- **선형 회귀 (Linear Regression):** 종속 변수 y와 한개 이상의 독립 변수 x와의 선형 상관 관계를 모델링하는 회귀분석 기법입니다. ([위키링크](https://ko.wikipedia.org/wiki/선형_회귀))\n- **자연어처리 (NLP):** 인간의 언어 형상을 컴퓨터와 같은 기계를 이용해서 모사 할 수 있도록 연구하고 이를 구현하는 인공지능의 주요 분야 중 하나입니다. ([위키링크](https://ko.wikipedia.org/wiki/자연어_처리))\n- **학습 데이터 (Training data):** 모델을 학습시킬 때 사용할 데이터입니다. 학습데이터로 학습 후 모델의 여러 파라미터들을 결정합니다.\n- **테스트 데이터 (Test data):** 실제 학습된 모델을 평가하는데 사용되는 데이터입니다.\n- **정밀도와 재현율 (precision / recall):** binary classification을 사용하는 분야에서, 정밀도는 모델이 추출한 내용 중 정답의 비율이고, 재현율은 정답 중 모델이 추출한 내용의 비율입니다.([위키링크](https://ko.wikipedia.org/wiki/정밀도와_재현율))\n\n빅데이터는 많은 양의 데이터를 분석하고, 이해하고, 예측하는 것. 이를 활용하는 다양한 방법론 중에 가장 많이 사용하고 있는 것이 '머신러닝'이다.\n\n데이터 마이닝은 구조화된 데이터를 활용함. 머신러닝은 이와는 다르게 비구조화 데이터를 활용하는게 주목적\n\n머신러닝은 AI의 일부분. 사람처럼 지능적인 컴퓨터를 만드는 방법 중의 하나. 데이터에 의존하고 통계적으로 분석해서 만드는 방법이 머신러닝이라고 정의할 수 있음\n\n통계학들이 수십년간 만들어놓은 통계와 데이터들을 적용시킨다. 통계학보다 훨씬 데이터 양이 많고, 노이즈도 많을 때 머신러닝의 기법을 통해 한계를 극복해나감\n\n\n\n머신러닝에서 다루는 기본적인 문제들\n\n- 지도 학습\n- 비지도 학습\n- 강화 학습\n"
},
{
"path": "New Technology/Big Data/DBSCAN 클러스터링 알고리즘.md",
"content": "## DBSCAN 클러스터링 알고리즘\n\n> 여러 클러스터링 알고리즘 中 '밀도 방식'을 사용\n\nK-Means나 Hierarchical 클러스터링처럼 군집간의 거리를 이용해 클러스터링하는 방법이 아닌, 점이 몰려있는 **밀도가 높은 부분으로 클러스터링 하는 방식**이다.\n\n`반경과 점의 수`로 군집을 만든다.\n\n
"
},
{
"path": "New Technology/AI/README.md",
"content": "### **AI/ML 용어 정리**\n\n---\n\n- **머신러닝:** 인공 지능의 한 분야로, 컴퓨터가 학습할 수 있도록 하는 알고리즘과 기술을 개발하는 분야입니다.\n- **데이터 마이닝:** 정형화된 데이터를 중심으로 분석하고 이해하고 예측하는 분야입니다.\n- **지도학습 (Supervised learning):** 정답을 주고 학습시키는 머신러닝의 방법론. 대표적으로 regression과 classification이 있습니다.\n- **비지도학습 (Unsupervised learning):** 정답이 없는 데이터가 어떻게 구성되었는지를 알아내는 머신러닝의 학습 방법론. 지도 학습 혹은 강화 학습과는 달리 입력값에 대한 목표치가 주어지지 않습니다.\n- **강화학습 (Reinforcement Learning):** 설정된 환경속에 보상을 주며 학습하는 머신러닝의 학습 방법론입니다.\n- **Representation Learning:** 부분적인 특징을 찾는 것이 아닌 하나의 뉴럴 넷 모델로 전체의 특징을 학습하는 것을 의미합니다.\n- **선형 회귀 (Linear Regression):** 종속 변수 y와 한개 이상의 독립 변수 x와의 선형 상관 관계를 모델링하는 회귀분석 기법입니다. ([위키링크](https://ko.wikipedia.org/wiki/선형_회귀))\n- **자연어처리 (NLP):** 인간의 언어 형상을 컴퓨터와 같은 기계를 이용해서 모사 할 수 있도록 연구하고 이를 구현하는 인공지능의 주요 분야 중 하나입니다. ([위키링크](https://ko.wikipedia.org/wiki/자연어_처리))\n- **학습 데이터 (Training data):** 모델을 학습시킬 때 사용할 데이터입니다. 학습데이터로 학습 후 모델의 여러 파라미터들을 결정합니다.\n- **테스트 데이터 (Test data):** 실제 학습된 모델을 평가하는데 사용되는 데이터입니다.\n- **정밀도와 재현율 (precision / recall):** binary classification을 사용하는 분야에서, 정밀도는 모델이 추출한 내용 중 정답의 비율이고, 재현율은 정답 중 모델이 추출한 내용의 비율입니다.([위키링크](https://ko.wikipedia.org/wiki/정밀도와_재현율))\n\n빅데이터는 많은 양의 데이터를 분석하고, 이해하고, 예측하는 것. 이를 활용하는 다양한 방법론 중에 가장 많이 사용하고 있는 것이 '머신러닝'이다.\n\n데이터 마이닝은 구조화된 데이터를 활용함. 머신러닝은 이와는 다르게 비구조화 데이터를 활용하는게 주목적\n\n머신러닝은 AI의 일부분. 사람처럼 지능적인 컴퓨터를 만드는 방법 중의 하나. 데이터에 의존하고 통계적으로 분석해서 만드는 방법이 머신러닝이라고 정의할 수 있음\n\n통계학들이 수십년간 만들어놓은 통계와 데이터들을 적용시킨다. 통계학보다 훨씬 데이터 양이 많고, 노이즈도 많을 때 머신러닝의 기법을 통해 한계를 극복해나감\n\n\n\n머신러닝에서 다루는 기본적인 문제들\n\n- 지도 학습\n- 비지도 학습\n- 강화 학습\n"
},
{
"path": "New Technology/Big Data/DBSCAN 클러스터링 알고리즘.md",
"content": "## DBSCAN 클러스터링 알고리즘\n\n> 여러 클러스터링 알고리즘 中 '밀도 방식'을 사용\n\nK-Means나 Hierarchical 클러스터링처럼 군집간의 거리를 이용해 클러스터링하는 방법이 아닌, 점이 몰려있는 **밀도가 높은 부분으로 클러스터링 하는 방식**이다.\n\n`반경과 점의 수`로 군집을 만든다.\n\n\n\n
 \n\n
\n\n\n\n반경 Epsilon과 최소 점의 수인 minpts를 정한다.\n\n하나의 점에서 Epsilon 안에 존재하는 점의 수를 센다. 이때, 반경 안에 속한 점이 minpts로 정한 수 이상이면 해당 점은 'core point'라고 부른다.\n\n
 \n\n> 현재 점 P에서 4개 이상의 점이 속했기 때문에, P는 core point다.\n\n
\n\n> 현재 점 P에서 4개 이상의 점이 속했기 때문에, P는 core point다.\n\n\n\nCore point에 속한 점들부터 또 Epsilon을 확인하여 체크한다. (DFS 활용)\n\n이때 4개 미만의 점이 속하게 되면, 해당 점은 'border point'라고 부른다.\n\n
 \n\n> P2는 Epsilon 안에 3개의 점만 존재하므로 minpts = 4 미만이기 때문에 border point이다.\n\n보통 이와 같은 border point는 군집화를 마쳤을 때 클러스터의 외곽에 해당한다. (해당 점에서는 확장되지 않게되기 때문)\n\n
\n\n> P2는 Epsilon 안에 3개의 점만 존재하므로 minpts = 4 미만이기 때문에 border point이다.\n\n보통 이와 같은 border point는 군집화를 마쳤을 때 클러스터의 외곽에 해당한다. (해당 점에서는 확장되지 않게되기 때문)\n\n\n\n마지막으로, 하나의 점에서 Epslion을 확인했을 때 어느 집군에도 속하지 않는 점들이 있을 것이다. 이러한 점들을 outlier라고 하고, 'noise point'에 해당한다.\n\n
 \n\n> P4는 반경 안에 속하는 점이 아무도 없으므로 noise point다.\n\nDBSCAN 알고리즘은 이와 같이 군집에 포함되지 않는 아웃라이어 검출에 효율적이다.\n\n
\n\n> P4는 반경 안에 속하는 점이 아무도 없으므로 noise point다.\n\nDBSCAN 알고리즘은 이와 같이 군집에 포함되지 않는 아웃라이어 검출에 효율적이다.\n\n\n\n
\n\n전체적으로 DBSCAN 알고리즘을 적용한 점들은 아래와 같이 구성된다.\n\n
 \n\n
\n\n\n\n##### 정리\n\n초반에 지정한 Epsilon 반경 안에 minpts 이상의 점으로 구성된다면, 해당 점을 중심으로 군집이 형성되고, core point로 지정한다. core point가 서로 다른 core point 군집의 일부가 되면 서로 연결되어 하나의 군집이 형성된다.\n\n이때 군집에는 속해있지만 core point가 아닌 점들을 border point라고 하며, 아무곳에도 속하지 않는 점은 noise point가 된다.\n\n
\n\n
\n\n#### DBSCAN 장점\n\n- 클러스터의 수를 미리 정하지 않아도 된다.\n\n > K-Means 알고리즘처럼 미리 점을 지정해놓고 군집화를 하지 않아도 된다.\n\n- 다양한 모양과 크기의 클러스터를 얻는 것이 가능하다.\n\n- 모양이 기하학적인 분포라도, 밀도 여부에 따라 군집도를 찾을 수 있다.\n\n- 아웃라이어 검출을 통해 필요하지 않은 noise 데이터를 검출하는 것이 가능하다.\n\n
\n\n#### DBSCAN 단점\n\n- Epslion에 너무 민감하다.\n\n > 반경으로 설정한 값에 상당히 민감하게 작용된다. 따라서 DBSCAN 알고리즘을 사용하려면 적절한 Epsilon 값을 설정하는 것이 중요하다.\n\n
\n\n
\n\n##### [참고 자료]\n\n[링크](
\n\n#### 데이터 분석\n\n스칼라 : 하나의 값을 가진 변수 `a = 'hello'`\n\n벡터 : 여러 값을 가진 변수 `b = ['hello', 'world']`\n\n> 데이터 분석은 주로 '벡터'를 다루고, DataFrame의 변수도 벡터\n\n이런 '벡터'를 pandas에서는 Series라고 부르고, numpy에서는 ndarray라 부름\n\n
\n\n##### 파이썬에서 제공하는 벡터 다루는 함수들\n\n```\n>>> all([1, 1, 1]) #벡터 데이터 모두 True면 True 반환\n>>> any([1,0,0]) #한 개라도 True면 True 반환\n>>> max([1,2,3]) #가장 큰 값을 반환한다.\n>>> min([1,2,3]) #가장 작은 값을 반환한다.\n>>> list(range(10)) #0부터 10까지 순열을 만듬\n>>> list(range(3,6)) #3부터 5까지 순열을 만듬\n>>> list(range(1, 6, 2)) #1부터 6까지 2단위로 순열을 만듬\n```\n\n
\n\n
\n\n#### pandas\n\n```python\nimport pandas as pd #pandas import\ndf = pd.read_csv(\"data.csv\") #csv파일 불러오기\n```\n\n
 \n\n
\n\n\n\n다양한 함수를 활용해서 데이터를 관측할 수 있다.\n\n```python\ndf.head() #맨 앞 5개를 보여줌\ndf.tail() #맨 뒤 5개를 보여줌\ndf[0:2] #특정 관측치 슬라이싱\ndf.columns #변수명 확인\ndf.describe() #count, mean(평균), std(표준편차), min, max\n```\n\n
 \n\n
\n\n\n\n##### 특정 변수 기준 그룹 통계값\n\n```python\n# column1 변수별로 column2 평균 값 구하기\ndf.groupby(['column1'])['column2'].mean() \n```\n\n
\n\n변수만 따로 저장해서 Series로 자세히 보기\n\n```python\ns = movies.movieId\ns.index = movies.title\ns\n```\n\n
 \n\nSeries는 크게 index와 value로 나누어짐 (왼쪽:index, 오른쪽:value)\n\n이를 통해 따로 불러오고, 연산하는 것도 가능해진다.\n\n```python\ns['Toy Story (1995)'] #이 컬럼이 가진 movieId가 출력됨\nprint(s*2) #movieId가 *2되어 출력\n```\n\n\n\n\n\n"
},
{
"path": "New Technology/IT Issues/2020 ICT 이슈.md",
"content": "## 2020 ICT 이슈\n\n> 2020 ICT 산업전망 컨퍼런스에서 선정된 이슈들\n\n
\n\nSeries는 크게 index와 value로 나누어짐 (왼쪽:index, 오른쪽:value)\n\n이를 통해 따로 불러오고, 연산하는 것도 가능해진다.\n\n```python\ns['Toy Story (1995)'] #이 컬럼이 가진 movieId가 출력됨\nprint(s*2) #movieId가 *2되어 출력\n```\n\n\n\n\n\n"
},
{
"path": "New Technology/IT Issues/2020 ICT 이슈.md",
"content": "## 2020 ICT 이슈\n\n> 2020 ICT 산업전망 컨퍼런스에서 선정된 이슈들\n\n\n\n- 5G\n- 보호무역주의\n- AI\n- 규제\n- 모빌리티\n- 신남방, 신북방 정책\n- 구독경제\n- 반도체\n- 4차 산업혁명 시대 노동의 변화\n- 친환경 ICT\n\n
\n\n##### 가장 큰 화두는 '5G'\n\n5G 인프라가 본격적으로 구축, B2B 시장이 열리면서 가속화될 예정\n\n
\n\n##### 온디바이스 AI\n\n클라우드 연결이 필요없는 하드웨어 기반 인공지능인 **온디바이스 AI** 대전이 본격화될 예정\n\n> 삼성전자는 앞서 NPU를 갖춘 모바일 AP인 '엑시노스9820'을 공개했음\n\n
" }, { "path": "New Technology/IT Issues/AMD vs Intel.md", "content": "## AMD와 Intel의 반백년 전쟁, 그리고 2020년의 '반도체'\n\n
\n\nAMD와 Intel은 잘 알려진 CPU 시장을 선도하고 있는 기업이다. 여태까지 Intel의 천하였다면, AMD가 빠르고 무서운 속도로 경쟁 상대로 치솟고 있다. 이 두 기업에 대해 알아보자\n\n
\n\nAMD는 2011년 '불도저'라는 x86구조 마이크로 아키텍처를 구축했지만, 많은 소비전력과 느린 처리속도로 대실패한다.\n\n당시 피해가 워낙 커서, 경쟁사였던 Intel CEO 브라이언 크르자니크는 \"앞으로 재기하지 못할 기업이고, 앞으로 신경쓰지 말고 새 경쟁자인 퀄컴에 집중하라\"이라는 이야기까지 언급되었다.\n\n
\n\n하지만, 2014년 리사 수가 AMD CEO에 앉으며 변화가 찾아왔다.\n\n리사 수의 입사 당시에는 AMD의 CPU 시장 점유율이 `30% → 10% 이하`로 감소했고, 주가는 `1/10`로 폭락한 상태였다. 또한 AMD의 핵심 엔지니어들은 삼성전자, NVIDIA 등으로 이직하는 최악의 상황이었다.\n\n
\n\n리사 수는 기업 내의 구조조정과 많은 변화를 시도했고, 2017년 새로운 제품인 '라이젠'을 발표한다.\n\n이 라이젠은 AMD가 다시 일어설 수 있는 계기가 되었다.\n\n```\n라이젠을 통해 2012~2016년까지 28억 달러 누적적자를 기록한 AMD가 \n2017년 4분기에 첫 흑자를 전환\n```\n\n그리고 2018년에는 여태까지 Intel에 꾸준히 밀려왔던 미세공정까지 역전하게 된다.\n\n
 \n\n
\n\n\n\n##### *미세 공정에 대한 파운드리 기업 경쟁 - TSMC vs 삼성전자*\n\n시장점유율을 선도하던 TSMC와 추격하고 있는 삼성전자의 경쟁은 지속 중이다.\n\nTSMC나 삼성전자와 같은 파운드리 업체에서는 Intel이나 AMD 등 개발한 CPU를 생산하기 위해 점점 더 작은 나노의 미세 공정 양산이 가능한 제품을 출시해나가고 있다. (현재 두 기업 모두 7나노 양산이 가능한 상태)\n\n> 두 기업은 지금도 치열한 경쟁을 이어가는 중이다. (3위 밖 기업은 아직 12나노 양산)\n>\n> (TSMC와 삼성전자는 2020년 올해 3나노 기술 개발에 대한 소식도 전해지는 상태)\n\n
\n\n##### *왜 많은 기업들이 반도체에 대한 투자에 열망하는가?*\n\n4차 산업혁명 이후 5G 산업이 발전하고 있다. 현재까지 5G 디바이스는 아주 미세한 보급 상태지만, 향후 3~4년 안에 대부분의 사람들이 5G를 이용하게 될 것이다.\n\n5G가 가능해짐으로써, `AI, 빅데이터, IoT, 자율주행` 등 다양한 신사업 기술들이 발전해나갈 것으로 보이는데, 이때 모든 영역에 필요한 제품이 바로 '반도체'다.\n\n따라서 현재 전세계 비메모리 시장에서는 각 분야에서 선도하기 위해 무한 경쟁에 돌입했으며 아낌없이 천문학적인 금액을 투자하고 있는 것이다.\n\n> 작년 메모리 반도체가 불황이었지만, 비메모리 반도체 (특히 파운드리)가 호황이었던 이유\n\n
\n\n
\n\n#### AMD의 성장, 앞으로의 기대감\n\nAMD가 2019년 신규 Zen 2 CPU와 Navi GPU 출시를 구체화하면서 시장 점유율 확대의 기대가 커지고 있다. 수년 만에 처음으로 `Intel CPU와 NVIDIA GPU` 대비 기술력에서 우위를 점한 제품들이 출시되기 때문이다.\n\n가격 경쟁력에 중심을 뒀던 AMD가 앞으로 성능 측면까지 뛰어나면 시장 경쟁 구도에 변화가 찾아올 수도 있다. (이를 통해 AMD의 주가가 미친 듯이 상승함 `2015년 1.98달러 → 2020년 50.93달러`)\n\n
\n\n#### Intel은 그럼 놀고 있나?\n\n
 \n\n
\n\n\n\n시장 점유율에 있어서 AMD가 많이 따라오긴 했지만, 아직도 7대3정도의 상황이다.\n\n마찬가지로 Intel의 주가도 똑같이 미친듯이 상승하고 있다. (`2015년 30달러 → 2020년 59.60달러`)\n\n현재 AMD에서 따라오고 있는 컴퓨터에 들어가는 CPU 말고, 서버 시장 CPU는 Intel이 압도적인 점유율을 보여주고 있다. (Intel이 2018년만 해도 시장 점유율 약 99%로 압도적인 유지를 기록)\n\nAMD도 서버에서 따라가려고 노력하고는 있다. 하지만 2019년 현재 시장점유율은 Intel이 약 96%, AMD가 약 3%로 거의 독점 수준인 것은 다름없다.\n\n하지만 현재가 아닌 미래를 봤을 때 Intel이 좋은 상황이 아닌 건 확실하다. 하지만 현재 Intel은 CPU 시장에 집중이 아닌 **자율주행**에 관심과 거액의 투자를 진행하고 있다.\n\n- Intel, 2017년 17조원에 자율주행 기업 '모빌아이' 인수\n\n
\n\n현재 Intel의 주목 8가지 산업 : 스마트시티, 금융서비스, 인더스트리얼, 게이밍, 교통, 홈/리테일, 로봇, 드론\n\n> 이는 즉, 선도를 유지하고 있는 CPU 시장과 함께 자율주행을 포함한 미래산업 또한 이끌어가겠다는 Intel의 목표를 볼 수 있다.\n\n심지어 Intel은 2019년 삼성전자를 넘어 반도체 시장 1위를 재탈환했다. (삼성전자 2위, TSMC 3위, 하이닉스 4위) - 매출에 변동이 없던 Intel과 TSMC에 달리, 메모리 중심이었던 삼성전자와 하이닉스는 약 30%의 이익 감소가 발생했다.\n\n
\n\n이처럼 수많은 기업들간 경쟁 속에서 각자 성장과 발전을 위해 꾸준한 투자가 지속되고 있다. 그리고 그 중심에는 '반도체'가 있는 상황이다.\n\n
\n\n**리사 수 CEO 인터뷰** - \"앞으로 반도체는 10년 간 유례없는 호황기가 지속될 것으로 본다. AI, IoT 등 혁신의 중심에 반도체가 핵심 역할을 할 것이다.\"\n\n
\n\n과연 정말로 IT버블의 시대가 올 것인지, 비메모리 반도체를 중심으로 세계 시장의 변화가 어떻게 이루어질 것인지 귀추가 주목되고 있다.\n\n
\n\n
\n\n##### [참고 자료]\n\n- [링크](https://www.youtube.com/watch?v=6dp4E5HIpRU)" }, { "path": "New Technology/IT Issues/README.md", "content": "# IT Issues\n\n최근 IT 이슈 동향 정리" }, { "path": "New Technology/IT Issues/[2019.08.07] 이메일 공격 증가로 보안업계 대응 비상.md", "content": "## 이주의 IT 이슈 (19.08.07)\n\n### 이메일 공격 증가로 보안업계 대응 비상\n\n---\n\n> 올해 악성메일 탐지 건수 약 342,800건 예상 (SK인포섹 발표)\n>\n> 전년보다 2배 이상, 4년전보다 5배 이상 증가함\n\n랜섬웨어 공격의 90%이상이 이메일로 시작됨 (KISA 발표)\n\n
\n\n해커가 '사회공학기법'을 활용해 사용자가 속을 수 밖에 없는 제목과 내용으로 지능화되고 있음\n\n> 이메일 유형 : 견적서, 대금청구서, 계약서, 발주서, 경찰청 및 국세청 사칭\n>\n> 최근에는 여름 휴가철 맞아 전자항공권 확인증 위장 이메일도 유포되는 中\n\n
\n\n#### 대응 상황\n\n- 안랩 : 이메일 위협 대응이 가능한 안랩MDS(지능형 위협 대응 솔루션) 신규 버전 발표\n\n > 이메일 헤더, 제목, 본문, 첨부파일로 필터링 설정 (파일 확장자 분석)\n\n ```\n * 안랩 MDS\n 다양한 공격 유입 경로별로 최적화된 대응 방안을 제공하는 지능형 위협 대응 솔루션\n - 사이버 킬체인 기반으로 네트워크, 이메일, 엔드포인트와 같은 경로의 침입 단계부터 최초 감염, 2차감염, 잠복 위협까지 최적화 대응 제공\n ```\n\n- 지란지교시큐리티 : 홈페이지에 최신 악성메일 트렌드 부분을 공지하여 예방 가이드 제시\n\n > 실제 악성 이메일 미리보기 기능, 첨부된 파일 유형과 정보, 바이러스 탐지 내역 등\n\n#### 예방책\n\n- 사용 중인 문서 작성 프로그램 최신 버전 업데이트\n- 오피스문서 매크로 기능 허용 X\n\n\n\n**엔드포인트** : 네트워크에 최종적으로 연결된 IT 장치를 의미 (스마트폰, 노트북 등)\n\n해커들의 궁극적인 목표가 바로 '엔드포인트' 해킹\n\n네트워크를 통한 공격이기 때문에, 각각 연결이 되는 공간마다 방화벽(Firewall)을 세워두는 것이 '엔드포인트 보안'" }, { "path": "New Technology/IT Issues/[2019.08.08] IT 수다 정리.md", "content": "## [모닝 스터디] IT 수다 정리(19.08.08)\n\n1. ##### 쿠팡 서비스 오류\n\n > 지난 7월 24일 오전 7시부터 쿠팡 판매 상품 재고가 모두 0으로 표시되는 오류 발생\n\n 재고 데이터베이스에서 데이터를 불러오는 'Redis DB'에서 버그가 발생함\n\n ***Redis란?***\n\n ```\n 오픈소스 기반 데이터베이스 관리 시스템(DBMS), 데이터를 메모리로 불러와서 처리하는 메모리 기반 시스템이다. \n 속도가 빠르고 사용이 칸편해서 트위터, 인스타그램 등에 사용 되고 있음\n ```\n\n 속도가 빠른 대신, 데이터가 많아지면 버그 발생 가능성도 증가. 처리 데이터가 많을 수록 더 많은 메모리를 요구해서 결국 용량 부족으로 장애가 발생한 것으로 보임\n\n
\n\n2. ##### GraphQL\n\n > facebook이 만든 쿼리 언어 : `A query language for your API`\n\n 기존의 웹앱에서 API를 구현할 때는, 통상적으로 `REST API` 사용함. 클라이언트 사이드에서 기능이 필요할 때마다 새로운 API를 만들어야하는 번거로움이 있었음\n\n → **클라이언트 측에서 쿼리를 만들어 서버로 보내면 편하지 않을까?**에서 탄생한 것이 GraphQL\n\n 특정 언어에 제한된 것이 아니기 때문에 Node, Ruby, PHP, Python 등에서 모두 사용이 가능함. 또한 HTTP 프로토콜 제한이 없어서 웹소켓에서 사용도 가능하고 모든 DB를 사용이 가능\n\n
\n\n3. ##### 현재 반도체 매출 세계 2위인 SK 하이닉스의 탄생은?\n\n > 1997년 외환 위기로 인해 LG반도체가 현대전자로 합병됨(인수 후 '현대반도체'로 변경)\n >\n > 2001년에 `현대전자 → 하이닉스 반도체`로 사명 변경, 메모리 사업부 제외한 나머지 사업부는 모두 독립자회사로 분사시킴. 이때 하이닉스는 현대그룹에서 분리가 되었음\n >\n > 2011년부터 하이닉스 인수에 많은 기업들이 관심을 보임 (현대 중공업, SK, STX)\n >\n > 결국 SK텔레콤이 3조4천억에 단독 입찰(SK텔레콤은 주파수 통신산업으로 매월 수천억씩 벌고 있었음)하면서 2012년 주주통회를 통해 SK그룹에 편입되어 `SK하이닉스`로 사명 변경\n\n SK그룹의 탄탄한 지원을 받음 + 경쟁 반도체 기업(엘피다) 파산으로 수익 증가, DRAM과 NAND의 호황기 시대를 맞아 2014년 이후 17조 이상의 연간매출 기록 中\n\n" }, { "path": "New Technology/IT Issues/[2019.08.20] Google, 크롬 브라우저에서 FTP 지원 중단 확정.md", "content": "## Google, 크롬 브라우저에서 FTP 지원 중단 확정\n\n
\n\n
 \n\n크롬 브라우저에서 보안상 위험 요소로 작용되는 FTP 지원을 중단하기로 결정함\n\n8월 15일, 구글은 암호화된 연결을 통한 파일 전송에 대한 지원도 부족하고, 사용량도 적어서 아예 기능을 제거하기로 결정함\n\n
\n\n크롬 브라우저에서 보안상 위험 요소로 작용되는 FTP 지원을 중단하기로 결정함\n\n8월 15일, 구글은 암호화된 연결을 통한 파일 전송에 대한 지원도 부족하고, 사용량도 적어서 아예 기능을 제거하기로 결정함\n\n\n\n***FTP (파일 전송 프로토콜)이란?***\n\n> TCP/IP 프로토콜을 가지고 서버와 클라이언트 사이에 파일 전송을 하기 위한 프로토콜\n\n
\n\n과거에는 인터넷을 통해 파일을 다운로드 할 때, 웹 브라우저로 FTP 서버에 접속하는 방식을 이용했음. 하지만 이제 네트워크가 발달하면서, 네트워크의 안정화를 위해서 FTP의 쓰임이 줄어들게 됨\n\n
\n\nFTP는 데이터를 주고받을 시, 암호화하지 않기 때문에 보안 위험에 노출되는 위험성 존재함. 또한 사용량도 현저히 적기 때문에 구글 개발자들이 오랫동안 FTP를 제거하자고 요청해왔음\n\n이런 FTP의 단점을 개선하기 위해 SFTP와 SSL 프로토콜을 사용하는 中\n\n현재 크롬에서 남은 FTP 기능 : 디렉토리 목록 보여주기, 암호화되지 않은 연결을 통해 리소스 다운로드\n\nFTP 기능을 없애고, FTP를 지원하는 소프트웨어를 활용하는 방식으로 바꿀 예정. 크롬80버전부터 점차 비활성화하고 크롬82버전에 완전히 제거될 예정이라고 함" }, { "path": "README.md", "content": "# tech-interview-for-developer\n\n[](https://gyoogle.github.io)\n[](https://gyoogle.github.io)\n[](https://github.com/gyoogle/tech-interview-for-developer/blob/master/LICENSE)\n[](https://hits.seeyoufarm.com)\n[](#contributors)\n[](http://makeapullrequest.com)\n\n[](https://github.com/gyoogle/tech-interview-for-developer/watchers)\n[](https://github.com/gyoogle/tech-interview-for-developer/stargazers)\n[](https://github.com/gyoogle/tech-interview-for-developer/network/members)\n\n
\n\n
\n\n### 👶🏻 신입 개발자 전공 지식 & 기술 면접 백과사전 📖\n\n
\n\n**Collaborator**\n\n| [
 ](https://github.com/gyoogle)| [
](https://github.com/gyoogle)| [ ](https://github.com/GimunLee) | [
](https://github.com/GimunLee) | [ ](https://github.com/b2narae) |\n| :-----------------------------------: | :---------------------------------------: | :-------------------------------------: |\n\n
](https://github.com/b2narae) |\n| :-----------------------------------: | :---------------------------------------: | :-------------------------------------: |\n\n\n\n**Commit convention rule** : 날짜-[주제]-내용-상태\n\n`ex) 2019-10-14 [Algorithm] Sort Add/Update/Delete`\n\n
\n\n잘못된 내용은 [이슈](https://github.com/gyoogle/tech-interview-for-developer/issues)와 [PR](https://github.com/gyoogle/tech-interview-for-developer/pulls)로 알려주세요 💡\n\n
\n\n\n\n
\n
\n\n\n
\n\n#### [💖후원하기💝](https://github.com/sponsors/gyoogle)\n\n
\n
\n\n## ⏩ ⏩ ⏩ [웹 사이트에서 편하게 공부하세요! Click!](https://gyoogle.dev/) ⏪ ⏪ ⏪\n\n
\n
\n\n
\n\n### 👨🏻🏫 [기술 면접 감 잡기](
\n\n## 📌 Computer Science\n\n- ### Computer Architecture\n\n - [컴퓨터 구조 기초](https://github.com/gyoogle/tech-interview-for-developer/blob/master/Computer%20Science/Computer%20Architecture/%EC%BB%B4%ED%93%A8%ED%84%B0%EA%B5%AC%EC%A1%B0%20%EA%B8%B0%EC%B4%88.pdf)\n - [컴퓨터의 구성](https://github.com/gyoogle/tech-interview-for-developer/blob/master/Computer%20Science/Computer%20Architecture/%EC%BB%B4%ED%93%A8%ED%84%B0%EC%9D%98%20%EA%B5%AC%EC%84%B1.md)\n - [중앙처리장치(CPU) 작동 원리](https://github.com/gyoogle/tech-interview-for-developer/blob/master/Computer%20Science/Computer%20Architecture/%EC%A4%91%EC%95%99%EC%B2%98%EB%A6%AC%EC%9E%A5%EC%B9%98(CPU)%20%EC%9E%91%EB%8F%99%20%EC%9B%90%EB%A6%AC.md)\n - [캐시 메모리](https://github.com/gyoogle/tech-interview-for-developer/blob/master/Computer%20Science/Computer%20Architecture/캐시%20메모리(Cache%20Memory).md)\n - [고정 소수점 & 부동 소수점](https://github.com/gyoogle/tech-interview-for-developer/blob/master/Computer%20Science/Computer%20Architecture/%EA%B3%A0%EC%A0%95%20%EC%86%8C%EC%88%98%EC%A0%90%20%26%20%EB%B6%80%EB%8F%99%20%EC%86%8C%EC%88%98%EC%A0%90.md)\n - [패리티 비트 & 해밍 코드](https://github.com/gyoogle/tech-interview-for-developer/blob/master/Computer%20Science/Computer%20Architecture/%ED%8C%A8%EB%A6%AC%ED%8B%B0%20%EB%B9%84%ED%8A%B8%20%26%20%ED%95%B4%EB%B0%8D%20%EC%BD%94%EB%93%9C.md)\n - [ARM 프로세서](https://github.com/gyoogle/tech-interview-for-developer/blob/master/Computer%20Science/Computer%20Architecture/ARM%20%ED%94%84%EB%A1%9C%EC%84%B8%EC%84%9C.md)\n\n
\n\n- ### Data Structure\n\n - [Array](https://github.com/gyoogle/tech-interview-for-developer/blob/master/Computer%20Science/Data%20Structure/Array.md)\n - [LinkedList](https://github.com/gyoogle/tech-interview-for-developer/blob/master/Computer%20Science/Data%20Structure/Linked%20List.md)\n - [Array & ArrayList & LinkedList](https://github.com/gyoogle/tech-interview-for-developer/blob/master/Computer%20Science/Data%20Structure/Array%20vs%20ArrayList%20vs%20LinkedList.md)\n - [스택(Stack) & 큐(Queue)](https://github.com/gyoogle/tech-interview-for-developer/blob/master/Computer%20Science/Data%20Structure/Stack%20%26%20Queue.md)\n - [힙(Heap)](https://github.com/gyoogle/tech-interview-for-developer/blob/master/Computer%20Science/Data%20Structure/Heap.md)\n - [트리(Tree)](https://github.com/gyoogle/tech-interview-for-developer/blob/master/Computer%20Science/Data%20Structure/Tree.md)\n - [이진탐색트리(Binary Search Tree)](
\n\n- ### Database\n\n - [키(Key) 정리](https://github.com/gyoogle/tech-interview-for-developer/blob/master/Computer%20Science/Database/%5BDB%5D%20Key.md)\n - [SQL - JOIN](https://github.com/gyoogle/tech-interview-for-developer/blob/master/Computer%20Science/Database/%5BDatabase%20SQL%5D%20JOIN.md)\n - [SQL Injection](https://github.com/gyoogle/tech-interview-for-developer/blob/master/Computer%20Science/Database/SQL%20Injection.md)\n - [SQL vs NoSQL](https://github.com/gyoogle/tech-interview-for-developer/blob/master/Computer%20Science/Database/SQL%EA%B3%BC%20NOSQL%EC%9D%98%20%EC%B0%A8%EC%9D%B4.md)\n - [정규화(Normalization)](https://github.com/gyoogle/tech-interview-for-developer/blob/master/Computer%20Science/Database/%EC%A0%95%EA%B7%9C%ED%99%94(Normalization).md)\n - [이상(Anomaly)](https://github.com/gyoogle/tech-interview-for-developer/blob/master/Computer%20Science/Database/%5BDB%5D%20Anomaly.md)\n - [인덱스(INDEX)](https://github.com/gyoogle/tech-interview-for-developer/blob/master/Computer%20Science/Database/%5BDB%5D%20Index.md)\n - [트랜잭션(Transaction)](https://github.com/gyoogle/tech-interview-for-developer/blob/master/Computer%20Science/Database/Transaction.md)\n - [트랜잭션 격리 수준(Transaction Isolation Level)](https://github.com/gyoogle/tech-interview-for-developer/blob/master/Computer%20Science/Database/Transaction%20Isolation%20Level.md)\n - [저장 프로시저(Stored PROCEDURE)](https://github.com/gyoogle/tech-interview-for-developer/blob/master/Computer%20Science/Database/%EC%A0%80%EC%9E%A5%20%ED%94%84%EB%A1%9C%EC%8B%9C%EC%A0%80(Stored%20PROCEDURE).md)\n - [레디스(Redis)](https://github.com/gyoogle/tech-interview-for-developer/blob/master/Computer%20Science/Database/Redis.md)\n\n
\n\n- ### Network\n\n - [OSI 7 계층](https://github.com/gyoogle/tech-interview-for-developer/blob/master/Computer%20Science/Network/OSI%207%20계층.md)\n - [TCP 3 way handshake & 4 way handshake](https://github.com/gyoogle/tech-interview-for-developer/blob/master/Computer%20Science/Network/TCP%203%20way%20handshake%20%26%204%20way%20handshake.md)\n - [TCP/IP 흐름제어 & 혼잡제어](https://github.com/gyoogle/tech-interview-for-developer/blob/master/Computer%20Science/Network/TCP%20(%ED%9D%90%EB%A6%84%EC%A0%9C%EC%96%B4%ED%98%BC%EC%9E%A1%EC%A0%9C%EC%96%B4).md#tcp-%ED%9D%90%EB%A6%84%EC%A0%9C%EC%96%B4%ED%98%BC%EC%9E%A1%EC%A0%9C%EC%96%B4)\n - [UDP](https://github.com/gyoogle/tech-interview-for-developer/blob/master/Computer%20Science/Network/UDP.md#20190826%EC%9B%94-bym-udp%EB%9E%80)\n - [대칭키 & 공개키](https://github.com/gyoogle/tech-interview-for-developer/blob/master/Computer%20Science/Network/%EB%8C%80%EC%B9%AD%ED%82%A4%20%26%20%EA%B3%B5%EA%B0%9C%ED%82%A4.md)\n - [HTTP & HTTPS](https://github.com/gyoogle/tech-interview-for-developer/blob/master/Computer%20Science/Network/HTTP%20%26%20HTTPS.md)\n - [TLS/SSL handshake](https://github.com/gyoogle/tech-interview-for-developer/blob/master/Computer%20Science/Network/TLS%20HandShake.md)\n - [로드 밸런싱(Load Balancing)](https://github.com/gyoogle/tech-interview-for-developer/blob/master/Computer%20Science/Network/%EB%A1%9C%EB%93%9C%20%EB%B0%B8%EB%9F%B0%EC%8B%B1(Load%20Balancing).md)\n - [Blocking,Non-blocking & Synchronous,Asynchronous](https://github.com/gyoogle/tech-interview-for-developer/blob/master/Computer%20Science/Network/%5BNetwork%5D%20Blocking%2CNon-blocking%20%26%20Synchronous%2CAsynchronous.md)\n - [Blocking & Non-Blocking I/O](https://github.com/gyoogle/tech-interview-for-developer/blob/master/Computer%20Science/Network/%5BNetwork%5D%20Blocking%20Non-Blocking%20IO.md)\n\n
\n\n- ### Operating System\n\n - [운영체제란](https://github.com/gyoogle/tech-interview-for-developer/blob/master/Computer%20Science/Operating%20System/Operation%20System.md)\n - [프로세스 vs 스레드](https://github.com/gyoogle/tech-interview-for-developer/blob/master/Computer%20Science/Operating%20System/Process%20vs%20Thread.md)\n - [프로세스 주소 공간](https://github.com/gyoogle/tech-interview-for-developer/blob/master/Computer%20Science/Operating%20System/Process%20Address%20Space.md)\n - [인터럽트(Interrupt)](https://github.com/gyoogle/tech-interview-for-developer/blob/master/Computer%20Science/Operating%20System/Interrupt.md)\n - [시스템 콜(System Call)](https://github.com/gyoogle/tech-interview-for-developer/blob/master/Computer%20Science/Operating%20System/%5BOS%5D%20System%20Call%20(Fork%20Wait%20Exec).md)\n - [PCB와 Context Switching](https://github.com/gyoogle/tech-interview-for-developer/blob/master/Computer%20Science/Operating%20System/PCB%20%26%20Context%20Switcing.md)\n - [IPC(Inter Process Communication)](https://github.com/gyoogle/tech-interview-for-developer/blob/master/Computer%20Science/Operating%20System/IPC(Inter%20Process%20Communication).md)\n - [CPU 스케줄링](https://github.com/gyoogle/tech-interview-for-developer/blob/master/Computer%20Science/Operating%20System/CPU%20Scheduling.md)\n - [데드락(DeadLock)](https://github.com/gyoogle/tech-interview-for-developer/blob/master/Computer%20Science/Operating%20System/DeadLock.md)\n - [Race Condition]( https://github.com/gyoogle/tech-interview-for-developer/blob/master/Computer%20Science/Operating%20System/Race%20Condition.md)\n - [세마포어(Semaphore) & 뮤텍스(Mutex)](https://github.com/gyoogle/tech-interview-for-developer/blob/master/Computer%20Science/Operating%20System/Semaphore%20%26%20Mutex.md)\n - [페이징 & 세그먼테이션](https://github.com/gyoogle/tech-interview-for-developer/blob/master/Computer%20Science/Operating%20System/Paging%20and%20Segmentation.md) ([PDF](https://github.com/gyoogle/tech-interview-for-developer/blob/master/Computer%20Science/Operating%20System/Paging%20and%20Segmentation.pdf))\n - [페이지 교체 알고리즘](https://github.com/gyoogle/tech-interview-for-developer/blob/master/Computer%20Science/Operating%20System/Page%20Replacement%20Algorithm.md)\n - [메모리(Memory)](https://github.com/gyoogle/tech-interview-for-developer/blob/master/Computer%20Science/Operating%20System/Memory.md)\n - [파일 시스템](https://github.com/gyoogle/tech-interview-for-developer/blob/master/Computer%20Science/Operating%20System/File%20System.md)\n\n
\n\n- ### Software Engineering\n\n - [클린코드 & 리팩토링](https://github.com/gyoogle/tech-interview-for-developer/blob/master/Computer%20Science/Software%20Engineering/Clean%20Code%20%26%20Refactoring.md) / [클린코드 & 시큐어코딩](https://github.com/gyoogle/tech-interview-for-developer/blob/master/Computer%20Science/Software%20Engineering/%ED%81%B4%EB%A6%B0%EC%BD%94%EB%93%9C(Clean%20Code)%20%26%20%EC%8B%9C%ED%81%90%EC%96%B4%EC%BD%94%EB%94%A9(Secure%20Coding).md)\n - [TDD(Test Driven Development)](https://github.com/gyoogle/tech-interview-for-developer/blob/master/Computer%20Science/Software%20Engineering/TDD(Test%20Driven%20Development).md)\n - [애자일(Agile) 정리1](https://github.com/gyoogle/tech-interview-for-developer/blob/master/Computer%20Science/Software%20Engineering/%EC%95%A0%EC%9E%90%EC%9D%BC(Agile).md) / [애자일(Agile) 정리2](https://github.com/gyoogle/tech-interview-for-developer/blob/master/Computer%20Science/Software%20Engineering/%EC%95%A0%EC%9E%90%EC%9D%BC(Agile)2.md)\n - [객체 지향 프로그래밍(Object-Oriented Programming)](https://github.com/gyoogle/tech-interview-for-developer/blob/master/Computer%20Science/Software%20Engineering/Object-Oriented%20Programming.md)\n - [함수형 프로그래밍(Fuctional Programming)](https://github.com/gyoogle/tech-interview-for-developer/blob/master/Computer%20Science/Software%20Engineering/Fuctional%20Programming.md)\n - [데브옵스(DevOps)](https://github.com/gyoogle/tech-interview-for-developer/blob/master/Computer%20Science/Software%20Engineering/%EB%8D%B0%EB%B8%8C%EC%98%B5%EC%8A%A4(DevOps).md)\n - [서드 파티(3rd party)란?](https://github.com/gyoogle/tech-interview-for-developer/blob/master/Computer%20Science/Software%20Engineering/%EC%8D%A8%EB%93%9C%ED%8C%8C%ED%8B%B0(3rd%20party)%EB%9E%80.md)\n - [마이크로서비스 아키텍처(MSA)](https://github.com/gyoogle/tech-interview-for-developer/blob/master/Computer%20Science/Software%20Engineering/%EB%A7%88%EC%9D%B4%ED%81%AC%EB%A1%9C%EC%84%9C%EB%B9%84%EC%8A%A4%20%EC%95%84%ED%82%A4%ED%85%8D%EC%B2%98(MSA).md)\n \n\n
\n\n
\n\n## 📌 Algorithm\n\n- [거품 정렬(Bubble Sort)](https://github.com/GimunLee/tech-refrigerator/blob/master/Algorithm/%EA%B1%B0%ED%92%88%20%EC%A0%95%EB%A0%AC%20(Bubble%20Sort).md#%EA%B1%B0%ED%92%88-%EC%A0%95%EB%A0%AC-bubble-sort)\n- [선택 정렬(Selection Sort)](https://github.com/GimunLee/tech-refrigerator/blob/master/Algorithm/%EC%84%A0%ED%83%9D%20%EC%A0%95%EB%A0%AC%20(Selection%20Sort).md#%EC%84%A0%ED%83%9D-%EC%A0%95%EB%A0%AC-selection-sort) \n- [삽입 정렬(Insertion Sort)](https://github.com/GimunLee/tech-refrigerator/blob/master/Algorithm/%EC%82%BD%EC%9E%85%20%EC%A0%95%EB%A0%AC%20(Insertion%20Sort).md#%EC%82%BD%EC%9E%85-%EC%A0%95%EB%A0%AC-insertion-sort)\n- [퀵 정렬(Quick Sort)](
\n\n- ##### ✏️ TEST\n\n - [삼성 소프트웨어 역량테스트 PRO 등급 준비](https://github.com/gyoogle/tech-interview-for-developer/blob/master/Algorithm/SAMSUNG%20Software%20PRO%EB%93%B1%EA%B8%89%20%EC%A4%80%EB%B9%84.md)\n\n
\n\n## 📌 Design Pattern\n\n- [디자인패턴 개요(Overview)](https://github.com/gyoogle/tech-interview-for-developer/blob/master/Design%20Pattern/%5BDesign%20Pattern%5D%20Overview.md)\n- [어댑터 패턴](https://github.com/gyoogle/tech-interview-for-developer/blob/master/Design%20Pattern/Adapter%20Pattern.md)\n- [싱글톤 패턴](https://github.com/gyoogle/tech-interview-for-developer/blob/master/Design%20Pattern/Singleton%20Pattern.md)\n- [탬플릿 메소드 패턴](https://github.com/gyoogle/tech-interview-for-developer/blob/master/Design%20Pattern/Design%20Pattern_Template%20Method.md)\n- [팩토리 메소드 패턴](https://github.com/gyoogle/tech-interview-for-developer/blob/master/Design%20Pattern/Design%20Pattern_Factory%20Method.md)\n- [옵저버 패턴](https://github.com/gyoogle/tech-interview-for-developer/blob/master/Design%20Pattern/Observer%20pattern.md)\n- [스트레티지 패턴](https://github.com/gyoogle/tech-interview-for-developer/blob/master/Design%20Pattern/Strategy%20Pattern.md)\n- [컴포지트 패턴](https://github.com/gyoogle/tech-interview-for-developer/blob/master/Design%20Pattern/Composite%20Pattern.md)\n- [SOLID](https://github.com/gyoogle/tech-interview-for-developer/blob/master/Design%20Pattern/SOLID.md)\n\n
\n\n## 📌 Interview\n\n- [언어(Java, C++ ... )](https://github.com/gyoogle/tech-interview-for-developer/blob/master/Interview/Interview%20List.md#언어)\n- [운영체제](https://github.com/gyoogle/tech-interview-for-developer/blob/master/Interview/Interview%20List.md#운영체제)\n- [데이터베이스](
\n\n## 📌 Language\n\n- ### C\n\n - [[C] C언어 컴파일 과정](https://github.com/gyoogle/tech-interview-for-developer/blob/master/Language/%5Bc%5D%20C%EC%96%B8%EC%96%B4%20%EC%BB%B4%ED%8C%8C%EC%9D%BC%20%EA%B3%BC%EC%A0%95.md)\n - [[C] 구조체 메모리 크기 계산](https://github.com/gyoogle/tech-interview-for-developer/blob/master/Language/%5BC%5D%20%EA%B5%AC%EC%A1%B0%EC%B2%B4%20%EB%A9%94%EB%AA%A8%EB%A6%AC%20%ED%81%AC%EA%B8%B0%20%EA%B3%84%EC%82%B0.md)\n - [[C] 포인터(Pointer)](
\n\n## 📌 Web\n\n- [브라우저 동작 방법](https://github.com/gyoogle/tech-interview-for-developer/blob/master/Web/%EB%B8%8C%EB%9D%BC%EC%9A%B0%EC%A0%80%20%EB%8F%99%EC%9E%91%20%EB%B0%A9%EB%B2%95.md)\n\n- [쿠키(Cookie) & 세션(Session)](https://github.com/gyoogle/tech-interview-for-developer/blob/master/Web/Cookie%20%26%20Session.md)\n\n- [HTTP Request Methods](https://github.com/gyoogle/tech-interview-for-developer/blob/master/Web/HTTP%20Request%20Methods.md)\n\n- [HTTP Status Code](https://github.com/gyoogle/tech-interview-for-developer/blob/master/Web/HTTP%20status%20code.md)\n\n- [REST API](https://github.com/gyoogle/tech-interview-for-developer/blob/master/Web/%5BWeb%5D%20REST%20API.md)\n\n- [웹 서버와 WAS의 차이점](https://github.com/gyoogle/tech-interview-for-developer/blob/master/Web/Web%20Server%EC%99%80%20WAS%EC%9D%98%20%EC%B0%A8%EC%9D%B4.md)\n\n- [OAuth](https://github.com/gyoogle/tech-interview-for-developer/blob/master/Web/OAuth.md)\n\n- [JWT(JSON Web Token)](https://github.com/gyoogle/tech-interview-for-developer/blob/master/Web/JWT(JSON%20Web%20Token).md)\n\n- [Authentication and Authorization](https://github.com/gyoogle/tech-interview-for-developer/blob/master/Web/%EC%9D%B8%EC%A6%9D%EB%B0%A9%EC%8B%9D.md)\n\n- [로그 레벨](https://github.com/gyoogle/tech-interview-for-developer/blob/master/Web/Logging%20Level.md)\n\n- [UI와 UX](https://github.com/gyoogle/tech-interview-for-developer/blob/master/Web/UI%EC%99%80%20UX.md)\n\n- [CSR & SSR](https://github.com/gyoogle/tech-interview-for-developer/blob/master/Web/CSR%20%26%20SSR.md)\n\n- [Vue.js vs React](https://github.com/gyoogle/tech-interview-for-developer/blob/master/Web/Vue.js%EC%99%80%20React%EC%9D%98%20%EC%B0%A8%EC%9D%B4.md)\n\n- [네이티브 앱 & 웹 앱 & 하이브리드 앱](https://github.com/gyoogle/tech-interview-for-developer/blob/master/Web/%EB%84%A4%EC%9D%B4%ED%8B%B0%EB%B8%8C%20%EC%95%B1%20%26%20%EC%9B%B9%20%EC%95%B1%20%26%20%ED%95%98%EC%9D%B4%EB%B8%8C%EB%A6%AC%EB%93%9C%20%EC%95%B1.md)\n\n- [PWA(Progressive Web App)](https://github.com/gyoogle/tech-interview-for-developer/blob/master/Web/PWA%20(Progressive%20Web%20App).md)\n\n- [CSRF & XSS](https://github.com/gyoogle/tech-interview-for-developer/blob/master/Web/CSRF%20%26%20XSS.md)\n\n- ##### Spring\n\n - [[Spring] Bean Scope](https://github.com/gyoogle/tech-interview-for-developer/blob/master/Web/Spring/%5BSpring%5D%20Bean%20Scope.md)\n - [[Spring] MVC Framework](https://github.com/gyoogle/tech-interview-for-developer/blob/master/Web/Spring/Spring%20MVC.md)\n - [[Spring Boot] SpringApplication](https://github.com/gyoogle/tech-interview-for-developer/blob/master/Web/Spring/%5BSpring%20Boot%5D%20SpringApplication.md)\n - [[Spring Boot] Test Code](https://github.com/gyoogle/tech-interview-for-developer/blob/master/Web/Spring/%5BSpring%20Boot%5D%20Test%20Code.md)\n - [JPA](https://github.com/gyoogle/tech-interview-for-developer/blob/master/Web/Spring/JPA.md)\n - [[Spring Data JPA] 더티 체킹(Dirty Checking)](https://github.com/gyoogle/tech-interview-for-developer/blob/master/Web/Spring/%5BSpring%20Data%20JPA%5D%20%EB%8D%94%ED%8B%B0%20%EC%B2%B4%ED%82%B9%20(Dirty%20Checking).md)\n - [Spring Security - 인증 및 권한 부여](https://github.com/gyoogle/tech-interview-for-developer/blob/master/Web/Spring/Spring%20Security%20-%20Authentication%20and%20Authorization.md)\n\n- ##### Vue.js\n \n - [Vue.js 라이프사이클](https://github.com/gyoogle/tech-interview-for-developer/blob/master/Web/Vue/Vue.js%20%EB%9D%BC%EC%9D%B4%ED%94%84%EC%82%AC%EC%9D%B4%ED%81%B4%20%EC%9D%B4%ED%95%B4%ED%95%98%EA%B8%B0.md)\n - [Vue CLI + Spring Boot 연동하여 환경 구축하기](https://github.com/gyoogle/tech-interview-for-developer/blob/master/Web/Vue/Vue%20CLI%20%2B%20Spring%20Boot%20%EC%97%B0%EB%8F%99%ED%95%98%EC%97%AC%20%ED%99%98%EA%B2%BD%20%EA%B5%AC%EC%B6%95%ED%95%98%EA%B8%B0.md)\n - [Vue.js + Firebase로 이메일 회원가입&로그인 구현하기](https://github.com/gyoogle/tech-interview-for-developer/blob/master/Web/Vue/Vue.js%20%2B%20Firebase%EB%A1%9C%20%EC%9D%B4%EB%A9%94%EC%9D%BC%20%ED%9A%8C%EC%9B%90%EA%B0%80%EC%9E%85%EB%A1%9C%EA%B7%B8%EC%9D%B8%20%EA%B5%AC%ED%98%84.md)\n - [Vue.js + Firebase로 Facebook 로그인 연동하기](https://github.com/gyoogle/tech-interview-for-developer/blob/master/Web/Vue/Vue.js%20%2B%20Firebase%EB%A1%9C%20%ED%8E%98%EC%9D%B4%EC%8A%A4%EB%B6%81(facebook)%20%EB%A1%9C%EA%B7%B8%EC%9D%B8%20%EC%97%B0%EB%8F%99%ED%95%98%EA%B8%B0.md)\n - [Nuxt.js란](
\n\n## 📌 Linux\n\n- [리눅스 기본 명령어](https://github.com/gyoogle/tech-interview-for-developer/blob/master/Linux/Linux%20Basic%20Command.md)\n- [폰 노이만 구조](https://github.com/gyoogle/tech-interview-for-developer/blob/master/Linux/Von%20Neumann%20Architecture.md)\n- [퍼미션 활용](https://github.com/gyoogle/tech-interview-for-developer/blob/master/Linux/Permission.md)\n\n
\n\n## 📌 New Technology\n\n- #### AI \n - [용어 정리](https://github.com/gyoogle/tech-interview-for-developer/blob/master/New%20Technology/AI/README.md)\n - [Tensorflow로 Linear Regression 알고리즘 구현](https://github.com/gyoogle/tech-interview-for-developer/blob/master/New%20Technology/AI/Linear%20regression%20%EC%8B%A4%EC%8A%B5.md)\n \n- #### Big Data\n - [데이터 분석](https://github.com/gyoogle/tech-interview-for-developer/blob/master/New%20Technology/Big%20Data/%EB%8D%B0%EC%9D%B4%ED%84%B0%20%EB%B6%84%EC%84%9D.md)\n - [DBSCAN 클러스터링 알고리즘](https://github.com/gyoogle/tech-interview-for-developer/blob/master/New%20Technology/Big%20Data/DBSCAN%20%ED%81%B4%EB%9F%AC%EC%8A%A4%ED%84%B0%EB%A7%81%20%EC%95%8C%EA%B3%A0%EB%A6%AC%EC%A6%98.md)\n \n- #### IT Issues\n - [이메일 공격 증가로 보안업계 대응 비상(19.08.07)](https://github.com/gyoogle/tech-interview-for-developer/blob/master/New%20Technology/IT%20Issues/%5B2019.08.07%5D%20%EC%9D%B4%EB%A9%94%EC%9D%BC%20%EA%B3%B5%EA%B2%A9%20%EC%A6%9D%EA%B0%80%EB%A1%9C%20%EB%B3%B4%EC%95%88%EC%97%85%EA%B3%84%20%EB%8C%80%EC%9D%91%20%EB%B9%84%EC%83%81.md)\n - [쿠팡 서비스 오류(19.08.08)](https://github.com/gyoogle/tech-interview-for-developer/blob/master/New%20Technology/IT%20Issues/%5B2019.08.08%5D%20IT%20%EC%88%98%EB%8B%A4%20%EC%A0%95%EB%A6%AC.md)\n - [GraphQL(19.08.08)](https://github.com/gyoogle/tech-interview-for-developer/blob/master/New%20Technology/IT%20Issues/%5B2019.08.08%5D%20IT%20%EC%88%98%EB%8B%A4%20%EC%A0%95%EB%A6%AC.md)\n - [SK 하이닉스의 탄생은?(19.08.08)](https://github.com/gyoogle/tech-interview-for-developer/blob/master/New%20Technology/IT%20Issues/%5B2019.08.08%5D%20IT%20%EC%88%98%EB%8B%A4%20%EC%A0%95%EB%A6%AC.md)\n - [구글, 크롬 브라우저에서 FTP 지원 중단 확정(19.08.20)](https://github.com/gyoogle/tech-interview-for-developer/blob/master/New%20Technology/IT%20Issues/%5B2019.08.20%5D%20Google%2C%20%ED%81%AC%EB%A1%AC%20%EB%B8%8C%EB%9D%BC%EC%9A%B0%EC%A0%80%EC%97%90%EC%84%9C%20FTP%20%EC%A7%80%EC%9B%90%20%EC%A4%91%EB%8B%A8%20%ED%99%95%EC%A0%95.md)\n - [2020 ICT 이슈](https://github.com/gyoogle/tech-interview-for-developer/blob/master/New%20Technology/IT%20Issues/2020%20ICT%20%EC%9D%B4%EC%8A%88.md)\n - [AMD와 Intel의 반백년 전쟁, 그리고 2020년의 '반도체'](https://github.com/gyoogle/tech-interview-for-developer/blob/master/New%20Technology/IT%20Issues/AMD%20vs%20Intel.md)\n\n
\n\n## 📌 Seminar\n\n- [2019 NHN OPEN TALK DAY](https://github.com/gyoogle/tech-interview-for-developer/blob/master/Seminar/NHN%202019%20OPEN%20TALK%20DAY.md)\n- [2019 삼성전자 비전캠프](https://github.com/gyoogle/tech-interview-for-developer/blob/master/Seminar/2019%20%EC%82%BC%EC%84%B1%EC%A0%84%EC%9E%90%20%EB%B9%84%EC%A0%84%EC%BA%A0%ED%94%84.md)\n- [2019 NCSOFT JOB Cafe](https://github.com/GimunLee/tech-interview-for-developer/blob/master/Seminar/NCSOFT%202019%20JOB%20Cafe.md#2019-10-02-ncsoft-job-cafe)\n- [2019 삼성전자 오픈소스 컨퍼런스](
\n\n## 📌 ETC\n\n- [Git Commit Message Convention](https://github.com/gyoogle/tech-interview-for-developer/blob/master/ETC/Git%20Commit%20Message%20Convention.md)\n- [GitHub Fork로 협업하기](https://github.com/gyoogle/tech-interview-for-developer/blob/master/ETC/GitHub%20Fork%EB%A1%9C%20%ED%98%91%EC%97%85%ED%95%98%EA%B8%B0.md#github-fork%EB%A1%9C-%ED%98%91%EC%97%85%ED%95%98%EA%B8%B0)\n- [GitHub 저장소(repository) 미러링](https://github.com/gyoogle/tech-interview-for-developer/blob/master/ETC/GitHub%20%EC%A0%80%EC%9E%A5%EC%86%8C(repository)%20%EB%AF%B8%EB%9F%AC%EB%A7%81.md#github-%EC%A0%80%EC%9E%A5%EC%86%8Crepository-%EB%AF%B8%EB%9F%AC%EB%A7%81)\n- [Git & GitHub & GitLab Flow](https://github.com/gyoogle/tech-interview-for-developer/blob/master/ETC/Git%20vs%20GitHub%20vs%20GitLab%20Flow.md)\n- [Javascript와 Node.js로 Git을 통해 협업하기](https://github.com/gyoogle/tech-interview-for-developer/blob/master/ETC/Collaborate%20with%20Git%20on%20Javascript%20and%20Node.js.md) \n\n
\n\n## License\n[](https://app.fossa.com/projects/git%2Bgithub.com%2Fgyoogle%2Ftech-interview-for-developer?ref=badge_small)\n\n
\n\n[
 ](https://www.buymeacoffee.com/gyoogle)\n\n\n"
},
{
"path": "Seminar/2019 삼성전자 비전캠프.md",
"content": "## [2019 삼성전자 비전캠프]\n\n#### 기업에 대해 새로 알게된 점\n\n------\n\n- 삼성전자 DS와 CE/IM은 완전히 다른 기업\n\n 그러므로, **반도체 공정을 돕는 데이터 분석**을 하고 싶다든지, **반도체 위에 SW를 올리겠다든지 하는 것**은 부적절 함.\n\n**박종찬 상무님 (무선사업부)**\n\n------\n\n- 설득의 3요소 (아리스토텔레스의 수사학)\n\n > 남을 설득하기 위해 필요한 3가지\n\n 1. logos : 논리와 증거\n 2. Pathos : 듣는 사람의 심리 상태\n 3. Ethos : 말하는 사람의 성품, 매력도, 카리스마, 진실성 (가장 중요)\n\n > 정리하면, 행동을 통해 나의 호감도와 진정성을 인지시키고, 신뢰의 다리를 구축 (Ethos)\n >\n > 나의 마음을 받아들일 마음 상태일 때 (Pathos)\n >\n > 논리적으로 설득을 진행 (Logos)\n\n- 개발자의 기쁨은 여러 사람이 나의 제품을 사용하는 데서 온다.\n\n => **삼성전자의 입사 동기** (motivation) 가 될 수 있음.\n\n- (상무님이 생각하는) 미래 프로그래밍에 필요한 3요소\n\n 1. 클라우드\n\n 2. 대용량 서버\n\n Battle-ground 게임은 인기가 많았음. 그러나, 서버 설계를 잘못하여, 유저수에 비례하여 비용이 증가함.\n\n 3. 데이터\n\n> 이 3가지는 반드시 잘하고 있어야 함. 그 외 모든 분야에서의 프로그래머는 사라질 수도 있다고 생각하심. 예를 들어, front-end 개발의 경우, AI 기술을 통해서 할 수 있음.\n\n- 신입 개발자의 자세\n - 초기에는 (5년) 다양한 분야에 대해서 전부 다뤄보아야 함.\n - 이후에는, 2가지 분야를 잘 할 수 있어야 함. 예) 백엔드 + 데이터 / 프론트엔드 + 백엔드 / 데이터 + ML\n- 패권 사회가 되고 있음\n - 미국 vs 중국, 한국 vs 일본\n 최근 상황을 보면, 우위에 서기 위해서 상대방을 괴롭힘\n **다른 IT 기업이 아닌 삼성전자에서 일하고 싶은 이유로 뽑을 수 있음**.\n - 한국이 잘할 수 있는 분야는 2가지 - IT / Contents"
},
{
"path": "Seminar/2019 삼성전자 오픈소스 컨퍼런스(SOSCON).md",
"content": "## 2019 SOSCON\n\n> 삼성전자 오픈소스 컨퍼런스\n\n2019.10.16~17 ( 삼성전자 R&D 캠퍼스 )\n\n
](https://www.buymeacoffee.com/gyoogle)\n\n\n"
},
{
"path": "Seminar/2019 삼성전자 비전캠프.md",
"content": "## [2019 삼성전자 비전캠프]\n\n#### 기업에 대해 새로 알게된 점\n\n------\n\n- 삼성전자 DS와 CE/IM은 완전히 다른 기업\n\n 그러므로, **반도체 공정을 돕는 데이터 분석**을 하고 싶다든지, **반도체 위에 SW를 올리겠다든지 하는 것**은 부적절 함.\n\n**박종찬 상무님 (무선사업부)**\n\n------\n\n- 설득의 3요소 (아리스토텔레스의 수사학)\n\n > 남을 설득하기 위해 필요한 3가지\n\n 1. logos : 논리와 증거\n 2. Pathos : 듣는 사람의 심리 상태\n 3. Ethos : 말하는 사람의 성품, 매력도, 카리스마, 진실성 (가장 중요)\n\n > 정리하면, 행동을 통해 나의 호감도와 진정성을 인지시키고, 신뢰의 다리를 구축 (Ethos)\n >\n > 나의 마음을 받아들일 마음 상태일 때 (Pathos)\n >\n > 논리적으로 설득을 진행 (Logos)\n\n- 개발자의 기쁨은 여러 사람이 나의 제품을 사용하는 데서 온다.\n\n => **삼성전자의 입사 동기** (motivation) 가 될 수 있음.\n\n- (상무님이 생각하는) 미래 프로그래밍에 필요한 3요소\n\n 1. 클라우드\n\n 2. 대용량 서버\n\n Battle-ground 게임은 인기가 많았음. 그러나, 서버 설계를 잘못하여, 유저수에 비례하여 비용이 증가함.\n\n 3. 데이터\n\n> 이 3가지는 반드시 잘하고 있어야 함. 그 외 모든 분야에서의 프로그래머는 사라질 수도 있다고 생각하심. 예를 들어, front-end 개발의 경우, AI 기술을 통해서 할 수 있음.\n\n- 신입 개발자의 자세\n - 초기에는 (5년) 다양한 분야에 대해서 전부 다뤄보아야 함.\n - 이후에는, 2가지 분야를 잘 할 수 있어야 함. 예) 백엔드 + 데이터 / 프론트엔드 + 백엔드 / 데이터 + ML\n- 패권 사회가 되고 있음\n - 미국 vs 중국, 한국 vs 일본\n 최근 상황을 보면, 우위에 서기 위해서 상대방을 괴롭힘\n **다른 IT 기업이 아닌 삼성전자에서 일하고 싶은 이유로 뽑을 수 있음**.\n - 한국이 잘할 수 있는 분야는 2가지 - IT / Contents"
},
{
"path": "Seminar/2019 삼성전자 오픈소스 컨퍼런스(SOSCON).md",
"content": "## 2019 SOSCON\n\n> 삼성전자 오픈소스 컨퍼런스\n\n2019.10.16~17 ( 삼성전자 R&D 캠퍼스 )\n\n\n\n#### 삼성전자 오픈소스 추진 현황\n\n- 2002 : PDA\n- 2009 : Galaxy, Smart TV, Exynos\n- 2012 : Z Phone, Tizen TV, Gear, Refrigerator, Washer\n- 2018 : IoT Devices\n- 2019 ~ : 5G, AI, Robot\n\n
\n\n#### 오픈소스 핵심 역할\n\n1. ##### OPENESS\n\n 소스코드/프로젝트 공개 확대 ( [삼성 오픈소스 GitHub](https://github.com/samsung) )\n\n 국내 주요 커뮤니티 협력 강화\n\n2. ##### Collaboration\n\n 글로벌 오픈소스 리딩\n\n 국내 주요 SW 단체 협력\n\n3. ##### Developemnt Culture\n\n 사내 개발 인프라 강화\n\n Inner Source 확대\n\n
\n\n오픈소스를 통해 미래 주요 기술을 확보 → 고객에게 더욱 새로운 가치와 경험을 제공\n\n
\n\n
\n\n#### 5G\n\n---\n\n- 2G : HUMAN to HUMAN\n\n- 3G/4G : HUMAN to MACHINE\n\n- 5G : MACHINE to MACHINE\n\n
\n\n2G/3G/4G : Voice & Data\n\n5G : Autonomous Driving, Smart City, Smart Factory, Drone, Immersive Media, Telecom Service\n\n " }, { "path": "Seminar/NCSOFT 2019 JOB Cafe.md", "content": "### 2019-10-02 NCSOFT JOB Cafe\n\n---\n\n- Micro Service Architecture 사용\n- 사용하는 언어와 프레임워크는 다양 (C++ 기반 자사 제품도 사용)\n- NC Test\n - 일반적인 기업 인적성과 유사\n - 회사에 대한 문제도 나옴 (연혁)\n - 직무에 따른 문제도 나옴\n - ex) Thread, Network(TCP/IP), OSI 7계층, 브라우저 동작 방법 등\n\n- NCSOFT 소개\n\n
 \n"
},
{
"path": "Seminar/NHN 2019 OPEN TALK DAY.md",
"content": "## NHN 2019 OPEN TALK DAY\n\n> 2019.08.29\n\n#### ※ NHN 주요 사업\n\n1. **TOAST** : 국내 클라우드 서비스\n2. **PAYCO** : 간편결제 핀테크 플랫폼\n3. **한게임** : 게임 개발 (웹게임 → 모바일화)\n\n
\n"
},
{
"path": "Seminar/NHN 2019 OPEN TALK DAY.md",
"content": "## NHN 2019 OPEN TALK DAY\n\n> 2019.08.29\n\n#### ※ NHN 주요 사업\n\n1. **TOAST** : 국내 클라우드 서비스\n2. **PAYCO** : 간편결제 핀테크 플랫폼\n3. **한게임** : 게임 개발 (웹게임 → 모바일화)\n\n\n\n#### ※ 채용 방식\n\n1차 온라인 코딩테스트 → 2차 지필 평가(CS과목) → 3차 Feel The Toast(체험형 1일 면접) → 4차 최종 인성+기술면접\n\n> **1차** : 2시간 4문제 출제(작년) - 지원자들 답 공유시 내부 솔루션으로 코드유사 검증 후 탈락 처리\n>\n> **2차** : 지필평가 (프로그래밍 기초, 운영체제, 컴퓨터구조, 네트워크, 알고리즘, 자료구조 등) 소프트웨어 지식 테스트 (출제위원이 회사에서 꾸려지고, 1~4학년 지식기반 문제 출제, 수능보는 느낌일 것)\n>\n> **3차** : 하루동안 면접 보는 시스템 (오전 2~3시간동안 기술과제 코딩테스트 → 오후에 면접관들 앞에서 코드리뷰 (다대다) + 커뮤니케이션 능력 검증) <작년 기출 유형: 트리+LCA>\n>\n> **4차** : 임원과 인성+기술면접 진행 (종이를 주고, 지원자가 글을 이해한 다음 질문 답변하는 방식)\n\n
\n\n#### ※ 세션 진행\n\n1. #### OTD 선배와의 대화 (작년 Open Talk Day를 듣고 입사)\n\n - NHN Edu (서버개발팀)\n\n > - 작년 하반기 신입채용으로 입사\n > - 서버개발팀에서 Edu에서 만든 '아이엠티처' 프론트엔드 업무 담당\n > - 현재 아이엠티처는 학교에서 애플리케이션으로 부모님이 자식들의 일정 관리나 알림장들을 받아보고, 방과후 학교 관리 등 서비스를 제공하여 이용률이 높은 서비스\n > - 작년 동아리원으로 설명회를 듣고, 지원했는데 한단계 한단계 힘들게 통과하며 입사\n > - 1차 코딩테스트는 힘겹게 2문제 풀었는데 턱걸이로 합격한 느낌\n > 2차 지필평가는 그냥 학교에서 배운 것을 토대로 풀었음\n > 3차는 문제를 못 풀어도 면접관들이 계속 힌트를 주며 최대한 맞출 수 있도록 도와주는 느낌\n > 4차는 간단한 알고리즘을 미리 풀고 설명하는 방식으로 진행\n\n
\n\n - NHN PAYCO (금융개발팀)\n\n > - 작년 수시 경력채용으로 입사\n > - OPEN API 예금/적금 금융 플랫폼을 개발하고, 현재 정부지원 프로젝트 진행중\n > - 책 추천 : 자바로 배우는 핵심 자료구조/알고리즘(보라색)\n > - 항상 깔끔한 코드를 작성하려고 했음\n > - 배운 내용들을 블로그에 기록 (예전에는 2~3일에 한번, 요즘은 일주일에 한번 포스팅) - 정리하는 습관은 개발자에게 상당히 좋다고 생각\n\n
\n\n2. #### 정말로 개발자가 되고 싶으세요?\n\n - 좋은 개발자는?\n\n - 말이 잘 통하는 사람\n - 남을 배려하는 사람\n - 안정적인 코드를 짧은 시간에 작성할 줄 아는 사람\n - 남들이 풀지 못하는 문제를 풀어낼 줄 아는 사람\n\n - 환경의 중요성\n\n - 람다로 개발할 수 있는 환경이 주어지는가 (아직도 예전 자바 버전으로 개발하는 곳인지)\n - Git을 포함한 개발 툴을 활용하는가\n - 더 어려운 문제를 해결하기 위해 일하고 있는가\n - 경영진이 개발자의 성장과 환경 개선을 염두하는가(★★)\n\n - 계속 배우는 개발자가 되길\n\n - 개발 일기를 작성하면 좋다 (내가 오늘 새로 배운게 뭔지 적는 습관가지기. 쌓고 쌓으면 다 지식이 됌)\n - 나는 이 기술이 좋아!가 아닌, 내가 뭘 해보고 싶은지부터 생각해보기\n\n - QnA\n\n - 상황에 맞게 알고리즘을 적절히 사용하는 개발자(신입)를 선호함\n\n > 검색시스템에선 BFS와 DFS 중에 뭘 선택해야 되는가?\n\n - 신입이 알아야 할 데이터베이스 지식은 진짜 그대로 지식정도\n\n > '쿼리'짜는 건 배우는게 아니라 직접 해보는 훈련이 있어야 함\n >\n > 현재 입사한 사원들도 다 교육받고 실습으로 경험을 쌓는 중\n >\n > 데이터베이스에 대한 질문에 대한 답변을 할 수 있을 정도 - Isolation level에 대한 설명, 데이터베이스에서 인덱스 저장방법으로 왜 B tree를 이용하는지?\n\n
\n\n3. #### Hello 월급, 취업준비하기\n\n - 일단 뭐든 만들어보자\n\n - 내가 필요했던 것, 또는 모두에게 서비스한다는 생각으로\n - 직접 만들어보면서 경험과 통찰력을 기를 수 있음.\n\n - 컴퓨터공학부에 오게 된 이유\n\n - 공책에 브루마블처럼 주사위로 하는 보드게임을 직접 만들어서 놀았음\n - 직접 그려야되는 번거러움에, 컴퓨터로 하면 편하지않을까? 게임 개발을 해보고 싶다는 생각에 컴퓨터공학부로 대학 진학\n - 창업을 준비하던 학교 선배가 1학년인 나한테 웹개발 알바 제안\n - html, css 등 웹개발을 해보니 직접 내가 만든 것들이 눈으로 보이는게 너무 재밌었음\n - '나는 게임 개발을 하고 싶었던 게 아니라 뭔가 만드는 걸 좋아했구나' 이때부터 개발자에 흥미를 갖고 여러 프로젝트를 진행\n\n - 토렌트 공유 프로그램\n\n - 사용자는 토렌트 파일을 다운받을 때, 악성 파일인지 걱정하게 됨. 대신해서 파일을 받아주고, 괜찮은 파일이면 메일로 받은 파일을 전송해주는 서비스가 어떨까?해서 만들기 시작\n - 집에 망가져도 괜찮은 컴퓨터를 서버로 두고, 요청하면 대신 받아주고 괜찮을 때 보내주는 방식으로 시작. 하지만 악성 파일이면 내 컴퓨터가 고장나고 서비스가 끝나게 되는 위험 존재\n - 가상 환경을 도입. 가상 환경을 생성하여 그 안에서 파일을 받고, 만약 에러나 제대로 파일정보를 얻어오지 못하면 false 처리. 온전한 파일 전송이 된다는 response가 들어오면 해당 파일을 사용자에게 전송해주는 방식으로 해결함\n - 야매(?) 방식으로 했다고 생각했는데, 실제로 보안 업무에서도 진행하는 하나의 방법이라고 해서 놀랐음\n\n - 이 밖에도 인턴 활동 등 다양한 회사 프로젝트에 참가해서 서버관리 등 일을 해왔음. 쏠쏠히 돈을 벌어 대학을 다니면서 등록금은 모두 자신이 번 돈으로 냄\n\n - 지금처럼 일하는 거면 '프리랜서'를 해도 되지 않을까?\n\n - 택도 없는 소리였음\n - 프리랜서를 하려면, 네트워킹이 매우 중요. 다양한 사람들을 알아야 그만큼 일도 들어옴\n - 일단 기업에 들어가자하고 취업 준비 시작 후 NHN 입사\n\n - 항상 서비스에 맞는 인프라를 구성하도록 노력하자\n\n - AWS Lambda 추천 (작은 규모에서는 무료로 사용 가능, serverless 장점)\n\n > Ddos 공격으로 요금 폭탄맞으면? → AWS Sheild, AWS CloundFront 기능으로 해결\n\n
\n\n
\n\n#### ※ 사전 코딩테스트 코드 리뷰 (NHN Lab 팀장)\n\n> 동아리별 제출한 코드 평균 점수 : 78점\n\n해당 문제는 작년 하반기 3차 기술과제 문제였음\n\n**적절한 해결방법** : Tree를 그리고 LCA or LCP 알고리즘을 통해 공통 조상 찾기\n\n
\n\n##### 코딩 테스트 문제를 볼 때 체크하는 중요한 점(★★★)\n\n- 트리를 그릴때는 정렬을 시켜놓고 Bottop-up으로 구성해야 빠르다\n\n- Main 함수 안에는 잘게 쪼개놓는 연습이 필요\n\n > main 함수를 simple하게 만들기\n\n- 함수나 변수 네이밍 잘하기\n\n > 다른 사람이 봐도 코드를 이해할 수 있어야 함. (코드 리뷰시 네이밍도 중요하게 봄)\n\n- 무분별한 static 변수 사용 줄이기\n\n > (public, private, protected) 차이점 잘 이해하고 사용하기\n >\n > 신입에게 이정도까지 바라지는 않지만, 개념은 잘 알고있기를 바람\n >\n > → static을 왜 쓰고, 언제 써야하는 지 등?\n\n- 사용한 자원은 항상 해제하기\n\n > scanner와 같은 것들 마지막에 항상 close로 닫는 습관\n\n- 예외 처리는 try-throw-catch 사용하기\n\n- 객체를 만들어 기능에 대한 것들을 메소드화 시키고 활용하는 코딩 습관 기르기\n\n
\n\n##### 좋은 코드를 짜기 위한 습관\n\n- 주어진 요구사항 잘 파악하기\n- 정적 분석 도구 활용하기\n- 코드 개선해보기\n- 테스트 코드 작성해보기\n\n
\n\n#### QnA\n\n---\n\n##### 신입 지원자들에게 바라는 점\n\n작년에 지원자에게 하노이 탑을 재귀로 그 자리에서 짜보라고 간단한 질문을 했었음\n\n생각보다 못푸는 지원자가 상당히 많아서 놀램\n\n> 재귀 문제의 핵심은 → 탈출조건, 파라미터 처리\n\n
\n\n**학교다닐 때 했던 프로젝트 설명보다, '진짜 스스로 만들고 싶어서 했던 개인적인 프로젝트에 대한 경험을 지니고 있기를 바람'**\n\n
\n\n**질문내용** : 사전 코딩테스트 문제를 풀면서 '트리+LCA' 방식도 알았지만, 배열과 규칙을 활용해 시간복잡도를 줄여 더 빨리 푸는 방식으로 했는데 틀린방식인가요?\n\n##### 답변\n\n우리가 내는 문제는, 실제 상황에서도 적용할 수 있는 유형임\n\n트리를 구성해서 짜는 걸 본다는 건 현재 상황에 '효율적인' 알고리즘과 자료구조를 선택해서 푸는 걸 확인하는 것\n\n결국 수많은 데이터가 들어왔을 때, 트리를 활용한 로직은 재사용성도 좋고 관리가 효율적임. 배열을 이용한 방식으로 인한 해결은 구두로 들어서 이해하기 힘들지만 '효율'적인 측면을 다시 한번 생각해보길 바람\n\n> 시간을 최대한 줄이려는 것보다, 자원 관리를 더욱 효율적으로 짜는 코딩 방식을 더 추구하는 느낌을 받았음\n\n" }, { "path": "Web/CSR & SSR.md", "content": "## CSR & SSR\n\n
\n\n> CSR : Client Side Rendering\n>\n> SSR : Server Side Rendering\n\n
\n\nCSR에는 모바일 시대에 들어서 SPA가 등장했다.\n\n##### SPA(Single Page Applictaion)\n\n> 최초 한 번 페이지 전체를 로딩한 뒤, 데이터만 변경하여 사용할 수 있는 애플리케이션\n\nSPA는 기본적으로 페이지 로드가 없고, 모든 페이지가 단순히 Html5 History에 의해 렌더링된다.\n\n
\n\n기존의 전통적 방법인 SSR 방식에는 성능 문제가 있었다.\n\n요즘 웹에서 제공되는 정보가 워낙 많다. 요청할 때마다 새로고침이 일어나면서 페이지를 로딩할 때마다 서버로부터 리소스를 전달받아 해석하고, 화면에 렌더링하는 방식인 SSR은 데이터가 많을 수록 성능문제가 발생했다.\n\n```\n현재 주소에서 동일한 주소를 가리키는 버튼을 눌렀을 때,\n설정페이지에서 필요한 데이터를 다시 가져올 수 없다.\n```\n\n이는, 인터랙션이 많은 환경에서 비효율적이다. 렌더링을 서버쪽에서 진행하면 그만큼 서버 자원이 많이 사용되기 때문에 불필요한 트래픽이 낭비된다.\n\n
\n\nCSR 방식은 사용자의 행동에 따라 필요한 부분만 다시 읽어온다. 따라서 서버 측에서 렌더링하여 전체 페이지를 다시 읽어들이는 것보다 빠른 인터렉션을 기대할 수 있다. 서버는 단지 JSON파일만 보내주고, HTML을 그리는 역할은 자바스크립트를 통해 클라이언트 측에서 수행하는 방식이다.\n\n
\n\n뷰 렌더링을 유저의 브라우저가 담당하고, 먼저 웹앱을 브라우저에게 로드한 다음 필요한 데이터만 전달받아 보여주는 CSR은 트래픽을 감소시키고, 사용자에게 더 나은 경험을 제공할 수 있도록 도와준다.\n\n
\n\n
\n\n#### CSR 장단점\n\n- ##### 장점\n\n - 트래픽 감소\n\n > 필요한 데이터만 받는다\n\n - 사용자 경험\n\n > 새로고침이 발생하지 않음. 사용자가 네이티브 앱과 같은 경험을 할 수 있음\n\n- ##### 단점\n\n - 검색 엔진\n\n > 크롬에서 리액트로 만든 웹앱 소스를 확인하면 내용이 비어있음. 이처럼 검색엔진 크롤러가 데이터 수집에 어려움이 있을 가능성 존재\n >\n > 구글 검색엔진은 자바스크립트 엔진이 내장되어있지만, 네이버나 다음 등 검색엔진은 크롤링에 어려움이 있어 SSR을 따로 구현해야하는 번거로움 존재\n\n
\n\n#### SSR 장단점\n\n- ##### 장점\n\n - 검색엔진 최적화\n\n - 초기로딩 성능개선\n\n > 첫 렌더링된 HTML을 클라이언트에서 전달해주기 때문에 초기로딩속도를 많이 줄여줌\n\n- ##### 단점\n\n - 프로젝트 복잡도\n\n > 라우터 사용하다보면 복잡도가 높아질 수 있음\n\n - 성능 악화 가능성\n\n
\n\n
\n\n##### [참고 자료]\n\n- [링크](https://velog.io/@zansol/%ED%99%95%EC%9D%B8%ED%95%98%EA%B8%B0-%EC%84%9C%EB%B2%84%EC%82%AC%EC%9D%B4%EB%93%9C%EB%A0%8C%EB%8D%94%EB%A7%81SSR-%ED%81%B4%EB%9D%BC%EC%9D%B4%EC%96%B8%ED%8A%B8%EC%82%AC%EC%9D%B4%EB%93%9C%EB%A0%8C%EB%8D%94%EB%A7%81CSR)" }, { "path": "Web/CSRF & XSS.md", "content": "# CSRF & XSS\n\n
\n\n### CSRF\n\n> Cross Site Request Forgery\n\n웹 어플리케이션 취약점 중 하나로, 인터넷 사용자가 자신의 의지와는 무관하게 공격자가 의도한 행위 (modify, delete, register 등)를 특정한 웹사이트에 request하도록 만드는 공격을 말한다.\n\n주로 해커들이 많이 이용하는 것으로, 유저의 권한을 도용해 중요한 기능을 실행하도록 한다. \n\n우리가 실생활에서 CSRF 공격을 볼 수 있는 건, 해커가 사용자의 SNS 계정으로 광고성 글을 올리는 것이다.\n\n정확히 말하면, CSRF는 해커가 사용자 컴퓨터를 감염시거나 서버를 해킹해서 공격하는 것이 아니다. CSRF 공격은 아래와 같은 조건이 만족할 때 실행된다.\n\n- 사용자가 해커가 만든 피싱 사이트에 접속한 경우\n- 위조 요청을 전송하는 서비스에 사용자가 로그인을 한 상황\n\n보통 자동 로그인을 해둔 경우에 이런 피싱 사이트에 접속하게 되면서 피해를 입는 경우가 많다. 또한, 해커가 XSS 공격을 성공시킨 사이트라면, 피싱 사이트가 아니더라도 CSRF 공격이 이루어질 수 있다.\n\n
\n\n#### 대응 기법\n\n- ##### 리퍼러(Refferer) 검증\n\n 백엔드 단에서 Refferer 검증을 통해 승인된 도메인으로 요청시에만 처리하도록 한다.\n\n- ##### Security Token 사용\n\n 사용자의 세션에 임의의 난수 값을 저장하고, 사용자의 요청시 해당 값을 포함하여 전송시킨다. 백엔드 단에서는 요청을 받을 때 세션에 저장된 토큰값과 요청 파라미터로 전달받는 토큰 값이 일치하는 지 검증 과정을 거치는 방법이다.\n\n> 하지만, XSS에 취약점이 있다면 공격을 받을 수도 있다.\n\n
\n\n### XSS\n\n> Cross Site Scription\n\nCSRF와 같이 웹 어플리케이션 취약점 중 하나로, 관리자가 아닌 권한이 없는 사용자가 웹 사이트에 스크립트를 삽입하는 공격 기법을 말한다.\n\n악의적으로 스크립트를 삽입하여 이를 열람한 사용자의 쿠키가 해커에게 전송시키며, 이 탈취한 쿠키를 통해 세션 하이재킹 공격을 한다. 해커는 세션ID를 가진 쿠키로 사용자의 계정에 로그인이 가능해지는 것이다.\n\n공격 종류로는 지속성, 반사형, DOM 기반 XSS 등이 있다.\n\n- **지속성** : 말 그대로 지속적으로 피해를 입히는 유형으로, XSS 취약점이 존재하는 웹 어플리케이션에 악성 스크립트를 삽입하여 열람한 사용자의 쿠키를 탈취하거나 리다이렉션 시키는 공격을 한다. 이때 삽입된 스크립트를 데이터베이스에 저장시켜 지속적으로 공격을 하기 때문에 Persistent XSS라고 불린다.\n- **반사형** : 사용자에게 입력 받은 값을 서버에서 되돌려 주는 곳에서 발생한다. 공격자는 악의 스크립트와 함께 URL을 사용자에게 누르도록 유도하고, 누른 사용자는 이 스크립트가 실행되어 공격을 당하게 되는 유형이다.\n- **DOM 기반** : 악성 스크립트가 포함된 URL을 사용자가 요청하게 되면서 브라우저를 해석하는 단계에서 발생하는 공격이다. 이 스크립트로 인해 클라이언트 측 코드가 원래 의도와 다르게 실행된다. 이는 다른 XSS 공격과는 달리 서버 측에서 탐지가 어렵다.\n\n
\n\n#### 대응 기법\n\n- ##### 입출력 값 검증\n\n XSS Cheat Sheet에 대한 필터 목록을 만들어 모든 Cheat Sheet에 대한 대응을 가능하도록 사전에 대비한다. XSS 필터링을 적용 후 스크립트가 실행되는지 직접 테스트 과정을 거쳐볼 수도 있다,\n\n- ##### XSS 방어 라이브러리, 확장앱 \n\n Anti XSS 라이브러리를 제공해주는 회사들이 많다. 이 라이브러리는 서버단에서 추가하며, 사용자들은 각자 브라우저에서 악성 스크립트가 실행되지 않도록 확장앱을 설치하여 방어할 수 있다.\n\n- ##### 웹 방화벽\n\n 웹 방화벽은 웹 공격에 특화된 것으로, 다양한 Injection을 한꺼번에 방어할 수 있는 장점이 있다.\n\n- ##### CORS, SOP 설정\n \n CORS(Cross-Origin Resource Sharing), SOP(Same-Origin-Policy)를 통해 리소스의 Source를 제한 하는것이 효과적인 방어 방법이 될 수 있다. 웹 서비스상 취약한 벡터에 공격 스크립트를 삽입 할 경우, 치명적인 공격을 하기 위해 스크립트를 작성하면 입력값 제한이나 기타 요인 때문에 공격 성공이 어렵다. 그러나 공격자의 서버에 위치한 스크립트를 불러 올 수 있다면 이는 상대적으로 쉬워진다. 그렇기 떄문에 CORS, SOP를 활용 하여 사전에 지정된 도메인이나 범위가 아니라면 리소스를 가져올 수 없게 제한해야 한다. \n\n
\n\n
\n\n#### [참고 사항]\n\n- [링크](https://itstory.tk/entry/CSRF-%EA%B3%B5%EA%B2%A9%EC%9D%B4%EB%9E%80-%EA%B7%B8%EB%A6%AC%EA%B3%A0-CSRF-%EB%B0%A9%EC%96%B4-%EB%B0%A9%EB%B2%95)\n\n- [링크](https://noirstar.tistory.com/266)\n\n- [링크](https://evan-moon.github.io/2020/05/21/about-cors/) \n" }, { "path": "Web/Cookie & Session.md", "content": "## Cookie & Session\n\n\n\n| | Cookie | Session |\n| :------: | :--------------------------------------------------: | :--------------: |\n| 저장위치 | Client | Server |\n| 저장형식 | Text | Object |\n| 만료시점 | 쿠키 저장시 설정
(설정 없으면 브라우저 종료 시) | 정확한 시점 모름 |\n| 리소스 | 클라이언트의 리소스 | 서버의 리소스 |\n| 용량제한 | 한 도메인 당 20개, 한 쿠키당 4KB | 제한없음 |\n\n\n\n#### 저장 위치\n\n- 쿠키 : 클라이언트의 웹 브라우저가 지정하는 메모리 or 하드디스크\n- 세션 : 서버의 메모리에 저장\n\n\n\n#### 만료 시점\n\n- 쿠키 : 저장할 때 expires 속성을 정의해 무효화시키면 삭제될 날짜 정할 수 있음\n- 세션 : 클라이언트가 로그아웃하거나, 설정 시간동안 반응이 없으면 무효화 되기 때문에 정확한 시점 알 수 없음\n\n\n\n#### 리소스\n\n- 쿠키 : 클라이언트에 저장되고 클라이언트의 메모리를 사용하기 때문에 서버 자원 사용하지 않음\n- 세션 : 세션은 서버에 저장되고, 서버 메모리로 로딩 되기 때문에 세션이 생길 때마다 리소스를 차지함\n\n\n\n#### 용량 제한\n\n- 쿠키 : 클라이언트도 모르게 접속되는 사이트에 의하여 설정될 수 있기 때문에 쿠키로 인해 문제가 발생하는 걸 막고자 한 도메인당 20개, 하나의 쿠키 당 4KB로 제한해 둠\n- 세션 : 클라이언트가 접속하면 서버에 의해 생성되므로 개수나 용량 제한 없음" }, { "path": "Web/DevOps/[AWS] 스프링 부트 배포 스크립트 생성.md", "content": "# [AWS] 스프링 부트 배포 스크립트 생성\n\n
\n\n
 \n\n
\n\n\n\nAWS에서 프로젝트를 배포하는 과정은 프로젝트가 수정할 때마다 똑같은 일을 반복해야한다.\n\n#### 프로젝트 배포 과정\n\n- `git pull`로 프로젝트 업데이트\n- gradle 프로젝트 빌드\n- ec2 인스턴스 서버에서 프로젝트 실행 및 배포\n\n
\n\n이를 자동화 시킬 수 있다면 편리할 것이다. 따라서 배포에 필요한 쉘 스크립트를 생성해보자.\n\n`deploy.sh` 파일을 ec2 상에서 생성하여 아래와 같이 작성한다.\n\n
\n\n```sh\n#!/bin/bash\n\nREPOSITORY=/home/ec2-user/app/{clone한 프로젝트 저장한 경로}\nPROJECT_NAME={프로젝트명}\n\ncd $REPOSITORY/$PROJECT_NAME/\n\necho \"> Git Pull\"\n\ngit pull\n\necho \"> 프로젝트 Build 시작\"\n\n./gradlew build\n\necho \"> step1 디렉토리로 이동\"\n\ncd $REPOSITORY\n\necho \"> Build 파일 복사\"\n\ncp $REPOSITORY/$PROJECT_NAME/build/libs/*.jar $REPOSITORY/\n\necho \"> 현재 구동중인 애플리케이션 pid 확인\"\n\nCURRENT_PID=$(pgrep -f ${PROJECT_NAME}.*.jar)\n\necho \"현재 구동 중인 애플리케이션 pid: $CURRENT_PID\"\n\nif [ -z \"$CURRENT_PID\" ]; then\n echo \"> 현재 구동 중인 애플리케이션이 없으므로 종료하지 않습니다.\"\nelse\n echo \"> kill -15 $CURRENT_PID\"\n kill -15 $CURRENT_PID\n sleep 5\nfi\n\necho \"> 새 애플리케이션 배포\"\n\nJAR_NAME=$(ls -tr $REPOSITORY/ | grep jar | tail -n 1)\n\necho \"> JAR Name: $JAR_NAME\"\n\nnohup java -jar \\\n -Dspring.config.location=classpath:/application.properties,classpath:/application-real.properties,/home/ec2-user/app/application-oauth.properties,/home/ec2-user/app/application-real-db.properties \\\n -Dspring.profiles.active=real \\\n $REPOSITORY/$JAR_NAME 2>&1 &\n```\n\n
\n\n쉘 스크립트 내 경로명 같은 경우에는 사용자의 환경마다 다를 수 있으므로 확인 후 진행하도록 하자.\n\n
\n\n스크립트 순서대로 간단히 설명하면 아래와 같다.\n\n```sh\nREPOSITORY=/home/ec2-user/app/{clone한 프로젝트 저장한 경로}\nPROJECT_NAME={프로젝트명}\n```\n\n자주 사용하는 프로젝트 명을 변수명으로 저장해둔 것이다.\n\n`REPOSITORY`는 ec2 서버 내에서 본인이 git 프로젝트를 clone한 곳의 경로로 지정하며, `PROJECT_NAME`은 해당 프로젝트명을 입력하자.\n\n
\n\n```SH\necho \"> Git Pull\"\n\ngit pull\n\necho \"> 프로젝트 Build 시작\"\n\n./gradlew build\n\necho \"> step1 디렉토리로 이동\"\n\ncd $REPOSITORY\n\necho \"> Build 파일 복사\"\n\ncp $REPOSITORY/$PROJECT_NAME/build/libs/*.jar $REPOSITORY/\n```\n\n
\n\n현재 해당 경로는 clone한 곳이기 때문에 바로 `git pull`이 가능하다. 프로젝트의 변경사항을 ec2 인스턴스 서버 내의 코드에도 update를 시켜주기 위해 pull을 진행한다.\n\n그 후 프로젝트 빌드를 진행한 뒤, 생성된 jar 파일을 현재 REPOSITORY 경로로 복사해서 가져오도록 설정했다.\n\n
\n\n```sh\nCURRENT_PID=$(pgrep -f ${PROJECT_NAME}.*.jar)\n\necho \"현재 구동 중인 애플리케이션 pid: $CURRENT_PID\"\n\nif [ -z \"$CURRENT_PID\" ]; then\n echo \"> 현재 구동 중인 애플리케이션이 없으므로 종료하지 않습니다.\"\nelse\n echo \"> kill -15 $CURRENT_PID\"\n kill -15 $CURRENT_PID\n sleep 5\nfi\n```\n\n
\n\n기존에 수행 중인 프로젝트를 종료 후 재실행해야 되기 때문에 pid 값을 얻어내 kill 하는 과정을 진행한다.\n\n현재 구동 중인 여부를 확인하기 위해서 `if else fi`로 체크하게 된다. 만약 존재하면 해당 pid 값에 해당하는 프로세스를 종료시킨다.\n\n
\n\n```sh\necho \"> JAR Name: $JAR_NAME\"\n\nnohup java -jar \\\n -Dspring.config.location=classpath:/application.properties,classpath:/application-real.properties,/home/ec2-user/app/application-oauth.properties,/home/ec2-user/app/application-real-db.properties \\\n -Dspring.profiles.active=real \\\n $REPOSITORY/$JAR_NAME 2>&1 &\n```\n\n
\n\n`nohup` 명령어는 터미널 종료 이후에도 애플리케이션이 계속 구동될 수 있도록 해준다. 따라서 이후에 ec2-user 터미널을 종료해도 현재 실행한 프로젝트 경로에 접속이 가능하다.\n\n`-Dspring.config.location`으로 처리된 부분은 우리가 git에 프로젝트를 올릴 때 보안상의 이유로 `.gitignore`로 제외시킨 파일들을 따로 등록하고, jar 내부에 존재하는 properties를 적용하기 위함이다.\n\n예제와 같이 `application-oauth.properties`, `application-real-db.properties`는 git으로 올라와 있지 않아 따로 ec2 서버에 사용자가 직접 생성한 외부 파일이므로, 절대경로를 통해 입력해줘야 한다.\n\n
\n\n프로젝트의 수정사항이 생기면, EC2 인스턴스 서버에서 `deploy.sh`를 실행해주면, 차례대로 명령어가 실행되면서 수정된 사항을 배포할 수 있다.\n\n
\n\n
\n\n#### [참고 사항]\n\n- [링크](https://github.com/jojoldu/freelec-springboot2-webservice)" }, { "path": "Web/DevOps/[Travis CI] 프로젝트 연동하기.md", "content": "# [Travis CI] 프로젝트 연동하기\n\n
\n\n
 \n\n
\n\n\n\n```\n자동으로 테스트 및 빌드가 될 수 있는 환경을 만들어 개발에만 집중할 수 있도록 하자\n```\n\n
\n\n#### CI(Continuous Integration)\n\n코드 버전 관리를 하는 Git과 같은 시스템에 PUSH가 되면 자동으로 빌드 및 테스트가 수행되어 안정적인 배포 파일을 만드는 과정을 말한다.\n\n
\n\n#### CD(Continuous Deployment)\n\n빌드한 결과를 자동으로 운영 서버에 무중단 배포하는 과정을 말한다.\n\n
\n\n### Travis CI 웹 서비스 설정하기\n\n[Travis 사이트](https://www.travis-ci.com/)로 접속하여 깃허브 계정으로 로그인 후, `Settings`로 들어간다.\n\nRepository 활성화를 통해 CI 연결을 할 프로젝트로 이동한다.\n\n
\n\n
 \n\n
\n\n\n\n
\n\n### 프로젝트 설정하기\n\n세부설정을 하려면 `yml`파일로 진행해야 한다. 프로젝트에서 `build.gradle`이 위치한 경로에 `.travis.yml`을 새로 생성하자\n\n```yml\nlanguage: java\njdk:\n - openjdk11\n\nbranches:\n only:\n - main\n\n# Travis CI 서버의 Home\ncache:\n directories:\n - '$HOME/.m2/repository'\n - '$HOME/.gradle'\n\nscript: \"./gradlew clean build\"\n\n# CI 실행 완료시 메일로 알람\nnotifications:\n email:\n recipients:\n - gyuseok6394@gmail.com\n```\n\n- `branches` : 어떤 브랜치가 push할 때 수행할지 지정\n- `cache` : 캐시를 통해 같은 의존성은 다음 배포하지 않도록 설정\n- `script` : 설정한 브랜치에 push되었을 때 수행하는 명령어\n- `notifications` : 실행 완료 시 자동 알람 전송 설정\n\n
\n\n생성 후, 해당 프로젝트에서 `Github`에 push를 진행하면 Travis CI 사이트의 해당 레포지토리 정보에서 빌드가 성공한 것을 확인할 수 있다.\n\n
\n\n
 \n\n
\n\n\n\n
\n\n#### *만약 Travis CI에서 push 후에도 아무런 반응이 없다면?*\n\n현재 진행 중인 프로젝트의 GitHub Repository가 바로 루트 경로에 있지 않은 확률이 높다.\n\n즉, 해당 레포지토리에서 추가로 폴더를 생성하여 프로젝트가 생성된 경우를 말한다.\n\n이럴 때는 `.travis.yml`을 `build.gradle`이 위치한 경로에 만드는 것이 아니라, 레포지토리 루트 경로에 생성해야 한다.\n\n
\n\n
 \n\n
\n\n\n\n그 이후 다음과 같이 코드를 추가해주자 (현재 위치로 부터 프로젝트 빌드를 진행할 곳으로 이동이 필요하기 때문)\n\n```yml\nlanguage: java\njdk:\n - openjdk11\n\nbranches:\n only:\n - main\n\n# ------------추가 부분----------------\n\nbefore_script:\n - cd {프로젝트명}/\n \n# ------------------------------------\n\n# Travis CI 서버의 Home\ncache:\n directories:\n - '$HOME/.m2/repository'\n - '$HOME/.gradle'\n\nscript: \"./gradlew clean build\"\n\n# CI 실행 완료시 메일로 알람\nnotifications:\n email:\n recipients:\n - gyuseok6394@gmail.com\n```\n\n
\n\n
\n\n#### [참고 자료]\n\n- [링크](https://github.com/jojoldu/freelec-springboot2-webservice)\n\n
" }, { "path": "Web/DevOps/시스템 규모 확장.md", "content": "# 시스템 규모 확장\n\n
\n\n```\n시스템 사용자 수에 따라 설계해야 하는 규모가 달라진다.\n수백만의 이용자가 존재하는 시스템을 개발해야 한다면, 어떤 것들을 고려해야 할 지 알아보자\n```\n\n
\n\n1. #### 무상태(stateless) 웹 계층\n\n 수평적으로 확장하기 위해 필요하다. 즉, 사용자 세션 정보와 같은 상태 정보를 데이터베이스와 같은 지속 가능한 저장소에 맡기고, 웹 계층에서는 필요할 때 가져다 사용하는 방식으로 만든다.\n\n 웹 계층에서는 무상태를 유지하면서, 어떤 사용자가 http 요청을 하더라도 따로 분리한 공유 저장소에서 해당 데이터를 불러올 수 있도록 구성한다.\n\n 수평적 확장은 여러 서버를 추가하여 Scale out하는 방식으로, 이처럼 웹 계층에서 상태를 지니고 있지 않으면, 트래픽이 늘어날 때 원활하게 서버를 추가할 수 있게 된다.\n\n
\n\n2. #### 모든 계층 다중화 도입\n\n 데이터베이스를 주-부로 나누어 운영하는 방식을 다중화라고 말한다. 다중화에 대한 장점은 아래와 같다.\n\n - 더 나은 성능 지원 : 모든 데이터 변경에 대한 연산은 주 데이터베이스 서버로 전달되는 반면, 읽기 연산은 부 데이터베이스 서버들로 분산된다. 병렬로 처리되는 쿼리 수가 늘어나 성능이 좋아지게 된다.\n - 안정성 : 데이터베이스 서버 가운데 일부분이 손상되더라도, 데이터를 보존할 수 있다.\n - 가용성 : 데이터를 여러 지역에 복제하여, 하나의 데이터베이스 서버에 장애가 발생해도 다른 서버에 있는 데이터를 가져와서 서비스를 유지시킬 수 있다.\n\n
\n\n3. #### 가능한 많은 데이터 캐시\n\n 캐시는 데이터베이스 호출을 최소화하고, 자주 참조되는 데이터를 메모리 안에 두면서 빠르게 요청을 처리할 수 있도록 지원해준다. 따라서 데이터 캐시를 활용하면, 시스템 성능이 개선되며 데이터베이스의 부하 또한 줄일 수 있다. 캐시 메모리가 너무 작으면, 액세스 패턴에 따라 데이터가 너무 자주 캐시에서 밀려나 성능이 떨어질 수 있다. 따라서 캐시 메모리를 과할당하여 캐시에 보관될 데이터가 갑자기 늘어났을 때 생길 문제를 방지할 수 있는 솔루션도 존재한다.\n\n
\n\n4. #### 여러 데이터 센터를 지원\n\n 데이터 센터에 장애가 나는 상황을 대비하기 위함이다. 실제 AWS를 이용할 때를 보더라도, 지역별로 다양하게 데이터 센터가 구축되어 있는 모습을 확인할 수 있다. 장애가 없는 상황에서 가장 가까운 데이터 센터로 사용자를 안내하는 절차를 보통 '지리적 라우팅'이라고 부른다. 만약 해당 데이터 센터에서 심각한 장애가 발생한다면, 모든 트래픽을 장애가 발생하지 않은 다른 데이터 센터로 전송하여 시스템이 다운되지 않도록 지원한다.\n\n
\n\n5. #### 정적 콘텐츠는 CDN을 통해 서비스\n\n CDN은 정적 콘텐츠를 전송할 때 사용하는 지리적으로 분산된 서버의 네트워크다. 주로 시스템 내에서 변동성이 없는 이미지, 비디오, CSS, Javascript 파일 등을 캐시한다.\n\n 시스템에 접속한 사용자의 가장 가까운 CDN 서버에서 정적 콘텐츠를 전달해주므로써 로딩 시간을 감소시켜준다. 즉, CDN 서버에서 사용자에게 필요한 데이터를 캐시처럼 먼저 찾고, 없으면 그때 서버에서 가져다가 전달하는 방식으로 좀 더 사이트 로딩 시간을 줄이고, 데이터베이스의 부하를 줄일 수 있는 장점이 있다.\n\n
\n\n6. #### 데이터 계층은 샤딩을 통해 규모를 확장\n\n 데이터베이스의 수평적 확장을 말한다. 샤딩은 대규모 데이터베이스를 shard라고 부르는 작은 단위로 분할하는 기술을 말한다. 모든 shard는 같은 스키마를 사용하지만, 보관하는 데이터 사이에 중복은 존재하지 않는다. 샤딩 키(파티션 키라고도 부름)을 적절히 정해서 데이터가 잘 분산될 수 있도록 전략을 짜는 것이 중요하다. 즉, 한 shard에 데이터가 몰려서 과부하가 걸리지 않도록 하는 것이 핵심이다.\n\n - 데이터의 재 샤딩 : 데이터가 너무 많아져서 일정 shard로 더이상 감당이 어려울 때 혹은 shard 간 데이터 분포가 균등하지 못하여 어떤 shard에 할당된 공간 소모가 다른 shard에 비해 빨리 진행될 때 시행해야 하는 것\n - 유명인사 문제 : 핫스팟 키라고도 부름. 특정 shard에 질의가 집중되어 과부하 되는 문제를 말한다.\n - 조인과 비 정규화 : 여러 shard로 쪼개고 나면, 조인하기 힘들어지는 문제가 있다. 이를 해결하기 위한 방법은 데이터베이스를 비정규화하여 하나의 테이블에서 질의가 수행가능하도록 한다.\n\n
\n\n7. #### 각 계층은 독립적 서비스로 분할\n\n 마이크로 서비스라고 많이 부른다. 서비스 별로 독립적인 체계를 구축하면, 하나의 서비스가 다운이 되더라도 최대한 다른 서비스들에 영향을 가지 않도록 할 수 있다. 따라서 시스템 규모가 커질수록 계층마다 독립된 서비스로 구축하는 것이 필요해질 수 있다.\n\n
\n\n8. #### 시스템에 대한 모니터링 및 자동화 도구 활용\n\n - 로그 : 에러 로그 모니터링. 시스템의 오류와 문제를 쉽게 찾아낼 수 있다.\n - 메트릭 : 사업 현황, 시스템 현재 상태 등에 대한 정보들을 수집할 수 있다.\n - 자동화 : CI/CD를 통해 빌드, 테스트, 배포 등의 검증 절차를 자동화하면 개발 생산성을 크게 향상시킨다.\n\n
\n\n
\n\n#### [참고 자료]\n\n- [가상 면접 사례로 배우는 대규모 시스템 설계 기초](http://www.kyobobook.co.kr/product/detailViewKor.laf?mallGb=KOR&ejkGb=KOR&barcode=9788966263158)" }, { "path": "Web/HTTP Request Methods.md", "content": "# HTTP Request Methods\n\n
\n\n```\n클라이언트가 웹서버에게 요청하는 목적 및 그 종류를 알리는 수단을 말한다.\n```\n\n
\n\n
\n\n1. #### GET\n\n 리소스(데이터)를 받기 위함\n\n URL(URI) 형식으로 서버 측에 리소스를 요청한다.\n\n
\n\n2. #### HEAD\n\n 메세지 헤더 정보를 받기 위함\n\n GET과 유사하지만, HEAD는 실제 문서 요청이 아닌 문서에 대한 정보 요청이다. 즉, Response 메세지를 받았을 때, Body는 비어있고, Header 정보만 들어있다.\n\n
\n\n3. #### POST\n\n 내용 및 파일 전송을 하기 위함\n\n 클라이언트에서 서버로 어떤 정보를 제출하기 위해 사용한다. Request 데이터를 HTTP Body에 담아 웹 서버로 전송한다.\n\n
\n\n4. #### PUT\n\n 리소스(데이터)를 갱신하기 위함\n\n POST와 유사하나, 기존 데이터를 갱신할 때 사용한다.\n\n
\n\n5. #### DELETE\n\n 리소스(데이터)를 삭제하기 위함\n\n 웹 서버측에 요청한 리소스를 삭제할 때 사용한다.\n\n > 실제로 클라이언트에서 서버 자원을 삭제하도록 하진 않아 비활성화로 구성한다.\n\n
\n\n6. #### CONNECT\n\n 클라이언트와 서버 사이의 중간 경유를 위함\n\n 보통 Proxy를 통해 SSL 통신을 하고자할 때 사용한다.\n\n
\n\n7. #### OPTIONS\n\n 서버 측 제공 메소드에 대한 질의를 하기 위함\n\n 웹 서버 측에서 지원하고 있는 메소드가 무엇인지 알기 위해 사용한다.\n\n
\n\n8. #### TRACE\n\n Request 리소스가 수신되는 경로를 보기 위함\n\n 웹 서버로부터 받은 내용을 확인하기 위해 loop-back 테스트를 할 때 사용한다.\n\n
\n\n9. #### PATCH\n\n 리소스(데이터)의 일부분만 갱신하기 위함\n\n PUT과 유사하나, 모든 데이터를 갱신하는 것이 아닌 리소스의 일부분만 수정할 때 쓰인다.\n\n
\n\n
\n\n
\n\n#### [참고자료]\n\n- [링크](https://www.quora.com/What-are-HTTP-methods-and-what-are-they-used-for)\n- [링크](http://www.ktword.co.kr/test/view/view.php?no=3791)\n\n" }, { "path": "Web/HTTP status code.md", "content": "## HTTP status code\n\n> 클라우드 환경에서 HTTP API를 통해 통신하는 것이 대부분임\n>\n> 이때, 응답 상태 코드를 통해 성공/실패 여부를 확인할 수 있으므로 API 문서를 작성할 때 꼭 알아야 할 것이 HTTP status code다\n\n
\n\n- 10x : 정보 확인\n- 20x : 통신 성공\n- 30x : 리다이렉트\n- 40x : 클라이언트 오류\n- 50x : 서버 오류\n\n
\n\n##### 200번대 : 통신 성공\n\n| 상태코드 | 이름 | 의미 |\n| :------: | :---------: | :----------------------: |\n| 200 | OK | 요청 성공(GET) |\n| 201 | Create | 생성 성공(POST) |\n| 202 | Accepted | 요청 접수O, 리소스 처리X |\n| 204 | No Contents | 요청 성공O, 내용 없음 |\n\n
\n\n##### 300번대 : 리다이렉트\n| 상태코드 | 이름 | 의미 |\n| :------: | :--------------: | :---------------------------: |\n| 300 | Multiple Choice | 요청 URI에 여러 리소스가 존재 |\n| 301 | Move Permanently | 요청 URI가 새 위치로 옮겨감 |\n| 304 | Not Modified | 요청 URI의 내용이 변경X |\n\n
\n\n##### 400번대 : 클라이언트 오류\n\n| 상태코드 | 이름 | 의미 |\n| :------: | :----------------: | :-------------------------------: |\n| 400 | Bad Request | API에서 정의되지 않은 요청 들어옴 |\n| 401 | Unauthorized | 인증 오류 |\n| 403 | Forbidden | 권한 밖의 접근 시도 |\n| 404 | Not Found | 요청 URI에 대한 리소스 존재X |\n| 405 | Method Not Allowed | API에서 정의되지 않은 메소드 호출 |\n| 406 | Not Acceptable | 처리 불가 |\n| 408 | Request Timeout | 요청 대기 시간 초과 |\n| 409 | Conflict | 모순 |\n| 429 | Too Many Request | 요청 횟수 상한 초과 |\n\n
\n\n##### 500번대 : 서버 오류\n\n| 상태코드 | 이름 | 의미 |\n| :------: | :-------------------: | :------------------: |\n| 500 | Internal Server Error | 서버 내부 오류 |\n| 502 | Bad Gateway | 게이트웨이 오류 |\n| 503 | Service Unavailable | 서비스 이용 불가 |\n| 504 | Gateway Timeout | 게이트웨이 시간 초과 |" }, { "path": "Web/JWT(JSON Web Token).md", "content": "# JWT (JSON Web Token)\n```\nJSON Web Tokens are an open, industry standard [RFC 7519]\nmethod for representing claims securely between two parties.\n출처 : https://jwt.io\n```\nJWT는 웹표준(RFC 7519)으로서 두 개체에서 JSON 객체를 사용하여 가볍고 자가수용적인 방식으로 정보를 안전성 있게 전달해줍니다.\n\n## 구성요소\nJWT는 `.` 을 구분자로 3가지의 문자열로 구성되어 있습니다.\n\naaaa.bbbbb.ccccc 의 구조로 앞부터 헤더(header), 내용(payload), 서명(signature)로 구성됩니다.\n\n### 헤더 (Header)\n헤더는 typ와 alg 두가지의 정보를 지니고 있습니다.\ntyp는 토큰의 타입을 지정합니다. JWT이기에 \"JWT\"라는 값이 들어갑니다.\nalg : 해싱 알고리즘을 지정합니다. 기본적으로 HMAC, SHA256, RSA가 사용되면 토큰을 검증 할 때 사용되는 signature부분에서 사용됩니다.\n```\n{\n\t\"typ\" : \"JWT\",\n\t\"alg\" : \"HS256\"\n}\n```\n\n### 정보(payload)\nPayload 부분에는 토큰을 담을 정보가 들어있습니다. 정보의 한 조각을 클레임(claim)이라고 부르고, 이는 name / value의 한 쌍으로 이뤄져있습니다. 토큰에는 여러개의 클레임들을 넣을 수 있지만 너무 많아질경우 토큰의 길이가 길어질 수 있습니다.\n\n클레임의 종류는 크게 세분류로 나누어집니다.\n1. 등록된(registered) 클레임\n등록된 클레임들은 서비스에서 필요한 정보들이 아닌, 토큰에 대한 정보들을 담기위하여 이름이 이미 정해진 클레임들입니다. 등록된 클레임의 사용은 모두 선택적(optional)이며, 이에 포함된 크레임 이름들은 다음과 같습니다.\n- `iss` : 토큰 발급자 (issuer)\n- `sub` : 토큰 제목 (subject)\n- `aud` : 토큰 대상자 (audience)\n- `exp` : 토큰의 만료시간(expiration), 시간은 NumericDate 형식으로 되어있어야 하며 언제나 현재 시간보다 이후로 설정되어 있어야 합니다.\n- `nbf` : Not before을 의미하며, 토큰의 활성 날짜와 비슷한 개념입니다. 여기에도 NumericDate형식으로 날짜를 지정하며, 이 날짜가 지정하며, 이 날짜가 지나기 전까지는 토큰이 처리되지 않습니다.\n- `iat` : 토큰이 발급된 시간(issued at), 이 값을 사용하여 토큰의 age가 얼마나 되었는지 판단 할 수 있습니다.\n- `jti` : JWT의 고유 식별자로서, 주로 중복적인 처리를 방지하기 위하여 사용됩니다. 일회용 토큰에 사용하면 유용합니다.\n\n2. 공개(public) 클레임\n공개 클레임들은 충돌이 방지된(collision-resistant)이름을 가지고 있어야 합니다. 충돌을 방지하기 위해서는, 클레임 이름을 URI형식으로 짓습니다.\n```\n{\n\t\"https://chup.tistory.com/jwt_claims/is_admin\" : true\n}\n```\n3. 비공개(private) 클레임\n등록된 클레임도 아니고, 공개된 클레임들도 아닙니다. 양 측간에(보통 클라이언트 <-> 서버) 합의하에 사용되는 클레임 이름들입니다. 공개 클레임과는 달리 이름이 중복되어 충돌이 될 수 있으니 사용할때에 유의해야합니다.\n\n### 서명(signature)\n서명은 헤더의 인코딩값과 정보의 인코딩값을 합친후 주어진 비밀키로 해쉬를 하여 생성합니다.\n이렇게 만든 해쉬를 `base64`형태로 나타내게 됩니다.\n\n
\n\n## 로그인 인증시 JWT 사용\n만약 유효기간이 짧은 Token을 발급하게되면 사용자 입장에서 자주 로그인을 해야하기 때문에 번거롭고 반대로 유효기간이 긴 Token을 발급하게되면 제 3자에게 토큰을 탈취당할 경우 보안에 취약하다는 약점이 있습니다.\n그 점들을 보완하기 위해 **Refresh Token** 을 사용하게 되었습니다.\nRefresh Token은 Access Token과 똑같은 JWT입니다. Access Token의 유효기간이 만료되었을 때, Refresh Token이 새로 발급해주는 열쇠가 됩니다.\n예를 들어, Refresh Token의 유효기간은 1주, Access Token의 유효기간은 1시간이라고 한다면, 사용자는 Access Token으로 1시간동안 API요청을 하다가 시간이 만료되면 Refresh Token을 이용하여 새롭게 발급해줍니다.\n이 방법또한 Access Token이 탈취당한다해도 정보가 유출이 되는걸 막을 수 없지만, 더 짧은 유효기간때문에 탈취되는 가능성이 적다는 점을 이용한 것입니다.\nRefresh Token또한 유효기간이 만료됐다면, 사용자는 새로 로그인해야 합니다. Refresh Token도 탈취 될 가능성이 있기 때문에 적절한 유효기간 설정이 필요합니다.\n\n
\n\n### Access Token + Refresh Token 인증 과정\n
 \n\n
\n\n\n\n
\n\n#### [참고 자료]\n\n- [링크](https://subscription.packtpub.com/book/application_development/9781784395407/8/ch08lvl1sec51/reference-pages)\n" }, { "path": "Web/Logging Level.md", "content": "## Logging Level\n\n
\n\n보통 log4j 라이브러리를 활용한다.\n\n크게 ERROR, WARN, INFO, DEBUG로 로그 레벨을 나누어 작성한다.\n\n
\n\n- #### ERROR\n\n 에러 로그는, 프로그램 동작에 큰 문제가 발생했다는 것으로 즉시 문제를 조사해야 하는 것\n\n `DB를 사용할 수 없는 상태, 중요 에러가 나오는 상황`\n\n
\n\n- #### WARN\n\n 주의해야 하지만, 프로세스는 계속 진행되는 상태. 하지만 WARN에서도 2가지의 부분에선 종료가 일어남\n\n - 명확한 문제 : 현재 데이터를 사용 불가, 캐시값 사용 등\n - 잠재적 문제 : 개발 모드로 프로그램 시작, 관리자 콘솔 비밀번호가 보호되지 않고 접속 등\n\n
\n\n- #### INFO\n\n 중요한 비즈니스 프로세스가 시작될 때와 종료될 때를 알려주는 로그\n\n `~가 ~를 실행했음`\n\n
\n\n- #### DEBUG\n\n 개발자가 기록할 가치가 있는 정보를 남기기 위해 사용하는 레벨\n\n
\n\n
\n\n##### [참고사항]\n\n- [링크](https://jangiloh.tistory.com/18)\n\n" }, { "path": "Web/Nuxt.js.md", "content": "# Nuxt.js\n\n
 \n\n
\n\n\n\n> vue.js를 서버에서 렌더링할 수 있도록 도와주는 오픈소스 프레임워크\n\n서버, 클라이언트 코드의 배포를 축약시켜 SPA(싱글페이지 앱)을 간편하게 만들어준다.\n\nVue.js 프로젝트를 진행할 때, 서버 부분을 미리 구성하고 정적 페이지를 만들어내는 기능을 통해 UI 렌더링을 보다 신속하게 제공해주는 기능이 있다.\n\n
\n\n
\n\n***들어가기에 앞서..***\n\n- SSR(Server Side Rendering) : 서버 쪽에서 페이지 컨텐츠들이 렌더링된 상태로 응답해줌\n- CSR(Client Side Rendering) : 클라이언트(웹브라우저) 쪽에서 컨텐츠들을 렌더링하는 것\n- SPA(Single Page Application) : 하나의 페이지로 구성된 웹사이트. index.html안에 모든 웹페이지들이 javascript로 구현되어 있는 형태\n\n> SPA는 보안 이슈나 검색 엔진 최적화에 있어서 단점이 존재. 이를 극복하기 위해 처음 불러오는 화면은 SSR로, 그 이후부터는 CSR로 진행하는 방식이 효율적이다.\n\n
\n\n***Nuxt.js는 왜 사용하나?***\n\nvue.js를 서버에서 렌더링하려면 설정해야할 것들이 한두개가 아니다ㅠ\n\n보통 babel과 같은 webpack을 통해 자바스크립트를 빌드하고 컴파일하는 과정을 거치게 된다. Node.js에서는 직접 빌드, 컴파일을 하지 않으므로, 이런 것들을 분리하여 SSR(서버 사이드 렌더링)이 가능하도록 미리 세팅해두는 것이 Nuxt.js다.\n\n> Vue에서는 Nuxt를, React에서는 Next 프레임워크를 사용함\n\n
\n\nNuxt CLI를 통해 쉽게 프로젝트를 만들고 진행할 수 있음\n\n```\n$ vue init nuxt/starter
\n\n#### 장점\n\n---\n\n- 일반적인 SPA 개발은, 검색 엔진에서 노출되지 않아 조회가 힘들다. 하지만 Nuxt를 이용하게 되면 서버사이드렌더링으로 화면을 보여주기 때문에, 검색엔진 봇이 화면들을 잘 긁어갈 수 있다. 따라서 **SPA로 개발하더라도 SEO(검색 엔진 최적화)를 걱정하지 않아도 된다.**\n\n > 일반적으로 많은 회사들은 검색엔진에 적절히 노출되는 것이 매우 중요함. 따라서 **검색 엔진 최적화**는 개발 시 반드시 고려해야 할 부분\n\n- SPA임에도 불구하고, Express가 서버로 뒤에서 돌고 있다. 이는 내가 원하는 API를 프로젝트에서 만들어서 사용할 수 있다는 뜻!\n\n\n\n#### 단점\n\n---\n\nNuxt를 사용할 때, 단순히 프론트/백엔드를 한 프로젝트에서 개발할 수 있지않을까로 접근하면 큰코 다칠 수 있다.\n\nex) API 요청시 에러가 발생하면, 프론트엔드에게 오류 발생 상태를 전달해줘야 예외처리를 진행할텐데 Nuxt에서 Express 에러까지 먹어버리고 리디렉션시킴\n\n> API부분을 Nuxt로 활용하는 게 상당히 어렵다고함\n\n" }, { "path": "Web/OAuth.md", "content": "## OAuth\n\n> Open Authorization\n\n인터넷 사용자들이 비밀번호를 제공하지 않고, 다른 웹사이트 상의 자신들의 정보에 대해 웹사이트나 애플리케이션의 접근 권한을 부여할 수있는 개방형 표준 방법\n\n
\n\n이러한 매커니즘은 구글, 페이스북, 트위터 등이 사용하고 있으며 타사 애플리케이션 및 웹사이트의 계정에 대한 정보를 공유할 수 있도록 허용해준다.\n\n
\n\n
\n\n#### 사용 용어\n\n---\n\n- **사용자** : 계정을 가지고 있는 개인\n- **소비자** : OAuth를 사용해 서비스 제공자에게 접근하는 웹사이트 or 애플리케이션\n- **서비스 제공자** : OAuth를 통해 접근을 지원하는 웹 애플리케이션\n- **소비자 비밀번호** : 서비스 제공자에서 소비자가 자신임을 인증하기 위한 키\n- **요청 토큰** : 소비자가 사용자에게 접근권한을 인증받기 위해 필요한 정보가 담겨있음\n- **접근 토큰** : 인증 후에 사용자가 서비스 제공자가 아닌 소비자를 통해 보호 자원에 접근하기 위한 키 값\n\n
\n\n토큰 종류로는 Access Token과 Refresh Token이 있다.\n\nAccess Token은 만료시간이 있고 끝나면 다시 요청해야 한다. Refresh Token은 만료되면 아예 처음부터 진행해야 한다. \n\n
\n\n#### 인증 과정\n\n---\n\n> 소비자 <-> 서비스 제공자\n\n1. 소비자가 서비스 제공자에게 요청토큰을 요청한다.\n2. 서비스 제공자가 소비자에게 요청토큰을 발급해준다.\n3. 소비자가 사용자를 서비스제공자로 이동시킨다. 여기서 사용자 인증이 수행된다.\n4. 서비스 제공자가 사용자를 소비자로 이동시킨다.\n5. 소비자가 접근토큰을 요청한다.\n6. 서비스제공자가 접근토큰을 발급한다.\n7. 발급된 접근토큰을 이용해서 소비자에서 사용자 정보에 접근한다.\n\n
\n" }, { "path": "Web/PWA (Progressive Web App).md", "content": "### PWA (Progressive Web App)\n\n> 웹의 장점과 앱의 장점을 결합한 환경\n>\n> `앱 수준과 같은 사용자 경험을 웹에서 제공하는 것이 목적!`\n\n
\n\n#### 특징\n\n확장성이 좋고, 깊이 있는 앱같은 웹을 만드는 것을 지향한다.\n\n웹 주소만 있다면, 누구나 접근하여 사용이 가능하고 스마트폰의 저장공간을 잡아 먹지 않음\n\n**서비스 작업자(Service Worker) API** : 웹앱의 중요한 부분을 캐싱하여 사용자가 다음에 열 때 빠르게 로딩할 수 있도록 도와줌\n\n→ 네트워크 환경이 좋지 않아도 빠르게 구동되며, 사용자에게 푸시 알림을 보낼 수도 있음\n\n
\n\n#### PWA 제공 기능\n\n- 프로그래시브 : 점진적 개선을 통해 작성돼서 어떤 브라우저든 상관없이 모든 사용자에게 적합\n- 반응형 : 데스크톱, 모바일, 테블릿 등 모든 폼 factor에 맞음\n- 연결 독립적 : 서비스 워커를 사용해 오프라인에서도 작동이 가능함\n- 안전 : HTTPS를 통해 제공이 되므로 스누핑이 차단되어 콘텐츠가 변조되지 않음\n- 검색 가능 : W3C 매니페스트 및 서비스 워커 등록 범위 덕분에 '앱'으로 식별되어 검색이 가능함\n- 재참여 가능 : 푸시 알림과 같은 기능을 통해 쉽게 재참여가 가능함\n" }, { "path": "Web/README.md", "content": "## Web\n\n- [브라우저 동작 방법](https://github.com/kim6394/tech-interview-for-developer/blob/master/Web/%EB%B8%8C%EB%9D%BC%EC%9A%B0%EC%A0%80%20%EB%8F%99%EC%9E%91%20%EB%B0%A9%EB%B2%95.md)\n- [쿠키(Cookie) & 세션(Session)](https://github.com/kim6394/tech-interview-for-developer/blob/master/Web/Cookie%20%26%20Session.md)\n- [웹 서버와 WAS의 차이점](https://github.com/kim6394/tech-interview-for-developer/blob/master/Web/Web%20Server%EC%99%80%20WAS%EC%9D%98%20%EC%B0%A8%EC%9D%B4.md)\n- [OAuth](
" }, { "path": "Web/React/React & Spring Boot 연동하여 환경 구축하기.md", "content": "## React & Spring Boot 연동해보기!\n\n
 \n\n작성일 : 2019.07.29\n\n프로젝트 진행에 앞서 연습해보기!\n\n
\n\n작성일 : 2019.07.29\n\n프로젝트 진행에 앞서 연습해보기!\n\n\n\n> **Front-end** : React\n>\n> **Back-end** : Spring Boot\n\n
\n\n**스프링 부트를 통해 서버 API 역할을 구축**하고, **UI 로직을 React에서 담당** \n( React는 컴포넌트화가 잘되어있어서 재사용성이 좋고, 수많은 오픈소스 라이브러리 활용 장점 존재)\n\n
\n\n##### 개발 환경도구 (설치할 것)\n\n> - VSCode : 확장 프로그램으로 Java Extension Pack, Spring Boot Extension Pack 설치\n> (메뉴-기본설정-설정에서 JDK 검색 후 'setting.json에서 편집'을 들어가 `java.home`으로 jdk 경로 넣어주기)\n>\n> ```\n> \"java.home\": \"C:\\\\Program Files\\\\Java\\\\jdk1.8.0_181\" // 자신의 경로에 맞추기\n> ```\n>\n> - Node.js : 10.16.0\n>\n> - JDK(8 이상)\n\n
\n\n### Spring Boot 웹 프로젝트 생성\n\n---\n\n1. VSCode에서 `ctrl-shift-p` 입력 후, spring 검색해서 \n `Spring Initalizr: Generate Maven Project Spring` 선택\n
\n\n2. 프로젝트를 선택하면 나오는 질문은 아래와 같이 입력\n\n > - **언어** : Java\n > - **Group Id** : no4gift\n > - **Artifact Id** : test\n > - **Spring boot version** : 2.1.6\n > - **Dependency** : DevTools, Spring Web Starter Web 검색 후 Selected\n\n
\n\n3. 프로젝트를 저장할 폴더를 지정하면 Spring Boot 프로젝트가 설치된다!\n\n
\n\n일단 React를 붙이기 전에, Spring Boot 자체로 잘 구동되는지 진행해보자\n\nJSP와 JSTL을 사용하기 위해 라이브러리를 추가한다. pom.xml의 dependencies 태그 안에 추가하자\n\n```\n
\n\n이제 서버를 구동해보자\n\nVSCode에서 터미널 창을 열고 `.\\mvnw spring-boot:run`을 입력하면 서버가 실행되는 모습을 확인할 수 있다.\n\n
\n\n***만약 아래와 같은 에러가 발생하면?***\n\n```\n***************************\nAPPLICATION FAILED TO START\n***************************\n \nDescription:\n \nThe Tomcat connector configured to listen on port 8080 failed to start. The port may already be in use or the connector may be misconfigured.\n```\n\n8080포트를 이미 사용 중이라 구동이 되지 않는 것이다.\n\ncmd창을 관리자 권한으로 열고 아래와 같이 진행하자\n\n```\nnetstat -ao |find /i \"listening\"\n```\n\n현재 구동 중인 포트들이 나온다. 이중에 8080 포트를 확인할 수 있을 것이다.\n\n가장 오른쪽에 나오는 숫자가 PID번호다. 이걸 kill 해줘야 한다.\n\n```\ntaskkill /f /im [pid번호]\n```\n\n다시 서버를 구동해보면 아래처럼 잘 동작하는 것을 확인할 수 있다!\n\n
 \n\n
\n\n\n\n
\n\n### React 환경 추가하기\n\n---\n\n터미널을 하나 더 추가로 열고, `npm init`을 입력해 pakage.json 파일이 생기도록 하자\n\n> 나오는 질문들은 모두 enter 누르고 넘어가도 괜찮음\n\n이제 React 개발에 필요한 의존 라이브러리를 설치한다.\n\n```\nnpm i react react-dom\n\nnpm i @babel/core @babel/preset-env @babel/preset-react babel-loader css-loader style-loader webpack webpack-cli -D\n```\n\n> create-react-app으로 한번에 설치도 가능함\n\n
\n\n##### webpack 설정하기\n\n> webpack을 통해 react 개발 시 자바스크립트 기능과 jsp에 포함할 .js 파일을 만들 수 있다.\n>\n> 프로젝트 루트 경로에 webpack.config.js 파일을 만들고 아래 코드를 붙여넣기\n\n```javascript\nvar path = require('path');\n \nmodule.exports = {\n context: path.resolve(__dirname, 'src/main/jsx'),\n entry: {\n main: './MainPage.jsx',\n page1: './Page1Page.jsx'\n },\n devtool: 'sourcemaps',\n cache: true,\n output: {\n path: __dirname,\n filename: './src/main/webapp/js/react/[name].bundle.js'\n },\n mode: 'none',\n module: {\n rules: [ {\n test: /\\.jsx?$/,\n exclude: /(node_modules)/,\n use: {\n loader: 'babel-loader',\n options: {\n presets: [ '@babel/preset-env', '@babel/preset-react' ]\n }\n }\n }, {\n test: /\\.css$/,\n use: [ 'style-loader', 'css-loader' ]\n } ]\n }\n};\n```\n\n> - 코드 내용\n>\n> React 소스 경로를 src/main/jsx로 설정\n>\n> MainPage와 Page1Page.jsx 빌드\n>\n> 빌드 결과 js 파일들을 src/main/webapp/js/react 아래 [페이지 이름].bundle.js로 놓음\n\n
\n\n
\n\n### 서버 코드 개발하기\n\n---\n\nVSCode에서 패키지 안에 MyController.java라는 클래스 파일을 만든다.\n\n```java\npackage no4gift.test;\n\nimport org.springframework.stereotype.Controller;\nimport org.springframework.ui.Model;\nimport org.springframework.web.bind.annotation.GetMapping;\nimport org.springframework.web.bind.annotation.PathVariable;\n \n@Controller\npublic class MyController {\n \n @GetMapping(\"/{name}.html\")\n public String page(@PathVariable String name, Model model) {\n model.addAttribute(\"pageName\", name);\n return \"page\";\n }\n\n}\n```\n\n
\n\n추가로 src/main에다가 webapp 폴더를 만들자\n\nwebapp 폴더 안에 jsp 폴더와 css 폴더를 생성한다.\n\n
\n\n그리고 jsp와 css 파일을 하나씩 넣어보자\n\n##### src/main/webapp/jsp/page.jsp\n\n```jsp\n<%@ page language=\"java\" contentType=\"text/html; charset=utf-8\"%>\n\n\n\n
\n\n##### src/main/webapp/css/custom.css\n\n```css\n.main { \n font-size: 24px; border-bottom: solid 1px black; \n}\n.page1 { \n font-size: 14px; background-color: yellow; \n}\n```\n\n
\n\n
\n\n### 클라이언트 코드 개발하기\n\n---\n\n이제 웹페이지에 보여줄 JSX 파일을 만들어보자\n\nsrc/main에 jsx 폴더를 만들고 MainPage.jsx와 Page1Page.jsx 2가지 jsx 파일을 만들었다.\n\n##### src/main/jsx/MainPage.jsx\n\n```jsx\nimport '../webapp/css/custom.css';\n \nimport React from 'react';\nimport ReactDOM from 'react-dom';\n \nclass MainPage extends React.Component {\n \n render() {\n return
no4gift 메인 페이지
;\n }\n \n}\n \nReactDOM.render(\n\n##### src/main/jsx/Page1Page.jsx\n\n```jsx\nimport '../webapp/css/custom.css';\n \nimport React from 'react';\nimport ReactDOM from 'react-dom';\n \nclass Page1Page extends React.Component {\n \n render() {\n return
no4gift의 Page1 페이지
;\n }\n \n}\n \nReactDOM.render(\n\n이제 우리가 만든 클라이언트 페이지를 서버 구동 후 볼 수 있도록 빌드시켜야 한다!\n\n
\n\n#### 클라이언트 스크립트 빌드시키기\n\njsx 파일을 수정할 때마다 자동으로 지속적 빌드를 시켜주는 것이 필요하다.\n\n이는 webpack의 watch 명령을 통해 가능하도록 만들 수 있다.\n\nVSCode 터미널에서 아래와 같이 입력하자\n\n```\nnode_modules\\.bin\\webpack --watch -d\n```\n\n> -d는 개발시\n>\n> -p는 운영시\n\n터미널 화면을 보면, `webpack.config.js`에서 우리가 설정한대로 정상적으로 빌드되는 것을 확인할 수 있다.\n\n
\n\n
 \n\n
\n\n\n\nsrc/main/webapp/js/react 아래에 우리가 만든 두 페이지에 대한 bundle.js 파일이 생성되었으면 제대로 된 것이다.\n\n
\n\n서버 구동이나, 번들링이나 명령어 입력이 상당히 길기 때문에 귀찮다ㅠㅠ \n`pakage.json`의 script에 등록해두면 간편하게 빌드과 서버 실행을 진행할 수 있다.\n\n```json\n \"scripts\": {\n \"test\": \"echo \\\"Error: no test specified\\\" && exit 1\",\n \"start\": \"set JAVA_HOME=C:\\\\Program Files\\\\Java\\\\jdk1.8.0_181&&mvnw spring-boot:run\",\n \"watch\": \"node_modules\\\\.bin\\\\webpack --watch -d\"\n },\n```\n\n이처럼 start와 watch를 등록해두는 것!\n\nstart의 jdk경로는 각자 자신의 경로를 입력해야한다.\n\n이제 우리는 빌드는 `npm run watch`로, 스프링 부트 서버 실행은 `npm run start`로 진행할 수 있다~\n\n
\n\n빌드가 이루어졌기 때문에 우리가 만든 페이지를 확인해볼 수 있다.\n\n해당 경로로 들어가면 우리가 jsx파일로 작성한 모습이 제대로 출력된다.\n\n
\n\nMainPage : http://localhost:8080/main.html\n\n
 \n\n
\n\n\n\nPage1Page : http://localhost:8080/page1.html\n\n
 \n\n
\n\n\n\n여기까지 진행한 프로젝트 경로\n\n
 \n\n\n\n이와 같은 과정을 토대로 구현할 웹페이지들을 생성해 나가면 된다.\n\n\n\n이상 React와 Spring Boot 연동해서 환경 설정하기 끝!"
},
{
"path": "Web/React/React Fragment.md",
"content": "# [React] Fragment\n\n
\n\n\n\n이와 같은 과정을 토대로 구현할 웹페이지들을 생성해 나가면 된다.\n\n\n\n이상 React와 Spring Boot 연동해서 환경 설정하기 끝!"
},
{
"path": "Web/React/React Fragment.md",
"content": "# [React] Fragment\n\n\n\n```\nJSX 파일 규칙상 return 시 하나의 태그로 묶어야한다.\n이런 상황에 Fragment를 사용하면 쉽게 그룹화가 가능하다.\n```\n\n
\n\n아래와 같이 Table 컴포넌트에서 Columns를 불렀다고 가정해보자\n\n```JSX\nimport { Component } from 'React'\nimport Columns from '../Components'\n\nclass Table extends Component {\n render() {\n return (\n
\n\nColumns 컴포넌트에서는 `
\n Hello \n World \n
\n );\n }\n}\n```\n\n여러 td 태그를 작성하기 위해 div 태그로 묶었다. (JSX 파일 규칙상 return 시 하나의 태그로 묶어야한다.)\n\n이제 Table 컴포넌트에서 DOM 트리를 그렸을 때 어떻게 결과가 나오는지 확인해보자\n\n\n\n```html\n
| Hello | \nWorld | \n
\n\nFragment로 명시하지 않고, 빈 태그로도 가능하다.\n\n```JSX\nimport { Component } from 'React'\n\nclass Columns extends Component {\n render() {\n return (\n <>\n
\n\n이 밖에도 부모, 자식과의 관계에서 flex, grid로 연결된 element가 있는 경우에는 div로 연결 시 레이아웃을 유지하는데 어려움을 겪을 수도 있다.\n\n따라서 위와 같은 개발이 필요할 때는 Fragment를 적절한 상황에 사용하면 된다.\n\n
\n\n
\n\n#### [참고 사항]\n\n- [링크](https://velog.io/@dolarge/React-Fragment%EB%9E%80)\n" }, { "path": "Web/React/React Hook.md", "content": "# React Hook \n\n> useState(), useEffect() 정의\n\n
 \n\n
\n\n\n\n리액트의 Component는 '클래스형'과 '함수형'으로 구성되어 있다.\n\n기존의 클래스형 컴포넌트에서는 몇 가지 어려움이 존재한다.\n\n1. 상태(State) 로직 재사용 어려움\n2. 코드가 복잡해짐\n3. 관련 없는 로직들이 함께 섞여 있어 이해가 힘듬\n\n이와 같은 어려움을 해결하기 위해, 'Hook'이 도입되었다. (16.8 버전부터)\n\n
\n\n### Hook\n\n- 함수형 컴포넌트에서 State와 Lifecycle 기능을 연동해주는 함수\n- '클래스형'에서는 동작하지 않으며, '함수형'에서만 사용 가능\n\n
\n\n#### useState\n\n기본적인 Hook으로 상태관리를 해야할 때 사용하면 된다.\n\n상태를 변경할 때는, `set`으로 준 이름의 함수를 호출한다. \n\n```jsx\nconst [posts, setPosts] = useState([]); // 비구조화 할당 문법\n```\n\n`useState([]);`와 같이 `( )` 안에 초기화를 설정해줄 수 있다. 현재 예제는 빈 배열을 만들어 둔 상황인 것이다.\n\n
\n\n#### useEffect\n\n컴포넌트가 렌더링 될 때마다 특정 작업을 수행하도록 설정할 수 있는 Hook\n\n> '클래스' 컴포넌트의 componentDidMount()와 componentDidUpdate()의 역할을 동시에 한다고 봐도 된다.\n\n```jsx\nuseEffect(() => {\n console.log(\"렌더링 완료\");\n console.log(posts);\n});\n```\n\nposts가 변경돼 리렌더링이 되면, useEffect가 실행된다.\n\n
\n\n
\n\n#### [참고자료]\n\n- [링크](https://ko.reactjs.org/docs/hooks-intro.html)\n" }, { "path": "Web/Spring/JPA.md", "content": "# JPA\n\n> Java Persistence API\n\n
\n\n```\n개발자가 직접 SQL을 작성하지 않고, JPA API를 활용해 DB를 저장하고 관리할 수 있다.\n```\n\n
\n\nJPA는 오늘날 스프링에서 많이 활용되고 있지만, 스프링이 제공하는 API가 아닌 **자바가 제공하는 API다.**\n\n자바 ORM 기술에 대한 표준 명세로, 자바 어플리케이션에서 관계형 데이터베이스를 사용하는 방식을 정의한 인터페이스다.\n\n
\n\n#### ORM(Object Relational Mapping)\n\nORM 프레임워크는 자바 객체와 관계형 DB를 매핑한다. 즉, 객체가 DB 테이블이 되도록 만들어주는 것이다. ORM을 사용하면, SQL을 작성하지 않아도 직관적인 메소드로 데이터를 조작할 수 있다는 장점이 있다. ( 개발자에게 생산성을 향상시켜줄 수 있음 )\n\n종류로는 Hibernate, EclipseLink, DataNucleus 등이 있다.\n\n
\n\n
 \n\n스프링 부트에서는 `spring-boot-starter-data-jpa`로 패키지를 가져와 사용하며, 이는 Hibernate 프레임워크를 활용한다.\n\n
\n\n스프링 부트에서는 `spring-boot-starter-data-jpa`로 패키지를 가져와 사용하며, 이는 Hibernate 프레임워크를 활용한다.\n\nJPA는 애플리케이션과 JDBC 사이에서 동작하며, 개발자가 JPA를 활용했을 때 JDBC API를 통해 SQL을 호출하여 데이터베이스와 호출하는 전개가 이루어진다.\n\n즉, 개발자는 JPA의 활용법만 익히면 DB 쿼리 구현없이 데이터베이스를 관리할 수 있다.\n\n
\n\n### JPA 특징\n\n1. ##### 객체 중심 개발 가능\n\n SQL 중심 개발이 이루어진다면, CRUD 작업이 반복해서 이루어져야한다.\n\n 하나의 테이블을 생성해야할 때 이에 해당하는 CRUD를 전부 만들어야 하며, 추후에 컬럼이 생성되면 관련 SQL을 모두 수정해야 하는 번거로움이 있다. 또한 개발 과정에서 실수할 가능성도 높아진다. \n\n
\n\n2. ##### 생산성 증가\n\n SQL 쿼리를 직접 생성하지 않고, 만들어진 객체에 JPA 메소드를 활용해 데이터베이스를 다루기 때문에 개발자에게 매우 편리성을 제공해준다.\n\n
\n\n3. ##### 유지보수 용이\n\n 쿼리 수정이 필요할 때, 이를 담아야 할 DTO 필드도 모두 변경해야 하는 작업이 필요하지만 JPA에서는 엔티티 클래스 정보만 변경하면 되므로 유지보수에 용이하다.\n\n4. ##### 성능 증가\n\n 사람이 직접 SQL을 짜는 것과 비교해서 JPA는 동일한 쿼리에 대한 캐시 기능을 지원해주기 때문에 비교적 높은 성능 효율을 경험할 수 있다.\n\n
\n\n#### 제약사항\n\nJPA는 복잡한 쿼리보다는 실시간 쿼리에 최적화되어있다. 예를 들어 통계 처리와 같은 복잡한 작업이 필요한 경우에는 기존의 Mybatis와 같은 Mapper 방식이 더 효율적일 수 있다.\n\n> Spring에서는 JPA와 Mybatis를 같이 사용할 수 있기 때문에, 상황에 맞는 방식을 택하여 개발하면 된다.\n\n
\n\n
\n\n#### [참고 사항]\n\n- [링크](https://velog.io/@modsiw/JPAJava-Persistence-API%EC%9D%98-%EA%B0%9C%EB%85%90)\n- [링크](https://wedul.site/506)\n\n" }, { "path": "Web/Spring/Spring MVC.md", "content": "# Spring MVC Framework\n\n
\n\n```\n스프링 MVC 프레임워크가 동작하는 원리를 이해하고 있어야 한다\n```\n\n
\n\n
 \n\n클라이언트가 서버에게 url을 통해 요청할 때 일어나는 스프링 프레임워크의 동작을 그림으로 표현한 것이다.\n\n
\n\n클라이언트가 서버에게 url을 통해 요청할 때 일어나는 스프링 프레임워크의 동작을 그림으로 표현한 것이다.\n\n\n\n### MVC 진행 과정\n\n----\n\n- 클라이언트가 url을 요청하면, 웹 브라우저에서 스프링으로 request가 보내진다.\n- `Dispatcher Servlet`이 request를 받으면, `Handler Mapping`을 통해 해당 url을 담당하는 Controller를 탐색 후 찾아낸다.\n- 찾아낸 `Controller`로 request를 보내주고, 보내주기 위해 필요한 Model을 구성한다.\n- `Model`에서는 페이지 처리에 필요한 정보들을 Database에 접근하여 쿼리문을 통해 가져온다.\n- 데이터를 통해 얻은 Model 정보를 Controller에게 response 해주면, Controller는 이를 받아 Model을 완성시켜 Dispatcher Servlet에게 전달해준다.\n- Dispatcher Servlet은 `View Resolver`를 통해 request에 해당하는 view 파일을 탐색 후 받아낸다.\n- 받아낸 View 페이지 파일에 Model을 보낸 후 클라이언트에게 보낼 페이지를 완성시켜 받아낸다.\n- 완성된 View 파일을 클라이언트에 response하여 화면에 출력한다.\n\n
\n\n### 구성 요소\n\n---\n\n#### Dispatcher Servlet\n\n모든 request를 처리하는 중심 컨트롤러라고 생각하면 된다. 서블릿 컨테이너에서 http 프로토콜을 통해 들어오는 모든 request에 대해 제일 앞단에서 중앙집중식으로 처리해주는 핵심적인 역할을 한다.\n\n기존에는 web.xml에 모두 등록해줘야 했지만, 디스패처 서블릿이 모든 request를 핸들링하면서 작업을 편리하게 할 수 있다. \n\n
\n\n#### Handler Mapping\n\n클라이언트의 request url을 어떤 컨트롤러가 처리해야 할 지 찾아서 Dispatcher Servlet에게 전달해주는 역할을 담당한다.\n\n> 컨트롤러 상에서 url을 매핑시키기 위해 `@RequestMapping`을 사용하는데, 핸들러가 이를 찾아주는 역할을 한다.\n\n
\n\n#### Controller\n\n실질적인 요청을 처리하는 곳이다. Dispatcher Servlet이 프론트 컨트롤러라면, 이 곳은 백엔드 컨트롤러라고 볼 수 있다.\n\n모델의 처리 결과를 담아 Dispatcher Servlet에게 반환해준다.\n\n
\n\n#### View Resolver\n\n컨트롤러의 처리 결과를 만들 view를 결정해주는 역할을 담당한다. 다양한 종류가 있기 때문에 상황에 맞게 활용하면 된다.\n\n
\n\n
\n\n#### [참고사항]\n\n- [링크](https://velog.io/@miscaminos/Spring-MVC-framework)\n- [링크](https://velog.io/@miscaminos/Spring-MVC-framework)" }, { "path": "Web/Spring/Spring Security - Authentication and Authorization.md", "content": "# Spring Security - Authentication and Authorization\n\n
\n\n```\nAPI에 권한 기능이 없으면, 아무나 회원 정보를 조회하고 수정하고 삭제할 수 있다. 따라서 이를 막기 위해 인증된 유저만 API를 사용할 수 있도록 해야하는데, 이때 사용할 수 있는 해결 책 중 하나가 Spring Security다.\n```\n\n
\n\n스프링 프레임워크에서는 인증 및 권한 부여로 리소스 사용을 컨트롤 할 수 있는 `Spring Security`를 제공한다. 이 프레임워크를 사용하면, 보안 처리를 자체적으로 구현하지 않아도 쉽게 필요한 기능을 구현할 수 있다.\n\n
\n\n
 \n\n
\n\n\n\nSpring Security는 스프링의 `DispatcherServlet` 앞단에 Filter 형태로 위치한다. Dispatcher로 넘어가기 전에 이 Filter가 요청을 가로채서, 클라이언트의 리소스 접근 권한을 확인하고, 없는 경우에는 인증 요청 화면으로 자동 리다이렉트한다.\n\n
\n\n### Spring Security Filter\n\n
 \n\nFilter의 종류는 상당히 많다. 위에서 예시로 든 클라이언트가 리소스에 대한 접근 권한이 없을 때 처리를 담당하는 필터는 `UsernamePasswordAuthenticationFilter`다.\n\n인증 권한이 없을 때 오류를 JSON으로 내려주기 위해 해당 필터가 실행되기 전 처리가 필요할 것이다.\n\n
\n\nFilter의 종류는 상당히 많다. 위에서 예시로 든 클라이언트가 리소스에 대한 접근 권한이 없을 때 처리를 담당하는 필터는 `UsernamePasswordAuthenticationFilter`다.\n\n인증 권한이 없을 때 오류를 JSON으로 내려주기 위해 해당 필터가 실행되기 전 처리가 필요할 것이다.\n\n\n\nAPI 인증 및 권한 부여를 위한 작업 순서는 아래와 같이 구성할 수 있다.\n\n1. 회원 가입, 로그인 API 구현\n2. 리소스 접근 가능한 ROLE_USER 권한을 가입 회원에게 부여\n3. Spring Security 설정에서 ROLE_USER 권한을 가지면 접근 가능하도록 세팅\n4. 권한이 있는 회원이 로그인 성공하면 리소스 접근 가능한 JWT 토큰 발급\n5. 해당 회원은 권한이 필요한 API 접근 시 JWT 보안 토큰을 사용\n\n
\n\n이처럼 접근 제한이 필요한 API에는 보안 토큰을 통해서 이 유저가 권한이 있는지 여부를 Spring Security를 통해 체크하고 리소스를 요청할 수 있도록 구성할 수 있다.\n\n
\n\n### Spring Security Configuration\n\n서버에 보안을 설정하기 위해 Configuration을 만든다. 기존 예시처럼, USER에 대한 권한을 설정하기 위한 작업도 여기서 진행된다.\n\n```JAVA\n@Override\n protected void configure(HttpSecurity http) throws Exception {\n http\n .httpBasic().disable() // rest api 이므로 기본설정 사용안함. 기본설정은 비인증시 로그인폼 화면으로 리다이렉트\n .cors().configurationSource(corsConfigurationSource())\n .and()\n .csrf().disable() // rest api이므로 csrf 보안이 필요없으므로 disable처리.\n .sessionManagement().sessionCreationPolicy(SessionCreationPolicy.STATELESS) // jwt token으로 인증하므로 세션은 필요없으므로 생성안함.\n .and()\n .authorizeRequests() // 다음 리퀘스트에 대한 사용권한 체크\n .antMatchers(\"/*/signin\", \"/*/signin/**\", \"/*/signup\", \"/*/signup/**\", \"/social/**\").permitAll() // 가입 및 인증 주소는 누구나 접근가능\n .antMatchers(HttpMethod.GET, \"home/**\").permitAll() // home으로 시작하는 GET요청 리소스는 누구나 접근가능\n .anyRequest().hasRole(\"USER\") // 그외 나머지 요청은 모두 인증된 회원만 접근 가능\n .and()\n .addFilterBefore(new JwtAuthenticationFilter(jwtTokenProvider), UsernamePasswordAuthenticationFilter.class); // jwt token 필터를 id/password 인증 필터 전에 넣는다\n\n }\n```\n\n
\n\n
\n\n#### [참고 자료]\n\n- [링크](https://dzone.com/articles/spring-security-authentication)\n- [링크](https://daddyprogrammer.org/post/636/springboot2-springsecurity-authentication-authorization/)\n- [링크](https://bravenamme.github.io/2019/08/01/spring-security-start/)" }, { "path": "Web/Spring/[Spring Boot] SpringApplication.md", "content": "## [Spring Boot] SpringApplication\n\n
\n\n스프링 부트로 프로젝트를 실행할 때 Application 클래스를 만든다.\n\n클래스명은 개발자가 프로젝트에 맞게 설정할 수 있지만, 큰 틀은 아래와 같다.\n\n```java\n@SpringBootApplication\npublic class Application {\n\n\tpublic static void main(String[] args) {\n\t\tSpringApplication.run(Application.class, args);\n\t}\n\n}\n```\n\n
\n\n`@SpringBootApplication` 어노테이션을 통해 스프링 Bean을 읽어와 자동으로 생성해준다.\n\n이 어노테이션이 있는 파일 위치부터 설정들을 읽어가므로, 반드시 프로젝트의 최상단에 만들어야 한다.\n\n`SpringApplication.run()`으로 해당 클래스를 run하면, 내장 WAS를 실행한다. 내장 WAS의 장점으로는 개발자가 따로 톰캣과 같은 외부 WAS를 설치 후 설정해두지 않아도 애플리케이션을 실행할 수 있다.\n\n또한, 외장 WAS를 사용할 시 이 프로젝트를 실행시키기 위한 서버에서 모두 외장 WAS의 종류와 버전, 설정을 일치시켜야만 한다. 따라서 내장 WAS를 사용하면 이런 신경은 쓰지 않아도 되기 때문에 매우 편리하다.\n\n> 실제로 많은 회사들이 이런 장점을 살려 내장 WAS를 사용하고 있고, 전환하고 있다.\n\n" }, { "path": "Web/Spring/[Spring Boot] Test Code.md", "content": "# [Spring Boot] Test Code\n\n
\n\n#### 테스트 코드를 작성해야 하는 이유\n\n- 개발단계 초기에 문제를 발견할 수 있음\n- 나중에 코드를 리팩토링하거나 라이브러리 업그레이드 시 기존 기능이 잘 작동하는 지 확인 가능함\n- 기능에 대한 불확실성 감소\n\n
\n\n개발 코드 이외에 테스트 코드를 작성하는 일은 개발 시간이 늘어날 것이라고 생각할 수 있다. 하지만 내 코드에 오류가 있는 지 검증할 때, 테스트 코드를 작성하지 않고 진행한다면 더 시간 소모가 클 것이다.\n\n```\n1. 코드를 작성한 뒤 프로그램을 실행하여 서버를 킨다.\n2. API 프로그램(ex. Postman)으로 HTTP 요청 후 결과를 Print로 찍어서 확인한다.\n3. 결과가 예상과 다르면, 다시 프로그램을 종료한 뒤 코드를 수정하고 반복한다.\n```\n\n위와 같은 방식이 얼마나 반복될 지 모른다. 그리고 하나의 기능마다 저렇게 테스트를 하면 서버를 키고 끄는 작업 또한 너무 비효율적이다.\n\n이 밖에도 Print로 눈으로 검증하는 것도 어느정도 선에서 한계가 있다. 테스트 코드는 자동으로 검증을 해주기 때문에 성공한다면 수동으로 검증할 필요 자체가 없어진다.\n\n새로운 기능이 추가되었을 때도 테스트 코드를 통해 만약 기존의 코드에 영향이 갔다면 어떤 부분을 수정해야 하는 지 알 수 있는 장점도 존재한다.\n\n
\n\n따라서 테스트 코드는 개발하는 데 있어서 필수적인 부분이며 반드시 활용해야 한다.\n\n
\n\n#### 테스트 코드 예제\n\n```java\nimport org.junit.Test;\nimport org.junit.runner.RunWith;\nimport org.springframework.beans.factory.annotation.Autowired;\nimport org.springframework.boot.test.autoconfigure.web.servlet.WebMvcTest;\nimport org.springframework.test.context.junit4.SpringRunner;\nimport org.springframework.test.web.servlet.MockMvc;\nimport static org.springframework.test.web.servlet.result.MockMvcResultMatchers.*;\nimport static org.springframework.test.web.servlet.request.MockMvcRequestBuilders.*;\n\n@RunWith(SpringRunner.class)\n@WebMvcTest(controllers = HomeController.class)\npublic class HomeControllerTest {\n\n @Autowired\n private MockMvc mvc;\n\n @Test\n public void home_return() throws Exception {\n //when\n String home = \"home\";\n\n //then\n mvc.perform(get(\"/home\"))\n .andExpect(status().isOk())\n .andExpect(content().string(home));\n }\n}\n```\n\n
\n\n1) `@RunWith(SpringRunner.class)`\n\n테스트를 진행할 때 JUnit에 내장된 실행자 외에 다른 실행자를 실행시킨다.\n\n스프링 부트 테스트와 JUnit 사이의 연결자 역할을 한다고 생각하면 된다.\n\n2) `@WebMvcTest`\n\n컨트롤러만 사용할 때 선언이 가능하며, Spring MVC에 집중할 수 있는 어노테이션이다.\n\n3) `@Autowired`\n\n스프링이 관리하는 Bean을 주입시켜준다.\n\n4) `MockMvc`\n\n웹 API를 테스트할 때 사용하며, 이를 통해 HTTP GET, POST, DELETE 등에 대한 API 테스트가 가능하다.\n\n5) `mvc.perform(get(\"/home\"))`\n\n`/home` 주소로 HTTP GET 요청을 한 상황이다.\n\n6) `.andExpect(status().isOk())`\n\n결과를 검증하는 `andExpect`로, 여러개를 붙여서 사용이 가능하다. `status()`는 HTTP Header를 검증하는 것으로 결과에 대한 HTTP Status 상태를 확인할 수 있다. 현재 `isOK()`는 200 코드가 맞는지 확인하고 있다.\n\n
\n\n프로젝트를 만들면서 다양한 기능들을 구현하게 되는데, 이처럼 테스트 코드로 견고한 프로젝트를 만들기 위한 기능별 단위 테스트를 진행하는 습관을 길러야 한다.\n\n
\n\n
\n\n#### [참고 자료]\n\n- [링크](http://www.yes24.com/Product/Goods/83849117)" }, { "path": "Web/Spring/[Spring Data JPA] 더티 체킹 (Dirty Checking).md", "content": "# [JPA] 더티 체킹 (Dirty Checking)\n\n
\n\n\n```\n트랜잭션 안에서 Entity의 변경이 일어났을 때\n변경한 내용을 자동으로 DB에 반영하는 것\n```\n\n
\n\nORM 구현체 개발 시 더티 체킹이라는 말을 자주 볼 수 있다.\n\n더티 체킹이 어떤 것을 뜻하는 지 간단히 살펴보자.\n\n
\n\nJPA로 개발하는 경우 구현한 한 가지 기능을 예로 들어보자\n\n##### ex) 주문 취소 기능\n\n```java\n@Transactional \npublic void cancelOrder(Long orderId) { \n //주문 엔티티 조회 \n Order order = orderRepository.findOne(orderId); \n\n //주문 취소 \n order.cancel(); \n}\n```\n\n`orderId`를 통해 주문을 취소하는 메소드다. 데이터베이스에 반영하기 위해선, `update`와 같은 쿼리가 있어야할 것 같은데 존재하지 않는다.\n\n하지만, 실제로 이 메소드를 실행하면 데이터베이스에 update가 잘 이루어진다.\n\n- 트랜잭션 시작\n- `orderId`로 주문 Entity 조회\n- 해당 Entity 주문 취소 상태로 **Update**\n- 트랜잭션 커밋\n\n이를 가능하게 하는 것이 바로 '더티 체킹(Dirty Checking)'이라고 보면 된다.\n\n
\n\n그냥 더티 체킹의 단어만 간단히 해석하면 `변경 감지`로 볼 수 있다. 좀 더 자세히 말하면, Entity에서 변경이 일어난 걸 감지한 뒤, 데이터베이스에 반영시켜준다는 의미다. (변경은 최초 조회 상태가 기준이다)\n\n> Dirty : 상태의 변화가 생김\n>\n> Checking : 검사\n\nJPA에서는 트랜잭션이 끝나는 시점에 변화가 있던 모든 엔티티의 객체를 데이터베이스로 알아서 반영을 시켜준다. 즉, 트랜잭션의 마지막 시점에서 다른 점을 발견했을 때 데이터베이스로 update 쿼리를 날려주는 것이다.\n\n- JPA에서 Entity를 조회\n- 조회된 상태의 Entity에 대한 스냅샷 생성\n- 트랜잭션 커밋 후 해당 스냅샷과 현재 Entity 상태의 다른 점을 체크\n- 다른 점들을 update 쿼리로 데이터베이스에 전달\n\n
\n\n이때 더티 체킹을 검사하는 대상은 `영속성 컨텍스트`가 관리하는 Entity로만 대상으로 한다.\n\n준영속, 비영속 Entity는 값을 변경할 지라도 데이터베이스에 반영시키지 않는다.\n\n
\n\n기본적으로 더티 체킹을 실행하면, SQL에서는 변경된 엔티티의 모든 내용을 update 쿼리로 만들어 전달하는데, 이때 필드가 많아지면 전체 필드를 update하는게 비효율적일 수도 있다.\n\n이때는 `@DynamicUpdate`를 해당 Entity에 선언하여 변경 필드만 반영시키도록 만들어줄 수 있다.\n\n```java\n@Getter\n@NoArgsConstructor\n@Entity\n@DynamicUpdate\npublic class Order {\n\n @Id\n @GeneratedValue(strategy = GenerationType.IDENTITY)\n private Long id;\n private String product;\n```\n\n
\n\n
\n\n#### [참고 자료]\n\n- [링크](https://velog.io/@jiny/JPA-%EB%8D%94%ED%8B%B0-%EC%B2%B4%ED%82%B9Dirty-Checking-%EC%9D%B4%EB%9E%80)\n- [링크](https://jojoldu.tistory.com/415)\n" }, { "path": "Web/Spring/[Spring] Bean Scope.md", "content": "# [Spring] Bean Scope\n\n
\n\n\n\n
\n\n```\nBean의 사용 범위를 말하는 Bean Scope의 종류에 대해 알아보자\n```\n\n
\n\nBean은 스프링에서 사용하는 POJO 기반 객체다.\n\n상황과 필요에 따라 Bean을 사용할 때 하나만 만들어야 할 수도 있고, 여러개가 필요할 때도 있고, 어떤 한 시점에서만 사용해야할 때가 있을 수 있다.\n\n이를 위해 Scope를 설정해서 Bean의 사용 범위를 개발자가 설정할 수 있다.\n\n
\n\n우선 따로 설정을 해주지 않으면, Spring에서 Bean은 `Singleton`으로 생성된다. 싱글톤 패턴처럼 특정 타입의 Bean을 딱 하나만 만들고 모두 공유해서 사용하기 위함이다. 보통은 Bean을 이렇게 하나만 만들어 사용하는 경우가 대부분이지만, 요구사항이나 구현에 따라 아닐 수도 있을 것이다.\n\n따라서 Bean Scope는 싱글톤 말고도 여러가지를 지원해준다.\n\n
\n\n### Scope 종류\n\n- #### singleton\n\n 해당 Bean에 대해 IoC 컨테이너에서 단 하나의 객체로만 존재한다.\n\n- #### prototype\n\n 해당 Bean에 대해 다수의 객체가 존재할 수 있다.\n\n- #### request\n\n 해당 Bean에 대해 하나의 HTTP Request의 라이프사이클에서 단 하나의 객체로만 존재한다.\n\n- #### session\n\n 해당 Bean에 대해 하나의 HTTP Session의 라이프사이클에서 단 하나의 객체로만 존재한다.\n\n- #### global session\n\n 해당 Bean에 대해 하나의 Global HTTP Session의 라이프사이클에서 단 하나의 객체로만 존재한다.\n\n> request, session, global session은 MVC 웹 어플리케이션에서만 사용함\n\n
\n\nScope들은 Bean으로 등록하는 클래스에 어노테이션으로 설정해줄 수 있다.\n\n```java\nimport org.springframework.context.annotation.Scope;\nimport org.springframework.stereotype.Service;\n \n@Scope(\"prototype\")\n@Component\npublic class UserController {\n}\n```\n\n
\n\n
\n\n#### [참고 자료]\n\n- [링크](https://gmlwjd9405.github.io/2018/11/10/spring-beans.html)" }, { "path": "Web/UI와 UX.md", "content": "## UI와 UX\n\n
\n\n많이 들어봤지만, 차이를 말하라고 하면 멈칫한다. 면접에서도 웹을 했다고 하면 나올 수 있는 질문.\n\n
\n\n### UI\n\n> User Interface\n\n사용자가 앱을 사용할 때 마주하는 디자인, 레이아웃, 기술적인 부분이다.\n\n디자인의 구성 요소인 폰트, 색깔, 줄간격 등 상세한 요소가 포함되고, 기술적 부분은 반응형이나 애니메이션효과 등이 포함된다.\n\n따라서 UI는 사용자가 사용할 때 큰 불편함이 없어야하며, 만족도를 높여야 한다.\n\n
\n\n
\n\n### UX\n\n> User eXperience\n\n앱을 주로 사용하는 사용자들의 경험을 분석하여 더 편하고 효율적인 방향으로 프로세스가 진행될 수 있도록 만드는 것이다.\n\n(터치 화면, 사용자의 선택 flow 등)\n\nUX는 통계자료, 데이터를 기반으로 앱을 사용하는 유저들의 특성을 분석하여 상황과 시점에 맞도록 변화시킬 수 있어야 한다.\n\n
\n\nUI를 포장물에 비유한다면, UX는 그 안의 내용물이라고 볼 수 있다.\n\n> 포장(UI)에 신경을 쓰는 것도 중요하고, 이를 사용할 사람을 분석해 알맞은 내용물(UX)로 채워서 제공해야한다.\n\n" }, { "path": "Web/Vue/Vue CLI + Spring Boot 연동하여 환경 구축하기.md", "content": "## Vue CLI + Spring Boot 연동하여 환경 구축하기\n\n\n\n
\n\n
 \n\n
\n\n\n\n프론트엔드는 Vue.js로, 백엔드는 Spring Boot를 이용해서 프로젝트를 진행하려고 한다.\n\n스프링에서 Jsp를 통해 view를 구축해봤지만, 이번엔 Vue.js를 활용해서 View를 모두 넘겨주려고 한다.\n\n
\n\n스프링에서 컨트롤러를 통해 DB 관리나 데이터에 관한 비즈니스 로직을 잘 처리하고, 이에 대한 값을 활용해 Vue에서 화면으로 뿌려줄 탬플릿을 만들어나가는 진행 방식이 되지 않을까 생각된다.\n\n
\n\n개발 툴은 VS Code로 진행한다.\n\n[VS Code 다운로드](https://code.visualstudio.com/download)\n\n
\n\nJava와 Node.js도 기본적으로 깔린 상태여야 한다.\n\n[Node.js 다운로드](https://nodejs.org/ko/download/)\n\n
\n\n
\n\nVS Code를 열고, 자신이 프로젝트를 생성할 폴더로 들어가자 (File → Open Folder)\n\n
\n\n시작하기에 앞서, VS Code에서 필요한 플러그인을 설치한다.\n\n왼쪽 메뉴탭에서 Extensions(단축키 : Ctrl + Shift + X)를 누르고, 검색창에서 아래 3가지를 입력 후 install 한다.\n\n```\n1. Vetur\n2. Java IDE Pack\n3. Lombok\n```\n\n
\n\n
\n\n#### VS Code 한글 인코딩\n\n현재 상태로는 VS Code에서 한글을 인식해주지 않는다. 인코딩을 따로 해줘야한다.\n\n
\n\nFile → Preferences → Settings로 들어간다.\n\n위의 검색창에 'settings.json'을 검색하면 아래와 같이 Edit할 수 있는 링크가 뜬다.\n\n
\n\n
 \n\n
\n\n\n\njson 파일이 나오게 되는데, 이곳에서 'java.jdt.ls.vmargs'를 찾는다.\n\n
\n\n이곳에 value 값으로 '-Dfile.encoding=utf-8'를 추가해줘야한다.\n\n추가 후에 java.jdt.ls.vmargs는 아래와 같이 될 것이다.\n\n
\n\n```\n\"java.jdt.ls.vmargs\": \"-Dfile.encoding=utf-8 -noverify -Xmx1G -XX:+UseG1GC -XX:+UseStringDeduplication -javaagent:\\\"lombok 경로~~\"\n```\n\n
\n\n
\n\n### 프로젝트 구성하기\n\n이제 프로젝트를 구성해보자!\n\n
\n\n#### 1.Spring Boot Project\n\n
\n\n먼저, 스프링 부트 프로젝트를 만든다. (우리는 스프링 부트 프로젝트 안에 Vue 프로젝트를 넣을 것이다)\n\n프로젝트는 [Spring Initializr](https://start.spring.io/)을 이용할 것이다. 스프링 부트 프로젝트를 매우 쉽고 간편하게 만들어주는 곳이다.\n\n
\n\n
 \n\n
\n\n\n\n자신이 만들 프로젝트 목적에 맞게 설정해주면 된다.\n\nDependencies도 미리 추가해놓을 수 있다. (Web, JDBC, Lombok, MySQL 등)\n\n나중에 따로 추가할 수 있으니 기억나는 것들만 지정해도 무방하다.\n\n
\n\n프로젝트 Metadata 부분은 생성할 프로젝트 패키지나 이름 등 옵션을 지정해줄 수 있다. 처음에는 demo로 되어있는데 자신이 만들고 싶은대로 수정할 수 있다.\n\n
\n\n마지막으로 'Generate the project' 버튼을 클릭하면, zip 파일로 프로젝트가 다운로드 된다. 해당 파일을 압축 해제하고 현재 VS Code에서 접속 중인 폴더에 복사하면 된다.\n\n
\n\n
\n\n
\n\n#### 2.Vue.js Project\n\n
\n\n이제 스프링 부트에서 Vue.js 프로젝트를 만들어보자. 프로젝트 생성은 Vue CLI를 이용할 것이다.\n\n
\n\nVue CLI는 Vue.js 개발을 위한 시스템으로, Vue.js Core에서 공식적으로 제공하는 CLI다. 개발에 집중할 수 있도록 프로젝트 구성을 빠르고 쉽게 도와주는 역할을 하고 있다.\n\n(따라서 반드시 이용해야 한다는 건 아니다. 다만 쉽게 구축할 수 있도록 만들어준거니 이용하면 편하다)\n\n
\n\n현재는 Vue CLI 버전 3가 나온 상태다. 2보다 더욱 편하고 많은 기능들을 제공한다고 하지만, 많은 정보가 없어서 일단 2로 진행하고자 한다.\n\n
\n\nNode.js를 설치한 상태기 때문에, npm을 통해 터미널에서 Vue CLI 설치가 가능하다.\n\n
\n\nVS Code에서 터미널을 열고, 아래와 같이 설치를 진행하자\n\n```\n$ npm i -g @vue/cli\n$ npm i -g @vue/cli-init\n```\n\n@vue/cli-init은 2버전 템플릿을 가져오기 위한 vue init을 제공해준다.\n\n이제 필요한 설치는 끝났다! Vue 프로젝트를 만들어보자. 이름은 그냥 frontend로 생성했다.\n\n
\n\n(현재 프로젝트 생성은, 스프링 부트 루트 폴더 위치에서 진행하는 것이다.)\n\n```\n$ vue init webpack frontend\n```\n\n
\n\n몇가지 설정하는 부분이 나온다.\n\n
\n\n> Project name\n>\n> Project description\n>\n> Author\n\n
\n\n이 3가지는 자신의 프로젝트에 맞게 작성해주면 된다.\n\n> Vue build는 standalone\n>\n> vue-router는 설치(Yes)\n>\n> Use ESLint to lint your code도 Yes\n>\n> ESLint preset은 Standard\n\n
\n\n그 이후 test부분은 진행할 사람들은 Yes, 안할사람은 No로 넘어가면 된다.\n\n터미널 창에서 열심히 파일들이 다운로드되는 모습을 볼 수 있다. (시간 조금 걸림)\n\n
\n\n끝나면 스프링부트 루트 폴더에 'frontend'라는 Vue 프로젝트 폴더가 생성된 모습을 확인할 수 있다.\n\n
\n\n
 \n\n
\n\n\n\n
\n\n#### Webpack 번들링 output 설정\n\n
\n\nVue에서 작성한 코드들을 번들링하고, 이 결과를 어느 위치에서 뽑아낼 지 정해야 한다.\n\n
\n\nSpring Boot에서는 자동설정으로 src/main/resources에 번들링한 결과들을 저장하도록 되어있다.\n\n(이곳에 index.html과 정적 파일(css, img, javascript)들이 인식됨)\n\n
\n\n이 구역에 잘 번들링 될 수 있도록, Vue 프로젝트에서 경로 지정을 해주자.\n\nconfig/index.js을 열어 build 부분에 정의한 곳을 수정해야 한다.\n\n
\n\n
 \n\n
\n\n\n\n해당 위치에 절대 경로로 위와 같이 수정해준다.\n\n
\n\n이제 터미널에서 'npm run build' 커맨드를 입력하여 빌드를 실행한다.\n\n
 \n\n이제 Spring Boot의 src/main/resources/static 경로에 들어가보면, 번들링 된 정적 파일들이 생성된 모습을 확인할 수 있다.\n\n
\n\n이제 Spring Boot의 src/main/resources/static 경로에 들어가보면, 번들링 된 정적 파일들이 생성된 모습을 확인할 수 있다.\n\n\n\n이제 스프링 부트 애플리케이션을 실행해보자\n\n.vscode 폴더의 launch.json에 들어가서 F5키를 누르면 스프링 부트 서버가 실행된다.\n\n
\n\n???\n\n에러가 뜰 것이다.\n\n```\n\n***************************\nAPPLICATION FAILED TO START\n*************************** \nDescription: \nFailed to configure a DataSource: 'url' attribute is not specified and no embedded datasource could be configured. \n\nReason: Failed to determine a suitable driver class\n\n```\n\ndatasource 내용이 없어서 뜬 에러다.\n\n
\n\n스프링부트에서 프로젝트를 생성할 때, application.properties 파일이 자동생성되나 확인해보면 빈 파일일 것이다.\n\n사용자가 원하는 데이터베이스를 선택하고, 그에 맞는 드라이버 라이브러리 설치와 jdbc 설정을 직접 해야한다.\n\n
\n\n이 공간이 비어있기 때문에 서버가 실행을 하고 있지 못하는 것이다. 현재는 어떤 데이터베이스를 지정할 지 결정이 되있는 상태가 아니기 때문에 스프링 부트의 메인 클래스에서 어노테이션을 추가해주자\n\n
\n\n\n ```\n\nimport org.springframework.boot.autoconfigure.EnableAutoConfiguration;\nimport org.springframework.boot.autoconfigure.jdbc.DataSourceAutoConfiguration;\n\n@EnableAutoConfiguration(exclude={DataSourceAutoConfiguration.class})\n\n ```\n\n이를 추가한 메인 클래스는 아래와 같이 된다.\n\n
\n\n```java\npackage com.example.mvc;\n\nimport org.springframework.boot.SpringApplication;\nimport org.springframework.boot.autoconfigure.SpringBootApplication;\nimport org.springframework.boot.autoconfigure.EnableAutoConfiguration;\nimport org.springframework.boot.autoconfigure.jdbc.DataSourceAutoConfiguration;\n\n@SpringBootApplication\n@EnableAutoConfiguration(exclude={DataSourceAutoConfiguration.class})\npublic class MvcApplication {\n\n public static void main(String[] args) {\n SpringApplication.run(MvcApplication.class, args);\n }\n\n}\n```\n\n
\n\n이제 다시 스프링 부트 메인 애플리케이션을 실행하면, 디버깅 창에서 에러가 없어진 걸 확인할 수 있다.\n\n
\n\n이제 localhost:8080/으로 접속하면, Vue에서 만든 화면이 잘 나오는 것을 확인할 수 있다.\n\n
\n\n
 \n\n
\n\n\n\nVue.js에서 View에 필요한 템플릿을 구성하고, 스프링 부트에 번들링하는 과정을 통해 연동하는 과정을 완료했다!\n\n
\n\n
\n\n" }, { "path": "Web/Vue/Vue.js + Firebase로 이메일 회원가입로그인 구현.md", "content": "## Vue.js + Firebase로 이메일 회원가입/로그인 구현\n\n***2019.07.08 (김규석)***\n\n
\n\nVue.js와 Firebase를 통한 이메일 로그인을 구현해보자~\n\n
\n\n우선 설치해야할 것\n\n```\n$ npm -i -g @vue/cli\n$ npm -i -g @vue/cli-init\n```\n\n> @vue/cli-init은 2.0버전을 사용하기 위한 설치!\n\n
\n\nvue-cli는 템플릿 기반 프로젝트 초기 구성을 간편하게 할 수 있도록 도와준다!\n\n
\n\n### 프로젝트 생성\n\n```\n$ vue init webpack \"프로젝트 이름\"\n```\n\n이름과 같은 환경설정을 해주면 vue 프로젝트가 생성된다.\n\n
 \n\n
\n\n\n\n이제 해당 경로로 들어가서 npm 설치를 진행한다.\n\n```\n$ cd \"프로젝트 이름\"\n$ npm install\n```\n\n> 만약 npm install 후에 `vulnerabilities` 알림이 뜨면, npm audit fix를 통해 충돌나는 부분에 대한 문제를 해결하자\n\n
\n\n이제 npm 설치가 끝났으니 프로젝트를 실행해보자\n\n```\n$ npm run dev\n```\n\n
 \n\n
\n\n\n\n화면이 잘 나온다! 순조롭게 잘 실행했다는 뜻~\n\n
\n\n현재 만들어진 기본적인 Vue.js 파일 구조를 이해하지 못한 사람은 먼저 구조를 이해하고 다음 과정을 진행합시다.\n\n
\n\n
\n\n### vue-router 활용하기\n\n회원가입과 로그인 과정을 진행하기 위해, 3개의 view에 해당하는 컴포넌트를 src/components 폴더 아래에 만들고 vue-router를 통해 이동해볼 것이다.\n\n- Login 컴포넌트 : 로그인 하는 곳\n- Signup 컴포넌트 : 회원가입 하는 곳\n- Show 컴포넌트 : 로그인해야 볼 수 있는 곳 (기존의 HelloWorld.vue)\n\n
\n\n
\n\n\n\n\n\n\n\n\n\n#### 로그인 구현\n\n---\n\nsrc/components에 Login.vue를 만들자\n\n```vue\n\n
\n
\n
\n \n
\n\n\n\n\n\n```\n\nLogin
\n\n
\n \n
만약 계정이 없다면, 회원가입을 먼저 진행해주세요!
\n\n\n이제 로그인을 router/index.js에 라우터를 추가해주자.\n\n```javascript\nimport Vue from 'vue'\nimport Router from 'vue-router'\n\nimport HelloWorld from '@/components/HelloWorld'\nimport Login from '@/components/Login'\n\nVue.use(Router)\n\nexport default new Router({\n mode: 'history',\n routes: [\n {\n path: '/',\n name: 'HelloWorld',\n component: HelloWorld\n },\n {\n path: '/login',\n name: 'Login',\n component: Login\n }\n ]\n})\n```\n\n\n\n> url 중간에 \"#\"을 지우기 위해서는 라우터에서 mode: 'history'를 위와 같이 추가해주면 된다.\n\n
\n\n이제
 \n\nstyle을 적용시켜서 이쁘게 화면을 구현시킬 수 있다ㅎㅎ\n\n
\n\nstyle을 적용시켜서 이쁘게 화면을 구현시킬 수 있다ㅎㅎ\n\n\n\n#### 회원가입 구현\n\n---\n\n로그인처럼 같은 방식으로 회원가입에 해당하는 컴포넌트와 라우터 연결을 진행해보자\n\n##### src/components/SignUp.vue\n\n```vue\n\n
\n
\n
\n \n 또는 로그인으로 돌아가기\n
\n\n\n\n\n\n```\n\n회원가입
\n\n
\n \n 또는 로그인으로 돌아가기\n
\n\n##### router/index.js\n\n```javascript\nimport Vue from 'vue'\nimport Router from 'vue-router'\n\nimport HelloWorld from '@/components/HelloWorld'\nimport Login from '@/components/Login'\nimport SignUp from '@/components/SignUp'\n\nVue.use(Router)\n\nexport default new Router({\n mode: 'history',\n routes: [\n {\n path: '/',\n name: 'HelloWorld',\n component: HelloWorld\n },\n {\n path: '/login',\n name: 'Login',\n component: Login\n },\n {\n path: '/signup',\n name: 'SignUp',\n component: SignUp\n }\n ]\n})\n```\n\n
\n\n이제
\n\n
 \n\n
\n\n\n\n
\n\n### 컴포넌트간 이동하기\n\n---\n\n컴포넌트와 컴포넌트간 이동을 하기 위해서는 `router-link`를 사용한다.\n\n\n\n로그인과 회원가입 vue 폴더에서 서로 이동하도록 link를 사용해보자\n\n##### Login.vue\n\n```vue\n\n
\n
\n
\n \n
\n\n```\n\n##### SignUp.vue\n\n```vue\n\n Login
\n\n
\n \n
만약 계정이 없다면,
\n
\n
\n \n 또는로그인 으로 돌아가기\n
\n\n```\n\n이처럼 link 태그에 to=\"/경로\"를 통해 컴포넌트 이동이 가능하다.\n\n다시 화면으로 돌아가면, a태그와 같이 링크가 걸려있고 클릭 시 컴포넌트가 잘 이동되는 것을 확인할 수 있을 것이다.\n\n회원가입
\n\n
\n \n 또는
\n\n
\n\n\n\n현재는 인증 단계가 진행되지 않은 상태이므로, 로그인이 완료되었을 때 helloWorld.vue 화면으로 이동이 되도록만 replace 메소드를 적용시켜보자\n\n##### Login.vue\n\n```vue\n\n
\n
\n
\n \n
\n\n\n\n\n\n```\n\n로그인 button에 `v-on:click`을 통해 버튼을 눌렀을 때 login() 메소드가 실행되도록 해둔 상태다. methods에서 구현한 login 메소드가 실행되며, hello라는 경로를 가진 페이지로 이동하는 메소드다.\n\n\n\n현재 hello라는 경로가 없기 때문에, 기존의 root 경로를 hello로 변경해주자\n\n```javascript\nimport Vue from 'vue'\nimport Router from 'vue-router'\n\nimport HelloWorld from '@/components/HelloWorld'\nimport Login from '@/components/Login'\nimport SignUp from '@/components/SignUp'\n\nVue.use(Router)\n\nexport default new Router({\n mode: 'history',\n routes: [\n {\n path: '/hello',\n name: 'HelloWorld',\n component: HelloWorld\n },\n {\n path: '/login',\n name: 'Login',\n component: Login\n },\n {\n path: '/signup',\n name: 'SignUp',\n component: SignUp\n }\n ]\n})\n```\n\nroot 경로의 path를 `/`에서 `/hello`로 변경했다.\n\n이제 로그인 창에서 이메일과 패스워드를 입력 후 로그인을 누르면 HelloWorld.vue로 이동하는 것을 확인할 수 있을 것이다.\n\nLogin
\n\n
\n \n
만약 계정이 없다면,
\n\n
\n\n\n\n\n\n\n\n\n\n### 파이어베이스 연동\n\n---\n\n프론트 구현은 끝났다. 이제 가장 중요한 파이어베이스 연동이다.\n\n\n\n파이어베이스를 사용하기 위해, 파이어베이스 콘솔에서 새로운 프로젝트를 생성하자\n\n[파이어베이스 콘솔 링크](
 \n\n프로젝트 추가버튼 클릭\n\n
\n\n프로젝트 추가버튼 클릭\n\n\n\n
 \n\n
\n\n\n\n이제 파이어베이스 프로젝트 생성이 완료되었다.\n\n해당 프로젝트에 들어가면 코드 스니펫 모양이 있는데, 웹 앱을 추가하는 곳이다. 클릭해서 웹 앱에 파이어베이스를 추가하자\n\n
 \n\n앱 닉네임을 정하고, 등록을 누르면 스크립트가 나올 것이다.\n\n이 스크립트에 있는 config를 우리 vue 프로젝트에 적용시킬 것이다.\n\n
\n\n앱 닉네임을 정하고, 등록을 누르면 스크립트가 나올 것이다.\n\n이 스크립트에 있는 config를 우리 vue 프로젝트에 적용시킬 것이다.\n\n\n\n```javascript\nvar firebaseConfig = {\n apiKey: \"개인 API KEY\",\n authDomain: \"개인 프로젝트 ID.firebaseapp.com\",\n databaseURL: \"https://vue-firebase-tutorial-da26f.firebaseio.com\",\n projectId: \"vue-firebase-tutorial-da26f\",\n storageBucket: \"\",\n messagingSenderId: \"173286603007\",\n appId: \"1:173286603007:web:2258c081f9102650\"\n };\n // Initialize Firebase\n firebase.initializeApp(firebaseConfig);\n```\n\n코드 중에서 이 부분만 가져와서 활용할 것이다.\n\n
\n\n적용시키기 전에 터미널에서 firebase를 설치하자\n\n```\n$ npm install --save firebase\n```\n\n설치가 끝나면, main.js 파일에다 Firebase를 아래와 같이 적용시키자\n\n
\n\n```javascript\nimport Vue from 'vue'\nimport App from './App'\nimport router from './router'\nimport firebase from 'firebase'\n\nVue.config.productionTip = false\n\nvar firebaseConfig = {\n apiKey: \"개인 API KEY\",\n authDomain: \"개인 프로젝트 ID.firebaseapp.com\",\n databaseURL: \"https://vue-firebase-tutorial-da26f.firebaseio.com\",\n projectId: \"vue-firebase-tutorial-da26f\",\n storageBucket: \"\",\n messagingSenderId: \"173286603007\",\n appId: \"1:173286603007:web:2258c081f9102650\"\n};\n// Initialize Firebase\nfirebase.initializeApp(firebaseConfig);\n\n/* eslint-disable no-new */\nnew Vue({\n el: '#app',\n router,\n render: h => h(App)\n})\n```\n\n
\n\n
\n\n#### 회원가입 컴포넌트에서 파이어베이스 사용자 생성하기\n\n---\n\n이제 회원가입을 통해 가입한 사용자 데이터를 파이어베이스에게 전송해줘야 한다.\n\n회원가입 시 필요한 email과 password를 받아서 전송해야 하는데, **양방향 데이터 바인딩을 지원하는 v-model을 활용**하자\n\n```vue\n
\n
\n\n```\n\n> 이처럼 회원가입의 template에서 v-model과 메소드를 실행할 v-on을 추가한다.\n\n
\n\n##### signUp() 메소드 구현\n\n```vue\n\n```\n\ncreateUserWithEmailAndPassword 메소드는 onResolve, onReject 콜백과 파이어베이스의 프로미스를 반환해준다.\n\n
\n\n
\n\n#### 파이어베이스 로그인 공급자 활성화시키기\n\n---\n\n다시 파이어베이스 콘솔로 돌아가자\n\n왼쪽 사이드바를 열고, DEVELOP의 Authentication으로 들어간다.\n\n
\n\n
 \n\n로그인 방법으로 들어가서 `이메일/비밀번호`를 활성화 시킨다.\n\n
\n\n로그인 방법으로 들어가서 `이메일/비밀번호`를 활성화 시킨다.\n\n\n\n
 \n\n사용 설정됨으로 표시되면, 이제 사용자 가입 시 파이어베이스에 저장이 가능하다!\n\n
\n\n사용 설정됨으로 표시되면, 이제 사용자 가입 시 파이어베이스에 저장이 가능하다!\n\n\n\n회원가입 view로 가서 이메일과 비밀번호를 입력하고 가입해보자\n\n
 \n\n\n\n회원가입이 정상적으로 완료되었다는 alert가 뜬다. 진짜 파이어베이스에 내 정보가 저장되어있나 확인하러 가보자\n\n
\n\n\n\n회원가입이 정상적으로 완료되었다는 alert가 뜬다. 진짜 파이어베이스에 내 정보가 저장되어있나 확인하러 가보자\n\n \n\n오오..사용자 목록을 눌러보면, 내가 가입한 이메일이 나오는 것을 확인할 수 있다.\n\n이제 다음 진행은 당연히 뭘까? 내가 로그인할 때 **파이어베이스에 등록된 이메일과 일치하는 비밀번호로만 진행**되야 된다.\n\n
\n\n오오..사용자 목록을 눌러보면, 내가 가입한 이메일이 나오는 것을 확인할 수 있다.\n\n이제 다음 진행은 당연히 뭘까? 내가 로그인할 때 **파이어베이스에 등록된 이메일과 일치하는 비밀번호로만 진행**되야 된다.\n\n\n\n
\n\n#### 사용자 로그인\n\n회원가입 시 진행했던 것처럼 v-model 설정과 로그인 버튼 클릭 시 진행되는 메소드를 파이어베이스의 signInWithEmailAndPassword로 수정하자\n\n```vue\n\n
\n
\n
\n \n
\n\n\n\n```\n\n이제 다 끝났다.\n\n로그인을 진행해보자! 우선 비밀번호를 제대로 입력하지 않고 로그인해본다\n\nLogin
\n\n
\n \n
만약 계정이 없다면,
 \n\n에러가 나오면서 로그인이 되지 않는다!\n\n
\n\n에러가 나오면서 로그인이 되지 않는다!\n\n\n\n다시 제대로 비밀번호를 치면?!\n\n
 \n\n제대로 로그인이 되는 것을 확인할 수 있다.\n\n
\n\n제대로 로그인이 되는 것을 확인할 수 있다.\n\n\n\n이제 로그인이 되었을 때 보여줘야 하는 화면으로 이동을 하거나 로그인한 사람이 관리자면 따로 페이지를 구성하거나를 구현하고 싶은 계획에 따라 만들어가면 된다.\n\n" }, { "path": "Web/Vue/Vue.js + Firebase로 페이스북(facebook) 로그인 연동하기.md", "content": "## Vue.js + Firebase로 페이스북(facebook) 로그인 연동하기\n\n
 \n\n
\n\n\n\n우선, 기존의 파이어베이스 콘솔에서 Authentication의 로그인 방법으로 들어가자\n\n우리는 이메일/비밀번호를 활성화 시켜서 회원가입과 로그인을 가능하도록 구현했었다.\n\n
\n\n
 \n\n
\n\n\n\n위 사진처럼 페이스북도 상태를 사용으로 만들어야 한다.\n\n
\n\n
 \n\n
\n\n\n\n아래에 나오는 OAuth 리디렉션 URI를 복사하고, facebook for developers로 이동한다.\n\n[Facebook for developers 링크](https://developers.facebook.com)\n\n
\n\n해당 사이트에서 페이스북 아이디를 통해 로그인이 가능하다.\n\n앱을 새로 하나 생성하자. 앱 이름은 알아서 정하면 된다.\n\n
\n\n
 \n\n
\n\n\n\n앱을 생성하면 대시보드 화면이 나올 것이다.\n\n(현재 스크린샷은 라이브 상태로 되어있지만, 처음 만들었을 때는 개발모드 상태일 것이다.)\n\n페이지를 아래로 내려보면 제품 추가 항목이 존재한다.\n\n
\n\n
 \n\n이중에 'Facebook 로그인'항목이 우리가 필요한 것이다.\n\n
\n\n이중에 'Facebook 로그인'항목이 우리가 필요한 것이다.\n\n\n\n
 \n\n
\n\n\n\n유효한 OAuth 리디렉션 URI의 공란에 아까 파이어베이스에서 복사한 URI를 붙여넣기 하고 저장해주면 된다.\n\n
\n\n이제 우리 Facebook 앱을 배포시에도 정상 작동할 수 있도록 공개상태로 전환시켜야한다.\n\n
\n\n
 \n\n
\n\n\n\n설정 → 기본 설정으로 들어가면, 다음과 같은 화면이 나올 것이다.\n\n여기서 '개인정보처리방침 URL'을 등록해야만 앱을 공개상태로 바꿀 수 있다.\n\n현재는 연습단계이므로, 아무 url이나 작성하고 저장한다.\n\n이제 중앙 위쪽에 설정을 키면, 앱이 정상적으로 실행될 것이다!\n\n
\n\n이제 설정창에 존재하는 앱 ID와 앱 시크릿 코드를 파이어베이스에서 페이스북 연동을 하기 위해 사용할 것이다.\n\n(시크릿 코드는 비밀번호를 한번더 입력하면 볼 수 있다.)\n\n
\n\n
 \n\n다시 파이어베이스로 돌아가서, 앱ID와 앱 비밀번호를 입력하자\n\n이제 Facebook 사용 설정이 모두 끝났다.\n\n
\n\n다시 파이어베이스로 돌아가서, 앱ID와 앱 비밀번호를 입력하자\n\n이제 Facebook 사용 설정이 모두 끝났다.\n\n\n\n코드로 파이어베이스를 로그인 화면에서 불러오는 메소드를 작성해주면 된다.\n\n
\n\n##### Login.vue의 템플릿 부분\n\n```vue\n\n
\n
\n
\n \n
\n\n```\n\n기존 화면에서 페이스북 로그인 부분을 추가했다.\n\n로그인
\n\n
\n \n
또는 페이스북 로그인
\n \n
만약 계정이 없다면,
\n\n인터넷에서 페이스북 로고 이미지(facebook-logo.png)를 다운받아서, 프로젝트 폴더의 src/assets에다가 추가하자.\n\n
\n\n##### 페이스북 로그인 연동 script\n\n```vue\n\n```\n\n파이어베이스에서 facebookauth를 불러오고, provider 변수로 작업한다.\n\nsetCustomParameters의 display를 popup으로 줘서, 버튼을 클릭했을 때 팝업창으로 페이스북 로그인이 진행되도록 한 것이다.\n\n버튼에 작성한 facebookLogin 메소드를 firebase.auth().signInWithPopup로 가져와서 페이스북 로그인을 진행할 수 있다.\n\n
\n\n##### Login.vue의 전체 소스코드\n\n```vue\n\n
\n
\n
\n \n
\n\n\n\n\n\n```\n\nstyle을 통해 페이스북 로그인 화면도 꾸민 상태다.\n\n로그인
\n\n
\n \n
또는 페이스북 로그인
\n \n
만약 계정이 없다면,
\n\n
\n\n이제 서버를 실행하고 로그인 화면을 보자\n\n
\n\n
 \n\n
\n\n\n\n페이스북 로고 사진을 누르면?\n\n
 \n\n페이스북 로그인 창이 팝업으로 뜨는걸 확인할 수 있다.\n\n이제 자신의 페이스북 아이디와 비밀번호로 로그인하면 welcome 페이지가 정상적으로 나올 것이다.\n\n
\n\n페이스북 로그인 창이 팝업으로 뜨는걸 확인할 수 있다.\n\n이제 자신의 페이스북 아이디와 비밀번호로 로그인하면 welcome 페이지가 정상적으로 나올 것이다.\n\n\n\n마지막으로 파이어베이스에 사용자 정보가 저장된 데이터를 확인해보자\n\n
 \n\n
\n\n\n\n페이스북으로 로그인한 사람의 정보도 저장되어있는 모습을 확인할 수 있다. 페이스북으로 로그인한 사람의 이메일이 등록되면 로컬에서 해당 이메일로 회원가입이 불가능하다.\n\n
\n\n위처럼 간단하게 웹페이지에서 페이스북 로그인 연동을 구현시킬 수 있고, 다른 소셜 네트워크 서비스들도 유사한 방법으로 가능하다." }, { "path": "Web/Vue/Vue.js 라이프사이클 이해하기.md", "content": "## Vue.js 라이프사이클 이해하기\n\n
\n\n무작정 프로젝트를 진행하면서 적용하다보니, 라이프사이클을 제대로 몰라서 애를 먹고있다. Vue가 가지는 라이프사이클을 제대로 이해하고 넘어가보자.\n\n
\n\nVue.js의 라이프사이클은 크게 4가지로 나누어진다.\n\n> Creation, Mounting, Updating, Destruction\n\n
\n\n
 \n\n
\n\n\n\n### Creation\n\n> 컴포넌트 초기화 단계\n\nCreation 단계에서 실행되는 훅(hook)들이 라이프사이클 중 가장 먼저 실행됨\n\n아직 컴포넌트가 DOM에 추가되기 전이며 서버 렌더링에서도 지원되는 훅임\n\n
\n\n클라이언트와 서버 렌더링 모두에서 처리해야 할 일이 있으면, 이 단계에 적용하자\n\n
\n\n- beforeCreate\n\n > 가장 먼저 실행되는 훅\n >\n > 아직 데이터나 이벤트가 세팅되지 않은 시점이므로 접근 불가능\n\n- created\n\n > 데이터, 이벤트가 활성화되어 접근이 가능함\n >\n > 하지만 아직 템플릿과 virtual DOM은 마운트 및 렌더링 되지 않은 상태임\n\n
\n\n
\n\n### Mounting\n\n> DOM 삽입 단계\n\n초기 렌더링 직전 컴포넌트에 직접 접근이 가능하다.\n\n컴포넌트 초기에 세팅되어야할 데이터들은 created에서 사용하는 것이 나음\n\n
\n\n- beforeMount\n\n > 템플릿이나 렌더 함수들이 컴파일된 후에 첫 렌더링이 일어나기 직전에 실행됨\n >\n > 많이 사용하지 않음\n\n- mounted\n\n > 컴포넌트, 템플릿, 렌더링된 DOM에 접근이 가능함\n >\n > 모든 화면이 렌더링 된 후에 실행\n\n
\n\n##### 주의할 점\n\n부모와 자식 관계의 컴포넌트에서 생각한 순서대로 mounted가 발생하지 않는다. 즉, 부모의 mounted가 자식의 mounted보다 먼저 실행되지 않음\n\n> 부모는 자식의 mounted 훅이 끝날 때까지 기다림\n\n
\n\n### Updating\n\n> 렌더링 단계\n\n컴포넌트에서 사용되는 반응형 속성들이 변경되거나 다시 렌더링되면 실행됨\n\n디버깅을 위해 컴포넌트가 다시 렌더링되는 시점을 알고 싶을때 사용 가능\n\n
\n\n- beforeUpdate\n\n > 컴포넌트의 데이터가 변하여 업데이트 사이클이 시작될 때 실행됨\n >\n > (돔이 재 렌더링되고 패치되기 직전 상태)\n\n- updated\n\n > 컴포넌트의 데이터가 변하여 다시 렌더링된 이후에 실행됨\n >\n > 업데이트가 완료된 상태이므로, DOM 종속적인 연산이 가능\n\n
\n\n### Destruction\n\n> 해체 단계\n\n
\n\n- beforeDestory\n\n > 해체되기 직전에 호출됨\n >\n > 이벤트 리스너를 제거하거나 reactive subscription을 제거하고자 할 때 유용함\n\n- destroyed\n\n > 해체된 이후에 호출됨\n >\n > Vue 인스턴스의 모든 디렉티브가 바인딩 해제되고 모든 이벤트 리스너가 제거됨\n\n
\n\n
\n\n\n\n#### 추가로 사용하는 속성들\n\n---\n\n\n\n- computed\n\n > 템플릿에 데이터 바인딩할 수 있음\n >\n > ```vue\n >
\n >
\n > \n > \n > ```\n >\n > message의 값이 바뀌면, reversedMessage의 값도 따라 바뀜\n\n 원본 메시지: \"{{ message }}\"
\n >역순으로 표시한 메시지: \"{{ reversedMessage }}\"
\n >\n\n `Date.now()`와 같이 의존할 곳이 없는 computed 속성은 업데이트 안됨\n\n ```\n computed: {\n now: function () {\n return Date.now() //업데이트 불가능\n }\n }\n ```\n\n 호출할 때마다 변경된 시간을 이용하고 싶으면 methods 이용\n\n
\n\n- watch\n\n > 데이터가 변경되었을 때 호출되는 콜백함수를 정의\n >\n > watch는 감시할 데이터를 지정하고, 그 데이터가 바뀌면 어떠한 함수를 실행하라는 방식으로 진행\n\n\n\n##### computed와 watch로 진행한 코드\n\n```vue\n//computed\n\n```\n\n
\n\n```vue\n//watch\n\n```\n\n
\n\ncomputed는 선언형, watch는 명령형 프로그래밍 방식\n\nwatch를 사용하면 API를 호출하고, 그 결과에 대한 응답을 받기 전 중간 상태를 설정할 수 있으나 computed는 불가능\n\n
\n\n대부분의 경우 선언형 방식인 computed 사용이 더 좋으나, 데이터 변경의 응답으로 비동기식 계산이 필요한 경우나 시간이 많이 소요되는 계산을 할 때는 watch를 사용하는 것이 좋다." }, { "path": "Web/Vue.js와 React의 차이.md", "content": "## Vue.js와 React의 차이\n\n
 \n\n
\n\n\n\n##### 개발 CLI\n\n- Vue.js : vue-cli\n- React : create-react-app\n\n##### CSS 파일 존재 유무\n\n- Vue.js : 없음. style이 실제 컴포넌트 파일 안에서 정의됨\n- React : 파일이 존재. 해당 파일을 통해 style 적용\n\n##### 데이터 변이\n\n- Vue.js : 반드시 데이터 객체를 생성한 이후 data를 업데이트 할 수 있음\n- React : state 객체를 만들고, 업데이트에 조금 더 작업이 필요\n\n```\nname: kim 값을 lee로 바꾸려면\nVue.js : this.name = 'lee'\nReact : this.setState({name:'lee'})\n```\n\nVue에서는 data를 업데이트할 때마다 setState를 알아서 결합해분다.\n\n
\n\n
\n\n\n\n#### [참고 사항]\n\n- [링크]( [https://medium.com/@erwinousy/%EB%82%9C-react%EC%99%80-vue%EC%97%90%EC%84%9C-%EC%99%84%EC%A0%84%ED%9E%88-%EA%B0%99%EC%9D%80-%EC%95%B1%EC%9D%84-%EB%A7%8C%EB%93%A4%EC%97%88%EB%8B%A4-%EC%9D%B4%EA%B2%83%EC%9D%80-%EA%B7%B8-%EC%B0%A8%EC%9D%B4%EC%A0%90%EC%9D%B4%EB%8B%A4-5cffcbfe287f](https://medium.com/@erwinousy/난-react와-vue에서-완전히-같은-앱을-만들었다-이것은-그-차이점이다-5cffcbfe287f) )\n- [링크](https://kr.vuejs.org/v2/guide/comparison.html)\n\n" }, { "path": "Web/Web Server와 WAS의 차이.md", "content": "## Web Server와 WAS의 차이\n\n
\n\n웹 서버와 was의 차이점은 무엇일까? 서버 개발에 있어서 기초적인 개념이다.\n\n먼저, 정적 페이지와 동적 페이지를 알아보자\n\n\n\n
 \n\n#### Static Pages\n\n> 바뀌지 않는 페이지\n\n웹 서버는 파일 경로 이름을 받고, 경로와 일치하는 file contents를 반환함\n\n항상 동일한 페이지를 반환함\n\n```\nimage, html, css, javascript 파일과 같이 컴퓨터에 저장된 파일들\n```\n\n
\n\n#### Static Pages\n\n> 바뀌지 않는 페이지\n\n웹 서버는 파일 경로 이름을 받고, 경로와 일치하는 file contents를 반환함\n\n항상 동일한 페이지를 반환함\n\n```\nimage, html, css, javascript 파일과 같이 컴퓨터에 저장된 파일들\n```\n\n\n\n#### Dynamic Pages\n\n> 인자에 따라 바뀌는 페이지\n\n인자의 내용에 맞게 동적인 contents를 반환함\n\n웹 서버에 의해 실행되는 프로그램을 통해 만들어진 결과물임\n(Servlet : was 위에서 돌아가는 자바 프로그램)\n\n개발자는 Servlet에 doGet() 메소드를 구현함\n\n
\n\n
\n\n#### 웹 서버와 WAS의 차이\n\n
\n\n
 \n\n\n\n#### 웹 서버\n\n개념에 있어서 하드웨어와 소프트웨어로 구분된다.\n\n**하드웨어** : Web 서버가 설치되어 있는 컴퓨터\n\n**소프트웨어** : 웹 브라우저 클라이언트로부터 HTTP 요청을 받고, 정적인 컨텐츠(html, css 등)를 제공하는 컴퓨터 프로그램\n\n
\n\n\n\n#### 웹 서버\n\n개념에 있어서 하드웨어와 소프트웨어로 구분된다.\n\n**하드웨어** : Web 서버가 설치되어 있는 컴퓨터\n\n**소프트웨어** : 웹 브라우저 클라이언트로부터 HTTP 요청을 받고, 정적인 컨텐츠(html, css 등)를 제공하는 컴퓨터 프로그램\n\n\n\n##### 웹 서버 기능\n\n> Http 프로토콜을 기반으로, 클라이언트의 요청을 서비스하는 기능을 담당\n\n요청에 맞게 두가지 기능 중 선택해서 제공해야 한다.\n\n- 정적 컨텐츠 제공\n\n > WAS를 거치지 않고 바로 자원 제공\n\n- 동적 컨텐츠 제공을 위한 요청 전달\n\n > 클라이언트 요청을 WAS에 보내고, WAS에서 처리한 결과를 클라이언트에게 전달\n\n
\n\n**웹 서버 종류** : Apache, Nginx, IIS 등\n\n
\n\n#### WAS\n\nWeb Application Server의 약자\n\n> DB 조회 및 다양한 로직 처리 요구시 **동적인 컨텐츠를 제공**하기 위해 만들어진 애플리케이션 서버\n\nHTTP를 통해 애플리케이션을 수행해주는 미들웨어다.\n\n**WAS는 웹 컨테이너 혹은 서블릿 컨테이너**라고도 불림\n\n(컨테이너란 JSP, Servlet을 실행시킬 수 있는 소프트웨어. 즉, WAS는 JSP, Servlet 구동 환경을 제공해줌)\n\n
\n\n##### 역할\n\nWAS = 웹 서버 + 웹 컨테이너\n\n웹 서버의 기능들을 구조적으로 분리하여 처리하는 역할\n\n> 보안, 스레드 처리, 분산 트랜잭션 등 분산 환경에서 사용됨 ( 주로 DB 서버와 함께 사용 )\n\n
\n\n##### WAS 주요 기능\n\n1.프로그램 실행 환경 및 DB 접속 기능 제공\n\n2.여러 트랜잭션 관리 기능\n\n3.업무 처리하는 비즈니스 로직 수행\n\n
\n\n**WAS 종류** : Tomcat, JBoss 등\n\n
\n\n
\n\n#### 그럼, 둘을 구분하는 이유는?\n\n
\n\n##### 웹 서버가 필요한 이유\n\n웹 서버에서는 정적 컨텐츠만 처리하도록 기능 분배를 해서 서버 부담을 줄이는 것\n\n```\n클라이언트가 이미지 파일(정적 컨텐츠)를 보낼 때..\n\n웹 문서(html 문서)가 클라이언트로 보내질 때 이미지 파일과 같은 정적 파일은 함께 보내지지 않음\n먼저 html 문서를 받고, 이에 필요한 이미지 파일들을 다시 서버로 요청해서 받아오는 것\n\n따라서 웹 서버를 통해서 정적인 파일을 애플리케이션 서버까지 가지 않고 앞단에 빠르게 보낼 수 있음!\n```\n\n
\n\n##### WAS가 필요한 이유\n\nWAS를 통해 요청에 맞는 데이터를 DB에서 가져와 비즈니스 로직에 맞게 그때마다 결과를 만들고 제공하면서 자원을 효율적으로 사용할 수 있음\n\n```\n동적인 컨텐츠를 제공해야 할때..\n\n웹 서버만으로는 사용자가 원하는 요청에 대한 결과값을 모두 미리 만들어놓고 서비스하기에는 자원이 절대적으로 부족함\n\n따라서 WAS를 통해 요청이 들어올 때마다 DB와 비즈니스 로직을 통해 결과물을 만들어 제공!\n```\n\n
\n\n##### 그러면 WAS로 웹 서버 역할까지 다 처리할 수 있는거 아닌가요?\n\n```\nWAS는 DB 조회, 다양한 로직을 처리하는 데 집중해야 함. 따라서 단순한 정적 컨텐츠는 웹 서버에게 맡기며 기능을 분리시켜 서버 부하를 방지하는 것\n\n만약 WAS가 정적 컨텐츠 요청까지 처리하면, 부하가 커지고 동적 컨텐츠 처리가 지연되면서 수행 속도가 느려짐 → 페이지 노출 시간 늘어나는 문제 발생\n```\n\n
\n\n또한, 여러 대의 WAS를 연결지어 사용이 가능하다.\n\n웹 서버를 앞 단에 두고, WAS에 오류가 발생하면 사용자가 이용하지 못하게 막아둔 뒤 재시작하여 해결할 수 있음 (사용자는 오류를 느끼지 못하고 이용 가능) \n\n
\n\n자원 이용의 효율성 및 장애 극복, 배포 및 유지 보수의 편의성 때문에 웹 서버와 WAS를 분리해서 사용하는 것이다.\n\n
\n\n##### 가장 효율적인 방법\n\n> 웹 서버를 WAS 앞에 두고, 필요한 WAS들을 웹 서버에 플러그인 형태로 설정하면 효율적인 분산 처리가 가능함\n\n
\n\n
 \n\n
\n\n\n\n클라이언트의 요청을 먼저 웹 서버가 받은 다음, WAS에게 보내 관련된 Servlet을 메모리에 올림\n\nWAS는 web.xml을 참조해 해당 Servlet에 대한 스레드를 생성 (스레드 풀 이용)\n\n이때 HttpServletRequest와 HttpServletResponse 객체를 생성해 Servlet에게 전달\n\n> 스레드는 Servlet의 service() 메소드를 호출\n>\n> service() 메소드는 요청에 맞게 doGet()이나 doPost() 메소드를 호출\n\ndoGet()이나 doPost() 메소드는 인자에 맞게 생성된 적절한 동적 페이지를 Response 객체에 담아 WAS에 전달\n\nWAS는 Response 객체를 HttpResponse 형태로 바꿔 웹 서버로 전달\n\n생성된 스레드 종료하고, HttpServletRequest와 HttpServletResponse 객체 제거\n\n
\n\n
\n\n**[참고자료]** : [링크](
\n\n
\n\n\n\n```\n자동으로 테스트 및 빌드가 될 수 있는 환경을 만들어 개발에만 집중할 수 있도록 하자\n```\n\n
\n\n#### CI(Continuous Integration)\n\n코드 버전 관리를 하는 Git과 같은 시스템에 PUSH가 되면 자동으로 빌드 및 테스트가 수행되어 안정적인 배포 파일을 만드는 과정을 말한다.\n\n
\n\n#### CD(Continuous Deployment)\n\n빌드한 결과를 자동으로 운영 서버에 무중단 배포하는 과정을 말한다.\n\n
\n\n### Travis CI 웹 서비스 설정하기\n\n[Travis 사이트](https://www.travis-ci.com/)로 접속하여 깃허브 계정으로 로그인 후, `Settings`로 들어간다.\n\nRepository 활성화를 통해 CI 연결을 할 프로젝트로 이동한다.\n\n
\n\n
\n\n\n\n
\n\n### 프로젝트 설정하기\n\n세부설정을 하려면 `yml`파일로 진행해야 한다. 프로젝트에서 `build.gradle`이 위치한 경로에 `.travis.yml`을 새로 생성하자\n\n```yml\nlanguage: java\njdk:\n - openjdk11\n\nbranches:\n only:\n - main\n\n# Travis CI 서버의 Home\ncache:\n directories:\n - '$HOME/.m2/repository'\n - '$HOME/.gradle'\n\nscript: \"./gradlew clean build\"\n\n# CI 실행 완료시 메일로 알람\nnotifications:\n email:\n recipients:\n - gyuseok6394@gmail.com\n```\n\n- `branches` : 어떤 브랜치가 push할 때 수행할지 지정\n- `cache` : 캐시를 통해 같은 의존성은 다음 배포하지 않도록 설정\n- `script` : 설정한 브랜치에 push되었을 때 수행하는 명령어\n- `notifications` : 실행 완료 시 자동 알람 전송 설정\n\n
\n\n생성 후, 해당 프로젝트에서 `Github`에 push를 진행하면 Travis CI 사이트의 해당 레포지토리 정보에서 빌드가 성공한 것을 확인할 수 있다.\n\n
\n\n
\n\n\n\n
\n\n#### *만약 Travis CI에서 push 후에도 아무런 반응이 없다면?*\n\n현재 진행 중인 프로젝트의 GitHub Repository가 바로 루트 경로에 있지 않은 확률이 높다.\n\n즉, 해당 레포지토리에서 추가로 폴더를 생성하여 프로젝트가 생성된 경우를 말한다.\n\n이럴 때는 `.travis.yml`을 `build.gradle`이 위치한 경로에 만드는 것이 아니라, 레포지토리 루트 경로에 생성해야 한다.\n\n
\n\n
\n\n\n\n그 이후 다음과 같이 코드를 추가해주자 (현재 위치로 부터 프로젝트 빌드를 진행할 곳으로 이동이 필요하기 때문)\n\n```yml\nlanguage: java\njdk:\n - openjdk11\n\nbranches:\n only:\n - main\n\n# ------------추가 부분----------------\n\nbefore_script:\n - cd {프로젝트명}/\n \n# ------------------------------------\n\n# Travis CI 서버의 Home\ncache:\n directories:\n - '$HOME/.m2/repository'\n - '$HOME/.gradle'\n\nscript: \"./gradlew clean build\"\n\n# CI 실행 완료시 메일로 알람\nnotifications:\n email:\n recipients:\n - gyuseok6394@gmail.com\n```\n\n
\n\n
\n\n#### [참고 자료]\n\n- [링크](https://github.com/jojoldu/freelec-springboot2-webservice)\n\n
" }, { "path": "Web/[Web] REST API.md", "content": "### REST API \n\n----\n\nREST : 웹 (HTTP) 의 장점을 활용한 아키텍쳐 \n\n#### 1. REST (REpresentational State Transfer) 기본\n\n* REST의 요소\n\n * Method\n\n | Method | 의미 | Idempotent |\n | ------ | ------ | ---------- |\n | POST | Create | No |\n | GET | Select | Yes |\n | PUT | Update | Yes |\n | DELETE | Delete | Yes |\n\n > Idempotent : 한 번 수행하냐, 여러 번 수행했을 때 결과가 같나?\n\n
\n\n * Resource\n\n * http://myweb/users와 같은 URI\n * 모든 것을 Resource (명사)로 표현하고, 세부 Resource에는 id를 붙임\n\n
\n\n * Message\n\n * 메시지 포맷이 존재\n\n : JSON, XML 과 같은 형태가 있음 (최근에는 JSON 을 씀)\n\n ```text\n HTTP POST, http://myweb/users/\n {\n \t\"users\" : {\n \t\t\"name\" : \"terry\"\n \t}\n }\n ```\n\n
\n\n* REST 특징\n\n * Uniform Interface\n\n * HTTP 표준만 맞는다면, 어떤 기술도 가능한 Interface 스타일\n\n 예) REST API 정의를 HTTP + JSON로 하였다면, C, Java, Python, IOS 플랫폼 등 특정 언어나 기술에 종속 받지 않고, 모든 플랫폼에 사용이 가능한 Loosely Coupling 구조\n\n * 포함\n * Self-Descriptive Messages\n\n * API 메시지만 보고, API를 이해할 수 있는 구조 (Resource, Method를 이용해 무슨 행위를 하는지 직관적으로 이해할 수 있음)\n\n * HATEOAS(Hypermedia As The Engine Of Application State)\n\n * Application의 상태(State)는 Hyperlink를 통해 전이되어야 함.\n * 서버는 현재 이용 가능한 다른 작업에 대한 하이퍼링크를 포함하여 응답해야 함.\n\n * Resource Identification In Requests\n\n * Resource Manipulation Through Representations\n\n * Statelessness\n\n * 즉, HTTP Session과 같은 컨텍스트 저장소에 **상태 정보 저장 안함**\n * **Request만 Message로 처리**하면 되고, 컨텍스트 정보를 신경쓰지 않아도 되므로, **구현이 단순해짐**.\n\n * 따라서, REST API 실행중 실패가 발생한 경우, Transaction 복구를 위해 기존의 상태를 저장할 필요가 있다. (POST Method 제외)\n\n * Resource 지향 아키텍쳐 (ROA : Resource Oriented Architecture)\n\n * Resource 기반의 복수형 명사 형태의 정의를 권장.\n \n * Client-Server Architecture\n \n * Cache Ability\n \n * Layered System\n \n * Code On Demand(Optional)\n" }, { "path": "Web/네이티브 앱 & 웹 앱 & 하이브리드 앱.md", "content": "## 네이티브 앱 & 웹 앱 & 하이브리드 앱\n\n
\n\n#### 네이티브 앱 (Native App)\n\n
 \n\n흔히 우리가 자주 사용하는 어플리케이션을 의미한다.\n\n모바일 기기에 최적화된 언어로 개발된 앱으로 안드로이드 SDK를 이용한 Java 언어나 iOS 기반 SDK를 이용한 Swift 언어로 만드는 앱이 네이티브 앱에 속한다.\n\n
\n\n흔히 우리가 자주 사용하는 어플리케이션을 의미한다.\n\n모바일 기기에 최적화된 언어로 개발된 앱으로 안드로이드 SDK를 이용한 Java 언어나 iOS 기반 SDK를 이용한 Swift 언어로 만드는 앱이 네이티브 앱에 속한다.\n\n\n\n##### 장점\n\n- 성능이 웹앱, 하이브리드 앱에 비해 가장 높음\n- 네이티브 API를 호출하여 사용함으로 플랫폼과 밀착되어있음\n- Java나 Swift에 익숙한 사용자면 쉽게 접근 가능함\n\n##### 단점\n\n- 플랫폼에 한정적\n- 언어에 제약적\n\n
\n\n
\n\n#### 모바일 웹 앱 (Mobile Wep App)\n\n
 \n\n모바일웹 + 네이티브 앱을 결합한 형태\n\n모바일 웹의 특징을 가지면서도, 네이티브 앱의 장점을 지녔다. 따라서 기존의 모바일 웹보다는 모바일에 최적화 된 앱이라고 말할 수 있다.\n\n웹앱은 SPA를 활용해 속도가 빠르다는 장점이 있다.\n\n> 쉽게 말해, PC용 홈페이지를 모바일 스크린 크기에 맞춰 줄여 놓은 것이라고 생각하면 편함\n\n
\n\n모바일웹 + 네이티브 앱을 결합한 형태\n\n모바일 웹의 특징을 가지면서도, 네이티브 앱의 장점을 지녔다. 따라서 기존의 모바일 웹보다는 모바일에 최적화 된 앱이라고 말할 수 있다.\n\n웹앱은 SPA를 활용해 속도가 빠르다는 장점이 있다.\n\n> 쉽게 말해, PC용 홈페이지를 모바일 스크린 크기에 맞춰 줄여 놓은 것이라고 생각하면 편함\n\n\n\n##### 장점\n\n- 웹 사이트를 보는 것이므로 따로 설치할 필요X\n- 모든 기기와 브라우저에서 접근 가능\n- 별도 설치 및 승인 과정이 필요치 않아 유지보수에 용이\n\n##### 단점\n\n- 플랫폼 API 사용 불가능. 오로지 브라우저 API만 사용가능\n- 친화적 터치 앱을 개발하기 약간 번거로움\n- 네이티브, 하이브리드 앱보다 실행 까다로움 (브라우저 열거 검색해서 들어가야함)\n\n
\n\n
\n\n#### 하이브리드 앱 (Hybrid App)\n\n
 \n\n> 네이티브 + 웹앱\n\n네이티브 웹에, 웹 view를 띄워 웹앱을 실행시킨다. 양쪽의 API를 모두 사용할 수 있는 것이 가장 큰 장점\n\n
\n\n> 네이티브 + 웹앱\n\n네이티브 웹에, 웹 view를 띄워 웹앱을 실행시킨다. 양쪽의 API를 모두 사용할 수 있는 것이 가장 큰 장점\n\n\n\n##### 장점\n\n- 네이티브 API, 브라우저 API를 모두 활용한 다양한 개발 가능\n- 웹 개발 기술로 앱 개발 가능\n- 한번의 개발로 다수 플랫폼에서 사용 가능\n\n##### 단점\n\n- 네이티브 기능 접근 위해 개발 지식 필요\n- UI 프레임도구 사용안하면 개발자가 직접 UI 제작\n\n
\n\n
\n\n#### 요약\n\n
 \n\n
\n\n\n\n
\n\n
\n\n##### [참고 자료]\n\n- [링크](https://m.blog.naver.com/acornedu/221012420292)\n\n" }, { "path": "Web/브라우저 동작 방법.md", "content": "# 브라우저 동작 방법\n\n
\n\n***\"브라우저가 어떻게 동작하는지 아세요?\"***\n\n웹 서핑하다보면 우리는 여러 url을 통해 사이트를 돌아다닌다. 이 url이 입력되었을 때 어떤 과정을 거쳐서 출력되는걸까?\n\nweb의 기본적인 개념이지만 설명하기 무지 어렵다.. 렌더링..? 파싱..?\n\n
\n\n브라우저 주소 창에 [http://naver.com](http://naver.com)을 입력했을 때 어떤 과정을 거쳐서 네이버 페이지가 화면에 보이는 지 알아보자\n\n> 오픈 소스 브라우저(크롬, 파이어폭스, 사파리 등)로 접속했을 때로 정리\n\n
\n\n
\n\n#### 브라우저 주요 기능\n\n---\n\n사용자가 선택한 자원을 서버에 요청, 브라우저에 표시\n\n자원은 html 문서, pdf, image 등 다양한 형태\n\n자원의 주소는 URI에 의해 정해짐\n\n
\n\n브라우저는 html과 css 명세에 따라 html 파일을 해석해서 표시함\n\n이 '명세'는 웹 표준화 기구인 `W3C(World wide web Consortium)`에서 정해짐\n\n> 예전 브라우저들은 일부만 명세에 따라 구현하고 독자적 방법으로 확장했음\n>\n> (결국 **심각한 호환성 문제** 발생... 그래서 요즘은 대부분 모두 표준 명세를 따름)\n\n
\n\n브라우저가 가진 인터페이스는 보통 비슷비슷한 요소들이 존재\n\n> 시간이 지나면서, 사용자에게 필요한 서비스들로 서로 모방하며 갖춰지게 된 것\n\n- URI 입력하는 주소 표시 줄\n- 이전 버튼, 다음 버튼\n- 북마크(즐겨찾기)\n- 새로 고침 버튼\n- 홈 버튼\n\n
\n\n
\n\n#### 브라우저 기본 구조\n\n---\n\n
 \n\n
\n\n\n\n##### 사용자 인터페이스\n\n주소 표시줄, 이전/다음 버튼, 북마크 등 사용자가 활용하는 서비스들\n(요청한 페이지를 보여주는 창을 제외한 나머지 부분)\n\n##### 브라우저 엔진\n\n사용자 인터페이스와 렌더링 엔진 사이의 동작 제어\n\n##### 렌더링 엔진\n\n요청한 콘텐츠 표시 (html 요청이 들어오면? → html, css 파싱해서 화면에 표시)\n\n##### 통신\n\nhttp 요청과 같은 네트워크 호출에 사용\n(플랫폼의 독립적인 인터페이스로 구성되어있음)\n\n##### UI 백엔드\n\n플랫폼에서 명시하지 않은 일반적 인터페이스. 콤보 박스 창같은 기본적 장치를 그림\n\n##### 자바스크립트 해석기\n\n자바스크립트 코드를 해석하고 실행\n\n##### 자료 저장소\n\n쿠키 등 모든 종류의 자원을 하드 디스크에 저장하는 계층\n\n
\n\n
\n\n#### ***렌더링이란?***\n\n웹 분야를 공부하다보면 **렌더링**이라는 말을 많이 본다. 동작 과정에 대해 좀 더 자세히 알아보자\n\n
\n\n렌더링 엔진은 요청 받은 내용을 브라우저 화면에 표시해준다.\n\n기본적으로 html, xml 문서와 이미지를 표시할 수 있음\n\n추가로 플러그인이나 브라우저 확장 기능으로 pdf 등 다른 유형도 표시가 가능함\n\n(추가로 확장이 필요한 유형은 바로 뜨지 않고 팝업으로 확장 여부를 묻는 것을 볼 수 있을 것임)\n\n
\n\n##### 렌더링 엔진 종류\n\n크롬, 사파리 : 웹킷(Webkit) 엔진 사용\n\n파이어폭스 : 게코(Gecko) 엔진 사용\n\n
\n\n**웹킷(Webkit)** : 최초 리눅스 플랫폼에 동작하기 위한 오픈소스 엔진\n(애플이 맥과 윈도우에서 사파리 브라우저를 지원하기 위해 수정을 더했음)\n\n
\n\n##### 렌더링 동작 과정\n\n
 \n\n
\n\n\n\n```\n먼저 html 문서를 파싱한다.\n\n그리고 콘텐츠 트리 내부에서 태그를 모두 DOM 노드로 변환한다.\n\n그 다음 외부 css 파일과 함께 포함된 스타일 요소를 파싱한다.\n\n이 스타일 정보와 html 표시 규칙은 렌더 트리라고 부르는 또 다른 트리를 생성한다.\n\n이렇게 생성된 렌더 트리는 정해진 순서대로 화면에 표시되는데, 생성 과정이 끝났을 때 배치가 진행되면서 노드가 화면의 정확한 위치에 표시되는 것을 의미한다.\n\n이후에 UI 백엔드에서 렌더 트리의 각 노드를 가로지으며 형상을 만드는 그리기 과정이 진행된다.\n\n이러한 과정이 점진적으로 진행되며, 렌더링 엔진은 좀더 빠르게 사용자에게 제공하기 위해 모든 html을 파싱할 때까지 기다리지 않고 배치와 그리기 과정을 시작한다. (마치 비동기처럼..?)\n\n전송을 받고 기다리는 동시에 받은 내용을 먼저 화면에 보여준다\n(우리가 웹페이지에 접속할 때 한꺼번에 뜨지 않고 점점 화면에 나오는 것이 이 때문!!!)\n```\n\n
\n\n***DOM이란?***\n\nDocument Object Model(문서 객체 모델)\n\n웹페이지 소스를 까보면 `, `와 같은 태그들이 존재한다. 이를 Javascript가 활용할 수 있는 객체로 만들면 `문서 객체`가 된다.\n\n모델은 말 그대로, 모듈화로 만들었다거나 객체를 인식한다라고 해석하면 된다.\n\n즉, **DOM은 웹 브라우저가 html 페이지를 인식하는 방식**을 말한다. (트리구조)\n\n
\n\n##### 웹킷 동작 구조\n\n
 \n\n> **어태치먼트** : 웹킷이 렌더 트리를 생성하기 위해 DOM 노드와 스타일 정보를 연결하는 과정\n\n이제 조금 트리 구조의 진행 방식이 이해되기 시작한다..ㅎㅎ\n\n
\n\n> **어태치먼트** : 웹킷이 렌더 트리를 생성하기 위해 DOM 노드와 스타일 정보를 연결하는 과정\n\n이제 조금 트리 구조의 진행 방식이 이해되기 시작한다..ㅎㅎ\n\n\n\n
\n\n#### 파싱과 DOM 트리 구축\n\n---\n\n파싱이라는 말도 많이 들어봤을 것이다.\n\n파싱은 렌더링 엔진에서 매우 중요한 과정이다.\n\n
\n\n##### 파싱(parsing)\n\n문서 파싱은, 브라우저가 코드를 이해하고 사용할 수 있는 구조로 변환하는 것\n\n
\n\n문서를 가지고, **어휘 분석과 구문 분석** 과정을 거쳐 파싱 트리를 구축한다.\n\n조금 복잡한데, 어휘 분석기를 통해 언어의 구문 규칙에 따라 문서 구조를 분석한다. 이 과정에서 구문 규칙과 일치하는 지 비교하고, 일치하는 노드만 파싱 트리에 추가시킨다. \n(끝까지 규칙이 맞지 않는 부분은 문서가 유효하지 않고 구문 오류가 포함되어 있다는 것)\n\n
\n\n파서 트리가 나왔다고 해서 끝이 아니다.\n\n컴파일의 과정일 뿐, 다시 기계코드 문서로 변환시키는 과정까지 완료되면 최종 결과물이 나오게 된다.\n\n
\n\n보통 이런 파서를 생성하는 것은 문법에 대한 규칙 부여 등 복잡하고 최적화하기 힘드므로, 자동으로 생성해주는 `파서 생성기`를 많이 활용한다.\n\n> 웹킷은 플렉스(flex)나 바이슨(bison)을 이용하여 유용하게 파싱이 가능\n\n
\n\n우리가 head 태그를 실수로 빠뜨려도, 파서가 돌면서 오류를 수정해줌 ( head 엘리먼트 객체를 암묵적으로 만들어준다)\n\n결국 이 파싱 과정을 거치면서 서버로부터 받은 문서를 브라우저가 이해하고 쉽게 사용할 수 있는 DOM 트리구조로 변환시켜주는 것이다!\n\n
\n\n
\n\n### 요약\n\n---\n\n- 주소창에 url을 입력하고 Enter를 누르면, **서버에 요청이 전송**됨\n- 해당 페이지에 존재하는 여러 자원들(text, image 등등)이 보내짐\n- 이제 브라우저는 해당 자원이 담긴 html과 스타일이 담긴 css를 W3C 명세에 따라 해석할 것임\n- 이 역할을 하는 것이 **'렌더링 엔진'**\n- 렌더링 엔진은 우선 html 파싱 과정을 시작함. html 파서가 문서에 존재하는 어휘와 구문을 분석하면서 DOM 트리를 구축\n- 다음엔 css 파싱 과정 시작. css 파서가 모든 css 정보를 스타일 구조체로 생성\n- 이 2가지를 연결시켜 **렌더 트리**를 만듬. 렌더 트리를 통해 문서가 **시각적 요소를 포함한 형태로 구성**된 상태\n- 화면에 배치를 시작하고, UI 백엔드가 노드를 돌며 형상을 그림\n- 이때 빠른 브라우저 화면 표시를 위해 '배치와 그리는 과정'은 페이지 정보를 모두 받고 한꺼번에 진행되지 않음. 자원을 전송받으면, **기다리는 동시에 일부분 먼저 진행하고 화면에 표시**함 \n\n
\n\n
\n\n##### [참고 자료]\n\n네이버 D2 : [링크](
\n\n
\n" }, { "path": "Web/인증방식.md", "content": "## API Key\n서비스들이 거대해짐에 따라 기능들을 분리하기 시작하였는데 이를위해 Module이나 Application들간의 공유와 독립성을 보장하기 위한 기능들이 등장하기 시작했다.\n그 중 제일 먼저 등장하고 가장 널리 보편적으로 쓰이는 기술이 API Key이다.\n\n### 동작방식\n1. 사용자는 API Key를 발급받는다. (발급 받는 과정은 서비스들마다 다르다. 예를들어 공공기관 API같은 경우에는 신청에 필요한 양식을 제출하면 관리자가 확인 후 Key를 발급해준다.\n2. 해당 API를 사용하기 위해 Key와 함께 요청을 보낸다.\n3. Application은 요청이 오면 Key를 통해 User정보를 확인하여 누구의 Key인지 권한이 무엇인지를 확인한다.\n4. 해당 Key의 인증과 인가에 따라 데이터를 사용자에게 반환한다.\n\n### 문제점\nAPI Key를 사용자에게 직접 발급하고 해당 Key를 통해 통신을 하기 때문에 통신구간이 암호화가 잘 되어 있더라도 Key가 유출된 경우에 대비하기 힘들다.\n그렇기때문에 주기적으로 Key를 업데이트를 해야하기 때문에 번거롭고 예기치 못한 상황(한쪽만 업데이트가 실행되어 서로 매치가 안된다는 등)이 발생할 수 있다. 또한, Key한가지로 정보를 제어하기 때문에 보안문제가 발생하기 쉬운편이다.\n\n## OAuth2\nAPI Key의 단점을 메꾸기 위해 등작한 방식이다. 대표적으로 페이스북, 트위터 등 SNS 로그인기능에서 쉽게 볼 수 있다. 요청하고 요청받는 단순한 방식이 아니라 인증하는 부분이 추가되어 독립적으로 세분화가 이루어졌다.\n\n### 동작방식\n1. 사용자가 Application의 기능을 사용하기 위한 요청을 보낸다. (로그인 기능, 특정 정보 열람 등 다양한 곳에서 쓰일 수 있다. 여기에서는 로그인으로 통일하여 설명하겠다.)\n2. Application은 해당 사용자가 로그인이 되어 있는지를 확인한다. 로그인이 되어 있지 않다면 다음 단계로 넘어간다.\n3. Application은 사용자가 로그인되어 있지 않으면 사용자를 인증서버로 Redirection한다.\n4. 간접적으로 Authorize 요청을 받은 인증서버는 해당 사용자가 회원인지 그리고 인증서버에 로그인 되어있는지를 확인한다.\n5. 인증을 거쳤으면 사용자가 최초의 요청에 대한 권한이 있는지를 확인한다. 이러한 과정을 Grant라고 하는데 대체적으로 인증서버는 사용자의 의지를 확인하는 Grant처리를 하게 되고, 각 Application은 다시 권한을 관리 할 수도 있다. 이 과정에서 사용자의 Grant가 확인이 되지않으면 다시 사용자에게 Grant요청을 보낸다.\n> *Grant란?*\n> Grant는 인가와는 다른 개념이다. 인가는 서비스 제공자 입장에서 사용자의 권한을 보는 것이지만, Grant는 사용자가 자신의 인증정보(보통 개인정보에 해당하는 이름, 이메일 등)를 Application에 넘길지 말지 결정하는 과정이다.\n6. 사용자가 Grant요청을 받게되면 사용자는 해당 인증정보에 대한 허가를 내려준다. 해당 요청을 통해 다시 인증서버에 인가 처리를 위해 요청을 보내게 된다.\n7. 인증서버에서 인증과 인가에 대한 과정이 모두 완료되면 Application에게 인가코드를 전달해준다. 인증서버는 해당 인가코드를 자신의 저장소에 저장을 해둔다. 해당 코드는 보안을 위해 매우 짧은 기간동안만 유효하다.\n8. 인가 코드는 짧은 시간 유지되기 떄문에 이제 Application은 해당 코드를 Request Token으로 사용하여 인증서버에 요청을 보내게된다.\n9. 해당 Request Token을 받은 인증서버는 자신의 저장소에 저장한 코드(7번 과정)과 일치하지를 확인하고 긴 유효기간을 가지고 실제 리소스 접근에 사용하게 될 Access Token을 Application에게 전달한다.\n10. 이제 Application은 Access Token을 통해 업무를 처리할 수 있다. 해당 Access Token을 통해 리소스 서버(인증서버와는 다름)에 요청을 하게된다. 하지만 이 과정에서도 리소스 서버는 바로 데이터를 전달하는 것이 아닌 인증서버에 연결하여 해당 토큰이 유효한지 확인을 거치게된다. 해당 토큰이 유효하다면 사용자는 드디어 요청한 정보를 받을 수 있다.\n\n### 문제점\n기존 API Key방식에 비해 좀 더 복잡한 구조를 가진다. 물론 많은 부분이 개선되었다.\n하지만 통신에 사용하는 Token은 무의미한 문자열을 가지고 기본적으로 정해진 규칙없이 발행되기 때문에 증명확인 필요하다. 그렇기에 인증서버에 어떤 식이든 DBMS 접근이든 다른 API를 활용하여 접근하는 등의 유효성 확인 작업이 필요하다는 공증 여부 문제가 있다. 이러한 공증여부 문제뿐만 아니라 유효기간 문제도 있다.\n\n## JWT\nJWT는 JSON Web Token의 줄임말로 인증 흐름의 규약이 아닌 Token 작성에 대한 규약이다. 기본적인 Access Token은 의미가 없는 문자열로 이루어져 있어 Token의 진위나 유효성을 매번 확인해야 하는 것임에 반하여, JWT는 인증여부 확인을 위한 값, 유효성 검증을 위한 값 그리고 인증 정보 자체를 담고 있기 때문에 인증서버에 묻지 않고도 사용할 수 있다.\n토큰에 대한 자세한 내용과 인증방식은 [JWT문서](https://github.com/kim6394/tech-interview-for-developer/blob/master/Web/JWT(JSON%20Web%20Token).md)를 참조하자.\n\n### 문제점\n서버에 직접 연결하여 인증을 학인하지 않아도 되기 때문에 생기는 장점들이 많다. 하지만 토큰 자체가 인증 정보를 가지고 있기때문에 민감한 정보는 인증서버에 다시 접속하는 과정이 필요하다.\n\n\n### 참고사이트\n[https://www.sauru.so/blog/basic-of-oauth2-and-jwt/](https://www.sauru.so/blog/basic-of-oauth2-and-jwt/)" } ]