Showing preview only (271K chars total). Download the full file or copy to clipboard to get everything.
Repository: PlayVoice/Grad-SVC
Branch: 20230920-V2-96
Commit: 491b0b6423d9
Files: 118
Total size: 252.2 KB
Directory structure:
gitextract_yhmj05_n/
├── LICENSE
├── README.md
├── assets/
│ └── singers/
│ ├── singer0001.npy
│ ├── singer0002.npy
│ ├── singer0003.npy
│ ├── singer0004.npy
│ ├── singer0005.npy
│ ├── singer0006.npy
│ ├── singer0007.npy
│ ├── singer0008.npy
│ ├── singer0009.npy
│ ├── singer0010.npy
│ ├── singer0011.npy
│ ├── singer0012.npy
│ ├── singer0013.npy
│ ├── singer0014.npy
│ ├── singer0015.npy
│ ├── singer0016.npy
│ ├── singer0017.npy
│ ├── singer0018.npy
│ ├── singer0019.npy
│ ├── singer0020.npy
│ ├── singer0021.npy
│ ├── singer0022.npy
│ ├── singer0023.npy
│ ├── singer0024.npy
│ ├── singer0025.npy
│ ├── singer0026.npy
│ ├── singer0027.npy
│ ├── singer0028.npy
│ ├── singer0029.npy
│ ├── singer0030.npy
│ ├── singer0031.npy
│ ├── singer0032.npy
│ ├── singer0033.npy
│ ├── singer0034.npy
│ ├── singer0035.npy
│ ├── singer0036.npy
│ ├── singer0037.npy
│ ├── singer0038.npy
│ ├── singer0039.npy
│ ├── singer0040.npy
│ ├── singer0041.npy
│ ├── singer0042.npy
│ ├── singer0043.npy
│ ├── singer0044.npy
│ ├── singer0045.npy
│ ├── singer0046.npy
│ ├── singer0047.npy
│ ├── singer0048.npy
│ ├── singer0049.npy
│ ├── singer0050.npy
│ ├── singer0051.npy
│ ├── singer0052.npy
│ ├── singer0053.npy
│ ├── singer0054.npy
│ ├── singer0055.npy
│ └── singer0056.npy
├── bigvgan/
│ ├── LICENSE
│ ├── README.md
│ ├── configs/
│ │ └── nsf_bigvgan.yaml
│ ├── inference.py
│ └── model/
│ ├── __init__.py
│ ├── alias/
│ │ ├── __init__.py
│ │ ├── act.py
│ │ ├── filter.py
│ │ └── resample.py
│ ├── bigv.py
│ ├── generator.py
│ └── nsf.py
├── bigvgan_pretrain/
│ └── README.md
├── configs/
│ └── base.yaml
├── grad/
│ ├── LICENSE
│ ├── __init__.py
│ ├── base.py
│ ├── diffusion.py
│ ├── encoder.py
│ ├── model.py
│ ├── reversal.py
│ ├── solver.py
│ ├── ssim.py
│ └── utils.py
├── grad_extend/
│ ├── data.py
│ ├── train.py
│ └── utils.py
├── grad_pretrain/
│ └── README.md
├── gvc_export.py
├── gvc_inference.py
├── gvc_trainer.py
├── hubert/
│ ├── __init__.py
│ ├── hubert_model.py
│ └── inference.py
├── hubert_pretrain/
│ └── README.md
├── pitch/
│ ├── __init__.py
│ └── inference.py
├── prepare/
│ ├── preprocess_a.py
│ ├── preprocess_f0.py
│ ├── preprocess_hubert.py
│ ├── preprocess_speaker.py
│ ├── preprocess_speaker_ave.py
│ ├── preprocess_spec.py
│ ├── preprocess_train.py
│ └── preprocess_zzz.py
├── requirements.txt
├── speaker/
│ ├── __init__.py
│ ├── config.py
│ ├── infer.py
│ ├── models/
│ │ ├── __init__.py
│ │ ├── lstm.py
│ │ └── resnet.py
│ └── utils/
│ ├── __init__.py
│ ├── audio.py
│ ├── coqpit.py
│ ├── io.py
│ └── shared_configs.py
├── speaker_pretrain/
│ ├── README.md
│ └── config.json
└── spec/
└── inference.py
================================================
FILE CONTENTS
================================================
================================================
FILE: LICENSE
================================================
MIT License
Copyright (c) 2023 PlayVoice
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE.
================================================
FILE: README.md
================================================
<div align="center">
<h1> Grad-SVC based on Grad-TTS from HUAWEI Noah's Ark Lab </h1>
[](https://huggingface.co/spaces/maxmax20160403/grad-svc)
<img alt="GitHub Repo stars" src="https://img.shields.io/github/stars/PlayVoice/Grad-SVC">
<img alt="GitHub forks" src="https://img.shields.io/github/forks/PlayVoice/Grad-SVC">
<img alt="GitHub issues" src="https://img.shields.io/github/issues/PlayVoice/Grad-SVC">
<img alt="GitHub" src="https://img.shields.io/github/license/PlayVoice/Grad-SVC">
This project is named as [Grad-SVC](), or [GVC]() for short. Its core technology is diffusion, but so different from other diffusion based SVC models. Codes are adapted from `Grad-TTS` and `whisper-vits-svc`. So the features from `whisper-vits-svc` are used in this project. By the way, [Diff-VC](https://github.com/huawei-noah/Speech-Backbones/tree/main/DiffVC) is a follow-up of [Grad-TTS](), [Diffusion-Based Any-to-Any Voice Conversion](https://arxiv.org/abs/2109.13821)
[Grad-TTS: A Diffusion Probabilistic Model for Text-to-Speech](https://arxiv.org/abs/2105.06337)


The framework of grad-svc-v1

The framework of grad-svc-v2 & v3, encoder:768->512, diffusion:64->96
https://github.com/PlayVoice/Grad-SVC/assets/16432329/f9b66af7-b5b5-4efb-b73d-adb0dc84a0ae
</div>
## Features
1. Such beautiful codes from Grad-TTS
`easy to read`
2. Multi-speaker based on speaker encoder
3. No speaker leaky based on `Perturbation` & `Instance Normlize` & `GRL`
[One-shot Voice Conversion by Separating Speaker and Content Representations with Instance Normalization](https://arxiv.org/abs/1904.05742)
4. No electronic sound
5. Integrated [DPM Solver-k](https://github.com/LuChengTHU/dpm-solver) for less steps
6. Integrated [Fast Maximum Likelihood Sampling Scheme](https://github.com/huawei-noah/Speech-Backbones/tree/main/DiffVC), for less steps
7. [Conditional Flow Matching](https://voicebox.metademolab.com/) (V3), first used in SVC
8. [Rectified Flow Matching](https://github.com/cantabile-kwok/VoiceFlow-TTS) (TODO)
## Setup Environment
1. Install project dependencies
```shell
pip install -r requirements.txt
```
2. Download the Timbre Encoder: [Speaker-Encoder by @mueller91](https://drive.google.com/drive/folders/15oeBYf6Qn1edONkVLXe82MzdIi3O_9m3), put `best_model.pth.tar` into `speaker_pretrain/`.
3. Download [hubert_soft model](https://github.com/bshall/hubert/releases/tag/v0.1),put `hubert-soft-0d54a1f4.pt` into `hubert_pretrain/`.
4. Download pretrained [nsf_bigvgan_pretrain_32K.pth](https://github.com/PlayVoice/NSF-BigVGAN/releases/augment), and put it into `bigvgan_pretrain/`.
**Performance Bottleneck: Generator and Discriminator are 116Mb, but Generator is only 22Mb**
**系统性能瓶颈:生成器和判别器一共116M,而生成器只有22M**
6. Download pretrain model [gvc.pretrain.pth](https://github.com/PlayVoice/Grad-SVC/releases/tag/20230920), and put it into `grad_pretrain/`.
```
python gvc_inference.py --model ./grad_pretrain/gvc.pretrain.pth --spk ./assets/singers/singer0001.npy --wave test.wav
```
For this pretrain model, `temperature` is set `temperature=1.015` in `gvc_inference.py` to get good result.
## Dataset preparation
Put the dataset into the `data_raw` directory following the structure below.
```
data_raw
├───speaker0
│ ├───000001.wav
│ ├───...
│ └───000xxx.wav
└───speaker1
├───000001.wav
├───...
└───000xxx.wav
```
## Data preprocessing
After preprocessing you will get an output with following structure.
```
data_gvc/
└── waves-16k
│ └── speaker0
│ │ ├── 000001.wav
│ │ └── 000xxx.wav
│ └── speaker1
│ ├── 000001.wav
│ └── 000xxx.wav
└── waves-32k
│ └── speaker0
│ │ ├── 000001.wav
│ │ └── 000xxx.wav
│ └── speaker1
│ ├── 000001.wav
│ └── 000xxx.wav
└── mel
│ └── speaker0
│ │ ├── 000001.mel.pt
│ │ └── 000xxx.mel.pt
│ └── speaker1
│ ├── 000001.mel.pt
│ └── 000xxx.mel.pt
└── pitch
│ └── speaker0
│ │ ├── 000001.pit.npy
│ │ └── 000xxx.pit.npy
│ └── speaker1
│ ├── 000001.pit.npy
│ └── 000xxx.pit.npy
└── hubert
│ └── speaker0
│ │ ├── 000001.vec.npy
│ │ └── 000xxx.vec.npy
│ └── speaker1
│ ├── 000001.vec.npy
│ └── 000xxx.vec.npy
└── speaker
│ └── speaker0
│ │ ├── 000001.spk.npy
│ │ └── 000xxx.spk.npy
│ └── speaker1
│ ├── 000001.spk.npy
│ └── 000xxx.spk.npy
└── singer
├── speaker0.spk.npy
└── speaker1.spk.npy
```
1. Re-sampling
- Generate audio with a sampling rate of 16000Hz in `./data_gvc/waves-16k`
```
python prepare/preprocess_a.py -w ./data_raw -o ./data_gvc/waves-16k -s 16000
```
- Generate audio with a sampling rate of 32000Hz in `./data_gvc/waves-32k`
```
python prepare/preprocess_a.py -w ./data_raw -o ./data_gvc/waves-32k -s 32000
```
2. Use 16K audio to extract pitch
```
python prepare/preprocess_f0.py -w data_gvc/waves-16k/ -p data_gvc/pitch
```
3. use 32k audio to extract mel
```
python prepare/preprocess_spec.py -w data_gvc/waves-32k/ -s data_gvc/mel
```
4. Use 16K audio to extract hubert
```
python prepare/preprocess_hubert.py -w data_gvc/waves-16k/ -v data_gvc/hubert
```
5. Use 16k audio to extract timbre code
```
python prepare/preprocess_speaker.py data_gvc/waves-16k/ data_gvc/speaker
```
6. Extract the average value of the timbre code for inference
```
python prepare/preprocess_speaker_ave.py data_gvc/speaker/ data_gvc/singer
```
8. Use 32k audio to generate training index
```
python prepare/preprocess_train.py
```
9. Training file debugging
```
python prepare/preprocess_zzz.py
```
## Train
1. Start training
```
python gvc_trainer.py
```
2. Resume training
```
python gvc_trainer.py -p logs/grad_svc/grad_svc_***.pth
```
3. Log visualization
```
tensorboard --logdir logs/
```
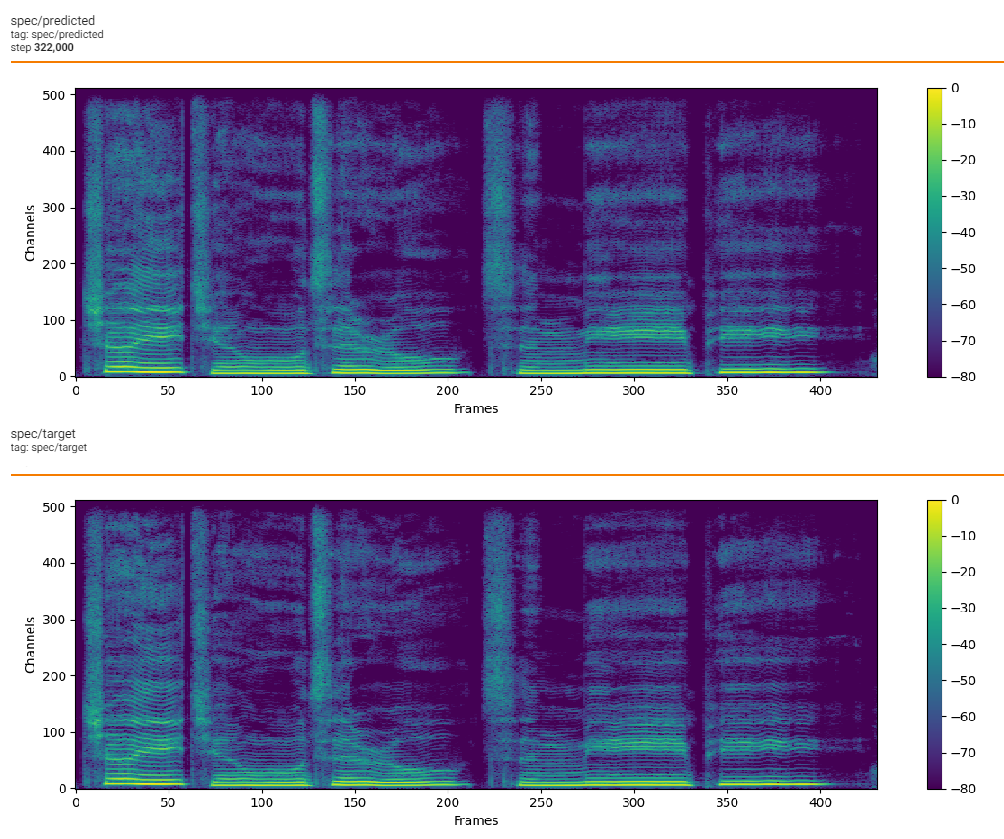
## Train Loss


## Inference
1. Export inference model
```
python gvc_export.py --checkpoint_path logs/grad_svc/grad_svc_***.pth
```
2. Inference
```
python gvc_inference.py --model gvc.pth --spk ./data_gvc/singer/your_singer.spk.npy --wave test.wav --rature 1.015 --shift 0
```
temperature=1.015, needs to be adjusted to get good results; Recommended range is (1.001, 1.035).
2. Inference step by step
- Extract hubert content vector
```
python hubert/inference.py -w test.wav -v test.vec.npy
```
- Extract pitch to the csv text format
```
python pitch/inference.py -w test.wav -p test.csv
```
- Convert hubert & pitch to wave
```
python gvc_inference.py --model gvc.pth --spk ./data_gvc/singer/your_singer.spk.npy --wave test.wav --vec test.vec.npy --pit test.csv --shift 0
```
## Data
| Name | URL |
| :--- | :--- |
|PopCS |https://github.com/MoonInTheRiver/DiffSinger/blob/master/resources/apply_form.md|
|opencpop |https://wenet.org.cn/opencpop/download/|
|Multi-Singer |https://github.com/Multi-Singer/Multi-Singer.github.io|
|M4Singer |https://github.com/M4Singer/M4Singer/blob/master/apply_form.md|
|VCTK |https://datashare.ed.ac.uk/handle/10283/2651|
## Code sources and references
https://github.com/huawei-noah/Speech-Backbones/blob/main/Grad-TTS
https://github.com/huawei-noah/Speech-Backbones/tree/main/DiffVC
https://github.com/facebookresearch/speech-resynthesis
https://github.com/cantabile-kwok/VoiceFlow-TTS
https://github.com/shivammehta25/Matcha-TTS
https://github.com/shivammehta25/Diff-TTSG
https://github.com/majidAdibian77/ResGrad
https://github.com/LuChengTHU/dpm-solver
https://github.com/gmltmd789/UnitSpeech
https://github.com/zhenye234/CoMoSpeech
https://github.com/seahore/PPG-GradVC
https://github.com/thuhcsi/LightGrad
https://github.com/lmnt-com/wavegrad
https://github.com/naver-ai/facetts
https://github.com/jaywalnut310/vits
https://github.com/NVIDIA/BigVGAN
https://github.com/bshall/soft-vc
https://github.com/mozilla/TTS
https://github.com/ubisoft/ubisoft-laforge-daft-exprt
##
https://github.com/yl4579/StyleTTS-VC
https://github.com/MingjieChen/DYGANVC
https://github.com/sony/ai-research-code/tree/master/nvcnet
================================================
FILE: bigvgan/LICENSE
================================================
MIT License
Copyright (c) 2022 PlayVoice
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE.
================================================
FILE: bigvgan/README.md
================================================
<div align="center">
<h1> Neural Source-Filter BigVGAN </h1>
Just For Fun
</div>
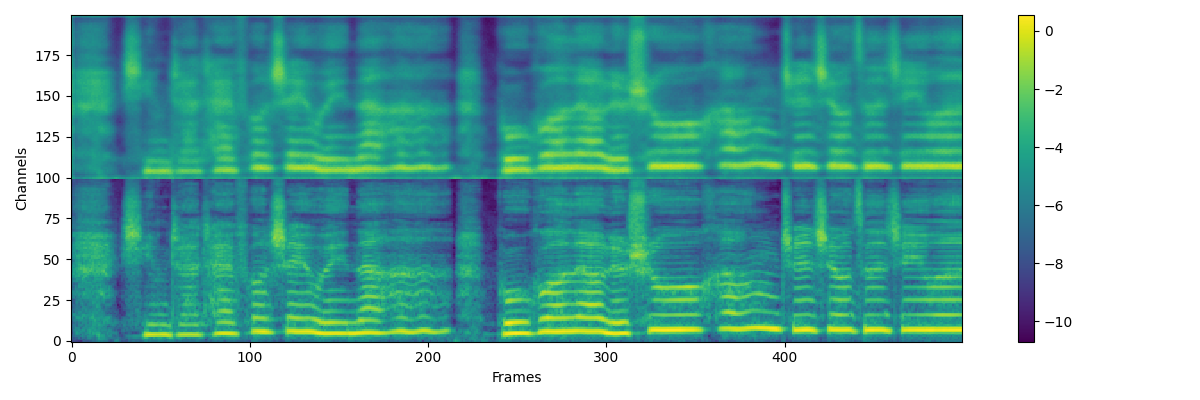
## Dataset preparation
Put the dataset into the data_raw directory according to the following file structure
```shell
data_raw
├───speaker0
│ ├───000001.wav
│ ├───...
│ └───000xxx.wav
└───speaker1
├───000001.wav
├───...
└───000xxx.wav
```
## Install dependencies
- 1 software dependency
> pip install -r requirements.txt
- 2 download [release](https://github.com/PlayVoice/NSF-BigVGAN/releases/tag/debug) model, and test
> python nsf_bigvgan_inference.py --config configs/nsf_bigvgan.yaml --model nsf_bigvgan_g.pth --wave test.wav
## Data preprocessing
- 1, re-sampling: 32kHz
> python prepare/preprocess_a.py -w ./data_raw -o ./data_bigvgan/waves-32k
- 3, extract pitch
> python prepare/preprocess_f0.py -w data_bigvgan/waves-32k/ -p data_bigvgan/pitch
- 4, extract mel: [100, length]
> python prepare/preprocess_spec.py -w data_bigvgan/waves-32k/ -s data_bigvgan/mel
- 5, generate training index
> python prepare/preprocess_train.py
```shell
data_bigvgan/
│
└── waves-32k
│ └── speaker0
│ │ ├── 000001.wav
│ │ └── 000xxx.wav
│ └── speaker1
│ ├── 000001.wav
│ └── 000xxx.wav
└── pitch
│ └── speaker0
│ │ ├── 000001.pit.npy
│ │ └── 000xxx.pit.npy
│ └── speaker1
│ ├── 000001.pit.npy
│ └── 000xxx.pit.npy
└── mel
└── speaker0
│ ├── 000001.mel.pt
│ └── 000xxx.mel.pt
└── speaker1
├── 000001.mel.pt
└── 000xxx.mel.pt
```
## Train
- 1, start training
> python nsf_bigvgan_trainer.py -c configs/nsf_bigvgan.yaml -n nsf_bigvgan
- 2, resume training
> python nsf_bigvgan_trainer.py -c configs/nsf_bigvgan.yaml -n nsf_bigvgan -p chkpt/nsf_bigvgan/***.pth
- 3, view log
> tensorboard --logdir logs/
## Inference
- 1, export inference model
> python nsf_bigvgan_export.py --config configs/maxgan.yaml --checkpoint_path chkpt/nsf_bigvgan/***.pt
- 2, extract mel
> python spec/inference.py -w test.wav -m test.mel.pt
- 3, extract F0
> python pitch/inference.py -w test.wav -p test.csv
- 4, infer
> python nsf_bigvgan_inference.py --config configs/nsf_bigvgan.yaml --model nsf_bigvgan_g.pth --wave test.wav
or
> python nsf_bigvgan_inference.py --config configs/nsf_bigvgan.yaml --model nsf_bigvgan_g.pth --mel test.mel.pt --pit test.csv
## Augmentation of mel
For the over smooth output of acoustic model, we use gaussian blur for mel when train vocoder
```
# gaussian blur
model_b = get_gaussian_kernel(kernel_size=5, sigma=2, channels=1).to(device)
# mel blur
mel_b = mel[:, None, :, :]
mel_b = model_b(mel_b)
mel_b = torch.squeeze(mel_b, 1)
mel_r = torch.rand(1).to(device) * 0.5
mel_b = (1 - mel_r) * mel_b + mel_r * mel
# generator
optim_g.zero_grad()
fake_audio = model_g(mel_b, pit)
```
## Source of code and References
https://github.com/nii-yamagishilab/project-NN-Pytorch-scripts/tree/master/project/01-nsf
https://github.com/mindslab-ai/univnet [[paper]](https://arxiv.org/abs/2106.07889)
https://github.com/NVIDIA/BigVGAN [[paper]](https://arxiv.org/abs/2206.04658)
================================================
FILE: bigvgan/configs/nsf_bigvgan.yaml
================================================
data:
train_file: 'files/train.txt'
val_file: 'files/valid.txt'
#############################
train:
num_workers: 4
batch_size: 8
optimizer: 'adam'
seed: 1234
adam:
lr: 0.0002
beta1: 0.8
beta2: 0.99
mel_lamb: 5
stft_lamb: 2.5
pretrain: ''
lora: False
#############################
audio:
n_mel_channels: 100
segment_length: 12800 # Should be multiple of 320
filter_length: 1024
hop_length: 320 # WARNING: this can't be changed.
win_length: 1024
sampling_rate: 32000
mel_fmin: 40.0
mel_fmax: 16000.0
#############################
gen:
mel_channels: 100
upsample_rates: [5,4,2,2,2,2]
upsample_kernel_sizes: [15,8,4,4,4,4]
upsample_initial_channel: 320
resblock_kernel_sizes: [3,7,11]
resblock_dilation_sizes: [[1,3,5], [1,3,5], [1,3,5]]
#############################
mpd:
periods: [2,3,5,7,11]
kernel_size: 5
stride: 3
use_spectral_norm: False
lReLU_slope: 0.2
#############################
mrd:
resolutions: "[(1024, 120, 600), (2048, 240, 1200), (4096, 480, 2400), (512, 50, 240)]" # (filter_length, hop_length, win_length)
use_spectral_norm: False
lReLU_slope: 0.2
#############################
dist_config:
dist_backend: "nccl"
dist_url: "tcp://localhost:54321"
world_size: 1
#############################
log:
info_interval: 100
eval_interval: 1000
save_interval: 10000
num_audio: 6
pth_dir: 'chkpt'
log_dir: 'logs'
================================================
FILE: bigvgan/inference.py
================================================
import sys,os
sys.path.append(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
import torch
import argparse
from omegaconf import OmegaConf
from scipy.io.wavfile import write
from bigvgan.model.generator import Generator
from pitch import load_csv_pitch
def load_bigv_model(checkpoint_path, model):
assert os.path.isfile(checkpoint_path)
checkpoint_dict = torch.load(checkpoint_path, map_location="cpu")
saved_state_dict = checkpoint_dict["model_g"]
state_dict = model.state_dict()
new_state_dict = {}
for k, v in state_dict.items():
try:
new_state_dict[k] = saved_state_dict[k]
except:
print("%s is not in the checkpoint" % k)
new_state_dict[k] = v
model.load_state_dict(new_state_dict)
return model
def main(args):
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
hp = OmegaConf.load(args.config)
model = Generator(hp)
load_bigv_model(args.model, model)
model.eval()
model.to(device)
mel = torch.load(args.mel)
pit = load_csv_pitch(args.pit)
pit = torch.FloatTensor(pit)
len_pit = pit.size()[0]
len_mel = mel.size()[1]
len_min = min(len_pit, len_mel)
pit = pit[:len_min]
mel = mel[:, :len_min]
with torch.no_grad():
mel = mel.unsqueeze(0).to(device)
pit = pit.unsqueeze(0).to(device)
audio = model.inference(mel, pit)
audio = audio.cpu().detach().numpy()
pitwav = model.pitch2wav(pit)
pitwav = pitwav.cpu().detach().numpy()
write("gvc_out.wav", hp.audio.sampling_rate, audio)
write("gvc_pitch.wav", hp.audio.sampling_rate, pitwav)
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--mel', type=str,
help="Path of content vector.")
parser.add_argument('--pit', type=str,
help="Path of pitch csv file.")
args = parser.parse_args()
args.config = "./bigvgan/configs/nsf_bigvgan.yaml"
args.model = "./bigvgan_pretrain/nsf_bigvgan_pretrain_32K.pth"
main(args)
================================================
FILE: bigvgan/model/__init__.py
================================================
from .alias.act import SnakeAlias
================================================
FILE: bigvgan/model/alias/__init__.py
================================================
# Adapted from https://github.com/junjun3518/alias-free-torch under the Apache License 2.0
# LICENSE is in incl_licenses directory.
from .filter import *
from .resample import *
from .act import *
================================================
FILE: bigvgan/model/alias/act.py
================================================
# Adapted from https://github.com/junjun3518/alias-free-torch under the Apache License 2.0
# LICENSE is in incl_licenses directory.
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch import sin, pow
from torch.nn import Parameter
from .resample import UpSample1d, DownSample1d
class Activation1d(nn.Module):
def __init__(self,
activation,
up_ratio: int = 2,
down_ratio: int = 2,
up_kernel_size: int = 12,
down_kernel_size: int = 12):
super().__init__()
self.up_ratio = up_ratio
self.down_ratio = down_ratio
self.act = activation
self.upsample = UpSample1d(up_ratio, up_kernel_size)
self.downsample = DownSample1d(down_ratio, down_kernel_size)
# x: [B,C,T]
def forward(self, x):
x = self.upsample(x)
x = self.act(x)
x = self.downsample(x)
return x
class SnakeBeta(nn.Module):
'''
A modified Snake function which uses separate parameters for the magnitude of the periodic components
Shape:
- Input: (B, C, T)
- Output: (B, C, T), same shape as the input
Parameters:
- alpha - trainable parameter that controls frequency
- beta - trainable parameter that controls magnitude
References:
- This activation function is a modified version based on this paper by Liu Ziyin, Tilman Hartwig, Masahito Ueda:
https://arxiv.org/abs/2006.08195
Examples:
>>> a1 = snakebeta(256)
>>> x = torch.randn(256)
>>> x = a1(x)
'''
def __init__(self, in_features, alpha=1.0, alpha_trainable=True, alpha_logscale=False):
'''
Initialization.
INPUT:
- in_features: shape of the input
- alpha - trainable parameter that controls frequency
- beta - trainable parameter that controls magnitude
alpha is initialized to 1 by default, higher values = higher-frequency.
beta is initialized to 1 by default, higher values = higher-magnitude.
alpha will be trained along with the rest of your model.
'''
super(SnakeBeta, self).__init__()
self.in_features = in_features
# initialize alpha
self.alpha_logscale = alpha_logscale
if self.alpha_logscale: # log scale alphas initialized to zeros
self.alpha = Parameter(torch.zeros(in_features) * alpha)
self.beta = Parameter(torch.zeros(in_features) * alpha)
else: # linear scale alphas initialized to ones
self.alpha = Parameter(torch.ones(in_features) * alpha)
self.beta = Parameter(torch.ones(in_features) * alpha)
self.alpha.requires_grad = alpha_trainable
self.beta.requires_grad = alpha_trainable
self.no_div_by_zero = 0.000000001
def forward(self, x):
'''
Forward pass of the function.
Applies the function to the input elementwise.
SnakeBeta = x + 1/b * sin^2 (xa)
'''
alpha = self.alpha.unsqueeze(
0).unsqueeze(-1) # line up with x to [B, C, T]
beta = self.beta.unsqueeze(0).unsqueeze(-1)
if self.alpha_logscale:
alpha = torch.exp(alpha)
beta = torch.exp(beta)
x = x + (1.0 / (beta + self.no_div_by_zero)) * pow(sin(x * alpha), 2)
return x
class Mish(nn.Module):
"""
Mish activation function is proposed in "Mish: A Self
Regularized Non-Monotonic Neural Activation Function"
paper, https://arxiv.org/abs/1908.08681.
"""
def __init__(self):
super().__init__()
def forward(self, x):
return x * torch.tanh(F.softplus(x))
class SnakeAlias(nn.Module):
def __init__(self,
channels,
up_ratio: int = 2,
down_ratio: int = 2,
up_kernel_size: int = 12,
down_kernel_size: int = 12):
super().__init__()
self.up_ratio = up_ratio
self.down_ratio = down_ratio
self.act = SnakeBeta(channels, alpha_logscale=True)
self.upsample = UpSample1d(up_ratio, up_kernel_size)
self.downsample = DownSample1d(down_ratio, down_kernel_size)
# x: [B,C,T]
def forward(self, x):
x = self.upsample(x)
x = self.act(x)
x = self.downsample(x)
return x
================================================
FILE: bigvgan/model/alias/filter.py
================================================
# Adapted from https://github.com/junjun3518/alias-free-torch under the Apache License 2.0
# LICENSE is in incl_licenses directory.
import torch
import torch.nn as nn
import torch.nn.functional as F
import math
if 'sinc' in dir(torch):
sinc = torch.sinc
else:
# This code is adopted from adefossez's julius.core.sinc under the MIT License
# https://adefossez.github.io/julius/julius/core.html
# LICENSE is in incl_licenses directory.
def sinc(x: torch.Tensor):
"""
Implementation of sinc, i.e. sin(pi * x) / (pi * x)
__Warning__: Different to julius.sinc, the input is multiplied by `pi`!
"""
return torch.where(x == 0,
torch.tensor(1., device=x.device, dtype=x.dtype),
torch.sin(math.pi * x) / math.pi / x)
# This code is adopted from adefossez's julius.lowpass.LowPassFilters under the MIT License
# https://adefossez.github.io/julius/julius/lowpass.html
# LICENSE is in incl_licenses directory.
def kaiser_sinc_filter1d(cutoff, half_width, kernel_size): # return filter [1,1,kernel_size]
even = (kernel_size % 2 == 0)
half_size = kernel_size // 2
#For kaiser window
delta_f = 4 * half_width
A = 2.285 * (half_size - 1) * math.pi * delta_f + 7.95
if A > 50.:
beta = 0.1102 * (A - 8.7)
elif A >= 21.:
beta = 0.5842 * (A - 21)**0.4 + 0.07886 * (A - 21.)
else:
beta = 0.
window = torch.kaiser_window(kernel_size, beta=beta, periodic=False)
# ratio = 0.5/cutoff -> 2 * cutoff = 1 / ratio
if even:
time = (torch.arange(-half_size, half_size) + 0.5)
else:
time = torch.arange(kernel_size) - half_size
if cutoff == 0:
filter_ = torch.zeros_like(time)
else:
filter_ = 2 * cutoff * window * sinc(2 * cutoff * time)
# Normalize filter to have sum = 1, otherwise we will have a small leakage
# of the constant component in the input signal.
filter_ /= filter_.sum()
filter = filter_.view(1, 1, kernel_size)
return filter
class LowPassFilter1d(nn.Module):
def __init__(self,
cutoff=0.5,
half_width=0.6,
stride: int = 1,
padding: bool = True,
padding_mode: str = 'replicate',
kernel_size: int = 12):
# kernel_size should be even number for stylegan3 setup,
# in this implementation, odd number is also possible.
super().__init__()
if cutoff < -0.:
raise ValueError("Minimum cutoff must be larger than zero.")
if cutoff > 0.5:
raise ValueError("A cutoff above 0.5 does not make sense.")
self.kernel_size = kernel_size
self.even = (kernel_size % 2 == 0)
self.pad_left = kernel_size // 2 - int(self.even)
self.pad_right = kernel_size // 2
self.stride = stride
self.padding = padding
self.padding_mode = padding_mode
filter = kaiser_sinc_filter1d(cutoff, half_width, kernel_size)
self.register_buffer("filter", filter)
#input [B, C, T]
def forward(self, x):
_, C, _ = x.shape
if self.padding:
x = F.pad(x, (self.pad_left, self.pad_right),
mode=self.padding_mode)
out = F.conv1d(x, self.filter.expand(C, -1, -1),
stride=self.stride, groups=C)
return out
================================================
FILE: bigvgan/model/alias/resample.py
================================================
# Adapted from https://github.com/junjun3518/alias-free-torch under the Apache License 2.0
# LICENSE is in incl_licenses directory.
import torch.nn as nn
from torch.nn import functional as F
from .filter import LowPassFilter1d
from .filter import kaiser_sinc_filter1d
class UpSample1d(nn.Module):
def __init__(self, ratio=2, kernel_size=None):
super().__init__()
self.ratio = ratio
self.kernel_size = int(6 * ratio // 2) * 2 if kernel_size is None else kernel_size
self.stride = ratio
self.pad = self.kernel_size // ratio - 1
self.pad_left = self.pad * self.stride + (self.kernel_size - self.stride) // 2
self.pad_right = self.pad * self.stride + (self.kernel_size - self.stride + 1) // 2
filter = kaiser_sinc_filter1d(cutoff=0.5 / ratio,
half_width=0.6 / ratio,
kernel_size=self.kernel_size)
self.register_buffer("filter", filter)
# x: [B, C, T]
def forward(self, x):
_, C, _ = x.shape
x = F.pad(x, (self.pad, self.pad), mode='replicate')
x = self.ratio * F.conv_transpose1d(
x, self.filter.expand(C, -1, -1), stride=self.stride, groups=C)
x = x[..., self.pad_left:-self.pad_right]
return x
class DownSample1d(nn.Module):
def __init__(self, ratio=2, kernel_size=None):
super().__init__()
self.ratio = ratio
self.kernel_size = int(6 * ratio // 2) * 2 if kernel_size is None else kernel_size
self.lowpass = LowPassFilter1d(cutoff=0.5 / ratio,
half_width=0.6 / ratio,
stride=ratio,
kernel_size=self.kernel_size)
def forward(self, x):
xx = self.lowpass(x)
return xx
================================================
FILE: bigvgan/model/bigv.py
================================================
import torch
import torch.nn as nn
from torch.nn import Conv1d
from torch.nn.utils import weight_norm, remove_weight_norm
from .alias.act import SnakeAlias
def init_weights(m, mean=0.0, std=0.01):
classname = m.__class__.__name__
if classname.find("Conv") != -1:
m.weight.data.normal_(mean, std)
def get_padding(kernel_size, dilation=1):
return int((kernel_size*dilation - dilation)/2)
class AMPBlock(torch.nn.Module):
def __init__(self, channels, kernel_size=3, dilation=(1, 3, 5)):
super(AMPBlock, self).__init__()
self.convs1 = nn.ModuleList([
weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=dilation[0],
padding=get_padding(kernel_size, dilation[0]))),
weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=dilation[1],
padding=get_padding(kernel_size, dilation[1]))),
weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=dilation[2],
padding=get_padding(kernel_size, dilation[2])))
])
self.convs1.apply(init_weights)
self.convs2 = nn.ModuleList([
weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=1,
padding=get_padding(kernel_size, 1))),
weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=1,
padding=get_padding(kernel_size, 1))),
weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=1,
padding=get_padding(kernel_size, 1)))
])
self.convs2.apply(init_weights)
# total number of conv layers
self.num_layers = len(self.convs1) + len(self.convs2)
# periodic nonlinearity with snakebeta function and anti-aliasing
self.activations = nn.ModuleList([
SnakeAlias(channels) for _ in range(self.num_layers)
])
def forward(self, x):
acts1, acts2 = self.activations[::2], self.activations[1::2]
for c1, c2, a1, a2 in zip(self.convs1, self.convs2, acts1, acts2):
xt = a1(x)
xt = c1(xt)
xt = a2(xt)
xt = c2(xt)
x = xt + x
return x
def remove_weight_norm(self):
for l in self.convs1:
remove_weight_norm(l)
for l in self.convs2:
remove_weight_norm(l)
================================================
FILE: bigvgan/model/generator.py
================================================
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
from torch.nn import Conv1d
from torch.nn import ConvTranspose1d
from torch.nn.utils import weight_norm
from torch.nn.utils import remove_weight_norm
from .nsf import SourceModuleHnNSF
from .bigv import init_weights, AMPBlock, SnakeAlias
class Generator(torch.nn.Module):
# this is our main BigVGAN model. Applies anti-aliased periodic activation for resblocks.
def __init__(self, hp):
super(Generator, self).__init__()
self.hp = hp
self.num_kernels = len(hp.gen.resblock_kernel_sizes)
self.num_upsamples = len(hp.gen.upsample_rates)
# pre conv
self.conv_pre = nn.utils.weight_norm(
Conv1d(hp.gen.mel_channels, hp.gen.upsample_initial_channel, 7, 1, padding=3))
# nsf
self.f0_upsamp = torch.nn.Upsample(
scale_factor=np.prod(hp.gen.upsample_rates))
self.m_source = SourceModuleHnNSF(sampling_rate=hp.audio.sampling_rate)
self.noise_convs = nn.ModuleList()
# transposed conv-based upsamplers. does not apply anti-aliasing
self.ups = nn.ModuleList()
for i, (u, k) in enumerate(zip(hp.gen.upsample_rates, hp.gen.upsample_kernel_sizes)):
# print(f'ups: {i} {k}, {u}, {(k - u) // 2}')
# base
self.ups.append(
weight_norm(
ConvTranspose1d(
hp.gen.upsample_initial_channel // (2 ** i),
hp.gen.upsample_initial_channel // (2 ** (i + 1)),
k,
u,
padding=(k - u) // 2)
)
)
# nsf
if i + 1 < len(hp.gen.upsample_rates):
stride_f0 = np.prod(hp.gen.upsample_rates[i + 1:])
stride_f0 = int(stride_f0)
self.noise_convs.append(
Conv1d(
1,
hp.gen.upsample_initial_channel // (2 ** (i + 1)),
kernel_size=stride_f0 * 2,
stride=stride_f0,
padding=stride_f0 // 2,
)
)
else:
self.noise_convs.append(
Conv1d(1, hp.gen.upsample_initial_channel //
(2 ** (i + 1)), kernel_size=1)
)
# residual blocks using anti-aliased multi-periodicity composition modules (AMP)
self.resblocks = nn.ModuleList()
for i in range(len(self.ups)):
ch = hp.gen.upsample_initial_channel // (2 ** (i + 1))
for k, d in zip(hp.gen.resblock_kernel_sizes, hp.gen.resblock_dilation_sizes):
self.resblocks.append(AMPBlock(ch, k, d))
# post conv
self.activation_post = SnakeAlias(ch)
self.conv_post = Conv1d(ch, 1, 7, 1, padding=3, bias=False)
# weight initialization
self.ups.apply(init_weights)
def forward(self, x, f0, train=True):
# nsf
f0 = f0[:, None]
f0 = self.f0_upsamp(f0).transpose(1, 2)
har_source = self.m_source(f0)
har_source = har_source.transpose(1, 2)
# pre conv
if train:
x = x + torch.randn_like(x) * 0.1 # Perturbation
x = self.conv_pre(x)
x = x * torch.tanh(F.softplus(x))
for i in range(self.num_upsamples):
# upsampling
x = self.ups[i](x)
# nsf
x_source = self.noise_convs[i](har_source)
x = x + x_source
# AMP blocks
xs = None
for j in range(self.num_kernels):
if xs is None:
xs = self.resblocks[i * self.num_kernels + j](x)
else:
xs += self.resblocks[i * self.num_kernels + j](x)
x = xs / self.num_kernels
# post conv
x = self.activation_post(x)
x = self.conv_post(x)
x = torch.tanh(x)
return x
def remove_weight_norm(self):
for l in self.ups:
remove_weight_norm(l)
for l in self.resblocks:
l.remove_weight_norm()
remove_weight_norm(self.conv_pre)
def eval(self, inference=False):
super(Generator, self).eval()
# don't remove weight norm while validation in training loop
if inference:
self.remove_weight_norm()
def inference(self, mel, f0):
MAX_WAV_VALUE = 32768.0
audio = self.forward(mel, f0, False)
audio = audio.squeeze() # collapse all dimension except time axis
audio = MAX_WAV_VALUE * audio
audio = audio.clamp(min=-MAX_WAV_VALUE, max=MAX_WAV_VALUE-1)
audio = audio.short()
return audio
def pitch2wav(self, f0):
MAX_WAV_VALUE = 32768.0
# nsf
f0 = f0[:, None]
f0 = self.f0_upsamp(f0).transpose(1, 2)
har_source = self.m_source(f0)
audio = har_source.transpose(1, 2)
audio = audio.squeeze() # collapse all dimension except time axis
audio = MAX_WAV_VALUE * audio
audio = audio.clamp(min=-MAX_WAV_VALUE, max=MAX_WAV_VALUE-1)
audio = audio.short()
return audio
================================================
FILE: bigvgan/model/nsf.py
================================================
import torch
import numpy as np
import sys
import torch.nn.functional as torch_nn_func
class PulseGen(torch.nn.Module):
"""Definition of Pulse train generator
There are many ways to implement pulse generator.
Here, PulseGen is based on SinGen. For a perfect
"""
def __init__(self, samp_rate, pulse_amp=0.1, noise_std=0.003, voiced_threshold=0):
super(PulseGen, self).__init__()
self.pulse_amp = pulse_amp
self.sampling_rate = samp_rate
self.voiced_threshold = voiced_threshold
self.noise_std = noise_std
self.l_sinegen = SineGen(
self.sampling_rate,
harmonic_num=0,
sine_amp=self.pulse_amp,
noise_std=0,
voiced_threshold=self.voiced_threshold,
flag_for_pulse=True,
)
def forward(self, f0):
"""Pulse train generator
pulse_train, uv = forward(f0)
input F0: tensor(batchsize=1, length, dim=1)
f0 for unvoiced steps should be 0
output pulse_train: tensor(batchsize=1, length, dim)
output uv: tensor(batchsize=1, length, 1)
Note: self.l_sine doesn't make sure that the initial phase of
a voiced segment is np.pi, the first pulse in a voiced segment
may not be at the first time step within a voiced segment
"""
with torch.no_grad():
sine_wav, uv, noise = self.l_sinegen(f0)
# sine without additive noise
pure_sine = sine_wav - noise
# step t corresponds to a pulse if
# sine[t] > sine[t+1] & sine[t] > sine[t-1]
# & sine[t-1], sine[t+1], and sine[t] are voiced
# or
# sine[t] is voiced, sine[t-1] is unvoiced
# we use torch.roll to simulate sine[t+1] and sine[t-1]
sine_1 = torch.roll(pure_sine, shifts=1, dims=1)
uv_1 = torch.roll(uv, shifts=1, dims=1)
uv_1[:, 0, :] = 0
sine_2 = torch.roll(pure_sine, shifts=-1, dims=1)
uv_2 = torch.roll(uv, shifts=-1, dims=1)
uv_2[:, -1, :] = 0
loc = (pure_sine > sine_1) * (pure_sine > sine_2) \
* (uv_1 > 0) * (uv_2 > 0) * (uv > 0) \
+ (uv_1 < 1) * (uv > 0)
# pulse train without noise
pulse_train = pure_sine * loc
# additive noise to pulse train
# note that noise from sinegen is zero in voiced regions
pulse_noise = torch.randn_like(pure_sine) * self.noise_std
# with additive noise on pulse, and unvoiced regions
pulse_train += pulse_noise * loc + pulse_noise * (1 - uv)
return pulse_train, sine_wav, uv, pulse_noise
class SignalsConv1d(torch.nn.Module):
"""Filtering input signal with time invariant filter
Note: FIRFilter conducted filtering given fixed FIR weight
SignalsConv1d convolves two signals
Note: this is based on torch.nn.functional.conv1d
"""
def __init__(self):
super(SignalsConv1d, self).__init__()
def forward(self, signal, system_ir):
"""output = forward(signal, system_ir)
signal: (batchsize, length1, dim)
system_ir: (length2, dim)
output: (batchsize, length1, dim)
"""
if signal.shape[-1] != system_ir.shape[-1]:
print("Error: SignalsConv1d expects shape:")
print("signal (batchsize, length1, dim)")
print("system_id (batchsize, length2, dim)")
print("But received signal: {:s}".format(str(signal.shape)))
print(" system_ir: {:s}".format(str(system_ir.shape)))
sys.exit(1)
padding_length = system_ir.shape[0] - 1
groups = signal.shape[-1]
# pad signal on the left
signal_pad = torch_nn_func.pad(signal.permute(0, 2, 1), (padding_length, 0))
# prepare system impulse response as (dim, 1, length2)
# also flip the impulse response
ir = torch.flip(system_ir.unsqueeze(1).permute(2, 1, 0), dims=[2])
# convolute
output = torch_nn_func.conv1d(signal_pad, ir, groups=groups)
return output.permute(0, 2, 1)
class CyclicNoiseGen_v1(torch.nn.Module):
"""CyclicnoiseGen_v1
Cyclic noise with a single parameter of beta.
Pytorch v1 implementation assumes f_t is also fixed
"""
def __init__(self, samp_rate, noise_std=0.003, voiced_threshold=0):
super(CyclicNoiseGen_v1, self).__init__()
self.samp_rate = samp_rate
self.noise_std = noise_std
self.voiced_threshold = voiced_threshold
self.l_pulse = PulseGen(
samp_rate,
pulse_amp=1.0,
noise_std=noise_std,
voiced_threshold=voiced_threshold,
)
self.l_conv = SignalsConv1d()
def noise_decay(self, beta, f0mean):
"""decayed_noise = noise_decay(beta, f0mean)
decayed_noise = n[t]exp(-t * f_mean / beta / samp_rate)
beta: (dim=1) or (batchsize=1, 1, dim=1)
f0mean (batchsize=1, 1, dim=1)
decayed_noise (batchsize=1, length, dim=1)
"""
with torch.no_grad():
# exp(-1.0 n / T) < 0.01 => n > -log(0.01)*T = 4.60*T
# truncate the noise when decayed by -40 dB
length = 4.6 * self.samp_rate / f0mean
length = length.int()
time_idx = torch.arange(0, length, device=beta.device)
time_idx = time_idx.unsqueeze(0).unsqueeze(2)
time_idx = time_idx.repeat(beta.shape[0], 1, beta.shape[2])
noise = torch.randn(time_idx.shape, device=beta.device)
# due to Pytorch implementation, use f0_mean as the f0 factor
decay = torch.exp(-time_idx * f0mean / beta / self.samp_rate)
return noise * self.noise_std * decay
def forward(self, f0s, beta):
"""Producde cyclic-noise"""
# pulse train
pulse_train, sine_wav, uv, noise = self.l_pulse(f0s)
pure_pulse = pulse_train - noise
# decayed_noise (length, dim=1)
if (uv < 1).all():
# all unvoiced
cyc_noise = torch.zeros_like(sine_wav)
else:
f0mean = f0s[uv > 0].mean()
decayed_noise = self.noise_decay(beta, f0mean)[0, :, :]
# convolute
cyc_noise = self.l_conv(pure_pulse, decayed_noise)
# add noise in invoiced segments
cyc_noise = cyc_noise + noise * (1.0 - uv)
return cyc_noise, pulse_train, sine_wav, uv, noise
class SineGen(torch.nn.Module):
"""Definition of sine generator
SineGen(samp_rate, harmonic_num = 0,
sine_amp = 0.1, noise_std = 0.003,
voiced_threshold = 0,
flag_for_pulse=False)
samp_rate: sampling rate in Hz
harmonic_num: number of harmonic overtones (default 0)
sine_amp: amplitude of sine-wavefrom (default 0.1)
noise_std: std of Gaussian noise (default 0.003)
voiced_thoreshold: F0 threshold for U/V classification (default 0)
flag_for_pulse: this SinGen is used inside PulseGen (default False)
Note: when flag_for_pulse is True, the first time step of a voiced
segment is always sin(np.pi) or cos(0)
"""
def __init__(
self,
samp_rate,
harmonic_num=0,
sine_amp=0.1,
noise_std=0.003,
voiced_threshold=0,
flag_for_pulse=False,
):
super(SineGen, self).__init__()
self.sine_amp = sine_amp
self.noise_std = noise_std
self.harmonic_num = harmonic_num
self.dim = self.harmonic_num + 1
self.sampling_rate = samp_rate
self.voiced_threshold = voiced_threshold
self.flag_for_pulse = flag_for_pulse
def _f02uv(self, f0):
# generate uv signal
uv = torch.ones_like(f0)
uv = uv * (f0 > self.voiced_threshold)
return uv
def _f02sine(self, f0_values):
"""f0_values: (batchsize, length, dim)
where dim indicates fundamental tone and overtones
"""
# convert to F0 in rad. The interger part n can be ignored
# because 2 * np.pi * n doesn't affect phase
rad_values = (f0_values / self.sampling_rate) % 1
# initial phase noise (no noise for fundamental component)
rand_ini = torch.rand(
f0_values.shape[0], f0_values.shape[2], device=f0_values.device
)
rand_ini[:, 0] = 0
rad_values[:, 0, :] = rad_values[:, 0, :] + rand_ini
# instantanouse phase sine[t] = sin(2*pi \sum_i=1 ^{t} rad)
if not self.flag_for_pulse:
# for normal case
# To prevent torch.cumsum numerical overflow,
# it is necessary to add -1 whenever \sum_k=1^n rad_value_k > 1.
# Buffer tmp_over_one_idx indicates the time step to add -1.
# This will not change F0 of sine because (x-1) * 2*pi = x * 2*pi
tmp_over_one = torch.cumsum(rad_values, 1) % 1
tmp_over_one_idx = (tmp_over_one[:, 1:, :] - tmp_over_one[:, :-1, :]) < 0
cumsum_shift = torch.zeros_like(rad_values)
cumsum_shift[:, 1:, :] = tmp_over_one_idx * -1.0
sines = torch.sin(
torch.cumsum(rad_values + cumsum_shift, dim=1) * 2 * np.pi
)
else:
# If necessary, make sure that the first time step of every
# voiced segments is sin(pi) or cos(0)
# This is used for pulse-train generation
# identify the last time step in unvoiced segments
uv = self._f02uv(f0_values)
uv_1 = torch.roll(uv, shifts=-1, dims=1)
uv_1[:, -1, :] = 1
u_loc = (uv < 1) * (uv_1 > 0)
# get the instantanouse phase
tmp_cumsum = torch.cumsum(rad_values, dim=1)
# different batch needs to be processed differently
for idx in range(f0_values.shape[0]):
temp_sum = tmp_cumsum[idx, u_loc[idx, :, 0], :]
temp_sum[1:, :] = temp_sum[1:, :] - temp_sum[0:-1, :]
# stores the accumulation of i.phase within
# each voiced segments
tmp_cumsum[idx, :, :] = 0
tmp_cumsum[idx, u_loc[idx, :, 0], :] = temp_sum
# rad_values - tmp_cumsum: remove the accumulation of i.phase
# within the previous voiced segment.
i_phase = torch.cumsum(rad_values - tmp_cumsum, dim=1)
# get the sines
sines = torch.cos(i_phase * 2 * np.pi)
return sines
def forward(self, f0):
"""sine_tensor, uv = forward(f0)
input F0: tensor(batchsize=1, length, dim=1)
f0 for unvoiced steps should be 0
output sine_tensor: tensor(batchsize=1, length, dim)
output uv: tensor(batchsize=1, length, 1)
"""
with torch.no_grad():
f0_buf = torch.zeros(f0.shape[0], f0.shape[1], self.dim, device=f0.device)
# fundamental component
f0_buf[:, :, 0] = f0[:, :, 0]
for idx in np.arange(self.harmonic_num):
# idx + 2: the (idx+1)-th overtone, (idx+2)-th harmonic
f0_buf[:, :, idx + 1] = f0_buf[:, :, 0] * (idx + 2)
# generate sine waveforms
sine_waves = self._f02sine(f0_buf) * self.sine_amp
# generate uv signal
# uv = torch.ones(f0.shape)
# uv = uv * (f0 > self.voiced_threshold)
uv = self._f02uv(f0)
# noise: for unvoiced should be similar to sine_amp
# std = self.sine_amp/3 -> max value ~ self.sine_amp
# . for voiced regions is self.noise_std
noise_amp = uv * self.noise_std + (1 - uv) * self.sine_amp / 3
noise = noise_amp * torch.randn_like(sine_waves)
# first: set the unvoiced part to 0 by uv
# then: additive noise
sine_waves = sine_waves * uv + noise
return sine_waves
class SourceModuleCycNoise_v1(torch.nn.Module):
"""SourceModuleCycNoise_v1
SourceModule(sampling_rate, noise_std=0.003, voiced_threshod=0)
sampling_rate: sampling_rate in Hz
noise_std: std of Gaussian noise (default: 0.003)
voiced_threshold: threshold to set U/V given F0 (default: 0)
cyc, noise, uv = SourceModuleCycNoise_v1(F0_upsampled, beta)
F0_upsampled (batchsize, length, 1)
beta (1)
cyc (batchsize, length, 1)
noise (batchsize, length, 1)
uv (batchsize, length, 1)
"""
def __init__(self, sampling_rate, noise_std=0.003, voiced_threshod=0):
super(SourceModuleCycNoise_v1, self).__init__()
self.sampling_rate = sampling_rate
self.noise_std = noise_std
self.l_cyc_gen = CyclicNoiseGen_v1(sampling_rate, noise_std, voiced_threshod)
def forward(self, f0_upsamped, beta):
"""
cyc, noise, uv = SourceModuleCycNoise_v1(F0, beta)
F0_upsampled (batchsize, length, 1)
beta (1)
cyc (batchsize, length, 1)
noise (batchsize, length, 1)
uv (batchsize, length, 1)
"""
# source for harmonic branch
cyc, pulse, sine, uv, add_noi = self.l_cyc_gen(f0_upsamped, beta)
# source for noise branch, in the same shape as uv
noise = torch.randn_like(uv) * self.noise_std / 3
return cyc, noise, uv
class SourceModuleHnNSF(torch.nn.Module):
def __init__(
self,
sampling_rate=32000,
sine_amp=0.1,
add_noise_std=0.003,
voiced_threshod=0,
):
super(SourceModuleHnNSF, self).__init__()
harmonic_num = 10
self.sine_amp = sine_amp
self.noise_std = add_noise_std
# to produce sine waveforms
self.l_sin_gen = SineGen(
sampling_rate, harmonic_num, sine_amp, add_noise_std, voiced_threshod
)
# to merge source harmonics into a single excitation
self.l_tanh = torch.nn.Tanh()
self.register_buffer('merge_w', torch.FloatTensor([[
0.2942, -0.2243, 0.0033, -0.0056, -0.0020, -0.0046,
0.0221, -0.0083, -0.0241, -0.0036, -0.0581]]))
self.register_buffer('merge_b', torch.FloatTensor([0.0008]))
def forward(self, x):
"""
Sine_source = SourceModuleHnNSF(F0_sampled)
F0_sampled (batchsize, length, 1)
Sine_source (batchsize, length, 1)
"""
# source for harmonic branch
sine_wavs = self.l_sin_gen(x)
sine_wavs = torch_nn_func.linear(
sine_wavs, self.merge_w) + self.merge_b
sine_merge = self.l_tanh(sine_wavs)
return sine_merge
================================================
FILE: bigvgan_pretrain/README.md
================================================
Path for:
nsf_bigvgan_pretrain_32K.pth
DownLoad link:https://github.com/PlayVoice/NSF-BigVGAN/releases/tag/augment
================================================
FILE: configs/base.yaml
================================================
train:
seed: 37
train_files: "files/train.txt"
valid_files: "files/valid.txt"
log_dir: 'logs/grad_svc'
full_epochs: 500
fast_epochs: 100
learning_rate: 2e-4
batch_size: 8
test_size: 4
test_step: 5
save_step: 10
pretrain: "grad_pretrain/gvc.pretrain.pth"
#############################
data:
segment_size: 16000 # WARNING: base on hop_length
max_wav_value: 32768.0
sampling_rate: 32000
filter_length: 1024
hop_length: 320
win_length: 1024
mel_channels: 100
mel_fmin: 40.0
mel_fmax: 16000.0
#############################
grad:
n_mels: 100
n_vecs: 256
n_pits: 256
n_spks: 256
n_embs: 64
# encoder parameters
n_enc_channels: 192
filter_channels: 512
# decoder parameters
dec_dim: 96
beta_min: 0.05
beta_max: 20.0
pe_scale: 1000
================================================
FILE: grad/LICENSE
================================================
Copyright (c) 2021 Huawei Technologies Co., Ltd.
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE.
================================================
FILE: grad/__init__.py
================================================
================================================
FILE: grad/base.py
================================================
import numpy as np
import torch
class BaseModule(torch.nn.Module):
def __init__(self):
super(BaseModule, self).__init__()
@property
def nparams(self):
"""
Returns number of trainable parameters of the module.
"""
num_params = 0
for name, param in self.named_parameters():
if param.requires_grad:
num_params += np.prod(param.detach().cpu().numpy().shape)
return num_params
def relocate_input(self, x: list):
"""
Relocates provided tensors to the same device set for the module.
"""
device = next(self.parameters()).device
for i in range(len(x)):
if isinstance(x[i], torch.Tensor) and x[i].device != device:
x[i] = x[i].to(device)
return x
================================================
FILE: grad/diffusion.py
================================================
import math
import torch
from einops import rearrange
from grad.base import BaseModule
from grad.solver import NoiseScheduleVP, MaxLikelihood, GradRaw
class Mish(BaseModule):
def forward(self, x):
return x * torch.tanh(torch.nn.functional.softplus(x))
class Upsample(BaseModule):
def __init__(self, dim):
super(Upsample, self).__init__()
self.conv = torch.nn.ConvTranspose2d(dim, dim, 4, 2, 1)
def forward(self, x):
return self.conv(x)
class Downsample(BaseModule):
def __init__(self, dim):
super(Downsample, self).__init__()
self.conv = torch.nn.Conv2d(dim, dim, 3, 2, 1)
def forward(self, x):
return self.conv(x)
class Rezero(BaseModule):
def __init__(self, fn):
super(Rezero, self).__init__()
self.fn = fn
self.g = torch.nn.Parameter(torch.zeros(1))
def forward(self, x):
return self.fn(x) * self.g
class Block(BaseModule):
def __init__(self, dim, dim_out, groups=8):
super(Block, self).__init__()
self.block = torch.nn.Sequential(torch.nn.Conv2d(dim, dim_out, 3,
padding=1), torch.nn.GroupNorm(
groups, dim_out), Mish())
def forward(self, x, mask):
output = self.block(x * mask)
return output * mask
class ResnetBlock(BaseModule):
def __init__(self, dim, dim_out, time_emb_dim, groups=8):
super(ResnetBlock, self).__init__()
self.mlp = torch.nn.Sequential(Mish(), torch.nn.Linear(time_emb_dim,
dim_out))
self.block1 = Block(dim, dim_out, groups=groups)
self.block2 = Block(dim_out, dim_out, groups=groups)
if dim != dim_out:
self.res_conv = torch.nn.Conv2d(dim, dim_out, 1)
else:
self.res_conv = torch.nn.Identity()
def forward(self, x, mask, time_emb):
h = self.block1(x, mask)
h += self.mlp(time_emb).unsqueeze(-1).unsqueeze(-1)
h = self.block2(h, mask)
output = h + self.res_conv(x * mask)
return output
class LinearAttention(BaseModule):
def __init__(self, dim, heads=4, dim_head=32):
super(LinearAttention, self).__init__()
self.heads = heads
hidden_dim = dim_head * heads
self.to_qkv = torch.nn.Conv2d(dim, hidden_dim * 3, 1, bias=False)
self.to_out = torch.nn.Conv2d(hidden_dim, dim, 1)
def forward(self, x):
b, c, h, w = x.shape
qkv = self.to_qkv(x)
q, k, v = rearrange(qkv, 'b (qkv heads c) h w -> qkv b heads c (h w)',
heads = self.heads, qkv=3)
k = k.softmax(dim=-1)
context = torch.einsum('bhdn,bhen->bhde', k, v)
out = torch.einsum('bhde,bhdn->bhen', context, q)
out = rearrange(out, 'b heads c (h w) -> b (heads c) h w',
heads=self.heads, h=h, w=w)
return self.to_out(out)
class Residual(BaseModule):
def __init__(self, fn):
super(Residual, self).__init__()
self.fn = fn
def forward(self, x, *args, **kwargs):
output = self.fn(x, *args, **kwargs) + x
return output
class SinusoidalPosEmb(BaseModule):
def __init__(self, dim):
super(SinusoidalPosEmb, self).__init__()
self.dim = dim
def forward(self, x, scale=1000):
device = x.device
half_dim = self.dim // 2
emb = math.log(10000) / (half_dim - 1)
emb = torch.exp(torch.arange(half_dim, device=device).float() * -emb)
emb = scale * x.unsqueeze(1) * emb.unsqueeze(0)
emb = torch.cat((emb.sin(), emb.cos()), dim=-1)
return emb
class GradLogPEstimator2d(BaseModule):
def __init__(self, dim, dim_mults=(1, 2, 4), emb_dim=64, n_mels=100,
groups=8, pe_scale=1000):
super(GradLogPEstimator2d, self).__init__()
self.dim = dim
self.dim_mults = dim_mults
self.emb_dim = emb_dim
self.groups = groups
self.pe_scale = pe_scale
self.spk_mlp = torch.nn.Sequential(torch.nn.Linear(emb_dim, emb_dim * 4), Mish(),
torch.nn.Linear(emb_dim * 4, n_mels))
self.time_pos_emb = SinusoidalPosEmb(dim)
self.mlp = torch.nn.Sequential(torch.nn.Linear(dim, dim * 4), Mish(),
torch.nn.Linear(dim * 4, dim))
dims = [2 + 1, *map(lambda m: dim * m, dim_mults)]
in_out = list(zip(dims[:-1], dims[1:]))
self.downs = torch.nn.ModuleList([])
self.ups = torch.nn.ModuleList([])
num_resolutions = len(in_out)
for ind, (dim_in, dim_out) in enumerate(in_out): # 2 downs
is_last = ind >= (num_resolutions - 1)
self.downs.append(torch.nn.ModuleList([
ResnetBlock(dim_in, dim_out, time_emb_dim=dim),
ResnetBlock(dim_out, dim_out, time_emb_dim=dim),
Residual(Rezero(LinearAttention(dim_out))),
Downsample(dim_out) if not is_last else torch.nn.Identity()]))
mid_dim = dims[-1]
self.mid_block1 = ResnetBlock(mid_dim, mid_dim, time_emb_dim=dim)
self.mid_attn = Residual(Rezero(LinearAttention(mid_dim)))
self.mid_block2 = ResnetBlock(mid_dim, mid_dim, time_emb_dim=dim)
for ind, (dim_in, dim_out) in enumerate(reversed(in_out[1:])): # 2 ups
self.ups.append(torch.nn.ModuleList([
ResnetBlock(dim_out * 2, dim_in, time_emb_dim=dim),
ResnetBlock(dim_in, dim_in, time_emb_dim=dim),
Residual(Rezero(LinearAttention(dim_in))),
Upsample(dim_in)]))
self.final_block = Block(dim, dim)
self.final_conv = torch.nn.Conv2d(dim, 1, 1)
def forward(self, spk, x, mask, mu, t):
s = self.spk_mlp(spk)
t = self.time_pos_emb(t, scale=self.pe_scale)
t = self.mlp(t)
s = s.unsqueeze(-1).repeat(1, 1, x.shape[-1])
x = torch.stack([mu, x, s], 1)
mask = mask.unsqueeze(1)
hiddens = []
masks = [mask]
for resnet1, resnet2, attn, downsample in self.downs:
mask_down = masks[-1]
x = resnet1(x, mask_down, t)
x = resnet2(x, mask_down, t)
x = attn(x)
hiddens.append(x)
x = downsample(x * mask_down)
masks.append(mask_down[:, :, :, ::2])
masks = masks[:-1]
mask_mid = masks[-1]
x = self.mid_block1(x, mask_mid, t)
x = self.mid_attn(x)
x = self.mid_block2(x, mask_mid, t)
for resnet1, resnet2, attn, upsample in self.ups:
mask_up = masks.pop()
x = torch.cat((x, hiddens.pop()), dim=1)
x = resnet1(x, mask_up, t)
x = resnet2(x, mask_up, t)
x = attn(x)
x = upsample(x * mask_up)
x = self.final_block(x, mask)
output = self.final_conv(x * mask)
return (output * mask).squeeze(1)
def get_noise(t, beta_init, beta_term, cumulative=False):
if cumulative:
noise = beta_init*t + 0.5*(beta_term - beta_init)*(t**2)
else:
noise = beta_init + (beta_term - beta_init)*t
return noise
class Diffusion(BaseModule):
def __init__(self, n_mels, dim, emb_dim=64,
beta_min=0.05, beta_max=20, pe_scale=1000):
super(Diffusion, self).__init__()
self.n_mels = n_mels
self.beta_min = beta_min
self.beta_max = beta_max
# self.solver = NoiseScheduleVP()
self.solver = MaxLikelihood()
# self.solver = GradRaw()
self.estimator = GradLogPEstimator2d(dim,
n_mels=n_mels,
emb_dim=emb_dim,
pe_scale=pe_scale)
def forward_diffusion(self, mel, mask, mu, t):
time = t.unsqueeze(-1).unsqueeze(-1)
cum_noise = get_noise(time, self.beta_min, self.beta_max, cumulative=True)
mean = mel*torch.exp(-0.5*cum_noise) + mu*(1.0 - torch.exp(-0.5*cum_noise))
variance = 1.0 - torch.exp(-cum_noise)
z = torch.randn(mel.shape, dtype=mel.dtype, device=mel.device,
requires_grad=False)
xt = mean + z * torch.sqrt(variance)
return xt * mask, z * mask
def forward(self, spk, z, mask, mu, n_timesteps, stoc=False):
return self.solver.reverse_diffusion(self.estimator, spk, z, mask, mu, n_timesteps, stoc)
def loss_t(self, spk, mel, mask, mu, t):
xt, z = self.forward_diffusion(mel, mask, mu, t)
time = t.unsqueeze(-1).unsqueeze(-1)
cum_noise = get_noise(time, self.beta_min, self.beta_max, cumulative=True)
noise_estimation = self.estimator(spk, xt, mask, mu, t)
noise_estimation *= torch.sqrt(1.0 - torch.exp(-cum_noise))
loss = torch.sum((noise_estimation + z)**2) / (torch.sum(mask)*self.n_mels)
return loss, xt
def compute_loss(self, spk, mel, mask, mu, offset=1e-5):
t = torch.rand(mel.shape[0], dtype=mel.dtype, device=mel.device, requires_grad=False)
t = torch.clamp(t, offset, 1.0 - offset)
return self.loss_t(spk, mel, mask, mu, t)
================================================
FILE: grad/encoder.py
================================================
import math
import torch
from grad.base import BaseModule
from grad.reversal import SpeakerClassifier
from grad.utils import sequence_mask, convert_pad_shape
class LayerNorm(BaseModule):
def __init__(self, channels, eps=1e-4):
super(LayerNorm, self).__init__()
self.channels = channels
self.eps = eps
self.gamma = torch.nn.Parameter(torch.ones(channels))
self.beta = torch.nn.Parameter(torch.zeros(channels))
def forward(self, x):
n_dims = len(x.shape)
mean = torch.mean(x, 1, keepdim=True)
variance = torch.mean((x - mean)**2, 1, keepdim=True)
x = (x - mean) * torch.rsqrt(variance + self.eps)
shape = [1, -1] + [1] * (n_dims - 2)
x = x * self.gamma.view(*shape) + self.beta.view(*shape)
return x
class ConvReluNorm(BaseModule):
def __init__(self, in_channels, hidden_channels, out_channels, kernel_size,
n_layers, p_dropout, eps=1e-5):
super(ConvReluNorm, self).__init__()
self.in_channels = in_channels
self.hidden_channels = hidden_channels
self.out_channels = out_channels
self.kernel_size = kernel_size
self.n_layers = n_layers
self.p_dropout = p_dropout
self.eps = eps
self.conv_layers = torch.nn.ModuleList()
self.conv_layers.append(torch.nn.Conv1d(in_channels, hidden_channels,
kernel_size, padding=kernel_size//2))
self.relu_drop = torch.nn.Sequential(torch.nn.ReLU(), torch.nn.Dropout(p_dropout))
for _ in range(n_layers - 1):
self.conv_layers.append(torch.nn.Conv1d(hidden_channels, hidden_channels,
kernel_size, padding=kernel_size//2))
self.proj = torch.nn.Conv1d(hidden_channels, out_channels, 1)
self.proj.weight.data.zero_()
self.proj.bias.data.zero_()
def forward(self, x, x_mask):
for i in range(self.n_layers):
x = self.conv_layers[i](x * x_mask)
x = self.instance_norm(x, x_mask)
x = self.relu_drop(x)
x = self.proj(x)
return x * x_mask
def instance_norm(self, x, mask, return_mean_std=False):
mean, std = self.calc_mean_std(x, mask)
x = (x - mean) / std
if return_mean_std:
return x, mean, std
else:
return x
def calc_mean_std(self, x, mask=None):
x = x * mask
B, C = x.shape[:2]
mn = x.view(B, C, -1).mean(-1)
sd = (x.view(B, C, -1).var(-1) + self.eps).sqrt()
mn = mn.view(B, C, *((len(x.shape) - 2) * [1]))
sd = sd.view(B, C, *((len(x.shape) - 2) * [1]))
return mn, sd
class MultiHeadAttention(BaseModule):
def __init__(self, channels, out_channels, n_heads, window_size=None,
heads_share=True, p_dropout=0.0, proximal_bias=False,
proximal_init=False):
super(MultiHeadAttention, self).__init__()
assert channels % n_heads == 0
self.channels = channels
self.out_channels = out_channels
self.n_heads = n_heads
self.window_size = window_size
self.heads_share = heads_share
self.proximal_bias = proximal_bias
self.p_dropout = p_dropout
self.attn = None
self.k_channels = channels // n_heads
self.conv_q = torch.nn.Conv1d(channels, channels, 1)
self.conv_k = torch.nn.Conv1d(channels, channels, 1)
self.conv_v = torch.nn.Conv1d(channels, channels, 1)
if window_size is not None:
n_heads_rel = 1 if heads_share else n_heads
rel_stddev = self.k_channels**-0.5
self.emb_rel_k = torch.nn.Parameter(torch.randn(n_heads_rel,
window_size * 2 + 1, self.k_channels) * rel_stddev)
self.emb_rel_v = torch.nn.Parameter(torch.randn(n_heads_rel,
window_size * 2 + 1, self.k_channels) * rel_stddev)
self.conv_o = torch.nn.Conv1d(channels, out_channels, 1)
self.drop = torch.nn.Dropout(p_dropout)
torch.nn.init.xavier_uniform_(self.conv_q.weight)
torch.nn.init.xavier_uniform_(self.conv_k.weight)
if proximal_init:
self.conv_k.weight.data.copy_(self.conv_q.weight.data)
self.conv_k.bias.data.copy_(self.conv_q.bias.data)
torch.nn.init.xavier_uniform_(self.conv_v.weight)
def forward(self, x, c, attn_mask=None):
q = self.conv_q(x)
k = self.conv_k(c)
v = self.conv_v(c)
x, self.attn = self.attention(q, k, v, mask=attn_mask)
x = self.conv_o(x)
return x
def attention(self, query, key, value, mask=None):
b, d, t_s, t_t = (*key.size(), query.size(2))
query = query.view(b, self.n_heads, self.k_channels, t_t).transpose(2, 3)
key = key.view(b, self.n_heads, self.k_channels, t_s).transpose(2, 3)
value = value.view(b, self.n_heads, self.k_channels, t_s).transpose(2, 3)
scores = torch.matmul(query, key.transpose(-2, -1)) / math.sqrt(self.k_channels)
if self.window_size is not None:
assert t_s == t_t, "Relative attention is only available for self-attention."
key_relative_embeddings = self._get_relative_embeddings(self.emb_rel_k, t_s)
rel_logits = self._matmul_with_relative_keys(query, key_relative_embeddings)
rel_logits = self._relative_position_to_absolute_position(rel_logits)
scores_local = rel_logits / math.sqrt(self.k_channels)
scores = scores + scores_local
if self.proximal_bias:
assert t_s == t_t, "Proximal bias is only available for self-attention."
scores = scores + self._attention_bias_proximal(t_s).to(device=scores.device,
dtype=scores.dtype)
if mask is not None:
scores = scores.masked_fill(mask == 0, -1e4)
p_attn = torch.nn.functional.softmax(scores, dim=-1)
p_attn = self.drop(p_attn)
output = torch.matmul(p_attn, value)
if self.window_size is not None:
relative_weights = self._absolute_position_to_relative_position(p_attn)
value_relative_embeddings = self._get_relative_embeddings(self.emb_rel_v, t_s)
output = output + self._matmul_with_relative_values(relative_weights,
value_relative_embeddings)
output = output.transpose(2, 3).contiguous().view(b, d, t_t)
return output, p_attn
def _matmul_with_relative_values(self, x, y):
ret = torch.matmul(x, y.unsqueeze(0))
return ret
def _matmul_with_relative_keys(self, x, y):
ret = torch.matmul(x, y.unsqueeze(0).transpose(-2, -1))
return ret
def _get_relative_embeddings(self, relative_embeddings, length):
pad_length = max(length - (self.window_size + 1), 0)
slice_start_position = max((self.window_size + 1) - length, 0)
slice_end_position = slice_start_position + 2 * length - 1
if pad_length > 0:
padded_relative_embeddings = torch.nn.functional.pad(
relative_embeddings, convert_pad_shape([[0, 0],
[pad_length, pad_length], [0, 0]]))
else:
padded_relative_embeddings = relative_embeddings
used_relative_embeddings = padded_relative_embeddings[:,
slice_start_position:slice_end_position]
return used_relative_embeddings
def _relative_position_to_absolute_position(self, x):
batch, heads, length, _ = x.size()
x = torch.nn.functional.pad(x, convert_pad_shape([[0,0],[0,0],[0,0],[0,1]]))
x_flat = x.view([batch, heads, length * 2 * length])
x_flat = torch.nn.functional.pad(x_flat, convert_pad_shape([[0,0],[0,0],[0,length-1]]))
x_final = x_flat.view([batch, heads, length+1, 2*length-1])[:, :, :length, length-1:]
return x_final
def _absolute_position_to_relative_position(self, x):
batch, heads, length, _ = x.size()
x = torch.nn.functional.pad(x, convert_pad_shape([[0, 0], [0, 0], [0, 0], [0, length-1]]))
x_flat = x.view([batch, heads, length**2 + length*(length - 1)])
x_flat = torch.nn.functional.pad(x_flat, convert_pad_shape([[0, 0], [0, 0], [length, 0]]))
x_final = x_flat.view([batch, heads, length, 2*length])[:,:,:,1:]
return x_final
def _attention_bias_proximal(self, length):
r = torch.arange(length, dtype=torch.float32)
diff = torch.unsqueeze(r, 0) - torch.unsqueeze(r, 1)
return torch.unsqueeze(torch.unsqueeze(-torch.log1p(torch.abs(diff)), 0), 0)
class FFN(BaseModule):
def __init__(self, in_channels, out_channels, filter_channels, kernel_size,
p_dropout=0.0):
super(FFN, self).__init__()
self.in_channels = in_channels
self.out_channels = out_channels
self.filter_channels = filter_channels
self.kernel_size = kernel_size
self.p_dropout = p_dropout
self.conv_1 = torch.nn.Conv1d(in_channels, filter_channels, kernel_size,
padding=kernel_size//2)
self.conv_2 = torch.nn.Conv1d(filter_channels, out_channels, kernel_size,
padding=kernel_size//2)
self.drop = torch.nn.Dropout(p_dropout)
def forward(self, x, x_mask):
x = self.conv_1(x * x_mask)
x = torch.relu(x)
x = self.drop(x)
x = self.conv_2(x * x_mask)
return x * x_mask
class Encoder(BaseModule):
def __init__(self, hidden_channels, filter_channels, n_heads, n_layers,
kernel_size=1, p_dropout=0.0, window_size=None, **kwargs):
super(Encoder, self).__init__()
self.hidden_channels = hidden_channels
self.filter_channels = filter_channels
self.n_heads = n_heads
self.n_layers = n_layers
self.kernel_size = kernel_size
self.p_dropout = p_dropout
self.window_size = window_size
self.drop = torch.nn.Dropout(p_dropout)
self.attn_layers = torch.nn.ModuleList()
self.norm_layers_1 = torch.nn.ModuleList()
self.ffn_layers = torch.nn.ModuleList()
self.norm_layers_2 = torch.nn.ModuleList()
for _ in range(self.n_layers):
self.attn_layers.append(MultiHeadAttention(hidden_channels, hidden_channels,
n_heads, window_size=window_size, p_dropout=p_dropout))
self.norm_layers_1.append(LayerNorm(hidden_channels))
self.ffn_layers.append(FFN(hidden_channels, hidden_channels,
filter_channels, kernel_size, p_dropout=p_dropout))
self.norm_layers_2.append(LayerNorm(hidden_channels))
def forward(self, x, x_mask):
attn_mask = x_mask.unsqueeze(2) * x_mask.unsqueeze(-1)
for i in range(self.n_layers):
x = x * x_mask
y = self.attn_layers[i](x, x, attn_mask)
y = self.drop(y)
x = self.norm_layers_1[i](x + y)
y = self.ffn_layers[i](x, x_mask)
y = self.drop(y)
x = self.norm_layers_2[i](x + y)
x = x * x_mask
return x
class TextEncoder(BaseModule):
def __init__(self, n_vecs, n_mels, n_embs,
n_channels,
filter_channels,
n_heads=2,
n_layers=6,
kernel_size=3,
p_dropout=0.1,
window_size=4):
super(TextEncoder, self).__init__()
self.n_vecs = n_vecs
self.n_mels = n_mels
self.n_embs = n_embs
self.n_channels = n_channels
self.filter_channels = filter_channels
self.n_heads = n_heads
self.n_layers = n_layers
self.kernel_size = kernel_size
self.p_dropout = p_dropout
self.window_size = window_size
self.prenet = ConvReluNorm(n_vecs,
n_channels,
n_channels,
kernel_size=5,
n_layers=5,
p_dropout=0.5)
self.speaker = SpeakerClassifier(
n_channels,
256, # n_spks: 256
)
self.encoder = Encoder(n_channels + n_embs + n_embs,
filter_channels,
n_heads,
n_layers,
kernel_size,
p_dropout,
window_size=window_size)
self.proj_m = torch.nn.Conv1d(n_channels + n_embs + n_embs, n_mels, 1)
def forward(self, x_lengths, x, pit, spk, training=False):
x_mask = torch.unsqueeze(sequence_mask(x_lengths, x.size(2)), 1).to(x.dtype)
# IN
x = self.prenet(x, x_mask)
if training:
r = self.speaker(x)
else:
r = None
# pitch + speaker
spk = spk.unsqueeze(-1).repeat(1, 1, x.shape[-1])
x = torch.cat([x, pit], dim=1)
x = torch.cat([x, spk], dim=1)
x = self.encoder(x, x_mask)
mu = self.proj_m(x) * x_mask
return mu, x_mask, r
def fine_tune(self):
for p in self.prenet.parameters():
p.requires_grad = False
for p in self.speaker.parameters():
p.requires_grad = False
================================================
FILE: grad/model.py
================================================
import math
import torch
from grad.ssim import SSIM
from grad.base import BaseModule
from grad.encoder import TextEncoder
from grad.diffusion import Diffusion
from grad.utils import f0_to_coarse, rand_ids_segments, slice_segments
SpeakerLoss = torch.nn.CosineEmbeddingLoss()
SsimLoss = SSIM()
class GradTTS(BaseModule):
def __init__(self, n_mels, n_vecs, n_pits, n_spks, n_embs,
n_enc_channels, filter_channels,
dec_dim, beta_min, beta_max, pe_scale):
super(GradTTS, self).__init__()
# common
self.n_mels = n_mels
self.n_vecs = n_vecs
self.n_spks = n_spks
self.n_embs = n_embs
# encoder
self.n_enc_channels = n_enc_channels
self.filter_channels = filter_channels
# decoder
self.dec_dim = dec_dim
self.beta_min = beta_min
self.beta_max = beta_max
self.pe_scale = pe_scale
self.pit_emb = torch.nn.Embedding(n_pits, n_embs)
self.spk_emb = torch.nn.Linear(n_spks, n_embs)
self.encoder = TextEncoder(n_vecs,
n_mels,
n_embs,
n_enc_channels,
filter_channels)
self.decoder = Diffusion(n_mels, dec_dim, n_embs, beta_min, beta_max, pe_scale)
def fine_tune(self):
for p in self.pit_emb.parameters():
p.requires_grad = False
for p in self.spk_emb.parameters():
p.requires_grad = False
self.encoder.fine_tune()
@torch.no_grad()
def forward(self, lengths, vec, pit, spk, n_timesteps, temperature=1.0, stoc=False):
"""
Generates mel-spectrogram from vec. Returns:
1. encoder outputs
2. decoder outputs
Args:
lengths (torch.Tensor): lengths of texts in batch.
vec (torch.Tensor): batch of speech vec
pit (torch.Tensor): batch of speech pit
spk (torch.Tensor): batch of speaker
n_timesteps (int): number of steps to use for reverse diffusion in decoder.
temperature (float, optional): controls variance of terminal distribution.
stoc (bool, optional): flag that adds stochastic term to the decoder sampler.
Usually, does not provide synthesis improvements.
"""
lengths, vec, pit, spk = self.relocate_input([lengths, vec, pit, spk])
# Get pitch embedding
pit = self.pit_emb(f0_to_coarse(pit))
# Get speaker embedding
spk = self.spk_emb(spk)
# Transpose
vec = torch.transpose(vec, 1, -1)
pit = torch.transpose(pit, 1, -1)
# Get encoder_outputs `mu_x`
mu_x, mask_x, _ = self.encoder(lengths, vec, pit, spk)
encoder_outputs = mu_x
# Sample latent representation from terminal distribution N(mu_y, I)
z = mu_x + torch.randn_like(mu_x, device=mu_x.device) / temperature
# Generate sample by performing reverse dynamics
decoder_outputs = self.decoder(spk, z, mask_x, mu_x, n_timesteps, stoc)
encoder_outputs = encoder_outputs + torch.randn_like(encoder_outputs)
return encoder_outputs, decoder_outputs
def compute_loss(self, lengths, vec, pit, spk, mel, out_size, skip_diff=False):
"""
Computes 2 losses:
1. prior loss: loss between mel-spectrogram and encoder outputs.
2. diffusion loss: loss between gaussian noise and its reconstruction by diffusion-based decoder.
Args:
lengths (torch.Tensor): lengths of texts in batch.
vec (torch.Tensor): batch of speech vec
pit (torch.Tensor): batch of speech pit
spk (torch.Tensor): batch of speaker
mel (torch.Tensor): batch of corresponding mel-spectrogram
out_size (int, optional): length (in mel's sampling rate) of segment to cut, on which decoder will be trained.
Should be divisible by 2^{num of UNet downsamplings}. Needed to increase batch size.
"""
lengths, vec, pit, spk, mel = self.relocate_input([lengths, vec, pit, spk, mel])
# Get pitch embedding
pit = self.pit_emb(f0_to_coarse(pit))
# Get speaker embedding
spk_64 = self.spk_emb(spk)
# Transpose
vec = torch.transpose(vec, 1, -1)
pit = torch.transpose(pit, 1, -1)
# Get encoder_outputs `mu_x`
mu_x, mask_x, spk_preds = self.encoder(lengths, vec, pit, spk_64, training=True)
# Compute loss between aligned encoder outputs and mel-spectrogram
prior_loss = torch.sum(0.5 * ((mel - mu_x) ** 2 + math.log(2 * math.pi)) * mask_x)
prior_loss = prior_loss / (torch.sum(mask_x) * self.n_mels)
# Mel ssim
mel_loss = SsimLoss(mu_x, mel, mask_x)
# Compute loss of speaker for GRL
spk_loss = SpeakerLoss(spk, spk_preds, torch.Tensor(spk_preds.size(0))
.to(spk.device).fill_(1.0))
# Compute loss of score-based decoder
if skip_diff:
diff_loss = prior_loss.clone()
diff_loss.fill_(0)
else:
# Cut a small segment of mel-spectrogram in order to increase batch size
if not isinstance(out_size, type(None)):
ids = rand_ids_segments(lengths, out_size)
mel = slice_segments(mel, ids, out_size)
mask_y = slice_segments(mask_x, ids, out_size)
mu_y = slice_segments(mu_x, ids, out_size)
mu_y = mu_y + torch.randn_like(mu_y)
diff_loss, xt = self.decoder.compute_loss(
spk_64, mel, mask_y, mu_y)
return prior_loss, diff_loss, mel_loss, spk_loss
================================================
FILE: grad/reversal.py
================================================
# Adapted from https://github.com/ubisoft/ubisoft-laforge-daft-exprt Apache License Version 2.0
# Unsupervised Domain Adaptation by Backpropagation
import torch
import torch.nn as nn
from torch.autograd import Function
from torch.nn.utils import weight_norm
class GradientReversalFunction(Function):
@staticmethod
def forward(ctx, x, lambda_):
ctx.lambda_ = lambda_
return x.clone()
@staticmethod
def backward(ctx, grads):
lambda_ = ctx.lambda_
lambda_ = grads.new_tensor(lambda_)
dx = -lambda_ * grads
return dx, None
class GradientReversal(torch.nn.Module):
''' Gradient Reversal Layer
Y. Ganin, V. Lempitsky,
"Unsupervised Domain Adaptation by Backpropagation",
in ICML, 2015.
Forward pass is the identity function
In the backward pass, upstream gradients are multiplied by -lambda (i.e. gradient are reversed)
'''
def __init__(self, lambda_reversal=1):
super(GradientReversal, self).__init__()
self.lambda_ = lambda_reversal
def forward(self, x):
return GradientReversalFunction.apply(x, self.lambda_)
class SpeakerClassifier(nn.Module):
def __init__(self, idim, odim):
super(SpeakerClassifier, self).__init__()
self.classifier = nn.Sequential(
GradientReversal(lambda_reversal=1),
weight_norm(nn.Conv1d(idim, 1024, kernel_size=5, padding=2)),
nn.ReLU(),
weight_norm(nn.Conv1d(1024, 1024, kernel_size=5, padding=2)),
nn.ReLU(),
weight_norm(nn.Conv1d(1024, odim, kernel_size=5, padding=2))
)
def forward(self, x):
''' Forward function of Speaker Classifier:
x = (B, idim, len)
'''
# pass through classifier
outputs = self.classifier(x) # (B, nb_speakers)
outputs = torch.mean(outputs, dim=-1)
return outputs
================================================
FILE: grad/solver.py
================================================
import torch
class NoiseScheduleVP:
def __init__(self, beta_min=0.05, beta_max=20):
self.beta_min = beta_min
self.beta_max = beta_max
self.T = 1.
def get_noise(self, t, beta_init, beta_term, cumulative=False):
if cumulative:
noise = beta_init*t + 0.5*(beta_term - beta_init)*(t**2)
else:
noise = beta_init + (beta_term - beta_init)*t
return noise
def marginal_log_mean_coeff(self, t):
return -0.25 * t**2 * (self.beta_max -
self.beta_min) - 0.5 * t * self.beta_min
def marginal_std(self, t):
return torch.sqrt(1. - torch.exp(2. * self.marginal_log_mean_coeff(t)))
def marginal_lambda(self, t):
log_mean_coeff = self.marginal_log_mean_coeff(t)
log_std = 0.5 * torch.log(1. - torch.exp(2. * log_mean_coeff))
return log_mean_coeff - log_std
def inverse_lambda(self, lamb):
tmp = 2. * (self.beta_max - self.beta_min) * torch.logaddexp(
-2. * lamb,
torch.zeros((1, )).to(lamb))
Delta = self.beta_min**2 + tmp
return tmp / (torch.sqrt(Delta) + self.beta_min) / (self.beta_max -
self.beta_min)
def get_time_steps(self, t_T, t_0, N):
lambda_T = self.marginal_lambda(torch.tensor(t_T))
lambda_0 = self.marginal_lambda(torch.tensor(t_0))
logSNR_steps = torch.linspace(lambda_T, lambda_0, N + 1)
return self.inverse_lambda(logSNR_steps)
@torch.no_grad()
def reverse_diffusion(self, estimator, spk, z, mask, mu, n_timesteps, stoc):
print("use dpm-solver reverse")
xt = z * mask
yt = xt - mu
T = 1
eps = 1e-3
time = self.get_time_steps(T, eps, n_timesteps)
for i in range(n_timesteps):
s = torch.ones((xt.shape[0], )).to(xt.device) * time[i]
t = torch.ones((xt.shape[0], )).to(xt.device) * time[i + 1]
lambda_s = self.marginal_lambda(s)
lambda_t = self.marginal_lambda(t)
h = lambda_t - lambda_s
log_alpha_s = self.marginal_log_mean_coeff(s)
log_alpha_t = self.marginal_log_mean_coeff(t)
sigma_t = self.marginal_std(t)
phi_1 = torch.expm1(h)
noise_s = estimator(spk, yt + mu, mask, mu, s)
lt = 1 - torch.exp(-self.get_noise(s, self.beta_min, self.beta_max, cumulative=True))
a = torch.exp(log_alpha_t - log_alpha_s)
b = sigma_t * phi_1 * torch.sqrt(lt)
yt = a * yt + (b * noise_s)
xt = yt + mu
return xt
class MaxLikelihood:
def __init__(self, beta_min=0.05, beta_max=20):
self.beta_min = beta_min
self.beta_max = beta_max
def get_noise(self, t, beta_init, beta_term, cumulative=False):
if cumulative:
noise = beta_init*t + 0.5*(beta_term - beta_init)*(t**2)
else:
noise = beta_init + (beta_term - beta_init)*t
return noise
def get_gamma(self, s, t, beta_init, beta_term):
gamma = beta_init*(t-s) + 0.5*(beta_term-beta_init)*(t**2-s**2)
gamma = torch.exp(-0.5*gamma)
return gamma
def get_mu(self, s, t):
gamma_0_s = self.get_gamma(0, s, self.beta_min, self.beta_max)
gamma_0_t = self.get_gamma(0, t, self.beta_min, self.beta_max)
gamma_s_t = self.get_gamma(s, t, self.beta_min, self.beta_max)
mu = gamma_s_t * ((1-gamma_0_s**2) / (1-gamma_0_t**2))
return mu
def get_nu(self, s, t):
gamma_0_s = self.get_gamma(0, s, self.beta_min, self.beta_max)
gamma_0_t = self.get_gamma(0, t, self.beta_min, self.beta_max)
gamma_s_t = self.get_gamma(s, t, self.beta_min, self.beta_max)
nu = gamma_0_s * ((1-gamma_s_t**2) / (1-gamma_0_t**2))
return nu
def get_sigma(self, s, t):
gamma_0_s = self.get_gamma(0, s, self.beta_min, self.beta_max)
gamma_0_t = self.get_gamma(0, t, self.beta_min, self.beta_max)
gamma_s_t = self.get_gamma(s, t, self.beta_min, self.beta_max)
sigma = torch.sqrt(((1 - gamma_0_s**2) * (1 - gamma_s_t**2)) / (1 - gamma_0_t**2))
return sigma
def get_kappa(self, t, h, noise):
nu = self.get_nu(t-h, t)
gamma_0_t = self.get_gamma(0, t, self.beta_min, self.beta_max)
kappa = (nu*(1-gamma_0_t**2)/(gamma_0_t*noise*h) - 1)
return kappa
def get_omega(self, t, h, noise):
mu = self.get_mu(t-h, t)
kappa = self.get_kappa(t, h, noise)
gamma_0_t = self.get_gamma(0, t, self.beta_min, self.beta_max)
omega = (mu-1)/(noise*h) + (1+kappa)/(1-gamma_0_t**2) - 0.5
return omega
@torch.no_grad()
def reverse_diffusion(self, estimator, spk, z, mask, mu, n_timesteps, stoc=False):
print("use MaxLikelihood reverse")
h = 1.0 / n_timesteps
xt = z * mask
for i in range(n_timesteps):
t = (1.0 - i*h) * torch.ones(z.shape[0], dtype=z.dtype,
device=z.device)
time = t.unsqueeze(-1).unsqueeze(-1)
noise_t = self.get_noise(time, self.beta_min, self.beta_max,
cumulative=False)
kappa_t_h = self.get_kappa(t, h, noise_t)
omega_t_h = self.get_omega(t, h, noise_t)
sigma_t_h = self.get_sigma(t-h, t)
es = estimator(spk, xt, mask, mu, t)
dxt = ((0.5+omega_t_h)*(xt - mu) + (1+kappa_t_h) * es)
dxt_stoc = torch.randn(z.shape, dtype=z.dtype, device=z.device,
requires_grad=False)
dxt_stoc = dxt_stoc * sigma_t_h
dxt = dxt * noise_t * h + dxt_stoc
xt = (xt + dxt) * mask
return xt
class GradRaw:
def __init__(self, beta_min=0.05, beta_max=20):
self.beta_min = beta_min
self.beta_max = beta_max
def get_noise(self, t, beta_init, beta_term, cumulative=False):
if cumulative:
noise = beta_init*t + 0.5*(beta_term - beta_init)*(t**2)
else:
noise = beta_init + (beta_term - beta_init)*t
return noise
@torch.no_grad()
def reverse_diffusion(self, estimator, spk, z, mask, mu, n_timesteps, stoc=False):
print("use grad-raw reverse")
h = 1.0 / n_timesteps
xt = z * mask
for i in range(n_timesteps):
t = (1.0 - (i + 0.5)*h) * \
torch.ones(z.shape[0], dtype=z.dtype, device=z.device)
time = t.unsqueeze(-1).unsqueeze(-1)
noise_t = self.get_noise(time, self.beta_min, self.beta_max,
cumulative=False)
if stoc: # adds stochastic term
dxt_det = 0.5 * (mu - xt) - estimator(spk, xt, mask, mu, t)
dxt_det = dxt_det * noise_t * h
dxt_stoc = torch.randn(z.shape, dtype=z.dtype, device=z.device,
requires_grad=False)
dxt_stoc = dxt_stoc * torch.sqrt(noise_t * h)
dxt = dxt_det + dxt_stoc
else:
dxt = 0.5 * (mu - xt - estimator(spk, xt, mask, mu, t))
dxt = dxt * noise_t * h
xt = (xt - dxt) * mask
return xt
================================================
FILE: grad/ssim.py
================================================
"""
Adapted from https://github.com/Po-Hsun-Su/pytorch-ssim
"""
import torch
import torch.nn.functional as F
from torch.autograd import Variable
from math import exp
def gaussian(window_size, sigma):
gauss = torch.Tensor([exp(-(x - window_size // 2) ** 2 / float(2 * sigma ** 2)) for x in range(window_size)])
return gauss / gauss.sum()
def create_window(window_size, channel):
_1D_window = gaussian(window_size, 1.5).unsqueeze(1)
_2D_window = _1D_window.mm(_1D_window.t()).float().unsqueeze(0).unsqueeze(0)
window = Variable(_2D_window.expand(channel, 1, window_size, window_size).contiguous())
return window
def _ssim(img1, img2, window, window_size, channel, size_average=True):
mu1 = F.conv2d(img1, window, padding=window_size // 2, groups=channel)
mu2 = F.conv2d(img2, window, padding=window_size // 2, groups=channel)
mu1_sq = mu1.pow(2)
mu2_sq = mu2.pow(2)
mu1_mu2 = mu1 * mu2
sigma1_sq = F.conv2d(img1 * img1, window, padding=window_size // 2, groups=channel) - mu1_sq
sigma2_sq = F.conv2d(img2 * img2, window, padding=window_size // 2, groups=channel) - mu2_sq
sigma12 = F.conv2d(img1 * img2, window, padding=window_size // 2, groups=channel) - mu1_mu2
C1 = 0.01 ** 2
C2 = 0.03 ** 2
ssim_map = ((2 * mu1_mu2 + C1) * (2 * sigma12 + C2)) / ((mu1_sq + mu2_sq + C1) * (sigma1_sq + sigma2_sq + C2))
if size_average:
return ssim_map.mean()
else:
return ssim_map.mean(1)
class SSIM(torch.nn.Module):
def __init__(self, window_size=11, size_average=True):
super(SSIM, self).__init__()
self.window_size = window_size
self.size_average = size_average
self.channel = 1
self.window = create_window(window_size, self.channel)
def forward(self, fake, real, mask, bias=6.0):
fake = fake[:, None, :, :] + bias # [B, 1, T, 80]
real = real[:, None, :, :] + bias # [B, 1, T, 80]
self.window = self.window.to(dtype=fake.dtype, device=fake.device)
loss = 1 - _ssim(fake, real, self.window, self.window_size, self.channel, self.size_average)
loss = (loss * mask).sum() / mask.sum()
return loss
================================================
FILE: grad/utils.py
================================================
import torch
import numpy as np
import inspect
def sequence_mask(length, max_length=None):
if max_length is None:
max_length = length.max()
x = torch.arange(int(max_length), dtype=length.dtype, device=length.device)
return x.unsqueeze(0) < length.unsqueeze(1)
def fix_len_compatibility(length, num_downsamplings_in_unet=2):
while True:
if length % (2**num_downsamplings_in_unet) == 0:
return length
length += 1
def convert_pad_shape(pad_shape):
l = pad_shape[::-1]
pad_shape = [item for sublist in l for item in sublist]
return pad_shape
def generate_path(duration, mask):
device = duration.device
b, t_x, t_y = mask.shape
cum_duration = torch.cumsum(duration, 1)
path = torch.zeros(b, t_x, t_y, dtype=mask.dtype).to(device=device)
cum_duration_flat = cum_duration.view(b * t_x)
path = sequence_mask(cum_duration_flat, t_y).to(mask.dtype)
path = path.view(b, t_x, t_y)
path = path - torch.nn.functional.pad(path, convert_pad_shape([[0, 0],
[1, 0], [0, 0]]))[:, :-1]
path = path * mask
return path
def duration_loss(logw, logw_, lengths):
loss = torch.sum((logw - logw_)**2) / torch.sum(lengths)
return loss
f0_bin = 256
f0_max = 1100.0
f0_min = 50.0
f0_mel_min = 1127 * np.log(1 + f0_min / 700)
f0_mel_max = 1127 * np.log(1 + f0_max / 700)
def f0_to_coarse(f0):
is_torch = isinstance(f0, torch.Tensor)
f0_mel = 1127 * (1 + f0 / 700).log() if is_torch else 1127 * \
np.log(1 + f0 / 700)
f0_mel[f0_mel > 0] = (f0_mel[f0_mel > 0] - f0_mel_min) * \
(f0_bin - 2) / (f0_mel_max - f0_mel_min) + 1
f0_mel[f0_mel <= 1] = 1
f0_mel[f0_mel > f0_bin - 1] = f0_bin - 1
f0_coarse = (
f0_mel + 0.5).long() if is_torch else np.rint(f0_mel).astype(np.int)
assert f0_coarse.max() <= 255 and f0_coarse.min(
) >= 1, (f0_coarse.max(), f0_coarse.min())
return f0_coarse
def rand_ids_segments(lengths, segment_size=200):
b = lengths.shape[0]
ids_str_max = lengths - segment_size
ids_str = (torch.rand([b]).to(device=lengths.device) * ids_str_max).to(dtype=torch.long)
return ids_str
def slice_segments(x, ids_str, segment_size=200):
ret = torch.zeros_like(x[:, :, :segment_size])
for i in range(x.size(0)):
idx_str = ids_str[i]
idx_end = idx_str + segment_size
ret[i] = x[i, :, idx_str:idx_end]
return ret
def retrieve_name(var):
for fi in reversed(inspect.stack()):
names = [var_name for var_name,
var_val in fi.frame.f_locals.items() if var_val is var]
if len(names) > 0:
return names[0]
Debug_Enable = True
def debug_shapes(var):
if Debug_Enable:
print(retrieve_name(var), var.shape)
================================================
FILE: grad_extend/data.py
================================================
import os
import random
import numpy as np
import torch
from grad.utils import fix_len_compatibility
from grad_extend.utils import parse_filelist
class TextMelSpeakerDataset(torch.utils.data.Dataset):
def __init__(self, filelist_path):
super().__init__()
self.filelist = parse_filelist(filelist_path, split_char='|')
self._filter()
print(f'----------{len(self.filelist)}----------')
def _filter(self):
items_new = []
# segment = 200
items_min = 250 # 10ms * 250 = 2.5 S
items_max = 500 # 10ms * 400 = 5.0 S
for mel, vec, pit, spk in self.filelist:
if not os.path.isfile(mel):
continue
if not os.path.isfile(vec):
continue
if not os.path.isfile(pit):
continue
if not os.path.isfile(spk):
continue
temp = np.load(pit)
usel = int(temp.shape[0] - 1) # useful length
if (usel < items_min):
continue
if (usel >= items_max):
usel = items_max
items_new.append([mel, vec, pit, spk, usel])
self.filelist = items_new
def get_triplet(self, item):
# print(item)
mel = item[0]
vec = item[1]
pit = item[2]
spk = item[3]
use = item[4]
mel = torch.load(mel)
vec = np.load(vec)
vec = np.repeat(vec, 2, 0) # 320 VEC -> 160 * 2
pit = np.load(pit)
spk = np.load(spk)
vec = torch.FloatTensor(vec)
pit = torch.FloatTensor(pit)
spk = torch.FloatTensor(spk)
vec = vec + torch.randn_like(vec) # Perturbation
len_vec = vec.size()[0] - 2 # for safe
len_pit = pit.size()[0]
len_min = min(len_pit, len_vec)
mel = mel[:, :len_min]
vec = vec[:len_min, :]
pit = pit[:len_min]
if len_min > use:
max_frame_start = vec.size(0) - use - 1
frame_start = random.randint(0, max_frame_start)
frame_end = frame_start + use
mel = mel[:, frame_start:frame_end]
vec = vec[frame_start:frame_end, :]
pit = pit[frame_start:frame_end]
# print(mel.shape)
# print(vec.shape)
# print(pit.shape)
# print(spk.shape)
return (mel, vec, pit, spk)
def __getitem__(self, index):
mel, vec, pit, spk = self.get_triplet(self.filelist[index])
item = {'mel': mel, 'vec': vec, 'pit': pit, 'spk': spk}
return item
def __len__(self):
return len(self.filelist)
def sample_test_batch(self, size):
idx = np.random.choice(range(len(self)), size=size, replace=False)
test_batch = []
for index in idx:
test_batch.append(self.__getitem__(index))
return test_batch
class TextMelSpeakerBatchCollate(object):
# mel: [freq, length]
# vec: [len, 256]
# pit: [len]
# spk: [256]
def __call__(self, batch):
B = len(batch)
mel_max_length = max([item['mel'].shape[-1] for item in batch])
max_length = fix_len_compatibility(mel_max_length)
d_mel = batch[0]['mel'].shape[0]
d_vec = batch[0]['vec'].shape[1]
d_spk = batch[0]['spk'].shape[0]
# print("d_mel", d_mel)
# print("d_vec", d_vec)
# print("d_spk", d_spk)
mel = torch.zeros((B, d_mel, max_length), dtype=torch.float32)
vec = torch.zeros((B, max_length, d_vec), dtype=torch.float32)
pit = torch.zeros((B, max_length), dtype=torch.float32)
spk = torch.zeros((B, d_spk), dtype=torch.float32)
lengths = torch.LongTensor(B)
for i, item in enumerate(batch):
y_, x_, p_, s_ = item['mel'], item['vec'], item['pit'], item['spk']
mel[i, :, :y_.shape[1]] = y_
vec[i, :x_.shape[0], :] = x_
pit[i, :p_.shape[0]] = p_
spk[i] = s_
lengths[i] = y_.shape[1]
# print("lengths", lengths.shape)
# print("vec", vec.shape)
# print("pit", pit.shape)
# print("spk", spk.shape)
# print("mel", mel.shape)
return {'lengths': lengths, 'vec': vec, 'pit': pit, 'spk': spk, 'mel': mel}
================================================
FILE: grad_extend/train.py
================================================
import os
import torch
import numpy as np
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
from tqdm import tqdm
from grad_extend.data import TextMelSpeakerDataset, TextMelSpeakerBatchCollate
from grad_extend.utils import plot_tensor, save_plot, load_model, print_error
from grad.utils import fix_len_compatibility
from grad.model import GradTTS
# 200 frames
out_size = fix_len_compatibility(200)
def train(hps, chkpt_path=None):
print('Initializing logger...')
logger = SummaryWriter(log_dir=hps.train.log_dir)
print('Initializing data loaders...')
train_dataset = TextMelSpeakerDataset(hps.train.train_files)
batch_collate = TextMelSpeakerBatchCollate()
loader = DataLoader(dataset=train_dataset,
batch_size=hps.train.batch_size,
collate_fn=batch_collate,
drop_last=True,
num_workers=8,
shuffle=True)
test_dataset = TextMelSpeakerDataset(hps.train.valid_files)
print('Initializing model...')
model = GradTTS(hps.grad.n_mels, hps.grad.n_vecs, hps.grad.n_pits, hps.grad.n_spks, hps.grad.n_embs,
hps.grad.n_enc_channels, hps.grad.filter_channels,
hps.grad.dec_dim, hps.grad.beta_min, hps.grad.beta_max, hps.grad.pe_scale).cuda()
print('Number of encoder parameters = %.2fm' % (model.encoder.nparams/1e6))
print('Number of decoder parameters = %.2fm' % (model.decoder.nparams/1e6))
# Load Pretrain
if os.path.isfile(hps.train.pretrain):
print("Start from Grad_SVC pretrain model: %s" % hps.train.pretrain)
checkpoint = torch.load(hps.train.pretrain, map_location='cpu')
load_model(model, checkpoint['model'])
hps.train.learning_rate = 2e-5
# fine_tune
model.fine_tune()
else:
print_error(10 * '~' + "No Pretrain Model" + 10 * '~')
print('Initializing optimizer...')
optim = torch.optim.Adam(params=model.parameters(), lr=hps.train.learning_rate)
initepoch = 1
iteration = 0
# Load Continue
if chkpt_path is not None:
print("Resuming from checkpoint: %s" % chkpt_path)
checkpoint = torch.load(chkpt_path, map_location='cpu')
model.load_state_dict(checkpoint['model'])
optim.load_state_dict(checkpoint['optim'])
initepoch = checkpoint['epoch']
iteration = checkpoint['steps']
print('Logging test batch...')
test_batch = test_dataset.sample_test_batch(size=hps.train.test_size)
for i, item in enumerate(test_batch):
mel = item['mel']
logger.add_image(f'image_{i}/ground_truth', plot_tensor(mel.squeeze()),
global_step=0, dataformats='HWC')
save_plot(mel.squeeze(), f'{hps.train.log_dir}/original_{i}.png')
print('Start training...')
skip_diff_train = True
if initepoch >= hps.train.fast_epochs:
skip_diff_train = False
for epoch in range(initepoch, hps.train.full_epochs + 1):
if epoch % hps.train.test_step == 0:
model.eval()
print('Synthesis...')
with torch.no_grad():
for i, item in enumerate(test_batch):
l_vec = item['vec'].shape[0]
d_vec = item['vec'].shape[1]
lengths_fix = fix_len_compatibility(l_vec)
lengths = torch.LongTensor([l_vec]).cuda()
vec = torch.zeros((1, lengths_fix, d_vec), dtype=torch.float32).cuda()
pit = torch.zeros((1, lengths_fix), dtype=torch.float32).cuda()
spk = item['spk'].to(torch.float32).unsqueeze(0).cuda()
vec[0, :l_vec, :] = item['vec']
pit[0, :l_vec] = item['pit']
y_enc, y_dec = model(lengths, vec, pit, spk, n_timesteps=50)
logger.add_image(f'image_{i}/generated_enc',
plot_tensor(y_enc.squeeze().cpu()),
global_step=iteration, dataformats='HWC')
logger.add_image(f'image_{i}/generated_dec',
plot_tensor(y_dec.squeeze().cpu()),
global_step=iteration, dataformats='HWC')
save_plot(y_enc.squeeze().cpu(),
f'{hps.train.log_dir}/generated_enc_{i}.png')
save_plot(y_dec.squeeze().cpu(),
f'{hps.train.log_dir}/generated_dec_{i}.png')
model.train()
prior_losses = []
diff_losses = []
mel_losses = []
spk_losses = []
with tqdm(loader, total=len(train_dataset)//hps.train.batch_size) as progress_bar:
for batch in progress_bar:
model.zero_grad()
lengths = batch['lengths'].cuda()
vec = batch['vec'].cuda()
pit = batch['pit'].cuda()
spk = batch['spk'].cuda()
mel = batch['mel'].cuda()
prior_loss, diff_loss, mel_loss, spk_loss = model.compute_loss(
lengths, vec, pit, spk,
mel, out_size=out_size,
skip_diff=skip_diff_train)
loss = sum([prior_loss, diff_loss, mel_loss, spk_loss])
loss.backward()
enc_grad_norm = torch.nn.utils.clip_grad_norm_(model.encoder.parameters(),
max_norm=1)
dec_grad_norm = torch.nn.utils.clip_grad_norm_(model.decoder.parameters(),
max_norm=1)
optim.step()
logger.add_scalar('training/mel_loss', mel_loss,
global_step=iteration)
logger.add_scalar('training/prior_loss', prior_loss,
global_step=iteration)
logger.add_scalar('training/diffusion_loss', diff_loss,
global_step=iteration)
logger.add_scalar('training/encoder_grad_norm', enc_grad_norm,
global_step=iteration)
logger.add_scalar('training/decoder_grad_norm', dec_grad_norm,
global_step=iteration)
msg = f'Epoch: {epoch}, iteration: {iteration} | '
msg = msg + f'prior_loss: {prior_loss.item():.3f}, '
msg = msg + f'diff_loss: {diff_loss.item():.3f}, '
msg = msg + f'mel_loss: {mel_loss.item():.3f}, '
msg = msg + f'spk_loss: {spk_loss.item():.3f}, '
progress_bar.set_description(msg)
prior_losses.append(prior_loss.item())
diff_losses.append(diff_loss.item())
mel_losses.append(mel_loss.item())
spk_losses.append(spk_loss.item())
iteration += 1
msg = 'Epoch %d: ' % (epoch)
msg += '| spk loss = %.3f ' % np.mean(spk_losses)
msg += '| mel loss = %.3f ' % np.mean(mel_losses)
msg += '| prior loss = %.3f ' % np.mean(prior_losses)
msg += '| diffusion loss = %.3f\n' % np.mean(diff_losses)
with open(f'{hps.train.log_dir}/train.log', 'a') as f:
f.write(msg)
# if (np.mean(prior_losses) < 1.05):
# skip_diff_train = False
if epoch > hps.train.fast_epochs:
skip_diff_train = False
if epoch % hps.train.save_step > 0:
continue
save_path = f"{hps.train.log_dir}/grad_svc_{epoch}.pt"
torch.save({
'model': model.state_dict(),
'optim': optim.state_dict(),
'epoch': epoch,
'steps': iteration,
}, save_path)
print("Saved checkpoint to: %s" % save_path)
================================================
FILE: grad_extend/utils.py
================================================
import os
import glob
import numpy as np
import matplotlib.pyplot as plt
import torch
def parse_filelist(filelist_path, split_char="|"):
with open(filelist_path, encoding='utf-8') as f:
filepaths_and_text = [line.strip().split(split_char) for line in f]
return filepaths_and_text
def load_model(model, saved_state_dict):
state_dict = model.state_dict()
new_state_dict = {}
for k, v in state_dict.items():
try:
new_state_dict[k] = saved_state_dict[k]
except:
print("%s is not in the checkpoint" % k)
new_state_dict[k] = v
model.load_state_dict(new_state_dict)
return model
def latest_checkpoint_path(dir_path, regex="grad_svc_*.pt"):
f_list = glob.glob(os.path.join(dir_path, regex))
f_list.sort(key=lambda f: int("".join(filter(str.isdigit, f))))
x = f_list[-1]
return x
def load_checkpoint(logdir, model, num=None):
if num is None:
model_path = latest_checkpoint_path(logdir, regex="grad_svc_*.pt")
else:
model_path = os.path.join(logdir, f"grad_svc_{num}.pt")
print(f'Loading checkpoint {model_path}...')
model_dict = torch.load(model_path, map_location=lambda loc, storage: loc)
model.load_state_dict(model_dict, strict=False)
return model
def save_figure_to_numpy(fig):
data = np.fromstring(fig.canvas.tostring_rgb(), dtype=np.uint8, sep='')
data = data.reshape(fig.canvas.get_width_height()[::-1] + (3,))
return data
def plot_tensor(tensor):
plt.style.use('default')
fig, ax = plt.subplots(figsize=(12, 3))
im = ax.imshow(tensor, aspect="auto", origin="lower", interpolation='none')
plt.colorbar(im, ax=ax)
plt.tight_layout()
fig.canvas.draw()
data = save_figure_to_numpy(fig)
plt.close()
return data
def save_plot(tensor, savepath):
plt.style.use('default')
fig, ax = plt.subplots(figsize=(12, 3))
im = ax.imshow(tensor, aspect="auto", origin="lower", interpolation='none')
plt.colorbar(im, ax=ax)
plt.tight_layout()
fig.canvas.draw()
plt.savefig(savepath)
plt.close()
return
def print_error(info):
print(f"\033[31m {info} \033[0m")
================================================
FILE: grad_pretrain/README.md
================================================
Path for:
gvc.pretrain.pth
================================================
FILE: gvc_export.py
================================================
import sys,os
sys.path.append(os.path.dirname(os.path.abspath(__file__)))
import torch
import argparse
from omegaconf import OmegaConf
from grad.model import GradTTS
def load_model(checkpoint_path, model):
assert os.path.isfile(checkpoint_path)
checkpoint_dict = torch.load(checkpoint_path, map_location="cpu")
saved_state_dict = checkpoint_dict["model"]
state_dict = model.state_dict()
new_state_dict = {}
for k, v in state_dict.items():
try:
new_state_dict[k] = saved_state_dict[k]
except:
print("%s is not in the checkpoint" % k)
new_state_dict[k] = v
model.load_state_dict(new_state_dict)
def main(args):
hps = OmegaConf.load(args.config)
print('Initializing Grad-TTS...')
model = GradTTS(hps.grad.n_mels, hps.grad.n_vecs, hps.grad.n_pits, hps.grad.n_spks, hps.grad.n_embs,
hps.grad.n_enc_channels, hps.grad.filter_channels,
hps.grad.dec_dim, hps.grad.beta_min, hps.grad.beta_max, hps.grad.pe_scale)
print('Number of encoder parameters = %.2fm' % (model.encoder.nparams/1e6))
print('Number of decoder parameters = %.2fm' % (model.decoder.nparams/1e6))
load_model(args.checkpoint_path, model)
torch.save({'model': model.state_dict()}, "gvc.pth")
torch.save({'model': model.state_dict()}, "gvc.pretrain.pth")
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('-c', '--config', type=str, default='./configs/base.yaml',
help="yaml file for config.")
parser.add_argument('-p', '--checkpoint_path', type=str, required=True,
help="path of checkpoint pt file for evaluation")
args = parser.parse_args()
main(args)
================================================
FILE: gvc_inference.py
================================================
import sys,os
sys.path.append(os.path.dirname(os.path.abspath(__file__)))
import torch
import argparse
import numpy as np
from omegaconf import OmegaConf
from pitch import load_csv_pitch
from spec.inference import print_mel
from grad_extend.utils import print_error
from grad.utils import fix_len_compatibility
from grad.model import GradTTS
from bigvgan.model.generator import Generator
from scipy.io.wavfile import write
def load_gvc_model(checkpoint_path, model):
assert os.path.isfile(checkpoint_path)
checkpoint_dict = torch.load(checkpoint_path, map_location="cpu")
saved_state_dict = checkpoint_dict["model"]
state_dict = model.state_dict()
new_state_dict = {}
for k, v in state_dict.items():
try:
new_state_dict[k] = saved_state_dict[k]
except:
print("%s is not in the checkpoint" % k)
new_state_dict[k] = v
model.load_state_dict(new_state_dict)
return model
def load_bigv_model(checkpoint_path, model):
assert os.path.isfile(checkpoint_path)
checkpoint_dict = torch.load(checkpoint_path, map_location="cpu")
saved_state_dict = checkpoint_dict["model_g"]
state_dict = model.state_dict()
new_state_dict = {}
for k, v in state_dict.items():
try:
new_state_dict[k] = saved_state_dict[k]
except:
print("%s is not in the checkpoint" % k)
new_state_dict[k] = v
model.load_state_dict(new_state_dict)
return model
@torch.no_grad()
def gvc_main(device, model, _vec, _pit, spk, rature=1.015):
l_vec = _vec.shape[0]
d_vec = _vec.shape[1]
lengths_fix = fix_len_compatibility(l_vec)
lengths = torch.LongTensor([l_vec]).to(device)
vec = torch.zeros((1, lengths_fix, d_vec), dtype=torch.float32).to(device)
pit = torch.zeros((1, lengths_fix), dtype=torch.float32).to(device)
vec[0, :l_vec, :] = _vec
pit[0, :l_vec] = _pit
y_enc, y_dec = model(lengths, vec, pit, spk, n_timesteps=20, temperature=rature)
y_dec = y_dec.squeeze(0)
y_dec = y_dec[:, :l_vec]
return y_dec
def main(args):
if (args.vec == None):
args.vec = "gvc_tmp.vec.npy"
print(
f"Auto run : python hubert/inference.py -w {args.wave} -v {args.vec}")
os.system(f"python hubert/inference.py -w {args.wave} -v {args.vec}")
if (args.pit == None):
args.pit = "gvc_tmp.pit.csv"
print(
f"Auto run : python pitch/inference.py -w {args.wave} -p {args.pit}")
os.system(f"python pitch/inference.py -w {args.wave} -p {args.pit}")
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
hps = OmegaConf.load(args.config)
print('Initializing Grad-TTS...')
model = GradTTS(hps.grad.n_mels, hps.grad.n_vecs, hps.grad.n_pits, hps.grad.n_spks, hps.grad.n_embs,
hps.grad.n_enc_channels, hps.grad.filter_channels,
hps.grad.dec_dim, hps.grad.beta_min, hps.grad.beta_max, hps.grad.pe_scale)
print('Number of encoder parameters = %.2fm' % (model.encoder.nparams/1e6))
print('Number of decoder parameters = %.2fm' % (model.decoder.nparams/1e6))
print_error(f'Temperature: {args.rature}')
load_gvc_model(args.model, model)
model.eval()
model.to(device)
spk = np.load(args.spk)
spk = torch.FloatTensor(spk)
vec = np.load(args.vec)
vec = np.repeat(vec, 2, 0)
vec = torch.FloatTensor(vec)
pit = load_csv_pitch(args.pit)
pit = np.array(pit)
pit = pit * 2 ** (args.shift / 12)
pit = torch.FloatTensor(pit)
len_pit = pit.size()[0]
len_vec = vec.size()[0]
len_min = min(len_pit, len_vec)
pit = pit[:len_min]
vec = vec[:len_min, :]
with torch.no_grad():
spk = spk.unsqueeze(0).to(device)
all_frame = len_min
hop_frame = 8
out_chunk = 2400 # 24 S
out_index = 0
mel = None
while (out_index < all_frame):
if (out_index == 0): # start frame
cut_s = 0
cut_s_out = 0
else:
cut_s = out_index - hop_frame
cut_s_out = hop_frame
if (out_index + out_chunk + hop_frame > all_frame): # end frame
cut_e = all_frame
cut_e_out = -1
else:
cut_e = out_index + out_chunk + hop_frame
cut_e_out = -1 * hop_frame
sub_vec = vec[cut_s:cut_e, :].to(device)
sub_pit = pit[cut_s:cut_e].to(device)
sub_out = gvc_main(device, model, sub_vec, sub_pit, spk, args.rature)
sub_out = sub_out[:, cut_s_out:cut_e_out]
out_index = out_index + out_chunk
if mel == None:
mel = sub_out
else:
mel = torch.cat((mel, sub_out), -1)
if cut_e == all_frame:
break
print_error(10 * '~' + "mel has been generated" + 10 * '~')
print_mel(mel, "gvc_out.mel.png")
del model
del hps
del spk
del vec
del sub_vec
del sub_pit
del sub_out
hps = OmegaConf.load(args.config_bigv)
model = Generator(hps)
load_bigv_model(args.model_bigv, model)
model.eval()
model.to(device)
len_pit = pit.size()[0]
len_mel = mel.size()[1]
len_min = min(len_pit, len_mel)
pit = pit[:len_min]
mel = mel[:, :len_min]
with torch.no_grad():
mel = mel.unsqueeze(0).to(device)
pit = pit.unsqueeze(0).to(device)
audio = model.inference(mel, pit)
audio = audio.cpu().detach().numpy()
pitwav = model.pitch2wav(pit)
pitwav = pitwav.cpu().detach().numpy()
print_error(10 * '~' + "wav has been generated" + 10 * '~')
write("gvc_out.wav", hps.audio.sampling_rate, audio)
write("gvc_pitch.wav", hps.audio.sampling_rate, pitwav)
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--config', type=str, default='./configs/base.yaml',
help="yaml file for config.")
parser.add_argument('--model', type=str, required=True,
help="path of model for evaluation")
parser.add_argument('--wave', type=str, required=True,
help="Path of raw audio.")
parser.add_argument('--spk', type=str, required=True,
help="Path of speaker.")
parser.add_argument('--vec', type=str,
help="Path of hubert vector.")
parser.add_argument('--pit', type=str,
help="Path of pitch csv file.")
parser.add_argument('--shift', type=int, default=0,
help="Pitch shift key.")
parser.add_argument('--rature', type=float, default=1.015,
help="Pitch shift key.")
args = parser.parse_args()
args.config_bigv = "./bigvgan/configs/nsf_bigvgan.yaml"
args.model_bigv = "./bigvgan_pretrain/nsf_bigvgan_pretrain_32K.pth"
assert os.path.isfile(args.config)
assert os.path.isfile(args.model)
assert os.path.isfile(args.config_bigv)
assert os.path.isfile(args.model_bigv)
main(args)
================================================
FILE: gvc_trainer.py
================================================
import sys,os
sys.path.append(os.path.dirname(os.path.abspath(__file__)))
import argparse
import torch
import numpy as np
from omegaconf import OmegaConf
from grad_extend.train import train
torch.backends.cudnn.benchmark = True
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('-c', '--config', type=str, default='./configs/base.yaml',
help="yaml file for configuration")
parser.add_argument('-p', '--checkpoint_path', type=str, default=None,
help="path of checkpoint pt file to resume training")
args = parser.parse_args()
assert torch.cuda.is_available()
print('Numbers of GPU :', torch.cuda.device_count())
hps = OmegaConf.load(args.config)
np.random.seed(hps.train.seed)
torch.manual_seed(hps.train.seed)
torch.cuda.manual_seed(hps.train.seed)
train(hps, args.checkpoint_path)
================================================
FILE: hubert/__init__.py
================================================
================================================
FILE: hubert/hubert_model.py
================================================
import copy
import random
from typing import Optional, Tuple
import torch
import torch.nn as nn
import torch.nn.functional as t_func
class Hubert(nn.Module):
def __init__(self, num_label_embeddings: int = 100, mask: bool = True):
super().__init__()
self._mask = mask
self.feature_extractor = FeatureExtractor()
self.feature_projection = FeatureProjection()
self.positional_embedding = PositionalConvEmbedding()
self.norm = nn.LayerNorm(768)
self.dropout = nn.Dropout(0.1)
self.encoder = TransformerEncoder(
nn.TransformerEncoderLayer(
768, 12, 3072, activation="gelu", batch_first=True
),
12,
)
self.proj = nn.Linear(768, 256)
self.masked_spec_embed = nn.Parameter(torch.FloatTensor(768).uniform_())
self.label_embedding = nn.Embedding(num_label_embeddings, 256)
def mask(self, x: torch.Tensor) -> Tuple[torch.Tensor, torch.Tensor]:
mask = None
if self.training and self._mask:
mask = _compute_mask((x.size(0), x.size(1)), 0.8, 10, x.device, 2)
x[mask] = self.masked_spec_embed.to(x.dtype)
return x, mask
def encode(
self, x: torch.Tensor, layer: Optional[int] = None
) -> Tuple[torch.Tensor, torch.Tensor]:
x = self.feature_extractor(x)
x = self.feature_projection(x.transpose(1, 2))
x, mask = self.mask(x)
x = x + self.positional_embedding(x)
x = self.dropout(self.norm(x))
x = self.encoder(x, output_layer=layer)
return x, mask
def logits(self, x: torch.Tensor) -> torch.Tensor:
logits = torch.cosine_similarity(
x.unsqueeze(2),
self.label_embedding.weight.unsqueeze(0).unsqueeze(0),
dim=-1,
)
return logits / 0.1
def forward(self, x: torch.Tensor) -> Tuple[torch.Tensor, torch.Tensor]:
x, mask = self.encode(x)
x = self.proj(x)
logits = self.logits(x)
return logits, mask
class HubertSoft(Hubert):
def __init__(self):
super().__init__()
@torch.inference_mode()
def units(self, wav: torch.Tensor) -> torch.Tensor:
wav = t_func.pad(wav, ((400 - 320) // 2, (400 - 320) // 2))
x, _ = self.encode(wav)
return self.proj(x)
class FeatureExtractor(nn.Module):
def __init__(self):
super().__init__()
self.conv0 = nn.Conv1d(1, 512, 10, 5, bias=False)
self.norm0 = nn.GroupNorm(512, 512)
self.conv1 = nn.Conv1d(512, 512, 3, 2, bias=False)
self.conv2 = nn.Conv1d(512, 512, 3, 2, bias=False)
self.conv3 = nn.Conv1d(512, 512, 3, 2, bias=False)
self.conv4 = nn.Conv1d(512, 512, 3, 2, bias=False)
self.conv5 = nn.Conv1d(512, 512, 2, 2, bias=False)
self.conv6 = nn.Conv1d(512, 512, 2, 2, bias=False)
def forward(self, x: torch.Tensor) -> torch.Tensor:
x = t_func.gelu(self.norm0(self.conv0(x)))
x = t_func.gelu(self.conv1(x))
x = t_func.gelu(self.conv2(x))
x = t_func.gelu(self.conv3(x))
x = t_func.gelu(self.conv4(x))
x = t_func.gelu(self.conv5(x))
x = t_func.gelu(self.conv6(x))
return x
class FeatureProjection(nn.Module):
def __init__(self):
super().__init__()
self.norm = nn.LayerNorm(512)
self.projection = nn.Linear(512, 768)
self.dropout = nn.Dropout(0.1)
def forward(self, x: torch.Tensor) -> torch.Tensor:
x = self.norm(x)
x = self.projection(x)
x = self.dropout(x)
return x
class PositionalConvEmbedding(nn.Module):
def __init__(self):
super().__init__()
self.conv = nn.Conv1d(
768,
768,
kernel_size=128,
padding=128 // 2,
groups=16,
)
self.conv = nn.utils.weight_norm(self.conv, name="weight", dim=2)
def forward(self, x: torch.Tensor) -> torch.Tensor:
x = self.conv(x.transpose(1, 2))
x = t_func.gelu(x[:, :, :-1])
return x.transpose(1, 2)
class TransformerEncoder(nn.Module):
def __init__(
self, encoder_layer: nn.TransformerEncoderLayer, num_layers: int
) -> None:
super(TransformerEncoder, self).__init__()
self.layers = nn.ModuleList(
[copy.deepcopy(encoder_layer) for _ in range(num_layers)]
)
self.num_layers = num_layers
def forward(
self,
src: torch.Tensor,
mask: torch.Tensor = None,
src_key_padding_mask: torch.Tensor = None,
output_layer: Optional[int] = None,
) -> torch.Tensor:
output = src
for layer in self.layers[:output_layer]:
output = layer(
output, src_mask=mask, src_key_padding_mask=src_key_padding_mask
)
return output
def _compute_mask(
shape: Tuple[int, int],
mask_prob: float,
mask_length: int,
device: torch.device,
min_masks: int = 0,
) -> torch.Tensor:
batch_size, sequence_length = shape
if mask_length < 1:
raise ValueError("`mask_length` has to be bigger than 0.")
if mask_length > sequence_length:
raise ValueError(
f"`mask_length` has to be smaller than `sequence_length`, but got `mask_length`: {mask_length} and `sequence_length`: {sequence_length}`"
)
# compute number of masked spans in batch
num_masked_spans = int(mask_prob * sequence_length / mask_length + random.random())
num_masked_spans = max(num_masked_spans, min_masks)
# make sure num masked indices <= sequence_length
if num_masked_spans * mask_length > sequence_length:
num_masked_spans = sequence_length // mask_length
# SpecAugment mask to fill
mask = torch.zeros((batch_size, sequence_length), device=device, dtype=torch.bool)
# uniform distribution to sample from, make sure that offset samples are < sequence_length
uniform_dist = torch.ones(
(batch_size, sequence_length - (mask_length - 1)), device=device
)
# get random indices to mask
mask_indices = torch.multinomial(uniform_dist, num_masked_spans)
# expand masked indices to masked spans
mask_indices = (
mask_indices.unsqueeze(dim=-1)
.expand((batch_size, num_masked_spans, mask_length))
.reshape(batch_size, num_masked_spans * mask_length)
)
offsets = (
torch.arange(mask_length, device=device)[None, None, :]
.expand((batch_size, num_masked_spans, mask_length))
.reshape(batch_size, num_masked_spans * mask_length)
)
mask_idxs = mask_indices + offsets
# scatter indices to mask
mask = mask.scatter(1, mask_idxs, True)
return mask
def consume_prefix(state_dict, prefix: str) -> None:
keys = sorted(state_dict.keys())
for key in keys:
if key.startswith(prefix):
newkey = key[len(prefix):]
state_dict[newkey] = state_dict.pop(key)
def hubert_soft(
path: str,
) -> HubertSoft:
r"""HuBERT-Soft from `"A Comparison of Discrete and Soft Speech Units for Improved Voice Conversion"`.
Args:
path (str): path of a pretrained model
"""
hubert = HubertSoft()
checkpoint = torch.load(path)
consume_prefix(checkpoint, "module.")
hubert.load_state_dict(checkpoint)
hubert.eval()
return hubert
================================================
FILE: hubert/inference.py
================================================
import sys,os
sys.path.append(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
import numpy as np
import argparse
import torch
import librosa
from hubert import hubert_model
def load_audio(file: str, sr: int = 16000):
x, sr = librosa.load(file, sr=sr)
return x
def load_model(path, device):
model = hubert_model.hubert_soft(path)
model.eval()
if not (device == "cpu"):
model.half()
model.to(device)
return model
def pred_vec(model, wavPath, vecPath, device):
audio = load_audio(wavPath)
audln = audio.shape[0]
vec_a = []
idx_s = 0
while (idx_s + 20 * 16000 < audln):
feats = audio[idx_s:idx_s + 20 * 16000]
feats = torch.from_numpy(feats).to(device)
feats = feats[None, None, :]
if not (device == "cpu"):
feats = feats.half()
with torch.no_grad():
vec = model.units(feats).squeeze().data.cpu().float().numpy()
vec_a.extend(vec)
idx_s = idx_s + 20 * 16000
if (idx_s < audln):
feats = audio[idx_s:audln]
feats = torch.from_numpy(feats).to(device)
feats = feats[None, None, :]
if not (device == "cpu"):
feats = feats.half()
with torch.no_grad():
vec = model.units(feats).squeeze().data.cpu().float().numpy()
# print(vec.shape) # [length, dim=256] hop=320
vec_a.extend(vec)
np.save(vecPath, vec_a, allow_pickle=False)
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument("-w", "--wav", help="wav", dest="wav")
parser.add_argument("-v", "--vec", help="vec", dest="vec")
args = parser.parse_args()
print(args.wav)
print(args.vec)
wavPath = args.wav
vecPath = args.vec
device = "cuda" if torch.cuda.is_available() else "cpu"
hubert = load_model(os.path.join(
"hubert_pretrain", "hubert-soft-0d54a1f4.pt"), device)
pred_vec(hubert, wavPath, vecPath, device)
================================================
FILE: hubert_pretrain/README.md
================================================
Path for:
hubert-soft-0d54a1f4.pt
================================================
FILE: pitch/__init__.py
================================================
from .inference import load_csv_pitch
================================================
FILE: pitch/inference.py
================================================
import sys,os
sys.path.append(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
import librosa
import argparse
import numpy as np
import parselmouth
# pip install praat-parselmouth
def compute_f0_mouth(path):
x, sr = librosa.load(path, sr=16000)
assert sr == 16000
lpad = 1024 // 160
rpad = lpad
f0 = parselmouth.Sound(x, sr).to_pitch_ac(
time_step=160 / sr,
voicing_threshold=0.5,
pitch_floor=30,
pitch_ceiling=1000).selected_array['frequency']
f0 = np.pad(f0, [[lpad, rpad]], mode='constant')
return f0
def compute_f0_crepe(filename):
import torch
import torchcrepe
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
audio, sr = librosa.load(filename, sr=16000)
assert sr == 16000
audio = torch.tensor(np.copy(audio))[None]
audio = audio + torch.randn_like(audio) * 0.001
# Here we'll use a 20 millisecond hop length
hop_length = 320
fmin = 50
fmax = 1000
model = "full"
batch_size = 512
pitch = torchcrepe.predict(
audio,
sr,
hop_length,
fmin,
fmax,
model,
batch_size=batch_size,
device=device,
return_periodicity=False,
)
pitch = np.repeat(pitch, 2, -1) # 320 -> 160 * 2
pitch = torchcrepe.filter.mean(pitch, 5)
pitch = pitch.squeeze(0)
return pitch
def save_csv_pitch(pitch, path):
with open(path, "w", encoding='utf-8') as pitch_file:
for i in range(len(pitch)):
t = i * 10
minute = t // 60000
seconds = (t - minute * 60000) // 1000
millisecond = t % 1000
print(
f"{minute}m {seconds}s {millisecond:3d},{int(pitch[i])}", file=pitch_file)
def load_csv_pitch(path):
pitch = []
with open(path, "r", encoding='utf-8') as pitch_file:
for line in pitch_file.readlines():
pit = line.strip().split(",")[-1]
pitch.append(int(pit))
return pitch
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument("-w", "--wav", help="wav", dest="wav")
parser.add_argument("-p", "--pit", help="pit", dest="pit") # csv for excel
args = parser.parse_args()
print(args.wav)
print(args.pit)
pitch = compute_f0_mouth(args.wav)
save_csv_pitch(pitch, args.pit)
#tmp = load_csv_pitch(args.pit)
#save_csv_pitch(tmp, "tmp.csv")
================================================
FILE: prepare/preprocess_a.py
================================================
import os
import librosa
import argparse
import numpy as np
from tqdm import tqdm
from concurrent.futures import ThreadPoolExecutor, as_completed
from scipy.io import wavfile
def resample_wave(wav_in, wav_out, sample_rate):
wav, _ = librosa.load(wav_in, sr=sample_rate)
wav = wav / np.abs(wav).max() * 0.6
wav = wav / max(0.01, np.max(np.abs(wav))) * 32767 * 0.6
wavfile.write(wav_out, sample_rate, wav.astype(np.int16))
def process_file(file, wavPath, spks, outPath, sr):
if file.endswith(".wav"):
file = file[:-4]
resample_wave(f"{wavPath}/{spks}/{file}.wav", f"{outPath}/{spks}/{file}.wav", sr)
def process_files_with_thread_pool(wavPath, spks, outPath, sr, thread_num=None):
files = [f for f in os.listdir(f"./{wavPath}/{spks}") if f.endswith(".wav")]
with ThreadPoolExecutor(max_workers=thread_num) as executor:
futures = {executor.submit(process_file, file, wavPath, spks, outPath, sr): file for file in files}
for future in tqdm(as_completed(futures), total=len(futures), desc=f'Processing {sr} {spks}'):
future.result()
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument("-w", "--wav", help="wav", dest="wav", required=True)
parser.add_argument("-o", "--out", help="out", dest="out", required=True)
parser.add_argument("-s", "--sr", help="sample rate", dest="sr", type=int, required=True)
parser.add_argument("-t", "--thread_count", help="thread count to process, set 0 to use all cpu cores", dest="thread_count", type=int, default=1)
args = parser.parse_args()
print(args.wav)
print(args.out)
print(args.sr)
os.makedirs(args.out, exist_ok=True)
wavPath = args.wav
outPath = args.out
assert args.sr == 16000 or args.sr == 32000
for spks in os.listdir(wavPath):
if os.path.isdir(f"./{wavPath}/{spks}"):
os.makedirs(f"./{outPath}/{spks}", exist_ok=True)
if args.thread_count == 0:
process_num = os.cpu_count() // 2 + 1
else:
process_num = args.thread_count
process_files_with_thread_pool(wavPath, spks, outPath, args.sr, process_num)
================================================
FILE: prepare/preprocess_f0.py
================================================
import os
import numpy as np
import librosa
import argparse
import parselmouth
# pip install praat-parselmouth
from tqdm import tqdm
from concurrent.futures import ProcessPoolExecutor, as_completed
def compute_f0(path, save):
x, sr = librosa.load(path, sr=16000)
assert sr == 16000
lpad = 1024 // 160
rpad = lpad
f0 = parselmouth.Sound(x, sr).to_pitch_ac(
time_step=160 / sr,
voicing_threshold=0.5,
pitch_floor=30,
pitch_ceiling=1000).selected_array['frequency']
f0 = np.pad(f0, [[lpad, rpad]], mode='constant')
for index, pitch in enumerate(f0):
f0[index] = round(pitch, 1)
np.save(save, f0, allow_pickle=False)
def process_file(file, wavPath, spks, pitPath):
if file.endswith(".wav"):
file = file[:-4]
compute_f0(f"{wavPath}/{spks}/{file}.wav", f"{pitPath}/{spks}/{file}.pit")
def process_files_with_process_pool(wavPath, spks, pitPath, process_num=None):
files = [f for f in os.listdir(f"./{wavPath}/{spks}") if f.endswith(".wav")]
with ProcessPoolExecutor(max_workers=process_num) as executor:
futures = {executor.submit(process_file, file, wavPath, spks, pitPath): file for file in files}
for future in tqdm(as_completed(futures), total=len(futures), desc=f'Processing f0 {spks}'):
future.result()
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument("-w", "--wav", help="wav", dest="wav", required=True)
parser.add_argument("-p", "--pit", help="pit", dest="pit", required=True)
parser.add_argument("-t", "--thread_count", help="thread count to process, set 0 to use all cpu cores", dest="thread_count", type=int, default=1)
args = parser.parse_args()
print(args.wav)
print(args.pit)
os.makedirs(args.pit, exist_ok=True)
wavPath = args.wav
pitPath = args.pit
for spks in os.listdir(wavPath):
if os.path.isdir(f"./{wavPath}/{spks}"):
os.makedirs(f"./{pitPath}/{spks}", exist_ok=True)
if args.thread_count == 0:
process_num = os.cpu_count() // 2 + 1
else:
process_num = args.thread_count
process_files_with_process_pool(wavPath, spks, pitPath, process_num)
================================================
FILE: prepare/preprocess_hubert.py
================================================
import sys,os
sys.path.append(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
import numpy as np
import argparse
import torch
import librosa
from tqdm import tqdm
from hubert import hubert_model
def load_audio(file: str, sr: int = 16000):
x, sr = librosa.load(file, sr=sr)
return x
def load_model(path, device):
model = hubert_model.hubert_soft(path)
model.eval()
model.half()
model.to(device)
return model
def pred_vec(model, wavPath, vecPath, device):
feats = load_audio(wavPath)
feats = torch.from_numpy(feats).to(device)
feats = feats[None, None, :].half()
with torch.no_grad():
vec = model.units(feats).squeeze().data.cpu().float().numpy()
# print(vec.shape) # [length, dim=256] hop=320
np.save(vecPath, vec, allow_pickle=False)
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument("-w", "--wav", help="wav", dest="wav", required=True)
parser.add_argument("-v", "--vec", help="vec", dest="vec", required=True)
args = parser.parse_args()
print(args.wav)
print(args.vec)
os.makedirs(args.vec, exist_ok=True)
wavPath = args.wav
vecPath = args.vec
device = "cuda" if torch.cuda.is_available() else "cpu"
hubert = load_model(os.path.join("hubert_pretrain", "hubert-soft-0d54a1f4.pt"), device)
for spks in os.listdir(wavPath):
if os.path.isdir(f"./{wavPath}/{spks}"):
os.makedirs(f"./{vecPath}/{spks}", exist_ok=True)
files = [f for f in os.listdir(f"./{wavPath}/{spks}") if f.endswith(".wav")]
for file in tqdm(files, desc=f'Processing vec {spks}'):
file = file[:-4]
pred_vec(hubert, f"{wavPath}/{spks}/{file}.wav", f"{vecPath}/{spks}/{file}.vec", device)
================================================
FILE: prepare/preprocess_speaker.py
================================================
import sys,os
sys.path.append(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
import torch
import numpy as np
import argparse
from tqdm import tqdm
from functools import partial
from argparse import RawTextHelpFormatter
from multiprocessing.pool import ThreadPool
from speaker.models.lstm import LSTMSpeakerEncoder
from speaker.config import SpeakerEncoderConfig
from speaker.utils.audio import AudioProcessor
from speaker.infer import read_json
def get_spk_wavs(dataset_path, output_path):
wav_files = []
os.makedirs(f"./{output_path}", exist_ok=True)
for spks in os.listdir(dataset_path):
if os.path.isdir(f"./{dataset_path}/{spks}"):
os.makedirs(f"./{output_path}/{spks}", exist_ok=True)
for file in os.listdir(f"./{dataset_path}/{spks}"):
if file.endswith(".wav"):
wav_files.append(f"./{dataset_path}/{spks}/{file}")
elif spks.endswith(".wav"):
wav_files.append(f"./{dataset_path}/{spks}")
return wav_files
def process_wav(wav_file, dataset_path, output_path, args, speaker_encoder_ap, speaker_encoder):
waveform = speaker_encoder_ap.load_wav(
wav_file, sr=speaker_encoder_ap.sample_rate
)
spec = speaker_encoder_ap.melspectrogram(waveform)
spec = torch.from_numpy(spec.T)
if args.use_cuda:
spec = spec.cuda()
spec = spec.unsqueeze(0)
embed = speaker_encoder.compute_embedding(spec).detach().cpu().numpy()
embed = embed.squeeze()
embed_path = wav_file.replace(dataset_path, output_path)
embed_path = embed_path.replace(".wav", ".spk")
np.save(embed_path, embed, allow_pickle=False)
def extract_speaker_embeddings(wav_files, dataset_path, output_path, args, speaker_encoder_ap, speaker_encoder, concurrency):
bound_process_wav = partial(process_wav, dataset_path=dataset_path, output_path=output_path, args=args, speaker_encoder_ap=speaker_encoder_ap, speaker_encoder=speaker_encoder)
with ThreadPool(concurrency) as pool:
list(tqdm(pool.imap(bound_process_wav, wav_files), total=len(wav_files)))
if __name__ == "__main__":
parser = argparse.ArgumentParser(
description="""Compute embedding vectors for each wav file in a dataset.""",
formatter_class=RawTextHelpFormatter,
)
parser.add_argument("dataset_path", type=str, help="Path to dataset waves.")
parser.add_argument(
"output_path", type=str, help="path for output speaker/speaker_wavs.npy."
)
parser.add_argument("--use_cuda", type=bool, help="flag to set cuda.", default=True)
parser.add_argument("-t", "--thread_count", help="thread count to process, set 0 to use all cpu cores", dest="thread_count", type=int, default=1)
args = parser.parse_args()
dataset_path = args.dataset_path
output_path = args.output_path
thread_count = args.thread_count
# model
args.model_path = os.path.join("speaker_pretrain", "best_model.pth.tar")
args.config_path = os.path.join("speaker_pretrain", "config.json")
# config
config_dict = read_json(args.config_path)
# model
config = SpeakerEncoderConfig(config_dict)
config.from_dict(config_dict)
speaker_encoder = LSTMSpeakerEncoder(
config.model_params["input_dim"],
config.model_params["proj_dim"],
config.model_params["lstm_dim"],
config.model_params["num_lstm_layers"],
)
speaker_encoder.load_checkpoint(args.model_path, eval=True, use_cuda=args.use_cuda)
# preprocess
speaker_encoder_ap = AudioProcessor(**config.audio)
# normalize the input audio level and trim silences
speaker_encoder_ap.do_sound_norm = True
speaker_encoder_ap.do_trim_silence = True
wav_files = get_spk_wavs(dataset_path, output_path)
if thread_count == 0:
process_num = os.cpu_count()
else:
process_num = thread_count
extract_speaker_embeddings(wav_files, dataset_path, output_path, args, speaker_encoder_ap, speaker_encoder, process_num)
================================================
FILE: prepare/preprocess_speaker_ave.py
================================================
import os
import torch
import argparse
import numpy as np
from tqdm import tqdm
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument("dataset_speaker", type=str)
parser.add_argument("dataset_singer", type=str)
data_speaker = parser.parse_args().dataset_speaker
data_singer = parser.parse_args().dataset_singer
os.makedirs(data_singer, exist_ok=True)
for speaker in os.listdir(data_speaker):
subfile_num = 0
speaker_ave = 0
for file in tqdm(os.listdir(os.path.join(data_speaker, speaker)), desc=f"average {speaker}"):
if not file.endswith(".npy"):
continue
source_embed = np.load(os.path.join(data_speaker, speaker, file))
source_embed = source_embed.astype(np.float32)
speaker_ave = speaker_ave + source_embed
subfile_num = subfile_num + 1
if subfile_num == 0:
continue
speaker_ave = speaker_ave / subfile_num
np.save(os.path.join(data_singer, f"{speaker}.spk.npy"),
speaker_ave, allow_pickle=False)
# rewrite timbre code by average, if similarity is larger than cmp_val
rewrite_timbre_code = True
if not rewrite_timbre_code:
continue
cmp_src = torch.FloatTensor(speaker_ave)
cmp_num = 0
cmp_val = 0.85
for file in tqdm(os.listdir(os.path.join(data_speaker, speaker)), desc=f"rewrite {speaker}"):
if not file.endswith(".npy"):
continue
cmp_tmp = np.load(os.path.join(data_speaker, speaker, file))
cmp_tmp = cmp_tmp.astype(np.float32)
cmp_tmp = torch.FloatTensor(cmp_tmp)
cmp_cos = torch.cosine_similarity(cmp_src, cmp_tmp, dim=0)
if (cmp_cos > cmp_val):
cmp_num += 1
np.save(os.path.join(data_speaker, speaker, file),
speaker_ave, allow_pickle=False)
print(f"rewrite timbre for {speaker} with :", cmp_num)
================================================
FILE: prepare/preprocess_spec.py
================================================
import sys,os
sys.path.append(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
import torch
import argparse
from concurrent.futures import ThreadPoolExecutor
from spec.inference import mel_spectrogram_file
from tqdm import tqdm
from omegaconf import OmegaConf
def compute_spec(hps, filename, specname):
spec = mel_spectrogram_file(filename, hps)
spec = torch.squeeze(spec, 0)
# print(spec.shape)
torch.save(spec, specname)
def process_file(file):
if file.endswith(".wav"):
file = file[:-4]
compute_spec(hps, f"{wavPath}/{spks}/{file}.wav", f"{spePath}/{spks}/{file}.mel.pt")
def process_files_with_thread_pool(wavPath, spks, thread_num):
files = os.listdir(f"./{wavPath}/{spks}")
with ThreadPoolExecutor(max_workers=thread_num) as executor:
list(tqdm(executor.map(process_file, files), total=len(files), desc=f'Processing spec {spks}'))
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument("-w", "--wav", help="wav", dest="wav", required=True)
parser.add_argument("-s", "--spe", help="spe", dest="spe", required=True)
parser.add_argument("-t", "--thread_count", help="thread count to process, set 0 to use all cpu cores", dest="thread_count", type=int, default=1)
args = parser.parse_args()
print(args.wav)
print(args.spe)
os.makedirs(args.spe, exist_ok=True)
wavPath = args.wav
spePath = args.spe
hps = OmegaConf.load("./configs/base.yaml")
for spks in os.listdir(wavPath):
if os.path.isdir(f"./{wavPath}/{spks}"):
os.makedirs(f"./{spePath}/{spks}", exist_ok=True)
if args.thread_count == 0:
process_num = os.cpu_count() // 2 + 1
else:
process_num = args.thread_count
process_files_with_thread_pool(wavPath, spks, process_num)
================================================
FILE: prepare/preprocess_train.py
================================================
import os
import random
def print_error(info):
print(f"\033[31m File isn't existed: {info}\033[0m")
if __name__ == "__main__":
os.makedirs("./files/", exist_ok=True)
rootPath = "./data_gvc/waves-32k/"
all_items = []
for spks in os.listdir(f"./{rootPath}"):
if not os.path.isdir(f"./{rootPath}/{spks}"):
continue
print(f"./{rootPath}/{spks}")
for file in os.listdir(f"./{rootPath}/{spks}"):
if file.endswith(".wav"):
file = file[:-4]
path_mel = f"./data_gvc/mel/{spks}/{file}.mel.pt"
path_vec = f"./data_gvc/hubert/{spks}/{file}.vec.npy"
path_pit = f"./data_gvc/pitch/{spks}/{file}.pit.npy"
path_spk = f"./data_gvc/speaker/{spks}/{file}.spk.npy"
has_error = 0
if not os.path.isfile(path_mel):
print_error(path_mel)
has_error = 1
if not os.path.isfile(path_vec):
print_error(path_vec)
has_error = 1
if not os.path.isfile(path_pit):
print_error(path_pit)
has_error = 1
if not os.path.isfile(path_spk):
print_error(path_spk)
has_error = 1
if has_error == 0:
all_items.append(
f"{path_mel}|{path_vec}|{path_pit}|{path_spk}")
random.shuffle(all_items)
valids = all_items[:10]
valids.sort()
trains = all_items[10:]
# trains.sort()
fw = open("./files/valid.txt", "w", encoding="utf-8")
for strs in valids:
print(strs, file=fw)
fw.close()
fw = open("./files/train.txt", "w", encoding="utf-8")
for strs in trains:
print(strs, file=fw)
fw.close()
================================================
FILE: prepare/preprocess_zzz.py
================================================
import sys,os
sys.path.append(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
from tqdm import tqdm
from torch.utils.data import DataLoader
from grad_extend.data import TextMelSpeakerDataset, TextMelSpeakerBatchCollate
if __name__ == "__main__":
filelist_path = "files/valid.txt"
dataset = TextMelSpeakerDataset(filelist_path)
collate = TextMelSpeakerBatchCollate()
loader = DataLoader(dataset=dataset,
batch_size=2,
collate_fn=collate,
drop_last=True,
num_workers=1,
shuffle=True)
for batch in tqdm(loader):
lengths = batch['lengths'].cuda()
vec = batch['vec'].cuda()
pit = batch['pit'].cuda()
spk = batch['spk'].cuda()
mel = batch['mel'].cuda()
print('len', lengths.shape)
print('vec', vec.shape)
print('pit', pit.shape)
print('spk', spk.shape)
print('mel', mel.shape)
================================================
FILE: requirements.txt
================================================
librosa
soundfile
matplotlib
tensorboard
transformers
tqdm
einops
fsspec
omegaconf
pyworld
praat-parselmouth
================================================
FILE: speaker/__init__.py
================================================
================================================
FILE: speaker/config.py
================================================
from dataclasses import asdict, dataclass, field
from typing import Dict, List
from .utils.coqpit import MISSING
from .utils.shared_configs import BaseAudioConfig, BaseDatasetConfig, BaseTrainingConfig
@dataclass
class SpeakerEncoderConfig(BaseTrainingConfig):
"""Defines parameters for Speaker Encoder model."""
model: str = "speaker_encoder"
audio: BaseAudioConfig = field(default_factory=BaseAudioConfig)
datasets: List[BaseDatasetConfig] = field(default_factory=lambda: [BaseDatasetConfig()])
# model params
model_params: Dict = field(
default_factory=lambda: {
"model_name": "lstm",
"input_dim": 80,
"proj_dim": 256,
"lstm_dim": 768,
"num_lstm_layers": 3,
"use_lstm_with_projection": True,
}
)
audio_augmentation: Dict = field(default_factory=lambda: {})
storage: Dict = field(
default_factory=lambda: {
"sample_from_storage_p": 0.66, # the probability with which we'll sample from the DataSet in-memory storage
"storage_size": 15, # the size of the in-memory storage with respect to a single batch
}
)
# training params
max_train_step: int = 1000000 # end training when number of training steps reaches this value.
loss: str = "angleproto"
grad_clip: float = 3.0
lr: float = 0.0001
lr_decay: bool = False
warmup_steps: int = 4000
wd: float = 1e-6
# logging params
tb_model_param_stats: bool = False
steps_plot_stats: int = 10
checkpoint: bool = True
save_step: int = 1000
print_step: int = 20
# data loader
num_speakers_in_batch: int = MISSING
num_utters_per_speaker: int = MISSING
num_loader_workers: int = MISSING
skip_speakers: bool = False
voice_len: float = 1.6
def check_values(self):
super().check_values()
c = asdict(self)
assert (
c["model_params"]["input_dim"] == self.audio.num_mels
), " [!] model input dimendion must be equal to melspectrogram dimension."
================================================
FILE: speaker/infer.py
================================================
import re
import json
import fsspec
import torch
import numpy as np
import argparse
from argparse import RawTextHelpFormatter
from .models.lstm import LSTMSpeakerEncoder
from .config import SpeakerEncoderConfig
from .utils.audio import AudioProcessor
def read_json(json_path):
config_dict = {}
try:
with fsspec.open(json_path, "r", encoding="utf-8") as f:
data = json.load(f)
except json.decoder.JSONDecodeError:
# backwards compat.
data = read_json_with_comments(json_path)
config_dict.update(data)
return config_dict
def read_json_with_comments(json_path):
"""for backward compat."""
# fallback to json
with fsspec.open(json_path, "r", encoding="utf-8") as f:
input_str = f.read()
# handle comments
input_str = re.sub(r"\\\n", "", input_str)
input_str = re.sub(r"//.*\n", "\n", input_str)
data = json.loads(input_str)
return data
if __name__ == "__main__":
parser = argparse.ArgumentParser(
description="""Compute embedding vectors for each wav file in a dataset.""",
formatter_class=RawTextHelpFormatter,
)
parser.add_argument("model_path", type=str, help="Path to model checkpoint file.")
parser.add_argument(
"config_path",
type=str,
help="Path to model config file.",
)
parser.add_argument("-s", "--source", help="input wave", dest="source")
parser.add_argument(
"-t", "--target", help="output 256d speaker embeddimg", dest="target"
)
parser.add_argument("--use_cuda", type=bool, help="flag to set cuda.", default=True)
parser.add_argument("--eval", type=bool, help="compute eval.", default=True)
args = parser.parse_args()
source_file = args.source
target_file = args.target
# config
config_dict = read_json(args.config_path)
# print(config_dict)
# model
config = SpeakerEncoderConfig(config_dict)
config.from_dict(config_dict)
speaker_encoder = LSTMSpeakerEncoder(
config.model_params["input_dim"],
config.model_params["proj_dim"],
config.model_params["lstm_dim"],
config.model_params["num_lstm_layers"],
)
speaker_encoder.load_checkpoint(args.model_path, eval=True, use_cuda=args.use_cuda)
# preprocess
speaker_encoder_ap = AudioProcessor(**config.audio)
# normalize the input audio level and trim silences
speaker_encoder_ap.do_sound_norm = True
speaker_encoder_ap.do_trim_silence = True
# compute speaker embeddings
# extract the embedding
waveform = speaker_encoder_ap.load_wav(
source_file, sr=speaker_encoder_ap.sample_rate
)
spec = speaker_encoder_ap.melspectrogram(waveform)
spec = torch.from_numpy(spec.T)
if args.use_cuda:
spec = spec.cuda()
spec = spec.unsqueeze(0)
embed = speaker_encoder.compute_embedding(spec).detach().cpu().numpy()
embed = embed.squeeze()
# print(embed)
# print(embed.size)
np.save(target_file, embed, allow_pickle=False)
if hasattr(speaker_encoder, 'module'):
state_dict = speaker_encoder.module.state_dict()
else:
state_dict = speaker_encoder.state_dict()
torch.save({'model': state_dict}, "model_small.pth")
================================================
FILE: speaker/models/__init__.py
================================================
================================================
FILE: speaker/models/lstm.py
================================================
import numpy as np
import torch
from torch import nn
from ..utils.io import load_fsspec
class LSTMWithProjection(nn.Module):
def __init__(self, input_size, hidden_size, proj_size):
super().__init__()
self.input_size = input_size
self.hidden_size = hidden_size
self.proj_size = proj_size
self.lstm = nn.LSTM(input_size, hidden_size, batch_first=True)
self.linear = nn.Linear(hidden_size, proj_size, bias=False)
def forward(self, x):
self.lstm.flatten_parameters()
o, (_, _) = self.lstm(x)
return self.linear(o)
class LSTMWithoutProjection(nn.Module):
def __init__(self, input_dim, lstm_dim, proj_dim, num_lstm_layers):
super().__init__()
self.lstm = nn.LSTM(input_size=input_dim, hidden_size=lstm_dim, num_layers=num_lstm_layers, batch_first=True)
self.linear = nn.Linear(lstm_dim, proj_dim, bias=True)
self.relu = nn.ReLU()
def forward(self, x):
_, (hidden, _) = self.lstm(x)
return self.relu(self.linear(hidden[-1]))
class LSTMSpeakerEncoder(nn.Module):
def __init__(self, input_dim, proj_dim=256, lstm_dim=768, num_lstm_layers=3, use_lstm_with_projection=True):
super().__init__()
self.use_lstm_with_projection = use_lstm_with_projection
layers = []
# choise LSTM layer
if use_lstm_with_projection:
layers.append(LSTMWithProjection(input_dim, lstm_dim, proj_dim))
for _ in range(num_lstm_layers - 1):
layers.append(LSTMWithProjection(proj_dim, lstm_dim, proj_dim))
self.layers = nn.Sequential(*layers)
else:
self.layers = LSTMWithoutProjection(input_dim, lstm_dim, proj_dim, num_lstm_layers)
self._init_layers()
def _init_layers(self):
for name, param in self.layers.named_parameters():
if "bias" in name:
nn.init.constant_(param, 0.0)
elif "weight" in name:
nn.init.xavier_normal_(param)
def forward(self, x):
# TODO: implement state passing for lstms
d = self.layers(x)
if self.use_lstm_with_projection:
d = torch.nn.functional.normalize(d[:, -1], p=2, dim=1)
else:
d = torch.nn.functional.normalize(d, p=2, dim=1)
return d
@torch.no_grad()
def inference(self, x):
d = self.layers.forward(x)
if self.use_lstm_with_projection:
d = torch.nn.functional.normalize(d[:, -1], p=2, dim=1)
else:
d = torch.nn.functional.normalize(d, p=2, dim=1)
return d
def compute_embedding(self, x, num_frames=250, num_eval=10, return_mean=True):
"""
Generate embeddings for a batch of utterances
x: 1xTxD
"""
max_len = x.shape[1]
if max_len < num_frames:
num_frames = max_len
offsets = np.linspace(0, max_len - num_frames, num=num_eval)
frames_batch = []
for offset in offsets:
offset = int(offset)
end_offset = int(offset + num_frames)
frames = x[:, offset:end_offset]
frames_batch.append(frames)
frames_batch = torch.cat(frames_batch, dim=0)
embeddings = self.inference(frames_batch)
if return_mean:
embeddings = torch.mean(embeddings, dim=0, keepdim=True)
return embeddings
def batch_compute_embedding(self, x, seq_lens, num_frames=160, overlap=0.5):
"""
Generate embeddings for a batch of utterances
x: BxTxD
"""
num_overlap = num_frames * overlap
max_len = x.shape[1]
embed = None
num_iters = seq_lens / (num_frames - num_overlap)
cur_iter = 0
for offset in range(0, max_len, num_frames - num_overlap):
cur_iter += 1
end_offset = min(x.shape[1], offset + num_frames)
frames = x[:, offset:end_offset]
if embed is None:
embed = self.inference(frames)
else:
embed[cur_iter <= num_iters, :] += self.inference(frames[cur_iter <= num_iters, :, :])
return embed / num_iters
# pylint: disable=unused-argument, redefined-builtin
def load_checkpoint(self, checkpoint_path: str, eval: bool = False, use_cuda: bool = False):
state = load_fsspec(checkpoint_path, map_location=torch.device("cpu"))
self.load_state_dict(state["model"])
if use_cuda:
self.cuda()
if eval:
self.eval()
assert not self.training
================================================
FILE: speaker/models/resnet.py
================================================
import numpy as np
import torch
from torch import nn
from TTS.utils.io import load_fsspec
class SELayer(nn.Module):
def __init__(self, channel, reduction=8):
super(SELayer, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Sequential(
nn.Linear(channel, channel // reduction),
nn.ReLU(inplace=True),
nn.Linear(channel // reduction, channel),
nn.Sigmoid(),
)
def forward(self, x):
b, c, _, _ = x.size()
y = self.avg_pool(x).view(b, c)
y = self.fc(y).view(b, c, 1, 1)
return x * y
class SEBasicBlock(nn.Module):
expansion = 1
def __init__(self, inplanes, planes, stride=1, downsample=None, reduction=8):
super(SEBasicBlock, self).__init__()
self.conv1 = nn.Conv2d(inplanes, planes, kernel_size=3, stride=stride, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(planes)
self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(planes)
self.relu = nn.ReLU(inplace=True)
self.se = SELayer(planes, reduction)
self.downsample = downsample
self.stride = stride
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.relu(out)
out = self.bn1(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.se(out)
if self.downsample is not None:
residual = self.downsample(x)
out += residual
out = self.relu(out)
return out
class ResNetSpeakerEncoder(nn.Module):
"""Implementation of the model H/ASP without batch normalization in speaker embedding. This model was proposed in: https://arxiv.org/abs/2009.14153
Adapted from: https://github.com/clovaai/voxceleb_trainer
"""
# pylint: disable=W0102
def __init__(
self,
input_dim=64,
proj_dim=512,
layers=[3, 4, 6, 3],
num_filters=[32, 64, 128, 256],
encoder_type="ASP",
log_input=False,
):
super(ResNetSpeakerEncoder, self).__init__()
self.encoder_type = encoder_type
self.input_dim = input_dim
self.log_input = log_input
self.conv1 = nn.Conv2d(1, num_filters[0], kernel_size=3, stride=1, padding=1)
self.relu = nn.ReLU(inplace=True)
self.bn1 = nn.BatchNorm2d(num_filters[0])
self.inplanes = num_filters[0]
self.layer1 = self.create_layer(SEBasicBlock, num_filters[0], layers[0])
self.layer2 = self.create_layer(SEBasicBlock, num_filters[1], layers[1], stride=(2, 2))
self.layer3 = self.create_layer(SEBasicBlock, num_filters[2], layers[2], stride=(2, 2))
self.layer4 = self.create_layer(SEBasicBlock, num_filters[3], layers[3], stride=(2, 2))
self.instancenorm = nn.InstanceNorm1d(input_dim)
outmap_size = int(self.input_dim / 8)
self.attention = nn.Sequential(
nn.Conv1d(num_filters[3] * outmap_size, 128, kernel_size=1),
nn.ReLU(),
nn.BatchNorm1d(128),
nn.Conv1d(128, num_filters[3] * outmap_size, kernel_size=1),
nn.Softmax(dim=2),
)
if self.encoder_type == "SAP":
out_dim = num_filters[3] * outmap_size
elif self.encoder_type == "ASP":
out_dim = num_filters[3] * outmap_size * 2
else:
raise ValueError("Undefined encoder")
self.fc = nn.Linear(out_dim, proj_dim)
self._init_layers()
def _init_layers(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode="fan_out", nonlinearity="relu")
elif isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
def create_layer(self, block, planes, blocks, stride=1):
downsample = None
if stride != 1 or self.inplanes != planes * block.expansion:
downsample = nn.Sequential(
nn.Conv2d(self.inplanes, planes * block.expansion, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(planes * block.expansion),
)
layers = []
layers.append(block(self.inplanes, planes, stride, downsample))
self.inplanes = planes * block.expansion
for _ in range(1, blocks):
layers.append(block(self.inplanes, planes))
return nn.Sequential(*layers)
# pylint: disable=R0201
def new_parameter(self, *size):
out = nn.Parameter(torch.FloatTensor(*size))
nn.init.xavier_normal_(out)
return out
def forward(self, x, l2_norm=False):
x = x.transpose(1, 2)
with torch.no_grad():
with torch.cuda.amp.autocast(enabled=False):
if self.log_input:
x = (x + 1e-6).log()
x = self.instancenorm(x).unsqueeze(1)
x = self.conv1(x)
x = self.relu(x)
x = self.bn1(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = x.reshape(x.size()[0], -1, x.size()[-1])
w = self.attention(x)
if self.encoder_type == "SAP":
x = torch.sum(x * w, dim=2)
elif self.encoder_type == "ASP":
mu = torch.sum(x * w, dim=2)
sg = torch.sqrt((torch.sum((x ** 2) * w, dim=2) - mu ** 2).clamp(min=1e-5))
x = torch.cat((mu, sg), 1)
x = x.view(x.size()[0], -1)
x = self.fc(x)
if l2_norm:
x = torch.nn.functional.normalize(x, p=2, dim=1)
return x
@torch.no_grad()
def compute_embedding(self, x, num_frames=250, num_eval=10, return_mean=True):
"""
Generate embeddings for a batch of utterances
x: 1xTxD
"""
max_len = x.shape[1]
if max_len < num_frames:
num_frames = max_len
offsets = np.linspace(0, max_len - num_frames, num=num_eval)
frames_batch = []
for offset in offsets:
offset = int(offset)
end_offset = int(offset + num_frames)
frames = x[:, offset:end_offset]
frames_batch.append(frames)
frames_batch = torch.cat(frames_batch, dim=0)
embeddings = self.forward(frames_batch, l2_norm=True)
if return_mean:
embeddings = torch.mean(embeddings, dim=0, keepdim=True)
return embeddings
def load_checkpoint(self, config: dict, checkpoint_path: str, eval: bool = False, use_cuda: bool = False):
state = load_fsspec(checkpoint_path, map_location=torch.device("cpu"))
self.load_state_dict(state["model"])
if use_cuda:
self.cuda()
if eval:
self.eval()
assert not self.training
================================================
FILE: speaker/utils/__init__.py
================================================
================================================
FILE: speaker/utils/audio.py
================================================
from typing import Dict, Tuple
import librosa
import numpy as np
import pyworld as pw
import scipy.io.wavfile
import scipy.signal
import soundfile as sf
import torch
from torch import nn
class StandardScaler:
"""StandardScaler for mean-scale normalization with the given mean and scale values."""
def __init__(self, mean: np.ndarray = None, scale: np.ndarray = None) -> None:
self.mean_ = mean
self.scale_ = scale
def set_stats(self, mean, scale):
self.mean_ = mean
self.scale_ = scale
def reset_stats(self):
delattr(self, "mean_")
delattr(self, "scale_")
def transform(self, X):
X = np.asarray(X)
X -= self.mean_
X /= self.scale_
return X
def inverse_transform(self, X):
X = np.asarray(X)
X *= self.scale_
X += self.mean_
return X
class TorchSTFT(nn.Module): # pylint: disable=abstract-method
"""Some of the audio processing funtions using Torch for faster batch processing.
TODO: Merge this with audio.py
"""
def __init__(
self,
n_fft,
hop_length,
win_length,
pad_wav=False,
window="hann_window",
sample_rate=None,
mel_fmin=0,
mel_fmax=None,
n_mels=80,
use_mel=False,
do_amp_to_db=False,
spec_gain=1.0,
):
super().__init__()
self.n_fft = n_fft
self.hop_length = hop_length
self.win_length = win_length
self.pad_wav = pad_wav
self.sample_rate = sample_rate
self.mel_fmin = mel_fmin
self.mel_fmax = mel_fmax
self.n_mels = n_mels
self.use_mel = use_mel
self.do_amp_to_db = do_amp_to_db
self.spec_gain = spec_gain
self.window = nn.Parameter(getattr(torch, window)(win_length), requires_grad=False)
self.mel_basis = None
if use_mel:
self._build_mel_basis()
def __call__(self, x):
"""Compute spectrogram frames by torch based stft.
Args:
x (Tensor): input waveform
Returns:
Tensor: spectrogram frames.
Shapes:
x: [B x T] or [:math:`[B, 1, T]`]
"""
if x.ndim == 2:
x = x.unsqueeze(1)
if self.pad_wav:
padding = int((self.n_fft - self.hop_length) / 2)
x = torch.nn.functional.pad(x, (padding, padding), mode="reflect")
# B x D x T x 2
o = torch.stft(
x.squeeze(1),
self.n_fft,
self.hop_length,
self.win_length,
self.window,
center=True,
pad_mode="reflect", # compatible with audio.py
normalized=False,
onesided=True,
return_complex=False,
)
M = o[:, :, :, 0]
P = o[:, :, :, 1]
S = torch.sqrt(torch.clamp(M ** 2 + P ** 2, min=1e-8))
if self.use_mel:
S = torch.matmul(self.mel_basis.to(x), S)
if self.do_amp_to_db:
S = self._amp_to_db(S, spec_gain=self.spec_gain)
return S
def _build_mel_basis(self):
mel_basis = librosa.filters.mel(
sr=self.sample_rate, n_fft=self.n_fft, n_mels=self.n_mels, fmin=self.mel_fmin, fmax=self.mel_fmax
)
self.mel_basis = torch.from_numpy(mel_basis).float()
@staticmethod
def _amp_to_db(x, spec_gain=1.0):
return torch.log(torch.clamp(x, min=1e-5) * spec_gain)
@staticmethod
def _db_to_amp(x, spec_gain=1.0):
return torch.exp(x) / spec_gain
# pylint: disable=too-many-public-methods
class AudioProcessor(object):
"""Audio Processor for TTS used by all the data pipelines.
Note:
All the class arguments are set to default values to enable a flexible initialization
of the class with the model config. They are not meaningful for all the arguments.
Args:
sample_rate (int, optional):
target audio sampling rate. Defaults to None.
resample (bool, optional):
enable/disable resampling of the audio clips when the target sampling rate does not match the original sampling rate. Defaults to False.
num_mels (int, optional):
number of melspectrogram dimensions. Defaults to None.
log_func (int, optional):
log exponent used for converting spectrogram aplitude to DB.
min_level_db (int, optional):
minimum db threshold for the computed melspectrograms. Defaults to None.
frame_shift_ms (int, optional):
milliseconds of frames between STFT columns. Defaults to None.
frame_length_ms (int, optional):
milliseconds of STFT window length. Defaults to None.
hop_length (int, optional):
number of frames between STFT columns. Used if ```frame_shift_ms``` is None. Defaults to None.
win_length (int, optional):
STFT window length. Used if ```frame_length_ms``` is None. Defaults to None.
ref_level_db (int, optional):
reference DB level to avoid background noise. In general <20DB corresponds to the air noise. Defaults to None.
fft_size (int, optional):
FFT window size for STFT. Defaults to 1024.
power (int, optional):
Exponent value applied to the spectrogram before GriffinLim. Defaults to None.
preemphasis (float, optional):
Preemphasis coefficient. Preemphasis is disabled if == 0.0. Defaults to 0.0.
signal_norm (bool, optional):
enable/disable signal normalization. Defaults to None.
symmetric_norm (bool, optional):
enable/disable symmetric normalization. If set True normalization is performed in the range [-k, k] else [0, k], Defaults to None.
max_norm (float, optional):
```k``` defining the normalization range. Defaults to None.
mel_fmin (int, optional):
minimum filter frequency for computing melspectrograms. Defaults to None.
mel_fmax (int, optional):
maximum filter frequency for computing melspectrograms.. Defaults to None.
spec_gain (int, optional):
gain applied when converting amplitude to DB. Defaults to 20.
stft_pad_mode (str, optional):
Padding mode for STFT. Defaults to 'reflect'.
clip_norm (bool, optional):
enable/disable clipping the our of range values in the normalized audio signal. Defaults to True.
griffin_lim_iters (int, optional):
Number of GriffinLim iterations. Defaults to None.
do_trim_silence (bool, optional):
enable/disable silence trimming when loading the audio signal. Defaults to False.
trim_db (int, optional):
DB threshold used for silence trimming. Defaults to 60.
do_sound_norm (bool, optional):
enable/disable signal normalization. Defaults to False.
do_amp_to_db_linear (bool, optional):
enable/disable amplitude to dB conversion of linear spectrograms. Defaults to True.
do_amp_to_db_mel (bool, optional):
enable/disable amplitude to dB conversion of mel spectrograms. Defaults to True.
stats_path (str, optional):
Path to the computed stats file. Defaults to None.
verbose (bool, optional):
enable/disable logging. Defaults to True.
"""
def __init__(
self,
sample_rate=None,
resample=False,
num_mels=None,
log_func="np.log10",
min_level_db=None,
frame_shift_ms=None,
frame_length_ms=None,
hop_length=None,
win_length=None,
ref_level_db=None,
fft_size=1024,
power=None,
preemphasis=0.0,
signal_norm=None,
symmetric_norm=None,
max_norm=None,
mel_fmin=None,
mel_fmax=None,
spec_gain=20,
stft_pad_mode="reflect",
clip_norm=True,
griffin_lim_iters=None,
do_trim_silence=False,
trim_db=60,
do_sound_norm=False,
do_amp_to_db_linear=True,
do_amp_to_db_mel=True,
stats_path=None,
verbose=True,
**_,
):
# setup class attributed
self.sample_rate = sample_rate
self.resample = resample
self.num_mels = num_mels
self.log_func = log_func
self.min_level_db = min_level_db or 0
self.frame_shift_ms = frame_shift_ms
self.frame_length_ms = frame_length_ms
self.ref_level_db = ref_level_db
self.fft_size = fft_size
self.power = power
self.preemphasis = preemphasis
self.griffin_lim_iters = griffin_lim_iters
self.signal_norm = signal_norm
self.symmetric_norm = symmetric_norm
self.mel_fmin = mel_fmin or 0
self.mel_fmax = mel_fmax
self.spec_gain = float(spec_gain)
self.stft_pad_mode = stft_pad_mode
self.max_norm = 1.0 if max_norm is None else float(max_norm)
self.clip_norm = clip_norm
self.do_trim_silence = do_trim_silence
self.trim_db = trim_db
self.do_sound_norm = do_sound_norm
self.do_amp_to_db_linear = do_amp_to_db_linear
self.do_amp_to_db_mel = do_amp_to_db_mel
self.stats_path = stats_path
# setup exp_func for db to amp conversion
if log_func == "np.log":
self.base = np.e
elif log_func == "np.log10":
self.base = 10
else:
raise ValueError(" [!] unknown `log_func` value.")
# setup stft parameters
if hop_length is None:
# compute stft parameters from given time values
self.hop_length, self.win_length = self._stft_parameters()
else:
# use stft parameters from config file
self.hop_length = hop_length
self.win_length = win_length
assert min_level_db != 0.0, " [!] min_level_db is 0"
assert self.win_length <= self.fft_size, " [!] win_length cannot be larger than fft_size"
members = vars(self)
if verbose:
print(" > Setting up Audio Processor...")
for key, value in members.items():
print(" | > {}:{}".format(key, value))
# create spectrogram utils
self.mel_basis = self._build_mel_basis()
self.inv_mel_basis = np.linalg.pinv(self._build_mel_basis())
# setup scaler
if stats_path and signal_norm:
mel_mean, mel_std, linear_mean, linear_std, _ = self.load_stats(stats_path)
self.setup_scaler(mel_mean, mel_std, linear_mean, linear_std)
self.signal_norm = True
self.max_norm = None
self.clip_norm = None
self.symmetric_norm = None
### setting up the parameters ###
def _build_mel_basis(
self,
) -> np.ndarray:
"""Build melspectrogram basis.
Returns:
np.ndarray: melspectrogram basis.
"""
if self.mel_fmax is not None:
assert self.mel_fmax <= self.sample_rate // 2
return librosa.filters.mel(
sr=self.sample_rate, n_fft=self.fft_size, n_mels=self.num_mels, fmin=self.mel_fmin, fmax=self.mel_fmax
)
def _stft_parameters(
self,
) -> Tuple[int, int]:
"""Compute the real STFT parameters from the time values.
Returns:
Tuple[int, int]: hop length and window length for STFT.
"""
factor = self.frame_length_ms / self.frame_shift_ms
assert (factor).is_integer(), " [!] frame_shift_ms should divide frame_length_ms"
hop_length = int(self.frame_shift_ms / 1000.0 * self.sample_rate)
win_length = int(hop_length * factor)
return hop_length, win_length
### normalization ###
def normalize(self, S: np.ndarray) -> np.ndarray:
"""Normalize values into `[0, self.max_norm]` or `[-self.max_norm, self.max_norm]`
Args:
S (np.ndarray): Spectrogram to normalize.
Raises:
RuntimeError: Mean and variance is computed from incompatible parameters.
Returns:
np.ndarray: Normalized spectrogram.
"""
# pylint: disable=no-else-return
S = S.copy()
if self.signal_norm:
# mean-var scaling
if hasattr(self, "mel_scaler"):
if S.shape[0] == self.num_mels:
return self.mel_scaler.transform(S.T).T
elif S.shape[0] == self.fft_size / 2:
return self.linear_scaler.transform(S.T).T
else:
raise RuntimeError(" [!] Mean-Var stats does not match the given feature dimensions.")
# range normalization
S -= self.ref_level_db # discard certain range of DB assuming it is air noise
S_norm = (S - self.min_level_db) / (-self.min_level_db)
if self.symmetric_norm:
S_norm = ((2 * self.max_norm) * S_norm) - self.max_norm
if self.clip_norm:
S_norm = np.clip(
S_norm, -self.max_norm, self.max_norm # pylint: disable=invalid-unary-operand-type
)
return S_norm
else:
S_norm = self.max_norm * S_norm
if self.clip_norm:
S_norm = np.clip(S_norm, 0, self.max_norm)
return S_norm
else:
return S
def denormalize(self, S: np.ndarray) -> np.ndarray:
"""Denormalize spectrogram values.
Args:
S (np.ndarray): Spectrogram to denormalize.
Raises:
RuntimeError: Mean and variance are incompatible.
Returns:
np.ndarray: Denormalized spectrogram.
"""
# pylint: disable=no-else-return
S_denorm = S.copy()
if self.signal_norm:
# mean-var scaling
if hasattr(self, "mel_scaler"):
if S_denorm.shape[0] == self.num_mels:
return self.mel_scaler.inverse_transform(S_denorm.T).T
elif S_denorm.shape[0] == self.fft_size / 2:
return self.linear_scaler.inverse_transform(S_denorm.T).T
else:
raise RuntimeError(" [!] Mean-Var stats does not match the given feature dimensions.")
if self.symmetric_norm:
if self.clip_norm:
S_denorm = np.clip(
S_denorm, -self.max_norm, self.max_norm # pylint: disable=invalid-unary-operand-type
)
S_denorm = ((S_denorm + self.max_norm) * -self.min_level_db / (2 * self.max_norm)) + self.min_level_db
return S_denorm + self.ref_level_db
else:
if self.clip_norm:
S_denorm = np.clip(S_denorm, 0, self.max_norm)
S_denorm = (S_denorm * -self.min_level_db / self.max_norm) + self.min_level_db
return S_denorm + self.ref_level_db
else:
return S_denorm
### Mean-STD scaling ###
def load_stats(self, stats_path: str) -> Tuple[np.array, np.array, np.array, np.array, Dict]:
"""Loading mean and variance statistics from a `npy` file.
Args:
stats_path (str): Path to the `npy` file containing
Returns:
Tuple[np.array, np.array, np.array, np.array, Dict]: loaded statistics and the config used to
compute them.
"""
stats = np.load(stats_path, allow_pickle=True).item() # pylint: disable=unexpected-keyword-arg
mel_mean = stats["mel_mean"]
mel_std = stats["mel_std"]
linear_mean = stats["linear_mean"]
linear_std = stats["linear_std"]
stats_config = stats["audio_config"]
# check all audio parameters used for computing stats
skip_parameters = ["griffin_lim_iters", "stats_path", "do_trim_silence", "ref_level_db", "power"]
for key in stats_config.keys():
if key in skip_parameters:
continue
if key not in ["sample_rate", "trim_db"]:
assert (
stats_config[key] == self.__dict__[key]
), f" [!] Audio param {key} does not match the value used for computing mean-var stats. {stats_config[key]} vs {self.__dict__[key]}"
return mel_mean, mel_std, linear_mean, linear_std, stats_config
# pylint: disable=attribute-defined-outside-init
def setup_scaler(
self, mel_mean: np.ndarray, mel_std: np.ndarray, linear_mean: np.ndarray, linear_std: np.ndarray
) -> None:
"""Initialize scaler objects used in mean-std normalization.
Args:
mel_mean (np.ndarray): Mean for melspectrograms.
mel_std (np.ndarray): STD for melspectrograms.
linear_mean (np.ndarray): Mean for full scale spectrograms.
linear_std (np.ndarray): STD for full scale spectrograms.
"""
self.mel_scaler = StandardScaler()
self.mel_scaler.set_stats(mel_mean, mel_std)
self.linear_scaler = StandardScaler()
self.linear_scaler.set_stats(linear_mean, linear_std)
### DB and AMP conversion ###
# pylint: disable=no-self-use
def _amp_to_db(self, x: np.ndarray) -> np.ndarray:
"""Convert amplitude values to decibels.
Args:
x (np.ndarray): Amplitude spectrogram.
Returns:
np.ndarray: Decibels spectrogram.
"""
return self.spec_gain * _log(np.maximum(1e-5, x), self.base)
# pylint: disable=no-self-use
def _db_to_amp(self, x: np.ndarray) -> np.ndarray:
"""Convert decibels spectrogram to amplitude spectrogram.
Args:
x (np.ndarray): Decibels spectrogram.
Returns:
np.ndarray: Amplitude spectrogram.
"""
return _exp(x / self.spec_gain, self.base)
### Preemphasis ###
def apply_preemphasis(self, x: np.ndarray) -> np.ndarray:
"""Apply pre-emphasis to the audio signal. Useful to reduce the correlation between neighbouring signal values.
Args:
x (np.ndarray): Audio signal.
Raises:
RuntimeError: Preemphasis coeff is set to 0.
Returns:
np.ndarray: Decorrelated audio signal.
"""
if self.preemphasis == 0:
raise RuntimeError(" [!] Preemphasis is set 0.0.")
return scipy.signal.lfilter([1, -self.preemphasis], [1], x)
def apply_inv_preemphasis(self, x: np.ndarray) -> np.ndarray:
"""Reverse pre-emphasis."""
if self.preemphasis == 0:
raise RuntimeError(" [!] Preemphasis is set 0.0.")
return scipy.signal.lfilter([1], [1, -self.preemphasis], x)
### SPECTROGRAMs ###
def _linear_to_mel(self, spectrogram: np.ndarray) -> np.ndarray:
"""Project a full scale spectrogram to a melspectrogram.
Args:
spectrogram (np.ndarray): Full scale spectrogram.
Returns:
np.ndarray: Melspectrogram
"""
return np.dot(self.mel_basis, spectrogram)
def _mel_to_linear(self, mel_spec: np.ndarray) -> np.ndarray:
"""Convert a melspectrogram to full scale spectrogram."""
return np.maximum(1e-10, np.dot(self.inv_mel_basis, mel_spec))
def spectrogram(self, y: np.ndarray) -> np.ndarray:
"""Compute a spectrogram from a waveform.
Args:
y (np.ndarray): Waveform.
Returns:
np.ndarray: Spectrogram.
"""
if self.preemphasis != 0:
D = self._stft(self.apply_preemphasis(y))
else:
D = self._stft(y)
if self.do_amp_to_db_linear:
S = self._amp_to_db(np.abs(D))
else:
S = np.abs(D)
return self.normalize(S).astype(np.float32)
def melspectrogram(self, y: np.ndarray) -> np.ndarray:
"""Compute a melspectrogram from a waveform."""
if self.preemphasis != 0:
D = self._stft(self.apply_preemphasis(y))
else:
D = self._stft(y)
if self.do_amp_to_db_mel:
S = self._amp_to_db(self._linear_to_mel(np.abs(D)))
else:
S = self._linear_to_mel(np.abs(D))
return self.normalize(S).astype(np.float32)
def inv_spectrogram(self, spectrogram: np.ndarray) -> np.ndarray:
"""Convert a spectrogram to a waveform using Griffi-Lim vocoder."""
S = self.denormalize(spectrogram)
S = self._db_to_amp(S)
# Reconstruct phase
if self.preemphasis != 0:
return self.apply_inv_preemphasis(self._griffin_lim(S ** self.power))
return self._griffin_lim(S ** self.power)
def inv_melspectrogram(self, mel_spectrogram: np.ndarray) -> np.ndarray:
"""Convert a melspectrogram to a waveform using Griffi-Lim vocoder."""
D = self.denormalize(mel_spectrogram)
S = self._db_to_amp(D)
S = self._mel_to_linear(S) # Convert back to linear
if self.preemphasis != 0:
return self.apply_inv_preemphasis(self._griffin_lim(S ** self.power))
return self._griffin_lim(S ** self.power)
def out_linear_to_mel(self, linear_spec: np.ndarray) -> np.ndarray:
"""Convert a full scale linear spectrogram output of a network to a melspectrogram.
Args:
linear_spec (np.ndarray): Normalized full scale linear spectrogram.
Returns:
np.ndarray: Normalized melspectrogram.
"""
S = self.denormalize(linear_spec)
S = self._db_to_amp(S)
S = self._linear_to_mel(np.abs(S))
S = self._amp_to_db(S)
mel = self.normalize(S)
return mel
### STFT and ISTFT ###
def _stft(self, y: np.ndarray) -> np.ndarray:
"""Librosa STFT wrapper.
Args:
y (np.ndarray): Audio signal.
Returns:
np.ndarray: Complex number array.
"""
return librosa.stft(
y=y,
n_fft=self.fft_size,
hop_length=self.hop_length,
win_length=self.win_length,
pad_mode=self.stft_pad_mode,
window="hann",
center=True,
)
def _istft(self, y: np.ndarray) -> np.ndarray:
"""Librosa iSTFT wrapper."""
return librosa.istft(y, hop_length=self.hop_length, win_length=self.win_length)
def _griffin_lim(self, S):
angles = np.exp(2j * np.pi * np.random.rand(*S.shape))
S_complex = np.abs(S).astype(np.complex)
y = self._istft(S_complex * angles)
if not np.isfinite(y).all():
print(" [!] Waveform is not finite everywhere. Skipping the GL.")
return np.array([0.0])
for _ in range(self.griffin_lim_iters):
angles = np.exp(1j * np.angle(self._stft(y)))
y = self._istft(S_complex * angles)
return y
def compute_stft_paddings(self, x, pad_sides=1):
"""Compute paddings used by Librosa's STFT. Compute right padding (final frame) or both sides padding
(first and final frames)"""
assert pad_sides in (1, 2)
pad = (x.shape[0] // self.hop_length + 1) * self.hop_length - x.shape[0]
if pad_sides == 1:
return 0, pad
return pad // 2, pad // 2 + pad % 2
def compute_f0(self, x: np.ndarray) -> np.ndarray:
"""Compute pitch (f0) of a waveform using the same parameters used for computing melspectrogram.
Args:
x (np.ndarray): Waveform.
Returns:
np.ndarray: Pitch.
Examples:
>>> WAV_FILE = filename = librosa.util.example_audio_file()
>>> from TTS.config import BaseAudioConfig
>>> from TTS.utils.audio import AudioProcessor
>>> conf = BaseAudioConfig(mel_fmax=8000)
>>> ap = AudioProcessor(**conf)
>>> wav = ap.load_wav(WAV_FILE, sr=22050)[:5 * 22050]
>>> pitch = ap.compute_f0(wav)
"""
f0, t = pw.dio(
x.astype(np.double),
fs=self.sample_rate,
f0_ceil=self.mel_fmax,
frame_period=1000 * self.hop_length / self.sample_rate,
)
f0 = pw.stonemask(x.astype(np.double), f0, t, self.sample_rate)
# pad = int((self.win_length / self.hop_length) / 2)
# f0 = [0.0] * pad + f0 + [0.0] * pad
# f0 = np.pad(f0, (pad, pad), mode="constant", constant_values=0)
# f0 = np.array(f0, dtype=np.float32)
# f01, _, _ = librosa.pyin(
# x,
# fmin=65 if self.mel_fmin == 0 else self.mel_fmin,
# fmax=self.mel_fmax,
# frame_length=self.win_length,
# sr=self.sample_rate,
# fill_na=0.0,
# )
# spec = self.melspectrogram(x)
return f0
### Audio Processing ###
def find_endpoint(self, wav: np.ndarray, threshold_db=-40, min_silence_sec=0.8) -> int:
"""Find the last point without silence at the end of a audio signal.
Args:
wav (np.ndarray): Audio signal.
threshold_db (int, optional): Silence threshold in decibels. Defaults to -40.
min_silence_sec (float, optional): Ignore silences that are shorter then this in secs. Defaults to 0.8.
Returns:
int: Last point without silence.
"""
window_length = int(self.sample_rate * min_silence_sec)
hop_length = int(window_length / 4)
threshold = self._db_to_amp(threshold_db)
for x in range(hop_length, len(wav) - window_length, hop_length):
if np.max(wav[x : x + window_length]) < threshold:
return x + hop_length
return len(wav)
def trim_silence(self, wav):
"""Trim silent parts with a threshold and 0.01 sec margin"""
margin = int(self.sample_rate * 0.01)
wav = wav[margin:-margin]
return
gitextract_yhmj05_n/
├── LICENSE
├── README.md
├── assets/
│ └── singers/
│ ├── singer0001.npy
│ ├── singer0002.npy
│ ├── singer0003.npy
│ ├── singer0004.npy
│ ├── singer0005.npy
│ ├── singer0006.npy
│ ├── singer0007.npy
│ ├── singer0008.npy
│ ├── singer0009.npy
│ ├── singer0010.npy
│ ├── singer0011.npy
│ ├── singer0012.npy
│ ├── singer0013.npy
│ ├── singer0014.npy
│ ├── singer0015.npy
│ ├── singer0016.npy
│ ├── singer0017.npy
│ ├── singer0018.npy
│ ├── singer0019.npy
│ ├── singer0020.npy
│ ├── singer0021.npy
│ ├── singer0022.npy
│ ├── singer0023.npy
│ ├── singer0024.npy
│ ├── singer0025.npy
│ ├── singer0026.npy
│ ├── singer0027.npy
│ ├── singer0028.npy
│ ├── singer0029.npy
│ ├── singer0030.npy
│ ├── singer0031.npy
│ ├── singer0032.npy
│ ├── singer0033.npy
│ ├── singer0034.npy
│ ├── singer0035.npy
│ ├── singer0036.npy
│ ├── singer0037.npy
│ ├── singer0038.npy
│ ├── singer0039.npy
│ ├── singer0040.npy
│ ├── singer0041.npy
│ ├── singer0042.npy
│ ├── singer0043.npy
│ ├── singer0044.npy
│ ├── singer0045.npy
│ ├── singer0046.npy
│ ├── singer0047.npy
│ ├── singer0048.npy
│ ├── singer0049.npy
│ ├── singer0050.npy
│ ├── singer0051.npy
│ ├── singer0052.npy
│ ├── singer0053.npy
│ ├── singer0054.npy
│ ├── singer0055.npy
│ └── singer0056.npy
├── bigvgan/
│ ├── LICENSE
│ ├── README.md
│ ├── configs/
│ │ └── nsf_bigvgan.yaml
│ ├── inference.py
│ └── model/
│ ├── __init__.py
│ ├── alias/
│ │ ├── __init__.py
│ │ ├── act.py
│ │ ├── filter.py
│ │ └── resample.py
│ ├── bigv.py
│ ├── generator.py
│ └── nsf.py
├── bigvgan_pretrain/
│ └── README.md
├── configs/
│ └── base.yaml
├── grad/
│ ├── LICENSE
│ ├── __init__.py
│ ├── base.py
│ ├── diffusion.py
│ ├── encoder.py
│ ├── model.py
│ ├── reversal.py
│ ├── solver.py
│ ├── ssim.py
│ └── utils.py
├── grad_extend/
│ ├── data.py
│ ├── train.py
│ └── utils.py
├── grad_pretrain/
│ └── README.md
├── gvc_export.py
├── gvc_inference.py
├── gvc_trainer.py
├── hubert/
│ ├── __init__.py
│ ├── hubert_model.py
│ └── inference.py
├── hubert_pretrain/
│ └── README.md
├── pitch/
│ ├── __init__.py
│ └── inference.py
├── prepare/
│ ├── preprocess_a.py
│ ├── preprocess_f0.py
│ ├── preprocess_hubert.py
│ ├── preprocess_speaker.py
│ ├── preprocess_speaker_ave.py
│ ├── preprocess_spec.py
│ ├── preprocess_train.py
│ └── preprocess_zzz.py
├── requirements.txt
├── speaker/
│ ├── __init__.py
│ ├── config.py
│ ├── infer.py
│ ├── models/
│ │ ├── __init__.py
│ │ ├── lstm.py
│ │ └── resnet.py
│ └── utils/
│ ├── __init__.py
│ ├── audio.py
│ ├── coqpit.py
│ ├── io.py
│ └── shared_configs.py
├── speaker_pretrain/
│ ├── README.md
│ └── config.json
└── spec/
└── inference.py
SYMBOL INDEX (417 symbols across 38 files)
FILE: bigvgan/inference.py
function load_bigv_model (line 12) | def load_bigv_model(checkpoint_path, model):
function main (line 28) | def main(args):
FILE: bigvgan/model/alias/act.py
class Activation1d (line 13) | class Activation1d(nn.Module):
method __init__ (line 14) | def __init__(self,
method forward (line 28) | def forward(self, x):
class SnakeBeta (line 36) | class SnakeBeta(nn.Module):
method __init__ (line 54) | def __init__(self, in_features, alpha=1.0, alpha_trainable=True, alpha...
method forward (line 79) | def forward(self, x):
class Mish (line 95) | class Mish(nn.Module):
method __init__ (line 102) | def __init__(self):
method forward (line 105) | def forward(self, x):
class SnakeAlias (line 109) | class SnakeAlias(nn.Module):
method __init__ (line 110) | def __init__(self,
method forward (line 124) | def forward(self, x):
FILE: bigvgan/model/alias/filter.py
function sinc (line 15) | def sinc(x: torch.Tensor):
function kaiser_sinc_filter1d (line 28) | def kaiser_sinc_filter1d(cutoff, half_width, kernel_size): # return filt...
class LowPassFilter1d (line 60) | class LowPassFilter1d(nn.Module):
method __init__ (line 61) | def __init__(self,
method forward (line 86) | def forward(self, x):
FILE: bigvgan/model/alias/resample.py
class UpSample1d (line 10) | class UpSample1d(nn.Module):
method __init__ (line 11) | def __init__(self, ratio=2, kernel_size=None):
method forward (line 25) | def forward(self, x):
class DownSample1d (line 36) | class DownSample1d(nn.Module):
method __init__ (line 37) | def __init__(self, ratio=2, kernel_size=None):
method forward (line 46) | def forward(self, x):
FILE: bigvgan/model/bigv.py
function init_weights (line 9) | def init_weights(m, mean=0.0, std=0.01):
function get_padding (line 15) | def get_padding(kernel_size, dilation=1):
class AMPBlock (line 19) | class AMPBlock(torch.nn.Module):
method __init__ (line 20) | def __init__(self, channels, kernel_size=3, dilation=(1, 3, 5)):
method forward (line 50) | def forward(self, x):
method remove_weight_norm (line 60) | def remove_weight_norm(self):
FILE: bigvgan/model/generator.py
class Generator (line 15) | class Generator(torch.nn.Module):
method __init__ (line 17) | def __init__(self, hp):
method forward (line 77) | def forward(self, x, f0, train=True):
method remove_weight_norm (line 110) | def remove_weight_norm(self):
method eval (line 117) | def eval(self, inference=False):
method inference (line 123) | def inference(self, mel, f0):
method pitch2wav (line 132) | def pitch2wav(self, f0):
FILE: bigvgan/model/nsf.py
class PulseGen (line 7) | class PulseGen(torch.nn.Module):
method __init__ (line 14) | def __init__(self, samp_rate, pulse_amp=0.1, noise_std=0.003, voiced_t...
method forward (line 29) | def forward(self, f0):
class SignalsConv1d (line 76) | class SignalsConv1d(torch.nn.Module):
method __init__ (line 84) | def __init__(self):
method forward (line 87) | def forward(self, signal, system_ir):
class CyclicNoiseGen_v1 (line 115) | class CyclicNoiseGen_v1(torch.nn.Module):
method __init__ (line 121) | def __init__(self, samp_rate, noise_std=0.003, voiced_threshold=0):
method noise_decay (line 135) | def noise_decay(self, beta, f0mean):
method forward (line 159) | def forward(self, f0s, beta):
class SineGen (line 181) | class SineGen(torch.nn.Module):
method __init__ (line 199) | def __init__(
method _f02uv (line 217) | def _f02uv(self, f0):
method _f02sine (line 223) | def _f02sine(self, f0_values):
method forward (line 284) | def forward(self, f0):
class SourceModuleCycNoise_v1 (line 319) | class SourceModuleCycNoise_v1(torch.nn.Module):
method __init__ (line 335) | def __init__(self, sampling_rate, noise_std=0.003, voiced_threshod=0):
method forward (line 341) | def forward(self, f0_upsamped, beta):
class SourceModuleHnNSF (line 358) | class SourceModuleHnNSF(torch.nn.Module):
method __init__ (line 359) | def __init__(
method forward (line 383) | def forward(self, x):
FILE: grad/base.py
class BaseModule (line 5) | class BaseModule(torch.nn.Module):
method __init__ (line 6) | def __init__(self):
method nparams (line 10) | def nparams(self):
method relocate_input (line 21) | def relocate_input(self, x: list):
FILE: grad/diffusion.py
class Mish (line 8) | class Mish(BaseModule):
method forward (line 9) | def forward(self, x):
class Upsample (line 13) | class Upsample(BaseModule):
method __init__ (line 14) | def __init__(self, dim):
method forward (line 18) | def forward(self, x):
class Downsample (line 22) | class Downsample(BaseModule):
method __init__ (line 23) | def __init__(self, dim):
method forward (line 27) | def forward(self, x):
class Rezero (line 31) | class Rezero(BaseModule):
method __init__ (line 32) | def __init__(self, fn):
method forward (line 37) | def forward(self, x):
class Block (line 41) | class Block(BaseModule):
method __init__ (line 42) | def __init__(self, dim, dim_out, groups=8):
method forward (line 48) | def forward(self, x, mask):
class ResnetBlock (line 53) | class ResnetBlock(BaseModule):
method __init__ (line 54) | def __init__(self, dim, dim_out, time_emb_dim, groups=8):
method forward (line 66) | def forward(self, x, mask, time_emb):
class LinearAttention (line 74) | class LinearAttention(BaseModule):
method __init__ (line 75) | def __init__(self, dim, heads=4, dim_head=32):
method forward (line 82) | def forward(self, x):
class Residual (line 95) | class Residual(BaseModule):
method __init__ (line 96) | def __init__(self, fn):
method forward (line 100) | def forward(self, x, *args, **kwargs):
class SinusoidalPosEmb (line 105) | class SinusoidalPosEmb(BaseModule):
method __init__ (line 106) | def __init__(self, dim):
method forward (line 110) | def forward(self, x, scale=1000):
class GradLogPEstimator2d (line 120) | class GradLogPEstimator2d(BaseModule):
method __init__ (line 121) | def __init__(self, dim, dim_mults=(1, 2, 4), emb_dim=64, n_mels=100,
method forward (line 164) | def forward(self, spk, x, mask, mu, t):
function get_noise (line 205) | def get_noise(t, beta_init, beta_term, cumulative=False):
class Diffusion (line 213) | class Diffusion(BaseModule):
method __init__ (line 214) | def __init__(self, n_mels, dim, emb_dim=64,
method forward_diffusion (line 228) | def forward_diffusion(self, mel, mask, mu, t):
method forward (line 238) | def forward(self, spk, z, mask, mu, n_timesteps, stoc=False):
method loss_t (line 241) | def loss_t(self, spk, mel, mask, mu, t):
method compute_loss (line 250) | def compute_loss(self, spk, mel, mask, mu, offset=1e-5):
FILE: grad/encoder.py
class LayerNorm (line 9) | class LayerNorm(BaseModule):
method __init__ (line 10) | def __init__(self, channels, eps=1e-4):
method forward (line 18) | def forward(self, x):
class ConvReluNorm (line 30) | class ConvReluNorm(BaseModule):
method __init__ (line 31) | def __init__(self, in_channels, hidden_channels, out_channels, kernel_...
method forward (line 53) | def forward(self, x, x_mask):
method instance_norm (line 61) | def instance_norm(self, x, mask, return_mean_std=False):
method calc_mean_std (line 69) | def calc_mean_std(self, x, mask=None):
class MultiHeadAttention (line 79) | class MultiHeadAttention(BaseModule):
method __init__ (line 80) | def __init__(self, channels, out_channels, n_heads, window_size=None,
method forward (line 116) | def forward(self, x, c, attn_mask=None):
method attention (line 126) | def attention(self, query, key, value, mask=None):
method _matmul_with_relative_values (line 157) | def _matmul_with_relative_values(self, x, y):
method _matmul_with_relative_keys (line 161) | def _matmul_with_relative_keys(self, x, y):
method _get_relative_embeddings (line 165) | def _get_relative_embeddings(self, relative_embeddings, length):
method _relative_position_to_absolute_position (line 179) | def _relative_position_to_absolute_position(self, x):
method _absolute_position_to_relative_position (line 187) | def _absolute_position_to_relative_position(self, x):
method _attention_bias_proximal (line 195) | def _attention_bias_proximal(self, length):
class FFN (line 201) | class FFN(BaseModule):
method __init__ (line 202) | def __init__(self, in_channels, out_channels, filter_channels, kernel_...
method forward (line 217) | def forward(self, x, x_mask):
class Encoder (line 225) | class Encoder(BaseModule):
method __init__ (line 226) | def __init__(self, hidden_channels, filter_channels, n_heads, n_layers,
method forward (line 250) | def forward(self, x, x_mask):
class TextEncoder (line 264) | class TextEncoder(BaseModule):
method __init__ (line 265) | def __init__(self, n_vecs, n_mels, n_embs,
method forward (line 307) | def forward(self, x_lengths, x, pit, spk, training=False):
method fine_tune (line 323) | def fine_tune(self):
FILE: grad/model.py
class GradTTS (line 13) | class GradTTS(BaseModule):
method __init__ (line 14) | def __init__(self, n_mels, n_vecs, n_pits, n_spks, n_embs,
method fine_tune (line 41) | def fine_tune(self):
method forward (line 49) | def forward(self, lengths, vec, pit, spk, n_timesteps, temperature=1.0...
method compute_loss (line 89) | def compute_loss(self, lengths, vec, pit, spk, mel, out_size, skip_dif...
FILE: grad/reversal.py
class GradientReversalFunction (line 11) | class GradientReversalFunction(Function):
method forward (line 13) | def forward(ctx, x, lambda_):
method backward (line 18) | def backward(ctx, grads):
class GradientReversal (line 25) | class GradientReversal(torch.nn.Module):
method __init__ (line 34) | def __init__(self, lambda_reversal=1):
method forward (line 38) | def forward(self, x):
class SpeakerClassifier (line 42) | class SpeakerClassifier(nn.Module):
method __init__ (line 44) | def __init__(self, idim, odim):
method forward (line 55) | def forward(self, x):
FILE: grad/solver.py
class NoiseScheduleVP (line 4) | class NoiseScheduleVP:
method __init__ (line 6) | def __init__(self, beta_min=0.05, beta_max=20):
method get_noise (line 11) | def get_noise(self, t, beta_init, beta_term, cumulative=False):
method marginal_log_mean_coeff (line 18) | def marginal_log_mean_coeff(self, t):
method marginal_std (line 22) | def marginal_std(self, t):
method marginal_lambda (line 25) | def marginal_lambda(self, t):
method inverse_lambda (line 30) | def inverse_lambda(self, lamb):
method get_time_steps (line 38) | def get_time_steps(self, t_T, t_0, N):
method reverse_diffusion (line 45) | def reverse_diffusion(self, estimator, spk, z, mask, mu, n_timesteps, ...
class MaxLikelihood (line 75) | class MaxLikelihood:
method __init__ (line 77) | def __init__(self, beta_min=0.05, beta_max=20):
method get_noise (line 81) | def get_noise(self, t, beta_init, beta_term, cumulative=False):
method get_gamma (line 88) | def get_gamma(self, s, t, beta_init, beta_term):
method get_mu (line 93) | def get_mu(self, s, t):
method get_nu (line 100) | def get_nu(self, s, t):
method get_sigma (line 107) | def get_sigma(self, s, t):
method get_kappa (line 114) | def get_kappa(self, t, h, noise):
method get_omega (line 120) | def get_omega(self, t, h, noise):
method reverse_diffusion (line 128) | def reverse_diffusion(self, estimator, spk, z, mask, mu, n_timesteps, ...
class GradRaw (line 155) | class GradRaw:
method __init__ (line 157) | def __init__(self, beta_min=0.05, beta_max=20):
method get_noise (line 161) | def get_noise(self, t, beta_init, beta_term, cumulative=False):
method reverse_diffusion (line 169) | def reverse_diffusion(self, estimator, spk, z, mask, mu, n_timesteps, ...
FILE: grad/ssim.py
function gaussian (line 10) | def gaussian(window_size, sigma):
function create_window (line 15) | def create_window(window_size, channel):
function _ssim (line 22) | def _ssim(img1, img2, window, window_size, channel, size_average=True):
class SSIM (line 45) | class SSIM(torch.nn.Module):
method __init__ (line 46) | def __init__(self, window_size=11, size_average=True):
method forward (line 53) | def forward(self, fake, real, mask, bias=6.0):
FILE: grad/utils.py
function sequence_mask (line 6) | def sequence_mask(length, max_length=None):
function fix_len_compatibility (line 13) | def fix_len_compatibility(length, num_downsamplings_in_unet=2):
function convert_pad_shape (line 20) | def convert_pad_shape(pad_shape):
function generate_path (line 26) | def generate_path(duration, mask):
function duration_loss (line 42) | def duration_loss(logw, logw_, lengths):
function f0_to_coarse (line 54) | def f0_to_coarse(f0):
function rand_ids_segments (line 70) | def rand_ids_segments(lengths, segment_size=200):
function slice_segments (line 77) | def slice_segments(x, ids_str, segment_size=200):
function retrieve_name (line 86) | def retrieve_name(var):
function debug_shapes (line 97) | def debug_shapes(var):
FILE: grad_extend/data.py
class TextMelSpeakerDataset (line 11) | class TextMelSpeakerDataset(torch.utils.data.Dataset):
method __init__ (line 12) | def __init__(self, filelist_path):
method _filter (line 18) | def _filter(self):
method get_triplet (line 41) | def get_triplet(self, item):
method __getitem__ (line 83) | def __getitem__(self, index):
method __len__ (line 88) | def __len__(self):
method sample_test_batch (line 91) | def sample_test_batch(self, size):
class TextMelSpeakerBatchCollate (line 99) | class TextMelSpeakerBatchCollate(object):
method __call__ (line 104) | def __call__(self, batch):
FILE: grad_extend/train.py
function train (line 19) | def train(hps, chkpt_path=None):
FILE: grad_extend/utils.py
function parse_filelist (line 9) | def parse_filelist(filelist_path, split_char="|"):
function load_model (line 15) | def load_model(model, saved_state_dict):
function latest_checkpoint_path (line 28) | def latest_checkpoint_path(dir_path, regex="grad_svc_*.pt"):
function load_checkpoint (line 35) | def load_checkpoint(logdir, model, num=None):
function save_figure_to_numpy (line 46) | def save_figure_to_numpy(fig):
function plot_tensor (line 52) | def plot_tensor(tensor):
function save_plot (line 64) | def save_plot(tensor, savepath):
function print_error (line 76) | def print_error(info):
FILE: gvc_export.py
function load_model (line 9) | def load_model(checkpoint_path, model):
function main (line 25) | def main(args):
FILE: gvc_inference.py
function load_gvc_model (line 18) | def load_gvc_model(checkpoint_path, model):
function load_bigv_model (line 34) | def load_bigv_model(checkpoint_path, model):
function gvc_main (line 51) | def gvc_main(device, model, _vec, _pit, spk, rature=1.015):
function main (line 66) | def main(args):
FILE: hubert/hubert_model.py
class Hubert (line 10) | class Hubert(nn.Module):
method __init__ (line 11) | def __init__(self, num_label_embeddings: int = 100, mask: bool = True):
method mask (line 30) | def mask(self, x: torch.Tensor) -> Tuple[torch.Tensor, torch.Tensor]:
method encode (line 37) | def encode(
method logits (line 48) | def logits(self, x: torch.Tensor) -> torch.Tensor:
method forward (line 56) | def forward(self, x: torch.Tensor) -> Tuple[torch.Tensor, torch.Tensor]:
class HubertSoft (line 63) | class HubertSoft(Hubert):
method __init__ (line 64) | def __init__(self):
method units (line 68) | def units(self, wav: torch.Tensor) -> torch.Tensor:
class FeatureExtractor (line 74) | class FeatureExtractor(nn.Module):
method __init__ (line 75) | def __init__(self):
method forward (line 86) | def forward(self, x: torch.Tensor) -> torch.Tensor:
class FeatureProjection (line 97) | class FeatureProjection(nn.Module):
method __init__ (line 98) | def __init__(self):
method forward (line 104) | def forward(self, x: torch.Tensor) -> torch.Tensor:
class PositionalConvEmbedding (line 111) | class PositionalConvEmbedding(nn.Module):
method __init__ (line 112) | def __init__(self):
method forward (line 123) | def forward(self, x: torch.Tensor) -> torch.Tensor:
class TransformerEncoder (line 129) | class TransformerEncoder(nn.Module):
method __init__ (line 130) | def __init__(
method forward (line 139) | def forward(
function _compute_mask (line 154) | def _compute_mask(
function consume_prefix (line 209) | def consume_prefix(state_dict, prefix: str) -> None:
function hubert_soft (line 217) | def hubert_soft(
FILE: hubert/inference.py
function load_audio (line 11) | def load_audio(file: str, sr: int = 16000):
function load_model (line 16) | def load_model(path, device):
function pred_vec (line 25) | def pred_vec(model, wavPath, vecPath, device):
FILE: pitch/inference.py
function compute_f0_mouth (line 9) | def compute_f0_mouth(path):
function compute_f0_crepe (line 23) | def compute_f0_crepe(filename):
function save_csv_pitch (line 55) | def save_csv_pitch(pitch, path):
function load_csv_pitch (line 66) | def load_csv_pitch(path):
FILE: prepare/preprocess_a.py
function resample_wave (line 10) | def resample_wave(wav_in, wav_out, sample_rate):
function process_file (line 17) | def process_file(file, wavPath, spks, outPath, sr):
function process_files_with_thread_pool (line 23) | def process_files_with_thread_pool(wavPath, spks, outPath, sr, thread_nu...
FILE: prepare/preprocess_f0.py
function compute_f0 (line 11) | def compute_f0(path, save):
function process_file (line 27) | def process_file(file, wavPath, spks, pitPath):
function process_files_with_process_pool (line 33) | def process_files_with_process_pool(wavPath, spks, pitPath, process_num=...
FILE: prepare/preprocess_hubert.py
function load_audio (line 12) | def load_audio(file: str, sr: int = 16000):
function load_model (line 17) | def load_model(path, device):
function pred_vec (line 25) | def pred_vec(model, wavPath, vecPath, device):
FILE: prepare/preprocess_speaker.py
function get_spk_wavs (line 18) | def get_spk_wavs(dataset_path, output_path):
function process_wav (line 32) | def process_wav(wav_file, dataset_path, output_path, args, speaker_encod...
function extract_speaker_embeddings (line 48) | def extract_speaker_embeddings(wav_files, dataset_path, output_path, arg...
FILE: prepare/preprocess_spec.py
function compute_spec (line 11) | def compute_spec(hps, filename, specname):
function process_file (line 18) | def process_file(file):
function process_files_with_thread_pool (line 24) | def process_files_with_thread_pool(wavPath, spks, thread_num):
FILE: prepare/preprocess_train.py
function print_error (line 5) | def print_error(info):
FILE: speaker/config.py
class SpeakerEncoderConfig (line 9) | class SpeakerEncoderConfig(BaseTrainingConfig):
method check_values (line 59) | def check_values(self):
FILE: speaker/infer.py
function read_json (line 14) | def read_json(json_path):
function read_json_with_comments (line 26) | def read_json_with_comments(json_path):
FILE: speaker/models/lstm.py
class LSTMWithProjection (line 8) | class LSTMWithProjection(nn.Module):
method __init__ (line 9) | def __init__(self, input_size, hidden_size, proj_size):
method forward (line 17) | def forward(self, x):
class LSTMWithoutProjection (line 23) | class LSTMWithoutProjection(nn.Module):
method __init__ (line 24) | def __init__(self, input_dim, lstm_dim, proj_dim, num_lstm_layers):
method forward (line 30) | def forward(self, x):
class LSTMSpeakerEncoder (line 35) | class LSTMSpeakerEncoder(nn.Module):
method __init__ (line 36) | def __init__(self, input_dim, proj_dim=256, lstm_dim=768, num_lstm_lay...
method _init_layers (line 51) | def _init_layers(self):
method forward (line 58) | def forward(self, x):
method inference (line 68) | def inference(self, x):
method compute_embedding (line 76) | def compute_embedding(self, x, num_frames=250, num_eval=10, return_mea...
method batch_compute_embedding (line 103) | def batch_compute_embedding(self, x, seq_lens, num_frames=160, overlap...
method load_checkpoint (line 124) | def load_checkpoint(self, checkpoint_path: str, eval: bool = False, us...
FILE: speaker/models/resnet.py
class SELayer (line 8) | class SELayer(nn.Module):
method __init__ (line 9) | def __init__(self, channel, reduction=8):
method forward (line 19) | def forward(self, x):
class SEBasicBlock (line 26) | class SEBasicBlock(nn.Module):
method __init__ (line 29) | def __init__(self, inplanes, planes, stride=1, downsample=None, reduct...
method forward (line 40) | def forward(self, x):
class ResNetSpeakerEncoder (line 59) | class ResNetSpeakerEncoder(nn.Module):
method __init__ (line 65) | def __init__(
method _init_layers (line 112) | def _init_layers(self):
method create_layer (line 120) | def create_layer(self, block, planes, blocks, stride=1):
method new_parameter (line 137) | def new_parameter(self, *size):
method forward (line 142) | def forward(self, x, l2_norm=False):
method compute_embedding (line 178) | def compute_embedding(self, x, num_frames=250, num_eval=10, return_mea...
method load_checkpoint (line 205) | def load_checkpoint(self, config: dict, checkpoint_path: str, eval: bo...
FILE: speaker/utils/audio.py
class StandardScaler (line 12) | class StandardScaler:
method __init__ (line 15) | def __init__(self, mean: np.ndarray = None, scale: np.ndarray = None) ...
method set_stats (line 19) | def set_stats(self, mean, scale):
method reset_stats (line 23) | def reset_stats(self):
method transform (line 27) | def transform(self, X):
method inverse_transform (line 33) | def inverse_transform(self, X):
class TorchSTFT (line 39) | class TorchSTFT(nn.Module): # pylint: disable=abstract-method
method __init__ (line 45) | def __init__(
method __call__ (line 77) | def __call__(self, x):
method _build_mel_basis (line 116) | def _build_mel_basis(self):
method _amp_to_db (line 123) | def _amp_to_db(x, spec_gain=1.0):
method _db_to_amp (line 127) | def _db_to_amp(x, spec_gain=1.0):
class AudioProcessor (line 132) | class AudioProcessor(object):
method __init__ (line 229) | def __init__(
method _build_mel_basis (line 325) | def _build_mel_basis(
method _stft_parameters (line 339) | def _stft_parameters(
method normalize (line 354) | def normalize(self, S: np.ndarray) -> np.ndarray:
method denormalize (line 395) | def denormalize(self, S: np.ndarray) -> np.ndarray:
method load_stats (line 434) | def load_stats(self, stats_path: str) -> Tuple[np.array, np.array, np....
method setup_scaler (line 462) | def setup_scaler(
method _amp_to_db (line 480) | def _amp_to_db(self, x: np.ndarray) -> np.ndarray:
method _db_to_amp (line 492) | def _db_to_amp(self, x: np.ndarray) -> np.ndarray:
method apply_preemphasis (line 504) | def apply_preemphasis(self, x: np.ndarray) -> np.ndarray:
method apply_inv_preemphasis (line 520) | def apply_inv_preemphasis(self, x: np.ndarray) -> np.ndarray:
method _linear_to_mel (line 527) | def _linear_to_mel(self, spectrogram: np.ndarray) -> np.ndarray:
method _mel_to_linear (line 538) | def _mel_to_linear(self, mel_spec: np.ndarray) -> np.ndarray:
method spectrogram (line 542) | def spectrogram(self, y: np.ndarray) -> np.ndarray:
method melspectrogram (line 561) | def melspectrogram(self, y: np.ndarray) -> np.ndarray:
method inv_spectrogram (line 573) | def inv_spectrogram(self, spectrogram: np.ndarray) -> np.ndarray:
method inv_melspectrogram (line 582) | def inv_melspectrogram(self, mel_spectrogram: np.ndarray) -> np.ndarray:
method out_linear_to_mel (line 591) | def out_linear_to_mel(self, linear_spec: np.ndarray) -> np.ndarray:
method _stft (line 608) | def _stft(self, y: np.ndarray) -> np.ndarray:
method _istft (line 627) | def _istft(self, y: np.ndarray) -> np.ndarray:
method _griffin_lim (line 631) | def _griffin_lim(self, S):
method compute_stft_paddings (line 643) | def compute_stft_paddings(self, x, pad_sides=1):
method compute_f0 (line 652) | def compute_f0(self, x: np.ndarray) -> np.ndarray:
method find_endpoint (line 695) | def find_endpoint(self, wav: np.ndarray, threshold_db=-40, min_silence...
method trim_silence (line 714) | def trim_silence(self, wav):
method sound_norm (line 723) | def sound_norm(x: np.ndarray) -> np.ndarray:
method load_wav (line 735) | def load_wav(self, filename: str, sr: int = None) -> np.ndarray:
method save_wav (line 761) | def save_wav(self, wav: np.ndarray, path: str, sr: int = None) -> None:
method mulaw_encode (line 773) | def mulaw_encode(wav: np.ndarray, qc: int) -> np.ndarray:
method mulaw_decode (line 784) | def mulaw_decode(wav, qc):
method encode_16bits (line 791) | def encode_16bits(x):
method quantize (line 795) | def quantize(x: np.ndarray, bits: int) -> np.ndarray:
method dequantize (line 808) | def dequantize(x, bits):
function _log (line 813) | def _log(x, base):
function _exp (line 819) | def _exp(x, base):
FILE: speaker/utils/coqpit.py
class _NoDefault (line 17) | class _NoDefault(Generic[T]):
function is_primitive_type (line 25) | def is_primitive_type(arg_type: Any) -> bool:
function is_list (line 40) | def is_list(arg_type: Any) -> bool:
function is_dict (line 55) | def is_dict(arg_type: Any) -> bool:
function is_union (line 70) | def is_union(arg_type: Any) -> bool:
function safe_issubclass (line 85) | def safe_issubclass(cls, classinfo) -> bool:
function _coqpit_json_default (line 103) | def _coqpit_json_default(obj: Any) -> Any:
function _default_value (line 109) | def _default_value(x: Field):
function _is_optional_field (line 125) | def _is_optional_field(field) -> bool:
function my_get_type_hints (line 138) | def my_get_type_hints(
function _serialize (line 155) | def _serialize(x):
function _deserialize_dict (line 177) | def _deserialize_dict(x: Dict) -> Dict:
function _deserialize_list (line 195) | def _deserialize_list(x: List, field_type: Type) -> List:
function _deserialize_union (line 225) | def _deserialize_union(x: Any, field_type: Type) -> Any:
function _deserialize_primitive_types (line 245) | def _deserialize_primitive_types(x: Union[int, float, str, bool], field_...
function _deserialize (line 269) | def _deserialize(x: Any, field_type: Any) -> Any:
function rsetattr (line 295) | def rsetattr(obj, attr, val):
function rgetattr (line 306) | def rgetattr(obj, attr, *args):
function rsetitem (line 318) | def rsetitem(obj, attr, val):
function rgetitem (line 324) | def rgetitem(obj, attr, *args):
class Serializable (line 332) | class Serializable:
method __post_init__ (line 335) | def __post_init__(self):
method _validate_contracts (line 341) | def _validate_contracts(self):
method validate (line 358) | def validate(self):
method to_dict (line 366) | def to_dict(self) -> dict:
method serialize (line 374) | def serialize(self) -> dict:
method deserialize (line 389) | def deserialize(self, data: dict) -> "Serializable":
method deserialize_immutable (line 419) | def deserialize_immutable(cls, data: dict) -> "Serializable":
function _get_help (line 457) | def _get_help(field):
function _init_argparse (line 465) | def _init_argparse(
class Coqpit (line 580) | class Coqpit(Serializable, MutableMapping):
method _is_initialized (line 589) | def _is_initialized(self):
method __post_init__ (line 594) | def __post_init__(self):
method __iter__ (line 603) | def __iter__(self):
method __len__ (line 606) | def __len__(self):
method __setitem__ (line 609) | def __setitem__(self, arg: str, value: Any):
method __getitem__ (line 612) | def __getitem__(self, arg: str):
method __delitem__ (line 616) | def __delitem__(self, arg: str):
method _keytransform (line 619) | def _keytransform(self, key): # pylint: disable=no-self-use
method __getattribute__ (line 624) | def __getattribute__(self, arg: str): # pylint: disable=no-self-use
method __contains__ (line 631) | def __contains__(self, arg: str):
method get (line 634) | def get(self, key: str, default: Any = None):
method items (line 639) | def items(self):
method merge (line 642) | def merge(self, coqpits: Union["Coqpit", List["Coqpit"]]):
method check_values (line 663) | def check_values(self):
method has (line 666) | def has(self, arg: str) -> bool:
method copy (line 669) | def copy(self):
method update (line 672) | def update(self, new: dict, allow_new=False) -> None:
method pprint (line 688) | def pprint(self) -> None:
method to_dict (line 692) | def to_dict(self) -> dict:
method from_dict (line 696) | def from_dict(self, data: dict) -> None:
method new_from_dict (line 700) | def new_from_dict(cls: Serializable, data: dict) -> "Coqpit":
method to_json (line 703) | def to_json(self) -> str:
method save_json (line 707) | def save_json(self, file_name: str) -> None:
method load_json (line 716) | def load_json(self, file_name: str) -> None:
method init_from_argparse (line 734) | def init_from_argparse(
method parse_args (line 782) | def parse_args(
method parse_known_args (line 814) | def parse_known_args(
method init_argparse (line 843) | def init_argparse(
function check_argument (line 889) | def check_argument(
FILE: speaker/utils/io.py
class RenamingUnpickler (line 13) | class RenamingUnpickler(pickle_tts.Unpickler):
method find_class (line 16) | def find_class(self, module, name):
class AttrDict (line 20) | class AttrDict(dict):
method __init__ (line 24) | def __init__(self, *args, **kwargs):
function copy_model_files (line 29) | def copy_model_files(config: Coqpit, out_path, new_fields):
function load_fsspec (line 56) | def load_fsspec(
function load_checkpoint (line 75) | def load_checkpoint(model, checkpoint_path, use_cuda=False, eval=False):...
function save_fsspec (line 89) | def save_fsspec(state: Any, path: str, **kwargs):
function save_model (line 101) | def save_model(config, model, optimizer, scaler, current_step, epoch, ou...
function save_checkpoint (line 132) | def save_checkpoint(
function save_best_model (line 157) | def save_best_model(
FILE: speaker/utils/shared_configs.py
class BaseAudioConfig (line 8) | class BaseAudioConfig(Coqpit):
method check_values (line 137) | def check_values(
class BaseDatasetConfig (line 173) | class BaseDatasetConfig(Coqpit):
method check_values (line 205) | def check_values(
class BaseTrainingConfig (line 218) | class BaseTrainingConfig(Coqpit):
FILE: spec/inference.py
function load_wav_to_torch (line 13) | def load_wav_to_torch(full_path, sample_rate):
function dynamic_range_compression (line 19) | def dynamic_range_compression(x, C=1, clip_val=1e-5):
function dynamic_range_decompression (line 23) | def dynamic_range_decompression(x, C=1):
function dynamic_range_compression_torch (line 27) | def dynamic_range_compression_torch(x, C=1, clip_val=1e-5):
function dynamic_range_decompression_torch (line 31) | def dynamic_range_decompression_torch(x, C=1):
function spectral_normalize_torch (line 35) | def spectral_normalize_torch(magnitudes):
function spectral_de_normalize_torch (line 40) | def spectral_de_normalize_torch(magnitudes):
function mel_spectrogram (line 49) | def mel_spectrogram(y, n_fft, num_mels, sampling_rate, hop_size, win_siz...
function mel_spectrogram_file (line 76) | def mel_spectrogram_file(path, hps):
function print_mel (line 88) | def print_mel(mel, path="mel.png"):
Condensed preview — 118 files, each showing path, character count, and a content snippet. Download the .json file or copy for the full structured content (272K chars).
[
{
"path": "LICENSE",
"chars": 1066,
"preview": "MIT License\n\nCopyright (c) 2023 PlayVoice\n\nPermission is hereby granted, free of charge, to any person obtaining a copy\n"
},
{
"path": "README.md",
"chars": 8639,
"preview": "<div align=\"center\">\n<h1> Grad-SVC based on Grad-TTS from HUAWEI Noah's Ark Lab </h1>\n\n[ 2022 PlayVoice\n\nPermission is hereby granted, free of charge, to any person obtaining a copy\n"
},
{
"path": "bigvgan/README.md",
"chars": 3438,
"preview": "<div align=\"center\">\n<h1> Neural Source-Filter BigVGAN </h1>\n Just For Fun\n</div>\n\n)))\nimport torch\nimport argparse\n"
},
{
"path": "bigvgan/model/__init__.py",
"chars": 33,
"preview": "from .alias.act import SnakeAlias"
},
{
"path": "bigvgan/model/alias/__init__.py",
"chars": 199,
"preview": "# Adapted from https://github.com/junjun3518/alias-free-torch under the Apache License 2.0\n# LICENSE is in incl_licens"
},
{
"path": "bigvgan/model/alias/act.py",
"chars": 4426,
"preview": "# Adapted from https://github.com/junjun3518/alias-free-torch under the Apache License 2.0\n# LICENSE is in incl_licens"
},
{
"path": "bigvgan/model/alias/filter.py",
"chars": 3456,
"preview": "# Adapted from https://github.com/junjun3518/alias-free-torch under the Apache License 2.0\n# LICENSE is in incl_licens"
},
{
"path": "bigvgan/model/alias/resample.py",
"chars": 1859,
"preview": "# Adapted from https://github.com/junjun3518/alias-free-torch under the Apache License 2.0\n# LICENSE is in incl_licens"
},
{
"path": "bigvgan/model/bigv.py",
"chars": 2450,
"preview": "import torch\nimport torch.nn as nn\n\nfrom torch.nn import Conv1d\nfrom torch.nn.utils import weight_norm, remove_weight_no"
},
{
"path": "bigvgan/model/generator.py",
"chars": 5295,
"preview": "import torch\nimport torch.nn as nn\nimport torch.nn.functional as F\nimport numpy as np\n\nfrom torch.nn import Conv1d\nfrom "
},
{
"path": "bigvgan/model/nsf.py",
"chars": 14682,
"preview": "import torch\nimport numpy as np\nimport sys\nimport torch.nn.functional as torch_nn_func\n\n\nclass PulseGen(torch.nn.Module)"
},
{
"path": "bigvgan_pretrain/README.md",
"chars": 125,
"preview": "Path for:\n\n nsf_bigvgan_pretrain_32K.pth\n\n DownLoad link:https://github.com/PlayVoice/NSF-BigVGAN/releases/tag/aug"
},
{
"path": "configs/base.yaml",
"chars": 795,
"preview": "train:\n seed: 37\n train_files: \"files/train.txt\"\n valid_files: \"files/valid.txt\"\n log_dir: 'logs/grad_svc'\n full_ep"
},
{
"path": "grad/LICENSE",
"chars": 1072,
"preview": "Copyright (c) 2021 Huawei Technologies Co., Ltd.\n\nPermission is hereby granted, free of charge, to any person obtaining "
},
{
"path": "grad/__init__.py",
"chars": 0,
"preview": ""
},
{
"path": "grad/base.py",
"chars": 819,
"preview": "import numpy as np\nimport torch\n\n\nclass BaseModule(torch.nn.Module):\n def __init__(self):\n super(BaseModule, s"
},
{
"path": "grad/diffusion.py",
"chars": 9387,
"preview": "import math\nimport torch\nfrom einops import rearrange\nfrom grad.base import BaseModule\nfrom grad.solver import NoiseSche"
},
{
"path": "grad/encoder.py",
"chars": 13705,
"preview": "import math\nimport torch\n\nfrom grad.base import BaseModule\nfrom grad.reversal import SpeakerClassifier\nfrom grad.utils i"
},
{
"path": "grad/model.py",
"chars": 5834,
"preview": "import math\nimport torch\n\nfrom grad.ssim import SSIM\nfrom grad.base import BaseModule\nfrom grad.encoder import TextEncod"
},
{
"path": "grad/reversal.py",
"chars": 1945,
"preview": "# Adapted from https://github.com/ubisoft/ubisoft-laforge-daft-exprt Apache License Version 2.0\n# Unsupervised Domain Ad"
},
{
"path": "grad/solver.py",
"chars": 7592,
"preview": "import torch\r\n\r\n\r\nclass NoiseScheduleVP:\r\n\r\n def __init__(self, beta_min=0.05, beta_max=20):\r\n self.beta_min ="
},
{
"path": "grad/ssim.py",
"chars": 2185,
"preview": "\"\"\"\nAdapted from https://github.com/Po-Hsun-Su/pytorch-ssim\n\"\"\"\nimport torch\nimport torch.nn.functional as F\nfrom torch."
},
{
"path": "grad/utils.py",
"chars": 2818,
"preview": "import torch\nimport numpy as np\nimport inspect\n\n\ndef sequence_mask(length, max_length=None):\n if max_length is None:\n"
},
{
"path": "grad_extend/data.py",
"chars": 4283,
"preview": "import os\nimport random\nimport numpy as np\n\nimport torch\n\nfrom grad.utils import fix_len_compatibility\nfrom grad_extend."
},
{
"path": "grad_extend/train.py",
"chars": 7956,
"preview": "import os\nimport torch\nimport numpy as np\n\nfrom torch.utils.data import DataLoader\nfrom torch.utils.tensorboard import S"
},
{
"path": "grad_extend/utils.py",
"chars": 2188,
"preview": "import os\nimport glob\nimport numpy as np\nimport matplotlib.pyplot as plt\n\nimport torch\n\n\ndef parse_filelist(filelist_pat"
},
{
"path": "grad_pretrain/README.md",
"chars": 31,
"preview": "Path for:\n\n gvc.pretrain.pth"
},
{
"path": "gvc_export.py",
"chars": 1772,
"preview": "import sys,os\nsys.path.append(os.path.dirname(os.path.abspath(__file__)))\nimport torch\nimport argparse\nfrom omegaconf im"
},
{
"path": "gvc_inference.py",
"chars": 7157,
"preview": "import sys,os\nsys.path.append(os.path.dirname(os.path.abspath(__file__)))\nimport torch\nimport argparse\nimport numpy as n"
},
{
"path": "gvc_trainer.py",
"chars": 914,
"preview": "import sys,os\nsys.path.append(os.path.dirname(os.path.abspath(__file__)))\nimport argparse\nimport torch\nimport numpy as n"
},
{
"path": "hubert/__init__.py",
"chars": 0,
"preview": ""
},
{
"path": "hubert/hubert_model.py",
"chars": 7469,
"preview": "import copy\nimport random\nfrom typing import Optional, Tuple\n\nimport torch\nimport torch.nn as nn\nimport torch.nn.functio"
},
{
"path": "hubert/inference.py",
"chars": 1992,
"preview": "import sys,os\nsys.path.append(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))\nimport numpy as np\nimport arg"
},
{
"path": "hubert_pretrain/README.md",
"chars": 38,
"preview": "Path for:\n\n hubert-soft-0d54a1f4.pt"
},
{
"path": "pitch/__init__.py",
"chars": 37,
"preview": "from .inference import load_csv_pitch"
},
{
"path": "pitch/inference.py",
"chars": 2454,
"preview": "import sys,os\nsys.path.append(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))\nimport librosa\nimport argpars"
},
{
"path": "prepare/preprocess_a.py",
"chars": 2201,
"preview": "import os\nimport librosa\nimport argparse\nimport numpy as np\nfrom tqdm import tqdm\nfrom concurrent.futures import ThreadP"
},
{
"path": "prepare/preprocess_f0.py",
"chars": 2266,
"preview": "import os\nimport numpy as np\nimport librosa\nimport argparse\nimport parselmouth\n# pip install praat-parselmouth\nfrom tqdm"
},
{
"path": "prepare/preprocess_hubert.py",
"chars": 1810,
"preview": "import sys,os\nsys.path.append(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))\nimport numpy as np\nimport arg"
},
{
"path": "prepare/preprocess_speaker.py",
"chars": 4014,
"preview": "import sys,os\nsys.path.append(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))\nimport torch\nimport numpy as "
},
{
"path": "prepare/preprocess_speaker_ave.py",
"chars": 2043,
"preview": "import os\nimport torch\nimport argparse\nimport numpy as np\nfrom tqdm import tqdm\n\n\nif __name__ == \"__main__\":\n parser "
},
{
"path": "prepare/preprocess_spec.py",
"chars": 1868,
"preview": "import sys,os\nsys.path.append(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))\nimport torch\nimport argparse\n"
},
{
"path": "prepare/preprocess_train.py",
"chars": 1852,
"preview": "import os\nimport random\n\n\ndef print_error(info):\n print(f\"\\033[31m File isn't existed: {info}\\033[0m\")\n\n\nif __name__ "
},
{
"path": "prepare/preprocess_zzz.py",
"chars": 1024,
"preview": "import sys,os\nsys.path.append(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))\nfrom tqdm import tqdm\nfrom to"
},
{
"path": "requirements.txt",
"chars": 109,
"preview": "librosa\nsoundfile\nmatplotlib\ntensorboard\ntransformers\ntqdm\neinops\nfsspec\nomegaconf\npyworld\npraat-parselmouth\n"
},
{
"path": "speaker/__init__.py",
"chars": 0,
"preview": ""
},
{
"path": "speaker/config.py",
"chars": 2084,
"preview": "from dataclasses import asdict, dataclass, field\nfrom typing import Dict, List\n\nfrom .utils.coqpit import MISSING\nfrom ."
},
{
"path": "speaker/infer.py",
"chars": 3256,
"preview": "import re\nimport json\nimport fsspec\nimport torch\nimport numpy as np\nimport argparse\n\nfrom argparse import RawTextHelpFor"
},
{
"path": "speaker/models/__init__.py",
"chars": 0,
"preview": ""
},
{
"path": "speaker/models/lstm.py",
"chars": 4602,
"preview": "import numpy as np\nimport torch\nfrom torch import nn\n\nfrom ..utils.io import load_fsspec\n\n\nclass LSTMWithProjection(nn.M"
},
{
"path": "speaker/models/resnet.py",
"chars": 6918,
"preview": "import numpy as np\nimport torch\nfrom torch import nn\n\nfrom TTS.utils.io import load_fsspec\n\n\nclass SELayer(nn.Module):\n "
},
{
"path": "speaker/utils/__init__.py",
"chars": 0,
"preview": ""
},
{
"path": "speaker/utils/audio.py",
"chars": 29528,
"preview": "from typing import Dict, Tuple\n\nimport librosa\nimport numpy as np\nimport pyworld as pw\nimport scipy.io.wavfile\nimport sc"
},
{
"path": "speaker/utils/coqpit.py",
"chars": 34063,
"preview": "import argparse\nimport functools\nimport json\nimport operator\nimport os\nfrom collections.abc import MutableMapping\nfrom d"
},
{
"path": "speaker/utils/io.py",
"chars": 6153,
"preview": "import datetime\nimport json\nimport os\nimport pickle as pickle_tts\nimport shutil\nfrom typing import Any, Callable, Dict, "
},
{
"path": "speaker/utils/shared_configs.py",
"chars": 12410,
"preview": "from dataclasses import asdict, dataclass\nfrom typing import List\n\nfrom .coqpit import Coqpit, check_argument\n\n\n@datacla"
},
{
"path": "speaker_pretrain/README.md",
"chars": 50,
"preview": "Path for:\n\n best_model.pth.tar\n\n config.json"
},
{
"path": "speaker_pretrain/config.json",
"chars": 5743,
"preview": "{\n \"model_name\": \"lstm\",\n \"run_name\": \"mueller91\",\n \"run_description\": \"train speaker encoder with voxceleb1, v"
},
{
"path": "spec/inference.py",
"chars": 3587,
"preview": "import argparse\nimport torch\nimport torch.utils.data\nimport numpy as np\nimport librosa\nfrom omegaconf import OmegaConf\nf"
}
]
// ... and 56 more files (download for full content)
About this extraction
This page contains the full source code of the PlayVoice/Grad-SVC GitHub repository, extracted and formatted as plain text for AI agents and large language models (LLMs). The extraction includes 118 files (252.2 KB), approximately 67.0k tokens, and a symbol index with 417 extracted functions, classes, methods, constants, and types. Use this with OpenClaw, Claude, ChatGPT, Cursor, Windsurf, or any other AI tool that accepts text input. You can copy the full output to your clipboard or download it as a .txt file.
Extracted by GitExtract — free GitHub repo to text converter for AI. Built by Nikandr Surkov.