Showing preview only (3,710K chars total). Download the full file or copy to clipboard to get everything.
Repository: NLeSC/litstudy
Branch: master
Commit: 391d3afb8830
Files: 102
Total size: 3.5 MB
Directory structure:
gitextract_v2zn9pxr/
├── .gitattributes
├── .github/
│ └── workflows/
│ ├── cffconvert.yml
│ ├── docs.yml
│ ├── python-action.yml
│ ├── python-app.yml
│ └── python-format.yml
├── .gitignore
├── .zenodo.json
├── CHANGELOG.md
├── CITATION.cff
├── CODE_OF_CONDUCT.md
├── CONTRIBUTING.md
├── LICENSE
├── MANIFEST.in
├── NOTICE
├── README.md
├── docs/
│ ├── Makefile
│ ├── _static/
│ │ ├── citation.html
│ │ └── css/
│ │ └── style.css
│ ├── api/
│ │ ├── index.rst
│ │ ├── network.rst
│ │ ├── nlp.rst
│ │ ├── plot.rst
│ │ ├── sources.rst
│ │ ├── stats.rst
│ │ └── types.rst
│ ├── citation.html
│ ├── conf.py
│ ├── faq.rst
│ ├── index.rst
│ ├── installation.rst
│ ├── license.rst
│ └── make.bat
├── litstudy/
│ ├── __init__.py
│ ├── clean.py
│ ├── common.py
│ ├── continent.py
│ ├── network.py
│ ├── nlp.py
│ ├── plot.py
│ ├── sources/
│ │ ├── __init__.py
│ │ ├── arxiv.py
│ │ ├── bibtex.py
│ │ ├── crossref.py
│ │ ├── csv.py
│ │ ├── dblp.py
│ │ ├── ieee.py
│ │ ├── ris.py
│ │ ├── scopus.py
│ │ ├── scopus_csv.py
│ │ ├── semanticscholar.py
│ │ └── springer.py
│ ├── stats.py
│ ├── stopwords.py
│ └── types.py
├── notebooks/
│ ├── citation.html
│ ├── data/
│ │ ├── exclude.ris
│ │ ├── ieee_1.csv
│ │ ├── ieee_2.csv
│ │ ├── ieee_3.csv
│ │ ├── ieee_4.csv
│ │ ├── ieee_5.csv
│ │ └── springer.csv
│ └── example.ipynb
├── pyproject.toml
├── requirements.txt
├── setup.cfg
├── setup.py
├── sonar-project.properties
└── tests/
├── __init__.py
├── common.py
├── requests/
│ ├── 245f82b3fdc09eaed6a726cd4bddaa2f1565ba90.pickle
│ ├── 4d39f93aa1c9ff4afee9f210b14ade9e5ccf3a58.pickle
│ ├── 4eea59c658fa3076445495dea5554977b85511ff.pickle
│ ├── 5122a6fa38e030c8876096317e7e19aa6534e70a.pickle
│ ├── 54f7b47eb9ceb574f63ec43e8b717364b75b3fa7.pickle
│ ├── 5dec8d884e7221dc8cad8d779c23884c91fde749.pickle
│ ├── 6028198cfd0c1f6c2e2b995ed4802d1c42fb07b2.pickle
│ ├── 6a9fff6a7064528fd44202e78690da248afa23b7.pickle
│ ├── 78a2bca757d42aced207b202458dfd3bf17f0c3d.pickle
│ ├── 7c4b7301a9ccb48f60f360dd28ec6f0dfec9613f.pickle
│ ├── 9b4fc567a80b12bae747c517a4890ce044307aa5.pickle
│ ├── c3c2090c3a0293d71314d226b24f9da74633e092.pickle
│ ├── cfca0170ac37869891777418ee9cf20f17faa581.pickle
│ ├── d1acbf3602743e93bf70589acb072ba87ef3b72b.pickle
│ ├── eeb9079866515efbc22fb670e78f14d11c099a9f.pickle
│ └── ff2a790d6047bbc6bf3ee8d5cc73c47237b95bf8.pickle
├── resources/
│ ├── example.ris
│ ├── ieee.csv
│ ├── retraction_watch.csv
│ ├── scopus.csv
│ └── springer.csv
├── test_common.py
├── test_nlp_corpus.py
├── test_sources_arxiv.py
├── test_sources_crossref.py
├── test_sources_csv.py
├── test_sources_ieee.py
├── test_sources_ris.py
├── test_sources_scopus_csv.py
├── test_sources_semanticscholar.py
└── test_sources_springer.py
================================================
FILE CONTENTS
================================================
================================================
FILE: .gitattributes
================================================
*.ipynb linguist-documentation
================================================
FILE: .github/workflows/cffconvert.yml
================================================
name: cffconvert
on:
push:
paths:
- CITATION.cff
jobs:
validate:
name: "validate"
runs-on: ubuntu-latest
steps:
- name: Check out a copy of the repository
uses: actions/checkout@v2
- name: Check whether the citation metadata from CITATION.cff is valid
uses: citation-file-format/cffconvert-github-action@2.0.0
with:
args: "--validate"
================================================
FILE: .github/workflows/docs.yml
================================================
# This is a basic workflow to help you get started with Actions
name: Build documentation
# Controls when the workflow will run
on:
# Triggers the workflow on push or pull request events but only for the master branch
push:
branches: [ master ]
# Allows you to run this workflow manually from the Actions tab
workflow_dispatch:
# A workflow run is made up of one or more jobs that can run sequentially or in parallel
jobs:
# This workflow contains a single job called "build"
build:
# The type of runner that the job will run on
runs-on: ubuntu-latest
steps:
- name: Setup python
uses: actions/setup-python@v2
with:
python-version: '3.8'
- name: Checkout
uses: actions/checkout@v2
with:
fetch-depth: 0 # otherwise, you will failed to push refs to dest repo
- name: Setup dependencies
run: |
sudo apt-get update
sudo apt-get install python3-sphinx pandoc
python -m pip install --upgrade pip
python -m pip install sphinx_rtd_theme unidecode nbsphinx wheel sphinx_mdinclude myst-parser
python -m pip install .[doc]
- name: Build and commit
uses: sphinx-notes/pages@v2
with:
documentation_path: './docs'
requirements_path: 'requirements.txt'
- name: Push documentation
uses: ad-m/github-push-action@master
with:
github_token: ${{ secrets.GITHUB_TOKEN }}
branch: gh-pages
================================================
FILE: .github/workflows/python-action.yml
================================================
# This workflow will install Python dependencies, run tests and lint with a single version of Python
# For more information see: https://help.github.com/actions/language-and-framework-guides/using-python-with-github-actions
name: Build and Test
on:
workflow_call:
inputs:
python-version:
required: true
type: string
jobs:
build-and-test:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v2
- name: Set up Python ${{ inputs.python-version }}
uses: actions/setup-python@v2
with:
python-version: ${{ inputs.python-version }}
- name: Install dependencies
run: |
python -m pip install --upgrade pip
pip install flake8 pytest
pip install .
- name: Lint with flake8
run: |
# stop the build if there are Python syntax errors or undefined names
flake8 . --count --select=E9,F63,F7,F82 --show-source --statistics
# exit-zero treats all errors as warnings. The GitHub editor is 127 chars wide
flake8 . --count --exit-zero --max-complexity=20 --max-line-length=127 --statistics
- name: Test with pytest
run: |
pytest
================================================
FILE: .github/workflows/python-app.yml
================================================
# This workflow will install Python dependencies, run tests and lint with a single version of Python
# For more information see: https://help.github.com/actions/language-and-framework-guides/using-python-with-github-actions
name: Build and Test
on:
[push, pull_request]
jobs:
# Check for Python 3.8 first. If this one fails,
# there is no need to check other versions of Python
build-python-38:
uses: ./.github/workflows/python-action.yml
with:
python-version: "3.8"
build-python-39:
needs: build-python-38
uses: ./.github/workflows/python-action.yml
with:
python-version: "3.9"
build-python-310:
needs: build-python-38
uses: ./.github/workflows/python-action.yml
with:
python-version: "3.10"
build-python-311:
needs: build-python-38
uses: ./.github/workflows/python-action.yml
with:
python-version: "3.11"
# build-python-311:
# needs: build-python-38
# uses: ./.github/workflows/python-action.yml
# with:
# python-version: "3.11"
================================================
FILE: .github/workflows/python-format.yml
================================================
name: Lint with black
on: [push, pull_request]
jobs:
lint:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v2
- uses: psf/black@stable
with:
options: "--check --verbose"
src: "./litstudy"
jupyter: true
version: "23.1.0"
================================================
FILE: .gitignore
================================================
# Byte-compiled / optimized / DLL files
__pycache__/
*.py[cod]
*$py.class
# C extensions
*.so
# Distribution / packaging
.Python
build/
develop-eggs/
dist/
downloads/
eggs/
.eggs/
lib/
lib64/
parts/
sdist/
var/
wheels/
*.egg-info/
.installed.cfg
*.egg
MANIFEST
# PyInstaller
# Usually these files are written by a python script from a template
# before PyInstaller builds the exe, so as to inject date/other infos into it.
*.manifest
*.spec
# Installer logs
pip-log.txt
pip-delete-this-directory.txt
# Unit test / coverage reports
htmlcov/
.tox/
.coverage
.coverage.*
.cache
nosetests.xml
coverage.xml
*.cover
.hypothesis/
.pytest_cache/
# Translations
*.mo
*.pot
# Django stuff:
*.log
local_settings.py
db.sqlite3
# Flask stuff:
instance/
.webassets-cache
# Scrapy stuff:
.scrapy
# Sphinx documentation
docs/_build/
doc/_build/
# PyBuilder
target/
# Jupyter Notebook
.ipynb_checkpoints
# pyenv
.python-version
# celery beat schedule file
celerybeat-schedule
# SageMath parsed files
*.sage.py
# Environments
.env
.venv
env/
venv/
ENV/
env.bak/
venv.bak/
# Spyder project settings
.spyderproject
.spyproject
# Rope project settings
.ropeproject
# mkdocs documentation
/site
# mypy
.mypy_cache/
# notebooks
notebooks/*.eps
notebooks/.*
# bibliometrix
.crossref*
.semantis*
================================================
FILE: .zenodo.json
================================================
{
"creators": [
{
"name": "Heldens, S",
"orcid": "0000-0001-8792-6305"
}
],
"license": {
"id": "Apache-2.0"
},
"title": "automated-literature-analysis"
}
================================================
FILE: CHANGELOG.md
================================================
# Changelog
All notable changes to this project will be documented in this file.
The format is based on [Keep a Changelog](https://keepachangelog.com/en/1.0.0/),
and this project adheres to [Semantic Versioning](https://semver.org/spec/v2.0.0.html).
## [Unreleased]
### Added
### Changed
- Fix unclear documentation of `search_semanticscholar` function, see PR #86 (thanks danibene!).
### Removed
### Fixed
## [1.0.6] 2023-10-05
### Added
- Add support for loading CSV files exported from Scopus (see PR #45, Thanks tleedepriest!)
### Changed
### Removed
### Fixed
- Fix incorrect return type of `load_ris_file` (fixes #34)
- Fix passing session as non-positional argument in `refine_semanticscholar`, see PR #35. (Thanks martinuray!)
- Fix incorrect filtering in `Corpus` when building corpus from docs (fixes #38)
- Fix error when calling `fetch_crossref` and `refine_crossref` with `session=None` as argument (fixes #40)
- Fix KeyError when loading CSV files from IEEE that have an incorrect format (fixed #55)
- Fix bug in nlp.py due to argument `square_distances` being removed in newer versions of sklearn, see PR #58 (Thanks rjavierch!)
## [1.0.5] - 2023-03-28
### Fixed
- Fix wrong argument in call to `matplotlib.pyplot.grid(...)` due to change in their API
- Fix semanticscholar backend not retrieving papers correctly
## [1.0.4] - 2023-03-02
### Added
- Add `load_csv` function
- Add `search_crossref` function
### Fixed
- Fix issue where CSV files could not be parsed due to BOM marker
## [1.0.3] - 2022-09-21
### Fixed
- Fix bug in the semantic scholar backend that did not fetch papers correctly
- Fix bug in `fetch_crossref` where document title was not extracted correctly
## [1.0.2] - 2022-05-25
### Changed
- Remove dependency on fa2. The version of fa2 on pip is broken under Python 3.9+.
### Fixed
- `litstudy` now works under Python 3.9+.
## [1.0.1] - 2022-05-16
### Added
- Support for the arXiv API (Thanks ksilo!)
### Changed
- Made project compatible with Python 3.6
## [1.0.0] - 2022-02-17
### Changed
- Complete rewrite of litstudy project for 1.0 release.
- Rename from "automated-literature-analysis" to "litstudy".
## [0.0.1] - 2019-09-04
### Added
Initial release of litstudy
================================================
FILE: CITATION.cff
================================================
# This CITATION.cff file was generated with cffinit.
# Visit https://bit.ly/cffinit to generate yours today!
cff-version: 1.2.0
title: litstudy
message: >-
If you use this software, please cite it using the
metadata from this file.
type: software
authors:
- given-names: Stijn
family-names: Heldens
email: s.heldens@esciencecenter.nl
affiliation: Netherlands eScience Center
orcid: 'https://orcid.org/0000-0001-8792-6305'
- given-names: Alessio
family-names: Sclocco
email: a.sclocco@esciencecenter.nl
affiliation: Netherlands eScience Center
orcid: 'https://orcid.org/0000-0003-3278-0518'
- given-names: Henk
family-names: Dreuning
email: h.h.h.dreuning@vu.nl
affiliation: University of Amsterdam
identifiers:
- type: doi
value: 10.5281/zenodo.3386071
doi: 10.5281/zenodo.3386071
repository-code: 'https://github.com/NLeSC/litstudy/'
url: 'https://nlesc.github.io/litstudy/'
keywords:
- python
- jupyter
- literature-review
license: Apache-2.0
================================================
FILE: CODE_OF_CONDUCT.md
================================================
# Contributor Covenant Code of Conduct
## Our Pledge
In the interest of fostering an open and welcoming environment, we as
contributors and maintainers pledge to making participation in our project and
our community a harassment-free experience for everyone, regardless of age, body
size, disability, ethnicity, gender identity and expression, level of experience,
education, socio-economic status, nationality, personal appearance, race,
religion, or sexual identity and orientation.
## Our Standards
Examples of behavior that contributes to creating a positive environment
include:
* Using welcoming and inclusive language
* Being respectful of differing viewpoints and experiences
* Gracefully accepting constructive criticism
* Focusing on what is best for the community
* Showing empathy towards other community members
Examples of unacceptable behavior by participants include:
* The use of sexualized language or imagery and unwelcome sexual attention or
advances
* Trolling, insulting/derogatory comments, and personal or political attacks
* Public or private harassment
* Publishing others' private information, such as a physical or electronic
address, without explicit permission
* Other conduct which could reasonably be considered inappropriate in a
professional setting
## Our Responsibilities
Project maintainers are responsible for clarifying the standards of acceptable
behavior and are expected to take appropriate and fair corrective action in
response to any instances of unacceptable behavior.
Project maintainers have the right and responsibility to remove, edit, or
reject comments, commits, code, wiki edits, issues, and other contributions
that are not aligned to this Code of Conduct, or to ban temporarily or
permanently any contributor for other behaviors that they deem inappropriate,
threatening, offensive, or harmful.
## Scope
This Code of Conduct applies both within project spaces and in public spaces
when an individual is representing the project or its community. Examples of
representing a project or community include using an official project e-mail
address, posting via an official social media account, or acting as an appointed
representative at an online or offline event. Representation of a project may be
further defined and clarified by project maintainers.
## Enforcement
Instances of abusive, harassing, or otherwise unacceptable behavior may be
reported by contacting the project team at s.heldens@esciencecenter.nl. All
complaints will be reviewed and investigated and will result in a response that
is deemed necessary and appropriate to the circumstances. The project team is
obligated to maintain confidentiality with regard to the reporter of an incident.
Further details of specific enforcement policies may be posted separately.
Project maintainers who do not follow or enforce the Code of Conduct in good
faith may face temporary or permanent repercussions as determined by other
members of the project's leadership.
## Attribution
This Code of Conduct is adapted from the [Contributor Covenant](https://www.contributor-covenant.org), version 1.4,
available at https://www.contributor-covenant.org/version/1/4/code-of-conduct.html
================================================
FILE: CONTRIBUTING.md
================================================
# Contributing guidelines
We welcome any kind of contribution to our software, from simple comment or question to a full fledged [pull request](https://help.github.com/articles/about-pull-requests/). Please read and follow our [Code of Conduct](CODE_OF_CONDUCT.md).
A contribution can be one of the following cases:
1. you have a question;
1. you think you may have found a bug (including unexpected behavior);
1. you want to make some kind of change to the code base (e.g. to fix a bug, to add a new feature, to update documentation);
1. you want to make a new release of the code base.
The sections below outline the steps in each case.
## You have a question
1. use the search functionality [here](https://github.com/nlesc/litstudy/issues) to see if someone already filed the same issue;
2. if your issue search did not yield any relevant results, make a new issue;
3. apply the "Question" label; apply other labels when relevant.
## You think you may have found a bug
1. use the search functionality [here](https://github.com/nlesc/litstudy/issues) to see if someone already filed the same issue;
1. if your issue search did not yield any relevant results, make a new issue, making sure to provide enough information to the rest of the community to understand the cause and context of the problem. Depending on the issue, you may want to include:
- the [SHA hashcode](https://help.github.com/articles/autolinked-references-and-urls/#commit-shas) of the commit that is causing your problem;
- some identifying information (name and version number) for dependencies you're using;
- information about the operating system;
1. apply relevant labels to the newly created issue.
## You want to make some kind of change to the code base
1. (**important**) announce your plan to the rest of the community *before you start working*. This announcement should be in the form of a (new) issue;
1. (**important**) wait until some kind of consensus is reached about your idea being a good idea;
1. if needed, fork the repository to your own Github profile and create your own feature branch off of the latest master commit. While working on your feature branch, make sure to stay up to date with the master branch by pulling in changes, possibly from the 'upstream' repository (follow the instructions [here](https://help.github.com/articles/configuring-a-remote-for-a-fork/) and [here](https://help.github.com/articles/syncing-a-fork/));
1. make sure the existing tests still work by running ``pytest``;
1. add your own tests (if necessary);
1. update or expand the documentation;
1. update the `CHANGELOG.md` file with change;
1. push your feature branch to (your fork of) the litstudy repository on GitHub;
1. create the pull request, e.g. following the instructions [here](https://help.github.com/articles/creating-a-pull-request/).
In case you feel like you've made a valuable contribution, but you don't know how to write or run tests for it, or how to generate the documentation: don't let this discourage you from making the pull request; we can help you! Just go ahead and submit the pull request, but keep in mind that you might be asked to append additional commits to your pull request.
================================================
FILE: LICENSE
================================================
Apache License
Version 2.0, January 2004
http://www.apache.org/licenses/
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
1. Definitions.
"License" shall mean the terms and conditions for use, reproduction,
and distribution as defined by Sections 1 through 9 of this document.
"Licensor" shall mean the copyright owner or entity authorized by
the copyright owner that is granting the License.
"Legal Entity" shall mean the union of the acting entity and all
other entities that control, are controlled by, or are under common
control with that entity. For the purposes of this definition,
"control" means (i) the power, direct or indirect, to cause the
direction or management of such entity, whether by contract or
otherwise, or (ii) ownership of fifty percent (50%) or more of the
outstanding shares, or (iii) beneficial ownership of such entity.
"You" (or "Your") shall mean an individual or Legal Entity
exercising permissions granted by this License.
"Source" form shall mean the preferred form for making modifications,
including but not limited to software source code, documentation
source, and configuration files.
"Object" form shall mean any form resulting from mechanical
transformation or translation of a Source form, including but
not limited to compiled object code, generated documentation,
and conversions to other media types.
"Work" shall mean the work of authorship, whether in Source or
Object form, made available under the License, as indicated by a
copyright notice that is included in or attached to the work
(an example is provided in the Appendix below).
"Derivative Works" shall mean any work, whether in Source or Object
form, that is based on (or derived from) the Work and for which the
editorial revisions, annotations, elaborations, or other modifications
represent, as a whole, an original work of authorship. For the purposes
of this License, Derivative Works shall not include works that remain
separable from, or merely link (or bind by name) to the interfaces of,
the Work and Derivative Works thereof.
"Contribution" shall mean any work of authorship, including
the original version of the Work and any modifications or additions
to that Work or Derivative Works thereof, that is intentionally
submitted to Licensor for inclusion in the Work by the copyright owner
or by an individual or Legal Entity authorized to submit on behalf of
the copyright owner. For the purposes of this definition, "submitted"
means any form of electronic, verbal, or written communication sent
to the Licensor or its representatives, including but not limited to
communication on electronic mailing lists, source code control systems,
and issue tracking systems that are managed by, or on behalf of, the
Licensor for the purpose of discussing and improving the Work, but
excluding communication that is conspicuously marked or otherwise
designated in writing by the copyright owner as "Not a Contribution."
"Contributor" shall mean Licensor and any individual or Legal Entity
on behalf of whom a Contribution has been received by Licensor and
subsequently incorporated within the Work.
2. Grant of Copyright License. Subject to the terms and conditions of
this License, each Contributor hereby grants to You a perpetual,
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
copyright license to reproduce, prepare Derivative Works of,
publicly display, publicly perform, sublicense, and distribute the
Work and such Derivative Works in Source or Object form.
3. Grant of Patent License. Subject to the terms and conditions of
this License, each Contributor hereby grants to You a perpetual,
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
(except as stated in this section) patent license to make, have made,
use, offer to sell, sell, import, and otherwise transfer the Work,
where such license applies only to those patent claims licensable
by such Contributor that are necessarily infringed by their
Contribution(s) alone or by combination of their Contribution(s)
with the Work to which such Contribution(s) was submitted. If You
institute patent litigation against any entity (including a
cross-claim or counterclaim in a lawsuit) alleging that the Work
or a Contribution incorporated within the Work constitutes direct
or contributory patent infringement, then any patent licenses
granted to You under this License for that Work shall terminate
as of the date such litigation is filed.
4. Redistribution. You may reproduce and distribute copies of the
Work or Derivative Works thereof in any medium, with or without
modifications, and in Source or Object form, provided that You
meet the following conditions:
(a) You must give any other recipients of the Work or
Derivative Works a copy of this License; and
(b) You must cause any modified files to carry prominent notices
stating that You changed the files; and
(c) You must retain, in the Source form of any Derivative Works
that You distribute, all copyright, patent, trademark, and
attribution notices from the Source form of the Work,
excluding those notices that do not pertain to any part of
the Derivative Works; and
(d) If the Work includes a "NOTICE" text file as part of its
distribution, then any Derivative Works that You distribute must
include a readable copy of the attribution notices contained
within such NOTICE file, excluding those notices that do not
pertain to any part of the Derivative Works, in at least one
of the following places: within a NOTICE text file distributed
as part of the Derivative Works; within the Source form or
documentation, if provided along with the Derivative Works; or,
within a display generated by the Derivative Works, if and
wherever such third-party notices normally appear. The contents
of the NOTICE file are for informational purposes only and
do not modify the License. You may add Your own attribution
notices within Derivative Works that You distribute, alongside
or as an addendum to the NOTICE text from the Work, provided
that such additional attribution notices cannot be construed
as modifying the License.
You may add Your own copyright statement to Your modifications and
may provide additional or different license terms and conditions
for use, reproduction, or distribution of Your modifications, or
for any such Derivative Works as a whole, provided Your use,
reproduction, and distribution of the Work otherwise complies with
the conditions stated in this License.
5. Submission of Contributions. Unless You explicitly state otherwise,
any Contribution intentionally submitted for inclusion in the Work
by You to the Licensor shall be under the terms and conditions of
this License, without any additional terms or conditions.
Notwithstanding the above, nothing herein shall supersede or modify
the terms of any separate license agreement you may have executed
with Licensor regarding such Contributions.
6. Trademarks. This License does not grant permission to use the trade
names, trademarks, service marks, or product names of the Licensor,
except as required for reasonable and customary use in describing the
origin of the Work and reproducing the content of the NOTICE file.
7. Disclaimer of Warranty. Unless required by applicable law or
agreed to in writing, Licensor provides the Work (and each
Contributor provides its Contributions) on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
implied, including, without limitation, any warranties or conditions
of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
PARTICULAR PURPOSE. You are solely responsible for determining the
appropriateness of using or redistributing the Work and assume any
risks associated with Your exercise of permissions under this License.
8. Limitation of Liability. In no event and under no legal theory,
whether in tort (including negligence), contract, or otherwise,
unless required by applicable law (such as deliberate and grossly
negligent acts) or agreed to in writing, shall any Contributor be
liable to You for damages, including any direct, indirect, special,
incidental, or consequential damages of any character arising as a
result of this License or out of the use or inability to use the
Work (including but not limited to damages for loss of goodwill,
work stoppage, computer failure or malfunction, or any and all
other commercial damages or losses), even if such Contributor
has been advised of the possibility of such damages.
9. Accepting Warranty or Additional Liability. While redistributing
the Work or Derivative Works thereof, You may choose to offer,
and charge a fee for, acceptance of support, warranty, indemnity,
or other liability obligations and/or rights consistent with this
License. However, in accepting such obligations, You may act only
on Your own behalf and on Your sole responsibility, not on behalf
of any other Contributor, and only if You agree to indemnify,
defend, and hold each Contributor harmless for any liability
incurred by, or claims asserted against, such Contributor by reason
of your accepting any such warranty or additional liability.
END OF TERMS AND CONDITIONS
APPENDIX: How to apply the Apache License to your work.
To apply the Apache License to your work, attach the following
boilerplate notice, with the fields enclosed by brackets "[]"
replaced with your own identifying information. (Don't include
the brackets!) The text should be enclosed in the appropriate
comment syntax for the file format. We also recommend that a
file or class name and description of purpose be included on the
same "printed page" as the copyright notice for easier
identification within third-party archives.
Copyright [yyyy] [name of copyright owner]
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
================================================
FILE: MANIFEST.in
================================================
include CITATION.cff
include LICENSE
include NOTICE
include README.md
================================================
FILE: NOTICE
================================================
This product includes litstudy, software developed by
Netherlands eScience Center.
================================================
FILE: README.md
================================================
# LitStudy

[](https://github.com/NLeSC/litstudy/)
[](https://zenodo.org/badge/latestdoi/206312286)
[](https://github.com/NLeSC/litstudy/blob/master/LICENSE)
[](https://pypi.org/project/litstudy/)
[](https://github.com/NLeSC/litstudy/actions/)
**LitStudy** is a Python package for analyzing scientific literature right from the comfort of a Jupyter Notebook. It lets you gather publications and explore their metadata through visualizations, network analysis, and natural-language processing.
The package offers five main features:
* **Extract** metadata from scientific documents sourced from various locations. A uniform interface allows combining different data sources.
* **Filter**, **select**, **deduplicate**, and **annotate** document collections.
* Compute and plot general **statistics** for document sets (authors, venues, publication years, and more).
* Generate and plot various **bibliographic networks** as interactive visualizations.
* Discover topics using **natural-language processing** (NLP) to automatically identify popular themes.
## Frequently Asked Questions
If you have any questions or run into an error, see the [_Frequently Asked Questions_](https://nlesc.github.io/litstudy/faq.html) section of the [documentation](https://nlesc.github.io/litstudy/).
If your question or error is not on the list, please check the [GitHub issue tracker](https://github.com/NLeSC/litstudy/issues) for a similar issue or
create a [new issue](https://github.com/NLeSC/litstudy/issues/new).
## Supported Source
LitStudy supports the following data sources. The table below lists which metadata is fully (✓) or partially (*) provided by each source.
| Name | Title | Authors | Venue | Abstract | Citations | References |
|-----------------|-------|---------|-------|----------|----------------|------------|
| [Scopus] | ✓ | ✓ | ✓ | ✓ | ✓ | ✓
| [SemanticScholar] | ✓ | ✓ | ✓ | ✓ | * <sup>(count only)</sup> | ✓
| [CrossRef] | ✓ | ✓ | ✓ | ✓ | * <sup>(count only)</sup> | ✓
| [DBLP] | ✓ | ✓ | ✓ | | |
| [arXiv] | ✓ | ✓ | | ✓ | |
| [IEEE Xplore] | ✓ | ✓ | ✓ | ✓ | * <sup>(count only)</sup> |
| [Springer Link] | ✓ | ✓ | ✓ | ✓ | * <sup>(count only)</sup> |
| CSV file | ✓ | ✓ | ✓ | ✓ | |
| bibtex file | ✓ | ✓ | ✓ | ✓ | |
| RIS file | ✓ | ✓ | ✓ | ✓ | |
[Scopus]: http://scopus.com/
[SemanticScholar]: https://www.semanticscholar.org/
[CrossRef]: https://www.crossref.org/
[DBLP]: https://dblp.org/
[arXiv]: https://arxiv.org/
[IEEE Xplore]: https://ieeexplore.ieee.org/
[Springer Link]: https://link.springer.com/
## Example
An example notebook is available in `notebooks/example.ipynb` and [here](https://nlesc.github.io/litstudy/example.html).
[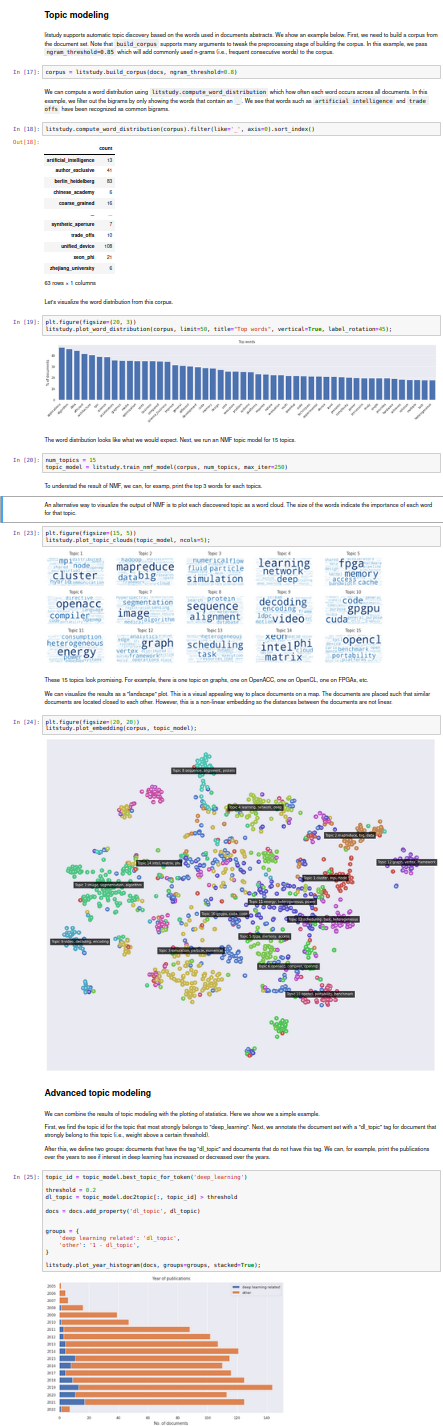](https://github.com/NLeSC/litstudy/blob/master/notebooks/example.ipynb)
## Installation Guide
LitStudy is available on PyPI!
Full installation guide is available [here](https://nlesc.github.io/litstudy/installation.html).
```bash
pip install litstudy
```
Or install the latest development version directly from GitHub:
```bash
pip install git+https://github.com/NLeSC/litstudy
```
## Documentation
Documentation is available [here](https://nlesc.github.io/litstudy/).
## Requirements
The package has been tested for Python 3.7. Required packages are available in `requirements.txt`.
`litstudy` supports several data sources.
Some of these sources (such as semantic Scholar, CrossRef, and arXiv) are openly available.
However to access the Scopus API, you (or your institute) requires a Scopus subscription and you need to request an Elsevier Developer API key (see [Elsevier Developers](https://dev.elsevier.com/index.jsp)).
For more information, see the [guide](https://pybliometrics.readthedocs.io/en/stable/access.html) by `pybliometrics`.
## License
Apache 2.0. See [LICENSE](https://github.com/NLeSC/litstudy/blob/master/LICENSE).
## Change log
See [CHANGELOG.md](https://github.com/NLeSC/litstudy/blob/master/CHANGELOG.md).
## Contributing
See [CONTRIBUTING.md](https://github.com/NLeSC/litstudy/blob/master/CONTRIBUTING.md).
## Citation
If you use LitStudy in your work, please cite the following publication:
> S. Heldens, A. Sclocco, H. Dreuning, B. van Werkhoven, P. Hijma, J. Maassen & R.V. van Nieuwpoort (2022), "litstudy: A Python package for literature reviews", SoftwareX 20
As BibTeX:
```Latex
@article{litstudy,
title = {litstudy: A Python package for literature reviews},
journal = {SoftwareX},
volume = {20},
pages = {101207},
year = {2022},
issn = {2352-7110},
doi = {https://doi.org/10.1016/j.softx.2022.101207},
url = {https://www.sciencedirect.com/science/article/pii/S235271102200125X},
author = {S. Heldens and A. Sclocco and H. Dreuning and B. {van Werkhoven} and P. Hijma and J. Maassen and R. V. {van Nieuwpoort}},
}
```
## Related work
Don't forget to check out these other amazing software packages!
* [ScientoPy](https://www.scientopy.com/): Open-source Python based scientometric analysis tool.
* [pybliometrics](https://github.com/pybliometrics-dev/pybliometrics): API-Wrapper to access Scopus.
* [ASReview](https://asreview.nl/): Active learning for systematic reviews.
* [metaknowledge](https://github.com/UWNETLAB/metaknowledge): Python library for doing bibliometric and network analysis in science.
* [tethne](https://github.com/diging/tethne): Python module for bibliographic network analysis.
* [VOSviewer](https://www.vosviewer.com/): Software tool for constructing and visualizing bibliometric networks.
================================================
FILE: docs/Makefile
================================================
# Minimal makefile for Sphinx documentation
#
# You can set these variables from the command line.
SPHINXOPTS =
SPHINXBUILD = sphinx-build
SOURCEDIR = .
BUILDDIR = _build
# Put it first so that "make" without argument is like "make help".
help:
@$(SPHINXBUILD) -M help "$(SOURCEDIR)" "$(BUILDDIR)" $(SPHINXOPTS) $(O)
.PHONY: help Makefile
# Catch-all target: route all unknown targets to Sphinx using the new
# "make mode" option. $(O) is meant as a shortcut for $(SPHINXOPTS).
%: Makefile
@$(SPHINXBUILD) -M $@ "$(SOURCEDIR)" "$(BUILDDIR)" $(SPHINXOPTS) $(O)
================================================
FILE: docs/_static/citation.html
================================================
<html>
<head>
<link rel="stylesheet" href="https://cdnjs.cloudflare.com/ajax/libs/vis/4.16.1/vis.css" type="text/css" />
<script type="text/javascript" src="https://cdnjs.cloudflare.com/ajax/libs/vis/4.16.1/vis-network.min.js"> </script>
<center>
<h1></h1>
</center>
<!-- <link rel="stylesheet" href="../node_modules/vis/dist/vis.min.css" type="text/css" />
<script type="text/javascript" src="../node_modules/vis/dist/vis.js"> </script>-->
<style type="text/css">
#mynetwork {
width: 100%;
height: 1000px;
background-color: #ffffff;
border: 1px solid lightgray;
position: relative;
float: left;
}
#loadingBar {
position:absolute;
top:0px;
left:0px;
width: 100%;
height: 1000px;
background-color:rgba(200,200,200,0.8);
-webkit-transition: all 0.5s ease;
-moz-transition: all 0.5s ease;
-ms-transition: all 0.5s ease;
-o-transition: all 0.5s ease;
transition: all 0.5s ease;
opacity:1;
}
#bar {
position:absolute;
top:0px;
left:0px;
width:20px;
height:20px;
margin:auto auto auto auto;
border-radius:11px;
border:2px solid rgba(30,30,30,0.05);
background: rgb(0, 173, 246); /* Old browsers */
box-shadow: 2px 0px 4px rgba(0,0,0,0.4);
}
#border {
position:absolute;
top:10px;
left:10px;
width:500px;
height:23px;
margin:auto auto auto auto;
box-shadow: 0px 0px 4px rgba(0,0,0,0.2);
border-radius:10px;
}
#text {
position:absolute;
top:8px;
left:530px;
width:30px;
height:50px;
margin:auto auto auto auto;
font-size:22px;
color: #000000;
}
div.outerBorder {
position:relative;
top:400px;
width:600px;
height:44px;
margin:auto auto auto auto;
border:8px solid rgba(0,0,0,0.1);
background: rgb(252,252,252); /* Old browsers */
background: -moz-linear-gradient(top, rgba(252,252,252,1) 0%, rgba(237,237,237,1) 100%); /* FF3.6+ */
background: -webkit-gradient(linear, left top, left bottom, color-stop(0%,rgba(252,252,252,1)), color-stop(100%,rgba(237,237,237,1))); /* Chrome,Safari4+ */
background: -webkit-linear-gradient(top, rgba(252,252,252,1) 0%,rgba(237,237,237,1) 100%); /* Chrome10+,Safari5.1+ */
background: -o-linear-gradient(top, rgba(252,252,252,1) 0%,rgba(237,237,237,1) 100%); /* Opera 11.10+ */
background: -ms-linear-gradient(top, rgba(252,252,252,1) 0%,rgba(237,237,237,1) 100%); /* IE10+ */
background: linear-gradient(to bottom, rgba(252,252,252,1) 0%,rgba(237,237,237,1) 100%); /* W3C */
filter: progid:DXImageTransform.Microsoft.gradient( startColorstr='#fcfcfc', endColorstr='#ededed',GradientType=0 ); /* IE6-9 */
border-radius:72px;
box-shadow: 0px 0px 10px rgba(0,0,0,0.2);
}
</style>
</head>
<body>
<div id = "mynetwork"></div>
<div id="loadingBar">
<div class="outerBorder">
<div id="text">0%</div>
<div id="border">
<div id="bar"></div>
</div>
</div>
</div>
<script type="text/javascript">
// initialize global variables.
var edges;
var nodes;
var network;
var container;
var options, data;
// This method is responsible for drawing the graph, returns the drawn network
function drawGraph() {
var container = document.getElementById('mynetwork');
// parsing and collecting nodes and edges from the python
nodes = new vis.DataSet([{"id": 13, "label": "Extending OpenSHMEM\nfor GPU computing", "labelHighlightBold": true, "shape": "dot", "size": 16.176471710205078, "title": "Extending OpenSHMEM for GPU computing", "x": 24.76389076112976, "y": 122.37293814381397}, {"id": 18, "label": "Physis: An\nimplicitly parallel\nprogramming model\nfor stencil\ncomputations on\nlarge-scale gpu-\naccelerated\nsupercomputers", "labelHighlightBold": true, "shape": "dot", "size": 27.352941513061523, "title": "Physis: An implicitly parallel programming model for stencil computations on large-scale gpu-accelerated supercomputers", "x": -18.7288326671725, "y": 8.611340066023798}, {"id": 34, "label": "Compiling and\nOptimizing Java 8\nPrograms for GPU\nExecution", "labelHighlightBold": true, "shape": "dot", "size": 16.176471710205078, "title": "Compiling and Optimizing Java 8 Programs for GPU Execution", "x": -33.01993303871408, "y": 28.518820586360636}, {"id": 51, "label": "Selective GPU caches\nto eliminate CPU-GPU\nHW cache coherence", "labelHighlightBold": true, "shape": "dot", "size": 10.588235855102539, "title": "Selective GPU caches to eliminate CPU-GPU HW cache coherence", "x": -24.697750295334995, "y": 34.938700881655784}, {"id": 53, "label": "PACXX: Towards a\nunified programming\nmodel for\nprogramming\naccelerators using\nC++14", "labelHighlightBold": true, "shape": "dot", "size": 10.588235855102539, "title": "PACXX: Towards a unified programming model for programming accelerators using C++14", "x": -137.55669543623773, "y": 153.10688317503357}, {"id": 60, "label": "Accelerating gene\nregulatory networks\ninference through\nGPU/CUDA programming", "labelHighlightBold": true, "shape": "dot", "size": 10.588235855102539, "title": "Accelerating gene regulatory networks inference through GPU/CUDA programming", "x": 16.119976757829036, "y": -42.8422717169076}, {"id": 64, "label": "Exploring the\nsuitability of\nremote GPGPU\nvirtualization for\nthe OpenACC\nprogramming model\nusing rCUDA", "labelHighlightBold": true, "shape": "dot", "size": 10.588235855102539, "title": "Exploring the suitability of remote GPGPU virtualization for the OpenACC programming model using rCUDA", "x": -37.10419622799762, "y": -50.07899169322814}, {"id": 67, "label": "DCUDA: Hardware\nSupported Overlap of\nComputation and\nCommunication", "labelHighlightBold": true, "shape": "dot", "size": 10.588235855102539, "title": "DCUDA: Hardware Supported Overlap of Computation and Communication", "x": -33.87332786054143, "y": 11.864933159981236}, {"id": 68, "label": "GPU computing", "labelHighlightBold": true, "shape": "dot", "size": 100.0, "title": "GPU computing", "x": 6.329250718754571, "y": -34.18733911463281}, {"id": 91, "label": "Designing a unified\nprogramming model\nfor heterogeneous\nmachines", "labelHighlightBold": true, "shape": "dot", "size": 24.55882453918457, "title": "Designing a unified programming model for heterogeneous machines", "x": -57.81566497580839, "y": -12.091708299014202}, {"id": 92, "label": "A case study of\nOpenCL on an Android\nmobile GPU", "labelHighlightBold": true, "shape": "dot", "size": 7.7941179275512695, "title": "A case study of OpenCL on an Android mobile GPU", "x": 3.936617293001404, "y": -44.37072024756895}, {"id": 106, "label": "An evaluation of\nunified memory\ntechnology on NVIDIA\nGPUs", "labelHighlightBold": true, "shape": "dot", "size": 16.176471710205078, "title": "An evaluation of unified memory technology on NVIDIA GPUs", "x": 4.322878604771536, "y": 25.792487247701676}, {"id": 115, "label": "Achieving\nportability and\nperformance through\nOpenACC", "labelHighlightBold": true, "shape": "dot", "size": 7.7941179275512695, "title": "Achieving portability and performance through OpenACC", "x": 14.655810467394069, "y": -73.16158321439497}, {"id": 121, "label": "An Enhanced\nProfiling Framework\nfor the Analysis and\nDevelopment of\nParallel Primitives\nfor GPUs", "labelHighlightBold": true, "shape": "dot", "size": 10.588235855102539, "title": "An Enhanced Profiling Framework for the Analysis and Development of Parallel Primitives for GPUs", "x": -6.790233183944989, "y": 47.559438616441106}, {"id": 125, "label": "GPU accelerated\nLanczos algorithm\nwith applications", "labelHighlightBold": true, "shape": "dot", "size": 7.7941179275512695, "title": "GPU accelerated Lanczos algorithm with applications", "x": 67.43624839486117, "y": -15.856550886523927}, {"id": 128, "label": "VOCL: An optimized\nenvironment for\ntransparent\nvirtualization of\ngraphics processing\nunits", "labelHighlightBold": true, "shape": "dot", "size": 16.176471710205078, "title": "VOCL: An optimized environment for transparent virtualization of graphics processing units", "x": -27.147883565553244, "y": -40.42330677872908}, {"id": 134, "label": "Parallel algorithms\nfor approximate\nstring matching with\nk mismatches on CUDA", "labelHighlightBold": true, "shape": "dot", "size": 7.7941179275512695, "title": "Parallel algorithms for approximate string matching with k mismatches on CUDA", "x": 24.027643499441634, "y": -3.5517468756445068}, {"id": 141, "label": "Record setting\nsoftware\nimplementation of\ndes using CUDA", "labelHighlightBold": true, "shape": "dot", "size": 18.97058868408203, "title": "Record setting software implementation of des using CUDA", "x": 43.10243901267682, "y": -50.668593214139456}, {"id": 146, "label": "An investigation of\nUnified Memory\nAccess performance\nin CUDA", "labelHighlightBold": true, "shape": "dot", "size": 24.55882453918457, "title": "An investigation of Unified Memory Access performance in CUDA", "x": 2.2677354694675125, "y": 19.53145343210315}, {"id": 155, "label": "Towards achieving\nperformance\nportability using\ndirectives for\naccelerators", "labelHighlightBold": true, "shape": "dot", "size": 7.7941179275512695, "title": "Towards achieving performance portability using directives for accelerators", "x": 41.05949316371812, "y": 6.748039881219046}, {"id": 181, "label": "Self-adaptive OmpSs\ntasks in\nheterogeneous\nenvironments", "labelHighlightBold": true, "shape": "dot", "size": 13.382352828979492, "title": "Self-adaptive OmpSs tasks in heterogeneous environments", "x": -73.93121825216481, "y": -9.764180678019299}, {"id": 182, "label": "Design and\nperformance\nevaluation of image\nprocessing\nalgorithms on GPUs", "labelHighlightBold": true, "shape": "dot", "size": 21.764705657958984, "title": "Design and performance evaluation of image processing algorithms on GPUs", "x": -89.64779293768946, "y": -0.014149852620478853}, {"id": 189, "label": "Parallel computing\nexperiences with\nCUDA", "labelHighlightBold": true, "shape": "dot", "size": 44.11764907836914, "title": "Parallel computing experiences with CUDA", "x": 58.71554548426513, "y": -27.265589152526406}, {"id": 200, "label": "Beyond the socket:\nNUMA-aware GPUs", "labelHighlightBold": true, "shape": "dot", "size": 13.382352828979492, "title": "Beyond the socket: NUMA-aware GPUs", "x": -11.522889031691046, "y": 41.99887434023165}, {"id": 202, "label": "Early evaluation of\ndirective-based GPU\nprogramming models\nfor productive\nexascale computing", "labelHighlightBold": true, "shape": "dot", "size": 32.94117736816406, "title": "Early evaluation of directive-based GPU programming models for productive exascale computing", "x": -35.81135870727286, "y": -12.013049124173278}, {"id": 204, "label": "Task scheduling for\ngpu heterogeneous\ncluster", "labelHighlightBold": true, "shape": "dot", "size": 10.588235855102539, "title": "Task scheduling for gpu heterogeneous cluster", "x": -43.08916620014689, "y": -18.10347665453183}, {"id": 222, "label": "Analyzing CUDA\nworkloads using a\ndetailed GPU\nsimulator", "labelHighlightBold": true, "shape": "dot", "size": 46.911766052246094, "title": "Analyzing CUDA workloads using a detailed GPU simulator", "x": -8.643175637062633, "y": 31.465316314064353}, {"id": 237, "label": "Hybrid map task\nscheduling for GPU-\nbased heterogeneous\nclusters", "labelHighlightBold": true, "shape": "dot", "size": 7.7941179275512695, "title": "Hybrid map task scheduling for GPU-based heterogeneous clusters", "x": -5.105039961657392, "y": -31.30110458915556}, {"id": 245, "label": "Stargazer: Automated\nregression-based GPU\ndesign space\nexploration", "labelHighlightBold": true, "shape": "dot", "size": 7.7941179275512695, "title": "Stargazer: Automated regression-based GPU design space exploration", "x": -14.85701484922424, "y": 35.488748315892266}, {"id": 249, "label": "Empowering visual\ncategorization with\nthe GPU", "labelHighlightBold": true, "shape": "dot", "size": 24.55882453918457, "title": "Empowering visual categorization with the GPU", "x": 4.239864280021133, "y": -52.67611387008494}, {"id": 259, "label": "StreamMR: An\noptimized MapReduce\nframework for AMD\nGPUs", "labelHighlightBold": true, "shape": "dot", "size": 13.382352828979492, "title": "StreamMR: An optimized MapReduce framework for AMD GPUs", "x": 89.30230942900809, "y": 160.83049239566935}, {"id": 262, "label": "Exploiting Task-\nParallelism on GPU\nClusters via OmpSs\nand rCUDA\nVirtualization", "labelHighlightBold": true, "shape": "dot", "size": 10.588235855102539, "title": "Exploiting Task-Parallelism on GPU Clusters via OmpSs and rCUDA Virtualization", "x": -34.48297340210872, "y": -52.42060344606631}, {"id": 267, "label": "Unlocking bandwidth\nfor GPUs in CC-NUMA\nsystems", "labelHighlightBold": true, "shape": "dot", "size": 13.382352828979492, "title": "Unlocking bandwidth for GPUs in CC-NUMA systems", "x": -2.341847324234936, "y": 22.700120533832603}, {"id": 276, "label": "OpenCL - An\neffective\nprogramming model\nfor data parallel\ncomputations at the\nCell Broadband\nEngine", "labelHighlightBold": true, "shape": "dot", "size": 7.7941179275512695, "title": "OpenCL - An effective programming model for data parallel computations at the Cell Broadband Engine", "x": -52.84143316139907, "y": 6.8604154729692635}, {"id": 277, "label": "GraphReduce:\nProcessing large-\nscale graphs on\naccelerator-based\nsystems", "labelHighlightBold": true, "shape": "dot", "size": 13.382352828979492, "title": "GraphReduce: Processing large-scale graphs on accelerator-based systems", "x": -157.0098718067881, "y": 185.76248211060502}, {"id": 289, "label": "Can GPGPU\nprogramming be\nliberated from the\ndata-parallel\nbottleneck?", "labelHighlightBold": true, "shape": "dot", "size": 10.588235855102539, "title": "Can GPGPU programming be liberated from the data-parallel bottleneck?", "x": -100.17011306674146, "y": 12.015917840606194}, {"id": 293, "label": "Massively parallel\nnetwork coding on\nGPUs", "labelHighlightBold": true, "shape": "dot", "size": 7.7941179275512695, "title": "Massively parallel network coding on GPUs", "x": -2.2374148817409494, "y": -37.13949126822989}, {"id": 311, "label": "OpenMPC: Extended\nOpenMP programming\nand tuning for GPUs", "labelHighlightBold": true, "shape": "dot", "size": 44.11764907836914, "title": "OpenMPC: Extended OpenMP programming and tuning for GPUs", "x": -41.58900065888275, "y": -1.8093634026342515}, {"id": 342, "label": "Throughput-effective\non-chip networks for\nmanycore\naccelerators", "labelHighlightBold": true, "shape": "dot", "size": 13.382352828979492, "title": "Throughput-effective on-chip networks for manycore accelerators", "x": -13.725111872890286, "y": 47.544673067902195}, {"id": 343, "label": "An MDE approach for\nautomatic code\ngeneration from\nUML/MARTE to openCL", "labelHighlightBold": true, "shape": "dot", "size": 10.588235855102539, "title": "An MDE approach for automatic code generation from UML/MARTE to openCL", "x": -90.34240394269759, "y": -64.0955909622676}, {"id": 344, "label": "Fast motion\nestimation on\ngraphics hardware\nfor h.264 video\nencoding", "labelHighlightBold": true, "shape": "dot", "size": 10.588235855102539, "title": "Fast motion estimation on graphics hardware for h.264 video encoding", "x": 92.16741901422802, "y": -62.21984092501383}, {"id": 347, "label": "CuMAPz: A tool to\nanalyze memory\naccess patterns in\nCUDA", "labelHighlightBold": true, "shape": "dot", "size": 13.382352828979492, "title": "CuMAPz: A tool to analyze memory access patterns in CUDA", "x": -106.22225371359201, "y": 15.71489347352919}, {"id": 351, "label": "Optimizing sparse\nmatrix-vector\nmultiplication on\nCUDA", "labelHighlightBold": true, "shape": "dot", "size": 16.176471710205078, "title": "Optimizing sparse matrix-vector multiplication on CUDA", "x": -114.08883280843102, "y": 105.02225395466465}, {"id": 358, "label": "A comparative study\nof SYCL, OpenCL, and\nOpenMP", "labelHighlightBold": true, "shape": "dot", "size": 10.588235855102539, "title": "A comparative study of SYCL, OpenCL, and OpenMP", "x": 34.5704220565808, "y": 2.1910642545011623}, {"id": 361, "label": "Implementation of\nXcalableMP device\nacceleration\nextention with\nOpenCL", "labelHighlightBold": true, "shape": "dot", "size": 10.588235855102539, "title": "Implementation of XcalableMP device acceleration extention with OpenCL", "x": 25.727119129471127, "y": 134.2974186952201}, {"id": 363, "label": "Coordinated static\nand dynamic cache\nbypassing for GPUs", "labelHighlightBold": true, "shape": "dot", "size": 13.382352828979492, "title": "Coordinated static and dynamic cache bypassing for GPUs", "x": -9.702073792609484, "y": 37.92453734809817}, {"id": 376, "label": "A comparison of\nperformance\ntunabilities between\nOpenCL and OpenACC", "labelHighlightBold": true, "shape": "dot", "size": 10.588235855102539, "title": "A comparison of performance tunabilities between OpenCL and OpenACC", "x": -3.7488175460497764, "y": 45.514812614569315}, {"id": 378, "label": "A comprehensive\nperformance\ncomparison of CUDA\nand OpenCL", "labelHighlightBold": true, "shape": "dot", "size": 32.94117736816406, "title": "A comprehensive performance comparison of CUDA and OpenCL", "x": 21.30053879004295, "y": -9.838769904988158}, {"id": 385, "label": "GasCL: A vertex-\ncentric graph model\nfor GPUs", "labelHighlightBold": true, "shape": "dot", "size": 13.382352828979492, "title": "GasCL: A vertex-centric graph model for GPUs", "x": -152.68282868026617, "y": 183.7421165431827}, {"id": 395, "label": "Liszt: A domain\nspecific language\nfor building\nportable mesh-based\nPDE solvers", "labelHighlightBold": true, "shape": "dot", "size": 13.382352828979492, "title": "Liszt: A domain specific language for building portable mesh-based PDE solvers", "x": -78.97863881376998, "y": -54.85530529666192}, {"id": 402, "label": "Scalable programming\nmodels for massively\nmulticore processors", "labelHighlightBold": true, "shape": "dot", "size": 10.588235855102539, "title": "Scalable programming models for massively multicore processors", "x": -6.076889811191757, "y": -10.602190939552877}, {"id": 419, "label": "A comparative study\nof GPU programming\nmodels and\narchitectures using\nneural networks", "labelHighlightBold": true, "shape": "dot", "size": 18.97058868408203, "title": "A comparative study of GPU programming models and architectures using neural networks", "x": 68.02800802073645, "y": -23.68261777817171}, {"id": 423, "label": "Porting and scaling\nOpenACC applications\non massively-\nparallel, GPU-\naccelerated\nsupercomputers", "labelHighlightBold": true, "shape": "dot", "size": 10.588235855102539, "title": "Porting and scaling OpenACC applications on massively-parallel, GPU-accelerated supercomputers", "x": 22.428007077264574, "y": 132.8488076534428}, {"id": 424, "label": "Providing source\ncode level\nportability between\nCPU and GPU with\nMapCG", "labelHighlightBold": true, "shape": "dot", "size": 7.7941179275512695, "title": "Providing source code level portability between CPU and GPU with MapCG", "x": 94.81746377478484, "y": 165.83516704649634}, {"id": 426, "label": "Accelerating\nincompressible flow\ncomputations with a\nPthreads-CUDA\nimplementation on\nsmall-footprint\nmulti-GPU platforms", "labelHighlightBold": true, "shape": "dot", "size": 18.97058868408203, "title": "Accelerating incompressible flow computations with a Pthreads-CUDA implementation on small-footprint multi-GPU platforms", "x": -8.560106741593499, "y": -63.2900076996156}, {"id": 429, "label": "Optimizing linpack\nbenchmark on GPU-\naccelerated\npetascale\nsupercomputer", "labelHighlightBold": true, "shape": "dot", "size": 16.176471710205078, "title": "Optimizing linpack benchmark on GPU-accelerated petascale supercomputer", "x": 13.680509220475168, "y": -28.71944765940697}, {"id": 433, "label": "An efficient\nparallel\ncollaborative\nfiltering algorithm\non multi-GPU\nplatform", "labelHighlightBold": true, "shape": "dot", "size": 10.588235855102539, "title": "An efficient parallel collaborative filtering algorithm on multi-GPU platform", "x": -28.011285265575538, "y": 9.01718653156487}, {"id": 440, "label": "CUDA compatible GPU\ncards as efficient\nhardware\naccelerators for\nSmith-Waterman\nsequence alignment", "labelHighlightBold": true, "shape": "dot", "size": 30.147058486938477, "title": "CUDA compatible GPU cards as efficient hardware accelerators for Smith-Waterman sequence alignment", "x": 139.98851437237437, "y": -17.0148749541904}, {"id": 442, "label": "Parallel programing\ntemplates for remote\nsensing image\nprocessing on GPU\narchitectures:\ndesign and\nimplementation", "labelHighlightBold": true, "shape": "dot", "size": 13.382352828979492, "title": "Parallel programing templates for remote sensing image processing on GPU architectures: design and implementation", "x": 4.772212668768481, "y": -129.57867950398318}, {"id": 445, "label": "Correlation\nacceleration in GNSS\nsoftware receivers\nusing a CUDA-enabled\nGPU", "labelHighlightBold": true, "shape": "dot", "size": 13.382352828979492, "title": "Correlation acceleration in GNSS software receivers using a CUDA-enabled GPU", "x": 9.761693107864195, "y": -130.57271298078822}, {"id": 447, "label": "A compound\nOpenMP/MPI program\ndevelopment toolkit\nfor hybrid CPU/GPU\nclusters", "labelHighlightBold": true, "shape": "dot", "size": 16.176471710205078, "title": "A compound OpenMP/MPI program development toolkit for hybrid CPU/GPU clusters", "x": 55.538507460794385, "y": 108.8698139947644}, {"id": 448, "label": "Accelerating\nMapReduce framework\non multi-GPU systems", "labelHighlightBold": true, "shape": "dot", "size": 13.382352828979492, "title": "Accelerating MapReduce framework on multi-GPU systems", "x": 71.3413247818473, "y": 149.86015109232585}, {"id": 458, "label": "MVAPICH2-GPU:\nOptimized GPU to GPU\ncommunication for\nInfiniBand clusters", "labelHighlightBold": true, "shape": "dot", "size": 21.764705657958984, "title": "MVAPICH2-GPU: Optimized GPU to GPU communication for InfiniBand clusters", "x": 26.974759022032, "y": 108.43819247539349}, {"id": 459, "label": "TH-1: China\u0027s first\npetaflop\nsupercomputer", "labelHighlightBold": true, "shape": "dot", "size": 16.176471710205078, "title": "TH-1: China\u0027s first petaflop supercomputer", "x": -48.785587401637116, "y": -15.521845441139185}, {"id": 463, "label": "SkelCL: A high-level\nextension of OpenCL\nfor multi-GPU\nsystems", "labelHighlightBold": true, "shape": "dot", "size": 16.176471710205078, "title": "SkelCL: A high-level extension of OpenCL for multi-GPU systems", "x": 50.329859835762434, "y": 88.19368847630268}, {"id": 466, "label": "OpenMC: Towards\nsimplifying\nprogramming for\ntianhe\nsupercomputers", "labelHighlightBold": true, "shape": "dot", "size": 10.588235855102539, "title": "OpenMC: Towards simplifying programming for tianhe supercomputers", "x": -47.953491604129894, "y": -48.79376392365089}, {"id": 470, "label": "Strategies for\nmaximizing\nutilization on\nmulti-CPU and multi-\nGPU heterogeneous\narchitectures", "labelHighlightBold": true, "shape": "dot", "size": 24.55882453918457, "title": "Strategies for maximizing utilization on multi-CPU and multi-GPU heterogeneous architectures", "x": 41.7858001289886, "y": 122.18182342678097}, {"id": 474, "label": "Cardiac simulation\non multi-GPU\nplatform", "labelHighlightBold": true, "shape": "dot", "size": 18.97058868408203, "title": "Cardiac simulation on multi-GPU platform", "x": -0.9545893829756837, "y": -65.22843358686634}, {"id": 481, "label": "MPtostream: An\nOpenMP compiler for\nCPU-GPU\nheterogeneous\nparallel systems", "labelHighlightBold": true, "shape": "dot", "size": 10.588235855102539, "title": "MPtostream: An OpenMP compiler for CPU-GPU heterogeneous parallel systems", "x": -42.20258800179363, "y": -24.897835869134394}, {"id": 482, "label": "Toward a software\ntransactional memory\nfor heterogeneous\nCPU\u2013GPU processors", "labelHighlightBold": true, "shape": "dot", "size": 16.176471710205078, "title": "Toward a software transactional memory for heterogeneous CPU\u2013GPU processors", "x": 5.586652278027756, "y": 188.21561588764524}, {"id": 491, "label": "CUDASW++ 3.0:\naccelerating Smith-\nWaterman protein\ndatabase search by\ncoupling CPU and GPU\nSIMD instructions.", "labelHighlightBold": true, "shape": "dot", "size": 27.352941513061523, "title": "CUDASW++ 3.0: accelerating Smith-Waterman protein database search by coupling CPU and GPU SIMD instructions.", "x": 152.0715442875626, "y": -13.285821650501893}, {"id": 492, "label": "DOPA: GPU-based\nprotein alignment\nusing database and\nmemory access\noptimizations", "labelHighlightBold": true, "shape": "dot", "size": 10.588235855102539, "title": "DOPA: GPU-based protein alignment using database and memory access optimizations", "x": 159.42147533046034, "y": -4.816874283059061}, {"id": 496, "label": "Addressing GPU on-\nchip shared memory\nbank conflicts using\nelastic pipeline", "labelHighlightBold": true, "shape": "dot", "size": 10.588235855102539, "title": "Addressing GPU on-chip shared memory bank conflicts using elastic pipeline", "x": 38.034083602151355, "y": -9.608048099250405}, {"id": 499, "label": "Scaling up\nMapReduce-based Big\nData Processing on\nMulti-GPU systems", "labelHighlightBold": true, "shape": "dot", "size": 18.97058868408203, "title": "Scaling up MapReduce-based Big Data Processing on Multi-GPU systems", "x": 51.680062213930086, "y": 134.53362260164351}, {"id": 508, "label": "Stencil computations\non heterogeneous\nplatforms for the\nJacobi method: GPUs\nversus Cell BE", "labelHighlightBold": true, "shape": "dot", "size": 27.352941513061523, "title": "Stencil computations on heterogeneous platforms for the Jacobi method: GPUs versus Cell BE", "x": -15.970573983939353, "y": -72.53740030776038}, {"id": 510, "label": "Introducing and\nimplementing the\nallpairs skeleton\nfor programming\nmulti-GPU Systems", "labelHighlightBold": true, "shape": "dot", "size": 10.588235855102539, "title": "Introducing and implementing the allpairs skeleton for programming multi-GPU Systems", "x": -122.73135406335528, "y": 127.57000024244564}, {"id": 512, "label": "Optimizing tensor\ncontraction\nexpressions for\nhybrid CPU-GPU\nexecution", "labelHighlightBold": true, "shape": "dot", "size": 16.176471710205078, "title": "Optimizing tensor contraction expressions for hybrid CPU-GPU execution", "x": -32.071114597693686, "y": 3.1914937580039604}, {"id": 539, "label": "Offloading data\nencryption to GPU in\ndatabase systems", "labelHighlightBold": true, "shape": "dot", "size": 16.176471710205078, "title": "Offloading data encryption to GPU in database systems", "x": 51.68768333093016, "y": -51.16714152165434}, {"id": 546, "label": "High-Level\nProgramming for\nMany-Cores Using\nC++14 and the STL", "labelHighlightBold": true, "shape": "dot", "size": 7.7941179275512695, "title": "High-Level Programming for Many-Cores Using C++14 and the STL", "x": -94.52396666171657, "y": 112.74251670489994}, {"id": 547, "label": "RT-CUDA: A Software\nTool for CUDA Code\nRestructuring", "labelHighlightBold": true, "shape": "dot", "size": 16.176471710205078, "title": "RT-CUDA: A Software Tool for CUDA Code Restructuring", "x": -116.13964046101879, "y": 101.68110655465996}, {"id": 548, "label": "Parallel data mining\ntechniques on\nGraphics Processing\nUnit with Compute\nUnified Device\nArchitecture (CUDA)", "labelHighlightBold": true, "shape": "dot", "size": 32.94117736816406, "title": "Parallel data mining techniques on Graphics Processing Unit with Compute Unified Device Architecture (CUDA)", "x": 57.441349887496955, "y": -39.19685861767704}, {"id": 561, "label": "A GPU implementation\nof a structural-\nsimilarity-based\naerial-image\nclassification", "labelHighlightBold": true, "shape": "dot", "size": 21.764705657958984, "title": "A GPU implementation of a structural-similarity-based aerial-image classification", "x": 38.932519705401624, "y": -44.156907568311944}, {"id": 564, "label": "GPU-accelerated\nlevel-set\nsegmentation", "labelHighlightBold": true, "shape": "dot", "size": 7.7941179275512695, "title": "GPU-accelerated level-set segmentation", "x": 61.82166515644974, "y": -71.40638848623834}, {"id": 570, "label": "Gene regulatory\nnetworks inference\nusing a multi-GPU\nexhaustive search\nalgorithm", "labelHighlightBold": true, "shape": "dot", "size": 7.7941179275512695, "title": "Gene regulatory networks inference using a multi-GPU exhaustive search algorithm", "x": 73.37425240799887, "y": 114.69458746538966}, {"id": 604, "label": "Extending OpenMP to\nsurvive the\nheterogeneous multi-\ncore era", "labelHighlightBold": true, "shape": "dot", "size": 16.176471710205078, "title": "Extending OpenMP to survive the heterogeneous multi-core era", "x": -66.65381036265713, "y": -8.016984732642927}, {"id": 605, "label": "Speeding up the\nevaluation phase of\nGP classification\nalgorithms on GPUs", "labelHighlightBold": true, "shape": "dot", "size": 18.97058868408203, "title": "Speeding up the evaluation phase of GP classification algorithms on GPUs", "x": 66.34991750796436, "y": -34.93620054791177}, {"id": 608, "label": "Medical image\nsegmentation with\ndeformable models on\ngraphics processing\nunits", "labelHighlightBold": true, "shape": "dot", "size": 18.97058868408203, "title": "Medical image segmentation with deformable models on graphics processing units", "x": 54.891101029922936, "y": -57.74073845936723}, {"id": 609, "label": "Correlating radio\nastronomy signals\nwith many-core\nhardware", "labelHighlightBold": true, "shape": "dot", "size": 13.382352828979492, "title": "Correlating radio astronomy signals with many-core hardware", "x": 44.218821632857804, "y": 12.69723759751845}, {"id": 620, "label": "High performance\ndata clustering: A\ncomparative analysis\nof performance for\nGPU, RASC, MPI, and\nOpenMP\nimplementations", "labelHighlightBold": true, "shape": "dot", "size": 10.588235855102539, "title": "High performance data clustering: A comparative analysis of performance for GPU, RASC, MPI, and OpenMP implementations", "x": 67.3309120475585, "y": 112.88918721287439}, {"id": 633, "label": "Adaptive fast\nmultipole methods on\nthe GPU", "labelHighlightBold": true, "shape": "dot", "size": 13.382352828979492, "title": "Adaptive fast multipole methods on the GPU", "x": -29.8689126742957, "y": -84.98851981439584}, {"id": 636, "label": "Parallelization of\nlarge vector\nsimilarity\ncomputations in a\nhybrid CPU+GPU\nenvironment", "labelHighlightBold": true, "shape": "dot", "size": 13.382352828979492, "title": "Parallelization of large vector similarity computations in a hybrid CPU+GPU environment", "x": 10.992900641315503, "y": 28.591738454512818}, {"id": 644, "label": "GASAL2: A GPU\naccelerated sequence\nalignment library\nfor high-throughput\nNGS data", "labelHighlightBold": true, "shape": "dot", "size": 10.588235855102539, "title": "GASAL2: A GPU accelerated sequence alignment library for high-throughput NGS data", "x": 160.28896666637868, "y": -14.551334859355702}, {"id": 655, "label": "GPU-accelerated\npreconditioned\niterative linear\nsolvers", "labelHighlightBold": true, "shape": "dot", "size": 13.382352828979492, "title": "GPU-accelerated preconditioned iterative linear solvers", "x": -31.919275631758673, "y": -88.45959322419276}, {"id": 656, "label": "GPU-based collision\nanalysis between a\nmulti-body system\nand numerous\nparticles", "labelHighlightBold": true, "shape": "dot", "size": 7.7941179275512695, "title": "GPU-based collision analysis between a multi-body system and numerous particles", "x": 120.52730488714306, "y": -24.818599022821363}, {"id": 660, "label": "Hybrid multi-GPU\ncomputing:\naccelerated kernels\nfor segmentation and\nobject detection\nwith medical image\nprocessing\napplications", "labelHighlightBold": true, "shape": "dot", "size": 13.382352828979492, "title": "Hybrid multi-GPU computing: accelerated kernels for segmentation and object detection with medical image processing applications", "x": -108.93643894444878, "y": -1.767799391573767}, {"id": 666, "label": "A parallel pattern\nfor iterative\nstencil + reduce", "labelHighlightBold": true, "shape": "dot", "size": 16.176471710205078, "title": "A parallel pattern for iterative stencil + reduce", "x": -109.21997335920058, "y": 102.31076950788147}, {"id": 670, "label": "Parallelization of\nFull Search Motion\nEstimation algorithm\nfor parallel and\ndistributed\nplatforms", "labelHighlightBold": true, "shape": "dot", "size": 13.382352828979492, "title": "Parallelization of Full Search Motion Estimation algorithm for parallel and distributed platforms", "x": 112.91299287397852, "y": -86.65823167839001}, {"id": 685, "label": "Design Flow for GPU\nand Multicore\nExecution of Dynamic\nDataflow Programs", "labelHighlightBold": true, "shape": "dot", "size": 10.588235855102539, "title": "Design Flow for GPU and Multicore Execution of Dynamic Dataflow Programs", "x": 12.183590994410205, "y": -53.324658941928575}, {"id": 705, "label": "Effective naive\nBayes nearest\nneighbor based image\nclassification on\nGPU", "labelHighlightBold": true, "shape": "dot", "size": 10.588235855102539, "title": "Effective naive Bayes nearest neighbor based image classification on GPU", "x": 63.85284676586857, "y": 145.09473959759873}, {"id": 711, "label": "Enhancing GPU\nparallelism in\nnature-inspired\nalgorithms", "labelHighlightBold": true, "shape": "dot", "size": 16.176471710205078, "title": "Enhancing GPU parallelism in nature-inspired algorithms", "x": 70.73540033371225, "y": -30.664432655226168}, {"id": 739, "label": "On GPU\u2013CUDA as\npreprocessing of\nfuzzy-rough data\nreduction by means\nof singular value\ndecomposition", "labelHighlightBold": true, "shape": "dot", "size": 10.588235855102539, "title": "On GPU\u2013CUDA as preprocessing of fuzzy-rough data reduction by means of singular value decomposition", "x": 4.323703892809986, "y": -4.135094352734839}, {"id": 741, "label": "MilkyWay-2\nsupercomputer:\nSystem and\napplication", "labelHighlightBold": true, "shape": "dot", "size": 18.97058868408203, "title": "MilkyWay-2 supercomputer: System and application", "x": -47.47611118530658, "y": -58.84040628735832}, {"id": 756, "label": "High performance\nevaluation of\nevolutionary-mined\nassociation rules on\nGPUs", "labelHighlightBold": true, "shape": "dot", "size": 13.382352828979492, "title": "High performance evaluation of evolutionary-mined association rules on GPUs", "x": 69.81864380109309, "y": -39.45019128602855}, {"id": 762, "label": "Energy cost\nevaluation of\nparallel algorithms\nfor multiprocessor\nsystems", "labelHighlightBold": true, "shape": "dot", "size": 7.7941179275512695, "title": "Energy cost evaluation of parallel algorithms for multiprocessor systems", "x": -13.310295668762771, "y": 10.753777440927363}, {"id": 771, "label": "Simultaneous CPU\u2013GPU\nExecution of Data\nParallel Algorithmic\nSkeletons", "labelHighlightBold": true, "shape": "dot", "size": 10.588235855102539, "title": "Simultaneous CPU\u2013GPU Execution of Data Parallel Algorithmic Skeletons", "x": -97.70404645512019, "y": 105.90164122992417}, {"id": 786, "label": "CUDASW++2.0:\nEnhanced Smith-\nWaterman protein\ndatabase search on\nCUDA-enabled GPUs\nbased on SIMT and\nvirtualized SIMD\nabstractions", "labelHighlightBold": true, "shape": "dot", "size": 21.764705657958984, "title": "CUDASW++2.0: Enhanced Smith-Waterman protein database search on CUDA-enabled GPUs based on SIMT and virtualized SIMD abstractions", "x": 134.4972719871022, "y": -17.228311976859647}, {"id": 788, "label": "Solving finite\ndifference linear\nsystems on GPUs:\nCUDA based parallel\nexplicit\npreconditioned\nbiconjugate\nconjugate gradient\ntype methods", "labelHighlightBold": true, "shape": "dot", "size": 18.97058868408203, "title": "Solving finite difference linear systems on GPUs: CUDA based parallel explicit preconditioned biconjugate conjugate gradient type methods", "x": -4.402681918762127, "y": -61.38878285147453}, {"id": 789, "label": "Data layout\ntransformation\nexploiting memory-\nlevel parallelism in\nstructured grid\nmany-core\napplications", "labelHighlightBold": true, "shape": "dot", "size": 7.7941179275512695, "title": "Data layout transformation exploiting memory-level parallelism in structured grid many-core applications", "x": -114.00574457651189, "y": 22.561438369418816}, {"id": 792, "label": "A framework for\naccelerating local\nfeature extraction\nwith OpenCL on\nmulti-core CPUs and\nco-processors", "labelHighlightBold": true, "shape": "dot", "size": 10.588235855102539, "title": "A framework for accelerating local feature extraction with OpenCL on multi-core CPUs and co-processors", "x": 121.24990689915224, "y": -93.99324846212228}, {"id": 825, "label": "PPModel: A modeling\ntool for source code\nmaintenance and\noptimization of\nparallel programs", "labelHighlightBold": true, "shape": "dot", "size": 10.588235855102539, "title": "PPModel: A modeling tool for source code maintenance and optimization of parallel programs", "x": -91.67219424116392, "y": -60.795848769406845}, {"id": 852, "label": "A view of\nprogramming scalable\ndata analysis: from\nclouds to exascale", "labelHighlightBold": true, "shape": "dot", "size": 7.7941179275512695, "title": "A view of programming scalable data analysis: from clouds to exascale", "x": 26.415483684681806, "y": -70.6538457878514}, {"id": 854, "label": "SkePU 2: Flexible\nand Type-Safe\nSkeleton Programming\nfor Heterogeneous\nParallel Systems", "labelHighlightBold": true, "shape": "dot", "size": 27.352941513061523, "title": "SkePU 2: Flexible and Type-Safe Skeleton Programming for Heterogeneous Parallel Systems", "x": -102.73055459157142, "y": 92.12197437434445}, {"id": 855, "label": "Generating custom\ncode for efficient\nquery execution on\nheterogeneous\nprocessors", "labelHighlightBold": true, "shape": "dot", "size": 7.7941179275512695, "title": "Generating custom code for efficient query execution on heterogeneous processors", "x": -41.076312009304395, "y": 35.280506100159016}, {"id": 862, "label": "Dawning nebulae: A\nPetaFLOPS\nsupercomputer with a\nheterogeneous\nstructure", "labelHighlightBold": true, "shape": "dot", "size": 7.7941179275512695, "title": "Dawning nebulae: A PetaFLOPS supercomputer with a heterogeneous structure", "x": -44.39410934008284, "y": -35.44785477992093}, {"id": 875, "label": "Fast and accurate\nprotein substructure\nsearching with\nsimulated annealing\nand GPUs", "labelHighlightBold": true, "shape": "dot", "size": 18.97058868408203, "title": "Fast and accurate protein substructure searching with simulated annealing and GPUs", "x": 149.08617606343037, "y": -18.794137195145904}, {"id": 878, "label": "Parallel mutual\ninformation\nestimation for\ninferring gene\nregulatory networks\non GPUs", "labelHighlightBold": true, "shape": "dot", "size": 10.588235855102539, "title": "Parallel mutual information estimation for inferring gene regulatory networks on GPUs", "x": 18.37011471492788, "y": -39.818400820136304}, {"id": 883, "label": "Performance\nevaluation of\nUnified Memory with\nprefetching and\noversubscription for\nselected parallel\nCUDA applications on\nNVIDIA Pascal and\nVolta GPUs", "labelHighlightBold": true, "shape": "dot", "size": 16.176471710205078, "title": "Performance evaluation of Unified Memory with prefetching and oversubscription for selected parallel CUDA applications on NVIDIA Pascal and Volta GPUs", "x": 7.689577836099897, "y": -111.27399025400528}, {"id": 895, "label": "Accelerating large-\nscale protein\nstructure alignments\nwith graphics\nprocessing units", "labelHighlightBold": true, "shape": "dot", "size": 16.176471710205078, "title": "Accelerating large-scale protein structure alignments with graphics processing units", "x": 155.43935533196031, "y": -20.96795900713483}, {"id": 913, "label": "Performance\nevaluation of\nunified memory and\ndynamic parallelism\nfor selected\nparallel CUDA\napplications", "labelHighlightBold": true, "shape": "dot", "size": 16.176471710205078, "title": "Performance evaluation of unified memory and dynamic parallelism for selected parallel CUDA applications", "x": 4.3004964807575625, "y": 29.527732043204335}, {"id": 920, "label": "A preliminary\nevaluation of\nOpenACC\nimplementations", "labelHighlightBold": true, "shape": "dot", "size": 13.382352828979492, "title": "A preliminary evaluation of OpenACC implementations", "x": 47.034685295115565, "y": -12.802539590182695}, {"id": 921, "label": "Optimizing the\nMatrix\nMultiplication Using\nStrassen and\nWinograd Algorithms\nwith Limited\nRecursions on Many-\nCore", "labelHighlightBold": true, "shape": "dot", "size": 16.176471710205078, "title": "Optimizing the Matrix Multiplication Using Strassen and Winograd Algorithms with Limited Recursions on Many-Core", "x": -111.46927725753929, "y": 98.77787186707079}, {"id": 926, "label": "Protein alignment\nalgorithms with an\nefficient\nbacktracking routine\non multiple GPUs", "labelHighlightBold": true, "shape": "dot", "size": 21.764705657958984, "title": "Protein alignment algorithms with an efficient backtracking routine on multiple GPUs", "x": 147.36538001505247, "y": -9.666702338626086}, {"id": 935, "label": "A scalable and fast\nOPTICS for\nclustering\ntrajectory big data", "labelHighlightBold": true, "shape": "dot", "size": 10.588235855102539, "title": "A scalable and fast OPTICS for clustering trajectory big data", "x": 18.59955379592442, "y": -52.61744421494949}, {"id": 939, "label": "Virtualizing high-\nend GPGPUs on ARM\nclusters for the\nnext generation of\nhigh performance\ncloud computing", "labelHighlightBold": true, "shape": "dot", "size": 16.176471710205078, "title": "Virtualizing high-end GPGPUs on ARM clusters for the next generation of high performance cloud computing", "x": 115.07099598172069, "y": -21.6762741226937}, {"id": 946, "label": "A parallel algorithm\nfor the Riesz\nfractional reaction-\ndiffusion equation\nwith explicit finite\ndifference method", "labelHighlightBold": true, "shape": "dot", "size": 18.97058868408203, "title": "A parallel algorithm for the Riesz fractional reaction-diffusion equation with explicit finite difference method", "x": -39.08759703174296, "y": -80.6772540534114}, {"id": 947, "label": "Formalised\nComposition and\nInteraction for\nHeterogeneous\nStructured\nParallelism", "labelHighlightBold": true, "shape": "dot", "size": 7.7941179275512695, "title": "Formalised Composition and Interaction for Heterogeneous Structured Parallelism", "x": -98.56343268368649, "y": 98.1720562616151}, {"id": 951, "label": "Toward fault-\ntolerant hybrid\nprogramming over\nlarge-scale\nheterogeneous\nclusters via checkpo\ninting/restart\noptimization", "labelHighlightBold": true, "shape": "dot", "size": 16.176471710205078, "title": "Toward fault-tolerant hybrid programming over large-scale heterogeneous clusters via checkpointing/restart optimization", "x": 1.6600122227860346, "y": 188.37721167803048}, {"id": 957, "label": "Efficient scheduling\nof streams on GPGPUs", "labelHighlightBold": true, "shape": "dot", "size": 13.382352828979492, "title": "Efficient scheduling of streams on GPGPUs", "x": 8.22802763999975, "y": -126.12783868888795}, {"id": 963, "label": "Accelerating MRI\nreconstruction via\nthree-dimensional\ndual-dictionary\nlearning using CUDA", "labelHighlightBold": true, "shape": "dot", "size": 13.382352828979492, "title": "Accelerating MRI reconstruction via three-dimensional dual-dictionary learning using CUDA", "x": -107.73396898045155, "y": 3.1544760512260845}, {"id": 966, "label": "CUDASW++: Optimizing\nSmith-Waterman\nsequence database\nsearches for CUDA-\nenabled graphics\nprocessing units", "labelHighlightBold": true, "shape": "dot", "size": 21.764705657958984, "title": "CUDASW++: Optimizing Smith-Waterman sequence database searches for CUDA-enabled graphics processing units", "x": 143.8882629608313, "y": -16.34871914778348}, {"id": 972, "label": "A Hybrid Task Graph\nScheduler for High\nPerformance Image\nProcessing Workflows", "labelHighlightBold": true, "shape": "dot", "size": 13.382352828979492, "title": "A Hybrid Task Graph Scheduler for High Performance Image Processing Workflows", "x": 12.83386949053449, "y": -61.59554885680468}, {"id": 990, "label": "Optimizing Monte\nCarlo radiosity on\ngraphics hardware", "labelHighlightBold": true, "shape": "dot", "size": 7.7941179275512695, "title": "Optimizing Monte Carlo radiosity on graphics hardware", "x": -1.4008314048889217, "y": -41.96140127049525}, {"id": 991, "label": "Parallel refinement\nof slanted 3D\nreconstruction using\ndense stereo induced\nfrom symmetry", "labelHighlightBold": true, "shape": "dot", "size": 13.382352828979492, "title": "Parallel refinement of slanted 3D reconstruction using dense stereo induced from symmetry", "x": -104.4184196384963, "y": 0.36334046894470023}, {"id": 992, "label": "Fast network\ncentrality analysis\nusing GPUs", "labelHighlightBold": true, "shape": "dot", "size": 13.382352828979492, "title": "Fast network centrality analysis using GPUs", "x": -157.21441204511777, "y": 180.9843178891049}, {"id": 998, "label": "A survey on\nplatforms for big\ndata analytics", "labelHighlightBold": true, "shape": "dot", "size": 13.382352828979492, "title": "A survey on platforms for big data analytics", "x": 22.39363609422927, "y": -60.16096070733966}, {"id": 1010, "label": "A statistical\nperformance analyzer\nframework for OpenCL\nkernels on Nvidia\nGPUs", "labelHighlightBold": true, "shape": "dot", "size": 7.7941179275512695, "title": "A statistical performance analyzer framework for OpenCL kernels on Nvidia GPUs", "x": -15.490595926809672, "y": 39.5777748604004}, {"id": 1016, "label": "Simulation of one-\nlayer shallow water\nsystems on multicore\nand CUDA\narchitectures", "labelHighlightBold": true, "shape": "dot", "size": 10.588235855102539, "title": "Simulation of one-layer shallow water systems on multicore and CUDA architectures", "x": 14.797675547772858, "y": -19.66472382629069}, {"id": 1029, "label": "The TianHe-1A\nsupercomputer: Its\nhardware and\nsoftware", "labelHighlightBold": true, "shape": "dot", "size": 41.32352828979492, "title": "The TianHe-1A supercomputer: Its hardware and software", "x": -34.819639072740465, "y": -30.192367096646926}, {"id": 1041, "label": "Energy efficiency of\nload balancing for\ndata-parallel\napplications in\nheterogeneous\nsystems", "labelHighlightBold": true, "shape": "dot", "size": 7.7941179275512695, "title": "Energy efficiency of load balancing for data-parallel applications in heterogeneous systems", "x": 3.163226368944035, "y": 174.59036584695892}, {"id": 1087, "label": "Hybrid\nstatic\u2013dynamic\nselection of\nimplementation\nalternatives in\nheterogeneous\nenvironments", "labelHighlightBold": true, "shape": "dot", "size": 16.176471710205078, "title": "Hybrid static\u2013dynamic selection of implementation alternatives in heterogeneous environments", "x": 6.264895738573001, "y": 194.05804935921628}, {"id": 1092, "label": "The Fraunhofer\nvirtual machine: A\ncommunication\nlibrary and runtime\nsystem based on the\nRDMA model", "labelHighlightBold": true, "shape": "dot", "size": 10.588235855102539, "title": "The Fraunhofer virtual machine: A communication library and runtime system based on the RDMA model", "x": 24.504875905181667, "y": 117.60150858306433}, {"id": 1113, "label": "Optimizing an APSP\nimplementation for\nNVIDIA GPUs using\nkernel\ncharacterization\ncriteria", "labelHighlightBold": true, "shape": "dot", "size": 16.176471710205078, "title": "Optimizing an APSP implementation for NVIDIA GPUs using kernel characterization criteria", "x": -150.99232124041473, "y": 175.39653681516148}, {"id": 1147, "label": "Prediction models\nfor performance,\npower, and energy\nefficiency of\nsoftware executed on\nheterogeneous\nhardware", "labelHighlightBold": true, "shape": "dot", "size": 16.176471710205078, "title": "Prediction models for performance, power, and energy efficiency of software executed on heterogeneous hardware", "x": 2.0923515159185126, "y": 193.71791590168144}, {"id": 1148, "label": "The 2D wavelet\ntransform on\nemerging\narchitectures: GPUs\nand multicores", "labelHighlightBold": true, "shape": "dot", "size": 10.588235855102539, "title": "The 2D wavelet transform on emerging architectures: GPUs and multicores", "x": 17.674311466524934, "y": -32.42904711149508}, {"id": 1150, "label": "High-performance\noptimizations on\ntiled many-core\nembedded systems: A\nmatrix\nmultiplication case\nstudy", "labelHighlightBold": true, "shape": "dot", "size": 13.382352828979492, "title": "High-performance optimizations on tiled many-core embedded systems: A matrix multiplication case study", "x": 50.18366022207218, "y": 106.19189835106421}, {"id": 1160, "label": "Applications of the\nMapReduce\nprogramming\nframework to\nclinical big data\nanalysis: Current\nlandscape and future\ntrends", "labelHighlightBold": true, "shape": "dot", "size": 13.382352828979492, "title": "Applications of the MapReduce programming framework to clinical big data analysis: Current landscape and future trends", "x": 40.58791008761934, "y": 127.73466258171474}, {"id": 1189, "label": "Message-passing\nprogramming for\nembedded multicore\nsignal-processing\nplatforms", "labelHighlightBold": true, "shape": "dot", "size": 13.382352828979492, "title": "Message-passing programming for embedded multicore signal-processing platforms", "x": -74.35588544553528, "y": -14.16311871607837}, {"id": 1207, "label": "Automatic code\ngeneration and\ntuning for stencil\nkernels on modern\nshared memory\narchitectures", "labelHighlightBold": true, "shape": "dot", "size": 13.382352828979492, "title": "Automatic code generation and tuning for stencil kernels on modern shared memory architectures", "x": -23.679792379725473, "y": -16.614420820944737}, {"id": 1220, "label": "Simultaneous\nmultiprocessing in a\nsoftware-defined\nheterogeneous FPGA", "labelHighlightBold": true, "shape": "dot", "size": 21.764705657958984, "title": "Simultaneous multiprocessing in a software-defined heterogeneous FPGA", "x": 10.871510177586414, "y": 177.40391397409473}, {"id": 1262, "label": "An efficient\nparallel solution\nfor Caputo\nfractional reaction-\ndiffusion equation", "labelHighlightBold": true, "shape": "dot", "size": 10.588235855102539, "title": "An efficient parallel solution for Caputo fractional reaction-diffusion equation", "x": -49.26363444944581, "y": -76.66234249030828}, {"id": 1302, "label": "HAT: History-based\nauto-tuning\nMapReduce in\nheterogeneous\nenvironments", "labelHighlightBold": true, "shape": "dot", "size": 7.7941179275512695, "title": "HAT: History-based auto-tuning MapReduce in heterogeneous environments", "x": 96.6905203562153, "y": 161.3642568387199}, {"id": 1309, "label": "Efficient\ncomputation of motif\ndiscovery on Intel\nMany Integrated Core\n(MIC) Architecture", "labelHighlightBold": true, "shape": "dot", "size": 7.7941179275512695, "title": "Efficient computation of motif discovery on Intel Many Integrated Core (MIC) Architecture", "x": -57.65868746214322, "y": -67.3003661721655}, {"id": 1311, "label": "pocl: A Performance-\nPortable OpenCL\nImplementation", "labelHighlightBold": true, "shape": "dot", "size": 10.588235855102539, "title": "pocl: A Performance-Portable OpenCL Implementation", "x": 118.60740866980356, "y": -96.35879241515582}]);
edges = new vis.DataSet([{"from": 13, "title": "2", "to": 458, "width": 2}, {"from": 13, "title": "1", "to": 1092, "width": 1}, {"from": 13, "title": "1", "to": 361, "width": 1}, {"from": 13, "title": "1", "to": 423, "width": 1}, {"from": 18, "title": "1", "to": 458, "width": 1}, {"from": 18, "title": "2", "to": 311, "width": 2}, {"from": 18, "title": "1", "to": 202, "width": 1}, {"from": 18, "title": "1", "to": 402, "width": 1}, {"from": 18, "title": "1", "to": 68, "width": 1}, {"from": 18, "title": "1", "to": 433, "width": 1}, {"from": 18, "title": "1", "to": 512, "width": 1}, {"from": 18, "title": "1", "to": 762, "width": 1}, {"from": 34, "title": "1", "to": 311, "width": 1}, {"from": 34, "title": "1", "to": 855, "width": 1}, {"from": 34, "title": "1", "to": 51, "width": 1}, {"from": 34, "title": "1", "to": 222, "width": 1}, {"from": 51, "title": "1", "to": 222, "width": 1}, {"from": 53, "title": "1", "to": 1113, "width": 1}, {"from": 53, "title": "1", "to": 510, "width": 1}, {"from": 60, "title": "1", "to": 68, "width": 1}, {"from": 60, "title": "1", "to": 878, "width": 1}, {"from": 64, "title": "1", "to": 128, "width": 1}, {"from": 64, "title": "1", "to": 262, "width": 1}, {"from": 67, "title": "1", "to": 222, "width": 1}, {"from": 67, "title": "2", "to": 311, "width": 2}, {"from": 68, "title": "1", "to": 92, "width": 1}, {"from": 68, "title": "1", "to": 141, "width": 1}, {"from": 68, "title": "1", "to": 237, "width": 1}, {"from": 68, "title": "1", "to": 548, "width": 1}, {"from": 68, "title": "4", "to": 189, "width": 4}, {"from": 68, "title": "1", "to": 293, "width": 1}, {"from": 68, "title": "1", "to": 609, "width": 1}, {"from": 68, "title": "1", "to": 990, "width": 1}, {"from": 68, "title": "1", "to": 1029, "width": 1}, {"from": 68, "title": "2", "to": 429, "width": 2}, {"from": 68, "title": "1", "to": 402, "width": 1}, {"from": 68, "title": "1", "to": 1207, "width": 1}, {"from": 68, "title": "1", "to": 311, "width": 1}, {"from": 68, "title": "1", "to": 202, "width": 1}, {"from": 68, "title": "1", "to": 508, "width": 1}, {"from": 68, "title": "1", "to": 788, "width": 1}, {"from": 68, "title": "1", "to": 474, "width": 1}, {"from": 68, "title": "2", "to": 249, "width": 2}, {"from": 68, "title": "1", "to": 426, "width": 1}, {"from": 68, "title": "1", "to": 878, "width": 1}, {"from": 68, "title": "1", "to": 1148, "width": 1}, {"from": 68, "title": "1", "to": 685, "width": 1}, {"from": 68, "title": "1", "to": 972, "width": 1}, {"from": 68, "title": "1", "to": 935, "width": 1}, {"from": 68, "title": "1", "to": 998, "width": 1}, {"from": 68, "title": "1", "to": 128, "width": 1}, {"from": 68, "title": "1", "to": 182, "width": 1}, {"from": 68, "title": "1", "to": 883, "width": 1}, {"from": 68, "title": "1", "to": 378, "width": 1}, {"from": 68, "title": "1", "to": 1016, "width": 1}, {"from": 68, "title": "1", "to": 739, "width": 1}, {"from": 68, "title": "1", "to": 146, "width": 1}, {"from": 91, "title": "2", "to": 311, "width": 2}, {"from": 91, "title": "1", "to": 604, "width": 1}, {"from": 91, "title": "1", "to": 1189, "width": 1}, {"from": 91, "title": "1", "to": 181, "width": 1}, {"from": 91, "title": "1", "to": 459, "width": 1}, {"from": 91, "title": "1", "to": 1029, "width": 1}, {"from": 91, "title": "1", "to": 202, "width": 1}, {"from": 106, "title": "1", "to": 222, "width": 1}, {"from": 106, "title": "2", "to": 913, "width": 2}, {"from": 106, "title": "3", "to": 146, "width": 3}, {"from": 106, "title": "1", "to": 636, "width": 1}, {"from": 115, "title": "1", "to": 972, "width": 1}, {"from": 121, "title": "1", "to": 376, "width": 1}, {"from": 121, "title": "1", "to": 222, "width": 1}, {"from": 125, "title": "1", "to": 189, "width": 1}, {"from": 128, "title": "1", "to": 202, "width": 1}, {"from": 128, "title": "1", "to": 262, "width": 1}, {"from": 134, "title": "1", "to": 378, "width": 1}, {"from": 141, "title": "1", "to": 608, "width": 1}, {"from": 141, "title": "1", "to": 561, "width": 1}, {"from": 141, "title": "1", "to": 548, "width": 1}, {"from": 141, "title": "1", "to": 539, "width": 1}, {"from": 146, "title": "2", "to": 267, "width": 2}, {"from": 146, "title": "3", "to": 222, "width": 3}, {"from": 146, "title": "2", "to": 913, "width": 2}, {"from": 146, "title": "1", "to": 636, "width": 1}, {"from": 146, "title": "1", "to": 739, "width": 1}, {"from": 155, "title": "1", "to": 358, "width": 1}, {"from": 181, "title": "1", "to": 604, "width": 1}, {"from": 181, "title": "1", "to": 1189, "width": 1}, {"from": 182, "title": "1", "to": 289, "width": 1}, {"from": 182, "title": "1", "to": 347, "width": 1}, {"from": 182, "title": "1", "to": 660, "width": 1}, {"from": 182, "title": "1", "to": 963, "width": 1}, {"from": 182, "title": "1", "to": 991, "width": 1}, {"from": 189, "title": "1", "to": 609, "width": 1}, {"from": 189, "title": "1", "to": 1029, "width": 1}, {"from": 189, "title": "1", "to": 429, "width": 1}, {"from": 189, "title": "1", "to": 756, "width": 1}, {"from": 189, "title": "2", "to": 605, "width": 2}, {"from": 189, "title": "2", "to": 548, "width": 2}, {"from": 189, "title": "1", "to": 786, "width": 1}, {"from": 189, "title": "1", "to": 440, "width": 1}, {"from": 189, "title": "1", "to": 939, "width": 1}, {"from": 189, "title": "1", "to": 711, "width": 1}, {"from": 189, "title": "1", "to": 419, "width": 1}, {"from": 189, "title": "1", "to": 344, "width": 1}, {"from": 200, "title": "2", "to": 222, "width": 2}, {"from": 200, "title": "1", "to": 342, "width": 1}, {"from": 200, "title": "1", "to": 363, "width": 1}, {"from": 202, "title": "6", "to": 311, "width": 6}, {"from": 202, "title": "1", "to": 459, "width": 1}, {"from": 202, "title": "2", "to": 1029, "width": 2}, {"from": 202, "title": "1", "to": 1207, "width": 1}, {"from": 202, "title": "1", "to": 481, "width": 1}, {"from": 202, "title": "1", "to": 512, "width": 1}, {"from": 204, "title": "1", "to": 1029, "width": 1}, {"from": 204, "title": "1", "to": 311, "width": 1}, {"from": 222, "title": "4", "to": 267, "width": 4}, {"from": 222, "title": "1", "to": 378, "width": 1}, {"from": 222, "title": "4", "to": 363, "width": 4}, {"from": 222, "title": "1", "to": 376, "width": 1}, {"from": 222, "title": "1", "to": 1010, "width": 1}, {"from": 222, "title": "1", "to": 913, "width": 1}, {"from": 222, "title": "1", "to": 342, "width": 1}, {"from": 222, "title": "1", "to": 245, "width": 1}, {"from": 249, "title": "1", "to": 508, "width": 1}, {"from": 249, "title": "1", "to": 788, "width": 1}, {"from": 249, "title": "1", "to": 474, "width": 1}, {"from": 249, "title": "1", "to": 426, "width": 1}, {"from": 249, "title": "1", "to": 561, "width": 1}, {"from": 249, "title": "1", "to": 378, "width": 1}, {"from": 259, "title": "1", "to": 1302, "width": 1}, {"from": 259, "title": "1", "to": 424, "width": 1}, {"from": 259, "title": "1", "to": 448, "width": 1}, {"from": 267, "title": "1", "to": 378, "width": 1}, {"from": 276, "title": "1", "to": 311, "width": 1}, {"from": 277, "title": "1", "to": 385, "width": 1}, {"from": 277, "title": "1", "to": 1113, "width": 1}, {"from": 277, "title": "1", "to": 992, "width": 1}, {"from": 289, "title": "1", "to": 347, "width": 1}, {"from": 311, "title": "1", "to": 604, "width": 1}, {"from": 311, "title": "2", "to": 1029, "width": 2}, {"from": 311, "title": "1", "to": 459, "width": 1}, {"from": 311, "title": "1", "to": 1207, "width": 1}, {"from": 311, "title": "1", "to": 854, "width": 1}, {"from": 311, "title": "1", "to": 512, "width": 1}, {"from": 342, "title": "1", "to": 363, "width": 1}, {"from": 343, "title": "1", "to": 825, "width": 1}, {"from": 343, "title": "1", "to": 395, "width": 1}, {"from": 344, "title": "1", "to": 670, "width": 1}, {"from": 347, "title": "1", "to": 789, "width": 1}, {"from": 351, "title": "1", "to": 666, "width": 1}, {"from": 351, "title": "1", "to": 854, "width": 1}, {"from": 351, "title": "1", "to": 921, "width": 1}, {"from": 351, "title": "1", "to": 547, "width": 1}, {"from": 358, "title": "1", "to": 378, "width": 1}, {"from": 361, "title": "1", "to": 423, "width": 1}, {"from": 378, "title": "1", "to": 496, "width": 1}, {"from": 378, "title": "1", "to": 920, "width": 1}, {"from": 378, "title": "1", "to": 561, "width": 1}, {"from": 378, "title": "1", "to": 1016, "width": 1}, {"from": 385, "title": "1", "to": 1113, "width": 1}, {"from": 385, "title": "1", "to": 992, "width": 1}, {"from": 395, "title": "1", "to": 1029, "width": 1}, {"from": 395, "title": "1", "to": 825, "width": 1}, {"from": 419, "title": "1", "to": 920, "width": 1}, {"from": 419, "title": "1", "to": 605, "width": 1}, {"from": 419, "title": "1", "to": 711, "width": 1}, {"from": 419, "title": "1", "to": 548, "width": 1}, {"from": 426, "title": "1", "to": 508, "width": 1}, {"from": 426, "title": "1", "to": 788, "width": 1}, {"from": 426, "title": "1", "to": 474, "width": 1}, {"from": 429, "title": "1", "to": 1029, "width": 1}, {"from": 429, "title": "1", "to": 1148, "width": 1}, {"from": 433, "title": "1", "to": 512, "width": 1}, {"from": 440, "title": "9", "to": 966, "width": 9}, {"from": 440, "title": "6", "to": 786, "width": 6}, {"from": 440, "title": "3", "to": 491, "width": 3}, {"from": 440, "title": "2", "to": 875, "width": 2}, {"from": 440, "title": "1", "to": 895, "width": 1}, {"from": 440, "title": "1", "to": 644, "width": 1}, {"from": 440, "title": "1", "to": 939, "width": 1}, {"from": 440, "title": "2", "to": 926, "width": 2}, {"from": 442, "title": "1", "to": 957, "width": 1}, {"from": 442, "title": "1", "to": 445, "width": 1}, {"from": 442, "title": "1", "to": 883, "width": 1}, {"from": 445, "title": "1", "to": 957, "width": 1}, {"from": 445, "title": "1", "to": 883, "width": 1}, {"from": 447, "title": "1", "to": 1150, "width": 1}, {"from": 447, "title": "1", "to": 470, "width": 1}, {"from": 447, "title": "1", "to": 463, "width": 1}, {"from": 447, "title": "1", "to": 620, "width": 1}, {"from": 448, "title": "1", "to": 705, "width": 1}, {"from": 448, "title": "1", "to": 499, "width": 1}, {"from": 458, "title": "1", "to": 1092, "width": 1}, {"from": 458, "title": "1", "to": 1160, "width": 1}, {"from": 458, "title": "1", "to": 499, "width": 1}, {"from": 458, "title": "1", "to": 470, "width": 1}, {"from": 459, "title": "1", "to": 1029, "width": 1}, {"from": 463, "title": "1", "to": 1150, "width": 1}, {"from": 463, "title": "1", "to": 470, "width": 1}, {"from": 463, "title": "1", "to": 609, "width": 1}, {"from": 466, "title": "1", "to": 1029, "width": 1}, {"from": 466, "title": "1", "to": 741, "width": 1}, {"from": 470, "title": "1", "to": 1160, "width": 1}, {"from": 470, "title": "1", "to": 499, "width": 1}, {"from": 470, "title": "1", "to": 1150, "width": 1}, {"from": 470, "title": "1", "to": 1220, "width": 1}, {"from": 474, "title": "1", "to": 508, "width": 1}, {"from": 474, "title": "1", "to": 788, "width": 1}, {"from": 481, "title": "1", "to": 1029, "width": 1}, {"from": 482, "title": "1", "to": 1147, "width": 1}, {"from": 482, "title": "1", "to": 1220, "width": 1}, {"from": 482, "title": "1", "to": 1087, "width": 1}, {"from": 482, "title": "1", "to": 951, "width": 1}, {"from": 491, "title": "2", "to": 966, "width": 2}, {"from": 491, "title": "1", "to": 875, "width": 1}, {"from": 491, "title": "1", "to": 895, "width": 1}, {"from": 491, "title": "1", "to": 644, "width": 1}, {"from": 491, "title": "1", "to": 492, "width": 1}, {"from": 491, "title": "2", "to": 926, "width": 2}, {"from": 491, "title": "1", "to": 786, "width": 1}, {"from": 492, "title": "1", "to": 926, "width": 1}, {"from": 496, "title": "1", "to": 920, "width": 1}, {"from": 499, "title": "1", "to": 1160, "width": 1}, {"from": 499, "title": "1", "to": 705, "width": 1}, {"from": 508, "title": "1", "to": 788, "width": 1}, {"from": 508, "title": "1", "to": 946, "width": 1}, {"from": 508, "title": "1", "to": 633, "width": 1}, {"from": 508, "title": "1", "to": 655, "width": 1}, {"from": 510, "title": "1", "to": 854, "width": 1}, {"from": 539, "title": "1", "to": 608, "width": 1}, {"from": 539, "title": "1", "to": 561, "width": 1}, {"from": 539, "title": "1", "to": 548, "width": 1}, {"from": 546, "title": "1", "to": 771, "width": 1}, {"from": 547, "title": "1", "to": 666, "width": 1}, {"from": 547, "title": "1", "to": 854, "width": 1}, {"from": 547, "title": "1", "to": 921, "width": 1}, {"from": 548, "title": "1", "to": 756, "width": 1}, {"from": 548, "title": "2", "to": 605, "width": 2}, {"from": 548, "title": "1", "to": 608, "width": 1}, {"from": 548, "title": "1", "to": 561, "width": 1}, {"from": 548, "title": "1", "to": 711, "width": 1}, {"from": 561, "title": "1", "to": 608, "width": 1}, {"from": 564, "title": "1", "to": 608, "width": 1}, {"from": 570, "title": "1", "to": 620, "width": 1}, {"from": 604, "title": "1", "to": 1189, "width": 1}, {"from": 605, "title": "2", "to": 756, "width": 2}, {"from": 605, "title": "1", "to": 711, "width": 1}, {"from": 633, "title": "1", "to": 946, "width": 1}, {"from": 633, "title": "1", "to": 655, "width": 1}, {"from": 636, "title": "1", "to": 913, "width": 1}, {"from": 655, "title": "1", "to": 946, "width": 1}, {"from": 656, "title": "1", "to": 939, "width": 1}, {"from": 660, "title": "1", "to": 963, "width": 1}, {"from": 660, "title": "1", "to": 991, "width": 1}, {"from": 666, "title": "1", "to": 854, "width": 1}, {"from": 666, "title": "1", "to": 921, "width": 1}, {"from": 670, "title": "1", "to": 792, "width": 1}, {"from": 670, "title": "1", "to": 1311, "width": 1}, {"from": 685, "title": "1", "to": 972, "width": 1}, {"from": 741, "title": "1", "to": 946, "width": 1}, {"from": 741, "title": "1", "to": 1262, "width": 1}, {"from": 741, "title": "2", "to": 1029, "width": 2}, {"from": 741, "title": "1", "to": 1309, "width": 1}, {"from": 771, "title": "1", "to": 854, "width": 1}, {"from": 786, "title": "6", "to": 966, "width": 6}, {"from": 786, "title": "1", "to": 939, "width": 1}, {"from": 786, "title": "1", "to": 926, "width": 1}, {"from": 792, "title": "1", "to": 1311, "width": 1}, {"from": 852, "title": "1", "to": 998, "width": 1}, {"from": 854, "title": "1", "to": 921, "width": 1}, {"from": 854, "title": "1", "to": 947, "width": 1}, {"from": 862, "title": "1", "to": 1029, "width": 1}, {"from": 875, "title": "2", "to": 966, "width": 2}, {"from": 875, "title": "1", "to": 895, "width": 1}, {"from": 875, "title": "1", "to": 926, "width": 1}, {"from": 883, "title": "1", "to": 957, "width": 1}, {"from": 895, "title": "1", "to": 966, "width": 1}, {"from": 926, "title": "2", "to": 966, "width": 2}, {"from": 935, "title": "1", "to": 998, "width": 1}, {"from": 946, "title": "1", "to": 1262, "width": 1}, {"from": 951, "title": "1", "to": 1147, "width": 1}, {"from": 951, "title": "1", "to": 1220, "width": 1}, {"from": 951, "title": "1", "to": 1087, "width": 1}, {"from": 963, "title": "1", "to": 991, "width": 1}, {"from": 992, "title": "1", "to": 1113, "width": 1}, {"from": 1041, "title": "1", "to": 1220, "width": 1}, {"from": 1087, "title": "1", "to": 1147, "width": 1}, {"from": 1087, "title": "1", "to": 1220, "width": 1}, {"from": 1147, "title": "1", "to": 1220, "width": 1}]);
// adding nodes and edges to the graph
data = {nodes: nodes, edges: edges};
var options = {"configure": {"enabled": false}, "nodes": {"font": {"size": 7}}, "edges": {"smooth": true, "color": {"opacity": 0.25}}, "physics": {"enabled": true, "forceAtlas2Based": {"springLength": 100}, "solver": "forceAtlas2Based"}};
network = new vis.Network(container, data, options);
network.on("stabilizationProgress", function(params) {
document.getElementById('loadingBar').removeAttribute("style");
var maxWidth = 496;
var minWidth = 20;
var widthFactor = params.iterations/params.total;
var width = Math.max(minWidth,maxWidth * widthFactor);
document.getElementById('bar').style.width = width + 'px';
document.getElementById('text').innerHTML = Math.round(widthFactor*100) + '%';
});
network.once("stabilizationIterationsDone", function() {
document.getElementById('text').innerHTML = '100%';
document.getElementById('bar').style.width = '496px';
document.getElementById('loadingBar').style.opacity = 0;
// really clean the dom element
setTimeout(function () {document.getElementById('loadingBar').style.display = 'none';}, 500);
});
return network;
}
drawGraph();
</script>
</body>
</html>
================================================
FILE: docs/_static/css/style.css
================================================
@import 'theme.css';
html.writer-html4 .rst-content dl:not(.docutils) .property,
html.writer-html5 .rst-content dl[class]:not(.option-list):not(.field-list):not(.footnote):not(.glossary):not(.simple) .property {
/* Fixes strange layout of class properties. */
display: inline;
}
================================================
FILE: docs/api/index.rst
================================================
API reference
====================================
This page provides the API documentation of litstudy.
All public functions are re-exported under the global `litstudy` namespace for convenience.
However, the code is structured hierachical meaning the documentation shows the hierarchical names.
For example:
.. code-block:: python
docs = litstudy.sources.scopus.search_scopus("example")
litstudy.plot.plot_author_histogram(docs)
# Is equivalent to
docs = litstudy.search_scopus("example")
litstudy.plot_author_histogram(docs)
The package is divided into 6 modules:
* Core data types such as `Document` and `DocumentSet`.
* Functions to retrieve or load scientific citations.
* Compute general statistics.
* Generate bibliographic networks.
* Automatic topic detection using natural language processing (NLP).
* Plot results. These functions are mostly useful inside a notebook.
.. toctree::
:maxdepth: 2
:caption: Contents
types
sources
stats
network
nlp
plot
================================================
FILE: docs/api/network.rst
================================================
Network Analysis
------------------------------------------
.. automodule:: litstudy.network
:members:
================================================
FILE: docs/api/nlp.rst
================================================
Language Processing
------------------------------------------
.. automodule:: litstudy.nlp
:members:
================================================
FILE: docs/api/plot.rst
================================================
Plotting Statistics
------------------------------------------
.. automodule:: litstudy.plot
:members:
================================================
FILE: docs/api/sources.rst
================================================
Literature Databases
====================
Scopus
------
.. automodule:: litstudy
:members: search_scopus, refine_scopus, load_scopus_csv
SemanticScholar
---------------
.. automodule:: litstudy
:members: fetch_semanticscholar, refine_semanticscholar, search_semanticscholar
CrossRef
---------------
.. automodule:: litstudy
:members: fetch_crossref, refine_crossref, search_crossref
CSV
---------------
.. automodule:: litstudy
:members: load_csv
IEEE Xplore
---------------
.. automodule:: litstudy
:members: load_ieee_csv
Springer Link
---------------
.. automodule:: litstudy
:members: load_springer_csv
bibtex
---------------
.. automodule:: litstudy
:members: load_bibtex
RIS
---------------
.. automodule:: litstudy
:members: load_ris_file
dblp
---------------
.. automodule:: litstudy
:members: search_dblp
arXiv
---------------
.. automodule:: litstudy
:members: search_arxiv
================================================
FILE: docs/api/stats.rst
================================================
Calculating Statistics
------------------------------------------
.. automodule:: litstudy.stats
:members:
================================================
FILE: docs/api/types.rst
================================================
Data Types
------------------------------------------
There are two core datatypes in litstudy: `Document` and `DocumentSet`.
`Document` is an abstract base class (ABC) that provides access to the metadata of documents in a unified way.
Different backends provide their own implements of this class (for example, `ScopusDocument`, `BibTexDocument`, etc.)
`DocumentSet` is set of `Document` objects.
All set operations are supported, making it possible to create a new set from existing sets.
For instance, it is possible to load documents from two sources (obtaining two `DocumentSets`) and merge them (obtaining one large `DocumentSet`).
.. automodule:: litstudy.types
:members:
================================================
FILE: docs/citation.html
================================================
<html>
<head>
<link rel="stylesheet" href="https://cdnjs.cloudflare.com/ajax/libs/vis/4.16.1/vis.css" type="text/css" />
<script type="text/javascript" src="https://cdnjs.cloudflare.com/ajax/libs/vis/4.16.1/vis-network.min.js"> </script>
<center>
<h1></h1>
</center>
<!-- <link rel="stylesheet" href="../node_modules/vis/dist/vis.min.css" type="text/css" />
<script type="text/javascript" src="../node_modules/vis/dist/vis.js"> </script>-->
<style type="text/css">
#mynetwork {
width: 100%;
height: 1000px;
background-color: #ffffff;
border: 1px solid lightgray;
position: relative;
float: left;
}
#loadingBar {
position:absolute;
top:0px;
left:0px;
width: 100%;
height: 1000px;
background-color:rgba(200,200,200,0.8);
-webkit-transition: all 0.5s ease;
-moz-transition: all 0.5s ease;
-ms-transition: all 0.5s ease;
-o-transition: all 0.5s ease;
transition: all 0.5s ease;
opacity:1;
}
#bar {
position:absolute;
top:0px;
left:0px;
width:20px;
height:20px;
margin:auto auto auto auto;
border-radius:11px;
border:2px solid rgba(30,30,30,0.05);
background: rgb(0, 173, 246); /* Old browsers */
box-shadow: 2px 0px 4px rgba(0,0,0,0.4);
}
#border {
position:absolute;
top:10px;
left:10px;
width:500px;
height:23px;
margin:auto auto auto auto;
box-shadow: 0px 0px 4px rgba(0,0,0,0.2);
border-radius:10px;
}
#text {
position:absolute;
top:8px;
left:530px;
width:30px;
height:50px;
margin:auto auto auto auto;
font-size:22px;
color: #000000;
}
div.outerBorder {
position:relative;
top:400px;
width:600px;
height:44px;
margin:auto auto auto auto;
border:8px solid rgba(0,0,0,0.1);
background: rgb(252,252,252); /* Old browsers */
background: -moz-linear-gradient(top, rgba(252,252,252,1) 0%, rgba(237,237,237,1) 100%); /* FF3.6+ */
background: -webkit-gradient(linear, left top, left bottom, color-stop(0%,rgba(252,252,252,1)), color-stop(100%,rgba(237,237,237,1))); /* Chrome,Safari4+ */
background: -webkit-linear-gradient(top, rgba(252,252,252,1) 0%,rgba(237,237,237,1) 100%); /* Chrome10+,Safari5.1+ */
background: -o-linear-gradient(top, rgba(252,252,252,1) 0%,rgba(237,237,237,1) 100%); /* Opera 11.10+ */
background: -ms-linear-gradient(top, rgba(252,252,252,1) 0%,rgba(237,237,237,1) 100%); /* IE10+ */
background: linear-gradient(to bottom, rgba(252,252,252,1) 0%,rgba(237,237,237,1) 100%); /* W3C */
filter: progid:DXImageTransform.Microsoft.gradient( startColorstr='#fcfcfc', endColorstr='#ededed',GradientType=0 ); /* IE6-9 */
border-radius:72px;
box-shadow: 0px 0px 10px rgba(0,0,0,0.2);
}
</style>
</head>
<body>
<div id = "mynetwork"></div>
<div id="loadingBar">
<div class="outerBorder">
<div id="text">0%</div>
<div id="border">
<div id="bar"></div>
</div>
</div>
</div>
<script type="text/javascript">
// initialize global variables.
var edges;
var nodes;
var network;
var container;
var options, data;
// This method is responsible for drawing the graph, returns the drawn network
function drawGraph() {
var container = document.getElementById('mynetwork');
// parsing and collecting nodes and edges from the python
nodes = new vis.DataSet([{"id": 13, "label": "Extending OpenSHMEM\nfor GPU computing", "labelHighlightBold": true, "shape": "dot", "size": 16.176471710205078, "title": "Extending OpenSHMEM for GPU computing", "x": 24.76389076112976, "y": 122.37293814381397}, {"id": 18, "label": "Physis: An\nimplicitly parallel\nprogramming model\nfor stencil\ncomputations on\nlarge-scale gpu-\naccelerated\nsupercomputers", "labelHighlightBold": true, "shape": "dot", "size": 27.352941513061523, "title": "Physis: An implicitly parallel programming model for stencil computations on large-scale gpu-accelerated supercomputers", "x": -18.7288326671725, "y": 8.611340066023798}, {"id": 34, "label": "Compiling and\nOptimizing Java 8\nPrograms for GPU\nExecution", "labelHighlightBold": true, "shape": "dot", "size": 16.176471710205078, "title": "Compiling and Optimizing Java 8 Programs for GPU Execution", "x": -33.01993303871408, "y": 28.518820586360636}, {"id": 51, "label": "Selective GPU caches\nto eliminate CPU-GPU\nHW cache coherence", "labelHighlightBold": true, "shape": "dot", "size": 10.588235855102539, "title": "Selective GPU caches to eliminate CPU-GPU HW cache coherence", "x": -24.697750295334995, "y": 34.938700881655784}, {"id": 53, "label": "PACXX: Towards a\nunified programming\nmodel for\nprogramming\naccelerators using\nC++14", "labelHighlightBold": true, "shape": "dot", "size": 10.588235855102539, "title": "PACXX: Towards a unified programming model for programming accelerators using C++14", "x": -137.55669543623773, "y": 153.10688317503357}, {"id": 60, "label": "Accelerating gene\nregulatory networks\ninference through\nGPU/CUDA programming", "labelHighlightBold": true, "shape": "dot", "size": 10.588235855102539, "title": "Accelerating gene regulatory networks inference through GPU/CUDA programming", "x": 16.119976757829036, "y": -42.8422717169076}, {"id": 64, "label": "Exploring the\nsuitability of\nremote GPGPU\nvirtualization for\nthe OpenACC\nprogramming model\nusing rCUDA", "labelHighlightBold": true, "shape": "dot", "size": 10.588235855102539, "title": "Exploring the suitability of remote GPGPU virtualization for the OpenACC programming model using rCUDA", "x": -37.10419622799762, "y": -50.07899169322814}, {"id": 67, "label": "DCUDA: Hardware\nSupported Overlap of\nComputation and\nCommunication", "labelHighlightBold": true, "shape": "dot", "size": 10.588235855102539, "title": "DCUDA: Hardware Supported Overlap of Computation and Communication", "x": -33.87332786054143, "y": 11.864933159981236}, {"id": 68, "label": "GPU computing", "labelHighlightBold": true, "shape": "dot", "size": 100.0, "title": "GPU computing", "x": 6.329250718754571, "y": -34.18733911463281}, {"id": 91, "label": "Designing a unified\nprogramming model\nfor heterogeneous\nmachines", "labelHighlightBold": true, "shape": "dot", "size": 24.55882453918457, "title": "Designing a unified programming model for heterogeneous machines", "x": -57.81566497580839, "y": -12.091708299014202}, {"id": 92, "label": "A case study of\nOpenCL on an Android\nmobile GPU", "labelHighlightBold": true, "shape": "dot", "size": 7.7941179275512695, "title": "A case study of OpenCL on an Android mobile GPU", "x": 3.936617293001404, "y": -44.37072024756895}, {"id": 106, "label": "An evaluation of\nunified memory\ntechnology on NVIDIA\nGPUs", "labelHighlightBold": true, "shape": "dot", "size": 16.176471710205078, "title": "An evaluation of unified memory technology on NVIDIA GPUs", "x": 4.322878604771536, "y": 25.792487247701676}, {"id": 115, "label": "Achieving\nportability and\nperformance through\nOpenACC", "labelHighlightBold": true, "shape": "dot", "size": 7.7941179275512695, "title": "Achieving portability and performance through OpenACC", "x": 14.655810467394069, "y": -73.16158321439497}, {"id": 121, "label": "An Enhanced\nProfiling Framework\nfor the Analysis and\nDevelopment of\nParallel Primitives\nfor GPUs", "labelHighlightBold": true, "shape": "dot", "size": 10.588235855102539, "title": "An Enhanced Profiling Framework for the Analysis and Development of Parallel Primitives for GPUs", "x": -6.790233183944989, "y": 47.559438616441106}, {"id": 125, "label": "GPU accelerated\nLanczos algorithm\nwith applications", "labelHighlightBold": true, "shape": "dot", "size": 7.7941179275512695, "title": "GPU accelerated Lanczos algorithm with applications", "x": 67.43624839486117, "y": -15.856550886523927}, {"id": 128, "label": "VOCL: An optimized\nenvironment for\ntransparent\nvirtualization of\ngraphics processing\nunits", "labelHighlightBold": true, "shape": "dot", "size": 16.176471710205078, "title": "VOCL: An optimized environment for transparent virtualization of graphics processing units", "x": -27.147883565553244, "y": -40.42330677872908}, {"id": 134, "label": "Parallel algorithms\nfor approximate\nstring matching with\nk mismatches on CUDA", "labelHighlightBold": true, "shape": "dot", "size": 7.7941179275512695, "title": "Parallel algorithms for approximate string matching with k mismatches on CUDA", "x": 24.027643499441634, "y": -3.5517468756445068}, {"id": 141, "label": "Record setting\nsoftware\nimplementation of\ndes using CUDA", "labelHighlightBold": true, "shape": "dot", "size": 18.97058868408203, "title": "Record setting software implementation of des using CUDA", "x": 43.10243901267682, "y": -50.668593214139456}, {"id": 146, "label": "An investigation of\nUnified Memory\nAccess performance\nin CUDA", "labelHighlightBold": true, "shape": "dot", "size": 24.55882453918457, "title": "An investigation of Unified Memory Access performance in CUDA", "x": 2.2677354694675125, "y": 19.53145343210315}, {"id": 155, "label": "Towards achieving\nperformance\nportability using\ndirectives for\naccelerators", "labelHighlightBold": true, "shape": "dot", "size": 7.7941179275512695, "title": "Towards achieving performance portability using directives for accelerators", "x": 41.05949316371812, "y": 6.748039881219046}, {"id": 181, "label": "Self-adaptive OmpSs\ntasks in\nheterogeneous\nenvironments", "labelHighlightBold": true, "shape": "dot", "size": 13.382352828979492, "title": "Self-adaptive OmpSs tasks in heterogeneous environments", "x": -73.93121825216481, "y": -9.764180678019299}, {"id": 182, "label": "Design and\nperformance\nevaluation of image\nprocessing\nalgorithms on GPUs", "labelHighlightBold": true, "shape": "dot", "size": 21.764705657958984, "title": "Design and performance evaluation of image processing algorithms on GPUs", "x": -89.64779293768946, "y": -0.014149852620478853}, {"id": 189, "label": "Parallel computing\nexperiences with\nCUDA", "labelHighlightBold": true, "shape": "dot", "size": 44.11764907836914, "title": "Parallel computing experiences with CUDA", "x": 58.71554548426513, "y": -27.265589152526406}, {"id": 200, "label": "Beyond the socket:\nNUMA-aware GPUs", "labelHighlightBold": true, "shape": "dot", "size": 13.382352828979492, "title": "Beyond the socket: NUMA-aware GPUs", "x": -11.522889031691046, "y": 41.99887434023165}, {"id": 202, "label": "Early evaluation of\ndirective-based GPU\nprogramming models\nfor productive\nexascale computing", "labelHighlightBold": true, "shape": "dot", "size": 32.94117736816406, "title": "Early evaluation of directive-based GPU programming models for productive exascale computing", "x": -35.81135870727286, "y": -12.013049124173278}, {"id": 204, "label": "Task scheduling for\ngpu heterogeneous\ncluster", "labelHighlightBold": true, "shape": "dot", "size": 10.588235855102539, "title": "Task scheduling for gpu heterogeneous cluster", "x": -43.08916620014689, "y": -18.10347665453183}, {"id": 222, "label": "Analyzing CUDA\nworkloads using a\ndetailed GPU\nsimulator", "labelHighlightBold": true, "shape": "dot", "size": 46.911766052246094, "title": "Analyzing CUDA workloads using a detailed GPU simulator", "x": -8.643175637062633, "y": 31.465316314064353}, {"id": 237, "label": "Hybrid map task\nscheduling for GPU-\nbased heterogeneous\nclusters", "labelHighlightBold": true, "shape": "dot", "size": 7.7941179275512695, "title": "Hybrid map task scheduling for GPU-based heterogeneous clusters", "x": -5.105039961657392, "y": -31.30110458915556}, {"id": 245, "label": "Stargazer: Automated\nregression-based GPU\ndesign space\nexploration", "labelHighlightBold": true, "shape": "dot", "size": 7.7941179275512695, "title": "Stargazer: Automated regression-based GPU design space exploration", "x": -14.85701484922424, "y": 35.488748315892266}, {"id": 249, "label": "Empowering visual\ncategorization with\nthe GPU", "labelHighlightBold": true, "shape": "dot", "size": 24.55882453918457, "title": "Empowering visual categorization with the GPU", "x": 4.239864280021133, "y": -52.67611387008494}, {"id": 259, "label": "StreamMR: An\noptimized MapReduce\nframework for AMD\nGPUs", "labelHighlightBold": true, "shape": "dot", "size": 13.382352828979492, "title": "StreamMR: An optimized MapReduce framework for AMD GPUs", "x": 89.30230942900809, "y": 160.83049239566935}, {"id": 262, "label": "Exploiting Task-\nParallelism on GPU\nClusters via OmpSs\nand rCUDA\nVirtualization", "labelHighlightBold": true, "shape": "dot", "size": 10.588235855102539, "title": "Exploiting Task-Parallelism on GPU Clusters via OmpSs and rCUDA Virtualization", "x": -34.48297340210872, "y": -52.42060344606631}, {"id": 267, "label": "Unlocking bandwidth\nfor GPUs in CC-NUMA\nsystems", "labelHighlightBold": true, "shape": "dot", "size": 13.382352828979492, "title": "Unlocking bandwidth for GPUs in CC-NUMA systems", "x": -2.341847324234936, "y": 22.700120533832603}, {"id": 276, "label": "OpenCL - An\neffective\nprogramming model\nfor data parallel\ncomputations at the\nCell Broadband\nEngine", "labelHighlightBold": true, "shape": "dot", "size": 7.7941179275512695, "title": "OpenCL - An effective programming model for data parallel computations at the Cell Broadband Engine", "x": -52.84143316139907, "y": 6.8604154729692635}, {"id": 277, "label": "GraphReduce:\nProcessing large-\nscale graphs on\naccelerator-based\nsystems", "labelHighlightBold": true, "shape": "dot", "size": 13.382352828979492, "title": "GraphReduce: Processing large-scale graphs on accelerator-based systems", "x": -157.0098718067881, "y": 185.76248211060502}, {"id": 289, "label": "Can GPGPU\nprogramming be\nliberated from the\ndata-parallel\nbottleneck?", "labelHighlightBold": true, "shape": "dot", "size": 10.588235855102539, "title": "Can GPGPU programming be liberated from the data-parallel bottleneck?", "x": -100.17011306674146, "y": 12.015917840606194}, {"id": 293, "label": "Massively parallel\nnetwork coding on\nGPUs", "labelHighlightBold": true, "shape": "dot", "size": 7.7941179275512695, "title": "Massively parallel network coding on GPUs", "x": -2.2374148817409494, "y": -37.13949126822989}, {"id": 311, "label": "OpenMPC: Extended\nOpenMP programming\nand tuning for GPUs", "labelHighlightBold": true, "shape": "dot", "size": 44.11764907836914, "title": "OpenMPC: Extended OpenMP programming and tuning for GPUs", "x": -41.58900065888275, "y": -1.8093634026342515}, {"id": 342, "label": "Throughput-effective\non-chip networks for\nmanycore\naccelerators", "labelHighlightBold": true, "shape": "dot", "size": 13.382352828979492, "title": "Throughput-effective on-chip networks for manycore accelerators", "x": -13.725111872890286, "y": 47.544673067902195}, {"id": 343, "label": "An MDE approach for\nautomatic code\ngeneration from\nUML/MARTE to openCL", "labelHighlightBold": true, "shape": "dot", "size": 10.588235855102539, "title": "An MDE approach for automatic code generation from UML/MARTE to openCL", "x": -90.34240394269759, "y": -64.0955909622676}, {"id": 344, "label": "Fast motion\nestimation on\ngraphics hardware\nfor h.264 video\nencoding", "labelHighlightBold": true, "shape": "dot", "size": 10.588235855102539, "title": "Fast motion estimation on graphics hardware for h.264 video encoding", "x": 92.16741901422802, "y": -62.21984092501383}, {"id": 347, "label": "CuMAPz: A tool to\nanalyze memory\naccess patterns in\nCUDA", "labelHighlightBold": true, "shape": "dot", "size": 13.382352828979492, "title": "CuMAPz: A tool to analyze memory access patterns in CUDA", "x": -106.22225371359201, "y": 15.71489347352919}, {"id": 351, "label": "Optimizing sparse\nmatrix-vector\nmultiplication on\nCUDA", "labelHighlightBold": true, "shape": "dot", "size": 16.176471710205078, "title": "Optimizing sparse matrix-vector multiplication on CUDA", "x": -114.08883280843102, "y": 105.02225395466465}, {"id": 358, "label": "A comparative study\nof SYCL, OpenCL, and\nOpenMP", "labelHighlightBold": true, "shape": "dot", "size": 10.588235855102539, "title": "A comparative study of SYCL, OpenCL, and OpenMP", "x": 34.5704220565808, "y": 2.1910642545011623}, {"id": 361, "label": "Implementation of\nXcalableMP device\nacceleration\nextention with\nOpenCL", "labelHighlightBold": true, "shape": "dot", "size": 10.588235855102539, "title": "Implementation of XcalableMP device acceleration extention with OpenCL", "x": 25.727119129471127, "y": 134.2974186952201}, {"id": 363, "label": "Coordinated static\nand dynamic cache\nbypassing for GPUs", "labelHighlightBold": true, "shape": "dot", "size": 13.382352828979492, "title": "Coordinated static and dynamic cache bypassing for GPUs", "x": -9.702073792609484, "y": 37.92453734809817}, {"id": 376, "label": "A comparison of\nperformance\ntunabilities between\nOpenCL and OpenACC", "labelHighlightBold": true, "shape": "dot", "size": 10.588235855102539, "title": "A comparison of performance tunabilities between OpenCL and OpenACC", "x": -3.7488175460497764, "y": 45.514812614569315}, {"id": 378, "label": "A comprehensive\nperformance\ncomparison of CUDA\nand OpenCL", "labelHighlightBold": true, "shape": "dot", "size": 32.94117736816406, "title": "A comprehensive performance comparison of CUDA and OpenCL", "x": 21.30053879004295, "y": -9.838769904988158}, {"id": 385, "label": "GasCL: A vertex-\ncentric graph model\nfor GPUs", "labelHighlightBold": true, "shape": "dot", "size": 13.382352828979492, "title": "GasCL: A vertex-centric graph model for GPUs", "x": -152.68282868026617, "y": 183.7421165431827}, {"id": 395, "label": "Liszt: A domain\nspecific language\nfor building\nportable mesh-based\nPDE solvers", "labelHighlightBold": true, "shape": "dot", "size": 13.382352828979492, "title": "Liszt: A domain specific language for building portable mesh-based PDE solvers", "x": -78.97863881376998, "y": -54.85530529666192}, {"id": 402, "label": "Scalable programming\nmodels for massively\nmulticore processors", "labelHighlightBold": true, "shape": "dot", "size": 10.588235855102539, "title": "Scalable programming models for massively multicore processors", "x": -6.076889811191757, "y": -10.602190939552877}, {"id": 419, "label": "A comparative study\nof GPU programming\nmodels and\narchitectures using\nneural networks", "labelHighlightBold": true, "shape": "dot", "size": 18.97058868408203, "title": "A comparative study of GPU programming models and architectures using neural networks", "x": 68.02800802073645, "y": -23.68261777817171}, {"id": 423, "label": "Porting and scaling\nOpenACC applications\non massively-\nparallel, GPU-\naccelerated\nsupercomputers", "labelHighlightBold": true, "shape": "dot", "size": 10.588235855102539, "title": "Porting and scaling OpenACC applications on massively-parallel, GPU-accelerated supercomputers", "x": 22.428007077264574, "y": 132.8488076534428}, {"id": 424, "label": "Providing source\ncode level\nportability between\nCPU and GPU with\nMapCG", "labelHighlightBold": true, "shape": "dot", "size": 7.7941179275512695, "title": "Providing source code level portability between CPU and GPU with MapCG", "x": 94.81746377478484, "y": 165.83516704649634}, {"id": 426, "label": "Accelerating\nincompressible flow\ncomputations with a\nPthreads-CUDA\nimplementation on\nsmall-footprint\nmulti-GPU platforms", "labelHighlightBold": true, "shape": "dot", "size": 18.97058868408203, "title": "Accelerating incompressible flow computations with a Pthreads-CUDA implementation on small-footprint multi-GPU platforms", "x": -8.560106741593499, "y": -63.2900076996156}, {"id": 429, "label": "Optimizing linpack\nbenchmark on GPU-\naccelerated\npetascale\nsupercomputer", "labelHighlightBold": true, "shape": "dot", "size": 16.176471710205078, "title": "Optimizing linpack benchmark on GPU-accelerated petascale supercomputer", "x": 13.680509220475168, "y": -28.71944765940697}, {"id": 433, "label": "An efficient\nparallel\ncollaborative\nfiltering algorithm\non multi-GPU\nplatform", "labelHighlightBold": true, "shape": "dot", "size": 10.588235855102539, "title": "An efficient parallel collaborative filtering algorithm on multi-GPU platform", "x": -28.011285265575538, "y": 9.01718653156487}, {"id": 440, "label": "CUDA compatible GPU\ncards as efficient\nhardware\naccelerators for\nSmith-Waterman\nsequence alignment", "labelHighlightBold": true, "shape": "dot", "size": 30.147058486938477, "title": "CUDA compatible GPU cards as efficient hardware accelerators for Smith-Waterman sequence alignment", "x": 139.98851437237437, "y": -17.0148749541904}, {"id": 442, "label": "Parallel programing\ntemplates for remote\nsensing image\nprocessing on GPU\narchitectures:\ndesign and\nimplementation", "labelHighlightBold": true, "shape": "dot", "size": 13.382352828979492, "title": "Parallel programing templates for remote sensing image processing on GPU architectures: design and implementation", "x": 4.772212668768481, "y": -129.57867950398318}, {"id": 445, "label": "Correlation\nacceleration in GNSS\nsoftware receivers\nusing a CUDA-enabled\nGPU", "labelHighlightBold": true, "shape": "dot", "size": 13.382352828979492, "title": "Correlation acceleration in GNSS software receivers using a CUDA-enabled GPU", "x": 9.761693107864195, "y": -130.57271298078822}, {"id": 447, "label": "A compound\nOpenMP/MPI program\ndevelopment toolkit\nfor hybrid CPU/GPU\nclusters", "labelHighlightBold": true, "shape": "dot", "size": 16.176471710205078, "title": "A compound OpenMP/MPI program development toolkit for hybrid CPU/GPU clusters", "x": 55.538507460794385, "y": 108.8698139947644}, {"id": 448, "label": "Accelerating\nMapReduce framework\non multi-GPU systems", "labelHighlightBold": true, "shape": "dot", "size": 13.382352828979492, "title": "Accelerating MapReduce framework on multi-GPU systems", "x": 71.3413247818473, "y": 149.86015109232585}, {"id": 458, "label": "MVAPICH2-GPU:\nOptimized GPU to GPU\ncommunication for\nInfiniBand clusters", "labelHighlightBold": true, "shape": "dot", "size": 21.764705657958984, "title": "MVAPICH2-GPU: Optimized GPU to GPU communication for InfiniBand clusters", "x": 26.974759022032, "y": 108.43819247539349}, {"id": 459, "label": "TH-1: China\u0027s first\npetaflop\nsupercomputer", "labelHighlightBold": true, "shape": "dot", "size": 16.176471710205078, "title": "TH-1: China\u0027s first petaflop supercomputer", "x": -48.785587401637116, "y": -15.521845441139185}, {"id": 463, "label": "SkelCL: A high-level\nextension of OpenCL\nfor multi-GPU\nsystems", "labelHighlightBold": true, "shape": "dot", "size": 16.176471710205078, "title": "SkelCL: A high-level extension of OpenCL for multi-GPU systems", "x": 50.329859835762434, "y": 88.19368847630268}, {"id": 466, "label": "OpenMC: Towards\nsimplifying\nprogramming for\ntianhe\nsupercomputers", "labelHighlightBold": true, "shape": "dot", "size": 10.588235855102539, "title": "OpenMC: Towards simplifying programming for tianhe supercomputers", "x": -47.953491604129894, "y": -48.79376392365089}, {"id": 470, "label": "Strategies for\nmaximizing\nutilization on\nmulti-CPU and multi-\nGPU heterogeneous\narchitectures", "labelHighlightBold": true, "shape": "dot", "size": 24.55882453918457, "title": "Strategies for maximizing utilization on multi-CPU and multi-GPU heterogeneous architectures", "x": 41.7858001289886, "y": 122.18182342678097}, {"id": 474, "label": "Cardiac simulation\non multi-GPU\nplatform", "labelHighlightBold": true, "shape": "dot", "size": 18.97058868408203, "title": "Cardiac simulation on multi-GPU platform", "x": -0.9545893829756837, "y": -65.22843358686634}, {"id": 481, "label": "MPtostream: An\nOpenMP compiler for\nCPU-GPU\nheterogeneous\nparallel systems", "labelHighlightBold": true, "shape": "dot", "size": 10.588235855102539, "title": "MPtostream: An OpenMP compiler for CPU-GPU heterogeneous parallel systems", "x": -42.20258800179363, "y": -24.897835869134394}, {"id": 482, "label": "Toward a software\ntransactional memory\nfor heterogeneous\nCPU\u2013GPU processors", "labelHighlightBold": true, "shape": "dot", "size": 16.176471710205078, "title": "Toward a software transactional memory for heterogeneous CPU\u2013GPU processors", "x": 5.586652278027756, "y": 188.21561588764524}, {"id": 491, "label": "CUDASW++ 3.0:\naccelerating Smith-\nWaterman protein\ndatabase search by\ncoupling CPU and GPU\nSIMD instructions.", "labelHighlightBold": true, "shape": "dot", "size": 27.352941513061523, "title": "CUDASW++ 3.0: accelerating Smith-Waterman protein database search by coupling CPU and GPU SIMD instructions.", "x": 152.0715442875626, "y": -13.285821650501893}, {"id": 492, "label": "DOPA: GPU-based\nprotein alignment\nusing database and\nmemory access\noptimizations", "labelHighlightBold": true, "shape": "dot", "size": 10.588235855102539, "title": "DOPA: GPU-based protein alignment using database and memory access optimizations", "x": 159.42147533046034, "y": -4.816874283059061}, {"id": 496, "label": "Addressing GPU on-\nchip shared memory\nbank conflicts using\nelastic pipeline", "labelHighlightBold": true, "shape": "dot", "size": 10.588235855102539, "title": "Addressing GPU on-chip shared memory bank conflicts using elastic pipeline", "x": 38.034083602151355, "y": -9.608048099250405}, {"id": 499, "label": "Scaling up\nMapReduce-based Big\nData Processing on\nMulti-GPU systems", "labelHighlightBold": true, "shape": "dot", "size": 18.97058868408203, "title": "Scaling up MapReduce-based Big Data Processing on Multi-GPU systems", "x": 51.680062213930086, "y": 134.53362260164351}, {"id": 508, "label": "Stencil computations\non heterogeneous\nplatforms for the\nJacobi method: GPUs\nversus Cell BE", "labelHighlightBold": true, "shape": "dot", "size": 27.352941513061523, "title": "Stencil computations on heterogeneous platforms for the Jacobi method: GPUs versus Cell BE", "x": -15.970573983939353, "y": -72.53740030776038}, {"id": 510, "label": "Introducing and\nimplementing the\nallpairs skeleton\nfor programming\nmulti-GPU Systems", "labelHighlightBold": true, "shape": "dot", "size": 10.588235855102539, "title": "Introducing and implementing the allpairs skeleton for programming multi-GPU Systems", "x": -122.73135406335528, "y": 127.57000024244564}, {"id": 512, "label": "Optimizing tensor\ncontraction\nexpressions for\nhybrid CPU-GPU\nexecution", "labelHighlightBold": true, "shape": "dot", "size": 16.176471710205078, "title": "Optimizing tensor contraction expressions for hybrid CPU-GPU execution", "x": -32.071114597693686, "y": 3.1914937580039604}, {"id": 539, "label": "Offloading data\nencryption to GPU in\ndatabase systems", "labelHighlightBold": true, "shape": "dot", "size": 16.176471710205078, "title": "Offloading data encryption to GPU in database systems", "x": 51.68768333093016, "y": -51.16714152165434}, {"id": 546, "label": "High-Level\nProgramming for\nMany-Cores Using\nC++14 and the STL", "labelHighlightBold": true, "shape": "dot", "size": 7.7941179275512695, "title": "High-Level Programming for Many-Cores Using C++14 and the STL", "x": -94.52396666171657, "y": 112.74251670489994}, {"id": 547, "label": "RT-CUDA: A Software\nTool for CUDA Code\nRestructuring", "labelHighlightBold": true, "shape": "dot", "size": 16.176471710205078, "title": "RT-CUDA: A Software Tool for CUDA Code Restructuring", "x": -116.13964046101879, "y": 101.68110655465996}, {"id": 548, "label": "Parallel data mining\ntechniques on\nGraphics Processing\nUnit with Compute\nUnified Device\nArchitecture (CUDA)", "labelHighlightBold": true, "shape": "dot", "size": 32.94117736816406, "title": "Parallel data mining techniques on Graphics Processing Unit with Compute Unified Device Architecture (CUDA)", "x": 57.441349887496955, "y": -39.19685861767704}, {"id": 561, "label": "A GPU implementation\nof a structural-\nsimilarity-based\naerial-image\nclassification", "labelHighlightBold": true, "shape": "dot", "size": 21.764705657958984, "title": "A GPU implementation of a structural-similarity-based aerial-image classification", "x": 38.932519705401624, "y": -44.156907568311944}, {"id": 564, "label": "GPU-accelerated\nlevel-set\nsegmentation", "labelHighlightBold": true, "shape": "dot", "size": 7.7941179275512695, "title": "GPU-accelerated level-set segmentation", "x": 61.82166515644974, "y": -71.40638848623834}, {"id": 570, "label": "Gene regulatory\nnetworks inference\nusing a multi-GPU\nexhaustive search\nalgorithm", "labelHighlightBold": true, "shape": "dot", "size": 7.7941179275512695, "title": "Gene regulatory networks inference using a multi-GPU exhaustive search algorithm", "x": 73.37425240799887, "y": 114.69458746538966}, {"id": 604, "label": "Extending OpenMP to\nsurvive the\nheterogeneous multi-\ncore era", "labelHighlightBold": true, "shape": "dot", "size": 16.176471710205078, "title": "Extending OpenMP to survive the heterogeneous multi-core era", "x": -66.65381036265713, "y": -8.016984732642927}, {"id": 605, "label": "Speeding up the\nevaluation phase of\nGP classification\nalgorithms on GPUs", "labelHighlightBold": true, "shape": "dot", "size": 18.97058868408203, "title": "Speeding up the evaluation phase of GP classification algorithms on GPUs", "x": 66.34991750796436, "y": -34.93620054791177}, {"id": 608, "label": "Medical image\nsegmentation with\ndeformable models on\ngraphics processing\nunits", "labelHighlightBold": true, "shape": "dot", "size": 18.97058868408203, "title": "Medical image segmentation with deformable models on graphics processing units", "x": 54.891101029922936, "y": -57.74073845936723}, {"id": 609, "label": "Correlating radio\nastronomy signals\nwith many-core\nhardware", "labelHighlightBold": true, "shape": "dot", "size": 13.382352828979492, "title": "Correlating radio astronomy signals with many-core hardware", "x": 44.218821632857804, "y": 12.69723759751845}, {"id": 620, "label": "High performance\ndata clustering: A\ncomparative analysis\nof performance for\nGPU, RASC, MPI, and\nOpenMP\nimplementations", "labelHighlightBold": true, "shape": "dot", "size": 10.588235855102539, "title": "High performance data clustering: A comparative analysis of performance for GPU, RASC, MPI, and OpenMP implementations", "x": 67.3309120475585, "y": 112.88918721287439}, {"id": 633, "label": "Adaptive fast\nmultipole methods on\nthe GPU", "labelHighlightBold": true, "shape": "dot", "size": 13.382352828979492, "title": "Adaptive fast multipole methods on the GPU", "x": -29.8689126742957, "y": -84.98851981439584}, {"id": 636, "label": "Parallelization of\nlarge vector\nsimilarity\ncomputations in a\nhybrid CPU+GPU\nenvironment", "labelHighlightBold": true, "shape": "dot", "size": 13.382352828979492, "title": "Parallelization of large vector similarity computations in a hybrid CPU+GPU environment", "x": 10.992900641315503, "y": 28.591738454512818}, {"id": 644, "label": "GASAL2: A GPU\naccelerated sequence\nalignment library\nfor high-throughput\nNGS data", "labelHighlightBold": true, "shape": "dot", "size": 10.588235855102539, "title": "GASAL2: A GPU accelerated sequence alignment library for high-throughput NGS data", "x": 160.28896666637868, "y": -14.551334859355702}, {"id": 655, "label": "GPU-accelerated\npreconditioned\niterative linear\nsolvers", "labelHighlightBold": true, "shape": "dot", "size": 13.382352828979492, "title": "GPU-accelerated preconditioned iterative linear solvers", "x": -31.919275631758673, "y": -88.45959322419276}, {"id": 656, "label": "GPU-based collision\nanalysis between a\nmulti-body system\nand numerous\nparticles", "labelHighlightBold": true, "shape": "dot", "size": 7.7941179275512695, "title": "GPU-based collision analysis between a multi-body system and numerous particles", "x": 120.52730488714306, "y": -24.818599022821363}, {"id": 660, "label": "Hybrid multi-GPU\ncomputing:\naccelerated kernels\nfor segmentation and\nobject detection\nwith medical image\nprocessing\napplications", "labelHighlightBold": true, "shape": "dot", "size": 13.382352828979492, "title": "Hybrid multi-GPU computing: accelerated kernels for segmentation and object detection with medical image processing applications", "x": -108.93643894444878, "y": -1.767799391573767}, {"id": 666, "label": "A parallel pattern\nfor iterative\nstencil + reduce", "labelHighlightBold": true, "shape": "dot", "size": 16.176471710205078, "title": "A parallel pattern for iterative stencil + reduce", "x": -109.21997335920058, "y": 102.31076950788147}, {"id": 670, "label": "Parallelization of\nFull Search Motion\nEstimation algorithm\nfor parallel and\ndistributed\nplatforms", "labelHighlightBold": true, "shape": "dot", "size": 13.382352828979492, "title": "Parallelization of Full Search Motion Estimation algorithm for parallel and distributed platforms", "x": 112.91299287397852, "y": -86.65823167839001}, {"id": 685, "label": "Design Flow for GPU\nand Multicore\nExecution of Dynamic\nDataflow Programs", "labelHighlightBold": true, "shape": "dot", "size": 10.588235855102539, "title": "Design Flow for GPU and Multicore Execution of Dynamic Dataflow Programs", "x": 12.183590994410205, "y": -53.324658941928575}, {"id": 705, "label": "Effective naive\nBayes nearest\nneighbor based image\nclassification on\nGPU", "labelHighlightBold": true, "shape": "dot", "size": 10.588235855102539, "title": "Effective naive Bayes nearest neighbor based image classification on GPU", "x": 63.85284676586857, "y": 145.09473959759873}, {"id": 711, "label": "Enhancing GPU\nparallelism in\nnature-inspired\nalgorithms", "labelHighlightBold": true, "shape": "dot", "size": 16.176471710205078, "title": "Enhancing GPU parallelism in nature-inspired algorithms", "x": 70.73540033371225, "y": -30.664432655226168}, {"id": 739, "label": "On GPU\u2013CUDA as\npreprocessing of\nfuzzy-rough data\nreduction by means\nof singular value\ndecomposition", "labelHighlightBold": true, "shape": "dot", "size": 10.588235855102539, "title": "On GPU\u2013CUDA as preprocessing of fuzzy-rough data reduction by means of singular value decomposition", "x": 4.323703892809986, "y": -4.135094352734839}, {"id": 741, "label": "MilkyWay-2\nsupercomputer:\nSystem and\napplication", "labelHighlightBold": true, "shape": "dot", "size": 18.97058868408203, "title": "MilkyWay-2 supercomputer: System and application", "x": -47.47611118530658, "y": -58.84040628735832}, {"id": 756, "label": "High performance\nevaluation of\nevolutionary-mined\nassociation rules on\nGPUs", "labelHighlightBold": true, "shape": "dot", "size": 13.382352828979492, "title": "High performance evaluation of evolutionary-mined association rules on GPUs", "x": 69.81864380109309, "y": -39.45019128602855}, {"id": 762, "label": "Energy cost\nevaluation of\nparallel algorithms\nfor multiprocessor\nsystems", "labelHighlightBold": true, "shape": "dot", "size": 7.7941179275512695, "title": "Energy cost evaluation of parallel algorithms for multiprocessor systems", "x": -13.310295668762771, "y": 10.753777440927363}, {"id": 771, "label": "Simultaneous CPU\u2013GPU\nExecution of Data\nParallel Algorithmic\nSkeletons", "labelHighlightBold": true, "shape": "dot", "size": 10.588235855102539, "title": "Simultaneous CPU\u2013GPU Execution of Data Parallel Algorithmic Skeletons", "x": -97.70404645512019, "y": 105.90164122992417}, {"id": 786, "label": "CUDASW++2.0:\nEnhanced Smith-\nWaterman protein\ndatabase search on\nCUDA-enabled GPUs\nbased on SIMT and\nvirtualized SIMD\nabstractions", "labelHighlightBold": true, "shape": "dot", "size": 21.764705657958984, "title": "CUDASW++2.0: Enhanced Smith-Waterman protein database search on CUDA-enabled GPUs based on SIMT and virtualized SIMD abstractions", "x": 134.4972719871022, "y": -17.228311976859647}, {"id": 788, "label": "Solving finite\ndifference linear\nsystems on GPUs:\nCUDA based parallel\nexplicit\npreconditioned\nbiconjugate\nconjugate gradient\ntype methods", "labelHighlightBold": true, "shape": "dot", "size": 18.97058868408203, "title": "Solving finite difference linear systems on GPUs: CUDA based parallel explicit preconditioned biconjugate conjugate gradient type methods", "x": -4.402681918762127, "y": -61.38878285147453}, {"id": 789, "label": "Data layout\ntransformation\nexploiting memory-\nlevel parallelism in\nstructured grid\nmany-core\napplications", "labelHighlightBold": true, "shape": "dot", "size": 7.7941179275512695, "title": "Data layout transformation exploiting memory-level parallelism in structured grid many-core applications", "x": -114.00574457651189, "y": 22.561438369418816}, {"id": 792, "label": "A framework for\naccelerating local\nfeature extraction\nwith OpenCL on\nmulti-core CPUs and\nco-processors", "labelHighlightBold": true, "shape": "dot", "size": 10.588235855102539, "title": "A framework for accelerating local feature extraction with OpenCL on multi-core CPUs and co-processors", "x": 121.24990689915224, "y": -93.99324846212228}, {"id": 825, "label": "PPModel: A modeling\ntool for source code\nmaintenance and\noptimization of\nparallel programs", "labelHighlightBold": true, "shape": "dot", "size": 10.588235855102539, "title": "PPModel: A modeling tool for source code maintenance and optimization of parallel programs", "x": -91.67219424116392, "y": -60.795848769406845}, {"id": 852, "label": "A view of\nprogramming scalable\ndata analysis: from\nclouds to exascale", "labelHighlightBold": true, "shape": "dot", "size": 7.7941179275512695, "title": "A view of programming scalable data analysis: from clouds to exascale", "x": 26.415483684681806, "y": -70.6538457878514}, {"id": 854, "label": "SkePU 2: Flexible\nand Type-Safe\nSkeleton Programming\nfor Heterogeneous\nParallel Systems", "labelHighlightBold": true, "shape": "dot", "size": 27.352941513061523, "title": "SkePU 2: Flexible and Type-Safe Skeleton Programming for Heterogeneous Parallel Systems", "x": -102.73055459157142, "y": 92.12197437434445}, {"id": 855, "label": "Generating custom\ncode for efficient\nquery execution on\nheterogeneous\nprocessors", "labelHighlightBold": true, "shape": "dot", "size": 7.7941179275512695, "title": "Generating custom code for efficient query execution on heterogeneous processors", "x": -41.076312009304395, "y": 35.280506100159016}, {"id": 862, "label": "Dawning nebulae: A\nPetaFLOPS\nsupercomputer with a\nheterogeneous\nstructure", "labelHighlightBold": true, "shape": "dot", "size": 7.7941179275512695, "title": "Dawning nebulae: A PetaFLOPS supercomputer with a heterogeneous structure", "x": -44.39410934008284, "y": -35.44785477992093}, {"id": 875, "label": "Fast and accurate\nprotein substructure\nsearching with\nsimulated annealing\nand GPUs", "labelHighlightBold": true, "shape": "dot", "size": 18.97058868408203, "title": "Fast and accurate protein substructure searching with simulated annealing and GPUs", "x": 149.08617606343037, "y": -18.794137195145904}, {"id": 878, "label": "Parallel mutual\ninformation\nestimation for\ninferring gene\nregulatory networks\non GPUs", "labelHighlightBold": true, "shape": "dot", "size": 10.588235855102539, "title": "Parallel mutual information estimation for inferring gene regulatory networks on GPUs", "x": 18.37011471492788, "y": -39.818400820136304}, {"id": 883, "label": "Performance\nevaluation of\nUnified Memory with\nprefetching and\noversubscription for\nselected parallel\nCUDA applications on\nNVIDIA Pascal and\nVolta GPUs", "labelHighlightBold": true, "shape": "dot", "size": 16.176471710205078, "title": "Performance evaluation of Unified Memory with prefetching and oversubscription for selected parallel CUDA applications on NVIDIA Pascal and Volta GPUs", "x": 7.689577836099897, "y": -111.27399025400528}, {"id": 895, "label": "Accelerating large-\nscale protein\nstructure alignments\nwith graphics\nprocessing units", "labelHighlightBold": true, "shape": "dot", "size": 16.176471710205078, "title": "Accelerating large-scale protein structure alignments with graphics processing units", "x": 155.43935533196031, "y": -20.96795900713483}, {"id": 913, "label": "Performance\nevaluation of\nunified memory and\ndynamic parallelism\nfor selected\nparallel CUDA\napplications", "labelHighlightBold": true, "shape": "dot", "size": 16.176471710205078, "title": "Performance evaluation of unified memory and dynamic parallelism for selected parallel CUDA applications", "x": 4.3004964807575625, "y": 29.527732043204335}, {"id": 920, "label": "A preliminary\nevaluation of\nOpenACC\nimplementations", "labelHighlightBold": true, "shape": "dot", "size": 13.382352828979492, "title": "A preliminary evaluation of OpenACC implementations", "x": 47.034685295115565, "y": -12.802539590182695}, {"id": 921, "label": "Optimizing the\nMatrix\nMultiplication Using\nStrassen and\nWinograd Algorithms\nwith Limited\nRecursions on Many-\nCore", "labelHighlightBold": true, "shape": "dot", "size": 16.176471710205078, "title": "Optimizing the Matrix Multiplication Using Strassen and Winograd Algorithms with Limited Recursions on Many-Core", "x": -111.46927725753929, "y": 98.77787186707079}, {"id": 926, "label": "Protein alignment\nalgorithms with an\nefficient\nbacktracking routine\non multiple GPUs", "labelHighlightBold": true, "shape": "dot", "size": 21.764705657958984, "title": "Protein alignment algorithms with an efficient backtracking routine on multiple GPUs", "x": 147.36538001505247, "y": -9.666702338626086}, {"id": 935, "label": "A scalable and fast\nOPTICS for\nclustering\ntrajectory big data", "labelHighlightBold": true, "shape": "dot", "size": 10.588235855102539, "title": "A scalable and fast OPTICS for clustering trajectory big data", "x": 18.59955379592442, "y": -52.61744421494949}, {"id": 939, "label": "Virtualizing high-\nend GPGPUs on ARM\nclusters for the\nnext generation of\nhigh performance\ncloud computing", "labelHighlightBold": true, "shape": "dot", "size": 16.176471710205078, "title": "Virtualizing high-end GPGPUs on ARM clusters for the next generation of high performance cloud computing", "x": 115.07099598172069, "y": -21.6762741226937}, {"id": 946, "label": "A parallel algorithm\nfor the Riesz\nfractional reaction-\ndiffusion equation\nwith explicit finite\ndifference method", "labelHighlightBold": true, "shape": "dot", "size": 18.97058868408203, "title": "A parallel algorithm for the Riesz fractional reaction-diffusion equation with explicit finite difference method", "x": -39.08759703174296, "y": -80.6772540534114}, {"id": 947, "label": "Formalised\nComposition and\nInteraction for\nHeterogeneous\nStructured\nParallelism", "labelHighlightBold": true, "shape": "dot", "size": 7.7941179275512695, "title": "Formalised Composition and Interaction for Heterogeneous Structured Parallelism", "x": -98.56343268368649, "y": 98.1720562616151}, {"id": 951, "label": "Toward fault-\ntolerant hybrid\nprogramming over\nlarge-scale\nheterogeneous\nclusters via checkpo\ninting/restart\noptimization", "labelHighlightBold": true, "shape": "dot", "size": 16.176471710205078, "title": "Toward fault-tolerant hybrid programming over large-scale heterogeneous clusters via checkpointing/restart optimization", "x": 1.6600122227860346, "y": 188.37721167803048}, {"id": 957, "label": "Efficient scheduling\nof streams on GPGPUs", "labelHighlightBold": true, "shape": "dot", "size": 13.382352828979492, "title": "Efficient scheduling of streams on GPGPUs", "x": 8.22802763999975, "y": -126.12783868888795}, {"id": 963, "label": "Accelerating MRI\nreconstruction via\nthree-dimensional\ndual-dictionary\nlearning using CUDA", "labelHighlightBold": true, "shape": "dot", "size": 13.382352828979492, "title": "Accelerating MRI reconstruction via three-dimensional dual-dictionary learning using CUDA", "x": -107.73396898045155, "y": 3.1544760512260845}, {"id": 966, "label": "CUDASW++: Optimizing\nSmith-Waterman\nsequence database\nsearches for CUDA-\nenabled graphics\nprocessing units", "labelHighlightBold": true, "shape": "dot", "size": 21.764705657958984, "title": "CUDASW++: Optimizing Smith-Waterman sequence database searches for CUDA-enabled graphics processing units", "x": 143.8882629608313, "y": -16.34871914778348}, {"id": 972, "label": "A Hybrid Task Graph\nScheduler for High\nPerformance Image\nProcessing Workflows", "labelHighlightBold": true, "shape": "dot", "size": 13.382352828979492, "title": "A Hybrid Task Graph Scheduler for High Performance Image Processing Workflows", "x": 12.83386949053449, "y": -61.59554885680468}, {"id": 990, "label": "Optimizing Monte\nCarlo radiosity on\ngraphics hardware", "labelHighlightBold": true, "shape": "dot", "size": 7.7941179275512695, "title": "Optimizing Monte Carlo radiosity on graphics hardware", "x": -1.4008314048889217, "y": -41.96140127049525}, {"id": 991, "label": "Parallel refinement\nof slanted 3D\nreconstruction using\ndense stereo induced\nfrom symmetry", "labelHighlightBold": true, "shape": "dot", "size": 13.382352828979492, "title": "Parallel refinement of slanted 3D reconstruction using dense stereo induced from symmetry", "x": -104.4184196384963, "y": 0.36334046894470023}, {"id": 992, "label": "Fast network\ncentrality analysis\nusing GPUs", "labelHighlightBold": true, "shape": "dot", "size": 13.382352828979492, "title": "Fast network centrality analysis using GPUs", "x": -157.21441204511777, "y": 180.9843178891049}, {"id": 998, "label": "A survey on\nplatforms for big\ndata analytics", "labelHighlightBold": true, "shape": "dot", "size": 13.382352828979492, "title": "A survey on platforms for big data analytics", "x": 22.39363609422927, "y": -60.16096070733966}, {"id": 1010, "label": "A statistical\nperformance analyzer\nframework for OpenCL\nkernels on Nvidia\nGPUs", "labelHighlightBold": true, "shape": "dot", "size": 7.7941179275512695, "title": "A statistical performance analyzer framework for OpenCL kernels on Nvidia GPUs", "x": -15.490595926809672, "y": 39.5777748604004}, {"id": 1016, "label": "Simulation of one-\nlayer shallow water\nsystems on multicore\nand CUDA\narchitectures", "labelHighlightBold": true, "shape": "dot", "size": 10.588235855102539, "title": "Simulation of one-layer shallow water systems on multicore and CUDA architectures", "x": 14.797675547772858, "y": -19.66472382629069}, {"id": 1029, "label": "The TianHe-1A\nsupercomputer: Its\nhardware and\nsoftware", "labelHighlightBold": true, "shape": "dot", "size": 41.32352828979492, "title": "The TianHe-1A supercomputer: Its hardware and software", "x": -34.819639072740465, "y": -30.192367096646926}, {"id": 1041, "label": "Energy efficiency of\nload balancing for\ndata-parallel\napplications in\nheterogeneous\nsystems", "labelHighlightBold": true, "shape": "dot", "size": 7.7941179275512695, "title": "Energy efficiency of load balancing for data-parallel applications in heterogeneous systems", "x": 3.163226368944035, "y": 174.59036584695892}, {"id": 1087, "label": "Hybrid\nstatic\u2013dynamic\nselection of\nimplementation\nalternatives in\nheterogeneous\nenvironments", "labelHighlightBold": true, "shape": "dot", "size": 16.176471710205078, "title": "Hybrid static\u2013dynamic selection of implementation alternatives in heterogeneous environments", "x": 6.264895738573001, "y": 194.05804935921628}, {"id": 1092, "label": "The Fraunhofer\nvirtual machine: A\ncommunication\nlibrary and runtime\nsystem based on the\nRDMA model", "labelHighlightBold": true, "shape": "dot", "size": 10.588235855102539, "title": "The Fraunhofer virtual machine: A communication library and runtime system based on the RDMA model", "x": 24.504875905181667, "y": 117.60150858306433}, {"id": 1113, "label": "Optimizing an APSP\nimplementation for\nNVIDIA GPUs using\nkernel\ncharacterization\ncriteria", "labelHighlightBold": true, "shape": "dot", "size": 16.176471710205078, "title": "Optimizing an APSP implementation for NVIDIA GPUs using kernel characterization criteria", "x": -150.99232124041473, "y": 175.39653681516148}, {"id": 1147, "label": "Prediction models\nfor performance,\npower, and energy\nefficiency of\nsoftware executed on\nheterogeneous\nhardware", "labelHighlightBold": true, "shape": "dot", "size": 16.176471710205078, "title": "Prediction models for performance, power, and energy efficiency of software executed on heterogeneous hardware", "x": 2.0923515159185126, "y": 193.71791590168144}, {"id": 1148, "label": "The 2D wavelet\ntransform on\nemerging\narchitectures: GPUs\nand multicores", "labelHighlightBold": true, "shape": "dot", "size": 10.588235855102539, "title": "The 2D wavelet transform on emerging architectures: GPUs and multicores", "x": 17.674311466524934, "y": -32.42904711149508}, {"id": 1150, "label": "High-performance\noptimizations on\ntiled many-core\nembedded systems: A\nmatrix\nmultiplication case\nstudy", "labelHighlightBold": true, "shape": "dot", "size": 13.382352828979492, "title": "High-performance optimizations on tiled many-core embedded systems: A matrix multiplication case study", "x": 50.18366022207218, "y": 106.19189835106421}, {"id": 1160, "label": "Applications of the\nMapReduce\nprogramming\nframework to\nclinical big data\nanalysis: Current\nlandscape and future\ntrends", "labelHighlightBold": true, "shape": "dot", "size": 13.382352828979492, "title": "Applications of the MapReduce programming framework to clinical big data analysis: Current landscape and future trends", "x": 40.58791008761934, "y": 127.73466258171474}, {"id": 1189, "label": "Message-passing\nprogramming for\nembedded multicore\nsignal-processing\nplatforms", "labelHighlightBold": true, "shape": "dot", "size": 13.382352828979492, "title": "Message-passing programming for embedded multicore signal-processing platforms", "x": -74.35588544553528, "y": -14.16311871607837}, {"id": 1207, "label": "Automatic code\ngeneration and\ntuning for stencil\nkernels on modern\nshared memory\narchitectures", "labelHighlightBold": true, "shape": "dot", "size": 13.382352828979492, "title": "Automatic code generation and tuning for stencil kernels on modern shared memory architectures", "x": -23.679792379725473, "y": -16.614420820944737}, {"id": 1220, "label": "Simultaneous\nmultiprocessing in a\nsoftware-defined\nheterogeneous FPGA", "labelHighlightBold": true, "shape": "dot", "size": 21.764705657958984, "title": "Simultaneous multiprocessing in a software-defined heterogeneous FPGA", "x": 10.871510177586414, "y": 177.40391397409473}, {"id": 1262, "label": "An efficient\nparallel solution\nfor Caputo\nfractional reaction-\ndiffusion equation", "labelHighlightBold": true, "shape": "dot", "size": 10.588235855102539, "title": "An efficient parallel solution for Caputo fractional reaction-diffusion equation", "x": -49.26363444944581, "y": -76.66234249030828}, {"id": 1302, "label": "HAT: History-based\nauto-tuning\nMapReduce in\nheterogeneous\nenvironments", "labelHighlightBold": true, "shape": "dot", "size": 7.7941179275512695, "title": "HAT: History-based auto-tuning MapReduce in heterogeneous environments", "x": 96.6905203562153, "y": 161.3642568387199}, {"id": 1309, "label": "Efficient\ncomputation of motif\ndiscovery on Intel\nMany Integrated Core\n(MIC) Architecture", "labelHighlightBold": true, "shape": "dot", "size": 7.7941179275512695, "title": "Efficient computation of motif discovery on Intel Many Integrated Core (MIC) Architecture", "x": -57.65868746214322, "y": -67.3003661721655}, {"id": 1311, "label": "pocl: A Performance-\nPortable OpenCL\nImplementation", "labelHighlightBold": true, "shape": "dot", "size": 10.588235855102539, "title": "pocl: A Performance-Portable OpenCL Implementation", "x": 118.60740866980356, "y": -96.35879241515582}]);
edges = new vis.DataSet([{"from": 13, "title": "2", "to": 458, "width": 2}, {"from": 13, "title": "1", "to": 1092, "width": 1}, {"from": 13, "title": "1", "to": 361, "width": 1}, {"from": 13, "title": "1", "to": 423, "width": 1}, {"from": 18, "title": "1", "to": 458, "width": 1}, {"from": 18, "title": "2", "to": 311, "width": 2}, {"from": 18, "title": "1", "to": 202, "width": 1}, {"from": 18, "title": "1", "to": 402, "width": 1}, {"from": 18, "title": "1", "to": 68, "width": 1}, {"from": 18, "title": "1", "to": 433, "width": 1}, {"from": 18, "title": "1", "to": 512, "width": 1}, {"from": 18, "title": "1", "to": 762, "width": 1}, {"from": 34, "title": "1", "to": 311, "width": 1}, {"from": 34, "title": "1", "to": 855, "width": 1}, {"from": 34, "title": "1", "to": 51, "width": 1}, {"from": 34, "title": "1", "to": 222, "width": 1}, {"from": 51, "title": "1", "to": 222, "width": 1}, {"from": 53, "title": "1", "to": 1113, "width": 1}, {"from": 53, "title": "1", "to": 510, "width": 1}, {"from": 60, "title": "1", "to": 68, "width": 1}, {"from": 60, "title": "1", "to": 878, "width": 1}, {"from": 64, "title": "1", "to": 128, "width": 1}, {"from": 64, "title": "1", "to": 262, "width": 1}, {"from": 67, "title": "1", "to": 222, "width": 1}, {"from": 67, "title": "2", "to": 311, "width": 2}, {"from": 68, "title": "1", "to": 92, "width": 1}, {"from": 68, "title": "1", "to": 141, "width": 1}, {"from": 68, "title": "1", "to": 237, "width": 1}, {"from": 68, "title": "1", "to": 548, "width": 1}, {"from": 68, "title": "4", "to": 189, "width": 4}, {"from": 68, "title": "1", "to": 293, "width": 1}, {"from": 68, "title": "1", "to": 609, "width": 1}, {"from": 68, "title": "1", "to": 990, "width": 1}, {"from": 68, "title": "1", "to": 1029, "width": 1}, {"from": 68, "title": "2", "to": 429, "width": 2}, {"from": 68, "title": "1", "to": 402, "width": 1}, {"from": 68, "title": "1", "to": 1207, "width": 1}, {"from": 68, "title": "1", "to": 311, "width": 1}, {"from": 68, "title": "1", "to": 202, "width": 1}, {"from": 68, "title": "1", "to": 508, "width": 1}, {"from": 68, "title": "1", "to": 788, "width": 1}, {"from": 68, "title": "1", "to": 474, "width": 1}, {"from": 68, "title": "2", "to": 249, "width": 2}, {"from": 68, "title": "1", "to": 426, "width": 1}, {"from": 68, "title": "1", "to": 878, "width": 1}, {"from": 68, "title": "1", "to": 1148, "width": 1}, {"from": 68, "title": "1", "to": 685, "width": 1}, {"from": 68, "title": "1", "to": 972, "width": 1}, {"from": 68, "title": "1", "to": 935, "width": 1}, {"from": 68, "title": "1", "to": 998, "width": 1}, {"from": 68, "title": "1", "to": 128, "width": 1}, {"from": 68, "title": "1", "to": 182, "width": 1}, {"from": 68, "title": "1", "to": 883, "width": 1}, {"from": 68, "title": "1", "to": 378, "width": 1}, {"from": 68, "title": "1", "to": 1016, "width": 1}, {"from": 68, "title": "1", "to": 739, "width": 1}, {"from": 68, "title": "1", "to": 146, "width": 1}, {"from": 91, "title": "2", "to": 311, "width": 2}, {"from": 91, "title": "1", "to": 604, "width": 1}, {"from": 91, "title": "1", "to": 1189, "width": 1}, {"from": 91, "title": "1", "to": 181, "width": 1}, {"from": 91, "title": "1", "to": 459, "width": 1}, {"from": 91, "title": "1", "to": 1029, "width": 1}, {"from": 91, "title": "1", "to": 202, "width": 1}, {"from": 106, "title": "1", "to": 222, "width": 1}, {"from": 106, "title": "2", "to": 913, "width": 2}, {"from": 106, "title": "3", "to": 146, "width": 3}, {"from": 106, "title": "1", "to": 636, "width": 1}, {"from": 115, "title": "1", "to": 972, "width": 1}, {"from": 121, "title": "1", "to": 376, "width": 1}, {"from": 121, "title": "1", "to": 222, "width": 1}, {"from": 125, "title": "1", "to": 189, "width": 1}, {"from": 128, "title": "1", "to": 202, "width": 1}, {"from": 128, "title": "1", "to": 262, "width": 1}, {"from": 134, "title": "1", "to": 378, "width": 1}, {"from": 141, "title": "1", "to": 608, "width": 1}, {"from": 141, "title": "1", "to": 561, "width": 1}, {"from": 141, "title": "1", "to": 548, "width": 1}, {"from": 141, "title": "1", "to": 539, "width": 1}, {"from": 146, "title": "2", "to": 267, "width": 2}, {"from": 146, "title": "3", "to": 222, "width": 3}, {"from": 146, "title": "2", "to": 913, "width": 2}, {"from": 146, "title": "1", "to": 636, "width": 1}, {"from": 146, "title": "1", "to": 739, "width": 1}, {"from": 155, "title": "1", "to": 358, "width": 1}, {"from": 181, "title": "1", "to": 604, "width": 1}, {"from": 181, "title": "1", "to": 1189, "width": 1}, {"from": 182, "title": "1", "to": 289, "width": 1}, {"from": 182, "title": "1", "to": 347, "width": 1}, {"from": 182, "title": "1", "to": 660, "width": 1}, {"from": 182, "title": "1", "to": 963, "width": 1}, {"from": 182, "title": "1", "to": 991, "width": 1}, {"from": 189, "title": "1", "to": 609, "width": 1}, {"from": 189, "title": "1", "to": 1029, "width": 1}, {"from": 189, "title": "1", "to": 429, "width": 1}, {"from": 189, "title": "1", "to": 756, "width": 1}, {"from": 189, "title": "2", "to": 605, "width": 2}, {"from": 189, "title": "2", "to": 548, "width": 2}, {"from": 189, "title": "1", "to": 786, "width": 1}, {"from": 189, "title": "1", "to": 440, "width": 1}, {"from": 189, "title": "1", "to": 939, "width": 1}, {"from": 189, "title": "1", "to": 711, "width": 1}, {"from": 189, "title": "1", "to": 419, "width": 1}, {"from": 189, "title": "1", "to": 344, "width": 1}, {"from": 200, "title": "2", "to": 222, "width": 2}, {"from": 200, "title": "1", "to": 342, "width": 1}, {"from": 200, "title": "1", "to": 363, "width": 1}, {"from": 202, "title": "6", "to": 311, "width": 6}, {"from": 202, "title": "1", "to": 459, "width": 1}, {"from": 202, "title": "2", "to": 1029, "width": 2}, {"from": 202, "title": "1", "to": 1207, "width": 1}, {"from": 202, "title": "1", "to": 481, "width": 1}, {"from": 202, "title": "1", "to": 512, "width": 1}, {"from": 204, "title": "1", "to": 1029, "width": 1}, {"from": 204, "title": "1", "to": 311, "width": 1}, {"from": 222, "title": "4", "to": 267, "width": 4}, {"from": 222, "title": "1", "to": 378, "width": 1}, {"from": 222, "title": "4", "to": 363, "width": 4}, {"from": 222, "title": "1", "to": 376, "width": 1}, {"from": 222, "title": "1", "to": 1010, "width": 1}, {"from": 222, "title": "1", "to": 913, "width": 1}, {"from": 222, "title": "1", "to": 342, "width": 1}, {"from": 222, "title": "1", "to": 245, "width": 1}, {"from": 249, "title": "1", "to": 508, "width": 1}, {"from": 249, "title": "1", "to": 788, "width": 1}, {"from": 249, "title": "1", "to": 474, "width": 1}, {"from": 249, "title": "1", "to": 426, "width": 1}, {"from": 249, "title": "1", "to": 561, "width": 1}, {"from": 249, "title": "1", "to": 378, "width": 1}, {"from": 259, "title": "1", "to": 1302, "width": 1}, {"from": 259, "title": "1", "to": 424, "width": 1}, {"from": 259, "title": "1", "to": 448, "width": 1}, {"from": 267, "title": "1", "to": 378, "width": 1}, {"from": 276, "title": "1", "to": 311, "width": 1}, {"from": 277, "title": "1", "to": 385, "width": 1}, {"from": 277, "title": "1", "to": 1113, "width": 1}, {"from": 277, "title": "1", "to": 992, "width": 1}, {"from": 289, "title": "1", "to": 347, "width": 1}, {"from": 311, "title": "1", "to": 604, "width": 1}, {"from": 311, "title": "2", "to": 1029, "width": 2}, {"from": 311, "title": "1", "to": 459, "width": 1}, {"from": 311, "title": "1", "to": 1207, "width": 1}, {"from": 311, "title": "1", "to": 854, "width": 1}, {"from": 311, "title": "1", "to": 512, "width": 1}, {"from": 342, "title": "1", "to": 363, "width": 1}, {"from": 343, "title": "1", "to": 825, "width": 1}, {"from": 343, "title": "1", "to": 395, "width": 1}, {"from": 344, "title": "1", "to": 670, "width": 1}, {"from": 347, "title": "1", "to": 789, "width": 1}, {"from": 351, "title": "1", "to": 666, "width": 1}, {"from": 351, "title": "1", "to": 854, "width": 1}, {"from": 351, "title": "1", "to": 921, "width": 1}, {"from": 351, "title": "1", "to": 547, "width": 1}, {"from": 358, "title": "1", "to": 378, "width": 1}, {"from": 361, "title": "1", "to": 423, "width": 1}, {"from": 378, "title": "1", "to": 496, "width": 1}, {"from": 378, "title": "1", "to": 920, "width": 1}, {"from": 378, "title": "1", "to": 561, "width": 1}, {"from": 378, "title": "1", "to": 1016, "width": 1}, {"from": 385, "title": "1", "to": 1113, "width": 1}, {"from": 385, "title": "1", "to": 992, "width": 1}, {"from": 395, "title": "1", "to": 1029, "width": 1}, {"from": 395, "title": "1", "to": 825, "width": 1}, {"from": 419, "title": "1", "to": 920, "width": 1}, {"from": 419, "title": "1", "to": 605, "width": 1}, {"from": 419, "title": "1", "to": 711, "width": 1}, {"from": 419, "title": "1", "to": 548, "width": 1}, {"from": 426, "title": "1", "to": 508, "width": 1}, {"from": 426, "title": "1", "to": 788, "width": 1}, {"from": 426, "title": "1", "to": 474, "width": 1}, {"from": 429, "title": "1", "to": 1029, "width": 1}, {"from": 429, "title": "1", "to": 1148, "width": 1}, {"from": 433, "title": "1", "to": 512, "width": 1}, {"from": 440, "title": "9", "to": 966, "width": 9}, {"from": 440, "title": "6", "to": 786, "width": 6}, {"from": 440, "title": "3", "to": 491, "width": 3}, {"from": 440, "title": "2", "to": 875, "width": 2}, {"from": 440, "title": "1", "to": 895, "width": 1}, {"from": 440, "title": "1", "to": 644, "width": 1}, {"from": 440, "title": "1", "to": 939, "width": 1}, {"from": 440, "title": "2", "to": 926, "width": 2}, {"from": 442, "title": "1", "to": 957, "width": 1}, {"from": 442, "title": "1", "to": 445, "width": 1}, {"from": 442, "title": "1", "to": 883, "width": 1}, {"from": 445, "title": "1", "to": 957, "width": 1}, {"from": 445, "title": "1", "to": 883, "width": 1}, {"from": 447, "title": "1", "to": 1150, "width": 1}, {"from": 447, "title": "1", "to": 470, "width": 1}, {"from": 447, "title": "1", "to": 463, "width": 1}, {"from": 447, "title": "1", "to": 620, "width": 1}, {"from": 448, "title": "1", "to": 705, "width": 1}, {"from": 448, "title": "1", "to": 499, "width": 1}, {"from": 458, "title": "1", "to": 1092, "width": 1}, {"from": 458, "title": "1", "to": 1160, "width": 1}, {"from": 458, "title": "1", "to": 499, "width": 1}, {"from": 458, "title": "1", "to": 470, "width": 1}, {"from": 459, "title": "1", "to": 1029, "width": 1}, {"from": 463, "title": "1", "to": 1150, "width": 1}, {"from": 463, "title": "1", "to": 470, "width": 1}, {"from": 463, "title": "1", "to": 609, "width": 1}, {"from": 466, "title": "1", "to": 1029, "width": 1}, {"from": 466, "title": "1", "to": 741, "width": 1}, {"from": 470, "title": "1", "to": 1160, "width": 1}, {"from": 470, "title": "1", "to": 499, "width": 1}, {"from": 470, "title": "1", "to": 1150, "width": 1}, {"from": 470, "title": "1", "to": 1220, "width": 1}, {"from": 474, "title": "1", "to": 508, "width": 1}, {"from": 474, "title": "1", "to": 788, "width": 1}, {"from": 481, "title": "1", "to": 1029, "width": 1}, {"from": 482, "title": "1", "to": 1147, "width": 1}, {"from": 482, "title": "1", "to": 1220, "width": 1}, {"from": 482, "title": "1", "to": 1087, "width": 1}, {"from": 482, "title": "1", "to": 951, "width": 1}, {"from": 491, "title": "2", "to": 966, "width": 2}, {"from": 491, "title": "1", "to": 875, "width": 1}, {"from": 491, "title": "1", "to": 895, "width": 1}, {"from": 491, "title": "1", "to": 644, "width": 1}, {"from": 491, "title": "1", "to": 492, "width": 1}, {"from": 491, "title": "2", "to": 926, "width": 2}, {"from": 491, "title": "1", "to": 786, "width": 1}, {"from": 492, "title": "1", "to": 926, "width": 1}, {"from": 496, "title": "1", "to": 920, "width": 1}, {"from": 499, "title": "1", "to": 1160, "width": 1}, {"from": 499, "title": "1", "to": 705, "width": 1}, {"from": 508, "title": "1", "to": 788, "width": 1}, {"from": 508, "title": "1", "to": 946, "width": 1}, {"from": 508, "title": "1", "to": 633, "width": 1}, {"from": 508, "title": "1", "to": 655, "width": 1}, {"from": 510, "title": "1", "to": 854, "width": 1}, {"from": 539, "title": "1", "to": 608, "width": 1}, {"from": 539, "title": "1", "to": 561, "width": 1}, {"from": 539, "title": "1", "to": 548, "width": 1}, {"from": 546, "title": "1", "to": 771, "width": 1}, {"from": 547, "title": "1", "to": 666, "width": 1}, {"from": 547, "title": "1", "to": 854, "width": 1}, {"from": 547, "title": "1", "to": 921, "width": 1}, {"from": 548, "title": "1", "to": 756, "width": 1}, {"from": 548, "title": "2", "to": 605, "width": 2}, {"from": 548, "title": "1", "to": 608, "width": 1}, {"from": 548, "title": "1", "to": 561, "width": 1}, {"from": 548, "title": "1", "to": 711, "width": 1}, {"from": 561, "title": "1", "to": 608, "width": 1}, {"from": 564, "title": "1", "to": 608, "width": 1}, {"from": 570, "title": "1", "to": 620, "width": 1}, {"from": 604, "title": "1", "to": 1189, "width": 1}, {"from": 605, "title": "2", "to": 756, "width": 2}, {"from": 605, "title": "1", "to": 711, "width": 1}, {"from": 633, "title": "1", "to": 946, "width": 1}, {"from": 633, "title": "1", "to": 655, "width": 1}, {"from": 636, "title": "1", "to": 913, "width": 1}, {"from": 655, "title": "1", "to": 946, "width": 1}, {"from": 656, "title": "1", "to": 939, "width": 1}, {"from": 660, "title": "1", "to": 963, "width": 1}, {"from": 660, "title": "1", "to": 991, "width": 1}, {"from": 666, "title": "1", "to": 854, "width": 1}, {"from": 666, "title": "1", "to": 921, "width": 1}, {"from": 670, "title": "1", "to": 792, "width": 1}, {"from": 670, "title": "1", "to": 1311, "width": 1}, {"from": 685, "title": "1", "to": 972, "width": 1}, {"from": 741, "title": "1", "to": 946, "width": 1}, {"from": 741, "title": "1", "to": 1262, "width": 1}, {"from": 741, "title": "2", "to": 1029, "width": 2}, {"from": 741, "title": "1", "to": 1309, "width": 1}, {"from": 771, "title": "1", "to": 854, "width": 1}, {"from": 786, "title": "6", "to": 966, "width": 6}, {"from": 786, "title": "1", "to": 939, "width": 1}, {"from": 786, "title": "1", "to": 926, "width": 1}, {"from": 792, "title": "1", "to": 1311, "width": 1}, {"from": 852, "title": "1", "to": 998, "width": 1}, {"from": 854, "title": "1", "to": 921, "width": 1}, {"from": 854, "title": "1", "to": 947, "width": 1}, {"from": 862, "title": "1", "to": 1029, "width": 1}, {"from": 875, "title": "2", "to": 966, "width": 2}, {"from": 875, "title": "1", "to": 895, "width": 1}, {"from": 875, "title": "1", "to": 926, "width": 1}, {"from": 883, "title": "1", "to": 957, "width": 1}, {"from": 895, "title": "1", "to": 966, "width": 1}, {"from": 926, "title": "2", "to": 966, "width": 2}, {"from": 935, "title": "1", "to": 998, "width": 1}, {"from": 946, "title": "1", "to": 1262, "width": 1}, {"from": 951, "title": "1", "to": 1147, "width": 1}, {"from": 951, "title": "1", "to": 1220, "width": 1}, {"from": 951, "title": "1", "to": 1087, "width": 1}, {"from": 963, "title": "1", "to": 991, "width": 1}, {"from": 992, "title": "1", "to": 1113, "width": 1}, {"from": 1041, "title": "1", "to": 1220, "width": 1}, {"from": 1087, "title": "1", "to": 1147, "width": 1}, {"from": 1087, "title": "1", "to": 1220, "width": 1}, {"from": 1147, "title": "1", "to": 1220, "width": 1}]);
// adding nodes and edges to the graph
data = {nodes: nodes, edges: edges};
var options = {"configure": {"enabled": false}, "nodes": {"font": {"size": 7}}, "edges": {"smooth": true, "color": {"opacity": 0.25}}, "physics": {"enabled": true, "forceAtlas2Based": {"springLength": 100}, "solver": "forceAtlas2Based"}};
network = new vis.Network(container, data, options);
network.on("stabilizationProgress", function(params) {
document.getElementById('loadingBar').removeAttribute("style");
var maxWidth = 496;
var minWidth = 20;
var widthFactor = params.iterations/params.total;
var width = Math.max(minWidth,maxWidth * widthFactor);
document.getElementById('bar').style.width = width + 'px';
document.getElementById('text').innerHTML = Math.round(widthFactor*100) + '%';
});
network.once("stabilizationIterationsDone", function() {
document.getElementById('text').innerHTML = '100%';
document.getElementById('bar').style.width = '496px';
document.getElementById('loadingBar').style.opacity = 0;
// really clean the dom element
setTimeout(function () {document.getElementById('loadingBar').style.display = 'none';}, 500);
});
return network;
}
drawGraph();
</script>
</body>
</html>
================================================
FILE: docs/conf.py
================================================
# -*- coding: utf-8 -*-
#
# Configuration file for the Sphinx documentation builder.
#
# This file does only contain a selection of the most common options. For a
# full list see the documentation:
# http://www.sphinx-doc.org/en/master/config
# -- Path setup --------------------------------------------------------------
# If extensions (or modules to document with autodoc) are in another directory,
# add these directories to sys.path here. If the directory is relative to the
# documentation root, use os.path.abspath to make it absolute, like shown here.
#
import os
import sys
sys.path.insert(0, os.path.abspath('..'))
# -- Project information -----------------------------------------------------
project = 'litstudy'
copyright = '2022, S. Heldens, H. Dreuning, A. Sclocco'
author = 'S. Heldens, H. Dreuning, A. Sclocco'
# The short X.Y version
version = ''
# The full version, including alpha/beta/rc tags
release = '0.1'
# -- General configuration ---------------------------------------------------
# If your documentation needs a minimal Sphinx version, state it here.
#
# needs_sphinx = '1.0'
# Add any Sphinx extension module names here, as strings. They can be
# extensions coming with Sphinx (named 'sphinx.ext.*') or your custom
# ones.
extensions = [
'nbsphinx',
'sphinx.ext.autodoc',
'sphinx.ext.githubpages',
'sphinx_mdinclude',
]
# Add any paths that contain templates here, relative to this directory.
templates_path = ['_templates']
# The suffix(es) of source filenames.
# You can specify multiple suffix as a list of string:
#
# source_suffix = ['.rst', '.md']
source_suffix = '.rst'
# The master toctree document.
master_doc = 'index'
# The language for content autogenerated by Sphinx. Refer to documentation
# for a list of supported languages.
#
# This is also used if you do content translation via gettext catalogs.
# Usually you set "language" from the command line for these cases.
language = "english"
# List of patterns, relative to source directory, that match files and
# directories to ignore when looking for source files.
# This pattern also affects html_static_path and html_extra_path.
exclude_patterns = ['_build', 'Thumbs.db', '.DS_Store']
# The name of the Pygments (syntax highlighting) style to use.
pygments_style = None
# -- Options for HTML output -------------------------------------------------
# The theme to use for HTML and HTML Help pages. See the documentation for
# a list of builtin themes.
#
html_theme = 'sphinx_rtd_theme'
# Theme options are theme-specific and customize the look and feel of a theme
# further. For a list of options available for each theme, see the
# documentation.
#
# html_theme_options = {}
# Add any paths that contain custom static files (such as style sheets) here,
# relative to this directory. They are copied after the builtin static files,
# so a file named "default.css" will overwrite the builtin "default.css".
html_static_path = ['_static']
html_extra_path = ['citation.html']
# Custom sidebar templates, must be a dictionary that maps document names
# to template names.
#
# The default sidebars (for documents that don't match any pattern) are
# defined by theme itself. Builtin themes are using these templates by
# default: ``['localtoc.html', 'relations.html', 'sourcelink.html',
# 'searchbox.html']``.
#
# html_sidebars = {}
html_style = "css/style.css"
# -- Options for HTMLHelp output ---------------------------------------------
# Output file base name for HTML help builder.
htmlhelp_basename = 'litstudydoc'
# -- Options for LaTeX output ------------------------------------------------
latex_elements = {
# The paper size ('letterpaper' or 'a4paper').
#
# 'papersize': 'letterpaper',
# The font size ('10pt', '11pt' or '12pt').
#
# 'pointsize': '10pt',
# Additional stuff for the LaTeX preamble.
#
# 'preamble': '',
# Latex figure (float) alignment
#
# 'figure_align': 'htbp',
}
# Grouping the document tree into LaTeX files. List of tuples
# (source start file, target name, title,
# author, documentclass [howto, manual, or own class]).
latex_documents = [
(master_doc, 'litstudy.tex', 'litstudy Documentation',
'S. Heldens, H. Dreuning, A. Sclocco', 'manual'),
]
# -- Options for manual page output ------------------------------------------
# One entry per manual page. List of tuples
# (source start file, name, description, authors, manual section).
man_pages = [
(master_doc, 'litstudy', 'litstudy Documentation',
[author], 1)
]
# -- Options for Texinfo output ----------------------------------------------
# Grouping the document tree into Texinfo files. List of tuples
# (source start file, target name, title, author,
# dir menu entry, description, category)
texinfo_documents = [
(master_doc, 'litstudy', 'litstudy Documentation',
author, 'litstudy', 'One line description of project.',
'Miscellaneous'),
]
# -- Options for Epub output -------------------------------------------------
# Bibliographic Dublin Core info.
epub_title = project
# The unique identifier of the text. This can be a ISBN number
# or the project homepage.
#
# epub_identifier = ''
# A unique identification for the text.
#
# epub_uid = ''
# A list of files that should not be packed into the epub file.
epub_exclude_files = ['search.html']
# -- Extension configuration -------------------------------------------------
autodoc_member_order = 'bysource'
================================================
FILE: docs/faq.rst
================================================
Frequently Asked Questions
==========================
This pages lists answers to several common issues that can occur when working with LitStudy.
If your question is not in this list, please create an issue on the `GitHub issue tracker <https://github.com/NLeSC/litstudy/issues>`_.
How to use Scopus?
---------------------
To use the Scopus API, you will need two things:
* An Elsevier API key obtainable through the `Elsevier Developer Portal <https://dev.elsevier.com/>`_. You or (your institute) must require a Scopus subscription.
* Be connected to the network of your University or Research Institute for which you obtained the API key.
LitStudy will ask for the API key on the first time that it launches.
For more information, see the [guide](https://pybliometrics.readthedocs.io/en/stable/access.html) by pybliometrics.
I'm having trouble connecting to Scopus!
----------------------------------------
LitStudy internally uses the Python package `pybliometrics <https://pybliometrics.readthedocs.io/en/stable/configuration.html>`_ to communicate with the Scopus API.
See the page on `pybliometrics configuration <https://pybliometrics.readthedocs.io/en/stable/configuration.html>`_ for more information.
Alternatively, you can use one of the free alternatives to Scopus (see :doc:`api/sources`) such as, for example, SemanticScholar (``litstudy.search_semanticscholar``) or CrossRef (``litstudy.search_crossref``).
Scopus400Error: ``Exceeds the maximum number allowed for the service level``
----------------------------------------------------------------------------
You Scopus query returns too many results. Please limit your query, for example, by restricting the publication year using ``... AND PUBYEAR > 2020``.
It could also be the case that your Scopus API key is invalid, in which case see `How to use Scopus?`
Scopus401Error: ``The requestor is not authorized to access the requested view or fields of the resource``
----------------------------------------------------------------------------------------------------------
It is likely that your Scopus API key is invalid, in which case see `How to use Scopus?`
My question is not in this list?
--------------------------------
If your question is not in this list, please create a new issue on `GitHub <https://github.com/NLeSC/litstudy/issues/new>`_.
================================================
FILE: docs/index.rst
================================================
.. litstudy documentation master file, created by
sphinx-quickstart on Tue Jan 4 13:31:10 2022.
You can adapt this file completely to your liking, but it should at least
contain the root `toctree` directive.
The LitStudy documentation
====================================
.. mdinclude:: ../README.md
.. toctree::
:maxdepth: 2
:hidden:
:caption: Contents:
Introduction <self>
installation
example
faq
api/index
license
Github repository <https://github.com/NLeSC/litstudy>
Indices and tables
==================
* :ref:`genindex`
* :ref:`modindex`
* :ref:`search`
================================================
FILE: docs/installation.rst
================================================
Installation Guide
==================
litStudy is available on pip! If you have Python installed (version 3.6 or greater), just use the following command to install litstudy.
.. code-block:: bash
pip install litstudy
Jupyter
-------
To use LitStudy from a Jupyter notebook, use the following command:
.. code-block:: bash
pip install notebook
jupyter notebook
Virtual environment
-------------------
It is recommended to use a virtual environment for Python.
We suggest to use `miniconda <https://docs.conda.io/en/latest/miniconda.html>`_.
================================================
FILE: docs/license.rst
================================================
License
=======
.. include:: ../LICENSE
================================================
FILE: docs/make.bat
================================================
@ECHO OFF
pushd %~dp0
REM Command file for Sphinx documentation
if "%SPHINXBUILD%" == "" (
set SPHINXBUILD=sphinx-build
)
set SOURCEDIR=.
set BUILDDIR=_build
if "%1" == "" goto help
%SPHINXBUILD% >NUL 2>NUL
if errorlevel 9009 (
echo.
echo.The 'sphinx-build' command was not found. Make sure you have Sphinx
echo.installed, then set the SPHINXBUILD environment variable to point
echo.to the full path of the 'sphinx-build' executable. Alternatively you
echo.may add the Sphinx directory to PATH.
echo.
echo.If you don't have Sphinx installed, grab it from
echo.http://sphinx-doc.org/
exit /b 1
)
%SPHINXBUILD% -M %1 %SOURCEDIR% %BUILDDIR% %SPHINXOPTS%
goto end
:help
%SPHINXBUILD% -M help %SOURCEDIR% %BUILDDIR% %SPHINXOPTS%
:end
popd
================================================
FILE: litstudy/__init__.py
================================================
from .sources import (
fetch_crossref,
fetch_scopus,
fetch_semanticscholar,
load_bibtex,
load_csv,
load_ieee_csv,
load_ris_file,
load_scopus_csv,
load_springer_csv,
refine_crossref,
refine_scopus,
refine_semanticscholar,
search_arxiv,
search_crossref,
search_dblp,
search_scopus,
search_semanticscholar,
)
from .stats import (
compute_year_histogram,
compute_author_histogram,
compute_author_affiliation_histogram,
compute_language_histogram,
compute_number_authors_histogram,
compute_source_histogram,
compute_source_type_histogram,
compute_affiliation_histogram,
compute_country_histogram,
compute_groups_histogram,
) # noqa: F401
from .plot import (
plot_year_histogram,
plot_author_histogram,
plot_number_authors_histogram,
plot_author_affiliation_histogram,
plot_language_histogram,
plot_source_histogram,
plot_source_type_histogram,
plot_affiliation_histogram,
plot_country_histogram,
plot_continent_histogram,
plot_groups_histogram,
plot_word_distribution,
plot_topic_clouds,
plot_document_topics,
plot_embedding,
) # noqa: F401
from .network import (
build_citation_network,
build_coauthor_network,
build_cocitation_network,
build_coupling_network,
plot_citation_network,
plot_coauthor_network,
plot_cocitation_network,
plot_coupling_network,
plot_network,
) # noqa: F401
from .nlp import (
build_corpus,
train_nmf_model,
train_lda_model,
train_elda_model,
compute_word_distribution,
calculate_embedding,
) # noqa: F401
from .types import (
Document,
DocumentSet,
DocumentIdentifier,
Affiliation,
Author,
) # noqa: F401
__all__ = [
"compute_year_histogram",
"compute_author_histogram",
"compute_author_affiliation_histogram",
"compute_language_histogram",
"compute_number_authors_histogram",
"compute_source_histogram",
"compute_source_type_histogram",
"compute_affiliation_histogram",
"compute_country_histogram",
"compute_groups_histogram",
"plot_year_histogram",
"plot_author_histogram",
"plot_number_authors_histogram",
"plot_author_affiliation_histogram",
"plot_language_histogram",
"plot_source_histogram",
"plot_source_type_histogram",
"plot_affiliation_histogram",
"plot_country_histogram",
"plot_continent_histogram",
"plot_groups_histogram",
"plot_word_distribution",
"plot_topic_clouds",
"plot_document_topics",
"plot_embedding",
"build_citation_network",
"build_coauthor_network",
"build_cocitation_network",
"build_coupling_network",
"plot_citation_network",
"plot_coauthor_network",
"plot_cocitation_network",
"plot_coupling_network",
"plot_network",
"build_corpus",
"train_nmf_model",
"train_lda_model",
"compute_word_distribution",
"calculate_embedding",
"fetch_crossref",
"fetch_scopus",
"fetch_semanticscholar",
"load_bibtex",
"load_csv",
"load_ieee_csv",
"load_ris_file",
"load_springer_csv",
"refine_crossref",
"refine_scopus",
"refine_semanticscholar",
"search_arxiv",
"search_crossref",
"search_dblp",
"search_scopus",
"search_semanticscholar",
"Affiliation",
"Author",
"Document",
"DocumentIdentifier",
"DocumentSet",
]
================================================
FILE: litstudy/clean.py
================================================
from collections import Counter
from .common import canonical
def generate_mapping(tokens, stopwords):
stopwords = set(stopwords)
mapping = dict()
result = dict()
for token, _count in Counter(tokens).most_common():
key = canonical(token, aggresive=True, stopwords=stopwords)
if key not in mapping:
mapping[key] = token
else:
result[token] = mapping[key]
return result
================================================
FILE: litstudy/common.py
================================================
import re
import io
import locale
from codecs import BOM_UTF8, BOM_UTF16_BE, BOM_UTF16_LE
from unidecode import unidecode
try:
from tqdm import tqdm
def progress_bar(it):
return tqdm(it)
except ImportError:
def progress_bar(it):
return it
STOPWORDS = set(
[
"",
"and",
"at",
"for",
"in",
"into",
"of",
"on",
"onto",
"over",
"the",
"to",
"ltd",
"corporation",
"corp",
]
)
def canonical(key, aggresive=True, stopwords=None):
if stopwords is None:
stopwords = STOPWORDS
if aggresive:
key = unidecode(key).lower()
tokens = re.split(r"[\W]+", key)
new_tokens = []
for token in tokens:
if not token or token[0].isdigit():
continue
if aggresive and (token in stopwords or len(token) <= 1):
continue
new_tokens.append(token)
return " ".join(new_tokens)
def fuzzy_match(lhs, rhs):
if lhs is None or rhs is None:
return False
return canonical(lhs) == canonical(rhs)
class FuzzyMatcher:
def __init__(self, initial=None):
mapping = dict()
unmapping = dict()
if initial is not None:
for src, dst in initial.items():
key = canonical(src)
dst_key = canonical(dst)
mapping[dst_key] = key
mapping[key] = key
unmapping[key] = dst
self.mapping = mapping
self.unmapping = unmapping
def get(self, name):
key = canonical(name)
if key in self.mapping:
return self.unmapping[self.mapping[key]]
nice_name = canonical(name, False)
self.mapping[key] = key
self.unmapping[key] = nice_name
return nice_name
def robust_open(path, errors="replace"):
"""This function can be used as a drop-in replacement when using
`with open(path) as f:` to read a file. However, the normal `open` function
is fragile since it attempts to open the file using the default system
character encoding and fails immediately when a character cannot be
decoded. This function is more robust in that it attempts to figure out
the encoding of the given file and ignores decoding errors.
"""
if hasattr(path, "read"):
return path
elif isinstance(path, bytes):
content = path
else:
with open(path, "rb") as f:
content = f.read()
# use the following options:
# - UTF-8 BOM: decode as UTF-8
# - UTF-16 BE BOM: decode as UTF-16-BE
# - UTF-16 LE BOM: decode as UTF-16-LE
# - otherwise, decode as utf-8 with strict errors
# - if that fails, decode using default charset
# - if that fails, decode using utf-8 but ignore errors
if content.startswith(BOM_UTF8):
n = len(BOM_UTF8)
result = content[n:].decode(errors=errors)
elif content.startswith(BOM_UTF16_BE):
n = len(BOM_UTF16_BE)
result = content[n:].decode("utf_16_be", errors=errors)
elif content.startswith(BOM_UTF16_LE):
n = len(BOM_UTF16_LE)
result = content[n:].decode("utf_16_le", errors=errors)
else:
try:
result = content.decode("utf-8", errors="strict")
except UnicodeError:
try:
default_charset = locale.getpreferredencoding()
result = content.decode(default_charset, errors=errors)
except UnicodeError:
result = content.decode("utf-8", errors=errors)
return io.StringIO(result)
================================================
FILE: litstudy/continent.py
================================================
COUNTRY_TO_CONTINENT = {
"afghanistan": "Asia",
"albania": "Europe",
"algeria": "Africa",
"american samoa": "Oceania",
"andorra": "Europe",
"angola": "Africa",
"anguilla": "North America",
"antigua and barbuda": "North America",
"argentina": "South America",
"armenia": "Asia",
"aruba": "North America",
"australia": "Oceania",
"austria": "Europe",
"azerbaijan": "Asia",
"bahamas": "North America",
"bahrain": "Asia",
"bangladesh": "Asia",
"barbados": "North America",
"belarus": "Europe",
"belgium": "Europe",
"belize": "North America",
"benin": "Africa",
"bermuda": "North America",
"bhutan": "Asia",
"bolivia, plurinational state of": "South America",
"bolivia": "South America",
"bonaire, sint eustatius and saba": "North America",
"bonaire": "North America",
"sint eustatius": "North America",
"saba": "North America",
"bosnia and herzegovina": "Europe",
"botswana": "Africa",
"brazil": "South America",
"british indian ocean territory": "Asia",
"brunei darussalam": "Asia",
"bulgaria": "Europe",
"burkina faso": "Africa",
"burundi": "Africa",
"cabo verde": "Africa",
"cambodia": "Asia",
"cameroon": "Africa",
"canada": "North America",
"cayman islands": "North America",
"cayman island": "North America",
"central african republic": "Africa",
"chad": "Africa",
"chile": "South America",
"china": "Asia",
"christmas island": "Asia",
"cocos (keeling) islands": "Asia",
"cocos keeling islands": "Asia",
"cocos islands": "Asia",
"colombia": "South America",
"comoros": "Africa",
"congo": "Africa",
"cook islands": "Oceania",
"costa rica": "North America",
"croatia": "Europe",
"cuba": "North America",
"curaçao": "North America",
"curacao": "North America",
"cyprus": "Asia",
"czechia": "Europe",
"côte d'ivoire": "Africa",
"denmark": "Europe",
"djibouti": "Africa",
"dominica": "North America",
"dominican republic": "North America",
"ecuador": "South America",
"egypt": "Africa",
"el salvador": "North America",
"equatorial guinea": "Africa",
"eritrea": "Africa",
"estonia": "Europe",
"eswatini": "Africa",
"ethiopia": "Africa",
"falkland islands (malvinas)": "South America",
"faroe islands": "Europe",
"fiji": "Oceania",
"finland": "Europe",
"france": "Europe",
"french guiana": "South America",
"french polynesia": "Oceania",
"gabon": "Africa",
"gambia": "Africa",
"georgia": "Asia",
"germany": "Europe",
"ghana": "Africa",
"gibraltar": "Europe",
"greece": "Europe",
"greenland": "North America",
"grenada": "North America",
"guadeloupe": "North America",
"guam": "Oceania",
"guatemala": "North America",
"guernsey": "Europe",
"guinea": "Africa",
"guinea-bissau": "Africa",
"guyana": "South America",
"haiti": "North America",
"honduras": "North America",
"hong kong": "Asia",
"hungary": "Europe",
"iceland": "Europe",
"india": "Asia",
"indonesia": "Asia",
"iran, islamic republic of": "Asia",
"iran": "Asia",
"repulic of
gitextract_v2zn9pxr/
├── .gitattributes
├── .github/
│ └── workflows/
│ ├── cffconvert.yml
│ ├── docs.yml
│ ├── python-action.yml
│ ├── python-app.yml
│ └── python-format.yml
├── .gitignore
├── .zenodo.json
├── CHANGELOG.md
├── CITATION.cff
├── CODE_OF_CONDUCT.md
├── CONTRIBUTING.md
├── LICENSE
├── MANIFEST.in
├── NOTICE
├── README.md
├── docs/
│ ├── Makefile
│ ├── _static/
│ │ ├── citation.html
│ │ └── css/
│ │ └── style.css
│ ├── api/
│ │ ├── index.rst
│ │ ├── network.rst
│ │ ├── nlp.rst
│ │ ├── plot.rst
│ │ ├── sources.rst
│ │ ├── stats.rst
│ │ └── types.rst
│ ├── citation.html
│ ├── conf.py
│ ├── faq.rst
│ ├── index.rst
│ ├── installation.rst
│ ├── license.rst
│ └── make.bat
├── litstudy/
│ ├── __init__.py
│ ├── clean.py
│ ├── common.py
│ ├── continent.py
│ ├── network.py
│ ├── nlp.py
│ ├── plot.py
│ ├── sources/
│ │ ├── __init__.py
│ │ ├── arxiv.py
│ │ ├── bibtex.py
│ │ ├── crossref.py
│ │ ├── csv.py
│ │ ├── dblp.py
│ │ ├── ieee.py
│ │ ├── ris.py
│ │ ├── scopus.py
│ │ ├── scopus_csv.py
│ │ ├── semanticscholar.py
│ │ └── springer.py
│ ├── stats.py
│ ├── stopwords.py
│ └── types.py
├── notebooks/
│ ├── citation.html
│ ├── data/
│ │ ├── exclude.ris
│ │ ├── ieee_1.csv
│ │ ├── ieee_2.csv
│ │ ├── ieee_3.csv
│ │ ├── ieee_4.csv
│ │ ├── ieee_5.csv
│ │ └── springer.csv
│ └── example.ipynb
├── pyproject.toml
├── requirements.txt
├── setup.cfg
├── setup.py
├── sonar-project.properties
└── tests/
├── __init__.py
├── common.py
├── requests/
│ ├── 245f82b3fdc09eaed6a726cd4bddaa2f1565ba90.pickle
│ ├── 4d39f93aa1c9ff4afee9f210b14ade9e5ccf3a58.pickle
│ ├── 4eea59c658fa3076445495dea5554977b85511ff.pickle
│ ├── 5122a6fa38e030c8876096317e7e19aa6534e70a.pickle
│ ├── 54f7b47eb9ceb574f63ec43e8b717364b75b3fa7.pickle
│ ├── 5dec8d884e7221dc8cad8d779c23884c91fde749.pickle
│ ├── 6028198cfd0c1f6c2e2b995ed4802d1c42fb07b2.pickle
│ ├── 6a9fff6a7064528fd44202e78690da248afa23b7.pickle
│ ├── 78a2bca757d42aced207b202458dfd3bf17f0c3d.pickle
│ ├── 7c4b7301a9ccb48f60f360dd28ec6f0dfec9613f.pickle
│ ├── 9b4fc567a80b12bae747c517a4890ce044307aa5.pickle
│ ├── c3c2090c3a0293d71314d226b24f9da74633e092.pickle
│ ├── cfca0170ac37869891777418ee9cf20f17faa581.pickle
│ ├── d1acbf3602743e93bf70589acb072ba87ef3b72b.pickle
│ ├── eeb9079866515efbc22fb670e78f14d11c099a9f.pickle
│ └── ff2a790d6047bbc6bf3ee8d5cc73c47237b95bf8.pickle
├── resources/
│ ├── example.ris
│ ├── ieee.csv
│ ├── retraction_watch.csv
│ ├── scopus.csv
│ └── springer.csv
├── test_common.py
├── test_nlp_corpus.py
├── test_sources_arxiv.py
├── test_sources_crossref.py
├── test_sources_csv.py
├── test_sources_ieee.py
├── test_sources_ris.py
├── test_sources_scopus_csv.py
├── test_sources_semanticscholar.py
└── test_sources_springer.py
SYMBOL INDEX (389 symbols across 29 files)
FILE: litstudy/clean.py
function generate_mapping (line 5) | def generate_mapping(tokens, stopwords):
FILE: litstudy/common.py
function progress_bar (line 10) | def progress_bar(it):
function progress_bar (line 15) | def progress_bar(it):
function canonical (line 40) | def canonical(key, aggresive=True, stopwords=None):
function fuzzy_match (line 62) | def fuzzy_match(lhs, rhs):
class FuzzyMatcher (line 69) | class FuzzyMatcher:
method __init__ (line 70) | def __init__(self, initial=None):
method get (line 86) | def get(self, name):
function robust_open (line 98) | def robust_open(path, errors="replace"):
FILE: litstudy/network.py
function calculate_layout (line 12) | def calculate_layout(g, iterations=1000, gravity=1):
function plot_network (line 31) | def plot_network(
function build_base_network (line 160) | def build_base_network(
function split_kwargs (line 224) | def split_kwargs(*names, **kwargs):
function build_citation_network (line 237) | def build_citation_network(docs: DocumentSet, **kwargs) -> nx.Graph:
function plot_citation_network (line 253) | def plot_citation_network(docs: DocumentSet, **kwargs):
function build_cocitation_network (line 261) | def build_cocitation_network(docs: DocumentSet, *, max_edges=None, **kwa...
function plot_cocitation_network (line 302) | def plot_cocitation_network(docs: DocumentSet, *, max_edges=None, node_s...
function build_coupling_network (line 315) | def build_coupling_network(docs: DocumentSet, max_edges=1000, **kwargs) ...
function plot_coupling_network (line 368) | def plot_coupling_network(docs: DocumentSet, *, max_edges=None, node_siz...
function build_coauthor_network (line 381) | def build_coauthor_network(docs: DocumentSet, *, max_authors=None) -> nx...
function plot_coauthor_network (line 427) | def plot_coauthor_network(docs: DocumentSet, *, max_authors=None, **kwar...
FILE: litstudy/nlp.py
function filter_tokens (line 14) | def filter_tokens(texts, predicate):
function preprocess_remove_short (line 19) | def preprocess_remove_short(texts, min_length=3):
function preprocess_remove_words (line 23) | def preprocess_remove_words(texts, remove_words):
function preprocess_stopwords (line 28) | def preprocess_stopwords(texts):
function preprocess_replace_words (line 32) | def preprocess_replace_words(texts, replace_words):
function preprocess_merge_bigrams (line 37) | def preprocess_merge_bigrams(texts, bigrams):
function preprocess_merge_ngrams (line 56) | def preprocess_merge_ngrams(texts, threshold):
function preprocess_outliers (line 68) | def preprocess_outliers(texts, min_docs, max_docs):
function preprocess_smart_stemming (line 84) | def preprocess_smart_stemming(texts):
class Corpus (line 109) | class Corpus:
method __init__ (line 114) | def __init__(self, docs, filters, max_tokens):
function build_corpus (line 141) | def build_corpus(
class TopicModel (line 213) | class TopicModel:
method __init__ (line 216) | def __init__(self, dictionary, doc2topic, topic2token):
method best_documents_for_topic (line 231) | def best_documents_for_topic(self, topic_id: int, limit=5) -> List[int]:
method document_topics (line 237) | def document_topics(self, doc_id: int):
method best_token_weights_for_topic (line 243) | def best_token_weights_for_topic(self, topic_id: int, limit=5):
method best_tokens_for_topic (line 253) | def best_tokens_for_topic(self, topic_id: int, limit=5):
method best_token_for_topic (line 259) | def best_token_for_topic(self, topic_id: int) -> str:
method best_topic_for_token (line 264) | def best_topic_for_token(self, token) -> int:
method best_topic_for_documents (line 270) | def best_topic_for_documents(self) -> List[int]:
function train_nmf_model (line 277) | def train_nmf_model(corpus: Corpus, num_topics: int, seed=0, max_iter=50...
function train_lda_model (line 309) | def train_lda_model(corpus: Corpus, num_topics, seed=0, **kwargs) -> Top...
function train_elda_model (line 344) | def train_elda_model(corpus: Corpus, num_topics, num_models=4, seed=0, *...
function compute_word_distribution (line 382) | def compute_word_distribution(corpus: Corpus, *, limit=None) -> pd.DataF...
function generate_topic_cloud (line 400) | def generate_topic_cloud(
function calculate_embedding (line 443) | def calculate_embedding(corpus: Corpus, *, rank=2, svd_dims=50, perplexi...
FILE: litstudy/plot.py
function plot_histogram (line 30) | def plot_histogram(
function wrapper (line 161) | def wrapper(docs, fun, default, **kwargs):
function plot_groups_histogram (line 179) | def plot_groups_histogram(docs, **kwargs):
function plot_year_histogram (line 189) | def plot_year_histogram(docs: DocumentSet, **kwargs):
function plot_author_histogram (line 198) | def plot_author_histogram(docs: DocumentSet, **kwargs):
function plot_number_authors_histogram (line 207) | def plot_number_authors_histogram(docs: DocumentSet, **kwargs):
function plot_author_affiliation_histogram (line 216) | def plot_author_affiliation_histogram(docs: DocumentSet, **kwargs):
function plot_language_histogram (line 226) | def plot_language_histogram(docs: DocumentSet, **kwargs):
function plot_source_histogram (line 232) | def plot_source_histogram(docs: DocumentSet, **kwargs):
function plot_source_type_histogram (line 238) | def plot_source_type_histogram(docs: DocumentSet, **kwargs):
function plot_affiliation_histogram (line 248) | def plot_affiliation_histogram(docs: DocumentSet, **kwargs):
function plot_country_histogram (line 257) | def plot_country_histogram(docs: DocumentSet, **kwargs):
function plot_continent_histogram (line 267) | def plot_continent_histogram(docs: DocumentSet, **kwargs):
function plot_word_distribution (line 277) | def plot_word_distribution(corpus: Corpus, *, limit=25, **kwargs):
function plot_embedding (line 287) | def plot_embedding(corpus: Corpus, model: TopicModel, layout=None, ax=No...
function plot_topic_clouds (line 350) | def plot_topic_clouds(model: TopicModel, *, fig=None, ncols=3, **kwargs):
function plot_topic_cloud (line 363) | def plot_topic_cloud(model: TopicModel, topic_id: int, *, ax=None, **kwa...
function plot_document_topics (line 376) | def plot_document_topics(model: TopicModel, document_id: int, *, ax=None):
FILE: litstudy/sources/arxiv.py
class ArXivAuthor (line 9) | class ArXivAuthor(Author):
method __init__ (line 10) | def __init__(self, entry):
method name (line 14) | def name(self):
class ArXivDocument (line 18) | class ArXivDocument(Document):
method __init__ (line 19) | def __init__(self, entry):
method doi (line 28) | def doi(self) -> Optional[str]:
method title (line 32) | def title(self) -> str:
method authors (line 36) | def authors(self) -> List:
method journal_ref (line 40) | def journal_ref(self) -> Optional[str]:
method publication_date (line 44) | def publication_date(self):
method abstract (line 49) | def abstract(self) -> Optional[str]:
method language (line 53) | def language(self) -> Optional[str]:
method category (line 57) | def category(self) -> Optional[List[str]]:
function search_arxiv (line 66) | def search_arxiv(
FILE: litstudy/sources/bibtex.py
function find_doi (line 37) | def find_doi(entry):
class BibDocument (line 75) | class BibDocument(Document):
method __init__ (line 76) | def __init__(self, entry):
method key (line 87) | def key(self) -> str:
method title (line 91) | def title(self) -> str:
method authors (line 95) | def authors(self):
method publisher (line 113) | def publisher(self):
method language (line 117) | def language(self):
method publication_date (line 121) | def publication_date(self):
method publication_year (line 131) | def publication_year(self):
method publication_month (line 144) | def publication_month(self):
method publication_source (line 149) | def publication_source(self):
method keywords (line 161) | def keywords(self):
method abstract (line 169) | def abstract(self):
class BibAuthor (line 173) | class BibAuthor(Author):
method __init__ (line 174) | def __init__(self, name):
method name (line 178) | def name(self):
method __repr__ (line 181) | def __repr__(self):
function load_bibtex (line 185) | def load_bibtex(path: str) -> DocumentSet:
FILE: litstudy/sources/crossref.py
class CrossRefAuthor (line 14) | class CrossRefAuthor(Author):
method __init__ (line 15) | def __init__(self, entry):
method name (line 19) | def name(self):
method orcid (line 29) | def orcid(self):
method affiliations (line 33) | def affiliations(self):
class CrossRefAffiliation (line 41) | class CrossRefAffiliation(Affiliation):
method __init__ (line 42) | def __init__(self, entry):
method name (line 46) | def name(self) -> str:
function _extract_title (line 50) | def _extract_title(entry):
class CrossRefDocument (line 60) | class CrossRefDocument(Document):
method __init__ (line 61) | def __init__(self, entry):
method title (line 69) | def title(self) -> str:
method authors (line 73) | def authors(self):
method publisher (line 78) | def publisher(self):
method language (line 82) | def language(self):
method publication_date (line 86) | def publication_date(self):
method publication_year (line 96) | def publication_year(self):
method publication_source (line 103) | def publication_source(self):
method abstract (line 111) | def abstract(self):
method citation_count (line 115) | def citation_count(self):
method references (line 122) | def references(self):
method __repr__ (line 134) | def __repr__(self):
method load (line 138) | def load(doi):
function fetch_crossref (line 146) | def fetch_crossref(doi: str, *, timeout=0.5, session=None) -> Optional[D...
function refine_crossref (line 196) | def refine_crossref(
function _fetch_dois (line 219) | def _fetch_dois(params: dict, timeout: float, limit: int, session):
function search_crossref (line 259) | def search_crossref(
FILE: litstudy/sources/csv.py
class CsvAuthor (line 8) | class CsvAuthor(Author):
method __init__ (line 9) | def __init__(self, name):
method name (line 13) | def name(self):
class CsvDocument (line 17) | class CsvDocument(Document):
method __init__ (line 18) | def __init__(self, record, fields):
method __getitem__ (line 25) | def __getitem__(self, key):
method __setitem__ (line 28) | def __setitem__(self, key, value):
method __iter__ (line 31) | def __iter__(self):
method _field (line 34) | def _field(self, field_name):
method title (line 39) | def title(self):
method abstract (line 43) | def abstract(self):
method publication_source (line 47) | def publication_source(self):
method language (line 51) | def language(self):
method publisher (line 55) | def publisher(self):
method citation_count (line 59) | def citation_count(self):
method keywords (line 66) | def keywords(self):
method publication_date (line 79) | def publication_date(self):
method publication_year (line 127) | def publication_year(self):
method authors (line 135) | def authors(self):
function find_field (line 151) | def find_field(columns, possible_names):
function load_csv (line 161) | def load_csv(
FILE: litstudy/sources/dblp.py
class DBLPDocument (line 7) | class DBLPDocument(Document):
method __init__ (line 8) | def __init__(self, entry, authors):
method title (line 16) | def title(self):
method publication_year (line 20) | def publication_year(self):
method publication_type (line 27) | def publication_type(self):
method publication_source (line 31) | def publication_source(self):
method publisher (line 35) | def publisher(self):
method authors (line 39) | def authors(self):
method __repr__ (line 42) | def __repr__(self):
class DBLPAuthor (line 46) | class DBLPAuthor(Author):
method __init__ (line 47) | def __init__(self, pid, name):
method pid (line 52) | def pid(self):
method name (line 56) | def name(self):
method __repr__ (line 59) | def __repr__(self):
function process_authors (line 63) | def process_authors(entry, author_cache):
function search_dblp (line 100) | def search_dblp(query: str, *, limit=None) -> DocumentSet:
FILE: litstudy/sources/ieee.py
class IEEEDocument (line 7) | class IEEEDocument(Document):
method __init__ (line 8) | def __init__(self, entry):
method title (line 16) | def title(self) -> str:
method authors (line 20) | def authors(self):
method affiliations (line 41) | def affiliations(self):
method publisher (line 46) | def publisher(self):
method publication_year (line 50) | def publication_year(self):
method keywords (line 57) | def keywords(self):
method abstract (line 77) | def abstract(self):
method citation_count (line 81) | def citation_count(self):
class IEEEAffiliation (line 88) | class IEEEAffiliation(Affiliation):
method __init__ (line 89) | def __init__(self, name):
method name (line 93) | def name(self):
class IEEEAuthor (line 97) | class IEEEAuthor(Author):
method __init__ (line 98) | def __init__(self, name, affiliation):
method name (line 103) | def name(self):
method affiliations (line 107) | def affiliations(self):
function load_ieee_csv (line 115) | def load_ieee_csv(path: str) -> DocumentSet:
FILE: litstudy/sources/ris.py
function extract_title (line 6) | def extract_title(attr):
class RISDocument (line 10) | class RISDocument(Document):
method __init__ (line 11) | def __init__(self, attr, keywords, authors):
method title (line 21) | def title(self) -> str:
method authors (line 25) | def authors(self):
method affiliations (line 29) | def affiliations(self):
method publisher (line 33) | def publisher(self):
method language (line 37) | def language(self):
method publication_year (line 41) | def publication_year(self):
method publication_source (line 48) | def publication_source(self):
method keywords (line 52) | def keywords(self):
method abstract (line 56) | def abstract(self):
class RISAuthor (line 60) | class RISAuthor(Author):
method __init__ (line 61) | def __init__(self, name):
method name (line 65) | def name(self):
function load_ris_file (line 69) | def load_ris_file(path: str) -> DocumentSet:
FILE: litstudy/sources/scopus.py
class ScopusAuthor (line 14) | class ScopusAuthor(Author):
method __init__ (line 15) | def __init__(self, name, affiliations):
method name (line 20) | def name(self):
method affiliations (line 24) | def affiliations(self):
class ScopusAffiliation (line 28) | class ScopusAffiliation(Affiliation):
method __init__ (line 29) | def __init__(self, affiliation):
method name (line 33) | def name(self) -> str:
method country (line 37) | def country(self):
method __repr__ (line 40) | def __repr__(self):
class ScopusDocument (line 44) | class ScopusDocument(Document):
method from_identifier (line 46) | def from_identifier(id, id_type, view="FULL"):
method from_eid (line 63) | def from_eid(eid, **kwargs):
method from_doi (line 67) | def from_doi(doi, **kwargs):
method __init__ (line 70) | def __init__(self, doc):
method title (line 82) | def title(self):
method authors (line 86) | def authors(self):
method publisher (line 103) | def publisher(self):
method language (line 107) | def language(self):
method keywords (line 111) | def keywords(self):
method abstract (line 115) | def abstract(self):
method citation_count (line 119) | def citation_count(self):
method references (line 125) | def references(self):
method publication_source (line 143) | def publication_source(self):
method source_type (line 147) | def source_type(self):
method publication_date (line 151) | def publication_date(self):
method __repr__ (line 165) | def __repr__(self):
function fetch_scopus (line 169) | def fetch_scopus(key: str) -> Optional[Document]:
function search_scopus (line 181) | def search_scopus(query: str, *, limit: int = None) -> DocumentSet:
function refine_scopus (line 204) | def refine_scopus(docs: DocumentSet, *, search_title=True) -> Tuple[Docu...
FILE: litstudy/sources/scopus_csv.py
class ScopusCsvAffiliation (line 11) | class ScopusCsvAffiliation(Affiliation):
method __init__ (line 12) | def __init__(self, name):
method name (line 16) | def name(self):
class ScopusCsvAuthor (line 20) | class ScopusCsvAuthor(Author):
method __init__ (line 21) | def __init__(self, name, affiliation):
method name (line 26) | def name(self):
method affiliations (line 30) | def affiliations(self):
class ScopusCsvDocument (line 34) | class ScopusCsvDocument(Document):
method __init__ (line 35) | def __init__(self, entry):
method title (line 45) | def title(self) -> Optional[str]:
method authors (line 49) | def authors(self) -> List[ScopusCsvAuthor]:
method publisher (line 65) | def publisher(self) -> Optional[str]:
method publication_year (line 69) | def publication_year(self) -> Optional[int]:
method keywords (line 80) | def keywords(self) -> Optional[List[str]]:
method abstract (line 87) | def abstract(self) -> Optional[str]:
method citation_count (line 94) | def citation_count(self) -> Optional[int]:
method language (line 101) | def language(self) -> Optional[str]:
method publication_source (line 105) | def publication_source(self) -> Optional[str]:
method source_type (line 109) | def source_type(self) -> Optional[str]:
function load_scopus_csv (line 113) | def load_scopus_csv(path: str) -> DocumentSet:
FILE: litstudy/sources/semanticscholar.py
function extract_id (line 12) | def extract_id(item):
function extract_ids (line 24) | def extract_ids(items):
class ScholarAuthor (line 31) | class ScholarAuthor(Author):
method __init__ (line 32) | def __init__(self, entry):
method name (line 36) | def name(self):
method orcid (line 40) | def orcid(self):
class ScholarDocument (line 44) | class ScholarDocument(Document):
method __init__ (line 45) | def __init__(self, entry):
method title (line 50) | def title(self) -> str:
method authors (line 54) | def authors(self):
method publication_year (line 62) | def publication_year(self):
method publication_source (line 66) | def publication_source(self):
method abstract (line 70) | def abstract(self):
method citations (line 74) | def citations(self):
method citation_count (line 78) | def citation_count(self):
method references (line 82) | def references(self):
method __repr__ (line 85) | def __repr__(self):
method load (line 89) | def load(id):
function request_query (line 99) | def request_query(query, offset, limit, cache, session, timeout=DEFAULT_...
function request_paper (line 117) | def request_paper(key, cache, session, timeout=DEFAULT_TIMEOUT):
function fetch_semanticscholar (line 139) | def fetch_semanticscholar(key: set, *, session=None) -> Optional[Document]:
function refine_semanticscholar (line 185) | def refine_semanticscholar(docs: DocumentSet, *, session=None) -> Tuple[...
function search_semanticscholar (line 204) | def search_semanticscholar(
FILE: litstudy/sources/springer.py
class SpringerDocument (line 6) | class SpringerDocument(Document):
method __init__ (line 7) | def __init__(self, entry):
method title (line 15) | def title(self) -> str:
method authors (line 19) | def authors(self):
method publisher (line 27) | def publisher(self):
method publication_year (line 31) | def publication_year(self):
function load_springer_csv (line 38) | def load_springer_csv(path: str) -> DocumentSet:
FILE: litstudy/stats.py
function compute_histogram (line 7) | def compute_histogram(docs, fun, keys=None, sort_by_key=False, groups=No...
function compute_groups_histogram (line 70) | def compute_groups_histogram(docs: DocumentSet, **kwargs) -> pd.DataFrame:
function compute_year_histogram (line 74) | def compute_year_histogram(docs: DocumentSet, **kwargs) -> pd.DataFrame:
function compute_number_authors_histogram (line 88) | def compute_number_authors_histogram(docs: DocumentSet, max_authors=10, ...
function compute_language_histogram (line 108) | def compute_language_histogram(docs: DocumentSet, **kwargs) -> pd.DataFr...
function default_mapper (line 118) | def default_mapper(mapper):
function compute_source_histogram (line 127) | def compute_source_histogram(docs: DocumentSet, mapper=None, **kwargs) -...
function compute_source_type_histogram (line 138) | def compute_source_type_histogram(docs: DocumentSet, **kwargs) -> pd.Dat...
function compute_author_histogram (line 147) | def compute_author_histogram(docs: DocumentSet, **kwargs) -> pd.DataFrame:
function compute_author_affiliation_histogram (line 157) | def compute_author_affiliation_histogram(docs: DocumentSet, **kwargs) ->...
function compute_affiliation_histogram (line 171) | def compute_affiliation_histogram(docs: DocumentSet, mapper=None, **kwar...
function extract_country (line 187) | def extract_country(aff):
function compute_country_histogram (line 205) | def compute_country_histogram(docs: DocumentSet, **kwargs) -> pd.DataFrame:
function compute_continent_histogram (line 221) | def compute_continent_histogram(docs: DocumentSet, **kwargs) -> pd.DataF...
FILE: litstudy/types.py
class DocumentSet (line 12) | class DocumentSet:
method __init__ (line 27) | def __init__(self, docs, data=None):
method _refine_docs (line 46) | def _refine_docs(self, callback):
method add_property (line 71) | def add_property(self, name: str, values) -> "DocumentSet":
method remove_property (line 83) | def remove_property(self, name: str) -> "DocumentSet":
method filter_docs (line 93) | def filter_docs(self, predicate) -> "DocumentSet":
method filter (line 101) | def filter(self, predicate) -> "DocumentSet":
method select (line 116) | def select(self, indices) -> "DocumentSet":
method _intersect_indices (line 130) | def _intersect_indices(self, other):
method _zip_with (line 146) | def _zip_with(self, left, other, right):
method intersect (line 164) | def intersect(self, other: "DocumentSet") -> "DocumentSet":
method difference (line 179) | def difference(self, other: "DocumentSet") -> "DocumentSet":
method union (line 191) | def union(self, other: "DocumentSet") -> "DocumentSet":
method concat (line 217) | def concat(self, other: "DocumentSet") -> "DocumentSet":
method unique (line 261) | def unique(self) -> "DocumentSet":
method sample (line 283) | def sample(self, n, seed=0) -> "DocumentSet":
method itertuples (line 297) | def itertuples(self):
method __or__ (line 303) | def __or__(self, other):
method __and__ (line 307) | def __and__(self, other):
method __add__ (line 311) | def __add__(self, other):
method __sub__ (line 315) | def __sub__(self, other):
method __len__ (line 319) | def __len__(self):
method __getitem__ (line 323) | def __getitem__(self, key):
method __iter__ (line 337) | def __iter__(self):
method __bool__ (line 341) | def __bool__(self):
method __repr__ (line 344) | def __repr__(self):
class DocumentIdentifier (line 348) | class DocumentIdentifier:
method __init__ (line 358) | def __init__(self, title, **attr):
method title (line 364) | def title(self) -> Optional[str]:
method doi (line 369) | def doi(self) -> Optional[str]:
method pubmed (line 374) | def pubmed(self) -> Optional[str]:
method arxivid (line 379) | def arxivid(self) -> Optional[str]:
method scopusid (line 384) | def scopusid(self) -> Optional[str]:
method s2id (line 389) | def s2id(self) -> Optional[str]:
method matches (line 393) | def matches(self, other: "DocumentIdentifier") -> bool:
method merge (line 417) | def merge(self, other) -> "DocumentIdentifier":
method __repr__ (line 426) | def __repr__(self):
class Document (line 430) | class Document(ABC):
method __init__ (line 438) | def __init__(self, identifier: DocumentIdentifier):
method id (line 442) | def id(self) -> DocumentIdentifier:
method title (line 448) | def title(self) -> str:
method authors (line 454) | def authors(self) -> Optional[List["Author"]]:
method affiliations (line 459) | def affiliations(self) -> Optional[List["Affiliation"]]:
method publisher (line 478) | def publisher(self) -> Optional[str]:
method language (line 483) | def language(self) -> Optional[str]:
method publication_date (line 488) | def publication_date(self) -> Optional[date]:
method publication_year (line 493) | def publication_year(self) -> Optional[int]:
method publication_source (line 501) | def publication_source(self) -> Optional[str]:
method source_type (line 508) | def source_type(self) -> Optional[str]:
method keywords (line 515) | def keywords(self) -> Optional[List[str]]:
method abstract (line 523) | def abstract(self) -> Optional[str]:
method citation_count (line 528) | def citation_count(self) -> Optional[int]:
method references (line 533) | def references(self) -> Optional[List[DocumentIdentifier]]:
method citations (line 538) | def citations(self) -> Optional[List[DocumentIdentifier]]:
method mentions (line 542) | def mentions(self, term: str) -> bool:
class Affiliation (line 557) | class Affiliation(ABC):
method name (line 562) | def name(self) -> str:
method city (line 567) | def city(self) -> Optional[str]:
method country (line 572) | def country(self) -> Optional[str]:
class Author (line 577) | class Author(ABC):
method name (line 582) | def name(self) -> str:
method orcid (line 587) | def orcid(self) -> Optional[str]:
method s2id (line 592) | def s2id(self) -> Optional[str]:
method affiliations (line 597) | def affiliations(self) -> "Optional[list[Affiliation]]":
class DocumentMapping (line 602) | class DocumentMapping:
method __init__ (line 603) | def __init__(self, docs=None):
method add (line 612) | def add(self, doc: DocumentIdentifier, value):
method get (line 622) | def get(self, doc: DocumentIdentifier):
FILE: tests/common.py
class MockResponse (line 9) | class MockResponse:
method __init__ (line 10) | def __init__(self, data):
method status_code (line 14) | def status_code(self):
method content (line 18) | def content(self):
method json (line 21) | def json(self):
class MockSession (line 25) | class MockSession:
method __init__ (line 26) | def __init__(self, directory=None, allow_requests=None):
method _clean_url (line 36) | def _clean_url(self, url):
method get (line 39) | def get(self, url):
class ExampleDocument (line 60) | class ExampleDocument(Document):
method __init__ (line 61) | def __init__(self, id: DocumentIdentifier):
method title (line 65) | def title(self):
method authors (line 69) | def authors(self):
function example_docs (line 73) | def example_docs() -> DocumentSet:
FILE: tests/test_common.py
function test_robust_open (line 5) | def test_robust_open():
FILE: tests/test_nlp_corpus.py
function test_build_corpus_should_instantiate_Corpus (line 6) | def test_build_corpus_should_instantiate_Corpus():
function test_build_corpus_should_filter_words (line 16) | def test_build_corpus_should_filter_words():
FILE: tests/test_sources_arxiv.py
function test_arxiv_query (line 4) | def test_arxiv_query():
FILE: tests/test_sources_crossref.py
function test_fetch_crossref (line 5) | def test_fetch_crossref():
function test_search_crossref (line 14) | def test_search_crossref():
FILE: tests/test_sources_csv.py
function test_load_ieee_csv (line 5) | def test_load_ieee_csv():
function test_load_springer_csv (line 25) | def test_load_springer_csv():
function test_load_scopus_csv (line 35) | def test_load_scopus_csv():
function test_load_retraction_watch_csv (line 52) | def test_load_retraction_watch_csv():
FILE: tests/test_sources_ieee.py
function test_load_ieee_csv (line 5) | def test_load_ieee_csv():
FILE: tests/test_sources_ris.py
function test_load_ris_file (line 5) | def test_load_ris_file():
FILE: tests/test_sources_scopus_csv.py
function test_load_scopus_csv (line 5) | def test_load_scopus_csv():
FILE: tests/test_sources_semanticscholar.py
function test_load_s2_file (line 9) | def test_load_s2_file():
function test_fetch_semanticscholar (line 19) | def test_fetch_semanticscholar():
function test_refine_semanticscholar (line 41) | def test_refine_semanticscholar():
FILE: tests/test_sources_springer.py
function test_load_springer_csv (line 5) | def test_load_springer_csv():
Condensed preview — 102 files, each showing path, character count, and a content snippet. Download the .json file or copy for the full structured content (3,790K chars).
[
{
"path": ".gitattributes",
"chars": 31,
"preview": "*.ipynb linguist-documentation\n"
},
{
"path": ".github/workflows/cffconvert.yml",
"chars": 410,
"preview": "name: cffconvert\n\non:\n push:\n paths:\n - CITATION.cff\n\njobs:\n validate:\n name: \"validate\"\n runs-on: ubunt"
},
{
"path": ".github/workflows/docs.yml",
"chars": 1514,
"preview": "# This is a basic workflow to help you get started with Actions\nname: Build documentation\n\n# Controls when the workflow "
},
{
"path": ".github/workflows/python-action.yml",
"chars": 1174,
"preview": "# This workflow will install Python dependencies, run tests and lint with a single version of Python\n# For more informat"
},
{
"path": ".github/workflows/python-app.yml",
"chars": 1035,
"preview": "# This workflow will install Python dependencies, run tests and lint with a single version of Python\n# For more informat"
},
{
"path": ".github/workflows/python-format.yml",
"chars": 299,
"preview": "name: Lint with black\n\non: [push, pull_request]\n\njobs:\n lint:\n runs-on: ubuntu-latest\n steps:\n - uses: actio"
},
{
"path": ".gitignore",
"chars": 1295,
"preview": "# Byte-compiled / optimized / DLL files\n__pycache__/\n*.py[cod]\n*$py.class\n\n# C extensions\n*.so\n\n# Distribution / packagi"
},
{
"path": ".zenodo.json",
"chars": 222,
"preview": "{\n \"creators\": [\n {\n \"name\": \"Heldens, S\",\n \"orcid\": \"0000-0001-8792-6305\"\n }\n "
},
{
"path": "CHANGELOG.md",
"chars": 2232,
"preview": "# Changelog\nAll notable changes to this project will be documented in this file.\n\nThe format is based on [Keep a Changel"
},
{
"path": "CITATION.cff",
"chars": 1013,
"preview": "# This CITATION.cff file was generated with cffinit.\n# Visit https://bit.ly/cffinit to generate yours today!\n\ncff-versio"
},
{
"path": "CODE_OF_CONDUCT.md",
"chars": 3213,
"preview": "# Contributor Covenant Code of Conduct\n\n## Our Pledge\n\nIn the interest of fostering an open and welcoming environment, w"
},
{
"path": "CONTRIBUTING.md",
"chars": 3213,
"preview": "# Contributing guidelines\n\nWe welcome any kind of contribution to our software, from simple comment or question to a ful"
},
{
"path": "LICENSE",
"chars": 11357,
"preview": " Apache License\n Version 2.0, January 2004\n "
},
{
"path": "MANIFEST.in",
"chars": 70,
"preview": "include CITATION.cff\ninclude LICENSE\ninclude NOTICE\ninclude README.md\n"
},
{
"path": "NOTICE",
"chars": 83,
"preview": "This product includes litstudy, software developed by\nNetherlands eScience Center.\n"
},
{
"path": "README.md",
"chars": 6403,
"preview": "# LitStudy\n\n\n\n[![github"
},
{
"path": "docs/Makefile",
"chars": 580,
"preview": "# Minimal makefile for Sphinx documentation\n#\n\n# You can set these variables from the command line.\nSPHINXOPTS =\nSPHI"
},
{
"path": "docs/_static/citation.html",
"chars": 68637,
"preview": "<html>\n<head>\n<link rel=\"stylesheet\" href=\"https://cdnjs.cloudflare.com/ajax/libs/vis/4.16.1/vis.css\" type=\"text/css\" />"
},
{
"path": "docs/_static/css/style.css",
"chars": 288,
"preview": "@import 'theme.css';\n\nhtml.writer-html4 .rst-content dl:not(.docutils) .property,\nhtml.writer-html5 .rst-content dl[clas"
},
{
"path": "docs/api/index.rst",
"chars": 1016,
"preview": "API reference\n====================================\n\nThis page provides the API documentation of litstudy.\nAll public fun"
},
{
"path": "docs/api/network.rst",
"chars": 105,
"preview": "Network Analysis\n------------------------------------------\n.. automodule:: litstudy.network\n :members:\n"
},
{
"path": "docs/api/nlp.rst",
"chars": 104,
"preview": "Language Processing\n------------------------------------------\n.. automodule:: litstudy.nlp\n :members:\n"
},
{
"path": "docs/api/plot.rst",
"chars": 105,
"preview": "Plotting Statistics\n------------------------------------------\n.. automodule:: litstudy.plot\n :members:\n"
},
{
"path": "docs/api/sources.rst",
"chars": 917,
"preview": "Literature Databases\n====================\n\n\nScopus\n------\n.. automodule:: litstudy\n :members: search_scopus, refine_sco"
},
{
"path": "docs/api/stats.rst",
"chars": 109,
"preview": "Calculating Statistics\n------------------------------------------\n.. automodule:: litstudy.stats\n :members:\n"
},
{
"path": "docs/api/types.rst",
"chars": 688,
"preview": "Data Types\n------------------------------------------\n\nThere are two core datatypes in litstudy: `Document` and `Documen"
},
{
"path": "docs/citation.html",
"chars": 68637,
"preview": "<html>\n<head>\n<link rel=\"stylesheet\" href=\"https://cdnjs.cloudflare.com/ajax/libs/vis/4.16.1/vis.css\" type=\"text/css\" />"
},
{
"path": "docs/conf.py",
"chars": 5493,
"preview": "# -*- coding: utf-8 -*-\n#\n# Configuration file for the Sphinx documentation builder.\n#\n# This file does only contain a s"
},
{
"path": "docs/faq.rst",
"chars": 2343,
"preview": "Frequently Asked Questions\n==========================\n\nThis pages lists answers to several common issues that can occur "
},
{
"path": "docs/index.rst",
"chars": 616,
"preview": ".. litstudy documentation master file, created by\n sphinx-quickstart on Tue Jan 4 13:31:10 2022.\n You can adapt thi"
},
{
"path": "docs/installation.rst",
"chars": 564,
"preview": "Installation Guide\n==================\n\nlitStudy is available on pip! If you have Python installed (version 3.6 or greate"
},
{
"path": "docs/license.rst",
"chars": 41,
"preview": "License\n=======\n\n.. include:: ../LICENSE\n"
},
{
"path": "docs/make.bat",
"chars": 787,
"preview": "@ECHO OFF\r\n\r\npushd %~dp0\r\n\r\nREM Command file for Sphinx documentation\r\n\r\nif \"%SPHINXBUILD%\" == \"\" (\r\n\tset SPHINXBUILD=sp"
},
{
"path": "litstudy/__init__.py",
"chars": 3445,
"preview": "from .sources import (\n fetch_crossref,\n fetch_scopus,\n fetch_semanticscholar,\n load_bibtex,\n load_csv,\n "
},
{
"path": "litstudy/clean.py",
"chars": 441,
"preview": "from collections import Counter\nfrom .common import canonical\n\n\ndef generate_mapping(tokens, stopwords):\n stopwords ="
},
{
"path": "litstudy/common.py",
"chars": 3639,
"preview": "import re\nimport io\nimport locale\nfrom codecs import BOM_UTF8, BOM_UTF16_BE, BOM_UTF16_LE\nfrom unidecode import unidecod"
},
{
"path": "litstudy/continent.py",
"chars": 7804,
"preview": "COUNTRY_TO_CONTINENT = {\n \"afghanistan\": \"Asia\",\n \"albania\": \"Europe\",\n \"algeria\": \"Africa\",\n \"american samo"
},
{
"path": "litstudy/network.py",
"chars": 12345,
"preview": "from .types import DocumentMapping, DocumentSet\nfrom collections import defaultdict\nfrom matplotlib.colors import to_hex"
},
{
"path": "litstudy/nlp.py",
"chars": 14853,
"preview": "from collections import defaultdict\nfrom gensim.matutils import corpus2dense\nfrom typing import List\nimport gensim\nimpor"
},
{
"path": "litstudy/plot.py",
"chars": 11826,
"preview": "from .stats import (\n compute_year_histogram,\n compute_author_histogram,\n compute_author_affiliation_histogram,"
},
{
"path": "litstudy/sources/__init__.py",
"chars": 894,
"preview": "from .scopus import search_scopus, refine_scopus, fetch_scopus\nfrom .bibtex import load_bibtex\nfrom .semanticscholar imp"
},
{
"path": "litstudy/sources/arxiv.py",
"chars": 3208,
"preview": "from litstudy.types import Document, DocumentSet, DocumentIdentifier, Author\nfrom typing import Optional, List\nimport fe"
},
{
"path": "litstudy/sources/bibtex.py",
"chars": 4894,
"preview": "from ..types import Document, DocumentSet, DocumentIdentifier, Author\nfrom ..common import robust_open\n\n# from bibtexpar"
},
{
"path": "litstudy/sources/crossref.py",
"chars": 8143,
"preview": "from ..common import progress_bar\nfrom datetime import date\nfrom time import sleep\nfrom typing import Tuple, Optional\nfr"
},
{
"path": "litstudy/sources/csv.py",
"chars": 9111,
"preview": "import csv\nimport datetime\n\nfrom ..types import Author, Document, DocumentSet, DocumentIdentifier\nfrom ..common import r"
},
{
"path": "litstudy/sources/dblp.py",
"chars": 3524,
"preview": "from ..types import Document, DocumentSet, DocumentIdentifier, Author\nimport requests\nimport shelve\nimport logging\n\n\ncla"
},
{
"path": "litstudy/sources/ieee.py",
"chars": 3486,
"preview": "from ..types import Document, Author, DocumentSet, DocumentIdentifier, Affiliation\nfrom ..common import robust_open\nimpo"
},
{
"path": "litstudy/sources/ris.py",
"chars": 2679,
"preview": "from ..types import Document, Author, DocumentSet, DocumentIdentifier\nfrom ..common import robust_open\nimport logging\n\n\n"
},
{
"path": "litstudy/sources/scopus.py",
"chars": 6794,
"preview": "from ..common import progress_bar, canonical\nfrom ..types import Document, DocumentSet, DocumentIdentifier, Author, Affi"
},
{
"path": "litstudy/sources/scopus_csv.py",
"chars": 3462,
"preview": "\"\"\"\nsupport loading Scopus CSV export.\n\"\"\"\n\nfrom typing import List, Optional\nfrom ..types import Document, Author, Docu"
},
{
"path": "litstudy/sources/semanticscholar.py",
"chars": 7279,
"preview": "from time import sleep\nfrom typing import Tuple, Optional\nfrom urllib.parse import urlencode, quote_plus\nimport logging\n"
},
{
"path": "litstudy/sources/springer.py",
"chars": 1251,
"preview": "import csv\nfrom ..types import Document, DocumentSet, DocumentIdentifier\nfrom ..common import robust_open\n\n\nclass Spring"
},
{
"path": "litstudy/stats.py",
"chars": 7458,
"preview": "from .common import FuzzyMatcher\nfrom collections import defaultdict, OrderedDict\nfrom .types import DocumentSet\nimport "
},
{
"path": "litstudy/stopwords.py",
"chars": 5816,
"preview": "STOPWORDS = [\n \"'d\",\n \"'ll\",\n \"'m\",\n \"'re\",\n \"'s\",\n \"'ve\",\n \"a\",\n \"about\",\n \"above\",\n \"ach"
},
{
"path": "litstudy/types.py",
"chars": 19278,
"preview": "from abc import ABC, abstractmethod\nfrom datetime import date\nfrom typing import Optional, List\nimport numpy as np\nimpor"
},
{
"path": "notebooks/citation.html",
"chars": 68612,
"preview": "<html>\n<head>\n<link rel=\"stylesheet\" href=\"https://cdnjs.cloudflare.com/ajax/libs/vis/4.16.1/vis.css\" type=\"text/css\" />"
},
{
"path": "notebooks/data/exclude.ris",
"chars": 515,
"preview": "TY - CONF\r\nTI - Integral image computation on GPU\r\nT2 - 10th International Multi-Conferences on Systems, Signals & De"
},
{
"path": "notebooks/data/ieee_1.csv",
"chars": 247973,
"preview": "\"Document Title\",Authors,\"Author Affiliations\",\"Publication Title\",Date Added To Xplore,\"Publication Year\",\"Volume\",\"Iss"
},
{
"path": "notebooks/data/ieee_2.csv",
"chars": 244883,
"preview": "\"Document Title\",Authors,\"Author Affiliations\",\"Publication Title\",Date Added To Xplore,\"Publication Year\",\"Volume\",\"Iss"
},
{
"path": "notebooks/data/ieee_3.csv",
"chars": 245181,
"preview": "\"Document Title\",Authors,\"Author Affiliations\",\"Publication Title\",Date Added To Xplore,\"Publication Year\",\"Volume\",\"Iss"
},
{
"path": "notebooks/data/ieee_4.csv",
"chars": 239436,
"preview": "\"Document Title\",Authors,\"Author Affiliations\",\"Publication Title\",Date Added To Xplore,\"Publication Year\",\"Volume\",\"Iss"
},
{
"path": "notebooks/data/ieee_5.csv",
"chars": 98254,
"preview": "\"Document Title\",Authors,\"Author Affiliations\",\"Publication Title\",Date Added To Xplore,\"Publication Year\",\"Volume\",\"Iss"
},
{
"path": "notebooks/data/springer.csv",
"chars": 295395,
"preview": "Item Title,Publication Title,Book Series Title,Journal Volume,Journal Issue,Item DOI,Authors,Publication Year,URL,Conten"
},
{
"path": "notebooks/example.ipynb",
"chars": 1221763,
"preview": "{\n \"cells\": [\n {\n \"cell_type\": \"markdown\",\n \"metadata\": {},\n \"source\": [\n \"# Example of using litstudy\\n\",\n "
},
{
"path": "pyproject.toml",
"chars": 122,
"preview": "[build-system]\nrequires = [\"setuptools\", \"wheel\"]\nbuild-backend = \"setuptools.build_meta\"\n\n[tool.black]\nline-length = 10"
},
{
"path": "requirements.txt",
"chars": 134,
"preview": "bibtexparser\ngensim\nmatplotlib\nnetworkx\nnumpy\npandas\npybliometrics\npyvis\nrequests\nseaborn\nscikit-learn\nunidecode\nwordclo"
},
{
"path": "setup.cfg",
"chars": 842,
"preview": "[metadata]\nname = litstudy\nversion = 1.0.6\nauthor = Stijn Heldens\nauthor_email = s.heldens@esciencecenter.nl\ndescription"
},
{
"path": "setup.py",
"chars": 77,
"preview": "#!/usr/bin/env python\nfrom setuptools import setup\n\n\n# see setup.cfg\nsetup()\n"
},
{
"path": "sonar-project.properties",
"chars": 502,
"preview": "sonar.organization=nlesc\nsonar.projectKey=nlesc_litstudy\nsonar.host.url=https://sonarcloud.io\nsonar.sources=litstudy/\nso"
},
{
"path": "tests/__init__.py",
"chars": 0,
"preview": ""
},
{
"path": "tests/common.py",
"chars": 2179,
"preview": "import hashlib\nimport json\nimport os\nimport pickle\nimport requests\nfrom litstudy.types import Document, DocumentIdentifi"
},
{
"path": "tests/resources/example.ris",
"chars": 43470,
"preview": "TY - JOUR\r\nTI - The European Approach to the Exascale Challenge\r\nT2 - Computing in Science & Engineering\r\nSP - 42\r\nE"
},
{
"path": "tests/resources/ieee.csv",
"chars": 25181,
"preview": "\"Document Title\",Authors,\"Author Affiliations\",\"Publication Title\",Date Added To Xplore,\"Publication Year\",\"Volume\",\"Iss"
},
{
"path": "tests/resources/retraction_watch.csv",
"chars": 653,
"preview": "Record ID,Title,Subject,Institution,Journal,Publisher,Country,Author,URLS,ArticleType,RetractionDate,RetractionDOI,Retra"
},
{
"path": "tests/resources/scopus.csv",
"chars": 615324,
"preview": "Authors,Author(s) ID,Title,Year,Source title,Volume,Issue,Art. No.,Page start,Page end,Page count,Cited by,DOI,Link,Aff"
},
{
"path": "tests/resources/springer.csv",
"chars": 5552,
"preview": "Item Title,Publication Title,Book Series Title,Journal Volume,Journal Issue,Item DOI,Authors,Publication Year,URL,Conten"
},
{
"path": "tests/test_common.py",
"chars": 714,
"preview": "import litstudy\nimport codecs\n\n\ndef test_robust_open():\n f = litstudy.common.robust_open\n expected = \"ABC \\U0001F6"
},
{
"path": "tests/test_nlp_corpus.py",
"chars": 988,
"preview": "import os\n\nfrom litstudy import load_csv\nfrom litstudy.nlp import build_corpus, Corpus\n\ndef test_build_corpus_should_ins"
},
{
"path": "tests/test_sources_arxiv.py",
"chars": 181,
"preview": "from litstudy.sources.arxiv import search_arxiv\n\n\ndef test_arxiv_query():\n docs = search_arxiv(\"all:positron\", start="
},
{
"path": "tests/test_sources_crossref.py",
"chars": 669,
"preview": "from litstudy.sources.crossref import fetch_crossref, search_crossref\nfrom .common import MockSession\n\n\ndef test_fetch_c"
},
{
"path": "tests/test_sources_csv.py",
"chars": 2487,
"preview": "from litstudy import load_csv\nimport os\n\n\ndef test_load_ieee_csv():\n path = os.path.dirname(__file__) + \"/resources/i"
},
{
"path": "tests/test_sources_ieee.py",
"chars": 1137,
"preview": "from litstudy.sources.ieee import load_ieee_csv\nimport os\n\n\ndef test_load_ieee_csv():\n path = os.path.dirname(__file_"
},
{
"path": "tests/test_sources_ris.py",
"chars": 551,
"preview": "from litstudy.sources.ris import load_ris_file\nimport os\n\n\ndef test_load_ris_file():\n path = os.path.dirname(__file__"
},
{
"path": "tests/test_sources_scopus_csv.py",
"chars": 1593,
"preview": "from litstudy.sources.scopus_csv import load_scopus_csv\nimport os\n\n\ndef test_load_scopus_csv():\n path = os.path.dirna"
},
{
"path": "tests/test_sources_semanticscholar.py",
"chars": 1518,
"preview": "from litstudy.sources.semanticscholar import (\n search_semanticscholar,\n fetch_semanticscholar,\n refine_semanti"
},
{
"path": "tests/test_sources_springer.py",
"chars": 403,
"preview": "from litstudy.sources.springer import load_springer_csv\nimport os\n\n\ndef test_load_springer_csv():\n path = os.path.dir"
}
]
// ... and 16 more files (download for full content)
About this extraction
This page contains the full source code of the NLeSC/litstudy GitHub repository, extracted and formatted as plain text for AI agents and large language models (LLMs). The extraction includes 102 files (3.5 MB), approximately 927.3k tokens, and a symbol index with 389 extracted functions, classes, methods, constants, and types. Use this with OpenClaw, Claude, ChatGPT, Cursor, Windsurf, or any other AI tool that accepts text input. You can copy the full output to your clipboard or download it as a .txt file.
Extracted by GitExtract — free GitHub repo to text converter for AI. Built by Nikandr Surkov.