Repository: MorvanZhou/Reinforcement-learning-with-tensorflow
Branch: master
Commit: 93e333484be0
Files: 60
Total size: 325.0 KB
Directory structure:
gitextract_8twtflmr/
├── .gitignore
├── LICENCE
├── README.md
├── contents/
│ ├── 10_A3C/
│ │ ├── A3C_RNN.py
│ │ ├── A3C_continuous_action.py
│ │ ├── A3C_discrete_action.py
│ │ └── A3C_distributed_tf.py
│ ├── 11_Dyna_Q/
│ │ ├── RL_brain.py
│ │ ├── maze_env.py
│ │ └── run_this.py
│ ├── 12_Proximal_Policy_Optimization/
│ │ ├── DPPO.py
│ │ ├── discrete_DPPO.py
│ │ └── simply_PPO.py
│ ├── 1_command_line_reinforcement_learning/
│ │ └── treasure_on_right.py
│ ├── 2_Q_Learning_maze/
│ │ ├── RL_brain.py
│ │ ├── maze_env.py
│ │ └── run_this.py
│ ├── 3_Sarsa_maze/
│ │ ├── RL_brain.py
│ │ ├── maze_env.py
│ │ └── run_this.py
│ ├── 4_Sarsa_lambda_maze/
│ │ ├── RL_brain.py
│ │ ├── maze_env.py
│ │ └── run_this.py
│ ├── 5.1_Double_DQN/
│ │ ├── RL_brain.py
│ │ └── run_Pendulum.py
│ ├── 5.2_Prioritized_Replay_DQN/
│ │ ├── RL_brain.py
│ │ └── run_MountainCar.py
│ ├── 5.3_Dueling_DQN/
│ │ ├── RL_brain.py
│ │ └── run_Pendulum.py
│ ├── 5_Deep_Q_Network/
│ │ ├── DQN_modified.py
│ │ ├── RL_brain.py
│ │ ├── maze_env.py
│ │ └── run_this.py
│ ├── 6_OpenAI_gym/
│ │ ├── RL_brain.py
│ │ ├── run_CartPole.py
│ │ └── run_MountainCar.py
│ ├── 7_Policy_gradient_softmax/
│ │ ├── RL_brain.py
│ │ ├── run_CartPole.py
│ │ └── run_MountainCar.py
│ ├── 8_Actor_Critic_Advantage/
│ │ ├── AC_CartPole.py
│ │ └── AC_continue_Pendulum.py
│ ├── 9_Deep_Deterministic_Policy_Gradient_DDPG/
│ │ ├── DDPG.py
│ │ ├── DDPG_update.py
│ │ └── DDPG_update2.py
│ └── Curiosity_Model/
│ ├── Curiosity.py
│ └── Random_Network_Distillation.py
└── experiments/
├── 2D_car/
│ ├── DDPG.py
│ ├── car_env.py
│ └── collision.py
├── Robot_arm/
│ ├── A3C.py
│ ├── DDPG.py
│ ├── DPPO.py
│ └── arm_env.py
├── Solve_BipedalWalker/
│ ├── A3C.py
│ ├── A3C_rnn.py
│ ├── DDPG.py
│ └── log/
│ └── events.out.tfevents.1490801027.Morvan
└── Solve_LunarLander/
├── A3C.py
├── DuelingDQNPrioritizedReplay.py
└── run_LunarLander.py
================================================
FILE CONTENTS
================================================
================================================
FILE: .gitignore
================================================
.idea
__pycache__
================================================
FILE: LICENCE
================================================
MIT License
Copyright (c) 2017
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE.
================================================
FILE: README.md
================================================

# Reinforcement Learning Methods and Tutorials
In these tutorials for reinforcement learning, it covers from the basic RL algorithms to advanced algorithms developed recent years.
**If you speak Chinese, visit [莫烦 Python](https://mofanpy.com) or my [Youtube channel](https://www.youtube.com/channel/UCdyjiB5H8Pu7aDTNVXTTpcg) for more.**
**As many requests about making these tutorials available in English, please find them in this playlist:** ([https://www.youtube.com/playlist?list=PLXO45tsB95cIplu-fLMpUEEZTwrDNh6Ba](https://www.youtube.com/playlist?list=PLXO45tsB95cIplu-fLMpUEEZTwrDNh6Ba))
# Table of Contents
* Tutorials
* [Simple entry example](contents/1_command_line_reinforcement_learning)
* [Q-learning](contents/2_Q_Learning_maze)
* [Sarsa](contents/3_Sarsa_maze)
* [Sarsa(lambda)](contents/4_Sarsa_lambda_maze)
* [Deep Q Network (DQN)](contents/5_Deep_Q_Network)
* [Using OpenAI Gym](contents/6_OpenAI_gym)
* [Double DQN](contents/5.1_Double_DQN)
* [DQN with Prioitized Experience Replay](contents/5.2_Prioritized_Replay_DQN)
* [Dueling DQN](contents/5.3_Dueling_DQN)
* [Policy Gradients](contents/7_Policy_gradient_softmax)
* [Actor-Critic](contents/8_Actor_Critic_Advantage)
* [Deep Deterministic Policy Gradient (DDPG)](contents/9_Deep_Deterministic_Policy_Gradient_DDPG)
* [A3C](contents/10_A3C)
* [Dyna-Q](contents/11_Dyna_Q)
* [Proximal Policy Optimization (PPO)](contents/12_Proximal_Policy_Optimization)
* [Curiosity Model](/contents/Curiosity_Model), [Random Network Distillation (RND)](/contents/Curiosity_Model/Random_Network_Distillation.py)
* [Some of my experiments](experiments)
* [2D Car](experiments/2D_car)
* [Robot arm](experiments/Robot_arm)
* [BipedalWalker](experiments/Solve_BipedalWalker)
* [LunarLander](experiments/Solve_LunarLander)
# Some RL Networks
### [Deep Q Network](contents/5_Deep_Q_Network)
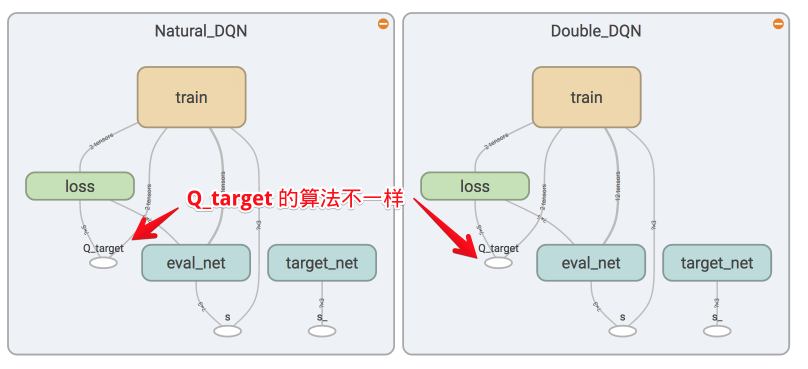
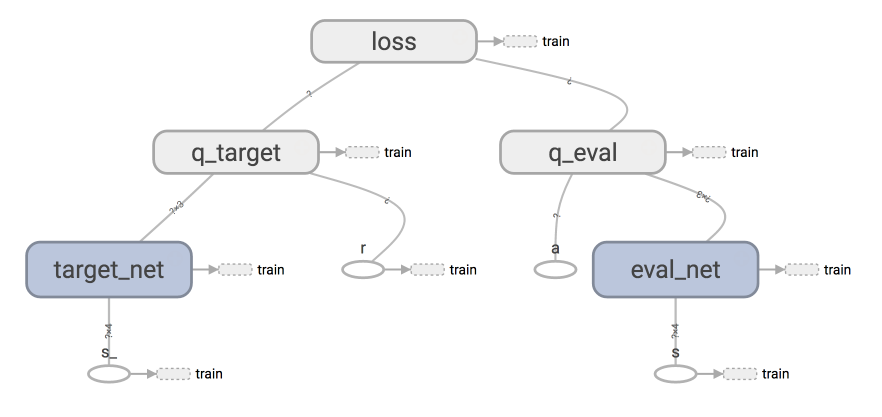 ### [Double DQN](contents/5.1_Double_DQN)
### [Double DQN](contents/5.1_Double_DQN)
 ### [Dueling DQN](contents/5.3_Dueling_DQN)
### [Dueling DQN](contents/5.3_Dueling_DQN)
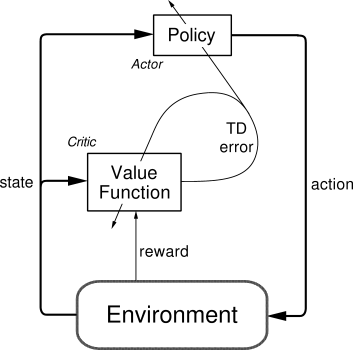
 ### [Actor Critic](contents/8_Actor_Critic_Advantage)
### [Actor Critic](contents/8_Actor_Critic_Advantage)
 ### [Deep Deterministic Policy Gradient](contents/9_Deep_Deterministic_Policy_Gradient_DDPG)
### [Deep Deterministic Policy Gradient](contents/9_Deep_Deterministic_Policy_Gradient_DDPG)
 ### [A3C](contents/10_A3C)
### [A3C](contents/10_A3C)
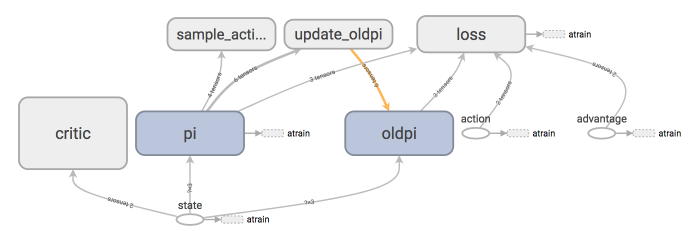
 ### [Proximal Policy Optimization (PPO)](contents/12_Proximal_Policy_Optimization)
### [Proximal Policy Optimization (PPO)](contents/12_Proximal_Policy_Optimization)
 ### [Curiosity Model](/contents/Curiosity_Model)
### [Curiosity Model](/contents/Curiosity_Model)
 # Donation
*If this does help you, please consider donating to support me for better tutorials. Any contribution is greatly appreciated!*
================================================
FILE: contents/10_A3C/A3C_RNN.py
================================================
"""
Asynchronous Advantage Actor Critic (A3C) + RNN with continuous action space, Reinforcement Learning.
The Pendulum example.
View more on my tutorial page: https://morvanzhou.github.io/tutorials/
Using:
tensorflow 1.8.0
gym 0.10.5
"""
import multiprocessing
import threading
import tensorflow as tf
import numpy as np
import gym
import os
import shutil
import matplotlib.pyplot as plt
GAME = 'Pendulum-v0'
OUTPUT_GRAPH = True
LOG_DIR = './log'
N_WORKERS = multiprocessing.cpu_count()
MAX_EP_STEP = 200
MAX_GLOBAL_EP = 1500
GLOBAL_NET_SCOPE = 'Global_Net'
UPDATE_GLOBAL_ITER = 5
GAMMA = 0.9
ENTROPY_BETA = 0.01
LR_A = 0.0001 # learning rate for actor
LR_C = 0.001 # learning rate for critic
GLOBAL_RUNNING_R = []
GLOBAL_EP = 0
env = gym.make(GAME)
N_S = env.observation_space.shape[0]
N_A = env.action_space.shape[0]
A_BOUND = [env.action_space.low, env.action_space.high]
class ACNet(object):
def __init__(self, scope, globalAC=None):
if scope == GLOBAL_NET_SCOPE: # get global network
with tf.variable_scope(scope):
self.s = tf.placeholder(tf.float32, [None, N_S], 'S')
self.a_params, self.c_params = self._build_net(scope)[-2:]
else: # local net, calculate losses
with tf.variable_scope(scope):
self.s = tf.placeholder(tf.float32, [None, N_S], 'S')
self.a_his = tf.placeholder(tf.float32, [None, N_A], 'A')
self.v_target = tf.placeholder(tf.float32, [None, 1], 'Vtarget')
mu, sigma, self.v, self.a_params, self.c_params = self._build_net(scope)
td = tf.subtract(self.v_target, self.v, name='TD_error')
with tf.name_scope('c_loss'):
self.c_loss = tf.reduce_mean(tf.square(td))
with tf.name_scope('wrap_a_out'):
mu, sigma = mu * A_BOUND[1], sigma + 1e-4
normal_dist = tf.distributions.Normal(mu, sigma)
with tf.name_scope('a_loss'):
log_prob = normal_dist.log_prob(self.a_his)
exp_v = log_prob * tf.stop_gradient(td)
entropy = normal_dist.entropy() # encourage exploration
self.exp_v = ENTROPY_BETA * entropy + exp_v
self.a_loss = tf.reduce_mean(-self.exp_v)
with tf.name_scope('choose_a'): # use local params to choose action
self.A = tf.clip_by_value(tf.squeeze(normal_dist.sample(1), axis=[0, 1]), A_BOUND[0], A_BOUND[1])
with tf.name_scope('local_grad'):
self.a_grads = tf.gradients(self.a_loss, self.a_params)
self.c_grads = tf.gradients(self.c_loss, self.c_params)
with tf.name_scope('sync'):
with tf.name_scope('pull'):
self.pull_a_params_op = [l_p.assign(g_p) for l_p, g_p in zip(self.a_params, globalAC.a_params)]
self.pull_c_params_op = [l_p.assign(g_p) for l_p, g_p in zip(self.c_params, globalAC.c_params)]
with tf.name_scope('push'):
self.update_a_op = OPT_A.apply_gradients(zip(self.a_grads, globalAC.a_params))
self.update_c_op = OPT_C.apply_gradients(zip(self.c_grads, globalAC.c_params))
def _build_net(self, scope):
w_init = tf.random_normal_initializer(0., .1)
with tf.variable_scope('critic'): # only critic controls the rnn update
cell_size = 64
s = tf.expand_dims(self.s, axis=1,
name='timely_input') # [time_step, feature] => [time_step, batch, feature]
rnn_cell = tf.contrib.rnn.BasicRNNCell(cell_size)
self.init_state = rnn_cell.zero_state(batch_size=1, dtype=tf.float32)
outputs, self.final_state = tf.nn.dynamic_rnn(
cell=rnn_cell, inputs=s, initial_state=self.init_state, time_major=True)
cell_out = tf.reshape(outputs, [-1, cell_size], name='flatten_rnn_outputs') # joined state representation
l_c = tf.layers.dense(cell_out, 50, tf.nn.relu6, kernel_initializer=w_init, name='lc')
v = tf.layers.dense(l_c, 1, kernel_initializer=w_init, name='v') # state value
with tf.variable_scope('actor'): # state representation is based on critic
l_a = tf.layers.dense(cell_out, 80, tf.nn.relu6, kernel_initializer=w_init, name='la')
mu = tf.layers.dense(l_a, N_A, tf.nn.tanh, kernel_initializer=w_init, name='mu')
sigma = tf.layers.dense(l_a, N_A, tf.nn.softplus, kernel_initializer=w_init, name='sigma')
a_params = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope=scope + '/actor')
c_params = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope=scope + '/critic')
return mu, sigma, v, a_params, c_params
def update_global(self, feed_dict): # run by a local
SESS.run([self.update_a_op, self.update_c_op], feed_dict) # local grads applies to global net
def pull_global(self): # run by a local
SESS.run([self.pull_a_params_op, self.pull_c_params_op])
def choose_action(self, s, cell_state): # run by a local
s = s[np.newaxis, :]
a, cell_state = SESS.run([self.A, self.final_state], {self.s: s, self.init_state: cell_state})
return a, cell_state
class Worker(object):
def __init__(self, name, globalAC):
self.env = gym.make(GAME).unwrapped
self.name = name
self.AC = ACNet(name, globalAC)
def work(self):
global GLOBAL_RUNNING_R, GLOBAL_EP
total_step = 1
buffer_s, buffer_a, buffer_r = [], [], []
while not COORD.should_stop() and GLOBAL_EP < MAX_GLOBAL_EP:
s = self.env.reset()
ep_r = 0
rnn_state = SESS.run(self.AC.init_state) # zero rnn state at beginning
keep_state = rnn_state.copy() # keep rnn state for updating global net
for ep_t in range(MAX_EP_STEP):
if self.name == 'W_0':
self.env.render()
a, rnn_state_ = self.AC.choose_action(s, rnn_state) # get the action and next rnn state
s_, r, done, info = self.env.step(a)
done = True if ep_t == MAX_EP_STEP - 1 else False
ep_r += r
buffer_s.append(s)
buffer_a.append(a)
buffer_r.append((r+8)/8) # normalize
if total_step % UPDATE_GLOBAL_ITER == 0 or done: # update global and assign to local net
if done:
v_s_ = 0 # terminal
else:
v_s_ = SESS.run(self.AC.v, {self.AC.s: s_[np.newaxis, :], self.AC.init_state: rnn_state_})[0, 0]
buffer_v_target = []
for r in buffer_r[::-1]: # reverse buffer r
v_s_ = r + GAMMA * v_s_
buffer_v_target.append(v_s_)
buffer_v_target.reverse()
buffer_s, buffer_a, buffer_v_target = np.vstack(buffer_s), np.vstack(buffer_a), np.vstack(buffer_v_target)
feed_dict = {
self.AC.s: buffer_s,
self.AC.a_his: buffer_a,
self.AC.v_target: buffer_v_target,
self.AC.init_state: keep_state,
}
self.AC.update_global(feed_dict)
buffer_s, buffer_a, buffer_r = [], [], []
self.AC.pull_global()
keep_state = rnn_state_.copy() # replace the keep_state as the new initial rnn state_
s = s_
rnn_state = rnn_state_ # renew rnn state
total_step += 1
if done:
if len(GLOBAL_RUNNING_R) == 0: # record running episode reward
GLOBAL_RUNNING_R.append(ep_r)
else:
GLOBAL_RUNNING_R.append(0.9 * GLOBAL_RUNNING_R[-1] + 0.1 * ep_r)
print(
self.name,
"Ep:", GLOBAL_EP,
"| Ep_r: %i" % GLOBAL_RUNNING_R[-1],
)
GLOBAL_EP += 1
break
if __name__ == "__main__":
SESS = tf.Session()
with tf.device("/cpu:0"):
OPT_A = tf.train.RMSPropOptimizer(LR_A, name='RMSPropA')
OPT_C = tf.train.RMSPropOptimizer(LR_C, name='RMSPropC')
GLOBAL_AC = ACNet(GLOBAL_NET_SCOPE) # we only need its params
workers = []
# Create worker
for i in range(N_WORKERS):
i_name = 'W_%i' % i # worker name
workers.append(Worker(i_name, GLOBAL_AC))
COORD = tf.train.Coordinator()
SESS.run(tf.global_variables_initializer())
if OUTPUT_GRAPH:
if os.path.exists(LOG_DIR):
shutil.rmtree(LOG_DIR)
tf.summary.FileWriter(LOG_DIR, SESS.graph)
worker_threads = []
for worker in workers:
job = lambda: worker.work()
t = threading.Thread(target=job)
t.start()
worker_threads.append(t)
COORD.join(worker_threads)
plt.plot(np.arange(len(GLOBAL_RUNNING_R)), GLOBAL_RUNNING_R)
plt.xlabel('step')
plt.ylabel('Total moving reward')
plt.show()
================================================
FILE: contents/10_A3C/A3C_continuous_action.py
================================================
"""
Asynchronous Advantage Actor Critic (A3C) with continuous action space, Reinforcement Learning.
The Pendulum example.
View more on my tutorial page: https://morvanzhou.github.io/tutorials/
Using:
tensorflow 1.8.0
gym 0.10.5
"""
import multiprocessing
import threading
import tensorflow as tf
import numpy as np
import gym
import os
import shutil
import matplotlib.pyplot as plt
GAME = 'Pendulum-v0'
OUTPUT_GRAPH = True
LOG_DIR = './log'
N_WORKERS = multiprocessing.cpu_count()
MAX_EP_STEP = 200
MAX_GLOBAL_EP = 2000
GLOBAL_NET_SCOPE = 'Global_Net'
UPDATE_GLOBAL_ITER = 10
GAMMA = 0.9
ENTROPY_BETA = 0.01
LR_A = 0.0001 # learning rate for actor
LR_C = 0.001 # learning rate for critic
GLOBAL_RUNNING_R = []
GLOBAL_EP = 0
env = gym.make(GAME)
N_S = env.observation_space.shape[0]
N_A = env.action_space.shape[0]
A_BOUND = [env.action_space.low, env.action_space.high]
class ACNet(object):
def __init__(self, scope, globalAC=None):
if scope == GLOBAL_NET_SCOPE: # get global network
with tf.variable_scope(scope):
self.s = tf.placeholder(tf.float32, [None, N_S], 'S')
self.a_params, self.c_params = self._build_net(scope)[-2:]
else: # local net, calculate losses
with tf.variable_scope(scope):
self.s = tf.placeholder(tf.float32, [None, N_S], 'S')
self.a_his = tf.placeholder(tf.float32, [None, N_A], 'A')
self.v_target = tf.placeholder(tf.float32, [None, 1], 'Vtarget')
mu, sigma, self.v, self.a_params, self.c_params = self._build_net(scope)
td = tf.subtract(self.v_target, self.v, name='TD_error')
with tf.name_scope('c_loss'):
self.c_loss = tf.reduce_mean(tf.square(td))
with tf.name_scope('wrap_a_out'):
mu, sigma = mu * A_BOUND[1], sigma + 1e-4
normal_dist = tf.distributions.Normal(mu, sigma)
with tf.name_scope('a_loss'):
log_prob = normal_dist.log_prob(self.a_his)
exp_v = log_prob * tf.stop_gradient(td)
entropy = normal_dist.entropy() # encourage exploration
self.exp_v = ENTROPY_BETA * entropy + exp_v
self.a_loss = tf.reduce_mean(-self.exp_v)
with tf.name_scope('choose_a'): # use local params to choose action
self.A = tf.clip_by_value(tf.squeeze(normal_dist.sample(1), axis=[0, 1]), A_BOUND[0], A_BOUND[1])
with tf.name_scope('local_grad'):
self.a_grads = tf.gradients(self.a_loss, self.a_params)
self.c_grads = tf.gradients(self.c_loss, self.c_params)
with tf.name_scope('sync'):
with tf.name_scope('pull'):
self.pull_a_params_op = [l_p.assign(g_p) for l_p, g_p in zip(self.a_params, globalAC.a_params)]
self.pull_c_params_op = [l_p.assign(g_p) for l_p, g_p in zip(self.c_params, globalAC.c_params)]
with tf.name_scope('push'):
self.update_a_op = OPT_A.apply_gradients(zip(self.a_grads, globalAC.a_params))
self.update_c_op = OPT_C.apply_gradients(zip(self.c_grads, globalAC.c_params))
def _build_net(self, scope):
w_init = tf.random_normal_initializer(0., .1)
with tf.variable_scope('actor'):
l_a = tf.layers.dense(self.s, 200, tf.nn.relu6, kernel_initializer=w_init, name='la')
mu = tf.layers.dense(l_a, N_A, tf.nn.tanh, kernel_initializer=w_init, name='mu')
sigma = tf.layers.dense(l_a, N_A, tf.nn.softplus, kernel_initializer=w_init, name='sigma')
with tf.variable_scope('critic'):
l_c = tf.layers.dense(self.s, 100, tf.nn.relu6, kernel_initializer=w_init, name='lc')
v = tf.layers.dense(l_c, 1, kernel_initializer=w_init, name='v') # state value
a_params = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope=scope + '/actor')
c_params = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope=scope + '/critic')
return mu, sigma, v, a_params, c_params
def update_global(self, feed_dict): # run by a local
SESS.run([self.update_a_op, self.update_c_op], feed_dict) # local grads applies to global net
def pull_global(self): # run by a local
SESS.run([self.pull_a_params_op, self.pull_c_params_op])
def choose_action(self, s): # run by a local
s = s[np.newaxis, :]
return SESS.run(self.A, {self.s: s})
class Worker(object):
def __init__(self, name, globalAC):
self.env = gym.make(GAME).unwrapped
self.name = name
self.AC = ACNet(name, globalAC)
def work(self):
global GLOBAL_RUNNING_R, GLOBAL_EP
total_step = 1
buffer_s, buffer_a, buffer_r = [], [], []
while not COORD.should_stop() and GLOBAL_EP < MAX_GLOBAL_EP:
s = self.env.reset()
ep_r = 0
for ep_t in range(MAX_EP_STEP):
# if self.name == 'W_0':
# self.env.render()
a = self.AC.choose_action(s)
s_, r, done, info = self.env.step(a)
done = True if ep_t == MAX_EP_STEP - 1 else False
ep_r += r
buffer_s.append(s)
buffer_a.append(a)
buffer_r.append((r+8)/8) # normalize
if total_step % UPDATE_GLOBAL_ITER == 0 or done: # update global and assign to local net
if done:
v_s_ = 0 # terminal
else:
v_s_ = SESS.run(self.AC.v, {self.AC.s: s_[np.newaxis, :]})[0, 0]
buffer_v_target = []
for r in buffer_r[::-1]: # reverse buffer r
v_s_ = r + GAMMA * v_s_
buffer_v_target.append(v_s_)
buffer_v_target.reverse()
buffer_s, buffer_a, buffer_v_target = np.vstack(buffer_s), np.vstack(buffer_a), np.vstack(buffer_v_target)
feed_dict = {
self.AC.s: buffer_s,
self.AC.a_his: buffer_a,
self.AC.v_target: buffer_v_target,
}
self.AC.update_global(feed_dict)
buffer_s, buffer_a, buffer_r = [], [], []
self.AC.pull_global()
s = s_
total_step += 1
if done:
if len(GLOBAL_RUNNING_R) == 0: # record running episode reward
GLOBAL_RUNNING_R.append(ep_r)
else:
GLOBAL_RUNNING_R.append(0.9 * GLOBAL_RUNNING_R[-1] + 0.1 * ep_r)
print(
self.name,
"Ep:", GLOBAL_EP,
"| Ep_r: %i" % GLOBAL_RUNNING_R[-1],
)
GLOBAL_EP += 1
break
if __name__ == "__main__":
SESS = tf.Session()
with tf.device("/cpu:0"):
OPT_A = tf.train.RMSPropOptimizer(LR_A, name='RMSPropA')
OPT_C = tf.train.RMSPropOptimizer(LR_C, name='RMSPropC')
GLOBAL_AC = ACNet(GLOBAL_NET_SCOPE) # we only need its params
workers = []
# Create worker
for i in range(N_WORKERS):
i_name = 'W_%i' % i # worker name
workers.append(Worker(i_name, GLOBAL_AC))
COORD = tf.train.Coordinator()
SESS.run(tf.global_variables_initializer())
if OUTPUT_GRAPH:
if os.path.exists(LOG_DIR):
shutil.rmtree(LOG_DIR)
tf.summary.FileWriter(LOG_DIR, SESS.graph)
worker_threads = []
for worker in workers:
job = lambda: worker.work()
t = threading.Thread(target=job)
t.start()
worker_threads.append(t)
COORD.join(worker_threads)
plt.plot(np.arange(len(GLOBAL_RUNNING_R)), GLOBAL_RUNNING_R)
plt.xlabel('step')
plt.ylabel('Total moving reward')
plt.show()
================================================
FILE: contents/10_A3C/A3C_discrete_action.py
================================================
"""
Asynchronous Advantage Actor Critic (A3C) with discrete action space, Reinforcement Learning.
The Cartpole example.
View more on my tutorial page: https://morvanzhou.github.io/tutorials/
Using:
tensorflow 1.8.0
gym 0.10.5
"""
import multiprocessing
import threading
import tensorflow as tf
import numpy as np
import gym
import os
import shutil
import matplotlib.pyplot as plt
GAME = 'CartPole-v0'
OUTPUT_GRAPH = True
LOG_DIR = './log'
N_WORKERS = multiprocessing.cpu_count()
MAX_GLOBAL_EP = 1000
GLOBAL_NET_SCOPE = 'Global_Net'
UPDATE_GLOBAL_ITER = 10
GAMMA = 0.9
ENTROPY_BETA = 0.001
LR_A = 0.001 # learning rate for actor
LR_C = 0.001 # learning rate for critic
GLOBAL_RUNNING_R = []
GLOBAL_EP = 0
env = gym.make(GAME)
N_S = env.observation_space.shape[0]
N_A = env.action_space.n
class ACNet(object):
def __init__(self, scope, globalAC=None):
if scope == GLOBAL_NET_SCOPE: # get global network
with tf.variable_scope(scope):
self.s = tf.placeholder(tf.float32, [None, N_S], 'S')
self.a_params, self.c_params = self._build_net(scope)[-2:]
else: # local net, calculate losses
with tf.variable_scope(scope):
self.s = tf.placeholder(tf.float32, [None, N_S], 'S')
self.a_his = tf.placeholder(tf.int32, [None, ], 'A')
self.v_target = tf.placeholder(tf.float32, [None, 1], 'Vtarget')
self.a_prob, self.v, self.a_params, self.c_params = self._build_net(scope)
td = tf.subtract(self.v_target, self.v, name='TD_error')
with tf.name_scope('c_loss'):
self.c_loss = tf.reduce_mean(tf.square(td))
with tf.name_scope('a_loss'):
log_prob = tf.reduce_sum(tf.log(self.a_prob + 1e-5) * tf.one_hot(self.a_his, N_A, dtype=tf.float32), axis=1, keep_dims=True)
exp_v = log_prob * tf.stop_gradient(td)
entropy = -tf.reduce_sum(self.a_prob * tf.log(self.a_prob + 1e-5),
axis=1, keep_dims=True) # encourage exploration
self.exp_v = ENTROPY_BETA * entropy + exp_v
self.a_loss = tf.reduce_mean(-self.exp_v)
with tf.name_scope('local_grad'):
self.a_grads = tf.gradients(self.a_loss, self.a_params)
self.c_grads = tf.gradients(self.c_loss, self.c_params)
with tf.name_scope('sync'):
with tf.name_scope('pull'):
self.pull_a_params_op = [l_p.assign(g_p) for l_p, g_p in zip(self.a_params, globalAC.a_params)]
self.pull_c_params_op = [l_p.assign(g_p) for l_p, g_p in zip(self.c_params, globalAC.c_params)]
with tf.name_scope('push'):
self.update_a_op = OPT_A.apply_gradients(zip(self.a_grads, globalAC.a_params))
self.update_c_op = OPT_C.apply_gradients(zip(self.c_grads, globalAC.c_params))
def _build_net(self, scope):
w_init = tf.random_normal_initializer(0., .1)
with tf.variable_scope('actor'):
l_a = tf.layers.dense(self.s, 200, tf.nn.relu6, kernel_initializer=w_init, name='la')
a_prob = tf.layers.dense(l_a, N_A, tf.nn.softmax, kernel_initializer=w_init, name='ap')
with tf.variable_scope('critic'):
l_c = tf.layers.dense(self.s, 100, tf.nn.relu6, kernel_initializer=w_init, name='lc')
v = tf.layers.dense(l_c, 1, kernel_initializer=w_init, name='v') # state value
a_params = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope=scope + '/actor')
c_params = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope=scope + '/critic')
return a_prob, v, a_params, c_params
def update_global(self, feed_dict): # run by a local
SESS.run([self.update_a_op, self.update_c_op], feed_dict) # local grads applies to global net
def pull_global(self): # run by a local
SESS.run([self.pull_a_params_op, self.pull_c_params_op])
def choose_action(self, s): # run by a local
prob_weights = SESS.run(self.a_prob, feed_dict={self.s: s[np.newaxis, :]})
action = np.random.choice(range(prob_weights.shape[1]),
p=prob_weights.ravel()) # select action w.r.t the actions prob
return action
class Worker(object):
def __init__(self, name, globalAC):
self.env = gym.make(GAME).unwrapped
self.name = name
self.AC = ACNet(name, globalAC)
def work(self):
global GLOBAL_RUNNING_R, GLOBAL_EP
total_step = 1
buffer_s, buffer_a, buffer_r = [], [], []
while not COORD.should_stop() and GLOBAL_EP < MAX_GLOBAL_EP:
s = self.env.reset()
ep_r = 0
while True:
# if self.name == 'W_0':
# self.env.render()
a = self.AC.choose_action(s)
s_, r, done, info = self.env.step(a)
if done: r = -5
ep_r += r
buffer_s.append(s)
buffer_a.append(a)
buffer_r.append(r)
if total_step % UPDATE_GLOBAL_ITER == 0 or done: # update global and assign to local net
if done:
v_s_ = 0 # terminal
else:
v_s_ = SESS.run(self.AC.v, {self.AC.s: s_[np.newaxis, :]})[0, 0]
buffer_v_target = []
for r in buffer_r[::-1]: # reverse buffer r
v_s_ = r + GAMMA * v_s_
buffer_v_target.append(v_s_)
buffer_v_target.reverse()
buffer_s, buffer_a, buffer_v_target = np.vstack(buffer_s), np.array(buffer_a), np.vstack(buffer_v_target)
feed_dict = {
self.AC.s: buffer_s,
self.AC.a_his: buffer_a,
self.AC.v_target: buffer_v_target,
}
self.AC.update_global(feed_dict)
buffer_s, buffer_a, buffer_r = [], [], []
self.AC.pull_global()
s = s_
total_step += 1
if done:
if len(GLOBAL_RUNNING_R) == 0: # record running episode reward
GLOBAL_RUNNING_R.append(ep_r)
else:
GLOBAL_RUNNING_R.append(0.99 * GLOBAL_RUNNING_R[-1] + 0.01 * ep_r)
print(
self.name,
"Ep:", GLOBAL_EP,
"| Ep_r: %i" % GLOBAL_RUNNING_R[-1],
)
GLOBAL_EP += 1
break
if __name__ == "__main__":
SESS = tf.Session()
with tf.device("/cpu:0"):
OPT_A = tf.train.RMSPropOptimizer(LR_A, name='RMSPropA')
OPT_C = tf.train.RMSPropOptimizer(LR_C, name='RMSPropC')
GLOBAL_AC = ACNet(GLOBAL_NET_SCOPE) # we only need its params
workers = []
# Create worker
for i in range(N_WORKERS):
i_name = 'W_%i' % i # worker name
workers.append(Worker(i_name, GLOBAL_AC))
COORD = tf.train.Coordinator()
SESS.run(tf.global_variables_initializer())
if OUTPUT_GRAPH:
if os.path.exists(LOG_DIR):
shutil.rmtree(LOG_DIR)
tf.summary.FileWriter(LOG_DIR, SESS.graph)
worker_threads = []
for worker in workers:
job = lambda: worker.work()
t = threading.Thread(target=job)
t.start()
worker_threads.append(t)
COORD.join(worker_threads)
plt.plot(np.arange(len(GLOBAL_RUNNING_R)), GLOBAL_RUNNING_R)
plt.xlabel('step')
plt.ylabel('Total moving reward')
plt.show()
================================================
FILE: contents/10_A3C/A3C_distributed_tf.py
================================================
"""
Asynchronous Advantage Actor Critic (A3C) with discrete action space, Reinforcement Learning.
The Cartpole example using distributed tensorflow + multiprocessing.
View more on my tutorial page: https://morvanzhou.github.io/
"""
import multiprocessing as mp
import tensorflow as tf
import numpy as np
import gym, time
import matplotlib.pyplot as plt
UPDATE_GLOBAL_ITER = 10
GAMMA = 0.9
ENTROPY_BETA = 0.001
LR_A = 0.001 # learning rate for actor
LR_C = 0.001 # learning rate for critic
env = gym.make('CartPole-v0')
N_S = env.observation_space.shape[0]
N_A = env.action_space.n
class ACNet(object):
sess = None
def __init__(self, scope, opt_a=None, opt_c=None, global_net=None):
if scope == 'global_net': # get global network
with tf.variable_scope(scope):
self.s = tf.placeholder(tf.float32, [None, N_S], 'S')
self.a_params, self.c_params = self._build_net(scope)[-2:]
else:
with tf.variable_scope(scope):
self.s = tf.placeholder(tf.float32, [None, N_S], 'S')
self.a_his = tf.placeholder(tf.int32, [None, ], 'A')
self.v_target = tf.placeholder(tf.float32, [None, 1], 'Vtarget')
self.a_prob, self.v, self.a_params, self.c_params = self._build_net(scope)
td = tf.subtract(self.v_target, self.v, name='TD_error')
with tf.name_scope('c_loss'):
self.c_loss = tf.reduce_mean(tf.square(td))
with tf.name_scope('a_loss'):
log_prob = tf.reduce_sum(
tf.log(self.a_prob) * tf.one_hot(self.a_his, N_A, dtype=tf.float32),
axis=1, keep_dims=True)
exp_v = log_prob * tf.stop_gradient(td)
entropy = -tf.reduce_sum(self.a_prob * tf.log(self.a_prob + 1e-5),
axis=1, keep_dims=True) # encourage exploration
self.exp_v = ENTROPY_BETA * entropy + exp_v
self.a_loss = tf.reduce_mean(-self.exp_v)
with tf.name_scope('local_grad'):
self.a_grads = tf.gradients(self.a_loss, self.a_params)
self.c_grads = tf.gradients(self.c_loss, self.c_params)
self.global_step = tf.train.get_or_create_global_step()
with tf.name_scope('sync'):
with tf.name_scope('pull'):
self.pull_a_params_op = [l_p.assign(g_p) for l_p, g_p in zip(self.a_params, global_net.a_params)]
self.pull_c_params_op = [l_p.assign(g_p) for l_p, g_p in zip(self.c_params, global_net.c_params)]
with tf.name_scope('push'):
self.update_a_op = opt_a.apply_gradients(zip(self.a_grads, global_net.a_params), global_step=self.global_step)
self.update_c_op = opt_c.apply_gradients(zip(self.c_grads, global_net.c_params))
def _build_net(self, scope):
w_init = tf.random_normal_initializer(0., .1)
with tf.variable_scope('actor'):
l_a = tf.layers.dense(self.s, 200, tf.nn.relu6, kernel_initializer=w_init, name='la')
a_prob = tf.layers.dense(l_a, N_A, tf.nn.softmax, kernel_initializer=w_init, name='ap')
with tf.variable_scope('critic'):
l_c = tf.layers.dense(self.s, 100, tf.nn.relu6, kernel_initializer=w_init, name='lc')
v = tf.layers.dense(l_c, 1, kernel_initializer=w_init, name='v') # state value
a_params = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope=scope + '/actor')
c_params = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope=scope + '/critic')
return a_prob, v, a_params, c_params
def choose_action(self, s): # run by a local
prob_weights = self.sess.run(self.a_prob, feed_dict={self.s: s[np.newaxis, :]})
action = np.random.choice(range(prob_weights.shape[1]),
p=prob_weights.ravel()) # select action w.r.t the actions prob
return action
def update_global(self, feed_dict): # run by a local
self.sess.run([self.update_a_op, self.update_c_op], feed_dict) # local grads applies to global net
def pull_global(self): # run by a local
self.sess.run([self.pull_a_params_op, self.pull_c_params_op])
def work(job_name, task_index, global_ep, lock, r_queue, global_running_r):
# set work's ip:port
cluster = tf.train.ClusterSpec({
"ps": ['localhost:2220', 'localhost:2221',],
"worker": ['localhost:2222', 'localhost:2223', 'localhost:2224', 'localhost:2225',]
})
server = tf.train.Server(cluster, job_name=job_name, task_index=task_index)
if job_name == 'ps':
print('Start Parameter Sever: ', task_index)
server.join()
else:
t1 = time.time()
env = gym.make('CartPole-v0').unwrapped
print('Start Worker: ', task_index)
with tf.device(tf.train.replica_device_setter(
worker_device="/job:worker/task:%d" % task_index,
cluster=cluster)):
opt_a = tf.train.RMSPropOptimizer(LR_A, name='opt_a')
opt_c = tf.train.RMSPropOptimizer(LR_C, name='opt_c')
global_net = ACNet('global_net')
local_net = ACNet('local_ac%d' % task_index, opt_a, opt_c, global_net)
# set training steps
hooks = [tf.train.StopAtStepHook(last_step=100000)]
with tf.train.MonitoredTrainingSession(master=server.target,
is_chief=True,
hooks=hooks,) as sess:
print('Start Worker Session: ', task_index)
local_net.sess = sess
total_step = 1
buffer_s, buffer_a, buffer_r = [], [], []
while (not sess.should_stop()) and (global_ep.value < 1000):
s = env.reset()
ep_r = 0
while True:
# if task_index:
# env.render()
a = local_net.choose_action(s)
s_, r, done, info = env.step(a)
if done: r = -5.
ep_r += r
buffer_s.append(s)
buffer_a.append(a)
buffer_r.append(r)
if total_step % UPDATE_GLOBAL_ITER == 0 or done: # update global and assign to local net
if done:
v_s_ = 0 # terminal
else:
v_s_ = sess.run(local_net.v, {local_net.s: s_[np.newaxis, :]})[0, 0]
buffer_v_target = []
for r in buffer_r[::-1]: # reverse buffer r
v_s_ = r + GAMMA * v_s_
buffer_v_target.append(v_s_)
buffer_v_target.reverse()
buffer_s, buffer_a, buffer_v_target = np.vstack(buffer_s), np.array(buffer_a), np.vstack(
buffer_v_target)
feed_dict = {
local_net.s: buffer_s,
local_net.a_his: buffer_a,
local_net.v_target: buffer_v_target,
}
local_net.update_global(feed_dict)
buffer_s, buffer_a, buffer_r = [], [], []
local_net.pull_global()
s = s_
total_step += 1
if done:
if r_queue.empty(): # record running episode reward
global_running_r.value = ep_r
else:
global_running_r.value = .99 * global_running_r.value + 0.01 * ep_r
r_queue.put(global_running_r.value)
print(
"Task: %i" % task_index,
"| Ep: %i" % global_ep.value,
"| Ep_r: %i" % global_running_r.value,
"| Global_step: %i" % sess.run(local_net.global_step),
)
with lock:
global_ep.value += 1
break
print('Worker Done: ', task_index, time.time()-t1)
if __name__ == "__main__":
# use multiprocessing to create a local cluster with 2 parameter servers and 2 workers
global_ep = mp.Value('i', 0)
lock = mp.Lock()
r_queue = mp.Queue()
global_running_r = mp.Value('d', 0)
jobs = [
('ps', 0), ('ps', 1),
('worker', 0), ('worker', 1), ('worker', 2), ('worker', 3)
]
ps = [mp.Process(target=work, args=(j, i, global_ep, lock, r_queue, global_running_r), ) for j, i in jobs]
[p.start() for p in ps]
[p.join() for p in ps[2:]]
ep_r = []
while not r_queue.empty():
ep_r.append(r_queue.get())
plt.plot(np.arange(len(ep_r)), ep_r)
plt.title('Distributed training')
plt.xlabel('Step')
plt.ylabel('Total moving reward')
plt.show()
================================================
FILE: contents/11_Dyna_Q/RL_brain.py
================================================
"""
This part of code is the Dyna-Q learning brain, which is a brain of the agent.
All decisions and learning processes are made in here.
View more on my tutorial page: https://morvanzhou.github.io/tutorials/
"""
import numpy as np
import pandas as pd
class QLearningTable:
def __init__(self, actions, learning_rate=0.01, reward_decay=0.9, e_greedy=0.9):
self.actions = actions # a list
self.lr = learning_rate
self.gamma = reward_decay
self.epsilon = e_greedy
## argmax type error
self.q_table = pd.DataFrame(columns=self.actions).astype('float32')
def choose_action(self, observation):
self.check_state_exist(observation)
# action selection
if np.random.uniform() < self.epsilon:
# choose best action
# state_action = self.q_table.ix[observation, :]
state_action = self.q_table.loc[observation, :] # for label indexing
state_action = state_action.reindex(np.random.permutation(state_action.index)) # some actions have same value
action = state_action.argmax()
else:
# choose random action
action = np.random.choice(self.actions)
return action
def learn(self, s, a, r, s_):
self.check_state_exist(s_)
q_predict = self.q_table.loc[s, a]
if s_ != 'terminal':
q_target = r + self.gamma * self.q_table.loc[s_, :].max() # next state is not terminal
else:
q_target = r # next state is terminal
self.q_table.loc[s, a] += self.lr * (q_target - q_predict) # update
def check_state_exist(self, state):
if state not in self.q_table.index:
# append new state to q table
self.q_table = self.q_table.append(
pd.Series(
[0]*len(self.actions),
index=self.q_table.columns,
name=state,
)
)
class EnvModel:
"""Similar to the memory buffer in DQN, you can store past experiences in here.
Alternatively, the model can generate next state and reward signal accurately."""
def __init__(self, actions):
# the simplest case is to think about the model is a memory which has all past transition information
self.actions = actions
self.database = pd.DataFrame(columns=actions, dtype=np.object)
def store_transition(self, s, a, r, s_):
if s not in self.database.index:
self.database = self.database.append(
pd.Series(
[None] * len(self.actions),
index=self.database.columns,
name=s,
))
self.database.set_value(s, a, (r, s_))
def sample_s_a(self):
s = np.random.choice(self.database.index)
a = np.random.choice(self.database.loc[s].dropna().index) # filter out the None value
return s, a
def get_r_s_(self, s, a):
r, s_ = self.database.loc[s, a]
return r, s_
================================================
FILE: contents/11_Dyna_Q/maze_env.py
================================================
"""
Reinforcement learning maze example.
Red rectangle: explorer.
Black rectangles: hells [reward = -1].
Yellow bin circle: paradise [reward = +1].
All other states: ground [reward = 0].
This script is the environment part of this example. The RL is in RL_brain.py.
View more on my tutorial page: https://morvanzhou.github.io/tutorials/
"""
import numpy as np
np.random.seed(1)
import tkinter as tk
import time
UNIT = 40 # pixels
MAZE_H = 4 # grid height
MAZE_W = 4 # grid width
class Maze(tk.Tk, object):
def __init__(self):
super(Maze, self).__init__()
self.action_space = ['u', 'd', 'l', 'r']
self.n_actions = len(self.action_space)
self.title('maze')
self.geometry('{0}x{1}'.format(MAZE_H * UNIT, MAZE_H * UNIT))
self._build_maze()
def _build_maze(self):
self.canvas = tk.Canvas(self, bg='white',
height=MAZE_H * UNIT,
width=MAZE_W * UNIT)
# create grids
for c in range(0, MAZE_W * UNIT, UNIT):
x0, y0, x1, y1 = c, 0, c, MAZE_H * UNIT
self.canvas.create_line(x0, y0, x1, y1)
for r in range(0, MAZE_H * UNIT, UNIT):
x0, y0, x1, y1 = 0, r, MAZE_H * UNIT, r
self.canvas.create_line(x0, y0, x1, y1)
# create origin
origin = np.array([20, 20])
# hell
hell1_center = origin + np.array([UNIT * 2, UNIT])
self.hell1 = self.canvas.create_rectangle(
hell1_center[0] - 15, hell1_center[1] - 15,
hell1_center[0] + 15, hell1_center[1] + 15,
fill='black')
# hell
hell2_center = origin + np.array([UNIT, UNIT * 2])
self.hell2 = self.canvas.create_rectangle(
hell2_center[0] - 15, hell2_center[1] - 15,
hell2_center[0] + 15, hell2_center[1] + 15,
fill='black')
# create oval
oval_center = origin + UNIT * 2
self.oval = self.canvas.create_oval(
oval_center[0] - 15, oval_center[1] - 15,
oval_center[0] + 15, oval_center[1] + 15,
fill='yellow')
# create red rect
self.rect = self.canvas.create_rectangle(
origin[0] - 15, origin[1] - 15,
origin[0] + 15, origin[1] + 15,
fill='red')
# pack all
self.canvas.pack()
def reset(self):
self.update()
time.sleep(0.5)
self.canvas.delete(self.rect)
origin = np.array([20, 20])
self.rect = self.canvas.create_rectangle(
origin[0] - 15, origin[1] - 15,
origin[0] + 15, origin[1] + 15,
fill='red')
# return observation
return self.canvas.coords(self.rect)
def step(self, action):
s = self.canvas.coords(self.rect)
base_action = np.array([0, 0])
if action == 0: # up
if s[1] > UNIT:
base_action[1] -= UNIT
elif action == 1: # down
if s[1] < (MAZE_H - 1) * UNIT:
base_action[1] += UNIT
elif action == 2: # right
if s[0] < (MAZE_W - 1) * UNIT:
base_action[0] += UNIT
elif action == 3: # left
if s[0] > UNIT:
base_action[0] -= UNIT
self.canvas.move(self.rect, base_action[0], base_action[1]) # move agent
s_ = self.canvas.coords(self.rect) # next state
# reward function
if s_ == self.canvas.coords(self.oval):
reward = 1
done = True
elif s_ in [self.canvas.coords(self.hell1), self.canvas.coords(self.hell2)]:
reward = -1
done = True
else:
reward = 0
done = False
return s_, reward, done
def render(self):
# time.sleep(0.1)
self.update()
================================================
FILE: contents/11_Dyna_Q/run_this.py
================================================
"""
Simplest model-based RL, Dyna-Q.
Red rectangle: explorer.
Black rectangles: hells [reward = -1].
Yellow bin circle: paradise [reward = +1].
All other states: ground [reward = 0].
This script is the main part which controls the update method of this example.
The RL is in RL_brain.py.
View more on my tutorial page: https://morvanzhou.github.io/tutorials/
"""
from maze_env import Maze
from RL_brain import QLearningTable, EnvModel
def update():
for episode in range(40):
s = env.reset()
while True:
env.render()
a = RL.choose_action(str(s))
s_, r, done = env.step(a)
RL.learn(str(s), a, r, str(s_))
# use a model to output (r, s_) by inputting (s, a)
# the model in dyna Q version is just like a memory replay buffer
env_model.store_transition(str(s), a, r, s_)
for n in range(10): # learn 10 more times using the env_model
ms, ma = env_model.sample_s_a() # ms in here is a str
mr, ms_ = env_model.get_r_s_(ms, ma)
RL.learn(ms, ma, mr, str(ms_))
s = s_
if done:
break
# end of game
print('game over')
env.destroy()
if __name__ == "__main__":
env = Maze()
RL = QLearningTable(actions=list(range(env.n_actions)))
env_model = EnvModel(actions=list(range(env.n_actions)))
env.after(0, update)
env.mainloop()
================================================
FILE: contents/12_Proximal_Policy_Optimization/DPPO.py
================================================
"""
A simple version of OpenAI's Proximal Policy Optimization (PPO). [https://arxiv.org/abs/1707.06347]
Distributing workers in parallel to collect data, then stop worker's roll-out and train PPO on collected data.
Restart workers once PPO is updated.
The global PPO updating rule is adopted from DeepMind's paper (DPPO):
Emergence of Locomotion Behaviours in Rich Environments (Google Deepmind): [https://arxiv.org/abs/1707.02286]
View more on my tutorial website: https://morvanzhou.github.io/tutorials
Dependencies:
tensorflow r1.3
gym 0.9.2
"""
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
import gym, threading, queue
EP_MAX = 1000
EP_LEN = 200
N_WORKER = 4 # parallel workers
GAMMA = 0.9 # reward discount factor
A_LR = 0.0001 # learning rate for actor
C_LR = 0.0002 # learning rate for critic
MIN_BATCH_SIZE = 64 # minimum batch size for updating PPO
UPDATE_STEP = 10 # loop update operation n-steps
EPSILON = 0.2 # for clipping surrogate objective
GAME = 'Pendulum-v0'
S_DIM, A_DIM = 3, 1 # state and action dimension
class PPO(object):
def __init__(self):
self.sess = tf.Session()
self.tfs = tf.placeholder(tf.float32, [None, S_DIM], 'state')
# critic
l1 = tf.layers.dense(self.tfs, 100, tf.nn.relu)
self.v = tf.layers.dense(l1, 1)
self.tfdc_r = tf.placeholder(tf.float32, [None, 1], 'discounted_r')
self.advantage = self.tfdc_r - self.v
self.closs = tf.reduce_mean(tf.square(self.advantage))
self.ctrain_op = tf.train.AdamOptimizer(C_LR).minimize(self.closs)
# actor
pi, pi_params = self._build_anet('pi', trainable=True)
oldpi, oldpi_params = self._build_anet('oldpi', trainable=False)
self.sample_op = tf.squeeze(pi.sample(1), axis=0) # operation of choosing action
self.update_oldpi_op = [oldp.assign(p) for p, oldp in zip(pi_params, oldpi_params)]
self.tfa = tf.placeholder(tf.float32, [None, A_DIM], 'action')
self.tfadv = tf.placeholder(tf.float32, [None, 1], 'advantage')
# ratio = tf.exp(pi.log_prob(self.tfa) - oldpi.log_prob(self.tfa))
ratio = pi.prob(self.tfa) / (oldpi.prob(self.tfa) + 1e-5)
surr = ratio * self.tfadv # surrogate loss
self.aloss = -tf.reduce_mean(tf.minimum( # clipped surrogate objective
surr,
tf.clip_by_value(ratio, 1. - EPSILON, 1. + EPSILON) * self.tfadv))
self.atrain_op = tf.train.AdamOptimizer(A_LR).minimize(self.aloss)
self.sess.run(tf.global_variables_initializer())
def update(self):
global GLOBAL_UPDATE_COUNTER
while not COORD.should_stop():
if GLOBAL_EP < EP_MAX:
UPDATE_EVENT.wait() # wait until get batch of data
self.sess.run(self.update_oldpi_op) # copy pi to old pi
data = [QUEUE.get() for _ in range(QUEUE.qsize())] # collect data from all workers
data = np.vstack(data)
s, a, r = data[:, :S_DIM], data[:, S_DIM: S_DIM + A_DIM], data[:, -1:]
adv = self.sess.run(self.advantage, {self.tfs: s, self.tfdc_r: r})
# update actor and critic in a update loop
[self.sess.run(self.atrain_op, {self.tfs: s, self.tfa: a, self.tfadv: adv}) for _ in range(UPDATE_STEP)]
[self.sess.run(self.ctrain_op, {self.tfs: s, self.tfdc_r: r}) for _ in range(UPDATE_STEP)]
UPDATE_EVENT.clear() # updating finished
GLOBAL_UPDATE_COUNTER = 0 # reset counter
ROLLING_EVENT.set() # set roll-out available
def _build_anet(self, name, trainable):
with tf.variable_scope(name):
l1 = tf.layers.dense(self.tfs, 200, tf.nn.relu, trainable=trainable)
mu = 2 * tf.layers.dense(l1, A_DIM, tf.nn.tanh, trainable=trainable)
sigma = tf.layers.dense(l1, A_DIM, tf.nn.softplus, trainable=trainable)
norm_dist = tf.distributions.Normal(loc=mu, scale=sigma)
params = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope=name)
return norm_dist, params
def choose_action(self, s):
s = s[np.newaxis, :]
a = self.sess.run(self.sample_op, {self.tfs: s})[0]
return np.clip(a, -2, 2)
def get_v(self, s):
if s.ndim < 2: s = s[np.newaxis, :]
return self.sess.run(self.v, {self.tfs: s})[0, 0]
class Worker(object):
def __init__(self, wid):
self.wid = wid
self.env = gym.make(GAME).unwrapped
self.ppo = GLOBAL_PPO
def work(self):
global GLOBAL_EP, GLOBAL_RUNNING_R, GLOBAL_UPDATE_COUNTER
while not COORD.should_stop():
s = self.env.reset()
ep_r = 0
buffer_s, buffer_a, buffer_r = [], [], []
for t in range(EP_LEN):
if not ROLLING_EVENT.is_set(): # while global PPO is updating
ROLLING_EVENT.wait() # wait until PPO is updated
buffer_s, buffer_a, buffer_r = [], [], [] # clear history buffer, use new policy to collect data
a = self.ppo.choose_action(s)
s_, r, done, _ = self.env.step(a)
buffer_s.append(s)
buffer_a.append(a)
buffer_r.append((r + 8) / 8) # normalize reward, find to be useful
s = s_
ep_r += r
GLOBAL_UPDATE_COUNTER += 1 # count to minimum batch size, no need to wait other workers
if t == EP_LEN - 1 or GLOBAL_UPDATE_COUNTER >= MIN_BATCH_SIZE:
v_s_ = self.ppo.get_v(s_)
discounted_r = [] # compute discounted reward
for r in buffer_r[::-1]:
v_s_ = r + GAMMA * v_s_
discounted_r.append(v_s_)
discounted_r.reverse()
bs, ba, br = np.vstack(buffer_s), np.vstack(buffer_a), np.array(discounted_r)[:, np.newaxis]
buffer_s, buffer_a, buffer_r = [], [], []
QUEUE.put(np.hstack((bs, ba, br))) # put data in the queue
if GLOBAL_UPDATE_COUNTER >= MIN_BATCH_SIZE:
ROLLING_EVENT.clear() # stop collecting data
UPDATE_EVENT.set() # globalPPO update
if GLOBAL_EP >= EP_MAX: # stop training
COORD.request_stop()
break
# record reward changes, plot later
if len(GLOBAL_RUNNING_R) == 0: GLOBAL_RUNNING_R.append(ep_r)
else: GLOBAL_RUNNING_R.append(GLOBAL_RUNNING_R[-1]*0.9+ep_r*0.1)
GLOBAL_EP += 1
print('{0:.1f}%'.format(GLOBAL_EP/EP_MAX*100), '|W%i' % self.wid, '|Ep_r: %.2f' % ep_r,)
if __name__ == '__main__':
GLOBAL_PPO = PPO()
UPDATE_EVENT, ROLLING_EVENT = threading.Event(), threading.Event()
UPDATE_EVENT.clear() # not update now
ROLLING_EVENT.set() # start to roll out
workers = [Worker(wid=i) for i in range(N_WORKER)]
GLOBAL_UPDATE_COUNTER, GLOBAL_EP = 0, 0
GLOBAL_RUNNING_R = []
COORD = tf.train.Coordinator()
QUEUE = queue.Queue() # workers putting data in this queue
threads = []
for worker in workers: # worker threads
t = threading.Thread(target=worker.work, args=())
t.start() # training
threads.append(t)
# add a PPO updating thread
threads.append(threading.Thread(target=GLOBAL_PPO.update,))
threads[-1].start()
COORD.join(threads)
# plot reward change and test
plt.plot(np.arange(len(GLOBAL_RUNNING_R)), GLOBAL_RUNNING_R)
plt.xlabel('Episode'); plt.ylabel('Moving reward'); plt.ion(); plt.show()
env = gym.make('Pendulum-v0')
while True:
s = env.reset()
for t in range(300):
env.render()
s = env.step(GLOBAL_PPO.choose_action(s))[0]
================================================
FILE: contents/12_Proximal_Policy_Optimization/discrete_DPPO.py
================================================
"""
A simple version of OpenAI's Proximal Policy Optimization (PPO). [https://arxiv.org/abs/1707.06347]
Distributing workers in parallel to collect data, then stop worker's roll-out and train PPO on collected data.
Restart workers once PPO is updated.
The global PPO updating rule is adopted from DeepMind's paper (DPPO):
Emergence of Locomotion Behaviours in Rich Environments (Google Deepmind): [https://arxiv.org/abs/1707.02286]
View more on my tutorial website: https://morvanzhou.github.io/tutorials
Dependencies:
tensorflow 1.8.0
gym 0.9.2
"""
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
import gym, threading, queue
EP_MAX = 1000
EP_LEN = 500
N_WORKER = 4 # parallel workers
GAMMA = 0.9 # reward discount factor
A_LR = 0.0001 # learning rate for actor
C_LR = 0.0001 # learning rate for critic
MIN_BATCH_SIZE = 64 # minimum batch size for updating PPO
UPDATE_STEP = 15 # loop update operation n-steps
EPSILON = 0.2 # for clipping surrogate objective
GAME = 'CartPole-v0'
env = gym.make(GAME)
S_DIM = env.observation_space.shape[0]
A_DIM = env.action_space.n
class PPONet(object):
def __init__(self):
self.sess = tf.Session()
self.tfs = tf.placeholder(tf.float32, [None, S_DIM], 'state')
# critic
w_init = tf.random_normal_initializer(0., .1)
lc = tf.layers.dense(self.tfs, 200, tf.nn.relu, kernel_initializer=w_init, name='lc')
self.v = tf.layers.dense(lc, 1)
self.tfdc_r = tf.placeholder(tf.float32, [None, 1], 'discounted_r')
self.advantage = self.tfdc_r - self.v
self.closs = tf.reduce_mean(tf.square(self.advantage))
self.ctrain_op = tf.train.AdamOptimizer(C_LR).minimize(self.closs)
# actor
self.pi, pi_params = self._build_anet('pi', trainable=True)
oldpi, oldpi_params = self._build_anet('oldpi', trainable=False)
self.update_oldpi_op = [oldp.assign(p) for p, oldp in zip(pi_params, oldpi_params)]
self.tfa = tf.placeholder(tf.int32, [None, ], 'action')
self.tfadv = tf.placeholder(tf.float32, [None, 1], 'advantage')
a_indices = tf.stack([tf.range(tf.shape(self.tfa)[0], dtype=tf.int32), self.tfa], axis=1)
pi_prob = tf.gather_nd(params=self.pi, indices=a_indices) # shape=(None, )
oldpi_prob = tf.gather_nd(params=oldpi, indices=a_indices) # shape=(None, )
ratio = pi_prob/(oldpi_prob + 1e-5)
surr = ratio * self.tfadv # surrogate loss
self.aloss = -tf.reduce_mean(tf.minimum( # clipped surrogate objective
surr,
tf.clip_by_value(ratio, 1. - EPSILON, 1. + EPSILON) * self.tfadv))
self.atrain_op = tf.train.AdamOptimizer(A_LR).minimize(self.aloss)
self.sess.run(tf.global_variables_initializer())
def update(self):
global GLOBAL_UPDATE_COUNTER
while not COORD.should_stop():
if GLOBAL_EP < EP_MAX:
UPDATE_EVENT.wait() # wait until get batch of data
self.sess.run(self.update_oldpi_op) # copy pi to old pi
data = [QUEUE.get() for _ in range(QUEUE.qsize())] # collect data from all workers
data = np.vstack(data)
s, a, r = data[:, :S_DIM], data[:, S_DIM: S_DIM + 1].ravel(), data[:, -1:]
adv = self.sess.run(self.advantage, {self.tfs: s, self.tfdc_r: r})
# update actor and critic in a update loop
[self.sess.run(self.atrain_op, {self.tfs: s, self.tfa: a, self.tfadv: adv}) for _ in range(UPDATE_STEP)]
[self.sess.run(self.ctrain_op, {self.tfs: s, self.tfdc_r: r}) for _ in range(UPDATE_STEP)]
UPDATE_EVENT.clear() # updating finished
GLOBAL_UPDATE_COUNTER = 0 # reset counter
ROLLING_EVENT.set() # set roll-out available
def _build_anet(self, name, trainable):
with tf.variable_scope(name):
l_a = tf.layers.dense(self.tfs, 200, tf.nn.relu, trainable=trainable)
a_prob = tf.layers.dense(l_a, A_DIM, tf.nn.softmax, trainable=trainable)
params = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope=name)
return a_prob, params
def choose_action(self, s): # run by a local
prob_weights = self.sess.run(self.pi, feed_dict={self.tfs: s[None, :]})
action = np.random.choice(range(prob_weights.shape[1]),
p=prob_weights.ravel()) # select action w.r.t the actions prob
return action
def get_v(self, s):
if s.ndim < 2: s = s[np.newaxis, :]
return self.sess.run(self.v, {self.tfs: s})[0, 0]
class Worker(object):
def __init__(self, wid):
self.wid = wid
self.env = gym.make(GAME).unwrapped
self.ppo = GLOBAL_PPO
def work(self):
global GLOBAL_EP, GLOBAL_RUNNING_R, GLOBAL_UPDATE_COUNTER
while not COORD.should_stop():
s = self.env.reset()
ep_r = 0
buffer_s, buffer_a, buffer_r = [], [], []
for t in range(EP_LEN):
if not ROLLING_EVENT.is_set(): # while global PPO is updating
ROLLING_EVENT.wait() # wait until PPO is updated
buffer_s, buffer_a, buffer_r = [], [], [] # clear history buffer, use new policy to collect data
a = self.ppo.choose_action(s)
s_, r, done, _ = self.env.step(a)
if done: r = -10
buffer_s.append(s)
buffer_a.append(a)
buffer_r.append(r-1) # 0 for not down, -11 for down. Reward engineering
s = s_
ep_r += r
GLOBAL_UPDATE_COUNTER += 1 # count to minimum batch size, no need to wait other workers
if t == EP_LEN - 1 or GLOBAL_UPDATE_COUNTER >= MIN_BATCH_SIZE or done:
if done:
v_s_ = 0 # end of episode
else:
v_s_ = self.ppo.get_v(s_)
discounted_r = [] # compute discounted reward
for r in buffer_r[::-1]:
v_s_ = r + GAMMA * v_s_
discounted_r.append(v_s_)
discounted_r.reverse()
bs, ba, br = np.vstack(buffer_s), np.vstack(buffer_a), np.array(discounted_r)[:, None]
buffer_s, buffer_a, buffer_r = [], [], []
QUEUE.put(np.hstack((bs, ba, br))) # put data in the queue
if GLOBAL_UPDATE_COUNTER >= MIN_BATCH_SIZE:
ROLLING_EVENT.clear() # stop collecting data
UPDATE_EVENT.set() # globalPPO update
if GLOBAL_EP >= EP_MAX: # stop training
COORD.request_stop()
break
if done: break
# record reward changes, plot later
if len(GLOBAL_RUNNING_R) == 0: GLOBAL_RUNNING_R.append(ep_r)
else: GLOBAL_RUNNING_R.append(GLOBAL_RUNNING_R[-1]*0.9+ep_r*0.1)
GLOBAL_EP += 1
print('{0:.1f}%'.format(GLOBAL_EP/EP_MAX*100), '|W%i' % self.wid, '|Ep_r: %.2f' % ep_r,)
if __name__ == '__main__':
GLOBAL_PPO = PPONet()
UPDATE_EVENT, ROLLING_EVENT = threading.Event(), threading.Event()
UPDATE_EVENT.clear() # not update now
ROLLING_EVENT.set() # start to roll out
workers = [Worker(wid=i) for i in range(N_WORKER)]
GLOBAL_UPDATE_COUNTER, GLOBAL_EP = 0, 0
GLOBAL_RUNNING_R = []
COORD = tf.train.Coordinator()
QUEUE = queue.Queue() # workers putting data in this queue
threads = []
for worker in workers: # worker threads
t = threading.Thread(target=worker.work, args=())
t.start() # training
threads.append(t)
# add a PPO updating thread
threads.append(threading.Thread(target=GLOBAL_PPO.update,))
threads[-1].start()
COORD.join(threads)
# plot reward change and test
plt.plot(np.arange(len(GLOBAL_RUNNING_R)), GLOBAL_RUNNING_R)
plt.xlabel('Episode'); plt.ylabel('Moving reward'); plt.ion(); plt.show()
env = gym.make('CartPole-v0')
while True:
s = env.reset()
for t in range(1000):
env.render()
s, r, done, info = env.step(GLOBAL_PPO.choose_action(s))
if done:
break
================================================
FILE: contents/12_Proximal_Policy_Optimization/simply_PPO.py
================================================
"""
A simple version of Proximal Policy Optimization (PPO) using single thread.
Based on:
1. Emergence of Locomotion Behaviours in Rich Environments (Google Deepmind): [https://arxiv.org/abs/1707.02286]
2. Proximal Policy Optimization Algorithms (OpenAI): [https://arxiv.org/abs/1707.06347]
View more on my tutorial website: https://morvanzhou.github.io/tutorials
Dependencies:
tensorflow r1.2
gym 0.9.2
"""
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
import gym
EP_MAX = 1000
EP_LEN = 200
GAMMA = 0.9
A_LR = 0.0001
C_LR = 0.0002
BATCH = 32
A_UPDATE_STEPS = 10
C_UPDATE_STEPS = 10
S_DIM, A_DIM = 3, 1
METHOD = [
dict(name='kl_pen', kl_target=0.01, lam=0.5), # KL penalty
dict(name='clip', epsilon=0.2), # Clipped surrogate objective, find this is better
][1] # choose the method for optimization
class PPO(object):
def __init__(self):
self.sess = tf.Session()
self.tfs = tf.placeholder(tf.float32, [None, S_DIM], 'state')
# critic
with tf.variable_scope('critic'):
l1 = tf.layers.dense(self.tfs, 100, tf.nn.relu)
self.v = tf.layers.dense(l1, 1)
self.tfdc_r = tf.placeholder(tf.float32, [None, 1], 'discounted_r')
self.advantage = self.tfdc_r - self.v
self.closs = tf.reduce_mean(tf.square(self.advantage))
self.ctrain_op = tf.train.AdamOptimizer(C_LR).minimize(self.closs)
# actor
pi, pi_params = self._build_anet('pi', trainable=True)
oldpi, oldpi_params = self._build_anet('oldpi', trainable=False)
with tf.variable_scope('sample_action'):
self.sample_op = tf.squeeze(pi.sample(1), axis=0) # choosing action
with tf.variable_scope('update_oldpi'):
self.update_oldpi_op = [oldp.assign(p) for p, oldp in zip(pi_params, oldpi_params)]
self.tfa = tf.placeholder(tf.float32, [None, A_DIM], 'action')
self.tfadv = tf.placeholder(tf.float32, [None, 1], 'advantage')
with tf.variable_scope('loss'):
with tf.variable_scope('surrogate'):
# ratio = tf.exp(pi.log_prob(self.tfa) - oldpi.log_prob(self.tfa))
ratio = pi.prob(self.tfa) / (oldpi.prob(self.tfa) + 1e-5)
surr = ratio * self.tfadv
if METHOD['name'] == 'kl_pen':
self.tflam = tf.placeholder(tf.float32, None, 'lambda')
kl = tf.distributions.kl_divergence(oldpi, pi)
self.kl_mean = tf.reduce_mean(kl)
self.aloss = -(tf.reduce_mean(surr - self.tflam * kl))
else: # clipping method, find this is better
self.aloss = -tf.reduce_mean(tf.minimum(
surr,
tf.clip_by_value(ratio, 1.-METHOD['epsilon'], 1.+METHOD['epsilon'])*self.tfadv))
with tf.variable_scope('atrain'):
self.atrain_op = tf.train.AdamOptimizer(A_LR).minimize(self.aloss)
tf.summary.FileWriter("log/", self.sess.graph)
self.sess.run(tf.global_variables_initializer())
def update(self, s, a, r):
self.sess.run(self.update_oldpi_op)
adv = self.sess.run(self.advantage, {self.tfs: s, self.tfdc_r: r})
# adv = (adv - adv.mean())/(adv.std()+1e-6) # sometimes helpful
# update actor
if METHOD['name'] == 'kl_pen':
for _ in range(A_UPDATE_STEPS):
_, kl = self.sess.run(
[self.atrain_op, self.kl_mean],
{self.tfs: s, self.tfa: a, self.tfadv: adv, self.tflam: METHOD['lam']})
if kl > 4*METHOD['kl_target']: # this in in google's paper
break
if kl < METHOD['kl_target'] / 1.5: # adaptive lambda, this is in OpenAI's paper
METHOD['lam'] /= 2
elif kl > METHOD['kl_target'] * 1.5:
METHOD['lam'] *= 2
METHOD['lam'] = np.clip(METHOD['lam'], 1e-4, 10) # sometimes explode, this clipping is my solution
else: # clipping method, find this is better (OpenAI's paper)
[self.sess.run(self.atrain_op, {self.tfs: s, self.tfa: a, self.tfadv: adv}) for _ in range(A_UPDATE_STEPS)]
# update critic
[self.sess.run(self.ctrain_op, {self.tfs: s, self.tfdc_r: r}) for _ in range(C_UPDATE_STEPS)]
def _build_anet(self, name, trainable):
with tf.variable_scope(name):
l1 = tf.layers.dense(self.tfs, 100, tf.nn.relu, trainable=trainable)
mu = 2 * tf.layers.dense(l1, A_DIM, tf.nn.tanh, trainable=trainable)
sigma = tf.layers.dense(l1, A_DIM, tf.nn.softplus, trainable=trainable)
norm_dist = tf.distributions.Normal(loc=mu, scale=sigma)
params = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope=name)
return norm_dist, params
def choose_action(self, s):
s = s[np.newaxis, :]
a = self.sess.run(self.sample_op, {self.tfs: s})[0]
return np.clip(a, -2, 2)
def get_v(self, s):
if s.ndim < 2: s = s[np.newaxis, :]
return self.sess.run(self.v, {self.tfs: s})[0, 0]
env = gym.make('Pendulum-v0').unwrapped
ppo = PPO()
all_ep_r = []
for ep in range(EP_MAX):
s = env.reset()
buffer_s, buffer_a, buffer_r = [], [], []
ep_r = 0
for t in range(EP_LEN): # in one episode
env.render()
a = ppo.choose_action(s)
s_, r, done, _ = env.step(a)
buffer_s.append(s)
buffer_a.append(a)
buffer_r.append((r+8)/8) # normalize reward, find to be useful
s = s_
ep_r += r
# update ppo
if (t+1) % BATCH == 0 or t == EP_LEN-1:
v_s_ = ppo.get_v(s_)
discounted_r = []
for r in buffer_r[::-1]:
v_s_ = r + GAMMA * v_s_
discounted_r.append(v_s_)
discounted_r.reverse()
bs, ba, br = np.vstack(buffer_s), np.vstack(buffer_a), np.array(discounted_r)[:, np.newaxis]
buffer_s, buffer_a, buffer_r = [], [], []
ppo.update(bs, ba, br)
if ep == 0: all_ep_r.append(ep_r)
else: all_ep_r.append(all_ep_r[-1]*0.9 + ep_r*0.1)
print(
'Ep: %i' % ep,
"|Ep_r: %i" % ep_r,
("|Lam: %.4f" % METHOD['lam']) if METHOD['name'] == 'kl_pen' else '',
)
plt.plot(np.arange(len(all_ep_r)), all_ep_r)
plt.xlabel('Episode');plt.ylabel('Moving averaged episode reward');plt.show()
================================================
FILE: contents/1_command_line_reinforcement_learning/treasure_on_right.py
================================================
"""
A simple example for Reinforcement Learning using table lookup Q-learning method.
An agent "o" is on the left of a 1 dimensional world, the treasure is on the rightmost location.
Run this program and to see how the agent will improve its strategy of finding the treasure.
View more on my tutorial page: https://morvanzhou.github.io/tutorials/
"""
import numpy as np
import pandas as pd
import time
np.random.seed(2) # reproducible
N_STATES = 6 # the length of the 1 dimensional world
ACTIONS = ['left', 'right'] # available actions
EPSILON = 0.9 # greedy police
ALPHA = 0.1 # learning rate
GAMMA = 0.9 # discount factor
MAX_EPISODES = 13 # maximum episodes
FRESH_TIME = 0.3 # fresh time for one move
def build_q_table(n_states, actions):
table = pd.DataFrame(
np.zeros((n_states, len(actions))), # q_table initial values
columns=actions, # actions's name
)
# print(table) # show table
return table
def choose_action(state, q_table):
# This is how to choose an action
state_actions = q_table.iloc[state, :]
if (np.random.uniform() > EPSILON) or ((state_actions == 0).all()): # act non-greedy or state-action have no value
action_name = np.random.choice(ACTIONS)
else: # act greedy
action_name = state_actions.idxmax() # replace argmax to idxmax as argmax means a different function in newer version of pandas
return action_name
def get_env_feedback(S, A):
# This is how agent will interact with the environment
if A == 'right': # move right
if S == N_STATES - 2: # terminate
S_ = 'terminal'
R = 1
else:
S_ = S + 1
R = 0
else: # move left
R = 0
if S == 0:
S_ = S # reach the wall
else:
S_ = S - 1
return S_, R
def update_env(S, episode, step_counter):
# This is how environment be updated
env_list = ['-']*(N_STATES-1) + ['T'] # '---------T' our environment
if S == 'terminal':
interaction = 'Episode %s: total_steps = %s' % (episode+1, step_counter)
print('\r{}'.format(interaction), end='')
time.sleep(2)
print('\r ', end='')
else:
env_list[S] = 'o'
interaction = ''.join(env_list)
print('\r{}'.format(interaction), end='')
time.sleep(FRESH_TIME)
def rl():
# main part of RL loop
q_table = build_q_table(N_STATES, ACTIONS)
for episode in range(MAX_EPISODES):
step_counter = 0
S = 0
is_terminated = False
update_env(S, episode, step_counter)
while not is_terminated:
A = choose_action(S, q_table)
S_, R = get_env_feedback(S, A) # take action & get next state and reward
q_predict = q_table.loc[S, A]
if S_ != 'terminal':
q_target = R + GAMMA * q_table.iloc[S_, :].max() # next state is not terminal
else:
q_target = R # next state is terminal
is_terminated = True # terminate this episode
q_table.loc[S, A] += ALPHA * (q_target - q_predict) # update
S = S_ # move to next state
update_env(S, episode, step_counter+1)
step_counter += 1
return q_table
if __name__ == "__main__":
q_table = rl()
print('\r\nQ-table:\n')
print(q_table)
================================================
FILE: contents/2_Q_Learning_maze/RL_brain.py
================================================
"""
This part of code is the Q learning brain, which is a brain of the agent.
All decisions are made in here.
View more on my tutorial page: https://morvanzhou.github.io/tutorials/
"""
import numpy as np
import pandas as pd
class QLearningTable:
def __init__(self, actions, learning_rate=0.01, reward_decay=0.9, e_greedy=0.9):
self.actions = actions # a list
self.lr = learning_rate
self.gamma = reward_decay
self.epsilon = e_greedy
self.q_table = pd.DataFrame(columns=self.actions, dtype=np.float64)
def choose_action(self, observation):
self.check_state_exist(observation)
# action selection
if np.random.uniform() < self.epsilon:
# choose best action
state_action = self.q_table.loc[observation, :]
# some actions may have the same value, randomly choose on in these actions
action = np.random.choice(state_action[state_action == np.max(state_action)].index)
else:
# choose random action
action = np.random.choice(self.actions)
return action
def learn(self, s, a, r, s_):
self.check_state_exist(s_)
q_predict = self.q_table.loc[s, a]
if s_ != 'terminal':
q_target = r + self.gamma * self.q_table.loc[s_, :].max() # next state is not terminal
else:
q_target = r # next state is terminal
self.q_table.loc[s, a] += self.lr * (q_target - q_predict) # update
def check_state_exist(self, state):
if state not in self.q_table.index:
# append new state to q table
self.q_table = self.q_table.append(
pd.Series(
[0]*len(self.actions),
index=self.q_table.columns,
name=state,
)
)
================================================
FILE: contents/2_Q_Learning_maze/maze_env.py
================================================
"""
Reinforcement learning maze example.
Red rectangle: explorer.
Black rectangles: hells [reward = -1].
Yellow bin circle: paradise [reward = +1].
All other states: ground [reward = 0].
This script is the environment part of this example. The RL is in RL_brain.py.
View more on my tutorial page: https://morvanzhou.github.io/tutorials/
"""
import numpy as np
import time
import sys
if sys.version_info.major == 2:
import Tkinter as tk
else:
import tkinter as tk
UNIT = 40 # pixels
MAZE_H = 4 # grid height
MAZE_W = 4 # grid width
class Maze(tk.Tk, object):
def __init__(self):
super(Maze, self).__init__()
self.action_space = ['u', 'd', 'l', 'r']
self.n_actions = len(self.action_space)
self.title('maze')
self.geometry('{0}x{1}'.format(MAZE_W * UNIT, MAZE_H * UNIT))
self._build_maze()
def _build_maze(self):
self.canvas = tk.Canvas(self, bg='white',
height=MAZE_H * UNIT,
width=MAZE_W * UNIT)
# create grids
for c in range(0, MAZE_W * UNIT, UNIT):
x0, y0, x1, y1 = c, 0, c, MAZE_H * UNIT
self.canvas.create_line(x0, y0, x1, y1)
for r in range(0, MAZE_H * UNIT, UNIT):
x0, y0, x1, y1 = 0, r, MAZE_W * UNIT, r
self.canvas.create_line(x0, y0, x1, y1)
# create origin
origin = np.array([20, 20])
# hell
hell1_center = origin + np.array([UNIT * 2, UNIT])
self.hell1 = self.canvas.create_rectangle(
hell1_center[0] - 15, hell1_center[1] - 15,
hell1_center[0] + 15, hell1_center[1] + 15,
fill='black')
# hell
hell2_center = origin + np.array([UNIT, UNIT * 2])
self.hell2 = self.canvas.create_rectangle(
hell2_center[0] - 15, hell2_center[1] - 15,
hell2_center[0] + 15, hell2_center[1] + 15,
fill='black')
# create oval
oval_center = origin + UNIT * 2
self.oval = self.canvas.create_oval(
oval_center[0] - 15, oval_center[1] - 15,
oval_center[0] + 15, oval_center[1] + 15,
fill='yellow')
# create red rect
self.rect = self.canvas.create_rectangle(
origin[0] - 15, origin[1] - 15,
origin[0] + 15, origin[1] + 15,
fill='red')
# pack all
self.canvas.pack()
def reset(self):
self.update()
time.sleep(0.5)
self.canvas.delete(self.rect)
origin = np.array([20, 20])
self.rect = self.canvas.create_rectangle(
origin[0] - 15, origin[1] - 15,
origin[0] + 15, origin[1] + 15,
fill='red')
# return observation
return self.canvas.coords(self.rect)
def step(self, action):
s = self.canvas.coords(self.rect)
base_action = np.array([0, 0])
if action == 0: # up
if s[1] > UNIT:
base_action[1] -= UNIT
elif action == 1: # down
if s[1] < (MAZE_H - 1) * UNIT:
base_action[1] += UNIT
elif action == 2: # right
if s[0] < (MAZE_W - 1) * UNIT:
base_action[0] += UNIT
elif action == 3: # left
if s[0] > UNIT:
base_action[0] -= UNIT
self.canvas.move(self.rect, base_action[0], base_action[1]) # move agent
s_ = self.canvas.coords(self.rect) # next state
# reward function
if s_ == self.canvas.coords(self.oval):
reward = 1
done = True
s_ = 'terminal'
elif s_ in [self.canvas.coords(self.hell1), self.canvas.coords(self.hell2)]:
reward = -1
done = True
s_ = 'terminal'
else:
reward = 0
done = False
return s_, reward, done
def render(self):
time.sleep(0.1)
self.update()
def update():
for t in range(10):
s = env.reset()
while True:
env.render()
a = 1
s, r, done = env.step(a)
if done:
break
if __name__ == '__main__':
env = Maze()
env.after(100, update)
env.mainloop()
================================================
FILE: contents/2_Q_Learning_maze/run_this.py
================================================
"""
Reinforcement learning maze example.
Red rectangle: explorer.
Black rectangles: hells [reward = -1].
Yellow bin circle: paradise [reward = +1].
All other states: ground [reward = 0].
This script is the main part which controls the update method of this example.
The RL is in RL_brain.py.
View more on my tutorial page: https://morvanzhou.github.io/tutorials/
"""
from maze_env import Maze
from RL_brain import QLearningTable
def update():
for episode in range(100):
# initial observation
observation = env.reset()
while True:
# fresh env
env.render()
# RL choose action based on observation
action = RL.choose_action(str(observation))
# RL take action and get next observation and reward
observation_, reward, done = env.step(action)
# RL learn from this transition
RL.learn(str(observation), action, reward, str(observation_))
# swap observation
observation = observation_
# break while loop when end of this episode
if done:
break
# end of game
print('game over')
env.destroy()
if __name__ == "__main__":
env = Maze()
RL = QLearningTable(actions=list(range(env.n_actions)))
env.after(100, update)
env.mainloop()
================================================
FILE: contents/3_Sarsa_maze/RL_brain.py
================================================
"""
This part of code is the Q learning brain, which is a brain of the agent.
All decisions are made in here.
View more on my tutorial page: https://morvanzhou.github.io/tutorials/
"""
import numpy as np
import pandas as pd
class RL(object):
def __init__(self, action_space, learning_rate=0.01, reward_decay=0.9, e_greedy=0.9):
self.actions = action_space # a list
self.lr = learning_rate
self.gamma = reward_decay
self.epsilon = e_greedy
self.q_table = pd.DataFrame(columns=self.actions, dtype=np.float64)
def check_state_exist(self, state):
if state not in self.q_table.index:
# append new state to q table
self.q_table = self.q_table.append(
pd.Series(
[0]*len(self.actions),
index=self.q_table.columns,
name=state,
)
)
def choose_action(self, observation):
self.check_state_exist(observation)
# action selection
if np.random.rand() < self.epsilon:
# choose best action
state_action = self.q_table.loc[observation, :]
# some actions may have the same value, randomly choose on in these actions
action = np.random.choice(state_action[state_action == np.max(state_action)].index)
else:
# choose random action
action = np.random.choice(self.actions)
return action
def learn(self, *args):
pass
# off-policy
class QLearningTable(RL):
def __init__(self, actions, learning_rate=0.01, reward_decay=0.9, e_greedy=0.9):
super(QLearningTable, self).__init__(actions, learning_rate, reward_decay, e_greedy)
def learn(self, s, a, r, s_):
self.check_state_exist(s_)
q_predict = self.q_table.loc[s, a]
if s_ != 'terminal':
q_target = r + self.gamma * self.q_table.loc[s_, :].max() # next state is not terminal
else:
q_target = r # next state is terminal
self.q_table.loc[s, a] += self.lr * (q_target - q_predict) # update
# on-policy
class SarsaTable(RL):
def __init__(self, actions, learning_rate=0.01, reward_decay=0.9, e_greedy=0.9):
super(SarsaTable, self).__init__(actions, learning_rate, reward_decay, e_greedy)
def learn(self, s, a, r, s_, a_):
self.check_state_exist(s_)
q_predict = self.q_table.loc[s, a]
if s_ != 'terminal':
q_target = r + self.gamma * self.q_table.loc[s_, a_] # next state is not terminal
else:
q_target = r # next state is terminal
self.q_table.loc[s, a] += self.lr * (q_target - q_predict) # update
================================================
FILE: contents/3_Sarsa_maze/maze_env.py
================================================
"""
Reinforcement learning maze example.
Red rectangle: explorer.
Black rectangles: hells [reward = -1].
Yellow bin circle: paradise [reward = +1].
All other states: ground [reward = 0].
This script is the environment part of this example.
The RL is in RL_brain.py.
View more on my tutorial page: https://morvanzhou.github.io/tutorials/
"""
import numpy as np
import time
import sys
if sys.version_info.major == 2:
import Tkinter as tk
else:
import tkinter as tk
UNIT = 40 # pixels
MAZE_H = 4 # grid height
MAZE_W = 4 # grid width
class Maze(tk.Tk, object):
def __init__(self):
super(Maze, self).__init__()
self.action_space = ['u', 'd', 'l', 'r']
self.n_actions = len(self.action_space)
self.title('maze')
self.geometry('{0}x{1}'.format(MAZE_W * UNIT, MAZE_H * UNIT))
self._build_maze()
def _build_maze(self):
self.canvas = tk.Canvas(self, bg='white',
height=MAZE_H * UNIT,
width=MAZE_W * UNIT)
# create grids
for c in range(0, MAZE_W * UNIT, UNIT):
x0, y0, x1, y1 = c, 0, c, MAZE_H * UNIT
self.canvas.create_line(x0, y0, x1, y1)
for r in range(0, MAZE_H * UNIT, UNIT):
x0, y0, x1, y1 = 0, r, MAZE_W * UNIT, r
self.canvas.create_line(x0, y0, x1, y1)
# create origin
origin = np.array([20, 20])
# hell
hell1_center = origin + np.array([UNIT * 2, UNIT])
self.hell1 = self.canvas.create_rectangle(
hell1_center[0] - 15, hell1_center[1] - 15,
hell1_center[0] + 15, hell1_center[1] + 15,
fill='black')
# hell
hell2_center = origin + np.array([UNIT, UNIT * 2])
self.hell2 = self.canvas.create_rectangle(
hell2_center[0] - 15, hell2_center[1] - 15,
hell2_center[0] + 15, hell2_center[1] + 15,
fill='black')
# create oval
oval_center = origin + UNIT * 2
self.oval = self.canvas.create_oval(
oval_center[0] - 15, oval_center[1] - 15,
oval_center[0] + 15, oval_center[1] + 15,
fill='yellow')
# create red rect
self.rect = self.canvas.create_rectangle(
origin[0] - 15, origin[1] - 15,
origin[0] + 15, origin[1] + 15,
fill='red')
# pack all
self.canvas.pack()
def reset(self):
self.update()
time.sleep(0.5)
self.canvas.delete(self.rect)
origin = np.array([20, 20])
self.rect = self.canvas.create_rectangle(
origin[0] - 15, origin[1] - 15,
origin[0] + 15, origin[1] + 15,
fill='red')
# return observation
return self.canvas.coords(self.rect)
def step(self, action):
s = self.canvas.coords(self.rect)
base_action = np.array([0, 0])
if action == 0: # up
if s[1] > UNIT:
base_action[1] -= UNIT
elif action == 1: # down
if s[1] < (MAZE_H - 1) * UNIT:
base_action[1] += UNIT
elif action == 2: # right
if s[0] < (MAZE_W - 1) * UNIT:
base_action[0] += UNIT
elif action == 3: # left
if s[0] > UNIT:
base_action[0] -= UNIT
self.canvas.move(self.rect, base_action[0], base_action[1]) # move agent
s_ = self.canvas.coords(self.rect) # next state
# reward function
if s_ == self.canvas.coords(self.oval):
reward = 1
done = True
s_ = 'terminal'
elif s_ in [self.canvas.coords(self.hell1), self.canvas.coords(self.hell2)]:
reward = -1
done = True
s_ = 'terminal'
else:
reward = 0
done = False
return s_, reward, done
def render(self):
time.sleep(0.1)
self.update()
================================================
FILE: contents/3_Sarsa_maze/run_this.py
================================================
"""
Sarsa is a online updating method for Reinforcement learning.
Unlike Q learning which is a offline updating method, Sarsa is updating while in the current trajectory.
You will see the sarsa is more coward when punishment is close because it cares about all behaviours,
while q learning is more brave because it only cares about maximum behaviour.
"""
from maze_env import Maze
from RL_brain import SarsaTable
def update():
for episode in range(100):
# initial observation
observation = env.reset()
# RL choose action based on observation
action = RL.choose_action(str(observation))
while True:
# fresh env
env.render()
# RL take action and get next observation and reward
observation_, reward, done = env.step(action)
# RL choose action based on next observation
action_ = RL.choose_action(str(observation_))
# RL learn from this transition (s, a, r, s, a) ==> Sarsa
RL.learn(str(observation), action, reward, str(observation_), action_)
# swap observation and action
observation = observation_
action = action_
# break while loop when end of this episode
if done:
break
# end of game
print('game over')
env.destroy()
if __name__ == "__main__":
env = Maze()
RL = SarsaTable(actions=list(range(env.n_actions)))
env.after(100, update)
env.mainloop()
================================================
FILE: contents/4_Sarsa_lambda_maze/RL_brain.py
================================================
"""
This part of code is the Q learning brain, which is a brain of the agent.
All decisions are made in here.
View more on my tutorial page: https://morvanzhou.github.io/tutorials/
"""
import numpy as np
import pandas as pd
class RL(object):
def __init__(self, action_space, learning_rate=0.01, reward_decay=0.9, e_greedy=0.9):
self.actions = action_space # a list
self.lr = learning_rate
self.gamma = reward_decay
self.epsilon = e_greedy
self.q_table = pd.DataFrame(columns=self.actions, dtype=np.float64)
def check_state_exist(self, state):
if state not in self.q_table.index:
# append new state to q table
self.q_table = self.q_table.append(
pd.Series(
[0]*len(self.actions),
index=self.q_table.columns,
name=state,
)
)
def choose_action(self, observation):
self.check_state_exist(observation)
# action selection
if np.random.rand() < self.epsilon:
# choose best action
state_action = self.q_table.loc[observation, :]
# some actions may have the same value, randomly choose on in these actions
action = np.random.choice(state_action[state_action == np.max(state_action)].index)
else:
# choose random action
action = np.random.choice(self.actions)
return action
def learn(self, *args):
pass
# backward eligibility traces
class SarsaLambdaTable(RL):
def __init__(self, actions, learning_rate=0.01, reward_decay=0.9, e_greedy=0.9, trace_decay=0.9):
super(SarsaLambdaTable, self).__init__(actions, learning_rate, reward_decay, e_greedy)
# backward view, eligibility trace.
self.lambda_ = trace_decay
self.eligibility_trace = self.q_table.copy()
def check_state_exist(self, state):
if state not in self.q_table.index:
# append new state to q table
to_be_append = pd.Series(
[0] * len(self.actions),
index=self.q_table.columns,
name=state,
)
self.q_table = self.q_table.append(to_be_append)
# also update eligibility trace
self.eligibility_trace = self.eligibility_trace.append(to_be_append)
def learn(self, s, a, r, s_, a_):
self.check_state_exist(s_)
q_predict = self.q_table.loc[s, a]
if s_ != 'terminal':
q_target = r + self.gamma * self.q_table.loc[s_, a_] # next state is not terminal
else:
q_target = r # next state is terminal
error = q_target - q_predict
# increase trace amount for visited state-action pair
# Method 1:
# self.eligibility_trace.loc[s, a] += 1
# Method 2:
self.eligibility_trace.loc[s, :] *= 0
self.eligibility_trace.loc[s, a] = 1
# Q update
self.q_table += self.lr * error * self.eligibility_trace
# decay eligibility trace after update
self.eligibility_trace *= self.gamma*self.lambda_
================================================
FILE: contents/4_Sarsa_lambda_maze/maze_env.py
================================================
"""
Reinforcement learning maze example.
Red rectangle: explorer.
Black rectangles: hells [reward = -1].
Yellow bin circle: paradise [reward = +1].
All other states: ground [reward = 0].
This script is the environment part of this example.
The RL is in RL_brain.py.
View more on my tutorial page: https://morvanzhou.github.io/tutorials/
"""
import numpy as np
import time
import sys
if sys.version_info.major == 2:
import Tkinter as tk
else:
import tkinter as tk
UNIT = 40 # pixels
MAZE_H = 4 # grid height
MAZE_W = 4 # grid width
class Maze(tk.Tk, object):
def __init__(self):
super(Maze, self).__init__()
self.action_space = ['u', 'd', 'l', 'r']
self.n_actions = len(self.action_space)
self.title('maze')
self.geometry('{0}x{1}'.format(MAZE_W * UNIT, MAZE_H * UNIT))
self._build_maze()
def _build_maze(self):
self.canvas = tk.Canvas(self, bg='white',
height=MAZE_H * UNIT,
width=MAZE_W * UNIT)
# create grids
for c in range(0, MAZE_W * UNIT, UNIT):
x0, y0, x1, y1 = c, 0, c, MAZE_H * UNIT
self.canvas.create_line(x0, y0, x1, y1)
for r in range(0, MAZE_H * UNIT, UNIT):
x0, y0, x1, y1 = 0, r, MAZE_W * UNIT, r
self.canvas.create_line(x0, y0, x1, y1)
# create origin
origin = np.array([20, 20])
# hell
hell1_center = origin + np.array([UNIT * 2, UNIT])
self.hell1 = self.canvas.create_rectangle(
hell1_center[0] - 15, hell1_center[1] - 15,
hell1_center[0] + 15, hell1_center[1] + 15,
fill='black')
# hell
hell2_center = origin + np.array([UNIT, UNIT * 2])
self.hell2 = self.canvas.create_rectangle(
hell2_center[0] - 15, hell2_center[1] - 15,
hell2_center[0] + 15, hell2_center[1] + 15,
fill='black')
# create oval
oval_center = origin + UNIT * 2
self.oval = self.canvas.create_oval(
oval_center[0] - 15, oval_center[1] - 15,
oval_center[0] + 15, oval_center[1] + 15,
fill='yellow')
# create red rect
self.rect = self.canvas.create_rectangle(
origin[0] - 15, origin[1] - 15,
origin[0] + 15, origin[1] + 15,
fill='red')
# pack all
self.canvas.pack()
def reset(self):
self.update()
time.sleep(0.5)
self.canvas.delete(self.rect)
origin = np.array([20, 20])
self.rect = self.canvas.create_rectangle(
origin[0] - 15, origin[1] - 15,
origin[0] + 15, origin[1] + 15,
fill='red')
# return observation
return self.canvas.coords(self.rect)
def step(self, action):
s = self.canvas.coords(self.rect)
base_action = np.array([0, 0])
if action == 0: # up
if s[1] > UNIT:
base_action[1] -= UNIT
elif action == 1: # down
if s[1] < (MAZE_H - 1) * UNIT:
base_action[1] += UNIT
elif action == 2: # right
if s[0] < (MAZE_W - 1) * UNIT:
base_action[0] += UNIT
elif action == 3: # left
if s[0] > UNIT:
base_action[0] -= UNIT
self.canvas.move(self.rect, base_action[0], base_action[1]) # move agent
s_ = self.canvas.coords(self.rect) # next state
# reward function
if s_ == self.canvas.coords(self.oval):
reward = 1
done = True
s_ = 'terminal'
elif s_ in [self.canvas.coords(self.hell1), self.canvas.coords(self.hell2)]:
reward = -1
done = True
s_ = 'terminal'
else:
reward = 0
done = False
return s_, reward, done
def render(self):
time.sleep(0.05)
self.update()
================================================
FILE: contents/4_Sarsa_lambda_maze/run_this.py
================================================
"""
Sarsa is a online updating method for Reinforcement learning.
Unlike Q learning which is a offline updating method, Sarsa is updating while in the current trajectory.
You will see the sarsa is more coward when punishment is close because it cares about all behaviours,
while q learning is more brave because it only cares about maximum behaviour.
"""
from maze_env import Maze
from RL_brain import SarsaLambdaTable
def update():
for episode in range(100):
# initial observation
observation = env.reset()
# RL choose action based on observation
action = RL.choose_action(str(observation))
# initial all zero eligibility trace
RL.eligibility_trace *= 0
while True:
# fresh env
env.render()
# RL take action and get next observation and reward
observation_, reward, done = env.step(action)
# RL choose action based on next observation
action_ = RL.choose_action(str(observation_))
# RL learn from this transition (s, a, r, s, a) ==> Sarsa
RL.learn(str(observation), action, reward, str(observation_), action_)
# swap observation and action
observation = observation_
action = action_
# break while loop when end of this episode
if done:
break
# end of game
print('game over')
env.destroy()
if __name__ == "__main__":
env = Maze()
RL = SarsaLambdaTable(actions=list(range(env.n_actions)))
env.after(100, update)
env.mainloop()
================================================
FILE: contents/5.1_Double_DQN/RL_brain.py
================================================
"""
The double DQN based on this paper: https://arxiv.org/abs/1509.06461
View more on my tutorial page: https://morvanzhou.github.io/tutorials/
Using:
Tensorflow: 1.0
gym: 0.8.0
"""
import numpy as np
import tensorflow as tf
np.random.seed(1)
tf.set_random_seed(1)
class DoubleDQN:
def __init__(
self,
n_actions,
n_features,
learning_rate=0.005,
reward_decay=0.9,
e_greedy=0.9,
replace_target_iter=200,
memory_size=3000,
batch_size=32,
e_greedy_increment=None,
output_graph=False,
double_q=True,
sess=None,
):
self.n_actions = n_actions
self.n_features = n_features
self.lr = learning_rate
self.gamma = reward_decay
self.epsilon_max = e_greedy
self.replace_target_iter = replace_target_iter
self.memory_size = memory_size
self.batch_size = batch_size
self.epsilon_increment = e_greedy_increment
self.epsilon = 0 if e_greedy_increment is not None else self.epsilon_max
self.double_q = double_q # decide to use double q or not
self.learn_step_counter = 0
self.memory = np.zeros((self.memory_size, n_features*2+2))
self._build_net()
t_params = tf.get_collection('target_net_params')
e_params = tf.get_collection('eval_net_params')
self.replace_target_op = [tf.assign(t, e) for t, e in zip(t_params, e_params)]
if sess is None:
self.sess = tf.Session()
self.sess.run(tf.global_variables_initializer())
else:
self.sess = sess
if output_graph:
tf.summary.FileWriter("logs/", self.sess.graph)
self.cost_his = []
def _build_net(self):
def build_layers(s, c_names, n_l1, w_initializer, b_initializer):
with tf.variable_scope('l1'):
w1 = tf.get_variable('w1', [self.n_features, n_l1], initializer=w_initializer, collections=c_names)
b1 = tf.get_variable('b1', [1, n_l1], initializer=b_initializer, collections=c_names)
l1 = tf.nn.relu(tf.matmul(s, w1) + b1)
with tf.variable_scope('l2'):
w2 = tf.get_variable('w2', [n_l1, self.n_actions], initializer=w_initializer, collections=c_names)
b2 = tf.get_variable('b2', [1, self.n_actions], initializer=b_initializer, collections=c_names)
out = tf.matmul(l1, w2) + b2
return out
# ------------------ build evaluate_net ------------------
self.s = tf.placeholder(tf.float32, [None, self.n_features], name='s') # input
self.q_target = tf.placeholder(tf.float32, [None, self.n_actions], name='Q_target') # for calculating loss
with tf.variable_scope('eval_net'):
c_names, n_l1, w_initializer, b_initializer = \
['eval_net_params', tf.GraphKeys.GLOBAL_VARIABLES], 20, \
tf.random_normal_initializer(0., 0.3), tf.constant_initializer(0.1) # config of layers
self.q_eval = build_layers(self.s, c_names, n_l1, w_initializer, b_initializer)
with tf.variable_scope('loss'):
self.loss = tf.reduce_mean(tf.squared_difference(self.q_target, self.q_eval))
with tf.variable_scope('train'):
self._train_op = tf.train.RMSPropOptimizer(self.lr).minimize(self.loss)
# ------------------ build target_net ------------------
self.s_ = tf.placeholder(tf.float32, [None, self.n_features], name='s_') # input
with tf.variable_scope('target_net'):
c_names = ['target_net_params', tf.GraphKeys.GLOBAL_VARIABLES]
self.q_next = build_layers(self.s_, c_names, n_l1, w_initializer, b_initializer)
def store_transition(self, s, a, r, s_):
if not hasattr(self, 'memory_counter'):
self.memory_counter = 0
transition = np.hstack((s, [a, r], s_))
index = self.memory_counter % self.memory_size
self.memory[index, :] = transition
self.memory_counter += 1
def choose_action(self, observation):
observation = observation[np.newaxis, :]
actions_value = self.sess.run(self.q_eval, feed_dict={self.s: observation})
action = np.argmax(actions_value)
if not hasattr(self, 'q'): # record action value it gets
self.q = []
self.running_q = 0
self.running_q = self.running_q*0.99 + 0.01 * np.max(actions_value)
self.q.append(self.running_q)
if np.random.uniform() > self.epsilon: # choosing action
action = np.random.randint(0, self.n_actions)
return action
def learn(self):
if self.learn_step_counter % self.replace_target_iter == 0:
self.sess.run(self.replace_target_op)
print('\ntarget_params_replaced\n')
if self.memory_counter > self.memory_size:
sample_index = np.random.choice(self.memory_size, size=self.batch_size)
else:
sample_index = np.random.choice(self.memory_counter, size=self.batch_size)
batch_memory = self.memory[sample_index, :]
q_next, q_eval4next = self.sess.run(
[self.q_next, self.q_eval],
feed_dict={self.s_: batch_memory[:, -self.n_features:], # next observation
self.s: batch_memory[:, -self.n_features:]}) # next observation
q_eval = self.sess.run(self.q_eval, {self.s: batch_memory[:, :self.n_features]})
q_target = q_eval.copy()
batch_index = np.arange(self.batch_size, dtype=np.int32)
eval_act_index = batch_memory[:, self.n_features].astype(int)
reward = batch_memory[:, self.n_features + 1]
if self.double_q:
max_act4next = np.argmax(q_eval4next, axis=1) # the action that brings the highest value is evaluated by q_eval
selected_q_next = q_next[batch_index, max_act4next] # Double DQN, select q_next depending on above actions
else:
selected_q_next = np.max(q_next, axis=1) # the natural DQN
q_target[batch_index, eval_act_index] = reward + self.gamma * selected_q_next
_, self.cost = self.sess.run([self._train_op, self.loss],
feed_dict={self.s: batch_memory[:, :self.n_features],
self.q_target: q_target})
self.cost_his.append(self.cost)
self.epsilon = self.epsilon + self.epsilon_increment if self.epsilon < self.epsilon_max else self.epsilon_max
self.learn_step_counter += 1
================================================
FILE: contents/5.1_Double_DQN/run_Pendulum.py
================================================
"""
Double DQN & Natural DQN comparison,
The Pendulum example.
View more on my tutorial page: https://morvanzhou.github.io/tutorials/
Using:
Tensorflow: 1.0
gym: 0.8.0
"""
import gym
from RL_brain import DoubleDQN
import numpy as np
import matplotlib.pyplot as plt
import tensorflow as tf
env = gym.make('Pendulum-v0')
env = env.unwrapped
env.seed(1)
MEMORY_SIZE = 3000
ACTION_SPACE = 11
sess = tf.Session()
with tf.variable_scope('Natural_DQN'):
natural_DQN = DoubleDQN(
n_actions=ACTION_SPACE, n_features=3, memory_size=MEMORY_SIZE,
e_greedy_increment=0.001, double_q=False, sess=sess
)
with tf.variable_scope('Double_DQN'):
double_DQN = DoubleDQN(
n_actions=ACTION_SPACE, n_features=3, memory_size=MEMORY_SIZE,
e_greedy_increment=0.001, double_q=True, sess=sess, output_graph=True)
sess.run(tf.global_variables_initializer())
def train(RL):
total_steps = 0
observation = env.reset()
while True:
# if total_steps - MEMORY_SIZE > 8000: env.render()
action = RL.choose_action(observation)
f_action = (action-(ACTION_SPACE-1)/2)/((ACTION_SPACE-1)/4) # convert to [-2 ~ 2] float actions
observation_, reward, done, info = env.step(np.array([f_action]))
reward /= 10 # normalize to a range of (-1, 0). r = 0 when get upright
# the Q target at upright state will be 0, because Q_target = r + gamma * Qmax(s', a') = 0 + gamma * 0
# so when Q at this state is greater than 0, the agent overestimates the Q. Please refer to the final result.
RL.store_transition(observation, action, reward, observation_)
if total_steps > MEMORY_SIZE: # learning
RL.learn()
if total_steps - MEMORY_SIZE > 20000: # stop game
break
observation = observation_
total_steps += 1
return RL.q
q_natural = train(natural_DQN)
q_double = train(double_DQN)
plt.plot(np.array(q_natural), c='r', label='natural')
plt.plot(np.array(q_double), c='b', label='double')
plt.legend(loc='best')
plt.ylabel('Q eval')
plt.xlabel('training steps')
plt.grid()
plt.show()
================================================
FILE: contents/5.2_Prioritized_Replay_DQN/RL_brain.py
================================================
"""
The DQN improvement: Prioritized Experience Replay (based on https://arxiv.org/abs/1511.05952)
View more on my tutorial page: https://morvanzhou.github.io/tutorials/
Using:
Tensorflow: 1.0
gym: 0.8.0
"""
import numpy as np
import tensorflow as tf
np.random.seed(1)
tf.set_random_seed(1)
class SumTree(object):
"""
This SumTree code is a modified version and the original code is from:
https://github.com/jaara/AI-blog/blob/master/SumTree.py
Story data with its priority in the tree.
"""
data_pointer = 0
def __init__(self, capacity):
self.capacity = capacity # for all priority values
self.tree = np.zeros(2 * capacity - 1)
# [--------------Parent nodes-------------][-------leaves to recode priority-------]
# size: capacity - 1 size: capacity
self.data = np.zeros(capacity, dtype=object) # for all transitions
# [--------------data frame-------------]
# size: capacity
def add(self, p, data):
tree_idx = self.data_pointer + self.capacity - 1
self.data[self.data_pointer] = data # update data_frame
self.update(tree_idx, p) # update tree_frame
self.data_pointer += 1
if self.data_pointer >= self.capacity: # replace when exceed the capacity
self.data_pointer = 0
def update(self, tree_idx, p):
change = p - self.tree[tree_idx]
self.tree[tree_idx] = p
# then propagate the change through tree
while tree_idx != 0: # this method is faster than the recursive loop in the reference code
tree_idx = (tree_idx - 1) // 2
self.tree[tree_idx] += change
def get_leaf(self, v):
"""
Tree structure and array storage:
Tree index:
0 -> storing priority sum
/ \
1 2
/ \ / \
3 4 5 6 -> storing priority for transitions
Array type for storing:
[0,1,2,3,4,5,6]
"""
parent_idx = 0
while True: # the while loop is faster than the method in the reference code
cl_idx = 2 * parent_idx + 1 # this leaf's left and right kids
cr_idx = cl_idx + 1
if cl_idx >= len(self.tree): # reach bottom, end search
leaf_idx = parent_idx
break
else: # downward search, always search for a higher priority node
if v <= self.tree[cl_idx]:
parent_idx = cl_idx
else:
v -= self.tree[cl_idx]
parent_idx = cr_idx
data_idx = leaf_idx - self.capacity + 1
return leaf_idx, self.tree[leaf_idx], self.data[data_idx]
@property
def total_p(self):
return self.tree[0] # the root
class Memory(object): # stored as ( s, a, r, s_ ) in SumTree
"""
This Memory class is modified based on the original code from:
https://github.com/jaara/AI-blog/blob/master/Seaquest-DDQN-PER.py
"""
epsilon = 0.01 # small amount to avoid zero priority
alpha = 0.6 # [0~1] convert the importance of TD error to priority
beta = 0.4 # importance-sampling, from initial value increasing to 1
beta_increment_per_sampling = 0.001
abs_err_upper = 1. # clipped abs error
def __init__(self, capacity):
self.tree = SumTree(capacity)
def store(self, transition):
max_p = np.max(self.tree.tree[-self.tree.capacity:])
if max_p == 0:
max_p = self.abs_err_upper
self.tree.add(max_p, transition) # set the max p for new p
def sample(self, n):
b_idx, b_memory, ISWeights = np.empty((n,), dtype=np.int32), np.empty((n, self.tree.data[0].size)), np.empty((n, 1))
pri_seg = self.tree.total_p / n # priority segment
self.beta = np.min([1., self.beta + self.beta_increment_per_sampling]) # max = 1
min_prob = np.min(self.tree.tree[-self.tree.capacity:]) / self.tree.total_p # for later calculate ISweight
for i in range(n):
a, b = pri_seg * i, pri_seg * (i + 1)
v = np.random.uniform(a, b)
idx, p, data = self.tree.get_leaf(v)
prob = p / self.tree.total_p
ISWeights[i, 0] = np.power(prob/min_prob, -self.beta)
b_idx[i], b_memory[i, :] = idx, data
return b_idx, b_memory, ISWeights
def batch_update(self, tree_idx, abs_errors):
abs_errors += self.epsilon # convert to abs and avoid 0
clipped_errors = np.minimum(abs_errors, self.abs_err_upper)
ps = np.power(clipped_errors, self.alpha)
for ti, p in zip(tree_idx, ps):
self.tree.update(ti, p)
class DQNPrioritizedReplay:
def __init__(
self,
n_actions,
n_features,
learning_rate=0.005,
reward_decay=0.9,
e_greedy=0.9,
replace_target_iter=500,
memory_size=10000,
batch_size=32,
e_greedy_increment=None,
output_graph=False,
prioritized=True,
sess=None,
):
self.n_actions = n_actions
self.n_features = n_features
self.lr = learning_rate
self.gamma = reward_decay
self.epsilon_max = e_greedy
self.replace_target_iter = replace_target_iter
self.memory_size = memory_size
self.batch_size = batch_size
self.epsilon_increment = e_greedy_increment
self.epsilon = 0 if e_greedy_increment is not None else self.epsilon_max
self.prioritized = prioritized # decide to use double q or not
self.learn_step_counter = 0
self._build_net()
t_params = tf.get_collection('target_net_params')
e_params = tf.get_collection('eval_net_params')
self.replace_target_op = [tf.assign(t, e) for t, e in zip(t_params, e_params)]
if self.prioritized:
self.memory = Memory(capacity=memory_size)
else:
self.memory = np.zeros((self.memory_size, n_features*2+2))
if sess is None:
self.sess = tf.Session()
self.sess.run(tf.global_variables_initializer())
else:
self.sess = sess
if output_graph:
tf.summary.FileWriter("logs/", self.sess.graph)
self.cost_his = []
def _build_net(self):
def build_layers(s, c_names, n_l1, w_initializer, b_initializer, trainable):
with tf.variable_scope('l1'):
w1 = tf.get_variable('w1', [self.n_features, n_l1], initializer=w_initializer, collections=c_names, trainable=trainable)
b1 = tf.get_variable('b1', [1, n_l1], initializer=b_initializer, collections=c_names, trainable=trainable)
l1 = tf.nn.relu(tf.matmul(s, w1) + b1)
with tf.variable_scope('l2'):
w2 = tf.get_variable('w2', [n_l1, self.n_actions], initializer=w_initializer, collections=c_names, trainable=trainable)
b2 = tf.get_variable('b2', [1, self.n_actions], initializer=b_initializer, collections=c_names, trainable=trainable)
out = tf.matmul(l1, w2) + b2
return out
# ------------------ build evaluate_net ------------------
self.s = tf.placeholder(tf.float32, [None, self.n_features], name='s') # input
self.q_target = tf.placeholder(tf.float32, [None, self.n_actions], name='Q_target') # for calculating loss
if self.prioritized:
self.ISWeights = tf.placeholder(tf.float32, [None, 1], name='IS_weights')
with tf.variable_scope('eval_net'):
c_names, n_l1, w_initializer, b_initializer = \
['eval_net_params', tf.GraphKeys.GLOBAL_VARIABLES], 20, \
tf.random_normal_initializer(0., 0.3), tf.constant_initializer(0.1) # config of layers
self.q_eval = build_layers(self.s, c_names, n_l1, w_initializer, b_initializer, True)
with tf.variable_scope('loss'):
if self.prioritized:
self.abs_errors = tf.reduce_sum(tf.abs(self.q_target - self.q_eval), axis=1) # for updating Sumtree
self.loss = tf.reduce_mean(self.ISWeights * tf.squared_difference(self.q_target, self.q_eval))
else:
self.loss = tf.reduce_mean(tf.squared_difference(self.q_target, self.q_eval))
with tf.variable_scope('train'):
self._train_op = tf.train.RMSPropOptimizer(self.lr).minimize(self.loss)
# ------------------ build target_net ------------------
self.s_ = tf.placeholder(tf.float32, [None, self.n_features], name='s_') # input
with tf.variable_scope('target_net'):
c_names = ['target_net_params', tf.GraphKeys.GLOBAL_VARIABLES]
self.q_next = build_layers(self.s_, c_names, n_l1, w_initializer, b_initializer, False)
def store_transition(self, s, a, r, s_):
if self.prioritized: # prioritized replay
transition = np.hstack((s, [a, r], s_))
self.memory.store(transition) # have high priority for newly arrived transition
else: # random replay
if not hasattr(self, 'memory_counter'):
self.memory_counter = 0
transition = np.hstack((s, [a, r], s_))
index = self.memory_counter % self.memory_size
self.memory[index, :] = transition
self.memory_counter += 1
def choose_action(self, observation):
observation = observation[np.newaxis, :]
if np.random.uniform() < self.epsilon:
actions_value = self.sess.run(self.q_eval, feed_dict={self.s: observation})
action = np.argmax(actions_value)
else:
action = np.random.randint(0, self.n_actions)
return action
def learn(self):
if self.learn_step_counter % self.replace_target_iter == 0:
self.sess.run(self.replace_target_op)
print('\ntarget_params_replaced\n')
if self.prioritized:
tree_idx, batch_memory, ISWeights = self.memory.sample(self.batch_size)
else:
sample_index = np.random.choice(self.memory_size, size=self.batch_size)
batch_memory = self.memory[sample_index, :]
q_next, q_eval = self.sess.run(
[self.q_next, self.q_eval],
feed_dict={self.s_: batch_memory[:, -self.n_features:],
self.s: batch_memory[:, :self.n_features]})
q_target = q_eval.copy()
batch_index = np.arange(self.batch_size, dtype=np.int32)
eval_act_index = batch_memory[:, self.n_features].astype(int)
reward = batch_memory[:, self.n_features + 1]
q_target[batch_index, eval_act_index] = reward + self.gamma * np.max(q_next, axis=1)
if self.prioritized:
_, abs_errors, self.cost = self.sess.run([self._train_op, self.abs_errors, self.loss],
feed_dict={self.s: batch_memory[:, :self.n_features],
self.q_target: q_target,
self.ISWeights: ISWeights})
self.memory.batch_update(tree_idx, abs_errors) # update priority
else:
_, self.cost = self.sess.run([self._train_op, self.loss],
feed_dict={self.s: batch_memory[:, :self.n_features],
self.q_target: q_target})
self.cost_his.append(self.cost)
self.epsilon = self.epsilon + self.epsilon_increment if self.epsilon < self.epsilon_max else self.epsilon_max
self.learn_step_counter += 1
================================================
FILE: contents/5.2_Prioritized_Replay_DQN/run_MountainCar.py
================================================
"""
The DQN improvement: Prioritized Experience Replay (based on https://arxiv.org/abs/1511.05952)
View more on my tutorial page: https://morvanzhou.github.io/tutorials/
Using:
Tensorflow: 1.0
gym: 0.8.0
"""
import gym
from RL_brain import DQNPrioritizedReplay
import matplotlib.pyplot as plt
import tensorflow as tf
import numpy as np
env = gym.make('MountainCar-v0')
env = env.unwrapped
env.seed(21)
MEMORY_SIZE = 10000
sess = tf.Session()
with tf.variable_scope('natural_DQN'):
RL_natural = DQNPrioritizedReplay(
n_actions=3, n_features=2, memory_size=MEMORY_SIZE,
e_greedy_increment=0.00005, sess=sess, prioritized=False,
)
with tf.variable_scope('DQN_with_prioritized_replay'):
RL_prio = DQNPrioritizedReplay(
n_actions=3, n_features=2, memory_size=MEMORY_SIZE,
e_greedy_increment=0.00005, sess=sess, prioritized=True, output_graph=True,
)
sess.run(tf.global_variables_initializer())
def train(RL):
total_steps = 0
steps = []
episodes = []
for i_episode in range(20):
observation = env.reset()
while True:
# env.render()
action = RL.choose_action(observation)
observation_, reward, done, info = env.step(action)
if done: reward = 10
RL.store_transition(observation, action, reward, observation_)
if total_steps > MEMORY_SIZE:
RL.learn()
if done:
print('episode ', i_episode, ' finished')
steps.append(total_steps)
episodes.append(i_episode)
break
observation = observation_
total_steps += 1
return np.vstack((episodes, steps))
his_natural = train(RL_natural)
his_prio = train(RL_prio)
# compare based on first success
plt.plot(his_natural[0, :], his_natural[1, :] - his_natural[1, 0], c='b', label='natural DQN')
plt.plot(his_prio[0, :], his_prio[1, :] - his_prio[1, 0], c='r', label='DQN with prioritized replay')
plt.legend(loc='best')
plt.ylabel('total training time')
plt.xlabel('episode')
plt.grid()
plt.show()
================================================
FILE: contents/5.3_Dueling_DQN/RL_brain.py
================================================
"""
The Dueling DQN based on this paper: https://arxiv.org/abs/1511.06581
View more on my tutorial page: https://morvanzhou.github.io/tutorials/
Using:
Tensorflow: 1.0
gym: 0.8.0
"""
import numpy as np
import tensorflow as tf
np.random.seed(1)
tf.set_random_seed(1)
class DuelingDQN:
def __init__(
self,
n_actions,
n_features,
learning_rate=0.001,
reward_decay=0.9,
e_greedy=0.9,
replace_target_iter=200,
memory_size=500,
batch_size=32,
e_greedy_increment=None,
output_graph=False,
dueling=True,
sess=None,
):
self.n_actions = n_actions
self.n_features = n_features
self.lr = learning_rate
self.gamma = reward_decay
self.epsilon_max = e_greedy
self.replace_target_iter = replace_target_iter
self.memory_size = memory_size
self.batch_size = batch_size
self.epsilon_increment = e_greedy_increment
self.epsilon = 0 if e_greedy_increment is not None else self.epsilon_max
self.dueling = dueling # decide to use dueling DQN or not
self.learn_step_counter = 0
self.memory = np.zeros((self.memory_size, n_features*2+2))
self._build_net()
t_params = tf.get_collection('target_net_params')
e_params = tf.get_collection('eval_net_params')
self.replace_target_op = [tf.assign(t, e) for t, e in zip(t_params, e_params)]
if sess is None:
self.sess = tf.Session()
self.sess.run(tf.global_variables_initializer())
else:
self.sess = sess
if output_graph:
tf.summary.FileWriter("logs/", self.sess.graph)
self.cost_his = []
def _build_net(self):
def build_layers(s, c_names, n_l1, w_initializer, b_initializer):
with tf.variable_scope('l1'):
w1 = tf.get_variable('w1', [self.n_features, n_l1], initializer=w_initializer, collections=c_names)
b1 = tf.get_variable('b1', [1, n_l1], initializer=b_initializer, collections=c_names)
l1 = tf.nn.relu(tf.matmul(s, w1) + b1)
if self.dueling:
# Dueling DQN
with tf.variable_scope('Value'):
w2 = tf.get_variable('w2', [n_l1, 1], initializer=w_initializer, collections=c_names)
b2 = tf.get_variable('b2', [1, 1], initializer=b_initializer, collections=c_names)
self.V = tf.matmul(l1, w2) + b2
with tf.variable_scope('Advantage'):
w2 = tf.get_variable('w2', [n_l1, self.n_actions], initializer=w_initializer, collections=c_names)
b2 = tf.get_variable('b2', [1, self.n_actions], initializer=b_initializer, collections=c_names)
self.A = tf.matmul(l1, w2) + b2
with tf.variable_scope('Q'):
out = self.V + (self.A - tf.reduce_mean(self.A, axis=1, keep_dims=True)) # Q = V(s) + A(s,a)
else:
with tf.variable_scope('Q'):
w2 = tf.get_variable('w2', [n_l1, self.n_actions], initializer=w_initializer, collections=c_names)
b2 = tf.get_variable('b2', [1, self.n_actions], initializer=b_initializer, collections=c_names)
out = tf.matmul(l1, w2) + b2
return out
# ------------------ build evaluate_net ------------------
self.s = tf.placeholder(tf.float32, [None, self.n_features], name='s') # input
self.q_target = tf.placeholder(tf.float32, [None, self.n_actions], name='Q_target') # for calculating loss
with tf.variable_scope('eval_net'):
c_names, n_l1, w_initializer, b_initializer = \
['eval_net_params', tf.GraphKeys.GLOBAL_VARIABLES], 20, \
tf.random_normal_initializer(0., 0.3), tf.constant_initializer(0.1) # config of layers
self.q_eval = build_layers(self.s, c_names, n_l1, w_initializer, b_initializer)
with tf.variable_scope('loss'):
self.loss = tf.reduce_mean(tf.squared_difference(self.q_target, self.q_eval))
with tf.variable_scope('train'):
self._train_op = tf.train.RMSPropOptimizer(self.lr).minimize(self.loss)
# ------------------ build target_net ------------------
self.s_ = tf.placeholder(tf.float32, [None, self.n_features], name='s_') # input
with tf.variable_scope('target_net'):
c_names = ['target_net_params', tf.GraphKeys.GLOBAL_VARIABLES]
self.q_next = build_layers(self.s_, c_names, n_l1, w_initializer, b_initializer)
def store_transition(self, s, a, r, s_):
if not hasattr(self, 'memory_counter'):
self.memory_counter = 0
transition = np.hstack((s, [a, r], s_))
index = self.memory_counter % self.memory_size
self.memory[index, :] = transition
self.memory_counter += 1
def choose_action(self, observation):
observation = observation[np.newaxis, :]
if np.random.uniform() < self.epsilon: # choosing action
actions_value = self.sess.run(self.q_eval, feed_dict={self.s: observation})
action = np.argmax(actions_value)
else:
action = np.random.randint(0, self.n_actions)
return action
def learn(self):
if self.learn_step_counter % self.replace_target_iter == 0:
self.sess.run(self.replace_target_op)
print('\ntarget_params_replaced\n')
sample_index = np.random.choice(self.memory_size, size=self.batch_size)
batch_memory = self.memory[sample_index, :]
q_next = self.sess.run(self.q_next, feed_dict={self.s_: batch_memory[:, -self.n_features:]}) # next observation
q_eval = self.sess.run(self.q_eval, {self.s: batch_memory[:, :self.n_features]})
q_target = q_eval.copy()
batch_index = np.arange(self.batch_size, dtype=np.int32)
eval_act_index = batch_memory[:, self.n_features].astype(int)
reward = batch_memory[:, self.n_features + 1]
q_target[batch_index, eval_act_index] = reward + self.gamma * np.max(q_next, axis=1)
_, self.cost = self.sess.run([self._train_op, self.loss],
feed_dict={self.s: batch_memory[:, :self.n_features],
self.q_target: q_target})
self.cost_his.append(self.cost)
self.epsilon = self.epsilon + self.epsilon_increment if self.epsilon < self.epsilon_max else self.epsilon_max
self.learn_step_counter += 1
================================================
FILE: contents/5.3_Dueling_DQN/run_Pendulum.py
================================================
"""
Dueling DQN & Natural DQN comparison
View more on my tutorial page: https://morvanzhou.github.io/tutorials/
Using:
Tensorflow: 1.0
gym: 0.8.0
"""
import gym
from RL_brain import DuelingDQN
import numpy as np
import matplotlib.pyplot as plt
import tensorflow as tf
env = gym.make('Pendulum-v0')
env = env.unwrapped
env.seed(1)
MEMORY_SIZE = 3000
ACTION_SPACE = 25
sess = tf.Session()
with tf.variable_scope('natural'):
natural_DQN = DuelingDQN(
n_actions=ACTION_SPACE, n_features=3, memory_size=MEMORY_SIZE,
e_greedy_increment=0.001, sess=sess, dueling=False)
with tf.variable_scope('dueling'):
dueling_DQN = DuelingDQN(
n_actions=ACTION_SPACE, n_features=3, memory_size=MEMORY_SIZE,
e_greedy_increment=0.001, sess=sess, dueling=True, output_graph=True)
sess.run(tf.global_variables_initializer())
def train(RL):
acc_r = [0]
total_steps = 0
observation = env.reset()
while True:
# if total_steps-MEMORY_SIZE > 9000: env.render()
action = RL.choose_action(observation)
f_action = (action-(ACTION_SPACE-1)/2)/((ACTION_SPACE-1)/4) # [-2 ~ 2] float actions
observation_, reward, done, info = env.step(np.array([f_action]))
reward /= 10 # normalize to a range of (-1, 0)
acc_r.append(reward + acc_r[-1]) # accumulated reward
RL.store_transition(observation, action, reward, observation_)
if total_steps > MEMORY_SIZE:
RL.learn()
if total_steps-MEMORY_SIZE > 15000:
break
observation = observation_
total_steps += 1
return RL.cost_his, acc_r
c_natural, r_natural = train(natural_DQN)
c_dueling, r_dueling = train(dueling_DQN)
plt.figure(1)
plt.plot(np.array(c_natural), c='r', label='natural')
plt.plot(np.array(c_dueling), c='b', label='dueling')
plt.legend(loc='best')
plt.ylabel('cost')
plt.xlabel('training steps')
plt.grid()
plt.figure(2)
plt.plot(np.array(r_natural), c='r', label='natural')
plt.plot(np.array(r_dueling), c='b', label='dueling')
plt.legend(loc='best')
plt.ylabel('accumulated reward')
plt.xlabel('training steps')
plt.grid()
plt.show()
================================================
FILE: contents/5_Deep_Q_Network/DQN_modified.py
================================================
"""
This part of code is the Deep Q Network (DQN) brain.
view the tensorboard picture about this DQN structure on: https://morvanzhou.github.io/tutorials/machine-learning/reinforcement-learning/4-3-DQN3/#modification
View more on my tutorial page: https://morvanzhou.github.io/tutorials/
Using:
Tensorflow: r1.2
"""
import numpy as np
import tensorflow as tf
np.random.seed(1)
tf.set_random_seed(1)
# Deep Q Network off-policy
class DeepQNetwork:
def __init__(
self,
n_actions,
n_features,
learning_rate=0.01,
reward_decay=0.9,
e_greedy=0.9,
replace_target_iter=300,
memory_size=500,
batch_size=32,
e_greedy_increment=None,
output_graph=False,
):
self.n_actions = n_actions
self.n_features = n_features
self.lr = learning_rate
self.gamma = reward_decay
self.epsilon_max = e_greedy
self.replace_target_iter = replace_target_iter
self.memory_size = memory_size
self.batch_size = batch_size
self.epsilon_increment = e_greedy_increment
self.epsilon = 0 if e_greedy_increment is not None else self.epsilon_max
# total learning step
self.learn_step_counter = 0
# initialize zero memory [s, a, r, s_]
self.memory = np.zeros((self.memory_size, n_features * 2 + 2))
# consist of [target_net, evaluate_net]
self._build_net()
t_params = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope='target_net')
e_params = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope='eval_net')
with tf.variable_scope('hard_replacement'):
self.target_replace_op = [tf.assign(t, e) for t, e in zip(t_params, e_params)]
self.sess = tf.Session()
if output_graph:
# $ tensorboard --logdir=logs
tf.summary.FileWriter("logs/", self.sess.graph)
self.sess.run(tf.global_variables_initializer())
self.cost_his = []
def _build_net(self):
# ------------------ all inputs ------------------------
self.s = tf.placeholder(tf.float32, [None, self.n_features], name='s') # input State
self.s_ = tf.placeholder(tf.float32, [None, self.n_features], name='s_') # input Next State
self.r = tf.placeholder(tf.float32, [None, ], name='r') # input Reward
self.a = tf.placeholder(tf.int32, [None, ], name='a') # input Action
w_initializer, b_initializer = tf.random_normal_initializer(0., 0.3), tf.constant_initializer(0.1)
# ------------------ build evaluate_net ------------------
with tf.variable_scope('eval_net'):
e1 = tf.layers.dense(self.s, 20, tf.nn.relu, kernel_initializer=w_initializer,
bias_initializer=b_initializer, name='e1')
self.q_eval = tf.layers.dense(e1, self.n_actions, kernel_initializer=w_initializer,
bias_initializer=b_initializer, name='q')
# ------------------ build target_net ------------------
with tf.variable_scope('target_net'):
t1 = tf.layers.dense(self.s_, 20, tf.nn.relu, kernel_initializer=w_initializer,
bias_initializer=b_initializer, name='t1')
self.q_next = tf.layers.dense(t1, self.n_actions, kernel_initializer=w_initializer,
bias_initializer=b_initializer, name='t2')
with tf.variable_scope('q_target'):
q_target = self.r + self.gamma * tf.reduce_max(self.q_next, axis=1, name='Qmax_s_') # shape=(None, )
self.q_target = tf.stop_gradient(q_target)
with tf.variable_scope('q_eval'):
a_indices = tf.stack([tf.range(tf.shape(self.a)[0], dtype=tf.int32), self.a], axis=1)
self.q_eval_wrt_a = tf.gather_nd(params=self.q_eval, indices=a_indices) # shape=(None, )
with tf.variable_scope('loss'):
self.loss = tf.reduce_mean(tf.squared_difference(self.q_target, self.q_eval_wrt_a, name='TD_error'))
with tf.variable_scope('train'):
self._train_op = tf.train.RMSPropOptimizer(self.lr).minimize(self.loss)
def store_transition(self, s, a, r, s_):
if not hasattr(self, 'memory_counter'):
self.memory_counter = 0
transition = np.hstack((s, [a, r], s_))
# replace the old memory with new memory
index = self.memory_counter % self.memory_size
self.memory[index, :] = transition
self.memory_counter += 1
def choose_action(self, observation):
# to have batch dimension when feed into tf placeholder
observation = observation[np.newaxis, :]
if np.random.uniform() < self.epsilon:
# forward feed the observation and get q value for every actions
actions_value = self.sess.run(self.q_eval, feed_dict={self.s: observation})
action = np.argmax(actions_value)
else:
action = np.random.randint(0, self.n_actions)
return action
def learn(self):
# check to replace target parameters
if self.learn_step_counter % self.replace_target_iter == 0:
self.sess.run(self.target_replace_op)
print('\ntarget_params_replaced\n')
# sample batch memory from all memory
if self.memory_counter > self.memory_size:
sample_index = np.random.choice(self.memory_size, size=self.batch_size)
else:
sample_index = np.random.choice(self.memory_counter, size=self.batch_size)
batch_memory = self.memory[sample_index, :]
_, cost = self.sess.run(
[self._train_op, self.loss],
feed_dict={
self.s: batch_memory[:, :self.n_features],
self.a: batch_memory[:, self.n_features],
self.r: batch_memory[:, self.n_features + 1],
self.s_: batch_memory[:, -self.n_features:],
})
self.cost_his.append(cost)
# increasing epsilon
self.epsilon = self.epsilon + self.epsilon_increment if self.epsilon < self.epsilon_max else self.epsilon_max
self.learn_step_counter += 1
def plot_cost(self):
import matplotlib.pyplot as plt
plt.plot(np.arange(len(self.cost_his)), self.cost_his)
plt.ylabel('Cost')
plt.xlabel('training steps')
plt.show()
if __name__ == '__main__':
DQN = DeepQNetwork(3,4, output_graph=True)
================================================
FILE: contents/5_Deep_Q_Network/RL_brain.py
================================================
"""
This part of code is the DQN brain, which is a brain of the agent.
All decisions are made in here.
Using Tensorflow to build the neural network.
View more on my tutorial page: https://morvanzhou.github.io/tutorials/
Using:
Tensorflow: 1.0
gym: 0.7.3
"""
import numpy as np
import pandas as pd
import tensorflow as tf
np.random.seed(1)
tf.set_random_seed(1)
# Deep Q Network off-policy
class DeepQNetwork:
def __init__(
self,
n_actions,
n_features,
learning_rate=0.01,
reward_decay=0.9,
e_greedy=0.9,
replace_target_iter=300,
memory_size=500,
batch_size=32,
e_greedy_increment=None,
output_graph=False,
):
self.n_actions = n_actions
self.n_features = n_features
self.lr = learning_rate
self.gamma = reward_decay
self.epsilon_max = e_greedy
self.replace_target_iter = replace_target_iter
self.memory_size = memory_size
self.batch_size = batch_size
self.epsilon_increment = e_greedy_increment
self.epsilon = 0 if e_greedy_increment is not None else self.epsilon_max
# total learning step
self.learn_step_counter = 0
# initialize zero memory [s, a, r, s_]
self.memory = np.zeros((self.memory_size, n_features * 2 + 2))
# consist of [target_net, evaluate_net]
self._build_net()
t_params = tf.get_collection('target_net_params')
e_params = tf.get_collection('eval_net_params')
self.replace_target_op = [tf.assign(t, e) for t, e in zip(t_params, e_params)]
self.sess = tf.Session()
if output_graph:
# $ tensorboard --logdir=logs
# tf.train.SummaryWriter soon be deprecated, use following
tf.summary.FileWriter("logs/", self.sess.graph)
self.sess.run(tf.global_variables_initializer())
self.cost_his = []
def _build_net(self):
# ------------------ build evaluate_net ------------------
self.s = tf.placeholder(tf.float32, [None, self.n_features], name='s') # input
self.q_target = tf.placeholder(tf.float32, [None, self.n_actions], name='Q_target') # for calculating loss
with tf.variable_scope('eval_net'):
# c_names(collections_names) are the collections to store variables
c_names, n_l1, w_initializer, b_initializer = \
['eval_net_params', tf.GraphKeys.GLOBAL_VARIABLES], 10, \
tf.random_normal_initializer(0., 0.3), tf.constant_initializer(0.1) # config of layers
# first layer. collections is used later when assign to target net
with tf.variable_scope('l1'):
w1 = tf.get_variable('w1', [self.n_features, n_l1], initializer=w_initializer, collections=c_names)
b1 = tf.get_variable('b1', [1, n_l1], initializer=b_initializer, collections=c_names)
l1 = tf.nn.relu(tf.matmul(self.s, w1) + b1)
# second layer. collections is used later when assign to target net
with tf.variable_scope('l2'):
w2 = tf.get_variable('w2', [n_l1, self.n_actions], initializer=w_initializer, collections=c_names)
b2 = tf.get_variable('b2', [1, self.n_actions], initializer=b_initializer, collections=c_names)
self.q_eval = tf.matmul(l1, w2) + b2
with tf.variable_scope('loss'):
self.loss = tf.reduce_mean(tf.squared_difference(self.q_target, self.q_eval))
with tf.variable_scope('train'):
self._train_op = tf.train.RMSPropOptimizer(self.lr).minimize(self.loss)
# ------------------ build target_net ------------------
self.s_ = tf.placeholder(tf.float32, [None, self.n_features], name='s_') # input
with tf.variable_scope('target_net'):
# c_names(collections_names) are the collections to store variables
c_names = ['target_net_params', tf.GraphKeys.GLOBAL_VARIABLES]
# first layer. collections is used later when assign to target net
with tf.variable_scope('l1'):
w1 = tf.get_variable('w1', [self.n_features, n_l1], initializer=w_initializer, collections=c_names)
b1 = tf.get_variable('b1', [1, n_l1], initializer=b_initializer, collections=c_names)
l1 = tf.nn.relu(tf.matmul(self.s_, w1) + b1)
# second layer. collections is used later when assign to target net
with tf.variable_scope('l2'):
w2 = tf.get_variable('w2', [n_l1, self.n_actions], initializer=w_initializer, collections=c_names)
b2 = tf.get_variable('b2', [1, self.n_actions], initializer=b_initializer, collections=c_names)
self.q_next = tf.matmul(l1, w2) + b2
def store_transition(self, s, a, r, s_):
if not hasattr(self, 'memory_counter'):
self.memory_counter = 0
transition = np.hstack((s, [a, r], s_))
# replace the old memory with new memory
index = self.memory_counter % self.memory_size
self.memory[index, :] = transition
self.memory_counter += 1
def choose_action(self, observation):
# to have batch dimension when feed into tf placeholder
observation = observation[np.newaxis, :]
if np.random.uniform() < self.epsilon:
# forward feed the observation and get q value for every actions
actions_value = self.sess.run(self.q_eval, feed_dict={self.s: observation})
action = np.argmax(actions_value)
else:
action = np.random.randint(0, self.n_actions)
return action
def learn(self):
# check to replace target parameters
if self.learn_step_counter % self.replace_target_iter == 0:
self.sess.run(self.replace_target_op)
print('\ntarget_params_replaced\n')
# sample batch memory from all memory
if self.memory_counter > self.memory_size:
sample_index = np.random.choice(self.memory_size, size=self.batch_size)
else:
sample_index = np.random.choice(self.memory_counter, size=self.batch_size)
batch_memory = self.memory[sample_index, :]
q_next, q_eval = self.sess.run(
[self.q_next, self.q_eval],
feed_dict={
self.s_: batch_memory[:, -self.n_features:], # fixed params
self.s: batch_memory[:, :self.n_features], # newest params
})
# change q_target w.r.t q_eval's action
q_target = q_eval.copy()
batch_index = np.arange(self.batch_size, dtype=np.int32)
eval_act_index = batch_memory[:, self.n_features].astype(int)
reward = batch_memory[:, self.n_features + 1]
q_target[batch_index, eval_act_index] = reward + self.gamma * np.max(q_next, axis=1)
"""
For example in this batch I have 2 samples and 3 actions:
q_eval =
[[1, 2, 3],
[4, 5, 6]]
q_target = q_eval =
[[1, 2, 3],
[4, 5, 6]]
Then change q_target with the real q_target value w.r.t the q_eval's action.
For example in:
sample 0, I took action 0, and the max q_target value is -1;
sample 1, I took action 2, and the max q_target value is -2:
q_target =
[[-1, 2, 3],
[4, 5, -2]]
So the (q_target - q_eval) becomes:
[[(-1)-(1), 0, 0],
[0, 0, (-2)-(6)]]
We then backpropagate this error w.r.t the corresponding action to network,
leave other action as error=0 cause we didn't choose it.
"""
# train eval network
_, self.cost = self.sess.run([self._train_op, self.loss],
feed_dict={self.s: batch_memory[:, :self.n_features],
self.q_target: q_target})
self.cost_his.append(self.cost)
# increasing epsilon
self.epsilon = self.epsilon + self.epsilon_increment if self.epsilon < self.epsilon_max else self.epsilon_max
self.learn_step_counter += 1
def plot_cost(self):
import matplotlib.pyplot as plt
plt.plot(np.arange(len(self.cost_his)), self.cost_his)
plt.ylabel('Cost')
plt.xlabel('training steps')
plt.show()
================================================
FILE: contents/5_Deep_Q_Network/maze_env.py
================================================
"""
Reinforcement learning maze example.
Red rectangle: explorer.
Black rectangles: hells [reward = -1].
Yellow bin circle: paradise [reward = +1].
All other states: ground [reward = 0].
This script is the environment part of this example.
The RL is in RL_brain.py.
View more on my tutorial page: https://morvanzhou.github.io/tutorials/
"""
import numpy as np
import time
import sys
if sys.version_info.major == 2:
import Tkinter as tk
else:
import tkinter as tk
UNIT = 40 # pixels
MAZE_H = 4 # grid height
MAZE_W = 4 # grid width
class Maze(tk.Tk, object):
def __init__(self):
super(Maze, self).__init__()
self.action_space = ['u', 'd', 'l', 'r']
self.n_actions = len(self.action_space)
self.n_features = 2
self.title('maze')
self.geometry('{0}x{1}'.format(MAZE_W * UNIT, MAZE_H * UNIT))
self._build_maze()
def _build_maze(self):
self.canvas = tk.Canvas(self, bg='white',
height=MAZE_H * UNIT,
width=MAZE_W * UNIT)
# create grids
for c in range(0, MAZE_W * UNIT, UNIT):
x0, y0, x1, y1 = c, 0, c, MAZE_H * UNIT
self.canvas.create_line(x0, y0, x1, y1)
for r in range(0, MAZE_H * UNIT, UNIT):
x0, y0, x1, y1 = 0, r, MAZE_W * UNIT, r
self.canvas.create_line(x0, y0, x1, y1)
# create origin
origin = np.array([20, 20])
# hell
hell1_center = origin + np.array([UNIT * 2, UNIT])
self.hell1 = self.canvas.create_rectangle(
hell1_center[0] - 15, hell1_center[1] - 15,
hell1_center[0] + 15, hell1_center[1] + 15,
fill='black')
# hell
# hell2_center = origin + np.array([UNIT, UNIT * 2])
# self.hell2 = self.canvas.create_rectangle(
# hell2_center[0] - 15, hell2_center[1] - 15,
# hell2_center[0] + 15, hell2_center[1] + 15,
# fill='black')
# create oval
oval_center = origin + UNIT * 2
self.oval = self.canvas.create_oval(
oval_center[0] - 15, oval_center[1] - 15,
oval_center[0] + 15, oval_center[1] + 15,
fill='yellow')
# create red rect
self.rect = self.canvas.create_rectangle(
origin[0] - 15, origin[1] - 15,
origin[0] + 15, origin[1] + 15,
fill='red')
# pack all
self.canvas.pack()
def reset(self):
self.update()
time.sleep(0.1)
self.canvas.delete(self.rect)
origin = np.array([20, 20])
self.rect = self.canvas.create_rectangle(
origin[0] - 15, origin[1] - 15,
origin[0] + 15, origin[1] + 15,
fill='red')
# return observation
return (np.array(self.canvas.coords(self.rect)[:2]) - np.array(self.canvas.coords(self.oval)[:2]))/(MAZE_H*UNIT)
def step(self, action):
s = self.canvas.coords(self.rect)
base_action = np.array([0, 0])
if action == 0: # up
if s[1] > UNIT:
base_action[1] -= UNIT
elif action == 1: # down
if s[1] < (MAZE_H - 1) * UNIT:
base_action[1] += UNIT
elif action == 2: # right
if s[0] < (MAZE_W - 1) * UNIT:
base_action[0] += UNIT
elif action == 3: # left
if s[0] > UNIT:
base_action[0] -= UNIT
self.canvas.move(self.rect, base_action[0], base_action[1]) # move agent
next_coords = self.canvas.coords(self.rect) # next state
# reward function
if next_coords == self.canvas.coords(self.oval):
reward = 1
done = True
elif next_coords in [self.canvas.coords(self.hell1)]:
reward = -1
done = True
else:
reward = 0
done = False
s_ = (np.array(next_coords[:2]) - np.array(self.canvas.coords(self.oval)[:2]))/(MAZE_H*UNIT)
return s_, reward, done
def render(self):
# time.sleep(0.01)
self.update()
================================================
FILE: contents/5_Deep_Q_Network/run_this.py
================================================
from maze_env import Maze
from RL_brain import DeepQNetwork
def run_maze():
step = 0
for episode in range(300):
# initial observation
observation = env.reset()
while True:
# fresh env
env.render()
# RL choose action based on observation
action = RL.choose_action(observation)
# RL take action and get next observation and reward
observation_, reward, done = env.step(action)
RL.store_transition(observation, action, reward, observation_)
if (step > 200) and (step % 5 == 0):
RL.learn()
# swap observation
observation = observation_
# break while loop when end of this episode
if done:
break
step += 1
# end of game
print('game over')
env.destroy()
if __name__ == "__main__":
# maze game
env = Maze()
RL = DeepQNetwork(env.n_actions, env.n_features,
learning_rate=0.01,
reward_decay=0.9,
e_greedy=0.9,
replace_target_iter=200,
memory_size=2000,
# output_graph=True
)
env.after(100, run_maze)
env.mainloop()
RL.plot_cost()
================================================
FILE: contents/6_OpenAI_gym/RL_brain.py
================================================
"""
This part of code is the DQN brain, which is a brain of the agent.
All decisions are made in here.
Using Tensorflow to build the neural network.
View more on my tutorial page: https://morvanzhou.github.io/tutorials/
Using:
Tensorflow: 1.0
gym: 0.8.0
"""
import numpy as np
import pandas as pd
import tensorflow as tf
# Deep Q Network off-policy
class DeepQNetwork:
def __init__(
self,
n_actions,
n_features,
learning_rate=0.01,
reward_decay=0.9,
e_greedy=0.9,
replace_target_iter=300,
memory_size=500,
batch_size=32,
e_greedy_increment=None,
output_graph=False,
):
self.n_actions = n_actions
self.n_features = n_features
self.lr = learning_rate
self.gamma = reward_decay
self.epsilon_max = e_greedy
self.replace_target_iter = replace_target_iter
self.memory_size = memory_size
self.batch_size = batch_size
self.epsilon_increment = e_greedy_increment
self.epsilon = 0 if e_greedy_increment is not None else self.epsilon_max
# total learning step
self.learn_step_counter = 0
# initialize zero memory [s, a, r, s_]
self.memory = np.zeros((self.memory_size, n_features * 2 + 2))
# consist of [target_net, evaluate_net]
self._build_net()
t_params = tf.get_collection('target_net_params')
e_params = tf.get_collection('eval_net_params')
self.replace_target_op = [tf.assign(t, e) for t, e in zip(t_params, e_params)]
self.sess = tf.Session()
if output_graph:
# $ tensorboard --logdir=logs
# tf.train.SummaryWriter soon be deprecated, use following
tf.summary.FileWriter("logs/", self.sess.graph)
self.sess.run(tf.global_variables_initializer())
self.cost_his = []
def _build_net(self):
# ------------------ build evaluate_net ------------------
self.s = tf.placeholder(tf.float32, [None, self.n_features], name='s') # input
self.q_target = tf.placeholder(tf.float32, [None, self.n_actions], name='Q_target') # for calculating loss
with tf.variable_scope('eval_net'):
# c_names(collections_names) are the collections to store variables
c_names, n_l1, w_initializer, b_initializer = \
['eval_net_params', tf.GraphKeys.GLOBAL_VARIABLES], 10, \
tf.random_normal_initializer(0., 0.3), tf.constant_initializer(0.1) # config of layers
# first layer. collections is used later when assign to target net
with tf.variable_scope('l1'):
w1 = tf.get_variable('w1', [self.n_features, n_l1], initializer=w_initializer, collections=c_names)
b1 = tf.get_variable('b1', [1, n_l1], initializer=b_initializer, collections=c_names)
l1 = tf.nn.relu(tf.matmul(self.s, w1) + b1)
# second layer. collections is used later when assign to target net
with tf.variable_scope('l2'):
w2 = tf.get_variable('w2', [n_l1, self.n_actions], initializer=w_initializer, collections=c_names)
b2 = tf.get_variable('b2', [1, self.n_actions], initializer=b_initializer, collections=c_names)
self.q_eval = tf.matmul(l1, w2) + b2
with tf.variable_scope('loss'):
self.loss = tf.reduce_mean(tf.squared_difference(self.q_target, self.q_eval))
with tf.variable_scope('train'):
self._train_op = tf.train.RMSPropOptimizer(self.lr).minimize(self.loss)
# ------------------ build target_net ------------------
self.s_ = tf.placeholder(tf.float32, [None, self.n_features], name='s_') # input
with tf.variable_scope('target_net'):
# c_names(collections_names) are the collections to store variables
c_names = ['target_net_params', tf.GraphKeys.GLOBAL_VARIABLES]
# first layer. collections is used later when assign to target net
with tf.variable_scope('l1'):
w1 = tf.get_variable('w1', [self.n_features, n_l1], initializer=w_initializer, collections=c_names)
b1 = tf.get_variable('b1', [1, n_l1], initializer=b_initializer, collections=c_names)
l1 = tf.nn.relu(tf.matmul(self.s_, w1) + b1)
# second layer. collections is used later when assign to target net
with tf.variable_scope('l2'):
w2 = tf.get_variable('w2', [n_l1, self.n_actions], initializer=w_initializer, collections=c_names)
b2 = tf.get_variable('b2', [1, self.n_actions], initializer=b_initializer, collections=c_names)
self.q_next = tf.matmul(l1, w2) + b2
def store_transition(self, s, a, r, s_):
if not hasattr(self, 'memory_counter'):
self.memory_counter = 0
transition = np.hstack((s, [a, r], s_))
# replace the old memory with new memory
index = self.memory_counter % self.memory_size
self.memory[index, :] = transition
self.memory_counter += 1
def choose_action(self, observation):
# to have batch dimension when feed into tf placeholder
observation = observation[np.newaxis, :]
if np.random.uniform() < self.epsilon:
# forward feed the observation and get q value for every actions
actions_value = self.sess.run(self.q_eval, feed_dict={self.s: observation})
action = np.argmax(actions_value)
else:
action = np.random.randint(0, self.n_actions)
return action
def learn(self):
# check to replace target parameters
if self.learn_step_counter % self.replace_target_iter == 0:
self.sess.run(self.replace_target_op)
print('\ntarget_params_replaced\n')
# sample batch memory from all memory
if self.memory_counter > self.memory_size:
sample_index = np.random.choice(self.memory_size, size=self.batch_size)
else:
sample_index = np.random.choice(self.memory_counter, size=self.batch_size)
batch_memory = self.memory[sample_index, :]
q_next, q_eval = self.sess.run(
[self.q_next, self.q_eval],
feed_dict={
self.s_: batch_memory[:, -self.n_features:], # fixed params
self.s: batch_memory[:, :self.n_features], # newest params
})
# change q_target w.r.t q_eval's action
q_target = q_eval.copy()
batch_index = np.arange(self.batch_size, dtype=np.int32)
eval_act_index = batch_memory[:, self.n_features].astype(int)
reward = batch_memory[:, self.n_features + 1]
q_target[batch_index, eval_act_index] = reward + self.gamma * np.max(q_next, axis=1)
"""
For example in this batch I have 2 samples and 3 actions:
q_eval =
[[1, 2, 3],
[4, 5, 6]]
q_target = q_eval =
[[1, 2, 3],
[4, 5, 6]]
Then change q_target with the real q_target value w.r.t the q_eval's action.
For example in:
sample 0, I took action 0, and the max q_target value is -1;
sample 1, I took action 2, and the max q_target value is -2:
q_target =
[[-1, 2, 3],
[4, 5, -2]]
So the (q_target - q_eval) becomes:
[[(-1)-(1), 0, 0],
[0, 0, (-2)-(6)]]
We then backpropagate this error w.r.t the corresponding action to network,
leave other action as error=0 cause we didn't choose it.
"""
# train eval network
_, self.cost = self.sess.run([self._train_op, self.loss],
feed_dict={self.s: batch_memory[:, :self.n_features],
self.q_target: q_target})
self.cost_his.append(self.cost)
# increasing epsilon
self.epsilon = self.epsilon + self.epsilon_increment if self.epsilon < self.epsilon_max else self.epsilon_max
self.learn_step_counter += 1
def plot_cost(self):
import matplotlib.pyplot as plt
plt.plot(np.arange(len(self.cost_his)), self.cost_his)
plt.ylabel('Cost')
plt.xlabel('training steps')
plt.show()
================================================
FILE: contents/6_OpenAI_gym/run_CartPole.py
================================================
"""
Deep Q network,
Using:
Tensorflow: 1.0
gym: 0.7.3
"""
import gym
from RL_brain import DeepQNetwork
env = gym.make('CartPole-v0')
env = env.unwrapped
print(env.action_space)
print(env.observation_space)
print(env.observation_space.high)
print(env.observation_space.low)
RL = DeepQNetwork(n_actions=env.action_space.n,
n_features=env.observation_space.shape[0],
learning_rate=0.01, e_greedy=0.9,
replace_target_iter=100, memory_size=2000,
e_greedy_increment=0.001,)
total_steps = 0
for i_episode in range(100):
observation = env.reset()
ep_r = 0
while True:
env.render()
action = RL.choose_action(observation)
observation_, reward, done, info = env.step(action)
# the smaller theta and closer to center the better
x, x_dot, theta, theta_dot = observation_
r1 = (env.x_threshold - abs(x))/env.x_threshold - 0.8
r2 = (env.theta_threshold_radians - abs(theta))/env.theta_threshold_radians - 0.5
reward = r1 + r2
RL.store_transition(observation, action, reward, observation_)
ep_r += reward
if total_steps > 1000:
RL.learn()
if done:
print('episode: ', i_episode,
'ep_r: ', round(ep_r, 2),
' epsilon: ', round(RL.epsilon, 2))
break
observation = observation_
total_steps += 1
RL.plot_cost()
================================================
FILE: contents/6_OpenAI_gym/run_MountainCar.py
================================================
"""
Deep Q network,
Using:
Tensorflow: 1.0
gym: 0.8.0
"""
import gym
from RL_brain import DeepQNetwork
env = gym.make('MountainCar-v0')
env = env.unwrapped
print(env.action_space)
print(env.observation_space)
print(env.observation_space.high)
print(env.observation_space.low)
RL = DeepQNetwork(n_actions=3, n_features=2, learning_rate=0.001, e_greedy=0.9,
replace_target_iter=300, memory_size=3000,
e_greedy_increment=0.0002,)
total_steps = 0
for i_episode in range(10):
observation = env.reset()
ep_r = 0
while True:
env.render()
action = RL.choose_action(observation)
observation_, reward, done, info = env.step(action)
position, velocity = observation_
# the higher the better
reward = abs(position - (-0.5)) # r in [0, 1]
RL.store_transition(observation, action, reward, observation_)
if total_steps > 1000:
RL.learn()
ep_r += reward
if done:
get = '| Get' if observation_[0] >= env.unwrapped.goal_position else '| ----'
print('Epi: ', i_episode,
get,
'| Ep_r: ', round(ep_r, 4),
'| Epsilon: ', round(RL.epsilon, 2))
break
observation = observation_
total_steps += 1
RL.plot_cost()
================================================
FILE: contents/7_Policy_gradient_softmax/RL_brain.py
================================================
"""
This part of code is the reinforcement learning brain, which is a brain of the agent.
All decisions are made in here.
Policy Gradient, Reinforcement Learning.
View more on my tutorial page: https://morvanzhou.github.io/tutorials/
Using:
Tensorflow: 1.0
gym: 0.8.0
"""
import numpy as np
import tensorflow as tf
# reproducible
np.random.seed(1)
tf.set_random_seed(1)
class PolicyGradient:
def __init__(
self,
n_actions,
n_features,
learning_rate=0.01,
reward_decay=0.95,
output_graph=False,
):
self.n_actions = n_actions
self.n_features = n_features
self.lr = learning_rate
self.gamma = reward_decay
self.ep_obs, self.ep_as, self.ep_rs = [], [], []
self._build_net()
self.sess = tf.Session()
if output_graph:
# $ tensorboard --logdir=logs
# http://0.0.0.0:6006/
# tf.train.SummaryWriter soon be deprecated, use following
tf.summary.FileWriter("logs/", self.sess.graph)
self.sess.run(tf.global_variables_initializer())
def _build_net(self):
with tf.name_scope('inputs'):
self.tf_obs = tf.placeholder(tf.float32, [None, self.n_features], name="observations")
self.tf_acts = tf.placeholder(tf.int32, [None, ], name="actions_num")
self.tf_vt = tf.placeholder(tf.float32, [None, ], name="actions_value")
# fc1
layer = tf.layers.dense(
inputs=self.tf_obs,
units=10,
activation=tf.nn.tanh, # tanh activation
kernel_initializer=tf.random_normal_initializer(mean=0, stddev=0.3),
bias_initializer=tf.constant_initializer(0.1),
name='fc1'
)
# fc2
all_act = tf.layers.dense(
inputs=layer,
units=self.n_actions,
activation=None,
kernel_initializer=tf.random_normal_initializer(mean=0, stddev=0.3),
bias_initializer=tf.constant_initializer(0.1),
name='fc2'
)
self.all_act_prob = tf.nn.softmax(all_act, name='act_prob') # use softmax to convert to probability
with tf.name_scope('loss'):
# to maximize total reward (log_p * R) is to minimize -(log_p * R), and the tf only have minimize(loss)
neg_log_prob = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=all_act, labels=self.tf_acts) # this is negative log of chosen action
# or in this way:
# neg_log_prob = tf.reduce_sum(-tf.log(self.all_act_prob)*tf.one_hot(self.tf_acts, self.n_actions), axis=1)
loss = tf.reduce_mean(neg_log_prob * self.tf_vt) # reward guided loss
with tf.name_scope('train'):
self.train_op = tf.train.AdamOptimizer(self.lr).minimize(loss)
def choose_action(self, observation):
prob_weights = self.sess.run(self.all_act_prob, feed_dict={self.tf_obs: observation[np.newaxis, :]})
action = np.random.choice(range(prob_weights.shape[1]), p=prob_weights.ravel()) # select action w.r.t the actions prob
return action
def store_transition(self, s, a, r):
self.ep_obs.append(s)
self.ep_as.append(a)
self.ep_rs.append(r)
def learn(self):
# discount and normalize episode reward
discounted_ep_rs_norm = self._discount_and_norm_rewards()
# train on episode
self.sess.run(self.train_op, feed_dict={
self.tf_obs: np.vstack(self.ep_obs), # shape=[None, n_obs]
self.tf_acts: np.array(self.ep_as), # shape=[None, ]
self.tf_vt: discounted_ep_rs_norm, # shape=[None, ]
})
self.ep_obs, self.ep_as, self.ep_rs = [], [], [] # empty episode data
return discounted_ep_rs_norm
def _discount_and_norm_rewards(self):
# discount episode rewards
discounted_ep_rs = np.zeros_like(self.ep_rs)
running_add = 0
for t in reversed(range(0, len(self.ep_rs))):
running_add = running_add * self.gamma + self.ep_rs[t]
discounted_ep_rs[t] = running_add
# normalize episode rewards
discounted_ep_rs -= np.mean(discounted_ep_rs)
discounted_ep_rs /= np.std(discounted_ep_rs)
return discounted_ep_rs
================================================
FILE: contents/7_Policy_gradient_softmax/run_CartPole.py
================================================
"""
Policy Gradient, Reinforcement Learning.
The cart pole example
View more on my tutorial page: https://morvanzhou.github.io/tutorials/
Using:
Tensorflow: 1.0
gym: 0.8.0
"""
import gym
from RL_brain import PolicyGradient
import matplotlib.pyplot as plt
DISPLAY_REWARD_THRESHOLD = 400 # renders environment if total episode reward is greater then this threshold
RENDER = False # rendering wastes time
env = gym.make('CartPole-v0')
env.seed(1) # reproducible, general Policy gradient has high variance
env = env.unwrapped
print(env.action_space)
print(env.observation_space)
print(env.observation_space.high)
print(env.observation_space.low)
RL = PolicyGradient(
n_actions=env.action_space.n,
n_features=env.observation_space.shape[0],
learning_rate=0.02,
reward_decay=0.99,
# output_graph=True,
)
for i_episode in range(3000):
observation = env.reset()
while True:
if RENDER: env.render()
action = RL.choose_action(observation)
observation_, reward, done, info = env.step(action)
RL.store_transition(observation, action, reward)
if done:
ep_rs_sum = sum(RL.ep_rs)
if 'running_reward' not in globals():
running_reward = ep_rs_sum
else:
running_reward = running_reward * 0.99 + ep_rs_sum * 0.01
if running_reward > DISPLAY_REWARD_THRESHOLD: RENDER = True # rendering
print("episode:", i_episode, " reward:", int(running_reward))
vt = RL.learn()
if i_episode == 0:
plt.plot(vt) # plot the episode vt
plt.xlabel('episode steps')
plt.ylabel('normalized state-action value')
plt.show()
break
observation = observation_
================================================
FILE: contents/7_Policy_gradient_softmax/run_MountainCar.py
================================================
"""
Policy Gradient, Reinforcement Learning.
The cart pole example
View more on my tutorial page: https://morvanzhou.github.io/tutorials/
Using:
Tensorflow: 1.0
gym: 0.8.0
"""
import gym
from RL_brain import PolicyGradient
import matplotlib.pyplot as plt
DISPLAY_REWARD_THRESHOLD = -2000 # renders environment if total episode reward is greater then this threshold
# episode: 154 reward: -10667
# episode: 387 reward: -2009
# episode: 489 reward: -1006
# episode: 628 reward: -502
RENDER = False # rendering wastes time
env = gym.make('MountainCar-v0')
env.seed(1) # reproducible, general Policy gradient has high variance
env = env.unwrapped
print(env.action_space)
print(env.observation_space)
print(env.observation_space.high)
print(env.observation_space.low)
RL = PolicyGradient(
n_actions=env.action_space.n,
n_features=env.observation_space.shape[0],
learning_rate=0.02,
reward_decay=0.995,
# output_graph=True,
)
for i_episode in range(1000):
observation = env.reset()
while True:
if RENDER: env.render()
action = RL.choose_action(observation)
observation_, reward, done, info = env.step(action) # reward = -1 in all cases
RL.store_transition(observation, action, reward)
if done:
# calculate running reward
ep_rs_sum = sum(RL.ep_rs)
if 'running_reward' not in globals():
running_reward = ep_rs_sum
else:
running_reward = running_reward * 0.99 + ep_rs_sum * 0.01
if running_reward > DISPLAY_REWARD_THRESHOLD: RENDER = True # rendering
print("episode:", i_episode, " reward:", int(running_reward))
vt = RL.learn() # train
if i_episode == 30:
plt.plot(vt) # plot the episode vt
plt.xlabel('episode steps')
plt.ylabel('normalized state-action value')
plt.show()
break
observation = observation_
================================================
FILE: contents/8_Actor_Critic_Advantage/AC_CartPole.py
================================================
"""
Actor-Critic using TD-error as the Advantage, Reinforcement Learning.
The cart pole example. Policy is oscillated.
View more on my tutorial page: https://morvanzhou.github.io/tutorials/
Using:
tensorflow 1.0
gym 0.8.0
"""
import numpy as np
import tensorflow as tf
import gym
np.random.seed(2)
tf.set_random_seed(2) # reproducible
# Superparameters
OUTPUT_GRAPH = False
MAX_EPISODE = 3000
DISPLAY_REWARD_THRESHOLD = 200 # renders environment if total episode reward is greater then this threshold
MAX_EP_STEPS = 1000 # maximum time step in one episode
RENDER = False # rendering wastes time
GAMMA = 0.9 # reward discount in TD error
LR_A = 0.001 # learning rate for actor
LR_C = 0.01 # learning rate for critic
env = gym.make('CartPole-v0')
env.seed(1) # reproducible
env = env.unwrapped
N_F = env.observation_space.shape[0]
N_A = env.action_space.n
class Actor(object):
def __init__(self, sess, n_features, n_actions, lr=0.001):
self.sess = sess
self.s = tf.placeholder(tf.float32, [1, n_features], "state")
self.a = tf.placeholder(tf.int32, None, "act")
self.td_error = tf.placeholder(tf.float32, None, "td_error") # TD_error
with tf.variable_scope('Actor'):
l1 = tf.layers.dense(
inputs=self.s,
units=20, # number of hidden units
activation=tf.nn.relu,
kernel_initializer=tf.random_normal_initializer(0., .1), # weights
bias_initializer=tf.constant_initializer(0.1), # biases
name='l1'
)
self.acts_prob = tf.layers.dense(
inputs=l1,
units=n_actions, # output units
activation=tf.nn.softmax, # get action probabilities
kernel_initializer=tf.random_normal_initializer(0., .1), # weights
bias_initializer=tf.constant_initializer(0.1), # biases
name='acts_prob'
)
with tf.variable_scope('exp_v'):
log_prob = tf.log(self.acts_prob[0, self.a])
self.exp_v = tf.reduce_mean(log_prob * self.td_error) # advantage (TD_error) guided loss
with tf.variable_scope('train'):
self.train_op = tf.train.AdamOptimizer(lr).minimize(-self.exp_v) # minimize(-exp_v) = maximize(exp_v)
def learn(self, s, a, td):
s = s[np.newaxis, :]
feed_dict = {self.s: s, self.a: a, self.td_error: td}
_, exp_v = self.sess.run([self.train_op, self.exp_v], feed_dict)
return exp_v
def choose_action(self, s):
s = s[np.newaxis, :]
probs = self.sess.run(self.acts_prob, {self.s: s}) # get probabilities for all actions
return np.random.choice(np.arange(probs.shape[1]), p=probs.ravel()) # return a int
class Critic(object):
def __init__(self, sess, n_features, lr=0.01):
self.sess = sess
self.s = tf.placeholder(tf.float32, [1, n_features], "state")
self.v_ = tf.placeholder(tf.float32, [1, 1], "v_next")
self.r = tf.placeholder(tf.float32, None, 'r')
with tf.variable_scope('Critic'):
l1 = tf.layers.dense(
inputs=self.s,
units=20, # number of hidden units
activation=tf.nn.relu, # None
# have to be linear to make sure the convergence of actor.
# But linear approximator seems hardly learns the correct Q.
kernel_initializer=tf.random_normal_initializer(0., .1), # weights
bias_initializer=tf.constant_initializer(0.1), # biases
name='l1'
)
self.v = tf.layers.dense(
inputs=l1,
units=1, # output units
activation=None,
kernel_initializer=tf.random_normal_initializer(0., .1), # weights
bias_initializer=tf.constant_initializer(0.1), # biases
name='V'
)
with tf.variable_scope('squared_TD_error'):
self.td_error = self.r + GAMMA * self.v_ - self.v
self.loss = tf.square(self.td_error) # TD_error = (r+gamma*V_next) - V_eval
with tf.variable_scope('train'):
self.train_op = tf.train.AdamOptimizer(lr).minimize(self.loss)
def learn(self, s, r, s_):
s, s_ = s[np.newaxis, :], s_[np.newaxis, :]
v_ = self.sess.run(self.v, {self.s: s_})
td_error, _ = self.sess.run([self.td_error, self.train_op],
{self.s: s, self.v_: v_, self.r: r})
return td_error
sess = tf.Session()
actor = Actor(sess, n_features=N_F, n_actions=N_A, lr=LR_A)
critic = Critic(sess, n_features=N_F, lr=LR_C) # we need a good teacher, so the teacher should learn faster than the actor
sess.run(tf.global_variables_initializer())
if OUTPUT_GRAPH:
tf.summary.FileWriter("logs/", sess.graph)
for i_episode in range(MAX_EPISODE):
s = env.reset()
t = 0
track_r = []
while True:
if RENDER: env.render()
a = actor.choose_action(s)
s_, r, done, info = env.step(a)
if done: r = -20
track_r.append(r)
td_error = critic.learn(s, r, s_) # gradient = grad[r + gamma * V(s_) - V(s)]
actor.learn(s, a, td_error) # true_gradient = grad[logPi(s,a) * td_error]
s = s_
t += 1
if done or t >= MAX_EP_STEPS:
ep_rs_sum = sum(track_r)
if 'running_reward' not in globals():
running_reward = ep_rs_sum
else:
running_reward = running_reward * 0.95 + ep_rs_sum * 0.05
if running_reward > DISPLAY_REWARD_THRESHOLD: RENDER = True # rendering
print("episode:", i_episode, " reward:", int(running_reward))
break
================================================
FILE: contents/8_Actor_Critic_Advantage/AC_continue_Pendulum.py
================================================
"""
Actor-Critic with continuous action using TD-error as the Advantage, Reinforcement Learning.
The Pendulum example (based on https://github.com/dennybritz/reinforcement-learning/blob/master/PolicyGradient/Continuous%20MountainCar%20Actor%20Critic%20Solution.ipynb)
Cannot converge!!! oscillate!!!
View more on my tutorial page: https://morvanzhou.github.io/tutorials/
Using:
tensorflow r1.3
gym 0.8.0
"""
import tensorflow as tf
import numpy as np
import gym
np.random.seed(2)
tf.set_random_seed(2) # reproducible
class Actor(object):
def __init__(self, sess, n_features, action_bound, lr=0.0001):
self.sess = sess
self.s = tf.placeholder(tf.float32, [1, n_features], "state")
self.a = tf.placeholder(tf.float32, None, name="act")
self.td_error = tf.placeholder(tf.float32, None, name="td_error") # TD_error
l1 = tf.layers.dense(
inputs=self.s,
units=30, # number of hidden units
activation=tf.nn.relu,
kernel_initializer=tf.random_normal_initializer(0., .1), # weights
bias_initializer=tf.constant_initializer(0.1), # biases
name='l1'
)
mu = tf.layers.dense(
inputs=l1,
units=1, # number of hidden units
activation=tf.nn.tanh,
kernel_initializer=tf.random_normal_initializer(0., .1), # weights
bias_initializer=tf.constant_initializer(0.1), # biases
name='mu'
)
sigma = tf.layers.dense(
inputs=l1,
units=1, # output units
activation=tf.nn.softplus, # get action probabilities
kernel_initializer=tf.random_normal_initializer(0., .1), # weights
bias_initializer=tf.constant_initializer(1.), # biases
name='sigma'
)
global_step = tf.Variable(0, trainable=False)
# self.e = epsilon = tf.train.exponential_decay(2., global_step, 1000, 0.9)
self.mu, self.sigma = tf.squeeze(mu*2), tf.squeeze(sigma+0.1)
self.normal_dist = tf.distributions.Normal(self.mu, self.sigma)
self.action = tf.clip_by_value(self.normal_dist.sample(1), action_bound[0], action_bound[1])
with tf.name_scope('exp_v'):
log_prob = self.normal_dist.log_prob(self.a) # loss without advantage
self.exp_v = log_prob * self.td_error # advantage (TD_error) guided loss
# Add cross entropy cost to encourage exploration
self.exp_v += 0.01*self.normal_dist.entropy()
with tf.name_scope('train'):
self.train_op = tf.train.AdamOptimizer(lr).minimize(-self.exp_v, global_step) # min(v) = max(-v)
def learn(self, s, a, td):
s = s[np.newaxis, :]
feed_dict = {self.s: s, self.a: a, self.td_error: td}
_, exp_v = self.sess.run([self.train_op, self.exp_v], feed_dict)
return exp_v
def choose_action(self, s):
s = s[np.newaxis, :]
return self.sess.run(self.action, {self.s: s}) # get probabilities for all actions
class Critic(object):
def __init__(self, sess, n_features, lr=0.01):
self.sess = sess
with tf.name_scope('inputs'):
self.s = tf.placeholder(tf.float32, [1, n_features], "state")
self.v_ = tf.placeholder(tf.float32, [1, 1], name="v_next")
self.r = tf.placeholder(tf.float32, name='r')
with tf.variable_scope('Critic'):
l1 = tf.layers.dense(
inputs=self.s,
units=30, # number of hidden units
activation=tf.nn.relu,
kernel_initializer=tf.random_normal_initializer(0., .1), # weights
bias_initializer=tf.constant_initializer(0.1), # biases
name='l1'
)
self.v = tf.layers.dense(
inputs=l1,
units=1, # output units
activation=None,
kernel_initializer=tf.random_normal_initializer(0., .1), # weights
bias_initializer=tf.constant_initializer(0.1), # biases
name='V'
)
with tf.variable_scope('squared_TD_error'):
self.td_error = tf.reduce_mean(self.r + GAMMA * self.v_ - self.v)
self.loss = tf.square(self.td_error) # TD_error = (r+gamma*V_next) - V_eval
with tf.variable_scope('train'):
self.train_op = tf.train.AdamOptimizer(lr).minimize(self.loss)
def learn(self, s, r, s_):
s, s_ = s[np.newaxis, :], s_[np.newaxis, :]
v_ = self.sess.run(self.v, {self.s: s_})
td_error, _ = self.sess.run([self.td_error, self.train_op],
{self.s: s, self.v_: v_, self.r: r})
return td_error
OUTPUT_GRAPH = False
MAX_EPISODE = 1000
MAX_EP_STEPS = 200
DISPLAY_REWARD_THRESHOLD = -100 # renders environment if total episode reward is greater then this threshold
RENDER = False # rendering wastes time
GAMMA = 0.9
LR_A = 0.001 # learning rate for actor
LR_C = 0.01 # learning rate for critic
env = gym.make('Pendulum-v0')
env.seed(1) # reproducible
env = env.unwrapped
N_S = env.observation_space.shape[0]
A_BOUND = env.action_space.high
sess = tf.Session()
actor = Actor(sess, n_features=N_S, lr=LR_A, action_bound=[-A_BOUND, A_BOUND])
critic = Critic(sess, n_features=N_S, lr=LR_C)
sess.run(tf.global_variables_initializer())
if OUTPUT_GRAPH:
tf.summary.FileWriter("logs/", sess.graph)
for i_episode in range(MAX_EPISODE):
s = env.reset()
t = 0
ep_rs = []
while True:
# if RENDER:
env.render()
a = actor.choose_action(s)
s_, r, done, info = env.step(a)
r /= 10
td_error = critic.learn(s, r, s_) # gradient = grad[r + gamma * V(s_) - V(s)]
actor.learn(s, a, td_error) # true_gradient = grad[logPi(s,a) * td_error]
s = s_
t += 1
ep_rs.append(r)
if t > MAX_EP_STEPS:
ep_rs_sum = sum(ep_rs)
if 'running_reward' not in globals():
running_reward = ep_rs_sum
else:
running_reward = running_reward * 0.9 + ep_rs_sum * 0.1
if running_reward > DISPLAY_REWARD_THRESHOLD: RENDER = True # rendering
print("episode:", i_episode, " reward:", int(running_reward))
break
================================================
FILE: contents/9_Deep_Deterministic_Policy_Gradient_DDPG/DDPG.py
================================================
"""
Deep Deterministic Policy Gradient (DDPG), Reinforcement Learning.
DDPG is Actor Critic based algorithm.
Pendulum example.
View more on my tutorial page: https://morvanzhou.github.io/tutorials/
Using:
tensorflow 1.0
gym 0.8.0
"""
import tensorflow as tf
import numpy as np
import gym
import time
np.random.seed(1)
tf.set_random_seed(1)
##################### hyper parameters ####################
MAX_EPISODES = 200
MAX_EP_STEPS = 200
LR_A = 0.001 # learning rate for actor
LR_C = 0.001 # learning rate for critic
GAMMA = 0.9 # reward discount
REPLACEMENT = [
dict(name='soft', tau=0.01),
dict(name='hard', rep_iter_a=600, rep_iter_c=500)
][0] # you can try different target replacement strategies
MEMORY_CAPACITY = 10000
BATCH_SIZE = 32
RENDER = False
OUTPUT_GRAPH = True
ENV_NAME = 'Pendulum-v0'
############################### Actor ####################################
class Actor(object):
def __init__(self, sess, action_dim, action_bound, learning_rate, replacement):
self.sess = sess
self.a_dim = action_dim
self.action_bound = action_bound
self.lr = learning_rate
self.replacement = replacement
self.t_replace_counter = 0
with tf.variable_scope('Actor'):
# input s, output a
self.a = self._build_net(S, scope='eval_net', trainable=True)
# input s_, output a, get a_ for critic
self.a_ = self._build_net(S_, scope='target_net', trainable=False)
self.e_params = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope='Actor/eval_net')
self.t_params = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope='Actor/target_net')
if self.replacement['name'] == 'hard':
self.t_replace_counter = 0
self.hard_replace = [tf.assign(t, e) for t, e in zip(self.t_params, self.e_params)]
else:
self.soft_replace = [tf.assign(t, (1 - self.replacement['tau']) * t + self.replacement['tau'] * e)
for t, e in zip(self.t_params, self.e_params)]
def _build_net(self, s, scope, trainable):
with tf.variable_scope(scope):
init_w = tf.random_normal_initializer(0., 0.3)
init_b = tf.constant_initializer(0.1)
net = tf.layers.dense(s, 30, activation=tf.nn.relu,
kernel_initializer=init_w, bias_initializer=init_b, name='l1',
trainable=trainable)
with tf.variable_scope('a'):
actions = tf.layers.dense(net, self.a_dim, activation=tf.nn.tanh, kernel_initializer=init_w,
bias_initializer=init_b, name='a', trainable=trainable)
scaled_a = tf.multiply(actions, self.action_bound, name='scaled_a') # Scale output to -action_bound to action_bound
return scaled_a
def learn(self, s): # batch update
self.sess.run(self.train_op, feed_dict={S: s})
if self.replacement['name'] == 'soft':
self.sess.run(self.soft_replace)
else:
if self.t_replace_counter % self.replacement['rep_iter_a'] == 0:
self.sess.run(self.hard_replace)
self.t_replace_counter += 1
def choose_action(self, s):
s = s[np.newaxis, :] # single state
return self.sess.run(self.a, feed_dict={S: s})[0] # single action
def add_grad_to_graph(self, a_grads):
with tf.variable_scope('policy_grads'):
# ys = policy;
# xs = policy's parameters;
# a_grads = the gradients of the policy to get more Q
# tf.gradients will calculate dys/dxs with a initial gradients for ys, so this is dq/da * da/dparams
self.policy_grads = tf.gradients(ys=self.a, xs=self.e_params, grad_ys=a_grads)
with tf.variable_scope('A_train'):
opt = tf.train.AdamOptimizer(-self.lr) # (- learning rate) for ascent policy
self.train_op = opt.apply_gradients(zip(self.policy_grads, self.e_params))
############################### Critic ####################################
class Critic(object):
def __init__(self, sess, state_dim, action_dim, learning_rate, gamma, replacement, a, a_):
self.sess = sess
self.s_dim = state_dim
self.a_dim = action_dim
self.lr = learning_rate
self.gamma = gamma
self.replacement = replacement
with tf.variable_scope('Critic'):
# Input (s, a), output q
self.a = tf.stop_gradient(a) # stop critic update flows to actor
self.q = self._build_net(S, self.a, 'eval_net', trainable=True)
# Input (s_, a_), output q_ for q_target
self.q_ = self._build_net(S_, a_, 'target_net', trainable=False) # target_q is based on a_ from Actor's target_net
self.e_params = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope='Critic/eval_net')
self.t_params = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope='Critic/target_net')
with tf.variable_scope('target_q'):
self.target_q = R + self.gamma * self.q_
with tf.variable_scope('TD_error'):
self.loss = tf.reduce_mean(tf.squared_difference(self.target_q, self.q))
with tf.variable_scope('C_train'):
self.train_op = tf.train.AdamOptimizer(self.lr).minimize(self.loss)
with tf.variable_scope('a_grad'):
self.a_grads = tf.gradients(self.q, self.a)[0] # tensor of gradients of each sample (None, a_dim)
if self.replacement['name'] == 'hard':
self.t_replace_counter = 0
self.hard_replacement = [tf.assign(t, e) for t, e in zip(self.t_params, self.e_params)]
else:
self.soft_replacement = [tf.assign(t, (1 - self.replacement['tau']) * t + self.replacement['tau'] * e)
for t, e in zip(self.t_params, self.e_params)]
def _build_net(self, s, a, scope, trainable):
with tf.variable_scope(scope):
init_w = tf.random_normal_initializer(0., 0.1)
init_b = tf.constant_initializer(0.1)
with tf.variable_scope('l1'):
n_l1 = 30
w1_s = tf.get_variable('w1_s', [self.s_dim, n_l1], initializer=init_w, trainable=trainable)
w1_a = tf.get_variable('w1_a', [self.a_dim, n_l1], initializer=init_w, trainable=trainable)
b1 = tf.get_variable('b1', [1, n_l1], initializer=init_b, trainable=trainable)
net = tf.nn.relu(tf.matmul(s, w1_s) + tf.matmul(a, w1_a) + b1)
with tf.variable_scope('q'):
q = tf.layers.dense(net, 1, kernel_initializer=init_w, bias_initializer=init_b, trainable=trainable) # Q(s,a)
return q
def learn(self, s, a, r, s_):
self.sess.run(self.train_op, feed_dict={S: s, self.a: a, R: r, S_: s_})
if self.replacement['name'] == 'soft':
self.sess.run(self.soft_replacement)
else:
if self.t_replace_counter % self.replacement['rep_iter_c'] == 0:
self.sess.run(self.hard_replacement)
self.t_replace_counter += 1
##################### Memory ####################
class Memory(object):
def __init__(self, capacity, dims):
self.capacity = capacity
self.data = np.zeros((capacity, dims))
self.pointer = 0
def store_transition(self, s, a, r, s_):
transition = np.hstack((s, a, [r], s_))
index = self.pointer % self.capacity # replace the old memory with new memory
self.data[index, :] = transition
self.pointer += 1
def sample(self, n):
assert self.pointer >= self.capacity, 'Memory has not been fulfilled'
indices = np.random.choice(self.capacity, size=n)
return self.data[indices, :]
env = gym.make(ENV_NAME)
env = env.unwrapped
env.seed(1)
state_dim = env.observation_space.shape[0]
action_dim = env.action_space.shape[0]
action_bound = env.action_space.high
# all placeholder for tf
with tf.name_scope('S'):
S = tf.placeholder(tf.float32, shape=[None, state_dim], name='s')
with tf.name_scope('R'):
R = tf.placeholder(tf.float32, [None, 1], name='r')
with tf.name_scope('S_'):
S_ = tf.placeholder(tf.float32, shape=[None, state_dim], name='s_')
sess = tf.Session()
# Create actor and critic.
# They are actually connected to each other, details can be seen in tensorboard or in this picture:
actor = Actor(sess, action_dim, action_bound, LR_A, REPLACEMENT)
critic = Critic(sess, state_dim, action_dim, LR_C, GAMMA, REPLACEMENT, actor.a, actor.a_)
actor.add_grad_to_graph(critic.a_grads)
sess.run(tf.global_variables_initializer())
M = Memory(MEMORY_CAPACITY, dims=2 * state_dim + action_dim + 1)
if OUTPUT_GRAPH:
tf.summary.FileWriter("logs/", sess.graph)
var = 3 # control exploration
t1 = time.time()
for i in range(MAX_EPISODES):
s = env.reset()
ep_reward = 0
for j in range(MAX_EP_STEPS):
if RENDER:
env.render()
# Add exploration noise
a = actor.choose_action(s)
a = np.clip(np.random.normal(a, var), -2, 2) # add randomness to action selection for exploration
s_, r, done, info = env.step(a)
M.store_transition(s, a, r / 10, s_)
if M.pointer > MEMORY_CAPACITY:
var *= .9995 # decay the action randomness
b_M = M.sample(BATCH_SIZE)
b_s = b_M[:, :state_dim]
b_a = b_M[:, state_dim: state_dim + action_dim]
b_r = b_M[:, -state_dim - 1: -state_dim]
b_s_ = b_M[:, -state_dim:]
critic.learn(b_s, b_a, b_r, b_s_)
actor.learn(b_s)
s = s_
ep_reward += r
if j == MAX_EP_STEPS-1:
print('Episode:', i, ' Reward: %i' % int(ep_reward), 'Explore: %.2f' % var, )
if ep_reward > -300:
RENDER = True
break
print('Running time: ', time.time()-t1)
================================================
FILE: contents/9_Deep_Deterministic_Policy_Gradient_DDPG/DDPG_update.py
================================================
"""
Deep Deterministic Policy Gradient (DDPG), Reinforcement Learning.
DDPG is Actor Critic based algorithm.
Pendulum example.
View more on my tutorial page: https://morvanzhou.github.io/tutorials/
Using:
tensorflow 1.0
gym 0.8.0
"""
import tensorflow as tf
import numpy as np
import gym
import time
##################### hyper parameters ####################
MAX_EPISODES = 200
MAX_EP_STEPS = 200
LR_A = 0.001 # learning rate for actor
LR_C = 0.002 # learning rate for critic
GAMMA = 0.9 # reward discount
TAU = 0.01 # soft replacement
MEMORY_CAPACITY = 10000
BATCH_SIZE = 32
RENDER = False
ENV_NAME = 'Pendulum-v0'
############################### DDPG ####################################
class DDPG(object):
def __init__(self, a_dim, s_dim, a_bound,):
self.memory = np.zeros((MEMORY_CAPACITY, s_dim * 2 + a_dim + 1), dtype=np.float32)
self.pointer = 0
self.sess = tf.Session()
self.a_dim, self.s_dim, self.a_bound = a_dim, s_dim, a_bound,
self.S = tf.placeholder(tf.float32, [None, s_dim], 's')
self.S_ = tf.placeholder(tf.float32, [None, s_dim], 's_')
self.R = tf.placeholder(tf.float32, [None, 1], 'r')
with tf.variable_scope('Actor'):
self.a = self._build_a(self.S, scope='eval', trainable=True)
a_ = self._build_a(self.S_, scope='target', trainable=False)
with tf.variable_scope('Critic'):
# assign self.a = a in memory when calculating q for td_error,
# otherwise the self.a is from Actor when updating Actor
q = self._build_c(self.S, self.a, scope='eval', trainable=True)
q_ = self._build_c(self.S_, a_, scope='target', trainable=False)
# networks parameters
self.ae_params = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope='Actor/eval')
self.at_params = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope='Actor/target')
self.ce_params = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope='Critic/eval')
self.ct_params = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope='Critic/target')
# target net replacement
self.soft_replace = [tf.assign(t, (1 - TAU) * t + TAU * e)
for t, e in zip(self.at_params + self.ct_params, self.ae_params + self.ce_params)]
q_target = self.R + GAMMA * q_
# in the feed_dic for the td_error, the self.a should change to actions in memory
td_error = tf.losses.mean_squared_error(labels=q_target, predictions=q)
self.ctrain = tf.train.AdamOptimizer(LR_C).minimize(td_error, var_list=self.ce_params)
a_loss = - tf.reduce_mean(q) # maximize the q
self.atrain = tf.train.AdamOptimizer(LR_A).minimize(a_loss, var_list=self.ae_params)
self.sess.run(tf.global_variables_initializer())
def choose_action(self, s):
return self.sess.run(self.a, {self.S: s[np.newaxis, :]})[0]
def learn(self):
# soft target replacement
self.sess.run(self.soft_replace)
indices = np.random.choice(MEMORY_CAPACITY, size=BATCH_SIZE)
bt = self.memory[indices, :]
bs = bt[:, :self.s_dim]
ba = bt[:, self.s_dim: self.s_dim + self.a_dim]
br = bt[:, -self.s_dim - 1: -self.s_dim]
bs_ = bt[:, -self.s_dim:]
self.sess.run(self.atrain, {self.S: bs})
self.sess.run(self.ctrain, {self.S: bs, self.a: ba, self.R: br, self.S_: bs_})
def store_transition(self, s, a, r, s_):
transition = np.hstack((s, a, [r], s_))
index = self.pointer % MEMORY_CAPACITY # replace the old memory with new memory
self.memory[index, :] = transition
self.pointer += 1
def _build_a(self, s, scope, trainable):
with tf.variable_scope(scope):
net = tf.layers.dense(s, 30, activation=tf.nn.relu, name='l1', trainable=trainable)
a = tf.layers.dense(net, self.a_dim, activation=tf.nn.tanh, name='a', trainable=trainable)
return tf.multiply(a, self.a_bound, name='scaled_a')
def _build_c(self, s, a, scope, trainable):
with tf.variable_scope(scope):
n_l1 = 30
w1_s = tf.get_variable('w1_s', [self.s_dim, n_l1], trainable=trainable)
w1_a = tf.get_variable('w1_a', [self.a_dim, n_l1], trainable=trainable)
b1 = tf.get_variable('b1', [1, n_l1], trainable=trainable)
net = tf.nn.relu(tf.matmul(s, w1_s) + tf.matmul(a, w1_a) + b1)
return tf.layers.dense(net, 1, trainable=trainable) # Q(s,a)
############################### training ####################################
env = gym.make(ENV_NAME)
env = env.unwrapped
env.seed(1)
s_dim = env.observation_space.shape[0]
a_dim = env.action_space.shape[0]
a_bound = env.action_space.high
ddpg = DDPG(a_dim, s_dim, a_bound)
var = 3 # control exploration
t1 = time.time()
for i in range(MAX_EPISODES):
s = env.reset()
ep_reward = 0
for j in range(MAX_EP_STEPS):
if RENDER:
env.render()
# Add exploration noise
a = ddpg.choose_action(s)
a = np.clip(np.random.normal(a, var), -2, 2) # add randomness to action selection for exploration
s_, r, done, info = env.step(a)
ddpg.store_transition(s, a, r / 10, s_)
if ddpg.pointer > MEMORY_CAPACITY:
var *= .9995 # decay the action randomness
ddpg.learn()
s = s_
ep_reward += r
if j == MAX_EP_STEPS-1:
print('Episode:', i, ' Reward: %i' % int(ep_reward), 'Explore: %.2f' % var, )
# if ep_reward > -300:RENDER = True
break
print('Running time: ', time.time() - t1)
================================================
FILE: contents/9_Deep_Deterministic_Policy_Gradient_DDPG/DDPG_update2.py
================================================
"""
Note: This is a updated version from my previous code,
for the target network, I use moving average to soft replace target parameters instead using assign function.
By doing this, it has 20% speed up on my machine (CPU).
Deep Deterministic Policy Gradient (DDPG), Reinforcement Learning.
DDPG is Actor Critic based algorithm.
Pendulum example.
View more on my tutorial page: https://morvanzhou.github.io/tutorials/
Using:
tensorflow 1.0
gym 0.8.0
"""
import tensorflow as tf
import numpy as np
import gym
import time
##################### hyper parameters ####################
MAX_EPISODES = 200
MAX_EP_STEPS = 200
LR_A = 0.001 # learning rate for actor
LR_C = 0.002 # learning rate for critic
GAMMA = 0.9 # reward discount
TAU = 0.01 # soft replacement
MEMORY_CAPACITY = 10000
BATCH_SIZE = 32
RENDER = False
ENV_NAME = 'Pendulum-v0'
############################### DDPG ####################################
class DDPG(object):
def __init__(self, a_dim, s_dim, a_bound,):
self.memory = np.zeros((MEMORY_CAPACITY, s_dim * 2 + a_dim + 1), dtype=np.float32)
self.pointer = 0
self.sess = tf.Session()
self.a_dim, self.s_dim, self.a_bound = a_dim, s_dim, a_bound,
self.S = tf.placeholder(tf.float32, [None, s_dim], 's')
self.S_ = tf.placeholder(tf.float32, [None, s_dim], 's_')
self.R = tf.placeholder(tf.float32, [None, 1], 'r')
self.a = self._build_a(self.S,)
q = self._build_c(self.S, self.a, )
a_params = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope='Actor')
c_params = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope='Critic')
ema = tf.train.ExponentialMovingAverage(decay=1 - TAU) # soft replacement
def ema_getter(getter, name, *args, **kwargs):
return ema.average(getter(name, *args, **kwargs))
target_update = [ema.apply(a_params), ema.apply(c_params)] # soft update operation
a_ = self._build_a(self.S_, reuse=True, custom_getter=ema_getter) # replaced target parameters
q_ = self._build_c(self.S_, a_, reuse=True, custom_getter=ema_getter)
a_loss = - tf.reduce_mean(q) # maximize the q
self.atrain = tf.train.AdamOptimizer(LR_A).minimize(a_loss, var_list=a_params)
with tf.control_dependencies(target_update): # soft replacement happened at here
q_target = self.R + GAMMA * q_
td_error = tf.losses.mean_squared_error(labels=q_target, predictions=q)
self.ctrain = tf.train.AdamOptimizer(LR_C).minimize(td_error, var_list=c_params)
self.sess.run(tf.global_variables_initializer())
def choose_action(self, s):
return self.sess.run(self.a, {self.S: s[np.newaxis, :]})[0]
def learn(self):
indices = np.random.choice(MEMORY_CAPACITY, size=BATCH_SIZE)
bt = self.memory[indices, :]
bs = bt[:, :self.s_dim]
ba = bt[:, self.s_dim: self.s_dim + self.a_dim]
br = bt[:, -self.s_dim - 1: -self.s_dim]
bs_ = bt[:, -self.s_dim:]
self.sess.run(self.atrain, {self.S: bs})
self.sess.run(self.ctrain, {self.S: bs, self.a: ba, self.R: br, self.S_: bs_})
def store_transition(self, s, a, r, s_):
transition = np.hstack((s, a, [r], s_))
index = self.pointer % MEMORY_CAPACITY # replace the old memory with new memory
self.memory[index, :] = transition
self.pointer += 1
def _build_a(self, s, reuse=None, custom_getter=None):
trainable = True if reuse is None else False
with tf.variable_scope('Actor', reuse=reuse, custom_getter=custom_getter):
net = tf.layers.dense(s, 30, activation=tf.nn.relu, name='l1', trainable=trainable)
a = tf.layers.dense(net, self.a_dim, activation=tf.nn.tanh, name='a', trainable=trainable)
return tf.multiply(a, self.a_bound, name='scaled_a')
def _build_c(self, s, a, reuse=None, custom_getter=None):
trainable = True if reuse is None else False
with tf.variable_scope('Critic', reuse=reuse, custom_getter=custom_getter):
n_l1 = 30
w1_s = tf.get_variable('w1_s', [self.s_dim, n_l1], trainable=trainable)
w1_a = tf.get_variable('w1_a', [self.a_dim, n_l1], trainable=trainable)
b1 = tf.get_variable('b1', [1, n_l1], trainable=trainable)
net = tf.nn.relu(tf.matmul(s, w1_s) + tf.matmul(a, w1_a) + b1)
return tf.layers.dense(net, 1, trainable=trainable) # Q(s,a)
############################### training ####################################
env = gym.make(ENV_NAME)
env = env.unwrapped
env.seed(1)
s_dim = env.observation_space.shape[0]
a_dim = env.action_space.shape[0]
a_bound = env.action_space.high
ddpg = DDPG(a_dim, s_dim, a_bound)
var = 3 # control exploration
t1 = time.time()
for i in range(MAX_EPISODES):
s = env.reset()
ep_reward = 0
for j in range(MAX_EP_STEPS):
if RENDER:
env.render()
# Add exploration noise
a = ddpg.choose_action(s)
a = np.clip(np.random.normal(a, var), -2, 2) # add randomness to action selection for exploration
s_, r, done, info = env.step(a)
ddpg.store_transition(s, a, r / 10, s_)
if ddpg.pointer > MEMORY_CAPACITY:
var *= .9995 # decay the action randomness
ddpg.learn()
s = s_
ep_reward += r
if j == MAX_EP_STEPS-1:
print('Episode:', i, ' Reward: %i' % int(ep_reward), 'Explore: %.2f' % var, )
# if ep_reward > -300:RENDER = True
break
print('Running time: ', time.time() - t1)
================================================
FILE: contents/Curiosity_Model/Curiosity.py
================================================
"""This is a simple implementation of [Large-Scale Study of Curiosity-Driven Learning](https://arxiv.org/abs/1808.04355)"""
import numpy as np
import tensorflow as tf
import gym
import matplotlib.pyplot as plt
class CuriosityNet:
def __init__(
self,
n_a,
n_s,
lr=0.01,
gamma=0.98,
epsilon=0.95,
replace_target_iter=300,
memory_size=10000,
batch_size=128,
output_graph=False,
):
self.n_a = n_a
self.n_s = n_s
self.lr = lr
self.gamma = gamma
self.epsilon = epsilon
self.replace_target_iter = replace_target_iter
self.memory_size = memory_size
self.batch_size = batch_size
# total learning step
self.learn_step_counter = 0
self.memory_counter = 0
# initialize zero memory [s, a, r, s_]
self.memory = np.zeros((self.memory_size, n_s * 2 + 2))
self.tfs, self.tfa, self.tfr, self.tfs_, self.dyn_train, self.dqn_train, self.q, self.int_r = \
self._build_nets()
t_params = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope='target_net')
e_params = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope='eval_net')
with tf.variable_scope('hard_replacement'):
self.target_replace_op = [tf.assign(t, e) for t, e in zip(t_params, e_params)]
self.sess = tf.Session()
if output_graph:
tf.summary.FileWriter("logs/", self.sess.graph)
self.sess.run(tf.global_variables_initializer())
def _build_nets(self):
tfs = tf.placeholder(tf.float32, [None, self.n_s], name="s") # input State
tfa = tf.placeholder(tf.int32, [None, ], name="a") # input Action
tfr = tf.placeholder(tf.float32, [None, ], name="ext_r") # extrinsic reward
tfs_ = tf.placeholder(tf.float32, [None, self.n_s], name="s_") # input Next State
# dynamics net
dyn_s_, curiosity, dyn_train = self._build_dynamics_net(tfs, tfa, tfs_)
# normal RL model
total_reward = tf.add(curiosity, tfr, name="total_r")
q, dqn_loss, dqn_train = self._build_dqn(tfs, tfa, total_reward, tfs_)
return tfs, tfa, tfr, tfs_, dyn_train, dqn_train, q, curiosity
def _build_dynamics_net(self, s, a, s_):
with tf.variable_scope("dyn_net"):
float_a = tf.expand_dims(tf.cast(a, dtype=tf.float32, name="float_a"), axis=1, name="2d_a")
sa = tf.concat((s, float_a), axis=1, name="sa")
encoded_s_ = s_ # here we use s_ as the encoded s_
dyn_l = tf.layers.dense(sa, 32, activation=tf.nn.relu)
dyn_s_ = tf.layers.dense(dyn_l, self.n_s) # predicted s_
with tf.name_scope("int_r"):
squared_diff = tf.reduce_sum(tf.square(encoded_s_ - dyn_s_), axis=1) # intrinsic reward
# It is better to reduce the learning rate in order to stay curious
train_op = tf.train.RMSPropOptimizer(self.lr, name="dyn_opt").minimize(tf.reduce_mean(squared_diff))
return dyn_s_, squared_diff, train_op
def _build_dqn(self, s, a, r, s_):
with tf.variable_scope('eval_net'):
e1 = tf.layers.dense(s, 128, tf.nn.relu)
q = tf.layers.dense(e1, self.n_a, name="q")
with tf.variable_scope('target_net'):
t1 = tf.layers.dense(s_, 128, tf.nn.relu)
q_ = tf.layers.dense(t1, self.n_a, name="q_")
with tf.variable_scope('q_target'):
q_target = r + self.gamma * tf.reduce_max(q_, axis=1, name="Qmax_s_")
with tf.variable_scope('q_wrt_a'):
a_indices = tf.stack([tf.range(tf.shape(a)[0], dtype=tf.int32), a], axis=1)
q_wrt_a = tf.gather_nd(params=q, indices=a_indices)
loss = tf.losses.mean_squared_error(labels=q_target, predictions=q_wrt_a) # TD error
train_op = tf.train.RMSPropOptimizer(self.lr, name="dqn_opt").minimize(
loss, var_list=tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, "eval_net"))
return q, loss, train_op
def store_transition(self, s, a, r, s_):
transition = np.hstack((s, [a, r], s_))
# replace the old memory with new memory
index = self.memory_counter % self.memory_size
self.memory[index, :] = transition
self.memory_counter += 1
def choose_action(self, observation):
# to have batch dimension when feed into tf placeholder
s = observation[np.newaxis, :]
if np.random.uniform() < self.epsilon:
# forward feed the observation and get q value for every actions
actions_value = self.sess.run(self.q, feed_dict={self.tfs: s})
action = np.argmax(actions_value)
else:
action = np.random.randint(0, self.n_a)
return action
def learn(self):
# check to replace target parameters
if self.learn_step_counter % self.replace_target_iter == 0:
self.sess.run(self.target_replace_op)
# sample batch memory from all memory
top = self.memory_size if self.memory_counter > self.memory_size else self.memory_counter
sample_index = np.random.choice(top, size=self.batch_size)
batch_memory = self.memory[sample_index, :]
bs, ba, br, bs_ = batch_memory[:, :self.n_s], batch_memory[:, self.n_s], \
batch_memory[:, self.n_s + 1], batch_memory[:, -self.n_s:]
self.sess.run(self.dqn_train, feed_dict={self.tfs: bs, self.tfa: ba, self.tfr: br, self.tfs_: bs_})
if self.learn_step_counter % 1000 == 0: # delay training in order to stay curious
self.sess.run(self.dyn_train, feed_dict={self.tfs: bs, self.tfa: ba, self.tfs_: bs_})
self.learn_step_counter += 1
env = gym.make('MountainCar-v0')
env = env.unwrapped
dqn = CuriosityNet(n_a=3, n_s=2, lr=0.01, output_graph=False)
ep_steps = []
for epi in range(200):
s = env.reset()
steps = 0
while True:
env.render()
a = dqn.choose_action(s)
s_, r, done, info = env.step(a)
dqn.store_transition(s, a, r, s_)
dqn.learn()
if done:
print('Epi: ', epi, "| steps: ", steps)
ep_steps.append(steps)
break
s = s_
steps += 1
plt.plot(ep_steps)
plt.ylabel("steps")
plt.xlabel("episode")
plt.show()
================================================
FILE: contents/Curiosity_Model/Random_Network_Distillation.py
================================================
"""This is a simple implementation of [Exploration by Random Network Distillation](https://arxiv.org/abs/1810.12894)"""
import numpy as np
import tensorflow as tf
import gym
import matplotlib.pyplot as plt
class CuriosityNet:
def __init__(
self,
n_a,
n_s,
lr=0.01,
gamma=0.95,
epsilon=1.,
replace_target_iter=300,
memory_size=10000,
batch_size=128,
output_graph=False,
):
self.n_a = n_a
self.n_s = n_s
self.lr = lr
self.gamma = gamma
self.epsilon = epsilon
self.replace_target_iter = replace_target_iter
self.memory_size = memory_size
self.batch_size = batch_size
self.s_encode_size = 1000 # give a hard job for predictor to learn
# total learning step
self.learn_step_counter = 0
self.memory_counter = 0
# initialize zero memory [s, a, r, s_]
self.memory = np.zeros((self.memory_size, n_s * 2 + 2))
self.tfs, self.tfa, self.tfr, self.tfs_, self.pred_train, self.dqn_train, self.q = \
self._build_nets()
t_params = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope='target_net')
e_params = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope='eval_net')
with tf.variable_scope('hard_replacement'):
self.target_replace_op = [tf.assign(t, e) for t, e in zip(t_params, e_params)]
self.sess = tf.Session()
if output_graph:
tf.summary.FileWriter("logs/", self.sess.graph)
self.sess.run(tf.global_variables_initializer())
def _build_nets(self):
tfs = tf.placeholder(tf.float32, [None, self.n_s], name="s") # input State
tfa = tf.placeholder(tf.int32, [None, ], name="a") # input Action
tfr = tf.placeholder(tf.float32, [None, ], name="ext_r") # extrinsic reward
tfs_ = tf.placeholder(tf.float32, [None, self.n_s], name="s_") # input Next State
# fixed random net
with tf.variable_scope("random_net"):
rand_encode_s_ = tf.layers.dense(tfs_, self.s_encode_size)
# predictor
ri, pred_train = self._build_predictor(tfs_, rand_encode_s_)
# normal RL model
q, dqn_loss, dqn_train = self._build_dqn(tfs, tfa, ri, tfr, tfs_)
return tfs, tfa, tfr, tfs_, pred_train, dqn_train, q
def _build_predictor(self, s_, rand_encode_s_):
with tf.variable_scope("predictor"):
net = tf.layers.dense(s_, 128, tf.nn.relu)
out = tf.layers.dense(net, self.s_encode_size)
with tf.name_scope("int_r"):
ri = tf.reduce_sum(tf.square(rand_encode_s_ - out), axis=1) # intrinsic reward
train_op = tf.train.RMSPropOptimizer(self.lr, name="predictor_opt").minimize(
tf.reduce_mean(ri), var_list=tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, "predictor"))
return ri, train_op
def _build_dqn(self, s, a, ri, re, s_):
with tf.variable_scope('eval_net'):
e1 = tf.layers.dense(s, 128, tf.nn.relu)
q = tf.layers.dense(e1, self.n_a, name="q")
with tf.variable_scope('target_net'):
t1 = tf.layers.dense(s_, 128, tf.nn.relu)
q_ = tf.layers.dense(t1, self.n_a, name="q_")
with tf.variable_scope('q_target'):
q_target = re + ri + self.gamma * tf.reduce_max(q_, axis=1, name="Qmax_s_")
with tf.variable_scope('q_wrt_a'):
a_indices = tf.stack([tf.range(tf.shape(a)[0], dtype=tf.int32), a], axis=1)
q_wrt_a = tf.gather_nd(params=q, indices=a_indices)
loss = tf.losses.mean_squared_error(labels=q_target, predictions=q_wrt_a) # TD error
train_op = tf.train.RMSPropOptimizer(self.lr, name="dqn_opt").minimize(
loss, var_list=tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, "eval_net"))
return q, loss, train_op
def store_transition(self, s, a, r, s_):
transition = np.hstack((s, [a, r], s_))
# replace the old memory with new memory
index = self.memory_counter % self.memory_size
self.memory[index, :] = transition
self.memory_counter += 1
def choose_action(self, observation):
# to have batch dimension when feed into tf placeholder
s = observation[np.newaxis, :]
if np.random.uniform() < self.epsilon:
# forward feed the observation and get q value for every actions
actions_value = self.sess.run(self.q, feed_dict={self.tfs: s})
action = np.argmax(actions_value)
else:
action = np.random.randint(0, self.n_a)
return action
def learn(self):
# check to replace target parameters
if self.learn_step_counter % self.replace_target_iter == 0:
self.sess.run(self.target_replace_op)
# sample batch memory from all memory
top = self.memory_size if self.memory_counter > self.memory_size else self.memory_counter
sample_index = np.random.choice(top, size=self.batch_size)
batch_memory = self.memory[sample_index, :]
bs, ba, br, bs_ = batch_memory[:, :self.n_s], batch_memory[:, self.n_s], \
batch_memory[:, self.n_s + 1], batch_memory[:, -self.n_s:]
self.sess.run(self.dqn_train, feed_dict={self.tfs: bs, self.tfa: ba, self.tfr: br, self.tfs_: bs_})
if self.learn_step_counter % 100 == 0: # delay training in order to stay curious
self.sess.run(self.pred_train, feed_dict={self.tfs_: bs_})
self.learn_step_counter += 1
env = gym.make('MountainCar-v0')
env = env.unwrapped
dqn = CuriosityNet(n_a=3, n_s=2, lr=0.01, output_graph=False)
ep_steps = []
for epi in range(200):
s = env.reset()
steps = 0
while True:
# env.render()
a = dqn.choose_action(s)
s_, r, done, info = env.step(a)
dqn.store_transition(s, a, r, s_)
dqn.learn()
if done:
print('Epi: ', epi, "| steps: ", steps)
ep_steps.append(steps)
break
s = s_
steps += 1
plt.plot(ep_steps)
plt.ylabel("steps")
plt.xlabel("episode")
plt.show()
================================================
FILE: experiments/2D_car/DDPG.py
================================================
"""
Environment is a 2D car.
Car has 5 sensors to obtain distance information.
Car collision => reward = -1, otherwise => reward = 0.
You can train this RL by using LOAD = False, after training, this model will be store in the a local folder.
Using LOAD = True to reload the trained model for playing.
You can customize this script in a way you want.
View more on [莫烦Python] : https://morvanzhou.github.io/tutorials/
Requirement:
pyglet >= 1.2.4
numpy >= 1.12.1
tensorflow >= 1.0.1
"""
import tensorflow as tf
import numpy as np
import os
import shutil
from car_env import CarEnv
np.random.seed(1)
tf.set_random_seed(1)
MAX_EPISODES = 500
MAX_EP_STEPS = 600
LR_A = 1e-4 # learning rate for actor
LR_C = 1e-4 # learning rate for critic
GAMMA = 0.9 # reward discount
REPLACE_ITER_A = 800
REPLACE_ITER_C = 700
MEMORY_CAPACITY = 2000
BATCH_SIZE = 16
VAR_MIN = 0.1
RENDER = True
LOAD = False
DISCRETE_ACTION = False
env = CarEnv(discrete_action=DISCRETE_ACTION)
STATE_DIM = env.state_dim
ACTION_DIM = env.action_dim
ACTION_BOUND = env.action_bound
# all placeholder for tf
with tf.name_scope('S'):
S = tf.placeholder(tf.float32, shape=[None, STATE_DIM], name='s')
with tf.name_scope('R'):
R = tf.placeholder(tf.float32, [None, 1], name='r')
with tf.name_scope('S_'):
S_ = tf.placeholder(tf.float32, shape=[None, STATE_DIM], name='s_')
class Actor(object):
def __init__(self, sess, action_dim, action_bound, learning_rate, t_replace_iter):
self.sess = sess
self.a_dim = action_dim
self.action_bound = action_bound
self.lr = learning_rate
self.t_replace_iter = t_replace_iter
self.t_replace_counter = 0
with tf.variable_scope('Actor'):
# input s, output a
self.a = self._build_net(S, scope='eval_net', trainable=True)
# input s_, output a, get a_ for critic
self.a_ = self._build_net(S_, scope='target_net', trainable=False)
self.e_params = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope='Actor/eval_net')
self.t_params = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope='Actor/target_net')
def _build_net(self, s, scope, trainable):
with tf.variable_scope(scope):
init_w = tf.contrib.layers.xavier_initializer()
init_b = tf.constant_initializer(0.001)
net = tf.layers.dense(s, 100, activation=tf.nn.relu,
kernel_initializer=init_w, bias_initializer=init_b, name='l1',
trainable=trainable)
net = tf.layers.dense(net, 20, activation=tf.nn.relu,
kernel_initializer=init_w, bias_initializer=init_b, name='l2',
trainable=trainable)
with tf.variable_scope('a'):
actions = tf.layers.dense(net, self.a_dim, activation=tf.nn.tanh, kernel_initializer=init_w,
name='a', trainable=trainable)
scaled_a = tf.multiply(actions, self.action_bound, name='scaled_a') # Scale output to -action_bound to action_bound
return scaled_a
def learn(self, s): # batch update
self.sess.run(self.train_op, feed_dict={S: s})
if self.t_replace_counter % self.t_replace_iter == 0:
self.sess.run([tf.assign(t, e) for t, e in zip(self.t_params, self.e_params)])
self.t_replace_counter += 1
def choose_action(self, s):
s = s[np.newaxis, :] # single state
return self.sess.run(self.a, feed_dict={S: s})[0] # single action
def add_grad_to_graph(self, a_grads):
with tf.variable_scope('policy_grads'):
self.policy_grads = tf.gradients(ys=self.a, xs=self.e_params, grad_ys=a_grads)
with tf.variable_scope('A_train'):
opt = tf.train.RMSPropOptimizer(-self.lr) # (- learning rate) for ascent policy
self.train_op = opt.apply_gradients(zip(self.policy_grads, self.e_params))
class Critic(object):
def __init__(self, sess, state_dim, action_dim, learning_rate, gamma, t_replace_iter, a, a_):
self.sess = sess
self.s_dim = state_dim
self.a_dim = action_dim
self.lr = learning_rate
self.gamma = gamma
self.t_replace_iter = t_replace_iter
self.t_replace_counter = 0
with tf.variable_scope('Critic'):
# Input (s, a), output q
self.a = a
self.q = self._build_net(S, self.a, 'eval_net', trainable=True)
# Input (s_, a_), output q_ for q_target
self.q_ = self._build_net(S_, a_, 'target_net', trainable=False) # target_q is based on a_ from Actor's target_net
self.e_params = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope='Critic/eval_net')
self.t_params = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope='Critic/target_net')
with tf.variable_scope('target_q'):
self.target_q = R + self.gamma * self.q_
with tf.variable_scope('TD_error'):
self.loss = tf.reduce_mean(tf.squared_difference(self.target_q, self.q))
with tf.variable_scope('C_train'):
self.train_op = tf.train.RMSPropOptimizer(self.lr).minimize(self.loss)
with tf.variable_scope('a_grad'):
self.a_grads = tf.gradients(self.q, a)[0] # tensor of gradients of each sample (None, a_dim)
def _build_net(self, s, a, scope, trainable):
with tf.variable_scope(scope):
init_w = tf.contrib.layers.xavier_initializer()
init_b = tf.constant_initializer(0.01)
with tf.variable_scope('l1'):
n_l1 = 100
w1_s = tf.get_variable('w1_s', [self.s_dim, n_l1], initializer=init_w, trainable=trainable)
w1_a = tf.get_variable('w1_a', [self.a_dim, n_l1], initializer=init_w, trainable=trainable)
b1 = tf.get_variable('b1', [1, n_l1], initializer=init_b, trainable=trainable)
net = tf.nn.relu6(tf.matmul(s, w1_s) + tf.matmul(a, w1_a) + b1)
net = tf.layers.dense(net, 20, activation=tf.nn.relu,
kernel_initializer=init_w, bias_initializer=init_b, name='l2',
trainable=trainable)
with tf.variable_scope('q'):
q = tf.layers.dense(net, 1, kernel_initializer=init_w, bias_initializer=init_b, trainable=trainable) # Q(s,a)
return q
def learn(self, s, a, r, s_):
self.sess.run(self.train_op, feed_dict={S: s, self.a: a, R: r, S_: s_})
if self.t_replace_counter % self.t_replace_iter == 0:
self.sess.run([tf.assign(t, e) for t, e in zip(self.t_params, self.e_params)])
self.t_replace_counter += 1
class Memory(object):
def __init__(self, capacity, dims):
self.capacity = capacity
self.data = np.zeros((capacity, dims))
self.pointer = 0
def store_transition(self, s, a, r, s_):
transition = np.hstack((s, a, [r], s_))
index = self.pointer % self.capacity # replace the old memory with new memory
self.data[index, :] = transition
self.pointer += 1
def sample(self, n):
assert self.pointer >= self.capacity, 'Memory has not been fulfilled'
indices = np.random.choice(self.capacity, size=n)
return self.data[indices, :]
sess = tf.Session()
# Create actor and critic.
actor = Actor(sess, ACTION_DIM, ACTION_BOUND[1], LR_A, REPLACE_ITER_A)
critic = Critic(sess, STATE_DIM, ACTION_DIM, LR_C, GAMMA, REPLACE_ITER_C, actor.a, actor.a_)
actor.add_grad_to_graph(critic.a_grads)
M = Memory(MEMORY_CAPACITY, dims=2 * STATE_DIM + ACTION_DIM + 1)
saver = tf.train.Saver()
path = './discrete' if DISCRETE_ACTION else './continuous'
if LOAD:
saver.restore(sess, tf.train.latest_checkpoint(path))
else:
sess.run(tf.global_variables_initializer())
def train():
var = 2. # control exploration
for ep in range(MAX_EPISODES):
s = env.reset()
ep_step = 0
for t in range(MAX_EP_STEPS):
# while True:
if RENDER:
env.render()
# Added exploration noise
a = actor.choose_action(s)
a = np.clip(np.random.normal(a, var), *ACTION_BOUND) # add randomness to action selection for exploration
s_, r, done = env.step(a)
M.store_transition(s, a, r, s_)
if M.pointer > MEMORY_CAPACITY:
var = max([var*.9995, VAR_MIN]) # decay the action randomness
b_M = M.sample(BATCH_SIZE)
b_s = b_M[:, :STATE_DIM]
b_a = b_M[:, STATE_DIM: STATE_DIM + ACTION_DIM]
b_r = b_M[:, -STATE_DIM - 1: -STATE_DIM]
b_s_ = b_M[:, -STATE_DIM:]
critic.learn(b_s, b_a, b_r, b_s_)
actor.learn(b_s)
s = s_
ep_step += 1
if done or t == MAX_EP_STEPS - 1:
# if done:
print('Ep:', ep,
'| Steps: %i' % int(ep_step),
'| Explore: %.2f' % var,
)
break
if os.path.isdir(path): shutil.rmtree(path)
os.mkdir(path)
ckpt_path = os.path.join(path, 'DDPG.ckpt')
save_path = saver.save(sess, ckpt_path, write_meta_graph=False)
print("\nSave Model %s\n" % save_path)
def eval():
env.set_fps(30)
while True:
s = env.reset()
while True:
env.render()
a = actor.choose_action(s)
s_, r, done = env.step(a)
s = s_
if done:
break
if __name__ == '__main__':
if LOAD:
eval()
else:
train()
================================================
FILE: experiments/2D_car/car_env.py
================================================
"""
Environment for 2D car driving.
You can customize this script in a way you want.
View more on [莫烦Python] : https://morvanzhou.github.io/tutorials/
Requirement:
pyglet >= 1.2.4
numpy >= 1.12.1
"""
import numpy as np
import pyglet
pyglet.clock.set_fps_limit(10000)
class CarEnv(object):
n_sensor = 5
action_dim = 1
state_dim = n_sensor
viewer = None
viewer_xy = (500, 500)
sensor_max = 150.
start_point = [450, 300]
speed = 50.
dt = 0.1
def __init__(self, discrete_action=False):
self.is_discrete_action = discrete_action
if discrete_action:
self.actions = [-1, 0, 1]
else:
self.action_bound = [-1, 1]
self.terminal = False
# node1 (x, y, r, w, l),
self.car_info = np.array([0, 0, 0, 20, 40], dtype=np.float64) # car coordination
self.obstacle_coords = np.array([
[120, 120],
[380, 120],
[380, 380],
[120, 380],
])
self.sensor_info = self.sensor_max + np.zeros((self.n_sensor, 3)) # n sensors, (distance, end_x, end_y)
def step(self, action):
if self.is_discrete_action:
action = self.actions[action]
else:
action = np.clip(action, *self.action_bound)[0]
self.car_info[2] += action * np.pi/30 # max r = 6 degree
self.car_info[:2] = self.car_info[:2] + \
self.speed * self.dt * np.array([np.cos(self.car_info[2]), np.sin(self.car_info[2])])
self._update_sensor()
s = self._get_state()
r = -1 if self.terminal else 0
return s, r, self.terminal
def reset(self):
self.terminal = False
self.car_info[:3] = np.array([*self.start_point, -np.pi/2])
self._update_sensor()
return self._get_state()
def render(self):
if self.viewer is None:
self.viewer = Viewer(*self.viewer_xy, self.car_info, self.sensor_info, self.obstacle_coords)
self.viewer.render()
def sample_action(self):
if self.is_discrete_action:
a = np.random.choice(list(range(3)))
else:
a = np.random.uniform(*self.action_bound, size=self.action_dim)
return a
def set_fps(self, fps=30):
pyglet.clock.set_fps_limit(fps)
def _get_state(self):
s = self.sensor_info[:, 0].flatten()/self.sensor_max
return s
def _update_sensor(self):
cx, cy, rotation = self.car_info[:3]
n_sensors = len(self.sensor_info)
sensor_theta = np.linspace(-np.pi / 2, np.pi / 2, n_sensors)
xs = cx + (np.zeros((n_sensors, ))+self.sensor_max) * np.cos(sensor_theta)
ys = cy + (np.zeros((n_sensors, ))+self.sensor_max) * np.sin(sensor_theta)
xys = np.array([[x, y] for x, y in zip(xs, ys)]) # shape (5 sensors, 2)
# sensors
tmp_x = xys[:, 0] - cx
tmp_y = xys[:, 1] - cy
# apply rotation
rotated_x = tmp_x * np.cos(rotation) - tmp_y * np.sin(rotation)
rotated_y = tmp_x * np.sin(rotation) + tmp_y * np.cos(rotation)
# rotated x y
self.sensor_info[:, -2:] = np.vstack([rotated_x+cx, rotated_y+cy]).T
q = np.array([cx, cy])
for si in range(len(self.sensor_info)):
s = self.sensor_info[si, -2:] - q
possible_sensor_distance = [self.sensor_max]
possible_intersections = [self.sensor_info[si, -2:]]
# obstacle collision
for oi in range(len(self.obstacle_coords)):
p = self.obstacle_coords[oi]
r = self.obstacle_coords[(oi + 1) % len(self.obstacle_coords)] - self.obstacle_coords[oi]
if np.cross(r, s) != 0: # may collision
t = np.cross((q - p), s) / np.cross(r, s)
u = np.cross((q - p), r) / np.cross(r, s)
if 0 <= t <= 1 and 0 <= u <= 1:
intersection = q + u * s
possible_intersections.append(intersection)
possible_sensor_distance.append(np.linalg.norm(u*s))
# window collision
win_coord = np.array([
[0, 0],
[self.viewer_xy[0], 0],
[*self.viewer_xy],
[0, self.viewer_xy[1]],
[0, 0],
])
for oi in range(4):
p = win_coord[oi]
r = win_coord[(oi + 1) % len(win_coord)] - win_coord[oi]
if np.cross(r, s) != 0: # may collision
t = np.cross((q - p), s) / np.cross(r, s)
u = np.cross((q - p), r) / np.cross(r, s)
if 0 <= t <= 1 and 0 <= u <= 1:
intersection = p + t * r
possible_intersections.append(intersection)
possible_sensor_distance.append(np.linalg.norm(intersection - q))
distance = np.min(possible_sensor_distance)
distance_index = np.argmin(possible_sensor_distance)
self.sensor_info[si, 0] = distance
self.sensor_info[si, -2:] = possible_intersections[distance_index]
if distance < self.car_info[-1]/2:
self.terminal = True
class Viewer(pyglet.window.Window):
color = {
'background': [1]*3 + [1]
}
fps_display = pyglet.clock.ClockDisplay()
bar_thc = 5
def __init__(self, width, height, car_info, sensor_info, obstacle_coords):
super(Viewer, self).__init__(width, height, resizable=False, caption='2D car', vsync=False) # vsync=False to not use the monitor FPS
self.set_location(x=80, y=10)
pyglet.gl.glClearColor(*self.color['background'])
self.car_info = car_info
self.sensor_info = sensor_info
self.batch = pyglet.graphics.Batch()
background = pyglet.graphics.OrderedGroup(0)
foreground = pyglet.graphics.OrderedGroup(1)
self.sensors = []
line_coord = [0, 0] * 2
c = (73, 73, 73) * 2
for i in range(len(self.sensor_info)):
self.sensors.append(self.batch.add(2, pyglet.gl.GL_LINES, foreground, ('v2f', line_coord), ('c3B', c)))
car_box = [0, 0] * 4
c = (249, 86, 86) * 4
self.car = self.batch.add(4, pyglet.gl.GL_QUADS, foreground, ('v2f', car_box), ('c3B', c))
c = (134, 181, 244) * 4
self.obstacle = self.batch.add(4, pyglet.gl.GL_QUADS, background, ('v2f', obstacle_coords.flatten()), ('c3B', c))
def render(self):
pyglet.clock.tick()
self._update()
self.switch_to()
self.dispatch_events()
self.dispatch_event('on_draw')
self.flip()
def on_draw(self):
self.clear()
self.batch.draw()
# self.fps_display.draw()
def _update(self):
cx, cy, r, w, l = self.car_info
# sensors
for i, sensor in enumerate(self.sensors):
sensor.vertices = [cx, cy, *self.sensor_info[i, -2:]]
# car
xys = [
[cx + l / 2, cy + w / 2],
[cx - l / 2, cy + w / 2],
[cx - l / 2, cy - w / 2],
[cx + l / 2, cy - w / 2],
]
r_xys = []
for x, y in xys:
tempX = x - cx
tempY = y - cy
# apply rotation
rotatedX = tempX * np.cos(r) - tempY * np.sin(r)
rotatedY = tempX * np.sin(r) + tempY * np.cos(r)
# rotated x y
x = rotatedX + cx
y = rotatedY + cy
r_xys += [x, y]
self.car.vertices = r_xys
if __name__ == '__main__':
np.random.seed(1)
env = CarEnv()
env.set_fps(30)
for ep in range(20):
s = env.reset()
# for t in range(100):
while True:
env.render()
s, r, done = env.step(env.sample_action())
if done:
break
================================================
FILE: experiments/2D_car/collision.py
================================================
import numpy as np
def intersection():
p = np.array([0, 0])
r = np.array([1, 1])
q = np.array([0.1, 0.1])
s = np.array([.1, .1])
if np.cross(r, s) == 0 and np.cross((q-p), r) == 0: # collinear
# t0 = (q − p) · r / (r · r)
# t1 = (q + s − p) · r / (r · r) = t0 + s · r / (r · r)
t0 = np.dot(q-p, r)/np.dot(r, r)
t1 = t0 + np.dot(s, r)/np.dot(r, r)
print(t1, t0)
if ((np.dot(s, r) > 0) and (0 <= t1 - t0 <= 1)) or ((np.dot(s, r) <= 0) and (0 <= t0 - t1 <= 1)):
print('collinear and overlapping, q_s in p_r')
else:
print('collinear and disjoint')
elif np.cross(r, s) == 0 and np.cross((q-p), r) != 0: # parallel r × s = 0 and (q − p) × r ≠ 0,
print('parallel')
else:
t = np.cross((q - p), s) / np.cross(r, s)
u = np.cross((q - p), r) / np.cross(r, s)
if 0 <= t <= 1 and 0 <= u <= 1:
# If r × s ≠ 0 and 0 ≤ t ≤ 1 and 0 ≤ u ≤ 1, the two line segments meet at the point p + t r = q + u s
print('intersection: ', p + t*r)
else:
print('not parallel and not intersect')
def point2segment():
p = np.array([-1, 1]) # coordination of point
a = np.array([0, 1]) # coordination of line segment end 1
b = np.array([1, 0]) # coordination of line segment end 2
ab = b-a # line ab
ap = p-a
distance = np.abs(np.cross(ab, ap)/np.linalg.norm(ab)) # d = (AB x AC)/|AB|
print(distance)
# angle Cos(θ) = A dot B /(|A||B|)
bp = p-b
cosTheta1 = np.dot(ap, ab) / (np.linalg.norm(ap) * np.linalg.norm(ab))
theta1 = np.arccos(cosTheta1)
cosTheta2 = np.dot(bp, ab) / (np.linalg.norm(bp) * np.linalg.norm(ab))
theta2 = np.arccos(cosTheta2)
if np.pi/2 <= (theta1 % (np.pi*2)) <= 3/2 * np.pi:
print('out of a')
elif -np.pi/2 <= (theta2 % (np.pi*2)) <= np.pi/2:
print('out of b')
else:
print('between a and b')
if __name__ == '__main__':
point2segment()
# intersection()
================================================
FILE: experiments/Robot_arm/A3C.py
================================================
"""
Environment is a Robot Arm. The arm tries to get to the blue point.
The environment will return a geographic (distance) information for the arm to learn.
The far away from blue point the less reward; touch blue r+=1; stop at blue for a while then get r=+10.
You can train this RL by using LOAD = False, after training, this model will be store in the a local folder.
Using LOAD = True to reload the trained model for playing.
You can customize this script in a way you want.
View more on [莫烦Python] : https://morvanzhou.github.io/tutorials/
Requirement:
pyglet >= 1.2.4
numpy >= 1.12.1
tensorflow >= 1.0.1
"""
import multiprocessing
import threading
import tensorflow as tf
import numpy as np
from arm_env import ArmEnv
# np.random.seed(1)
# tf.set_random_seed(1)
MAX_GLOBAL_EP = 2000
MAX_EP_STEP = 300
UPDATE_GLOBAL_ITER = 5
N_WORKERS = multiprocessing.cpu_count()
LR_A = 1e-4 # learning rate for actor
LR_C = 2e-4 # learning rate for critic
GAMMA = 0.9 # reward discount
MODE = ['easy', 'hard']
n_model = 1
GLOBAL_NET_SCOPE = 'Global_Net'
ENTROPY_BETA = 0.01
GLOBAL_RUNNING_R = []
GLOBAL_EP = 0
env = ArmEnv(mode=MODE[n_model])
N_S = env.state_dim
N_A = env.action_dim
A_BOUND = env.action_bound
del env
class ACNet(object):
def __init__(self, scope, globalAC=None):
if scope == GLOBAL_NET_SCOPE: # get global network
with tf.variable_scope(scope):
self.s = tf.placeholder(tf.float32, [None, N_S], 'S')
self._build_net()
self.a_params = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope=scope + '/actor')
self.c_params = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope=scope + '/critic')
else: # local net, calculate losses
with tf.variable_scope(scope):
self.s = tf.placeholder(tf.float32, [None, N_S], 'S')
self.a_his = tf.placeholder(tf.float32, [None, N_A], 'A')
self.v_target = tf.placeholder(tf.float32, [None, 1], 'Vtarget')
mu, sigma, self.v = self._build_net()
td = tf.subtract(self.v_target, self.v, name='TD_error')
with tf.name_scope('c_loss'):
self.c_loss = tf.reduce_mean(tf.square(td))
with tf.name_scope('wrap_a_out'):
self.test = sigma[0]
mu, sigma = mu * A_BOUND[1], sigma + 1e-5
normal_dist = tf.contrib.distributions.Normal(mu, sigma)
with tf.name_scope('a_loss'):
log_prob = normal_dist.log_prob(self.a_his)
exp_v = log_prob * td
entropy = normal_dist.entropy() # encourage exploration
self.exp_v = ENTROPY_BETA * entropy + exp_v
self.a_loss = tf.reduce_mean(-self.exp_v)
with tf.name_scope('choose_a'): # use local params to choose action
self.A = tf.clip_by_value(tf.squeeze(normal_dist.sample(1), axis=0), *A_BOUND)
with tf.name_scope('local_grad'):
self.a_params = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope=scope + '/actor')
self.c_params = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope=scope + '/critic')
self.a_grads = tf.gradients(self.a_loss, self.a_params)
self.c_grads = tf.gradients(self.c_loss, self.c_params)
with tf.name_scope('sync'):
with tf.name_scope('pull'):
self.pull_a_params_op = [l_p.assign(g_p) for l_p, g_p in zip(self.a_params, globalAC.a_params)]
self.pull_c_params_op = [l_p.assign(g_p) for l_p, g_p in zip(self.c_params, globalAC.c_params)]
with tf.name_scope('push'):
self.update_a_op = OPT_A.apply_gradients(zip(self.a_grads, globalAC.a_params))
self.update_c_op = OPT_C.apply_gradients(zip(self.c_grads, globalAC.c_params))
def _build_net(self):
w_init = tf.contrib.layers.xavier_initializer()
with tf.variable_scope('actor'):
l_a = tf.layers.dense(self.s, 400, tf.nn.relu6, kernel_initializer=w_init, name='la')
l_a = tf.layers.dense(l_a, 300, tf.nn.relu6, kernel_initializer=w_init, name='la2')
mu = tf.layers.dense(l_a, N_A, tf.nn.tanh, kernel_initializer=w_init, name='mu')
sigma = tf.layers.dense(l_a, N_A, tf.nn.softplus, kernel_initializer=w_init, name='sigma')
with tf.variable_scope('critic'):
l_c = tf.layers.dense(self.s, 400, tf.nn.relu6, kernel_initializer=w_init, name='lc')
l_c = tf.layers.dense(l_c, 200, tf.nn.relu6, kernel_initializer=w_init, name='lc2')
v = tf.layers.dense(l_c, 1, kernel_initializer=w_init, name='v') # state value
return mu, sigma, v
def update_global(self, feed_dict): # run by a local
_, _, t = SESS.run([self.update_a_op, self.update_c_op, self.test], feed_dict) # local grads applies to global net
return t
def pull_global(self): # run by a local
SESS.run([self.pull_a_params_op, self.pull_c_params_op])
def choose_action(self, s): # run by a local
s = s[np.newaxis, :]
return SESS.run(self.A, {self.s: s})[0]
class Worker(object):
def __init__(self, name, globalAC):
self.env = ArmEnv(mode=MODE[n_model])
self.name = name
self.AC = ACNet(name, globalAC)
def work(self):
global GLOBAL_RUNNING_R, GLOBAL_EP
total_step = 1
buffer_s, buffer_a, buffer_r = [], [], []
while not COORD.should_stop() and GLOBAL_EP < MAX_GLOBAL_EP:
s = self.env.reset()
ep_r = 0
for ep_t in range(MAX_EP_STEP):
if self.name == 'W_0':
self.env.render()
a = self.AC.choose_action(s)
s_, r, done = self.env.step(a)
if ep_t == MAX_EP_STEP - 1: done = True
ep_r += r
buffer_s.append(s)
buffer_a.append(a)
buffer_r.append(r)
if total_step % UPDATE_GLOBAL_ITER == 0 or done: # update global and assign to local net
if done:
v_s_ = 0 # terminal
else:
v_s_ = SESS.run(self.AC.v, {self.AC.s: s_[np.newaxis, :]})[0, 0]
buffer_v_target = []
for r in buffer_r[::-1]: # reverse buffer r
v_s_ = r + GAMMA * v_s_
buffer_v_target.append(v_s_)
buffer_v_target.reverse()
buffer_s, buffer_a, buffer_v_target = np.vstack(buffer_s), np.vstack(buffer_a), np.vstack(buffer_v_target)
feed_dict = {
self.AC.s: buffer_s,
self.AC.a_his: buffer_a,
self.AC.v_target: buffer_v_target,
}
test = self.AC.update_global(feed_dict)
buffer_s, buffer_a, buffer_r = [], [], []
self.AC.pull_global()
s = s_
total_step += 1
if done:
if len(GLOBAL_RUNNING_R) == 0: # record running episode reward
GLOBAL_RUNNING_R.append(ep_r)
else:
GLOBAL_RUNNING_R.append(0.9 * GLOBAL_RUNNING_R[-1] + 0.1 * ep_r)
print(
self.name,
"Ep:", GLOBAL_EP,
"| Ep_r: %i" % GLOBAL_RUNNING_R[-1],
'| Var:', test,
)
GLOBAL_EP += 1
break
if __name__ == "__main__":
SESS = tf.Session()
with tf.device("/cpu:0"):
OPT_A = tf.train.RMSPropOptimizer(LR_A, name='RMSPropA')
OPT_C = tf.train.RMSPropOptimizer(LR_C, name='RMSPropC')
GLOBAL_AC = ACNet(GLOBAL_NET_SCOPE) # we only need its params
workers = []
# Create worker
for i in range(N_WORKERS):
i_name = 'W_%i' % i # worker name
workers.append(Worker(i_name, GLOBAL_AC))
COORD = tf.train.Coordinator()
SESS.run(tf.global_variables_initializer())
worker_threads = []
for worker in workers:
job = lambda: worker.work()
t = threading.Thread(target=job)
t.start()
worker_threads.append(t)
COORD.join(worker_threads)
================================================
FILE: experiments/Robot_arm/DDPG.py
================================================
"""
Environment is a Robot Arm. The arm tries to get to the blue point.
The environment will return a geographic (distance) information for the arm to learn.
The far away from blue point the less reward; touch blue r+=1; stop at blue for a while then get r=+10.
You can train this RL by using LOAD = False, after training, this model will be store in the a local folder.
Using LOAD = True to reload the trained model for playing.
You can customize this script in a way you want.
View more on [莫烦Python] : https://morvanzhou.github.io/tutorials/
Requirement:
pyglet >= 1.2.4
numpy >= 1.12.1
tensorflow >= 1.0.1
"""
import tensorflow as tf
import numpy as np
import os
import shutil
from arm_env import ArmEnv
np.random.seed(1)
tf.set_random_seed(1)
MAX_EPISODES = 600
MAX_EP_STEPS = 200
LR_A = 1e-4 # learning rate for actor
LR_C = 1e-4 # learning rate for critic
GAMMA = 0.9 # reward discount
REPLACE_ITER_A = 1100
REPLACE_ITER_C = 1000
MEMORY_CAPACITY = 5000
BATCH_SIZE = 16
VAR_MIN = 0.1
RENDER = True
LOAD = False
MODE = ['easy', 'hard']
n_model = 1
env = ArmEnv(mode=MODE[n_model])
STATE_DIM = env.state_dim
ACTION_DIM = env.action_dim
ACTION_BOUND = env.action_bound
# all placeholder for tf
with tf.name_scope('S'):
S = tf.placeholder(tf.float32, shape=[None, STATE_DIM], name='s')
with tf.name_scope('R'):
R = tf.placeholder(tf.float32, [None, 1], name='r')
with tf.name_scope('S_'):
S_ = tf.placeholder(tf.float32, shape=[None, STATE_DIM], name='s_')
class Actor(object):
def __init__(self, sess, action_dim, action_bound, learning_rate, t_replace_iter):
self.sess = sess
self.a_dim = action_dim
self.action_bound = action_bound
self.lr = learning_rate
self.t_replace_iter = t_replace_iter
self.t_replace_counter = 0
with tf.variable_scope('Actor'):
# input s, output a
self.a = self._build_net(S, scope='eval_net', trainable=True)
# input s_, output a, get a_ for critic
self.a_ = self._build_net(S_, scope='target_net', trainable=False)
self.e_params = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope='Actor/eval_net')
self.t_params = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope='Actor/target_net')
self.replace = [tf.assign(t, e) for t, e in zip(self.t_params, self.e_params)]
def _build_net(self, s, scope, trainable):
with tf.variable_scope(scope):
init_w = tf.contrib.layers.xavier_initializer()
init_b = tf.constant_initializer(0.001)
net = tf.layers.dense(s, 200, activation=tf.nn.relu6,
kernel_initializer=init_w, bias_initializer=init_b, name='l1',
trainable=trainable)
net = tf.layers.dense(net, 200, activation=tf.nn.relu6,
kernel_initializer=init_w, bias_initializer=init_b, name='l2',
trainable=trainable)
net = tf.layers.dense(net, 10, activation=tf.nn.relu,
kernel_initializer=init_w, bias_initializer=init_b, name='l3',
trainable=trainable)
with tf.variable_scope('a'):
actions = tf.layers.dense(net, self.a_dim, activation=tf.nn.tanh, kernel_initializer=init_w,
name='a', trainable=trainable)
scaled_a = tf.multiply(actions, self.action_bound, name='scaled_a') # Scale output to -action_bound to action_bound
return scaled_a
def learn(self, s): # batch update
self.sess.run(self.train_op, feed_dict={S: s})
if self.t_replace_counter % self.t_replace_iter == 0:
self.sess.run(self.replace)
self.t_replace_counter += 1
def choose_action(self, s):
s = s[np.newaxis, :] # single state
return self.sess.run(self.a, feed_dict={S: s})[0] # single action
def add_grad_to_graph(self, a_grads):
with tf.variable_scope('policy_grads'):
self.policy_grads = tf.gradients(ys=self.a, xs=self.e_params, grad_ys=a_grads)
with tf.variable_scope('A_train'):
opt = tf.train.RMSPropOptimizer(-self.lr) # (- learning rate) for ascent policy
self.train_op = opt.apply_gradients(zip(self.policy_grads, self.e_params))
class Critic(object):
def __init__(self, sess, state_dim, action_dim, learning_rate, gamma, t_replace_iter, a, a_):
self.sess = sess
self.s_dim = state_dim
self.a_dim = action_dim
self.lr = learning_rate
self.gamma = gamma
self.t_replace_iter = t_replace_iter
self.t_replace_counter = 0
with tf.variable_scope('Critic'):
# Input (s, a), output q
self.a = a
self.q = self._build_net(S, self.a, 'eval_net', trainable=True)
# Input (s_, a_), output q_ for q_target
self.q_ = self._build_net(S_, a_, 'target_net', trainable=False) # target_q is based on a_ from Actor's target_net
self.e_params = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope='Critic/eval_net')
self.t_params = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope='Critic/target_net')
with tf.variable_scope('target_q'):
self.target_q = R + self.gamma * self.q_
with tf.variable_scope('TD_error'):
self.loss = tf.reduce_mean(tf.squared_difference(self.target_q, self.q))
with tf.variable_scope('C_train'):
self.train_op = tf.train.RMSPropOptimizer(self.lr).minimize(self.loss)
with tf.variable_scope('a_grad'):
self.a_grads = tf.gradients(self.q, a)[0] # tensor of gradients of each sample (None, a_dim)
self.replace = [tf.assign(t, e) for t, e in zip(self.t_params, self.e_params)]
def _build_net(self, s, a, scope, trainable):
with tf.variable_scope(scope):
init_w = tf.contrib.layers.xavier_initializer()
init_b = tf.constant_initializer(0.01)
with tf.variable_scope('l1'):
n_l1 = 200
w1_s = tf.get_variable('w1_s', [self.s_dim, n_l1], initializer=init_w, trainable=trainable)
w1_a = tf.get_variable('w1_a', [self.a_dim, n_l1], initializer=init_w, trainable=trainable)
b1 = tf.get_variable('b1', [1, n_l1], initializer=init_b, trainable=trainable)
net = tf.nn.relu6(tf.matmul(s, w1_s) + tf.matmul(a, w1_a) + b1)
net = tf.layers.dense(net, 200, activation=tf.nn.relu6,
kernel_initializer=init_w, bias_initializer=init_b, name='l2',
trainable=trainable)
net = tf.layers.dense(net, 10, activation=tf.nn.relu,
kernel_initializer=init_w, bias_initializer=init_b, name='l3',
trainable=trainable)
with tf.variable_scope('q'):
q = tf.layers.dense(net, 1, kernel_initializer=init_w, bias_initializer=init_b, trainable=trainable) # Q(s,a)
return q
def learn(self, s, a, r, s_):
self.sess.run(self.train_op, feed_dict={S: s, self.a: a, R: r, S_: s_})
if self.t_replace_counter % self.t_replace_iter == 0:
self.sess.run(self.replace)
self.t_replace_counter += 1
class Memory(object):
def __init__(self, capacity, dims):
self.capacity = capacity
self.data = np.zeros((capacity, dims))
self.pointer = 0
def store_transition(self, s, a, r, s_):
transition = np.hstack((s, a, [r], s_))
index = self.pointer % self.capacity # replace the old memory with new memory
self.data[index, :] = transition
self.pointer += 1
def sample(self, n):
assert self.pointer >= self.capacity, 'Memory has not been fulfilled'
indices = np.random.choice(self.capacity, size=n)
return self.data[indices, :]
sess = tf.Session()
# Create actor and critic.
actor = Actor(sess, ACTION_DIM, ACTION_BOUND[1], LR_A, REPLACE_ITER_A)
critic = Critic(sess, STATE_DIM, ACTION_DIM, LR_C, GAMMA, REPLACE_ITER_C, actor.a, actor.a_)
actor.add_grad_to_graph(critic.a_grads)
M = Memory(MEMORY_CAPACITY, dims=2 * STATE_DIM + ACTION_DIM + 1)
saver = tf.train.Saver()
path = './'+MODE[n_model]
if LOAD:
saver.restore(sess, tf.train.latest_checkpoint(path))
else:
sess.run(tf.global_variables_initializer())
def train():
var = 2. # control exploration
for ep in range(MAX_EPISODES):
s = env.reset()
ep_reward = 0
for t in range(MAX_EP_STEPS):
# while True:
if RENDER:
env.render()
# Added exploration noise
a = actor.choose_action(s)
a = np.clip(np.random.normal(a, var), *ACTION_BOUND) # add randomness to action selection for exploration
s_, r, done = env.step(a)
M.store_transition(s, a, r, s_)
if M.pointer > MEMORY_CAPACITY:
var = max([var*.9999, VAR_MIN]) # decay the action randomness
b_M = M.sample(BATCH_SIZE)
b_s = b_M[:, :STATE_DIM]
b_a = b_M[:, STATE_DIM: STATE_DIM + ACTION_DIM]
b_r = b_M[:, -STATE_DIM - 1: -STATE_DIM]
b_s_ = b_M[:, -STATE_DIM:]
critic.learn(b_s, b_a, b_r, b_s_)
actor.learn(b_s)
s = s_
ep_reward += r
if t == MAX_EP_STEPS-1 or done:
# if done:
result = '| done' if done else '| ----'
print('Ep:', ep,
result,
'| R: %i' % int(ep_reward),
'| Explore: %.2f' % var,
)
break
if os.path.isdir(path): shutil.rmtree(path)
os.mkdir(path)
ckpt_path = os.path.join('./'+MODE[n_model], 'DDPG.ckpt')
save_path = saver.save(sess, ckpt_path, write_meta_graph=False)
print("\nSave Model %s\n" % save_path)
def eval():
env.set_fps(30)
s = env.reset()
while True:
if RENDER:
env.render()
a = actor.choose_action(s)
s_, r, done = env.step(a)
s = s_
if __name__ == '__main__':
if LOAD:
eval()
else:
train()
================================================
FILE: experiments/Robot_arm/DPPO.py
================================================
"""
A simple version of OpenAI's Proximal Policy Optimization (PPO). [http://adsabs.harvard.edu/abs/2017arXiv170706347S]
Distributing workers in parallel to collect data, then stop worker's roll-out and train PPO on collected data.
Restart workers once PPO is updated.
The global PPO updating rule is adopted from DeepMind's paper (DPPO):
Emergence of Locomotion Behaviours in Rich Environments (Google Deepmind): [http://adsabs.harvard.edu/abs/2017arXiv170702286H]
View more on my tutorial website: https://morvanzhou.github.io/tutorials
Dependencies:
tensorflow r1.2
gym 0.9.2
"""
import tensorflow as tf
from tensorflow.contrib.distributions import Normal
import numpy as np
import matplotlib.pyplot as plt
import threading, queue
from arm_env import ArmEnv
EP_MAX = 2000
EP_LEN = 300
N_WORKER = 4 # parallel workers
GAMMA = 0.9 # reward discount factor
A_LR = 0.0001 # learning rate for actor
C_LR = 0.0005 # learning rate for critic
MIN_BATCH_SIZE = 64 # minimum batch size for updating PPO
UPDATE_STEP = 5 # loop update operation n-steps
EPSILON = 0.2 # Clipped surrogate objective
MODE = ['easy', 'hard']
n_model = 1
env = ArmEnv(mode=MODE[n_model])
S_DIM = env.state_dim
A_DIM = env.action_dim
A_BOUND = env.action_bound[1]
class PPO(object):
def __init__(self):
self.sess = tf.Session()
self.tfs = tf.placeholder(tf.float32, [None, S_DIM], 'state')
# critic
l1 = tf.layers.dense(self.tfs, 100, tf.nn.relu)
self.v = tf.layers.dense(l1, 1)
self.tfdc_r = tf.placeholder(tf.float32, [None, 1], 'discounted_r')
self.advantage = self.tfdc_r - self.v
self.closs = tf.reduce_mean(tf.square(self.advantage))
self.ctrain_op = tf.train.AdamOptimizer(C_LR).minimize(self.closs)
# actor
pi, pi_params = self._build_anet('pi', trainable=True)
oldpi, oldpi_params = self._build_anet('oldpi', trainable=False)
self.sample_op = tf.squeeze(pi.sample(1), axis=0) # choosing action
self.update_oldpi_op = [oldp.assign(p) for p, oldp in zip(pi_params, oldpi_params)]
self.tfa = tf.placeholder(tf.float32, [None, A_DIM], 'action')
self.tfadv = tf.placeholder(tf.float32, [None, 1], 'advantage')
# ratio = tf.exp(pi.log_prob(self.tfa) - oldpi.log_prob(self.tfa))
ratio = pi.prob(self.tfa) / (oldpi.prob(self.tfa) + 1e-5)
surr = ratio * self.tfadv # surrogate loss
self.aloss = -tf.reduce_mean(tf.minimum(
surr,
tf.clip_by_value(ratio, 1. - EPSILON, 1. + EPSILON) * self.tfadv))
self.atrain_op = tf.train.AdamOptimizer(A_LR).minimize(self.aloss)
self.sess.run(tf.global_variables_initializer())
def update(self):
global GLOBAL_UPDATE_COUNTER
while not COORD.should_stop():
if GLOBAL_EP < EP_MAX:
UPDATE_EVENT.wait() # wait until get batch of data
self.sess.run(self.update_oldpi_op) # old pi to pi
data = [QUEUE.get() for _ in range(QUEUE.qsize())]
data = np.vstack(data)
s, a, r = data[:, :S_DIM], data[:, S_DIM: S_DIM + A_DIM], data[:, -1:]
adv = self.sess.run(self.advantage, {self.tfs: s, self.tfdc_r: r})
[self.sess.run(self.atrain_op, {self.tfs: s, self.tfa: a, self.tfadv: adv}) for _ in range(UPDATE_STEP)]
[self.sess.run(self.ctrain_op, {self.tfs: s, self.tfdc_r: r}) for _ in range(UPDATE_STEP)]
UPDATE_EVENT.clear() # updating finished
GLOBAL_UPDATE_COUNTER = 0 # reset counter
ROLLING_EVENT.set() # set roll-out available
def _build_anet(self, name, trainable):
with tf.variable_scope(name):
l1 = tf.layers.dense(self.tfs, 200, tf.nn.relu, trainable=trainable)
mu = A_BOUND * tf.layers.dense(l1, A_DIM, tf.nn.tanh, trainable=trainable)
sigma = tf.layers.dense(l1, A_DIM, tf.nn.softplus, trainable=trainable)
norm_dist = Normal(loc=mu, scale=sigma)
params = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope=name)
return norm_dist, params
def choose_action(self, s):
s = s[np.newaxis, :]
a = self.sess.run(self.sample_op, {self.tfs: s})[0]
return np.clip(a, -2, 2)
def get_v(self, s):
if s.ndim < 2: s = s[np.newaxis, :]
return self.sess.run(self.v, {self.tfs: s})[0, 0]
class Worker(object):
def __init__(self, wid):
self.wid = wid
self.env = ArmEnv(mode=MODE[n_model])
self.ppo = GLOBAL_PPO
def work(self):
global GLOBAL_EP, GLOBAL_RUNNING_R, GLOBAL_UPDATE_COUNTER
while not COORD.should_stop():
s = self.env.reset()
ep_r = 0
buffer_s, buffer_a, buffer_r = [], [], []
for t in range(EP_LEN):
if not ROLLING_EVENT.is_set(): # while global PPO is updating
ROLLING_EVENT.wait() # wait until PPO is updated
buffer_s, buffer_a, buffer_r = [], [], [] # clear history buffer
a = self.ppo.choose_action(s)
s_, r, done = self.env.step(a)
buffer_s.append(s)
buffer_a.append(a)
buffer_r.append(r) # normalize reward, find to be useful
s = s_
ep_r += r
GLOBAL_UPDATE_COUNTER += 1 # count to minimum batch size
if t == EP_LEN - 1 or GLOBAL_UPDATE_COUNTER >= MIN_BATCH_SIZE:
v_s_ = self.ppo.get_v(s_)
discounted_r = [] # compute discounted reward
for r in buffer_r[::-1]:
v_s_ = r + GAMMA * v_s_
discounted_r.append(v_s_)
discounted_r.reverse()
bs, ba, br = np.vstack(buffer_s), np.vstack(buffer_a), np.array(discounted_r)[:, np.newaxis]
buffer_s, buffer_a, buffer_r = [], [], []
QUEUE.put(np.hstack((bs, ba, br)))
if GLOBAL_UPDATE_COUNTER >= MIN_BATCH_SIZE:
ROLLING_EVENT.clear() # stop collecting data
UPDATE_EVENT.set() # globalPPO update
if GLOBAL_EP >= EP_MAX: # stop training
COORD.request_stop()
break
# record reward changes, plot later
if len(GLOBAL_RUNNING_R) == 0: GLOBAL_RUNNING_R.append(ep_r)
else: GLOBAL_RUNNING_R.append(GLOBAL_RUNNING_R[-1]*0.9+ep_r*0.1)
GLOBAL_EP += 1
print('{0:.1f}%'.format(GLOBAL_EP/EP_MAX*100), '|W%i' % self.wid, '|Ep_r: %.2f' % ep_r,)
if __name__ == '__main__':
GLOBAL_PPO = PPO()
UPDATE_EVENT, ROLLING_EVENT = threading.Event(), threading.Event()
UPDATE_EVENT.clear() # no update now
ROLLING_EVENT.set() # start to roll out
workers = [Worker(wid=i) for i in range(N_WORKER)]
GLOBAL_UPDATE_COUNTER, GLOBAL_EP = 0, 0
GLOBAL_RUNNING_R = []
COORD = tf.train.Coordinator()
QUEUE = queue.Queue()
threads = []
for worker in workers: # worker threads
t = threading.Thread(target=worker.work, args=())
t.start()
threads.append(t)
# add a PPO updating thread
threads.append(threading.Thread(target=GLOBAL_PPO.update,))
threads[-1].start()
COORD.join(threads)
# plot reward change and testing
plt.plot(np.arange(len(GLOBAL_RUNNING_R)), GLOBAL_RUNNING_R)
plt.xlabel('Episode'); plt.ylabel('Moving reward'); plt.ion(); plt.show()
env.set_fps(30)
while True:
s = env.reset()
for t in range(400):
env.render()
s = env.step(GLOBAL_PPO.choose_action(s))[0]
================================================
FILE: experiments/Robot_arm/arm_env.py
================================================
"""
Environment for Robot Arm.
You can customize this script in a way you want.
View more on [莫烦Python] : https://morvanzhou.github.io/tutorials/
Requirement:
pyglet >= 1.2.4
numpy >= 1.12.1
"""
import numpy as np
import pyglet
pyglet.clock.set_fps_limit(10000)
class ArmEnv(object):
action_bound = [-1, 1]
action_dim = 2
state_dim = 7
dt = .1 # refresh rate
arm1l = 100
arm2l = 100
viewer = None
viewer_xy = (400, 400)
get_point = False
mouse_in = np.array([False])
point_l = 15
grab_counter = 0
def __init__(self, mode='easy'):
# node1 (l, d_rad, x, y),
# node2 (l, d_rad, x, y)
self.mode = mode
self.arm_info = np.zeros((2, 4))
self.arm_info[0, 0] = self.arm1l
self.arm_info[1, 0] = self.arm2l
self.point_info = np.array([250, 303])
self.point_info_init = self.point_info.copy()
self.center_coord = np.array(self.viewer_xy)/2
def step(self, action):
# action = (node1 angular v, node2 angular v)
action = np.clip(action, *self.action_bound)
self.arm_info[:, 1] += action * self.dt
self.arm_info[:, 1] %= np.pi * 2
arm1rad = self.arm_info[0, 1]
arm2rad = self.arm_info[1, 1]
arm1dx_dy = np.array([self.arm_info[0, 0] * np.cos(arm1rad), self.arm_info[0, 0] * np.sin(arm1rad)])
arm2dx_dy = np.array([self.arm_info[1, 0] * np.cos(arm2rad), self.arm_info[1, 0] * np.sin(arm2rad)])
self.arm_info[0, 2:4] = self.center_coord + arm1dx_dy # (x1, y1)
self.arm_info[1, 2:4] = self.arm_info[0, 2:4] + arm2dx_dy # (x2, y2)
s, arm2_distance = self._get_state()
r = self._r_func(arm2_distance)
return s, r, self.get_point
def reset(self):
self.get_point = False
self.grab_counter = 0
if self.mode == 'hard':
pxy = np.clip(np.random.rand(2) * self.viewer_xy[0], 100, 300)
self.point_info[:] = pxy
else:
arm1rad, arm2rad = np.random.rand(2) * np.pi * 2
self.arm_info[0, 1] = arm1rad
self.arm_info[1, 1] = arm2rad
arm1dx_dy = np.array([self.arm_info[0, 0] * np.cos(arm1rad), self.arm_info[0, 0] * np.sin(arm1rad)])
arm2dx_dy = np.array([self.arm_info[1, 0] * np.cos(arm2rad), self.arm_info[1, 0] * np.sin(arm2rad)])
self.arm_info[0, 2:4] = self.center_coord + arm1dx_dy # (x1, y1)
self.arm_info[1, 2:4] = self.arm_info[0, 2:4] + arm2dx_dy # (x2, y2)
self.point_info[:] = self.point_info_init
return self._get_state()[0]
def render(self):
if self.viewer is None:
self.viewer = Viewer(*self.viewer_xy, self.arm_info, self.point_info, self.point_l, self.mouse_in)
self.viewer.render()
def sample_action(self):
return np.random.uniform(*self.action_bound, size=self.action_dim)
def set_fps(self, fps=30):
pyglet.clock.set_fps_limit(fps)
def _get_state(self):
# return the distance (dx, dy) between arm finger point with blue point
arm_end = self.arm_info[:, 2:4]
t_arms = np.ravel(arm_end - self.point_info)
center_dis = (self.center_coord - self.point_info)/200
in_point = 1 if self.grab_counter > 0 else 0
return np.hstack([in_point, t_arms/200, center_dis,
# arm1_distance_p, arm1_distance_b,
]), t_arms[-2:]
def _r_func(self, distance):
t = 50
abs_distance = np.sqrt(np.sum(np.square(distance)))
r = -abs_distance/200
if abs_distance < self.point_l and (not self.get_point):
r += 1.
self.grab_counter += 1
if self.grab_counter > t:
r += 10.
self.get_point = True
elif abs_distance > self.point_l:
self.grab_counter = 0
self.get_point = False
return r
class Viewer(pyglet.window.Window):
color = {
'background': [1]*3 + [1]
}
fps_display = pyglet.clock.ClockDisplay()
bar_thc = 5
def __init__(self, width, height, arm_info, point_info, point_l, mouse_in):
super(Viewer, self).__init__(width, height, resizable=False, caption='Arm', vsync=False) # vsync=False to not use the monitor FPS
self.set_location(x=80, y=10)
pyglet.gl.glClearColor(*self.color['background'])
self.arm_info = arm_info
self.point_info = point_info
self.mouse_in = mouse_in
self.point_l = point_l
self.center_coord = np.array((min(width, height)/2, ) * 2)
self.batch = pyglet.graphics.Batch()
arm1_box, arm2_box, point_box = [0]*8, [0]*8, [0]*8
c1, c2, c3 = (249, 86, 86)*4, (86, 109, 249)*4, (249, 39, 65)*4
self.point = self.batch.add(4, pyglet.gl.GL_QUADS, None, ('v2f', point_box), ('c3B', c2))
self.arm1 = self.batch.add(4, pyglet.gl.GL_QUADS, None, ('v2f', arm1_box), ('c3B', c1))
self.arm2 = self.batch.add(4, pyglet.gl.GL_QUADS, None, ('v2f', arm2_box), ('c3B', c1))
def render(self):
pyglet.clock.tick()
self._update_arm()
self.switch_to()
self.dispatch_events()
self.dispatch_event('on_draw')
self.flip()
def on_draw(self):
self.clear()
self.batch.draw()
# self.fps_display.draw()
def _update_arm(self):
point_l = self.point_l
point_box = (self.point_info[0] - point_l, self.point_info[1] - point_l,
self.point_info[0] + point_l, self.point_info[1] - point_l,
self.point_info[0] + point_l, self.point_info[1] + point_l,
self.point_info[0] - point_l, self.point_info[1] + point_l)
self.point.vertices = point_box
arm1_coord = (*self.center_coord, *(self.arm_info[0, 2:4])) # (x0, y0, x1, y1)
arm2_coord = (*(self.arm_info[0, 2:4]), *(self.arm_info[1, 2:4])) # (x1, y1, x2, y2)
arm1_thick_rad = np.pi / 2 - self.arm_info[0, 1]
x01, y01 = arm1_coord[0] - np.cos(arm1_thick_rad) * self.bar_thc, arm1_coord[1] + np.sin(
arm1_thick_rad) * self.bar_thc
x02, y02 = arm1_coord[0] + np.cos(arm1_thick_rad) * self.bar_thc, arm1_coord[1] - np.sin(
arm1_thick_rad) * self.bar_thc
x11, y11 = arm1_coord[2] + np.cos(arm1_thick_rad) * self.bar_thc, arm1_coord[3] - np.sin(
arm1_thick_rad) * self.bar_thc
x12, y12 = arm1_coord[2] - np.cos(arm1_thick_rad) * self.bar_thc, arm1_coord[3] + np.sin(
arm1_thick_rad) * self.bar_thc
arm1_box = (x01, y01, x02, y02, x11, y11, x12, y12)
arm2_thick_rad = np.pi / 2 - self.arm_info[1, 1]
x11_, y11_ = arm2_coord[0] + np.cos(arm2_thick_rad) * self.bar_thc, arm2_coord[1] - np.sin(
arm2_thick_rad) * self.bar_thc
x12_, y12_ = arm2_coord[0] - np.cos(arm2_thick_rad) * self.bar_thc, arm2_coord[1] + np.sin(
arm2_thick_rad) * self.bar_thc
x21, y21 = arm2_coord[2] - np.cos(arm2_thick_rad) * self.bar_thc, arm2_coord[3] + np.sin(
arm2_thick_rad) * self.bar_thc
x22, y22 = arm2_coord[2] + np.cos(arm2_thick_rad) * self.bar_thc, arm2_coord[3] - np.sin(
arm2_thick_rad) * self.bar_thc
arm2_box = (x11_, y11_, x12_, y12_, x21, y21, x22, y22)
self.arm1.vertices = arm1_box
self.arm2.vertices = arm2_box
def on_key_press(self, symbol, modifiers):
if symbol == pyglet.window.key.UP:
self.arm_info[0, 1] += .1
print(self.arm_info[:, 2:4] - self.point_info)
elif symbol == pyglet.window.key.DOWN:
self.arm_info[0, 1] -= .1
print(self.arm_info[:, 2:4] - self.point_info)
elif symbol == pyglet.window.key.LEFT:
self.arm_info[1, 1] += .1
print(self.arm_info[:, 2:4] - self.point_info)
elif symbol == pyglet.window.key.RIGHT:
self.arm_info[1, 1] -= .1
print(self.arm_info[:, 2:4] - self.point_info)
elif symbol == pyglet.window.key.Q:
pyglet.clock.set_fps_limit(1000)
elif symbol == pyglet.window.key.A:
pyglet.clock.set_fps_limit(30)
def on_mouse_motion(self, x, y, dx, dy):
self.point_info[:] = [x, y]
def on_mouse_enter(self, x, y):
self.mouse_in[0] = True
def on_mouse_leave(self, x, y):
self.mouse_in[0] = False
================================================
FILE: experiments/Solve_BipedalWalker/A3C.py
================================================
"""
Asynchronous Advantage Actor Critic (A3C), Reinforcement Learning.
The BipedalWalker example.
View more on [莫烦Python] : https://morvanzhou.github.io/tutorials/
Using:
tensorflow 1.8.0
gym 0.10.5
"""
import multiprocessing
import threading
import tensorflow as tf
import numpy as np
import gym
import os
import shutil
GAME = 'BipedalWalker-v2'
OUTPUT_GRAPH = False
LOG_DIR = './log'
N_WORKERS = multiprocessing.cpu_count()
MAX_GLOBAL_EP = 8000
GLOBAL_NET_SCOPE = 'Global_Net'
UPDATE_GLOBAL_ITER = 10
GAMMA = 0.99
ENTROPY_BETA = 0.005
LR_A = 0.00005 # learning rate for actor
LR_C = 0.0001 # learning rate for critic
GLOBAL_RUNNING_R = []
GLOBAL_EP = 0
env = gym.make(GAME)
N_S = env.observation_space.shape[0]
N_A = env.action_space.shape[0]
A_BOUND = [env.action_space.low, env.action_space.high]
del env
class ACNet(object):
def __init__(self, scope, globalAC=None):
if scope == GLOBAL_NET_SCOPE: # get global network
with tf.variable_scope(scope):
self.s = tf.placeholder(tf.float32, [None, N_S], 'S')
self._build_net()
self.a_params = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope=scope + '/actor')
self.c_params = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope=scope + '/critic')
else: # local net, calculate losses
with tf.variable_scope(scope):
self.s = tf.placeholder(tf.float32, [None, N_S], 'S')
self.a_his = tf.placeholder(tf.float32, [None, N_A], 'A')
self.v_target = tf.placeholder(tf.float32, [None, 1], 'Vtarget')
mu, sigma, self.v = self._build_net()
td = tf.subtract(self.v_target, self.v, name='TD_error')
with tf.name_scope('c_loss'):
self.c_loss = tf.reduce_mean(tf.square(td))
with tf.name_scope('wrap_a_out'):
self.test = sigma[0]
mu, sigma = mu * A_BOUND[1], sigma + 1e-5
normal_dist = tf.contrib.distributions.Normal(mu, sigma)
with tf.name_scope('a_loss'):
log_prob = normal_dist.log_prob(self.a_his)
exp_v = log_prob * td
entropy = normal_dist.entropy() # encourage exploration
self.exp_v = ENTROPY_BETA * entropy + exp_v
self.a_loss = tf.reduce_mean(-self.exp_v)
with tf.name_scope('choose_a'): # use local params to choose action
self.A = tf.clip_by_value(tf.squeeze(normal_dist.sample(1)), *A_BOUND)
with tf.name_scope('local_grad'):
self.a_params = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope=scope + '/actor')
self.c_params = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope=scope + '/critic')
self.a_grads = tf.gradients(self.a_loss, self.a_params)
self.c_grads = tf.gradients(self.c_loss, self.c_params)
with tf.name_scope('sync'):
with tf.name_scope('pull'):
self.pull_a_params_op = [l_p.assign(g_p) for l_p, g_p in zip(self.a_params, globalAC.a_params)]
self.pull_c_params_op = [l_p.assign(g_p) for l_p, g_p in zip(self.c_params, globalAC.c_params)]
with tf.name_scope('push'):
self.update_a_op = OPT_A.apply_gradients(zip(self.a_grads, globalAC.a_params))
self.update_c_op = OPT_C.apply_gradients(zip(self.c_grads, globalAC.c_params))
def _build_net(self):
w_init = tf.contrib.layers.xavier_initializer()
with tf.variable_scope('actor'):
l_a = tf.layers.dense(self.s, 500, tf.nn.relu6, kernel_initializer=w_init, name='la')
l_a = tf.layers.dense(l_a, 300, tf.nn.relu6, kernel_initializer=w_init, name='la2')
mu = tf.layers.dense(l_a, N_A, tf.nn.tanh, kernel_initializer=w_init, name='mu')
sigma = tf.layers.dense(l_a, N_A, tf.nn.softplus, kernel_initializer=w_init, name='sigma')
with tf.variable_scope('critic'):
l_c = tf.layers.dense(self.s, 500, tf.nn.relu6, kernel_initializer=w_init, name='lc')
l_c = tf.layers.dense(l_c, 300, tf.nn.relu6, kernel_initializer=w_init, name='lc2')
v = tf.layers.dense(l_c, 1, kernel_initializer=w_init, name='v') # state value
return mu, sigma, v
def update_global(self, feed_dict): # run by a local
_, _, t = SESS.run([self.update_a_op, self.update_c_op, self.test], feed_dict) # local grads applies to global net
return t
def pull_global(self): # run by a local
SESS.run([self.pull_a_params_op, self.pull_c_params_op])
def choose_action(self, s): # run by a local
s = s[np.newaxis, :]
return SESS.run(self.A, {self.s: s})
class Worker(object):
def __init__(self, name, globalAC):
self.env = gym.make(GAME)
self.name = name
self.AC = ACNet(name, globalAC)
def work(self):
global GLOBAL_RUNNING_R, GLOBAL_EP
total_step = 1
buffer_s, buffer_a, buffer_r = [], [], []
while not COORD.should_stop() and GLOBAL_EP < MAX_GLOBAL_EP:
s = self.env.reset()
ep_r = 0
while True:
if self.name == 'W_0' and total_step % 30 == 0:
self.env.render()
a = self.AC.choose_action(s)
s_, r, done, info = self.env.step(a)
if r == -100: r = -2
ep_r += r
buffer_s.append(s)
buffer_a.append(a)
buffer_r.append(r)
if total_step % UPDATE_GLOBAL_ITER == 0 or done: # update global and assign to local net
if done:
v_s_ = 0 # terminal
else:
v_s_ = SESS.run(self.AC.v, {self.AC.s: s_[np.newaxis, :]})[0, 0]
buffer_v_target = []
for r in buffer_r[::-1]: # reverse buffer r
v_s_ = r + GAMMA * v_s_
buffer_v_target.append(v_s_)
buffer_v_target.reverse()
buffer_s, buffer_a, buffer_v_target = np.vstack(buffer_s), np.vstack(buffer_a), np.vstack(buffer_v_target)
feed_dict = {
self.AC.s: buffer_s,
self.AC.a_his: buffer_a,
self.AC.v_target: buffer_v_target,
}
test = self.AC.update_global(feed_dict)
buffer_s, buffer_a, buffer_r = [], [], []
self.AC.pull_global()
s = s_
total_step += 1
if done:
achieve = '| Achieve' if self.env.unwrapped.hull.position[0] >= 88 else '| -------'
if len(GLOBAL_RUNNING_R) == 0: # record running episode reward
GLOBAL_RUNNING_R.append(ep_r)
else:
GLOBAL_RUNNING_R.append(0.95 * GLOBAL_RUNNING_R[-1] + 0.05 * ep_r)
print(
self.name,
"Ep:", GLOBAL_EP,
achieve,
"| Pos: %i" % self.env.unwrapped.hull.position[0],
"| RR: %.1f" % GLOBAL_RUNNING_R[-1],
'| EpR: %.1f' % ep_r,
'| var:', test,
)
GLOBAL_EP += 1
break
if __name__ == "__main__":
SESS = tf.Session()
with tf.device("/cpu:0"):
OPT_A = tf.train.RMSPropOptimizer(LR_A, name='RMSPropA')
OPT_C = tf.train.RMSPropOptimizer(LR_C, name='RMSPropC')
GLOBAL_AC = ACNet(GLOBAL_NET_SCOPE) # we only need its params
workers = []
# Create worker
for i in range(N_WORKERS):
i_name = 'W_%i' % i # worker name
workers.append(Worker(i_name, GLOBAL_AC))
COORD = tf.train.Coordinator()
SESS.run(tf.global_variables_initializer())
worker_threads = []
for worker in workers:
job = lambda: worker.work()
t = threading.Thread(target=job)
t.start()
worker_threads.append(t)
COORD.join(worker_threads)
import matplotlib.pyplot as plt
plt.plot(GLOBAL_RUNNING_R)
plt.xlabel('episode')
plt.ylabel('global running reward')
plt.show()
================================================
FILE: experiments/Solve_BipedalWalker/A3C_rnn.py
================================================
"""
Asynchronous Advantage Actor Critic (A3C), Reinforcement Learning.
The BipedalWalker example.
View more on [莫烦Python] : https://morvanzhou.github.io/tutorials/
Using:
tensorflow 1.8.0
gym 0.10.5
"""
import multiprocessing
import threading
import tensorflow as tf
import numpy as np
import gym
import os
import shutil
GAME = 'BipedalWalker-v2'
OUTPUT_GRAPH = False
LOG_DIR = './log'
N_WORKERS = multiprocessing.cpu_count()
MAX_GLOBAL_EP = 8000
GLOBAL_NET_SCOPE = 'Global_Net'
UPDATE_GLOBAL_ITER = 10
GAMMA = 0.9
ENTROPY_BETA = 0.001
LR_A = 0.00002 # learning rate for actor
LR_C = 0.0001 # learning rate for critic
GLOBAL_RUNNING_R = []
GLOBAL_EP = 0
env = gym.make(GAME)
N_S = env.observation_space.shape[0]
N_A = env.action_space.shape[0]
A_BOUND = [env.action_space.low, env.action_space.high]
del env
class ACNet(object):
def __init__(self, scope, globalAC=None):
if scope == GLOBAL_NET_SCOPE: # get global network
with tf.variable_scope(scope):
self.s = tf.placeholder(tf.float32, [None, N_S], 'S')
self._build_net()
self.a_params = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope=scope + '/actor')
self.c_params = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope=scope + '/critic')
else: # local net, calculate losses
with tf.variable_scope(scope):
self.s = tf.placeholder(tf.float32, [None, N_S], 'S')
self.a_his = tf.placeholder(tf.float32, [None, N_A], 'A')
self.v_target = tf.placeholder(tf.float32, [None, 1], 'Vtarget')
mu, sigma, self.v = self._build_net()
td = tf.subtract(self.v_target, self.v, name='TD_error')
with tf.name_scope('c_loss'):
self.c_loss = tf.reduce_mean(tf.square(td))
with tf.name_scope('wrap_a_out'):
self.test = sigma[0]
mu, sigma = mu * A_BOUND[1], sigma + 1e-5
normal_dist = tf.contrib.distributions.Normal(mu, sigma)
with tf.name_scope('a_loss'):
log_prob = normal_dist.log_prob(self.a_his)
exp_v = log_prob * td
entropy = normal_dist.entropy() # encourage exploration
self.exp_v = ENTROPY_BETA * entropy + exp_v
self.a_loss = tf.reduce_mean(-self.exp_v)
with tf.name_scope('choose_a'): # use local params to choose action
self.A = tf.clip_by_value(tf.squeeze(normal_dist.sample(1)), A_BOUND[0], A_BOUND[1])
with tf.name_scope('local_grad'):
self.a_params = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope=scope + '/actor')
self.c_params = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope=scope + '/critic')
self.a_grads = tf.gradients(self.a_loss, self.a_params)
self.c_grads = tf.gradients(self.c_loss, self.c_params)
with tf.name_scope('sync'):
with tf.name_scope('pull'):
self.pull_a_params_op = [l_p.assign(g_p) for l_p, g_p in
zip(self.a_params, globalAC.a_params)]
self.pull_c_params_op = [l_p.assign(g_p) for l_p, g_p in
zip(self.c_params, globalAC.c_params)]
with tf.name_scope('push'):
self.update_a_op = OPT_A.apply_gradients(zip(self.a_grads, globalAC.a_params))
self.update_c_op = OPT_C.apply_gradients(zip(self.c_grads, globalAC.c_params))
def _build_net(self):
w_init = tf.random_normal_initializer(0., .1)
with tf.variable_scope('critic'): # only critic controls the rnn update
cell_size = 126
s = tf.expand_dims(self.s, axis=1,
name='timely_input') # [time_step, feature] => [time_step, batch, feature]
rnn_cell = tf.contrib.rnn.BasicRNNCell(cell_size)
self.init_state = rnn_cell.zero_state(batch_size=1, dtype=tf.float32)
outputs, self.final_state = tf.nn.dynamic_rnn(
cell=rnn_cell, inputs=s, initial_state=self.init_state, time_major=True)
cell_out = tf.reshape(outputs, [-1, cell_size], name='flatten_rnn_outputs') # joined state representation
l_c = tf.layers.dense(cell_out, 512, tf.nn.relu6, kernel_initializer=w_init, name='lc')
v = tf.layers.dense(l_c, 1, kernel_initializer=w_init, name='v') # state value
with tf.variable_scope('actor'): # state representation is based on critic
cell_out = tf.stop_gradient(cell_out, name='c_cell_out') # from what critic think it is
l_a = tf.layers.dense(cell_out, 512, tf.nn.relu6, kernel_initializer=w_init, name='la')
mu = tf.layers.dense(l_a, N_A, tf.nn.tanh, kernel_initializer=w_init, name='mu')
sigma = tf.layers.dense(l_a, N_A, tf.nn.softplus, kernel_initializer=w_init, name='sigma') # restrict variance
return mu, sigma, v
def update_global(self, feed_dict): # run by a local
_, _, t = SESS.run([self.update_a_op, self.update_c_op, self.test], feed_dict) # local grads applies to global net
return t
def pull_global(self): # run by a local
SESS.run([self.pull_a_params_op, self.pull_c_params_op])
def choose_action(self, s, cell_state): # run by a local
s = s[np.newaxis, :]
a, cell_state = SESS.run([self.A, self.final_state], {self.s: s, self.init_state: cell_state})
return a, cell_state
class Worker(object):
def __init__(self, name, globalAC):
self.env = gym.make(GAME)
self.name = name
self.AC = ACNet(name, globalAC)
def work(self):
global GLOBAL_RUNNING_R, GLOBAL_EP
total_step = 1
buffer_s, buffer_a, buffer_r = [], [], []
while not COORD.should_stop() and GLOBAL_EP < MAX_GLOBAL_EP:
s = self.env.reset()
ep_r = 0
rnn_state = SESS.run(self.AC.init_state) # zero rnn state at beginning
keep_state = rnn_state.copy() # keep rnn state for updating global net
while True:
if self.name == 'W_0' and total_step % 30 == 0:
self.env.render()
a, rnn_state_ = self.AC.choose_action(s, rnn_state) # get the action and next rnn state
s_, r, done, info = self.env.step(a)
if r == -100: r = -2
ep_r += r
buffer_s.append(s)
buffer_a.append(a)
buffer_r.append(r)
if total_step % UPDATE_GLOBAL_ITER == 0 or done: # update global and assign to local net
if done:
v_s_ = 0 # terminal
else:
v_s_ = SESS.run(self.AC.v, {self.AC.s: s_[np.newaxis, :], self.AC.init_state: rnn_state_})[
0, 0]
buffer_v_target = []
for r in buffer_r[::-1]: # reverse buffer r
v_s_ = r + GAMMA * v_s_
buffer_v_target.append(v_s_)
buffer_v_target.reverse()
buffer_s, buffer_a, buffer_v_target = np.vstack(buffer_s), np.vstack(buffer_a), np.vstack(
buffer_v_target)
feed_dict = {
self.AC.s: buffer_s,
self.AC.a_his: buffer_a,
self.AC.v_target: buffer_v_target,
self.AC.init_state: keep_state,
}
test = self.AC.update_global(feed_dict)
buffer_s, buffer_a, buffer_r = [], [], []
self.AC.pull_global()
keep_state = rnn_state_.copy() # replace the keep_state as the new initial rnn state_
s = s_
rnn_state = rnn_state_ # renew rnn state
total_step += 1
if done:
achieve = '| Achieve' if self.env.unwrapped.hull.position[0] >= 88 else '| -------'
if len(GLOBAL_RUNNING_R) == 0: # record running episode reward
GLOBAL_RUNNING_R.append(ep_r)
else:
GLOBAL_RUNNING_R.append(0.95 * GLOBAL_RUNNING_R[-1] + 0.05 * ep_r)
print(
self.name,
"Ep:", GLOBAL_EP,
achieve,
"| Pos: %i" % self.env.unwrapped.hull.position[0],
"| RR: %.1f" % GLOBAL_RUNNING_R[-1],
'| EpR: %.1f' % ep_r,
'| var:', test,
)
GLOBAL_EP += 1
break
if __name__ == "__main__":
SESS = tf.Session()
with tf.device("/cpu:0"):
OPT_A = tf.train.RMSPropOptimizer(LR_A, name='RMSPropA', decay=0.95)
OPT_C = tf.train.RMSPropOptimizer(LR_C, name='RMSPropC', decay=0.95)
GLOBAL_AC = ACNet(GLOBAL_NET_SCOPE) # we only need its params
workers = []
# Create worker
for i in range(N_WORKERS):
i_name = 'W_%i' % i # worker name
workers.append(Worker(i_name, GLOBAL_AC))
COORD = tf.train.Coordinator()
SESS.run(tf.global_variables_initializer())
if OUTPUT_GRAPH:
if os.path.exists(LOG_DIR):
shutil.rmtree(LOG_DIR)
tf.summary.FileWriter(LOG_DIR, SESS.graph)
worker_threads = []
for worker in workers:
t = threading.Thread(target=worker.work)
t.start()
worker_threads.append(t)
COORD.join(worker_threads)
import matplotlib.pyplot as plt
plt.plot(GLOBAL_RUNNING_R)
plt.xlabel('episode')
plt.ylabel('global running reward')
plt.show()
================================================
FILE: experiments/Solve_BipedalWalker/DDPG.py
================================================
import tensorflow as tf
import numpy as np
import gym
import os
import shutil
np.random.seed(1)
tf.set_random_seed(1)
MAX_EPISODES = 2000
LR_A = 0.0005 # learning rate for actor
LR_C = 0.0005 # learning rate for critic
GAMMA = 0.999 # reward discount
REPLACE_ITER_A = 1700
REPLACE_ITER_C = 1500
MEMORY_CAPACITY = 200000
BATCH_SIZE = 32
DISPLAY_THRESHOLD = 100 # display until the running reward > 100
DATA_PATH = './data'
LOAD_MODEL = False
SAVE_MODEL_ITER = 100000
RENDER = False
OUTPUT_GRAPH = False
ENV_NAME = 'BipedalWalker-v2'
GLOBAL_STEP = tf.Variable(0, trainable=False)
INCREASE_GS = GLOBAL_STEP.assign(tf.add(GLOBAL_STEP, 1))
LR_A = tf.train.exponential_decay(LR_A, GLOBAL_STEP, 10000, .97, staircase=True)
LR_C = tf.train.exponential_decay(LR_C, GLOBAL_STEP, 10000, .97, staircase=True)
END_POINT = (200 - 10) * (14/30) # from game
env = gym.make(ENV_NAME)
env.seed(1)
STATE_DIM = env.observation_space.shape[0] # 24
ACTION_DIM = env.action_space.shape[0] # 4
ACTION_BOUND = env.action_space.high # [1, 1, 1, 1]
# all placeholder for tf
with tf.name_scope('S'):
S = tf.placeholder(tf.float32, shape=[None, STATE_DIM], name='s')
with tf.name_scope('R'):
R = tf.placeholder(tf.float32, [None, 1], name='r')
with tf.name_scope('S_'):
S_ = tf.placeholder(tf.float32, shape=[None, STATE_DIM], name='s_')
############################### Actor ####################################
class Actor(object):
def __init__(self, sess, action_dim, action_bound, learning_rate, t_replace_iter):
self.sess = sess
self.a_dim = action_dim
self.action_bound = action_bound
self.lr = learning_rate
self.t_replace_iter = t_replace_iter
self.t_replace_counter = 0
with tf.variable_scope('Actor'):
# input s, output a
self.a = self._build_net(S, scope='eval_net', trainable=True)
# input s_, output a, get a_ for critic
self.a_ = self._build_net(S_, scope='target_net', trainable=False)
self.e_params = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope='Actor/eval_net')
self.t_params = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope='Actor/target_net')
def _build_net(self, s, scope, trainable):
with tf.variable_scope(scope):
init_w = tf.random_normal_initializer(0., 0.01)
init_b = tf.constant_initializer(0.01)
net = tf.layers.dense(s, 500, activation=tf.nn.relu,
kernel_initializer=init_w, bias_initializer=init_b, name='l1', trainable=trainable)
net = tf.layers.dense(net, 200, activation=tf.nn.relu,
kernel_initializer=init_w, bias_initializer=init_b, name='l2', trainable=trainable)
with tf.variable_scope('a'):
actions = tf.layers.dense(net, self.a_dim, activation=tf.nn.tanh, kernel_initializer=init_w,
bias_initializer=init_b, name='a', trainable=trainable)
scaled_a = tf.multiply(actions, self.action_bound, name='scaled_a') # Scale output to -action_bound to action_bound
return scaled_a
def learn(self, s): # batch update
self.sess.run(self.train_op, feed_dict={S: s})
if self.t_replace_counter % self.t_replace_iter == 0:
self.sess.run([tf.assign(t, e) for t, e in zip(self.t_params, self.e_params)])
self.t_replace_counter += 1
def choose_action(self, s):
s = s[np.newaxis, :] # single state
return self.sess.run(self.a, feed_dict={S: s})[0] # single action
def add_grad_to_graph(self, a_grads):
with tf.variable_scope('policy_grads'):
# ys = policy;
# xs = policy's parameters;
# self.a_grads = the gradients of the policy to get more Q
# tf.gradients will calculate dys/dxs with a initial gradients for ys, so this is dq/da * da/dparams
self.policy_grads_and_vars = tf.gradients(ys=self.a, xs=self.e_params, grad_ys=a_grads)
with tf.variable_scope('A_train'):
opt = tf.train.RMSPropOptimizer(-self.lr) # (- learning rate) for ascent policy
self.train_op = opt.apply_gradients(zip(self.policy_grads_and_vars, self.e_params), global_step=GLOBAL_STEP)
############################### Critic ####################################
class Critic(object):
def __init__(self, sess, state_dim, action_dim, learning_rate, gamma, t_replace_iter, a, a_):
self.sess = sess
self.s_dim = state_dim
self.a_dim = action_dim
self.lr = learning_rate
self.gamma = gamma
self.t_replace_iter = t_replace_iter
self.t_replace_counter = 0
with tf.variable_scope('Critic'):
# Input (s, a), output q
self.a = a
self.q = self._build_net(S, self.a, 'eval_net', trainable=True)
# Input (s_, a_), output q_ for q_target
self.q_ = self._build_net(S_, a_, 'target_net', trainable=False) # target_q is based on a_ from Actor's target_net
self.e_params = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope='Critic/eval_net')
self.t_params = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope='Critic/target_net')
with tf.variable_scope('target_q'):
self.target_q = R + self.gamma * self.q_
with tf.variable_scope('abs_TD'):
self.abs_td = tf.abs(self.target_q - self.q)
self.ISWeights = tf.placeholder(tf.float32, [None, 1], name='IS_weights')
with tf.variable_scope('TD_error'):
self.loss = tf.reduce_mean(self.ISWeights * tf.squared_difference(self.target_q, self.q))
with tf.variable_scope('C_train'):
self.train_op = tf.train.AdamOptimizer(self.lr).minimize(self.loss, global_step=GLOBAL_STEP)
with tf.variable_scope('a_grad'):
self.a_grads = tf.gradients(self.q, a)[0] # tensor of gradients of each sample (None, a_dim)
def _build_net(self, s, a, scope, trainable):
with tf.variable_scope(scope):
init_w = tf.random_normal_initializer(0., 0.01)
init_b = tf.constant_initializer(0.01)
with tf.variable_scope('l1'):
n_l1 = 700
# combine the action and states together in this way
w1_s = tf.get_variable('w1_s', [self.s_dim, n_l1], initializer=init_w, trainable=trainable)
w1_a = tf.get_variable('w1_a', [self.a_dim, n_l1], initializer=init_w, trainable=trainable)
b1 = tf.get_variable('b1', [1, n_l1], initializer=init_b, trainable=trainable)
net = tf.nn.relu(tf.matmul(s, w1_s) + tf.matmul(a, w1_a) + b1)
with tf.variable_scope('l2'):
net = tf.layers.dense(net, 20, activation=tf.nn.relu, kernel_initializer=init_w,
bias_initializer=init_b, name='l2', trainable=trainable)
with tf.variable_scope('q'):
q = tf.layers.dense(net, 1, kernel_initializer=init_w, bias_initializer=init_b, trainable=trainable) # Q(s,a)
return q
def learn(self, s, a, r, s_, ISW):
_, abs_td = self.sess.run([self.train_op, self.abs_td], feed_dict={S: s, self.a: a, R: r, S_: s_, self.ISWeights: ISW})
if self.t_replace_counter % self.t_replace_iter == 0:
self.sess.run([tf.assign(t, e) for t, e in zip(self.t_params, self.e_params)])
self.t_replace_counter += 1
return abs_td
class SumTree(object):
"""
This SumTree code is modified version and the original code is from:
https://github.com/jaara/AI-blog/blob/master/SumTree.py
Story the data with it priority in tree and data frameworks.
"""
data_pointer = 0
def __init__(self, capacity):
self.capacity = capacity # for all priority values
self.tree = np.zeros(2 * capacity - 1)+1e-5
# [--------------Parent nodes-------------][-------leaves to recode priority-------]
# size: capacity - 1 size: capacity
self.data = np.zeros(capacity, dtype=object) # for all transitions
# [--------------data frame-------------]
# size: capacity
def add_new_priority(self, p, data):
leaf_idx = self.data_pointer + self.capacity - 1
self.data[self.data_pointer] = data # update data_frame
self.update(leaf_idx, p) # update tree_frame
self.data_pointer += 1
if self.data_pointer >= self.capacity: # replace when exceed the capacity
self.data_pointer = 0
def update(self, tree_idx, p):
change = p - self.tree[tree_idx]
self.tree[tree_idx] = p
self._propagate_change(tree_idx, change)
def _propagate_change(self, tree_idx, change):
"""change the sum of priority value in all parent nodes"""
parent_idx = (tree_idx - 1) // 2
self.tree[parent_idx] += change
if parent_idx != 0:
self._propagate_change(parent_idx, change)
def get_leaf(self, lower_bound):
leaf_idx = self._retrieve(lower_bound) # search the max leaf priority based on the lower_bound
data_idx = leaf_idx - self.capacity + 1
return [leaf_idx, self.tree[leaf_idx], self.data[data_idx]]
def _retrieve(self, lower_bound, parent_idx=0):
"""
Tree structure and array storage:
Tree index:
0 -> storing priority sum
/ \
1 2
/ \ / \
3 4 5 6 -> storing priority for transitions
Array type for storing:
[0,1,2,3,4,5,6]
"""
left_child_idx = 2 * parent_idx + 1
right_child_idx = left_child_idx + 1
if left_child_idx >= len(self.tree): # end search when no more child
return parent_idx
if self.tree[left_child_idx] == self.tree[right_child_idx]:
return self._retrieve(lower_bound, np.random.choice([left_child_idx, right_child_idx]))
if lower_bound <= self.tree[left_child_idx]: # downward search, always search for a higher priority node
return self._retrieve(lower_bound, left_child_idx)
else:
return self._retrieve(lower_bound - self.tree[left_child_idx], right_child_idx)
@property
def root_priority(self):
return self.tree[0] # the root
class Memory(object): # stored as ( s, a, r, s_ ) in SumTree
"""
This SumTree code is modified version and the original code is from:
https://github.com/jaara/AI-blog/blob/master/Seaquest-DDQN-PER.py
"""
epsilon = 0.001 # small amount to avoid zero priority
alpha = 0.6 # [0~1] convert the importance of TD error to priority
beta = 0.4 # importance-sampling, from initial value increasing to 1
beta_increment_per_sampling = 1e-5 # annealing the bias
abs_err_upper = 1 # for stability refer to paper
def __init__(self, capacity):
self.tree = SumTree(capacity)
def store(self, error, transition):
p = self._get_priority(error)
self.tree.add_new_priority(p, transition)
def prio_sample(self, n):
batch_idx, batch_memory, ISWeights = [], [], []
segment = self.tree.root_priority / n
self.beta = np.min([1, self.beta + self.beta_increment_per_sampling]) # max = 1
min_prob = np.min(self.tree.tree[-self.tree.capacity:]) / self.tree.root_priority
maxiwi = np.power(self.tree.capacity * min_prob, -self.beta) # for later normalizing ISWeights
for i in range(n):
a = segment * i
b = segment * (i + 1)
lower_bound = np.random.uniform(a, b)
while True:
idx, p, data = self.tree.get_leaf(lower_bound)
if type(data) is int:
i -= 1
lower_bound = np.random.uniform(segment * i, segment * (i+1))
else:
break
prob = p / self.tree.root_priority
ISWeights.append(self.tree.capacity * prob)
batch_idx.append(idx)
batch_memory.append(data)
ISWeights = np.vstack(ISWeights)
ISWeights = np.power(ISWeights, -self.beta) / maxiwi # normalize
return batch_idx, np.vstack(batch_memory), ISWeights
def random_sample(self, n):
idx = np.random.randint(0, self.tree.capacity, size=n, dtype=np.int)
return np.vstack(self.tree.data[idx])
def update(self, idx, error):
p = self._get_priority(error)
self.tree.update(idx, p)
def _get_priority(self, error):
error += self.epsilon # avoid 0
clipped_error = np.clip(error, 0, self.abs_err_upper)
return np.power(clipped_error, self.alpha)
sess = tf.Session()
# Create actor and critic.
actor = Actor(sess, ACTION_DIM, ACTION_BOUND, LR_A, REPLACE_ITER_A)
critic = Critic(sess, STATE_DIM, ACTION_DIM, LR_C, GAMMA, REPLACE_ITER_C, actor.a, actor.a_)
actor.add_grad_to_graph(critic.a_grads)
M = Memory(MEMORY_CAPACITY)
saver = tf.train.Saver(max_to_keep=100)
if LOAD_MODEL:
all_ckpt = tf.train.get_checkpoint_state('./data', 'checkpoint').all_model_checkpoint_paths
saver.restore(sess, all_ckpt[-1])
else:
if os.path.isdir(DATA_PATH): shutil.rmtree(DATA_PATH)
os.mkdir(DATA_PATH)
sess.run(tf.global_variables_initializer())
if OUTPUT_GRAPH:
tf.summary.FileWriter('logs', graph=sess.graph)
var = 3 # control exploration
var_min = 0.01
for i_episode in range(MAX_EPISODES):
# s = (hull angle speed, angular velocity, horizontal speed, vertical speed, position of joints and joints angular speed, legs contact with ground, and 10 lidar rangefinder measurements.)
s = env.reset()
ep_r = 0
while True:
if RENDER:
env.render()
a = actor.choose_action(s)
a = np.clip(np.random.normal(a, var), -1, 1) # add randomness to action selection for exploration
s_, r, done, _ = env.step(a) # r = total 300+ points up to the far end. If the robot falls, it gets -100.
if r == -100: r = -2
ep_r += r
transition = np.hstack((s, a, [r], s_))
max_p = np.max(M.tree.tree[-M.tree.capacity:])
M.store(max_p, transition)
if GLOBAL_STEP.eval(sess) > MEMORY_CAPACITY/20:
var = max([var*0.9999, var_min]) # decay the action randomness
tree_idx, b_M, ISWeights = M.prio_sample(BATCH_SIZE) # for critic update
b_s = b_M[:, :STATE_DIM]
b_a = b_M[:, STATE_DIM: STATE_DIM + ACTION_DIM]
b_r = b_M[:, -STATE_DIM - 1: -STATE_DIM]
b_s_ = b_M[:, -STATE_DIM:]
abs_td = critic.learn(b_s, b_a, b_r, b_s_, ISWeights)
actor.learn(b_s)
for i in range(len(tree_idx)): # update priority
idx = tree_idx[i]
M.update(idx, abs_td[i])
if GLOBAL_STEP.eval(sess) % SAVE_MODEL_ITER == 0:
ckpt_path = os.path.join(DATA_PATH, 'DDPG.ckpt')
save_path = saver.save(sess, ckpt_path, global_step=GLOBAL_STEP, write_meta_graph=False)
print("\nSave Model %s\n" % save_path)
if done:
if "running_r" not in globals():
running_r = ep_r
else:
running_r = 0.95*running_r + 0.05*ep_r
if running_r > DISPLAY_THRESHOLD: RENDER = True
else: RENDER = False
done = '| Achieve ' if env.unwrapped.hull.position[0] >= END_POINT else '| -----'
print('Episode:', i_episode,
done,
'| Running_r: %i' % int(running_r),
'| Epi_r: %.2f' % ep_r,
'| Exploration: %.3f' % var,
'| Pos: %.i' % int(env.unwrapped.hull.position[0]),
'| LR_A: %.6f' % sess.run(LR_A),
'| LR_C: %.6f' % sess.run(LR_C),
)
break
s = s_
sess.run(INCREASE_GS)
================================================
FILE: experiments/Solve_LunarLander/A3C.py
================================================
"""
Asynchronous Advantage Actor Critic (A3C) with continuous action space, Reinforcement Learning.
The Pendulum example. Convergence promised, but difficult environment, this code hardly converge.
View more on [莫烦Python] : https://morvanzhou.github.io/tutorials/
Using:
tensorflow 1.0
gym 0.8.0
"""
import multiprocessing
import threading
import tensorflow as tf
import numpy as np
import gym
import os
import shutil
import matplotlib.pyplot as plt
GAME = 'LunarLander-v2'
OUTPUT_GRAPH = False
LOG_DIR = './log'
N_WORKERS = multiprocessing.cpu_count()
MAX_GLOBAL_EP = 5000
GLOBAL_NET_SCOPE = 'Global_Net'
UPDATE_GLOBAL_ITER = 5
GAMMA = 0.99
ENTROPY_BETA = 0.001 # not useful in this case
LR_A = 0.0005 # learning rate for actor
LR_C = 0.001 # learning rate for critic
GLOBAL_RUNNING_R = []
GLOBAL_EP = 0
env = gym.make(GAME)
N_S = env.observation_space.shape[0]
N_A = env.action_space.n
del env
class ACNet(object):
def __init__(self, scope, globalAC=None):
if scope == GLOBAL_NET_SCOPE: # get global network
with tf.variable_scope(scope):
self.s = tf.placeholder(tf.float32, [None, N_S], 'S')
self._build_net(N_A)
self.a_params = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope=scope + '/actor')
self.c_params = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope=scope + '/critic')
else: # local net, calculate losses
with tf.variable_scope(scope):
self.s = tf.placeholder(tf.float32, [None, N_S], 'S')
self.a_his = tf.placeholder(tf.int32, [None, ], 'A')
self.v_target = tf.placeholder(tf.float32, [None, 1], 'Vtarget')
self.a_prob, self.v = self._build_net(N_A)
td = tf.subtract(self.v_target, self.v, name='TD_error')
with tf.name_scope('c_loss'):
self.c_loss = tf.reduce_mean(tf.square(td))
with tf.name_scope('a_loss'):
log_prob = tf.reduce_sum(tf.log(self.a_prob) * tf.one_hot(self.a_his, N_A, dtype=tf.float32), axis=1, keep_dims=True)
exp_v = log_prob * td
entropy = -tf.reduce_sum(self.a_prob * tf.log(self.a_prob), axis=1, keep_dims=True) # encourage exploration
self.exp_v = ENTROPY_BETA * entropy + exp_v
self.a_loss = tf.reduce_mean(-self.exp_v)
with tf.name_scope('local_grad'):
self.a_params = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope=scope + '/actor')
self.c_params = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope=scope + '/critic')
self.a_grads = tf.gradients(self.a_loss, self.a_params)
self.c_grads = tf.gradients(self.c_loss, self.c_params)
with tf.name_scope('sync'):
with tf.name_scope('pull'):
self.pull_a_params_op = [l_p.assign(g_p) for l_p, g_p in zip(self.a_params, globalAC.a_params)]
self.pull_c_params_op = [l_p.assign(g_p) for l_p, g_p in zip(self.c_params, globalAC.c_params)]
with tf.name_scope('push'):
self.update_a_op = OPT_A.apply_gradients(zip(self.a_grads, globalAC.a_params))
self.update_c_op = OPT_C.apply_gradients(zip(self.c_grads, globalAC.c_params))
def _build_net(self, n_a):
w_init = tf.random_normal_initializer(0., .01)
with tf.variable_scope('critic'):
cell_size = 64
s = tf.expand_dims(self.s, axis=1,
name='timely_input') # [time_step, feature] => [time_step, batch, feature]
rnn_cell = tf.contrib.rnn.BasicRNNCell(cell_size)
self.init_state = rnn_cell.zero_state(batch_size=1, dtype=tf.float32)
outputs, self.final_state = tf.nn.dynamic_rnn(
cell=rnn_cell, inputs=s, initial_state=self.init_state, time_major=True)
cell_out = tf.reshape(outputs, [-1, cell_size], name='flatten_rnn_outputs') # joined state representation
l_c = tf.layers.dense(cell_out, 200, tf.nn.relu6, kernel_initializer=w_init, name='lc')
v = tf.layers.dense(l_c, 1, kernel_initializer=w_init, name='v') # state value
with tf.variable_scope('actor'):
cell_out = tf.stop_gradient(cell_out, name='c_cell_out')
l_a = tf.layers.dense(cell_out, 300, tf.nn.relu6, kernel_initializer=w_init, name='la')
a_prob = tf.layers.dense(l_a, n_a, tf.nn.softmax, kernel_initializer=w_init, name='ap')
return a_prob, v
def update_global(self, feed_dict): # run by a local
SESS.run([self.update_a_op, self.update_c_op], feed_dict) # local grads applies to global net
def pull_global(self): # run by a local
SESS.run([self.pull_a_params_op, self.pull_c_params_op])
def choose_action(self, s, cell_state): # run by a local
prob_weights, cell_state = SESS.run([self.a_prob, self.final_state], feed_dict={self.s: s[np.newaxis, :],
self.init_state: cell_state})
action = np.random.choice(range(prob_weights.shape[1]),
p=prob_weights.ravel()) # select action w.r.t the actions prob
return action, cell_state
class Worker(object):
def __init__(self, name, globalAC):
self.env = gym.make(GAME)
self.name = name
self.AC = ACNet(name, globalAC)
def work(self):
global GLOBAL_RUNNING_R, GLOBAL_EP
total_step = 1
r_scale = 100
buffer_s, buffer_a, buffer_r = [], [], []
while not COORD.should_stop() and GLOBAL_EP < MAX_GLOBAL_EP:
s = self.env.reset()
ep_r = 0
ep_t = 0
rnn_state = SESS.run(self.AC.init_state) # zero rnn state at beginning
keep_state = rnn_state.copy() # keep rnn state for updating global net
while True:
# if self.name == 'W_0' and total_step % 10 == 0:
# self.env.render()
a, rnn_state_ = self.AC.choose_action(s, rnn_state) # get the action and next rnn state
s_, r, done, info = self.env.step(a)
if r == -100: r = -10
ep_r += r
buffer_s.append(s)
buffer_a.append(a)
buffer_r.append(r/r_scale)
if total_step % UPDATE_GLOBAL_ITER == 0 or done: # update global and assign to local net
if done:
v_s_ = 0 # terminal
else:
v_s_ = SESS.run(self.AC.v, {self.AC.s: s_[np.newaxis, :], self.AC.init_state: rnn_state_})[0,0]
buffer_v_target = []
for r in buffer_r[::-1]: # reverse buffer r
v_s_ = r + GAMMA * v_s_
buffer_v_target.append(v_s_)
buffer_v_target.reverse()
buffer_s, buffer_a, buffer_v_target = np.vstack(buffer_s), np.array(buffer_a), np.vstack(buffer_v_target)
feed_dict = {
self.AC.s: buffer_s,
self.AC.a_his: buffer_a,
self.AC.v_target: buffer_v_target,
self.AC.init_state: keep_state,
}
self.AC.update_global(feed_dict)
buffer_s, buffer_a, buffer_r = [], [], []
self.AC.pull_global()
keep_state = rnn_state_.copy() # replace the keep_state as the new initial rnn state_
s = s_
total_step += 1
rnn_state = rnn_state_ # renew rnn state
ep_t += 1
if done:
if len(GLOBAL_RUNNING_R) == 0: # record running episode reward
GLOBAL_RUNNING_R.append(ep_r)
else:
GLOBAL_RUNNING_R.append(0.99 * GLOBAL_RUNNING_R[-1] + 0.01 * ep_r)
if not self.env.unwrapped.lander.awake: solve = '| Landed'
else: solve = '| ------'
print(
self.name,
"Ep:", GLOBAL_EP,
solve,
"| Ep_r: %i" % GLOBAL_RUNNING_R[-1],
)
GLOBAL_EP += 1
break
if __name__ == "__main__":
SESS = tf.Session()
with tf.device("/cpu:0"):
OPT_A = tf.train.RMSPropOptimizer(LR_A, name='RMSPropA')
OPT_C = tf.train.RMSPropOptimizer(LR_C, name='RMSPropC')
GLOBAL_AC = ACNet(GLOBAL_NET_SCOPE) # we only need its params
workers = []
# Create worker
for i in range(N_WORKERS):
i_name = 'W_%i' % i # worker name
workers.append(Worker(i_name, GLOBAL_AC))
COORD = tf.train.Coordinator()
SESS.run(tf.global_variables_initializer())
if OUTPUT_GRAPH:
if os.path.exists(LOG_DIR):
shutil.rmtree(LOG_DIR)
tf.summary.FileWriter(LOG_DIR, SESS.graph)
worker_threads = []
for worker in workers:
job = lambda: worker.work()
t = threading.Thread(target=job)
t.start()
worker_threads.append(t)
COORD.join(worker_threads)
plt.plot(np.arange(len(GLOBAL_RUNNING_R)), GLOBAL_RUNNING_R)
plt.xlabel('step')
plt.ylabel('Total moving reward')
plt.show()
================================================
FILE: experiments/Solve_LunarLander/DuelingDQNPrioritizedReplay.py
================================================
"""
The DQN improvement: Prioritized Experience Replay (based on https://arxiv.org/abs/1511.05952)
View more on 莫烦Python: https://morvanzhou.github.io/tutorials/
Using:
Tensorflow: 1.0
"""
import numpy as np
import tensorflow as tf
np.random.seed(1)
tf.set_random_seed(1)
class SumTree(object):
"""
This SumTree code is modified version and the original code is from:
https://github.com/jaara/AI-blog/blob/master/SumTree.py
Story the data with it priority in tree and data frameworks.
"""
data_pointer = 0
def __init__(self, capacity):
self.capacity = capacity # for all priority values
self.tree = np.zeros(2 * capacity - 1)
# [--------------Parent nodes-------------][-------leaves to recode priority-------]
# size: capacity - 1 size: capacity
self.data = np.zeros(capacity, dtype=object) # for all transitions
# [--------------data frame-------------]
# size: capacity
def add_new_priority(self, p, data):
leaf_idx = self.data_pointer + self.capacity - 1
self.data[self.data_pointer] = data # update data_frame
self.update(leaf_idx, p) # update tree_frame
self.data_pointer += 1
if self.data_pointer >= self.capacity: # replace when exceed the capacity
self.data_pointer = 0
def update(self, tree_idx, p):
change = p - self.tree[tree_idx]
self.tree[tree_idx] = p
self._propagate_change(tree_idx, change)
def _propagate_change(self, tree_idx, change):
"""change the sum of priority value in all parent nodes"""
parent_idx = (tree_idx - 1) // 2
self.tree[parent_idx] += change
if parent_idx != 0:
self._propagate_change(parent_idx, change)
def get_leaf(self, lower_bound):
leaf_idx = self._retrieve(lower_bound) # search the max leaf priority based on the lower_bound
data_idx = leaf_idx - self.capacity + 1
return [leaf_idx, self.tree[leaf_idx], self.data[data_idx]]
def _retrieve(self, lower_bound, parent_idx=0):
"""
Tree structure and array storage:
Tree index:
0 -> storing priority sum
/ \
1 2
/ \ / \
3 4 5 6 -> storing priority for transitions
Array type for storing:
[0,1,2,3,4,5,6]
"""
left_child_idx = 2 * parent_idx + 1
right_child_idx = left_child_idx + 1
if left_child_idx >= len(self.tree): # end search when no more child
return parent_idx
if self.tree[left_child_idx] == self.tree[right_child_idx]:
return self._retrieve(lower_bound, np.random.choice([left_child_idx, right_child_idx]))
if lower_bound <= self.tree[left_child_idx]: # downward search, always search for a higher priority node
return self._retrieve(lower_bound, left_child_idx)
else:
return self._retrieve(lower_bound - self.tree[left_child_idx], right_child_idx)
@property
def root_priority(self):
return self.tree[0] # the root
class Memory(object): # stored as ( s, a, r, s_ ) in SumTree
"""
This SumTree code is modified version and the original code is from:
https://github.com/jaara/AI-blog/blob/master/Seaquest-DDQN-PER.py
"""
epsilon = 0.001 # small amount to avoid zero priority
alpha = 0.6 # [0~1] convert the importance of TD error to priority
beta = 0.4 # importance-sampling, from initial value increasing to 1
beta_increment_per_sampling = 1e-4 # annealing the bias
abs_err_upper = 1 # for stability refer to paper
def __init__(self, capacity):
self.tree = SumTree(capacity)
def store(self, error, transition):
p = self._get_priority(error)
self.tree.add_new_priority(p, transition)
def sample(self, n):
batch_idx, batch_memory, ISWeights = [], [], []
segment = self.tree.root_priority / n
self.beta = np.min([1, self.beta + self.beta_increment_per_sampling]) # max = 1
min_prob = np.min(self.tree.tree[-self.tree.capacity:]) / self.tree.root_priority
maxiwi = np.power(self.tree.capacity * min_prob, -self.beta) # for later normalizing ISWeights
for i in range(n):
a = segment * i
b = segment * (i + 1)
lower_bound = np.random.uniform(a, b)
idx, p, data = self.tree.get_leaf(lower_bound)
prob = p / self.tree.root_priority
ISWeights.append(self.tree.capacity * prob)
batch_idx.append(idx)
batch_memory.append(data)
ISWeights = np.vstack(ISWeights)
ISWeights = np.power(ISWeights, -self.beta) / maxiwi # normalize
return batch_idx, np.vstack(batch_memory), ISWeights
def update(self, idx, error):
p = self._get_priority(error)
self.tree.update(idx, p)
def _get_priority(self, error):
error += self.epsilon # avoid 0
clipped_error = np.clip(error, 0, self.abs_err_upper)
return np.power(clipped_error, self.alpha)
class DuelingDQNPrioritizedReplay:
def __init__(
self,
n_actions,
n_features,
learning_rate=0.005,
reward_decay=0.9,
e_greedy=0.9,
replace_target_iter=500,
memory_size=10000,
batch_size=32,
e_greedy_increment=None,
hidden=[100, 50],
output_graph=False,
sess=None,
):
self.n_actions = n_actions
self.n_features = n_features
self.lr = learning_rate
self.gamma = reward_decay
self.epsilon_max = e_greedy
self.replace_target_iter = replace_target_iter
self.memory_size = memory_size
self.batch_size = batch_size
self.hidden = hidden
self.epsilon_increment = e_greedy_increment
self.epsilon = 0.5 if e_greedy_increment is not None else self.epsilon_max
self.learn_step_counter = 0
self._build_net()
self.memory = Memory(capacity=memory_size)
if sess is None:
self.sess = tf.Session()
self.sess.run(tf.global_variables_initializer())
else:
self.sess = sess
if output_graph:
tf.summary.FileWriter("logs/", self.sess.graph)
self.cost_his = []
def _build_net(self):
def build_layers(s, c_names, w_initializer, b_initializer):
for i, h in enumerate(self.hidden):
if i == 0:
in_units, out_units, inputs = self.n_features, self.hidden[i], s
else:
in_units, out_units, inputs = self.hidden[i-1], self.hidden[i], l
with tf.variable_scope('l%i' % i):
w = tf.get_variable('w', [in_units, out_units], initializer=w_initializer, collections=c_names)
b = tf.get_variable('b', [1, out_units], initializer=b_initializer, collections=c_names)
l = tf.nn.relu(tf.matmul(inputs, w) + b)
with tf.variable_scope('Value'):
w = tf.get_variable('w', [self.hidden[-1], 1], initializer=w_initializer, collections=c_names)
b = tf.get_variable('b', [1, 1], initializer=b_initializer, collections=c_names)
self.V = tf.matmul(l, w) + b
with tf.variable_scope('Advantage'):
w = tf.get_variable('w', [self.hidden[-1], self.n_actions], initializer=w_initializer, collections=c_names)
b = tf.get_variable('b', [1, self.n_actions], initializer=b_initializer, collections=c_names)
self.A = tf.matmul(l, w) + b
with tf.variable_scope('Q'):
out = self.V + (self.A - tf.reduce_mean(self.A, axis=1, keep_dims=True)) # Q = V(s) + A(s,a)
# with tf.variable_scope('out'):
# w = tf.get_variable('w', [self.hidden[-1], self.n_actions], initializer=w_initializer, collections=c_names)
# b = tf.get_variable('b', [1, self.n_actions], initializer=b_initializer, collections=c_names)
# out = tf.matmul(l, w) + b
return out
# ------------------ build evaluate_net ------------------
self.s = tf.placeholder(tf.float32, [None, self.n_features], name='s') # input
self.q_target = tf.placeholder(tf.float32, [None, self.n_actions], name='Q_target') # for calculating loss
self.ISWeights = tf.placeholder(tf.float32, [None, 1], name='IS_weights')
with tf.variable_scope('eval_net'):
c_names, w_initializer, b_initializer = \
['eval_net_params', tf.GraphKeys.GLOBAL_VARIABLES], \
tf.random_normal_initializer(0., 0.01), tf.constant_initializer(0.01) # config of layers
self.q_eval = build_layers(self.s, c_names, w_initializer, b_initializer)
with tf.variable_scope('loss'):
self.abs_errors = tf.abs(tf.reduce_sum(self.q_target - self.q_eval, axis=1)) # for updating Sumtree
self.loss = tf.reduce_mean(self.ISWeights * tf.squared_difference(self.q_target, self.q_eval))
with tf.variable_scope('train'):
self._train_op = tf.train.AdamOptimizer(self.lr).minimize(self.loss)
# ------------------ build target_net ------------------
self.s_ = tf.placeholder(tf.float32, [None, self.n_features], name='s_') # input
with tf.variable_scope('target_net'):
c_names = ['target_net_params', tf.GraphKeys.GLOBAL_VARIABLES]
self.q_next = build_layers(self.s_, c_names, w_initializer, b_initializer)
def store_transition(self, s, a, r, s_):
transition = np.hstack((s, [a, r], s_))
max_p = np.max(self.memory.tree.tree[-self.memory.tree.capacity:])
self.memory.store(max_p, transition)
def choose_action(self, observation):
observation = observation[np.newaxis, :]
if np.random.uniform() < self.epsilon:
actions_value = self.sess.run(self.q_eval, feed_dict={self.s: observation})
action = np.argmax(actions_value)
else:
action = np.random.randint(0, self.n_actions)
return action
def _replace_target_params(self):
t_params = tf.get_collection('target_net_params')
e_params = tf.get_collection('eval_net_params')
self.sess.run([tf.assign(t, e) for t, e in zip(t_params, e_params)])
def learn(self):
if self.learn_step_counter % self.replace_target_iter == 0:
self._replace_target_params()
tree_idx, batch_memory, ISWeights = self.memory.sample(self.batch_size)
# double DQN
q_next, q_eval4next = self.sess.run(
[self.q_next, self.q_eval],
feed_dict={self.s_: batch_memory[:, -self.n_features:], # next observation
self.s: batch_memory[:, -self.n_features:]}) # next observation
q_eval = self.sess.run(self.q_eval, {self.s: batch_memory[:, :self.n_features]})
q_target = q_eval.copy()
batch_index = np.arange(self.batch_size, dtype=np.int32)
eval_act_index = batch_memory[:, self.n_features].astype(int)
reward = batch_memory[:, self.n_features + 1]
max_act4next = np.argmax(q_eval4next,
axis=1) # the action that brings the highest value is evaluated by q_eval
selected_q_next = q_next[batch_index, max_act4next] # Double DQN, select q_next depending on above actions
q_target[batch_index, eval_act_index] = reward + self.gamma * selected_q_next
# q_next, q_eval = self.sess.run(
# [self.q_next, self.q_eval],
# feed_dict={self.s_: batch_memory[:, -self.n_features:],
# self.s: batch_memory[:, :self.n_features]})
#
# q_target = q_eval.copy()
# batch_index = np.arange(self.batch_size, dtype=np.int32)
# eval_act_index = batch_memory[:, self.n_features].astype(int)
# reward = batch_memory[:, self.n_features + 1]
#
# q_target[batch_index, eval_act_index] = reward + self.gamma * np.max(q_next, axis=1)
_, abs_errors, self.cost = self.sess.run([self._train_op, self.abs_errors, self.loss],
feed_dict={self.s: batch_memory[:, :self.n_features],
self.q_target: q_target,
self.ISWeights: ISWeights})
for i in range(len(tree_idx)): # update priority
idx = tree_idx[i]
self.memory.update(idx, abs_errors[i])
self.cost_his.append(self.cost)
self.epsilon = self.epsilon + self.epsilon_increment if self.epsilon < self.epsilon_max else self.epsilon_max
self.learn_step_counter += 1
================================================
FILE: experiments/Solve_LunarLander/run_LunarLander.py
================================================
"""
Deep Q network,
LunarLander-v2 example
Using:
Tensorflow: 1.0
gym: 0.8.0
"""
import gym
from gym import wrappers
from DuelingDQNPrioritizedReplay import DuelingDQNPrioritizedReplay
env = gym.make('LunarLander-v2')
# env = env.unwrapped
env.seed(1)
N_A = env.action_space.n
N_S = env.observation_space.shape[0]
MEMORY_CAPACITY = 50000
TARGET_REP_ITER = 2000
MAX_EPISODES = 900
E_GREEDY = 0.95
E_INCREMENT = 0.00001
GAMMA = 0.99
LR = 0.0001
BATCH_SIZE = 32
HIDDEN = [400, 400]
RENDER = True
RL = DuelingDQNPrioritizedReplay(
n_actions=N_A, n_features=N_S, learning_rate=LR, e_greedy=E_GREEDY, reward_decay=GAMMA,
hidden=HIDDEN, batch_size=BATCH_SIZE, replace_target_iter=TARGET_REP_ITER,
memory_size=MEMORY_CAPACITY, e_greedy_increment=E_INCREMENT,)
total_steps = 0
running_r = 0
r_scale = 100
for i_episode in range(MAX_EPISODES):
s = env.reset() # (coord_x, coord_y, vel_x, vel_y, angle, angular_vel, l_leg_on_ground, r_leg_on_ground)
ep_r = 0
while True:
if total_steps > MEMORY_CAPACITY: env.render()
a = RL.choose_action(s)
s_, r, done, _ = env.step(a)
if r == -100: r = -30
r /= r_scale
ep_r += r
RL.store_transition(s, a, r, s_)
if total_steps > MEMORY_CAPACITY:
RL.learn()
if done:
land = '| Landed' if r == 100/r_scale else '| ------'
running_r = 0.99 * running_r + 0.01 * ep_r
print('Epi: ', i_episode,
land,
'| Epi_R: ', round(ep_r, 2),
'| Running_R: ', round(running_r, 2),
'| Epsilon: ', round(RL.epsilon, 3))
break
s = s_
total_steps += 1
# Donation
*If this does help you, please consider donating to support me for better tutorials. Any contribution is greatly appreciated!*
================================================
FILE: contents/10_A3C/A3C_RNN.py
================================================
"""
Asynchronous Advantage Actor Critic (A3C) + RNN with continuous action space, Reinforcement Learning.
The Pendulum example.
View more on my tutorial page: https://morvanzhou.github.io/tutorials/
Using:
tensorflow 1.8.0
gym 0.10.5
"""
import multiprocessing
import threading
import tensorflow as tf
import numpy as np
import gym
import os
import shutil
import matplotlib.pyplot as plt
GAME = 'Pendulum-v0'
OUTPUT_GRAPH = True
LOG_DIR = './log'
N_WORKERS = multiprocessing.cpu_count()
MAX_EP_STEP = 200
MAX_GLOBAL_EP = 1500
GLOBAL_NET_SCOPE = 'Global_Net'
UPDATE_GLOBAL_ITER = 5
GAMMA = 0.9
ENTROPY_BETA = 0.01
LR_A = 0.0001 # learning rate for actor
LR_C = 0.001 # learning rate for critic
GLOBAL_RUNNING_R = []
GLOBAL_EP = 0
env = gym.make(GAME)
N_S = env.observation_space.shape[0]
N_A = env.action_space.shape[0]
A_BOUND = [env.action_space.low, env.action_space.high]
class ACNet(object):
def __init__(self, scope, globalAC=None):
if scope == GLOBAL_NET_SCOPE: # get global network
with tf.variable_scope(scope):
self.s = tf.placeholder(tf.float32, [None, N_S], 'S')
self.a_params, self.c_params = self._build_net(scope)[-2:]
else: # local net, calculate losses
with tf.variable_scope(scope):
self.s = tf.placeholder(tf.float32, [None, N_S], 'S')
self.a_his = tf.placeholder(tf.float32, [None, N_A], 'A')
self.v_target = tf.placeholder(tf.float32, [None, 1], 'Vtarget')
mu, sigma, self.v, self.a_params, self.c_params = self._build_net(scope)
td = tf.subtract(self.v_target, self.v, name='TD_error')
with tf.name_scope('c_loss'):
self.c_loss = tf.reduce_mean(tf.square(td))
with tf.name_scope('wrap_a_out'):
mu, sigma = mu * A_BOUND[1], sigma + 1e-4
normal_dist = tf.distributions.Normal(mu, sigma)
with tf.name_scope('a_loss'):
log_prob = normal_dist.log_prob(self.a_his)
exp_v = log_prob * tf.stop_gradient(td)
entropy = normal_dist.entropy() # encourage exploration
self.exp_v = ENTROPY_BETA * entropy + exp_v
self.a_loss = tf.reduce_mean(-self.exp_v)
with tf.name_scope('choose_a'): # use local params to choose action
self.A = tf.clip_by_value(tf.squeeze(normal_dist.sample(1), axis=[0, 1]), A_BOUND[0], A_BOUND[1])
with tf.name_scope('local_grad'):
self.a_grads = tf.gradients(self.a_loss, self.a_params)
self.c_grads = tf.gradients(self.c_loss, self.c_params)
with tf.name_scope('sync'):
with tf.name_scope('pull'):
self.pull_a_params_op = [l_p.assign(g_p) for l_p, g_p in zip(self.a_params, globalAC.a_params)]
self.pull_c_params_op = [l_p.assign(g_p) for l_p, g_p in zip(self.c_params, globalAC.c_params)]
with tf.name_scope('push'):
self.update_a_op = OPT_A.apply_gradients(zip(self.a_grads, globalAC.a_params))
self.update_c_op = OPT_C.apply_gradients(zip(self.c_grads, globalAC.c_params))
def _build_net(self, scope):
w_init = tf.random_normal_initializer(0., .1)
with tf.variable_scope('critic'): # only critic controls the rnn update
cell_size = 64
s = tf.expand_dims(self.s, axis=1,
name='timely_input') # [time_step, feature] => [time_step, batch, feature]
rnn_cell = tf.contrib.rnn.BasicRNNCell(cell_size)
self.init_state = rnn_cell.zero_state(batch_size=1, dtype=tf.float32)
outputs, self.final_state = tf.nn.dynamic_rnn(
cell=rnn_cell, inputs=s, initial_state=self.init_state, time_major=True)
cell_out = tf.reshape(outputs, [-1, cell_size], name='flatten_rnn_outputs') # joined state representation
l_c = tf.layers.dense(cell_out, 50, tf.nn.relu6, kernel_initializer=w_init, name='lc')
v = tf.layers.dense(l_c, 1, kernel_initializer=w_init, name='v') # state value
with tf.variable_scope('actor'): # state representation is based on critic
l_a = tf.layers.dense(cell_out, 80, tf.nn.relu6, kernel_initializer=w_init, name='la')
mu = tf.layers.dense(l_a, N_A, tf.nn.tanh, kernel_initializer=w_init, name='mu')
sigma = tf.layers.dense(l_a, N_A, tf.nn.softplus, kernel_initializer=w_init, name='sigma')
a_params = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope=scope + '/actor')
c_params = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope=scope + '/critic')
return mu, sigma, v, a_params, c_params
def update_global(self, feed_dict): # run by a local
SESS.run([self.update_a_op, self.update_c_op], feed_dict) # local grads applies to global net
def pull_global(self): # run by a local
SESS.run([self.pull_a_params_op, self.pull_c_params_op])
def choose_action(self, s, cell_state): # run by a local
s = s[np.newaxis, :]
a, cell_state = SESS.run([self.A, self.final_state], {self.s: s, self.init_state: cell_state})
return a, cell_state
class Worker(object):
def __init__(self, name, globalAC):
self.env = gym.make(GAME).unwrapped
self.name = name
self.AC = ACNet(name, globalAC)
def work(self):
global GLOBAL_RUNNING_R, GLOBAL_EP
total_step = 1
buffer_s, buffer_a, buffer_r = [], [], []
while not COORD.should_stop() and GLOBAL_EP < MAX_GLOBAL_EP:
s = self.env.reset()
ep_r = 0
rnn_state = SESS.run(self.AC.init_state) # zero rnn state at beginning
keep_state = rnn_state.copy() # keep rnn state for updating global net
for ep_t in range(MAX_EP_STEP):
if self.name == 'W_0':
self.env.render()
a, rnn_state_ = self.AC.choose_action(s, rnn_state) # get the action and next rnn state
s_, r, done, info = self.env.step(a)
done = True if ep_t == MAX_EP_STEP - 1 else False
ep_r += r
buffer_s.append(s)
buffer_a.append(a)
buffer_r.append((r+8)/8) # normalize
if total_step % UPDATE_GLOBAL_ITER == 0 or done: # update global and assign to local net
if done:
v_s_ = 0 # terminal
else:
v_s_ = SESS.run(self.AC.v, {self.AC.s: s_[np.newaxis, :], self.AC.init_state: rnn_state_})[0, 0]
buffer_v_target = []
for r in buffer_r[::-1]: # reverse buffer r
v_s_ = r + GAMMA * v_s_
buffer_v_target.append(v_s_)
buffer_v_target.reverse()
buffer_s, buffer_a, buffer_v_target = np.vstack(buffer_s), np.vstack(buffer_a), np.vstack(buffer_v_target)
feed_dict = {
self.AC.s: buffer_s,
self.AC.a_his: buffer_a,
self.AC.v_target: buffer_v_target,
self.AC.init_state: keep_state,
}
self.AC.update_global(feed_dict)
buffer_s, buffer_a, buffer_r = [], [], []
self.AC.pull_global()
keep_state = rnn_state_.copy() # replace the keep_state as the new initial rnn state_
s = s_
rnn_state = rnn_state_ # renew rnn state
total_step += 1
if done:
if len(GLOBAL_RUNNING_R) == 0: # record running episode reward
GLOBAL_RUNNING_R.append(ep_r)
else:
GLOBAL_RUNNING_R.append(0.9 * GLOBAL_RUNNING_R[-1] + 0.1 * ep_r)
print(
self.name,
"Ep:", GLOBAL_EP,
"| Ep_r: %i" % GLOBAL_RUNNING_R[-1],
)
GLOBAL_EP += 1
break
if __name__ == "__main__":
SESS = tf.Session()
with tf.device("/cpu:0"):
OPT_A = tf.train.RMSPropOptimizer(LR_A, name='RMSPropA')
OPT_C = tf.train.RMSPropOptimizer(LR_C, name='RMSPropC')
GLOBAL_AC = ACNet(GLOBAL_NET_SCOPE) # we only need its params
workers = []
# Create worker
for i in range(N_WORKERS):
i_name = 'W_%i' % i # worker name
workers.append(Worker(i_name, GLOBAL_AC))
COORD = tf.train.Coordinator()
SESS.run(tf.global_variables_initializer())
if OUTPUT_GRAPH:
if os.path.exists(LOG_DIR):
shutil.rmtree(LOG_DIR)
tf.summary.FileWriter(LOG_DIR, SESS.graph)
worker_threads = []
for worker in workers:
job = lambda: worker.work()
t = threading.Thread(target=job)
t.start()
worker_threads.append(t)
COORD.join(worker_threads)
plt.plot(np.arange(len(GLOBAL_RUNNING_R)), GLOBAL_RUNNING_R)
plt.xlabel('step')
plt.ylabel('Total moving reward')
plt.show()
================================================
FILE: contents/10_A3C/A3C_continuous_action.py
================================================
"""
Asynchronous Advantage Actor Critic (A3C) with continuous action space, Reinforcement Learning.
The Pendulum example.
View more on my tutorial page: https://morvanzhou.github.io/tutorials/
Using:
tensorflow 1.8.0
gym 0.10.5
"""
import multiprocessing
import threading
import tensorflow as tf
import numpy as np
import gym
import os
import shutil
import matplotlib.pyplot as plt
GAME = 'Pendulum-v0'
OUTPUT_GRAPH = True
LOG_DIR = './log'
N_WORKERS = multiprocessing.cpu_count()
MAX_EP_STEP = 200
MAX_GLOBAL_EP = 2000
GLOBAL_NET_SCOPE = 'Global_Net'
UPDATE_GLOBAL_ITER = 10
GAMMA = 0.9
ENTROPY_BETA = 0.01
LR_A = 0.0001 # learning rate for actor
LR_C = 0.001 # learning rate for critic
GLOBAL_RUNNING_R = []
GLOBAL_EP = 0
env = gym.make(GAME)
N_S = env.observation_space.shape[0]
N_A = env.action_space.shape[0]
A_BOUND = [env.action_space.low, env.action_space.high]
class ACNet(object):
def __init__(self, scope, globalAC=None):
if scope == GLOBAL_NET_SCOPE: # get global network
with tf.variable_scope(scope):
self.s = tf.placeholder(tf.float32, [None, N_S], 'S')
self.a_params, self.c_params = self._build_net(scope)[-2:]
else: # local net, calculate losses
with tf.variable_scope(scope):
self.s = tf.placeholder(tf.float32, [None, N_S], 'S')
self.a_his = tf.placeholder(tf.float32, [None, N_A], 'A')
self.v_target = tf.placeholder(tf.float32, [None, 1], 'Vtarget')
mu, sigma, self.v, self.a_params, self.c_params = self._build_net(scope)
td = tf.subtract(self.v_target, self.v, name='TD_error')
with tf.name_scope('c_loss'):
self.c_loss = tf.reduce_mean(tf.square(td))
with tf.name_scope('wrap_a_out'):
mu, sigma = mu * A_BOUND[1], sigma + 1e-4
normal_dist = tf.distributions.Normal(mu, sigma)
with tf.name_scope('a_loss'):
log_prob = normal_dist.log_prob(self.a_his)
exp_v = log_prob * tf.stop_gradient(td)
entropy = normal_dist.entropy() # encourage exploration
self.exp_v = ENTROPY_BETA * entropy + exp_v
self.a_loss = tf.reduce_mean(-self.exp_v)
with tf.name_scope('choose_a'): # use local params to choose action
self.A = tf.clip_by_value(tf.squeeze(normal_dist.sample(1), axis=[0, 1]), A_BOUND[0], A_BOUND[1])
with tf.name_scope('local_grad'):
self.a_grads = tf.gradients(self.a_loss, self.a_params)
self.c_grads = tf.gradients(self.c_loss, self.c_params)
with tf.name_scope('sync'):
with tf.name_scope('pull'):
self.pull_a_params_op = [l_p.assign(g_p) for l_p, g_p in zip(self.a_params, globalAC.a_params)]
self.pull_c_params_op = [l_p.assign(g_p) for l_p, g_p in zip(self.c_params, globalAC.c_params)]
with tf.name_scope('push'):
self.update_a_op = OPT_A.apply_gradients(zip(self.a_grads, globalAC.a_params))
self.update_c_op = OPT_C.apply_gradients(zip(self.c_grads, globalAC.c_params))
def _build_net(self, scope):
w_init = tf.random_normal_initializer(0., .1)
with tf.variable_scope('actor'):
l_a = tf.layers.dense(self.s, 200, tf.nn.relu6, kernel_initializer=w_init, name='la')
mu = tf.layers.dense(l_a, N_A, tf.nn.tanh, kernel_initializer=w_init, name='mu')
sigma = tf.layers.dense(l_a, N_A, tf.nn.softplus, kernel_initializer=w_init, name='sigma')
with tf.variable_scope('critic'):
l_c = tf.layers.dense(self.s, 100, tf.nn.relu6, kernel_initializer=w_init, name='lc')
v = tf.layers.dense(l_c, 1, kernel_initializer=w_init, name='v') # state value
a_params = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope=scope + '/actor')
c_params = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope=scope + '/critic')
return mu, sigma, v, a_params, c_params
def update_global(self, feed_dict): # run by a local
SESS.run([self.update_a_op, self.update_c_op], feed_dict) # local grads applies to global net
def pull_global(self): # run by a local
SESS.run([self.pull_a_params_op, self.pull_c_params_op])
def choose_action(self, s): # run by a local
s = s[np.newaxis, :]
return SESS.run(self.A, {self.s: s})
class Worker(object):
def __init__(self, name, globalAC):
self.env = gym.make(GAME).unwrapped
self.name = name
self.AC = ACNet(name, globalAC)
def work(self):
global GLOBAL_RUNNING_R, GLOBAL_EP
total_step = 1
buffer_s, buffer_a, buffer_r = [], [], []
while not COORD.should_stop() and GLOBAL_EP < MAX_GLOBAL_EP:
s = self.env.reset()
ep_r = 0
for ep_t in range(MAX_EP_STEP):
# if self.name == 'W_0':
# self.env.render()
a = self.AC.choose_action(s)
s_, r, done, info = self.env.step(a)
done = True if ep_t == MAX_EP_STEP - 1 else False
ep_r += r
buffer_s.append(s)
buffer_a.append(a)
buffer_r.append((r+8)/8) # normalize
if total_step % UPDATE_GLOBAL_ITER == 0 or done: # update global and assign to local net
if done:
v_s_ = 0 # terminal
else:
v_s_ = SESS.run(self.AC.v, {self.AC.s: s_[np.newaxis, :]})[0, 0]
buffer_v_target = []
for r in buffer_r[::-1]: # reverse buffer r
v_s_ = r + GAMMA * v_s_
buffer_v_target.append(v_s_)
buffer_v_target.reverse()
buffer_s, buffer_a, buffer_v_target = np.vstack(buffer_s), np.vstack(buffer_a), np.vstack(buffer_v_target)
feed_dict = {
self.AC.s: buffer_s,
self.AC.a_his: buffer_a,
self.AC.v_target: buffer_v_target,
}
self.AC.update_global(feed_dict)
buffer_s, buffer_a, buffer_r = [], [], []
self.AC.pull_global()
s = s_
total_step += 1
if done:
if len(GLOBAL_RUNNING_R) == 0: # record running episode reward
GLOBAL_RUNNING_R.append(ep_r)
else:
GLOBAL_RUNNING_R.append(0.9 * GLOBAL_RUNNING_R[-1] + 0.1 * ep_r)
print(
self.name,
"Ep:", GLOBAL_EP,
"| Ep_r: %i" % GLOBAL_RUNNING_R[-1],
)
GLOBAL_EP += 1
break
if __name__ == "__main__":
SESS = tf.Session()
with tf.device("/cpu:0"):
OPT_A = tf.train.RMSPropOptimizer(LR_A, name='RMSPropA')
OPT_C = tf.train.RMSPropOptimizer(LR_C, name='RMSPropC')
GLOBAL_AC = ACNet(GLOBAL_NET_SCOPE) # we only need its params
workers = []
# Create worker
for i in range(N_WORKERS):
i_name = 'W_%i' % i # worker name
workers.append(Worker(i_name, GLOBAL_AC))
COORD = tf.train.Coordinator()
SESS.run(tf.global_variables_initializer())
if OUTPUT_GRAPH:
if os.path.exists(LOG_DIR):
shutil.rmtree(LOG_DIR)
tf.summary.FileWriter(LOG_DIR, SESS.graph)
worker_threads = []
for worker in workers:
job = lambda: worker.work()
t = threading.Thread(target=job)
t.start()
worker_threads.append(t)
COORD.join(worker_threads)
plt.plot(np.arange(len(GLOBAL_RUNNING_R)), GLOBAL_RUNNING_R)
plt.xlabel('step')
plt.ylabel('Total moving reward')
plt.show()
================================================
FILE: contents/10_A3C/A3C_discrete_action.py
================================================
"""
Asynchronous Advantage Actor Critic (A3C) with discrete action space, Reinforcement Learning.
The Cartpole example.
View more on my tutorial page: https://morvanzhou.github.io/tutorials/
Using:
tensorflow 1.8.0
gym 0.10.5
"""
import multiprocessing
import threading
import tensorflow as tf
import numpy as np
import gym
import os
import shutil
import matplotlib.pyplot as plt
GAME = 'CartPole-v0'
OUTPUT_GRAPH = True
LOG_DIR = './log'
N_WORKERS = multiprocessing.cpu_count()
MAX_GLOBAL_EP = 1000
GLOBAL_NET_SCOPE = 'Global_Net'
UPDATE_GLOBAL_ITER = 10
GAMMA = 0.9
ENTROPY_BETA = 0.001
LR_A = 0.001 # learning rate for actor
LR_C = 0.001 # learning rate for critic
GLOBAL_RUNNING_R = []
GLOBAL_EP = 0
env = gym.make(GAME)
N_S = env.observation_space.shape[0]
N_A = env.action_space.n
class ACNet(object):
def __init__(self, scope, globalAC=None):
if scope == GLOBAL_NET_SCOPE: # get global network
with tf.variable_scope(scope):
self.s = tf.placeholder(tf.float32, [None, N_S], 'S')
self.a_params, self.c_params = self._build_net(scope)[-2:]
else: # local net, calculate losses
with tf.variable_scope(scope):
self.s = tf.placeholder(tf.float32, [None, N_S], 'S')
self.a_his = tf.placeholder(tf.int32, [None, ], 'A')
self.v_target = tf.placeholder(tf.float32, [None, 1], 'Vtarget')
self.a_prob, self.v, self.a_params, self.c_params = self._build_net(scope)
td = tf.subtract(self.v_target, self.v, name='TD_error')
with tf.name_scope('c_loss'):
self.c_loss = tf.reduce_mean(tf.square(td))
with tf.name_scope('a_loss'):
log_prob = tf.reduce_sum(tf.log(self.a_prob + 1e-5) * tf.one_hot(self.a_his, N_A, dtype=tf.float32), axis=1, keep_dims=True)
exp_v = log_prob * tf.stop_gradient(td)
entropy = -tf.reduce_sum(self.a_prob * tf.log(self.a_prob + 1e-5),
axis=1, keep_dims=True) # encourage exploration
self.exp_v = ENTROPY_BETA * entropy + exp_v
self.a_loss = tf.reduce_mean(-self.exp_v)
with tf.name_scope('local_grad'):
self.a_grads = tf.gradients(self.a_loss, self.a_params)
self.c_grads = tf.gradients(self.c_loss, self.c_params)
with tf.name_scope('sync'):
with tf.name_scope('pull'):
self.pull_a_params_op = [l_p.assign(g_p) for l_p, g_p in zip(self.a_params, globalAC.a_params)]
self.pull_c_params_op = [l_p.assign(g_p) for l_p, g_p in zip(self.c_params, globalAC.c_params)]
with tf.name_scope('push'):
self.update_a_op = OPT_A.apply_gradients(zip(self.a_grads, globalAC.a_params))
self.update_c_op = OPT_C.apply_gradients(zip(self.c_grads, globalAC.c_params))
def _build_net(self, scope):
w_init = tf.random_normal_initializer(0., .1)
with tf.variable_scope('actor'):
l_a = tf.layers.dense(self.s, 200, tf.nn.relu6, kernel_initializer=w_init, name='la')
a_prob = tf.layers.dense(l_a, N_A, tf.nn.softmax, kernel_initializer=w_init, name='ap')
with tf.variable_scope('critic'):
l_c = tf.layers.dense(self.s, 100, tf.nn.relu6, kernel_initializer=w_init, name='lc')
v = tf.layers.dense(l_c, 1, kernel_initializer=w_init, name='v') # state value
a_params = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope=scope + '/actor')
c_params = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope=scope + '/critic')
return a_prob, v, a_params, c_params
def update_global(self, feed_dict): # run by a local
SESS.run([self.update_a_op, self.update_c_op], feed_dict) # local grads applies to global net
def pull_global(self): # run by a local
SESS.run([self.pull_a_params_op, self.pull_c_params_op])
def choose_action(self, s): # run by a local
prob_weights = SESS.run(self.a_prob, feed_dict={self.s: s[np.newaxis, :]})
action = np.random.choice(range(prob_weights.shape[1]),
p=prob_weights.ravel()) # select action w.r.t the actions prob
return action
class Worker(object):
def __init__(self, name, globalAC):
self.env = gym.make(GAME).unwrapped
self.name = name
self.AC = ACNet(name, globalAC)
def work(self):
global GLOBAL_RUNNING_R, GLOBAL_EP
total_step = 1
buffer_s, buffer_a, buffer_r = [], [], []
while not COORD.should_stop() and GLOBAL_EP < MAX_GLOBAL_EP:
s = self.env.reset()
ep_r = 0
while True:
# if self.name == 'W_0':
# self.env.render()
a = self.AC.choose_action(s)
s_, r, done, info = self.env.step(a)
if done: r = -5
ep_r += r
buffer_s.append(s)
buffer_a.append(a)
buffer_r.append(r)
if total_step % UPDATE_GLOBAL_ITER == 0 or done: # update global and assign to local net
if done:
v_s_ = 0 # terminal
else:
v_s_ = SESS.run(self.AC.v, {self.AC.s: s_[np.newaxis, :]})[0, 0]
buffer_v_target = []
for r in buffer_r[::-1]: # reverse buffer r
v_s_ = r + GAMMA * v_s_
buffer_v_target.append(v_s_)
buffer_v_target.reverse()
buffer_s, buffer_a, buffer_v_target = np.vstack(buffer_s), np.array(buffer_a), np.vstack(buffer_v_target)
feed_dict = {
self.AC.s: buffer_s,
self.AC.a_his: buffer_a,
self.AC.v_target: buffer_v_target,
}
self.AC.update_global(feed_dict)
buffer_s, buffer_a, buffer_r = [], [], []
self.AC.pull_global()
s = s_
total_step += 1
if done:
if len(GLOBAL_RUNNING_R) == 0: # record running episode reward
GLOBAL_RUNNING_R.append(ep_r)
else:
GLOBAL_RUNNING_R.append(0.99 * GLOBAL_RUNNING_R[-1] + 0.01 * ep_r)
print(
self.name,
"Ep:", GLOBAL_EP,
"| Ep_r: %i" % GLOBAL_RUNNING_R[-1],
)
GLOBAL_EP += 1
break
if __name__ == "__main__":
SESS = tf.Session()
with tf.device("/cpu:0"):
OPT_A = tf.train.RMSPropOptimizer(LR_A, name='RMSPropA')
OPT_C = tf.train.RMSPropOptimizer(LR_C, name='RMSPropC')
GLOBAL_AC = ACNet(GLOBAL_NET_SCOPE) # we only need its params
workers = []
# Create worker
for i in range(N_WORKERS):
i_name = 'W_%i' % i # worker name
workers.append(Worker(i_name, GLOBAL_AC))
COORD = tf.train.Coordinator()
SESS.run(tf.global_variables_initializer())
if OUTPUT_GRAPH:
if os.path.exists(LOG_DIR):
shutil.rmtree(LOG_DIR)
tf.summary.FileWriter(LOG_DIR, SESS.graph)
worker_threads = []
for worker in workers:
job = lambda: worker.work()
t = threading.Thread(target=job)
t.start()
worker_threads.append(t)
COORD.join(worker_threads)
plt.plot(np.arange(len(GLOBAL_RUNNING_R)), GLOBAL_RUNNING_R)
plt.xlabel('step')
plt.ylabel('Total moving reward')
plt.show()
================================================
FILE: contents/10_A3C/A3C_distributed_tf.py
================================================
"""
Asynchronous Advantage Actor Critic (A3C) with discrete action space, Reinforcement Learning.
The Cartpole example using distributed tensorflow + multiprocessing.
View more on my tutorial page: https://morvanzhou.github.io/
"""
import multiprocessing as mp
import tensorflow as tf
import numpy as np
import gym, time
import matplotlib.pyplot as plt
UPDATE_GLOBAL_ITER = 10
GAMMA = 0.9
ENTROPY_BETA = 0.001
LR_A = 0.001 # learning rate for actor
LR_C = 0.001 # learning rate for critic
env = gym.make('CartPole-v0')
N_S = env.observation_space.shape[0]
N_A = env.action_space.n
class ACNet(object):
sess = None
def __init__(self, scope, opt_a=None, opt_c=None, global_net=None):
if scope == 'global_net': # get global network
with tf.variable_scope(scope):
self.s = tf.placeholder(tf.float32, [None, N_S], 'S')
self.a_params, self.c_params = self._build_net(scope)[-2:]
else:
with tf.variable_scope(scope):
self.s = tf.placeholder(tf.float32, [None, N_S], 'S')
self.a_his = tf.placeholder(tf.int32, [None, ], 'A')
self.v_target = tf.placeholder(tf.float32, [None, 1], 'Vtarget')
self.a_prob, self.v, self.a_params, self.c_params = self._build_net(scope)
td = tf.subtract(self.v_target, self.v, name='TD_error')
with tf.name_scope('c_loss'):
self.c_loss = tf.reduce_mean(tf.square(td))
with tf.name_scope('a_loss'):
log_prob = tf.reduce_sum(
tf.log(self.a_prob) * tf.one_hot(self.a_his, N_A, dtype=tf.float32),
axis=1, keep_dims=True)
exp_v = log_prob * tf.stop_gradient(td)
entropy = -tf.reduce_sum(self.a_prob * tf.log(self.a_prob + 1e-5),
axis=1, keep_dims=True) # encourage exploration
self.exp_v = ENTROPY_BETA * entropy + exp_v
self.a_loss = tf.reduce_mean(-self.exp_v)
with tf.name_scope('local_grad'):
self.a_grads = tf.gradients(self.a_loss, self.a_params)
self.c_grads = tf.gradients(self.c_loss, self.c_params)
self.global_step = tf.train.get_or_create_global_step()
with tf.name_scope('sync'):
with tf.name_scope('pull'):
self.pull_a_params_op = [l_p.assign(g_p) for l_p, g_p in zip(self.a_params, global_net.a_params)]
self.pull_c_params_op = [l_p.assign(g_p) for l_p, g_p in zip(self.c_params, global_net.c_params)]
with tf.name_scope('push'):
self.update_a_op = opt_a.apply_gradients(zip(self.a_grads, global_net.a_params), global_step=self.global_step)
self.update_c_op = opt_c.apply_gradients(zip(self.c_grads, global_net.c_params))
def _build_net(self, scope):
w_init = tf.random_normal_initializer(0., .1)
with tf.variable_scope('actor'):
l_a = tf.layers.dense(self.s, 200, tf.nn.relu6, kernel_initializer=w_init, name='la')
a_prob = tf.layers.dense(l_a, N_A, tf.nn.softmax, kernel_initializer=w_init, name='ap')
with tf.variable_scope('critic'):
l_c = tf.layers.dense(self.s, 100, tf.nn.relu6, kernel_initializer=w_init, name='lc')
v = tf.layers.dense(l_c, 1, kernel_initializer=w_init, name='v') # state value
a_params = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope=scope + '/actor')
c_params = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope=scope + '/critic')
return a_prob, v, a_params, c_params
def choose_action(self, s): # run by a local
prob_weights = self.sess.run(self.a_prob, feed_dict={self.s: s[np.newaxis, :]})
action = np.random.choice(range(prob_weights.shape[1]),
p=prob_weights.ravel()) # select action w.r.t the actions prob
return action
def update_global(self, feed_dict): # run by a local
self.sess.run([self.update_a_op, self.update_c_op], feed_dict) # local grads applies to global net
def pull_global(self): # run by a local
self.sess.run([self.pull_a_params_op, self.pull_c_params_op])
def work(job_name, task_index, global_ep, lock, r_queue, global_running_r):
# set work's ip:port
cluster = tf.train.ClusterSpec({
"ps": ['localhost:2220', 'localhost:2221',],
"worker": ['localhost:2222', 'localhost:2223', 'localhost:2224', 'localhost:2225',]
})
server = tf.train.Server(cluster, job_name=job_name, task_index=task_index)
if job_name == 'ps':
print('Start Parameter Sever: ', task_index)
server.join()
else:
t1 = time.time()
env = gym.make('CartPole-v0').unwrapped
print('Start Worker: ', task_index)
with tf.device(tf.train.replica_device_setter(
worker_device="/job:worker/task:%d" % task_index,
cluster=cluster)):
opt_a = tf.train.RMSPropOptimizer(LR_A, name='opt_a')
opt_c = tf.train.RMSPropOptimizer(LR_C, name='opt_c')
global_net = ACNet('global_net')
local_net = ACNet('local_ac%d' % task_index, opt_a, opt_c, global_net)
# set training steps
hooks = [tf.train.StopAtStepHook(last_step=100000)]
with tf.train.MonitoredTrainingSession(master=server.target,
is_chief=True,
hooks=hooks,) as sess:
print('Start Worker Session: ', task_index)
local_net.sess = sess
total_step = 1
buffer_s, buffer_a, buffer_r = [], [], []
while (not sess.should_stop()) and (global_ep.value < 1000):
s = env.reset()
ep_r = 0
while True:
# if task_index:
# env.render()
a = local_net.choose_action(s)
s_, r, done, info = env.step(a)
if done: r = -5.
ep_r += r
buffer_s.append(s)
buffer_a.append(a)
buffer_r.append(r)
if total_step % UPDATE_GLOBAL_ITER == 0 or done: # update global and assign to local net
if done:
v_s_ = 0 # terminal
else:
v_s_ = sess.run(local_net.v, {local_net.s: s_[np.newaxis, :]})[0, 0]
buffer_v_target = []
for r in buffer_r[::-1]: # reverse buffer r
v_s_ = r + GAMMA * v_s_
buffer_v_target.append(v_s_)
buffer_v_target.reverse()
buffer_s, buffer_a, buffer_v_target = np.vstack(buffer_s), np.array(buffer_a), np.vstack(
buffer_v_target)
feed_dict = {
local_net.s: buffer_s,
local_net.a_his: buffer_a,
local_net.v_target: buffer_v_target,
}
local_net.update_global(feed_dict)
buffer_s, buffer_a, buffer_r = [], [], []
local_net.pull_global()
s = s_
total_step += 1
if done:
if r_queue.empty(): # record running episode reward
global_running_r.value = ep_r
else:
global_running_r.value = .99 * global_running_r.value + 0.01 * ep_r
r_queue.put(global_running_r.value)
print(
"Task: %i" % task_index,
"| Ep: %i" % global_ep.value,
"| Ep_r: %i" % global_running_r.value,
"| Global_step: %i" % sess.run(local_net.global_step),
)
with lock:
global_ep.value += 1
break
print('Worker Done: ', task_index, time.time()-t1)
if __name__ == "__main__":
# use multiprocessing to create a local cluster with 2 parameter servers and 2 workers
global_ep = mp.Value('i', 0)
lock = mp.Lock()
r_queue = mp.Queue()
global_running_r = mp.Value('d', 0)
jobs = [
('ps', 0), ('ps', 1),
('worker', 0), ('worker', 1), ('worker', 2), ('worker', 3)
]
ps = [mp.Process(target=work, args=(j, i, global_ep, lock, r_queue, global_running_r), ) for j, i in jobs]
[p.start() for p in ps]
[p.join() for p in ps[2:]]
ep_r = []
while not r_queue.empty():
ep_r.append(r_queue.get())
plt.plot(np.arange(len(ep_r)), ep_r)
plt.title('Distributed training')
plt.xlabel('Step')
plt.ylabel('Total moving reward')
plt.show()
================================================
FILE: contents/11_Dyna_Q/RL_brain.py
================================================
"""
This part of code is the Dyna-Q learning brain, which is a brain of the agent.
All decisions and learning processes are made in here.
View more on my tutorial page: https://morvanzhou.github.io/tutorials/
"""
import numpy as np
import pandas as pd
class QLearningTable:
def __init__(self, actions, learning_rate=0.01, reward_decay=0.9, e_greedy=0.9):
self.actions = actions # a list
self.lr = learning_rate
self.gamma = reward_decay
self.epsilon = e_greedy
## argmax type error
self.q_table = pd.DataFrame(columns=self.actions).astype('float32')
def choose_action(self, observation):
self.check_state_exist(observation)
# action selection
if np.random.uniform() < self.epsilon:
# choose best action
# state_action = self.q_table.ix[observation, :]
state_action = self.q_table.loc[observation, :] # for label indexing
state_action = state_action.reindex(np.random.permutation(state_action.index)) # some actions have same value
action = state_action.argmax()
else:
# choose random action
action = np.random.choice(self.actions)
return action
def learn(self, s, a, r, s_):
self.check_state_exist(s_)
q_predict = self.q_table.loc[s, a]
if s_ != 'terminal':
q_target = r + self.gamma * self.q_table.loc[s_, :].max() # next state is not terminal
else:
q_target = r # next state is terminal
self.q_table.loc[s, a] += self.lr * (q_target - q_predict) # update
def check_state_exist(self, state):
if state not in self.q_table.index:
# append new state to q table
self.q_table = self.q_table.append(
pd.Series(
[0]*len(self.actions),
index=self.q_table.columns,
name=state,
)
)
class EnvModel:
"""Similar to the memory buffer in DQN, you can store past experiences in here.
Alternatively, the model can generate next state and reward signal accurately."""
def __init__(self, actions):
# the simplest case is to think about the model is a memory which has all past transition information
self.actions = actions
self.database = pd.DataFrame(columns=actions, dtype=np.object)
def store_transition(self, s, a, r, s_):
if s not in self.database.index:
self.database = self.database.append(
pd.Series(
[None] * len(self.actions),
index=self.database.columns,
name=s,
))
self.database.set_value(s, a, (r, s_))
def sample_s_a(self):
s = np.random.choice(self.database.index)
a = np.random.choice(self.database.loc[s].dropna().index) # filter out the None value
return s, a
def get_r_s_(self, s, a):
r, s_ = self.database.loc[s, a]
return r, s_
================================================
FILE: contents/11_Dyna_Q/maze_env.py
================================================
"""
Reinforcement learning maze example.
Red rectangle: explorer.
Black rectangles: hells [reward = -1].
Yellow bin circle: paradise [reward = +1].
All other states: ground [reward = 0].
This script is the environment part of this example. The RL is in RL_brain.py.
View more on my tutorial page: https://morvanzhou.github.io/tutorials/
"""
import numpy as np
np.random.seed(1)
import tkinter as tk
import time
UNIT = 40 # pixels
MAZE_H = 4 # grid height
MAZE_W = 4 # grid width
class Maze(tk.Tk, object):
def __init__(self):
super(Maze, self).__init__()
self.action_space = ['u', 'd', 'l', 'r']
self.n_actions = len(self.action_space)
self.title('maze')
self.geometry('{0}x{1}'.format(MAZE_H * UNIT, MAZE_H * UNIT))
self._build_maze()
def _build_maze(self):
self.canvas = tk.Canvas(self, bg='white',
height=MAZE_H * UNIT,
width=MAZE_W * UNIT)
# create grids
for c in range(0, MAZE_W * UNIT, UNIT):
x0, y0, x1, y1 = c, 0, c, MAZE_H * UNIT
self.canvas.create_line(x0, y0, x1, y1)
for r in range(0, MAZE_H * UNIT, UNIT):
x0, y0, x1, y1 = 0, r, MAZE_H * UNIT, r
self.canvas.create_line(x0, y0, x1, y1)
# create origin
origin = np.array([20, 20])
# hell
hell1_center = origin + np.array([UNIT * 2, UNIT])
self.hell1 = self.canvas.create_rectangle(
hell1_center[0] - 15, hell1_center[1] - 15,
hell1_center[0] + 15, hell1_center[1] + 15,
fill='black')
# hell
hell2_center = origin + np.array([UNIT, UNIT * 2])
self.hell2 = self.canvas.create_rectangle(
hell2_center[0] - 15, hell2_center[1] - 15,
hell2_center[0] + 15, hell2_center[1] + 15,
fill='black')
# create oval
oval_center = origin + UNIT * 2
self.oval = self.canvas.create_oval(
oval_center[0] - 15, oval_center[1] - 15,
oval_center[0] + 15, oval_center[1] + 15,
fill='yellow')
# create red rect
self.rect = self.canvas.create_rectangle(
origin[0] - 15, origin[1] - 15,
origin[0] + 15, origin[1] + 15,
fill='red')
# pack all
self.canvas.pack()
def reset(self):
self.update()
time.sleep(0.5)
self.canvas.delete(self.rect)
origin = np.array([20, 20])
self.rect = self.canvas.create_rectangle(
origin[0] - 15, origin[1] - 15,
origin[0] + 15, origin[1] + 15,
fill='red')
# return observation
return self.canvas.coords(self.rect)
def step(self, action):
s = self.canvas.coords(self.rect)
base_action = np.array([0, 0])
if action == 0: # up
if s[1] > UNIT:
base_action[1] -= UNIT
elif action == 1: # down
if s[1] < (MAZE_H - 1) * UNIT:
base_action[1] += UNIT
elif action == 2: # right
if s[0] < (MAZE_W - 1) * UNIT:
base_action[0] += UNIT
elif action == 3: # left
if s[0] > UNIT:
base_action[0] -= UNIT
self.canvas.move(self.rect, base_action[0], base_action[1]) # move agent
s_ = self.canvas.coords(self.rect) # next state
# reward function
if s_ == self.canvas.coords(self.oval):
reward = 1
done = True
elif s_ in [self.canvas.coords(self.hell1), self.canvas.coords(self.hell2)]:
reward = -1
done = True
else:
reward = 0
done = False
return s_, reward, done
def render(self):
# time.sleep(0.1)
self.update()
================================================
FILE: contents/11_Dyna_Q/run_this.py
================================================
"""
Simplest model-based RL, Dyna-Q.
Red rectangle: explorer.
Black rectangles: hells [reward = -1].
Yellow bin circle: paradise [reward = +1].
All other states: ground [reward = 0].
This script is the main part which controls the update method of this example.
The RL is in RL_brain.py.
View more on my tutorial page: https://morvanzhou.github.io/tutorials/
"""
from maze_env import Maze
from RL_brain import QLearningTable, EnvModel
def update():
for episode in range(40):
s = env.reset()
while True:
env.render()
a = RL.choose_action(str(s))
s_, r, done = env.step(a)
RL.learn(str(s), a, r, str(s_))
# use a model to output (r, s_) by inputting (s, a)
# the model in dyna Q version is just like a memory replay buffer
env_model.store_transition(str(s), a, r, s_)
for n in range(10): # learn 10 more times using the env_model
ms, ma = env_model.sample_s_a() # ms in here is a str
mr, ms_ = env_model.get_r_s_(ms, ma)
RL.learn(ms, ma, mr, str(ms_))
s = s_
if done:
break
# end of game
print('game over')
env.destroy()
if __name__ == "__main__":
env = Maze()
RL = QLearningTable(actions=list(range(env.n_actions)))
env_model = EnvModel(actions=list(range(env.n_actions)))
env.after(0, update)
env.mainloop()
================================================
FILE: contents/12_Proximal_Policy_Optimization/DPPO.py
================================================
"""
A simple version of OpenAI's Proximal Policy Optimization (PPO). [https://arxiv.org/abs/1707.06347]
Distributing workers in parallel to collect data, then stop worker's roll-out and train PPO on collected data.
Restart workers once PPO is updated.
The global PPO updating rule is adopted from DeepMind's paper (DPPO):
Emergence of Locomotion Behaviours in Rich Environments (Google Deepmind): [https://arxiv.org/abs/1707.02286]
View more on my tutorial website: https://morvanzhou.github.io/tutorials
Dependencies:
tensorflow r1.3
gym 0.9.2
"""
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
import gym, threading, queue
EP_MAX = 1000
EP_LEN = 200
N_WORKER = 4 # parallel workers
GAMMA = 0.9 # reward discount factor
A_LR = 0.0001 # learning rate for actor
C_LR = 0.0002 # learning rate for critic
MIN_BATCH_SIZE = 64 # minimum batch size for updating PPO
UPDATE_STEP = 10 # loop update operation n-steps
EPSILON = 0.2 # for clipping surrogate objective
GAME = 'Pendulum-v0'
S_DIM, A_DIM = 3, 1 # state and action dimension
class PPO(object):
def __init__(self):
self.sess = tf.Session()
self.tfs = tf.placeholder(tf.float32, [None, S_DIM], 'state')
# critic
l1 = tf.layers.dense(self.tfs, 100, tf.nn.relu)
self.v = tf.layers.dense(l1, 1)
self.tfdc_r = tf.placeholder(tf.float32, [None, 1], 'discounted_r')
self.advantage = self.tfdc_r - self.v
self.closs = tf.reduce_mean(tf.square(self.advantage))
self.ctrain_op = tf.train.AdamOptimizer(C_LR).minimize(self.closs)
# actor
pi, pi_params = self._build_anet('pi', trainable=True)
oldpi, oldpi_params = self._build_anet('oldpi', trainable=False)
self.sample_op = tf.squeeze(pi.sample(1), axis=0) # operation of choosing action
self.update_oldpi_op = [oldp.assign(p) for p, oldp in zip(pi_params, oldpi_params)]
self.tfa = tf.placeholder(tf.float32, [None, A_DIM], 'action')
self.tfadv = tf.placeholder(tf.float32, [None, 1], 'advantage')
# ratio = tf.exp(pi.log_prob(self.tfa) - oldpi.log_prob(self.tfa))
ratio = pi.prob(self.tfa) / (oldpi.prob(self.tfa) + 1e-5)
surr = ratio * self.tfadv # surrogate loss
self.aloss = -tf.reduce_mean(tf.minimum( # clipped surrogate objective
surr,
tf.clip_by_value(ratio, 1. - EPSILON, 1. + EPSILON) * self.tfadv))
self.atrain_op = tf.train.AdamOptimizer(A_LR).minimize(self.aloss)
self.sess.run(tf.global_variables_initializer())
def update(self):
global GLOBAL_UPDATE_COUNTER
while not COORD.should_stop():
if GLOBAL_EP < EP_MAX:
UPDATE_EVENT.wait() # wait until get batch of data
self.sess.run(self.update_oldpi_op) # copy pi to old pi
data = [QUEUE.get() for _ in range(QUEUE.qsize())] # collect data from all workers
data = np.vstack(data)
s, a, r = data[:, :S_DIM], data[:, S_DIM: S_DIM + A_DIM], data[:, -1:]
adv = self.sess.run(self.advantage, {self.tfs: s, self.tfdc_r: r})
# update actor and critic in a update loop
[self.sess.run(self.atrain_op, {self.tfs: s, self.tfa: a, self.tfadv: adv}) for _ in range(UPDATE_STEP)]
[self.sess.run(self.ctrain_op, {self.tfs: s, self.tfdc_r: r}) for _ in range(UPDATE_STEP)]
UPDATE_EVENT.clear() # updating finished
GLOBAL_UPDATE_COUNTER = 0 # reset counter
ROLLING_EVENT.set() # set roll-out available
def _build_anet(self, name, trainable):
with tf.variable_scope(name):
l1 = tf.layers.dense(self.tfs, 200, tf.nn.relu, trainable=trainable)
mu = 2 * tf.layers.dense(l1, A_DIM, tf.nn.tanh, trainable=trainable)
sigma = tf.layers.dense(l1, A_DIM, tf.nn.softplus, trainable=trainable)
norm_dist = tf.distributions.Normal(loc=mu, scale=sigma)
params = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope=name)
return norm_dist, params
def choose_action(self, s):
s = s[np.newaxis, :]
a = self.sess.run(self.sample_op, {self.tfs: s})[0]
return np.clip(a, -2, 2)
def get_v(self, s):
if s.ndim < 2: s = s[np.newaxis, :]
return self.sess.run(self.v, {self.tfs: s})[0, 0]
class Worker(object):
def __init__(self, wid):
self.wid = wid
self.env = gym.make(GAME).unwrapped
self.ppo = GLOBAL_PPO
def work(self):
global GLOBAL_EP, GLOBAL_RUNNING_R, GLOBAL_UPDATE_COUNTER
while not COORD.should_stop():
s = self.env.reset()
ep_r = 0
buffer_s, buffer_a, buffer_r = [], [], []
for t in range(EP_LEN):
if not ROLLING_EVENT.is_set(): # while global PPO is updating
ROLLING_EVENT.wait() # wait until PPO is updated
buffer_s, buffer_a, buffer_r = [], [], [] # clear history buffer, use new policy to collect data
a = self.ppo.choose_action(s)
s_, r, done, _ = self.env.step(a)
buffer_s.append(s)
buffer_a.append(a)
buffer_r.append((r + 8) / 8) # normalize reward, find to be useful
s = s_
ep_r += r
GLOBAL_UPDATE_COUNTER += 1 # count to minimum batch size, no need to wait other workers
if t == EP_LEN - 1 or GLOBAL_UPDATE_COUNTER >= MIN_BATCH_SIZE:
v_s_ = self.ppo.get_v(s_)
discounted_r = [] # compute discounted reward
for r in buffer_r[::-1]:
v_s_ = r + GAMMA * v_s_
discounted_r.append(v_s_)
discounted_r.reverse()
bs, ba, br = np.vstack(buffer_s), np.vstack(buffer_a), np.array(discounted_r)[:, np.newaxis]
buffer_s, buffer_a, buffer_r = [], [], []
QUEUE.put(np.hstack((bs, ba, br))) # put data in the queue
if GLOBAL_UPDATE_COUNTER >= MIN_BATCH_SIZE:
ROLLING_EVENT.clear() # stop collecting data
UPDATE_EVENT.set() # globalPPO update
if GLOBAL_EP >= EP_MAX: # stop training
COORD.request_stop()
break
# record reward changes, plot later
if len(GLOBAL_RUNNING_R) == 0: GLOBAL_RUNNING_R.append(ep_r)
else: GLOBAL_RUNNING_R.append(GLOBAL_RUNNING_R[-1]*0.9+ep_r*0.1)
GLOBAL_EP += 1
print('{0:.1f}%'.format(GLOBAL_EP/EP_MAX*100), '|W%i' % self.wid, '|Ep_r: %.2f' % ep_r,)
if __name__ == '__main__':
GLOBAL_PPO = PPO()
UPDATE_EVENT, ROLLING_EVENT = threading.Event(), threading.Event()
UPDATE_EVENT.clear() # not update now
ROLLING_EVENT.set() # start to roll out
workers = [Worker(wid=i) for i in range(N_WORKER)]
GLOBAL_UPDATE_COUNTER, GLOBAL_EP = 0, 0
GLOBAL_RUNNING_R = []
COORD = tf.train.Coordinator()
QUEUE = queue.Queue() # workers putting data in this queue
threads = []
for worker in workers: # worker threads
t = threading.Thread(target=worker.work, args=())
t.start() # training
threads.append(t)
# add a PPO updating thread
threads.append(threading.Thread(target=GLOBAL_PPO.update,))
threads[-1].start()
COORD.join(threads)
# plot reward change and test
plt.plot(np.arange(len(GLOBAL_RUNNING_R)), GLOBAL_RUNNING_R)
plt.xlabel('Episode'); plt.ylabel('Moving reward'); plt.ion(); plt.show()
env = gym.make('Pendulum-v0')
while True:
s = env.reset()
for t in range(300):
env.render()
s = env.step(GLOBAL_PPO.choose_action(s))[0]
================================================
FILE: contents/12_Proximal_Policy_Optimization/discrete_DPPO.py
================================================
"""
A simple version of OpenAI's Proximal Policy Optimization (PPO). [https://arxiv.org/abs/1707.06347]
Distributing workers in parallel to collect data, then stop worker's roll-out and train PPO on collected data.
Restart workers once PPO is updated.
The global PPO updating rule is adopted from DeepMind's paper (DPPO):
Emergence of Locomotion Behaviours in Rich Environments (Google Deepmind): [https://arxiv.org/abs/1707.02286]
View more on my tutorial website: https://morvanzhou.github.io/tutorials
Dependencies:
tensorflow 1.8.0
gym 0.9.2
"""
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
import gym, threading, queue
EP_MAX = 1000
EP_LEN = 500
N_WORKER = 4 # parallel workers
GAMMA = 0.9 # reward discount factor
A_LR = 0.0001 # learning rate for actor
C_LR = 0.0001 # learning rate for critic
MIN_BATCH_SIZE = 64 # minimum batch size for updating PPO
UPDATE_STEP = 15 # loop update operation n-steps
EPSILON = 0.2 # for clipping surrogate objective
GAME = 'CartPole-v0'
env = gym.make(GAME)
S_DIM = env.observation_space.shape[0]
A_DIM = env.action_space.n
class PPONet(object):
def __init__(self):
self.sess = tf.Session()
self.tfs = tf.placeholder(tf.float32, [None, S_DIM], 'state')
# critic
w_init = tf.random_normal_initializer(0., .1)
lc = tf.layers.dense(self.tfs, 200, tf.nn.relu, kernel_initializer=w_init, name='lc')
self.v = tf.layers.dense(lc, 1)
self.tfdc_r = tf.placeholder(tf.float32, [None, 1], 'discounted_r')
self.advantage = self.tfdc_r - self.v
self.closs = tf.reduce_mean(tf.square(self.advantage))
self.ctrain_op = tf.train.AdamOptimizer(C_LR).minimize(self.closs)
# actor
self.pi, pi_params = self._build_anet('pi', trainable=True)
oldpi, oldpi_params = self._build_anet('oldpi', trainable=False)
self.update_oldpi_op = [oldp.assign(p) for p, oldp in zip(pi_params, oldpi_params)]
self.tfa = tf.placeholder(tf.int32, [None, ], 'action')
self.tfadv = tf.placeholder(tf.float32, [None, 1], 'advantage')
a_indices = tf.stack([tf.range(tf.shape(self.tfa)[0], dtype=tf.int32), self.tfa], axis=1)
pi_prob = tf.gather_nd(params=self.pi, indices=a_indices) # shape=(None, )
oldpi_prob = tf.gather_nd(params=oldpi, indices=a_indices) # shape=(None, )
ratio = pi_prob/(oldpi_prob + 1e-5)
surr = ratio * self.tfadv # surrogate loss
self.aloss = -tf.reduce_mean(tf.minimum( # clipped surrogate objective
surr,
tf.clip_by_value(ratio, 1. - EPSILON, 1. + EPSILON) * self.tfadv))
self.atrain_op = tf.train.AdamOptimizer(A_LR).minimize(self.aloss)
self.sess.run(tf.global_variables_initializer())
def update(self):
global GLOBAL_UPDATE_COUNTER
while not COORD.should_stop():
if GLOBAL_EP < EP_MAX:
UPDATE_EVENT.wait() # wait until get batch of data
self.sess.run(self.update_oldpi_op) # copy pi to old pi
data = [QUEUE.get() for _ in range(QUEUE.qsize())] # collect data from all workers
data = np.vstack(data)
s, a, r = data[:, :S_DIM], data[:, S_DIM: S_DIM + 1].ravel(), data[:, -1:]
adv = self.sess.run(self.advantage, {self.tfs: s, self.tfdc_r: r})
# update actor and critic in a update loop
[self.sess.run(self.atrain_op, {self.tfs: s, self.tfa: a, self.tfadv: adv}) for _ in range(UPDATE_STEP)]
[self.sess.run(self.ctrain_op, {self.tfs: s, self.tfdc_r: r}) for _ in range(UPDATE_STEP)]
UPDATE_EVENT.clear() # updating finished
GLOBAL_UPDATE_COUNTER = 0 # reset counter
ROLLING_EVENT.set() # set roll-out available
def _build_anet(self, name, trainable):
with tf.variable_scope(name):
l_a = tf.layers.dense(self.tfs, 200, tf.nn.relu, trainable=trainable)
a_prob = tf.layers.dense(l_a, A_DIM, tf.nn.softmax, trainable=trainable)
params = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope=name)
return a_prob, params
def choose_action(self, s): # run by a local
prob_weights = self.sess.run(self.pi, feed_dict={self.tfs: s[None, :]})
action = np.random.choice(range(prob_weights.shape[1]),
p=prob_weights.ravel()) # select action w.r.t the actions prob
return action
def get_v(self, s):
if s.ndim < 2: s = s[np.newaxis, :]
return self.sess.run(self.v, {self.tfs: s})[0, 0]
class Worker(object):
def __init__(self, wid):
self.wid = wid
self.env = gym.make(GAME).unwrapped
self.ppo = GLOBAL_PPO
def work(self):
global GLOBAL_EP, GLOBAL_RUNNING_R, GLOBAL_UPDATE_COUNTER
while not COORD.should_stop():
s = self.env.reset()
ep_r = 0
buffer_s, buffer_a, buffer_r = [], [], []
for t in range(EP_LEN):
if not ROLLING_EVENT.is_set(): # while global PPO is updating
ROLLING_EVENT.wait() # wait until PPO is updated
buffer_s, buffer_a, buffer_r = [], [], [] # clear history buffer, use new policy to collect data
a = self.ppo.choose_action(s)
s_, r, done, _ = self.env.step(a)
if done: r = -10
buffer_s.append(s)
buffer_a.append(a)
buffer_r.append(r-1) # 0 for not down, -11 for down. Reward engineering
s = s_
ep_r += r
GLOBAL_UPDATE_COUNTER += 1 # count to minimum batch size, no need to wait other workers
if t == EP_LEN - 1 or GLOBAL_UPDATE_COUNTER >= MIN_BATCH_SIZE or done:
if done:
v_s_ = 0 # end of episode
else:
v_s_ = self.ppo.get_v(s_)
discounted_r = [] # compute discounted reward
for r in buffer_r[::-1]:
v_s_ = r + GAMMA * v_s_
discounted_r.append(v_s_)
discounted_r.reverse()
bs, ba, br = np.vstack(buffer_s), np.vstack(buffer_a), np.array(discounted_r)[:, None]
buffer_s, buffer_a, buffer_r = [], [], []
QUEUE.put(np.hstack((bs, ba, br))) # put data in the queue
if GLOBAL_UPDATE_COUNTER >= MIN_BATCH_SIZE:
ROLLING_EVENT.clear() # stop collecting data
UPDATE_EVENT.set() # globalPPO update
if GLOBAL_EP >= EP_MAX: # stop training
COORD.request_stop()
break
if done: break
# record reward changes, plot later
if len(GLOBAL_RUNNING_R) == 0: GLOBAL_RUNNING_R.append(ep_r)
else: GLOBAL_RUNNING_R.append(GLOBAL_RUNNING_R[-1]*0.9+ep_r*0.1)
GLOBAL_EP += 1
print('{0:.1f}%'.format(GLOBAL_EP/EP_MAX*100), '|W%i' % self.wid, '|Ep_r: %.2f' % ep_r,)
if __name__ == '__main__':
GLOBAL_PPO = PPONet()
UPDATE_EVENT, ROLLING_EVENT = threading.Event(), threading.Event()
UPDATE_EVENT.clear() # not update now
ROLLING_EVENT.set() # start to roll out
workers = [Worker(wid=i) for i in range(N_WORKER)]
GLOBAL_UPDATE_COUNTER, GLOBAL_EP = 0, 0
GLOBAL_RUNNING_R = []
COORD = tf.train.Coordinator()
QUEUE = queue.Queue() # workers putting data in this queue
threads = []
for worker in workers: # worker threads
t = threading.Thread(target=worker.work, args=())
t.start() # training
threads.append(t)
# add a PPO updating thread
threads.append(threading.Thread(target=GLOBAL_PPO.update,))
threads[-1].start()
COORD.join(threads)
# plot reward change and test
plt.plot(np.arange(len(GLOBAL_RUNNING_R)), GLOBAL_RUNNING_R)
plt.xlabel('Episode'); plt.ylabel('Moving reward'); plt.ion(); plt.show()
env = gym.make('CartPole-v0')
while True:
s = env.reset()
for t in range(1000):
env.render()
s, r, done, info = env.step(GLOBAL_PPO.choose_action(s))
if done:
break
================================================
FILE: contents/12_Proximal_Policy_Optimization/simply_PPO.py
================================================
"""
A simple version of Proximal Policy Optimization (PPO) using single thread.
Based on:
1. Emergence of Locomotion Behaviours in Rich Environments (Google Deepmind): [https://arxiv.org/abs/1707.02286]
2. Proximal Policy Optimization Algorithms (OpenAI): [https://arxiv.org/abs/1707.06347]
View more on my tutorial website: https://morvanzhou.github.io/tutorials
Dependencies:
tensorflow r1.2
gym 0.9.2
"""
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
import gym
EP_MAX = 1000
EP_LEN = 200
GAMMA = 0.9
A_LR = 0.0001
C_LR = 0.0002
BATCH = 32
A_UPDATE_STEPS = 10
C_UPDATE_STEPS = 10
S_DIM, A_DIM = 3, 1
METHOD = [
dict(name='kl_pen', kl_target=0.01, lam=0.5), # KL penalty
dict(name='clip', epsilon=0.2), # Clipped surrogate objective, find this is better
][1] # choose the method for optimization
class PPO(object):
def __init__(self):
self.sess = tf.Session()
self.tfs = tf.placeholder(tf.float32, [None, S_DIM], 'state')
# critic
with tf.variable_scope('critic'):
l1 = tf.layers.dense(self.tfs, 100, tf.nn.relu)
self.v = tf.layers.dense(l1, 1)
self.tfdc_r = tf.placeholder(tf.float32, [None, 1], 'discounted_r')
self.advantage = self.tfdc_r - self.v
self.closs = tf.reduce_mean(tf.square(self.advantage))
self.ctrain_op = tf.train.AdamOptimizer(C_LR).minimize(self.closs)
# actor
pi, pi_params = self._build_anet('pi', trainable=True)
oldpi, oldpi_params = self._build_anet('oldpi', trainable=False)
with tf.variable_scope('sample_action'):
self.sample_op = tf.squeeze(pi.sample(1), axis=0) # choosing action
with tf.variable_scope('update_oldpi'):
self.update_oldpi_op = [oldp.assign(p) for p, oldp in zip(pi_params, oldpi_params)]
self.tfa = tf.placeholder(tf.float32, [None, A_DIM], 'action')
self.tfadv = tf.placeholder(tf.float32, [None, 1], 'advantage')
with tf.variable_scope('loss'):
with tf.variable_scope('surrogate'):
# ratio = tf.exp(pi.log_prob(self.tfa) - oldpi.log_prob(self.tfa))
ratio = pi.prob(self.tfa) / (oldpi.prob(self.tfa) + 1e-5)
surr = ratio * self.tfadv
if METHOD['name'] == 'kl_pen':
self.tflam = tf.placeholder(tf.float32, None, 'lambda')
kl = tf.distributions.kl_divergence(oldpi, pi)
self.kl_mean = tf.reduce_mean(kl)
self.aloss = -(tf.reduce_mean(surr - self.tflam * kl))
else: # clipping method, find this is better
self.aloss = -tf.reduce_mean(tf.minimum(
surr,
tf.clip_by_value(ratio, 1.-METHOD['epsilon'], 1.+METHOD['epsilon'])*self.tfadv))
with tf.variable_scope('atrain'):
self.atrain_op = tf.train.AdamOptimizer(A_LR).minimize(self.aloss)
tf.summary.FileWriter("log/", self.sess.graph)
self.sess.run(tf.global_variables_initializer())
def update(self, s, a, r):
self.sess.run(self.update_oldpi_op)
adv = self.sess.run(self.advantage, {self.tfs: s, self.tfdc_r: r})
# adv = (adv - adv.mean())/(adv.std()+1e-6) # sometimes helpful
# update actor
if METHOD['name'] == 'kl_pen':
for _ in range(A_UPDATE_STEPS):
_, kl = self.sess.run(
[self.atrain_op, self.kl_mean],
{self.tfs: s, self.tfa: a, self.tfadv: adv, self.tflam: METHOD['lam']})
if kl > 4*METHOD['kl_target']: # this in in google's paper
break
if kl < METHOD['kl_target'] / 1.5: # adaptive lambda, this is in OpenAI's paper
METHOD['lam'] /= 2
elif kl > METHOD['kl_target'] * 1.5:
METHOD['lam'] *= 2
METHOD['lam'] = np.clip(METHOD['lam'], 1e-4, 10) # sometimes explode, this clipping is my solution
else: # clipping method, find this is better (OpenAI's paper)
[self.sess.run(self.atrain_op, {self.tfs: s, self.tfa: a, self.tfadv: adv}) for _ in range(A_UPDATE_STEPS)]
# update critic
[self.sess.run(self.ctrain_op, {self.tfs: s, self.tfdc_r: r}) for _ in range(C_UPDATE_STEPS)]
def _build_anet(self, name, trainable):
with tf.variable_scope(name):
l1 = tf.layers.dense(self.tfs, 100, tf.nn.relu, trainable=trainable)
mu = 2 * tf.layers.dense(l1, A_DIM, tf.nn.tanh, trainable=trainable)
sigma = tf.layers.dense(l1, A_DIM, tf.nn.softplus, trainable=trainable)
norm_dist = tf.distributions.Normal(loc=mu, scale=sigma)
params = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope=name)
return norm_dist, params
def choose_action(self, s):
s = s[np.newaxis, :]
a = self.sess.run(self.sample_op, {self.tfs: s})[0]
return np.clip(a, -2, 2)
def get_v(self, s):
if s.ndim < 2: s = s[np.newaxis, :]
return self.sess.run(self.v, {self.tfs: s})[0, 0]
env = gym.make('Pendulum-v0').unwrapped
ppo = PPO()
all_ep_r = []
for ep in range(EP_MAX):
s = env.reset()
buffer_s, buffer_a, buffer_r = [], [], []
ep_r = 0
for t in range(EP_LEN): # in one episode
env.render()
a = ppo.choose_action(s)
s_, r, done, _ = env.step(a)
buffer_s.append(s)
buffer_a.append(a)
buffer_r.append((r+8)/8) # normalize reward, find to be useful
s = s_
ep_r += r
# update ppo
if (t+1) % BATCH == 0 or t == EP_LEN-1:
v_s_ = ppo.get_v(s_)
discounted_r = []
for r in buffer_r[::-1]:
v_s_ = r + GAMMA * v_s_
discounted_r.append(v_s_)
discounted_r.reverse()
bs, ba, br = np.vstack(buffer_s), np.vstack(buffer_a), np.array(discounted_r)[:, np.newaxis]
buffer_s, buffer_a, buffer_r = [], [], []
ppo.update(bs, ba, br)
if ep == 0: all_ep_r.append(ep_r)
else: all_ep_r.append(all_ep_r[-1]*0.9 + ep_r*0.1)
print(
'Ep: %i' % ep,
"|Ep_r: %i" % ep_r,
("|Lam: %.4f" % METHOD['lam']) if METHOD['name'] == 'kl_pen' else '',
)
plt.plot(np.arange(len(all_ep_r)), all_ep_r)
plt.xlabel('Episode');plt.ylabel('Moving averaged episode reward');plt.show()
================================================
FILE: contents/1_command_line_reinforcement_learning/treasure_on_right.py
================================================
"""
A simple example for Reinforcement Learning using table lookup Q-learning method.
An agent "o" is on the left of a 1 dimensional world, the treasure is on the rightmost location.
Run this program and to see how the agent will improve its strategy of finding the treasure.
View more on my tutorial page: https://morvanzhou.github.io/tutorials/
"""
import numpy as np
import pandas as pd
import time
np.random.seed(2) # reproducible
N_STATES = 6 # the length of the 1 dimensional world
ACTIONS = ['left', 'right'] # available actions
EPSILON = 0.9 # greedy police
ALPHA = 0.1 # learning rate
GAMMA = 0.9 # discount factor
MAX_EPISODES = 13 # maximum episodes
FRESH_TIME = 0.3 # fresh time for one move
def build_q_table(n_states, actions):
table = pd.DataFrame(
np.zeros((n_states, len(actions))), # q_table initial values
columns=actions, # actions's name
)
# print(table) # show table
return table
def choose_action(state, q_table):
# This is how to choose an action
state_actions = q_table.iloc[state, :]
if (np.random.uniform() > EPSILON) or ((state_actions == 0).all()): # act non-greedy or state-action have no value
action_name = np.random.choice(ACTIONS)
else: # act greedy
action_name = state_actions.idxmax() # replace argmax to idxmax as argmax means a different function in newer version of pandas
return action_name
def get_env_feedback(S, A):
# This is how agent will interact with the environment
if A == 'right': # move right
if S == N_STATES - 2: # terminate
S_ = 'terminal'
R = 1
else:
S_ = S + 1
R = 0
else: # move left
R = 0
if S == 0:
S_ = S # reach the wall
else:
S_ = S - 1
return S_, R
def update_env(S, episode, step_counter):
# This is how environment be updated
env_list = ['-']*(N_STATES-1) + ['T'] # '---------T' our environment
if S == 'terminal':
interaction = 'Episode %s: total_steps = %s' % (episode+1, step_counter)
print('\r{}'.format(interaction), end='')
time.sleep(2)
print('\r ', end='')
else:
env_list[S] = 'o'
interaction = ''.join(env_list)
print('\r{}'.format(interaction), end='')
time.sleep(FRESH_TIME)
def rl():
# main part of RL loop
q_table = build_q_table(N_STATES, ACTIONS)
for episode in range(MAX_EPISODES):
step_counter = 0
S = 0
is_terminated = False
update_env(S, episode, step_counter)
while not is_terminated:
A = choose_action(S, q_table)
S_, R = get_env_feedback(S, A) # take action & get next state and reward
q_predict = q_table.loc[S, A]
if S_ != 'terminal':
q_target = R + GAMMA * q_table.iloc[S_, :].max() # next state is not terminal
else:
q_target = R # next state is terminal
is_terminated = True # terminate this episode
q_table.loc[S, A] += ALPHA * (q_target - q_predict) # update
S = S_ # move to next state
update_env(S, episode, step_counter+1)
step_counter += 1
return q_table
if __name__ == "__main__":
q_table = rl()
print('\r\nQ-table:\n')
print(q_table)
================================================
FILE: contents/2_Q_Learning_maze/RL_brain.py
================================================
"""
This part of code is the Q learning brain, which is a brain of the agent.
All decisions are made in here.
View more on my tutorial page: https://morvanzhou.github.io/tutorials/
"""
import numpy as np
import pandas as pd
class QLearningTable:
def __init__(self, actions, learning_rate=0.01, reward_decay=0.9, e_greedy=0.9):
self.actions = actions # a list
self.lr = learning_rate
self.gamma = reward_decay
self.epsilon = e_greedy
self.q_table = pd.DataFrame(columns=self.actions, dtype=np.float64)
def choose_action(self, observation):
self.check_state_exist(observation)
# action selection
if np.random.uniform() < self.epsilon:
# choose best action
state_action = self.q_table.loc[observation, :]
# some actions may have the same value, randomly choose on in these actions
action = np.random.choice(state_action[state_action == np.max(state_action)].index)
else:
# choose random action
action = np.random.choice(self.actions)
return action
def learn(self, s, a, r, s_):
self.check_state_exist(s_)
q_predict = self.q_table.loc[s, a]
if s_ != 'terminal':
q_target = r + self.gamma * self.q_table.loc[s_, :].max() # next state is not terminal
else:
q_target = r # next state is terminal
self.q_table.loc[s, a] += self.lr * (q_target - q_predict) # update
def check_state_exist(self, state):
if state not in self.q_table.index:
# append new state to q table
self.q_table = self.q_table.append(
pd.Series(
[0]*len(self.actions),
index=self.q_table.columns,
name=state,
)
)
================================================
FILE: contents/2_Q_Learning_maze/maze_env.py
================================================
"""
Reinforcement learning maze example.
Red rectangle: explorer.
Black rectangles: hells [reward = -1].
Yellow bin circle: paradise [reward = +1].
All other states: ground [reward = 0].
This script is the environment part of this example. The RL is in RL_brain.py.
View more on my tutorial page: https://morvanzhou.github.io/tutorials/
"""
import numpy as np
import time
import sys
if sys.version_info.major == 2:
import Tkinter as tk
else:
import tkinter as tk
UNIT = 40 # pixels
MAZE_H = 4 # grid height
MAZE_W = 4 # grid width
class Maze(tk.Tk, object):
def __init__(self):
super(Maze, self).__init__()
self.action_space = ['u', 'd', 'l', 'r']
self.n_actions = len(self.action_space)
self.title('maze')
self.geometry('{0}x{1}'.format(MAZE_W * UNIT, MAZE_H * UNIT))
self._build_maze()
def _build_maze(self):
self.canvas = tk.Canvas(self, bg='white',
height=MAZE_H * UNIT,
width=MAZE_W * UNIT)
# create grids
for c in range(0, MAZE_W * UNIT, UNIT):
x0, y0, x1, y1 = c, 0, c, MAZE_H * UNIT
self.canvas.create_line(x0, y0, x1, y1)
for r in range(0, MAZE_H * UNIT, UNIT):
x0, y0, x1, y1 = 0, r, MAZE_W * UNIT, r
self.canvas.create_line(x0, y0, x1, y1)
# create origin
origin = np.array([20, 20])
# hell
hell1_center = origin + np.array([UNIT * 2, UNIT])
self.hell1 = self.canvas.create_rectangle(
hell1_center[0] - 15, hell1_center[1] - 15,
hell1_center[0] + 15, hell1_center[1] + 15,
fill='black')
# hell
hell2_center = origin + np.array([UNIT, UNIT * 2])
self.hell2 = self.canvas.create_rectangle(
hell2_center[0] - 15, hell2_center[1] - 15,
hell2_center[0] + 15, hell2_center[1] + 15,
fill='black')
# create oval
oval_center = origin + UNIT * 2
self.oval = self.canvas.create_oval(
oval_center[0] - 15, oval_center[1] - 15,
oval_center[0] + 15, oval_center[1] + 15,
fill='yellow')
# create red rect
self.rect = self.canvas.create_rectangle(
origin[0] - 15, origin[1] - 15,
origin[0] + 15, origin[1] + 15,
fill='red')
# pack all
self.canvas.pack()
def reset(self):
self.update()
time.sleep(0.5)
self.canvas.delete(self.rect)
origin = np.array([20, 20])
self.rect = self.canvas.create_rectangle(
origin[0] - 15, origin[1] - 15,
origin[0] + 15, origin[1] + 15,
fill='red')
# return observation
return self.canvas.coords(self.rect)
def step(self, action):
s = self.canvas.coords(self.rect)
base_action = np.array([0, 0])
if action == 0: # up
if s[1] > UNIT:
base_action[1] -= UNIT
elif action == 1: # down
if s[1] < (MAZE_H - 1) * UNIT:
base_action[1] += UNIT
elif action == 2: # right
if s[0] < (MAZE_W - 1) * UNIT:
base_action[0] += UNIT
elif action == 3: # left
if s[0] > UNIT:
base_action[0] -= UNIT
self.canvas.move(self.rect, base_action[0], base_action[1]) # move agent
s_ = self.canvas.coords(self.rect) # next state
# reward function
if s_ == self.canvas.coords(self.oval):
reward = 1
done = True
s_ = 'terminal'
elif s_ in [self.canvas.coords(self.hell1), self.canvas.coords(self.hell2)]:
reward = -1
done = True
s_ = 'terminal'
else:
reward = 0
done = False
return s_, reward, done
def render(self):
time.sleep(0.1)
self.update()
def update():
for t in range(10):
s = env.reset()
while True:
env.render()
a = 1
s, r, done = env.step(a)
if done:
break
if __name__ == '__main__':
env = Maze()
env.after(100, update)
env.mainloop()
================================================
FILE: contents/2_Q_Learning_maze/run_this.py
================================================
"""
Reinforcement learning maze example.
Red rectangle: explorer.
Black rectangles: hells [reward = -1].
Yellow bin circle: paradise [reward = +1].
All other states: ground [reward = 0].
This script is the main part which controls the update method of this example.
The RL is in RL_brain.py.
View more on my tutorial page: https://morvanzhou.github.io/tutorials/
"""
from maze_env import Maze
from RL_brain import QLearningTable
def update():
for episode in range(100):
# initial observation
observation = env.reset()
while True:
# fresh env
env.render()
# RL choose action based on observation
action = RL.choose_action(str(observation))
# RL take action and get next observation and reward
observation_, reward, done = env.step(action)
# RL learn from this transition
RL.learn(str(observation), action, reward, str(observation_))
# swap observation
observation = observation_
# break while loop when end of this episode
if done:
break
# end of game
print('game over')
env.destroy()
if __name__ == "__main__":
env = Maze()
RL = QLearningTable(actions=list(range(env.n_actions)))
env.after(100, update)
env.mainloop()
================================================
FILE: contents/3_Sarsa_maze/RL_brain.py
================================================
"""
This part of code is the Q learning brain, which is a brain of the agent.
All decisions are made in here.
View more on my tutorial page: https://morvanzhou.github.io/tutorials/
"""
import numpy as np
import pandas as pd
class RL(object):
def __init__(self, action_space, learning_rate=0.01, reward_decay=0.9, e_greedy=0.9):
self.actions = action_space # a list
self.lr = learning_rate
self.gamma = reward_decay
self.epsilon = e_greedy
self.q_table = pd.DataFrame(columns=self.actions, dtype=np.float64)
def check_state_exist(self, state):
if state not in self.q_table.index:
# append new state to q table
self.q_table = self.q_table.append(
pd.Series(
[0]*len(self.actions),
index=self.q_table.columns,
name=state,
)
)
def choose_action(self, observation):
self.check_state_exist(observation)
# action selection
if np.random.rand() < self.epsilon:
# choose best action
state_action = self.q_table.loc[observation, :]
# some actions may have the same value, randomly choose on in these actions
action = np.random.choice(state_action[state_action == np.max(state_action)].index)
else:
# choose random action
action = np.random.choice(self.actions)
return action
def learn(self, *args):
pass
# off-policy
class QLearningTable(RL):
def __init__(self, actions, learning_rate=0.01, reward_decay=0.9, e_greedy=0.9):
super(QLearningTable, self).__init__(actions, learning_rate, reward_decay, e_greedy)
def learn(self, s, a, r, s_):
self.check_state_exist(s_)
q_predict = self.q_table.loc[s, a]
if s_ != 'terminal':
q_target = r + self.gamma * self.q_table.loc[s_, :].max() # next state is not terminal
else:
q_target = r # next state is terminal
self.q_table.loc[s, a] += self.lr * (q_target - q_predict) # update
# on-policy
class SarsaTable(RL):
def __init__(self, actions, learning_rate=0.01, reward_decay=0.9, e_greedy=0.9):
super(SarsaTable, self).__init__(actions, learning_rate, reward_decay, e_greedy)
def learn(self, s, a, r, s_, a_):
self.check_state_exist(s_)
q_predict = self.q_table.loc[s, a]
if s_ != 'terminal':
q_target = r + self.gamma * self.q_table.loc[s_, a_] # next state is not terminal
else:
q_target = r # next state is terminal
self.q_table.loc[s, a] += self.lr * (q_target - q_predict) # update
================================================
FILE: contents/3_Sarsa_maze/maze_env.py
================================================
"""
Reinforcement learning maze example.
Red rectangle: explorer.
Black rectangles: hells [reward = -1].
Yellow bin circle: paradise [reward = +1].
All other states: ground [reward = 0].
This script is the environment part of this example.
The RL is in RL_brain.py.
View more on my tutorial page: https://morvanzhou.github.io/tutorials/
"""
import numpy as np
import time
import sys
if sys.version_info.major == 2:
import Tkinter as tk
else:
import tkinter as tk
UNIT = 40 # pixels
MAZE_H = 4 # grid height
MAZE_W = 4 # grid width
class Maze(tk.Tk, object):
def __init__(self):
super(Maze, self).__init__()
self.action_space = ['u', 'd', 'l', 'r']
self.n_actions = len(self.action_space)
self.title('maze')
self.geometry('{0}x{1}'.format(MAZE_W * UNIT, MAZE_H * UNIT))
self._build_maze()
def _build_maze(self):
self.canvas = tk.Canvas(self, bg='white',
height=MAZE_H * UNIT,
width=MAZE_W * UNIT)
# create grids
for c in range(0, MAZE_W * UNIT, UNIT):
x0, y0, x1, y1 = c, 0, c, MAZE_H * UNIT
self.canvas.create_line(x0, y0, x1, y1)
for r in range(0, MAZE_H * UNIT, UNIT):
x0, y0, x1, y1 = 0, r, MAZE_W * UNIT, r
self.canvas.create_line(x0, y0, x1, y1)
# create origin
origin = np.array([20, 20])
# hell
hell1_center = origin + np.array([UNIT * 2, UNIT])
self.hell1 = self.canvas.create_rectangle(
hell1_center[0] - 15, hell1_center[1] - 15,
hell1_center[0] + 15, hell1_center[1] + 15,
fill='black')
# hell
hell2_center = origin + np.array([UNIT, UNIT * 2])
self.hell2 = self.canvas.create_rectangle(
hell2_center[0] - 15, hell2_center[1] - 15,
hell2_center[0] + 15, hell2_center[1] + 15,
fill='black')
# create oval
oval_center = origin + UNIT * 2
self.oval = self.canvas.create_oval(
oval_center[0] - 15, oval_center[1] - 15,
oval_center[0] + 15, oval_center[1] + 15,
fill='yellow')
# create red rect
self.rect = self.canvas.create_rectangle(
origin[0] - 15, origin[1] - 15,
origin[0] + 15, origin[1] + 15,
fill='red')
# pack all
self.canvas.pack()
def reset(self):
self.update()
time.sleep(0.5)
self.canvas.delete(self.rect)
origin = np.array([20, 20])
self.rect = self.canvas.create_rectangle(
origin[0] - 15, origin[1] - 15,
origin[0] + 15, origin[1] + 15,
fill='red')
# return observation
return self.canvas.coords(self.rect)
def step(self, action):
s = self.canvas.coords(self.rect)
base_action = np.array([0, 0])
if action == 0: # up
if s[1] > UNIT:
base_action[1] -= UNIT
elif action == 1: # down
if s[1] < (MAZE_H - 1) * UNIT:
base_action[1] += UNIT
elif action == 2: # right
if s[0] < (MAZE_W - 1) * UNIT:
base_action[0] += UNIT
elif action == 3: # left
if s[0] > UNIT:
base_action[0] -= UNIT
self.canvas.move(self.rect, base_action[0], base_action[1]) # move agent
s_ = self.canvas.coords(self.rect) # next state
# reward function
if s_ == self.canvas.coords(self.oval):
reward = 1
done = True
s_ = 'terminal'
elif s_ in [self.canvas.coords(self.hell1), self.canvas.coords(self.hell2)]:
reward = -1
done = True
s_ = 'terminal'
else:
reward = 0
done = False
return s_, reward, done
def render(self):
time.sleep(0.1)
self.update()
================================================
FILE: contents/3_Sarsa_maze/run_this.py
================================================
"""
Sarsa is a online updating method for Reinforcement learning.
Unlike Q learning which is a offline updating method, Sarsa is updating while in the current trajectory.
You will see the sarsa is more coward when punishment is close because it cares about all behaviours,
while q learning is more brave because it only cares about maximum behaviour.
"""
from maze_env import Maze
from RL_brain import SarsaTable
def update():
for episode in range(100):
# initial observation
observation = env.reset()
# RL choose action based on observation
action = RL.choose_action(str(observation))
while True:
# fresh env
env.render()
# RL take action and get next observation and reward
observation_, reward, done = env.step(action)
# RL choose action based on next observation
action_ = RL.choose_action(str(observation_))
# RL learn from this transition (s, a, r, s, a) ==> Sarsa
RL.learn(str(observation), action, reward, str(observation_), action_)
# swap observation and action
observation = observation_
action = action_
# break while loop when end of this episode
if done:
break
# end of game
print('game over')
env.destroy()
if __name__ == "__main__":
env = Maze()
RL = SarsaTable(actions=list(range(env.n_actions)))
env.after(100, update)
env.mainloop()
================================================
FILE: contents/4_Sarsa_lambda_maze/RL_brain.py
================================================
"""
This part of code is the Q learning brain, which is a brain of the agent.
All decisions are made in here.
View more on my tutorial page: https://morvanzhou.github.io/tutorials/
"""
import numpy as np
import pandas as pd
class RL(object):
def __init__(self, action_space, learning_rate=0.01, reward_decay=0.9, e_greedy=0.9):
self.actions = action_space # a list
self.lr = learning_rate
self.gamma = reward_decay
self.epsilon = e_greedy
self.q_table = pd.DataFrame(columns=self.actions, dtype=np.float64)
def check_state_exist(self, state):
if state not in self.q_table.index:
# append new state to q table
self.q_table = self.q_table.append(
pd.Series(
[0]*len(self.actions),
index=self.q_table.columns,
name=state,
)
)
def choose_action(self, observation):
self.check_state_exist(observation)
# action selection
if np.random.rand() < self.epsilon:
# choose best action
state_action = self.q_table.loc[observation, :]
# some actions may have the same value, randomly choose on in these actions
action = np.random.choice(state_action[state_action == np.max(state_action)].index)
else:
# choose random action
action = np.random.choice(self.actions)
return action
def learn(self, *args):
pass
# backward eligibility traces
class SarsaLambdaTable(RL):
def __init__(self, actions, learning_rate=0.01, reward_decay=0.9, e_greedy=0.9, trace_decay=0.9):
super(SarsaLambdaTable, self).__init__(actions, learning_rate, reward_decay, e_greedy)
# backward view, eligibility trace.
self.lambda_ = trace_decay
self.eligibility_trace = self.q_table.copy()
def check_state_exist(self, state):
if state not in self.q_table.index:
# append new state to q table
to_be_append = pd.Series(
[0] * len(self.actions),
index=self.q_table.columns,
name=state,
)
self.q_table = self.q_table.append(to_be_append)
# also update eligibility trace
self.eligibility_trace = self.eligibility_trace.append(to_be_append)
def learn(self, s, a, r, s_, a_):
self.check_state_exist(s_)
q_predict = self.q_table.loc[s, a]
if s_ != 'terminal':
q_target = r + self.gamma * self.q_table.loc[s_, a_] # next state is not terminal
else:
q_target = r # next state is terminal
error = q_target - q_predict
# increase trace amount for visited state-action pair
# Method 1:
# self.eligibility_trace.loc[s, a] += 1
# Method 2:
self.eligibility_trace.loc[s, :] *= 0
self.eligibility_trace.loc[s, a] = 1
# Q update
self.q_table += self.lr * error * self.eligibility_trace
# decay eligibility trace after update
self.eligibility_trace *= self.gamma*self.lambda_
================================================
FILE: contents/4_Sarsa_lambda_maze/maze_env.py
================================================
"""
Reinforcement learning maze example.
Red rectangle: explorer.
Black rectangles: hells [reward = -1].
Yellow bin circle: paradise [reward = +1].
All other states: ground [reward = 0].
This script is the environment part of this example.
The RL is in RL_brain.py.
View more on my tutorial page: https://morvanzhou.github.io/tutorials/
"""
import numpy as np
import time
import sys
if sys.version_info.major == 2:
import Tkinter as tk
else:
import tkinter as tk
UNIT = 40 # pixels
MAZE_H = 4 # grid height
MAZE_W = 4 # grid width
class Maze(tk.Tk, object):
def __init__(self):
super(Maze, self).__init__()
self.action_space = ['u', 'd', 'l', 'r']
self.n_actions = len(self.action_space)
self.title('maze')
self.geometry('{0}x{1}'.format(MAZE_W * UNIT, MAZE_H * UNIT))
self._build_maze()
def _build_maze(self):
self.canvas = tk.Canvas(self, bg='white',
height=MAZE_H * UNIT,
width=MAZE_W * UNIT)
# create grids
for c in range(0, MAZE_W * UNIT, UNIT):
x0, y0, x1, y1 = c, 0, c, MAZE_H * UNIT
self.canvas.create_line(x0, y0, x1, y1)
for r in range(0, MAZE_H * UNIT, UNIT):
x0, y0, x1, y1 = 0, r, MAZE_W * UNIT, r
self.canvas.create_line(x0, y0, x1, y1)
# create origin
origin = np.array([20, 20])
# hell
hell1_center = origin + np.array([UNIT * 2, UNIT])
self.hell1 = self.canvas.create_rectangle(
hell1_center[0] - 15, hell1_center[1] - 15,
hell1_center[0] + 15, hell1_center[1] + 15,
fill='black')
# hell
hell2_center = origin + np.array([UNIT, UNIT * 2])
self.hell2 = self.canvas.create_rectangle(
hell2_center[0] - 15, hell2_center[1] - 15,
hell2_center[0] + 15, hell2_center[1] + 15,
fill='black')
# create oval
oval_center = origin + UNIT * 2
self.oval = self.canvas.create_oval(
oval_center[0] - 15, oval_center[1] - 15,
oval_center[0] + 15, oval_center[1] + 15,
fill='yellow')
# create red rect
self.rect = self.canvas.create_rectangle(
origin[0] - 15, origin[1] - 15,
origin[0] + 15, origin[1] + 15,
fill='red')
# pack all
self.canvas.pack()
def reset(self):
self.update()
time.sleep(0.5)
self.canvas.delete(self.rect)
origin = np.array([20, 20])
self.rect = self.canvas.create_rectangle(
origin[0] - 15, origin[1] - 15,
origin[0] + 15, origin[1] + 15,
fill='red')
# return observation
return self.canvas.coords(self.rect)
def step(self, action):
s = self.canvas.coords(self.rect)
base_action = np.array([0, 0])
if action == 0: # up
if s[1] > UNIT:
base_action[1] -= UNIT
elif action == 1: # down
if s[1] < (MAZE_H - 1) * UNIT:
base_action[1] += UNIT
elif action == 2: # right
if s[0] < (MAZE_W - 1) * UNIT:
base_action[0] += UNIT
elif action == 3: # left
if s[0] > UNIT:
base_action[0] -= UNIT
self.canvas.move(self.rect, base_action[0], base_action[1]) # move agent
s_ = self.canvas.coords(self.rect) # next state
# reward function
if s_ == self.canvas.coords(self.oval):
reward = 1
done = True
s_ = 'terminal'
elif s_ in [self.canvas.coords(self.hell1), self.canvas.coords(self.hell2)]:
reward = -1
done = True
s_ = 'terminal'
else:
reward = 0
done = False
return s_, reward, done
def render(self):
time.sleep(0.05)
self.update()
================================================
FILE: contents/4_Sarsa_lambda_maze/run_this.py
================================================
"""
Sarsa is a online updating method for Reinforcement learning.
Unlike Q learning which is a offline updating method, Sarsa is updating while in the current trajectory.
You will see the sarsa is more coward when punishment is close because it cares about all behaviours,
while q learning is more brave because it only cares about maximum behaviour.
"""
from maze_env import Maze
from RL_brain import SarsaLambdaTable
def update():
for episode in range(100):
# initial observation
observation = env.reset()
# RL choose action based on observation
action = RL.choose_action(str(observation))
# initial all zero eligibility trace
RL.eligibility_trace *= 0
while True:
# fresh env
env.render()
# RL take action and get next observation and reward
observation_, reward, done = env.step(action)
# RL choose action based on next observation
action_ = RL.choose_action(str(observation_))
# RL learn from this transition (s, a, r, s, a) ==> Sarsa
RL.learn(str(observation), action, reward, str(observation_), action_)
# swap observation and action
observation = observation_
action = action_
# break while loop when end of this episode
if done:
break
# end of game
print('game over')
env.destroy()
if __name__ == "__main__":
env = Maze()
RL = SarsaLambdaTable(actions=list(range(env.n_actions)))
env.after(100, update)
env.mainloop()
================================================
FILE: contents/5.1_Double_DQN/RL_brain.py
================================================
"""
The double DQN based on this paper: https://arxiv.org/abs/1509.06461
View more on my tutorial page: https://morvanzhou.github.io/tutorials/
Using:
Tensorflow: 1.0
gym: 0.8.0
"""
import numpy as np
import tensorflow as tf
np.random.seed(1)
tf.set_random_seed(1)
class DoubleDQN:
def __init__(
self,
n_actions,
n_features,
learning_rate=0.005,
reward_decay=0.9,
e_greedy=0.9,
replace_target_iter=200,
memory_size=3000,
batch_size=32,
e_greedy_increment=None,
output_graph=False,
double_q=True,
sess=None,
):
self.n_actions = n_actions
self.n_features = n_features
self.lr = learning_rate
self.gamma = reward_decay
self.epsilon_max = e_greedy
self.replace_target_iter = replace_target_iter
self.memory_size = memory_size
self.batch_size = batch_size
self.epsilon_increment = e_greedy_increment
self.epsilon = 0 if e_greedy_increment is not None else self.epsilon_max
self.double_q = double_q # decide to use double q or not
self.learn_step_counter = 0
self.memory = np.zeros((self.memory_size, n_features*2+2))
self._build_net()
t_params = tf.get_collection('target_net_params')
e_params = tf.get_collection('eval_net_params')
self.replace_target_op = [tf.assign(t, e) for t, e in zip(t_params, e_params)]
if sess is None:
self.sess = tf.Session()
self.sess.run(tf.global_variables_initializer())
else:
self.sess = sess
if output_graph:
tf.summary.FileWriter("logs/", self.sess.graph)
self.cost_his = []
def _build_net(self):
def build_layers(s, c_names, n_l1, w_initializer, b_initializer):
with tf.variable_scope('l1'):
w1 = tf.get_variable('w1', [self.n_features, n_l1], initializer=w_initializer, collections=c_names)
b1 = tf.get_variable('b1', [1, n_l1], initializer=b_initializer, collections=c_names)
l1 = tf.nn.relu(tf.matmul(s, w1) + b1)
with tf.variable_scope('l2'):
w2 = tf.get_variable('w2', [n_l1, self.n_actions], initializer=w_initializer, collections=c_names)
b2 = tf.get_variable('b2', [1, self.n_actions], initializer=b_initializer, collections=c_names)
out = tf.matmul(l1, w2) + b2
return out
# ------------------ build evaluate_net ------------------
self.s = tf.placeholder(tf.float32, [None, self.n_features], name='s') # input
self.q_target = tf.placeholder(tf.float32, [None, self.n_actions], name='Q_target') # for calculating loss
with tf.variable_scope('eval_net'):
c_names, n_l1, w_initializer, b_initializer = \
['eval_net_params', tf.GraphKeys.GLOBAL_VARIABLES], 20, \
tf.random_normal_initializer(0., 0.3), tf.constant_initializer(0.1) # config of layers
self.q_eval = build_layers(self.s, c_names, n_l1, w_initializer, b_initializer)
with tf.variable_scope('loss'):
self.loss = tf.reduce_mean(tf.squared_difference(self.q_target, self.q_eval))
with tf.variable_scope('train'):
self._train_op = tf.train.RMSPropOptimizer(self.lr).minimize(self.loss)
# ------------------ build target_net ------------------
self.s_ = tf.placeholder(tf.float32, [None, self.n_features], name='s_') # input
with tf.variable_scope('target_net'):
c_names = ['target_net_params', tf.GraphKeys.GLOBAL_VARIABLES]
self.q_next = build_layers(self.s_, c_names, n_l1, w_initializer, b_initializer)
def store_transition(self, s, a, r, s_):
if not hasattr(self, 'memory_counter'):
self.memory_counter = 0
transition = np.hstack((s, [a, r], s_))
index = self.memory_counter % self.memory_size
self.memory[index, :] = transition
self.memory_counter += 1
def choose_action(self, observation):
observation = observation[np.newaxis, :]
actions_value = self.sess.run(self.q_eval, feed_dict={self.s: observation})
action = np.argmax(actions_value)
if not hasattr(self, 'q'): # record action value it gets
self.q = []
self.running_q = 0
self.running_q = self.running_q*0.99 + 0.01 * np.max(actions_value)
self.q.append(self.running_q)
if np.random.uniform() > self.epsilon: # choosing action
action = np.random.randint(0, self.n_actions)
return action
def learn(self):
if self.learn_step_counter % self.replace_target_iter == 0:
self.sess.run(self.replace_target_op)
print('\ntarget_params_replaced\n')
if self.memory_counter > self.memory_size:
sample_index = np.random.choice(self.memory_size, size=self.batch_size)
else:
sample_index = np.random.choice(self.memory_counter, size=self.batch_size)
batch_memory = self.memory[sample_index, :]
q_next, q_eval4next = self.sess.run(
[self.q_next, self.q_eval],
feed_dict={self.s_: batch_memory[:, -self.n_features:], # next observation
self.s: batch_memory[:, -self.n_features:]}) # next observation
q_eval = self.sess.run(self.q_eval, {self.s: batch_memory[:, :self.n_features]})
q_target = q_eval.copy()
batch_index = np.arange(self.batch_size, dtype=np.int32)
eval_act_index = batch_memory[:, self.n_features].astype(int)
reward = batch_memory[:, self.n_features + 1]
if self.double_q:
max_act4next = np.argmax(q_eval4next, axis=1) # the action that brings the highest value is evaluated by q_eval
selected_q_next = q_next[batch_index, max_act4next] # Double DQN, select q_next depending on above actions
else:
selected_q_next = np.max(q_next, axis=1) # the natural DQN
q_target[batch_index, eval_act_index] = reward + self.gamma * selected_q_next
_, self.cost = self.sess.run([self._train_op, self.loss],
feed_dict={self.s: batch_memory[:, :self.n_features],
self.q_target: q_target})
self.cost_his.append(self.cost)
self.epsilon = self.epsilon + self.epsilon_increment if self.epsilon < self.epsilon_max else self.epsilon_max
self.learn_step_counter += 1
================================================
FILE: contents/5.1_Double_DQN/run_Pendulum.py
================================================
"""
Double DQN & Natural DQN comparison,
The Pendulum example.
View more on my tutorial page: https://morvanzhou.github.io/tutorials/
Using:
Tensorflow: 1.0
gym: 0.8.0
"""
import gym
from RL_brain import DoubleDQN
import numpy as np
import matplotlib.pyplot as plt
import tensorflow as tf
env = gym.make('Pendulum-v0')
env = env.unwrapped
env.seed(1)
MEMORY_SIZE = 3000
ACTION_SPACE = 11
sess = tf.Session()
with tf.variable_scope('Natural_DQN'):
natural_DQN = DoubleDQN(
n_actions=ACTION_SPACE, n_features=3, memory_size=MEMORY_SIZE,
e_greedy_increment=0.001, double_q=False, sess=sess
)
with tf.variable_scope('Double_DQN'):
double_DQN = DoubleDQN(
n_actions=ACTION_SPACE, n_features=3, memory_size=MEMORY_SIZE,
e_greedy_increment=0.001, double_q=True, sess=sess, output_graph=True)
sess.run(tf.global_variables_initializer())
def train(RL):
total_steps = 0
observation = env.reset()
while True:
# if total_steps - MEMORY_SIZE > 8000: env.render()
action = RL.choose_action(observation)
f_action = (action-(ACTION_SPACE-1)/2)/((ACTION_SPACE-1)/4) # convert to [-2 ~ 2] float actions
observation_, reward, done, info = env.step(np.array([f_action]))
reward /= 10 # normalize to a range of (-1, 0). r = 0 when get upright
# the Q target at upright state will be 0, because Q_target = r + gamma * Qmax(s', a') = 0 + gamma * 0
# so when Q at this state is greater than 0, the agent overestimates the Q. Please refer to the final result.
RL.store_transition(observation, action, reward, observation_)
if total_steps > MEMORY_SIZE: # learning
RL.learn()
if total_steps - MEMORY_SIZE > 20000: # stop game
break
observation = observation_
total_steps += 1
return RL.q
q_natural = train(natural_DQN)
q_double = train(double_DQN)
plt.plot(np.array(q_natural), c='r', label='natural')
plt.plot(np.array(q_double), c='b', label='double')
plt.legend(loc='best')
plt.ylabel('Q eval')
plt.xlabel('training steps')
plt.grid()
plt.show()
================================================
FILE: contents/5.2_Prioritized_Replay_DQN/RL_brain.py
================================================
"""
The DQN improvement: Prioritized Experience Replay (based on https://arxiv.org/abs/1511.05952)
View more on my tutorial page: https://morvanzhou.github.io/tutorials/
Using:
Tensorflow: 1.0
gym: 0.8.0
"""
import numpy as np
import tensorflow as tf
np.random.seed(1)
tf.set_random_seed(1)
class SumTree(object):
"""
This SumTree code is a modified version and the original code is from:
https://github.com/jaara/AI-blog/blob/master/SumTree.py
Story data with its priority in the tree.
"""
data_pointer = 0
def __init__(self, capacity):
self.capacity = capacity # for all priority values
self.tree = np.zeros(2 * capacity - 1)
# [--------------Parent nodes-------------][-------leaves to recode priority-------]
# size: capacity - 1 size: capacity
self.data = np.zeros(capacity, dtype=object) # for all transitions
# [--------------data frame-------------]
# size: capacity
def add(self, p, data):
tree_idx = self.data_pointer + self.capacity - 1
self.data[self.data_pointer] = data # update data_frame
self.update(tree_idx, p) # update tree_frame
self.data_pointer += 1
if self.data_pointer >= self.capacity: # replace when exceed the capacity
self.data_pointer = 0
def update(self, tree_idx, p):
change = p - self.tree[tree_idx]
self.tree[tree_idx] = p
# then propagate the change through tree
while tree_idx != 0: # this method is faster than the recursive loop in the reference code
tree_idx = (tree_idx - 1) // 2
self.tree[tree_idx] += change
def get_leaf(self, v):
"""
Tree structure and array storage:
Tree index:
0 -> storing priority sum
/ \
1 2
/ \ / \
3 4 5 6 -> storing priority for transitions
Array type for storing:
[0,1,2,3,4,5,6]
"""
parent_idx = 0
while True: # the while loop is faster than the method in the reference code
cl_idx = 2 * parent_idx + 1 # this leaf's left and right kids
cr_idx = cl_idx + 1
if cl_idx >= len(self.tree): # reach bottom, end search
leaf_idx = parent_idx
break
else: # downward search, always search for a higher priority node
if v <= self.tree[cl_idx]:
parent_idx = cl_idx
else:
v -= self.tree[cl_idx]
parent_idx = cr_idx
data_idx = leaf_idx - self.capacity + 1
return leaf_idx, self.tree[leaf_idx], self.data[data_idx]
@property
def total_p(self):
return self.tree[0] # the root
class Memory(object): # stored as ( s, a, r, s_ ) in SumTree
"""
This Memory class is modified based on the original code from:
https://github.com/jaara/AI-blog/blob/master/Seaquest-DDQN-PER.py
"""
epsilon = 0.01 # small amount to avoid zero priority
alpha = 0.6 # [0~1] convert the importance of TD error to priority
beta = 0.4 # importance-sampling, from initial value increasing to 1
beta_increment_per_sampling = 0.001
abs_err_upper = 1. # clipped abs error
def __init__(self, capacity):
self.tree = SumTree(capacity)
def store(self, transition):
max_p = np.max(self.tree.tree[-self.tree.capacity:])
if max_p == 0:
max_p = self.abs_err_upper
self.tree.add(max_p, transition) # set the max p for new p
def sample(self, n):
b_idx, b_memory, ISWeights = np.empty((n,), dtype=np.int32), np.empty((n, self.tree.data[0].size)), np.empty((n, 1))
pri_seg = self.tree.total_p / n # priority segment
self.beta = np.min([1., self.beta + self.beta_increment_per_sampling]) # max = 1
min_prob = np.min(self.tree.tree[-self.tree.capacity:]) / self.tree.total_p # for later calculate ISweight
for i in range(n):
a, b = pri_seg * i, pri_seg * (i + 1)
v = np.random.uniform(a, b)
idx, p, data = self.tree.get_leaf(v)
prob = p / self.tree.total_p
ISWeights[i, 0] = np.power(prob/min_prob, -self.beta)
b_idx[i], b_memory[i, :] = idx, data
return b_idx, b_memory, ISWeights
def batch_update(self, tree_idx, abs_errors):
abs_errors += self.epsilon # convert to abs and avoid 0
clipped_errors = np.minimum(abs_errors, self.abs_err_upper)
ps = np.power(clipped_errors, self.alpha)
for ti, p in zip(tree_idx, ps):
self.tree.update(ti, p)
class DQNPrioritizedReplay:
def __init__(
self,
n_actions,
n_features,
learning_rate=0.005,
reward_decay=0.9,
e_greedy=0.9,
replace_target_iter=500,
memory_size=10000,
batch_size=32,
e_greedy_increment=None,
output_graph=False,
prioritized=True,
sess=None,
):
self.n_actions = n_actions
self.n_features = n_features
self.lr = learning_rate
self.gamma = reward_decay
self.epsilon_max = e_greedy
self.replace_target_iter = replace_target_iter
self.memory_size = memory_size
self.batch_size = batch_size
self.epsilon_increment = e_greedy_increment
self.epsilon = 0 if e_greedy_increment is not None else self.epsilon_max
self.prioritized = prioritized # decide to use double q or not
self.learn_step_counter = 0
self._build_net()
t_params = tf.get_collection('target_net_params')
e_params = tf.get_collection('eval_net_params')
self.replace_target_op = [tf.assign(t, e) for t, e in zip(t_params, e_params)]
if self.prioritized:
self.memory = Memory(capacity=memory_size)
else:
self.memory = np.zeros((self.memory_size, n_features*2+2))
if sess is None:
self.sess = tf.Session()
self.sess.run(tf.global_variables_initializer())
else:
self.sess = sess
if output_graph:
tf.summary.FileWriter("logs/", self.sess.graph)
self.cost_his = []
def _build_net(self):
def build_layers(s, c_names, n_l1, w_initializer, b_initializer, trainable):
with tf.variable_scope('l1'):
w1 = tf.get_variable('w1', [self.n_features, n_l1], initializer=w_initializer, collections=c_names, trainable=trainable)
b1 = tf.get_variable('b1', [1, n_l1], initializer=b_initializer, collections=c_names, trainable=trainable)
l1 = tf.nn.relu(tf.matmul(s, w1) + b1)
with tf.variable_scope('l2'):
w2 = tf.get_variable('w2', [n_l1, self.n_actions], initializer=w_initializer, collections=c_names, trainable=trainable)
b2 = tf.get_variable('b2', [1, self.n_actions], initializer=b_initializer, collections=c_names, trainable=trainable)
out = tf.matmul(l1, w2) + b2
return out
# ------------------ build evaluate_net ------------------
self.s = tf.placeholder(tf.float32, [None, self.n_features], name='s') # input
self.q_target = tf.placeholder(tf.float32, [None, self.n_actions], name='Q_target') # for calculating loss
if self.prioritized:
self.ISWeights = tf.placeholder(tf.float32, [None, 1], name='IS_weights')
with tf.variable_scope('eval_net'):
c_names, n_l1, w_initializer, b_initializer = \
['eval_net_params', tf.GraphKeys.GLOBAL_VARIABLES], 20, \
tf.random_normal_initializer(0., 0.3), tf.constant_initializer(0.1) # config of layers
self.q_eval = build_layers(self.s, c_names, n_l1, w_initializer, b_initializer, True)
with tf.variable_scope('loss'):
if self.prioritized:
self.abs_errors = tf.reduce_sum(tf.abs(self.q_target - self.q_eval), axis=1) # for updating Sumtree
self.loss = tf.reduce_mean(self.ISWeights * tf.squared_difference(self.q_target, self.q_eval))
else:
self.loss = tf.reduce_mean(tf.squared_difference(self.q_target, self.q_eval))
with tf.variable_scope('train'):
self._train_op = tf.train.RMSPropOptimizer(self.lr).minimize(self.loss)
# ------------------ build target_net ------------------
self.s_ = tf.placeholder(tf.float32, [None, self.n_features], name='s_') # input
with tf.variable_scope('target_net'):
c_names = ['target_net_params', tf.GraphKeys.GLOBAL_VARIABLES]
self.q_next = build_layers(self.s_, c_names, n_l1, w_initializer, b_initializer, False)
def store_transition(self, s, a, r, s_):
if self.prioritized: # prioritized replay
transition = np.hstack((s, [a, r], s_))
self.memory.store(transition) # have high priority for newly arrived transition
else: # random replay
if not hasattr(self, 'memory_counter'):
self.memory_counter = 0
transition = np.hstack((s, [a, r], s_))
index = self.memory_counter % self.memory_size
self.memory[index, :] = transition
self.memory_counter += 1
def choose_action(self, observation):
observation = observation[np.newaxis, :]
if np.random.uniform() < self.epsilon:
actions_value = self.sess.run(self.q_eval, feed_dict={self.s: observation})
action = np.argmax(actions_value)
else:
action = np.random.randint(0, self.n_actions)
return action
def learn(self):
if self.learn_step_counter % self.replace_target_iter == 0:
self.sess.run(self.replace_target_op)
print('\ntarget_params_replaced\n')
if self.prioritized:
tree_idx, batch_memory, ISWeights = self.memory.sample(self.batch_size)
else:
sample_index = np.random.choice(self.memory_size, size=self.batch_size)
batch_memory = self.memory[sample_index, :]
q_next, q_eval = self.sess.run(
[self.q_next, self.q_eval],
feed_dict={self.s_: batch_memory[:, -self.n_features:],
self.s: batch_memory[:, :self.n_features]})
q_target = q_eval.copy()
batch_index = np.arange(self.batch_size, dtype=np.int32)
eval_act_index = batch_memory[:, self.n_features].astype(int)
reward = batch_memory[:, self.n_features + 1]
q_target[batch_index, eval_act_index] = reward + self.gamma * np.max(q_next, axis=1)
if self.prioritized:
_, abs_errors, self.cost = self.sess.run([self._train_op, self.abs_errors, self.loss],
feed_dict={self.s: batch_memory[:, :self.n_features],
self.q_target: q_target,
self.ISWeights: ISWeights})
self.memory.batch_update(tree_idx, abs_errors) # update priority
else:
_, self.cost = self.sess.run([self._train_op, self.loss],
feed_dict={self.s: batch_memory[:, :self.n_features],
self.q_target: q_target})
self.cost_his.append(self.cost)
self.epsilon = self.epsilon + self.epsilon_increment if self.epsilon < self.epsilon_max else self.epsilon_max
self.learn_step_counter += 1
================================================
FILE: contents/5.2_Prioritized_Replay_DQN/run_MountainCar.py
================================================
"""
The DQN improvement: Prioritized Experience Replay (based on https://arxiv.org/abs/1511.05952)
View more on my tutorial page: https://morvanzhou.github.io/tutorials/
Using:
Tensorflow: 1.0
gym: 0.8.0
"""
import gym
from RL_brain import DQNPrioritizedReplay
import matplotlib.pyplot as plt
import tensorflow as tf
import numpy as np
env = gym.make('MountainCar-v0')
env = env.unwrapped
env.seed(21)
MEMORY_SIZE = 10000
sess = tf.Session()
with tf.variable_scope('natural_DQN'):
RL_natural = DQNPrioritizedReplay(
n_actions=3, n_features=2, memory_size=MEMORY_SIZE,
e_greedy_increment=0.00005, sess=sess, prioritized=False,
)
with tf.variable_scope('DQN_with_prioritized_replay'):
RL_prio = DQNPrioritizedReplay(
n_actions=3, n_features=2, memory_size=MEMORY_SIZE,
e_greedy_increment=0.00005, sess=sess, prioritized=True, output_graph=True,
)
sess.run(tf.global_variables_initializer())
def train(RL):
total_steps = 0
steps = []
episodes = []
for i_episode in range(20):
observation = env.reset()
while True:
# env.render()
action = RL.choose_action(observation)
observation_, reward, done, info = env.step(action)
if done: reward = 10
RL.store_transition(observation, action, reward, observation_)
if total_steps > MEMORY_SIZE:
RL.learn()
if done:
print('episode ', i_episode, ' finished')
steps.append(total_steps)
episodes.append(i_episode)
break
observation = observation_
total_steps += 1
return np.vstack((episodes, steps))
his_natural = train(RL_natural)
his_prio = train(RL_prio)
# compare based on first success
plt.plot(his_natural[0, :], his_natural[1, :] - his_natural[1, 0], c='b', label='natural DQN')
plt.plot(his_prio[0, :], his_prio[1, :] - his_prio[1, 0], c='r', label='DQN with prioritized replay')
plt.legend(loc='best')
plt.ylabel('total training time')
plt.xlabel('episode')
plt.grid()
plt.show()
================================================
FILE: contents/5.3_Dueling_DQN/RL_brain.py
================================================
"""
The Dueling DQN based on this paper: https://arxiv.org/abs/1511.06581
View more on my tutorial page: https://morvanzhou.github.io/tutorials/
Using:
Tensorflow: 1.0
gym: 0.8.0
"""
import numpy as np
import tensorflow as tf
np.random.seed(1)
tf.set_random_seed(1)
class DuelingDQN:
def __init__(
self,
n_actions,
n_features,
learning_rate=0.001,
reward_decay=0.9,
e_greedy=0.9,
replace_target_iter=200,
memory_size=500,
batch_size=32,
e_greedy_increment=None,
output_graph=False,
dueling=True,
sess=None,
):
self.n_actions = n_actions
self.n_features = n_features
self.lr = learning_rate
self.gamma = reward_decay
self.epsilon_max = e_greedy
self.replace_target_iter = replace_target_iter
self.memory_size = memory_size
self.batch_size = batch_size
self.epsilon_increment = e_greedy_increment
self.epsilon = 0 if e_greedy_increment is not None else self.epsilon_max
self.dueling = dueling # decide to use dueling DQN or not
self.learn_step_counter = 0
self.memory = np.zeros((self.memory_size, n_features*2+2))
self._build_net()
t_params = tf.get_collection('target_net_params')
e_params = tf.get_collection('eval_net_params')
self.replace_target_op = [tf.assign(t, e) for t, e in zip(t_params, e_params)]
if sess is None:
self.sess = tf.Session()
self.sess.run(tf.global_variables_initializer())
else:
self.sess = sess
if output_graph:
tf.summary.FileWriter("logs/", self.sess.graph)
self.cost_his = []
def _build_net(self):
def build_layers(s, c_names, n_l1, w_initializer, b_initializer):
with tf.variable_scope('l1'):
w1 = tf.get_variable('w1', [self.n_features, n_l1], initializer=w_initializer, collections=c_names)
b1 = tf.get_variable('b1', [1, n_l1], initializer=b_initializer, collections=c_names)
l1 = tf.nn.relu(tf.matmul(s, w1) + b1)
if self.dueling:
# Dueling DQN
with tf.variable_scope('Value'):
w2 = tf.get_variable('w2', [n_l1, 1], initializer=w_initializer, collections=c_names)
b2 = tf.get_variable('b2', [1, 1], initializer=b_initializer, collections=c_names)
self.V = tf.matmul(l1, w2) + b2
with tf.variable_scope('Advantage'):
w2 = tf.get_variable('w2', [n_l1, self.n_actions], initializer=w_initializer, collections=c_names)
b2 = tf.get_variable('b2', [1, self.n_actions], initializer=b_initializer, collections=c_names)
self.A = tf.matmul(l1, w2) + b2
with tf.variable_scope('Q'):
out = self.V + (self.A - tf.reduce_mean(self.A, axis=1, keep_dims=True)) # Q = V(s) + A(s,a)
else:
with tf.variable_scope('Q'):
w2 = tf.get_variable('w2', [n_l1, self.n_actions], initializer=w_initializer, collections=c_names)
b2 = tf.get_variable('b2', [1, self.n_actions], initializer=b_initializer, collections=c_names)
out = tf.matmul(l1, w2) + b2
return out
# ------------------ build evaluate_net ------------------
self.s = tf.placeholder(tf.float32, [None, self.n_features], name='s') # input
self.q_target = tf.placeholder(tf.float32, [None, self.n_actions], name='Q_target') # for calculating loss
with tf.variable_scope('eval_net'):
c_names, n_l1, w_initializer, b_initializer = \
['eval_net_params', tf.GraphKeys.GLOBAL_VARIABLES], 20, \
tf.random_normal_initializer(0., 0.3), tf.constant_initializer(0.1) # config of layers
self.q_eval = build_layers(self.s, c_names, n_l1, w_initializer, b_initializer)
with tf.variable_scope('loss'):
self.loss = tf.reduce_mean(tf.squared_difference(self.q_target, self.q_eval))
with tf.variable_scope('train'):
self._train_op = tf.train.RMSPropOptimizer(self.lr).minimize(self.loss)
# ------------------ build target_net ------------------
self.s_ = tf.placeholder(tf.float32, [None, self.n_features], name='s_') # input
with tf.variable_scope('target_net'):
c_names = ['target_net_params', tf.GraphKeys.GLOBAL_VARIABLES]
self.q_next = build_layers(self.s_, c_names, n_l1, w_initializer, b_initializer)
def store_transition(self, s, a, r, s_):
if not hasattr(self, 'memory_counter'):
self.memory_counter = 0
transition = np.hstack((s, [a, r], s_))
index = self.memory_counter % self.memory_size
self.memory[index, :] = transition
self.memory_counter += 1
def choose_action(self, observation):
observation = observation[np.newaxis, :]
if np.random.uniform() < self.epsilon: # choosing action
actions_value = self.sess.run(self.q_eval, feed_dict={self.s: observation})
action = np.argmax(actions_value)
else:
action = np.random.randint(0, self.n_actions)
return action
def learn(self):
if self.learn_step_counter % self.replace_target_iter == 0:
self.sess.run(self.replace_target_op)
print('\ntarget_params_replaced\n')
sample_index = np.random.choice(self.memory_size, size=self.batch_size)
batch_memory = self.memory[sample_index, :]
q_next = self.sess.run(self.q_next, feed_dict={self.s_: batch_memory[:, -self.n_features:]}) # next observation
q_eval = self.sess.run(self.q_eval, {self.s: batch_memory[:, :self.n_features]})
q_target = q_eval.copy()
batch_index = np.arange(self.batch_size, dtype=np.int32)
eval_act_index = batch_memory[:, self.n_features].astype(int)
reward = batch_memory[:, self.n_features + 1]
q_target[batch_index, eval_act_index] = reward + self.gamma * np.max(q_next, axis=1)
_, self.cost = self.sess.run([self._train_op, self.loss],
feed_dict={self.s: batch_memory[:, :self.n_features],
self.q_target: q_target})
self.cost_his.append(self.cost)
self.epsilon = self.epsilon + self.epsilon_increment if self.epsilon < self.epsilon_max else self.epsilon_max
self.learn_step_counter += 1
================================================
FILE: contents/5.3_Dueling_DQN/run_Pendulum.py
================================================
"""
Dueling DQN & Natural DQN comparison
View more on my tutorial page: https://morvanzhou.github.io/tutorials/
Using:
Tensorflow: 1.0
gym: 0.8.0
"""
import gym
from RL_brain import DuelingDQN
import numpy as np
import matplotlib.pyplot as plt
import tensorflow as tf
env = gym.make('Pendulum-v0')
env = env.unwrapped
env.seed(1)
MEMORY_SIZE = 3000
ACTION_SPACE = 25
sess = tf.Session()
with tf.variable_scope('natural'):
natural_DQN = DuelingDQN(
n_actions=ACTION_SPACE, n_features=3, memory_size=MEMORY_SIZE,
e_greedy_increment=0.001, sess=sess, dueling=False)
with tf.variable_scope('dueling'):
dueling_DQN = DuelingDQN(
n_actions=ACTION_SPACE, n_features=3, memory_size=MEMORY_SIZE,
e_greedy_increment=0.001, sess=sess, dueling=True, output_graph=True)
sess.run(tf.global_variables_initializer())
def train(RL):
acc_r = [0]
total_steps = 0
observation = env.reset()
while True:
# if total_steps-MEMORY_SIZE > 9000: env.render()
action = RL.choose_action(observation)
f_action = (action-(ACTION_SPACE-1)/2)/((ACTION_SPACE-1)/4) # [-2 ~ 2] float actions
observation_, reward, done, info = env.step(np.array([f_action]))
reward /= 10 # normalize to a range of (-1, 0)
acc_r.append(reward + acc_r[-1]) # accumulated reward
RL.store_transition(observation, action, reward, observation_)
if total_steps > MEMORY_SIZE:
RL.learn()
if total_steps-MEMORY_SIZE > 15000:
break
observation = observation_
total_steps += 1
return RL.cost_his, acc_r
c_natural, r_natural = train(natural_DQN)
c_dueling, r_dueling = train(dueling_DQN)
plt.figure(1)
plt.plot(np.array(c_natural), c='r', label='natural')
plt.plot(np.array(c_dueling), c='b', label='dueling')
plt.legend(loc='best')
plt.ylabel('cost')
plt.xlabel('training steps')
plt.grid()
plt.figure(2)
plt.plot(np.array(r_natural), c='r', label='natural')
plt.plot(np.array(r_dueling), c='b', label='dueling')
plt.legend(loc='best')
plt.ylabel('accumulated reward')
plt.xlabel('training steps')
plt.grid()
plt.show()
================================================
FILE: contents/5_Deep_Q_Network/DQN_modified.py
================================================
"""
This part of code is the Deep Q Network (DQN) brain.
view the tensorboard picture about this DQN structure on: https://morvanzhou.github.io/tutorials/machine-learning/reinforcement-learning/4-3-DQN3/#modification
View more on my tutorial page: https://morvanzhou.github.io/tutorials/
Using:
Tensorflow: r1.2
"""
import numpy as np
import tensorflow as tf
np.random.seed(1)
tf.set_random_seed(1)
# Deep Q Network off-policy
class DeepQNetwork:
def __init__(
self,
n_actions,
n_features,
learning_rate=0.01,
reward_decay=0.9,
e_greedy=0.9,
replace_target_iter=300,
memory_size=500,
batch_size=32,
e_greedy_increment=None,
output_graph=False,
):
self.n_actions = n_actions
self.n_features = n_features
self.lr = learning_rate
self.gamma = reward_decay
self.epsilon_max = e_greedy
self.replace_target_iter = replace_target_iter
self.memory_size = memory_size
self.batch_size = batch_size
self.epsilon_increment = e_greedy_increment
self.epsilon = 0 if e_greedy_increment is not None else self.epsilon_max
# total learning step
self.learn_step_counter = 0
# initialize zero memory [s, a, r, s_]
self.memory = np.zeros((self.memory_size, n_features * 2 + 2))
# consist of [target_net, evaluate_net]
self._build_net()
t_params = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope='target_net')
e_params = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope='eval_net')
with tf.variable_scope('hard_replacement'):
self.target_replace_op = [tf.assign(t, e) for t, e in zip(t_params, e_params)]
self.sess = tf.Session()
if output_graph:
# $ tensorboard --logdir=logs
tf.summary.FileWriter("logs/", self.sess.graph)
self.sess.run(tf.global_variables_initializer())
self.cost_his = []
def _build_net(self):
# ------------------ all inputs ------------------------
self.s = tf.placeholder(tf.float32, [None, self.n_features], name='s') # input State
self.s_ = tf.placeholder(tf.float32, [None, self.n_features], name='s_') # input Next State
self.r = tf.placeholder(tf.float32, [None, ], name='r') # input Reward
self.a = tf.placeholder(tf.int32, [None, ], name='a') # input Action
w_initializer, b_initializer = tf.random_normal_initializer(0., 0.3), tf.constant_initializer(0.1)
# ------------------ build evaluate_net ------------------
with tf.variable_scope('eval_net'):
e1 = tf.layers.dense(self.s, 20, tf.nn.relu, kernel_initializer=w_initializer,
bias_initializer=b_initializer, name='e1')
self.q_eval = tf.layers.dense(e1, self.n_actions, kernel_initializer=w_initializer,
bias_initializer=b_initializer, name='q')
# ------------------ build target_net ------------------
with tf.variable_scope('target_net'):
t1 = tf.layers.dense(self.s_, 20, tf.nn.relu, kernel_initializer=w_initializer,
bias_initializer=b_initializer, name='t1')
self.q_next = tf.layers.dense(t1, self.n_actions, kernel_initializer=w_initializer,
bias_initializer=b_initializer, name='t2')
with tf.variable_scope('q_target'):
q_target = self.r + self.gamma * tf.reduce_max(self.q_next, axis=1, name='Qmax_s_') # shape=(None, )
self.q_target = tf.stop_gradient(q_target)
with tf.variable_scope('q_eval'):
a_indices = tf.stack([tf.range(tf.shape(self.a)[0], dtype=tf.int32), self.a], axis=1)
self.q_eval_wrt_a = tf.gather_nd(params=self.q_eval, indices=a_indices) # shape=(None, )
with tf.variable_scope('loss'):
self.loss = tf.reduce_mean(tf.squared_difference(self.q_target, self.q_eval_wrt_a, name='TD_error'))
with tf.variable_scope('train'):
self._train_op = tf.train.RMSPropOptimizer(self.lr).minimize(self.loss)
def store_transition(self, s, a, r, s_):
if not hasattr(self, 'memory_counter'):
self.memory_counter = 0
transition = np.hstack((s, [a, r], s_))
# replace the old memory with new memory
index = self.memory_counter % self.memory_size
self.memory[index, :] = transition
self.memory_counter += 1
def choose_action(self, observation):
# to have batch dimension when feed into tf placeholder
observation = observation[np.newaxis, :]
if np.random.uniform() < self.epsilon:
# forward feed the observation and get q value for every actions
actions_value = self.sess.run(self.q_eval, feed_dict={self.s: observation})
action = np.argmax(actions_value)
else:
action = np.random.randint(0, self.n_actions)
return action
def learn(self):
# check to replace target parameters
if self.learn_step_counter % self.replace_target_iter == 0:
self.sess.run(self.target_replace_op)
print('\ntarget_params_replaced\n')
# sample batch memory from all memory
if self.memory_counter > self.memory_size:
sample_index = np.random.choice(self.memory_size, size=self.batch_size)
else:
sample_index = np.random.choice(self.memory_counter, size=self.batch_size)
batch_memory = self.memory[sample_index, :]
_, cost = self.sess.run(
[self._train_op, self.loss],
feed_dict={
self.s: batch_memory[:, :self.n_features],
self.a: batch_memory[:, self.n_features],
self.r: batch_memory[:, self.n_features + 1],
self.s_: batch_memory[:, -self.n_features:],
})
self.cost_his.append(cost)
# increasing epsilon
self.epsilon = self.epsilon + self.epsilon_increment if self.epsilon < self.epsilon_max else self.epsilon_max
self.learn_step_counter += 1
def plot_cost(self):
import matplotlib.pyplot as plt
plt.plot(np.arange(len(self.cost_his)), self.cost_his)
plt.ylabel('Cost')
plt.xlabel('training steps')
plt.show()
if __name__ == '__main__':
DQN = DeepQNetwork(3,4, output_graph=True)
================================================
FILE: contents/5_Deep_Q_Network/RL_brain.py
================================================
"""
This part of code is the DQN brain, which is a brain of the agent.
All decisions are made in here.
Using Tensorflow to build the neural network.
View more on my tutorial page: https://morvanzhou.github.io/tutorials/
Using:
Tensorflow: 1.0
gym: 0.7.3
"""
import numpy as np
import pandas as pd
import tensorflow as tf
np.random.seed(1)
tf.set_random_seed(1)
# Deep Q Network off-policy
class DeepQNetwork:
def __init__(
self,
n_actions,
n_features,
learning_rate=0.01,
reward_decay=0.9,
e_greedy=0.9,
replace_target_iter=300,
memory_size=500,
batch_size=32,
e_greedy_increment=None,
output_graph=False,
):
self.n_actions = n_actions
self.n_features = n_features
self.lr = learning_rate
self.gamma = reward_decay
self.epsilon_max = e_greedy
self.replace_target_iter = replace_target_iter
self.memory_size = memory_size
self.batch_size = batch_size
self.epsilon_increment = e_greedy_increment
self.epsilon = 0 if e_greedy_increment is not None else self.epsilon_max
# total learning step
self.learn_step_counter = 0
# initialize zero memory [s, a, r, s_]
self.memory = np.zeros((self.memory_size, n_features * 2 + 2))
# consist of [target_net, evaluate_net]
self._build_net()
t_params = tf.get_collection('target_net_params')
e_params = tf.get_collection('eval_net_params')
self.replace_target_op = [tf.assign(t, e) for t, e in zip(t_params, e_params)]
self.sess = tf.Session()
if output_graph:
# $ tensorboard --logdir=logs
# tf.train.SummaryWriter soon be deprecated, use following
tf.summary.FileWriter("logs/", self.sess.graph)
self.sess.run(tf.global_variables_initializer())
self.cost_his = []
def _build_net(self):
# ------------------ build evaluate_net ------------------
self.s = tf.placeholder(tf.float32, [None, self.n_features], name='s') # input
self.q_target = tf.placeholder(tf.float32, [None, self.n_actions], name='Q_target') # for calculating loss
with tf.variable_scope('eval_net'):
# c_names(collections_names) are the collections to store variables
c_names, n_l1, w_initializer, b_initializer = \
['eval_net_params', tf.GraphKeys.GLOBAL_VARIABLES], 10, \
tf.random_normal_initializer(0., 0.3), tf.constant_initializer(0.1) # config of layers
# first layer. collections is used later when assign to target net
with tf.variable_scope('l1'):
w1 = tf.get_variable('w1', [self.n_features, n_l1], initializer=w_initializer, collections=c_names)
b1 = tf.get_variable('b1', [1, n_l1], initializer=b_initializer, collections=c_names)
l1 = tf.nn.relu(tf.matmul(self.s, w1) + b1)
# second layer. collections is used later when assign to target net
with tf.variable_scope('l2'):
w2 = tf.get_variable('w2', [n_l1, self.n_actions], initializer=w_initializer, collections=c_names)
b2 = tf.get_variable('b2', [1, self.n_actions], initializer=b_initializer, collections=c_names)
self.q_eval = tf.matmul(l1, w2) + b2
with tf.variable_scope('loss'):
self.loss = tf.reduce_mean(tf.squared_difference(self.q_target, self.q_eval))
with tf.variable_scope('train'):
self._train_op = tf.train.RMSPropOptimizer(self.lr).minimize(self.loss)
# ------------------ build target_net ------------------
self.s_ = tf.placeholder(tf.float32, [None, self.n_features], name='s_') # input
with tf.variable_scope('target_net'):
# c_names(collections_names) are the collections to store variables
c_names = ['target_net_params', tf.GraphKeys.GLOBAL_VARIABLES]
# first layer. collections is used later when assign to target net
with tf.variable_scope('l1'):
w1 = tf.get_variable('w1', [self.n_features, n_l1], initializer=w_initializer, collections=c_names)
b1 = tf.get_variable('b1', [1, n_l1], initializer=b_initializer, collections=c_names)
l1 = tf.nn.relu(tf.matmul(self.s_, w1) + b1)
# second layer. collections is used later when assign to target net
with tf.variable_scope('l2'):
w2 = tf.get_variable('w2', [n_l1, self.n_actions], initializer=w_initializer, collections=c_names)
b2 = tf.get_variable('b2', [1, self.n_actions], initializer=b_initializer, collections=c_names)
self.q_next = tf.matmul(l1, w2) + b2
def store_transition(self, s, a, r, s_):
if not hasattr(self, 'memory_counter'):
self.memory_counter = 0
transition = np.hstack((s, [a, r], s_))
# replace the old memory with new memory
index = self.memory_counter % self.memory_size
self.memory[index, :] = transition
self.memory_counter += 1
def choose_action(self, observation):
# to have batch dimension when feed into tf placeholder
observation = observation[np.newaxis, :]
if np.random.uniform() < self.epsilon:
# forward feed the observation and get q value for every actions
actions_value = self.sess.run(self.q_eval, feed_dict={self.s: observation})
action = np.argmax(actions_value)
else:
action = np.random.randint(0, self.n_actions)
return action
def learn(self):
# check to replace target parameters
if self.learn_step_counter % self.replace_target_iter == 0:
self.sess.run(self.replace_target_op)
print('\ntarget_params_replaced\n')
# sample batch memory from all memory
if self.memory_counter > self.memory_size:
sample_index = np.random.choice(self.memory_size, size=self.batch_size)
else:
sample_index = np.random.choice(self.memory_counter, size=self.batch_size)
batch_memory = self.memory[sample_index, :]
q_next, q_eval = self.sess.run(
[self.q_next, self.q_eval],
feed_dict={
self.s_: batch_memory[:, -self.n_features:], # fixed params
self.s: batch_memory[:, :self.n_features], # newest params
})
# change q_target w.r.t q_eval's action
q_target = q_eval.copy()
batch_index = np.arange(self.batch_size, dtype=np.int32)
eval_act_index = batch_memory[:, self.n_features].astype(int)
reward = batch_memory[:, self.n_features + 1]
q_target[batch_index, eval_act_index] = reward + self.gamma * np.max(q_next, axis=1)
"""
For example in this batch I have 2 samples and 3 actions:
q_eval =
[[1, 2, 3],
[4, 5, 6]]
q_target = q_eval =
[[1, 2, 3],
[4, 5, 6]]
Then change q_target with the real q_target value w.r.t the q_eval's action.
For example in:
sample 0, I took action 0, and the max q_target value is -1;
sample 1, I took action 2, and the max q_target value is -2:
q_target =
[[-1, 2, 3],
[4, 5, -2]]
So the (q_target - q_eval) becomes:
[[(-1)-(1), 0, 0],
[0, 0, (-2)-(6)]]
We then backpropagate this error w.r.t the corresponding action to network,
leave other action as error=0 cause we didn't choose it.
"""
# train eval network
_, self.cost = self.sess.run([self._train_op, self.loss],
feed_dict={self.s: batch_memory[:, :self.n_features],
self.q_target: q_target})
self.cost_his.append(self.cost)
# increasing epsilon
self.epsilon = self.epsilon + self.epsilon_increment if self.epsilon < self.epsilon_max else self.epsilon_max
self.learn_step_counter += 1
def plot_cost(self):
import matplotlib.pyplot as plt
plt.plot(np.arange(len(self.cost_his)), self.cost_his)
plt.ylabel('Cost')
plt.xlabel('training steps')
plt.show()
================================================
FILE: contents/5_Deep_Q_Network/maze_env.py
================================================
"""
Reinforcement learning maze example.
Red rectangle: explorer.
Black rectangles: hells [reward = -1].
Yellow bin circle: paradise [reward = +1].
All other states: ground [reward = 0].
This script is the environment part of this example.
The RL is in RL_brain.py.
View more on my tutorial page: https://morvanzhou.github.io/tutorials/
"""
import numpy as np
import time
import sys
if sys.version_info.major == 2:
import Tkinter as tk
else:
import tkinter as tk
UNIT = 40 # pixels
MAZE_H = 4 # grid height
MAZE_W = 4 # grid width
class Maze(tk.Tk, object):
def __init__(self):
super(Maze, self).__init__()
self.action_space = ['u', 'd', 'l', 'r']
self.n_actions = len(self.action_space)
self.n_features = 2
self.title('maze')
self.geometry('{0}x{1}'.format(MAZE_W * UNIT, MAZE_H * UNIT))
self._build_maze()
def _build_maze(self):
self.canvas = tk.Canvas(self, bg='white',
height=MAZE_H * UNIT,
width=MAZE_W * UNIT)
# create grids
for c in range(0, MAZE_W * UNIT, UNIT):
x0, y0, x1, y1 = c, 0, c, MAZE_H * UNIT
self.canvas.create_line(x0, y0, x1, y1)
for r in range(0, MAZE_H * UNIT, UNIT):
x0, y0, x1, y1 = 0, r, MAZE_W * UNIT, r
self.canvas.create_line(x0, y0, x1, y1)
# create origin
origin = np.array([20, 20])
# hell
hell1_center = origin + np.array([UNIT * 2, UNIT])
self.hell1 = self.canvas.create_rectangle(
hell1_center[0] - 15, hell1_center[1] - 15,
hell1_center[0] + 15, hell1_center[1] + 15,
fill='black')
# hell
# hell2_center = origin + np.array([UNIT, UNIT * 2])
# self.hell2 = self.canvas.create_rectangle(
# hell2_center[0] - 15, hell2_center[1] - 15,
# hell2_center[0] + 15, hell2_center[1] + 15,
# fill='black')
# create oval
oval_center = origin + UNIT * 2
self.oval = self.canvas.create_oval(
oval_center[0] - 15, oval_center[1] - 15,
oval_center[0] + 15, oval_center[1] + 15,
fill='yellow')
# create red rect
self.rect = self.canvas.create_rectangle(
origin[0] - 15, origin[1] - 15,
origin[0] + 15, origin[1] + 15,
fill='red')
# pack all
self.canvas.pack()
def reset(self):
self.update()
time.sleep(0.1)
self.canvas.delete(self.rect)
origin = np.array([20, 20])
self.rect = self.canvas.create_rectangle(
origin[0] - 15, origin[1] - 15,
origin[0] + 15, origin[1] + 15,
fill='red')
# return observation
return (np.array(self.canvas.coords(self.rect)[:2]) - np.array(self.canvas.coords(self.oval)[:2]))/(MAZE_H*UNIT)
def step(self, action):
s = self.canvas.coords(self.rect)
base_action = np.array([0, 0])
if action == 0: # up
if s[1] > UNIT:
base_action[1] -= UNIT
elif action == 1: # down
if s[1] < (MAZE_H - 1) * UNIT:
base_action[1] += UNIT
elif action == 2: # right
if s[0] < (MAZE_W - 1) * UNIT:
base_action[0] += UNIT
elif action == 3: # left
if s[0] > UNIT:
base_action[0] -= UNIT
self.canvas.move(self.rect, base_action[0], base_action[1]) # move agent
next_coords = self.canvas.coords(self.rect) # next state
# reward function
if next_coords == self.canvas.coords(self.oval):
reward = 1
done = True
elif next_coords in [self.canvas.coords(self.hell1)]:
reward = -1
done = True
else:
reward = 0
done = False
s_ = (np.array(next_coords[:2]) - np.array(self.canvas.coords(self.oval)[:2]))/(MAZE_H*UNIT)
return s_, reward, done
def render(self):
# time.sleep(0.01)
self.update()
================================================
FILE: contents/5_Deep_Q_Network/run_this.py
================================================
from maze_env import Maze
from RL_brain import DeepQNetwork
def run_maze():
step = 0
for episode in range(300):
# initial observation
observation = env.reset()
while True:
# fresh env
env.render()
# RL choose action based on observation
action = RL.choose_action(observation)
# RL take action and get next observation and reward
observation_, reward, done = env.step(action)
RL.store_transition(observation, action, reward, observation_)
if (step > 200) and (step % 5 == 0):
RL.learn()
# swap observation
observation = observation_
# break while loop when end of this episode
if done:
break
step += 1
# end of game
print('game over')
env.destroy()
if __name__ == "__main__":
# maze game
env = Maze()
RL = DeepQNetwork(env.n_actions, env.n_features,
learning_rate=0.01,
reward_decay=0.9,
e_greedy=0.9,
replace_target_iter=200,
memory_size=2000,
# output_graph=True
)
env.after(100, run_maze)
env.mainloop()
RL.plot_cost()
================================================
FILE: contents/6_OpenAI_gym/RL_brain.py
================================================
"""
This part of code is the DQN brain, which is a brain of the agent.
All decisions are made in here.
Using Tensorflow to build the neural network.
View more on my tutorial page: https://morvanzhou.github.io/tutorials/
Using:
Tensorflow: 1.0
gym: 0.8.0
"""
import numpy as np
import pandas as pd
import tensorflow as tf
# Deep Q Network off-policy
class DeepQNetwork:
def __init__(
self,
n_actions,
n_features,
learning_rate=0.01,
reward_decay=0.9,
e_greedy=0.9,
replace_target_iter=300,
memory_size=500,
batch_size=32,
e_greedy_increment=None,
output_graph=False,
):
self.n_actions = n_actions
self.n_features = n_features
self.lr = learning_rate
self.gamma = reward_decay
self.epsilon_max = e_greedy
self.replace_target_iter = replace_target_iter
self.memory_size = memory_size
self.batch_size = batch_size
self.epsilon_increment = e_greedy_increment
self.epsilon = 0 if e_greedy_increment is not None else self.epsilon_max
# total learning step
self.learn_step_counter = 0
# initialize zero memory [s, a, r, s_]
self.memory = np.zeros((self.memory_size, n_features * 2 + 2))
# consist of [target_net, evaluate_net]
self._build_net()
t_params = tf.get_collection('target_net_params')
e_params = tf.get_collection('eval_net_params')
self.replace_target_op = [tf.assign(t, e) for t, e in zip(t_params, e_params)]
self.sess = tf.Session()
if output_graph:
# $ tensorboard --logdir=logs
# tf.train.SummaryWriter soon be deprecated, use following
tf.summary.FileWriter("logs/", self.sess.graph)
self.sess.run(tf.global_variables_initializer())
self.cost_his = []
def _build_net(self):
# ------------------ build evaluate_net ------------------
self.s = tf.placeholder(tf.float32, [None, self.n_features], name='s') # input
self.q_target = tf.placeholder(tf.float32, [None, self.n_actions], name='Q_target') # for calculating loss
with tf.variable_scope('eval_net'):
# c_names(collections_names) are the collections to store variables
c_names, n_l1, w_initializer, b_initializer = \
['eval_net_params', tf.GraphKeys.GLOBAL_VARIABLES], 10, \
tf.random_normal_initializer(0., 0.3), tf.constant_initializer(0.1) # config of layers
# first layer. collections is used later when assign to target net
with tf.variable_scope('l1'):
w1 = tf.get_variable('w1', [self.n_features, n_l1], initializer=w_initializer, collections=c_names)
b1 = tf.get_variable('b1', [1, n_l1], initializer=b_initializer, collections=c_names)
l1 = tf.nn.relu(tf.matmul(self.s, w1) + b1)
# second layer. collections is used later when assign to target net
with tf.variable_scope('l2'):
w2 = tf.get_variable('w2', [n_l1, self.n_actions], initializer=w_initializer, collections=c_names)
b2 = tf.get_variable('b2', [1, self.n_actions], initializer=b_initializer, collections=c_names)
self.q_eval = tf.matmul(l1, w2) + b2
with tf.variable_scope('loss'):
self.loss = tf.reduce_mean(tf.squared_difference(self.q_target, self.q_eval))
with tf.variable_scope('train'):
self._train_op = tf.train.RMSPropOptimizer(self.lr).minimize(self.loss)
# ------------------ build target_net ------------------
self.s_ = tf.placeholder(tf.float32, [None, self.n_features], name='s_') # input
with tf.variable_scope('target_net'):
# c_names(collections_names) are the collections to store variables
c_names = ['target_net_params', tf.GraphKeys.GLOBAL_VARIABLES]
# first layer. collections is used later when assign to target net
with tf.variable_scope('l1'):
w1 = tf.get_variable('w1', [self.n_features, n_l1], initializer=w_initializer, collections=c_names)
b1 = tf.get_variable('b1', [1, n_l1], initializer=b_initializer, collections=c_names)
l1 = tf.nn.relu(tf.matmul(self.s_, w1) + b1)
# second layer. collections is used later when assign to target net
with tf.variable_scope('l2'):
w2 = tf.get_variable('w2', [n_l1, self.n_actions], initializer=w_initializer, collections=c_names)
b2 = tf.get_variable('b2', [1, self.n_actions], initializer=b_initializer, collections=c_names)
self.q_next = tf.matmul(l1, w2) + b2
def store_transition(self, s, a, r, s_):
if not hasattr(self, 'memory_counter'):
self.memory_counter = 0
transition = np.hstack((s, [a, r], s_))
# replace the old memory with new memory
index = self.memory_counter % self.memory_size
self.memory[index, :] = transition
self.memory_counter += 1
def choose_action(self, observation):
# to have batch dimension when feed into tf placeholder
observation = observation[np.newaxis, :]
if np.random.uniform() < self.epsilon:
# forward feed the observation and get q value for every actions
actions_value = self.sess.run(self.q_eval, feed_dict={self.s: observation})
action = np.argmax(actions_value)
else:
action = np.random.randint(0, self.n_actions)
return action
def learn(self):
# check to replace target parameters
if self.learn_step_counter % self.replace_target_iter == 0:
self.sess.run(self.replace_target_op)
print('\ntarget_params_replaced\n')
# sample batch memory from all memory
if self.memory_counter > self.memory_size:
sample_index = np.random.choice(self.memory_size, size=self.batch_size)
else:
sample_index = np.random.choice(self.memory_counter, size=self.batch_size)
batch_memory = self.memory[sample_index, :]
q_next, q_eval = self.sess.run(
[self.q_next, self.q_eval],
feed_dict={
self.s_: batch_memory[:, -self.n_features:], # fixed params
self.s: batch_memory[:, :self.n_features], # newest params
})
# change q_target w.r.t q_eval's action
q_target = q_eval.copy()
batch_index = np.arange(self.batch_size, dtype=np.int32)
eval_act_index = batch_memory[:, self.n_features].astype(int)
reward = batch_memory[:, self.n_features + 1]
q_target[batch_index, eval_act_index] = reward + self.gamma * np.max(q_next, axis=1)
"""
For example in this batch I have 2 samples and 3 actions:
q_eval =
[[1, 2, 3],
[4, 5, 6]]
q_target = q_eval =
[[1, 2, 3],
[4, 5, 6]]
Then change q_target with the real q_target value w.r.t the q_eval's action.
For example in:
sample 0, I took action 0, and the max q_target value is -1;
sample 1, I took action 2, and the max q_target value is -2:
q_target =
[[-1, 2, 3],
[4, 5, -2]]
So the (q_target - q_eval) becomes:
[[(-1)-(1), 0, 0],
[0, 0, (-2)-(6)]]
We then backpropagate this error w.r.t the corresponding action to network,
leave other action as error=0 cause we didn't choose it.
"""
# train eval network
_, self.cost = self.sess.run([self._train_op, self.loss],
feed_dict={self.s: batch_memory[:, :self.n_features],
self.q_target: q_target})
self.cost_his.append(self.cost)
# increasing epsilon
self.epsilon = self.epsilon + self.epsilon_increment if self.epsilon < self.epsilon_max else self.epsilon_max
self.learn_step_counter += 1
def plot_cost(self):
import matplotlib.pyplot as plt
plt.plot(np.arange(len(self.cost_his)), self.cost_his)
plt.ylabel('Cost')
plt.xlabel('training steps')
plt.show()
================================================
FILE: contents/6_OpenAI_gym/run_CartPole.py
================================================
"""
Deep Q network,
Using:
Tensorflow: 1.0
gym: 0.7.3
"""
import gym
from RL_brain import DeepQNetwork
env = gym.make('CartPole-v0')
env = env.unwrapped
print(env.action_space)
print(env.observation_space)
print(env.observation_space.high)
print(env.observation_space.low)
RL = DeepQNetwork(n_actions=env.action_space.n,
n_features=env.observation_space.shape[0],
learning_rate=0.01, e_greedy=0.9,
replace_target_iter=100, memory_size=2000,
e_greedy_increment=0.001,)
total_steps = 0
for i_episode in range(100):
observation = env.reset()
ep_r = 0
while True:
env.render()
action = RL.choose_action(observation)
observation_, reward, done, info = env.step(action)
# the smaller theta and closer to center the better
x, x_dot, theta, theta_dot = observation_
r1 = (env.x_threshold - abs(x))/env.x_threshold - 0.8
r2 = (env.theta_threshold_radians - abs(theta))/env.theta_threshold_radians - 0.5
reward = r1 + r2
RL.store_transition(observation, action, reward, observation_)
ep_r += reward
if total_steps > 1000:
RL.learn()
if done:
print('episode: ', i_episode,
'ep_r: ', round(ep_r, 2),
' epsilon: ', round(RL.epsilon, 2))
break
observation = observation_
total_steps += 1
RL.plot_cost()
================================================
FILE: contents/6_OpenAI_gym/run_MountainCar.py
================================================
"""
Deep Q network,
Using:
Tensorflow: 1.0
gym: 0.8.0
"""
import gym
from RL_brain import DeepQNetwork
env = gym.make('MountainCar-v0')
env = env.unwrapped
print(env.action_space)
print(env.observation_space)
print(env.observation_space.high)
print(env.observation_space.low)
RL = DeepQNetwork(n_actions=3, n_features=2, learning_rate=0.001, e_greedy=0.9,
replace_target_iter=300, memory_size=3000,
e_greedy_increment=0.0002,)
total_steps = 0
for i_episode in range(10):
observation = env.reset()
ep_r = 0
while True:
env.render()
action = RL.choose_action(observation)
observation_, reward, done, info = env.step(action)
position, velocity = observation_
# the higher the better
reward = abs(position - (-0.5)) # r in [0, 1]
RL.store_transition(observation, action, reward, observation_)
if total_steps > 1000:
RL.learn()
ep_r += reward
if done:
get = '| Get' if observation_[0] >= env.unwrapped.goal_position else '| ----'
print('Epi: ', i_episode,
get,
'| Ep_r: ', round(ep_r, 4),
'| Epsilon: ', round(RL.epsilon, 2))
break
observation = observation_
total_steps += 1
RL.plot_cost()
================================================
FILE: contents/7_Policy_gradient_softmax/RL_brain.py
================================================
"""
This part of code is the reinforcement learning brain, which is a brain of the agent.
All decisions are made in here.
Policy Gradient, Reinforcement Learning.
View more on my tutorial page: https://morvanzhou.github.io/tutorials/
Using:
Tensorflow: 1.0
gym: 0.8.0
"""
import numpy as np
import tensorflow as tf
# reproducible
np.random.seed(1)
tf.set_random_seed(1)
class PolicyGradient:
def __init__(
self,
n_actions,
n_features,
learning_rate=0.01,
reward_decay=0.95,
output_graph=False,
):
self.n_actions = n_actions
self.n_features = n_features
self.lr = learning_rate
self.gamma = reward_decay
self.ep_obs, self.ep_as, self.ep_rs = [], [], []
self._build_net()
self.sess = tf.Session()
if output_graph:
# $ tensorboard --logdir=logs
# http://0.0.0.0:6006/
# tf.train.SummaryWriter soon be deprecated, use following
tf.summary.FileWriter("logs/", self.sess.graph)
self.sess.run(tf.global_variables_initializer())
def _build_net(self):
with tf.name_scope('inputs'):
self.tf_obs = tf.placeholder(tf.float32, [None, self.n_features], name="observations")
self.tf_acts = tf.placeholder(tf.int32, [None, ], name="actions_num")
self.tf_vt = tf.placeholder(tf.float32, [None, ], name="actions_value")
# fc1
layer = tf.layers.dense(
inputs=self.tf_obs,
units=10,
activation=tf.nn.tanh, # tanh activation
kernel_initializer=tf.random_normal_initializer(mean=0, stddev=0.3),
bias_initializer=tf.constant_initializer(0.1),
name='fc1'
)
# fc2
all_act = tf.layers.dense(
inputs=layer,
units=self.n_actions,
activation=None,
kernel_initializer=tf.random_normal_initializer(mean=0, stddev=0.3),
bias_initializer=tf.constant_initializer(0.1),
name='fc2'
)
self.all_act_prob = tf.nn.softmax(all_act, name='act_prob') # use softmax to convert to probability
with tf.name_scope('loss'):
# to maximize total reward (log_p * R) is to minimize -(log_p * R), and the tf only have minimize(loss)
neg_log_prob = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=all_act, labels=self.tf_acts) # this is negative log of chosen action
# or in this way:
# neg_log_prob = tf.reduce_sum(-tf.log(self.all_act_prob)*tf.one_hot(self.tf_acts, self.n_actions), axis=1)
loss = tf.reduce_mean(neg_log_prob * self.tf_vt) # reward guided loss
with tf.name_scope('train'):
self.train_op = tf.train.AdamOptimizer(self.lr).minimize(loss)
def choose_action(self, observation):
prob_weights = self.sess.run(self.all_act_prob, feed_dict={self.tf_obs: observation[np.newaxis, :]})
action = np.random.choice(range(prob_weights.shape[1]), p=prob_weights.ravel()) # select action w.r.t the actions prob
return action
def store_transition(self, s, a, r):
self.ep_obs.append(s)
self.ep_as.append(a)
self.ep_rs.append(r)
def learn(self):
# discount and normalize episode reward
discounted_ep_rs_norm = self._discount_and_norm_rewards()
# train on episode
self.sess.run(self.train_op, feed_dict={
self.tf_obs: np.vstack(self.ep_obs), # shape=[None, n_obs]
self.tf_acts: np.array(self.ep_as), # shape=[None, ]
self.tf_vt: discounted_ep_rs_norm, # shape=[None, ]
})
self.ep_obs, self.ep_as, self.ep_rs = [], [], [] # empty episode data
return discounted_ep_rs_norm
def _discount_and_norm_rewards(self):
# discount episode rewards
discounted_ep_rs = np.zeros_like(self.ep_rs)
running_add = 0
for t in reversed(range(0, len(self.ep_rs))):
running_add = running_add * self.gamma + self.ep_rs[t]
discounted_ep_rs[t] = running_add
# normalize episode rewards
discounted_ep_rs -= np.mean(discounted_ep_rs)
discounted_ep_rs /= np.std(discounted_ep_rs)
return discounted_ep_rs
================================================
FILE: contents/7_Policy_gradient_softmax/run_CartPole.py
================================================
"""
Policy Gradient, Reinforcement Learning.
The cart pole example
View more on my tutorial page: https://morvanzhou.github.io/tutorials/
Using:
Tensorflow: 1.0
gym: 0.8.0
"""
import gym
from RL_brain import PolicyGradient
import matplotlib.pyplot as plt
DISPLAY_REWARD_THRESHOLD = 400 # renders environment if total episode reward is greater then this threshold
RENDER = False # rendering wastes time
env = gym.make('CartPole-v0')
env.seed(1) # reproducible, general Policy gradient has high variance
env = env.unwrapped
print(env.action_space)
print(env.observation_space)
print(env.observation_space.high)
print(env.observation_space.low)
RL = PolicyGradient(
n_actions=env.action_space.n,
n_features=env.observation_space.shape[0],
learning_rate=0.02,
reward_decay=0.99,
# output_graph=True,
)
for i_episode in range(3000):
observation = env.reset()
while True:
if RENDER: env.render()
action = RL.choose_action(observation)
observation_, reward, done, info = env.step(action)
RL.store_transition(observation, action, reward)
if done:
ep_rs_sum = sum(RL.ep_rs)
if 'running_reward' not in globals():
running_reward = ep_rs_sum
else:
running_reward = running_reward * 0.99 + ep_rs_sum * 0.01
if running_reward > DISPLAY_REWARD_THRESHOLD: RENDER = True # rendering
print("episode:", i_episode, " reward:", int(running_reward))
vt = RL.learn()
if i_episode == 0:
plt.plot(vt) # plot the episode vt
plt.xlabel('episode steps')
plt.ylabel('normalized state-action value')
plt.show()
break
observation = observation_
================================================
FILE: contents/7_Policy_gradient_softmax/run_MountainCar.py
================================================
"""
Policy Gradient, Reinforcement Learning.
The cart pole example
View more on my tutorial page: https://morvanzhou.github.io/tutorials/
Using:
Tensorflow: 1.0
gym: 0.8.0
"""
import gym
from RL_brain import PolicyGradient
import matplotlib.pyplot as plt
DISPLAY_REWARD_THRESHOLD = -2000 # renders environment if total episode reward is greater then this threshold
# episode: 154 reward: -10667
# episode: 387 reward: -2009
# episode: 489 reward: -1006
# episode: 628 reward: -502
RENDER = False # rendering wastes time
env = gym.make('MountainCar-v0')
env.seed(1) # reproducible, general Policy gradient has high variance
env = env.unwrapped
print(env.action_space)
print(env.observation_space)
print(env.observation_space.high)
print(env.observation_space.low)
RL = PolicyGradient(
n_actions=env.action_space.n,
n_features=env.observation_space.shape[0],
learning_rate=0.02,
reward_decay=0.995,
# output_graph=True,
)
for i_episode in range(1000):
observation = env.reset()
while True:
if RENDER: env.render()
action = RL.choose_action(observation)
observation_, reward, done, info = env.step(action) # reward = -1 in all cases
RL.store_transition(observation, action, reward)
if done:
# calculate running reward
ep_rs_sum = sum(RL.ep_rs)
if 'running_reward' not in globals():
running_reward = ep_rs_sum
else:
running_reward = running_reward * 0.99 + ep_rs_sum * 0.01
if running_reward > DISPLAY_REWARD_THRESHOLD: RENDER = True # rendering
print("episode:", i_episode, " reward:", int(running_reward))
vt = RL.learn() # train
if i_episode == 30:
plt.plot(vt) # plot the episode vt
plt.xlabel('episode steps')
plt.ylabel('normalized state-action value')
plt.show()
break
observation = observation_
================================================
FILE: contents/8_Actor_Critic_Advantage/AC_CartPole.py
================================================
"""
Actor-Critic using TD-error as the Advantage, Reinforcement Learning.
The cart pole example. Policy is oscillated.
View more on my tutorial page: https://morvanzhou.github.io/tutorials/
Using:
tensorflow 1.0
gym 0.8.0
"""
import numpy as np
import tensorflow as tf
import gym
np.random.seed(2)
tf.set_random_seed(2) # reproducible
# Superparameters
OUTPUT_GRAPH = False
MAX_EPISODE = 3000
DISPLAY_REWARD_THRESHOLD = 200 # renders environment if total episode reward is greater then this threshold
MAX_EP_STEPS = 1000 # maximum time step in one episode
RENDER = False # rendering wastes time
GAMMA = 0.9 # reward discount in TD error
LR_A = 0.001 # learning rate for actor
LR_C = 0.01 # learning rate for critic
env = gym.make('CartPole-v0')
env.seed(1) # reproducible
env = env.unwrapped
N_F = env.observation_space.shape[0]
N_A = env.action_space.n
class Actor(object):
def __init__(self, sess, n_features, n_actions, lr=0.001):
self.sess = sess
self.s = tf.placeholder(tf.float32, [1, n_features], "state")
self.a = tf.placeholder(tf.int32, None, "act")
self.td_error = tf.placeholder(tf.float32, None, "td_error") # TD_error
with tf.variable_scope('Actor'):
l1 = tf.layers.dense(
inputs=self.s,
units=20, # number of hidden units
activation=tf.nn.relu,
kernel_initializer=tf.random_normal_initializer(0., .1), # weights
bias_initializer=tf.constant_initializer(0.1), # biases
name='l1'
)
self.acts_prob = tf.layers.dense(
inputs=l1,
units=n_actions, # output units
activation=tf.nn.softmax, # get action probabilities
kernel_initializer=tf.random_normal_initializer(0., .1), # weights
bias_initializer=tf.constant_initializer(0.1), # biases
name='acts_prob'
)
with tf.variable_scope('exp_v'):
log_prob = tf.log(self.acts_prob[0, self.a])
self.exp_v = tf.reduce_mean(log_prob * self.td_error) # advantage (TD_error) guided loss
with tf.variable_scope('train'):
self.train_op = tf.train.AdamOptimizer(lr).minimize(-self.exp_v) # minimize(-exp_v) = maximize(exp_v)
def learn(self, s, a, td):
s = s[np.newaxis, :]
feed_dict = {self.s: s, self.a: a, self.td_error: td}
_, exp_v = self.sess.run([self.train_op, self.exp_v], feed_dict)
return exp_v
def choose_action(self, s):
s = s[np.newaxis, :]
probs = self.sess.run(self.acts_prob, {self.s: s}) # get probabilities for all actions
return np.random.choice(np.arange(probs.shape[1]), p=probs.ravel()) # return a int
class Critic(object):
def __init__(self, sess, n_features, lr=0.01):
self.sess = sess
self.s = tf.placeholder(tf.float32, [1, n_features], "state")
self.v_ = tf.placeholder(tf.float32, [1, 1], "v_next")
self.r = tf.placeholder(tf.float32, None, 'r')
with tf.variable_scope('Critic'):
l1 = tf.layers.dense(
inputs=self.s,
units=20, # number of hidden units
activation=tf.nn.relu, # None
# have to be linear to make sure the convergence of actor.
# But linear approximator seems hardly learns the correct Q.
kernel_initializer=tf.random_normal_initializer(0., .1), # weights
bias_initializer=tf.constant_initializer(0.1), # biases
name='l1'
)
self.v = tf.layers.dense(
inputs=l1,
units=1, # output units
activation=None,
kernel_initializer=tf.random_normal_initializer(0., .1), # weights
bias_initializer=tf.constant_initializer(0.1), # biases
name='V'
)
with tf.variable_scope('squared_TD_error'):
self.td_error = self.r + GAMMA * self.v_ - self.v
self.loss = tf.square(self.td_error) # TD_error = (r+gamma*V_next) - V_eval
with tf.variable_scope('train'):
self.train_op = tf.train.AdamOptimizer(lr).minimize(self.loss)
def learn(self, s, r, s_):
s, s_ = s[np.newaxis, :], s_[np.newaxis, :]
v_ = self.sess.run(self.v, {self.s: s_})
td_error, _ = self.sess.run([self.td_error, self.train_op],
{self.s: s, self.v_: v_, self.r: r})
return td_error
sess = tf.Session()
actor = Actor(sess, n_features=N_F, n_actions=N_A, lr=LR_A)
critic = Critic(sess, n_features=N_F, lr=LR_C) # we need a good teacher, so the teacher should learn faster than the actor
sess.run(tf.global_variables_initializer())
if OUTPUT_GRAPH:
tf.summary.FileWriter("logs/", sess.graph)
for i_episode in range(MAX_EPISODE):
s = env.reset()
t = 0
track_r = []
while True:
if RENDER: env.render()
a = actor.choose_action(s)
s_, r, done, info = env.step(a)
if done: r = -20
track_r.append(r)
td_error = critic.learn(s, r, s_) # gradient = grad[r + gamma * V(s_) - V(s)]
actor.learn(s, a, td_error) # true_gradient = grad[logPi(s,a) * td_error]
s = s_
t += 1
if done or t >= MAX_EP_STEPS:
ep_rs_sum = sum(track_r)
if 'running_reward' not in globals():
running_reward = ep_rs_sum
else:
running_reward = running_reward * 0.95 + ep_rs_sum * 0.05
if running_reward > DISPLAY_REWARD_THRESHOLD: RENDER = True # rendering
print("episode:", i_episode, " reward:", int(running_reward))
break
================================================
FILE: contents/8_Actor_Critic_Advantage/AC_continue_Pendulum.py
================================================
"""
Actor-Critic with continuous action using TD-error as the Advantage, Reinforcement Learning.
The Pendulum example (based on https://github.com/dennybritz/reinforcement-learning/blob/master/PolicyGradient/Continuous%20MountainCar%20Actor%20Critic%20Solution.ipynb)
Cannot converge!!! oscillate!!!
View more on my tutorial page: https://morvanzhou.github.io/tutorials/
Using:
tensorflow r1.3
gym 0.8.0
"""
import tensorflow as tf
import numpy as np
import gym
np.random.seed(2)
tf.set_random_seed(2) # reproducible
class Actor(object):
def __init__(self, sess, n_features, action_bound, lr=0.0001):
self.sess = sess
self.s = tf.placeholder(tf.float32, [1, n_features], "state")
self.a = tf.placeholder(tf.float32, None, name="act")
self.td_error = tf.placeholder(tf.float32, None, name="td_error") # TD_error
l1 = tf.layers.dense(
inputs=self.s,
units=30, # number of hidden units
activation=tf.nn.relu,
kernel_initializer=tf.random_normal_initializer(0., .1), # weights
bias_initializer=tf.constant_initializer(0.1), # biases
name='l1'
)
mu = tf.layers.dense(
inputs=l1,
units=1, # number of hidden units
activation=tf.nn.tanh,
kernel_initializer=tf.random_normal_initializer(0., .1), # weights
bias_initializer=tf.constant_initializer(0.1), # biases
name='mu'
)
sigma = tf.layers.dense(
inputs=l1,
units=1, # output units
activation=tf.nn.softplus, # get action probabilities
kernel_initializer=tf.random_normal_initializer(0., .1), # weights
bias_initializer=tf.constant_initializer(1.), # biases
name='sigma'
)
global_step = tf.Variable(0, trainable=False)
# self.e = epsilon = tf.train.exponential_decay(2., global_step, 1000, 0.9)
self.mu, self.sigma = tf.squeeze(mu*2), tf.squeeze(sigma+0.1)
self.normal_dist = tf.distributions.Normal(self.mu, self.sigma)
self.action = tf.clip_by_value(self.normal_dist.sample(1), action_bound[0], action_bound[1])
with tf.name_scope('exp_v'):
log_prob = self.normal_dist.log_prob(self.a) # loss without advantage
self.exp_v = log_prob * self.td_error # advantage (TD_error) guided loss
# Add cross entropy cost to encourage exploration
self.exp_v += 0.01*self.normal_dist.entropy()
with tf.name_scope('train'):
self.train_op = tf.train.AdamOptimizer(lr).minimize(-self.exp_v, global_step) # min(v) = max(-v)
def learn(self, s, a, td):
s = s[np.newaxis, :]
feed_dict = {self.s: s, self.a: a, self.td_error: td}
_, exp_v = self.sess.run([self.train_op, self.exp_v], feed_dict)
return exp_v
def choose_action(self, s):
s = s[np.newaxis, :]
return self.sess.run(self.action, {self.s: s}) # get probabilities for all actions
class Critic(object):
def __init__(self, sess, n_features, lr=0.01):
self.sess = sess
with tf.name_scope('inputs'):
self.s = tf.placeholder(tf.float32, [1, n_features], "state")
self.v_ = tf.placeholder(tf.float32, [1, 1], name="v_next")
self.r = tf.placeholder(tf.float32, name='r')
with tf.variable_scope('Critic'):
l1 = tf.layers.dense(
inputs=self.s,
units=30, # number of hidden units
activation=tf.nn.relu,
kernel_initializer=tf.random_normal_initializer(0., .1), # weights
bias_initializer=tf.constant_initializer(0.1), # biases
name='l1'
)
self.v = tf.layers.dense(
inputs=l1,
units=1, # output units
activation=None,
kernel_initializer=tf.random_normal_initializer(0., .1), # weights
bias_initializer=tf.constant_initializer(0.1), # biases
name='V'
)
with tf.variable_scope('squared_TD_error'):
self.td_error = tf.reduce_mean(self.r + GAMMA * self.v_ - self.v)
self.loss = tf.square(self.td_error) # TD_error = (r+gamma*V_next) - V_eval
with tf.variable_scope('train'):
self.train_op = tf.train.AdamOptimizer(lr).minimize(self.loss)
def learn(self, s, r, s_):
s, s_ = s[np.newaxis, :], s_[np.newaxis, :]
v_ = self.sess.run(self.v, {self.s: s_})
td_error, _ = self.sess.run([self.td_error, self.train_op],
{self.s: s, self.v_: v_, self.r: r})
return td_error
OUTPUT_GRAPH = False
MAX_EPISODE = 1000
MAX_EP_STEPS = 200
DISPLAY_REWARD_THRESHOLD = -100 # renders environment if total episode reward is greater then this threshold
RENDER = False # rendering wastes time
GAMMA = 0.9
LR_A = 0.001 # learning rate for actor
LR_C = 0.01 # learning rate for critic
env = gym.make('Pendulum-v0')
env.seed(1) # reproducible
env = env.unwrapped
N_S = env.observation_space.shape[0]
A_BOUND = env.action_space.high
sess = tf.Session()
actor = Actor(sess, n_features=N_S, lr=LR_A, action_bound=[-A_BOUND, A_BOUND])
critic = Critic(sess, n_features=N_S, lr=LR_C)
sess.run(tf.global_variables_initializer())
if OUTPUT_GRAPH:
tf.summary.FileWriter("logs/", sess.graph)
for i_episode in range(MAX_EPISODE):
s = env.reset()
t = 0
ep_rs = []
while True:
# if RENDER:
env.render()
a = actor.choose_action(s)
s_, r, done, info = env.step(a)
r /= 10
td_error = critic.learn(s, r, s_) # gradient = grad[r + gamma * V(s_) - V(s)]
actor.learn(s, a, td_error) # true_gradient = grad[logPi(s,a) * td_error]
s = s_
t += 1
ep_rs.append(r)
if t > MAX_EP_STEPS:
ep_rs_sum = sum(ep_rs)
if 'running_reward' not in globals():
running_reward = ep_rs_sum
else:
running_reward = running_reward * 0.9 + ep_rs_sum * 0.1
if running_reward > DISPLAY_REWARD_THRESHOLD: RENDER = True # rendering
print("episode:", i_episode, " reward:", int(running_reward))
break
================================================
FILE: contents/9_Deep_Deterministic_Policy_Gradient_DDPG/DDPG.py
================================================
"""
Deep Deterministic Policy Gradient (DDPG), Reinforcement Learning.
DDPG is Actor Critic based algorithm.
Pendulum example.
View more on my tutorial page: https://morvanzhou.github.io/tutorials/
Using:
tensorflow 1.0
gym 0.8.0
"""
import tensorflow as tf
import numpy as np
import gym
import time
np.random.seed(1)
tf.set_random_seed(1)
##################### hyper parameters ####################
MAX_EPISODES = 200
MAX_EP_STEPS = 200
LR_A = 0.001 # learning rate for actor
LR_C = 0.001 # learning rate for critic
GAMMA = 0.9 # reward discount
REPLACEMENT = [
dict(name='soft', tau=0.01),
dict(name='hard', rep_iter_a=600, rep_iter_c=500)
][0] # you can try different target replacement strategies
MEMORY_CAPACITY = 10000
BATCH_SIZE = 32
RENDER = False
OUTPUT_GRAPH = True
ENV_NAME = 'Pendulum-v0'
############################### Actor ####################################
class Actor(object):
def __init__(self, sess, action_dim, action_bound, learning_rate, replacement):
self.sess = sess
self.a_dim = action_dim
self.action_bound = action_bound
self.lr = learning_rate
self.replacement = replacement
self.t_replace_counter = 0
with tf.variable_scope('Actor'):
# input s, output a
self.a = self._build_net(S, scope='eval_net', trainable=True)
# input s_, output a, get a_ for critic
self.a_ = self._build_net(S_, scope='target_net', trainable=False)
self.e_params = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope='Actor/eval_net')
self.t_params = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope='Actor/target_net')
if self.replacement['name'] == 'hard':
self.t_replace_counter = 0
self.hard_replace = [tf.assign(t, e) for t, e in zip(self.t_params, self.e_params)]
else:
self.soft_replace = [tf.assign(t, (1 - self.replacement['tau']) * t + self.replacement['tau'] * e)
for t, e in zip(self.t_params, self.e_params)]
def _build_net(self, s, scope, trainable):
with tf.variable_scope(scope):
init_w = tf.random_normal_initializer(0., 0.3)
init_b = tf.constant_initializer(0.1)
net = tf.layers.dense(s, 30, activation=tf.nn.relu,
kernel_initializer=init_w, bias_initializer=init_b, name='l1',
trainable=trainable)
with tf.variable_scope('a'):
actions = tf.layers.dense(net, self.a_dim, activation=tf.nn.tanh, kernel_initializer=init_w,
bias_initializer=init_b, name='a', trainable=trainable)
scaled_a = tf.multiply(actions, self.action_bound, name='scaled_a') # Scale output to -action_bound to action_bound
return scaled_a
def learn(self, s): # batch update
self.sess.run(self.train_op, feed_dict={S: s})
if self.replacement['name'] == 'soft':
self.sess.run(self.soft_replace)
else:
if self.t_replace_counter % self.replacement['rep_iter_a'] == 0:
self.sess.run(self.hard_replace)
self.t_replace_counter += 1
def choose_action(self, s):
s = s[np.newaxis, :] # single state
return self.sess.run(self.a, feed_dict={S: s})[0] # single action
def add_grad_to_graph(self, a_grads):
with tf.variable_scope('policy_grads'):
# ys = policy;
# xs = policy's parameters;
# a_grads = the gradients of the policy to get more Q
# tf.gradients will calculate dys/dxs with a initial gradients for ys, so this is dq/da * da/dparams
self.policy_grads = tf.gradients(ys=self.a, xs=self.e_params, grad_ys=a_grads)
with tf.variable_scope('A_train'):
opt = tf.train.AdamOptimizer(-self.lr) # (- learning rate) for ascent policy
self.train_op = opt.apply_gradients(zip(self.policy_grads, self.e_params))
############################### Critic ####################################
class Critic(object):
def __init__(self, sess, state_dim, action_dim, learning_rate, gamma, replacement, a, a_):
self.sess = sess
self.s_dim = state_dim
self.a_dim = action_dim
self.lr = learning_rate
self.gamma = gamma
self.replacement = replacement
with tf.variable_scope('Critic'):
# Input (s, a), output q
self.a = tf.stop_gradient(a) # stop critic update flows to actor
self.q = self._build_net(S, self.a, 'eval_net', trainable=True)
# Input (s_, a_), output q_ for q_target
self.q_ = self._build_net(S_, a_, 'target_net', trainable=False) # target_q is based on a_ from Actor's target_net
self.e_params = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope='Critic/eval_net')
self.t_params = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope='Critic/target_net')
with tf.variable_scope('target_q'):
self.target_q = R + self.gamma * self.q_
with tf.variable_scope('TD_error'):
self.loss = tf.reduce_mean(tf.squared_difference(self.target_q, self.q))
with tf.variable_scope('C_train'):
self.train_op = tf.train.AdamOptimizer(self.lr).minimize(self.loss)
with tf.variable_scope('a_grad'):
self.a_grads = tf.gradients(self.q, self.a)[0] # tensor of gradients of each sample (None, a_dim)
if self.replacement['name'] == 'hard':
self.t_replace_counter = 0
self.hard_replacement = [tf.assign(t, e) for t, e in zip(self.t_params, self.e_params)]
else:
self.soft_replacement = [tf.assign(t, (1 - self.replacement['tau']) * t + self.replacement['tau'] * e)
for t, e in zip(self.t_params, self.e_params)]
def _build_net(self, s, a, scope, trainable):
with tf.variable_scope(scope):
init_w = tf.random_normal_initializer(0., 0.1)
init_b = tf.constant_initializer(0.1)
with tf.variable_scope('l1'):
n_l1 = 30
w1_s = tf.get_variable('w1_s', [self.s_dim, n_l1], initializer=init_w, trainable=trainable)
w1_a = tf.get_variable('w1_a', [self.a_dim, n_l1], initializer=init_w, trainable=trainable)
b1 = tf.get_variable('b1', [1, n_l1], initializer=init_b, trainable=trainable)
net = tf.nn.relu(tf.matmul(s, w1_s) + tf.matmul(a, w1_a) + b1)
with tf.variable_scope('q'):
q = tf.layers.dense(net, 1, kernel_initializer=init_w, bias_initializer=init_b, trainable=trainable) # Q(s,a)
return q
def learn(self, s, a, r, s_):
self.sess.run(self.train_op, feed_dict={S: s, self.a: a, R: r, S_: s_})
if self.replacement['name'] == 'soft':
self.sess.run(self.soft_replacement)
else:
if self.t_replace_counter % self.replacement['rep_iter_c'] == 0:
self.sess.run(self.hard_replacement)
self.t_replace_counter += 1
##################### Memory ####################
class Memory(object):
def __init__(self, capacity, dims):
self.capacity = capacity
self.data = np.zeros((capacity, dims))
self.pointer = 0
def store_transition(self, s, a, r, s_):
transition = np.hstack((s, a, [r], s_))
index = self.pointer % self.capacity # replace the old memory with new memory
self.data[index, :] = transition
self.pointer += 1
def sample(self, n):
assert self.pointer >= self.capacity, 'Memory has not been fulfilled'
indices = np.random.choice(self.capacity, size=n)
return self.data[indices, :]
env = gym.make(ENV_NAME)
env = env.unwrapped
env.seed(1)
state_dim = env.observation_space.shape[0]
action_dim = env.action_space.shape[0]
action_bound = env.action_space.high
# all placeholder for tf
with tf.name_scope('S'):
S = tf.placeholder(tf.float32, shape=[None, state_dim], name='s')
with tf.name_scope('R'):
R = tf.placeholder(tf.float32, [None, 1], name='r')
with tf.name_scope('S_'):
S_ = tf.placeholder(tf.float32, shape=[None, state_dim], name='s_')
sess = tf.Session()
# Create actor and critic.
# They are actually connected to each other, details can be seen in tensorboard or in this picture:
actor = Actor(sess, action_dim, action_bound, LR_A, REPLACEMENT)
critic = Critic(sess, state_dim, action_dim, LR_C, GAMMA, REPLACEMENT, actor.a, actor.a_)
actor.add_grad_to_graph(critic.a_grads)
sess.run(tf.global_variables_initializer())
M = Memory(MEMORY_CAPACITY, dims=2 * state_dim + action_dim + 1)
if OUTPUT_GRAPH:
tf.summary.FileWriter("logs/", sess.graph)
var = 3 # control exploration
t1 = time.time()
for i in range(MAX_EPISODES):
s = env.reset()
ep_reward = 0
for j in range(MAX_EP_STEPS):
if RENDER:
env.render()
# Add exploration noise
a = actor.choose_action(s)
a = np.clip(np.random.normal(a, var), -2, 2) # add randomness to action selection for exploration
s_, r, done, info = env.step(a)
M.store_transition(s, a, r / 10, s_)
if M.pointer > MEMORY_CAPACITY:
var *= .9995 # decay the action randomness
b_M = M.sample(BATCH_SIZE)
b_s = b_M[:, :state_dim]
b_a = b_M[:, state_dim: state_dim + action_dim]
b_r = b_M[:, -state_dim - 1: -state_dim]
b_s_ = b_M[:, -state_dim:]
critic.learn(b_s, b_a, b_r, b_s_)
actor.learn(b_s)
s = s_
ep_reward += r
if j == MAX_EP_STEPS-1:
print('Episode:', i, ' Reward: %i' % int(ep_reward), 'Explore: %.2f' % var, )
if ep_reward > -300:
RENDER = True
break
print('Running time: ', time.time()-t1)
================================================
FILE: contents/9_Deep_Deterministic_Policy_Gradient_DDPG/DDPG_update.py
================================================
"""
Deep Deterministic Policy Gradient (DDPG), Reinforcement Learning.
DDPG is Actor Critic based algorithm.
Pendulum example.
View more on my tutorial page: https://morvanzhou.github.io/tutorials/
Using:
tensorflow 1.0
gym 0.8.0
"""
import tensorflow as tf
import numpy as np
import gym
import time
##################### hyper parameters ####################
MAX_EPISODES = 200
MAX_EP_STEPS = 200
LR_A = 0.001 # learning rate for actor
LR_C = 0.002 # learning rate for critic
GAMMA = 0.9 # reward discount
TAU = 0.01 # soft replacement
MEMORY_CAPACITY = 10000
BATCH_SIZE = 32
RENDER = False
ENV_NAME = 'Pendulum-v0'
############################### DDPG ####################################
class DDPG(object):
def __init__(self, a_dim, s_dim, a_bound,):
self.memory = np.zeros((MEMORY_CAPACITY, s_dim * 2 + a_dim + 1), dtype=np.float32)
self.pointer = 0
self.sess = tf.Session()
self.a_dim, self.s_dim, self.a_bound = a_dim, s_dim, a_bound,
self.S = tf.placeholder(tf.float32, [None, s_dim], 's')
self.S_ = tf.placeholder(tf.float32, [None, s_dim], 's_')
self.R = tf.placeholder(tf.float32, [None, 1], 'r')
with tf.variable_scope('Actor'):
self.a = self._build_a(self.S, scope='eval', trainable=True)
a_ = self._build_a(self.S_, scope='target', trainable=False)
with tf.variable_scope('Critic'):
# assign self.a = a in memory when calculating q for td_error,
# otherwise the self.a is from Actor when updating Actor
q = self._build_c(self.S, self.a, scope='eval', trainable=True)
q_ = self._build_c(self.S_, a_, scope='target', trainable=False)
# networks parameters
self.ae_params = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope='Actor/eval')
self.at_params = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope='Actor/target')
self.ce_params = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope='Critic/eval')
self.ct_params = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope='Critic/target')
# target net replacement
self.soft_replace = [tf.assign(t, (1 - TAU) * t + TAU * e)
for t, e in zip(self.at_params + self.ct_params, self.ae_params + self.ce_params)]
q_target = self.R + GAMMA * q_
# in the feed_dic for the td_error, the self.a should change to actions in memory
td_error = tf.losses.mean_squared_error(labels=q_target, predictions=q)
self.ctrain = tf.train.AdamOptimizer(LR_C).minimize(td_error, var_list=self.ce_params)
a_loss = - tf.reduce_mean(q) # maximize the q
self.atrain = tf.train.AdamOptimizer(LR_A).minimize(a_loss, var_list=self.ae_params)
self.sess.run(tf.global_variables_initializer())
def choose_action(self, s):
return self.sess.run(self.a, {self.S: s[np.newaxis, :]})[0]
def learn(self):
# soft target replacement
self.sess.run(self.soft_replace)
indices = np.random.choice(MEMORY_CAPACITY, size=BATCH_SIZE)
bt = self.memory[indices, :]
bs = bt[:, :self.s_dim]
ba = bt[:, self.s_dim: self.s_dim + self.a_dim]
br = bt[:, -self.s_dim - 1: -self.s_dim]
bs_ = bt[:, -self.s_dim:]
self.sess.run(self.atrain, {self.S: bs})
self.sess.run(self.ctrain, {self.S: bs, self.a: ba, self.R: br, self.S_: bs_})
def store_transition(self, s, a, r, s_):
transition = np.hstack((s, a, [r], s_))
index = self.pointer % MEMORY_CAPACITY # replace the old memory with new memory
self.memory[index, :] = transition
self.pointer += 1
def _build_a(self, s, scope, trainable):
with tf.variable_scope(scope):
net = tf.layers.dense(s, 30, activation=tf.nn.relu, name='l1', trainable=trainable)
a = tf.layers.dense(net, self.a_dim, activation=tf.nn.tanh, name='a', trainable=trainable)
return tf.multiply(a, self.a_bound, name='scaled_a')
def _build_c(self, s, a, scope, trainable):
with tf.variable_scope(scope):
n_l1 = 30
w1_s = tf.get_variable('w1_s', [self.s_dim, n_l1], trainable=trainable)
w1_a = tf.get_variable('w1_a', [self.a_dim, n_l1], trainable=trainable)
b1 = tf.get_variable('b1', [1, n_l1], trainable=trainable)
net = tf.nn.relu(tf.matmul(s, w1_s) + tf.matmul(a, w1_a) + b1)
return tf.layers.dense(net, 1, trainable=trainable) # Q(s,a)
############################### training ####################################
env = gym.make(ENV_NAME)
env = env.unwrapped
env.seed(1)
s_dim = env.observation_space.shape[0]
a_dim = env.action_space.shape[0]
a_bound = env.action_space.high
ddpg = DDPG(a_dim, s_dim, a_bound)
var = 3 # control exploration
t1 = time.time()
for i in range(MAX_EPISODES):
s = env.reset()
ep_reward = 0
for j in range(MAX_EP_STEPS):
if RENDER:
env.render()
# Add exploration noise
a = ddpg.choose_action(s)
a = np.clip(np.random.normal(a, var), -2, 2) # add randomness to action selection for exploration
s_, r, done, info = env.step(a)
ddpg.store_transition(s, a, r / 10, s_)
if ddpg.pointer > MEMORY_CAPACITY:
var *= .9995 # decay the action randomness
ddpg.learn()
s = s_
ep_reward += r
if j == MAX_EP_STEPS-1:
print('Episode:', i, ' Reward: %i' % int(ep_reward), 'Explore: %.2f' % var, )
# if ep_reward > -300:RENDER = True
break
print('Running time: ', time.time() - t1)
================================================
FILE: contents/9_Deep_Deterministic_Policy_Gradient_DDPG/DDPG_update2.py
================================================
"""
Note: This is a updated version from my previous code,
for the target network, I use moving average to soft replace target parameters instead using assign function.
By doing this, it has 20% speed up on my machine (CPU).
Deep Deterministic Policy Gradient (DDPG), Reinforcement Learning.
DDPG is Actor Critic based algorithm.
Pendulum example.
View more on my tutorial page: https://morvanzhou.github.io/tutorials/
Using:
tensorflow 1.0
gym 0.8.0
"""
import tensorflow as tf
import numpy as np
import gym
import time
##################### hyper parameters ####################
MAX_EPISODES = 200
MAX_EP_STEPS = 200
LR_A = 0.001 # learning rate for actor
LR_C = 0.002 # learning rate for critic
GAMMA = 0.9 # reward discount
TAU = 0.01 # soft replacement
MEMORY_CAPACITY = 10000
BATCH_SIZE = 32
RENDER = False
ENV_NAME = 'Pendulum-v0'
############################### DDPG ####################################
class DDPG(object):
def __init__(self, a_dim, s_dim, a_bound,):
self.memory = np.zeros((MEMORY_CAPACITY, s_dim * 2 + a_dim + 1), dtype=np.float32)
self.pointer = 0
self.sess = tf.Session()
self.a_dim, self.s_dim, self.a_bound = a_dim, s_dim, a_bound,
self.S = tf.placeholder(tf.float32, [None, s_dim], 's')
self.S_ = tf.placeholder(tf.float32, [None, s_dim], 's_')
self.R = tf.placeholder(tf.float32, [None, 1], 'r')
self.a = self._build_a(self.S,)
q = self._build_c(self.S, self.a, )
a_params = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope='Actor')
c_params = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope='Critic')
ema = tf.train.ExponentialMovingAverage(decay=1 - TAU) # soft replacement
def ema_getter(getter, name, *args, **kwargs):
return ema.average(getter(name, *args, **kwargs))
target_update = [ema.apply(a_params), ema.apply(c_params)] # soft update operation
a_ = self._build_a(self.S_, reuse=True, custom_getter=ema_getter) # replaced target parameters
q_ = self._build_c(self.S_, a_, reuse=True, custom_getter=ema_getter)
a_loss = - tf.reduce_mean(q) # maximize the q
self.atrain = tf.train.AdamOptimizer(LR_A).minimize(a_loss, var_list=a_params)
with tf.control_dependencies(target_update): # soft replacement happened at here
q_target = self.R + GAMMA * q_
td_error = tf.losses.mean_squared_error(labels=q_target, predictions=q)
self.ctrain = tf.train.AdamOptimizer(LR_C).minimize(td_error, var_list=c_params)
self.sess.run(tf.global_variables_initializer())
def choose_action(self, s):
return self.sess.run(self.a, {self.S: s[np.newaxis, :]})[0]
def learn(self):
indices = np.random.choice(MEMORY_CAPACITY, size=BATCH_SIZE)
bt = self.memory[indices, :]
bs = bt[:, :self.s_dim]
ba = bt[:, self.s_dim: self.s_dim + self.a_dim]
br = bt[:, -self.s_dim - 1: -self.s_dim]
bs_ = bt[:, -self.s_dim:]
self.sess.run(self.atrain, {self.S: bs})
self.sess.run(self.ctrain, {self.S: bs, self.a: ba, self.R: br, self.S_: bs_})
def store_transition(self, s, a, r, s_):
transition = np.hstack((s, a, [r], s_))
index = self.pointer % MEMORY_CAPACITY # replace the old memory with new memory
self.memory[index, :] = transition
self.pointer += 1
def _build_a(self, s, reuse=None, custom_getter=None):
trainable = True if reuse is None else False
with tf.variable_scope('Actor', reuse=reuse, custom_getter=custom_getter):
net = tf.layers.dense(s, 30, activation=tf.nn.relu, name='l1', trainable=trainable)
a = tf.layers.dense(net, self.a_dim, activation=tf.nn.tanh, name='a', trainable=trainable)
return tf.multiply(a, self.a_bound, name='scaled_a')
def _build_c(self, s, a, reuse=None, custom_getter=None):
trainable = True if reuse is None else False
with tf.variable_scope('Critic', reuse=reuse, custom_getter=custom_getter):
n_l1 = 30
w1_s = tf.get_variable('w1_s', [self.s_dim, n_l1], trainable=trainable)
w1_a = tf.get_variable('w1_a', [self.a_dim, n_l1], trainable=trainable)
b1 = tf.get_variable('b1', [1, n_l1], trainable=trainable)
net = tf.nn.relu(tf.matmul(s, w1_s) + tf.matmul(a, w1_a) + b1)
return tf.layers.dense(net, 1, trainable=trainable) # Q(s,a)
############################### training ####################################
env = gym.make(ENV_NAME)
env = env.unwrapped
env.seed(1)
s_dim = env.observation_space.shape[0]
a_dim = env.action_space.shape[0]
a_bound = env.action_space.high
ddpg = DDPG(a_dim, s_dim, a_bound)
var = 3 # control exploration
t1 = time.time()
for i in range(MAX_EPISODES):
s = env.reset()
ep_reward = 0
for j in range(MAX_EP_STEPS):
if RENDER:
env.render()
# Add exploration noise
a = ddpg.choose_action(s)
a = np.clip(np.random.normal(a, var), -2, 2) # add randomness to action selection for exploration
s_, r, done, info = env.step(a)
ddpg.store_transition(s, a, r / 10, s_)
if ddpg.pointer > MEMORY_CAPACITY:
var *= .9995 # decay the action randomness
ddpg.learn()
s = s_
ep_reward += r
if j == MAX_EP_STEPS-1:
print('Episode:', i, ' Reward: %i' % int(ep_reward), 'Explore: %.2f' % var, )
# if ep_reward > -300:RENDER = True
break
print('Running time: ', time.time() - t1)
================================================
FILE: contents/Curiosity_Model/Curiosity.py
================================================
"""This is a simple implementation of [Large-Scale Study of Curiosity-Driven Learning](https://arxiv.org/abs/1808.04355)"""
import numpy as np
import tensorflow as tf
import gym
import matplotlib.pyplot as plt
class CuriosityNet:
def __init__(
self,
n_a,
n_s,
lr=0.01,
gamma=0.98,
epsilon=0.95,
replace_target_iter=300,
memory_size=10000,
batch_size=128,
output_graph=False,
):
self.n_a = n_a
self.n_s = n_s
self.lr = lr
self.gamma = gamma
self.epsilon = epsilon
self.replace_target_iter = replace_target_iter
self.memory_size = memory_size
self.batch_size = batch_size
# total learning step
self.learn_step_counter = 0
self.memory_counter = 0
# initialize zero memory [s, a, r, s_]
self.memory = np.zeros((self.memory_size, n_s * 2 + 2))
self.tfs, self.tfa, self.tfr, self.tfs_, self.dyn_train, self.dqn_train, self.q, self.int_r = \
self._build_nets()
t_params = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope='target_net')
e_params = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope='eval_net')
with tf.variable_scope('hard_replacement'):
self.target_replace_op = [tf.assign(t, e) for t, e in zip(t_params, e_params)]
self.sess = tf.Session()
if output_graph:
tf.summary.FileWriter("logs/", self.sess.graph)
self.sess.run(tf.global_variables_initializer())
def _build_nets(self):
tfs = tf.placeholder(tf.float32, [None, self.n_s], name="s") # input State
tfa = tf.placeholder(tf.int32, [None, ], name="a") # input Action
tfr = tf.placeholder(tf.float32, [None, ], name="ext_r") # extrinsic reward
tfs_ = tf.placeholder(tf.float32, [None, self.n_s], name="s_") # input Next State
# dynamics net
dyn_s_, curiosity, dyn_train = self._build_dynamics_net(tfs, tfa, tfs_)
# normal RL model
total_reward = tf.add(curiosity, tfr, name="total_r")
q, dqn_loss, dqn_train = self._build_dqn(tfs, tfa, total_reward, tfs_)
return tfs, tfa, tfr, tfs_, dyn_train, dqn_train, q, curiosity
def _build_dynamics_net(self, s, a, s_):
with tf.variable_scope("dyn_net"):
float_a = tf.expand_dims(tf.cast(a, dtype=tf.float32, name="float_a"), axis=1, name="2d_a")
sa = tf.concat((s, float_a), axis=1, name="sa")
encoded_s_ = s_ # here we use s_ as the encoded s_
dyn_l = tf.layers.dense(sa, 32, activation=tf.nn.relu)
dyn_s_ = tf.layers.dense(dyn_l, self.n_s) # predicted s_
with tf.name_scope("int_r"):
squared_diff = tf.reduce_sum(tf.square(encoded_s_ - dyn_s_), axis=1) # intrinsic reward
# It is better to reduce the learning rate in order to stay curious
train_op = tf.train.RMSPropOptimizer(self.lr, name="dyn_opt").minimize(tf.reduce_mean(squared_diff))
return dyn_s_, squared_diff, train_op
def _build_dqn(self, s, a, r, s_):
with tf.variable_scope('eval_net'):
e1 = tf.layers.dense(s, 128, tf.nn.relu)
q = tf.layers.dense(e1, self.n_a, name="q")
with tf.variable_scope('target_net'):
t1 = tf.layers.dense(s_, 128, tf.nn.relu)
q_ = tf.layers.dense(t1, self.n_a, name="q_")
with tf.variable_scope('q_target'):
q_target = r + self.gamma * tf.reduce_max(q_, axis=1, name="Qmax_s_")
with tf.variable_scope('q_wrt_a'):
a_indices = tf.stack([tf.range(tf.shape(a)[0], dtype=tf.int32), a], axis=1)
q_wrt_a = tf.gather_nd(params=q, indices=a_indices)
loss = tf.losses.mean_squared_error(labels=q_target, predictions=q_wrt_a) # TD error
train_op = tf.train.RMSPropOptimizer(self.lr, name="dqn_opt").minimize(
loss, var_list=tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, "eval_net"))
return q, loss, train_op
def store_transition(self, s, a, r, s_):
transition = np.hstack((s, [a, r], s_))
# replace the old memory with new memory
index = self.memory_counter % self.memory_size
self.memory[index, :] = transition
self.memory_counter += 1
def choose_action(self, observation):
# to have batch dimension when feed into tf placeholder
s = observation[np.newaxis, :]
if np.random.uniform() < self.epsilon:
# forward feed the observation and get q value for every actions
actions_value = self.sess.run(self.q, feed_dict={self.tfs: s})
action = np.argmax(actions_value)
else:
action = np.random.randint(0, self.n_a)
return action
def learn(self):
# check to replace target parameters
if self.learn_step_counter % self.replace_target_iter == 0:
self.sess.run(self.target_replace_op)
# sample batch memory from all memory
top = self.memory_size if self.memory_counter > self.memory_size else self.memory_counter
sample_index = np.random.choice(top, size=self.batch_size)
batch_memory = self.memory[sample_index, :]
bs, ba, br, bs_ = batch_memory[:, :self.n_s], batch_memory[:, self.n_s], \
batch_memory[:, self.n_s + 1], batch_memory[:, -self.n_s:]
self.sess.run(self.dqn_train, feed_dict={self.tfs: bs, self.tfa: ba, self.tfr: br, self.tfs_: bs_})
if self.learn_step_counter % 1000 == 0: # delay training in order to stay curious
self.sess.run(self.dyn_train, feed_dict={self.tfs: bs, self.tfa: ba, self.tfs_: bs_})
self.learn_step_counter += 1
env = gym.make('MountainCar-v0')
env = env.unwrapped
dqn = CuriosityNet(n_a=3, n_s=2, lr=0.01, output_graph=False)
ep_steps = []
for epi in range(200):
s = env.reset()
steps = 0
while True:
env.render()
a = dqn.choose_action(s)
s_, r, done, info = env.step(a)
dqn.store_transition(s, a, r, s_)
dqn.learn()
if done:
print('Epi: ', epi, "| steps: ", steps)
ep_steps.append(steps)
break
s = s_
steps += 1
plt.plot(ep_steps)
plt.ylabel("steps")
plt.xlabel("episode")
plt.show()
================================================
FILE: contents/Curiosity_Model/Random_Network_Distillation.py
================================================
"""This is a simple implementation of [Exploration by Random Network Distillation](https://arxiv.org/abs/1810.12894)"""
import numpy as np
import tensorflow as tf
import gym
import matplotlib.pyplot as plt
class CuriosityNet:
def __init__(
self,
n_a,
n_s,
lr=0.01,
gamma=0.95,
epsilon=1.,
replace_target_iter=300,
memory_size=10000,
batch_size=128,
output_graph=False,
):
self.n_a = n_a
self.n_s = n_s
self.lr = lr
self.gamma = gamma
self.epsilon = epsilon
self.replace_target_iter = replace_target_iter
self.memory_size = memory_size
self.batch_size = batch_size
self.s_encode_size = 1000 # give a hard job for predictor to learn
# total learning step
self.learn_step_counter = 0
self.memory_counter = 0
# initialize zero memory [s, a, r, s_]
self.memory = np.zeros((self.memory_size, n_s * 2 + 2))
self.tfs, self.tfa, self.tfr, self.tfs_, self.pred_train, self.dqn_train, self.q = \
self._build_nets()
t_params = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope='target_net')
e_params = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope='eval_net')
with tf.variable_scope('hard_replacement'):
self.target_replace_op = [tf.assign(t, e) for t, e in zip(t_params, e_params)]
self.sess = tf.Session()
if output_graph:
tf.summary.FileWriter("logs/", self.sess.graph)
self.sess.run(tf.global_variables_initializer())
def _build_nets(self):
tfs = tf.placeholder(tf.float32, [None, self.n_s], name="s") # input State
tfa = tf.placeholder(tf.int32, [None, ], name="a") # input Action
tfr = tf.placeholder(tf.float32, [None, ], name="ext_r") # extrinsic reward
tfs_ = tf.placeholder(tf.float32, [None, self.n_s], name="s_") # input Next State
# fixed random net
with tf.variable_scope("random_net"):
rand_encode_s_ = tf.layers.dense(tfs_, self.s_encode_size)
# predictor
ri, pred_train = self._build_predictor(tfs_, rand_encode_s_)
# normal RL model
q, dqn_loss, dqn_train = self._build_dqn(tfs, tfa, ri, tfr, tfs_)
return tfs, tfa, tfr, tfs_, pred_train, dqn_train, q
def _build_predictor(self, s_, rand_encode_s_):
with tf.variable_scope("predictor"):
net = tf.layers.dense(s_, 128, tf.nn.relu)
out = tf.layers.dense(net, self.s_encode_size)
with tf.name_scope("int_r"):
ri = tf.reduce_sum(tf.square(rand_encode_s_ - out), axis=1) # intrinsic reward
train_op = tf.train.RMSPropOptimizer(self.lr, name="predictor_opt").minimize(
tf.reduce_mean(ri), var_list=tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, "predictor"))
return ri, train_op
def _build_dqn(self, s, a, ri, re, s_):
with tf.variable_scope('eval_net'):
e1 = tf.layers.dense(s, 128, tf.nn.relu)
q = tf.layers.dense(e1, self.n_a, name="q")
with tf.variable_scope('target_net'):
t1 = tf.layers.dense(s_, 128, tf.nn.relu)
q_ = tf.layers.dense(t1, self.n_a, name="q_")
with tf.variable_scope('q_target'):
q_target = re + ri + self.gamma * tf.reduce_max(q_, axis=1, name="Qmax_s_")
with tf.variable_scope('q_wrt_a'):
a_indices = tf.stack([tf.range(tf.shape(a)[0], dtype=tf.int32), a], axis=1)
q_wrt_a = tf.gather_nd(params=q, indices=a_indices)
loss = tf.losses.mean_squared_error(labels=q_target, predictions=q_wrt_a) # TD error
train_op = tf.train.RMSPropOptimizer(self.lr, name="dqn_opt").minimize(
loss, var_list=tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, "eval_net"))
return q, loss, train_op
def store_transition(self, s, a, r, s_):
transition = np.hstack((s, [a, r], s_))
# replace the old memory with new memory
index = self.memory_counter % self.memory_size
self.memory[index, :] = transition
self.memory_counter += 1
def choose_action(self, observation):
# to have batch dimension when feed into tf placeholder
s = observation[np.newaxis, :]
if np.random.uniform() < self.epsilon:
# forward feed the observation and get q value for every actions
actions_value = self.sess.run(self.q, feed_dict={self.tfs: s})
action = np.argmax(actions_value)
else:
action = np.random.randint(0, self.n_a)
return action
def learn(self):
# check to replace target parameters
if self.learn_step_counter % self.replace_target_iter == 0:
self.sess.run(self.target_replace_op)
# sample batch memory from all memory
top = self.memory_size if self.memory_counter > self.memory_size else self.memory_counter
sample_index = np.random.choice(top, size=self.batch_size)
batch_memory = self.memory[sample_index, :]
bs, ba, br, bs_ = batch_memory[:, :self.n_s], batch_memory[:, self.n_s], \
batch_memory[:, self.n_s + 1], batch_memory[:, -self.n_s:]
self.sess.run(self.dqn_train, feed_dict={self.tfs: bs, self.tfa: ba, self.tfr: br, self.tfs_: bs_})
if self.learn_step_counter % 100 == 0: # delay training in order to stay curious
self.sess.run(self.pred_train, feed_dict={self.tfs_: bs_})
self.learn_step_counter += 1
env = gym.make('MountainCar-v0')
env = env.unwrapped
dqn = CuriosityNet(n_a=3, n_s=2, lr=0.01, output_graph=False)
ep_steps = []
for epi in range(200):
s = env.reset()
steps = 0
while True:
# env.render()
a = dqn.choose_action(s)
s_, r, done, info = env.step(a)
dqn.store_transition(s, a, r, s_)
dqn.learn()
if done:
print('Epi: ', epi, "| steps: ", steps)
ep_steps.append(steps)
break
s = s_
steps += 1
plt.plot(ep_steps)
plt.ylabel("steps")
plt.xlabel("episode")
plt.show()
================================================
FILE: experiments/2D_car/DDPG.py
================================================
"""
Environment is a 2D car.
Car has 5 sensors to obtain distance information.
Car collision => reward = -1, otherwise => reward = 0.
You can train this RL by using LOAD = False, after training, this model will be store in the a local folder.
Using LOAD = True to reload the trained model for playing.
You can customize this script in a way you want.
View more on [莫烦Python] : https://morvanzhou.github.io/tutorials/
Requirement:
pyglet >= 1.2.4
numpy >= 1.12.1
tensorflow >= 1.0.1
"""
import tensorflow as tf
import numpy as np
import os
import shutil
from car_env import CarEnv
np.random.seed(1)
tf.set_random_seed(1)
MAX_EPISODES = 500
MAX_EP_STEPS = 600
LR_A = 1e-4 # learning rate for actor
LR_C = 1e-4 # learning rate for critic
GAMMA = 0.9 # reward discount
REPLACE_ITER_A = 800
REPLACE_ITER_C = 700
MEMORY_CAPACITY = 2000
BATCH_SIZE = 16
VAR_MIN = 0.1
RENDER = True
LOAD = False
DISCRETE_ACTION = False
env = CarEnv(discrete_action=DISCRETE_ACTION)
STATE_DIM = env.state_dim
ACTION_DIM = env.action_dim
ACTION_BOUND = env.action_bound
# all placeholder for tf
with tf.name_scope('S'):
S = tf.placeholder(tf.float32, shape=[None, STATE_DIM], name='s')
with tf.name_scope('R'):
R = tf.placeholder(tf.float32, [None, 1], name='r')
with tf.name_scope('S_'):
S_ = tf.placeholder(tf.float32, shape=[None, STATE_DIM], name='s_')
class Actor(object):
def __init__(self, sess, action_dim, action_bound, learning_rate, t_replace_iter):
self.sess = sess
self.a_dim = action_dim
self.action_bound = action_bound
self.lr = learning_rate
self.t_replace_iter = t_replace_iter
self.t_replace_counter = 0
with tf.variable_scope('Actor'):
# input s, output a
self.a = self._build_net(S, scope='eval_net', trainable=True)
# input s_, output a, get a_ for critic
self.a_ = self._build_net(S_, scope='target_net', trainable=False)
self.e_params = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope='Actor/eval_net')
self.t_params = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope='Actor/target_net')
def _build_net(self, s, scope, trainable):
with tf.variable_scope(scope):
init_w = tf.contrib.layers.xavier_initializer()
init_b = tf.constant_initializer(0.001)
net = tf.layers.dense(s, 100, activation=tf.nn.relu,
kernel_initializer=init_w, bias_initializer=init_b, name='l1',
trainable=trainable)
net = tf.layers.dense(net, 20, activation=tf.nn.relu,
kernel_initializer=init_w, bias_initializer=init_b, name='l2',
trainable=trainable)
with tf.variable_scope('a'):
actions = tf.layers.dense(net, self.a_dim, activation=tf.nn.tanh, kernel_initializer=init_w,
name='a', trainable=trainable)
scaled_a = tf.multiply(actions, self.action_bound, name='scaled_a') # Scale output to -action_bound to action_bound
return scaled_a
def learn(self, s): # batch update
self.sess.run(self.train_op, feed_dict={S: s})
if self.t_replace_counter % self.t_replace_iter == 0:
self.sess.run([tf.assign(t, e) for t, e in zip(self.t_params, self.e_params)])
self.t_replace_counter += 1
def choose_action(self, s):
s = s[np.newaxis, :] # single state
return self.sess.run(self.a, feed_dict={S: s})[0] # single action
def add_grad_to_graph(self, a_grads):
with tf.variable_scope('policy_grads'):
self.policy_grads = tf.gradients(ys=self.a, xs=self.e_params, grad_ys=a_grads)
with tf.variable_scope('A_train'):
opt = tf.train.RMSPropOptimizer(-self.lr) # (- learning rate) for ascent policy
self.train_op = opt.apply_gradients(zip(self.policy_grads, self.e_params))
class Critic(object):
def __init__(self, sess, state_dim, action_dim, learning_rate, gamma, t_replace_iter, a, a_):
self.sess = sess
self.s_dim = state_dim
self.a_dim = action_dim
self.lr = learning_rate
self.gamma = gamma
self.t_replace_iter = t_replace_iter
self.t_replace_counter = 0
with tf.variable_scope('Critic'):
# Input (s, a), output q
self.a = a
self.q = self._build_net(S, self.a, 'eval_net', trainable=True)
# Input (s_, a_), output q_ for q_target
self.q_ = self._build_net(S_, a_, 'target_net', trainable=False) # target_q is based on a_ from Actor's target_net
self.e_params = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope='Critic/eval_net')
self.t_params = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope='Critic/target_net')
with tf.variable_scope('target_q'):
self.target_q = R + self.gamma * self.q_
with tf.variable_scope('TD_error'):
self.loss = tf.reduce_mean(tf.squared_difference(self.target_q, self.q))
with tf.variable_scope('C_train'):
self.train_op = tf.train.RMSPropOptimizer(self.lr).minimize(self.loss)
with tf.variable_scope('a_grad'):
self.a_grads = tf.gradients(self.q, a)[0] # tensor of gradients of each sample (None, a_dim)
def _build_net(self, s, a, scope, trainable):
with tf.variable_scope(scope):
init_w = tf.contrib.layers.xavier_initializer()
init_b = tf.constant_initializer(0.01)
with tf.variable_scope('l1'):
n_l1 = 100
w1_s = tf.get_variable('w1_s', [self.s_dim, n_l1], initializer=init_w, trainable=trainable)
w1_a = tf.get_variable('w1_a', [self.a_dim, n_l1], initializer=init_w, trainable=trainable)
b1 = tf.get_variable('b1', [1, n_l1], initializer=init_b, trainable=trainable)
net = tf.nn.relu6(tf.matmul(s, w1_s) + tf.matmul(a, w1_a) + b1)
net = tf.layers.dense(net, 20, activation=tf.nn.relu,
kernel_initializer=init_w, bias_initializer=init_b, name='l2',
trainable=trainable)
with tf.variable_scope('q'):
q = tf.layers.dense(net, 1, kernel_initializer=init_w, bias_initializer=init_b, trainable=trainable) # Q(s,a)
return q
def learn(self, s, a, r, s_):
self.sess.run(self.train_op, feed_dict={S: s, self.a: a, R: r, S_: s_})
if self.t_replace_counter % self.t_replace_iter == 0:
self.sess.run([tf.assign(t, e) for t, e in zip(self.t_params, self.e_params)])
self.t_replace_counter += 1
class Memory(object):
def __init__(self, capacity, dims):
self.capacity = capacity
self.data = np.zeros((capacity, dims))
self.pointer = 0
def store_transition(self, s, a, r, s_):
transition = np.hstack((s, a, [r], s_))
index = self.pointer % self.capacity # replace the old memory with new memory
self.data[index, :] = transition
self.pointer += 1
def sample(self, n):
assert self.pointer >= self.capacity, 'Memory has not been fulfilled'
indices = np.random.choice(self.capacity, size=n)
return self.data[indices, :]
sess = tf.Session()
# Create actor and critic.
actor = Actor(sess, ACTION_DIM, ACTION_BOUND[1], LR_A, REPLACE_ITER_A)
critic = Critic(sess, STATE_DIM, ACTION_DIM, LR_C, GAMMA, REPLACE_ITER_C, actor.a, actor.a_)
actor.add_grad_to_graph(critic.a_grads)
M = Memory(MEMORY_CAPACITY, dims=2 * STATE_DIM + ACTION_DIM + 1)
saver = tf.train.Saver()
path = './discrete' if DISCRETE_ACTION else './continuous'
if LOAD:
saver.restore(sess, tf.train.latest_checkpoint(path))
else:
sess.run(tf.global_variables_initializer())
def train():
var = 2. # control exploration
for ep in range(MAX_EPISODES):
s = env.reset()
ep_step = 0
for t in range(MAX_EP_STEPS):
# while True:
if RENDER:
env.render()
# Added exploration noise
a = actor.choose_action(s)
a = np.clip(np.random.normal(a, var), *ACTION_BOUND) # add randomness to action selection for exploration
s_, r, done = env.step(a)
M.store_transition(s, a, r, s_)
if M.pointer > MEMORY_CAPACITY:
var = max([var*.9995, VAR_MIN]) # decay the action randomness
b_M = M.sample(BATCH_SIZE)
b_s = b_M[:, :STATE_DIM]
b_a = b_M[:, STATE_DIM: STATE_DIM + ACTION_DIM]
b_r = b_M[:, -STATE_DIM - 1: -STATE_DIM]
b_s_ = b_M[:, -STATE_DIM:]
critic.learn(b_s, b_a, b_r, b_s_)
actor.learn(b_s)
s = s_
ep_step += 1
if done or t == MAX_EP_STEPS - 1:
# if done:
print('Ep:', ep,
'| Steps: %i' % int(ep_step),
'| Explore: %.2f' % var,
)
break
if os.path.isdir(path): shutil.rmtree(path)
os.mkdir(path)
ckpt_path = os.path.join(path, 'DDPG.ckpt')
save_path = saver.save(sess, ckpt_path, write_meta_graph=False)
print("\nSave Model %s\n" % save_path)
def eval():
env.set_fps(30)
while True:
s = env.reset()
while True:
env.render()
a = actor.choose_action(s)
s_, r, done = env.step(a)
s = s_
if done:
break
if __name__ == '__main__':
if LOAD:
eval()
else:
train()
================================================
FILE: experiments/2D_car/car_env.py
================================================
"""
Environment for 2D car driving.
You can customize this script in a way you want.
View more on [莫烦Python] : https://morvanzhou.github.io/tutorials/
Requirement:
pyglet >= 1.2.4
numpy >= 1.12.1
"""
import numpy as np
import pyglet
pyglet.clock.set_fps_limit(10000)
class CarEnv(object):
n_sensor = 5
action_dim = 1
state_dim = n_sensor
viewer = None
viewer_xy = (500, 500)
sensor_max = 150.
start_point = [450, 300]
speed = 50.
dt = 0.1
def __init__(self, discrete_action=False):
self.is_discrete_action = discrete_action
if discrete_action:
self.actions = [-1, 0, 1]
else:
self.action_bound = [-1, 1]
self.terminal = False
# node1 (x, y, r, w, l),
self.car_info = np.array([0, 0, 0, 20, 40], dtype=np.float64) # car coordination
self.obstacle_coords = np.array([
[120, 120],
[380, 120],
[380, 380],
[120, 380],
])
self.sensor_info = self.sensor_max + np.zeros((self.n_sensor, 3)) # n sensors, (distance, end_x, end_y)
def step(self, action):
if self.is_discrete_action:
action = self.actions[action]
else:
action = np.clip(action, *self.action_bound)[0]
self.car_info[2] += action * np.pi/30 # max r = 6 degree
self.car_info[:2] = self.car_info[:2] + \
self.speed * self.dt * np.array([np.cos(self.car_info[2]), np.sin(self.car_info[2])])
self._update_sensor()
s = self._get_state()
r = -1 if self.terminal else 0
return s, r, self.terminal
def reset(self):
self.terminal = False
self.car_info[:3] = np.array([*self.start_point, -np.pi/2])
self._update_sensor()
return self._get_state()
def render(self):
if self.viewer is None:
self.viewer = Viewer(*self.viewer_xy, self.car_info, self.sensor_info, self.obstacle_coords)
self.viewer.render()
def sample_action(self):
if self.is_discrete_action:
a = np.random.choice(list(range(3)))
else:
a = np.random.uniform(*self.action_bound, size=self.action_dim)
return a
def set_fps(self, fps=30):
pyglet.clock.set_fps_limit(fps)
def _get_state(self):
s = self.sensor_info[:, 0].flatten()/self.sensor_max
return s
def _update_sensor(self):
cx, cy, rotation = self.car_info[:3]
n_sensors = len(self.sensor_info)
sensor_theta = np.linspace(-np.pi / 2, np.pi / 2, n_sensors)
xs = cx + (np.zeros((n_sensors, ))+self.sensor_max) * np.cos(sensor_theta)
ys = cy + (np.zeros((n_sensors, ))+self.sensor_max) * np.sin(sensor_theta)
xys = np.array([[x, y] for x, y in zip(xs, ys)]) # shape (5 sensors, 2)
# sensors
tmp_x = xys[:, 0] - cx
tmp_y = xys[:, 1] - cy
# apply rotation
rotated_x = tmp_x * np.cos(rotation) - tmp_y * np.sin(rotation)
rotated_y = tmp_x * np.sin(rotation) + tmp_y * np.cos(rotation)
# rotated x y
self.sensor_info[:, -2:] = np.vstack([rotated_x+cx, rotated_y+cy]).T
q = np.array([cx, cy])
for si in range(len(self.sensor_info)):
s = self.sensor_info[si, -2:] - q
possible_sensor_distance = [self.sensor_max]
possible_intersections = [self.sensor_info[si, -2:]]
# obstacle collision
for oi in range(len(self.obstacle_coords)):
p = self.obstacle_coords[oi]
r = self.obstacle_coords[(oi + 1) % len(self.obstacle_coords)] - self.obstacle_coords[oi]
if np.cross(r, s) != 0: # may collision
t = np.cross((q - p), s) / np.cross(r, s)
u = np.cross((q - p), r) / np.cross(r, s)
if 0 <= t <= 1 and 0 <= u <= 1:
intersection = q + u * s
possible_intersections.append(intersection)
possible_sensor_distance.append(np.linalg.norm(u*s))
# window collision
win_coord = np.array([
[0, 0],
[self.viewer_xy[0], 0],
[*self.viewer_xy],
[0, self.viewer_xy[1]],
[0, 0],
])
for oi in range(4):
p = win_coord[oi]
r = win_coord[(oi + 1) % len(win_coord)] - win_coord[oi]
if np.cross(r, s) != 0: # may collision
t = np.cross((q - p), s) / np.cross(r, s)
u = np.cross((q - p), r) / np.cross(r, s)
if 0 <= t <= 1 and 0 <= u <= 1:
intersection = p + t * r
possible_intersections.append(intersection)
possible_sensor_distance.append(np.linalg.norm(intersection - q))
distance = np.min(possible_sensor_distance)
distance_index = np.argmin(possible_sensor_distance)
self.sensor_info[si, 0] = distance
self.sensor_info[si, -2:] = possible_intersections[distance_index]
if distance < self.car_info[-1]/2:
self.terminal = True
class Viewer(pyglet.window.Window):
color = {
'background': [1]*3 + [1]
}
fps_display = pyglet.clock.ClockDisplay()
bar_thc = 5
def __init__(self, width, height, car_info, sensor_info, obstacle_coords):
super(Viewer, self).__init__(width, height, resizable=False, caption='2D car', vsync=False) # vsync=False to not use the monitor FPS
self.set_location(x=80, y=10)
pyglet.gl.glClearColor(*self.color['background'])
self.car_info = car_info
self.sensor_info = sensor_info
self.batch = pyglet.graphics.Batch()
background = pyglet.graphics.OrderedGroup(0)
foreground = pyglet.graphics.OrderedGroup(1)
self.sensors = []
line_coord = [0, 0] * 2
c = (73, 73, 73) * 2
for i in range(len(self.sensor_info)):
self.sensors.append(self.batch.add(2, pyglet.gl.GL_LINES, foreground, ('v2f', line_coord), ('c3B', c)))
car_box = [0, 0] * 4
c = (249, 86, 86) * 4
self.car = self.batch.add(4, pyglet.gl.GL_QUADS, foreground, ('v2f', car_box), ('c3B', c))
c = (134, 181, 244) * 4
self.obstacle = self.batch.add(4, pyglet.gl.GL_QUADS, background, ('v2f', obstacle_coords.flatten()), ('c3B', c))
def render(self):
pyglet.clock.tick()
self._update()
self.switch_to()
self.dispatch_events()
self.dispatch_event('on_draw')
self.flip()
def on_draw(self):
self.clear()
self.batch.draw()
# self.fps_display.draw()
def _update(self):
cx, cy, r, w, l = self.car_info
# sensors
for i, sensor in enumerate(self.sensors):
sensor.vertices = [cx, cy, *self.sensor_info[i, -2:]]
# car
xys = [
[cx + l / 2, cy + w / 2],
[cx - l / 2, cy + w / 2],
[cx - l / 2, cy - w / 2],
[cx + l / 2, cy - w / 2],
]
r_xys = []
for x, y in xys:
tempX = x - cx
tempY = y - cy
# apply rotation
rotatedX = tempX * np.cos(r) - tempY * np.sin(r)
rotatedY = tempX * np.sin(r) + tempY * np.cos(r)
# rotated x y
x = rotatedX + cx
y = rotatedY + cy
r_xys += [x, y]
self.car.vertices = r_xys
if __name__ == '__main__':
np.random.seed(1)
env = CarEnv()
env.set_fps(30)
for ep in range(20):
s = env.reset()
# for t in range(100):
while True:
env.render()
s, r, done = env.step(env.sample_action())
if done:
break
================================================
FILE: experiments/2D_car/collision.py
================================================
import numpy as np
def intersection():
p = np.array([0, 0])
r = np.array([1, 1])
q = np.array([0.1, 0.1])
s = np.array([.1, .1])
if np.cross(r, s) == 0 and np.cross((q-p), r) == 0: # collinear
# t0 = (q − p) · r / (r · r)
# t1 = (q + s − p) · r / (r · r) = t0 + s · r / (r · r)
t0 = np.dot(q-p, r)/np.dot(r, r)
t1 = t0 + np.dot(s, r)/np.dot(r, r)
print(t1, t0)
if ((np.dot(s, r) > 0) and (0 <= t1 - t0 <= 1)) or ((np.dot(s, r) <= 0) and (0 <= t0 - t1 <= 1)):
print('collinear and overlapping, q_s in p_r')
else:
print('collinear and disjoint')
elif np.cross(r, s) == 0 and np.cross((q-p), r) != 0: # parallel r × s = 0 and (q − p) × r ≠ 0,
print('parallel')
else:
t = np.cross((q - p), s) / np.cross(r, s)
u = np.cross((q - p), r) / np.cross(r, s)
if 0 <= t <= 1 and 0 <= u <= 1:
# If r × s ≠ 0 and 0 ≤ t ≤ 1 and 0 ≤ u ≤ 1, the two line segments meet at the point p + t r = q + u s
print('intersection: ', p + t*r)
else:
print('not parallel and not intersect')
def point2segment():
p = np.array([-1, 1]) # coordination of point
a = np.array([0, 1]) # coordination of line segment end 1
b = np.array([1, 0]) # coordination of line segment end 2
ab = b-a # line ab
ap = p-a
distance = np.abs(np.cross(ab, ap)/np.linalg.norm(ab)) # d = (AB x AC)/|AB|
print(distance)
# angle Cos(θ) = A dot B /(|A||B|)
bp = p-b
cosTheta1 = np.dot(ap, ab) / (np.linalg.norm(ap) * np.linalg.norm(ab))
theta1 = np.arccos(cosTheta1)
cosTheta2 = np.dot(bp, ab) / (np.linalg.norm(bp) * np.linalg.norm(ab))
theta2 = np.arccos(cosTheta2)
if np.pi/2 <= (theta1 % (np.pi*2)) <= 3/2 * np.pi:
print('out of a')
elif -np.pi/2 <= (theta2 % (np.pi*2)) <= np.pi/2:
print('out of b')
else:
print('between a and b')
if __name__ == '__main__':
point2segment()
# intersection()
================================================
FILE: experiments/Robot_arm/A3C.py
================================================
"""
Environment is a Robot Arm. The arm tries to get to the blue point.
The environment will return a geographic (distance) information for the arm to learn.
The far away from blue point the less reward; touch blue r+=1; stop at blue for a while then get r=+10.
You can train this RL by using LOAD = False, after training, this model will be store in the a local folder.
Using LOAD = True to reload the trained model for playing.
You can customize this script in a way you want.
View more on [莫烦Python] : https://morvanzhou.github.io/tutorials/
Requirement:
pyglet >= 1.2.4
numpy >= 1.12.1
tensorflow >= 1.0.1
"""
import multiprocessing
import threading
import tensorflow as tf
import numpy as np
from arm_env import ArmEnv
# np.random.seed(1)
# tf.set_random_seed(1)
MAX_GLOBAL_EP = 2000
MAX_EP_STEP = 300
UPDATE_GLOBAL_ITER = 5
N_WORKERS = multiprocessing.cpu_count()
LR_A = 1e-4 # learning rate for actor
LR_C = 2e-4 # learning rate for critic
GAMMA = 0.9 # reward discount
MODE = ['easy', 'hard']
n_model = 1
GLOBAL_NET_SCOPE = 'Global_Net'
ENTROPY_BETA = 0.01
GLOBAL_RUNNING_R = []
GLOBAL_EP = 0
env = ArmEnv(mode=MODE[n_model])
N_S = env.state_dim
N_A = env.action_dim
A_BOUND = env.action_bound
del env
class ACNet(object):
def __init__(self, scope, globalAC=None):
if scope == GLOBAL_NET_SCOPE: # get global network
with tf.variable_scope(scope):
self.s = tf.placeholder(tf.float32, [None, N_S], 'S')
self._build_net()
self.a_params = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope=scope + '/actor')
self.c_params = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope=scope + '/critic')
else: # local net, calculate losses
with tf.variable_scope(scope):
self.s = tf.placeholder(tf.float32, [None, N_S], 'S')
self.a_his = tf.placeholder(tf.float32, [None, N_A], 'A')
self.v_target = tf.placeholder(tf.float32, [None, 1], 'Vtarget')
mu, sigma, self.v = self._build_net()
td = tf.subtract(self.v_target, self.v, name='TD_error')
with tf.name_scope('c_loss'):
self.c_loss = tf.reduce_mean(tf.square(td))
with tf.name_scope('wrap_a_out'):
self.test = sigma[0]
mu, sigma = mu * A_BOUND[1], sigma + 1e-5
normal_dist = tf.contrib.distributions.Normal(mu, sigma)
with tf.name_scope('a_loss'):
log_prob = normal_dist.log_prob(self.a_his)
exp_v = log_prob * td
entropy = normal_dist.entropy() # encourage exploration
self.exp_v = ENTROPY_BETA * entropy + exp_v
self.a_loss = tf.reduce_mean(-self.exp_v)
with tf.name_scope('choose_a'): # use local params to choose action
self.A = tf.clip_by_value(tf.squeeze(normal_dist.sample(1), axis=0), *A_BOUND)
with tf.name_scope('local_grad'):
self.a_params = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope=scope + '/actor')
self.c_params = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope=scope + '/critic')
self.a_grads = tf.gradients(self.a_loss, self.a_params)
self.c_grads = tf.gradients(self.c_loss, self.c_params)
with tf.name_scope('sync'):
with tf.name_scope('pull'):
self.pull_a_params_op = [l_p.assign(g_p) for l_p, g_p in zip(self.a_params, globalAC.a_params)]
self.pull_c_params_op = [l_p.assign(g_p) for l_p, g_p in zip(self.c_params, globalAC.c_params)]
with tf.name_scope('push'):
self.update_a_op = OPT_A.apply_gradients(zip(self.a_grads, globalAC.a_params))
self.update_c_op = OPT_C.apply_gradients(zip(self.c_grads, globalAC.c_params))
def _build_net(self):
w_init = tf.contrib.layers.xavier_initializer()
with tf.variable_scope('actor'):
l_a = tf.layers.dense(self.s, 400, tf.nn.relu6, kernel_initializer=w_init, name='la')
l_a = tf.layers.dense(l_a, 300, tf.nn.relu6, kernel_initializer=w_init, name='la2')
mu = tf.layers.dense(l_a, N_A, tf.nn.tanh, kernel_initializer=w_init, name='mu')
sigma = tf.layers.dense(l_a, N_A, tf.nn.softplus, kernel_initializer=w_init, name='sigma')
with tf.variable_scope('critic'):
l_c = tf.layers.dense(self.s, 400, tf.nn.relu6, kernel_initializer=w_init, name='lc')
l_c = tf.layers.dense(l_c, 200, tf.nn.relu6, kernel_initializer=w_init, name='lc2')
v = tf.layers.dense(l_c, 1, kernel_initializer=w_init, name='v') # state value
return mu, sigma, v
def update_global(self, feed_dict): # run by a local
_, _, t = SESS.run([self.update_a_op, self.update_c_op, self.test], feed_dict) # local grads applies to global net
return t
def pull_global(self): # run by a local
SESS.run([self.pull_a_params_op, self.pull_c_params_op])
def choose_action(self, s): # run by a local
s = s[np.newaxis, :]
return SESS.run(self.A, {self.s: s})[0]
class Worker(object):
def __init__(self, name, globalAC):
self.env = ArmEnv(mode=MODE[n_model])
self.name = name
self.AC = ACNet(name, globalAC)
def work(self):
global GLOBAL_RUNNING_R, GLOBAL_EP
total_step = 1
buffer_s, buffer_a, buffer_r = [], [], []
while not COORD.should_stop() and GLOBAL_EP < MAX_GLOBAL_EP:
s = self.env.reset()
ep_r = 0
for ep_t in range(MAX_EP_STEP):
if self.name == 'W_0':
self.env.render()
a = self.AC.choose_action(s)
s_, r, done = self.env.step(a)
if ep_t == MAX_EP_STEP - 1: done = True
ep_r += r
buffer_s.append(s)
buffer_a.append(a)
buffer_r.append(r)
if total_step % UPDATE_GLOBAL_ITER == 0 or done: # update global and assign to local net
if done:
v_s_ = 0 # terminal
else:
v_s_ = SESS.run(self.AC.v, {self.AC.s: s_[np.newaxis, :]})[0, 0]
buffer_v_target = []
for r in buffer_r[::-1]: # reverse buffer r
v_s_ = r + GAMMA * v_s_
buffer_v_target.append(v_s_)
buffer_v_target.reverse()
buffer_s, buffer_a, buffer_v_target = np.vstack(buffer_s), np.vstack(buffer_a), np.vstack(buffer_v_target)
feed_dict = {
self.AC.s: buffer_s,
self.AC.a_his: buffer_a,
self.AC.v_target: buffer_v_target,
}
test = self.AC.update_global(feed_dict)
buffer_s, buffer_a, buffer_r = [], [], []
self.AC.pull_global()
s = s_
total_step += 1
if done:
if len(GLOBAL_RUNNING_R) == 0: # record running episode reward
GLOBAL_RUNNING_R.append(ep_r)
else:
GLOBAL_RUNNING_R.append(0.9 * GLOBAL_RUNNING_R[-1] + 0.1 * ep_r)
print(
self.name,
"Ep:", GLOBAL_EP,
"| Ep_r: %i" % GLOBAL_RUNNING_R[-1],
'| Var:', test,
)
GLOBAL_EP += 1
break
if __name__ == "__main__":
SESS = tf.Session()
with tf.device("/cpu:0"):
OPT_A = tf.train.RMSPropOptimizer(LR_A, name='RMSPropA')
OPT_C = tf.train.RMSPropOptimizer(LR_C, name='RMSPropC')
GLOBAL_AC = ACNet(GLOBAL_NET_SCOPE) # we only need its params
workers = []
# Create worker
for i in range(N_WORKERS):
i_name = 'W_%i' % i # worker name
workers.append(Worker(i_name, GLOBAL_AC))
COORD = tf.train.Coordinator()
SESS.run(tf.global_variables_initializer())
worker_threads = []
for worker in workers:
job = lambda: worker.work()
t = threading.Thread(target=job)
t.start()
worker_threads.append(t)
COORD.join(worker_threads)
================================================
FILE: experiments/Robot_arm/DDPG.py
================================================
"""
Environment is a Robot Arm. The arm tries to get to the blue point.
The environment will return a geographic (distance) information for the arm to learn.
The far away from blue point the less reward; touch blue r+=1; stop at blue for a while then get r=+10.
You can train this RL by using LOAD = False, after training, this model will be store in the a local folder.
Using LOAD = True to reload the trained model for playing.
You can customize this script in a way you want.
View more on [莫烦Python] : https://morvanzhou.github.io/tutorials/
Requirement:
pyglet >= 1.2.4
numpy >= 1.12.1
tensorflow >= 1.0.1
"""
import tensorflow as tf
import numpy as np
import os
import shutil
from arm_env import ArmEnv
np.random.seed(1)
tf.set_random_seed(1)
MAX_EPISODES = 600
MAX_EP_STEPS = 200
LR_A = 1e-4 # learning rate for actor
LR_C = 1e-4 # learning rate for critic
GAMMA = 0.9 # reward discount
REPLACE_ITER_A = 1100
REPLACE_ITER_C = 1000
MEMORY_CAPACITY = 5000
BATCH_SIZE = 16
VAR_MIN = 0.1
RENDER = True
LOAD = False
MODE = ['easy', 'hard']
n_model = 1
env = ArmEnv(mode=MODE[n_model])
STATE_DIM = env.state_dim
ACTION_DIM = env.action_dim
ACTION_BOUND = env.action_bound
# all placeholder for tf
with tf.name_scope('S'):
S = tf.placeholder(tf.float32, shape=[None, STATE_DIM], name='s')
with tf.name_scope('R'):
R = tf.placeholder(tf.float32, [None, 1], name='r')
with tf.name_scope('S_'):
S_ = tf.placeholder(tf.float32, shape=[None, STATE_DIM], name='s_')
class Actor(object):
def __init__(self, sess, action_dim, action_bound, learning_rate, t_replace_iter):
self.sess = sess
self.a_dim = action_dim
self.action_bound = action_bound
self.lr = learning_rate
self.t_replace_iter = t_replace_iter
self.t_replace_counter = 0
with tf.variable_scope('Actor'):
# input s, output a
self.a = self._build_net(S, scope='eval_net', trainable=True)
# input s_, output a, get a_ for critic
self.a_ = self._build_net(S_, scope='target_net', trainable=False)
self.e_params = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope='Actor/eval_net')
self.t_params = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope='Actor/target_net')
self.replace = [tf.assign(t, e) for t, e in zip(self.t_params, self.e_params)]
def _build_net(self, s, scope, trainable):
with tf.variable_scope(scope):
init_w = tf.contrib.layers.xavier_initializer()
init_b = tf.constant_initializer(0.001)
net = tf.layers.dense(s, 200, activation=tf.nn.relu6,
kernel_initializer=init_w, bias_initializer=init_b, name='l1',
trainable=trainable)
net = tf.layers.dense(net, 200, activation=tf.nn.relu6,
kernel_initializer=init_w, bias_initializer=init_b, name='l2',
trainable=trainable)
net = tf.layers.dense(net, 10, activation=tf.nn.relu,
kernel_initializer=init_w, bias_initializer=init_b, name='l3',
trainable=trainable)
with tf.variable_scope('a'):
actions = tf.layers.dense(net, self.a_dim, activation=tf.nn.tanh, kernel_initializer=init_w,
name='a', trainable=trainable)
scaled_a = tf.multiply(actions, self.action_bound, name='scaled_a') # Scale output to -action_bound to action_bound
return scaled_a
def learn(self, s): # batch update
self.sess.run(self.train_op, feed_dict={S: s})
if self.t_replace_counter % self.t_replace_iter == 0:
self.sess.run(self.replace)
self.t_replace_counter += 1
def choose_action(self, s):
s = s[np.newaxis, :] # single state
return self.sess.run(self.a, feed_dict={S: s})[0] # single action
def add_grad_to_graph(self, a_grads):
with tf.variable_scope('policy_grads'):
self.policy_grads = tf.gradients(ys=self.a, xs=self.e_params, grad_ys=a_grads)
with tf.variable_scope('A_train'):
opt = tf.train.RMSPropOptimizer(-self.lr) # (- learning rate) for ascent policy
self.train_op = opt.apply_gradients(zip(self.policy_grads, self.e_params))
class Critic(object):
def __init__(self, sess, state_dim, action_dim, learning_rate, gamma, t_replace_iter, a, a_):
self.sess = sess
self.s_dim = state_dim
self.a_dim = action_dim
self.lr = learning_rate
self.gamma = gamma
self.t_replace_iter = t_replace_iter
self.t_replace_counter = 0
with tf.variable_scope('Critic'):
# Input (s, a), output q
self.a = a
self.q = self._build_net(S, self.a, 'eval_net', trainable=True)
# Input (s_, a_), output q_ for q_target
self.q_ = self._build_net(S_, a_, 'target_net', trainable=False) # target_q is based on a_ from Actor's target_net
self.e_params = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope='Critic/eval_net')
self.t_params = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope='Critic/target_net')
with tf.variable_scope('target_q'):
self.target_q = R + self.gamma * self.q_
with tf.variable_scope('TD_error'):
self.loss = tf.reduce_mean(tf.squared_difference(self.target_q, self.q))
with tf.variable_scope('C_train'):
self.train_op = tf.train.RMSPropOptimizer(self.lr).minimize(self.loss)
with tf.variable_scope('a_grad'):
self.a_grads = tf.gradients(self.q, a)[0] # tensor of gradients of each sample (None, a_dim)
self.replace = [tf.assign(t, e) for t, e in zip(self.t_params, self.e_params)]
def _build_net(self, s, a, scope, trainable):
with tf.variable_scope(scope):
init_w = tf.contrib.layers.xavier_initializer()
init_b = tf.constant_initializer(0.01)
with tf.variable_scope('l1'):
n_l1 = 200
w1_s = tf.get_variable('w1_s', [self.s_dim, n_l1], initializer=init_w, trainable=trainable)
w1_a = tf.get_variable('w1_a', [self.a_dim, n_l1], initializer=init_w, trainable=trainable)
b1 = tf.get_variable('b1', [1, n_l1], initializer=init_b, trainable=trainable)
net = tf.nn.relu6(tf.matmul(s, w1_s) + tf.matmul(a, w1_a) + b1)
net = tf.layers.dense(net, 200, activation=tf.nn.relu6,
kernel_initializer=init_w, bias_initializer=init_b, name='l2',
trainable=trainable)
net = tf.layers.dense(net, 10, activation=tf.nn.relu,
kernel_initializer=init_w, bias_initializer=init_b, name='l3',
trainable=trainable)
with tf.variable_scope('q'):
q = tf.layers.dense(net, 1, kernel_initializer=init_w, bias_initializer=init_b, trainable=trainable) # Q(s,a)
return q
def learn(self, s, a, r, s_):
self.sess.run(self.train_op, feed_dict={S: s, self.a: a, R: r, S_: s_})
if self.t_replace_counter % self.t_replace_iter == 0:
self.sess.run(self.replace)
self.t_replace_counter += 1
class Memory(object):
def __init__(self, capacity, dims):
self.capacity = capacity
self.data = np.zeros((capacity, dims))
self.pointer = 0
def store_transition(self, s, a, r, s_):
transition = np.hstack((s, a, [r], s_))
index = self.pointer % self.capacity # replace the old memory with new memory
self.data[index, :] = transition
self.pointer += 1
def sample(self, n):
assert self.pointer >= self.capacity, 'Memory has not been fulfilled'
indices = np.random.choice(self.capacity, size=n)
return self.data[indices, :]
sess = tf.Session()
# Create actor and critic.
actor = Actor(sess, ACTION_DIM, ACTION_BOUND[1], LR_A, REPLACE_ITER_A)
critic = Critic(sess, STATE_DIM, ACTION_DIM, LR_C, GAMMA, REPLACE_ITER_C, actor.a, actor.a_)
actor.add_grad_to_graph(critic.a_grads)
M = Memory(MEMORY_CAPACITY, dims=2 * STATE_DIM + ACTION_DIM + 1)
saver = tf.train.Saver()
path = './'+MODE[n_model]
if LOAD:
saver.restore(sess, tf.train.latest_checkpoint(path))
else:
sess.run(tf.global_variables_initializer())
def train():
var = 2. # control exploration
for ep in range(MAX_EPISODES):
s = env.reset()
ep_reward = 0
for t in range(MAX_EP_STEPS):
# while True:
if RENDER:
env.render()
# Added exploration noise
a = actor.choose_action(s)
a = np.clip(np.random.normal(a, var), *ACTION_BOUND) # add randomness to action selection for exploration
s_, r, done = env.step(a)
M.store_transition(s, a, r, s_)
if M.pointer > MEMORY_CAPACITY:
var = max([var*.9999, VAR_MIN]) # decay the action randomness
b_M = M.sample(BATCH_SIZE)
b_s = b_M[:, :STATE_DIM]
b_a = b_M[:, STATE_DIM: STATE_DIM + ACTION_DIM]
b_r = b_M[:, -STATE_DIM - 1: -STATE_DIM]
b_s_ = b_M[:, -STATE_DIM:]
critic.learn(b_s, b_a, b_r, b_s_)
actor.learn(b_s)
s = s_
ep_reward += r
if t == MAX_EP_STEPS-1 or done:
# if done:
result = '| done' if done else '| ----'
print('Ep:', ep,
result,
'| R: %i' % int(ep_reward),
'| Explore: %.2f' % var,
)
break
if os.path.isdir(path): shutil.rmtree(path)
os.mkdir(path)
ckpt_path = os.path.join('./'+MODE[n_model], 'DDPG.ckpt')
save_path = saver.save(sess, ckpt_path, write_meta_graph=False)
print("\nSave Model %s\n" % save_path)
def eval():
env.set_fps(30)
s = env.reset()
while True:
if RENDER:
env.render()
a = actor.choose_action(s)
s_, r, done = env.step(a)
s = s_
if __name__ == '__main__':
if LOAD:
eval()
else:
train()
================================================
FILE: experiments/Robot_arm/DPPO.py
================================================
"""
A simple version of OpenAI's Proximal Policy Optimization (PPO). [http://adsabs.harvard.edu/abs/2017arXiv170706347S]
Distributing workers in parallel to collect data, then stop worker's roll-out and train PPO on collected data.
Restart workers once PPO is updated.
The global PPO updating rule is adopted from DeepMind's paper (DPPO):
Emergence of Locomotion Behaviours in Rich Environments (Google Deepmind): [http://adsabs.harvard.edu/abs/2017arXiv170702286H]
View more on my tutorial website: https://morvanzhou.github.io/tutorials
Dependencies:
tensorflow r1.2
gym 0.9.2
"""
import tensorflow as tf
from tensorflow.contrib.distributions import Normal
import numpy as np
import matplotlib.pyplot as plt
import threading, queue
from arm_env import ArmEnv
EP_MAX = 2000
EP_LEN = 300
N_WORKER = 4 # parallel workers
GAMMA = 0.9 # reward discount factor
A_LR = 0.0001 # learning rate for actor
C_LR = 0.0005 # learning rate for critic
MIN_BATCH_SIZE = 64 # minimum batch size for updating PPO
UPDATE_STEP = 5 # loop update operation n-steps
EPSILON = 0.2 # Clipped surrogate objective
MODE = ['easy', 'hard']
n_model = 1
env = ArmEnv(mode=MODE[n_model])
S_DIM = env.state_dim
A_DIM = env.action_dim
A_BOUND = env.action_bound[1]
class PPO(object):
def __init__(self):
self.sess = tf.Session()
self.tfs = tf.placeholder(tf.float32, [None, S_DIM], 'state')
# critic
l1 = tf.layers.dense(self.tfs, 100, tf.nn.relu)
self.v = tf.layers.dense(l1, 1)
self.tfdc_r = tf.placeholder(tf.float32, [None, 1], 'discounted_r')
self.advantage = self.tfdc_r - self.v
self.closs = tf.reduce_mean(tf.square(self.advantage))
self.ctrain_op = tf.train.AdamOptimizer(C_LR).minimize(self.closs)
# actor
pi, pi_params = self._build_anet('pi', trainable=True)
oldpi, oldpi_params = self._build_anet('oldpi', trainable=False)
self.sample_op = tf.squeeze(pi.sample(1), axis=0) # choosing action
self.update_oldpi_op = [oldp.assign(p) for p, oldp in zip(pi_params, oldpi_params)]
self.tfa = tf.placeholder(tf.float32, [None, A_DIM], 'action')
self.tfadv = tf.placeholder(tf.float32, [None, 1], 'advantage')
# ratio = tf.exp(pi.log_prob(self.tfa) - oldpi.log_prob(self.tfa))
ratio = pi.prob(self.tfa) / (oldpi.prob(self.tfa) + 1e-5)
surr = ratio * self.tfadv # surrogate loss
self.aloss = -tf.reduce_mean(tf.minimum(
surr,
tf.clip_by_value(ratio, 1. - EPSILON, 1. + EPSILON) * self.tfadv))
self.atrain_op = tf.train.AdamOptimizer(A_LR).minimize(self.aloss)
self.sess.run(tf.global_variables_initializer())
def update(self):
global GLOBAL_UPDATE_COUNTER
while not COORD.should_stop():
if GLOBAL_EP < EP_MAX:
UPDATE_EVENT.wait() # wait until get batch of data
self.sess.run(self.update_oldpi_op) # old pi to pi
data = [QUEUE.get() for _ in range(QUEUE.qsize())]
data = np.vstack(data)
s, a, r = data[:, :S_DIM], data[:, S_DIM: S_DIM + A_DIM], data[:, -1:]
adv = self.sess.run(self.advantage, {self.tfs: s, self.tfdc_r: r})
[self.sess.run(self.atrain_op, {self.tfs: s, self.tfa: a, self.tfadv: adv}) for _ in range(UPDATE_STEP)]
[self.sess.run(self.ctrain_op, {self.tfs: s, self.tfdc_r: r}) for _ in range(UPDATE_STEP)]
UPDATE_EVENT.clear() # updating finished
GLOBAL_UPDATE_COUNTER = 0 # reset counter
ROLLING_EVENT.set() # set roll-out available
def _build_anet(self, name, trainable):
with tf.variable_scope(name):
l1 = tf.layers.dense(self.tfs, 200, tf.nn.relu, trainable=trainable)
mu = A_BOUND * tf.layers.dense(l1, A_DIM, tf.nn.tanh, trainable=trainable)
sigma = tf.layers.dense(l1, A_DIM, tf.nn.softplus, trainable=trainable)
norm_dist = Normal(loc=mu, scale=sigma)
params = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope=name)
return norm_dist, params
def choose_action(self, s):
s = s[np.newaxis, :]
a = self.sess.run(self.sample_op, {self.tfs: s})[0]
return np.clip(a, -2, 2)
def get_v(self, s):
if s.ndim < 2: s = s[np.newaxis, :]
return self.sess.run(self.v, {self.tfs: s})[0, 0]
class Worker(object):
def __init__(self, wid):
self.wid = wid
self.env = ArmEnv(mode=MODE[n_model])
self.ppo = GLOBAL_PPO
def work(self):
global GLOBAL_EP, GLOBAL_RUNNING_R, GLOBAL_UPDATE_COUNTER
while not COORD.should_stop():
s = self.env.reset()
ep_r = 0
buffer_s, buffer_a, buffer_r = [], [], []
for t in range(EP_LEN):
if not ROLLING_EVENT.is_set(): # while global PPO is updating
ROLLING_EVENT.wait() # wait until PPO is updated
buffer_s, buffer_a, buffer_r = [], [], [] # clear history buffer
a = self.ppo.choose_action(s)
s_, r, done = self.env.step(a)
buffer_s.append(s)
buffer_a.append(a)
buffer_r.append(r) # normalize reward, find to be useful
s = s_
ep_r += r
GLOBAL_UPDATE_COUNTER += 1 # count to minimum batch size
if t == EP_LEN - 1 or GLOBAL_UPDATE_COUNTER >= MIN_BATCH_SIZE:
v_s_ = self.ppo.get_v(s_)
discounted_r = [] # compute discounted reward
for r in buffer_r[::-1]:
v_s_ = r + GAMMA * v_s_
discounted_r.append(v_s_)
discounted_r.reverse()
bs, ba, br = np.vstack(buffer_s), np.vstack(buffer_a), np.array(discounted_r)[:, np.newaxis]
buffer_s, buffer_a, buffer_r = [], [], []
QUEUE.put(np.hstack((bs, ba, br)))
if GLOBAL_UPDATE_COUNTER >= MIN_BATCH_SIZE:
ROLLING_EVENT.clear() # stop collecting data
UPDATE_EVENT.set() # globalPPO update
if GLOBAL_EP >= EP_MAX: # stop training
COORD.request_stop()
break
# record reward changes, plot later
if len(GLOBAL_RUNNING_R) == 0: GLOBAL_RUNNING_R.append(ep_r)
else: GLOBAL_RUNNING_R.append(GLOBAL_RUNNING_R[-1]*0.9+ep_r*0.1)
GLOBAL_EP += 1
print('{0:.1f}%'.format(GLOBAL_EP/EP_MAX*100), '|W%i' % self.wid, '|Ep_r: %.2f' % ep_r,)
if __name__ == '__main__':
GLOBAL_PPO = PPO()
UPDATE_EVENT, ROLLING_EVENT = threading.Event(), threading.Event()
UPDATE_EVENT.clear() # no update now
ROLLING_EVENT.set() # start to roll out
workers = [Worker(wid=i) for i in range(N_WORKER)]
GLOBAL_UPDATE_COUNTER, GLOBAL_EP = 0, 0
GLOBAL_RUNNING_R = []
COORD = tf.train.Coordinator()
QUEUE = queue.Queue()
threads = []
for worker in workers: # worker threads
t = threading.Thread(target=worker.work, args=())
t.start()
threads.append(t)
# add a PPO updating thread
threads.append(threading.Thread(target=GLOBAL_PPO.update,))
threads[-1].start()
COORD.join(threads)
# plot reward change and testing
plt.plot(np.arange(len(GLOBAL_RUNNING_R)), GLOBAL_RUNNING_R)
plt.xlabel('Episode'); plt.ylabel('Moving reward'); plt.ion(); plt.show()
env.set_fps(30)
while True:
s = env.reset()
for t in range(400):
env.render()
s = env.step(GLOBAL_PPO.choose_action(s))[0]
================================================
FILE: experiments/Robot_arm/arm_env.py
================================================
"""
Environment for Robot Arm.
You can customize this script in a way you want.
View more on [莫烦Python] : https://morvanzhou.github.io/tutorials/
Requirement:
pyglet >= 1.2.4
numpy >= 1.12.1
"""
import numpy as np
import pyglet
pyglet.clock.set_fps_limit(10000)
class ArmEnv(object):
action_bound = [-1, 1]
action_dim = 2
state_dim = 7
dt = .1 # refresh rate
arm1l = 100
arm2l = 100
viewer = None
viewer_xy = (400, 400)
get_point = False
mouse_in = np.array([False])
point_l = 15
grab_counter = 0
def __init__(self, mode='easy'):
# node1 (l, d_rad, x, y),
# node2 (l, d_rad, x, y)
self.mode = mode
self.arm_info = np.zeros((2, 4))
self.arm_info[0, 0] = self.arm1l
self.arm_info[1, 0] = self.arm2l
self.point_info = np.array([250, 303])
self.point_info_init = self.point_info.copy()
self.center_coord = np.array(self.viewer_xy)/2
def step(self, action):
# action = (node1 angular v, node2 angular v)
action = np.clip(action, *self.action_bound)
self.arm_info[:, 1] += action * self.dt
self.arm_info[:, 1] %= np.pi * 2
arm1rad = self.arm_info[0, 1]
arm2rad = self.arm_info[1, 1]
arm1dx_dy = np.array([self.arm_info[0, 0] * np.cos(arm1rad), self.arm_info[0, 0] * np.sin(arm1rad)])
arm2dx_dy = np.array([self.arm_info[1, 0] * np.cos(arm2rad), self.arm_info[1, 0] * np.sin(arm2rad)])
self.arm_info[0, 2:4] = self.center_coord + arm1dx_dy # (x1, y1)
self.arm_info[1, 2:4] = self.arm_info[0, 2:4] + arm2dx_dy # (x2, y2)
s, arm2_distance = self._get_state()
r = self._r_func(arm2_distance)
return s, r, self.get_point
def reset(self):
self.get_point = False
self.grab_counter = 0
if self.mode == 'hard':
pxy = np.clip(np.random.rand(2) * self.viewer_xy[0], 100, 300)
self.point_info[:] = pxy
else:
arm1rad, arm2rad = np.random.rand(2) * np.pi * 2
self.arm_info[0, 1] = arm1rad
self.arm_info[1, 1] = arm2rad
arm1dx_dy = np.array([self.arm_info[0, 0] * np.cos(arm1rad), self.arm_info[0, 0] * np.sin(arm1rad)])
arm2dx_dy = np.array([self.arm_info[1, 0] * np.cos(arm2rad), self.arm_info[1, 0] * np.sin(arm2rad)])
self.arm_info[0, 2:4] = self.center_coord + arm1dx_dy # (x1, y1)
self.arm_info[1, 2:4] = self.arm_info[0, 2:4] + arm2dx_dy # (x2, y2)
self.point_info[:] = self.point_info_init
return self._get_state()[0]
def render(self):
if self.viewer is None:
self.viewer = Viewer(*self.viewer_xy, self.arm_info, self.point_info, self.point_l, self.mouse_in)
self.viewer.render()
def sample_action(self):
return np.random.uniform(*self.action_bound, size=self.action_dim)
def set_fps(self, fps=30):
pyglet.clock.set_fps_limit(fps)
def _get_state(self):
# return the distance (dx, dy) between arm finger point with blue point
arm_end = self.arm_info[:, 2:4]
t_arms = np.ravel(arm_end - self.point_info)
center_dis = (self.center_coord - self.point_info)/200
in_point = 1 if self.grab_counter > 0 else 0
return np.hstack([in_point, t_arms/200, center_dis,
# arm1_distance_p, arm1_distance_b,
]), t_arms[-2:]
def _r_func(self, distance):
t = 50
abs_distance = np.sqrt(np.sum(np.square(distance)))
r = -abs_distance/200
if abs_distance < self.point_l and (not self.get_point):
r += 1.
self.grab_counter += 1
if self.grab_counter > t:
r += 10.
self.get_point = True
elif abs_distance > self.point_l:
self.grab_counter = 0
self.get_point = False
return r
class Viewer(pyglet.window.Window):
color = {
'background': [1]*3 + [1]
}
fps_display = pyglet.clock.ClockDisplay()
bar_thc = 5
def __init__(self, width, height, arm_info, point_info, point_l, mouse_in):
super(Viewer, self).__init__(width, height, resizable=False, caption='Arm', vsync=False) # vsync=False to not use the monitor FPS
self.set_location(x=80, y=10)
pyglet.gl.glClearColor(*self.color['background'])
self.arm_info = arm_info
self.point_info = point_info
self.mouse_in = mouse_in
self.point_l = point_l
self.center_coord = np.array((min(width, height)/2, ) * 2)
self.batch = pyglet.graphics.Batch()
arm1_box, arm2_box, point_box = [0]*8, [0]*8, [0]*8
c1, c2, c3 = (249, 86, 86)*4, (86, 109, 249)*4, (249, 39, 65)*4
self.point = self.batch.add(4, pyglet.gl.GL_QUADS, None, ('v2f', point_box), ('c3B', c2))
self.arm1 = self.batch.add(4, pyglet.gl.GL_QUADS, None, ('v2f', arm1_box), ('c3B', c1))
self.arm2 = self.batch.add(4, pyglet.gl.GL_QUADS, None, ('v2f', arm2_box), ('c3B', c1))
def render(self):
pyglet.clock.tick()
self._update_arm()
self.switch_to()
self.dispatch_events()
self.dispatch_event('on_draw')
self.flip()
def on_draw(self):
self.clear()
self.batch.draw()
# self.fps_display.draw()
def _update_arm(self):
point_l = self.point_l
point_box = (self.point_info[0] - point_l, self.point_info[1] - point_l,
self.point_info[0] + point_l, self.point_info[1] - point_l,
self.point_info[0] + point_l, self.point_info[1] + point_l,
self.point_info[0] - point_l, self.point_info[1] + point_l)
self.point.vertices = point_box
arm1_coord = (*self.center_coord, *(self.arm_info[0, 2:4])) # (x0, y0, x1, y1)
arm2_coord = (*(self.arm_info[0, 2:4]), *(self.arm_info[1, 2:4])) # (x1, y1, x2, y2)
arm1_thick_rad = np.pi / 2 - self.arm_info[0, 1]
x01, y01 = arm1_coord[0] - np.cos(arm1_thick_rad) * self.bar_thc, arm1_coord[1] + np.sin(
arm1_thick_rad) * self.bar_thc
x02, y02 = arm1_coord[0] + np.cos(arm1_thick_rad) * self.bar_thc, arm1_coord[1] - np.sin(
arm1_thick_rad) * self.bar_thc
x11, y11 = arm1_coord[2] + np.cos(arm1_thick_rad) * self.bar_thc, arm1_coord[3] - np.sin(
arm1_thick_rad) * self.bar_thc
x12, y12 = arm1_coord[2] - np.cos(arm1_thick_rad) * self.bar_thc, arm1_coord[3] + np.sin(
arm1_thick_rad) * self.bar_thc
arm1_box = (x01, y01, x02, y02, x11, y11, x12, y12)
arm2_thick_rad = np.pi / 2 - self.arm_info[1, 1]
x11_, y11_ = arm2_coord[0] + np.cos(arm2_thick_rad) * self.bar_thc, arm2_coord[1] - np.sin(
arm2_thick_rad) * self.bar_thc
x12_, y12_ = arm2_coord[0] - np.cos(arm2_thick_rad) * self.bar_thc, arm2_coord[1] + np.sin(
arm2_thick_rad) * self.bar_thc
x21, y21 = arm2_coord[2] - np.cos(arm2_thick_rad) * self.bar_thc, arm2_coord[3] + np.sin(
arm2_thick_rad) * self.bar_thc
x22, y22 = arm2_coord[2] + np.cos(arm2_thick_rad) * self.bar_thc, arm2_coord[3] - np.sin(
arm2_thick_rad) * self.bar_thc
arm2_box = (x11_, y11_, x12_, y12_, x21, y21, x22, y22)
self.arm1.vertices = arm1_box
self.arm2.vertices = arm2_box
def on_key_press(self, symbol, modifiers):
if symbol == pyglet.window.key.UP:
self.arm_info[0, 1] += .1
print(self.arm_info[:, 2:4] - self.point_info)
elif symbol == pyglet.window.key.DOWN:
self.arm_info[0, 1] -= .1
print(self.arm_info[:, 2:4] - self.point_info)
elif symbol == pyglet.window.key.LEFT:
self.arm_info[1, 1] += .1
print(self.arm_info[:, 2:4] - self.point_info)
elif symbol == pyglet.window.key.RIGHT:
self.arm_info[1, 1] -= .1
print(self.arm_info[:, 2:4] - self.point_info)
elif symbol == pyglet.window.key.Q:
pyglet.clock.set_fps_limit(1000)
elif symbol == pyglet.window.key.A:
pyglet.clock.set_fps_limit(30)
def on_mouse_motion(self, x, y, dx, dy):
self.point_info[:] = [x, y]
def on_mouse_enter(self, x, y):
self.mouse_in[0] = True
def on_mouse_leave(self, x, y):
self.mouse_in[0] = False
================================================
FILE: experiments/Solve_BipedalWalker/A3C.py
================================================
"""
Asynchronous Advantage Actor Critic (A3C), Reinforcement Learning.
The BipedalWalker example.
View more on [莫烦Python] : https://morvanzhou.github.io/tutorials/
Using:
tensorflow 1.8.0
gym 0.10.5
"""
import multiprocessing
import threading
import tensorflow as tf
import numpy as np
import gym
import os
import shutil
GAME = 'BipedalWalker-v2'
OUTPUT_GRAPH = False
LOG_DIR = './log'
N_WORKERS = multiprocessing.cpu_count()
MAX_GLOBAL_EP = 8000
GLOBAL_NET_SCOPE = 'Global_Net'
UPDATE_GLOBAL_ITER = 10
GAMMA = 0.99
ENTROPY_BETA = 0.005
LR_A = 0.00005 # learning rate for actor
LR_C = 0.0001 # learning rate for critic
GLOBAL_RUNNING_R = []
GLOBAL_EP = 0
env = gym.make(GAME)
N_S = env.observation_space.shape[0]
N_A = env.action_space.shape[0]
A_BOUND = [env.action_space.low, env.action_space.high]
del env
class ACNet(object):
def __init__(self, scope, globalAC=None):
if scope == GLOBAL_NET_SCOPE: # get global network
with tf.variable_scope(scope):
self.s = tf.placeholder(tf.float32, [None, N_S], 'S')
self._build_net()
self.a_params = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope=scope + '/actor')
self.c_params = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope=scope + '/critic')
else: # local net, calculate losses
with tf.variable_scope(scope):
self.s = tf.placeholder(tf.float32, [None, N_S], 'S')
self.a_his = tf.placeholder(tf.float32, [None, N_A], 'A')
self.v_target = tf.placeholder(tf.float32, [None, 1], 'Vtarget')
mu, sigma, self.v = self._build_net()
td = tf.subtract(self.v_target, self.v, name='TD_error')
with tf.name_scope('c_loss'):
self.c_loss = tf.reduce_mean(tf.square(td))
with tf.name_scope('wrap_a_out'):
self.test = sigma[0]
mu, sigma = mu * A_BOUND[1], sigma + 1e-5
normal_dist = tf.contrib.distributions.Normal(mu, sigma)
with tf.name_scope('a_loss'):
log_prob = normal_dist.log_prob(self.a_his)
exp_v = log_prob * td
entropy = normal_dist.entropy() # encourage exploration
self.exp_v = ENTROPY_BETA * entropy + exp_v
self.a_loss = tf.reduce_mean(-self.exp_v)
with tf.name_scope('choose_a'): # use local params to choose action
self.A = tf.clip_by_value(tf.squeeze(normal_dist.sample(1)), *A_BOUND)
with tf.name_scope('local_grad'):
self.a_params = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope=scope + '/actor')
self.c_params = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope=scope + '/critic')
self.a_grads = tf.gradients(self.a_loss, self.a_params)
self.c_grads = tf.gradients(self.c_loss, self.c_params)
with tf.name_scope('sync'):
with tf.name_scope('pull'):
self.pull_a_params_op = [l_p.assign(g_p) for l_p, g_p in zip(self.a_params, globalAC.a_params)]
self.pull_c_params_op = [l_p.assign(g_p) for l_p, g_p in zip(self.c_params, globalAC.c_params)]
with tf.name_scope('push'):
self.update_a_op = OPT_A.apply_gradients(zip(self.a_grads, globalAC.a_params))
self.update_c_op = OPT_C.apply_gradients(zip(self.c_grads, globalAC.c_params))
def _build_net(self):
w_init = tf.contrib.layers.xavier_initializer()
with tf.variable_scope('actor'):
l_a = tf.layers.dense(self.s, 500, tf.nn.relu6, kernel_initializer=w_init, name='la')
l_a = tf.layers.dense(l_a, 300, tf.nn.relu6, kernel_initializer=w_init, name='la2')
mu = tf.layers.dense(l_a, N_A, tf.nn.tanh, kernel_initializer=w_init, name='mu')
sigma = tf.layers.dense(l_a, N_A, tf.nn.softplus, kernel_initializer=w_init, name='sigma')
with tf.variable_scope('critic'):
l_c = tf.layers.dense(self.s, 500, tf.nn.relu6, kernel_initializer=w_init, name='lc')
l_c = tf.layers.dense(l_c, 300, tf.nn.relu6, kernel_initializer=w_init, name='lc2')
v = tf.layers.dense(l_c, 1, kernel_initializer=w_init, name='v') # state value
return mu, sigma, v
def update_global(self, feed_dict): # run by a local
_, _, t = SESS.run([self.update_a_op, self.update_c_op, self.test], feed_dict) # local grads applies to global net
return t
def pull_global(self): # run by a local
SESS.run([self.pull_a_params_op, self.pull_c_params_op])
def choose_action(self, s): # run by a local
s = s[np.newaxis, :]
return SESS.run(self.A, {self.s: s})
class Worker(object):
def __init__(self, name, globalAC):
self.env = gym.make(GAME)
self.name = name
self.AC = ACNet(name, globalAC)
def work(self):
global GLOBAL_RUNNING_R, GLOBAL_EP
total_step = 1
buffer_s, buffer_a, buffer_r = [], [], []
while not COORD.should_stop() and GLOBAL_EP < MAX_GLOBAL_EP:
s = self.env.reset()
ep_r = 0
while True:
if self.name == 'W_0' and total_step % 30 == 0:
self.env.render()
a = self.AC.choose_action(s)
s_, r, done, info = self.env.step(a)
if r == -100: r = -2
ep_r += r
buffer_s.append(s)
buffer_a.append(a)
buffer_r.append(r)
if total_step % UPDATE_GLOBAL_ITER == 0 or done: # update global and assign to local net
if done:
v_s_ = 0 # terminal
else:
v_s_ = SESS.run(self.AC.v, {self.AC.s: s_[np.newaxis, :]})[0, 0]
buffer_v_target = []
for r in buffer_r[::-1]: # reverse buffer r
v_s_ = r + GAMMA * v_s_
buffer_v_target.append(v_s_)
buffer_v_target.reverse()
buffer_s, buffer_a, buffer_v_target = np.vstack(buffer_s), np.vstack(buffer_a), np.vstack(buffer_v_target)
feed_dict = {
self.AC.s: buffer_s,
self.AC.a_his: buffer_a,
self.AC.v_target: buffer_v_target,
}
test = self.AC.update_global(feed_dict)
buffer_s, buffer_a, buffer_r = [], [], []
self.AC.pull_global()
s = s_
total_step += 1
if done:
achieve = '| Achieve' if self.env.unwrapped.hull.position[0] >= 88 else '| -------'
if len(GLOBAL_RUNNING_R) == 0: # record running episode reward
GLOBAL_RUNNING_R.append(ep_r)
else:
GLOBAL_RUNNING_R.append(0.95 * GLOBAL_RUNNING_R[-1] + 0.05 * ep_r)
print(
self.name,
"Ep:", GLOBAL_EP,
achieve,
"| Pos: %i" % self.env.unwrapped.hull.position[0],
"| RR: %.1f" % GLOBAL_RUNNING_R[-1],
'| EpR: %.1f' % ep_r,
'| var:', test,
)
GLOBAL_EP += 1
break
if __name__ == "__main__":
SESS = tf.Session()
with tf.device("/cpu:0"):
OPT_A = tf.train.RMSPropOptimizer(LR_A, name='RMSPropA')
OPT_C = tf.train.RMSPropOptimizer(LR_C, name='RMSPropC')
GLOBAL_AC = ACNet(GLOBAL_NET_SCOPE) # we only need its params
workers = []
# Create worker
for i in range(N_WORKERS):
i_name = 'W_%i' % i # worker name
workers.append(Worker(i_name, GLOBAL_AC))
COORD = tf.train.Coordinator()
SESS.run(tf.global_variables_initializer())
worker_threads = []
for worker in workers:
job = lambda: worker.work()
t = threading.Thread(target=job)
t.start()
worker_threads.append(t)
COORD.join(worker_threads)
import matplotlib.pyplot as plt
plt.plot(GLOBAL_RUNNING_R)
plt.xlabel('episode')
plt.ylabel('global running reward')
plt.show()
================================================
FILE: experiments/Solve_BipedalWalker/A3C_rnn.py
================================================
"""
Asynchronous Advantage Actor Critic (A3C), Reinforcement Learning.
The BipedalWalker example.
View more on [莫烦Python] : https://morvanzhou.github.io/tutorials/
Using:
tensorflow 1.8.0
gym 0.10.5
"""
import multiprocessing
import threading
import tensorflow as tf
import numpy as np
import gym
import os
import shutil
GAME = 'BipedalWalker-v2'
OUTPUT_GRAPH = False
LOG_DIR = './log'
N_WORKERS = multiprocessing.cpu_count()
MAX_GLOBAL_EP = 8000
GLOBAL_NET_SCOPE = 'Global_Net'
UPDATE_GLOBAL_ITER = 10
GAMMA = 0.9
ENTROPY_BETA = 0.001
LR_A = 0.00002 # learning rate for actor
LR_C = 0.0001 # learning rate for critic
GLOBAL_RUNNING_R = []
GLOBAL_EP = 0
env = gym.make(GAME)
N_S = env.observation_space.shape[0]
N_A = env.action_space.shape[0]
A_BOUND = [env.action_space.low, env.action_space.high]
del env
class ACNet(object):
def __init__(self, scope, globalAC=None):
if scope == GLOBAL_NET_SCOPE: # get global network
with tf.variable_scope(scope):
self.s = tf.placeholder(tf.float32, [None, N_S], 'S')
self._build_net()
self.a_params = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope=scope + '/actor')
self.c_params = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope=scope + '/critic')
else: # local net, calculate losses
with tf.variable_scope(scope):
self.s = tf.placeholder(tf.float32, [None, N_S], 'S')
self.a_his = tf.placeholder(tf.float32, [None, N_A], 'A')
self.v_target = tf.placeholder(tf.float32, [None, 1], 'Vtarget')
mu, sigma, self.v = self._build_net()
td = tf.subtract(self.v_target, self.v, name='TD_error')
with tf.name_scope('c_loss'):
self.c_loss = tf.reduce_mean(tf.square(td))
with tf.name_scope('wrap_a_out'):
self.test = sigma[0]
mu, sigma = mu * A_BOUND[1], sigma + 1e-5
normal_dist = tf.contrib.distributions.Normal(mu, sigma)
with tf.name_scope('a_loss'):
log_prob = normal_dist.log_prob(self.a_his)
exp_v = log_prob * td
entropy = normal_dist.entropy() # encourage exploration
self.exp_v = ENTROPY_BETA * entropy + exp_v
self.a_loss = tf.reduce_mean(-self.exp_v)
with tf.name_scope('choose_a'): # use local params to choose action
self.A = tf.clip_by_value(tf.squeeze(normal_dist.sample(1)), A_BOUND[0], A_BOUND[1])
with tf.name_scope('local_grad'):
self.a_params = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope=scope + '/actor')
self.c_params = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope=scope + '/critic')
self.a_grads = tf.gradients(self.a_loss, self.a_params)
self.c_grads = tf.gradients(self.c_loss, self.c_params)
with tf.name_scope('sync'):
with tf.name_scope('pull'):
self.pull_a_params_op = [l_p.assign(g_p) for l_p, g_p in
zip(self.a_params, globalAC.a_params)]
self.pull_c_params_op = [l_p.assign(g_p) for l_p, g_p in
zip(self.c_params, globalAC.c_params)]
with tf.name_scope('push'):
self.update_a_op = OPT_A.apply_gradients(zip(self.a_grads, globalAC.a_params))
self.update_c_op = OPT_C.apply_gradients(zip(self.c_grads, globalAC.c_params))
def _build_net(self):
w_init = tf.random_normal_initializer(0., .1)
with tf.variable_scope('critic'): # only critic controls the rnn update
cell_size = 126
s = tf.expand_dims(self.s, axis=1,
name='timely_input') # [time_step, feature] => [time_step, batch, feature]
rnn_cell = tf.contrib.rnn.BasicRNNCell(cell_size)
self.init_state = rnn_cell.zero_state(batch_size=1, dtype=tf.float32)
outputs, self.final_state = tf.nn.dynamic_rnn(
cell=rnn_cell, inputs=s, initial_state=self.init_state, time_major=True)
cell_out = tf.reshape(outputs, [-1, cell_size], name='flatten_rnn_outputs') # joined state representation
l_c = tf.layers.dense(cell_out, 512, tf.nn.relu6, kernel_initializer=w_init, name='lc')
v = tf.layers.dense(l_c, 1, kernel_initializer=w_init, name='v') # state value
with tf.variable_scope('actor'): # state representation is based on critic
cell_out = tf.stop_gradient(cell_out, name='c_cell_out') # from what critic think it is
l_a = tf.layers.dense(cell_out, 512, tf.nn.relu6, kernel_initializer=w_init, name='la')
mu = tf.layers.dense(l_a, N_A, tf.nn.tanh, kernel_initializer=w_init, name='mu')
sigma = tf.layers.dense(l_a, N_A, tf.nn.softplus, kernel_initializer=w_init, name='sigma') # restrict variance
return mu, sigma, v
def update_global(self, feed_dict): # run by a local
_, _, t = SESS.run([self.update_a_op, self.update_c_op, self.test], feed_dict) # local grads applies to global net
return t
def pull_global(self): # run by a local
SESS.run([self.pull_a_params_op, self.pull_c_params_op])
def choose_action(self, s, cell_state): # run by a local
s = s[np.newaxis, :]
a, cell_state = SESS.run([self.A, self.final_state], {self.s: s, self.init_state: cell_state})
return a, cell_state
class Worker(object):
def __init__(self, name, globalAC):
self.env = gym.make(GAME)
self.name = name
self.AC = ACNet(name, globalAC)
def work(self):
global GLOBAL_RUNNING_R, GLOBAL_EP
total_step = 1
buffer_s, buffer_a, buffer_r = [], [], []
while not COORD.should_stop() and GLOBAL_EP < MAX_GLOBAL_EP:
s = self.env.reset()
ep_r = 0
rnn_state = SESS.run(self.AC.init_state) # zero rnn state at beginning
keep_state = rnn_state.copy() # keep rnn state for updating global net
while True:
if self.name == 'W_0' and total_step % 30 == 0:
self.env.render()
a, rnn_state_ = self.AC.choose_action(s, rnn_state) # get the action and next rnn state
s_, r, done, info = self.env.step(a)
if r == -100: r = -2
ep_r += r
buffer_s.append(s)
buffer_a.append(a)
buffer_r.append(r)
if total_step % UPDATE_GLOBAL_ITER == 0 or done: # update global and assign to local net
if done:
v_s_ = 0 # terminal
else:
v_s_ = SESS.run(self.AC.v, {self.AC.s: s_[np.newaxis, :], self.AC.init_state: rnn_state_})[
0, 0]
buffer_v_target = []
for r in buffer_r[::-1]: # reverse buffer r
v_s_ = r + GAMMA * v_s_
buffer_v_target.append(v_s_)
buffer_v_target.reverse()
buffer_s, buffer_a, buffer_v_target = np.vstack(buffer_s), np.vstack(buffer_a), np.vstack(
buffer_v_target)
feed_dict = {
self.AC.s: buffer_s,
self.AC.a_his: buffer_a,
self.AC.v_target: buffer_v_target,
self.AC.init_state: keep_state,
}
test = self.AC.update_global(feed_dict)
buffer_s, buffer_a, buffer_r = [], [], []
self.AC.pull_global()
keep_state = rnn_state_.copy() # replace the keep_state as the new initial rnn state_
s = s_
rnn_state = rnn_state_ # renew rnn state
total_step += 1
if done:
achieve = '| Achieve' if self.env.unwrapped.hull.position[0] >= 88 else '| -------'
if len(GLOBAL_RUNNING_R) == 0: # record running episode reward
GLOBAL_RUNNING_R.append(ep_r)
else:
GLOBAL_RUNNING_R.append(0.95 * GLOBAL_RUNNING_R[-1] + 0.05 * ep_r)
print(
self.name,
"Ep:", GLOBAL_EP,
achieve,
"| Pos: %i" % self.env.unwrapped.hull.position[0],
"| RR: %.1f" % GLOBAL_RUNNING_R[-1],
'| EpR: %.1f' % ep_r,
'| var:', test,
)
GLOBAL_EP += 1
break
if __name__ == "__main__":
SESS = tf.Session()
with tf.device("/cpu:0"):
OPT_A = tf.train.RMSPropOptimizer(LR_A, name='RMSPropA', decay=0.95)
OPT_C = tf.train.RMSPropOptimizer(LR_C, name='RMSPropC', decay=0.95)
GLOBAL_AC = ACNet(GLOBAL_NET_SCOPE) # we only need its params
workers = []
# Create worker
for i in range(N_WORKERS):
i_name = 'W_%i' % i # worker name
workers.append(Worker(i_name, GLOBAL_AC))
COORD = tf.train.Coordinator()
SESS.run(tf.global_variables_initializer())
if OUTPUT_GRAPH:
if os.path.exists(LOG_DIR):
shutil.rmtree(LOG_DIR)
tf.summary.FileWriter(LOG_DIR, SESS.graph)
worker_threads = []
for worker in workers:
t = threading.Thread(target=worker.work)
t.start()
worker_threads.append(t)
COORD.join(worker_threads)
import matplotlib.pyplot as plt
plt.plot(GLOBAL_RUNNING_R)
plt.xlabel('episode')
plt.ylabel('global running reward')
plt.show()
================================================
FILE: experiments/Solve_BipedalWalker/DDPG.py
================================================
import tensorflow as tf
import numpy as np
import gym
import os
import shutil
np.random.seed(1)
tf.set_random_seed(1)
MAX_EPISODES = 2000
LR_A = 0.0005 # learning rate for actor
LR_C = 0.0005 # learning rate for critic
GAMMA = 0.999 # reward discount
REPLACE_ITER_A = 1700
REPLACE_ITER_C = 1500
MEMORY_CAPACITY = 200000
BATCH_SIZE = 32
DISPLAY_THRESHOLD = 100 # display until the running reward > 100
DATA_PATH = './data'
LOAD_MODEL = False
SAVE_MODEL_ITER = 100000
RENDER = False
OUTPUT_GRAPH = False
ENV_NAME = 'BipedalWalker-v2'
GLOBAL_STEP = tf.Variable(0, trainable=False)
INCREASE_GS = GLOBAL_STEP.assign(tf.add(GLOBAL_STEP, 1))
LR_A = tf.train.exponential_decay(LR_A, GLOBAL_STEP, 10000, .97, staircase=True)
LR_C = tf.train.exponential_decay(LR_C, GLOBAL_STEP, 10000, .97, staircase=True)
END_POINT = (200 - 10) * (14/30) # from game
env = gym.make(ENV_NAME)
env.seed(1)
STATE_DIM = env.observation_space.shape[0] # 24
ACTION_DIM = env.action_space.shape[0] # 4
ACTION_BOUND = env.action_space.high # [1, 1, 1, 1]
# all placeholder for tf
with tf.name_scope('S'):
S = tf.placeholder(tf.float32, shape=[None, STATE_DIM], name='s')
with tf.name_scope('R'):
R = tf.placeholder(tf.float32, [None, 1], name='r')
with tf.name_scope('S_'):
S_ = tf.placeholder(tf.float32, shape=[None, STATE_DIM], name='s_')
############################### Actor ####################################
class Actor(object):
def __init__(self, sess, action_dim, action_bound, learning_rate, t_replace_iter):
self.sess = sess
self.a_dim = action_dim
self.action_bound = action_bound
self.lr = learning_rate
self.t_replace_iter = t_replace_iter
self.t_replace_counter = 0
with tf.variable_scope('Actor'):
# input s, output a
self.a = self._build_net(S, scope='eval_net', trainable=True)
# input s_, output a, get a_ for critic
self.a_ = self._build_net(S_, scope='target_net', trainable=False)
self.e_params = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope='Actor/eval_net')
self.t_params = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope='Actor/target_net')
def _build_net(self, s, scope, trainable):
with tf.variable_scope(scope):
init_w = tf.random_normal_initializer(0., 0.01)
init_b = tf.constant_initializer(0.01)
net = tf.layers.dense(s, 500, activation=tf.nn.relu,
kernel_initializer=init_w, bias_initializer=init_b, name='l1', trainable=trainable)
net = tf.layers.dense(net, 200, activation=tf.nn.relu,
kernel_initializer=init_w, bias_initializer=init_b, name='l2', trainable=trainable)
with tf.variable_scope('a'):
actions = tf.layers.dense(net, self.a_dim, activation=tf.nn.tanh, kernel_initializer=init_w,
bias_initializer=init_b, name='a', trainable=trainable)
scaled_a = tf.multiply(actions, self.action_bound, name='scaled_a') # Scale output to -action_bound to action_bound
return scaled_a
def learn(self, s): # batch update
self.sess.run(self.train_op, feed_dict={S: s})
if self.t_replace_counter % self.t_replace_iter == 0:
self.sess.run([tf.assign(t, e) for t, e in zip(self.t_params, self.e_params)])
self.t_replace_counter += 1
def choose_action(self, s):
s = s[np.newaxis, :] # single state
return self.sess.run(self.a, feed_dict={S: s})[0] # single action
def add_grad_to_graph(self, a_grads):
with tf.variable_scope('policy_grads'):
# ys = policy;
# xs = policy's parameters;
# self.a_grads = the gradients of the policy to get more Q
# tf.gradients will calculate dys/dxs with a initial gradients for ys, so this is dq/da * da/dparams
self.policy_grads_and_vars = tf.gradients(ys=self.a, xs=self.e_params, grad_ys=a_grads)
with tf.variable_scope('A_train'):
opt = tf.train.RMSPropOptimizer(-self.lr) # (- learning rate) for ascent policy
self.train_op = opt.apply_gradients(zip(self.policy_grads_and_vars, self.e_params), global_step=GLOBAL_STEP)
############################### Critic ####################################
class Critic(object):
def __init__(self, sess, state_dim, action_dim, learning_rate, gamma, t_replace_iter, a, a_):
self.sess = sess
self.s_dim = state_dim
self.a_dim = action_dim
self.lr = learning_rate
self.gamma = gamma
self.t_replace_iter = t_replace_iter
self.t_replace_counter = 0
with tf.variable_scope('Critic'):
# Input (s, a), output q
self.a = a
self.q = self._build_net(S, self.a, 'eval_net', trainable=True)
# Input (s_, a_), output q_ for q_target
self.q_ = self._build_net(S_, a_, 'target_net', trainable=False) # target_q is based on a_ from Actor's target_net
self.e_params = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope='Critic/eval_net')
self.t_params = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope='Critic/target_net')
with tf.variable_scope('target_q'):
self.target_q = R + self.gamma * self.q_
with tf.variable_scope('abs_TD'):
self.abs_td = tf.abs(self.target_q - self.q)
self.ISWeights = tf.placeholder(tf.float32, [None, 1], name='IS_weights')
with tf.variable_scope('TD_error'):
self.loss = tf.reduce_mean(self.ISWeights * tf.squared_difference(self.target_q, self.q))
with tf.variable_scope('C_train'):
self.train_op = tf.train.AdamOptimizer(self.lr).minimize(self.loss, global_step=GLOBAL_STEP)
with tf.variable_scope('a_grad'):
self.a_grads = tf.gradients(self.q, a)[0] # tensor of gradients of each sample (None, a_dim)
def _build_net(self, s, a, scope, trainable):
with tf.variable_scope(scope):
init_w = tf.random_normal_initializer(0., 0.01)
init_b = tf.constant_initializer(0.01)
with tf.variable_scope('l1'):
n_l1 = 700
# combine the action and states together in this way
w1_s = tf.get_variable('w1_s', [self.s_dim, n_l1], initializer=init_w, trainable=trainable)
w1_a = tf.get_variable('w1_a', [self.a_dim, n_l1], initializer=init_w, trainable=trainable)
b1 = tf.get_variable('b1', [1, n_l1], initializer=init_b, trainable=trainable)
net = tf.nn.relu(tf.matmul(s, w1_s) + tf.matmul(a, w1_a) + b1)
with tf.variable_scope('l2'):
net = tf.layers.dense(net, 20, activation=tf.nn.relu, kernel_initializer=init_w,
bias_initializer=init_b, name='l2', trainable=trainable)
with tf.variable_scope('q'):
q = tf.layers.dense(net, 1, kernel_initializer=init_w, bias_initializer=init_b, trainable=trainable) # Q(s,a)
return q
def learn(self, s, a, r, s_, ISW):
_, abs_td = self.sess.run([self.train_op, self.abs_td], feed_dict={S: s, self.a: a, R: r, S_: s_, self.ISWeights: ISW})
if self.t_replace_counter % self.t_replace_iter == 0:
self.sess.run([tf.assign(t, e) for t, e in zip(self.t_params, self.e_params)])
self.t_replace_counter += 1
return abs_td
class SumTree(object):
"""
This SumTree code is modified version and the original code is from:
https://github.com/jaara/AI-blog/blob/master/SumTree.py
Story the data with it priority in tree and data frameworks.
"""
data_pointer = 0
def __init__(self, capacity):
self.capacity = capacity # for all priority values
self.tree = np.zeros(2 * capacity - 1)+1e-5
# [--------------Parent nodes-------------][-------leaves to recode priority-------]
# size: capacity - 1 size: capacity
self.data = np.zeros(capacity, dtype=object) # for all transitions
# [--------------data frame-------------]
# size: capacity
def add_new_priority(self, p, data):
leaf_idx = self.data_pointer + self.capacity - 1
self.data[self.data_pointer] = data # update data_frame
self.update(leaf_idx, p) # update tree_frame
self.data_pointer += 1
if self.data_pointer >= self.capacity: # replace when exceed the capacity
self.data_pointer = 0
def update(self, tree_idx, p):
change = p - self.tree[tree_idx]
self.tree[tree_idx] = p
self._propagate_change(tree_idx, change)
def _propagate_change(self, tree_idx, change):
"""change the sum of priority value in all parent nodes"""
parent_idx = (tree_idx - 1) // 2
self.tree[parent_idx] += change
if parent_idx != 0:
self._propagate_change(parent_idx, change)
def get_leaf(self, lower_bound):
leaf_idx = self._retrieve(lower_bound) # search the max leaf priority based on the lower_bound
data_idx = leaf_idx - self.capacity + 1
return [leaf_idx, self.tree[leaf_idx], self.data[data_idx]]
def _retrieve(self, lower_bound, parent_idx=0):
"""
Tree structure and array storage:
Tree index:
0 -> storing priority sum
/ \
1 2
/ \ / \
3 4 5 6 -> storing priority for transitions
Array type for storing:
[0,1,2,3,4,5,6]
"""
left_child_idx = 2 * parent_idx + 1
right_child_idx = left_child_idx + 1
if left_child_idx >= len(self.tree): # end search when no more child
return parent_idx
if self.tree[left_child_idx] == self.tree[right_child_idx]:
return self._retrieve(lower_bound, np.random.choice([left_child_idx, right_child_idx]))
if lower_bound <= self.tree[left_child_idx]: # downward search, always search for a higher priority node
return self._retrieve(lower_bound, left_child_idx)
else:
return self._retrieve(lower_bound - self.tree[left_child_idx], right_child_idx)
@property
def root_priority(self):
return self.tree[0] # the root
class Memory(object): # stored as ( s, a, r, s_ ) in SumTree
"""
This SumTree code is modified version and the original code is from:
https://github.com/jaara/AI-blog/blob/master/Seaquest-DDQN-PER.py
"""
epsilon = 0.001 # small amount to avoid zero priority
alpha = 0.6 # [0~1] convert the importance of TD error to priority
beta = 0.4 # importance-sampling, from initial value increasing to 1
beta_increment_per_sampling = 1e-5 # annealing the bias
abs_err_upper = 1 # for stability refer to paper
def __init__(self, capacity):
self.tree = SumTree(capacity)
def store(self, error, transition):
p = self._get_priority(error)
self.tree.add_new_priority(p, transition)
def prio_sample(self, n):
batch_idx, batch_memory, ISWeights = [], [], []
segment = self.tree.root_priority / n
self.beta = np.min([1, self.beta + self.beta_increment_per_sampling]) # max = 1
min_prob = np.min(self.tree.tree[-self.tree.capacity:]) / self.tree.root_priority
maxiwi = np.power(self.tree.capacity * min_prob, -self.beta) # for later normalizing ISWeights
for i in range(n):
a = segment * i
b = segment * (i + 1)
lower_bound = np.random.uniform(a, b)
while True:
idx, p, data = self.tree.get_leaf(lower_bound)
if type(data) is int:
i -= 1
lower_bound = np.random.uniform(segment * i, segment * (i+1))
else:
break
prob = p / self.tree.root_priority
ISWeights.append(self.tree.capacity * prob)
batch_idx.append(idx)
batch_memory.append(data)
ISWeights = np.vstack(ISWeights)
ISWeights = np.power(ISWeights, -self.beta) / maxiwi # normalize
return batch_idx, np.vstack(batch_memory), ISWeights
def random_sample(self, n):
idx = np.random.randint(0, self.tree.capacity, size=n, dtype=np.int)
return np.vstack(self.tree.data[idx])
def update(self, idx, error):
p = self._get_priority(error)
self.tree.update(idx, p)
def _get_priority(self, error):
error += self.epsilon # avoid 0
clipped_error = np.clip(error, 0, self.abs_err_upper)
return np.power(clipped_error, self.alpha)
sess = tf.Session()
# Create actor and critic.
actor = Actor(sess, ACTION_DIM, ACTION_BOUND, LR_A, REPLACE_ITER_A)
critic = Critic(sess, STATE_DIM, ACTION_DIM, LR_C, GAMMA, REPLACE_ITER_C, actor.a, actor.a_)
actor.add_grad_to_graph(critic.a_grads)
M = Memory(MEMORY_CAPACITY)
saver = tf.train.Saver(max_to_keep=100)
if LOAD_MODEL:
all_ckpt = tf.train.get_checkpoint_state('./data', 'checkpoint').all_model_checkpoint_paths
saver.restore(sess, all_ckpt[-1])
else:
if os.path.isdir(DATA_PATH): shutil.rmtree(DATA_PATH)
os.mkdir(DATA_PATH)
sess.run(tf.global_variables_initializer())
if OUTPUT_GRAPH:
tf.summary.FileWriter('logs', graph=sess.graph)
var = 3 # control exploration
var_min = 0.01
for i_episode in range(MAX_EPISODES):
# s = (hull angle speed, angular velocity, horizontal speed, vertical speed, position of joints and joints angular speed, legs contact with ground, and 10 lidar rangefinder measurements.)
s = env.reset()
ep_r = 0
while True:
if RENDER:
env.render()
a = actor.choose_action(s)
a = np.clip(np.random.normal(a, var), -1, 1) # add randomness to action selection for exploration
s_, r, done, _ = env.step(a) # r = total 300+ points up to the far end. If the robot falls, it gets -100.
if r == -100: r = -2
ep_r += r
transition = np.hstack((s, a, [r], s_))
max_p = np.max(M.tree.tree[-M.tree.capacity:])
M.store(max_p, transition)
if GLOBAL_STEP.eval(sess) > MEMORY_CAPACITY/20:
var = max([var*0.9999, var_min]) # decay the action randomness
tree_idx, b_M, ISWeights = M.prio_sample(BATCH_SIZE) # for critic update
b_s = b_M[:, :STATE_DIM]
b_a = b_M[:, STATE_DIM: STATE_DIM + ACTION_DIM]
b_r = b_M[:, -STATE_DIM - 1: -STATE_DIM]
b_s_ = b_M[:, -STATE_DIM:]
abs_td = critic.learn(b_s, b_a, b_r, b_s_, ISWeights)
actor.learn(b_s)
for i in range(len(tree_idx)): # update priority
idx = tree_idx[i]
M.update(idx, abs_td[i])
if GLOBAL_STEP.eval(sess) % SAVE_MODEL_ITER == 0:
ckpt_path = os.path.join(DATA_PATH, 'DDPG.ckpt')
save_path = saver.save(sess, ckpt_path, global_step=GLOBAL_STEP, write_meta_graph=False)
print("\nSave Model %s\n" % save_path)
if done:
if "running_r" not in globals():
running_r = ep_r
else:
running_r = 0.95*running_r + 0.05*ep_r
if running_r > DISPLAY_THRESHOLD: RENDER = True
else: RENDER = False
done = '| Achieve ' if env.unwrapped.hull.position[0] >= END_POINT else '| -----'
print('Episode:', i_episode,
done,
'| Running_r: %i' % int(running_r),
'| Epi_r: %.2f' % ep_r,
'| Exploration: %.3f' % var,
'| Pos: %.i' % int(env.unwrapped.hull.position[0]),
'| LR_A: %.6f' % sess.run(LR_A),
'| LR_C: %.6f' % sess.run(LR_C),
)
break
s = s_
sess.run(INCREASE_GS)
================================================
FILE: experiments/Solve_LunarLander/A3C.py
================================================
"""
Asynchronous Advantage Actor Critic (A3C) with continuous action space, Reinforcement Learning.
The Pendulum example. Convergence promised, but difficult environment, this code hardly converge.
View more on [莫烦Python] : https://morvanzhou.github.io/tutorials/
Using:
tensorflow 1.0
gym 0.8.0
"""
import multiprocessing
import threading
import tensorflow as tf
import numpy as np
import gym
import os
import shutil
import matplotlib.pyplot as plt
GAME = 'LunarLander-v2'
OUTPUT_GRAPH = False
LOG_DIR = './log'
N_WORKERS = multiprocessing.cpu_count()
MAX_GLOBAL_EP = 5000
GLOBAL_NET_SCOPE = 'Global_Net'
UPDATE_GLOBAL_ITER = 5
GAMMA = 0.99
ENTROPY_BETA = 0.001 # not useful in this case
LR_A = 0.0005 # learning rate for actor
LR_C = 0.001 # learning rate for critic
GLOBAL_RUNNING_R = []
GLOBAL_EP = 0
env = gym.make(GAME)
N_S = env.observation_space.shape[0]
N_A = env.action_space.n
del env
class ACNet(object):
def __init__(self, scope, globalAC=None):
if scope == GLOBAL_NET_SCOPE: # get global network
with tf.variable_scope(scope):
self.s = tf.placeholder(tf.float32, [None, N_S], 'S')
self._build_net(N_A)
self.a_params = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope=scope + '/actor')
self.c_params = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope=scope + '/critic')
else: # local net, calculate losses
with tf.variable_scope(scope):
self.s = tf.placeholder(tf.float32, [None, N_S], 'S')
self.a_his = tf.placeholder(tf.int32, [None, ], 'A')
self.v_target = tf.placeholder(tf.float32, [None, 1], 'Vtarget')
self.a_prob, self.v = self._build_net(N_A)
td = tf.subtract(self.v_target, self.v, name='TD_error')
with tf.name_scope('c_loss'):
self.c_loss = tf.reduce_mean(tf.square(td))
with tf.name_scope('a_loss'):
log_prob = tf.reduce_sum(tf.log(self.a_prob) * tf.one_hot(self.a_his, N_A, dtype=tf.float32), axis=1, keep_dims=True)
exp_v = log_prob * td
entropy = -tf.reduce_sum(self.a_prob * tf.log(self.a_prob), axis=1, keep_dims=True) # encourage exploration
self.exp_v = ENTROPY_BETA * entropy + exp_v
self.a_loss = tf.reduce_mean(-self.exp_v)
with tf.name_scope('local_grad'):
self.a_params = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope=scope + '/actor')
self.c_params = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope=scope + '/critic')
self.a_grads = tf.gradients(self.a_loss, self.a_params)
self.c_grads = tf.gradients(self.c_loss, self.c_params)
with tf.name_scope('sync'):
with tf.name_scope('pull'):
self.pull_a_params_op = [l_p.assign(g_p) for l_p, g_p in zip(self.a_params, globalAC.a_params)]
self.pull_c_params_op = [l_p.assign(g_p) for l_p, g_p in zip(self.c_params, globalAC.c_params)]
with tf.name_scope('push'):
self.update_a_op = OPT_A.apply_gradients(zip(self.a_grads, globalAC.a_params))
self.update_c_op = OPT_C.apply_gradients(zip(self.c_grads, globalAC.c_params))
def _build_net(self, n_a):
w_init = tf.random_normal_initializer(0., .01)
with tf.variable_scope('critic'):
cell_size = 64
s = tf.expand_dims(self.s, axis=1,
name='timely_input') # [time_step, feature] => [time_step, batch, feature]
rnn_cell = tf.contrib.rnn.BasicRNNCell(cell_size)
self.init_state = rnn_cell.zero_state(batch_size=1, dtype=tf.float32)
outputs, self.final_state = tf.nn.dynamic_rnn(
cell=rnn_cell, inputs=s, initial_state=self.init_state, time_major=True)
cell_out = tf.reshape(outputs, [-1, cell_size], name='flatten_rnn_outputs') # joined state representation
l_c = tf.layers.dense(cell_out, 200, tf.nn.relu6, kernel_initializer=w_init, name='lc')
v = tf.layers.dense(l_c, 1, kernel_initializer=w_init, name='v') # state value
with tf.variable_scope('actor'):
cell_out = tf.stop_gradient(cell_out, name='c_cell_out')
l_a = tf.layers.dense(cell_out, 300, tf.nn.relu6, kernel_initializer=w_init, name='la')
a_prob = tf.layers.dense(l_a, n_a, tf.nn.softmax, kernel_initializer=w_init, name='ap')
return a_prob, v
def update_global(self, feed_dict): # run by a local
SESS.run([self.update_a_op, self.update_c_op], feed_dict) # local grads applies to global net
def pull_global(self): # run by a local
SESS.run([self.pull_a_params_op, self.pull_c_params_op])
def choose_action(self, s, cell_state): # run by a local
prob_weights, cell_state = SESS.run([self.a_prob, self.final_state], feed_dict={self.s: s[np.newaxis, :],
self.init_state: cell_state})
action = np.random.choice(range(prob_weights.shape[1]),
p=prob_weights.ravel()) # select action w.r.t the actions prob
return action, cell_state
class Worker(object):
def __init__(self, name, globalAC):
self.env = gym.make(GAME)
self.name = name
self.AC = ACNet(name, globalAC)
def work(self):
global GLOBAL_RUNNING_R, GLOBAL_EP
total_step = 1
r_scale = 100
buffer_s, buffer_a, buffer_r = [], [], []
while not COORD.should_stop() and GLOBAL_EP < MAX_GLOBAL_EP:
s = self.env.reset()
ep_r = 0
ep_t = 0
rnn_state = SESS.run(self.AC.init_state) # zero rnn state at beginning
keep_state = rnn_state.copy() # keep rnn state for updating global net
while True:
# if self.name == 'W_0' and total_step % 10 == 0:
# self.env.render()
a, rnn_state_ = self.AC.choose_action(s, rnn_state) # get the action and next rnn state
s_, r, done, info = self.env.step(a)
if r == -100: r = -10
ep_r += r
buffer_s.append(s)
buffer_a.append(a)
buffer_r.append(r/r_scale)
if total_step % UPDATE_GLOBAL_ITER == 0 or done: # update global and assign to local net
if done:
v_s_ = 0 # terminal
else:
v_s_ = SESS.run(self.AC.v, {self.AC.s: s_[np.newaxis, :], self.AC.init_state: rnn_state_})[0,0]
buffer_v_target = []
for r in buffer_r[::-1]: # reverse buffer r
v_s_ = r + GAMMA * v_s_
buffer_v_target.append(v_s_)
buffer_v_target.reverse()
buffer_s, buffer_a, buffer_v_target = np.vstack(buffer_s), np.array(buffer_a), np.vstack(buffer_v_target)
feed_dict = {
self.AC.s: buffer_s,
self.AC.a_his: buffer_a,
self.AC.v_target: buffer_v_target,
self.AC.init_state: keep_state,
}
self.AC.update_global(feed_dict)
buffer_s, buffer_a, buffer_r = [], [], []
self.AC.pull_global()
keep_state = rnn_state_.copy() # replace the keep_state as the new initial rnn state_
s = s_
total_step += 1
rnn_state = rnn_state_ # renew rnn state
ep_t += 1
if done:
if len(GLOBAL_RUNNING_R) == 0: # record running episode reward
GLOBAL_RUNNING_R.append(ep_r)
else:
GLOBAL_RUNNING_R.append(0.99 * GLOBAL_RUNNING_R[-1] + 0.01 * ep_r)
if not self.env.unwrapped.lander.awake: solve = '| Landed'
else: solve = '| ------'
print(
self.name,
"Ep:", GLOBAL_EP,
solve,
"| Ep_r: %i" % GLOBAL_RUNNING_R[-1],
)
GLOBAL_EP += 1
break
if __name__ == "__main__":
SESS = tf.Session()
with tf.device("/cpu:0"):
OPT_A = tf.train.RMSPropOptimizer(LR_A, name='RMSPropA')
OPT_C = tf.train.RMSPropOptimizer(LR_C, name='RMSPropC')
GLOBAL_AC = ACNet(GLOBAL_NET_SCOPE) # we only need its params
workers = []
# Create worker
for i in range(N_WORKERS):
i_name = 'W_%i' % i # worker name
workers.append(Worker(i_name, GLOBAL_AC))
COORD = tf.train.Coordinator()
SESS.run(tf.global_variables_initializer())
if OUTPUT_GRAPH:
if os.path.exists(LOG_DIR):
shutil.rmtree(LOG_DIR)
tf.summary.FileWriter(LOG_DIR, SESS.graph)
worker_threads = []
for worker in workers:
job = lambda: worker.work()
t = threading.Thread(target=job)
t.start()
worker_threads.append(t)
COORD.join(worker_threads)
plt.plot(np.arange(len(GLOBAL_RUNNING_R)), GLOBAL_RUNNING_R)
plt.xlabel('step')
plt.ylabel('Total moving reward')
plt.show()
================================================
FILE: experiments/Solve_LunarLander/DuelingDQNPrioritizedReplay.py
================================================
"""
The DQN improvement: Prioritized Experience Replay (based on https://arxiv.org/abs/1511.05952)
View more on 莫烦Python: https://morvanzhou.github.io/tutorials/
Using:
Tensorflow: 1.0
"""
import numpy as np
import tensorflow as tf
np.random.seed(1)
tf.set_random_seed(1)
class SumTree(object):
"""
This SumTree code is modified version and the original code is from:
https://github.com/jaara/AI-blog/blob/master/SumTree.py
Story the data with it priority in tree and data frameworks.
"""
data_pointer = 0
def __init__(self, capacity):
self.capacity = capacity # for all priority values
self.tree = np.zeros(2 * capacity - 1)
# [--------------Parent nodes-------------][-------leaves to recode priority-------]
# size: capacity - 1 size: capacity
self.data = np.zeros(capacity, dtype=object) # for all transitions
# [--------------data frame-------------]
# size: capacity
def add_new_priority(self, p, data):
leaf_idx = self.data_pointer + self.capacity - 1
self.data[self.data_pointer] = data # update data_frame
self.update(leaf_idx, p) # update tree_frame
self.data_pointer += 1
if self.data_pointer >= self.capacity: # replace when exceed the capacity
self.data_pointer = 0
def update(self, tree_idx, p):
change = p - self.tree[tree_idx]
self.tree[tree_idx] = p
self._propagate_change(tree_idx, change)
def _propagate_change(self, tree_idx, change):
"""change the sum of priority value in all parent nodes"""
parent_idx = (tree_idx - 1) // 2
self.tree[parent_idx] += change
if parent_idx != 0:
self._propagate_change(parent_idx, change)
def get_leaf(self, lower_bound):
leaf_idx = self._retrieve(lower_bound) # search the max leaf priority based on the lower_bound
data_idx = leaf_idx - self.capacity + 1
return [leaf_idx, self.tree[leaf_idx], self.data[data_idx]]
def _retrieve(self, lower_bound, parent_idx=0):
"""
Tree structure and array storage:
Tree index:
0 -> storing priority sum
/ \
1 2
/ \ / \
3 4 5 6 -> storing priority for transitions
Array type for storing:
[0,1,2,3,4,5,6]
"""
left_child_idx = 2 * parent_idx + 1
right_child_idx = left_child_idx + 1
if left_child_idx >= len(self.tree): # end search when no more child
return parent_idx
if self.tree[left_child_idx] == self.tree[right_child_idx]:
return self._retrieve(lower_bound, np.random.choice([left_child_idx, right_child_idx]))
if lower_bound <= self.tree[left_child_idx]: # downward search, always search for a higher priority node
return self._retrieve(lower_bound, left_child_idx)
else:
return self._retrieve(lower_bound - self.tree[left_child_idx], right_child_idx)
@property
def root_priority(self):
return self.tree[0] # the root
class Memory(object): # stored as ( s, a, r, s_ ) in SumTree
"""
This SumTree code is modified version and the original code is from:
https://github.com/jaara/AI-blog/blob/master/Seaquest-DDQN-PER.py
"""
epsilon = 0.001 # small amount to avoid zero priority
alpha = 0.6 # [0~1] convert the importance of TD error to priority
beta = 0.4 # importance-sampling, from initial value increasing to 1
beta_increment_per_sampling = 1e-4 # annealing the bias
abs_err_upper = 1 # for stability refer to paper
def __init__(self, capacity):
self.tree = SumTree(capacity)
def store(self, error, transition):
p = self._get_priority(error)
self.tree.add_new_priority(p, transition)
def sample(self, n):
batch_idx, batch_memory, ISWeights = [], [], []
segment = self.tree.root_priority / n
self.beta = np.min([1, self.beta + self.beta_increment_per_sampling]) # max = 1
min_prob = np.min(self.tree.tree[-self.tree.capacity:]) / self.tree.root_priority
maxiwi = np.power(self.tree.capacity * min_prob, -self.beta) # for later normalizing ISWeights
for i in range(n):
a = segment * i
b = segment * (i + 1)
lower_bound = np.random.uniform(a, b)
idx, p, data = self.tree.get_leaf(lower_bound)
prob = p / self.tree.root_priority
ISWeights.append(self.tree.capacity * prob)
batch_idx.append(idx)
batch_memory.append(data)
ISWeights = np.vstack(ISWeights)
ISWeights = np.power(ISWeights, -self.beta) / maxiwi # normalize
return batch_idx, np.vstack(batch_memory), ISWeights
def update(self, idx, error):
p = self._get_priority(error)
self.tree.update(idx, p)
def _get_priority(self, error):
error += self.epsilon # avoid 0
clipped_error = np.clip(error, 0, self.abs_err_upper)
return np.power(clipped_error, self.alpha)
class DuelingDQNPrioritizedReplay:
def __init__(
self,
n_actions,
n_features,
learning_rate=0.005,
reward_decay=0.9,
e_greedy=0.9,
replace_target_iter=500,
memory_size=10000,
batch_size=32,
e_greedy_increment=None,
hidden=[100, 50],
output_graph=False,
sess=None,
):
self.n_actions = n_actions
self.n_features = n_features
self.lr = learning_rate
self.gamma = reward_decay
self.epsilon_max = e_greedy
self.replace_target_iter = replace_target_iter
self.memory_size = memory_size
self.batch_size = batch_size
self.hidden = hidden
self.epsilon_increment = e_greedy_increment
self.epsilon = 0.5 if e_greedy_increment is not None else self.epsilon_max
self.learn_step_counter = 0
self._build_net()
self.memory = Memory(capacity=memory_size)
if sess is None:
self.sess = tf.Session()
self.sess.run(tf.global_variables_initializer())
else:
self.sess = sess
if output_graph:
tf.summary.FileWriter("logs/", self.sess.graph)
self.cost_his = []
def _build_net(self):
def build_layers(s, c_names, w_initializer, b_initializer):
for i, h in enumerate(self.hidden):
if i == 0:
in_units, out_units, inputs = self.n_features, self.hidden[i], s
else:
in_units, out_units, inputs = self.hidden[i-1], self.hidden[i], l
with tf.variable_scope('l%i' % i):
w = tf.get_variable('w', [in_units, out_units], initializer=w_initializer, collections=c_names)
b = tf.get_variable('b', [1, out_units], initializer=b_initializer, collections=c_names)
l = tf.nn.relu(tf.matmul(inputs, w) + b)
with tf.variable_scope('Value'):
w = tf.get_variable('w', [self.hidden[-1], 1], initializer=w_initializer, collections=c_names)
b = tf.get_variable('b', [1, 1], initializer=b_initializer, collections=c_names)
self.V = tf.matmul(l, w) + b
with tf.variable_scope('Advantage'):
w = tf.get_variable('w', [self.hidden[-1], self.n_actions], initializer=w_initializer, collections=c_names)
b = tf.get_variable('b', [1, self.n_actions], initializer=b_initializer, collections=c_names)
self.A = tf.matmul(l, w) + b
with tf.variable_scope('Q'):
out = self.V + (self.A - tf.reduce_mean(self.A, axis=1, keep_dims=True)) # Q = V(s) + A(s,a)
# with tf.variable_scope('out'):
# w = tf.get_variable('w', [self.hidden[-1], self.n_actions], initializer=w_initializer, collections=c_names)
# b = tf.get_variable('b', [1, self.n_actions], initializer=b_initializer, collections=c_names)
# out = tf.matmul(l, w) + b
return out
# ------------------ build evaluate_net ------------------
self.s = tf.placeholder(tf.float32, [None, self.n_features], name='s') # input
self.q_target = tf.placeholder(tf.float32, [None, self.n_actions], name='Q_target') # for calculating loss
self.ISWeights = tf.placeholder(tf.float32, [None, 1], name='IS_weights')
with tf.variable_scope('eval_net'):
c_names, w_initializer, b_initializer = \
['eval_net_params', tf.GraphKeys.GLOBAL_VARIABLES], \
tf.random_normal_initializer(0., 0.01), tf.constant_initializer(0.01) # config of layers
self.q_eval = build_layers(self.s, c_names, w_initializer, b_initializer)
with tf.variable_scope('loss'):
self.abs_errors = tf.abs(tf.reduce_sum(self.q_target - self.q_eval, axis=1)) # for updating Sumtree
self.loss = tf.reduce_mean(self.ISWeights * tf.squared_difference(self.q_target, self.q_eval))
with tf.variable_scope('train'):
self._train_op = tf.train.AdamOptimizer(self.lr).minimize(self.loss)
# ------------------ build target_net ------------------
self.s_ = tf.placeholder(tf.float32, [None, self.n_features], name='s_') # input
with tf.variable_scope('target_net'):
c_names = ['target_net_params', tf.GraphKeys.GLOBAL_VARIABLES]
self.q_next = build_layers(self.s_, c_names, w_initializer, b_initializer)
def store_transition(self, s, a, r, s_):
transition = np.hstack((s, [a, r], s_))
max_p = np.max(self.memory.tree.tree[-self.memory.tree.capacity:])
self.memory.store(max_p, transition)
def choose_action(self, observation):
observation = observation[np.newaxis, :]
if np.random.uniform() < self.epsilon:
actions_value = self.sess.run(self.q_eval, feed_dict={self.s: observation})
action = np.argmax(actions_value)
else:
action = np.random.randint(0, self.n_actions)
return action
def _replace_target_params(self):
t_params = tf.get_collection('target_net_params')
e_params = tf.get_collection('eval_net_params')
self.sess.run([tf.assign(t, e) for t, e in zip(t_params, e_params)])
def learn(self):
if self.learn_step_counter % self.replace_target_iter == 0:
self._replace_target_params()
tree_idx, batch_memory, ISWeights = self.memory.sample(self.batch_size)
# double DQN
q_next, q_eval4next = self.sess.run(
[self.q_next, self.q_eval],
feed_dict={self.s_: batch_memory[:, -self.n_features:], # next observation
self.s: batch_memory[:, -self.n_features:]}) # next observation
q_eval = self.sess.run(self.q_eval, {self.s: batch_memory[:, :self.n_features]})
q_target = q_eval.copy()
batch_index = np.arange(self.batch_size, dtype=np.int32)
eval_act_index = batch_memory[:, self.n_features].astype(int)
reward = batch_memory[:, self.n_features + 1]
max_act4next = np.argmax(q_eval4next,
axis=1) # the action that brings the highest value is evaluated by q_eval
selected_q_next = q_next[batch_index, max_act4next] # Double DQN, select q_next depending on above actions
q_target[batch_index, eval_act_index] = reward + self.gamma * selected_q_next
# q_next, q_eval = self.sess.run(
# [self.q_next, self.q_eval],
# feed_dict={self.s_: batch_memory[:, -self.n_features:],
# self.s: batch_memory[:, :self.n_features]})
#
# q_target = q_eval.copy()
# batch_index = np.arange(self.batch_size, dtype=np.int32)
# eval_act_index = batch_memory[:, self.n_features].astype(int)
# reward = batch_memory[:, self.n_features + 1]
#
# q_target[batch_index, eval_act_index] = reward + self.gamma * np.max(q_next, axis=1)
_, abs_errors, self.cost = self.sess.run([self._train_op, self.abs_errors, self.loss],
feed_dict={self.s: batch_memory[:, :self.n_features],
self.q_target: q_target,
self.ISWeights: ISWeights})
for i in range(len(tree_idx)): # update priority
idx = tree_idx[i]
self.memory.update(idx, abs_errors[i])
self.cost_his.append(self.cost)
self.epsilon = self.epsilon + self.epsilon_increment if self.epsilon < self.epsilon_max else self.epsilon_max
self.learn_step_counter += 1
================================================
FILE: experiments/Solve_LunarLander/run_LunarLander.py
================================================
"""
Deep Q network,
LunarLander-v2 example
Using:
Tensorflow: 1.0
gym: 0.8.0
"""
import gym
from gym import wrappers
from DuelingDQNPrioritizedReplay import DuelingDQNPrioritizedReplay
env = gym.make('LunarLander-v2')
# env = env.unwrapped
env.seed(1)
N_A = env.action_space.n
N_S = env.observation_space.shape[0]
MEMORY_CAPACITY = 50000
TARGET_REP_ITER = 2000
MAX_EPISODES = 900
E_GREEDY = 0.95
E_INCREMENT = 0.00001
GAMMA = 0.99
LR = 0.0001
BATCH_SIZE = 32
HIDDEN = [400, 400]
RENDER = True
RL = DuelingDQNPrioritizedReplay(
n_actions=N_A, n_features=N_S, learning_rate=LR, e_greedy=E_GREEDY, reward_decay=GAMMA,
hidden=HIDDEN, batch_size=BATCH_SIZE, replace_target_iter=TARGET_REP_ITER,
memory_size=MEMORY_CAPACITY, e_greedy_increment=E_INCREMENT,)
total_steps = 0
running_r = 0
r_scale = 100
for i_episode in range(MAX_EPISODES):
s = env.reset() # (coord_x, coord_y, vel_x, vel_y, angle, angular_vel, l_leg_on_ground, r_leg_on_ground)
ep_r = 0
while True:
if total_steps > MEMORY_CAPACITY: env.render()
a = RL.choose_action(s)
s_, r, done, _ = env.step(a)
if r == -100: r = -30
r /= r_scale
ep_r += r
RL.store_transition(s, a, r, s_)
if total_steps > MEMORY_CAPACITY:
RL.learn()
if done:
land = '| Landed' if r == 100/r_scale else '| ------'
running_r = 0.99 * running_r + 0.01 * ep_r
print('Epi: ', i_episode,
land,
'| Epi_R: ', round(ep_r, 2),
'| Running_R: ', round(running_r, 2),
'| Epsilon: ', round(RL.epsilon, 3))
break
s = s_
total_steps += 1

