Copy disabled (too large)
Download .txt
Showing preview only (29,424K chars total). Download the full file to get everything.
Repository: PaddlePaddle/PaddleHub
Branch: develop
Commit: dd107683c324
Files: 2810
Total size: 157.0 MB
Directory structure:
gitextract_e8vmpf1l/
├── .github/
│ └── ISSUE_TEMPLATE/
│ ├── ----.md
│ └── bug--.md
├── .gitignore
├── .pre-commit-config.yaml
├── .style.yapf
├── .travis.yml
├── AUTHORS.md
├── LICENSE
├── README.md
├── README_ch.md
├── demo/
│ ├── README.md
│ ├── audio_classification/
│ │ ├── README.md
│ │ ├── audioset_predict.py
│ │ ├── predict.py
│ │ └── train.py
│ ├── autoaug/
│ │ ├── README.md
│ │ ├── hub_fitter.py
│ │ ├── paddlehub_utils/
│ │ │ ├── __init__.py
│ │ │ ├── reader.py
│ │ │ └── trainer.py
│ │ ├── pba_classifier_example.yaml
│ │ ├── search.py
│ │ ├── search.sh
│ │ ├── train.py
│ │ └── train.sh
│ ├── colorization/
│ │ ├── README.md
│ │ ├── predict.py
│ │ └── train.py
│ ├── image_classification/
│ │ ├── README.md
│ │ ├── predict.py
│ │ └── train.py
│ ├── semantic_segmentation/
│ │ ├── README.md
│ │ ├── predict.py
│ │ └── train.py
│ ├── sequence_labeling/
│ │ ├── README.md
│ │ ├── predict.py
│ │ └── train.py
│ ├── serving/
│ │ ├── bentoml/
│ │ │ └── cloud-native-model-serving-with-bentoml.ipynb
│ │ ├── lexical_analysis_lac/
│ │ │ └── templates/
│ │ │ ├── lac_gpu_serving_config.json
│ │ │ └── lac_serving_config.json
│ │ └── module_serving/
│ │ ├── lexical_analysis_lac/
│ │ │ ├── README.md
│ │ │ └── lac_serving_demo.py
│ │ └── object_detection_pyramidbox_lite_server_mask/
│ │ └── pyramidbox_lite_server_mask_serving_demo.py
│ ├── style_transfer/
│ │ ├── README.md
│ │ ├── predict.py
│ │ └── train.py
│ ├── text_classification/
│ │ ├── README.md
│ │ ├── embedding/
│ │ │ ├── model.py
│ │ │ ├── predict.py
│ │ │ └── train.py
│ │ ├── predict.py
│ │ └── train.py
│ └── text_matching/
│ ├── README.md
│ ├── predict.py
│ └── train.py
├── docker/
│ └── Dockerfile
├── docs/
│ ├── Makefile
│ ├── conf.py
│ ├── docs_ch/
│ │ ├── Makefile
│ │ ├── api/
│ │ │ ├── datasets/
│ │ │ │ ├── canvas.rst
│ │ │ │ ├── chnsenticorp.rst
│ │ │ │ ├── esc50.rst
│ │ │ │ ├── flowers.rst
│ │ │ │ ├── lcqmc.rst
│ │ │ │ ├── minicoco.rst
│ │ │ │ ├── msra_ner.rst
│ │ │ │ └── opticdisc.rst
│ │ │ ├── datasets_index.rst
│ │ │ ├── env.rst
│ │ │ ├── module.rst
│ │ │ ├── module_decorator.rst
│ │ │ ├── module_manager.rst
│ │ │ └── trainer.rst
│ │ ├── api_index.rst
│ │ ├── community/
│ │ │ ├── contribute_code.md
│ │ │ └── more_demos.md
│ │ ├── community_index.rst
│ │ ├── conf.py
│ │ ├── faq.md
│ │ ├── figures.md
│ │ ├── finetune/
│ │ │ ├── audio_classification.md
│ │ │ ├── customized_dataset.md
│ │ │ ├── image_classification.md
│ │ │ ├── image_colorization.md
│ │ │ ├── semantic_segmentation.md
│ │ │ ├── sequence_labeling.md
│ │ │ ├── style_transfer.md
│ │ │ └── text_matching.md
│ │ ├── get_start/
│ │ │ ├── installation.rst
│ │ │ ├── linux_quickstart.md
│ │ │ ├── mac_quickstart.md
│ │ │ ├── python_use_hub.rst
│ │ │ └── windows_quickstart.md
│ │ ├── get_start_index.rst
│ │ ├── index.rst
│ │ ├── make.bat
│ │ ├── release.md
│ │ ├── transfer_learning_index.rst
│ │ ├── tutorial/
│ │ │ ├── cmd_usage.rst
│ │ │ ├── custom_module.rst
│ │ │ └── serving.md
│ │ ├── tutorial_index.rst
│ │ └── visualization.md
│ ├── docs_en/
│ │ ├── Makefile
│ │ ├── api/
│ │ │ ├── datasets/
│ │ │ │ ├── canvas.rst
│ │ │ │ ├── chnsenticorp.rst
│ │ │ │ ├── esc50.rst
│ │ │ │ ├── flowers.rst
│ │ │ │ ├── lcqmc.rst
│ │ │ │ ├── minicoco.rst
│ │ │ │ ├── msra_ner.rst
│ │ │ │ └── opticdisc.rst
│ │ │ ├── datasets_index.rst
│ │ │ ├── env.rst
│ │ │ ├── module.rst
│ │ │ ├── module_decorator.rst
│ │ │ ├── module_manager.rst
│ │ │ └── trainer.rst
│ │ ├── api_index.rst
│ │ ├── community/
│ │ │ ├── contribute_code.md
│ │ │ └── more_demos.md
│ │ ├── community_index.rst
│ │ ├── conf.py
│ │ ├── faq.md
│ │ ├── figures.md
│ │ ├── finetune/
│ │ │ ├── audio_classification.md
│ │ │ ├── customized_dataset.md
│ │ │ ├── image_classification.md
│ │ │ ├── image_colorization.md
│ │ │ ├── semantic_segmentation.md
│ │ │ ├── sequence_labeling.md
│ │ │ ├── style_transfer.md
│ │ │ └── text_matching.md
│ │ ├── get_start/
│ │ │ ├── installation.rst
│ │ │ ├── linux_quickstart.md
│ │ │ ├── mac_quickstart.md
│ │ │ ├── python_use_hub.rst
│ │ │ └── windows_quickstart.md
│ │ ├── get_start_index.rst
│ │ ├── index.rst
│ │ ├── make.bat
│ │ ├── release.md
│ │ ├── transfer_learning_index.rst
│ │ ├── tutorial/
│ │ │ ├── cmd_usage.rst
│ │ │ ├── custom_module.rst
│ │ │ └── serving.md
│ │ ├── tutorial_index.rst
│ │ └── visualization.md
│ ├── make.bat
│ └── requirements.txt
├── modules/
│ ├── README.md
│ ├── README_ch.md
│ ├── audio/
│ │ ├── README.md
│ │ ├── README_en.md
│ │ ├── asr/
│ │ │ ├── deepspeech2_aishell/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── assets/
│ │ │ │ │ ├── conf/
│ │ │ │ │ │ ├── augmentation.json
│ │ │ │ │ │ └── deepspeech2.yaml
│ │ │ │ │ └── data/
│ │ │ │ │ ├── mean_std.json
│ │ │ │ │ └── vocab.txt
│ │ │ │ ├── deepspeech_tester.py
│ │ │ │ ├── module.py
│ │ │ │ └── requirements.txt
│ │ │ ├── deepspeech2_librispeech/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── assets/
│ │ │ │ │ └── conf/
│ │ │ │ │ ├── augmentation.json
│ │ │ │ │ └── deepspeech2.yaml
│ │ │ │ ├── deepspeech_tester.py
│ │ │ │ ├── module.py
│ │ │ │ └── requirements.txt
│ │ │ ├── u2_conformer_aishell/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── assets/
│ │ │ │ │ ├── conf/
│ │ │ │ │ │ ├── augmentation.json
│ │ │ │ │ │ └── conformer.yaml
│ │ │ │ │ └── data/
│ │ │ │ │ ├── mean_std.json
│ │ │ │ │ └── vocab.txt
│ │ │ │ ├── module.py
│ │ │ │ ├── requirements.txt
│ │ │ │ └── u2_conformer_tester.py
│ │ │ ├── u2_conformer_librispeech/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── assets/
│ │ │ │ │ ├── conf/
│ │ │ │ │ │ ├── augmentation.json
│ │ │ │ │ │ └── conformer.yaml
│ │ │ │ │ └── data/
│ │ │ │ │ ├── bpe_unigram_5000.model
│ │ │ │ │ ├── bpe_unigram_5000.vocab
│ │ │ │ │ ├── mean_std.json
│ │ │ │ │ └── vocab.txt
│ │ │ │ ├── module.py
│ │ │ │ ├── requirements.txt
│ │ │ │ └── u2_conformer_tester.py
│ │ │ └── u2_conformer_wenetspeech/
│ │ │ ├── README.md
│ │ │ ├── __init__.py
│ │ │ ├── module.py
│ │ │ └── requirements.txt
│ │ ├── audio_classification/
│ │ │ └── PANNs/
│ │ │ ├── cnn10/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── module.py
│ │ │ │ ├── network.py
│ │ │ │ └── requirements.txt
│ │ │ ├── cnn14/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── module.py
│ │ │ │ ├── network.py
│ │ │ │ └── requirements.txt
│ │ │ └── cnn6/
│ │ │ ├── README.md
│ │ │ ├── __init__.py
│ │ │ ├── module.py
│ │ │ ├── network.py
│ │ │ └── requirements.txt
│ │ ├── keyword_spotting/
│ │ │ └── kwmlp_speech_commands/
│ │ │ ├── README.md
│ │ │ ├── __init__.py
│ │ │ ├── feature.py
│ │ │ ├── kwmlp.py
│ │ │ ├── module.py
│ │ │ └── requirements.txt
│ │ ├── language_identification/
│ │ │ └── ecapa_tdnn_common_language/
│ │ │ ├── README.md
│ │ │ ├── __init__.py
│ │ │ ├── ecapa_tdnn.py
│ │ │ ├── feature.py
│ │ │ ├── module.py
│ │ │ └── requirements.txt
│ │ ├── speaker_recognition/
│ │ │ └── ecapa_tdnn_voxceleb/
│ │ │ ├── README.md
│ │ │ ├── __init__.py
│ │ │ ├── ecapa_tdnn.py
│ │ │ ├── feature.py
│ │ │ ├── module.py
│ │ │ └── requirements.txt
│ │ ├── svs/
│ │ │ └── diffsinger/
│ │ │ ├── README.md
│ │ │ ├── __init__.py
│ │ │ ├── configs/
│ │ │ │ ├── config_base.yaml
│ │ │ │ ├── singing/
│ │ │ │ │ ├── base.yaml
│ │ │ │ │ └── fs2.yaml
│ │ │ │ └── tts/
│ │ │ │ ├── base.yaml
│ │ │ │ ├── base_zh.yaml
│ │ │ │ ├── fs2.yaml
│ │ │ │ ├── hifigan.yaml
│ │ │ │ ├── lj/
│ │ │ │ │ ├── base_mel2wav.yaml
│ │ │ │ │ ├── base_text2mel.yaml
│ │ │ │ │ ├── fs2.yaml
│ │ │ │ │ ├── hifigan.yaml
│ │ │ │ │ └── pwg.yaml
│ │ │ │ └── pwg.yaml
│ │ │ ├── infer.py
│ │ │ ├── inference/
│ │ │ │ └── svs/
│ │ │ │ └── opencpop/
│ │ │ │ ├── cpop_pinyin2ph.txt
│ │ │ │ └── map.py
│ │ │ ├── module.py
│ │ │ ├── requirements.txt
│ │ │ ├── test.py
│ │ │ ├── usr/
│ │ │ │ └── configs/
│ │ │ │ ├── base.yaml
│ │ │ │ ├── lj_ds_beta6.yaml
│ │ │ │ ├── midi/
│ │ │ │ │ ├── cascade/
│ │ │ │ │ │ └── opencs/
│ │ │ │ │ │ ├── aux_rel.yaml
│ │ │ │ │ │ ├── ds60_rel.yaml
│ │ │ │ │ │ └── opencpop_statis.yaml
│ │ │ │ │ ├── e2e/
│ │ │ │ │ │ ├── opencpop/
│ │ │ │ │ │ │ ├── ds1000.yaml
│ │ │ │ │ │ │ └── ds100_adj_rel.yaml
│ │ │ │ │ │ └── popcs/
│ │ │ │ │ │ └── ds100_adj_rel.yaml
│ │ │ │ │ └── pe.yaml
│ │ │ │ ├── popcs_ds_beta6.yaml
│ │ │ │ ├── popcs_ds_beta6_offline.yaml
│ │ │ │ └── popcs_fs2.yaml
│ │ │ └── utils/
│ │ │ ├── __init__.py
│ │ │ ├── audio.py
│ │ │ ├── cwt.py
│ │ │ ├── hparams.py
│ │ │ ├── multiprocess_utils.py
│ │ │ ├── text_encoder.py
│ │ │ └── text_norm.py
│ │ ├── tts/
│ │ │ ├── deepvoice3_ljspeech/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── module.py
│ │ │ │ └── requirements.txt
│ │ │ ├── fastspeech2_baker/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── assets/
│ │ │ │ │ ├── fastspeech2_nosil_baker_ckpt_0.4/
│ │ │ │ │ │ ├── default.yaml
│ │ │ │ │ │ └── phone_id_map.txt
│ │ │ │ │ └── pwg_baker_ckpt_0.4/
│ │ │ │ │ └── pwg_default.yaml
│ │ │ │ ├── module.py
│ │ │ │ └── requirements.txt
│ │ │ ├── fastspeech2_ljspeech/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── assets/
│ │ │ │ │ ├── fastspeech2_nosil_ljspeech_ckpt_0.5/
│ │ │ │ │ │ ├── default.yaml
│ │ │ │ │ │ └── phone_id_map.txt
│ │ │ │ │ └── pwg_ljspeech_ckpt_0.5/
│ │ │ │ │ └── pwg_default.yaml
│ │ │ │ ├── module.py
│ │ │ │ └── requirements.txt
│ │ │ ├── fastspeech_ljspeech/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── module.py
│ │ │ │ └── requirements.txt
│ │ │ └── transformer_tts_ljspeech/
│ │ │ ├── README.md
│ │ │ ├── __init__.py
│ │ │ ├── module.py
│ │ │ └── requirements.txt
│ │ └── voice_cloning/
│ │ ├── ge2e_fastspeech2_pwgan/
│ │ │ ├── README.md
│ │ │ ├── __init__.py
│ │ │ ├── module.py
│ │ │ └── requirements.txt
│ │ └── lstm_tacotron2/
│ │ ├── README.md
│ │ ├── __init__.py
│ │ ├── audio_processor.py
│ │ ├── chinese_g2p.py
│ │ ├── module.py
│ │ ├── preprocess_transcription.py
│ │ └── requirements.txt
│ ├── demo/
│ │ ├── README.md
│ │ ├── senta_test/
│ │ │ ├── __init__.py
│ │ │ ├── module.py
│ │ │ ├── processor.py
│ │ │ └── vocab.list
│ │ └── test.py
│ ├── image/
│ │ ├── Image_editing/
│ │ │ ├── README.md
│ │ │ ├── README_en.md
│ │ │ ├── colorization/
│ │ │ │ ├── deoldify/
│ │ │ │ │ ├── README.md
│ │ │ │ │ ├── README_en.md
│ │ │ │ │ ├── base_module.py
│ │ │ │ │ ├── module.py
│ │ │ │ │ ├── test.py
│ │ │ │ │ └── utils.py
│ │ │ │ ├── photo_restoration/
│ │ │ │ │ ├── README.md
│ │ │ │ │ ├── README_en.md
│ │ │ │ │ ├── module.py
│ │ │ │ │ ├── test.py
│ │ │ │ │ └── utils.py
│ │ │ │ └── user_guided_colorization/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── data_feed.py
│ │ │ │ ├── module.py
│ │ │ │ └── test.py
│ │ │ ├── enhancement/
│ │ │ │ ├── fbcnn_color/
│ │ │ │ │ ├── README.md
│ │ │ │ │ ├── fbcnn.py
│ │ │ │ │ ├── module.py
│ │ │ │ │ └── test.py
│ │ │ │ └── fbcnn_gray/
│ │ │ │ ├── README.md
│ │ │ │ ├── fbcnn.py
│ │ │ │ ├── module.py
│ │ │ │ └── test.py
│ │ │ └── super_resolution/
│ │ │ ├── dcscn/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── data_feed.py
│ │ │ │ ├── module.py
│ │ │ │ ├── processor.py
│ │ │ │ └── test.py
│ │ │ ├── falsr_a/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── data_feed.py
│ │ │ │ ├── module.py
│ │ │ │ ├── processor.py
│ │ │ │ └── test.py
│ │ │ ├── falsr_b/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── data_feed.py
│ │ │ │ ├── module.py
│ │ │ │ ├── processor.py
│ │ │ │ └── test.py
│ │ │ ├── falsr_c/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── data_feed.py
│ │ │ │ ├── module.py
│ │ │ │ ├── processor.py
│ │ │ │ └── test.py
│ │ │ ├── realsr/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── module.py
│ │ │ │ ├── rrdb.py
│ │ │ │ ├── test.py
│ │ │ │ └── utils.py
│ │ │ ├── swin2sr_real_sr_x4/
│ │ │ │ ├── README.md
│ │ │ │ ├── module.py
│ │ │ │ ├── swin2sr.py
│ │ │ │ └── test.py
│ │ │ ├── swinir_l_real_sr_x4/
│ │ │ │ ├── README.md
│ │ │ │ ├── module.py
│ │ │ │ ├── swinir.py
│ │ │ │ └── test.py
│ │ │ ├── swinir_m_real_sr_x2/
│ │ │ │ ├── README.md
│ │ │ │ ├── module.py
│ │ │ │ ├── swinir.py
│ │ │ │ └── test.py
│ │ │ └── swinir_m_real_sr_x4/
│ │ │ ├── README.md
│ │ │ ├── module.py
│ │ │ ├── swinir.py
│ │ │ └── test.py
│ │ ├── Image_gan/
│ │ │ ├── README.md
│ │ │ ├── README_en.md
│ │ │ ├── attgan_celeba/
│ │ │ │ ├── README.md
│ │ │ │ └── README_en.md
│ │ │ ├── cyclegan_cityscapes/
│ │ │ │ ├── README.md
│ │ │ │ └── README_en.md
│ │ │ ├── gan/
│ │ │ │ ├── README.md
│ │ │ │ ├── first_order_motion/
│ │ │ │ │ ├── README.md
│ │ │ │ │ ├── model.py
│ │ │ │ │ ├── module.py
│ │ │ │ │ └── requirements.txt
│ │ │ │ ├── photopen/
│ │ │ │ │ ├── README.md
│ │ │ │ │ ├── model.py
│ │ │ │ │ ├── module.py
│ │ │ │ │ ├── photopen.yaml
│ │ │ │ │ ├── requirements.txt
│ │ │ │ │ └── util.py
│ │ │ │ ├── pixel2style2pixel/
│ │ │ │ │ ├── README.md
│ │ │ │ │ ├── model.py
│ │ │ │ │ ├── module.py
│ │ │ │ │ ├── requirements.txt
│ │ │ │ │ └── util.py
│ │ │ │ ├── stgan_bald/
│ │ │ │ │ ├── README.md
│ │ │ │ │ ├── README_en.md
│ │ │ │ │ ├── data_feed.py
│ │ │ │ │ ├── module.py
│ │ │ │ │ ├── processor.py
│ │ │ │ │ └── test.py
│ │ │ │ ├── styleganv2_editing/
│ │ │ │ │ ├── README.md
│ │ │ │ │ ├── basemodel.py
│ │ │ │ │ ├── model.py
│ │ │ │ │ ├── module.py
│ │ │ │ │ ├── requirements.txt
│ │ │ │ │ └── util.py
│ │ │ │ ├── styleganv2_mixing/
│ │ │ │ │ ├── README.md
│ │ │ │ │ ├── basemodel.py
│ │ │ │ │ ├── model.py
│ │ │ │ │ ├── module.py
│ │ │ │ │ ├── requirements.txt
│ │ │ │ │ └── util.py
│ │ │ │ └── wav2lip/
│ │ │ │ ├── README.md
│ │ │ │ ├── model.py
│ │ │ │ ├── module.py
│ │ │ │ └── requirements.txt
│ │ │ ├── stargan_celeba/
│ │ │ │ ├── README.md
│ │ │ │ └── README_en.md
│ │ │ ├── stgan_celeba/
│ │ │ │ ├── README.md
│ │ │ │ └── README_en.md
│ │ │ └── style_transfer/
│ │ │ ├── ID_Photo_GEN/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ └── module.py
│ │ │ ├── Photo2Cartoon/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── model/
│ │ │ │ │ ├── __init__.py
│ │ │ │ │ └── networks.py
│ │ │ │ └── module.py
│ │ │ ├── U2Net_Portrait/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── module.py
│ │ │ │ ├── processor.py
│ │ │ │ └── u2net.py
│ │ │ ├── UGATIT_100w/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── model.py
│ │ │ │ ├── module.py
│ │ │ │ └── processor.py
│ │ │ ├── UGATIT_83w/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── model.py
│ │ │ │ ├── module.py
│ │ │ │ └── processor.py
│ │ │ ├── UGATIT_92w/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── model.py
│ │ │ │ ├── module.py
│ │ │ │ └── processor.py
│ │ │ ├── animegan_v1_hayao_60/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── model.py
│ │ │ │ ├── module.py
│ │ │ │ ├── processor.py
│ │ │ │ └── test.py
│ │ │ ├── animegan_v2_hayao_64/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── model.py
│ │ │ │ ├── module.py
│ │ │ │ ├── processor.py
│ │ │ │ └── test.py
│ │ │ ├── animegan_v2_hayao_99/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── model.py
│ │ │ │ ├── module.py
│ │ │ │ ├── processor.py
│ │ │ │ └── test.py
│ │ │ ├── animegan_v2_paprika_54/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── model.py
│ │ │ │ ├── module.py
│ │ │ │ ├── processor.py
│ │ │ │ └── test.py
│ │ │ ├── animegan_v2_paprika_74/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── model.py
│ │ │ │ ├── module.py
│ │ │ │ ├── processor.py
│ │ │ │ └── test.py
│ │ │ ├── animegan_v2_paprika_97/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── model.py
│ │ │ │ ├── module.py
│ │ │ │ ├── processor.py
│ │ │ │ └── test.py
│ │ │ ├── animegan_v2_paprika_98/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── model.py
│ │ │ │ ├── module.py
│ │ │ │ ├── processor.py
│ │ │ │ └── test.py
│ │ │ ├── animegan_v2_shinkai_33/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── model.py
│ │ │ │ ├── module.py
│ │ │ │ ├── processor.py
│ │ │ │ └── test.py
│ │ │ ├── animegan_v2_shinkai_53/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── model.py
│ │ │ │ ├── module.py
│ │ │ │ ├── processor.py
│ │ │ │ └── test.py
│ │ │ ├── face_parse/
│ │ │ │ ├── README.md
│ │ │ │ ├── model.py
│ │ │ │ ├── module.py
│ │ │ │ ├── requirements.txt
│ │ │ │ └── util.py
│ │ │ ├── lapstyle_circuit/
│ │ │ │ ├── README.md
│ │ │ │ ├── model.py
│ │ │ │ ├── module.py
│ │ │ │ ├── requirements.txt
│ │ │ │ └── util.py
│ │ │ ├── lapstyle_ocean/
│ │ │ │ ├── README.md
│ │ │ │ ├── model.py
│ │ │ │ ├── module.py
│ │ │ │ ├── requirements.txt
│ │ │ │ └── util.py
│ │ │ ├── lapstyle_starrynew/
│ │ │ │ ├── README.md
│ │ │ │ ├── model.py
│ │ │ │ ├── module.py
│ │ │ │ ├── requirements.txt
│ │ │ │ └── util.py
│ │ │ ├── lapstyle_stars/
│ │ │ │ ├── README.md
│ │ │ │ ├── model.py
│ │ │ │ ├── module.py
│ │ │ │ ├── requirements.txt
│ │ │ │ └── util.py
│ │ │ ├── msgnet/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ └── module.py
│ │ │ ├── paint_transformer/
│ │ │ │ ├── README.md
│ │ │ │ ├── inference.py
│ │ │ │ ├── model.py
│ │ │ │ ├── module.py
│ │ │ │ ├── render_parallel.py
│ │ │ │ ├── render_serial.py
│ │ │ │ ├── render_utils.py
│ │ │ │ ├── requirements.txt
│ │ │ │ └── util.py
│ │ │ ├── psgan/
│ │ │ │ ├── README.md
│ │ │ │ ├── makeup.yaml
│ │ │ │ ├── model.py
│ │ │ │ ├── module.py
│ │ │ │ ├── requirements.txt
│ │ │ │ └── util.py
│ │ │ └── stylepro_artistic/
│ │ │ ├── README.md
│ │ │ ├── README_en.md
│ │ │ ├── __init__.py
│ │ │ ├── data_feed.py
│ │ │ ├── module.py
│ │ │ └── processor.py
│ │ ├── README.md
│ │ ├── classification/
│ │ │ ├── DriverStatusRecognition/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── assets/
│ │ │ │ │ └── model.yml
│ │ │ │ ├── module.py
│ │ │ │ ├── requirements.txt
│ │ │ │ └── serving_client_demo.py
│ │ │ ├── README.md
│ │ │ ├── README_en.md
│ │ │ ├── SnakeIdentification/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── assets/
│ │ │ │ │ └── model.yml
│ │ │ │ ├── module.py
│ │ │ │ ├── requirements.txt
│ │ │ │ └── serving_client_demo.py
│ │ │ ├── SpinalNet_Gemstones/
│ │ │ │ ├── README.md
│ │ │ │ ├── gem_dataset.py
│ │ │ │ ├── spinalnet_res101_gemstone/
│ │ │ │ │ ├── README.md
│ │ │ │ │ ├── label_list.txt
│ │ │ │ │ └── module.py
│ │ │ │ ├── spinalnet_res50_gemstone/
│ │ │ │ │ ├── README.md
│ │ │ │ │ ├── label_list.txt
│ │ │ │ │ └── module.py
│ │ │ │ └── spinalnet_vgg16_gemstone/
│ │ │ │ ├── README.md
│ │ │ │ ├── label_list.txt
│ │ │ │ └── module.py
│ │ │ ├── alexnet_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ └── README_en.md
│ │ │ ├── darknet53_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── darknet.py
│ │ │ │ ├── data_feed.py
│ │ │ │ ├── label_file.txt
│ │ │ │ ├── module.py
│ │ │ │ └── processor.py
│ │ │ ├── densenet121_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ └── README_en.md
│ │ │ ├── densenet161_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ └── README_en.md
│ │ │ ├── densenet169_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ └── README_en.md
│ │ │ ├── densenet201_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ └── README_en.md
│ │ │ ├── densenet264_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ └── README_en.md
│ │ │ ├── dpn107_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ └── README_en.md
│ │ │ ├── dpn131_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ └── README_en.md
│ │ │ ├── dpn68_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ └── README_en.md
│ │ │ ├── dpn92_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ └── README_en.md
│ │ │ ├── dpn98_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ └── README_en.md
│ │ │ ├── efficientnetb0_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── data_feed.py
│ │ │ │ ├── label_list.txt
│ │ │ │ ├── module.py
│ │ │ │ ├── processor.py
│ │ │ │ └── test.py
│ │ │ ├── efficientnetb0_small_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── data_feed.py
│ │ │ │ ├── label_list.txt
│ │ │ │ ├── module.py
│ │ │ │ ├── processor.py
│ │ │ │ └── test.py
│ │ │ ├── efficientnetb1_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── data_feed.py
│ │ │ │ ├── label_list.txt
│ │ │ │ ├── module.py
│ │ │ │ ├── processor.py
│ │ │ │ └── test.py
│ │ │ ├── efficientnetb2_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── data_feed.py
│ │ │ │ ├── label_list.txt
│ │ │ │ ├── module.py
│ │ │ │ ├── processor.py
│ │ │ │ └── test.py
│ │ │ ├── efficientnetb3_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── data_feed.py
│ │ │ │ ├── label_list.txt
│ │ │ │ ├── module.py
│ │ │ │ ├── processor.py
│ │ │ │ └── test.py
│ │ │ ├── efficientnetb4_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── data_feed.py
│ │ │ │ ├── label_list.txt
│ │ │ │ ├── module.py
│ │ │ │ ├── processor.py
│ │ │ │ └── test.py
│ │ │ ├── efficientnetb5_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── data_feed.py
│ │ │ │ ├── label_list.txt
│ │ │ │ ├── module.py
│ │ │ │ ├── processor.py
│ │ │ │ └── test.py
│ │ │ ├── efficientnetb6_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── data_feed.py
│ │ │ │ ├── label_list.txt
│ │ │ │ ├── module.py
│ │ │ │ ├── processor.py
│ │ │ │ └── test.py
│ │ │ ├── efficientnetb7_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── data_feed.py
│ │ │ │ ├── label_list.txt
│ │ │ │ ├── module.py
│ │ │ │ ├── processor.py
│ │ │ │ └── test.py
│ │ │ ├── esnet_x0_25_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ ├── model.py
│ │ │ │ ├── module.py
│ │ │ │ ├── processor.py
│ │ │ │ └── utils.py
│ │ │ ├── esnet_x0_5_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ ├── model.py
│ │ │ │ ├── module.py
│ │ │ │ ├── processor.py
│ │ │ │ └── utils.py
│ │ │ ├── fix_resnext101_32x48d_wsl_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── data_feed.py
│ │ │ │ ├── label_list.txt
│ │ │ │ ├── module.py
│ │ │ │ ├── processor.py
│ │ │ │ └── test.py
│ │ │ ├── food_classification/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── module.py
│ │ │ │ └── requirements.txt
│ │ │ ├── ghostnet_x0_5_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ ├── label_list.txt
│ │ │ │ └── module.py
│ │ │ ├── ghostnet_x1_0_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ ├── label_list.txt
│ │ │ │ └── module.py
│ │ │ ├── ghostnet_x1_3_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ ├── label_list.txt
│ │ │ │ └── module.py
│ │ │ ├── ghostnet_x1_3_imagenet_ssld/
│ │ │ │ ├── README.md
│ │ │ │ ├── label_list.txt
│ │ │ │ └── module.py
│ │ │ ├── googlenet_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ └── module.py
│ │ │ ├── hrnet18_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ ├── label_list.txt
│ │ │ │ └── module.py
│ │ │ ├── hrnet18_imagenet_ssld/
│ │ │ │ ├── README.md
│ │ │ │ ├── label_list.txt
│ │ │ │ └── module.py
│ │ │ ├── hrnet30_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ ├── label_list.txt
│ │ │ │ └── module.py
│ │ │ ├── hrnet32_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ ├── label_list.txt
│ │ │ │ └── module.py
│ │ │ ├── hrnet40_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ ├── label_list.txt
│ │ │ │ └── module.py
│ │ │ ├── hrnet44_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ ├── label_list.txt
│ │ │ │ └── module.py
│ │ │ ├── hrnet48_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ ├── label_list.txt
│ │ │ │ └── module.py
│ │ │ ├── hrnet48_imagenet_ssld/
│ │ │ │ ├── README.md
│ │ │ │ ├── label_list.txt
│ │ │ │ └── module.py
│ │ │ ├── hrnet64_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ ├── label_list.txt
│ │ │ │ └── module.py
│ │ │ ├── inception_v4_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ └── README_en.md
│ │ │ ├── inceptionv4_imagenet/
│ │ │ │ └── module.py
│ │ │ ├── levit_128_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ ├── model.py
│ │ │ │ ├── module.py
│ │ │ │ ├── processor.py
│ │ │ │ └── utils.py
│ │ │ ├── levit_128s_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ ├── model.py
│ │ │ │ ├── module.py
│ │ │ │ ├── processor.py
│ │ │ │ └── utils.py
│ │ │ ├── levit_192_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ ├── model.py
│ │ │ │ ├── module.py
│ │ │ │ ├── processor.py
│ │ │ │ └── utils.py
│ │ │ ├── levit_256_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ ├── model.py
│ │ │ │ ├── module.py
│ │ │ │ ├── processor.py
│ │ │ │ └── utils.py
│ │ │ ├── levit_384_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ ├── model.py
│ │ │ │ ├── module.py
│ │ │ │ ├── processor.py
│ │ │ │ └── utils.py
│ │ │ ├── marine_biometrics/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── module.py
│ │ │ │ ├── requirements.txt
│ │ │ │ └── serving_client_demo.py
│ │ │ ├── mobilenet_v1_imagenet/
│ │ │ │ └── module.py
│ │ │ ├── mobilenet_v1_imagenet_ssld/
│ │ │ │ └── module.py
│ │ │ ├── mobilenet_v2_animals/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── data_feed.py
│ │ │ │ ├── label_list.txt
│ │ │ │ ├── module.py
│ │ │ │ ├── processor.py
│ │ │ │ └── test.py
│ │ │ ├── mobilenet_v2_dishes/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── data_feed.py
│ │ │ │ ├── label_list.txt
│ │ │ │ ├── module.py
│ │ │ │ ├── processor.py
│ │ │ │ └── test.py
│ │ │ ├── mobilenet_v2_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ └── module.py
│ │ │ ├── mobilenet_v2_imagenet_ssld/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ └── module.py
│ │ │ ├── mobilenet_v3_large_imagenet_ssld/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ └── module.py
│ │ │ ├── mobilenet_v3_small_imagenet_ssld/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ └── module.py
│ │ │ ├── nasnet_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ └── README_en.md
│ │ │ ├── pnasnet_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ └── README_en.md
│ │ │ ├── pplcnet_x0_25_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ ├── model.py
│ │ │ │ ├── module.py
│ │ │ │ ├── processor.py
│ │ │ │ └── utils.py
│ │ │ ├── pplcnet_x0_35_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ ├── model.py
│ │ │ │ ├── module.py
│ │ │ │ ├── processor.py
│ │ │ │ └── utils.py
│ │ │ ├── pplcnet_x0_5_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ ├── model.py
│ │ │ │ ├── module.py
│ │ │ │ ├── processor.py
│ │ │ │ └── utils.py
│ │ │ ├── pplcnet_x0_75_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ ├── model.py
│ │ │ │ ├── module.py
│ │ │ │ ├── processor.py
│ │ │ │ └── utils.py
│ │ │ ├── pplcnet_x1_0_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ ├── model.py
│ │ │ │ ├── module.py
│ │ │ │ ├── processor.py
│ │ │ │ └── utils.py
│ │ │ ├── pplcnet_x1_5_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ ├── model.py
│ │ │ │ ├── module.py
│ │ │ │ ├── processor.py
│ │ │ │ └── utils.py
│ │ │ ├── pplcnet_x2_0_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ ├── model.py
│ │ │ │ ├── module.py
│ │ │ │ ├── processor.py
│ │ │ │ └── utils.py
│ │ │ ├── pplcnet_x2_5_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ ├── model.py
│ │ │ │ ├── module.py
│ │ │ │ ├── processor.py
│ │ │ │ └── utils.py
│ │ │ ├── repvgg_a0_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ ├── label_list.txt
│ │ │ │ └── module.py
│ │ │ ├── repvgg_a1_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ ├── label_list.txt
│ │ │ │ └── module.py
│ │ │ ├── repvgg_a2_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ ├── label_list.txt
│ │ │ │ └── module.py
│ │ │ ├── repvgg_b0_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ ├── label_list.txt
│ │ │ │ └── module.py
│ │ │ ├── repvgg_b1_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ ├── label_list.txt
│ │ │ │ └── module.py
│ │ │ ├── repvgg_b1g2_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ ├── label_list.txt
│ │ │ │ └── module.py
│ │ │ ├── repvgg_b1g4_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ ├── label_list.txt
│ │ │ │ └── module.py
│ │ │ ├── repvgg_b2_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ ├── label_list.txt
│ │ │ │ └── module.py
│ │ │ ├── repvgg_b2g4_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ ├── label_list.txt
│ │ │ │ └── module.py
│ │ │ ├── repvgg_b3g4_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ ├── label_list.txt
│ │ │ │ └── module.py
│ │ │ ├── res2net101_vd_26w_4s_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── data_feed.py
│ │ │ │ ├── label_list.txt
│ │ │ │ ├── module.py
│ │ │ │ ├── processor.py
│ │ │ │ └── test.py
│ │ │ ├── resnet101_imagenet/
│ │ │ │ └── module.py
│ │ │ ├── resnet101_vd_imagenet/
│ │ │ │ └── module.py
│ │ │ ├── resnet101_vd_imagenet_ssld/
│ │ │ │ └── module.py
│ │ │ ├── resnet152_imagenet/
│ │ │ │ └── module.py
│ │ │ ├── resnet152_vd_imagenet/
│ │ │ │ └── module.py
│ │ │ ├── resnet18_imagenet/
│ │ │ │ └── module.py
│ │ │ ├── resnet18_vd_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ └── module.py
│ │ │ ├── resnet200_vd_imagenet/
│ │ │ │ └── module.py
│ │ │ ├── resnet34_imagenet/
│ │ │ │ └── module.py
│ │ │ ├── resnet34_v2_imagenet/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── data_feed.py
│ │ │ │ ├── label_file.txt
│ │ │ │ ├── module.py
│ │ │ │ ├── name_adapter.py
│ │ │ │ ├── nonlocal_helper.py
│ │ │ │ ├── processor.py
│ │ │ │ └── resnet.py
│ │ │ ├── resnet34_vd_imagenet/
│ │ │ │ └── module.py
│ │ │ ├── resnet34_vd_imagenet_ssld/
│ │ │ │ └── module.py
│ │ │ ├── resnet50_imagenet/
│ │ │ │ └── module.py
│ │ │ ├── resnet50_v2_imagenet/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── data_feed.py
│ │ │ │ ├── label_file.txt
│ │ │ │ ├── module.py
│ │ │ │ ├── name_adapter.py
│ │ │ │ ├── nonlocal_helper.py
│ │ │ │ ├── processor.py
│ │ │ │ └── resnet.py
│ │ │ ├── resnet50_vd_10w/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ └── module.py
│ │ │ ├── resnet50_vd_animals/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── data_feed.py
│ │ │ │ ├── label_list.txt
│ │ │ │ ├── module.py
│ │ │ │ ├── processor.py
│ │ │ │ └── test.py
│ │ │ ├── resnet50_vd_dishes/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── data_feed.py
│ │ │ │ ├── label_list.txt
│ │ │ │ ├── module.py
│ │ │ │ ├── processor.py
│ │ │ │ └── test.py
│ │ │ ├── resnet50_vd_imagenet/
│ │ │ │ └── module.py
│ │ │ ├── resnet50_vd_imagenet_ssld/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── label_list.txt
│ │ │ │ └── module.py
│ │ │ ├── resnet50_vd_wildanimals/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── data_feed.py
│ │ │ │ ├── label_list.txt
│ │ │ │ ├── module.py
│ │ │ │ ├── processor.py
│ │ │ │ └── test.py
│ │ │ ├── resnet_v2_101_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ └── README_en.md
│ │ │ ├── resnet_v2_152_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ └── README_en.md
│ │ │ ├── resnet_v2_18_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ └── README_en.md
│ │ │ ├── resnet_v2_34_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ └── README_en.md
│ │ │ ├── resnet_v2_50_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ └── README_en.md
│ │ │ ├── resnext101_32x16d_wsl/
│ │ │ │ ├── README.md
│ │ │ │ └── README_en.md
│ │ │ ├── resnext101_32x32d_wsl/
│ │ │ │ ├── README.md
│ │ │ │ └── README_en.md
│ │ │ ├── resnext101_32x48d_wsl/
│ │ │ │ ├── README.md
│ │ │ │ └── README_en.md
│ │ │ ├── resnext101_32x4d_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ └── module.py
│ │ │ ├── resnext101_32x8d_wsl/
│ │ │ │ ├── README.md
│ │ │ │ └── README_en.md
│ │ │ ├── resnext101_64x4d_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ └── module.py
│ │ │ ├── resnext101_vd_32x4d_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ └── module.py
│ │ │ ├── resnext101_vd_64x4d_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ └── module.py
│ │ │ ├── resnext152_32x4d_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ └── module.py
│ │ │ ├── resnext152_64x4d_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ └── module.py
│ │ │ ├── resnext152_vd_32x4d_imagenet/
│ │ │ │ └── module.py
│ │ │ ├── resnext152_vd_64x4d_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ └── module.py
│ │ │ ├── resnext50_32x4d_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ └── module.py
│ │ │ ├── resnext50_64x4d_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ └── module.py
│ │ │ ├── resnext50_vd_32x4d_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ └── module.py
│ │ │ ├── resnext50_vd_64x4d_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ └── module.py
│ │ │ ├── rexnet_1_0_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ ├── label_list.txt
│ │ │ │ └── module.py
│ │ │ ├── rexnet_1_3_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ ├── label_list.txt
│ │ │ │ └── module.py
│ │ │ ├── rexnet_1_5_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ ├── label_list.txt
│ │ │ │ └── module.py
│ │ │ ├── rexnet_2_0_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ ├── label_list.txt
│ │ │ │ └── module.py
│ │ │ ├── rexnet_3_0_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ ├── label_list.txt
│ │ │ │ └── module.py
│ │ │ ├── se_hrnet64_imagenet_ssld/
│ │ │ │ ├── README.md
│ │ │ │ ├── label_list.txt
│ │ │ │ └── module.py
│ │ │ ├── se_resnet18_vd_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── data_feed.py
│ │ │ │ ├── label_list.txt
│ │ │ │ ├── module.py
│ │ │ │ ├── processor.py
│ │ │ │ └── test.py
│ │ │ ├── se_resnext101_32x4d_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ └── README_en.md
│ │ │ ├── se_resnext50_32x4d_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ └── README_en.md
│ │ │ ├── shufflenet_v2_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ └── module.py
│ │ │ ├── spinalnet_res101_gemstone/
│ │ │ │ ├── README.md
│ │ │ │ └── README_en.md
│ │ │ ├── spinalnet_res50_gemstone/
│ │ │ │ ├── README.md
│ │ │ │ └── README_en.md
│ │ │ ├── spinalnet_vgg16_gemstone/
│ │ │ │ ├── README.md
│ │ │ │ └── README_en.md
│ │ │ ├── vgg11_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ └── README_en.md
│ │ │ ├── vgg13_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ └── README_en.md
│ │ │ ├── vgg16_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── data_feed.py
│ │ │ │ ├── label_file.txt
│ │ │ │ ├── module.py
│ │ │ │ ├── processor.py
│ │ │ │ └── vgg.py
│ │ │ ├── vgg19_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ └── README_en.md
│ │ │ ├── xception41_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ └── module.py
│ │ │ ├── xception65_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ └── module.py
│ │ │ └── xception71_imagenet/
│ │ │ ├── README.md
│ │ │ ├── README_en.md
│ │ │ └── module.py
│ │ ├── depth_estimation/
│ │ │ ├── MiDaS_Large/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── inference.py
│ │ │ │ ├── module.py
│ │ │ │ ├── transforms.py
│ │ │ │ └── utils.py
│ │ │ └── MiDaS_Small/
│ │ │ ├── README.md
│ │ │ ├── inference.py
│ │ │ ├── module.py
│ │ │ ├── transforms.py
│ │ │ └── utils.py
│ │ ├── face_detection/
│ │ │ ├── README.md
│ │ │ ├── README_en.md
│ │ │ ├── pyramidbox_face_detection/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── data_feed.py
│ │ │ │ ├── module.py
│ │ │ │ ├── processor.py
│ │ │ │ └── test.py
│ │ │ ├── pyramidbox_lite_mobile/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── data_feed.py
│ │ │ │ ├── label_list.txt
│ │ │ │ ├── module.py
│ │ │ │ ├── processor.py
│ │ │ │ └── test.py
│ │ │ ├── pyramidbox_lite_mobile_mask/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── data_feed.py
│ │ │ │ ├── label_list.txt
│ │ │ │ ├── module.py
│ │ │ │ ├── processor.py
│ │ │ │ └── test.py
│ │ │ ├── pyramidbox_lite_server/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── data_feed.py
│ │ │ │ ├── label_list.txt
│ │ │ │ ├── module.py
│ │ │ │ ├── processor.py
│ │ │ │ └── test.py
│ │ │ ├── pyramidbox_lite_server_mask/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── data_feed.py
│ │ │ │ ├── label_list.txt
│ │ │ │ ├── module.py
│ │ │ │ ├── processor.py
│ │ │ │ └── test.py
│ │ │ ├── ultra_light_fast_generic_face_detector_1mb_320/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── data_feed.py
│ │ │ │ ├── module.py
│ │ │ │ ├── processor.py
│ │ │ │ └── test.py
│ │ │ └── ultra_light_fast_generic_face_detector_1mb_640/
│ │ │ ├── README.md
│ │ │ ├── README_en.md
│ │ │ ├── __init__.py
│ │ │ ├── data_feed.py
│ │ │ ├── module.py
│ │ │ ├── processor.py
│ │ │ └── test.py
│ │ ├── image_processing/
│ │ │ ├── enlightengan/
│ │ │ │ ├── README.md
│ │ │ │ ├── enlighten_inference/
│ │ │ │ │ └── pd_model/
│ │ │ │ │ └── x2paddle_code.py
│ │ │ │ ├── module.py
│ │ │ │ └── util.py
│ │ │ ├── prnet/
│ │ │ │ ├── README.md
│ │ │ │ ├── api.py
│ │ │ │ ├── module.py
│ │ │ │ ├── pd_model/
│ │ │ │ │ └── x2paddle_code.py
│ │ │ │ ├── predictor.py
│ │ │ │ ├── requirements.txt
│ │ │ │ ├── util.py
│ │ │ │ └── utils/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── cv_plot.py
│ │ │ │ ├── estimate_pose.py
│ │ │ │ ├── render.py
│ │ │ │ ├── render_app.py
│ │ │ │ ├── rotate_vertices.py
│ │ │ │ └── write.py
│ │ │ └── seeinthedark/
│ │ │ ├── README.md
│ │ │ ├── module.py
│ │ │ └── requirements.txt
│ │ ├── industrial_application/
│ │ │ └── meter_readings/
│ │ │ └── barometer_reader/
│ │ │ ├── README.md
│ │ │ ├── module.py
│ │ │ └── requirements.txt
│ │ ├── instance_segmentation/
│ │ │ └── solov2/
│ │ │ ├── README.md
│ │ │ ├── data_feed.py
│ │ │ ├── module.py
│ │ │ ├── processor.py
│ │ │ └── test.py
│ │ ├── keypoint_detection/
│ │ │ ├── README.md
│ │ │ ├── README_en.md
│ │ │ ├── face_landmark_localization/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── data_feed.py
│ │ │ │ ├── module.py
│ │ │ │ ├── processor.py
│ │ │ │ └── test.py
│ │ │ ├── hand_pose_localization/
│ │ │ │ ├── model.py
│ │ │ │ ├── module.py
│ │ │ │ ├── processor.py
│ │ │ │ ├── readme.md
│ │ │ │ └── test.py
│ │ │ ├── human_pose_estimation_resnet50_mpii/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── data_feed.py
│ │ │ │ ├── module.py
│ │ │ │ ├── processor.py
│ │ │ │ └── test.py
│ │ │ ├── openpose_body_estimation/
│ │ │ │ ├── module.py
│ │ │ │ ├── processor.py
│ │ │ │ ├── readme.md
│ │ │ │ └── test.py
│ │ │ ├── openpose_hands_estimation/
│ │ │ │ ├── module.py
│ │ │ │ ├── processor.py
│ │ │ │ ├── readme.md
│ │ │ │ └── test.py
│ │ │ └── pp-tinypose/
│ │ │ ├── README.md
│ │ │ ├── __init__.py
│ │ │ ├── det_keypoint_unite_infer.py
│ │ │ ├── infer.py
│ │ │ ├── keypoint_infer.py
│ │ │ ├── keypoint_postprocess.py
│ │ │ ├── keypoint_preprocess.py
│ │ │ ├── module.py
│ │ │ ├── preprocess.py
│ │ │ ├── test.py
│ │ │ └── visualize.py
│ │ ├── matting/
│ │ │ ├── dim_vgg16_matting/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── module.py
│ │ │ │ ├── processor.py
│ │ │ │ ├── requirements.txt
│ │ │ │ └── vgg.py
│ │ │ ├── gfm_resnet34_matting/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── gfm.py
│ │ │ │ ├── module.py
│ │ │ │ ├── processor.py
│ │ │ │ ├── requirements.txt
│ │ │ │ └── resnet.py
│ │ │ ├── modnet_hrnet18_matting/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── hrnet.py
│ │ │ │ ├── module.py
│ │ │ │ └── processor.py
│ │ │ ├── modnet_mobilenetv2_matting/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── mobilenetv2.py
│ │ │ │ ├── module.py
│ │ │ │ ├── processor.py
│ │ │ │ └── requirements.py
│ │ │ └── modnet_resnet50vd_matting/
│ │ │ ├── README.md
│ │ │ ├── README_en.md
│ │ │ ├── __init__.py
│ │ │ ├── module.py
│ │ │ ├── processor.py
│ │ │ ├── requirements.txt
│ │ │ └── resnet.py
│ │ ├── object_detection/
│ │ │ ├── README.md
│ │ │ ├── README_en.md
│ │ │ ├── faster_rcnn_resnet50_coco2017/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── data_feed.py
│ │ │ │ ├── label_file.txt
│ │ │ │ ├── module.py
│ │ │ │ ├── processor.py
│ │ │ │ └── test.py
│ │ │ ├── faster_rcnn_resnet50_fpn_coco2017/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── data_feed.py
│ │ │ │ ├── label_file.txt
│ │ │ │ ├── module.py
│ │ │ │ ├── processor.py
│ │ │ │ └── test.py
│ │ │ ├── faster_rcnn_resnet50_fpn_venus/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── bbox_assigner.py
│ │ │ │ ├── bbox_head.py
│ │ │ │ ├── data_feed.py
│ │ │ │ ├── fpn.py
│ │ │ │ ├── module.py
│ │ │ │ ├── name_adapter.py
│ │ │ │ ├── nonlocal_helper.py
│ │ │ │ ├── processor.py
│ │ │ │ ├── resnet.py
│ │ │ │ ├── roi_extractor.py
│ │ │ │ └── rpn_head.py
│ │ │ ├── ssd_mobilenet_v1_pascal/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── config.yml
│ │ │ │ ├── data_feed.py
│ │ │ │ ├── label_file.txt
│ │ │ │ ├── module.py
│ │ │ │ ├── processor.py
│ │ │ │ └── test.py
│ │ │ ├── ssd_vgg16_300_coco2017/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── config.yml
│ │ │ │ ├── data_feed.py
│ │ │ │ ├── label_file.txt
│ │ │ │ ├── module.py
│ │ │ │ ├── processor.py
│ │ │ │ └── test.py
│ │ │ ├── ssd_vgg16_512_coco2017/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── config.yml
│ │ │ │ ├── data_feed.py
│ │ │ │ ├── label_file.txt
│ │ │ │ ├── module.py
│ │ │ │ ├── processor.py
│ │ │ │ └── test.py
│ │ │ ├── yolov3_darknet53_coco2017/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── data_feed.py
│ │ │ │ ├── label_file.txt
│ │ │ │ ├── module.py
│ │ │ │ ├── processor.py
│ │ │ │ └── test.py
│ │ │ ├── yolov3_darknet53_pedestrian/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── data_feed.py
│ │ │ │ ├── label_file.txt
│ │ │ │ ├── module.py
│ │ │ │ ├── processor.py
│ │ │ │ └── test.py
│ │ │ ├── yolov3_darknet53_vehicles/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── data_feed.py
│ │ │ │ ├── label_file.txt
│ │ │ │ ├── module.py
│ │ │ │ ├── processor.py
│ │ │ │ └── test.py
│ │ │ ├── yolov3_darknet53_venus/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── darknet.py
│ │ │ │ ├── data_feed.py
│ │ │ │ ├── module.py
│ │ │ │ ├── processor.py
│ │ │ │ └── yolo_head.py
│ │ │ ├── yolov3_mobilenet_v1_coco2017/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── data_feed.py
│ │ │ │ ├── label_file.txt
│ │ │ │ ├── module.py
│ │ │ │ ├── processor.py
│ │ │ │ └── test.py
│ │ │ ├── yolov3_resnet34_coco2017/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── data_feed.py
│ │ │ │ ├── label_file.txt
│ │ │ │ ├── module.py
│ │ │ │ ├── processor.py
│ │ │ │ └── test.py
│ │ │ └── yolov3_resnet50_vd_coco2017/
│ │ │ ├── README.md
│ │ │ ├── README_en.md
│ │ │ ├── __init__.py
│ │ │ ├── data_feed.py
│ │ │ ├── label_file.txt
│ │ │ ├── module.py
│ │ │ ├── processor.py
│ │ │ └── test.py
│ │ ├── semantic_segmentation/
│ │ │ ├── Extract_Line_Draft/
│ │ │ │ ├── Readme.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── function.py
│ │ │ │ ├── module.py
│ │ │ │ └── test.py
│ │ │ ├── ExtremeC3_Portrait_Segmentation/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ └── module.py
│ │ │ ├── FCN_HRNet_W18_Face_Seg/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── model/
│ │ │ │ │ ├── __init__.py
│ │ │ │ │ ├── fcn.py
│ │ │ │ │ ├── hrnet.py
│ │ │ │ │ └── layers.py
│ │ │ │ └── module.py
│ │ │ ├── Pneumonia_CT_LKM_PP/
│ │ │ │ ├── README.md
│ │ │ │ └── README_en.md
│ │ │ ├── Pneumonia_CT_LKM_PP_lung/
│ │ │ │ ├── README.md
│ │ │ │ └── README_en.md
│ │ │ ├── README.md
│ │ │ ├── README_en.md
│ │ │ ├── SINet_Portrait_Segmentation/
│ │ │ │ ├── README.md
│ │ │ │ └── module.py
│ │ │ ├── U2Net/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── module.py
│ │ │ │ ├── processor.py
│ │ │ │ └── u2net.py
│ │ │ ├── U2Netp/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── module.py
│ │ │ │ ├── processor.py
│ │ │ │ └── u2net.py
│ │ │ ├── WatermeterSegmentation/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── assets/
│ │ │ │ │ └── model.yml
│ │ │ │ ├── module.py
│ │ │ │ └── serving_client_demo.py
│ │ │ ├── ace2p/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── data_feed.py
│ │ │ │ ├── label_list.txt
│ │ │ │ ├── module.py
│ │ │ │ ├── processor.py
│ │ │ │ └── test.py
│ │ │ ├── ann_resnet50_cityscapes/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── layers.py
│ │ │ │ ├── module.py
│ │ │ │ └── resnet.py
│ │ │ ├── ann_resnet50_voc/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── layers.py
│ │ │ │ ├── module.py
│ │ │ │ └── resnet.py
│ │ │ ├── bisenet_lane_segmentation/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── lane_processor/
│ │ │ │ │ ├── get_lane_coords.py
│ │ │ │ │ ├── lane.py
│ │ │ │ │ └── tusimple_processor.py
│ │ │ │ ├── module.py
│ │ │ │ └── processor.py
│ │ │ ├── bisenetv2_cityscapes/
│ │ │ │ ├── README.md
│ │ │ │ ├── layers.py
│ │ │ │ └── module.py
│ │ │ ├── danet_resnet50_cityscapes/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── layers.py
│ │ │ │ ├── module.py
│ │ │ │ └── resnet.py
│ │ │ ├── danet_resnet50_voc/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── layers.py
│ │ │ │ ├── module.py
│ │ │ │ └── resnet.py
│ │ │ ├── deeplabv3p_resnet50_cityscapes/
│ │ │ │ ├── README.md
│ │ │ │ ├── layers.py
│ │ │ │ ├── module.py
│ │ │ │ └── resnet.py
│ │ │ ├── deeplabv3p_resnet50_voc/
│ │ │ │ ├── README.md
│ │ │ │ ├── layers.py
│ │ │ │ ├── module.py
│ │ │ │ └── resnet.py
│ │ │ ├── deeplabv3p_xception65_humanseg/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── data_feed.py
│ │ │ │ ├── module.py
│ │ │ │ ├── processor.py
│ │ │ │ └── test.py
│ │ │ ├── fastscnn_cityscapes/
│ │ │ │ ├── README.md
│ │ │ │ ├── layers.py
│ │ │ │ └── module.py
│ │ │ ├── fcn_hrnetw18_cityscapes/
│ │ │ │ ├── README.md
│ │ │ │ ├── hrnet.py
│ │ │ │ ├── layers.py
│ │ │ │ └── module.py
│ │ │ ├── fcn_hrnetw18_voc/
│ │ │ │ ├── README.md
│ │ │ │ ├── hrnet.py
│ │ │ │ ├── layers.py
│ │ │ │ └── module.py
│ │ │ ├── fcn_hrnetw48_cityscapes/
│ │ │ │ ├── README.md
│ │ │ │ ├── hrnet.py
│ │ │ │ ├── layers.py
│ │ │ │ └── module.py
│ │ │ ├── fcn_hrnetw48_voc/
│ │ │ │ ├── README.md
│ │ │ │ ├── hrnet.py
│ │ │ │ ├── layers.py
│ │ │ │ └── module.py
│ │ │ ├── ginet_resnet101vd_ade20k/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── layers.py
│ │ │ │ ├── module.py
│ │ │ │ ├── requirements.txt
│ │ │ │ └── resnet.py
│ │ │ ├── ginet_resnet101vd_cityscapes/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── layers.py
│ │ │ │ ├── module.py
│ │ │ │ ├── requirements.txt
│ │ │ │ └── resnet.py
│ │ │ ├── ginet_resnet101vd_voc/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── layers.py
│ │ │ │ ├── module.py
│ │ │ │ ├── requirements.txt
│ │ │ │ └── resnet.py
│ │ │ ├── ginet_resnet50vd_ade20k/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── layers.py
│ │ │ │ ├── module.py
│ │ │ │ ├── requirements.txt
│ │ │ │ └── resnet.py
│ │ │ ├── ginet_resnet50vd_cityscapes/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── layers.py
│ │ │ │ ├── module.py
│ │ │ │ ├── requirements.txt
│ │ │ │ └── resnet.py
│ │ │ ├── ginet_resnet50vd_voc/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── layers.py
│ │ │ │ ├── module.py
│ │ │ │ ├── requirements.txt
│ │ │ │ └── resnet.py
│ │ │ ├── hardnet_cityscapes/
│ │ │ │ ├── README.md
│ │ │ │ ├── layers.py
│ │ │ │ └── module.py
│ │ │ ├── humanseg_lite/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── data_feed.py
│ │ │ │ ├── module.py
│ │ │ │ ├── optimal.py
│ │ │ │ ├── processor.py
│ │ │ │ └── test.py
│ │ │ ├── humanseg_mobile/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── data_feed.py
│ │ │ │ ├── module.py
│ │ │ │ ├── optimal.py
│ │ │ │ ├── processor.py
│ │ │ │ └── test.py
│ │ │ ├── humanseg_server/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── data_feed.py
│ │ │ │ ├── module.py
│ │ │ │ ├── optimal.py
│ │ │ │ ├── processor.py
│ │ │ │ └── test.py
│ │ │ ├── isanet_resnet50_cityscapes/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── layers.py
│ │ │ │ ├── module.py
│ │ │ │ └── resnet.py
│ │ │ ├── isanet_resnet50_voc/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── layers.py
│ │ │ │ ├── module.py
│ │ │ │ └── resnet.py
│ │ │ ├── lseg/
│ │ │ │ ├── README.md
│ │ │ │ ├── models/
│ │ │ │ │ ├── __init__.py
│ │ │ │ │ ├── clip.py
│ │ │ │ │ ├── lseg.py
│ │ │ │ │ ├── scratch.py
│ │ │ │ │ └── vit.py
│ │ │ │ ├── module.py
│ │ │ │ ├── requirements.txt
│ │ │ │ └── test.py
│ │ │ ├── ocrnet_hrnetw18_cityscapes/
│ │ │ │ ├── README.md
│ │ │ │ ├── hrnet.py
│ │ │ │ ├── layers.py
│ │ │ │ └── module.py
│ │ │ ├── ocrnet_hrnetw18_voc/
│ │ │ │ ├── README.md
│ │ │ │ ├── hrnet.py
│ │ │ │ ├── layers.py
│ │ │ │ └── module.py
│ │ │ ├── pspnet_resnet50_cityscapes/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── layers.py
│ │ │ │ ├── module.py
│ │ │ │ └── resnet.py
│ │ │ ├── pspnet_resnet50_voc/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── layers.py
│ │ │ │ ├── module.py
│ │ │ │ └── resnet.py
│ │ │ ├── stdc1_seg_cityscapes/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── layers.py
│ │ │ │ ├── module.py
│ │ │ │ └── stdcnet.py
│ │ │ ├── stdc1_seg_voc/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── layers.py
│ │ │ │ ├── module.py
│ │ │ │ └── stdcnet.py
│ │ │ └── unet_cityscapes/
│ │ │ ├── README.md
│ │ │ ├── layers.py
│ │ │ └── module.py
│ │ ├── text_recognition/
│ │ │ ├── README.md
│ │ │ ├── README_en.md
│ │ │ ├── Vehicle_License_Plate_Recognition/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ └── module.py
│ │ │ ├── arabic_ocr_db_crnn_mobile/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── module.py
│ │ │ │ └── requirements.txt
│ │ │ ├── ch_pp-ocrv3/
│ │ │ │ ├── README.md
│ │ │ │ ├── character.py
│ │ │ │ ├── module.py
│ │ │ │ ├── test.py
│ │ │ │ └── utils.py
│ │ │ ├── ch_pp-ocrv3_det/
│ │ │ │ ├── README.md
│ │ │ │ ├── module.py
│ │ │ │ ├── processor.py
│ │ │ │ ├── requirements.txt
│ │ │ │ └── test.py
│ │ │ ├── chinese_cht_ocr_db_crnn_mobile/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── module.py
│ │ │ │ └── requirements.txt
│ │ │ ├── chinese_ocr_db_crnn_mobile/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── character.py
│ │ │ │ ├── module.py
│ │ │ │ ├── test.py
│ │ │ │ └── utils.py
│ │ │ ├── chinese_ocr_db_crnn_server/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── character.py
│ │ │ │ ├── module.py
│ │ │ │ ├── test.py
│ │ │ │ └── utils.py
│ │ │ ├── chinese_text_detection_db_mobile/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── module.py
│ │ │ │ ├── processor.py
│ │ │ │ ├── requirements.txt
│ │ │ │ └── test.py
│ │ │ ├── chinese_text_detection_db_server/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── module.py
│ │ │ │ ├── processor.py
│ │ │ │ ├── requirements.txt
│ │ │ │ └── test.py
│ │ │ ├── cyrillic_ocr_db_crnn_mobile/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── module.py
│ │ │ │ └── requirements.txt
│ │ │ ├── devanagari_ocr_db_crnn_mobile/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── module.py
│ │ │ │ └── requirements.txt
│ │ │ ├── french_ocr_db_crnn_mobile/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── module.py
│ │ │ │ └── requirements.txt
│ │ │ ├── german_ocr_db_crnn_mobile/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── module.py
│ │ │ │ └── requirements.txt
│ │ │ ├── japan_ocr_db_crnn_mobile/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── module.py
│ │ │ │ └── requirements.txt
│ │ │ ├── kannada_ocr_db_crnn_mobile/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── module.py
│ │ │ │ └── requirements.txt
│ │ │ ├── korean_ocr_db_crnn_mobile/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── module.py
│ │ │ │ └── requirements.txt
│ │ │ ├── latin_ocr_db_crnn_mobile/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── module.py
│ │ │ │ └── requirements.txt
│ │ │ ├── multi_languages_ocr_db_crnn/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── module.py
│ │ │ │ ├── requirements.txt
│ │ │ │ ├── test.py
│ │ │ │ └── utils.py
│ │ │ ├── tamil_ocr_db_crnn_mobile/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── module.py
│ │ │ │ └── requirements.txt
│ │ │ └── telugu_ocr_db_crnn_mobile/
│ │ │ ├── README.md
│ │ │ ├── __init__.py
│ │ │ ├── module.py
│ │ │ └── requirements.txt
│ │ └── text_to_image/
│ │ ├── disco_diffusion_clip_rn101/
│ │ │ ├── README.md
│ │ │ ├── README_en.md
│ │ │ ├── clip/
│ │ │ │ ├── README.md
│ │ │ │ └── clip/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── layers.py
│ │ │ │ ├── model.py
│ │ │ │ ├── simple_tokenizer.py
│ │ │ │ └── utils.py
│ │ │ ├── module.py
│ │ │ ├── requirements.txt
│ │ │ ├── resize_right/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── interp_methods.py
│ │ │ │ └── resize_right.py
│ │ │ └── reverse_diffusion/
│ │ │ ├── README.md
│ │ │ ├── __init__.py
│ │ │ ├── config.py
│ │ │ ├── helper.py
│ │ │ ├── model/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── gaussian_diffusion.py
│ │ │ │ ├── losses.py
│ │ │ │ ├── make_cutouts.py
│ │ │ │ ├── nn.py
│ │ │ │ ├── perlin_noises.py
│ │ │ │ ├── respace.py
│ │ │ │ ├── script_util.py
│ │ │ │ ├── sec_diff.py
│ │ │ │ ├── transforms.py
│ │ │ │ └── unet.py
│ │ │ ├── resources/
│ │ │ │ ├── default.yml
│ │ │ │ └── docstrings.yml
│ │ │ └── runner.py
│ │ ├── disco_diffusion_clip_rn50/
│ │ │ ├── README.md
│ │ │ ├── README_en.md
│ │ │ ├── clip/
│ │ │ │ ├── README.md
│ │ │ │ └── clip/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── layers.py
│ │ │ │ ├── model.py
│ │ │ │ ├── simple_tokenizer.py
│ │ │ │ └── utils.py
│ │ │ ├── module.py
│ │ │ ├── requirements.txt
│ │ │ ├── resize_right/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── interp_methods.py
│ │ │ │ └── resize_right.py
│ │ │ └── reverse_diffusion/
│ │ │ ├── README.md
│ │ │ ├── __init__.py
│ │ │ ├── config.py
│ │ │ ├── helper.py
│ │ │ ├── model/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── gaussian_diffusion.py
│ │ │ │ ├── losses.py
│ │ │ │ ├── make_cutouts.py
│ │ │ │ ├── nn.py
│ │ │ │ ├── perlin_noises.py
│ │ │ │ ├── respace.py
│ │ │ │ ├── script_util.py
│ │ │ │ ├── sec_diff.py
│ │ │ │ ├── transforms.py
│ │ │ │ └── unet.py
│ │ │ ├── resources/
│ │ │ │ ├── default.yml
│ │ │ │ └── docstrings.yml
│ │ │ └── runner.py
│ │ ├── disco_diffusion_clip_vitb32/
│ │ │ ├── README.md
│ │ │ ├── README_en.md
│ │ │ ├── clip/
│ │ │ │ ├── README.md
│ │ │ │ └── clip/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── layers.py
│ │ │ │ ├── model.py
│ │ │ │ ├── simple_tokenizer.py
│ │ │ │ └── utils.py
│ │ │ ├── module.py
│ │ │ ├── requirements.txt
│ │ │ ├── resize_right/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── interp_methods.py
│ │ │ │ └── resize_right.py
│ │ │ └── reverse_diffusion/
│ │ │ ├── README.md
│ │ │ ├── __init__.py
│ │ │ ├── config.py
│ │ │ ├── helper.py
│ │ │ ├── model/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── gaussian_diffusion.py
│ │ │ │ ├── losses.py
│ │ │ │ ├── make_cutouts.py
│ │ │ │ ├── nn.py
│ │ │ │ ├── perlin_noises.py
│ │ │ │ ├── respace.py
│ │ │ │ ├── script_util.py
│ │ │ │ ├── sec_diff.py
│ │ │ │ ├── transforms.py
│ │ │ │ └── unet.py
│ │ │ ├── resources/
│ │ │ │ ├── default.yml
│ │ │ │ └── docstrings.yml
│ │ │ └── runner.py
│ │ ├── disco_diffusion_cnclip_vitb16/
│ │ │ ├── README.md
│ │ │ ├── README_en.md
│ │ │ ├── cn_clip/
│ │ │ │ └── clip/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── bert_tokenizer.py
│ │ │ │ ├── configuration_bert.py
│ │ │ │ ├── model.py
│ │ │ │ ├── model_configs/
│ │ │ │ │ ├── RoBERTa-wwm-ext-base-chinese.json
│ │ │ │ │ ├── RoBERTa-wwm-ext-large-chinese.json
│ │ │ │ │ ├── ViT-B-16.json
│ │ │ │ │ ├── ViT-B-32.json
│ │ │ │ │ └── ViT-L-14.json
│ │ │ │ ├── modeling_bert.py
│ │ │ │ └── utils.py
│ │ │ ├── module.py
│ │ │ ├── requirements.txt
│ │ │ ├── resize_right/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── interp_methods.py
│ │ │ │ └── resize_right.py
│ │ │ └── reverse_diffusion/
│ │ │ ├── README.md
│ │ │ ├── __init__.py
│ │ │ ├── config.py
│ │ │ ├── helper.py
│ │ │ ├── model/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── gaussian_diffusion.py
│ │ │ │ ├── losses.py
│ │ │ │ ├── make_cutouts.py
│ │ │ │ ├── nn.py
│ │ │ │ ├── perlin_noises.py
│ │ │ │ ├── respace.py
│ │ │ │ ├── script_util.py
│ │ │ │ ├── sec_diff.py
│ │ │ │ ├── transforms.py
│ │ │ │ └── unet.py
│ │ │ ├── resources/
│ │ │ │ ├── default.yml
│ │ │ │ └── docstrings.yml
│ │ │ └── runner.py
│ │ ├── disco_diffusion_ernievil_base/
│ │ │ ├── README.md
│ │ │ ├── README_en.md
│ │ │ ├── module.py
│ │ │ ├── requirements.txt
│ │ │ ├── resize_right/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── interp_methods.py
│ │ │ │ └── resize_right.py
│ │ │ ├── reverse_diffusion/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── config.py
│ │ │ │ ├── helper.py
│ │ │ │ ├── model/
│ │ │ │ │ ├── __init__.py
│ │ │ │ │ ├── gaussian_diffusion.py
│ │ │ │ │ ├── losses.py
│ │ │ │ │ ├── make_cutouts.py
│ │ │ │ │ ├── nn.py
│ │ │ │ │ ├── perlin_noises.py
│ │ │ │ │ ├── respace.py
│ │ │ │ │ ├── script_util.py
│ │ │ │ │ ├── sec_diff.py
│ │ │ │ │ ├── transforms.py
│ │ │ │ │ └── unet.py
│ │ │ │ ├── resources/
│ │ │ │ │ ├── default.yml
│ │ │ │ │ └── docstrings.yml
│ │ │ │ └── runner.py
│ │ │ └── vit_b_16x/
│ │ │ ├── ernievil2/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── transformers/
│ │ │ │ │ ├── __init__.py
│ │ │ │ │ ├── clip_vision_transformer.py
│ │ │ │ │ ├── droppath.py
│ │ │ │ │ ├── efficientnet.py
│ │ │ │ │ ├── ernie2.py
│ │ │ │ │ ├── ernie_modeling.py
│ │ │ │ │ ├── ernie_tokenizer.py
│ │ │ │ │ ├── file_utils.py
│ │ │ │ │ ├── multimodal.py
│ │ │ │ │ ├── paddle_vision_transformer.py
│ │ │ │ │ └── resnet.py
│ │ │ │ └── utils/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── tokenizer.py
│ │ │ │ └── utils.py
│ │ │ └── packages/
│ │ │ ├── configs/
│ │ │ │ └── vit_ernie_base.yaml
│ │ │ └── ernie_base_3.0/
│ │ │ └── ernie_config.base.json
│ │ ├── ernie_vilg/
│ │ │ ├── README.md
│ │ │ ├── __init__.py
│ │ │ ├── module.py
│ │ │ ├── requirements.txt
│ │ │ └── test.py
│ │ ├── stable_diffusion/
│ │ │ ├── LICENSE
│ │ │ ├── README.md
│ │ │ ├── README_en.md
│ │ │ ├── clip/
│ │ │ │ ├── README.md
│ │ │ │ └── clip/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── layers.py
│ │ │ │ ├── model.py
│ │ │ │ ├── simple_tokenizer.py
│ │ │ │ └── utils.py
│ │ │ ├── diffusers/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── configuration_utils.py
│ │ │ │ ├── models/
│ │ │ │ │ ├── README.md
│ │ │ │ │ ├── __init__.py
│ │ │ │ │ ├── attention.py
│ │ │ │ │ ├── embeddings.py
│ │ │ │ │ ├── resnet.py
│ │ │ │ │ ├── unet_2d.py
│ │ │ │ │ ├── unet_2d_condition.py
│ │ │ │ │ ├── unet_blocks.py
│ │ │ │ │ └── vae.py
│ │ │ │ └── schedulers/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── scheduling_ddim.py
│ │ │ │ ├── scheduling_ddpm.py
│ │ │ │ ├── scheduling_karras_ve.py
│ │ │ │ ├── scheduling_lms_discrete.py
│ │ │ │ ├── scheduling_pndm.py
│ │ │ │ ├── scheduling_sde_ve.py
│ │ │ │ ├── scheduling_sde_vp.py
│ │ │ │ └── scheduling_utils.py
│ │ │ ├── module.py
│ │ │ └── requirements.txt
│ │ ├── stable_diffusion_img2img/
│ │ │ ├── LICENSE
│ │ │ ├── README.md
│ │ │ ├── clip/
│ │ │ │ ├── README.md
│ │ │ │ └── clip/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── layers.py
│ │ │ │ ├── model.py
│ │ │ │ ├── simple_tokenizer.py
│ │ │ │ └── utils.py
│ │ │ ├── diffusers/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── configuration_utils.py
│ │ │ │ ├── models/
│ │ │ │ │ ├── README.md
│ │ │ │ │ ├── __init__.py
│ │ │ │ │ ├── attention.py
│ │ │ │ │ ├── embeddings.py
│ │ │ │ │ ├── resnet.py
│ │ │ │ │ ├── unet_2d.py
│ │ │ │ │ ├── unet_2d_condition.py
│ │ │ │ │ ├── unet_blocks.py
│ │ │ │ │ └── vae.py
│ │ │ │ └── schedulers/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── scheduling_ddim.py
│ │ │ │ ├── scheduling_ddpm.py
│ │ │ │ ├── scheduling_karras_ve.py
│ │ │ │ ├── scheduling_lms_discrete.py
│ │ │ │ ├── scheduling_pndm.py
│ │ │ │ ├── scheduling_sde_ve.py
│ │ │ │ ├── scheduling_sde_vp.py
│ │ │ │ └── scheduling_utils.py
│ │ │ ├── module.py
│ │ │ ├── requirements.txt
│ │ │ └── utils.py
│ │ ├── stable_diffusion_inpainting/
│ │ │ ├── LICENSE
│ │ │ ├── README.md
│ │ │ ├── clip/
│ │ │ │ ├── README.md
│ │ │ │ └── clip/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── layers.py
│ │ │ │ ├── model.py
│ │ │ │ ├── simple_tokenizer.py
│ │ │ │ └── utils.py
│ │ │ ├── diffusers/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── configuration_utils.py
│ │ │ │ ├── models/
│ │ │ │ │ ├── README.md
│ │ │ │ │ ├── __init__.py
│ │ │ │ │ ├── attention.py
│ │ │ │ │ ├── embeddings.py
│ │ │ │ │ ├── resnet.py
│ │ │ │ │ ├── unet_2d.py
│ │ │ │ │ ├── unet_2d_condition.py
│ │ │ │ │ ├── unet_blocks.py
│ │ │ │ │ └── vae.py
│ │ │ │ └── schedulers/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── scheduling_ddim.py
│ │ │ │ ├── scheduling_ddpm.py
│ │ │ │ ├── scheduling_karras_ve.py
│ │ │ │ ├── scheduling_lms_discrete.py
│ │ │ │ ├── scheduling_pndm.py
│ │ │ │ ├── scheduling_sde_ve.py
│ │ │ │ ├── scheduling_sde_vp.py
│ │ │ │ └── scheduling_utils.py
│ │ │ ├── module.py
│ │ │ ├── requirements.txt
│ │ │ └── utils.py
│ │ └── stable_diffusion_waifu/
│ │ ├── LICENSE
│ │ ├── README.md
│ │ ├── clip/
│ │ │ ├── README.md
│ │ │ └── clip/
│ │ │ ├── __init__.py
│ │ │ ├── layers.py
│ │ │ ├── model.py
│ │ │ ├── simple_tokenizer.py
│ │ │ └── utils.py
│ │ ├── diffusers/
│ │ │ ├── __init__.py
│ │ │ ├── configuration_utils.py
│ │ │ ├── models/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── attention.py
│ │ │ │ ├── embeddings.py
│ │ │ │ ├── resnet.py
│ │ │ │ ├── unet_2d.py
│ │ │ │ ├── unet_2d_condition.py
│ │ │ │ ├── unet_blocks.py
│ │ │ │ └── vae.py
│ │ │ └── schedulers/
│ │ │ ├── README.md
│ │ │ ├── __init__.py
│ │ │ ├── scheduling_ddim.py
│ │ │ ├── scheduling_ddpm.py
│ │ │ ├── scheduling_karras_ve.py
│ │ │ ├── scheduling_lms_discrete.py
│ │ │ ├── scheduling_pndm.py
│ │ │ ├── scheduling_sde_ve.py
│ │ │ ├── scheduling_sde_vp.py
│ │ │ └── scheduling_utils.py
│ │ ├── module.py
│ │ └── requirements.txt
│ ├── text/
│ │ ├── README.md
│ │ ├── embedding/
│ │ │ ├── README.md
│ │ │ ├── fasttext_crawl_target_word-word_dim300_en/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── fasttext_wiki-news_target_word-word_dim300_en/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── glove_twitter_target_word-word_dim100_en/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── glove_twitter_target_word-word_dim200_en/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── glove_twitter_target_word-word_dim25_en/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── glove_twitter_target_word-word_dim50_en/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── glove_wiki2014-gigaword_target_word-word_dim100_en/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── glove_wiki2014-gigaword_target_word-word_dim200_en/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── glove_wiki2014-gigaword_target_word-word_dim300_en/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── glove_wiki2014-gigaword_target_word-word_dim50_en/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── w2v_baidu_encyclopedia_context_word-character_char1-1_dim300/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── w2v_baidu_encyclopedia_context_word-character_char1-2_dim300/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── w2v_baidu_encyclopedia_context_word-character_char1-4_dim300/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── w2v_baidu_encyclopedia_context_word-ngram_1-2_dim300/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── w2v_baidu_encyclopedia_context_word-ngram_1-3_dim300/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── w2v_baidu_encyclopedia_context_word-ngram_2-2_dim300/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── w2v_baidu_encyclopedia_context_word-wordLR_dim300/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── w2v_baidu_encyclopedia_context_word-wordPosition_dim300/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── w2v_baidu_encyclopedia_context_word-word_dim300/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── w2v_baidu_encyclopedia_target_bigram-char_dim300/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── w2v_baidu_encyclopedia_target_word-character_char1-1_dim300/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── w2v_baidu_encyclopedia_target_word-character_char1-2_dim300/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── w2v_baidu_encyclopedia_target_word-character_char1-4_dim300/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── w2v_baidu_encyclopedia_target_word-ngram_1-2_dim300/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── w2v_baidu_encyclopedia_target_word-ngram_1-3_dim300/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── w2v_baidu_encyclopedia_target_word-ngram_2-2_dim300/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── w2v_baidu_encyclopedia_target_word-wordLR_dim300/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── w2v_baidu_encyclopedia_target_word-wordPosition_dim300/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── w2v_baidu_encyclopedia_target_word-word_dim300/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── w2v_financial_target_bigram-char_dim300/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── w2v_financial_target_word-bigram_dim300/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── w2v_financial_target_word-char_dim300/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── w2v_financial_target_word-word_dim300/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── w2v_literature_target_bigram-char_dim300/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── w2v_literature_target_word-bigram_dim300/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── w2v_literature_target_word-char_dim300/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── w2v_literature_target_word-word_dim300/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── w2v_mixed-large_target_word-char_dim300/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── w2v_mixed-large_target_word-word_dim300/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── w2v_people_daily_target_bigram-char_dim300/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── w2v_people_daily_target_word-bigram_dim300/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── w2v_people_daily_target_word-char_dim300/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── w2v_people_daily_target_word-word_dim300/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── w2v_sikuquanshu_target_word-bigram_dim300/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── w2v_sikuquanshu_target_word-word_dim300/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── w2v_sogou_target_bigram-char_dim300/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── w2v_sogou_target_word-bigram_dim300/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── w2v_sogou_target_word-char_dim300/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── w2v_sogou_target_word-word_dim300/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── w2v_weibo_target_bigram-char_dim300/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── w2v_weibo_target_word-bigram_dim300/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── w2v_weibo_target_word-char_dim300/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── w2v_weibo_target_word-word_dim300/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── w2v_wiki_target_bigram-char_dim300/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── w2v_wiki_target_word-bigram_dim300/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── w2v_wiki_target_word-char_dim300/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── w2v_wiki_target_word-word_dim300/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── w2v_zhihu_target_bigram-char_dim300/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── w2v_zhihu_target_word-bigram_dim300/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── w2v_zhihu_target_word-char_dim300/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── w2v_zhihu_target_word-word_dim300/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ └── word2vec_skipgram/
│ │ │ ├── README.md
│ │ │ └── module.py
│ │ ├── language_model/
│ │ │ ├── README.md
│ │ │ ├── README_en.md
│ │ │ ├── albert-base-v1/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── albert-base-v2/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── albert-chinese-base/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── albert-chinese-large/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── albert-chinese-small/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── albert-chinese-tiny/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── albert-chinese-xlarge/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── albert-chinese-xxlarge/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── albert-xxlarge-v1/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── albert-xxlarge-v2/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── bert-base-cased/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── bert-base-chinese/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── bert-base-multilingual-cased/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── bert-base-multilingual-uncased/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── bert-base-uncased/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── bert-large-cased/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── bert-large-uncased/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── chinese_bert_wwm/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── chinese_bert_wwm_ext/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── chinese_electra_base/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── chinese_electra_small/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── electra_base/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── electra_large/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── electra_small/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── ernie/
│ │ │ │ ├── README.md
│ │ │ │ └── module.py
│ │ │ ├── ernie_tiny/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── ernie_v2_eng_base/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── ernie_v2_eng_large/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── lda_news/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── config.py
│ │ │ │ ├── document.py
│ │ │ │ ├── inference_engine.py
│ │ │ │ ├── model.py
│ │ │ │ ├── module.py
│ │ │ │ ├── sampler.py
│ │ │ │ ├── semantic_matching.py
│ │ │ │ ├── tokenizer.py
│ │ │ │ ├── util.py
│ │ │ │ ├── vocab.py
│ │ │ │ └── vose_alias.py
│ │ │ ├── lda_novel/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── config.py
│ │ │ │ ├── document.py
│ │ │ │ ├── inference_engine.py
│ │ │ │ ├── model.py
│ │ │ │ ├── module.py
│ │ │ │ ├── sampler.py
│ │ │ │ ├── semantic_matching.py
│ │ │ │ ├── tokenizer.py
│ │ │ │ ├── util.py
│ │ │ │ ├── vocab.py
│ │ │ │ └── vose_alias.py
│ │ │ ├── lda_webpage/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── config.py
│ │ │ │ ├── document.py
│ │ │ │ ├── inference_engine.py
│ │ │ │ ├── model.py
│ │ │ │ ├── module.py
│ │ │ │ ├── sampler.py
│ │ │ │ ├── semantic_matching.py
│ │ │ │ ├── tokenizer.py
│ │ │ │ ├── util.py
│ │ │ │ ├── vocab.py
│ │ │ │ └── vose_alias.py
│ │ │ ├── rbt3/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── rbtl3/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── roberta-wwm-ext/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── roberta-wwm-ext-large/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── simnet_bow/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── assets/
│ │ │ │ │ ├── params.txt
│ │ │ │ │ └── vocab.txt
│ │ │ │ ├── module.py
│ │ │ │ └── processor.py
│ │ │ ├── slda_news/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── config.py
│ │ │ │ ├── document.py
│ │ │ │ ├── inference_engine.py
│ │ │ │ ├── model.py
│ │ │ │ ├── module.py
│ │ │ │ ├── sampler.py
│ │ │ │ ├── semantic_matching.py
│ │ │ │ ├── tokenizer.py
│ │ │ │ ├── util.py
│ │ │ │ ├── vocab.py
│ │ │ │ └── vose_alias.py
│ │ │ ├── slda_novel/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── config.py
│ │ │ │ ├── document.py
│ │ │ │ ├── inference_engine.py
│ │ │ │ ├── model.py
│ │ │ │ ├── module.py
│ │ │ │ ├── sampler.py
│ │ │ │ ├── semantic_matching.py
│ │ │ │ ├── tokenizer.py
│ │ │ │ ├── util.py
│ │ │ │ ├── vocab.py
│ │ │ │ └── vose_alias.py
│ │ │ ├── slda_webpage/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── config.py
│ │ │ │ ├── document.py
│ │ │ │ ├── inference_engine.py
│ │ │ │ ├── model.py
│ │ │ │ ├── module.py
│ │ │ │ ├── sampler.py
│ │ │ │ ├── semantic_matching.py
│ │ │ │ ├── tokenizer.py
│ │ │ │ ├── util.py
│ │ │ │ ├── vocab.py
│ │ │ │ └── vose_alias.py
│ │ │ └── slda_weibo/
│ │ │ ├── README.md
│ │ │ ├── __init__.py
│ │ │ ├── config.py
│ │ │ ├── document.py
│ │ │ ├── inference_engine.py
│ │ │ ├── model.py
│ │ │ ├── module.py
│ │ │ ├── sampler.py
│ │ │ ├── semantic_matching.py
│ │ │ ├── tokenizer.py
│ │ │ ├── util.py
│ │ │ ├── vocab.py
│ │ │ └── vose_alias.py
│ │ ├── lexical_analysis/
│ │ │ ├── README.md
│ │ │ ├── README_en.md
│ │ │ ├── jieba_paddle/
│ │ │ │ ├── README.md
│ │ │ │ └── module.py
│ │ │ └── lac/
│ │ │ ├── README.md
│ │ │ ├── __init__.py
│ │ │ ├── ahocorasick.py
│ │ │ ├── assets/
│ │ │ │ ├── q2b.dic
│ │ │ │ ├── tag.dic
│ │ │ │ ├── tag_file.txt
│ │ │ │ ├── unigram.dict
│ │ │ │ └── word.dic
│ │ │ ├── custom.py
│ │ │ ├── module.py
│ │ │ ├── processor.py
│ │ │ └── test.py
│ │ ├── machine_translation/
│ │ │ └── transformer/
│ │ │ ├── en-de/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── module.py
│ │ │ │ ├── requirements.txt
│ │ │ │ └── utils.py
│ │ │ └── zh-en/
│ │ │ ├── README.md
│ │ │ ├── __init__.py
│ │ │ ├── module.py
│ │ │ ├── requirements.txt
│ │ │ └── utils.py
│ │ ├── punctuation_restoration/
│ │ │ └── auto_punc/
│ │ │ ├── README.md
│ │ │ ├── __init__.py
│ │ │ └── module.py
│ │ ├── sentiment_analysis/
│ │ │ ├── README.md
│ │ │ ├── README_en.md
│ │ │ ├── emotion_detection_textcnn/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── assets/
│ │ │ │ │ └── vocab.txt
│ │ │ │ ├── module.py
│ │ │ │ └── processor.py
│ │ │ ├── ernie_skep_sentiment_analysis/
│ │ │ │ ├── README.md
│ │ │ │ ├── assets/
│ │ │ │ │ ├── ernie_1.0_large_ch.config.json
│ │ │ │ │ └── ernie_1.0_large_ch.vocab.txt
│ │ │ │ ├── model/
│ │ │ │ │ ├── __init__.py
│ │ │ │ │ └── ernie.py
│ │ │ │ └── module.py
│ │ │ ├── senta_bilstm/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── assets/
│ │ │ │ │ └── vocab.txt
│ │ │ │ ├── module.py
│ │ │ │ └── processor.py
│ │ │ ├── senta_bow/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── assets/
│ │ │ │ │ └── vocab.txt
│ │ │ │ ├── module.py
│ │ │ │ └── processor.py
│ │ │ ├── senta_cnn/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── assets/
│ │ │ │ │ └── vocab.txt
│ │ │ │ ├── module.py
│ │ │ │ └── processor.py
│ │ │ ├── senta_gru/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── assets/
│ │ │ │ │ └── vocab.txt
│ │ │ │ ├── module.py
│ │ │ │ └── processor.py
│ │ │ └── senta_lstm/
│ │ │ ├── README.md
│ │ │ ├── __init__.py
│ │ │ ├── assets/
│ │ │ │ └── vocab.txt
│ │ │ ├── module.py
│ │ │ └── processor.py
│ │ ├── simultaneous_translation/
│ │ │ └── stacl/
│ │ │ ├── transformer_nist_wait_1/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── model.py
│ │ │ │ ├── module.py
│ │ │ │ ├── processor.py
│ │ │ │ └── requirements.txt
│ │ │ ├── transformer_nist_wait_3/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── model.py
│ │ │ │ ├── module.py
│ │ │ │ ├── processor.py
│ │ │ │ └── requirements.txt
│ │ │ ├── transformer_nist_wait_5/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── model.py
│ │ │ │ ├── module.py
│ │ │ │ ├── processor.py
│ │ │ │ └── requirements.txt
│ │ │ ├── transformer_nist_wait_7/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── model.py
│ │ │ │ ├── module.py
│ │ │ │ ├── processor.py
│ │ │ │ └── requirements.txt
│ │ │ └── transformer_nist_wait_all/
│ │ │ ├── README.md
│ │ │ ├── __init__.py
│ │ │ ├── model.py
│ │ │ ├── module.py
│ │ │ ├── processor.py
│ │ │ └── requirements.txt
│ │ ├── syntactic_analysis/
│ │ │ ├── DDParser/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── module.py
│ │ │ │ └── requirements.txt
│ │ │ ├── README.md
│ │ │ └── README_en.md
│ │ ├── text_correction/
│ │ │ └── ernie-csc/
│ │ │ ├── README.md
│ │ │ ├── __init__.py
│ │ │ ├── module.py
│ │ │ └── requirements.txt
│ │ ├── text_generation/
│ │ │ ├── CPM_LM/
│ │ │ │ └── readme.md
│ │ │ ├── GPT2_Base_CN/
│ │ │ │ ├── README.md
│ │ │ │ └── module.py
│ │ │ ├── GPT2_CPM_LM/
│ │ │ │ ├── README.md
│ │ │ │ └── module.py
│ │ │ ├── README.md
│ │ │ ├── README_en.md
│ │ │ ├── Rumor_prediction/
│ │ │ │ ├── README.md
│ │ │ │ ├── dict.txt
│ │ │ │ └── module.py
│ │ │ ├── ernie_gen/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── decode.py
│ │ │ │ ├── encode.py
│ │ │ │ ├── model.py
│ │ │ │ ├── module.py
│ │ │ │ ├── template/
│ │ │ │ │ ├── __init__.py
│ │ │ │ │ ├── decode.py
│ │ │ │ │ └── module.temp
│ │ │ │ └── test_data/
│ │ │ │ ├── dev.txt
│ │ │ │ └── train.txt
│ │ │ ├── ernie_gen_acrostic_poetry/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── decode.py
│ │ │ │ └── module.py
│ │ │ ├── ernie_gen_couplet/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── decode.py
│ │ │ │ └── module.py
│ │ │ ├── ernie_gen_lover_words/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── decode.py
│ │ │ │ └── module.py
│ │ │ ├── ernie_gen_poetry/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── decode.py
│ │ │ │ └── module.py
│ │ │ ├── ernie_tiny_couplet/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── ernie_zeus/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── module.py
│ │ │ │ ├── requirements.txt
│ │ │ │ └── test.py
│ │ │ ├── plato-mini/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── module.py
│ │ │ │ ├── requirements.txt
│ │ │ │ └── utils.py
│ │ │ ├── plato2_en_base/
│ │ │ │ ├── README.md
│ │ │ │ ├── model.py
│ │ │ │ ├── module.py
│ │ │ │ ├── readers/
│ │ │ │ │ ├── dialog_reader.py
│ │ │ │ │ ├── nsp_reader.py
│ │ │ │ │ └── plato_reader.py
│ │ │ │ └── utils/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── args.py
│ │ │ │ ├── masking.py
│ │ │ │ └── tokenization.py
│ │ │ ├── plato2_en_large/
│ │ │ │ ├── README.md
│ │ │ │ ├── model.py
│ │ │ │ ├── module.py
│ │ │ │ ├── readers/
│ │ │ │ │ ├── dialog_reader.py
│ │ │ │ │ ├── nsp_reader.py
│ │ │ │ │ └── plato_reader.py
│ │ │ │ └── utils/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── args.py
│ │ │ │ ├── masking.py
│ │ │ │ └── tokenization.py
│ │ │ ├── reading_pictures_writing_poems/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── module.py
│ │ │ │ ├── readme.md
│ │ │ │ └── requirements.txt
│ │ │ ├── reading_pictures_writing_poems_for_midautumn/
│ │ │ │ ├── MidAutumnDetection/
│ │ │ │ │ ├── __init__.py
│ │ │ │ │ └── module.py
│ │ │ │ ├── MidAutumnPoetry/
│ │ │ │ │ ├── __init__.py
│ │ │ │ │ ├── model/
│ │ │ │ │ │ ├── decode.py
│ │ │ │ │ │ ├── file_utils.py
│ │ │ │ │ │ ├── modeling_ernie.py
│ │ │ │ │ │ ├── modeling_ernie_gen.py
│ │ │ │ │ │ └── tokenizing_ernie.py
│ │ │ │ │ └── module.py
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── unified_transformer-12L-cn/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── module.py
│ │ │ │ ├── requirements.txt
│ │ │ │ └── utils.py
│ │ │ └── unified_transformer-12L-cn-luge/
│ │ │ ├── README.md
│ │ │ ├── __init__.py
│ │ │ ├── module.py
│ │ │ ├── requirements.txt
│ │ │ └── utils.py
│ │ ├── text_review/
│ │ │ ├── README.md
│ │ │ ├── README_en.md
│ │ │ ├── porn_detection_cnn/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── assets/
│ │ │ │ │ ├── params.txt
│ │ │ │ │ ├── vocab.txt
│ │ │ │ │ └── word_dict.txt
│ │ │ │ ├── module.py
│ │ │ │ └── processor.py
│ │ │ ├── porn_detection_gru/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── assets/
│ │ │ │ │ ├── params.txt
│ │ │ │ │ ├── vocab.txt
│ │ │ │ │ └── word_dict.txt
│ │ │ │ ├── module.py
│ │ │ │ └── processor.py
│ │ │ └── porn_detection_lstm/
│ │ │ ├── README.md
│ │ │ ├── __init__.py
│ │ │ ├── assets/
│ │ │ │ ├── params.txt
│ │ │ │ ├── vocab.txt
│ │ │ │ └── word_dict.txt
│ │ │ ├── module.py
│ │ │ └── processor.py
│ │ └── text_to_knowledge/
│ │ ├── nptag/
│ │ │ ├── README.md
│ │ │ ├── __init__.py
│ │ │ ├── module.py
│ │ │ └── requirements.txt
│ │ └── wordtag/
│ │ ├── README.md
│ │ ├── __init__.py
│ │ ├── module.py
│ │ └── requirements.txt
│ └── video/
│ ├── README.md
│ ├── README_en.md
│ ├── Video_editing/
│ │ └── SkyAR/
│ │ ├── README.md
│ │ ├── README_en.md
│ │ ├── __init__.py
│ │ ├── module.py
│ │ ├── rain.py
│ │ ├── skybox.py
│ │ ├── skyfilter.py
│ │ └── utils.py
│ ├── classification/
│ │ ├── README.md
│ │ ├── nonlocal_kinetics400/
│ │ │ └── README.md
│ │ ├── stnet_kinetics400/
│ │ │ └── README.md
│ │ ├── tsm_kinetics400/
│ │ │ └── README.md
│ │ ├── tsn_kinetics400/
│ │ │ └── README.md
│ │ └── videotag_tsn_lstm/
│ │ ├── README.md
│ │ ├── __init__.py
│ │ ├── module.py
│ │ └── resource/
│ │ ├── __init__.py
│ │ ├── configs/
│ │ │ ├── attention_lstm.yaml
│ │ │ └── tsn.yaml
│ │ ├── label_3396.txt
│ │ ├── metrics/
│ │ │ ├── __init__.py
│ │ │ ├── metrics_util.py
│ │ │ └── youtube8m/
│ │ │ ├── __init__.py
│ │ │ ├── average_precision_calculator.py
│ │ │ ├── eval_util.py
│ │ │ └── mean_average_precision_calculator.py
│ │ ├── models/
│ │ │ ├── __init__.py
│ │ │ ├── attention_lstm/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── attention_lstm.py
│ │ │ │ └── lstm_attention.py
│ │ │ ├── model.py
│ │ │ └── tsn/
│ │ │ ├── __init__.py
│ │ │ ├── name.py
│ │ │ ├── name1
│ │ │ ├── name2
│ │ │ ├── name_map.json
│ │ │ ├── tsn.py
│ │ │ └── tsn_res_model.py
│ │ ├── reader/
│ │ │ ├── __init__.py
│ │ │ ├── kinetics_reader.py
│ │ │ └── reader_utils.py
│ │ └── utils/
│ │ ├── __init__.py
│ │ ├── config_utils.py
│ │ ├── train_utils.py
│ │ └── utility.py
│ └── multiple_object_tracking/
│ ├── fairmot_dla34/
│ │ ├── README.md
│ │ ├── config/
│ │ │ ├── _base_/
│ │ │ │ ├── fairmot_dla34.yml
│ │ │ │ ├── fairmot_reader_1088x608.yml
│ │ │ │ ├── mot.yml
│ │ │ │ ├── optimizer_30e.yml
│ │ │ │ └── runtime.yml
│ │ │ └── fairmot_dla34_30e_1088x608.yml
│ │ ├── dataset.py
│ │ ├── modeling/
│ │ │ └── mot/
│ │ │ ├── __init__.py
│ │ │ ├── matching/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── deepsort_matching.py
│ │ │ │ └── jde_matching.py
│ │ │ ├── motion/
│ │ │ │ ├── __init__.py
│ │ │ │ └── kalman_filter.py
│ │ │ ├── tracker/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── base_jde_tracker.py
│ │ │ │ ├── base_sde_tracker.py
│ │ │ │ └── jde_tracker.py
│ │ │ ├── utils.py
│ │ │ └── visualization.py
│ │ ├── module.py
│ │ ├── requirements.txt
│ │ ├── tracker.py
│ │ └── utils.py
│ └── jde_darknet53/
│ ├── README.md
│ ├── config/
│ │ ├── _base_/
│ │ │ ├── jde_darknet53.yml
│ │ │ ├── jde_reader_1088x608.yml
│ │ │ ├── mot.yml
│ │ │ ├── optimizer_30e.yml
│ │ │ ├── optimizer_60e.yml
│ │ │ └── runtime.yml
│ │ └── jde_darknet53_30e_1088x608.yml
│ ├── dataset.py
│ ├── modeling/
│ │ └── mot/
│ │ ├── __init__.py
│ │ ├── matching/
│ │ │ ├── __init__.py
│ │ │ ├── deepsort_matching.py
│ │ │ └── jde_matching.py
│ │ ├── motion/
│ │ │ ├── __init__.py
│ │ │ └── kalman_filter.py
│ │ ├── tracker/
│ │ │ ├── __init__.py
│ │ │ ├── base_jde_tracker.py
│ │ │ ├── base_sde_tracker.py
│ │ │ └── jde_tracker.py
│ │ ├── utils.py
│ │ └── visualization.py
│ ├── module.py
│ ├── requirements.txt
│ ├── tracker.py
│ └── utils.py
├── paddlehub/
│ ├── __init__.py
│ ├── commands/
│ │ ├── __init__.py
│ │ ├── clear.py
│ │ ├── config.py
│ │ ├── convert.py
│ │ ├── download.py
│ │ ├── help.py
│ │ ├── hub.py
│ │ ├── install.py
│ │ ├── list.py
│ │ ├── run.py
│ │ ├── search.py
│ │ ├── serving.py
│ │ ├── show.py
│ │ ├── tmpl/
│ │ │ ├── init_py.tmpl
│ │ │ ├── serving_demo.tmpl
│ │ │ └── x_model.tmpl
│ │ ├── uninstall.py
│ │ ├── utils.py
│ │ └── version.py
│ ├── compat/
│ │ ├── __init__.py
│ │ ├── datasets/
│ │ │ ├── __init__.py
│ │ │ ├── base_dataset.py
│ │ │ ├── couplet.py
│ │ │ └── nlp_dataset.py
│ │ ├── module/
│ │ │ ├── __init__.py
│ │ │ ├── module_desc.proto
│ │ │ ├── module_desc_pb2.py
│ │ │ ├── module_v1.py
│ │ │ ├── module_v1_utils.py
│ │ │ ├── nlp_module.py
│ │ │ └── processor.py
│ │ ├── paddle_utils.py
│ │ ├── task/
│ │ │ ├── __init__.py
│ │ │ ├── base_task.py
│ │ │ ├── batch.py
│ │ │ ├── checkpoint.proto
│ │ │ ├── checkpoint.py
│ │ │ ├── checkpoint_pb2.py
│ │ │ ├── config.py
│ │ │ ├── hook.py
│ │ │ ├── metrics.py
│ │ │ ├── reader.py
│ │ │ ├── task_utils.py
│ │ │ ├── text_generation_task.py
│ │ │ ├── tokenization.py
│ │ │ └── transformer_emb_task.py
│ │ └── type.py
│ ├── config.py
│ ├── datasets/
│ │ ├── __init__.py
│ │ ├── base_audio_dataset.py
│ │ ├── base_nlp_dataset.py
│ │ ├── base_seg_dataset.py
│ │ ├── canvas.py
│ │ ├── chnsenticorp.py
│ │ ├── esc50.py
│ │ ├── flowers.py
│ │ ├── lcqmc.py
│ │ ├── minicoco.py
│ │ ├── msra_ner.py
│ │ ├── opticdiscseg.py
│ │ └── pascalvoc.py
│ ├── env.py
│ ├── finetune/
│ │ ├── __init__.py
│ │ └── trainer.py
│ ├── module/
│ │ ├── __init__.py
│ │ ├── audio_module.py
│ │ ├── cv_module.py
│ │ ├── manager.py
│ │ ├── module.py
│ │ └── nlp_module.py
│ ├── server/
│ │ ├── __init__.py
│ │ ├── git_source.py
│ │ ├── server.py
│ │ └── server_source.py
│ ├── serving/
│ │ ├── __init__.py
│ │ ├── app_compat.py
│ │ ├── client.py
│ │ ├── device.py
│ │ ├── http_server.py
│ │ ├── model_service/
│ │ │ ├── __init__.py
│ │ │ └── base_model_service.py
│ │ └── worker.py
│ ├── text/
│ │ ├── __init__.py
│ │ ├── bert_tokenizer.py
│ │ ├── tokenizer.py
│ │ └── utils.py
│ ├── utils/
│ │ ├── __init__.py
│ │ ├── download.py
│ │ ├── io.py
│ │ ├── log.py
│ │ ├── paddlex.py
│ │ ├── parser.py
│ │ ├── platform.py
│ │ ├── pypi.py
│ │ ├── utils.py
│ │ └── xarfile.py
│ └── vision/
│ ├── __init__.py
│ ├── detect_transforms.py
│ ├── functional.py
│ ├── segmentation_transforms.py
│ ├── transforms.py
│ └── utils.py
├── requirements.txt
├── scripts/
│ ├── check_code_style.sh
│ ├── gen_contributors_info.py
│ ├── gen_proto.sh
│ └── test_cml.sh
├── setup.py
└── tests/
└── test_module.py
================================================
FILE CONTENTS
================================================
================================================
FILE: .github/ISSUE_TEMPLATE/----.md
================================================
---
name: 需求反馈
about: 需求建议
title: ''
labels: ''
assignees: ''
---
欢迎您对PaddleHub提出建议,非常感谢您对PaddleHub的贡献!
在留下您的建议时,辛苦您同步提供如下信息:
- 您想要增加什么新特性?
- 什么样的场景下需要该特性?
- 没有该特性的条件下,PaddleHub目前是否能间接满足该需求?
- 增加该特性,PaddleHub可能需要变化的部分。
- 如果可以的话,简要描述下您的解决方案
================================================
FILE: .github/ISSUE_TEMPLATE/bug--.md
================================================
---
name: BUG反馈
about: PaddleHub Bug反馈
title: ''
labels: ''
assignees: ''
---
欢迎您反馈PaddleHub使用问题,非常感谢您对PaddleHub的贡献!
在留下您的问题时,辛苦您同步提供如下信息:
- 版本、环境信息
1)PaddleHub和PaddlePaddle版本:请提供您的PaddleHub和PaddlePaddle版本号,例如PaddleHub1.4.1,PaddlePaddle1.6.2
2)系统环境:请您描述系统类型,例如Linux/Windows/MacOS/,python版本
- 复现信息:如为报错,请给出复现环境、复现步骤
================================================
FILE: .gitignore
================================================
# Byte-compiled / optimized / DLL files
__pycache__/
*.py[cod]
*$py.class
# C extensions
*.so
# Distribution / packaging
.Python
build/
develop-eggs/
dist/
downloads/
eggs/
.eggs/
lib/
lib64/
parts/
sdist/
var/
wheels/
share/python-wheels/
*.egg-info/
.installed.cfg
*.egg
MANIFEST
# PyInstaller
# Usually these files are written by a python script from a template
# before PyInstaller builds the exe, so as to inject date/other infos into it.
*.manifest
*.spec
# Installer logs
pip-log.txt
pip-delete-this-directory.txt
# Unit test / coverage reports
htmlcov/
.tox/
.nox/
.coverage
.coverage.*
.cache
nosetests.xml
coverage.xml
*.cover
.hypothesis/
.pytest_cache/
# Translations
*.mo
*.pot
# Django stuff:
*.log
local_settings.py
db.sqlite3
# Flask stuff:
instance/
.webassets-cache
# Scrapy stuff:
.scrapy
# Sphinx documentation
docs/_build/
# PyBuilder
target/
# Jupyter Notebook
.ipynb_checkpoints
# IPython
profile_default/
ipython_config.py
# pyenv
.python-version
# celery beat schedule file
celerybeat-schedule
# SageMath parsed files
*.sage.py
# Environments
.env
.venv
env/
venv/
ENV/
env.bak/
venv.bak/
# Spyder project settings
.spyderproject
.spyproject
# Rope project settings
.ropeproject
# mkdocs documentation
/site
# mypy
.mypy_cache/
.dmypy.json
dmypy.json
# Pyre type checker
.pyre/
# pycharm
.DS_Store
.idea/
FETCH_HEAD
================================================
FILE: .pre-commit-config.yaml
================================================
- repo: local
hooks:
- id: yapf
name: yapf
entry: yapf
language: system
args: [-i, --style .style.yapf]
files: \.py$
- repo: https://github.com/pre-commit/pre-commit-hooks
sha: a11d9314b22d8f8c7556443875b731ef05965464
hooks:
- id: check-merge-conflict
- id: check-symlinks
- id: end-of-file-fixer
- id: trailing-whitespace
- id: detect-private-key
- id: check-symlinks
- id: check-added-large-files
- repo: local
hooks:
- id: flake8
name: flake8
entry: flake8
language: system
args:
- --count
- --select=E9,F63,F7,F82
- --show-source
- --statistics
files: \.py$
- repo: https://github.com/asottile/reorder_python_imports
rev: v2.4.0
hooks:
- id: reorder-python-imports
exclude: (?=third_party).*(\.py)$
================================================
FILE: .style.yapf
================================================
[style]
based_on_style = pep8
column_limit = 120
================================================
FILE: .travis.yml
================================================
language: python
jobs:
include:
- name: "CI on Windows/Python3.6"
os: windows
language: shell
before_install:
- choco install python --version 3.6.2
- python -m pip install --upgrade pip
env: PATH=/c/Python36:/c/Python36/Scripts:$PATH
- name: "CI on MacOS/Python3.6"
os: osx
language: shell
- name: "CI on Linux/Python3.6"
os: linux
python: 3.6
script: /bin/bash ./scripts/check_code_style.sh
env:
- PYTHONPATH=${PWD}
install:
- if [[ $TRAVIS_OS_NAME == osx ]]; then
pip3 install --upgrade paddlepaddle;
pip3 install -r requirements.txt;
else
pip install --upgrade paddlepaddle;
pip install -r requirements.txt;
pip install yapf==0.26.0;
fi
notifications:
email:
on_success: change
on_failure: always
================================================
FILE: AUTHORS.md
================================================
| Github account | name |
|---|---|
| ZeyuChen | Zeyu Chen |
| nepeplwu | Zewu Wu |
| sjtubinlong | Bin Long |
| Steffy-zxf | Xuefei Zhang |
| kinghuin | Jinxuan Qiu |
| ShenYuhan | Yuhan Shen |
|haoyuying|Yuying Hao|
|KPatr1ck|Xiaojie Chen|
================================================
FILE: LICENSE
================================================
Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved
Apache License
Version 2.0, January 2004
http://www.apache.org/licenses/
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
1. Definitions.
"License" shall mean the terms and conditions for use, reproduction,
and distribution as defined by Sections 1 through 9 of this document.
"Licensor" shall mean the copyright owner or entity authorized by
the copyright owner that is granting the License.
"Legal Entity" shall mean the union of the acting entity and all
other entities that control, are controlled by, or are under common
control with that entity. For the purposes of this definition,
"control" means (i) the power, direct or indirect, to cause the
direction or management of such entity, whether by contract or
otherwise, or (ii) ownership of fifty percent (50%) or more of the
outstanding shares, or (iii) beneficial ownership of such entity.
"You" (or "Your") shall mean an individual or Legal Entity
exercising permissions granted by this License.
"Source" form shall mean the preferred form for making modifications,
including but not limited to software source code, documentation
source, and configuration files.
"Object" form shall mean any form resulting from mechanical
transformation or translation of a Source form, including but
not limited to compiled object code, generated documentation,
and conversions to other media types.
"Work" shall mean the work of authorship, whether in Source or
Object form, made available under the License, as indicated by a
copyright notice that is included in or attached to the work
(an example is provided in the Appendix below).
"Derivative Works" shall mean any work, whether in Source or Object
form, that is based on (or derived from) the Work and for which the
editorial revisions, annotations, elaborations, or other modifications
represent, as a whole, an original work of authorship. For the purposes
of this License, Derivative Works shall not include works that remain
separable from, or merely link (or bind by name) to the interfaces of,
the Work and Derivative Works thereof.
"Contribution" shall mean any work of authorship, including
the original version of the Work and any modifications or additions
to that Work or Derivative Works thereof, that is intentionally
submitted to Licensor for inclusion in the Work by the copyright owner
or by an individual or Legal Entity authorized to submit on behalf of
the copyright owner. For the purposes of this definition, "submitted"
means any form of electronic, verbal, or written communication sent
to the Licensor or its representatives, including but not limited to
communication on electronic mailing lists, source code control systems,
and issue tracking systems that are managed by, or on behalf of, the
Licensor for the purpose of discussing and improving the Work, but
excluding communication that is conspicuously marked or otherwise
designated in writing by the copyright owner as "Not a Contribution."
"Contributor" shall mean Licensor and any individual or Legal Entity
on behalf of whom a Contribution has been received by Licensor and
subsequently incorporated within the Work.
2. Grant of Copyright License. Subject to the terms and conditions of
this License, each Contributor hereby grants to You a perpetual,
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
copyright license to reproduce, prepare Derivative Works of,
publicly display, publicly perform, sublicense, and distribute the
Work and such Derivative Works in Source or Object form.
3. Grant of Patent License. Subject to the terms and conditions of
this License, each Contributor hereby grants to You a perpetual,
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
(except as stated in this section) patent license to make, have made,
use, offer to sell, sell, import, and otherwise transfer the Work,
where such license applies only to those patent claims licensable
by such Contributor that are necessarily infringed by their
Contribution(s) alone or by combination of their Contribution(s)
with the Work to which such Contribution(s) was submitted. If You
institute patent litigation against any entity (including a
cross-claim or counterclaim in a lawsuit) alleging that the Work
or a Contribution incorporated within the Work constitutes direct
or contributory patent infringement, then any patent licenses
granted to You under this License for that Work shall terminate
as of the date such litigation is filed.
4. Redistribution. You may reproduce and distribute copies of the
Work or Derivative Works thereof in any medium, with or without
modifications, and in Source or Object form, provided that You
meet the following conditions:
(a) You must give any other recipients of the Work or
Derivative Works a copy of this License; and
(b) You must cause any modified files to carry prominent notices
stating that You changed the files; and
(c) You must retain, in the Source form of any Derivative Works
that You distribute, all copyright, patent, trademark, and
attribution notices from the Source form of the Work,
excluding those notices that do not pertain to any part of
the Derivative Works; and
(d) If the Work includes a "NOTICE" text file as part of its
distribution, then any Derivative Works that You distribute must
include a readable copy of the attribution notices contained
within such NOTICE file, excluding those notices that do not
pertain to any part of the Derivative Works, in at least one
of the following places: within a NOTICE text file distributed
as part of the Derivative Works; within the Source form or
documentation, if provided along with the Derivative Works; or,
within a display generated by the Derivative Works, if and
wherever such third-party notices normally appear. The contents
of the NOTICE file are for informational purposes only and
do not modify the License. You may add Your own attribution
notices within Derivative Works that You distribute, alongside
or as an addendum to the NOTICE text from the Work, provided
that such additional attribution notices cannot be construed
as modifying the License.
You may add Your own copyright statement to Your modifications and
may provide additional or different license terms and conditions
for use, reproduction, or distribution of Your modifications, or
for any such Derivative Works as a whole, provided Your use,
reproduction, and distribution of the Work otherwise complies with
the conditions stated in this License.
5. Submission of Contributions. Unless You explicitly state otherwise,
any Contribution intentionally submitted for inclusion in the Work
by You to the Licensor shall be under the terms and conditions of
this License, without any additional terms or conditions.
Notwithstanding the above, nothing herein shall supersede or modify
the terms of any separate license agreement you may have executed
with Licensor regarding such Contributions.
6. Trademarks. This License does not grant permission to use the trade
names, trademarks, service marks, or product names of the Licensor,
except as required for reasonable and customary use in describing the
origin of the Work and reproducing the content of the NOTICE file.
7. Disclaimer of Warranty. Unless required by applicable law or
agreed to in writing, Licensor provides the Work (and each
Contributor provides its Contributions) on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
implied, including, without limitation, any warranties or conditions
of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
PARTICULAR PURPOSE. You are solely responsible for determining the
appropriateness of using or redistributing the Work and assume any
risks associated with Your exercise of permissions under this License.
8. Limitation of Liability. In no event and under no legal theory,
whether in tort (including negligence), contract, or otherwise,
unless required by applicable law (such as deliberate and grossly
negligent acts) or agreed to in writing, shall any Contributor be
liable to You for damages, including any direct, indirect, special,
incidental, or consequential damages of any character arising as a
result of this License or out of the use or inability to use the
Work (including but not limited to damages for loss of goodwill,
work stoppage, computer failure or malfunction, or any and all
other commercial damages or losses), even if such Contributor
has been advised of the possibility of such damages.
9. Accepting Warranty or Additional Liability. While redistributing
the Work or Derivative Works thereof, You may choose to offer,
and charge a fee for, acceptance of support, warranty, indemnity,
or other liability obligations and/or rights consistent with this
License. However, in accepting such obligations, You may act only
on Your own behalf and on Your sole responsibility, not on behalf
of any other Contributor, and only if You agree to indemnify,
defend, and hold each Contributor harmless for any liability
incurred by, or claims asserted against, such Contributor by reason
of your accepting any such warranty or additional liability.
END OF TERMS AND CONDITIONS
APPENDIX: How to apply the Apache License to your work.
To apply the Apache License to your work, attach the following
boilerplate notice, with the fields enclosed by brackets "[]"
replaced with your own identifying information. (Don't include
the brackets!) The text should be enclosed in the appropriate
comment syntax for the file format. We also recommend that a
file or class name and description of purpose be included on the
same "printed page" as the copyright notice for easier
identification within third-party archives.
Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
================================================
FILE: README.md
================================================
English | [简体中文](README_ch.md)
<p align="center">
<img src="./docs/imgs/paddlehub_logo.jpg" align="middle" width="400" />
<p align="center">
<div align="center">
<h3> <a href=#QuickStart> Quick Start </a> | <a href="./modules"> Model List </a> | <a href=#demos> Demos </a> </h3>
</div>
------------------------------------------------------------------------------------------
<p align="center">
<a href="./LICENSE"><img src="https://img.shields.io/badge/license-Apache%202-dfd.svg"></a>
<a href=""><img src="https://img.shields.io/badge/python-3.6.2+-aff.svg"></a>
<a href=""><img src="https://img.shields.io/badge/os-linux%2C%20win%2C%20mac-pink.svg"></a>
<a href=""><img src="https://img.shields.io/pypi/format/paddlehub?color=c77"></a>
<a href="https://pypi.org/project/paddlehub/"><img src="https://img.shields.io/pypi/dm/paddlehub?color=9cf"></a>
<a href="https://github.com/PaddlePaddle/PaddleHub/stargazers"><img src="https://img.shields.io/github/stars/PaddlePaddle/PaddleHub?color=ccf"></a>
<a href="https://huggingface.co/PaddlePaddle"><img src="https://img.shields.io/badge/%F0%9F%A4%97-Hugging%20Face-blue"></a>
</p>
## ⭐Features
- **📦400+ AI Models**: Rich, high-quality AI models, including CV, NLP, Speech, Video and Cross-Modal.
- **🧒Easy to Use**: 3 lines of code to predict 400+ AI models.
- **💁Model As Service**: Easy to serve model with only one line of command.
- **💻Cross-platform**: Support Linux, Windows and MacOS.
### 💥Recent Updates
- **🔥2022.08.19:** The v2.3.0 version is released 🎉
- Supports [**ERNIE-ViLG**](./modules/image/text_to_image/ernie_vilg)([HuggingFace Space Demo](https://huggingface.co/spaces/PaddlePaddle/ERNIE-ViLG))
- Supports [**Disco Diffusion (DD)**](./modules/image/text_to_image/disco_diffusion_clip_vitb32) and [**Stable Diffusion (SD)**](./modules/image/text_to_image/stable_diffusion)
- **2022.02.18:** Release models to HuggingFace [PaddlePaddle Space](https://huggingface.co/PaddlePaddle)
- For more previous release please refer to [**PaddleHub Release Note**](./docs/docs_en/release.md)
<a name="demos"></a>
## 🌈Visualization Demo
#### 🏜️ [Text-to-Image Models](https://github.com/PaddlePaddle/PaddleHub/tree/develop/modules/image/text_to_image)
<div align="center">
<table>
<tr>
<td><img src="https://user-images.githubusercontent.com/59186797/200235049-fefa7642-6c4c-4f93-bd84-3b36a8a80595.gif" width = "100%"></td>
<td><img src="https://user-images.githubusercontent.com/59186797/200244625-77310db8-c9b2-4293-8fe9-c9aae27ee462.gif" width = "80%"></td>
<td><img src="https://user-images.githubusercontent.com/59186797/200245387-daaf576d-8224-4937-82b8-27e31ee2df16.gif" width = "100%"></td>
<tr>
<tr>
<td align="center"><a href="https://github.com/PaddlePaddle/PaddleHub/tree/develop/modules/image/text_to_image/ernie_vilg">Wenxin Big Models</a></td>
<td align="center"><a href="https://github.com/PaddlePaddle/PaddleHub/tree/develop/modules/image/text_to_image/stable_diffusion">Stable_Diffusion series</a></td>
<td align="center"><a href="https://github.com/PaddlePaddle/PaddleHub/tree/develop/modules/image/text_to_image/disco_diffusion_ernievil_base">Disco Diffusion series</a></td>
<tr>
<tr>
<td align="center">Include ERNIE-ViLG, ERNIE-ViL, ERNIE 3.0 Zeus, supports applications such as text-to-image, writing essays, summarization, couplets, question answering, writing novels and completing text。</td>
<td align="center">Supports functions such as text_to_image, image_to_image, inpainting, ACGN external service, etc.</td>
<td align="center">Support Chinese and English input</td>
<tr>
</table>
</div>
#### 👓 [Computer Vision Models](./modules#Image)
<div align="center">
<img src="./docs/imgs/Readme_Related/Image_all.gif" width = "530" height = "400" />
</div>
- Many thanks to CopyRight@[PaddleOCR](https://github.com/PaddlePaddle/PaddleOCR), [PaddleDetection](https://github.com/PaddlePaddle/PaddleDetection)、[PaddleGAN](https://github.com/PaddlePaddle/PaddleGAN), [AnimeGAN](https://github.com/TachibanaYoshino/AnimeGANv2)、[openpose](https://github.com/CMU-Perceptual-Computing-Lab/openpose)、[PaddleSeg](https://github.com/PaddlePaddle/PaddleSeg), [Zhengxia Zou](https://github.com/jiupinjia/SkyAR)、[PaddleClas](https://github.com/PaddlePaddle/PaddleClas) for the pre-trained models, you can try to train your models with them.
#### 🎤 [Natural Language Processing Models](./modules#Text)
<div align="center">
<img src="./docs/imgs/Readme_Related/Text_all.gif" width = "640" height = "240" />
</div>
- Many thanks to CopyRight@[ERNIE](https://github.com/PaddlePaddle/ERNIE)、[LAC](https://github.com/baidu/LAC)、[DDParser](https://github.com/baidu/DDParser)for the pre-trained models, you can try to train your models with them.
#### 🎧 [Speech Models](./modules#Audio)
<div align="center">
<table>
<thead>
<tr>
<th width=250> Input Audio </th>
<th width=550> Recognition Result </th>
</tr>
</thead>
<tbody>
<tr>
<td align = "center">
<a href="https://paddlespeech.bj.bcebos.com/PaddleAudio/en.wav" rel="nofollow">
<img align="center" src="./docs/imgs/Readme_Related/audio_icon.png" width=250 ></a><br>
</td>
<td >I knocked at the door on the ancient side of the building.</td>
</tr>
<tr>
<td align = "center">
<a href="https://paddlespeech.bj.bcebos.com/PaddleAudio/zh.wav" rel="nofollow">
<img align="center" src="./docs/imgs/Readme_Related/audio_icon.png" width=250></a><br>
</td>
<td>我认为跑步最重要的就是给我带来了身体健康。</td>
</tr>
</tbody>
</table>
</div>
<div align="center">
<table>
<thead>
</thead>
<tbody>
<tr>
<th>Input Text </th>
<th>Output Audio </th>
</tr>
<tr>
<th>Life was like a box of chocolates, you never know what you're gonna get.</th>
<th>
<a href="https://paddlehub.bj.bcebos.com/resources/fastspeech_ljspeech-0.wav">
<img src="./docs/imgs/Readme_Related/audio_icon.png" width=250 /></a><br>
</th>
</tr>
</tbody>
</table>
</div>
- Many thanks to CopyRight@[PaddleSpeech](https://github.com/PaddlePaddle/PaddleSpeech) for the pre-trained models, you can try to train your models with PaddleSpeech.
### ⭐ Thanks for Your Star
- All the above pre-trained models are all **open source and free**, and the number of models is continuously updated. Welcome **Star** to pay attention.
<div align="center">
<a href="https://github.com/PaddlePaddle/PaddleHub/stargazers">
<img src="./docs/imgs/Readme_Related/star_en.png" width = "411" height = "100" /></a>
</div>
<a name="Welcome_joinus"></a>
## 🍻Welcome to join PaddleHub technical group
- If you have any questions during the use of the model, you can join the official WeChat group to get more efficient questions and answers, and fully communicate with developers from all walks of life. We look forward to your joining.
<div align="center">
<img src="./docs/imgs/joinus.PNG" width = "200" height = "200" />
</div>
- please add WeChat above and send "Hub" to the robot, the robot will invite you to join the group automatically.
<a name="QuickStart"></a>
## ✈️QuickStart
#### 🚁The installation of required components.
```python
# install paddlepaddle with gpu
# !pip install --upgrade paddlepaddle-gpu
# or install paddlepaddle with cpu
!pip install --upgrade paddlepaddle
# install paddlehub
!pip install --upgrade paddlehub
```
#### 🛫The simplest cases of Chinese word segmentation.
```python
import paddlehub as hub
lac = hub.Module(name="lac")
test_text = ["今天是个好天气。"]
results = lac.cut(text=test_text, use_gpu=False, batch_size=1, return_tag=True)
print(results)
#{'word': ['今天', '是', '个', '好天气', '。'], 'tag': ['TIME', 'v', 'q', 'n', 'w']}
```
#### 🛰️The simplest command of deploying lac service.
</div>
```python
!hub serving start -m lac
```
- 📣More model description, please refer [Models List](./modules)
<a name="License"></a>
## 📚License
The release of this project is certified by the <a href="./LICENSE">Apache 2.0 license</a>.
<a name="Contribution"></a>
## 👨👨👧👦Contribution
<p align="center">
<a href="https://github.com/nepeplwu"><img src="https://avatars.githubusercontent.com/u/45024560?v=4" width=75 height=75></a>
<a href="https://github.com/Steffy-zxf"><img src="https://avatars.githubusercontent.com/u/48793257?v=4" width=75 height=75></a>
<a href="https://github.com/ZeyuChen"><img src="https://avatars.githubusercontent.com/u/1371212?v=4" width=75 height=75></a>
<a href="https://github.com/ShenYuhan"><img src="https://avatars.githubusercontent.com/u/28444161?v=4" width=75 height=75></a>
<a href="https://github.com/kinghuin"><img src="https://avatars.githubusercontent.com/u/11913168?v=4" width=75 height=75></a>
<a href="https://github.com/grasswolfs"><img src="https://avatars.githubusercontent.com/u/23690325?v=4" width=75 height=75></a>
<a href="https://github.com/haoyuying"><img src="https://avatars.githubusercontent.com/u/35907364?v=4" width=75 height=75></a>
<a href="https://github.com/sjtubinlong"><img src="https://avatars.githubusercontent.com/u/2063170?v=4" width=75 height=75></a>
<a href="https://github.com/KPatr1ck"><img src="https://avatars.githubusercontent.com/u/22954146?v=4" width=75 height=75></a>
<a href="https://github.com/jm12138"><img src="https://avatars.githubusercontent.com/u/15712990?v=4" width=75 height=75></a>
<a href="https://github.com/DesmonDay"><img src="https://avatars.githubusercontent.com/u/20554008?v=4" width=75 height=75></a>
<a href="https://github.com/chunzhang-hub"><img src="https://avatars.githubusercontent.com/u/63036966?v=4" width=75 height=75></a>
<a href="https://github.com/rainyfly"><img src="https://avatars.githubusercontent.com/u/22424850?v=4" width=75 height=75></a>
<a href="https://github.com/adaxiadaxi"><img src="https://avatars.githubusercontent.com/u/58928121?v=4" width=75 height=75></a>
<a href="https://github.com/linjieccc"><img src="https://avatars.githubusercontent.com/u/40840292?v=4" width=75 height=75></a>
<a href="https://github.com/linshuliang"><img src="https://avatars.githubusercontent.com/u/15993091?v=4" width=75 height=75></a>
<a href="https://github.com/eepgxxy"><img src="https://avatars.githubusercontent.com/u/15946195?v=4" width=75 height=75></a>
<a href="https://github.com/paopjian"><img src="https://avatars.githubusercontent.com/u/20377352?v=4" width=75 height=75></a>
<a href="https://github.com/zbp-xxxp"><img src="https://avatars.githubusercontent.com/u/58476312?v=4" width=75 height=75></a>
<a href="https://github.com/houj04"><img src="https://avatars.githubusercontent.com/u/35131887?v=4" width=75 height=75></a>
<a href="https://github.com/Wgm-Inspur"><img src="https://avatars.githubusercontent.com/u/89008682?v=4" width=75 height=75></a>
<a href="https://github.com/AK391"><img src="https://avatars.githubusercontent.com/u/81195143?v=4" width=75 height=75></a>
<a href="https://github.com/apps/dependabot"><img src="https://avatars.githubusercontent.com/in/29110?v=4" width=75 height=75></a>
<a href="https://github.com/dxxxp"><img src="https://avatars.githubusercontent.com/u/15886898?v=4" width=75 height=75></a>
<a href="https://github.com/jianganbai"><img src="https://avatars.githubusercontent.com/u/50263321?v=4" width=75 height=75></a>
<a href="https://github.com/1084667371"><img src="https://avatars.githubusercontent.com/u/50902619?v=4" width=75 height=75></a>
<a href="https://github.com/Channingss"><img src="https://avatars.githubusercontent.com/u/12471701?v=4" width=75 height=75></a>
<a href="https://github.com/Austendeng"><img src="https://avatars.githubusercontent.com/u/16330293?v=4" width=75 height=75></a>
<a href="https://github.com/BurrowsWang"><img src="https://avatars.githubusercontent.com/u/478717?v=4" width=75 height=75></a>
<a href="https://github.com/cqvu"><img src="https://avatars.githubusercontent.com/u/37096589?v=4" width=75 height=75></a>
<a href="https://github.com/DeepGeGe"><img src="https://avatars.githubusercontent.com/u/51083814?v=4" width=75 height=75></a>
<a href="https://github.com/Haijunlv"><img src="https://avatars.githubusercontent.com/u/28926237?v=4" width=75 height=75></a>
<a href="https://github.com/holyseven"><img src="https://avatars.githubusercontent.com/u/13829174?v=4" width=75 height=75></a>
<a href="https://github.com/MRXLT"><img src="https://avatars.githubusercontent.com/u/16594411?v=4" width=75 height=75></a>
<a href="https://github.com/cclauss"><img src="https://avatars.githubusercontent.com/u/3709715?v=4" width=75 height=75></a>
<a href="https://github.com/hu-qi"><img src="https://avatars.githubusercontent.com/u/17986122?v=4" width=75 height=75></a>
<a href="https://github.com/itegel"><img src="https://avatars.githubusercontent.com/u/8164474?v=4" width=75 height=75></a>
<a href="https://github.com/jayhenry"><img src="https://avatars.githubusercontent.com/u/4285375?v=4" width=75 height=75></a>
<a href="https://github.com/hlmu"><img src="https://avatars.githubusercontent.com/u/30133236?v=4" width=75 height=75></a>
<a href="https://github.com/shinichiye"><img src="https://avatars.githubusercontent.com/u/76040149?v=4" width=75 height=75></a>
<a href="https://github.com/will-jl944"><img src="https://avatars.githubusercontent.com/u/68210528?v=4" width=75 height=75></a>
<a href="https://github.com/yma-admin"><img src="https://avatars.githubusercontent.com/u/40477813?v=4" width=75 height=75></a>
<a href="https://github.com/zl1271"><img src="https://avatars.githubusercontent.com/u/22902089?v=4" width=75 height=75></a>
<a href="https://github.com/brooklet"><img src="https://avatars.githubusercontent.com/u/1585799?v=4" width=75 height=75></a>
<a href="https://github.com/wj-Mcat"><img src="https://avatars.githubusercontent.com/u/10242208?v=4" width=75 height=75></a>
</p>
We welcome you to contribute code to PaddleHub, and thank you for your feedback.
* Many thanks to [肖培楷](https://github.com/jm12138), Contributed to street scene cartoonization, portrait cartoonization, gesture key point recognition, sky replacement, depth estimation, portrait segmentation and other modules
* Many thanks to [Austendeng](https://github.com/Austendeng) for fixing the SequenceLabelReader
* Many thanks to [cclauss](https://github.com/cclauss) optimizing travis-ci check
* Many thanks to [奇想天外](http://www.cheerthink.com/),Contributed a demo of mask detection
* Many thanks to [mhlwsk](https://github.com/mhlwsk),Contributed the repair sequence annotation prediction demo
* Many thanks to [zbp-xxxp](https://github.com/zbp-xxxp),Contributed modules for viewing pictures and writing poems
* Many thanks to [zbp-xxxp](https://github.com/zbp-xxxp) and [七年期限](https://github.com/1084667371),Jointly contributed to the Mid-Autumn Festival Special Edition Module
* Many thanks to [livingbody](https://github.com/livingbody),Contributed models for style transfer based on PaddleHub's capabilities and Mid-Autumn Festival WeChat Mini Program
* Many thanks to [BurrowsWang](https://github.com/BurrowsWang) for fixing Markdown table display problem
* Many thanks to [huqi](https://github.com/hu-qi) for fixing readme typo
* Many thanks to [parano](https://github.com/parano) [cqvu](https://github.com/cqvu) [deehrlic](https://github.com/deehrlic) for contributing this feature in PaddleHub
* Many thanks to [paopjian](https://github.com/paopjian) for correcting the wrong website address [#1424](https://github.com/PaddlePaddle/PaddleHub/issues/1424)
* Many thanks to [Wgm-Inspur](https://github.com/Wgm-Inspur) for correcting the demo errors in readme, and updating the RNN illustration in the text classification and sequence labeling demo
* Many thanks to [zl1271](https://github.com/zl1271) for fixing serving docs typo
* Many thanks to [AK391](https://github.com/AK391) for adding the webdemo of UGATIT and deoldify models in Hugging Face spaces
* Many thanks to [itegel](https://github.com/itegel) for fixing quick start docs typo
* Many thanks to [AK391](https://github.com/AK391) for adding the webdemo of Photo2Cartoon model in Hugging Face spaces
================================================
FILE: README_ch.md
================================================
简体中文 | [English](README.md)
<p align="center">
<img src="./docs/imgs/paddlehub_logo.jpg" align="middle">
<p align="center">
<div align="center">
<h3> <a href=#QuickStart> 快速开始 </a> | <a href="https://paddlehub.readthedocs.io/zh_CN/release-v2.1//"> 教程文档 </a> | <a href="./modules/README_ch.md"> 模型库 </a> | <a href="https://www.paddlepaddle.org.cn/hub"> 演示Demo </a>
</h3>
</div>
------------------------------------------------------------------------------------------
<p align="center">
<a href="./LICENSE"><img src="https://img.shields.io/badge/license-Apache%202-dfd.svg"></a>
<a href="https://github.com/PaddlePaddle/PaddleHub/releases"><img src="https://img.shields.io/github/v/release/PaddlePaddle/PaddleHub?color=ffa"></a>
<a href=""><img src="https://img.shields.io/badge/python-3.6.2+-aff.svg"></a>
<a href=""><img src="https://img.shields.io/badge/os-linux%2C%20win%2C%20mac-pink.svg"></a>
<a href=""><img src="https://img.shields.io/pypi/format/paddlehub?color=c77"></a>
</p>
<p align="center">
<a href="https://github.com/PaddlePaddle/PaddleHub/graphs/contributors"><img src="https://img.shields.io/github/contributors/PaddlePaddle/PaddleHub?color=9ea"></a>
<a href="https://github.com/PaddlePaddle/PaddleHub/commits"><img src="https://img.shields.io/github/commit-activity/m/PaddlePaddle/PaddleHub?color=3af"></a>
<a href="https://pypi.org/project/paddlehub/"><img src="https://img.shields.io/pypi/dm/paddlehub?color=9cf"></a>
<a href="https://github.com/PaddlePaddle/PaddleHub/issues"><img src="https://img.shields.io/github/issues/PaddlePaddle/PaddleHub?color=9cc"></a>
<a href="https://github.com/PaddlePaddle/PaddleHub/stargazers"><img src="https://img.shields.io/github/stars/PaddlePaddle/PaddleHub?color=ccf"></a>
</p>
## 简介与特性
- PaddleHub旨在为开发者提供丰富的、高质量的、直接可用的预训练模型
- **【模型种类丰富】**: 涵盖大模型、CV、NLP、Audio、Video、工业应用主流六大品类的 **400+** 预训练模型,全部开源下载,离线可运行
- **【超低使用门槛】**:无需深度学习背景、无需数据与训练过程,可快速使用AI模型
- **【一键模型快速预测】**:通过一行命令行或者极简的Python API实现模型调用,可快速体验模型效果
- **【一键模型转服务化】**:一行命令,搭建深度学习模型API服务化部署能力
- **【跨平台兼容性】**:可运行于Linux、Windows、MacOS等多种操作系统
## 近期更新
- **🔥2022.10.20:** 发布v2.3.1版本新增Stable_Diffusion系列模型和超分模型
- 支持[文生图](https://github.com/PaddlePaddle/PaddleHub/tree/develop/modules/image/text_to_image/stable_diffusion)、[图生图](https://github.com/PaddlePaddle/PaddleHub/tree/develop/modules/image/text_to_image/stable_diffusion_img2img)、[图修复](https://github.com/PaddlePaddle/PaddleHub/tree/develop/modules/image/text_to_image/stable_diffusion_inpainting)、[二次元专属waifu](https://github.com/PaddlePaddle/PaddleHub/tree/develop/modules/image/text_to_image/stable_diffusion_waifu)等4个模型。
- 基于 [SwinIR-L](https://www.paddlepaddle.org.cn/hubdetail?name=swinir_l_real_sr_x4&en_category=ImageEditing) 的 4 倍现实图像超分辨率模型
- **🔥2022.08.19:** 发布v2.3.0版本新增[文心大模型](https://github.com/PaddlePaddle/PaddleHub/tree/develop/modules/image/text_to_image/ernie_vilg)和[disco diffusion(dd)](https://www.paddlepaddle.org.cn/hubdetail?name=disco_diffusion_ernievil_base&en_category=TextToImage)系列文图生成模型。
- 支持对[文心大模型API](https://wenxin.baidu.com/moduleApi)的调用, 包括 文图生成模型ERNIE-ViLG, 以及支持写作文、写文案、写摘要、对对联、自由问答、写小说、补全文本等多个应用的语言模型ERNIE 3.0 Zeus
- 新增基于disco diffusion技术的文图生成dd系列模型([免费GPU体验Demo](https://aistudio.baidu.com/aistudio/projectdetail/4462918))。
- **2022.02.18:** 加入Huggingface,创建了PaddlePaddle的可视化空间并上传了模型: [PaddlePaddle Huggingface](https://huggingface.co/PaddlePaddle)。
- **🔥2021.12.22**,发布v2.2.0版本新增[预训练模型库官网](https://www.paddlepaddle.org.cn/hublist),新增100+高质量模型,涵盖对话、语音处理、语义分割、文字识别、文本处理、图像生成等多个领域,预训练模型总量达到【360+】;
- [More](./docs/docs_ch/release.md)
## **精品模型效果展示[【更多】](./docs/docs_ch/visualization.md)[【模型库】](./modules/README_ch.md)**
### **[大模型(10个)](./modules/README_ch.md#图像)**
<div align="center">
<table>
<tr>
<td><img src="https://user-images.githubusercontent.com/59186797/200235049-fefa7642-6c4c-4f93-bd84-3b36a8a80595.gif" width = "100%"></td>
<td><img src="https://user-images.githubusercontent.com/59186797/200244625-77310db8-c9b2-4293-8fe9-c9aae27ee462.gif" width = "90%"></td>
<td><img src="https://user-images.githubusercontent.com/59186797/200245387-daaf576d-8224-4937-82b8-27e31ee2df16.gif" width = "100%"></td>
<tr>
<tr>
<td align="center"><a href="https://github.com/PaddlePaddle/PaddleHub/tree/develop/modules/image/text_to_image/ernie_vilg">文心大模型</a></td>
<td align="center"><a href="https://github.com/PaddlePaddle/PaddleHub/tree/develop/modules/image/text_to_image/stable_diffusion">Stable_Diffusion系列模型</a></td>
<td align="center"><a href="https://github.com/PaddlePaddle/PaddleHub/tree/develop/modules/image/text_to_image/disco_diffusion_ernievil_base">Disco Diffusion系列模型</a></td>
<tr>
<tr>
<td align="center">支持文图生成、写作文、写文案、写摘要、对对联、自由问答、写小说、补全文本等多个应用。</td>
<td align="center">支持文生图、图生图、图修复、二次元专属waifu等功能</td>
<td align="center">支持中英输入</td>
<tr>
</table>
</div>
### **[图像类(212个)](./modules/README_ch.md#图像)**
- 包括图像分类、人脸检测、口罩检测、车辆检测、人脸/人体/手部关键点检测、人像分割、80+语言文本识别、图像超分/上色/动漫化等
<div align="center">
<img src="./docs/imgs/Readme_Related/Image_all.gif" width = "530" height = "400" />
</div>
- 感谢CopyRight@[PaddleOCR](https://github.com/PaddlePaddle/PaddleOCR)、[PaddleDetection](https://github.com/PaddlePaddle/PaddleDetection)、[PaddleGAN](https://github.com/PaddlePaddle/PaddleGAN)、[AnimeGAN](https://github.com/TachibanaYoshino/AnimeGANv2)、[openpose](https://github.com/CMU-Perceptual-Computing-Lab/openpose)、[PaddleSeg](https://github.com/PaddlePaddle/PaddleSeg)、[Zhengxia Zou](https://github.com/jiupinjia/SkyAR)、[PaddleClas](https://github.com/PaddlePaddle/PaddleClas) 提供相关预训练模型,训练能力开放,欢迎体验。
### **[文本类(130个)](./modules/README_ch.md#文本)**
- 包括中文分词、词性标注与命名实体识别、句法分析、AI写诗/对联/情话/藏头诗、中文的评论情感分析、中文色情文本审核等
<div align="center">
<img src="./docs/imgs/Readme_Related/Text_all.gif" width = "640" height = "240" />
</div>
- 感谢CopyRight@[ERNIE](https://github.com/PaddlePaddle/ERNIE)、[LAC](https://github.com/baidu/LAC)、[DDParser](https://github.com/baidu/DDParser)提供相关预训练模型,训练能力开放,欢迎体验。
### **[语音类(15个)](./modules/README_ch.md#语音)**
- ASR语音识别算法,多种算法可选
- 语音识别效果如下:
<div align="center">
<table>
<thead>
<tr>
<th width=250> Input Audio </th>
<th width=550> Recognition Result </th>
</tr>
</thead>
<tbody>
<tr>
<td align = "center">
<a href="https://paddlespeech.bj.bcebos.com/PaddleAudio/en.wav" rel="nofollow">
<img align="center" src="./docs/imgs/Readme_Related/audio_icon.png" width=250 ></a><br>
</td>
<td >I knocked at the door on the ancient side of the building.</td>
</tr>
<tr>
<td align = "center">
<a href="https://paddlespeech.bj.bcebos.com/PaddleAudio/zh.wav" rel="nofollow">
<img align="center" src="./docs/imgs/Readme_Related/audio_icon.png" width=250></a><br>
</td>
<td>我认为跑步最重要的就是给我带来了身体健康。</td>
</tr>
</tbody>
</table>
</div>
- TTS语音合成算法,多种算法可选
- 输入:`Life was like a box of chocolates, you never know what you're gonna get.`
- 合成效果如下:
<div align="center">
<table>
<thead>
</thead>
<tbody>
<tr>
<th>deepvoice3 </th>
<th>fastspeech </th>
<th>transformer</th>
</tr>
<tr>
<th>
<a href="https://paddlehub.bj.bcebos.com/resources/deepvoice3_ljspeech-0.wav">
<img src="./docs/imgs/Readme_Related/audio_icon.png" width=250 /></a><br>
</th>
<th>
<a href="https://paddlehub.bj.bcebos.com/resources/fastspeech_ljspeech-0.wav">
<img src="./docs/imgs/Readme_Related/audio_icon.png" width=250 /></a><br>
</th>
<th>
<a href="https://paddlehub.bj.bcebos.com/resources/transformer_tts_ljspeech-0.wav">
<img src="./docs/imgs/Readme_Related/audio_icon.png" width=250 /></a><br>
</th>
</tr>
</tbody>
</table>
</div>
- 感谢CopyRight@[PaddleSpeech](https://github.com/PaddlePaddle/PaddleSpeech)提供预训练模型,训练能力开放,欢迎体验。
### **[视频类(8个)](./modules/README_ch.md#视频)**
- 包含短视频分类,支持3000+标签种类,可输出TOP-K标签,多种算法可选。
- 感谢CopyRight@[PaddleVideo](https://github.com/PaddlePaddle/PaddleVideo)提供预训练模型,训练能力开放,欢迎体验。
- `举例:输入一段游泳的短视频,算法可以输出"游泳"结果`
<div align="center">
<img src="./docs/imgs/Readme_Related/Text_Video.gif" width = "400" height = "400" />
</div>
## ===划重点===
- 以上所有预训练模型全部开源,模型数量持续更新,欢迎**⭐Star⭐**关注。
<div align="center">
<a href="https://github.com/PaddlePaddle/PaddleHub/stargazers">
<img src="./docs/imgs/Readme_Related/star.png" width = "411" height = "100" /></a>
</div>
<a name="欢迎加入PaddleHub技术交流群"></a>
## 欢迎加入PaddleHub技术交流群
- 在使用模型过程中有任何问题,可以加入官方微信群,获得更高效的问题答疑,与各行各业开发者充分交流,期待您的加入。
<div align="center">
<img src="./docs/imgs/joinus.PNG" width = "200" height = "200" />
</div>
扫码备注"Hub"加好友之后,再发送“Hub”,会自动邀请您入群。
<div id="QuickStart">
## 快速开始
[【零基础windows安装并实现图像风格迁移】](./docs/docs_ch/get_start/windows_quickstart.md)
[【零基础mac安装并实现图像风格迁移】](./docs/docs_ch/get_start/mac_quickstart.md)
[【零基础linux安装并实现图像风格迁移】](./docs/docs_ch/get_start/linux_quickstart.md)
### 快速安装相关组件
</div>
```python
!pip install --upgrade paddlepaddle -i https://mirror.baidu.com/pypi/simple
!pip install --upgrade paddlehub -i https://mirror.baidu.com/pypi/simple
```
### 极简中文分词案例
</div>
```python
import paddlehub as hub
lac = hub.Module(name="lac")
test_text = ["今天是个好天气。"]
results = lac.cut(text=test_text, use_gpu=False, batch_size=1, return_tag=True)
print(results)
#{'word': ['今天', '是', '个', '好天气', '。'], 'tag': ['TIME', 'v', 'q', 'n', 'w']}
```
### 一行代码部署lac(词法分析)模型
</div>
```python
!hub serving start -m lac
```
欢迎用户通过[模型搜索](https://www.paddlepaddle.org.cn/hublist)发现更多实用的预训练模型!
更多迁移学习能力可以参考[教程文档](https://paddlehub.readthedocs.io/zh_CN/release-v2.1/transfer_learning_index.html)
<a name="许可证书"></a>
## 许可证书
本项目的发布受<a href="./LICENSE">Apache 2.0 license</a>许可认证。
<a name="致谢"></a>
## 致谢开发者
<p align="center">
<a href="https://github.com/nepeplwu"><img src="https://avatars.githubusercontent.com/u/45024560?v=4" width=75 height=75></a>
<a href="https://github.com/Steffy-zxf"><img src="https://avatars.githubusercontent.com/u/48793257?v=4" width=75 height=75></a>
<a href="https://github.com/ZeyuChen"><img src="https://avatars.githubusercontent.com/u/1371212?v=4" width=75 height=75></a>
<a href="https://github.com/ShenYuhan"><img src="https://avatars.githubusercontent.com/u/28444161?v=4" width=75 height=75></a>
<a href="https://github.com/kinghuin"><img src="https://avatars.githubusercontent.com/u/11913168?v=4" width=75 height=75></a>
<a href="https://github.com/grasswolfs"><img src="https://avatars.githubusercontent.com/u/23690325?v=4" width=75 height=75></a>
<a href="https://github.com/haoyuying"><img src="https://avatars.githubusercontent.com/u/35907364?v=4" width=75 height=75></a>
<a href="https://github.com/sjtubinlong"><img src="https://avatars.githubusercontent.com/u/2063170?v=4" width=75 height=75></a>
<a href="https://github.com/KPatr1ck"><img src="https://avatars.githubusercontent.com/u/22954146?v=4" width=75 height=75></a>
<a href="https://github.com/jm12138"><img src="https://avatars.githubusercontent.com/u/15712990?v=4" width=75 height=75></a>
<a href="https://github.com/DesmonDay"><img src="https://avatars.githubusercontent.com/u/20554008?v=4" width=75 height=75></a>
<a href="https://github.com/chunzhang-hub"><img src="https://avatars.githubusercontent.com/u/63036966?v=4" width=75 height=75></a>
<a href="https://github.com/rainyfly"><img src="https://avatars.githubusercontent.com/u/22424850?v=4" width=75 height=75></a>
<a href="https://github.com/adaxiadaxi"><img src="https://avatars.githubusercontent.com/u/58928121?v=4" width=75 height=75></a>
<a href="https://github.com/linjieccc"><img src="https://avatars.githubusercontent.com/u/40840292?v=4" width=75 height=75></a>
<a href="https://github.com/linshuliang"><img src="https://avatars.githubusercontent.com/u/15993091?v=4" width=75 height=75></a>
<a href="https://github.com/eepgxxy"><img src="https://avatars.githubusercontent.com/u/15946195?v=4" width=75 height=75></a>
<a href="https://github.com/paopjian"><img src="https://avatars.githubusercontent.com/u/20377352?v=4" width=75 height=75></a>
<a href="https://github.com/zbp-xxxp"><img src="https://avatars.githubusercontent.com/u/58476312?v=4" width=75 height=75></a>
<a href="https://github.com/houj04"><img src="https://avatars.githubusercontent.com/u/35131887?v=4" width=75 height=75></a>
<a href="https://github.com/Wgm-Inspur"><img src="https://avatars.githubusercontent.com/u/89008682?v=4" width=75 height=75></a>
<a href="https://github.com/AK391"><img src="https://avatars.githubusercontent.com/u/81195143?v=4" width=75 height=75></a>
<a href="https://github.com/apps/dependabot"><img src="https://avatars.githubusercontent.com/in/29110?v=4" width=75 height=75></a>
<a href="https://github.com/dxxxp"><img src="https://avatars.githubusercontent.com/u/15886898?v=4" width=75 height=75></a>
<a href="https://github.com/jianganbai"><img src="https://avatars.githubusercontent.com/u/50263321?v=4" width=75 height=75></a>
<a href="https://github.com/1084667371"><img src="https://avatars.githubusercontent.com/u/50902619?v=4" width=75 height=75></a>
<a href="https://github.com/Channingss"><img src="https://avatars.githubusercontent.com/u/12471701?v=4" width=75 height=75></a>
<a href="https://github.com/Austendeng"><img src="https://avatars.githubusercontent.com/u/16330293?v=4" width=75 height=75></a>
<a href="https://github.com/BurrowsWang"><img src="https://avatars.githubusercontent.com/u/478717?v=4" width=75 height=75></a>
<a href="https://github.com/cqvu"><img src="https://avatars.githubusercontent.com/u/37096589?v=4" width=75 height=75></a>
<a href="https://github.com/DeepGeGe"><img src="https://avatars.githubusercontent.com/u/51083814?v=4" width=75 height=75></a>
<a href="https://github.com/Haijunlv"><img src="https://avatars.githubusercontent.com/u/28926237?v=4" width=75 height=75></a>
<a href="https://github.com/holyseven"><img src="https://avatars.githubusercontent.com/u/13829174?v=4" width=75 height=75></a>
<a href="https://github.com/MRXLT"><img src="https://avatars.githubusercontent.com/u/16594411?v=4" width=75 height=75></a>
<a href="https://github.com/cclauss"><img src="https://avatars.githubusercontent.com/u/3709715?v=4" width=75 height=75></a>
<a href="https://github.com/hu-qi"><img src="https://avatars.githubusercontent.com/u/17986122?v=4" width=75 height=75></a>
<a href="https://github.com/itegel"><img src="https://avatars.githubusercontent.com/u/8164474?v=4" width=75 height=75></a>
<a href="https://github.com/jayhenry"><img src="https://avatars.githubusercontent.com/u/4285375?v=4" width=75 height=75></a>
<a href="https://github.com/hlmu"><img src="https://avatars.githubusercontent.com/u/30133236?v=4" width=75 height=75></a>
<a href="https://github.com/shinichiye"><img src="https://avatars.githubusercontent.com/u/76040149?v=4" width=75 height=75></a>
<a href="https://github.com/will-jl944"><img src="https://avatars.githubusercontent.com/u/68210528?v=4" width=75 height=75></a>
<a href="https://github.com/yma-admin"><img src="https://avatars.githubusercontent.com/u/40477813?v=4" width=75 height=75></a>
<a href="https://github.com/zl1271"><img src="https://avatars.githubusercontent.com/u/22902089?v=4" width=75 height=75></a>
<a href="https://github.com/brooklet"><img src="https://avatars.githubusercontent.com/u/1585799?v=4" width=75 height=75></a>
<a href="https://github.com/wj-Mcat"><img src="https://avatars.githubusercontent.com/u/10242208?v=4" width=75 height=75></a>
</p>
我们非常欢迎您为PaddleHub贡献代码,也十分感谢您的反馈。
* 非常感谢[肖培楷](https://github.com/jm12138)贡献了街景动漫化,人像动漫化、手势关键点识别、天空置换、深度估计、人像分割等module
* 非常感谢[Austendeng](https://github.com/Austendeng)贡献了修复SequenceLabelReader的pr
* 非常感谢[cclauss](https://github.com/cclauss)贡献了优化travis-ci检查的pr
* 非常感谢[奇想天外](http://www.cheerthink.com/)贡献了口罩检测的demo
* 非常感谢[mhlwsk](https://github.com/mhlwsk)贡献了修复序列标注预测demo的pr
* 非常感谢[zbp-xxxp](https://github.com/zbp-xxxp)和[七年期限](https://github.com/1084667371)联合贡献了看图写诗中秋特别版module、谣言预测、请假条生成等module
* 非常感谢[livingbody](https://github.com/livingbody)贡献了基于PaddleHub能力的风格迁移和中秋看图写诗微信小程序
* 非常感谢[BurrowsWang](https://github.com/BurrowsWang)修复Markdown表格显示问题
* 非常感谢[huqi](https://github.com/hu-qi)修复了readme中的错别字
* 非常感谢[parano](https://github.com/parano)、[cqvu](https://github.com/cqvu)、[deehrlic](https://github.com/deehrlic)三位的贡献与支持
* 非常感谢[paopjian](https://github.com/paopjian)修改了中文readme模型搜索指向的的网站地址错误[#1424](https://github.com/PaddlePaddle/PaddleHub/issues/1424)
* 非常感谢[Wgm-Inspur](https://github.com/Wgm-Inspur)修复了readme中的代码示例问题,并优化了文本分类、序列标注demo中的RNN示例图
* 非常感谢[zl1271](https://github.com/zl1271)修复了serving文档中的错别字
* 非常感谢[AK391](https://github.com/AK391)在Hugging Face spaces中添加了UGATIT和deoldify模型的web demo
* 非常感谢[itegel](https://github.com/itegel)修复了快速开始文档中的错别字
* 非常感谢[AK391](https://github.com/AK391)在Hugging Face spaces中添加了Photo2Cartoon模型的web demo
================================================
FILE: demo/README.md
================================================
### PaddleHub Office Website:https://www.paddlepaddle.org.cn/hub
### PaddleHub Module Searching:https://www.paddlepaddle.org.cn/hublist
================================================
FILE: demo/audio_classification/README.md
================================================
# PaddleHub 声音分类
本示例展示如何使用PaddleHub Fine-tune API以及CNN14等预训练模型完成声音分类和Tagging的任务。
CNN14等预训练模型的详情,请参考论文[PANNs: Large-Scale Pretrained Audio Neural Networks for Audio Pattern Recognition](https://arxiv.org/pdf/1912.10211.pdf)和代码[audioset_tagging_cnn](https://github.com/qiuqiangkong/audioset_tagging_cnn)。
## 如何开始Fine-tune
我们以环境声音分类公开数据集[ESC50](https://github.com/karolpiczak/ESC-50)为示例数据集,可以运行下面的命令,在训练集(train.npz)上进行模型训练,并在开发集(dev.npz)验证。通过如下命令,即可启动训练。
```python
# 设置使用的GPU卡号
export CUDA_VISIBLE_DEVICES=0
python train.py
```
## 代码步骤
使用PaddleHub Fine-tune API进行Fine-tune可以分为4个步骤。
### Step1: 选择模型
```python
import paddle
import paddlehub as hub
from paddlehub.datasets import ESC50
model = hub.Module(name='panns_cnn14', version='1.0.0', task='sound-cls', num_class=ESC50.num_class)
```
其中,参数:
- `name`: 模型名称,可以选择`panns_cnn14`、`panns_cnn10` 和`panns_cnn6`,具体的模型参数信息可见下表。
- `version`: module版本号
- `task`:模型的执行任务。`sound-cls`表示声音分类任务;`None`表示Audio Tagging任务。
- `num_classes`:表示当前声音分类任务的类别数,根据具体使用的数据集确定。
目前可选用的预训练模型:
模型名 | PaddleHub Module
-----------| :------:
CNN14 | `hub.Module(name='panns_cnn14')`
CNN10 | `hub.Module(name='panns_cnn10')`
CNN6 | `hub.Module(name='panns_cnn6')`
### Step2: 加载数据集
```python
train_dataset = ESC50(mode='train')
dev_dataset = ESC50(mode='dev')
```
### Step3: 选择优化策略和运行配置
```python
optimizer = paddle.optimizer.AdamW(learning_rate=5e-5, parameters=model.parameters())
trainer = hub.Trainer(model, optimizer, checkpoint_dir='./', use_gpu=True)
```
#### 优化策略
Paddle2.0提供了多种优化器选择,如`SGD`, `AdamW`, `Adamax`等,详细参见[策略](https://www.paddlepaddle.org.cn/documentation/docs/zh/api/paddle/optimizer/Overview_cn.html)。
其中`AdamW`:
- `learning_rate`: 全局学习率。默认为1e-3;
- `parameters`: 待优化模型参数。
其余可配置参数请参考[AdamW](https://www.paddlepaddle.org.cn/documentation/docs/zh/api/paddle/optimizer/adamw/AdamW_cn.html#cn-api-paddle-optimizer-adamw)。
#### 运行配置
`Trainer` 主要控制Fine-tune的训练,包含以下可控制的参数:
- `model`: 被优化模型;
- `optimizer`: 优化器选择;
- `use_vdl`: 是否使用vdl可视化训练过程;
- `checkpoint_dir`: 保存模型参数的地址;
- `compare_metrics`: 保存最优模型的衡量指标;
### Step4: 执行训练和模型评估
```python
trainer.train(
train_dataset,
epochs=50,
batch_size=16,
eval_dataset=dev_dataset,
save_interval=10,
)
trainer.evaluate(dev_dataset, batch_size=16)
```
`trainer.train`执行模型的训练,其参数可以控制具体的训练过程,主要的参数包含:
- `train_dataset`: 训练时所用的数据集;
- `epochs`: 训练轮数;
- `batch_size`: 训练时每一步用到的样本数目,如果使用GPU,请根据实际情况调整batch_size;
- `num_workers`: works的数量,默认为0;
- `eval_dataset`: 验证集;
- `log_interval`: 打印日志的间隔, 单位为执行批训练的次数。
- `save_interval`: 保存模型的间隔频次,单位为执行训练的轮数。
`trainer.evaluate`执行模型的评估,主要的参数包含:
- `eval_dataset`: 模型评估时所用的数据集;
- `batch_size`: 模型评估时每一步用到的样本数目,如果使用GPU,请根据实际情况调整batch_size
## 模型预测
当完成Fine-tune后,Fine-tune过程在验证集上表现最优的模型会被保存在`${CHECKPOINT_DIR}/best_model`目录下,其中`${CHECKPOINT_DIR}`目录为Fine-tune时所选择的保存checkpoint的目录。
以下代码将本地的音频文件`./cat.wav`作为预测数据,使用训好的模型对它进行分类,输出结果。
```python
import os
import librosa
import paddlehub as hub
from paddlehub.datasets import ESC50
wav = './cat.wav' # 存储在本地的需要预测的wav文件
sr = 44100 # 音频文件的采样率
checkpoint = './best_model/model.pdparams' # 模型checkpoint
label_map = {idx: label for idx, label in enumerate(ESC50.label_list)}
model = hub.Module(name='panns_cnn14',
version='1.0.0',
task='sound-cls',
num_class=ESC50.num_class,
label_map=label_map,
load_checkpoint=checkpoint)
data = [librosa.load(wav, sr=sr)[0]]
result = model.predict(data, sample_rate=sr, batch_size=1, feat_type='mel', use_gpu=True)
print(result[0]) # result[0]包含音频文件属于各类别的概率值
```
## Audio Tagging
当前使用的模型是基于[Audioset数据集](https://research.google.com/audioset/)的预训练模型,除了以上的针对特定声音分类数据集的finetune任务,模型还支持基于Audioset 527个标签的Tagging功能。
以下代码将本地的音频文件`./cat.wav`作为预测数据,使用预训练模型对它进行打分,输出top 10的标签和对应的得分。
```python
import os
import librosa
import numpy as np
import paddlehub as hub
from paddlehub.env import MODULE_HOME
wav = './cat.wav' # 存储在本地的需要预测的wav文件
sr = 44100 # 音频文件的采样率
topk = 10 # 展示音频得分前10的标签和分数
# 读取audioset数据集的label文件
label_file = os.path.join(MODULE_HOME, 'panns_cnn14', 'audioset_labels.txt')
label_map = {}
with open(label_file, 'r') as f:
for i, l in enumerate(f.readlines()):
label_map[i] = l.strip()
model = hub.Module(name='panns_cnn14', version='1.0.0', task=None, label_map=label_map)
data = [librosa.load(wav, sr=sr)[0]]
result = model.predict(data, sample_rate=sr, batch_size=1, feat_type='mel', use_gpu=True)
# 打印topk的类别和对应得分
msg = ''
for label, score in list(result[0].items())[:topk]:
msg += f'{label}: {score}\n'
print(msg)
```
### 依赖
paddlepaddle >= 2.0.0
paddlehub >= 2.1.0
================================================
FILE: demo/audio_classification/audioset_predict.py
================================================
# Copyright (c) 2021 PaddlePaddle Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import argparse
import ast
import os
import librosa
import numpy as np
import paddlehub as hub
from paddlehub.env import MODULE_HOME
parser = argparse.ArgumentParser(__doc__)
parser.add_argument("--wav", type=str, required=True, help="Audio file to infer.")
parser.add_argument("--sr", type=int, default=32000, help="Sample rate of inference audio.")
parser.add_argument("--model_type", type=str, default='panns_cnn14', help="Select model to to inference.")
parser.add_argument("--topk", type=int, default=10, help="Show top k results of audioset labels.")
args = parser.parse_args()
if __name__ == '__main__':
label_file = os.path.join(MODULE_HOME, args.model_type, 'audioset_labels.txt')
label_map = {}
with open(label_file, 'r') as f:
for i, l in enumerate(f.readlines()):
label_map[i] = l.strip()
model = hub.Module(name=args.model_type, version='1.0.0', task=None, label_map=label_map)
data = [librosa.load(args.wav, sr=args.sr)[0]] # (t, num_mel_bins)
result = model.predict(data, sample_rate=args.sr, batch_size=1, feat_type='mel', use_gpu=True)
msg = f'[{args.wav}]\n'
for label, score in list(result[0].items())[:args.topk]:
msg += f'{label}: {score}\n'
print(msg)
================================================
FILE: demo/audio_classification/predict.py
================================================
# Copyright (c) 2021 PaddlePaddle Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import argparse
import ast
import os
import librosa
import paddlehub as hub
from paddlehub.datasets import ESC50
parser = argparse.ArgumentParser(__doc__)
parser.add_argument("--wav", type=str, required=True, help="Audio file to infer.")
parser.add_argument("--sr", type=int, default=44100, help="Sample rate of inference audio.")
parser.add_argument("--model_type", type=str, default='panns_cnn14', help="Select model to to inference.")
parser.add_argument("--topk", type=int, default=1, help="Show top k results of prediction labels.")
parser.add_argument(
"--checkpoint", type=str, default='./checkpoint/best_model/model.pdparams', help="Checkpoint of model.")
args = parser.parse_args()
if __name__ == '__main__':
label_map = {idx: label for idx, label in enumerate(ESC50.label_list)}
model = hub.Module(
name=args.model_type,
version='1.0.0',
task='sound-cls',
num_class=ESC50.num_class,
label_map=label_map,
load_checkpoint=args.checkpoint)
data = [librosa.load(args.wav, sr=args.sr)[0]]
result = model.predict(data, sample_rate=args.sr, batch_size=1, feat_type='mel', use_gpu=True)
msg = f'[{args.wav}]\n'
for label, score in list(result[0].items())[:args.topk]:
msg += f'{label}: {score}\n'
print(msg)
================================================
FILE: demo/audio_classification/train.py
================================================
# Copyright (c) 2021 PaddlePaddle Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import argparse
import ast
import paddle
import paddlehub as hub
from paddlehub.datasets import ESC50
parser = argparse.ArgumentParser(__doc__)
parser.add_argument("--num_epoch", type=int, default=50, help="Number of epoches for fine-tuning.")
parser.add_argument(
"--use_gpu",
type=ast.literal_eval,
default=True,
help="Whether use GPU for fine-tuning, input should be True or False")
parser.add_argument("--learning_rate", type=float, default=5e-5, help="Learning rate used to train with warmup.")
parser.add_argument("--batch_size", type=int, default=16, help="Total examples' number in batch for training.")
parser.add_argument("--checkpoint_dir", type=str, default='./checkpoint', help="Directory to model checkpoint")
parser.add_argument("--save_interval", type=int, default=10, help="Save checkpoint every n epoch.")
args = parser.parse_args()
if __name__ == "__main__":
model = hub.Module(name='panns_cnn14', task='sound-cls', num_class=ESC50.num_class)
train_dataset = ESC50(mode='train')
dev_dataset = ESC50(mode='dev')
optimizer = paddle.optimizer.AdamW(learning_rate=args.learning_rate, parameters=model.parameters())
trainer = hub.Trainer(model, optimizer, checkpoint_dir=args.checkpoint_dir, use_gpu=args.use_gpu)
trainer.train(
train_dataset,
epochs=args.num_epoch,
batch_size=args.batch_size,
eval_dataset=dev_dataset,
save_interval=args.save_interval,
)
================================================
FILE: demo/autoaug/README.md
================================================
# PaddleHub 自动数据增强
本示例将展示如何使用PaddleHub搜索最适合数据的数据增强策略,并将其应用到模型训练中。
## 依赖
请预先从pip下载auto-augment软件包
```
pip install auto-augment
```
## auto-augment简述
auto-augment软件包目前支持Paddle的图像分类任务和物体检测任务。
应用时分成搜索(search)和训练(train)两个阶段
**搜索阶段在预置模型上对不同算子的组合进行策略搜索,输出最优数据增强调度策略组合**
**训练阶段在特定模型上应用最优调度数据增强策略组合 **
详细关于auto-augment的使用及benchmark可参考auto_augment/doc里的readme
## 支持任务
目前auto-augment支持paddlhub的图像分类任务。
后续会扩充到其他任务
## 图像分类任务
### 参数配置
参数配置支持yaml格式描述及json格式描述,项目中仅提供yaml格式配置模板。模板统一于configs/路径下
用户可配置参数分为task_config(任务配置),data_config(数据配置), resource_config(资源配置),algo_config(算法配置), search_space(搜索空间配置)。
#### task_config(任务配置)
任务配置细节,包括任务类型及模型细节
具体字段如下:
run_mode: ["ray", "automl_service"], #表示后端采用服务,目前支持单机ray框架
work_space: 用户工作空间
task_type: ["classifier"] #任务类型,目前PaddleHub支持图像分类单标签,需要请使用物体检测单标签任务的增强请参考auto_augment/doc
classifier: 具体任务类型的配置细节,
##### classifier任务配置细节
- model_name: paddlehub模型名称
- epochs: int, 任务搜索轮数, **必填** , 该参数需要特殊指定
- Input_size: 模型输入尺寸
- scale_size: 数据预处理尺寸
- no_cache_image: 不缓存数据, 默认False
- use_class_map: 使用label_list 映射
#### data_config(数据配置)
数据配置支持多种格式输入, 包括图像分类txt标注格式, 物体检测voc标注格式, 物体检测coco标注格式.
- train_img_prefix:str. 训练集数据路径前缀
- train_ann_file:str, 训练集数据描述文件,
- val_img_prefix:str, 验证集数据路径前缀
- val_ann_file:str,验证集数据描述文件
- label_list:str, 标签文件
- delimiter: "," 数据描述文件采用的分隔符
#### resource_config(资源配置)
- gpu:float, 表示每个搜索进程的gpu分配资源,run_mode=="ray"模式下支持小数分配
- cpu: float, 表示每个搜索进程的cpu分配资源,run_mode=="ray"模式下支持小数分配
#### algo_config(算法配置)
算法配置目前仅支持PBA,后续会进一步拓展。
##### PBA配置
- algo_name: str, ["PBA"], 搜索算法
- algo_param:
- perturbation_interval: 搜索扰动周期
- num_samples:搜索进程数
#### search_space(搜索空间配置)
搜索空间定义, 策略搜索阶段必填, 策略应用训练会忽略。
- operators_repeat: int,默认1, 表示搜索算子的重复次数。
- operator_space: 搜索的算子空间
1. 自定义算子模式:
htype: str, ["choice"] 超参类型,目前支持choice枚举
value: list, [0,0.5,1] 枚举数据

2. 缩略版算子模式:
用户只需要指定需要搜索的算子,prob, magtitue搜索空间为系统默认配置,为0-1之间。

支持1,2模式混合定议
##### 图像分类算子
["Sharpness", "Rotate", "Invert", "Brightness", "Cutout", "Equalize","TranslateY", "AutoContrast", "Color","TranslateX", "Solarize", "ShearX","Contrast", "Posterize", "ShearY", "FlipLR"]
### 搜索阶段
用于数据增强策略的搜索
### 训练阶段
在训练中应用搜索出来的数据增强策略
### 示例demo
#### Flower数据组织
```
cd PaddleHub/demo/autaug/
mkdir -p ./dataset
cd dataset
wget https://bj.bcebos.com/paddlehub-dataset/flower_photos.tar.gz
tar -xvf flower_photos.tar.gz
```
#### 搜索流程
```
cd PaddleHub/demo/autaug/
bash search.sh
# 结果会以json形式dump到workspace中,用户可利用这个json文件进行训练
```
#### 训练阶段
```
cd PaddleHub/demo/autaug/
bash train.sh
```
================================================
FILE: demo/autoaug/hub_fitter.py
================================================
# -*- coding: utf-8 -*-
#*******************************************************************************
#
# Copyright (c) 2020 Baidu.com, Inc. All Rights Reserved
#
#*******************************************************************************
"""
Authors: lvhaijun01@baidu.com
Date: 2020-11-24 20:43
"""
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import time
import six
import os
from typing import Dict, List, Optional, Union, Tuple
from auto_augment.autoaug.utils import log
import logging
logger = log.get_logger(level=logging.INFO)
import auto_augment
auto_augment_path = auto_augment.__file__
class HubFitterClassifer(object):
"""Trains an instance of the Model class."""
def __init__(self, hparams: dict) -> None:
"""
定义分类任务的数据、模型
Args:
hparams:
"""
def set_paddle_flags(**kwargs):
for key, value in kwargs.items():
if os.environ.get(key, None) is None:
os.environ[key] = str(value)
# NOTE(paddle-dev): All of these flags should be set before
# `import paddle`. Otherwise, it would not take any effect.
set_paddle_flags(
# enable GC to save memory
FLAGS_fraction_of_gpu_memory_to_use=hparams.resource_config.gpu, )
import paddle
import paddlehub as hub
from paddlehub_utils.trainer import CustomTrainer
from paddlehub_utils.reader import _init_loader
# todo now does not support fleet distribute training
# from paddle.fluid.incubate.fleet.base import role_maker
# from paddle.fluid.incubate.fleet.collective import fleet
# role = role_maker.PaddleCloudRoleMaker(is_collective=True)
# fleet.init(role)
logger.info("classficiation data augment search begin")
self.hparams = hparams
# param compatible
self._fit_param(show=True)
paddle.disable_static(paddle.CUDAPlace(paddle.distributed.get_rank()))
train_dataset, eval_dataset = _init_loader(self.hparams)
model = hub.Module(
name=hparams["task_config"]["classifier"]["model_name"],
label_list=self.class_to_id_dict.keys(),
load_checkpoint=None)
optimizer = paddle.optimizer.Adam(learning_rate=0.001, parameters=model.parameters())
trainer = CustomTrainer(model=model, optimizer=optimizer, checkpoint_dir='img_classification_ckpt')
self.model = model
self.optimizer = optimizer
trainer.init_train_and_eval(
train_dataset, epochs=100, batch_size=32, eval_dataset=eval_dataset, save_interval=1)
self.trainer = trainer
def _fit_param(self, show: bool = False) -> None:
"""
param fit
Args:
hparams:
Returns:
"""
hparams = self.hparams
self._get_label_info(hparams)
def _get_label_info(self, hparams: dict) -> None:
"""
Args:
hparams:
Returns:
"""
from paddlehub_utils.reader import _read_classes
data_config = hparams.data_config
label_list = data_config.label_list
if os.path.isfile(label_list):
class_to_id_dict = _read_classes(label_list)
else:
assert 0, "label_list:{} not exist".format(label_list)
self.num_classes = len(class_to_id_dict)
self.class_to_id_dict = class_to_id_dict
def reset_config(self, new_hparams: dict) -> None:
"""
reset config, used by search stage
Args:
new_hparams:
Returns:
"""
self.hparams = new_hparams
self.trainer.train_loader.dataset.reset_policy(new_hparams.search_space)
return None
def save_model(self, checkpoint_dir: str, step: Optional[str] = None) -> str:
"""Dumps model into the backup_dir.
Args:
step: If provided, creates a checkpoint with the given step
number, instead of overwriting the existing checkpoints.
"""
checkpoint_path = os.path.join(checkpoint_dir, 'epoch') + '-' + str(step)
logger.info('Saving model checkpoint to {}'.format(checkpoint_path))
self.trainer.save_model(os.path.join(checkpoint_path, "checkpoint"))
return checkpoint_path
def extract_model_spec(self, checkpoint_path: str) -> None:
"""Loads a checkpoint with the architecture structure stored in the name."""
ckpt_path = os.path.join(checkpoint_path, "checkpoint")
self.trainer.load_model(ckpt_path)
logger.info('Loaded child model checkpoint from {}'.format(checkpoint_path))
def eval_child_model(self, mode: str, pass_id: int = 0) -> dict:
"""Evaluate the child model.
Args:
model: image model that will be evaluated.
data_loader: dataset object to extract eval data from.
mode: will the model be evalled on train, val or test.
Returns:
Accuracy of the model on the specified dataset.
"""
eval_loader = self.trainer.eval_loader
res = self.trainer.evaluate_process(eval_loader)
top1_acc = res["metrics"]["acc"]
if mode == "val":
return {"val_acc": top1_acc}
elif mode == "test":
return {"test_acc": top1_acc}
else:
raise NotImplementedError
def train_one_epoch(self, pass_id: int) -> dict:
"""
Args:
model:
train_loader:
optimizer:
Returns:
"""
from paddlehub.utils.utils import Timer
batch_sampler = self.trainer.batch_sampler
train_loader = self.trainer.train_loader
steps_per_epoch = len(batch_sampler)
task_config = self.hparams.task_config
task_type = task_config.task_type
epochs = task_config.classifier.epochs
timer = Timer(steps_per_epoch * epochs)
timer.start()
self.trainer.train_one_epoch(
loader=train_loader,
timer=timer,
current_epoch=pass_id,
epochs=epochs,
log_interval=10,
steps_per_epoch=steps_per_epoch)
return {"train_acc": 0}
def _run_training_loop(self, curr_epoch: int) -> dict:
"""Trains the model `m` for one epoch."""
start_time = time.time()
train_acc = self.train_one_epoch(curr_epoch)
logger.info('Epoch:{} time(min): {}'.format(curr_epoch, (time.time() - start_time) / 60.0))
return train_acc
def _compute_final_accuracies(self, iteration: int) -> dict:
"""Run once training is finished to compute final test accuracy."""
task_config = self.hparams.task_config
task_type = task_config.task_type
if (iteration >= task_config[task_type].epochs - 1):
test_acc = self.eval_child_model('test', iteration)
pass
else:
test_acc = {"test_acc": 0}
logger.info('Test acc: {}'.format(test_acc))
return test_acc
def run_model(self, epoch: int) -> dict:
"""Trains and evalutes the image model."""
self._fit_param()
train_acc = self._run_training_loop(epoch)
valid_acc = self.eval_child_model(mode="val", pass_id=epoch)
logger.info('valid acc: {}'.format(valid_acc))
all_metric = {}
all_metric.update(train_acc)
all_metric.update(valid_acc)
return all_metric
================================================
FILE: demo/autoaug/paddlehub_utils/__init__.py
================================================
# -*- coding: utf-8 -*-
#*******************************************************************************
#
# Copyright (c) 2019 Baidu.com, Inc. All Rights Reserved
#
#*******************************************************************************
"""
Authors: lvhaijun01@baidu.com
Date: 2019-09-17 14:15
"""
================================================
FILE: demo/autoaug/paddlehub_utils/reader.py
================================================
# coding:utf-8
# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License"
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# -*- coding: utf-8 -*-
# *******************************************************************************
#
# Copyright (c) 2020 Baidu.com, Inc. All Rights Reserved
#
# *******************************************************************************
"""
Authors: lvhaijun01@baidu.com
Date: 2019-06-30 00:10
"""
import re
import numpy as np
from typing import Dict, List, Optional, Union, Tuple
import six
import cv2
import os
import paddle
import paddlehub.vision.transforms as transforms
from PIL import ImageFile
from auto_augment.autoaug.transform.autoaug_transform import AutoAugTransform
ImageFile.LOAD_TRUNCATED_IMAGES = True
__imagenet_stats = {'mean': [0.485, 0.456, 0.406], 'std': [0.229, 0.224, 0.225]}
class PbaAugment(object):
"""
pytorch 分类 PbaAugment transform
"""
def __init__(self,
input_size: int = 224,
scale_size: int = 256,
normalize: Optional[list] = None,
pre_transform: bool = True,
stage: str = "search",
**kwargs) -> None:
"""
Args:
input_size:
scale_size:
normalize:
pre_transform:
**kwargs:
"""
if normalize is None:
normalize = {'mean': [0.485, 0.456, 0.406], 'std': [0.229, 0.224, 0.225]}
policy = kwargs["policy"]
assert stage in ["search", "train"]
train_epochs = kwargs["hp_policy_epochs"]
self.auto_aug_transform = AutoAugTransform.create(policy, stage=stage, train_epochs=train_epochs)
#self.auto_aug_transform = PbtAutoAugmentClassiferTransform(conf)
if pre_transform:
self.pre_transform = transforms.Resize(input_size)
self.post_transform = transforms.Compose(
transforms=[transforms.Permute(),
transforms.Normalize(**normalize, channel_first=True)],
channel_first=False)
self.cur_epoch = 0
def set_epoch(self, indx: int) -> None:
"""
Args:
indx:
Returns:
"""
self.auto_aug_transform.set_epoch(indx)
def reset_policy(self, new_hparams: dict) -> None:
"""
Args:
new_hparams:
Returns:
"""
self.auto_aug_transform.reset_policy(new_hparams)
def __call__(self, img: np.ndarray):
"""
Args:
img: PIL image
Returns:
"""
# tensform resize
if self.pre_transform:
img = self.pre_transform(img)
img = self.auto_aug_transform.apply(img)
img = img.astype(np.uint8)
img = self.post_transform(img)
return img
class PicRecord(object):
"""
PicRecord
"""
def __init__(self, row: list) -> None:
"""
Args:
row:
"""
self._data = row
@property
def sub_path(self) -> str:
"""
Returns:
"""
return self._data[0]
@property
def label(self) -> str:
"""
Returns:
"""
return self._data[1]
class PicReader(paddle.io.Dataset):
"""
PicReader
"""
def __init__(self,
root_path: str,
list_file: str,
meta: bool = False,
transform: Optional[callable] = None,
class_to_id_dict: Optional[dict] = None,
cache_img: bool = False,
**kwargs) -> None:
"""
Args:
root_path:
list_file:
meta:
transform:
class_to_id_dict:
cache_img:
**kwargs:
"""
self.root_path = root_path
self.list_file = list_file
self.transform = transform
self.meta = meta
self.class_to_id_dict = class_to_id_dict
self.train_type = kwargs["conf"].get("train_type", "single_label")
self.class_num = kwargs["conf"].get("class_num", 0)
self._parse_list(**kwargs)
self.cache_img = cache_img
self.cache_img_buff = dict()
if self.cache_img:
self._get_all_img(**kwargs)
def _get_all_img(self, **kwargs) -> None:
"""
缓存图片进行预resize, 减少内存占用
Returns:
"""
scale_size = kwargs.get("scale_size", 256)
for idx in range(len(self)):
record = self.pic_list[idx]
relative_path = record.sub_path
if self.root_path is not None:
image_path = os.path.join(self.root_path, relative_path)
else:
image_path = relative_path
try:
img = cv2.imread(image_path, cv2.IMREAD_COLOR)
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
img = cv2.resize(img, (scale_size, scale_size))
self.cache_img_buff[image_path] = img
except BaseException:
print("img_path:{} can not by cv2".format(image_path).format(image_path))
pass
def _load_image(self, directory: str) -> np.ndarray:
"""
Args:
directory:
Returns:
"""
if not self.cache_img:
img = cv2.imread(directory, cv2.IMREAD_COLOR).astype('float32')
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
# img = Image.open(directory).convert('RGB')
else:
if directory in self.cache_img_buff:
img = self.cache_img_buff[directory]
else:
img = cv2.imread(directory, cv2.IMREAD_COLOR).astype('float32')
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
# img = Image.open(directory).convert('RGB')
return img
def _parse_list(self, **kwargs) -> None:
"""
Args:
**kwargs:
Returns:
"""
delimiter = kwargs.get("delimiter", " ")
self.pic_list = []
with open(self.list_file) as f:
lines = f.read().splitlines()
print("PicReader:: found {} picture in `{}'".format(len(lines), self.list_file))
for i, line in enumerate(lines):
record = re.split(delimiter, line)
# record = line.split()
assert len(record) == 2, "length of record is not 2!"
if not os.path.splitext(record[0])[1]:
# 适配线上分类数据转无后缀的情况
record[0] = record[0] + ".jpg"
# 线上单标签情况兼容多标签,后续需去除
record[1] = re.split(",", record[1])[0]
self.pic_list.append(PicRecord(record))
def __getitem__(self, index: int):
"""
Args:
index:
Returns:
"""
record = self.pic_list[index]
return self.get(record)
def get(self, record: PicRecord) -> tuple:
"""
Args:
record:
Returns:
"""
relative_path = record.sub_path
if self.root_path is not None:
image_path = os.path.join(self.root_path, relative_path)
else:
image_path = relative_path
img = self._load_image(image_path)
# print("org img sum:{}".format(np.sum(np.asarray(img))))
process_data = self.transform(img)
if self.train_type == "single_label":
if self.class_to_id_dict:
label = self.class_to_id_dict[record.label]
else:
label = int(record.label)
elif self.train_type == "multi_labels":
label_tensor = np.zeros((1, self.class_num))
for label in record.label.split(","):
label_tensor[0, int(label)] = 1
label_tensor = np.squeeze(label_tensor)
label = label_tensor
if self.meta:
return process_data, label, relative_path
else:
return process_data, label
def __len__(self) -> int:
"""
Returns:
"""
return len(self.pic_list)
def set_meta(self, meta: bool) -> None:
"""
Args:
meta:
Returns:
"""
self.meta = meta
def set_epoch(self, epoch: int) -> None:
"""
Args:
epoch:
Returns:
"""
if self.transform is not None:
self.transform.set_epoch(epoch)
# only use in search
def reset_policy(self, new_hparams: dict) -> None:
"""
Args:
new_hparams:
Returns:
"""
if self.transform is not None:
self.transform.reset_policy(new_hparams)
def _parse(value: str, function: callable, fmt: str) -> None:
"""
Parse a string into a value, and format a nice ValueError if it fails.
Returns `function(value)`.
Any `ValueError` raised is catched and a new `ValueError` is raised
with message `fmt.format(e)`, where `e` is the caught `ValueError`.
"""
try:
return function(value)
except ValueError as e:
six.raise_from(ValueError(fmt.format(e)), None)
def _read_classes(csv_file: str) -> dict:
""" Parse the classes file.
"""
result = {}
with open(csv_file) as csv_reader:
for line, row in enumerate(csv_reader):
try:
class_name = row.strip()
# print(class_id, class_name)
except ValueError:
six.raise_from(ValueError('line {}: format should be \'class_name\''.format(line)), None)
class_id = _parse(line, int, 'line {}: malformed class ID: {{}}'.format(line))
if class_name in result:
raise ValueError('line {}: duplicate class name: \'{}\''.format(line, class_name))
result[class_name] = class_id
return result
def _init_loader(hparams: dict, TrainTransform=None) -> tuple:
"""
Args:
hparams:
Returns:
"""
train_data_root = hparams.data_config.train_img_prefix
val_data_root = hparams.data_config.val_img_prefix
train_list = hparams.data_config.train_ann_file
val_list = hparams.data_config.val_ann_file
input_size = hparams.task_config.classifier.input_size
scale_size = hparams.task_config.classifier.scale_size
search_space = hparams.search_space
search_space["task_type"] = hparams.task_config.task_type
epochs = hparams.task_config.classifier.epochs
no_cache_img = hparams.task_config.classifier.get("no_cache_img", False)
normalize = {'mean': [0.485, 0.456, 0.406], 'std': [0.229, 0.224, 0.225]}
if TrainTransform is None:
TrainTransform = PbaAugment(
input_size=input_size,
scale_size=scale_size,
normalize=normalize,
policy=search_space,
hp_policy_epochs=epochs,
)
delimiter = hparams.data_config.delimiter
kwargs = dict(conf=hparams, delimiter=delimiter)
if hparams.task_config.classifier.use_class_map:
class_to_id_dict = _read_classes(label_list=hparams.data_config.label_list)
else:
class_to_id_dict = None
train_data = PicReader(
root_path=train_data_root,
list_file=train_list,
transform=TrainTransform,
class_to_id_dict=class_to_id_dict,
cache_img=not no_cache_img,
**kwargs)
val_data = PicReader(
root_path=val_data_root,
list_file=val_list,
transform=transforms.Compose(
transforms=[
transforms.Resize((224, 224)),
transforms.Permute(),
transforms.Normalize(**normalize, channel_first=True)
],
channel_first=False),
class_to_id_dict=class_to_id_dict,
cache_img=not no_cache_img,
**kwargs)
return train_data, val_data
================================================
FILE: demo/autoaug/paddlehub_utils/trainer.py
================================================
# -*- coding: utf-8 -*-
#*******************************************************************************
#
# Copyright (c) 2019 Baidu.com, Inc. All Rights Reserved
#
#*******************************************************************************
"""
Authors: lvhaijun01@baidu.com
Date: 2020-11-24 20:46
"""
import os
from collections import defaultdict
import paddle
from paddle.distributed import ParallelEnv
from paddlehub.finetune.trainer import Trainer
from paddlehub.utils.log import logger
from paddlehub.utils.utils import Timer
class CustomTrainer(Trainer):
def __init__(self, **kwargs) -> None:
super(CustomTrainer, self).__init__(**kwargs)
def init_train_and_eval(self,
train_dataset: paddle.io.Dataset,
epochs: int = 1,
batch_size: int = 1,
num_workers: int = 0,
eval_dataset: paddle.io.Dataset = None,
log_interval: int = 10,
save_interval: int = 10) -> None:
self.batch_sampler, self.train_loader = self.init_train(train_dataset, batch_size, num_workers)
self.eval_loader = self.init_evaluate(eval_dataset, batch_size, num_workers)
def init_train(self, train_dataset: paddle.io.Dataset, batch_size: int = 1, num_workers: int = 0) -> tuple:
use_gpu = True
place = paddle.CUDAPlace(ParallelEnv().dev_id) if use_gpu else paddle.CPUPlace()
paddle.disable_static(place)
batch_sampler = paddle.io.DistributedBatchSampler(train_dataset,
batch_size=batch_size,
shuffle=True,
drop_last=False)
loader = paddle.io.DataLoader(train_dataset,
batch_sampler=batch_sampler,
places=place,
num_workers=num_workers,
return_list=True)
return batch_sampler, loader
def train_one_epoch(self, loader: paddle.io.DataLoader, timer: Timer, current_epoch: int, epochs: int,
log_interval: int, steps_per_epoch: int) -> None:
avg_loss = 0
avg_metrics = defaultdict(int)
self.model.train()
for batch_idx, batch in enumerate(loader):
loss, metrics = self.training_step(batch, batch_idx)
self.optimizer_step(current_epoch, batch_idx, self.optimizer, loss)
self.optimizer_zero_grad(current_epoch, batch_idx, self.optimizer)
# calculate metrics and loss
avg_loss += float(loss)
for metric, value in metrics.items():
avg_metrics[metric] += float(value)
timer.count()
if (batch_idx + 1) % log_interval == 0 and self.local_rank == 0:
lr = self.optimizer.get_lr()
avg_loss /= log_interval
if self.use_vdl:
self.log_writer.add_scalar(tag='TRAIN/loss', step=timer.current_step, value=avg_loss)
print_msg = 'Epoch={}/{}, Step={}/{}'.format(current_epoch, epochs, batch_idx + 1, steps_per_epoch)
print_msg += ' loss={:.4f}'.format(avg_loss)
for metric, value in avg_metrics.items():
value /= log_interval
if self.use_vdl:
self.log_writer.add_scalar(tag='TRAIN/{}'.format(metric), step=timer.current_step, value=value)
print_msg += ' {}={:.4f}'.format(metric, value)
print_msg += ' lr={:.6f} step/sec={:.2f} | ETA {}'.format(lr, timer.timing, timer.eta)
logger.train(print_msg)
avg_loss = 0
avg_metrics = defaultdict(int)
def train(self,
train_dataset: paddle.io.Dataset,
epochs: int = 1,
batch_size: int = 1,
num_workers: int = 0,
eval_dataset: paddle.io.Dataset = None,
log_interval: int = 10,
save_interval: int = 10):
'''
Train a model with specific config.
Args:
train_dataset(paddle.io.Dataset) : Dataset to train the model
epochs(int) : Number of training loops, default is 1.
batch_size(int) : Batch size of per step, default is 1.
num_workers(int) : Number of subprocess to load data, default is 0.
eval_dataset(paddle.io.Dataset) : The validation dataset, deafult is None. If set, the Trainer will
execute evaluate function every `save_interval` epochs.
log_interval(int) : Log the train infomation every `log_interval` steps.
save_interval(int) : Save the checkpoint every `save_interval` epochs.
'''
batch_sampler, loader = self.init_train(train_dataset, batch_size, num_workers)
steps_per_epoch = len(batch_sampler)
timer = Timer(steps_per_epoch * epochs)
timer.start()
for i in range(epochs):
loader.dataset.set_epoch(epochs)
self.current_epoch += 1
self.train_one_epoch(loader, timer, self.current_epoch, epochs, log_interval, steps_per_epoch)
# todo, why paddlehub put save, eval in batch?
if self.current_epoch % save_interval == 0 and self.local_rank == 0:
if eval_dataset:
result = self.evaluate(eval_dataset, batch_size, num_workers)
eval_loss = result.get('loss', None)
eval_metrics = result.get('metrics', {})
if self.use_vdl:
if eval_loss:
self.log_writer.add_scalar(tag='EVAL/loss', step=timer.current_step, value=eval_loss)
for metric, value in eval_metrics.items():
self.log_writer.add_scalar(tag='EVAL/{}'.format(metric),
step=timer.current_step,
value=value)
if not self.best_metrics or self.compare_metrics(self.best_metrics, eval_metrics):
self.best_metrics = eval_metrics
best_model_path = os.path.join(self.checkpoint_dir, 'best_model')
self.save_model(best_model_path)
self._save_metrics()
metric_msg = ['{}={:.4f}'.format(metric, value) for metric, value in self.best_metrics.items()]
metric_msg = ' '.join(metric_msg)
logger.eval('Saving best model to {} [best {}]'.format(best_model_path, metric_msg))
self._save_checkpoint()
def init_evaluate(self, eval_dataset: paddle.io.Dataset, batch_size: int, num_workers: int) -> paddle.io.DataLoader:
use_gpu = True
place = paddle.CUDAPlace(ParallelEnv().dev_id) if use_gpu else paddle.CPUPlace()
paddle.disable_static(place)
batch_sampler = paddle.io.DistributedBatchSampler(eval_dataset,
batch_size=batch_size,
shuffle=False,
drop_last=False)
loader = paddle.io.DataLoader(eval_dataset,
batch_sampler=batch_sampler,
places=place,
num_workers=num_workers,
return_list=True)
return loader
def evaluate_process(self, loader: paddle.io.DataLoader) -> dict:
self.model.eval()
avg_loss = num_samples = 0
sum_metrics = defaultdict(int)
avg_metrics = defaultdict(int)
for batch_idx, batch in enumerate(loader):
result = self.validation_step(batch, batch_idx)
loss = result.get('loss', None)
metrics = result.get('metrics', {})
bs = batch[0].shape[0]
num_samples += bs
if loss:
avg_loss += float(loss) * bs
for metric, value in metrics.items():
sum_metrics[metric] += float(value) * bs
# print avg metrics and loss
print_msg = '[Evaluation result]'
if loss:
avg_loss /= num_samples
print_msg += ' avg_loss={:.4f}'.format(avg_loss)
for metric, value in sum_metrics.items():
avg_metrics[metric] = value / num_samples
print_msg += ' avg_{}={:.4f}'.format(metric, avg_metrics[metric])
logger.eval(print_msg)
if loss:
return {'loss': avg_loss, 'metrics': avg_metrics}
return {'metrics': avg_metrics}
def evaluate(self, eval_dataset: paddle.io.Dataset, batch_size: int = 1, num_workers: int = 0) -> dict:
'''
Run evaluation and returns metrics.
Args:
eval_dataset(paddle.io.Dataset) : The validation dataset
batch_size(int) : Batch size of per step, default is 1.
num_workers(int) : Number of subprocess to load data, default is 0.
'''
loader = self.init_evaluate(eval_dataset, batch_size, num_workers)
res = self.evaluate_process(loader)
return res
================================================
FILE: demo/autoaug/pba_classifier_example.yaml
================================================
task_config:
run_mode: "ray"
workspace: "./work_dirs/pbt_hub_classifer/test_autoaug"
task_type: "classifier"
classifier:
model_name: "resnet50_vd_imagenet_ssld"
epochs: 100
input_size: 224
scale_size: 256
no_cache_img: false
use_class_map: false
data_config:
train_img_prefix: "./dataset/flower_photos"
train_ann_file: "./dataset/flower_photos/train_list.txt"
val_img_prefix: "./dataset/flower_photos"
val_ann_file: "./dataset/flower_photos/validate_list.txt"
label_list: "./dataset/flower_photos/label_list.txt"
delimiter: " "
resource_config:
gpu: 0.4
cpu: 1
algo_config:
algo_name: "PBA"
algo_param:
perturbation_interval: 3
num_samples: 8
search_space:
operator_space:
-
name: Sharpness
prob:
htype: choice
value: [0, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1]
magtitude:
htype: choice
value: [0, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1]
-
name: Rotate
prob:
htype: choice
value: [0, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1]
magtitude:
htype: choice
value: [0, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1]
-
name: Invert
prob:
htype: choice
value: [0, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1]
magtitude:
htype: choice
value: [0, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1]
-
name: Brightness
prob:
htype: choice
value: [0, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1]
magtitude:
htype: choice
value: [0, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1]
-
name: Cutout
prob:
htype: choice
value: [0, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1]
magtitude:
htype: choice
value: [0, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1]
-
name: Equalize
prob:
htype: choice
value: [0, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1]
magtitude:
htype: choice
value: [0, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1]
-
name: TranslateY
prob:
htype: choice
value: [0, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1]
magtitude:
htype: choice
value: [0, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1]
-
name: AutoContrast
prob:
htype: choice
value: [0, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1]
magtitude:
htype: choice
value: [0, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1]
-
name: Color
prob:
htype: choice
value: [0, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1]
magtitude:
htype: choice
value: [0, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1]
-
name: TranslateX
prob:
htype: choice
value: [0, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1]
magtitude:
htype: choice
value: [0, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1]
-
name: Solarize
prob:
htype: choice
value: [0, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1]
magtitude:
htype: choice
value: [0, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1]
-
name: ShearX
prob:
htype: choice
value: [0, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1]
magtitude:
htype: choice
value: [0, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1]
-
name: Contrast
prob:
htype: choice
value: [0, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1]
magtitude:
htype: choice
value: [0, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1]
-
name: Posterize
prob:
htype: choice
value: [0, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1]
magtitude:
htype: choice
value: [0, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1]
-
name: ShearY
prob:
htype: choice
value: [0, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1]
magtitude:
htype: choice
value: [0, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1]
-
name: FlipLR
prob:
htype: choice
value: [0, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1]
magtitude:
htype: choice
value: [0, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1]
================================================
FILE: demo/autoaug/search.py
================================================
from auto_augment.autoaug.experiment.experiment import AutoAugExperiment
from auto_augment.autoaug.utils.yaml_config import get_config
from hub_fitter import HubFitterClassifer
import os
import argparse
import logging
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
parser = argparse.ArgumentParser()
parser.add_argument(
"--config",
help="config file",
)
parser.add_argument(
"--workspace",
default=None,
help="work_space",
)
def main():
search_test()
def search_test():
args = parser.parse_args()
config = args.config
config = get_config(config, show=True)
task_config = config.task_config
data_config = config.data_config
resource_config = config.resource_config
algo_config = config.algo_config
search_space = config.get("search_space", None)
if args.workspace is not None:
task_config["workspace"] = args.workspace
workspace = task_config["workspace"]
# 算法,任务,资源,数据,搜索空间(optional)配置导入,
exper = AutoAugExperiment.create(
algo_config=algo_config,
task_config=task_config,
resource_config=resource_config,
data_config=data_config,
search_space=search_space,
fitter=HubFitterClassifer)
result = exper.search() # 开始搜索任务
policy = result.get_best_policy() # 最佳策略获取, policy格式见 搜索结果应用格式
print("policy is:{}".format(policy))
dump_path = os.path.join(workspace, "auto_aug_config.json")
result.dump_best_policy(path=dump_path)
if __name__ == "__main__":
main()
================================================
FILE: demo/autoaug/search.sh
================================================
#!/usr/bin/env bash
export FLAGS_fast_eager_deletion_mode=1
export FLAGS_eager_delete_tensor_gb=0.0
config="./pba_classifier_example.yaml"
workspace="./work_dirs//autoaug_flower_mobilenetv2"
# workspace工作空间需要初始化
rm -rf ${workspace}
mkdir -p ${workspace}
CUDA_VISIBLE_DEVICES=0,1 python -u search.py \
--config=${config} \
--workspace=${workspace} 2>&1 | tee -a ${workspace}/log.txt
================================================
FILE: demo/autoaug/train.py
================================================
# -*- coding: utf-8 -*-
#*******************************************************************************
#
# Copyright (c) 2020 Baidu.com, Inc. All Rights Reserved
#
#*******************************************************************************
"""
Authors: lvhaijun01@baidu.com
Date: 2020-11-26 20:57
"""
from auto_augment.autoaug.utils.yaml_config import get_config
from hub_fitter import HubFitterClassifer
import os
import argparse
import logging
import paddlehub as hub
import paddle
import paddlehub.vision.transforms as transforms
from paddlehub_utils.reader import _init_loader, PbaAugment
from paddlehub_utils.reader import _read_classes
from paddlehub_utils.trainer import CustomTrainer
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
parser = argparse.ArgumentParser()
parser.add_argument(
"--config",
help="config file",
)
parser.add_argument(
"--workspace",
default=None,
help="work_space",
)
parser.add_argument(
"--policy",
default=None,
help="data aug policy",
)
if __name__ == '__main__':
args = parser.parse_args()
config = args.config
config = get_config(config, show=True)
task_config = config.task_config
data_config = config.data_config
resource_config = config.resource_config
algo_config = config.algo_config
input_size = task_config.classifier.input_size
scale_size = task_config.classifier.scale_size
normalize = {'mean': [0.485, 0.456, 0.406], 'std': [0.229, 0.224, 0.225]}
epochs = task_config.classifier.epochs
policy = args.policy
if policy is None:
print("use normal train transform")
TrainTransform = transforms.Compose(
transforms=[
transforms.Resize((input_size, input_size)),
transforms.Permute(),
transforms.Normalize(**normalize, channel_first=True)
],
channel_first=False)
else:
TrainTransform = PbaAugment(
input_size=input_size,
scale_size=scale_size,
normalize=normalize,
policy=policy,
hp_policy_epochs=epochs,
stage="train")
train_dataset, eval_dataset = _init_loader(config, TrainTransform=TrainTransform)
class_to_id_dict = _read_classes(config.data_config.label_list)
model = hub.Module(
name=config.task_config.classifier.model_name, label_list=class_to_id_dict.keys(), load_checkpoint=None)
optimizer = paddle.optimizer.Adam(learning_rate=0.001, parameters=model.parameters())
trainer = CustomTrainer(model=model, optimizer=optimizer, checkpoint_dir='img_classification_ckpt')
trainer.train(train_dataset, epochs=epochs, batch_size=32, eval_dataset=eval_dataset, save_interval=10)
================================================
FILE: demo/autoaug/train.sh
================================================
#!/usr/bin/env bash
export FLAGS_fast_eager_deletion_mode=1
export FLAGS_eager_delete_tensor_gb=0.0
config="./pba_classifier_example.yaml"
workspace="./work_dirs//autoaug_flower_mobilenetv2"
# workspace工作空间需要初始化
mkdir -p ${workspace}
policy=./work_dirs//autoaug_flower_mobilenetv2/auto_aug_config.json
CUDA_VISIBLE_DEVICES=0,1 python train.py \
--config=${config} \
--policy=${policy} \
--workspace=${workspace} 2>&1 | tee -a ${workspace}/log.txt
================================================
FILE: demo/colorization/README.md
================================================
# PaddleHub 图像着色
本示例将展示如何使用PaddleHub对预训练模型进行finetune并完成预测任务。
## 命令行预测
```
$ hub run user_guided_colorization --input_path "/PATH/TO/IMAGE"
```
## 如何开始Fine-tune
在完成安装PaddlePaddle与PaddleHub后,通过执行`python train.py`即可开始使用user_guided_colorization模型对[Canvas](../../docs/reference/datasets.md#class-hubdatasetsCanvas)等数据集进行Fine-tune。
## 代码步骤
使用PaddleHub Fine-tune API进行Fine-tune可以分为4个步骤。
### Step1: 定义数据预处理方式
```python
import paddlehub.vision.transforms as T
transform = T.Compose([T.Resize((256, 256), interpolation='NEAREST'),
T.RandomPaddingCrop(crop_size=176),
T.RGB2LAB()], to_rgb=True)
```
`transforms`数据增强模块定义了丰富的数据预处理方式,用户可按照需求替换自己需要的数据预处理方式。
**NOTE:** 要将`T.Compose`中`to_rgb`设定为True.
### Step2: 下载数据集并使用
```python
from paddlehub.datasets import Canvas
color_set = Canvas(transform=transform, mode='train')
```
* `transform`: 数据预处理方式。
* `mode`: 选择数据模式,可选项有 `train`, `test` 默认为`train`。
数据集的准备代码可以参考 [canvas.py](../../paddlehub/datasets/canvas.py)。`hub.datasets.Canvas()` 会自动从网络下载数据集并解压到用户目录下`$HOME/.paddlehub/dataset`目录。
### Step3: 加载预训练模型
```python
model = hub.Module(name='user_guided_colorization', load_checkpoint=None)
model.set_config(classification=True, prob=1)
```
* `name`:加载模型的名字。
* `load_checkpoint`: 是否加载自己训练的模型,若为None,则加载提供的模型默认参数。
* `classification`: 着色模型分两部分训练,开始阶段`classification`设置为True, 用于浅层网络训练。训练后期将`classification`设置为False, 用于训练网络的输出层。
* `prob`: 每张输入图不加一个先验彩色块的概率,默认为1,即不加入先验彩色块。例如,当`prob`设定为0.9时,一张图上有两个先验彩色块的概率为(1-0.9)*(1-0.9)*0.9=0.009.
### Step4: 选择优化策略和运行配置
```python
optimizer = paddle.optimizer.Adam(learning_rate=0.0001, parameters=model.parameters())
trainer = Trainer(model, optimizer, checkpoint_dir='img_colorization_ckpt_cls_1')
trainer.train(color_set, epochs=201, batch_size=25, eval_dataset=color_set, log_interval=10, save_interval=10)
```
#### 优化策略
Paddle2.0-rc提供了多种优化器选择,如`SGD`, `Adam`, `Adamax`等,详细参见[策略](https://www.paddlepaddle.org.cn/documentation/docs/zh/2.0-rc/api/paddle/optimizer/optimizer/Optimizer_cn.html)。
其中`Adam`:
* `learning_rate`: 全局学习率。默认为1e-4;
* `parameters`: 待优化模型参数。
#### 运行配置
`Trainer` 主要控制Fine-tune的训练,包含以下可控制的参数:
* `model`: 被优化模型;
* `optimizer`: 优化器选择;
* `use_vdl`: 是否使用vdl可视化训练过程;
* `checkpoint_dir`: 保存模型参数的地址;
* `compare_metrics`: 保存最优模型的衡量指标;
`trainer.train` 主要控制具体的训练过程,包含以下可控制的参数:
* `train_dataset`: 训练时所用的数据集;
* `epochs`: 训练轮数;
* `batch_size`: 训练的批大小,如果使用GPU,请根据实际情况调整batch_size;
* `num_workers`: works的数量,默认为0;
* `eval_dataset`: 验证过程所用的数据集;
* `log_interval`: 打印日志的间隔, 单位为执行批训练的次数。
* `save_interval`: 保存模型的间隔频次,单位为执行训练的轮数。
## 模型预测
当完成Fine-tune后,Fine-tune过程在验证集上表现最优的模型会被保存在`${CHECKPOINT_DIR}/best_model`目录下,其中`${CHECKPOINT_DIR}`目录为Fine-tune时所选择的保存checkpoint的目录。
我们使用该模型来进行预测。predict.py脚本如下:
```python
import paddle
import paddlehub as hub
if __name__ == '__main__':
model = hub.Module(name='user_guided_colorization', load_checkpoint='/PATH/TO/CHECKPOINT')
model.set_config(prob=0.1)
result = model.predict(images=['house.png'])
```
参数配置正确后,请执行脚本`python predict.py`, 加载模型具体可参见[加载](https://www.paddlepaddle.org.cn/documentation/docs/zh/2.0-rc/api/paddle/framework/io/load_cn.html#load)。
**NOTE:** 进行预测时,所选择的module,checkpoint_dir,dataset必须和Fine-tune所用的一样。若想获取油画风着色效果,请下载参数文件[油画着色](https://paddlehub.bj.bcebos.com/dygraph/models/canvas_rc.pdparams)
**Args**
* `images`:原始图像路径或者BGR格式图片;
* `visualization`: 是否可视化,默认为True;
* `save_path`: 保存结果的路径,默认为'result'。
## 服务部署
PaddleHub Serving可以部署一个在线着色任务服务。
### Step1: 启动PaddleHub Serving
运行启动命令:
```shell
$ hub serving start -m user_guided_colorization
```
这样就完成了一个着色任务服务化API的部署,默认端口号为8866。
**NOTE:** 如使用GPU预测,则需要在启动服务之前,请设置CUDA_VISIBLE_DEVICES环境变量,否则不用设置。
### Step2: 发送预测请求
配置好服务端,以下数行代码即可实现发送预测请求,获取预测结果
```python
import requests
import json
import cv2
import base64
import numpy as np
def cv2_to_base64(image):
data = cv2.imencode('.jpg', image)[1]
return base64.b64encode(data.tostring()).decode('utf8')
def base64_to_cv2(b64str):
data = base64.b64decode(b64str.encode('utf8'))
data = np.fromstring(data, np.uint8)
data = cv2.imdecode(data, cv2.IMREAD_COLOR)
return data
# 发送HTTP请求
org_im = cv2.imread('/PATH/TO/IMAGE')
data = {'images':[cv2_to_base64(org_im)]}
headers = {"Content-type": "application/json"}
url = "http://127.0.0.1:8866/predict/user_guided_colorization"
r = requests.post(url=url, headers=headers, data=json.dumps(data))
data = base64_to_cv2(r.json()["results"]['data'][0]['fake_reg'])
cv2.imwrite('color.png', data)
```
### 查看代码
https://github.com/richzhang/colorization-pytorch
### 依赖
paddlepaddle >= 2.0.0rc
paddlehub >= 2.0.0
================================================
FILE: demo/colorization/predict.py
================================================
import paddle
import paddlehub as hub
if __name__ == '__main__':
model = hub.Module(name='user_guided_colorization', load_checkpoint='/PATH/TO/CHECKPOINT')
model.set_config(prob=0.1)
result = model.predict(images=['house.png'])
================================================
FILE: demo/colorization/train.py
================================================
import paddle
import paddlehub as hub
import paddlehub.vision.transforms as T
from paddlehub.finetune.trainer import Trainer
from paddlehub.datasets import Canvas
if __name__ == '__main__':
transform = T.Compose(
[T.Resize((256, 256), interpolation='NEAREST'),
T.RandomPaddingCrop(crop_size=176),
T.RGB2LAB()], to_rgb=True)
color_set = Canvas(transform=transform, mode='train')
model = hub.Module(name='user_guided_colorization', load_checkpoint='/PATH/TO/CHECKPOINT')
model.set_config(classification=True, prob=1)
optimizer = paddle.optimizer.Adam(learning_rate=0.0001, parameters=model.parameters())
trainer = Trainer(model, optimizer, checkpoint_dir='img_colorization_ckpt_cls_1')
trainer.train(color_set, epochs=201, batch_size=25, eval_dataset=color_set, log_interval=10, save_interval=10)
model.set_config(classification=False, prob=0.125)
optimizer = paddle.optimizer.Adam(learning_rate=0.00001, parameters=model.parameters())
trainer = Trainer(model, optimizer, checkpoint_dir='img_colorization_ckpt_reg_1')
trainer.train(color_set, epochs=101, batch_size=25, log_interval=10, save_interval=10)
================================================
FILE: demo/image_classification/README.md
================================================
# PaddleHub 图像分类
本示例将展示如何使用PaddleHub对预训练模型进行finetune并完成预测任务。
## 命令行预测
```shell
$ hub run resnet50_vd_imagenet_ssld --input_path "/PATH/TO/IMAGE" --top_k 5
```
## 脚本预测
```python
import paddle
import paddlehub as hub
if __name__ == '__main__':
model = hub.Module(name='resnet50_vd_imagenet_ssld',)
result = model.predict([PATH/TO/IMAGE])
```
## 如何开始Fine-tune
在完成安装PaddlePaddle与PaddleHub后,通过执行`python train.py`即可开始使用resnet50_vd_imagenet_ssld对[Flowers](../../docs/reference/datasets.md#class-hubdatasetsflowers)等数据集进行Fine-tune。
## 代码步骤
使用PaddleHub Fine-tune API进行Fine-tune可以分为4个步骤。
### Step1: 定义数据预处理方式
```python
import paddlehub.vision.transforms as T
transforms = T.Compose([T.Resize((256, 256)),
T.CenterCrop(224),
T.Normalize(mean=[0.485, 0.456, 0.406], std = [0.229, 0.224, 0.225])],
to_rgb=True)
```
`transforms` 数据增强模块定义了丰富的数据预处理方式,用户可按照需求替换自己需要的数据预处理方式。
### Step2: 下载数据集并使用
```python
from paddlehub.datasets import Flowers
flowers = Flowers(transforms)
flowers_validate = Flowers(transforms, mode='val')
```
* `transforms`: 数据预处理方式。
* `mode`: 选择数据模式,可选项有 `train`, `test`, `val`, 默认为`train`。
数据集的准备代码可以参考 [flowers.py](../../paddlehub/datasets/flowers.py)。`hub.datasets.Flowers()` 会自动从网络下载数据集并解压到用户目录下`$HOME/.paddlehub/dataset`目录。
### Step3: 加载预训练模型
```python
model = hub.Module(name="resnet50_vd_imagenet_ssld", label_list=["roses", "tulips", "daisy", "sunflowers", "dandelion"])
```
* `name`: 选择预训练模型的名字。
* `label_list`: 设置输出分类类别,默认为Imagenet2012类别。
PaddleHub提供许多图像分类预训练模型,如xception、mobilenet、efficientnet等,详细信息参见[图像分类模型](https://www.paddlepaddle.org.cn/hub?filter=en_category&value=ImageClassification)。
如果想尝试efficientnet模型,只需要更换Module中的`name`参数即可.
```python
# 更换name参数即可无缝切换efficientnet模型, 代码示例如下
model = hub.Module(name="efficientnetb7_imagenet")
```
**NOTE:**目前部分模型还没有完全升级到2.0版本,敬请期待。
### Step4: 选择优化策略和运行配置
```python
optimizer = paddle.optimizer.Adam(learning_rate=0.001, parameters=model.parameters())
trainer = Trainer(model, optimizer, checkpoint_dir='img_classification_ckpt')
trainer.train(flowers, epochs=100, batch_size=32, eval_dataset=flowers_validate, save_interval=1)
```
#### 优化策略
Paddle2.0提供了多种优化器选择,如`SGD`, `Adam`, `Adamax`等,其中`Adam`:
* `learning_rate`: 全局学习率。默认为1e-3;
* `parameters`: 待优化模型参数。
#### 运行配置
`Trainer` 主要控制Fine-tune的训练,包含以下可控制的参数:
* `model`: 被优化模型;
* `optimizer`: 优化器选择;
* `use_vdl`: 是否使用vdl可视化训练过程;
* `checkpoint_dir`: 保存模型参数的地址;
* `compare_metrics`: 保存最优模型的衡量指标;
`trainer.train` 主要控制具体的训练过程,包含以下可控制的参数:
* `train_dataset`: 训练时所用的数据集;
* `epochs`: 训练轮数;
* `batch_size`: 训练的批大小,如果使用GPU,请根据实际情况调整batch_size;
* `num_workers`: works的数量,默认为0;
* `eval_dataset`: 验证集;
* `log_interval`: 打印日志的间隔, 单位为执行批训练的次数。
* `save_interval`: 保存模型的间隔频次,单位为执行训练的轮数。
## 模型预测
当完成Fine-tune后,Fine-tune过程在验证集上表现最优的模型会被保存在`${CHECKPOINT_DIR}/best_model`目录下,其中`${CHECKPOINT_DIR}`目录为Fine-tune时所选择的保存checkpoint的目录。
我们使用该模型来进行预测。predict.py脚本如下:
```python
import paddle
import paddlehub as hub
if __name__ == '__main__':
model = hub.Module(name='resnet50_vd_imagenet_ssld', label_list=["roses", "tulips", "daisy", "sunflowers", "dandelion"], load_checkpoint='/PATH/TO/CHECKPOINT')
result = model.predict(['flower.jpg'])
```
参数配置正确后,请执行脚本`python predict.py`, 加载模型具体可参见[加载](https://www.paddlepaddle.org.cn/documentation/docs/zh/2.0-rc/api/paddle/framework/io/load_cn.html#load)。
**NOTE:** 进行预测时,所选择的module,checkpoint_dir,dataset必须和Fine-tune所用的一样。
## 服务部署
PaddleHub Serving可以部署一个在线分类任务服务。
### Step1: 启动PaddleHub Serving
运行启动命令:
```shell
$ hub serving start -m resnet50_vd_imagenet_ssld
```
这样就完成了一个分类任务服务化API的部署,默认端口号为8866。
**NOTE:** 如使用GPU预测,则需要在启动服务之前,请设置CUDA_VISIBLE_DEVICES环境变量,否则不用设置。
### Step2: 发送预测请求
配置好服务端,以下数行代码即可实现发送预测请求,获取预测结果
```python
import requests
import json
import cv2
import base64
import numpy as np
def cv2_to_base64(image):
data = cv2.imencode('.jpg', image)[1]
return base64.b64encode(data.tostring()).decode('utf8')
def base64_to_cv2(b64str):
data = base64.b64decode(b64str.encode('utf8'))
data = np.fromstring(data, np.uint8)
data = cv2.imdecode(data, cv2.IMREAD_COLOR)
return data
# 发送HTTP请求
org_im = cv2.imread('/PATH/TO/IMAGE')
data = {'images':[cv2_to_base64(org_im)], 'top_k':2}
headers = {"Content-type": "application/json"}
url = "http://127.0.0.1:8866/predict/resnet50_vd_imagenet_ssld"
r = requests.post(url=url, headers=headers, data=json.dumps(data))
data =r.json()["results"]['data']
```
### 查看代码
https://github.com/PaddlePaddle/models/tree/develop/PaddleCV/image_classification
### 依赖
paddlepaddle >= 2.0.0rc
paddlehub >= 2.0.0
================================================
FILE: demo/image_classification/predict.py
================================================
import paddle
import paddlehub as hub
if __name__ == '__main__':
model = hub.Module(
name='resnet50_vd_imagenet_ssld',
label_list=["roses", "tulips", "daisy", "sunflowers", "dandelion"],
load_checkpoint='/PATH/TO/CHECKPOINT')
result = model.predict(['flower.jpg'])
================================================
FILE: demo/image_classification/train.py
================================================
import paddle
import paddlehub as hub
import paddlehub.vision.transforms as T
from paddlehub.finetune.trainer import Trainer
from paddlehub.datasets import Flowers
if __name__ == '__main__':
transforms = T.Compose(
[T.Resize((256, 256)),
T.CenterCrop(224),
T.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])],
to_rgb=True)
flowers = Flowers(transforms)
flowers_validate = Flowers(transforms, mode='val')
model = hub.Module(
name='resnet50_vd_imagenet_ssld',
label_list=["roses", "tulips", "daisy", "sunflowers", "dandelion"],
load_checkpoint=None)
optimizer = paddle.optimizer.Adam(learning_rate=0.001, parameters=model.parameters())
trainer = Trainer(model, optimizer, checkpoint_dir='img_classification_ckpt', use_gpu=True)
trainer.train(flowers, epochs=100, batch_size=32, eval_dataset=flowers_validate, save_interval=10)
================================================
FILE: demo/semantic_segmentation/README.md
================================================
# PaddleHub 图像分割
本示例将展示如何使用PaddleHub对预训练模型进行finetune并完成预测任务。
## 如何开始Fine-tune
在完成安装PaddlePaddle与PaddleHub后,通过执行`python train.py`即可开始使用ocrnet_hrnetw18_voc模型对OpticDiscSeg等数据集进行Fine-tune。
## 代码步骤
使用PaddleHub Fine-tune API进行Fine-tune可以分为4个步骤。
### Step1: 定义数据预处理方式
```python
from paddlehub.vision.segmentation_transforms import Compose, Resize, Normalize
transform = Compose([Resize(target_size=(512, 512)), Normalize()])
```
`segmentation_transforms` 数据增强模块定义了丰富的针对图像分割数据的预处理方式,用户可按照需求替换自己需要的数据预处理方式。
### Step2: 下载数据集并使用
```python
from paddlehub.datasets import OpticDiscSeg
train_reader = OpticDiscSeg(transform, mode='train')
```
* `transform`: 数据预处理方式。
* `mode`: 选择数据模式,可选项有 `train`, `test`, `val`, 默认为`train`。
数据集的准备代码可以参考 [opticdiscseg.py](../../paddlehub/datasets/opticdiscseg.py)。`hub.datasets.OpticDiscSeg()`会自动从网络下载数据集并解压到用户目录下`$HOME/.paddlehub/dataset`目录。
### Step3: 加载预训练模型
```python
model = hub.Module(name='ocrnet_hrnetw18_voc', num_classes=2, pretrained=None)
```
* `name`: 选择预训练模型的名字。
* `num_classes`: 分割模型的类别数目。
* `pretrained`: 是否加载自己训练的模型,若为None,则加载提供的模型默认参数。
### Step4: 选择优化策略和运行配置
```python
scheduler = paddle.optimizer.lr.PolynomialDecay(learning_rate=0.01, decay_steps=1000, power=0.9, end_lr=0.0001)
optimizer = paddle.optimizer.Adam(learning_rate=scheduler, parameters=model.parameters())
trainer = Trainer(model, optimizer, checkpoint_dir='test_ckpt_img_ocr', use_gpu=True)
```
#### 优化策略
其中`Adam`:
* `learning_rate`: 全局学习率。
* `parameters`: 待优化模型参数。
#### 运行配置
`Trainer` 主要控制Fine-tune的训练,包含以下可控制的参数:
* `model`: 被优化模型;
* `optimizer`: 优化器选择;
* `use_gpu`: 是否使用gpu,默认为False;
* `use_vdl`: 是否使用vdl可视化训练过程;
* `checkpoint_dir`: 保存模型参数的地址;
* `compare_metrics`: 保存最优模型的衡量指标;
`trainer.train` 主要控制具体的训练过程,包含以下可控制的参数:
* `train_dataset`: 训练时所用的数据集;
* `epochs`: 训练轮数;
* `batch_size`: 训练的批大小,如果使用GPU,请根据实际情况调整batch_size;
* `num_workers`: works的数量,默认为0;
* `eval_dataset`: 验证集;
* `log_interval`: 打印日志的间隔, 单位为执行批训练的次数。
* `save_interval`: 保存模型的间隔频次,单位为执行训练的轮数。
## 模型预测
当完成Fine-tune后,Fine-tune过程在验证集上表现最优的模型会被保存在`${CHECKPOINT_DIR}/best_model`目录下,其中`${CHECKPOINT_DIR}`目录为Fine-tune时所选择的保存checkpoint的目录。
我们使用该模型来进行预测。predict.py脚本如下:
```python
import paddle
import cv2
import paddlehub as hub
if __name__ == '__main__':
model = hub.Module(name='ocrnet_hrnetw18_voc', pretrained='/PATH/TO/CHECKPOINT')
img = cv2.imread("/PATH/TO/IMAGE")
model.predict(images=[img], visualization=True)
```
参数配置正确后,请执行脚本`python predict.py`。
**Args**
* `images`:原始图像路径或BGR格式图片;
* `visualization`: 是否可视化,默认为True;
* `save_path`: 保存结果的路径,默认保存路径为'seg_result'。
**NOTE:** 进行预测时,所选择的module,checkpoint_dir,dataset必须和Fine-tune所用的一样。
## 服务部署
PaddleHub Serving可以部署一个在线图像分割服务。
### Step1: 启动PaddleHub Serving
运行启动命令:
```shell
$ hub serving start -m ocrnet_hrnetw18_voc
```
这样就完成了一个图像分割服务化API的部署,默认端口号为8866。
**NOTE:** 如使用GPU预测,则需要在启动服务之前,请设置CUDA_VISIBLE_DEVICES环境变量,否则不用设置。
### Step2: 发送预测请求
配置好服务端,以下数行代码即可实现发送预测请求,获取预测结果
```python
import requests
import json
import cv2
import base64
import numpy as np
def cv2_to_base64(image):
data = cv2.imencode('.jpg', image)[1]
return base64.b64encode(data.tostring()).decode('utf8')
def base64_to_cv2(b64str):
data = base64.b64decode(b64str.encode('utf8'))
data = np.fromstring(data, np.uint8)
data = cv2.imdecode(data, cv2.IMREAD_COLOR)
return data
# 发送HTTP请求
org_im = cv2.imread('/PATH/TO/IMAGE')
data = {'images':[cv2_to_base64(org_im)]}
headers = {"Content-type": "application/json"}
url = "http://127.0.0.1:8866/predict/ocrnet_hrnetw18_voc"
r = requests.post(url=url, headers=headers, data=json.dumps(data))
mask = base64_to_cv2(r.json()["results"][0])
```
### 查看代码
https://github.com/PaddlePaddle/PaddleSeg
### 依赖
paddlepaddle >= 2.0.0
paddlehub >= 2.0.0
================================================
FILE: demo/semantic_segmentation/predict.py
================================================
import paddle
import paddlehub as hub
if __name__ == '__main__':
model = hub.Module(name='ocrnet_hrnetw18_voc', num_classes=2, pretrained='/PATH/TO/CHECKPOINT')
model.predict(images=["N0007.jpg"], visualization=True)
================================================
FILE: demo/semantic_segmentation/train.py
================================================
import paddle
import numpy as np
import paddlehub as hub
from paddlehub.finetune.trainer import Trainer
from paddlehub.datasets import OpticDiscSeg
from paddlehub.vision.segmentation_transforms import Compose, Resize, Normalize
from paddlehub.vision.utils import ConfusionMatrix
if __name__ == "__main__":
train_transforms = Compose([Resize(target_size=(512, 512)), Normalize()])
eval_transforms = Compose([Normalize()])
train_reader = OpticDiscSeg(train_transforms)
eval_reader = OpticDiscSeg(eval_transforms, mode='val')
model = hub.Module(name='ocrnet_hrnetw18_voc', num_classes=2)
scheduler = paddle.optimizer.lr.PolynomialDecay(learning_rate=0.01, decay_steps=1000, power=0.9, end_lr=0.0001)
optimizer = paddle.optimizer.Momentum(learning_rate=scheduler, parameters=model.parameters())
trainer = Trainer(model, optimizer, checkpoint_dir='test_ckpt_img_seg', use_gpu=True)
trainer.train(train_reader, epochs=10, batch_size=4, log_interval=10, save_interval=4)
cfm = ConfusionMatrix(eval_reader.num_classes, streaming=True)
model.eval()
for imgs, labels in eval_reader:
imgs = imgs[np.newaxis, :, :, :]
preds = model(paddle.to_tensor(imgs))[0]
preds = paddle.argmax(preds, axis=1, keepdim=True).numpy()
labels = labels[np.newaxis, :, :, :]
ignores = labels != eval_reader.ignore_index
cfm.calculate(preds, labels, ignores)
_, miou = cfm.mean_iou()
print('miou: {:.4f}'.format(miou))
================================================
FILE: demo/sequence_labeling/README.md
================================================
# PaddleHub Transformer模型fine-tune序列标注(动态图)
在2017年之前,工业界和学术界对NLP文本处理依赖于序列模型[Recurrent Neural Network (RNN)](https://baike.baidu.com/item/%E5%BE%AA%E7%8E%AF%E7%A5%9E%E7%BB%8F%E7%BD%91%E7%BB%9C/23199490?fromtitle=RNN&fromid=5707183&fr=aladdin).

近年来随着深度学习的发展,模型参数数量飞速增长,为了训练这些参数,需要更大的数据集来避免过拟合。然而,对于大部分NLP任务来说,构建大规模的标注数据集成本过高,非常困难,特别是对于句法和语义相关的任务。相比之下,大规模的未标注语料库的构建则相对容易。最近的研究表明,基于大规模未标注语料库的预训练模型(Pretrained Models, PTM) 能够习得通用的语言表示,将预训练模型Fine-tune到下游任务,能够获得出色的表现。另外,预训练模型能够避免从零开始训练模型。
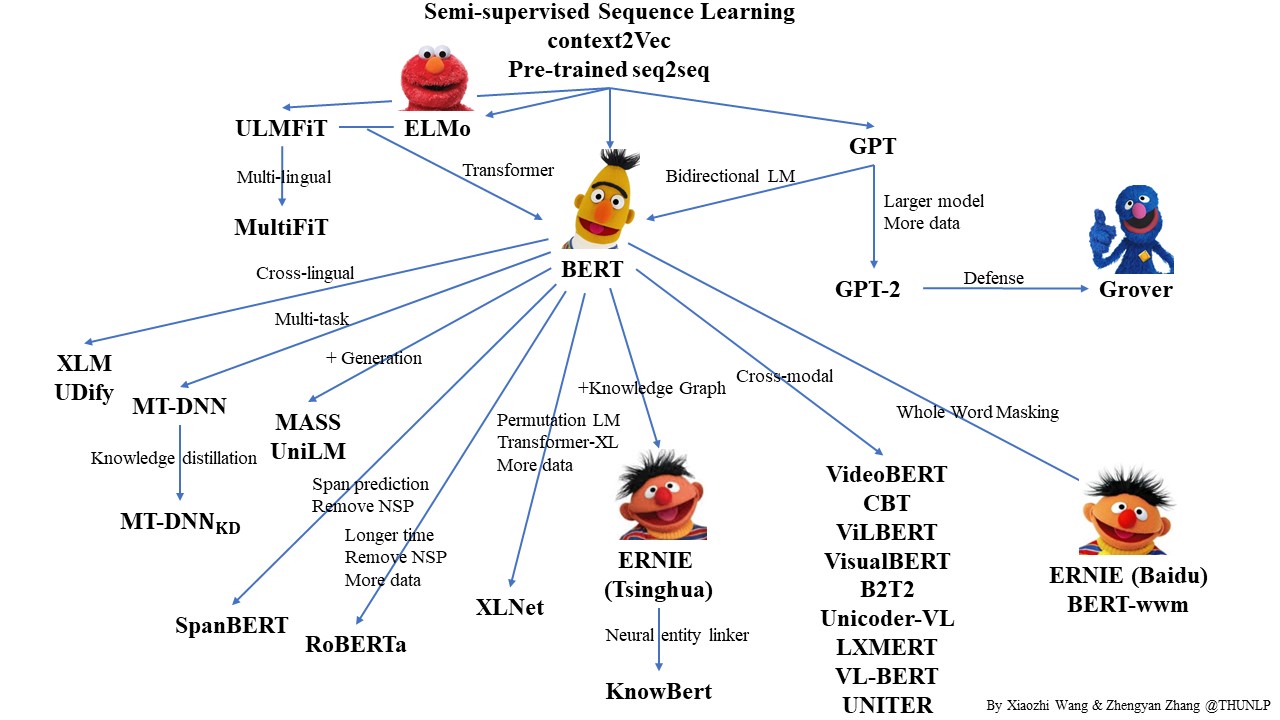
本示例将展示如何使用PaddleHub Transformer模型(如 ERNIE、BERT、RoBERTa等模型)Module 以动态图方式fine-tune并完成预测任务。
## 如何开始Fine-tune
我们以微软亚洲研究院发布的中文实体识别数据集MSRA-NER为示例数据集,可以运行下面的命令,在训练集(train.tsv)上进行模型训练,并在开发集(dev.tsv)验证。通过如下命令,即可启动训练。
```shell
# 设置使用的GPU卡号
export CUDA_VISIBLE_DEVICES=0
python train.py
```
## 代码步骤
使用PaddleHub Fine-tune API进行Fine-tune可以分为4个步骤。
### Step1: 选择模型
在命名实体识别的任务中,因不同的数据集标识实体的标签不同,评测的方式也有所差异。因此,在初始化模型的之前,需要先确定实际标签的形式,下方的`label_list`则是MSRA-NER数据集中使用的标签类别。
如果用户使用的实体识别的数据集的标签方式与MSRA-NER不同,则需要自行根据数据集确定。
```python
label_list = hub.datasets.MSRA_NER.label_list
label_map = {
idx: label for idx, label in enumerate(label_list)
}
```
接下来创建任务所使用的`model`
```python
import paddlehub as hub
model = hub.Module(name='ernie_tiny', version='2.0.1', task='token-cls', label_map=label_map)
```
其中,参数:
* `name`:模型名称,可以选择`ernie`,`ernie_tiny`,`bert-base-cased`, `bert-base-chinese`, `roberta-wwm-ext`,`roberta-wwm-ext-large`等。
* `version`:module版本号
* `task`:fine-tune任务。此处为`token-cls`,表示序列标注任务。
* `label_map`:数据集中的标签信息,实体识别任务中需要根据不同标签种类对模型性能进行评价。
PaddleHub还提供BERT等模型可供选择, 当前支持序列标注任务的模型对应的加载示例如下:
模型名 | PaddleHub Module
---------------------------------- | :------:
ERNIE, Chinese | `hub.Module(name='ernie')`
ERNIE tiny, Chinese | `hub.Module(name='ernie_tiny')`
ERNIE 2.0 Base, English | `hub.Module(name='ernie_v2_eng_base')`
ERNIE 2.0 Large, English | `hub.Module(name='ernie_v2_eng_large')`
BERT-Base, English Cased | `hub.Module(name='bert-base-cased')`
BERT-Base, English Uncased | `hub.Module(name='bert-base-uncased')`
BERT-Large, English Cased | `hub.Module(name='bert-large-cased')`
BERT-Large, English Uncased | `hub.Module(name='bert-large-uncased')`
BERT-Base, Multilingual Cased | `hub.Module(nane='bert-base-multilingual-cased')`
BERT-Base, Multilingual Uncased | `hub.Module(nane='bert-base-multilingual-uncased')`
BERT-Base, Chinese | `hub.Module(name='bert-base-chinese')`
BERT-wwm, Chinese | `hub.Module(name='chinese-bert-wwm')`
BERT-wwm-ext, Chinese | `hub.Module(name='chinese-bert-wwm-ext')`
RoBERTa-wwm-ext, Chinese | `hub.Module(name='roberta-wwm-ext')`
RoBERTa-wwm-ext-large, Chinese | `hub.Module(name='roberta-wwm-ext-large')`
RBT3, Chinese | `hub.Module(name='rbt3')`
RBTL3, Chinese | `hub.Module(name='rbtl3')`
ELECTRA-Small, English | `hub.Module(name='electra-small')`
ELECTRA-Base, English | `hub.Module(name='electra-base')`
ELECTRA-Large, English | `hub.Module(name='electra-large')`
ELECTRA-Base, Chinese | `hub.Module(name='chinese-electra-base')`
ELECTRA-Small, Chinese | `hub.Module(name='chinese-electra-small')`
通过以上的一行代码,`model`初始化为一个适用于序列标注任务的模型,为ERNIE Tiny的预训练模型后拼接上一个输出token共享的全连接网络(Full Connected)。

以上图片来自于:https://arxiv.org/pdf/1810.04805.pdf
### Step2: 下载并加载数据集
```python
train_dataset = hub.datasets.MSRA_NER(
tokenizer=model.get_tokenizer(), max_seq_len=128, mode='train')
dev_dataset = hub.datasets.MSRA_NER(
tokenizer=model.get_tokenizer(), max_seq_len=128, mode='dev')
test_dataset = hub.datasets.MSRA_NER(
tokenizer=model.get_tokenizer(), max_seq_len=128, mode='test')
```
* `tokenizer`:表示该module所需用到的tokenizer,其将对输入文本完成切词,并转化成module运行所需模型输入格式。
* `mode`:选择数据模式,可选项有 `train`, `test`, `dev`, 默认为`train`。
* `max_seq_len`:ERNIE/BERT模型使用的最大序列长度,若出现显存不足,请适当调低这一参数。
预训练模型ERNIE对中文数据的处理是以字为单位,tokenizer作用为将原始输入文本转化成模型model可以接受的输入数据形式。 PaddleHub 2.0中的各种预训练模型已经内置了相应的tokenizer,可以通过`model.get_tokenizer`方法获取。
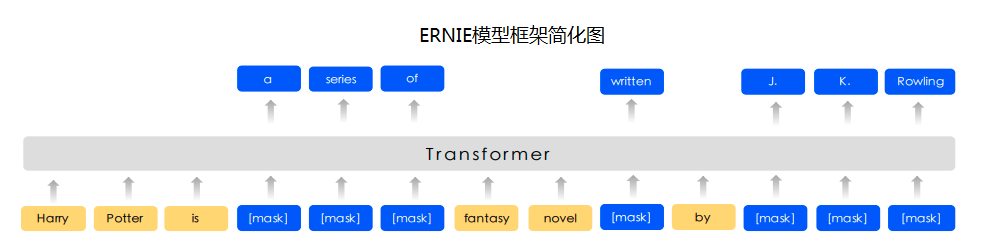
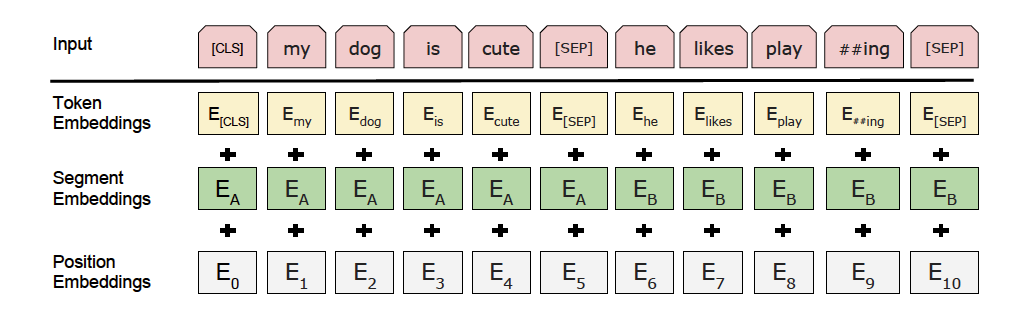
### Step3: 选择优化策略和运行配置
```python
optimizer = paddle.optimizer.AdamW(learning_rate=5e-5, parameters=model.parameters())
trainer = hub.Trainer(model, optimizer, checkpoint_dir='test_ernie_token_cls', use_gpu=True)
trainer.train(train_dataset, epochs=3, batch_size=32, eval_dataset=dev_dataset)
# 在测试集上评估当前训练模型
trainer.evaluate(test_dataset, batch_size=32)
```
#### 优化策略
Paddle2.0-rc提供了多种优化器选择,如`SGD`, `Adam`, `Adamax`, `AdamW`等,详细参见[策略](https://www.paddlepaddle.org.cn/documentation/docs/zh/2.0-rc/api/paddle/optimizer/optimizer/Optimizer_cn.html)。
其中`AdamW`:
* `learning_rate`: 全局学习率。默认为1e-3;
* `parameters`: 待优化模型参数。
#### 运行配置
`Trainer` 主要控制Fine-tune的训练,包含以下可控制的参数:
* `model`: 被优化模型;
* `optimizer`: 优化器选择;
* `use_gpu`: 是否使用GPU训练,默认为False;
* `use_vdl`: 是否使用vdl可视化训练过程;
* `checkpoint_dir`: 保存模型参数的地址;
* `compare_metrics`: 保存最优模型的衡量指标;
`trainer.train` 主要控制具体的训练过程,包含以下可控制的参数:
* `train_dataset`: 训练时所用的数据集;
* `epochs`: 训练轮数;
* `batch_size`: 训练的批大小,如果使用GPU,请根据实际情况调整batch_size;
* `num_workers`: workers的数量,默认为0;
* `eval_dataset`: 验证集;
* `log_interval`: 打印日志的间隔, 单位为执行批训练的次数。
* `save_interval`: 保存模型的间隔频次,单位为执行训练的轮数。
## 模型预测
当完成Fine-tune后,Fine-tune过程在验证集上表现最优的模型会被保存在`${CHECKPOINT_DIR}/best_model`目录下,其中`${CHECKPOINT_DIR}`目录为Fine-tune时所选择的保存checkpoint的目录。
我们以以下数据为待预测数据,使用该模型来进行预测
```text
去年十二月二十四日,市委书记张敬涛召集县市主要负责同志研究信访工作时,提出三问:『假如上访群众是我们的父母姐妹,你会用什么样的感情对待他们?
新华社北京5月7日电国务院副总理李岚清今天在中南海会见了美国前商务部长芭芭拉·弗兰克林。
根据测算,海卫1表面温度已经从“旅行者”号探测器1989年造访时的零下236摄氏度上升到零下234摄氏度。
华裔作家韩素音女士曾三次到大足,称“大足石窟是一座未被开发的金矿”。
```
```python
import paddlehub as hub
split_char = "\002"
label_list = ["B-PER", "I-PER", "B-ORG", "I-ORG", "B-LOC", "I-LOC", "O"]
text_a = [
'去年十二月二十四日,市委书记张敬涛召集县市主要负责同志研究信访工作时,提出三问:『假如上访群众是我们的父母姐妹,你会用什么样的感情对待他们?',
'新华社北京5月7日电国务院副总理李岚清今天在中南海会见了美国前商务部长芭芭拉·弗兰克林。',
'根据测算,海卫1表面温度已经从“旅行者”号探测器1989年造访时的零下236摄氏度上升到零下234摄氏度。',
'华裔作家韩素音女士曾三次到大足,称“大足石窟是一座未被开发的金矿”。',
]
data = [[split_char.join(text)] for text in text_a]
label_map = {
idx: label for idx, label in enumerate(label_list)
}
model = hub.Module(
name='ernie_tiny',
version='2.0.1',
task='token-cls',
load_checkpoint='./token_cls_save_dir/best_model/model.pdparams',
label_map=label_map,
)
results = model.predict(data, max_seq_len=128, batch_size=1, use_gpu=True)
for idx, text in enumerate(text_a):
print(f'Data: {text} \t Lable: {", ".join(results[idx][1:len(text)+1])}')
```
参数配置正确后,请执行脚本`python predict.py`, 加载模型具体可参见[加载](https://www.paddlepaddle.org.cn/documentation/docs/zh/2.0-rc/api/paddle/framework/io/load_cn.html#load)。
### 依赖
paddlepaddle >= 2.0.0rc
paddlehub >= 2.0.0
================================================
FILE: demo/sequence_labeling/predict.py
================================================
# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import paddlehub as hub
if __name__ == '__main__':
split_char = "\002"
label_list = ["B-PER", "I-PER", "B-ORG", "I-ORG", "B-LOC", "I-LOC", "O"]
text_a = [
'去年十二月二十四日,市委书记张敬涛召集县市主要负责同志研究信访工作时,提出三问:『假如上访群众是我们的父母姐妹,你会用什么样的感情对待他们?',
'新华社北京5月7日电国务院副总理李岚清今天在中南海会见了美国前商务部长芭芭拉·弗兰克林。',
'根据测算,海卫1表面温度已经从“旅行者”号探测器1989年造访时的零下236摄氏度上升到零下234摄氏度。',
'华裔作家韩素音女士曾三次到大足,称“大足石窟是一座未被开发的金矿”。',
]
data = [[split_char.join(text)] for text in text_a]
label_map = {idx: label for idx, label in enumerate(label_list)}
model = hub.Module(
name='ernie_tiny',
version='2.0.1',
task='token-cls',
load_checkpoint='./token_cls_save_dir/best/model.pdparams',
label_map=label_map,
)
results = model.predict(data=data, max_seq_len=128, batch_size=1, use_gpu=True)
for idx, text in enumerate(text_a):
print(f'Text:\n{text} \nLable: \n{", ".join(results[idx][1:len(text)+1])} \n')
================================================
FILE: demo/sequence_labeling/train.py
================================================
# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import paddle
import paddlehub as hub
from paddlehub.datasets import MSRA_NER
import ast
import argparse
parser = argparse.ArgumentParser(__doc__)
parser.add_argument("--num_epoch", type=int, default=3, help="Number of epoches for fine-tuning.")
parser.add_argument(
"--use_gpu",
type=ast.literal_eval,
default=True,
help="Whether use GPU for fine-tuning, input should be True or False")
parser.add_argument("--learning_rate", type=float, default=5e-5, help="Learning rate used to train with warmup.")
parser.add_argument("--max_seq_len", type=int, default=128, help="Number of words of the longest seqence.")
parser.add_argument("--batch_size", type=int, default=32, help="Total examples' number in batch for training.")
parser.add_argument("--checkpoint_dir", type=str, default='./checkpoint', help="Directory to model checkpoint")
parser.add_argument("--save_interval", type=int, default=1, help="Save checkpoint every n epoch.")
args = parser.parse_args()
if __name__ == '__main__':
label_list = MSRA_NER.label_list
label_map = {idx: label for idx, label in enumerate(label_list)}
model = hub.Module(
name='ernie_tiny',
version='2.0.1',
task='token-cls',
label_map=label_map, # Required for token classification task
)
tokenizer = model.get_tokenizer()
train_dataset = MSRA_NER(tokenizer=tokenizer, max_seq_len=args.max_seq_len, mode='train')
dev_dataset = MSRA_NER(tokenizer=tokenizer, max_seq_len=args.max_seq_len, mode='dev')
test_dataset = MSRA_NER(tokenizer=tokenizer, max_seq_len=args.max_seq_len, mode='test')
optimizer = paddle.optimizer.AdamW(learning_rate=args.learning_rate, parameters=model.parameters())
trainer = hub.Trainer(model, optimizer, checkpoint_dir=args.checkpoint_dir, use_gpu=args.use_gpu)
trainer.train(
train_dataset,
epochs=args.num_epoch,
batch_size=args.batch_size,
eval_dataset=dev_dataset,
save_interval=args.save_interval,
)
trainer.evaluate(test_dataset, batch_size=args.batch_size)
================================================
FILE: demo/serving/bentoml/cloud-native-model-serving-with-bentoml.ipynb
================================================
{
"cells": [
{
"cell_type": "markdown",
"metadata": {
"id": "erfOlc-T8kY3"
},
"source": [
"# **BentoML Example: Image Segmentation with PaddleHub**\n",
"**BentoML makes moving trained ML models to production easy:**\n",
"\n",
"\n",
"\n",
"* Package models trained with any ML framework and reproduce them for model serving in production\n",
"* **Deploy anywhere** for online API serving or offline batch serving\n",
"* High-Performance API model server with adaptive micro-batching support\n",
"* Central hub for managing models and deployment process via Web UI and APIs\n",
"* Modular and flexible design making it adaptable to your infrastrcuture\n",
"\n",
"BentoML is a framework for serving, managing, and deploying machine learning models. It is aiming to bridge the gap between Data Science and DevOps, and enable teams to deliver prediction services in a fast, repeatable, and scalable way.\n",
"\n",
"Before reading this example project, be sure to check out the [Getting started guide](https://github.com/bentoml/BentoML/blob/master/guides/quick-start/bentoml-quick-start-guide.ipynb) to learn about the basic concepts in BentoML.\n",
"\n",
"This notebook demonstrates how to use BentoML to turn a Paddlehub module into a docker image containing a REST API server serving this model, how to use your ML service built with BentoML as a CLI tool, and how to distribute it a pypi package.\n",
"\n",
"This example notebook is based on the [Python quick guide from PaddleHub](https://github.com/PaddlePaddle/PaddleHub/blob/release/v2.0/docs/docs_en/quick_experience/python_use_hub_en.md).\n"
],
"outputs": [],
"execution_count": null
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "54jFhiru8NWO"
},
"outputs": [],
"source": [
"%reload_ext autoreload\n",
"%autoreload 2\n",
"%matplotlib inline"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "XHOPuMGm-Nl2"
},
"outputs": [],
"source": [
"!pip3 install -q bentoml paddlepaddle paddlehub"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "KXz5IFU94P9D"
},
"outputs": [],
"source": [
"!hub install deeplabv3p_xception65_humanseg"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "bWx5VF_LLTef"
},
"source": [
"## Prepare Input Data"
],
"outputs": [],
"execution_count": null
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "yayroXhE-sos"
},
"outputs": [],
"source": [
"!wget https://paddlehub.bj.bcebos.com/resources/test_image.jpg"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "zcrHdbJxAHh0"
},
"source": [
"## Create BentoService with PaddleHub Module Instantiation"
],
"outputs": [],
"execution_count": null
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "s_T8YQRjALqg"
},
"outputs": [],
"source": [
"%%writefile paddlehub_service.py\n",
"import paddlehub as hub\n",
"import bentoml\n",
"from bentoml import env, artifacts, api, BentoService\n",
"import imageio\n",
"from bentoml.adapters import ImageInput\n",
"\n",
"\n",
"@env(infer_pip_packages=True)\n",
"class PaddleHubService(bentoml.BentoService):\n",
" def __init__(self):\n",
" super(PaddleHubService, self).__init__()\n",
" self.module = hub.Module(name=\"deeplabv3p_xception65_humanseg\")\n",
"\n",
" @api(input=ImageInput(), batch=True)\n",
" def predict(self, images):\n",
" results = self.module.segmentation(images=images, visualization=True)\n",
" return [result['data'] for result in results]\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "ESc4D_muCWNx"
},
"outputs": [],
"source": [
"# Import the custom BentoService defined above\n",
"from paddlehub_service import PaddleHubService\n",
"import numpy as np\n",
"import cv2\n",
"\n",
"# Pack it with required artifacts\n",
"bento_svc = PaddleHubService()"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "ondQXpNCy_TV"
},
"outputs": [],
"source": [
"# Predict with the initialized module\n",
"image = cv2.imread(\"test_image.jpg\")\n",
"images = [image]\n",
"segmentation_results = bento_svc.predict(images)"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "f-61QUPd6w9h"
},
"source": [
"### Visualizing the result"
],
"outputs": [],
"execution_count": null
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "jNnyhPQt59ey"
},
"outputs": [],
"source": [
"# View the segmentation mask layer\n",
"from matplotlib import pyplot as plt\n",
"\n",
"for result in segmentation_results:\n",
" plt.imshow(cv2.cvtColor(result, cv2.COLOR_BGR2RGB))\n",
" plt.axis('off')\n",
" plt.show()"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "kmJkYFPNRnmA"
},
"outputs": [],
"source": [
"# Get the segmented image of the original image\n",
"for result, original in zip(segmentation_results, images):\n",
" result = cv2.cvtColor(result, cv2.COLOR_GRAY2RGB)\n",
" original_mod = cv2.cvtColor(original, cv2.COLOR_RGB2RGBA)\n",
" mask = result / 255\n",
" *_, alpha = cv2.split(mask)\n",
" mask = cv2.merge((mask, alpha))\n",
" segmented_image = (original_mod * mask).clip(0, 255).astype(np.uint8)\n",
" \n",
" plt.imshow(cv2.cvtColor(segmented_image, cv2.COLOR_BGRA2RGBA))\n",
" plt.axis('off')\n",
" plt.show()"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "07YXA0ne7ZBc"
},
"source": [
"### Start dev server for testing"
],
"outputs": [],
"execution_count": null
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "pUM64JEKaRWt"
},
"outputs": [],
"source": [
"# Start a dev model server\n",
"bento_svc.start_dev_server()"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "3valpr2oa_OM"
},
"source": [
"!curl -i \\\n",
" -F image=@test_image.jpg \\\n",
" localhost:5000/predict"
],
"outputs": []
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "oCW5xuPebByD"
},
"outputs": [],
"source": [
"# Stop the dev model server\n",
"bento_svc.stop_dev_server()"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "qwSpmZ1u7gez"
},
"source": [
"### Save the BentoService for deployment"
],
"outputs": [],
"execution_count": null
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "kCHUw-_Hy6tH"
},
"outputs": [],
"source": [
"saved_path = bento_svc.save()"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "IvUU0k0JCxYk"
},
"source": [
"## REST API Model Serving"
],
"outputs": [],
"execution_count": null
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "CeJEIDyj_xGK"
},
"outputs": [],
"source": [
"!bentoml serve PaddleHubService:latest"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "FPoKbR6cCq8_"
},
"source": [
"If you are running this notebook from Google Colab, you can start the dev server with --run-with-ngrok option, to gain acccess to the API endpoint via a public endpoint managed by ngrok:"
],
"outputs": [],
"execution_count": null
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "RodE8ooiCqRw"
},
"outputs": [],
"source": [
"!bentoml serve PaddleHubService:latest --run-with-ngrok"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "FMCrkYb5DDHB"
},
"source": [
"## Make request to the REST server\n",
"\n",
"*After navigating to the location of this notebook, copy and paste the following code to your terminal and run it to make request*"
],
"outputs": [],
"execution_count": null
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "fMyLXOIUDXSn"
},
"outputs": [],
"source": [
"curl -i \\\n",
" --header \"Content-Type: image/jpeg\" \\\n",
" --request POST \\\n",
" --data-binary @test_image.jpg \\\n",
" localhost:5000/predict"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "DlGTKeMnEEyE"
},
"source": [
"## Launch inference job from CLI"
],
"outputs": [],
"execution_count": null
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "CBqvdN9-iyQu"
},
"outputs": [],
"source": [
"!bentoml run PaddleHubService:latest predict --input-file test_image.jpg"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "6RA0JpPjDMt8"
},
"source": [
"## Containerize model server with Docker\n",
"\n",
"One common way of distributing this model API server for production deployment, is via Docker containers. And BentoML provides a convenient way to do that.\n",
"\n",
"Note that docker is **not available in Google Colab**. You will need to download and run this notebook locally to try out this containerization with docker feature.\n",
"\n",
"If you already have docker configured, simply run the follow command to product a docker container serving the PaddeHub prediction service created above:"
],
"outputs": [],
"execution_count": null
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "JKUGBMNWDJnr"
},
"outputs": [],
"source": [
"!bentoml containerize PaddleHubService:latest"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "0nyRChqMDwv4"
},
"outputs": [],
"source": [
"!docker run --rm -p 5000:5000 PaddleHubService:latest"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "Jb-srm9RENeh"
},
"source": [
"# **Deployment Options**\n",
"\n",
"If you are at a small team with limited engineering or DevOps resources, try out automated deployment with BentoML CLI, currently supporting AWS Lambda, AWS SageMaker, and Azure Functions:\n",
"\n",
"* [AWS Lambda Deployment Guide](https://docs.bentoml.org/en/latest/deployment/aws_lambda.html)\n",
"* [AWS SageMaker Deployment Guide](https://docs.bentoml.org/en/latest/deployment/aws_sagemaker.html)\n",
"* [Azure Functions Deployment Guide](https://docs.bentoml.org/en/latest/deployment/azure_functions.html)\n",
"\n",
"If the cloud platform you are working with is not on the list above, try out these step-by-step guide on manually deploying BentoML packaged model to cloud platforms:\n",
"\n",
"* [AWS ECS Deployment](https://docs.bentoml.org/en/latest/deployment/aws_ecs.html)\n",
"* [Google Cloud Run Deployment](https://docs.bentoml.org/en/latest/deployment/google_cloud_run.html)\n",
"* [Azure container instance Deployment](https://docs.bentoml.org/en/latest/deployment/azure_container_instance.html)\n",
"* [Heroku Deployment](https://docs.bentoml.org/en/latest/deployment/heroku.html)\n",
"\n",
"Lastly, if you have a DevOps or ML Engineering team who's operating a Kubernetes or OpenShift cluster, use the following guides as references for implementating your deployment strategy:\n",
"\n",
"* [Kubernetes Deployment](https://docs.bentoml.org/en/latest/deployment/kubernetes.html)\n",
"* [Knative Deployment](https://docs.bentoml.org/en/latest/deployment/knative.html)\n",
"* [Kubeflow Deployment](https://docs.bentoml.org/en/latest/deployment/kubeflow.html)\n",
"* [KFServing Deployment](https://docs.bentoml.org/en/latest/deployment/kfserving.html)\n",
"* [Clipper.ai Deployment Guide](https://docs.bentoml.org/en/latest/deployment/clipper.html)"
],
"outputs": [],
"execution_count": null
}
],
"metadata": {
"colab": {
"collapsed_sections": [],
"name": "PaddleHub_deeplabv3p_xception65_humanseg.ipynb",
"provenance": [],
"toc_visible": true
},
"kernelspec": {
"display_name": "Python 3",
"language": "python",
"name": "python3"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.8.5"
}
},
"nbformat": 4,
"nbformat_minor": 1
}
================================================
FILE: demo/serving/lexical_analysis_lac/templates/lac_gpu_serving_config.json
================================================
{
"modules_info": {
"lac": {
"init_args": {
"version": "2.1.0"
},
"predict_args": {
"batch_size": 1
}
}
},
"use_gpu": true,
"port": 8866,
"gpu": "0,1,2"
}
================================================
FILE: demo/serving/lexical_analysis_lac/templates/lac_serving_config.json
================================================
{
"modules_info": {
"lac": {
"init_args": {
"version": "2.1.0"
},
"predict_args": {
"batch_size": 1,
"use_gpu": false
}
}
},
"port": 8866,
"use_multiprocess": true,
"workers": 2,
"timeout": 30
}
================================================
FILE: demo/serving/module_serving/lexical_analysis_lac/README.md
================================================
# 部署词法分析服务-以lac为例
## 简介
`Lexical Analysis of Chinese`,简称`LAC`,是一个联合的词法分析模型,能整体性地完成中文分词、词性标注、专名识别任务。关于`LAC`的具体信息请参见[LAC](https://paddlepaddle.org.cn/hubdetail?name=lac&en_category=LexicalAnalysis)。
使用PaddleHub Serving可以部署一个在线词法分析服务,可以将此接口用于词法分析、在线分词等在线web应用。
这里就带领大家使用PaddleHub Serving,通过简单几步部署一个词法分析在线服务。
## Step1:启动PaddleHub Serving
启动命令如下
```shell
$ hub serving start -m lac
```
启动时会显示加载模型过程,启动成功后显示
```shell
Loading lac successful.
```
这样就完成了一个词法分析服务化API的部署,默认端口号为8866。
## Step2:测试语言模型在线API
### 不使用自定义词典
在服务部署好之后,我们可以进行测试,用来测试的文本为`今天是个好日子`和`天气预报说今天要下雨`。
首先指定编码格式及引入需要的包:
```python
>>> # coding: utf8
>>> import requests
>>> import json
```
准备的数据格式为:
```python
{"text": [text_1, text_2, ...]}
```
**NOTE:** 字典的key为"text"。
根据文本和数据格式,代码如下:
```python
>>> # 指定用于用于预测的文本并生成字典{"text": [text_1, text_2, ... ]}
>>> text_list = ["今天是个好日子", "天气预报说今天要下雨"]
>>> text = {"text": text_list}
```
## Step3:获取并验证结果
接下来发送请求到词法分析API,并得到结果,代码如下:
```python
# 指定预测方法为lac并发送post请求
>>> url = "http://127.0.0.1:8866/predict/text/lac"
>>> r = requests.post(url=url, data=text)
```
`LAC`模型返回的结果为每个文本分词后的结果,我们尝试打印接口返回结果:
```python
# 打印预测结果
>>> print(json.dumps(r.json(), indent=4, ensure_ascii=False))
{
"msg": "",
"results": [
{
"tag": [
"TIME", "v", "q", "n"
],
"word": [
"今天", "是", "个", "好日子"
]
},
{
"tag": [
"n", "v", "TIME", "v", "v"
],
"word": [
"天气预报", "说", "今天", "要", "下雨"
]
}
],
"status": "0"
}
```
这样我们就完成了对词法分析的预测服务化部署和测试。
完整的测试代码见[lac_serving_demo.py](./lac_serving_demo.py)。
### 使用自定义词典
`LAC`模型在预测时还可以使用自定义词典干预默认分词结果,这种情况只需要将自定义词典以文件的形式附加到request请求即可,数据格式如下:
```python
{"user_dict": user_dict.txt}
```
根据数据格式,具体代码如下:
```python
>>> # 指定自定义词典{"user_dict": dict.txt}
>>> file = {"user_dict": open("dict.txt", "rb")}
>>> # 请求接口时以文件的形式附加自定义词典,其余和不使用自定义词典的请求方式相同,此处不再赘述
>>> url = "http://127.0.0.1:8866/predict/text/lac"
>>> r = requests.post(url=url, files=file, data=text)
```
完整的测试代码见[lac_with_dict_serving_demo.py](./lac_with_dict_serving_demo.py)。
### 客户端请求新版模型的方式
对某些新版模型,客户端请求方式有所变化,更接近本地预测的请求方式,以降低学习成本。
以lac(2.1.0)为例,使用上述方法进行请求将提示:
```python
{
"Warnning": "This usage is out of date, please use 'application/json' as content-type to post to /predict/lac. See 'https://github.com/PaddlePaddle/PaddleHub/blob/release/v1.6/docs/tutorial/serving.md' for more details."
}
```
对于lac(2.1.0),请求的方式如下:
```python
# coding: utf8
import requests
import json
if __name__ == "__main__":
# 指定用于预测的文本并生成字典[text_1, text_2, ... ]
text = ["今天是个好日子", "天气预报说今天要下雨"]
# 以key的方式指定text传入预测方法的时的参数,此例中为"texts"
# 对应本地部署,则为lac.analysis_lexical(text=[text1, text2])
data = {"texts": text, "batch_size": 1}
# 指定预测方法为lac并发送post请求
url = "http://127.0.0.1:8866/predict/lac"
# 指定post请求的headers为application/json方式
headers = {"Content-Type": "application/json"}
r = requests.post(url=url, headers=headers, data=json.dumps(data))
# 打印预测结果
print(json.dumps(r.json(), indent=4, ensure_ascii=False))
```
对结果的解析等与前种方式一致,显示如下:
```python
{
"results": [
{
"tag": [
"TIME", "v", "q", "n"
],
"word": [
"今天", "是", "个", "好日子"
]
},
{
"tag": [
"n", "v", "TIME", "v", "v"
],
"word": [
"天气预报", "说", "今天", "要", "下雨"
]
}
]
}
```
此Demo的具体信息和代码请参见[LAC Serving_2.1.0](./lac_2.1.0_serving_demo.py)。
================================================
FILE: demo/serving/module_serving/lexical_analysis_lac/lac_serving_demo.py
================================================
# coding: utf8
import requests
import json
if __name__ == "__main__":
# 指定用于预测的文本并生成字典{"text": [text_1, text_2, ... ]}
text = ["今天是个好日子", "天气预报说今天要下雨"]
# 以key的方式指定text传入预测方法的时的参数,此例中为"data"
# 对应本地部署,则为lac.analysis_lexical(data=text, batch_size=1)
# 若使用lac版本低于2.2.0,需要将`text`参数改为`texts`
data = {"text": text, "batch_size": 1}
# 指定预测方法为lac并发送post请求,content-type类型应指定json方式
url = "http://127.0.0.1:8866/predict/lac"
# 指定post请求的headers为application/json方式
headers = {"Content-Type": "application/json"}
r = requests.post(url=url, headers=headers, data=json.dumps(data))
# 打印预测结果
print(json.dumps(r.json(), indent=4, ensure_ascii=False))
================================================
FILE: demo/serving/module_serving/object_detection_pyramidbox_lite_server_mask/pyramidbox_lite_server_mask_serving_demo.py
================================================
# coding: utf8
import requests
import json
import cv2
import base64
def cv2_to_base64(image):
data = cv2.imencode('.jpg', image)[1]
return base64.b64encode(data.tostring()).decode('utf8')
if __name__ == '__main__':
# 获取图片的base64编码格式
img1 = cv2_to_base64(cv2.imread("../../../../docs/imgs/family_mask.jpg"))
img2 = cv2_to_base64(cv2.imread("../../../../docs/imgs/woman_mask.jpg"))
data = {'images': [img1, img2]}
# 指定content-type
headers = {"Content-type": "application/json"}
# 发送HTTP请求
url = "http://127.0.0.1:8866/predict/pyramidbox_lite_server_mask"
r = requests.post(url=url, headers=headers, data=json.dumps(data))
# 打印预测结果
print(r.json())
================================================
FILE: demo/style_transfer/README.md
================================================
# PaddleHub 图像风格迁移
本示例将展示如何使用PaddleHub对预训练模型进行finetune并完成预测任务。
## 命令行预测
```
$ hub run msgnet --input_path "/PATH/TO/ORIGIN/IMAGE" --style_path "/PATH/TO/STYLE/IMAGE"
```
## 脚本预测
```python
import paddle
import paddlehub as hub
if __name__ == '__main__':
model = hub.Module(name='msgnet')
result = model.predict(origin=["venice-boat.jpg"], style="candy.jpg", visualization=True, save_path ='style_tranfer')
```
## 如何开始Fine-tune
在完成安装PaddlePaddle与PaddleHub后,通过执行`python train.py`即可开始使用msgnet模型对[MiniCOCO](../../docs/reference/datasets.md#class-hubdatasetsMiniCOCO)等数据集进行Fine-tune。
## 代码步骤
使用PaddleHub Fine-tune API进行Fine-tune可以分为4个步骤。
### Step1: 定义数据预处理方式
```python
import paddlehub.vision.transforms as T
transform = T.Compose([T.Resize((256, 256), interpolation='LINEAR')])
```
`transforms` 数据增强模块定义了丰富的数据预处理方式,用户可按照需求替换自己需要的数据预处理方式。
### Step2: 下载数据集并使用
```python
from paddlehub.datasets.minicoco import MiniCOCO
styledata = MiniCOCO(transform=transform, mode='train')
```
* `transforms`: 数据预处理方式。
* `mode`: 选择数据模式,可选项有 `train`, `test`, 默认为`train`。
数据集的准备代码可以参考 [minicoco.py](../../paddlehub/datasets/flowers.py)。`hub.datasets.MiniCOCO()`会自动从网络下载数据集并解压到用户目录下`$HOME/.paddlehub/dataset`目录。
### Step3: 加载预训练模型
```python
model = hub.Module(name='msgnet', load_checkpoint=None)
```
* `name`: 选择预训练模型的名字。
* `load_checkpoint`: 是否加载自己训练的模型,若为None,则加载提供的模型默认参数。
### Step4: 选择优化策略和运行配置
```python
optimizer = paddle.optimizer.Adam(learning_rate=0.0001, parameters=model.parameters())
trainer = Trainer(model, optimizer, checkpoint_dir='test_style_ckpt')
trainer.train(styledata, epochs=101, batch_size=4, eval_dataset=styledata, log_interval=10, save_interval=10)
```
#### 优化策略
Paddle2.0rc提供了多种优化器选择,如`SGD`, `Adam`, `Adamax`等,详细参见[策略](https://www.paddlepaddle.org.cn/documentation/docs/zh/2.0-rc/api/paddle/optimizer/optimizer/Optimizer_cn.html)。
其中`Adam`:
* `learning_rate`: 全局学习率。默认为1e-4;
* `parameters`: 待优化模型参数。
#### 运行配置
`Trainer` 主要控制Fine-tune的训练,包含以下可控制的参数:
* `model`: 被优化模型;
* `optimizer`: 优化器选择;
* `use_vdl`: 是否使用vdl可视化训练过程;
* `checkpoint_dir`: 保存模型参数的地址;
* `compare_metrics`: 保存最优模型的衡量指标;
`trainer.train` 主要控制具体的训练过程,包含以下可控制的参数:
* `train_dataset`: 训练时所用的数据集;
* `epochs`: 训练轮数;
* `batch_size`: 训练的批大小,如果使用GPU,请根据实际情况调整batch_size;
* `num_workers`: works的数量,默认为0;
* `eval_dataset`: 验证集;
* `log_interval`: 打印日志的间隔, 单位为执行批训练的次数。
* `save_interval`: 保存模型的间隔频次,单位为执行训练的轮数。
## 模型预测
当完成Fine-tune后,Fine-tune过程在验证集上表现最优的模型会被保存在`${CHECKPOINT_DIR}/best_model`目录下,其中`${CHECKPOINT_DIR}`目录为Fine-tune时所选择的保存checkpoint的目录。
我们使用该模型来进行预测。predict.py脚本如下:
```python
import paddle
import paddlehub as hub
if __name__ == '__main__':
model = hub.Module(name='msgnet', load_checkpoint="/PATH/TO/CHECKPOINT")
result = model.predict(origin=["venice-boat.jpg"], style="candy.jpg", visualization=True, save_path ='style_tranfer')
```
参数配置正确后,请执行脚本`python predict.py`, 加载模型具体可参见[加载](https://www.paddlepaddle.org.cn/documentation/docs/zh/2.0-rc/api/paddle/framework/io/load_cn.html#load)。
**Args**
* `origin`:原始图像路径或BGR格式图片;
* `style`: 风格图像路径;
* `visualization`: 是否可视化,默认为True;
* `save_path`: 保存结果的路径,默认保存路径为'style_tranfer'。
**NOTE:** 进行预测时,所选择的module,checkpoint_dir,dataset必须和Fine-tune所用的一样。
## 服务部署
PaddleHub Serving可以部署一个在线风格迁移服务。
### Step1: 启动PaddleHub Serving
运行启动命令:
```shell
$ hub serving start -m msgnet
```
这样就完成了一个风格迁移服务化API的部署,默认端口号为8866。
**NOTE:** 如使用GPU预测,则需要在启动服务之前,请设置CUDA_VISIBLE_DEVICES环境变量,否则不用设置。
### Step2: 发送预测请求
配置好服务端,以下数行代码即可实现发送预测请求,获取预测结果
```python
import requests
import json
import cv2
import base64
import numpy as np
def cv2_to_base64(image):
data = cv2.imencode('.jpg', image)[1]
return base64.b64encode(data.tostring()).decode('utf8')
def base64_to_cv2(b64str):
data = base64.b64decode(b64str.encode('utf8'))
data = np.fromstring(data, np.uint8)
data = cv2.imdecode(data, cv2.IMREAD_COLOR)
return data
# 发送HTTP请求
org_im = cv2.imread('/PATH/TO/ORIGIN/IMAGE')
style_im = cv2.imread('/PATH/TO/STYLE/IMAGE')
data = {'images':[[cv2_to_base64(org_im)], cv2_to_base64(style_im)]}
headers = {"Content-type": "application/json"}
url = "http://127.0.0.1:8866/predict/msgnet"
r = requests.post(url=url, headers=headers, data=json.dumps(data))
data = base64_to_cv2(r.json()["results"]['data'][0])
cv2.imwrite('style.png', data)
```
### 查看代码
https://github.com/zhanghang1989/PyTorch-Multi-Style-Transfer
### 依赖
paddlepaddle >= 2.0.0rc
paddlehub >= 2.0.0
================================================
FILE: demo/style_transfer/predict.py
================================================
import paddle
import paddlehub as hub
if __name__ == '__main__':
model = hub.Module(name='msgnet', load_checkpoint="/PATH/TO/CHECKPOINT")
result = model.predict(origin=["venice-boat.jpg"], style="candy.jpg", visualization=True, save_path='style_tranfer')
================================================
FILE: demo/style_transfer/train.py
================================================
import paddle
import paddlehub as hub
from paddlehub.finetune.trainer import Trainer
from paddlehub.datasets.minicoco import MiniCOCO
import paddlehub.vision.transforms as T
if __name__ == "__main__":
model = hub.Module(name='msgnet')
transform = T.Compose([T.Resize((256, 256), interpolation='LINEAR')])
styledata = MiniCOCO(transform)
optimizer = paddle.optimizer.Adam(learning_rate=0.0001, parameters=model.parameters())
trainer = Trainer(model, optimizer, checkpoint_dir='test_style_ckpt')
trainer.train(styledata, epochs=101, batch_size=4, log_interval=10, save_interval=10)
================================================
FILE: demo/text_classification/README.md
================================================
# PaddleHub Transformer模型fine-tune文本分类(动态图)
在2017年之前,工业界和学术界对NLP文本处理依赖于序列模型[Recurrent Neural Network (RNN)](https://baike.baidu.com/item/%E5%BE%AA%E7%8E%AF%E7%A5%9E%E7%BB%8F%E7%BD%91%E7%BB%9C/23199490?fromtitle=RNN&fromid=5707183&fr=aladdin).

近年来随着深度学习的发展,模型参数数量飞速增长,为了训练这些参数,需要更大的数据集来避免过拟合。然而,对于大部分NLP任务来说,构建大规模的标注数据集成本过高,非常困难,特别是对于句法和语义相关的任务。相比之下,大规模的未标注语料库的构建则相对容易。最近的研究表明,基于大规模未标注语料库的预训练模型(Pretrained Models, PTM) 能够习得通用的语言表示,将预训练模型Fine-tune到下游任务,能够获得出色的表现。另外,预训练模型能够避免从零开始训练模型。

本示例将展示如何使用PaddleHub Transformer模型(如 ERNIE、BERT、RoBERTa等模型)Module 以动态图方式fine-tune并完成预测任务。
## 如何开始Fine-tune
我们以中文情感分类公开数据集ChnSentiCorp为示例数据集,可以运行下面的命令,在训练集(train.tsv)上进行模型训练,并在开发集(dev.tsv)验证。通过如下命令,即可启动训练。
```shell
# 设置使用的GPU卡号
export CUDA_VISIBLE_DEVICES=0
python train.py
```
## 代码步骤
使用PaddleHub Fine-tune API进行Fine-tune可以分为4个步骤。
### Step1: 选择模型
```python
import paddlehub as hub
model = hub.Module(name='ernie_tiny', version='2.0.1', task='seq-cls', num_classes=2)
```
其中,参数:
* `name`:模型名称,可以选择`ernie`,`ernie_tiny`,`bert-base-cased`, `bert-base-chinese`, `roberta-wwm-ext`,`roberta-wwm-ext-large`等。
* `version`:module版本号
* `task`:fine-tune任务。此处为`seq-cls`,表示文本分类任务。
* `num_classes`:表示当前文本分类任务的类别数,根据具体使用的数据集确定,默认为2。
PaddleHub还提供BERT等模型可供选择, 当前支持文本分类任务的模型对应的加载示例如下:
模型名 | PaddleHub Module
---------------------------------- | :------:
ERNIE, Chinese | `hub.Module(name='ernie')`
ERNIE tiny, Chinese | `hub.Module(name='ernie_tiny')`
ERNIE 2.0 Base, English | `hub.Module(name='ernie_v2_eng_base')`
ERNIE 2.0 Large, English | `hub.Module(name='ernie_v2_eng_large')`
BERT-Base, English Cased | `hub.Module(name='bert-base-cased')`
BERT-Base, English Uncased | `hub.Module(name='bert-base-uncased')`
BERT-Large, English Cased | `hub.Module(name='bert-large-cased')`
BERT-Large, English Uncased | `hub.Module(name='bert-large-uncased')`
BERT-Base, Multilingual Cased | `hub.Module(nane='bert-base-multilingual-cased')`
BERT-Base, Multilingual Uncased | `hub.Module(nane='bert-base-multilingual-uncased')`
BERT-Base, Chinese | `hub.Module(name='bert-base-chinese')`
BERT-wwm, Chinese | `hub.Module(name='chinese-bert-wwm')`
BERT-wwm-ext, Chinese | `hub.Module(name='chinese-bert-wwm-ext')`
RoBERTa-wwm-ext, Chinese | `hub.Module(name='roberta-wwm-ext')`
RoBERTa-wwm-ext-large, Chinese | `hub.Module(name='roberta-wwm-ext-large')`
RBT3, Chinese | `hub.Module(name='rbt3')`
RBTL3, Chinese | `hub.Module(name='rbtl3')`
ELECTRA-Small, English | `hub.Module(name='electra-small')`
ELECTRA-Base, English | `hub.Module(name='electra-base')`
ELECTRA-Large, English | `hub.Module(name='electra-large')`
ELECTRA-Base, Chinese | `hub.Module(name='chinese-electra-base')`
ELECTRA-Small, Chinese | `hub.Module(name='chinese-electra-small')`
通过以上的一行代码,`model`初始化为一个适用于文本分类任务的模型,为ERNIE Tiny的预训练模型后拼接上一个全连接网络(Full Connected)。

以上图片来自于:https://arxiv.org/pdf/1810.04805.pdf
### Step2: 下载并加载数据集
```python
train_dataset = hub.datasets.ChnSentiCorp(
tokenizer=model.get_tokenizer(), max_seq_len=128, mode='train')
dev_dataset = hub.datasets.ChnSentiCorp(
tokenizer=model.get_tokenizer(), max_seq_len=128, mode='dev')
test_dataset = hub.datasets.ChnSentiCorp(
tokenizer=model.get_tokenizer(), max_seq_len=128, mode='test')
```
* `tokenizer`:表示该module所需用到的tokenizer,其将对输入文本完成切词,并转化成module运行所需模型输入格式。
* `mode`:选择数据模式,可选项有 `train`, `test`, `dev`, 默认为`train`。
* `max_seq_len`:ERNIE/BERT模型使用的最大序列长度,若出现显存不足,请适当调低这一参数。
预训练模型ERNIE对中文数据的处理是以字为单位,tokenizer作用为将原始输入文本转化成模型model可以接受的输入数据形式。 PaddleHub 2.0中的各种预训练模型已经内置了相应的tokenizer,可以通过`model.get_tokenizer`方法获取。


### Step3: 选择优化策略和运行配置
```python
optimizer = paddle.optimizer.Adam(learning_rate=5e-5, parameters=model.parameters())
trainer = hub.Trainer(model, optimizer, checkpoint_dir='test_ernie_text_cls', use_gpu=True)
trainer.train(train_dataset, epochs=3, batch_size=32, eval_dataset=dev_dataset)
# 在测试集上评估当前训练模型
trainer.evaluate(test_dataset, batch_size=32)
```
#### 优化策略
Paddle2.0-rc提供了多种优化器选择,如`SGD`, `Adam`, `Adamax`等,详细参见[策略](https://www.paddlepaddle.org.cn/documentation/docs/zh/2.0-rc/api/paddle/optimizer/optimizer/Optimizer_cn.html)。
其中`Adam`:
* `learning_rate`: 全局学习率。默认为1e-3;
* `parameters`: 待优化模型参数。
#### 运行配置
`Trainer` 主要控制Fine-tune的训练,包含以下可控制的参数:
* `model`: 被优化模型;
* `optimizer`: 优化器选择;
* `use_vdl`: 是否使用vdl可视化训练过程;
* `checkpoint_dir`: 保存模型参数的地址;
* `compare_metrics`: 保存最优模型的衡量指标;
`trainer.train` 主要控制具体的训练过程,包含以下可控制的参数:
* `train_dataset`: 训练时所用的数据集;
* `epochs`: 训练轮数;
* `batch_size`: 训练的批大小,如果使用GPU,请根据实际情况调整batch_size;
* `num_workers`: works的数量,默认为0;
* `eval_dataset`: 验证集;
* `log_interval`: 打印日志的间隔, 单位为执行批训练的次数。
* `save_interval`: 保存模型的间隔频次,单位为执行训练的轮数。
## 模型预测
当完成Fine-tune后,Fine-tune过程在验证集上表现最优的模型会被保存在`${CHECKPOINT_DIR}/best_model`目录下,其中`${CHECKPOINT_DIR}`目录为Fine-tune时所选择的保存checkpoint的目录。
我们以以下数据为待预测数据,使用该模型来进行预测
```text
这个宾馆比较陈旧了,特价的房间也很一般。总体来说一般
怀着十分激动的心情放映,可是看着看着发现,在放映完毕后,出现一集米老鼠的动画片
作为老的四星酒店,房间依然很整洁,相当不错。机场接机服务很好,可以在车上办理入住手续,节省时间。
```
```python
import paddlehub as hub
data = [
['这个宾馆比较陈旧了,特价的房间也很一般。总体来说一般'],
['怀着十分激动的心情放映,可是看着看着发现,在放映完毕后,出现一集米老鼠的动画片'],
['作为老的四星酒店,房间依然很整洁,相当不错。机场接机服务很好,可以在车上办理入住手续,节省时间。'],
]
label_map = {0: 'negative', 1: 'positive'}
model = hub.Module(
name='ernie_tiny',
version='2.0.1',
task='seq-cls',
load_checkpoint='./test_ernie_text_cls/best_model/model.pdparams',
label_map=label_map)
results, probs = model.predict(data, max_seq_len=50, batch_size=1, use_gpu=False, return_prob=True)
for idx, text in enumerate(data):
print('Data: {} \t Lable: {} \t Prob: {}'.format(text[0], results[idx], probs[idx]))
```
参数配置正确后,请执行脚本`python predict.py`, 加载模型具体可参见[加载](https://www.paddlepaddle.org.cn/documentation/docs/zh/2.0-rc/api/paddle/framework/io/load_cn.html#load)。
================================================
FILE: demo/text_classification/embedding/model.py
================================================
# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License"
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import os
from typing import List
import paddle
import paddle.nn as nn
import paddle.nn.functional as F
import paddlenlp as nlp
from paddlenlp.embeddings import TokenEmbedding
from paddlenlp.data import JiebaTokenizer
from paddlehub.utils.log import logger
from paddlehub.utils.utils import pad_sequence, trunc_sequence
class BoWModel(nn.Layer):
"""
This class implements the Bag of Words Classification Network model to classify texts.
At a high level, the model starts by embedding the tokens and running them through
a word embedding. Then, we encode these epresentations with a `BoWEncoder`.
Lastly, we take the output of the encoder to create a final representation,
which is passed through some feed-forward layers to output a logits (`output_layer`).
Args:
vocab_size (obj:`int`): The vocabulary size.
emb_dim (obj:`int`, optional, defaults to 300): The embedding dimension.
hidden_size (obj:`int`, optional, defaults to 128): The first full-connected layer hidden size.
fc_hidden_size (obj:`int`, optional, defaults to 96): The second full-connected layer hidden size.
num_classes (obj:`int`): All the labels that the data has.
"""
def __init__(self,
num_classes: int = 2,
embedder: TokenEmbedding = None,
tokenizer: JiebaTokenizer = None,
hidden_size: int = 128,
fc_hidden_size: int = 96,
load_checkpoint: str = None,
label_map: dict = None):
super().__init__()
self.embedder = embedder
self.tokenizer = tokenizer
self.label_map = label_map
emb_dim = self.embedder.embedding_dim
self.bow_encoder = nlp.seq2vec.BoWEncoder(emb_dim)
self.fc1 = nn.Linear(self.bow_encoder.get_output_dim(), hidden_size)
self.fc2 = nn.Linear(hidden_size, fc_hidden_size)
self.dropout = nn.Dropout(p=0.3, axis=1)
self.output_layer = nn.Linear(fc_hidden_size, num_classes)
self.criterion = nn.loss.CrossEntropyLoss()
self.metric = paddle.metric.Accuracy()
if load_checkpoint is not None and os.path.isfile(load_checkpoint):
state_dict = paddle.load(load_checkpoint)
self.set_state_dict(state_dict)
logger.info('Loaded parameters from %s' % os.path.abspath(load_checkpoint))
def training_step(self, batch: List[paddle.Tensor], batch_idx: int):
"""
One step for training, which should be called as forward computation.
Args:
batch(:obj:List[paddle.Tensor]): The one batch data, which contains the model needed,
such as input_ids, sent_ids, pos_ids, input_mask and labels.
batch_idx(int): The index of batch.
Returns:
results(:obj: Dict) : The model outputs, such as loss and metrics.
"""
_, avg_loss, metric = self(ids=batch[0], labels=batch[1])
self.metric.reset()
return {'loss': avg_loss, 'metrics': metric}
def validation_step(self, batch: List[paddle.Tensor], batch_idx: int):
"""
One step for validation, which should be called as forward computation.
Args:
batch(:obj:List[paddle.Tensor]): The one batch data, which contains the model needed,
such as input_ids, sent_ids, pos_ids, input_mask and labels.
batch_idx(int): The index of batch.
Returns:
results(:obj: Dict) : The model outputs, such as metrics.
"""
_, _, metric = self(ids=batch[0], labels=batch[1])
self.metric.reset()
return {'metrics': metric}
def forward(self, ids: paddle.Tensor, labels: paddle.Tensor = None):
# Shape: (batch_size, num_tokens, embedding_dim)
embedded_text = self.embedder(ids)
# Shape: (batch_size, embedding_dim)
summed = self.bow_encoder(embedded_text)
summed = self.dropout(summed)
encoded_text = paddle.tanh(summed)
# Shape: (batch_size, hidden_size)
fc1_out = paddle.tanh(self.fc1(encoded_text))
# Shape: (batch_size, fc_hidden_size)
fc2_out = paddle.tanh(self.fc2(fc1_out))
# Shape: (batch_size, num_classes)
logits = self.output_layer(fc2_out)
probs = F.softmax(logits, axis=1)
if labels is not None:
loss = self.criterion(logits, labels)
correct = self.metric.compute(probs, labels)
acc = self.metric.update(correct)
return probs, loss, {'acc': acc}
else:
return probs
def _batchify(self, data: List[List[str]], max_seq_len: int, batch_size: int):
examples = []
for item in data:
ids = self.tokenizer.encode(sentence=item[0])
if len(ids) > max_seq_len:
ids = trunc_sequence(ids, max_seq_len)
else:
pad_token = self.tokenizer.vocab.pad_token
pad_token_id = self.tokenizer.vocab.to_indices(pad_token)
ids = pad_sequence(ids, max_seq_len, pad_token_id)
examples.append(ids)
# Seperates data into some batches.
one_batch = []
for example in examples:
one_batch.append(example)
if len(one_batch) == batch_size:
yield one_batch
one_batch = []
if one_batch:
# The last batch whose size is less than the config batch_size setting.
yield one_batch
def predict(
self,
data: List[List[str]],
max_seq_len: int = 128,
batch_size: int = 1,
use_gpu: bool = False,
return_result: bool = True,
):
paddle.set_device('gpu') if use_gpu else paddle.set_device('cpu')
batches = self._batchify(data, max_seq_len, batch_size)
results = []
self.eval()
for batch in batches:
ids = paddle.to_tensor(batch)
probs = self(ids)
idx = paddle.argmax(probs, axis=1).numpy()
if return_result:
idx = idx.tolist()
labels = [self.label_map[i] for i in idx]
results.extend(labels)
else:
results.extend(probs.numpy())
return results
================================================
FILE: demo/text_classification/embedding/predict.py
================================================
# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License"
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import paddlehub as hub
from paddlenlp.data import JiebaTokenizer
from model import BoWModel
import ast
import argparse
parser = argparse.ArgumentParser(__doc__)
parser.add_argument("--hub_embedding_name", type=str, default='w2v_baidu_encyclopedia_target_word-word_dim300', help="")
parser.add_argument("--max_seq_len", type=int, default=128, help="Number of words of the longest seqence.")
parser.add_argument("--batch_size", type=int, default=64, help="Total examples' number in batch for training.")
parser.add_argument("--checkpoint", type=str, default='./checkpoint/best_model/model.pdparams', help="Model checkpoint")
parser.add_argument(
"--use_gpu",
type=ast.literal_eval,
default=True,
help="Whether use GPU for fine-tuning, input should be True or False")
args = parser.parse_args()
if __name__ == '__main__':
# Data to be prdicted
data = [
["这个宾馆比较陈旧了,特价的房间也很一般。总体来说一般"],
["交通方便;环境很好;服务态度很好 房间较小"],
["还稍微重了点,可能是硬盘大的原故,还要再轻半斤就好了。其他要进一步验证。贴的几种膜气泡较多,用不了多久就要更换了,屏幕膜稍好点,但比没有要强多了。建议配赠几张膜让用用户自己贴。"],
["前台接待太差,酒店有A B楼之分,本人check-in后,前台未告诉B楼在何处,并且B楼无明显指示;房间太小,根本不像4星级设施,下次不会再选择入住此店啦"],
["19天硬盘就罢工了~~~算上运来的一周都没用上15天~~~可就是不能换了~~~唉~~~~你说这算什么事呀~~~"],
]
label_map = {0: 'negative', 1: 'positive'}
embedder = hub.Module(name=args.hub_embedding_name)
tokenizer = embedder.get_tokenizer()
model = BoWModel(embedder=embedder, tokenizer=tokenizer, load_checkpoint=args.checkpoint, label_map=label_map)
results = model.predict(
data, max_seq_len=args.max_seq_len, batch_size=args.batch_size, use_gpu=args.use_gpu, return_result=False)
for idx, text in enumerate(data):
print('Data: {} \t Lable: {}'.format(text[0], results[idx]))
================================================
FILE: demo/text_classification/embedding/train.py
================================================
# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License"
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import paddle
import paddlehub as hub
from paddlehub.datasets import ChnSentiCorp
from paddlenlp.data import JiebaTokenizer
from model import BoWModel
import ast
import argparse
parser = argparse.ArgumentParser(__doc__)
parser.add_argument("--hub_embedding_name", type=str, default='w2v_baidu_encyclopedia_target_word-word_dim300', help="")
parser.add_argument("--num_epoch", type=int, default=10, help="Number of epoches for fine-tuning.")
parser.add_argument("--learning_rate", type=float, default=5e-4, help="Learning rate used to train with warmup.")
parser.add_argument("--max_seq_len", type=int, default=128, help="Number of words of the longest seqence.")
parser.add_argument("--batch_size", type=int, default=64, help="Total examples' number in batch for training.")
parser.add_argument("--checkpoint_dir", type=str, default='./checkpoint', help="Directory to model checkpoint")
parser.add_argument("--save_interval", type=int, default=5, help="Save checkpoint every n epoch.")
parser.add_argument(
"--use_gpu",
type=ast.literal_eval,
default=True,
help="Whether use GPU for fine-tuning, input should be True or False")
args = parser.parse_args()
if __name__ == '__main__':
embedder = hub.Module(name=args.hub_embedding_name)
tokenizer = embedder.get_tokenizer()
train_dataset = ChnSentiCorp(tokenizer=tokenizer, max_seq_len=args.max_seq_len, mode='train')
dev_dataset = ChnSentiCorp(tokenizer=tokenizer, max_seq_len=args.max_seq_len, mode='dev')
test_dataset = ChnSentiCorp(tokenizer=tokenizer, max_seq_len=args.max_seq_len, mode='test')
model = BoWModel(embedder=embedder)
optimizer = paddle.optimizer.AdamW(learning_rate=args.learning_rate, parameters=model.parameters())
trainer = hub.Trainer(model, optimizer, checkpoint_dir=args.checkpoint_dir, use_gpu=args.use_gpu)
trainer.train(
train_dataset,
epochs=args.num_epoch,
batch_size=args.batch_size,
eval_dataset=dev_dataset,
save_interval=args.save_interval,
)
trainer.evaluate(test_dataset, batch_size=args.batch_size)
================================================
FILE: demo/text_classification/predict.py
================================================
# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import paddlehub as hub
if __name__ == '__main__':
data = [
['这个宾馆比较陈旧了,特价的房间也很一般。总体来说一般'],
['怀着十分激动的心情放映,可是看着看着发现,在放映完毕后,出现一集米老鼠的动画片'],
['作为老的四星酒店,房间依然很整洁,相当不错。机场接机服务很好,可以在车上办理入住手续,节省时间。'],
]
label_map = {0: 'negative', 1: 'positive'}
model = hub.Module(
name='ernie_tiny',
version='2.0.1',
task='seq-cls',
load_checkpoint='./test_ernie_text_cls/best_model/model.pdparams',
label_map=label_map)
results, probs = model.predict(data, max_seq_len=50, batch_size=1, use_gpu=False, return_prob=True)
for idx, text in enumerate(data):
print('Data: {} \t Lable: {} \t Prob: {}'.format(text[0], results[idx], probs[idx]))
================================================
FILE: demo/text_classification/train.py
================================================
# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import paddle
import paddlehub as hub
from paddlehub.datasets import ChnSentiCorp
import ast
import argparse
parser = argparse.ArgumentParser(__doc__)
parser.add_argument("--num_epoch", type=int, default=3, help="Number of epoches for fine-tuning.")
parser.add_argument(
"--use_gpu",
type=ast.literal_eval,
default=True,
help="Whether use GPU for fine-tuning, input should be True or False")
parser.add_argument("--learning_rate", type=float, default=5e-5, help="Learning rate used to train with warmup.")
parser.add_argument("--max_seq_len", type=int, default=128, help="Number of words of the longest seqence.")
parser.add_argument("--batch_size", type=int, default=32, help="Total examples' number in batch for training.")
parser.add_argument("--checkpoint_dir", type=str, default='./checkpoint', help="Directory to model checkpoint")
parser.add_argument("--save_interval", type=int, default=1, help="Save checkpoint every n epoch.")
args = parser.parse_args()
if __name__ == '__main__':
model = hub.Module(name='ernie_tiny', version='2.0.1', task='seq-cls')
train_dataset = ChnSentiCorp(tokenizer=model.get_tokenizer(), max_seq_len=args.max_seq_len, mode='train')
dev_dataset = ChnSentiCorp(tokenizer=model.get_tokenizer(), max_seq_len=args.max_seq_len, mode='dev')
test_dataset = ChnSentiCorp(tokenizer=model.get_tokenizer(), max_seq_len=args.max_seq_len, mode='test')
optimizer = paddle.optimizer.AdamW(learning_rate=args.learning_rate, parameters=model.parameters())
trainer = hub.Trainer(model, optimizer, checkpoint_dir=args.checkpoint_dir, use_gpu=args.use_gpu)
trainer.train(
train_dataset,
epochs=args.num_epoch,
batch_size=args.batch_size,
eval_dataset=dev_dataset,
save_interval=args.save_interval,
)
trainer.evaluate(test_dataset, batch_size=args.batch_size)
================================================
FILE: demo/text_matching/README.md
================================================
# PaddleHub Transformer模型fine-tune文本匹配(动态图)
在2017年之前,工业界和学术界对NLP文本处理依赖于序列模型[Recurrent Neural Network (RNN)](https://baike.baidu.com/item/%E5%BE%AA%E7%8E%AF%E7%A5%9E%E7%BB%8F%E7%BD%91%E7%BB%9C/23199490?fromtitle=RNN&fromid=5707183&fr=aladdin).
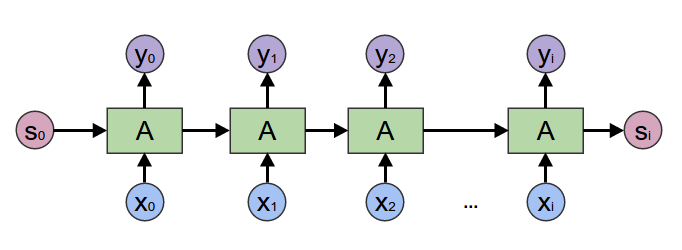
近年来随着深度学习的发展,模型参数数量飞速增长,为了训练这些参数,需要更大的数据集来避免过拟合。然而,对于大部分NLP任务来说,构建大规模的标注数据集成本过高,非常困难,特别是对于句法和语义相关的任务。相比之下,大规模的未标注语料库的构建则相对容易。最近的研究表明,基于大规模未标注语料库的预训练模型(Pretrained Models, PTM) 能够习得通用的语言表示,将预训练模型Fine-tune到下游任务,能够获得出色的表现。另外,预训练模型能够避免从零开始训练模型。

本示例将展示如何使用PaddleHub Transformer模型(如 ERNIE、BERT、RoBERTa等模型)Module 以动态图方式fine-tune并完成预测任务。
## 文本匹配
使用预训练模型ERNIE完成文本匹配任务,大家可能会想到将query和title文本拼接,之后输入ERNIE中,取`CLS`特征(pooled_output),之后输出全连接层,进行二分类。如下图ERNIE用于句对分类任务的用法:

然而,以上用法的问题在于,ERNIE的模型参数非常庞大,导致计算量非常大,预测的速度也不够理想。从而达不到线上业务的要求。针对该问题,使用Sentence Transformer网络可以优化计算量。
Sentence Transformer采用了双塔(Siamese)的网络结构。Query和Title分别输入Transformer网络,共享网络参数,得到各自的token embedding特征。之后对token embedding进行pooling(此处教程使用mean pooling操作),之后输出分别记作u,v。之后将三个表征(u,v,|u-v|)拼接起来,进行二分类。网络结构如下图所示。

更多关于Sentence Transformer的信息可以参考论文:https://arxiv.org/abs/1908.10084
## 如何开始Fine-tune
我们以中文文本匹配数据集LCQMC为示例数据集,可以运行下面的命令,在训练集(train.tsv)上进行模型训练,并在开发集(dev.tsv)验证和测试集测试(test.tsv)。通过如下命令,即可启动训练。
使用PaddleHub Fine-tune API进行Fine-tune可以分为4个步骤。
### Step1: 选择模型
```python
import paddlehub as hub
model = hub.Module(name='ernie_tiny', version='2.0.2', task='text-matching')
```
其中,参数:
* `name`:模型名称,可以选择`ernie`,`ernie_tiny`,`bert-base-cased`, `bert-base-chinese`, `roberta-wwm-ext`,`roberta-wwm-ext-large`等。
* `version`:module版本号
* `task`:fine-tune任务。此处为`text-matching`,表示文本匹配任务。
PaddleHub还提供BERT等模型可供选择, 当前支持文本分类任务的模型对应的加载示例如下:
模型名 | PaddleHub Module
---------------------------------- | :------:
ERNIE, Chinese | `hub.Module(name='ernie')`
ERNIE tiny, Chinese | `hub.Module(name='ernie_tiny')`
ERNIE 2.0 Base, English | `hub.Module(name='ernie_v2_eng_base')`
ERNIE 2.0 Large, English | `hub.Module(name='ernie_v2_eng_large')`
BERT-Base, English Cased | `hub.Module(name='bert-base-cased')`
BERT-Base, English Uncased | `hub.Module(name='bert-base-uncased')`
BERT-Large, English Cased | `hub.Module(name='bert-large-cased')`
BERT-Large, English Uncased | `hub.Module(name='bert-large-uncased')`
BERT-Base, Multilingual Cased | `hub.Module(nane='bert-base-multilingual-cased')`
BERT-Base, Multilingual Uncased | `hub.Module(nane='bert-base-multilingual-uncased')`
BERT-Base, Chinese | `hub.Module(name='bert-base-chinese')`
BERT-wwm, Chinese | `hub.Module(name='chinese-bert-wwm')`
BERT-wwm-ext, Chinese | `hub.Module(name='chinese-bert-wwm-ext')`
RoBERTa-wwm-ext, Chinese | `hub.Module(name='roberta-wwm-ext')`
RoBERTa-wwm-ext-large, Chinese | `hub.Module(name='roberta-wwm-ext-large')`
RBT3, Chinese | `hub.Module(name='rbt3')`
RBTL3, Chinese | `hub.Module(name='rbtl3')`
ELECTRA-Small, English | `hub.Module(name='electra-small')`
ELECTRA-Base, English | `hub.Module(name='electra-base')`
ELECTRA-Large, English | `hub.Module(name='electra-large')`
ELECTRA-Base, Chinese | `hub.Module(name='chinese-electra-base')`
ELECTRA-Small, Chinese | `hub.Module(name='chinese-electra-small')`
通过以上的一行代码,`model`初始化为一个适用于文本匹配任务的双塔(Siamese)结构模型,。
### Step2: 下载并加载数据集
```python
train_dataset = LCQMC(tokenizer=model.get_tokenizer(), max_seq_len=128, mode='train')
dev_dataset = LCQMC(tokenizer=model.get_tokenizer(), max_seq_len=128, mode='dev')
test_dataset = LCQMC(tokenizer=model.get_tokenizer(), max_seq_len=128, mode='test')
```
* `tokenizer`:表示该module所需用到的tokenizer,其将对输入文本完成切词,并转化成module运行所需模型输入格式。
* `mode`:选择数据模式,可选项有 `train`, `dev`, `test`,默认为`train`。
* `max_seq_len`:ERNIE/BERT模型使用的最大序列长度,若出现显存不足,请适当调低这一参数。
预训练模型ERNIE对中文数据的处理是以字为单位,tokenizer作用为将原始输入文本转化成模型model可以接受的输入数据形式。 PaddleHub 2.0中的各种预训练模型已经内置了相应的tokenizer,可以通过`model.get_tokenizer`方法获取。
### Step3: 选择优化策略和运行配置
```python
optimizer = paddle.optimizer.AdamW(learning_rate=5e-5, parameters=model.parameters())
trainer = hub.Trainer(model, optimizer, checkpoint_dir='./', use_gpu=True)
```
#### 优化策略
Paddle2.0提供了多种优化器选择,如`SGD`, `AdamW`, `Adamax`等,详细参见[策略](https://www.paddlepaddle.org.cn/documentation/docs/zh/api/paddle/optimizer/Overview_cn.html)。
其中`AdamW`:
- `learning_rate`: 全局学习率。默认为1e-3;
- `parameters`: 待优化模型参数。
其余可配置参数请参考[AdamW](https://www.paddlepaddle.org.cn/documentation/docs/zh/api/paddle/optimizer/adamw/AdamW_cn.html#cn-api-paddle-optimizer-adamw)。
#### 运行配置
`Trainer` 主要控制Fine-tune的训练,包含以下可控制的参数:
- `model`: 被优化模型;
- `optimizer`: 优化器选择;
- `use_vdl`: 是否使用vdl可视化训练过程;
- `checkpoint_dir`: 保存模型参数的地址;
- `compare_metrics`: 保存最优模型的衡量指标;
### Step4: 执行训练和模型评估
```python
trainer.train(
train_dataset,
epochs=10,
batch_size=32,
eval_dataset=dev_dataset,
save_interval=2,
)
trainer.evaluate(test_dataset, batch_size=32)
```
`trainer.train`执行模型的训练,其参数可以控制具体的训练过程,主要的参数包含:
- `train_dataset`: 训练时所用的数据集;
- `epochs`: 训练轮数;
- `batch_size`: 训练时每一步用到的样本数目,如果使用GPU,请根据实际情况调整batch_size;
- `num_workers`: works的数量,默认为0;
- `eval_dataset`: 验证集;
- `log_interval`: 打印日志的间隔, 单位为执行批训练的次数。
- `save_interval`: 保存模型的间隔频次,单位为执行训练的轮数。
`trainer.evaluate`执行模型的评估,主要的参数包含:
- `eval_dataset`: 模型评估时所用的数据集;
- `batch_size`: 模型评估时每一步用到的样本数目,如果使用GPU,请根据实际情况调整batch_size
## 模型预测
当完成Fine-tune后,Fine-tune过程在验证集上表现最优的模型会被保存在`${CHECKPOINT_DIR}/best_model`目录下,其中`${CHECKPOINT_DIR}`目录为Fine-tune时所选择的保存checkpoint的目录。
以下代码将使用最优模型来进行预测:
```python
import paddlehub as hub
data = [
['这个表情叫什么', '这个猫的表情叫什么'],
['什么是智能手环', '智能手环有什么用'],
['介绍几本好看的都市异能小说,要完结的!', '求一本好看点的都市异能小说,要完结的'],
['一只蜜蜂落在日历上(打一成语)', '一只蜜蜂停在日历上(猜一成语)'],
['一盒香烟不拆开能存放多久?', '一条没拆封的香烟能存放多久。'],
]
label_map = {0: 'similar', 1: 'dissimilar'}
model = hub.Module(
name='ernie_tiny',
version='2.0.2',
task='text-matching',
load_checkpoint='./checkpoint/best_model/model.pdparams',
label_map=label_map)
results = model.predict(data, max_seq_len=128, batch_size=1, use_gpu=True)
for idx, texts in enumerate(data):
print('TextA: {}\tTextB: {}\t Label: {}'.format(texts[0], texts[1], results[idx]))
```
### 依赖
paddlepaddle >= 2.0.0
paddlehub >= 2.0.0
================================================
FILE: demo/text_matching/predict.py
================================================
# Copyright (c) 2021 PaddlePaddle Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import paddlehub as hub
if __name__ == '__main__':
data = [
['这个表情叫什么', '这个猫的表情叫什么'],
['什么是智能手环', '智能手环有什么用'],
['介绍几本好看的都市异能小说,要完结的!', '求一本好看点的都市异能小说,要完结的'],
['一只蜜蜂落在日历上(打一成语)', '一只蜜蜂停在日历上(猜一成语)'],
['一盒香烟不拆开能存放多久?', '一条没拆封的香烟能存放多久。'],
]
label_map = {0: 'similar', 1: 'dissimilar'}
model = hub.Module(
name='ernie_tiny',
version='2.0.2',
task='text-matching',
load_checkpoint='./checkpoint/best_model/model.pdparams',
label_map=label_map)
results = model.predict(data, max_seq_len=50, batch_size=1, use_gpu=True)
for idx, texts in enumerate(data):
print('TextA: {}\tTextB: {}\t Label: {}'.format(texts[0], texts[1], results[idx]))
================================================
FILE: demo/text_matching/train.py
================================================
# Copyright (c) 2021 PaddlePaddle Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import paddle
import paddlehub as hub
from paddlehub.datasets import LCQMC
import ast
import argparse
parser = argparse.ArgumentParser(__doc__)
parser.add_argument("--num_epoch", type=int, default=10, help="Number of epoches for fine-tuning.")
parser.add_argument(
"--use_gpu",
type=ast.literal_eval,
default=True,
help="Whether use GPU for fine-tuning, input should be True or False")
parser.add_argument("--learning_rate", type=float, default=5e-5, help="Learning rate used to train with warmup.")
parser.add_argument("--max_seq_len", type=int, default=64, help="Number of words of the longest seqence.")
parser.add_argument("--batch_size", type=int, default=128, help="Total examples' number in batch for training.")
parser.add_argument("--checkpoint_dir", type=str, default='./checkpoint', help="Directory to model checkpoint")
parser.add_argument("--save_interval", type=int, default=2, help="Save checkpoint every n epoch.")
args = parser.parse_args()
if __name__ == '__main__':
model = hub.Module(name='ernie_tiny', version='2.0.2', task='text-matching')
tokenizer = model.get_tokenizer()
train_dataset = LCQMC(tokenizer=tokenizer, max_seq_len=args.max_seq_len, mode='train')
dev_dataset = LCQMC(tokenizer=tokenizer, max_seq_len=args.max_seq_len, mode='dev')
test_dataset = LCQMC(tokenizer=tokenizer, max_seq_len=args.max_seq_len, mode='test')
optimizer = paddle.optimizer.AdamW(learning_rate=args.learning_rate, parameters=model.parameters())
trainer = hub.Trainer(model, optimizer, checkpoint_dir=args.checkpoint_dir, use_gpu=args.use_gpu)
trainer.train(
train_dataset,
epochs=args.num_epoch,
batch_size=args.batch_size,
eval_dataset=dev_dataset,
save_interval=args.save_interval,
)
trainer.evaluate(test_dataset, batch_size=args.batch_size)
================================================
FILE: docker/Dockerfile
================================================
FROM ubuntu:16.04
RUN echo "deb [trusted=true] http://mirrors.tuna.tsinghua.edu.cn/ubuntu/ xenial main restricted \n\
deb [trusted=true] http://mirrors.tuna.tsinghua.edu.cn/ubuntu/ xenial-updates main restricted \n\
deb [trusted=true] http://mirrors.tuna.tsinghua.edu.cn/ubuntu/ xenial universe \n\
deb [trusted=true] http://mirrors.tuna.tsinghua.edu.cn/ubuntu/ xenial-updates universe \n\
deb [trusted=true] http://mirrors.tuna.tsinghua.edu.cn/ubuntu/ xenial multiverse \n\
deb [trusted=true] http://mirrors.tuna.tsinghua.edu.cn/ubuntu/ xenial-updates multiverse \n\
deb [trusted=true] http://mirrors.tuna.tsinghua.edu.cn/ubuntu/ xenial-backports main restricted universe multiverse \n\
deb [trusted=true] http://mirrors.tuna.tsinghua.edu.cn/ubuntu/ xenial-security main restricted \n\
deb [trusted=true] http://mirrors.tuna.tsinghua.edu.cn/ubuntu/ xenial-security universe \n\
deb [trusted=true] http://mirrors.tuna.tsinghua.edu.cn/ubuntu/ xenial-security multiverse" > /etc/apt/sources.list
RUN apt-get update && apt-get install -y inetutils-ping wget vim curl cmake git sox libsndfile1 libpng12-dev \
libpng-dev swig libzip-dev openssl bc libflac* libgdk-pixbuf2.0-dev libpango1.0-dev libcairo2-dev \
libgtk2.0-dev pkg-config zip unzip zlib1g-dev libreadline-dev libbz2-dev liblapack-dev libjpeg-turbo8-dev \
sudo lrzsz libsqlite3-dev libx11-dev libsm6 apt-utils libopencv-dev libavcodec-dev libavformat-dev \
libswscale-dev locales liblzma-dev python-lzma m4 libxext-dev strace libibverbs-dev libpcre3 libpcre3-dev \
build-essential libncurses5-dev libgdbm-dev libnss3-dev libssl-dev libreadline-dev libffi-dev xz-utils \
libfreetype6-dev libxslt1-dev libxml2-dev libgeos-3.5.0 libgeos-dev && apt-get install -y --allow-downgrades \
--allow-change-held-packages && DEBIAN_FRONTEND=noninteractive apt-get install -y tzdata \
&& /bin/cp /usr/share/zoneinfo/Asia/Shanghai /etc/localtime && dpkg-reconfigure -f noninteractive tzdata
RUN echo "set meta-flag on" >> /etc/inputrc && echo "set convert-meta off" >> /etc/inputrc && \
locale-gen en_US.UTF-8 && /sbin/ldconfig -v && groupadd -g 10001 paddlehub && \
useradd -m -s /bin/bash -N -u 10001 paddlehub -g paddlehub && chmod g+w /etc/passwd && \
echo "paddlehub ALL=(ALL) NOPASSWD: ALL" >> /etc/sudoers
ENV LANG=en_US.UTF-8 LC_ALL=en_US.UTF-8 LANGUAGE=en_US.UTF-8 TZ=Asia/Shanghai
# official download site: https://www.python.org/ftp/python/3.7.13/Python-3.7.13.tgz
RUN wget https://cdn.npmmirror.com/binaries/python/3.7.13/Python-3.7.13.tgz && tar xvf Python-3.7.13.tgz && \
cd Python-3.7.13 && ./configure --prefix=/home/paddlehub/python3.7 && make -j8 && make install && \
rm -rf ../Python-3.7.13 ../Python-3.7.13.tgz && chown -R paddlehub:paddlehub /home/paddlehub/python3.7
RUN cd /tmp && wget https://mirrors.sjtug.sjtu.edu.cn/gnu/gmp/gmp-6.1.0.tar.bz2 && tar xvf gmp-6.1.0.tar.bz2 && \
cd gmp-6.1.0 && ./configure --prefix=/usr/local && make -j8 && make install && \
rm -rf ../gmp-6.1.0.tar.bz2 ../gmp-6.1.0 && cd /tmp && \
wget https://www.mpfr.org/mpfr-3.1.4/mpfr-3.1.4.tar.bz2 && tar xvf mpfr-3.1.4.tar.bz2 && cd mpfr-3.1.4 && \
./configure --prefix=/usr/local && make -j8 && make install && rm -rf ../mpfr-3.1.4.tar.bz2 ../mpfr-3.1.4 && \
cd /tmp && wget https://mirrors.sjtug.sjtu.edu.cn/gnu/mpc/mpc-1.0.3.tar.gz && tar xvf mpc-1.0.3.tar.gz && \
cd mpc-1.0.3 && ./configure -
gitextract_e8vmpf1l/
├── .github/
│ └── ISSUE_TEMPLATE/
│ ├── ----.md
│ └── bug--.md
├── .gitignore
├── .pre-commit-config.yaml
├── .style.yapf
├── .travis.yml
├── AUTHORS.md
├── LICENSE
├── README.md
├── README_ch.md
├── demo/
│ ├── README.md
│ ├── audio_classification/
│ │ ├── README.md
│ │ ├── audioset_predict.py
│ │ ├── predict.py
│ │ └── train.py
│ ├── autoaug/
│ │ ├── README.md
│ │ ├── hub_fitter.py
│ │ ├── paddlehub_utils/
│ │ │ ├── __init__.py
│ │ │ ├── reader.py
│ │ │ └── trainer.py
│ │ ├── pba_classifier_example.yaml
│ │ ├── search.py
│ │ ├── search.sh
│ │ ├── train.py
│ │ └── train.sh
│ ├── colorization/
│ │ ├── README.md
│ │ ├── predict.py
│ │ └── train.py
│ ├── image_classification/
│ │ ├── README.md
│ │ ├── predict.py
│ │ └── train.py
│ ├── semantic_segmentation/
│ │ ├── README.md
│ │ ├── predict.py
│ │ └── train.py
│ ├── sequence_labeling/
│ │ ├── README.md
│ │ ├── predict.py
│ │ └── train.py
│ ├── serving/
│ │ ├── bentoml/
│ │ │ └── cloud-native-model-serving-with-bentoml.ipynb
│ │ ├── lexical_analysis_lac/
│ │ │ └── templates/
│ │ │ ├── lac_gpu_serving_config.json
│ │ │ └── lac_serving_config.json
│ │ └── module_serving/
│ │ ├── lexical_analysis_lac/
│ │ │ ├── README.md
│ │ │ └── lac_serving_demo.py
│ │ └── object_detection_pyramidbox_lite_server_mask/
│ │ └── pyramidbox_lite_server_mask_serving_demo.py
│ ├── style_transfer/
│ │ ├── README.md
│ │ ├── predict.py
│ │ └── train.py
│ ├── text_classification/
│ │ ├── README.md
│ │ ├── embedding/
│ │ │ ├── model.py
│ │ │ ├── predict.py
│ │ │ └── train.py
│ │ ├── predict.py
│ │ └── train.py
│ └── text_matching/
│ ├── README.md
│ ├── predict.py
│ └── train.py
├── docker/
│ └── Dockerfile
├── docs/
│ ├── Makefile
│ ├── conf.py
│ ├── docs_ch/
│ │ ├── Makefile
│ │ ├── api/
│ │ │ ├── datasets/
│ │ │ │ ├── canvas.rst
│ │ │ │ ├── chnsenticorp.rst
│ │ │ │ ├── esc50.rst
│ │ │ │ ├── flowers.rst
│ │ │ │ ├── lcqmc.rst
│ │ │ │ ├── minicoco.rst
│ │ │ │ ├── msra_ner.rst
│ │ │ │ └── opticdisc.rst
│ │ │ ├── datasets_index.rst
│ │ │ ├── env.rst
│ │ │ ├── module.rst
│ │ │ ├── module_decorator.rst
│ │ │ ├── module_manager.rst
│ │ │ └── trainer.rst
│ │ ├── api_index.rst
│ │ ├── community/
│ │ │ ├── contribute_code.md
│ │ │ └── more_demos.md
│ │ ├── community_index.rst
│ │ ├── conf.py
│ │ ├── faq.md
│ │ ├── figures.md
│ │ ├── finetune/
│ │ │ ├── audio_classification.md
│ │ │ ├── customized_dataset.md
│ │ │ ├── image_classification.md
│ │ │ ├── image_colorization.md
│ │ │ ├── semantic_segmentation.md
│ │ │ ├── sequence_labeling.md
│ │ │ ├── style_transfer.md
│ │ │ └── text_matching.md
│ │ ├── get_start/
│ │ │ ├── installation.rst
│ │ │ ├── linux_quickstart.md
│ │ │ ├── mac_quickstart.md
│ │ │ ├── python_use_hub.rst
│ │ │ └── windows_quickstart.md
│ │ ├── get_start_index.rst
│ │ ├── index.rst
│ │ ├── make.bat
│ │ ├── release.md
│ │ ├── transfer_learning_index.rst
│ │ ├── tutorial/
│ │ │ ├── cmd_usage.rst
│ │ │ ├── custom_module.rst
│ │ │ └── serving.md
│ │ ├── tutorial_index.rst
│ │ └── visualization.md
│ ├── docs_en/
│ │ ├── Makefile
│ │ ├── api/
│ │ │ ├── datasets/
│ │ │ │ ├── canvas.rst
│ │ │ │ ├── chnsenticorp.rst
│ │ │ │ ├── esc50.rst
│ │ │ │ ├── flowers.rst
│ │ │ │ ├── lcqmc.rst
│ │ │ │ ├── minicoco.rst
│ │ │ │ ├── msra_ner.rst
│ │ │ │ └── opticdisc.rst
│ │ │ ├── datasets_index.rst
│ │ │ ├── env.rst
│ │ │ ├── module.rst
│ │ │ ├── module_decorator.rst
│ │ │ ├── module_manager.rst
│ │ │ └── trainer.rst
│ │ ├── api_index.rst
│ │ ├── community/
│ │ │ ├── contribute_code.md
│ │ │ └── more_demos.md
│ │ ├── community_index.rst
│ │ ├── conf.py
│ │ ├── faq.md
│ │ ├── figures.md
│ │ ├── finetune/
│ │ │ ├── audio_classification.md
│ │ │ ├── customized_dataset.md
│ │ │ ├── image_classification.md
│ │ │ ├── image_colorization.md
│ │ │ ├── semantic_segmentation.md
│ │ │ ├── sequence_labeling.md
│ │ │ ├── style_transfer.md
│ │ │ └── text_matching.md
│ │ ├── get_start/
│ │ │ ├── installation.rst
│ │ │ ├── linux_quickstart.md
│ │ │ ├── mac_quickstart.md
│ │ │ ├── python_use_hub.rst
│ │ │ └── windows_quickstart.md
│ │ ├── get_start_index.rst
│ │ ├── index.rst
│ │ ├── make.bat
│ │ ├── release.md
│ │ ├── transfer_learning_index.rst
│ │ ├── tutorial/
│ │ │ ├── cmd_usage.rst
│ │ │ ├── custom_module.rst
│ │ │ └── serving.md
│ │ ├── tutorial_index.rst
│ │ └── visualization.md
│ ├── make.bat
│ └── requirements.txt
├── modules/
│ ├── README.md
│ ├── README_ch.md
│ ├── audio/
│ │ ├── README.md
│ │ ├── README_en.md
│ │ ├── asr/
│ │ │ ├── deepspeech2_aishell/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── assets/
│ │ │ │ │ ├── conf/
│ │ │ │ │ │ ├── augmentation.json
│ │ │ │ │ │ └── deepspeech2.yaml
│ │ │ │ │ └── data/
│ │ │ │ │ ├── mean_std.json
│ │ │ │ │ └── vocab.txt
│ │ │ │ ├── deepspeech_tester.py
│ │ │ │ ├── module.py
│ │ │ │ └── requirements.txt
│ │ │ ├── deepspeech2_librispeech/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── assets/
│ │ │ │ │ └── conf/
│ │ │ │ │ ├── augmentation.json
│ │ │ │ │ └── deepspeech2.yaml
│ │ │ │ ├── deepspeech_tester.py
│ │ │ │ ├── module.py
│ │ │ │ └── requirements.txt
│ │ │ ├── u2_conformer_aishell/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── assets/
│ │ │ │ │ ├── conf/
│ │ │ │ │ │ ├── augmentation.json
│ │ │ │ │ │ └── conformer.yaml
│ │ │ │ │ └── data/
│ │ │ │ │ ├── mean_std.json
│ │ │ │ │ └── vocab.txt
│ │ │ │ ├── module.py
│ │ │ │ ├── requirements.txt
│ │ │ │ └── u2_conformer_tester.py
│ │ │ ├── u2_conformer_librispeech/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── assets/
│ │ │ │ │ ├── conf/
│ │ │ │ │ │ ├── augmentation.json
│ │ │ │ │ │ └── conformer.yaml
│ │ │ │ │ └── data/
│ │ │ │ │ ├── bpe_unigram_5000.model
│ │ │ │ │ ├── bpe_unigram_5000.vocab
│ │ │ │ │ ├── mean_std.json
│ │ │ │ │ └── vocab.txt
│ │ │ │ ├── module.py
│ │ │ │ ├── requirements.txt
│ │ │ │ └── u2_conformer_tester.py
│ │ │ └── u2_conformer_wenetspeech/
│ │ │ ├── README.md
│ │ │ ├── __init__.py
│ │ │ ├── module.py
│ │ │ └── requirements.txt
│ │ ├── audio_classification/
│ │ │ └── PANNs/
│ │ │ ├── cnn10/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── module.py
│ │ │ │ ├── network.py
│ │ │ │ └── requirements.txt
│ │ │ ├── cnn14/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── module.py
│ │ │ │ ├── network.py
│ │ │ │ └── requirements.txt
│ │ │ └── cnn6/
│ │ │ ├── README.md
│ │ │ ├── __init__.py
│ │ │ ├── module.py
│ │ │ ├── network.py
│ │ │ └── requirements.txt
│ │ ├── keyword_spotting/
│ │ │ └── kwmlp_speech_commands/
│ │ │ ├── README.md
│ │ │ ├── __init__.py
│ │ │ ├── feature.py
│ │ │ ├── kwmlp.py
│ │ │ ├── module.py
│ │ │ └── requirements.txt
│ │ ├── language_identification/
│ │ │ └── ecapa_tdnn_common_language/
│ │ │ ├── README.md
│ │ │ ├── __init__.py
│ │ │ ├── ecapa_tdnn.py
│ │ │ ├── feature.py
│ │ │ ├── module.py
│ │ │ └── requirements.txt
│ │ ├── speaker_recognition/
│ │ │ └── ecapa_tdnn_voxceleb/
│ │ │ ├── README.md
│ │ │ ├── __init__.py
│ │ │ ├── ecapa_tdnn.py
│ │ │ ├── feature.py
│ │ │ ├── module.py
│ │ │ └── requirements.txt
│ │ ├── svs/
│ │ │ └── diffsinger/
│ │ │ ├── README.md
│ │ │ ├── __init__.py
│ │ │ ├── configs/
│ │ │ │ ├── config_base.yaml
│ │ │ │ ├── singing/
│ │ │ │ │ ├── base.yaml
│ │ │ │ │ └── fs2.yaml
│ │ │ │ └── tts/
│ │ │ │ ├── base.yaml
│ │ │ │ ├── base_zh.yaml
│ │ │ │ ├── fs2.yaml
│ │ │ │ ├── hifigan.yaml
│ │ │ │ ├── lj/
│ │ │ │ │ ├── base_mel2wav.yaml
│ │ │ │ │ ├── base_text2mel.yaml
│ │ │ │ │ ├── fs2.yaml
│ │ │ │ │ ├── hifigan.yaml
│ │ │ │ │ └── pwg.yaml
│ │ │ │ └── pwg.yaml
│ │ │ ├── infer.py
│ │ │ ├── inference/
│ │ │ │ └── svs/
│ │ │ │ └── opencpop/
│ │ │ │ ├── cpop_pinyin2ph.txt
│ │ │ │ └── map.py
│ │ │ ├── module.py
│ │ │ ├── requirements.txt
│ │ │ ├── test.py
│ │ │ ├── usr/
│ │ │ │ └── configs/
│ │ │ │ ├── base.yaml
│ │ │ │ ├── lj_ds_beta6.yaml
│ │ │ │ ├── midi/
│ │ │ │ │ ├── cascade/
│ │ │ │ │ │ └── opencs/
│ │ │ │ │ │ ├── aux_rel.yaml
│ │ │ │ │ │ ├── ds60_rel.yaml
│ │ │ │ │ │ └── opencpop_statis.yaml
│ │ │ │ │ ├── e2e/
│ │ │ │ │ │ ├── opencpop/
│ │ │ │ │ │ │ ├── ds1000.yaml
│ │ │ │ │ │ │ └── ds100_adj_rel.yaml
│ │ │ │ │ │ └── popcs/
│ │ │ │ │ │ └── ds100_adj_rel.yaml
│ │ │ │ │ └── pe.yaml
│ │ │ │ ├── popcs_ds_beta6.yaml
│ │ │ │ ├── popcs_ds_beta6_offline.yaml
│ │ │ │ └── popcs_fs2.yaml
│ │ │ └── utils/
│ │ │ ├── __init__.py
│ │ │ ├── audio.py
│ │ │ ├── cwt.py
│ │ │ ├── hparams.py
│ │ │ ├── multiprocess_utils.py
│ │ │ ├── text_encoder.py
│ │ │ └── text_norm.py
│ │ ├── tts/
│ │ │ ├── deepvoice3_ljspeech/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── module.py
│ │ │ │ └── requirements.txt
│ │ │ ├── fastspeech2_baker/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── assets/
│ │ │ │ │ ├── fastspeech2_nosil_baker_ckpt_0.4/
│ │ │ │ │ │ ├── default.yaml
│ │ │ │ │ │ └── phone_id_map.txt
│ │ │ │ │ └── pwg_baker_ckpt_0.4/
│ │ │ │ │ └── pwg_default.yaml
│ │ │ │ ├── module.py
│ │ │ │ └── requirements.txt
│ │ │ ├── fastspeech2_ljspeech/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── assets/
│ │ │ │ │ ├── fastspeech2_nosil_ljspeech_ckpt_0.5/
│ │ │ │ │ │ ├── default.yaml
│ │ │ │ │ │ └── phone_id_map.txt
│ │ │ │ │ └── pwg_ljspeech_ckpt_0.5/
│ │ │ │ │ └── pwg_default.yaml
│ │ │ │ ├── module.py
│ │ │ │ └── requirements.txt
│ │ │ ├── fastspeech_ljspeech/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── module.py
│ │ │ │ └── requirements.txt
│ │ │ └── transformer_tts_ljspeech/
│ │ │ ├── README.md
│ │ │ ├── __init__.py
│ │ │ ├── module.py
│ │ │ └── requirements.txt
│ │ └── voice_cloning/
│ │ ├── ge2e_fastspeech2_pwgan/
│ │ │ ├── README.md
│ │ │ ├── __init__.py
│ │ │ ├── module.py
│ │ │ └── requirements.txt
│ │ └── lstm_tacotron2/
│ │ ├── README.md
│ │ ├── __init__.py
│ │ ├── audio_processor.py
│ │ ├── chinese_g2p.py
│ │ ├── module.py
│ │ ├── preprocess_transcription.py
│ │ └── requirements.txt
│ ├── demo/
│ │ ├── README.md
│ │ ├── senta_test/
│ │ │ ├── __init__.py
│ │ │ ├── module.py
│ │ │ ├── processor.py
│ │ │ └── vocab.list
│ │ └── test.py
│ ├── image/
│ │ ├── Image_editing/
│ │ │ ├── README.md
│ │ │ ├── README_en.md
│ │ │ ├── colorization/
│ │ │ │ ├── deoldify/
│ │ │ │ │ ├── README.md
│ │ │ │ │ ├── README_en.md
│ │ │ │ │ ├── base_module.py
│ │ │ │ │ ├── module.py
│ │ │ │ │ ├── test.py
│ │ │ │ │ └── utils.py
│ │ │ │ ├── photo_restoration/
│ │ │ │ │ ├── README.md
│ │ │ │ │ ├── README_en.md
│ │ │ │ │ ├── module.py
│ │ │ │ │ ├── test.py
│ │ │ │ │ └── utils.py
│ │ │ │ └── user_guided_colorization/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── data_feed.py
│ │ │ │ ├── module.py
│ │ │ │ └── test.py
│ │ │ ├── enhancement/
│ │ │ │ ├── fbcnn_color/
│ │ │ │ │ ├── README.md
│ │ │ │ │ ├── fbcnn.py
│ │ │ │ │ ├── module.py
│ │ │ │ │ └── test.py
│ │ │ │ └── fbcnn_gray/
│ │ │ │ ├── README.md
│ │ │ │ ├── fbcnn.py
│ │ │ │ ├── module.py
│ │ │ │ └── test.py
│ │ │ └── super_resolution/
│ │ │ ├── dcscn/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── data_feed.py
│ │ │ │ ├── module.py
│ │ │ │ ├── processor.py
│ │ │ │ └── test.py
│ │ │ ├── falsr_a/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── data_feed.py
│ │ │ │ ├── module.py
│ │ │ │ ├── processor.py
│ │ │ │ └── test.py
│ │ │ ├── falsr_b/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── data_feed.py
│ │ │ │ ├── module.py
│ │ │ │ ├── processor.py
│ │ │ │ └── test.py
│ │ │ ├── falsr_c/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── data_feed.py
│ │ │ │ ├── module.py
│ │ │ │ ├── processor.py
│ │ │ │ └── test.py
│ │ │ ├── realsr/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── module.py
│ │ │ │ ├── rrdb.py
│ │ │ │ ├── test.py
│ │ │ │ └── utils.py
│ │ │ ├── swin2sr_real_sr_x4/
│ │ │ │ ├── README.md
│ │ │ │ ├── module.py
│ │ │ │ ├── swin2sr.py
│ │ │ │ └── test.py
│ │ │ ├── swinir_l_real_sr_x4/
│ │ │ │ ├── README.md
│ │ │ │ ├── module.py
│ │ │ │ ├── swinir.py
│ │ │ │ └── test.py
│ │ │ ├── swinir_m_real_sr_x2/
│ │ │ │ ├── README.md
│ │ │ │ ├── module.py
│ │ │ │ ├── swinir.py
│ │ │ │ └── test.py
│ │ │ └── swinir_m_real_sr_x4/
│ │ │ ├── README.md
│ │ │ ├── module.py
│ │ │ ├── swinir.py
│ │ │ └── test.py
│ │ ├── Image_gan/
│ │ │ ├── README.md
│ │ │ ├── README_en.md
│ │ │ ├── attgan_celeba/
│ │ │ │ ├── README.md
│ │ │ │ └── README_en.md
│ │ │ ├── cyclegan_cityscapes/
│ │ │ │ ├── README.md
│ │ │ │ └── README_en.md
│ │ │ ├── gan/
│ │ │ │ ├── README.md
│ │ │ │ ├── first_order_motion/
│ │ │ │ │ ├── README.md
│ │ │ │ │ ├── model.py
│ │ │ │ │ ├── module.py
│ │ │ │ │ └── requirements.txt
│ │ │ │ ├── photopen/
│ │ │ │ │ ├── README.md
│ │ │ │ │ ├── model.py
│ │ │ │ │ ├── module.py
│ │ │ │ │ ├── photopen.yaml
│ │ │ │ │ ├── requirements.txt
│ │ │ │ │ └── util.py
│ │ │ │ ├── pixel2style2pixel/
│ │ │ │ │ ├── README.md
│ │ │ │ │ ├── model.py
│ │ │ │ │ ├── module.py
│ │ │ │ │ ├── requirements.txt
│ │ │ │ │ └── util.py
│ │ │ │ ├── stgan_bald/
│ │ │ │ │ ├── README.md
│ │ │ │ │ ├── README_en.md
│ │ │ │ │ ├── data_feed.py
│ │ │ │ │ ├── module.py
│ │ │ │ │ ├── processor.py
│ │ │ │ │ └── test.py
│ │ │ │ ├── styleganv2_editing/
│ │ │ │ │ ├── README.md
│ │ │ │ │ ├── basemodel.py
│ │ │ │ │ ├── model.py
│ │ │ │ │ ├── module.py
│ │ │ │ │ ├── requirements.txt
│ │ │ │ │ └── util.py
│ │ │ │ ├── styleganv2_mixing/
│ │ │ │ │ ├── README.md
│ │ │ │ │ ├── basemodel.py
│ │ │ │ │ ├── model.py
│ │ │ │ │ ├── module.py
│ │ │ │ │ ├── requirements.txt
│ │ │ │ │ └── util.py
│ │ │ │ └── wav2lip/
│ │ │ │ ├── README.md
│ │ │ │ ├── model.py
│ │ │ │ ├── module.py
│ │ │ │ └── requirements.txt
│ │ │ ├── stargan_celeba/
│ │ │ │ ├── README.md
│ │ │ │ └── README_en.md
│ │ │ ├── stgan_celeba/
│ │ │ │ ├── README.md
│ │ │ │ └── README_en.md
│ │ │ └── style_transfer/
│ │ │ ├── ID_Photo_GEN/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ └── module.py
│ │ │ ├── Photo2Cartoon/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── model/
│ │ │ │ │ ├── __init__.py
│ │ │ │ │ └── networks.py
│ │ │ │ └── module.py
│ │ │ ├── U2Net_Portrait/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── module.py
│ │ │ │ ├── processor.py
│ │ │ │ └── u2net.py
│ │ │ ├── UGATIT_100w/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── model.py
│ │ │ │ ├── module.py
│ │ │ │ └── processor.py
│ │ │ ├── UGATIT_83w/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── model.py
│ │ │ │ ├── module.py
│ │ │ │ └── processor.py
│ │ │ ├── UGATIT_92w/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── model.py
│ │ │ │ ├── module.py
│ │ │ │ └── processor.py
│ │ │ ├── animegan_v1_hayao_60/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── model.py
│ │ │ │ ├── module.py
│ │ │ │ ├── processor.py
│ │ │ │ └── test.py
│ │ │ ├── animegan_v2_hayao_64/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── model.py
│ │ │ │ ├── module.py
│ │ │ │ ├── processor.py
│ │ │ │ └── test.py
│ │ │ ├── animegan_v2_hayao_99/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── model.py
│ │ │ │ ├── module.py
│ │ │ │ ├── processor.py
│ │ │ │ └── test.py
│ │ │ ├── animegan_v2_paprika_54/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── model.py
│ │ │ │ ├── module.py
│ │ │ │ ├── processor.py
│ │ │ │ └── test.py
│ │ │ ├── animegan_v2_paprika_74/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── model.py
│ │ │ │ ├── module.py
│ │ │ │ ├── processor.py
│ │ │ │ └── test.py
│ │ │ ├── animegan_v2_paprika_97/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── model.py
│ │ │ │ ├── module.py
│ │ │ │ ├── processor.py
│ │ │ │ └── test.py
│ │ │ ├── animegan_v2_paprika_98/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── model.py
│ │ │ │ ├── module.py
│ │ │ │ ├── processor.py
│ │ │ │ └── test.py
│ │ │ ├── animegan_v2_shinkai_33/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── model.py
│ │ │ │ ├── module.py
│ │ │ │ ├── processor.py
│ │ │ │ └── test.py
│ │ │ ├── animegan_v2_shinkai_53/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── model.py
│ │ │ │ ├── module.py
│ │ │ │ ├── processor.py
│ │ │ │ └── test.py
│ │ │ ├── face_parse/
│ │ │ │ ├── README.md
│ │ │ │ ├── model.py
│ │ │ │ ├── module.py
│ │ │ │ ├── requirements.txt
│ │ │ │ └── util.py
│ │ │ ├── lapstyle_circuit/
│ │ │ │ ├── README.md
│ │ │ │ ├── model.py
│ │ │ │ ├── module.py
│ │ │ │ ├── requirements.txt
│ │ │ │ └── util.py
│ │ │ ├── lapstyle_ocean/
│ │ │ │ ├── README.md
│ │ │ │ ├── model.py
│ │ │ │ ├── module.py
│ │ │ │ ├── requirements.txt
│ │ │ │ └── util.py
│ │ │ ├── lapstyle_starrynew/
│ │ │ │ ├── README.md
│ │ │ │ ├── model.py
│ │ │ │ ├── module.py
│ │ │ │ ├── requirements.txt
│ │ │ │ └── util.py
│ │ │ ├── lapstyle_stars/
│ │ │ │ ├── README.md
│ │ │ │ ├── model.py
│ │ │ │ ├── module.py
│ │ │ │ ├── requirements.txt
│ │ │ │ └── util.py
│ │ │ ├── msgnet/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ └── module.py
│ │ │ ├── paint_transformer/
│ │ │ │ ├── README.md
│ │ │ │ ├── inference.py
│ │ │ │ ├── model.py
│ │ │ │ ├── module.py
│ │ │ │ ├── render_parallel.py
│ │ │ │ ├── render_serial.py
│ │ │ │ ├── render_utils.py
│ │ │ │ ├── requirements.txt
│ │ │ │ └── util.py
│ │ │ ├── psgan/
│ │ │ │ ├── README.md
│ │ │ │ ├── makeup.yaml
│ │ │ │ ├── model.py
│ │ │ │ ├── module.py
│ │ │ │ ├── requirements.txt
│ │ │ │ └── util.py
│ │ │ └── stylepro_artistic/
│ │ │ ├── README.md
│ │ │ ├── README_en.md
│ │ │ ├── __init__.py
│ │ │ ├── data_feed.py
│ │ │ ├── module.py
│ │ │ └── processor.py
│ │ ├── README.md
│ │ ├── classification/
│ │ │ ├── DriverStatusRecognition/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── assets/
│ │ │ │ │ └── model.yml
│ │ │ │ ├── module.py
│ │ │ │ ├── requirements.txt
│ │ │ │ └── serving_client_demo.py
│ │ │ ├── README.md
│ │ │ ├── README_en.md
│ │ │ ├── SnakeIdentification/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── assets/
│ │ │ │ │ └── model.yml
│ │ │ │ ├── module.py
│ │ │ │ ├── requirements.txt
│ │ │ │ └── serving_client_demo.py
│ │ │ ├── SpinalNet_Gemstones/
│ │ │ │ ├── README.md
│ │ │ │ ├── gem_dataset.py
│ │ │ │ ├── spinalnet_res101_gemstone/
│ │ │ │ │ ├── README.md
│ │ │ │ │ ├── label_list.txt
│ │ │ │ │ └── module.py
│ │ │ │ ├── spinalnet_res50_gemstone/
│ │ │ │ │ ├── README.md
│ │ │ │ │ ├── label_list.txt
│ │ │ │ │ └── module.py
│ │ │ │ └── spinalnet_vgg16_gemstone/
│ │ │ │ ├── README.md
│ │ │ │ ├── label_list.txt
│ │ │ │ └── module.py
│ │ │ ├── alexnet_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ └── README_en.md
│ │ │ ├── darknet53_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── darknet.py
│ │ │ │ ├── data_feed.py
│ │ │ │ ├── label_file.txt
│ │ │ │ ├── module.py
│ │ │ │ └── processor.py
│ │ │ ├── densenet121_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ └── README_en.md
│ │ │ ├── densenet161_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ └── README_en.md
│ │ │ ├── densenet169_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ └── README_en.md
│ │ │ ├── densenet201_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ └── README_en.md
│ │ │ ├── densenet264_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ └── README_en.md
│ │ │ ├── dpn107_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ └── README_en.md
│ │ │ ├── dpn131_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ └── README_en.md
│ │ │ ├── dpn68_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ └── README_en.md
│ │ │ ├── dpn92_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ └── README_en.md
│ │ │ ├── dpn98_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ └── README_en.md
│ │ │ ├── efficientnetb0_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── data_feed.py
│ │ │ │ ├── label_list.txt
│ │ │ │ ├── module.py
│ │ │ │ ├── processor.py
│ │ │ │ └── test.py
│ │ │ ├── efficientnetb0_small_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── data_feed.py
│ │ │ │ ├── label_list.txt
│ │ │ │ ├── module.py
│ │ │ │ ├── processor.py
│ │ │ │ └── test.py
│ │ │ ├── efficientnetb1_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── data_feed.py
│ │ │ │ ├── label_list.txt
│ │ │ │ ├── module.py
│ │ │ │ ├── processor.py
│ │ │ │ └── test.py
│ │ │ ├── efficientnetb2_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── data_feed.py
│ │ │ │ ├── label_list.txt
│ │ │ │ ├── module.py
│ │ │ │ ├── processor.py
│ │ │ │ └── test.py
│ │ │ ├── efficientnetb3_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── data_feed.py
│ │ │ │ ├── label_list.txt
│ │ │ │ ├── module.py
│ │ │ │ ├── processor.py
│ │ │ │ └── test.py
│ │ │ ├── efficientnetb4_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── data_feed.py
│ │ │ │ ├── label_list.txt
│ │ │ │ ├── module.py
│ │ │ │ ├── processor.py
│ │ │ │ └── test.py
│ │ │ ├── efficientnetb5_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── data_feed.py
│ │ │ │ ├── label_list.txt
│ │ │ │ ├── module.py
│ │ │ │ ├── processor.py
│ │ │ │ └── test.py
│ │ │ ├── efficientnetb6_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── data_feed.py
│ │ │ │ ├── label_list.txt
│ │ │ │ ├── module.py
│ │ │ │ ├── processor.py
│ │ │ │ └── test.py
│ │ │ ├── efficientnetb7_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── data_feed.py
│ │ │ │ ├── label_list.txt
│ │ │ │ ├── module.py
│ │ │ │ ├── processor.py
│ │ │ │ └── test.py
│ │ │ ├── esnet_x0_25_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ ├── model.py
│ │ │ │ ├── module.py
│ │ │ │ ├── processor.py
│ │ │ │ └── utils.py
│ │ │ ├── esnet_x0_5_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ ├── model.py
│ │ │ │ ├── module.py
│ │ │ │ ├── processor.py
│ │ │ │ └── utils.py
│ │ │ ├── fix_resnext101_32x48d_wsl_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── data_feed.py
│ │ │ │ ├── label_list.txt
│ │ │ │ ├── module.py
│ │ │ │ ├── processor.py
│ │ │ │ └── test.py
│ │ │ ├── food_classification/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── module.py
│ │ │ │ └── requirements.txt
│ │ │ ├── ghostnet_x0_5_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ ├── label_list.txt
│ │ │ │ └── module.py
│ │ │ ├── ghostnet_x1_0_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ ├── label_list.txt
│ │ │ │ └── module.py
│ │ │ ├── ghostnet_x1_3_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ ├── label_list.txt
│ │ │ │ └── module.py
│ │ │ ├── ghostnet_x1_3_imagenet_ssld/
│ │ │ │ ├── README.md
│ │ │ │ ├── label_list.txt
│ │ │ │ └── module.py
│ │ │ ├── googlenet_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ └── module.py
│ │ │ ├── hrnet18_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ ├── label_list.txt
│ │ │ │ └── module.py
│ │ │ ├── hrnet18_imagenet_ssld/
│ │ │ │ ├── README.md
│ │ │ │ ├── label_list.txt
│ │ │ │ └── module.py
│ │ │ ├── hrnet30_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ ├── label_list.txt
│ │ │ │ └── module.py
│ │ │ ├── hrnet32_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ ├── label_list.txt
│ │ │ │ └── module.py
│ │ │ ├── hrnet40_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ ├── label_list.txt
│ │ │ │ └── module.py
│ │ │ ├── hrnet44_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ ├── label_list.txt
│ │ │ │ └── module.py
│ │ │ ├── hrnet48_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ ├── label_list.txt
│ │ │ │ └── module.py
│ │ │ ├── hrnet48_imagenet_ssld/
│ │ │ │ ├── README.md
│ │ │ │ ├── label_list.txt
│ │ │ │ └── module.py
│ │ │ ├── hrnet64_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ ├── label_list.txt
│ │ │ │ └── module.py
│ │ │ ├── inception_v4_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ └── README_en.md
│ │ │ ├── inceptionv4_imagenet/
│ │ │ │ └── module.py
│ │ │ ├── levit_128_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ ├── model.py
│ │ │ │ ├── module.py
│ │ │ │ ├── processor.py
│ │ │ │ └── utils.py
│ │ │ ├── levit_128s_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ ├── model.py
│ │ │ │ ├── module.py
│ │ │ │ ├── processor.py
│ │ │ │ └── utils.py
│ │ │ ├── levit_192_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ ├── model.py
│ │ │ │ ├── module.py
│ │ │ │ ├── processor.py
│ │ │ │ └── utils.py
│ │ │ ├── levit_256_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ ├── model.py
│ │ │ │ ├── module.py
│ │ │ │ ├── processor.py
│ │ │ │ └── utils.py
│ │ │ ├── levit_384_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ ├── model.py
│ │ │ │ ├── module.py
│ │ │ │ ├── processor.py
│ │ │ │ └── utils.py
│ │ │ ├── marine_biometrics/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── module.py
│ │ │ │ ├── requirements.txt
│ │ │ │ └── serving_client_demo.py
│ │ │ ├── mobilenet_v1_imagenet/
│ │ │ │ └── module.py
│ │ │ ├── mobilenet_v1_imagenet_ssld/
│ │ │ │ └── module.py
│ │ │ ├── mobilenet_v2_animals/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── data_feed.py
│ │ │ │ ├── label_list.txt
│ │ │ │ ├── module.py
│ │ │ │ ├── processor.py
│ │ │ │ └── test.py
│ │ │ ├── mobilenet_v2_dishes/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── data_feed.py
│ │ │ │ ├── label_list.txt
│ │ │ │ ├── module.py
│ │ │ │ ├── processor.py
│ │ │ │ └── test.py
│ │ │ ├── mobilenet_v2_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ └── module.py
│ │ │ ├── mobilenet_v2_imagenet_ssld/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ └── module.py
│ │ │ ├── mobilenet_v3_large_imagenet_ssld/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ └── module.py
│ │ │ ├── mobilenet_v3_small_imagenet_ssld/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ └── module.py
│ │ │ ├── nasnet_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ └── README_en.md
│ │ │ ├── pnasnet_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ └── README_en.md
│ │ │ ├── pplcnet_x0_25_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ ├── model.py
│ │ │ │ ├── module.py
│ │ │ │ ├── processor.py
│ │ │ │ └── utils.py
│ │ │ ├── pplcnet_x0_35_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ ├── model.py
│ │ │ │ ├── module.py
│ │ │ │ ├── processor.py
│ │ │ │ └── utils.py
│ │ │ ├── pplcnet_x0_5_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ ├── model.py
│ │ │ │ ├── module.py
│ │ │ │ ├── processor.py
│ │ │ │ └── utils.py
│ │ │ ├── pplcnet_x0_75_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ ├── model.py
│ │ │ │ ├── module.py
│ │ │ │ ├── processor.py
│ │ │ │ └── utils.py
│ │ │ ├── pplcnet_x1_0_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ ├── model.py
│ │ │ │ ├── module.py
│ │ │ │ ├── processor.py
│ │ │ │ └── utils.py
│ │ │ ├── pplcnet_x1_5_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ ├── model.py
│ │ │ │ ├── module.py
│ │ │ │ ├── processor.py
│ │ │ │ └── utils.py
│ │ │ ├── pplcnet_x2_0_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ ├── model.py
│ │ │ │ ├── module.py
│ │ │ │ ├── processor.py
│ │ │ │ └── utils.py
│ │ │ ├── pplcnet_x2_5_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ ├── model.py
│ │ │ │ ├── module.py
│ │ │ │ ├── processor.py
│ │ │ │ └── utils.py
│ │ │ ├── repvgg_a0_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ ├── label_list.txt
│ │ │ │ └── module.py
│ │ │ ├── repvgg_a1_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ ├── label_list.txt
│ │ │ │ └── module.py
│ │ │ ├── repvgg_a2_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ ├── label_list.txt
│ │ │ │ └── module.py
│ │ │ ├── repvgg_b0_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ ├── label_list.txt
│ │ │ │ └── module.py
│ │ │ ├── repvgg_b1_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ ├── label_list.txt
│ │ │ │ └── module.py
│ │ │ ├── repvgg_b1g2_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ ├── label_list.txt
│ │ │ │ └── module.py
│ │ │ ├── repvgg_b1g4_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ ├── label_list.txt
│ │ │ │ └── module.py
│ │ │ ├── repvgg_b2_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ ├── label_list.txt
│ │ │ │ └── module.py
│ │ │ ├── repvgg_b2g4_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ ├── label_list.txt
│ │ │ │ └── module.py
│ │ │ ├── repvgg_b3g4_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ ├── label_list.txt
│ │ │ │ └── module.py
│ │ │ ├── res2net101_vd_26w_4s_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── data_feed.py
│ │ │ │ ├── label_list.txt
│ │ │ │ ├── module.py
│ │ │ │ ├── processor.py
│ │ │ │ └── test.py
│ │ │ ├── resnet101_imagenet/
│ │ │ │ └── module.py
│ │ │ ├── resnet101_vd_imagenet/
│ │ │ │ └── module.py
│ │ │ ├── resnet101_vd_imagenet_ssld/
│ │ │ │ └── module.py
│ │ │ ├── resnet152_imagenet/
│ │ │ │ └── module.py
│ │ │ ├── resnet152_vd_imagenet/
│ │ │ │ └── module.py
│ │ │ ├── resnet18_imagenet/
│ │ │ │ └── module.py
│ │ │ ├── resnet18_vd_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ └── module.py
│ │ │ ├── resnet200_vd_imagenet/
│ │ │ │ └── module.py
│ │ │ ├── resnet34_imagenet/
│ │ │ │ └── module.py
│ │ │ ├── resnet34_v2_imagenet/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── data_feed.py
│ │ │ │ ├── label_file.txt
│ │ │ │ ├── module.py
│ │ │ │ ├── name_adapter.py
│ │ │ │ ├── nonlocal_helper.py
│ │ │ │ ├── processor.py
│ │ │ │ └── resnet.py
│ │ │ ├── resnet34_vd_imagenet/
│ │ │ │ └── module.py
│ │ │ ├── resnet34_vd_imagenet_ssld/
│ │ │ │ └── module.py
│ │ │ ├── resnet50_imagenet/
│ │ │ │ └── module.py
│ │ │ ├── resnet50_v2_imagenet/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── data_feed.py
│ │ │ │ ├── label_file.txt
│ │ │ │ ├── module.py
│ │ │ │ ├── name_adapter.py
│ │ │ │ ├── nonlocal_helper.py
│ │ │ │ ├── processor.py
│ │ │ │ └── resnet.py
│ │ │ ├── resnet50_vd_10w/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ └── module.py
│ │ │ ├── resnet50_vd_animals/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── data_feed.py
│ │ │ │ ├── label_list.txt
│ │ │ │ ├── module.py
│ │ │ │ ├── processor.py
│ │ │ │ └── test.py
│ │ │ ├── resnet50_vd_dishes/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── data_feed.py
│ │ │ │ ├── label_list.txt
│ │ │ │ ├── module.py
│ │ │ │ ├── processor.py
│ │ │ │ └── test.py
│ │ │ ├── resnet50_vd_imagenet/
│ │ │ │ └── module.py
│ │ │ ├── resnet50_vd_imagenet_ssld/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── label_list.txt
│ │ │ │ └── module.py
│ │ │ ├── resnet50_vd_wildanimals/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── data_feed.py
│ │ │ │ ├── label_list.txt
│ │ │ │ ├── module.py
│ │ │ │ ├── processor.py
│ │ │ │ └── test.py
│ │ │ ├── resnet_v2_101_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ └── README_en.md
│ │ │ ├── resnet_v2_152_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ └── README_en.md
│ │ │ ├── resnet_v2_18_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ └── README_en.md
│ │ │ ├── resnet_v2_34_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ └── README_en.md
│ │ │ ├── resnet_v2_50_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ └── README_en.md
│ │ │ ├── resnext101_32x16d_wsl/
│ │ │ │ ├── README.md
│ │ │ │ └── README_en.md
│ │ │ ├── resnext101_32x32d_wsl/
│ │ │ │ ├── README.md
│ │ │ │ └── README_en.md
│ │ │ ├── resnext101_32x48d_wsl/
│ │ │ │ ├── README.md
│ │ │ │ └── README_en.md
│ │ │ ├── resnext101_32x4d_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ └── module.py
│ │ │ ├── resnext101_32x8d_wsl/
│ │ │ │ ├── README.md
│ │ │ │ └── README_en.md
│ │ │ ├── resnext101_64x4d_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ └── module.py
│ │ │ ├── resnext101_vd_32x4d_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ └── module.py
│ │ │ ├── resnext101_vd_64x4d_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ └── module.py
│ │ │ ├── resnext152_32x4d_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ └── module.py
│ │ │ ├── resnext152_64x4d_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ └── module.py
│ │ │ ├── resnext152_vd_32x4d_imagenet/
│ │ │ │ └── module.py
│ │ │ ├── resnext152_vd_64x4d_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ └── module.py
│ │ │ ├── resnext50_32x4d_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ └── module.py
│ │ │ ├── resnext50_64x4d_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ └── module.py
│ │ │ ├── resnext50_vd_32x4d_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ └── module.py
│ │ │ ├── resnext50_vd_64x4d_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ └── module.py
│ │ │ ├── rexnet_1_0_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ ├── label_list.txt
│ │ │ │ └── module.py
│ │ │ ├── rexnet_1_3_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ ├── label_list.txt
│ │ │ │ └── module.py
│ │ │ ├── rexnet_1_5_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ ├── label_list.txt
│ │ │ │ └── module.py
│ │ │ ├── rexnet_2_0_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ ├── label_list.txt
│ │ │ │ └── module.py
│ │ │ ├── rexnet_3_0_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ ├── label_list.txt
│ │ │ │ └── module.py
│ │ │ ├── se_hrnet64_imagenet_ssld/
│ │ │ │ ├── README.md
│ │ │ │ ├── label_list.txt
│ │ │ │ └── module.py
│ │ │ ├── se_resnet18_vd_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── data_feed.py
│ │ │ │ ├── label_list.txt
│ │ │ │ ├── module.py
│ │ │ │ ├── processor.py
│ │ │ │ └── test.py
│ │ │ ├── se_resnext101_32x4d_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ └── README_en.md
│ │ │ ├── se_resnext50_32x4d_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ └── README_en.md
│ │ │ ├── shufflenet_v2_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ └── module.py
│ │ │ ├── spinalnet_res101_gemstone/
│ │ │ │ ├── README.md
│ │ │ │ └── README_en.md
│ │ │ ├── spinalnet_res50_gemstone/
│ │ │ │ ├── README.md
│ │ │ │ └── README_en.md
│ │ │ ├── spinalnet_vgg16_gemstone/
│ │ │ │ ├── README.md
│ │ │ │ └── README_en.md
│ │ │ ├── vgg11_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ └── README_en.md
│ │ │ ├── vgg13_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ └── README_en.md
│ │ │ ├── vgg16_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── data_feed.py
│ │ │ │ ├── label_file.txt
│ │ │ │ ├── module.py
│ │ │ │ ├── processor.py
│ │ │ │ └── vgg.py
│ │ │ ├── vgg19_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ └── README_en.md
│ │ │ ├── xception41_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ └── module.py
│ │ │ ├── xception65_imagenet/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ └── module.py
│ │ │ └── xception71_imagenet/
│ │ │ ├── README.md
│ │ │ ├── README_en.md
│ │ │ └── module.py
│ │ ├── depth_estimation/
│ │ │ ├── MiDaS_Large/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── inference.py
│ │ │ │ ├── module.py
│ │ │ │ ├── transforms.py
│ │ │ │ └── utils.py
│ │ │ └── MiDaS_Small/
│ │ │ ├── README.md
│ │ │ ├── inference.py
│ │ │ ├── module.py
│ │ │ ├── transforms.py
│ │ │ └── utils.py
│ │ ├── face_detection/
│ │ │ ├── README.md
│ │ │ ├── README_en.md
│ │ │ ├── pyramidbox_face_detection/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── data_feed.py
│ │ │ │ ├── module.py
│ │ │ │ ├── processor.py
│ │ │ │ └── test.py
│ │ │ ├── pyramidbox_lite_mobile/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── data_feed.py
│ │ │ │ ├── label_list.txt
│ │ │ │ ├── module.py
│ │ │ │ ├── processor.py
│ │ │ │ └── test.py
│ │ │ ├── pyramidbox_lite_mobile_mask/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── data_feed.py
│ │ │ │ ├── label_list.txt
│ │ │ │ ├── module.py
│ │ │ │ ├── processor.py
│ │ │ │ └── test.py
│ │ │ ├── pyramidbox_lite_server/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── data_feed.py
│ │ │ │ ├── label_list.txt
│ │ │ │ ├── module.py
│ │ │ │ ├── processor.py
│ │ │ │ └── test.py
│ │ │ ├── pyramidbox_lite_server_mask/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── data_feed.py
│ │ │ │ ├── label_list.txt
│ │ │ │ ├── module.py
│ │ │ │ ├── processor.py
│ │ │ │ └── test.py
│ │ │ ├── ultra_light_fast_generic_face_detector_1mb_320/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── data_feed.py
│ │ │ │ ├── module.py
│ │ │ │ ├── processor.py
│ │ │ │ └── test.py
│ │ │ └── ultra_light_fast_generic_face_detector_1mb_640/
│ │ │ ├── README.md
│ │ │ ├── README_en.md
│ │ │ ├── __init__.py
│ │ │ ├── data_feed.py
│ │ │ ├── module.py
│ │ │ ├── processor.py
│ │ │ └── test.py
│ │ ├── image_processing/
│ │ │ ├── enlightengan/
│ │ │ │ ├── README.md
│ │ │ │ ├── enlighten_inference/
│ │ │ │ │ └── pd_model/
│ │ │ │ │ └── x2paddle_code.py
│ │ │ │ ├── module.py
│ │ │ │ └── util.py
│ │ │ ├── prnet/
│ │ │ │ ├── README.md
│ │ │ │ ├── api.py
│ │ │ │ ├── module.py
│ │ │ │ ├── pd_model/
│ │ │ │ │ └── x2paddle_code.py
│ │ │ │ ├── predictor.py
│ │ │ │ ├── requirements.txt
│ │ │ │ ├── util.py
│ │ │ │ └── utils/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── cv_plot.py
│ │ │ │ ├── estimate_pose.py
│ │ │ │ ├── render.py
│ │ │ │ ├── render_app.py
│ │ │ │ ├── rotate_vertices.py
│ │ │ │ └── write.py
│ │ │ └── seeinthedark/
│ │ │ ├── README.md
│ │ │ ├── module.py
│ │ │ └── requirements.txt
│ │ ├── industrial_application/
│ │ │ └── meter_readings/
│ │ │ └── barometer_reader/
│ │ │ ├── README.md
│ │ │ ├── module.py
│ │ │ └── requirements.txt
│ │ ├── instance_segmentation/
│ │ │ └── solov2/
│ │ │ ├── README.md
│ │ │ ├── data_feed.py
│ │ │ ├── module.py
│ │ │ ├── processor.py
│ │ │ └── test.py
│ │ ├── keypoint_detection/
│ │ │ ├── README.md
│ │ │ ├── README_en.md
│ │ │ ├── face_landmark_localization/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── data_feed.py
│ │ │ │ ├── module.py
│ │ │ │ ├── processor.py
│ │ │ │ └── test.py
│ │ │ ├── hand_pose_localization/
│ │ │ │ ├── model.py
│ │ │ │ ├── module.py
│ │ │ │ ├── processor.py
│ │ │ │ ├── readme.md
│ │ │ │ └── test.py
│ │ │ ├── human_pose_estimation_resnet50_mpii/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── data_feed.py
│ │ │ │ ├── module.py
│ │ │ │ ├── processor.py
│ │ │ │ └── test.py
│ │ │ ├── openpose_body_estimation/
│ │ │ │ ├── module.py
│ │ │ │ ├── processor.py
│ │ │ │ ├── readme.md
│ │ │ │ └── test.py
│ │ │ ├── openpose_hands_estimation/
│ │ │ │ ├── module.py
│ │ │ │ ├── processor.py
│ │ │ │ ├── readme.md
│ │ │ │ └── test.py
│ │ │ └── pp-tinypose/
│ │ │ ├── README.md
│ │ │ ├── __init__.py
│ │ │ ├── det_keypoint_unite_infer.py
│ │ │ ├── infer.py
│ │ │ ├── keypoint_infer.py
│ │ │ ├── keypoint_postprocess.py
│ │ │ ├── keypoint_preprocess.py
│ │ │ ├── module.py
│ │ │ ├── preprocess.py
│ │ │ ├── test.py
│ │ │ └── visualize.py
│ │ ├── matting/
│ │ │ ├── dim_vgg16_matting/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── module.py
│ │ │ │ ├── processor.py
│ │ │ │ ├── requirements.txt
│ │ │ │ └── vgg.py
│ │ │ ├── gfm_resnet34_matting/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── gfm.py
│ │ │ │ ├── module.py
│ │ │ │ ├── processor.py
│ │ │ │ ├── requirements.txt
│ │ │ │ └── resnet.py
│ │ │ ├── modnet_hrnet18_matting/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── hrnet.py
│ │ │ │ ├── module.py
│ │ │ │ └── processor.py
│ │ │ ├── modnet_mobilenetv2_matting/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── mobilenetv2.py
│ │ │ │ ├── module.py
│ │ │ │ ├── processor.py
│ │ │ │ └── requirements.py
│ │ │ └── modnet_resnet50vd_matting/
│ │ │ ├── README.md
│ │ │ ├── README_en.md
│ │ │ ├── __init__.py
│ │ │ ├── module.py
│ │ │ ├── processor.py
│ │ │ ├── requirements.txt
│ │ │ └── resnet.py
│ │ ├── object_detection/
│ │ │ ├── README.md
│ │ │ ├── README_en.md
│ │ │ ├── faster_rcnn_resnet50_coco2017/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── data_feed.py
│ │ │ │ ├── label_file.txt
│ │ │ │ ├── module.py
│ │ │ │ ├── processor.py
│ │ │ │ └── test.py
│ │ │ ├── faster_rcnn_resnet50_fpn_coco2017/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── data_feed.py
│ │ │ │ ├── label_file.txt
│ │ │ │ ├── module.py
│ │ │ │ ├── processor.py
│ │ │ │ └── test.py
│ │ │ ├── faster_rcnn_resnet50_fpn_venus/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── bbox_assigner.py
│ │ │ │ ├── bbox_head.py
│ │ │ │ ├── data_feed.py
│ │ │ │ ├── fpn.py
│ │ │ │ ├── module.py
│ │ │ │ ├── name_adapter.py
│ │ │ │ ├── nonlocal_helper.py
│ │ │ │ ├── processor.py
│ │ │ │ ├── resnet.py
│ │ │ │ ├── roi_extractor.py
│ │ │ │ └── rpn_head.py
│ │ │ ├── ssd_mobilenet_v1_pascal/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── config.yml
│ │ │ │ ├── data_feed.py
│ │ │ │ ├── label_file.txt
│ │ │ │ ├── module.py
│ │ │ │ ├── processor.py
│ │ │ │ └── test.py
│ │ │ ├── ssd_vgg16_300_coco2017/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── config.yml
│ │ │ │ ├── data_feed.py
│ │ │ │ ├── label_file.txt
│ │ │ │ ├── module.py
│ │ │ │ ├── processor.py
│ │ │ │ └── test.py
│ │ │ ├── ssd_vgg16_512_coco2017/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── config.yml
│ │ │ │ ├── data_feed.py
│ │ │ │ ├── label_file.txt
│ │ │ │ ├── module.py
│ │ │ │ ├── processor.py
│ │ │ │ └── test.py
│ │ │ ├── yolov3_darknet53_coco2017/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── data_feed.py
│ │ │ │ ├── label_file.txt
│ │ │ │ ├── module.py
│ │ │ │ ├── processor.py
│ │ │ │ └── test.py
│ │ │ ├── yolov3_darknet53_pedestrian/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── data_feed.py
│ │ │ │ ├── label_file.txt
│ │ │ │ ├── module.py
│ │ │ │ ├── processor.py
│ │ │ │ └── test.py
│ │ │ ├── yolov3_darknet53_vehicles/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── data_feed.py
│ │ │ │ ├── label_file.txt
│ │ │ │ ├── module.py
│ │ │ │ ├── processor.py
│ │ │ │ └── test.py
│ │ │ ├── yolov3_darknet53_venus/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── darknet.py
│ │ │ │ ├── data_feed.py
│ │ │ │ ├── module.py
│ │ │ │ ├── processor.py
│ │ │ │ └── yolo_head.py
│ │ │ ├── yolov3_mobilenet_v1_coco2017/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── data_feed.py
│ │ │ │ ├── label_file.txt
│ │ │ │ ├── module.py
│ │ │ │ ├── processor.py
│ │ │ │ └── test.py
│ │ │ ├── yolov3_resnet34_coco2017/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── data_feed.py
│ │ │ │ ├── label_file.txt
│ │ │ │ ├── module.py
│ │ │ │ ├── processor.py
│ │ │ │ └── test.py
│ │ │ └── yolov3_resnet50_vd_coco2017/
│ │ │ ├── README.md
│ │ │ ├── README_en.md
│ │ │ ├── __init__.py
│ │ │ ├── data_feed.py
│ │ │ ├── label_file.txt
│ │ │ ├── module.py
│ │ │ ├── processor.py
│ │ │ └── test.py
│ │ ├── semantic_segmentation/
│ │ │ ├── Extract_Line_Draft/
│ │ │ │ ├── Readme.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── function.py
│ │ │ │ ├── module.py
│ │ │ │ └── test.py
│ │ │ ├── ExtremeC3_Portrait_Segmentation/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ └── module.py
│ │ │ ├── FCN_HRNet_W18_Face_Seg/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── model/
│ │ │ │ │ ├── __init__.py
│ │ │ │ │ ├── fcn.py
│ │ │ │ │ ├── hrnet.py
│ │ │ │ │ └── layers.py
│ │ │ │ └── module.py
│ │ │ ├── Pneumonia_CT_LKM_PP/
│ │ │ │ ├── README.md
│ │ │ │ └── README_en.md
│ │ │ ├── Pneumonia_CT_LKM_PP_lung/
│ │ │ │ ├── README.md
│ │ │ │ └── README_en.md
│ │ │ ├── README.md
│ │ │ ├── README_en.md
│ │ │ ├── SINet_Portrait_Segmentation/
│ │ │ │ ├── README.md
│ │ │ │ └── module.py
│ │ │ ├── U2Net/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── module.py
│ │ │ │ ├── processor.py
│ │ │ │ └── u2net.py
│ │ │ ├── U2Netp/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── module.py
│ │ │ │ ├── processor.py
│ │ │ │ └── u2net.py
│ │ │ ├── WatermeterSegmentation/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── assets/
│ │ │ │ │ └── model.yml
│ │ │ │ ├── module.py
│ │ │ │ └── serving_client_demo.py
│ │ │ ├── ace2p/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── data_feed.py
│ │ │ │ ├── label_list.txt
│ │ │ │ ├── module.py
│ │ │ │ ├── processor.py
│ │ │ │ └── test.py
│ │ │ ├── ann_resnet50_cityscapes/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── layers.py
│ │ │ │ ├── module.py
│ │ │ │ └── resnet.py
│ │ │ ├── ann_resnet50_voc/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── layers.py
│ │ │ │ ├── module.py
│ │ │ │ └── resnet.py
│ │ │ ├── bisenet_lane_segmentation/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── lane_processor/
│ │ │ │ │ ├── get_lane_coords.py
│ │ │ │ │ ├── lane.py
│ │ │ │ │ └── tusimple_processor.py
│ │ │ │ ├── module.py
│ │ │ │ └── processor.py
│ │ │ ├── bisenetv2_cityscapes/
│ │ │ │ ├── README.md
│ │ │ │ ├── layers.py
│ │ │ │ └── module.py
│ │ │ ├── danet_resnet50_cityscapes/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── layers.py
│ │ │ │ ├── module.py
│ │ │ │ └── resnet.py
│ │ │ ├── danet_resnet50_voc/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── layers.py
│ │ │ │ ├── module.py
│ │ │ │ └── resnet.py
│ │ │ ├── deeplabv3p_resnet50_cityscapes/
│ │ │ │ ├── README.md
│ │ │ │ ├── layers.py
│ │ │ │ ├── module.py
│ │ │ │ └── resnet.py
│ │ │ ├── deeplabv3p_resnet50_voc/
│ │ │ │ ├── README.md
│ │ │ │ ├── layers.py
│ │ │ │ ├── module.py
│ │ │ │ └── resnet.py
│ │ │ ├── deeplabv3p_xception65_humanseg/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── data_feed.py
│ │ │ │ ├── module.py
│ │ │ │ ├── processor.py
│ │ │ │ └── test.py
│ │ │ ├── fastscnn_cityscapes/
│ │ │ │ ├── README.md
│ │ │ │ ├── layers.py
│ │ │ │ └── module.py
│ │ │ ├── fcn_hrnetw18_cityscapes/
│ │ │ │ ├── README.md
│ │ │ │ ├── hrnet.py
│ │ │ │ ├── layers.py
│ │ │ │ └── module.py
│ │ │ ├── fcn_hrnetw18_voc/
│ │ │ │ ├── README.md
│ │ │ │ ├── hrnet.py
│ │ │ │ ├── layers.py
│ │ │ │ └── module.py
│ │ │ ├── fcn_hrnetw48_cityscapes/
│ │ │ │ ├── README.md
│ │ │ │ ├── hrnet.py
│ │ │ │ ├── layers.py
│ │ │ │ └── module.py
│ │ │ ├── fcn_hrnetw48_voc/
│ │ │ │ ├── README.md
│ │ │ │ ├── hrnet.py
│ │ │ │ ├── layers.py
│ │ │ │ └── module.py
│ │ │ ├── ginet_resnet101vd_ade20k/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── layers.py
│ │ │ │ ├── module.py
│ │ │ │ ├── requirements.txt
│ │ │ │ └── resnet.py
│ │ │ ├── ginet_resnet101vd_cityscapes/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── layers.py
│ │ │ │ ├── module.py
│ │ │ │ ├── requirements.txt
│ │ │ │ └── resnet.py
│ │ │ ├── ginet_resnet101vd_voc/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── layers.py
│ │ │ │ ├── module.py
│ │ │ │ ├── requirements.txt
│ │ │ │ └── resnet.py
│ │ │ ├── ginet_resnet50vd_ade20k/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── layers.py
│ │ │ │ ├── module.py
│ │ │ │ ├── requirements.txt
│ │ │ │ └── resnet.py
│ │ │ ├── ginet_resnet50vd_cityscapes/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── layers.py
│ │ │ │ ├── module.py
│ │ │ │ ├── requirements.txt
│ │ │ │ └── resnet.py
│ │ │ ├── ginet_resnet50vd_voc/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── layers.py
│ │ │ │ ├── module.py
│ │ │ │ ├── requirements.txt
│ │ │ │ └── resnet.py
│ │ │ ├── hardnet_cityscapes/
│ │ │ │ ├── README.md
│ │ │ │ ├── layers.py
│ │ │ │ └── module.py
│ │ │ ├── humanseg_lite/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── data_feed.py
│ │ │ │ ├── module.py
│ │ │ │ ├── optimal.py
│ │ │ │ ├── processor.py
│ │ │ │ └── test.py
│ │ │ ├── humanseg_mobile/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── data_feed.py
│ │ │ │ ├── module.py
│ │ │ │ ├── optimal.py
│ │ │ │ ├── processor.py
│ │ │ │ └── test.py
│ │ │ ├── humanseg_server/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── data_feed.py
│ │ │ │ ├── module.py
│ │ │ │ ├── optimal.py
│ │ │ │ ├── processor.py
│ │ │ │ └── test.py
│ │ │ ├── isanet_resnet50_cityscapes/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── layers.py
│ │ │ │ ├── module.py
│ │ │ │ └── resnet.py
│ │ │ ├── isanet_resnet50_voc/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── layers.py
│ │ │ │ ├── module.py
│ │ │ │ └── resnet.py
│ │ │ ├── lseg/
│ │ │ │ ├── README.md
│ │ │ │ ├── models/
│ │ │ │ │ ├── __init__.py
│ │ │ │ │ ├── clip.py
│ │ │ │ │ ├── lseg.py
│ │ │ │ │ ├── scratch.py
│ │ │ │ │ └── vit.py
│ │ │ │ ├── module.py
│ │ │ │ ├── requirements.txt
│ │ │ │ └── test.py
│ │ │ ├── ocrnet_hrnetw18_cityscapes/
│ │ │ │ ├── README.md
│ │ │ │ ├── hrnet.py
│ │ │ │ ├── layers.py
│ │ │ │ └── module.py
│ │ │ ├── ocrnet_hrnetw18_voc/
│ │ │ │ ├── README.md
│ │ │ │ ├── hrnet.py
│ │ │ │ ├── layers.py
│ │ │ │ └── module.py
│ │ │ ├── pspnet_resnet50_cityscapes/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── layers.py
│ │ │ │ ├── module.py
│ │ │ │ └── resnet.py
│ │ │ ├── pspnet_resnet50_voc/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── layers.py
│ │ │ │ ├── module.py
│ │ │ │ └── resnet.py
│ │ │ ├── stdc1_seg_cityscapes/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── layers.py
│ │ │ │ ├── module.py
│ │ │ │ └── stdcnet.py
│ │ │ ├── stdc1_seg_voc/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── layers.py
│ │ │ │ ├── module.py
│ │ │ │ └── stdcnet.py
│ │ │ └── unet_cityscapes/
│ │ │ ├── README.md
│ │ │ ├── layers.py
│ │ │ └── module.py
│ │ ├── text_recognition/
│ │ │ ├── README.md
│ │ │ ├── README_en.md
│ │ │ ├── Vehicle_License_Plate_Recognition/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ └── module.py
│ │ │ ├── arabic_ocr_db_crnn_mobile/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── module.py
│ │ │ │ └── requirements.txt
│ │ │ ├── ch_pp-ocrv3/
│ │ │ │ ├── README.md
│ │ │ │ ├── character.py
│ │ │ │ ├── module.py
│ │ │ │ ├── test.py
│ │ │ │ └── utils.py
│ │ │ ├── ch_pp-ocrv3_det/
│ │ │ │ ├── README.md
│ │ │ │ ├── module.py
│ │ │ │ ├── processor.py
│ │ │ │ ├── requirements.txt
│ │ │ │ └── test.py
│ │ │ ├── chinese_cht_ocr_db_crnn_mobile/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── module.py
│ │ │ │ └── requirements.txt
│ │ │ ├── chinese_ocr_db_crnn_mobile/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── character.py
│ │ │ │ ├── module.py
│ │ │ │ ├── test.py
│ │ │ │ └── utils.py
│ │ │ ├── chinese_ocr_db_crnn_server/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── character.py
│ │ │ │ ├── module.py
│ │ │ │ ├── test.py
│ │ │ │ └── utils.py
│ │ │ ├── chinese_text_detection_db_mobile/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── module.py
│ │ │ │ ├── processor.py
│ │ │ │ ├── requirements.txt
│ │ │ │ └── test.py
│ │ │ ├── chinese_text_detection_db_server/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── module.py
│ │ │ │ ├── processor.py
│ │ │ │ ├── requirements.txt
│ │ │ │ └── test.py
│ │ │ ├── cyrillic_ocr_db_crnn_mobile/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── module.py
│ │ │ │ └── requirements.txt
│ │ │ ├── devanagari_ocr_db_crnn_mobile/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── module.py
│ │ │ │ └── requirements.txt
│ │ │ ├── french_ocr_db_crnn_mobile/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── module.py
│ │ │ │ └── requirements.txt
│ │ │ ├── german_ocr_db_crnn_mobile/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── module.py
│ │ │ │ └── requirements.txt
│ │ │ ├── japan_ocr_db_crnn_mobile/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── module.py
│ │ │ │ └── requirements.txt
│ │ │ ├── kannada_ocr_db_crnn_mobile/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── module.py
│ │ │ │ └── requirements.txt
│ │ │ ├── korean_ocr_db_crnn_mobile/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── module.py
│ │ │ │ └── requirements.txt
│ │ │ ├── latin_ocr_db_crnn_mobile/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── module.py
│ │ │ │ └── requirements.txt
│ │ │ ├── multi_languages_ocr_db_crnn/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── module.py
│ │ │ │ ├── requirements.txt
│ │ │ │ ├── test.py
│ │ │ │ └── utils.py
│ │ │ ├── tamil_ocr_db_crnn_mobile/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── module.py
│ │ │ │ └── requirements.txt
│ │ │ └── telugu_ocr_db_crnn_mobile/
│ │ │ ├── README.md
│ │ │ ├── __init__.py
│ │ │ ├── module.py
│ │ │ └── requirements.txt
│ │ └── text_to_image/
│ │ ├── disco_diffusion_clip_rn101/
│ │ │ ├── README.md
│ │ │ ├── README_en.md
│ │ │ ├── clip/
│ │ │ │ ├── README.md
│ │ │ │ └── clip/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── layers.py
│ │ │ │ ├── model.py
│ │ │ │ ├── simple_tokenizer.py
│ │ │ │ └── utils.py
│ │ │ ├── module.py
│ │ │ ├── requirements.txt
│ │ │ ├── resize_right/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── interp_methods.py
│ │ │ │ └── resize_right.py
│ │ │ └── reverse_diffusion/
│ │ │ ├── README.md
│ │ │ ├── __init__.py
│ │ │ ├── config.py
│ │ │ ├── helper.py
│ │ │ ├── model/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── gaussian_diffusion.py
│ │ │ │ ├── losses.py
│ │ │ │ ├── make_cutouts.py
│ │ │ │ ├── nn.py
│ │ │ │ ├── perlin_noises.py
│ │ │ │ ├── respace.py
│ │ │ │ ├── script_util.py
│ │ │ │ ├── sec_diff.py
│ │ │ │ ├── transforms.py
│ │ │ │ └── unet.py
│ │ │ ├── resources/
│ │ │ │ ├── default.yml
│ │ │ │ └── docstrings.yml
│ │ │ └── runner.py
│ │ ├── disco_diffusion_clip_rn50/
│ │ │ ├── README.md
│ │ │ ├── README_en.md
│ │ │ ├── clip/
│ │ │ │ ├── README.md
│ │ │ │ └── clip/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── layers.py
│ │ │ │ ├── model.py
│ │ │ │ ├── simple_tokenizer.py
│ │ │ │ └── utils.py
│ │ │ ├── module.py
│ │ │ ├── requirements.txt
│ │ │ ├── resize_right/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── interp_methods.py
│ │ │ │ └── resize_right.py
│ │ │ └── reverse_diffusion/
│ │ │ ├── README.md
│ │ │ ├── __init__.py
│ │ │ ├── config.py
│ │ │ ├── helper.py
│ │ │ ├── model/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── gaussian_diffusion.py
│ │ │ │ ├── losses.py
│ │ │ │ ├── make_cutouts.py
│ │ │ │ ├── nn.py
│ │ │ │ ├── perlin_noises.py
│ │ │ │ ├── respace.py
│ │ │ │ ├── script_util.py
│ │ │ │ ├── sec_diff.py
│ │ │ │ ├── transforms.py
│ │ │ │ └── unet.py
│ │ │ ├── resources/
│ │ │ │ ├── default.yml
│ │ │ │ └── docstrings.yml
│ │ │ └── runner.py
│ │ ├── disco_diffusion_clip_vitb32/
│ │ │ ├── README.md
│ │ │ ├── README_en.md
│ │ │ ├── clip/
│ │ │ │ ├── README.md
│ │ │ │ └── clip/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── layers.py
│ │ │ │ ├── model.py
│ │ │ │ ├── simple_tokenizer.py
│ │ │ │ └── utils.py
│ │ │ ├── module.py
│ │ │ ├── requirements.txt
│ │ │ ├── resize_right/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── interp_methods.py
│ │ │ │ └── resize_right.py
│ │ │ └── reverse_diffusion/
│ │ │ ├── README.md
│ │ │ ├── __init__.py
│ │ │ ├── config.py
│ │ │ ├── helper.py
│ │ │ ├── model/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── gaussian_diffusion.py
│ │ │ │ ├── losses.py
│ │ │ │ ├── make_cutouts.py
│ │ │ │ ├── nn.py
│ │ │ │ ├── perlin_noises.py
│ │ │ │ ├── respace.py
│ │ │ │ ├── script_util.py
│ │ │ │ ├── sec_diff.py
│ │ │ │ ├── transforms.py
│ │ │ │ └── unet.py
│ │ │ ├── resources/
│ │ │ │ ├── default.yml
│ │ │ │ └── docstrings.yml
│ │ │ └── runner.py
│ │ ├── disco_diffusion_cnclip_vitb16/
│ │ │ ├── README.md
│ │ │ ├── README_en.md
│ │ │ ├── cn_clip/
│ │ │ │ └── clip/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── bert_tokenizer.py
│ │ │ │ ├── configuration_bert.py
│ │ │ │ ├── model.py
│ │ │ │ ├── model_configs/
│ │ │ │ │ ├── RoBERTa-wwm-ext-base-chinese.json
│ │ │ │ │ ├── RoBERTa-wwm-ext-large-chinese.json
│ │ │ │ │ ├── ViT-B-16.json
│ │ │ │ │ ├── ViT-B-32.json
│ │ │ │ │ └── ViT-L-14.json
│ │ │ │ ├── modeling_bert.py
│ │ │ │ └── utils.py
│ │ │ ├── module.py
│ │ │ ├── requirements.txt
│ │ │ ├── resize_right/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── interp_methods.py
│ │ │ │ └── resize_right.py
│ │ │ └── reverse_diffusion/
│ │ │ ├── README.md
│ │ │ ├── __init__.py
│ │ │ ├── config.py
│ │ │ ├── helper.py
│ │ │ ├── model/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── gaussian_diffusion.py
│ │ │ │ ├── losses.py
│ │ │ │ ├── make_cutouts.py
│ │ │ │ ├── nn.py
│ │ │ │ ├── perlin_noises.py
│ │ │ │ ├── respace.py
│ │ │ │ ├── script_util.py
│ │ │ │ ├── sec_diff.py
│ │ │ │ ├── transforms.py
│ │ │ │ └── unet.py
│ │ │ ├── resources/
│ │ │ │ ├── default.yml
│ │ │ │ └── docstrings.yml
│ │ │ └── runner.py
│ │ ├── disco_diffusion_ernievil_base/
│ │ │ ├── README.md
│ │ │ ├── README_en.md
│ │ │ ├── module.py
│ │ │ ├── requirements.txt
│ │ │ ├── resize_right/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── interp_methods.py
│ │ │ │ └── resize_right.py
│ │ │ ├── reverse_diffusion/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── config.py
│ │ │ │ ├── helper.py
│ │ │ │ ├── model/
│ │ │ │ │ ├── __init__.py
│ │ │ │ │ ├── gaussian_diffusion.py
│ │ │ │ │ ├── losses.py
│ │ │ │ │ ├── make_cutouts.py
│ │ │ │ │ ├── nn.py
│ │ │ │ │ ├── perlin_noises.py
│ │ │ │ │ ├── respace.py
│ │ │ │ │ ├── script_util.py
│ │ │ │ │ ├── sec_diff.py
│ │ │ │ │ ├── transforms.py
│ │ │ │ │ └── unet.py
│ │ │ │ ├── resources/
│ │ │ │ │ ├── default.yml
│ │ │ │ │ └── docstrings.yml
│ │ │ │ └── runner.py
│ │ │ └── vit_b_16x/
│ │ │ ├── ernievil2/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── transformers/
│ │ │ │ │ ├── __init__.py
│ │ │ │ │ ├── clip_vision_transformer.py
│ │ │ │ │ ├── droppath.py
│ │ │ │ │ ├── efficientnet.py
│ │ │ │ │ ├── ernie2.py
│ │ │ │ │ ├── ernie_modeling.py
│ │ │ │ │ ├── ernie_tokenizer.py
│ │ │ │ │ ├── file_utils.py
│ │ │ │ │ ├── multimodal.py
│ │ │ │ │ ├── paddle_vision_transformer.py
│ │ │ │ │ └── resnet.py
│ │ │ │ └── utils/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── tokenizer.py
│ │ │ │ └── utils.py
│ │ │ └── packages/
│ │ │ ├── configs/
│ │ │ │ └── vit_ernie_base.yaml
│ │ │ └── ernie_base_3.0/
│ │ │ └── ernie_config.base.json
│ │ ├── ernie_vilg/
│ │ │ ├── README.md
│ │ │ ├── __init__.py
│ │ │ ├── module.py
│ │ │ ├── requirements.txt
│ │ │ └── test.py
│ │ ├── stable_diffusion/
│ │ │ ├── LICENSE
│ │ │ ├── README.md
│ │ │ ├── README_en.md
│ │ │ ├── clip/
│ │ │ │ ├── README.md
│ │ │ │ └── clip/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── layers.py
│ │ │ │ ├── model.py
│ │ │ │ ├── simple_tokenizer.py
│ │ │ │ └── utils.py
│ │ │ ├── diffusers/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── configuration_utils.py
│ │ │ │ ├── models/
│ │ │ │ │ ├── README.md
│ │ │ │ │ ├── __init__.py
│ │ │ │ │ ├── attention.py
│ │ │ │ │ ├── embeddings.py
│ │ │ │ │ ├── resnet.py
│ │ │ │ │ ├── unet_2d.py
│ │ │ │ │ ├── unet_2d_condition.py
│ │ │ │ │ ├── unet_blocks.py
│ │ │ │ │ └── vae.py
│ │ │ │ └── schedulers/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── scheduling_ddim.py
│ │ │ │ ├── scheduling_ddpm.py
│ │ │ │ ├── scheduling_karras_ve.py
│ │ │ │ ├── scheduling_lms_discrete.py
│ │ │ │ ├── scheduling_pndm.py
│ │ │ │ ├── scheduling_sde_ve.py
│ │ │ │ ├── scheduling_sde_vp.py
│ │ │ │ └── scheduling_utils.py
│ │ │ ├── module.py
│ │ │ └── requirements.txt
│ │ ├── stable_diffusion_img2img/
│ │ │ ├── LICENSE
│ │ │ ├── README.md
│ │ │ ├── clip/
│ │ │ │ ├── README.md
│ │ │ │ └── clip/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── layers.py
│ │ │ │ ├── model.py
│ │ │ │ ├── simple_tokenizer.py
│ │ │ │ └── utils.py
│ │ │ ├── diffusers/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── configuration_utils.py
│ │ │ │ ├── models/
│ │ │ │ │ ├── README.md
│ │ │ │ │ ├── __init__.py
│ │ │ │ │ ├── attention.py
│ │ │ │ │ ├── embeddings.py
│ │ │ │ │ ├── resnet.py
│ │ │ │ │ ├── unet_2d.py
│ │ │ │ │ ├── unet_2d_condition.py
│ │ │ │ │ ├── unet_blocks.py
│ │ │ │ │ └── vae.py
│ │ │ │ └── schedulers/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── scheduling_ddim.py
│ │ │ │ ├── scheduling_ddpm.py
│ │ │ │ ├── scheduling_karras_ve.py
│ │ │ │ ├── scheduling_lms_discrete.py
│ │ │ │ ├── scheduling_pndm.py
│ │ │ │ ├── scheduling_sde_ve.py
│ │ │ │ ├── scheduling_sde_vp.py
│ │ │ │ └── scheduling_utils.py
│ │ │ ├── module.py
│ │ │ ├── requirements.txt
│ │ │ └── utils.py
│ │ ├── stable_diffusion_inpainting/
│ │ │ ├── LICENSE
│ │ │ ├── README.md
│ │ │ ├── clip/
│ │ │ │ ├── README.md
│ │ │ │ └── clip/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── layers.py
│ │ │ │ ├── model.py
│ │ │ │ ├── simple_tokenizer.py
│ │ │ │ └── utils.py
│ │ │ ├── diffusers/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── configuration_utils.py
│ │ │ │ ├── models/
│ │ │ │ │ ├── README.md
│ │ │ │ │ ├── __init__.py
│ │ │ │ │ ├── attention.py
│ │ │ │ │ ├── embeddings.py
│ │ │ │ │ ├── resnet.py
│ │ │ │ │ ├── unet_2d.py
│ │ │ │ │ ├── unet_2d_condition.py
│ │ │ │ │ ├── unet_blocks.py
│ │ │ │ │ └── vae.py
│ │ │ │ └── schedulers/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── scheduling_ddim.py
│ │ │ │ ├── scheduling_ddpm.py
│ │ │ │ ├── scheduling_karras_ve.py
│ │ │ │ ├── scheduling_lms_discrete.py
│ │ │ │ ├── scheduling_pndm.py
│ │ │ │ ├── scheduling_sde_ve.py
│ │ │ │ ├── scheduling_sde_vp.py
│ │ │ │ └── scheduling_utils.py
│ │ │ ├── module.py
│ │ │ ├── requirements.txt
│ │ │ └── utils.py
│ │ └── stable_diffusion_waifu/
│ │ ├── LICENSE
│ │ ├── README.md
│ │ ├── clip/
│ │ │ ├── README.md
│ │ │ └── clip/
│ │ │ ├── __init__.py
│ │ │ ├── layers.py
│ │ │ ├── model.py
│ │ │ ├── simple_tokenizer.py
│ │ │ └── utils.py
│ │ ├── diffusers/
│ │ │ ├── __init__.py
│ │ │ ├── configuration_utils.py
│ │ │ ├── models/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── attention.py
│ │ │ │ ├── embeddings.py
│ │ │ │ ├── resnet.py
│ │ │ │ ├── unet_2d.py
│ │ │ │ ├── unet_2d_condition.py
│ │ │ │ ├── unet_blocks.py
│ │ │ │ └── vae.py
│ │ │ └── schedulers/
│ │ │ ├── README.md
│ │ │ ├── __init__.py
│ │ │ ├── scheduling_ddim.py
│ │ │ ├── scheduling_ddpm.py
│ │ │ ├── scheduling_karras_ve.py
│ │ │ ├── scheduling_lms_discrete.py
│ │ │ ├── scheduling_pndm.py
│ │ │ ├── scheduling_sde_ve.py
│ │ │ ├── scheduling_sde_vp.py
│ │ │ └── scheduling_utils.py
│ │ ├── module.py
│ │ └── requirements.txt
│ ├── text/
│ │ ├── README.md
│ │ ├── embedding/
│ │ │ ├── README.md
│ │ │ ├── fasttext_crawl_target_word-word_dim300_en/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── fasttext_wiki-news_target_word-word_dim300_en/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── glove_twitter_target_word-word_dim100_en/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── glove_twitter_target_word-word_dim200_en/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── glove_twitter_target_word-word_dim25_en/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── glove_twitter_target_word-word_dim50_en/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── glove_wiki2014-gigaword_target_word-word_dim100_en/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── glove_wiki2014-gigaword_target_word-word_dim200_en/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── glove_wiki2014-gigaword_target_word-word_dim300_en/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── glove_wiki2014-gigaword_target_word-word_dim50_en/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── w2v_baidu_encyclopedia_context_word-character_char1-1_dim300/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── w2v_baidu_encyclopedia_context_word-character_char1-2_dim300/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── w2v_baidu_encyclopedia_context_word-character_char1-4_dim300/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── w2v_baidu_encyclopedia_context_word-ngram_1-2_dim300/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── w2v_baidu_encyclopedia_context_word-ngram_1-3_dim300/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── w2v_baidu_encyclopedia_context_word-ngram_2-2_dim300/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── w2v_baidu_encyclopedia_context_word-wordLR_dim300/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── w2v_baidu_encyclopedia_context_word-wordPosition_dim300/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── w2v_baidu_encyclopedia_context_word-word_dim300/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── w2v_baidu_encyclopedia_target_bigram-char_dim300/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── w2v_baidu_encyclopedia_target_word-character_char1-1_dim300/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── w2v_baidu_encyclopedia_target_word-character_char1-2_dim300/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── w2v_baidu_encyclopedia_target_word-character_char1-4_dim300/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── w2v_baidu_encyclopedia_target_word-ngram_1-2_dim300/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── w2v_baidu_encyclopedia_target_word-ngram_1-3_dim300/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── w2v_baidu_encyclopedia_target_word-ngram_2-2_dim300/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── w2v_baidu_encyclopedia_target_word-wordLR_dim300/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── w2v_baidu_encyclopedia_target_word-wordPosition_dim300/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── w2v_baidu_encyclopedia_target_word-word_dim300/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── w2v_financial_target_bigram-char_dim300/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── w2v_financial_target_word-bigram_dim300/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── w2v_financial_target_word-char_dim300/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── w2v_financial_target_word-word_dim300/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── w2v_literature_target_bigram-char_dim300/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── w2v_literature_target_word-bigram_dim300/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── w2v_literature_target_word-char_dim300/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── w2v_literature_target_word-word_dim300/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── w2v_mixed-large_target_word-char_dim300/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── w2v_mixed-large_target_word-word_dim300/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── w2v_people_daily_target_bigram-char_dim300/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── w2v_people_daily_target_word-bigram_dim300/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── w2v_people_daily_target_word-char_dim300/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── w2v_people_daily_target_word-word_dim300/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── w2v_sikuquanshu_target_word-bigram_dim300/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── w2v_sikuquanshu_target_word-word_dim300/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── w2v_sogou_target_bigram-char_dim300/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── w2v_sogou_target_word-bigram_dim300/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── w2v_sogou_target_word-char_dim300/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── w2v_sogou_target_word-word_dim300/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── w2v_weibo_target_bigram-char_dim300/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── w2v_weibo_target_word-bigram_dim300/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── w2v_weibo_target_word-char_dim300/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── w2v_weibo_target_word-word_dim300/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── w2v_wiki_target_bigram-char_dim300/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── w2v_wiki_target_word-bigram_dim300/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── w2v_wiki_target_word-char_dim300/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── w2v_wiki_target_word-word_dim300/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── w2v_zhihu_target_bigram-char_dim300/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── w2v_zhihu_target_word-bigram_dim300/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── w2v_zhihu_target_word-char_dim300/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── w2v_zhihu_target_word-word_dim300/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ └── word2vec_skipgram/
│ │ │ ├── README.md
│ │ │ └── module.py
│ │ ├── language_model/
│ │ │ ├── README.md
│ │ │ ├── README_en.md
│ │ │ ├── albert-base-v1/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── albert-base-v2/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── albert-chinese-base/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── albert-chinese-large/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── albert-chinese-small/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── albert-chinese-tiny/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── albert-chinese-xlarge/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── albert-chinese-xxlarge/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── albert-xxlarge-v1/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── albert-xxlarge-v2/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── bert-base-cased/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── bert-base-chinese/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── bert-base-multilingual-cased/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── bert-base-multilingual-uncased/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── bert-base-uncased/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── bert-large-cased/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── bert-large-uncased/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── chinese_bert_wwm/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── chinese_bert_wwm_ext/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── chinese_electra_base/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── chinese_electra_small/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── electra_base/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── electra_large/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── electra_small/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── ernie/
│ │ │ │ ├── README.md
│ │ │ │ └── module.py
│ │ │ ├── ernie_tiny/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── ernie_v2_eng_base/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── ernie_v2_eng_large/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── lda_news/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── config.py
│ │ │ │ ├── document.py
│ │ │ │ ├── inference_engine.py
│ │ │ │ ├── model.py
│ │ │ │ ├── module.py
│ │ │ │ ├── sampler.py
│ │ │ │ ├── semantic_matching.py
│ │ │ │ ├── tokenizer.py
│ │ │ │ ├── util.py
│ │ │ │ ├── vocab.py
│ │ │ │ └── vose_alias.py
│ │ │ ├── lda_novel/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── config.py
│ │ │ │ ├── document.py
│ │ │ │ ├── inference_engine.py
│ │ │ │ ├── model.py
│ │ │ │ ├── module.py
│ │ │ │ ├── sampler.py
│ │ │ │ ├── semantic_matching.py
│ │ │ │ ├── tokenizer.py
│ │ │ │ ├── util.py
│ │ │ │ ├── vocab.py
│ │ │ │ └── vose_alias.py
│ │ │ ├── lda_webpage/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── config.py
│ │ │ │ ├── document.py
│ │ │ │ ├── inference_engine.py
│ │ │ │ ├── model.py
│ │ │ │ ├── module.py
│ │ │ │ ├── sampler.py
│ │ │ │ ├── semantic_matching.py
│ │ │ │ ├── tokenizer.py
│ │ │ │ ├── util.py
│ │ │ │ ├── vocab.py
│ │ │ │ └── vose_alias.py
│ │ │ ├── rbt3/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── rbtl3/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── roberta-wwm-ext/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── roberta-wwm-ext-large/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── simnet_bow/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── assets/
│ │ │ │ │ ├── params.txt
│ │ │ │ │ └── vocab.txt
│ │ │ │ ├── module.py
│ │ │ │ └── processor.py
│ │ │ ├── slda_news/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── config.py
│ │ │ │ ├── document.py
│ │ │ │ ├── inference_engine.py
│ │ │ │ ├── model.py
│ │ │ │ ├── module.py
│ │ │ │ ├── sampler.py
│ │ │ │ ├── semantic_matching.py
│ │ │ │ ├── tokenizer.py
│ │ │ │ ├── util.py
│ │ │ │ ├── vocab.py
│ │ │ │ └── vose_alias.py
│ │ │ ├── slda_novel/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── config.py
│ │ │ │ ├── document.py
│ │ │ │ ├── inference_engine.py
│ │ │ │ ├── model.py
│ │ │ │ ├── module.py
│ │ │ │ ├── sampler.py
│ │ │ │ ├── semantic_matching.py
│ │ │ │ ├── tokenizer.py
│ │ │ │ ├── util.py
│ │ │ │ ├── vocab.py
│ │ │ │ └── vose_alias.py
│ │ │ ├── slda_webpage/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── config.py
│ │ │ │ ├── document.py
│ │ │ │ ├── inference_engine.py
│ │ │ │ ├── model.py
│ │ │ │ ├── module.py
│ │ │ │ ├── sampler.py
│ │ │ │ ├── semantic_matching.py
│ │ │ │ ├── tokenizer.py
│ │ │ │ ├── util.py
│ │ │ │ ├── vocab.py
│ │ │ │ └── vose_alias.py
│ │ │ └── slda_weibo/
│ │ │ ├── README.md
│ │ │ ├── __init__.py
│ │ │ ├── config.py
│ │ │ ├── document.py
│ │ │ ├── inference_engine.py
│ │ │ ├── model.py
│ │ │ ├── module.py
│ │ │ ├── sampler.py
│ │ │ ├── semantic_matching.py
│ │ │ ├── tokenizer.py
│ │ │ ├── util.py
│ │ │ ├── vocab.py
│ │ │ └── vose_alias.py
│ │ ├── lexical_analysis/
│ │ │ ├── README.md
│ │ │ ├── README_en.md
│ │ │ ├── jieba_paddle/
│ │ │ │ ├── README.md
│ │ │ │ └── module.py
│ │ │ └── lac/
│ │ │ ├── README.md
│ │ │ ├── __init__.py
│ │ │ ├── ahocorasick.py
│ │ │ ├── assets/
│ │ │ │ ├── q2b.dic
│ │ │ │ ├── tag.dic
│ │ │ │ ├── tag_file.txt
│ │ │ │ ├── unigram.dict
│ │ │ │ └── word.dic
│ │ │ ├── custom.py
│ │ │ ├── module.py
│ │ │ ├── processor.py
│ │ │ └── test.py
│ │ ├── machine_translation/
│ │ │ └── transformer/
│ │ │ ├── en-de/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── module.py
│ │ │ │ ├── requirements.txt
│ │ │ │ └── utils.py
│ │ │ └── zh-en/
│ │ │ ├── README.md
│ │ │ ├── __init__.py
│ │ │ ├── module.py
│ │ │ ├── requirements.txt
│ │ │ └── utils.py
│ │ ├── punctuation_restoration/
│ │ │ └── auto_punc/
│ │ │ ├── README.md
│ │ │ ├── __init__.py
│ │ │ └── module.py
│ │ ├── sentiment_analysis/
│ │ │ ├── README.md
│ │ │ ├── README_en.md
│ │ │ ├── emotion_detection_textcnn/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── assets/
│ │ │ │ │ └── vocab.txt
│ │ │ │ ├── module.py
│ │ │ │ └── processor.py
│ │ │ ├── ernie_skep_sentiment_analysis/
│ │ │ │ ├── README.md
│ │ │ │ ├── assets/
│ │ │ │ │ ├── ernie_1.0_large_ch.config.json
│ │ │ │ │ └── ernie_1.0_large_ch.vocab.txt
│ │ │ │ ├── model/
│ │ │ │ │ ├── __init__.py
│ │ │ │ │ └── ernie.py
│ │ │ │ └── module.py
│ │ │ ├── senta_bilstm/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── assets/
│ │ │ │ │ └── vocab.txt
│ │ │ │ ├── module.py
│ │ │ │ └── processor.py
│ │ │ ├── senta_bow/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── assets/
│ │ │ │ │ └── vocab.txt
│ │ │ │ ├── module.py
│ │ │ │ └── processor.py
│ │ │ ├── senta_cnn/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── assets/
│ │ │ │ │ └── vocab.txt
│ │ │ │ ├── module.py
│ │ │ │ └── processor.py
│ │ │ ├── senta_gru/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── assets/
│ │ │ │ │ └── vocab.txt
│ │ │ │ ├── module.py
│ │ │ │ └── processor.py
│ │ │ └── senta_lstm/
│ │ │ ├── README.md
│ │ │ ├── __init__.py
│ │ │ ├── assets/
│ │ │ │ └── vocab.txt
│ │ │ ├── module.py
│ │ │ └── processor.py
│ │ ├── simultaneous_translation/
│ │ │ └── stacl/
│ │ │ ├── transformer_nist_wait_1/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── model.py
│ │ │ │ ├── module.py
│ │ │ │ ├── processor.py
│ │ │ │ └── requirements.txt
│ │ │ ├── transformer_nist_wait_3/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── model.py
│ │ │ │ ├── module.py
│ │ │ │ ├── processor.py
│ │ │ │ └── requirements.txt
│ │ │ ├── transformer_nist_wait_5/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── model.py
│ │ │ │ ├── module.py
│ │ │ │ ├── processor.py
│ │ │ │ └── requirements.txt
│ │ │ ├── transformer_nist_wait_7/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── model.py
│ │ │ │ ├── module.py
│ │ │ │ ├── processor.py
│ │ │ │ └── requirements.txt
│ │ │ └── transformer_nist_wait_all/
│ │ │ ├── README.md
│ │ │ ├── __init__.py
│ │ │ ├── model.py
│ │ │ ├── module.py
│ │ │ ├── processor.py
│ │ │ └── requirements.txt
│ │ ├── syntactic_analysis/
│ │ │ ├── DDParser/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── module.py
│ │ │ │ └── requirements.txt
│ │ │ ├── README.md
│ │ │ └── README_en.md
│ │ ├── text_correction/
│ │ │ └── ernie-csc/
│ │ │ ├── README.md
│ │ │ ├── __init__.py
│ │ │ ├── module.py
│ │ │ └── requirements.txt
│ │ ├── text_generation/
│ │ │ ├── CPM_LM/
│ │ │ │ └── readme.md
│ │ │ ├── GPT2_Base_CN/
│ │ │ │ ├── README.md
│ │ │ │ └── module.py
│ │ │ ├── GPT2_CPM_LM/
│ │ │ │ ├── README.md
│ │ │ │ └── module.py
│ │ │ ├── README.md
│ │ │ ├── README_en.md
│ │ │ ├── Rumor_prediction/
│ │ │ │ ├── README.md
│ │ │ │ ├── dict.txt
│ │ │ │ └── module.py
│ │ │ ├── ernie_gen/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── decode.py
│ │ │ │ ├── encode.py
│ │ │ │ ├── model.py
│ │ │ │ ├── module.py
│ │ │ │ ├── template/
│ │ │ │ │ ├── __init__.py
│ │ │ │ │ ├── decode.py
│ │ │ │ │ └── module.temp
│ │ │ │ └── test_data/
│ │ │ │ ├── dev.txt
│ │ │ │ └── train.txt
│ │ │ ├── ernie_gen_acrostic_poetry/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── decode.py
│ │ │ │ └── module.py
│ │ │ ├── ernie_gen_couplet/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── decode.py
│ │ │ │ └── module.py
│ │ │ ├── ernie_gen_lover_words/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── decode.py
│ │ │ │ └── module.py
│ │ │ ├── ernie_gen_poetry/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── decode.py
│ │ │ │ └── module.py
│ │ │ ├── ernie_tiny_couplet/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── ernie_zeus/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── module.py
│ │ │ │ ├── requirements.txt
│ │ │ │ └── test.py
│ │ │ ├── plato-mini/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── module.py
│ │ │ │ ├── requirements.txt
│ │ │ │ └── utils.py
│ │ │ ├── plato2_en_base/
│ │ │ │ ├── README.md
│ │ │ │ ├── model.py
│ │ │ │ ├── module.py
│ │ │ │ ├── readers/
│ │ │ │ │ ├── dialog_reader.py
│ │ │ │ │ ├── nsp_reader.py
│ │ │ │ │ └── plato_reader.py
│ │ │ │ └── utils/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── args.py
│ │ │ │ ├── masking.py
│ │ │ │ └── tokenization.py
│ │ │ ├── plato2_en_large/
│ │ │ │ ├── README.md
│ │ │ │ ├── model.py
│ │ │ │ ├── module.py
│ │ │ │ ├── readers/
│ │ │ │ │ ├── dialog_reader.py
│ │ │ │ │ ├── nsp_reader.py
│ │ │ │ │ └── plato_reader.py
│ │ │ │ └── utils/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── args.py
│ │ │ │ ├── masking.py
│ │ │ │ └── tokenization.py
│ │ │ ├── reading_pictures_writing_poems/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── module.py
│ │ │ │ ├── readme.md
│ │ │ │ └── requirements.txt
│ │ │ ├── reading_pictures_writing_poems_for_midautumn/
│ │ │ │ ├── MidAutumnDetection/
│ │ │ │ │ ├── __init__.py
│ │ │ │ │ └── module.py
│ │ │ │ ├── MidAutumnPoetry/
│ │ │ │ │ ├── __init__.py
│ │ │ │ │ ├── model/
│ │ │ │ │ │ ├── decode.py
│ │ │ │ │ │ ├── file_utils.py
│ │ │ │ │ │ ├── modeling_ernie.py
│ │ │ │ │ │ ├── modeling_ernie_gen.py
│ │ │ │ │ │ └── tokenizing_ernie.py
│ │ │ │ │ └── module.py
│ │ │ │ ├── __init__.py
│ │ │ │ └── module.py
│ │ │ ├── unified_transformer-12L-cn/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── module.py
│ │ │ │ ├── requirements.txt
│ │ │ │ └── utils.py
│ │ │ └── unified_transformer-12L-cn-luge/
│ │ │ ├── README.md
│ │ │ ├── __init__.py
│ │ │ ├── module.py
│ │ │ ├── requirements.txt
│ │ │ └── utils.py
│ │ ├── text_review/
│ │ │ ├── README.md
│ │ │ ├── README_en.md
│ │ │ ├── porn_detection_cnn/
│ │ │ │ ├── README.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── assets/
│ │ │ │ │ ├── params.txt
│ │ │ │ │ ├── vocab.txt
│ │ │ │ │ └── word_dict.txt
│ │ │ │ ├── module.py
│ │ │ │ └── processor.py
│ │ │ ├── porn_detection_gru/
│ │ │ │ ├── README.md
│ │ │ │ ├── README_en.md
│ │ │ │ ├── __init__.py
│ │ │ │ ├── assets/
│ │ │ │ │ ├── params.txt
│ │ │ │ │ ├── vocab.txt
│ │ │ │ │ └── word_dict.txt
│ │ │ │ ├── module.py
│ │ │ │ └── processor.py
│ │ │ └── porn_detection_lstm/
│ │ │ ├── README.md
│ │ │ ├── __init__.py
│ │ │ ├── assets/
│ │ │ │ ├── params.txt
│ │ │ │ ├── vocab.txt
│ │ │ │ └── word_dict.txt
│ │ │ ├── module.py
│ │ │ └── processor.py
│ │ └── text_to_knowledge/
│ │ ├── nptag/
│ │ │ ├── README.md
│ │ │ ├── __init__.py
│ │ │ ├── module.py
│ │ │ └── requirements.txt
│ │ └── wordtag/
│ │ ├── README.md
│ │ ├── __init__.py
│ │ ├── module.py
│ │ └── requirements.txt
│ └── video/
│ ├── README.md
│ ├── README_en.md
│ ├── Video_editing/
│ │ └── SkyAR/
│ │ ├── README.md
│ │ ├── README_en.md
│ │ ├── __init__.py
│ │ ├── module.py
│ │ ├── rain.py
│ │ ├── skybox.py
│ │ ├── skyfilter.py
│ │ └── utils.py
│ ├── classification/
│ │ ├── README.md
│ │ ├── nonlocal_kinetics400/
│ │ │ └── README.md
│ │ ├── stnet_kinetics400/
│ │ │ └── README.md
│ │ ├── tsm_kinetics400/
│ │ │ └── README.md
│ │ ├── tsn_kinetics400/
│ │ │ └── README.md
│ │ └── videotag_tsn_lstm/
│ │ ├── README.md
│ │ ├── __init__.py
│ │ ├── module.py
│ │ └── resource/
│ │ ├── __init__.py
│ │ ├── configs/
│ │ │ ├── attention_lstm.yaml
│ │ │ └── tsn.yaml
│ │ ├── label_3396.txt
│ │ ├── metrics/
│ │ │ ├── __init__.py
│ │ │ ├── metrics_util.py
│ │ │ └── youtube8m/
│ │ │ ├── __init__.py
│ │ │ ├── average_precision_calculator.py
│ │ │ ├── eval_util.py
│ │ │ └── mean_average_precision_calculator.py
│ │ ├── models/
│ │ │ ├── __init__.py
│ │ │ ├── attention_lstm/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── attention_lstm.py
│ │ │ │ └── lstm_attention.py
│ │ │ ├── model.py
│ │ │ └── tsn/
│ │ │ ├── __init__.py
│ │ │ ├── name.py
│ │ │ ├── name1
│ │ │ ├── name2
│ │ │ ├── name_map.json
│ │ │ ├── tsn.py
│ │ │ └── tsn_res_model.py
│ │ ├── reader/
│ │ │ ├── __init__.py
│ │ │ ├── kinetics_reader.py
│ │ │ └── reader_utils.py
│ │ └── utils/
│ │ ├── __init__.py
│ │ ├── config_utils.py
│ │ ├── train_utils.py
│ │ └── utility.py
│ └── multiple_object_tracking/
│ ├── fairmot_dla34/
│ │ ├── README.md
│ │ ├── config/
│ │ │ ├── _base_/
│ │ │ │ ├── fairmot_dla34.yml
│ │ │ │ ├── fairmot_reader_1088x608.yml
│ │ │ │ ├── mot.yml
│ │ │ │ ├── optimizer_30e.yml
│ │ │ │ └── runtime.yml
│ │ │ └── fairmot_dla34_30e_1088x608.yml
│ │ ├── dataset.py
│ │ ├── modeling/
│ │ │ └── mot/
│ │ │ ├── __init__.py
│ │ │ ├── matching/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── deepsort_matching.py
│ │ │ │ └── jde_matching.py
│ │ │ ├── motion/
│ │ │ │ ├── __init__.py
│ │ │ │ └── kalman_filter.py
│ │ │ ├── tracker/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── base_jde_tracker.py
│ │ │ │ ├── base_sde_tracker.py
│ │ │ │ └── jde_tracker.py
│ │ │ ├── utils.py
│ │ │ └── visualization.py
│ │ ├── module.py
│ │ ├── requirements.txt
│ │ ├── tracker.py
│ │ └── utils.py
│ └── jde_darknet53/
│ ├── README.md
│ ├── config/
│ │ ├── _base_/
│ │ │ ├── jde_darknet53.yml
│ │ │ ├── jde_reader_1088x608.yml
│ │ │ ├── mot.yml
│ │ │ ├── optimizer_30e.yml
│ │ │ ├── optimizer_60e.yml
│ │ │ └── runtime.yml
│ │ └── jde_darknet53_30e_1088x608.yml
│ ├── dataset.py
│ ├── modeling/
│ │ └── mot/
│ │ ├── __init__.py
│ │ ├── matching/
│ │ │ ├── __init__.py
│ │ │ ├── deepsort_matching.py
│ │ │ └── jde_matching.py
│ │ ├── motion/
│ │ │ ├── __init__.py
│ │ │ └── kalman_filter.py
│ │ ├── tracker/
│ │ │ ├── __init__.py
│ │ │ ├── base_jde_tracker.py
│ │ │ ├── base_sde_tracker.py
│ │ │ └── jde_tracker.py
│ │ ├── utils.py
│ │ └── visualization.py
│ ├── module.py
│ ├── requirements.txt
│ ├── tracker.py
│ └── utils.py
├── paddlehub/
│ ├── __init__.py
│ ├── commands/
│ │ ├── __init__.py
│ │ ├── clear.py
│ │ ├── config.py
│ │ ├── convert.py
│ │ ├── download.py
│ │ ├── help.py
│ │ ├── hub.py
│ │ ├── install.py
│ │ ├── list.py
│ │ ├── run.py
│ │ ├── search.py
│ │ ├── serving.py
│ │ ├── show.py
│ │ ├── tmpl/
│ │ │ ├── init_py.tmpl
│ │ │ ├── serving_demo.tmpl
│ │ │ └── x_model.tmpl
│ │ ├── uninstall.py
│ │ ├── utils.py
│ │ └── version.py
│ ├── compat/
│ │ ├── __init__.py
│ │ ├── datasets/
│ │ │ ├── __init__.py
│ │ │ ├── base_dataset.py
│ │ │ ├── couplet.py
│ │ │ └── nlp_dataset.py
│ │ ├── module/
│ │ │ ├── __init__.py
│ │ │ ├── module_desc.proto
│ │ │ ├── module_desc_pb2.py
│ │ │ ├── module_v1.py
│ │ │ ├── module_v1_utils.py
│ │ │ ├── nlp_module.py
│ │ │ └── processor.py
│ │ ├── paddle_utils.py
│ │ ├── task/
│ │ │ ├── __init__.py
│ │ │ ├── base_task.py
│ │ │ ├── batch.py
│ │ │ ├── checkpoint.proto
│ │ │ ├── checkpoint.py
│ │ │ ├── checkpoint_pb2.py
│ │ │ ├── config.py
│ │ │ ├── hook.py
│ │ │ ├── metrics.py
│ │ │ ├── reader.py
│ │ │ ├── task_utils.py
│ │ │ ├── text_generation_task.py
│ │ │ ├── tokenization.py
│ │ │ └── transformer_emb_task.py
│ │ └── type.py
│ ├── config.py
│ ├── datasets/
│ │ ├── __init__.py
│ │ ├── base_audio_dataset.py
│ │ ├── base_nlp_dataset.py
│ │ ├── base_seg_dataset.py
│ │ ├── canvas.py
│ │ ├── chnsenticorp.py
│ │ ├── esc50.py
│ │ ├── flowers.py
│ │ ├── lcqmc.py
│ │ ├── minicoco.py
│ │ ├── msra_ner.py
│ │ ├── opticdiscseg.py
│ │ └── pascalvoc.py
│ ├── env.py
│ ├── finetune/
│ │ ├── __init__.py
│ │ └── trainer.py
│ ├── module/
│ │ ├── __init__.py
│ │ ├── audio_module.py
│ │ ├── cv_module.py
│ │ ├── manager.py
│ │ ├── module.py
│ │ └── nlp_module.py
│ ├── server/
│ │ ├── __init__.py
│ │ ├── git_source.py
│ │ ├── server.py
│ │ └── server_source.py
│ ├── serving/
│ │ ├── __init__.py
│ │ ├── app_compat.py
│ │ ├── client.py
│ │ ├── device.py
│ │ ├── http_server.py
│ │ ├── model_service/
│ │ │ ├── __init__.py
│ │ │ └── base_model_service.py
│ │ └── worker.py
│ ├── text/
│ │ ├── __init__.py
│ │ ├── bert_tokenizer.py
│ │ ├── tokenizer.py
│ │ └── utils.py
│ ├── utils/
│ │ ├── __init__.py
│ │ ├── download.py
│ │ ├── io.py
│ │ ├── log.py
│ │ ├── paddlex.py
│ │ ├── parser.py
│ │ ├── platform.py
│ │ ├── pypi.py
│ │ ├── utils.py
│ │ └── xarfile.py
│ └── vision/
│ ├── __init__.py
│ ├── detect_transforms.py
│ ├── functional.py
│ ├── segmentation_transforms.py
│ ├── transforms.py
│ └── utils.py
├── requirements.txt
├── scripts/
│ ├── check_code_style.sh
│ ├── gen_contributors_info.py
│ ├── gen_proto.sh
│ └── test_cml.sh
├── setup.py
└── tests/
└── test_module.py
Showing preview only (1,142K chars total). Download the full file or copy to clipboard to get everything.
SYMBOL INDEX (14415 symbols across 1363 files)
FILE: demo/autoaug/hub_fitter.py
class HubFitterClassifer (line 27) | class HubFitterClassifer(object):
method __init__ (line 30) | def __init__(self, hparams: dict) -> None:
method _fit_param (line 80) | def _fit_param(self, show: bool = False) -> None:
method _get_label_info (line 92) | def _get_label_info(self, hparams: dict) -> None:
method reset_config (line 111) | def reset_config(self, new_hparams: dict) -> None:
method save_model (line 124) | def save_model(self, checkpoint_dir: str, step: Optional[str] = None) ...
method extract_model_spec (line 137) | def extract_model_spec(self, checkpoint_path: str) -> None:
method eval_child_model (line 143) | def eval_child_model(self, mode: str, pass_id: int = 0) -> dict:
method train_one_epoch (line 165) | def train_one_epoch(self, pass_id: int) -> dict:
method _run_training_loop (line 195) | def _run_training_loop(self, curr_epoch: int) -> dict:
method _compute_final_accuracies (line 202) | def _compute_final_accuracies(self, iteration: int) -> dict:
method run_model (line 215) | def run_model(self, epoch: int) -> dict:
FILE: demo/autoaug/paddlehub_utils/reader.py
class PbaAugment (line 41) | class PbaAugment(object):
method __init__ (line 46) | def __init__(self,
method set_epoch (line 80) | def set_epoch(self, indx: int) -> None:
method reset_policy (line 91) | def reset_policy(self, new_hparams: dict) -> None:
method __call__ (line 102) | def __call__(self, img: np.ndarray):
class PicRecord (line 120) | class PicRecord(object):
method __init__ (line 125) | def __init__(self, row: list) -> None:
method sub_path (line 134) | def sub_path(self) -> str:
method label (line 143) | def label(self) -> str:
class PicReader (line 152) | class PicReader(paddle.io.Dataset):
method __init__ (line 157) | def __init__(self,
method _get_all_img (line 191) | def _get_all_img(self, **kwargs) -> None:
method _load_image (line 218) | def _load_image(self, directory: str) -> np.ndarray:
method _parse_list (line 242) | def _parse_list(self, **kwargs) -> None:
method __getitem__ (line 271) | def __getitem__(self, index: int):
method get (line 284) | def get(self, record: PicRecord) -> tuple:
method __len__ (line 321) | def __len__(self) -> int:
method set_meta (line 329) | def set_meta(self, meta: bool) -> None:
method set_epoch (line 340) | def set_epoch(self, epoch: int) -> None:
method reset_policy (line 353) | def reset_policy(self, new_hparams: dict) -> None:
function _parse (line 366) | def _parse(value: str, function: callable, fmt: str) -> None:
function _read_classes (line 380) | def _read_classes(csv_file: str) -> dict:
function _init_loader (line 400) | def _init_loader(hparams: dict, TrainTransform=None) -> tuple:
FILE: demo/autoaug/paddlehub_utils/trainer.py
class CustomTrainer (line 23) | class CustomTrainer(Trainer):
method __init__ (line 25) | def __init__(self, **kwargs) -> None:
method init_train_and_eval (line 28) | def init_train_and_eval(self,
method init_train (line 39) | def init_train(self, train_dataset: paddle.io.Dataset, batch_size: int...
method train_one_epoch (line 55) | def train_one_epoch(self, loader: paddle.io.DataLoader, timer: Timer, ...
method train (line 95) | def train(self,
method init_evaluate (line 153) | def init_evaluate(self, eval_dataset: paddle.io.Dataset, batch_size: i...
method evaluate_process (line 170) | def evaluate_process(self, loader: paddle.io.DataLoader) -> dict:
method evaluate (line 205) | def evaluate(self, eval_dataset: paddle.io.Dataset, batch_size: int = ...
FILE: demo/autoaug/search.py
function main (line 22) | def main():
function search_test (line 26) | def search_test():
FILE: demo/serving/module_serving/object_detection_pyramidbox_lite_server_mask/pyramidbox_lite_server_mask_serving_demo.py
function cv2_to_base64 (line 8) | def cv2_to_base64(image):
FILE: demo/text_classification/embedding/model.py
class BoWModel (line 30) | class BoWModel(nn.Layer):
method __init__ (line 45) | def __init__(self,
method training_step (line 72) | def training_step(self, batch: List[paddle.Tensor], batch_idx: int):
method validation_step (line 86) | def validation_step(self, batch: List[paddle.Tensor], batch_idx: int):
method forward (line 100) | def forward(self, ids: paddle.Tensor, labels: paddle.Tensor = None):
method _batchify (line 126) | def _batchify(self, data: List[List[str]], max_seq_len: int, batch_siz...
method predict (line 150) | def predict(
FILE: docs/conf.py
function setup (line 80) | def setup(app):
FILE: modules/audio/asr/deepspeech2_aishell/deepspeech_tester.py
class DeepSpeech2Tester (line 28) | class DeepSpeech2Tester:
method __init__ (line 29) | def __init__(self, config):
method compute_result_transcripts (line 34) | def compute_result_transcripts(self, audio, audio_len, vocab_list, cfg):
method test (line 54) | def test(self, audio_file):
method setup_model (line 67) | def setup_model(self):
method resume (line 76) | def resume(self, checkpoint):
FILE: modules/audio/asr/deepspeech2_aishell/module.py
class DeepSpeech2 (line 49) | class DeepSpeech2(paddle.nn.Layer):
method __init__ (line 50) | def __init__(self):
method check_audio (line 82) | def check_audio(audio_file):
method speech_recognize (line 87) | def speech_recognize(self, audio_file, device='cpu'):
FILE: modules/audio/asr/deepspeech2_librispeech/deepspeech_tester.py
class DeepSpeech2Tester (line 28) | class DeepSpeech2Tester:
method __init__ (line 29) | def __init__(self, config):
method compute_result_transcripts (line 34) | def compute_result_transcripts(self, audio, audio_len, vocab_list, cfg):
method test (line 54) | def test(self, audio_file):
method setup_model (line 67) | def setup_model(self):
method resume (line 76) | def resume(self, checkpoint):
FILE: modules/audio/asr/deepspeech2_librispeech/module.py
class DeepSpeech2 (line 50) | class DeepSpeech2(paddle.nn.Layer):
method __init__ (line 51) | def __init__(self):
method check_audio (line 83) | def check_audio(audio_file):
method speech_recognize (line 88) | def speech_recognize(self, audio_file, device='cpu'):
FILE: modules/audio/asr/u2_conformer_aishell/module.py
class U2Conformer (line 35) | class U2Conformer(paddle.nn.Layer):
method __init__ (line 36) | def __init__(self):
method check_audio (line 63) | def check_audio(audio_file):
method speech_recognize (line 68) | def speech_recognize(self, audio_file, device='cpu'):
FILE: modules/audio/asr/u2_conformer_aishell/u2_conformer_tester.py
class U2ConformerTester (line 27) | class U2ConformerTester:
method __init__ (line 28) | def __init__(self, config):
method test (line 36) | def test(self, audio_file):
method setup_model (line 67) | def setup_model(self):
method resume (line 75) | def resume(self, checkpoint):
FILE: modules/audio/asr/u2_conformer_librispeech/module.py
class U2Conformer (line 36) | class U2Conformer(paddle.nn.Layer):
method __init__ (line 37) | def __init__(self):
method check_audio (line 64) | def check_audio(audio_file):
method speech_recognize (line 69) | def speech_recognize(self, audio_file, device='cpu'):
FILE: modules/audio/asr/u2_conformer_librispeech/u2_conformer_tester.py
class U2ConformerTester (line 27) | class U2ConformerTester:
method __init__ (line 28) | def __init__(self, config):
method test (line 36) | def test(self, audio_file):
method setup_model (line 67) | def setup_model(self):
method resume (line 75) | def resume(self, checkpoint):
FILE: modules/audio/asr/u2_conformer_wenetspeech/module.py
class U2Conformer (line 26) | class U2Conformer(paddle.nn.Layer):
method __init__ (line 27) | def __init__(self):
method check_audio (line 39) | def check_audio(audio_file):
method speech_recognize (line 52) | def speech_recognize(self, audio_file, device='cpu'):
FILE: modules/audio/audio_classification/PANNs/cnn10/module.py
class PANN (line 38) | class PANN(nn.Layer):
method __init__ (line 39) | def __init__(
method forward (line 72) | def forward(self, feats, labels=None):
FILE: modules/audio/audio_classification/PANNs/cnn10/network.py
class ConvBlock (line 24) | class ConvBlock(nn.Layer):
method __init__ (line 25) | def __init__(self, in_channels, out_channels):
method forward (line 45) | def forward(self, x, pool_size=(2, 2), pool_type='avg'):
class CNN10 (line 66) | class CNN10(nn.Layer):
method __init__ (line 69) | def __init__(self, extract_embedding: bool = True, checkpoint: str = N...
method forward (line 90) | def forward(self, x):
FILE: modules/audio/audio_classification/PANNs/cnn14/module.py
class PANN (line 38) | class PANN(nn.Layer):
method __init__ (line 39) | def __init__(
method forward (line 72) | def forward(self, feats, labels=None):
FILE: modules/audio/audio_classification/PANNs/cnn14/network.py
class ConvBlock (line 24) | class ConvBlock(nn.Layer):
method __init__ (line 25) | def __init__(self, in_channels, out_channels):
method forward (line 45) | def forward(self, x, pool_size=(2, 2), pool_type='avg'):
class CNN14 (line 66) | class CNN14(nn.Layer):
method __init__ (line 69) | def __init__(self, extract_embedding: bool = True, checkpoint: str = N...
method forward (line 92) | def forward(self, x):
FILE: modules/audio/audio_classification/PANNs/cnn6/module.py
class PANN (line 38) | class PANN(nn.Layer):
method __init__ (line 39) | def __init__(
method forward (line 72) | def forward(self, feats, labels=None):
FILE: modules/audio/audio_classification/PANNs/cnn6/network.py
class ConvBlock5x5 (line 24) | class ConvBlock5x5(nn.Layer):
method __init__ (line 25) | def __init__(self, in_channels, out_channels):
method forward (line 37) | def forward(self, x, pool_size=(2, 2), pool_type='avg'):
class CNN6 (line 54) | class CNN6(nn.Layer):
method __init__ (line 57) | def __init__(self, extract_embedding: bool = True, checkpoint: str = N...
method forward (line 78) | def forward(self, x):
FILE: modules/audio/keyword_spotting/kwmlp_speech_commands/feature.py
function create_dct (line 21) | def create_dct(n_mfcc: int, n_mels: int, norm: str = 'ortho'):
function compute_mfcc (line 34) | def compute_mfcc(
FILE: modules/audio/keyword_spotting/kwmlp_speech_commands/kwmlp.py
class Residual (line 19) | class Residual(nn.Layer):
method __init__ (line 20) | def __init__(self, fn):
method forward (line 24) | def forward(self, x):
class PreNorm (line 28) | class PreNorm(nn.Layer):
method __init__ (line 29) | def __init__(self, dim, fn):
method forward (line 34) | def forward(self, x, **kwargs):
class PostNorm (line 39) | class PostNorm(nn.Layer):
method __init__ (line 40) | def __init__(self, dim, fn):
method forward (line 45) | def forward(self, x, **kwargs):
class SpatialGatingUnit (line 49) | class SpatialGatingUnit(nn.Layer):
method __init__ (line 50) | def __init__(self, dim, dim_seq, act=nn.Identity(), init_eps=1e-3):
method forward (line 61) | def forward(self, x):
class gMLPBlock (line 71) | class gMLPBlock(nn.Layer):
method __init__ (line 72) | def __init__(self, *, dim, dim_ff, seq_len, act=nn.Identity()):
method forward (line 79) | def forward(self, x):
class Rearrange (line 86) | class Rearrange(nn.Layer):
method __init__ (line 87) | def __init__(self):
method forward (line 90) | def forward(self, x):
class Reduce (line 95) | class Reduce(nn.Layer):
method __init__ (line 96) | def __init__(self, axis=1):
method forward (line 100) | def forward(self, x):
class KW_MLP (line 105) | class KW_MLP(nn.Layer):
method __init__ (line 108) | def __init__(self,
method forward (line 139) | def forward(self, x):
FILE: modules/audio/keyword_spotting/kwmlp_speech_commands/module.py
class KWS (line 33) | class KWS(paddle.nn.Layer):
method __init__ (line 34) | def __init__(self):
method load_audio (line 59) | def load_audio(self, wav):
method keyword_recognize (line 65) | def keyword_recognize(self, wav):
method forward (line 79) | def forward(self, x):
FILE: modules/audio/language_identification/ecapa_tdnn_common_language/ecapa_tdnn.py
function length_to_mask (line 22) | def length_to_mask(length, max_len=None, dtype=None):
class Conv1d (line 36) | class Conv1d(nn.Layer):
method __init__ (line 37) | def __init__(
method forward (line 68) | def forward(self, x):
method _manage_padding (line 76) | def _manage_padding(self, x, kernel_size: int, dilation: int, stride: ...
method _get_padding_elem (line 82) | def _get_padding_elem(self, L_in: int, stride: int, kernel_size: int, ...
class BatchNorm1d (line 95) | class BatchNorm1d(nn.Layer):
method __init__ (line 96) | def __init__(
method forward (line 118) | def forward(self, x):
class TDNNBlock (line 123) | class TDNNBlock(nn.Layer):
method __init__ (line 124) | def __init__(
method forward (line 142) | def forward(self, x):
class Res2NetBlock (line 146) | class Res2NetBlock(nn.Layer):
method __init__ (line 147) | def __init__(self, in_channels, out_channels, scale=8, dilation=1):
method forward (line 159) | def forward(self, x):
class SEBlock (line 173) | class SEBlock(nn.Layer):
method __init__ (line 174) | def __init__(self, in_channels, se_channels, out_channels):
method forward (line 182) | def forward(self, x, lengths=None):
class AttentiveStatisticsPooling (line 198) | class AttentiveStatisticsPooling(nn.Layer):
method __init__ (line 199) | def __init__(self, channels, attention_channels=128, global_context=Tr...
method forward (line 211) | def forward(self, x, lengths=None):
class SERes2NetBlock (line 253) | class SERes2NetBlock(nn.Layer):
method __init__ (line 254) | def __init__(
method forward (line 291) | def forward(self, x, lengths=None):
class ECAPA_TDNN (line 304) | class ECAPA_TDNN(nn.Layer):
method __init__ (line 305) | def __init__(
method forward (line 372) | def forward(self, x, lengths=None):
class Classifier (line 395) | class Classifier(nn.Layer):
method __init__ (line 396) | def __init__(self, backbone, num_class, dtype=paddle.float32):
method forward (line 402) | def forward(self, x):
FILE: modules/audio/language_identification/ecapa_tdnn_common_language/feature.py
function compute_fbank_matrix (line 23) | def compute_fbank_matrix(sample_rate: int = 16000,
function compute_log_fbank (line 51) | def compute_log_fbank(
function compute_stats (line 84) | def compute_stats(x: paddle.Tensor, mean_norm: bool = True, std_norm: bo...
function normalize (line 100) | def normalize(
FILE: modules/audio/language_identification/ecapa_tdnn_common_language/module.py
class LanguageIdentification (line 38) | class LanguageIdentification(paddle.nn.Layer):
method __init__ (line 39) | def __init__(self):
method load_audio (line 65) | def load_audio(self, wav):
method language_identify (line 71) | def language_identify(self, wav):
method forward (line 77) | def forward(self, x):
FILE: modules/audio/speaker_recognition/ecapa_tdnn_voxceleb/ecapa_tdnn.py
function length_to_mask (line 22) | def length_to_mask(length, max_len=None, dtype=None):
class Conv1d (line 36) | class Conv1d(nn.Layer):
method __init__ (line 37) | def __init__(
method forward (line 68) | def forward(self, x):
method _manage_padding (line 76) | def _manage_padding(self, x, kernel_size: int, dilation: int, stride: ...
method _get_padding_elem (line 82) | def _get_padding_elem(self, L_in: int, stride: int, kernel_size: int, ...
class BatchNorm1d (line 95) | class BatchNorm1d(nn.Layer):
method __init__ (line 96) | def __init__(
method forward (line 118) | def forward(self, x):
class TDNNBlock (line 123) | class TDNNBlock(nn.Layer):
method __init__ (line 124) | def __init__(
method forward (line 142) | def forward(self, x):
class Res2NetBlock (line 146) | class Res2NetBlock(nn.Layer):
method __init__ (line 147) | def __init__(self, in_channels, out_channels, scale=8, dilation=1):
method forward (line 159) | def forward(self, x):
class SEBlock (line 173) | class SEBlock(nn.Layer):
method __init__ (line 174) | def __init__(self, in_channels, se_channels, out_channels):
method forward (line 182) | def forward(self, x, lengths=None):
class AttentiveStatisticsPooling (line 198) | class AttentiveStatisticsPooling(nn.Layer):
method __init__ (line 199) | def __init__(self, channels, attention_channels=128, global_context=Tr...
method forward (line 211) | def forward(self, x, lengths=None):
class SERes2NetBlock (line 253) | class SERes2NetBlock(nn.Layer):
method __init__ (line 254) | def __init__(
method forward (line 291) | def forward(self, x, lengths=None):
class ECAPA_TDNN (line 304) | class ECAPA_TDNN(nn.Layer):
method __init__ (line 305) | def __init__(
method forward (line 372) | def forward(self, x, lengths=None):
FILE: modules/audio/speaker_recognition/ecapa_tdnn_voxceleb/feature.py
function compute_fbank_matrix (line 23) | def compute_fbank_matrix(sample_rate: int = 16000,
function compute_log_fbank (line 51) | def compute_log_fbank(
function compute_stats (line 84) | def compute_stats(x: paddle.Tensor, mean_norm: bool = True, std_norm: bo...
function normalize (line 100) | def normalize(
FILE: modules/audio/speaker_recognition/ecapa_tdnn_voxceleb/module.py
class SpeakerRecognition (line 37) | class SpeakerRecognition(paddle.nn.Layer):
method __init__ (line 38) | def __init__(self, threshold=0.25):
method load_audio (line 63) | def load_audio(self, wav):
method speaker_embedding (line 69) | def speaker_embedding(self, wav):
method speaker_verify (line 74) | def speaker_verify(self, wav1, wav2):
method forward (line 84) | def forward(self, x):
FILE: modules/audio/svs/diffsinger/infer.py
class Infer (line 15) | class Infer:
method __init__ (line 17) | def __init__(self, root='.', providers=None):
method model (line 55) | def model(self, txt_tokens, **kwargs):
method norm_spec (line 131) | def norm_spec(self, x):
method denorm_spec (line 134) | def denorm_spec(self, x):
method forward_model (line 137) | def forward_model(self, inp):
method run_vocoder (line 164) | def run_vocoder(self, c, **kwargs):
method preprocess_word_level_input (line 179) | def preprocess_word_level_input(self, inp):
method preprocess_phoneme_level_input (line 249) | def preprocess_phoneme_level_input(self, inp):
method preprocess_input (line 263) | def preprocess_input(self, inp, input_type='word'):
method input_to_batch (line 315) | def input_to_batch(self, item):
method infer_once (line 340) | def infer_once(self, inp):
FILE: modules/audio/svs/diffsinger/inference/svs/opencpop/map.py
function cpop_pinyin2ph_func (line 1) | def cpop_pinyin2ph_func(path):
FILE: modules/audio/svs/diffsinger/module.py
class DiffSinger (line 23) | class DiffSinger:
method __init__ (line 25) | def __init__(self, providers: List[str] = None) -> None:
method singing_voice_synthesis (line 32) | def singing_voice_synthesis(self,
method run_cmd (line 65) | def run_cmd(self, argvs: List[str]) -> str:
FILE: modules/audio/svs/diffsinger/test.py
class TestHubModule (line 7) | class TestHubModule(unittest.TestCase):
method setUpClass (line 10) | def setUpClass(cls) -> None:
method tearDownClass (line 14) | def tearDownClass(cls) -> None:
method test_singing_voice_synthesis1 (line 17) | def test_singing_voice_synthesis1(self):
method test_singing_voice_synthesis2 (line 35) | def test_singing_voice_synthesis2(self):
FILE: modules/audio/svs/diffsinger/utils/__init__.py
class AvgrageMeter (line 8) | class AvgrageMeter(object):
method __init__ (line 10) | def __init__(self):
method reset (line 13) | def reset(self):
method update (line 18) | def update(self, val, n=1):
function collate_1d (line 24) | def collate_1d(values, pad_idx=0, left_pad=False, shift_right=False, max...
function collate_2d (line 42) | def collate_2d(values, pad_idx=0, left_pad=False, shift_right=False, max...
function _is_batch_full (line 59) | def _is_batch_full(batch, num_tokens, max_tokens, max_sentences):
function batch_by_size (line 69) | def batch_by_size(indices,
function unpack_dict_to_list (line 125) | def unpack_dict_to_list(samples):
function remove_padding (line 139) | def remove_padding(x, padding_idx=0):
class Timer (line 149) | class Timer:
method __init__ (line 152) | def __init__(self, name, print_time=False):
method __enter__ (line 158) | def __enter__(self):
method __exit__ (line 161) | def __exit__(self, exc_type, exc_val, exc_tb):
FILE: modules/audio/svs/diffsinger/utils/audio.py
function save_wav (line 13) | def save_wav(wav, path, sr, norm=False):
function get_hop_size (line 21) | def get_hop_size(hparams):
function _stft (line 30) | def _stft(y, hparams):
function _istft (line 38) | def _istft(y, hparams):
function librosa_pad_lr (line 42) | def librosa_pad_lr(x, fsize, fshift, pad_sides=1):
function amp_to_db (line 55) | def amp_to_db(x):
function normalize (line 59) | def normalize(S, hparams):
FILE: modules/audio/svs/diffsinger/utils/cwt.py
function load_wav (line 7) | def load_wav(wav_file, sr):
function convert_continuos_f0 (line 12) | def convert_continuos_f0(f0):
function get_cont_lf0 (line 46) | def get_cont_lf0(f0, frame_period=5.0):
function get_lf0_cwt (line 53) | def get_lf0_cwt(lf0):
function norm_scale (line 72) | def norm_scale(Wavelet_lf0):
function normalize_cwt_lf0 (line 80) | def normalize_cwt_lf0(f0, mean, std):
function get_lf0_cwt_norm (line 89) | def get_lf0_cwt_norm(f0s, mean, std):
function inverse_cwt (line 118) | def inverse_cwt(Wavelet_lf0, scales):
FILE: modules/audio/svs/diffsinger/utils/hparams.py
class Args (line 10) | class Args:
method __init__ (line 12) | def __init__(self, **kwargs):
function override_config (line 17) | def override_config(old_config: dict, new_config: dict):
function set_hparams (line 25) | def set_hparams(config='', exp_name='', hparams_str='', print_hparams=Tr...
FILE: modules/audio/svs/diffsinger/utils/multiprocess_utils.py
function chunked_worker (line 7) | def chunked_worker(worker_id, map_func, args, results_queue=None, init_c...
function chunked_multiprocess_run (line 21) | def chunked_multiprocess_run(map_func, args, num_workers=None, ordered=T...
FILE: modules/audio/svs/diffsinger/utils/text_encoder.py
function strip_ids (line 28) | def strip_ids(ids, ids_to_strip):
class TextEncoder (line 36) | class TextEncoder(object):
method __init__ (line 39) | def __init__(self, num_reserved_ids=NUM_RESERVED_TOKENS):
method num_reserved_ids (line 43) | def num_reserved_ids(self):
method encode (line 46) | def encode(self, s):
method decode (line 62) | def decode(self, ids, strip_extraneous=False):
method decode_list (line 79) | def decode_list(self, ids):
method vocab_size (line 101) | def vocab_size(self):
class ByteTextEncoder (line 105) | class ByteTextEncoder(TextEncoder):
method encode (line 108) | def encode(self, s):
method decode (line 112) | def decode(self, ids, strip_extraneous=False):
method decode_list (line 128) | def decode_list(self, ids):
method vocab_size (line 141) | def vocab_size(self):
class ByteTextEncoderWithEos (line 145) | class ByteTextEncoderWithEos(ByteTextEncoder):
method encode (line 148) | def encode(self, s):
class TokenTextEncoder (line 152) | class TokenTextEncoder(TextEncoder):
method __init__ (line 155) | def __init__(self,
method encode (line 192) | def encode(self, s):
method decode (line 201) | def decode(self, ids, strip_eos=False, strip_padding=False):
method decode_list (line 210) | def decode_list(self, ids):
method vocab_size (line 215) | def vocab_size(self):
method __len__ (line 218) | def __len__(self):
method _safe_id_to_token (line 221) | def _safe_id_to_token(self, idx):
method _init_vocab_from_file (line 224) | def _init_vocab_from_file(self, filename):
method _init_vocab_from_list (line 239) | def _init_vocab_from_list(self, vocab_list):
method _init_vocab (line 256) | def _init_vocab(self, token_generator, add_reserved_tokens=True):
method pad (line 271) | def pad(self):
method eos (line 274) | def eos(self):
method unk (line 277) | def unk(self):
method seg (line 280) | def seg(self):
method store_to_file (line 283) | def store_to_file(self, filename):
method sil_phonemes (line 296) | def sil_phonemes(self):
FILE: modules/audio/svs/diffsinger/utils/text_norm.py
class ChineseChar (line 61) | class ChineseChar(object):
method __init__ (line 69) | def __init__(self, simplified, traditional):
method __str__ (line 74) | def __str__(self):
method __repr__ (line 77) | def __repr__(self):
class ChineseNumberUnit (line 81) | class ChineseNumberUnit(ChineseChar):
method __init__ (line 88) | def __init__(self, power, simplified, traditional, big_s, big_t):
method __str__ (line 94) | def __str__(self):
method create (line 98) | def create(cls, index, value, numbering_type=NUMBERING_TYPES[1], small...
class ChineseNumberDigit (line 128) | class ChineseNumberDigit(ChineseChar):
method __init__ (line 133) | def __init__(self, value, simplified, traditional, big_s, big_t, alt_s...
method __str__ (line 141) | def __str__(self):
method create (line 145) | def create(cls, i, v):
class ChineseMath (line 149) | class ChineseMath(ChineseChar):
method __init__ (line 154) | def __init__(self, simplified, traditional, symbol, expression=None):
class NumberSystem (line 165) | class NumberSystem(object):
class MathSymbol (line 172) | class MathSymbol(object):
method __init__ (line 180) | def __init__(self, positive, negative, point):
method __iter__ (line 185) | def __iter__(self):
function create_system (line 206) | def create_system(numbering_type=NUMBERING_TYPES[1]):
function chn2num (line 242) | def chn2num(chinese_string, numbering_type=NUMBERING_TYPES[1]):
function num2chn (line 326) | def num2chn(number_string,
class Cardinal (line 427) | class Cardinal:
method __init__ (line 432) | def __init__(self, cardinal=None, chntext=None):
method chntext2cardinal (line 436) | def chntext2cardinal(self):
method cardinal2chntext (line 439) | def cardinal2chntext(self):
class Digit (line 443) | class Digit:
method __init__ (line 448) | def __init__(self, digit=None, chntext=None):
method digit2chntext (line 455) | def digit2chntext(self):
class TelePhone (line 459) | class TelePhone:
method __init__ (line 464) | def __init__(self, telephone=None, raw_chntext=None, chntext=None):
method telephone2chntext (line 476) | def telephone2chntext(self, fixed=False):
class Fraction (line 489) | class Fraction:
method __init__ (line 494) | def __init__(self, fraction=None, chntext=None):
method chntext2fraction (line 498) | def chntext2fraction(self):
method fraction2chntext (line 502) | def fraction2chntext(self):
class Date (line 507) | class Date:
method __init__ (line 512) | def __init__(self, date=None, chntext=None):
method date2chntext (line 540) | def date2chntext(self):
class Money (line 565) | class Money:
method __init__ (line 570) | def __init__(self, money=None, chntext=None):
method money2chntext (line 577) | def money2chntext(self):
class Percentage (line 588) | class Percentage:
method __init__ (line 593) | def __init__(self, percentage=None, chntext=None):
method chntext2percentage (line 597) | def chntext2percentage(self):
method percentage2chntext (line 600) | def percentage2chntext(self):
class NSWNormalizer (line 607) | class NSWNormalizer:
method __init__ (line 609) | def __init__(self, raw_text):
method _particular (line 613) | def _particular(self):
method normalize (line 624) | def normalize(self, remove_punc=True):
function nsw_test_case (line 717) | def nsw_test_case(raw_text):
function nsw_test (line 723) | def nsw_test():
FILE: modules/audio/tts/deepvoice3_ljspeech/module.py
class AttrDict (line 68) | class AttrDict(dict):
method __init__ (line 69) | def __init__(self, *args, **kwargs):
class WaveflowVocoder (line 74) | class WaveflowVocoder(object):
method __init__ (line 75) | def __init__(self, config_path, checkpoint_path):
method __call__ (line 86) | def __call__(self, mel):
class GriffinLimVocoder (line 94) | class GriffinLimVocoder(object):
method __init__ (line 95) | def __init__(self, sharpening_factor=1.4, sample_rate=22050, n_fft=102...
method __call__ (line 102) | def __call__(self, mel):
class DeepVoice3 (line 118) | class DeepVoice3(hub.NLPPredictionModule):
method _initialize (line 119) | def _initialize(self):
method synthesize (line 183) | def synthesize(self, texts, use_gpu=False, vocoder="griffin-lim"):
method serving_method (line 248) | def serving_method(self, texts, use_gpu=False, vocoder="griffin-lim"):
method add_module_config_arg (line 257) | def add_module_config_arg(self):
method add_module_output_arg (line 267) | def add_module_output_arg(self):
method run_cmd (line 278) | def run_cmd(self, argvs):
FILE: modules/audio/tts/fastspeech2_baker/module.py
class FastSpeech (line 36) | class FastSpeech(paddle.nn.Layer):
method __init__ (line 37) | def __init__(self, output_dir='./wavs'):
method forward (line 96) | def forward(self, text: str):
method generate (line 112) | def generate(self, sentences: List[str], device='cpu'):
FILE: modules/audio/tts/fastspeech2_ljspeech/module.py
class FastSpeech (line 36) | class FastSpeech(paddle.nn.Layer):
method __init__ (line 37) | def __init__(self, output_dir='./wavs'):
method forward (line 101) | def forward(self, text: str):
method generate (line 117) | def generate(self, sentences: List[str], device='cpu'):
FILE: modules/audio/tts/fastspeech_ljspeech/module.py
class AttrDict (line 68) | class AttrDict(dict):
method __init__ (line 69) | def __init__(self, *args, **kwargs):
class FastSpeech (line 83) | class FastSpeech(hub.NLPPredictionModule):
method _initialize (line 84) | def _initialize(self):
method synthesize (line 107) | def synthesize(self, texts, use_gpu=False, speed=1.0, vocoder="griffin...
method synthesis_with_griffinlim (line 164) | def synthesis_with_griffinlim(self, mel_output, cfg):
method synthesis_with_waveflow (line 176) | def synthesis_with_waveflow(self, mel_output, sigma):
method serving_method (line 189) | def serving_method(self, texts, use_gpu=False, speed=1.0, vocoder="gri...
method add_module_config_arg (line 198) | def add_module_config_arg(self):
method add_module_output_arg (line 208) | def add_module_output_arg(self):
method run_cmd (line 219) | def run_cmd(self, argvs):
FILE: modules/audio/tts/transformer_tts_ljspeech/module.py
class AttrDict (line 69) | class AttrDict(dict):
method __init__ (line 70) | def __init__(self, *args, **kwargs):
class TransformerTTS (line 84) | class TransformerTTS(hub.NLPPredictionModule):
method _initialize (line 85) | def _initialize(self):
method synthesize (line 120) | def synthesize(self, texts, use_gpu=False, vocoder="griffin-lim"):
method synthesis_with_griffinlim (line 181) | def synthesis_with_griffinlim(self, mel_output, cfg):
method synthesis_with_waveflow (line 193) | def synthesis_with_waveflow(self, mel_output, sigma):
method serving_method (line 206) | def serving_method(self, texts, use_gpu=False, vocoder="griffin-lim"):
method add_module_config_arg (line 215) | def add_module_config_arg(self):
method add_module_output_arg (line 225) | def add_module_output_arg(self):
method run_cmd (line 236) | def run_cmd(self, argvs):
FILE: modules/audio/voice_cloning/ge2e_fastspeech2_pwgan/module.py
class VoiceCloner (line 45) | class VoiceCloner(paddle.nn.Layer):
method __init__ (line 46) | def __init__(self, speaker_audio: str = None, output_dir: str = './'):
method get_speaker_embedding (line 127) | def get_speaker_embedding(self):
method set_speaker_embedding (line 131) | def set_speaker_embedding(self, speaker_audio: str):
method generate (line 140) | def generate(self, data: Union[str, List[str]], use_gpu: bool = False):
FILE: modules/audio/voice_cloning/lstm_tacotron2/audio_processor.py
function normalize_volume (line 32) | def normalize_volume(wav, target_dBFS, increase_only=False, decrease_onl...
function trim_long_silences (line 49) | def trim_long_silences(wav, vad_window_length: int, vad_moving_average_w...
function compute_partial_slices (line 92) | def compute_partial_slices(n_samples: int,
class SpeakerVerificationPreprocessor (line 148) | class SpeakerVerificationPreprocessor(object):
method __init__ (line 149) | def __init__(self,
method preprocess_wav (line 176) | def preprocess_wav(self, fpath_or_wav, source_sr=None):
method melspectrogram (line 196) | def melspectrogram(self, wav):
method extract_mel_partials (line 202) | def extract_mel_partials(self, wav):
FILE: modules/audio/voice_cloning/lstm_tacotron2/chinese_g2p.py
function convert_to_pinyin (line 21) | def convert_to_pinyin(text: str) -> List[str]:
function convert_sentence (line 29) | def convert_sentence(text: str) -> List[Tuple[str]]:
FILE: modules/audio/voice_cloning/lstm_tacotron2/module.py
class VoiceCloner (line 43) | class VoiceCloner(nn.Layer):
method __init__ (line 44) | def __init__(self, speaker_audio: str = None, output_dir: str = './'):
method get_speaker_embedding (line 119) | def get_speaker_embedding(self):
method set_speaker_embedding (line 122) | def set_speaker_embedding(self, speaker_audio: str):
method forward (line 129) | def forward(self, phones: paddle.Tensor, tones: paddle.Tensor, speaker...
method _convert_text_to_input (line 135) | def _convert_text_to_input(self, text: str):
method _batchify (line 144) | def _batchify(self, data: List[str], batch_size: int):
method generate (line 170) | def generate(self, data: List[str], batch_size: int = 1, use_gpu: bool...
FILE: modules/audio/voice_cloning/lstm_tacotron2/preprocess_transcription.py
function is_zh (line 108) | def is_zh(word):
function ernized (line 114) | def ernized(syllable):
function convert (line 118) | def convert(syllable):
function split_syllable (line 148) | def split_syllable(syllable: str):
FILE: modules/demo/senta_test/module.py
class SentaTest (line 18) | class SentaTest:
method __init__ (line 19) | def __init__(self):
method sentiment_classify (line 29) | def sentiment_classify(self, texts):
method run_cmd (line 42) | def run_cmd(self, argvs):
FILE: modules/demo/senta_test/processor.py
function load_vocab (line 1) | def load_vocab(vocab_path):
FILE: modules/image/Image_editing/colorization/deoldify/base_module.py
class SequentialEx (line 10) | class SequentialEx(nn.Layer):
method __init__ (line 13) | def __init__(self, *layers):
method forward (line 17) | def forward(self, x):
method __getitem__ (line 28) | def __getitem__(self, i):
method append (line 31) | def append(self, l):
method extend (line 34) | def extend(self, l):
method insert (line 37) | def insert(self, i, l):
class Deoldify (line 41) | class Deoldify(SequentialEx):
method __init__ (line 43) | def __init__(self,
function custom_conv_layer (line 107) | def custom_conv_layer(ni: int,
function relu (line 145) | def relu(inplace: bool = False, leaky: float = None):
class UnetBlockWide (line 150) | class UnetBlockWide(nn.Layer):
method __init__ (line 153) | def __init__(self,
method forward (line 172) | def forward(self, up_in):
class UnetBlockDeep (line 182) | class UnetBlockDeep(nn.Layer):
method __init__ (line 185) | def __init__(
method forward (line 206) | def forward(self, up_in):
function ifnone (line 216) | def ifnone(a, b):
class PixelShuffle_ICNR (line 221) | class PixelShuffle_ICNR(nn.Layer):
method __init__ (line 225) | def __init__(self,
method forward (line 242) | def forward(self, x):
function conv_layer (line 247) | def conv_layer(ni: int,
class CustomPixelShuffle_ICNR (line 279) | class CustomPixelShuffle_ICNR(nn.Layer):
method __init__ (line 283) | def __init__(self, ni: int, nf: int = None, scale: int = 2, blur: bool...
method forward (line 294) | def forward(self, x):
class MergeLayer (line 299) | class MergeLayer(nn.Layer):
method __init__ (line 302) | def __init__(self, dense: bool = False):
method forward (line 307) | def forward(self, x):
function res_block (line 313) | def res_block(nf, dense: bool = False, norm_type='Batch', bottle: bool =...
class SigmoidRange (line 322) | class SigmoidRange(nn.Layer):
method __init__ (line 325) | def __init__(self, low, high):
method forward (line 329) | def forward(self, x):
function sigmoid_range (line 333) | def sigmoid_range(x, low, high):
class PixelShuffle (line 338) | class PixelShuffle(nn.Layer):
method __init__ (line 340) | def __init__(self, upscale_factor):
method forward (line 344) | def forward(self, x):
class ReplicationPad2d (line 348) | class ReplicationPad2d(nn.Layer):
method __init__ (line 350) | def __init__(self, size):
method forward (line 354) | def forward(self, x):
function conv1d (line 358) | def conv1d(ni: int, no: int, ks: int = 1, stride: int = 1, padding: int ...
class SelfAttention (line 364) | class SelfAttention(nn.Layer):
method __init__ (line 367) | def __init__(self, n_channels):
method forward (line 375) | def forward(self, x):
function _get_sfs_idxs (line 386) | def _get_sfs_idxs(sizes):
function build_model (line 395) | def build_model():
FILE: modules/image/Image_editing/colorization/deoldify/module.py
class DeOldifyPredictor (line 37) | class DeOldifyPredictor(nn.Layer):
method __init__ (line 39) | def __init__(self, render_factor: int = 32, output_path: int = 'output...
method norm (line 59) | def norm(self, img, render_factor=32, render_base=16):
method denorm (line 72) | def denorm(self, img):
method post_process (line 82) | def post_process(self, raw_color, orig):
method run_image (line 92) | def run_image(self, img):
method run_video (line 111) | def run_video(self, video):
method predict (line 144) | def predict(self, input):
method serving_method (line 158) | def serving_method(self, images, **kwargs):
method create_gradio_app (line 167) | def create_gradio_app(self):
FILE: modules/image/Image_editing/colorization/deoldify/test.py
class TestHubModule (line 14) | class TestHubModule(unittest.TestCase):
method setUpClass (line 17) | def setUpClass(cls) -> None:
method tearDownClass (line 28) | def tearDownClass(cls) -> None:
method test_run_image1 (line 32) | def test_run_image1(self):
method test_run_image2 (line 36) | def test_run_image2(self):
method test_run_image3 (line 40) | def test_run_image3(self):
method test_predict1 (line 43) | def test_predict1(self):
method test_predict2 (line 48) | def test_predict2(self):
FILE: modules/image/Image_editing/colorization/deoldify/utils.py
function cv2_to_base64 (line 12) | def cv2_to_base64(image):
function base64_to_cv2 (line 17) | def base64_to_cv2(b64str):
function is_listy (line 24) | def is_listy(x):
class Hook (line 28) | class Hook():
method __init__ (line 31) | def __init__(self, m, hook_func, is_forward=True, detach=True):
method hook_fn (line 37) | def hook_fn(self, module, input, output):
method remove (line 44) | def remove(self):
method __enter__ (line 50) | def __enter__(self, *args):
method __exit__ (line 53) | def __exit__(self, *args):
class Hooks (line 57) | class Hooks():
method __init__ (line 60) | def __init__(self, ms, hook_func, is_forward=True, detach=True):
method __getitem__ (line 68) | def __getitem__(self, i: int) -> Hook:
method __len__ (line 71) | def __len__(self) -> int:
method __iter__ (line 74) | def __iter__(self):
method stored (line 78) | def stored(self):
method remove (line 81) | def remove(self):
method __enter__ (line 86) | def __enter__(self, *args):
method __exit__ (line 89) | def __exit__(self, *args):
function _hook_inner (line 93) | def _hook_inner(m, i, o):
function hook_output (line 97) | def hook_output(module, detach=True, grad=False):
function hook_outputs (line 102) | def hook_outputs(modules, detach=True, grad=False):
function model_sizes (line 107) | def model_sizes(m, size=(64, 64)):
function dummy_eval (line 114) | def dummy_eval(m, size=(64, 64)):
function dummy_batch (line 120) | def dummy_batch(size=(64, 64), ch_in=3):
class _SpectralNorm (line 126) | class _SpectralNorm(nn.SpectralNorm):
method __init__ (line 128) | def __init__(self, weight_shape, dim=0, power_iters=1, eps=1e-12, dtyp...
method forward (line 131) | def forward(self, weight):
class Spectralnorm (line 149) | class Spectralnorm(paddle.nn.Layer):
method __init__ (line 151) | def __init__(self, layer, dim=0, power_iters=1, eps=1e-12, dtype='floa...
method forward (line 163) | def forward(self, x):
function video2frames (line 170) | def video2frames(video_path, outpath, **kargs):
function frames2video (line 200) | def frames2video(frame_path, video_path, r):
function is_image (line 211) | def is_image(input):
FILE: modules/image/Image_editing/colorization/photo_restoration/module.py
class PhotoRestoreModel (line 32) | class PhotoRestoreModel(nn.Layer):
method __init__ (line 41) | def __init__(self, visualization: bool = False):
method run_image (line 47) | def run_image(self,
method serving_method (line 75) | def serving_method(self, images, model_select):
FILE: modules/image/Image_editing/colorization/photo_restoration/test.py
class TestHubModule (line 14) | class TestHubModule(unittest.TestCase):
method setUpClass (line 16) | def setUpClass(cls) -> None:
method tearDownClass (line 27) | def tearDownClass(cls) -> None:
method test_run_image1 (line 31) | def test_run_image1(self):
method test_run_image2 (line 37) | def test_run_image2(self):
method test_run_image3 (line 43) | def test_run_image3(self):
FILE: modules/image/Image_editing/colorization/photo_restoration/utils.py
function cv2_to_base64 (line 6) | def cv2_to_base64(image):
function base64_to_cv2 (line 11) | def base64_to_cv2(b64str):
FILE: modules/image/Image_editing/colorization/user_guided_colorization/data_feed.py
class ColorizeHint (line 5) | class ColorizeHint:
method __init__ (line 22) | def __init__(self, percent: float, num_points: int = None, samp: str =...
method __call__ (line 28) | def __call__(self, data: np.ndarray, hint: np.ndarray, mask: np.ndarray):
class ColorizePreprocess (line 69) | class ColorizePreprocess:
method __init__ (line 85) | def __init__(self,
method __call__ (line 98) | def __call__(self, data_lab):
FILE: modules/image/Image_editing/colorization/user_guided_colorization/module.py
class UserGuidedColorization (line 34) | class UserGuidedColorization(nn.Layer):
method __init__ (line 44) | def __init__(self, use_tanh: bool = True, load_checkpoint: str = None):
method transforms (line 186) | def transforms(self, images: str) -> callable:
method set_config (line 191) | def set_config(self, classification: bool = True, prob: float = 1., nu...
method preprocess (line 195) | def preprocess(self, inputs: paddle.Tensor):
method forward (line 199) | def forward(self,
FILE: modules/image/Image_editing/colorization/user_guided_colorization/test.py
class TestHubModule (line 14) | class TestHubModule(unittest.TestCase):
method setUpClass (line 16) | def setUpClass(cls) -> None:
method tearDownClass (line 27) | def tearDownClass(cls) -> None:
method test_predict1 (line 31) | def test_predict1(self):
method test_predict2 (line 46) | def test_predict2(self):
method test_predict3 (line 61) | def test_predict3(self):
method test_predict4 (line 76) | def test_predict4(self):
FILE: modules/image/Image_editing/enhancement/fbcnn_color/fbcnn.py
function sequential (line 13) | def sequential(*args):
function conv (line 37) | def conv(in_channels=64,
class ResBlock (line 99) | class ResBlock(nn.Layer):
method __init__ (line 101) | def __init__(self,
method forward (line 118) | def forward(self, x):
function upsample_pixelshuffle (line 126) | def upsample_pixelshuffle(in_channels=64,
function upsample_upconv (line 149) | def upsample_upconv(in_channels=64,
function upsample_convtranspose (line 172) | def upsample_convtranspose(in_channels=64,
function downsample_strideconv (line 203) | def downsample_strideconv(in_channels=64,
function downsample_maxpool (line 222) | def downsample_maxpool(in_channels=64,
function downsample_avgpool (line 249) | def downsample_avgpool(in_channels=64,
class QFAttention (line 273) | class QFAttention(nn.Layer):
method __init__ (line 275) | def __init__(self,
method forward (line 292) | def forward(self, x, gamma, beta):
class FBCNN (line 299) | class FBCNN(nn.Layer):
method __init__ (line 301) | def __init__(self,
method forward (line 378) | def forward(self, x, qf_input=None):
FILE: modules/image/Image_editing/enhancement/fbcnn_color/module.py
function cv2_to_base64 (line 18) | def cv2_to_base64(image):
function base64_to_cv2 (line 23) | def base64_to_cv2(b64str):
class FBCNNColor (line 38) | class FBCNNColor(nn.Layer):
method __init__ (line 40) | def __init__(self):
method preprocess (line 48) | def preprocess(self, img: np.ndarray) -> np.ndarray:
method postprocess (line 54) | def postprocess(self, img: np.ndarray) -> np.ndarray:
method artifacts_removal (line 61) | def artifacts_removal(self,
method run_cmd (line 97) | def run_cmd(self, argvs):
method serving_method (line 119) | def serving_method(self, image, **kwargs):
FILE: modules/image/Image_editing/enhancement/fbcnn_color/test.py
class TestHubModule (line 14) | class TestHubModule(unittest.TestCase):
method setUpClass (line 17) | def setUpClass(cls) -> None:
method tearDownClass (line 28) | def tearDownClass(cls) -> None:
method test_artifacts_removal1 (line 32) | def test_artifacts_removal1(self):
method test_artifacts_removal2 (line 37) | def test_artifacts_removal2(self):
method test_artifacts_removal3 (line 44) | def test_artifacts_removal3(self):
method test_artifacts_removal4 (line 51) | def test_artifacts_removal4(self):
method test_artifacts_removal5 (line 54) | def test_artifacts_removal5(self):
FILE: modules/image/Image_editing/enhancement/fbcnn_gray/fbcnn.py
function sequential (line 13) | def sequential(*args):
function conv (line 37) | def conv(in_channels=64,
class ResBlock (line 99) | class ResBlock(nn.Layer):
method __init__ (line 101) | def __init__(self,
method forward (line 118) | def forward(self, x):
function upsample_pixelshuffle (line 126) | def upsample_pixelshuffle(in_channels=64,
function upsample_upconv (line 149) | def upsample_upconv(in_channels=64,
function upsample_convtranspose (line 172) | def upsample_convtranspose(in_channels=64,
function downsample_strideconv (line 203) | def downsample_strideconv(in_channels=64,
function downsample_maxpool (line 222) | def downsample_maxpool(in_channels=64,
function downsample_avgpool (line 249) | def downsample_avgpool(in_channels=64,
class QFAttention (line 273) | class QFAttention(nn.Layer):
method __init__ (line 275) | def __init__(self,
method forward (line 292) | def forward(self, x, gamma, beta):
class FBCNN (line 299) | class FBCNN(nn.Layer):
method __init__ (line 301) | def __init__(self,
method forward (line 378) | def forward(self, x, qf_input=None):
FILE: modules/image/Image_editing/enhancement/fbcnn_gray/module.py
function cv2_to_base64 (line 18) | def cv2_to_base64(image):
function base64_to_cv2 (line 23) | def base64_to_cv2(b64str):
class FBCNNGary (line 38) | class FBCNNGary(nn.Layer):
method __init__ (line 40) | def __init__(self):
method preprocess (line 48) | def preprocess(self, img: np.ndarray) -> np.ndarray:
method postprocess (line 53) | def postprocess(self, img: np.ndarray) -> np.ndarray:
method artifacts_removal (line 58) | def artifacts_removal(self,
method run_cmd (line 94) | def run_cmd(self, argvs):
method serving_method (line 116) | def serving_method(self, image, **kwargs):
FILE: modules/image/Image_editing/enhancement/fbcnn_gray/test.py
class TestHubModule (line 14) | class TestHubModule(unittest.TestCase):
method setUpClass (line 17) | def setUpClass(cls) -> None:
method tearDownClass (line 28) | def tearDownClass(cls) -> None:
method test_artifacts_removal1 (line 32) | def test_artifacts_removal1(self):
method test_artifacts_removal2 (line 37) | def test_artifacts_removal2(self):
method test_artifacts_removal3 (line 44) | def test_artifacts_removal3(self):
method test_artifacts_removal4 (line 51) | def test_artifacts_removal4(self):
method test_artifacts_removal5 (line 54) | def test_artifacts_removal5(self):
FILE: modules/image/Image_editing/super_resolution/dcscn/data_feed.py
function reader (line 13) | def reader(images=None, paths=None):
FILE: modules/image/Image_editing/super_resolution/dcscn/module.py
class Dcscn (line 38) | class Dcscn:
method __init__ (line 39) | def __init__(self):
method _set_config (line 43) | def _set_config(self):
method reconstruct (line 66) | def reconstruct(self, images=None, paths=None, use_gpu=False, visualiz...
method serving_method (line 128) | def serving_method(self, images, **kwargs):
method run_cmd (line 138) | def run_cmd(self, argvs):
method add_module_config_arg (line 162) | def add_module_config_arg(self):
method add_module_input_arg (line 175) | def add_module_input_arg(self):
FILE: modules/image/Image_editing/super_resolution/dcscn/processor.py
function cv2_to_base64 (line 12) | def cv2_to_base64(image):
function base64_to_cv2 (line 17) | def base64_to_cv2(b64str):
function postprocess (line 24) | def postprocess(data_out, org_im, org_im_shape, org_im_path, output_dir,...
function check_dir (line 61) | def check_dir(dir_path):
function get_save_image_name (line 69) | def get_save_image_name(org_im, org_im_path, output_dir):
FILE: modules/image/Image_editing/super_resolution/dcscn/test.py
class TestHubModule (line 14) | class TestHubModule(unittest.TestCase):
method setUpClass (line 16) | def setUpClass(cls) -> None:
method tearDownClass (line 27) | def tearDownClass(cls) -> None:
method test_reconstruct1 (line 32) | def test_reconstruct1(self):
method test_reconstruct2 (line 40) | def test_reconstruct2(self):
method test_reconstruct3 (line 48) | def test_reconstruct3(self):
method test_reconstruct4 (line 56) | def test_reconstruct4(self):
method test_reconstruct5 (line 64) | def test_reconstruct5(self):
method test_reconstruct6 (line 71) | def test_reconstruct6(self):
method test_save_inference_model (line 78) | def test_save_inference_model(self):
FILE: modules/image/Image_editing/super_resolution/falsr_a/data_feed.py
function reader (line 11) | def reader(images=None, paths=None):
FILE: modules/image/Image_editing/super_resolution/falsr_a/module.py
class Falsr_A (line 38) | class Falsr_A:
method __init__ (line 40) | def __init__(self):
method _set_config (line 44) | def _set_config(self):
method reconstruct (line 67) | def reconstruct(self, images=None, paths=None, use_gpu=False, visualiz...
method serving_method (line 124) | def serving_method(self, images, **kwargs):
method run_cmd (line 134) | def run_cmd(self, argvs):
method add_module_config_arg (line 159) | def add_module_config_arg(self):
method add_module_input_arg (line 180) | def add_module_input_arg(self):
method create_gradio_app (line 186) | def create_gradio_app(self):
FILE: modules/image/Image_editing/super_resolution/falsr_a/processor.py
function cv2_to_base64 (line 11) | def cv2_to_base64(image):
function base64_to_cv2 (line 16) | def base64_to_cv2(b64str):
function postprocess (line 23) | def postprocess(data_out, org_im, org_im_shape, org_im_path, output_dir,...
function check_dir (line 58) | def check_dir(dir_path):
function get_save_image_name (line 66) | def get_save_image_name(org_im, org_im_path, output_dir):
FILE: modules/image/Image_editing/super_resolution/falsr_a/test.py
class TestHubModule (line 14) | class TestHubModule(unittest.TestCase):
method setUpClass (line 17) | def setUpClass(cls) -> None:
method tearDownClass (line 28) | def tearDownClass(cls) -> None:
method test_reconstruct1 (line 33) | def test_reconstruct1(self):
method test_reconstruct2 (line 37) | def test_reconstruct2(self):
method test_reconstruct3 (line 41) | def test_reconstruct3(self):
method test_reconstruct4 (line 45) | def test_reconstruct4(self):
method test_reconstruct5 (line 49) | def test_reconstruct5(self):
method test_reconstruct6 (line 52) | def test_reconstruct6(self):
method test_save_inference_model (line 55) | def test_save_inference_model(self):
FILE: modules/image/Image_editing/super_resolution/falsr_b/data_feed.py
function reader (line 11) | def reader(images=None, paths=None):
FILE: modules/image/Image_editing/super_resolution/falsr_b/module.py
class Falsr_B (line 38) | class Falsr_B:
method __init__ (line 40) | def __init__(self):
method _set_config (line 44) | def _set_config(self):
method reconstruct (line 67) | def reconstruct(self, images=None, paths=None, use_gpu=False, visualiz...
method serving_method (line 124) | def serving_method(self, images, **kwargs):
method run_cmd (line 134) | def run_cmd(self, argvs):
method add_module_config_arg (line 159) | def add_module_config_arg(self):
method add_module_input_arg (line 180) | def add_module_input_arg(self):
method create_gradio_app (line 186) | def create_gradio_app(self):
FILE: modules/image/Image_editing/super_resolution/falsr_b/processor.py
function cv2_to_base64 (line 11) | def cv2_to_base64(image):
function base64_to_cv2 (line 16) | def base64_to_cv2(b64str):
function postprocess (line 23) | def postprocess(data_out, org_im, org_im_shape, org_im_path, output_dir,...
function check_dir (line 58) | def check_dir(dir_path):
function get_save_image_name (line 66) | def get_save_image_name(org_im, org_im_path, output_dir):
FILE: modules/image/Image_editing/super_resolution/falsr_b/test.py
class TestHubModule (line 14) | class TestHubModule(unittest.TestCase):
method setUpClass (line 17) | def setUpClass(cls) -> None:
method tearDownClass (line 28) | def tearDownClass(cls) -> None:
method test_reconstruct1 (line 33) | def test_reconstruct1(self):
method test_reconstruct2 (line 37) | def test_reconstruct2(self):
method test_reconstruct3 (line 41) | def test_reconstruct3(self):
method test_reconstruct4 (line 45) | def test_reconstruct4(self):
method test_reconstruct5 (line 49) | def test_reconstruct5(self):
method test_reconstruct6 (line 52) | def test_reconstruct6(self):
method test_save_inference_model (line 55) | def test_save_inference_model(self):
FILE: modules/image/Image_editing/super_resolution/falsr_c/data_feed.py
function reader (line 11) | def reader(images=None, paths=None):
FILE: modules/image/Image_editing/super_resolution/falsr_c/module.py
class Falsr_C (line 39) | class Falsr_C:
method __init__ (line 41) | def __init__(self):
method _set_config (line 45) | def _set_config(self):
method reconstruct (line 68) | def reconstruct(self, images=None, paths=None, use_gpu=False, visualiz...
method serving_method (line 125) | def serving_method(self, images, **kwargs):
method run_cmd (line 135) | def run_cmd(self, argvs):
method add_module_config_arg (line 160) | def add_module_config_arg(self):
method add_module_input_arg (line 181) | def add_module_input_arg(self):
method create_gradio_app (line 187) | def create_gradio_app(self):
FILE: modules/image/Image_editing/super_resolution/falsr_c/processor.py
function cv2_to_base64 (line 11) | def cv2_to_base64(image):
function base64_to_cv2 (line 16) | def base64_to_cv2(b64str):
function postprocess (line 23) | def postprocess(data_out, org_im, org_im_shape, org_im_path, output_dir,...
function check_dir (line 58) | def check_dir(dir_path):
function get_save_image_name (line 66) | def get_save_image_name(org_im, org_im_path, output_dir):
FILE: modules/image/Image_editing/super_resolution/falsr_c/test.py
class TestHubModule (line 14) | class TestHubModule(unittest.TestCase):
method setUpClass (line 17) | def setUpClass(cls) -> None:
method tearDownClass (line 28) | def tearDownClass(cls) -> None:
method test_reconstruct1 (line 33) | def test_reconstruct1(self):
method test_reconstruct2 (line 37) | def test_reconstruct2(self):
method test_reconstruct3 (line 41) | def test_reconstruct3(self):
method test_reconstruct4 (line 45) | def test_reconstruct4(self):
method test_reconstruct5 (line 49) | def test_reconstruct5(self):
method test_reconstruct6 (line 52) | def test_reconstruct6(self):
method test_save_inference_model (line 55) | def test_save_inference_model(self):
FILE: modules/image/Image_editing/super_resolution/realsr/module.py
class RealSRPredictor (line 36) | class RealSRPredictor(nn.Layer):
method __init__ (line 37) | def __init__(self, output='output', weight_path=None, load_checkpoint:...
method norm (line 58) | def norm(self, img):
method denorm (line 62) | def denorm(self, img):
method run_image (line 66) | def run_image(self, img):
method run_video (line 85) | def run_video(self, video):
method predict (line 119) | def predict(self, input):
method serving_method (line 140) | def serving_method(self, images, **kwargs):
FILE: modules/image/Image_editing/super_resolution/realsr/rrdb.py
class Registry (line 7) | class Registry(object):
method __init__ (line 23) | def __init__(self, name):
method _do_register (line 32) | def _do_register(self, name, obj):
method register (line 38) | def register(self, obj=None, name=None):
method get (line 58) | def get(self, name):
class ResidualDenseBlock_5C (line 66) | class ResidualDenseBlock_5C(nn.Layer):
method __init__ (line 67) | def __init__(self, nf=64, gc=32, bias=True):
method forward (line 77) | def forward(self, x):
class RRDB (line 86) | class RRDB(nn.Layer):
method __init__ (line 88) | def __init__(self, nf, gc=32):
method forward (line 94) | def forward(self, x):
function make_layer (line 101) | def make_layer(block, n_layers):
class RRDBNet (line 110) | class RRDBNet(nn.Layer):
method __init__ (line 111) | def __init__(self, in_nc, out_nc, nf, nb, gc=32):
method forward (line 126) | def forward(self, x):
FILE: modules/image/Image_editing/super_resolution/realsr/test.py
class TestHubModule (line 14) | class TestHubModule(unittest.TestCase):
method setUpClass (line 16) | def setUpClass(cls) -> None:
method tearDownClass (line 27) | def tearDownClass(cls) -> None:
method test_run_image1 (line 31) | def test_run_image1(self):
method test_run_image2 (line 37) | def test_run_image2(self):
method test_run_image3 (line 43) | def test_run_image3(self):
method test_predict1 (line 50) | def test_predict1(self):
method test_predict2 (line 57) | def test_predict2(self):
FILE: modules/image/Image_editing/super_resolution/realsr/utils.py
function video2frames (line 10) | def video2frames(video_path, outpath, **kargs):
function frames2video (line 39) | def frames2video(frame_path, video_path, r):
function is_image (line 52) | def is_image(input):
function cv2_to_base64 (line 61) | def cv2_to_base64(image):
function base64_to_cv2 (line 66) | def base64_to_cv2(b64str):
FILE: modules/image/Image_editing/super_resolution/swin2sr_real_sr_x4/module.py
function cv2_to_base64 (line 18) | def cv2_to_base64(image):
function base64_to_cv2 (line 23) | def base64_to_cv2(b64str):
class SwinIRMRealSR (line 38) | class SwinIRMRealSR(nn.Layer):
method __init__ (line 40) | def __init__(self):
method preprocess (line 59) | def preprocess(self, img: np.ndarray) -> np.ndarray:
method postprocess (line 65) | def postprocess(self, img: np.ndarray) -> np.ndarray:
method real_sr (line 72) | def real_sr(self,
method run_cmd (line 104) | def run_cmd(self, argvs):
method serving_method (line 122) | def serving_method(self, image, **kwargs):
FILE: modules/image/Image_editing/super_resolution/swin2sr_real_sr_x4/swin2sr.py
function _ntuple (line 11) | def _ntuple(n):
class Mlp (line 24) | class Mlp(nn.Layer):
method __init__ (line 26) | def __init__(self, in_features, hidden_features=None, out_features=Non...
method forward (line 35) | def forward(self, x):
function window_partition (line 44) | def window_partition(x, window_size):
function window_reverse (line 58) | def window_reverse(windows, window_size, H, W):
class WindowAttention (line 74) | class WindowAttention(nn.Layer):
method __init__ (line 87) | def __init__(self,
method forward (line 159) | def forward(self, x, mask=None):
method extra_repr (line 203) | def extra_repr(self) -> str:
method flops (line 207) | def flops(self, N):
class SwinTransformerBlock (line 221) | class SwinTransformerBlock(nn.Layer):
method __init__ (line 239) | def __init__(self,
method calculate_mask (line 288) | def calculate_mask(self, x_size):
method forward (line 317) | def forward(self, x, x_size):
method extra_repr (line 361) | def extra_repr(self) -> str:
method flops (line 365) | def flops(self):
class PatchMerging (line 380) | class PatchMerging(nn.Layer):
method __init__ (line 388) | def __init__(self, input_resolution, dim, norm_layer=nn.LayerNorm):
method forward (line 395) | def forward(self, x):
method extra_repr (line 418) | def extra_repr(self) -> str:
method flops (line 421) | def flops(self):
class BasicLayer (line 428) | class BasicLayer(nn.Layer):
method __init__ (line 447) | def __init__(self,
method forward (line 491) | def forward(self, x, x_size):
method extra_repr (line 498) | def extra_repr(self) -> str:
method flops (line 501) | def flops(self):
class PatchEmbed (line 510) | class PatchEmbed(nn.Layer):
method __init__ (line 520) | def __init__(self, img_size=224, patch_size=4, in_chans=3, embed_dim=9...
method forward (line 539) | def forward(self, x):
method flops (line 549) | def flops(self):
class RSTB (line 558) | class RSTB(nn.Layer):
method __init__ (line 579) | def __init__(self,
method forward (line 635) | def forward(self, x, x_size):
method flops (line 638) | def flops(self):
class PatchUnEmbed (line 649) | class PatchUnEmbed(nn.Layer):
method __init__ (line 659) | def __init__(self, img_size=224, patch_size=4, in_chans=3, embed_dim=9...
method forward (line 672) | def forward(self, x, x_size):
method flops (line 677) | def flops(self):
class Upsample (line 682) | class Upsample(nn.Sequential):
method __init__ (line 689) | def __init__(self, scale, num_feat):
class Upsample_hf (line 704) | class Upsample_hf(nn.Sequential):
method __init__ (line 711) | def __init__(self, scale, num_feat):
class UpsampleOneStep (line 726) | class UpsampleOneStep(nn.Sequential):
method __init__ (line 734) | def __init__(self, scale, num_feat, num_out_ch, input_resolution=None):
method flops (line 742) | def flops(self):
class Swin2SR (line 748) | class Swin2SR(nn.Layer):
method __init__ (line 774) | def __init__(self,
method check_image_size (line 951) | def check_image_size(self, x):
method forward_features (line 958) | def forward_features(self, x):
method forward_features_hf (line 973) | def forward_features_hf(self, x):
method forward (line 988) | def forward(self, x):
method flops (line 1059) | def flops(self):
FILE: modules/image/Image_editing/super_resolution/swin2sr_real_sr_x4/test.py
class TestHubModule (line 14) | class TestHubModule(unittest.TestCase):
method setUpClass (line 17) | def setUpClass(cls) -> None:
method tearDownClass (line 31) | def tearDownClass(cls) -> None:
method test_real_sr1 (line 35) | def test_real_sr1(self):
method test_real_sr2 (line 40) | def test_real_sr2(self):
method test_real_sr3 (line 45) | def test_real_sr3(self):
method test_real_sr4 (line 50) | def test_real_sr4(self):
method test_real_sr5 (line 53) | def test_real_sr5(self):
FILE: modules/image/Image_editing/super_resolution/swinir_l_real_sr_x4/module.py
function cv2_to_base64 (line 18) | def cv2_to_base64(image):
function base64_to_cv2 (line 23) | def base64_to_cv2(b64str):
class SwinIRMRealSR (line 38) | class SwinIRMRealSR(nn.Layer):
method __init__ (line 40) | def __init__(self):
method preprocess (line 59) | def preprocess(self, img: np.ndarray) -> np.ndarray:
method postprocess (line 65) | def postprocess(self, img: np.ndarray) -> np.ndarray:
method real_sr (line 72) | def real_sr(self,
method run_cmd (line 104) | def run_cmd(self, argvs):
method serving_method (line 122) | def serving_method(self, image, **kwargs):
FILE: modules/image/Image_editing/super_resolution/swinir_l_real_sr_x4/swinir.py
function to_2tuple (line 8) | def to_2tuple(x):
class Mlp (line 15) | class Mlp(nn.Layer):
method __init__ (line 17) | def __init__(self, in_features, hidden_features=None, out_features=Non...
method forward (line 26) | def forward(self, x):
function window_partition (line 35) | def window_partition(x, window_size):
function window_reverse (line 49) | def window_reverse(windows, window_size, H, W):
class WindowAttention (line 65) | class WindowAttention(nn.Layer):
method __init__ (line 78) | def __init__(self, dim, window_size, num_heads, qkv_bias=True, qk_scal...
method forward (line 113) | def forward(self, x, mask=None):
method extra_repr (line 147) | def extra_repr(self) -> str:
method flops (line 150) | def flops(self, N):
class SwinTransformerBlock (line 164) | class SwinTransformerBlock(nn.Layer):
method __init__ (line 182) | def __init__(self,
method calculate_mask (line 230) | def calculate_mask(self, x_size):
method forward (line 257) | def forward(self, x, x_size):
method extra_repr (line 299) | def extra_repr(self) -> str:
method flops (line 303) | def flops(self):
class PatchMerging (line 318) | class PatchMerging(nn.Layer):
method __init__ (line 326) | def __init__(self, input_resolution, dim, norm_layer=nn.LayerNorm):
method forward (line 333) | def forward(self, x):
method extra_repr (line 356) | def extra_repr(self) -> str:
method flops (line 359) | def flops(self):
class BasicLayer (line 366) | class BasicLayer(nn.Layer):
method __init__ (line 385) | def __init__(self,
method forward (line 429) | def forward(self, x, x_size):
method extra_repr (line 436) | def extra_repr(self) -> str:
method flops (line 439) | def flops(self):
class RSTB (line 448) | class RSTB(nn.Layer):
method __init__ (line 470) | def __init__(self,
method forward (line 528) | def forward(self, x, x_size):
method flops (line 531) | def flops(self):
class PatchEmbed (line 542) | class PatchEmbed(nn.Layer):
method __init__ (line 552) | def __init__(self, img_size=224, patch_size=4, in_chans=3, embed_dim=9...
method forward (line 570) | def forward(self, x):
method flops (line 576) | def flops(self):
class PatchUnEmbed (line 584) | class PatchUnEmbed(nn.Layer):
method __init__ (line 594) | def __init__(self, img_size=224, patch_size=4, in_chans=3, embed_dim=9...
method forward (line 607) | def forward(self, x, x_size):
method flops (line 612) | def flops(self):
class Upsample (line 617) | class Upsample(nn.Sequential):
method __init__ (line 624) | def __init__(self, scale, num_feat):
class UpsampleOneStep (line 639) | class UpsampleOneStep(nn.Sequential):
method __init__ (line 647) | def __init__(self, scale, num_feat, num_out_ch, input_resolution=None):
method flops (line 655) | def flops(self):
class SwinIR (line 661) | class SwinIR(nn.Layer):
method __init__ (line 688) | def __init__(self,
method _init_weights (line 827) | def _init_weights(self, m):
method check_image_size (line 835) | def check_image_size(self, x):
method forward_features (line 842) | def forward_features(self, x):
method forward (line 857) | def forward(self, x):
method flops (line 894) | def flops(self):
FILE: modules/image/Image_editing/super_resolution/swinir_l_real_sr_x4/test.py
class TestHubModule (line 14) | class TestHubModule(unittest.TestCase):
method setUpClass (line 17) | def setUpClass(cls) -> None:
method tearDownClass (line 31) | def tearDownClass(cls) -> None:
method test_real_sr1 (line 35) | def test_real_sr1(self):
method test_real_sr2 (line 40) | def test_real_sr2(self):
method test_real_sr3 (line 45) | def test_real_sr3(self):
method test_real_sr4 (line 50) | def test_real_sr4(self):
method test_real_sr5 (line 53) | def test_real_sr5(self):
FILE: modules/image/Image_editing/super_resolution/swinir_m_real_sr_x2/module.py
function cv2_to_base64 (line 18) | def cv2_to_base64(image):
function base64_to_cv2 (line 23) | def base64_to_cv2(b64str):
class SwinIRMRealSR (line 38) | class SwinIRMRealSR(nn.Layer):
method __init__ (line 40) | def __init__(self):
method preprocess (line 59) | def preprocess(self, img: np.ndarray) -> np.ndarray:
method postprocess (line 65) | def postprocess(self, img: np.ndarray) -> np.ndarray:
method real_sr (line 72) | def real_sr(self,
method run_cmd (line 104) | def run_cmd(self, argvs):
method serving_method (line 122) | def serving_method(self, image, **kwargs):
FILE: modules/image/Image_editing/super_resolution/swinir_m_real_sr_x2/swinir.py
function to_2tuple (line 8) | def to_2tuple(x):
class Mlp (line 15) | class Mlp(nn.Layer):
method __init__ (line 17) | def __init__(self, in_features, hidden_features=None, out_features=Non...
method forward (line 26) | def forward(self, x):
function window_partition (line 35) | def window_partition(x, window_size):
function window_reverse (line 49) | def window_reverse(windows, window_size, H, W):
class WindowAttention (line 65) | class WindowAttention(nn.Layer):
method __init__ (line 78) | def __init__(self, dim, window_size, num_heads, qkv_bias=True, qk_scal...
method forward (line 113) | def forward(self, x, mask=None):
method extra_repr (line 147) | def extra_repr(self) -> str:
method flops (line 150) | def flops(self, N):
class SwinTransformerBlock (line 164) | class SwinTransformerBlock(nn.Layer):
method __init__ (line 182) | def __init__(self,
method calculate_mask (line 230) | def calculate_mask(self, x_size):
method forward (line 257) | def forward(self, x, x_size):
method extra_repr (line 299) | def extra_repr(self) -> str:
method flops (line 303) | def flops(self):
class PatchMerging (line 318) | class PatchMerging(nn.Layer):
method __init__ (line 326) | def __init__(self, input_resolution, dim, norm_layer=nn.LayerNorm):
method forward (line 333) | def forward(self, x):
method extra_repr (line 356) | def extra_repr(self) -> str:
method flops (line 359) | def flops(self):
class BasicLayer (line 366) | class BasicLayer(nn.Layer):
method __init__ (line 385) | def __init__(self,
method forward (line 429) | def forward(self, x, x_size):
method extra_repr (line 436) | def extra_repr(self) -> str:
method flops (line 439) | def flops(self):
class RSTB (line 448) | class RSTB(nn.Layer):
method __init__ (line 470) | def __init__(self,
method forward (line 528) | def forward(self, x, x_size):
method flops (line 531) | def flops(self):
class PatchEmbed (line 542) | class PatchEmbed(nn.Layer):
method __init__ (line 552) | def __init__(self, img_size=224, patch_size=4, in_chans=3, embed_dim=9...
method forward (line 570) | def forward(self, x):
method flops (line 576) | def flops(self):
class PatchUnEmbed (line 584) | class PatchUnEmbed(nn.Layer):
method __init__ (line 594) | def __init__(self, img_size=224, patch_size=4, in_chans=3, embed_dim=9...
method forward (line 607) | def forward(self, x, x_size):
method flops (line 612) | def flops(self):
class Upsample (line 617) | class Upsample(nn.Sequential):
method __init__ (line 624) | def __init__(self, scale, num_feat):
class UpsampleOneStep (line 639) | class UpsampleOneStep(nn.Sequential):
method __init__ (line 647) | def __init__(self, scale, num_feat, num_out_ch, input_resolution=None):
method flops (line 655) | def flops(self):
class SwinIR (line 661) | class SwinIR(nn.Layer):
method __init__ (line 688) | def __init__(self,
method _init_weights (line 827) | def _init_weights(self, m):
method check_image_size (line 835) | def check_image_size(self, x):
method forward_features (line 842) | def forward_features(self, x):
method forward (line 857) | def forward(self, x):
method flops (line 894) | def flops(self):
FILE: modules/image/Image_editing/super_resolution/swinir_m_real_sr_x2/test.py
class TestHubModule (line 14) | class TestHubModule(unittest.TestCase):
method setUpClass (line 17) | def setUpClass(cls) -> None:
method tearDownClass (line 31) | def tearDownClass(cls) -> None:
method test_real_sr1 (line 35) | def test_real_sr1(self):
method test_real_sr2 (line 40) | def test_real_sr2(self):
method test_real_sr3 (line 45) | def test_real_sr3(self):
method test_real_sr4 (line 50) | def test_real_sr4(self):
method test_real_sr5 (line 53) | def test_real_sr5(self):
FILE: modules/image/Image_editing/super_resolution/swinir_m_real_sr_x4/module.py
function cv2_to_base64 (line 18) | def cv2_to_base64(image):
function base64_to_cv2 (line 23) | def base64_to_cv2(b64str):
class SwinIRMRealSR (line 38) | class SwinIRMRealSR(nn.Layer):
method __init__ (line 40) | def __init__(self):
method preprocess (line 59) | def preprocess(self, img: np.ndarray) -> np.ndarray:
method postprocess (line 65) | def postprocess(self, img: np.ndarray) -> np.ndarray:
method real_sr (line 72) | def real_sr(self,
method run_cmd (line 104) | def run_cmd(self, argvs):
method serving_method (line 122) | def serving_method(self, image, **kwargs):
FILE: modules/image/Image_editing/super_resolution/swinir_m_real_sr_x4/swinir.py
function to_2tuple (line 8) | def to_2tuple(x):
class Mlp (line 15) | class Mlp(nn.Layer):
method __init__ (line 17) | def __init__(self, in_features, hidden_features=None, out_features=Non...
method forward (line 26) | def forward(self, x):
function window_partition (line 35) | def window_partition(x, window_size):
function window_reverse (line 49) | def window_reverse(windows, window_size, H, W):
class WindowAttention (line 65) | class WindowAttention(nn.Layer):
method __init__ (line 78) | def __init__(self, dim, window_size, num_heads, qkv_bias=True, qk_scal...
method forward (line 113) | def forward(self, x, mask=None):
method extra_repr (line 147) | def extra_repr(self) -> str:
method flops (line 150) | def flops(self, N):
class SwinTransformerBlock (line 164) | class SwinTransformerBlock(nn.Layer):
method __init__ (line 182) | def __init__(self,
method calculate_mask (line 230) | def calculate_mask(self, x_size):
method forward (line 257) | def forward(self, x, x_size):
method extra_repr (line 299) | def extra_repr(self) -> str:
method flops (line 303) | def flops(self):
class PatchMerging (line 318) | class PatchMerging(nn.Layer):
method __init__ (line 326) | def __init__(self, input_resolution, dim, norm_layer=nn.LayerNorm):
method forward (line 333) | def forward(self, x):
method extra_repr (line 356) | def extra_repr(self) -> str:
method flops (line 359) | def flops(self):
class BasicLayer (line 366) | class BasicLayer(nn.Layer):
method __init__ (line 385) | def __init__(self,
method forward (line 429) | def forward(self, x, x_size):
method extra_repr (line 436) | def extra_repr(self) -> str:
method flops (line 439) | def flops(self):
class RSTB (line 448) | class RSTB(nn.Layer):
method __init__ (line 470) | def __init__(self,
method forward (line 528) | def forward(self, x, x_size):
method flops (line 531) | def flops(self):
class PatchEmbed (line 542) | class PatchEmbed(nn.Layer):
method __init__ (line 552) | def __init__(self, img_size=224, patch_size=4, in_chans=3, embed_dim=9...
method forward (line 570) | def forward(self, x):
method flops (line 576) | def flops(self):
class PatchUnEmbed (line 584) | class PatchUnEmbed(nn.Layer):
method __init__ (line 594) | def __init__(self, img_size=224, patch_size=4, in_chans=3, embed_dim=9...
method forward (line 607) | def forward(self, x, x_size):
method flops (line 612) | def flops(self):
class Upsample (line 617) | class Upsample(nn.Sequential):
method __init__ (line 624) | def __init__(self, scale, num_feat):
class UpsampleOneStep (line 639) | class UpsampleOneStep(nn.Sequential):
method __init__ (line 647) | def __init__(self, scale, num_feat, num_out_ch, input_resolution=None):
method flops (line 655) | def flops(self):
class SwinIR (line 661) | class SwinIR(nn.Layer):
method __init__ (line 688) | def __init__(self,
method _init_weights (line 827) | def _init_weights(self, m):
method check_image_size (line 835) | def check_image_size(self, x):
method forward_features (line 842) | def forward_features(self, x):
method forward (line 857) | def forward(self, x):
method flops (line 894) | def flops(self):
FILE: modules/image/Image_editing/super_resolution/swinir_m_real_sr_x4/test.py
class TestHubModule (line 14) | class TestHubModule(unittest.TestCase):
method setUpClass (line 17) | def setUpClass(cls) -> None:
method tearDownClass (line 31) | def tearDownClass(cls) -> None:
method test_real_sr1 (line 35) | def test_real_sr1(self):
method test_real_sr2 (line 40) | def test_real_sr2(self):
method test_real_sr3 (line 45) | def test_real_sr3(self):
method test_real_sr4 (line 50) | def test_real_sr4(self):
method test_real_sr5 (line 53) | def test_real_sr5(self):
FILE: modules/image/Image_gan/gan/first_order_motion/model.py
class FirstOrderPredictor (line 34) | class FirstOrderPredictor:
method __init__ (line 35) | def __init__(self,
method read_img (line 111) | def read_img(self, path):
method run (line 120) | def run(self, source_image, driving_video, ratio, image_size, output_d...
method load_checkpoints (line 212) | def load_checkpoints(self, config, checkpoint_path):
method make_animation (line 229) | def make_animation(self,
method find_best_frame_func (line 274) | def find_best_frame_func(self, source, driving):
method extract_bbox (line 299) | def extract_bbox(self, image):
method IOU (line 342) | def IOU(self, ax1, ay1, ax2, ay2, sa, bx1, by1, bx2, by2, sb):
FILE: modules/image/Image_gan/gan/first_order_motion/module.py
class FirstOrderMotion (line 32) | class FirstOrderMotion:
method __init__ (line 33) | def __init__(self):
method generate (line 37) | def generate(self,
method run_cmd (line 63) | def run_cmd(self, argvs: list):
method add_module_config_arg (line 88) | def add_module_config_arg(self):
method add_module_input_arg (line 98) | def add_module_input_arg(self):
FILE: modules/image/Image_gan/gan/photopen/model.py
class PhotoPenPredictor (line 26) | class PhotoPenPredictor:
method __init__ (line 27) | def __init__(self, weight_path, gen_cfg):
method run (line 50) | def run(self, image):
FILE: modules/image/Image_gan/gan/photopen/module.py
class Photopen (line 36) | class Photopen:
method __init__ (line 37) | def __init__(self):
method photo_transfer (line 42) | def photo_transfer(self,
method run_cmd (line 86) | def run_cmd(self, argvs: list):
method serving_method (line 110) | def serving_method(self, images, **kwargs):
method add_module_config_arg (line 119) | def add_module_config_arg(self):
method add_module_input_arg (line 129) | def add_module_input_arg(self):
FILE: modules/image/Image_gan/gan/photopen/util.py
function base64_to_cv2 (line 7) | def base64_to_cv2(b64str):
FILE: modules/image/Image_gan/gan/pixel2style2pixel/model.py
function run_alignment (line 69) | def run_alignment(image):
class AttrDict (line 148) | class AttrDict(dict):
method __init__ (line 149) | def __init__(self, *args, **kwargs):
class Pixel2Style2PixelPredictor (line 154) | class Pixel2Style2PixelPredictor:
method __init__ (line 155) | def __init__(self,
method run (line 195) | def run(self, image):
FILE: modules/image/Image_gan/gan/pixel2style2pixel/module.py
class pixel2style2pixel (line 38) | class pixel2style2pixel:
method __init__ (line 39) | def __init__(self):
method style_transfer (line 44) | def style_transfer(self,
method run_cmd (line 90) | def run_cmd(self, argvs: list):
method serving_method (line 114) | def serving_method(self, images, **kwargs):
method add_module_config_arg (line 123) | def add_module_config_arg(self):
method add_module_input_arg (line 133) | def add_module_input_arg(self):
FILE: modules/image/Image_gan/gan/pixel2style2pixel/util.py
function base64_to_cv2 (line 6) | def base64_to_cv2(b64str):
FILE: modules/image/Image_gan/gan/stgan_bald/data_feed.py
function reader (line 12) | def reader(images=None, paths=None, org_labels=None, target_labels=None):
FILE: modules/image/Image_gan/gan/stgan_bald/module.py
function check_attribute_conflict (line 26) | def check_attribute_conflict(label_batch):
class StganBald (line 50) | class StganBald:
method __init__ (line 51) | def __init__(self):
method _set_config (line 56) | def _set_config(self):
method bald (line 83) | def bald(self,
method serving_method (line 172) | def serving_method(self, images, **kwargs):
FILE: modules/image/Image_gan/gan/stgan_bald/processor.py
function cv2_to_base64 (line 12) | def cv2_to_base64(image):
function base64_to_cv2 (line 17) | def base64_to_cv2(b64str):
function postprocess (line 24) | def postprocess(data_out,
function check_dir (line 64) | def check_dir(dir_path):
function get_save_image_name (line 72) | def get_save_image_name(org_im_path, output_dir, num):
FILE: modules/image/Image_gan/gan/stgan_bald/test.py
class TestHubModule (line 11) | class TestHubModule(unittest.TestCase):
method setUpClass (line 13) | def setUpClass(cls) -> None:
method tearDownClass (line 24) | def tearDownClass(cls) -> None:
method test_bald1 (line 29) | def test_bald1(self):
method test_bald2 (line 40) | def test_bald2(self):
method test_bald3 (line 51) | def test_bald3(self):
method test_bald4 (line 63) | def test_bald4(self):
method test_bald5 (line 70) | def test_bald5(self):
method test_save_inference_model (line 77) | def test_save_inference_model(self):
FILE: modules/image/Image_gan/gan/styleganv2_editing/basemodel.py
function get_mean_style (line 42) | def get_mean_style(generator):
function sample (line 59) | def sample(generator, mean_style, n_sample):
function style_mixing (line 70) | def style_mixing(generator, mean_style, n_source, n_target):
class StyleGANv2Predictor (line 97) | class StyleGANv2Predictor:
method __init__ (line 98) | def __init__(self,
method run (line 131) | def run(self, n_row=3, n_col=5):
FILE: modules/image/Image_gan/gan/styleganv2_editing/model.py
function make_image (line 30) | def make_image(tensor):
class StyleGANv2EditingPredictor (line 34) | class StyleGANv2EditingPredictor(StyleGANv2Predictor):
method __init__ (line 35) | def __init__(self, model_type=None, direction_path=None, **kwargs):
method run (line 44) | def run(self, latent, direction, offset):
FILE: modules/image/Image_gan/gan/styleganv2_editing/module.py
class styleganv2_editing (line 38) | class styleganv2_editing:
method __init__ (line 39) | def __init__(self):
method generate (line 45) | def generate(self,
method run_cmd (line 98) | def run_cmd(self, argvs: list):
method serving_method (line 124) | def serving_method(self, images, **kwargs):
method add_module_config_arg (line 133) | def add_module_config_arg(self):
method add_module_input_arg (line 143) | def add_module_input_arg(self):
FILE: modules/image/Image_gan/gan/styleganv2_editing/util.py
function base64_to_cv2 (line 6) | def base64_to_cv2(b64str):
FILE: modules/image/Image_gan/gan/styleganv2_mixing/basemodel.py
function get_mean_style (line 42) | def get_mean_style(generator):
function sample (line 59) | def sample(generator, mean_style, n_sample):
function style_mixing (line 70) | def style_mixing(generator, mean_style, n_source, n_target):
class StyleGANv2Predictor (line 97) | class StyleGANv2Predictor:
method __init__ (line 98) | def __init__(self,
method run (line 131) | def run(self, n_row=3, n_col=5):
FILE: modules/image/Image_gan/gan/styleganv2_mixing/model.py
function make_image (line 23) | def make_image(tensor):
class StyleGANv2MixingPredictor (line 27) | class StyleGANv2MixingPredictor(StyleGANv2Predictor):
method run (line 29) | def run(self, latent1, latent2, weights=[0.5] * 18):
FILE: modules/image/Image_gan/gan/styleganv2_mixing/module.py
class styleganv2_mixing (line 38) | class styleganv2_mixing:
method __init__ (line 39) | def __init__(self):
method generate (line 44) | def generate(self,
method run_cmd (line 100) | def run_cmd(self, argvs: list):
method serving_method (line 128) | def serving_method(self, images, **kwargs):
method add_module_config_arg (line 140) | def add_module_config_arg(self):
method add_module_input_arg (line 150) | def add_module_input_arg(self):
FILE: modules/image/Image_gan/gan/styleganv2_mixing/util.py
function base64_to_cv2 (line 6) | def base64_to_cv2(b64str):
FILE: modules/image/Image_gan/gan/wav2lip/model.py
class Wav2LipPredictor (line 18) | class Wav2LipPredictor:
method __init__ (line 19) | def __init__(self,
method get_smoothened_boxes (line 52) | def get_smoothened_boxes(self, boxes, T):
method face_detect (line 61) | def face_detect(self, images):
method datagen (line 102) | def datagen(self, frames, mels):
method run (line 150) | def run(self, face, audio_seq, output_dir, visualization=True):
FILE: modules/image/Image_gan/gan/wav2lip/module.py
class wav2lip (line 29) | class wav2lip:
method __init__ (line 30) | def __init__(self):
method wav2lip_transfer (line 48) | def wav2lip_transfer(self, face, audio, output_dir='./output_result/',...
method run_cmd (line 62) | def run_cmd(self, argvs: list):
method add_module_config_arg (line 86) | def add_module_config_arg(self):
method add_module_input_arg (line 96) | def add_module_input_arg(self):
FILE: modules/image/Image_gan/style_transfer/ID_Photo_GEN/module.py
class ID_Photo_GEN (line 19) | class ID_Photo_GEN(nn.Layer):
method __init__ (line 20) | def __init__(self):
method load_datas (line 30) | def load_datas(paths, images):
method preprocess (line 47) | def preprocess(self, images, batch_size, use_gpu):
method predict (line 133) | def predict(self, input_datas):
method postprocess (line 151) | def postprocess(faces, masks, visualization, output_dir):
method Photo_GEN (line 175) | def Photo_GEN(self, images=None, paths=None, batch_size=1, output_dir=...
FILE: modules/image/Image_gan/style_transfer/Photo2Cartoon/model/networks.py
class ResnetGenerator (line 6) | class ResnetGenerator(nn.Layer):
method __init__ (line 7) | def __init__(self, ngf=32, img_size=256, n_blocks=4, light=True):
method forward (line 91) | def forward(self, x):
class ConvBlock (line 131) | class ConvBlock(nn.Layer):
method __init__ (line 132) | def __init__(self, dim_in, dim_out):
method __convblock (line 147) | def __convblock(dim_in, dim_out):
method forward (line 152) | def forward(self, x):
class HourGlassBlock (line 166) | class HourGlassBlock(nn.Layer):
method __init__ (line 167) | def __init__(self, dim_in):
method forward (line 179) | def forward(self, x):
class HourGlass (line 196) | class HourGlass(nn.Layer):
method __init__ (line 197) | def __init__(self, dim_in, dim_out, use_res=True):
method forward (line 212) | def forward(self, x):
class ResnetBlock (line 225) | class ResnetBlock(nn.Layer):
method __init__ (line 226) | def __init__(self, dim, use_bias=False):
method forward (line 244) | def forward(self, x):
class ResnetSoftAdaLINBlock (line 249) | class ResnetSoftAdaLINBlock(nn.Layer):
method __init__ (line 250) | def __init__(self, dim, use_bias=False):
method forward (line 261) | def forward(self, x, content_features, style_features):
class SoftAdaLIN (line 273) | class SoftAdaLIN(nn.Layer):
method __init__ (line 274) | def __init__(self, num_features, eps=1e-5):
method forward (line 290) | def forward(self, x, content_features, style_features):
class AdaLIN (line 305) | class AdaLIN(nn.Layer):
method __init__ (line 306) | def __init__(self, num_features, eps=1e-5):
method forward (line 311) | def forward(self, x, gamma, beta):
class LIN (line 323) | class LIN(nn.Layer):
method __init__ (line 324) | def __init__(self, num_features, eps=1e-5):
method forward (line 331) | def forward(self, x):
FILE: modules/image/Image_gan/style_transfer/Photo2Cartoon/module.py
class Photo2Cartoon (line 20) | class Photo2Cartoon(nn.Layer):
method __init__ (line 21) | def __init__(self):
method load_datas (line 41) | def load_datas(paths, images):
method preprocess (line 58) | def preprocess(self, images, batch_size, use_gpu):
method predict (line 167) | def predict(self, input_datas):
method postprocess (line 185) | def postprocess(outputs, masks, visualization, output_dir):
method Cartoon_GEN (line 210) | def Cartoon_GEN(self,
FILE: modules/image/Image_gan/style_transfer/U2Net_Portrait/module.py
class U2Net_Portrait (line 18) | class U2Net_Portrait(nn.Layer):
method __init__ (line 19) | def __init__(self):
method predict (line 26) | def predict(self, input_datas):
method Portrait_GEN (line 37) | def Portrait_GEN(self,
FILE: modules/image/Image_gan/style_transfer/U2Net_Portrait/processor.py
class Processor (line 9) | class Processor():
method __init__ (line 10) | def __init__(self, paths, images, batch_size, face_detection=True, sca...
method load_datas (line 18) | def load_datas(self, paths, images):
method preprocess (line 35) | def preprocess(self, imgs, batch_size=1, face_detection=True, scale=1):
method normPRED (line 110) | def normPRED(self, d):
method postprocess (line 119) | def postprocess(self, outputs, visualization=False, output_dir='output'):
FILE: modules/image/Image_gan/style_transfer/U2Net_Portrait/u2net.py
class REBNCONV (line 8) | class REBNCONV(nn.Layer):
method __init__ (line 9) | def __init__(self, in_ch=3, out_ch=3, dirate=1):
method forward (line 16) | def forward(self, x):
function _upsample_like (line 25) | def _upsample_like(src, tar):
class RSU7 (line 33) | class RSU7(nn.Layer): #UNet07DRES(nn.Layer):
method __init__ (line 34) | def __init__(self, in_ch=3, mid_ch=12, out_ch=3):
method forward (line 65) | def forward(self, x):
class RSU6 (line 110) | class RSU6(nn.Layer): #UNet06DRES(nn.Layer):
method __init__ (line 111) | def __init__(self, in_ch=3, mid_ch=12, out_ch=3):
method forward (line 138) | def forward(self, x):
class RSU5 (line 178) | class RSU5(nn.Layer): #UNet05DRES(nn.Layer):
method __init__ (line 179) | def __init__(self, in_ch=3, mid_ch=12, out_ch=3):
method forward (line 202) | def forward(self, x):
class RSU4 (line 236) | class RSU4(nn.Layer): #UNet04DRES(nn.Layer):
method __init__ (line 237) | def __init__(self, in_ch=3, mid_ch=12, out_ch=3):
method forward (line 256) | def forward(self, x):
class RSU4F (line 284) | class RSU4F(nn.Layer): #UNet04FRES(nn.Layer):
method __init__ (line 285) | def __init__(self, in_ch=3, mid_ch=12, out_ch=3):
method forward (line 300) | def forward(self, x):
class U2NET (line 320) | class U2NET(nn.Layer):
method __init__ (line 321) | def __init__(self, in_ch=3, out_ch=1):
method forward (line 357) | def forward(self, x):
class U2NETP (line 424) | class U2NETP(nn.Layer):
method __init__ (line 425) | def __init__(self, in_ch=3, out_ch=1):
method forward (line 461) | def forward(self, x):
FILE: modules/image/Image_gan/style_transfer/UGATIT_100w/model.py
class Model (line 9) | class Model():
method __init__ (line 11) | def __init__(self, modelpath, use_gpu=False, use_mkldnn=True, combined...
method load_model (line 22) | def load_model(self, modelpath, use_gpu, use_mkldnn, combined):
method predict (line 61) | def predict(self, input_datas):
FILE: modules/image/Image_gan/style_transfer/UGATIT_100w/module.py
class UGATIT_100w (line 18) | class UGATIT_100w(Module):
method __init__ (line 20) | def __init__(self, name=None, use_gpu=False):
method style_transfer (line 28) | def style_transfer(self, images=None, paths=None, batch_size=1, output...
method serving_method (line 43) | def serving_method(self, images, **kwargs):
FILE: modules/image/Image_gan/style_transfer/UGATIT_100w/processor.py
function check_dir (line 10) | def check_dir(dir_path):
function base64_to_cv2 (line 19) | def base64_to_cv2(b64str):
function cv2_to_base64 (line 27) | def cv2_to_base64(image):
class Processor (line 33) | class Processor():
method __init__ (line 35) | def __init__(self, images=None, paths=None, output_dir='output', batch...
method load_datas (line 49) | def load_datas(self):
method preprocess (line 66) | def preprocess(self):
method postprocess (line 95) | def postprocess(self, outputs, visualization):
FILE: modules/image/Image_gan/style_transfer/UGATIT_83w/model.py
class Model (line 9) | class Model():
method __init__ (line 11) | def __init__(self, modelpath, use_gpu=False, use_mkldnn=True, combined...
method load_model (line 22) | def load_model(self, modelpath, use_gpu, use_mkldnn, combined):
method predict (line 61) | def predict(self, input_datas):
FILE: modules/image/Image_gan/style_transfer/UGATIT_83w/module.py
class UGATIT_83w (line 18) | class UGATIT_83w(Module):
method __init__ (line 20) | def __init__(self, name=None, use_gpu=False):
method style_transfer (line 28) | def style_transfer(self, images=None, paths=None, batch_size=1, output...
method serving_method (line 43) | def serving_method(self, images, **kwargs):
FILE: modules/image/Image_gan/style_transfer/UGATIT_83w/processor.py
function check_dir (line 10) | def check_dir(dir_path):
function base64_to_cv2 (line 19) | def base64_to_cv2(b64str):
function cv2_to_base64 (line 27) | def cv2_to_base64(image):
class Processor (line 33) | class Processor():
method __init__ (line 35) | def __init__(self, images=None, paths=None, output_dir='output', batch...
method load_datas (line 49) | def load_datas(self):
method preprocess (line 66) | def preprocess(self):
method postprocess (line 95) | def postprocess(self, outputs, visualization):
FILE: modules/image/Image_gan/style_transfer/UGATIT_92w/model.py
class Model (line 9) | class Model():
method __init__ (line 11) | def __init__(self, modelpath, use_gpu=False, use_mkldnn=True, combined...
method load_model (line 22) | def load_model(self, modelpath, use_gpu, use_mkldnn, combined):
method predict (line 61) | def predict(self, input_datas):
FILE: modules/image/Image_gan/style_transfer/UGATIT_92w/module.py
class UGATIT_92w (line 18) | class UGATIT_92w(Module):
method __init__ (line 20) | def __init__(self, name=None, use_gpu=False):
method style_transfer (line 28) | def style_transfer(self, images=None, paths=None, batch_size=1, output...
method serving_method (line 43) | def serving_method(self, images, **kwargs):
FILE: modules/image/Image_gan/style_transfer/UGATIT_92w/processor.py
function check_dir (line 10) | def check_dir(dir_path):
function base64_to_cv2 (line 19) | def base64_to_cv2(b64str):
function cv2_to_base64 (line 27) | def cv2_to_base64(image):
class Processor (line 33) | class Processor():
method __init__ (line 35) | def __init__(self, images=None, paths=None, output_dir='output', batch...
method load_datas (line 49) | def load_datas(self):
method preprocess (line 66) | def preprocess(self):
method postprocess (line 95) | def postprocess(self, outputs, visualization):
FILE: modules/image/Image_gan/style_transfer/animegan_v1_hayao_60/model.py
class InferenceModel (line 10) | class InferenceModel:
method __init__ (line 12) | def __init__(self, modelpath, use_gpu=False, gpu_id=0, use_mkldnn=Fals...
method __repr__ (line 23) | def __repr__(self):
method __call__ (line 31) | def __call__(self, *input_datas, batch_size=1):
method load_config (line 38) | def load_config(self, modelpath, use_gpu, gpu_id, use_mkldnn, cpu_thre...
method eval (line 98) | def eval(self):
method forward (line 124) | def forward(self, *input_datas, batch_size=1):
FILE: modules/image/Image_gan/style_transfer/animegan_v1_hayao_60/module.py
class Animegan_V1_Hayao_60 (line 19) | class Animegan_V1_Hayao_60:
method __init__ (line 21) | def __init__(self, use_gpu=False, use_mkldnn=False):
method style_transfer (line 31) | def style_transfer(self,
method serving_method (line 60) | def serving_method(self, images, **kwargs):
FILE: modules/image/Image_gan/style_transfer/animegan_v1_hayao_60/processor.py
function check_dir (line 11) | def check_dir(dir_path):
function base64_to_cv2 (line 20) | def base64_to_cv2(b64str):
function cv2_to_base64 (line 28) | def cv2_to_base64(image):
class Processor (line 34) | class Processor():
method __init__ (line 36) | def __init__(self, images=None, paths=None, batch_size=1, output_dir='...
method load_datas (line 53) | def load_datas(self):
method preprocess (line 70) | def preprocess(self):
method postprocess (line 109) | def postprocess(self, outputs, visualization):
FILE: modules/image/Image_gan/style_transfer/animegan_v1_hayao_60/test.py
class TestHubModule (line 14) | class TestHubModule(unittest.TestCase):
method setUpClass (line 17) | def setUpClass(cls) -> None:
method tearDownClass (line 31) | def tearDownClass(cls) -> None:
method test_style_transfer1 (line 35) | def test_style_transfer1(self):
method test_style_transfer2 (line 39) | def test_style_transfer2(self):
method test_style_transfer3 (line 43) | def test_style_transfer3(self):
method test_style_transfer4 (line 47) | def test_style_transfer4(self):
method test_style_transfer5 (line 51) | def test_style_transfer5(self):
method test_style_transfer6 (line 54) | def test_style_transfer6(self):
FILE: modules/image/Image_gan/style_transfer/animegan_v2_hayao_64/model.py
class InferenceModel (line 10) | class InferenceModel:
method __init__ (line 12) | def __init__(self, modelpath, use_gpu=False, gpu_id=0, use_mkldnn=Fals...
method __repr__ (line 23) | def __repr__(self):
method __call__ (line 31) | def __call__(self, *input_datas, batch_size=1):
method load_config (line 38) | def load_config(self, modelpath, use_gpu, gpu_id, use_mkldnn, cpu_thre...
method eval (line 98) | def eval(self):
method forward (line 124) | def forward(self, *input_datas, batch_size=1):
FILE: modules/image/Image_gan/style_transfer/animegan_v2_hayao_64/module.py
class Animegan_V2_Hayao_64 (line 19) | class Animegan_V2_Hayao_64:
method __init__ (line 21) | def __init__(self, use_gpu=False, use_mkldnn=False):
method style_transfer (line 31) | def style_transfer(self,
method serving_method (line 60) | def serving_method(self, images, **kwargs):
FILE: modules/image/Image_gan/style_transfer/animegan_v2_hayao_64/processor.py
function check_dir (line 11) | def check_dir(dir_path):
function base64_to_cv2 (line 20) | def base64_to_cv2(b64str):
function cv2_to_base64 (line 28) | def cv2_to_base64(image):
class Processor (line 34) | class Processor():
method __init__ (line 36) | def __init__(self, images=None, paths=None, batch_size=1, output_dir='...
method load_datas (line 53) | def load_datas(self):
method preprocess (line 70) | def preprocess(self):
method postprocess (line 109) | def postprocess(self, outputs, visualization):
FILE: modules/image/Image_gan/style_transfer/animegan_v2_hayao_64/test.py
class TestHubModule (line 14) | class TestHubModule(unittest.TestCase):
method setUpClass (line 17) | def setUpClass(cls) -> None:
method tearDownClass (line 31) | def tearDownClass(cls) -> None:
method test_style_transfer1 (line 35) | def test_style_transfer1(self):
method test_style_transfer2 (line 39) | def test_style_transfer2(self):
method test_style_transfer3 (line 43) | def test_style_transfer3(self):
method test_style_transfer4 (line 47) | def test_style_transfer4(self):
method test_style_transfer5 (line 51) | def test_style_transfer5(self):
method test_style_transfer6 (line 54) | def test_style_transfer6(self):
FILE: modules/image/Image_gan/style_transfer/animegan_v2_hayao_99/model.py
class InferenceModel (line 10) | class InferenceModel:
method __init__ (line 12) | def __init__(self, modelpath, use_gpu=False, gpu_id=0, use_mkldnn=Fals...
method __repr__ (line 23) | def __repr__(self):
method __call__ (line 31) | def __call__(self, *input_datas, batch_size=1):
method load_config (line 38) | def load_config(self, modelpath, use_gpu, gpu_id, use_mkldnn, cpu_thre...
method eval (line 98) | def eval(self):
method forward (line 124) | def forward(self, *input_datas, batch_size=1):
FILE: modules/image/Image_gan/style_transfer/animegan_v2_hayao_99/module.py
class Animegan_V2_Hayao_99 (line 19) | class Animegan_V2_Hayao_99:
method __init__ (line 21) | def __init__(self, use_gpu=False, use_mkldnn=False):
method style_transfer (line 31) | def style_transfer(self,
method serving_method (line 60) | def serving_method(self, images, **kwargs):
FILE: modules/image/Image_gan/style_transfer/animegan_v2_hayao_99/processor.py
function check_dir (line 11) | def check_dir(dir_path):
function base64_to_cv2 (line 20) | def base64_to_cv2(b64str):
function cv2_to_base64 (line 28) | def cv2_to_base64(image):
class Processor (line 34) | class Processor():
method __init__ (line 36) | def __init__(self, images=None, paths=None, batch_size=1, output_dir='...
method load_datas (line 53) | def load_datas(self):
method preprocess (line 70) | def preprocess(self):
method postprocess (line 109) | def postprocess(self, outputs, visualization):
FILE: modules/image/Image_gan/style_transfer/animegan_v2_hayao_99/test.py
class TestHubModule (line 14) | class TestHubModule(unittest.TestCase):
method setUpClass (line 17) | def setUpClass(cls) -> None:
method tearDownClass (line 31) | def tearDownClass(cls) -> None:
method test_style_transfer1 (line 35) | def test_style_transfer1(self):
method test_style_transfer2 (line 39) | def test_style_transfer2(self):
method test_style_transfer3 (line 43) | def test_style_transfer3(self):
method test_style_transfer4 (line 47) | def test_style_transfer4(self):
method test_style_transfer5 (line 51) | def test_style_transfer5(self):
method test_style_transfer6 (line 54) | def test_style_transfer6(self):
FILE: modules/image/Image_gan/style_transfer/animegan_v2_paprika_54/model.py
class InferenceModel (line 10) | class InferenceModel:
method __init__ (line 12) | def __init__(self, modelpath, use_gpu=False, gpu_id=0, use_mkldnn=Fals...
method __repr__ (line 23) | def __repr__(self):
method __call__ (line 31) | def __call__(self, *input_datas, batch_size=1):
method load_config (line 38) | def load_config(self, modelpath, use_gpu, gpu_id, use_mkldnn, cpu_thre...
method eval (line 98) | def eval(self):
method forward (line 124) | def forward(self, *input_datas, batch_size=1):
FILE: modules/image/Image_gan/style_transfer/animegan_v2_paprika_54/module.py
class Animegan_V2_Paprika_54 (line 19) | class Animegan_V2_Paprika_54:
method __init__ (line 21) | def __init__(self, use_gpu=False, use_mkldnn=False):
method style_transfer (line 31) | def style_transfer(self,
method serving_method (line 60) | def serving_method(self, images, **kwargs):
FILE: modules/image/Image_gan/style_transfer/animegan_v2_paprika_54/processor.py
function check_dir (line 11) | def check_dir(dir_path):
function base64_to_cv2 (line 20) | def base64_to_cv2(b64str):
function cv2_to_base64 (line 28) | def cv2_to_base64(image):
class Processor (line 34) | class Processor():
method __init__ (line 36) | def __init__(self, images=None, paths=None, batch_size=1, output_dir='...
method load_datas (line 53) | def load_datas(self):
method preprocess (line 70) | def preprocess(self):
method postprocess (line 109) | def postprocess(self, outputs, visualization):
FILE: modules/image/Image_gan/style_transfer/animegan_v2_paprika_54/test.py
class TestHubModule (line 14) | class TestHubModule(unittest.TestCase):
method setUpClass (line 17) | def setUpClass(cls) -> None:
method tearDownClass (line 31) | def tearDownClass(cls) -> None:
method test_style_transfer1 (line 35) | def test_style_transfer1(self):
method test_style_transfer2 (line 39) | def test_style_transfer2(self):
method test_style_transfer3 (line 43) | def test_style_transfer3(self):
method test_style_transfer4 (line 47) | def test_style_transfer4(self):
method test_style_transfer5 (line 51) | def test_style_transfer5(self):
method test_style_transfer6 (line 54) | def test_style_transfer6(self):
FILE: modules/image/Image_gan/style_transfer/animegan_v2_paprika_74/model.py
class InferenceModel (line 10) | class InferenceModel:
method __init__ (line 12) | def __init__(self, modelpath, use_gpu=False, gpu_id=0, use_mkldnn=Fals...
method __repr__ (line 23) | def __repr__(self):
method __call__ (line 31) | def __call__(self, *input_datas, batch_size=1):
method load_config (line 38) | def load_config(self, modelpath, use_gpu, gpu_id, use_mkldnn, cpu_thre...
method eval (line 98) | def eval(self):
method forward (line 124) | def forward(self, *input_datas, batch_size=1):
FILE: modules/image/Image_gan/style_transfer/animegan_v2_paprika_74/module.py
class Animegan_V2_Paprika_74 (line 19) | class Animegan_V2_Paprika_74:
method __init__ (line 21) | def __init__(self, use_gpu=False, use_mkldnn=False):
method style_transfer (line 31) | def style_transfer(self,
method serving_method (line 60) | def serving_method(self, images, **kwargs):
FILE: modules/image/Image_gan/style_transfer/animegan_v2_paprika_74/processor.py
function check_dir (line 11) | def check_dir(dir_path):
function base64_to_cv2 (line 20) | def base64_to_cv2(b64str):
function cv2_to_base64 (line 28) | def cv2_to_base64(image):
class Processor (line 34) | class Processor():
method __init__ (line 36) | def __init__(self, images=None, paths=None, batch_size=1, output_dir='...
method load_datas (line 53) | def load_datas(self):
method preprocess (line 70) | def preprocess(self):
method postprocess (line 109) | def postprocess(self, outputs, visualization):
FILE: modules/image/Image_gan/style_transfer/animegan_v2_paprika_74/test.py
class TestHubModule (line 14) | class TestHubModule(unittest.TestCase):
method setUpClass (line 17) | def setUpClass(cls) -> None:
method tearDownClass (line 31) | def tearDownClass(cls) -> None:
method test_style_transfer1 (line 35) | def test_style_transfer1(self):
method test_style_transfer2 (line 39) | def test_style_transfer2(self):
method test_style_transfer3 (line 43) | def test_style_transfer3(self):
method test_style_transfer4 (line 47) | def test_style_transfer4(self):
method test_style_transfer5 (line 51) | def test_style_transfer5(self):
method test_style_transfer6 (line 54) | def test_style_transfer6(self):
FILE: modules/image/Image_gan/style_transfer/animegan_v2_paprika_97/model.py
class InferenceModel (line 10) | class InferenceModel:
method __init__ (line 12) | def __init__(self, modelpath, use_gpu=False, gpu_id=0, use_mkldnn=Fals...
method __repr__ (line 23) | def __repr__(self):
method __call__ (line 31) | def __call__(self, *input_datas, batch_size=1):
method load_config (line 38) | def load_config(self, modelpath, use_gpu, gpu_id, use_mkldnn, cpu_thre...
method eval (line 98) | def eval(self):
method forward (line 124) | def forward(self, *input_datas, batch_size=1):
FILE: modules/image/Image_gan/style_transfer/animegan_v2_paprika_97/module.py
class Animegan_V2_Paprika_97 (line 19) | class Animegan_V2_Paprika_97:
method __init__ (line 21) | def __init__(self, use_gpu=False, use_mkldnn=False):
method style_transfer (line 31) | def style_transfer(self,
method serving_method (line 60) | def serving_method(self, images, **kwargs):
FILE: modules/image/Image_gan/style_transfer/animegan_v2_paprika_97/processor.py
function check_dir (line 11) | def check_dir(dir_path):
function base64_to_cv2 (line 20) | def base64_to_cv2(b64str):
function cv2_to_base64 (line 28) | def cv2_to_base64(image):
class Processor (line 34) | class Processor():
method __init__ (line 36) | def __init__(self, images=None, paths=None, batch_size=1, output_dir='...
method load_datas (line 53) | def load_datas(self):
method preprocess (line 70) | def preprocess(self):
method postprocess (line 109) | def postprocess(self, outputs, visualization):
FILE: modules/image/Image_gan/style_transfer/animegan_v2_paprika_97/test.py
class TestHubModule (line 14) | class TestHubModule(unittest.TestCase):
method setUpClass (line 17) | def setUpClass(cls) -> None:
method tearDownClass (line 31) | def tearDownClass(cls) -> None:
method test_style_transfer1 (line 35) | def test_style_transfer1(self):
method test_style_transfer2 (line 39) | def test_style_transfer2(self):
method test_style_transfer3 (line 43) | def test_style_transfer3(self):
method test_style_transfer4 (line 47) | def test_style_transfer4(self):
method test_style_transfer5 (line 51) | def test_style_transfer5(self):
method test_style_transfer6 (line 54) | def test_style_transfer6(self):
FILE: modules/image/Image_gan/style_transfer/animegan_v2_paprika_98/model.py
class InferenceModel (line 10) | class InferenceModel:
method __init__ (line 12) | def __init__(self, modelpath, use_gpu=False, gpu_id=0, use_mkldnn=Fals...
method __repr__ (line 23) | def __repr__(self):
method __call__ (line 31) | def __call__(self, *input_datas, batch_size=1):
method load_config (line 38) | def load_config(self, modelpath, use_gpu, gpu_id, use_mkldnn, cpu_thre...
method eval (line 98) | def eval(self):
method forward (line 124) | def forward(self, *input_datas, batch_size=1):
FILE: modules/image/Image_gan/style_transfer/animegan_v2_paprika_98/module.py
class Animegan_V2_Paprika_98 (line 19) | class Animegan_V2_Paprika_98:
method __init__ (line 21) | def __init__(self, use_gpu=False, use_mkldnn=False):
method style_transfer (line 31) | def style_transfer(self,
method serving_method (line 60) | def serving_method(self, images, **kwargs):
FILE: modules/image/Image_gan/style_transfer/animegan_v2_paprika_98/processor.py
function check_dir (line 11) | def check_dir(dir_path):
function base64_to_cv2 (line 20) | def base64_to_cv2(b64str):
function cv2_to_base64 (line 28) | def cv2_to_base64(image):
class Processor (line 34) | class Processor():
method __init__ (line 36) | def __init__(self, images=None, paths=None, batch_size=1, output_dir='...
method load_datas (line 53) | def load_datas(self):
method preprocess (line 70) | def preprocess(self):
method postprocess (line 109) | def postprocess(self, outputs, visualization):
FILE: modules/image/Image_gan/style_transfer/animegan_v2_paprika_98/test.py
class TestHubModule (line 14) | class TestHubModule(unittest.TestCase):
method setUpClass (line 17) | def setUpClass(cls) -> None:
method tearDownClass (line 31) | def tearDownClass(cls) -> None:
method test_style_transfer1 (line 35) | def test_style_transfer1(self):
method test_style_transfer2 (line 39) | def test_style_transfer2(self):
method test_style_transfer3 (line 43) | def test_style_transfer3(self):
method test_style_transfer4 (line 47) | def test_style_transfer4(self):
method test_style_transfer5 (line 51) | def test_style_transfer5(self):
method test_style_transfer6 (line 54) | def test_style_transfer6(self):
FILE: modules/image/Image_gan/style_transfer/animegan_v2_shinkai_33/model.py
class InferenceModel (line 10) | class InferenceModel:
method __init__ (line 12) | def __init__(self, modelpath, use_gpu=False, gpu_id=0, use_mkldnn=Fals...
method __repr__ (line 23) | def __repr__(self):
method __call__ (line 31) | def __call__(self, *input_datas, batch_size=1):
method load_config (line 38) | def load_config(self, modelpath, use_gpu, gpu_id, use_mkldnn, cpu_thre...
method eval (line 98) | def eval(self):
method forward (line 124) | def forward(self, *input_datas, batch_size=1):
FILE: modules/image/Image_gan/style_transfer/animegan_v2_shinkai_33/module.py
class Animegan_V2_Shinkai_33 (line 19) | class Animegan_V2_Shinkai_33:
method __init__ (line 21) | def __init__(self, use_gpu=False, use_mkldnn=False):
method style_transfer (line 31) | def style_transfer(self,
method serving_method (line 60) | def serving_method(self, images, **kwargs):
FILE: modules/image/Image_gan/style_transfer/animegan_v2_shinkai_33/processor.py
function check_dir (line 11) | def check_dir(dir_path):
function base64_to_cv2 (line 20) | def base64_to_cv2(b64str):
function cv2_to_base64 (line 28) | def cv2_to_base64(image):
class Processor (line 34) | class Processor():
method __init__ (line 36) | def __init__(self, images=None, paths=None, batch_size=1, output_dir='...
method load_datas (line 53) | def load_datas(self):
method preprocess (line 70) | def preprocess(self):
method postprocess (line 109) | def postprocess(self, outputs, visualization):
FILE: modules/image/Image_gan/style_transfer/animegan_v2_shinkai_33/test.py
class TestHubModule (line 14) | class TestHubModule(unittest.TestCase):
method setUpClass (line 17) | def setUpClass(cls) -> None:
method tearDownClass (line 31) | def tearDownClass(cls) -> None:
method test_style_transfer1 (line 35) | def test_style_transfer1(self):
method test_style_transfer2 (line 39) | def test_style_transfer2(self):
method test_style_transfer3 (line 43) | def test_style_transfer3(self):
method test_style_transfer4 (line 47) | def test_style_transfer4(self):
method test_style_transfer5 (line 51) | def test_style_transfer5(self):
method test_style_transfer6 (line 54) | def test_style_transfer6(self):
FILE: modules/image/Image_gan/style_transfer/animegan_v2_shinkai_53/model.py
class InferenceModel (line 10) | class InferenceModel:
method __init__ (line 12) | def __init__(self, modelpath, use_gpu=False, gpu_id=0, use_mkldnn=Fals...
method __repr__ (line 23) | def __repr__(self):
method __call__ (line 31) | def __call__(self, *input_datas, batch_size=1):
method load_config (line 38) | def load_config(self, modelpath, use_gpu, gpu_id, use_mkldnn, cpu_thre...
method eval (line 98) | def eval(self):
method forward (line 124) | def forward(self, *input_datas, batch_size=1):
FILE: modules/image/Image_gan/style_transfer/animegan_v2_shinkai_53/module.py
class Animegan_V2_Shinkai_53 (line 19) | class Animegan_V2_Shinkai_53:
method __init__ (line 21) | def __init__(self, use_gpu=False, use_mkldnn=False):
method style_transfer (line 31) | def style_transfer(self,
method serving_method (line 60) | def serving_method(self, images, **kwargs):
FILE: modules/image/Image_gan/style_transfer/animegan_v2_shinkai_53/processor.py
function check_dir (line 11) | def check_dir(dir_path):
function base64_to_cv2 (line 20) | def base64_to_cv2(b64str):
function cv2_to_base64 (line 28) | def cv2_to_base64(image):
class Processor (line 34) | class Processor():
method __init__ (line 36) | def __init__(self, images=None, paths=None, batch_size=1, output_dir='...
method load_datas (line 53) | def load_datas(self):
method preprocess (line 70) | def preprocess(self):
method postprocess (line 109) | def postprocess(self, outputs, visualization):
FILE: modules/image/Image_gan/style_transfer/animegan_v2_shinkai_53/test.py
class TestHubModule (line 14) | class TestHubModule(unittest.TestCase):
method setUpClass (line 17) | def setUpClass(cls) -> None:
method tearDownClass (line 31) | def tearDownClass(cls) -> None:
method test_style_transfer1 (line 35) | def test_style_transfer1(self):
method test_style_transfer2 (line 39) | def test_style_transfer2(self):
method test_style_transfer3 (line 43) | def test_style_transfer3(self):
method test_style_transfer4 (line 47) | def test_style_transfer4(self):
method test_style_transfer5 (line 51) | def test_style_transfer5(self):
method test_style_transfer6 (line 54) | def test_style_transfer6(self):
FILE: modules/image/Image_gan/style_transfer/face_parse/model.py
class FaceParsePredictor (line 28) | class FaceParsePredictor:
method __init__ (line 29) | def __init__(self):
method run (line 36) | def run(self, image):
FILE: modules/image/Image_gan/style_transfer/face_parse/module.py
class Face_parse (line 35) | class Face_parse:
method __init__ (line 36) | def __init__(self):
method style_transfer (line 41) | def style_transfer(self,
method run_cmd (line 86) | def run_cmd(self, argvs: list):
method serving_method (line 110) | def serving_method(self, images, **kwargs):
method add_module_config_arg (line 119) | def add_module_config_arg(self):
method add_module_input_arg (line 129) | def add_module_input_arg(self):
FILE: modules/image/Image_gan/style_transfer/face_parse/util.py
function base64_to_cv2 (line 6) | def base64_to_cv2(b64str):
FILE: modules/image/Image_gan/style_transfer/lapstyle_circuit/model.py
function img (line 29) | def img(img):
function img_totensor (line 37) | def img_totensor(content_img, style_img):
function tensor_resample (line 61) | def tensor_resample(tensor, dst_size, mode='bilinear'):
function laplacian (line 65) | def laplacian(x):
function make_laplace_pyramid (line 75) | def make_laplace_pyramid(x, levels):
function fold_laplace_pyramid (line 88) | def fold_laplace_pyramid(pyramid):
class LapStylePredictor (line 99) | class LapStylePredictor:
method __init__ (line 100) | def __init__(self, weight_path=None):
method run (line 116) | def run(self, content_img, style_image):
FILE: modules/image/Image_gan/style_transfer/lapstyle_circuit/module.py
class Lapstyle_circuit (line 40) | class Lapstyle_circuit:
method __init__ (line 41) | def __init__(self):
method style_transfer (line 46) | def style_transfer(self,
method run_cmd (line 96) | def run_cmd(self, argvs: list):
method serving_method (line 123) | def serving_method(self, images, **kwargs):
method add_module_config_arg (line 135) | def add_module_config_arg(self):
method add_module_input_arg (line 145) | def add_module_input_arg(self):
FILE: modules/image/Image_gan/style_transfer/lapstyle_circuit/util.py
function base64_to_cv2 (line 7) | def base64_to_cv2(b64str):
FILE: modules/image/Image_gan/style_transfer/lapstyle_ocean/model.py
function img (line 29) | def img(img):
function img_totensor (line 37) | def img_totensor(content_img, style_img):
function tensor_resample (line 61) | def tensor_resample(tensor, dst_size, mode='bilinear'):
function laplacian (line 65) | def laplacian(x):
function make_laplace_pyramid (line 75) | def make_laplace_pyramid(x, levels):
function fold_laplace_pyramid (line 88) | def fold_laplace_pyramid(pyramid):
class LapStylePredictor (line 99) | class LapStylePredictor:
method __init__ (line 100) | def __init__(self, weight_path=None):
method run (line 116) | def run(self, content_img, style_image):
FILE: modules/image/Image_gan/style_transfer/lapstyle_ocean/module.py
class Lapstyle_ocean (line 40) | class Lapstyle_ocean:
method __init__ (line 41) | def __init__(self):
method style_transfer (line 46) | def style_transfer(self,
method run_cmd (line 95) | def run_cmd(self, argvs: list):
method serving_method (line 122) | def serving_method(self, images, **kwargs):
method add_module_config_arg (line 134) | def add_module_config_arg(self):
method add_module_input_arg (line 144) | def add_module_input_arg(self):
FILE: modules/image/Image_gan/style_transfer/lapstyle_ocean/util.py
function base64_to_cv2 (line 7) | def base64_to_cv2(b64str):
FILE: modules/image/Image_gan/style_transfer/lapstyle_starrynew/model.py
function img (line 29) | def img(img):
function img_totensor (line 37) | def img_totensor(content_img, style_img):
function tensor_resample (line 61) | def tensor_resample(tensor, dst_size, mode='bilinear'):
function laplacian (line 65) | def laplacian(x):
function make_laplace_pyramid (line 75) | def make_laplace_pyramid(x, levels):
function fold_laplace_pyramid (line 88) | def fold_laplace_pyramid(pyramid):
class LapStylePredictor (line 99) | class LapStylePredictor:
method __init__ (line 100) | def __init__(self, weight_path=None):
method run (line 116) | def run(self, content_img, style_image):
FILE: modules/image/Image_gan/style_transfer/lapstyle_starrynew/module.py
class Lapstyle_starrynew (line 40) | class Lapstyle_starrynew:
method __init__ (line 41) | def __init__(self):
method style_transfer (line 46) | def style_transfer(self,
method run_cmd (line 94) | def run_cmd(self, argvs: list):
method serving_method (line 121) | def serving_method(self, images, **kwargs):
method add_module_config_arg (line 133) | def add_module_config_arg(self):
method add_module_input_arg (line 143) | def add_module_input_arg(self):
FILE: modules/image/Image_gan/style_transfer/lapstyle_starrynew/util.py
function base64_to_cv2 (line 7) | def base64_to_cv2(b64str):
FILE: modules/image/Image_gan/style_transfer/lapstyle_stars/model.py
function img (line 29) | def img(img):
function img_totensor (line 37) | def img_totensor(content_img, style_img):
function tensor_resample (line 61) | def tensor_resample(tensor, dst_size, mode='bilinear'):
function laplacian (line 65) | def laplacian(x):
function make_laplace_pyramid (line 75) | def make_laplace_pyramid(x, levels):
function fold_laplace_pyramid (line 88) | def fold_laplace_pyramid(pyramid):
class LapStylePredictor (line 99) | class LapStylePredictor:
method __init__ (line 100) | def __init__(self, weight_path=None):
method run (line 116) | def run(self, content_img, style_image):
FILE: modules/image/Image_gan/style_transfer/lapstyle_stars/module.py
class Lapstyle_stars (line 40) | class Lapstyle_stars:
method __init__ (line 41) | def __init__(self):
method style_transfer (line 46) | def style_transfer(self,
method run_cmd (line 95) | def run_cmd(self, argvs: list):
method serving_method (line 122) | def serving_method(self, images, **kwargs):
method add_module_config_arg (line 134) | def add_module_config_arg(self):
method add_module_input_arg (line 144) | def add_module_input_arg(self):
FILE: modules/image/Image_gan/style_transfer/lapstyle_stars/util.py
function base64_to_cv2 (line 7) | def base64_to_cv2(b64str):
FILE: modules/image/Image_gan/style_transfer/msgnet/module.py
class GramMatrix (line 15) | class GramMatrix(nn.Layer):
method forward (line 18) | def forward(self, y):
class ConvLayer (line 26) | class ConvLayer(nn.Layer):
method __init__ (line 29) | def __init__(self, in_channels: int, out_channels: int, kernel_size: i...
method forward (line 35) | def forward(self, x: paddle.Tensor):
class UpsampleConvLayer (line 41) | class UpsampleConvLayer(nn.Layer):
method __init__ (line 57) | def __init__(self, in_channels: int, out_channels: int, kernel_size: i...
method forward (line 67) | def forward(self, x):
class Bottleneck (line 76) | class Bottleneck(nn.Layer):
method __init__ (line 92) | def __init__(self,
method forward (line 109) | def forward(self, x: paddle.Tensor):
class UpBottleneck (line 118) | class UpBottleneck(nn.Layer):
method __init__ (line 133) | def __init__(self, inplanes: int, planes: int, stride: int = 2, norm_l...
method forward (line 152) | def forward(self, x: paddle.Tensor):
class Inspiration (line 156) | class Inspiration(nn.Layer):
method __init__ (line 169) | def __init__(self, C: int, B: int = 1):
method setTarget (line 177) | def setTarget(self, target: paddle.Tensor):
method forward (line 180) | def forward(self, X: paddle.Tensor):
method __repr__ (line 189) | def __repr__(self):
class Vgg16 (line 194) | class Vgg16(nn.Layer):
method __init__ (line 197) | def __init__(self):
method forward (line 222) | def forward(self, X):
class MSGNet (line 255) | class MSGNet(nn.Layer):
method __init__ (line 272) | def __init__(self, input_nc=3, output_nc=3, ngf=128, n_blocks=6, norm_...
method transform (line 328) | def transform(self, path: str):
method setTarget (line 332) | def setTarget(self, Xs: paddle.Tensor):
method getFeature (line 338) | def getFeature(self, input: paddle.Tensor):
method forward (line 343) | def forward(self, input: paddle.Tensor):
FILE: modules/image/Image_gan/style_transfer/paint_transformer/inference.py
function main (line 15) | def main(input_path, model_path, output_dir, need_animation=False, resiz...
FILE: modules/image/Image_gan/style_transfer/paint_transformer/model.py
class Painter (line 6) | class Painter(nn.Layer):
method __init__ (line 11) | def __init__(self, param_per_stroke, total_strokes, hidden_dim, n_head...
method forward (line 46) | def forward(self, img, canvas):
FILE: modules/image/Image_gan/style_transfer/paint_transformer/module.py
class paint_transformer (line 40) | class paint_transformer:
method __init__ (line 41) | def __init__(self):
method style_transfer (line 54) | def style_transfer(self,
method run_cmd (line 110) | def run_cmd(self, argvs: list):
method serving_method (line 135) | def serving_method(self, images, **kwargs):
method add_module_config_arg (line 144) | def add_module_config_arg(self):
method add_module_input_arg (line 156) | def add_module_input_arg(self):
FILE: modules/image/Image_gan/style_transfer/paint_transformer/render_parallel.py
function crop (line 9) | def crop(img, h, w):
function stroke_net_predict (line 19) | def stroke_net_predict(img_patch, result_patch, patch_size, net_g, strok...
function param2img_parallel (line 44) | def param2img_parallel(param, decision, meta_brushes, cur_canvas, stroke...
function render_parallel (line 201) | def render_parallel(original_img, net_g, meta_brushes):
FILE: modules/image/Image_gan/style_transfer/paint_transformer/render_serial.py
function get_single_layer_lists (line 16) | def get_single_layer_lists(param, decision, ori_img, render_size_x, rend...
function get_single_stroke_on_full_image_A (line 85) | def get_single_stroke_on_full_image_A(x_id, y_id, valid_foregrounds, val...
function get_single_stroke_on_full_image_B (line 114) | def get_single_stroke_on_full_image_B(x_id, y_id, valid_foregrounds, val...
function stroke_net_predict (line 141) | def stroke_net_predict(img_patch, result_patch, patch_size, net_g, strok...
function sort_strokes (line 165) | def sort_strokes(params, decision, scores):
function render_serial (line 179) | def render_serial(original_img, net_g, meta_brushes):
FILE: modules/image/Image_gan/style_transfer/paint_transformer/render_utils.py
class Erosion2d (line 10) | class Erosion2d(nn.Layer):
method __init__ (line 15) | def __init__(self, m=1):
method forward (line 20) | def forward(self, x):
class Dilation2d (line 28) | class Dilation2d(nn.Layer):
method __init__ (line 33) | def __init__(self, m=1):
method forward (line 38) | def forward(self, x):
function param2stroke (line 46) | def param2stroke(param, H, W, meta_brushes):
function read_img (line 76) | def read_img(img_path, img_type='RGB', h=None, w=None):
function preprocess (line 91) | def preprocess(img, w=512, h=512):
function totensor (line 98) | def totensor(img):
function pad (line 104) | def pad(img, H, W):
FILE: modules/image/Image_gan/style_transfer/paint_transformer/util.py
function base64_to_cv2 (line 6) | def base64_to_cv2(b64str):
FILE: modules/image/Image_gan/style_transfer/psgan/model.py
function toImage (line 32) | def toImage(net_output):
class PreProcess (line 43) | class PreProcess:
method __init__ (line 44) | def __init__(self, config, need_parser=True):
method __call__ (line 57) | def __call__(self, image):
class PostProcess (line 85) | class PostProcess:
method __init__ (line 86) | def __init__(self, config):
method __call__ (line 90) | def __call__(self, source: Image, result: Image):
class Inference (line 105) | class Inference:
method __init__ (line 106) | def __init__(self, config, model_path=''):
method transfer (line 111) | def transfer(self, source, reference, with_face=False):
class PSGANPredictor (line 154) | class PSGANPredictor:
method __init__ (line 155) | def __init__(self, cfg, weight_path):
method run (line 159) | def run(self, source, reference):
FILE: modules/image/Image_gan/style_transfer/psgan/module.py
class psgan (line 35) | class psgan:
method __init__ (line 36) | def __init__(self):
method makeup_transfer (line 41) | def makeup_transfer(self,
method run_cmd (line 90) | def run_cmd(self, argvs: list):
method serving_method (line 117) | def serving_method(self, images, **kwargs):
method add_module_config_arg (line 129) | def add_module_config_arg(self):
method add_module_input_arg (line 139) | def add_module_input_arg(self):
FILE: modules/image/Image_gan/style_transfer/psgan/util.py
function base64_to_cv2 (line 7) | def base64_to_cv2(b64str):
FILE: modules/image/Image_gan/style_transfer/stylepro_artistic/data_feed.py
function reader (line 13) | def reader(images=None, paths=None):
function _handle_single (line 61) | def _handle_single(im_path=None, im_arr=None):
FILE: modules/image/Image_gan/style_transfer/stylepro_artistic/module.py
class StyleProjection (line 35) | class StyleProjection(hub.Module):
method _initialize (line 37) | def _initialize(self):
method _set_config (line 42) | def _set_config(self):
method style_transfer (line 75) | def style_transfer(self,
method save_inference_model (line 147) | def save_inference_model(self, dirname, model_filename=None, params_fi...
method _save_encode_model (line 153) | def _save_encode_model(self, dirname, model_filename=None, params_file...
method _save_decode_model (line 171) | def _save_decode_model(self, dirname, model_filename=None, params_file...
method serving_method (line 190) | def serving_method(self, images, **kwargs):
method run_cmd (line 203) | def run_cmd(self, argvs):
method add_module_config_arg (line 229) | def add_module_config_arg(self):
method add_module_input_arg (line 246) | def add_module_input_arg(self):
FILE: modules/image/Image_gan/style_transfer/stylepro_artistic/processor.py
function cv2_to_base64 (line 15) | def cv2_to_base64(image):
function base64_to_cv2 (line 20) | def base64_to_cv2(b64str):
function postprocess (line 27) | def postprocess(im, output_dir, save_im_name, visualization, size):
function fr (line 52) | def fr(content_feat, style_feat, alpha):
function scatter_numpy (line 65) | def scatter_numpy(dim, index, src):
FILE: modules/image/classification/DriverStatusRecognition/module.py
function base64_to_cv2 (line 15) | def base64_to_cv2(b64str):
function cv2_to_base64 (line 22) | def cv2_to_base64(image):
function read_images (line 28) | def read_images(paths):
class MODULE (line 42) | class MODULE(hub.Module):
method _initialize (line 43) | def _initialize(self, **kwargs):
method predict (line 47) | def predict(self, images=None, paths=None, data=None, batch_size=1, us...
method serving_method (line 67) | def serving_method(self, images, **kwargs):
method run_cmd (line 96) | def run_cmd(self, argvs):
method add_module_config_arg (line 114) | def add_module_config_arg(self):
method add_module_input_arg (line 120) | def add_module_input_arg(self):
FILE: modules/image/classification/DriverStatusRecognition/serving_client_demo.py
function cv2_to_base64 (line 8) | def cv2_to_base64(image):
FILE: modules/image/classification/SnakeIdentification/module.py
function base64_to_cv2 (line 15) | def base64_to_cv2(b64str):
function cv2_to_base64 (line 22) | def cv2_to_base64(image):
function read_images (line 28) | def read_images(paths):
class MODULE (line 42) | class MODULE(hub.Module):
method _initialize (line 43) | def _initialize(self, **kwargs):
method predict (line 47) | def predict(self, images=None, paths=None, data=None, batch_size=1, us...
method serving_method (line 67) | def serving_method(self, images, **kwargs):
method run_cmd (line 96) | def run_cmd(self, argvs):
method add_module_config_arg (line 114) | def add_module_config_arg(self):
method add_module_input_arg (line 120) | def add_module_input_arg(self):
FILE: modules/image/classification/SnakeIdentification/serving_client_demo.py
function cv2_to_base64 (line 8) | def cv2_to_base64(image):
FILE: modules/image/classification/SpinalNet_Gemstones/gem_dataset.py
class GemStones (line 7) | class GemStones(paddle.io.Dataset):
method __init__ (line 12) | def __init__(self, transforms: Callable, mode: str = 'train'):
method __getitem__ (line 38) | def __getitem__(self, index):
method __len__ (line 50) | def __len__(self):
FILE: modules/image/classification/SpinalNet_Gemstones/spinalnet_res101_gemstone/module.py
class BottleneckBlock (line 25) | class BottleneckBlock(nn.Layer):
method __init__ (line 29) | def __init__(self,
method forward (line 56) | def forward(self, x):
class ResNet (line 79) | class ResNet(nn.Layer):
method __init__ (line 80) | def __init__(self, block=BottleneckBlock, depth=101, with_pool=True):
method _make_layer (line 101) | def _make_layer(self, block, planes, blocks, stride=1, dilate=False):
method forward (line 122) | def forward(self, x):
class SpinalNet_ResNet101 (line 147) | class SpinalNet_ResNet101(nn.Layer):
method __init__ (line 148) | def __init__(self, label_list: list = None, load_checkpoint: str = None):
method transforms (line 198) | def transforms(self, images: Union[str, np.ndarray]):
method forward (line 207) | def forward(self, inputs: paddle.Tensor):
FILE: modules/image/classification/SpinalNet_Gemstones/spinalnet_res50_gemstone/module.py
class BottleneckBlock (line 25) | class BottleneckBlock(nn.Layer):
method __init__ (line 29) | def __init__(self,
method forward (line 56) | def forward(self, x):
class ResNet (line 79) | class ResNet(nn.Layer):
method __init__ (line 80) | def __init__(self, block=BottleneckBlock, depth=50, with_pool=True):
method _make_layer (line 101) | def _make_layer(self, block, planes, blocks, stride=1, dilate=False):
method forward (line 122) | def forward(self, x):
class SpinalNet_ResNet50 (line 147) | class SpinalNet_ResNet50(nn.Layer):
method __init__ (line 148) | def __init__(self, label_list: list = None, load_checkpoint: str = None):
method transforms (line 198) | def transforms(self, images: Union[str, np.ndarray]):
method forward (line 207) | def forward(self, inputs: paddle.Tensor):
FILE: modules/image/classification/SpinalNet_Gemstones/spinalnet_vgg16_gemstone/module.py
class VGG (line 28) | class VGG(nn.Layer):
method __init__ (line 29) | def __init__(self, features, with_pool=True):
method forward (line 37) | def forward(self, x):
function make_layers (line 46) | def make_layers(cfg, batch_norm=False):
function _vgg (line 70) | def _vgg(arch, cfg, batch_norm, **kwargs):
function vgg16 (line 75) | def vgg16(batch_norm=False, **kwargs):
class SpinalNet_VGG16 (line 91) | class SpinalNet_VGG16(nn.Layer):
method __init__ (line 92) | def __init__(self, label_list: list = None, load_checkpoint: str = None):
method transforms (line 152) | def transforms(self, images: Union[str, np.ndarray]):
method forward (line 161) | def forward(self, inputs: paddle.Tensor):
FILE: modules/image/classification/darknet53_imagenet/darknet.py
class DarkNet (line 16) | class DarkNet(object):
method __init__ (line 26) | def __init__(self,
method _conv_norm (line 42) | def _conv_norm(self, input, ch_out, filter_size, stride, padding, act=...
method _downsample (line 72) | def _downsample(self, input, ch_out, filter_size=3, stride=2, padding=...
method basicblock (line 75) | def basicblock(self, input, ch_out, name=None):
method layer_warp (line 81) | def layer_warp(self, block_func, input, ch_out, count, name=None):
method __call__ (line 87) | def __call__(self, input):
FILE: modules/image/classification/darknet53_imagenet/data_feed.py
function resize_short (line 19) | def resize_short(img, target_size):
function crop_image (line 27) | def crop_image(img, target_size, center):
function process_image (line 42) | def process_image(img):
function test_reader (line 54) | def test_reader(paths=None, images=None):
FILE: modules/image/classification/darknet53_imagenet/module.py
class DarkNet53 (line 25) | class DarkNet53(hub.Module):
method _initialize (line 26) | def _initialize(self):
method get_expected_image_width (line 33) | def get_expected_image_width(self):
method get_expected_image_height (line 36) | def get_expected_image_height(self):
method get_pretrained_images_mean (line 39) | def get_pretrained_images_mean(self):
method get_pretrained_images_std (line 43) | def get_pretrained_images_std(self):
method _set_config (line 47) | def _set_config(self):
method context (line 68) | def context(self, input_image=None, trainable=True, pretrained=True, p...
method classification (line 111) | def classification(self, paths=None, images=None, use_gpu=False, batch...
method add_module_config_arg (line 164) | def add_module_config_arg(self):
method add_module_input_arg (line 173) | def add_module_input_arg(self):
method check_input_data (line 181) | def check_input_data(self, args):
method run_cmd (line 193) | def run_cmd(self, argvs):
FILE: modules/image/classification/darknet53_imagenet/processor.py
function load_label_info (line 2) | def load_label_info(file_path):
FILE: modules/image/classification/efficientnetb0_imagenet/data_feed.py
function resize_short (line 28) | def resize_short(img, target_size):
function crop_image (line 36) | def crop_image(img, target_size, center):
function process_image (line 51) | def process_image(img):
function reader (line 62) | def reader(images=None, paths=None):
FILE: modules/image/classification/efficientnetb0_imagenet/module.py
class EfficientNetB0ImageNet (line 39) | class EfficientNetB0ImageNet:
method __init__ (line 41) | def __init__(self):
method get_expected_image_width (line 49) | def get_expected_image_width(self):
method get_expected_image_height (line 52) | def get_expected_image_height(self):
method get_pretrained_images_mean (line 55) | def get_pretrained_images_mean(self):
method get_pretrained_images_std (line 59) | def get_pretrained_images_std(self):
method _set_config (line 63) | def _set_config(self):
method classification (line 86) | def classification(self, images=None, paths=None, batch_size=1, use_gp...
method serving_method (line 141) | def serving_method(self, images, **kwargs):
method run_cmd (line 150) | def run_cmd(self, argvs):
method add_module_config_arg (line 167) | def add_module_config_arg(self):
method add_module_input_arg (line 178) | def add_module_input_arg(self):
FILE: modules/image/classification/efficientnetb0_imagenet/processor.py
function base64_to_cv2 (line 24) | def base64_to_cv2(b64str):
function softmax (line 31) | def softmax(x):
function postprocess (line 47) | def postprocess(data_out, label_list, top_k):
FILE: modules/image/classification/efficientnetb0_imagenet/test.py
class TestHubModule (line 13) | class TestHubModule(unittest.TestCase):
method setUpClass (line 16) | def setUpClass(cls) -> None:
method tearDownClass (line 27) | def tearDownClass(cls) -> None:
method test_classification1 (line 31) | def test_classification1(self):
method test_classification2 (line 37) | def test_classification2(self):
method test_classification3 (line 43) | def test_classification3(self):
method test_classification4 (line 49) | def test_classification4(self):
method test_classification5 (line 52) | def test_classification5(self):
method test_save_inference_model (line 55) | def test_save_inference_model(self):
FILE: modules/image/classification/efficientnetb0_small_imagenet/data_feed.py
function resize_short (line 28) | def resize_short(img, target_size):
function crop_image (line 36) | def crop_image(img, target_size, center):
function process_image (line 51) | def process_image(img):
function reader (line 62) | def reader(images=None, paths=None):
FILE: modules/image/classification/efficientnetb0_small_imagenet/module.py
class EfficientNetB0SmallImageNet (line 39) | class EfficientNetB0SmallImageNet:
method __init__ (line 41) | def __init__(self):
method get_expected_image_width (line 49) | def get_expected_image_width(self):
method get_expected_image_height (line 52) | def get_expected_image_height(self):
method get_pretrained_images_mean (line 55) | def get_pretrained_images_mean(self):
method get_pretrained_images_std (line 59) | def get_pretrained_images_std(self):
method _set_config (line 63) | def _set_config(self):
method classification (line 86) | def classification(self, images=None, paths=None, batch_size=1, use_gp...
method serving_method (line 141) | def serving_method(self, images, **kwargs):
method run_cmd (line 150) | def run_cmd(self, argvs):
method add_module_config_arg (line 167) | def add_module_config_arg(self):
method add_module_input_arg (line 178) | def add_module_input_arg(self):
FILE: modules/image/classification/efficientnetb0_small_imagenet/processor.py
function base64_to_cv2 (line 24) | def base64_to_cv2(b64str):
function softmax (line 31) | def softmax(x):
function postprocess (line 48) | def postprocess(data_out, label_list, top_k):
FILE: modules/image/classification/efficientnetb0_small_imagenet/test.py
class TestHubModule (line 13) | class TestHubModule(unittest.TestCase):
method setUpClass (line 16) | def setUpClass(cls) -> None:
method tearDownClass (line 27) | def tearDownClass(cls) -> None:
method test_classification1 (line 31) | def test_classification1(self):
method test_classification2 (line 37) | def test_classification2(self):
method test_classification3 (line 43) | def test_classification3(self):
method test_classification4 (line 49) | def test_classification4(self):
method test_classification5 (line 52) | def test_classification5(self):
method test_save_inference_model (line 55) | def test_save_inference_model(self):
FILE: modules/image/classification/efficientnetb1_imagenet/data_feed.py
function resize_short (line 28) | def resize_short(img, target_size):
function crop_image (line 36) | def crop_image(img, target_size, center):
function process_image (line 51) | def process_image(img):
function reader (line 62) | def reader(images=None, paths=None):
FILE: modules/image/classification/efficientnetb1_imagenet/module.py
class EfficientNetB1ImageNet (line 39) | class EfficientNetB1ImageNet:
method __init__ (line 41) | def __init__(self):
method get_expected_image_width (line 49) | def get_expected_image_width(self):
method get_expected_image_height (line 52) | def get_expected_image_height(self):
method get_pretrained_images_mean (line 55) | def get_pretrained_images_mean(self):
method get_pretrained_images_std (line 59) | def get_pretrained_images_std(self):
method _set_config (line 63) | def _set_config(self):
method classification (line 86) | def classification(self, images=None, paths=None, batch_size=1, use_gp...
method serving_method (line 141) | def serving_method(self, images, **kwargs):
method run_cmd (line 150) | def run_cmd(self, argvs):
method add_module_config_arg (line 167) | def add_module_config_arg(self):
method add_module_input_arg (line 178) | def add_module_input_arg(self):
FILE: modules/image/classification/efficientnetb1_imagenet/processor.py
function base64_to_cv2 (line 24) | def base64_to_cv2(b64str):
function softmax (line 31) | def softmax(x):
function postprocess (line 47) | def postprocess(data_out, label_list, top_k):
FILE: modules/image/classification/efficientnetb1_imagenet/test.py
class TestHubModule (line 13) | class TestHubModule(unittest.TestCase):
method setUpClass (line 16) | def setUpClass(cls) -> None:
method tearDownClass (line 27) | def tearDownClass(cls) -> None:
method test_classification1 (line 31) | def test_classification1(self):
method test_classification2 (line 37) | def test_classification2(self):
method test_classification3 (line 43) | def test_classification3(self):
method test_classification4 (line 49) | def test_classification4(self):
method test_classification5 (line 52) | def test_classification5(self):
method test_save_inference_model (line 55) | def test_save_inference_model(self):
FILE: modules/image/classification/efficientnetb2_imagenet/data_feed.py
function resize_short (line 28) | def resize_short(img, target_size):
function crop_image (line 36) | def crop_image(img, target_size, center):
function process_image (line 51) | def process_image(img):
function reader (line 62) | def reader(images=None, paths=None):
FILE: modules/image/classification/efficientnetb2_imagenet/module.py
class EfficientNetB2ImageNet (line 39) | class EfficientNetB2ImageNet:
method __init__ (line 41) | def __init__(self):
method get_expected_image_width (line 49) | def get_expected_image_width(self):
method get_expected_image_height (line 52) | def get_expected_image_height(self):
method get_pretrained_images_mean (line 55) | def get_pretrained_images_mean(self):
method get_pretrained_images_std (line 59) | def get_pretrained_images_std(self):
method _set_config (line 63) | def _set_config(self):
method classification (line 86) | def classification(self, images=None, paths=None, batch_size=1, use_gp...
method serving_method (line 140) | def serving_method(self, images, **kwargs):
method run_cmd (line 149) | def run_cmd(self, argvs):
method add_module_config_arg (line 166) | def add_module_config_arg(self):
method add_module_input_arg (line 177) | def add_module_input_arg(self):
FILE: modules/image/classification/efficientnetb2_imagenet/processor.py
function base64_to_cv2 (line 24) | def base64_to_cv2(b64str):
function softmax (line 31) | def softmax(x):
function postprocess (line 47) | def postprocess(data_out, label_list, top_k):
FILE: modules/image/classification/efficientnetb2_imagenet/test.py
class TestHubModule (line 13) | class TestHubModule(unittest.TestCase):
method setUpClass (line 16) | def setUpClass(cls) -> None:
method tearDownClass (line 27) | def tearDownClass(cls) -> None:
method test_classification1 (line 31) | def test_classification1(self):
method test_classification2 (line 37) | def test_classification2(self):
method test_classification3 (line 43) | def test_classification3(self):
method test_classification4 (line 49) | def test_classification4(self):
method test_classification5 (line 52) | def test_classification5(self):
method test_save_inference_model (line 55) | def test_save_inference_model(self):
FILE: modules/image/classification/efficientnetb3_imagenet/data_feed.py
function resize_short (line 28) | def resize_short(img, target_size):
function crop_image (line 36) | def crop_image(img, target_size, center):
function process_image (line 51) | def process_image(img):
function reader (line 62) | def reader(images=None, paths=None):
FILE: modules/image/classification/efficientnetb3_imagenet/module.py
class EfficientNetB3ImageNet (line 39) | class EfficientNetB3ImageNet:
method __init__ (line 41) | def __init__(self):
method get_expected_image_width (line 49) | def get_expected_image_width(self):
method get_expected_image_height (line 52) | def get_expected_image_height(self):
method get_pretrained_images_mean (line 55) | def get_pretrained_images_mean(self):
method get_pretrained_images_std (line 59) | def get_pretrained_images_std(self):
method _set_config (line 63) | def _set_config(self):
method classification (line 86) | def classification(self, images=None, paths=None, batch_size=1, use_gp...
method serving_method (line 142) | def serving_method(self, images, **kwargs):
method run_cmd (line 151) | def run_cmd(self, argvs):
method add_module_config_arg (line 168) | def add_module_config_arg(self):
method add_module_input_arg (line 179) | def add_module_input_arg(self):
FILE: modules/image/classification/efficientnetb3_imagenet/processor.py
function base64_to_cv2 (line 24) | def base64_to_cv2(b64str):
function softmax (line 31) | def softmax(x):
function postprocess (line 47) | def postprocess(data_out, label_list, top_k):
FILE: modules/image/classification/efficientnetb3_imagenet/test.py
class TestHubModule (line 13) | class TestHubModule(unittest.TestCase):
method setUpClass (line 16) | def setUpClass(cls) -> None:
method tearDownClass (line 27) | def tearDownClass(cls) -> None:
method test_classification1 (line 31) | def test_classification1(self):
method test_classification2 (line 37) | def test_classification2(self):
method test_classification3 (line 43) | def test_classification3(self):
method test_classification4 (line 49) | def test_classification4(self):
method test_classification5 (line 52) | def test_classification5(self):
method test_save_inference_model (line 55) | def test_save_inference_model(self):
FILE: modules/image/classification/efficientnetb4_imagenet/data_feed.py
function resize_short (line 28) | def resize_short(img, target_size):
function crop_image (line 36) | def crop_image(img, target_size, center):
function process_image (line 51) | def process_image(img):
function reader (line 62) | def reader(images=None, paths=None):
FILE: modules/image/classification/efficientnetb4_imagenet/module.py
class EfficientNetB4ImageNet (line 39) | class EfficientNetB4ImageNet:
method __init__ (line 41) | def __init__(self):
method get_expected_image_width (line 49) | def get_expected_image_width(self):
method get_expected_image_height (line 52) | def get_expected_image_height(self):
method get_pretrained_images_mean (line 55) | def get_pretrained_images_mean(self):
method get_pretrained_images_std (line 59) | def get_pretrained_images_std(self):
method _set_config (line 63) | def _set_config(self):
method classification (line 86) | def classification(self, images=None, paths=None, batch_size=1, use_gp...
method serving_method (line 141) | def serving_method(self, images, **kwargs):
method run_cmd (line 150) | def run_cmd(self, argvs):
method add_module_config_arg (line 167) | def add_module_config_arg(self):
method add_module_input_arg (line 178) | def add_module_input_arg(self):
FILE: modules/image/classification/efficientnetb4_imagenet/processor.py
function base64_to_cv2 (line 24) | def base64_to_cv2(b64str):
function softmax (line 31) | def softmax(x):
function postprocess (line 47) | def postprocess(data_out, label_list, top_k):
FILE: modules/image/classification/efficientnetb4_imagenet/test.py
class TestHubModule (line 13) | class TestHubModule(unittest.TestCase):
method setUpClass (line 16) | def setUpClass(cls) -> None:
method tearDownClass (line 27) | def tearDownClass(cls) -> None:
method test_classification1 (line 31) | def test_classification1(self):
method test_classification2 (line 37) | def test_classification2(self):
method test_classification3 (line 43) | def test_classification3(self):
method test_classification4 (line 49) | def test_classification4(self):
method test_classification5 (line 52) | def test_classification5(self):
method test_save_inference_model (line 55) | def test_save_inference_model(self):
FILE: modules/image/classification/efficientnetb5_imagenet/data_feed.py
function resize_short (line 28) | def resize_short(img, target_size):
function crop_image (line 36) | def crop_image(img, target_size, center):
function process_image (line 51) | def process_image(img):
function reader (line 62) | def reader(images=None, paths=None):
FILE: modules/image/classification/efficientnetb5_imagenet/module.py
class EfficientNetB5ImageNet (line 39) | class EfficientNetB5ImageNet:
method __init__ (line 41) | def __init__(self):
method get_expected_image_width (line 49) | def get_expected_image_width(self):
method get_expected_image_height (line 52) | def get_expected_image_height(self):
method get_pretrained_images_mean (line 55) | def get_pretrained_images_mean(self):
method get_pretrained_images_std (line 59) | def get_pretrained_images_std(self):
method _set_config (line 63) | def _set_config(self):
method classification (line 86) | def classification(self, images=None, paths=None, batch_size=1, use_gp...
method serving_method (line 141) | def serving_method(self, images, **kwargs):
method run_cmd (line 150) | def run_cmd(self, argvs):
method add_module_config_arg (line 167) | def add_module_config_arg(self):
method add_module_input_arg (line 178) | def add_module_input_arg(self):
FILE: modules/image/classification/efficientnetb5_imagenet/processor.py
function base64_to_cv2 (line 24) | def base64_to_cv2(b64str):
function softmax (line 31) | def softmax(x):
function postprocess (line 47) | def postprocess(data_out, label_list, top_k):
FILE: modules/image/classification/efficientnetb5_imagenet/test.py
class TestHubModule (line 13) | class TestHubModule(unittest.TestCase):
method setUpClass (line 16) | def setUpClass(cls) -> None:
method tearDownClass (line 27) | def tearDownClass(cls) -> None:
method test_classification1 (line 31) | def test_classification1(self):
method test_classification2 (line 37) | def test_classification2(self):
method test_classification3 (line 43) | def test_classification3(self):
method test_classification4 (line 49) | def test_classification4(self):
method test_classification5 (line 52) | def test_classification5(self):
method test_save_inference_model (line 55) | def test_save_inference_model(self):
FILE: modules/image/classification/efficientnetb6_imagenet/data_feed.py
function resize_short (line 28) | def resize_short(img, target_size):
function crop_image (line 36) | def crop_image(img, target_size, center):
function process_image (line 51) | def process_image(img):
function reader (line 62) | def reader(images=None, paths=None):
FILE: modules/image/classification/efficientnetb6_imagenet/module.py
class EfficientNetB6ImageNet (line 39) | class EfficientNetB6ImageNet:
method __init__ (line 41) | def __init__(self):
method get_expected_image_width (line 49) | def get_expected_image_width(self):
method get_expected_image_height (line 52) | def get_expected_image_height(self):
method get_pretrained_images_mean (line 55) | def get_pretrained_images_mean(self):
method get_pretrained_images_std (line 59) | def get_pretrained_images_std(self):
method _set_config (line 63) | def _set_config(self):
method classification (line 86) | def classification(self, images=None, paths=None, batch_size=1, use_gp...
method serving_method (line 141) | def serving_method(self, images, **kwargs):
method run_cmd (line 150) | def run_cmd(self, argvs):
method add_module_config_arg (line 167) | def add_module_config_arg(self):
method add_module_input_arg (line 178) | def add_module_input_arg(self):
FILE: modules/image/classification/efficientnetb6_imagenet/processor.py
function base64_to_cv2 (line 25) | def base64_to_cv2(b64str):
function softmax (line 32) | def softmax(x):
function postprocess (line 48) | def postprocess(data_out, label_list, top_k):
FILE: modules/image/classification/efficientnetb6_imagenet/test.py
class TestHubModule (line 13) | class TestHubModule(unittest.TestCase):
method setUpClass (line 16) | def setUpClass(cls) -> None:
method tearDownClass (line 27) | def tearDownClass(cls) -> None:
method test_classification1 (line 31) | def test_classification1(self):
method test_classification2 (line 37) | def test_classification2(self):
method test_classification3 (line 43) | def test_classification3(self):
method test_classification4 (line 49) | def test_classification4(self):
method test_classification5 (line 52) | def test_classification5(self):
method test_save_inference_model (line 55) | def test_save_inference_model(self):
FILE: modules/image/classification/efficientnetb7_imagenet/data_feed.py
function resize_short (line 28) | def resize_short(img, target_size):
function crop_image (line 36) | def crop_image(img, target_size, center):
function process_image (line 51) | def process_image(img):
function reader (line 62) | def reader(images=None, paths=None):
FILE: modules/image/classification/efficientnetb7_imagenet/module.py
class EfficientNetB7ImageNet (line 39) | class EfficientNetB7ImageNet:
method __init__ (line 41) | def __init__(self):
method get_expected_image_width (line 49) | def get_expected_image_width(self):
method get_expected_image_height (line 52) | def get_expected_image_height(self):
method get_pretrained_images_mean (line 55) | def get_pretrained_images_mean(self):
method get_pretrained_images_std (line 59) | def get_pretrained_images_std(self):
method _set_config (line 63) | def _set_config(self):
method classification (line 86) | def classification(self, images=None, paths=None, batch_size=1, use_gp...
method serving_method (line 141) | def serving_method(self, images, **kwargs):
method run_cmd (line 150) | def run_cmd(self, argvs):
method add_module_config_arg (line 167) | def add_module_config_arg(self):
method add_module_input_arg (line 178) | def add_module_input_arg(self):
FILE: modules/image/classification/efficientnetb7_imagenet/processor.py
function base64_to_cv2 (line 24) | def base64_to_cv2(b64str):
function softmax (line 31) | def softmax(x):
function postprocess (line 47) | def postprocess(data_out, label_list, top_k):
FILE: modules/image/classification/efficientnetb7_imagenet/test.py
class TestHubModule (line 13) | class TestHubModule(unittest.TestCase):
method setUpClass (line 16) | def setUpClass(cls) -> None:
method tearDownClass (line 27) | def tearDownClass(cls) -> None:
method test_classification1 (line 31) | def test_classification1(self):
method test_classification2 (line 37) | def test_classification2(self):
method test_classification3 (line 43) | def test_classification3(self):
method test_classification4 (line 49) | def test_classification4(self):
method test_classification5 (line 52) | def test_classification5(self):
method test_save_inference_model (line 55) | def test_save_inference_model(self):
FILE: modules/image/classification/esnet_x0_25_imagenet/model.py
class Identity (line 41) | class Identity(nn.Layer):
method __init__ (line 43) | def __init__(self):
method forward (line 46) | def forward(self, inputs):
class TheseusLayer (line 50) | class TheseusLayer(nn.Layer):
method __init__ (line 52) | def __init__(self, *args, **kwargs):
method _return_dict_hook (line 59) | def _return_dict_hook(self, layer, input, output):
method init_res (line 67) | def init_res(self, stages_pattern, return_patterns=None, return_stages...
method replace_sub (line 86) | def replace_sub(self, *args, **kwargs) -> None:
method upgrade_sublayer (line 90) | def upgrade_sublayer(self, layer_name_pattern: Union[str, List[str]],
method stop_after (line 146) | def stop_after(self, stop_layer_name: str) -> bool:
method update_res (line 170) | def update_res(self, return_patterns: Union[str, List[str]]) -> Dict[s...
function save_sub_res_hook (line 208) | def save_sub_res_hook(layer, input, output):
function set_identity (line 212) | def set_identity(parent_layer: nn.Layer, layer_name: str, layer_index: s...
function parse_pattern_str (line 244) | def parse_pattern_str(pattern: str, parent_layer: nn.Layer) -> Union[Non...
function channel_shuffle (line 294) | def channel_shuffle(x, groups):
function make_divisible (line 303) | def make_divisible(v, divisor=8, min_value=None):
class ConvBNLayer (line 312) | class ConvBNLayer(TheseusLayer):
method __init__ (line 314) | def __init__(self, in_channels, out_channels, kernel_size, stride=1, g...
method forward (line 331) | def forward(self, x):
class SEModule (line 339) | class SEModule(TheseusLayer):
method __init__ (line 341) | def __init__(self, channel, reduction=4):
method forward (line 349) | def forward(self, x):
class ESBlock1 (line 360) | class ESBlock1(TheseusLayer):
method __init__ (line 362) | def __init__(self, in_channels, out_channels):
method forward (line 375) | def forward(self, x):
class ESBlock2 (line 386) | class ESBlock2(TheseusLayer):
method __init__ (line 388) | def __init__(self, in_channels, out_channels):
method forward (line 415) | def forward(self, x):
class ESNet (line 428) | class ESNet(TheseusLayer):
method __init__ (line 430) | def __init__(self,
method forward (line 481) | def forward(self, x):
function ESNet_x0_25 (line 495) | def ESNet_x0_25(pretrained=False, use_ssld=False, **kwargs):
FILE: modules/image/classification/esnet_x0_25_imagenet/module.py
class Esnet_x0_25_Imagenet (line 42) | class Esnet_x0_25_Imagenet:
method __init__ (line 44) | def __init__(self):
method classification (line 54) | def classification(self,
method run_cmd (line 111) | def run_cmd(self, argvs: list):
method serving_method (line 133) | def serving_method(self, images, **kwargs):
method add_module_config_arg (line 141) | def add_module_config_arg(self):
method add_module_input_arg (line 150) | def add_module_input_arg(self):
FILE: modules/image/classification/esnet_x0_25_imagenet/processor.py
function create_operators (line 36) | def create_operators(params, class_num=None):
class UnifiedResize (line 59) | class UnifiedResize(object):
method __init__ (line 61) | def __init__(self, interpolation=None, backend="cv2"):
method __call__ (line 97) | def __call__(self, src, size):
class OperatorParamError (line 101) | class OperatorParamError(ValueError):
class DecodeImage (line 107) | class DecodeImage(object):
method __init__ (line 110) | def __init__(self, to_rgb=True, to_np=False, channel_first=False):
method __call__ (line 115) | def __call__(self, img):
class ResizeImage (line 132) | class ResizeImage(object):
method __init__ (line 135) | def __init__(self, size=None, resize_short=None, interpolation=None, b...
method __call__ (line 150) | def __call__(self, img):
class CropImage (line 162) | class CropImage(object):
method __init__ (line 165) | def __init__(self, size):
method __call__ (line 171) | def __call__(self, img):
class RandCropImage (line 182) | class RandCropImage(object):
method __init__ (line 185) | def __init__(self, size, scale=None, ratio=None, interpolation=None, b...
method __call__ (line 196) | def __call__(self, img):
class RandFlipImage (line 224) | class RandFlipImage(object):
method __init__ (line 232) | def __init__(self, flip_code=1):
method __call__ (line 236) | def __call__(self, img):
class NormalizeImage (line 243) | class NormalizeImage(object):
method __init__ (line 247) | def __init__(self, scale=None, mean=None, std=None, order='chw', outpu...
method __call__ (line 262) | def __call__(self, img):
class ToCHWImage (line 280) | class ToCHWImage(object):
method __init__ (line 284) | def __init__(self):
method __call__ (line 287) | def __call__(self, img):
class ColorJitter (line 295) | class ColorJitter(RawColorJitter):
method __init__ (line 299) | def __init__(self, *args, **kwargs):
method __call__ (line 302) | def __call__(self, img):
function base64_to_cv2 (line 312) | def base64_to_cv2(b64str):
class Topk (line 319) | class Topk(object):
method __init__ (line 321) | def __init__(self, topk=1, class_id_map_file=None):
method parse_class_id_map (line 326) | def parse_class_id_map(self, class_id_map_file):
method __call__ (line 347) | def __call__(self, x, file_names=None, multilabel=False):
FILE: modules/image/classification/esnet_x0_25_imagenet/utils.py
class AttrDict (line 23) | class AttrDict(dict):
method __getattr__ (line 25) | def __getattr__(self, key):
method __setattr__ (line 28) | def __setattr__(self, key, value):
method __deepcopy__ (line 34) | def __deepcopy__(self, content):
function create_attr_dict (line 38) | def create_attr_dict(yaml_config):
function parse_config (line 54) | def parse_config(cfg_file):
function override (line 62) | def override(dl, ks, v):
function override_config (line 96) | def override_config(config, options=None):
function get_config (line 122) | def get_config(fname, overrides=None, show=False):
FILE: modules/image/classification/esnet_x0_5_imagenet/model.py
class Identity (line 41) | class Identity(nn.Layer):
method __init__ (line 43) | def __init__(self):
method forward (line 46) | def forward(self, inputs):
class TheseusLayer (line 50) | class TheseusLayer(nn.Layer):
method __init__ (line 52) | def __init__(self, *args, **kwargs):
method _return_dict_hook (line 59) | def _return_dict_hook(self, layer, input, output):
method init_res (line 67) | def init_res(self, stages_pattern, return_patterns=None, return_stages...
method replace_sub (line 86) | def replace_sub(self, *args, **kwargs) -> None:
method upgrade_sublayer (line 90) | def upgrade_sublayer(self, layer_name_pattern: Union[str, List[str]],
method stop_after (line 146) | def stop_after(self, stop_layer_name: str) -> bool:
method update_res (line 170) | def update_res(self, return_patterns: Union[str, List[str]]) -> Dict[s...
function save_sub_res_hook (line 208) | def save_sub_res_hook(layer, input, output):
function set_identity (line 212) | def set_identity(parent_layer: nn.Layer, layer_name: str, layer_index: s...
function parse_pattern_str (line 244) | def parse_pattern_str(pattern: str, parent_layer: nn.Layer) -> Union[Non...
function channel_shuffle (line 294) | def channel_shuffle(x, groups):
function make_divisible (line 303) | def make_divisible(v, divisor=8, min_value=None):
class ConvBNLayer (line 312) | class ConvBNLayer(TheseusLayer):
method __init__ (line 314) | def __init__(self, in_channels, out_channels, kernel_size, stride=1, g...
method forward (line 331) | def forward(self, x):
class SEModule (line 339) | class SEModule(TheseusLayer):
method __init__ (line 341) | def __init__(self, channel, reduction=4):
method forward (line 349) | def forward(self, x):
class ESBlock1 (line 360) | class ESBlock1(TheseusLayer):
method __init__ (line 362) | def __init__(self, in_channels, out_channels):
method forward (line 375) | def forward(self, x):
class ESBlock2 (line 386) | class ESBlock2(TheseusLayer):
method __init__ (line 388) | def __init__(self, in_channels, out_channels):
method forward (line 415) | def forward(self, x):
class ESNet (line 428) | class ESNet(TheseusLayer):
method __init__ (line 430) | def __init__(self,
method forward (line 481) | def forward(self, x):
function ESNet_x0_5 (line 495) | def ESNet_x0_5(pretrained=False, use_ssld=False, **kwargs):
FILE: modules/image/classification/esnet_x0_5_imagenet/module.py
class Esnet_x0_5_Imagenet (line 42) | class Esnet_x0_5_Imagenet:
method __init__ (line 44) | def __init__(self):
method classification (line 54) | def classification(self,
method run_cmd (line 111) | def run_cmd(self, argvs: list):
method serving_method (line 133) | def serving_method(self, images, **kwargs):
method add_module_config_arg (line 141) | def add_module_config_arg(self):
method add_module_input_arg (line 150) | def add_module_input_arg(self):
FILE: modules/image/classification/esnet_x0_5_imagenet/processor.py
function create_operators (line 36) | def create_operators(params, class_num=None):
class UnifiedResize (line 59) | class UnifiedResize(object):
method __init__ (line 61) | def __init__(self, interpolation=None, backend="cv2"):
method __call__ (line 97) | def __call__(self, src, size):
class OperatorParamError (line 101) | class OperatorParamError(ValueError):
class DecodeImage (line 107) | class DecodeImage(object):
method __init__ (line 110) | def __init__(self, to_rgb=True, to_np=False, channel_first=False):
method __call__ (line 115) | def __call__(self, img):
class ResizeImage (line 132) | class ResizeImage(object):
method __init__ (line 135) | def __init__(self, size=None, resize_short=None, interpolation=None, b...
method __call__ (line 150) | def __call__(self, img):
class CropImage (line 162) | class CropImage(object):
method __init__ (line 165) | def __init__(self, size):
method __call__ (line 171) | def __call__(self, img):
class RandCropImage (line 182) | class RandCropImage(object):
method __init__ (line 185) | def __init__(self, size, scale=None, ratio=None, interpolation=None, b...
method __call__ (line 196) | def __call__(self, img):
class RandFlipImage (line 224) | class RandFlipImage(object):
method __init__ (line 232) | def __init__(self, flip_code=1):
method __call__ (line 236) | def __call__(self, img):
class NormalizeImage (line 243) | class NormalizeImage(object):
method __init__ (line 247) | def __init__(self, scale=None, mean=None, std=None, order='chw', outpu...
method __call__ (line 262) | def __call__(self, img):
class ToCHWImage (line 280) | class ToCHWImage(object):
method __init__ (line 284) | def __init__(self):
method __call__ (line 287) | def __call__(self, img):
class ColorJitter (line 295) | class ColorJitter(RawColorJitter):
method __init__ (line 299) | def __init__(self, *args, **kwargs):
method __call__ (line 302) | def __call__(self, img):
function base64_to_cv2 (line 312) | def base64_to_cv2(b64str):
class Topk (line 319) | class Topk(object):
method __init__ (line 321) | def __init__(self, topk=1, class_id_map_file=None):
method parse_class_id_map (line 326) | def parse_class_id_map(self, class_id_map_file):
method __call__ (line 347) | def __call__(self, x, file_names=None, multilabel=False):
FILE: modules/image/classification/esnet_x0_5_imagenet/utils.py
class AttrDict (line 23) | class AttrDict(dict):
method __getattr__ (line 25) | def __getattr__(self, key):
method __setattr__ (line 28) | def __setattr__(self, key, value):
method __deepcopy__ (line 34) | def __deepcopy__(self, content):
function create_attr_dict (line 38) | def create_attr_dict(yaml_config):
function parse_config (line 54) | def parse_config(cfg_file):
function override (line 62) | def override(dl, ks, v):
function override_config (line 96) | def override_config(config, options=None):
function get_config (line 122) | def get_config(fname, overrides=None, show=False):
FILE: modules/image/classification/fix_resnext101_32x48d_wsl_imagenet/data_feed.py
function resize_short (line 15) | def resize_short(img, target_size):
function crop_image (line 23) | def crop_image(img, target_size, center):
function process_image (line 38) | def process_image(img):
function reader (line 49) | def reader(images=None, paths=None):
FILE: modules/image/classification/fix_resnext101_32x48d_wsl_imagenet/module.py
class FixResnext10132x48dwslImagenet (line 27) | class FixResnext10132x48dwslImagenet:
method __init__ (line 29) | def __init__(self):
method get_expected_image_width (line 36) | def get_expected_image_width(self):
method get_expected_image_height (line 39) | def get_expected_image_height(self):
method get_pretrained_images_mean (line 42) | def get_pretrained_images_mean(self):
method get_pretrained_images_std (line 46) | def get_pretrained_images_std(self):
method _set_config (line 50) | def _set_config(self):
method classification (line 73) | def classification(self, images=None, paths=None, batch_size=1, use_gp...
method serving_method (line 132) | def serving_method(self, images, **kwargs):
method run_cmd (line 141) | def run_cmd(self, argvs):
method add_module_config_arg (line 158) | def add_module_config_arg(self):
method add_module_input_arg (line 169) | def add_module_input_arg(self):
FILE: modules/image/classification/fix_resnext101_32x48d_wsl_imagenet/processor.py
function base64_to_cv2 (line 11) | def base64_to_cv2(b64str):
function softmax (line 18) | def softmax(x):
function postprocess (line 34) | def postprocess(data_out, label_list, top_k):
FILE: modules/image/classification/fix_resnext101_32x48d_wsl_imagenet/test.py
class TestHubModule (line 13) | class TestHubModule(unittest.TestCase):
method setUpClass (line 16) | def setUpClass(cls) -> None:
method tearDownClass (line 27) | def tearDownClass(cls) -> None:
method test_classification1 (line 31) | def test_classification1(self):
method test_classification2 (line 37) | def test_classification2(self):
method test_classification3 (line 43) | def test_classification3(self):
method test_classification4 (line 49) | def test_classification4(self):
method test_classification5 (line 52) | def test_classification5(self):
method test_save_inference_model (line 55) | def test_save_inference_model(self):
FILE: modules/image/classification/food_classification/module.py
function base64_to_cv2 (line 15) | def base64_to_cv2(b64str):
function cv2_to_base64 (line 22) | def cv2_to_base64(image):
function read_images (line 28) | def read_images(paths):
class MODULE (line 42) | class MODULE(hub.Module):
method _initialize (line 43) | def _initialize(self, **kwargs):
method predict (line 47) | def predict(self, images=None, paths=None, data=None, batch_size=1, us...
method serving_method (line 67) | def serving_method(self, images, **kwargs):
method run_cmd (line 96) | def run_cmd(self, argvs):
method add_module_config_arg (line 114) | def add_module_config_arg(self):
method add_module_input_arg (line 120) | def add_module_input_arg(self):
FILE: modules/image/classification/ghostnet_x0_5_imagenet/module.py
class ConvBNLayer (line 29) | class ConvBNLayer(nn.Layer):
method __init__ (line 30) | def __init__(self, in_channels, out_channels, kernel_size, stride=1, g...
method forward (line 51) | def forward(self, inputs):
class SEBlock (line 57) | class SEBlock(nn.Layer):
method __init__ (line 58) | def __init__(self, num_channels, reduction_ratio=4, name=None):
method forward (line 76) | def forward(self, inputs):
class GhostModule (line 88) | class GhostModule(nn.Layer):
method __init__ (line 89) | def __init__(self, in_channels, output_channels, kernel_size=1, ratio=...
method forward (line 110) | def forward(self, inputs):
class GhostBottleneck (line 117) | class GhostBottleneck(nn.Layer):
method __init__ (line 118) | def __init__(self, in_channels, hidden_dim, output_channels, kernel_si...
method forward (line 168) | def forward(self, inputs):
class GhostNet (line 192) | class GhostNet(nn.Layer):
method __init__ (line 193) | def __init__(self, label_list: list = None, load_checkpoint: str = None):
method transforms (line 290) | def transforms(self, images: Union[str, np.ndarray]):
method forward (line 299) | def forward(self, inputs):
method _make_divisible (line 311) | def _make_divisible(self, v, divisor, min_value=None):
FILE: modules/image/classification/ghostnet_x1_0_imagenet/module.py
class ConvBNLayer (line 29) | class ConvBNLayer(nn.Layer):
method __init__ (line 30) | def __init__(self, in_channels, out_channels, kernel_size, stride=1, g...
method forward (line 51) | def forward(self, inputs):
class SEBlock (line 57) | class SEBlock(nn.Layer):
method __init__ (line 58) | def __init__(self, num_channels, reduction_ratio=4, name=None):
method forward (line 76) | def forward(self, inputs):
class GhostModule (line 88) | class GhostModule(nn.Layer):
method __init__ (line 89) | def __init__(self, in_channels, output_channels, kernel_size=1, ratio=...
method forward (line 110) | def forward(self, inputs):
class GhostBottleneck (line 117) | class GhostBottleneck(nn.Layer):
method __init__ (line 118) | def __init__(self, in_channels, hidden_dim, output_channels, kernel_si...
method forward (line 168) | def forward(self, inputs):
class GhostNet (line 192) | class GhostNet(nn.Layer):
method __init__ (line 193) | def __init__(self, label_list: list = None, load_checkpoint: str = None):
method transforms (line 290) | def transforms(self, images: Union[str, np.ndarray]):
method forward (line 299) | def forward(self, inputs):
method _make_divisible (line 311) | def _make_divisible(self, v, divisor, min_value=None):
FILE: modules/image/classification/ghostnet_x1_3_imagenet/module.py
class ConvBNLayer (line 29) | class ConvBNLayer(nn.Layer):
method __init__ (line 30) | def __init__(self, in_channels, out_channels, kernel_size, stride=1, g...
method forward (line 51) | def forward(self, inputs):
class SEBlock (line 57) | class SEBlock(nn.Layer):
method __init__ (line 58) | def __init__(self, num_channels, reduction_ratio=4, name=None):
method forward (line 76) | def forward(self, inputs):
class GhostModule (line 88) | class GhostModule(nn.Layer):
method __init__ (line 89) | def __init__(self, in_channels, output_channels, kernel_size=1, ratio=...
method forward (line 110) | def forward(self, inputs):
class GhostBottleneck (line 117) | class GhostBottleneck(nn.Layer):
method __init__ (line 118) | def __init__(self, in_channels, hidden_dim, output_channels, kernel_si...
method forward (line 168) | def forward(self, inputs):
class GhostNet (line 192) | class GhostNet(nn.Layer):
method __init__ (line 193) | def __init__(self, label_list: list = None, load_checkpoint: str = None):
method transforms (line 290) | def transforms(self, images: Union[str, np.ndarray]):
method forward (line 299) | def forward(self, inputs):
method _make_divisible (line 311) | def _make_divisible(self, v, divisor, min_value=None):
FILE: modules/image/classification/ghostnet_x1_3_imagenet_ssld/module.py
class ConvBNLayer (line 29) | class ConvBNLayer(nn.Layer):
method __init__ (line 30) | def __init__(self, in_channels, out_channels, kernel_size, stride=1, g...
method forward (line 51) | def forward(self, inputs):
class SEBlock (line 57) | class SEBlock(nn.Layer):
method __init__ (line 58) | def __init__(self, num_channels, reduction_ratio=4, name=None):
method forward (line 76) | def forward(self, inputs):
class GhostModule (line 88) | class GhostModule(nn.Layer):
method __init__ (line 89) | def __init__(self, in_channels, output_channels, kernel_size=1, ratio=...
method forward (line 110) | def forward(self, inputs):
class GhostBottleneck (line 117) | class GhostBottleneck(nn.Layer):
method __init__ (line 118) | def __init__(self, in_channels, hidden_dim, output_channels, kernel_si...
method forward (line 168) | def forward(self, inputs):
class GhostNet (line 192) | class GhostNet(nn.Layer):
method __init__ (line 193) | def __init__(self, label_list: list = None, load_checkpoint: str = None):
method transforms (line 290) | def transforms(self, images: Union[str, np.ndarray]):
method forward (line 299) | def forward(self, inputs):
method _make_divisible (line 311) | def _make_divisible(self, v, divisor, min_value=None):
FILE: modules/image/classification/googlenet_imagenet/module.py
function xavier (line 28) | def xavier(channels: int, filter_size: int, name: str):
class ConvLayer (line 35) | class ConvLayer(nn.Layer):
method __init__ (line 38) | def __init__(self,
method forward (line 57) | def forward(self, inputs: paddle.Tensor):
class Inception (line 62) | class Inception(nn.Layer):
method __init__ (line 65) | def __init__(self,
method forward (line 86) | def forward(self, inputs: paddle.Tensor):
class GoogleNet (line 112) | class GoogleNet(nn.Layer):
method __init__ (line 115) | def __init__(self, class_dim: int = 1000, load_checkpoint: str = None):
method forward (line 155) | def forward(self, inputs: paddle.Tensor):
FILE: modules/image/classification/hrnet18_imagenet/module.py
class ConvBNLayer (line 30) | class ConvBNLayer(nn.Layer):
method __init__ (line 31) | def __init__(self, num_channels, num_filters, filter_size, stride=1, g...
method forward (line 52) | def forward(self, input):
class Layer1 (line 58) | class Layer1(nn.Layer):
method __init__ (line 59) | def __init__(self, num_channels, has_se=False, name=None):
method forward (line 76) | def forward(self, input):
class TransitionLayer (line 83) | class TransitionLayer(nn.Layer):
method __init__ (line 84) | def __init__(self, in_channels, out_channels, name=None):
method forward (line 113) | def forward(self, input):
class Branches (line 126) | class Branches(nn.Layer):
method __init__ (line 127) | def __init__(self, block_num, in_channels, out_channels, has_se=False,...
method forward (line 145) | def forward(self, inputs):
class BottleneckBlock (line 156) | class BottleneckBlock(nn.Layer):
method __init__ (line 157) | def __init__(self, num_channels, num_filters, has_se, stride=1, downsa...
method forward (line 192) | def forward(self, input):
class BasicBlock (line 209) | class BasicBlock(nn.Layer):
method __init__ (line 210) | def __init__(self, num_channels, num_filters, stride=1, has_se=False, ...
method forward (line 237) | def forward(self, input):
class SELayer (line 253) | class SELayer(nn.Layer):
method __init__ (line 254) | def __init__(self, num_channels, num_filters, reduction_ratio, name=No...
method forward (line 276) | def forward(self, input):
class Stage (line 288) | class Stage(nn.Layer):
method __init__ (line 289) | def __init__(self, num_channels, num_modules, num_filters, has_se=Fals...
method forward (line 314) | def forward(self, input):
class HighResolutionModule (line 321) | class HighResolutionModule(nn.Layer):
method __init__ (line 322) | def __init__(self, num_channels, num_filters, has_se=False, multi_scal...
method forward (line 331) | def forward(self, input):
class FuseLayers (line 337) | class FuseLayers(nn.Layer):
method __init__ (line 338) | def __init__(self, in_channels, out_channels, multi_scale_output=True,...
method forward (line 386) | def forward(self, input):
class LastClsOut (line 412) | class LastClsOut(nn.Layer):
method __init__ (line 413) | def __init__(self, num_channel_list, has_se, num_filters_list=[32, 64,...
method forward (line 428) | def forward(self, inputs):
class HRNet18 (line 445) | class HRNet18(nn.Layer):
method __init__ (line 446) | def __init__(self, label_list: list = None, load_checkpoint: str = None):
method transforms (line 545) | def transforms(self, images: Union[str, np.ndarray]):
method forward (line 554) | def forward(self, input):
FILE: modules/image/classification/hrnet18_imagenet_ssld/module.py
class ConvBNLayer (line 30) | class ConvBNLayer(nn.Layer):
method __init__ (line 31) | def __init__(self, num_channels, num_filters, filter_size, stride=1, g...
method forward (line 52) | def forward(self, input):
class Layer1 (line 58) | class Layer1(nn.Layer):
method __init__ (line 59) | def __init__(self, num_channels, has_se=False, name=None):
method forward (line 76) | def forward(self, input):
class TransitionLayer (line 83) | class TransitionLayer(nn.Layer):
method __init__ (line 84) | def __init__(self, in_channels, out_channels, name=None):
method forward (line 113) | def forward(self, input):
class Branches (line 126) | class Branches(nn.Layer):
method __init__ (line 127) | def __init__(self, block_num, in_channels, out_channels, has_se=False,...
method forward (line 145) | def forward(self, inputs):
class BottleneckBlock (line 156) | class BottleneckBlock(nn.Layer):
method __init__ (line 157) | def __init__(self, num_channels, num_filters, has_se, stride=1, downsa...
method forward (line 192) | def forward(self, input):
class BasicBlock (line 209) | class BasicBlock(nn.Layer):
method __init__ (line 210) | def __init__(self, num_channels, num_filters, stride=1, has_se=False, ...
method forward (line 237) | def forward(self, input):
class SELayer (line 253) | class SELayer(nn.Layer):
method __init__ (line 254) | def __init__(self, num_channels, num_filters, reduction_ratio, name=No...
method forward (line 276) | def forward(self, input):
class Stage (line 288) | class Stage(nn.Layer):
method __init__ (line 289) | def __init__(self, num_channels, num_modules, num_filters, has_se=Fals...
method forward (line 314) | def forward(self, input):
class HighResolutionModule (line 321) | class HighResolutionModule(nn.Layer):
method __init__ (line 322) | def __init__(self, num_channels, num_filters, has_se=False, multi_scal...
method forward (line 331) | def forward(self, input):
class FuseLayers (line 337) | class FuseLayers(nn.Layer):
method __init__ (line 338) | def __init__(self, in_channels, out_channels, multi_scale_output=True,...
method forward (line 386) | def forward(self, input):
class LastClsOut (line 412) | class LastClsOut(nn.Layer):
method __init__ (line 413) | def __init__(self, num_channel_list, has_se, num_filters_list=[32, 64,...
method forward (line 428) | def forward(self, inputs):
class HRNet18 (line 445) | class HRNet18(nn.Layer):
method __init__ (line 446) | def __init__(self, label_list: list = None, load_checkpoint: str = None):
method transforms (line 545) | def transforms(self, images: Union[str, np.ndarray]):
method forward (line 554) | def forward(self, input):
FILE: modules/image/classification/hrnet30_imagenet/module.py
class ConvBNLayer (line 30) | class ConvBNLayer(nn.Layer):
method __init__ (line 31) | def __init__(self, num_channels, num_filters, filter_size, stride=1, g...
method forward (line 52) | def forward(self, input):
class Layer1 (line 58) | class Layer1(nn.Layer):
method __init__ (line 59) | def __init__(self, num_channels, has_se=False, name=None):
method forward (line 76) | def forward(self, input):
class TransitionLayer (line 83) | class TransitionLayer(nn.Layer):
method __init__ (line 84) | def __init__(self, in_channels, out_channels, name=None):
method forward (line 113) | def forward(self, input):
class Branches (line 126) | class Branches(nn.Layer):
method __init__ (line 127) | def __init__(self, block_num, in_channels, out_channels, has_se=False,...
method forward (line 145) | def forward(self, inputs):
class BottleneckBlock (line 156) | class BottleneckBlock(nn.Layer):
method __init__ (line 157) | def __init__(self, num_channels, num_filters, has_se, stride=1, downsa...
method forward (line 192) | def forward(self, input):
class BasicBlock (line 209) | class BasicBlock(nn.Layer):
method __init__ (line 210) | def __init__(self, num_channels, num_filters, stride=1, has_se=False, ...
method forward (line 237) | def forward(self, input):
class SELayer (line 253) | class SELayer(nn.Layer):
method __init__ (line 254) | def __init__(self, num_channels, num_filters, reduction_ratio, name=No...
method forward (line 276) | def forward(self, input):
class Stage (line 288) | class Stage(nn.Layer):
method __init__ (line 289) | def __init__(self, num_channels, num_modules, num_filters, has_se=Fals...
method forward (line 314) | def forward(self, input):
class HighResolutionModule (line 321) | class HighResolutionModule(nn.Layer):
method __init__ (line 322) | def __init__(self, num_channels, num_filters, has_se=False, multi_scal...
method forward (line 331) | def forward(self, input):
class FuseLayers (line 337) | class FuseLayers(nn.Layer):
method __init__ (line 338) | def __init__(self, in_channels, out_channels, multi_scale_output=True,...
method forward (line 386) | def forward(self, input):
class LastClsOut (line 412) | class LastClsOut(nn.Layer):
method __init__ (line 413) | def __init__(self, num_channel_list, has_se, num_filters_list=[32, 64,...
method forward (line 428) | def forward(self, inputs):
class HRNet30 (line 445) | class HRNet30(nn.Layer):
method __init__ (line 446) | def __init__(self, label_list: list = None, load_checkpoint: str = None):
method transforms (line 545) | def transforms(self, images: Union[str, np.ndarray]):
method forward (line 554) | def forward(self, input):
FILE: modules/image/classification/hrnet32_imagenet/module.py
class ConvBNLayer (line 30) | class ConvBNLayer(nn.Layer):
method __init__ (line 31) | def __init__(self, num_channels, num_filters, filter_size, stride=1, g...
method forward (line 52) | def forward(self, input):
class Layer1 (line 58) | class Layer1(nn.Layer):
method __init__ (line 59) | def __init__(self, num_channels, has_se=False, name=None):
method forward (line 76) | def forward(self, input):
class TransitionLayer (line 83) | class TransitionLayer(nn.Layer):
method __init__ (line 84) | def __init__(self, in_channels, out_channels, name=None):
method forward (line 113) | def forward(self, input):
class Branches (line 126) | class Branches(nn.Layer):
method __init__ (line 127) | def __init__(self, block_num, in_channels, out_channels, has_se=False,...
method forward (line 145) | def forward(self, inputs):
class BottleneckBlock (line 156) | class BottleneckBlock(nn.Layer):
method __init__ (line 157) | def __init__(self, num_channels, num_filters, has_se, stride=1, downsa...
method forward (line 192) | def forward(self, input):
class BasicBlock (line 209) | class BasicBlock(nn.Layer):
method __init__ (line 210) | def __init__(self, num_channels, num_filters, stride=1, has_se=False, ...
method forward (line 237) | def forward(self, input):
class SELayer (line 253) | class SELayer(nn.Layer):
method __init__ (line 254) | def __init__(self, num_channels, num_filters, reduction_ratio, name=No...
method forward (line 276) | def forward(self, input):
class Stage (line 288) | class Stage(nn.Layer):
method __init__ (line 289) | def __init__(self, num_channels, num_modules, num_filters, has_se=Fals...
method forward (line 314) | def forward(self, input):
class HighResolutionModule (line 321) | class HighResolutionModule(nn.Layer):
method __init__ (line 322) | def __init__(self, num_channels, num_filters, has_se=False, multi_scal...
method forward (line 331) | def forward(self, input):
class FuseLayers (line 337) | class FuseLayers(nn.Layer):
method __init__ (line 338) | def __init__(self, in_channels, out_channels, multi_scale_output=True,...
method forward (line 386) | def forward(self, input):
class LastClsOut (line 412) | class LastClsOut(nn.Layer):
method __init__ (line 413) | def __init__(self, num_channel_list, has_se, num_filters_list=[32, 64,...
method forward (line 428) | def forward(self, inputs):
class HRNet32 (line 445) | class HRNet32(nn.Layer):
method __init__ (line 446) | def __init__(self, label_list: list = None, load_checkpoint: str = None):
method transforms (line 545) | def transforms(self, images: Union[str, np.ndarray]):
method forward (line 554) | def forward(self, input):
FILE: modules/image/classification/hrnet40_imagenet/module.py
class ConvBNLayer (line 30) | class ConvBNLayer(nn.Layer):
method __init__ (line 31) | def __init__(self, num_channels, num_filters, filter_size, stride=1, g...
method forward (line 52) | def forward(self, input):
class Layer1 (line 58) | class Layer1(nn.Layer):
method __init__ (line 59) | def __init__(self, num_channels, has_se=False, name=None):
method forward (line 76) | def forward(self, input):
class TransitionLayer (line 83) | class TransitionLayer(nn.Layer):
method __init__ (line 84) | def __init__(self, in_channels, out_channels, name=None):
method forward (line 113) | def forward(self, input):
class Branches (line 126) | class Branches(nn.Layer):
method __init__ (line 127) | def __init__(self, block_num, in_channels, out_channels, has_se=False,...
method forward (line 145) | def forward(self, inputs):
class BottleneckBlock (line 156) | class BottleneckBlock(nn.Layer):
method __init__ (line 157) | def __init__(self, num_channels, num_filters, has_se, stride=1, downsa...
method forward (line 192) | def forward(self, input):
class BasicBlock (line 209) | class BasicBlock(nn.Layer):
method __init__ (line 210) | def __init__(self, num_channels, num_filters, stride=1, has_se=False, ...
method forward (line 237) | def forward(self, input):
class SELayer (line 253) | class SELayer(nn.Layer):
method __init__ (line 254) | def __init__(self, num_channels, num_filters, reduction_ratio, name=No...
method forward (line 276) | def forward(self, input):
class Stage (line 288) | class Stage(nn.Layer):
method __init__ (line 289) | def __init__(self, num_channels, num_modules, num_filters, has_se=Fals...
method forward (line 314) | def forward(self, input):
class HighResolutionModule (line 321) | class HighResolutionModule(nn.Layer):
method __init__ (line 322) | def __init__(self, num_channels, num_filters, has_se=False, multi_scal...
method forward (line 331) | def forward(self, input):
class FuseLayers (line 337) | class FuseLayers(nn.Layer):
method __init__ (line 338) | def __init__(self, in_channels, out_channels, multi_scale_output=True,...
method forward (line 386) | def forward(self, input):
class LastClsOut (line 412) | class LastClsOut(nn.Layer):
method __init__ (line 413) | def __init__(self, num_channel_list, has_se, num_filters_list=[32, 64,...
method forward (line 428) | def forward(self, inputs):
class HRNet40 (line 445) | class HRNet40(nn.Layer):
method __init__ (line 446) | def __init__(self, label_list: list = None, load_checkpoint: str = None):
method transforms (line 545) | def transforms(self, images: Union[str, np.ndarray]):
method forward (line 554) | def forward(self, input):
FILE: modules/image/classification/hrnet44_imagenet/module.py
class ConvBNLayer (line 30) | class ConvBNLayer(nn.Layer):
method __init__ (line 31) | def __init__(self, num_channels, num_filters, filter_size, stride=1, g...
method forward (line 52) | def forward(self, input):
class Layer1 (line 58) | class Layer1(nn.Layer):
method __init__ (line 59) | def __init__(self, num_channels, has_se=False, name=None):
method forward (line 76) | def forward(self, input):
class TransitionLayer (line 83) | class TransitionLayer(nn.Layer):
method __init__ (line 84) | def __init__(self, in_channels, out_channels, name=None):
method forward (line 113) | def forward(self, input):
class Branches (line 126) | class Branches(nn.Layer):
method __init__ (line 127) | def __init__(self, block_num, in_channels, out_channels, has_se=False,...
method forward (line 145) | def forward(self, inputs):
class BottleneckBlock (line 156) | class BottleneckBlock(nn.Layer):
method __init__ (line 157) | def __init__(self, num_channels, num_filters, has_se, stride=1, downsa...
method forward (line 192) | def forward(self, input):
class BasicBlock (line 209) | class BasicBlock(nn.Layer):
method __init__ (line 210) | def __init__(self, num_channels, num_filters, stride=1, has_se=False, ...
method forward (line 237) | def forward(self, input):
class SELayer (line 253) | class SELayer(nn.Layer):
method __init__ (line 254) | def __init__(self, num_channels, num_filters, reduction_ratio, name=No...
method forward (line 276) | def forward(self, input):
class Stage (line 288) | class Stage(nn.Layer):
method __init__ (line 289) | def __init__(self, num_channels, num_modules, num_filters, has_se=Fals...
method forward (line 314) | def forward(self, input):
class HighResolutionModule (line 321) | class HighResolutionModule(nn.Layer):
method __init__ (line 322) | def __init__(self, num_chann
Copy disabled (too large)
Download .json
Condensed preview — 2810 files, each showing path, character count, and a content snippet. Download the .json file for the full structured content (31,260K chars).
[
{
"path": ".github/ISSUE_TEMPLATE/----.md",
"chars": 242,
"preview": "---\nname: 需求反馈\nabout: 需求建议\ntitle: ''\nlabels: ''\nassignees: ''\n\n---\n\n欢迎您对PaddleHub提出建议,非常感谢您对PaddleHub的贡献!\n在留下您的建议时,辛苦您同步"
},
{
"path": ".github/ISSUE_TEMPLATE/bug--.md",
"chars": 317,
"preview": "---\nname: BUG反馈\nabout: PaddleHub Bug反馈\ntitle: ''\nlabels: ''\nassignees: ''\n\n---\n\n欢迎您反馈PaddleHub使用问题,非常感谢您对PaddleHub的贡献!\n在"
},
{
"path": ".gitignore",
"chars": 1365,
"preview": "# Byte-compiled / optimized / DLL files\n__pycache__/\n*.py[cod]\n*$py.class\n\n# C extensions\n*.so\n\n# Distribution / packagi"
},
{
"path": ".pre-commit-config.yaml",
"chars": 926,
"preview": "- repo: local\n hooks:\n - id: yapf\n name: yapf\n entry: yapf\n language: system\n args"
},
{
"path": ".style.yapf",
"chars": 49,
"preview": "[style]\nbased_on_style = pep8\ncolumn_limit = 120\n"
},
{
"path": ".travis.yml",
"chars": 841,
"preview": "language: python\n\njobs:\n include:\n - name: \"CI on Windows/Python3.6\"\n os: windows\n language: shell\n b"
},
{
"path": "AUTHORS.md",
"chars": 242,
"preview": "| Github account | name |\n|---|---|\n| ZeyuChen | Zeyu Chen |\n| nepeplwu | Zewu Wu |\n| sjtubinlong | Bin Long |\n| Steffy-"
},
{
"path": "LICENSE",
"chars": 11438,
"preview": "Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved\n\n Apache License\n "
},
{
"path": "README.md",
"chars": 16536,
"preview": "English | [简体中文](README_ch.md)\n\n<p align=\"center\">\n <img src=\"./docs/imgs/paddlehub_logo.jpg\" align=\"middle\" width=\"400\""
},
{
"path": "README_ch.md",
"chars": 17288,
"preview": "简体中文 | [English](README.md)\n\n<p align=\"center\">\n <img src=\"./docs/imgs/paddlehub_logo.jpg\" align=\"middle\">\n<p align=\"cen"
},
{
"path": "demo/README.md",
"chars": 138,
"preview": "### PaddleHub Office Website:https://www.paddlepaddle.org.cn/hub\r\n### PaddleHub Module Searching:https://www.paddlepaddl"
},
{
"path": "demo/audio_classification/README.md",
"chars": 4664,
"preview": "# PaddleHub 声音分类\n\n本示例展示如何使用PaddleHub Fine-tune API以及CNN14等预训练模型完成声音分类和Tagging的任务。\n\nCNN14等预训练模型的详情,请参考论文[PANNs: Large-Sca"
},
{
"path": "demo/audio_classification/audioset_predict.py",
"chars": 1857,
"preview": "# Copyright (c) 2021 PaddlePaddle Authors. All Rights Reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the "
},
{
"path": "demo/audio_classification/predict.py",
"chars": 1916,
"preview": "# Copyright (c) 2021 PaddlePaddle Authors. All Rights Reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the "
},
{
"path": "demo/audio_classification/train.py",
"chars": 2073,
"preview": "# Copyright (c) 2021 PaddlePaddle Authors. All Rights Reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the "
},
{
"path": "demo/autoaug/README.md",
"chars": 2699,
"preview": "# PaddleHub 自动数据增强\n\n本示例将展示如何使用PaddleHub搜索最适合数据的数据增强策略,并将其应用到模型训练中。\n\n## 依赖\n\n请预先从pip下载auto-augment软件包\n\n```\npip install aut"
},
{
"path": "demo/autoaug/hub_fitter.py",
"chars": 7550,
"preview": "# -*- coding: utf-8 -*-\n#*******************************************************************************\n#\n# Copyright ("
},
{
"path": "demo/autoaug/paddlehub_utils/__init__.py",
"chars": 313,
"preview": "# -*- coding: utf-8 -*-\n#*******************************************************************************\n#\n# Copyright ("
},
{
"path": "demo/autoaug/paddlehub_utils/reader.py",
"chars": 12487,
"preview": "# coding:utf-8\n# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.\n#\n# Licensed under the Apache License, V"
},
{
"path": "demo/autoaug/paddlehub_utils/trainer.py",
"chars": 9571,
"preview": "# -*- coding: utf-8 -*-\n#*******************************************************************************\n#\n# Copyright ("
},
{
"path": "demo/autoaug/pba_classifier_example.yaml",
"chars": 5418,
"preview": "task_config:\n run_mode: \"ray\"\n workspace: \"./work_dirs/pbt_hub_classifer/test_autoaug\"\n task_type: \"classifier\""
},
{
"path": "demo/autoaug/search.py",
"chars": 1546,
"preview": "from auto_augment.autoaug.experiment.experiment import AutoAugExperiment\nfrom auto_augment.autoaug.utils.yaml_config imp"
},
{
"path": "demo/autoaug/search.sh",
"chars": 391,
"preview": "#!/usr/bin/env bash\n\nexport FLAGS_fast_eager_deletion_mode=1\nexport FLAGS_eager_delete_tensor_gb=0.0\nconfig=\"./pba_class"
},
{
"path": "demo/autoaug/train.py",
"chars": 2770,
"preview": "# -*- coding: utf-8 -*-\n#*******************************************************************************\n#\n# Copyright ("
},
{
"path": "demo/autoaug/train.sh",
"chars": 459,
"preview": "#!/usr/bin/env bash\nexport FLAGS_fast_eager_deletion_mode=1\nexport FLAGS_eager_delete_tensor_gb=0.0\nconfig=\"./pba_classi"
},
{
"path": "demo/colorization/README.md",
"chars": 4595,
"preview": "# PaddleHub 图像着色\n\n本示例将展示如何使用PaddleHub对预训练模型进行finetune并完成预测任务。\n\n## 命令行预测\n\n```\n$ hub run user_guided_colorization --input_"
},
{
"path": "demo/colorization/predict.py",
"chars": 241,
"preview": "import paddle\nimport paddlehub as hub\n\nif __name__ == '__main__':\n model = hub.Module(name='user_guided_colorization'"
},
{
"path": "demo/colorization/train.py",
"chars": 1178,
"preview": "import paddle\nimport paddlehub as hub\nimport paddlehub.vision.transforms as T\nfrom paddlehub.finetune.trainer import Tra"
},
{
"path": "demo/image_classification/README.md",
"chars": 4637,
"preview": "# PaddleHub 图像分类\n\n本示例将展示如何使用PaddleHub对预训练模型进行finetune并完成预测任务。\n\n## 命令行预测\n\n```shell\n$ hub run resnet50_vd_imagenet_ssld --"
},
{
"path": "demo/image_classification/predict.py",
"chars": 298,
"preview": "import paddle\nimport paddlehub as hub\n\nif __name__ == '__main__':\n model = hub.Module(\n name='resnet50_vd_imag"
},
{
"path": "demo/image_classification/train.py",
"chars": 929,
"preview": "import paddle\nimport paddlehub as hub\nimport paddlehub.vision.transforms as T\nfrom paddlehub.finetune.trainer import Tra"
},
{
"path": "demo/semantic_segmentation/README.md",
"chars": 3752,
"preview": "# PaddleHub 图像分割\n\n本示例将展示如何使用PaddleHub对预训练模型进行finetune并完成预测任务。\n\n\n## 如何开始Fine-tune\n\n在完成安装PaddlePaddle与PaddleHub后,通过执行`pyth"
},
{
"path": "demo/semantic_segmentation/predict.py",
"chars": 226,
"preview": "import paddle\nimport paddlehub as hub\n\nif __name__ == '__main__':\n model = hub.Module(name='ocrnet_hrnetw18_voc', num"
},
{
"path": "demo/semantic_segmentation/train.py",
"chars": 1493,
"preview": "import paddle\nimport numpy as np\nimport paddlehub as hub\nfrom paddlehub.finetune.trainer import Trainer\nfrom paddlehub.d"
},
{
"path": "demo/sequence_labeling/README.md",
"chars": 7137,
"preview": "# PaddleHub Transformer模型fine-tune序列标注(动态图)\n\n在2017年之前,工业界和学术界对NLP文本处理依赖于序列模型[Recurrent Neural Network (RNN)](https://bai"
},
{
"path": "demo/sequence_labeling/predict.py",
"chars": 1577,
"preview": "# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the "
},
{
"path": "demo/sequence_labeling/train.py",
"chars": 2680,
"preview": "# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the "
},
{
"path": "demo/serving/bentoml/cloud-native-model-serving-with-bentoml.ipynb",
"chars": 12963,
"preview": "{\n \"cells\": [\n {\n \"cell_type\": \"markdown\",\n \"metadata\": {\n \"id\": \"erfOlc-T8kY3\"\n },\n \"source\": [\n \"# **Be"
},
{
"path": "demo/serving/lexical_analysis_lac/templates/lac_gpu_serving_config.json",
"chars": 213,
"preview": "{\n \"modules_info\": {\n \"lac\": {\n \"init_args\": {\n \"version\": \"2.1.0\"\n },\n \"predict_args\": {\n "
},
{
"path": "demo/serving/lexical_analysis_lac/templates/lac_serving_config.json",
"chars": 263,
"preview": "{\n \"modules_info\": {\n \"lac\": {\n \"init_args\": {\n \"version\": \"2.1.0\"\n },\n \"predict_args\": {\n "
},
{
"path": "demo/serving/module_serving/lexical_analysis_lac/README.md",
"chars": 3603,
"preview": "# 部署词法分析服务-以lac为例\n## 简介\n`Lexical Analysis of Chinese`,简称`LAC`,是一个联合的词法分析模型,能整体性地完成中文分词、词性标注、专名识别任务。关于`LAC`的具体信息请参见[LAC]("
},
{
"path": "demo/serving/module_serving/lexical_analysis_lac/lac_serving_demo.py",
"chars": 687,
"preview": "# coding: utf8\nimport requests\nimport json\n\nif __name__ == \"__main__\":\n # 指定用于预测的文本并生成字典{\"text\": [text_1, text_2, ..."
},
{
"path": "demo/serving/module_serving/object_detection_pyramidbox_lite_server_mask/pyramidbox_lite_server_mask_serving_demo.py",
"chars": 702,
"preview": "# coding: utf8\nimport requests\nimport json\nimport cv2\nimport base64\n\n\ndef cv2_to_base64(image):\n data = cv2.imencode("
},
{
"path": "demo/style_transfer/README.md",
"chars": 4435,
"preview": "# PaddleHub 图像风格迁移\n\n本示例将展示如何使用PaddleHub对预训练模型进行finetune并完成预测任务。\n\n## 命令行预测\n\n```\n$ hub run msgnet --input_path \"/PATH/TO/O"
},
{
"path": "demo/style_transfer/predict.py",
"chars": 264,
"preview": "import paddle\nimport paddlehub as hub\n\nif __name__ == '__main__':\n model = hub.Module(name='msgnet', load_checkpoint="
},
{
"path": "demo/style_transfer/train.py",
"chars": 606,
"preview": "import paddle\nimport paddlehub as hub\n\nfrom paddlehub.finetune.trainer import Trainer\nfrom paddlehub.datasets.minicoco i"
},
{
"path": "demo/text_classification/README.md",
"chars": 6352,
"preview": "# PaddleHub Transformer模型fine-tune文本分类(动态图)\n\n在2017年之前,工业界和学术界对NLP文本处理依赖于序列模型[Recurrent Neural Network (RNN)](https://bai"
},
{
"path": "demo/text_classification/embedding/model.py",
"chars": 6963,
"preview": "# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the "
},
{
"path": "demo/text_classification/embedding/predict.py",
"chars": 2344,
"preview": "# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the "
},
{
"path": "demo/text_classification/embedding/train.py",
"chars": 2698,
"preview": "# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the "
},
{
"path": "demo/text_classification/predict.py",
"chars": 1324,
"preview": "# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the "
},
{
"path": "demo/text_classification/train.py",
"chars": 2483,
"preview": "# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the "
},
{
"path": "demo/text_matching/README.md",
"chars": 7165,
"preview": "# PaddleHub Transformer模型fine-tune文本匹配(动态图)\n\n在2017年之前,工业界和学术界对NLP文本处理依赖于序列模型[Recurrent Neural Network (RNN)](https://bai"
},
{
"path": "demo/text_matching/predict.py",
"chars": 1354,
"preview": "# Copyright (c) 2021 PaddlePaddle Authors. All Rights Reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the "
},
{
"path": "demo/text_matching/train.py",
"chars": 2464,
"preview": "# Copyright (c) 2021 PaddlePaddle Authors. All Rights Reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the "
},
{
"path": "docker/Dockerfile",
"chars": 5047,
"preview": "FROM ubuntu:16.04\n\nRUN echo \"deb [trusted=true] http://mirrors.tuna.tsinghua.edu.cn/ubuntu/ xenial main restricted \\n\\\nd"
},
{
"path": "docs/Makefile",
"chars": 634,
"preview": "# Minimal makefile for Sphinx documentation\n#\n\n# You can set these variables from the command line, and also\n# from the "
},
{
"path": "docs/conf.py",
"chars": 2740,
"preview": "# Configuration file for the Sphinx documentation builder.\n#\n# This file only contains a selection of the most common op"
},
{
"path": "docs/docs_ch/Makefile",
"chars": 634,
"preview": "# Minimal makefile for Sphinx documentation\n#\n\n# You can set these variables from the command line, and also\n# from the "
},
{
"path": "docs/docs_ch/api/datasets/canvas.rst",
"chars": 555,
"preview": "==============\nCanvas\n==============\n\n.. code-block:: python\n\n class paddlehub.datasets.Canvas(transform: Callable, m"
},
{
"path": "docs/docs_ch/api/datasets/chnsenticorp.rst",
"chars": 820,
"preview": "==============\nChnSentiCorp\n==============\n\n.. code-block:: python\n\n class paddlehub.datasets.ChnSentiCorp(tokenizer:"
},
{
"path": "docs/docs_ch/api/datasets/esc50.rst",
"chars": 595,
"preview": "==============\nESC50\n==============\n\n.. code-block:: python\n\n class paddlehub.datasets.ESC50(mode: str = 'train', fea"
},
{
"path": "docs/docs_ch/api/datasets/flowers.rst",
"chars": 392,
"preview": "==============\nFlowers\n==============\n\n.. code-block:: python\n\n class paddlehub.datasets.Flowers(transform: Callable,"
},
{
"path": "docs/docs_ch/api/datasets/lcqmc.rst",
"chars": 721,
"preview": "==============\nLCQMC\n==============\n\n.. code-block:: python\n\n class paddlehub.datasets.LCQMC(tokenizer: Union[BertTok"
},
{
"path": "docs/docs_ch/api/datasets/minicoco.rst",
"chars": 571,
"preview": "==============\nMiniCOCO\n==============\n\n.. code-block:: python\n\n class paddlehub.datasets.MiniCOCO(transform: Callabl"
},
{
"path": "docs/docs_ch/api/datasets/msra_ner.rst",
"chars": 937,
"preview": "==============\nMSRA_NER\n==============\n\n.. code-block:: python\n\n class paddlehub.datasets.MSRA_NER(tokenizer: Union[B"
},
{
"path": "docs/docs_ch/api/datasets/opticdisc.rst",
"chars": 480,
"preview": "==============\nOpticDiscSeg\n==============\n\n.. code-block:: python\n\n class paddlehub.datasets.OpticDiscSeg(transform:"
},
{
"path": "docs/docs_ch/api/datasets_index.rst",
"chars": 513,
"preview": "==============\nDatasets\n==============\n\n\nCV\n==============\n.. toctree::\n :maxdepth: 2\n :titlesonly:\n\n Canvas<datas"
},
{
"path": "docs/docs_ch/api/env.rst",
"chars": 1411,
"preview": "================\nHub Environment\n================\n\n.. code-block:: console\n\n HUB_HOME\n ├── MODULE_HOME\n ├── CAC"
},
{
"path": "docs/docs_ch/api/module.rst",
"chars": 6022,
"preview": "==============\nModule\n==============\n\n.. code-block:: python\n\n class paddlehub.Module(\n name: str = None,\n "
},
{
"path": "docs/docs_ch/api/module_decorator.rst",
"chars": 1515,
"preview": "=================\nModule Decorator\n=================\n\nmoduleinfo\n============\n\n.. code-block:: python\n\n def paddlehub"
},
{
"path": "docs/docs_ch/api/module_manager.rst",
"chars": 2584,
"preview": "=======================\nLocalModuleManager\n=======================\n\n.. code-block:: python\n\n class paddlehub.module.m"
},
{
"path": "docs/docs_ch/api/trainer.rst",
"chars": 3345,
"preview": "==============\nTrainer\n==============\n\n.. code-block:: python\n\n class paddlehub.Trainer(\n model: paddle.nn.Lay"
},
{
"path": "docs/docs_ch/api_index.rst",
"chars": 473,
"preview": "==============\nAPI Reference\n==============\n\n\nModule\n==============\n.. toctree::\n :maxdepth: 2\n :titlesonly:\n\n Mod"
},
{
"path": "docs/docs_ch/community/contribute_code.md",
"chars": 2502,
"preview": "# 贡献代码\n\nPaddleHub非常欢迎贡献者。\n\n首先,如果有什么不确定的事情,可随时提交问题或拉取请求。 不会有人因此而抱怨。我们会感激任何形式的贡献,不想用一堆规则来阻止这些贡献。\n\n本文档包括了所有在贡献中需要注意的要点,会加快合"
},
{
"path": "docs/docs_ch/community/more_demos.md",
"chars": 2610,
"preview": "# 第三方趣味案例\n\n以下为前期PaddleHub课程或活动中,开发者们基于PaddleHub创作的趣味实践作品,均收录在AI Studio中,可在线运行,欢迎访问,希望对您有所启发。\n1. [布剪刀石头【人脸识别切换本地窗口】](http"
},
{
"path": "docs/docs_ch/community_index.rst",
"chars": 526,
"preview": "===================\n活跃社区\n===================\n.. toctree::\n :maxdepth: 2\n :titlesonly:\n\n community/more_demos.m"
},
{
"path": "docs/docs_ch/conf.py",
"chars": 2511,
"preview": "# Configuration file for the Sphinx documentation builder.\n#\n# This file only contains a selection of the most common op"
},
{
"path": "docs/docs_ch/faq.md",
"chars": 1000,
"preview": "# 常见问题\n\n## 使用pip install paddlehub时提示\n`Could not find a version that satisfies the requirement paddlehub (from versions:"
},
{
"path": "docs/docs_ch/figures.md",
"chars": 6798,
"preview": "## 特性详解\n<a name=\"丰富的预训练模型\"></a>\n\n### 1、丰富的预训练模型\n\n#### 1.1、图像\n\n| | **精品模型举例** "
},
{
"path": "docs/docs_ch/finetune/audio_classification.md",
"chars": 4654,
"preview": "# 声音分类\n\n本示例展示如何使用PaddleHub Fine-tune API以及CNN14等预训练模型完成声音分类和Tagging的任务。\n\nCNN14等预训练模型的详情,请参考论文[PANNs: Large-Scale Pretrai"
},
{
"path": "docs/docs_ch/finetune/customized_dataset.md",
"chars": 7329,
"preview": "# 自定义数据\n\n训练一个新任务时,如果从零开始训练时,这将是一个耗时的过程,并且效果可能达不到理想的效果,此时您可以利用PaddleHub提供的预训练模型进行具体任务的Fine-tune。您只需要对自定义数据进行相应的预处理,随后输入预训"
},
{
"path": "docs/docs_ch/finetune/image_classification.md",
"chars": 4435,
"preview": "# 图像分类\n\n本示例将展示如何使用PaddleHub对预训练模型进行finetune并完成预测任务。\n\n## 命令行预测\n\n```shell\n$ hub run resnet50_vd_imagenet_ssld --input_path"
},
{
"path": "docs/docs_ch/finetune/image_colorization.md",
"chars": 4585,
"preview": "# 图像着色\n\n本示例将展示如何使用PaddleHub对预训练模型进行finetune并完成预测任务。\n\n## 命令行预测\n\n```\n$ hub run user_guided_colorization --input_path \"/PAT"
},
{
"path": "docs/docs_ch/finetune/semantic_segmentation.md",
"chars": 3742,
"preview": "# 图像分割\n\n本示例将展示如何使用PaddleHub对预训练模型进行finetune并完成预测任务。\n\n\n## 如何开始Fine-tune\n\n在完成安装PaddlePaddle与PaddleHub后,通过执行`python train.p"
},
{
"path": "docs/docs_ch/finetune/sequence_labeling.md",
"chars": 7034,
"preview": "# 序列标注\n\n在2017年之前,工业界和学术界对NLP文本处理依赖于序列模型[Recurrent Neural Network (RNN)](https://baike.baidu.com/item/%E5%BE%AA%E7%8E%AF%"
},
{
"path": "docs/docs_ch/finetune/style_transfer.md",
"chars": 4174,
"preview": "# 风格迁移\n\n本示例将展示如何使用PaddleHub对预训练模型进行finetune并完成预测任务。\n\n## 命令行预测\n\n```\n$ hub run msgnet --input_path \"/PATH/TO/ORIGIN/IMAGE\""
},
{
"path": "docs/docs_ch/finetune/text_matching.md",
"chars": 7128,
"preview": "# 文本匹配\n\n在2017年之前,工业界和学术界对NLP文本处理依赖于序列模型[Recurrent Neural Network (RNN)](https://baike.baidu.com/item/%E5%BE%AA%E7%8E%AF%"
},
{
"path": "docs/docs_ch/get_start/installation.rst",
"chars": 886,
"preview": "============\n安装\n============\n\n\n环境依赖\n========================\n\n* 操作系统:Windows/Mac/Linux\n* Python >= 3.6.2\n* PaddlePaddle "
},
{
"path": "docs/docs_ch/get_start/linux_quickstart.md",
"chars": 5459,
"preview": "# 零基础Linux安装并实现图像风格迁移\n\n## 第1步:安装Anaconda\n\n- 说明:使用paddlepaddle需要先安装python环境,这里我们选择python集成环境Anaconda工具包\n - Anaconda是1个常用"
},
{
"path": "docs/docs_ch/get_start/mac_quickstart.md",
"chars": 5227,
"preview": "# 零基础mac安装并实现图像风格迁移\n\n## 第1步:安装Anaconda\n\n- 说明:使用paddlepaddle需要先安装python环境,这里我们选择python集成环境Anaconda工具包\n - Anaconda是1个常用的p"
},
{
"path": "docs/docs_ch/get_start/python_use_hub.rst",
"chars": 4661,
"preview": "=================\n快速体验\n=================\n\n在PaddleHub中,Module代表一个可执行模块,一般来讲就是一个可以端到端预测的预训练模型(例如目标检测模型、中文词法分析模型),又或者是一个需要根"
},
{
"path": "docs/docs_ch/get_start/windows_quickstart.md",
"chars": 4504,
"preview": "# 零基础windows安装并实现图像风格迁移\n\n## 第1步:安装Anaconda\n\n- 说明:使用paddlepaddle需要先安装python环境,这里我们选择python集成环境Anaconda工具包\n - Anaconda是1个"
},
{
"path": "docs/docs_ch/get_start_index.rst",
"chars": 168,
"preview": "===============================\n快速入门PaddleHub\n===============================\n\n.. toctree::\n :maxdepth: 2\n\n get_star"
},
{
"path": "docs/docs_ch/index.rst",
"chars": 609,
"preview": "===========================\n关于PaddleHub\n===========================\n\n欢迎使用PaddleHub!这是一个基于飞桨框架的预训练模型应用工具,旨在降低AI模型的使用门槛并促动"
},
{
"path": "docs/docs_ch/make.bat",
"chars": 795,
"preview": "@ECHO OFF\r\n\r\npushd %~dp0\r\n\r\nREM Command file for Sphinx documentation\r\n\r\nif \"%SPHINXBUILD%\" == \"\" (\r\n\tset SPHINXBUILD=sp"
},
{
"path": "docs/docs_ch/release.md",
"chars": 8681,
"preview": "# 更新历史\n\n## `v2.3.0`\n\n### 【1、支持文图生成新场景】\n - 新增基于disco diffusion技术的文图生成dd系列模型5个,其中英文模型3个,中文模型2个,其中中文文图生成模型[disco_diffusion"
},
{
"path": "docs/docs_ch/transfer_learning_index.rst",
"chars": 971,
"preview": "==================\n迁移学习\n==================\n\n迁移学习 (Transfer Learning) 是属于深度学习的一个子研究领域,该研究领域的目标在于利用数据、任务、或模型之间的相似性,将在旧领域学习"
},
{
"path": "docs/docs_ch/tutorial/cmd_usage.rst",
"chars": 2330,
"preview": "===========================\nPaddleHub命令行工具\n===========================\n\nPaddleHub为预训练模型的管理和使用提供了命令行工具。\n\n我们一共提供了11个命令,涵盖了"
},
{
"path": "docs/docs_ch/tutorial/custom_module.rst",
"chars": 7175,
"preview": "======================\n如何创建自己的Module\n======================\n\n\n一、 准备工作\n=======================\n\n模型基本信息\n------------------"
},
{
"path": "docs/docs_ch/tutorial/serving.md",
"chars": 5526,
"preview": "# PaddleHub Serving模型一键服务部署\n## 简介\n### 为什么使用一键服务部署\n使用PaddleHub能够快速进行模型预测,但开发者常面临本地预测过程迁移线上的需求。无论是对外开放服务端口,还是在局域网中搭建预测服务,都"
},
{
"path": "docs/docs_ch/tutorial_index.rst",
"chars": 203,
"preview": "========\n教程\n========\n\n\n\n.. toctree::\n :maxdepth: 2\n :titlesonly:\n\n 命令行使用方法<tutorial/cmd_usage>\n 一键服务化部署<tutorial"
},
{
"path": "docs/docs_ch/visualization.md",
"chars": 5203,
"preview": "## 精品模型效果展示\n\n### 文本识别\n- 包含超轻量中英文OCR模型,高精度中英文、多语种德语、法语、日语、韩语OCR识别。\n- 感谢CopyRight@[PaddleOCR](https://github.com/PaddlePad"
},
{
"path": "docs/docs_en/Makefile",
"chars": 634,
"preview": "# Minimal makefile for Sphinx documentation\n#\n\n# You can set these variables from the command line, and also\n# from the "
},
{
"path": "docs/docs_en/api/datasets/canvas.rst",
"chars": 555,
"preview": "==============\nCanvas\n==============\n\n.. code-block:: python\n\n class paddlehub.datasets.Canvas(transform: Callable, m"
},
{
"path": "docs/docs_en/api/datasets/chnsenticorp.rst",
"chars": 820,
"preview": "==============\nChnSentiCorp\n==============\n\n.. code-block:: python\n\n class paddlehub.datasets.ChnSentiCorp(tokenizer:"
},
{
"path": "docs/docs_en/api/datasets/esc50.rst",
"chars": 595,
"preview": "==============\nESC50\n==============\n\n.. code-block:: python\n\n class paddlehub.datasets.ESC50(mode: str = 'train', fea"
},
{
"path": "docs/docs_en/api/datasets/flowers.rst",
"chars": 392,
"preview": "==============\nFlowers\n==============\n\n.. code-block:: python\n\n class paddlehub.datasets.Flowers(transform: Callable,"
},
{
"path": "docs/docs_en/api/datasets/lcqmc.rst",
"chars": 721,
"preview": "==============\nLCQMC\n==============\n\n.. code-block:: python\n\n class paddlehub.datasets.LCQMC(tokenizer: Union[BertTok"
},
{
"path": "docs/docs_en/api/datasets/minicoco.rst",
"chars": 571,
"preview": "==============\nMiniCOCO\n==============\n\n.. code-block:: python\n\n class paddlehub.datasets.MiniCOCO(transform: Callabl"
},
{
"path": "docs/docs_en/api/datasets/msra_ner.rst",
"chars": 937,
"preview": "==============\nMSRA_NER\n==============\n\n.. code-block:: python\n\n class paddlehub.datasets.MSRA_NER(tokenizer: Union[B"
},
{
"path": "docs/docs_en/api/datasets/opticdisc.rst",
"chars": 480,
"preview": "==============\nOpticDiscSeg\n==============\n\n.. code-block:: python\n\n class paddlehub.datasets.OpticDiscSeg(transform:"
},
{
"path": "docs/docs_en/api/datasets_index.rst",
"chars": 513,
"preview": "==============\nDatasets\n==============\n\n\nCV\n==============\n.. toctree::\n :maxdepth: 2\n :titlesonly:\n\n Canvas<datas"
},
{
"path": "docs/docs_en/api/env.rst",
"chars": 1411,
"preview": "================\nHub Environment\n================\n\n.. code-block:: console\n\n HUB_HOME\n ├── MODULE_HOME\n ├── CAC"
},
{
"path": "docs/docs_en/api/module.rst",
"chars": 6022,
"preview": "==============\nModule\n==============\n\n.. code-block:: python\n\n class paddlehub.Module(\n name: str = None,\n "
},
{
"path": "docs/docs_en/api/module_decorator.rst",
"chars": 1515,
"preview": "=================\nModule Decorator\n=================\n\nmoduleinfo\n============\n\n.. code-block:: python\n\n def paddlehub"
},
{
"path": "docs/docs_en/api/module_manager.rst",
"chars": 2584,
"preview": "=======================\nLocalModuleManager\n=======================\n\n.. code-block:: python\n\n class paddlehub.module.m"
},
{
"path": "docs/docs_en/api/trainer.rst",
"chars": 3346,
"preview": "==============\nTrainer\n==============\n\n.. code-block:: python\n\n class paddlehub.Trainer(\n model: paddle.nn.Lay"
},
{
"path": "docs/docs_en/api_index.rst",
"chars": 473,
"preview": "==============\nAPI Reference\n==============\n\n\nModule\n==============\n.. toctree::\n :maxdepth: 2\n :titlesonly:\n\n Mod"
},
{
"path": "docs/docs_en/community/contribute_code.md",
"chars": 9928,
"preview": "# How to contribution code\n\nPaddleHub welcomes contributors.\n\nFirst of all, feel free to submit a question or pull reque"
},
{
"path": "docs/docs_en/community/more_demos.md",
"chars": 3835,
"preview": "# Interesting cases of third parties\n\nThe following are some of the interesting and practical works created by developer"
},
{
"path": "docs/docs_en/community_index.rst",
"chars": 602,
"preview": "===================\nActive community\n===================\n.. toctree::\n :maxdepth: 2\n :titlesonly:\n\n community/"
},
{
"path": "docs/docs_en/conf.py",
"chars": 2511,
"preview": "# Configuration file for the Sphinx documentation builder.\n#\n# This file only contains a selection of the most common op"
},
{
"path": "docs/docs_en/faq.md",
"chars": 1532,
"preview": "# FAQ\n\n## Failed to install paddlehub via pip\n`Could not find a version that satisfies the requirement paddlehub (from v"
},
{
"path": "docs/docs_en/figures.md",
"chars": 8423,
"preview": "## Detailed Features\n\n<a name=\"Various Pre-training Models\"></a>\n\n### 1\\. Various Pre-training Models\n\n#### 1.1. Image\n\n"
},
{
"path": "docs/docs_en/finetune/audio_classification.md",
"chars": 4654,
"preview": "# 声音分类\n\n本示例展示如何使用PaddleHub Fine-tune API以及CNN14等预训练模型完成声音分类和Tagging的任务。\n\nCNN14等预训练模型的详情,请参考论文[PANNs: Large-Scale Pretrai"
},
{
"path": "docs/docs_en/finetune/customized_dataset.md",
"chars": 5060,
"preview": "# Customized Data\n\nIn the training of a new task, it is a time-consuming process starting from zero, without producing t"
},
{
"path": "docs/docs_en/finetune/image_classification.md",
"chars": 4435,
"preview": "# 图像分类\n\n本示例将展示如何使用PaddleHub对预训练模型进行finetune并完成预测任务。\n\n## 命令行预测\n\n```shell\n$ hub run resnet50_vd_imagenet_ssld --input_path"
},
{
"path": "docs/docs_en/finetune/image_colorization.md",
"chars": 4585,
"preview": "# 图像着色\n\n本示例将展示如何使用PaddleHub对预训练模型进行finetune并完成预测任务。\n\n## 命令行预测\n\n```\n$ hub run user_guided_colorization --input_path \"/PAT"
},
{
"path": "docs/docs_en/finetune/semantic_segmentation.md",
"chars": 3742,
"preview": "# 图像分割\n\n本示例将展示如何使用PaddleHub对预训练模型进行finetune并完成预测任务。\n\n\n## 如何开始Fine-tune\n\n在完成安装PaddlePaddle与PaddleHub后,通过执行`python train.p"
},
{
"path": "docs/docs_en/finetune/sequence_labeling.md",
"chars": 7034,
"preview": "# 序列标注\n\n在2017年之前,工业界和学术界对NLP文本处理依赖于序列模型[Recurrent Neural Network (RNN)](https://baike.baidu.com/item/%E5%BE%AA%E7%8E%AF%"
},
{
"path": "docs/docs_en/finetune/style_transfer.md",
"chars": 4174,
"preview": "# 风格迁移\n\n本示例将展示如何使用PaddleHub对预训练模型进行finetune并完成预测任务。\n\n## 命令行预测\n\n```\n$ hub run msgnet --input_path \"/PATH/TO/ORIGIN/IMAGE\""
},
{
"path": "docs/docs_en/finetune/text_matching.md",
"chars": 7128,
"preview": "# 文本匹配\n\n在2017年之前,工业界和学术界对NLP文本处理依赖于序列模型[Recurrent Neural Network (RNN)](https://baike.baidu.com/item/%E5%BE%AA%E7%8E%AF%"
},
{
"path": "docs/docs_en/get_start/installation.rst",
"chars": 1427,
"preview": "============\nInstallation\n============\n\n\nEnvironment Dependency\n========================\n\n* Operating System: Windows/Ma"
},
{
"path": "docs/docs_en/get_start/linux_quickstart.md",
"chars": 8865,
"preview": "# Zero base Linux installation and image style transfer\n\n## Step 1: Install Anaconda\n\n- Note: To use paddlepaddle, you n"
},
{
"path": "docs/docs_en/get_start/mac_quickstart.md",
"chars": 8308,
"preview": "# Zero base mac installation and image style transfer\n\n## Step 1: Install Anaconda\n\n- Note: To use paddlepaddle, you nee"
},
{
"path": "docs/docs_en/get_start/python_use_hub.rst",
"chars": 6283,
"preview": "=================\nQuick experience\n=================\n\nIn PaddleHub, the concept `Module` represents an executable module"
},
{
"path": "docs/docs_en/get_start/windows_quickstart.md",
"chars": 7206,
"preview": "# Zero base Windows installation and image style transfer\n\n## Step 1: Install Anaconda\n\n- Note: To use paddlepaddle, you"
},
{
"path": "docs/docs_en/get_start_index.rst",
"chars": 179,
"preview": "===============================\nGet start with PaddleHub\n===============================\n\n.. toctree::\n :maxdepth: 2\n\n"
},
{
"path": "docs/docs_en/index.rst",
"chars": 1432,
"preview": "===========================\nIntroduction to PaddleHub\n===========================\n\nWelcome to PaddleHub! This is an Awes"
},
{
"path": "docs/docs_en/make.bat",
"chars": 795,
"preview": "@ECHO OFF\r\n\r\npushd %~dp0\r\n\r\nREM Command file for Sphinx documentation\r\n\r\nif \"%SPHINXBUILD%\" == \"\" (\r\n\tset SPHINXBUILD=sp"
},
{
"path": "docs/docs_en/release.md",
"chars": 9731,
"preview": "# Release Note\n\n## `v2.3.0`\n\n### [1、Support text-to-image domain model]\n - Add five text-to-image domain models based o"
},
{
"path": "docs/docs_en/transfer_learning_index.rst",
"chars": 2121,
"preview": "==================\nTransfer Learning\n==================\n\nTransfer Learning is a subfield of deep learning that aims to u"
},
{
"path": "docs/docs_en/tutorial/cmd_usage.rst",
"chars": 4823,
"preview": "===========================\nPaddleHub Command Line Tool\n===========================\n\nPaddleHub provides the command line"
},
{
"path": "docs/docs_en/tutorial/custom_module.rst",
"chars": 9108,
"preview": "======================\nHow to custom Module\n======================\n\n\nI. Preparation\n=======================\n\nBasic Model"
},
{
"path": "docs/docs_en/tutorial/serving.md",
"chars": 8339,
"preview": "# PaddleHub Serving : One-Key Deploy Models as Services\n\n## Introduction\n\n### Background\n\nPaddleHub enables the rapid mo"
},
{
"path": "docs/docs_en/tutorial_index.rst",
"chars": 239,
"preview": "========\nTutorial\n========\n\n\n\n.. toctree::\n :maxdepth: 2\n :titlesonly:\n\n Command Usage<tutorial/cmd_usage>\n Hub "
},
{
"path": "docs/docs_en/visualization.md",
"chars": 8255,
"preview": "### Text Recognition\n- Contain ultra-lightweight Chinese and English OCR models, high-precision Chinese and English, mul"
},
{
"path": "docs/make.bat",
"chars": 795,
"preview": "@ECHO OFF\r\n\r\npushd %~dp0\r\n\r\nREM Command file for Sphinx documentation\r\n\r\nif \"%SPHINXBUILD%\" == \"\" (\r\n\tset SPHINXBUILD=sp"
},
{
"path": "docs/requirements.txt",
"chars": 304,
"preview": "sphinx==3.1.2\nsphinx-markdown-tables==0.0.15\nsphinx_materialdesign_theme==0.1.11\nrecommonmark==0.6.0\nsphinx-serve==1.0.1"
},
{
"path": "modules/README.md",
"chars": 48889,
"preview": "English | [简体中文](README_ch.md)\n\n# CONTENTS\n|[Image](#Image) (212)|[Text](#Text) (130)|[Audio](#Audio) (15)|[Video](#Vide"
},
{
"path": "modules/README_ch.md",
"chars": 40172,
"preview": "简体中文 | [English](README.md)\r\n\r\n# 目录\r\n|[图像](#图像) (222个)|[文本](#文本) (130个)|[语音](#语音) (15个)|[视频](#视频) (8个)|[工业应用](#工业应用) (1个"
},
{
"path": "modules/audio/README.md",
"chars": 1025,
"preview": "## **更好用户体验,建议参考WEB端官方文档 -> [【语音合成】](https://www.paddlepaddle.org.cn/hublist)**\n\n### 文字识别\n语音合成(TTS)任务可以实现讲文字转化为语音,已经广泛应用"
},
{
"path": "modules/audio/README_en.md",
"chars": 1625,
"preview": "## **For better user experience, refer to the official documentation on WEB -> [Text-to-speech](https://www.paddlepaddle"
},
{
"path": "modules/audio/asr/deepspeech2_aishell/README.md",
"chars": 3269,
"preview": "# deepspeech2_aishell\n\n|模型名称|deepspeech2_aishell|\n| :--- | :---: |\n|类别|语音-语音识别|\n|网络|DeepSpeech2|\n|数据集|AISHELL-1|\n|是否支持Fi"
},
{
"path": "modules/audio/asr/deepspeech2_aishell/__init__.py",
"chars": 0,
"preview": ""
},
{
"path": "modules/audio/asr/deepspeech2_aishell/assets/conf/augmentation.json",
"chars": 3,
"preview": "{}\n"
},
{
"path": "modules/audio/asr/deepspeech2_aishell/assets/conf/deepspeech2.yaml",
"chars": 1425,
"preview": "# https://yaml.org/type/float.html\ndata:\n train_manifest: data/manifest.train\n dev_manifest: data/manifest.dev\n test_"
},
{
"path": "modules/audio/asr/deepspeech2_aishell/assets/data/mean_std.json",
"chars": 6475,
"preview": "{\"mean_stat\": [-13505966.65209869, -12778154.889588555, -13487728.30750011, -12897344.94123812, -12472281.490772562, -12"
},
{
"path": "modules/audio/asr/deepspeech2_aishell/assets/data/vocab.txt",
"chars": 8616,
"preview": "<blank>\n<unk>\n一\n丁\n七\n万\n丈\n三\n上\n下\n不\n与\n丐\n丑\n专\n且\n世\n丘\n丙\n业\n丛\n东\n丝\n丞\n丢\n两\n严\n丧\n个\n丫\n中\n丰\n串\n临\n丸\n丹\n为\n主\n丽\n举\n乃\n久\n么\n义\n之\n乌\n乍\n乎\n乏\n乐\n乒\n乓\n乔\n乖\n乘\n"
},
{
"path": "modules/audio/asr/deepspeech2_aishell/deepspeech_tester.py",
"chars": 3175,
"preview": "# Copyright (c) 2021 PaddlePaddle Authors. All Rights Reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the "
},
{
"path": "modules/audio/asr/deepspeech2_aishell/module.py",
"chars": 3919,
"preview": "# Copyright (c) 2021 PaddlePaddle Authors. All Rights Reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the "
},
{
"path": "modules/audio/asr/deepspeech2_aishell/requirements.txt",
"chars": 158,
"preview": "# system level: libsnd swig\nloguru\nyacs\njsonlines\nscipy==1.2.1\nsentencepiece\nresampy==0.2.2\nSoundFile==0.9.0.post1\nsoxbi"
},
{
"path": "modules/audio/asr/deepspeech2_librispeech/README.md",
"chars": 3302,
"preview": "# deepspeech2_librispeech\n\n|模型名称|deepspeech2_librispeech|\n| :--- | :---: |\n|类别|语音-语音识别|\n|网络|DeepSpeech2|\n|数据集|LibriSpeec"
},
{
"path": "modules/audio/asr/deepspeech2_librispeech/__init__.py",
"chars": 0,
"preview": ""
},
{
"path": "modules/audio/asr/deepspeech2_librispeech/assets/conf/augmentation.json",
"chars": 3,
"preview": "{}\n"
},
{
"path": "modules/audio/asr/deepspeech2_librispeech/assets/conf/deepspeech2.yaml",
"chars": 1432,
"preview": "# https://yaml.org/type/float.html\ndata:\n train_manifest: data/manifest.train\n dev_manifest: data/manifest.dev-clean\n "
},
{
"path": "modules/audio/asr/deepspeech2_librispeech/deepspeech_tester.py",
"chars": 3175,
"preview": "# Copyright (c) 2021 PaddlePaddle Authors. All Rights Reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the "
},
{
"path": "modules/audio/asr/deepspeech2_librispeech/module.py",
"chars": 3938,
"preview": "# Copyright (c) 2021 PaddlePaddle Authors. All Rights Reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the "
},
{
"path": "modules/audio/asr/deepspeech2_librispeech/requirements.txt",
"chars": 130,
"preview": "loguru\nyacs\njsonlines\nscipy==1.2.1\nsentencepiece\nresampy==0.2.2\nSoundFile==0.9.0.post1\nsoxbindings\nkaldiio\ntypeguard\nedi"
},
{
"path": "modules/audio/asr/u2_conformer_aishell/README.md",
"chars": 3328,
"preview": "# u2_conformer_aishell\n\n|模型名称|u2_conformer_aishell|\n| :--- | :---: |\n|类别|语音-语音识别|\n|网络|Conformer|\n|数据集|AISHELL-1|\n|是否支持Fi"
},
{
"path": "modules/audio/asr/u2_conformer_aishell/__init__.py",
"chars": 0,
"preview": ""
},
{
"path": "modules/audio/asr/u2_conformer_aishell/assets/conf/augmentation.json",
"chars": 3,
"preview": "{}\n"
},
{
"path": "modules/audio/asr/u2_conformer_aishell/assets/conf/conformer.yaml",
"chars": 2335,
"preview": "data:\n train_manifest: data/manifest.train\n dev_manifest: data/manifest.dev\n test_manifest: data/manifest.test\n min_"
},
{
"path": "modules/audio/asr/u2_conformer_aishell/assets/data/mean_std.json",
"chars": 3074,
"preview": "{\"mean_stat\": [533749178.75492024, 537379151.9412827, 553560684.251823, 587164297.7995199, 631868827.5506272, 662598279."
},
{
"path": "modules/audio/asr/u2_conformer_aishell/assets/data/vocab.txt",
"chars": 8480,
"preview": "<blank>\n<unk>\n一\n丁\n七\n万\n丈\n三\n上\n下\n不\n与\n丐\n丑\n专\n且\n世\n丘\n丙\n业\n丛\n东\n丝\n丞\n丢\n两\n严\n丧\n个\n丫\n中\n丰\n串\n临\n丸\n丹\n为\n主\n丽\n举\n乃\n久\n么\n义\n之\n乌\n乍\n乎\n乏\n乐\n乒\n乓\n乔\n乖\n乘\n"
},
{
"path": "modules/audio/asr/u2_conformer_aishell/module.py",
"chars": 2992,
"preview": "# Copyright (c) 2021 PaddlePaddle Authors. All Rights Reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the "
},
{
"path": "modules/audio/asr/u2_conformer_aishell/requirements.txt",
"chars": 139,
"preview": "loguru\nyacs\njsonlines\nscipy==1.2.1\nsentencepiece\nresampy==0.2.2\nSoundFile==0.9.0.post1\nsoxbindings\nkaldiio\ntypeguard\nedi"
},
{
"path": "modules/audio/asr/u2_conformer_aishell/u2_conformer_tester.py",
"chars": 3103,
"preview": "# Copyright (c) 2021 PaddlePaddle Authors. All Rights Reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the "
},
{
"path": "modules/audio/asr/u2_conformer_librispeech/README.md",
"chars": 3369,
"preview": "# u2_conformer_librispeech\n\n|模型名称|u2_conformer_librispeech|\n| :--- | :---: |\n|类别|语音-语音识别|\n|网络|Conformer|\n|数据集|LibriSpeec"
},
{
"path": "modules/audio/asr/u2_conformer_librispeech/__init__.py",
"chars": 0,
"preview": ""
},
{
"path": "modules/audio/asr/u2_conformer_librispeech/assets/conf/augmentation.json",
"chars": 3,
"preview": "{}\n"
},
{
"path": "modules/audio/asr/u2_conformer_librispeech/assets/conf/conformer.yaml",
"chars": 3330,
"preview": "# https://yaml.org/type/float.html\ndata:\n train_manifest: data/manifest.test-clean\n dev_manifest: data/manifest.test-c"
},
{
"path": "modules/audio/asr/u2_conformer_librispeech/assets/data/bpe_unigram_5000.vocab",
"chars": 82894,
"preview": "<unk>\t0\n<s>\t0\n</s>\t0\n▁the\t-2.9911\ns\t-3.44691\n▁and\t-3.58286\n▁of\t-3.70894\n▁to\t-3.78001\n▁a\t-3.89871\n▁in\t-4.20996\n▁i\t-4.3614"
},
{
"path": "modules/audio/asr/u2_conformer_librispeech/assets/data/mean_std.json",
"chars": 3084,
"preview": "{\"mean_stat\": [3419817384.9589553, 3554070049.1888413, 3818511309.9166613, 4066044518.3850017, 4291564631.2871633, 44478"
},
{
"path": "modules/audio/asr/u2_conformer_librispeech/assets/data/vocab.txt",
"chars": 38448,
"preview": "<blank>\n<unk>\n'\na\nabeth\nability\nable\nably\nabout\nac\nach\nacious\nad\nade\nag\nage\nah\nak\nal\nally\nam\nan\nance\nand\nang\nans\nant\nap\n"
},
{
"path": "modules/audio/asr/u2_conformer_librispeech/module.py",
"chars": 3007,
"preview": "# Copyright (c) 2021 PaddlePaddle Authors. All Rights Reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the "
},
{
"path": "modules/audio/asr/u2_conformer_librispeech/requirements.txt",
"chars": 139,
"preview": "loguru\nyacs\njsonlines\nscipy==1.2.1\nsentencepiece\nresampy==0.2.2\nSoundFile==0.9.0.post1\nsoxbindings\nkaldiio\ntypeguard\nedi"
},
{
"path": "modules/audio/asr/u2_conformer_librispeech/u2_conformer_tester.py",
"chars": 3103,
"preview": "# Copyright (c) 2021 PaddlePaddle Authors. All Rights Reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the "
},
{
"path": "modules/audio/asr/u2_conformer_wenetspeech/README.md",
"chars": 3528,
"preview": "# u2_conformer_wenetspeech\n\n|模型名称|u2_conformer_wenetspeech|\n| :--- | :---: |\n|类别|语音-语音识别|\n|网络|Conformer|\n|数据集|WenetSpeec"
},
{
"path": "modules/audio/asr/u2_conformer_wenetspeech/__init__.py",
"chars": 0,
"preview": ""
},
{
"path": "modules/audio/asr/u2_conformer_wenetspeech/module.py",
"chars": 2244,
"preview": "# Copyright (c) 2021 PaddlePaddle Authors. All Rights Reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the "
},
{
"path": "modules/audio/asr/u2_conformer_wenetspeech/requirements.txt",
"chars": 22,
"preview": "paddlespeech==0.1.0a9\n"
},
{
"path": "modules/audio/audio_classification/PANNs/cnn10/README.md",
"chars": 4402,
"preview": "# panns_cnn10\n\n|模型名称|panns_cnn10|\n| :--- | :---: |\n|类别|语音-声音分类|\n|网络|PANNs|\n|数据集|Google Audioset|\n|是否支持Fine-tuning|是|\n|模型"
},
{
"path": "modules/audio/audio_classification/PANNs/cnn10/__init__.py",
"chars": 0,
"preview": ""
},
{
"path": "modules/audio/audio_classification/PANNs/cnn10/module.py",
"chars": 3179,
"preview": "# Copyright (c) 2021 PaddlePaddle Authors. All Rights Reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the "
},
{
"path": "modules/audio/audio_classification/PANNs/cnn10/network.py",
"chars": 4068,
"preview": "# Copyright (c) 2021 PaddlePaddle Authors. All Rights Reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the "
},
{
"path": "modules/audio/audio_classification/PANNs/cnn10/requirements.txt",
"chars": 8,
"preview": "librosa\n"
},
{
"path": "modules/audio/audio_classification/PANNs/cnn14/README.md",
"chars": 4406,
"preview": "# panns_cnn14\n\n|模型名称|panns_cnn14|\n| :--- | :---: |\n|类别|语音-声音分类|\n|网络|PANNs|\n|数据集|Google Audioset|\n|是否支持Fine-tuning|是|\n|模型"
},
{
"path": "modules/audio/audio_classification/PANNs/cnn14/__init__.py",
"chars": 0,
"preview": ""
}
]
// ... and 2610 more files (download for full content)
About this extraction
This page contains the full source code of the PaddlePaddle/PaddleHub GitHub repository, extracted and formatted as plain text for AI agents and large language models (LLMs). The extraction includes 2810 files (157.0 MB), approximately 6.1M tokens, and a symbol index with 14415 extracted functions, classes, methods, constants, and types. Use this with OpenClaw, Claude, ChatGPT, Cursor, Windsurf, or any other AI tool that accepts text input. You can copy the full output to your clipboard or download it as a .txt file.
Extracted by GitExtract — free GitHub repo to text converter for AI. Built by Nikandr Surkov.