{{ content }}
{{ page.title | escape }}
{{ content }}
Page not found :(
The requested page could not be found.
 {%- if page_paths -%}
{%- endif -%}
{%- if page_paths -%}
{%- endif -%}
Every human is unique. The original vision of the personal computer was as a companion tool for creating intelligence, and the internet was born as a way to connect people and data together around the world. Today, artificial intelligence is upending the way that we interact with data and information, but control of these systems is most often provided through an API endpoint, run in the cloud, and abstracting away deep personal agency in favor of productivity.
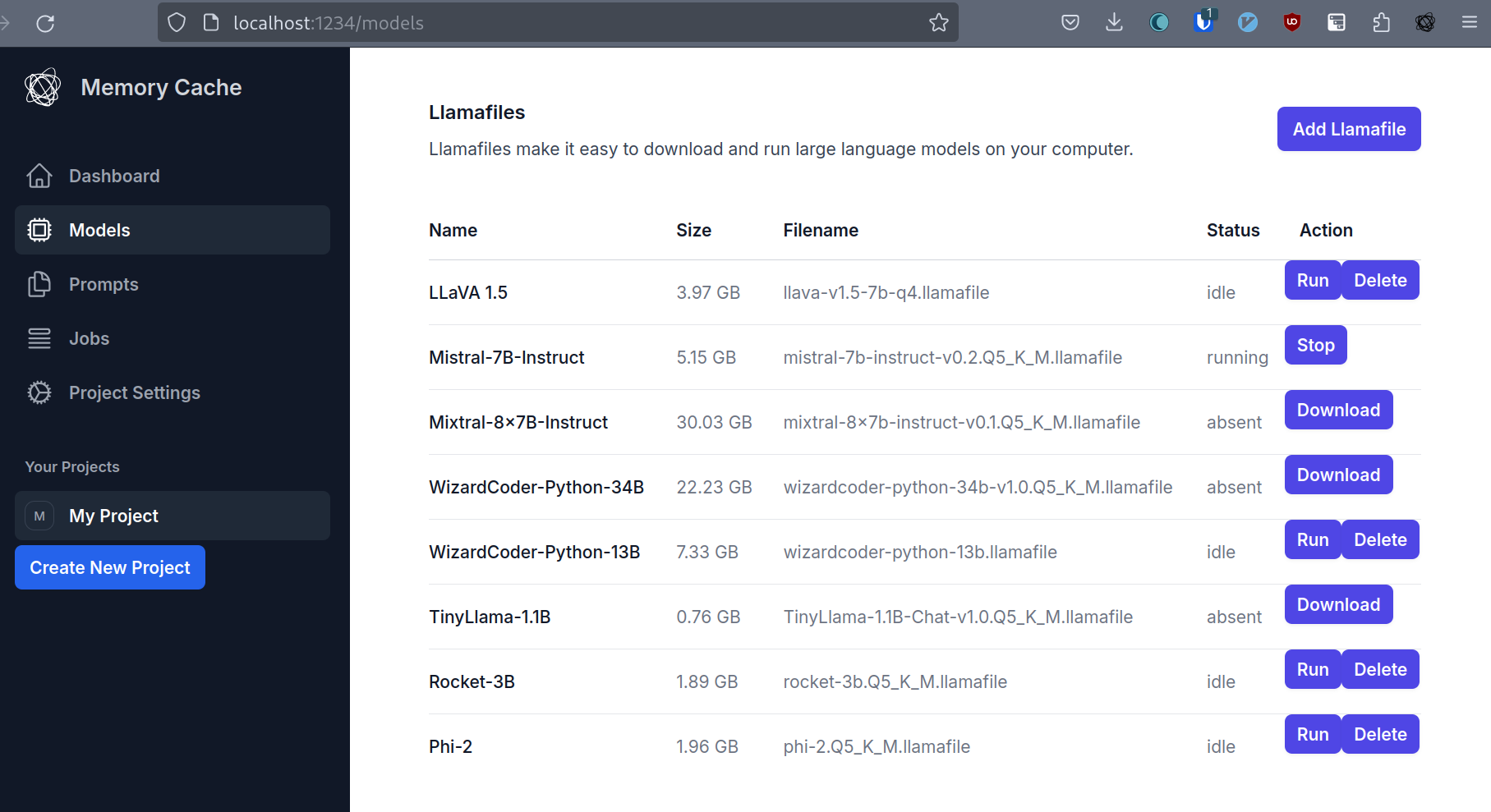
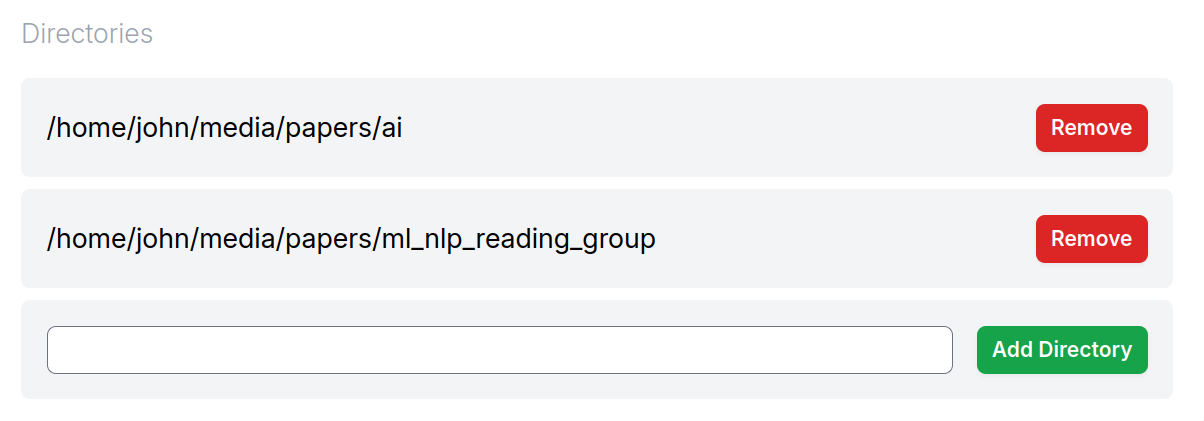
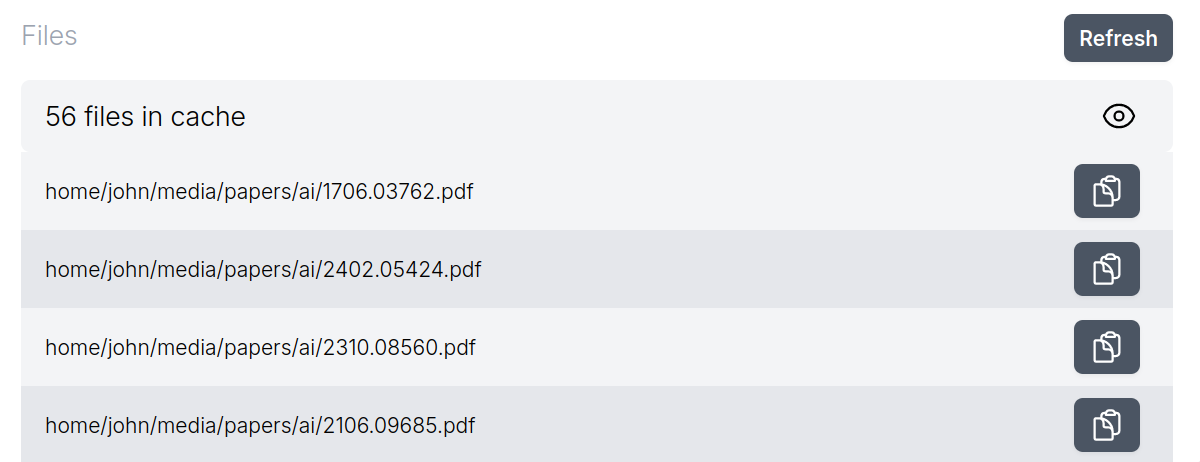
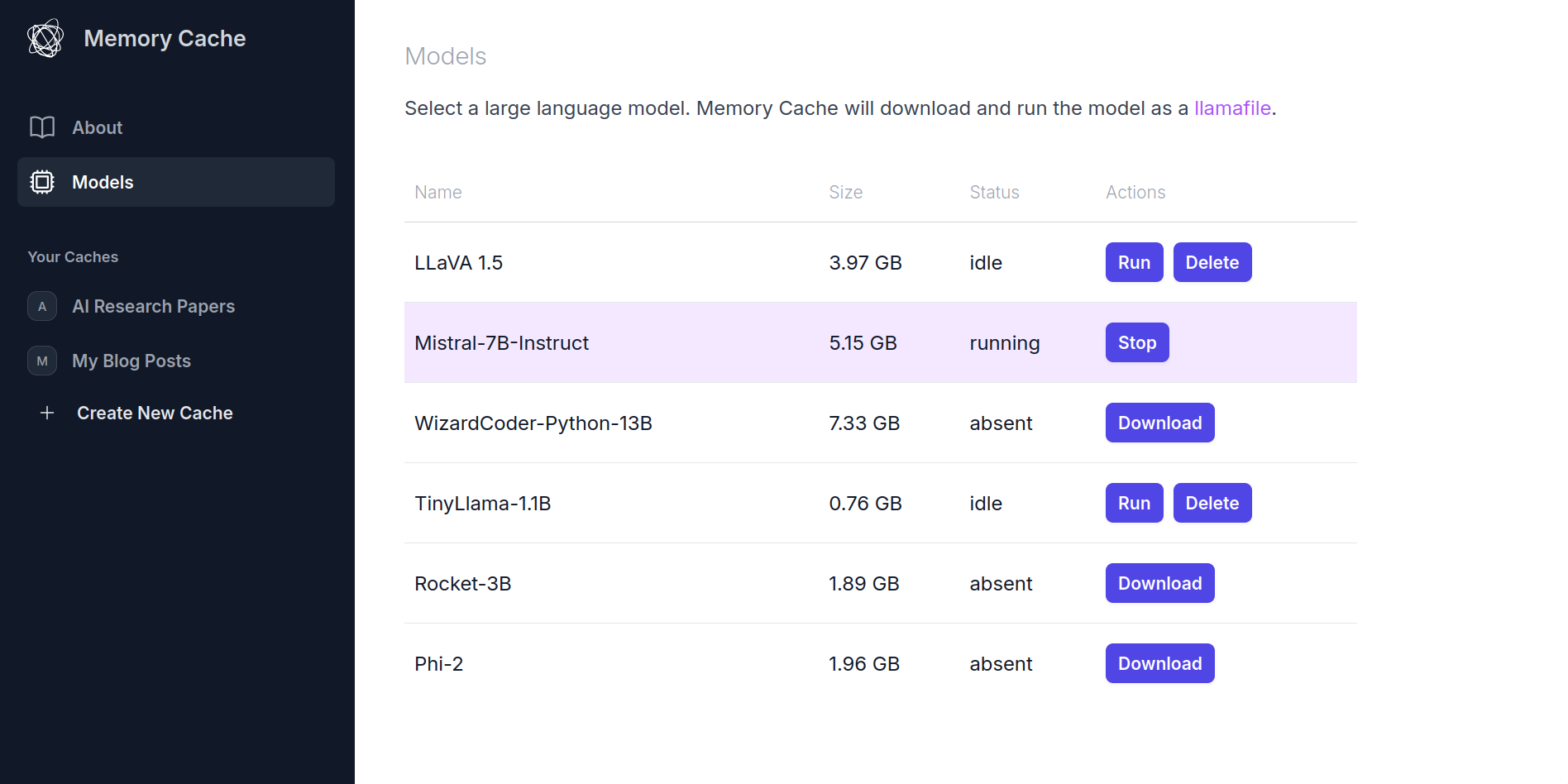
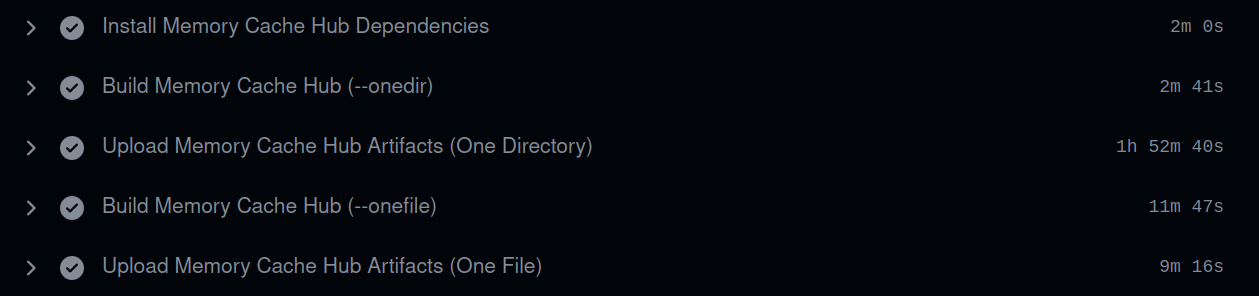
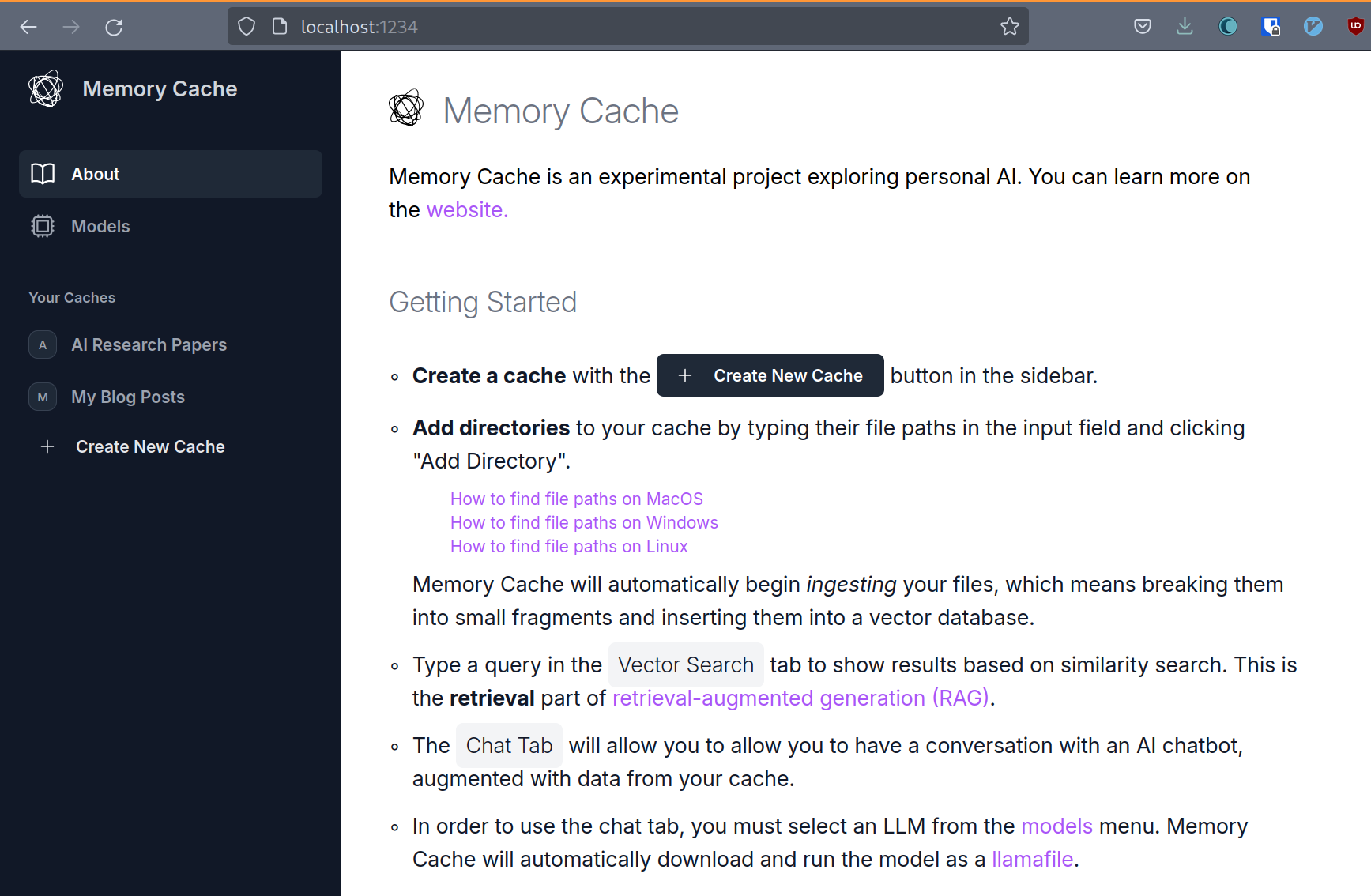
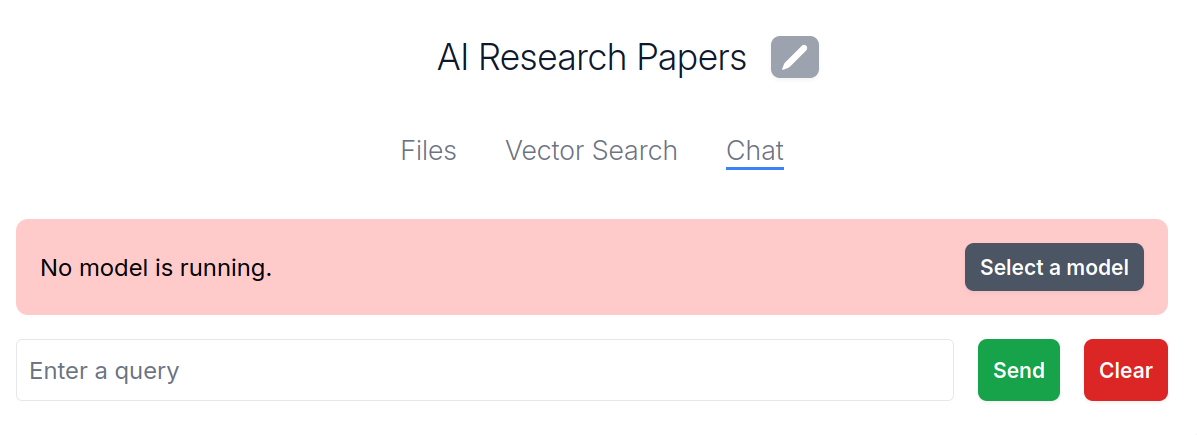
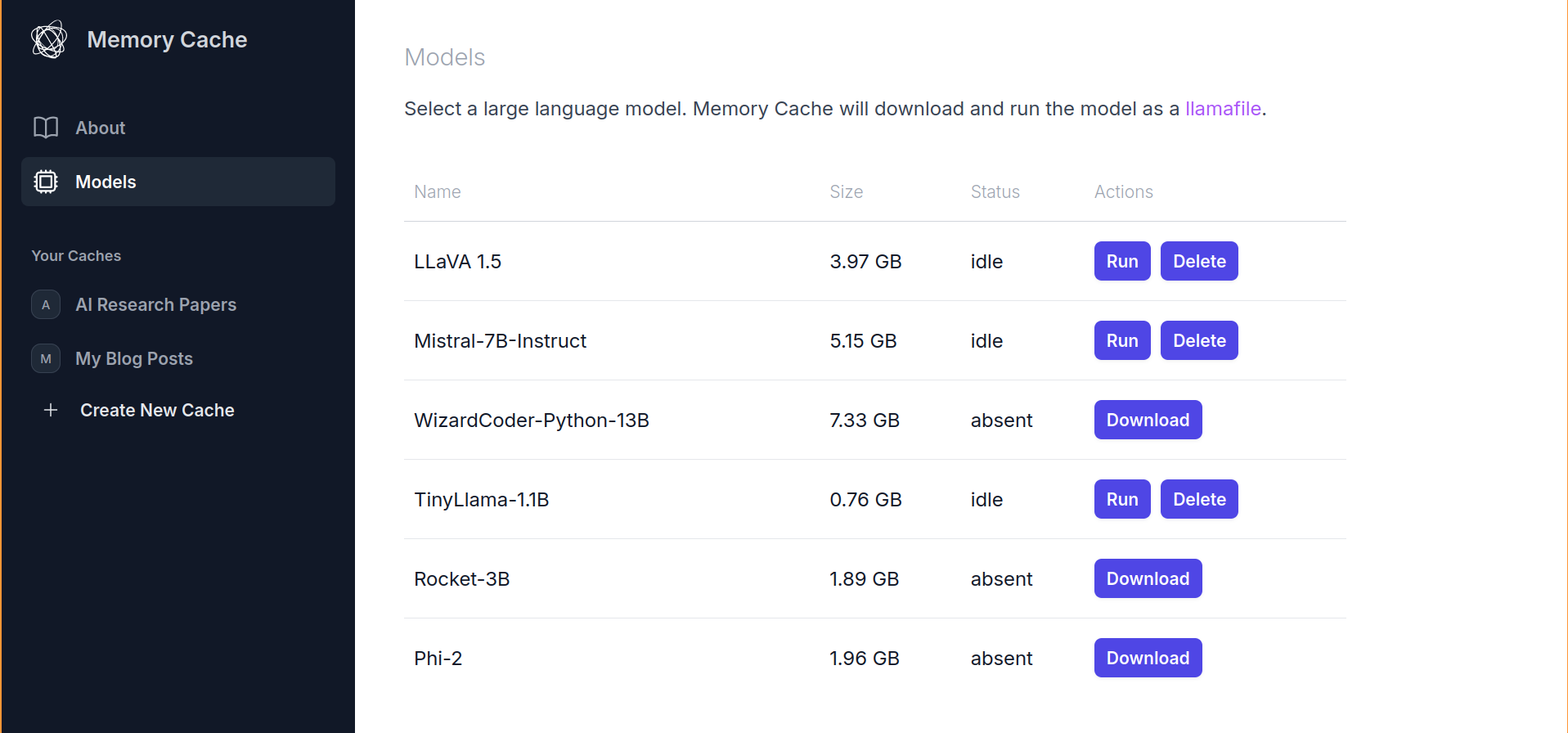
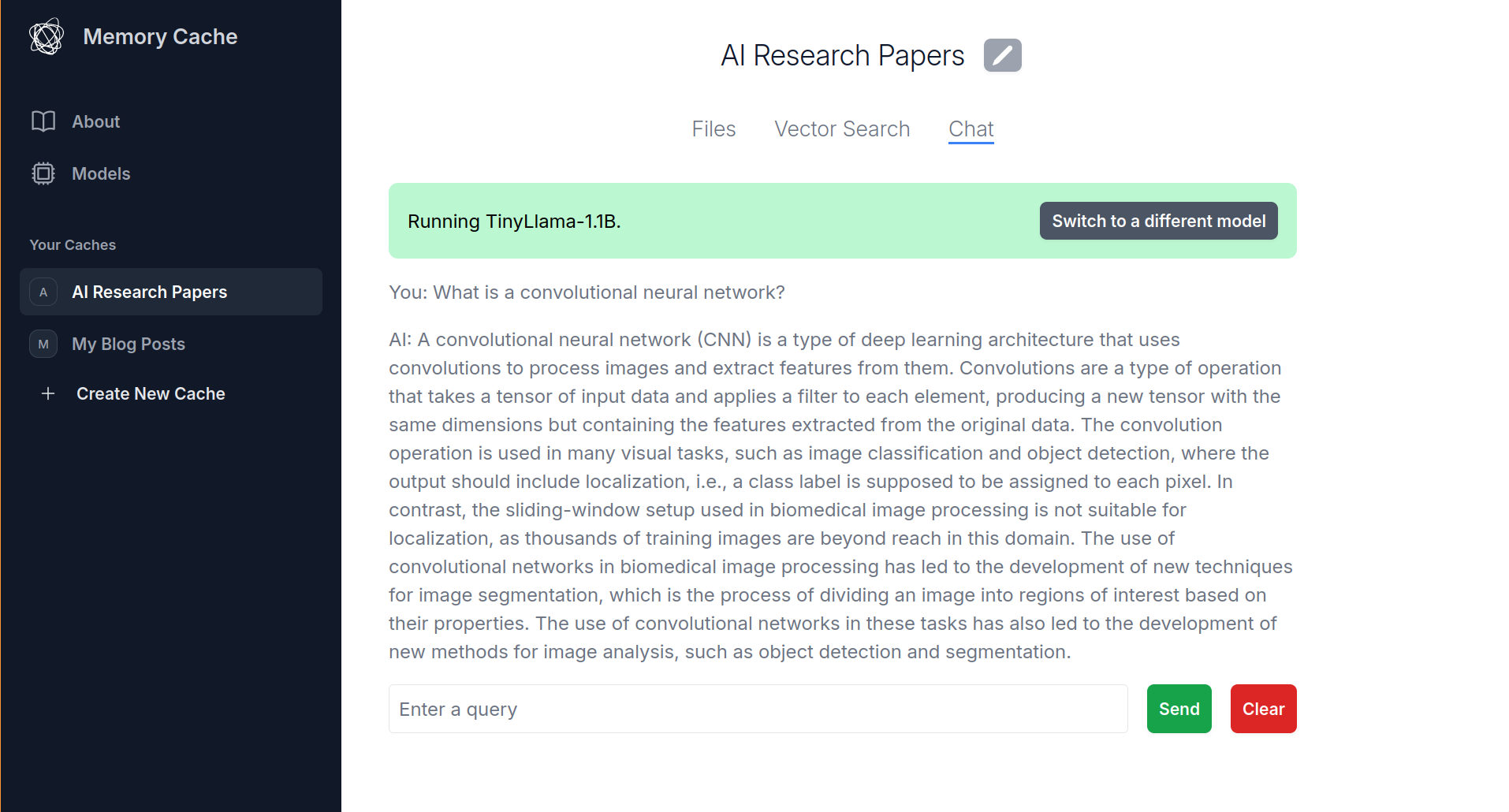
MemoryCache, a Mozilla Innovation Project, is an experimental AI Firefox add-on that partners with privateGPT to quickly save your browser history to your local machine and have a local AI model ingest these - and any other local files you give it - to augment responses to a chat interface that comes built-in with privateGPT. We have an ambition to use MemoryCache to move beyond the chat interface, and find a way to utilize idle compute time to generate net new insights that reflect what you've actually read and learned - not the entirety of the internet at scale.

We're not breaking ground on AI innovation (in fact, we're using an old, "deprecated" file format from a whole six months ago), by design. MemoryCache is a project that allows us to sow some seeds of exploration into creating a deeply personalized AI experience that returns to the original vision of the computer as a companion for our own thought. With MemoryCache, weirdness and unpredictability is part of the charm.
We're a small team working on MemoryCache as a part-time project within Mozilla's innovation group, looking at ways that our personal data and files are used to form insights and new neural connections for our own creative purpose. We're working in the open not because we have answers, but because we want to contribute our way of thinking to one another in a way where others can join in.
subscribe via RSS
{%- endif -%}