Showing preview only (2,589K chars total). Download the full file or copy to clipboard to get everything.
Repository: MemoriLabs/Memori
Branch: main
Commit: aee3af0f382d
Files: 454
Total size: 2.4 MB
Directory structure:
gitextract_gi5dzs00/
├── .dockerignore
├── .github/
│ ├── ISSUE_TEMPLATE/
│ │ ├── bug_report.yml
│ │ ├── config.yml
│ │ └── feature_request.yml
│ └── workflows/
│ ├── ci.yml
│ ├── integration.yml
│ ├── publish-npm.yml
│ ├── publish-openclaw-plugin.yml
│ ├── publish.yml
│ ├── ts-ci.yml
│ └── ts-openclaw-ci.yml
├── .gitignore
├── .pre-commit-config.yaml
├── CHANGELOG.md
├── CONTRIBUTING.md
├── Dockerfile
├── LICENSE
├── MANIFEST.in
├── Makefile
├── README.md
├── SECURITY.md
├── benchmarks/
│ ├── README.md
│ ├── locomo/
│ │ ├── _run_impl.py
│ │ ├── _types.py
│ │ ├── loader.py
│ │ ├── preprocess.py
│ │ ├── provenance.py
│ │ ├── report.py
│ │ ├── retrieval.py
│ │ ├── run.py
│ │ └── scoring.py
│ ├── perf/
│ │ ├── README.md
│ │ ├── _results.py
│ │ ├── conftest.py
│ │ ├── fixtures/
│ │ │ ├── sample_data.py
│ │ │ └── sample_facts.py
│ │ ├── generate_percentile_report.py
│ │ ├── memory_utils.py
│ │ ├── run_benchmarks_ec2.sh
│ │ ├── setup_ec2_benchmarks.sh
│ │ ├── test_cloud_recall_benchmarks.py
│ │ ├── test_hosted_recall_benchmarks.py
│ │ └── test_recall_benchmarks.py
│ └── scripts/
│ └── fetch_locomo.py
├── conftest.py
├── docker-compose.yml
├── docs/
│ ├── memori-byodb/
│ │ ├── concepts/
│ │ │ ├── advanced-augmentation.mdx
│ │ │ ├── architecture.mdx
│ │ │ ├── async-patterns.mdx
│ │ │ ├── cli-quickstart.mdx
│ │ │ ├── how-memory-works.mdx
│ │ │ ├── knowledge-graph.mdx
│ │ │ └── multi-user-support.mdx
│ │ ├── contribute/
│ │ │ ├── development-setup.mdx
│ │ │ └── overview.mdx
│ │ ├── dashboard/
│ │ │ └── api-keys.mdx
│ │ ├── databases/
│ │ │ ├── cockroachdb.mdx
│ │ │ ├── mongodb.mdx
│ │ │ ├── mysql.mdx
│ │ │ ├── oracle.mdx
│ │ │ ├── overview.mdx
│ │ │ ├── postgres.mdx
│ │ │ └── sqlite.mdx
│ │ ├── getting-started/
│ │ │ ├── installation.mdx
│ │ │ ├── python-quickstart.mdx
│ │ │ └── use-cases.mdx
│ │ ├── index.mdx
│ │ ├── llm/
│ │ │ ├── agno.mdx
│ │ │ ├── anthropic.mdx
│ │ │ ├── aws-bedrock.mdx
│ │ │ ├── deepseek.mdx
│ │ │ ├── gemini.mdx
│ │ │ ├── langchain.mdx
│ │ │ ├── nebius.mdx
│ │ │ ├── openai.mdx
│ │ │ ├── overview.mdx
│ │ │ ├── pydantic-ai.mdx
│ │ │ └── xai-grok.mdx
│ │ └── support/
│ │ ├── faq.mdx
│ │ └── troubleshooting.mdx
│ └── memori-cloud/
│ ├── benchmark/
│ │ ├── experiments.mdx
│ │ ├── overview.mdx
│ │ └── results.mdx
│ ├── concepts/
│ │ ├── advanced-augmentation.mdx
│ │ ├── architecture.mdx
│ │ ├── async-patterns.mdx
│ │ ├── how-memory-works.mdx
│ │ ├── knowledge-graph.mdx
│ │ └── multi-user-support.mdx
│ ├── dashboard/
│ │ ├── analytics.mdx
│ │ ├── api-keys.mdx
│ │ ├── memories.mdx
│ │ ├── overview.mdx
│ │ └── playground.mdx
│ ├── getting-started/
│ │ ├── installation.mdx
│ │ ├── python-quickstart.mdx
│ │ ├── typescript-quickstart.mdx
│ │ └── use-cases.mdx
│ ├── index.mdx
│ ├── llm/
│ │ ├── agno.mdx
│ │ ├── anthropic.mdx
│ │ ├── aws-bedrock.mdx
│ │ ├── deepseek.mdx
│ │ ├── gemini.mdx
│ │ ├── langchain.mdx
│ │ ├── nebius.mdx
│ │ ├── openai.mdx
│ │ ├── overview.mdx
│ │ ├── pydantic-ai.mdx
│ │ └── xai-grok.mdx
│ ├── mcp/
│ │ ├── agent-skills.mdx
│ │ ├── client-setup.mdx
│ │ └── overview.mdx
│ ├── openclaw/
│ │ ├── overview.mdx
│ │ └── quickstart.mdx
│ └── support/
│ ├── faq.mdx
│ └── troubleshooting.mdx
├── examples/
│ ├── agno/
│ │ ├── README.md
│ │ ├── main.py
│ │ └── pyproject.toml
│ ├── cockroachdb/
│ │ ├── README.md
│ │ ├── main.py
│ │ └── pyproject.toml
│ ├── digitalocean/
│ │ ├── README.md
│ │ ├── main.py
│ │ └── pyproject.toml
│ ├── mongodb/
│ │ ├── README.md
│ │ ├── main.py
│ │ └── pyproject.toml
│ ├── nebius/
│ │ ├── README.md
│ │ ├── main.py
│ │ └── pyproject.toml
│ ├── neon/
│ │ ├── README.md
│ │ ├── main.py
│ │ └── pyproject.toml
│ ├── oceanbase/
│ │ ├── README.md
│ │ └── main.py
│ ├── postgres/
│ │ ├── README.md
│ │ ├── main.py
│ │ └── pyproject.toml
│ └── sqlite/
│ ├── README.md
│ ├── main.py
│ └── pyproject.toml
├── integrations/
│ └── openclaw/
│ ├── .prettierrc.json
│ ├── README.md
│ ├── eslint.config.js
│ ├── openclaw.plugin.json
│ ├── package-lock.json
│ ├── package.json
│ ├── src/
│ │ ├── constants.ts
│ │ ├── handlers/
│ │ │ ├── augmentation.ts
│ │ │ └── recall.ts
│ │ ├── index.ts
│ │ ├── sanitizer.ts
│ │ ├── types.ts
│ │ ├── utils/
│ │ │ ├── context.ts
│ │ │ ├── index.ts
│ │ │ ├── logger.ts
│ │ │ └── memori-client.ts
│ │ └── version.ts
│ ├── tests/
│ │ ├── handlers/
│ │ │ ├── augmentation.test.ts
│ │ │ └── recall.test.ts
│ │ ├── index.test.ts
│ │ ├── sanitizer.test.ts
│ │ └── utils/
│ │ ├── context.test.ts
│ │ ├── logger.test.ts
│ │ └── memori-client.test.ts
│ ├── tsconfig.json
│ └── vitest.config.ts
├── memori/
│ ├── __init__.py
│ ├── __main__.py
│ ├── _cli.py
│ ├── _config.py
│ ├── _exceptions.py
│ ├── _logging.py
│ ├── _network.py
│ ├── _setup.py
│ ├── _utils.py
│ ├── api/
│ │ ├── _quota.py
│ │ └── _sign_up.py
│ ├── embeddings/
│ │ ├── __init__.py
│ │ ├── _api.py
│ │ ├── _chunking.py
│ │ ├── _format.py
│ │ ├── _sentence_transformers.py
│ │ ├── _tei.py
│ │ ├── _tei_embed.py
│ │ └── _utils.py
│ ├── llm/
│ │ ├── __init__.py
│ │ ├── _base.py
│ │ ├── _clients.py
│ │ ├── _constants.py
│ │ ├── _invoke.py
│ │ ├── _iterable.py
│ │ ├── _iterator.py
│ │ ├── _providers.py
│ │ ├── _registry.py
│ │ ├── _streaming.py
│ │ ├── _utils.py
│ │ ├── _xai_wrappers.py
│ │ └── adapters/
│ │ ├── anthropic/
│ │ │ ├── __init__.py
│ │ │ └── _adapter.py
│ │ ├── bedrock/
│ │ │ ├── __init__.py
│ │ │ └── _adapter.py
│ │ ├── google/
│ │ │ ├── __init__.py
│ │ │ └── _adapter.py
│ │ ├── openai/
│ │ │ ├── __init__.py
│ │ │ └── _adapter.py
│ │ └── xai/
│ │ ├── __init__.py
│ │ └── _adapter.py
│ ├── memory/
│ │ ├── _collector.py
│ │ ├── _conversation_messages.py
│ │ ├── _manager.py
│ │ ├── _struct.py
│ │ ├── _writer.py
│ │ ├── augmentation/
│ │ │ ├── __init__.py
│ │ │ ├── _base.py
│ │ │ ├── _db_writer.py
│ │ │ ├── _handler.py
│ │ │ ├── _manager.py
│ │ │ ├── _message.py
│ │ │ ├── _models.py
│ │ │ ├── _registry.py
│ │ │ ├── _runtime.py
│ │ │ ├── augmentations/
│ │ │ │ └── memori/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── _augmentation.py
│ │ │ │ └── models.py
│ │ │ ├── input.py
│ │ │ └── memories/
│ │ │ ├── _conversation.py
│ │ │ ├── _entity.py
│ │ │ └── _process.py
│ │ └── recall.py
│ ├── py.typed
│ ├── search/
│ │ ├── __init__.py
│ │ ├── _api.py
│ │ ├── _core.py
│ │ ├── _faiss.py
│ │ ├── _lexical.py
│ │ ├── _parsing.py
│ │ └── _types.py
│ └── storage/
│ ├── __init__.py
│ ├── _base.py
│ ├── _builder.py
│ ├── _connection.py
│ ├── _manager.py
│ ├── _registry.py
│ ├── adapters/
│ │ ├── dbapi/
│ │ │ ├── __init__.py
│ │ │ └── _adapter.py
│ │ ├── django/
│ │ │ ├── __init__.py
│ │ │ └── _adapter.py
│ │ ├── mongodb/
│ │ │ ├── __init__.py
│ │ │ └── _adapter.py
│ │ └── sqlalchemy/
│ │ ├── __init__.py
│ │ └── _adapter.py
│ ├── cockroachdb/
│ │ ├── _cluster_manager.py
│ │ ├── _display.py
│ │ └── _files.py
│ ├── drivers/
│ │ ├── mongodb/
│ │ │ ├── __init__.py
│ │ │ └── _driver.py
│ │ ├── mysql/
│ │ │ ├── __init__.py
│ │ │ └── _driver.py
│ │ ├── oceanbase/
│ │ │ ├── __init__.py
│ │ │ └── _driver.py
│ │ ├── oracle/
│ │ │ ├── __init__.py
│ │ │ └── _driver.py
│ │ ├── postgresql/
│ │ │ ├── __init__.py
│ │ │ └── _driver.py
│ │ └── sqlite/
│ │ ├── __init__.py
│ │ └── _driver.py
│ └── migrations/
│ ├── _mongodb.py
│ ├── _mysql.py
│ ├── _oceanbase.py
│ ├── _oracle.py
│ ├── _postgresql.py
│ └── _sqlite.py
├── memori-ts/
│ ├── .npmignore
│ ├── .prettierrc.json
│ ├── README.md
│ ├── eslint.config.js
│ ├── examples/
│ │ └── cloud/
│ │ └── simple.ts
│ ├── package-lock.json
│ ├── package.json
│ ├── src/
│ │ ├── bin/
│ │ │ └── cli.ts
│ │ ├── cli/
│ │ │ ├── commands/
│ │ │ │ ├── help.ts
│ │ │ │ └── quota.ts
│ │ │ ├── router.ts
│ │ │ └── utils.ts
│ │ ├── core/
│ │ │ ├── config.ts
│ │ │ ├── errors.ts
│ │ │ ├── network.ts
│ │ │ └── session.ts
│ │ ├── engines/
│ │ │ ├── augmentation.ts
│ │ │ ├── persistence.ts
│ │ │ └── recall.ts
│ │ ├── index.ts
│ │ ├── integrations/
│ │ │ ├── base.ts
│ │ │ ├── index.ts
│ │ │ └── openclaw.ts
│ │ ├── memori.ts
│ │ ├── types/
│ │ │ ├── api.ts
│ │ │ └── integrations.ts
│ │ ├── utils/
│ │ │ └── utils.ts
│ │ └── version.ts
│ ├── tests/
│ │ ├── cli/
│ │ │ ├── bin/
│ │ │ │ └── router.test.ts
│ │ │ ├── commands/
│ │ │ │ ├── help.test.ts
│ │ │ │ └── quota.test.ts
│ │ │ └── utils.test.ts
│ │ ├── core/
│ │ │ ├── config.test.ts
│ │ │ ├── network.test.ts
│ │ │ └── session.test.ts
│ │ ├── engines/
│ │ │ ├── augmentation.test.ts
│ │ │ ├── persistence.test.ts
│ │ │ └── recall.test.ts
│ │ ├── integrations/
│ │ │ ├── base.test.ts
│ │ │ └── openclaw.test.ts
│ │ ├── memori.test.ts
│ │ └── utils/
│ │ └── utils.test.ts
│ ├── tsconfig.build.json
│ ├── tsconfig.json
│ └── vitest.config.ts
├── pyproject.toml
└── tests/
├── benchmarks_locomo/
│ ├── test_locomo_aa_pairing.py
│ ├── test_locomo_loader.py
│ ├── test_locomo_preprocess.py
│ ├── test_locomo_provenance.py
│ └── test_locomo_run_and_report.py
├── build/
│ ├── mongodb.py
│ ├── mysql.py
│ ├── oceanbase.py
│ ├── oracle.py
│ ├── postgresql.py
│ └── sqlite.py
├── database/
│ ├── core.py
│ └── init_db.py
├── embeddings/
│ └── test_tei_chunking.py
├── integration/
│ ├── __init__.py
│ ├── cloud/
│ │ ├── __init__.py
│ │ ├── conftest.py
│ │ ├── test_cloud_anthropic.py
│ │ ├── test_cloud_bedrock.py
│ │ ├── test_cloud_gemini.py
│ │ ├── test_cloud_openai.py
│ │ └── test_cloud_xai.py
│ ├── conftest.py
│ ├── databases/
│ │ ├── __init__.py
│ │ ├── conftest.py
│ │ └── test_database_storage.py
│ ├── providers/
│ │ ├── __init__.py
│ │ ├── test_anthropic.py
│ │ ├── test_bedrock.py
│ │ ├── test_google.py
│ │ ├── test_openai.py
│ │ └── test_xai.py
│ └── test_aa_payload.py
├── llm/
│ ├── adapters/
│ │ ├── anthropic/
│ │ │ └── test_llm_adapters_anthropic_adapter.py
│ │ ├── bedrock/
│ │ │ └── test_llm_adapters_bedrock_adapter.py
│ │ ├── google/
│ │ │ └── test_llm_adapters_google_adapter.py
│ │ ├── openai/
│ │ │ └── test_llm_adapters_openai_adapter.py
│ │ └── xai/
│ │ └── test_llm_adapters_xai_adapter.py
│ ├── clients/
│ │ └── oss/
│ │ ├── agno/
│ │ │ ├── anthropic_async.py
│ │ │ ├── anthropic_sync.py
│ │ │ ├── gemini_async.py
│ │ │ ├── gemini_streaming.py
│ │ │ ├── gemini_sync.py
│ │ │ ├── openai_async.py
│ │ │ ├── openai_streaming.py
│ │ │ ├── openai_sync.py
│ │ │ ├── xai_async.py
│ │ │ ├── xai_streaming.py
│ │ │ └── xai_sync.py
│ │ ├── anthropic/
│ │ │ ├── async.py
│ │ │ └── sync.py
│ │ ├── gemini/
│ │ │ ├── async.py
│ │ │ ├── async_streaming.py
│ │ │ └── sync.py
│ │ ├── langchain/
│ │ │ ├── chatbedrock/
│ │ │ │ └── async_runnable.py
│ │ │ ├── chatgooglegenai/
│ │ │ │ ├── async_runnable.py
│ │ │ │ ├── async_streaming.py
│ │ │ │ ├── sync.py
│ │ │ │ ├── sync_runnable.py
│ │ │ │ └── sync_runnable_structured_output.py
│ │ │ ├── chatopenai/
│ │ │ │ ├── async_ainvoke.py
│ │ │ │ ├── async_runnable.py
│ │ │ │ ├── async_streaming.py
│ │ │ │ ├── sync.py
│ │ │ │ ├── sync_runnable.py
│ │ │ │ └── sync_runnable_structured_output.py
│ │ │ └── chatvertexai/
│ │ │ └── sync.py
│ │ ├── openai/
│ │ │ ├── async.py
│ │ │ ├── async_streaming.py
│ │ │ └── sync.py
│ │ └── xai/
│ │ ├── async.py
│ │ ├── async_stream.py
│ │ └── sync.py
│ ├── providers/
│ │ ├── __init__.py
│ │ ├── azure_openai/
│ │ │ ├── __init__.py
│ │ │ └── test_azure_openai.py
│ │ └── google_genai/
│ │ ├── __init__.py
│ │ └── test_google_genai.py
│ ├── test_llm_base.py
│ ├── test_llm_clients.py
│ ├── test_llm_deprecation_warnings.py
│ ├── test_llm_embeddings.py
│ ├── test_llm_embeddings_bundled.py
│ ├── test_llm_provider_sdk_version.py
│ ├── test_llm_registry.py
│ ├── test_llm_utils.py
│ ├── test_llm_xai_wrappers.py
│ └── unit_test_objects.py
├── memory/
│ ├── augmentation/
│ │ ├── test_aa_payload_unit.py
│ │ ├── test_advanced_augmentation.py
│ │ ├── test_base.py
│ │ ├── test_handler.py
│ │ ├── test_manager.py
│ │ ├── test_manager_quota.py
│ │ ├── test_models.py
│ │ ├── test_quota_propagation.py
│ │ └── test_registry.py
│ ├── test_conversation_messages.py
│ ├── test_manager_enterprise_retry.py
│ ├── test_memory_augmentation_db_writer.py
│ ├── test_memory_struct.py
│ ├── test_memory_struct_triples.py
│ ├── test_memory_writer.py
│ ├── test_recall.py
│ └── test_recall_eval_harness.py
├── storage/
│ ├── adapters/
│ │ ├── conftest.py
│ │ ├── dbapi/
│ │ │ ├── test_dbapi_no_conflicts.py
│ │ │ └── test_storage_adapters_dbapi_adapter.py
│ │ ├── django/
│ │ │ └── test_storage_adapters_django_adapter.py
│ │ └── sqlalchemy/
│ │ └── test_storage_adaptors_sqlalchemy_adapter.py
│ ├── cockroachdb/
│ │ ├── test_storage_cockroachdb_display.py
│ │ └── test_storage_cockroachdb_files.py
│ ├── drivers/
│ │ ├── conftest.py
│ │ ├── test_mongodb_driver.py
│ │ ├── test_mysql_driver.py
│ │ ├── test_oceanbase_driver.py
│ │ ├── test_oracle_driver.py
│ │ ├── test_postgresql_driver.py
│ │ └── test_sqlite_driver.py
│ ├── test_connection.py
│ ├── test_connection_factory.py
│ ├── test_storage_builder.py
│ ├── test_storage_init.py
│ ├── test_storage_manager.py
│ └── test_storage_registry.py
├── test_cli.py
├── test_config.py
├── test_init.py
├── test_legacy_package_warning.py
├── test_llm_auto_registration.py
├── test_network.py
├── test_search.py
└── test_utils.py
================================================
FILE CONTENTS
================================================
================================================
FILE: .dockerignore
================================================
# Python
__pycache__/
*.py[cod]
*$py.class
*.so
.Python
build/
develop-eggs/
dist/
downloads/
eggs/
.eggs/
lib/
lib64/
parts/
sdist/
var/
wheels/
*.egg-info/
.installed.cfg
*.egg
# Virtual environments
.venv/
venv/
ENV/
env/
# Testing
.pytest_cache/
.coverage
htmlcov/
.tox/
# IDEs
.vscode/
.idea/
*.swp
*.swo
*~
# Git
.git/
.gitignore
# Docker development files (not part of the SDK package)
Dockerfile
docker-compose.yml
.dockerignore
Makefile
# OS
.DS_Store
Thumbs.db
# Documentation
docs/_build/
# Local dev files
*.log
.env
.env.*
!.env.example
================================================
FILE: .github/ISSUE_TEMPLATE/bug_report.yml
================================================
name: Bug Report
description: Create a report to help us improve Memori
title: "[Bug] "
labels: ["bug"]
body:
- type: markdown
attributes:
value: |
Thanks for taking the time to fill out this bug report! Please provide as much detail as possible.
- type: checkboxes
id: checks
attributes:
label: First Check
description: Please ensure you have done the following before submitting your issue.
options:
- label: I added a very descriptive title to this issue.
required: true
- label: I searched existing issues and documentation.
required: true
- type: input
id: version
attributes:
label: Memori Version
description: What version of the sdk are you using?
placeholder: e.g., 3.0.0
validations:
required: true
- type: input
id: environment
attributes:
label: OS / Python Version
description: e.g., Windows 10 / Python 3.10, or Ubuntu 22.04 / Python 3.11
placeholder: macOS / Python 3.12
validations:
required: true
- type: dropdown
id: llm_provider
attributes:
label: LLM Provider
description: Which LLM provider are you using?
options:
- OpenAI
- Anthropic
- Gemini
- Bedrock
- Grok (xAI)
- Ollama / Local
- Other
validations:
required: true
- type: input
id: llm_details
attributes:
label: LLM Model & Version
description: Please specify the model name/version.
placeholder: e.g., gpt-4o or claude-3-5-sonnet
validations:
required: true
- type: dropdown
id: database
attributes:
label: Database
description: Which database integration are you using?
options:
- Postgres
- MySQL
- MongoDB
- Oracle
- SQLite
- Neon
- Supabase
- Other
validations:
required: true
- type: textarea
id: description
attributes:
label: Description
description: Please describe the bug clearly. What happened? What did you expect to happen?
validations:
required: true
- type: textarea
id: reproduction
attributes:
label: Minimal Reproducible Example
description: Please provide a code snippet that reproduces the issue.
render: python
placeholder: |
from memori import Memori
# Your code here...
- type: textarea
id: logs
attributes:
label: Log Output / Stack Trace
description: Please copy and paste any relevant log output or error messages here.
render: shell
- type: checkboxes
id: terms
attributes:
label: Participation
options:
- label: I am willing to submit a pull request for this issue.
================================================
FILE: .github/ISSUE_TEMPLATE/config.yml
================================================
blank_issues_enabled: false
================================================
FILE: .github/ISSUE_TEMPLATE/feature_request.yml
================================================
name: Feature Request
description: Suggest an idea or improvement for Memori
title: "[Feature] "
labels: ["enhancement"]
body:
- type: markdown
attributes:
value: |
Thanks for your interest in improving Memori! Please describe your idea in detail.
- type: textarea
id: problem
attributes:
label: Is your feature request related to a problem?
description: A clear and concise description of what the problem is.
placeholder: Ex. I'm always frustrated when I try to integrate with...
validations:
required: true
- type: textarea
id: solution
attributes:
label: The Solution
description: Describe the solution you'd like.
placeholder: |
I would like a new method `memori.recall_batch()` that accepts...
validations:
required: true
- type: textarea
id: alternatives
attributes:
label: Alternatives Considered
description: Describe any alternative solutions or features you've considered.
placeholder: I thought about using a loop, but it's too slow for my use case...
- type: dropdown
id: context
attributes:
label: Affected Components
description: Which parts of Memori would this feature touch?
multiple: true
options:
- LLM Provider / Adapter
- Vector Store / Memory
- Database Schema
- CLI
- Documentation
- Other
- type: checkboxes
id: help
attributes:
label: Participation
description: Would you be willing to help implement this?
options:
- label: I am willing to submit a pull request for this feature.
================================================
FILE: .github/workflows/ci.yml
================================================
name: CI
on:
push:
branches: [main]
paths:
- 'memori/**'
pull_request:
branches: [main]
paths:
- 'memori/**'
jobs:
lint:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v5
- name: Install uv
uses: astral-sh/setup-uv@v7
- name: Set up Python
run: uv python install 3.12
- name: Install dependencies
run: uv sync --dev
- name: Run ruff linting
run: uv run ruff check .
- name: Run ruff format check
run: uv run ruff format --check .
security:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v5
- name: Install uv
uses: astral-sh/setup-uv@v7
- name: Set up Python
run: uv python install 3.12
- name: Install dependencies
run: uv sync --dev
- name: Run Bandit security checks
run: uv run bandit -r memori -ll -ii
- name: Run pip-audit for dependency vulnerabilities
run: uv run pip-audit --require-hashes --disable-pip
continue-on-error: true
type-check:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v5
- name: Install uv
uses: astral-sh/setup-uv@v7
- name: Set up Python
run: uv python install 3.12
- name: Install dependencies
run: uv sync --dev
- name: Run type checking with ty
run: uvx ty check --exclude 'tests/llm/clients/**/*.py' --exclude 'tests/integration/**/*.py' --exclude 'benchmarks/**/*.py' --exclude 'examples/**/*.py'
test:
runs-on: ubuntu-latest
strategy:
matrix:
python-version: ["3.10", "3.11", "3.12", "3.13", "3.14"]
steps:
- uses: actions/checkout@v5
- name: Install uv
uses: astral-sh/setup-uv@v7
- name: Set up Python ${{ matrix.python-version }}
run: uv python install ${{ matrix.python-version }}
- name: Install dependencies
run: uv sync --dev
- name: Run pytest with coverage
run: uv run pytest --ignore=tests/benchmarks
- name: Upload coverage to Codecov
if: matrix.python-version == '3.12'
uses: codecov/codecov-action@v5
with:
files: ./coverage.xml
fail_ci_if_error: false
================================================
FILE: .github/workflows/integration.yml
================================================
name: Integration Tests
on:
workflow_dispatch:
workflow_call:
secrets:
OPENAI_API_KEY:
required: true
ANTHROPIC_API_KEY:
required: false
GOOGLE_API_KEY:
required: false
XAI_API_KEY:
required: false
AWS_ACCESS_KEY_ID:
required: false
AWS_SECRET_ACCESS_KEY:
required: false
MEMORI_API_KEY:
required: false
permissions:
contents: read
jobs:
integration-tests:
runs-on: ubuntu-latest
timeout-minutes: 30
services:
postgres:
image: postgres:15
env:
POSTGRES_USER: memori
POSTGRES_PASSWORD: memori
POSTGRES_DB: memori_test
ports:
- 5432:5432
options: >-
--health-cmd pg_isready
--health-interval 10s
--health-timeout 5s
--health-retries 5
mysql:
image: mysql:8
env:
MYSQL_ROOT_PASSWORD: memori
MYSQL_DATABASE: memori_test
MYSQL_USER: memori
MYSQL_PASSWORD: memori
ports:
- 3306:3306
options: >-
--health-cmd "mysqladmin ping"
--health-interval 10s
--health-timeout 5s
--health-retries 5
mongodb:
image: mongo:6
env:
MONGO_INITDB_ROOT_USERNAME: memori
MONGO_INITDB_ROOT_PASSWORD: memori
ports:
- 27017:27017
env:
MEMORI_TEST_MODE: "1"
OPENAI_API_KEY: ${{ secrets.OPENAI_API_KEY }}
ANTHROPIC_API_KEY: ${{ secrets.ANTHROPIC_API_KEY }}
GOOGLE_API_KEY: ${{ secrets.GOOGLE_API_KEY }}
XAI_API_KEY: ${{ secrets.XAI_API_KEY }}
AWS_ACCESS_KEY_ID: ${{ secrets.AWS_ACCESS_KEY_ID }}
AWS_SECRET_ACCESS_KEY: ${{ secrets.AWS_SECRET_ACCESS_KEY }}
AWS_REGION: us-east-1
MEMORI_API_KEY: ${{ secrets.MEMORI_API_KEY }}
SQLITE_DATABASE_URL: sqlite:///test_memori.db
POSTGRES_DATABASE_URL: postgresql://memori:memori@localhost:5432/memori_test
MYSQL_DATABASE_URL: mysql+pymysql://memori:memori@localhost:3306/memori_test
MONGODB_URL: mongodb://memori:memori@localhost:27017/memori_test?authSource=admin
steps:
- uses: actions/checkout@v5
- name: Install uv
uses: astral-sh/setup-uv@v7
with:
enable-cache: true
- name: Set up Python
run: uv python install 3.12
- name: Install dependencies
run: uv sync --dev
- name: Run AA Payload Unit Tests (no API keys needed)
run: |
echo "Running AA payload unit tests..."
uv run pytest tests/memory/augmentation/test_aa_payload_unit.py -v --tb=short
- name: Run AA Integration Tests (staging API)
if: env.OPENAI_API_KEY
run: |
echo "Running AA integration tests against staging..."
uv run pytest tests/integration/test_aa_payload.py -v -m integration --tb=short
- name: Run OpenAI Integration Tests
if: env.OPENAI_API_KEY
run: |
echo "Running OpenAI integration tests..."
uv run pytest tests/integration/providers/test_openai.py -v -m integration --tb=short
- name: Run Anthropic Integration Tests
if: env.ANTHROPIC_API_KEY
run: |
echo "Running Anthropic integration tests..."
uv run pytest tests/integration/providers/test_anthropic.py -v -m integration --tb=short
- name: Run Google Integration Tests
if: env.GOOGLE_API_KEY
run: |
echo "Running Google integration tests..."
uv run pytest tests/integration/providers/test_google.py -v -m integration --tb=short
- name: Run xAI Integration Tests
if: env.XAI_API_KEY
run: |
echo "Running xAI integration tests..."
uv run pytest tests/integration/providers/test_xai.py -v -m integration --tb=short
- name: Run Bedrock Integration Tests
if: env.AWS_ACCESS_KEY_ID && env.AWS_SECRET_ACCESS_KEY
run: |
echo "Running Bedrock integration tests..."
uv run pytest tests/integration/providers/test_bedrock.py -v -m integration --tb=short
- name: Run cloud OpenAI Integration Tests
if: env.OPENAI_API_KEY && env.MEMORI_API_KEY
run: |
echo "Running cloud OpenAI integration tests..."
uv run pytest tests/integration/cloud/test_cloud_openai.py -v -m integration --tb=short
- name: Run cloud Anthropic Integration Tests
if: env.ANTHROPIC_API_KEY && env.MEMORI_API_KEY
run: |
echo "Running cloud Anthropic integration tests..."
uv run pytest tests/integration/cloud/test_cloud_anthropic.py -v -m integration --tb=short
- name: Run cloud Google Integration Tests
if: env.GOOGLE_API_KEY && env.MEMORI_API_KEY
run: |
echo "Running cloud Google integration tests..."
uv run pytest tests/integration/cloud/test_cloud_gemini.py -v -m integration --tb=short
- name: Run cloud xAI Integration Tests
if: env.XAI_API_KEY && env.MEMORI_API_KEY
run: |
echo "Running cloud xAI integration tests..."
uv run pytest tests/integration/cloud/test_cloud_xai.py -v -m integration --tb=short
- name: Run cloud Bedrock Integration Tests
if: env.AWS_ACCESS_KEY_ID && env.AWS_SECRET_ACCESS_KEY && env.MEMORI_API_KEY
run: |
echo "Running cloud Bedrock integration tests..."
uv run pytest tests/integration/cloud/test_cloud_bedrock.py -v -m integration --tb=short
- name: Run Database Integration Tests
if: env.OPENAI_API_KEY
run: |
echo "Running database integration tests..."
uv run pytest tests/integration/databases/ -v -m integration --tb=short
- name: Integration Test Summary
if: always()
run: |
echo "=========================================="
echo "Integration Test Summary"
echo "=========================================="
echo "MEMORI_TEST_MODE: $MEMORI_TEST_MODE (staging)"
echo ""
echo "Tests run:"
echo " - AA Payload Unit Tests: Yes (no API keys needed)"
if [ "$OPENAI_API_KEY" ]; then echo " - AA Integration Tests: Yes"; else echo " - AA Integration Tests: Skipped (no key)"; fi
if [ "$OPENAI_API_KEY" ]; then echo " - Database Integration Tests: Yes"; else echo " - Database Integration Tests: Skipped (no key)"; fi
echo ""
echo "Databases tested:"
echo " - SQLite: Yes"
echo " - PostgreSQL: Yes"
echo " - MySQL: Yes"
echo " - MongoDB: Yes"
echo ""
echo "Providers tested:"
if [ "$OPENAI_API_KEY" ]; then echo " - OpenAI: Yes"; else echo " - OpenAI: Skipped (no key)"; fi
if [ "$ANTHROPIC_API_KEY" ]; then echo " - Anthropic: Yes"; else echo " - Anthropic: Skipped (no key)"; fi
if [ "$GOOGLE_API_KEY" ]; then echo " - Google: Yes"; else echo " - Google: Skipped (no key)"; fi
if [ "$XAI_API_KEY" ]; then echo " - xAI: Yes"; else echo " - xAI: Skipped (no key)"; fi
if [ "$AWS_ACCESS_KEY_ID" ]; then echo " - Bedrock: Yes"; else echo " - Bedrock: Skipped (no key)"; fi
echo ""
echo "Cloud (requires MEMORI_API_KEY) tests:"
if [ "$MEMORI_API_KEY" ] && [ "$OPENAI_API_KEY" ]; then echo " - Cloud OpenAI: Yes"; else echo " - Cloud OpenAI: Skipped (no key)"; fi
if [ "$MEMORI_API_KEY" ] && [ "$ANTHROPIC_API_KEY" ]; then echo " - Cloud Anthropic: Yes"; else echo " - Cloud Anthropic: Skipped (no key)"; fi
if [ "$MEMORI_API_KEY" ] && [ "$GOOGLE_API_KEY" ]; then echo " - Cloud Google: Yes"; else echo " - Cloud Google: Skipped (no key)"; fi
if [ "$MEMORI_API_KEY" ] && [ "$XAI_API_KEY" ]; then echo " - Cloud xAI: Yes"; else echo " - Cloud xAI: Skipped (no key)"; fi
if [ "$MEMORI_API_KEY" ] && [ "$AWS_ACCESS_KEY_ID" ]; then echo " - Cloud Bedrock: Yes"; else echo " - Cloud Bedrock: Skipped (no key)"; fi
echo "=========================================="
================================================
FILE: .github/workflows/publish-npm.yml
================================================
name: Publish to npm (TS)
on:
workflow_dispatch:
permissions:
contents: read
id-token: write
jobs:
publish:
runs-on: ubuntu-latest
defaults:
run:
working-directory: ./memori-ts
steps:
- name: Checkout repository
uses: actions/checkout@v5
- name: Setup Node.js
uses: actions/setup-node@v6
with:
node-version: "24"
registry-url: "https://registry.npmjs.org"
- name: Install dependencies
run: npm ci
- name: Generate version.ts
run: |
VERSION=$(node -p "require('./package.json').version")
echo "export const SDK_VERSION = '${VERSION}';" > src/version.ts
- name: Build project
run: npm run build --if-present
- name: Run tests
run: npm test --if-present
- name: Publish Package
run: npm publish --access public --tag latest
================================================
FILE: .github/workflows/publish-openclaw-plugin.yml
================================================
name: Publish OpenClaw to NPM
on:
workflow_dispatch:
permissions:
contents: read
id-token: write
jobs:
publish:
runs-on: ubuntu-latest
defaults:
run:
working-directory: ./integrations/openclaw
steps:
- name: Checkout repository
uses: actions/checkout@v5
- name: Setup Node.js
uses: actions/setup-node@v6
with:
node-version: "24"
registry-url: "https://registry.npmjs.org"
- name: Install dependencies
run: npm ci
- name: Generate version.ts
run: |
VERSION=$(node -p "require('./package.json').version")
echo "export const SDK_VERSION = '${VERSION}';" > src/version.ts
- name: Build project
run: npm run build --if-present
- name: Publish Package
run: npm publish --access public --tag latest
================================================
FILE: .github/workflows/publish.yml
================================================
name: Publish to PyPI
on:
release:
types: [published]
workflow_dispatch:
permissions:
contents: read
id-token: write
concurrency:
group: publish-pypi-${{ github.ref }}
cancel-in-progress: false
jobs:
# Run integration tests before publishing
integration-tests:
uses: ./.github/workflows/integration.yml
secrets:
OPENAI_API_KEY: ${{ secrets.OPENAI_API_KEY }}
ANTHROPIC_API_KEY: ${{ secrets.ANTHROPIC_API_KEY }}
GOOGLE_API_KEY: ${{ secrets.GOOGLE_API_KEY }}
XAI_API_KEY: ${{ secrets.XAI_API_KEY }}
AWS_ACCESS_KEY_ID: ${{ secrets.AWS_ACCESS_KEY_ID }}
AWS_SECRET_ACCESS_KEY: ${{ secrets.AWS_SECRET_ACCESS_KEY }}
deploy:
needs: integration-tests
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v5
- name: Set up Python
uses: actions/setup-python@v5
with:
python-version: '3.x'
cache: 'pip'
- name: Install build tools
run: pip install --upgrade pip build twine toml
- name: Build memori package
run: python -m build --outdir dist/memori
- name: Verify memori distribution
run: twine check dist/memori/*
- name: Publish memori to PyPI
uses: pypa/gh-action-pypi-publish@release/v1
with:
packages-dir: dist/memori/
user: __token__
password: ${{ secrets.PYPI_API_TOKEN }}
- name: Update package name to memorisdk
run: |
python -c "
import toml
with open('pyproject.toml', 'r') as f:
config = toml.load(f)
config['project']['name'] = 'memorisdk'
with open('pyproject.toml', 'w') as f:
toml.dump(config, f)
"
- name: Build memorisdk package
run: python -m build --outdir dist/memorisdk
- name: Verify memorisdk distribution
run: twine check dist/memorisdk/*
- name: Publish memorisdk to PyPI
uses: pypa/gh-action-pypi-publish@release/v1
with:
packages-dir: dist/memorisdk/
user: __token__
password: ${{ secrets.PYPI_SDK_API_TOKEN }}
================================================
FILE: .github/workflows/ts-ci.yml
================================================
name: CI Code Check (TS)
on:
push:
branches: [ "main" ]
paths:
- 'memori-ts/**'
pull_request:
branches: [ "main" ]
paths:
- 'memori-ts/**'
jobs:
build-and-test:
runs-on: ubuntu-latest
strategy:
matrix:
node-version: [18, 20, 22, 24]
defaults:
run:
working-directory: ./memori-ts
steps:
- name: Checkout repository
uses: actions/checkout@v5
- name: Setup Node.js ${{ matrix.node-version }}
uses: actions/setup-node@v6
with:
node-version: ${{ matrix.node-version }}
- name: Install dependencies
run: npm ci
- name: Generate version.ts
run: |
VERSION=$(node -p "require('./package.json').version")
echo "export const SDK_VERSION = '${VERSION}';" > src/version.ts
- name: Run Linter
run: npm run lint
- name: Run Tests
run: npm test
- name: Verify Build
run: npm run build
================================================
FILE: .github/workflows/ts-openclaw-ci.yml
================================================
name: CI Code Check (TS)
on:
push:
branches: [ "main" ]
paths:
- 'integrations/openclaw/**'
pull_request:
branches: [ "main" ]
paths:
- 'integrations/openclaw/**'
jobs:
build-and-test:
runs-on: ubuntu-latest
strategy:
matrix:
node-version: [22, 24]
defaults:
run:
working-directory: ./integrations/openclaw
steps:
- name: Checkout repository
uses: actions/checkout@v5
- name: Setup Node.js ${{ matrix.node-version }}
uses: actions/setup-node@v6
with:
node-version: ${{ matrix.node-version }}
- name: Install dependencies
run: npm ci
- name: Generate version.ts
run: |
VERSION=$(node -p "require('./package.json').version")
echo "export const SDK_VERSION = '${VERSION}';" > src/version.ts
- name: Run Linter
run: npm run lint
- name: Verify Build
run: npm run build
================================================
FILE: .gitignore
================================================
# Python
*.pyc
*.pyo
*.pyd
__pycache__
*.so
*.egg
*.egg-info
dist/
/build/
*.swp
# Testing
.pytest_cache
.coverage
coverage.xml
htmlcov/
.tox
# IDEs
.DS_Store
.idea
.vscode
*.swo
# Virtual environments
venv/
env/
.venv/
# Environment variables
.env
# SQLite databases
*.db
*.db-journal
# UV
uv.lock
# Python packaging
*.egg-info/
dist/
/build/
# Sensitive files (do not commit)
google-credentials.json
*.pem
*.key
AGENTS.md
tests/examples/*
# Benchmarking results
tests/benchmarks/results/
results/
*.json
*.csv
!pyproject.toml
!package.json
!composer.json
# Node / TypeScript
node_modules/
dist/
*.tsbuildinfo
coverage
!package-lock.json
!tsconfig.json
!tsconfig.build.json
!.prettierrc.json
!openclaw.plugin.json
================================================
FILE: .pre-commit-config.yaml
================================================
repos:
- repo: https://github.com/pre-commit/pre-commit-hooks
rev: v4.5.0
hooks:
- id: check-yaml
- id: end-of-file-fixer
- id: trailing-whitespace
- id: debug-statements
- repo: https://github.com/astral-sh/ruff-pre-commit
rev: v0.15.1
hooks:
- id: ruff-check
args: [--fix]
- id: ruff-format
- repo: local
hooks:
# - id: ty
# name: ty type checker
# entry: uvx ty check
# language: system
# types: [python]
# pass_filenames: false
# always_run: true
- id: pytest
name: pytest
entry: uv run pytest --ignore=tests/benchmarks --ignore=tests/integration
language: system
pass_filenames: false
always_run: true
- id: ts-format
name: format (memori-ts)
entry: bash -c 'cd memori-ts && npm run format'
language: system
pass_filenames: false
files: ^memori-ts/
- id: ts-lint
name: lint (memori-ts)
entry: bash -c 'cd memori-ts && npm run lint:fix'
language: system
pass_filenames: false
files: ^memori-ts/
- id: ts-typecheck
name: typecheck (memori-ts)
entry: bash -c 'cd memori-ts && npm run typecheck'
language: system
pass_filenames: false
files: ^memori-ts/
- id: ts-test
name: test (memori-ts)
entry: bash -c 'cd memori-ts && npm run test'
language: system
pass_filenames: false
files: ^memori-ts/
================================================
FILE: CHANGELOG.md
================================================
# Changelog
All notable changes to the Memori Python SDK will be documented in this file.
The format is based on [Keep a Changelog](https://keepachangelog.com/en/1.0.0/),
and this project adheres to [Semantic Versioning](https://semver.org/spec/v2.0.0.html).
## [Unreleased]
### Fixed
- Fixed multi-turn conversation ingestion for AzureOpenAI and OpenAI clients. Previously, only the first conversation turn was being recorded. Now `conversation_id` is resolved early in the request lifecycle, ensuring all conversation turns are properly ingested into the same conversation. (Fixes #83)
[3.0.0]: https://github.com/MemoriLabs/Memori/releases/tag/v3.0.0
================================================
FILE: CONTRIBUTING.md
================================================
[](https://memorilabs.ai/)
# Contributing to Memori Python SDK
Thank you for your interest in contributing to Memori!
## Development Setup
We use `uv` for fast dependency management and Docker for integration testing. You can develop locally or use our Docker environment.
### Prerequisites
- Python 3.10+ (3.12 recommended)
- [uv](https://github.com/astral-sh/uv) - Fast Python package installer
- Docker and Docker Compose (for integration tests)
- Make
### Quick Start (Local Development)
```bash
# Install uv if you haven't already
curl -LsSf https://astral.sh/uv/install.sh | sh
# Clone the repository
git clone https://github.com/MemoriLabs/Memori.git
cd Memori
# Install dependencies
uv sync
# Install pre-commit hooks
uv run pre-commit install
# Run unit tests
uv run pytest
```
### Quick Start (Docker)
```bash
# Copy the example environment file
cp .env.example .env
# Edit .env and add your API keys (optional for unit tests)
# Required for integration tests: OPENAI_API_KEY, ANTHROPIC_API_KEY, GOOGLE_API_KEY
# Start the environment
make dev-up
```
This will:
- Build the Docker container with Python 3.12
- Install all dependencies with uv
- Start PostgreSQL, MySQL, and MongoDB for integration tests
- Start Mongo Express (web UI for MongoDB at http://localhost:8081)
### Development Commands
#### Local Development
```bash
# Run unit tests
uv run pytest
# Format code
uv run ruff format .
# Check linting
uv run ruff check .
# Run with coverage
uv run pytest --cov=memori
# Run security scans
uv run bandit -r memori -ll -ii
uv run pip-audit --require-hashes --disable-pip || true
```
#### Docker Development
```bash
# Enter the development container
make dev-shell
# Run unit tests (fast, no external dependencies)
make test
# Initialize database schemas
make init-postgres # PostgreSQL
make init-mysql # MySQL
make init-oceanbase # OceanBase
make init-mongodb # MongoDB
make init-sqlite # SQLite
# Run a specific integration test script
make run-integration FILE=tests/llm/clients/oss/openai/async.py
# Format code
make format
# Check linting
make lint
# Run security scans
make security
# Stop the environment
make dev-down
# Clean up everything (containers, volumes, cache)
make clean
```
## Testing
We use `pytest` with coverage reporting and `pytest-mock` for mocking.
### Unit Tests
Unit tests use mocks and run without external dependencies:
```bash
# Local
uv run pytest
# Docker
make test
```
### Integration Tests
Integration tests require:
- Database instances (PostgreSQL, MySQL, MongoDB, or SQLite)
- LLM API keys (OpenAI, Anthropic, Google)
```bash
# Set API keys in .env first
# OPENAI_API_KEY=sk-...
# ANTHROPIC_API_KEY=sk-ant-...
# GOOGLE_API_KEY=...
# Initialize database schema
make init-postgres # or init-mysql, init-oceanbase, init-mongodb, init-sqlite
# Run integration test scripts
make run-integration FILE=tests/llm/clients/oss/openai/sync.py
```
### Test Coverage
We maintain high test coverage. Coverage reports are generated automatically:
- Terminal output (summary)
- HTML report in `htmlcov/`
- XML report in `coverage.xml`
View HTML coverage:
```bash
open htmlcov/index.html # macOS
xdg-open htmlcov/index.html # Linux
```
## Project Structure
```
memori/ # SDK source code
llm/ # LLM provider integrations (OpenAI, Anthropic, Google, etc.)
memory/ # Memory system and augmentation
storage/ # Storage adapters (PostgreSQL, MySQL, MongoDB, SQLite, etc.)
api/ # API client for Memori Advanced Augmentation
__init__.py # Main Memori class and public API
py.typed # PEP 561 type hint marker
tests/ # Test files
build/ # Database initialization scripts
llm/ # LLM provider tests (unit & integration)
memory/ # Memory system tests
storage/ # Storage adapter tests
conftest.py # Pytest fixtures
pyproject.toml # Project metadata and dependencies
uv.lock # Locked dependency versions
CHANGELOG.md # Version history
```
## Code Quality
We use [Ruff](https://docs.astral.sh/ruff/) for linting and formatting (configured in `pyproject.toml`):
```bash
# Format code
uv run ruff format . # or: make format
# Check linting
uv run ruff check . # or: make lint
# Auto-fix issues
uv run ruff check --fix .
# Run security scans (Bandit + pip-audit)
uv run bandit -r memori -ll -ii
uv run pip-audit --require-hashes --disable-pip || true
```
### Pre-commit Hooks
We use pre-commit to automatically format and lint code:
```bash
# Install hooks (one-time setup)
uv run pre-commit install
# Run manually
uv run pre-commit run --all-files
```
### Code Standards
- Follow PEP 8 standards
- Line length: 88 characters (Black-compatible)
- Python 3.10+ syntax (use modern type hints)
- All public APIs must have type hints
- Lean, simple code preferred over complex solutions (KISS, YAGNI)
- Minimize unnecessary comments - code should be self-documenting
## Pull Request Guidelines
1. **Fork and branch**: Create a feature branch from `main`
2. **Write tests**: Add/update tests for your changes
3. **Pass all checks**: Ensure tests, linting, and formatting pass
4. **Update docs**: Update README or docs if adding features
5. **Changelog**: Add entry to CHANGELOG.md under "Unreleased"
6. **Atomic commits**: Keep commits focused and well-described
## Supported Integrations
### LLM Providers
- OpenAI (sync/async, streaming)
- Anthropic Claude (sync/async, streaming)
- Google Gemini (sync/async, streaming)
- AWS Bedrock
### Frameworks
- Agno
- LangChain
### Database Adapters
- PostgreSQL (via psycopg2, psycopg3)
- MySQL / MariaDB (via pymysql)
- MongoDB (via pymongo)
- Oracle (via cx_Oracle, python-oracledb)
- SQLite (stdlib)
- CockroachDB
- Neon, Supabase (PostgreSQL-compatible)
- Django ORM
- DB-API 2.0 compatible connections
## CLI Commands
Memori provides CLI commands for managing your account and quota:
```bash
# Check your API quota
python3 -m memori quota
# Sign up for Memori Advanced Augmentation
python3 -m memori sign-up <email_address>
```
These commands help you:
- Monitor your memory quota and usage
- Sign up for increased limits (always free for developers)
- Obtain API keys for Advanced Augmentation features
## Development Notes
- Docker files (Dockerfile, docker-compose.yml, Makefile) are for development only
- They are NOT included in the PyPI package
- The SDK has minimal runtime dependencies - fully self-contained
- Development dependencies (LLM clients, database drivers) are in `[dependency-groups]`
================================================
FILE: Dockerfile
================================================
# Use Python 3.12 as base image
FROM python:3.12-slim
# Set working directory
WORKDIR /app
# Install system dependencies
RUN apt-get update && apt-get install -y \
git \
curl \
build-essential \
&& rm -rf /var/lib/apt/lists/*
# Install uv for faster dependency management
RUN pip install uv
# Copy dependency files
COPY pyproject.toml uv.lock* ./
# Install dependencies (including dev dependencies)
RUN uv sync --all-extras
# Copy the rest of the application
COPY . .
# Install pre-commit hooks
RUN pip install pre-commit && pre-commit install || true
# Add venv to PATH so all tools are available
ENV PATH="/app/.venv/bin:$PATH"
# Default command opens a bash shell
CMD ["/bin/bash"]
================================================
FILE: LICENSE
================================================
Apache License
Version 2.0, January 2004
http://www.apache.org/licenses/
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
1. Definitions.
"License" shall mean the terms and conditions for use, reproduction,
and distribution as defined by Sections 1 through 9 of this document.
"Licensor" shall mean the copyright owner or entity granting the License.
"Legal Entity" shall mean the union of the acting entity and all
other entities that control, are controlled by, or are under common
control with that entity. For the purposes of this definition,
"control" means (i) the power, direct or indirect, to cause the
direction or management of such entity, whether by contract or
otherwise, or (ii) ownership of fifty percent (50%) or more of the
outstanding shares, or (iii) beneficial ownership of such entity.
"You" (or "Your") shall mean an individual or Legal Entity
exercising permissions granted by this License.
"Source" form shall mean the preferred form for making modifications,
including but not limited to software source code, documentation
source, and configuration files.
"Object" form shall mean any form resulting from mechanical
transformation or translation of a Source form, including but
not limited to compiled object code, generated documentation,
and conversions to other media types.
"Work" shall mean the work of authorship, whether in Source or
Object form, made available under the License, as indicated by a
copyright notice that is included in or attached to the work
(which shall not include communications that are reasonably
considered separate from, or merely to link to (or bind by name)
the interfaces of, the Work and separate works which communicate
with the Work solely through the Work's public interfaces).
"Derivative Works" shall mean any work, whether in Source or Object
form, that is based upon (or derived from) the Work and for which the
editorial revisions, annotations, elaborations, or other modifications
represent, as a whole, an original work of authorship. For the purposes
of this License, Derivative Works shall not include works that remain
separable from, or merely link (or bind by name) to the interfaces of,
the Work and separate works which communicate with the Work solely
through the Work's public interfaces.
"Contribution" shall mean any work of authorship, including
the original version of the Work and any modifications or additions
to that Work or Derivative Works thereof, that is intentionally
submitted to Licensor for inclusion in the Work by the copyright owner
or by an individual or Legal Entity authorized to submit on behalf of
the copyright owner. For the purposes of this definition, "submitted"
means any form of electronic, verbal, or written communication sent
to the Licensor or its representatives, including but not limited to
communication on electronic mailing lists, source code control
systems, and issue tracking systems that are managed by, or on behalf
of, the Licensor for the purpose of discussing and improving the Work,
but excluding communication that is conspicuously marked or otherwise
designated in writing by the copyright owner as "Not a Contribution."
"Contributor" shall mean Licensor and any individual or Legal Entity
on behalf of whom a Contribution has been received by Licensor and
subsequently incorporated within the Work.
2. Grant of Copyright License. Subject to the terms and conditions of
this License, each Contributor hereby grants to You a perpetual,
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
copyright license to use, reproduce, modify, distribute, and prepare
Derivative Works of the Work, and to publicly display and perform the
Work and such Derivative Works in all media and formats whether now
known or hereafter devised.
3. Grant of Patent License. Subject to the terms and conditions of
this License, each Contributor hereby grants to You a perpetual,
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
(except as stated in this section) patent license to make, have made,
use, offer to sell, sell, import, and otherwise transfer the Work,
where such license applies only to those patent claims licensable
by such Contributor that are necessarily infringed by their
Contribution(s) alone or by combination of their Contribution(s)
with the Work to which such Contribution(s) was submitted. If You
institute patent litigation against any entity (including a
cross-claim or counterclaim in a lawsuit) alleging that the Work
or a Contribution incorporated within the Work constitutes direct
or contributory patent infringement, then any patent licenses
granted to You under this License for that Work shall terminate
as of the date such litigation is filed.
4. Redistribution. You may reproduce and distribute copies of the
Work or Derivative Works thereof in any medium, with or without
modifications, and in Source or Object form, provided that You
meet the following conditions:
(a) You must give any other recipients of the Work or
Derivative Works a copy of this License; and
(b) You must cause any modified files to carry prominent notices
stating that You changed the files; and
(c) You must retain, in the Source form of any Derivative Works
that You distribute, all copyright, trademark, patent,
attribution and other notices from the Source form of the Work,
excluding those notices that do not pertain to any part of
the Derivative Works; and
(d) If the Work includes a "NOTICE" text file as part of its
distribution, then any Derivative Works that You distribute must
include a readable copy of the attribution notices contained
within such NOTICE file, excluding those notices that do not
pertain to any part of the Derivative Works, in at least one
of the following places: within a NOTICE text file distributed
as part of the Derivative Works; within the Source form or
documentation, if provided along with the Derivative Works; or,
within a display generated by the Derivative Works, if and
wherever such third-party notices normally appear. The contents
of the NOTICE file are for informational purposes only and
do not modify the License. You may add Your own attribution
notices within Derivative Works that You distribute, alongside
or as an addendum to the NOTICE text from the Work, provided
that such additional attribution notices cannot be construed
as modifying the License.
You may add Your own copyright notice to Your modifications and
may provide additional or different license terms and conditions
for use, reproduction, or distribution of Your modifications, or
for any such Derivative Works as a whole, provided Your use,
reproduction, and distribution of the Work otherwise complies with
the conditions stated in this License.
5. Submission of Contributions. Unless You explicitly state otherwise,
any Contribution intentionally submitted for inclusion in the Work
by You to the Licensor shall be under the terms and conditions of
this License, without any additional terms or conditions.
Notwithstanding the above, nothing herein shall supersede or modify
the terms of any separate license agreement you may have executed
with Licensor regarding such Contributions.
6. Trademarks. This License does not grant permission to use the trade
names, trademarks, service marks, or product names of the Licensor,
except as required for reasonable and customary use in describing the
origin of the Work and reproducing the content of the NOTICE file.
7. Disclaimer of Warranty. Unless required by applicable law or
agreed to in writing, Licensor provides the Work (and each
Contributor provides its Contributions) on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
implied, including, without limitation, any warranties or conditions
of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
PARTICULAR PURPOSE. You are solely responsible for determining the
appropriateness of using or redistributing the Work and assume any
risks associated with Your exercise of permissions under this License.
8. Limitation of Liability. In no event and under no legal theory,
whether in tort (including negligence), contract, or otherwise,
unless required by applicable law (such as deliberate and grossly
negligent acts) or agreed to in writing, shall any Contributor be
liable to You for damages, including any direct, indirect, special,
incidental, or consequential damages of any character arising as a
result of this License or out of the use or inability to use the
Work (including but not limited to damages for loss of goodwill,
work stoppage, computer failure or malfunction, or any and all
other commercial damages or losses), even if such Contributor
has been advised of the possibility of such damages.
9. Accepting Warranty or Support. You may choose to offer, and to
charge a fee for, warranty, support, indemnity or other liability
obligations and/or rights consistent with this License. However, in
accepting such obligations, You may act only on Your own behalf and on
Your sole responsibility, not on behalf of any other Contributor, and
only if You agree to indemnify, defend, and hold each Contributor
harmless for any liability incurred by, or claims asserted against,
such Contributor by reason of your accepting any such warranty or support.
END OF TERMS AND CONDITIONS
APPENDIX: How to apply the Apache License to your work.
To apply the Apache License to your work, attach the following
boilerplate notice, with the fields enclosed by brackets "[]"
replaced with your own identifying information. (Don't include
the brackets!) The text should be enclosed in the appropriate
comment syntax for the file format. We also recommend that a
file or class name and description of purpose be included on the
same "printed page" as the copyright notice for easier
identification within third-party archives.
Copyright [2025] [Memori Team]
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
================================================
FILE: MANIFEST.in
================================================
# Include essential files
include README.md
include LICENSE
# Exclude all development and Docker files
exclude Dockerfile
exclude docker-compose.yml
exclude .dockerignore
exclude Makefile
exclude .env.example
exclude conftest.py
exclude CONTRIBUTING.md
exclude .pre-commit-config.yaml
exclude uv.lock
exclude google-credentials.json
exclude .coverage
exclude coverage.xml
exclude CHANGELOG.md
exclude insert_facts.py
exclude memori_test.db
# Exclude test directories
prune tests
# Exclude documentation build artifacts
prune docs
prune htmlcov
# Exclude TypeScript SDK (not shipped to PyPI)
prune memori-ts
prune integrations
# Exclude benchmarks (not shipped with the SDK)
prune benchmarks
# Exclude version control and CI
prune .git
prune .github
exclude .gitignore
# Exclude IDE and editor files
prune .vscode
prune .venv
prune .pytest_cache
prune .ruff_cache
global-exclude .DS_Store
global-exclude *.pyc
global-exclude *.pyo
global-exclude __pycache__
================================================
FILE: Makefile
================================================
.PHONY: help dev-up dev-down dev-shell dev-build dev-clean test lint format clean run-unit run-integration run-integration-provider run-integration-cloud
help: ## Show this help message
@echo 'Usage: make [target]'
@echo ''
@echo 'Available targets:'
@awk 'BEGIN {FS = ":.*?## "} /^[a-zA-Z_-]+:.*?## / {printf " %-20s %s\n", $$1, $$2}' $(MAKEFILE_LIST)
dev-up: ## Start development environment (builds and runs containers)
docker compose up -d --build
@echo ""
@echo "✓ Development environment is ready!"
@echo " Run 'make dev-shell' to enter the development container"
@echo " Run 'make test' to run tests"
dev-down: ## Stop development environment
docker compose down
dev-shell: ## Open a shell in the development container
docker compose exec dev /bin/bash
init-db: ## Initialize database schema for integration tests
docker compose exec -e PYTHONPATH=/app dev python tests/database/init_db.py
init-postgres: ## Initialize PostgreSQL schema
docker compose exec -e PYTHONPATH=/app dev python tests/build/postgresql.py
init-mysql: ## Initialize MySQL schema
docker compose exec -e PYTHONPATH=/app dev python tests/build/mysql.py
init-oceanbase: ## Initialize OceanBase schema
docker compose exec -e PYTHONPATH=/app dev python tests/build/oceanbase.py
init-oracle: ## Initialize Oracle schema
docker compose exec -e PYTHONPATH=/app dev python tests/build/oracle.py
init-mongodb: ## Initialize MongoDB schema
docker compose exec -e PYTHONPATH=/app dev python tests/build/mongodb.py
init-sqlite: ## Initialize SQLite schema
docker compose exec -e PYTHONPATH=/app dev python tests/build/sqlite.py
dev-build: ## Rebuild the development container
docker compose build --no-cache
dev-clean: ## Complete teardown: stop containers, remove images, prune build cache
docker compose down -v
docker builder prune -f
docker compose rm -f
@echo "✓ Docker environment cleaned (containers, volumes, and build cache removed)"
test: ## Run tests in the container
docker compose exec dev pytest
run-unit: ## Run unit tests (no API keys needed)
@echo "Running unit tests..."
uv run pytest tests/ --ignore=tests/integration --ignore=tests/benchmarks -v --tb=short
run-integration: ## Run all integration tests (requires API keys)
@echo "Running all integration tests with MEMORI_TEST_MODE=1..."
MEMORI_TEST_MODE=1 uv run pytest tests/integration/ -v -m integration --tb=short
run-integration-provider: ## Run specific provider tests (e.g., make run-integration-provider P=openai)
@echo "Running $(P) integration tests..."
MEMORI_TEST_MODE=1 uv run pytest tests/integration/providers/test_$(P).py -v -m integration --tb=short
run-integration-cloud: ## Run cloud integration tests (production API, requires MEMORI_API_KEY)
@echo "Running cloud integration tests..."
uv run pytest tests/integration/cloud/ -v -m integration --tb=short
lint: ## Run linting (format check)
docker compose exec dev uv run ruff check .
security: ## Run security scans (Bandit + pip-audit)
docker compose exec dev uv run bandit -r memori -ll -ii
docker compose exec dev uv run pip-audit --require-hashes --disable-pip || true
format: ## Format code
docker compose exec dev uv run ruff format .
clean: ## Clean up containers, volumes, and Python cache files
docker compose down -v
find . -type d -name __pycache__ -exec rm -rf {} + 2>/dev/null || true
find . -type d -name .pytest_cache -exec rm -rf {} + 2>/dev/null || true
find . -type d -name "*.egg-info" -exec rm -rf {} + 2>/dev/null || true
================================================
FILE: README.md
================================================
[](https://memorilabs.ai/)
<p align="center">
<strong>The memory fabric for enterprise AI</strong>
</p>
<p align="center">
<i>Memori plugs into the software and infrastructure you already use. It is LLM, datastore and framework agnostic and seamlessly integrates into the architecture you've already designed.</i>
</p>
<p align="center">
<strong>→ <a href="https://memorilabs.ai/docs/memori-cloud/">Memori Cloud</a></strong> — Zero config. Get an API key and start building in minutes.
</p>
<p align="center">
<a href="https://trendshift.io/repositories/15418">
<img src="https://trendshift.io/_next/image?url=https%3A%2F%2Ftrendshift.io%2Fapi%2Fbadge%2Frepositories%2F15418&w=640&q=75" alt="Memori%2fLabs%2FMemori | Trendshif">
</a>
</p>
<p align="center">
<a href="https://badge.fury.io/py/memori">
<img src="https://badge.fury.io/py/memori.svg" alt="PyPI version">
</a>
<a href="https://www.npmjs.com/package/@memorilabs/memori">
<img src="https://img.shields.io/npm/v/@memorilabs/memori.svg" alt="NPM version">
</a>
<a href="https://pepy.tech/projects/memori">
<img src="https://static.pepy.tech/badge/memori" alt="Downloads">
</a>
<a href="https://opensource.org/license/apache-2-0">
<img src="https://img.shields.io/badge/license-Apache%202.0-blue" alt="License">
</a>
<a href="https://discord.gg/abD4eGym6v">
<img src="https://img.shields.io/discord/1042405378304004156?logo=discord" alt="Discord">
</a>
</p>
<p align="center">
<a href="https://github.com/MemoriLabs/Memori/stargazers">
<img src="https://img.shields.io/badge/⭐%20Give%20a%20Star-Support%20the%20project-orange?style=for-the-badge" alt="Give a Star">
</a>
</p>
---
## Getting Started
### Installation
<details open>
<summary><b>TypeScript SDK</b></summary>
```bash
npm install @memorilabs/memori
```
</details>
<details>
<summary><b>Python SDK</b></summary>
```bash
pip install memori
```
</details>
### Quickstart
Sign up at [app.memorilabs.ai](https://app.memorilabs.ai), get a Memori API key, and start building. Full docs: [memorilabs.ai/docs/memori-cloud/](https://memorilabs.ai/docs/memori-cloud/).
Set `MEMORI_API_KEY` and your LLM API key (e.g. `OPENAI_API_KEY`), then:
<details open>
<summary><b>TypeScript SDK</b></summary>
```typescript
import { OpenAI } from 'openai';
import { Memori } from '@memorilabs/memori';
// Requires MEMORI_API_KEY and OPENAI_API_KEY in your environment
const client = new OpenAI();
const mem = new Memori().llm
.register(client)
.attribution('user_123', 'support_agent');
async function main() {
await client.chat.completions.create({
model: 'gpt-4o-mini',
messages: [{ role: 'user', content: 'My favorite color is blue.' }],
});
// Conversations are persisted and recalled automatically in the background.
const response = await client.chat.completions.create({
model: 'gpt-4o-mini',
messages: [{ role: 'user', content: "What's my favorite color?" }],
});
// Memori recalls that your favorite color is blue.
}
```
</details>
<details>
<summary><b>Python SDK</b></summary>
```python
from memori import Memori
from openai import OpenAI
# Requires MEMORI_API_KEY and OPENAI_API_KEY in your environment
client = OpenAI()
mem = Memori().llm.register(client)
mem.attribution(entity_id="user_123", process_id="support_agent")
response = client.chat.completions.create(
model="gpt-4o-mini",
messages=[{"role": "user", "content": "My favorite color is blue."}]
)
# Conversations are persisted and recalled automatically.
response = client.chat.completions.create(
model="gpt-4o-mini",
messages=[{"role": "user", "content": "What's my favorite color?"}]
)
# Memori recalls that your favorite color is blue.
```
</details>
## Explore the Memories
Use the [Dashboard](https://app.memorilabs.ai) — Memories, Analytics, Playground, and API Keys.
> [!TIP]
> Want to use your own database? Check out docs for Memori BYODB here:
> [https://memorilabs.ai/docs/memori-byodb/](https://memorilabs.ai/docs/memori-byodb/).
## LoCoMo Benchmark
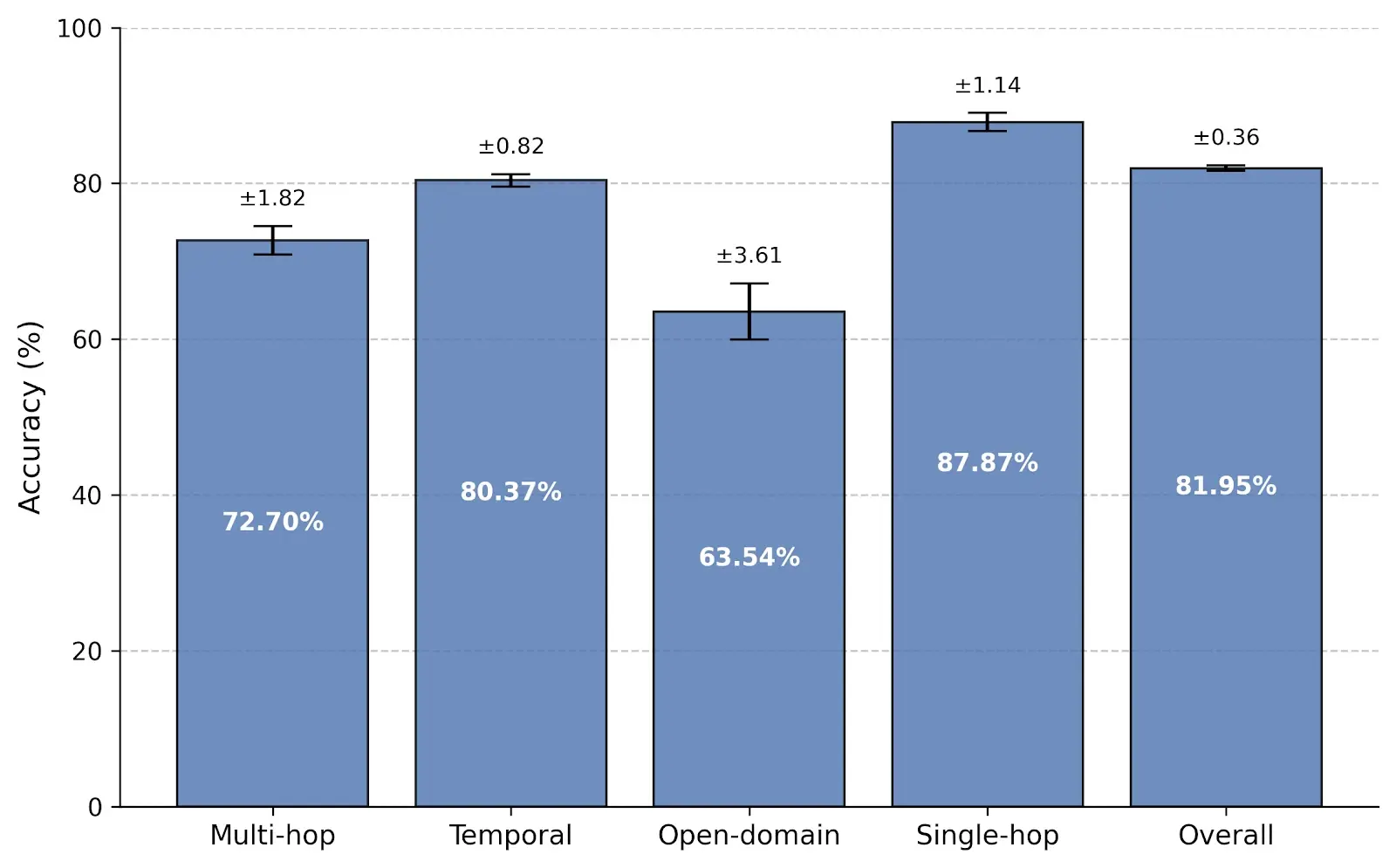
Memori was evaluated on the LoCoMo benchmark for long-conversation memory and achieved **81.95% overall accuracy** while using an average of **1,294 tokens per query**. That is just **4.97% of the full-context footprint**, showing that structured memory can preserve reasoning quality without forcing large prompts into every request.
Compared with other retrieval-based memory systems, Memori outperformed Zep, LangMem, and Mem0 while reducing prompt size by roughly **67% vs. Zep** and lowering context cost by more than **20x vs. full-context prompting**.
Read the [benchmark overview](docs/memori-cloud/benchmark/overview.mdx), see the [results](docs/memori-cloud/benchmark/results.mdx), or download the [paper](https://s3.us-east-1.amazonaws.com/images.memorilabs.ai/docs/memori-locomo-benchmark.pdf).
## OpenClaw (Persistent Memory for Your Gateway)
By default, OpenClaw agents forget everything between sessions. The Memori plugin fixes that. It captures durable facts and preferences after each conversation, then injects the most relevant context back into future prompts automatically.
No changes to your agent code or prompts are required. The plugin hooks into OpenClaw's lifecycle, so you get structured memory, Intelligent Recall, and Advanced Augmentation with a drop-in plugin.
```bash
openclaw plugins install @memorilabs/openclaw-memori
openclaw plugins enable openclaw-memori
openclaw config set plugins.entries.openclaw-memori.config.apiKey "YOUR_MEMORI_API_KEY"
openclaw config set plugins.entries.openclaw-memori.config.entityId "your-app-user-id"
openclaw gateway restart
```
For setup and configuration, see the [OpenClaw Quickstart](docs/memori-cloud/openclaw/quickstart.mdx). For architecture and lifecycle details, see the [OpenClaw Overview](docs/memori-cloud/openclaw/overview.mdx).
## MCP (Connect Your Agent in One Command)
Your agent forgets everything between sessions. Memori fixes that. It remembers your stack, your conventions, and how you like things done so you stop repeating yourself.
Works for solo developers and teams. Your agent learns coding patterns, reviewer preferences, and project conventions over time. For teams, that means shared context that new engineers pick up on day one instead of absorbing tribal knowledge over months.
If you use Claude Code, Cursor, Codex, Warp, or Antigravity, you can connect Memori with no SDK integration needed:
```bash
claude mcp add --transport http memori https://api.memorilabs.ai/mcp/ \
--header "X-Memori-API-Key: ${MEMORI_API_KEY}" \
--header "X-Memori-Entity-Id: your_username" \
--header "X-Memori-Process-Id: claude-code"
```
For Cursor, Codex, Warp, and other clients, see the [MCP client setup guide](docs/memori-cloud/mcp/client-setup.mdx).
## Attribution
To get the most out of Memori, you want to attribute your LLM interactions to an entity (think person, place or thing; like a user) and a process (think your agent, LLM interaction or program).
If you do not provide any attribution, Memori cannot make memories for you.
<details open>
<summary><b>TypeScript SDK</b></summary>
```typescript
mem.attribution("12345", "my-ai-bot");
```
</details>
<details>
<summary><b>Python SDK</b></summary>
```python
mem.attribution(entity_id="12345", process_id="my-ai-bot")
```
</details>
## Session Management
Memori uses sessions to group your LLM interactions together. For example, if you have an agent that executes multiple steps you want those to be recorded in a single session.
By default, Memori handles setting the session for you but you can start a new session or override the session by executing the following:
<details open>
<summary><b>TypeScript SDK</b></summary>
```typescript
mem.resetSession();
// or
mem.setSession(sessionId);
```
</details>
<details>
<summary><b>Python SDK</b></summary>
```python
mem.new_session()
# or
mem.set_session(session_id)
```
</details>
## Supported LLMs
- Anthropic
- Bedrock
- DeepSeek
- Gemini
- Grok (xAI)
- OpenAI (Chat Completions & Responses API)
_(unstreamed, streamed, synchronous and asynchronous)_
## Supported Frameworks
- Agno
- LangChain
- Pydantic AI
## Supported Platforms
- DeepSeek
- Nebius AI Studio
## Examples
For more examples and demos, check out the [Memori Cookbook](https://github.com/MemoriLabs/memori-cookbook).
## Memori Advanced Augmentation
Memories are tracked at several different levels:
- **entity**: think person, place, or thing; like a user
- **process**: think your agent, LLM interaction or program
- **session**: the current interactions between the entity, process and the LLM
[Memori's Advanced Augmentation](docs/memori-cloud/concepts/advanced-augmentation.mdx) enhances memories at each of these levels with:
- attributes
- events
- facts
- people
- preferences
- relationships
- rules
- skills
Memori knows who your user is, what tasks your agent handles and creates unparalleled context between the two. Augmentation occurs in the background incurring no latency.
By default, Memori Advanced Augmentation is available without an account but rate limited. When you need increased limits, [sign up for Memori Advanced Augmentation](https://app.memorilabs.ai/signup) or use the Memori CLI:
```bash
# Install the CLI via pip to manage your account
python -m memori sign-up <email_address>
```
Memori Advanced Augmentation is always free for developers!
Once you've obtained an API key, set the following environment variable (used by both Python and TypeScript SDKs):
```bash
export MEMORI_API_KEY=[api_key]
```
## Managing Your Quota
At any time, you can check your quota using the Memori CLI (works for both SDKs):
```bash
python -m memori quota
```
Or by checking your account at [https://app.memorilabs.ai/](https://app.memorilabs.ai/). If you have reached your IP address quota, sign up and get an API key for increased limits.
If your API key exceeds its quota limits we will email you and let you know.
## Command Line Interface (CLI)
The Memori CLI is the unified tool for managing your account, keys, and quotas across all SDKs. To use it, execute the following from the command line:
```bash
# Requires Python installed
python -m memori
```
This will display a menu of the available options. For more information about what you can do with the Memori CLI, please reference [Command Line Interface](docs/memori-byodb/concepts/cli-quickstart.mdx).
## Contributing
We welcome contributions from the community! Please see our [Contributing Guidelines](https://github.com/MemoriLabs/Memori/blob/main/CONTRIBUTING.md) for details on:
- Setting up your development environment
- Code style and standards
- Submitting pull requests
- Reporting issues
---
## Support
- **Memori Cloud Documentation**: [memorilabs.ai/docs/memori-cloud/](https://memorilabs.ai/docs/memori-cloud/)
- **Memori BYODB Documentation**: [https://memorilabs.ai/docs/memori-byodb/](https://memorilabs.ai/docs/memori-byodb/)
- **Discord**: [https://discord.gg/abD4eGym6v](https://discord.gg/abD4eGym6v)
- **Issues**: [GitHub Issues](https://github.com/MemoriLabs/Memori/issues)
---
## License
Apache 2.0 - see [LICENSE](https://github.com/MemoriLabs/Memori/blob/main/LICENSE)
================================================
FILE: SECURITY.md
================================================
[](https://memorilabs.ai/)
## Security Policy
If you believe you have discovered a security vulnerability in Memori, please **do not** open a public GitHub issue.
Instead, responsibly disclose it by:
- Going to the **Security** tab of this repository
- Clicking **"Report a vulnerability"**
Please provide as much detail as possible in your private report, including:
- A clear description of the issue
- Steps to reproduce (a minimal reproducible example is greatly appreciated)
- Potential impact and any proof-of-concept if available
This allows us to investigate and address the issue quickly and safely before public disclosure.
Thank you for helping keep Memori secure!
================================================
FILE: benchmarks/README.md
================================================
## Benchmarks
This directory contains **benchmark harnesses** that are intentionally **not** part of the
default `pytest` unit test suite.
### Performance / latency (pytest-benchmark)
Performance benchmarks (including **end-to-end recall latency**) live in `benchmarks/perf/`.
Run locally (example):
```bash
uv run pytest -m benchmark --benchmark-only benchmarks/perf/test_recall_benchmarks.py -v
```
For EC2 / VPC-adjacent database benchmarking, see `benchmarks/perf/README.md` and the helper
scripts in `benchmarks/perf/`.
### LoCoMo (retrieval evaluation)
LoCoMo is a benchmark dataset by Snap Research for long conversation memory.
In Memori, we treat LoCoMo as a **retrieval evaluation** problem: given a question, does
Memori retrieve the right supporting context (evidence)?
#### Dataset
LoCoMo is not vendored in this repo. Download the dataset JSON locally, then point the
harness at that file path.
Upstream: `https://github.com/snap-research/locomo`
#### Preprocess (recommended for Memori)
The upstream LoCoMo format is a **third-person** dialogue between two speakers, and some
conversations include multimodal fields (e.g., image URLs + captions) that Memori does not
currently handle well.
To make evaluation more representative of Memori usage, we provide a small preprocessing step
that:
- Skips any conversation that contains multimodal turn fields (`img_url`, `blip_caption`, `query`)
- Rewrites speakers so `conversation.speaker_b` becomes `assistant` and the other speaker becomes `user`
Run:
```bash
uv run python benchmarks/locomo/preprocess.py \
--in benchmarks/locomo10.json \
--out benchmarks/locomo10_memori.json
```
#### What gets written (artifacts)
Each run writes:
- `predictions.jsonl`: one row per QA question (retrieved top-k + hit@k/MRR metrics)
- `summary.json`: aggregated metrics (overall + by category)
- `locomo.sqlite`: SQLite DB used by Memori storage during the run
- `locomo_provenance.sqlite`: (AA mode only) benchmark-only mapping of `fact_id → dia_id` for scoring
#### Modes (ingestion)
LoCoMo ingestion always uses **Advanced Augmentation**:
- Stores turns as `conversation_message`s and runs Memori **Advanced Augmentation** to produce
derived `entity_fact`s (closest to real usage).
- Because LoCoMo evidence is turn-level, we write a **benchmark-only provenance DB**
(`locomo_provenance.sqlite`) that maps each derived fact back to the LoCoMo `dia_id` turn(s),
then score hit@k/MRR against evidence.
- **Requires**: `MEMORI_API_KEY`.
- **Note**: may be non-deterministic (API + model changes).
#### Quickstart (advanced_augmentation, seeds + scores)
Prerequisite:
- `MEMORI_API_KEY` set (Advanced Augmentation API access)
- LoCoMo harness forces staging routing (`MEMORI_TEST_MODE=1`)
Run:
```bash
export MEMORI_API_KEY="..."
# Optional: increase AA request timeout (default is 30s)
export MEMORI_AUGMENTATION_TIMEOUT_SECONDS=120
uv run python benchmarks/locomo/run.py \
--dataset benchmarks/locomo10.json \
--out results/locomo/aa_run \
--aa-batch per_pair
```
#### Score-only (reuse an existing DB, no AA calls)
If you already seeded a SQLite DB (and, for AA runs, a provenance DB), you can skip ingestion and
run retrieval+scoring directly from the existing DB:
```bash
uv run python benchmarks/locomo/run.py \
--dataset benchmarks/locomo10.json \
--out results/locomo/score_only \
--sqlite-db results/locomo/aa_run/locomo.sqlite \
--provenance-db results/locomo/aa_run/locomo_provenance.sqlite \
--reuse-db
```
If the DB contains multiple prior LoCoMo runs, pass `--run-id` to choose which one to score.
#### Useful knobs (AA mode)
- **Batching**:
- `--aa-batch per_pair` (one AA request per user+assistant pair)
- **Dry-run** (inspect payload; no network call):
- `--aa-dry-run` writes `aa_payload_preview.json` and prints the payload + URL.
- **Metadata** (only if your AA endpoint requires it; defaults are provided):
- `--meta-llm-provider`
- `--meta-llm-version`
- `--meta-llm-sdk-version`
- `--meta-framework-provider`
- `--meta-platform-provider`
- **Timeout**:
- AA HTTP timeout is configured via `MEMORI_AUGMENTATION_TIMEOUT_SECONDS`.
================================================
FILE: benchmarks/locomo/_run_impl.py
================================================
from __future__ import annotations
import datetime
import json
import os
import sqlite3
from dataclasses import dataclass
from pathlib import Path
from uuid import uuid4
from benchmarks.locomo._types import LoCoMoSample
from benchmarks.locomo.loader import load_locomo_json
from benchmarks.locomo.provenance import (
FactAttribution,
ProvenanceStore,
attribute_facts_to_turn_ids,
)
from benchmarks.locomo.retrieval import (
build_turn_facts,
evidence_to_turn_ids,
)
from benchmarks.locomo.scoring import hit_at_k_groups, mrr_groups
from memori import Memori
from memori.embeddings import embed_texts
from memori.memory.augmentation.input import AugmentationInput
from memori.memory.recall import Recall
CATEGORY_LABELS: dict[str, str] = {
# LoCoMo category IDs are numeric in the dataset JSON.
# Mapping here matches the upstream LoCoMo taxonomy:
# 1=multi-hop, 2=temporal, 3=open-domain knowledge, 4=single-hop, 5=adversarial.
"1": "multi-hop",
"2": "temporal",
"3": "open-domain",
"4": "single-hop",
"5": "adversarial",
"unknown": "unknown",
}
@dataclass(frozen=True, slots=True)
class RunConfig:
dataset: str
out: str
sqlite_db: str = ""
provenance_db: str = ""
reuse_db: bool = False
run_id: str = ""
k: int = 5
aa_timeout: float = 180.0
aa_batch: str = "per_pair"
aa_dry_run: bool = False
aa_max_requests: int = 0
meta_llm_provider: str = "openai"
meta_llm_version: str = "gpt-4.1-mini"
meta_llm_sdk_version: str = "unknown"
meta_framework_provider: str = "memori"
meta_platform_provider: str = "benchmark"
aa_provenance_top_n: int = 1
aa_provenance_min_score: float = 0.25
aa_provenance_mode: str = "similarity"
rebuild_provenance: bool = False
allow_prod_aa: bool = False
max_samples: int = 0
max_questions: int = 0
only_sample_id: str = ""
max_sessions: int = 0
verbose: bool = False
log_every_questions: int = 0
seed_only: bool = False
@dataclass(frozen=True, slots=True)
class PairRequest:
messages: list[dict[str, str]]
pair_turn_ids: tuple[str, str]
def run_locomo(cfg: RunConfig) -> dict:
out_dir = Path(cfg.out)
out_dir.mkdir(parents=True, exist_ok=True)
predictions_path = out_dir / "predictions.jsonl"
summary_path = out_dir / "summary.json"
sqlite_path = (
Path(cfg.sqlite_db).expanduser()
if cfg.sqlite_db
else (out_dir / "locomo.sqlite")
)
provenance_path = (
Path(cfg.provenance_db).expanduser()
if cfg.provenance_db
else (out_dir / "locomo_provenance.sqlite")
)
samples = load_locomo_json(cfg.dataset)
if cfg.only_sample_id:
samples = [s for s in samples if s.sample_id == cfg.only_sample_id]
if cfg.max_samples and cfg.max_samples > 0:
samples = samples[: cfg.max_samples]
run_id = _resolve_run_id(
cfg=cfg,
out_dir=out_dir,
sqlite_path=sqlite_path,
provenance_path=provenance_path,
)
ts = datetime.datetime.now(datetime.timezone.utc).isoformat()
mem = _init_memori(sqlite_path)
recall = Recall(mem.config)
prov_store = ProvenanceStore(provenance_path)
if (
not cfg.reuse_db
and not cfg.aa_dry_run
and not cfg.allow_prod_aa
and os.environ.get("MEMORI_TEST_MODE") != "1"
):
raise RuntimeError(
"Advanced Augmentation LoCoMo runs must target staging. "
"Set MEMORI_TEST_MODE=1 (recommended) or pass --allow-prod-aa to override."
)
if cfg.verbose:
from memori._network import Api
url = Api(mem.config).url("sdk/augmentation")
print(
f"[locomo][aa] resolved_api_url={url} MEMORI_TEST_MODE={os.environ.get('MEMORI_TEST_MODE')!r}"
)
totals = _Totals()
with predictions_path.open("w", encoding="utf-8") as f:
if cfg.verbose:
print(
f"[locomo] start ingest=advanced_augmentation aa_batch={cfg.aa_batch} "
f"samples={len(samples)} k={cfg.k} seed_only={cfg.seed_only}"
)
for sample in samples:
if cfg.max_sessions and cfg.max_sessions > 0:
sample = LoCoMoSample(
sample_id=sample.sample_id,
sessions=sample.sessions[: cfg.max_sessions],
qa=sample.qa,
)
entity_external_id = f"locomo:{run_id}:{sample.sample_id}"
if cfg.reuse_db:
entity_db_id = _get_entity_id_sqlite(
sqlite_path=sqlite_path,
entity_external_id=entity_external_id,
)
if entity_db_id is None:
raise RuntimeError(
f"--reuse-db was set but entity was not found in sqlite DB: external_id={entity_external_id}. "
"Run ingestion first (omit --reuse-db) or pass the correct --run-id."
)
else:
mem.attribution(
entity_id=entity_external_id, process_id="locomo-benchmark"
)
entity_db_id = mem.config.storage.driver.entity.create(
entity_external_id
)
turn_facts, turn_index = build_turn_facts(sample)
if cfg.reuse_db:
fact_count = _count_entity_facts_sqlite(
sqlite_path=sqlite_path, entity_db_id=entity_db_id
)
if fact_count <= 0:
raise RuntimeError(
f"--reuse-db was set but no facts were found for entity external_id={entity_external_id}. "
"Run ingestion first (omit --reuse-db) or pass the correct --run-id."
)
mem.config.recall_embeddings_limit = fact_count
if cfg.rebuild_provenance and not cfg.seed_only:
_build_aa_provenance(
mem=mem,
prov_store=prov_store,
run_id=run_id,
sample_id=sample.sample_id,
entity_db_id=entity_db_id,
turn_facts=turn_facts,
top_n=cfg.aa_provenance_top_n,
min_score=cfg.aa_provenance_min_score,
)
elif not cfg.seed_only and not prov_store.has_any(
run_id=run_id, sample_id=sample.sample_id
):
raise RuntimeError(
f"--reuse-db was set but no provenance rows were found for run_id={run_id} sample_id={sample.sample_id}. "
"Seed AA ingestion once (omit --reuse-db) to generate locomo_provenance.sqlite, "
"or point --provenance-db at an existing provenance DB, "
"or pass --rebuild-provenance to recompute provenance offline."
)
if cfg.verbose:
print(
f"[locomo][reuse] sample={sample.sample_id} facts={fact_count}"
)
else:
_configure_aa_meta(mem, cfg)
if cfg.aa_dry_run:
_write_aa_payload_preview(
out_dir=out_dir,
mem=mem,
sample=sample,
cfg=cfg,
entity_external_id=entity_external_id,
process_id="locomo-benchmark",
)
# Exit before any network call.
return {
"run_id": run_id,
"timestamp_utc": ts,
"dataset_path": str(Path(cfg.dataset).resolve()),
"sqlite_db_path": str(sqlite_path),
"provenance_db_path": str(provenance_path),
"ingest": "advanced_augmentation",
"sample_count": len(samples),
"question_count": 0,
"questions_by_category": {},
"metrics_overall": {},
"metrics_by_category": {},
"phase": 2,
"note": "AA dry-run: printed/wrote payload preview and exited before network calls.",
}
conv_id = _ingest_with_advanced_augmentation(
mem=mem,
prov_store=prov_store,
run_id=run_id,
entity_external_id=entity_external_id,
entity_db_id=entity_db_id,
sample=sample,
cfg=cfg,
)
if conv_id is not None:
summary_val = _read_conversation_summary(mem, conv_id) or ""
print(
f"[locomo][aa] sample={sample.sample_id} "
f"conversation_id={conv_id} summary_is_set={bool(summary_val)}"
)
if summary_val:
print(f"[locomo][aa] summary={summary_val}")
if cfg.seed_only:
continue
if cfg.verbose:
fact_count = len(
mem.config.storage.driver.entity_fact.get_embeddings(
entity_db_id, limit=100000
)
)
print(
f"[locomo][seed] sample={sample.sample_id} mode=advanced_augmentation "
f"turns={len(turn_facts)} facts_written={fact_count}"
)
if cfg.aa_provenance_mode == "similarity":
_build_aa_provenance(
mem=mem,
prov_store=prov_store,
run_id=run_id,
sample_id=sample.sample_id,
entity_db_id=entity_db_id,
turn_facts=turn_facts,
top_n=cfg.aa_provenance_top_n,
min_score=cfg.aa_provenance_min_score,
)
# Keep recall bounded to the facts created for this entity.
entity_fact_driver = mem.config.storage.driver.entity_fact
mem.config.recall_embeddings_limit = (
len(entity_fact_driver.get_embeddings(entity_db_id, limit=100000))
or 1
)
qa = list(sample.qa)
if cfg.max_questions and cfg.max_questions > 0:
qa = qa[: cfg.max_questions]
available_turn_ids = {t.turn_id for t in turn_facts}
for q in qa:
if (
cfg.verbose
and cfg.log_every_questions
and totals.question_count % cfg.log_every_questions == 0
):
print(
f"[locomo][score] questions={totals.question_count} "
f"sample={sample.sample_id}"
)
relevant = evidence_to_turn_ids(q.evidence, turn_index=turn_index)
if not relevant:
if cfg.verbose:
print(
f"[locomo][skip] sample={sample.sample_id} "
f"question_id={q.question_id} reason=no_evidence"
)
continue
missing = sorted(
tid for tid in relevant if tid not in available_turn_ids
)
if missing:
if cfg.verbose:
preview = ", ".join(missing[:5])
more = (
"" if len(missing) <= 5 else f" (+{len(missing) - 5} more)"
)
print(
f"[locomo][skip] sample={sample.sample_id} "
f"question_id={q.question_id} reason=missing_evidence "
f"missing={preview}{more}"
)
continue
totals.count_question(q.category)
results = recall.search_facts(
query=q.question,
limit=max(cfg.k, 1),
entity_id=entity_db_id,
)
# Scoring in AA mode needs a mapping from fact_id -> dia_id (LoCoMo turn id).
# A single fact can plausibly map to multiple turns; we score using any-match
# semantics per retrieved rank.
retrieved_ids: list[str] = []
retrieved_groups: list[set[str]] = []
top_k = _format_top_k(
results=results[: max(cfg.k, 1)],
prov_store=prov_store,
run_id=run_id,
sample_id=sample.sample_id,
retrieved_ids_out=retrieved_ids,
retrieved_groups_out=retrieved_groups,
provenance_limit=max(int(cfg.aa_provenance_top_n), 1),
)
metrics = {
"hit@1": hit_at_k_groups(relevant, retrieved_groups, 1),
"hit@3": hit_at_k_groups(relevant, retrieved_groups, 3),
"hit@5": hit_at_k_groups(relevant, retrieved_groups, 5),
"hit@10": hit_at_k_groups(relevant, retrieved_groups, 10),
"hit@20": hit_at_k_groups(relevant, retrieved_groups, 20),
"hit@30": hit_at_k_groups(relevant, retrieved_groups, 30),
"mrr": mrr_groups(relevant, retrieved_groups),
}
totals.add_metrics(category=q.category or "unknown", metrics=metrics)
row = {
"run_id": run_id,
"timestamp_utc": ts,
"sample_id": sample.sample_id,
"question_id": q.question_id,
"category": q.category,
"question": q.question,
"answers": list(q.answers),
"evidence": q.evidence,
"retrieval": {
"status": "ok",
"ingest": "advanced_augmentation",
"k": cfg.k,
"relevant_turn_ids": sorted(relevant),
"top_k": top_k,
"metrics": metrics,
},
}
f.write(json.dumps(row, ensure_ascii=False) + "\n")
summary = totals.to_summary(
run_id=run_id,
timestamp_utc=ts,
dataset_path=str(Path(cfg.dataset).resolve()),
sqlite_db_path=str(sqlite_path),
provenance_db_path=str(provenance_path),
ingest="advanced_augmentation",
sample_count=len(samples),
)
summary_path.write_text(json.dumps(summary, indent=2), encoding="utf-8")
return summary
def _resolve_run_id(
*, cfg: RunConfig, out_dir: Path, sqlite_path: Path, provenance_path: Path
) -> str:
if cfg.run_id:
return cfg.run_id
if not cfg.reuse_db:
return str(uuid4())
summary_path = out_dir / "summary.json"
if summary_path.exists():
try:
obj = json.loads(summary_path.read_text(encoding="utf-8"))
rid = obj.get("run_id")
if isinstance(rid, str) and rid:
return rid
except Exception:
pass
run_ids: set[str] = set()
if provenance_path.exists():
run_ids |= _distinct_run_ids_from_provenance_sqlite(provenance_path)
if sqlite_path.exists():
run_ids |= _distinct_run_ids_from_memori_sqlite(sqlite_path)
if len(run_ids) == 1:
return next(iter(run_ids))
if not run_ids:
raise RuntimeError(
"--reuse-db was set but no prior LoCoMo run_id was found in the DB(s). "
"Pass --run-id or run ingestion once without --reuse-db."
)
raise RuntimeError(
"--reuse-db was set but multiple run_ids were found in the DB(s). "
f"Pass --run-id to choose one. found={sorted(run_ids)}"
)
def _distinct_run_ids_from_provenance_sqlite(path: Path) -> set[str]:
with sqlite3.connect(str(path), check_same_thread=False) as conn:
try:
cur = conn.execute(
"SELECT DISTINCT run_id FROM bench_locomo_fact_provenance"
)
except sqlite3.OperationalError:
return set()
return {r[0] for r in cur.fetchall() if r and isinstance(r[0], str) and r[0]}
def _distinct_run_ids_from_memori_sqlite(path: Path) -> set[str]:
with sqlite3.connect(str(path), check_same_thread=False) as conn:
try:
cur = conn.execute(
"SELECT external_id FROM memori_entity WHERE external_id LIKE 'locomo:%'"
)
except sqlite3.OperationalError:
return set()
out: set[str] = set()
for row in cur.fetchall():
if not row:
continue
external_id = row[0]
if not isinstance(external_id, str) or not external_id.startswith(
"locomo:"
):
continue
parts = external_id.split(":")
if len(parts) >= 3 and parts[1]:
out.add(parts[1])
return out
def _get_entity_id_sqlite(*, sqlite_path: Path, entity_external_id: str) -> int | None:
with sqlite3.connect(str(sqlite_path), check_same_thread=False) as conn:
cur = conn.execute(
"SELECT id FROM memori_entity WHERE external_id = ?",
(entity_external_id,),
)
row = cur.fetchone()
if not row:
return None
try:
return int(row[0])
except (TypeError, ValueError):
return None
def _count_entity_facts_sqlite(*, sqlite_path: Path, entity_db_id: int) -> int:
with sqlite3.connect(str(sqlite_path), check_same_thread=False) as conn:
cur = conn.execute(
"SELECT COUNT(*) FROM memori_entity_fact WHERE entity_id = ?",
(int(entity_db_id),),
)
row = cur.fetchone()
if not row:
return 0
try:
return int(row[0])
except (TypeError, ValueError):
return 0
def _init_memori(sqlite_path: Path) -> Memori:
def _conn():
return sqlite3.connect(str(sqlite_path), check_same_thread=False)
mem = Memori(conn=_conn)
mem.config.storage.build()
return mem
def _configure_aa_meta(mem: Memori, cfg: RunConfig) -> None:
mem.config.framework.provider = cfg.meta_framework_provider
mem.config.platform.provider = cfg.meta_platform_provider
mem.config.llm.provider = cfg.meta_llm_provider
mem.config.llm.version = cfg.meta_llm_version
mem.config.llm.provider_sdk_version = cfg.meta_llm_sdk_version
def _ingest_with_advanced_augmentation(
*,
mem: Memori,
prov_store: ProvenanceStore,
run_id: str,
entity_external_id: str,
entity_db_id: int,
sample,
cfg: RunConfig,
) -> int | None:
if cfg.aa_batch == "per_pair":
return _aa_enqueue_pairs_sequential(
mem=mem,
prov_store=prov_store,
run_id=run_id,
entity_external_id=entity_external_id,
entity_db_id=entity_db_id,
sample_id=sample.sample_id,
sample=sample,
timeout=cfg.aa_timeout,
max_requests=int(cfg.aa_max_requests or 0),
verbose=bool(cfg.verbose),
)
raise ValueError(f"unknown aa batch: {cfg.aa_batch}")
def _aa_enqueue_pairs_sequential(
*,
mem: Memori,
prov_store: ProvenanceStore,
run_id: str,
entity_external_id: str,
entity_db_id: int,
sample_id: str,
sample,
timeout: float,
max_requests: int = 0,
verbose: bool = False,
) -> int | None:
all_msgs, all_turn_ids = _build_aa_messages_and_turn_ids_for_sample(sample)
conv_id = _create_conversation_and_persist_messages(mem, all_msgs)
reqs = _build_per_pair_requests(all_msgs, all_turn_ids)
max_n = int(max_requests or 0)
if max_n > 0:
reqs = reqs[:max_n]
entity_fact_driver = mem.config.storage.driver.entity_fact
known_fact_ids = {
int(r["id"])
for r in entity_fact_driver.get_embeddings(int(entity_db_id), limit=100000)
}
for idx, req in enumerate(reqs):
_enqueue_aa(mem, conv_id, entity_external_id, req.messages)
mem.augmentation.wait(timeout=timeout)
after = {
int(r["id"])
for r in entity_fact_driver.get_embeddings(int(entity_db_id), limit=100000)
}
new_fact_ids = sorted(after - known_fact_ids)
known_fact_ids = after
if new_fact_ids:
rows: list[FactAttribution] = []
for fid in new_fact_ids:
for dia_id in req.pair_turn_ids:
if dia_id:
rows.append(
FactAttribution(fact_id=fid, dia_id=dia_id, score=1.0)
)
prov_store.upsert_many(rows, run_id=run_id, sample_id=sample_id)
if verbose:
summary_val = _read_conversation_summary(mem, int(conv_id)) or ""
print(
f"[locomo][aa][pair] idx={idx} new_facts={len(new_fact_ids)} "
f"pair_turn_ids={req.pair_turn_ids} summary_is_set={bool(summary_val)}"
)
return int(conv_id)
def _read_conversation_summary(mem: Memori, conversation_id: int) -> str | None:
try:
obj = mem.config.storage.driver.conversation.read(int(conversation_id))
except Exception:
return None
if not isinstance(obj, dict):
return None
summary = obj.get("summary")
return summary if isinstance(summary, str) and summary.strip() else None
def _create_conversation_and_persist_messages(
mem: Memori, msgs: list[dict[str, str]]
) -> int:
mem.new_session()
conv_id = mem.config.storage.driver.conversation.create(
str(mem.config.session_id), mem.config.session_timeout_minutes
)
for m in msgs:
mem.config.storage.driver.conversation.message.create(
conv_id, m["role"], "text", m["content"]
)
if mem.config.storage.adapter is not None:
mem.config.storage.adapter.commit()
return int(conv_id)
def _enqueue_aa(
mem: Memori, conv_id: int, entity_external_id: str, msgs: list[dict[str, str]]
) -> None:
from memori.memory.augmentation._message import ConversationMessage
mem.augmentation.enqueue(
AugmentationInput(
conversation_id=str(conv_id),
entity_id=entity_external_id,
process_id="locomo-benchmark",
conversation_messages=[
ConversationMessage(role=m["role"], content=m["content"]) for m in msgs
],
system_prompt=None,
)
)
def _build_aa_messages_for_sample(sample) -> list[dict[str, str]]:
msgs, _turn_ids = _build_aa_messages_and_turn_ids_for_sample(sample)
return msgs
def _build_aa_messages_for_session(sample, session) -> list[dict[str, str]]:
speaker_to_role = _speaker_to_role(sample)
msgs, _turn_ids = _build_aa_messages_and_turn_ids_for_turns(
sample, session, speaker_to_role
)
return msgs
def _build_aa_messages_for_turns(
sample, session, speaker_to_role: dict[str, str]
) -> list[dict[str, str]]:
msgs, _turn_ids = _build_aa_messages_and_turn_ids_for_turns(
sample, session, speaker_to_role
)
return msgs
def _build_aa_messages_and_turn_ids_for_sample(
sample,
) -> tuple[list[dict[str, str]], list[str]]:
speaker_to_role = _speaker_to_role(sample)
msgs: list[dict[str, str]] = []
turn_ids: list[str] = []
for session in sample.sessions:
m, t = _build_aa_messages_and_turn_ids_for_turns(
sample, session, speaker_to_role
)
msgs.extend(m)
turn_ids.extend(t)
return msgs, turn_ids
def _build_aa_messages_and_turn_ids_for_turns(
sample, session, speaker_to_role: dict[str, str]
) -> tuple[list[dict[str, str]], list[str]]:
msgs: list[dict[str, str]] = []
turn_ids: list[str] = []
session_id = session.session_id or ""
for t_idx, turn in enumerate(session.turns):
speaker = (turn.speaker or "").strip()
role = speaker_to_role.get(speaker, "assistant")
turn_id = (
turn.turn_id or ""
).strip() or f"{sample.sample_id}:{session_id}:{t_idx}"
content = _format_turn_content(
turn_id=turn_id,
speaker=speaker,
text=turn.text,
session_date_time=session.date_time,
)
msgs.append({"role": role, "content": content})
turn_ids.append(turn_id)
return msgs, turn_ids
def _format_turn_content(
*, turn_id: str, speaker: str, text: str, session_date_time: str | None
) -> str:
# Mirror real-world Memori payloads: content is the plain message text only.
# Keep turn_id/speaker/session_time out of the message body (benchmark-only metadata).
return str(text).strip()
def _speaker_to_role(sample) -> dict[str, str]:
"""
Heuristic mapping: first unique speaker => user, second => assistant, others => assistant.
"""
out: dict[str, str] = {}
ordered: list[str] = []
for session in sample.sessions:
for turn in session.turns:
speaker = (turn.speaker or "").strip()
if not speaker or speaker in out:
continue
ordered.append(speaker)
out[speaker] = "user" if len(ordered) == 1 else "assistant"
return out
def _build_aa_provenance(
*,
mem: Memori,
prov_store: ProvenanceStore,
run_id: str,
sample_id: str,
entity_db_id: int,
turn_facts,
top_n: int,
min_score: float,
) -> None:
turn_ids = [t.turn_id for t in turn_facts]
turn_texts = [t.content for t in turn_facts]
turn_embs = embed_texts(
turn_texts,
model=mem.config.embeddings.model,
)
entity_fact_driver = mem.config.storage.driver.entity_fact
rows = entity_fact_driver.get_embeddings(entity_db_id, limit=100000)
fact_ids = [int(r["id"]) for r in rows]
facts = entity_fact_driver.get_facts_by_ids(fact_ids)
content_by_id = {int(r["id"]): r["content"] for r in facts}
fact_ids_aligned = [i for i in fact_ids if i in content_by_id]
fact_texts = [content_by_id[i] for i in fact_ids_aligned]
fact_embs = embed_texts(
fact_texts,
model=mem.config.embeddings.model,
)
# Clear any prior mappings for this run/sample to avoid mixing old/new strategies.
prov_store.delete_sample(run_id=run_id, sample_id=sample_id)
mapping = attribute_facts_to_turn_ids(
turn_ids=turn_ids,
turn_embeddings=turn_embs,
turn_texts=turn_texts,
fact_ids=fact_ids_aligned,
fact_embeddings=fact_embs,
fact_texts=fact_texts,
top_n=top_n,
min_score=min_score,
)
prov_rows: list[FactAttribution] = []
for fid, mapped in mapping.items():
for dia_id, score in mapped:
prov_rows.append(FactAttribution(fact_id=fid, dia_id=dia_id, score=score))
prov_store.upsert_many(prov_rows, run_id=run_id, sample_id=sample_id)
def _write_aa_payload_preview(
*,
out_dir: Path,
mem: Memori,
sample,
cfg: RunConfig,
entity_external_id: str,
process_id: str,
) -> None:
"""
Build and print the exact AA request payload (no network call).
This is useful for debugging staging/prod routing, payload structure, and metadata.
"""
import hashlib
from memori._network import Api
from memori.memory.augmentation.augmentations.memori._augmentation import (
AdvancedAugmentation,
)
dialect = (
mem.config.storage.adapter.get_dialect()
if mem.config.storage and mem.config.storage.adapter
else "unknown"
)
aug = AdvancedAugmentation(config=mem.config, enabled=True)
url = Api(mem.config).url("sdk/augmentation")
all_msgs, all_turn_ids = _build_aa_messages_and_turn_ids_for_sample(sample)
requests: list[dict[str, object]] = []
if cfg.aa_batch != "per_pair":
raise ValueError(f"unknown aa batch: {cfg.aa_batch}")
for i, req in enumerate(_build_per_pair_requests(all_msgs, all_turn_ids)):
payload = aug._build_api_payload( # noqa: SLF001 - benchmark-only debug path
req.messages,
"",
None,
dialect,
entity_external_id,
process_id,
)
requests.append(
{
"request_index": i,
"pair_turn_ids": list(req.pair_turn_ids),
"messages": req.messages,
"payload": payload,
}
)
api_key = mem.config.api_key or ""
api_key_preview = ""
api_key_sha256 = ""
if api_key:
api_key_preview = (
f"{api_key[:4]}…{api_key[-4:]}" if len(api_key) >= 8 else "set"
)
api_key_sha256 = hashlib.sha256(api_key.encode("utf-8")).hexdigest()
preview = {
"url": url,
"ingest": "advanced_augmentation",
"aa_batch": cfg.aa_batch,
"entity_id": entity_external_id,
"process_id": process_id,
"memori_api_key": {
"is_set": bool(api_key),
"length": len(api_key),
"preview": api_key_preview,
"sha256": api_key_sha256,
},
"requests": requests,
}
out_path = out_dir / "aa_payload_preview.json"
out_path.write_text(json.dumps(preview, indent=2), encoding="utf-8")
print(f"[locomo][aa-dry-run] url={url}")
print(f"[locomo][aa-dry-run] wrote={out_path}")
# Avoid flooding stdout for large datasets.
max_print = 5
preview_print = dict(preview)
preview_print["requests_total"] = len(requests)
preview_print["requests_printed"] = min(max_print, len(requests))
preview_print["requests"] = requests[:max_print]
print(json.dumps(preview_print, indent=2))
def _build_per_pair_requests(
msgs: list[dict[str, str]],
turn_ids: list[str],
) -> list[PairRequest]:
"""
Build per-pair AA requests that mirror SDK behavior.
Each request includes *all* prior messages (oldest -> newest) plus the next
strict user->assistant pair at the end.
Any messages that can't be paired as a strict consecutive user+assistant pair
are skipped as pair boundaries, but still remain in the context for later requests.
"""
if len(msgs) != len(turn_ids):
raise ValueError("msgs and turn_ids must be aligned")
out: list[PairRequest] = []
i = 0
while i < len(msgs) - 1:
role0 = (msgs[i].get("role") or "").strip()
role1 = (msgs[i + 1].get("role") or "").strip()
if role0 == "user" and role1 == "assistant":
tid0 = (turn_ids[i] or "").strip()
tid1 = (turn_ids[i + 1] or "").strip()
out.append(
PairRequest(messages=list(msgs[: i + 2]), pair_turn_ids=(tid0, tid1))
)
i += 2
continue
i += 1
return out
def _format_top_k(
*,
results: list,
prov_store: ProvenanceStore,
run_id: str,
sample_id: str,
retrieved_ids_out: list[str],
retrieved_groups_out: list[set[str]],
provenance_limit: int = 1,
) -> list[dict[str, object]]:
out: list[dict[str, object]] = []
for r in results:
if isinstance(r, dict):
content = r.get("content", "")
fact_id = r.get("id")
similarity = r.get("similarity")
else:
# Assume FactSearchResult or similar object with attributes
content = getattr(r, "content", "")
fact_id = getattr(r, "id", None)
similarity = getattr(r, "similarity", None)
turn_ids: list[str] = []
if isinstance(fact_id, int):
dia_ids = prov_store.best_dia_ids_for_fact(
run_id=run_id,
sample_id=sample_id,
fact_id=fact_id,
limit=max(int(provenance_limit), 1),
)
turn_ids = [d for d in dia_ids if d]
# For backward compatibility, keep a single primary turn_id field (first).
turn_id = turn_ids[0] if turn_ids else ""
if turn_id:
retrieved_ids_out.append(turn_id)
retrieved_groups_out.append(set(turn_ids))
out.append(
{
"turn_id": turn_id,
"turn_ids": turn_ids,
"fact_id": fact_id,
"similarity": similarity,
"content": content,
}
)
return out
class _Totals:
def __init__(self) -> None:
self.question_count = 0
self.questions_by_category: dict[str, int] = {}
self.sums = {
"hit@1": 0.0,
"hit@3": 0.0,
"hit@5": 0.0,
"hit@10": 0.0,
"hit@20": 0.0,
"hit@30": 0.0,
"mrr": 0.0,
}
self.sums_by_cat: dict[str, dict[str, float]] = {}
self.counts_by_cat: dict[str, int] = {}
def count_question(self, category: str | None) -> None:
self.question_count += 1
cat = category or "unknown"
self.questions_by_category[cat] = self.questions_by_category.get(cat, 0) + 1
def add_metrics(self, *, category: str, metrics: dict[str, float]) -> None:
for key in self.sums:
self.sums[key] += float(metrics[key])
self.sums_by_cat.setdefault(
category,
{
"hit@1": 0.0,
"hit@3": 0.0,
"hit@5": 0.0,
"hit@10": 0.0,
"hit@20": 0.0,
"hit@30": 0.0,
"mrr": 0.0,
},
)
for key in self.sums_by_cat[category]:
self.sums_by_cat[category][key] += float(metrics[key])
self.counts_by_cat[category] = self.counts_by_cat.get(category, 0) + 1
def to_summary(
self,
*,
run_id: str,
timestamp_utc: str,
dataset_path: str,
sqlite_db_path: str,
provenance_db_path: str,
ingest: str,
sample_count: int,
) -> dict:
denom = float(self.question_count) if self.question_count else 1.0
metrics_overall = {k: (self.sums[k] / denom) for k in self.sums}
metrics_by_category: dict[str, dict[str, float]] = {}
for cat, sums_cat in self.sums_by_cat.items():
denom_cat = float(self.counts_by_cat.get(cat, 0)) or 1.0
metrics_by_category[cat] = {k: (sums_cat[k] / denom_cat) for k in sums_cat}
questions_by_category_labeled = {
CATEGORY_LABELS.get(cat, cat): count
for cat, count in self.questions_by_category.items()
}
metrics_by_category_labeled = {
CATEGORY_LABELS.get(cat, cat): vals
for cat, vals in metrics_by_category.items()
}
return {
"run_id": run_id,
"timestamp_utc": timestamp_utc,
"dataset_path": dataset_path,
"sqlite_db_path": sqlite_db_path,
"provenance_db_path": provenance_db_path,
"ingest": ingest,
"sample_count": sample_count,
"question_count": self.question_count,
"category_labels": dict(CATEGORY_LABELS),
"questions_by_category": dict(
sorted(self.questions_by_category.items(), key=lambda kv: kv[0])
),
"questions_by_category_labeled": dict(
sorted(questions_by_category_labeled.items(), key=lambda kv: kv[0])
),
"metrics_overall": metrics_overall,
"metrics_by_category": dict(
sorted(metrics_by_category.items(), key=lambda kv: kv[0])
),
"metrics_by_category_labeled": dict(
sorted(metrics_by_category_labeled.items(), key=lambda kv: kv[0])
),
"phase": 2,
}
================================================
FILE: benchmarks/locomo/_types.py
================================================
from __future__ import annotations
from dataclasses import dataclass
from typing import Any
@dataclass(frozen=True, slots=True)
class LoCoMoTurn:
speaker: str
text: str
turn_id: str | None = None
timestamp: str | None = None
@dataclass(frozen=True, slots=True)
class LoCoMoSession:
session_id: str | None
turns: tuple[LoCoMoTurn, ...]
date_time: str | None = None
@dataclass(frozen=True, slots=True)
class LoCoMoQA:
question_id: str
question: str
answers: tuple[str, ...]
category: str | None = None
evidence: Any | None = None
@dataclass(frozen=True, slots=True)
class LoCoMoSample:
sample_id: str
sessions: tuple[LoCoMoSession, ...]
qa: tuple[LoCoMoQA, ...]
================================================
FILE: benchmarks/locomo/loader.py
================================================
from __future__ import annotations
import json
import re
from pathlib import Path
from typing import Any
from benchmarks.locomo._types import LoCoMoQA, LoCoMoSample, LoCoMoSession, LoCoMoTurn
def load_locomo_json(path: str | Path) -> list[LoCoMoSample]:
raw = Path(path).read_text(encoding="utf-8")
data = json.loads(raw)
if not isinstance(data, list):
raise ValueError("LoCoMo JSON must be a list of samples")
samples: list[LoCoMoSample] = []
for i, item in enumerate(data):
if not isinstance(item, dict):
raise ValueError(f"Sample at index {i} must be an object")
sample_id = _coerce_str(item.get("sample_id")) or _coerce_str(item.get("id"))
if not sample_id:
raise ValueError(f"Sample at index {i} is missing 'sample_id'")
sessions = _parse_conversation(item.get("conversation"))
qa = _parse_qa(item.get("qa"))
samples.append(LoCoMoSample(sample_id=sample_id, sessions=sessions, qa=qa))
return samples
def _parse_conversation(value: Any) -> tuple[LoCoMoSession, ...]:
if value is None:
return ()
if isinstance(value, dict):
return _parse_conversation_dict(value)
if not isinstance(value, list):
raise ValueError("'conversation' must be a list of sessions or an object")
out: list[LoCoMoSession] = []
for idx, session in enumerate(value):
if not isinstance(session, dict):
raise ValueError(f"conversation[{idx}] must be an object")
session_id = _coerce_str(session.get("session_id")) or _coerce_str(
session.get("id")
)
turns_raw = (
session.get("dialogue") or session.get("turns") or session.get("messages")
)
turns = _parse_turns(turns_raw, context=f"conversation[{idx}]")
out.append(LoCoMoSession(session_id=session_id, turns=turns, date_time=None))
return tuple(out)
_SESSION_KEY_RE = re.compile(r"^session_(?P<n>\d+)$")
def _parse_conversation_dict(value: dict[str, Any]) -> tuple[LoCoMoSession, ...]:
sessions: list[tuple[int, str]] = []
for key, v in value.items():
if not isinstance(key, str):
continue
m = _SESSION_KEY_RE.match(key)
if not m:
continue
if not isinstance(v, list):
continue
sessions.append((int(m.group("n")), key))
sessions.sort(key=lambda t: t[0])
out: list[LoCoMoSession] = []
for n, key in sessions:
date_time = _coerce_str(value.get(f"session_{n}_date_time"))
turns = _parse_turns(value.get(key), context=f"conversation[{key}]")
out.append(LoCoMoSession(session_id=key, turns=turns, date_time=date_time))
return tuple(out)
def _parse_turns(value: Any, *, context: str) -> tuple[LoCoMoTurn, ...]:
if value is None:
return ()
if not isinstance(value, list):
raise ValueError(f"{context}.dialogue must be a list of turns")
out: list[LoCoMoTurn] = []
for idx, turn in enumerate(value):
if not isinstance(turn, dict):
raise ValueError(f"{context}.dialogue[{idx}] must be an object")
turn_id = _coerce_str(turn.get("dia_id")) or _coerce_str(turn.get("turn_id"))
speaker = (
_coerce_str(turn.get("speaker")) or _coerce_str(turn.get("role")) or ""
)
text = _coerce_str(turn.get("text")) or _coerce_str(turn.get("content")) or ""
if not text:
continue
timestamp = _coerce_str(turn.get("timestamp"))
out.append(
LoCoMoTurn(turn_id=turn_id, speaker=speaker, text=text, timestamp=timestamp)
)
return tuple(out)
def _parse_qa(value: Any) -> tuple[LoCoMoQA, ...]:
if value is None:
return ()
if not isinstance(value, list):
raise ValueError("'qa' must be a list")
out: list[LoCoMoQA] = []
for idx, qa in enumerate(value):
if not isinstance(qa, dict):
raise ValueError(f"qa[{idx}] must be an object")
qid = (
_coerce_str(qa.get("question_id")) or _coerce_str(qa.get("id")) or f"q{idx}"
)
question = _coerce_str(qa.get("question")) or ""
if not question:
continue
answers_raw = qa.get("answer") if "answer" in qa else qa.get("answers")
answers = _coerce_answers(answers_raw)
category = _coerce_str(qa.get("category")) or _coerce_str(qa.get("type"))
evidence = (
qa.get("evidence") if "evidence" in qa else qa.get("supporting_facts")
)
out.append(
LoCoMoQA(
question_id=qid,
question=question,
answers=answers,
category=category,
evidence=evidence,
)
)
return tuple(out)
def _coerce_str(value: Any) -> str | None:
if value is None:
return None
if isinstance(value, str):
v = value.strip()
return v or None
return str(value).strip() or None
def _coerce_answers(value: Any) -> tuple[str, ...]:
if value is None:
return ()
if isinstance(value, str):
v = value.strip()
return (v,) if v else ()
if isinstance(value, list):
out: list[str] = []
for item in value:
s = _coerce_str(item)
if s:
out.append(s)
return tuple(out)
s = _coerce_str(value)
return (s,) if s else ()
================================================
FILE: benchmarks/locomo/preprocess.py
================================================
from __future__ import annotations
import argparse
import json
import re
from collections import Counter
from pathlib import Path
from typing import Any
_SESSION_KEY_RE = re.compile(r"^session_(?P<n>\d+)$")
_MULTIMODAL_KEYS = ("img_url", "blip_caption", "query")
def preprocess_locomo_json(in_path: str | Path, out_path: str | Path) -> dict[str, int]:
"""
Preprocess LoCoMo into a Memori-friendly role format.
- Removes multimodal turn fields (img_url, blip_caption, query).
- Rewrites turn speakers so conversation.speaker_b becomes "assistant" and all others "user".
If conversation.speaker_b is missing, the sample is kept and left unchanged.
"""
src = Path(in_path)
dst = Path(out_path)
data = json.loads(src.read_text(encoding="utf-8"))
if not isinstance(data, list):
raise ValueError("LoCoMo JSON must be a list of samples")
kept: list[dict[str, Any]] = []
dropped_reasons: Counter[str] = Counter()
removed_multimodal_turns = 0
for _idx, sample in enumerate(data):
if not isinstance(sample, dict):
dropped_reasons["invalid_sample"] += 1
continue
conv = sample.get("conversation")
removed_multimodal_turns += _strip_multimodal_fields_inplace(conv)
speaker_b = None
if isinstance(conv, dict):
speaker_b = _coerce_str(conv.get("speaker_b"))
if speaker_b:
_rewrite_speakers_inplace(conv, assistant_speaker=speaker_b)
else:
# Keep unchanged when we can't confidently map assistant roles.
dropped_reasons["missing_speaker_b"] += 0
kept.append(sample)
dst.parent.mkdir(parents=True, exist_ok=True)
dst.write_text(json.dumps(kept, ensure_ascii=False), encoding="utf-8")
return {
"samples_in": len(data),
"samples_out": len(kept),
"removed_multimodal_turns": int(removed_multimodal_turns),
"dropped_invalid_sample": int(dropped_reasons.get("invalid_sample", 0)),
}
def _strip_multimodal_fields_inplace(conversation: Any) -> int:
removed = 0
for turn in _iter_turn_dicts(conversation):
if not isinstance(turn, dict):
continue
before = len(turn)
for k in _MULTIMODAL_KEYS:
turn.pop(k, None)
removed += int(len(turn) != before)
return removed
def _rewrite_speakers_inplace(conversation: Any, *, assistant_speaker: str) -> None:
for turn in _iter_turn_dicts(conversation):
speaker = _coerce_str(turn.get("speaker")) or ""
turn["speaker"] = "assistant" if speaker == assistant_speaker else "user"
def _iter_turn_dicts(conversation: Any):
if conversation is None:
return
if isinstance(conversation, list):
for session in conversation:
if not isinstance(session, dict):
continue
turns = (
session.get("dialogue")
or session.get("turns")
or session.get("messages")
)
if not isinstance(turns, list):
continue
for t in turns:
if isinstance(t, dict):
yield t
return
if isinstance(conversation, dict):
sessions: list[tuple[int, str]] = []
for key, v in conversation.items():
if not isinstance(key, str):
continue
m = _SESSION_KEY_RE.match(key)
if not m:
continue
if isinstance(v, list):
sessions.append((int(m.group("n")), key))
sessions.sort(key=lambda x: x[0])
for _, key in sessions:
v = conversation.get(key)
if not isinstance(v, list):
continue
for t in v:
if isinstance(t, dict):
yield t
return
def _coerce_str(value: Any) -> str | None:
if value is None:
return None
if isinstance(value, str):
v = value.strip()
return v or None
return str(value).strip() or None
def main(argv: list[str] | None = None) -> int:
parser = argparse.ArgumentParser(
description="Preprocess LoCoMo: strip multimodal fields and map speaker_b -> assistant."
)
parser.add_argument(
"--in", dest="in_path", required=True, help="Input LoCoMo JSON path."
)
parser.add_argument(
"--out", dest="out_path", required=True, help="Output JSON path."
)
args = parser.parse_args(argv)
stats = preprocess_locomo_json(args.in_path, args.out_path)
print(
"[locomo][preprocess] "
f"samples_in={stats['samples_in']} samples_out={stats['samples_out']} "
f"removed_multimodal_turns={stats['removed_multimodal_turns']} "
f"dropped_invalid_sample={stats['dropped_invalid_sample']}"
)
return 0
if __name__ == "__main__":
raise SystemExit(main())
================================================
FILE: benchmarks/locomo/provenance.py
================================================
from __future__ import annotations
import math
import re
import sqlite3
from dataclasses import dataclass
from pathlib import Path
from typing import TYPE_CHECKING, Any, cast
from memori.search import find_similar_embeddings
if TYPE_CHECKING:
from memori.search._types import FactId
@dataclass(frozen=True, slots=True)
class FactAttribution:
fact_id: int
dia_id: str
score: float
class ProvenanceStore:
def __init__(self, path: str | Path) -> None:
self.path = Path(path)
self.path.parent.mkdir(parents=True, exist_ok=True)
self._ensure_schema()
def _connect(self) -> sqlite3.Connection:
return sqlite3.connect(str(self.path), check_same_thread=False)
def _ensure_schema(self) -> None:
with self._connect() as conn:
conn.execute(
"""
CREATE TABLE IF NOT EXISTS bench_locomo_fact_provenance(
run_id TEXT NOT NULL,
sample_id TEXT NOT NULL,
fact_id INTEGER NOT NULL,
dia_id TEXT NOT NULL,
score REAL NOT NULL,
PRIMARY KEY (run_id, sample_id, fact_id, dia_id)
)
"""
)
conn.execute(
"""
CREATE INDEX IF NOT EXISTS idx_bench_locomo_fact_prov_lookup
ON bench_locomo_fact_provenance(run_id, sample_id, fact_id, score DESC)
"""
)
conn.commit()
def upsert_many(
self, rows: list[FactAttribution], *, run_id: str, sample_id: str
) -> None:
if not rows:
return
with self._connect() as conn:
conn.executemany(
"""
INSERT OR REPLACE INTO bench_locomo_fact_provenance(
run_id, sample_id, fact_id, dia_id, score
) VALUES (?, ?, ?, ?, ?)
""",
[
(run_id, sample_id, r.fact_id, r.dia_id, float(r.score))
for r in rows
],
)
conn.commit()
def best_dia_ids_for_fact(
self, *, run_id: str, sample_id: str, fact_id: int, limit: int = 1
) -> list[str]:
if limit <= 0:
return []
with self._connect() as conn:
cur = conn.execute(
"""
SELECT dia_id
FROM bench_locomo_fact_provenance
WHERE run_id = ? AND sample_id = ? AND fact_id = ?
ORDER BY score DESC
LIMIT ?
""",
(run_id, sample_id, fact_id, limit),
)
return [r[0] for r in cur.fetchall() if r and r[0]]
def has_any(self, *, run_id: str, sample_id: str) -> bool:
with self._connect() as conn:
cur = conn.execute(
"""
SELECT 1
FROM bench_locomo_fact_provenance
WHERE run_id = ? AND sample_id = ?
LIMIT 1
""",
(run_id, sample_id),
)
return cur.fetchone() is not None
def delete_sample(self, *, run_id: str, sample_id: str) -> None:
with self._connect() as conn:
conn.execute(
"""
DELETE FROM bench_locomo_fact_provenance
WHERE run_id = ? AND sample_id = ?
""",
(run_id, sample_id),
)
conn.commit()
def attribute_facts_to_turn_ids(
*,
turn_ids: list[str],
turn_embeddings: list[list[float]],
turn_texts: list[str] | None = None,
fact_ids: list[int],
fact_embeddings: list[list[float]],
fact_texts: list[str] | None = None,
top_n: int = 1,
min_score: float | None = None,
) -> dict[int, list[tuple[str, float]]]:
"""
Map each fact to the most similar LoCoMo turn_id(s).
This is intentionally heuristic: it enables benchmark-only provenance without
changing Memori's product schema.
"""
if top_n <= 0:
return {}
if len(turn_ids) != len(turn_embeddings):
raise ValueError("turn_ids and turn_embeddings must be the same length")
if len(fact_ids) != len(fact_embeddings):
raise ValueError("fact_ids and fact_embeddings must be the same length")
if turn_texts is not None and len(turn_texts) != len(turn_ids):
raise ValueError("turn_texts and turn_ids must be the same length")
if fact_texts is not None and len(fact_texts) != len(fact_ids):
raise ValueError("fact_texts and fact_ids must be the same length")
embeddings: list[tuple[FactId, Any]] = cast(
"list[tuple[FactId, Any]]", list(enumerate(turn_embeddings))
)
out: dict[int, list[tuple[str, float]]] = {}
for i, (fact_id, qemb) in enumerate(zip(fact_ids, fact_embeddings, strict=True)):
# Use a larger semantic pool before reranking to improve coverage.
semantic_pool = max(top_n, min(len(turn_ids), max(top_n * 10, 50)))
similar = find_similar_embeddings(embeddings, qemb, limit=semantic_pool)
fact_text = (fact_texts[i] if fact_texts is not None else "") or ""
lexical_scores = (
_lexical_scores(query_text=fact_text, docs=turn_texts)
if turn_texts is not None
else None
)
mapped: list[tuple[str, float]] = []
scored: list[tuple[int, float]] = []
for raw_idx, score in similar:
# idx is always int here (from enumerate), cast for type checker
idx = cast(int, raw_idx)
if idx < 0 or idx >= len(turn_ids):
continue
lex = float(lexical_scores[idx]) if lexical_scores is not None else 0.0
combined = (0.8 * float(score)) + (0.2 * lex)
scored.append((idx, combined))
scored.sort(key=lambda t: t[1], reverse=True)
for idx, score in scored[:top_n]:
if min_score is not None and score < min_score:
continue
mapped.append((turn_ids[idx], float(score)))
# If the threshold filtered everything, prefer some attribution over none.
if not mapped and scored:
idx_best, score_best = scored[0]
mapped.append((turn_ids[idx_best], float(score_best)))
out[int(fact_id)] = mapped
return out
_TOKEN_RE = re.compile(r"[a-z0-9]+")
_STOPWORDS = {
"a",
"an",
"and",
"are",
"as",
"at",
"be",
"by",
"did",
"do",
"does",
"for",
"from",
"had",
"has",
"have",
"how",
"i",
"in",
"is",
"it",
"of",
"on",
"or",
"that",
"the",
"their",
"then",
"there",
"to",
"was",
"were",
"what",
"when",
"where",
"which",
"who",
"why",
"with",
"you",
"your",
}
def _tokenize(text: str) -> list[str]:
tokens = [t for t in _TOKEN_RE.findall((text or "").lower()) if t]
return [t for t in tokens if t not in _STOPWORDS]
def _lexical_scores(*, query_text: str, docs: list[str]) -> list[float]:
q_tokens = _tokenize(query_text)
if not q_tokens or not docs:
return [0.0 for _ in docs]
doc_tokens = [set(_tokenize(d)) for d in docs]
n = float(len(docs)) or 1.0
df: dict[str, int] = {}
for t in set(q_tokens):
df[t] = sum(1 for toks in doc_tokens if t in toks)
idf = {t: (math.log((n + 1.0) / (float(df[t]) + 1.0)) + 1.0) for t in df}
denom = sum(idf.get(t, 0.0) for t in q_tokens) or 1.0
out: list[float] = []
for toks in doc_tokens:
num = sum(idf.get(t, 0.0) for t in q_tokens if t in toks)
out.append(float(num / denom))
return out
================================================
FILE: benchmarks/locomo/report.py
================================================
from __future__ import annotations
import argparse
import json
from pathlib import Path
from typing import Any
from benchmarks.locomo._run_impl import CATEGORY_LABELS
def main(argv: list[str] | None = None) -> int:
parser = argparse.ArgumentParser(
description="Aggregate LoCoMo predictions.jsonl into summary.json"
)
parser.add_argument(
"--predictions",
required=True,
help="Path to predictions.jsonl created by benchmarks/locomo/run.py",
)
parser.add_argument(
"--out",
required=True,
help="Path to write summary.json",
)
args = parser.parse_args(argv)
categories: dict[str, int] = {}
sample_ids: set[str] = set()
total = 0
run_id: str | None = None
timestamp_utc: str | None = None
sums = {
"hit@1": 0.0,
"hit@3": 0.0,
"hit@5": 0.0,
"hit@10": 0.0,
"hit@20": 0.0,
"hit@30": 0.0,
"mrr": 0.0,
}
sums_by_cat: dict[str, dict[str, float]] = {}
counts_by_cat: dict[str, int] = {}
for row in _read_jsonl(Path(args.predictions)):
total += 1
sample_id = str(row.get("sample_id", "")).strip()
if sample_id:
sample_ids.add(sample_id)
cat = str(row.get("category") or "unknown")
categories[cat] = categories.get(cat, 0) + 1
metrics = (
(row.get("retrieval") or {}).get("metrics")
if isinstance(row.get("retrieval"), dict)
else None
)
if isinstance(metrics, dict):
for key in sums:
if key in metrics:
sums[key] += float(metrics[key])
sums_by_cat.setdefault(
cat,
{
"hit@1": 0.0,
"hit@3": 0.0,
"hit@5": 0.0,
"hit@10": 0.0,
"hit@20": 0.0,
"hit@30": 0.0,
"mrr": 0.0,
},
)
for key in sums_by_cat[cat]:
if key in metrics:
sums_by_cat[cat][key] += float(metrics[key])
counts_by_cat[cat] = counts_by_cat.get(cat, 0) + 1
run_id = run_id or _coerce_str(row.get("run_id"))
timestamp_utc = timestamp_utc or _coerce_str(row.get("timestamp_utc"))
denom = float(total) if total else 1.0
metrics_overall = {k: (sums[k] / denom) for k in sums}
metrics_by_category: dict[str, dict[str, float]] = {}
for cat, sums_cat in sums_by_cat.items():
denom_cat = float(counts_by_cat.get(cat, 0)) or 1.0
metrics_by_category[cat] = {k: (sums_cat[k] / denom_cat) for k in sums_cat}
questions_by_category_labeled = {
CATEGORY_LABELS.get(cat, cat): count for cat, count in categories.items()
}
metrics_by_category_labeled = {
CATEGORY_LABELS.get(cat, cat): vals for cat, vals in metrics_by_category.items()
}
out = {
"run_id": run_id,
"timestamp_utc": timestamp_utc,
"sample_count": len(sample_ids),
"question_count": total,
"category_labels": dict(CATEGORY_LABELS),
"questions_by_category": dict(sorted(categories.items(), key=lambda kv: kv[0])),
"questions_by_category_labeled": dict(
sorted(questions_by_category_labeled.items(), key=lambda kv: kv[0])
),
"metrics_overall": metrics_overall,
"metrics_by_category": dict(
sorted(metrics_by_category.items(), key=lambda kv: kv[0])
),
"metrics_by_category_labeled": dict(
sorted(metrics_by_category_labeled.items(), key=lambda kv: kv[0])
),
}
Path(args.out).write_text(json.dumps(out, indent=2), encoding="utf-8")
return 0
def _read_jsonl(path: Path) -> list[dict[str, Any]]:
rows: list[dict[str, Any]] = []
for line in path.read_text(encoding="utf-8").splitlines():
if not line.strip():
continue
rows.append(json.loads(line))
return rows
def _coerce_str(value: Any) -> str | None:
if value is None:
return None
if isinstance(value, str):
v = value.strip()
return v or None
return str(value).strip() or None
if __name__ == "__main__":
raise SystemExit(main())
================================================
FILE: benchmarks/locomo/retrieval.py
================================================
from __future__ import annotations
import re
from dataclasses import dataclass
from typing import Any
from benchmarks.locomo._types import LoCoMoSample
@dataclass(frozen=True, slots=True)
class TurnFact:
turn_id: str
content: str
_TURN_ID_RE = re.compile(r"^\[(?P<turn_id>[^\]]+)\]\s*")
def build_turn_facts(
sample: LoCoMoSample,
) -> tuple[tuple[TurnFact, ...], dict[tuple[str, int], str]]:
facts: list[TurnFact] = []
index: dict[tuple[str, int], str] = {}
for s_idx, session in enumerate(sample.sessions):
session_id = session.session_id or f"session-{s_idx}"
for t_idx, turn in enumerate(session.turns):
turn_id = turn.turn_id or f"{sample.sample_id}:{session_id}:{t_idx}"
index[(session_id, t_idx)] = turn_id
speaker = (turn.speaker or "").strip()
prefix = f"[{turn_id}]"
body = f"{speaker}: {turn.text}" if speaker else turn.text
if session.date_time:
body = f"{body} (session_time: {session.date_time})"
if turn.timestamp:
body = f"{body} (ts: {turn.timestamp})"
facts.append(TurnFact(turn_id=turn_id, content=f"{prefix} {body}".strip()))
return tuple(facts), index
def extract_turn_id_from_content(content: str) -> str | None:
m = _TURN_ID_RE.match(content or "")
if not m:
return None
v = m.group("turn_id").strip()
return v or None
def evidence_to_turn_ids(
evidence: Any, *, turn_index: dict[tuple[str, int], str]
) -> set[str]:
if evidence is None:
return set()
out: set[str] = set()
if isinstance(evidence, dict):
_add_evidence_obj(evidence, out=out, turn_index=turn_index)
return out
if isinstance(evidence, list):
for item in evidence:
if isinstance(item, dict):
_add_evidence_obj(item, out=out, turn_index=turn_index)
elif isinstance(item, int):
# If evidence is a bare turn index, only safe when there's a single session.
_add_evidence_turn_index(item, out=out, turn_index=turn_index)
elif isinstance(item, str):
if item:
out.add(item)
return out
if isinstance(evidence, int):
_add_evidence_turn_index(evidence, out=out, turn_index=turn_index)
return out
if isinstance(evidence, str) and evidence:
out.add(evidence)
return out
def _add_evidence_obj(
obj: dict[str, Any], *, out: set[str], turn_index: dict[tuple[str, int], str]
) -> None:
session_id = _coerce_str(obj.get("session_id")) or _coerce_str(obj.get("session"))
turn_idx = _coerce_int(obj.get("turn_index"))
if session_id is not None and turn_idx is not None:
tid = turn_index.get((session_id, turn_idx))
if tid:
out.add(tid)
return
turn_id = _coerce_str(obj.get("turn_id")) or _coerce_str(obj.get("evidence_id"))
if turn_id:
out.add(turn_id)
def _add_evidence_turn_index(
idx: int, *, out: set[str], turn_index: dict[tuple[str, int], str]
) -> None:
sessions = {session_id for (session_id, _), _tid in turn_index.items()}
if len(sessions) != 1:
return
(session_id,) = sessions
tid = turn_index.get((session_id, idx))
if tid:
out.add(tid)
def _coerce_str(value: Any) -> str | None:
if value is None:
return None
if isinstance(value, str):
v = value.strip()
return v or None
return str(value).strip() or None
def _coerce_int(value: Any) -> int | None:
if value is None:
return None
if isinstance(value, int):
return value
try:
return int(str(value).strip())
except Exception:
return None
================================================
FILE: benchmarks/locomo/run.py
================================================
import argparse
import os
from benchmarks.locomo._run_impl import RunConfig, run_locomo
def main(argv: list[str] | None = None) -> int:
parser = argparse.ArgumentParser(description="LoCoMo benchmark harness (Phase 2)")
parser.add_argument(
"--allow-prod-aa",
action="store_true",
help="(Deprecated) Allow Advanced Augmentation calls without MEMORI_TEST_MODE=1 (production).",
)
parser.add_argument(
"--dataset",
required=True,
help="Path to a LoCoMo JSON file (downloaded locally).",
)
parser.add_argument(
"--out",
required=True,
help="Output directory for artifacts (predictions.jsonl, summary.json).",
)
parser.add_argument(
"--sqlite-db",
default="",
help="SQLite DB file path used for the run (default: <out>/locomo.sqlite).",
)
parser.add_argument(
"--provenance-db",
default="",
help="Benchmark-only provenance DB (default: <out>/locomo_provenance.sqlite).",
)
parser.add_argument(
"--reuse-db",
action="store_true",
help="Skip ingestion and reuse the existing SQLite/provenance DB for retrieval+scoring.",
)
parser.add_argument(
"--run-id",
default="",
help="Run namespace used for entity external IDs/provenance (required when --reuse-db and multiple runs exist in the DB).",
)
parser.add_argument(
"--k",
type=int,
default=5,
help="Retrieval top-k to store and score (default: 5).",
)
parser.add_argument(
"--aa-timeout",
type=float,
default=180.0,
help="Timeout (seconds) to wait for Advanced Augmentation to finish per sample.",
)
parser.add_argument(
"--aa-batch",
choices=["per_pair"],
default="per_pair",
help="How to batch messages when calling Advanced Augmentation (default: per_pair).",
)
parser.add_argument(
"--aa-dry-run",
action="store_true",
help="Print/write AA request payload and exit before making any network calls.",
)
parser.add_argument(
"--aa-max-requests",
type=int,
default=0,
help="Limit the number of AA requests to enqueue during ingestion (0 = no limit).",
)
parser.add_argument(
"--seed-only",
action="store_true",
help="Run ingestion only (no retrieval/scoring). Useful for AA payload/summary validation.",
)
parser.add_argument(
"--meta-llm-provider",
default="openai",
help="Metadata only: LLM provider to report to Advanced Augmentation (default: openai).",
)
parser.add_argument(
"--meta-llm-version",
default="gpt-4.1-mini",
help="Metadata only: LLM model version to report (default: gpt-4.1-mini).",
)
parser.add_argument(
"--meta-llm-sdk-version",
default="unknown",
help="Metadata only: LLM SDK version to report (default: unknown).",
)
parser.add_argument(
"--meta-framework-provider",
default="memori",
help="Metadata only: framework provider to report (default: memori).",
)
parser.add_argument(
"--meta-platform-provider",
default="benchmark",
help="Metadata only: platform provider to report (default: benchmark).",
)
parser.add_argument(
"--aa-provenance-top-n",
type=int,
default=1,
help="How many turn_ids to attribute to each augmented fact (default: 1).",
)
parser.add_argument(
"--aa-provenance-min-score",
type=float,
default=0.25,
help="Min cosine similarity to accept a fact->turn attribution (default: 0.25).",
)
parser.add_argument(
"--aa-provenance-mode",
choices=["similarity"],
default="similarity",
help=(
"How to attribute AA facts back to LoCoMo turn IDs for scoring. "
"'similarity' maps facts to turns post-hoc using embedding/text similarity (default). "
),
)
parser.add_argument(
"--rebuild-provenance",
action="store_true",
help="When --reuse-db: recompute provenance offline from the SQLite DB (no AA calls).",
)
parser.add_argument(
"--max-samples",
type=int,
default=0,
help="Limit number of samples (0 = no limit).",
)
parser.add_argument(
"--only-sample-id",
default="",
help="Run only a single sample_id (exact match).",
)
parser.add_argument(
"--max-sessions",
type=int,
default=0,
help="Limit number of sessions per sample (0 = no limit).",
)
parser.add_argument(
"--max-questions",
type=int,
default=0,
help="Limit questions per sample (0 = no limit).",
)
parser.add_argument(
"--verbose",
action="store_true",
help="Print progress/logging about seeding and scoring.",
)
parser.add_argument(
"--log-every-questions",
type=int,
default=0,
help="When --verbose, log progress every N questions (0 = disabled).",
)
args = parser.parse_args(argv)
# LoCoMo benchmarks should never hit production AA. Force staging routing.
os.environ["MEMORI_TEST_MODE"] = "1"
run_locomo(
RunConfig(
dataset=args.dataset,
out=args.out,
sqlite_db=args.sqlite_db,
provenance_db=args.provenance_db,
reuse_db=args.reuse_db,
run_id=args.run_id,
k=args.k,
aa_timeout=args.aa_timeout,
aa_batch=args.aa_batch,
aa_dry_run=args.aa_dry_run,
aa_max_requests=args.aa_max_requests,
meta_llm_provider=args.meta_llm_provider,
meta_llm_version=args.meta_llm_version,
meta_llm_sdk_version=args.meta_llm_sdk_version,
meta_framework_provider=args.meta_framework_provider,
meta_platform_provider=args.meta_platform_provider,
aa_provenance_top_n=args.aa_provenance_top_n,
aa_provenance_min_score=args.aa_provenance_min_score,
aa_provenance_mode=args.aa_provenance_mode,
rebuild_provenance=args.rebuild_provenance,
allow_prod_aa=args.allow_prod_aa,
max_samples=args.max_samples,
only_sample_id=args.only_sample_id,
max_sessions=args.max_sessions,
max_questions=args.max_questions,
seed_only=args.seed_only,
verbose=args.verbose,
log_every_questions=args.log_every_questions,
)
)
return 0
if __name__ == "__main__":
raise SystemExit(main())
================================================
FILE: benchmarks/locomo/scoring.py
================================================
from __future__ import annotations
def hit_at_k(relevant: set[str], retrieved: list[str], k: int) -> float:
if not relevant or not retrieved or k <= 0:
return 0.0
top = retrieved[:k]
return 1.0 if any(item in relevant for item in top) else 0.0
def mrr(relevant: set[str], retrieved: list[str]) -> float:
if not relevant or not retrieved:
return 0.0
for i, item in enumerate(retrieved, start=1):
if item in relevant:
return 1.0 / float(i)
return 0.0
def hit_at_k_groups(relevant: set[str], retrieved: list[set[str]], k: int) -> float:
"""
Variant of hit@k where each retrieved rank can map to multiple IDs.
This is useful when a retrieved item (e.g., an AA fact) may plausibly originate
from multiple LoCoMo turns (dia_id).
"""
if not relevant or not retrieved or k <= 0:
return 0.0
for group in retrieved[:k]:
if group and (group & relevant):
return 1.0
return 0.0
def mrr_groups(relevant: set[str], retrieved: list[set[str]]) -> float:
if not relevant or not retrieved:
return 0.0
for i, group in enumerate(retrieved, start=1):
if group and (group & relevant):
return 1.0 / float(i)
return 0.0
================================================
FILE: benchmarks/perf/README.md
================================================
# Performance / latency benchmarks
This folder contains **performance benchmarks** for Memori recall, powered by `pytest-benchmark`.
## Run locally
```bash
uv run pytest -m benchmark --benchmark-only benchmarks/perf/test_recall_benchmarks.py -v
```
## Run on EC2 (recommended for realistic DB latency)
Use an EC2 instance in the same VPC as your database (RDS Postgres/MySQL).
- Setup:
```bash
chmod +x benchmarks/perf/setup_ec2_benchmarks.sh
./benchmarks/perf/setup_ec2_benchmarks.sh
```
- Run:
```bash
export BENCHMARK_POSTGRES_URL="CHANGEME"
DB_TYPE=postgres TEST_TYPE=all ./benchmarks/perf/run_benchmarks_ec2.sh
```
### Environment variables
- `DB_TYPE`: `postgres` (default) or `mysql`
- `TEST_TYPE`: `all` (default), `end_to_end`, `db_retrieval`, `semantic_search`, `embedding`
- `BENCHMARK_POSTGRES_URL`: Postgres connection string
- `BENCHMARK_MYSQL_URL`: MySQL connection string
## Outputs
Results are saved to `./results`:
- JSON: `results_{db}_{type}_{timestamp}.json`
- CSV: `report_{db}_{type}_{timestamp}.csv`
================================================
FILE: benchmarks/perf/_results.py
================================================
from __future__ import annotations
import csv
from pathlib import Path
from typing import Any
def repo_root() -> Path:
return Path(__file__).resolve().parents[2]
def results_dir() -> Path:
path = repo_root() / "results"
path.mkdir(parents=True, exist_ok=True)
return path
def append_csv_row(path: str | Path, *, header: list[str], row: dict[str, Any]) -> None:
out_path = Path(path)
out_path.parent.mkdir(parents=True, exist_ok=True)
file_exists = out_path.exists()
with out_path.open("a", newline="") as f:
writer = csv.DictWriter(f, fieldnames=header)
if not file_exists:
writer.writeheader()
writer.writerow(row)
================================================
FILE: benchmarks/perf/conftest.py
================================================
"""Pytest fixtures for performance benchmarks."""
import os
import pytest
from sqlalchemy import create_engine
from sqlalchemy.orm import sessionmaker
from benchmarks.perf.fixtures.sample_data import (
generate_facts_with_size,
generate_sample_queries,
)
from memori import Memori
from memori.embeddings import embed_texts
@pytest.fixture
def postgres_db_connection():
"""Create a PostgreSQL database connection factory for benchmarking (via AWS/Docker)."""
postgres_uri = os.environ.get(
"BENCHMARK_POSTGRES_URL",
# Matches docker-compose.yml default DB name
"postgresql://memori:memori@localhost:5432/memori_test",
)
from sqlalchemy import text
# Support SSL root certificate via environment variable (for AWS RDS)
connect_args = {}
sslrootcert = os.environ.get("BENCHMARK_POSTGRES_SSLROOTCERT")
if sslrootcert:
connect_args["sslrootcert"] = sslrootcert
# Ensure sslmode is set if using SSL cert
if "sslmode" not in postgres_uri:
# Add sslmode=require if not already in URI
separator = "&" if "?" in postgres_uri else "?"
postgres_uri = f"{postgres_uri}{separator}sslmode=require"
engine = create_engine(
postgres_uri,
pool_pre_ping=True,
pool_recycle=300,
connect_args=connect_args,
)
try:
with engine.connect() as conn:
conn.execute(text("SELECT 1"))
except Exception as e:
pytest.skip(
f"PostgreSQL not available at {postgres_uri}: {e}. "
"Set BENCHMARK_POSTGRES_URL to a database that exists."
)
Session = sessionmaker(autocommit=False, autoflush=False, bind=engine)
yield Session
engine.dispose()
@pytest.fixture
def mysql_db_connection():
"""Create a MySQL database connection factory for benchmarking (via AWS/Docker)."""
mysql_uri = os.environ.get(
"BENCHMARK_MYSQL_URL",
"mysql+pymysql://memori:memori@localhost:3306/memori_test",
)
from sqlalchemy import text
engine = create_engine(
mysql_uri,
pool_pre_ping=True,
pool_recycle=300,
)
try:
with engine.connect() as conn:
conn.execute(text("SELECT 1"))
except Exception as e:
pytest.skip(f"MySQL not available at {mysql_uri}: {e}")
Session = sessionmaker(autocommit=False, autoflush=False, bind=engine)
yield Session
engine.dispose()
@pytest.fixture(
params=["postgres", "mysql"],
ids=["postgres", "mysql"],
)
def db_connection(request):
"""Parameterized fixture for realistic database types (no SQLite)."""
db_type = request.param
if db_type == "postgres":
return request.getfixturevalue("postgres_db_connection")
elif db_type == "mysql":
return request.getfixturevalue("mysql_db_connection")
pytest.skip(f"Unsupported benchmark database type: {db_type}")
@pytest.fixture
def memori_instance(db_connection, request):
"""Create a Memori instance with the specified database for benchmarking."""
mem = Memori(conn=db_connection)
mem.config.storage.build()
db_type_param = None
for marker in request.node.iter_markers("parametrize"):
if "db_connection" in marker.args[0]:
db_type_param = marker.args[1][0] if marker.args[1] else None
break
# Try to infer from connection
if not db_type_param:
try:
# SQLAlchemy sessionmaker is callable, so detect it first by presence of a bind.
bind = getattr(db_connection, "kw", {}).get("bind", None)
if bind is not None:
db_type_param = bind.dialect.name
else:
db_type_param = "unknown"
except Exception:
db_type_param = "unknown"
mem._benchmark_db_type = db_type_param
return mem
@pytest.fixture
def sample_queries():
"""Provide sample queries of varying lengths."""
return generate_sample_queries()
@pytest.fixture
def fact_content_size():
"""Fixture for fact content size.
Note: Embeddings are always 768 dimensions (3072 bytes binary) regardless of text size.
"""
return "small"
@pytest.fixture(
params=[5, 50, 100, 300, 600, 1000],
ids=lambda x: f"n{x}",
)
def entity_with_n_facts(memori_instance, fact_content_size, request):
"""Create an entity with N facts for benchmarking database retrieval."""
fact_count = request.param
entity_id = f"benchmark-entity-{fact_count}-{fact_content_size}"
memori_instance.attribution(entity_id=entity_id, process_id="benchmark-process")
facts = generate_facts_with_size(fact_count, fact_content_size)
fact_embeddings = embed_texts(
facts,
model=memori_instance.config.embeddings.model,
)
entity_db_id = memori_instance.config.storage.driver.entity.create(entity_id)
memori_instance.config.storage.driver.entity_fact.create(
entity_db_id, facts, fact_embeddings
)
db_type = getattr(memori_instance, "_benchmark_db_type", "unknown")
return {
"entity_id": entity_id,
"entity_db_id": entity_db_id,
"fact_count": fact_count,
"content_size": fact_content_size,
"db_type": db_type,
"facts": facts,
}
================================================
FILE: benchmarks/perf/fixtures/sample_data.py
================================================
"""Helper functions for generating sample test data for benchmarks."""
import random
import string
random.seed(42)
def generate_random_string(length: int = 10) -> str:
"""Generate a random string of specified length."""
return "".join(random.choices(string.ascii_letters + string.digits, k=length))
def generate_sample_fact() -> str:
"""Generate a realistic sample fact for testing."""
templates = [
"User likes {item}",
"User lives in {location}",
"User works at {company}",
"User's favorite color is {color}",
"User prefers {preference}",
"User has {count} {item}",
"User enjoys {activity}",
"User's birthday is {date}",
]
items = ["pizza", "coffee", "books", "music", "movies", "travel", "coding"]
locations = ["New York", "San Francisco", "London", "Tokyo", "Paris"]
companies = ["Tech Corp", "Startup Inc", "Big Company", "Small Business"]
colors = ["blue", "red", "green", "purple", "yellow"]
preferences = ["dark mode", "light mode", "minimalist design", "detailed UI"]
activities = ["reading", "hiking", "cooking", "gaming", "photography"]
dates = ["January 1st", "March 15th", "June 30th", "December 25th"]
template = random.choice(templates)
fact = template.format(
item=random.choice(items),
location=random.choice(locations),
company=random.choice(companies),
color=random.choice(colors),
preference=random.choice(preferences),
count=random.randint(1, 10),
activity=random.choice(activities),
date=random.choice(dates),
)
return fact
def generate_sample_queries() -> dict[str, list[str]]:
"""Generate sample queries of varying lengths for benchmarking."""
return {
"short": [
"What do I like?",
"Where do I live?",
"My preferences?",
"Favorite color?",
"Birthday?",
],
"medium": [
"What are my favorite things?",
"Tell me about where I live",
"What are my preferences for software?",
"What is my favorite color and why?",
"When is my birthday and how do I celebrate?",
],
"long": [
"Can you tell me about all the things I like and enjoy doing?",
"I want to know more about where I currently live and work",
"What are all my preferences when it comes to software and design?",
"Please provide details about my favorite color and any related memories",
"I'd like to know when my birthday is and how I typically celebrate it",
],
}
def generate_facts(count: int) -> list[str]:
"""Generate a list of unique sample facts."""
facts = []
seen = set()
while len(facts) < count:
fact = generate_sample_fact()
# Add unique identifier to ensure no duplicates
unique_fact = f"{fact} (id: {len(facts)})"
# Double-check uniqueness (shouldn't be needed with id, but safe)
if unique_fact not in seen:
facts.append(unique_fact)
seen.add(unique_fact)
return facts
def generate_facts_with_size(count: int, size: str = "small") -> list[str]:
"""Generate facts for benchmarking.
Args:
count: Number of facts to generate
size: Content size
Returns:
List of unique facts
"""
base_facts = generate_facts(count)
def with_id_suffix(text: str, idx: int, max_len: int) -> str:
suffix = f" (id: {idx})"
if max_len <= len(suffix):
return suffix[-max_len:]
return text[: max_len - len(suffix)] + suffix
return [with_id_suffix(fact, i, 60) for i, fact in enumerate(base_facts)]
================================================
FILE: benchmarks/perf/fixtures/sample_facts.py
================================================
# 1,000 synthetic user facts as semantic triples (subject, predicate, object)
# Copy/paste into your project. Produces: user_data = {"user": "John", "facts": [(s,p,o), ...]}
def build_user_data() -> dict:
facts: list[tuple[str, str, str]] = []
def add(s: str, p: str, o: str) -> None:
facts.append((s, p, o))
# -----------------------------
# Core profile facts (diverse)
# -----------------------------
add("John", "type", "Person")
add("John", "has_given_name", "John")
add("John", "prefers_language", "English")
add("John", "prefers_time_format", "12-hour")
add("John", "prefers_temperature_unit", "Fahrenheit")
add("John", "prefers_distance_unit", "miles")
add("John", "has_home_city", "St_Louis")
add("John", "has_home_state", "Missouri")
add("John", "has_home_country", "United_States")
add("John", "has_role", "Software_Engineer")
add("John", "works_in", "Technology")
add("John", "interested_in", "AI")
add("John", "interested_in", "cloud_infrastructure")
add("John", "interested_in", "personal_finance")
add("John", "interested_in", "fitness")
add("John", "interested_in", "cooking")
add("John", "interested_in", "travel")
add("John", "interested_in", "productivity")
add("John", "interested_in", "home_improvement")
add("John", "uses_llm_for", "writing_assistance")
add("John", "uses_llm_for", "coding_help")
add("John", "uses_llm_for", "travel_planning")
add("John", "uses_llm_for", "learning_new_topics")
add("John", "uses_llm_for", "recipe_ideas")
add("John", "uses_llm_for", "career_advice")
add("John", "uses_llm_for", "data_analysis")
add("John", "uses_llm_for", "brainstorming")
add("John", "prefers_response_style", "structured")
add("John", "prefers_response_style", "actionable")
add("John", "concerned_about", "latency")
add("John", "concerned_about", "cost")
add("John", "concerned_about", "privacy")
add("John", "primary_os", "macOS")
add("John", "primary_browser", "Chrome")
add("John", "primary_editor", "VS_Code")
add("John", "primary_shell", "zsh")
add("John", "primary_email_provider", "Gmail")
add("John", "primary_calendar", "Google_Calendar")
add("John", "primary_messaging_app", "Slack")
add("John", "primary_code_host", "GitHub")
add("John", "prefers_document_format", "Markdown")
add("John", "prefers_spreadsheet_tool", "Google_Sheets")
add("John", "uses_password_manager", "1Password")
add("John", "uses_cloud_storage", "Google_Drive")
add("John", "uses_issue_tracker", "GitHub_Issues")
add("John", "uses_ci_cd", "GitHub_Actions")
add("John", "prefers_container_runtime", "Docker")
add("John", "prefers_database", "PostgreSQL")
add("John", "prefers_cache", "Redis")
add("John", "prefers_language_for_backend", "Python")
add("John", "knows_language", "JavaScript")
add("John", "knows_language", "SQL")
add("John", "knows_language", "Bash")
add("John", "learning_language", "Rust")
add("John", "prefers_testing_framework", "pytest")
add("John", "prefers_package_manager", "uv")
add("John", "uses_llm_provider", "OpenAI")
add("John", "uses_llm_provider", "Anthropic")
add("John", "uses_model_family", "GPT")
add("John", "uses_model_family", "Claude")
add("John", "has_hobby", "fantasy_football")
add("John", "follows_sport", "NFL")
add("John", "follows_sport", "NHL")
add("John", "prefers_coffee_drink", "latte")
add("John", "prefers_breakfast", "oatmeal")
add("John", "prefers_lunch", "salad")
add("John", "prefers_dinner", "grilled_chicken")
add("John", "commutes_by", "car")
add("John", "prefers_meeting_platform", "Zoom")
# -----------------------------
# Family / household facts
# -----------------------------
family = [
("Spouse_01", "spouse"),
("Child_01", "child"),
("Child_02", "child"),
("Parent_01", "parent"),
("Parent_02", "parent"),
("Sibling_01", "sibling"),
("Sibling_02", "sibling"),
("Pet_01", "pet"),
]
for i, (entity, rel) in enumerate(family, start=1):
add(entity, "type", "Person" if "Pet" not in entity else "Animal")
add("John", f"has_{rel}", entity)
add(entity, "has_first_name", entity.split("_")[0])
add(entity, "located_in", f"City_{(i % 25) + 1:03d}")
add(
entity,
"preferred_contact_method",
["text", "call", "email"][i % 3] if "Pet" not in entity else "n/a",
)
# -----------------------------
# Friends (varied interests)
# -----------------------------
friend_interests = [
"music",
"travel",
"tech",
"food",
"sports",
"finance",
"fitness",
"gaming",
"books",
"photography",
]
contact_methods = ["email", "text", "slack", "signal", "call"]
for i in range(1, 61): # 60 friends
f = f"Friend_{i:03d}"
add(f, "type", "Person")
add("John", "has_friend", f)
add(f, "located_in", f"City_{(i % 80) + 1:03d}")
add(f, "interested_in", friend_interests[i % len(friend_interests)])
add(f, "preferred_contact_method", contact_methods[i % len(contact_methods)])
# -----------------------------
# Coworkers (teams, roles, tools)
# -----------------------------
roles = [
"Backend_Engineer",
"Frontend_Engineer",
"DevOps_Engineer",
"Product_Manager",
"Designer",
"Data_Engineer",
]
teams = ["Platform", "Infra", "Product", "Data", "Security", "Growth"]
tools = ["Jira", "Linear", "Confluence", "Notion", "Figma", "Datadog", "Grafana"]
for i in range(1, 41): # 40 coworkers
c = f"Coworker_{i:03d}"
add(c, "type", "Person")
add("John", "works_with", c)
add(c, "has_role", roles[i % len(roles)])
add(c, "member_of_team", teams[i % len(teams)])
add(c, "uses_tool", tools[i % len(tools)])
# -----------------------------
# Places: cities, venues, travel
# -----------------------------
for i in range(1, 81): # 80 cities
city = f"City_{i:03d}"
add(city, "type", "City")
add(city, "in_country", "United_States" if i <= 60 else "International")
add("John", "has_visited", city if i <= 45 else f"Planned_{city}")
add(
city,
"has_timezone",
"America/Chicago"
if i % 3 == 0
else "America/New_York"
if i % 3 == 1
else "America/Los_Angeles",
)
venue_types = [
"Restaurant",
"Coffee_Shop",
"Gym",
"Airport",
"Hotel",
"Park",
"Museum",
"Stadium",
]
for i in range(1, 81): # 80 venues
v = f"Venue_{i:03d}"
add(v, "type", venue_types[i % len(venue_types)])
add(v, "located_in", f"City_{(i % 80) + 1:03d}")
add("John", "likes_place", v if i % 4 != 0 else f"Neutral_{v}")
add(v, "has_price_tier", ["$", "$$", "$$$"][i % 3])
# -----------------------------
# Devices, apps, services, accounts
# -----------------------------
devices = [
"MacBook_Pro",
"iPhone",
"iPad",
"AirPods",
"Smart_TV",
"Router",
"NAS",
"Mechanical_Keyboard",
"Gaming_PC",
"Monitor_34inch",
"Standing_Desk",
"Ergonomic_Chair",
"Fitness_Tracker",
"Smart_Speaker",
"Kindle",
"External_SSD",
"Webcam",
"Microphone",
"Printer",
"Smart_Thermostat",
]
for d in devices:
add(d, "type", "Device")
add("John", "owns_device", d)
add(d, "used_for", "work" if "MacBook" in d or "Monitor" in d else "personal")
add(d, "has_status", "active")
apps = [
"Notion",
"Slack",
"Gmail",
"Google_Calendar",
"Spotify",
"YouTube",
"Netflix",
"Amazon",
"GitHub",
"Figma",
"Jira",
"Linear",
"Zoom",
"1Password",
"Google_Drive",
]
for i, app in enumerate(apps, start=1):
add(app, "type", "App")
add("John", "uses_app", app)
add(app, "has_version", f"{(i % 5) + 1}.{(i % 10)}.{(i % 20)}")
return {"user": "John", "facts": facts}
================================================
FILE: benchmarks/perf/generate_percentile_report.py
================================================
"""Generate percentile report (p50/p95/p99) from benchmark JSON results."""
import json
import sys
from pathlib import Path
def calculate_percentile(data, percentile):
"""Calculate percentile from sorted data."""
if not data:
return None
sorted_data = sorted(data)
index = (len(sorted_data) - 1) * percentile / 100
lower = int(index)
upper = lower + 1
weight = index - lower
if upper >= len(sorted_data):
return sorted_data[lower]
return sorted_data[lower] * (1 - weight) + sorted_data[upper] * weight
def extract_n_from_test_name(test_name):
"""Extract N (number of records) from test name."""
import re
# Our parametrized ids use "n{N}" (e.g. "[n1000-postgres-small]")
match = re.search(r"n(\d+)", test_name)
if match:
return int(match.group(1))
# Backwards-compatible: plain numeric parameter (e.g. "[1000]")
match = re.search(r"\[(\d+)\]", test_name)
return int(match.group(1)) if match else None
def extract_db_type_from_test_name(test_name):
"""Extract database type from test name."""
import re
# Look for database type in test name (postgres, mysql)
match = re.search(r"\[(postgres|mysql)[-\]]", test_name)
if not match:
match = re.search(r"-(postgres|mysql)[-\]]", test_name)
if not match:
match = re.search(r"(postgres|mysql)", test_name)
return match.group(1) if match else "unknown"
def extract_content_size_from_test_name(test_name):
"""Extract content size from test name."""
import re
match = re.search(r"\[small[-\]]", test_name)
if not match:
match = re.search(r"-small[-\]]", test_name)
if not match:
match = re.search(r"small", test_name)
return match.group(0) if match else "small"
def extract_benchmark_id_from_test_name(test_name):
"""
Extract a stable benchmark identifier from pytest-benchmark's name field.
Examples:
"test_benchmark_end_to_end_recall[n1000-sqlite-small]" -> "test_benchmark_end_to_end_recall"
"test_benchmark_query_embedding_short" -> "test_benchmark_query_embedding_short"
"""
import re
match = re.match(r"([^\[]+)", test_name)
return match.group(1) if match else test_name
def generate_percentile_report(json_file_path, max_n=None):
"""Generate p50/p95/p99 report from benchmark JSON.
Args:
json_file_path: Path to pytest-benchmark JSON output
max_n: Optional maximum N value to include (filters out tests with N > max_n)
"""
with open(json_file_path) as f:
data = json.load(f)
benchmarks = {}
for benchmark in data.get("benchmarks", []):
test_name = benchmark.get("name", "")
benchmark_id = extract_benchmark_id_from_test_name(test_name)
n = extract_n_from_test_name(test_name)
# Skip if N is None (couldn't extract) or exceeds max_n filter
if n is None:
continue
if max_n is not None and n > max_n:
continue
db_type = extract_db_type_from_test_name(test_name)
content_size = extract_content_size_from_test_name(test_name)
extra_info = benchmark.get("extra_info", {}) or {}
stats = benchmark.get("stats", {})
times = stats.get("data", [])
if not times:
continue
peak_rss_bytes = extra_info.get("peak_rss_bytes")
p50 = calculate_percentile(times, 50)
p95 = calculate_percentile(times, 95)
p99 = calculate_percentile(times, 99)
# Create composite key. We include benchmark_id so different benchmark types
# don't overwrite each other (e.g. end-to-end vs db fetch for same N/db/size).
key = (benchmark_id, n, db_type, content_size)
benchmarks[key] = {
"benchmark_id": benchmark_id,
"n": n,
"db_type": db_type,
"content_size": content_size,
"p50": p50,
"p95": p95,
"p99": p99,
"mean": stats.get("mean", 0),
"min": stats.get("min", 0),
"max": stats.get("max", 0),
"peak_rss_bytes": peak_rss_bytes,
}
return benchmarks
def generate_report(benchmarks, output_format="table"):
"""Generate percentile report in specified format as string."""
lines = []
if output_format == "table":
lines.append("\n" + "=" * 100)
lines.append(
"PERCENTILE REPORT (p50/p95/p99) per N, Database Type, and Content Size"
)
lines.append("=" * 100)
lines.append(
f"{'Benchmark':<34} {'N':<8} {'DB':<12} {'Size':<8} {'p50 (ms)':<12} {'p95 (ms)':<12} "
f"{'p99 (ms)':<12} {'Mean (ms)':<12} {'Peak RSS (MB)':<14}"
)
lines.append("-" * 100)
for key in sorted(benchmarks.keys()):
stats = benchmarks[key]
peak_rss_mb = (
(stats["peak_rss_bytes"] / (1024 * 1024))
if stats.get("peak_rss_bytes") is not None
else None
)
lines.append(
f"{stats['benchmark_id']:<34} "
f"{stats['n']:<8} "
f"{stats['db_type']:<12} "
f"{stats['content_size']:<8} "
f"{stats['p50'] * 1000:<12.4f} "
f"{stats['p95'] * 1000:<12.4f} "
f"{stats['p99'] * 1000:<12.4f} "
f"{stats['mean'] * 1000:<12.4f} "
f"{(f'{peak_rss_mb:.1f}' if peak_rss_mb is not None else ''):<14}"
)
lines.append("=" * 100)
return "\n".join(lines)
if output_format == "csv":
lines.append(
"benchmark_id,N,db_type,content_size,p50_ms,p95_ms,p99_ms,mean_ms,min_ms,max_ms,peak_rss_mb"
)
for key in sorted(benchmarks.keys()):
stats = benchmarks[key]
peak_rss_mb = (
(stats["peak_rss_bytes"] / (1024 * 1024))
if stats.get("peak_rss_bytes") is not None
else None
)
lines.append(
f"{stats['benchmark_id']},"
f"{stats['n']},"
f"{stats['db_type']},"
f"{stats['content_size']},"
f"{stats['p50'] * 1000:.4f},"
f"{stats['p95'] * 1000:.4f},"
f"{stats['p99'] * 1000:.4f},"
f"{stats['mean'] * 1000:.4f},"
f"{stats['min'] * 1000:.4f},"
f"{stats['max'] * 1000:.4f},"
f"{(f'{peak_rss_mb:.4f}' if peak_rss_mb is not None else '')}"
)
return "\n".join(lines)
if output_format == "json":
output = {}
for key in sorted(benchmarks.keys()):
stats = benchmarks[key]
output_key = f"{stats['benchmark_id']}_{stats['n']}_{stats['db_type']}_{stats['content_size']}"
peak_rss_mb = (
(stats["peak_rss_bytes"] / (1024 * 1024))
if stats.get("peak_rss_bytes") is not None
else None
)
output[output_key] = {
"benchmark_id": stats["benchmark_id"],
"n": stats["n"],
"db_type": stats["db_type"],
"content_size": stats["content_size"],
"p50_ms": stats["p50"] * 1000,
"p95_ms": stats["p95"] * 1000,
"p99_ms": stats["p99"] * 1000,
"mean_ms": stats["mean"] * 1000,
"min_ms": stats["min"] * 1000,
"max_ms": stats["max"] * 1000,
"peak_rss_mb": peak_rss_mb,
}
return json.dumps(output, indent=2)
return ""
def main():
if len(sys.argv) < 2:
print(
"Usage: python generate_percentile_report.py <benchmark.json> [format] [output_file] [max_n]"
)
print(" format: table (default), csv, or json")
print(" output_file: optional file path to write report (default: stdout)")
print(
" max_n: optional maximum N value to include (filters out tests with N > max_n)"
)
sys.exit(1)
json_file = Path(sys.argv[1])
if not json_file.exists():
print(f"Error: File not found: {json_file}")
sys.exit(1)
output_format = sys.argv[2] if len(sys.argv) > 2 else "table"
if output_format not in ["table", "csv", "json"]:
print(f"Error: Invalid format '{output_format}'. Use: table, csv, or json")
sys.exit(1)
output_file = sys.argv[3] if len(sys.argv) > 3 else None
max_n = int(sys.argv[4]) if len(sys.argv) > 4 else None
benchmarks = generate_percentile_report(json_file, max_n=max_n)
if not benchmarks:
print("No benchmark data found.")
sys.exit(1)
report = generate_report(benchmarks, output_format)
if output_file:
Path(output_file).write_text(report, encoding="utf-8")
print(f"Report written to: {output_file}")
else:
print(report)
if __name__ == "__main__":
main()
================================================
FILE: benchmarks/perf/memory_utils.py
================================================
import threading
import time
from collections.abc import Callable
from typing import TypeVar
T = TypeVar("T")
def measure_peak_rss_bytes(
fn: Callable[[], T], *, sample_interval_seconds: float = 0.005
) -> tuple[T, int | None]:
"""
Measure approximate peak RSS (process resident set size) while running fn.
Returns (result, peak_rss_bytes). If psutil isn't available, peak is None.
"""
try:
import psutil
except Exception:
return fn(), None
proc = psutil.Process()
peak = {"rss": proc.memory_info().rss}
stop = threading.Event()
def _sampler() -> None:
while not stop.is_set():
try:
rss = proc.memory_info().rss
if rss > peak["rss"]:
peak["rss"] = rss
except Exception:
pass
time.sleep(sample_interval_seconds)
t = threading.Thread(target=_sampler, daemon=True)
t.start()
try:
result = fn()
finally:
stop.set()
t.join(timeout=1.0)
return result, int(peak["rss"])
================================================
FILE: benchmarks/perf/run_benchmarks_ec2.sh
================================================
#!/bin/bash
# Shared benchmark execution functions for AWS EC2 environment
set -e
# Get script location to handle relative paths correctly
BENCHMARK_DIR="$(cd "$(dirname "${BASH_SOURCE[0]}")" && pwd)"
REPO_ROOT="$(cd "$BENCHMARK_DIR/../.." && pwd)"
# Default settings
DB_TYPE=${DB_TYPE:-"postgres"}
TEST_TYPE=${TEST_TYPE:-"all"} # options: all, end_to_end, db_retrieval, semantic_search, embedding
OUTPUT_DIR=${OUTPUT_DIR:-"$REPO_ROOT/results"}
mkdir -p "$OUTPUT_DIR"
run_benchmarks() {
local db=$1
local type=$2
local timestamp=$(date +%Y%m%d_%H%M%S)
local output_json="$OUTPUT_DIR/results_${db}_${type}_${timestamp}.json"
local output_csv="$OUTPUT_DIR/report_${db}_${type}_${timestamp}.csv"
echo "===================================================="
echo "Running benchmarks for: DB=$db, Type=$type"
echo "Output JSON: $output_json"
echo "Output CSV: $output_csv"
echo "===================================================="
# Determine pytest filter (-k) based on test type
local filter=""
case $type in
"end_to_end") filter="TestEndToEndRecallBenchmarks" ;;
"db_retrieval") filter="DatabaseEmbeddingRetrievalBenchmarks or DatabaseFactContentRetrievalBenchmarks" ;;
"semantic_search") filter="TestSemanticSearchBenchmarks" ;;
"embedding") filter="TestQueryEmbeddingBenchmarks" ;;
"all") filter="" ;;
*) echo "Unknown test type: $type"; exit 1 ;;
esac
# Add database filter
if [[ -n "$filter" ]]; then
filter="($filter) and $db"
else
filter="$db"
fi
# Run benchmarks from repo root
(
cd "$REPO_ROOT"
uv run pytest -m benchmark \
--benchmark-only \
benchmarks/perf/test_recall_benchmarks.py \
-k "$filter" \
-v \
--benchmark-json="$output_json"
# Automatically convert to CSV
if [[ -f "$output_json" ]]; then
echo "Converting results to CSV..."
uv run python benchmarks/perf/generate_percentile_report.py \
"$output_json" \
csv \
"$output_csv"
echo "CSV Report generated: $output_csv"
else
echo "Warning: JSON results file not found, skipping CSV generation."
fi
)
}
# If script is executed directly (not sourced), run based on env vars
if [[ "${BASH_SOURCE[0]}" == "${0}" ]]; then
# Print usage info if help requested
if [[ "$1" == "--help" || "$1" == "-h" ]]; then
echo "Usage: DB_TYPE=[postgres|mysql] TEST_TYPE=[all|end_to_end|db_retrieval|semantic_search|embedding] $0"
exit 0
fi
run_benchmarks "$DB_TYPE" "$TEST_TYPE"
echo "===================================================="
echo "Benchmark Run Complete"
echo "===================================================="
fi
================================================
FILE: benchmarks/perf/setup_ec2_benchmarks.sh
================================================
#!/bin/bash
# Setup script for running benchmarks on AWS EC2
set -e
echo "Setting up Memori benchmarks on EC2..."
# Install system dependencies
sudo apt-get update
sudo apt-get install -y \
python3.12 \
python3.12-venv \
git \
curl \
build-essential \
postgresql-client \
default-mysql-client
# Install uv
curl -LsSf https://astral.sh/uv/install.sh | sh
source $HOME/.cargo/env
# Clone repository (replace with your repo URL if not already cloned)
# git clone https://github.com/MemoriLabs/Memori.git
# cd Memori
# Sync dependencies
uv sync --all-extras
# Source the runner to get run_benchmarks function
SCRIPT_DIR="$(cd "$(dirname "${BASH_SOURCE[0]}")" && pwd)"
source "$SCRIPT_DIR/run_benchmarks_ec2.sh"
echo "Setup complete!"
echo ""
echo "To run all benchmarks for Postgres:"
echo " DB_TYPE=postgres TEST_TYPE=all ./benchmarks/perf/run_benchmarks_ec2.sh"
echo ""
echo "To run end-to-end benchmarks for MySQL:"
echo " DB_TYPE=mysql TEST_TYPE=end_to_end ./benchmarks/perf/run_benchmarks_ec2.sh"
echo ""
echo "Results will be automatically saved to the ./results directory as CSV."
================================================
FILE: benchmarks/perf/test_cloud_recall_benchmarks.py
================================================
"""Cloud (Memori API) performance / latency benchmarks.
These benchmarks exercise the cloud recall path (network + API latency) rather than
local DB-backed recall.
"""
from __future__ import annotations
import os
from uuid import uuid4
import pytest
from memori._config import Config
from memori.llm._base import BaseInvoke
from memori.llm._constants import OPENAI_LLM_PROVIDER
from memori.memory._manager import Manager
from memori.memory.recall import Recall
def _make_cloud_cfg(*, entity_id: str, process_id: str) -> Config:
cfg = Config()
cfg.cloud = True
cfg.entity_id = entity_id
cfg.process_id = process_id
if cfg.session_id is None:
cfg.session_id = uuid4()
# Pick a provider so injection rules are deterministic.
cfg.llm.provider = OPENAI_LLM_PROVIDER
cfg.framework.provider = "bench"
return cfg
def _seed_cloud_messages(
cfg: Config, *, n_messages: int, entity_id: str, process_id: str
) -> None:
cfg.cloud = True
cfg.entity_id = entity_id
cfg.process_id = process_id
if cfg.session_id is None:
cfg.session_id = uuid4()
messages: list[dict[str, object]] = []
for i in range(n_messages):
messages.append({"role": "user", "type": None, "text": f"I like item_{i}."})
messages.append({"role": "assistant", "type": None, "text": "Ok."})
Manager(cfg).execute(
{
"attribution": {
"entity": {"id": str(entity_id)},
"process": {"id": str(process_id)},
},
"messages": messages,
"session": {"id": str(cfg.session_id)},
}
)
@pytest.mark.benchmark
@pytest.mark.parametrize("n_messages", [20, 100], ids=["n20", "n100"])
def test_benchmark_cloud_recall_latency(benchmark, n_messages: int) -> None:
"""Benchmark end-to-end cloud recall latency.
Includes: HTTP request + cloud service time. Excludes: local DB retrieval.
"""
os.environ["MEMORI_TEST_MODE"] = "1"
api_key = os.environ.get("MEMORI_API_KEY")
if not api_key:
pytest.skip("Set MEMORI_API_KEY to benchmark cloud recall.")
cfg = Config()
entity_id = os.environ.get("BENCHMARK_CLOUD_ENTITY_ID", "bench-cloud-entity")
process_id = os.environ.get("BENCHMARK_CLOUD_PROCESS_ID", "bench-cloud-process")
_seed_cloud_messages(
cfg,
n_messages=n_messages,
entity_id=entity_id,
process_id=process_id,
)
recall = Recall(cfg)
def _call():
return recall.search_facts(query="What do I like?", limit=5)
result = benchmark(_call)
assert isinstance(result, list)
@pytest.mark.benchmark
@pytest.mark.parametrize("n_history_pairs", [20, 100], ids=["n20", "n100"])
def test_benchmark_cloud_pre_llm_overhead(benchmark, n_history_pairs: int) -> None:
"""Benchmark Memori overhead up to the LLM call (cloud mode).
This measures the "added latency" before calling an LLM:
- (optional) fetch cloud conversation history
- cloud recall request (server-side embeddings + retrieval)
- prompt/message injection logic
It intentionally does NOT call an LLM provider.
"""
if not os.environ.get("MEMORI_API_KEY"):
pytest.skip("Set MEMORI_API_KEY to benchmark cloud pre-LLM overhead.")
entity_id = os.environ.get("BENCHMARK_CLOUD_ENTITY_ID", "bench-cloud-entity")
process_id = os.environ.get("BENCHMARK_CLOUD_PROCESS_ID", "bench-cloud-process")
cfg = _make_cloud_cfg(entity_id=entity_id, process_id=process_id)
# Seed a stable session for cloud history fetch.
_seed_cloud_messages(
cfg,
n_messages=n_history_pairs,
entity_id=entity_id,
process_id=process_id,
)
query = "What do I like?"
def _prepare():
invoke = BaseInvoke(cfg, lambda **_kwargs: None)
kwargs = {"messages": [{"role": "user", "content": query}]}
kwargs = invoke.inject_conversation_messages(kwargs)
kwargs = invoke.inject_recalled_facts(kwargs)
return kwargs
result = benchmark(_prepare)
assert isinstance(result, dict)
@pytest.mark.benchmark
@pytest.mark.parametrize("n_history_pairs", [20, 100], ids=["n20", "n100"])
def test_benchmark_cloud_network_history_get(benchmark, n_history_pairs: int) -> None:
"""cloud conversation history fetched via recall (POST), no injection."""
if not os.environ.get("MEMORI_API_KEY"):
pytest.skip("Set MEMORI_API_KEY to benchmark cloud history GET.")
entity_id = os.environ.get("BENCHMARK_CLOUD_ENTITY_ID", "bench-cloud-entity")
process_id = os.environ.get("BENCHMARK_CLOUD_PROCESS_ID", "bench-cloud-process")
cfg = _make_cloud_cfg(entity_id=entity_id, process_id=process_id)
_seed_cloud_messages(
cfg,
n_messages=n_history_pairs,
entity_id=entity_id,
process_id=process_id,
)
def _call():
recall = Recall(cfg)
data = recall._cloud_recall(query="History fetch benchmark")
_facts, messages = recall._parse_cloud_recall_response(data)
return messages
result = benchmark(_call)
assert isinstance(result, list)
@pytest.mark.benchmark
@pytest.mark.parametrize("n_history_pairs", [20, 100], ids=["n20", "n100"])
def test_benchmark_cloud_network_recall_post(benchmark, n_history_pairs: int) -> None:
"""ONLY cloud recall call (POST /recall), no injection.
We seed N history pairs first so cloud has a consistent amount of data.
"""
if not os.environ.get("MEMORI_API_KEY"):
pytest.skip("Set MEMORI_API_KEY to benchmark cloud recall POST.")
entity_id = os.environ.get("BENCHMARK_CLOUD_ENTITY_ID", "bench-cloud-entity")
process_id = os.environ.get("BENCHMARK_cloud_PROCESS_ID", "bench-cloud-process")
cfg = _make_cloud_cfg(entity_id=entity_id, process_id=process_id)
_seed_cloud_messages(
cfg,
n_messages=n_history_pairs,
entity_id=entity_id,
process_id=process_id,
)
recall = Recall(cfg)
def _call():
return recall.search_facts(query="What do I like?", limit=5)
result = benchmark(_call)
assert isinstance(result, list)
@pytest.mark.benchmark
@pytest.mark.parametrize("n_history_pairs", [20, 100], ids=["n20", "n100"])
def test_benchmark_cloud_network_only_history_plus_recall(
benchmark, n_history_pairs: int
) -> None:
"""ONLY the cloud recall call (history + facts), no injection."""
if not os.environ.get("MEMORI_API_KEY"):
pytest.skip("Set MEMORI_API_KEY to benchmark cloud network-only overhead.")
entity_id = os.environ.get("BENCHMARK_cloud_ENTITY_ID", "bench-cloud-entity")
process_id = os.environ.get("BENCHMARK_CLOUD_PROCESS_ID", "bench-cloud-process")
cfg = _make_cloud_cfg(entity_id=entity_id, process_id=process_id)
_seed_cloud_messages(
cfg,
n_messages=n_history_pairs,
entity_id=entity_id,
process_id=process_id,
)
recall = Recall(cfg)
def _call():
data = recall._cloud_recall(query="What do I like?")
facts, _messages = recall._parse_cloud_recall_response(data)
return facts
result = benchmark(_call)
assert isinstance(result, list)
def _make_invoke_with_stubbed_history(
cfg: Config, *, n_history_pairs: int
) -> BaseInvoke:
history: list[dict[str, str]] = []
for i in range(n_history_pairs):
history.append({"role": "user", "content": f"I like item_{i}."})
history.append({"role": "assistant", "content": "Ok."})
invoke = BaseInvoke(cfg, lambda **_kwargs: None)
invoke._cloud_conversation_messages = history
return invoke
@pytest.mark.benchmark
@pytest.mark.parametrize("n_history_pairs", [20, 100], ids=["n20", "n100"])
def test_benchmark_cloud_injection_only_history(
benchmark, n_history_pairs: int
) -> None:
"""ONLY Python-side history injection (no network)."""
entity_id = os.environ.get("BENCHMARK_CLOUD_ENTITY_ID", "bench-cloud-entity")
process_id = os.environ.get("BENCHMARK_CLOUD_PROCESS_ID", "bench-cloud-process")
cfg = _make_cloud_cfg(entity_id=entity_id, process_id=process_id)
query = "What do I like?"
invoke = _make_invoke_with_stubbed_history(cfg, n_history_pairs=n_history_pairs)
def _call():
kwargs = {"messages": [{"role": "user", "content": query}]}
return invoke.inject_conversation_messages(kwargs)
result = benchmark(_call)
assert isinstance(result, dict)
@pytest.mark.benchmark
@pytest.mark.parametrize("n_recalled_facts", [5, 20], ids=["n5", "n20"])
def test_benchmark_cloud_injection_only_recalled_facts(
benchmark, n_recalled_facts: int, mocker
) -> None:
"""ONLY Python-side recalled-facts injection (no network)."""
entity_id = os.environ.get("BENCHMARK_CLOUD_ENTITY_ID", "bench-cloud-entity")
process_id = os.environ.get("BENCHMARK_CLOUD_PROCESS_ID", "bench-cloud-process")
cfg = _make_cloud_cfg(entity_id=entity_id, process_id=process_id)
fake_facts: list[dict[str, object]] = [
{"content": f"User likes item_{i}", "rank_score": 1.0, "date_created": None}
for i in range(n_recalled_facts)
]
mocker.patch("memori.memory.recall.Recall.search_facts", return_value=fake_facts)
invoke = BaseInvoke(cfg, lambda **_kwargs: None)
query = "What do I like?"
def _call():
kwargs = {"messages": [{"role": "user", "content": query}]}
return invoke.inject_recalled_facts(kwargs)
result = benchmark(_call)
assert isinstance(result, dict)
================================================
FILE: benchmarks/perf/test_hosted_recall_benchmarks.py
================================================
"""Cloud (Memori API) performance / latency benchmarks.
These benchmarks exercise the cloud recall path (network + API latency) rather than
local DB-backed recall.
"""
from __future__ import annotations
import os
from uuid import uuid4
import pytest
from memori._config import Config
from memori.llm._base import BaseInvoke
from memori.llm._constants import OPENAI_LLM_PROVIDER
from memori.memory._manager import Manager
from memori.memory.recall import Recall
def _make_cloud_cfg(*, entity_id: str, process_id: str) -> Config:
cfg = Config()
cfg.cloud = True
cfg.entity_id = entity_id
cfg.process_id = process_id
if cfg.session_id is None:
cfg.session_id = uuid4()
# Pick a provider so injection rules are deterministic.
cfg.llm.provider = OPENAI_LLM_PROVIDER
cfg.framework.provider = "bench"
return cfg
def _seed_cloud_messages(
cfg: Config, *, n_messages: int, entity_id: str, process_id: str
) -> None:
cfg.cloud = True
cfg.entity_id = entity_id
cfg.process_id = process_id
if cfg.session_id is None:
cfg.session_id = uuid4()
messages: list[dict[str, object]] = []
for i in range(n_messages):
messages.append({"role": "user", "type": None, "text": f"I like item_{i}."})
messages.append({"role": "assistant", "type": None, "text": "Ok."})
Manager(cfg).execute(
{
"attribution": {
"entity": {"id": str(entity_id)},
"process": {"id": str(process_id)},
},
"messages": messages,
"session": {"id": str(cfg.session_id)},
}
)
@pytest.mark.benchmark
@pytest.mark.parametrize("n_messages", [20, 100], ids=["n20", "n100"])
def test_benchmark_cloud_recall_latency(benchmark, n_messages: int) -> None:
"""Benchmark end-to-end cloud recall latency.
Includes: HTTP request + cloud service time. Excludes: local DB retrieval.
"""
os.environ["MEMORI_TEST_MODE"] = "1"
api_key = os.environ.get("MEMORI_API_KEY")
if not api_key:
pytest.skip("Set MEMORI_API_KEY to benchmark cloud recall.")
cfg = Config()
entity_id = os.environ.get("BENCHMARK_CLOUD_ENTITY_ID", "bench-cloud-entity")
process_id = os.environ.get("BENCHMARK_CLOUD_PROCESS_ID", "bench-cloud-process")
_seed_cloud_messages(
cfg,
n_messages=n_messages,
entity_id=entity_id,
process_id=process_id,
)
recall = Recall(cfg)
def _call():
return recall.search_facts(query="What do I like?", limit=5)
result = benchmark(_call)
assert isinstance(result, list)
@pytest.mark.benchmark
@pytest.mark.parametrize("n_history_pairs", [20, 100], ids=["n20", "n100"])
def test_benchmark_cloud_pre_llm_overhead(benchmark, n_history_pairs: int) -> None:
"""Benchmark Memori overhead up to the LLM call (cloud mode).
This measures the "added latency" before calling an LLM:
- (optional) fetch cloud conversation history
- cloud recall request (server-side embeddings + retrieval)
- prompt/message injection logic
It intentionally does NOT call an LLM provider.
"""
if not os.environ.get("MEMORI_API_KEY"):
pytest.skip("Set MEMORI_API_KEY to benchmark cloud pre-LLM overhead.")
entity_id = os.environ.get("BENCHMARK_CLOUD_ENTITY_ID", "bench-cloud-entity")
process_id = os.environ.get("BENCHMARK_CLOUD_PROCESS_ID", "bench-cloud-process")
cfg = _make_cloud_cfg(entity_id=entity_id, process_id=process_id)
# Seed a stable session for cloud history fetch.
_seed_cloud_messages(
cfg,
n_messages=n_history_pairs,
entity_id=entity_id,
process_id=process_id,
)
query = "What do I like?"
def _prepare():
invoke = BaseInvoke(cfg, lambda **_kwargs: None)
kwargs = {"messages": [{"role": "user", "content": query}]}
kwargs = invoke.inject_conversation_messages(kwargs)
kwargs = invoke.inject_recalled_facts(kwargs)
return kwargs
result = benchmark(_prepare)
assert isinstance(result, dict)
@pytest.mark.benchmark
@pytest.mark.parametrize("n_history_pairs", [20, 100], ids=["n20", "n100"])
def test_benchmark_cloud_network_history_get(benchmark, n_history_pairs: int) -> None:
"""cloud conversation history fetched via recall (POST), no injection."""
if not os.environ.get("MEMORI_API_KEY"):
pytest.skip("Set MEMORI_API_KEY to benchmark cloud history GET.")
entity_id = os.environ.get("BENCHMARK_CLOUD_ENTITY_ID", "bench-cloud-entity")
process_id = os.environ.get("BENCHMARK_CLOUD_PROCESS_ID", "bench-cloud-process")
cfg = _make_cloud_cfg(entity_id=entity_id, process_id=process_id)
_seed_cloud_messages(
cfg,
n_messages=n_history_pairs,
entity_id=entity_id,
process_id=process_id,
)
def _call():
recall = Recall(cfg)
data = recall._cloud_recall(query="History fetch benchmark")
_facts, messages = recall._parse_cloud_recall_response(data)
return messages
result = benchmark(_call)
assert isinstance(result, list)
@pytest.mark.benchmark
@pytest.mark.parametrize("n_history_pairs", [20, 100], ids=["n20", "n100"])
def test_benchmark_cloud_network_recall_post(benchmark, n_history_pairs: int) -> None:
"""ONLY cloud recall call (POST /recall), no injection.
We seed N history pairs first so cloud has a consistent amount of data.
"""
if not os.environ.get("MEMORI_API_KEY"):
pytest.skip("Set MEMORI_API_KEY to benchmark cloud recall POST.")
entity_id = os.environ.get("BENCHMARK_CLOUD_ENTITY_ID", "bench-cloud-entity")
process_id = os.environ.get("BENCHMARK_cloud_PROCESS_ID", "bench-cloud-process")
cfg = _make_cloud_cfg(entity_id=entity_id, process_id=process_id)
_seed_cloud_messages(
cfg,
n_messages=n_history_pairs,
entity_id=entity_id,
process_id=process_id,
)
recall = Recall(cfg)
def _call():
return recall.search_facts(query="What do I like?", limit=5)
result = benchmark(_call)
assert isinstance(result, list)
@pytest.mark.benchmark
@pytest.mark.parametrize("n_history_pairs", [20, 100], ids=["n20", "n100"])
def test_benchmark_cloud_network_only_history_plus_recall(
benchmark, n_history_pairs: int
) -> None:
"""ONLY the cloud recall call (history + facts), no injection."""
if not os.environ.get("MEMORI_API_KEY"):
pytest.skip("Set MEMORI_API_KEY to benchmark cloud network-only overhead.")
entity_id = os.environ.get("BENCHMARK_cloud_ENTITY_ID", "bench-cloud-entity")
process_id = os.environ.get("BENCHMARK_CLOUD_PROCESS_ID", "bench-cloud-process")
cfg = _make_cloud_cfg(entity_id=entity_id, process_id=process_id)
_seed_cloud_messages(
cfg,
n_messages=n_history_pairs,
entity_id=entity_id,
process_id=process_id,
)
recall = Recall(cfg)
def _call():
data = recall._cloud_recall(query="What do I like?")
facts, _messages = recall._parse_cloud_recall_response(data)
return facts
result = benchmark(_call)
assert isinstance(result, list)
def _make_invoke_with_stubbed_history(
cfg: Config, *, n_history_pairs: int
) -> BaseInvoke:
history: list[dict[str, str]] = []
for i in range(n_history_pairs):
history.append({"role": "user", "content": f"I like item_{i}."})
history.append({"role": "assistant", "content": "Ok."})
invoke = BaseInvoke(cfg, lambda **_kwargs: None)
invoke._cloud_conversation_messages = history
return invoke
@pytest.mark.benchmark
@pytest.mark.parametrize("n_history_pairs", [20, 100], ids=["n20", "n100"])
def test_benchmark_cloud_injection_only_history(
benchmark, n_history_pairs: int
) -> None:
"""ONLY Python-side history injection (no network)."""
entity_id = os.environ.get("BENCHMARK_CLOUD_ENTITY_ID", "bench-cloud-entity")
process_id = os.environ.get("BENCHMARK_CLOUD_PROCESS_ID", "bench-cloud-process")
cfg = _make_cloud_cfg(entity_id=entity_id, process_id=process_id)
query = "What do I like?"
invoke = _make_invoke_with_stubbed_history(cfg, n_history_pairs=n_history_pairs)
def _call():
kwargs = {"messages": [{"role": "user", "content": query}]}
return invoke.inject_conversation_messages(kwargs)
result = benchmark(_call)
assert isinstance(result, dict)
@pytest.mark.benchmark
@pytest.mark.parametrize("n_recalled_facts", [5, 20], ids=["n5", "n20"])
def test_benchmark_cloud_injection_only_recalled_facts(
benchmark, n_recalled_facts: int, mocker
) -> None:
"""ONLY Python-side recalled-facts injection (no network)."""
entity_id = os.environ.get("BENCHMARK_CLOUD_ENTITY_ID", "bench-cloud-entity")
process_id = os.environ.get("BENCHMARK_CLOUD_PROCESS_ID", "bench-cloud-process")
cfg = _make_cloud_cfg(entity_id=entity_id, process_id=process_id)
fake_facts: list[dict[str, object]] = [
{"content": f"User likes item_{i}", "rank_score": 1.0, "date_created": None}
for i in range(n_recalled_facts)
]
mocker.patch("memori.memory.recall.Recall.search_facts", return_value=fake_facts)
invoke = BaseInvoke(cfg, lambda **_kwargs: None)
query = "What do I like?"
def _call():
kwargs = {"messages": [{"role": "user", "content": query}]}
return invoke.inject_recalled_facts(kwargs)
result = benchmark(_call)
assert isinstance(result, dict)
================================================
FILE: benchmarks/perf/test_recall_benchmarks.py
================================================
"""Performance benchmarks for Memori recall functionality."""
import datetime
import os
from time import perf_counter
from typing import cast
import pytest
from benchmarks.perf._results import append_csv_row, results_dir
from benchmarks.perf.memory_utils import measure_peak_rss_bytes
from memori._config import Config
from memori.embeddings import embed_texts
from memori.memory.recall import Recall
from memori.search import find_similar_embeddings
from memori.search._lexical import lexical_scores_for_ids # noqa: PLC2701
from memori.search._types import FactId
def _default_benchmark_csv_path() -> str:
return str(results_dir() / "recall_benchmarks.csv")
def _write_benchmark_row(*, benchmark, row: dict[str, object]) -> None:
csv_path = (
os.environ.get("BENCHMARK_RESULTS_CSV_PATH") or _default_benchmark_csv_path()
)
stats = getattr(benchmark, "stats", None)
row_out: dict[str, object] = dict(row)
row_out["timestamp_utc"] = datetime.datetime.now(datetime.timezone.utc).isoformat()
for key in (
"mean",
"stddev",
"median",
"min",
"max",
"rounds",
"iterations",
"ops",
):
value = getattr(stats, key, None) if stats is not None else None
if value is not None:
row_out[key] = value
header = [
"timestamp_utc",
"test",
"db",
"fact_count",
"query_size",
"retrieval_limit",
"one_shot_seconds",
"peak_rss_bytes",
"mean",
"stddev",
"median",
"min",
"max",
"rounds",
"iterations",
"ops",
]
append_csv_row(csv_path, header=header, row=row_out)
@pytest.mark.benchmark
class TestQueryEmbeddingBenchmarks:
"""Benchmarks for query embedding generation."""
def test_benchmark_query_embedding_short(self, benchmark, sample_queries):
"""Benchmark embedding generation for short queries."""
query = sample_queries["short"][0]
cfg = Config()
def _embed():
return embed_texts(
query,
model=cfg.embeddings.model,
)
start = perf_counter()
result = benchmark(_embed)
one_shot_seconds = perf_counter() - start
assert len(result) > 0
assert len(result[0]) > 0
_write_benchmark_row(
benchmark=benchmark,
row={
"test": "query_embedding_short",
"db": "",
"fact_count": "",
"query_size": "short",
"retrieval_limit": "",
"one_shot_seconds": one_shot_seconds,
"peak_rss_bytes": benchmark.extra_info.get("peak_rss_bytes", ""),
},
)
def test_benchmark_query_embedding_medium(self, benchmark, sample_queries):
"""Benchmark embedding generation for medium-length queries."""
query = sample_queries["medium"][0]
cfg = Config()
def _embed():
return embed_texts(
query,
model=cfg.embeddings.model,
)
start = perf_counter()
result = benchmark(_embed)
one_shot_seconds = perf_counter() - start
assert len(result) > 0
assert len(result[0]) > 0
_write_benchmark_row(
benchmark=benchmark,
row={
"test": "query_embedding_medium",
"db": "",
"fact_count": "",
"query_size": "medium",
"retrieval_limit": "",
"one_shot_seconds": one_shot_seconds,
"peak_rss_bytes": benchmark.extra_info.get("peak_rss_bytes", ""),
},
)
def test_benchmark_query_embedding_long(self, benchmark, sample_queries):
"""Benchmark embedding generation for long queries."""
query = sample_queries["long"][0]
cfg = Config()
def _embed():
return embed_texts(
query,
model=cfg.embeddings.model,
)
start = perf_counter()
result = benchmark(_embed)
one_shot_seconds = perf_counter() - start
assert len(result) > 0
assert len(result[0]) > 0
_write_benchmark_row(
benchmark=benchmark,
row={
"test": "query_embedding_long",
"db": "",
"fact_count": "",
"query_size": "long",
"retrieval_limit": "",
"one_shot_seconds": one_shot_seconds,
"peak_rss_bytes": benchmark.extra_info.get("peak_rss_bytes", ""),
},
)
def test_benchmark_query_embedding_batch(self, benchmark, sample_queries):
"""Benchmark embedding generation for multiple queries at once."""
queries = sample_queries["short"][:5]
cfg = Config()
def _embed():
return embed_texts(
queries,
model=cfg.embeddings.model,
)
start = perf_counter()
result = benchmark(_embed)
one_shot_seconds = perf_counter() - start
assert len(result) == len(queries)
assert all(len(emb) > 0 for emb in result)
_write_benchmark_row(
benchmark=benchmark,
row={
"test": "query_embedding_batch",
"db": "",
"fact_count": "",
"query_size": "batch",
"retrieval_limit": "",
"one_shot_seconds": one_shot_seconds,
"peak_rss_bytes": benchmark.extra_info.get("peak_rss_bytes", ""),
},
)
@pytest.mark.benchmark
class TestDatabaseEmbeddingRetrievalBenchmarks:
"""Benchmarks for database embedding retrieval."""
def test_benchmark_db_embedding_retrieval(
self, benchmark, memori_instance, entity_with_n_facts
):
"""Benchmark retrieving embeddings from database for different fact counts."""
entity_db_id = entity_with_n_facts["entity_db_id"]
fact_count = entity_with_n_facts["fact_count"]
entity_fact_driver = memori_instance.config.storage.driver.entity_fact
def _retrieve():
return entity_fact_driver.get_embeddings(entity_db_id, limit=fact_count)
_, peak_rss = measure_peak_rss_bytes(_retrieve)
if peak_rss is not None:
benchmark.extra_info["peak_rss_bytes"] = peak_rss
result = benchmark(_retrieve)
assert len(result) == fact_count
assert all("id" in row and "content_embedding" in row for row in result)
_write_benchmark_row(
benchmark=benchmark,
row={
"test": "db_embedding_retrieval",
"db": entity_with_n_facts["db_type"],
"fact_count": fact_count,
"query_size": "",
"retrieval_limit": "",
"one_shot_secon
gitextract_gi5dzs00/
├── .dockerignore
├── .github/
│ ├── ISSUE_TEMPLATE/
│ │ ├── bug_report.yml
│ │ ├── config.yml
│ │ └── feature_request.yml
│ └── workflows/
│ ├── ci.yml
│ ├── integration.yml
│ ├── publish-npm.yml
│ ├── publish-openclaw-plugin.yml
│ ├── publish.yml
│ ├── ts-ci.yml
│ └── ts-openclaw-ci.yml
├── .gitignore
├── .pre-commit-config.yaml
├── CHANGELOG.md
├── CONTRIBUTING.md
├── Dockerfile
├── LICENSE
├── MANIFEST.in
├── Makefile
├── README.md
├── SECURITY.md
├── benchmarks/
│ ├── README.md
│ ├── locomo/
│ │ ├── _run_impl.py
│ │ ├── _types.py
│ │ ├── loader.py
│ │ ├── preprocess.py
│ │ ├── provenance.py
│ │ ├── report.py
│ │ ├── retrieval.py
│ │ ├── run.py
│ │ └── scoring.py
│ ├── perf/
│ │ ├── README.md
│ │ ├── _results.py
│ │ ├── conftest.py
│ │ ├── fixtures/
│ │ │ ├── sample_data.py
│ │ │ └── sample_facts.py
│ │ ├── generate_percentile_report.py
│ │ ├── memory_utils.py
│ │ ├── run_benchmarks_ec2.sh
│ │ ├── setup_ec2_benchmarks.sh
│ │ ├── test_cloud_recall_benchmarks.py
│ │ ├── test_hosted_recall_benchmarks.py
│ │ └── test_recall_benchmarks.py
│ └── scripts/
│ └── fetch_locomo.py
├── conftest.py
├── docker-compose.yml
├── docs/
│ ├── memori-byodb/
│ │ ├── concepts/
│ │ │ ├── advanced-augmentation.mdx
│ │ │ ├── architecture.mdx
│ │ │ ├── async-patterns.mdx
│ │ │ ├── cli-quickstart.mdx
│ │ │ ├── how-memory-works.mdx
│ │ │ ├── knowledge-graph.mdx
│ │ │ └── multi-user-support.mdx
│ │ ├── contribute/
│ │ │ ├── development-setup.mdx
│ │ │ └── overview.mdx
│ │ ├── dashboard/
│ │ │ └── api-keys.mdx
│ │ ├── databases/
│ │ │ ├── cockroachdb.mdx
│ │ │ ├── mongodb.mdx
│ │ │ ├── mysql.mdx
│ │ │ ├── oracle.mdx
│ │ │ ├── overview.mdx
│ │ │ ├── postgres.mdx
│ │ │ └── sqlite.mdx
│ │ ├── getting-started/
│ │ │ ├── installation.mdx
│ │ │ ├── python-quickstart.mdx
│ │ │ └── use-cases.mdx
│ │ ├── index.mdx
│ │ ├── llm/
│ │ │ ├── agno.mdx
│ │ │ ├── anthropic.mdx
│ │ │ ├── aws-bedrock.mdx
│ │ │ ├── deepseek.mdx
│ │ │ ├── gemini.mdx
│ │ │ ├── langchain.mdx
│ │ │ ├── nebius.mdx
│ │ │ ├── openai.mdx
│ │ │ ├── overview.mdx
│ │ │ ├── pydantic-ai.mdx
│ │ │ └── xai-grok.mdx
│ │ └── support/
│ │ ├── faq.mdx
│ │ └── troubleshooting.mdx
│ └── memori-cloud/
│ ├── benchmark/
│ │ ├── experiments.mdx
│ │ ├── overview.mdx
│ │ └── results.mdx
│ ├── concepts/
│ │ ├── advanced-augmentation.mdx
│ │ ├── architecture.mdx
│ │ ├── async-patterns.mdx
│ │ ├── how-memory-works.mdx
│ │ ├── knowledge-graph.mdx
│ │ └── multi-user-support.mdx
│ ├── dashboard/
│ │ ├── analytics.mdx
│ │ ├── api-keys.mdx
│ │ ├── memories.mdx
│ │ ├── overview.mdx
│ │ └── playground.mdx
│ ├── getting-started/
│ │ ├── installation.mdx
│ │ ├── python-quickstart.mdx
│ │ ├── typescript-quickstart.mdx
│ │ └── use-cases.mdx
│ ├── index.mdx
│ ├── llm/
│ │ ├── agno.mdx
│ │ ├── anthropic.mdx
│ │ ├── aws-bedrock.mdx
│ │ ├── deepseek.mdx
│ │ ├── gemini.mdx
│ │ ├── langchain.mdx
│ │ ├── nebius.mdx
│ │ ├── openai.mdx
│ │ ├── overview.mdx
│ │ ├── pydantic-ai.mdx
│ │ └── xai-grok.mdx
│ ├── mcp/
│ │ ├── agent-skills.mdx
│ │ ├── client-setup.mdx
│ │ └── overview.mdx
│ ├── openclaw/
│ │ ├── overview.mdx
│ │ └── quickstart.mdx
│ └── support/
│ ├── faq.mdx
│ └── troubleshooting.mdx
├── examples/
│ ├── agno/
│ │ ├── README.md
│ │ ├── main.py
│ │ └── pyproject.toml
│ ├── cockroachdb/
│ │ ├── README.md
│ │ ├── main.py
│ │ └── pyproject.toml
│ ├── digitalocean/
│ │ ├── README.md
│ │ ├── main.py
│ │ └── pyproject.toml
│ ├── mongodb/
│ │ ├── README.md
│ │ ├── main.py
│ │ └── pyproject.toml
│ ├── nebius/
│ │ ├── README.md
│ │ ├── main.py
│ │ └── pyproject.toml
│ ├── neon/
│ │ ├── README.md
│ │ ├── main.py
│ │ └── pyproject.toml
│ ├── oceanbase/
│ │ ├── README.md
│ │ └── main.py
│ ├── postgres/
│ │ ├── README.md
│ │ ├── main.py
│ │ └── pyproject.toml
│ └── sqlite/
│ ├── README.md
│ ├── main.py
│ └── pyproject.toml
├── integrations/
│ └── openclaw/
│ ├── .prettierrc.json
│ ├── README.md
│ ├── eslint.config.js
│ ├── openclaw.plugin.json
│ ├── package-lock.json
│ ├── package.json
│ ├── src/
│ │ ├── constants.ts
│ │ ├── handlers/
│ │ │ ├── augmentation.ts
│ │ │ └── recall.ts
│ │ ├── index.ts
│ │ ├── sanitizer.ts
│ │ ├── types.ts
│ │ ├── utils/
│ │ │ ├── context.ts
│ │ │ ├── index.ts
│ │ │ ├── logger.ts
│ │ │ └── memori-client.ts
│ │ └── version.ts
│ ├── tests/
│ │ ├── handlers/
│ │ │ ├── augmentation.test.ts
│ │ │ └── recall.test.ts
│ │ ├── index.test.ts
│ │ ├── sanitizer.test.ts
│ │ └── utils/
│ │ ├── context.test.ts
│ │ ├── logger.test.ts
│ │ └── memori-client.test.ts
│ ├── tsconfig.json
│ └── vitest.config.ts
├── memori/
│ ├── __init__.py
│ ├── __main__.py
│ ├── _cli.py
│ ├── _config.py
│ ├── _exceptions.py
│ ├── _logging.py
│ ├── _network.py
│ ├── _setup.py
│ ├── _utils.py
│ ├── api/
│ │ ├── _quota.py
│ │ └── _sign_up.py
│ ├── embeddings/
│ │ ├── __init__.py
│ │ ├── _api.py
│ │ ├── _chunking.py
│ │ ├── _format.py
│ │ ├── _sentence_transformers.py
│ │ ├── _tei.py
│ │ ├── _tei_embed.py
│ │ └── _utils.py
│ ├── llm/
│ │ ├── __init__.py
│ │ ├── _base.py
│ │ ├── _clients.py
│ │ ├── _constants.py
│ │ ├── _invoke.py
│ │ ├── _iterable.py
│ │ ├── _iterator.py
│ │ ├── _providers.py
│ │ ├── _registry.py
│ │ ├── _streaming.py
│ │ ├── _utils.py
│ │ ├── _xai_wrappers.py
│ │ └── adapters/
│ │ ├── anthropic/
│ │ │ ├── __init__.py
│ │ │ └── _adapter.py
│ │ ├── bedrock/
│ │ │ ├── __init__.py
│ │ │ └── _adapter.py
│ │ ├── google/
│ │ │ ├── __init__.py
│ │ │ └── _adapter.py
│ │ ├── openai/
│ │ │ ├── __init__.py
│ │ │ └── _adapter.py
│ │ └── xai/
│ │ ├── __init__.py
│ │ └── _adapter.py
│ ├── memory/
│ │ ├── _collector.py
│ │ ├── _conversation_messages.py
│ │ ├── _manager.py
│ │ ├── _struct.py
│ │ ├── _writer.py
│ │ ├── augmentation/
│ │ │ ├── __init__.py
│ │ │ ├── _base.py
│ │ │ ├── _db_writer.py
│ │ │ ├── _handler.py
│ │ │ ├── _manager.py
│ │ │ ├── _message.py
│ │ │ ├── _models.py
│ │ │ ├── _registry.py
│ │ │ ├── _runtime.py
│ │ │ ├── augmentations/
│ │ │ │ └── memori/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── _augmentation.py
│ │ │ │ └── models.py
│ │ │ ├── input.py
│ │ │ └── memories/
│ │ │ ├── _conversation.py
│ │ │ ├── _entity.py
│ │ │ └── _process.py
│ │ └── recall.py
│ ├── py.typed
│ ├── search/
│ │ ├── __init__.py
│ │ ├── _api.py
│ │ ├── _core.py
│ │ ├── _faiss.py
│ │ ├── _lexical.py
│ │ ├── _parsing.py
│ │ └── _types.py
│ └── storage/
│ ├── __init__.py
│ ├── _base.py
│ ├── _builder.py
│ ├── _connection.py
│ ├── _manager.py
│ ├── _registry.py
│ ├── adapters/
│ │ ├── dbapi/
│ │ │ ├── __init__.py
│ │ │ └── _adapter.py
│ │ ├── django/
│ │ │ ├── __init__.py
│ │ │ └── _adapter.py
│ │ ├── mongodb/
│ │ │ ├── __init__.py
│ │ │ └── _adapter.py
│ │ └── sqlalchemy/
│ │ ├── __init__.py
│ │ └── _adapter.py
│ ├── cockroachdb/
│ │ ├── _cluster_manager.py
│ │ ├── _display.py
│ │ └── _files.py
│ ├── drivers/
│ │ ├── mongodb/
│ │ │ ├── __init__.py
│ │ │ └── _driver.py
│ │ ├── mysql/
│ │ │ ├── __init__.py
│ │ │ └── _driver.py
│ │ ├── oceanbase/
│ │ │ ├── __init__.py
│ │ │ └── _driver.py
│ │ ├── oracle/
│ │ │ ├── __init__.py
│ │ │ └── _driver.py
│ │ ├── postgresql/
│ │ │ ├── __init__.py
│ │ │ └── _driver.py
│ │ └── sqlite/
│ │ ├── __init__.py
│ │ └── _driver.py
│ └── migrations/
│ ├── _mongodb.py
│ ├── _mysql.py
│ ├── _oceanbase.py
│ ├── _oracle.py
│ ├── _postgresql.py
│ └── _sqlite.py
├── memori-ts/
│ ├── .npmignore
│ ├── .prettierrc.json
│ ├── README.md
│ ├── eslint.config.js
│ ├── examples/
│ │ └── cloud/
│ │ └── simple.ts
│ ├── package-lock.json
│ ├── package.json
│ ├── src/
│ │ ├── bin/
│ │ │ └── cli.ts
│ │ ├── cli/
│ │ │ ├── commands/
│ │ │ │ ├── help.ts
│ │ │ │ └── quota.ts
│ │ │ ├── router.ts
│ │ │ └── utils.ts
│ │ ├── core/
│ │ │ ├── config.ts
│ │ │ ├── errors.ts
│ │ │ ├── network.ts
│ │ │ └── session.ts
│ │ ├── engines/
│ │ │ ├── augmentation.ts
│ │ │ ├── persistence.ts
│ │ │ └── recall.ts
│ │ ├── index.ts
│ │ ├── integrations/
│ │ │ ├── base.ts
│ │ │ ├── index.ts
│ │ │ └── openclaw.ts
│ │ ├── memori.ts
│ │ ├── types/
│ │ │ ├── api.ts
│ │ │ └── integrations.ts
│ │ ├── utils/
│ │ │ └── utils.ts
│ │ └── version.ts
│ ├── tests/
│ │ ├── cli/
│ │ │ ├── bin/
│ │ │ │ └── router.test.ts
│ │ │ ├── commands/
│ │ │ │ ├── help.test.ts
│ │ │ │ └── quota.test.ts
│ │ │ └── utils.test.ts
│ │ ├── core/
│ │ │ ├── config.test.ts
│ │ │ ├── network.test.ts
│ │ │ └── session.test.ts
│ │ ├── engines/
│ │ │ ├── augmentation.test.ts
│ │ │ ├── persistence.test.ts
│ │ │ └── recall.test.ts
│ │ ├── integrations/
│ │ │ ├── base.test.ts
│ │ │ └── openclaw.test.ts
│ │ ├── memori.test.ts
│ │ └── utils/
│ │ └── utils.test.ts
│ ├── tsconfig.build.json
│ ├── tsconfig.json
│ └── vitest.config.ts
├── pyproject.toml
└── tests/
├── benchmarks_locomo/
│ ├── test_locomo_aa_pairing.py
│ ├── test_locomo_loader.py
│ ├── test_locomo_preprocess.py
│ ├── test_locomo_provenance.py
│ └── test_locomo_run_and_report.py
├── build/
│ ├── mongodb.py
│ ├── mysql.py
│ ├── oceanbase.py
│ ├── oracle.py
│ ├── postgresql.py
│ └── sqlite.py
├── database/
│ ├── core.py
│ └── init_db.py
├── embeddings/
│ └── test_tei_chunking.py
├── integration/
│ ├── __init__.py
│ ├── cloud/
│ │ ├── __init__.py
│ │ ├── conftest.py
│ │ ├── test_cloud_anthropic.py
│ │ ├── test_cloud_bedrock.py
│ │ ├── test_cloud_gemini.py
│ │ ├── test_cloud_openai.py
│ │ └── test_cloud_xai.py
│ ├── conftest.py
│ ├── databases/
│ │ ├── __init__.py
│ │ ├── conftest.py
│ │ └── test_database_storage.py
│ ├── providers/
│ │ ├── __init__.py
│ │ ├── test_anthropic.py
│ │ ├── test_bedrock.py
│ │ ├── test_google.py
│ │ ├── test_openai.py
│ │ └── test_xai.py
│ └── test_aa_payload.py
├── llm/
│ ├── adapters/
│ │ ├── anthropic/
│ │ │ └── test_llm_adapters_anthropic_adapter.py
│ │ ├── bedrock/
│ │ │ └── test_llm_adapters_bedrock_adapter.py
│ │ ├── google/
│ │ │ └── test_llm_adapters_google_adapter.py
│ │ ├── openai/
│ │ │ └── test_llm_adapters_openai_adapter.py
│ │ └── xai/
│ │ └── test_llm_adapters_xai_adapter.py
│ ├── clients/
│ │ └── oss/
│ │ ├── agno/
│ │ │ ├── anthropic_async.py
│ │ │ ├── anthropic_sync.py
│ │ │ ├── gemini_async.py
│ │ │ ├── gemini_streaming.py
│ │ │ ├── gemini_sync.py
│ │ │ ├── openai_async.py
│ │ │ ├── openai_streaming.py
│ │ │ ├── openai_sync.py
│ │ │ ├── xai_async.py
│ │ │ ├── xai_streaming.py
│ │ │ └── xai_sync.py
│ │ ├── anthropic/
│ │ │ ├── async.py
│ │ │ └── sync.py
│ │ ├── gemini/
│ │ │ ├── async.py
│ │ │ ├── async_streaming.py
│ │ │ └── sync.py
│ │ ├── langchain/
│ │ │ ├── chatbedrock/
│ │ │ │ └── async_runnable.py
│ │ │ ├── chatgooglegenai/
│ │ │ │ ├── async_runnable.py
│ │ │ │ ├── async_streaming.py
│ │ │ │ ├── sync.py
│ │ │ │ ├── sync_runnable.py
│ │ │ │ └── sync_runnable_structured_output.py
│ │ │ ├── chatopenai/
│ │ │ │ ├── async_ainvoke.py
│ │ │ │ ├── async_runnable.py
│ │ │ │ ├── async_streaming.py
│ │ │ │ ├── sync.py
│ │ │ │ ├── sync_runnable.py
│ │ │ │ └── sync_runnable_structured_output.py
│ │ │ └── chatvertexai/
│ │ │ └── sync.py
│ │ ├── openai/
│ │ │ ├── async.py
│ │ │ ├── async_streaming.py
│ │ │ └── sync.py
│ │ └── xai/
│ │ ├── async.py
│ │ ├── async_stream.py
│ │ └── sync.py
│ ├── providers/
│ │ ├── __init__.py
│ │ ├── azure_openai/
│ │ │ ├── __init__.py
│ │ │ └── test_azure_openai.py
│ │ └── google_genai/
│ │ ├── __init__.py
│ │ └── test_google_genai.py
│ ├── test_llm_base.py
│ ├── test_llm_clients.py
│ ├── test_llm_deprecation_warnings.py
│ ├── test_llm_embeddings.py
│ ├── test_llm_embeddings_bundled.py
│ ├── test_llm_provider_sdk_version.py
│ ├── test_llm_registry.py
│ ├── test_llm_utils.py
│ ├── test_llm_xai_wrappers.py
│ └── unit_test_objects.py
├── memory/
│ ├── augmentation/
│ │ ├── test_aa_payload_unit.py
│ │ ├── test_advanced_augmentation.py
│ │ ├── test_base.py
│ │ ├── test_handler.py
│ │ ├── test_manager.py
│ │ ├── test_manager_quota.py
│ │ ├── test_models.py
│ │ ├── test_quota_propagation.py
│ │ └── test_registry.py
│ ├── test_conversation_messages.py
│ ├── test_manager_enterprise_retry.py
│ ├── test_memory_augmentation_db_writer.py
│ ├── test_memory_struct.py
│ ├── test_memory_struct_triples.py
│ ├── test_memory_writer.py
│ ├── test_recall.py
│ └── test_recall_eval_harness.py
├── storage/
│ ├── adapters/
│ │ ├── conftest.py
│ │ ├── dbapi/
│ │ │ ├── test_dbapi_no_conflicts.py
│ │ │ └── test_storage_adapters_dbapi_adapter.py
│ │ ├── django/
│ │ │ └── test_storage_adapters_django_adapter.py
│ │ └── sqlalchemy/
│ │ └── test_storage_adaptors_sqlalchemy_adapter.py
│ ├── cockroachdb/
│ │ ├── test_storage_cockroachdb_display.py
│ │ └── test_storage_cockroachdb_files.py
│ ├── drivers/
│ │ ├── conftest.py
│ │ ├── test_mongodb_driver.py
│ │ ├── test_mysql_driver.py
│ │ ├── test_oceanbase_driver.py
│ │ ├── test_oracle_driver.py
│ │ ├── test_postgresql_driver.py
│ │ └── test_sqlite_driver.py
│ ├── test_connection.py
│ ├── test_connection_factory.py
│ ├── test_storage_builder.py
│ ├── test_storage_init.py
│ ├── test_storage_manager.py
│ └── test_storage_registry.py
├── test_cli.py
├── test_config.py
├── test_init.py
├── test_legacy_package_warning.py
├── test_llm_auto_registration.py
├── test_network.py
├── test_search.py
└── test_utils.py
Showing preview only (237K chars total). Download the full file or copy to clipboard to get everything.
SYMBOL INDEX (2376 symbols across 232 files)
FILE: benchmarks/locomo/_run_impl.py
class RunConfig (line 42) | class RunConfig:
class PairRequest (line 74) | class PairRequest:
function run_locomo (line 79) | def run_locomo(cfg: RunConfig) -> dict:
function _resolve_run_id (line 386) | def _resolve_run_id(
function _distinct_run_ids_from_provenance_sqlite (line 424) | def _distinct_run_ids_from_provenance_sqlite(path: Path) -> set[str]:
function _distinct_run_ids_from_memori_sqlite (line 435) | def _distinct_run_ids_from_memori_sqlite(path: Path) -> set[str]:
function _get_entity_id_sqlite (line 458) | def _get_entity_id_sqlite(*, sqlite_path: Path, entity_external_id: str)...
function _count_entity_facts_sqlite (line 473) | def _count_entity_facts_sqlite(*, sqlite_path: Path, entity_db_id: int) ...
function _init_memori (line 488) | def _init_memori(sqlite_path: Path) -> Memori:
function _configure_aa_meta (line 497) | def _configure_aa_meta(mem: Memori, cfg: RunConfig) -> None:
function _ingest_with_advanced_augmentation (line 505) | def _ingest_with_advanced_augmentation(
function _aa_enqueue_pairs_sequential (line 532) | def _aa_enqueue_pairs_sequential(
function _read_conversation_summary (line 590) | def _read_conversation_summary(mem: Memori, conversation_id: int) -> str...
function _create_conversation_and_persist_messages (line 601) | def _create_conversation_and_persist_messages(
function _enqueue_aa (line 617) | def _enqueue_aa(
function _build_aa_messages_for_sample (line 635) | def _build_aa_messages_for_sample(sample) -> list[dict[str, str]]:
function _build_aa_messages_for_session (line 640) | def _build_aa_messages_for_session(sample, session) -> list[dict[str, st...
function _build_aa_messages_for_turns (line 648) | def _build_aa_messages_for_turns(
function _build_aa_messages_and_turn_ids_for_sample (line 657) | def _build_aa_messages_and_turn_ids_for_sample(
function _build_aa_messages_and_turn_ids_for_turns (line 672) | def _build_aa_messages_and_turn_ids_for_turns(
function _format_turn_content (line 695) | def _format_turn_content(
function _speaker_to_role (line 703) | def _speaker_to_role(sample) -> dict[str, str]:
function _build_aa_provenance (line 719) | def _build_aa_provenance(
function _write_aa_payload_preview (line 771) | def _write_aa_payload_preview(
function _build_per_pair_requests (line 861) | def _build_per_pair_requests(
function _format_top_k (line 894) | def _format_top_k(
class _Totals (line 945) | class _Totals:
method __init__ (line 946) | def __init__(self) -> None:
method count_question (line 961) | def count_question(self, category: str | None) -> None:
method add_metrics (line 966) | def add_metrics(self, *, category: str, metrics: dict[str, float]) -> ...
method to_summary (line 985) | def to_summary(
FILE: benchmarks/locomo/_types.py
class LoCoMoTurn (line 8) | class LoCoMoTurn:
class LoCoMoSession (line 16) | class LoCoMoSession:
class LoCoMoQA (line 23) | class LoCoMoQA:
class LoCoMoSample (line 32) | class LoCoMoSample:
FILE: benchmarks/locomo/loader.py
function load_locomo_json (line 11) | def load_locomo_json(path: str | Path) -> list[LoCoMoSample]:
function _parse_conversation (line 34) | def _parse_conversation(value: Any) -> tuple[LoCoMoSession, ...]:
function _parse_conversation_dict (line 62) | def _parse_conversation_dict(value: dict[str, Any]) -> tuple[LoCoMoSessi...
function _parse_turns (line 84) | def _parse_turns(value: Any, *, context: str) -> tuple[LoCoMoTurn, ...]:
function _parse_qa (line 111) | def _parse_qa(value: Any) -> tuple[LoCoMoQA, ...]:
function _coerce_str (line 148) | def _coerce_str(value: Any) -> str | None:
function _coerce_answers (line 157) | def _coerce_answers(value: Any) -> tuple[str, ...]:
FILE: benchmarks/locomo/preprocess.py
function preprocess_locomo_json (line 14) | def preprocess_locomo_json(in_path: str | Path, out_path: str | Path) ->...
function _strip_multimodal_fields_inplace (line 64) | def _strip_multimodal_fields_inplace(conversation: Any) -> int:
function _rewrite_speakers_inplace (line 76) | def _rewrite_speakers_inplace(conversation: Any, *, assistant_speaker: s...
function _iter_turn_dicts (line 82) | def _iter_turn_dicts(conversation: Any):
function _coerce_str (line 124) | def _coerce_str(value: Any) -> str | None:
function main (line 133) | def main(argv: list[str] | None = None) -> int:
FILE: benchmarks/locomo/provenance.py
class FactAttribution (line 17) | class FactAttribution:
class ProvenanceStore (line 23) | class ProvenanceStore:
method __init__ (line 24) | def __init__(self, path: str | Path) -> None:
method _connect (line 29) | def _connect(self) -> sqlite3.Connection:
method _ensure_schema (line 32) | def _ensure_schema(self) -> None:
method upsert_many (line 54) | def upsert_many(
method best_dia_ids_for_fact (line 73) | def best_dia_ids_for_fact(
method has_any (line 91) | def has_any(self, *, run_id: str, sample_id: str) -> bool:
method delete_sample (line 104) | def delete_sample(self, *, run_id: str, sample_id: str) -> None:
function attribute_facts_to_turn_ids (line 116) | def attribute_facts_to_turn_ids(
function _tokenize (line 232) | def _tokenize(text: str) -> list[str]:
function _lexical_scores (line 237) | def _lexical_scores(*, query_text: str, docs: list[str]) -> list[float]:
FILE: benchmarks/locomo/report.py
function main (line 11) | def main(argv: list[str] | None = None) -> int:
function _read_jsonl (line 119) | def _read_jsonl(path: Path) -> list[dict[str, Any]]:
function _coerce_str (line 128) | def _coerce_str(value: Any) -> str | None:
FILE: benchmarks/locomo/retrieval.py
class TurnFact (line 11) | class TurnFact:
function build_turn_facts (line 19) | def build_turn_facts(
function extract_turn_id_from_content (line 43) | def extract_turn_id_from_content(content: str) -> str | None:
function evidence_to_turn_ids (line 51) | def evidence_to_turn_ids(
function _add_evidence_obj (line 85) | def _add_evidence_obj(
function _add_evidence_turn_index (line 101) | def _add_evidence_turn_index(
function _coerce_str (line 113) | def _coerce_str(value: Any) -> str | None:
function _coerce_int (line 122) | def _coerce_int(value: Any) -> int | None:
FILE: benchmarks/locomo/run.py
function main (line 7) | def main(argv: list[str] | None = None) -> int:
FILE: benchmarks/locomo/scoring.py
function hit_at_k (line 4) | def hit_at_k(relevant: set[str], retrieved: list[str], k: int) -> float:
function mrr (line 11) | def mrr(relevant: set[str], retrieved: list[str]) -> float:
function hit_at_k_groups (line 20) | def hit_at_k_groups(relevant: set[str], retrieved: list[set[str]], k: in...
function mrr_groups (line 35) | def mrr_groups(relevant: set[str], retrieved: list[set[str]]) -> float:
FILE: benchmarks/perf/_results.py
function repo_root (line 8) | def repo_root() -> Path:
function results_dir (line 12) | def results_dir() -> Path:
function append_csv_row (line 18) | def append_csv_row(path: str | Path, *, header: list[str], row: dict[str...
FILE: benchmarks/perf/conftest.py
function postgres_db_connection (line 18) | def postgres_db_connection():
function mysql_db_connection (line 62) | def mysql_db_connection():
function db_connection (line 93) | def db_connection(request):
function memori_instance (line 106) | def memori_instance(db_connection, request):
function sample_queries (line 134) | def sample_queries():
function fact_content_size (line 140) | def fact_content_size():
function entity_with_n_facts (line 152) | def entity_with_n_facts(memori_instance, fact_content_size, request):
FILE: benchmarks/perf/fixtures/sample_data.py
function generate_random_string (line 9) | def generate_random_string(length: int = 10) -> str:
function generate_sample_fact (line 14) | def generate_sample_fact() -> str:
function generate_sample_queries (line 50) | def generate_sample_queries() -> dict[str, list[str]]:
function generate_facts (line 77) | def generate_facts(count: int) -> list[str]:
function generate_facts_with_size (line 95) | def generate_facts_with_size(count: int, size: str = "small") -> list[str]:
FILE: benchmarks/perf/fixtures/sample_facts.py
function build_user_data (line 5) | def build_user_data() -> dict:
FILE: benchmarks/perf/generate_percentile_report.py
function calculate_percentile (line 8) | def calculate_percentile(data, percentile):
function extract_n_from_test_name (line 24) | def extract_n_from_test_name(test_name):
function extract_db_type_from_test_name (line 38) | def extract_db_type_from_test_name(test_name):
function extract_content_size_from_test_name (line 51) | def extract_content_size_from_test_name(test_name):
function extract_benchmark_id_from_test_name (line 63) | def extract_benchmark_id_from_test_name(test_name):
function generate_percentile_report (line 76) | def generate_percentile_report(json_file_path, max_n=None):
function generate_report (line 136) | def generate_report(benchmarks, output_format="table"):
function main (line 227) | def main():
FILE: benchmarks/perf/memory_utils.py
function measure_peak_rss_bytes (line 9) | def measure_peak_rss_bytes(
FILE: benchmarks/perf/test_cloud_recall_benchmarks.py
function _make_cloud_cfg (line 21) | def _make_cloud_cfg(*, entity_id: str, process_id: str) -> Config:
function _seed_cloud_messages (line 34) | def _seed_cloud_messages(
function test_benchmark_cloud_recall_latency (line 62) | def test_benchmark_cloud_recall_latency(benchmark, n_messages: int) -> N...
function test_benchmark_cloud_pre_llm_overhead (line 95) | def test_benchmark_cloud_pre_llm_overhead(benchmark, n_history_pairs: in...
function test_benchmark_cloud_network_history_get (line 135) | def test_benchmark_cloud_network_history_get(benchmark, n_history_pairs:...
function test_benchmark_cloud_network_recall_post (line 163) | def test_benchmark_cloud_network_recall_post(benchmark, n_history_pairs:...
function test_benchmark_cloud_network_only_history_plus_recall (line 193) | def test_benchmark_cloud_network_only_history_plus_recall(
function _make_invoke_with_stubbed_history (line 222) | def _make_invoke_with_stubbed_history(
function test_benchmark_cloud_injection_only_history (line 236) | def test_benchmark_cloud_injection_only_history(
function test_benchmark_cloud_injection_only_recalled_facts (line 257) | def test_benchmark_cloud_injection_only_recalled_facts(
FILE: benchmarks/perf/test_hosted_recall_benchmarks.py
function _make_cloud_cfg (line 21) | def _make_cloud_cfg(*, entity_id: str, process_id: str) -> Config:
function _seed_cloud_messages (line 34) | def _seed_cloud_messages(
function test_benchmark_cloud_recall_latency (line 62) | def test_benchmark_cloud_recall_latency(benchmark, n_messages: int) -> N...
function test_benchmark_cloud_pre_llm_overhead (line 95) | def test_benchmark_cloud_pre_llm_overhead(benchmark, n_history_pairs: in...
function test_benchmark_cloud_network_history_get (line 135) | def test_benchmark_cloud_network_history_get(benchmark, n_history_pairs:...
function test_benchmark_cloud_network_recall_post (line 163) | def test_benchmark_cloud_network_recall_post(benchmark, n_history_pairs:...
function test_benchmark_cloud_network_only_history_plus_recall (line 193) | def test_benchmark_cloud_network_only_history_plus_recall(
function _make_invoke_with_stubbed_history (line 222) | def _make_invoke_with_stubbed_history(
function test_benchmark_cloud_injection_only_history (line 236) | def test_benchmark_cloud_injection_only_history(
function test_benchmark_cloud_injection_only_recalled_facts (line 257) | def test_benchmark_cloud_injection_only_recalled_facts(
FILE: benchmarks/perf/test_recall_benchmarks.py
function _default_benchmark_csv_path (line 20) | def _default_benchmark_csv_path() -> str:
function _write_benchmark_row (line 24) | def _write_benchmark_row(*, benchmark, row: dict[str, object]) -> None:
class TestQueryEmbeddingBenchmarks (line 68) | class TestQueryEmbeddingBenchmarks:
method test_benchmark_query_embedding_short (line 71) | def test_benchmark_query_embedding_short(self, benchmark, sample_queri...
method test_benchmark_query_embedding_medium (line 100) | def test_benchmark_query_embedding_medium(self, benchmark, sample_quer...
method test_benchmark_query_embedding_long (line 129) | def test_benchmark_query_embedding_long(self, benchmark, sample_queries):
method test_benchmark_query_embedding_batch (line 158) | def test_benchmark_query_embedding_batch(self, benchmark, sample_queri...
class TestDatabaseEmbeddingRetrievalBenchmarks (line 189) | class TestDatabaseEmbeddingRetrievalBenchmarks:
method test_benchmark_db_embedding_retrieval (line 192) | def test_benchmark_db_embedding_retrieval(
class TestDatabaseFactContentRetrievalBenchmarks (line 225) | class TestDatabaseFactContentRetrievalBenchmarks:
method test_benchmark_db_fact_content_retrieval (line 234) | def test_benchmark_db_fact_content_retrieval(
class TestSemanticSearchBenchmarks (line 278) | class TestSemanticSearchBenchmarks:
method test_benchmark_semantic_search (line 281) | def test_benchmark_semantic_search(
class TestLexicalBenchmarks (line 326) | class TestLexicalBenchmarks:
method test_benchmark_bm25_scoring (line 330) | def test_benchmark_bm25_scoring(self, benchmark, fact_count):
class TestEndToEndRecallBenchmarks (line 364) | class TestEndToEndRecallBenchmarks:
method test_benchmark_end_to_end_recall (line 372) | def test_benchmark_end_to_end_recall(
FILE: benchmarks/scripts/fetch_locomo.py
function main (line 10) | def main(argv: list[str] | None = None) -> int:
function _default_dest (line 61) | def _default_dest() -> Path:
function _sha256 (line 65) | def _sha256(path: Path) -> str:
FILE: conftest.py
function mock_mysql_session (line 8) | def mock_mysql_session(mocker):
function mock_postgres_session (line 22) | def mock_postgres_session(mocker):
function session (line 36) | def session(mock_mysql_session):
function postgres_session (line 41) | def postgres_session(mock_postgres_session):
function config (line 46) | def config(mocker, session):
FILE: examples/cockroachdb/main.py
function get_conn (line 17) | def get_conn():
FILE: integrations/openclaw/src/constants.ts
constant PLUGIN_CONFIG (line 1) | const PLUGIN_CONFIG = {
constant RECALL_CONFIG (line 7) | const RECALL_CONFIG = {
constant AUGMENTATION_CONFIG (line 11) | const AUGMENTATION_CONFIG = {
FILE: integrations/openclaw/src/handlers/augmentation.ts
function extractLLMMetadata (line 8) | function extractLLMMetadata(event: OpenClawEvent): IntegrationMetadata {
function handleAugmentation (line 21) | async function handleAugmentation(
FILE: integrations/openclaw/src/handlers/recall.ts
function handleRecall (line 6) | async function handleRecall(
FILE: integrations/openclaw/src/index.ts
method register (line 13) | register(api: OpenClawPluginApi) {
FILE: integrations/openclaw/src/sanitizer.ts
constant SYSTEM_MESSAGE_PATTERNS (line 3) | const SYSTEM_MESSAGE_PATTERNS = [
constant TIMESTAMP_PREFIX_REGEX (line 10) | const TIMESTAMP_PREFIX_REGEX =
function isMessageBlockArray (line 13) | function isMessageBlockArray(value: unknown): value is OpenClawMessageBl...
function isSystemMessage (line 17) | function isSystemMessage(text: string): boolean {
function extractRawUserMessage (line 30) | function extractRawUserMessage(content: string): string {
function extractMessageText (line 48) | function extractMessageText(content: unknown): string {
function cleanText (line 65) | function cleanText(rawContent: unknown): string {
FILE: integrations/openclaw/src/types.ts
type MemoriPluginConfig (line 1) | interface MemoriPluginConfig {
type OpenClawMessageBlock (line 6) | interface OpenClawMessageBlock {
type OpenClawMessage (line 13) | interface OpenClawMessage {
type OpenClawEvent (line 20) | interface OpenClawEvent {
type OpenClawContext (line 32) | interface OpenClawContext {
FILE: integrations/openclaw/src/utils/context.ts
type ExtractedContext (line 6) | interface ExtractedContext {
function extractContext (line 22) | function extractContext(
FILE: integrations/openclaw/src/utils/logger.ts
class MemoriLogger (line 4) | class MemoriLogger {
method constructor (line 5) | constructor(private api: OpenClawPluginApi) {}
method prefix (line 7) | private prefix(msg: string): string {
method info (line 11) | info(message: string): void {
method warn (line 15) | warn(message: string): void {
method error (line 19) | error(message: string): void {
method section (line 23) | section(title: string): void {
method endSection (line 27) | endSection(title: string): void {
FILE: integrations/openclaw/src/utils/memori-client.ts
function initializeMemoriClient (line 12) | function initializeMemoriClient(
FILE: integrations/openclaw/src/version.ts
constant SDK_VERSION (line 2) | const SDK_VERSION = '0.0.0';
FILE: memori-ts/examples/cloud/simple.ts
function main (line 20) | async function main() {
FILE: memori-ts/src/cli/commands/help.ts
function helpCommand (line 3) | function helpCommand(_args: string[]): Promise<void> {
FILE: memori-ts/src/cli/commands/quota.ts
type QuotaResponse (line 5) | interface QuotaResponse {
function quotaCommand (line 13) | async function quotaCommand(_args: string[]): Promise<void> {
FILE: memori-ts/src/cli/router.ts
function main (line 9) | async function main() {
FILE: memori-ts/src/core/config.ts
function getEnv (line 6) | function getEnv(key: string): string | undefined {
class Config (line 13) | class Config {
method constructor (line 60) | constructor() {
FILE: memori-ts/src/core/errors.ts
class MemoriError (line 4) | class MemoriError extends Error {
method constructor (line 5) | constructor(message: string) {
class QuotaExceededError (line 13) | class QuotaExceededError extends MemoriError {
method constructor (line 14) | constructor(message?: string) {
class MemoriApiClientError (line 24) | class MemoriApiClientError extends MemoriError {
method constructor (line 28) | constructor(statusCode: number, message?: string, details?: unknown) {
class MemoriApiValidationError (line 37) | class MemoriApiValidationError extends MemoriApiClientError {
method constructor (line 38) | constructor(statusCode: number, message: string, details?: unknown) {
class MemoriApiRequestRejectedError (line 45) | class MemoriApiRequestRejectedError extends MemoriApiClientError {
method constructor (line 46) | constructor(statusCode: number, message: string, details?: unknown) {
class MissingMemoriApiKeyError (line 53) | class MissingMemoriApiKeyError extends MemoriError {
method constructor (line 54) | constructor(envVar = 'MEMORI_API_KEY') {
class TimeoutError (line 63) | class TimeoutError extends MemoriError {
method constructor (line 64) | constructor(timeout: number) {
FILE: memori-ts/src/core/network.ts
type ApiSubdomain (line 10) | enum ApiSubdomain {
constant PUBLIC_PROD_KEY (line 15) | const PUBLIC_PROD_KEY = '96a7ea3e-11c2-428c-b9ae-5a168363dc80';
constant PUBLIC_STAGING_KEY (line 16) | const PUBLIC_STAGING_KEY = 'c18b1022-7fe2-42af-ab01-b1f9139184f0';
type FetchOptions (line 18) | interface FetchOptions extends RequestInit {
class Api (line 24) | class Api {
method constructor (line 29) | constructor(config: Config, subdomain: ApiSubdomain = ApiSubdomain.DEF...
method getHeaders (line 43) | private getHeaders(): HeadersInit {
method request (line 60) | private async request<T>(
method executeAttempt (line 106) | private async executeAttempt<T>(url: string, init: RequestInit): Promi...
method throwOnApiError (line 134) | private async throwOnApiError(response: Response): Promise<void> {
method get (line 164) | public get<T>(route: string): Promise<T> {
method post (line 168) | public post<T>(route: string, body?: unknown): Promise<T> {
method patch (line 172) | public patch<T>(route: string, body?: unknown): Promise<T> {
method delete (line 176) | public delete<T>(route: string): Promise<T> {
FILE: memori-ts/src/core/session.ts
class SessionManager (line 7) | class SessionManager {
method constructor (line 10) | constructor() {
method id (line 17) | public get id(): string {
method reset (line 25) | public reset(): this {
method set (line 36) | public set(id: string): this {
FILE: memori-ts/src/engines/augmentation.ts
class AugmentationEngine (line 8) | class AugmentationEngine {
method constructor (line 9) | constructor(
method handleAugmentation (line 15) | public handleAugmentation(
method buildMeta (line 45) | private buildMeta(req: LLMRequest, ctx: CallContext): Record<string, u...
FILE: memori-ts/src/engines/persistence.ts
class PersistenceEngine (line 7) | class PersistenceEngine {
method constructor (line 8) | constructor(
method handlePersistence (line 14) | public async handlePersistence(
FILE: memori-ts/src/engines/recall.ts
class RecallEngine (line 9) | class RecallEngine {
method constructor (line 10) | constructor(
method recall (line 16) | public async recall(query: string): Promise<ParsedFact[]> {
method handleRecall (line 35) | public async handleRecall(req: LLMRequest, _ctx: CallContext): Promise...
FILE: memori-ts/src/integrations/base.ts
method constructor (line 16) | constructor(protected readonly core: MemoriCore) {}
method executeAugmentation (line 25) | protected async executeAugmentation(req: IntegrationRequest): Promise<vo...
method executeRecall (line 58) | protected async executeRecall(userMessage: string): Promise<string | und...
FILE: memori-ts/src/integrations/openclaw.ts
class OpenClawIntegration (line 8) | class OpenClawIntegration extends BaseIntegration {
method setAttribution (line 16) | public setAttribution(entityId: string, processId?: string): this {
method setSession (line 28) | public setSession(sessionId: string): this {
method augmentation (line 41) | public async augmentation(req: IntegrationRequest): Promise<void> {
method recall (line 53) | public async recall(promptText: string): Promise<string | undefined> {
FILE: memori-ts/src/memori.ts
class Memori (line 20) | class Memori {
method constructor (line 60) | constructor() {
method attribution (line 88) | public attribution(entityId?: string, processId?: string): this {
method recall (line 101) | public async recall(query: string): Promise<ParsedFact[]> {
method resetSession (line 109) | public resetSession(): this {
method setSession (line 120) | public setSession(id: string): this {
method integrate (line 132) | public integrate<T extends SupportedIntegration>(IntegrationClass: Int...
FILE: memori-ts/src/types/api.ts
type RecallObject (line 6) | interface RecallObject {
type RecallItem (line 16) | type RecallItem = string | RecallObject;
type CloudRecallResponse (line 22) | interface CloudRecallResponse {
type ParsedFact (line 39) | interface ParsedFact {
FILE: memori-ts/src/types/integrations.ts
type MemoriCore (line 13) | interface MemoriCore {
type IntegrationRequest (line 26) | interface IntegrationRequest {
type IntegrationMetadata (line 50) | interface IntegrationMetadata {
type SupportedIntegration (line 86) | type SupportedIntegration = OpenClawIntegration;
type IntegrationConstructor (line 93) | type IntegrationConstructor<T extends SupportedIntegration> = new (core:...
FILE: memori-ts/src/utils/utils.ts
function formatDate (line 5) | function formatDate(dateStr?: string): string | undefined {
function stringifyContent (line 21) | function stringifyContent(content: unknown): string {
function extractFacts (line 49) | function extractFacts(response: CloudRecallResponse): ParsedFact[] {
function extractHistory (line 75) | function extractHistory(response: CloudRecallResponse): unknown[] {
function extractLastUserMessage (line 87) | function extractLastUserMessage(messages: Message[]): string | undefined {
FILE: memori-ts/src/version.ts
constant SDK_VERSION (line 2) | const SDK_VERSION = '0.0.0';
FILE: memori-ts/tests/integrations/base.test.ts
class TestIntegration (line 7) | class TestIntegration extends BaseIntegration {
method testCapture (line 8) | public testCapture(req: IntegrationRequest) {
method testRecall (line 11) | public testRecall(userMessage: string) {
FILE: memori/__init__.py
class LlmRegistry (line 41) | class LlmRegistry:
method __init__ (line 42) | def __init__(self, memori):
method register (line 45) | def register(
class Memori (line 73) | class Memori:
method __init__ (line 74) | def __init__(
method _get_default_connection (line 105) | def _get_default_connection(self) -> Callable[[], Any] | None:
method attribution (line 122) | def attribution(self, entity_id=None, process_id=None):
method new_session (line 140) | def new_session(self):
method set_session (line 145) | def set_session(self, id):
method recall (line 149) | def recall(self, query: str, limit: int | None = None):
method close (line 152) | def close(self) -> None:
method __enter__ (line 167) | def __enter__(self) -> "Memori":
method __exit__ (line 170) | def __exit__(self, exc_type, exc, tb) -> None:
method embed_texts (line 173) | def embed_texts(self, texts: str | list[str], *, async_: bool = False)...
FILE: memori/__main__.py
function main (line 24) | def main():
FILE: memori/_cli.py
class Cli (line 16) | class Cli:
method __init__ (line 17) | def __init__(self, config: Config):
method banner (line 20) | def banner(self):
method newline (line 26) | def newline(self):
method notice (line 29) | def notice(self, message, ident=0, end=None):
method print (line 36) | def print(self, message, end=None):
FILE: memori/_config.py
function _env_bool (line 16) | def _env_bool(name: str, default: bool) -> bool:
function _env_int (line 23) | def _env_int(name: str, default: int) -> int:
function _env_str (line 33) | def _env_str(name: str, default: str | None) -> str | None:
class Cache (line 41) | class Cache:
method __init__ (line 42) | def __init__(self):
class Storage (line 49) | class Storage:
method __init__ (line 50) | def __init__(self):
class Embeddings (line 54) | class Embeddings:
method __init__ (line 55) | def __init__(self):
class Config (line 59) | class Config:
method __init__ (line 60) | def __init__(self):
method is_test_mode (line 90) | def is_test_mode(self):
method reset_cache (line 93) | def reset_cache(self):
class Framework (line 98) | class Framework:
method __init__ (line 99) | def __init__(self):
class Platform (line 103) | class Platform:
method __init__ (line 104) | def __init__(self):
class Llm (line 108) | class Llm:
method __init__ (line 109) | def __init__(self):
FILE: memori/_exceptions.py
class QuotaExceededError (line 15) | class QuotaExceededError(Exception):
method __init__ (line 16) | def __init__(
class MemoriApiError (line 27) | class MemoriApiError(Exception):
class MemoriApiClientError (line 31) | class MemoriApiClientError(MemoriApiError):
method __init__ (line 32) | def __init__(
class MemoriApiValidationError (line 45) | class MemoriApiValidationError(MemoriApiClientError):
class MemoriApiRequestRejectedError (line 49) | class MemoriApiRequestRejectedError(MemoriApiClientError):
class MissingMemoriApiKeyError (line 53) | class MissingMemoriApiKeyError(RuntimeError):
method __init__ (line 56) | def __init__(self, env_var: str = "MEMORI_API_KEY"):
class MissingPsycopgError (line 63) | class MissingPsycopgError(ImportError):
method __init__ (line 66) | def __init__(self, database: str = "PostgreSQL/CockroachDB"):
class UnsupportedLLMProviderError (line 73) | class UnsupportedLLMProviderError(RuntimeError):
method __init__ (line 76) | def __init__(self, provider: str):
class UnsupportedDatabaseError (line 82) | class UnsupportedDatabaseError(RuntimeError):
method __init__ (line 85) | def __init__(self, database: str | None = None):
class MemoriLegacyPackageWarning (line 96) | class MemoriLegacyPackageWarning(UserWarning):
function warn_if_legacy_memorisdk_installed (line 100) | def warn_if_legacy_memorisdk_installed() -> None:
FILE: memori/_logging.py
function set_truncate_enabled (line 20) | def set_truncate_enabled(enabled: bool) -> None:
function truncate (line 27) | def truncate(text: str, max_len: int = 200) -> str:
function sanitize_payload (line 50) | def sanitize_payload(payload: dict) -> dict:
FILE: memori/_network.py
class ApiSubdomain (line 35) | class ApiSubdomain(str, Enum):
class Api (line 40) | class Api:
method __init__ (line 41) | def __init__(self, config: Config, subdomain: ApiSubdomain = ApiSubdom...
method augmentation_async (line 61) | async def augmentation_async(self, payload: dict) -> dict:
method delete (line 160) | def delete(self, route):
method get (line 169) | def get(self, route):
method get_async (line 178) | async def get_async(self, route):
method patch (line 181) | def patch(self, route, json=None):
method patch_async (line 190) | async def patch_async(self, route, json=None):
method post (line 193) | def post(self, route, json=None, status_code: bool = False):
method post_async (line 205) | async def post_async(self, route, json=None):
method headers (line 208) | def headers(self):
method _is_anonymous (line 217) | def _is_anonymous(self):
method __request_async (line 220) | async def __request_async(self, method: str, route: str, json=None):
method __session (line 300) | def __session(self):
method url (line 317) | def url(self, route):
class _ApiRetryRecoverable (line 321) | class _ApiRetryRecoverable(Retry):
method is_retry (line 322) | def is_retry(self, method, status_code, has_retry_after=False):
FILE: memori/_setup.py
class Manager (line 17) | class Manager:
method __init__ (line 18) | def __init__(self, config: Config):
method execute (line 21) | def execute(self):
FILE: memori/_utils.py
function bytes_to_json (line 17) | def bytes_to_json(obj):
function generate_uniq (line 46) | def generate_uniq(terms: list):
function merge_chunk (line 56) | def merge_chunk(data: dict, chunk: dict):
function format_date_created (line 73) | def format_date_created(value) -> str | None:
FILE: memori/api/_quota.py
class Manager (line 16) | class Manager:
method __init__ (line 17) | def __init__(self, config: Config):
method execute (line 20) | def execute(self):
FILE: memori/api/_sign_up.py
class Manager (line 19) | class Manager:
method __init__ (line 20) | def __init__(self, config: Config):
method execute (line 23) | def execute(self):
method usage (line 35) | def usage(self):
FILE: memori/embeddings/_api.py
function _embed_texts (line 28) | def _embed_texts(
function _embed_texts_async (line 56) | async def _embed_texts_async(
function embed_texts (line 77) | def embed_texts(
function embed_texts (line 89) | def embed_texts(
function embed_texts (line 100) | def embed_texts(
FILE: memori/embeddings/_chunking.py
function chunk_text_by_tokens (line 19) | def chunk_text_by_tokens(
FILE: memori/embeddings/_format.py
function format_embedding_for_db (line 18) | def format_embedding_for_db(embedding: list[float], dialect: str) -> Any:
FILE: memori/embeddings/_sentence_transformers.py
class SentenceTransformersEmbedder (line 28) | class SentenceTransformersEmbedder:
method __init__ (line 29) | def __init__(self, model_name: str) -> None:
method _get_model (line 35) | def _get_model(self) -> SentenceTransformer:
method _load_encoder (line 41) | def _load_encoder(self, *, fallback_dimension: int) -> SentenceTransfo...
method _encode_batch (line 50) | def _encode_batch(
method _encode_one_by_one (line 59) | def _encode_one_by_one(
method _chunk_size_tokens (line 76) | def _chunk_size_tokens(self, encoder: SentenceTransformer) -> int | None:
method _tokenizer (line 111) | def _tokenizer(self, encoder: SentenceTransformer) -> Any | None:
method _chunk_text (line 114) | def _chunk_text(
method _mean_pool_and_normalize (line 150) | def _mean_pool_and_normalize(self, vectors: np.ndarray) -> np.ndarray:
method _encode_chunks (line 157) | def _encode_chunks(
method _encode_inputs (line 175) | def _encode_inputs(
method _zero_result (line 213) | def _zero_result(
method embed (line 232) | def embed(self, inputs: list[str], *, fallback_dimension: int) -> list...
function get_sentence_transformers_embedder (line 290) | def get_sentence_transformers_embedder(model_name: str) -> SentenceTrans...
FILE: memori/embeddings/_tei.py
class TEI (line 19) | class TEI:
method _request_headers (line 24) | def _request_headers(self) -> dict[str, str]:
method _post_embeddings (line 30) | def _post_embeddings(self, inputs: list[str], *, model: str) -> list[l...
method embed (line 47) | def embed(self, texts: list[str], *, model: str) -> list[list[float]]:
FILE: memori/embeddings/_tei_embed.py
function embed_texts_via_tei (line 24) | def embed_texts_via_tei(
FILE: memori/embeddings/_utils.py
function prepare_text_inputs (line 17) | def prepare_text_inputs(texts: str | Iterable[str]) -> list[str]:
function embedding_dimension (line 23) | def embedding_dimension(model: Any, default: int) -> int:
function zero_vectors (line 31) | def zero_vectors(count: int, dim: int) -> list[list[float]]:
FILE: memori/llm/_base.py
function _score_for_recall_threshold (line 48) | def _score_for_recall_threshold(
class BaseClient (line 76) | class BaseClient:
method __init__ (line 77) | def __init__(self, config: Config):
method register (line 81) | def register(self, *args, **kwargs):
method _wrap_method (line 84) | def _wrap_method(
class BaseInvoke (line 136) | class BaseInvoke:
method __init__ (line 137) | def __init__(self, config: Config, method):
method _ensure_cached_conversation_id (line 144) | def _ensure_cached_conversation_id(self) -> bool:
method configure_for_streaming_usage (line 172) | def configure_for_streaming_usage(self, kwargs: dict) -> dict:
method _convert_to_json (line 191) | def _convert_to_json(self, obj, _seen=None):
method dict_to_json (line 233) | def dict_to_json(self, dict_: dict) -> dict:
method _format_kwargs (line 236) | def _format_kwargs(self, kwargs):
method _format_payload (line 268) | def _format_payload(
method _format_augmentation_input (line 326) | def _format_augmentation_input(self, payload: dict) -> AugmentationInp...
method _safe_copy (line 341) | def _safe_copy(self, obj):
method _format_response (line 383) | def _format_response(self, raw_response):
method get_response_content (line 424) | def get_response_content(self, raw_response):
method _extract_text_from_parts (line 449) | def _extract_text_from_parts(self, parts: list) -> str:
method _extract_from_contents (line 461) | def _extract_from_contents(self, contents) -> str:
method _extract_user_query (line 480) | def _extract_user_query(self, kwargs: dict) -> str:
method _append_to_google_system_instruction_dict (line 523) | def _append_to_google_system_instruction_dict(self, config: dict, cont...
method _append_to_google_system_instruction_obj (line 542) | def _append_to_google_system_instruction_obj(self, config, context: str):
method _append_to_list (line 560) | def _append_to_list(self, lst: list, context: str, parent: dict, key: ...
method _append_to_list_obj (line 571) | def _append_to_list_obj(self, config, context: str):
method _append_to_content_dict (line 583) | def _append_to_content_dict(
method _append_to_part_obj (line 600) | def _append_to_part_obj(self, part, context: str):
method _append_to_content_obj (line 607) | def _append_to_content_obj(self, content, context: str):
method _inject_google_system_instruction (line 619) | def _inject_google_system_instruction(self, kwargs: dict, context: str):
method _format_recalled_fact_lines (line 642) | def _format_recalled_fact_lines(
method inject_recalled_facts (line 668) | def inject_recalled_facts(self, kwargs: dict) -> dict:
method inject_conversation_messages (line 761) | def inject_conversation_messages(self, kwargs: dict) -> dict:
method set_client (line 1012) | def set_client(self, framework_provider, llm_provider, provider_sdk_ve...
method uses_protobuf (line 1018) | def uses_protobuf(self):
method handle_post_response (line 1022) | def handle_post_response(self, kwargs, start_time, raw_response):
class BaseIterator (line 1069) | class BaseIterator:
method __init__ (line 1070) | def __init__(self, config: Config, source_iterator):
method configure_invoke (line 1076) | def configure_invoke(self, invoke: BaseInvoke):
method configure_request (line 1080) | def configure_request(self, kwargs, time_start):
method process_chunk (line 1085) | def process_chunk(self, chunk):
method set_raw_response (line 1138) | def set_raw_response(self):
class BaseLlmAdaptor (line 1149) | class BaseLlmAdaptor:
method _exclude_injected_messages (line 1150) | def _exclude_injected_messages(self, messages, payload):
method get_formatted_query (line 1158) | def get_formatted_query(self, payload):
method get_formatted_response (line 1161) | def get_formatted_response(self, payload):
class BaseProvider (line 1165) | class BaseProvider:
method __init__ (line 1166) | def __init__(self, entity):
FILE: memori/llm/_clients.py
class Anthropic (line 37) | class Anthropic(BaseClient):
method register (line 38) | def register(self, client, _provider=None):
class Google (line 82) | class Google(BaseClient):
method register (line 83) | def register(self, client, _provider=None):
class LangChain (line 162) | class LangChain(BaseClient):
method register (line 163) | def register(
function _detect_platform (line 491) | def _detect_platform(client):
class OpenAi (line 505) | class OpenAi(BaseClient):
method register (line 506) | def register(self, client, _provider=None, stream=False):
class PydanticAi (line 562) | class PydanticAi(BaseClient):
method register (line 563) | def register(self, client):
class XAi (line 591) | class XAi(BaseClient):
method register (line 600) | def register(self, client, _provider=None, stream=False):
class Agno (line 666) | class Agno(BaseClient):
method register (line 667) | def register(self, openai_chat=None, claude=None, gemini=None, xai=None):
method _is_agno_openai_model (line 798) | def _is_agno_openai_model(self, model):
method _is_agno_anthropic_model (line 801) | def _is_agno_anthropic_model(self, model):
method _is_agno_google_model (line 804) | def _is_agno_google_model(self, model):
method _is_agno_xai_model (line 807) | def _is_agno_xai_model(self, model):
FILE: memori/llm/_invoke.py
class Invoke (line 31) | class Invoke(BaseInvoke):
method invoke (line 32) | def invoke(self, **kwargs):
class InvokeAsync (line 74) | class InvokeAsync(BaseInvoke):
method invoke (line 75) | async def invoke(self, **kwargs):
class InvokeAsyncIterator (line 92) | class InvokeAsyncIterator(BaseInvoke):
method invoke (line 93) | async def invoke(self, **kwargs):
class InvokeAsyncStream (line 114) | class InvokeAsyncStream(BaseInvoke):
method invoke (line 115) | async def invoke(self, **kwargs):
class InvokeStream (line 132) | class InvokeStream(BaseInvoke):
method invoke (line 133) | async def invoke(self, **kwargs):
FILE: memori/llm/_iterable.py
class Iterable (line 21) | class Iterable:
method __init__ (line 22) | def __init__(self, config: Config, source_iterable):
method __getattr__ (line 27) | def __getattr__(self, name):
method configure_invoke (line 30) | def configure_invoke(self, invoke: BaseInvoke):
method configure_request (line 34) | def configure_request(self, kwargs, time_start):
method __iter__ (line 43) | def __iter__(self):
FILE: memori/llm/_iterator.py
class AsyncIterator (line 17) | class AsyncIterator(BaseIterator):
method __aiter__ (line 18) | def __aiter__(self):
method __anext__ (line 22) | async def __anext__(self):
method __aenter__ (line 46) | async def __aenter__(self):
method __aexit__ (line 51) | async def __aexit__(self, exc_type, exc, tb):
class Iterator (line 57) | class Iterator(BaseIterator):
method __iter__ (line 58) | def __iter__(self):
method __next__ (line 61) | def __next__(self):
method __enter__ (line 84) | def __enter__(self):
method __exit__ (line 89) | def __exit__(self, exc_type, exc, tb):
FILE: memori/llm/_providers.py
class Agno (line 23) | class Agno(BaseProvider):
method register (line 24) | def register(self, openai_chat=None, claude=None, gemini=None, xai=None):
class Anthropic (line 41) | class Anthropic(BaseProvider):
method register (line 42) | def register(self, client):
class Google (line 54) | class Google(BaseProvider):
method register (line 55) | def register(self, client):
class LangChain (line 67) | class LangChain(BaseProvider):
method register (line 68) | def register(
class OpenAi (line 87) | class OpenAi(BaseProvider):
method register (line 88) | def register(self, client, stream=False):
class PydanticAi (line 102) | class PydanticAi(BaseProvider):
method register (line 103) | def register(self, client):
class XAi (line 115) | class XAi(BaseProvider):
method register (line 116) | def register(self, client, stream=False):
FILE: memori/llm/_registry.py
class Registry (line 18) | class Registry:
method register_client (line 23) | def register_client(cls, matcher: Callable[[Any], bool]):
method register_adapter (line 31) | def register_adapter(cls, matcher: Callable[[str | None, str | None], ...
method client (line 38) | def client(self, client_obj: Any, config) -> BaseClient:
method adapter (line 55) | def adapter(self, provider: str | None, title: str | None) -> BaseLlmA...
function register_llm (line 64) | def register_llm(
FILE: memori/llm/_streaming.py
class StreamingBody (line 21) | class StreamingBody:
method __init__ (line 22) | def __init__(self, config: Config, source_streaming_body):
method __getattr__ (line 27) | def __getattr__(self, name):
method configure_invoke (line 30) | def configure_invoke(self, invoke: BaseInvoke):
method configure_request (line 34) | def configure_request(self, kwargs, time_start):
method read (line 43) | def read(self, *args, **kwargs):
FILE: memori/llm/_utils.py
function client_is_bedrock (line 29) | def client_is_bedrock(provider, title):
function llm_is_anthropic (line 35) | def llm_is_anthropic(provider, title):
function llm_is_bedrock (line 39) | def llm_is_bedrock(provider, title):
function llm_is_google (line 45) | def llm_is_google(provider, title):
function llm_is_openai (line 53) | def llm_is_openai(provider, title):
function llm_is_xai (line 61) | def llm_is_xai(provider, title):
function agno_is_anthropic (line 65) | def agno_is_anthropic(provider, title):
function agno_is_google (line 69) | def agno_is_google(provider, title):
function agno_is_openai (line 73) | def agno_is_openai(provider, title):
function agno_is_xai (line 77) | def agno_is_xai(provider, title):
function provider_is_agno (line 81) | def provider_is_agno(provider):
function provider_is_langchain (line 85) | def provider_is_langchain(provider):
FILE: memori/llm/_xai_wrappers.py
class XAiWrappers (line 20) | class XAiWrappers:
method __init__ (line 32) | def __init__(self, config):
method _ensure_cached_conversation_id (line 35) | def _ensure_cached_conversation_id(self) -> bool:
method inject_conversation_history (line 63) | def inject_conversation_history(self, kwargs):
method wrap_chat_methods (line 90) | def wrap_chat_methods(self, chat_obj, client_version, model=None):
method _create_sync_sample_wrapper (line 114) | def _create_sync_sample_wrapper(self, chat_obj, client_version):
method _create_async_sample_wrapper (line 161) | def _create_async_sample_wrapper(self, chat_obj, client_version):
method _create_stream_wrapper (line 208) | def _create_stream_wrapper(self, chat_obj, client_version):
method _build_payload (line 271) | def _build_payload(
method _normalize_role (line 298) | def _normalize_role(self, response):
FILE: memori/llm/adapters/anthropic/_adapter.py
class Adapter (line 18) | class Adapter(BaseLlmAdaptor):
method get_formatted_query (line 19) | def get_formatted_query(self, payload):
method get_formatted_response (line 35) | def get_formatted_response(self, payload):
FILE: memori/llm/adapters/bedrock/_adapter.py
class Adapter (line 17) | class Adapter(BaseLlmAdaptor):
method get_formatted_query (line 18) | def get_formatted_query(self, payload):
method get_formatted_response (line 34) | def get_formatted_response(self, payload):
FILE: memori/llm/adapters/google/_adapter.py
class Adapter (line 18) | class Adapter(BaseLlmAdaptor):
method get_formatted_query (line 19) | def get_formatted_query(self, payload):
method get_formatted_response (line 89) | def get_formatted_response(self, payload):
FILE: memori/llm/adapters/openai/_adapter.py
class Adapter (line 18) | class Adapter(BaseLlmAdaptor):
method get_formatted_query (line 19) | def get_formatted_query(self, payload):
method get_formatted_response (line 76) | def get_formatted_response(self, payload):
FILE: memori/llm/adapters/xai/_adapter.py
class Adapter (line 18) | class Adapter(BaseLlmAdaptor):
method get_formatted_query (line 19) | def get_formatted_query(self, payload):
method get_formatted_response (line 58) | def get_formatted_response(self, payload):
FILE: memori/memory/_collector.py
class Api (line 23) | class Api:
method __init__ (line 24) | def __init__(self, config: Config):
method get (line 31) | def get(self, route):
method patch (line 40) | def patch(self, route, json=None):
method post (line 53) | def post(self, route, json=None):
method __session (line 66) | def __session(self):
method url (line 83) | def url(self, route):
class _ApiRetryRecoverable (line 87) | class _ApiRetryRecoverable(Retry):
method is_retry (line 88) | def is_retry(self, method, status_code, has_retry_after=False):
class Collector (line 92) | class Collector:
method __init__ (line 93) | def __init__(self, config: Config):
method fire_and_forget (line 100) | def fire_and_forget(self, payload):
FILE: memori/memory/_conversation_messages.py
class ConversationMessage (line 16) | class ConversationMessage(TypedDict):
function _stringify_content (line 22) | def _stringify_content(content: Any) -> str:
function parse_payload_conversation_messages (line 28) | def parse_payload_conversation_messages(
FILE: memori/memory/_manager.py
class Manager (line 22) | class Manager:
method __init__ (line 23) | def __init__(self, config: Config):
method execute (line 26) | def execute(self, payload):
method _handle_cloud (line 44) | def _handle_cloud(self, payload):
method _ensure_cached_id (line 76) | def _ensure_cached_id(self, cache_attr: str, create_func, *create_args...
method _persist_cloud_messages_locally (line 85) | def _persist_cloud_messages_locally(self, payload: dict) -> None:
FILE: memori/memory/_struct.py
function build_fact_text_from_triple_entry (line 12) | def build_fact_text_from_triple_entry(entry: dict) -> str | None:
class Conversation (line 29) | class Conversation:
method __init__ (line 30) | def __init__(self):
method configure_from_advanced_augmentation (line 33) | def configure_from_advanced_augmentation(self, json_: dict) -> "Conver...
class Entity (line 43) | class Entity:
method __init__ (line 44) | def __init__(self):
method configure_from_advanced_augmentation (line 49) | def configure_from_advanced_augmentation(self, json_: dict) -> "Entity":
method _parse_semantic_triple (line 75) | def _parse_semantic_triple(self, entry: dict) -> "SemanticTriple | None":
class Memories (line 102) | class Memories:
method __init__ (line 103) | def __init__(self):
method configure_from_advanced_augmentation (line 108) | def configure_from_advanced_augmentation(self, json_: dict) -> "Memori...
class Process (line 115) | class Process:
method __init__ (line 116) | def __init__(self):
method configure_from_advanced_augmentation (line 119) | def configure_from_advanced_augmentation(self, json_: dict) -> "Process":
class SemanticTriple (line 129) | class SemanticTriple:
method __init__ (line 130) | def __init__(self):
FILE: memori/memory/_writer.py
class Writer (line 24) | class Writer:
method __init__ (line 25) | def __init__(self, config: Config):
method execute (line 28) | def execute(self, payload: dict, max_retries: int = MAX_RETRIES) -> "W...
method _ensure_cached_id (line 51) | def _ensure_cached_id(self, cache_attr: str, create_func, *create_args...
method _execute_transaction (line 61) | def _execute_transaction(self, payload: dict) -> None:
FILE: memori/memory/augmentation/_base.py
class AugmentationContext (line 14) | class AugmentationContext:
method __init__ (line 15) | def __init__(self, payload: AugmentationInput):
method add_write (line 20) | def add_write(self, method_path: str, *args, **kwargs):
class BaseAugmentation (line 25) | class BaseAugmentation:
method __init__ (line 26) | def __init__(self, config=None, enabled: bool = True):
method process (line 30) | async def process(self, ctx: AugmentationContext, driver) -> Augmentat...
FILE: memori/memory/augmentation/_db_writer.py
class WriteTask (line 22) | class WriteTask:
method __init__ (line 23) | def __init__(
method execute (line 36) | def execute(self, driver):
method _resolve_method (line 41) | def _resolve_method(self, driver, method_path: str):
class DbWriterRuntime (line 53) | class DbWriterRuntime:
method __init__ (line 54) | def __init__(self):
method configure (line 62) | def configure(self, config):
method ensure_started (line 71) | def ensure_started(self) -> None:
method enqueue_write (line 82) | def enqueue_write(self, task: WriteTask, timeout: float = 5.0) -> bool:
method _run_loop (line 91) | def _run_loop(self) -> None:
method _drain_batches (line 102) | def _drain_batches(self) -> None:
method _collect_batch (line 145) | def _collect_batch(self) -> list[WriteTask]:
function get_db_writer (line 163) | def get_db_writer() -> DbWriterRuntime:
FILE: memori/memory/augmentation/_handler.py
function _build_meta (line 25) | def _build_meta(config) -> dict[str, object]:
function _post_cloud_augmentation (line 74) | def _post_cloud_augmentation(config, payload: dict) -> None:
function _send_cloud_augmentation_background (line 102) | def _send_cloud_augmentation_background(config, payload: dict) -> None:
function handle_augmentation (line 109) | def handle_augmentation(
FILE: memori/memory/augmentation/_manager.py
class Manager (line 34) | class Manager:
method __init__ (line 35) | def __init__(self, config: Config) -> None:
method start (line 47) | def start(self, conn: Callable | Any) -> "Manager":
method enqueue (line 73) | def enqueue(self, input_data: AugmentationInput) -> "Manager":
method _handle_augmentation_result (line 97) | def _handle_augmentation_result(self, future: Future[Any]) -> None:
method _process_augmentations (line 112) | async def _process_augmentations(self, input_data: AugmentationInput) ...
method _enqueue_writes (line 154) | def _enqueue_writes(self, writes: list[dict[str, Any]]) -> None:
method wait (line 168) | def wait(self, timeout: float | None = None) -> bool:
FILE: memori/memory/augmentation/_message.py
class ConversationMessage (line 15) | class ConversationMessage:
method to_dict (line 19) | def to_dict(self) -> dict[str, str]:
FILE: memori/memory/augmentation/_models.py
function hash_id (line 15) | def hash_id(value: str | None) -> str | None:
class ConversationData (line 22) | class ConversationData:
class SdkVersionData (line 30) | class SdkVersionData:
class ModelData (line 37) | class ModelData:
class FrameworkData (line 46) | class FrameworkData:
class LlmData (line 53) | class LlmData:
class PlatformData (line 60) | class PlatformData:
class SdkData (line 67) | class SdkData:
class StorageData (line 75) | class StorageData:
class EntityData (line 83) | class EntityData:
class ProcessData (line 90) | class ProcessData:
class AttributionData (line 97) | class AttributionData:
class MetaData (line 105) | class MetaData:
class AugmentationPayload (line 117) | class AugmentationPayload:
method to_dict (line 123) | def to_dict(self) -> dict:
FILE: memori/memory/augmentation/_registry.py
class Registry (line 12) | class Registry:
method register (line 16) | def register(cls, name: str):
method augmentations (line 23) | def augmentations(self, config=None):
FILE: memori/memory/augmentation/_runtime.py
class AugmentationRuntime (line 15) | class AugmentationRuntime:
method __init__ (line 16) | def __init__(self):
method ensure_started (line 25) | def ensure_started(self, max_workers: int):
method _run_loop (line 44) | def _run_loop(self) -> None:
function get_runtime (line 55) | def get_runtime() -> AugmentationRuntime:
FILE: memori/memory/augmentation/augmentations/memori/_augmentation.py
class AdvancedAugmentation (line 40) | class AdvancedAugmentation(BaseAugmentation):
method __init__ (line 41) | def __init__(self, config=None, enabled: bool = True):
method _get_conversation_summary (line 44) | def _get_conversation_summary(self, driver, conversation_id: str) -> str:
method _select_messages_for_summary (line 53) | def _select_messages_for_summary(self, messages: list, summary: str) -...
method _build_api_payload (line 86) | def _build_api_payload(
method process (line 125) | async def process(self, ctx: AugmentationContext, driver) -> Augmentat...
method _process_api_response (line 182) | async def _process_api_response(self, api_response: dict) -> Memories:
method _schedule_entity_writes (line 205) | async def _schedule_entity_writes(
method _schedule_process_writes (line 253) | def _schedule_process_writes(
method _schedule_conversation_writes (line 265) | def _schedule_conversation_writes(
FILE: memori/memory/augmentation/augmentations/memori/models.py
class EntityData (line 17) | class EntityData:
class ProcessData (line 24) | class ProcessData:
class AttributionData (line 31) | class AttributionData:
method to_dict (line 37) | def to_dict(self) -> dict[str, object]:
class SessionData (line 45) | class SessionData:
method to_dict (line 50) | def to_dict(self) -> dict[str, object]:
class AugmentationInputData (line 55) | class AugmentationInputData:
method messages_as_dicts (line 60) | def messages_as_dicts(self) -> list[dict[str, str]]:
method to_dict (line 63) | def to_dict(self) -> dict[str, object]:
FILE: memori/memory/augmentation/input.py
class AugmentationInput (line 17) | class AugmentationInput:
FILE: memori/memory/augmentation/memories/_conversation.py
class Conversation (line 12) | class Conversation:
method __init__ (line 13) | def __init__(self):
FILE: memori/memory/augmentation/memories/_entity.py
class Entity (line 12) | class Entity:
method __init__ (line 13) | def __init__(self):
FILE: memori/memory/augmentation/memories/_process.py
class Process (line 12) | class Process:
method __init__ (line 13) | def __init__(self):
FILE: memori/memory/recall.py
function _is_str_object_mapping (line 31) | def _is_str_object_mapping(value: object) -> TypeGuard[Mapping[str, obje...
class Recall (line 37) | class Recall:
method __init__ (line 38) | def __init__(self, config: Config) -> None:
method _resolve_entity_id (line 41) | def _resolve_entity_id(self, entity_id: int | None) -> int | None:
method _resolve_limit (line 55) | def _resolve_limit(self, limit: int | None) -> int:
method _embed_query (line 58) | def _embed_query(self, query: str) -> list[float]:
method _search_with_retries (line 66) | def _search_with_retries(
method _search_with_retries_cloud (line 96) | def _search_with_retries_cloud(
method _cloud_recall (line 103) | def _cloud_recall(self, query: str, *, limit: int | None = None) -> ob...
method _parse_cloud_recall_response (line 125) | def _parse_cloud_recall_response(
method search_facts (line 183) | def search_facts(
FILE: memori/search/_api.py
function search_facts (line 23) | def search_facts(
FILE: memori/search/_core.py
function _candidate_pool_from_candidates (line 22) | def _candidate_pool_from_candidates(
function _get_embeddings_rows (line 56) | def _get_embeddings_rows(
function _candidate_limit (line 72) | def _candidate_limit(
function _fetch_content_maps (line 80) | def _fetch_content_maps(
function _rank_candidates (line 103) | def _rank_candidates(
function _build_fact_rows (line 140) | def _build_fact_rows(
function search_entity_facts_core (line 170) | def search_entity_facts_core(
FILE: memori/search/_faiss.py
function _query_dim (line 25) | def _query_dim(query_embedding: list[float]) -> int:
function _parse_valid_embeddings (line 29) | def _parse_valid_embeddings(
function _stack_embeddings (line 50) | def _stack_embeddings(embeddings_list: list[np.ndarray]) -> np.ndarray |...
function _faiss_search (line 57) | def _faiss_search(
function find_similar_embeddings (line 91) | def find_similar_embeddings(
FILE: memori/search/_lexical.py
function _tokenize (line 69) | def _tokenize(text: str) -> list[str]:
function lexical_scores_for_ids (line 74) | def lexical_scores_for_ids(
function dense_lexical_weights (line 127) | def dense_lexical_weights(*, query_text: str) -> tuple[float, float]:
FILE: memori/search/_parsing.py
function parse_embedding (line 19) | def parse_embedding(raw: Any) -> np.ndarray:
FILE: memori/search/_types.py
class FactCandidate (line 25) | class FactCandidate:
class FactSearchResult (line 33) | class FactSearchResult:
method to_dict (line 40) | def to_dict(self) -> dict[str, object]:
FILE: memori/storage/__init__.py
function _import_optional_module (line 16) | def _import_optional_module(module_path: str) -> None:
FILE: memori/storage/_base.py
class BaseStorageAdapter (line 12) | class BaseStorageAdapter:
method __init__ (line 13) | def __init__(self, conn):
method close (line 43) | def close(self):
method _is_managed_resource (line 58) | def _is_managed_resource(obj) -> bool:
method commit (line 86) | def commit(self):
method execute (line 89) | def execute(self, *args, **kwargs):
method flush (line 92) | def flush(self):
method get_dialect (line 95) | def get_dialect(self):
method rollback (line 98) | def rollback(self):
class BaseConversation (line 102) | class BaseConversation:
method __init__ (line 103) | def __init__(self, conn: BaseStorageAdapter):
method create (line 106) | def create(self, session_id: int, timeout_minutes: int):
method update (line 109) | def update(self, id: int, summary: str):
method read (line 112) | def read(self, id: int) -> dict | None:
class BaseConversationMessage (line 116) | class BaseConversationMessage:
method __init__ (line 117) | def __init__(self, conn: BaseStorageAdapter):
method create (line 120) | def create(self, conversation_id: int, role: str, type: str, content: ...
class BaseConversationMessages (line 124) | class BaseConversationMessages:
method __init__ (line 125) | def __init__(self, conn: BaseStorageAdapter):
method read (line 128) | def read(self, conversation_id: int):
class BaseKnowledgeGraph (line 132) | class BaseKnowledgeGraph:
method __init__ (line 133) | def __init__(self, conn: BaseStorageAdapter):
method create (line 136) | def create(self, entity_id: int, semantic_triples: list):
class BaseEntity (line 140) | class BaseEntity:
method __init__ (line 141) | def __init__(self, conn: BaseStorageAdapter):
method create (line 144) | def create(self, external_id: str):
class BaseEntityFact (line 148) | class BaseEntityFact:
method __init__ (line 149) | def __init__(self, conn: BaseStorageAdapter):
method create (line 152) | def create(self, entity_id: int, facts: list, fact_embeddings: list | ...
method get_embeddings (line 155) | def get_embeddings(self, entity_id: int, limit: int = 1000):
method get_facts_by_ids (line 158) | def get_facts_by_ids(self, fact_ids: list[int]):
class BaseProcess (line 162) | class BaseProcess:
method __init__ (line 163) | def __init__(self, conn: BaseStorageAdapter):
method create (line 166) | def create(self, external_id: str):
class BaseProcessAttribute (line 170) | class BaseProcessAttribute:
method __init__ (line 171) | def __init__(self, conn: BaseStorageAdapter):
method create (line 174) | def create(self, process_id: int, attributes: list):
class BaseSession (line 178) | class BaseSession:
method __init__ (line 179) | def __init__(self, conn: BaseStorageAdapter):
method create (line 182) | def create(self, uuid: str, entity_id: int, process_id: int):
class BaseSchema (line 186) | class BaseSchema:
method __init__ (line 187) | def __init__(self, conn: BaseStorageAdapter):
class BaseSchemaVersion (line 191) | class BaseSchemaVersion:
method __init__ (line 192) | def __init__(self, conn: BaseStorageAdapter):
method create (line 195) | def create(self, num: int):
method delete (line 198) | def delete(self):
method read (line 201) | def read(self):
FILE: memori/storage/_builder.py
class Builder (line 16) | class Builder:
method __init__ (line 17) | def __init__(self, config: Config):
method create_data_structures (line 23) | def create_data_structures(self):
method disable_banner (line 93) | def disable_banner(self):
method execute (line 97) | def execute(self):
method _get_supported_dialects (line 114) | def _get_supported_dialects(self):
method _get_dialect_family (line 117) | def _get_dialect_family(self, dialect):
method _requires_rollback (line 124) | def _requires_rollback(self, dialect):
FILE: memori/storage/_connection.py
function connection_context (line 20) | def connection_context(
FILE: memori/storage/_manager.py
class Manager (line 17) | class Manager:
method __init__ (line 18) | def __init__(self, config: Config) -> None:
method conn (line 25) | def conn(self):
method build (line 28) | def build(self) -> "Manager":
method start (line 36) | def start(self, conn) -> "Manager":
FILE: memori/storage/_registry.py
class Registry (line 18) | class Registry:
method register_adapter (line 23) | def register_adapter(cls, matcher: Callable[[Any], bool]):
method register_driver (line 31) | def register_driver(cls, dialect: str):
method adapter (line 38) | def adapter(self, conn: Any) -> BaseStorageAdapter:
method driver (line 63) | def driver(self, conn: BaseStorageAdapter):
FILE: memori/storage/adapters/dbapi/_adapter.py
class CursorWrapper (line 15) | class CursorWrapper:
method __init__ (line 16) | def __init__(self, cursor):
method mappings (line 19) | def mappings(self):
method __getattr__ (line 22) | def __getattr__(self, name):
class MappingResult (line 26) | class MappingResult:
method __init__ (line 27) | def __init__(self, cursor):
method fetchone (line 30) | def fetchone(self):
method fetchall (line 37) | def fetchall(self):
function is_dbapi_connection (line 43) | def is_dbapi_connection(conn):
class Adapter (line 68) | class Adapter(BaseStorageAdapter):
method commit (line 69) | def commit(self):
method execute (line 73) | def execute(self, operation, binds=()):
method flush (line 82) | def flush(self):
method get_dialect (line 85) | def get_dialect(self):
method rollback (line 101) | def rollback(self):
FILE: memori/storage/adapters/django/_adapter.py
class CursorWrapper (line 15) | class CursorWrapper:
method __init__ (line 16) | def __init__(self, cursor):
method mappings (line 19) | def mappings(self):
method __getattr__ (line 22) | def __getattr__(self, name):
class MappingResult (line 26) | class MappingResult:
method __init__ (line 27) | def __init__(self, cursor):
method fetchone (line 30) | def fetchone(self):
method fetchall (line 37) | def fetchall(self):
function is_django_connection (line 43) | def is_django_connection(conn):
class Adapter (line 58) | class Adapter(BaseStorageAdapter):
method commit (line 59) | def commit(self):
method execute (line 63) | def execute(self, operation, binds=()):
method flush (line 72) | def flush(self):
method get_dialect (line 75) | def get_dialect(self):
method rollback (line 87) | def rollback(self):
FILE: memori/storage/adapters/mongodb/_adapter.py
class Adapter (line 20) | class Adapter(BaseStorageAdapter):
method execute (line 23) | def execute(self, collection_name_or_ops, operation=None, *args, **kwa...
method commit (line 51) | def commit(self):
method flush (line 55) | def flush(self):
method rollback (line 59) | def rollback(self):
method close (line 63) | def close(self):
method get_dialect (line 71) | def get_dialect(self):
method _execute_operation (line 74) | def _execute_operation(self, db, op):
FILE: memori/storage/adapters/sqlalchemy/_adapter.py
class Adapter (line 18) | class Adapter(BaseStorageAdapter):
method commit (line 19) | def commit(self):
method execute (line 23) | def execute(self, operation, binds=()):
method flush (line 26) | def flush(self):
method get_dialect (line 30) | def get_dialect(self):
method rollback (line 37) | def rollback(self):
FILE: memori/storage/cockroachdb/_cluster_manager.py
class ClusterManager (line 28) | class ClusterManager:
method __init__ (line 29) | def __init__(self, config: Config):
method claim (line 34) | def claim(self, cli: Cli):
method delete (line 51) | def delete(self, cli: Cli):
method execute (line 71) | def execute(self):
method start (line 88) | def start(self, cli: Cli):
method cluster_finalize_failed (line 170) | def cluster_finalize_failed(self):
method cluster_is_started (line 173) | def cluster_is_started(self):
method usage (line 176) | def usage(self):
FILE: memori/storage/cockroachdb/_display.py
class Display (line 14) | class Display:
method __init__ (line 15) | def __init__(self):
method cluster_already_started (line 18) | def cluster_already_started(self):
method cluster_was_not_started (line 25) | def cluster_was_not_started(self):
FILE: memori/storage/cockroachdb/_files.py
class Files (line 14) | class Files:
method __init__ (line 15) | def __init__(self):
method cluster_dir (line 18) | def cluster_dir(self):
method cluster_id (line 21) | def cluster_id(self):
method makedirs (line 24) | def makedirs(self):
method read_id (line 28) | def read_id(self):
method remove_id (line 35) | def remove_id(self):
method storage_dir (line 43) | def storage_dir(self):
method write_id (line 55) | def write_id(self, id):
FILE: memori/storage/drivers/mongodb/_driver.py
class Conversation (line 32) | class Conversation(BaseConversation):
method __init__ (line 33) | def __init__(self, conn: BaseStorageAdapter):
method create (line 38) | def create(self, session_id, timeout_minutes: int):
method update (line 78) | def update(self, id: int, summary: str):
method read (line 91) | def read(self, id: int) -> dict | None:
method read_id_by_session_id (line 108) | def read_id_by_session_id(self, session_id):
class ConversationMessage (line 117) | class ConversationMessage(BaseConversationMessage):
method create (line 118) | def create(self, conversation_id: int, role: str, type: str, content: ...
class ConversationMessages (line 132) | class ConversationMessages(BaseConversationMessages):
method read (line 133) | def read(self, conversation_id: int):
class Entity (line 148) | class Entity(BaseEntity):
method create (line 149) | def create(self, external_id: str):
class EntityFact (line 171) | class EntityFact(BaseEntityFact):
method create (line 172) | def create(self, entity_id: int, facts: list, fact_embeddings: list | ...
method get_embeddings (line 224) | def get_embeddings(self, entity_id: int, limit: int = 1000):
method get_facts_by_ids (line 260) | def get_facts_by_ids(self, fact_ids: list[int]):
class KnowledgeGraph (line 284) | class KnowledgeGraph(BaseKnowledgeGraph):
method create (line 285) | def create(self, entity_id: int, semantic_triples: list):
class Process (line 404) | class Process(BaseProcess):
method create (line 405) | def create(self, external_id: str):
class ProcessAttribute (line 427) | class ProcessAttribute(BaseProcessAttribute):
method create (line 428) | def create(self, process_id: int, attributes: list):
class Session (line 472) | class Session(BaseSession):
method create (line 473) | def create(self, uuid: str, entity_id: int, process_id: int):
method read (line 493) | def read(self, uuid: str):
class Schema (line 500) | class Schema(BaseSchema):
method __init__ (line 501) | def __init__(self, conn: BaseStorageAdapter):
class SchemaVersion (line 506) | class SchemaVersion(BaseSchemaVersion):
method create (line 507) | def create(self, num: int):
method delete (line 512) | def delete(self):
method read (line 515) | def read(self):
class Driver (line 527) | class Driver:
method __init__ (line 539) | def __init__(self, conn: BaseStorageAdapter):
FILE: memori/storage/drivers/mysql/_driver.py
class Conversation (line 32) | class Conversation(BaseConversation):
method __init__ (line 33) | def __init__(self, conn: BaseStorageAdapter):
method create (line 38) | def create(self, session_id, timeout_minutes: int):
method update (line 95) | def update(self, id: int, summary: str):
method read (line 114) | def read(self, id: int) -> dict | None:
method read_id_by_session_id (line 133) | def read_id_by_session_id(self, session_id) -> int | None:
class ConversationMessage (line 151) | class ConversationMessage(BaseConversationMessage):
method create (line 152) | def create(self, conversation_id: int, role: str, type: str, content: ...
class ConversationMessages (line 179) | class ConversationMessages(BaseConversationMessages):
method read (line 180) | def read(self, conversation_id: int):
class KnowledgeGraph (line 202) | class KnowledgeGraph(BaseKnowledgeGraph):
method create (line 203) | def create(self, entity_id: int, semantic_triples: list):
class Entity (line 362) | class Entity(BaseEntity):
method create (line 363) | def create(self, external_id: str):
class EntityFact (line 393) | class EntityFact(BaseEntityFact):
method create (line 394) | def create(self, entity_id: int, facts: list, fact_embeddings: list | ...
method get_embeddings (line 445) | def get_embeddings(self, entity_id: int, limit: int = 1000):
method get_facts_by_ids (line 464) | def get_facts_by_ids(self, fact_ids: list[int]):
class Process (line 479) | class Process(BaseProcess):
method create (line 480) | def create(self, external_id: str):
class ProcessAttribute (line 513) | class ProcessAttribute(BaseProcessAttribute):
method create (line 514) | def create(self, process_id: int, attributes: list):
class Session (line 554) | class Session(BaseSession):
method create (line 555) | def create(self, uuid: str, entity_id: int, process_id: int):
method read (line 590) | def read(self, uuid: str) -> int | None:
class Schema (line 608) | class Schema(BaseSchema):
method __init__ (line 609) | def __init__(self, conn: BaseStorageAdapter):
class SchemaVersion (line 614) | class SchemaVersion(BaseSchemaVersion):
method create (line 615) | def create(self, num: int):
method delete (line 627) | def delete(self):
method read (line 634) | def read(self):
class Driver (line 650) | class Driver:
method __init__ (line 662) | def __init__(self, conn: BaseStorageAdapter):
FILE: memori/storage/drivers/oceanbase/_driver.py
class EntityFact (line 20) | class EntityFact(MysqlEntityFact):
method create (line 21) | def create(self, entity_id: int, facts: list, fact_embeddings: list | ...
class Driver (line 76) | class Driver(MysqlDriver):
method __init__ (line 82) | def __init__(self, conn):
FILE: memori/storage/drivers/oracle/_driver.py
class Conversation (line 31) | class Conversation(BaseConversation):
method __init__ (line 32) | def __init__(self, conn: BaseStorageAdapter):
method create (line 37) | def create(self, session_id, timeout_minutes: int):
method update (line 97) | def update(self, id: int, summary: str):
method read (line 116) | def read(self, id: int) -> dict | None:
method read_id_by_session_id (line 135) | def read_id_by_session_id(self, session_id) -> int | None:
class ConversationMessage (line 153) | class ConversationMessage(BaseConversationMessage):
method create (line 154) | def create(self, conversation_id: int, role: str, type: str, content: ...
class ConversationMessages (line 181) | class ConversationMessages(BaseConversationMessages):
method read (line 182) | def read(self, conversation_id: int):
class Entity (line 205) | class Entity(BaseEntity):
method create (line 206) | def create(self, external_id: str):
class EntityFact (line 235) | class EntityFact(BaseEntityFact):
method create (line 236) | def create(self, entity_id: int, facts: list, fact_embeddings: list | ...
method get_embeddings (line 281) | def get_embeddings(self, entity_id: int, limit: int = 1000):
method get_facts_by_ids (line 304) | def get_facts_by_ids(self, fact_ids: list[int]):
class KnowledgeGraph (line 321) | class KnowledgeGraph(BaseKnowledgeGraph):
method create (line 322) | def create(self, entity_id: int, semantic_triples: list):
class Process (line 463) | class Process(BaseProcess):
method create (line 464) | def create(self, external_id: str):
class ProcessAttribute (line 493) | class ProcessAttribute(BaseProcessAttribute):
method create (line 494) | def create(self, process_id: int, attributes: list):
class Session (line 527) | class Session(BaseSession):
method create (line 528) | def create(self, uuid: str, entity_id: int, process_id: int):
method read (line 556) | def read(self, uuid: str) -> int | None:
class Schema (line 574) | class Schema(BaseSchema):
method __init__ (line 575) | def __init__(self, conn: BaseStorageAdapter):
class SchemaVersion (line 580) | class SchemaVersion(BaseSchemaVersion):
method create (line 581) | def create(self, num: int):
method delete (line 593) | def delete(self):
method read (line 600) | def read(self):
class Driver (line 615) | class Driver:
method __init__ (line 627) | def __init__(self, conn: BaseStorageAdapter):
FILE: memori/storage/drivers/postgresql/_driver.py
class Conversation (line 31) | class Conversation(BaseConversation):
method __init__ (line 32) | def __init__(self, conn: BaseStorageAdapter):
method create (line 37) | def create(self, session_id, timeout_minutes: int):
method update (line 95) | def update(self, id: int, summary: str):
method read (line 114) | def read(self, id: int) -> dict | None:
method read_id_by_session_id (line 133) | def read_id_by_session_id(self, session_id) -> int | None:
class ConversationMessage (line 151) | class ConversationMessage(BaseConversationMessage):
method create (line 152) | def create(self, conversation_id: int, role: str, type: str, content: ...
class ConversationMessages (line 179) | class ConversationMessages(BaseConversationMessages):
method read (line 180) | def read(self, conversation_id: int):
class Entity (line 202) | class Entity(BaseEntity):
method create (line 203) | def create(self, external_id: str):
class EntityFact (line 234) | class EntityFact(BaseEntityFact):
method create (line 235) | def create(self, entity_id: int, facts: list, fact_embeddings: list | ...
method get_embeddings (line 287) | def get_embeddings(self, entity_id: int, limit: int = 1000):
method get_facts_by_ids (line 306) | def get_facts_by_ids(self, fact_ids: list[int]):
class KnowledgeGraph (line 323) | class KnowledgeGraph(BaseKnowledgeGraph):
method create (line 324) | def create(self, entity_id: int, semantic_triples: list):
class Process (line 487) | class Process(BaseProcess):
method create (line 488) | def create(self, external_id: str):
class ProcessAttribute (line 519) | class ProcessAttribute(BaseProcessAttribute):
method create (line 520) | def create(self, process_id: int, attributes: list):
class Session (line 561) | class Session(BaseSession):
method create (line 562) | def create(self, uuid: str, entity_id: int, process_id: int):
method read (line 594) | def read(self, uuid: str) -> int | None:
class Schema (line 612) | class Schema(BaseSchema):
method __init__ (line 613) | def __init__(self, conn: BaseStorageAdapter):
class SchemaVersion (line 618) | class SchemaVersion(BaseSchemaVersion):
method create (line 619) | def create(self, num: int):
method delete (line 631) | def delete(self):
method read (line 638) | def read(self):
class Driver (line 654) | class Driver:
method __init__ (line 666) | def __init__(self, conn: BaseStorageAdapter):
FILE: memori/storage/drivers/sqlite/_driver.py
class Conversation (line 31) | class Conversation(BaseConversation):
method __init__ (line 32) | def __init__(self, conn: BaseStorageAdapter):
method create (line 37) | def create(self, session_id, timeout_minutes: int):
method update (line 94) | def update(self, id: int, summary: str):
method read (line 113) | def read(self, id: int) -> dict | None:
method read_id_by_session_id (line 132) | def read_id_by_session_id(self, session_id) -> int | None:
class ConversationMessage (line 150) | class ConversationMessage(BaseConversationMessage):
method create (line 151) | def create(self, conversation_id: int, role: str, type: str, content: ...
class ConversationMessages (line 178) | class ConversationMessages(BaseConversationMessages):
method read (line 179) | def read(self, conversation_id: int):
class Entity (line 202) | class Entity(BaseEntity):
method create (line 203) | def create(self, external_id: str):
class EntityFact (line 233) | class EntityFact(BaseEntityFact):
method create (line 234) | def create(self, entity_id: int, facts: list, fact_embeddings: list | ...
method get_embeddings (line 287) | def get_embeddings(self, entity_id: int, limit: int = 1000):
method get_facts_by_ids (line 306) | def get_facts_by_ids(self, fact_ids: list[int]):
class KnowledgeGraph (line 321) | class KnowledgeGraph(BaseKnowledgeGraph):
method create (line 322) | def create(self, entity_id: int, semantic_triples: list):
class Process (line 453) | class Process(BaseProcess):
method create (line 454) | def create(self, external_id: str):
class ProcessAttribute (line 484) | class ProcessAttribute(BaseProcessAttribute):
method create (line 485) | def create(self, process_id: int, attributes: list):
class Session (line 515) | class Session(BaseSession):
method create (line 516) | def create(self, uuid: str, entity_id: int, process_id: int):
method read (line 547) | def read(self, uuid: str) -> int | None:
class Schema (line 565) | class Schema(BaseSchema):
method __init__ (line 566) | def __init__(self, conn: BaseStorageAdapter):
class SchemaVersion (line 571) | class SchemaVersion(BaseSchemaVersion):
method create (line 572) | def create(self, num: int):
method delete (line 584) | def delete(self):
method read (line 591) | def read(self):
class Driver (line 606) | class Driver:
method __init__ (line 618) | def __init__(self, conn: BaseStorageAdapter):
FILE: tests/benchmarks_locomo/test_locomo_aa_pairing.py
function test_build_per_pair_requests_cumulative (line 6) | def test_build_per_pair_requests_cumulative() -> None:
function test_build_per_pair_requests_skips_unpairable_pair_boundaries (line 22) | def test_build_per_pair_requests_skips_unpairable_pair_boundaries() -> N...
FILE: tests/benchmarks_locomo/test_locomo_loader.py
function _write_locomo_tiny (line 9) | def _write_locomo_tiny(path: Path) -> Path:
function test_load_locomo_tiny_fixture (line 46) | def test_load_locomo_tiny_fixture(tmp_path: Path):
FILE: tests/benchmarks_locomo/test_locomo_preprocess.py
function test_preprocess_strips_multimodal_fields (line 9) | def test_preprocess_strips_multimodal_fields(tmp_path: Path) -> None:
function test_preprocess_rewrites_speaker_b_to_assistant (line 47) | def test_preprocess_rewrites_speaker_b_to_assistant(tmp_path: Path) -> N...
function test_preprocess_keeps_speakers_when_speaker_b_missing (line 77) | def test_preprocess_keeps_speakers_when_speaker_b_missing(tmp_path: Path...
FILE: tests/benchmarks_locomo/test_locomo_provenance.py
function test_attribute_facts_to_turn_ids_maps_best_match (line 10) | def test_attribute_facts_to_turn_ids_maps_best_match():
function test_attribute_facts_to_turn_ids_can_use_lexical_signal (line 36) | def test_attribute_facts_to_turn_ids_can_use_lexical_signal(monkeypatch):
function test_provenance_store_delete_sample (line 64) | def test_provenance_store_delete_sample(tmp_path: Path):
function test_group_scoring_any_match (line 79) | def test_group_scoring_any_match():
function test_format_top_k_includes_turn_ids_for_aa_mode (line 91) | def test_format_top_k_includes_turn_ids_for_aa_mode(tmp_path: Path):
FILE: tests/benchmarks_locomo/test_locomo_run_and_report.py
function _write_locomo_tiny (line 10) | def _write_locomo_tiny(path: Path) -> Path:
function _fake_embed_texts (line 47) | def _fake_embed_texts(
function _seed_reuse_db (line 68) | def _seed_reuse_db(
function test_run_writes_predictions_and_summary (line 121) | def test_run_writes_predictions_and_summary(tmp_path: Path, monkeypatch):
function test_run_skips_questions_with_evidence_in_removed_sessions (line 183) | def test_run_skips_questions_with_evidence_in_removed_sessions(
function test_report_aggregates_predictions (line 268) | def test_report_aggregates_predictions(tmp_path: Path, monkeypatch):
function test_run_can_reuse_existing_sqlite_db_without_ingestion (line 319) | def test_run_can_reuse_existing_sqlite_db_without_ingestion(
FILE: tests/database/core.py
function set_sqlite_pragma (line 75) | def set_sqlite_pragma(dbapi_conn, connection_record):
function OracleTestDBSession (line 94) | def OracleTestDBSession():
function MongoTestDBSession (line 109) | def MongoTestDBSession():
FILE: tests/database/init_db.py
function init_db (line 5) | def init_db():
FILE: tests/embeddings/test_tei_chunking.py
function test_chunk_text_by_tokens_list_input_ids (line 18) | def test_chunk_text_by_tokens_list_input_ids(mocker):
function test_chunk_text_by_tokens_numpy_input_ids (line 28) | def test_chunk_text_by_tokens_numpy_input_ids(mocker):
function test_embed_texts_via_tei_no_tokenizer_calls_server_once (line 38) | def test_embed_texts_via_tei_no_tokenizer_calls_server_once(mocker):
function test_embed_texts_via_tei_tokenizer_chunks_and_pools (line 53) | def test_embed_texts_via_tei_tokenizer_chunks_and_pools(mocker):
FILE: tests/integration/cloud/conftest.py
function cloud_test_mode (line 15) | def cloud_test_mode():
function cloud_memori_instance (line 31) | def cloud_memori_instance(sqlite_session_factory, cloud_test_mode):
function cloud_registered_openai_client (line 54) | def cloud_registered_openai_client(cloud_memori_instance, openai_client):
function cloud_registered_async_openai_client (line 63) | def cloud_registered_async_openai_client(cloud_memori_instance, async_op...
function cloud_registered_anthropic_client (line 72) | def cloud_registered_anthropic_client(cloud_memori_instance, anthropic_c...
function cloud_registered_async_anthropic_client (line 81) | def cloud_registered_async_anthropic_client(
function cloud_registered_google_client (line 92) | def cloud_registered_google_client(cloud_memori_instance, google_client):
function cloud_registered_xai_client (line 101) | def cloud_registered_xai_client(cloud_memori_instance, xai_client):
function cloud_registered_async_xai_client (line 110) | def cloud_registered_async_xai_client(cloud_memori_instance, async_xai_c...
function cloud_registered_bedrock_client (line 119) | def cloud_registered_bedrock_client(cloud_memori_instance, bedrock_client):
FILE: tests/integration/cloud/test_cloud_anthropic.py
class TestCloudAnthropicSync (line 14) | class TestCloudAnthropicSync:
method test_sync_message_through_cloud_pipeline (line 17) | def test_sync_message_through_cloud_pipeline(
method test_sync_message_stores_conversation (line 40) | def test_sync_message_stores_conversation(
method test_sync_message_stores_messages (line 62) | def test_sync_message_stores_messages(
class TestCloudAnthropicAsync (line 93) | class TestCloudAnthropicAsync:
method test_async_message_through_cloud_pipeline (line 97) | async def test_async_message_through_cloud_pipeline(
method test_async_message_stores_conversation (line 122) | async def test_async_message_stores_conversation(
class TestCloudAnthropicStreaming (line 143) | class TestCloudAnthropicStreaming:
method test_sync_streaming_through_cloud_pipeline (line 146) | def test_sync_streaming_through_cloud_pipeline(
method test_async_streaming_through_cloud_pipeline (line 163) | async def test_async_streaming_through_cloud_pipeline(
class TestCloudAnthropicAugmentation (line 182) | class TestCloudAnthropicAugmentation:
method test_augmentation_completes_without_error (line 185) | def test_augmentation_completes_without_error(
method test_multi_turn_triggers_augmentation (line 198) | def test_multi_turn_triggers_augmentation(
class TestCloudAnthropicSessionManagement (line 214) | class TestCloudAnthropicSessionManagement:
method test_multiple_calls_same_session (line 217) | def test_multiple_calls_same_session(
method test_new_session_resets_context (line 232) | def test_new_session_resets_context(
FILE: tests/integration/cloud/test_cloud_bedrock.py
class TestCloudBedrockSync (line 17) | class TestCloudBedrockSync:
method test_sync_invocation_through_cloud_pipeline (line 20) | def test_sync_invocation_through_cloud_pipeline(
method test_sync_invocation_stores_conversation (line 44) | def test_sync_invocation_stores_conversation(
method test_sync_invocation_stores_messages (line 62) | def test_sync_invocation_stores_messages(
class TestCloudBedrockAsync (line 84) | class TestCloudBedrockAsync:
method test_async_invocation_through_cloud_pipeline (line 88) | async def test_async_invocation_through_cloud_pipeline(
method test_async_invocation_stores_conversation (line 114) | async def test_async_invocation_stores_conversation(
class TestCloudBedrockStreaming (line 131) | class TestCloudBedrockStreaming:
method test_sync_streaming_through_cloud_pipeline (line 134) | def test_sync_streaming_through_cloud_pipeline(
method test_async_streaming_through_cloud_pipeline (line 150) | async def test_async_streaming_through_cloud_pipeline(
class TestCloudBedrockAugmentation (line 165) | class TestCloudBedrockAugmentation:
method test_augmentation_completes_without_error (line 168) | def test_augmentation_completes_without_error(
method test_multi_turn_triggers_augmentation (line 177) | def test_multi_turn_triggers_augmentation(
class TestCloudBedrockSessionManagement (line 193) | class TestCloudBedrockSessionManagement:
method test_multiple_calls_same_session (line 196) | def test_multiple_calls_same_session(
method test_new_session_resets_context (line 207) | def test_new_session_resets_context(
FILE: tests/integration/cloud/test_cloud_gemini.py
class TestCloudGeminiSync (line 17) | class TestCloudGeminiSync:
method test_sync_generation_through_cloud_pipeline (line 20) | def test_sync_generation_through_cloud_pipeline(
method test_sync_generation_stores_conversation (line 47) | def test_sync_generation_stores_conversation(
method test_sync_generation_stores_messages (line 68) | def test_sync_generation_stores_messages(
class TestCloudGeminiAsync (line 94) | class TestCloudGeminiAsync:
method test_async_generation_through_cloud_pipeline (line 98) | async def test_async_generation_through_cloud_pipeline(
method test_async_generation_stores_conversation (line 127) | async def test_async_generation_stores_conversation(
class TestCloudGeminiStreaming (line 147) | class TestCloudGeminiStreaming:
method test_sync_streaming_through_cloud_pipeline (line 150) | def test_sync_streaming_through_cloud_pipeline(
method test_async_streaming_through_cloud_pipeline (line 171) | async def test_async_streaming_through_cloud_pipeline(
class TestCloudGeminiAugmentation (line 193) | class TestCloudGeminiAugmentation:
method test_augmentation_completes_without_error (line 196) | def test_augmentation_completes_without_error(
method test_multi_turn_triggers_augmentation (line 208) | def test_multi_turn_triggers_augmentation(
class TestCloudGeminiSessionManagement (line 225) | class TestCloudGeminiSessionManagement:
method test_multiple_calls_same_session (line 228) | def test_multiple_calls_same_session(
method test_new_session_resets_context (line 242) | def test_new_session_resets_context(
FILE: tests/integration/cloud/test_cloud_openai.py
class TestCloudOpenAISync (line 15) | class TestCloudOpenAISync:
method test_sync_completion_through_cloud_pipeline (line 18) | def test_sync_completion_through_cloud_pipeline(
method test_sync_completion_stores_conversation (line 40) | def test_sync_completion_stores_conversation(
method test_sync_completion_stores_messages (line 62) | def test_sync_completion_stores_messages(
class TestCloudOpenAIAsync (line 93) | class TestCloudOpenAIAsync:
method test_async_completion_through_cloud_pipeline (line 97) | async def test_async_completion_through_cloud_pipeline(
method test_async_completion_stores_conversation (line 121) | async def test_async_completion_stores_conversation(
class TestCloudOpenAIStreaming (line 142) | class TestCloudOpenAIStreaming:
method test_sync_streaming_through_cloud_pipeline (line 145) | def test_sync_streaming_through_cloud_pipeline(
method test_async_streaming_through_cloud_pipeline (line 168) | async def test_async_streaming_through_cloud_pipeline(
class TestCloudOpenAIAugmentation (line 190) | class TestCloudOpenAIAugmentation:
method test_augmentation_completes_without_error (line 193) | def test_augmentation_completes_without_error(
method test_multi_turn_triggers_augmentation (line 206) | def test_multi_turn_triggers_augmentation(
method test_cloud_memori_instance_is_configured (line 224) | def test_cloud_memori_instance_is_configured(self, cloud_memori_instan...
class TestCloudOpenAIResponses (line 230) | class TestCloudOpenAIResponses:
method test_responses_api_through_cloud_pipeline (line 233) | def test_responses_api_through_cloud_pipeline(
method test_responses_streaming_through_cloud_pipeline (line 250) | def test_responses_streaming_through_cloud_pipeline(
class TestCloudOpenAISessionManagement (line 269) | class TestCloudOpenAISessionManagement:
method test_multiple_calls_same_session (line 272) | def test_multiple_calls_same_session(
method test_new_session_resets_context (line 287) | def test_new_session_resets_context(
FILE: tests/integration/cloud/test_cloud_xai.py
class TestcloudXAISync (line 15) | class TestcloudXAISync:
method test_sync_completion_through_cloud_pipeline (line 18) | def test_sync_completion_through_cloud_pipeline(
method test_sync_completion_stores_conversation (line 40) | def test_sync_completion_stores_conversation(
method test_sync_completion_stores_messages (line 62) | def test_sync_completion_stores_messages(
class TestcloudXAIAsync (line 93) | class TestcloudXAIAsync:
method test_async_completion_through_cloud_pipeline (line 97) | async def test_async_completion_through_cloud_pipeline(
method test_async_completion_stores_conversation (line 121) | async def test_async_completion_stores_conversation(
class TestcloudXAIStreaming (line 142) | class TestcloudXAIStreaming:
method test_sync_streaming_through_cloud_pipeline (line 145) | def test_sync_streaming_through_cloud_pipeline(
method test_async_streaming_through_cloud_pipeline (line 168) | async def test_async_streaming_through_cloud_pipeline(
class TestcloudXAIAugmentation (line 190) | class TestcloudXAIAugmentation:
method test_augmentation_completes_without_error (line 193) | def test_augmentation_completes_without_error(
method test_multi_turn_triggers_augmentation (line 206) | def test_multi_turn_triggers_augmentation(
class TestcloudXAISessionManagement (line 223) | class TestcloudXAISessionManagement:
method test_multiple_calls_same_session (line 226) | def test_multiple_calls_same_session(
method test_new_session_resets_context (line 241) | def test_new_session_resets_context(
FILE: tests/integration/conftest.py
function openai_api_key (line 59) | def openai_api_key():
function sqlite_session_factory (line 66) | def sqlite_session_factory(tmp_path):
function memori_test_mode (line 90) | def memori_test_mode():
function openai_client (line 101) | def openai_client(openai_api_key):
function async_openai_client (line 108) | def async_openai_client(openai_api_key):
function memori_instance (line 115) | def memori_instance(sqlite_session_factory, memori_test_mode):
function registered_openai_client (line 127) | def registered_openai_client(memori_instance, openai_client):
function registered_async_openai_client (line 134) | def registered_async_openai_client(memori_instance, async_openai_client):
function anthropic_api_key (line 141) | def anthropic_api_key():
function anthropic_client (line 148) | def anthropic_client(anthropic_api_key):
function async_anthropic_client (line 155) | def async_anthropic_client(anthropic_api_key):
function registered_anthropic_client (line 162) | def registered_anthropic_client(memori_instance, anthropic_client):
function registered_async_anthropic_client (line 169) | def registered_async_anthropic_client(memori_instance, async_anthropic_c...
function google_api_key (line 176) | def google_api_key():
function google_client (line 183) | def google_client(google_api_key):
function registered_google_client (line 195) | def registered_google_client(memori_instance, google_client):
function xai_api_key (line 202) | def xai_api_key():
function xai_client (line 209) | def xai_client(xai_api_key):
function async_xai_client (line 219) | def async_xai_client(xai_api_key):
function registered_xai_client (line 229) | def registered_xai_client(memori_instance, xai_client):
function registered_async_xai_client (line 236) | def registered_async_xai_client(memori_instance, async_xai_client):
function aws_credentials (line 243) | def aws_credentials():
function bedrock_client (line 254) | def bedrock_client(aws_credentials):
function registered_bedrock_client (line 267) | def registered_bedrock_client(memori_instance, bedrock_client):
class CapturedPayload (line 274) | class CapturedPayload:
method capture (line 277) | def capture(self, payload: dict) -> dict:
method last (line 286) | def last(self) -> dict | None:
method count (line 290) | def count(self) -> int:
method validate_structure (line 293) | def validate_structure(self, payload: dict | None = None) -> list[str]:
method is_valid (line 368) | def is_valid(self, payload: dict | None = None) -> bool:
function aa_payload_capture (line 373) | def aa_payload_capture():
function memori_instance_with_capture (line 384) | def memori_instance_with_capture(
FILE: tests/integration/databases/conftest.py
function sqlite_session_factory (line 43) | def sqlite_session_factory(tmp_path):
function postgres_session_factory (line 68) | def postgres_session_factory():
function mysql_session_factory (line 89) | def mysql_session_factory():
function mongodb_client (line 110) | def mongodb_client():
function memori_test_mode (line 123) | def memori_test_mode():
function sqlite_memori (line 135) | def sqlite_memori(sqlite_session_factory, memori_test_mode):
function postgres_memori (line 149) | def postgres_memori(postgres_session_factory, memori_test_mode):
function mysql_memori (line 163) | def mysql_memori(mysql_session_factory, memori_test_mode):
function mongodb_memori (line 177) | def mongodb_memori(mongodb_client, memori_test_mode):
function openai_api_key (line 191) | def openai_api_key():
function openai_client (line 199) | def openai_client(openai_api_key):
FILE: tests/integration/databases/test_database_storage.py
class TestSQLiteStorage (line 21) | class TestSQLiteStorage:
method test_store_and_search_facts (line 27) | def test_store_and_search_facts(self, sqlite_memori, openai_api_key):
method test_multiple_entities_isolation (line 55) | def test_multiple_entities_isolation(self, sqlite_memori, openai_api_k...
method test_conversation_storage (line 89) | def test_conversation_storage(self, sqlite_memori, openai_api_key):
class TestPostgresStorage (line 119) | class TestPostgresStorage:
method test_store_and_search_facts (line 125) | def test_store_and_search_facts(self, postgres_memori, openai_api_key):
method test_multiple_entities_isolation (line 151) | def test_multiple_entities_isolation(self, postgres_memori, openai_api...
method test_conversation_storage (line 184) | def test_conversation_storage(self, postgres_memori, openai_api_key):
class TestMySQLStorage (line 213) | class TestMySQLStorage:
method test_store_and_search_facts (line 219) | def test_store_and_search_facts(self, mysql_memori, openai_api_key):
method test_multiple_entities_isolation (line 248) | def test_multiple_entities_isolation(self, mysql_memori, openai_api_key):
method test_conversation_storage (line 281) | def test_conversation_storage(self, mysql_memori, openai_api_key):
class TestMongoDBStorage (line 310) | class TestMongoDBStorage:
method test_store_and_search_facts (line 316) | def test_store_and_search_facts(self, mongodb_memori, openai_api_key):
method test_multiple_entities_isolation (line 342) | def test_multiple_entities_isolation(self, mongodb_memori, openai_api_...
method test_conversation_storage (line 375) | def test_conversation_storage(self, mongodb_memori, openai_api_key):
FILE: tests/integration/providers/test_anthropic.py
class TestClientRegistration (line 11) | class TestClientRegistration:
method test_sync_client_registration_marks_installed (line 14) | def test_sync_client_registration_marks_installed(
method test_async_client_registration_marks_installed (line 28) | def test_async_client_registration_marks_installed(
method test_multiple_registrations_are_idempotent (line 42) | def test_multiple_registrations_are_idempotent(
method test_registration_preserves_original_methods (line 57) | def test_registration_preserves_original_methods(
class TestSyncMessages (line 67) | class TestSyncMessages:
method test_sync_message_returns_response (line 70) | def test_sync_message_returns_response(self, registered_anthropic_clie...
method test_sync_message_response_structure (line 84) | def test_sync_message_response_structure(self, registered_anthropic_cl...
method test_sync_message_with_system_message (line 105) | def test_sync_message_with_system_message(self, registered_anthropic_c...
method test_sync_message_multi_turn (line 118) | def test_sync_message_multi_turn(self, registered_anthropic_client):
class TestAsyncMessages (line 134) | class TestAsyncMessages:
method test_async_message_returns_response (line 138) | async def test_async_message_returns_response(
method test_async_message_response_structure (line 155) | async def test_async_message_response_structure(
method test_async_message_with_system (line 175) | async def test_async_message_with_system(self, registered_async_anthro...
class TestSyncStreaming (line 187) | class TestSyncStreaming:
method test_sync_streaming_returns_events (line 190) | def test_sync_streaming_returns_events(self, registered_anthropic_clie...
method test_sync_streaming_assembles_content (line 202) | def test_sync_streaming_assembles_content(self, registered_anthropic_c...
method test_sync_streaming_event_structure (line 214) | def test_sync_streaming_event_structure(self, registered_anthropic_cli...
class TestAsyncStreaming (line 226) | class TestAsyncStreaming:
method test_async_streaming_returns_events (line 230) | async def test_async_streaming_returns_events(
method test_async_streaming_assembles_content (line 247) | async def test_async_streaming_assembles_content(
method test_async_streaming_chunk_structure (line 265) | async def test_async_streaming_chunk_structure(
method test_async_streaming_final_message (line 284) | async def test_async_streaming_final_message(
method test_async_streaming_with_usage_info (line 303) | async def test_async_streaming_with_usage_info(
class TestErrorHandling (line 322) | class TestErrorHandling:
method test_invalid_api_key_raises_authentication_error (line 324) | def test_invalid_api_key_raises_authentication_error(self, memori_inst...
method test_invalid_model_raises_error (line 337) | def test_invalid_model_raises_error(self, registered_anthropic_client):
method test_async_invalid_api_key_raises_error (line 347) | async def test_async_invalid_api_key_raises_error(self, memori_instance):
class TestResponseFormatValidation (line 359) | class TestResponseFormatValidation:
method test_response_contains_usage_metadata (line 362) | def test_response_contains_usage_metadata(self, registered_anthropic_c...
method test_response_model_matches_request (line 375) | def test_response_model_matches_request(self, registered_anthropic_cli...
method test_response_stop_reason_is_valid (line 386) | def test_response_stop_reason_is_valid(self, registered_anthropic_clie...
method test_async_response_contains_usage_metadata (line 399) | async def test_async_response_contains_usage_metadata(
class TestMemoriIntegration (line 413) | class TestMemoriIntegration:
method test_memori_wrapper_does_not_modify_response_type (line 416) | def test_memori_wrapper_does_not_modify_response_type(
method test_config_captures_provider_info (line 441) | def test_config_captures_provider_info(self, memori_instance, anthropi...
method test_attribution_is_preserved_across_calls (line 449) | def test_attribution_is_preserved_across_calls(
class TestStorageVerification (line 473) | class TestStorageVerification:
method test_conversation_stored_after_sync_call (line 476) | def test_conversation_stored_after_sync_call(
method test_messages_stored_with_content (line 496) | def test_messages_stored_with_content(
method test_conversation_stored_after_async_call (line 527) | async def test_conversation_stored_after_async_call(
method test_multiple_calls_accumulate_messages (line 546) | def test_multiple_calls_accumulate_messages(
FILE: tests/integration/providers/test_bedrock.py
class TestClientRegistration (line 14) | class TestClientRegistration:
method test_client_registration_marks_installed (line 17) | def test_client_registration_marks_installed(
method test_multiple_registrations_are_idempotent (line 36) | def test_multiple_registrations_are_idempotent(
method test_registration_preserves_original_methods (line 57) | def test_registration_preserves_original_methods(
class TestSyncInvocation (line 73) | class TestSyncInvocation:
method test_sync_invoke_returns_response (line 76) | def test_sync_invoke_returns_response(self, registered_bedrock_client):
method test_sync_invoke_response_structure (line 85) | def test_sync_invoke_response_structure(self, registered_bedrock_client):
method test_sync_invoke_with_messages (line 94) | def test_sync_invoke_with_messages(self, registered_bedrock_client):
method test_sync_invoke_multi_turn (line 109) | def test_sync_invoke_multi_turn(self, registered_bedrock_client):
class TestAsyncInvocation (line 125) | class TestAsyncInvocation:
method test_async_invoke_returns_response (line 129) | async def test_async_invoke_returns_response(self, registered_bedrock_...
method test_async_invoke_response_structure (line 139) | async def test_async_invoke_response_structure(self, registered_bedroc...
method test_async_invoke_with_system_message (line 149) | async def test_async_invoke_with_system_message(self, registered_bedro...
class TestSyncStreaming (line 163) | class TestSyncStreaming:
method test_sync_streaming_returns_chunks (line 166) | def test_sync_streaming_returns_chunks(self, registered_bedrock_client):
method test_sync_streaming_assembles_content (line 173) | def test_sync_streaming_assembles_content(self, registered_bedrock_cli...
method test_sync_streaming_chunk_structure (line 184) | def test_sync_streaming_chunk_structure(self, registered_bedrock_client):
class TestAsyncStreaming (line 189) | class TestAsyncStreaming:
method test_async_streaming_returns_chunks (line 193) | async def test_async_streaming_returns_chunks(self, registered_bedrock...
method test_async_streaming_assembles_content (line 203) | async def test_async_streaming_assembles_content(self, registered_bedr...
method test_async_streaming_chunk_structure (line 215) | async def test_async_streaming_chunk_structure(self, registered_bedroc...
method test_async_streaming_with_usage_info (line 222) | async def test_async_streaming_with_usage_info(self, registered_bedroc...
class TestErrorHandling (line 234) | class TestErrorHandling:
method test_invalid_credentials_raises_error (line 236) | def test_invalid_credentials_raises_error(self, memori_instance):
method test_invalid_model_raises_error (line 260) | def test_invalid_model_raises_error(self, memori_instance, aws_credent...
method test_async_invalid_model_raises_error (line 275) | async def test_async_invalid_model_raises_error(
class TestResponseFormatValidation (line 290) | class TestResponseFormatValidation:
method test_response_contains_usage_metadata (line 293) | def test_response_contains_usage_metadata(self, registered_bedrock_cli...
method test_response_model_matches_requested (line 302) | def test_response_model_matches_requested(self, registered_bedrock_cli...
method test_response_finish_reason_is_valid (line 310) | def test_response_finish_reason_is_valid(self, registered_bedrock_clie...
method test_async_response_contains_usage_metadata (line 321) | async def test_async_response_contains_usage_metadata(
class TestMemoriIntegration (line 329) | class TestMemoriIntegration:
method test_memori_wrapper_does_not_modify_response_type (line 332) | def test_memori_wrapper_does_not_modify_response_type(
method test_config_captures_provider_info (line 356) | def test_config_captures_provider_info(self, memori_instance, aws_cred...
method test_attribution_is_preserved_across_calls (line 369) | def test_attribution_is_preserved_across_calls(
class TestStorageVerification (line 385) | class TestStorageVerification:
method test_conversation_stored_after_sync_call (line 388) | def test_conversation_stored_after_sync_call(
method test_messages_stored_with_content (line 404) | def test_messages_stored_with_content(
method test_conversation_stored_after_async_call (line 426) | async def test_conversation_stored_after_async_call(
method test_multiple_calls_accumulate_messages (line 441) | def test_multiple_calls_accumulate_messages(
FILE: tests/integration/providers/test_google.py
class TestClientRegistration (line 14) | class TestClientRegistration:
method test_client_registration_marks_installed (line 17) | def test_client_registration_marks_installed(self, memori_instance, go...
method test_multiple_registrations_are_idempotent (line 33) | def test_multiple_registrations_are_idempotent(
method test_registration_preserves_original_methods (line 52) | def test_registration_preserves_original_methods(
class TestSyncContentGeneration (line 67) | class TestSyncContentGeneration:
method test_sync_generate_returns_response (line 70) | def test_sync_generate_returns_response(self, registered_google_client):
method test_sync_generate_response_structure (line 82) | def test_sync_generate_response_structure(self, registered_google_clie...
method test_sync_generate_with_config (line 96) | def test_sync_generate_with_config(self, registered_google_client):
method test_sync_generate_multi_turn (line 113) | def test_sync_generate_multi_turn(self, registered_google_client):
class TestAsyncContentGeneration (line 130) | class TestAsyncContentGeneration:
method test_async_generate_returns_response (line 134) | async def test_async_generate_returns_response(self, registered_google...
method test_async_generate_response_structure (line 147) | async def test_async_generate_response_structure(self, registered_goog...
method test_async_generate_with_system_instruction (line 160) | async def test_async_generate_with_system_instruction(
class TestSyncStreaming (line 178) | class TestSyncStreaming:
method test_sync_streaming_returns_chunks (line 181) | def test_sync_streaming_returns_chunks(self, registered_google_client):
method test_sync_streaming_assembles_content (line 192) | def test_sync_streaming_assembles_content(self, registered_google_clie...
method test_sync_streaming_chunk_structure (line 208) | def test_sync_streaming_chunk_structure(self, registered_google_client):
class TestAsyncStreaming (line 218) | class TestAsyncStreaming:
method test_async_streaming_returns_chunks (line 222) | async def test_async_streaming_returns_chunks(self, registered_google_...
method test_async_streaming_assembles_content (line 237) | async def test_async_streaming_assembles_content(self, registered_goog...
method test_async_streaming_chunk_structure (line 254) | async def test_async_streaming_chunk_structure(self, registered_google...
method test_async_streaming_with_usage_info (line 266) | async def test_async_streaming_with_usage_info(self, registered_google...
class TestErrorHandling (line 284) | class TestErrorHandling:
method test_invalid_api_key_raises_error (line 286) | def test_invalid_api_key_raises_error(self, memori_instance):
method test_invalid_model_raises_error (line 303) | def test_invalid_model_raises_error(self, registered_google_client):
method test_async_invalid_api_key_raises_error (line 314) | async def test_async_invalid_api_key_raises_error(self, memori_instance):
class TestResponseFormatValidation (line 330) | class TestResponseFormatValidation:
method test_response_contains_usage_metadata (line 333) | def test_response_contains_usage_metadata(self, registered_google_clie...
method test_response_finish_reason_is_valid (line 343) | def test_response_finish_reason_is_valid(self, registered_google_client):
method test_response_model_info_is_present (line 355) | def test_response_model_info_is_present(self, registered_google_client):
method test_async_response_contains_usage_metadata (line 366) | async def test_async_response_contains_usage_metadata(
class TestMemoriIntegration (line 377) | class TestMemoriIntegration:
method test_memori_wrapper_does_not_modify_response_type (line 380) | def test_memori_wrapper_does_not_modify_response_type(
method test_config_captures_provider_info (line 407) | def test_config_captures_provider_info(self, memori_instance, google_a...
method test_attribution_is_preserved_across_calls (line 419) | def test_attribution_is_preserved_across_calls(
class TestStorageVerification (line 441) | class TestStorageVerification:
method test_conversation_stored_after_sync_call (line 444) | def test_conversation_stored_after_sync_call(
method test_messages_stored_with_content (line 463) | def test_messages_stored_with_content(
method test_conversation_stored_after_async_call (line 489) | async def test_conversation_stored_after_async_call(
method test_multiple_calls_accumulate_messages (line 507) | def test_multiple_calls_accumulate_messages(
FILE: tests/integration/providers/test_openai.py
class TestClientRegistration (line 18) | class TestClientRegistration:
method test_sync_client_registration_marks_installed (line 21) | def test_sync_client_registration_marks_installed(
method test_async_client_registration_marks_installed (line 35) | def test_async_client_registration_marks_installed(
method test_multiple_registrations_are_idempotent (line 49) | def test_multiple_registrations_are_idempotent(
method test_registration_preserves_original_methods (line 64) | def test_registration_preserves_original_methods(
method test_sync_client_registration_wraps_responses (line 76) | def test_sync_client_registration_wraps_responses(
method test_async_client_registration_wraps_responses (line 92) | def test_async_client_registration_wraps_responses(
method test_multiple_registrations_preserve_responses_wrapper (line 106) | def test_multiple_registrations_preserve_responses_wrapper(
class TestSyncChatCompletions (line 119) | class TestSyncChatCompletions:
method test_sync_chat_completion_returns_response (line 122) | def test_sync_chat_completion_returns_response(self, registered_openai...
method test_sync_chat_completion_response_structure (line 136) | def test_sync_chat_completion_response_structure(self, registered_open...
method test_sync_chat_completion_with_system_message (line 157) | def test_sync_chat_completion_with_system_message(self, registered_ope...
method test_sync_chat_completion_multi_turn (line 172) | def test_sync_chat_completion_multi_turn(self, registered_openai_client):
class TestAsyncChatCompletions (line 188) | class TestAsyncChatCompletions:
method test_async_chat_completion_returns_response (line 192) | async def test_async_chat_completion_returns_response(
method test_async_chat_completion_response_structure (line 209) | async def test_async_chat_completion_response_structure(
method test_async_chat_completion_with_system_message (line 230) | async def test_async_chat_completion_with_system_message(
class TestSyncStreaming (line 246) | class TestSyncStreaming:
method test_sync_streaming_returns_chunks (line 249) | def test_sync_streaming_returns_chunks(self, registered_openai_client):
method test_sync_streaming_assembles_content (line 263) | def test_sync_streaming_assembles_content(self, registered_openai_clie...
method test_sync_streaming_chunk_structure (line 281) | def test_sync_streaming_chunk_structure(self, registered_openai_client):
class TestAsyncStreaming (line 295) | class TestAsyncStreaming:
method test_async_streaming_returns_chunks (line 299) | async def test_async_streaming_returns_chunks(self, registered_async_o...
method test_async_streaming_assembles_content (line 316) | async def test_async_streaming_assembles_content(
method test_async_streaming_chunk_structure (line 337) | async def test_async_streaming_chunk_structure(
method test_async_streaming_with_usage_info (line 355) | async def test_async_streaming_with_usage_info(
class TestErrorHandling (line 373) | class TestErrorHandling:
method test_invalid_api_key_raises_authentication_error (line 375) | def test_invalid_api_key_raises_authentication_error(self, memori_inst...
method test_invalid_model_raises_error (line 388) | def test_invalid_model_raises_error(self, registered_openai_client):
method test_async_invalid_api_key_raises_error (line 398) | async def test_async_invalid_api_key_raises_error(self, memori_instance):
class TestResponseFormatValidation (line 410) | class TestResponseFormatValidation:
method test_response_contains_usage_metadata (line 413) | def test_response_contains_usage_metadata(self, registered_openai_clie...
method test_response_model_matches_request (line 427) | def test_response_model_matches_request(self, registered_openai_client):
method test_response_finish_reason_is_valid (line 438) | def test_response_finish_reason_is_valid(self, registered_openai_client):
method test_async_response_contains_usage_metadata (line 457) | async def test_async_response_contains_usage_metadata(
class TestMemoriIntegration (line 471) | class TestMemoriIntegration:
method test_memori_wrapper_does_not_modify_response_type (line 474) | def test_memori_wrapper_does_not_modify_response_type(
method test_config_captures_provider_info (line 499) | def test_config_captures_provider_info(self, memori_instance, openai_a...
method test_attribution_is_preserved_across_calls (line 507) | def test_attribution_is_preserved_across_calls(
class TestBetaApi (line 531) | class TestBetaApi:
method test_beta_parse_registration (line 534) | def test_beta_parse_registration(self, memori_instance, openai_api_key):
class TestStorageVerification (line 541) | class TestStorageVerification:
method test_conversation_stored_after_sync_call (line 544) | def test_conversation_stored_after_sync_call(
method test_conversation_stored_after_async_call (line 565) | async def test_conversation_stored_after_async_call(
method test_messages_stored_with_content (line 584) | def test_messages_stored_with_content(
method test_multiple_calls_accumulate_messages (line 614) | def test_multiple_calls_accumulate_messages(
class TestSyncResponses (line 650) | class TestSyncResponses:
method test_sync_responses_returns_response (line 653) | def test_sync_responses_returns_response(self, registered_openai_client):
method test_sync_responses_response_structure (line 667) | def test_sync_responses_response_structure(self, registered_openai_cli...
method test_sync_responses_with_instructions (line 682) | def test_sync_responses_with_instructions(self, registered_openai_clie...
method test_sync_responses_simple_math (line 695) | def test_sync_responses_simple_math(self, registered_openai_client):
class TestAsyncResponses (line 707) | class TestAsyncResponses:
method test_async_responses_returns_response (line 711) | async def test_async_responses_returns_response(
method test_async_responses_response_structure (line 728) | async def test_async_responses_response_structure(
method test_async_responses_with_instructions (line 745) | async def test_async_responses_with_instructions(
class TestResponsesConversationStorage (line 759) | class TestResponsesConversationStorage:
method test_conversation_id_created_after_call (line 762) | def test_conversation_id_created_after_call(self, memori_instance, ope...
method test_conversation_continuity (line 779) | def test_conversation_continuity(self, memori_instance, openai_api_key):
class TestResponsesErrorHandling (line 801) | class TestResponsesErrorHandling:
method test_invalid_api_key_raises_error (line 803) | def test_invalid_api_key_raises_error(self, memori_instance):
method test_invalid_model_raises_error (line 816) | def test_invalid_model_raises_error(self, registered_openai_client):
method test_async_invalid_api_key_raises_error (line 826) | async def test_async_invalid_api_key_raises_error(self, memori_instance):
class TestResponsesWithChatCompletionsCoexistence (line 838) | class TestResponsesWithChatCompletionsCoexistence:
method test_both_apis_work_with_same_client (line 841) | def test_both_apis_work_with_same_client(self, registered_openai_client):
method test_async_both_apis_work_with_same_client (line 861) | async def test_async_both_apis_work_with_same_client(
class TestResponsesStreaming (line 881) | class TestResponsesStreaming:
method test_sync_streaming_returns_events (line 884) | def test_sync_streaming_returns_events(self, registered_openai_client):
method test_sync_streaming_final_response_structure (line 900) | def test_sync_streaming_final_response_structure(self, registered_open...
method test_sync_streaming_yields_text_deltas (line 928) | def test_sync_streaming_yields_text_deltas(self, registered_openai_cli...
method test_sync_streaming_context_manager (line 945) | def test_sync_streaming_context_manager(self, registered_openai_client):
method test_async_streaming_returns_events (line 959) | async def test_async_streaming_returns_events(self, registered_async_o...
method test_async_streaming_final_response_structure (line 978) | async def test_async_streaming_final_response_structure(
method test_async_streaming_context_manager (line 1012) | async def test_async_streaming_context_manager(
method test_async_streaming_event_structure (line 1030) | async def test_async_streaming_event_structure(
method test_async_streaming_yields_text_deltas (line 1046) | async def test_async_streaming_yields_text_deltas(
class TestResponsesInputFormats (line 1064) | class TestResponsesInputFormats:
method test_string_input (line 1067) | def test_string_input(self, registered_openai_client):
method test_list_input_with_messages (line 1079) | def test_list_input_with_messages(self, registered_openai_client):
class TestResponsesFormatValidation (line 1094) | class TestResponsesFormatValidation:
method test_responses_contains_usage_metadata (line 1097) | def test_responses_contains_usage_metadata(self, registered_openai_cli...
method test_responses_model_matches_request (line 1111) | def test_responses_model_matches_request(self, registered_openai_client):
method test_responses_status_is_valid (line 1122) | def test_responses_status_is_valid(self, registered_openai_client):
method test_async_responses_contains_usage_metadata (line 1135) | async def test_async_responses_contains_usage_metadata(
class TestResponsesMemoriIntegration (line 1149) | class TestResponsesMemoriIntegration:
method test_memori_wrapper_does_not_modify_response_type (line 1152) | def test_memori_wrapper_does_not_modify_response_type(
method test_config_captures_provider_info (line 1177) | def test_config_captures_provider_info(self, memori_instance, openai_a...
method test_attribution_is_preserved_across_calls (line 1185) | def test_attribution_is_preserved_across_calls(
class TestResponsesStorageVerification (line 1209) | class TestResponsesStorageVerification:
method test_conversation_stored_after_sync_call (line 1212) | def test_conversation_stored_after_sync_call(
method test_conversation_stored_after_async_call (line 1233) | async def test_conversation_stored_after_async_call(
method test_messages_stored_with_content (line 1252) | def test_messages_stored_with_content(
method test_multiple_calls_accumulate_messages (line 1282) | def test_multiple_calls_accumulate_messages(
FILE: tests/integration/providers/test_xai.py
class TestClientRegistration (line 18) | class TestClientRegistration:
method test_sync_client_registration_marks_installed (line 21) | def test_sync_client_registration_marks_installed(
method test_async_client_registration_marks_installed (line 35) | def test_async_client_registration_marks_installed(
method test_multiple_registrations_are_idempotent (line 49) | def test_multiple_registrations_are_idempotent(self, memori_instance, ...
method test_registration_preserves_original_methods (line 62) | def test_registration_preserves_original_methods(
class TestSyncChatCompletions (line 72) | class TestSyncChatCompletions:
method test_sync_chat_completion_returns_response (line 75) | def test_sync_chat_completion_returns_response(self, registered_xai_cl...
method test_sync_chat_completion_response_structure (line 89) | def test_sync_chat_completion_response_structure(self, registered_xai_...
method test_sync_chat_completion_with_system_message (line 110) | def test_sync_chat_completion_with_system_message(self, registered_xai...
method test_sync_chat_completion_multi_turn (line 125) | def test_sync_chat_completion_multi_turn(self, registered_xai_client):
class TestAsyncChatCompletions (line 141) | class TestAsyncChatCompletions:
method test_async_chat_completion_returns_response (line 145) | async def test_async_chat_completion_returns_response(
method test_async_chat_completion_response_structure (line 162) | async def test_async_chat_completion_response_structure(
method test_async_chat_completion_with_system_message (line 183) | async def test_async_chat_completion_with_system_message(
class TestSyncStreaming (line 199) | class TestSyncStreaming:
method test_sync_streaming_returns_chunks (line 202) | def test_sync_streaming_returns_chunks(self, registered_xai_client):
method test_sync_streaming_assembles_content (line 216) | def test_sync_streaming_assembles_content(self, registered_xai_client):
method test_sync_streaming_chunk_structure (line 234) | def test_sync_streaming_chunk_structure(self, registered_xai_client):
class TestAsyncStreaming (line 248) | class TestAsyncStreaming:
method test_async_streaming_returns_chunks (line 252) | async def test_async_streaming_returns_chunks(self, registered_async_x...
method test_async_streaming_assembles_content (line 269) | async def test_async_streaming_assembles_content(self, registered_asyn...
method test_async_streaming_chunk_structure (line 288) | async def test_async_streaming_chunk_structure(self, registered_async_...
method test_async_streaming_with_usage_info (line 304) | async def test_async_streaming_with_usage_info(self, registered_async_...
class TestErrorHandling (line 320) | class TestErrorHandling:
method test_invalid_api_key_raises_error (line 322) | def test_invalid_api_key_raises_error(self, memori_instance):
method test_invalid_model_raises_error (line 335) | def test_invalid_model_raises_error(self, registered_xai_client):
method test_async_invalid_api_key_raises_error (line 345) | async def test_async_invalid_api_key_raises_error(self, memori_instance):
class TestResponseFormatValidation (line 357) | class TestResponseFormatValidation:
method test_response_contains_usage_metadata (line 360) | def test_response_contains_usage_metadata(self, registered_xai_client):
method test_response_model_matches_request (line 374) | def test_response_model_matches_request(self, registered_xai_client):
method test_response_finish_reason_is_valid (line 385) | def test_response_finish_reason_is_valid(self, registered_xai_client):
method test_async_response_contains_usage_metadata (line 404) | async def test_async_response_contains_usage_metadata(
class TestMemoriIntegration (line 418) | class TestMemoriIntegration:
method test_memori_wrapper_does_not_modify_response_type (line 421) | def test_memori_wrapper_does_not_modify_response_type(
method test_config_captures_provider_info (line 446) | def test_config_captures_provider_info(self, memori_instance, xai_api_...
method test_attribution_is_preserved_across_calls (line 454) | def test_attribution_is_preserved_across_calls(
class TestStorageVerification (line 478) | class TestStorageVerification:
method test_conversation_stored_after_sync_call (line 481) | def test_conversation_stored_after_sync_call(
method test_messages_stored_with_content (line 501) | def test_messages_stored_with_content(self, registered_xai_client, mem...
method test_conversation_stored_after_async_call (line 530) | async def test_conversation_stored_after_async_call(
method test_multiple_calls_accumulate_messages (line 549) | def test_multiple_calls_accumulate_messages(
FILE: tests/integration/test_aa_payload.py
class TestSyncAAIntegration (line 17) | class TestSyncAAIntegration:
method test_sync_call_triggers_aa_pipeline (line 20) | def test_sync_call_triggers_aa_pipeline(self, memori_instance, openai_...
method test_sync_streaming_triggers_aa_pipeline (line 42) | def test_sync_streaming_triggers_aa_pipeline(self, memori_instance, op...
method test_multi_turn_conversation_triggers_aa (line 69) | def test_multi_turn_conversation_triggers_aa(self, memori_instance, op...
class TestAsyncAAIntegration (line 100) | class TestAsyncAAIntegration:
method test_async_call_triggers_aa_pipeline (line 104) | async def test_async_call_triggers_aa_pipeline(
method test_async_streaming_triggers_aa_pipeline (line 130) | async def test_async_streaming_triggers_aa_pipeline(
class TestAAEdgeCases (line 159) | class TestAAEdgeCases:
method test_no_aa_without_attribution (line 162) | def test_no_aa_without_attribution(self, memori_instance, openai_api_k...
method test_aa_with_entity_only (line 181) | def test_aa_with_entity_only(self, memori_instance, openai_api_key):
method test_multiple_calls_same_session (line 201) | def test_multiple_calls_same_session(self, memori_instance, openai_api...
class TestTestModeConfiguration (line 221) | class TestTestModeConfiguration:
method test_memori_test_mode_is_enabled (line 222) | def test_memori_test_mode_is_enabled(self):
method test_memori_instance_in_test_mode (line 227) | def test_memori_instance_in_test_mode(self, memori_instance):
FILE: tests/llm/adapters/anthropic/test_llm_adapters_anthropic_adapter.py
function test_get_formatted_query (line 4) | def test_get_formatted_query():
function test_get_formatted_response_unstreamed (line 22) | def test_get_formatted_response_unstreamed():
function test_get_formatted_query_with_injected_messages (line 44) | def test_get_formatted_query_with_injected_messages():
FILE: tests/llm/adapters/bedrock/test_llm_adapters_bedrock_adapter.py
function test_get_formatted_query (line 4) | def test_get_formatted_query():
function test_get_formatted_response_streamed (line 24) | def test_get_formatted_response_streamed():
function test_get_formatted_query_with_injected_messages (line 41) | def test_get_formatted_query_with_injected_messages():
FILE: tests/llm/adapters/google/test_llm_adapters_google_adapter.py
function test_get_formatted_query (line 4) | def test_get_formatted_query():
function test_get_formatted_response_streamed (line 22) | def test_get_formatted_response_streamed():
function test_get_formatted_response_unstreamed (line 51) | def test_get_formatted_response_unstreamed():
function test_get_formatted_query_with_injected_messages (line 72) | def test_get_formatted_query_with_injected_messages():
FILE: tests/llm/adapters/openai/test_llm_adapters_openai_adapter.py
class MockEvent (line 12) | class MockEvent:
method __init__ (line 13) | def __init__(self, event_type: str, response=None):
class MockResponse (line 19) | class MockResponse:
method __init__ (line 20) | def __init__(self, output_text: str):
method model_dump (line 29) | def model_dump(self):
class MockResponsesResponse (line 33) | class MockResponsesResponse:
method __init__ (line 34) | def __init__(self):
method model_dump (line 38) | def model_dump(self):
function test_get_formatted_query (line 42) | def test_get_formatted_query():
function test_get_formatted_response_streamed (line 60) | def test_get_formatted_response_streamed():
function test_get_formatted_response_unstreamed (line 89) | def test_get_formatted_response_unstreamed():
function test_get_formatted_query_with_injected_messages (line 111) | def test_get_formatted_query_with_injected_messages():
function test_responses_get_formatted_query_string_input (line 132) | def test_responses_get_formatted_query_string_input():
function test_responses_get_formatted_query_list_input (line 147) | def test_responses_get_formatted_query_list_input():
function test_responses_get_formatted_query_strips_memori_context (line 164) | def test_responses_get_formatted_query_strips_memori_context():
function test_responses_get_formatted_query_with_injected_messages (line 178) | def test_responses_get_formatted_query_with_injected_messages():
function test_responses_get_formatted_response_with_output_message (line 196) | def test_responses_get_formatted_response_with_output_message():
function test_responses_get_formatted_response_fallback_to_output_text (line 215) | def test_responses_get_formatted_response_fallback_to_output_text():
function test_iterator_iter_returns_self (line 227) | def test_iterator_iter_returns_self():
function test_iterator_yields_all_events (line 234) | def test_iterator_yields_all_events(mock_memory_manager):
function test_iterator_captures_response_on_completed_event (line 255) | def test_iterator_captures_response_on_completed_event(mock_memory_manag...
function test_async_iterator_aiter_returns_self (line 273) | def test_async_iterator_aiter_returns_self():
function test_async_iterator_yields_all_events (line 283) | async def test_async_iterator_yields_all_events(mock_memory_manager):
function test_async_iterator_raises_runtime_error_if_not_initialized (line 312) | async def test_async_iterator_raises_runtime_error_if_not_initialized():
function test_extract_user_query_from_string_input (line 319) | def test_extract_user_query_from_string_input():
function test_extract_user_query_from_list_input (line 325) | def test_extract_user_query_from_list_input():
function test_extract_user_query_from_missing_input (line 337) | def test_extract_user_query_from_missing_input():
function test_inject_recalled_facts_returns_kwargs_when_no_storage (line 343) | def test_inject_recalled_facts_returns_kwargs_when_no_storage():
function test_inject_recalled_facts_appends_facts_to_instructions (line 351) | def test_inject_recalled_facts_appends_facts_to_instructions():
function test_inject_conversation_messages_returns_kwargs_when_no_conversation_id (line 373) | def test_inject_conversation_messages_returns_kwargs_when_no_conversatio...
function test_inject_conversation_messages_converts_string_input_to_list (line 381) | def test_inject_conversation_messages_converts_string_input_to_list():
function test_invoke_calls_method (line 399) | def test_invoke_calls_method():
function test_async_invoke_calls_method (line 415) | async def test_async_invoke_calls_method():
FILE: tests/llm/adapters/xai/test_llm_adapters_xai_adapter.py
function test_get_formatted_query_empty_payload (line 4) | def test_get_formatted_query_empty_payload():
function test_get_formatted_query_missing_messages (line 8) | def test_get_formatted_query_missing_messages():
function test_get_formatted_query_with_user_message (line 12) | def test_get_formatted_query_with_user_message():
function test_get_formatted_query_with_assistant_message (line 29) | def test_get_formatted_query_with_assistant_message():
function test_get_formatted_query_with_system_message (line 46) | def test_get_formatted_query_with_system_message():
function test_get_formatted_query_with_multiple_messages (line 63) | def test_get_formatted_query_with_multiple_messages():
function test_get_formatted_query_with_multiple_content_parts (line 92) | def test_get_formatted_query_with_multiple_content_parts():
function test_get_formatted_query_with_missing_role (line 113) | def test_get_formatted_query_with_missing_role():
function test_get_formatted_query_with_unknown_role (line 132) | def test_get_formatted_query_with_unknown_role():
function test_get_formatted_query_with_empty_content (line 152) | def test_get_formatted_query_with_empty_content():
function test_get_formatted_query_with_content_without_text (line 172) | def test_get_formatted_query_with_content_without_text():
function test_get_formatted_query_with_injected_messages (line 192) | def test_get_formatted_query_with_injected_messages():
function test_get_formatted_response_empty_payload (line 225) | def test_get_formatted_response_empty_payload():
function test_get_formatted_response_missing_response (line 229) | def test_get_formatted_response_missing_response():
function test_get_formatted_response_with_string_content (line 233) | def test_get_formatted_response_with_string_content():
function test_get_formatted_response_with_list_of_dicts (line 246) | def test_get_formatted_response_with_list_of_dicts():
function test_get_formatted_response_with_list_of_strings (line 265) | def test_get_formatted_response_with_list_of_strings():
function test_get_formatted_response_with_mixed_list (line 281) | def test_get_formatted_response_with_mixed_list():
function test_get_formatted_response_with_missing_role (line 302) | def test_get_formatted_response_with_missing_role():
function test_get_formatted_response_with_missing_content (line 317) | def test_get_formatted_response_with_missing_content():
function test_get_formatted_response_with_dict_without_text (line 332) | def test_get_formatted_response_with_dict_without_text():
FILE: tests/llm/clients/oss/agno/anthropic_async.py
function main (line 18) | async def main():
FILE: tests/llm/clients/oss/agno/gemini_async.py
function main (line 18) | async def main():
FILE: tests/llm/clients/oss/agno/openai_async.py
function main (line 18) | async def main():
FILE: tests/llm/clients/oss/agno/xai_async.py
function main (line 18) | async def main():
FILE: tests/llm/clients/oss/anthropic/async.py
function run (line 17) | async def run():
FILE: tests/llm/clients/oss/gemini/async.py
function main (line 17) | async def main():
FILE: tests/llm/clients/oss/gemini/async_streaming.py
function main (line 17) | async def main():
FILE: tests/llm/clients/oss/langchain/chatbedrock/async_runnable.py
function main (line 19) | async def main():
FILE: tests/llm/clients/oss/langchain/chatgooglegenai/async_runnable.py
function main (line 19) | async def main():
FILE: tests/llm/clients/oss/langchain/chatgooglegenai/async_streaming.py
function main (line 18) | async def main():
FILE: tests/llm/clients/oss/langchain/chatgooglegenai/sync_runnable_structured_output.py
class Color (line 18) | class Color(BaseModel):
class Order (line 22) | class Order(BaseModel):
FILE: tests/llm/clients/oss/langchain/chatopenai/async_ainvoke.py
function run (line 18) | async def run():
FILE: tests/llm/clients/oss/langchain/chatopenai/async_runnable.py
function main (line 19) | async def main():
FILE: tests/llm/clients/oss/langchain/chatopenai/async_streaming.py
function main (line 18) | async def main():
FILE: tests/llm/clients/oss/langchain/chatopenai/sync_runnable_structured_output.py
class Color (line 18) | class Color(BaseModel):
class Order (line 22) | class Order(BaseModel):
FILE: tests/llm/clients/oss/openai/async.py
function run (line 24) | async def run(db_backend: str = "default"):
FILE: tests/llm/clients/oss/openai/async_streaming.py
function run (line 17) | async def run():
FILE: tests/llm/clients/oss/xai/async.py
function run (line 26) | async def run(db_backend: str = "default"):
FILE: tests/llm/clients/oss/xai/async_stream.py
function run (line 26) | async def run(db_backend: str = "default"):
FILE: tests/llm/providers/azure_openai/test_azure_openai.py
function config (line 16) | def config():
function openai_handler (line 21) | def openai_handler(config):
class TestAzureOpenAIModuleDetection (line 25) | class TestAzureOpenAIModuleDetection:
method test_openai_module_path (line 28) | def test_openai_module_path(self):
method test_azure_openai_module_path (line 34) | def test_azure_openai_module_path(self):
method test_azure_openai_startswith_openai (line 40) | def test_azure_openai_startswith_openai(self):
method test_openai_startswith_openai (line 46) | def test_openai_startswith_openai(self):
class TestAzureOpenAIInheritance (line 53) | class TestAzureOpenAIInheritance:
method test_azure_openai_is_subclass_of_openai (line 56) | def test_azure_openai_is_subclass_of_openai(self):
method test_azure_openai_has_chat_attribute (line 62) | def test_azure_openai_has_chat_attribute(self):
method test_azure_openai_has_beta_attribute (line 68) | def test_azure_openai_has_beta_attribute(self):
class TestAzureOpenAIRegistryDetection (line 75) | class TestAzureOpenAIRegistryDetection:
method test_registry_detects_openai_client (line 78) | def test_registry_detects_openai_client(self):
method test_registry_detects_azure_openai_client (line 85) | def test_registry_detects_azure_openai_client(self):
method test_registry_does_not_detect_anthropic (line 92) | def test_registry_does_not_detect_anthropic(self):
method test_registry_does_not_detect_langchain_openai (line 98) | def test_registry_does_not_detect_langchain_openai(self):
class TestAzureOpenAIClientRegistration (line 105) | class TestAzureOpenAIClientRegistration:
method test_openai_handler_registers_openai_client (line 108) | def test_openai_handler_registers_openai_client(self, openai_handler, ...
method test_openai_handler_registers_azure_openai_client (line 124) | def test_openai_handler_registers_azure_openai_client(self, openai_han...
method test_openai_handler_wraps_chat_completions_create (line 145) | def test_openai_handler_wraps_chat_completions_create(self, openai_han...
method test_openai_handler_wraps_beta_parse (line 159) | def test_openai_handler_wraps_beta_parse(self, openai_handler, mocker):
class TestAzureOpenAINoFalsePositives (line 174) | class TestAzureOpenAINoFalsePositives:
method test_anthropic_not_matched (line 177) | def test_anthropic_not_matched(self):
method test_google_not_matched (line 181) | def test_google_not_matched(self):
method test_langchain_openai_not_matched (line 185) | def test_langchain_openai_not_matched(self):
method test_pydantic_ai_not_matched (line 189) | def test_pydantic_ai_not_matched(self):
method test_xai_not_matched (line 193) | def test_xai_not_matched(self):
method test_openai_submodules_matched (line 197) | def test_openai_submodules_matched(self):
FILE: tests/llm/providers/google_genai/test_google_genai.py
function config (line 16) | def config():
class MockGoogleGenaiPart (line 20) | class MockGoogleGenaiPart:
method __init__ (line 23) | def __init__(self, text):
class MockGoogleGenaiContent (line 27) | class MockGoogleGenaiContent:
method __init__ (line 30) | def __init__(self, parts, role="model"):
class MockGoogleGenaiCandidate (line 35) | class MockGoogleGenaiCandidate:
method __init__ (line 38) | def __init__(self, content):
class MockGoogleGenaiResponse (line 42) | class MockGoogleGenaiResponse:
method __init__ (line 45) | def __init__(self, text, role="model"):
class MockGoogleGenaiChunk (line 52) | class MockGoogleGenaiChunk:
method __init__ (line 55) | def __init__(self, text, role="model"):
class TestGoogleGenaiFormatDetection (line 62) | class TestGoogleGenaiFormatDetection:
method test_response_has_no_pb_attribute (line 65) | def test_response_has_no_pb_attribute(self):
method test_response_has_candidates_attribute (line 71) | def test_response_has_candidates_attribute(self):
method test_chunk_has_no_pb_attribute (line 77) | def test_chunk_has_no_pb_attribute(self):
method test_chunk_has_candidates_attribute (line 83) | def test_chunk_has_candidates_attribute(self):
class TestGoogleGenaiNonStreamingFormat (line 89) | class TestGoogleGenaiNonStreamingFormat:
method test_format_response_with_google_genai_format (line 92) | def test_format_response_with_google_genai_format(self, config):
method test_format_response_with_empty_candidates (line 109) | def test_format_response_with_empty_candidates(self, config):
method test_format_response_preserves_role (line 121) | def test_format_response_preserves_role(self, config):
class TestGoogleGenaiStreamingFormat (line 132) | class TestGoogleGenaiStreamingFormat:
method test_process_chunk_with_google_genai_format (line 135) | def test_process_chunk_with_google_genai_format(self, config):
method test_process_multiple_chunks (line 154) | def test_process_multiple_chunks(self, config):
method test_process_chunk_preserves_role (line 186) | def test_process_chunk_preserves_role(self, config):
class TestGoogleGenaiBackwardsCompatibility (line 201) | class TestGoogleGenaiBackwardsCompatibility:
method test_format_response_with_pb_format (line 204) | def test_format_response_with_pb_format(self, config):
method test_non_protobuf_response_unchanged (line 219) | def test_non_protobuf_response_unchanged(self, config):
FILE: tests/llm/test_llm_base.py
function test_dict_to_json_dict (line 13) | def test_dict_to_json_dict():
function test_dist_to_json_dict_has_dict (line 20) | def test_dist_to_json_dict_has_dict():
function test_configure_for_streaming_usage_openai (line 26) | def test_configure_for_streaming_usage_openai():
function test_configure_for_streaming_usage_streaming_options_is_not_dict_openai (line 45) | def test_configure_for_streaming_usage_streaming_options_is_not_dict_ope...
function test_configure_for_streaming_usage_only_if_stream_is_true_openai (line 58) | def test_configure_for_streaming_usage_only_if_stream_is_true_openai():
function test_configure_for_streaming_usage_langchain_openai (line 65) | def test_configure_for_streaming_usage_langchain_openai():
function test_configure_for_streaming_usage_streaming_opts_is_not_dict_langchain_openai (line 85) | def test_configure_for_streaming_usage_streaming_opts_is_not_dict_langch...
function test_configure_for_streaming_usage_only_if_stream_is_true_langchain_openai (line 99) | def test_configure_for_streaming_usage_only_if_stream_is_true_langchain_...
function test_get_response_content (line 107) | def test_get_response_content():
function test_exclude_injected_messages (line 123) | def test_exclude_injected_messages():
function test_handle_post_response_without_augmentation (line 146) | def test_handle_post_response_without_augmentation():
function test_handle_post_response_with_augmentation_no_conversation (line 170) | def test_handle_post_response_with_augmentation_no_conversation():
function test_handle_post_response_with_augmentation_and_conversation (line 202) | def test_handle_post_response_with_augmentation_and_conversation():
function test_extract_user_query_with_user_message (line 235) | def test_extract_user_query_with_user_message():
function test_extract_user_query_with_multiple_user_messages (line 246) | def test_extract_user_query_with_multiple_user_messages():
function test_extract_user_query_no_messages (line 258) | def test_extract_user_query_no_messages():
function test_extract_user_query_no_user_messages (line 264) | def test_extract_user_query_no_user_messages():
function test_extract_user_query_google_contents_string (line 275) | def test_extract_user_query_google_contents_string():
function test_extract_user_query_google_contents_list_of_strings (line 281) | def test_extract_user_query_google_contents_list_of_strings():
function test_extract_user_query_google_contents_list_of_dicts (line 287) | def test_extract_user_query_google_contents_list_of_dicts():
function test_extract_user_query_google_contents_with_string_parts (line 299) | def test_extract_user_query_google_contents_with_string_parts():
function test_extract_user_query_google_contents_empty (line 309) | def test_extract_user_query_google_contents_empty():
function test_extract_text_from_parts_with_strings (line 315) | def test_extract_text_from_parts_with_strings():
function test_extract_text_from_parts_with_dicts (line 321) | def test_extract_text_from_parts_with_dicts():
function test_extract_text_from_parts_mixed (line 327) | def test_extract_text_from_parts_mixed():
function test_extract_text_from_parts_empty (line 333) | def test_extract_text_from_parts_empty():
function test_extract_from_contents_string (line 338) | def test_extract_from_contents_string():
function test_extract_from_contents_list_strings (line 343) | def test_extract_from_contents_list_strings():
function test_extract_from_contents_list_dicts (line 348) | def test_extract_from_contents_list_dicts():
function test_inject_recalled_facts_no_storage (line 356) | def test_inject_recalled_facts_no_storage():
function test_inject_recalled_facts_no_entity_id (line 367) | def test_inject_recalled_facts_no_entity_id():
function test_inject_recalled_facts_no_user_query (line 379) | def test_inject_recalled_facts_no_user_query():
function test_inject_recalled_facts_no_facts_found (line 393) | def test_inject_recalled_facts_no_facts_found():
function test_inject_recalled_facts_no_relevant_facts (line 411) | def test_inject_recalled_facts_no_relevant_facts():
function test_inject_recalled_facts_success (line 431) | def test_inject_recalled_facts_success():
function test_inject_recalled_facts_filters_by_relevance (line 467) | def test_inject_recalled_facts_filters_by_relevance():
function test_inject_recalled_facts_extends_existing_system_message (line 489) | def test_inject_recalled_facts_extends_existing_system_message():
function test_inject_recalled_facts_creates_system_message_when_none_exists (line 520) | def test_inject_recalled_facts_creates_system_message_when_none_exists():
function test_inject_recalled_facts_google_creates_config (line 545) | def test_inject_recalled_facts_google_creates_config():
function test_inject_recalled_facts_google_extends_existing_config (line 568) | def test_inject_recalled_facts_google_extends_existing_config():
function test_inject_recalled_facts_google_with_contents_list (line 593) | def test_inject_recalled_facts_google_with_contents_list():
function test_append_to_google_system_instruction_dict_empty (line 620) | def test_append_to_google_system_instruction_dict_empty():
function test_append_to_google_system_instruction_dict_string (line 627) | def test_append_to_google_system_instruction_dict_string():
function test_append_to_google_system_instruction_dict_list_of_dicts (line 634) | def test_append_to_google_system_instruction_dict_list_of_dicts():
function test_append_to_google_system_instruction_dict_list_of_strings (line 641) | def test_append_to_google_system_instruction_dict_list_of_strings():
function test_append_to_list_empty (line 648) | def test_append_to_list_empty():
function test_append_to_list_dict_with_text (line 655) | def test_append_to_list_dict_with_text():
function test_append_to_list_strings (line 663) | def test_append_to_list_strings():
function test_append_to_content_dict_with_parts (line 671) | def test_append_to_content_dict_with_parts():
function test_append_to_content_dict_with_text (line 679) | def test_append_to_content_dict_with_text():
function test_inject_conversation_messages_no_conversation_id (line 687) | def test_inject_conversation_messages_no_conversation_id():
function test_inject_conversation_messages_no_storage (line 698) | def test_inject_conversation_messages_no_storage():
function test_inject_conversation_messages_no_messages (line 710) | def test_inject_conversation_messages_no_messages():
function test_inject_conversation_messages_openai_success (line 725) | def test_inject_conversation_messages_openai_success():
function test_inject_conversation_messages_cache_miss_loads_from_session (line 747) | def test_inject_conversation_messages_cache_miss_loads_from_session(mock...
function test_inject_conversation_messages_cloud_fetches_from_cloud (line 781) | def test_inject_conversation_messages_cloud_fetches_from_cloud(mocker):
FILE: tests/llm/test_llm_clients.py
function config (line 16) | def config():
function anthropic_client (line 21) | def anthropic_client(config):
function google_client (line 26) | def google_client(config):
function openai_client (line 31) | def openai_client(config):
function pydantic_client (line 36) | def pydantic_client(config):
function langchain_client (line 41) | def langchain_client(config):
function xai_client (line 46) | def xai_client(config):
function agno_client (line 51) | def agno_client(config):
function test_anthropic_register_adds_memori_wrappers_sync (line 55) | def test_anthropic_register_adds_memori_wrappers_sync(anthropic_client, ...
function test_anthropic_register_wraps_real_client_and_injects_recall (line 73) | def test_anthropic_register_wraps_real_client_and_injects_recall(config,...
function test_anthropic_register_adds_memori_wrappers_async (line 122) | async def test_anthropic_register_adds_memori_wrappers_async(anthropic_c...
function test_anthropic_register_skips_if_already_installed (line 136) | def test_anthropic_register_skips_if_already_installed(anthropic_client,...
function test_anthropic_register_raises_without_messages_attr (line 148) | def test_anthropic_register_raises_without_messages_attr(anthropic_clien...
function test_google_register_adds_memori_wrappers (line 155) | def test_google_register_adds_memori_wrappers(google_client, mocker):
function test_google_register_wraps_real_google_genai_client_and_injects_recall (line 169) | def test_google_register_wraps_real_google_genai_client_and_injects_recall(
function test_google_register_skips_if_already_installed (line 219) | def test_google_register_skips_if_already_installed(google_client, mocker):
function test_google_register_raises_without_models_attr (line 231) | def test_google_register_raises_without_models_attr(google_client, mocker):
function test_openai_register_adds_memori_wrappers_sync (line 238) | def test_openai_register_adds_memori_wrappers_sync(openai_client, mocker):
function test_openai_register_wraps_real_client_and_injects_recall (line 256) | def test_openai_register_wraps_real_client_and_injects_recall(config, mo...
function test_openai_register_with_streaming_sync (line 307) | def test_openai_register_with_streaming_sync(openai_client, mocker):
function test_openai_register_adds_memori_wrappers_async (line 323) | async def test_openai_register_adds_memori_wrappers_async(openai_client,...
function test_openai_register_with_streaming_async (line 337) | async def test_openai_register_with_streaming_async(openai_client, mocker):
function test_openai_register_skips_if_already_installed (line 350) | def test_openai_register_skips_if_already_installed(openai_client, mocker):
function test_openai_register_raises_without_chat_attr (line 362) | def test_openai_register_raises_without_chat_attr(openai_client, mocker):
function test_pydantic_ai_register_adds_memori_wrappers (line 369) | def test_pydantic_ai_register_adds_memori_wrappers(pydantic_client, mock...
function test_pydantic_ai_register_skips_if_already_installed (line 383) | def test_pydantic_ai_register_skips_if_already_installed(pydantic_client...
function test_pydantic_ai_register_raises_without_chat_attr (line 395) | def test_pydantic_ai_register_raises_without_chat_attr(pydantic_client, ...
function test_langchain_register_without_any_client_raises (line 402) | def test_langchain_register_without_any_client_raises(langchain_client):
function test_langchain_register_chatbedrock (line 407) | def test_langchain_register_chatbedrock(langchain_client, mocker):
function test_langchain_register_chatgooglegenai (line 421) | def test_langchain_register_chatgooglegenai(langchain_client, mocker):
function test_langchain_register_chatgooglegenai_with_async_client (line 434) | def test_langchain_register_chatgooglegenai_with_async_client(langchain_...
function test_langchain_register_chatgooglegenai_new_sdk (line 446) | def test_langchain_register_chatgooglegenai_new_sdk(langchain_client, mo...
function test_langchain_register_chatgooglegenai_new_sdk_with_async (line 465) | def test_langchain_register_chatgooglegenai_new_sdk_with_async(
function test_langchain_register_chatopenai (line 490) | def test_langchain_register_chatopenai(langchain_client, mocker):
function test_langchain_register_chatvertexai (line 517) | def test_langchain_register_chatvertexai(langchain_client, mocker):
function test_langchain_register_chatbedrock_raises_without_client_attr (line 529) | def test_langchain_register_chatbedrock_raises_without_client_attr(
function test_langchain_register_chatgooglegenai_raises_without_client_attr (line 538) | def test_langchain_register_chatgooglegenai_raises_without_client_attr(
function test_langchain_register_chatopenai_raises_without_client_attrs (line 547) | def test_langchain_register_chatopenai_raises_without_client_attrs(
function test_langchain_register_chatvertexai_raises_without_prediction_client (line 556) | def test_langchain_register_chatvertexai_raises_without_prediction_client(
function test_xai_register_adds_memori_wrappers (line 565) | def test_xai_register_adds_memori_wrappers(xai_client, mocker):
function test_xai_register_skips_if_already_installed (line 579) | def test_xai_register_skips_if_already_installed(xai_client, mocker):
function test_xai_register_raises_without_chat_attr (line 591) | def test_xai_register_raises_without_chat_attr(xai_client, mocker):
function test_agno_register_openai_chat_sync (line 598) | def test_agno_register_openai_chat_sync(agno_client, mocker):
function test_agno_register_openai_chat_async (line 621) | async def test_agno_register_openai_chat_async(agno_client, mocker):
function test_agno_register_claude_sync (line 639) | def test_agno_register_claude_sync(agno_client, mocker):
function test_agno_register_gemini_sync (line 661) | def test_agno_register_gemini_sync(agno_client, mocker):
function test_agno_register_gemini_async (line 683) | async def test_agno_register_gemini_async(agno_client, mocker):
function test_agno_register_skips_if_already_installed (line 701) | def test_agno_register_skips_if_already_installed(agno_client, mocker):
function test_agno_register_raises_without_models (line 718) | def test_agno_register_raises_without_models(agno_client):
function test_agno_register_raises_with_invalid_openai_model (line 723) | def test_agno_register_raises_with_invalid_openai_model(agno_client, moc...
function test_agno_register_raises_with_invalid_gemini_model (line 733) | def test_agno_register_raises_with_invalid_gemini_model(agno_client, moc...
function test_agno_register_xai_sync (line 741) | def test_agno_register_xai_sync(agno_client, mocker):
function test_agno_register_xai_async (line 764) | async def test_agno_register_xai_async(agno_client, mocker):
function test_agno_register_raises_with_invalid_xai_model (line 782) | def test_agno_register_raises_with_invalid_xai_model(agno_client, mocker):
FILE: tests/llm/test_llm_deprecation_warnings.py
function memori_instance (line 7) | def memori_instance(mocker):
function test_openai_register_shows_deprecation_warning (line 17) | def test_openai_register_shows_deprecation_warning(memori_instance, mock...
function test_anthropic_register_shows_deprecation_warning (line 34) | def test_anthropic_register_shows_deprecation_warning(memori_instance, m...
function test_google_register_shows_deprecation_warning (line 52) | def test_google_register_shows_deprecation_warning(memori_instance, mock...
function test_xai_register_shows_deprecation_warning (line 75) | def test_xai_register_shows_deprecation_warning(memori_instance, mocker):
function test_pydantic_ai_register_shows_deprecation_warning (line 92) | def test_pydantic_ai_register_shows_deprecation_warning(memori_instance,...
function test_langchain_register_shows_deprecation_warning (line 105) | def test_langchain_register_shows_deprecation_warning(memori_instance, m...
function test_agno_register_shows_deprecation_warning (line 118) | def test_agno_register_shows_deprecation_warning(memori_instance, mocker):
function test_llm_register_no_deprecation_warning (line 138) | def test_llm_register_no_deprecation_warning(memori_instance, mocker):
FILE: tests/llm/test_llm_embeddings.py
function test_format_embedding_for_db_mysql (line 22) | def test_format_embedding_for_db_mysql():
function test_format_embedding_for_db_postgresql (line 30) | def test_format_embedding_for_db_postgresql():
function test_format_embedding_for_db_cockroachdb (line 38) | def test_format_embedding_for_db_cockroachdb():
function test_format_embedding_for_db_sqlite (line 46) | def test_format_embedding_for_db_sqlite():
function test_format_embedding_for_db_mongodb (line 54) | def test_format_embedding_for_db_mongodb(mocker):
function test_format_embedding_for_db_mongodb_no_bson (line 73) | def test_format_embedding_for_db_mongodb_no_bson():
function test_format_embedding_for_db_oceanbase_uses_pyobvector (line 84) | def test_format_embedding_for_db_oceanbase_uses_pyobvector(mocker):
function test_format_embedding_for_db_unknown_dialect (line 100) | def test_format_embedding_for_db_unknown_dialect():
function test_format_embedding_for_db_high_dimensional (line 108) | def test_format_embedding_for_db_high_dimensional():
function test_get_model_caches_model (line 121) | def test_get_model_caches_model():
function test_get_model_different_models (line 137) | def test_get_model_different_models():
function test_embed_texts_single_string (line 153) | def test_embed_texts_single_string():
function test_embed_texts_list_of_strings (line 174) | def test_embed_texts_list_of_strings():
function test_embed_texts_empty_list (line 195) | def test_embed_texts_empty_list():
function test_embed_texts_empty_string (line 205) | def test_embed_texts_empty_string():
function test_embed_texts_filters_empty_strings (line 227) | def test_embed_texts_filters_empty_strings():
function test_embed_texts_chunks_long_text_and_pools (line 249) | def test_embed_texts_chunks_long_text_and_pools(mocker):
function test_embed_texts_custom_model (line 280) | def test_embed_texts_custom_model():
function test_embed_texts_model_load_failure (line 294) | def test_embed_texts_model_load_failure():
function test_embed_texts_encode_failure (line 310) | def test_embed_texts_encode_failure():
function test_embed_texts_shape_error_retries_and_pools (line 326) | def test_embed_texts_shape_error_retries_and_pools(mocker):
function test_embed_texts_encode_failure_with_dimension_error (line 348) | def test_embed_texts_encode_failure_with_dimension_error():
function test_embed_texts_model_load_runtime_error (line 367) | def test_embed_texts_model_load_runtime_error():
function test_embed_texts_model_load_value_error (line 381) | def test_embed_texts_model_load_value_error():
function test_embed_texts_async_single_string (line 396) | async def test_embed_texts_async_single_string():
function test_embed_texts_async_list (line 417) | async def test_embed_texts_async_list():
function test_embed_texts_async_custom_model (line 439) | async def test_embed_texts_async_custom_model():
function test_embed_texts_uses_tei_remote (line 454) | def test_embed_texts_uses_tei_remote(mocker):
function test_embed_texts_tei_token_chunks_and_pools (line 477) | def test_embed_texts_tei_token_chunks_and_pools(mocker):
FILE: tests/llm/test_llm_embeddings_bundled.py
function test_get_model_downloads_from_huggingface (line 6) | def test_get_model_downloads_from_huggingface():
function test_get_model_caching (line 22) | def test_get_model_caching():
function test_get_model_different_models (line 38) | def test_get_model_different_models():
FILE: tests/llm/test_llm_provider_sdk_version.py
function config (line 8) | def config():
function anthropic_client (line 13) | def anthropic_client(config):
function google_client (line 18) | def google_client(config):
function openai_client (line 23) | def openai_client(config):
function xai_client (line 28) | def xai_client(config):
function test_anthropic_captures_provider_sdk_version (line 32) | def test_anthropic_captures_provider_sdk_version(anthropic_client, mocker):
function test_anthropic_handles_missing_version_gracefully (line 49) | def test_anthropic_handles_missing_version_gracefully(anthropic_client, ...
function test_google_captures_provider_sdk_version (line 66) | def test_google_captures_provider_sdk_version(google_client, mocker):
function test_google_falls_back_to_importlib_metadata (line 88) | def test_google_falls_back_to_importlib_metadata(google_client, mocker):
function test_google_handles_missing_version_gracefully (line 113) | def test_google_handles_missing_version_gracefully(google_client, mocker):
function test_openai_captures_provider_sdk_version_from_client (line 136) | def test_openai_captures_provider_sdk_version_from_client(openai_client,...
function test_xai_captures_provider_sdk_version (line 152) | def test_xai_captures_provider_sdk_version(xai_client, mocker):
function test_xai_handles_missing_version_gracefully (line 168) | def test_xai_handles_missing_version_gracefully(xai_client, mocker):
function test_xai_with_completions_captures_provider_sdk_version (line 184) | def test_xai_with_completions_captures_provider_sdk_version(xai_client, ...
function test_openai_with_nebius_platform (line 202) | def test_openai_with_nebius_platform(openai_client, mocker):
function test_nvidia_with_nim_platform (line 219) | def test_nvidia_with_nim_platform(openai_client, mocker):
function test_deepseek_platform (line 236) | def test_deepseek_platform(openai_client, mocker):
function test_provider_sdk_version_separate_from_model_version (line 253) | def test_provider_sdk_version_separate_from_model_version(openai_client,...
FILE: tests/llm/test_llm_registry.py
function test_llm_anthropic (line 18) | def test_llm_anthropic():
function test_llm_bedrock (line 24) | def test_llm_bedrock():
function test_llm_google (line 33) | def test_llm_google():
function test_llm_openai (line 37) | def test_llm_openai():
function test_llm_adapter_raises_for_none_provider (line 41) | def test_llm_adapter_raises_for_none_provider():
function test_llm_adapter_raises_for_unsupported_provider (line 48) | def test_llm_adapter_raises_for_unsupported_provider():
function test_llm_client_raises_for_unsupported_client_type (line 55) | def test_llm_client_raises_for_unsupported_client_type():
function test_llm_client_raises_helpful_error_for_langchain (line 68) | def test_llm_client_raises_helpful_error_for_langchain():
FILE: tests/llm/test_llm_utils.py
function test_client_is_bedrock (line 31) | def test_client_is_bedrock():
function test_llm_is_anthropic (line 43) | def test_llm_is_anthropic():
function test_llm_is_bedrock (line 49) | def test_llm_is_bedrock():
function test_llm_is_google (line 59) | def test_llm_is_google():
function test_llm_is_openai (line 75) | def test_llm_is_openai():
function test_provider_is_langchain (line 85) | def test_provider_is_langchain():
function test_provider_is_agno (line 91) | def test_provider_is_agno():
function test_agno_is_openai (line 97) | def test_agno_is_openai():
function test_agno_is_anthropic (line 104) | def test_agno_is_anthropic():
function test_agno_is_google (line 113) | def test_agno_is_google():
function test_agno_is_xai (line 120) | def test_agno_is_xai():
FILE: tests/llm/test_llm_xai_wrappers.py
function config (line 10) | def config():
function xai_wrappers (line 15) | def xai_wrappers(config):
function test_inject_conversation_history_no_conversation_id (line 19) | def test_inject_conversation_history_no_conversation_id(xai_wrappers):
function test_inject_conversation_history_cache_miss_loads_from_session (line 25) | def test_inject_conversation_history_cache_miss_loads_from_session(
function test_inject_conversation_history_empty_messages (line 58) | def test_inject_conversation_history_empty_messages(xai_wrappers, config...
function test_inject_conversation_history_with_user_messages (line 73) | def test_inject_conversation_history_with_user_messages(xai_wrappers, co...
function test_inject_conversation_history_with_assistant_messages (line 96) | def test_inject_conversation_history_with_assistant_messages(
function test_inject_conversation_history_with_multiple_messages (line 121) | def test_inject_conversation_history_with_multiple_messages(
function test_inject_conversation_history_ignores_unknown_roles (line 149) | def test_inject_conversation_history_ignores_unknown_roles(
function test_wrap_chat_methods_already_installed (line 173) | def test_wrap_chat_methods_already_installed(xai_wrappers):
function test_wrap_chat_methods_sync (line 183) | def test_wrap_chat_methods_sync(xai_wrappers):
function test_wrap_chat_methods_async (line 195) | def test_wrap_chat_methods_async(xai_wrappers):
function test_wrap_chat_methods_with_stream (line 207) | def test_wrap_chat_methods_with_stream(xai_wrappers):
function test_normalize_role_assistant (line 219) | def test_normalize_role_assistant(xai_wrappers):
function test_normalize_role_user (line 226) | def test_normalize_role_user(xai_wrappers):
function test_normalize_role_system (line 233) | def test_normalize_role_system(xai_wrappers):
function test_normalize_role_unknown (line 240) | def test_normalize_role_unknown(xai_wrappers):
function test_normalize_role_without_name_attr (line 247) | def test_normalize_role_without_name_attr(xai_wrappers):
function test_build_payload (line 257) | def test_build_payload(xai_wrappers, config):
function test_create_sync_sample_wrapper (line 280) | def test_create_sync_sample_wrapper(xai_wrappers, mocker):
function test_create_async_sample_wrapper (line 299) | async def test_create_async_sample_wrapper(xai_wrappers, mocker):
function test_create_stream_wrapper_with_tuple_items (line 318) | async def test_create_stream_wrapper_with_tuple_items(xai_wrappers, mock...
function test_create_stream_wrapper_with_content_items (line 347) | async def test_create_stream_wrapper_with_content_items(xai_wrappers, mo...
function test_create_stream_wrapper_without_content (line 376) | async def test_create_stream_wrapper_without_content(xai_wrappers, mocker):
FILE: tests/llm/unit_test_objects.py
class UnitTestX (line 1) | class UnitTestX:
method __init__ (line 2) | def __init__(self):
class UnitTestY (line 7) | class UnitTestY:
method __init__ (line 8) | def __init__(self):
FILE: tests/memory/augmentation/test_aa_payload_unit.py
class TestHashId (line 23) | class TestHashId:
method test_hash_id_returns_64_chars (line 24) | def test_hash_id_returns_64_chars(self):
method test_hash_id_returns_none_for_none (line 30) | def test_hash_id_returns_none_for_none(self):
method test_hash_id_returns_none_for_empty_string (line 33) | def test_hash_id_returns_none_for_empty_string(self):
method test_hash_id_is_deterministic (line 36) | def test_hash_id_is_deterministic(self):
method test_hash_id_different_inputs_different_hashes (line 41) | def test_hash_id_different_inputs_different_hashes(self):
class TestDataclassModels (line 47) | class TestDataclassModels:
method test_conversation_data_structure (line 48) | def test_conversation_data_structure(self):
method test_conversation_data_summary_optional (line 55) | def test_conversation_data_summary_optional(self):
method test_entity_data_structure (line 59) | def test_entity_data_structure(self):
method test_attribution_data_structure (line 64) | def test_attribution_data_structure(self):
method test_meta_data_has_all_required_fields (line 72) | def test_meta_data_has_all_required_fields(self):
method test_sdk_data_defaults_to_python (line 82) | def test_sdk_data_defaults_to_python(self):
method test_storage_data_defaults (line 86) | def test_storage_data_defaults(self):
class TestAugmentationPayloadToDict (line 92) | class TestAugmentationPayloadToDict:
method test_payload_has_required_top_level_keys (line 93) | def test_payload_has_required_top_level_keys(self):
method test_payload_conversation_structure (line 103) | def test_payload_conversation_structure(self):
method test_payload_meta_has_all_required_keys (line 120) | def test_payload_meta_has_all_required_keys(self):
method test_payload_attribution_structure (line 151) | def test_payload_attribution_structure(self):
method test_payload_llm_structure (line 172) | def test_payload_llm_structure(self):
method test_payload_sdk_structure (line 193) | def test_payload_sdk_structure(self):
method test_payload_storage_structure (line 204) | def test_payload_storage_structure(self):
class TestBuildApiPayload (line 216) | class TestBuildApiPayload:
method mock_config (line 218) | def mock_config(self):
method augmentation (line 230) | def augmentation(self, mock_config):
method test_build_payload_returns_dict (line 238) | def test_build_payload_returns_dict(self, augmentation):
method test_build_payload_has_required_keys (line 250) | def test_build_payload_has_required_keys(self, augmentation):
method test_build_payload_hashes_entity_id (line 263) | def test_build_payload_hashes_entity_id(self, augmentation):
method test_build_payload_hashes_process_id (line 278) | def test_build_payload_hashes_process_id(self, augmentation):
method test_build_payload_includes_messages (line 293) | def test_build_payload_includes_messages(self, augmentation):
method test_build_payload_includes_summary (line 311) | def test_build_payload_includes_summary(self, augmentation):
method test_build_payload_includes_dialect (line 323) | def test_build_payload_includes_dialect(self, augmentation):
method test_build_payload_includes_llm_provider (line 335) | def test_build_payload_includes_llm_provider(self, augmentation):
method test_build_payload_includes_sdk_info (line 348) | def test_build_payload_includes_sdk_info(self, augmentation):
method test_build_payload_includes_framework_provider (line 361) | def test_build_payload_includes_framework_provider(self, augmentation):
method test_build_payload_none_entity_id (line 373) | def test_build_payload_none_entity_id(self, augmentation):
method test_build_payload_none_process_id (line 385) | def test_build_payload_none_process_id(self, augmentation):
class TestPayloadValidator (line 398) | class TestPayloadValidator:
method validate_payload_structure (line 399) | def validate_payload_structure(self, payload: dict) -> list[str]:
method test_valid_payload_passes_validation (line 473) | def test_valid_payload_passes_validation(self):
method test_missing_conversation_fails_validation (line 501) | def test_missing_conversation_fails_validation(self):
method test_missing_meta_fails_validation (line 506) | def test_missing_meta_fails_validation(self):
method test_unhashed_entity_id_fails_validation (line 511) | def test_unhashed_entity_id_fails_validation(self):
class TestProviderSpecificPayloads (line 531) | class TestProviderSpecificPayloads:
method make_augmentation (line 533) | def make_augmentation(self):
method test_openai_payload (line 552) | def test_openai_payload(self, make_augmentation):
method test_anthropic_payload (line 567) | def test_anthropic_payload(self, make_augmentation):
method test_google_payload (line 582) | def test_google_payload(self, make_augmentation):
method test_bedrock_payload (line 596) | def test_bedrock_payload(self, make_augmentation):
method test_xai_payload (line 612) | def test_xai_payload(self, make_augmentation):
FILE: tests/memory/augmentation/test_advanced_augmentation.py
function config (line 16) | def config():
function augmentation (line 26) | def augmentation(config):
function driver (line 31) | def driver():
function augmentation_input (line 41) | def augmentation_input():
function test_process_with_summary_sends_only_last_user_assistant_pair (line 54) | async def test_process_with_summary_sends_only_last_user_assistant_pair(
function test_process_without_summary_sends_full_message_history (line 90) | async def test_process_without_summary_sends_full_message_history(
function test_process_no_entity_id (line 124) | async def test_process_no_entity_id(augmentation, driver):
function test_process_no_conversation_id (line 140) | async def test_process_no_conversation_id(augmentation, driver):
function test_build_api_payload_with_system_prompt (line 156) | async def test_build_api_payload_with_system_prompt(augmentation):
function test_build_api_payload_without_system_prompt (line 177) | async def test_build_api_payload_without_system_prompt(augmentation):
function test_build_api_payload_hashes_ids_consistently (line 198) | async def test_build_api_payload_hashes_ids_consistently(augmentation):
function test_get_conversation_summary_success (line 228) | async def test_get_conversation_summary_success(augmentation, driver):
function test_get_conversation_summary_no_summary (line 236) | async def test_get_conversation_summary_no_summary(augmentation, driver):
function test_get_conversation_summary_exception (line 245) | async def test_get_conversation_summary_exception(augmentation, driver):
function test_process_api_response_dict_to_memories (line 254) | async def test_process_api_response_dict_to_memories(augmentation):
function test_process_api_response_triples_to_facts (line 275) | async def test_process_api_response_triples_to_facts(augmentation):
function test_process_api_response_triples_prefers_content_field (line 309) | async def test_process_api_response_triples_prefers_content_field(augmen...
function test_schedule_entity_writes (line 341) | async def test_schedule_entity_writes(augmentation, driver, augmentation...
function test_schedule_entity_writes_with_semantic_triples (line 354) | async def test_schedule_entity_writes_with_semantic_triples(
function test_schedule_process_writes (line 378) | async def test_schedule_process_writes(augmentation, driver, augmentatio...
function test_schedule_conversation_writes (line 390) | async def test_schedule_conversation_writes(augmentation, augmentation_i...
function test_schedule_writes_skips_if_no_data (line 403) | async def test_schedule_writes_skips_if_no_data(
FILE: tests/memory/augmentation/test_base.py
function test_base_augmentation_init_default (line 6) | def test_base_augmentation_init_default():
function test_base_augmentation_init_disabled (line 11) | def test_base_augmentation_init_disabled():
function test_base_augmentation_process_not_implemented (line 17) | async def test_base_augmentation_process_not_implemented():
FILE: tests/memory/augmentation/test_handler.py
function test_handle_augmentation_cloud_posts_cloud_payload (line 13) | def test_handle_augmentation_cloud_posts_cloud_payload(mocker):
function test_handle_augmentation_non_cloud_enqueues (line 72) | def test_handle_augmentation_non_cloud_enqueues(mocker):
function test_handle_augmentation_cloud_logs_error_on_failed_post (line 105) | def test_handle_augmentation_cloud_logs_error_on_failed_post(mocker):
function test_handle_augmentation_no_attribution_noops (line 140) | def test_handle_augmentation_no_attribution_noops(mocker):
function test_handle_augmentation_cloud_without_executor_posts_inline (line 169) | def test_handle_augmentation_cloud_without_executor_posts_inline(mocker):
FILE: tests/memory/augmentation/test_manager.py
function test_augmentation_runtime_init (line 13) | def test_augmentation_runtime_init():
function test_manager_init (line 21) | def test_manager_init():
function test_manager_start_sets_max_workers (line 33) | def test_manager_start_sets_max_workers():
function test_manager_start_with_none_conn (line 45) | def test_manager_start_with_none_conn():
function test_manager_start_with_conn (line 56) | def test_manager_start_with_conn():
function test_manager_enqueue_inactive (line 68) | def test_manager_enqueue_inactive():
function test_manager_enqueue_no_conn_factory (line 82) | def test_manager_enqueue_no_conn_factory():
function test_runtime_ensure_started (line 97) | def test_runtime_ensure_started():
function test_manager_process_augmentations_no_augmentations (line 111) | async def test_manager_process_augmentations_no_augmentations():
function test_manager_wait_no_pending_futures (line 132) | def test_manager_wait_no_pending_futures():
function test_manager_wait_with_completed_futures (line 141) | def test_manager_wait_with_completed_futures():
function test_manager_wait_with_timeout (line 158) | def test_manager_wait_with_timeout():
function test_manager_wait_for_db_writer_queue (line 171) | def test_manager_wait_for_db_writer_queue():
FILE: tests/memory/augmentation/test_manager_quota.py
function mock_conn_factory (line 15) | def mock_conn_factory():
function augmentation_input (line 20) | def augmentation_input():
function test_quota_error_prevents_subsequent_augmentations (line 30) | def test_quota_error_prevents_subsequent_augmentations(
function test_quota_error_does_not_prevent_when_authenticated (line 70) | def test_quota_error_does_not_prevent_when_authenticated():
FILE: tests/memory/augmentation/test_models.py
function test_conversation_data_with_summary (line 16) | def test_conversation_data_with_summary():
function test_conversation_data_without_summary (line 27) | def test_conversation_data_without_summary():
function test_model_data_structure (line 37) | def test_model_data_structure():
function test_meta_data_defaults (line 50) | def test_meta_data_defaults():
function test_augmentation_payload_to_dict (line 61) | def test_augmentation_payload_to_dict():
function test_augmentation_payload_with_none_values (line 101) | def test_augmentation_payload_with_none_values():
function test_sdk_data_default_lang (line 135) | def test_sdk_data_default_lang():
function test_storage_data_defaults (line 143) | def test_storage_data_defaults():
function test_hash_id_returns_sha256 (line 151) | def test_hash_id_returns_sha256():
function test_hash_id_is_consistent (line 160) | def test_hash_id_is_consistent():
function test_hash_id_different_inputs (line 170) | def test_hash_id_different_inputs():
function test_hash_id_none_input (line 178) | def test_hash_id_none_input():
function test_hash_id_empty_string (line 185) | def test_hash_id_empty_string():
function test_meta_data_with_hashed_ids (line 192) | def test_meta_data_with_hashed_ids():
function test_augmentation_payload_includes_hashed_ids (line 211) | def test_augmentation_payload_includes_hashed_ids():
FILE: tests/memory/augmentation/test_quota_propagation.py
function test_quota_exceeded_error_propagates_for_anonymous_users (line 17) | async def test_quota_exceeded_error_propagates_for_anonymous_users():
function test_other_exceptions_caught_gracefully (line 51) | async def test_other_exceptions_caught_gracefully():
FILE: tests/memory/augmentation/test_registry.py
function test_registry_register (line 5) | def test_registry_register():
function test_registry_augmentations (line 20) | def test_registry_augmentations():
FILE: tests/memory/test_conversation_messages.py
function test_parse_payload_conversation_messages_stringifies (line 6) | def test_parse_payload_conversation_messages_stringifies(mocker):
function test_parse_payload_conversation_messages_uses_registry_when_no_adapter (line 34) | def test_parse_payload_conversation_messages_uses_registry_when_no_adapt...
function test_parse_payload_conversation_messages_passthrough_existing_messages (line 51) | def test_parse_payload_conversation_messages_passthrough_existing_messag...
function test_parse_payload_conversation_messages_preserves_response_type (line 68) | def test_parse_payload_conversation_messages_preserves_response_type(moc...
FILE: tests/memory/test_manager_enterprise_retry.py
function test_manager_cloud_retries_until_201 (line 8) | def test_manager_cloud_retries_until_201(mocker):
function test_manager_cloud_raises_after_exhausting_attempts (line 26) | def test_manager_cloud_raises_after_exhausting_attempts(mocker):
FILE: tests/memory/test_memory_augmentation_db_writer.py
class TestWriteTask (line 8) | class TestWriteTask:
method test_write_task_execution (line 9) | def test_write_task_execution(self):
class TestDbWriterRuntime (line 27) | class TestDbWriterRuntime:
method test_enqueue_write_success (line 28) | def test_enqueue_write_success(self):
method test_enqueue_write_full_queue (line 43) | def test_enqueue_write_full_queue(self):
method test_drain_batches_opens_connection_only_when_work (line 59) | def test_drain_batches_opens_connection_only_when_work(self, mocker):
FILE: tests/memory/test_memory_struct.py
function test_conversation_configure_from_advanced_augmentation (line 4) | def test_conversation_configure_from_advanced_augmentation():
function test_entity_configure_from_advanced_augmentation (line 19) | def test_entity_configure_from_advanced_augmentation():
function test_process_configure_from_advanced_augmentation (line 51) | def test_process_configure_from_advanced_augmentation():
function test_memories_configure_from_advanced_augmentation (line 64) | def test_memories_configure_from_advanced_augmentation():
FILE: tests/memory/test_memory_struct_triples.py
function test_entity_configure_with_triples_field (line 4) | def test_entity_configure_with_triples_field():
function test_entity_configure_with_both_semantic_triples_and_triples (line 29) | def test_entity_configure_with_both_semantic_triples_and_triples():
function test_entity_triples_generates_fact_text (line 58) | def test_entity_triples_generates_fact_text():
function test_entity_triples_prefers_content_field_for_fact_text (line 83) | def test_entity_triples_prefers_content_field_for_fact_text():
function test_entity_triples_with_existing_facts (line 103) | def test_entity_triples_with_existing_facts():
function test_entity_triples_with_missing_fields_skipped (line 125) | def test_entity_triples_with_missing_fields_skipped():
function test_entity_semantic_triples_only_not_added_to_facts (line 148) | def test_entity_semantic_triples_only_not_added_to_facts():
function test_entity_triples_empty_list (line 167) | def test_entity_triples_empty_list():
function test_entity_triples_type_normalization (line 174) | def test_entity_triples_type_normalization():
FILE: tests/memory/test_memory_writer.py
function test_execute (line 4) | def test_execute(config, mocker):
function test_execute_with_entity_and_process (line 31) | def test_execute_with_entity_and_process(config, mocker):
function test_execute_includes_system_messages (line 64) | def test_execute_includes_system_messages(config, mocker):
function test_execute_writes_response_type (line 90) | def test_execute_writes_response_type(config, mocker):
function test_execute_multiple_turns_ingests_all_messages (line 105) | def test_execute_multiple_turns_ingests_all_messages(config, mocker):
FILE: tests/memory/test_recall.py
function test_recall_init (line 21) | def test_recall_init():
function test_search_facts_no_storage (line 27) | def test_search_facts_no_storage():
function test_search_facts_no_driver (line 37) | def test_search_facts_no_driver():
function test_search_facts_no_entity_id_in_config (line 48) | def test_search_facts_no_entity_id_in_config():
function test_search_facts_entity_create_returns_none (line 60) | def test_search_facts_entity_create_returns_none():
function test_search_facts_uses_provided_entity_id (line 74) | def test_search_facts_uses_provided_entity_id():
function test_search_facts_success (line 103) | def test_search_facts_success():
function test_search_facts_with_custom_limit (line 152) | def test_search_facts_with_custom_limit():
function test_search_facts_retry_on_operational_error (line 171) | def test_search_facts_retry_on_operational_error():
function test_search_facts_retry_multiple_times (line 197) | def test_search_facts_retry_multiple_times():
function test_search_facts_raises_after_max_retries (line 227) | def test_search_facts_raises_after_max_retries():
function test_search_facts_raises_on_non_restart_error (line 248) | def test_search_facts_raises_on_non_restart_error():
function test_search_facts_returns_empty_on_no_results (line 268) | def test_search_facts_returns_empty_on_no_results():
function test_search_facts_embeds_query_correctly (line 285) | def test_search_facts_embeds_query_correctly():
function test_search_facts_cloud_includes_explicit_limit_in_payload (line 307) | def test_search_facts_cloud_includes_explicit_limit_in_payload(mocker):
function test_search_facts_cloud_defaults_to_config_recall_facts_limit (line 329) | def test_search_facts_cloud_defaults_to_config_recall_facts_limit(mocker):
function test_search_facts_cloud_uses_none_for_missing_process_id (line 351) | def test_search_facts_cloud_uses_none_for_missing_process_id(mocker):
function test_constants (line 372) | def test_constants():
FILE: tests/memory/test_recall_eval_harness.py
function _pack_embedding (line 22) | def _pack_embedding(vec: list[float]) -> bytes:
class _Case (line 27) | class _Case:
class _FakeEntityFactDriver (line 32) | class _FakeEntityFactDriver:
method __init__ (line 33) | def __init__(self, *, facts: dict[int, str], embeddings: dict[int, lis...
method get_embeddings (line 37) | def get_embeddings(self, entity_id: int, limit: int = 1000):
method get_facts_by_ids (line 44) | def get_facts_by_ids(self, fact_ids: list[int]):
class _FakeEntityDriver (line 53) | class _FakeEntityDriver:
method create (line 54) | def create(self, entity_id: str) -> int:
class _FakeStorageDriver (line 59) | class _FakeStorageDriver:
method __init__ (line 60) | def __init__(self, entity_fact: _FakeEntityFactDriver):
class _FakeStorage (line 65) | class _FakeStorage:
method __init__ (line 66) | def __init__(self, driver: _FakeStorageDriver):
function _recall_at_k (line 70) | def _recall_at_k(*, cases: list[_Case], results_by_query: dict[str, list...
function _mrr_at_k (line 79) | def _mrr_at_k(*, cases: list[_Case], results_by_query: dict[str, list[in...
function _ndcg_at_k (line 92) | def _ndcg_at_k(*, cases: list[_Case], results_by_query: dict[str, list[i...
function test_recall_eval_harness_reports_expected_metrics (line 109) | def test_recall_eval_harness_reports_expected_metrics(mocker):
FILE: tests/storage/adapters/conftest.py
function mongodb_conn (line 5) | def mongodb_conn(mocker):
FILE: tests/storage/adapters/dbapi/test_dbapi_no_conflicts.py
function test_sqlalchemy_session_not_detected_as_dbapi (line 12) | def test_sqlalchemy_session_not_detected_as_dbapi(session):
function test_registry_routes_sqlalchemy_to_sqlalchemy_adapter (line 16) | def test_registry_routes_sqlalchemy_to_sqlalchemy_adapter(session):
function test_registry_routes_postgres_session_to_sqlalchemy_adapter (line 23) | def test_registry_routes_postgres_session_to_sqlalchemy_adapter(postgres...
function test_django_connection_not_detected_as_dbapi (line 30) | def test_django_connection_not_detected_as_dbapi(mocker):
function test_registry_routes_django_to_django_adapter (line 37) | def test_registry_routes_django_to_django_adapter(mocker):
FILE: tests/storage/adapters/dbapi/test_storage_adapters_dbapi_adapter.py
function mock_psycopg2_conn (line 13) | def mock_psycopg2_conn(mocker):
function mock_pymysql_conn (line 29) | def mock_pymysql_conn(mocker):
function mock_pyobvector_conn (line 45) | def mock_pyobvector_conn(mocker):
function mock_sqlite3_conn (line 61) | def mock_sqlite3_conn(mocker):
function test_commit_psycopg2 (line 76) | def test_commit_psycopg2(mock_psycopg2_conn):
function test_execute_psycopg2 (line 84) | def test_execute_psycopg2(mock_psycopg2_conn):
function test_execute_with_binds_psycopg2 (line 92) | def test_execute_with_binds_psycopg2(mock_psycopg2_conn):
function test_flush_psycopg2 (line 103) | def test_flush_psycopg2(mock_psycopg2_conn):
function test_get_dialect_psycopg2 (line 110) | def test_get_dialect_psycopg2(mock_psycopg2_conn):
function test_rollback_psycopg2 (line 115) | def test_rollback_psycopg2(mock_psycopg2_conn):
function test_commit_pymysql (line 123) | def test_commit_pymysql(mock_pymysql_conn):
function test_execute_pymysql (line 131) | def test_execute_pymysql(mock_pymysql_conn):
function test_get_dialect_pymysql (line 139) | def test_get_dialect_pymysql(mock_pymysql_conn):
function test_get_dialect_pyobvector (line 144) | def test_get_dialect_pyobvector(mock_pyobvector_conn):
function test_rollback_pymysql (line 149) | def test_rollback_pymysql(mock_pymysql_conn):
function test_commit_sqlite3 (line 157) | def test_commit_sqlite3(mock_sqlite3_conn):
function test_execute_sqlite3 (line 165) | def test_execute_sqlite3(mock_sqlite3_conn):
function test_get_dialect_sqlite3 (line 173) | def test_get_dialect_sqlite3(mock_sqlite3_conn):
function test_rollback_sqlite3 (line 178) | def test_rollback_sqlite3(mock_sqlite3_conn):
function test_execute_closes_cursor_on_exception (line 186) | def test_execute_closes_cursor_on_exception(mock_psycopg2_conn):
function test_get_dialect_unknown_raises_error (line 197) | def test_get_dialect_unknown_raises_error(mocker):
function test_is_dbapi_connection_psycopg2 (line 211) | def test_is_dbapi_connection_psycopg2(mock_psycopg2_conn):
function test_is_dbapi_connection_pymysql (line 215) | def test_is_dbapi_connection_pymysql(mock_pymysql_conn):
function test_is_dbapi_connection_pyobvector (line 219) | def test_is_dbapi_connection_pyobvector(mock_pyobvector_conn):
function test_is_dbapi_connection_sqlite3 (line 223) | def test_is_dbapi_connection_sqlite3(mock_sqlite3_conn):
function test_is_dbapi_connection_rejects_non_dbapi (line 227) | def test_is_dbapi_connection_rejects_non_dbapi(mocker):
function test_is_dbapi_connection_rejects_non_callable_methods (line 233) | def test_is_dbapi_connection_rejects_non_callable_methods(mocker):
function test_registry_routes_psycopg2_to_dbapi_adapter (line 241) | def test_registry_routes_psycopg2_to_dbapi_adapter(mock_psycopg2_conn):
function test_registry_routes_pymysql_to_dbapi_adapter (line 247) | def test_registry_routes_pymysql_to_dbapi_adapter(mock_pymysql_conn):
function test_registry_routes_sqlite3_to_dbapi_adapter (line 253) | def test_registry_routes_sqlite3_to_dbapi_adapter(mock_sqlite3_conn):
FILE: tests/storage/adapters/django/test_storage_adapters_django_adapter.py
function mock_django_postgresql_conn (line 13) | def mock_django_postgresql_conn(mocker):
function mock_django_mysql_conn (line 31) | def mock_django_mysql_conn(mocker):
function mock_django_sqlite_conn (line 49) | def mock_django_sqlite_conn(mocker):
function test_commit_postgresql (line 66) | def test_commit_postgresql(mock_django_postgresql_conn):
function test_execute_postgresql (line 74) | def test_execute_postgresql(mock_django_postgresql_conn):
function test_execute_with_binds_postgresql (line 82) | def test_execute_with_binds_postgresql(mock_django_postgresql_conn):
function test_flush_postgresql (line 93) | def test_flush_postgresql(mock_django_postgresql_conn):
function test_get_dialect_postgresql (line 100) | def test_get_dialect_postgresql(mock_django_postgresql_conn):
function test_rollback_postgresql (line 105) | def test_rollback_postgresql(mock_django_postgresql_conn):
function test_commit_mysql (line 113) | def test_commit_mysql(mock_django_mysql_conn):
function test_execute_mysql (line 121) | def test_execute_mysql(mock_django_mysql_conn):
function test_get_dialect_mysql (line 129) | def test_get_dialect_mysql(mock_django_mysql_conn):
function test_rollback_mysql (line 134) | def test_rollback_mysql(mock_django_mysql_conn):
function test_commit_sqlite (line 142) | def test_commit_sqlite(mock_django_sqlite_conn):
function test_execute_sqlite (line 150) | def test_execute_sqlite(mock_django_sqlite_conn):
function test_get_dialect_sqlite (line 158) | def test_get_dialect_sqlite(mock_django_sqlite_conn):
function test_rollback_sqlite (line 163) | def test_rollback_sqlite(mock_django_sqlite_conn):
function test_execute_closes_cursor_on_exception (line 171) | def test_execute_closes_cursor_on_exception(mock_django_postgresql_conn):
function test_get_dialect_unknown_raises_error (line 182) | def test_get_dialect_unknown_raises_error(mocker):
function test_is_django_connection_postgresql (line 196) | def test_is_django_connection_postgresql(mock_django_postgresql_conn):
function test_is_django_connection_mysql (line 200) | def test_is_django_connection_mysql(mock_django_mysql_conn):
function test_is_django_connection_sqlite (line 204) | def test_is_django_connection_sqlite(mock_django_sqlite_conn):
function test_is_django_connection_rejects_non_django (line 208) | def test_is_django_connection_rejects_non_django(mocker):
function test_is_django_connection_rejects_non_callable_cursor (line 214) | def test_is_django_connection_rejects_non_callable_cursor(mocker):
function test_registry_routes_postgresql_to_django_adapter (line 221) | def test_registry_routes_postgresql_to_django_adapter(mock_django_postgr...
function test_registry_routes_mysql_to_django_adapter (line 227) | def test_registry_routes_mysql_to_django_adapter(mock_django_mysql_conn):
function test_registry_routes_sqlite_to_django_adapter (line 233) | def test_registry_routes_sqlite_to_django_adapter(mock_django_sqlite_conn):
FILE: tests/storage/adapters/sqlalchemy/test_storage_adaptors_sqlalchemy_adapter.py
function test_commit (line 5) | def test_commit(session):
function test_execute (line 10) | def test_execute(session):
function test_flush (line 16) | def test_flush(session):
function test_get_dialect (line 21) | def test_get_dialect(session):
function test_get_dialect_oceanbase (line 26) | def test_get_dialect_oceanbase(mocker):
function test_rollback (line 41) | def test_rollback(session):
function test_commit_postgres (line 47) | def test_commit_postgres(postgres_session):
function test_execute_postgres (line 52) | def test_execute_postgres(postgres_session):
function test_flush_postgres (line 58) | def test_flush_postgres(postgres_session):
function test_get_dialect_postgres (line 63)
Condensed preview — 454 files, each showing path, character count, and a content snippet. Download the .json file or copy for the full structured content (2,694K chars).
[
{
"path": ".dockerignore",
"chars": 558,
"preview": "# Python\n__pycache__/\n*.py[cod]\n*$py.class\n*.so\n.Python\nbuild/\ndevelop-eggs/\ndist/\ndownloads/\neggs/\n.eggs/\nlib/\nlib64/\np"
},
{
"path": ".github/ISSUE_TEMPLATE/bug_report.yml",
"chars": 2818,
"preview": "name: Bug Report\ndescription: Create a report to help us improve Memori\ntitle: \"[Bug] \"\nlabels: [\"bug\"]\nbody:\n - type: "
},
{
"path": ".github/ISSUE_TEMPLATE/config.yml",
"chars": 28,
"preview": "blank_issues_enabled: false\n"
},
{
"path": ".github/ISSUE_TEMPLATE/feature_request.yml",
"chars": 1662,
"preview": "name: Feature Request\ndescription: Suggest an idea or improvement for Memori\ntitle: \"[Feature] \"\nlabels: [\"enhancement\"]"
},
{
"path": ".github/workflows/ci.yml",
"chars": 2277,
"preview": "name: CI\n\non:\n push:\n branches: [main]\n paths:\n - 'memori/**' \n pull_request:\n branches: [main]\n path"
},
{
"path": ".github/workflows/integration.yml",
"chars": 8184,
"preview": "name: Integration Tests\n\non:\n workflow_dispatch:\n workflow_call:\n secrets:\n OPENAI_API_KEY:\n required: "
},
{
"path": ".github/workflows/publish-npm.yml",
"chars": 926,
"preview": "name: Publish to npm (TS)\n\non:\n workflow_dispatch: \n\npermissions:\n contents: read\n id-token: write\n\njobs:\n publish:\n"
},
{
"path": ".github/workflows/publish-openclaw-plugin.yml",
"chars": 874,
"preview": "name: Publish OpenClaw to NPM\n\non:\n workflow_dispatch: \n\npermissions:\n contents: read\n id-token: write\n\njobs:\n publi"
},
{
"path": ".github/workflows/publish.yml",
"chars": 2157,
"preview": "name: Publish to PyPI\n\non:\n release:\n types: [published]\n workflow_dispatch:\n\npermissions:\n contents: read\n id-to"
},
{
"path": ".github/workflows/ts-ci.yml",
"chars": 999,
"preview": "name: CI Code Check (TS)\n\non:\n push:\n branches: [ \"main\" ]\n paths:\n - 'memori-ts/**' \n pull_request:\n br"
},
{
"path": ".github/workflows/ts-openclaw-ci.yml",
"chars": 979,
"preview": "name: CI Code Check (TS)\n\non:\n push:\n branches: [ \"main\" ]\n paths:\n - 'integrations/openclaw/**' \n pull_req"
},
{
"path": ".gitignore",
"chars": 726,
"preview": "# Python\n*.pyc\n*.pyo\n*.pyd\n__pycache__\n*.so\n*.egg\n*.egg-info\ndist/\n/build/\n*.swp\n\n# Testing\n.pytest_cache\n.coverage\ncove"
},
{
"path": ".pre-commit-config.yaml",
"chars": 1364,
"preview": "repos:\n- repo: https://github.com/pre-commit/pre-commit-hooks\n rev: v4.5.0\n hooks:\n - id: check-yaml\n - id: end-of-f"
},
{
"path": "CHANGELOG.md",
"chars": 660,
"preview": "# Changelog\n\nAll notable changes to the Memori Python SDK will be documented in this file.\n\nThe format is based on [Keep"
},
{
"path": "CONTRIBUTING.md",
"chars": 6737,
"preview": "[](https://memorilabs.ai/)\n\n# Contribu"
},
{
"path": "Dockerfile",
"chars": 710,
"preview": "# Use Python 3.12 as base image\nFROM python:3.12-slim\n\n# Set working directory\nWORKDIR /app\n\n# Install system dependenci"
},
{
"path": "LICENSE",
"chars": 10431,
"preview": "Apache License\nVersion 2.0, January 2004\nhttp://www.apache.org/licenses/\n\nTERMS AND CONDITIONS FOR USE, REPRODUCTION, AN"
},
{
"path": "MANIFEST.in",
"chars": 964,
"preview": "# Include essential files\ninclude README.md\ninclude LICENSE\n\n# Exclude all development and Docker files\nexclude Dockerfi"
},
{
"path": "Makefile",
"chars": 3515,
"preview": ".PHONY: help dev-up dev-down dev-shell dev-build dev-clean test lint format clean run-unit run-integration run-integrati"
},
{
"path": "README.md",
"chars": 11518,
"preview": "[](https://memorilabs.ai/)\n\n<p align=\""
},
{
"path": "SECURITY.md",
"chars": 764,
"preview": "[](https://memorilabs.ai/)\n\n## Securit"
},
{
"path": "benchmarks/README.md",
"chars": 4180,
"preview": "## Benchmarks\n\nThis directory contains **benchmark harnesses** that are intentionally **not** part of the\ndefault `pytes"
},
{
"path": "benchmarks/locomo/_run_impl.py",
"chars": 36588,
"preview": "from __future__ import annotations\n\nimport datetime\nimport json\nimport os\nimport sqlite3\nfrom dataclasses import datacla"
},
{
"path": "benchmarks/locomo/_types.py",
"chars": 729,
"preview": "from __future__ import annotations\n\nfrom dataclasses import dataclass\nfrom typing import Any\n\n\n@dataclass(frozen=True, s"
},
{
"path": "benchmarks/locomo/loader.py",
"chars": 5467,
"preview": "from __future__ import annotations\n\nimport json\nimport re\nfrom pathlib import Path\nfrom typing import Any\n\nfrom benchmar"
},
{
"path": "benchmarks/locomo/preprocess.py",
"chars": 4936,
"preview": "from __future__ import annotations\n\nimport argparse\nimport json\nimport re\nfrom collections import Counter\nfrom pathlib i"
},
{
"path": "benchmarks/locomo/provenance.py",
"chars": 7796,
"preview": "from __future__ import annotations\n\nimport math\nimport re\nimport sqlite3\nfrom dataclasses import dataclass\nfrom pathlib "
},
{
"path": "benchmarks/locomo/report.py",
"chars": 4314,
"preview": "from __future__ import annotations\n\nimport argparse\nimport json\nfrom pathlib import Path\nfrom typing import Any\n\nfrom be"
},
{
"path": "benchmarks/locomo/retrieval.py",
"chars": 3798,
"preview": "from __future__ import annotations\n\nimport re\nfrom dataclasses import dataclass\nfrom typing import Any\n\nfrom benchmarks."
},
{
"path": "benchmarks/locomo/run.py",
"chars": 6784,
"preview": "import argparse\nimport os\n\nfrom benchmarks.locomo._run_impl import RunConfig, run_locomo\n\n\ndef main(argv: list[str] | No"
},
{
"path": "benchmarks/locomo/scoring.py",
"chars": 1264,
"preview": "from __future__ import annotations\n\n\ndef hit_at_k(relevant: set[str], retrieved: list[str], k: int) -> float:\n if not"
},
{
"path": "benchmarks/perf/README.md",
"chars": 1038,
"preview": "# Performance / latency benchmarks\n\nThis folder contains **performance benchmarks** for Memori recall, powered by `pytes"
},
{
"path": "benchmarks/perf/_results.py",
"chars": 691,
"preview": "from __future__ import annotations\n\nimport csv\nfrom pathlib import Path\nfrom typing import Any\n\n\ndef repo_root() -> Path"
},
{
"path": "benchmarks/perf/conftest.py",
"chars": 5300,
"preview": "\"\"\"Pytest fixtures for performance benchmarks.\"\"\"\n\nimport os\n\nimport pytest\nfrom sqlalchemy import create_engine\nfrom sq"
},
{
"path": "benchmarks/perf/fixtures/sample_data.py",
"chars": 3784,
"preview": "\"\"\"Helper functions for generating sample test data for benchmarks.\"\"\"\n\nimport random\nimport string\n\nrandom.seed(42)\n\n\nd"
},
{
"path": "benchmarks/perf/fixtures/sample_facts.py",
"chars": 8521,
"preview": "# 1,000 synthetic user facts as semantic triples (subject, predicate, object)\n# Copy/paste into your project. Produces: "
},
{
"path": "benchmarks/perf/generate_percentile_report.py",
"chars": 9053,
"preview": "\"\"\"Generate percentile report (p50/p95/p99) from benchmark JSON results.\"\"\"\n\nimport json\nimport sys\nfrom pathlib import "
},
{
"path": "benchmarks/perf/memory_utils.py",
"chars": 1087,
"preview": "import threading\nimport time\nfrom collections.abc import Callable\nfrom typing import TypeVar\n\nT = TypeVar(\"T\")\n\n\ndef mea"
},
{
"path": "benchmarks/perf/run_benchmarks_ec2.sh",
"chars": 2888,
"preview": "#!/bin/bash\n# Shared benchmark execution functions for AWS EC2 environment\n\nset -e\n\n# Get script location to handle rela"
},
{
"path": "benchmarks/perf/setup_ec2_benchmarks.sh",
"chars": 1122,
"preview": "#!/bin/bash\n# Setup script for running benchmarks on AWS EC2\n\nset -e\n\necho \"Setting up Memori benchmarks on EC2...\"\n\n# I"
},
{
"path": "benchmarks/perf/test_cloud_recall_benchmarks.py",
"chars": 9512,
"preview": "\"\"\"Cloud (Memori API) performance / latency benchmarks.\n\nThese benchmarks exercise the cloud recall path (network + API "
},
{
"path": "benchmarks/perf/test_hosted_recall_benchmarks.py",
"chars": 9512,
"preview": "\"\"\"Cloud (Memori API) performance / latency benchmarks.\n\nThese benchmarks exercise the cloud recall path (network + API "
},
{
"path": "benchmarks/perf/test_recall_benchmarks.py",
"chars": 14106,
"preview": "\"\"\"Performance benchmarks for Memori recall functionality.\"\"\"\n\nimport datetime\nimport os\nfrom time import perf_counter\nf"
},
{
"path": "benchmarks/scripts/fetch_locomo.py",
"chars": 1966,
"preview": "from __future__ import annotations\n\nimport argparse\nimport hashlib\nimport shutil\nimport sys\nfrom pathlib import Path\n\n\nd"
},
{
"path": "conftest.py",
"chars": 1453,
"preview": "import pytest\n\nfrom memori._config import Config\nfrom memori.storage import Manager as StorageManager\n\n\n@pytest.fixture\n"
},
{
"path": "docker-compose.yml",
"chars": 3606,
"preview": "services:\n dev:\n build:\n context: .\n dockerfile: Dockerfile\n volumes:\n - .:/app\n - /app/.venv"
},
{
"path": "docs/memori-byodb/concepts/advanced-augmentation.mdx",
"chars": 5794,
"preview": "---\ntitle: Advanced Augmentation\ndescription: How Memori's Advanced Augmentation engine extracts structured facts, prefe"
},
{
"path": "docs/memori-byodb/concepts/architecture.mdx",
"chars": 2915,
"preview": "---\ntitle: Architecture\ndescription: Understand how Memori's open-source architecture works — from your app to your own "
},
{
"path": "docs/memori-byodb/concepts/async-patterns.mdx",
"chars": 3103,
"preview": "---\ntitle: Async Patterns\ndescription: Best practices for using Memori with async/await — AsyncOpenAI, AsyncAnthropic, F"
},
{
"path": "docs/memori-byodb/concepts/cli-quickstart.mdx",
"chars": 2196,
"preview": "---\ntitle: CLI Quickstart\ndescription: Get started with the Memori command line interface for setup, diagnostics, and ma"
},
{
"path": "docs/memori-byodb/concepts/how-memory-works.mdx",
"chars": 5312,
"preview": "---\ntitle: How Memori Works\ndescription: Understand the core concepts behind Memori — entities, processes, sessions, mem"
},
{
"path": "docs/memori-byodb/concepts/knowledge-graph.mdx",
"chars": 4679,
"preview": "---\ntitle: Knowledge Graph\ndescription: How Memori automatically builds a knowledge graph from your AI conversations usi"
},
{
"path": "docs/memori-byodb/concepts/multi-user-support.mdx",
"chars": 5354,
"preview": "---\ntitle: Multi-User Support\ndescription: How Memori isolates memories across users, applications, and sessions so each"
},
{
"path": "docs/memori-byodb/contribute/development-setup.mdx",
"chars": 4023,
"preview": "---\ntitle: Development Setup\ndescription: Set up your local development environment for contributing to the Memori open-"
},
{
"path": "docs/memori-byodb/contribute/overview.mdx",
"chars": 3624,
"preview": "---\ntitle: Contributing to Memori\ndescription: How to contribute to the Memori open-source project — code, documentation"
},
{
"path": "docs/memori-byodb/dashboard/api-keys.mdx",
"chars": 1610,
"preview": "---\ntitle: API Keys\ndescription: Create and manage Memori API keys from the dashboard.\n---\n\n# API Keys\n\nUse the **API ke"
},
{
"path": "docs/memori-byodb/databases/cockroachdb.mdx",
"chars": 2944,
"preview": "---\ntitle: CockroachDB\ndescription: Set up Memori with CockroachDB — distributed SQL database with PostgreSQL compatibil"
},
{
"path": "docs/memori-byodb/databases/mongodb.mdx",
"chars": 2174,
"preview": "---\ntitle: MongoDB\ndescription: Set up Memori with MongoDB — document-oriented AI memory using PyMongo.\n---\n\n# MongoDB\n\n"
},
{
"path": "docs/memori-byodb/databases/mysql.mdx",
"chars": 2714,
"preview": "---\ntitle: MySQL\ndescription: Set up Memori with MySQL — use your existing MySQL infrastructure for AI agent memory.\n---"
},
{
"path": "docs/memori-byodb/databases/oracle.mdx",
"chars": 3067,
"preview": "---\ntitle: Oracle\ndescription: Set up Memori with Oracle Database — enterprise-grade AI memory for Oracle infrastructure"
},
{
"path": "docs/memori-byodb/databases/overview.mdx",
"chars": 6914,
"preview": "---\ntitle: Databases Overview\ndescription: Memori supports SQLite, PostgreSQL, MySQL, MariaDB, Oracle, MongoDB, Cockroac"
},
{
"path": "docs/memori-byodb/databases/postgres.mdx",
"chars": 3296,
"preview": "---\ntitle: PostgreSQL\ndescription: Set up Memori with PostgreSQL — recommended for production with connection pooling an"
},
{
"path": "docs/memori-byodb/databases/sqlite.mdx",
"chars": 2371,
"preview": "---\ntitle: SQLite\ndescription: Set up Memori with SQLite — zero install, file-based storage perfect for development and "
},
{
"path": "docs/memori-byodb/getting-started/installation.mdx",
"chars": 5726,
"preview": "---\ntitle: Installation\ndescription: Install Memori and set up your database for the Memori BYODB.\n---\n\n# Installation\n\n"
},
{
"path": "docs/memori-byodb/getting-started/python-quickstart.mdx",
"chars": 4499,
"preview": "---\ntitle: Python SDK Quickstart\ndescription: Get started with Memori BYODB in under 3 minutes using SQLite and OpenAI.\n"
},
{
"path": "docs/memori-byodb/getting-started/use-cases.mdx",
"chars": 3864,
"preview": "---\ntitle: Use Cases\ndescription: Common use cases and applications for Memori open source.\n---\n\n# Use Cases\n\nMemori is "
},
{
"path": "docs/memori-byodb/index.mdx",
"chars": 5669,
"preview": "---\ntitle: Introduction\ndescription: Memori is an open-source, structured memory layer for AI agents — own your data, ch"
},
{
"path": "docs/memori-byodb/llm/agno.mdx",
"chars": 4145,
"preview": "---\ntitle: Agno\ndescription: Using Memori with Agno agents and Memori BYODB.\n---\n\n# Agno\n\nMemori integrates with Agno at"
},
{
"path": "docs/memori-byodb/llm/anthropic.mdx",
"chars": 3144,
"preview": "---\ntitle: Anthropic\ndescription: Using Memori with Anthropic Claude models and Memori BYODB.\n---\n\n# Anthropic\n\nMemori s"
},
{
"path": "docs/memori-byodb/llm/aws-bedrock.mdx",
"chars": 3052,
"preview": "---\ntitle: AWS Bedrock\ndescription: Using Memori with AWS Bedrock models via the LangChain ChatBedrock adapter and Memor"
},
{
"path": "docs/memori-byodb/llm/deepseek.mdx",
"chars": 3024,
"preview": "---\ntitle: DeepSeek\ndescription: Using Memori with DeepSeek models via the OpenAI-compatible API and Memori BYODB.\n---\n\n"
},
{
"path": "docs/memori-byodb/llm/gemini.mdx",
"chars": 3010,
"preview": "---\ntitle: Google Gemini\ndescription: Using Memori with Google Gemini models and Memori BYODB.\n---\n\n# Google Gemini\n\nMem"
},
{
"path": "docs/memori-byodb/llm/langchain.mdx",
"chars": 3681,
"preview": "---\ntitle: LangChain\ndescription: Using Memori with LangChain chat models and Memori BYODB.\n---\n\n# LangChain\n\nMemori sup"
},
{
"path": "docs/memori-byodb/llm/nebius.mdx",
"chars": 3148,
"preview": "---\ntitle: Nebius AI Studio\ndescription: Using Memori with Nebius AI Studio models via the OpenAI-compatible API and Mem"
},
{
"path": "docs/memori-byodb/llm/openai.mdx",
"chars": 4299,
"preview": "---\ntitle: OpenAI\ndescription: Using Memori with OpenAI models including GPT-4o, GPT-4.1, and the Responses API with Mem"
},
{
"path": "docs/memori-byodb/llm/overview.mdx",
"chars": 4225,
"preview": "---\ntitle: LLM Providers Overview\ndescription: Memori is LLM-agnostic. Register any supported client with a local databa"
},
{
"path": "docs/memori-byodb/llm/pydantic-ai.mdx",
"chars": 2301,
"preview": "---\ntitle: Pydantic AI\ndescription: Using Memori with Pydantic AI agents and Memori BYODB.\n---\n\n# Pydantic AI\n\nMemori in"
},
{
"path": "docs/memori-byodb/llm/xai-grok.mdx",
"chars": 2969,
"preview": "---\ntitle: xAI Grok\ndescription: Using Memori with xAI Grok models via the OpenAI-compatible API and Memori BYODB.\n---\n\n"
},
{
"path": "docs/memori-byodb/support/faq.mdx",
"chars": 2970,
"preview": "---\ntitle: FAQ\ndescription: Frequently asked questions about Memori open source.\n---\n\n# FAQ\n\n<Note>\n Want a zero-setup "
},
{
"path": "docs/memori-byodb/support/troubleshooting.mdx",
"chars": 3318,
"preview": "---\ntitle: Troubleshooting\ndescription: Common issues and solutions when using Memori open source.\n---\n\n# Troubleshootin"
},
{
"path": "docs/memori-cloud/benchmark/experiments.mdx",
"chars": 3291,
"preview": "---\ntitle: LoCoMo Benchmark Experiments\ndescription: These experiments evaluate the quality and accuracy of the memory a"
},
{
"path": "docs/memori-cloud/benchmark/overview.mdx",
"chars": 8558,
"preview": "---\ntitle: LoCoMo Benchmark Overview\ndescription: Memori - A Persistent Memory Layer for Efficient, Context-Aware LLM Ag"
},
{
"path": "docs/memori-cloud/benchmark/results.mdx",
"chars": 8595,
"preview": "---\ntitle: LoCoMo Benchmark Results\ndescription: See how Memori’s Advanced Augmentation performed on the LoCoMo benchmar"
},
{
"path": "docs/memori-cloud/concepts/advanced-augmentation.mdx",
"chars": 4461,
"preview": "---\ntitle: Advanced Augmentation\ndescription: How Memori's Advanced Augmentation engine extracts structured facts, prefe"
},
{
"path": "docs/memori-cloud/concepts/architecture.mdx",
"chars": 2874,
"preview": "---\ntitle: Architecture\ndescription: Understand how Memori's Cloud platform is designed — from your app to Memori Cloud,"
},
{
"path": "docs/memori-cloud/concepts/async-patterns.mdx",
"chars": 3329,
"preview": "---\ntitle: Async Patterns\ndescription: Best practices for using Memori with async/await in Python and TypeScript.\n---\n\n#"
},
{
"path": "docs/memori-cloud/concepts/how-memory-works.mdx",
"chars": 6130,
"preview": "---\ntitle: How Memori Works\ndescription: Understand the core concepts behind Memori — entities, processes, sessions, mem"
},
{
"path": "docs/memori-cloud/concepts/knowledge-graph.mdx",
"chars": 3589,
"preview": "---\ntitle: Knowledge Graph\ndescription: How Memori automatically builds a knowledge graph from your AI conversations usi"
},
{
"path": "docs/memori-cloud/concepts/multi-user-support.mdx",
"chars": 7484,
"preview": "---\ntitle: Multi-User Support\ndescription: How Memori isolates memories across users, applications, and sessions so each"
},
{
"path": "docs/memori-cloud/dashboard/analytics.mdx",
"chars": 2959,
"preview": "---\ntitle: Analytics\ndescription: Understand memory volume, retrieval performance, usage quotas, and top subjects in Mem"
},
{
"path": "docs/memori-cloud/dashboard/api-keys.mdx",
"chars": 1610,
"preview": "---\ntitle: API Keys\ndescription: Create and manage Memori API keys from the dashboard.\n---\n\n# API Keys\n\nUse the **API ke"
},
{
"path": "docs/memori-cloud/dashboard/memories.mdx",
"chars": 2990,
"preview": "---\ntitle: Memories\ndescription: Explore memories and entities in table and graph views, then drill into details, associ"
},
{
"path": "docs/memori-cloud/dashboard/overview.mdx",
"chars": 2161,
"preview": "---\ntitle: Dashboard Overview\ndescription: An overview of the Memori Cloud dashboard at app.memorilabs.ai for managing A"
},
{
"path": "docs/memori-cloud/dashboard/playground.mdx",
"chars": 2283,
"preview": "---\ntitle: Playground\ndescription: Use Playground to validate memory extraction end to end with chat, extracted memories"
},
{
"path": "docs/memori-cloud/getting-started/installation.mdx",
"chars": 3097,
"preview": "---\ntitle: Installation\ndescription: Install Memori and set up your API key for the Memori Cloud.\n---\n\n# Installation\n\nG"
},
{
"path": "docs/memori-cloud/getting-started/python-quickstart.mdx",
"chars": 3185,
"preview": "---\ntitle: Python SDK Quickstart\ndescription: Get started with Memori Cloud in under 3 minutes.\n---\n\n# Python SDK Quicks"
},
{
"path": "docs/memori-cloud/getting-started/typescript-quickstart.mdx",
"chars": 3226,
"preview": "---\ntitle: Typescript SDK Quickstart\ndescription: Get started with Memori Cloud and the TypeScript SDK in under 3 minute"
},
{
"path": "docs/memori-cloud/getting-started/use-cases.mdx",
"chars": 5310,
"preview": "---\ntitle: Use Cases\ndescription: Common use cases and applications for Memori.\n---\n\n# Use Cases\n\nMemori is designed for"
},
{
"path": "docs/memori-cloud/index.mdx",
"chars": 4623,
"preview": "---\ntitle: Introduction\ndescription: Memori gives your AI agents structured, persistent memory — no database setup requi"
},
{
"path": "docs/memori-cloud/llm/agno.mdx",
"chars": 3574,
"preview": "---\ntitle: Agno\ndescription: Using Memori with Agno agents on Memori Cloud.\n---\n\n# Agno\n\nMemori Cloud integrates with Ag"
},
{
"path": "docs/memori-cloud/llm/anthropic.mdx",
"chars": 4426,
"preview": "---\ntitle: Anthropic\ndescription: Using Memori with Anthropic Claude models on Memori Cloud.\n---\n\n# Anthropic\n\nMemori Cl"
},
{
"path": "docs/memori-cloud/llm/aws-bedrock.mdx",
"chars": 2535,
"preview": "---\ntitle: AWS Bedrock\ndescription: Using Memori with AWS Bedrock models via the LangChain ChatBedrock adapter on Memori"
},
{
"path": "docs/memori-cloud/llm/deepseek.mdx",
"chars": 2519,
"preview": "---\ntitle: DeepSeek\ndescription: Using Memori with DeepSeek models via the OpenAI-compatible API on Memori Cloud.\n---\n\n#"
},
{
"path": "docs/memori-cloud/llm/gemini.mdx",
"chars": 4510,
"preview": "---\ntitle: Google Gemini\ndescription: Using Memori with Google Gemini models on Memori Cloud.\n---\n\n# Google Gemini\n\nMemo"
},
{
"path": "docs/memori-cloud/llm/langchain.mdx",
"chars": 3222,
"preview": "---\ntitle: LangChain\ndescription: Using Memori with LangChain chat models on Memori Cloud.\n---\n\n# LangChain\n\nMemori Clou"
},
{
"path": "docs/memori-cloud/llm/nebius.mdx",
"chars": 2651,
"preview": "---\ntitle: Nebius AI Studio\ndescription: Using Memori with Nebius AI Studio models via the OpenAI-compatible API on Memo"
},
{
"path": "docs/memori-cloud/llm/openai.mdx",
"chars": 5247,
"preview": "---\ntitle: OpenAI\ndescription: Using Memori with OpenAI models including GPT-4o, GPT-4.1, and the Responses API on Memor"
},
{
"path": "docs/memori-cloud/llm/overview.mdx",
"chars": 4175,
"preview": "---\ntitle: Integration Overview\ndescription: Memori is LLM-agnostic. Register any supported client and Memori handles me"
},
{
"path": "docs/memori-cloud/llm/pydantic-ai.mdx",
"chars": 1957,
"preview": "---\ntitle: Pydantic AI\ndescription: Using Memori with Pydantic AI agents on Memori Cloud.\n---\n\n# Pydantic AI\n\nMemori int"
},
{
"path": "docs/memori-cloud/llm/xai-grok.mdx",
"chars": 2464,
"preview": "---\ntitle: xAI Grok\ndescription: Using Memori with xAI Grok models via the OpenAI-compatible API on Memori Cloud.\n---\n\n#"
},
{
"path": "docs/memori-cloud/mcp/agent-skills.mdx",
"chars": 9004,
"preview": "---\ntitle: Agent Skills\ndescription: Add a SKILL.md file to teach your IDE agent when and how to use Memori MCP tools fo"
},
{
"path": "docs/memori-cloud/mcp/client-setup.mdx",
"chars": 5431,
"preview": "---\ntitle: Client Setup\ndescription: Configure the Memori MCP server in Cursor, Claude Code, Codex, Warp, Antigravity, a"
},
{
"path": "docs/memori-cloud/mcp/overview.mdx",
"chars": 3676,
"preview": "---\ntitle: Memori MCP Overview\ndescription: Use the Model Context Protocol (MCP) to connect AI agents directly to Memori"
},
{
"path": "docs/memori-cloud/openclaw/overview.mdx",
"chars": 4059,
"preview": "---\ntitle: OpenClaw Overview\ndescription: Give your OpenClaw agents structured, persistent memory with the Memori plugin"
},
{
"path": "docs/memori-cloud/openclaw/quickstart.mdx",
"chars": 3334,
"preview": "---\ntitle: Quickstart\ndescription: Install and configure the Memori plugin for OpenClaw in under 5 minutes.\n---\n\n# OpenC"
},
{
"path": "docs/memori-cloud/support/faq.mdx",
"chars": 2809,
"preview": "---\ntitle: FAQ\ndescription: Frequently asked questions about Memori Cloud.\n---\n\n# FAQ\n\n## What is Memori?\n\n__Memori__ is"
},
{
"path": "docs/memori-cloud/support/troubleshooting.mdx",
"chars": 2940,
"preview": "---\ntitle: Troubleshooting\ndescription: Common issues and solutions when using Memori Cloud.\n---\n\n# Troubleshooting\n\nQui"
},
{
"path": "examples/agno/README.md",
"chars": 735,
"preview": "# Memori + Agno Example\n\nExample showing how to use Memori with Agno agents to add persistent memory across conversation"
},
{
"path": "examples/agno/main.py",
"chars": 1725,
"preview": "\"\"\"\nMemori + Agno + SQLite Example\n\nDemonstrates how Memori adds persistent memory to Agno agents.\n\"\"\"\n\nimport os\n\nfrom "
},
{
"path": "examples/agno/pyproject.toml",
"chars": 167,
"preview": "[project]\nname = \"memori-agno-example\"\nversion = \"0.1.0\"\nrequires-python = \">=3.9\"\ndependencies = [\n \"memori\",\n \"a"
},
{
"path": "examples/cockroachdb/README.md",
"chars": 1671,
"preview": "# Memori + CockroachDB Example\n\n**Memori + CockroachDB** brings durable, distributed memory to AI - instantly, globally,"
},
{
"path": "examples/cockroachdb/main.py",
"chars": 1555,
"preview": "\"\"\"\nQuickstart: Memori + OpenAI + CockroachDB\n\nDemonstrates how Memori adds memory across conversations.\n\"\"\"\n\nimport os\n"
},
{
"path": "examples/cockroachdb/pyproject.toml",
"chars": 284,
"preview": "[project]\nname = \"memori-cockroachdb-example\"\nversion = \"0.1.0\"\ndescription = \"Memori SDK example with CockroachDB\"\nread"
},
{
"path": "examples/digitalocean/README.md",
"chars": 957,
"preview": "# Memori + DigitalOcean Gradient Example\n\nExample showing how to use Memori with DigitalOcean Gradient AI Agents to add "
},
{
"path": "examples/digitalocean/main.py",
"chars": 2188,
"preview": "\"\"\"\nMemori + DigitalOcean Gradient AI Example\n\nDemonstrates how Memori adds persistent memory to DigitalOcean Gradient A"
},
{
"path": "examples/digitalocean/pyproject.toml",
"chars": 315,
"preview": "[project]\nname = \"memori-digitalocean-example\"\nversion = \"0.1.0\"\ndescription = \"Memori SDK example with DigitalOcean Gra"
},
{
"path": "examples/mongodb/README.md",
"chars": 878,
"preview": "# Memori + MongoDB Example\n\nExample showing how to use Memori with MongoDB.\n\n## Quick Start\n\n1. **Install dependencies**"
},
{
"path": "examples/mongodb/main.py",
"chars": 1574,
"preview": "\"\"\"\nQuickstart: Memori + OpenAI + MongoDB\n\nDemonstrates how Memori adds memory across conversations.\n\"\"\"\n\nimport os\n\nfro"
},
{
"path": "examples/mongodb/pyproject.toml",
"chars": 267,
"preview": "[project]\nname = \"memori-mongodb-example\"\nversion = \"0.1.0\"\ndescription = \"Memori SDK example with MongoDB\"\nreadme = \"RE"
},
{
"path": "examples/nebius/README.md",
"chars": 1732,
"preview": "# Memori + Nebius AI Studio Example\n\nExample showing how to use Memori with Nebius AI Studio to add persistent memory ac"
},
{
"path": "examples/nebius/main.py",
"chars": 2010,
"preview": "\"\"\"\nMemori + Nebius AI Studio + SQLite Example\n\nDemonstrates how Memori adds persistent memory to Nebius AI Studio LLMs."
},
{
"path": "examples/nebius/pyproject.toml",
"chars": 171,
"preview": "[project]\nname = \"memori-nebius-example\"\nversion = \"0.1.0\"\nrequires-python = \">=3.9\"\ndependencies = [\n \"memori\",\n "
},
{
"path": "examples/neon/README.md",
"chars": 1026,
"preview": "# Memori + Neon Example\n\nSign up for [Neon serverless Postgres](https://neon.tech).\n\nYou may need to record the database"
},
{
"path": "examples/neon/main.py",
"chars": 1772,
"preview": "\"\"\"\nQuickstart: Memori + OpenAI + Neon\n\nDemonstrates how Memori adds memory across conversations.\n\"\"\"\n\nimport os\n\nfrom o"
},
{
"path": "examples/neon/pyproject.toml",
"chars": 404,
"preview": "[project]\nname = \"memori-neon-example\"\nversion = \"0.1.0\"\ndescription = \"Memori SDK example with Neon serverless Postgres"
},
{
"path": "examples/oceanbase/README.md",
"chars": 721,
"preview": "# Memori + OceanBase Example\n\nExample showing how to use Memori with OceanBase (or SeekDB).\n\n## Quick Start\n\n1. **Instal"
},
{
"path": "examples/oceanbase/main.py",
"chars": 1905,
"preview": "\"\"\"\nQuickstart: Memori + OpenAI + OceanBase\n\nDemonstrates how Memori adds memory across conversations.\n\"\"\"\n\nimport os\n\nf"
},
{
"path": "examples/postgres/README.md",
"chars": 857,
"preview": "# Memori + PostgreSQL Example\n\nExample showing how to use Memori with PostgreSQL.\n\n## Quick Start\n\n1. **Install dependen"
},
{
"path": "examples/postgres/main.py",
"chars": 1798,
"preview": "\"\"\"\nQuickstart: Memori + OpenAI + PostgreSQL\n\nDemonstrates how Memori adds memory across conversations.\n\"\"\"\n\nimport os\n\n"
},
{
"path": "examples/postgres/pyproject.toml",
"chars": 304,
"preview": "[project]\nname = \"memori-postgres-example\"\nversion = \"0.1.0\"\ndescription = \"Memori SDK example with PostgreSQL\"\nreadme ="
},
{
"path": "examples/sqlite/README.md",
"chars": 720,
"preview": "# Memori + SQLite Example\n\nExample showing how to use Memori with SQLite.\n\n## Quick Start\n\n1. **Install dependencies**:\n"
},
{
"path": "examples/sqlite/main.py",
"chars": 1840,
"preview": "\"\"\"\nQuickstart: Memori + OpenAI + SQLite\n\nDemonstrates how Memori adds memory across conversations.\n\"\"\"\n\nimport os\n\nfrom"
},
{
"path": "examples/sqlite/pyproject.toml",
"chars": 268,
"preview": "[project]\nname = \"memori-sqlite-example\"\nversion = \"0.1.0\"\ndescription = \"Memori SDK example with SQLite\"\nreadme = \"READ"
},
{
"path": "integrations/openclaw/.prettierrc.json",
"chars": 133,
"preview": "{\n \"semi\": true,\n \"trailingComma\": \"es5\",\n \"singleQuote\": true,\n \"printWidth\": 100,\n \"tabWidth\": 2,\n \"arrowParens\""
},
{
"path": "integrations/openclaw/README.md",
"chars": 8653,
"preview": "[](https://memorilabs.ai/)\n\n<p align=\""
},
{
"path": "integrations/openclaw/eslint.config.js",
"chars": 1557,
"preview": "import eslint from '@eslint/js';\nimport tseslint from 'typescript-eslint';\nimport prettier from 'eslint-config-prettier'"
},
{
"path": "integrations/openclaw/openclaw.plugin.json",
"chars": 953,
"preview": "{\n \"id\": \"openclaw-memori\",\n \"name\": \"Memori System\",\n \"version\": \"0.0.2\",\n \"description\": \"Hosted memory backend\",\n"
},
{
"path": "integrations/openclaw/package-lock.json",
"chars": 512328,
"preview": "{\n \"name\": \"@memorilabs/openclaw-memori\",\n \"version\": \"0.0.4\",\n \"lockfileVersion\": 3,\n \"requires\": true,\n \"packages"
},
{
"path": "integrations/openclaw/package.json",
"chars": 1720,
"preview": "{\n \"name\": \"@memorilabs/openclaw-memori\",\n \"version\": \"0.0.4\",\n \"description\": \"Official MemoriLabs.ai long-term memo"
},
{
"path": "integrations/openclaw/src/constants.ts",
"chars": 264,
"preview": "export const PLUGIN_CONFIG = {\n ID: 'openclaw-memori',\n NAME: 'Memori System',\n LOG_PREFIX: '[Memori]',\n} as const;\n\n"
},
{
"path": "integrations/openclaw/src/handlers/augmentation.ts",
"chars": 3436,
"preview": "import { IntegrationRequest, IntegrationMetadata } from '@memorilabs/memori/integrations';\nimport { OpenClawEvent, OpenC"
},
{
"path": "integrations/openclaw/src/handlers/recall.ts",
"chars": 1507,
"preview": "import { cleanText, isSystemMessage } from '../sanitizer.js';\nimport { OpenClawEvent, OpenClawContext, MemoriPluginConfi"
},
{
"path": "integrations/openclaw/src/index.ts",
"chars": 1444,
"preview": "import type { OpenClawPluginApi } from 'openclaw/plugin-sdk';\nimport { handleRecall } from './handlers/recall.js';\nimpor"
},
{
"path": "integrations/openclaw/src/sanitizer.ts",
"chars": 2121,
"preview": "import { OpenClawMessageBlock } from './types.js';\n\nconst SYSTEM_MESSAGE_PATTERNS = [\n 'a new session was started',\n '"
},
{
"path": "integrations/openclaw/src/types.ts",
"chars": 770,
"preview": "export interface MemoriPluginConfig {\n apiKey: string;\n entityId: string;\n}\n\nexport interface OpenClawMessageBlock {\n "
},
{
"path": "integrations/openclaw/src/utils/context.ts",
"chars": 1285,
"preview": "import { OpenClawEvent, OpenClawContext } from '../types.js';\n\n/**\n * Extracted context information from OpenClaw events"
},
{
"path": "integrations/openclaw/src/utils/index.ts",
"chars": 175,
"preview": "export { extractContext, type ExtractedContext } from './context.js';\nexport { MemoriLogger } from './logger.js';\nexport"
},
{
"path": "integrations/openclaw/src/utils/logger.ts",
"chars": 743,
"preview": "import type { OpenClawPluginApi } from 'openclaw/plugin-sdk';\nimport { PLUGIN_CONFIG } from '../constants.js';\n\nexport c"
},
{
"path": "integrations/openclaw/src/utils/memori-client.ts",
"chars": 743,
"preview": "import { Memori } from '@memorilabs/memori';\nimport { OpenClawIntegration } from '@memorilabs/memori/integrations';\nimpo"
},
{
"path": "integrations/openclaw/src/version.ts",
"chars": 85,
"preview": "// This file is auto-generated during CI builds.\nexport const SDK_VERSION = '0.0.0';\n"
},
{
"path": "integrations/openclaw/tests/handlers/augmentation.test.ts",
"chars": 13775,
"preview": "import { describe, it, expect, vi, beforeEach } from 'vitest';\nimport { handleAugmentation } from '../../src/handlers/au"
},
{
"path": "integrations/openclaw/tests/handlers/recall.test.ts",
"chars": 7308,
"preview": "import { describe, it, expect, vi, beforeEach } from 'vitest';\nimport { handleRecall } from '../../src/handlers/recall.j"
},
{
"path": "integrations/openclaw/tests/index.test.ts",
"chars": 6101,
"preview": "import { describe, it, expect, vi, beforeEach } from 'vitest';\nimport memoriPlugin from '../src/index.js';\nimport type {"
},
{
"path": "integrations/openclaw/tests/sanitizer.test.ts",
"chars": 5934,
"preview": "import { describe, it, expect } from 'vitest';\nimport { isSystemMessage, cleanText } from '../src/sanitizer.js';\nimport "
},
{
"path": "integrations/openclaw/tests/utils/context.test.ts",
"chars": 4201,
"preview": "import { describe, it, expect } from 'vitest';\nimport { extractContext } from '../../src/utils/context.js';\nimport type "
},
{
"path": "integrations/openclaw/tests/utils/logger.test.ts",
"chars": 3580,
"preview": "import { describe, it, expect, vi, beforeEach } from 'vitest';\nimport { MemoriLogger } from '../../src/utils/logger.js';"
},
{
"path": "integrations/openclaw/tests/utils/memori-client.test.ts",
"chars": 4499,
"preview": "import { describe, it, expect, vi, beforeEach } from 'vitest';\nimport { initializeMemoriClient } from '../../src/utils/m"
},
{
"path": "integrations/openclaw/tsconfig.json",
"chars": 367,
"preview": "{\n \"compilerOptions\": {\n \"target\": \"ES2023\",\n \"lib\": [\"ES2023\", \"DOM\"],\n \"module\": \"NodeNext\",\n \"moduleReso"
},
{
"path": "integrations/openclaw/vitest.config.ts",
"chars": 645,
"preview": "import { defineConfig } from 'vitest/config';\nimport path from 'node:path';\n\nexport default defineConfig({\n test: {\n "
},
{
"path": "memori/__init__.py",
"chars": 5715,
"preview": "r\"\"\"\n __ __ _\n| \\/ | ___ _ __ ___ ___ _ __(_)\n| |\\/| |/ _ \\ '_ ` _ \\ / _ \\| '__| |\n| | "
},
{
"path": "memori/__main__.py",
"chars": 2319,
"preview": "r\"\"\"\n __ __ _\n| \\/ | ___ _ __ ___ ___ _ __(_)\n| |\\/| |/ _ \\ '_ ` _ \\ / _ \\| '__| |\n| | "
},
{
"path": "memori/_cli.py",
"chars": 989,
"preview": "r\"\"\"\n __ __ _\n| \\/ | ___ _ __ ___ ___ _ __(_)\n| |\\/| |/ _ \\ '_ ` _ \\ / _ \\| '__| |\n| | "
},
{
"path": "memori/_config.py",
"chars": 2930,
"preview": "r\"\"\"\n __ __ _\n| \\/ | ___ _ __ ___ ___ _ __(_)\n| |\\/| |/ _ \\ '_ ` _ \\ / _ \\| '__| |\n| | "
},
{
"path": "memori/_exceptions.py",
"chars": 3315,
"preview": "r\"\"\"\n _ __ _\n| \\/ | ___ _ __ ___ ___ _ __(_)\n| |\\/| |/ _ \\ '_ ` _ \\ / _ \\| '__| |\n| | |"
},
{
"path": "memori/_logging.py",
"chars": 1852,
"preview": "r\"\"\"\n __ __ _\n| \\/ | ___ _ __ ___ ___ _ __(_)\n| |\\/| |/ _ \\ '_ ` _ \\ / _ \\| '__| |\n| | "
},
{
"path": "memori/_network.py",
"chars": 11659,
"preview": "r\"\"\"\n __ __ _\n| \\/ | ___ _ __ ___ ___ _ __(_)\n| |\\/| |/ _ \\ '_ ` _ \\ / _ \\| '__| |\n| | "
},
{
"path": "memori/_setup.py",
"chars": 781,
"preview": "r\"\"\"\n __ __ _\n| \\/ | ___ _ __ ___ ___ _ __(_)\n| |\\/| |/ _ \\ '_ ` _ \\ / _ \\| '__| |\n| | "
},
{
"path": "memori/_utils.py",
"chars": 2813,
"preview": "r\"\"\"\n __ __ _\n| \\/ | ___ _ __ ___ ___ _ __(_)\n| |\\/| |/ _ \\ '_ ` _ \\ / _ \\| '__| |\n| | "
},
{
"path": "memori/api/_quota.py",
"chars": 773,
"preview": "r\"\"\"\n __ __ _\n| \\/ | ___ _ __ ___ ___ _ __(_)\n| |\\/| |/ _ \\ '_ ` _ \\ / _ \\| '__| |\n| | "
},
{
"path": "memori/api/_sign_up.py",
"chars": 954,
"preview": "r\"\"\"\n __ __ _\n| \\/ | ___ _ __ ___ ___ _ __(_)\n| |\\/| |/ _ \\ '_ ` _ \\ / _ \\| '__| |\n| | "
},
{
"path": "memori/embeddings/__init__.py",
"chars": 569,
"preview": "r\"\"\"\n __ __ _\n| \\/ | ___ _ __ ___ ___ _ __(_)\n| |\\/| |/ _ \\ '_ ` _ \\ / _ \\| '__| |\n| | "
},
{
"path": "memori/embeddings/_api.py",
"chars": 2998,
"preview": "r\"\"\"\n __ __ _\n| \\/ | ___ _ __ ___ ___ _ __(_)\n| |\\/| |/ _ \\ '_ ` _ \\ / _ \\| '__| |\n| | "
},
{
"path": "memori/embeddings/_chunking.py",
"chars": 1059,
"preview": "r\"\"\"\n __ __ _\n| \\/ | ___ _ __ ___ ___ _ __(_)\n| |\\/| |/ _ \\ '_ ` _ \\ / _ \\| '__| |\n| | "
},
{
"path": "memori/embeddings/_format.py",
"chars": 891,
"preview": "r\"\"\"\n __ __ _\n| \\/ | ___ _ __ ___ ___ _ __(_)\n| |\\/| |/ _ \\ '_ ` _ \\ / _ \\| '__| |\n| | "
},
{
"path": "memori/embeddings/_sentence_transformers.py",
"chars": 9530,
"preview": "r\"\"\"\n __ __ _\n| \\/ | ___ _ __ ___ ___ _ __(_)\n| |\\/| |/ _ \\ '_ ` _ \\ / _ \\| '__| |\n| | "
},
{
"path": "memori/embeddings/_tei.py",
"chars": 1467,
"preview": "r\"\"\"\n __ __ _\n| \\/ | ___ _ __ ___ ___ _ __(_)\n| |\\/| |/ _ \\ '_ ` _ \\ / _ \\| '__| |\n| | "
},
{
"path": "memori/embeddings/_tei_embed.py",
"chars": 1587,
"preview": "r\"\"\"\n __ __ _\n| \\/ | ___ _ __ ___ ___ _ __(_)\n| |\\/| |/ _ \\ '_ ` _ \\ / _ \\| '__| |\n| | "
},
{
"path": "memori/embeddings/_utils.py",
"chars": 918,
"preview": "r\"\"\"\n __ __ _\n| \\/ | ___ _ __ ___ ___ _ __(_)\n| |\\/| |/ _ \\ '_ ` _ \\ / _ \\| '__| |\n| | "
},
{
"path": "memori/llm/__init__.py",
"chars": 466,
"preview": "r\"\"\"\n __ __ _\n| \\/ | ___ _ __ ___ ___ _ __(_)\n| |\\/| |/ _ \\ '_ ` _ \\ / _ \\| '__| |\n| | "
},
{
"path": "memori/llm/_base.py",
"chars": 45677,
"preview": "r\"\"\"\n __ __ _\n| \\/ | ___ _ __ ___ ___ _ __(_)\n| |\\/| |/ _ \\ '_ ` _ \\ / _ \\| '__| |\n| | "
},
{
"path": "memori/llm/_clients.py",
"chars": 32391,
"preview": "r\"\"\"\n __ __ _\n| \\/ | ___ _ __ ___ ___ _ __(_)\n| |\\/| |/ _ \\ '_ ` _ \\ / _ \\| '__| |\n| | "
},
{
"path": "memori/llm/_constants.py",
"chars": 909,
"preview": "r\"\"\"\n __ __ _\n| \\/ | ___ _ __ ___ ___ _ __(_)\n| |\\/| |/ _ \\ '_ ` _ \\ / _ \\| '__| |\n| | "
},
{
"path": "memori/llm/_invoke.py",
"chars": 4692,
"preview": "r\"\"\"\n __ __ _\n| \\/ | ___ _ __ ___ ___ _ __(_)\n| |\\/| |/ _ \\ '_ ` _ \\ / _ \\| '__| |\n| | "
},
{
"path": "memori/llm/_iterable.py",
"chars": 2000,
"preview": "r\"\"\"\n __ __ _\n| \\/ | ___ _ __ ___ ___ _ __(_)\n| |\\/| |/ _ \\ '_ ` _ \\ / _ \\| '__| |\n| | "
},
{
"path": "memori/llm/_iterator.py",
"chars": 2821,
"preview": "r\"\"\"\n __ __ _\n| \\/ | ___ _ __ ___ ___ _ __(_)\n| |\\/| |/ _ \\ '_ ` _ \\ / _ \\| '__| |\n| | "
},
{
"path": "memori/llm/_providers.py",
"chars": 3996,
"preview": "r\"\"\"\n __ __ _\n| \\/ | ___ _ __ ___ ___ _ __(_)\n| |\\/| |/ _ \\ '_ ` _ \\ / _ \\| '__| |\n| | "
},
{
"path": "memori/llm/_registry.py",
"chars": 5785,
"preview": "r\"\"\"\n __ __ _\n| \\/ | ___ _ __ ___ ___ _ __(_)\n| |\\/| |/ _ \\ '_ ` _ \\ / _ \\| '__| |\n| | "
},
{
"path": "memori/llm/_streaming.py",
"chars": 1760,
"preview": "r\"\"\"\n __ __ _\n| \\/ | ___ _ __ ___ ___ _ __(_)\n| |\\/| |/ _ \\ '_ ` _ \\ / _ \\| '__| |\n| | "
},
{
"path": "memori/llm/_utils.py",
"chars": 2287,
"preview": "r\"\"\"\n __ __ _\n| \\/ | ___ _ __ ___ ___ _ __(_)\n| |\\/| |/ _ \\ '_ ` _ \\ / _ \\| '__| |\n| | "
},
{
"path": "memori/llm/_xai_wrappers.py",
"chars": 11731,
"preview": "r\"\"\"\n __ __ _\n| \\/ | ___ _ __ ___ ___ _ __(_)\n| |\\/| |/ _ \\ '_ ` _ \\ / _ \\| '__| |\n| | "
}
]
// ... and 254 more files (download for full content)
About this extraction
This page contains the full source code of the MemoriLabs/Memori GitHub repository, extracted and formatted as plain text for AI agents and large language models (LLMs). The extraction includes 454 files (2.4 MB), approximately 649.7k tokens, and a symbol index with 2376 extracted functions, classes, methods, constants, and types. Use this with OpenClaw, Claude, ChatGPT, Cursor, Windsurf, or any other AI tool that accepts text input. You can copy the full output to your clipboard or download it as a .txt file.
Extracted by GitExtract — free GitHub repo to text converter for AI. Built by Nikandr Surkov.