Repository: PyJun/Mooc_Downloader
Branch: master
Commit: fe0338bc494f
Files: 22
Total size: 45.3 KB
Directory structure:
gitextract_45xe85x4/
├── .gitignore
├── HELP.md
├── Mooc/
│ ├── Icourse163/
│ │ ├── Icourse163_Base.py
│ │ ├── Icourse163_Config.py
│ │ ├── Icourse163_Mooc.py
│ │ └── __init__.py
│ ├── Icourses/
│ │ ├── Icourse_Base.py
│ │ ├── Icourse_Config.py
│ │ ├── Icourse_Cuoc.py
│ │ ├── Icourse_Mooc.py
│ │ └── __init__.py
│ ├── Mooc_Base.py
│ ├── Mooc_Config.py
│ ├── Mooc_Download.py
│ ├── Mooc_Interface.py
│ ├── Mooc_Main.py
│ ├── Mooc_Potplayer.py
│ ├── Mooc_Request.py
│ ├── __init__.py
│ └── __main__.py
├── Mooc.spec
└── README.md
================================================
FILE CONTENTS
================================================
================================================
FILE: .gitignore
================================================
.vscode
Mooc/__pycache__
Mooc/Icourse163/__pycache__
Mooc/Icourses/__pycache__
build
dist
================================================
FILE: HELP.md
================================================
### 学无止网课下载器帮助文档
#### 一. 软件下载:
------
1. [Github Releases](https://github.com/PyJun/Mooc_Downloader/releases)
2. [百度云链接](https://pan.baidu.com/s/1G43ZZCTc5XtYCeZWUs4uTA)
3. [蓝奏云](https://lanzouw.com/b00n4ln4b)
#### 二. 使用说明
------
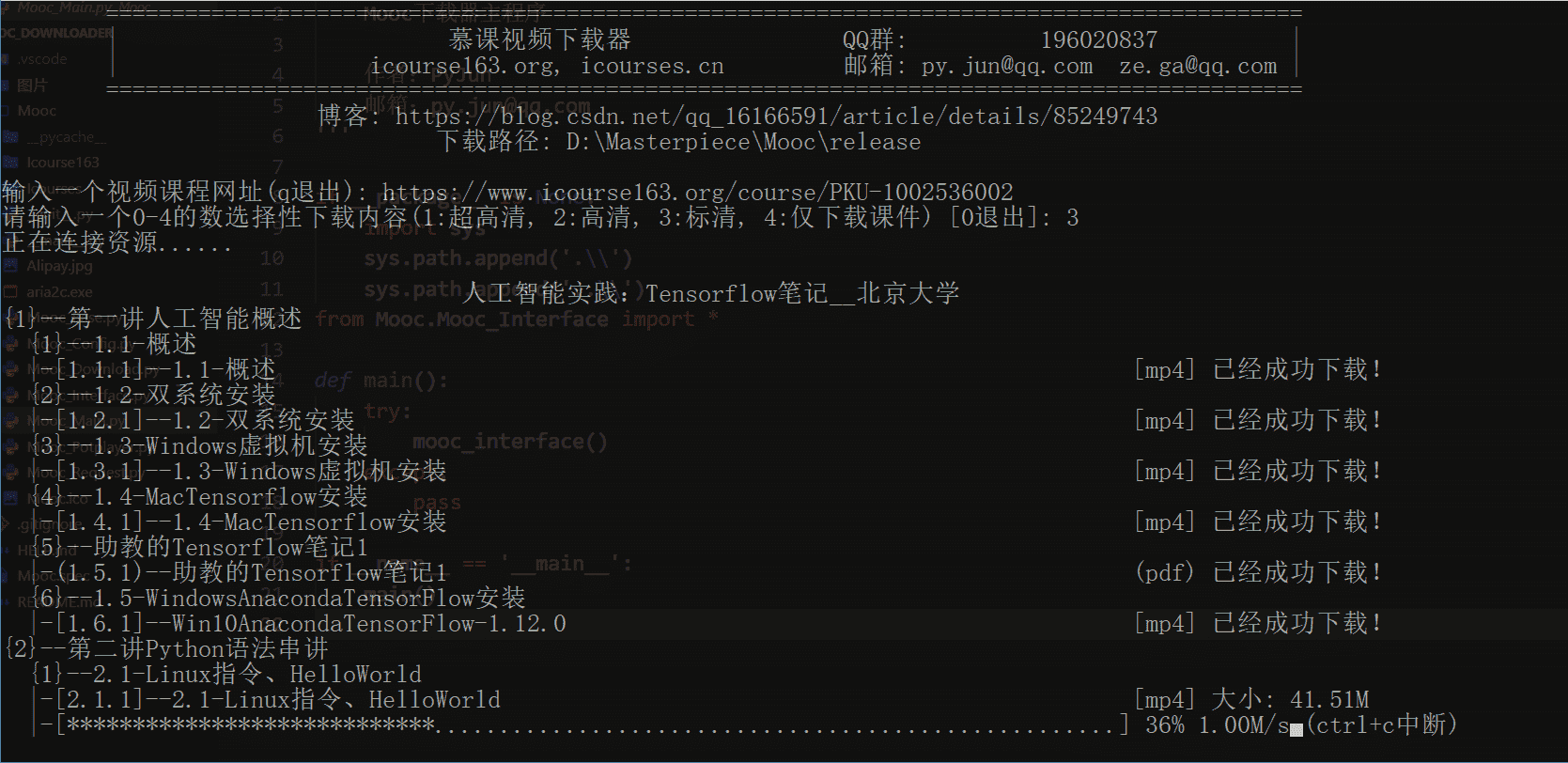
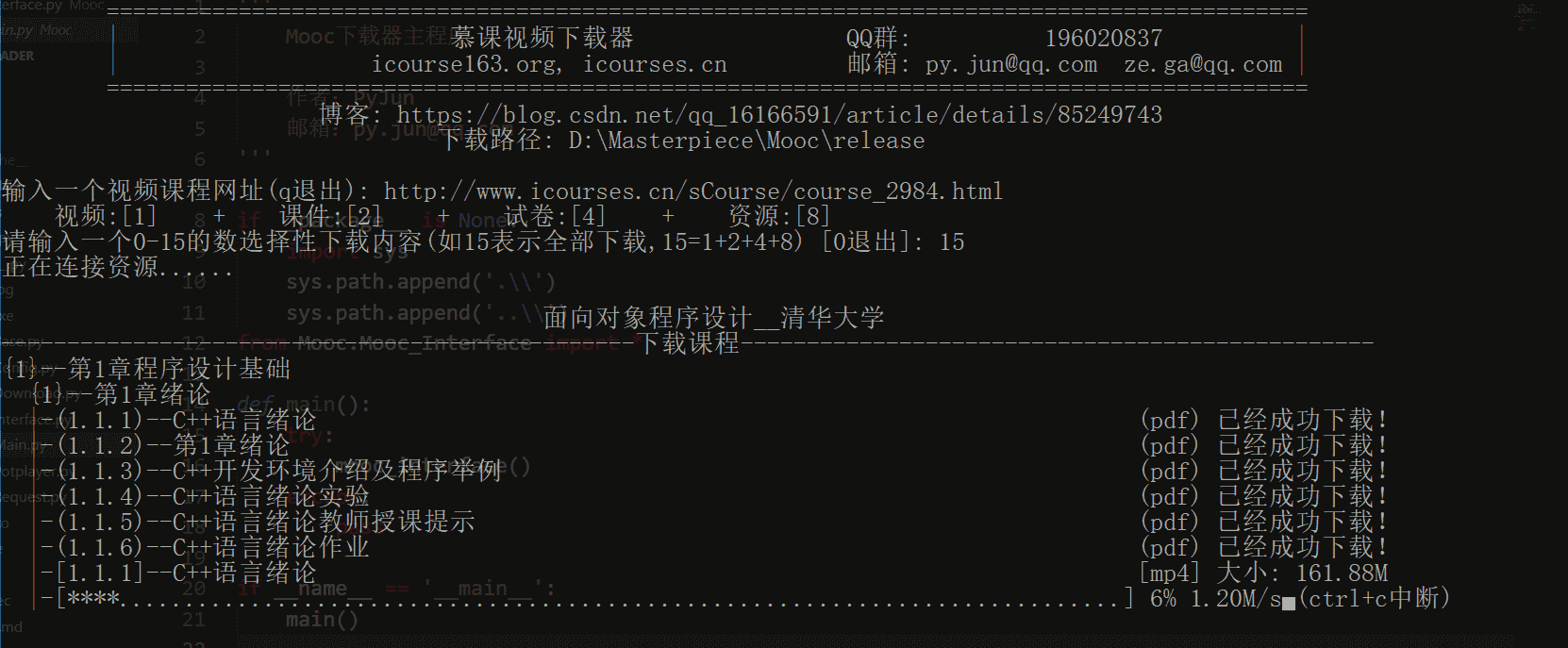
##### 1.从课程官网下选择任意一个课程复制其网址,如下图:


##### 2.然后粘贴到下载器中,并按要求输入指令,会自动下载相应课程的视频和课件,如下图:


#### 三.常见问题
------
##### 1.学无止下载器支持哪些网站的视频下载?
答:目前已支持以下网课网站视频课程下载,官方网址如下:
1. [腾讯课堂](https://ke.qq.com/)
2. [网易云课堂](https://study.163.com/)
3. [有道精品课](https://ke.youdao.com/)
4. [有道领世](https://c.youdao.com/ydls/pc-download.html)
5. [高途课堂](https://www.gaotu.cn/)
6. [途途课堂](https://gaotu100.com/)
7. [高途高中规划](https://www.gtgz.cn/)
8. [中国大学](https://www.icourse163.org/)
9. [哔哩哔哩](https://www.bilibili.com/)
10. [抖音课堂](https://www.xuelangapp.com/)
11. [中公网校](https://www.eoffcn.com/)
12. [新东方在线](https://www.koolearn.com/)
13. [新东方云教室](https://roombox.xdf.cn/)
14. [伯索云学堂](https://www.plaso.cn/app/)
15. [橙啦](https://www.orangevip.com/)
16. [千聊](https://www.qlchat.com/)
17. [兴趣岛](https://m.qianliao.net/)
18. [超星学习通(学银在线)](http://www.xueyinonline.com/)
19. [知到智慧树](https://www.zhihuishu.com/)
20. [智慧职教(职教云)](https://www.icve.com.cn/)
21. [爱课程](http://www.icourses.cn/)
22. [学堂在线](https://next.xuetangx.com/)
有关更多慕课网站的课程下载,敬请期待
##### 2.关于课程还未开课无法下载, 或者正在开课无法下载全部课程问题?
答:若课程有前几次开课,选择图片的版本一般选择最近一次的开课,然后复制链接进行下载。
PS:关于每次开课内容一般大致相同,新课程可能会有少量更新等。一般不会影响学习。

------
##### 3.是否可以下载已经结束的课程?
答:丝毫没影响,依然可以下载,直接复制链接到下载器中下载即可
##### 4.收费视频可以下载吗?
答:因为版权问题,未购买的收费视频该软件不提供下载
##### 5. “播放列表.dpl” 文件有什么用?
答:电脑下载安装 **Potplayer** 播放器后,然后右键用potplayer打开“播放列表.dpl”文件,
即可顺序播放器所有视频,可以更方便的观看
##### 6.“修复播放列表.bat” 文件有什么用?
答:当你手动把整个课程目录拷贝到其它地方后,你会发现 “播放列表.dpl”文件会失效,这时可以通过双击“修复播放列表.bat”文件来修复它。
##### 7.软件出现请求异常和下载异常的问题?
答:一般情况是你的本地网络出现的问题,请检查网络是否正常连接。如果确认网络良好还是出现了这样的问题,那么欢迎反馈给我们
================================================
FILE: Mooc/Icourse163/Icourse163_Base.py
================================================
'''
Icourse163 抽象基类
'''
import os
if __package__ is None:
import sys
sys.path.append('../')
from Mooc.Mooc_Base import *
from Mooc.Mooc_Download import *
from Mooc.Mooc_Request import *
from Mooc.Mooc_Potplayer import *
__all__ = [
"Icourse163_Base"
]
class Icourse163_Base(Mooc_Base):
potplayer = Mooc_Potplayer()
def __init__(self):
super().__init__()
self.infos = {} # 课程视频和文件的链接请求信息,包含id等
self.__term_id = None # 下载课程的标题 ID
@property
def term_id(self):
return self.__term_id
@term_id.setter
def term_id(self, term_id):
self.__term_id = term_id
def set_mode(self):
while True:
try:
instr = input("请输入一个0-4的数选择性下载内容(1:超高清, 2:高清, 3:标清, 4:仅下载课件) [0退出]: ")
if not instr:
continue
try:
innum = int(instr)
if innum == 0:
return False
elif 1 <= innum <= 4:
self.mode = innum
return True
else:
print("请输入一个0-4之间的整数!")
continue
except ValueError:
print("请输入一个0-4之间的整数!")
except KeyboardInterrupt:
pass
@classmethod
@potplayer
def download_video(cls, video_url, video_name, video_dir):
return super().download_video(video_url, video_name, video_dir)
================================================
FILE: Mooc/Icourse163/Icourse163_Config.py
================================================
'''
Icourse163 模块包的配置文件
'''
COURSENAME = '{1}--课程'
IS_SHD, IS_HD, IS_SD, ONLY_PDF = 1, 2, 3, 4
LEN_S = 96
================================================
FILE: Mooc/Icourse163/Icourse163_Mooc.py
================================================
'''
www.icourse163.org 下所有免费课程的下载和解析
'''
import os
import re
if __package__ is None:
import sys
sys.path.append('..\\')
sys.path.append("..\\..\\")
from Mooc.Mooc_Config import *
from Mooc.Mooc_Base import *
from Mooc.Mooc_Download import *
from Mooc.Mooc_Request import *
from Mooc.Mooc_Potplayer import *
from Mooc.Icourse163.Icourse163_Config import *
from Mooc.Icourse163.Icourse163_Base import *
__all__ = [
"Icourse163_Mooc"
]
class Icourse163_Mooc(Icourse163_Base):
course_url = "https://www.icourse163.org/course/"
infos_url = 'https://www.icourse163.org/dwr/call/plaincall/CourseBean.getMocTermDto.dwr'
parse_url = 'https://www.icourse163.org/dwr/call/plaincall/CourseBean.getLessonUnitLearnVo.dwr'
infos_data = {
'callCount':'1',
'scriptSessionId':'${scriptSessionId}190',
'c0-scriptName':'CourseBean',
'c0-methodName':'getMocTermDto',
'c0-id':'0',
'c0-param0':None, # 'number:'+self.term_id,
'c0-param1':'number:0',
'c0-param2':'boolean:true',
'batchId':'1543633161622'
}
parse_data = {
'callCount': '1',
'scriptSessionId': '${scriptSessionId}190',
'c0-scriptName':'CourseBean',
'c0-methodName':'getLessonUnitLearnVo',
'httpSessionId':'5531d06316b34b9486a6891710115ebc',
'c0-id': '0',
'c0-param0':None, #'number:'+meta[0],
'c0-param1':None, #'number:'+meta[1],
'c0-param2':'number:0',
'c0-param3':None, #'number:'+meta[2],
'batchId': '1543633161622'
}
def __init__(self, mode=IS_SHD):
super().__init__()
self.mode = mode
def _get_cid(self, url):
self.cid = None
match = courses_re['icourse163_mooc'].match(url)
if match and match.group(4):
self.cid = match.group(4)
def _get_title(self):
if self.cid is None:
return
self.title = self.term_id = None
url = self.course_url + self.cid
text = request_get(url)
match = re.search(r'termId : "(\d+)"', text)
if match:
self.term_id = match.group(1)
names = re.findall(r'name:"(.+)"', text)
if names:
title = '__'.join(names)
self.title = winre.sub('', title)[:WIN_LENGTH] # 用于除去win文件非法字符
def _get_infos(self):
if self.term_id is None:
return
self.infos = {}
self.infos_data['c0-param0'] = 'number:'+self.term_id
text = request_post(self.infos_url, self.infos_data, decoding='unicode_escape')
chapters = re.findall(r'homeworks=\w+;.+?id=(\d+).+?name="((.|\n)+?)";',text)
for i,chapter in enumerate(chapters,1):
chapter_title = winre.sub('', '{'+str(i)+'}--'+chapter[1])[:WIN_LENGTH]
self.infos[chapter_title] = {}
lessons = re.findall(r'chapterId='+chapter[0]+r'.+?contentType=1.+?id=(\d+).+?isTestChecked=false.+?name="((.|\n)+?)".+?test', text)
for j,lesson in enumerate(lessons,1):
lesson_title = winre.sub('', '{'+str(j)+'}--'+lesson[1])[:WIN_LENGTH]
self.infos[chapter_title][lesson_title] = {}
videos = re.findall(r'contentId=(\d+).+contentType=(1).+id=(\d+).+lessonId=' +
lesson[0] + r'.+name="(.+)"', text)
pdfs = re.findall(r'contentId=(\d+).+contentType=(3).+id=(\d+).+lessonId=' +
lesson[0] + r'.+name="(.+)"', text)
video_source = [{'params':video[:3], 'name':winre.sub('','[{}.{}.{}]--{}'.format(i,j,k,video[3])).rstrip('.mp4')[:WIN_LENGTH]} for k,video in enumerate(videos,1)]
pdf_source = [{'params':pdf[:3], 'name':winre.sub('','({}.{}.{})--{}'.format(i,j,k,pdf[3])).rstrip('.pdf')[:WIN_LENGTH]} for k,pdf in enumerate(pdfs,1)]
self.infos[chapter_title][lesson_title]['videos'] = video_source
self.infos[chapter_title][lesson_title]['pdfs'] = pdf_source
def _get_source_text(self, params):
self.parse_data['c0-param0'] = params[0]
self.parse_data['c0-param1'] = params[1]
self.parse_data['c0-param3'] = params[2]
text = request_post(self.parse_url, self.parse_data, decoding='unicode_escape')
return text
def _get_pdf_url(self, params):
text = self._get_source_text(params)
pdf_match = re.search(r'textOrigUrl:"(.*?)"', text)
pdf_url = None
if pdf_match:
pdf_url = pdf_match.group(1)
return pdf_url
def _get_video_url(self, params):
text = self._get_source_text(params)
sub_match = re.search(r'name=".+";.*url="(.*?)"', text)
video_url = sub_url = None
if sub_match:
sub_url = sub_match.group(1)
resolutions = ['Shd', 'Hd', 'Sd']
for index, sp in enumerate(resolutions,1):
video_match = re.search(r'(?P<ext>mp4)%sUrl="(?P<url>.*?\.(?P=ext).*?)"' % sp, text)
if video_match:
video_url, _ = video_match.group('url', 'ext')
if index >= self.mode: break
return video_url, sub_url
def _download(self): # 根据课程视频链接来下载高清MP4慕课视频, 成功下载完毕返回 True
print('\n{:^{}s}'.format(self.title, LEN_S))
self.rootDir = rootDir = os.path.join(PATH, self.title)
courseDir = os.path.join(rootDir, COURSENAME)
if not os.path.exists(courseDir):
os.makedirs(courseDir)
Icourse163_Base.potplayer.init(rootDir)
Icourse163_Base.potplayer.enable()
for i,chapter in enumerate(self.infos,1): # 去除 win 文价夹中的非法字符
print(chapter)
chapterDir = os.path.join(courseDir, chapter)
if not os.path.exists(chapterDir):
os.mkdir(chapterDir)
for j,lesson in enumerate(self.infos[chapter],1):
lessonDir = os.path.join(chapterDir, lesson)
if not os.path.exists(lessonDir):
os.mkdir(lessonDir)
print(" "+lesson)
sources = self.infos[chapter][lesson]
for k,pdf_source in enumerate(sources['pdfs'],1):
params, pdf_name = pdf_source['params'], pdf_source['name']
pdf_url= self._get_pdf_url(params)
if pdf_url:
self.download_pdf(pdf_url, pdf_name, lessonDir)
if self.mode == ONLY_PDF:
continue
for k,video_source in enumerate(sources['videos'],1):
params, name = video_source['params'], video_source['name']
video_name = sub_name = name
video_url, sub_url = self._get_video_url(params)
if video_url:
self.download_video(video_url=video_url, video_name=video_name, video_dir=lessonDir)
if sub_url:
self.download_sub(sub_url, sub_name, lessonDir)
def prepare(self, url):
self._get_cid(url)
self._get_title()
self._get_infos()
def download(self):
if self.cid and self.title and self.term_id and self.infos:
self._download()
return True
return False
def main():
# url = 'http://www.icourse163.org/course/GDUFS-1002493010'
# url = 'https://www.icourse163.org/course/WHU-1001539003'
url = 'https://www.icourse163.org/course/XHDX-1205600803'
icourse163_mooc = Icourse163_Mooc()
if (icourse163_mooc.set_mode()):
icourse163_mooc.prepare(url)
icourse163_mooc.download()
if __name__ == '__main__':
main()
================================================
FILE: Mooc/Icourse163/__init__.py
================================================
================================================
FILE: Mooc/Icourses/Icourse_Base.py
================================================
'''
定义一个爱课程 Icourse 的虚基类
用于派生 Icourse_Cuoc 和 Icourse_Mooc
'''
import os
from abc import abstractmethod
if __package__ is None:
import sys
sys.path.append('../')
from Mooc.Mooc_Config import *
from Mooc.Mooc_Base import *
from Mooc.Mooc_Download import *
from Mooc.Mooc_Request import *
from Mooc.Mooc_Potplayer import *
__all__ = [
"Icourse_Base"
]
class Icourse_Base(Mooc_Base):
potplayer = Mooc_Potplayer()
def __init__(self):
super().__init__()
self.__infos = []
self.__cid = None
def prepare(self, url):
getattr(self, "_get_cid")(url)
getattr(self, "_get_title")()
getattr(self, "_get_infos")()
def download(self):
if self.cid and self.title and self.infos:
getattr(self, "_download")()
return True
return False
@property
def cid(self):
return self.__cid
@cid.setter
def cid(self, cid):
self.__cid = cid
@abstractmethod
def _get_cid(self, url):
pass
def set_mode(self):
return True
@classmethod
@potplayer
def download_video(cls, video_url, video_name, video_dir):
return super().download_video(video_url, video_name, video_dir)
@classmethod
def download_video_list(cls, dirpath, mp4list, prefix=''):
for cnt, videos in enumerate(mp4list,1):
mp4_url, mp4_name = videos
mp4_name = winre.sub('', '['+prefix+str(cnt)+']--'+mp4_name).rstrip('.mp4')[:WIN_LENGTH]
cls.download_video(video_url=mp4_url, video_name=mp4_name, video_dir=dirpath)
@classmethod
def download_pdf_list(cls, dirpath, pdflist, prefix=''):
for cnt, pdfs in enumerate(pdflist,1):
pdf_url, pdf_name = pdfs
pdf_name = winre.sub('', '('+prefix+str(cnt)+')--'+pdf_name).rstrip('.pdf')[:WIN_LENGTH]
cls.download_pdf(pdf_url, pdf_name, dirpath)
================================================
FILE: Mooc/Icourses/Icourse_Config.py
================================================
'''
Icourse 模块包的配置文件
'''
COURSENAME = '{1}--课程'
PAPERNAME = '{2}--试卷'
SOURCENAME = '{3}--资源'
IS_MP4, IS_PDF, IS_PAPER, IS_SOURCE = 1, 2, 4, 8
LEN_S = 96
LEN_ = 48
================================================
FILE: Mooc/Icourses/Icourse_Cuoc.py
================================================
'''
www.icourses.cn/cuoc/ 下的视频公开课下载解析
'''
import os
import re
import json
if __package__ is None:
import sys
sys.path.append('..\\')
sys.path.append('..\\..\\')
from Mooc.Mooc_Config import *
from Mooc.Mooc_Request import *
from Mooc.Icourses.Icourse_Config import *
from Mooc.Icourses.Icourse_Base import *
__all__ = [
"Icourse_Cuoc"
]
class Icourse_Cuoc(Icourse_Base):
url_course = "http://www.icourses.cn/web/sword/portal/videoDetail?courseId="
def __init__(self):
super().__init__()
def _get_cid(self, url):
self.cid = None
match = courses_re.get('icourse_cuoc').match(url)
if match:
self.cid = match.group(1)
def _get_title(self):
if self.cid is None:
return
self.title = None
url = self.url_course + self.cid
text = request_get(url)
match_title = re.search(r"_courseTitle.*?=.*?'(.*?)';", text)
match_school = re.search(r'<a +?class *?= *?"teacher-infor-from">(.*?)</a>', text)
if match_title and match_school:
title_name = match_title.group(1)+'__'+match_school.group(1)
self.title = winre.sub('', title_name)[:WIN_LENGTH]
def _get_infos(self):
if self.cid is None:
return
self.infos = []
url = self.url_course + self.cid
text = request_get(url)
match_courses = re.search(r'_sourceArrStr *?= *?(\[.*?\]);\s*?var +?_shareUrl', text)
if match_courses:
#!!! except json.decoder.JSONDecodeError
courses = json.loads(match_courses.group(1))
self.infos = [{'url':course['fullLinkUrl'], 'name':winre.sub('',course['title'])[:WIN_LENGTH]} for course in courses]
def _download(self):
print('\n{:^{}s}'.format(self.title, LEN_S))
self.rootDir = rootDir = os.path.join(PATH, self.title)
courseDir = os.path.join(rootDir, COURSENAME)
if not os.path.exists(courseDir):
os.makedirs(courseDir)
print(COURSENAME)
Icourse_Base.potplayer.init(rootDir)
mp4_list = [(info['url'], info['name']) for info in self.infos]
Icourse_Base.potplayer.enable()
self.download_video_list(courseDir, mp4_list)
def main():
# url = 'http://www.icourses.cn/web/sword/portal/videoDetail?courseId=9fe9d456-1327-1000-9193-4876d02411f6'
url = 'http://www.icourses.cn/web/sword/portal/videoDetail?courseId=9fe99900-1327-1000-9191-4876d02411f6#/?resId=d0fff67d-1334-1000-8f6b-1d109e90c3cf'
# url = 'http://www.icourses.cn/web/sword/portal/videoDetail?courseId=9feeeee3-1327-1000-91e3-4876d02411f6#/?resId=d119afd8-1334-1000-9042-1d109e90c3cf'
icourse_cuoc = Icourse_Cuoc()
icourse_cuoc.prepare(url)
icourse_cuoc.download()
if __name__ == '__main__':
main()
================================================
FILE: Mooc/Icourses/Icourse_Mooc.py
================================================
'''
www.icourses.cn/mooc/ 下的资源共享课下载解析
'''
import os
import re
import json
if __package__ is None:
import sys
sys.path.append('..\\')
sys.path.append('..\\..\\')
from Mooc.Mooc_Config import *
from Mooc.Mooc_Download import *
from Mooc.Mooc_Request import *
from Mooc.Icourses.Icourse_Config import *
from Mooc.Icourses.Icourse_Base import *
__all__ = [
"Icourse_Mooc"
]
class Icourse_Mooc(Icourse_Base):
url_title = 'http://www.icourses.cn/sCourse/course_{}.html'
url_id = 'http://www.icourses.cn/web/sword/portal/shareChapter?cid='
url_course = 'http://www.icourses.cn/web//sword/portal/getRess'
url_assign = 'http://www.icourses.cn/web/sword/portal/assignments?cid='
url_paper = 'http://www.icourses.cn/web/sword/portal/testPaper?cid='
url_source = 'http://www.icourses.cn/web/sword/portal/sharerSource?cid='
def __init__(self, mode=IS_MP4|IS_PDF|IS_PAPER|IS_SOURCE):
super().__init__()
self.mode = mode
def _get_cid(self, url):
self.cid = None
match = courses_re.get('icourse_mooc').match(url)
if match:
cid = match.group(3) or match.group(5)
self.cid = cid
def _get_title(self):
if not self.cid:
return
self.title = None
url = self.url_title.format(self.cid)
text = request_get(url)
match_name = re.search(r'<div +class="course-title clearfix">\s*<p +class="pull-left">(.*?)</p>', text)
match_school = re.search(r'<span +class="pull-left">学校:</span>\s*<p +class="course-information-hour pull-left">(.*?)</p>', text)
if match_name and match_school:
title_name = match_name.group(1) + '__' + match_school.group(1)
self.title = winre.sub('', title_name)[:WIN_LENGTH]
def _get_infos(self):
if not self.cid:
return
self.infos = []
url1 = self.url_id + self.cid
url2 = self.url_assign + self.cid
text1 = request_get(url1)
text2 = request_get(url2)
chapter_ids = re.findall(r'<li +data-id="(\d+)" +class="chapter-bind-click panel[\s\S]*?">', text1)
chapter_names = re.findall(r'<a +class="chapter-title-text"[\s\S]*?>([\s\S]*?)</a>', text1)
chapter_ptext = re.findall(r'<div[\s\S]*?id="collapse(\d+)"[\s\S]*?<div([\s\S]*?)</div>', text2)
match_str = r'<div[\s\S]*?id="collapse{}-{}"([\s\S]*?)</div>'
re_pdf = re.compile(r'data-class="media"[\s\S]*?data-title="([\s\S]*?)"[\s\S]*?data-url="(.*?)"')
for _id, name in zip(chapter_ids, chapter_names):
self.infos.append({'id': _id, 'name': winre.sub('',name)[:WIN_LENGTH], 'units':[], 'pdfs':[]})
for index, ptext in chapter_ptext:
inx = int(index)-1
pdfs = re_pdf.findall(ptext)
pdf_list = [{'name':winre.sub('', pdf[0])[:WIN_LENGTH], 'url':pdf[1]} for pdf in pdfs]
self.infos[inx]['pdfs'] = pdf_list
unit_list = re.findall(r'<a +class="chapter-body-content-text section-event-t no-load"[\s\S]*?data-secId="(\d+)"[\s\S]*?<span +class="chapter-s">(\d+)</span><span>.</span>\s*?<span +class="chapter-t">(\d+)</span>(.*?)</a>', text1)
for unit_id,unit_inx1, unit_inx2,unit_name in unit_list:
inx1 = int(unit_inx1)-1
inx2 = int(unit_inx2)-1
self.infos[inx1]['units'].append({'id': unit_id, 'name': winre.sub('',unit_name)[:WIN_LENGTH], 'pdfs':[]})
m_str = match_str.format(unit_inx1, unit_inx2)
match_ptext = re.search(m_str, text2)
if match_ptext:
ptext = match_ptext.group(1)
pdfs = re_pdf.findall(ptext)
pdf_list = [{'name':winre.sub('', pdf[0])[:WIN_LENGTH], 'url':pdf[1]} for pdf in pdfs]
self.infos[inx1]['units'][inx2]['pdfs'] = pdf_list
def _get_course_links(self, sid):
mp4_list = []
pdf_list = []
data = {'sectionId': sid}
text = request_post(self.url_course, data)
#!!! except json.decoder.JSONDecodeError
infos = json.loads(text)
if infos['model']['listRes'] :
reslist = infos['model']['listRes']
for res in reslist:
if res['mediaType'] == 'mp4':
if 'fullResUrl' in res:
mp4_list.append((res['fullResUrl'], res['title']))
elif res['mediaType'] in ('ppt', 'pdf'):
if 'fullResUrl' in res:
pdf_list.append((res['fullResUrl'], res['title']))
return mp4_list, pdf_list
def _get_paper_links(self):
url = self.url_paper + self.cid
paper_list = []
text = request_get(url)
match_text = re.findall(r'<a +data-class="media"((.|\n)+?)>', text)
re_url = re.compile(r'data-url="(.*?)"')
re_title = re.compile(r'data-title="(.*?)"')
for m_text in match_text:
link_list = re_url.findall(m_text[0])
title_list = re_title.findall(m_text[0])
paper_list += list(zip(link_list, title_list))
return paper_list
def _get_source_links(self):
url = self.url_source + self.cid
source_list = []
text = request_get(url)
match_text = re.findall(r'<a +class="courseshareresources-content clearfix"((.|\n)+?)>', text)
re_url = re.compile(r'data-url="(.*?)"')
re_title = re.compile(r'data-title="(.*?)"')
for m_text in match_text:
link_list = re_url.findall(m_text[0])
title_list = re_title.findall(m_text[0])
source_list += list(zip(link_list, title_list))
return source_list
def _download(self):
print('\n{:^{}s}'.format(self.title, LEN_S))
self.rootDir = rootDir = os.path.join(PATH, self.title)
if not os.path.exists(rootDir):
os.mkdir(rootDir)
Icourse_Base.potplayer.init(rootDir)
if (self.mode & IS_MP4) or (self.mode & IS_PDF):
courseDir = os.path.join(rootDir, COURSENAME)
if not os.path.exists(courseDir):
os.mkdir(courseDir)
print('-'*LEN_+'下载课程'+'-'*LEN_)
Icourse_Base.potplayer.enable()
for cnt1, info in enumerate(self.infos, 1):
chapter = '{'+str(cnt1)+'}--'+info['name']
print(chapter)
chapterDir = os.path.join(courseDir, chapter)
if not os.path.exists(chapterDir):
os.mkdir(chapterDir)
mp4_list, pdf_list = self._get_course_links(info['id'])
pdf_list += [(pdf['url'], pdf['name']) for pdf in info['pdfs']]
if self.mode & IS_PDF:
self.download_pdf_list(chapterDir, pdf_list, '{}.'.format(cnt1))
if self.mode & IS_MP4:
self.download_video_list(chapterDir, mp4_list, '{}.'.format(cnt1))
for cnt2, unit in enumerate(info['units'],1):
lesson = '{'+str(cnt2)+'}--'+unit['name']
print(" "+lesson)
lessonDir = os.path.join(chapterDir, lesson)
if not os.path.exists(lessonDir):
os.mkdir(lessonDir)
mp4_list, pdf_list = self._get_course_links(unit['id'])
pdf_list += [(pdf['url'], pdf['name']) for pdf in unit['pdfs']]
if self.mode & IS_PDF:
self.download_pdf_list(lessonDir, pdf_list, '{}.{}.'.format(cnt1,cnt2))
if self.mode & IS_MP4:
self.download_video_list(lessonDir, mp4_list, '{}.{}.'.format(cnt1,cnt2))
if self.mode & IS_PAPER:
paperDir = os.path.join(rootDir, PAPERNAME)
if not os.path.exists(paperDir):
os.mkdir(paperDir)
print("-"*LEN_+"下载试卷"+"-"*LEN_)
paper_list = self._get_paper_links()
self.download_pdf_list(paperDir, paper_list)
if self.mode & IS_SOURCE:
sourceDir = os.path.join(rootDir, SOURCENAME)
if not os.path.exists(sourceDir):
os.mkdir(sourceDir)
print("-"*LEN_+"下载资源"+"-"*LEN_)
Icourse_Base.potplayer.disable()
source_list = self._get_source_links()
pdf_list = list(filter(lambda x:x[0].endswith('.pdf'), source_list))
mp4_list = list(filter(lambda x:x[0].endswith('.mp4'), source_list))
self.download_pdf_list(sourceDir, pdf_list)
self.download_video_list(sourceDir, mp4_list)
def set_mode(self):
while True:
try:
instr = input(
" 视频:[1] + 课件:[2] + 试卷:[4] + 资源:[8]\n"
"请输入一个0-15的数选择性下载内容(如15表示全部下载,15=1+2+4+8) [0退出]: "
)
if not instr:
continue
try:
innum = int(instr)
if innum == 0:
return False
elif 1 <= innum <= 15:
self.mode = innum
return True
else:
print("请输入一个0-15之间的整数!")
continue
except ValueError:
print("请输入一个0-15之间的整数!")
except KeyboardInterrupt:
print()
def main():
# url = 'http://www.icourses.cn/sCourse/course_4860.html'
url = 'http://www.icourses.cn/web/sword/portal/shareDetails?cId=4860#/course/chapter'
# url = 'https://www.icourses.cn/sCourse/course_6661.html'
# url = 'http://www.icourses.cn/sCourse/course_3459.html'
icourse_mooc = Icourse_Mooc()
if (icourse_mooc.set_mode()):
icourse_mooc.prepare(url)
icourse_mooc.download()
if __name__ == '__main__':
main()
================================================
FILE: Mooc/Icourses/__init__.py
================================================
================================================
FILE: Mooc/Mooc_Base.py
================================================
'''
Mooc 的虚基类:用于派生所有Mooc子类
'''
import os
from abc import ABC, abstractmethod
from Mooc.Mooc_Config import *
from Mooc.Mooc_Download import *
from Mooc.Mooc_Request import *
__all__ = [
"Mooc_Base"
]
class Mooc_Base(ABC):
def __init__(self):
self.__mode = None
self.__cid = None
self.__title = None
self.__infos = None
self.__rootDir = None
@property
def mode(self):
'''下载模式: 用于选择性下载'''
return self.__mode
@mode.setter
def mode(self, mode):
self.__mode = mode
@property
def cid(self):
'''课程的 ID'''
return self.__cid
@cid.setter
def cid(self, cid):
self.__cid = cid
@property
def title(self):
'''课程的标题'''
return self.__title
@title.setter
def title(self, title):
self.__title = title
@property
def infos(self):
'''解析后的课程信息'''
return self.__infos
@property
def rootDir(self):
return self.__rootDir
@rootDir.setter
def rootDir(self, rootDir):
self.__rootDir = rootDir
@infos.setter
def infos(self, infos):
self.__infos = infos
@abstractmethod
def _get_cid(self):
pass
@abstractmethod
def _get_title(self):
pass
@abstractmethod
def _get_infos(self):
pass
@abstractmethod
def _download(self):
pass
@abstractmethod
def set_mode(self):
pass
@abstractmethod
def prepare(self, url):
pass
@abstractmethod
def download(self):
pass
@classmethod
def download_video(cls, video_url, video_name, video_dir):
'''下载 MP4 视频文件'''
succeed = True
if not cls.judge_file_existed(video_dir, video_name, '.mp4'):
try:
header = request_head(video_url)
size = float(header['Content-Length']) / (1024*1024)
print(" |-{} [mp4] 大小: {:.2f}M".format(cls.align(video_name,LENGTH), size))
aria2_download_file(video_url, video_name+'.mp4', video_dir)
except DownloadFailed:
print(" |-{} [mp4] 资源无法下载!".format(cls.align(video_name,LENGTH)))
succeed = False
else:
print(" |-{} [mp4] 已经成功下载!".format(cls.align(video_name,LENGTH)))
return succeed
@classmethod
def download_pdf(cls, pdf_url, pdf_name, pdf_dir):
'''下载 PDF '''
succeed = True
if not cls.judge_file_existed(pdf_dir, pdf_name, '.pdf'):
try:
aria2_download_file(pdf_url, pdf_name+'.pdf', pdf_dir)
print(" |-{} (pdf) 已经成功下载!".format(cls.align(pdf_name,LENGTH)))
except DownloadFailed:
print(" |-{} (pdf) 资源无法下载!".format(cls.align(pdf_name,LENGTH)))
succeed = False
else:
print(" |-{} (pdf) 已经成功下载!".format(cls.align(pdf_name,LENGTH)))
return succeed
@classmethod
def download_sub(cls, sub_url, sub_name, sub_dir):
'''下载字幕'''
succeed = True
if not cls.judge_file_existed(sub_dir, sub_name, '.srt'):
try:
aria2_download_file(sub_url, sub_name+'.srt', sub_dir)
except DownloadFailed:
succeed = False
return succeed
@staticmethod
def judge_file_existed(dirname, filename, fmt):
'''
judge_file_existed(dirname, filename, fmt)
判断在 dirname 目录下是否存在已下载成功的格式为 fmt 且文件名为 filename 的文件
'''
filepath = os.path.join(dirname, filename)
exist1 = os.path.exists(filepath+fmt)
exist2 = os.path.exists(filepath+fmt+'.aria2')
return exist1 and not exist2
@staticmethod
def align(string, width): # 对齐汉字字符窜,同时截断多余输出
'''
align(string, width) 根据width宽度居中对齐字符窜 string,主要用于汉字居中
'''
res = ""
size = 0
for ch in string:
if (size+3 > width):
break
size += 1 if ord(ch) <= 127 else 2
res += ch
res += (width-size)*' '
return res
================================================
FILE: Mooc/Mooc_Config.py
================================================
'''
Mooc 总项目的配置文件
'''
import sys
import os
import re
# 常量,固定参数
__QQgroup__ = "196020837"
__email__ = "py.jun@qq.com"
if hasattr(sys, 'frozen'):
PATH = os.path.dirname(sys.executable)
else:
PATH = os.path.dirname(os.path.abspath(__file__)) # 程序当前路径
winre = re.compile(r'[?*|<>:"/\\\s]') # windoes 文件非法字符匹配
WIN_LENGTH = 64
TIMEOUT = 60 # 请求超时时间
PLAYLIST = '播放列表.dpl'
PALYBACK = 'DPL_PYJUN'
BATNAME = '修复播放列表.bat'
BATSTRING = '''\
@echo off
copy {0} {1}
echo 成功修复“{1}”
echo 请用Potplayer播放器打开“{1}”观看视频(未安装Potplayer自行百度下载安装)
pause
'''.format(PALYBACK, PLAYLIST)
LENGTH = 80
# 变量,可修改的参数
download_speed = "0"
if getattr(sys, 'frozen', False): #是否打包
aria2_path = os.path.join(sys._MEIPASS, "aria2c.exe")
alipay_path = os.path.join(sys._MEIPASS, "Alipay.jpg")
else:
aria2_path = os.path.join(PATH, "aria2c.exe")
alipay_path = os.path.join(PATH, "Alipay.jpg")
aira2_cmd = '%s --header "User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36 -- fUcIvJ01pZVQhNq23lXm9gjazkeonsCx" --check-certificate=false -x 16 -s 64 -j 64 -k 2M --disk-cache 128M --max-overall-download-limit %s "{url:}" -d "{dirname:}" -o "{filename:}"'%(aria2_path, download_speed)
# 课程链接的正则匹配
courses_re = {
"icourse163_mooc": re.compile(r'\s*https?://www.icourse163.org/((learn)|(course))/(.*?)(#/.*)?$'),
"icourse_cuoc": re.compile(r'\s*https?://www.icourses.cn/web/sword/portal/videoDetail\?courseId=([\w-]*)'),
"icourse_mooc": re.compile(r'\s*((https?://www.icourses.cn/sCourse/course_(\d+).html)|'
r'(https?://www.icourses.cn/web/sword/portal/shareDetails\?cId=(\d+)))')
}
__all__ = [
"__QQgroup__", "__email__", "PATH", "winre", "TIMEOUT", "PLAYLIST", "PALYBACK",
"BATNAME", "BATSTRING", "LENGTH", "WIN_LENGTH",
"download_speed", "aria2_path", "aira2_cmd", "courses_re", "alipay_path"
]
================================================
FILE: Mooc/Mooc_Download.py
================================================
'''
Mooc 下载功能模块:调用 aria2c.exe 下载文件
'''
import os
import re
import subprocess
from time import sleep
from Mooc.Mooc_Config import *
__all__ = [
"aria2_download_file", "DownloadFailed"
]
RE_SPEED = re.compile(r'\d+MiB/(\d+)MiB\((\d+)%\).*?DL:(\d*?\.?\d*?)([KM])iB')
RE_AVESPEED = re.compile(r'\|\s*?([\S]*?)([KM])iB/s\|')
class DownloadFailed(Exception):
pass
def aria2_download_file(url, filename, dirname='.'):
cnt = 0
while cnt < 3:
p = None
try:
cmd = aira2_cmd.format(url=url, dirname=dirname, filename=filename)
p = subprocess.Popen(cmd, shell=True, stdout=subprocess.PIPE, universal_newlines=True, encoding='utf8')
lines = ''
while p.poll() is None:
line = p.stdout.readline().strip()
if filename.endswith('.mp4') and line:
lines += line
match = RE_SPEED.search(line)
if match:
size, percent, speed, unit = match.groups()
percent = float(percent)
speed = float(speed)
if unit == 'K':
speed /= 1024
per = min(int(LENGTH*percent/100) , LENGTH)
print('\r |-['+per*'*'+(LENGTH-per)*'.'+'] {:.0f}% {:.2f}M/s'.format(percent,speed),end=' (ctrl+c中断)')
if p.returncode != 0:
cnt += 1
if cnt==1:
clear_files(dirname, filename)
sleep(0.16)
else:
if filename.endswith('.mp4'):
match = RE_AVESPEED.search(lines)
if match:
ave_speed, unit = match.groups()
ave_speed = float(ave_speed)
if unit == 'K':
ave_speed /= 1024
print('\r |-['+LENGTH*'*'+'] {:.0f}% {:.2f}M/s'.format(100,ave_speed),end=' (完成) \n')
return
finally:
if p:
p.kill() # 保证子进程已终止
clear_files(dirname, filename)
raise DownloadFailed("download failed")
def clear_files(dirname, filename):
filepath = os.path.join(dirname, filename)
if os.path.exists(filepath):
os.remove(filepath)
if os.path.exists(filepath+'.aria2'):
os.remove(filepath+'.aria2')
================================================
FILE: Mooc/Mooc_Interface.py
================================================
'''
Mooc 人机交互的接口函数
'''
import os
import re
if __package__ is None:
import sys
sys.path.append('.\\')
sys.path.append("..\\")
from Mooc.Mooc_Config import *
from Mooc.Mooc_Request import *
from Mooc.Mooc_Download import *
from Mooc.Icourse163.Icourse163_Mooc import *
from Mooc.Icourses.Icourse_Cuoc import *
from Mooc.Icourses.Icourse_Mooc import *
__all__ = [
"mooc_interface"
]
# 课程名对应的Mooc类
courses_mooc = {
"icourse163_mooc": Icourse163_Mooc,
"icourse_cuoc": Icourse_Cuoc,
"icourse_mooc": Icourse_Mooc
}
def mooc_interface():
try:
while True:
os.system("cls")
print("\t"+"="*91)
print('\t|\t\t 慕课下载器(免费版v3.4.2) \tQQ群: {:^27s} |'.format(__QQgroup__))
print("\t|\t\t icourse163.org, icourses.cn \t邮箱: {:^27s} |".format(__email__))
print("\t"+"="*91)
print("\t{:^90}".format("Github: https://github.com/PyJun/Mooc_Downloader"))
print("\t{:^90}".format("博客: https://blog.csdn.net/qq_16166591/article/details/85249743"))
print("\t{:^90}".format("下载路径: "+PATH))
urlstr = None
while not urlstr:
try:
urlstr = input('\n输入一个视频课程网址(q退出): ')
except KeyboardInterrupt:
print()
if urlstr == 'q':
break
mooc = match_mooc(urlstr)
if not mooc:
input("视频课程链接不合法,请回车继续...")
continue
if not mooc.set_mode():
continue
print("正在连接资源......")
try:
mooc.prepare(urlstr)
except RequestFailed:
print("网路请求异常!")
input("请按回车键返回主界面...")
continue
while True:
try:
isdownload = mooc.download()
if isdownload:
print('"{}" 下载完毕!'.format(mooc.title))
print("下载路径: {}".format(mooc.rootDir))
os.startfile(mooc.rootDir)
else:
print('"{}" 还未开课!'.format(mooc.title))
input("请按回车键返回主界面...")
break
except (RequestFailed, DownloadFailed) as err:
if isinstance(err, RequestFailed):
print("网路请求异常!")
else:
print("文件下载异常!")
if inquire():
continue
else:
break
except KeyboardInterrupt:
print()
if inquire():
continue
else:
break
except:
print("程序异常退出,希望反馈作者!")
return
except KeyboardInterrupt:
input("程序退出...")
finally:
# if (input("\n小哥哥,小姐姐,打个赏再走呗 …(⊙_⊙)… [y/n]: ") != 'n'):
# os.startfile(alipay_path)
os.system("pause")
def inquire():
redown = None
while redown not in ('y','n'):
try:
redown = input("是否继续[y/n]: ")
except (KeyboardInterrupt, EOFError):
print()
return redown=='y'
def match_mooc(url):
mooc = None
for mooc_name in courses_mooc:
if courses_re.get(mooc_name).match(url):
mooc = courses_mooc.get(mooc_name)()
break
return mooc
def main():
mooc_interface()
if __name__ == '__main__':
main()
================================================
FILE: Mooc/Mooc_Main.py
================================================
'''
Mooc下载器主程序
作者:PyJun
邮箱:py.jun@qq.com
'''
if __package__ is None:
import sys
sys.path.append('.\\')
sys.path.append('..\\')
from Mooc.Mooc_Interface import *
def main():
try:
mooc_interface()
except:
pass
if __name__ == '__main__':
main()
================================================
FILE: Mooc/Mooc_Potplayer.py
================================================
'''
Mooc 生成 potplayer 播放列表 dpl 文件的类
'''
import os
from functools import wraps
from Mooc.Mooc_Config import *
__all__ = [
"Mooc_Potplayer"
]
class Mooc_Potplayer():
def __init__(self):
self.cnt = 0
self.lines = []
self.available = False
def init(self, rootdir):
self.rootdir = rootdir
self.listpath = os.path.join(rootdir, PLAYLIST)
self.listpath_back = os.path.join(rootdir, PALYBACK)
self.batpath = os.path.join(rootdir, BATNAME)
def __call__(self, func):
@wraps(func)
def wrap_func(*args, **kwargs):
succeed = func(*args, **kwargs)
if self.available and succeed:
self.cnt += 1
video_dir = kwargs['video_dir']
video_name = kwargs['video_name']
video_path = os.path.join(video_dir, video_name+'.mp4')
video_relpath = os.path.relpath(video_path, self.rootdir)
if self.lines == [] and self.cnt == 1:
self.lines.append('DAUMPLAYLIST\n')
self.lines.append("playname=%s\n"%(video_relpath))
with open(self.batpath, 'w') as batfile:
batfile.write(BATSTRING)
self.lines.append("%d*file*%s\n"%(self.cnt,video_relpath))
self.lines.append("%d*title*%s\n"%(self.cnt,video_name))
self.update()
return succeed
return wrap_func
def update(self):
with open(self.listpath, 'w', encoding='utf8') as listfile:
listfile.writelines(self.lines)
with open(self.listpath_back, 'w', encoding='utf8') as listfile:
listfile.writelines(self.lines)
def enable(self):
self.cnt = 0
self.lines = []
self.available = True
def disable(self):
self.available = False
================================================
FILE: Mooc/Mooc_Request.py
================================================
'''
Mooc 的请求模块:包含 get, post, head 常用的三大请求
'''
from time import sleep
from functools import wraps
from socket import timeout, setdefaulttimeout
from urllib import request, parse
from urllib.error import ContentTooShortError, URLError, HTTPError
from Mooc.Mooc_Config import *
__all__ = [
'RequestFailed', 'request_get', 'request_post', 'request_head', 'request_check'
]
headers = ("User-Agent","Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36") #这里模拟浏览器
opener = request.build_opener()
opener.addheaders = [headers]
request.install_opener(opener)
setdefaulttimeout(TIMEOUT)
class RequestFailed(Exception):
pass
def request_decorate(count=3):
def decorate(func):
@wraps(func)
def wrap_func(*args, **kwargs):
cnt = 0
while True:
try:
return func(*args, **kwargs)
except (ContentTooShortError, URLError, HTTPError, ConnectionResetError):
cnt += 1
if cnt >= count:
break
sleep(0.32)
except (timeout):
break
raise RequestFailed("request failed")
return wrap_func
return decorate
@request_decorate()
def request_get(url, decoding='utf8'):
'''get请求'''
req = request.Request(url=url)
response = request.urlopen(req, timeout=TIMEOUT)
text = response.read().decode(decoding)
response.close()
return text
@request_decorate()
def request_post(url, data, decoding='utf8'):
'''post请求'''
data = parse.urlencode(data).encode('utf8')
req = request.Request(url=url, data=data, method='POST')
response = request.urlopen(req, timeout=TIMEOUT)
text = response.read().decode(decoding)
response.close()
return text
@request_decorate()
def request_head(url):
'''head请求'''
req = request.Request(url=url);
response = request.urlopen(req, timeout=TIMEOUT)
header = dict(response.getheaders())
response.close()
return header
@request_decorate(1)
def request_check(url):
'''检查url是否可以访问'''
req = request.Request(url=url);
response = request.urlopen(req, timeout=TIMEOUT//10)
response.close()
================================================
FILE: Mooc/__init__.py
================================================
'''
Mooc下载器版本 3.4.1
作者 PyJun
邮箱 py.jun@qq.com
github https://github.com/PyJun/Mooc_Downloader
博客 https://blog.csdn.net/qq_16166591/article/details/85249743
'''
__version__ = 'Mooc-3.4.1'
__author__ = 'PyJun'
__email__ = 'py.jun@qq.com'
__github__ = 'https://github.com/PyJun/Mooc_Downloader'
__blog__ = 'https://blog.csdn.net/qq_16166591/article/details/85249743'
================================================
FILE: Mooc/__main__.py
================================================
from Mooc.Mooc_Main import main
main()
================================================
FILE: Mooc.spec
================================================
# -*- mode: python -*-
block_cipher = None
a = Analysis(['Mooc\\Mooc_Main.py'],
pathex=['.'],
binaries=[],
datas=[
('Mooc\\aria2c.exe', '.'),
('Mooc\\Alipay.jpg', '.')
],
hiddenimports=[],
hookspath=[],
runtime_hooks=[],
excludes=[],
win_no_prefer_redirects=False,
win_private_assemblies=False,
cipher=block_cipher,
noarchive=False)
pyz = PYZ(a.pure, a.zipped_data,
cipher=block_cipher)
exe = EXE(pyz,
a.scripts,
a.binaries,
a.zipfiles,
a.datas,
[],
name='Mooc-3.4.2',
debug=False,
bootloader_ignore_signals=False,
strip=False,
upx=True,
runtime_tmpdir=None,
console=True , icon='Mooc\\Mooc.ico')
================================================
FILE: README.md
================================================
### 基于Python 爬虫的慕课视频下载【开源代码停止维护,软件仍在维护更新】
##### 1. 项目简介:
- 项目环境为 Windows10, Python3
- 用 Python3.6 urllib3 模块爬虫,涉及模块包括标准库、三方库和其它开源组件,已打包成exe文件
- 支持Mooc视频,字幕,课件下载,课程以目录树形式下载到硬盘,支持Potplayer播放
- 支持中国大学,网易云课堂,网易公开课,有道精品课,有道领世,启航教育,腾讯课堂,腾讯会议,钉钉,飞书,中公网校,荔枝微课,海豚知道,伯索云学堂,爱问云,家辉云,百家云,学浪,抖音课堂,B站课堂,希望学,希望学素养,希望优课,研途考研,高途,途途,高途高中规划,高途素养,千聊,兴趣岛,橙啦,爱课程,学堂在线,超星学习通(学银在线),知到智慧树,智慧职教,华尔街学堂,等网课的视频课程下载,核心下载调用 Aria2c
- 用户可以直接下载 Release 下的 [学无止下载器](https://github.com/PyJun/Mooc_Downloader/releases) 安装即可使用
- 有关下载器的使用以及相关问题,点击查看[Mooc下载器帮助文档](https://github.com/PyJun/Mooc_Downloader/wiki)
##### 2. 功能演示:
##### 4.项目文件
- Mooc_Main.py 整个项目的主程序, 其实是调用了 Mooc_Interface
- Mooc_Interface.py 人机交互接口模块
- Mooc_Config.py Mooc 的配置文件
- Mooc_Base.py Mooc 抽象基类
- Mooc_Potplayer.py 用于生成专用于 Potplayer 播放的 dpl 文件
- Mooc_Request.py 用 urllib 包装的一个Mooc请求库
- Mooc_Download.py 调用 Aira2c 下载的命令接口
- Icourses 有关爱课程的模块包
- Icourse_Base.py 爱课程下载器的基类,继承自 Mooc_Base
- Icourse_Config.py 配置文件
- Icourse_Cuoc.py 爱课程视频公开课的下载的子类,http://www.icourses.cn/cuoc/
- Icourse_Mooc.py 爱课程资源共享课的下载的子类,http://www.icourses.cn/mooc/
- Icourse163 有关中国大学慕课的模块包
- Icourse163_Base.py 中国大学慕课下载器的基类,继承自 Mooc_Base
- Icourse163_Config.py 配置文件
- Icourse163_Mooc.py 中国大学慕课下载器得子类,继承自 Icourse163_Base.py
##### 5.运行项目
请确保在项目工程的根目录下,然后在终端输入以下指令(python3 环境,无依赖的第三方模块)
```powershell
python -m Mooc
```
##### 6.打包指令
1. 首先确保已经安装 **pyinstaller**,若未安装,则用 pip 安装,打开终端,输入:
```powershell
pip install pyinstaller
```
2. 然后在项目工程的根目录下,终端输入:
```powershell
pyinstaller Mooc.spec
```
3. 最后会在项目工程根目录下出现一个**dist**文件夹,该文件夹会出现一个**Mooc-3.4.0.exe**程序
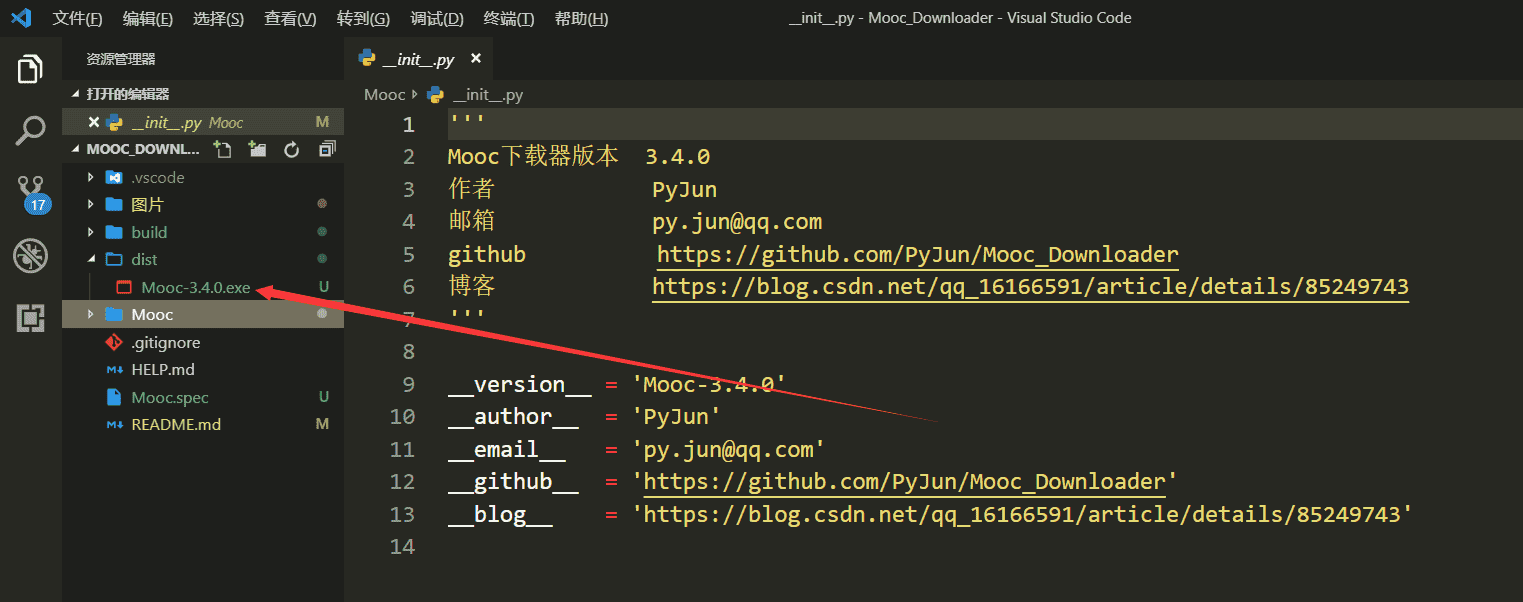
##### 7.注意事项
项目代码已好久未更新,Releases下有我打包好的exe文件,可直接下载使用~
【该项目为早期开源的代码,最新版本代码未开源】
1. 新版代码涉及网站爬虫、解析、解密,开源后容易和谐失效
2. 新版本涉及太多的模块依赖(包括且不限于nodejs,electron,ariac2,annie,ffmpeg,wkhtmltopdf和一些自编译的python依赖库),难以分离出可独立可用的开源版
3. 实在没有精力同时维护二个开源和闭源版本的代码
4. 该项目并非完整的开源项目,提供的软件无病毒,可免费使用(也包含付费功能)
gitextract_45xe85x4/ ├── .gitignore ├── HELP.md ├── Mooc/ │ ├── Icourse163/ │ │ ├── Icourse163_Base.py │ │ ├── Icourse163_Config.py │ │ ├── Icourse163_Mooc.py │ │ └── __init__.py │ ├── Icourses/ │ │ ├── Icourse_Base.py │ │ ├── Icourse_Config.py │ │ ├── Icourse_Cuoc.py │ │ ├── Icourse_Mooc.py │ │ └── __init__.py │ ├── Mooc_Base.py │ ├── Mooc_Config.py │ ├── Mooc_Download.py │ ├── Mooc_Interface.py │ ├── Mooc_Main.py │ ├── Mooc_Potplayer.py │ ├── Mooc_Request.py │ ├── __init__.py │ └── __main__.py ├── Mooc.spec └── README.md
SYMBOL INDEX (92 symbols across 11 files)
FILE: Mooc/Icourse163/Icourse163_Base.py
class Icourse163_Base (line 18) | class Icourse163_Base(Mooc_Base):
method __init__ (line 21) | def __init__(self):
method term_id (line 27) | def term_id(self):
method term_id (line 31) | def term_id(self, term_id):
method set_mode (line 34) | def set_mode(self):
method download_video (line 57) | def download_video(cls, video_url, video_name, video_dir):
FILE: Mooc/Icourse163/Icourse163_Mooc.py
class Icourse163_Mooc (line 23) | class Icourse163_Mooc(Icourse163_Base):
method __init__ (line 52) | def __init__(self, mode=IS_SHD):
method _get_cid (line 56) | def _get_cid(self, url):
method _get_title (line 62) | def _get_title(self):
method _get_infos (line 76) | def _get_infos(self):
method _get_source_text (line 99) | def _get_source_text(self, params):
method _get_pdf_url (line 106) | def _get_pdf_url(self, params):
method _get_video_url (line 114) | def _get_video_url(self, params):
method _download (line 128) | def _download(self): # 根据课程视频链接来下载高清MP4慕课视频, 成功下载完毕返回 True
method prepare (line 163) | def prepare(self, url):
method download (line 168) | def download(self):
function main (line 175) | def main():
FILE: Mooc/Icourses/Icourse_Base.py
class Icourse_Base (line 21) | class Icourse_Base(Mooc_Base):
method __init__ (line 24) | def __init__(self):
method prepare (line 29) | def prepare(self, url):
method download (line 34) | def download(self):
method cid (line 41) | def cid(self):
method cid (line 45) | def cid(self, cid):
method _get_cid (line 49) | def _get_cid(self, url):
method set_mode (line 52) | def set_mode(self):
method download_video (line 57) | def download_video(cls, video_url, video_name, video_dir):
method download_video_list (line 61) | def download_video_list(cls, dirpath, mp4list, prefix=''):
method download_pdf_list (line 68) | def download_pdf_list(cls, dirpath, pdflist, prefix=''):
FILE: Mooc/Icourses/Icourse_Cuoc.py
class Icourse_Cuoc (line 21) | class Icourse_Cuoc(Icourse_Base):
method __init__ (line 23) | def __init__(self):
method _get_cid (line 26) | def _get_cid(self, url):
method _get_title (line 32) | def _get_title(self):
method _get_infos (line 44) | def _get_infos(self):
method _download (line 56) | def _download(self):
function main (line 69) | def main():
FILE: Mooc/Icourses/Icourse_Mooc.py
class Icourse_Mooc (line 22) | class Icourse_Mooc(Icourse_Base):
method __init__ (line 30) | def __init__(self, mode=IS_MP4|IS_PDF|IS_PAPER|IS_SOURCE):
method _get_cid (line 34) | def _get_cid(self, url):
method _get_title (line 41) | def _get_title(self):
method _get_infos (line 53) | def _get_infos(self):
method _get_course_links (line 86) | def _get_course_links(self, sid):
method _get_paper_links (line 104) | def _get_paper_links(self):
method _get_source_links (line 117) | def _get_source_links(self):
method _download (line 130) | def _download(self):
method set_mode (line 185) | def set_mode(self):
function main (line 210) | def main():
FILE: Mooc/Mooc_Base.py
class Mooc_Base (line 15) | class Mooc_Base(ABC):
method __init__ (line 16) | def __init__(self):
method mode (line 24) | def mode(self):
method mode (line 29) | def mode(self, mode):
method cid (line 33) | def cid(self):
method cid (line 38) | def cid(self, cid):
method title (line 42) | def title(self):
method title (line 47) | def title(self, title):
method infos (line 51) | def infos(self):
method rootDir (line 56) | def rootDir(self):
method rootDir (line 60) | def rootDir(self, rootDir):
method infos (line 64) | def infos(self, infos):
method _get_cid (line 68) | def _get_cid(self):
method _get_title (line 72) | def _get_title(self):
method _get_infos (line 76) | def _get_infos(self):
method _download (line 80) | def _download(self):
method set_mode (line 84) | def set_mode(self):
method prepare (line 88) | def prepare(self, url):
method download (line 92) | def download(self):
method download_video (line 96) | def download_video(cls, video_url, video_name, video_dir):
method download_pdf (line 113) | def download_pdf(cls, pdf_url, pdf_name, pdf_dir):
method download_sub (line 128) | def download_sub(cls, sub_url, sub_name, sub_dir):
method judge_file_existed (line 139) | def judge_file_existed(dirname, filename, fmt):
method align (line 150) | def align(string, width): # 对齐汉字字符窜,同时截断多余输出
FILE: Mooc/Mooc_Download.py
class DownloadFailed (line 18) | class DownloadFailed(Exception):
function aria2_download_file (line 21) | def aria2_download_file(url, filename, dirname='.'):
function clear_files (line 64) | def clear_files(dirname, filename):
FILE: Mooc/Mooc_Interface.py
function mooc_interface (line 29) | def mooc_interface():
function inquire (line 97) | def inquire():
function match_mooc (line 106) | def match_mooc(url):
function main (line 114) | def main():
FILE: Mooc/Mooc_Main.py
function main (line 14) | def main():
FILE: Mooc/Mooc_Potplayer.py
class Mooc_Potplayer (line 13) | class Mooc_Potplayer():
method __init__ (line 14) | def __init__(self):
method init (line 19) | def init(self, rootdir):
method __call__ (line 25) | def __call__(self, func):
method update (line 46) | def update(self):
method enable (line 52) | def enable(self):
method disable (line 57) | def disable(self):
FILE: Mooc/Mooc_Request.py
class RequestFailed (line 22) | class RequestFailed(Exception):
function request_decorate (line 25) | def request_decorate(count=3):
function request_get (line 45) | def request_get(url, decoding='utf8'):
function request_post (line 54) | def request_post(url, data, decoding='utf8'):
function request_head (line 64) | def request_head(url):
function request_check (line 73) | def request_check(url):
Condensed preview — 22 files, each showing path, character count, and a content snippet. Download the .json file or copy for the full structured content (54K chars).
[
{
"path": ".gitignore",
"chars": 89,
"preview": ".vscode\nMooc/__pycache__\nMooc/Icourse163/__pycache__\nMooc/Icourses/__pycache__\nbuild\ndist"
},
{
"path": "HELP.md",
"chars": 2064,
"preview": "### 学无止网课下载器帮助文档\n\n\n\n#### 一. 软件下载:\n\n------\n\n1. [Github Releases](https://github.com/PyJun/Mooc_Downloader/releases)\n2. ["
},
{
"path": "Mooc/Icourse163/Icourse163_Base.py",
"chars": 1513,
"preview": "'''\n Icourse163 抽象基类\n'''\n\nimport os\nif __package__ is None:\n import sys\n sys.path.append('../')\nfrom Mooc.Mooc_"
},
{
"path": "Mooc/Icourse163/Icourse163_Config.py",
"chars": 110,
"preview": "'''\n Icourse163 模块包的配置文件\n'''\n\nCOURSENAME = '{1}--课程'\nIS_SHD, IS_HD, IS_SD, ONLY_PDF = 1, 2, 3, 4\nLEN_S = 96"
},
{
"path": "Mooc/Icourse163/Icourse163_Mooc.py",
"chars": 7696,
"preview": "'''\n www.icourse163.org 下所有免费课程的下载和解析\n'''\n\nimport os\nimport re\nif __package__ is None:\n import sys\n sys.path.ap"
},
{
"path": "Mooc/Icourse163/__init__.py",
"chars": 0,
"preview": ""
},
{
"path": "Mooc/Icourses/Icourse_Base.py",
"chars": 1929,
"preview": "'''\n 定义一个爱课程 Icourse 的虚基类\n 用于派生 Icourse_Cuoc 和 Icourse_Mooc\n'''\n\nimport os\nfrom abc import abstractmethod\nif __pac"
},
{
"path": "Mooc/Icourses/Icourse_Config.py",
"chars": 168,
"preview": "'''\n Icourse 模块包的配置文件\n'''\n\n\nCOURSENAME = '{1}--课程'\nPAPERNAME = '{2}--试卷'\nSOURCENAME = '{3}--资源'\nIS_MP4, IS_PDF, IS_PA"
},
{
"path": "Mooc/Icourses/Icourse_Cuoc.py",
"chars": 2820,
"preview": "'''\n www.icourses.cn/cuoc/ 下的视频公开课下载解析\n'''\n\nimport os\nimport re\nimport json\nif __package__ is None:\n import sys\n "
},
{
"path": "Mooc/Icourses/Icourse_Mooc.py",
"chars": 9894,
"preview": "'''\n www.icourses.cn/mooc/ 下的资源共享课下载解析\n'''\n\nimport os\nimport re\nimport json\nif __package__ is None:\n import sys\n "
},
{
"path": "Mooc/Icourses/__init__.py",
"chars": 0,
"preview": ""
},
{
"path": "Mooc/Mooc_Base.py",
"chars": 4150,
"preview": "'''\n Mooc 的虚基类:用于派生所有Mooc子类\n'''\n\nimport os\nfrom abc import ABC, abstractmethod\nfrom Mooc.Mooc_Config import *\nfrom Mo"
},
{
"path": "Mooc/Mooc_Config.py",
"chars": 1915,
"preview": "'''\n Mooc 总项目的配置文件\n'''\n\nimport sys\nimport os\nimport re\n\n\n# 常量,固定参数\n__QQgroup__ = \"196020837\"\n__email__ = \"py.jun@qq."
},
{
"path": "Mooc/Mooc_Download.py",
"chars": 2428,
"preview": "'''\n Mooc 下载功能模块:调用 aria2c.exe 下载文件\n'''\n\nimport os\nimport re\nimport subprocess\nfrom time import sleep\nfrom Mooc.Mooc_"
},
{
"path": "Mooc/Mooc_Interface.py",
"chars": 3583,
"preview": "'''\n Mooc 人机交互的接口函数\n'''\n\nimport os\nimport re\nif __package__ is None:\n import sys\n sys.path.append('.\\\\')\n sy"
},
{
"path": "Mooc/Mooc_Main.py",
"chars": 298,
"preview": "'''\n Mooc下载器主程序\n\n 作者:PyJun\n 邮箱:py.jun@qq.com\n'''\n\nif __package__ is None:\n import sys\n sys.path.append('."
},
{
"path": "Mooc/Mooc_Potplayer.py",
"chars": 1889,
"preview": "'''\n Mooc 生成 potplayer 播放列表 dpl 文件的类\n'''\n\nimport os\nfrom functools import wraps\nfrom Mooc.Mooc_Config import * \n\n__al"
},
{
"path": "Mooc/Mooc_Request.py",
"chars": 2288,
"preview": "'''\n Mooc 的请求模块:包含 get, post, head 常用的三大请求\n'''\n\nfrom time import sleep\nfrom functools import wraps\nfrom socket import"
},
{
"path": "Mooc/__init__.py",
"chars": 415,
"preview": "'''\nMooc下载器版本 3.4.1\n作者 PyJun\n邮箱 py.jun@qq.com\ngithub https://github.com/PyJun/Mooc_Downl"
},
{
"path": "Mooc/__main__.py",
"chars": 40,
"preview": "from Mooc.Mooc_Main import main\n\nmain()\n"
},
{
"path": "Mooc.spec",
"chars": 917,
"preview": "# -*- mode: python -*-\n\nblock_cipher = None\n\n\na = Analysis(['Mooc\\\\Mooc_Main.py'],\n pathex=['.'],\n "
},
{
"path": "README.md",
"chars": 2217,
"preview": "### \t\t\t\t基于Python 爬虫的慕课视频下载【开源代码停止维护,软件仍在维护更新】\n\n##### 1. 项目简介:\n\n- 项目环境为 Windows10, Python3\n- 用 Python3.6 urllib3 模块爬虫,涉"
}
]
About this extraction
This page contains the full source code of the PyJun/Mooc_Downloader GitHub repository, extracted and formatted as plain text for AI agents and large language models (LLMs). The extraction includes 22 files (45.3 KB), approximately 13.9k tokens, and a symbol index with 92 extracted functions, classes, methods, constants, and types. Use this with OpenClaw, Claude, ChatGPT, Cursor, Windsurf, or any other AI tool that accepts text input. You can copy the full output to your clipboard or download it as a .txt file.
Extracted by GitExtract — free GitHub repo to text converter for AI. Built by Nikandr Surkov.