Repository: RUCAIBox/CRSLab
Branch: main
Commit: 649793891999
Files: 253
Total size: 590.2 KB
Directory structure:
gitextract_o03n7yor/
├── .gitattributes
├── .gitignore
├── .readthedocs.yml
├── LICENSE
├── README.md
├── README_CN.md
├── config/
│ ├── conversation/
│ │ ├── gpt2/
│ │ │ ├── durecdial.yaml
│ │ │ ├── gorecdial.yaml
│ │ │ ├── inspired.yaml
│ │ │ ├── opendialkg.yaml
│ │ │ ├── redial.yaml
│ │ │ └── tgredial.yaml
│ │ └── transformer/
│ │ ├── durecdial.yaml
│ │ ├── gorecdial.yaml
│ │ ├── inspired.yaml
│ │ ├── opendialkg.yaml
│ │ ├── redial.yaml
│ │ └── tgredial.yaml
│ ├── crs/
│ │ ├── inspired/
│ │ │ ├── durecdial.yaml
│ │ │ ├── gorecdial.yaml
│ │ │ ├── inspired.yaml
│ │ │ ├── opendialkg.yaml
│ │ │ ├── redial.yaml
│ │ │ └── tgredial.yaml
│ │ ├── kbrd/
│ │ │ ├── durecdial.yaml
│ │ │ ├── gorecdial.yaml
│ │ │ ├── inspired.yaml
│ │ │ ├── opendialkg.yaml
│ │ │ ├── redial.yaml
│ │ │ └── tgredial.yaml
│ │ ├── kgsf/
│ │ │ ├── durecdial.yaml
│ │ │ ├── gorecdial.yaml
│ │ │ ├── inspired.yaml
│ │ │ ├── opendialkg.yaml
│ │ │ ├── redial.yaml
│ │ │ └── tgredial.yaml
│ │ ├── ntrd/
│ │ │ └── tgredial.yaml
│ │ ├── redial/
│ │ │ ├── durecdial.yaml
│ │ │ ├── gorecdial.yaml
│ │ │ ├── inspired.yaml
│ │ │ ├── opendialkg.yaml
│ │ │ ├── redial.yaml
│ │ │ └── tgredial.yaml
│ │ └── tgredial/
│ │ ├── durecdial.yaml
│ │ ├── gorecdial.yaml
│ │ ├── inspired.yaml
│ │ ├── opendialkg.yaml
│ │ ├── redial.yaml
│ │ └── tgredial.yaml
│ ├── policy/
│ │ ├── conv_bert/
│ │ │ └── tgredial.yaml
│ │ ├── mgcg/
│ │ │ └── tgredial.yaml
│ │ ├── pmi/
│ │ │ └── tgredial.yaml
│ │ ├── profile_bert/
│ │ │ └── tgredial.yaml
│ │ └── topic_bert/
│ │ └── tgredial.yaml
│ └── recommendation/
│ ├── bert/
│ │ ├── durecdial.yaml
│ │ ├── gorecdial.yaml
│ │ ├── inspired.yaml
│ │ ├── opendialkg.yaml
│ │ ├── redial.yaml
│ │ └── tgredial.yaml
│ ├── gru4rec/
│ │ ├── durecdial.yaml
│ │ ├── gorecdial.yaml
│ │ ├── inspired.yaml
│ │ ├── opendialkg.yaml
│ │ ├── redial.yaml
│ │ └── tgredial.yaml
│ ├── popularity/
│ │ ├── durecdial.yaml
│ │ ├── gorecdial.yaml
│ │ ├── inspired.yaml
│ │ ├── opendialkg.yaml
│ │ ├── redial.yaml
│ │ └── tgredial.yaml
│ ├── sasrec/
│ │ ├── durecdial.yaml
│ │ ├── gorecdial.yaml
│ │ ├── inspired.yaml
│ │ ├── opendialkg.yaml
│ │ ├── redial.yaml
│ │ └── tgredial.yaml
│ └── textcnn/
│ ├── durecdial.yaml
│ ├── gorecdial.yaml
│ ├── inspired.yaml
│ ├── opendialkg.yaml
│ ├── redial.yaml
│ └── tgredial.yaml
├── crslab/
│ ├── __init__.py
│ ├── config/
│ │ ├── __init__.py
│ │ └── config.py
│ ├── data/
│ │ ├── __init__.py
│ │ ├── dataloader/
│ │ │ ├── __init__.py
│ │ │ ├── base.py
│ │ │ ├── inspired.py
│ │ │ ├── kbrd.py
│ │ │ ├── kgsf.py
│ │ │ ├── ntrd.py
│ │ │ ├── redial.py
│ │ │ ├── tgredial.py
│ │ │ └── utils.py
│ │ └── dataset/
│ │ ├── __init__.py
│ │ ├── base.py
│ │ ├── durecdial/
│ │ │ ├── __init__.py
│ │ │ ├── durecdial.py
│ │ │ └── resources.py
│ │ ├── gorecdial/
│ │ │ ├── __init__.py
│ │ │ ├── gorecdial.py
│ │ │ └── resources.py
│ │ ├── inspired/
│ │ │ ├── __init__.py
│ │ │ ├── inspired.py
│ │ │ └── resources.py
│ │ ├── opendialkg/
│ │ │ ├── __init__.py
│ │ │ ├── opendialkg.py
│ │ │ └── resources.py
│ │ ├── redial/
│ │ │ ├── __init__.py
│ │ │ ├── redial.py
│ │ │ └── resources.py
│ │ └── tgredial/
│ │ ├── __init__.py
│ │ ├── resources.py
│ │ └── tgredial.py
│ ├── download.py
│ ├── evaluator/
│ │ ├── __init__.py
│ │ ├── base.py
│ │ ├── conv.py
│ │ ├── embeddings.py
│ │ ├── end2end.py
│ │ ├── metrics/
│ │ │ ├── __init__.py
│ │ │ ├── base.py
│ │ │ ├── gen.py
│ │ │ └── rec.py
│ │ ├── rec.py
│ │ ├── standard.py
│ │ └── utils.py
│ ├── model/
│ │ ├── __init__.py
│ │ ├── base.py
│ │ ├── conversation/
│ │ │ ├── __init__.py
│ │ │ ├── gpt2/
│ │ │ │ ├── __init__.py
│ │ │ │ └── gpt2.py
│ │ │ └── transformer/
│ │ │ ├── __init__.py
│ │ │ └── transformer.py
│ │ ├── crs/
│ │ │ ├── __init__.py
│ │ │ ├── inspired/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── inspired_conv.py
│ │ │ │ ├── inspired_rec.py
│ │ │ │ └── modules.py
│ │ │ ├── kbrd/
│ │ │ │ ├── __init__.py
│ │ │ │ └── kbrd.py
│ │ │ ├── kgsf/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── kgsf.py
│ │ │ │ ├── modules.py
│ │ │ │ └── resources.py
│ │ │ ├── ntrd/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── modules.py
│ │ │ │ ├── ntrd.py
│ │ │ │ └── resources.py
│ │ │ ├── redial/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── modules.py
│ │ │ │ ├── redial_conv.py
│ │ │ │ └── redial_rec.py
│ │ │ └── tgredial/
│ │ │ ├── __init__.py
│ │ │ ├── tg_conv.py
│ │ │ ├── tg_policy.py
│ │ │ └── tg_rec.py
│ │ ├── policy/
│ │ │ ├── __init__.py
│ │ │ ├── conv_bert/
│ │ │ │ ├── __init__.py
│ │ │ │ └── conv_bert.py
│ │ │ ├── mgcg/
│ │ │ │ ├── __init__.py
│ │ │ │ └── mgcg.py
│ │ │ ├── pmi/
│ │ │ │ ├── __init__.py
│ │ │ │ └── pmi.py
│ │ │ ├── profile_bert/
│ │ │ │ ├── __init__.py
│ │ │ │ └── profile_bert.py
│ │ │ └── topic_bert/
│ │ │ ├── __init__.py
│ │ │ └── topic_bert.py
│ │ ├── pretrained_models.py
│ │ ├── recommendation/
│ │ │ ├── __init__.py
│ │ │ ├── bert/
│ │ │ │ ├── __init__.py
│ │ │ │ └── bert.py
│ │ │ ├── gru4rec/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── gru4rec.py
│ │ │ │ └── modules.py
│ │ │ ├── popularity/
│ │ │ │ ├── __init__.py
│ │ │ │ └── popularity.py
│ │ │ ├── sasrec/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── modules.py
│ │ │ │ └── sasrec.py
│ │ │ └── textcnn/
│ │ │ ├── __init__.py
│ │ │ └── textcnn.py
│ │ └── utils/
│ │ ├── __init__.py
│ │ ├── functions.py
│ │ └── modules/
│ │ ├── __init__.py
│ │ ├── attention.py
│ │ └── transformer.py
│ ├── quick_start/
│ │ ├── __init__.py
│ │ └── quick_start.py
│ └── system/
│ ├── __init__.py
│ ├── base.py
│ ├── inspired.py
│ ├── kbrd.py
│ ├── kgsf.py
│ ├── ntrd.py
│ ├── redial.py
│ ├── tgredial.py
│ └── utils/
│ ├── __init__.py
│ ├── functions.py
│ └── lr_scheduler.py
├── docs/
│ ├── Makefile
│ ├── make.bat
│ ├── requirements.txt
│ ├── requirements_geometric.txt
│ ├── requirements_sphinx.txt
│ ├── requirements_torch.txt
│ └── source/
│ ├── api/
│ │ ├── crslab.config.rst
│ │ ├── crslab.data.dataloader.rst
│ │ ├── crslab.data.dataset.durecdial.rst
│ │ ├── crslab.data.dataset.gorecdial.rst
│ │ ├── crslab.data.dataset.inspired.rst
│ │ ├── crslab.data.dataset.opendialkg.rst
│ │ ├── crslab.data.dataset.redial.rst
│ │ ├── crslab.data.dataset.rst
│ │ ├── crslab.data.dataset.tgredial.rst
│ │ ├── crslab.data.rst
│ │ ├── crslab.evaluator.metrics.rst
│ │ ├── crslab.evaluator.rst
│ │ ├── crslab.model.conversation.gpt2.rst
│ │ ├── crslab.model.conversation.rst
│ │ ├── crslab.model.conversation.transformer.rst
│ │ ├── crslab.model.crs.kbrd.rst
│ │ ├── crslab.model.crs.kgsf.rst
│ │ ├── crslab.model.crs.redial.rst
│ │ ├── crslab.model.crs.rst
│ │ ├── crslab.model.crs.tgredial.rst
│ │ ├── crslab.model.policy.conv_bert.rst
│ │ ├── crslab.model.policy.mgcg.rst
│ │ ├── crslab.model.policy.pmi.rst
│ │ ├── crslab.model.policy.profile_bert.rst
│ │ ├── crslab.model.policy.rst
│ │ ├── crslab.model.policy.topic_bert.rst
│ │ ├── crslab.model.recommendation.bert.rst
│ │ ├── crslab.model.recommendation.gru4rec.rst
│ │ ├── crslab.model.recommendation.popularity.rst
│ │ ├── crslab.model.recommendation.rst
│ │ ├── crslab.model.recommendation.sasrec.rst
│ │ ├── crslab.model.recommendation.textcnn.rst
│ │ ├── crslab.model.rst
│ │ ├── crslab.model.utils.modules.rst
│ │ ├── crslab.model.utils.rst
│ │ ├── crslab.quick_start.rst
│ │ ├── crslab.rst
│ │ ├── crslab.system.rst
│ │ └── modules.rst
│ ├── conf.py
│ └── index.md
├── requirements.txt
├── run_crslab.py
└── setup.py
================================================
FILE CONTENTS
================================================
================================================
FILE: .gitattributes
================================================
* text=auto eol=lf
*.{cmd,[cC][mM][dD]} text eol=crlf
*.{bat,[bB][aA][tT]} text eol=crlf
================================================
FILE: .gitignore
================================================
# Created by .ignore support plugin (hsz.mobi)
### Project
data
log
save
!crslab/data
runs
### VisualStudioCode template
.vscode/*
!.vscode/settings.json
!.vscode/tasks.json
!.vscode/launch.json
!.vscode/extensions.json
*.code-workspace
# Local History for Visual Studio Code
.history/
### Python template
# Byte-compiled / optimized / DLL files
__pycache__/
*.py[cod]
*$py.class
# C extensions
*.so
# Distribution / packaging
.Python
build/
develop-eggs/
dist/
downloads/
eggs/
.eggs/
lib/
lib64/
parts/
sdist/
var/
wheels/
share/python-wheels/
*.egg-info/
.installed.cfg
*.egg
MANIFEST
# PyInstaller
# Usually these files are written by a python script from a template
# before PyInstaller builds the exe, so as to inject date/other infos into it.
*.manifest
*.spec
# Installer logs
pip-log.txt
pip-delete-this-directory.txt
# Unit test / coverage reports
htmlcov/
.tox/
.nox/
.coverage
.coverage.*
.cache
nosetests.xml
coverage.xml
*.cover
*.py,cover
.hypothesis/
.pytest_cache/
cover/
# Translations
*.mo
*.pot
# Django stuff:
*.log
local_settings.py
db.sqlite3
db.sqlite3-journal
# Flask stuff:
instance/
.webassets-cache
# Scrapy stuff:
.scrapy
# Sphinx documentation
docs/_build/
# PyBuilder
.pybuilder/
target/
# Jupyter Notebook
.ipynb_checkpoints
# IPython
profile_default/
ipython_config.py
# pyenv
# For a library or package, you might want to ignore these files since the code is
# intended to run in multiple environments; otherwise, check them in:
# .python-version
# pipenv
# According to pypa/pipenv#598, it is recommended to include Pipfile.lock in version control.
# However, in case of collaboration, if having platform-specific dependencies or dependencies
# having no cross-platform support, pipenv may install dependencies that don't work, or not
# install all needed dependencies.
#Pipfile.lock
# PEP 582; used by e.g. github.com/David-OConnor/pyflow
__pypackages__/
# Celery stuff
celerybeat-schedule
celerybeat.pid
# SageMath parsed files
*.sage.py
# Environments
.env
.venv
env/
venv/
ENV/
env.bak/
venv.bak/
# Spyder project settings
.spyderproject
.spyproject
# Rope project settings
.ropeproject
# mkdocs documentation
/site
# mypy
.mypy_cache/
.dmypy.json
dmypy.json
# Pyre type checker
.pyre/
# pytype static type analyzer
.pytype/
# Cython debug symbols
cython_debug/
### JetBrains template
# Covers JetBrains IDEs: IntelliJ, RubyMine, PhpStorm, AppCode, PyCharm, CLion, Android Studio, WebStorm and Rider
# Reference: https://intellij-support.jetbrains.com/hc/en-us/articles/206544839
# User-specific stuff
.idea/**/workspace.xml
.idea/**/tasks.xml
.idea/**/usage.statistics.xml
.idea/**/dictionaries
.idea/**/shelf
# Generated files
.idea/**/contentModel.xml
# Sensitive or high-churn files
.idea/**/dataSources/
.idea/**/dataSources.ids
.idea/**/dataSources.local.xml
.idea/**/sqlDataSources.xml
.idea/**/dynamic.xml
.idea/**/uiDesigner.xml
.idea/**/dbnavigator.xml
# Gradle
.idea/**/gradle.xml
.idea/**/libraries
# Gradle and Maven with auto-import
# When using Gradle or Maven with auto-import, you should exclude module files,
# since they will be recreated, and may cause churn. Uncomment if using
# auto-import.
# .idea/artifacts
# .idea/compiler.xml
# .idea/jarRepositories.xml
# .idea/modules.xml
# .idea/*.iml
# .idea/modules
# *.iml
# *.ipr
# CMake
cmake-build-*/
# Mongo Explorer plugin
.idea/**/mongoSettings.xml
# File-based project format
*.iws
# IntelliJ
.idea
*.iml
out
gen
# mpeltonen/sbt-idea plugin
.idea_modules/
# JIRA plugin
atlassian-ide-plugin.xml
# Cursive Clojure plugin
.idea/replstate.xml
# Crashlytics plugin (for Android Studio and IntelliJ)
com_crashlytics_export_strings.xml
crashlytics.properties
crashlytics-build.properties
fabric.properties
# Editor-based Rest Client
.idea/httpRequests
# Android studio 3.1+ serialized cache file
.idea/caches/build_file_checksums.ser
### JupyterNotebooks template
# gitignore template for Jupyter Notebooks
# website: http://jupyter.org/
*/.ipynb_checkpoints/*
# Remove previous ipynb_checkpoints
# git rm -r .ipynb_checkpoints/
### macOS template
# General
.DS_Store
.AppleDouble
.LSOverride
# Icon must end with two \r
Icon
# Thumbnails
._*
# Files that might appear in the root of a volume
.DocumentRevisions-V100
.fseventsd
.Spotlight-V100
.TemporaryItems
.Trashes
.VolumeIcon.icns
.com.apple.timemachine.donotpresent
# Directories potentially created on remote AFP share
.AppleDB
.AppleDesktop
Network Trash Folder
Temporary Items
.apdisk
================================================
FILE: .readthedocs.yml
================================================
# Required
version: 2
# Build documentation in the docs/ directory with Sphinx
sphinx:
configuration: docs/source/conf.py
# Build documentation with MkDocs
#mkdocs:
# configuration: mkdocs.yml
# Optionally build your docs in additional formats such as PDF
formats: all
# Optionally set the version of Python and requirements required to build your docs
python:
version: 3.6
install:
- requirements: docs/requirements_torch.txt
- requirements: docs/requirements_geometric.txt
- requirements: docs/requirements.txt
- requirements: docs/requirements_sphinx.txt
================================================
FILE: LICENSE
================================================
MIT License
Copyright (c) 2021 RUCAIBox
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE.
================================================
FILE: README.md
================================================
# CRSLab
[](https://pypi.org/project/crslab)
[](https://github.com/rucaibox/crslab/releases)
[](./LICENSE)
[](https://arxiv.org/abs/2101.00939)
[](https://crslab.readthedocs.io/en/latest/?badge=latest)
[Paper](https://arxiv.org/pdf/2101.00939.pdf) | [Docs](https://crslab.readthedocs.io/en/latest/?badge=latest)
| [中文版](./README_CN.md)
**CRSLab** is an open-source toolkit for building Conversational Recommender System (CRS). It is developed based on
Python and PyTorch. CRSLab has the following highlights:
- **Comprehensive benchmark models and datasets**: We have integrated commonly-used 6 datasets and 18 models, including graph neural network and pre-training models such as R-GCN, BERT and GPT-2. We have preprocessed these datasets to support these models, and release for downloading.
- **Extensive and standard evaluation protocols**: We support a series of widely-adopted evaluation protocols for testing and comparing different CRS.
- **General and extensible structure**: We design a general and extensible structure to unify various conversational recommendation datasets and models, in which we integrate various built-in interfaces and functions for quickly development.
- **Easy to get started**: We provide simple yet flexible configuration for new researchers to quickly start in our library.
- **Human-machine interaction interfaces**: We provide flexible human-machine interaction interfaces for researchers to conduct qualitative analysis.
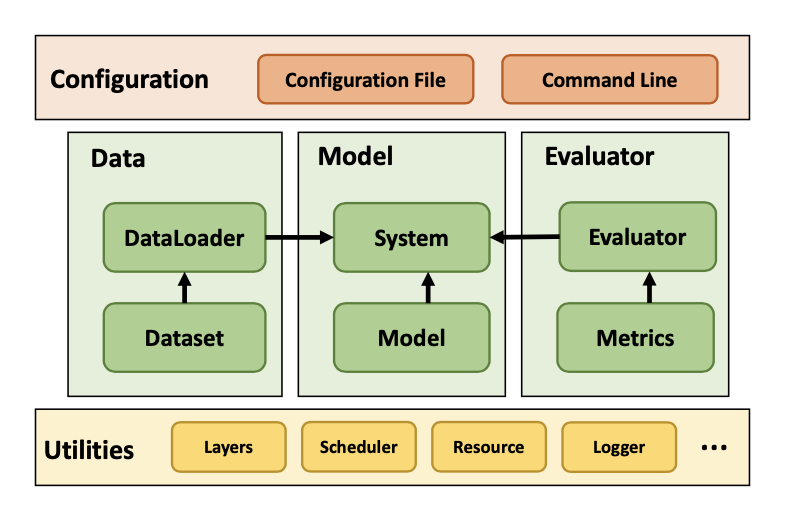
Figure 1: The overall framework of CRSLab
- [Installation](#Installation)
- [Quick-Start](#Quick-Start)
- [Models](#Models)
- [Datasets](#Datasets)
- [Performance](#Performance)
- [Releases](#Releases)
- [Contributions](#Contributions)
- [Citing](#Citing)
- [Team](#Team)
- [License](#License)
## Installation
CRSLab works with the following operating systems:
- Linux
- Windows 10
- macOS X
CRSLab requires Python version 3.7 or later.
CRSLab requires torch version 1.8. If you want to use CRSLab with GPU, please ensure that CUDA or CUDAToolkit version is 10.2 or later. Please use the combinations shown in this [Link](https://pytorch-geometric.com/whl/) to ensure the normal operation of PyTorch Geometric.
### Install PyTorch
Use PyTorch [Locally Installation](https://pytorch.org/get-started/locally/) or [Previous Versions Installation](https://pytorch.org/get-started/previous-versions/) commands to install PyTorch. For example, on Linux and Windows 10:
```bash
# CUDA 10.2
conda install pytorch==1.8.0 torchvision==0.9.0 torchaudio==0.8.0 cudatoolkit=10.2 -c pytorch
# CUDA 11.1
conda install pytorch==1.8.0 torchvision==0.9.0 torchaudio==0.8.0 cudatoolkit=11.1 -c pytorch -c conda-forge
# CPU Only
conda install pytorch==1.8.0 torchvision==0.9.0 torchaudio==0.8.0 cpuonly -c pytorch
```
If you want to use CRSLab with GPU, make sure the following command prints `True` after installation:
```bash
$ python -c "import torch; print(torch.cuda.is_available())"
>>> True
```
### Install PyTorch Geometric
Ensure that at least PyTorch 1.8.0 is installed:
```bash
$ python -c "import torch; print(torch.__version__)"
>>> 1.8.0
```
Find the CUDA version PyTorch was installed with:
```bash
$ python -c "import torch; print(torch.version.cuda)"
>>> 11.1
```
For Linux:
Install the relevant packages:
```
conda install pyg -c pyg
```
For others:
Check PyG [installation documents](https://pytorch-geometric.readthedocs.io/en/latest/install/installation.html) to install the relevant packages.
### Install CRSLab
You can install from pip:
```bash
pip install crslab
```
OR install from source:
```bash
git clone https://github.com/RUCAIBox/CRSLab && cd CRSLab
pip install -e .
```
## Quick-Start
With the source code, you can use the provided script for initial usage of our library with cpu by default:
```bash
python run_crslab.py --config config/crs/kgsf/redial.yaml
```
The system will complete the data preprocessing, and training, validation, testing of each model in turn. Finally it will get the evaluation results of specified models.
If you want to save pre-processed datasets and training results of models, you can use the following command:
```bash
python run_crslab.py --config config/crs/kgsf/redial.yaml --save_data --save_system
```
In summary, there are following arguments in `run_crslab.py`:
- `--config` or `-c`: relative path for configuration file(yaml).
- `--gpu` or `-g`: specify GPU id(s) to use, we now support multiple GPUs. Defaults to CPU(-1).
- `--save_data` or `-sd`: save pre-processed dataset.
- `--restore_data` or `-rd`: restore pre-processed dataset from file.
- `--save_system` or `-ss`: save trained system.
- `--restore_system` or `-rs`: restore trained system from file.
- `--debug` or `-d`: use validation dataset to debug your system.
- `--interact` or `-i`: interact with your system instead of training.
- `--tensorboard` or `-tb`: enable tensorboard to monitor train performance.
## Models
In CRSLab, we unify the task description of conversational recommendation into three sub-tasks, namely recommendation (recommend user-preferred items), conversation (generate proper responses) and policy (select proper interactive action). The recommendation and conversation sub-tasks are the core of a CRS and have been studied in most of works. The policy sub-task is needed by recent works, by which the CRS can interact with users through purposeful strategy.
As the first release version, we have implemented 18 models in the four categories of CRS model, Recommendation model, Conversation model and Policy model.
| Category | Model | Graph Neural Network? | Pre-training Model? |
| :------------------: | :----------------------------------------------------------: | :-----------------------------: | :-----------------------------: |
| CRS Model | [ReDial](https://arxiv.org/abs/1812.07617)
[KBRD](https://arxiv.org/abs/1908.05391)
[KGSF](https://arxiv.org/abs/2007.04032)
[TG-ReDial](https://arxiv.org/abs/2010.04125)
[INSPIRED](https://www.aclweb.org/anthology/2020.emnlp-main.654.pdf) | ×
√
√
×
× | ×
×
×
√
√ |
| Recommendation model | Popularity
[GRU4Rec](https://arxiv.org/abs/1511.06939)
[SASRec](https://arxiv.org/abs/1808.09781)
[TextCNN](https://arxiv.org/abs/1408.5882)
[R-GCN](https://arxiv.org/abs/1703.06103)
[BERT](https://arxiv.org/abs/1810.04805) | ×
×
×
×
√
× | ×
×
×
×
×
√ |
| Conversation model | [HERD](https://arxiv.org/abs/1507.04808)
[Transformer](https://arxiv.org/abs/1706.03762)
[GPT-2](http://www.persagen.com/files/misc/radford2019language.pdf) | ×
×
× | ×
×
√ |
| Policy model | PMI
[MGCG](https://arxiv.org/abs/2005.03954)
[Conv-BERT](https://arxiv.org/abs/2010.04125)
[Topic-BERT](https://arxiv.org/abs/2010.04125)
[Profile-BERT](https://arxiv.org/abs/2010.04125) | ×
×
×
×
× | ×
×
√
√
√ |
Among them, the four CRS models integrate the recommendation model and the conversation model to improve each other, while others only specify an individual task.
For Recommendation model and Conversation model, we have respectively implemented the following commonly-used automatic evaluation metrics:
| Category | Metrics |
| :--------------------: | :----------------------------------------------------------: |
| Recommendation Metrics | Hit@{1, 10, 50}, MRR@{1, 10, 50}, NDCG@{1, 10, 50} |
| Conversation Metrics | PPL, BLEU-{1, 2, 3, 4}, Embedding Average/Extreme/Greedy, Distinct-{1, 2, 3, 4} |
| Policy Metrics | Accuracy, Hit@{1,3,5} |
## Datasets
We have collected and preprocessed 6 commonly-used human-annotated datasets, and each dataset was matched with proper KGs as shown below:
| Dataset | Dialogs | Utterances | Domains | Task Definition | Entity KG | Word KG |
| :----------------------------------------------------------: | :-----: | :--------: | :----------: | :-------------: | :--------: | :--------: |
| [ReDial](https://redialdata.github.io/website/) | 10,006 | 182,150 | Movie | -- | DBpedia | ConceptNet |
| [TG-ReDial](https://github.com/RUCAIBox/TG-ReDial) | 10,000 | 129,392 | Movie | Topic Guide | CN-DBpedia | HowNet |
| [GoRecDial](https://arxiv.org/abs/1909.03922) | 9,125 | 170,904 | Movie | Action Choice | DBpedia | ConceptNet |
| [DuRecDial](https://arxiv.org/abs/2005.03954) | 10,200 | 156,000 | Movie, Music | Goal Plan | CN-DBpedia | HowNet |
| [INSPIRED](https://github.com/sweetpeach/Inspired) | 1,001 | 35,811 | Movie | Social Strategy | DBpedia | ConceptNet |
| [OpenDialKG](https://github.com/facebookresearch/opendialkg) | 13,802 | 91,209 | Movie, Book | Path Generate | DBpedia | ConceptNet |
## Performance
We have trained and test the integrated models on the TG-Redial dataset, which is split into training, validation and test sets using a ratio of 8:1:1. For each conversation, we start from the first utterance, and generate reply utterances or recommendations in turn by our model. We perform the evaluation on the three sub-tasks.
### Recommendation Task
| Model | Hit@1 | Hit@10 | Hit@50 | MRR@1 | MRR@10 | MRR@50 | NDCG@1 | NDCG@10 | NDCG@50 |
| :-------: | :---------: | :--------: | :--------: | :---------: | :--------: | :--------: | :---------: | :--------: | :--------: |
| SASRec | 0.000446 | 0.00134 | 0.0160 | 0.000446 | 0.000576 | 0.00114 | 0.000445 | 0.00075 | 0.00380 |
| TextCNN | 0.00267 | 0.0103 | 0.0236 | 0.00267 | 0.00434 | 0.00493 | 0.00267 | 0.00570 | 0.00860 |
| BERT | 0.00722 | 0.00490 | 0.0281 | 0.00722 | 0.0106 | 0.0124 | 0.00490 | 0.0147 | 0.0239 |
| KBRD | 0.00401 | 0.0254 | 0.0588 | 0.00401 | 0.00891 | 0.0103 | 0.00401 | 0.0127 | 0.0198 |
| KGSF | 0.00535 | **0.0285** | **0.0771** | 0.00535 | 0.0114 | **0.0135** | 0.00535 | **0.0154** | **0.0259** |
| TG-ReDial | **0.00793** | 0.0251 | 0.0524 | **0.00793** | **0.0122** | 0.0134 | **0.00793** | 0.0152 | 0.0211 |
### Conversation Task
| Model | BLEU@1 | BLEU@2 | BLEU@3 | BLEU@4 | Dist@1 | Dist@2 | Dist@3 | Dist@4 | Average | Extreme | Greedy | PPL |
| :---------: | :-------: | :-------: | :--------: | :--------: | :------: | :------: | :------: | :------: | :-------: | :-------: | :-------: | :------: |
| HERD | 0.120 | 0.0141 | 0.00136 | 0.000350 | 0.181 | 0.369 | 0.847 | 1.30 | 0.697 | 0.382 | 0.639 | 472 |
| Transformer | 0.266 | 0.0440 | 0.0145 | 0.00651 | 0.324 | 0.837 | 2.02 | 3.06 | 0.879 | 0.438 | 0.680 | 30.9 |
| GPT2 | 0.0858 | 0.0119 | 0.00377 | 0.0110 | **2.35** | **4.62** | **8.84** | **12.5** | 0.763 | 0.297 | 0.583 | 9.26 |
| KBRD | 0.267 | 0.0458 | 0.0134 | 0.00579 | 0.469 | 1.50 | 3.40 | 4.90 | 0.863 | 0.398 | 0.710 | 52.5 |
| KGSF | **0.383** | **0.115** | **0.0444** | **0.0200** | 0.340 | 0.910 | 3.50 | 6.20 | **0.888** | **0.477** | **0.767** | 50.1 |
| TG-ReDial | 0.125 | 0.0204 | 0.00354 | 0.000803 | 0.881 | 1.75 | 7.00 | 12.0 | 0.810 | 0.332 | 0.598 | **7.41** |
### Policy Task
| Model | Hit@1 | Hit@10 | Hit@50 | MRR@1 | MRR@10 | MRR@50 | NDCG@1 | NDCG@10 | NDCG@50 |
| :--------: | :-------: | :-------: | :-------: | :-------: | :-------: | :-------: | :-------: | :-------: | :-------: |
| MGCG | 0.591 | 0.818 | 0.883 | 0.591 | 0.680 | 0.683 | 0.591 | 0.712 | 0.729 |
| Conv-BERT | 0.597 | 0.814 | 0.881 | 0.597 | 0.684 | 0.687 | 0.597 | 0.716 | 0.731 |
| Topic-BERT | 0.598 | 0.828 | 0.885 | 0.598 | 0.690 | 0.693 | 0.598 | 0.724 | 0.737 |
| TG-ReDial | **0.600** | **0.830** | **0.893** | **0.600** | **0.693** | **0.696** | **0.600** | **0.727** | **0.741** |
The above results were obtained from our CRSLab in preliminary experiments. However, these algorithms were implemented and tuned based on our understanding and experiences, which may not achieve their optimal performance. If you could yield a better result for some specific algorithm, please kindly let us know. We will update this table after the results are verified.
## Releases
| Releases | Date | Features |
| :------: | :-----------: | :----------: |
| v0.1.1 | 1 / 4 / 2021 | Basic CRSLab |
| v0.1.2 | 3 / 28 / 2021 | CRSLab |
## Contributions
Please let us know if you encounter a bug or have any suggestions by [filing an issue](https://github.com/RUCAIBox/CRSLab/issues).
We welcome all contributions from bug fixes to new features and extensions.
We expect all contributions discussed in the issue tracker and going through PRs.
We thank the nice contributions through PRs from [@shubaoyu](https://github.com/shubaoyu), [@ToheartZhang](https://github.com/ToheartZhang).
## Citing
If you find CRSLab useful for your research or development, please cite our [Paper](https://arxiv.org/pdf/2101.00939.pdf):
```
@article{crslab,
title={CRSLab: An Open-Source Toolkit for Building Conversational Recommender System},
author={Kun Zhou, Xiaolei Wang, Yuanhang Zhou, Chenzhan Shang, Yuan Cheng, Wayne Xin Zhao, Yaliang Li, Ji-Rong Wen},
year={2021},
journal={arXiv preprint arXiv:2101.00939}
}
```
## Team
**CRSLab** was developed and maintained by [AI Box](http://aibox.ruc.edu.cn/) group in RUC.
## License
**CRSLab** uses [MIT License](./LICENSE).
================================================
FILE: README_CN.md
================================================
# CRSLab
[](https://pypi.org/project/crslab)
[](https://github.com/rucaibox/crslab/releases)
[](./LICENSE)
[](https://arxiv.org/abs/2101.00939)
[](https://crslab.readthedocs.io/en/latest/?badge=latest)
[论文](https://arxiv.org/pdf/2101.00939.pdf) | [文档](https://crslab.readthedocs.io/en/latest/?badge=latest)
| [English Version](./README.md)
**CRSLab** 是一个用于构建对话推荐系统(CRS)的开源工具包,其基于 PyTorch 实现、主要面向研究者使用,并具有如下特色:
- **全面的基准模型和数据集**:我们集成了常用的 6 个数据集和 18 个模型,包括基于图神经网络和预训练模型,比如 GCN,BERT 和 GPT-2;我们还对数据集进行相关处理以支持这些模型,并提供预处理后的版本供大家下载。
- **大规模的标准评测**:我们支持一系列被广泛认可的评估方式来测试和比较不同的 CRS。
- **通用和可扩展的结构**:我们设计了通用和可扩展的结构来统一各种对话推荐数据集和模型,并集成了多种内置接口和函数以便于快速开发。
- **便捷的使用方法**:我们为新手提供了简单而灵活的配置,方便其快速启动集成在 CRSLab 中的模型。
- **人性化的人机交互接口**:我们提供了人性化的人机交互界面,以供研究者对比和测试不同的模型系统。
图片: CRSLab 的总体架构
- [安装](#安装)
- [快速上手](#快速上手)
- [模型](#模型)
- [数据集](#数据集)
- [评测结果](#评测结果)
- [发行版本](#发行版本)
- [贡献](#贡献)
- [引用](#引用)
- [项目团队](#项目团队)
- [免责声明](#免责声明)
## 安装
CRSLab 可以在以下几种系统上运行:
- Linux
- Windows 10
- macOS X
CRSLab 需要在 Python 3.7 或更高的环境下运行。
CRSLab 要求 torch 版本为1.8,如果你想在 GPU 上运行 CRSLab,请确保你的 CUDA 版本或者 CUDAToolkit 版本在 10.2 及以上。为保证 PyTorch Geometric 库的正常运行,请使用[链接](https://pytorch-geometric.com/whl/)所示的安装方式。
### 安装 PyTorch
使用 PyTorch [本地安装](https://pytorch.org/get-started/locally/)命令或者[先前版本安装](https://pytorch.org/get-started/previous-versions/)命令安装 PyTorch,比如在 Linux 和 Windows 下:
```bash
# CUDA 10.2
conda install pytorch==1.8.0 torchvision==0.9.0 torchaudio==0.8.0 cudatoolkit=10.2 -c pytorch
# CUDA 11.1
conda install pytorch==1.8.0 torchvision==0.9.0 torchaudio==0.8.0 cudatoolkit=11.1 -c pytorch -c conda-forge
# CPU Only
conda install pytorch==1.8.0 torchvision==0.9.0 torchaudio==0.8.0 cpuonly -c pytorch
```
安装完成后,如果你想在 GPU 上运行 CRSLab,请确保如下命令输出`True`:
```bash
$ python -c "import torch; print(torch.cuda.is_available())"
>>> True
```
### 安装 PyTorch Geometric
确保安装的 PyTorch 版本至少为 1.8.0:
```bash
$ python -c "import torch; print(torch.__version__)"
>>> 1.8.0
```
找到安装好的 PyTorch 对应的 CUDA 版本:
```bash
$ python -c "import torch; print(torch.version.cuda)"
>>> 11.1
```
在Linux下:
安装相关的包:
```bash
conda install pyg -c pyg
```
在其他系统下:
查看PyG[官方下载文档](https://pytorch-geometric.readthedocs.io/en/latest/install/installation.html)安装相关的包。
### 安装 CRSLab
你可以通过 pip 来安装:
```bash
pip install crslab
```
也可以通过源文件进行进行安装:
```bash
git clone https://github.com/RUCAIBox/CRSLab && cd CRSLab
pip install -e .
```
## 快速上手
从 GitHub 下载 CRSLab 后,可以使用提供的脚本快速运行和测试,默认使用CPU:
```bash
python run_crslab.py --config config/crs/kgsf/redial.yaml
```
系统将依次完成数据的预处理,以及各模块的训练、验证和测试,并得到指定的模型评测结果。
如果你希望保存数据预处理结果与模型训练结果,可以使用如下命令:
```bash
python run_crslab.py --config config/crs/kgsf/redial.yaml --save_data --save_system
```
总的来说,`run_crslab.py`有如下参数可供调用:
- `--config` 或 `-c`:配置文件的相对路径,以指定运行的模型与数据集。
- `--gpu` or `-g`:指定 GPU id,支持多 GPU,默认使用 CPU(-1)。
- `--save_data` 或 `-sd`:保存预处理的数据。
- `--restore_data` 或 `-rd`:从文件读取预处理的数据。
- `--save_system` 或 `-ss`:保存训练好的 CRS 系统。
- `--restore_system` 或 `-rs`:从文件载入提前训练好的系统。
- `--debug` 或 `-d`:用验证集代替训练集以方便调试。
- `--interact` 或 `-i`:与你的系统进行对话交互,而非进行训练。
- `--tensorboard` or `-tb`:使用 tensorboardX 组件来监测训练表现。
## 模型
在第一个发行版中,我们实现了 4 类共 18 个模型。这里我们将对话推荐任务主要拆分成三个任务:推荐任务(生成推荐的商品),对话任务(生成对话的回复)和策略任务(规划对话推荐的策略)。其中所有的对话推荐系统都具有对话和推荐任务,他们是对话推荐系统的核心功能。而策略任务是一个辅助任务,其致力于更好的控制对话推荐系统,在不同的模型中的实现也可能不同(如 TG-ReDial 采用一个主题预测模型,DuRecDial 中采用一个对话规划模型等):
| 类别 | 模型 | Graph Neural Network? | Pre-training Model? |
| :------: | :----------------------------------------------------------: | :-----------------------------: | :-----------------------------: |
| CRS 模型 | [ReDial](https://arxiv.org/abs/1812.07617)
[KBRD](https://arxiv.org/abs/1908.05391)
[KGSF](https://arxiv.org/abs/2007.04032)
[TG-ReDial](https://arxiv.org/abs/2010.04125)
[INSPIRED](https://www.aclweb.org/anthology/2020.emnlp-main.654.pdf) | ×
√
√
×
× | ×
×
×
√
√ |
| 推荐模型 | Popularity
[GRU4Rec](https://arxiv.org/abs/1511.06939)
[SASRec](https://arxiv.org/abs/1808.09781)
[TextCNN](https://arxiv.org/abs/1408.5882)
[R-GCN](https://arxiv.org/abs/1703.06103)
[BERT](https://arxiv.org/abs/1810.04805) | ×
×
×
×
√
× | ×
×
×
×
×
√ |
| 对话模型 | [HERD](https://arxiv.org/abs/1507.04808)
[Transformer](https://arxiv.org/abs/1706.03762)
[GPT-2](http://www.persagen.com/files/misc/radford2019language.pdf) | ×
×
× | ×
×
√ |
| 策略模型 | PMI
[MGCG](https://arxiv.org/abs/2005.03954)
[Conv-BERT](https://arxiv.org/abs/2010.04125)
[Topic-BERT](https://arxiv.org/abs/2010.04125)
[Profile-BERT](https://arxiv.org/abs/2010.04125) | ×
×
×
×
× | ×
×
√
√
√ |
其中,CRS 模型是指直接融合推荐模型和对话模型,以相互增强彼此的效果,故其内部往往已经包含了推荐、对话和策略模型。其他如推荐模型、对话模型、策略模型往往只关注以上任务中的某一个。
我们对于这几类模型,我们还分别实现了如下的自动评测指标模块:
| 类别 | 指标 |
| :------: | :----------------------------------------------------------: |
| 推荐指标 | Hit@{1, 10, 50}, MRR@{1, 10, 50}, NDCG@{1, 10, 50} |
| 对话指标 | PPL, BLEU-{1, 2, 3, 4}, Embedding Average/Extreme/Greedy, Distinct-{1, 2, 3, 4} |
| 策略指标 | Accuracy, Hit@{1,3,5} |
## 数据集
我们收集了 6 个常用的人工标注数据集,并对它们进行了预处理(包括引入外部知识图谱),以融入统一的 CRS 任务中。如下为相关数据集的统计数据:
| Dataset | Dialogs | Utterances | Domains | Task Definition | Entity KG | Word KG |
| :----------------------------------------------------------: | :-----: | :--------: | :----------: | :-------------: | :--------: | :--------: |
| [ReDial](https://redialdata.github.io/website/) | 10,006 | 182,150 | Movie | -- | DBpedia | ConceptNet |
| [TG-ReDial](https://github.com/RUCAIBox/TG-ReDial) | 10,000 | 129,392 | Movie | Topic Guide | CN-DBpedia | HowNet |
| [GoRecDial](https://arxiv.org/abs/1909.03922) | 9,125 | 170,904 | Movie | Action Choice | DBpedia | ConceptNet |
| [DuRecDial](https://arxiv.org/abs/2005.03954) | 10,200 | 156,000 | Movie, Music | Goal Plan | CN-DBpedia | HowNet |
| [INSPIRED](https://github.com/sweetpeach/Inspired) | 1,001 | 35,811 | Movie | Social Strategy | DBpedia | ConceptNet |
| [OpenDialKG](https://github.com/facebookresearch/opendialkg) | 13,802 | 91,209 | Movie, Book | Path Generate | DBpedia | ConceptNet |
## 评测结果
我们在 TG-ReDial 数据集上对模型进行了训练和测试,这里我们将数据集按照 8:1:1 切分。其中对于每条数据,我们从对话的第一轮开始,一轮一轮的进行推荐、策略生成、回复生成任务。下表记录了相关的评测结果。
### 推荐任务
| 模型 | Hit@1 | Hit@10 | Hit@50 | MRR@1 | MRR@10 | MRR@50 | NDCG@1 | NDCG@10 | NDCG@50 |
| :-------: | :---------: | :--------: | :--------: | :---------: | :--------: | :--------: | :---------: | :--------: | :--------: |
| SASRec | 0.000446 | 0.00134 | 0.0160 | 0.000446 | 0.000576 | 0.00114 | 0.000445 | 0.00075 | 0.00380 |
| TextCNN | 0.00267 | 0.0103 | 0.0236 | 0.00267 | 0.00434 | 0.00493 | 0.00267 | 0.00570 | 0.00860 |
| BERT | 0.00722 | 0.00490 | 0.0281 | 0.00722 | 0.0106 | 0.0124 | 0.00490 | 0.0147 | 0.0239 |
| KBRD | 0.00401 | 0.0254 | 0.0588 | 0.00401 | 0.00891 | 0.0103 | 0.00401 | 0.0127 | 0.0198 |
| KGSF | 0.00535 | **0.0285** | **0.0771** | 0.00535 | 0.0114 | **0.0135** | 0.00535 | **0.0154** | **0.0259** |
| TG-ReDial | **0.00793** | 0.0251 | 0.0524 | **0.00793** | **0.0122** | 0.0134 | **0.00793** | 0.0152 | 0.0211 |
### 对话任务
| 模型 | BLEU@1 | BLEU@2 | BLEU@3 | BLEU@4 | Dist@1 | Dist@2 | Dist@3 | Dist@4 | Average | Extreme | Greedy | PPL |
| :---------: | :-------: | :-------: | :--------: | :--------: | :------: | :------: | :------: | :------: | :-------: | :-------: | :-------: | :------: |
| HERD | 0.120 | 0.0141 | 0.00136 | 0.000350 | 0.181 | 0.369 | 0.847 | 1.30 | 0.697 | 0.382 | 0.639 | 472 |
| Transformer | 0.266 | 0.0440 | 0.0145 | 0.00651 | 0.324 | 0.837 | 2.02 | 3.06 | 0.879 | 0.438 | 0.680 | 30.9 |
| GPT2 | 0.0858 | 0.0119 | 0.00377 | 0.0110 | **2.35** | **4.62** | **8.84** | **12.5** | 0.763 | 0.297 | 0.583 | 9.26 |
| KBRD | 0.267 | 0.0458 | 0.0134 | 0.00579 | 0.469 | 1.50 | 3.40 | 4.90 | 0.863 | 0.398 | 0.710 | 52.5 |
| KGSF | **0.383** | **0.115** | **0.0444** | **0.0200** | 0.340 | 0.910 | 3.50 | 6.20 | **0.888** | **0.477** | **0.767** | 50.1 |
| TG-ReDial | 0.125 | 0.0204 | 0.00354 | 0.000803 | 0.881 | 1.75 | 7.00 | 12.0 | 0.810 | 0.332 | 0.598 | **7.41** |
### 策略任务
| 模型 | Hit@1 | Hit@10 | Hit@50 | MRR@1 | MRR@10 | MRR@50 | NDCG@1 | NDCG@10 | NDCG@50 |
| :--------: | :-------: | :-------: | :-------: | :-------: | :-------: | :-------: | :-------: | :-------: | :-------: |
| MGCG | 0.591 | 0.818 | 0.883 | 0.591 | 0.680 | 0.683 | 0.591 | 0.712 | 0.729 |
| Conv-BERT | 0.597 | 0.814 | 0.881 | 0.597 | 0.684 | 0.687 | 0.597 | 0.716 | 0.731 |
| Topic-BERT | 0.598 | 0.828 | 0.885 | 0.598 | 0.690 | 0.693 | 0.598 | 0.724 | 0.737 |
| TG-ReDial | **0.600** | **0.830** | **0.893** | **0.600** | **0.693** | **0.696** | **0.600** | **0.727** | **0.741** |
上述结果是我们使用 CRSLab 进行实验得到的。然而,这些算法是根据我们的经验和理解来实现和调参的,可能还没有达到它们的最佳性能。如果您能在某个具体算法上得到更好的结果,请告知我们。验证结果后,我们会更新该表。
## 发行版本
| 版本号 | 发行日期 | 特性 |
| :----: | :-----------: | :----------: |
| v0.1.1 | 1 / 4 / 2021 | Basic CRSLab |
| v0.1.2 | 3 / 28 / 2021 | CRSLab |
## 贡献
如果您遇到错误或有任何建议,请通过 [Issue](https://github.com/RUCAIBox/CRSLab/issues) 进行反馈
我们欢迎关于修复错误、添加新特性的任何贡献。
如果想贡献代码,请先在 Issue 中提出问题,然后再提 PR。
我们感谢 [@shubaoyu](https://github.com/shubaoyu), [@ToheartZhang](https://github.com/ToheartZhang) 通过 PR 为项目贡献的新特性。
## 引用
如果你觉得 CRSLab 对你的科研工作有帮助,请引用我们的[论文](https://arxiv.org/pdf/2101.00939.pdf):
```
@article{crslab,
title={CRSLab: An Open-Source Toolkit for Building Conversational Recommender System},
author={Kun Zhou, Xiaolei Wang, Yuanhang Zhou, Chenzhan Shang, Yuan Cheng, Wayne Xin Zhao, Yaliang Li, Ji-Rong Wen},
year={2021},
journal={arXiv preprint arXiv:2101.00939}
}
```
## 项目团队
**CRSLab** 由中国人民大学 [AI Box](http://aibox.ruc.edu.cn/) 小组开发和维护。
## 免责声明
**CRSLab** 基于 [MIT License](./LICENSE) 进行开发,本项目的所有数据和代码只能被用于学术目的。
================================================
FILE: config/conversation/gpt2/durecdial.yaml
================================================
# dataset
dataset: DuRecDial
tokenize:
conv: gpt2
# dataloader
context_truncate: 256
response_truncate: 30
item_truncate: 100
scale: 1
# model
conv_model: GPT2
# optim
conv:
epoch: 1
batch_size: 8
gradient_clip: 1.0
update_freq: 1
optimizer:
name: AdamW
lr: !!float 1.5e-4
lr_scheduler:
name: TransformersLinearLR
warmup_steps: 2000
================================================
FILE: config/conversation/gpt2/gorecdial.yaml
================================================
# dataset
dataset: GoRecDial
tokenize:
conv: gpt2
# dataloader
context_truncate: 256
response_truncate: 30
item_truncate: 100
scale: 1
# model
conv_model: GPT2
# optim
conv:
epoch: 1
batch_size: 4
gradient_clip: 1.0
update_freq: 1
optimizer:
name: AdamW
lr: !!float 1.5e-4
lr_scheduler:
name: TransformersLinearLR
warmup_steps: 2000
================================================
FILE: config/conversation/gpt2/inspired.yaml
================================================
# dataset
dataset: Inspired
tokenize:
conv: gpt2
# dataloader
context_truncate: 256
response_truncate: 30
item_truncate: 100
scale: 1
# model
conv_model: GPT2
# optim
conv:
epoch: 1
batch_size: 8
gradient_clip: 1.0
update_freq: 1
optimizer:
name: AdamW
lr: !!float 1.5e-4
lr_scheduler:
name: TransformersLinearLR
warmup_steps: 2000
================================================
FILE: config/conversation/gpt2/opendialkg.yaml
================================================
# dataset
dataset: OpenDialKG
tokenize:
conv: gpt2
# dataloader
context_truncate: 256
response_truncate: 30
item_truncate: 100
scale: 1
# model
conv_model: GPT2
# optim
conv:
epoch: 1
batch_size: 8
gradient_clip: 1.0
update_freq: 1
optimizer:
name: AdamW
lr: !!float 1.5e-4
lr_scheduler:
name: TransformersLinearLR
warmup_steps: 2000
================================================
FILE: config/conversation/gpt2/redial.yaml
================================================
# dataset
dataset: ReDial
tokenize:
conv: gpt2
# dataloader
context_truncate: 256
response_truncate: 30
item_truncate: 100
scale: 1
# model
conv_model: GPT2
# optim
conv:
epoch: 1
batch_size: 8
gradient_clip: 1.0
update_freq: 1
optimizer:
name: AdamW
lr: !!float 1.5e-4
lr_scheduler:
name: TransformersLinearLR
warmup_steps: 2000
================================================
FILE: config/conversation/gpt2/tgredial.yaml
================================================
# dataset
dataset: TGReDial
tokenize:
conv: gpt2
# dataloader
context_truncate: 256
response_truncate: 30
item_truncate: 100
scale: 1
# model
conv_model: GPT2
# optim
conv:
epoch: 50
batch_size: 8
gradient_clip: 1.0
update_freq: 1
early_stop: true
stop_mode: min
impatience: 3
optimizer:
name: AdamW
lr: !!float 1.5e-4
lr_scheduler:
name: TransformersLinearLR
warmup_steps: 2000
================================================
FILE: config/conversation/transformer/durecdial.yaml
================================================
# dataset
dataset: DuRecDial
tokenize:
conv: jieba
# dataloader
context_truncate: 1024
response_truncate: 1024
scale: 1
# model
conv_model: Transformer
token_emb_dim: 300
kg_emb_dim: 128
num_bases: 8
n_heads: 2
n_layers: 2
ffn_size: 300
dropout: 0.1
attention_dropout: 0.0
relu_dropout: 0.1
learn_positional_embeddings: false
embeddings_scale: true
reduction: false
n_positions: 1024
# optim
conv:
epoch: 1
batch_size: 64
early_stop: True
stop_mode: min
optimizer:
name: Adam
lr: !!float 1e-3
lr_scheduler:
name: ReduceLROnPlateau
patience: 3
factor: 0.5
================================================
FILE: config/conversation/transformer/gorecdial.yaml
================================================
# dataset
dataset: GoRecDial
tokenize:
conv: nltk
# dataloader
context_truncate: 1024
response_truncate: 1024
scale: 1
# model
conv_model: Transformer
token_emb_dim: 300
kg_emb_dim: 128
num_bases: 8
n_heads: 2
n_layers: 2
ffn_size: 300
dropout: 0.1
attention_dropout: 0.0
relu_dropout: 0.1
learn_positional_embeddings: false
embeddings_scale: true
reduction: false
n_positions: 1024
# optim
conv:
epoch: 1
batch_size: 256
optimizer:
name: Adam
lr: !!float 3e-3
lr_scheduler:
name: ReduceLROnPlateau
patience: 3
factor: 0.5
gradient_clip: 0.1
early_stop: true
stop_mode: min
impatience: 3
================================================
FILE: config/conversation/transformer/inspired.yaml
================================================
# dataset
dataset: Inspired
tokenize:
conv: nltk
# dataloader
context_truncate: 1024
response_truncate: 1024
scale: 1
# model
conv_model: Transformer
token_emb_dim: 300
kg_emb_dim: 128
num_bases: 8
n_heads: 2
n_layers: 2
ffn_size: 300
dropout: 0.1
attention_dropout: 0.0
relu_dropout: 0.1
learn_positional_embeddings: false
embeddings_scale: true
reduction: false
n_positions: 1024
# optim
conv:
epoch: 1
batch_size: 256
optimizer:
name: Adam
lr: !!float 3e-3
lr_scheduler:
name: ReduceLROnPlateau
patience: 3
factor: 0.5
gradient_clip: 0.1
early_stop: true
stop_mode: min
impatience: 3
================================================
FILE: config/conversation/transformer/opendialkg.yaml
================================================
# dataset
dataset: OpenDialKG
tokenize:
conv: nltk
# dataloader
context_truncate: 1024
response_truncate: 1024
scale: 1
# model
conv_model: Transformer
token_emb_dim: 300
kg_emb_dim: 128
num_bases: 8
n_heads: 2
n_layers: 2
ffn_size: 300
dropout: 0.1
attention_dropout: 0.0
relu_dropout: 0.1
learn_positional_embeddings: false
embeddings_scale: true
reduction: false
n_positions: 1024
# optim
conv:
epoch: 1
batch_size: 256
optimizer:
name: Adam
lr: !!float 3e-3
lr_scheduler:
name: ReduceLROnPlateau
patience: 3
factor: 0.5
gradient_clip: 0.1
early_stop: true
stop_mode: min
impatience: 3
================================================
FILE: config/conversation/transformer/redial.yaml
================================================
# dataset
dataset: ReDial
tokenize:
conv: nltk
# dataloader
context_truncate: 1024
response_truncate: 1024
scale: 1
# model
conv_model: Transformer
token_emb_dim: 300
kg_emb_dim: 128
num_bases: 8
n_heads: 2
n_layers: 2
ffn_size: 300
dropout: 0.1
attention_dropout: 0.0
relu_dropout: 0.1
learn_positional_embeddings: false
embeddings_scale: true
reduction: false
n_positions: 1024
# optim
conv:
epoch: 1
batch_size: 64
early_stop: True
stop_mode: min
optimizer:
name: Adam
lr: !!float 1e-3
lr_scheduler:
name: ReduceLROnPlateau
patience: 3
factor: 0.5
================================================
FILE: config/conversation/transformer/tgredial.yaml
================================================
# dataset
dataset: TGReDial
tokenize:
conv: pkuseg
# dataloader
context_truncate: 1024
response_truncate: 1024
scale: 1
# model
conv_model: Transformer
token_emb_dim: 300
kg_emb_dim: 128
num_bases: 8
n_heads: 2
n_layers: 2
ffn_size: 300
dropout: 0.1
attention_dropout: 0.0
relu_dropout: 0.1
learn_positional_embeddings: false
embeddings_scale: true
reduction: false
n_positions: 1024
# optim
conv:
epoch: 50
batch_size: 64
early_stop: True
stop_mode: min
patience: 3
optimizer:
name: Adam
lr: !!float 1e-3
lr_scheduler:
name: ReduceLROnPlateau
factor: 0.5
================================================
FILE: config/crs/inspired/durecdial.yaml
================================================
# dataset
dataset: DuRecDial
tokenize:
rec: bert
conv: gpt2
# dataloader
context_truncate: 256
response_truncate: 30
item_truncate: 100
scale: 1
# model
# rec
rec_model: InspiredRec
# conv
conv_model: InspiredConv
# embedding: word2vec
embedding_dim: 300
use_dropout: False
dropout: 0.3
decoder_hidden_size: 256
decoder_num_layers: 1
# optim
rec:
epoch: 1
batch_size: 8
optimizer:
name: AdamW
lr: !!float 1e-3
weight_decay: !!float 0.0000
early_stop: true
stop_mode: max
impatience: 3
lr_bert: !!float 1e-5
conv:
epoch: 1
batch_size: 8
optimizer:
name: AdamW
lr: !!float 3e-5
eps: !!float 1e-06
weight_decay: !!float 0.01
lr_scheduler:
name: TransformersLinearLR
warmup_steps: 100
early_stop: true
impatience: 3
stop_mode: min
================================================
FILE: config/crs/inspired/gorecdial.yaml
================================================
# dataset
dataset: GoRecDial
tokenize:
rec: bert
conv: gpt2
# dataloader
context_truncate: 256
response_truncate: 30
item_truncate: 100
scale: 1
# model
# rec
rec_model: InspiredRec
# conv
conv_model: InspiredConv
# embedding: word2vec
embedding_dim: 300
use_dropout: False
dropout: 0.3
decoder_hidden_size: 256
decoder_num_layers: 1
# optim
rec:
epoch: 1
batch_size: 8
optimizer:
name: AdamW
lr: !!float 1e-3
weight_decay: !!float 0.0000
early_stop: true
stop_mode: max
impatience: 3
lr_bert: !!float 1e-5
conv:
epoch: 1
batch_size: 8
optimizer:
name: AdamW
lr: !!float 3e-5
eps: !!float 1e-06
weight_decay: !!float 0.01
lr_scheduler:
name: TransformersLinearLR
warmup_steps: 100
early_stop: true
impatience: 3
stop_mode: min
================================================
FILE: config/crs/inspired/inspired.yaml
================================================
# dataset
dataset: Inspired
tokenize:
rec: bert
conv: gpt2
# dataloader
context_truncate: 256
response_truncate: 30
item_truncate: 100
scale: 1
# model
# rec
rec_model: InspiredRec
# conv
conv_model: InspiredConv
# optim
rec:
epoch: 1
batch_size: 8
optimizer:
name: AdamW
lr: !!float 1e-3
weight_decay: !!float 0.0000
early_stop: true
stop_mode: max
impatience: 3
lr_bert: !!float 1e-5
conv:
epoch: 50
batch_size: 1
optimizer:
name: AdamW
lr: !!float 3e-5
eps: !!float 1e-06
weight_decay: !!float 0.01
lr_scheduler:
name: TransformersLinearLR
warmup_steps: 100
early_stop: true
impatience: 3
stop_mode: min
label_smoothing: -1
================================================
FILE: config/crs/inspired/opendialkg.yaml
================================================
# dataset
dataset: OpenDialKG
tokenize:
rec: bert
conv: gpt2
# dataloader
context_truncate: 256
response_truncate: 30
item_truncate: 100
scale: 1
# model
# rec
rec_model: InspiredRec
# conv
conv_model: InspiredConv
# embedding: word2vec
embedding_dim: 300
use_dropout: False
dropout: 0.3
decoder_hidden_size: 256
decoder_num_layers: 1
# optim
rec:
epoch: 1
batch_size: 8
optimizer:
name: AdamW
lr: !!float 1e-3
weight_decay: !!float 0.0000
early_stop: true
stop_mode: max
impatience: 3
lr_bert: !!float 1e-5
conv:
epoch: 1
batch_size: 8
optimizer:
name: AdamW
lr: !!float 3e-5
eps: !!float 1e-06
weight_decay: !!float 0.01
lr_scheduler:
name: TransformersLinearLR
warmup_steps: 100
early_stop: true
impatience: 3
stop_mode: min
================================================
FILE: config/crs/inspired/redial.yaml
================================================
# dataset
dataset: ReDial
tokenize:
rec: bert
conv: gpt2
# dataloader
context_truncate: 256
response_truncate: 30
item_truncate: 100
scale: 1
# model
# rec
rec_model: InspiredRec
# conv
conv_model: InspiredConv
# embedding: word2vec
embedding_dim: 300
use_dropout: False
dropout: 0.3
decoder_hidden_size: 256
decoder_num_layers: 1
# optim
rec:
epoch: 1
batch_size: 8
optimizer:
name: AdamW
lr: !!float 1e-3
weight_decay: !!float 0.0000
early_stop: true
stop_mode: max
impatience: 3
lr_bert: !!float 1e-5
conv:
epoch: 1
batch_size: 8
optimizer:
name: AdamW
lr: !!float 3e-5
eps: !!float 1e-06
weight_decay: !!float 0.01
lr_scheduler:
name: TransformersLinearLR
warmup_steps: 100
early_stop: true
impatience: 3
stop_mode: min
================================================
FILE: config/crs/inspired/tgredial.yaml
================================================
# dataset
dataset: TGReDial
tokenize:
rec: bert
conv: gpt2
# dataloader
context_truncate: 256
response_truncate: 30
item_truncate: 100
scale: 1
# model
# rec
rec_model: InspiredRec
# conv
conv_model: InspiredConv
# embedding: word2vec
embedding_dim: 300
use_dropout: False
dropout: 0.3
decoder_hidden_size: 256
decoder_num_layers: 1
# optim
rec:
epoch: 1
batch_size: 8
optimizer:
name: AdamW
lr: !!float 1e-3
weight_decay: !!float 0.0000
early_stop: true
stop_mode: max
impatience: 3
lr_bert: !!float 1e-5
conv:
epoch: 1
batch_size: 8
optimizer:
name: AdamW
lr: !!float 3e-5
eps: !!float 1e-06
weight_decay: !!float 0.01
lr_scheduler:
name: TransformersLinearLR
warmup_steps: 100
early_stop: true
impatience: 3
stop_mode: min
================================================
FILE: config/crs/kbrd/durecdial.yaml
================================================
# dataset
dataset: DuRecDial
tokenize: jieba
# dataloader
context_truncate: 1024
response_truncate: 1024
scale: 1
# model
model: KBRD
token_emb_dim: 300
kg_emb_dim: 128
num_bases: 8
n_heads: 2
n_layers: 2
ffn_size: 300
dropout: 0.1
attention_dropout: 0.0
relu_dropout: 0.1
learn_positional_embeddings: false
embeddings_scale: true
reduction: false
n_positions: 1024
user_proj_dim: 512
# optim
rec:
epoch: 1
batch_size: 4096
optimizer:
name: Adam
lr: !!float 3e-3
conv:
epoch: 1
batch_size: 64
early_stop: True
stop_mode: min
optimizer:
name: Adam
lr: !!float 1e-3
lr_scheduler:
name: ReduceLROnPlateau
patience: 3
factor: 0.5
================================================
FILE: config/crs/kbrd/gorecdial.yaml
================================================
# dataset
dataset: GoRecDial
tokenize: nltk
# dataloader
context_truncate: 1024
response_truncate: 1024
scale: 1
# model
model: KBRD
token_emb_dim: 300
kg_emb_dim: 128
num_bases: 8
n_heads: 2
n_layers: 2
ffn_size: 300
dropout: 0.1
attention_dropout: 0.0
relu_dropout: 0.1
learn_positional_embeddings: false
embeddings_scale: true
reduction: false
n_positions: 1024
user_proj_dim: 512
# optim
rec:
epoch: 1
batch_size: 4096
optimizer:
name: Adam
lr: !!float 3e-3
conv:
epoch: 1
batch_size: 256
optimizer:
name: Adam
lr: !!float 3e-3
lr_scheduler:
name: ReduceLROnPlateau
patience: 3
factor: 0.5
gradient_clip: 0.1
early_stop: true
stop_mode: min
impatience: 3
================================================
FILE: config/crs/kbrd/inspired.yaml
================================================
# dataset
dataset: Inspired
tokenize: nltk
# dataloader
context_truncate: 1024
response_truncate: 1024
scale: 1
# model
model: KBRD
token_emb_dim: 300
kg_emb_dim: 128
num_bases: 8
n_heads: 2
n_layers: 2
ffn_size: 300
dropout: 0.1
attention_dropout: 0.0
relu_dropout: 0.1
learn_positional_embeddings: false
embeddings_scale: true
reduction: false
n_positions: 1024
user_proj_dim: 512
# optim
rec:
epoch: 1
batch_size: 1024
optimizer:
name: Adam
lr: !!float 3e-3
conv:
epoch: 1
batch_size: 64
early_stop: True
stop_mode: min
optimizer:
name: Adam
lr: !!float 1e-3
lr_scheduler:
name: ReduceLROnPlateau
patience: 3
factor: 0.5
================================================
FILE: config/crs/kbrd/opendialkg.yaml
================================================
# dataset
dataset: OpenDialKG
tokenize: nltk
# dataloader
context_truncate: 1024
response_truncate: 1024
scale: 1
# model
model: KBRD
token_emb_dim: 300
kg_emb_dim: 128
num_bases: 8
n_heads: 2
n_layers: 2
ffn_size: 300
dropout: 0.1
attention_dropout: 0.0
relu_dropout: 0.1
learn_positional_embeddings: false
embeddings_scale: true
reduction: false
n_positions: 1024
user_proj_dim: 512
# optim
rec:
epoch: 1
batch_size: 1024
optimizer:
name: Adam
lr: !!float 3e-3
conv:
epoch: 1
batch_size: 64
early_stop: True
stop_mode: min
optimizer:
name: Adam
lr: !!float 1e-3
lr_scheduler:
name: ReduceLROnPlateau
patience: 3
factor: 0.5
================================================
FILE: config/crs/kbrd/redial.yaml
================================================
# dataset
dataset: ReDial
tokenize: nltk
# dataloader
context_truncate: 1024
response_truncate: 1024
scale: 1
# model
model: KBRD
token_emb_dim: 300
kg_emb_dim: 128
num_bases: 8
n_heads: 2
n_layers: 2
ffn_size: 300
dropout: 0.1
attention_dropout: 0.0
relu_dropout: 0.1
learn_positional_embeddings: false
embeddings_scale: true
reduction: false
n_positions: 1024
user_proj_dim: 512
# optim
rec:
epoch: 10
batch_size: 4096
optimizer:
name: Adam
lr: !!float 3e-3
conv:
epoch: 10
batch_size: 32
early_stop: True
stop_mode: min
optimizer:
name: Adam
lr: !!float 1e-3
lr_scheduler:
name: ReduceLROnPlateau
patience: 3
factor: 0.5
================================================
FILE: config/crs/kbrd/tgredial.yaml
================================================
# dataset
dataset: TGReDial
tokenize: pkuseg
# dataloader
context_truncate: 1024
response_truncate: 1024
scale: 1
# model
model: KBRD
token_emb_dim: 300
n_relation: 56
kg_emb_dim: 128
num_bases: 8
n_heads: 2
n_layers: 2
ffn_size: 300
dropout: 0.1
attention_dropout: 0.0
relu_dropout: 0.1
learn_positional_embeddings: false
embeddings_scale: true
reduction: false
n_positions: 1024
user_proj_dim: 512
# optim
rec:
epoch: 100
batch_size: 64
early_stop: True
stop_mode: max
patience: 3
optimizer:
name: Adam
lr: !!float 3e-3
conv:
epoch: 100
batch_size: 16
early_stop: True
stop_mode: min
optimizer:
name: Adam
lr: !!float 1e-3
lr_scheduler:
name: ReduceLROnPlateau
patience: 3
factor: 0.5
================================================
FILE: config/crs/kgsf/durecdial.yaml
================================================
# dataset
dataset: DuRecDial
tokenize: jieba
embedding: word2vec.npy
# dataloader
context_truncate: 256
response_truncate: 30
scale: 1
# model
model: KGSF
token_emb_dim: 300
kg_emb_dim: 128
num_bases: 8
n_heads: 2
n_layers: 2
ffn_size: 300
dropout: 0.1
attention_dropout: 0.0
relu_dropout: 0.1
learn_positional_embeddings: false
embeddings_scale: true
reduction: false
n_positions: 1024
# optim
pretrain:
epoch: 1
batch_size: 4096
optimizer:
name: Adam
lr: !!float 3e-3
rec:
epoch: 1
batch_size: 1024
optimizer:
name: Adam
lr: !!float 3e-3
early_stop: true
stop_mode: max
impatience: 3
conv:
epoch: 1
batch_size: 256
optimizer:
name: Adam
lr: !!float 3e-3
lr_scheduler:
name: ReduceLROnPlateau
patience: 3
factor: 0.5
gradient_clip: 0.1
================================================
FILE: config/crs/kgsf/gorecdial.yaml
================================================
# dataset
dataset: GoRecDial
tokenize: nltk
embedding: word2vec.npy
# dataloader
context_truncate: 256
response_truncate: 30
scale: 1
# model
model: KGSF
token_emb_dim: 300
kg_emb_dim: 128
num_bases: 8
n_heads: 2
n_layers: 2
ffn_size: 300
dropout: 0.1
attention_dropout: 0.0
relu_dropout: 0.1
learn_positional_embeddings: false
embeddings_scale: true
reduction: false
n_positions: 1024
# optim
pretrain:
epoch: 1
batch_size: 64
optimizer:
name: Adam
lr: !!float 3e-3
rec:
epoch: 1
batch_size: 64
optimizer:
name: Adam
lr: !!float 3e-3
early_stop: true
stop_mode: max
impatience: 3
conv:
epoch: 1
batch_size: 64
optimizer:
name: Adam
lr: !!float 3e-3
lr_scheduler:
name: ReduceLROnPlateau
patience: 3
factor: 0.5
gradient_clip: 0.1
================================================
FILE: config/crs/kgsf/inspired.yaml
================================================
# dataset
dataset: Inspired
tokenize: nltk
embedding: word2vec.npy
# dataloader
context_truncate: 256
response_truncate: 30
scale: 1
# model
model: KGSF
token_emb_dim: 300
kg_emb_dim: 128
num_bases: 8
n_heads: 2
n_layers: 2
ffn_size: 300
dropout: 0.1
attention_dropout: 0.0
relu_dropout: 0.1
learn_positional_embeddings: false
embeddings_scale: true
reduction: false
n_positions: 1024
# optim
pretrain:
epoch: 1
batch_size: 4096
optimizer:
name: Adam
lr: !!float 3e-3
rec:
epoch: 1
batch_size: 1024
optimizer:
name: Adam
lr: !!float 3e-3
early_stop: true
stop_mode: max
impatience: 3
conv:
epoch: 1
batch_size: 256
optimizer:
name: Adam
lr: !!float 3e-3
lr_scheduler:
name: ReduceLROnPlateau
patience: 3
factor: 0.5
gradient_clip: 0.1
================================================
FILE: config/crs/kgsf/opendialkg.yaml
================================================
# dataset
dataset: OpenDialKG
tokenize: nltk
embedding: word2vec.npy
# dataloader
context_truncate: 256
response_truncate: 30
scale: 1
# model
model: KGSF
token_emb_dim: 300
kg_emb_dim: 128
num_bases: 8
n_heads: 2
n_layers: 2
ffn_size: 300
dropout: 0.1
attention_dropout: 0.0
relu_dropout: 0.1
learn_positional_embeddings: false
embeddings_scale: true
reduction: false
n_positions: 1024
# optim
pretrain:
epoch: 1
batch_size: 4096
optimizer:
name: Adam
lr: !!float 3e-3
rec:
epoch: 1
batch_size: 1024
optimizer:
name: Adam
lr: !!float 3e-3
early_stop: true
stop_mode: max
impatience: 3
conv:
epoch: 1
batch_size: 256
optimizer:
name: Adam
lr: !!float 3e-3
lr_scheduler:
name: ReduceLROnPlateau
patience: 3
factor: 0.5
gradient_clip: 0.1
================================================
FILE: config/crs/kgsf/redial.yaml
================================================
# dataset
dataset: ReDial
tokenize: nltk
embedding: word2vec.npy
# dataloader
context_truncate: 256
response_truncate: 30
scale: 1
# model
model: KGSF
token_emb_dim: 300
kg_emb_dim: 128
num_bases: 8
n_heads: 2
n_layers: 2
ffn_size: 300
dropout: 0.1
attention_dropout: 0.0
relu_dropout: 0.1
learn_positional_embeddings: false
embeddings_scale: true
reduction: false
n_positions: 1024
# optim
pretrain:
epoch: 3
batch_size: 128
optimizer:
name: Adam
lr: !!float 1e-3
rec:
epoch: 9
batch_size: 128
optimizer:
name: Adam
lr: !!float 1e-3
conv:
epoch: 90
batch_size: 128
optimizer:
name: Adam
lr: !!float 1e-3
lr_scheduler:
name: ReduceLROnPlateau
patience: 3
factor: 0.5
gradient_clip: 0.1
================================================
FILE: config/crs/kgsf/tgredial.yaml
================================================
# dataset
dataset: TGReDial
tokenize: pkuseg
embedding: word2vec.npy
# dataloader
context_truncate: 256
response_truncate: 30
scale: 1
# model
model: KGSF
token_emb_dim: 300
kg_emb_dim: 128
num_bases: 8
n_heads: 2
n_layers: 2
ffn_size: 300
dropout: 0.1
attention_dropout: 0.0
relu_dropout: 0.1
learn_positional_embeddings: false
embeddings_scale: true
reduction: false
n_positions: 1024
# optim
pretrain:
epoch: 50
batch_size: 128
optimizer:
name: Adam
lr: !!float 1e-3
rec:
epoch: 20
batch_size: 128
optimizer:
name: Adam
lr: !!float 1e-3
early_stop: true
stop_mode: max
impatience: 3
conv:
epoch: 10
batch_size: 128
optimizer:
name: Adam
lr: !!float 1e-3
lr_scheduler:
name: ReduceLROnPlateau
patience: 3
factor: 0.5
gradient_clip: 0.1
================================================
FILE: config/crs/ntrd/tgredial.yaml
================================================
# dataset
dataset: TGReDial
tokenize: pkuseg
embedding: word2vec.npy
# dataloader
context_truncate: 256
response_truncate: 30
scale: 1
# model
model: NTRD
token_emb_dim: 300
kg_emb_dim: 128
num_bases: 8
n_heads: 2
n_layers: 2
ffn_size: 300
dropout: 0.1
attention_dropout: 0.0
relu_dropout: 0.1
learn_positional_embeddings: false
embeddings_scale: true
reduction: false
n_positions: 1024
gen_loss_weight: 5
n_movies: 62287
replace_token: '[ITEM]'
# optim
pretrain:
epoch: 50
batch_size: 128
optimizer:
name: Adam
lr: !!float 1e-3
rec:
epoch: 20
batch_size: 128
optimizer:
name: Adam
lr: !!float 1e-3
early_stop: true
stop_mode: max
impatience: 3
conv:
epoch: 10
batch_size: 64
optimizer:
name: Adam
lr: !!float 1e-3
lr_scheduler:
name: ReduceLROnPlateau
patience: 3
factor: 0.5
gradient_clip: 0.1
================================================
FILE: config/crs/redial/durecdial.yaml
================================================
# dataset
dataset: DuRecDial
tokenize:
rec: jieba
conv: jieba
# dataloader
utterance_truncate: 80
conversation_truncate: 40
scale: 1
# model
# rec
rec_model: ReDialRec
autorec_layer_sizes: [ 1000 ]
autorec_f: sigmoid
autorec_g: sigmoid
# conv
conv_model: ReDialConv
# embedding: word2vec
embedding_dim: 300
utterance_encoder_hidden_size: 256
dialog_encoder_hidden_size: 256
dialog_encoder_num_layers: 1
use_dropout: False
dropout: 0.3
decoder_hidden_size: 256
decoder_num_layers: 1
# optim
rec:
epoch: 1
batch_size: 1024
optimizer:
name: Adam
lr: !!float 1e-3
early_stop: true
impatience: 3
stop_mode: min
conv:
epoch: 1
batch_size: 128
optimizer:
name: Adam
lr: !!float 1e-3
early_stop: true
impatience: 3
stop_mode: min
================================================
FILE: config/crs/redial/gorecdial.yaml
================================================
# dataset
dataset: GoRecDial
tokenize:
rec: nltk
conv: nltk
# dataloader
utterance_truncate: 80
conversation_truncate: 40
scale: 1
# model
# rec
rec_model: ReDialRec
autorec_layer_sizes: [ 1000 ]
autorec_f: sigmoid
autorec_g: sigmoid
# conv
conv_model: ReDialConv
#embedding: word2vec
embedding_dim: 300
utterance_encoder_hidden_size: 256
dialog_encoder_hidden_size: 256
dialog_encoder_num_layers: 1
use_dropout: False
dropout: 0.3
decoder_hidden_size: 256
decoder_num_layers: 1
# optim
rec:
epoch: 1
batch_size: 1024
optimizer:
name: Adam
lr: !!float 1e-3
early_stop: true
impatience: 3
stop_mode: min
conv:
epoch: 1
batch_size: 128
optimizer:
name: Adam
lr: !!float 1e-3
early_stop: true
impatience: 3
stop_mode: min
================================================
FILE: config/crs/redial/inspired.yaml
================================================
# dataset
dataset: Inspired
tokenize:
rec: nltk
conv: nltk
# dataloader
utterance_truncate: 80
conversation_truncate: 40
scale: 1
# model
# rec
rec_model: ReDialRec
autorec_layer_sizes: [ 1000 ]
autorec_f: sigmoid
autorec_g: sigmoid
# conv
conv_model: ReDialConv
# embedding: word2vec
embedding_dim: 300
utterance_encoder_hidden_size: 256
dialog_encoder_hidden_size: 256
dialog_encoder_num_layers: 1
use_dropout: False
dropout: 0.3
decoder_hidden_size: 256
decoder_num_layers: 1
# optim
rec:
epoch: 1
batch_size: 1024
optimizer:
name: Adam
lr: !!float 1e-3
early_stop: true
impatience: 3
stop_mode: min
conv:
epoch: 1
batch_size: 128
optimizer:
name: Adam
lr: !!float 1e-3
early_stop: true
impatience: 3
stop_mode: min
================================================
FILE: config/crs/redial/opendialkg.yaml
================================================
# dataset
dataset: OpenDialKG
tokenize:
rec: nltk
conv: nltk
# dataloader
utterance_truncate: 80
conversation_truncate: 40
scale: 1
# model
# rec
rec_model: ReDialRec
autorec_layer_sizes: [ 1000 ]
autorec_f: sigmoid
autorec_g: sigmoid
# conv
conv_model: ReDialConv
# embedding: word2vec
embedding_dim: 300
utterance_encoder_hidden_size: 256
dialog_encoder_hidden_size: 256
dialog_encoder_num_layers: 1
use_dropout: False
dropout: 0.3
decoder_hidden_size: 256
decoder_num_layers: 1
# optim
rec:
epoch: 1
batch_size: 1024
optimizer:
name: Adam
lr: !!float 1e-3
early_stop: true
impatience: 3
stop_mode: min
conv:
epoch: 1
batch_size: 128
optimizer:
name: Adam
lr: !!float 1e-3
early_stop: true
impatience: 3
stop_mode: min
================================================
FILE: config/crs/redial/redial.yaml
================================================
# dataset
dataset: ReDial
tokenize:
rec: nltk
conv: nltk
# dataloader
utterance_truncate: 80
conversation_truncate: 40
scale: 1
# model
# rec
rec_model: ReDialRec
autorec_layer_sizes: [ 1000 ]
autorec_f: sigmoid
autorec_g: sigmoid
# conv
conv_model: ReDialConv
# embedding: word2vec
embedding_dim: 300
utterance_encoder_hidden_size: 256
dialog_encoder_hidden_size: 256
dialog_encoder_num_layers: 1
use_dropout: False
dropout: 0.3
decoder_hidden_size: 256
decoder_num_layers: 1
# optim
rec:
epoch: 50
batch_size: 1024
optimizer:
name: Adam
lr: !!float 1e-3
early_stop: true
impatience: 3
stop_mode: min
conv:
epoch: 50
batch_size: 128
optimizer:
name: Adam
lr: !!float 1e-3
early_stop: true
impatience: 3
stop_mode: min
================================================
FILE: config/crs/redial/tgredial.yaml
================================================
# dataset
dataset: TGReDial
tokenize:
rec: pkuseg
conv: pkuseg
# dataloader
utterance_truncate: 80
conversation_truncate: 40
scale: 1
# model
# rec
rec_model: ReDialRec
autorec_layer_sizes: [ 1000 ]
autorec_f: sigmoid
autorec_g: sigmoid
# conv
conv_model: ReDialConv
#embedding: word2vec
embedding_dim: 300
utterance_encoder_hidden_size: 256
dialog_encoder_hidden_size: 256
dialog_encoder_num_layers: 1
use_dropout: False
dropout: 0.3
decoder_hidden_size: 256
decoder_num_layers: 1
# optim
rec:
epoch: 1
batch_size: 1024
optimizer:
name: Adam
lr: !!float 1e-3
early_stop: true
impatience: 3
stop_mode: min
conv:
epoch: 1
batch_size: 128
optimizer:
name: Adam
lr: !!float 1e-3
early_stop: true
impatience: 3
stop_mode: min
================================================
FILE: config/crs/tgredial/durecdial.yaml
================================================
# dataset
dataset: DuRecDial
tokenize:
rec: bert
conv: gpt2
# dataloader
context_truncate: 256
response_truncate: 30
item_truncate: 100
scale: 1
# model
rec_model: TGRec
conv_model: TGConv
hidden_dropout_prob: 0.2
initializer_range: 0.02
hidden_size: 50
max_history_items: 100
num_attention_heads: 1
attention_probs_dropout_prob: 0.2
hidden_act: gelu
num_hidden_layers: 2
# optim
rec:
epoch: 1
batch_size: 8
optimizer:
name: AdamW
lr: !!float 1e-3
weight_decay: !!float 0.0000
lr_bert: !!float 1e-5
early_stop: true
impatience: 3
stop_mode: max
conv:
epoch: 1
batch_size: 8
gradient_clip: 1.0
update_freq: 1
optimizer:
name: AdamW
lr: !!float 1.5e-4
lr_scheduler:
name: TransformersLinearLR
warmup_steps: 2000
early_stop: true
impatience: 3
stop_mode: min
================================================
FILE: config/crs/tgredial/gorecdial.yaml
================================================
# dataset
dataset: GoRecDial
tokenize:
rec: bert
conv: gpt2
# dataloader
context_truncate: 256
response_truncate: 30
item_truncate: 100
scale: 1
# model
rec_model: TGRec
conv_model: TGConv
hidden_dropout_prob: 0.2
initializer_range: 0.02
hidden_size: 50
max_history_items: 100
num_attention_heads: 1
attention_probs_dropout_prob: 0.2
hidden_act: gelu
num_hidden_layers: 2
# optim
rec:
epoch: 1
batch_size: 8
optimizer:
name: AdamW
lr: !!float 1e-3
weight_decay: !!float 0.0000
lr_bert: !!float 1e-5
early_stop: true
impatience: 3
stop_mode: max
conv:
epoch: 1
batch_size: 4
gradient_clip: 1.0
update_freq: 1
optimizer:
name: AdamW
lr: !!float 1.5e-4
lr_scheduler:
name: TransformersLinearLR
warmup_steps: 2000
early_stop: true
impatience: 3
stop_mode: min
================================================
FILE: config/crs/tgredial/inspired.yaml
================================================
# dataset
dataset: Inspired
tokenize:
rec: bert
conv: gpt2
# dataloader
context_truncate: 256
response_truncate: 30
item_truncate: 100
scale: 1
# model
rec_model: TGRec
conv_model: TGConv
hidden_dropout_prob: 0.2
initializer_range: 0.02
hidden_size: 50
max_history_items: 100
num_attention_heads: 1
attention_probs_dropout_prob: 0.2
hidden_act: gelu
num_hidden_layers: 2
# optim
rec:
epoch: 1
batch_size: 8
optimizer:
name: AdamW
lr: !!float 1e-3
weight_decay: !!float 0.0000
lr_bert: !!float 1e-5
early_stop: true
impatience: 3
stop_mode: max
conv:
epoch: 1
batch_size: 8
gradient_clip: 1.0
update_freq: 1
optimizer:
name: AdamW
lr: !!float 1.5e-4
lr_scheduler:
name: TransformersLinearLR
warmup_steps: 2000
early_stop: true
impatience: 3
stop_mode: min
================================================
FILE: config/crs/tgredial/opendialkg.yaml
================================================
# dataset
dataset: OpenDialKG
tokenize:
rec: bert
conv: gpt2
# dataloader
context_truncate: 256
response_truncate: 30
item_truncate: 100
scale: 1
# model
rec_model: TGRec
conv_model: TGConv
hidden_dropout_prob: 0.2
initializer_range: 0.02
hidden_size: 50
max_history_items: 100
num_attention_heads: 1
attention_probs_dropout_prob: 0.2
hidden_act: gelu
num_hidden_layers: 2
# optim
rec:
epoch: 1
batch_size: 8
optimizer:
name: AdamW
lr: !!float 1e-3
weight_decay: !!float 0.0000
lr_bert: !!float 1e-5
early_stop: true
impatience: 3
stop_mode: max
conv:
epoch: 1
batch_size: 8
gradient_clip: 1.0
update_freq: 1
optimizer:
name: AdamW
lr: !!float 1.5e-4
lr_scheduler:
name: TransformersLinearLR
warmup_steps: 2000
early_stop: true
impatience: 3
stop_mode: min
================================================
FILE: config/crs/tgredial/redial.yaml
================================================
# dataset
dataset: ReDial
tokenize:
rec: bert
conv: gpt2
# dataloader
context_truncate: 256
response_truncate: 30
item_truncate: 100
scale: 1
# model
rec_model: TGRec
conv_model: TGConv
hidden_dropout_prob: 0.2
initializer_range: 0.02
hidden_size: 50
max_history_items: 100
num_attention_heads: 1
attention_probs_dropout_prob: 0.2
hidden_act: gelu
num_hidden_layers: 2
# optim
rec:
epoch: 10
batch_size: 8
optimizer:
name: AdamW
lr: !!float 1e-4
weight_decay: 0
lr_bert: !!float 1e-5
early_stop: true
impatience: 3
stop_mode: max
conv:
epoch: 10
batch_size: 8
gradient_clip: 1.0
update_freq: 1
optimizer:
name: AdamW
lr: !!float 1e-4
lr_scheduler:
name: TransformersLinearLR
warmup_steps: 2000
early_stop: true
impatience: 3
stop_mode: min
================================================
FILE: config/crs/tgredial/tgredial.yaml
================================================
# dataset
dataset: TGReDial
tokenize:
rec: bert
conv: gpt2
policy: bert
# dataloader
context_truncate: 256
response_truncate: 30
item_truncate: 100
scale: 1
# model
rec_model: TGRec
conv_model: TGConv
policy_model: TGPolicy
hidden_dropout_prob: 0.2
initializer_range: 0.02
hidden_size: 50
max_history_items: 100
num_attention_heads: 1
attention_probs_dropout_prob: 0.2
hidden_act: gelu
num_hidden_layers: 2
# optim
rec:
epoch: 50
batch_size: 8
optimizer:
name: AdamW
lr: !!float 1e-3
weight_decay: !!float 0.0000
lr_bert: !!float 1e-5
early_stop: true
impatience: 3
stop_mode: max
conv:
epoch: 50
batch_size: 8
gradient_clip: 1.0
update_freq: 1
optimizer:
name: AdamW
lr: !!float 1.5e-4
lr_scheduler:
name: TransformersLinearLR
warmup_steps: 2000
early_stop: true
impatience: 3
stop_mode: min
policy:
epoch: 50
batch_size: 8
weight_decay: 0.01
optimizer:
name: AdamW
lr: !!float 1e-5
early_stop: true
stop_mode: max
impatience: 3
================================================
FILE: config/policy/conv_bert/tgredial.yaml
================================================
# dataset
dataset: TGReDial
tokenize:
policy: bert
# dataloader
context_truncate: 256
response_truncate: 30
item_truncate: 100
scale: 1
# model
policy_model: ConvBERT
# optim
policy:
epoch: 50
batch_size: 8
weight_decay: 0.01
optimizer:
name: AdamW
lr: !!float 1e-5
early_stop: true
stop_mode: max
impatience: 3
================================================
FILE: config/policy/mgcg/tgredial.yaml
================================================
# dataset
dataset: TGReDial
tokenize:
policy: bert
# dataloader
context_truncate: 256
response_truncate: 30
item_truncate: 100
scale: 1
# model
policy_model: MGCG
dropout_hidden: 0
num_layers: 1
hidden_size: 300
embedding_dim: 300
n_sent: 10
# optim
policy:
epoch: 100
batch_size: 1024
weight_decay: 0.01
optimizer:
name: AdamW
lr: !!float 1e-4
early_stop: true
stop_mode: max
impatience: 3
================================================
FILE: config/policy/pmi/tgredial.yaml
================================================
# dataset
dataset: TGReDial
tokenize:
policy: bert
# dataloader
context_truncate: 256
response_truncate: 30
item_truncate: 100
scale: 1
# model
policy_model: PMI
# optim
policy:
epoch: 1
batch_size: 1024
weight_decay: 0.01
optimizer:
name: AdamW
lr: !!float 1e-5
early_stop: true
stop_mode: max
impatience: 3
================================================
FILE: config/policy/profile_bert/tgredial.yaml
================================================
# dataset
dataset: TGReDial
tokenize:
policy: bert
# dataloader
context_truncate: 256
response_truncate: 30
item_truncate: 100
scale: 1
# model
policy_model: ProfileBERT
n_sent: 10
# optim
policy:
epoch: 50
batch_size: 8
weight_decay: 0.01
optimizer:
name: AdamW
lr: !!float 1e-5
early_stop: true
stop_mode: max
impatience: 3
================================================
FILE: config/policy/topic_bert/tgredial.yaml
================================================
# dataset
dataset: TGReDial
tokenize:
policy: bert
# dataloader
context_truncate: 256
response_truncate: 30
item_truncate: 100
scale: 1
# model
policy_model: TopicBERT
# optim
policy:
epoch: 50
batch_size: 8
weight_decay: 0.01
optimizer:
name: AdamW
lr: !!float 1e-5
early_stop: true
stop_mode: max
impatience: 3
================================================
FILE: config/recommendation/bert/durecdial.yaml
================================================
# dataset
dataset: DuRecDial
tokenize:
rec: bert
# dataloader
context_truncate: 256
response_truncate: 30
item_truncate: 100
scale: 1
# model
rec_model: BERT
# optim
rec:
epoch: 1
batch_size: 8
optimizer:
name: AdamW
lr: !!float 1e-3
weight_decay: !!float 0.0000
lr_bert: !!float 1e-5
================================================
FILE: config/recommendation/bert/gorecdial.yaml
================================================
# dataset
dataset: GoRecDial
tokenize:
rec: bert
# dataloader
context_truncate: 256
response_truncate: 30
item_truncate: 100
scale: 1
# model
rec_model: BERT
# optim
rec:
epoch: 1
batch_size: 8
optimizer:
name: AdamW
lr: !!float 1e-3
weight_decay: !!float 0.0000
lr_bert: !!float 1e-5
================================================
FILE: config/recommendation/bert/inspired.yaml
================================================
# dataset
dataset: Inspired
tokenize:
rec: bert
# dataloader
context_truncate: 256
response_truncate: 30
item_truncate: 100
scale: 1
# model
rec_model: BERT
# optim
rec:
epoch: 1
batch_size: 8
optimizer:
name: AdamW
lr: !!float 1e-3
weight_decay: !!float 0.0000
lr_bert: !!float 1e-5
================================================
FILE: config/recommendation/bert/opendialkg.yaml
================================================
# dataset
dataset: OpenDialKG
tokenize:
rec: bert
# dataloader
context_truncate: 256
response_truncate: 30
item_truncate: 100
scale: 1
# model
rec_model: BERT
# optim
rec:
epoch: 1
batch_size: 8
optimizer:
name: AdamW
lr: !!float 1e-3
weight_decay: !!float 0.0000
lr_bert: !!float 1e-5
================================================
FILE: config/recommendation/bert/redial.yaml
================================================
# dataset
dataset: ReDial
tokenize:
rec: bert
# dataloader
context_truncate: 256
response_truncate: 30
item_truncate: 100
scale: 1
# model
rec_model: BERT
# optim
rec:
epoch: 1
batch_size: 8
optimizer:
name: AdamW
lr: !!float 1e-3
weight_decay: !!float 0.0000
lr_bert: !!float 1e-5
================================================
FILE: config/recommendation/bert/tgredial.yaml
================================================
# dataset
dataset: TGReDial
tokenize:
rec: bert
# dataloader
context_truncate: 256
response_truncate: 30
item_truncate: 100
scale: 1
# model
rec_model: BERT
# optim
rec:
epoch: 20
batch_size: 8
optimizer:
name: AdamW
lr: !!float 1e-3
weight_decay: !!float 0.0000
early_stop: true
stop_mode: max
impatience: 3
lr_bert: !!float 1e-5
================================================
FILE: config/recommendation/gru4rec/durecdial.yaml
================================================
# dataset
dataset: DuRecDial
tokenize:
rec: bert
# dataloader
context_truncate: 256
response_truncate: 30
item_truncate: 100
scale: 1
# model
rec_model: GRU4REC
gru_hidden_size: 50
num_layers: 3
embedding_dim: 50
dropout_input: 0
dropout_hidden: 0.0
hidden_size: 50
# optim
rec:
epoch: 1
batch_size: 8
optimizer:
name: AdamW
lr: !!float 1e-3
weight_decay: !!float 0.0000
lr_bert: !!float 1e-5
================================================
FILE: config/recommendation/gru4rec/gorecdial.yaml
================================================
# dataset
dataset: GoRecDial
tokenize:
rec: bert
# dataloader
context_truncate: 256
response_truncate: 30
item_truncate: 100
scale: 1
# model
rec_model: GRU4REC
gru_hidden_size: 50
num_layers: 3
embedding_dim: 50
dropout_input: 0
dropout_hidden: 0.0
hidden_size: 50
# optim
rec:
epoch: 1
batch_size: 8
optimizer:
name: AdamW
lr: !!float 1e-2
weight_decay: !!float 0.0000
lr_bert: !!float 1e-5
================================================
FILE: config/recommendation/gru4rec/inspired.yaml
================================================
# dataset
dataset: Inspired
tokenize:
rec: bert
# dataloader
context_truncate: 256
response_truncate: 30
item_truncate: 100
scale: 1
# model
rec_model: GRU4REC
gru_hidden_size: 50
num_layers: 3
embedding_dim: 50
dropout_input: 0
dropout_hidden: 0.0
hidden_size: 50
# optim
rec:
epoch: 1
batch_size: 8
optimizer:
name: AdamW
lr: !!float 1e-3
weight_decay: !!float 0.0000
lr_bert: !!float 1e-5
================================================
FILE: config/recommendation/gru4rec/opendialkg.yaml
================================================
# dataset
dataset: OpenDialKG
tokenize:
rec: bert
# dataloader
context_truncate: 256
response_truncate: 30
item_truncate: 100
scale: 1
# model
rec_model: GRU4REC
gru_hidden_size: 50
num_layers: 3
embedding_dim: 50
dropout_input: 0
dropout_hidden: 0.0
hidden_size: 50
# optim
rec:
epoch: 1
batch_size: 8
optimizer:
name: AdamW
lr: !!float 1e-3
weight_decay: !!float 0.0000
lr_bert: !!float 1e-5
================================================
FILE: config/recommendation/gru4rec/redial.yaml
================================================
# dataset
dataset: ReDial
tokenize:
rec: bert
# dataloader
context_truncate: 256
response_truncate: 30
item_truncate: 100
scale: 1
# model
rec_model: GRU4REC
gru_hidden_size: 50
num_layers: 3
embedding_dim: 50
dropout_input: 0
dropout_hidden: 0.0
hidden_size: 50
# optim
rec:
epoch: 1
batch_size: 8
optimizer:
name: AdamW
lr: !!float 1e-2
weight_decay: !!float 0.0000
lr_bert: !!float 1e-5
================================================
FILE: config/recommendation/gru4rec/tgredial.yaml
================================================
# dataset
dataset: TGReDial
tokenize:
rec: bert
# dataloader
context_truncate: 256
response_truncate: 30
item_truncate: 100
scale: 1
# model
rec_model: GRU4REC
gru_hidden_size: 50
num_layers: 3
embedding_dim: 50
dropout_input: 0
dropout_hidden: 0.0
hidden_size: 50
# optim
rec:
epoch: 50
batch_size: 64
optimizer:
name: Adam
lr: !!float 1e-3
weight_decay: !!float 0.0000
lr_bert: !!float 1e-5
early_stop: true
stop_mode: max
impatience: 3
================================================
FILE: config/recommendation/popularity/durecdial.yaml
================================================
# dataset
dataset: DuRecDial
tokenize:
rec: bert
# dataloader
context_truncate: 256
response_truncate: 30
item_truncate: 100
scale: 1
# model
rec_model: Popularity
# optim
rec:
epoch: 1
batch_size: 1024
optimizer:
name: AdamW
lr: !!float 1e-3
weight_decay: !!float 0.0000
lr_bert: !!float 1e-5
================================================
FILE: config/recommendation/popularity/gorecdial.yaml
================================================
# dataset
dataset: GoRecDial
tokenize:
rec: bert
# dataloader
context_truncate: 256
response_truncate: 30
item_truncate: 100
scale: 1
# model
rec_model: Popularity
# optim
rec:
epoch: 1
batch_size: 1024
optimizer:
name: AdamW
lr: !!float 1e-3
weight_decay: !!float 0.0000
lr_bert: !!float 1e-5
================================================
FILE: config/recommendation/popularity/inspired.yaml
================================================
# dataset
dataset: Inspired
tokenize:
rec: bert
# dataloader
context_truncate: 256
response_truncate: 30
item_truncate: 100
scale: 1
# model
rec_model: Popularity
# optim
rec:
epoch: 1
batch_size: 1024
optimizer:
name: AdamW
lr: !!float 1e-3
weight_decay: !!float 0.0000
lr_bert: !!float 1e-5
================================================
FILE: config/recommendation/popularity/opendialkg.yaml
================================================
# dataset
dataset: OpenDialKG
tokenize:
rec: bert
# dataloader
context_truncate: 256
response_truncate: 30
item_truncate: 100
scale: 1
# model
rec_model: Popularity
# optim
rec:
epoch: 1
batch_size: 1024
optimizer:
name: AdamW
lr: !!float 1e-3
weight_decay: !!float 0.0000
lr_bert: !!float 1e-5
================================================
FILE: config/recommendation/popularity/redial.yaml
================================================
# dataset
dataset: ReDial
tokenize:
rec: bert
# dataloader
context_truncate: 256
response_truncate: 30
item_truncate: 100
scale: 1
# model
rec_model: Popularity
# optim
rec:
epoch: 1
batch_size: 1024
optimizer:
name: AdamW
lr: !!float 1e-3
weight_decay: !!float 0.0000
lr_bert: !!float 1e-5
================================================
FILE: config/recommendation/popularity/tgredial.yaml
================================================
# dataset
dataset: TGReDial
tokenize:
rec: bert
# dataloader
context_truncate: 256
response_truncate: 30
item_truncate: 100
scale: 1
# model
rec_model: Popularity
# optim
rec:
epoch: 1
batch_size: 1024
optimizer:
name: AdamW
lr: !!float 1e-3
weight_decay: !!float 0.0000
lr_bert: !!float 1e-5
================================================
FILE: config/recommendation/sasrec/durecdial.yaml
================================================
# dataset
dataset: DuRecDial
tokenize:
rec: bert
# dataloader
context_truncate: 256
response_truncate: 30
item_truncate: 100
scale: 1
# model
rec_model: SASREC
hidden_dropout_prob: 0.2
initializer_range: 0.02
hidden_size: 50
max_history_items: 100
num_attention_heads: 1
attention_probs_dropout_prob: 0.2
hidden_act: gelu
num_hidden_layers: 2
# optim
rec:
epoch: 1
batch_size: 8
optimizer:
name: AdamW
lr: !!float 1e-3
weight_decay: !!float 0.0000
lr_bert: !!float 1e-5
================================================
FILE: config/recommendation/sasrec/gorecdial.yaml
================================================
# dataset
dataset: GoRecDial
tokenize:
rec: bert
# dataloader
context_truncate: 256
response_truncate: 30
item_truncate: 100
scale: 1
# model
rec_model: SASREC
hidden_dropout_prob: 0.2
initializer_range: 0.02
hidden_size: 50
max_history_items: 100
num_attention_heads: 1
attention_probs_dropout_prob: 0.2
hidden_act: gelu
num_hidden_layers: 2
# optim
rec:
epoch: 1
batch_size: 8
optimizer:
name: AdamW
lr: !!float 1e-2
weight_decay: !!float 0.0000
lr_bert: !!float 1e-5
================================================
FILE: config/recommendation/sasrec/inspired.yaml
================================================
# dataset
dataset: Inspired
tokenize:
rec: bert
# dataloader
context_truncate: 256
response_truncate: 30
item_truncate: 100
scale: 1
# model
rec_model: SASREC
hidden_dropout_prob: 0.2
initializer_range: 0.02
hidden_size: 50
max_history_items: 100
num_attention_heads: 1
attention_probs_dropout_prob: 0.2
hidden_act: gelu
num_hidden_layers: 2
# optim
rec:
epoch: 1
batch_size: 8
optimizer:
name: AdamW
lr: !!float 1e-3
weight_decay: !!float 0.0000
lr_bert: !!float 1e-5
================================================
FILE: config/recommendation/sasrec/opendialkg.yaml
================================================
# dataset
dataset: OpenDialKG
tokenize:
rec: bert
# dataloader
context_truncate: 256
response_truncate: 30
item_truncate: 100
scale: 1
# model
rec_model: SASREC
hidden_dropout_prob: 0.2
initializer_range: 0.02
hidden_size: 50
max_history_items: 100
num_attention_heads: 1
attention_probs_dropout_prob: 0.2
hidden_act: gelu
num_hidden_layers: 2
# optim
rec:
epoch: 1
batch_size: 8
optimizer:
name: AdamW
lr: !!float 1e-3
weight_decay: !!float 0.0000
lr_bert: !!float 1e-5
================================================
FILE: config/recommendation/sasrec/redial.yaml
================================================
# dataset
dataset: ReDial
tokenize:
rec: bert
# dataloader
context_truncate: 256
response_truncate: 30
item_truncate: 100
scale: 1
# model
rec_model: SASREC
hidden_dropout_prob: 0.2
initializer_range: 0.02
hidden_size: 50
max_history_items: 100
num_attention_heads: 1
attention_probs_dropout_prob: 0.2
hidden_act: gelu
num_hidden_layers: 2
# optim
rec:
epoch: 1
batch_size: 8
optimizer:
name: AdamW
lr: !!float 1e-3
weight_decay: !!float 0.0000
lr_bert: !!float 1e-5
================================================
FILE: config/recommendation/sasrec/tgredial.yaml
================================================
# dataset
dataset: TGReDial
tokenize:
rec: bert
# dataloader
context_truncate: 256
response_truncate: 30
item_truncate: 100
scale: 1
# model
rec_model: SASREC
hidden_dropout_prob: 0.2
initializer_range: 0.02
hidden_size: 50
max_history_items: 100
num_attention_heads: 1
attention_probs_dropout_prob: 0.2
hidden_act: gelu
num_hidden_layers: 2
# optim
rec:
epoch: 50
batch_size: 256
optimizer:
name: Adam
lr: !!float 1e-3
weight_decay: !!float 0.0000
lr_bert: !!float 1e-5
early_stop: true
stop_mode: max
impatience: 3
================================================
FILE: config/recommendation/textcnn/durecdial.yaml
================================================
# dataset
dataset: DuRecDial
tokenize:
rec: jieba
# dataloader
context_truncate: 256
response_truncate: 30
item_truncate: 100
scale: 1
# model
rec_model: TextCNN
hidden_dropout_prob: 0.2
initializer_range: 0.02
hidden_size: 50
max_history_items: 100
num_attention_heads: 1
attention_probs_dropout_prob: 0.2
hidden_act: gelu
num_hidden_layers: 2
num_filters: 256
embed: 300
filter_sizes: (2, 3, 4)
dropout: 0.5
# optim
rec:
epoch: 1
batch_size: 8
optimizer:
name: AdamW
lr: !!float 1e-3
weight_decay: !!float 0.0000
lr_bert: !!float 1e-5
================================================
FILE: config/recommendation/textcnn/gorecdial.yaml
================================================
# dataset
dataset: GoRecDial
tokenize:
rec: nltk
# dataloader
context_truncate: 256
response_truncate: 30
item_truncate: 100
scale: 1
# model
rec_model: TextCNN
hidden_dropout_prob: 0.2
initializer_range: 0.02
hidden_size: 50
max_history_items: 100
num_attention_heads: 1
attention_probs_dropout_prob: 0.2
hidden_act: gelu
num_hidden_layers: 2
num_filters: 256
embed: 300
filter_sizes: (2, 3, 4)
dropout: 0.5
# optim
rec:
epoch: 1
batch_size: 8
optimizer:
name: AdamW
lr: !!float 1e-3
weight_decay: !!float 0.0000
lr_bert: !!float 1e-5
================================================
FILE: config/recommendation/textcnn/inspired.yaml
================================================
# dataset
dataset: Inspired
tokenize:
rec: nltk
# dataloader
context_truncate: 256
response_truncate: 30
item_truncate: 100
scale: 1
# model
rec_model: TextCNN
hidden_dropout_prob: 0.2
initializer_range: 0.02
hidden_size: 50
max_history_items: 100
num_attention_heads: 1
attention_probs_dropout_prob: 0.2
hidden_act: gelu
num_hidden_layers: 2
num_filters: 256
embed: 300
filter_sizes: (2, 3, 4)
dropout: 0.5
# optim
rec:
epoch: 1
batch_size: 8
optimizer:
name: AdamW
lr: !!float 1e-3
weight_decay: !!float 0.0000
lr_bert: !!float 1e-5
================================================
FILE: config/recommendation/textcnn/opendialkg.yaml
================================================
# dataset
dataset: OpenDialKG
tokenize:
rec: nltk
# dataloader
context_truncate: 256
response_truncate: 30
item_truncate: 100
scale: 1
# model
rec_model: TextCNN
hidden_dropout_prob: 0.2
initializer_range: 0.02
hidden_size: 50
max_history_items: 100
num_attention_heads: 1
attention_probs_dropout_prob: 0.2
hidden_act: gelu
num_hidden_layers: 2
num_filters: 256
embed: 300
filter_sizes: (2, 3, 4)
dropout: 0.5
# optim
rec:
epoch: 1
batch_size: 8
optimizer:
name: AdamW
lr: !!float 1e-3
weight_decay: !!float 0.0000
lr_bert: !!float 1e-5
================================================
FILE: config/recommendation/textcnn/redial.yaml
================================================
# dataset
dataset: ReDial
tokenize:
rec: nltk
# dataloader
context_truncate: 256
response_truncate: 30
item_truncate: 100
scale: 1
# model
rec_model: TextCNN
hidden_dropout_prob: 0.2
initializer_range: 0.02
hidden_size: 50
max_history_items: 100
num_attention_heads: 1
attention_probs_dropout_prob: 0.2
hidden_act: gelu
num_hidden_layers: 2
num_filters: 256
embed: 300
filter_sizes: (2, 3, 4)
dropout: 0.5
# optim
rec:
epoch: 1
batch_size: 8
optimizer:
name: AdamW
lr: !!float 1e-3
weight_decay: !!float 0.0000
lr_bert: !!float 1e-5
================================================
FILE: config/recommendation/textcnn/tgredial.yaml
================================================
# dataset
dataset: TGReDial
tokenize:
rec: sougou
# dataloader
context_truncate: 256
response_truncate: 30
item_truncate: 100
scale: 1
# model
rec_model: TextCNN
hidden_dropout_prob: 0.2
initializer_range: 0.02
hidden_size: 50
max_history_items: 100
num_attention_heads: 1
attention_probs_dropout_prob: 0.2
hidden_act: gelu
num_hidden_layers: 2
num_filters: 256
embed: 300
filter_sizes: (2, 3, 4)
dropout: 0.5
# optim
rec:
epoch: 50
batch_size: 64
optimizer:
name: Adam
lr: !!float 1e-3
weight_decay: !!float 0.0000
lr_bert: !!float 1e-5
early_stop: true
stop_mode: max
impatience: 3
================================================
FILE: crslab/__init__.py
================================================
__version__ = '0.0.1'
================================================
FILE: crslab/config/__init__.py
================================================
# -*- encoding: utf-8 -*-
# @Time : 2020/12/22
# @Author : Xiaolei Wang
# @email : wxl1999@foxmail.com
# UPDATE
# @Time : 2020/12/29
# @Author : Xiaolei Wang
# @email : wxl1999@foxmail.com
"""Config module which loads parameters for the whole system.
Attributes:
SAVE_PATH (str): where system to save.
DATASET_PATH (str): where dataset to save.
MODEL_PATH (str): where model related data to save.
PRETRAIN_PATH (str): where pretrained model to save.
EMBEDDING_PATH (str): where pretrained embedding to save, used for evaluate embedding related metrics.
"""
import os
from os.path import dirname, realpath
from .config import Config
ROOT_PATH = dirname(dirname(dirname(realpath(__file__))))
SAVE_PATH = os.path.join(ROOT_PATH, 'save')
DATA_PATH = os.path.join(ROOT_PATH, 'data')
DATASET_PATH = os.path.join(DATA_PATH, 'dataset')
MODEL_PATH = os.path.join(DATA_PATH, 'model')
PRETRAIN_PATH = os.path.join(MODEL_PATH, 'pretrain')
EMBEDDING_PATH = os.path.join(DATA_PATH, 'embedding')
================================================
FILE: crslab/config/config.py
================================================
# @Time : 2020/11/22
# @Author : Kun Zhou
# @Email : francis_kun_zhou@163.com
# UPDATE:
# @Time : 2020/11/23, 2021/1/9
# @Author : Kun Zhou, Xiaolei Wang
# @Email : francis_kun_zhou@163.com, wxl1999@foxmail.com
import json
import os
import time
from pprint import pprint
import yaml
import torch
from loguru import logger
from tqdm import tqdm
class Config:
"""Configurator module that load the defined parameters."""
def __init__(self, config_file, gpu='-1', debug=False):
"""Load parameters and set log level.
Args:
config_file (str): path to the config file, which should be in ``yaml`` format.
You can use default config provided in the `Github repo`_, or write it by yourself.
debug (bool, optional): whether to enable debug function during running. Defaults to False.
.. _Github repo:
https://github.com/RUCAIBox/CRSLab
"""
self.opt = self.load_yaml_configs(config_file)
# gpu
os.environ['CUDA_VISIBLE_DEVICES'] = gpu
if gpu != '-1':
self.opt['gpu'] = [i for i in range(len(gpu.split(',')))]
else:
self.opt['gpu'] = [-1]
# dataset
dataset = self.opt['dataset']
tokenize = self.opt['tokenize']
if isinstance(tokenize, dict):
tokenize = ', '.join(tokenize.values())
# model
model = self.opt.get('model', None)
rec_model = self.opt.get('rec_model', None)
conv_model = self.opt.get('conv_model', None)
policy_model = self.opt.get('policy_model', None)
if model:
model_name = model
else:
models = []
if rec_model:
models.append(rec_model)
if conv_model:
models.append(conv_model)
if policy_model:
models.append(policy_model)
model_name = '_'.join(models)
self.opt['model_name'] = model_name
# log
log_name = self.opt.get("log_name", dataset + '_' + model_name + '_' + time.strftime("%Y-%m-%d-%H-%M-%S",
time.localtime())) + ".log"
if not os.path.exists("log"):
os.makedirs("log")
logger.remove()
if debug:
level = 'DEBUG'
else:
level = 'INFO'
logger.add(os.path.join("log", log_name), level=level)
logger.add(lambda msg: tqdm.write(msg, end=''), colorize=True, level=level)
logger.info(f"[Dataset: {dataset} tokenized in {tokenize}]")
if model:
logger.info(f'[Model: {model}]')
if rec_model:
logger.info(f'[Recommendation Model: {rec_model}]')
if conv_model:
logger.info(f'[Conversation Model: {conv_model}]')
if policy_model:
logger.info(f'[Policy Model: {policy_model}]')
logger.info("[Config]" + '\n' + json.dumps(self.opt, indent=4))
@staticmethod
def load_yaml_configs(filename):
"""This function reads ``yaml`` file to build config dictionary
Args:
filename (str): path to ``yaml`` config
Returns:
dict: config
"""
config_dict = dict()
with open(filename, 'r', encoding='utf-8') as f:
config_dict.update(yaml.safe_load(f.read()))
return config_dict
def __setitem__(self, key, value):
if not isinstance(key, str):
raise TypeError("index must be a str.")
self.opt[key] = value
def __getitem__(self, item):
if item in self.opt:
return self.opt[item]
else:
return None
def get(self, item, default=None):
"""Get value of corrsponding item in config
Args:
item (str): key to query in config
default (optional): default value for item if not found in config. Defaults to None.
Returns:
value of corrsponding item in config
"""
if item in self.opt:
return self.opt[item]
else:
return default
def __contains__(self, key):
if not isinstance(key, str):
raise TypeError("index must be a str.")
return key in self.opt
def __str__(self):
return str(self.opt)
def __repr__(self):
return self.__str__()
if __name__ == '__main__':
opt_dict = Config('../../config/crs/kbrd/redial.yaml')
pprint(opt_dict)
================================================
FILE: crslab/data/__init__.py
================================================
# @Time : 2020/11/22
# @Author : Kun Zhou
# @Email : francis_kun_zhou@163.com
# UPDATE:
# @Time : 2020/11/24, 2020/12/29, 2020/12/17
# @Author : Kun Zhou, Xiaolei Wang, Yuanhang Zhou
# @Email : francis_kun_zhou@163.com, wxl1999@foxmail.com, sdzyh002@gmail.com
# @Time : 2021/10/06
# @Author : Zhipeng Zhao
# @Email : oran_official@outlook.com
"""Data module which reads, processes and batches data for the whole system
Attributes:
dataset_register_table (dict): record all supported dataset
dataset_language_map (dict): record all dataset corresponding language
dataloader_register_table (dict): record all model corresponding dataloader
"""
from crslab.data.dataloader import *
from crslab.data.dataset import *
dataset_register_table = {
'ReDial': ReDialDataset,
'TGReDial': TGReDialDataset,
'GoRecDial': GoRecDialDataset,
'OpenDialKG': OpenDialKGDataset,
'Inspired': InspiredDataset,
'DuRecDial': DuRecDialDataset
}
dataset_language_map = {
'ReDial': 'en',
'TGReDial': 'zh',
'GoRecDial': 'en',
'OpenDialKG': 'en',
'Inspired': 'en',
'DuRecDial': 'zh'
}
dataloader_register_table = {
'KGSF': KGSFDataLoader,
'KBRD': KBRDDataLoader,
'TGReDial': TGReDialDataLoader,
'TGRec': TGReDialDataLoader,
'TGConv': TGReDialDataLoader,
'TGPolicy': TGReDialDataLoader,
'TGRec_TGConv': TGReDialDataLoader,
'TGRec_TGConv_TGPolicy': TGReDialDataLoader,
'ReDialRec': ReDialDataLoader,
'ReDialConv': ReDialDataLoader,
'ReDialRec_ReDialConv': ReDialDataLoader,
'InspiredRec_InspiredConv': InspiredDataLoader,
'BERT': TGReDialDataLoader,
'SASREC': TGReDialDataLoader,
'TextCNN': TGReDialDataLoader,
'GRU4REC': TGReDialDataLoader,
'Popularity': TGReDialDataLoader,
'Transformer': KGSFDataLoader,
'GPT2': TGReDialDataLoader,
'ConvBERT': TGReDialDataLoader,
'TopicBERT': TGReDialDataLoader,
'ProfileBERT': TGReDialDataLoader,
'MGCG': TGReDialDataLoader,
'PMI': TGReDialDataLoader,
'NTRD': NTRDDataLoader
}
def get_dataset(opt, tokenize, restore, save) -> BaseDataset:
"""get and process dataset
Args:
opt (Config or dict): config for dataset or the whole system.
tokenize (str): how to tokenize the dataset.
restore (bool): whether to restore saved dataset which has been processed.
save (bool): whether to save dataset after processing.
Returns:
processed dataset
"""
dataset = opt['dataset']
if dataset in dataset_register_table:
return dataset_register_table[dataset](opt, tokenize, restore, save)
else:
raise NotImplementedError(f'The dataloader [{dataset}] has not been implemented')
def get_dataloader(opt, dataset, vocab) -> BaseDataLoader:
"""get dataloader to batchify dataset
Args:
opt (Config or dict): config for dataloader or the whole system.
dataset: processed raw data, no side data.
vocab (dict): all kinds of useful size, idx and map between token and idx.
Returns:
dataloader
"""
model_name = opt['model_name']
if model_name in dataloader_register_table:
return dataloader_register_table[model_name](opt, dataset, vocab)
else:
raise NotImplementedError(f'The dataloader [{model_name}] has not been implemented')
================================================
FILE: crslab/data/dataloader/__init__.py
================================================
from .base import BaseDataLoader
from .inspired import InspiredDataLoader
from .kbrd import KBRDDataLoader
from .kgsf import KGSFDataLoader
from .redial import ReDialDataLoader
from .tgredial import TGReDialDataLoader
from .ntrd import NTRDDataLoader
================================================
FILE: crslab/data/dataloader/base.py
================================================
# @Time : 2020/11/22
# @Author : Kun Zhou
# @Email : francis_kun_zhou@163.com
# UPDATE:
# @Time : 2020/11/23, 2020/12/29
# @Author : Kun Zhou, Xiaolei Wang
# @Email : francis_kun_zhou@163.com, wxl1999@foxmail.com
import random
from abc import ABC
from loguru import logger
from math import ceil
from tqdm import tqdm
class BaseDataLoader(ABC):
"""Abstract class of dataloader
Notes:
``'scale'`` can be set in config to limit the size of dataset.
"""
def __init__(self, opt, dataset):
"""
Args:
opt (Config or dict): config for dataloader or the whole system.
dataset: dataset
"""
self.opt = opt
self.dataset = dataset
self.scale = opt.get('scale', 1)
assert 0 < self.scale <= 1
def get_data(self, batch_fn, batch_size, shuffle=True, process_fn=None):
"""Collate batch data for system to fit
Args:
batch_fn (func): function to collate data
batch_size (int):
shuffle (bool, optional): Defaults to True.
process_fn (func, optional): function to process dataset before batchify. Defaults to None.
Yields:
tuple or dict of torch.Tensor: batch data for system to fit
"""
dataset = self.dataset
if process_fn is not None:
dataset = process_fn()
logger.info('[Finish dataset process before batchify]')
dataset = dataset[:ceil(len(dataset) * self.scale)]
logger.debug(f'[Dataset size: {len(dataset)}]')
batch_num = ceil(len(dataset) / batch_size)
idx_list = list(range(len(dataset)))
if shuffle:
random.shuffle(idx_list)
for start_idx in tqdm(range(batch_num)):
batch_idx = idx_list[start_idx * batch_size: (start_idx + 1) * batch_size]
batch = [dataset[idx] for idx in batch_idx]
batch = batch_fn(batch)
if batch == False:
continue
else:
yield(batch)
def get_conv_data(self, batch_size, shuffle=True):
"""get_data wrapper for conversation.
You can implement your own process_fn in ``conv_process_fn``, batch_fn in ``conv_batchify``.
Args:
batch_size (int):
shuffle (bool, optional): Defaults to True.
Yields:
tuple or dict of torch.Tensor: batch data for conversation.
"""
return self.get_data(self.conv_batchify, batch_size, shuffle, self.conv_process_fn)
def get_rec_data(self, batch_size, shuffle=True):
"""get_data wrapper for recommendation.
You can implement your own process_fn in ``rec_process_fn``, batch_fn in ``rec_batchify``.
Args:
batch_size (int):
shuffle (bool, optional): Defaults to True.
Yields:
tuple or dict of torch.Tensor: batch data for recommendation.
"""
return self.get_data(self.rec_batchify, batch_size, shuffle, self.rec_process_fn)
def get_policy_data(self, batch_size, shuffle=True):
"""get_data wrapper for policy.
You can implement your own process_fn in ``self.policy_process_fn``, batch_fn in ``policy_batchify``.
Args:
batch_size (int):
shuffle (bool, optional): Defaults to True.
Yields:
tuple or dict of torch.Tensor: batch data for policy.
"""
return self.get_data(self.policy_batchify, batch_size, shuffle, self.policy_process_fn)
def conv_process_fn(self):
"""Process whole data for conversation before batch_fn.
Returns:
processed dataset. Defaults to return the same as `self.dataset`.
"""
return self.dataset
def conv_batchify(self, batch):
"""batchify data for conversation after process.
Args:
batch (list): processed batch dataset.
Returns:
batch data for the system to train conversation part.
"""
raise NotImplementedError('dataloader must implement conv_batchify() method')
def rec_process_fn(self):
"""Process whole data for recommendation before batch_fn.
Returns:
processed dataset. Defaults to return the same as `self.dataset`.
"""
return self.dataset
def rec_batchify(self, batch):
"""batchify data for recommendation after process.
Args:
batch (list): processed batch dataset.
Returns:
batch data for the system to train recommendation part.
"""
raise NotImplementedError('dataloader must implement rec_batchify() method')
def policy_process_fn(self):
"""Process whole data for policy before batch_fn.
Returns:
processed dataset. Defaults to return the same as `self.dataset`.
"""
return self.dataset
def policy_batchify(self, batch):
"""batchify data for policy after process.
Args:
batch (list): processed batch dataset.
Returns:
batch data for the system to train policy part.
"""
raise NotImplementedError('dataloader must implement policy_batchify() method')
def retain_recommender_target(self):
"""keep data whose role is recommender.
Returns:
Recommender part of ``self.dataset``.
"""
dataset = []
for conv_dict in tqdm(self.dataset):
if conv_dict['role'] == 'Recommender':
dataset.append(conv_dict)
return dataset
def rec_interact(self, data):
"""process user input data for system to recommend.
Args:
data: user input data.
Returns:
data for system to recommend.
"""
pass
def conv_interact(self, data):
"""Process user input data for system to converse.
Args:
data: user input data.
Returns:
data for system in converse.
"""
pass
================================================
FILE: crslab/data/dataloader/inspired.py
================================================
# @Time : 2021/3/11
# @Author : Beichen Zhang
# @Email : zhangbeichen724@gmail.com
from copy import deepcopy
import torch
from tqdm import tqdm
from crslab.data.dataloader.base import BaseDataLoader
from crslab.data.dataloader.utils import add_start_end_token_idx, padded_tensor, truncate, merge_utt
class InspiredDataLoader(BaseDataLoader):
"""Dataloader for model Inspired.
Notes:
You can set the following parameters in config:
- ``'context_truncate'``: the maximum length of context.
- ``'response_truncate'``: the maximum length of response.
- ``'entity_truncate'``: the maximum length of mentioned entities in context.
- ``'word_truncate'``: the maximum length of mentioned words in context.
- ``'item_truncate'``: the maximum length of mentioned items in context.
The following values must be specified in ``vocab``:
- ``'pad'``
- ``'start'``
- ``'end'``
- ``'unk'``
- ``'pad_entity'``
- ``'pad_word'``
the above values specify the id of needed special token.
- ``'ind2tok'``: map from index to token.
- ``'tok2ind'``: map from token to index.
- ``'vocab_size'``: size of vocab.
- ``'id2entity'``: map from index to entity.
- ``'n_entity'``: number of entities in the entity KG of dataset.
- ``'sent_split'`` (optional): token used to split sentence. Defaults to ``'end'``.
- ``'word_split'`` (optional): token used to split word. Defaults to ``'end'``.
"""
def __init__(self, opt, dataset, vocab):
"""
Args:
opt (Config or dict): config for dataloader or the whole system.
dataset: data for model.
vocab (dict): all kinds of useful size, idx and map between token and idx.
"""
super().__init__(opt, dataset)
self.n_entity = vocab['n_entity']
self.pad_token_idx = vocab['pad']
self.start_token_idx = vocab['start']
self.end_token_idx = vocab['end']
self.unk_token_idx = vocab['unk']
self.conv_bos_id = vocab['start']
self.cls_id = vocab['start']
self.sep_id = vocab['end']
if 'sent_split' in vocab:
self.sent_split_idx = vocab['sent_split']
else:
self.sent_split_idx = vocab['end']
self.pad_entity_idx = vocab['pad_entity']
self.pad_word_idx = vocab['pad_word']
self.tok2ind = vocab['tok2ind']
self.ind2tok = vocab['ind2tok']
self.id2entity = vocab['id2entity']
self.context_truncate = opt.get('context_truncate', None)
self.response_truncate = opt.get('response_truncate', None)
def rec_process_fn(self, *args, **kwargs):
augment_dataset = []
for conv_dict in tqdm(self.dataset):
if conv_dict['role'] == 'Recommender':
for movie in conv_dict['items']:
augment_conv_dict = deepcopy(conv_dict)
augment_conv_dict['item'] = movie
augment_dataset.append(augment_conv_dict)
return augment_dataset
def _process_rec_context(self, context_tokens):
compact_context = []
for i, utterance in enumerate(context_tokens):
if i != 0:
utterance.insert(0, self.sent_split_idx)
compact_context.append(utterance)
compat_context = truncate(merge_utt(compact_context),
self.context_truncate - 2,
truncate_tail=False)
compat_context = add_start_end_token_idx(compat_context,
self.start_token_idx,
self.end_token_idx)
return compat_context
def rec_batchify(self, batch):
batch_context = []
batch_movie_id = []
for conv_dict in batch:
context = self._process_rec_context(conv_dict['context_tokens'])
batch_context.append(context)
item_id = conv_dict['item']
batch_movie_id.append(item_id)
batch_context = padded_tensor(batch_context,
self.pad_token_idx,
max_len=self.context_truncate)
batch_mask = (batch_context != self.pad_token_idx).long()
return (batch_context, batch_mask, torch.tensor(batch_movie_id))
def conv_batchify(self, batch):
"""get batch and corresponding roles
"""
batch_roles = []
batch_context_tokens = []
batch_response = []
for conv_dict in batch:
batch_roles.append(0 if conv_dict['role'] == 'Seeker' else 1)
context_tokens = [utter + [self.conv_bos_id] for utter in conv_dict['context_tokens']]
context_tokens[-1] = context_tokens[-1][:-1]
batch_context_tokens.append(
truncate(merge_utt(context_tokens), max_length=self.context_truncate, truncate_tail=False),
)
batch_response.append(
add_start_end_token_idx(
truncate(conv_dict['response'], max_length=self.response_truncate - 2),
start_token_idx=self.start_token_idx,
end_token_idx=self.end_token_idx
)
)
batch_context_tokens = padded_tensor(items=batch_context_tokens,
pad_idx=self.pad_token_idx,
max_len=self.context_truncate,
pad_tail=False)
batch_response = padded_tensor(batch_response,
pad_idx=self.pad_token_idx,
max_len=self.response_truncate,
pad_tail=True)
batch_input_ids = torch.cat((batch_context_tokens, batch_response), dim=1)
batch_roles = torch.tensor(batch_roles)
return (batch_roles,
batch_input_ids,
batch_context_tokens,
batch_response)
def policy_batchify(self, batch):
pass
================================================
FILE: crslab/data/dataloader/kbrd.py
================================================
# @Time : 2020/11/27
# @Author : Xiaolei Wang
# @Email : wxl1999@foxmail.com
# UPDATE:
# @Time : 2020/12/2
# @Author : Xiaolei Wang
# @Email : wxl1999@foxmail.com
import torch
from tqdm import tqdm
from crslab.data.dataloader.base import BaseDataLoader
from crslab.data.dataloader.utils import add_start_end_token_idx, padded_tensor, truncate, merge_utt
class KBRDDataLoader(BaseDataLoader):
"""Dataloader for model KBRD.
Notes:
You can set the following parameters in config:
- ``'context_truncate'``: the maximum length of context.
- ``'response_truncate'``: the maximum length of response.
- ``'entity_truncate'``: the maximum length of mentioned entities in context.
The following values must be specified in ``vocab``:
- ``'pad'``
- ``'start'``
- ``'end'``
- ``'pad_entity'``
the above values specify the id of needed special token.
"""
def __init__(self, opt, dataset, vocab):
"""
Args:
opt (Config or dict): config for dataloader or the whole system.
dataset: data for model.
vocab (dict): all kinds of useful size, idx and map between token and idx.
"""
super().__init__(opt, dataset)
self.pad_token_idx = vocab['pad']
self.start_token_idx = vocab['start']
self.end_token_idx = vocab['end']
self.pad_entity_idx = vocab['pad_entity']
self.context_truncate = opt.get('context_truncate', None)
self.response_truncate = opt.get('response_truncate', None)
self.entity_truncate = opt.get('entity_truncate', None)
def rec_process_fn(self):
augment_dataset = []
for conv_dict in tqdm(self.dataset):
if conv_dict['role'] == 'Recommender':
for movie in conv_dict['items']:
augment_conv_dict = {'context_entities': conv_dict['context_entities'], 'item': movie}
augment_dataset.append(augment_conv_dict)
return augment_dataset
def rec_batchify(self, batch):
batch_context_entities = []
batch_movies = []
for conv_dict in batch:
batch_context_entities.append(conv_dict['context_entities'])
batch_movies.append(conv_dict['item'])
return {
"context_entities": batch_context_entities,
"item": torch.tensor(batch_movies, dtype=torch.long)
}
def conv_process_fn(self, *args, **kwargs):
return self.retain_recommender_target()
def conv_batchify(self, batch):
batch_context_tokens = []
batch_context_entities = []
batch_response = []
for conv_dict in batch:
batch_context_tokens.append(
truncate(merge_utt(conv_dict['context_tokens']), self.context_truncate, truncate_tail=False))
batch_context_entities.append(conv_dict['context_entities'])
batch_response.append(
add_start_end_token_idx(truncate(conv_dict['response'], self.response_truncate - 2),
start_token_idx=self.start_token_idx,
end_token_idx=self.end_token_idx))
return {
"context_tokens": padded_tensor(batch_context_tokens, self.pad_token_idx, pad_tail=False),
"context_entities": batch_context_entities,
"response": padded_tensor(batch_response, self.pad_token_idx)
}
def policy_batchify(self, *args, **kwargs):
pass
================================================
FILE: crslab/data/dataloader/kgsf.py
================================================
# @Time : 2020/11/22
# @Author : Kun Zhou
# @Email : francis_kun_zhou@163.com
# UPDATE:
# @Time : 2020/11/23, 2020/12/2
# @Author : Kun Zhou, Xiaolei Wang
# @Email : francis_kun_zhou@163.com, wxl1999@foxmail.com
from copy import deepcopy
import torch
from tqdm import tqdm
from crslab.data.dataloader.base import BaseDataLoader
from crslab.data.dataloader.utils import add_start_end_token_idx, padded_tensor, get_onehot, truncate, merge_utt
class KGSFDataLoader(BaseDataLoader):
"""Dataloader for model KGSF.
Notes:
You can set the following parameters in config:
- ``'context_truncate'``: the maximum length of context.
- ``'response_truncate'``: the maximum length of response.
- ``'entity_truncate'``: the maximum length of mentioned entities in context.
- ``'word_truncate'``: the maximum length of mentioned words in context.
The following values must be specified in ``vocab``:
- ``'pad'``
- ``'start'``
- ``'end'``
- ``'pad_entity'``
- ``'pad_word'``
the above values specify the id of needed special token.
- ``'n_entity'``: the number of entities in the entity KG of dataset.
"""
def __init__(self, opt, dataset, vocab):
"""
Args:
opt (Config or dict): config for dataloader or the whole system.
dataset: data for model.
vocab (dict): all kinds of useful size, idx and map between token and idx.
"""
super().__init__(opt, dataset)
self.n_entity = vocab['n_entity']
self.pad_token_idx = vocab['pad']
self.start_token_idx = vocab['start']
self.end_token_idx = vocab['end']
self.pad_entity_idx = vocab['pad_entity']
self.pad_word_idx = vocab['pad_word']
self.context_truncate = opt.get('context_truncate', None)
self.response_truncate = opt.get('response_truncate', None)
self.entity_truncate = opt.get('entity_truncate', None)
self.word_truncate = opt.get('word_truncate', None)
def get_pretrain_data(self, batch_size, shuffle=True):
return self.get_data(self.pretrain_batchify, batch_size, shuffle, self.retain_recommender_target)
def pretrain_batchify(self, batch):
batch_context_entities = []
batch_context_words = []
for conv_dict in batch:
batch_context_entities.append(
truncate(conv_dict['context_entities'], self.entity_truncate, truncate_tail=False))
batch_context_words.append(truncate(conv_dict['context_words'], self.word_truncate, truncate_tail=False))
return (padded_tensor(batch_context_words, self.pad_word_idx, pad_tail=False),
get_onehot(batch_context_entities, self.n_entity))
def rec_process_fn(self):
augment_dataset = []
for conv_dict in tqdm(self.dataset):
if conv_dict['role'] == 'Recommender':
for movie in conv_dict['items']:
augment_conv_dict = deepcopy(conv_dict)
augment_conv_dict['item'] = movie
augment_dataset.append(augment_conv_dict)
return augment_dataset
def rec_batchify(self, batch):
batch_context_entities = []
batch_context_words = []
batch_item = []
for conv_dict in batch:
batch_context_entities.append(
truncate(conv_dict['context_entities'], self.entity_truncate, truncate_tail=False))
batch_context_words.append(truncate(conv_dict['context_words'], self.word_truncate, truncate_tail=False))
batch_item.append(conv_dict['item'])
return (padded_tensor(batch_context_entities, self.pad_entity_idx, pad_tail=False),
padded_tensor(batch_context_words, self.pad_word_idx, pad_tail=False),
get_onehot(batch_context_entities, self.n_entity),
torch.tensor(batch_item, dtype=torch.long))
def conv_process_fn(self, *args, **kwargs):
return self.retain_recommender_target()
def conv_batchify(self, batch):
batch_context_tokens = []
batch_context_entities = []
batch_context_words = []
batch_response = []
for conv_dict in batch:
batch_context_tokens.append(
truncate(merge_utt(conv_dict['context_tokens']), self.context_truncate, truncate_tail=False))
batch_context_entities.append(
truncate(conv_dict['context_entities'], self.entity_truncate, truncate_tail=False))
batch_context_words.append(truncate(conv_dict['context_words'], self.word_truncate, truncate_tail=False))
batch_response.append(
add_start_end_token_idx(truncate(conv_dict['response'], self.response_truncate - 2),
start_token_idx=self.start_token_idx,
end_token_idx=self.end_token_idx))
return (padded_tensor(batch_context_tokens, self.pad_token_idx, pad_tail=False),
padded_tensor(batch_context_entities, self.pad_entity_idx, pad_tail=False),
padded_tensor(batch_context_words, self.pad_word_idx, pad_tail=False),
padded_tensor(batch_response, self.pad_token_idx))
def policy_batchify(self, *args, **kwargs):
pass
================================================
FILE: crslab/data/dataloader/ntrd.py
================================================
# @Time : 2021/10/06
# @Author : Zhipeng Zhao
# @Email : oran_official@outlook.com
from copy import deepcopy
import torch
from tqdm import tqdm
from crslab.data.dataloader.base import BaseDataLoader
from crslab.data.dataloader.utils import add_start_end_token_idx, merge_utt_replace, padded_tensor, get_onehot, truncate, merge_utt
class NTRDDataLoader(BaseDataLoader):
def __init__(self, opt, dataset, vocab):
"""
Args:
opt (Config or dict): config for dataloader or the whole system.
dataset: data for model.
vocab (dict): all kinds of useful size, idx and map between token and idx.
"""
super().__init__(opt, dataset)
self.n_entity = vocab['n_entity']
self.pad_token_idx = vocab['pad']
self.start_token_idx = vocab['start']
self.end_token_idx = vocab['end']
self.pad_entity_idx = vocab['pad_entity']
self.pad_word_idx = vocab['pad_word']
self.context_truncate = opt.get('context_truncate', None)
self.response_truncate = opt.get('response_truncate', None)
self.entity_truncate = opt.get('entity_truncate', None)
self.word_truncate = opt.get('word_truncate', None)
self.replace_token = opt.get('replace_token',None)
self.replace_token_idx = vocab[self.replace_token]
def get_pretrain_data(self, batch_size, shuffle=True):
return self.get_data(self.pretrain_batchify, batch_size, shuffle, self.retain_recommender_target)
def pretrain_batchify(self, batch):
batch_context_entities = []
batch_context_words = []
for conv_dict in batch:
batch_context_entities.append(
truncate(conv_dict['context_entities'], self.entity_truncate, truncate_tail=False))
batch_context_words.append(truncate(conv_dict['context_words'], self.word_truncate, truncate_tail=False))
return (padded_tensor(batch_context_words, self.pad_word_idx, pad_tail=False),
get_onehot(batch_context_entities, self.n_entity))
def rec_process_fn(self):
augment_dataset = []
for conv_dict in tqdm(self.dataset):
if conv_dict['role'] == 'Recommender':
for movie in conv_dict['items']:
augment_conv_dict = deepcopy(conv_dict)
augment_conv_dict['item'] = movie
augment_dataset.append(augment_conv_dict)
return augment_dataset
def rec_batchify(self, batch):
batch_context_entities = []
batch_context_words = []
batch_item = []
for conv_dict in batch:
batch_context_entities.append(
truncate(conv_dict['context_entities'], self.entity_truncate, truncate_tail=False))
batch_context_words.append(truncate(conv_dict['context_words'], self.word_truncate, truncate_tail=False))
batch_item.append(conv_dict['item'])
return (padded_tensor(batch_context_entities, self.pad_entity_idx, pad_tail=False),
padded_tensor(batch_context_words, self.pad_word_idx, pad_tail=False),
get_onehot(batch_context_entities, self.n_entity),
torch.tensor(batch_item, dtype=torch.long))
def conv_process_fn(self, *args, **kwargs):
return self.retain_recommender_target()
def conv_batchify(self, batch):
batch_context_tokens = []
batch_context_entities = []
batch_context_words = []
batch_response = []
flag = False
batch_all_movies = []
for conv_dict in batch:
temp = add_start_end_token_idx(truncate(conv_dict['response'], self.response_truncate - 2),
start_token_idx=self.start_token_idx,
end_token_idx=self.end_token_idx)
if temp.count(self.replace_token_idx) != 0:
flag = True
batch_context_tokens.append(
truncate(merge_utt(conv_dict['context_tokens']), self.context_truncate, truncate_tail=False))
batch_context_entities.append(
truncate(conv_dict['context_entities'], self.entity_truncate, truncate_tail=False))
batch_context_words.append(truncate(conv_dict['context_words'], self.word_truncate, truncate_tail=False))
batch_response.append(
add_start_end_token_idx(truncate(conv_dict['response'], self.response_truncate - 2),
start_token_idx=self.start_token_idx,
end_token_idx=self.end_token_idx))
batch_all_movies.append(
truncate(conv_dict['items'], temp.count(self.replace_token_idx), truncate_tail=False)) #only use movies, not all entities.
if flag == False:# zero slot in a batch
return False
return (padded_tensor(batch_context_tokens, self.pad_token_idx, pad_tail=False),
padded_tensor(batch_context_entities, self.pad_entity_idx, pad_tail=False),
padded_tensor(batch_context_words, self.pad_word_idx, pad_tail=False),
padded_tensor(batch_response, self.pad_token_idx),
padded_tensor(batch_all_movies, self.pad_entity_idx, pad_tail=False))
def policy_batchify(self, *args, **kwargs):
pass
================================================
FILE: crslab/data/dataloader/redial.py
================================================
# @Time : 2020/11/22
# @Author : Chenzhan Shang
# @Email : czshang@outlook.com
# UPDATE:
# @Time : 2020/12/16
# @Author : Xiaolei Wang
# @Email : wxl1999@foxmail.com
import re
from copy import copy
import torch
from tqdm import tqdm
from crslab.data.dataloader.base import BaseDataLoader
from crslab.data.dataloader.utils import padded_tensor, get_onehot, truncate
movie_pattern = re.compile(r'^@\d{5,6}$')
class ReDialDataLoader(BaseDataLoader):
"""Dataloader for model ReDial.
Notes:
You can set the following parameters in config:
- ``'utterance_truncate'``: the maximum length of a single utterance.
- ``'conversation_truncate'``: the maximum length of the whole conversation.
The following values must be specified in ``vocab``:
- ``'pad'``
- ``'start'``
- ``'end'``
- ``'unk'``
the above values specify the id of needed special token.
- ``'ind2tok'``: map from index to token.
- ``'n_entity'``: number of entities in the entity KG of dataset.
- ``'vocab_size'``: size of vocab.
"""
def __init__(self, opt, dataset, vocab):
"""
Args:
opt (Config or dict): config for dataloader or the whole system.
dataset: data for model.
vocab (dict): all kinds of useful size, idx and map between token and idx.
"""
super().__init__(opt, dataset)
self.ind2tok = vocab['ind2tok']
self.n_entity = vocab['n_entity']
self.pad_token_idx = vocab['pad']
self.start_token_idx = vocab['start']
self.end_token_idx = vocab['end']
self.unk_token_idx = vocab['unk']
self.item_token_idx = vocab['vocab_size']
self.conversation_truncate = self.opt.get('conversation_truncate', None)
self.utterance_truncate = self.opt.get('utterance_truncate', None)
def rec_process_fn(self, *args, **kwargs):
dataset = []
for conversation in self.dataset:
if conversation['role'] == 'Recommender':
for item in conversation['items']:
context_entities = conversation['context_entities']
dataset.append({'context_entities': context_entities, 'item': item})
return dataset
def rec_batchify(self, batch):
batch_context_entities = []
batch_item = []
for conversation in batch:
batch_context_entities.append(conversation['context_entities'])
batch_item.append(conversation['item'])
context_entities = get_onehot(batch_context_entities, self.n_entity)
return {'context_entities': context_entities, 'item': torch.tensor(batch_item, dtype=torch.long)}
def conv_process_fn(self):
dataset = []
for conversation in tqdm(self.dataset):
if conversation['role'] != 'Recommender':
continue
context_tokens = [truncate(utterance, self.utterance_truncate, truncate_tail=True) for utterance in
conversation['context_tokens']]
context_tokens = truncate(context_tokens, self.conversation_truncate, truncate_tail=True)
context_length = len(context_tokens)
utterance_lengths = [len(utterance) for utterance in context_tokens]
request = context_tokens[-1]
response = truncate(conversation['response'], self.utterance_truncate, truncate_tail=True)
dataset.append({'context_tokens': context_tokens, 'context_length': context_length,
'utterance_lengths': utterance_lengths, 'request': request, 'response': response})
return dataset
def conv_batchify(self, batch):
max_utterance_length = max([max(conversation['utterance_lengths']) for conversation in batch])
max_response_length = max([len(conversation['response']) for conversation in batch])
max_utterance_length = max(max_utterance_length, max_response_length)
max_context_length = max([conversation['context_length'] for conversation in batch])
batch_context = []
batch_context_length = []
batch_utterance_lengths = []
batch_request = [] # tensor
batch_request_length = []
batch_response = []
for conversation in batch:
padded_context = padded_tensor(conversation['context_tokens'], pad_idx=self.pad_token_idx,
pad_tail=True, max_len=max_utterance_length)
if len(conversation['context_tokens']) < max_context_length:
pad_tensor = padded_context.new_full(
(max_context_length - len(conversation['context_tokens']), max_utterance_length), self.pad_token_idx
)
padded_context = torch.cat((padded_context, pad_tensor), 0)
batch_context.append(padded_context)
batch_context_length.append(conversation['context_length'])
batch_utterance_lengths.append(conversation['utterance_lengths'] +
[0] * (max_context_length - len(conversation['context_tokens'])))
request = conversation['request']
batch_request_length.append(len(request))
batch_request.append(request)
response = copy(conversation['response'])
# replace '^\d{5,6}$' by '__item__'
for i in range(len(response)):
if movie_pattern.match(self.ind2tok[response[i]]):
response[i] = self.item_token_idx
batch_response.append(response)
context = torch.stack(batch_context, dim=0)
request = padded_tensor(batch_request, self.pad_token_idx, pad_tail=True, max_len=max_utterance_length)
response = padded_tensor(batch_response, self.pad_token_idx, pad_tail=True,
max_len=max_utterance_length) # (bs, utt_len)
return {'context': context, 'context_lengths': torch.tensor(batch_context_length),
'utterance_lengths': torch.tensor(batch_utterance_lengths), 'request': request,
'request_lengths': torch.tensor(batch_request_length), 'response': response}
def policy_batchify(self, batch):
pass
================================================
FILE: crslab/data/dataloader/tgredial.py
================================================
# @Time : 2020/12/9
# @Author : Yuanhang Zhou
# @Email : sdzyh002@gmail.com
# UPDATE:
# @Time : 2020/12/29, 2020/12/15
# @Author : Xiaolei Wang, Yuanhang Zhou
# @Email : wxl1999@foxmail.com, sdzyh002@gmail
import random
from copy import deepcopy
import torch
from tqdm import tqdm
from crslab.data.dataloader.base import BaseDataLoader
from crslab.data.dataloader.utils import add_start_end_token_idx, padded_tensor, truncate, merge_utt
class TGReDialDataLoader(BaseDataLoader):
"""Dataloader for model TGReDial.
Notes:
You can set the following parameters in config:
- ``'context_truncate'``: the maximum length of context.
- ``'response_truncate'``: the maximum length of response.
- ``'entity_truncate'``: the maximum length of mentioned entities in context.
- ``'word_truncate'``: the maximum length of mentioned words in context.
- ``'item_truncate'``: the maximum length of mentioned items in context.
The following values must be specified in ``vocab``:
- ``'pad'``
- ``'start'``
- ``'end'``
- ``'unk'``
- ``'pad_entity'``
- ``'pad_word'``
the above values specify the id of needed special token.
- ``'ind2tok'``: map from index to token.
- ``'tok2ind'``: map from token to index.
- ``'vocab_size'``: size of vocab.
- ``'id2entity'``: map from index to entity.
- ``'n_entity'``: number of entities in the entity KG of dataset.
- ``'sent_split'`` (optional): token used to split sentence. Defaults to ``'end'``.
- ``'word_split'`` (optional): token used to split word. Defaults to ``'end'``.
- ``'pad_topic'`` (optional): token used to pad topic.
- ``'ind2topic'`` (optional): map from index to topic.
"""
def __init__(self, opt, dataset, vocab):
"""
Args:
opt (Config or dict): config for dataloader or the whole system.
dataset: data for model.
vocab (dict): all kinds of useful size, idx and map between token and idx.
"""
super().__init__(opt, dataset)
self.n_entity = vocab['n_entity']
self.item_size = self.n_entity
self.pad_token_idx = vocab['pad']
self.start_token_idx = vocab['start']
self.end_token_idx = vocab['end']
self.unk_token_idx = vocab['unk']
self.conv_bos_id = vocab['start']
self.cls_id = vocab['start']
self.sep_id = vocab['end']
if 'sent_split' in vocab:
self.sent_split_idx = vocab['sent_split']
else:
self.sent_split_idx = vocab['end']
if 'word_split' in vocab:
self.word_split_idx = vocab['word_split']
else:
self.word_split_idx = vocab['end']
self.pad_entity_idx = vocab['pad_entity']
self.pad_word_idx = vocab['pad_word']
if 'pad_topic' in vocab:
self.pad_topic_idx = vocab['pad_topic']
self.tok2ind = vocab['tok2ind']
self.ind2tok = vocab['ind2tok']
self.id2entity = vocab['id2entity']
if 'ind2topic' in vocab:
self.ind2topic = vocab['ind2topic']
self.context_truncate = opt.get('context_truncate', None)
self.response_truncate = opt.get('response_truncate', None)
self.entity_truncate = opt.get('entity_truncate', None)
self.word_truncate = opt.get('word_truncate', None)
self.item_truncate = opt.get('item_truncate', None)
def rec_process_fn(self, *args, **kwargs):
augment_dataset = []
for conv_dict in tqdm(self.dataset):
for movie in conv_dict['items']:
augment_conv_dict = deepcopy(conv_dict)
augment_conv_dict['item'] = movie
augment_dataset.append(augment_conv_dict)
return augment_dataset
def _process_rec_context(self, context_tokens):
compact_context = []
for i, utterance in enumerate(context_tokens):
if i != 0:
utterance.insert(0, self.sent_split_idx)
compact_context.append(utterance)
compat_context = truncate(merge_utt(compact_context),
self.context_truncate - 2,
truncate_tail=False)
compat_context = add_start_end_token_idx(compat_context,
self.start_token_idx,
self.end_token_idx)
return compat_context
def _neg_sample(self, item_set):
item = random.randint(1, self.item_size)
while item in item_set:
item = random.randint(1, self.item_size)
return item
def _process_history(self, context_items, item_id=None):
input_ids = truncate(context_items,
max_length=self.item_truncate,
truncate_tail=False)
input_mask = [1] * len(input_ids)
sample_negs = []
seq_set = set(input_ids)
for _ in input_ids:
sample_negs.append(self._neg_sample(seq_set))
if item_id is not None:
target_pos = input_ids[1:] + [item_id]
return input_ids, target_pos, input_mask, sample_negs
else:
return input_ids, input_mask, sample_negs
def rec_batchify(self, batch):
batch_context = []
batch_movie_id = []
batch_input_ids = []
batch_target_pos = []
batch_input_mask = []
batch_sample_negs = []
for conv_dict in batch:
context = self._process_rec_context(conv_dict['context_tokens'])
batch_context.append(context)
item_id = conv_dict['item']
batch_movie_id.append(item_id)
if 'interaction_history' in conv_dict:
context_items = conv_dict['interaction_history'] + conv_dict[
'context_items']
else:
context_items = conv_dict['context_items']
input_ids, target_pos, input_mask, sample_negs = self._process_history(
context_items, item_id)
batch_input_ids.append(input_ids)
batch_target_pos.append(target_pos)
batch_input_mask.append(input_mask)
batch_sample_negs.append(sample_negs)
batch_context = padded_tensor(batch_context,
self.pad_token_idx,
max_len=self.context_truncate)
batch_mask = (batch_context != self.pad_token_idx).long()
return (batch_context, batch_mask,
padded_tensor(batch_input_ids,
pad_idx=self.pad_token_idx,
pad_tail=False,
max_len=self.item_truncate),
padded_tensor(batch_target_pos,
pad_idx=self.pad_token_idx,
pad_tail=False,
max_len=self.item_truncate),
padded_tensor(batch_input_mask,
pad_idx=self.pad_token_idx,
pad_tail=False,
max_len=self.item_truncate),
padded_tensor(batch_sample_negs,
pad_idx=self.pad_token_idx,
pad_tail=False,
max_len=self.item_truncate),
torch.tensor(batch_movie_id))
def rec_interact(self, data):
context = [self._process_rec_context(data['context_tokens'])]
if 'interaction_history' in data:
context_items = data['interaction_history'] + data['context_items']
else:
context_items = data['context_items']
input_ids, input_mask, sample_negs = self._process_history(context_items)
input_ids, input_mask, sample_negs = [input_ids], [input_mask], [sample_negs]
context = padded_tensor(context,
self.pad_token_idx,
max_len=self.context_truncate)
mask = (context != self.pad_token_idx).long()
return (context, mask,
padded_tensor(input_ids,
pad_idx=self.pad_token_idx,
pad_tail=False,
max_len=self.item_truncate),
None,
padded_tensor(input_mask,
pad_idx=self.pad_token_idx,
pad_tail=False,
max_len=self.item_truncate),
padded_tensor(sample_negs,
pad_idx=self.pad_token_idx,
pad_tail=False,
max_len=self.item_truncate),
None)
def conv_batchify(self, batch):
batch_context_tokens = []
batch_enhanced_context_tokens = []
batch_response = []
batch_context_entities = []
batch_context_words = []
for conv_dict in batch:
context_tokens = [utter + [self.conv_bos_id] for utter in conv_dict['context_tokens']]
context_tokens[-1] = context_tokens[-1][:-1]
batch_context_tokens.append(
truncate(merge_utt(context_tokens), max_length=self.context_truncate, truncate_tail=False),
)
batch_response.append(
add_start_end_token_idx(
truncate(conv_dict['response'], max_length=self.response_truncate - 2),
start_token_idx=self.start_token_idx,
end_token_idx=self.end_token_idx
)
)
batch_context_entities.append(
truncate(conv_dict['context_entities'],
self.entity_truncate,
truncate_tail=False))
batch_context_words.append(
truncate(conv_dict['context_words'],
self.word_truncate,
truncate_tail=False))
enhanced_topic = []
if 'target' in conv_dict:
for target_policy in conv_dict['target']:
topic_variable = target_policy[1]
if isinstance(topic_variable, list):
for topic in topic_variable:
enhanced_topic.append(topic)
enhanced_topic = [[
self.tok2ind.get(token, self.unk_token_idx) for token in self.ind2topic[topic_id]
] for topic_id in enhanced_topic]
enhanced_topic = merge_utt(enhanced_topic, self.word_split_idx, False, self.sent_split_idx)
enhanced_movie = []
if 'items' in conv_dict:
for movie_id in conv_dict['items']:
enhanced_movie.append(movie_id)
enhanced_movie = [
[self.tok2ind.get(token, self.unk_token_idx) for token in self.id2entity[movie_id].split('(')[0]]
for movie_id in enhanced_movie]
enhanced_movie = truncate(merge_utt(enhanced_movie, self.word_split_idx, self.sent_split_idx),
self.item_truncate, truncate_tail=False)
if len(enhanced_movie) != 0:
enhanced_context_tokens = enhanced_movie + truncate(batch_context_tokens[-1],
max_length=self.context_truncate - len(
enhanced_movie), truncate_tail=False)
elif len(enhanced_topic) != 0:
enhanced_context_tokens = enhanced_topic + truncate(batch_context_tokens[-1],
max_length=self.context_truncate - len(
enhanced_topic), truncate_tail=False)
else:
enhanced_context_tokens = batch_context_tokens[-1]
batch_enhanced_context_tokens.append(
enhanced_context_tokens
)
batch_context_tokens = padded_tensor(items=batch_context_tokens,
pad_idx=self.pad_token_idx,
max_len=self.context_truncate,
pad_tail=False)
batch_response = padded_tensor(batch_response,
pad_idx=self.pad_token_idx,
max_len=self.response_truncate,
pad_tail=True)
batch_input_ids = torch.cat((batch_context_tokens, batch_response), dim=1)
batch_enhanced_context_tokens = padded_tensor(items=batch_enhanced_context_tokens,
pad_idx=self.pad_token_idx,
max_len=self.context_truncate,
pad_tail=False)
batch_enhanced_input_ids = torch.cat((batch_enhanced_context_tokens, batch_response), dim=1)
return (batch_enhanced_input_ids, batch_enhanced_context_tokens,
batch_input_ids, batch_context_tokens,
padded_tensor(batch_context_entities,
self.pad_entity_idx,
pad_tail=False),
padded_tensor(batch_context_words,
self.pad_word_idx,
pad_tail=False), batch_response)
def conv_interact(self, data):
context_tokens = [utter + [self.conv_bos_id] for utter in data['context_tokens']]
context_tokens[-1] = context_tokens[-1][:-1]
context_tokens = [truncate(merge_utt(context_tokens), max_length=self.context_truncate, truncate_tail=False)]
context_tokens = padded_tensor(items=context_tokens,
pad_idx=self.pad_token_idx,
max_len=self.context_truncate,
pad_tail=False)
context_entities = [truncate(data['context_entities'], self.entity_truncate, truncate_tail=False)]
context_words = [truncate(data['context_words'], self.word_truncate, truncate_tail=False)]
return (context_tokens, context_tokens,
context_tokens, context_tokens,
padded_tensor(context_entities,
self.pad_entity_idx,
pad_tail=False),
padded_tensor(context_words,
self.pad_word_idx,
pad_tail=False), None)
def policy_process_fn(self, *args, **kwargs):
augment_dataset = []
for conv_dict in tqdm(self.dataset):
for target_policy in conv_dict['target']:
topic_variable = target_policy[1]
for topic in topic_variable:
augment_conv_dict = deepcopy(conv_dict)
augment_conv_dict['target_topic'] = topic
augment_dataset.append(augment_conv_dict)
return augment_dataset
def policy_batchify(self, batch):
batch_context = []
batch_context_policy = []
batch_user_profile = []
batch_target = []
for conv_dict in batch:
final_topic = conv_dict['final']
final_topic = [[
self.tok2ind.get(token, self.unk_token_idx) for token in self.ind2topic[topic_id]
] for topic_id in final_topic[1]]
final_topic = merge_utt(final_topic, self.word_split_idx, False, self.sep_id)
context = conv_dict['context_tokens']
context = merge_utt(context,
self.sent_split_idx,
False,
self.sep_id)
context += final_topic
context = add_start_end_token_idx(
truncate(context, max_length=self.context_truncate - 1, truncate_tail=False),
start_token_idx=self.cls_id)
batch_context.append(context)
# [topic, topic, ..., topic]
context_policy = []
for policies_one_turn in conv_dict['context_policy']:
if len(policies_one_turn) != 0:
for policy in policies_one_turn:
for topic_id in policy[1]:
if topic_id != self.pad_topic_idx:
policy = []
for token in self.ind2topic[topic_id]:
policy.append(self.tok2ind.get(token, self.unk_token_idx))
context_policy.append(policy)
context_policy = merge_utt(context_policy, self.word_split_idx, False)
context_policy = add_start_end_token_idx(
context_policy,
start_token_idx=self.cls_id,
end_token_idx=self.sep_id)
context_policy += final_topic
batch_context_policy.append(context_policy)
batch_user_profile.extend(conv_dict['user_profile'])
batch_target.append(conv_dict['target_topic'])
batch_context = padded_tensor(batch_context,
pad_idx=self.pad_token_idx,
pad_tail=True,
max_len=self.context_truncate)
batch_cotnext_mask = (batch_context != self.pad_token_idx).long()
batch_context_policy = padded_tensor(batch_context_policy,
pad_idx=self.pad_token_idx,
pad_tail=True)
batch_context_policy_mask = (batch_context_policy != 0).long()
batch_user_profile = padded_tensor(batch_user_profile,
pad_idx=self.pad_token_idx,
pad_tail=True)
batch_user_profile_mask = (batch_user_profile != 0).long()
batch_target = torch.tensor(batch_target, dtype=torch.long)
return (batch_context, batch_cotnext_mask, batch_context_policy,
batch_context_policy_mask, batch_user_profile,
batch_user_profile_mask, batch_target)
================================================
FILE: crslab/data/dataloader/utils.py
================================================
# -*- encoding: utf-8 -*-
# @Time : 2020/12/10
# @Author : Xiaolei Wang
# @email : wxl1999@foxmail.com
# UPDATE
# @Time : 2020/12/20, 2020/12/15
# @Author : Xiaolei Wang, Yuanhang Zhou
# @email : wxl1999@foxmail.com, sdzyh002@gmail
# UPDATE
# @Time : 2021/10/06
# @Author : Zhipeng Zhao
# @Email : oran_official@outlook.com
from copy import copy
import torch
from typing import List, Union, Optional
def padded_tensor(
items: List[Union[List[int], torch.LongTensor]],
pad_idx: int = 0,
pad_tail: bool = True,
max_len: Optional[int] = None,
) -> torch.LongTensor:
"""Create a padded matrix from an uneven list of lists.
Returns padded matrix.
Matrix is right-padded (filled to the right) by default, but can be
left padded if the flag is set to True.
Matrix can also be placed on cuda automatically.
:param list[iter[int]] items: List of items
:param int pad_idx: the value to use for padding
:param bool pad_tail:
:param int max_len: if None, the max length is the maximum item length
:returns: padded tensor.
:rtype: Tensor[int64]
"""
# number of items
n = len(items)
# length of each item
lens: List[int] = [len(item) for item in items] # type: ignore
# max in time dimension
t = max(lens) if max_len is None else max_len
# if input tensors are empty, we should expand to nulls
t = max(t, 1)
if isinstance(items[0], torch.Tensor):
# keep type of input tensors, they may already be cuda ones
output = items[0].new(n, t) # type: ignore
else:
output = torch.LongTensor(n, t) # type: ignore
output.fill_(pad_idx)
for i, (item, length) in enumerate(zip(items, lens)):
if length == 0:
# skip empty items
continue
if not isinstance(item, torch.Tensor):
# put non-tensors into a tensor
item = torch.tensor(item, dtype=torch.long) # type: ignore
if pad_tail:
# place at beginning
output[i, :length] = item
else:
# place at end
output[i, t - length:] = item
return output
def get_onehot(data_list, categories) -> torch.Tensor:
"""Transform lists of label into one-hot.
Args:
data_list (list of list of int): source data.
categories (int): #label class.
Returns:
torch.Tensor: one-hot labels.
"""
onehot_labels = []
for label_list in data_list:
onehot_label = torch.zeros(categories)
for label in label_list:
onehot_label[label] = 1.0 / len(label_list)
onehot_labels.append(onehot_label)
return torch.stack(onehot_labels, dim=0)
def add_start_end_token_idx(vec: list, start_token_idx: int = None, end_token_idx: int = None):
"""Can choose to add start token in the beginning and end token in the end.
Args:
vec: source list composed of indexes.
start_token_idx: index of start token.
end_token_idx: index of end token.
Returns:
list: list added start or end token index.
"""
res = copy(vec)
if start_token_idx:
res.insert(0, start_token_idx)
if end_token_idx:
res.append(end_token_idx)
return res
def truncate(vec, max_length, truncate_tail=True):
"""truncate vec to make its length no more than max length.
Args:
vec (list): source list.
max_length (int)
truncate_tail (bool, optional): Defaults to True.
Returns:
list: truncated vec.
"""
if max_length is None:
return vec
if len(vec) <= max_length:
return vec
if max_length == 0:
return []
if truncate_tail:
return vec[:max_length]
else:
return vec[-max_length:]
def merge_utt(conversation, split_token_idx=None, keep_split_in_tail=False, final_token_idx=None):
"""merge utterances in one conversation.
Args:
conversation (list of list of int): conversation consist of utterances consist of tokens.
split_token_idx (int): index of split token. Defaults to None.
keep_split_in_tail (bool): split in tail or head. Defaults to False.
final_token_idx (int): index of final token. Defaults to None.
Returns:
list: tokens of all utterances in one list.
"""
merged_conv = []
for utt in conversation:
for token in utt:
merged_conv.append(token)
if split_token_idx:
merged_conv.append(split_token_idx)
if split_token_idx and not keep_split_in_tail:
merged_conv = merged_conv[:-1]
if final_token_idx:
merged_conv.append(final_token_idx)
return merged_conv
def merge_utt_replace(conversation,detect_token=None,replace_token=None,method="in"):
if method == 'in':
replaced_conv = []
for utt in conversation:
for token in utt:
if detect_token in token:
replaced_conv.append(replace_token)
else:
replaced_conv.append(token)
return replaced_conv
else:
return [token.replace(detect_token,replace_token) for utt in conversation for token in utt]
================================================
FILE: crslab/data/dataset/__init__.py
================================================
from .base import BaseDataset
from .durecdial import DuRecDialDataset
from .gorecdial import GoRecDialDataset
from .inspired import InspiredDataset
from .opendialkg import OpenDialKGDataset
from .redial import ReDialDataset
from .tgredial import TGReDialDataset
================================================
FILE: crslab/data/dataset/base.py
================================================
# @Time : 2020/11/22
# @Author : Kun Zhou
# @Email : francis_kun_zhou@163.com
# UPDATE:
# @Time : 2020/11/23, 2020/12/13
# @Author : Kun Zhou, Xiaolei Wang
# @Email : francis_kun_zhou@163.com, wxl1999@foxmail.com
import os
import pickle as pkl
from abc import ABC, abstractmethod
import numpy as np
from loguru import logger
from crslab.download import build
class BaseDataset(ABC):
"""Abstract class of dataset
Notes:
``'embedding'`` can be specified in config to use pretrained word embedding.
"""
def __init__(self, opt, dpath, resource, restore=False, save=False):
"""Download resource, load, process data. Support restore and save processed dataset.
Args:
opt (Config or dict): config for dataset or the whole system.
dpath (str): where to store dataset.
resource (dict): version, download file and special token idx of tokenized dataset.
restore (bool): whether to restore saved dataset which has been processed. Defaults to False.
save (bool): whether to save dataset after processing. Defaults to False.
"""
self.opt = opt
self.dpath = dpath
# download
dfile = resource['file']
build(dpath, dfile, version=resource['version'])
if not restore:
# load and process
train_data, valid_data, test_data, self.vocab = self._load_data()
logger.info('[Finish data load]')
self.train_data, self.valid_data, self.test_data, self.side_data = self._data_preprocess(train_data,
valid_data,
test_data)
embedding = opt.get('embedding', None)
if embedding:
self.side_data["embedding"] = np.load(os.path.join(self.dpath, embedding))
logger.debug(f'[Load pretrained embedding {embedding}]')
logger.info('[Finish data preprocess]')
else:
self.train_data, self.valid_data, self.test_data, self.side_data, self.vocab = self._load_from_restore()
if save:
data = (self.train_data, self.valid_data, self.test_data, self.side_data, self.vocab)
self._save_to_one(data)
@abstractmethod
def _load_data(self):
"""Load dataset.
Returns:
(any, any, any, dict):
raw train, valid and test data.
vocab: all kinds of useful size, idx and map between token and idx.
"""
pass
@abstractmethod
def _data_preprocess(self, train_data, valid_data, test_data):
"""Process raw train, valid, test data.
Args:
train_data: train dataset.
valid_data: valid dataset.
test_data: test dataset.
Returns:
(list of dict, dict):
train/valid/test_data, each dict is in the following format::
{
'role' (str):
'Seeker' or 'Recommender',
'user_profile' (list of list of int):
id of tokens of sentences of user profile,
'context_tokens' (list of list int):
token ids of preprocessed contextual dialogs,
'response' (list of int):
token ids of the ground-truth response,
'interaction_history' (list of int):
id of items which have interaction of the user in current turn,
'context_items' (list of int):
item ids mentioned in context,
'items' (list of int):
item ids mentioned in current turn, we only keep
those in entity kg for comparison,
'context_entities' (list of int):
if necessary, id of entities in context,
'context_words' (list of int):
if necessary, id of words in context,
'context_policy' (list of list of list):
policy of each context turn, one turn may have several policies,
where first is action and second is keyword,
'target' (list): policy of current turn,
'final' (list): final goal for current turn
}
side_data, which is in the following format::
{
'entity_kg': {
'edge' (list of tuple): (head_entity_id, tail_entity_id, relation_id),
'n_relation' (int): number of distinct relations,
'entity' (list of str): str of entities, used for entity linking
}
'word_kg': {
'edge' (list of tuple): (head_entity_id, tail_entity_id),
'entity' (list of str): str of entities, used for entity linking
}
'item_entity_ids' (list of int): entity id of each item;
}
"""
pass
def _load_from_restore(self, file_name="all_data.pkl"):
"""Restore saved dataset.
Args:
file_name (str): file of saved dataset. Defaults to "all_data.pkl".
"""
if not os.path.exists(os.path.join(self.dpath, file_name)):
raise ValueError(f'Saved dataset [{file_name}] does not exist')
with open(os.path.join(self.dpath, file_name), 'rb') as f:
dataset = pkl.load(f)
logger.info(f'Restore dataset from [{file_name}]')
return dataset
def _save_to_one(self, data, file_name="all_data.pkl"):
"""Save all processed dataset and vocab into one file.
Args:
data (tuple): all dataset and vocab.
file_name (str, optional): file to save dataset. Defaults to "all_data.pkl".
"""
if not os.path.exists(self.dpath):
os.makedirs(self.dpath)
save_path = os.path.join(self.dpath, file_name)
with open(save_path, 'wb') as f:
pkl.dump(data, f)
logger.info(f'[Save dataset to {file_name}]')
================================================
FILE: crslab/data/dataset/durecdial/__init__.py
================================================
from .durecdial import DuRecDialDataset
================================================
FILE: crslab/data/dataset/durecdial/durecdial.py
================================================
# @Time : 2020/12/21
# @Author : Kun Zhou
# @Email : francis_kun_zhou@163.com
# UPDATE:
# @Time : 2020/12/21, 2021/1/2
# @Author : Kun Zhou, Xiaolei Wang
# @Email : francis_kun_zhou@163.com, wxl1999@foxmail.com
r"""
DuRecDial
=========
References:
Liu, Zeming, et al. `"Towards Conversational Recommendation over Multi-Type Dialogs."`_ in ACL 2020.
.. _"Towards Conversational Recommendation over Multi-Type Dialogs.":
https://www.aclweb.org/anthology/2020.acl-main.98/
"""
import json
import os
from copy import copy
from loguru import logger
from tqdm import tqdm
from crslab.config import DATASET_PATH
from crslab.data.dataset.base import BaseDataset
from .resources import resources
class DuRecDialDataset(BaseDataset):
"""
Attributes:
train_data: train dataset.
valid_data: valid dataset.
test_data: test dataset.
vocab (dict): ::
{
'tok2ind': map from token to index,
'ind2tok': map from index to token,
'entity2id': map from entity to index,
'id2entity': map from index to entity,
'word2id': map from word to index,
'vocab_size': len(self.tok2ind),
'n_entity': max(self.entity2id.values()) + 1,
'n_word': max(self.word2id.values()) + 1,
}
Notes:
``'unk'`` must be specified in ``'special_token_idx'`` in ``resources.py``.
"""
def __init__(self, opt, tokenize, restore=False, save=False):
"""
Args:
opt (Config or dict): config for dataset or the whole system.
tokenize (str): how to tokenize dataset.
restore (bool): whether to restore saved dataset which has been processed. Defaults to False.
save (bool): whether to save dataset after processing. Defaults to False.
"""
resource = resources[tokenize]
self.special_token_idx = resource['special_token_idx']
self.unk_token_idx = self.special_token_idx['unk']
dpath = os.path.join(DATASET_PATH, 'durecdial', tokenize)
super().__init__(opt, dpath, resource, restore, save)
def _load_data(self):
train_data, valid_data, test_data = self._load_raw_data()
self._load_vocab()
self._load_other_data()
vocab = {
'tok2ind': self.tok2ind,
'ind2tok': self.ind2tok,
'entity2id': self.entity2id,
'id2entity': self.id2entity,
'word2id': self.word2id,
'vocab_size': len(self.tok2ind),
'n_entity': self.n_entity,
'n_word': self.n_word,
}
vocab.update(self.special_token_idx)
return train_data, valid_data, test_data, vocab
def _load_raw_data(self):
with open(os.path.join(self.dpath, 'train_data.json'), 'r', encoding='utf-8') as f:
train_data = json.load(f)
logger.debug(f"[Load train data from {os.path.join(self.dpath, 'train_data.json')}]")
with open(os.path.join(self.dpath, 'valid_data.json'), 'r', encoding='utf-8') as f:
valid_data = json.load(f)
logger.debug(f"[Load valid data from {os.path.join(self.dpath, 'valid_data.json')}]")
with open(os.path.join(self.dpath, 'test_data.json'), 'r', encoding='utf-8') as f:
test_data = json.load(f)
logger.debug(f"[Load test data from {os.path.join(self.dpath, 'test_data.json')}]")
return train_data, valid_data, test_data
def _load_vocab(self):
self.tok2ind = json.load(open(os.path.join(self.dpath, 'token2id.json'), 'r', encoding='utf-8'))
self.ind2tok = {idx: word for word, idx in self.tok2ind.items()}
logger.debug(f"[Load vocab from {os.path.join(self.dpath, 'token2id.json')}]")
logger.debug(f"[The size of token2index dictionary is {len(self.tok2ind)}]")
logger.debug(f"[The size of index2token dictionary is {len(self.ind2tok)}]")
def _load_other_data(self):
# entity kg
with open(os.path.join(self.dpath, 'entity2id.json'), encoding='utf-8') as f:
self.entity2id = json.load(f) # {entity: entity_id}
self.id2entity = {idx: entity for entity, idx in self.entity2id.items()}
self.n_entity = max(self.entity2id.values()) + 1
# {head_entity_id: [(relation_id, tail_entity_id)]}
self.entity_kg = open(os.path.join(self.dpath, 'entity_subkg.txt'), encoding='utf-8')
logger.debug(
f"[Load entity dictionary and KG from {os.path.join(self.dpath, 'entity2id.json')} and {os.path.join(self.dpath, 'entity_subkg.txt')}]")
# hownet
# {concept: concept_id}
with open(os.path.join(self.dpath, 'word2id.json'), 'r', encoding='utf-8') as f:
self.word2id = json.load(f)
self.n_word = max(self.word2id.values()) + 1
# {concept \t relation\t concept}
self.word_kg = open(os.path.join(self.dpath, 'hownet_subkg.txt'), encoding='utf-8')
logger.debug(
f"[Load word dictionary and KG from {os.path.join(self.dpath, 'word2id.json')} and {os.path.join(self.dpath, 'hownet_subkg.txt')}]")
def _data_preprocess(self, train_data, valid_data, test_data):
processed_train_data = self._raw_data_process(train_data)
logger.debug("[Finish train data process]")
processed_valid_data = self._raw_data_process(valid_data)
logger.debug("[Finish valid data process]")
processed_test_data = self._raw_data_process(test_data)
logger.debug("[Finish test data process]")
processed_side_data = self._side_data_process()
logger.debug("[Finish side data process]")
return processed_train_data, processed_valid_data, processed_test_data, processed_side_data
def _raw_data_process(self, raw_data):
augmented_convs = [self._convert_to_id(conversation) for conversation in tqdm(raw_data)]
augmented_conv_dicts = []
for conv in tqdm(augmented_convs):
augmented_conv_dicts.extend(self._augment_and_add(conv))
return augmented_conv_dicts
def _convert_to_id(self, conversation):
augmented_convs = []
last_role = None
for utt in conversation['dialog']:
assert utt['role'] != last_role, print(utt)
text_token_ids = [self.tok2ind.get(word, self.unk_token_idx) for word in utt["text"]]
item_ids = [self.entity2id[movie] for movie in utt['item'] if movie in self.entity2id]
entity_ids = [self.entity2id[entity] for entity in utt['entity'] if entity in self.entity2id]
word_ids = [self.word2id[word] for word in utt['word'] if word in self.word2id]
augmented_convs.append({
"role": utt["role"],
"text": text_token_ids,
"entity": entity_ids,
"movie": item_ids,
"word": word_ids
})
last_role = utt["role"]
return augmented_convs
def _augment_and_add(self, raw_conv_dict):
augmented_conv_dicts = []
context_tokens, context_entities, context_words, context_items = [], [], [], []
entity_set, word_set = set(), set()
for i, conv in enumerate(raw_conv_dict):
text_tokens, entities, movies, words = conv["text"], conv["entity"], conv["movie"], conv["word"]
if len(context_tokens) > 0:
conv_dict = {
'role': conv['role'],
"context_tokens": copy(context_tokens),
"response": text_tokens,
"context_entities": copy(context_entities),
"context_words": copy(context_words),
'context_items': copy(context_items),
"items": movies
}
augmented_conv_dicts.append(conv_dict)
context_tokens.append(text_tokens)
context_items += movies
for entity in entities + movies:
if entity not in entity_set:
entity_set.add(entity)
context_entities.append(entity)
for word in words:
if word not in word_set:
word_set.add(word)
context_words.append(word)
return augmented_conv_dicts
def _side_data_process(self):
processed_entity_kg = self._entity_kg_process()
logger.debug("[Finish entity KG process]")
processed_word_kg = self._word_kg_process()
logger.debug("[Finish word KG process]")
with open(os.path.join(self.dpath, 'item_ids.json'), 'r', encoding='utf-8') as f:
item_entity_ids = json.load(f)
logger.debug('[Load movie entity ids]')
side_data = {
"entity_kg": processed_entity_kg,
"word_kg": processed_word_kg,
"item_entity_ids": item_entity_ids,
}
return side_data
def _entity_kg_process(self):
edge_list = [] # [(entity, entity, relation)]
for line in self.entity_kg:
triple = line.strip().split('\t')
e0 = self.entity2id[triple[0]]
e1 = self.entity2id[triple[2]]
r = triple[1]
edge_list.append((e0, e1, r))
edge_list.append((e1, e0, r))
edge_list.append((e0, e0, 'SELF_LOOP'))
if e1 != e0:
edge_list.append((e1, e1, 'SELF_LOOP'))
relation2id, edges, entities = dict(), set(), set()
for h, t, r in edge_list:
if r not in relation2id:
relation2id[r] = len(relation2id)
edges.add((h, t, relation2id[r]))
entities.add(self.id2entity[h])
entities.add(self.id2entity[t])
return {
'edge': list(edges),
'n_relation': len(relation2id),
'entity': list(entities)
}
def _word_kg_process(self):
edges = set() # {(entity, entity)}
entities = set()
for line in self.word_kg:
triple = line.strip().split('\t')
entities.add(triple[0])
entities.add(triple[2])
e0 = self.word2id[triple[0]]
e1 = self.word2id[triple[2]]
edges.add((e0, e1))
edges.add((e1, e0))
# edge_set = [[co[0] for co in list(edges)], [co[1] for co in list(edges)]]
return {
'edge': list(edges),
'entity': list(entities)
}
================================================
FILE: crslab/data/dataset/durecdial/resources.py
================================================
# -*- encoding: utf-8 -*-
# @Time : 2020/12/22
# @Author : Xiaolei Wang
# @email : wxl1999@foxmail.com
# UPDATE
# @Time : 2020/12/22
# @Author : Xiaolei Wang
# @email : wxl1999@foxmail.com
from crslab.download import DownloadableFile
resources = {
'jieba': {
'version': '0.3',
'file': DownloadableFile(
'https://pkueducn-my.sharepoint.com/:u:/g/personal/franciszhou_pkueducn_onmicrosoft_com/EQ5u_Mos1JBFo4MAN8DinUQB7dPWuTsIHGjjvMougLfYaQ?download=1',
'durecdial_jieba.zip',
'c2d24f7d262e24e45a9105161b5eb15057c96c291edb3a2a7b23c9c637fd3813',
),
'special_token_idx': {
'pad': 0,
'start': 1,
'end': 2,
'unk': 3,
'pad_entity': 0,
'pad_word': 0,
},
},
'bert': {
'version': '0.3',
'file': DownloadableFile(
'https://pkueducn-my.sharepoint.com/:u:/g/personal/franciszhou_pkueducn_onmicrosoft_com/ETGpJYjEM9tFhze2VfD33cQBDwa7zq07EUr94zoPZvMPtA?download=1',
'durecdial_bert.zip',
'0126803aee62a5a4d624d8401814c67bee724ad0af5226d421318ac4eec496f5'
),
'special_token_idx': {
'pad': 0,
'start': 101,
'end': 102,
'unk': 100,
'sent_split': 2,
'word_split': 3,
'pad_entity': 0,
'pad_word': 0,
'pad_topic': 0
},
},
'gpt2': {
'version': '0.3',
'file': DownloadableFile(
'https://pkueducn-my.sharepoint.com/:u:/g/personal/franciszhou_pkueducn_onmicrosoft_com/ETxJk-3Kd6tDgFvPhLo9bLUBfVsVZlF80QCnGFcVgusdJg?download=1',
'durecdial_gpt2.zip',
'a7a93292b4e4b8a5e5a2c644f85740e625e04fbd3da76c655150c00f97d405e4'
),
'special_token_idx': {
'pad': 0,
'start': 101,
'end': 102,
'unk': 100,
'cls': 101,
'sep': 102,
'sent_split': 2,
'word_split': 3,
'pad_entity': 0,
'pad_word': 0,
'pad_topic': 0,
},
}
}
================================================
FILE: crslab/data/dataset/gorecdial/__init__.py
================================================
from .gorecdial import GoRecDialDataset
================================================
FILE: crslab/data/dataset/gorecdial/gorecdial.py
================================================
# @Time : 2020/12/12
# @Author : Kun Zhou
# @Email : francis_kun_zhou@163.com
# UPDATE:
# @Time : 2020/12/13, 2021/1/2, 2020/12/19
# @Author : Kun Zhou, Xiaolei Wang, Yuanhang Zhou
# @Email : francis_kun_zhou@163.com, wxl1999@foxmail.com, sdzyh002@gmail
r"""
GoRecDial
=========
References:
Kang, Dongyeop, et al. `"Recommendation as a Communication Game: Self-Supervised Bot-Play for Goal-oriented Dialogue."`_ in EMNLP 2019.
.. _`"Recommendation as a Communication Game: Self-Supervised Bot-Play for Goal-oriented Dialogue."`:
https://www.aclweb.org/anthology/D19-1203/
"""
import json
import os
from copy import copy
from loguru import logger
from tqdm import tqdm
from crslab.config import DATASET_PATH
from crslab.data.dataset.base import BaseDataset
from .resources import resources
class GoRecDialDataset(BaseDataset):
"""
Attributes:
train_data: train dataset.
valid_data: valid dataset.
test_data: test dataset.
vocab (dict): ::
{
'tok2ind': map from token to index,
'ind2tok': map from index to token,
'entity2id': map from entity to index,
'id2entity': map from index to entity,
'word2id': map from word to index,
'vocab_size': len(self.tok2ind),
'n_entity': max(self.entity2id.values()) + 1,
'n_word': max(self.word2id.values()) + 1,
}
Notes:
``'unk'`` must be specified in ``'special_token_idx'`` in ``resources.py``.
"""
def __init__(self, opt, tokenize, restore=False, save=False):
"""Specify tokenized resource and init base dataset.
Args:
opt (Config or dict): config for dataset or the whole system.
tokenize (str): how to tokenize dataset.
restore (bool): whether to restore saved dataset which has been processed. Defaults to False.
save (bool): whether to save dataset after processing. Defaults to False.
"""
resource = resources[tokenize]
self.special_token_idx = resource['special_token_idx']
self.unk_token_idx = self.special_token_idx['unk']
dpath = os.path.join(DATASET_PATH, 'gorecdial', tokenize)
super().__init__(opt, dpath, resource, restore, save)
def _load_data(self):
train_data, valid_data, test_data = self._load_raw_data()
self._load_vocab()
self._load_other_data()
vocab = {
'tok2ind': self.tok2ind,
'ind2tok': self.ind2tok,
'entity2id': self.entity2id,
'id2entity': self.id2entity,
'word2id': self.word2id,
'vocab_size': len(self.tok2ind),
'n_entity': self.n_entity,
'n_word': self.n_word,
}
vocab.update(self.special_token_idx)
return train_data, valid_data, test_data, vocab
def _load_raw_data(self):
# load train/valid/test data
with open(os.path.join(self.dpath, 'train_data.json'), 'r', encoding='utf-8') as f:
train_data = json.load(f)
logger.debug(f"[Load train data from {os.path.join(self.dpath, 'train_data.json')}]")
with open(os.path.join(self.dpath, 'valid_data.json'), 'r', encoding='utf-8') as f:
valid_data = json.load(f)
logger.debug(f"[Load valid data from {os.path.join(self.dpath, 'valid_data.json')}]")
with open(os.path.join(self.dpath, 'test_data.json'), 'r', encoding='utf-8') as f:
test_data = json.load(f)
logger.debug(f"[Load test data from {os.path.join(self.dpath, 'test_data.json')}]")
return train_data, valid_data, test_data
def _load_vocab(self):
self.tok2ind = json.load(open(os.path.join(self.dpath, 'token2id.json'), 'r', encoding='utf-8'))
self.ind2tok = {idx: word for word, idx in self.tok2ind.items()}
logger.debug(f"[Load vocab from {os.path.join(self.dpath, 'token2id.json')}]")
logger.debug(f"[The size of token2index dictionary is {len(self.tok2ind)}]")
logger.debug(f"[The size of index2token dictionary is {len(self.ind2tok)}]")
def _load_other_data(self):
# dbpedia
self.entity2id = json.load(
open(os.path.join(self.dpath, 'entity2id.json'), encoding='utf-8')) # {entity: entity_id}
self.id2entity = {idx: entity for entity, idx in self.entity2id.items()}
self.n_entity = max(self.entity2id.values()) + 1
# {head_entity_id: [(relation_id, tail_entity_id)]}
self.entity_kg = open(os.path.join(self.dpath, 'dbpedia_subkg.txt'), encoding='utf-8')
logger.debug(
f"[Load entity dictionary and KG from {os.path.join(self.dpath, 'entity2id.json')} and {os.path.join(self.dpath, 'entity_subkg.txt')}]")
# conceptnet
# {concept: concept_id}
self.word2id = json.load(open(os.path.join(self.dpath, 'word2id.json'), 'r', encoding='utf-8'))
self.n_word = max(self.word2id.values()) + 1
# {concept \t relation\t concept}
self.word_kg = open(os.path.join(self.dpath, 'conceptnet_subkg.txt'), encoding='utf-8')
logger.debug(
f"[Load word dictionary and KG from {os.path.join(self.dpath, 'word2id.json')} and {os.path.join(self.dpath, 'concept_subkg.txt')}]")
def _data_preprocess(self, train_data, valid_data, test_data):
processed_train_data = self._raw_data_process(train_data)
logger.debug("[Finish train data process]")
processed_valid_data = self._raw_data_process(valid_data)
logger.debug("[Finish valid data process]")
processed_test_data = self._raw_data_process(test_data)
logger.debug("[Finish test data process]")
processed_side_data = self._side_data_process()
logger.debug("[Finish side data process]")
return processed_train_data, processed_valid_data, processed_test_data, processed_side_data
def _raw_data_process(self, raw_data):
augmented_convs = [self._convert_to_id(conversation) for conversation in tqdm(raw_data)]
augmented_conv_dicts = []
for conv in tqdm(augmented_convs):
augmented_conv_dicts.extend(self._augment_and_add(conv))
return augmented_conv_dicts
def _convert_to_id(self, conversation):
augmented_convs = []
last_role = None
for utt in conversation['dialog']:
assert utt['role'] != last_role
text_token_ids = [self.tok2ind.get(word, self.unk_token_idx) for word in utt["text"]]
movie_ids = [self.entity2id[movie] for movie in utt['movies'] if movie in self.entity2id]
entity_ids = [self.entity2id[entity] for entity in utt['entity'] if entity in self.entity2id]
word_ids = [self.word2id[word] for word in utt['word'] if word in self.word2id]
policy = utt['decide']
augmented_convs.append({
"role": utt["role"],
"text": text_token_ids,
"entity": entity_ids,
"movie": movie_ids,
"word": word_ids,
'policy': policy
})
last_role = utt["role"]
return augmented_convs
def _augment_and_add(self, raw_conv_dict):
augmented_conv_dicts = []
context_tokens, context_entities, context_words, context_items = [], [], [], []
entity_set, word_set = set(), set()
for i, conv in enumerate(raw_conv_dict):
text_tokens, entities, movies, words, policies = conv["text"], conv["entity"], conv["movie"], conv["word"], \
conv['policy']
if len(context_tokens) > 0 and len(text_tokens) > 0:
conv_dict = {
'role': conv['role'],
"context_tokens": copy(context_tokens),
"response": text_tokens,
"context_entities": copy(context_entities),
"context_words": copy(context_words),
'context_items': copy(context_items),
"items": movies,
'policy': policies,
}
augmented_conv_dicts.append(conv_dict)
if len(text_tokens) > 0:
context_tokens.append(text_tokens)
context_items += movies
for entity in entities + movies:
if entity not in entity_set:
entity_set.add(entity)
context_entities.append(entity)
for word in words:
if word not in word_set:
word_set.add(word)
context_words.append(word)
return augmented_conv_dicts
def _side_data_process(self):
processed_entity_kg = self._entity_kg_process()
logger.debug("[Finish entity KG process]")
processed_word_kg = self._word_kg_process()
logger.debug("[Finish word KG process]")
movie_entity_ids = json.load(open(os.path.join(self.dpath, 'movie_ids.json'), 'r', encoding='utf-8'))
logger.debug('[Load movie entity ids]')
side_data = {
"entity_kg": processed_entity_kg,
"word_kg": processed_word_kg,
"item_entity_ids": movie_entity_ids,
}
return side_data
def _entity_kg_process(self):
edge_list = [] # [(entity, entity, relation)]
for line in self.entity_kg:
triple = line.strip().split('\t')
e0 = self.entity2id[triple[0]]
e1 = self.entity2id[triple[2]]
r = triple[1]
edge_list.append((e0, e1, r))
edge_list.append((e1, e0, r))
edge_list.append((e0, e0, 'SELF_LOOP'))
if e1 != e0:
edge_list.append((e1, e1, 'SELF_LOOP'))
relation2id, edges, entities = dict(), set(), set()
for h, t, r in edge_list:
if r not in relation2id:
relation2id[r] = len(relation2id)
edges.add((h, t, relation2id[r]))
entities.add(self.id2entity[h])
entities.add(self.id2entity[t])
return {
'edge': list(edges),
'n_relation': len(relation2id),
'entity': list(entities)
}
def _word_kg_process(self):
edges = set() # {(entity, entity)}
entities = set()
for line in self.word_kg:
triple = line.strip().split('\t')
entities.add(triple[0])
entities.add(triple[2])
e0 = self.word2id[triple[0]]
e1 = self.word2id[triple[2]]
edges.add((e0, e1))
edges.add((e1, e0))
# edge_set = [[co[0] for co in list(edges)], [co[1] for co in list(edges)]]
return {
'edge': list(edges),
'entity': list(entities)
}
================================================
FILE: crslab/data/dataset/gorecdial/resources.py
================================================
# -*- encoding: utf-8 -*-
# @Time : 2020/12/14
# @Author : Xiaolei Wang
# @email : wxl1999@foxmail.com
# UPDATE
# @Time : 2020/12/22
# @Author : Xiaolei Wang
# @email : wxl1999@foxmail.com
from crslab.download import DownloadableFile
resources = {
'nltk': {
'version': '0.31',
'file': DownloadableFile(
'https://pkueducn-my.sharepoint.com/:u:/g/personal/franciszhou_pkueducn_onmicrosoft_com/ESIqjwAg0ItAu7WGfukIt3cBXjzi7AZ9L_lcbFT1aS1qYQ?download=1',
'gorecdial_nltk.zip',
'58cd368f8f83c0c8555becc314a0017990545f71aefb7e93a52581c97d1b8e9b',
),
'special_token_idx': {
'pad': 0,
'start': 1,
'end': 2,
'unk': 3,
'pad_entity': 0,
'pad_word': 0,
'pad_topic': 0
},
},
'bert': {
'version': '0.31',
'file': DownloadableFile(
'https://pkueducn-my.sharepoint.com/:u:/g/personal/franciszhou_pkueducn_onmicrosoft_com/Ed1HT8gzvRpDosVT83BEj5QBnzKpjR3Zbf5u49yyWP-k6Q?download=1',
'gorecdial_bert.zip',
'4fa10c3fe8ba538af0f393c99892739fcb376d832616aa7028334c594b3fec10'
),
'special_token_idx': {
'pad': 0,
'start': 101,
'end': 102,
'unk': 100,
'sent_split': 2,
'word_split': 3,
'pad_entity': 0,
'pad_word': 0,
'pad_topic': 0
}
},
'gpt2': {
'version': '0.31',
'file': DownloadableFile(
'https://pkueducn-my.sharepoint.com/:u:/g/personal/franciszhou_pkueducn_onmicrosoft_com/EUJOHmX8v79DkZMq0x5r9d4B0UJlfw85v-VdciwKfAhpng?download=1',
'gorecdial_gpt2.zip',
'44a15637e014b2e6628102ff654e1aef7ec1cbfa34b7ada1a03f294f72ddd4b1'
),
'special_token_idx': {
'pad': 0,
'start': 1,
'end': 2,
'unk': 3,
'sent_split': 4,
'word_split': 5,
'pad_entity': 0,
'pad_word': 0
},
}
}
================================================
FILE: crslab/data/dataset/inspired/__init__.py
================================================
from .inspired import InspiredDataset
================================================
FILE: crslab/data/dataset/inspired/inspired.py
================================================
# @Time : 2020/12/19
# @Author : Kun Zhou
# @Email : francis_kun_zhou@163.com
# UPDATE:
# @Time : 2020/12/20, 2021/1/2
# @Author : Kun Zhou, Xiaolei Wang
# @Email : francis_kun_zhou@163.com, wxl1999@foxmail.com
r"""
Inspired
========
References:
Hayati, Shirley Anugrah, et al. `"INSPIRED: Toward Sociable Recommendation Dialog Systems."`_ in EMNLP 2020.
.. _`"INSPIRED: Toward Sociable Recommendation Dialog Systems."`:
https://www.aclweb.org/anthology/2020.emnlp-main.654/
"""
import json
import os
from copy import copy
from loguru import logger
from tqdm import tqdm
from crslab.config import DATASET_PATH
from crslab.data.dataset.base import BaseDataset
from .resources import resources
class InspiredDataset(BaseDataset):
"""
Attributes:
train_data: train dataset.
valid_data: valid dataset.
test_data: test dataset.
vocab (dict): ::
{
'tok2ind': map from token to index,
'ind2tok': map from index to token,
'entity2id': map from entity to index,
'id2entity': map from index to entity,
'word2id': map from word to index,
'vocab_size': len(self.tok2ind),
'n_entity': max(self.entity2id.values()) + 1,
'n_word': max(self.word2id.values()) + 1,
}
Notes:
``'unk'`` must be specified in ``'special_token_idx'`` in ``resources.py``.
"""
def __init__(self, opt, tokenize, restore=False, save=False):
"""Specify tokenized resource and init base dataset.
Args:
opt (Config or dict): config for dataset or the whole system.
tokenize (str): how to tokenize dataset.
restore (bool): whether to restore saved dataset which has been processed. Defaults to False.
save (bool): whether to save dataset after processing. Defaults to False.
"""
resource = resources[tokenize]
self.special_token_idx = resource['special_token_idx']
self.unk_token_idx = self.special_token_idx['unk']
dpath = os.path.join(DATASET_PATH, 'inspired', tokenize)
super().__init__(opt, dpath, resource, restore, save)
def _load_data(self):
train_data, valid_data, test_data = self._load_raw_data()
self._load_vocab()
self._load_other_data()
vocab = {
'tok2ind': self.tok2ind,
'ind2tok': self.ind2tok,
'entity2id': self.entity2id,
'id2entity': self.id2entity,
'word2id': self.word2id,
'vocab_size': len(self.tok2ind),
'n_entity': self.n_entity,
'n_word': self.n_word,
}
vocab.update(self.special_token_idx)
return train_data, valid_data, test_data, vocab
def _load_raw_data(self):
# load train/valid/test data
with open(os.path.join(self.dpath, 'train_data.json'), 'r', encoding='utf-8') as f:
train_data = json.load(f)
logger.debug(f"[Load train data from {os.path.join(self.dpath, 'train_data.json')}]")
with open(os.path.join(self.dpath, 'valid_data.json'), 'r', encoding='utf-8') as f:
valid_data = json.load(f)
logger.debug(f"[Load valid data from {os.path.join(self.dpath, 'valid_data.json')}]")
with open(os.path.join(self.dpath, 'test_data.json'), 'r', encoding='utf-8') as f:
test_data = json.load(f)
logger.debug(f"[Load test data from {os.path.join(self.dpath, 'test_data.json')}]")
return train_data, valid_data, test_data
def _load_vocab(self):
with open(os.path.join(self.dpath, 'token2id.json'), 'r', encoding='utf-8') as f:
self.tok2ind = json.load(f)
self.ind2tok = {idx: word for word, idx in self.tok2ind.items()}
logger.debug(f"[Load vocab from {os.path.join(self.dpath, 'token2id.json')}]")
logger.debug(f"[The size of token2index dictionary is {len(self.tok2ind)}]")
logger.debug(f"[The size of index2token dictionary is {len(self.ind2tok)}]")
def _load_other_data(self):
# dbpedia
with open(os.path.join(self.dpath, 'entity2id.json'), encoding='utf-8') as f:
self.entity2id = json.load(f) # {entity: entity_id}
self.id2entity = {idx: entity for entity, idx in self.entity2id.items()}
self.n_entity = max(self.entity2id.values()) + 1
# {head_entity_id: [(relation_id, tail_entity_id)]}
self.entity_kg = open(os.path.join(self.dpath, 'dbpedia_subkg.txt'), encoding='utf-8')
logger.debug(
f"[Load entity dictionary and KG from {os.path.join(self.dpath, 'entity2id.json')} and {os.path.join(self.dpath, 'entity_subkg.txt')}]")
# conceptnet
# {concept: concept_id}
with open(os.path.join(self.dpath, 'word2id.json'), 'r', encoding='utf-8') as f:
self.word2id = json.load(f)
self.n_word = max(self.word2id.values()) + 1
# {concept \t relation\t concept}
self.word_kg = open(os.path.join(self.dpath, 'concept_subkg.txt'), encoding='utf-8')
logger.debug(
f"[Load word dictionary and KG from {os.path.join(self.dpath, 'word2id.json')} and {os.path.join(self.dpath, 'concept_subkg.txt')}]")
def _data_preprocess(self, train_data, valid_data, test_data):
processed_train_data = self._raw_data_process(train_data)
logger.debug("[Finish train data process]")
processed_valid_data = self._raw_data_process(valid_data)
logger.debug("[Finish valid data process]")
processed_test_data = self._raw_data_process(test_data)
logger.debug("[Finish test data process]")
processed_side_data = self._side_data_process()
logger.debug("[Finish side data process]")
return processed_train_data, processed_valid_data, processed_test_data, processed_side_data
def _raw_data_process(self, raw_data):
augmented_convs = [self._convert_to_id(conversation) for conversation in tqdm(raw_data)]
augmented_conv_dicts = []
for conv in tqdm(augmented_convs):
augmented_conv_dicts.extend(self._augment_and_add(conv))
return augmented_conv_dicts
def _convert_to_id(self, conversation):
augmented_convs = []
last_role = None
for utt in conversation['dialog']:
text_token_ids = [self.tok2ind.get(word, self.unk_token_idx) for word in utt["text"]]
movie_ids = [self.entity2id[movie] for movie in utt['movies'] if movie in self.entity2id]
entity_ids = [self.entity2id[entity] for entity in utt['entity'] if entity in self.entity2id]
word_ids = [self.word2id[word] for word in utt['word'] if word in self.word2id]
if utt["role"] == last_role:
augmented_convs[-1]["text"] += text_token_ids
augmented_convs[-1]["movie"] += movie_ids
augmented_convs[-1]["entity"] += entity_ids
augmented_convs[-1]["word"] += word_ids
else:
augmented_convs.append({
"role": utt["role"],
"text": text_token_ids,
"entity": entity_ids,
"movie": movie_ids,
"word": word_ids
})
last_role = utt["role"]
return augmented_convs
def _augment_and_add(self, raw_conv_dict):
augmented_conv_dicts = []
context_tokens, context_entities, context_words, context_items = [], [], [], []
entity_set, word_set = set(), set()
for i, conv in enumerate(raw_conv_dict):
text_tokens, entities, movies, words = conv["text"], conv["entity"], conv["movie"], conv["word"]
if len(context_tokens) > 0:
conv_dict = {
'role': conv['role'],
"context_tokens": copy(context_tokens),
"response": text_tokens,
"context_entities": copy(context_entities),
"context_words": copy(context_words),
'context_items': copy(context_items),
"items": movies,
}
augmented_conv_dicts.append(conv_dict)
context_tokens.append(text_tokens)
context_items += movies
for entity in entities + movies:
if entity not in entity_set:
entity_set.add(entity)
context_entities.append(entity)
for word in words:
if word not in word_set:
word_set.add(word)
context_words.append(word)
return augmented_conv_dicts
def _side_data_process(self):
processed_entity_kg = self._entity_kg_process()
logger.debug("[Finish entity KG process]")
processed_word_kg = self._word_kg_process()
logger.debug("[Finish word KG process]")
with open(os.path.join(self.dpath, 'movie_ids.json'), 'r', encoding='utf-8') as f:
movie_entity_ids = json.load(f)
logger.debug('[Load movie entity ids]')
side_data = {
"entity_kg": processed_entity_kg,
"word_kg": processed_word_kg,
"item_entity_ids": movie_entity_ids,
}
return side_data
def _entity_kg_process(self):
edge_list = [] # [(entity, entity, relation)]
for line in self.entity_kg:
triple = line.strip().split('\t')
e0 = self.entity2id[triple[0]]
e1 = self.entity2id[triple[2]]
r = triple[1]
edge_list.append((e0, e1, r))
edge_list.append((e1, e0, r))
edge_list.append((e0, e0, 'SELF_LOOP'))
if e1 != e0:
edge_list.append((e1, e1, 'SELF_LOOP'))
relation2id, edges, entities = dict(), set(), set()
for h, t, r in edge_list:
if r not in relation2id:
relation2id[r] = len(relation2id)
edges.add((h, t, relation2id[r]))
entities.add(self.id2entity[h])
entities.add(self.id2entity[t])
return {
'edge': list(edges),
'n_relation': len(relation2id),
'entity': list(entities)
}
def _word_kg_process(self):
edges = set() # {(entity, entity)}
entities = set()
for line in self.word_kg:
triple = line.strip().split('\t')
entities.add(triple[0])
entities.add(triple[2])
e0 = self.word2id[triple[0]]
e1 = self.word2id[triple[2]]
edges.add((e0, e1))
edges.add((e1, e0))
# edge_set = [[co[0] for co in list(edges)], [co[1] for co in list(edges)]]
return {
'edge': list(edges),
'entity': list(entities)
}
================================================
FILE: crslab/data/dataset/inspired/resources.py
================================================
# -*- encoding: utf-8 -*-
# @Time : 2020/12/22
# @Author : Xiaolei Wang
# @email : wxl1999@foxmail.com
# UPDATE
# @Time : 2020/12/22
# @Author : Xiaolei Wang
# @email : wxl1999@foxmail.com
from crslab.download import DownloadableFile
resources = {
'nltk': {
'version': '0.3',
'file': DownloadableFile(
'https://pkueducn-my.sharepoint.com/:u:/g/personal/franciszhou_pkueducn_onmicrosoft_com/EdDgeChYguFLvz8hmkNdRhABmQF-LBfYtdb7rcdnB3kUgA?download=1',
'inspired_nltk.zip',
'776cadc7585abdbca2738addae40488826c82de3cfd4c2dc13dcdd63aefdc5c4',
),
'special_token_idx': {
'pad': 0,
'start': 1,
'end': 2,
'unk': 3,
'pad_entity': 0,
'pad_word': 0,
},
},
'bert': {
'version': '0.3',
'file': DownloadableFile(
'https://pkueducn-my.sharepoint.com/:u:/g/personal/franciszhou_pkueducn_onmicrosoft_com/EfBfyxLideBDsupMWb2tANgB6WxySTPQW11uM1F4UV5mTQ?download=1',
'inspired_bert.zip',
'9affea30978a6cd48b8038dddaa36f4cb4d8491cf8ae2de44a6d3dde2651f29c'
),
'special_token_idx': {
'pad': 0,
'start': 101,
'end': 102,
'unk': 100,
'sent_split': 2,
'word_split': 3,
'pad_entity': 0,
'pad_word': 0,
},
},
'gpt2': {
'version': '0.3',
'file': DownloadableFile(
'https://pkueducn-my.sharepoint.com/:u:/g/personal/franciszhou_pkueducn_onmicrosoft_com/EVwbqtjDReZHnvb_l9TxaaIBAC63BjbqkN5ZKb24Mhsm_A?download=1',
'inspired_gpt2.zip',
'261ad7e5325258d5cb8ffef0751925a58270fb6d9f17490f8552f6b86ef1eed2'
),
'special_token_idx': {
'pad': 0,
'start': 1,
'end': 2,
'unk': 3,
'sent_split': 4,
'word_split': 5,
'pad_entity': 0,
'pad_word': 0
},
}
}
================================================
FILE: crslab/data/dataset/opendialkg/__init__.py
================================================
from .opendialkg import OpenDialKGDataset
================================================
FILE: crslab/data/dataset/opendialkg/opendialkg.py
================================================
# @Time : 2020/12/19
# @Author : Kun Zhou
# @Email : francis_kun_zhou@163.com
# UPDATE:
# @Time : 2020/12/20, 2021/1/2
# @Author : Kun Zhou, Xiaolei Wang
# @Email : francis_kun_zhou@163.com, wxl1999@foxmail.com
r"""
OpenDialKG
==========
References:
Moon, Seungwhan, et al. `"Opendialkg: Explainable conversational reasoning with attention-based walks over knowledge graphs."`_ in ACL 2019.
.. _`"Opendialkg: Explainable conversational reasoning with attention-based walks over knowledge graphs."`:
https://www.aclweb.org/anthology/P19-1081/
"""
import json
import os
from collections import defaultdict
from copy import copy
from loguru import logger
from tqdm import tqdm
from crslab.config import DATASET_PATH
from crslab.data.dataset.base import BaseDataset
from .resources import resources
class OpenDialKGDataset(BaseDataset):
"""
Attributes:
train_data: train dataset.
valid_data: valid dataset.
test_data: test dataset.
vocab (dict): ::
{
'tok2ind': map from token to index,
'ind2tok': map from index to token,
'entity2id': map from entity to index,
'id2entity': map from index to entity,
'word2id': map from word to index,
'vocab_size': len(self.tok2ind),
'n_entity': max(self.entity2id.values()) + 1,
'n_word': max(self.word2id.values()) + 1,
}
Notes:
``'unk'`` must be specified in ``'special_token_idx'`` in ``resources.py``.
"""
def __init__(self, opt, tokenize, restore=False, save=False):
"""Specify tokenized resource and init base dataset.
Args:
opt (Config or dict): config for dataset or the whole system.
tokenize (str): how to tokenize dataset.
restore (bool): whether to restore saved dataset which has been processed. Defaults to False.
save (bool): whether to save dataset after processing. Defaults to False.
"""
resource = resources[tokenize]
self.special_token_idx = resource['special_token_idx']
self.unk_token_idx = self.special_token_idx['unk']
dpath = os.path.join(DATASET_PATH, 'opendialkg', tokenize)
super().__init__(opt, dpath, resource, restore, save)
def _load_data(self):
train_data, valid_data, test_data = self._load_raw_data()
self._load_vocab()
self._load_other_data()
vocab = {
'tok2ind': self.tok2ind,
'ind2tok': self.ind2tok,
'entity2id': self.entity2id,
'id2entity': self.id2entity,
'word2id': self.word2id,
'vocab_size': len(self.tok2ind),
'n_entity': self.n_entity,
'n_word': self.n_word,
}
vocab.update(self.special_token_idx)
return train_data, valid_data, test_data, vocab
def _load_raw_data(self):
# load train/valid/test data
with open(os.path.join(self.dpath, 'train_data.json'), 'r', encoding='utf-8') as f:
train_data = json.load(f)
logger.debug(f"[Load train data from {os.path.join(self.dpath, 'train_data.json')}]")
with open(os.path.join(self.dpath, 'valid_data.json'), 'r', encoding='utf-8') as f:
valid_data = json.load(f)
logger.debug(f"[Load valid data from {os.path.join(self.dpath, 'valid_data.json')}]")
with open(os.path.join(self.dpath, 'test_data.json'), 'r', encoding='utf-8') as f:
test_data = json.load(f)
logger.debug(f"[Load test data from {os.path.join(self.dpath, 'test_data.json')}]")
return train_data, valid_data, test_data
def _load_vocab(self):
self.tok2ind = json.load(open(os.path.join(self.dpath, 'token2id.json'), 'r', encoding='utf-8'))
self.ind2tok = {idx: word for word, idx in self.tok2ind.items()}
logger.debug(f"[Load vocab from {os.path.join(self.dpath, 'token2id.json')}]")
logger.debug(f"[The size of token2index dictionary is {len(self.tok2ind)}]")
logger.debug(f"[The size of index2token dictionary is {len(self.ind2tok)}]")
def _load_other_data(self):
# opendialkg
self.entity2id = json.load(
open(os.path.join(self.dpath, 'entity2id.json'), encoding='utf-8')) # {entity: entity_id}
self.id2entity = {idx: entity for entity, idx in self.entity2id.items()}
self.n_entity = max(self.entity2id.values()) + 1
# {head_entity_id: [(relation_id, tail_entity_id)]}
self.entity_kg = open(os.path.join(self.dpath, 'opendialkg_subkg.txt'), encoding='utf-8')
logger.debug(
f"[Load entity dictionary and KG from {os.path.join(self.dpath, 'opendialkg_subkg.json')} and {os.path.join(self.dpath, 'opendialkg_triples.txt')}]")
# conceptnet
# {concept: concept_id}
self.word2id = json.load(open(os.path.join(self.dpath, 'word2id.json'), 'r', encoding='utf-8'))
self.n_word = max(self.word2id.values()) + 1
# {concept \t relation\t concept}
self.word_kg = open(os.path.join(self.dpath, 'concept_subkg.txt'), encoding='utf-8')
logger.debug(
f"[Load word dictionary and KG from {os.path.join(self.dpath, 'word2id.json')} and {os.path.join(self.dpath, 'concept_subkg.txt')}]")
def _data_preprocess(self, train_data, valid_data, test_data):
processed_train_data = self._raw_data_process(train_data)
logger.debug("[Finish train data process]")
processed_valid_data = self._raw_data_process(valid_data)
logger.debug("[Finish valid data process]")
processed_test_data = self._raw_data_process(test_data)
logger.debug("[Finish test data process]")
processed_side_data = self._side_data_process()
logger.debug("[Finish side data process]")
return processed_train_data, processed_valid_data, processed_test_data, processed_side_data
def _raw_data_process(self, raw_data):
augmented_convs = [self._convert_to_id(conversation) for conversation in tqdm(raw_data)]
augmented_conv_dicts = []
for conv in tqdm(augmented_convs):
augmented_conv_dicts.extend(self._augment_and_add(conv))
return augmented_conv_dicts
def _convert_to_id(self, conversation):
augmented_convs = []
last_role = None
for utt in conversation['dialog']:
text_token_ids = [self.tok2ind.get(word, self.unk_token_idx) for word in utt["text"]]
item_ids = [self.entity2id[movie] for movie in utt['item'] if movie in self.entity2id]
entity_ids = [self.entity2id[entity] for entity in utt['entity'] if entity in self.entity2id]
word_ids = [self.word2id[word] for word in utt['word'] if word in self.word2id]
if utt["role"] == last_role:
augmented_convs[-1]["text"] += text_token_ids
augmented_convs[-1]["item"] += item_ids
augmented_convs[-1]["entity"] += entity_ids
augmented_convs[-1]["word"] += word_ids
else:
augmented_convs.append({
"role": utt["role"],
"text": text_token_ids,
"entity": entity_ids,
"item": item_ids,
"word": word_ids
})
last_role = utt["role"]
return augmented_convs
def _augment_and_add(self, raw_conv_dict):
augmented_conv_dicts = []
context_tokens, context_entities, context_words, context_items = [], [], [], []
entity_set, word_set = set(), set()
for i, conv in enumerate(raw_conv_dict):
text_tokens, entities, items, words = conv["text"], conv["entity"], conv["item"], conv["word"]
if len(context_tokens) > 0:
conv_dict = {
'role': conv['role'],
"context_tokens": copy(context_tokens),
"response": text_tokens,
"context_entities": copy(context_entities),
"context_words": copy(context_words),
'context_items': copy(context_items),
"items": items,
}
augmented_conv_dicts.append(conv_dict)
context_tokens.append(text_tokens)
context_items += items
for entity in entities + items:
if entity not in entity_set:
entity_set.add(entity)
context_entities.append(entity)
for word in words:
if word not in word_set:
word_set.add(word)
context_words.append(word)
return augmented_conv_dicts
def _side_data_process(self):
processed_entity_kg = self._entity_kg_process()
logger.debug("[Finish entity KG process]")
processed_word_kg = self._word_kg_process()
logger.debug("[Finish word KG process]")
item_entity_ids = json.load(open(os.path.join(self.dpath, 'item_ids.json'), 'r', encoding='utf-8'))
logger.debug('[Load item entity ids]')
side_data = {
"entity_kg": processed_entity_kg,
"word_kg": processed_word_kg,
"item_entity_ids": item_entity_ids,
}
return side_data
def _entity_kg_process(self):
edge_list = [] # [(entity, entity, relation)]
for line in self.entity_kg:
triple = line.strip().split('\t')
if len(triple) != 3 or triple[0] not in self.entity2id or triple[2] not in self.entity2id:
continue
e0 = self.entity2id[triple[0]]
e1 = self.entity2id[triple[2]]
r = triple[1]
edge_list.append((e0, e1, r))
# edge_list.append((e1, e0, r))
edge_list.append((e0, e0, 'SELF_LOOP'))
if e1 != e0:
edge_list.append((e1, e1, 'SELF_LOOP'))
relation_cnt, relation2id, edges, entities = defaultdict(int), dict(), set(), set()
for h, t, r in edge_list:
relation_cnt[r] += 1
for h, t, r in edge_list:
if relation_cnt[r] > 20000:
if r not in relation2id:
relation2id[r] = len(relation2id)
edges.add((h, t, relation2id[r]))
entities.add(self.id2entity[h])
entities.add(self.id2entity[t])
return {
'edge': list(edges),
'n_relation': len(relation2id),
'entity': list(entities)
}
def _word_kg_process(self):
edges = set() # {(entity, entity)}
entities = set()
for line in self.word_kg:
triple = line.strip().split('\t')
entities.add(triple[0])
entities.add(triple[2])
e0 = self.word2id[triple[0]]
e1 = self.word2id[triple[2]]
edges.add((e0, e1))
edges.add((e1, e0))
# edge_set = [[co[0] for co in list(edges)], [co[1] for co in list(edges)]]
return {
'edge': list(edges),
'entity': list(entities)
}
================================================
FILE: crslab/data/dataset/opendialkg/resources.py
================================================
# -*- encoding: utf-8 -*-
# @Time : 2020/12/21
# @Author : Xiaolei Wang
# @email : wxl1999@foxmail.com
# UPDATE
# @Time : 2020/12/22
# @Author : Xiaolei Wang
# @email : wxl1999@foxmail.com
from crslab.download import DownloadableFile
resources = {
'nltk': {
'version': '0.3',
'file': DownloadableFile(
'https://pkueducn-my.sharepoint.com/:u:/g/personal/franciszhou_pkueducn_onmicrosoft_com/ESB7grlJlehKv7XmYgMgq5AB85LhRu_rSW93_kL8Arfrhw?download=1',
'opendialkg_nltk.zip',
'6487f251ac74911e35bec690469fba52a7df14908575229b63ee30f63885c32f'
),
'special_token_idx': {
'pad': 0,
'start': 1,
'end': 2,
'unk': 3,
'pad_entity': 0,
'pad_word': 0,
},
},
'bert': {
'version': '0.3',
'file': DownloadableFile(
'https://pkueducn-my.sharepoint.com/:u:/g/personal/franciszhou_pkueducn_onmicrosoft_com/EWab0Pzgb4JOiecUHZxVaEEBRDBMoeLZDlStrr7YxentRA?download=1',
'opendialkg_bert.zip',
'0ec3ff45214fac9af570744e9b5893f224aab931744c70b7eeba7e1df13a4f07'
),
'special_token_idx': {
'pad': 0,
'start': 101,
'end': 102,
'unk': 100,
'sent_split': 2,
'word_split': 3,
'pad_entity': 0,
'pad_word': 0,
},
},
'gpt2': {
'version': '0.3',
'file': DownloadableFile(
'https://pkueducn-my.sharepoint.com/:u:/g/personal/franciszhou_pkueducn_onmicrosoft_com/EdE5iyKIoAhLvCwwBN4MdJwB2wsDADxJCs_KRaH-G3b7kg?download=1',
'opendialkg_gpt2.zip',
'dec20b01247cfae733988d7f7bfd1c99f4bb8ba7786b3fdaede5c9a618c6d71e'
),
'special_token_idx': {
'pad': 0,
'start': 1,
'end': 2,
'unk': 3,
'sent_split': 4,
'word_split': 5,
'pad_entity': 0,
'pad_word': 0
},
}
}
================================================
FILE: crslab/data/dataset/redial/__init__.py
================================================
from .redial import ReDialDataset
================================================
FILE: crslab/data/dataset/redial/redial.py
================================================
# @Time : 2020/11/22
# @Author : Kun Zhou
# @Email : francis_kun_zhou@163.com
# UPDATE:
# @Time : 2020/11/23, 2021/1/3, 2020/12/19
# @Author : Kun Zhou, Xiaolei Wang, Yuanhang Zhou
# @Email : francis_kun_zhou@163.com, wxl1999@foxmail.com, sdzyh002@gmail
r"""
ReDial
======
References:
Li, Raymond, et al. `"Towards deep conversational recommendations."`_ in NeurIPS 2018.
.. _`"Towards deep conversational recommendations."`:
https://papers.nips.cc/paper/2018/hash/800de15c79c8d840f4e78d3af937d4d4-Abstract.html
"""
import json
import os
from collections import defaultdict
from copy import copy
from loguru import logger
from tqdm import tqdm
from crslab.config import DATASET_PATH
from crslab.data.dataset.base import BaseDataset
from .resources import resources
class ReDialDataset(BaseDataset):
"""
Attributes:
train_data: train dataset.
valid_data: valid dataset.
test_data: test dataset.
vocab (dict): ::
{
'tok2ind': map from token to index,
'ind2tok': map from index to token,
'entity2id': map from entity to index,
'id2entity': map from index to entity,
'word2id': map from word to index,
'vocab_size': len(self.tok2ind),
'n_entity': max(self.entity2id.values()) + 1,
'n_word': max(self.word2id.values()) + 1,
}
Notes:
``'unk'`` must be specified in ``'special_token_idx'`` in ``resources.py``.
"""
def __init__(self, opt, tokenize, restore=False, save=False):
"""Specify tokenized resource and init base dataset.
Args:
opt (Config or dict): config for dataset or the whole system.
tokenize (str): how to tokenize dataset.
restore (bool): whether to restore saved dataset which has been processed. Defaults to False.
save (bool): whether to save dataset after processing. Defaults to False.
"""
resource = resources[tokenize]
self.special_token_idx = resource['special_token_idx']
self.unk_token_idx = self.special_token_idx['unk']
dpath = os.path.join(DATASET_PATH, "redial", tokenize)
super().__init__(opt, dpath, resource, restore, save)
def _load_data(self):
train_data, valid_data, test_data = self._load_raw_data()
self._load_vocab()
self._load_other_data()
vocab = {
'tok2ind': self.tok2ind,
'ind2tok': self.ind2tok,
'entity2id': self.entity2id,
'id2entity': self.id2entity,
'word2id': self.word2id,
'vocab_size': len(self.tok2ind),
'n_entity': self.n_entity,
'n_word': self.n_word,
}
vocab.update(self.special_token_idx)
return train_data, valid_data, test_data, vocab
def _load_raw_data(self):
# load train/valid/test data
with open(os.path.join(self.dpath, 'train_data.json'), 'r', encoding='utf-8') as f:
train_data = json.load(f)
logger.debug(f"[Load train data from {os.path.join(self.dpath, 'train_data.json')}]")
with open(os.path.join(self.dpath, 'valid_data.json'), 'r', encoding='utf-8') as f:
valid_data = json.load(f)
logger.debug(f"[Load valid data from {os.path.join(self.dpath, 'valid_data.json')}]")
with open(os.path.join(self.dpath, 'test_data.json'), 'r', encoding='utf-8') as f:
test_data = json.load(f)
logger.debug(f"[Load test data from {os.path.join(self.dpath, 'test_data.json')}]")
return train_data, valid_data, test_data
def _load_vocab(self):
self.tok2ind = json.load(open(os.path.join(self.dpath, 'token2id.json'), 'r', encoding='utf-8'))
self.ind2tok = {idx: word for word, idx in self.tok2ind.items()}
logger.debug(f"[Load vocab from {os.path.join(self.dpath, 'token2id.json')}]")
logger.debug(f"[The size of token2index dictionary is {len(self.tok2ind)}]")
logger.debug(f"[The size of index2token dictionary is {len(self.ind2tok)}]")
def _load_other_data(self):
# dbpedia
self.entity2id = json.load(
open(os.path.join(self.dpath, 'entity2id.json'), 'r', encoding='utf-8')) # {entity: entity_id}
self.id2entity = {idx: entity for entity, idx in self.entity2id.items()}
self.n_entity = max(self.entity2id.values()) + 1
# {head_entity_id: [(relation_id, tail_entity_id)]}
self.entity_kg = json.load(open(os.path.join(self.dpath, 'dbpedia_subkg.json'), 'r', encoding='utf-8'))
logger.debug(
f"[Load entity dictionary and KG from {os.path.join(self.dpath, 'entity2id.json')} and {os.path.join(self.dpath, 'dbpedia_subkg.json')}]")
# conceptNet
# {concept: concept_id}
self.word2id = json.load(open(os.path.join(self.dpath, 'concept2id.json'), 'r', encoding='utf-8'))
self.n_word = max(self.word2id.values()) + 1
# {relation\t concept \t concept}
self.word_kg = open(os.path.join(self.dpath, 'conceptnet_subkg.txt'), 'r', encoding='utf-8')
logger.debug(
f"[Load word dictionary and KG from {os.path.join(self.dpath, 'concept2id.json')} and {os.path.join(self.dpath, 'conceptnet_subkg.txt')}]")
def _data_preprocess(self, train_data, valid_data, test_data):
processed_train_data = self._raw_data_process(train_data)
logger.debug("[Finish train data process]")
processed_valid_data = self._raw_data_process(valid_data)
logger.debug("[Finish valid data process]")
processed_test_data = self._raw_data_process(test_data)
logger.debug("[Finish test data process]")
processed_side_data = self._side_data_process()
logger.debug("[Finish side data process]")
return processed_train_data, processed_valid_data, processed_test_data, processed_side_data
def _raw_data_process(self, raw_data):
augmented_convs = [self._merge_conv_data(conversation["dialog"]) for conversation in tqdm(raw_data)]
augmented_conv_dicts = []
for conv in tqdm(augmented_convs):
augmented_conv_dicts.extend(self._augment_and_add(conv))
return augmented_conv_dicts
def _merge_conv_data(self, dialog):
augmented_convs = []
last_role = None
for utt in dialog:
text_token_ids = [self.tok2ind.get(word, self.unk_token_idx) for word in utt["text"]]
movie_ids = [self.entity2id[movie] for movie in utt['movies'] if movie in self.entity2id]
entity_ids = [self.entity2id[entity] for entity in utt['entity'] if entity in self.entity2id]
word_ids = [self.word2id[word] for word in utt['word'] if word in self.word2id]
if utt["role"] == last_role:
augmented_convs[-1]["text"] += text_token_ids
augmented_convs[-1]["movie"] += movie_ids
augmented_convs[-1]["entity"] += entity_ids
augmented_convs[-1]["word"] += word_ids
else:
augmented_convs.append({
"role": utt["role"],
"text": text_token_ids,
"entity": entity_ids,
"movie": movie_ids,
"word": word_ids
})
last_role = utt["role"]
return augmented_convs
def _augment_and_add(self, raw_conv_dict):
augmented_conv_dicts = []
context_tokens, context_entities, context_words, context_items = [], [], [], []
entity_set, word_set = set(), set()
for i, conv in enumerate(raw_conv_dict):
text_tokens, entities, movies, words = conv["text"], conv["entity"], conv["movie"], conv["word"]
if len(context_tokens) > 0:
conv_dict = {
"role": conv['role'],
"context_tokens": copy(context_tokens),
"response": text_tokens,
"context_entities": copy(context_entities),
"context_words": copy(context_words),
"context_items": copy(context_items),
"items": movies,
}
augmented_conv_dicts.append(conv_dict)
context_tokens.append(text_tokens)
context_items += movies
for entity in entities + movies:
if entity not in entity_set:
entity_set.add(entity)
context_entities.append(entity)
for word in words:
if word not in word_set:
word_set.add(word)
context_words.append(word)
return augmented_conv_dicts
def _side_data_process(self):
processed_entity_kg = self._entity_kg_process()
logger.debug("[Finish entity KG process]")
processed_word_kg = self._word_kg_process()
logger.debug("[Finish word KG process]")
movie_entity_ids = json.load(open(os.path.join(self.dpath, 'movie_ids.json'), 'r', encoding='utf-8'))
logger.debug('[Load movie entity ids]')
side_data = {
"entity_kg": processed_entity_kg,
"word_kg": processed_word_kg,
"item_entity_ids": movie_entity_ids,
}
return side_data
def _entity_kg_process(self, SELF_LOOP_ID=185):
edge_list = [] # [(entity, entity, relation)]
for entity in range(self.n_entity):
if str(entity) not in self.entity_kg:
continue
edge_list.append((entity, entity, SELF_LOOP_ID)) # add self loop
for tail_and_relation in self.entity_kg[str(entity)]:
if entity != tail_and_relation[1] and tail_and_relation[0] != SELF_LOOP_ID:
edge_list.append((entity, tail_and_relation[1], tail_and_relation[0]))
edge_list.append((tail_and_relation[1], entity, tail_and_relation[0]))
relation_cnt, relation2id, edges, entities = defaultdict(int), dict(), set(), set()
for h, t, r in edge_list:
relation_cnt[r] += 1
for h, t, r in edge_list:
if relation_cnt[r] > 1000:
if r not in relation2id:
relation2id[r] = len(relation2id)
edges.add((h, t, relation2id[r]))
entities.add(self.id2entity[h])
entities.add(self.id2entity[t])
return {
'edge': list(edges),
'n_relation': len(relation2id),
'entity': list(entities)
}
def _word_kg_process(self):
edges = set() # {(entity, entity)}
entities = set()
for line in self.word_kg:
kg = line.strip().split('\t')
entities.add(kg[1].split('/')[0])
entities.add(kg[2].split('/')[0])
e0 = self.word2id[kg[1].split('/')[0]]
e1 = self.word2id[kg[2].split('/')[0]]
edges.add((e0, e1))
edges.add((e1, e0))
# edge_set = [[co[0] for co in list(edges)], [co[1] for co in list(edges)]]
return {
'edge': list(edges),
'entity': list(entities)
}
================================================
FILE: crslab/data/dataset/redial/resources.py
================================================
# -*- encoding: utf-8 -*-
# @Time : 2020/12/1
# @Author : Xiaolei Wang
# @email : wxl1999@foxmail.com
# UPDATE
# @Time : 2020/12/22
# @Author : Xiaolei Wang
# @email : wxl1999@foxmail.com
from crslab.download import DownloadableFile
resources = {
'nltk': {
'version': '0.31',
'file': DownloadableFile(
'https://pkueducn-my.sharepoint.com/:u:/g/personal/franciszhou_pkueducn_onmicrosoft_com/EdVnNcteOkpAkLdNL-ejvAABPieUd8jIty3r1jcdJvGLzw?download=1',
'redial_nltk.zip',
'01dc2ebf15a0988a92112daa7015ada3e95d855e80cc1474037a86e536de3424',
),
'special_token_idx': {
'pad': 0,
'start': 1,
'end': 2,
'unk': 3,
'pad_entity': 0,
'pad_word': 0
},
},
'bert': {
'version': '0.31',
'file': DownloadableFile(
'https://pkueducn-my.sharepoint.com/:u:/g/personal/franciszhou_pkueducn_onmicrosoft_com/EXe_sjFhfqpJoTbNcoUPJf8Bl_4U-lnduct0z8Dw5HVCPw?download=1',
'redial_bert.zip',
'fb55516c22acfd3ba073e05101415568ed3398c86ff56792f82426b9258c92fd',
),
'special_token_idx': {
'pad': 0,
'start': 101,
'end': 102,
'unk': 100,
'sent_split': 2,
'word_split': 3,
'pad_entity': 0,
'pad_word': 0,
},
},
'gpt2': {
'version': '0.31',
'file': DownloadableFile(
'https://pkueducn-my.sharepoint.com/:u:/g/personal/franciszhou_pkueducn_onmicrosoft_com/EQHOlW2m6mFEqHgt94PfoLsBbmQQeKQEOMyL1lLEHz7LvA?download=1',
'redial_gpt2.zip',
'15661f1cb126210a09e30228e9477cf57bbec42140d2b1029cc50489beff4eb8',
),
'special_token_idx': {
'pad': -100,
'start': 1,
'end': 2,
'unk': 3,
'sent_split': 4,
'word_split': 5,
'pad_entity': 0,
'pad_word': 0
},
}
}
================================================
FILE: crslab/data/dataset/tgredial/__init__.py
================================================
from .tgredial import TGReDialDataset
================================================
FILE: crslab/data/dataset/tgredial/resources.py
================================================
# -*- encoding: utf-8 -*-
# @Time : 2020/12/4
# @Author : Xiaolei Wang
# @email : wxl1999@foxmail.com
# UPDATE
# @Time : 2020/12/22
# @Author : Xiaolei Wang
# @email : wxl1999@foxmail.com
from crslab.download import DownloadableFile
resources = {
'pkuseg': {
'version': '0.3',
'file': DownloadableFile(
'https://pkueducn-my.sharepoint.com/:u:/g/personal/franciszhou_pkueducn_onmicrosoft_com/Ee7FleGfEStCimV4XRKvo-kBR8ABdPKo0g_XqgLJPxP6tg?download=1',
'tgredial_pkuseg.zip',
'8b7e23205778db4baa012eeb129cf8d26f4871ae98cdfe81fde6adc27a73a8d6',
),
'special_token_idx': {
'pad': 0,
'start': 1,
'end': 2,
'unk': 3,
'pad_entity': 0,
'pad_word': 0,
'pad_topic': 0
},
},
'bert': {
'version': '0.3',
'file': DownloadableFile(
'https://pkueducn-my.sharepoint.com/:u:/g/personal/franciszhou_pkueducn_onmicrosoft_com/ETC9vIeFtOdElXL10Hbh4L0BGm20-lckCJ3a4u7VFCzpIg?download=1',
'tgredial_bert.zip',
'd40f7072173c1dc49d4a3125f9985aaf0bd0801d7b437348ece9a894f485193b'
),
'special_token_idx': {
'pad': 0,
'start': 101,
'end': 102,
'unk': 100,
'sent_split': 2,
'word_split': 3,
'pad_entity': 0,
'pad_word': 0,
'pad_topic': 0
},
},
'gpt2': {
'version': '0.3',
'file': DownloadableFile(
'https://pkueducn-my.sharepoint.com/:u:/g/personal/franciszhou_pkueducn_onmicrosoft_com/EcVEcxrDMF1BrbOUD8jEXt4BJeCzUjbNFL6m6UY5W3Hm3g?download=1',
'tgredial_gpt2.zip',
'2077f137b6a11c2fd523ca63b06e75cc19411cd515b7d5b997704d9e81778df9'
),
'special_token_idx': {
'pad': 0,
'start': 101,
'end': 102,
'unk': 100,
'cls': 101,
'sep': 102,
'sent_split': 2,
'word_split': 3,
'pad_entity': 0,
'pad_word': 0,
'pad_topic': 0,
},
}
}
================================================
FILE: crslab/data/dataset/tgredial/tgredial.py
================================================
# @Time : 2020/12/4
# @Author : Kun Zhou
# @Email : francis_kun_zhou@163.com
# UPDATE:
# @Time : 2020/12/6, 2021/1/2, 2020/12/19
# @Author : Kun Zhou, Xiaolei Wang, Yuanhang Zhou
# @Email : francis_kun_zhou@163.com, sdzyh002@gmail
r"""
TGReDial
========
References:
Zhou, Kun, et al. `"Towards Topic-Guided Conversational Recommender System."`_ in COLING 2020.
.. _`"Towards Topic-Guided Conversational Recommender System."`:
https://www.aclweb.org/anthology/2020.coling-main.365/
"""
import json
import os
from collections import defaultdict
from copy import copy
import numpy as np
from loguru import logger
from tqdm import tqdm
from crslab.config import DATASET_PATH
from crslab.data.dataset.base import BaseDataset
from .resources import resources
class TGReDialDataset(BaseDataset):
"""
Attributes:
train_data: train dataset.
valid_data: valid dataset.
test_data: test dataset.
vocab (dict): ::
{
'tok2ind': map from token to index,
'ind2tok': map from index to token,
'topic2ind': map from topic to index,
'ind2topic': map from index to topic,
'entity2id': map from entity to index,
'id2entity': map from index to entity,
'word2id': map from word to index,
'vocab_size': len(self.tok2ind),
'n_topic': len(self.topic2ind) + 1,
'n_entity': max(self.entity2id.values()) + 1,
'n_word': max(self.word2id.values()) + 1,
}
Notes:
``'unk'`` and ``'pad_topic'`` must be specified in ``'special_token_idx'`` in ``resources.py``.
"""
def __init__(self, opt, tokenize, restore=False, save=False):
"""Specify tokenized resource and init base dataset.
Args:
opt (Config or dict): config for dataset or the whole system.
tokenize (str): how to tokenize dataset.
restore (bool): whether to restore saved dataset which has been processed. Defaults to False.
save (bool): whether to save dataset after processing. Defaults to False.
"""
resource = resources[tokenize]
self.special_token_idx = resource['special_token_idx']
self.unk_token_idx = self.special_token_idx['unk']
self.pad_topic_idx = self.special_token_idx['pad_topic']
dpath = os.path.join(DATASET_PATH, 'tgredial', tokenize)
self.replace_token = opt.get('replace_token',None)
self.replace_token_idx = opt.get('replace_token_idx',None)
super().__init__(opt, dpath, resource, restore, save)
if self.replace_token:
if self.replace_token_idx:
self.side_data["embedding"][self.replace_token_idx] = self.side_data['embedding'][0]
else:
self.side_data["embedding"] = np.insert(self.side_data["embedding"],len(self.side_data["embedding"]),self.side_data['embedding'][0],axis=0)
def _load_data(self):
train_data, valid_data, test_data = self._load_raw_data()
self._load_vocab()
self._load_other_data()
vocab = {
'tok2ind': self.tok2ind,
'ind2tok': self.ind2tok,
'topic2ind': self.topic2ind,
'ind2topic': self.ind2topic,
'entity2id': self.entity2id,
'id2entity': self.id2entity,
'word2id': self.word2id,
'vocab_size': len(self.tok2ind),
'n_topic': len(self.topic2ind) + 1,
'n_entity': self.n_entity,
'n_word': self.n_word,
}
vocab.update(self.special_token_idx)
return train_data, valid_data, test_data, vocab
def _load_raw_data(self):
# load train/valid/test data
with open(os.path.join(self.dpath, 'train_data.json'), 'r', encoding='utf-8') as f:
train_data = json.load(f)
logger.debug(f"[Load train data from {os.path.join(self.dpath, 'train_data.json')}]")
with open(os.path.join(self.dpath, 'valid_data.json'), 'r', encoding='utf-8') as f:
valid_data = json.load(f)
logger.debug(f"[Load valid data from {os.path.join(self.dpath, 'valid_data.json')}]")
with open(os.path.join(self.dpath, 'test_data.json'), 'r', encoding='utf-8') as f:
test_data = json.load(f)
logger.debug(f"[Load test data from {os.path.join(self.dpath, 'test_data.json')}]")
return train_data, valid_data, test_data
def _load_vocab(self):
self.tok2ind = json.load(open(os.path.join(self.dpath, 'token2id.json'), 'r', encoding='utf-8'))
self.ind2tok = {idx: word for word, idx in self.tok2ind.items()}
# add special tokens
if self.replace_token:
if self.replace_token not in self.tok2ind:
if self.replace_token_idx:
self.ind2tok[self.replace_token_idx] = self.replace_token
self.tok2ind[self.replace_token] = self.replace_token_idx
self.special_token_idx[self.replace_token] = self.replace_token_idx
else:
self.ind2tok[len(self.tok2ind)] = self.replace_token
self.tok2ind[self.replace_token] = len(self.tok2ind)
self.special_token_idx[self.replace_token] = len(self.tok2ind)-1
logger.debug(f"[Load vocab from {os.path.join(self.dpath, 'token2id.json')}]")
logger.debug(f"[The size of token2index dictionary is {len(self.tok2ind)}]")
logger.debug(f"[The size of index2token dictionary is {len(self.ind2tok)}]")
self.topic2ind = json.load(open(os.path.join(self.dpath, 'topic2id.json'), 'r', encoding='utf-8'))
self.ind2topic = {idx: word for word, idx in self.topic2ind.items()}
logger.debug(f"[Load vocab from {os.path.join(self.dpath, 'topic2id.json')}]")
logger.debug(f"[The size of token2index dictionary is {len(self.topic2ind)}]")
logger.debug(f"[The size of index2token dictionary is {len(self.ind2topic)}]")
def _load_other_data(self):
# cn-dbpedia
self.entity2id = json.load(
open(os.path.join(self.dpath, 'entity2id.json'), encoding='utf-8')) # {entity: entity_id}
self.id2entity = {idx: entity for entity, idx in self.entity2id.items()}
self.n_entity = max(self.entity2id.values()) + 1
# {head_entity_id: [(relation_id, tail_entity_id)]}
self.entity_kg = open(os.path.join(self.dpath, 'cn-dbpedia.txt'), encoding='utf-8')
logger.debug(
f"[Load entity dictionary and KG from {os.path.join(self.dpath, 'entity2id.json')} and {os.path.join(self.dpath, 'cn-dbpedia.txt')}]")
# hownet
# {concept: concept_id}
self.word2id = json.load(open(os.path.join(self.dpath, 'word2id.json'), 'r', encoding='utf-8'))
self.n_word = max(self.word2id.values()) + 1
# {relation\t concept \t concept}
self.word_kg = open(os.path.join(self.dpath, 'hownet.txt'), encoding='utf-8')
logger.debug(
f"[Load word dictionary and KG from {os.path.join(self.dpath, 'word2id.json')} and {os.path.join(self.dpath, 'hownet.txt')}]")
# user interaction history dictionary
self.conv2history = json.load(open(os.path.join(self.dpath, 'user2history.json'), 'r', encoding='utf-8'))
logger.debug(f"[Load user interaction history from {os.path.join(self.dpath, 'user2history.json')}]")
# user profile
self.user2profile = json.load(open(os.path.join(self.dpath, 'user2profile.json'), 'r', encoding='utf-8'))
logger.debug(f"[Load user profile from {os.path.join(self.dpath, 'user2profile.json')}")
def _data_preprocess(self, train_data, valid_data, test_data):
processed_train_data = self._raw_data_process(train_data)
logger.debug("[Finish train data process]")
processed_valid_data = self._raw_data_process(valid_data)
logger.debug("[Finish valid data process]")
processed_test_data = self._raw_data_process(test_data)
logger.debug("[Finish test data process]")
processed_side_data = self._side_data_process()
logger.debug("[Finish side data process]")
return processed_train_data, processed_valid_data, processed_test_data, processed_side_data
def _raw_data_process(self, raw_data):
augmented_convs = [self._convert_to_id(conversation) for conversation in tqdm(raw_data)]
augmented_conv_dicts = []
for conv in tqdm(augmented_convs):
augmented_conv_dicts.extend(self._augment_and_add(conv))
return augmented_conv_dicts
def _convert_to_id(self, conversation):
augmented_convs = []
last_role = None
for utt in conversation['messages']:
assert utt['role'] != last_role
# change movies into slots
if self.replace_token:
if len(utt['movie']) != 0:
while '《' in utt['text'] :
begin = utt['text'].index("《")
end = utt['text'].index("》")
utt['text'] = utt['text'][:begin] + [self.replace_token] + utt['text'][end+1:]
text_token_ids = [self.tok2ind.get(word, self.unk_token_idx) for word in utt["text"]]
movie_ids = [self.entity2id[movie] for movie in utt['movie'] if movie in self.entity2id]
entity_ids = [self.entity2id[entity] for entity in utt['entity'] if entity in self.entity2id]
word_ids = [self.word2id[word] for word in utt['word'] if word in self.word2id]
policy = []
for action, kw in zip(utt['target'][1::2], utt['target'][2::2]):
if kw is None or action == '推荐电影':
continue
if isinstance(kw, str):
kw = [kw]
kw = [self.topic2ind.get(k, self.pad_topic_idx) for k in kw]
policy.append([action, kw])
final_kws = [self.topic2ind[kw] if kw is not None else self.pad_topic_idx for kw in utt['final'][1]]
final = [utt['final'][0], final_kws]
conv_utt_id = str(conversation['conv_id']) + '/' + str(utt['local_id'])
interaction_history = self.conv2history.get(conv_utt_id, [])
user_profile = self.user2profile[conversation['user_id']]
user_profile = [[self.tok2ind.get(token, self.unk_token_idx) for token in sent] for sent in user_profile]
augmented_convs.append({
"role": utt["role"],
"text": text_token_ids,
"entity": entity_ids,
"movie": movie_ids,
"word": word_ids,
'policy': policy,
'final': final,
'interaction_history': interaction_history,
'user_profile': user_profile
})
last_role = utt["role"]
return augmented_convs
def _augment_and_add(self, raw_conv_dict):
augmented_conv_dicts = []
context_tokens, context_entities, context_words, context_policy, context_items = [], [], [], [], []
entity_set, word_set = set(), set()
for i, conv in enumerate(raw_conv_dict):
text_tokens, entities, movies, words, policies = conv["text"], conv["entity"], conv["movie"], conv["word"], \
conv['policy']
if self.replace_token is not None:
if text_tokens.count(30000) != len(movies):
continue # the number of slots doesn't equal to the number of movies
if len(context_tokens) > 0:
conv_dict = {
'role': conv['role'],
'user_profile': conv['user_profile'],
"context_tokens": copy(context_tokens),
"response": text_tokens,
"context_entities": copy(context_entities),
"context_words": copy(context_words),
'interaction_history': conv['interaction_history'],
'context_items': copy(context_items),
"items": movies,
'context_policy': copy(context_policy),
'target': policies,
'final': conv['final'],
}
augmented_conv_dicts.append(conv_dict)
context_tokens.append(text_tokens)
context_policy.append(policies)
context_items += movies
for entity in entities + movies:
if entity not in entity_set:
entity_set.add(entity)
context_entities.append(entity)
for word in words:
if word not in word_set:
word_set.add(word)
context_words.append(word)
return augmented_conv_dicts
def _side_data_process(self):
processed_entity_kg = self._entity_kg_process()
logger.debug("[Finish entity KG process]")
processed_word_kg = self._word_kg_process()
logger.debug("[Finish word KG process]")
movie_entity_ids = json.load(open(os.path.join(self.dpath, 'movie_ids.json'), 'r', encoding='utf-8'))
logger.debug('[Load movie entity ids]')
side_data = {
"entity_kg": processed_entity_kg,
"word_kg": processed_word_kg,
"item_entity_ids": movie_entity_ids,
}
return side_data
def _entity_kg_process(self):
edge_list = [] # [(entity, entity, relation)]
for line in self.entity_kg:
triple = line.strip().split('\t')
e0 = self.entity2id[triple[0]]
e1 = self.entity2id[triple[2]]
r = triple[1]
edge_list.append((e0, e1, r))
edge_list.append((e1, e0, r))
edge_list.append((e0, e0, 'SELF_LOOP'))
if e1 != e0:
edge_list.append((e1, e1, 'SELF_LOOP'))
relation_cnt, relation2id, edges, entities = defaultdict(int), dict(), set(), set()
for h, t, r in edge_list:
relation_cnt[r] += 1
for h, t, r in edge_list:
if r not in relation2id:
relation2id[r] = len(relation2id)
edges.add((h, t, relation2id[r]))
entities.add(self.id2entity[h])
entities.add(self.id2entity[t])
return {
'edge': list(edges),
'n_relation': len(relation2id),
'entity': list(entities)
}
def _word_kg_process(self):
edges = set() # {(entity, entity)}
entities = set()
for line in self.word_kg:
triple = line.strip().split('\t')
entities.add(triple[0])
entities.add(triple[2])
e0 = self.word2id[triple[0]]
e1 = self.word2id[triple[2]]
edges.add((e0, e1))
edges.add((e1, e0))
# edge_set = [[co[0] for co in list(edges)], [co[1] for co in list(edges)]]
return {
'edge': list(edges),
'entity': list(entities)
}
================================================
FILE: crslab/download.py
================================================
# -*- encoding: utf-8 -*-
# @Time : 2020/12/7
# @Author : Xiaolei Wang
# @email : wxl1999@foxmail.com
# UPDATE
# @Time : 2020/12/7
# @Author : Xiaolei Wang
# @email : wxl1999@foxmail.com
import hashlib
import os
import shutil
import time
import datetime
import requests
import tqdm
from loguru import logger
class DownloadableFile:
"""
A class used to abstract any file that has to be downloaded online.
Any task that needs to download a file needs to have a list RESOURCES
that have objects of this class as elements.
This class provides the following functionality:
- Download a file from a URL
- Untar the file if zipped
- Checksum for the downloaded file
An object of this class needs to be created with:
- url : URL or Google Drive id to download from
- file_name : File name that the file should be named
- hashcode : SHA256 hashcode of the downloaded file
- zipped : False if the file is not compressed
- from_google : True if the file is from Google Drive
"""
def __init__(self, url, file_name, hashcode, zipped=True, from_google=False):
self.url = url
self.file_name = file_name
self.hashcode = hashcode
self.zipped = zipped
self.from_google = from_google
def checksum(self, dpath):
"""
Checksum on a given file.
:param dpath: path to the downloaded file.
"""
sha256_hash = hashlib.sha256()
with open(os.path.join(dpath, self.file_name), "rb") as f:
for byte_block in iter(lambda: f.read(65536), b""):
sha256_hash.update(byte_block)
if sha256_hash.hexdigest() != self.hashcode:
# remove_dir(dpath)
raise AssertionError(
f"[ Checksum for {self.file_name} from \n{self.url}\n"
"does not match the expected checksum. Please try again. ]"
)
else:
logger.debug("Checksum Successful")
pass
def download_file(self, dpath):
if self.from_google:
download_from_google_drive(self.url, os.path.join(dpath, self.file_name))
else:
download(self.url, dpath, self.file_name)
self.checksum(dpath)
if self.zipped:
untar(dpath, self.file_name)
def download(url, path, fname, redownload=False, num_retries=5):
"""
Download file using `requests`.
If ``redownload`` is set to false, then will not download tar file again if it is
present (default ``False``).
"""
outfile = os.path.join(path, fname)
download = not os.path.exists(outfile) or redownload
logger.info(f"Downloading {url} to {outfile}")
retry = num_retries
exp_backoff = [2 ** r for r in reversed(range(retry))]
pbar = tqdm.tqdm(unit='B', unit_scale=True, desc='Downloading {}'.format(fname))
while download and retry > 0:
response = None
try:
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36 Edg/87.0.664.60',
}
response = requests.get(url, stream=True, headers=headers)
# negative reply could be 'none' or just missing
CHUNK_SIZE = 32768
total_size = int(response.headers.get('Content-Length', -1))
# server returns remaining size if resuming, so adjust total
pbar.total = total_size
done = 0
with open(outfile, 'wb') as f:
for chunk in response.iter_content(CHUNK_SIZE):
if chunk: # filter out keep-alive new chunks
f.write(chunk)
if total_size > 0:
done += len(chunk)
if total_size < done:
# don't freak out if content-length was too small
total_size = done
pbar.total = total_size
pbar.update(len(chunk))
break
except (
requests.exceptions.ConnectionError,
requests.exceptions.ReadTimeout,
):
retry -= 1
pbar.clear()
if retry > 0:
pl = 'y' if retry == 1 else 'ies'
logger.debug(
f'Connection error, retrying. ({retry} retr{pl} left)'
)
time.sleep(exp_backoff[retry])
else:
logger.error('Retried too many times, stopped retrying.')
finally:
if response:
response.close()
if retry <= 0:
raise RuntimeError('Connection broken too many times. Stopped retrying.')
if download and retry > 0:
pbar.update(done - pbar.n)
if done < total_size:
raise RuntimeError(
f'Received less data than specified in Content-Length header for '
f'{url}. There may be a download problem.'
)
pbar.close()
def _get_confirm_token(response):
for key, value in response.cookies.items():
if key.startswith('download_warning'):
return value
return None
def download_from_google_drive(gd_id, destination):
"""
Use the requests package to download a file from Google Drive.
"""
URL = 'https://docs.google.com/uc?export=download'
with requests.Session() as session:
response = session.get(URL, params={'id': gd_id}, stream=True)
token = _get_confirm_token(response)
if token:
response.close()
params = {'id': gd_id, 'confirm': token}
response = session.get(URL, params=params, stream=True)
CHUNK_SIZE = 32768
with open(destination, 'wb') as f:
for chunk in response.iter_content(CHUNK_SIZE):
if chunk: # filter out keep-alive new chunks
f.write(chunk)
response.close()
def move(path1, path2):
"""
Rename the given file.
"""
shutil.move(path1, path2)
def untar(path, fname, deleteTar=True):
"""
Unpack the given archive file to the same directory.
:param str path:
The folder containing the archive. Will contain the contents.
:param str fname:
The filename of the archive file.
:param bool deleteTar:
If true, the archive will be deleted after extraction.
"""
logger.debug(f'unpacking {fname}')
fullpath = os.path.join(path, fname)
shutil.unpack_archive(fullpath, path)
if deleteTar:
os.remove(fullpath)
def make_dir(path):
"""
Make the directory and any nonexistent parent directories (`mkdir -p`).
"""
# the current working directory is a fine path
if path != '':
os.makedirs(path, exist_ok=True)
def remove_dir(path):
"""
Remove the given directory, if it exists.
"""
shutil.rmtree(path, ignore_errors=True)
def check_build(path, version_string=None):
"""
Check if '.built' flag has been set for that task.
If a version_string is provided, this has to match, or the version is regarded as
not built.
"""
if version_string:
fname = os.path.join(path, '.built')
if not os.path.isfile(fname):
return False
else:
with open(fname, 'r') as read:
text = read.read().split('\n')
return len(text) > 1 and text[1] == version_string
else:
return os.path.isfile(os.path.join(path, '.built'))
def mark_done(path, version_string=None):
"""
Mark this path as prebuilt.
Marks the path as done by adding a '.built' file with the current timestamp
plus a version description string if specified.
:param str path:
The file path to mark as built.
:param str version_string:
The version of this dataset.
"""
with open(os.path.join(path, '.built'), 'w') as write:
write.write(str(datetime.datetime.today()))
if version_string:
write.write('\n' + version_string)
def build(dpath, dfile, version=None):
if not check_build(dpath, version):
logger.info('[Building data: ' + dpath + ']')
if check_build(dpath):
remove_dir(dpath)
make_dir(dpath)
# Download the data.
downloadable_file = dfile
downloadable_file.download_file(dpath)
mark_done(dpath, version)
================================================
FILE: crslab/evaluator/__init__.py
================================================
# -*- encoding: utf-8 -*-
# @Time : 2020/12/22
# @Author : Xiaolei Wang
# @email : wxl1999@foxmail.com
# UPDATE
# @Time : 2020/12/22
# @Author : Xiaolei Wang
# @email : wxl1999@foxmail.com
from loguru import logger
from .conv import ConvEvaluator
from .rec import RecEvaluator
from .standard import StandardEvaluator
from ..data import dataset_language_map
Evaluator_register_table = {
'rec': RecEvaluator,
'conv': ConvEvaluator,
'standard': StandardEvaluator
}
def get_evaluator(evaluator_name, dataset, tensorboard=False):
if evaluator_name in Evaluator_register_table:
if evaluator_name in ('conv', 'standard'):
language = dataset_language_map[dataset]
evaluator = Evaluator_register_table[evaluator_name](language, tensorboard=tensorboard)
else:
evaluator = Evaluator_register_table[evaluator_name](tensorboard=tensorboard)
logger.info(f'[Build evaluator {evaluator_name}]')
return evaluator
else:
raise NotImplementedError(f'Model [{evaluator_name}] has not been implemented')
================================================
FILE: crslab/evaluator/base.py
================================================
# @Time : 2020/11/30
# @Author : Xiaolei Wang
# @Email : wxl1999@foxmail.com
# UPDATE:
# @Time : 2020/11/30
# @Author : Xiaolei Wang
# @Email : wxl1999@foxmail.com
from abc import ABC, abstractmethod
class BaseEvaluator(ABC):
"""Base class for evaluator"""
def rec_evaluate(self, preds, label):
pass
def gen_evaluate(self, preds, label):
pass
def policy_evaluate(self, preds, label):
pass
@abstractmethod
def report(self, epoch, mode):
pass
@abstractmethod
def reset_metrics(self):
pass
================================================
FILE: crslab/evaluator/conv.py
================================================
# @Time : 2020/11/30
# @Author : Xiaolei Wang
# @Email : wxl1999@foxmail.com
# UPDATE:
# @Time : 2020/12/18
# @Author : Xiaolei Wang
# @Email : wxl1999@foxmail.com
import os
import time
from collections import defaultdict
import fasttext
from loguru import logger
from nltk import ngrams
from torch.utils.tensorboard import SummaryWriter
from crslab.evaluator.base import BaseEvaluator
from crslab.evaluator.utils import nice_report
from .embeddings import resources
from .metrics import *
from ..config import EMBEDDING_PATH
from ..download import build
class ConvEvaluator(BaseEvaluator):
"""The evaluator specially for conversational model
Args:
dist_set: the set to record dist n-gram
dist_cnt: the count of dist n-gram evaluation
gen_metrics: the metrics to evaluate conversational model, including bleu, dist, embedding metrics, f1
optim_metrics: the metrics to optimize in training
"""
def __init__(self, tensorboard=False):
super(ConvEvaluator, self).__init__()
self.dist_set = defaultdict(set)
self.dist_cnt = 0
self.gen_metrics = Metrics()
self.optim_metrics = Metrics()
self.tensorboard = tensorboard
if self.tensorboard:
self.writer = SummaryWriter(log_dir='runs/' + time.strftime("%Y-%m-%d-%H-%M-%S", time.localtime()))
self.reports_name = ['Generation Metrics', 'Optimization Metrics']
def _load_embedding(self, language):
resource = resources[language]
dpath = os.path.join(EMBEDDING_PATH, language)
build(dpath, resource['file'], resource['version'])
model_file = os.path.join(dpath, f'cc.{language}.300.bin')
self.ft = fasttext.load_model(model_file)
logger.info(f'[Load {model_file} for embedding metric')
def _get_sent_embedding(self, sent):
return [self.ft[token] for token in sent.split()]
def gen_evaluate(self, hyp, refs):
if hyp:
self.gen_metrics.add("f1", F1Metric.compute(hyp, refs))
for k in range(1, 5):
self.gen_metrics.add(f"bleu@{k}", BleuMetric.compute(hyp, refs, k))
# split sentence to tokens here
hyp_token = hyp.split()
for token in ngrams(hyp_token, k):
self.dist_set[f"dist@{k}"].add(token)
self.dist_cnt += 1
hyp_emb = self._get_sent_embedding(hyp)
ref_embs = [self._get_sent_embedding(ref) for ref in refs]
self.gen_metrics.add('greedy', GreedyMatch.compute(hyp_emb, ref_embs))
self.gen_metrics.add('average', EmbeddingAverage.compute(hyp_emb, ref_embs))
self.gen_metrics.add('extreme', VectorExtrema.compute(hyp_emb, ref_embs))
def report(self, epoch=-1, mode='test'):
for k, v in self.dist_set.items():
self.gen_metrics.add(k, AverageMetric(len(v) / self.dist_cnt))
reports = [self.gen_metrics.report(), self.optim_metrics.report()]
if self.tensorboard and mode != 'test':
for idx, task_report in enumerate(reports):
for each_metric, value in task_report.items():
self.writer.add_scalars(f'{self.reports_name[idx]}/{each_metric}', {mode: value.value()}, epoch)
logger.info('\n' + nice_report(aggregate_unnamed_reports(reports)))
def reset_metrics(self):
self.gen_metrics.clear()
self.dist_cnt = 0
self.dist_set.clear()
self.optim_metrics.clear()
================================================
FILE: crslab/evaluator/embeddings.py
================================================
# -*- encoding: utf-8 -*-
# @Time : 2020/12/18
# @Author : Xiaolei Wang
# @email : wxl1999@foxmail.com
# UPDATE
# @Time : 2020/12/18
# @Author : Xiaolei Wang
# @email : wxl1999@foxmail.com
from crslab.download import DownloadableFile
resources = {
'zh': {
'version': '0.2',
'file': DownloadableFile(
'https://pkueducn-my.sharepoint.com/:u:/g/personal/franciszhou_pkueducn_onmicrosoft_com/EVyPGnSEWZlGsLn0tpCa7BABjY7u3Ii6o_6aqYzDmw0xNw?download=1',
'cc.zh.300.zip',
'effd9806809a1db106b5166b817aaafaaf3f005846f730d4c49f88c7a28a0ac3'
)
},
'en': {
'version': '0.2',
'file': DownloadableFile(
'https://pkueducn-my.sharepoint.com/:u:/g/personal/franciszhou_pkueducn_onmicrosoft_com/Ee3JyLp8wblAoQfFY7balSYB8g2wRebRek8QLOmYs8jcKw?download=1',
'cc.en.300.zip',
'96a06a77da70325997eaa52bfd9acb1359a7c3754cb1c1aed2fc27c04936d53e'
)
}
}
================================================
FILE: crslab/evaluator/end2end.py
================================================
================================================
FILE: crslab/evaluator/metrics/__init__.py
================================================
from .base import Metric, Metrics, aggregate_unnamed_reports, AverageMetric
from .gen import BleuMetric, ExactMatchMetric, F1Metric, DistMetric, EmbeddingAverage, VectorExtrema, \
GreedyMatch
from .rec import HitMetric, NDCGMetric, MRRMetric
================================================
FILE: crslab/evaluator/metrics/base.py
================================================
# @Time : 2020/11/22
# @Author : Kun Zhou
# @Email : francis_kun_zhou@163.com
# UPDATE:
# @Time : 2020/11/24, 2020/12/2
# @Author : Kun Zhou, Xiaolei Wang
# @Email : francis_kun_zhou@163.com, wxl1999@foxmail.com
import functools
from abc import ABC, abstractmethod
import torch
from typing import Any, Union, List, Optional, Dict
TScalar = Union[int, float, torch.Tensor]
TVector = Union[List[TScalar], torch.Tensor]
@functools.total_ordering
class Metric(ABC):
"""
Base class for storing metrics.
Subclasses should define .value(). Examples are provided for each subclass.
"""
@abstractmethod
def value(self) -> float:
"""
Return the value of the metric as a float.
"""
pass
@abstractmethod
def __add__(self, other: Any) -> 'Metric':
raise NotImplementedError
def __iadd__(self, other):
return self.__radd__(other)
def __radd__(self, other: Any):
if other is None:
return self
return self.__add__(other)
def __str__(self) -> str:
return f'{self.value():.4g}'
def __repr__(self) -> str:
return f'{self.__class__.__name__}({self.value():.4g})'
def __float__(self) -> float:
return float(self.value())
def __int__(self) -> int:
return int(self.value())
def __eq__(self, other: Any) -> bool:
if isinstance(other, Metric):
return self.value() == other.value()
else:
return self.value() == other
def __lt__(self, other: Any) -> bool:
if isinstance(other, Metric):
return self.value() < other.value()
else:
return self.value() < other
def __sub__(self, other: Any) -> float:
"""
Used heavily for assertAlmostEqual.
"""
if not isinstance(other, float):
raise TypeError('Metrics.__sub__ is intentionally limited to floats.')
return self.value() - other
def __rsub__(self, other: Any) -> float:
"""
Used heavily for assertAlmostEqual.
NOTE: This is not necessary in python 3.7+.
"""
if not isinstance(other, float):
raise TypeError('Metrics.__rsub__ is intentionally limited to floats.')
return other - self.value()
@classmethod
def as_number(cls, obj: TScalar) -> Union[int, float]:
if isinstance(obj, torch.Tensor):
obj_as_number: Union[int, float] = obj.item()
else:
obj_as_number = obj # type: ignore
assert isinstance(obj_as_number, int) or isinstance(obj_as_number, float)
return obj_as_number
@classmethod
def as_float(cls, obj: TScalar) -> float:
return float(cls.as_number(obj))
@classmethod
def as_int(cls, obj: TScalar) -> int:
return int(cls.as_number(obj))
@classmethod
def many(cls, *objs: List[TVector]) -> List['Metric']:
"""
Construct many of a Metric from the base parts.
Useful if you separately compute numerators and denomenators, etc.
"""
lengths = [len(o) for o in objs]
if len(set(lengths)) != 1:
raise IndexError(f'Uneven {cls.__name__} constructions: {lengths}')
return [cls(*items) for items in zip(*objs)]
class SumMetric(Metric):
"""
Class that keeps a running sum of some metric.
Examples of SumMetric include things like "exs", the number of examples seen since
the last report, which depends exactly on a teacher.
"""
__slots__ = ('_sum',)
def __init__(self, sum_: TScalar = 0):
if isinstance(sum_, torch.Tensor):
self._sum = sum_.item()
else:
assert isinstance(sum_, (int, float))
self._sum = sum_
def __add__(self, other: Optional['SumMetric']) -> 'SumMetric':
# NOTE: hinting can be cleaned up with "from __future__ import annotations" when
# we drop Python 3.6
if other is None:
return self
full_sum = self._sum + other._sum
# always keep the same return type
return type(self)(sum_=full_sum)
def value(self) -> float:
return self._sum
class AverageMetric(Metric):
"""
Class that keeps a running average of some metric.
Examples of AverageMetrics include hits@1, F1, accuracy, etc. These metrics all have
per-example values that can be directly mapped back to a teacher.
"""
__slots__ = ('_numer', '_denom')
def __init__(self, numer: TScalar, denom: TScalar = 1):
self._numer = self.as_number(numer)
self._denom = self.as_number(denom)
def __add__(self, other: Optional['AverageMetric']) -> 'AverageMetric':
# NOTE: hinting can be cleaned up with "from __future__ import annotations" when
# we drop Python 3.6
if other is None:
return self
full_numer: TScalar = self._numer + other._numer
full_denom: TScalar = self._denom + other._denom
# always keep the same return type
return type(self)(numer=full_numer, denom=full_denom)
def value(self) -> float:
if self._numer == 0 and self._denom == 0:
# don't nan out if we haven't counted anything
return 0.0
if self._denom == 0:
return float('nan')
return self._numer / self._denom
def aggregate_unnamed_reports(reports: List[Dict[str, Metric]]) -> Dict[str, Metric]:
"""
Combines metrics without regard for tracking provenence.
"""
m: Dict[str, Metric] = {}
for task_report in reports:
for each_metric, value in task_report.items():
m[each_metric] = m.get(each_metric) + value
return m
class Metrics(object):
"""
Metrics aggregator.
"""
def __init__(self):
self._data = {}
def __str__(self):
return str(self._data)
def __repr__(self):
return f'Metrics({repr(self._data)})'
def get(self, key: str):
if key in self._data.keys():
return self._data[key].value()
else:
raise
def __getitem__(self, item):
return self.get(item)
def add(self, key: str, value: Optional[Metric]) -> None:
"""
Record an accumulation to a metric.
"""
self._data[key] = self._data.get(key) + value
def report(self):
"""
Report the metrics over all data seen so far.
"""
return {k: v for k, v in self._data.items()}
def clear(self):
"""
Clear all the metrics.
"""
self._data.clear()
================================================
FILE: crslab/evaluator/metrics/gen.py
================================================
# @Time : 2020/11/30
# @Author : Xiaolei Wang
# @Email : wxl1999@foxmail.com
# UPDATE:
# @Time : 2020/12/18
# @Author : Xiaolei Wang
# @Email : wxl1999@foxmail.com
import re
from collections import Counter
import math
import numpy as np
from nltk import ngrams
from nltk.translate.bleu_score import sentence_bleu
from sklearn.metrics.pairwise import cosine_similarity
from typing import List, Optional
from crslab.evaluator.metrics.base import AverageMetric, SumMetric
re_art = re.compile(r'\b(a|an|the)\b')
re_punc = re.compile(r'[!"#$%&()*+,-./:;<=>?@\[\]\\^`{|}~_\']')
re_space = re.compile(r'\s+')
class PPLMetric(AverageMetric):
def value(self):
return math.exp(super().value())
def normalize_answer(s):
"""
Lower text and remove punctuation, articles and extra whitespace.
"""
s = s.lower()
s = re_punc.sub(' ', s)
s = re_art.sub(' ', s)
s = re_space.sub(' ', s)
# s = ' '.join(s.split())
return s
class ExactMatchMetric(AverageMetric):
@staticmethod
def compute(guess: str, answers: List[str]) -> 'ExactMatchMetric':
if guess is None or answers is None:
return None
for a in answers:
if guess == a:
return ExactMatchMetric(1)
return ExactMatchMetric(0)
class F1Metric(AverageMetric):
"""
Helper class which computes token-level F1.
"""
@staticmethod
def _prec_recall_f1_score(pred_items, gold_items):
"""
Compute precision, recall and f1 given a set of gold and prediction items.
:param pred_items: iterable of predicted values
:param gold_items: iterable of gold values
:return: tuple (p, r, f1) for precision, recall, f1
"""
common = Counter(gold_items) & Counter(pred_items)
num_same = sum(common.values())
if num_same == 0:
return 0
precision = 1.0 * num_same / len(pred_items)
recall = 1.0 * num_same / len(gold_items)
f1 = (2 * precision * recall) / (precision + recall)
return f1
@staticmethod
def compute(guess: str, answers: List[str]) -> 'F1Metric':
if guess is None or answers is None:
return AverageMetric(0, 0)
g_tokens = guess.split()
scores = [
F1Metric._prec_recall_f1_score(g_tokens, a.split())
for a in answers
]
return F1Metric(max(scores), 1)
class BleuMetric(AverageMetric):
@staticmethod
def compute(guess: str, answers: List[str], k: int) -> Optional['BleuMetric']:
"""
Compute approximate BLEU score between guess and a set of answers.
"""
weights = [0] * 4
weights[k - 1] = 1
score = sentence_bleu(
[a.split(" ") for a in answers],
guess.split(" "),
weights=weights,
)
return BleuMetric(score)
class DistMetric(SumMetric):
@staticmethod
def compute(sent: str, k: int) -> 'DistMetric':
token_set = set()
for token in ngrams(sent.split(), k):
token_set.add(token)
return DistMetric(len(token_set))
class EmbeddingAverage(AverageMetric):
@staticmethod
def _avg_embedding(embedding):
return np.sum(embedding, axis=0) / (np.linalg.norm(np.sum(embedding, axis=0)) + 1e-12)
@staticmethod
def compute(hyp_embedding, ref_embeddings) -> 'EmbeddingAverage':
hyp_avg_emb = EmbeddingAverage._avg_embedding(hyp_embedding).reshape(1, -1)
ref_avg_embs = [EmbeddingAverage._avg_embedding(emb) for emb in ref_embeddings]
ref_avg_embs = np.array(ref_avg_embs)
return EmbeddingAverage(float(cosine_similarity(hyp_avg_emb, ref_avg_embs).max()))
class VectorExtrema(AverageMetric):
@staticmethod
def _extreme_embedding(embedding):
max_emb = np.max(embedding, axis=0)
min_emb = np.min(embedding, axis=0)
extreme_emb = np.fromiter(
map(lambda x, y: x if ((x > y or x < -y) and y > 0) or ((x < y or x > -y) and y < 0) else y, max_emb,
min_emb), dtype=float)
return extreme_emb
@staticmethod
def compute(hyp_embedding, ref_embeddings) -> 'VectorExtrema':
hyp_ext_emb = VectorExtrema._extreme_embedding(hyp_embedding).reshape(1, -1)
ref_ext_embs = [VectorExtrema._extreme_embedding(emb) for emb in ref_embeddings]
ref_ext_embs = np.asarray(ref_ext_embs)
return VectorExtrema(float(cosine_similarity(hyp_ext_emb, ref_ext_embs).max()))
class GreedyMatch(AverageMetric):
@staticmethod
def compute(hyp_embedding, ref_embeddings) -> 'GreedyMatch':
hyp_emb = np.asarray(hyp_embedding)
ref_embs = (np.asarray(ref_embedding) for ref_embedding in ref_embeddings)
score_max = 0
for ref_emb in ref_embs:
sim_mat = cosine_similarity(hyp_emb, ref_emb)
score_max = max(score_max, (sim_mat.max(axis=0).mean() + sim_mat.max(axis=1).mean()) / 2)
return GreedyMatch(score_max)
================================================
FILE: crslab/evaluator/metrics/rec.py
================================================
# @Time : 2020/11/30
# @Author : Xiaolei Wang
# @Email : wxl1999@foxmail.com
# UPDATE:
# @Time : 2020/12/2
# @Author : Xiaolei Wang
# @Email : wxl1999@foxmail.com
import math
from crslab.evaluator.metrics.base import AverageMetric
class HitMetric(AverageMetric):
@staticmethod
def compute(ranks, label, k) -> 'HitMetric':
return HitMetric(int(label in ranks[:k]))
class NDCGMetric(AverageMetric):
@staticmethod
def compute(ranks, label, k) -> 'NDCGMetric':
if label in ranks[:k]:
label_rank = ranks.index(label)
return NDCGMetric(1 / math.log2(label_rank + 2))
return NDCGMetric(0)
class MRRMetric(AverageMetric):
@staticmethod
def compute(ranks, label, k) -> 'MRRMetric':
if label in ranks[:k]:
label_rank = ranks.index(label)
return MRRMetric(1 / (label_rank + 1))
return MRRMetric(0)
================================================
FILE: crslab/evaluator/rec.py
================================================
# @Time : 2020/11/30
# @Author : Xiaolei Wang
# @Email : wxl1999@foxmail.com
# UPDATE:
# @Time : 2020/12/17
# @Author : Xiaolei Wang
# @Email : wxl1999@foxmail.com
import time
from loguru import logger
from torch.utils.tensorboard import SummaryWriter
from crslab.evaluator.base import BaseEvaluator
from crslab.evaluator.utils import nice_report
from .metrics import *
class RecEvaluator(BaseEvaluator):
"""The evaluator specially for reommender model
Args:
rec_metrics: the metrics to evaluate recommender model, including hit@K, ndcg@K and mrr@K
optim_metrics: the metrics to optimize in training
"""
def __init__(self, tensorboard=False):
super(RecEvaluator, self).__init__()
self.rec_metrics = Metrics()
self.optim_metrics = Metrics()
self.tensorboard = tensorboard
if self.tensorboard:
self.writer = SummaryWriter(log_dir='runs/' + time.strftime("%Y-%m-%d-%H-%M-%S", time.localtime()))
self.reports_name = ['Recommendation Metrics', 'Optimization Metrics']
def rec_evaluate(self, ranks, label):
for k in [1, 10, 50]:
if len(ranks) >= k:
self.rec_metrics.add(f"hit@{k}", HitMetric.compute(ranks, label, k))
self.rec_metrics.add(f"ndcg@{k}", NDCGMetric.compute(ranks, label, k))
self.rec_metrics.add(f"mrr@{k}", MRRMetric.compute(ranks, label, k))
def report(self, epoch=-1, mode='test'):
reports = [self.rec_metrics.report(), self.optim_metrics.report()]
if self.tensorboard and mode != 'test':
for idx, task_report in enumerate(reports):
for each_metric, value in task_report.items():
self.writer.add_scalars(f'{self.reports_name[idx]}/{each_metric}', {mode: value.value()}, epoch)
logger.info('\n' + nice_report(aggregate_unnamed_reports(reports)))
def reset_metrics(self):
self.rec_metrics.clear()
self.optim_metrics.clear()
================================================
FILE: crslab/evaluator/standard.py
================================================
# @Time : 2020/11/30
# @Author : Xiaolei Wang
# @Email : wxl1999@foxmail.com
# UPDATE:
# @Time : 2020/12/18
# @Author : Xiaolei Wang
# @Email : wxl1999@foxmail.com
import os
import time
from collections import defaultdict
import fasttext
from loguru import logger
from nltk import ngrams
from torch.utils.tensorboard import SummaryWriter
from crslab.evaluator.base import BaseEvaluator
from crslab.evaluator.utils import nice_report
from .embeddings import resources
from .metrics import *
from ..config import EMBEDDING_PATH
from ..download import build
class StandardEvaluator(BaseEvaluator):
"""The evaluator for all kind of model(recommender, conversation, policy)
Args:
rec_metrics: the metrics to evaluate recommender model, including hit@K, ndcg@K and mrr@K
dist_set: the set to record dist n-gram
dist_cnt: the count of dist n-gram evaluation
gen_metrics: the metrics to evaluate conversational model, including bleu, dist, embedding metrics, f1
optim_metrics: the metrics to optimize in training
"""
def __init__(self, language, tensorboard=False):
super(StandardEvaluator, self).__init__()
# rec
self.rec_metrics = Metrics()
# gen
self.dist_set = defaultdict(set)
self.dist_cnt = 0
self.gen_metrics = Metrics()
self._load_embedding(language)
# optim
self.optim_metrics = Metrics()
# tensorboard
self.tensorboard = tensorboard
if self.tensorboard:
self.writer = SummaryWriter(log_dir='runs/' + time.strftime("%Y-%m-%d-%H-%M-%S", time.localtime()))
self.reports_name = ['Recommendation Metrics', 'Generation Metrics', 'Optimization Metrics']
def _load_embedding(self, language):
resource = resources[language]
dpath = os.path.join(EMBEDDING_PATH, language)
build(dpath, resource['file'], resource['version'])
model_file = os.path.join(dpath, f'cc.{language}.300.bin')
self.ft = fasttext.load_model(model_file)
logger.info(f'[Load {model_file} for embedding metric')
def _get_sent_embedding(self, sent):
return [self.ft[token] for token in sent.split()]
def rec_evaluate(self, ranks, label):
for k in [1, 10, 50]:
if len(ranks) >= k:
self.rec_metrics.add(f"hit@{k}", HitMetric.compute(ranks, label, k))
self.rec_metrics.add(f"ndcg@{k}", NDCGMetric.compute(ranks, label, k))
self.rec_metrics.add(f"mrr@{k}", MRRMetric.compute(ranks, label, k))
def gen_evaluate(self, hyp, refs):
if hyp:
self.gen_metrics.add("f1", F1Metric.compute(hyp, refs))
for k in range(1, 5):
self.gen_metrics.add(f"bleu@{k}", BleuMetric.compute(hyp, refs, k))
for token in ngrams(hyp, k):
self.dist_set[f"dist@{k}"].add(token)
self.dist_cnt += 1
hyp_emb = self._get_sent_embedding(hyp)
ref_embs = [self._get_sent_embedding(ref) for ref in refs]
self.gen_metrics.add('greedy', GreedyMatch.compute(hyp_emb, ref_embs))
self.gen_metrics.add('average', EmbeddingAverage.compute(hyp_emb, ref_embs))
self.gen_metrics.add('extreme', VectorExtrema.compute(hyp_emb, ref_embs))
def report(self, epoch=-1, mode='test'):
for k, v in self.dist_set.items():
self.gen_metrics.add(k, AverageMetric(len(v) / self.dist_cnt))
reports = [self.rec_metrics.report(), self.gen_metrics.report(), self.optim_metrics.report()]
if self.tensorboard and mode != 'test':
for idx, task_report in enumerate(reports):
for each_metric, value in task_report.items():
self.writer.add_scalars(f'{self.reports_name[idx]}/{each_metric}', {mode: value.value()}, epoch)
logger.info('\n' + nice_report(aggregate_unnamed_reports(reports)))
def reset_metrics(self):
# rec
self.rec_metrics.clear()
# conv
self.gen_metrics.clear()
self.dist_cnt = 0
self.dist_set.clear()
# optim
self.optim_metrics.clear()
================================================
FILE: crslab/evaluator/utils.py
================================================
# -*- encoding: utf-8 -*-
# @Time : 2020/12/17
# @Author : Xiaolei Wang
# @email : wxl1999@foxmail.com
# UPDATE
# @Time : 2020/12/17
# @Author : Xiaolei Wang
# @email : wxl1999@foxmail.com
import json
import re
import shutil
from collections import OrderedDict
import math
import torch
from typing import Union, Tuple
from .metrics import Metric
def _line_width():
try:
# if we're in an interactive ipython notebook, hardcode a longer width
__IPYTHON__
return 128
except NameError:
return shutil.get_terminal_size((88, 24)).columns
def float_formatter(f: Union[float, int]) -> str:
"""
Format a float as a pretty string.
"""
if f != f:
# instead of returning nan, return "" so it shows blank in table
return ""
if isinstance(f, int):
# don't do any rounding of integers, leave them alone
return str(f)
if f >= 1000:
# numbers > 1000 just round to the nearest integer
s = f'{f:.0f}'
else:
# otherwise show 4 significant figures, regardless of decimal spot
s = f'{f:.4g}'
# replace leading 0's with blanks for easier reading
# example: -0.32 to -.32
s = s.replace('-0.', '-.')
if s.startswith('0.'):
s = s[1:]
# Add the trailing 0's to always show 4 digits
# example: .32 to .3200
if s[0] == '.' and len(s) < 5:
s += '0' * (5 - len(s))
return s
def round_sigfigs(x: Union[float, 'torch.Tensor'], sigfigs=4) -> float:
"""
Round value to specified significant figures.
:param x: input number
:param sigfigs: number of significant figures to return
:returns: float number rounded to specified sigfigs
"""
x_: float
if isinstance(x, torch.Tensor):
x_ = x.item()
else:
x_ = x # type: ignore
try:
if x_ == 0:
return 0
return round(x_, -math.floor(math.log10(abs(x_)) - sigfigs + 1))
except (ValueError, OverflowError) as ex:
if x_ in [float('inf'), float('-inf')] or x_ != x_: # inf or nan
return x_
else:
raise ex
def _report_sort_key(report_key: str) -> Tuple[str, str]:
"""
Sorting name for reports.
Sorts by main metric alphabetically, then by task.
"""
# if metric is on its own, like "f1", we will return ('', 'f1')
# if metric is from multitask, we denote it.
# e.g. "convai2/f1" -> ('convai2', 'f1')
# we handle multiple cases of / because sometimes teacher IDs have
# filenames.
fields = report_key.split("/")
main_key = fields.pop(-1)
sub_key = '/'.join(fields)
return (sub_key or 'all', main_key)
def nice_report(report) -> str:
"""
Render an agent Report as a beautiful string.
If pandas is installed, we will use it to render as a table. Multitask
metrics will be shown per row, e.g.
.. code-block:
f1 ppl
all .410 27.0
task1 .400 32.0
task2 .420 22.0
If pandas is not available, we will use a dict with like-metrics placed
next to each other.
"""
if not report:
return ""
try:
import pandas as pd
use_pandas = True
except ImportError:
use_pandas = False
sorted_keys = sorted(report.keys(), key=_report_sort_key)
output: OrderedDict[Union[str, Tuple[str, str]], float] = OrderedDict()
for k in sorted_keys:
v = report[k]
if isinstance(v, Metric):
v = v.value()
if use_pandas:
output[_report_sort_key(k)] = v
else:
output[k] = v
if use_pandas:
line_width = _line_width()
df = pd.DataFrame([output])
df.columns = pd.MultiIndex.from_tuples(df.columns)
df = df.stack().transpose().droplevel(0, axis=1)
result = " " + df.to_string(
na_rep="",
line_width=line_width - 3, # -3 for the extra spaces we add
float_format=float_formatter,
index=df.shape[0] > 1,
).replace("\n\n", "\n").replace("\n", "\n ")
result = re.sub(r"\s+$", "", result)
return result
else:
return json.dumps(
{
k: round_sigfigs(v, 4) if isinstance(v, float) else v
for k, v in output.items()
}
)
================================================
FILE: crslab/model/__init__.py
================================================
# @Time : 2020/11/22
# @Author : Kun Zhou
# @Email : francis_kun_zhou@163.com
# UPDATE:
# @Time : 2020/11/24, 2020/12/24
# @Author : Kun Zhou, Xiaolei Wang
# @Email : francis_kun_zhou@163.com, wxl1999@foxmail.com
# @Time : 2021/10/06
# @Author : Zhipeng Zhao
# @Email : oran_official@outlook.com
import torch
from loguru import logger
from .conversation import *
from .crs import *
from .policy import *
from .recommendation import *
Model_register_table = {
'KGSF': KGSFModel,
'KBRD': KBRDModel,
'TGRec': TGRecModel,
'TGConv': TGConvModel,
'TGPolicy': TGPolicyModel,
'ReDialRec': ReDialRecModel,
'ReDialConv': ReDialConvModel,
'InspiredRec': InspiredRecModel,
'InspiredConv': InspiredConvModel,
'GPT2': GPT2Model,
'Transformer': TransformerModel,
'ConvBERT': ConvBERTModel,
'ProfileBERT': ProfileBERTModel,
'TopicBERT': TopicBERTModel,
'PMI': PMIModel,
'MGCG': MGCGModel,
'BERT': BERTModel,
'SASREC': SASRECModel,
'GRU4REC': GRU4RECModel,
'Popularity': PopularityModel,
'TextCNN': TextCNNModel,
'NTRD': NTRDModel
}
def get_model(config, model_name, device, vocab, side_data=None):
if model_name in Model_register_table:
model = Model_register_table[model_name](config, device, vocab, side_data)
logger.info(f'[Build model {model_name}]')
if config.opt["gpu"] == [-1]:
return model
else:
if len(config.opt["gpu"]) > 1:
if model_name == 'PMI' or model_name == 'KBRD':
logger.info(f'[PMI/KBRD model does not support multi GPUs yet, using single GPU now]')
return model.to(device)
else:
return torch.nn.DataParallel(model, device_ids=config["gpu"])
else:
return model.to(device)
else:
raise NotImplementedError('Model [{}] has not been implemented'.format(model_name))
================================================
FILE: crslab/model/base.py
================================================
# @Time : 2020/11/22
# @Author : Kun Zhou
# @Email : francis_kun_zhou@163.com
# UPDATE:
# @Time : 2020/11/24, 2020/12/29
# @Author : Kun Zhou, Xiaolei Wang
# @Email : francis_kun_zhou@163.com, wxl1999@foxmail.com
from abc import ABC, abstractmethod
from torch import nn
from crslab.download import build
class BaseModel(ABC, nn.Module):
"""Base class for all models"""
def __init__(self, opt, device, dpath=None, resource=None):
super(BaseModel, self).__init__()
self.opt = opt
self.device = device
if resource is not None:
self.dpath = dpath
dfile = resource['file']
build(dpath, dfile, version=resource['version'])
self.build_model()
@abstractmethod
def build_model(self, *args, **kwargs):
"""build model"""
pass
def recommend(self, batch, mode):
"""calculate loss and prediction of recommendation for batch under certain mode
Args:
batch (dict or tuple): batch data
mode (str, optional): train/valid/test.
"""
pass
def converse(self, batch, mode):
"""calculate loss and prediction of conversation for batch under certain mode
Args:
batch (dict or tuple): batch data
mode (str, optional): train/valid/test.
"""
pass
def guide(self, batch, mode):
"""calculate loss and prediction of guidance for batch under certain mode
Args:
batch (dict or tuple): batch data
mode (str, optional): train/valid/test.
"""
pass
================================================
FILE: crslab/model/conversation/__init__.py
================================================
from .gpt2 import GPT2Model
from .transformer import TransformerModel
================================================
FILE: crslab/model/conversation/gpt2/__init__.py
================================================
from .gpt2 import GPT2Model
================================================
FILE: crslab/model/conversation/gpt2/gpt2.py
================================================
# @Time : 2020/12/14
# @Author : Yuanhang Zhou
# @Email : sdzyh002@gmail.com
# UPDATE
# @Time : 2021/1/7
# @Author : Xiaolei Wang
# @email : wxl1999@foxmail.com
r"""
GPT2
====
References:
Radford, Alec, et al. `"Language Models are Unsupervised Multitask Learners."`_.
.. _`"Language Models are Unsupervised Multitask Learners."`:
https://cdn.openai.com/better-language-models/language_models_are_unsupervised_multitask_learners.pdf
"""
import os
import torch
from torch.nn import CrossEntropyLoss
from transformers import GPT2LMHeadModel
from crslab.config import PRETRAIN_PATH
from crslab.data import dataset_language_map
from crslab.model.base import BaseModel
from crslab.model.pretrained_models import resources
class GPT2Model(BaseModel):
"""
Attributes:
context_truncate: A integer indicating the length of dialogue context.
response_truncate: A integer indicating the length of dialogue response.
pad_id: A integer indicating the id of padding token.
"""
def __init__(self, opt, device, vocab, side_data):
"""
Args:
opt (dict): A dictionary record the hyper parameters.
device (torch.device): A variable indicating which device to place the data and model.
vocab (dict): A dictionary record the vocabulary information.
side_data (dict): A dictionary record the side data.
"""
self.context_truncate = opt['context_truncate']
self.response_truncate = opt['response_truncate']
self.pad_id = vocab['pad']
language = dataset_language_map[opt['dataset']]
resource = resources['gpt2'][language]
dpath = os.path.join(PRETRAIN_PATH, "gpt2", language)
super(GPT2Model, self).__init__(opt, device, dpath, resource)
def build_model(self):
"""build model"""
self.model = GPT2LMHeadModel.from_pretrained(self.dpath)
self.loss = CrossEntropyLoss(ignore_index=self.pad_id)
def forward(self, batch, mode):
_, _, input_ids, context, _, _, y = batch
if mode != 'test':
# torch.tensor's shape = (bs, seq_len, v_s); tuple's length = 12
lm_logits = self.model(input_ids).logits
# index from 1 to self.reponse_truncate is valid response
loss = self.calculate_loss(
lm_logits[:, -self.response_truncate:-1, :],
input_ids[:, -self.response_truncate + 1:])
pred = torch.max(lm_logits, dim=2)[1] # [bs, seq_len]
pred = pred[:, -self.response_truncate:]
return loss, pred
else:
return self.generate(context)
def generate(self, context):
"""
Args:
context: torch.tensor, shape=(bs, context_turncate)
Returns:
generated_response: torch.tensor, shape=(bs, reponse_turncate-1)
"""
generated_response = []
former_hidden_state = None
context = context[..., -self.response_truncate + 1:]
for i in range(self.response_truncate - 1):
outputs = self.model(context, former_hidden_state) # (bs, c_t, v_s),
last_hidden_state, former_hidden_state = outputs.logits, outputs.past_key_values
next_token_logits = last_hidden_state[:, -1, :] # (bs, v_s)
preds = next_token_logits.argmax(dim=-1).long() # (bs)
context = preds.unsqueeze(1)
generated_response.append(preds)
generated_response = torch.stack(generated_response).T
return generated_response
def calculate_loss(self, logit, labels):
"""
Args:
preds: torch.FloatTensor, shape=(bs, response_truncate, vocab_size)
labels: torch.LongTensor, shape=(bs, response_truncate)
"""
loss = self.loss(logit.reshape(-1, logit.size(-1)), labels.reshape(-1))
return loss
def generate_bs(self, context, beam=4):
context = context[..., -self.response_truncate + 1:]
context_former = context
batch_size = context.shape[0]
sequences = [[[list(), 1.0]]] * batch_size
for i in range(self.response_truncate - 1):
if sequences != [[[list(), 1.0]]] * batch_size:
context = []
for i in range(batch_size):
for cand in sequences[i]:
text = torch.cat(
(context_former[i], torch.tensor(cand[0]).to(self.device))) # 由于取消了state,与之前的context拼接
context.append(text)
context = torch.stack(context)
with torch.no_grad():
outputs = self.model(context)
last_hidden_state, state = outputs.logits, outputs.past_key_values
next_token_logits = last_hidden_state[:, -1, :]
next_token_probs = torch.nn.functional.softmax(next_token_logits)
topk = torch.topk(next_token_probs, beam, dim=-1)
probs = topk.values.reshape([batch_size, -1, beam]) # (bs, candidate, beam)
preds = topk.indices.reshape([batch_size, -1, beam]) # (bs, candidate, beam)
for j in range(batch_size):
all_candidates = []
for n in range(len(sequences[j])):
for k in range(beam):
seq = sequences[j][n][0]
prob = sequences[j][n][1]
seq_tmp = seq.copy()
seq_tmp.append(preds[j][n][k])
candidate = [seq_tmp, prob * probs[j][n][k]]
all_candidates.append(candidate)
ordered = sorted(all_candidates, key=lambda tup: tup[1], reverse=True)
sequences[j] = ordered[:beam]
res = []
for i in range(batch_size):
res.append(torch.stack(sequences[i][0][0]))
res = torch.stack(res)
return res
================================================
FILE: crslab/model/conversation/transformer/__init__.py
================================================
from .transformer import TransformerModel
================================================
FILE: crslab/model/conversation/transformer/transformer.py
================================================
# @Time : 2020/12/17
# @Author : Yuanhang Zhou
# @Email : sdzyh002@gmail.com
# UPDATE
# @Time : 2020/12/29, 2021/1/4
# @Author : Xiaolei Wang, Yuanhang Zhou
# @email : wxl1999@foxmail.com, sdzyh002@gmail.com
r"""
Transformer
===========
References:
Zhou, Kun, et al. `"Towards Topic-Guided Conversational Recommender System."`_ in COLING 2020.
.. _`"Towards Topic-Guided Conversational Recommender System."`:
https://www.aclweb.org/anthology/2020.coling-main.365/
"""
import torch
import torch.nn.functional as F
from loguru import logger
from torch import nn
from crslab.model.base import BaseModel
from crslab.model.utils.functions import edge_to_pyg_format
from crslab.model.utils.modules.transformer import TransformerEncoder, TransformerDecoder
class TransformerModel(BaseModel):
"""
Attributes:
vocab_size: A integer indicating the vocabulary size.
pad_token_idx: A integer indicating the id of padding token.
start_token_idx: A integer indicating the id of start token.
end_token_idx: A integer indicating the id of end token.
token_emb_dim: A integer indicating the dimension of token embedding layer.
pretrain_embedding: A string indicating the path of pretrained embedding.
n_word: A integer indicating the number of words.
n_entity: A integer indicating the number of entities.
pad_word_idx: A integer indicating the id of word padding.
pad_entity_idx: A integer indicating the id of entity padding.
num_bases: A integer indicating the number of bases.
kg_emb_dim: A integer indicating the dimension of kg embedding.
n_heads: A integer indicating the number of heads.
n_layers: A integer indicating the number of layer.
ffn_size: A integer indicating the size of ffn hidden.
dropout: A float indicating the drouput rate.
attention_dropout: A integer indicating the drouput rate of attention layer.
relu_dropout: A integer indicating the drouput rate of relu layer.
learn_positional_embeddings: A boolean indicating if we learn the positional embedding.
embeddings_scale: A boolean indicating if we use the embeddings scale.
reduction: A boolean indicating if we use the reduction.
n_positions: A integer indicating the number of position.
longest_label: A integer indicating the longest length for response generation.
"""
def __init__(self, opt, device, vocab, side_data):
"""
Args:
opt (dict): A dictionary record the hyper parameters.
device (torch.device): A variable indicating which device to place the data and model.
vocab (dict): A dictionary record the vocabulary information.
side_data (dict): A dictionary record the side data.
"""
# vocab
self.vocab_size = vocab['vocab_size']
self.pad_token_idx = vocab['pad']
self.start_token_idx = vocab['start']
self.end_token_idx = vocab['end']
self.token_emb_dim = opt['token_emb_dim']
self.pretrain_embedding = side_data.get('embedding', None)
# kg
self.n_word = vocab['n_word']
self.n_entity = vocab['n_entity']
self.pad_word_idx = vocab['pad_word']
self.pad_entity_idx = vocab['pad_entity']
entity_kg = side_data['entity_kg']
self.n_relation = entity_kg['n_relation']
entity_edges = entity_kg['edge']
self.entity_edge_idx, self.entity_edge_type = edge_to_pyg_format(entity_edges, 'RGCN')
self.entity_edge_idx = self.entity_edge_idx.to(device)
self.entity_edge_type = self.entity_edge_type.to(device)
word_edges = side_data['word_kg']['edge']
self.word_edges = edge_to_pyg_format(word_edges, 'GCN').to(device)
self.num_bases = opt['num_bases']
self.kg_emb_dim = opt['kg_emb_dim']
# transformer
self.n_heads = opt['n_heads']
self.n_layers = opt['n_layers']
self.ffn_size = opt['ffn_size']
self.dropout = opt['dropout']
self.attention_dropout = opt['attention_dropout']
self.relu_dropout = opt['relu_dropout']
self.learn_positional_embeddings = opt['learn_positional_embeddings']
self.embeddings_scale = opt['embeddings_scale']
self.reduction = opt['reduction']
self.n_positions = opt['n_positions']
self.longest_label = opt.get('longest_label', 1)
super(TransformerModel, self).__init__(opt, device)
def build_model(self):
self._init_embeddings()
self._build_conversation_layer()
def _init_embeddings(self):
if self.pretrain_embedding is not None:
self.token_embedding = nn.Embedding.from_pretrained(
torch.as_tensor(self.pretrain_embedding, dtype=torch.float), freeze=False,
padding_idx=self.pad_token_idx)
else:
self.token_embedding = nn.Embedding(self.vocab_size, self.token_emb_dim, self.pad_token_idx)
nn.init.normal_(self.token_embedding.weight, mean=0, std=self.kg_emb_dim ** -0.5)
nn.init.constant_(self.token_embedding.weight[self.pad_token_idx], 0)
logger.debug('[Finish init embeddings]')
def _build_conversation_layer(self):
self.register_buffer('START', torch.tensor([self.start_token_idx], dtype=torch.long))
self.conv_encoder = TransformerEncoder(
n_heads=self.n_heads,
n_layers=self.n_layers,
embedding_size=self.token_emb_dim,
ffn_size=self.ffn_size,
vocabulary_size=self.vocab_size,
embedding=self.token_embedding,
dropout=self.dropout,
attention_dropout=self.attention_dropout,
relu_dropout=self.relu_dropout,
padding_idx=self.pad_token_idx,
learn_positional_embeddings=self.learn_positional_embeddings,
embeddings_scale=self.embeddings_scale,
reduction=self.reduction,
n_positions=self.n_positions,
)
self.conv_decoder = TransformerDecoder(
self.n_heads, self.n_layers, self.token_emb_dim, self.ffn_size, self.vocab_size,
embedding=self.token_embedding,
dropout=self.dropout,
attention_dropout=self.attention_dropout,
relu_dropout=self.relu_dropout,
embeddings_scale=self.embeddings_scale,
learn_positional_embeddings=self.learn_positional_embeddings,
padding_idx=self.pad_token_idx,
n_positions=self.n_positions
)
self.conv_loss = nn.CrossEntropyLoss(ignore_index=self.pad_token_idx)
logger.debug('[Finish build conv layer]')
def _starts(self, batch_size):
"""Return bsz start tokens."""
return self.START.detach().expand(batch_size, 1)
def _decode_forced_with_kg(self, token_encoding, response):
batch_size, seq_len = response.shape
start = self._starts(batch_size)
inputs = torch.cat((start, response[:, :-1]), dim=-1).long()
dialog_latent, _ = self.conv_decoder(inputs, token_encoding) # (bs, seq_len, dim)
gen_logits = F.linear(dialog_latent, self.token_embedding.weight) # (bs, seq_len, vocab_size)
preds = gen_logits.argmax(dim=-1)
return gen_logits, preds
def _decode_greedy_with_kg(self, token_encoding):
batch_size = token_encoding[0].shape[0]
inputs = self._starts(batch_size).long()
incr_state = None
logits = []
for _ in range(self.longest_label):
dialog_latent, incr_state = self.conv_decoder(inputs, token_encoding, incr_state)
dialog_latent = dialog_latent[:, -1:, :] # (bs, 1, dim)
gen_logits = F.linear(dialog_latent, self.token_embedding.weight)
preds = gen_logits.argmax(dim=-1).long()
logits.append(gen_logits)
inputs = torch.cat((inputs, preds), dim=1)
finished = ((inputs == self.end_token_idx).sum(dim=-1) > 0).sum().item() == batch_size
if finished:
break
logits = torch.cat(logits, dim=1)
return logits, inputs
def _decode_beam_search_with_kg(self, token_encoding, beam=4):
batch_size = token_encoding[0].shape[0]
xs = self._starts(batch_size).long().reshape(1, batch_size, -1)
incr_state = None
sequences = [[[list(), list(), 1.0]]] * batch_size
for i in range(self.longest_label):
# at beginning there is 1 candidate, when i!=0 there are 4 candidates
if i == 1:
token_encoding = (token_encoding[0].repeat(beam, 1, 1),
token_encoding[1].repeat(beam, 1, 1))
if i != 0:
xs = []
for d in range(len(sequences[0])):
for j in range(batch_size):
text = sequences[j][d][0]
xs.append(text)
xs = torch.stack(xs).reshape(beam, batch_size, -1) # (beam, batch_size, _)
dialog_latent, incr_state = self.conv_decoder(xs.reshape(len(sequences[0]) * batch_size, -1),
token_encoding,
incr_state)
dialog_latent = dialog_latent[:, -1:, :] # (bs, 1, dim)
gen_logits = F.linear(dialog_latent, self.token_embedding.weight)
logits = gen_logits.reshape(len(sequences[0]), batch_size, 1, -1)
# turn into probabilities,in case of negative numbers
probs, preds = torch.nn.functional.softmax(logits).topk(beam, dim=-1)
# (candeidate, bs, 1 , beam) during first loop, candidate=1, otherwise candidate=beam
for j in range(batch_size):
all_candidates = []
for n in range(len(sequences[j])):
for k in range(beam):
prob = sequences[j][n][2]
logit = sequences[j][n][1]
if logit == []:
logit_tmp = logits[n][j][0].unsqueeze(0)
else:
logit_tmp = torch.cat((logit, logits[n][j][0].unsqueeze(0)), dim=0)
seq_tmp = torch.cat((xs[n][j].reshape(-1), preds[n][j][0][k].reshape(-1)))
candidate = [seq_tmp, logit_tmp, prob * probs[n][j][0][k]]
all_candidates.append(candidate)
ordered = sorted(all_candidates, key=lambda tup: tup[2], reverse=True)
sequences[j] = ordered[:beam]
# check if everyone has generated an end token
all_finished = ((xs == self.end_token_idx).sum(dim=1) > 0).sum().item() == batch_size
if all_finished:
break
logits = torch.stack([seq[0][1] for seq in sequences])
xs = torch.stack([seq[0][0] for seq in sequences])
return logits, xs
def forward(self, batch, mode):
context_tokens, context_entities, context_words, response = batch
# encoder-decoder
tokens_encoding = self.conv_encoder(context_tokens)
if mode != 'test':
self.longest_label = max(self.longest_label, response.shape[1])
logits, preds = self._decode_forced_with_kg(tokens_encoding,
response)
logits = logits.view(-1, logits.shape[-1])
response = response.view(-1)
loss = self.conv_loss(logits, response)
return loss, preds
else:
logits, preds = self._decode_greedy_with_kg(tokens_encoding)
return preds
================================================
FILE: crslab/model/crs/__init__.py
================================================
from .inspired import *
from .kbrd import *
from .kgsf import *
from .redial import *
from .tgredial import *
from .ntrd import *
================================================
FILE: crslab/model/crs/inspired/__init__.py
================================================
from .inspired_conv import InspiredConvModel
from .inspired_rec import InspiredRecModel
================================================
FILE: crslab/model/crs/inspired/inspired_conv.py
================================================
# @Time : 2021/3/10
# @Author : Beichen Zhang
# @Email : zhangbeichen724@gmail.com
import os
import torch
from transformers import GPT2LMHeadModel
from crslab.config import PRETRAIN_PATH
from crslab.data import dataset_language_map
from crslab.model.base import BaseModel
from crslab.model.pretrained_models import resources
from .modules import SequenceCrossEntropyLoss
class InspiredConvModel(BaseModel):
"""
Attributes:
context_truncate: A integer indicating the length of dialogue context.
response_truncate: A integer indicating the length of dialogue response.
pad_id: A integer indicating the id of padding token.
"""
def __init__(self, opt, device, vocab, side_data):
"""
Args:
opt (dict): A dictionary record the hyper parameters.
device (torch.device): A variable indicating which device to place the data and model.
vocab (dict): A dictionary record the vocabulary information.
side_data (dict): A dictionary record the side data.
"""
self.context_truncate = opt['context_truncate']
self.response_truncate = opt['response_truncate']
self.pad_id = vocab['pad']
self.label_smoothing = opt['conv']['label_smoothing'] if 'label_smoothing' in opt['conv'] else -1
language = dataset_language_map[opt['dataset']]
resource = resources['gpt2'][language]
dpath = os.path.join(PRETRAIN_PATH, "gpt2", language)
super(InspiredConvModel, self).__init__(opt, device, dpath, resource)
def build_model(self):
"""build model for seeker and recommender separately"""
self.model_sk = GPT2LMHeadModel.from_pretrained(self.dpath)
self.model_rm = GPT2LMHeadModel.from_pretrained(self.dpath)
self.loss = SequenceCrossEntropyLoss(self.pad_id, self.label_smoothing)
def converse(self, batch, mode):
"""
Args:
batch: ::
{
'roles': (batch_size),
'input_ids': (batch_size, max_seq_length),
'context': (batch_size, context_truncate)
}
"""
roles, input_ids, context, _ = batch
input_ids_iters = input_ids.unsqueeze(1)
past = None
lm_logits_all = []
if mode != 'test':
for turn, iter in enumerate(input_ids_iters):
if (roles[turn] == 0):
# considering that gpt2 only supports up to 1024 tokens
if past is not None and past[0].shape[3] + iter.shape[1] > 1024:
past = None
outputs = self.model_sk(iter, past_key_values=past)
lm_logits, past = outputs.logits, outputs.past_key_values
lm_logits_all.append(lm_logits)
else:
if past is not None and past[0].shape[3] + iter.shape[1] > 1024:
past = None
outputs = self.model_rm(iter, past_key_values=past)
lm_logits, past = outputs.logits, outputs.past_key_values
lm_logits_all.append(lm_logits)
lm_logits_all = torch.cat(lm_logits_all, dim=0) # (b_s, seq_len, vocab_size)
# index from 1 to self.reponse_truncate is valid response
loss = self.calculate_loss(
lm_logits_all[:, -self.response_truncate:-1, :],
input_ids[:, -self.response_truncate + 1:])
pred = torch.max(lm_logits_all, dim=2)[1] # (b_s, seq_len)
pred = pred[:, -self.response_truncate:]
return loss, pred
else:
return self.generate(roles, context)
def generate(self, roles, context):
"""
Args:
roles: the role of each speak corresponding to the utterance in batch, shape=(b_s)
context: torch.tensor, shape=(b_s, context_turncate)
Returns:
generated_response: torch.tensor, shape=(b_s, reponse_turncate-1)
"""
generated_response = []
former_hidden_state = None
context = context[..., -self.response_truncate + 1:]
for i in range(self.response_truncate - 1):
last_hidden_state_all = []
context_iters = context.unsqueeze(1)
for turn, iter in enumerate(context_iters):
if roles[turn] == 0:
outputs = self.model_sk(iter, former_hidden_state) # (1, s_l, v_s),
else:
outputs = self.model_rm(iter, former_hidden_state) # (1, s_l, v_s),
last_hidden_state, former_hidden_state = outputs.logits, outputs.past_key_values
last_hidden_state_all.append(last_hidden_state)
last_hidden_state_all = torch.cat(last_hidden_state_all, dim=0)
next_token_logits = last_hidden_state_all[:, -1, :] # (b_s, v_s)
preds = next_token_logits.argmax(dim=-1).long() # (b_s)
context = preds.unsqueeze(1)
generated_response.append(preds)
generated_response = torch.stack(generated_response).T
return generated_response
def calculate_loss(self, logit, labels):
"""
Args:
preds: torch.FloatTensor, shape=(b_s, response_truncate, vocab_size)
labels: torch.LongTensor, shape=(b_s, response_truncate)
"""
loss = self.loss(logit, labels)
return loss
================================================
FILE: crslab/model/crs/inspired/inspired_rec.py
================================================
# @Time : 2020/12/16
# @Author : Yuanhang Zhou
# @Email : sdzyh002@gmail.com
# UPDATE
# @Time : 2021/1/7, 2021/1/4
# @Author : Xiaolei Wang, Yuanhang Zhou
# @email : wxl1999@foxmail.com, sdzyh002@gmail.com
r"""
BERT
====
References:
Devlin, Jacob, et al. `"BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding."`_ in NAACL 2019.
.. _`"BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding."`:
https://www.aclweb.org/anthology/N19-1423/
"""
import os
from loguru import logger
from torch import nn
from transformers import BertModel
from crslab.config import PRETRAIN_PATH
from crslab.data import dataset_language_map
from crslab.model.base import BaseModel
from crslab.model.pretrained_models import resources
class InspiredRecModel(BaseModel):
"""
Attributes:
item_size: A integer indicating the number of items.
"""
def __init__(self, opt, device, vocab, side_data):
"""
Args:
opt (dict): A dictionary record the hyper parameters.
device (torch.device): A variable indicating which device to place the data and model.
vocab (dict): A dictionary record the vocabulary information.
side_data (dict): A dictionary record the side data.
"""
self.item_size = vocab['n_entity']
language = dataset_language_map[opt['dataset']]
resource = resources['bert'][language]
dpath = os.path.join(PRETRAIN_PATH, "bert", language)
super(InspiredRecModel, self).__init__(opt, device, dpath, resource)
def build_model(self):
# build BERT layer, give the architecture, load pretrained parameters
self.bert = BertModel.from_pretrained(self.dpath)
# print(self.item_size)
self.bert_hidden_size = self.bert.config.hidden_size
self.mlp = nn.Linear(self.bert_hidden_size, self.item_size)
# this loss may conduct to some weakness
self.rec_loss = nn.CrossEntropyLoss()
logger.debug('[Finish build rec layer]')
def recommend(self, batch, mode='train'):
context, mask, y = batch
bert_embed = self.bert(context, attention_mask=mask).pooler_output
rec_scores = self.mlp(bert_embed) # bs, item_size
rec_loss = self.rec_loss(rec_scores, y)
return rec_loss, rec_scores
================================================
FILE: crslab/model/crs/inspired/modules.py
================================================
# @Time : 2021/3/10
# @Author : Beichen Zhang
# @Email : zhangbeichen724@gmail.com
import torch
import torch.nn as nn
import torch.nn.functional as F
class SequenceCrossEntropyLoss(nn.Module):
"""
Attributes:
ignore_index: indices corresponding tokens which should be ignored in calculating loss.
label_smoothing: determine smoothing value in cross entropy loss. should be less than 1.0.
"""
def __init__(self, ignore_index=None, label_smoothing=-1):
super().__init__()
self.ignore_index = ignore_index
self.label_smoothing = label_smoothing
def forward(self, logits, labels):
"""
Args:
logits: (batch_size, max_seq_len, vocal_size)
labels: (batch_size, max_seq_len)
"""
if self.label_smoothing > 1.0:
raise ValueError('The param label_smoothing should be in the range of 0.0 to 1.0.')
if self.ignore_index == None:
mask = torch.ones_like(labels, dtype=torch.float)
else:
mask = (labels != self.ignore_index).float()
logits_flat = logits.reshape(-1, logits.size(-1)) # (b_s * s_l, num_classes)
log_probs_flat = F.log_softmax(logits_flat, dim=-1)
labels_flat = labels.reshape(-1, 1).long() # (b_s * s_l, 1)
if self.label_smoothing > 0.0:
num_classes = logits.size(-1)
smoothing_value = self.label_smoothing / float(num_classes)
one_hot_labels = torch.zeros_like(log_probs_flat).scatter_(-1, labels_flat,
1.0 - self.label_smoothing) # fill all the correct indices with 1 - smoothing value.
smoothed_labels = one_hot_labels + smoothing_value
negative_log_likelihood_flat = -log_probs_flat * smoothed_labels
negative_log_likelihood_flat = negative_log_likelihood_flat.sum(-1, keepdim=True)
else:
negative_log_likelihood_flat = -torch.gather(log_probs_flat, dim=1, index=labels_flat) # (b_s * s_l, 1)
negative_log_likelihood = negative_log_likelihood_flat.view(-1, logits.shape[1]) # (b_s, s_l)
loss = negative_log_likelihood * mask
loss = loss.sum(1) / (mask.sum(1) + 1e-13)
loss = loss.mean()
return loss
================================================
FILE: crslab/model/crs/kbrd/__init__.py
================================================
from .kbrd import KBRDModel
================================================
FILE: crslab/model/crs/kbrd/kbrd.py
================================================
# -*- encoding: utf-8 -*-
# @Time : 2020/12/4
# @Author : Xiaolei Wang
# @email : wxl1999@foxmail.com
# UPDATE
# @Time : 2020/1/3, 2021/1/4
# @Author : Xiaolei Wang, Yuanhang Zhou
# @email : wxl1999@foxmail.com, sdzyh002@gmail.com
r"""
KBRD
====
References:
Chen, Qibin, et al. `"Towards Knowledge-Based Recommender Dialog System."`_ in EMNLP 2019.
.. _`"Towards Knowledge-Based Recommender Dialog System."`:
https://www.aclweb.org/anthology/D19-1189/
"""
import torch
import torch.nn.functional as F
from loguru import logger
from torch import nn
from torch_geometric.nn import RGCNConv
from crslab.model.base import BaseModel
from crslab.model.utils.functions import edge_to_pyg_format
from crslab.model.utils.modules.attention import SelfAttentionBatch
from crslab.model.utils.modules.transformer import TransformerDecoder, TransformerEncoder
class KBRDModel(BaseModel):
"""
Attributes:
vocab_size: A integer indicating the vocabulary size.
pad_token_idx: A integer indicating the id of padding token.
start_token_idx: A integer indicating the id of start token.
end_token_idx: A integer indicating the id of end token.
token_emb_dim: A integer indicating the dimension of token embedding layer.
pretrain_embedding: A string indicating the path of pretrained embedding.
n_entity: A integer indicating the number of entities.
n_relation: A integer indicating the number of relation in KG.
num_bases: A integer indicating the number of bases.
kg_emb_dim: A integer indicating the dimension of kg embedding.
user_emb_dim: A integer indicating the dimension of user embedding.
n_heads: A integer indicating the number of heads.
n_layers: A integer indicating the number of layer.
ffn_size: A integer indicating the size of ffn hidden.
dropout: A float indicating the dropout rate.
attention_dropout: A integer indicating the dropout rate of attention layer.
relu_dropout: A integer indicating the dropout rate of relu layer.
learn_positional_embeddings: A boolean indicating if we learn the positional embedding.
embeddings_scale: A boolean indicating if we use the embeddings scale.
reduction: A boolean indicating if we use the reduction.
n_positions: A integer indicating the number of position.
longest_label: A integer indicating the longest length for response generation.
user_proj_dim: A integer indicating dim to project for user embedding.
"""
def __init__(self, opt, device, vocab, side_data):
"""
Args:
opt (dict): A dictionary record the hyper parameters.
device (torch.device): A variable indicating which device to place the data and model.
vocab (dict): A dictionary record the vocabulary information.
side_data (dict): A dictionary record the side data.
"""
self.device = device
self.gpu = opt.get("gpu", [-1])
# vocab
self.pad_token_idx = vocab['pad']
self.start_token_idx = vocab['start']
self.end_token_idx = vocab['end']
self.vocab_size = vocab['vocab_size']
self.token_emb_dim = opt.get('token_emb_dim', 300)
self.pretrain_embedding = side_data.get('embedding', None)
# kg
self.n_entity = vocab['n_entity']
entity_kg = side_data['entity_kg']
self.n_relation = entity_kg['n_relation']
self.edge_idx, self.edge_type = edge_to_pyg_format(entity_kg['edge'], 'RGCN')
self.edge_idx = self.edge_idx.to(device)
self.edge_type = self.edge_type.to(device)
self.num_bases = opt.get('num_bases', 8)
self.kg_emb_dim = opt.get('kg_emb_dim', 300)
self.user_emb_dim = self.kg_emb_dim
# transformer
self.n_heads = opt.get('n_heads', 2)
self.n_layers = opt.get('n_layers', 2)
self.ffn_size = opt.get('ffn_size', 300)
self.dropout = opt.get('dropout', 0.1)
self.attention_dropout = opt.get('attention_dropout', 0.0)
self.relu_dropout = opt.get('relu_dropout', 0.1)
self.embeddings_scale = opt.get('embedding_scale', True)
self.learn_positional_embeddings = opt.get('learn_positional_embeddings', False)
self.reduction = opt.get('reduction', False)
self.n_positions = opt.get('n_positions', 1024)
self.longest_label = opt.get('longest_label', 1)
self.user_proj_dim = opt.get('user_proj_dim', 512)
super(KBRDModel, self).__init__(opt, device)
def build_model(self, *args, **kwargs):
self._build_embedding()
self._build_kg_layer()
self._build_recommendation_layer()
self._build_conversation_layer()
def _build_embedding(self):
if self.pretrain_embedding is not None:
self.token_embedding = nn.Embedding.from_pretrained(
torch.as_tensor(self.pretrain_embedding, dtype=torch.float), freeze=False,
padding_idx=self.pad_token_idx)
else:
self.token_embedding = nn.Embedding(self.vocab_size, self.token_emb_dim, self.pad_token_idx)
nn.init.normal_(self.token_embedding.weight, mean=0, std=self.kg_emb_dim ** -0.5)
nn.init.constant_(self.token_embedding.weight[self.pad_token_idx], 0)
logger.debug('[Build embedding]')
def _build_kg_layer(self):
self.kg_encoder = RGCNConv(self.n_entity, self.kg_emb_dim, self.n_relation, num_bases=self.num_bases)
self.kg_attn = SelfAttentionBatch(self.kg_emb_dim, self.kg_emb_dim)
logger.debug('[Build kg layer]')
def _build_recommendation_layer(self):
self.rec_bias = nn.Linear(self.kg_emb_dim, self.n_entity)
self.rec_loss = nn.CrossEntropyLoss()
logger.debug('[Build recommendation layer]')
def _build_conversation_layer(self):
self.register_buffer('START', torch.tensor([self.start_token_idx], dtype=torch.long))
self.dialog_encoder = TransformerEncoder(
self.n_heads,
self.n_layers,
self.token_emb_dim,
self.ffn_size,
self.vocab_size,
self.token_embedding,
self.dropout,
self.attention_dropout,
self.relu_dropout,
self.pad_token_idx,
self.learn_positional_embeddings,
self.embeddings_scale,
self.reduction,
self.n_positions
)
self.decoder = TransformerDecoder(
self.n_heads,
self.n_layers,
self.token_emb_dim,
self.ffn_size,
self.vocab_size,
self.token_embedding,
self.dropout,
self.attention_dropout,
self.relu_dropout,
self.embeddings_scale,
self.learn_positional_embeddings,
self.pad_token_idx,
self.n_positions
)
self.user_proj_1 = nn.Linear(self.user_emb_dim, self.user_proj_dim)
self.user_proj_2 = nn.Linear(self.user_proj_dim, self.vocab_size)
self.conv_loss = nn.CrossEntropyLoss(ignore_index=self.pad_token_idx)
logger.debug('[Build conversation layer]')
def encode_user(self, entity_lists, kg_embedding):
user_repr_list = []
for entity_list in entity_lists:
if entity_list is None:
user_repr_list.append(torch.zeros(self.user_emb_dim, device=self.device))
continue
user_repr = kg_embedding[entity_list]
user_repr = self.kg_attn(user_repr)
user_repr_list.append(user_repr)
return torch.stack(user_repr_list, dim=0) # (bs, dim)
def recommend(self, batch, mode):
context_entities, item = batch['context_entities'], batch['item']
kg_embedding = self.kg_encoder(None, self.edge_idx, self.edge_type)
user_embedding = self.encode_user(context_entities, kg_embedding)
scores = F.linear(user_embedding, kg_embedding, self.rec_bias.bias)
loss = self.rec_loss(scores, item)
return loss, scores
def _starts(self, batch_size):
"""Return bsz start tokens."""
return self.START.detach().expand(batch_size, 1)
def decode_forced(self, encoder_states, user_embedding, resp):
bsz = resp.size(0)
seqlen = resp.size(1)
inputs = resp.narrow(1, 0, seqlen - 1)
inputs = torch.cat([self._starts(bsz), inputs], 1)
latent, _ = self.decoder(inputs, encoder_states)
token_logits = F.linear(latent, self.token_embedding.weight)
user_logits = self.user_proj_2(torch.relu(self.user_proj_1(user_embedding))).unsqueeze(1)
sum_logits = token_logits + user_logits
_, preds = sum_logits.max(dim=-1)
return sum_logits, preds
def decode_greedy(self, encoder_states, user_embedding):
bsz = encoder_states[0].shape[0]
xs = self._starts(bsz)
incr_state = None
logits = []
for i in range(self.longest_label):
scores, incr_state = self.decoder(xs, encoder_states, incr_state) # incr_state is always None
scores = scores[:, -1:, :]
token_logits = F.linear(scores, self.token_embedding.weight)
user_logits = self.user_proj_2(torch.relu(self.user_proj_1(user_embedding))).unsqueeze(1)
sum_logits = token_logits + user_logits
probs, preds = sum_logits.max(dim=-1)
logits.append(scores)
xs = torch.cat([xs, preds], dim=1)
# check if everyone has generated an end token
all_finished = ((xs == self.end_token_idx).sum(dim=1) > 0).sum().item() == bsz
if all_finished:
break
logits = torch.cat(logits, 1)
return logits, xs
def decode_beam_search(self, encoder_states, user_embedding, beam=4):
bsz = encoder_states[0].shape[0]
xs = self._starts(bsz).reshape(1, bsz, -1) # (batch_size, _)
sequences = [[[list(), list(), 1.0]]] * bsz
for i in range(self.longest_label):
# at beginning there is 1 candidate, when i!=0 there are 4 candidates
if i != 0:
xs = []
for d in range(len(sequences[0])):
for j in range(bsz):
text = sequences[j][d][0]
xs.append(text)
xs = torch.stack(xs).reshape(beam, bsz, -1) # (beam, batch_size, _)
with torch.no_grad():
if i == 1:
user_embedding = user_embedding.repeat(beam, 1)
encoder_states = (encoder_states[0].repeat(beam, 1, 1),
encoder_states[1].repeat(beam, 1, 1))
scores, _ = self.decoder(xs.reshape(len(sequences[0]) * bsz, -1), encoder_states)
scores = scores[:, -1:, :]
token_logits = F.linear(scores, self.token_embedding.weight)
user_logits = self.user_proj_2(torch.relu(self.user_proj_1(user_embedding))).unsqueeze(1)
sum_logits = token_logits + user_logits
logits = sum_logits.reshape(len(sequences[0]), bsz, 1, -1)
scores = scores.reshape(len(sequences[0]), bsz, 1, -1)
logits = torch.nn.functional.softmax(logits) # turn into probabilities,in case of negative numbers
probs, preds = logits.topk(beam, dim=-1)
# (candeidate, bs, 1 , beam) during first loop, candidate=1, otherwise candidate=beam
for j in range(bsz):
all_candidates = []
for n in range(len(sequences[j])):
for k in range(beam):
prob = sequences[j][n][2]
score = sequences[j][n][1]
if score == []:
score_tmp = scores[n][j][0].unsqueeze(0)
else:
score_tmp = torch.cat((score, scores[n][j][0].unsqueeze(0)), dim=0)
seq_tmp = torch.cat((xs[n][j].reshape(-1), preds[n][j][0][k].reshape(-1)))
candidate = [seq_tmp, score_tmp, prob * probs[n][j][0][k]]
all_candidates.append(candidate)
ordered = sorted(all_candidates, key=lambda tup: tup[2], reverse=True)
sequences[j] = ordered[:beam]
# check if everyone has generated an end token
all_finished = ((xs == self.end_token_idx).sum(dim=1) > 0).sum().item() == bsz
if all_finished:
break
logits = torch.stack([seq[0][1] for seq in sequences])
xs = torch.stack([seq[0][0] for seq in sequences])
return logits, xs
def converse(self, batch, mode):
context_tokens, context_entities, response = batch['context_tokens'], batch['context_entities'], batch[
'response']
kg_embedding = self.kg_encoder(None, self.edge_idx, self.edge_type)
user_embedding = self.encode_user(context_entities, kg_embedding)
encoder_state = self.dialog_encoder(context_tokens)
if mode != 'test':
self.longest_label = max(self.longest_label, response.shape[1])
logits, preds = self.decode_forced(encoder_state, user_embedding, response)
logits = logits.view(-1, logits.shape[-1])
labels = response.view(-1)
return self.conv_loss(logits, labels), preds
else:
_, preds = self.decode_greedy(encoder_state, user_embedding)
return preds
def forward(self, batch, mode, stage):
if len(self.gpu) >= 2:
self.edge_idx = self.edge_idx.cuda(torch.cuda.current_device())
self.edge_type = self.edge_type.cuda(torch.cuda.current_device())
if stage == "conv":
return self.converse(batch, mode)
if stage == "rec":
return self.recommend(batch, mode)
def freeze_parameters(self):
freeze_models = [self.kg_encoder, self.kg_attn, self.rec_bias]
for model in freeze_models:
for p in model.parameters():
p.requires_grad = False
================================================
FILE: crslab/model/crs/kgsf/__init__.py
================================================
from .kgsf import KGSFModel
================================================
FILE: crslab/model/crs/kgsf/kgsf.py
================================================
# @Time : 2020/11/22
# @Author : Kun Zhou
# @Email : francis_kun_zhou@163.com
# UPDATE:
# @Time : 2020/11/24, 2020/12/29, 2021/1/4
# @Author : Kun Zhou, Xiaolei Wang, Yuanhang Zhou
# @Email : francis_kun_zhou@163.com, wxl1999@foxmail.com, sdzyh002@gmail.com
r"""
KGSF
====
References:
Zhou, Kun, et al. `"Improving Conversational Recommender Systems via Knowledge Graph based Semantic Fusion."`_ in KDD 2020.
.. _`"Improving Conversational Recommender Systems via Knowledge Graph based Semantic Fusion."`:
https://dl.acm.org/doi/abs/10.1145/3394486.3403143
"""
import os
import numpy as np
import torch
import torch.nn.functional as F
from loguru import logger
from torch import nn
from torch_geometric.nn import GCNConv, RGCNConv
from crslab.config import MODEL_PATH
from crslab.model.base import BaseModel
from crslab.model.utils.functions import edge_to_pyg_format
from crslab.model.utils.modules.attention import SelfAttentionSeq
from crslab.model.utils.modules.transformer import TransformerEncoder
from .modules import GateLayer, TransformerDecoderKG
from .resources import resources
class KGSFModel(BaseModel):
"""
Attributes:
vocab_size: A integer indicating the vocabulary size.
pad_token_idx: A integer indicating the id of padding token.
start_token_idx: A integer indicating the id of start token.
end_token_idx: A integer indicating the id of end token.
token_emb_dim: A integer indicating the dimension of token embedding layer.
pretrain_embedding: A string indicating the path of pretrained embedding.
n_word: A integer indicating the number of words.
n_entity: A integer indicating the number of entities.
pad_word_idx: A integer indicating the id of word padding.
pad_entity_idx: A integer indicating the id of entity padding.
num_bases: A integer indicating the number of bases.
kg_emb_dim: A integer indicating the dimension of kg embedding.
n_heads: A integer indicating the number of heads.
n_layers: A integer indicating the number of layer.
ffn_size: A integer indicating the size of ffn hidden.
dropout: A float indicating the dropout rate.
attention_dropout: A integer indicating the dropout rate of attention layer.
relu_dropout: A integer indicating the dropout rate of relu layer.
learn_positional_embeddings: A boolean indicating if we learn the positional embedding.
embeddings_scale: A boolean indicating if we use the embeddings scale.
reduction: A boolean indicating if we use the reduction.
n_positions: A integer indicating the number of position.
response_truncate = A integer indicating the longest length for response generation.
pretrained_embedding: A string indicating the path of pretrained embedding.
"""
def __init__(self, opt, device, vocab, side_data):
"""
Args:
opt (dict): A dictionary record the hyper parameters.
device (torch.device): A variable indicating which device to place the data and model.
vocab (dict): A dictionary record the vocabulary information.
side_data (dict): A dictionary record the side data.
"""
self.device = device
self.gpu = opt.get("gpu", [-1])
# vocab
self.vocab_size = vocab['vocab_size']
self.pad_token_idx = vocab['pad']
self.start_token_idx = vocab['start']
self.end_token_idx = vocab['end']
self.token_emb_dim = opt['token_emb_dim']
self.pretrained_embedding = side_data.get('embedding', None)
# kg
self.n_word = vocab['n_word']
self.n_entity = vocab['n_entity']
self.pad_word_idx = vocab['pad_word']
self.pad_entity_idx = vocab['pad_entity']
entity_kg = side_data['entity_kg']
self.n_relation = entity_kg['n_relation']
entity_edges = entity_kg['edge']
self.entity_edge_idx, self.entity_edge_type = edge_to_pyg_format(entity_edges, 'RGCN')
self.entity_edge_idx = self.entity_edge_idx.to(device)
self.entity_edge_type = self.entity_edge_type.to(device)
word_edges = side_data['word_kg']['edge']
self.word_edges = edge_to_pyg_format(word_edges, 'GCN').to(device)
self.num_bases = opt['num_bases']
self.kg_emb_dim = opt['kg_emb_dim']
# transformer
self.n_heads = opt['n_heads']
self.n_layers = opt['n_layers']
self.ffn_size = opt['ffn_size']
self.dropout = opt['dropout']
self.attention_dropout = opt['attention_dropout']
self.relu_dropout = opt['relu_dropout']
self.learn_positional_embeddings = opt['learn_positional_embeddings']
self.embeddings_scale = opt['embeddings_scale']
self.reduction = opt['reduction']
self.n_positions = opt['n_positions']
self.response_truncate = opt.get('response_truncate', 20)
# copy mask
dataset = opt['dataset']
dpath = os.path.join(MODEL_PATH, "kgsf", dataset)
resource = resources[dataset]
super(KGSFModel, self).__init__(opt, device, dpath, resource)
def build_model(self):
self._init_embeddings()
self._build_kg_layer()
self._build_infomax_layer()
self._build_recommendation_layer()
self._build_conversation_layer()
def _init_embeddings(self):
if self.pretrained_embedding is not None:
self.token_embedding = nn.Embedding.from_pretrained(
torch.as_tensor(self.pretrained_embedding, dtype=torch.float), freeze=False,
padding_idx=self.pad_token_idx)
else:
self.token_embedding = nn.Embedding(self.vocab_size, self.token_emb_dim, self.pad_token_idx)
nn.init.normal_(self.token_embedding.weight, mean=0, std=self.kg_emb_dim ** -0.5)
nn.init.constant_(self.token_embedding.weight[self.pad_token_idx], 0)
self.word_kg_embedding = nn.Embedding(self.n_word, self.kg_emb_dim, self.pad_word_idx)
nn.init.normal_(self.word_kg_embedding.weight, mean=0, std=self.kg_emb_dim ** -0.5)
nn.init.constant_(self.word_kg_embedding.weight[self.pad_word_idx], 0)
logger.debug('[Finish init embeddings]')
def _build_kg_layer(self):
# db encoder
self.entity_encoder = RGCNConv(self.n_entity, self.kg_emb_dim, self.n_relation, self.num_bases)
self.entity_self_attn = SelfAttentionSeq(self.kg_emb_dim, self.kg_emb_dim)
# concept encoder
self.word_encoder = GCNConv(self.kg_emb_dim, self.kg_emb_dim)
self.word_self_attn = SelfAttentionSeq(self.kg_emb_dim, self.kg_emb_dim)
# gate mechanism
self.gate_layer = GateLayer(self.kg_emb_dim)
logger.debug('[Finish build kg layer]')
def _build_infomax_layer(self):
self.infomax_norm = nn.Linear(self.kg_emb_dim, self.kg_emb_dim)
self.infomax_bias = nn.Linear(self.kg_emb_dim, self.n_entity)
self.infomax_loss = nn.MSELoss(reduction='sum')
logger.debug('[Finish build infomax layer]')
def _build_recommendation_layer(self):
self.rec_bias = nn.Linear(self.kg_emb_dim, self.n_entity)
self.rec_loss = nn.CrossEntropyLoss()
logger.debug('[Finish build rec layer]')
def _build_conversation_layer(self):
self.register_buffer('START', torch.tensor([self.start_token_idx], dtype=torch.long))
self.conv_encoder = TransformerEncoder(
n_heads=self.n_heads,
n_layers=self.n_layers,
embedding_size=self.token_emb_dim,
ffn_size=self.ffn_size,
vocabulary_size=self.vocab_size,
embedding=self.token_embedding,
dropout=self.dropout,
attention_dropout=self.attention_dropout,
relu_dropout=self.relu_dropout,
padding_idx=self.pad_token_idx,
learn_positional_embeddings=self.learn_positional_embeddings,
embeddings_scale=self.embeddings_scale,
reduction=self.reduction,
n_positions=self.n_positions,
)
self.conv_entity_norm = nn.Linear(self.kg_emb_dim, self.ffn_size)
self.conv_entity_attn_norm = nn.Linear(self.kg_emb_dim, self.ffn_size)
self.conv_word_norm = nn.Linear(self.kg_emb_dim, self.ffn_size)
self.conv_word_attn_norm = nn.Linear(self.kg_emb_dim, self.ffn_size)
self.copy_norm = nn.Linear(self.ffn_size * 3, self.token_emb_dim)
self.copy_output = nn.Linear(self.token_emb_dim, self.vocab_size)
self.copy_mask = torch.as_tensor(np.load(os.path.join(self.dpath, "copy_mask.npy")).astype(bool),
).to(self.device)
self.conv_decoder = TransformerDecoderKG(
self.n_heads, self.n_layers, self.token_emb_dim, self.ffn_size, self.vocab_size,
embedding=self.token_embedding,
dropout=self.dropout,
attention_dropout=self.attention_dropout,
relu_dropout=self.relu_dropout,
embeddings_scale=self.embeddings_scale,
learn_positional_embeddings=self.learn_positional_embeddings,
padding_idx=self.pad_token_idx,
n_positions=self.n_positions
)
self.conv_loss = nn.CrossEntropyLoss(ignore_index=self.pad_token_idx)
logger.debug('[Finish build conv layer]')
def pretrain_infomax(self, batch):
"""
words: (batch_size, word_length)
entity_labels: (batch_size, n_entity)
"""
words, entity_labels = batch
loss_mask = torch.sum(entity_labels)
if loss_mask.item() == 0:
return None
entity_graph_representations = self.entity_encoder(None, self.entity_edge_idx, self.entity_edge_type)
word_graph_representations = self.word_encoder(self.word_kg_embedding.weight, self.word_edges)
word_representations = word_graph_representations[words]
word_padding_mask = words.eq(self.pad_word_idx) # (bs, seq_len)
word_attn_rep = self.word_self_attn(word_representations, word_padding_mask)
word_info_rep = self.infomax_norm(word_attn_rep) # (bs, dim)
info_predict = F.linear(word_info_rep, entity_graph_representations, self.infomax_bias.bias) # (bs, #entity)
loss = self.infomax_loss(info_predict, entity_labels) / loss_mask
return loss
def recommend(self, batch, mode):
"""
context_entities: (batch_size, entity_length)
context_words: (batch_size, word_length)
movie: (batch_size)
"""
context_entities, context_words, entities, movie = batch
entity_graph_representations = self.entity_encoder(None, self.entity_edge_idx, self.entity_edge_type)
word_graph_representations = self.word_encoder(self.word_kg_embedding.weight, self.word_edges)
entity_padding_mask = context_entities.eq(self.pad_entity_idx) # (bs, entity_len)
word_padding_mask = context_words.eq(self.pad_word_idx) # (bs, word_len)
entity_representations = entity_graph_representations[context_entities]
word_representations = word_graph_representations[context_words]
entity_attn_rep = self.entity_self_attn(entity_representations, entity_padding_mask)
word_attn_rep = self.word_self_attn(word_representations, word_padding_mask)
user_rep = self.gate_layer(entity_attn_rep, word_attn_rep)
rec_scores = F.linear(user_rep, entity_graph_representations, self.rec_bias.bias) # (bs, #entity)
rec_loss = self.rec_loss(rec_scores, movie)
info_loss_mask = torch.sum(entities)
if info_loss_mask.item() == 0:
info_loss = None
else:
word_info_rep = self.infomax_norm(word_attn_rep) # (bs, dim)
info_predict = F.linear(word_info_rep, entity_graph_representations,
self.infomax_bias.bias) # (bs, #entity)
info_loss = self.infomax_loss(info_predict, entities) / info_loss_mask
return rec_loss, info_loss, rec_scores
def freeze_parameters(self):
freeze_models = [self.word_kg_embedding, self.entity_encoder, self.entity_self_attn, self.word_encoder,
self.word_self_attn, self.gate_layer, self.infomax_bias, self.infomax_norm, self.rec_bias]
for model in freeze_models:
for p in model.parameters():
p.requires_grad = False
def _starts(self, batch_size):
"""Return bsz start tokens."""
return self.START.detach().expand(batch_size, 1)
def _decode_forced_with_kg(self, token_encoding, entity_reps, entity_emb_attn, entity_mask,
word_reps, word_emb_attn, word_mask, response):
batch_size, seq_len = response.shape
start = self._starts(batch_size)
inputs = torch.cat((start, response[:, :-1]), dim=-1).long()
dialog_latent, _ = self.conv_decoder(inputs, token_encoding, word_reps, word_mask,
entity_reps, entity_mask) # (bs, seq_len, dim)
entity_latent = entity_emb_attn.unsqueeze(1).expand(-1, seq_len, -1)
word_latent = word_emb_attn.unsqueeze(1).expand(-1, seq_len, -1)
copy_latent = self.copy_norm(
torch.cat((entity_latent, word_latent, dialog_latent), dim=-1)) # (bs, seq_len, dim)
copy_logits = self.copy_output(copy_latent) * self.copy_mask.unsqueeze(0).unsqueeze(
0) # (bs, seq_len, vocab_size)
gen_logits = F.linear(dialog_latent, self.token_embedding.weight) # (bs, seq_len, vocab_size)
sum_logits = copy_logits + gen_logits
preds = sum_logits.argmax(dim=-1)
return sum_logits, preds
def _decode_greedy_with_kg(self, token_encoding, entity_reps, entity_emb_attn, entity_mask,
word_reps, word_emb_attn, word_mask):
batch_size = token_encoding[0].shape[0]
inputs = self._starts(batch_size).long()
incr_state = None
logits = []
for _ in range(self.response_truncate):
dialog_latent, incr_state = self.conv_decoder(inputs, token_encoding, word_reps, word_mask,
entity_reps, entity_mask, incr_state)
dialog_latent = dialog_latent[:, -1:, :] # (bs, 1, dim)
db_latent = entity_emb_attn.unsqueeze(1)
concept_latent = word_emb_attn.unsqueeze(1)
copy_latent = self.copy_norm(torch.cat((db_latent, concept_latent, dialog_latent), dim=-1))
copy_logits = self.copy_output(copy_latent) * self.copy_mask.unsqueeze(0).unsqueeze(0)
gen_logits = F.linear(dialog_latent, self.token_embedding.weight)
sum_logits = copy_logits + gen_logits
preds = sum_logits.argmax(dim=-1).long()
logits.append(sum_logits)
inputs = torch.cat((inputs, preds), dim=1)
finished = ((inputs == self.end_token_idx).sum(dim=-1) > 0).sum().item() == batch_size
if finished:
break
logits = torch.cat(logits, dim=1)
return logits, inputs
def _decode_beam_search_with_kg(self, token_encoding, entity_reps, entity_emb_attn, entity_mask,
word_reps, word_emb_attn, word_mask, beam=4):
batch_size = token_encoding[0].shape[0]
inputs = self._starts(batch_size).long().reshape(1, batch_size, -1)
incr_state = None
sequences = [[[list(), list(), 1.0]]] * batch_size
for i in range(self.response_truncate):
if i == 1:
token_encoding = (token_encoding[0].repeat(beam, 1, 1),
token_encoding[1].repeat(beam, 1, 1))
entity_reps = entity_reps.repeat(beam, 1, 1)
entity_emb_attn = entity_emb_attn.repeat(beam, 1)
entity_mask = entity_mask.repeat(beam, 1)
word_reps = word_reps.repeat(beam, 1, 1)
word_emb_attn = word_emb_attn.repeat(beam, 1)
word_mask = word_mask.repeat(beam, 1)
# at beginning there is 1 candidate, when i!=0 there are 4 candidates
if i != 0:
inputs = []
for d in range(len(sequences[0])):
for j in range(batch_size):
text = sequences[j][d][0]
inputs.append(text)
inputs = torch.stack(inputs).reshape(beam, batch_size, -1) # (beam, batch_size, _)
with torch.no_grad():
dialog_latent, incr_state = self.conv_decoder(
inputs.reshape(len(sequences[0]) * batch_size, -1),
token_encoding, word_reps, word_mask,
entity_reps, entity_mask, incr_state
)
dialog_latent = dialog_latent[:, -1:, :] # (bs, 1, dim)
db_latent = entity_emb_attn.unsqueeze(1)
concept_latent = word_emb_attn.unsqueeze(1)
copy_latent = self.copy_norm(torch.cat((db_latent, concept_latent, dialog_latent), dim=-1))
copy_logits = self.copy_output(copy_latent) * self.copy_mask.unsqueeze(0).unsqueeze(0)
gen_logits = F.linear(dialog_latent, self.token_embedding.weight)
sum_logits = copy_logits + gen_logits
logits = sum_logits.reshape(len(sequences[0]), batch_size, 1, -1)
# turn into probabilities,in case of negative numbers
probs, preds = torch.nn.functional.softmax(logits).topk(beam, dim=-1)
# (candeidate, bs, 1 , beam) during first loop, candidate=1, otherwise candidate=beam
for j in range(batch_size):
all_candidates = []
for n in range(len(sequences[j])):
for k in range(beam):
prob = sequences[j][n][2]
logit = sequences[j][n][1]
if logit == []:
logit_tmp = logits[n][j][0].unsqueeze(0)
else:
logit_tmp = torch.cat((logit, logits[n][j][0].unsqueeze(0)), dim=0)
seq_tmp = torch.cat((inputs[n][j].reshape(-1), preds[n][j][0][k].reshape(-1)))
candidate = [seq_tmp, logit_tmp, prob * probs[n][j][0][k]]
all_candidates.append(candidate)
ordered = sorted(all_candidates, key=lambda tup: tup[2], reverse=True)
sequences[j] = ordered[:beam]
# check if everyone has generated an end token
all_finished = ((inputs == self.end_token_idx).sum(dim=1) > 0).sum().item() == batch_size
if all_finished:
break
logits = torch.stack([seq[0][1] for seq in sequences])
inputs = torch.stack([seq[0][0] for seq in sequences])
return logits, inputs
def converse(self, batch, mode):
context_tokens, context_entities, context_words, response = batch
entity_graph_representations = self.entity_encoder(None, self.entity_edge_idx, self.entity_edge_type)
word_graph_representations = self.word_encoder(self.word_kg_embedding.weight, self.word_edges)
entity_padding_mask = context_entities.eq(self.pad_entity_idx) # (bs, entity_len)
word_padding_mask = context_words.eq(self.pad_word_idx) # (bs, seq_len)
entity_representations = entity_graph_representations[context_entities]
word_representations = word_graph_representations[context_words]
entity_attn_rep = self.entity_self_attn(entity_representations, entity_padding_mask)
word_attn_rep = self.word_self_attn(word_representations, word_padding_mask)
# encoder-decoder
tokens_encoding = self.conv_encoder(context_tokens)
conv_entity_emb = self.conv_entity_attn_norm(entity_attn_rep)
conv_word_emb = self.conv_word_attn_norm(word_attn_rep)
conv_entity_reps = self.conv_entity_norm(entity_representations)
conv_word_reps = self.conv_word_norm(word_representations)
if mode != 'test':
logits, preds = self._decode_forced_with_kg(tokens_encoding, conv_entity_reps, conv_entity_emb,
entity_padding_mask,
conv_word_reps, conv_word_emb, word_padding_mask,
response)
logits = logits.view(-1, logits.shape[-1])
response = response.view(-1)
loss = self.conv_loss(logits, response)
return loss, preds
else:
logits, preds = self._decode_greedy_with_kg(tokens_encoding, conv_entity_reps, conv_entity_emb,
entity_padding_mask,
conv_word_reps, conv_word_emb, word_padding_mask)
return preds
def forward(self, batch, stage, mode):
if len(self.gpu) >= 2:
# forward function operates on different gpus, the weight of graph network need to be copied to other gpu
self.entity_edge_idx = self.entity_edge_idx.cuda(torch.cuda.current_device())
self.entity_edge_type = self.entity_edge_type.cuda(torch.cuda.current_device())
self.word_edges = self.word_edges.cuda(torch.cuda.current_device())
self.copy_mask = torch.as_tensor(np.load(os.path.join(self.dpath, "copy_mask.npy")).astype(bool),
).cuda(torch.cuda.current_device())
if stage == "pretrain":
loss = self.pretrain_infomax(batch)
elif stage == "rec":
loss = self.recommend(batch, mode)
elif stage == "conv":
loss = self.converse(batch, mode)
return loss
================================================
FILE: crslab/model/crs/kgsf/modules.py
================================================
import numpy as np
import torch
from torch import nn as nn
from crslab.model.utils.modules.transformer import MultiHeadAttention, TransformerFFN, _create_selfattn_mask, \
_normalize, \
create_position_codes
class GateLayer(nn.Module):
def __init__(self, input_dim):
super(GateLayer, self).__init__()
self._norm_layer1 = nn.Linear(input_dim * 2, input_dim)
self._norm_layer2 = nn.Linear(input_dim, 1)
def forward(self, input1, input2):
norm_input = self._norm_layer1(torch.cat([input1, input2], dim=-1))
gate = torch.sigmoid(self._norm_layer2(norm_input)) # (bs, 1)
gated_emb = gate * input1 + (1 - gate) * input2 # (bs, dim)
return gated_emb
class TransformerDecoderLayerKG(nn.Module):
def __init__(
self,
n_heads,
embedding_size,
ffn_size,
attention_dropout=0.0,
relu_dropout=0.0,
dropout=0.0,
):
super().__init__()
self.dim = embedding_size
self.ffn_dim = ffn_size
self.dropout = nn.Dropout(p=dropout)
self.self_attention = MultiHeadAttention(
n_heads, embedding_size, dropout=attention_dropout
)
self.norm1 = nn.LayerNorm(embedding_size)
self.encoder_attention = MultiHeadAttention(
n_heads, embedding_size, dropout=attention_dropout
)
self.norm2 = nn.LayerNorm(embedding_size)
self.encoder_db_attention = MultiHeadAttention(
n_heads, embedding_size, dropout=attention_dropout
)
self.norm2_db = nn.LayerNorm(embedding_size)
self.encoder_kg_attention = MultiHeadAttention(
n_heads, embedding_size, dropout=attention_dropout
)
self.norm2_kg = nn.LayerNorm(embedding_size)
self.ffn = TransformerFFN(embedding_size, ffn_size, relu_dropout=relu_dropout)
self.norm3 = nn.LayerNorm(embedding_size)
def forward(self, x, encoder_output, encoder_mask, kg_encoder_output, kg_encoder_mask, db_encoder_output,
db_encoder_mask):
decoder_mask = _create_selfattn_mask(x)
# first self attn
residual = x
# don't peak into the future!
x = self.self_attention(query=x, mask=decoder_mask)
x = self.dropout(x) # --dropout
x = x + residual
x = _normalize(x, self.norm1)
residual = x
x = self.encoder_db_attention(
query=x,
key=db_encoder_output,
value=db_encoder_output,
mask=db_encoder_mask
)
x = self.dropout(x) # --dropout
x = residual + x
x = _normalize(x, self.norm2_db)
residual = x
x = self.encoder_kg_attention(
query=x,
key=kg_encoder_output,
value=kg_encoder_output,
mask=kg_encoder_mask
)
x = self.dropout(x) # --dropout
x = residual + x
x = _normalize(x, self.norm2_kg)
residual = x
x = self.encoder_attention(
query=x,
key=encoder_output,
value=encoder_output,
mask=encoder_mask
)
x = self.dropout(x) # --dropout
x = residual + x
x = _normalize(x, self.norm2)
# finally the ffn
residual = x
x = self.ffn(x)
x = self.dropout(x) # --dropout
x = residual + x
x = _normalize(x, self.norm3)
return x
class TransformerDecoderKG(nn.Module):
"""
Transformer Decoder layer.
:param int n_heads: the number of multihead attention heads.
:param int n_layers: number of transformer layers.
:param int embedding_size: the embedding sizes. Must be a multiple of n_heads.
:param int ffn_size: the size of the hidden layer in the FFN
:param embedding: an embedding matrix for the bottom layer of the transformer.
If none, one is created for this encoder.
:param float dropout: Dropout used around embeddings and before layer
layer normalizations. This is used in Vaswani 2017 and works well on
large datasets.
:param float attention_dropout: Dropout performed after the multhead attention
softmax. This is not used in Vaswani 2017.
:param float relu_dropout: Dropout used after the ReLU in the FFN. Not used
in Vaswani 2017, but used in Tensor2Tensor.
:param int padding_idx: Reserved padding index in the embeddings matrix.
:param bool learn_positional_embeddings: If off, sinusoidal embeddings are
used. If on, position embeddings are learned from scratch.
:param bool embeddings_scale: Scale embeddings relative to their dimensionality.
Found useful in fairseq.
:param int n_positions: Size of the position embeddings matrix.
"""
def __init__(
self,
n_heads,
n_layers,
embedding_size,
ffn_size,
vocabulary_size,
embedding,
dropout=0.0,
attention_dropout=0.0,
relu_dropout=0.0,
embeddings_scale=True,
learn_positional_embeddings=False,
padding_idx=None,
n_positions=1024,
):
super().__init__()
self.embedding_size = embedding_size
self.ffn_size = ffn_size
self.n_layers = n_layers
self.n_heads = n_heads
self.dim = embedding_size
self.embeddings_scale = embeddings_scale
self.dropout = nn.Dropout(dropout) # --dropout
self.out_dim = embedding_size
assert embedding_size % n_heads == 0, \
'Transformer embedding size must be a multiple of n_heads'
self.embeddings = embedding
# create the positional embeddings
self.position_embeddings = nn.Embedding(n_positions, embedding_size)
if not learn_positional_embeddings:
create_position_codes(
n_positions, embedding_size, out=self.position_embeddings.weight
)
else:
nn.init.normal_(self.position_embeddings.weight, 0, embedding_size ** -0.5)
# build the model
self.layers = nn.ModuleList()
for _ in range(self.n_layers):
self.layers.append(TransformerDecoderLayerKG(
n_heads, embedding_size, ffn_size,
attention_dropout=attention_dropout,
relu_dropout=relu_dropout,
dropout=dropout,
))
def forward(self, input, encoder_state, kg_encoder_output, kg_encoder_mask,
db_encoder_output, db_encoder_mask, incr_state=None):
encoder_output, encoder_mask = encoder_state
seq_len = input.size(1)
positions = input.new(seq_len).long() # (seq_len)
positions = torch.arange(seq_len, out=positions).unsqueeze(0) # (1, seq_len)
tensor = self.embeddings(input) # (bs, seq_len, embed_dim)
if self.embeddings_scale:
tensor = tensor * np.sqrt(self.dim)
tensor = tensor + self.position_embeddings(positions).expand_as(tensor)
tensor = self.dropout(tensor) # --dropout
for layer in self.layers:
tensor = layer(tensor, encoder_output, encoder_mask, kg_encoder_output, kg_encoder_mask, db_encoder_output,
db_encoder_mask)
return tensor, None
================================================
FILE: crslab/model/crs/kgsf/resources.py
================================================
# -*- encoding: utf-8 -*-
# @Time : 2020/12/13
# @Author : Xiaolei Wang
# @email : wxl1999@foxmail.com
# UPDATE
# @Time : 2020/12/15
# @Author : Xiaolei Wang
# @email : wxl1999@foxmail.com
from crslab.download import DownloadableFile
resources = {
'ReDial': {
'version': '0.2',
'file': DownloadableFile(
'https://pkueducn-my.sharepoint.com/:u:/g/personal/franciszhou_pkueducn_onmicrosoft_com/EXl2bhU82O5Itp9K4Mh41mYB69BKPEvMcKwZRstfYZUB1g?download=1',
'kgsf_redial.zip',
'f627841644a184079acde1b0185e3a223945061c3a591f4bc0d7f62e7263f548',
),
},
'TGReDial': {
'version': '0.2',
'file': DownloadableFile(
'https://pkueducn-my.sharepoint.com/:u:/g/personal/franciszhou_pkueducn_onmicrosoft_com/ETzJ0-QnguRKiKO_ktrTDZQBZHKom4-V5SJ9mhesfXzrWQ?download=1',
'kgsf_tgredial.zip',
'c9d054b653808795035f77cb783227e6e9a938e5bedca4d7f88c6dfb539be5d1',
),
},
'GoRecDial': {
'version': '0.1',
'file': DownloadableFile(
'https://pkueducn-my.sharepoint.com/:u:/g/personal/franciszhou_pkueducn_onmicrosoft_com/ER5u2yMmgDNFvHuW6lKZLEkBKZkOkxMtZGK0bBQ-jvfLNw?download=1',
'kgsf_gorecdial.zip',
'f2f57ebb8f688f38a98ee41fe3a87e9362aed945ec9078869407f799da322633',
)
},
'OpenDialKG': {
'version': '0.1',
'file': DownloadableFile(
'https://pkueducn-my.sharepoint.com/:u:/g/personal/franciszhou_pkueducn_onmicrosoft_com/EQgebOKypMlPr18KJ6uGeDABtqTbMQYVYNWNR_DaAZ1Wvg?download=1',
'kgsf_opendialkg.zip',
'89b785b23478b1d91d6ab4f34a3658e82b52dcbb73828713a9b369fa49db9e61'
)
},
'Inspired': {
'version': '0.1',
'file': DownloadableFile(
'https://pkueducn-my.sharepoint.com/:u:/g/personal/franciszhou_pkueducn_onmicrosoft_com/EXQGUxjGQ-ZKpzTnUYOMavABMUAxb0JwkiIMAPp5DIvsNw?download=1',
'kgsf_inspired.zip',
'23dfc031a3c71f2a52e29fe0183e1a501771b8d431852102ba6fd83d971f928d'
)
},
'DuRecDial': {
'version': '0.1',
'file': DownloadableFile(
'https://pkueducn-my.sharepoint.com/:u:/g/personal/franciszhou_pkueducn_onmicrosoft_com/Ed9-qLkK0bNCk5AAvJpWU3cBC-cXks-6JlclYp08AFovyw?download=1',
'kgsf_durecdial.zip',
'f9a39c2382efe88d80ef14d7db8b4cbaf3a6eb92a33e018dfc9afba546ba08ef'
)
}
}
================================================
FILE: crslab/model/crs/ntrd/__init__.py
================================================
from .ntrd import NTRDModel
================================================
FILE: crslab/model/crs/ntrd/modules.py
================================================
# @Time : 2021/10/06
# @Author : Zhipeng Zhao
# @Email : oran_official@outlook.com
import numpy as np
import torch
from torch import nn as nn
from crslab.model.utils.modules.transformer import MultiHeadAttention, TransformerFFN, _create_selfattn_mask, \
_normalize, \
create_position_codes
class GateLayer(nn.Module):
def __init__(self, input_dim):
super(GateLayer, self).__init__()
self._norm_layer1 = nn.Linear(input_dim * 2, input_dim)
self._norm_layer2 = nn.Linear(input_dim, 1)
def forward(self, input1, input2):
norm_input = self._norm_layer1(torch.cat([input1, input2], dim=-1))
gate = torch.sigmoid(self._norm_layer2(norm_input)) # (bs, 1)
gated_emb = gate * input1 + (1 - gate) * input2 # (bs, dim)
return gated_emb
class TransformerDecoderLayerKG(nn.Module):
def __init__(
self,
n_heads,
embedding_size,
ffn_size,
attention_dropout=0.0,
relu_dropout=0.0,
dropout=0.0,
):
super().__init__()
self.dim = embedding_size
self.ffn_dim = ffn_size
self.dropout = nn.Dropout(p=dropout)
self.self_attention = MultiHeadAttention(
n_heads, embedding_size, dropout=attention_dropout
)
self.norm1 = nn.LayerNorm(embedding_size)
self.encoder_attention = MultiHeadAttention(
n_heads, embedding_size, dropout=attention_dropout
)
self.norm2 = nn.LayerNorm(embedding_size)
self.encoder_db_attention = MultiHeadAttention(
n_heads, embedding_size, dropout=attention_dropout
)
self.norm2_db = nn.LayerNorm(embedding_size)
self.encoder_kg_attention = MultiHeadAttention(
n_heads, embedding_size, dropout=attention_dropout
)
self.norm2_kg = nn.LayerNorm(embedding_size)
self.ffn = TransformerFFN(embedding_size, ffn_size, relu_dropout=relu_dropout)
self.norm3 = nn.LayerNorm(embedding_size)
def forward(self, x, encoder_output, encoder_mask, kg_encoder_output, kg_encoder_mask, db_encoder_output,
db_encoder_mask):
decoder_mask = _create_selfattn_mask(x)
# first self attn
residual = x
# don't peak into the future!
x = self.self_attention(query=x, mask=decoder_mask)
x = self.dropout(x) # --dropout
x = x + residual
x = _normalize(x, self.norm1)
residual = x
x = self.encoder_db_attention(
query=x,
key=db_encoder_output,
value=db_encoder_output,
mask=db_encoder_mask
)
x = self.dropout(x) # --dropout
x = residual + x
x = _normalize(x, self.norm2_db)
residual = x
x = self.encoder_kg_attention(
query=x,
key=kg_encoder_output,
value=kg_encoder_output,
mask=kg_encoder_mask
)
x = self.dropout(x) # --dropout
x = residual + x
x = _normalize(x, self.norm2_kg)
residual = x
x = self.encoder_attention(
query=x,
key=encoder_output,
value=encoder_output,
mask=encoder_mask
)
x = self.dropout(x) # --dropout
x = residual + x
x = _normalize(x, self.norm2)
# finally the ffn
residual = x
x = self.ffn(x)
x = self.dropout(x) # --dropout
x = residual + x
x = _normalize(x, self.norm3)
return x
class TransformerDecoderLayerSelection(nn.Module):
def __init__(
self,
n_heads,
embedding_size,
ffn_size,
attention_dropout=0.0,
relu_dropout=0.0,
dropout=0.0,
):
super().__init__()
self.dim = embedding_size
self.ffn_dim = ffn_size
self.dropout = nn.Dropout(p=dropout)
self.encoder_attention = MultiHeadAttention(
n_heads, embedding_size, dropout=attention_dropout
)
self.norm1 = nn.LayerNorm(embedding_size)
self.movie_attention = MultiHeadAttention(
n_heads, embedding_size, dropout=attention_dropout
)
self.norm2 = nn.LayerNorm(embedding_size)
self.ffn = TransformerFFN(embedding_size, ffn_size, relu_dropout=relu_dropout)
self.norm3 = nn.LayerNorm(embedding_size)
def forward(self, x, encoder_output, encoder_mask, movie_embed, movie_embed_mask):
residual = x
x = self.movie_attention(
query=x,
key=movie_embed,
value=movie_embed,
mask=movie_embed_mask
)
x = self.dropout(x) # --dropout
x = residual + x
x = _normalize(x, self.norm1)
residual = x
x = self.encoder_attention(
query=x,
key=encoder_output,
value=encoder_output,
mask=encoder_mask
)
x = self.dropout(x) # --dropout
x = residual + x
x = _normalize(x, self.norm2)
# finally the ffn
residual = x
x = self.ffn(x)
x = self.dropout(x) # --dropout
x = residual + x
x = _normalize(x, self.norm3)
return x
class TransformerDecoderKG(nn.Module):
"""
Transformer Decoder layer.
:param int n_heads: the number of multihead attention heads.
:param int n_layers: number of transformer layers.
:param int embedding_size: the embedding sizes. Must be a multiple of n_heads.
:param int ffn_size: the size of the hidden layer in the FFN
:param embedding: an embedding matrix for the bottom layer of the transformer.
If none, one is created for this encoder.
:param float dropout: Dropout used around embeddings and before layer
layer normalizations. This is used in Vaswani 2017 and works well on
large datasets.
:param float attention_dropout: Dropout performed after the multhead attention
softmax. This is not used in Vaswani 2017.
:param float relu_dropout: Dropout used after the ReLU in the FFN. Not used
in Vaswani 2017, but used in Tensor2Tensor.
:param int padding_idx: Reserved padding index in the embeddings matrix.
:param bool learn_positional_embeddings: If off, sinusoidal embeddings are
used. If on, position embeddings are learned from scratch.
:param bool embeddings_scale: Scale embeddings relative to their dimensionality.
Found useful in fairseq.
:param int n_positions: Size of the position embeddings matrix.
"""
def __init__(
self,
n_heads,
n_layers,
embedding_size,
ffn_size,
vocabulary_size,
embedding,
dropout=0.0,
attention_dropout=0.0,
relu_dropout=0.0,
embeddings_scale=True,
learn_positional_embeddings=False,
padding_idx=None,
n_positions=1024,
):
super().__init__()
self.embedding_size = embedding_size
self.ffn_size = ffn_size
self.n_layers = n_layers
self.n_heads = n_heads
self.dim = embedding_size
self.embeddings_scale = embeddings_scale
self.dropout = nn.Dropout(dropout) # --dropout
self.out_dim = embedding_size
assert embedding_size % n_heads == 0, \
'Transformer embedding size must be a multiple of n_heads'
self.embeddings = embedding
# create the positional embeddings
self.position_embeddings = nn.Embedding(n_positions, embedding_size)
if not learn_positional_embeddings:
create_position_codes(
n_positions, embedding_size, out=self.position_embeddings.weight
)
else:
nn.init.normal_(self.position_embeddings.weight, 0, embedding_size ** -0.5)
# build the model
self.layers = nn.ModuleList()
for _ in range(self.n_layers):
self.layers.append(TransformerDecoderLayerKG(
n_heads, embedding_size, ffn_size,
attention_dropout=attention_dropout,
relu_dropout=relu_dropout,
dropout=dropout,
))
def forward(self, input, encoder_state, kg_encoder_output, kg_encoder_mask,
db_encoder_output, db_encoder_mask, incr_state=None):
encoder_output, encoder_mask = encoder_state
seq_len = input.size(1)
positions = input.new(seq_len).long() # (seq_len)
positions = torch.arange(seq_len, out=positions).unsqueeze(0) # (1, seq_len)
tensor = self.embeddings(input) # (bs, seq_len, embed_dim)
if self.embeddings_scale:
tensor = tensor * np.sqrt(self.dim)
tensor = tensor + self.position_embeddings(positions).expand_as(tensor)
tensor = self.dropout(tensor) # --dropout
for layer in self.layers:
tensor = layer(tensor, encoder_output, encoder_mask, kg_encoder_output, kg_encoder_mask, db_encoder_output,
db_encoder_mask)
return tensor, None
class TransformerDecoderSelection(nn.Module):
def __init__(
self,
n_heads,
n_layers,
embedding_size,
ffn_size,
vocabulary_size,
# embedding,
dropout=0.0,
attention_dropout=0.0,
relu_dropout=0.0,
embeddings_scale=True,
learn_positional_embeddings=False,
padding_idx=None,
n_positions=1024,
):
super().__init__()
self.embedding_size = embedding_size
self.ffn_size = ffn_size
self.n_layers = n_layers
self.n_heads = n_heads
self.dim = embedding_size
self.embeddings_scale = embeddings_scale
self.dropout = nn.Dropout(p=dropout) # --dropout
self.out_dim = embedding_size
assert embedding_size % n_heads == 0, \
'Transformer embedding size must be a multiple of n_heads'
# build the model
self.layers = nn.ModuleList()
for _ in range(self.n_layers):
self.layers.append(TransformerDecoderLayerSelection(
n_heads, embedding_size, ffn_size,
attention_dropout=attention_dropout,
relu_dropout=relu_dropout,
dropout=dropout,
))
def forward(self, input, encoder_state,movie_embed,movie_embed_mask,incr_state=None):
encoder_output,encoder_mask = encoder_state
tensor = input # -- No dropout
for layer in self.layers:
tensor = layer(tensor,encoder_output,encoder_mask,movie_embed,movie_embed_mask)
return tensor, None
================================================
FILE: crslab/model/crs/ntrd/ntrd.py
================================================
# -*- encoding: utf-8 -*-
# @Time : 2021/10/1
# @Author : Zhipeng Zhao
# @email : oran_official@outlook.com
r"""
NTRD
====
References:
Liang, Zujie, et al. `"Learning Neural Templates for Recommender Dialogue System."`_ in EMNLP 2021.
.. _`"Learning Neural Templates for Recommender Dialogue System."`:
https://arxiv.org/pdf/2109.12302.pdf
"""
import os
import numpy as np
import torch
import torch.nn.functional as F
from loguru import logger
from torch import nn
from torch_geometric.nn import GCNConv, RGCNConv
from crslab.config import MODEL_PATH
from crslab.model.base import BaseModel
from crslab.model.utils.functions import edge_to_pyg_format
from crslab.model.utils.modules.attention import SelfAttentionSeq
from crslab.model.utils.modules.transformer import TransformerEncoder
from .modules import GateLayer, TransformerDecoderKG,TransformerDecoderSelection
from .resources import resources
class NTRDModel(BaseModel):
def __init__(self, opt, device, vocab, side_data):
"""
Args:
opt (dict): A dictionary record the hyper parameters.
device (torch.device): A variable indicating which device to place the data and model.
vocab (dict): A dictionary record the vocabulary information.
side_data (dict): A dictionary record the side data.
"""
self.device = device
self.gpu = opt.get("gpu", [-1])
# vocab
self.vocab_size = vocab['vocab_size']
self.pad_token_idx = vocab['pad']
self.start_token_idx = vocab['start']
self.end_token_idx = vocab['end']
self.token_emb_dim = opt['token_emb_dim']
self.pretrained_embedding = side_data.get('embedding', None)
self.replace_token = opt.get('replace_token',None)
self.replace_token_idx = vocab[self.replace_token]
# kg
self.n_word = vocab['n_word']
self.n_entity = vocab['n_entity']
self.pad_word_idx = vocab['pad_word']
self.pad_entity_idx = vocab['pad_entity']
entity_kg = side_data['entity_kg']
self.n_relation = entity_kg['n_relation']
entity_edges = entity_kg['edge']
self.entity_edge_idx, self.entity_edge_type = edge_to_pyg_format(entity_edges, 'RGCN')
self.entity_edge_idx = self.entity_edge_idx.to(device)
self.entity_edge_type = self.entity_edge_type.to(device)
word_edges = side_data['word_kg']['edge']
self.word_edges = edge_to_pyg_format(word_edges, 'GCN').to(device)
self.num_bases = opt['num_bases']
self.kg_emb_dim = opt['kg_emb_dim']
# transformer
self.n_heads = opt['n_heads']
self.n_layers = opt['n_layers']
self.ffn_size = opt['ffn_size']
self.dropout = opt['dropout']
self.attention_dropout = opt['attention_dropout']
self.relu_dropout = opt['relu_dropout']
self.learn_positional_embeddings = opt['learn_positional_embeddings']
self.embeddings_scale = opt['embeddings_scale']
self.reduction = opt['reduction']
self.n_positions = opt['n_positions']
self.response_truncate = opt.get('response_truncate', 20)
# selector
self.n_movies = opt['n_movies']
# self.n_movies_label = opt['n_movies_label']
self.n_movies_label = 64362 # the number of entity2id
# copy mask
dataset = opt['dataset']
dpath = os.path.join(MODEL_PATH, "kgsf", dataset)
resource = resources[dataset]
# loss weight
self.gen_loss_weight = opt['gen_loss_weight']
super(NTRDModel, self).__init__(opt, device, dpath, resource)
def build_model(self):
self._init_embeddings()
self._build_kg_layer()
self._build_infomax_layer()
self._build_recommendation_layer()
self._build_conversation_layer()
self._build_movie_selector()
def _init_embeddings(self):
if self.pretrained_embedding is not None:
self.token_embedding = nn.Embedding.from_pretrained(
torch.as_tensor(self.pretrained_embedding, dtype=torch.float), freeze=False,
padding_idx=self.pad_token_idx)
else:
self.token_embedding = nn.Embedding(self.vocab_size, self.token_emb_dim, self.pad_token_idx)
nn.init.normal_(self.token_embedding.weight, mean=0, std=self.kg_emb_dim ** -0.5)
nn.init.constant_(self.token_embedding.weight[self.pad_token_idx], 0)
self.word_kg_embedding = nn.Embedding(self.n_word, self.kg_emb_dim, self.pad_word_idx)
nn.init.normal_(self.word_kg_embedding.weight, mean=0, std=self.kg_emb_dim ** -0.5)
nn.init.constant_(self.word_kg_embedding.weight[self.pad_word_idx], 0)
logger.debug('[Finish init embeddings]')
def _build_kg_layer(self):
# db encoder
self.entity_encoder = RGCNConv(self.n_entity, self.kg_emb_dim, self.n_relation, self.num_bases)
self.entity_self_attn = SelfAttentionSeq(self.kg_emb_dim, self.kg_emb_dim)
# concept encoder
self.word_encoder = GCNConv(self.kg_emb_dim, self.kg_emb_dim)
self.word_self_attn = SelfAttentionSeq(self.kg_emb_dim, self.kg_emb_dim)
# gate mechanism
self.gate_layer = GateLayer(self.kg_emb_dim)
logger.debug('[Finish build kg layer]')
def _build_infomax_layer(self):
self.infomax_norm = nn.Linear(self.kg_emb_dim, self.kg_emb_dim)
self.infomax_bias = nn.Linear(self.kg_emb_dim, self.n_entity)
self.infomax_loss = nn.MSELoss(reduction='sum')
logger.debug('[Finish build infomax layer]')
def _build_recommendation_layer(self):
self.rec_bias = nn.Linear(self.kg_emb_dim, self.n_entity)
self.rec_loss = nn.CrossEntropyLoss()
logger.debug('[Finish build rec layer]')
def _build_conversation_layer(self):
self.register_buffer('START', torch.tensor([self.start_token_idx], dtype=torch.long))
self.conv_encoder = TransformerEncoder(
n_heads=self.n_heads,
n_layers=self.n_layers,
embedding_size=self.token_emb_dim,
ffn_size=self.ffn_size,
vocabulary_size=self.vocab_size,
embedding=self.token_embedding,
dropout=self.dropout,
attention_dropout=self.attention_dropout,
relu_dropout=self.relu_dropout,
padding_idx=self.pad_token_idx,
learn_positional_embeddings=self.learn_positional_embeddings,
embeddings_scale=self.embeddings_scale,
reduction=self.reduction,
n_positions=self.n_positions,
)
self.conv_entity_norm = nn.Linear(self.kg_emb_dim, self.ffn_size)
self.conv_entity_attn_norm = nn.Linear(self.kg_emb_dim, self.ffn_size)
self.conv_word_norm = nn.Linear(self.kg_emb_dim, self.ffn_size)
self.conv_word_attn_norm = nn.Linear(self.kg_emb_dim, self.ffn_size)
self.copy_norm = nn.Linear(self.ffn_size * 3, self.token_emb_dim)
self.copy_output = nn.Linear(self.token_emb_dim, self.vocab_size)
copy_mask = np.load(os.path.join(self.dpath, "copy_mask.npy")).astype(bool)
if self.replace_token:
if self.replace_token_idx < len(copy_mask):
copy_mask[self.replace_token_idx] = False
else:
copy_mask = np.insert(copy_mask,len(copy_mask),False)
self.copy_mask = torch.as_tensor(copy_mask).to(self.device)
self.conv_decoder = TransformerDecoderKG(
self.n_heads, self.n_layers, self.token_emb_dim, self.ffn_size, self.vocab_size,
embedding=self.token_embedding,
dropout=self.dropout,
attention_dropout=self.attention_dropout,
relu_dropout=self.relu_dropout,
embeddings_scale=self.embeddings_scale,
learn_positional_embeddings=self.learn_positional_embeddings,
padding_idx=self.pad_token_idx,
n_positions=self.n_positions
)
self.conv_loss = nn.CrossEntropyLoss(ignore_index=self.pad_token_idx)
logger.debug('[Finish build conv layer]')
def pretrain_infomax(self, batch):
"""
words: (batch_size, word_length)
entity_labels: (batch_size, n_entity)
"""
words, entity_labels = batch
loss_mask = torch.sum(entity_labels)
if loss_mask.item() == 0:
return None
entity_graph_representations = self.entity_encoder(None, self.entity_edge_idx, self.entity_edge_type)
word_graph_representations = self.word_encoder(self.word_kg_embedding.weight, self.word_edges)
word_representations = word_graph_representations[words]
word_padding_mask = words.eq(self.pad_word_idx) # (bs, seq_len)
word_attn_rep = self.word_self_attn(word_representations, word_padding_mask)
word_info_rep = self.infomax_norm(word_attn_rep) # (bs, dim)
info_predict = F.linear(word_info_rep, entity_graph_representations, self.infomax_bias.bias) # (bs, #entity)
loss = self.infomax_loss(info_predict, entity_labels) / loss_mask
return loss
def _build_movie_selector(self):
self.movie_selector = TransformerDecoderSelection(
n_heads=self.n_heads,
n_layers=self.n_layers,
embedding_size=self.token_emb_dim,
ffn_size=self.ffn_size,
vocabulary_size=self.n_movies_label,
# embedding=self.token_embedding,
dropout=self.dropout,
attention_dropout=self.attention_dropout,
relu_dropout=self.relu_dropout,
padding_idx=self.pad_token_idx,
learn_positional_embeddings=self.learn_positional_embeddings,
embeddings_scale=self.embeddings_scale,
n_positions=self.n_positions,
)
self.matching_linear = nn.Linear(self.token_emb_dim,self.n_movies_label)
self.sel_loss = nn.CrossEntropyLoss(ignore_index=self.pad_token_idx)
def recommend(self, batch, mode):
"""
context_entities: (batch_size, entity_length)
context_words: (batch_size, word_length)
movie: (batch_size)
"""
context_entities, context_words, entities, movie = batch
entity_graph_representations = self.entity_encoder(None, self.entity_edge_idx, self.entity_edge_type)
word_graph_representations = self.word_encoder(self.word_kg_embedding.weight, self.word_edges)
entity_padding_mask = context_entities.eq(self.pad_entity_idx) # (bs, entity_len)
word_padding_mask = context_words.eq(self.pad_word_idx) # (bs, word_len)
entity_representations = entity_graph_representations[context_entities]
word_representations = word_graph_representations[context_words]
entity_attn_rep = self.entity_self_attn(entity_representations, entity_padding_mask)
word_attn_rep = self.word_self_attn(word_representations, word_padding_mask)
user_rep = self.gate_layer(entity_attn_rep, word_attn_rep)
rec_scores = F.linear(user_rep, entity_graph_representations, self.rec_bias.bias) # (bs, #entity)
rec_loss = self.rec_loss(rec_scores, movie)
info_loss_mask = torch.sum(entities)
if info_loss_mask.item() == 0:
info_loss = None
else:
word_info_rep = self.infomax_norm(word_attn_rep) # (bs, dim)
info_predict = F.linear(word_info_rep, entity_graph_representations,
self.infomax_bias.bias) # (bs, #entity)
info_loss = self.infomax_loss(info_predict, entities) / info_loss_mask
return rec_loss, info_loss, rec_scores
def freeze_parameters(self):
freeze_models = [self.word_kg_embedding, self.entity_encoder, self.entity_self_attn, self.word_encoder,
self.word_self_attn, self.gate_layer, self.infomax_bias, self.infomax_norm, self.rec_bias]
for model in freeze_models:
for p in model.parameters():
p.requires_grad = False
def _starts(self, batch_size):
"""Return bsz start tokens."""
return self.START.detach().expand(batch_size, 1)
def converse(self, batch, mode):
context_tokens, context_entities, context_words, response, all_movies = batch
entity_graph_representations = self.entity_encoder(None, self.entity_edge_idx, self.entity_edge_type)
word_graph_representations = self.word_encoder(self.word_kg_embedding.weight, self.word_edges)
entity_padding_mask = context_entities.eq(self.pad_entity_idx) # (bs, entity_len)
word_padding_mask = context_words.eq(self.pad_word_idx) # (bs, seq_len)
entity_representations = entity_graph_representations[context_entities]
word_representations = word_graph_representations[context_words]
entity_attn_rep = self.entity_self_attn(entity_representations, entity_padding_mask)
word_attn_rep = self.word_self_attn(word_representations, word_padding_mask)
# encoder-decoder
tokens_encoding = self.conv_encoder(context_tokens)
conv_entity_emb = self.conv_entity_attn_norm(entity_attn_rep)
conv_word_emb = self.conv_word_attn_norm(word_attn_rep)
conv_entity_reps = self.conv_entity_norm(entity_representations)
conv_word_reps = self.conv_word_norm(word_representations)
if mode != 'test':
logits, preds,latent = self._decode_forced_with_kg(tokens_encoding, conv_entity_reps, conv_entity_emb,
entity_padding_mask,
conv_word_reps, conv_word_emb, word_padding_mask,
response)
logits_ = logits.view(-1, logits.shape[-1])
response_ = response.view(-1)
gen_loss = self.conv_loss(logits_, response_)
assert torch.sum(all_movies!=0, dim=(0,1)) == torch.sum((response == 30000), dim=(0,1)) #30000 means the idx of [ITEM]
masked_for_selection_token = (response == self.replace_token_idx)
matching_tensor,_ = self.movie_selector(latent,tokens_encoding,conv_word_reps,word_padding_mask)
matching_logits_ = self.matching_linear(matching_tensor)
matching_logits = torch.masked_select(matching_logits_, masked_for_selection_token.unsqueeze(-1).expand_as(matching_logits_)).view(-1, matching_logits_.shape[-1])
all_movies = torch.masked_select(all_movies,(all_movies != 0))
matching_logits = matching_logits.view(-1,matching_logits.shape[-1])
all_movies = all_movies.view(-1)
selection_loss = self.sel_loss(matching_logits,all_movies)
return gen_loss,selection_loss, preds
else:
logits, preds,latent = self._decode_greedy_with_kg(tokens_encoding, conv_entity_reps, conv_entity_emb,
entity_padding_mask,
conv_word_reps, conv_word_emb, word_padding_mask)
preds_for_selection = preds[:, 1:] # skip the start_ind
masked_for_selection_token = (preds_for_selection == self.replace_token_idx)
matching_tensor,_ = self.movie_selector(latent,tokens_encoding,conv_word_reps,word_padding_mask)
matching_logits_ = self.matching_linear(matching_tensor)
matching_logits = torch.masked_select(matching_logits_, masked_for_selection_token.unsqueeze(-1).expand_as(matching_logits_)).view(-1, matching_logits_.shape[-1])
if matching_logits.shape[0] is not 0:
#W1: greedy
_, matching_pred = matching_logits.max(dim=-1) # [bsz * dynamic_movie_nums]
else:
matching_pred = None
return preds,matching_pred,matching_logits_
def _decode_greedy_with_kg(self, token_encoding, entity_reps, entity_emb_attn, entity_mask,
word_reps, word_emb_attn, word_mask):
batch_size = token_encoding[0].shape[0]
inputs = self._starts(batch_size).long()
incr_state = None
logits = []
latents = []
for _ in range(self.response_truncate):
dialog_latent, incr_state = self.conv_decoder(inputs, token_encoding, word_reps, word_mask,
entity_reps, entity_mask, incr_state)
dialog_latent = dialog_latent[:, -1:, :] # (bs, 1, dim)
latents.append(dialog_latent)
db_latent = entity_emb_attn.unsqueeze(1)
concept_latent = word_emb_attn.unsqueeze(1)
copy_latent = self.copy_norm(torch.cat((db_latent, concept_latent, dialog_latent), dim=-1))
copy_logits = self.copy_output(copy_latent) * self.copy_mask.unsqueeze(0).unsqueeze(0)
gen_logits = F.linear(dialog_latent, self.token_embedding.weight)
sum_logits = copy_logits + gen_logits
preds = sum_logits.argmax(dim=-1).long()
logits.append(sum_logits)
inputs = torch.cat((inputs, preds), dim=1)
finished = ((inputs == self.end_token_idx).sum(dim=-1) > 0).sum().item() == batch_size
if finished:
break
logits = torch.cat(logits, dim=1)
latents = torch.cat(latents, dim=1)
return logits, inputs, latents
def _decode_forced_with_kg(self, token_encoding, entity_reps, entity_emb_attn, entity_mask,
word_reps, word_emb_attn, word_mask, response):
batch_size, seq_len = response.shape
start = self._starts(batch_size)
inputs = torch.cat((start, response[:, :-1]), dim=-1).long()
dialog_latent, _ = self.conv_decoder(inputs, token_encoding, word_reps, word_mask,
entity_reps, entity_mask) # (bs, seq_len, dim)
entity_latent = entity_emb_attn.unsqueeze(1).expand(-1, seq_len, -1)
word_latent = word_emb_attn.unsqueeze(1).expand(-1, seq_len, -1)
copy_latent = self.copy_norm(
torch.cat((entity_latent, word_latent, dialog_latent), dim=-1)) # (bs, seq_len, dim)
copy_logits = self.copy_output(copy_latent) * self.copy_mask.unsqueeze(0).unsqueeze(
0) # (bs, seq_len, vocab_size)
gen_logits = F.linear(dialog_latent, self.token_embedding.weight) # (bs, seq_len, vocab_size)
sum_logits = copy_logits + gen_logits
preds = sum_logits.argmax(dim=-1)
return sum_logits, preds, dialog_latent
def forward(self, batch, stage, mode):
if len(self.gpu) >= 2:
# forward function operates on different gpus, the weight of graph network need to be copied to other gpu
self.entity_edge_idx = self.entity_edge_idx.cuda(torch.cuda.current_device())
self.entity_edge_type = self.entity_edge_type.cuda(torch.cuda.current_device())
self.word_edges = self.word_edges.cuda(torch.cuda.current_device())
self.copy_mask = torch.as_tensor(np.load(os.path.join(self.dpath, "copy_mask.npy")).astype(bool),
).cuda(torch.cuda.current_device())
if stage == "pretrain":
loss = self.pretrain_infomax(batch)
elif stage == "rec":
loss = self.recommend(batch, mode)
elif stage == "conv":
loss = self.converse(batch, mode)
return loss
================================================
FILE: crslab/model/crs/ntrd/resources.py
================================================
# -*- encoding: utf-8 -*-
# @Time : 2020/12/13
# @Author : Xiaolei Wang
# @email : wxl1999@foxmail.com
# UPDATE
# @Time : 2020/12/15
# @Author : Xiaolei Wang
# @email : wxl1999@foxmail.com
from crslab.download import DownloadableFile
resources = {
'ReDial': {
'version': '0.2',
'file': DownloadableFile(
'https://pkueducn-my.sharepoint.com/:u:/g/personal/franciszhou_pkueducn_onmicrosoft_com/EXl2bhU82O5Itp9K4Mh41mYB69BKPEvMcKwZRstfYZUB1g?download=1',
'kgsf_redial.zip',
'f627841644a184079acde1b0185e3a223945061c3a591f4bc0d7f62e7263f548',
),
},
'TGReDial': {
'version': '0.2',
'file': DownloadableFile(
'https://pkueducn-my.sharepoint.com/:u:/g/personal/franciszhou_pkueducn_onmicrosoft_com/ETzJ0-QnguRKiKO_ktrTDZQBZHKom4-V5SJ9mhesfXzrWQ?download=1',
'kgsf_tgredial.zip',
'c9d054b653808795035f77cb783227e6e9a938e5bedca4d7f88c6dfb539be5d1',
),
},
'GoRecDial': {
'version': '0.1',
'file': DownloadableFile(
'https://pkueducn-my.sharepoint.com/:u:/g/personal/franciszhou_pkueducn_onmicrosoft_com/ER5u2yMmgDNFvHuW6lKZLEkBKZkOkxMtZGK0bBQ-jvfLNw?download=1',
'kgsf_gorecdial.zip',
'f2f57ebb8f688f38a98ee41fe3a87e9362aed945ec9078869407f799da322633',
)
},
'OpenDialKG': {
'version': '0.1',
'file': DownloadableFile(
'https://pkueducn-my.sharepoint.com/:u:/g/personal/franciszhou_pkueducn_onmicrosoft_com/EQgebOKypMlPr18KJ6uGeDABtqTbMQYVYNWNR_DaAZ1Wvg?download=1',
'kgsf_opendialkg.zip',
'89b785b23478b1d91d6ab4f34a3658e82b52dcbb73828713a9b369fa49db9e61'
)
},
'Inspired': {
'version': '0.1',
'file': DownloadableFile(
'https://pkueducn-my.sharepoint.com/:u:/g/personal/franciszhou_pkueducn_onmicrosoft_com/EXQGUxjGQ-ZKpzTnUYOMavABMUAxb0JwkiIMAPp5DIvsNw?download=1',
'kgsf_inspired.zip',
'23dfc031a3c71f2a52e29fe0183e1a501771b8d431852102ba6fd83d971f928d'
)
},
'DuRecDial': {
'version': '0.1',
'file': DownloadableFile(
'https://pkueducn-my.sharepoint.com/:u:/g/personal/franciszhou_pkueducn_onmicrosoft_com/Ed9-qLkK0bNCk5AAvJpWU3cBC-cXks-6JlclYp08AFovyw?download=1',
'kgsf_durecdial.zip',
'f9a39c2382efe88d80ef14d7db8b4cbaf3a6eb92a33e018dfc9afba546ba08ef'
)
}
}
================================================
FILE: crslab/model/crs/redial/__init__.py
================================================
from .redial_conv import ReDialConvModel
from .redial_rec import ReDialRecModel
================================================
FILE: crslab/model/crs/redial/modules.py
================================================
# @Time : 2020/12/4
# @Author : Chenzhan Shang
# @Email : czshang@outlook.com
# UPDATE:
# @Time : 2020/12/16
# @Author : Xiaolei Wang
# @Email : wxl1999@foxmail.com
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.nn.utils.rnn import pad_packed_sequence, pack_padded_sequence
from crslab.model.utils.functions import sort_for_packed_sequence
class HRNN(nn.Module):
def __init__(self,
utterance_encoder_hidden_size,
dialog_encoder_hidden_size,
dialog_encoder_num_layers,
pad_token_idx,
embedding=None,
use_dropout=False,
dropout=0.3):
super(HRNN, self).__init__()
self.pad_token_idx = pad_token_idx
# embedding
self.embedding_size = embedding.weight.shape[1]
self.embedding = embedding
# utterance encoder
self.utterance_encoder_hidden_size = utterance_encoder_hidden_size
self.utterance_encoder = nn.GRU(
input_size=self.embedding_size,
hidden_size=self.utterance_encoder_hidden_size,
batch_first=True,
bidirectional=True
)
# conversation encoder
self.dialog_encoder = nn.GRU(
input_size=(2 * self.utterance_encoder_hidden_size),
hidden_size=dialog_encoder_hidden_size,
num_layers=dialog_encoder_num_layers,
batch_first=True
)
# dropout
self.use_dropout = use_dropout
if self.use_dropout:
self.dropout = nn.Dropout(p=dropout)
def get_utterance_encoding(self, context, utterance_lengths):
"""
:param context: (batch_size, max_conversation_length, max_utterance_length)
:param utterance_lengths: (batch_size, max_conversation_length)
:return utterance_encoding: (batch_size, max_conversation_length, 2 * utterance_encoder_hidden_size)
"""
batch_size, max_conv_length = context.shape[:2]
utterance_lengths = utterance_lengths.reshape(-1) # (bs * conv_len)
sorted_lengths, sorted_idx, rev_idx = sort_for_packed_sequence(utterance_lengths)
# reshape and reorder
sorted_utterances = context.view(batch_size * max_conv_length, -1).index_select(0, sorted_idx)
# consider valid sequences only(length > 0)
num_positive_lengths = torch.sum(utterance_lengths > 0)
sorted_utterances = sorted_utterances[:num_positive_lengths]
sorted_lengths = sorted_lengths[:num_positive_lengths]
embedded = self.embedding(sorted_utterances)
if self.use_dropout:
embedded = self.dropout(embedded)
packed_utterances = pack_padded_sequence(embedded, sorted_lengths, batch_first=True)
_, utterance_encoding = self.utterance_encoder(packed_utterances)
# concat the hidden states of the last layer (two directions of the GRU)
utterance_encoding = torch.cat((utterance_encoding[-1], utterance_encoding[-2]), 1)
if self.use_dropout:
utterance_encoding = self.dropout(utterance_encoding)
# complete the missing sequences (of length 0)
if num_positive_lengths < batch_size * max_conv_length:
pad_tensor = utterance_encoding.new_full(
(batch_size * max_conv_length - num_positive_lengths, 2 * self.utterance_encoder_hidden_size),
self.pad_token_idx)
utterance_encoding = torch.cat((utterance_encoding, pad_tensor), 0)
# retrieve original utterance order and Reshape to separate contexts
utterance_encoding = utterance_encoding.index_select(0, rev_idx)
utterance_encoding = utterance_encoding.view(batch_size, max_conv_length,
2 * self.utterance_encoder_hidden_size)
return utterance_encoding
def forward(self, context, utterance_lengths, dialog_lengths):
"""
:param context: (batch_size, max_context_length, max_utterance_length)
:param utterance_lengths: (batch_size, max_context_length)
:param dialog_lengths: (batch_size)
:return context_state: (batch_size, context_encoder_hidden_size)
"""
utterance_encoding = self.get_utterance_encoding(context, utterance_lengths) # (bs, conv_len, 2 * utt_dim)
sorted_lengths, sorted_idx, rev_idx = sort_for_packed_sequence(dialog_lengths)
# reorder in decreasing sequence length
sorted_representations = utterance_encoding.index_select(0, sorted_idx)
packed_sequences = pack_padded_sequence(sorted_representations, sorted_lengths, batch_first=True)
_, context_state = self.dialog_encoder(packed_sequences)
context_state = context_state.index_select(1, rev_idx)
if self.use_dropout:
context_state = self.dropout(context_state)
return context_state[-1]
class SwitchingDecoder(nn.Module):
def __init__(self, hidden_size, context_size, num_layers, vocab_size, embedding, pad_token_idx):
super(SwitchingDecoder, self).__init__()
self.pad_token_idx = pad_token_idx
self.hidden_size = hidden_size
self.context_size = context_size
self.num_layers = num_layers
if context_size != hidden_size:
raise ValueError("The context size {} must match the hidden size {} in DecoderGRU".format(
context_size, hidden_size))
self.embedding = embedding
embedding_dim = embedding.weight.shape[1]
self.decoder = nn.GRU(input_size=embedding_dim, hidden_size=hidden_size,
num_layers=num_layers, batch_first=True)
self.out = nn.Linear(hidden_size, vocab_size)
self.switch = nn.Linear(hidden_size + context_size, 1)
def forward(self, request, request_lengths, context_state):
"""
:param request: (batch_size, max_utterance_length)
:param request_lengths: (batch_size)
:param context_state: (batch_size, context_encoder_hidden_size)
:return log_probabilities: (batch_size, max_utterance_length, vocab_size + 1)
"""
batch_size, max_utterance_length = request.shape
# sort for pack
sorted_lengths, sorted_idx, rev_idx = sort_for_packed_sequence(request_lengths)
sorted_request = request.index_select(0, sorted_idx)
embedded_request = self.embedding(sorted_request) # (batch_size, max_utterance_length, embed_dim)
packed_request = pack_padded_sequence(embedded_request, sorted_lengths, batch_first=True)
sorted_context_state = context_state.index_select(0, sorted_idx)
h_0 = sorted_context_state.unsqueeze(0).expand(
self.num_layers, batch_size, self.hidden_size
).contiguous() # require context_size == hidden_size
sorted_vocab_state, _ = self.decoder(packed_request, h_0)
sorted_vocab_state, _ = pad_packed_sequence(sorted_vocab_state,
batch_first=True) # (batch_size, max_request_length, decoder_hidden_size)
_, max_request_length, decoder_hidden_size = sorted_vocab_state.shape
pad_tensor = sorted_vocab_state.new_full(
(batch_size, max_utterance_length - max_request_length, decoder_hidden_size), self.pad_token_idx)
sorted_vocab_state = torch.cat((sorted_vocab_state, pad_tensor),
dim=1) # (batch_size, max_utterance_length, decoder_hidden_size)
sorted_language_output = self.out(sorted_vocab_state) # (batch_size, max_utterance_length, vocab_size)
# expand context to each time step
expanded_sorted_context_state = sorted_context_state.unsqueeze(1).expand(
batch_size, max_utterance_length, self.context_size
).contiguous() # (batch_size, max_utterance_length, context_size)
# compute switch
switch_input = torch.cat((expanded_sorted_context_state, sorted_vocab_state),
dim=2) # (batch_size, max_utterance_length, context_size + decoder_hidden_size)
switch = self.switch(switch_input) # (batch_size, max_utterance_length, 1)
sorted_output = torch.cat((
F.logsigmoid(switch) + F.log_softmax(sorted_language_output, dim=2),
F.logsigmoid(-switch) # for item
), dim=2)
output = sorted_output.index_select(0, rev_idx) # (batch_size, max_utterance_length, vocab_size + 1)
return output
================================================
FILE: crslab/model/crs/redial/redial_conv.py
================================================
# @Time : 2020/12/4
# @Author : Chenzhan Shang
# @Email : czshang@outlook.com
# UPDATE
# @Time : 2020/12/29, 2021/1/4
# @Author : Xiaolei Wang, Yuanhang Zhou
# @email : wxl1999@foxmail.com, sdzyh002@gmail.com
r"""
ReDial_Conv
===========
References:
Li, Raymond, et al. `"Towards deep conversational recommendations."`_ in NeurIPS.
.. _`"Towards deep conversational recommendations."`:
https://papers.nips.cc/paper/2018/hash/800de15c79c8d840f4e78d3af937d4d4-Abstract.html
"""
import torch
from torch import nn
from crslab.model.base import BaseModel
from .modules import HRNN, SwitchingDecoder
class ReDialConvModel(BaseModel):
"""
Attributes:
vocab_size: A integer indicating the vocabulary size.
pad_token_idx: A integer indicating the id of padding token.
start_token_idx: A integer indicating the id of start token.
end_token_idx: A integer indicating the id of end token.
unk_token_idx: A integer indicating the id of unk token.
pretrained_embedding: A string indicating the path of pretrained embedding.
embedding_dim: A integer indicating the dimension of item embedding.
utterance_encoder_hidden_size: A integer indicating the size of hidden size in utterance encoder.
dialog_encoder_hidden_size: A integer indicating the size of hidden size in dialog encoder.
dialog_encoder_num_layers: A integer indicating the number of layers in dialog encoder.
use_dropout: A boolean indicating if we use the dropout.
dropout: A float indicating the dropout rate.
decoder_hidden_size: A integer indicating the size of hidden size in decoder.
decoder_num_layers: A integer indicating the number of layer in decoder.
decoder_embedding_dim: A integer indicating the dimension of embedding in decoder.
"""
def __init__(self, opt, device, vocab, side_data):
"""
Args:
opt (dict): A dictionary record the hyper parameters.
device (torch.device): A variable indicating which device to place the data and model.
vocab (dict): A dictionary record the vocabulary information.
side_data (dict): A dictionary record the side data.
"""
# dataset
self.vocab_size = vocab['vocab_size']
self.pad_token_idx = vocab['pad']
self.start_token_idx = vocab['start']
self.end_token_idx = vocab['end']
self.unk_token_idx = vocab['unk']
self.pretrained_embedding = side_data.get('embedding', None)
self.embedding_dim = opt.get('embedding_dim', None)
if opt.get('embedding', None) and self.embedding_dim is None:
raise
# HRNN
self.utterance_encoder_hidden_size = opt['utterance_encoder_hidden_size']
self.dialog_encoder_hidden_size = opt['dialog_encoder_hidden_size']
self.dialog_encoder_num_layers = opt['dialog_encoder_num_layers']
self.use_dropout = opt['use_dropout']
self.dropout = opt['dropout']
# SwitchingDecoder
self.decoder_hidden_size = opt['decoder_hidden_size']
self.decoder_num_layers = opt['decoder_num_layers']
self.decoder_embedding_dim = opt['decoder_embedding_dim']
super(ReDialConvModel, self).__init__(opt, device)
def build_model(self):
if self.opt.get('embedding', None) and self.pretrained_embedding is not None:
embedding = nn.Embedding.from_pretrained(
torch.as_tensor(self.pretrained_embedding, dtype=torch.float), freeze=False,
padding_idx=self.pad_token_idx)
else:
embedding = nn.Embedding(self.vocab_size, self.embedding_dim)
self.encoder = HRNN(
embedding=embedding,
utterance_encoder_hidden_size=self.utterance_encoder_hidden_size,
dialog_encoder_hidden_size=self.dialog_encoder_hidden_size,
dialog_encoder_num_layers=self.dialog_encoder_num_layers,
use_dropout=self.use_dropout,
dropout=self.dropout,
pad_token_idx=self.pad_token_idx
)
self.decoder = SwitchingDecoder(
hidden_size=self.decoder_hidden_size,
context_size=self.dialog_encoder_hidden_size,
num_layers=self.decoder_num_layers,
vocab_size=self.vocab_size,
embedding=embedding,
pad_token_idx=self.pad_token_idx
)
self.loss = nn.CrossEntropyLoss(ignore_index=self.pad_token_idx)
def forward(self, batch, mode):
"""
Args:
batch: ::
{
'context': (batch_size, max_context_length, max_utterance_length),
'context_lengths': (batch_size),
'utterance_lengths': (batch_size, max_context_length),
'request': (batch_size, max_utterance_length),
'request_lengths': (batch_size),
'response': (batch_size, max_utterance_length)
}
"""
assert mode in ('train', 'valid', 'test')
if mode == 'train':
self.train()
else:
self.eval()
context = batch['context']
utterance_lengths = batch['utterance_lengths']
context_lengths = batch['context_lengths']
context_state = self.encoder(context, utterance_lengths,
context_lengths) # (batch_size, context_encoder_hidden_size)
request = batch['request']
request_lengths = batch['request_lengths']
log_probs = self.decoder(request, request_lengths,
context_state) # (batch_size, max_utterance_length, vocab_size + 1)
preds = log_probs.argmax(dim=-1) # (batch_size, max_utterance_length)
log_probs = log_probs.view(-1, log_probs.shape[-1])
response = batch['response'].view(-1)
loss = self.loss(log_probs, response)
return loss, preds
================================================
FILE: crslab/model/crs/redial/redial_rec.py
================================================
# @Time : 2020/12/4
# @Author : Chenzhan Shang
# @Email : czshang@outlook.com
# UPDATE
# @Time : 2020/12/29, 2021/1/4
# @Author : Xiaolei Wang, Yuanhang Zhou
# @email : wxl1999@foxmail.com, sdzyh002@gmail.com
r"""
ReDial_Rec
==========
References:
Li, Raymond, et al. `"Towards deep conversational recommendations."`_ in NeurIPS.
.. _`"Towards deep conversational recommendations."`:
https://papers.nips.cc/paper/2018/hash/800de15c79c8d840f4e78d3af937d4d4-Abstract.html
"""
import torch.nn as nn
from crslab.model.base import BaseModel
class ReDialRecModel(BaseModel):
"""
Attributes:
n_entity: A integer indicating the number of entities.
layer_sizes: A integer indicating the size of layer in autorec.
pad_entity_idx: A integer indicating the id of entity padding.
"""
def __init__(self, opt, device, vocab, side_data):
"""
Args:
opt (dict): A dictionary record the hyper parameters.
device (torch.device): A variable indicating which device to place the data and model.
vocab (dict): A dictionary record the vocabulary information.
side_data (dict): A dictionary record the side data.
"""
self.n_entity = vocab['n_entity']
self.layer_sizes = opt['autorec_layer_sizes']
self.pad_entity_idx = vocab['pad_entity']
super(ReDialRecModel, self).__init__(opt, device)
def build_model(self):
# AutoRec
if self.opt['autorec_f'] == 'identity':
self.f = lambda x: x
elif self.opt['autorec_f'] == 'sigmoid':
self.f = nn.Sigmoid()
elif self.opt['autorec_f'] == 'relu':
self.f = nn.ReLU()
else:
raise ValueError("Got invalid function name for f : {}".format(self.opt['autorec_f']))
if self.opt['autorec_g'] == 'identity':
self.g = lambda x: x
elif self.opt['autorec_g'] == 'sigmoid':
self.g = nn.Sigmoid()
elif self.opt['autorec_g'] == 'relu':
self.g = nn.ReLU()
else:
raise ValueError("Got invalid function name for g : {}".format(self.opt['autorec_g']))
self.encoder = nn.ModuleList([nn.Linear(self.n_entity, self.layer_sizes[0]) if i == 0
else nn.Linear(self.layer_sizes[i - 1], self.layer_sizes[i])
for i in range(len(self.layer_sizes))])
self.user_repr_dim = self.layer_sizes[-1]
self.decoder = nn.Linear(self.user_repr_dim, self.n_entity)
self.loss = nn.CrossEntropyLoss()
def forward(self, batch, mode):
"""
Args:
batch: ::
{
'context_entities': (batch_size, n_entity),
'item': (batch_size)
}
mode (str)
"""
context_entities = batch['context_entities']
for i, layer in enumerate(self.encoder):
context_entities = self.f(layer(context_entities))
scores = self.g(self.decoder(context_entities))
loss = self.loss(scores, batch['item'])
return loss, scores
================================================
FILE: crslab/model/crs/tgredial/__init__.py
================================================
from .tg_conv import TGConvModel
from .tg_policy import TGPolicyModel
from .tg_rec import TGRecModel
================================================
FILE: crslab/model/crs/tgredial/tg_conv.py
================================================
# @Time : 2020/12/9
# @Author : Yuanhang Zhou
# @Email : sdzyh002@gmail.com
# UPDATE:
# @Time : 2021/1/7, 2020/12/15, 2021/1/4
# @Author : Xiaolei Wang, Yuanhang Zhou, Yuanhang Zhou
# @Email : wxl1999@foxmail.com, sdzyh002@gmail, sdzyh002@gmail.com
r"""
TGReDial_Conv
=============
References:
Zhou, Kun, et al. `"Towards Topic-Guided Conversational Recommender System."`_ in COLING 2020.
.. _`"Towards Topic-Guided Conversational Recommender System."`:
https://www.aclweb.org/anthology/2020.coling-main.365/
"""
import os
import torch
from torch.nn import CrossEntropyLoss
from transformers import GPT2LMHeadModel
from crslab.config import PRETRAIN_PATH
from crslab.data import dataset_language_map
from crslab.model.base import BaseModel
from crslab.model.pretrained_models import resources
class TGConvModel(BaseModel):
"""
Attributes:
context_truncate: A integer indicating the length of dialogue context.
response_truncate: A integer indicating the length of dialogue response.
pad_id: A integer indicating the id of padding token.
"""
def __init__(self, opt, device, vocab, side_data):
"""
Args:
opt (dict): A dictionary record the hyper parameters.
device (torch.device): A variable indicating which device to place the data and model.
vocab (dict): A dictionary record the vocabulary information.
side_data (dict): A dictionary record the side data.
"""
self.context_truncate = opt['context_truncate']
self.response_truncate = opt['response_truncate']
self.pad_id = vocab['pad']
language = dataset_language_map[opt['dataset']]
resource = resources['gpt2'][language]
dpath = os.path.join(PRETRAIN_PATH, 'gpt2', language)
super(TGConvModel, self).__init__(opt, device, dpath, resource)
def build_model(self):
"""build model"""
self.model = GPT2LMHeadModel.from_pretrained(self.dpath)
self.loss = CrossEntropyLoss(ignore_index=self.pad_id)
def forward(self, batch, mode):
if mode == 'test' or mode == 'infer':
enhanced_context = batch[1]
return self.generate(enhanced_context)
else:
enhanced_input_ids = batch[0]
# torch.tensor's shape = (bs, seq_len, v_s); tuple's length = 12
lm_logits = self.model(enhanced_input_ids).logits
# index from 1 to self.reponse_truncate is valid response
loss = self.calculate_loss(
lm_logits[:, -self.response_truncate:-1, :],
enhanced_input_ids[:, -self.response_truncate + 1:])
pred = torch.max(lm_logits, dim=2)[1] # [bs, seq_len]
pred = pred[:, -self.response_truncate:]
return loss, pred
def generate(self, context):
"""
Args:
context: torch.tensor, shape=(bs, context_turncate)
Returns:
generated_response: torch.tensor, shape=(bs, reponse_turncate-1)
"""
generated_response = []
former_hidden_state = None
context = context[..., -self.response_truncate + 1:]
for i in range(self.response_truncate - 1):
outputs = self.model(context, former_hidden_state) # (bs, c_t, v_s),
last_hidden_state, former_hidden_state = outputs.logits, outputs.past_key_values
next_token_logits = last_hidden_state[:, -1, :] # (bs, v_s)
preds = next_token_logits.argmax(dim=-1).long() # (bs)
context = preds.unsqueeze(1)
generated_response.append(preds)
generated_response = torch.stack(generated_response).T
return generated_response
def generate_bs(self, context, beam=4):
context = context[..., -self.response_truncate + 1:]
context_former = context
batch_size = context.shape[0]
sequences = [[[list(), 1.0]]] * batch_size
for i in range(self.response_truncate - 1):
if sequences != [[[list(), 1.0]]] * batch_size:
context = []
for i in range(batch_size):
for cand in sequences[i]:
text = torch.cat(
(context_former[i], torch.tensor(cand[0]).to(self.device))) # 由于取消了state,与之前的context拼接
context.append(text)
context = torch.stack(context)
with torch.no_grad():
outputs = self.model(context)
last_hidden_state, state = outputs.logits, outputs.past_key_values
next_token_logits = last_hidden_state[:, -1, :]
next_token_probs = torch.nn.functional.softmax(next_token_logits)
topk = torch.topk(next_token_probs, beam, dim=-1)
probs = topk.values.reshape([batch_size, -1, beam]) # (bs, candidate, beam)
preds = topk.indices.reshape([batch_size, -1, beam]) # (bs, candidate, beam)
for j in range(batch_size):
all_candidates = []
for n in range(len(sequences[j])):
for k in range(beam):
seq = sequences[j][n][0]
prob = sequences[j][n][1]
seq_tmp = seq.copy()
seq_tmp.append(preds[j][n][k])
candidate = [seq_tmp, prob * probs[j][n][k]]
all_candidates.append(candidate)
ordered = sorted(all_candidates, key=lambda tup: tup[1], reverse=True)
sequences[j] = ordered[:beam]
res = []
for i in range(batch_size):
res.append(torch.stack(sequences[i][0][0]))
res = torch.stack(res)
return res
def calculate_loss(self, logit, labels):
"""
Args:
preds: torch.FloatTensor, shape=(bs, response_truncate, vocab_size)
labels: torch.LongTensor, shape=(bs, response_truncate)
"""
loss = self.loss(logit.reshape(-1, logit.size(-1)), labels.reshape(-1))
return loss
================================================
FILE: crslab/model/crs/tgredial/tg_policy.py
================================================
# @Time : 2020/12/9
# @Author : Yuanhang Zhou
# @Email : sdzyh002@gmail.com
# UPDATE:
# @Time : 2021/1/7, 2020/12/15, 2021/1/4
# @Author : Xiaolei Wang, Yuanhang Zhou, Yuanhang Zhou
# @Email : wxl1999@foxmail.com, sdzyh002@gmail, sdzyh002@gmail.com
r"""
TGReDial_Policy
===============
References:
Zhou, Kun, et al. `"Towards Topic-Guided Conversational Recommender System."`_ in COLING 2020.
.. _`"Towards Topic-Guided Conversational Recommender System."`:
https://www.aclweb.org/anthology/2020.coling-main.365/
"""
import os
import torch
from torch import nn
from transformers import BertModel
from crslab.config import PRETRAIN_PATH
from crslab.data import dataset_language_map
from crslab.model.base import BaseModel
from crslab.model.pretrained_models import resources
class TGPolicyModel(BaseModel):
def __init__(self, opt, device, vocab, side_data):
"""
Args:
opt (dict): A dictionary record the hyper parameters.
device (torch.device): A variable indicating which device to place the data and model.
vocab (dict): A dictionary record the vocabulary information.
side_data (dict): A dictionary record the side data.
"""
self.topic_class_num = vocab['n_topic']
self.n_sent = opt.get('n_sent', 10)
language = dataset_language_map[opt['dataset']]
resource = resources['bert'][language]
dpath = os.path.join(PRETRAIN_PATH, "bert", language)
super(TGPolicyModel, self).__init__(opt, device, dpath, resource)
def build_model(self, *args, **kwargs):
"""build model"""
self.context_bert = BertModel.from_pretrained(self.dpath)
self.topic_bert = BertModel.from_pretrained(self.dpath)
self.profile_bert = BertModel.from_pretrained(self.dpath)
self.bert_hidden_size = self.context_bert.config.hidden_size
self.state2topic_id = nn.Linear(self.bert_hidden_size * 3,
self.topic_class_num)
self.loss = nn.CrossEntropyLoss()
def forward(self, batch, mode):
# conv_id, message_id, context, context_mask, topic_path_kw, tp_mask, user_profile, profile_mask, y = batch
context, context_mask, topic_path_kw, tp_mask, user_profile, profile_mask, y = batch
context_rep = self.context_bert(
context,
context_mask).pooler_output # (bs, hidden_size)
topic_rep = self.topic_bert(
topic_path_kw,
tp_mask).pooler_output # (bs, hidden_size)
bs = user_profile.shape[0] // self.n_sent
profile_rep = self.profile_bert(user_profile, profile_mask).pooler_output # (bs, word_num, hidden)
profile_rep = profile_rep.view(bs, self.n_sent, -1)
profile_rep = torch.mean(profile_rep, dim=1) # (bs, hidden)
state_rep = torch.cat((context_rep, topic_rep, profile_rep), dim=1) # [bs, hidden_size*3]
topic_scores = self.state2topic_id(state_rep)
topic_loss = self.loss(topic_scores, y)
return topic_loss, topic_scores
================================================
FILE: crslab/model/crs/tgredial/tg_rec.py
================================================
# @Time : 2020/12/9
# @Author : Yuanhang Zhou
# @Email : sdzyh002@gmail.com
# UPDATE:
# @Time : 2021/1/7, 2021/1/4
# @Author : Xiaolei Wang, Yuanhang Zhou
# @Email : wxl1999@foxmail.com, sdzyh002@gmail.com
r"""
TGReDial_Rec
============
References:
Zhou, Kun, et al. `"Towards Topic-Guided Conversational Recommender System."`_ in COLING 2020.
.. _`"Towards Topic-Guided Conversational Recommender System."`:
https://www.aclweb.org/anthology/2020.coling-main.365/
"""
import os
import torch
from loguru import logger
from torch import nn
from transformers import BertModel
from crslab.config import PRETRAIN_PATH
from crslab.data import dataset_language_map
from crslab.model.base import BaseModel
from crslab.model.pretrained_models import resources
from crslab.model.recommendation.sasrec.modules import SASRec
class TGRecModel(BaseModel):
"""
Attributes:
hidden_dropout_prob: A float indicating the dropout rate to dropout hidden state in SASRec.
initializer_range: A float indicating the range of parameters initization in SASRec.
hidden_size: A integer indicating the size of hidden state in SASRec.
max_seq_length: A integer indicating the max interaction history length.
item_size: A integer indicating the number of items.
num_attention_heads: A integer indicating the head number in SASRec.
attention_probs_dropout_prob: A float indicating the dropout rate in attention layers.
hidden_act: A string indicating the activation function type in SASRec.
num_hidden_layers: A integer indicating the number of hidden layers in SASRec.
"""
def __init__(self, opt, device, vocab, side_data):
"""
Args:
opt (dict): A dictionary record the hyper parameters.
device (torch.device): A variable indicating which device to place the data and model.
vocab (dict): A dictionary record the vocabulary information.
side_data (dict): A dictionary record the side data.
"""
self.hidden_dropout_prob = opt['hidden_dropout_prob']
self.initializer_range = opt['initializer_range']
self.hidden_size = opt['hidden_size']
self.max_seq_length = opt['max_history_items']
self.item_size = vocab['n_entity'] + 1
self.num_attention_heads = opt['num_attention_heads']
self.attention_probs_dropout_prob = opt['attention_probs_dropout_prob']
self.hidden_act = opt['hidden_act']
self.num_hidden_layers = opt['num_hidden_layers']
language = dataset_language_map[opt['dataset']]
resource = resources['bert'][language]
dpath = os.path.join(PRETRAIN_PATH, "bert", language)
super(TGRecModel, self).__init__(opt, device, dpath, resource)
def build_model(self):
# build BERT layer, give the architecture, load pretrained parameters
self.bert = BertModel.from_pretrained(self.dpath)
self.bert_hidden_size = self.bert.config.hidden_size
self.concat_embed_size = self.bert_hidden_size + self.hidden_size
self.fusion = nn.Linear(self.concat_embed_size, self.item_size)
self.SASREC = SASRec(self.hidden_dropout_prob, self.device,
self.initializer_range, self.hidden_size,
self.max_seq_length, self.item_size,
self.num_attention_heads,
self.attention_probs_dropout_prob,
self.hidden_act, self.num_hidden_layers)
# this loss may conduct to some weakness
self.rec_loss = nn.CrossEntropyLoss()
logger.debug('[Finish build rec layer]')
def forward(self, batch, mode):
context, mask, input_ids, target_pos, input_mask, sample_negs, y = batch
bert_embed = self.bert(context, attention_mask=mask).pooler_output
sequence_output = self.SASREC(input_ids, input_mask) # bs, max_len, hidden_size2
sas_embed = sequence_output[:, -1, :] # bs, hidden_size2
embed = torch.cat((sas_embed, bert_embed), dim=1)
rec_scores = self.fusion(embed) # bs, item_size
if mode == 'infer':
return rec_scores
else:
rec_loss = self.rec_loss(rec_scores, y)
return rec_loss, rec_scores
================================================
FILE: crslab/model/policy/__init__.py
================================================
from .conv_bert import ConvBERTModel
from .mgcg import MGCGModel
from .pmi import PMIModel
from .profile_bert import ProfileBERTModel
from .topic_bert import TopicBERTModel
================================================
FILE: crslab/model/policy/conv_bert/__init__.py
================================================
from .conv_bert import ConvBERTModel
================================================
FILE: crslab/model/policy/conv_bert/conv_bert.py
================================================
# @Time : 2020/12/17
# @Author : Yuanhang Zhou
# @Email : sdzyh002@gmail
# UPDATE
# @Time : 2021/1/7, 2021/1/4
# @Author : Xiaolei Wang, Yuanhang Zhou
# @email : wxl1999@foxmail.com, sdzyh002@gmail.com
r"""
Conv_BERT
=========
References:
Zhou, Kun, et al. `"Towards Topic-Guided Conversational Recommender System."`_ in COLING 2020.
.. _`"Towards Topic-Guided Conversational Recommender System."`:
https://www.aclweb.org/anthology/2020.coling-main.365/
"""
import os
from torch import nn
from transformers import BertModel
from crslab.config import PRETRAIN_PATH
from crslab.data import dataset_language_map
from crslab.model.base import BaseModel
from ...pretrained_models import resources
class ConvBERTModel(BaseModel):
"""
Attributes:
topic_class_num: the number of topic.
"""
def __init__(self, opt, device, vocab, side_data):
"""
Args:
opt (dict): A dictionary record the hyper parameters.
device (torch.device): A variable indicating which device to place the data and model.
vocab (dict): A dictionary record the vocabulary information.
side_data (dict): A dictionary record the side data.
"""
self.topic_class_num = vocab['n_topic']
language = dataset_language_map[opt['dataset']]
resource = resources['bert'][language]
dpath = os.path.join(PRETRAIN_PATH, "bert", language)
super(ConvBERTModel, self).__init__(opt, device, dpath, resource)
def build_model(self, *args, **kwargs):
"""build model"""
self.context_bert = BertModel.from_pretrained(self.dpath)
self.bert_hidden_size = self.context_bert.config.hidden_size
self.state2topic_id = nn.Linear(self.bert_hidden_size,
self.topic_class_num)
self.loss = nn.CrossEntropyLoss()
def forward(self, batch, mode):
# conv_id, message_id, context, context_mask, topic_path_kw, tp_mask, user_profile, profile_mask, y = batch
context, context_mask, topic_path_kw, tp_mask, user_profile, profile_mask, y = batch
context_rep = self.context_bert(
context,
context_mask).pooler_output # [bs, hidden_size]
topic_scores = self.state2topic_id(context_rep)
topic_loss = self.loss(topic_scores, y)
return topic_loss, topic_scores
================================================
FILE: crslab/model/policy/mgcg/__init__.py
================================================
from .mgcg import MGCGModel
================================================
FILE: crslab/model/policy/mgcg/mgcg.py
================================================
# @Time : 2020/12/17
# @Author : Yuanhang Zhou
# @Email : sdzyh002@gmail
# UPDATE
# @Time : 2020/12/29, 2021/1/4
# @Author : Xiaolei Wang, Yuanhang Zhou
# @email : wxl1999@foxmail.com, sdzyh002@gmail.com
r"""
MGCG
====
References:
Liu, Zeming, et al. `"Towards Conversational Recommendation over Multi-Type Dialogs."`_ in ACL 2020.
.. _"Towards Conversational Recommendation over Multi-Type Dialogs.":
https://www.aclweb.org/anthology/2020.acl-main.98/
"""
import torch
from torch import nn
from torch.nn.utils.rnn import pack_padded_sequence
from crslab.model.base import BaseModel
class MGCGModel(BaseModel):
"""
Attributes:
topic_class_num: A integer indicating the number of topic.
vocab_size: A integer indicating the size of vocabulary.
embedding_dim: A integer indicating the dimension of embedding layer.
hidden_size: A integer indicating the size of hidden state.
num_layers: A integer indicating the number of layers in GRU.
dropout_hidden: A float indicating the dropout rate of hidden state.
n_sent: A integer indicating sequence length in user profile.
"""
def __init__(self, opt, device, vocab, side_data):
"""
Args:
opt (dict): A dictionary record the hyper parameters.
device (torch.device): A variable indicating which device to place the data and model.
vocab (dict): A dictionary record the vocabulary information.
side_data (dict): A dictionary record the side data.
"""
self.topic_class_num = vocab['n_topic']
self.vocab_size = vocab['vocab_size']
self.embedding_dim = opt['embedding_dim']
self.hidden_size = opt['hidden_size']
self.num_layers = opt['num_layers']
self.dropout_hidden = opt['dropout_hidden']
self.n_sent = opt.get('n_sent', 10)
super(MGCGModel, self).__init__(opt, device)
def build_model(self, *args, **kwargs):
"""build model"""
self.embeddings = nn.Embedding(self.vocab_size, self.embedding_dim)
self.context_lstm = nn.LSTM(self.embedding_dim,
self.hidden_size,
self.num_layers,
dropout=self.dropout_hidden,
batch_first=True)
self.topic_lstm = nn.LSTM(self.embedding_dim,
self.hidden_size,
self.num_layers,
dropout=self.dropout_hidden,
batch_first=True)
self.profile_lstm = nn.LSTM(self.embedding_dim,
self.hidden_size,
self.num_layers,
dropout=self.dropout_hidden,
batch_first=True)
self.state2topic_id = nn.Linear(self.hidden_size * 3,
self.topic_class_num)
self.loss = nn.CrossEntropyLoss()
def get_length(self, input):
return [torch.sum((ids != 0).long()).item() for ids in input]
def forward(self, batch, mode):
# conv_id, message_id, context, context_mask, topic_path_kw, tp_mask, user_profile, profile_mask, y = batch
context, context_mask, topic_path_kw, tp_mask, user_profile, profile_mask, y = batch
len_context = self.get_length(context)
len_tp = self.get_length(topic_path_kw)
len_profile = self.get_length(user_profile)
bs_, word_num = user_profile.shape
bs = bs_ // self.n_sent
context = self.embeddings(context)
topic_path_kw = self.embeddings(topic_path_kw)
user_profile = self.embeddings(user_profile)
context = pack_padded_sequence(context,
len_context,
enforce_sorted=False,
batch_first=True)
topic_path_kw = pack_padded_sequence(topic_path_kw,
len_tp,
enforce_sorted=False,
batch_first=True)
user_profile = pack_padded_sequence(user_profile,
len_profile,
enforce_sorted=False,
batch_first=True)
init_h0 = (torch.zeros(self.num_layers, bs,
self.hidden_size).to(self.device),
torch.zeros(self.num_layers, bs,
self.hidden_size).to(self.device))
# batch, seq_len, num_directions * hidden_size # num_layers * num_directions, batch, hidden_size
context_output, (context_h, _) = self.context_lstm(context, init_h0)
topic_output, (topic_h, _) = self.topic_lstm(topic_path_kw, init_h0)
# batch*sent_num, seq_len, num_directions * hidden_size
init_h0 = (torch.zeros(self.num_layers, bs * self.n_sent,
self.hidden_size).to(self.device),
torch.zeros(self.num_layers, bs * self.n_sent,
self.hidden_size).to(self.device))
profile_output, (profile_h,
_) = self.profile_lstm(user_profile, init_h0)
# batch, hidden_size
context_rep = context_h[-1]
topic_rep = topic_h[-1]
profile_rep = profile_h[-1]
profile_rep = profile_rep.view(bs, self.n_sent, -1)
# batch, hidden_size
profile_rep = torch.mean(profile_rep, dim=1)
state_rep = torch.cat((context_rep, topic_rep, profile_rep), 1)
topic_scores = self.state2topic_id(state_rep)
topic_loss = self.loss(topic_scores, y)
return topic_loss, topic_scores
================================================
FILE: crslab/model/policy/pmi/__init__.py
================================================
from .pmi import PMIModel
================================================
FILE: crslab/model/policy/pmi/pmi.py
================================================
# @Time : 2020/12/17
# @Author : Yuanhang Zhou
# @Email : sdzyh002@gmail
# UPDATE
# @Time : 2020/12/29, 2021/1/4
# @Author : Xiaolei Wang, Yuanhang Zhou
# @email : wxl1999@foxmail.com, sdzyh002@gmail.com
r"""
PMI
===
"""
from collections import defaultdict
import torch
from crslab.model.base import BaseModel
class PMIModel(BaseModel):
"""
Attributes:
topic_class_num: A integer indicating the number of topic.
pad_topic: A integer indicating the id of topic padding.
"""
def __init__(self, opt, device, vocab, side_data):
"""
Args:
opt (dict): A dictionary record the hyper parameters.
device (torch.device): A variable indicating which device to place the data and model.
vocab (dict): A dictionary record the vocabulary information.
side_data (dict): A dictionary record the side data.
"""
self.topic_class_num = vocab['n_topic']
self.pad_topic = vocab['pad_topic']
super(PMIModel, self).__init__(opt, device)
def build_model(self, *args, **kwargs):
"""build model"""
self.topic_to_num = defaultdict(int)
self.t2gram_to_num = defaultdict(int)
self.last_topic_to_target_topic = defaultdict(int)
def forward(self, batch, mode):
# conv_id, message_id, context, context_mask, topic_path_kw, tp_mask, user_profile, profile_mask, y = batch
context, context_mask, topic_path_kw, tp_mask, user_profile, profile_mask, target = batch
if mode == 'train':
for topic_path in topic_path_kw:
topic_path = [topic_id.item() for topic_id in topic_path if topic_id.item() != self.pad_topic]
for topic in topic_path:
self.topic_to_num[topic] += 1
for i in range(1, len(topic_path)):
self.t2gram_to_num[(topic_path[i - 1], topic_path[i])] += 1
self.last_topic_to_target_topic[(topic_path[-1], target[0])] += 1
test_last_topic_to_target_topic = defaultdict(int)
for topic_path in topic_path_kw:
topic_path = [topic_id.item() for topic_id in topic_path if topic_id.item() != self.pad_topic]
test_last_topic_to_target_topic[(topic_path[-1], target[0])] += 1
total_1_gram = sum(self.topic_to_num.values())
total_2_gram = sum(self.t2gram_to_num.values())
p_1_gram = {topic: num / total_1_gram for topic, num in self.topic_to_num.items()}
p_2_gram = {topic_tuple: num / total_2_gram for topic_tuple, num in self.t2gram_to_num.items()}
topic_scores = []
for (last_topic, target_topic), num in test_last_topic_to_target_topic.items():
candidate_topic_to_PMI = {}
for cnad_topic in self.topic_to_num:
if (last_topic, cnad_topic) in p_2_gram:
candidate_topic_to_PMI[cnad_topic] = p_2_gram.get((last_topic, cnad_topic), 0) / (
p_1_gram.get(last_topic, 0) * p_1_gram.get(cnad_topic, 0))
top_cand = dict(sorted(candidate_topic_to_PMI.items(), key=lambda x: x[1], reverse=True))
# top_cand = [topic for topic, num in top_cand]
topic_scores.append([top_cand.get(topic_id, 0) for topic_id in range(self.topic_class_num)])
return None, torch.tensor(topic_scores, dtype=torch.long)
================================================
FILE: crslab/model/policy/profile_bert/__init__.py
================================================
from .profile_bert import ProfileBERTModel
================================================
FILE: crslab/model/policy/profile_bert/profile_bert.py
================================================
# @Time : 2020/12/17
# @Author : Yuanhang Zhou
# @Email : sdzyh002@gmail
# UPDATE
# @Time : 2021/1/7, 2021/1/4
# @Author : Xiaolei Wang, Yuanhang Zhou
# @email : wxl1999@foxmail.com, sdzyh002@gmail.com
r"""
Profile_BERT
============
References:
Zhou, Kun, et al. `"Towards Topic-Guided Conversational Recommender System."`_ in COLING 2020.
.. _`"Towards Topic-Guided Conversational Recommender System."`:
https://www.aclweb.org/anthology/2020.coling-main.365/
"""
import os
import torch
from torch import nn
from transformers import BertModel
from crslab.config import PRETRAIN_PATH
from crslab.data import dataset_language_map
from crslab.model.base import BaseModel
from crslab.model.pretrained_models import resources
class ProfileBERTModel(BaseModel):
"""
Attributes:
topic_class_num: A integer indicating the number of topic.
n_sent: A integer indicating sequence length in user profile.
"""
def __init__(self, opt, device, vocab, side_data):
"""
Args:
opt (dict): A dictionary record the hyper parameters.
device (torch.device): A variable indicating which device to place the data and model.
vocab (dict): A dictionary record the vocabulary information.
side_data (dict): A dictionary record the side data.
"""
self.topic_class_num = vocab['n_topic']
self.n_sent = opt.get('n_sent', 10)
language = dataset_language_map[opt['dataset']]
resource = resources['bert'][language]
dpath = os.path.join(PRETRAIN_PATH, "bert", language)
super(ProfileBERTModel, self).__init__(opt, device, dpath, resource)
def build_model(self, *args, **kwargs):
"""build model"""
self.profile_bert = BertModel.from_pretrained(self.dpath)
self.bert_hidden_size = self.profile_bert.config.hidden_size
self.state2topic_id = nn.Linear(self.bert_hidden_size,
self.topic_class_num)
self.loss = nn.CrossEntropyLoss()
def forward(self, batch, mode):
# conv_id, message_id, context, context_mask, topic_path_kw, tp_mask, user_profile, profile_mask, y = batch
context, context_mask, topic_path_kw, tp_mask, user_profile, profile_mask, y = batch
bs = user_profile.size(0) // self.n_sent
profile_rep = self.profile_bert(
user_profile, profile_mask).pooler_output # (bs, word_num, hidden)
profile_rep = profile_rep.view(bs, self.n_sent, -1)
profile_rep = torch.mean(profile_rep, dim=1) # (bs, hidden)
topic_scores = self.state2topic_id(profile_rep)
topic_loss = self.loss(topic_scores, y)
return topic_loss, topic_scores
================================================
FILE: crslab/model/policy/topic_bert/__init__.py
================================================
from .topic_bert import TopicBERTModel
================================================
FILE: crslab/model/policy/topic_bert/topic_bert.py
================================================
# @Time : 2020/12/17
# @Author : Yuanhang Zhou
# @Email : sdzyh002@gmail
# UPDATE
# @Time : 2021/1/7, 2021/1/4
# @Author : Xiaolei Wang, Yuanhang Zhou
# @email : wxl1999@foxmail.com, sdzyh002@gmail.com
r"""
Topic_BERT
==========
References:
Zhou, Kun, et al. `"Towards Topic-Guided Conversational Recommender System."`_ in COLING 2020.
.. _`"Towards Topic-Guided Conversational Recommender System."`:
https://www.aclweb.org/anthology/2020.coling-main.365/
"""
import os
from torch import nn
from transformers import BertModel
from crslab.config import PRETRAIN_PATH
from crslab.data import dataset_language_map
from crslab.model.base import BaseModel
from crslab.model.pretrained_models import resources
class TopicBERTModel(BaseModel):
"""
Attributes:
topic_class_num: A integer indicating the number of topic.
"""
def __init__(self, opt, device, vocab, side_data):
"""
Args:
opt (dict): A dictionary record the hyper parameters.
device (torch.device): A variable indicating which device to place the data and model.
vocab (dict): A dictionary record the vocabulary information.
side_data (dict): A dictionary record the side data.
"""
self.topic_class_num = vocab['n_topic']
language = dataset_language_map[opt['dataset']]
dpath = os.path.join(PRETRAIN_PATH, "bert", language)
resource = resources['bert'][language]
super(TopicBERTModel, self).__init__(opt, device, dpath, resource)
def build_model(self, *args, **kwargs):
"""build model"""
self.topic_bert = BertModel.from_pretrained(self.dpath)
self.bert_hidden_size = self.topic_bert.config.hidden_size
self.state2topic_id = nn.Linear(self.bert_hidden_size,
self.topic_class_num)
self.loss = nn.CrossEntropyLoss()
def forward(self, batch, mode):
# conv_id, message_id, context, context_mask, topic_path_kw, tp_mask, user_profile, profile_mask, y = batch
context, context_mask, topic_path_kw, tp_mask, user_profile, profile_mask, y = batch
topic_rep = self.topic_bert(
topic_path_kw,
tp_mask).pooler_output # (bs, hidden_size)
topic_scores = self.state2topic_id(topic_rep)
topic_loss = self.loss(topic_scores, y)
return topic_loss, topic_scores
================================================
FILE: crslab/model/pretrained_models.py
================================================
# -*- encoding: utf-8 -*-
# @Time : 2021/1/6
# @Author : Xiaolei Wang
# @email : wxl1999@foxmail.com
# UPDATE
# @Time : 2021/1/7
# @Author : Xiaolei Wang
# @email : wxl1999@foxmail.com
from crslab.download import DownloadableFile
"""Download links of pretrain models.
Now we provide the following models:
- `BERT`_: zh, en
- `GPT2`_: zh, en
.. _BERT:
https://www.aclweb.org/anthology/N19-1423/
.. _GPT2:
https://cdn.openai.com/better-language-models/language_models_are_unsupervised_multitask_learners.pdf
"""
resources = {
'bert': {
'zh': {
'version': '0.1',
'file': DownloadableFile(
'https://pkueducn-my.sharepoint.com/:u:/g/personal/franciszhou_pkueducn_onmicrosoft_com/EXm6uTgSkO1PgDD3TV9UtzMBfsAlJOun12vwB-hVkPRbXw?download=1',
'bert_zh.zip',
'e48ff2f3c2409bb766152dc5577cd5600838c9052622fd6172813dce31806ed3'
)
},
'en': {
'version': '0.1',
'file': DownloadableFile(
'https://pkueducn-my.sharepoint.com/:u:/g/personal/franciszhou_pkueducn_onmicrosoft_com/EfcnG_CkYAtKvEFUWvRF8i0BwmtCKnhnjOBwPW0W1tXqMQ?download=1',
'bert_en.zip',
'61b08202e8ad09088c9af78ab3f8902cd990813f6fa5b8b296d0da9d370006e3'
)
},
},
'gpt2': {
'zh': {
'version': '0.1',
'file': DownloadableFile(
'https://pkueducn-my.sharepoint.com/:u:/g/personal/franciszhou_pkueducn_onmicrosoft_com/EdwPgkE_-_BCsVSqo4Ao9D8BKj6H_0wWGGxHxt_kPmoSwA?download=1',
'gpt2_zh.zip',
'5f366b729e509164bfd55026e6567e22e101bfddcfaac849bae96fc263c7de43'
)
},
'en': {
'version': '0.1',
'file': DownloadableFile(
'https://pkueducn-my.sharepoint.com/:u:/g/personal/franciszhou_pkueducn_onmicrosoft_com/Ebe4PS0rYQ9InxmGvJ9JNXgBMI808ibQc93N-dAubtbTgQ?download=1',
'gpt2_en.zip',
'518c1c8a1868d4433d93688f2bf7f34b6216334395d1800d66308a80f4cac35e'
)
}
}
}
================================================
FILE: crslab/model/recommendation/__init__.py
================================================
from .bert import BERTModel
from .gru4rec import GRU4RECModel
from .popularity import PopularityModel
from .sasrec import SASRECModel
from .textcnn import TextCNNModel
================================================
FILE: crslab/model/recommendation/bert/__init__.py
================================================
from .bert import BERTModel
================================================
FILE: crslab/model/recommendation/bert/bert.py
================================================
# @Time : 2020/12/16
# @Author : Yuanhang Zhou
# @Email : sdzyh002@gmail.com
# UPDATE
# @Time : 2021/1/7, 2021/1/4
# @Author : Xiaolei Wang, Yuanhang Zhou
# @email : wxl1999@foxmail.com, sdzyh002@gmail.com
r"""
BERT
====
References:
Devlin, Jacob, et al. `"BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding."`_ in NAACL 2019.
.. _`"BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding."`:
https://www.aclweb.org/anthology/N19-1423/
"""
import os
from loguru import logger
from torch import nn
from transformers import BertModel
from crslab.config import PRETRAIN_PATH
from crslab.data import dataset_language_map
from crslab.model.base import BaseModel
from crslab.model.pretrained_models import resources
class BERTModel(BaseModel):
"""
Attributes:
item_size: A integer indicating the number of items.
"""
def __init__(self, opt, device, vocab, side_data):
"""
Args:
opt (dict): A dictionary record the hyper parameters.
device (torch.device): A variable indicating which device to place the data and model.
vocab (dict): A dictionary record the vocabulary information.
side_data (dict): A dictionary record the side data.
"""
self.item_size = vocab['n_entity']
language = dataset_language_map[opt['dataset']]
resource = resources['bert'][language]
dpath = os.path.join(PRETRAIN_PATH, "bert", language)
super(BERTModel, self).__init__(opt, device, dpath, resource)
def build_model(self):
# build BERT layer, give the architecture, load pretrained parameters
self.bert = BertModel.from_pretrained(self.dpath)
# print(self.item_size)
self.bert_hidden_size = self.bert.config.hidden_size
self.mlp = nn.Linear(self.bert_hidden_size, self.item_size)
# this loss may conduct to some weakness
self.rec_loss = nn.CrossEntropyLoss()
logger.debug('[Finish build rec layer]')
def forward(self, batch, mode='train'):
context, mask, input_ids, target_pos, input_mask, sample_negs, y = batch
bert_embed = self.bert(context, attention_mask=mask).pooler_output
rec_scores = self.mlp(bert_embed) # bs, item_size
rec_loss = self.rec_loss(rec_scores, y)
return rec_loss, rec_scores
================================================
FILE: crslab/model/recommendation/gru4rec/__init__.py
================================================
from .gru4rec import GRU4RECModel
================================================
FILE: crslab/model/recommendation/gru4rec/gru4rec.py
================================================
# @Time : 2020/12/16
# @Author : Yuanhang Zhou
# @Email : sdzyh002@gmail.com
# UPDATE
# @Time : 2020/12/29, 2021/1/4
# @Author : Xiaolei Wang, Yuanhang Zhou
# @email : wxl1999@foxmail.com, sdzyh002@gmail.com
r"""
GRU4REC
=======
References:
Hidasi, Balázs, et al. `"Session-Based Recommendations with Recurrent Neural Networks."`_ in ICLR 2016.
.. _`"Session-Based Recommendations with Recurrent Neural Networks."`:
https://arxiv.org/abs/1511.06939
"""
import torch
from loguru import logger
from torch import nn
from torch.nn.utils.rnn import pack_padded_sequence
from torch.nn.utils.rnn import pad_packed_sequence
from crslab.model.base import BaseModel
class GRU4RECModel(BaseModel):
"""
Attributes:
item_size: A integer indicating the number of items.
hidden_size: A integer indicating the hidden state size in GRU.
num_layers: A integer indicating the number of GRU layers.
dropout_hidden: A float indicating the dropout rate to dropout hidden state.
dropout_input: A integer indicating if we dropout the input of model.
embedding_dim: A integer indicating the dimension of item embedding.
batch_size: A integer indicating the batch size.
"""
def __init__(self, opt, device, vocab, side_data):
"""
Args:
opt (dict): A dictionary record the hyper parameters.
device (torch.device): A variable indicating which device to place the data and model.
vocab (dict): A dictionary record the vocabulary information.
side_data (dict): A dictionary record the side data.
"""
self.item_size = vocab['n_entity'] + 1
self.hidden_size = opt['gru_hidden_size']
self.num_layers = opt['num_layers']
self.dropout_hidden = opt['dropout_hidden']
self.dropout_input = opt['dropout_input']
self.embedding_dim = opt['embedding_dim']
self.batch_size = opt['batch_size']
super(GRU4RECModel, self).__init__(opt, device)
def build_model(self):
self.item_embeddings = nn.Embedding(self.item_size, self.embedding_dim)
self.gru = nn.GRU(self.embedding_dim,
self.hidden_size,
self.num_layers,
dropout=self.dropout_hidden,
batch_first=True)
logger.debug('[Finish build rec layer]')
def reconstruct_input(self, input_ids):
"""
convert the padding from left to right
"""
def reverse_padding(ids):
ans = [0] * len(ids)
idx = 0
for m_id in ids:
m_id = m_id.item()
if m_id != 0:
ans[idx] = m_id
idx += 1
return ans
input_len = [torch.sum((ids != 0).long()).item() for ids in input_ids]
input_ids = [reverse_padding(ids) for ids in input_ids]
input_ids = torch.tensor(input_ids, dtype=torch.long)
input_mask = (input_ids != 0).long()
return input_ids.to(self.device), input_len, input_mask.to(self.device)
def cross_entropy(self, seq_out, pos_ids, neg_ids, input_mask):
# [batch seq_len hidden_size]
pos_emb = self.item_embeddings(pos_ids)
neg_emb = self.item_embeddings(neg_ids)
# [batch*seq_len hidden_size]
pos = pos_emb.view(-1, pos_emb.size(2))
neg = neg_emb.view(-1, neg_emb.size(2))
# [batch*seq_len hidden_size]
seq_emb = seq_out.contiguous().view(-1, self.hidden_size)
# [batch*seq_len]
pos_logits = torch.sum(pos * seq_emb, -1)
neg_logits = torch.sum(neg * seq_emb, -1)
# [batch*seq_len]
istarget = (pos_ids > 0).view(pos_ids.size(0) * pos_ids.size(1)).float()
loss = torch.sum(
- torch.log(torch.sigmoid(pos_logits) + 1e-24) * istarget -
torch.log(1 - torch.sigmoid(neg_logits) + 1e-24) * istarget
) / torch.sum(istarget)
return loss
def forward(self, batch, mode):
"""
Args:
input_ids: padding in left, [pad, pad, id1, id2, ..., idn]
target_ids: padding in left, [pad, pad, id2, id3, ..., y]
"""
context, mask, input_ids, target_pos, input_mask, sample_negs, y = batch
input_ids, input_len, input_mask = self.reconstruct_input(input_ids)
target_pos, _, _ = self.reconstruct_input(target_pos)
sample_negs, _, _ = self.reconstruct_input(sample_negs)
embedded = self.item_embeddings(input_ids) # (batch, seq_len, hidden_size)
input_len = [len_ if len_ > 0 else 1 for len_ in input_len]
embedded = pack_padded_sequence(
embedded, input_len, enforce_sorted=False,
batch_first=True) # (num_layers , batch, hidden_size)
output, hidden = self.gru(embedded)
output, output_len = pad_packed_sequence(output, batch_first=True)
batch, seq_len, hidden_size = output.size()
logit = output.view(batch, seq_len, hidden_size)
last_logit = logit[:, -1, :]
rec_scores = torch.matmul(last_logit, self.item_embeddings.weight.data.T)
rec_scores = rec_scores.squeeze(1)
max_out_len = max([len_ for len_ in output_len])
rec_loss = self.cross_entropy(logit, target_pos[:, :max_out_len],
sample_negs[:, :max_out_len], input_mask)
return rec_loss, rec_scores
================================================
FILE: crslab/model/recommendation/gru4rec/modules.py
================================================
import torch
from torch import nn
class Embedding(nn.Module):
def __init__(self, item_size, embedding_dim):
super(Embedding, self).__init__()
self.embedding = nn.Embedding(item_size, embedding_dim)
def forward(self, input: torch.Tensor):
return self.embedding(input)
class GRU4REC(nn.Module):
def __init__(self, item_size, embedding_dim, hidden_size, num_layers, dropout_hidden):
super(GRU4REC, self).__init__()
self.module_dict = nn.ModuleDict({
'gru': nn.GRU(embedding_dim,
hidden_size,
num_layers,
dropout=dropout_hidden,
batch_first=True),
'item_embeddings': Embedding(item_size, embedding_dim),
})
# self.param = nn.ParameterDict({
# 'hidden_size': hidden_size
# })
self.hidden_size = hidden_size
# self.item_embeddings = Embedding(item_size, embedding_dim)
# self.gru = nn.GRU(embedding_dim,
# hidden_size,
# num_layers,
# dropout=dropout_hidden,
# batch_first=True)
# self.rec_loss = self.cross_entropy
def cross_entropy(self, seq_out, pos_ids, neg_ids):
# [batch seq_len hidden_size]
pos_emb = self.module_dict['item_embeddings'](pos_ids)
neg_emb = self.module_dict['item_embeddings'](neg_ids)
# [batch*seq_len hidden_size]
pos = pos_emb.view(-1, pos_emb.size(2))
neg = neg_emb.view(-1, neg_emb.size(2))
# [batch*seq_len hidden_size]
seq_emb = seq_out.contiguous().view(-1, self.hidden_size)
# [batch*seq_len]
pos_logits = torch.sum(pos * seq_emb, -1)
neg_logits = torch.sum(neg * seq_emb, -1)
# [batch*seq_len]
istarget = (pos_ids > 0).view(pos_ids.size(0) * pos_ids.size(1)).float()
loss = torch.sum(
- torch.log(torch.sigmoid(pos_logits) + 1e-24) * istarget -
torch.log(1 - torch.sigmoid(neg_logits) + 1e-24) * istarget
) / torch.sum(istarget)
return loss
def forward(self, input: torch.Tensor):
return self.module_dict['gru'](input)
================================================
FILE: crslab/model/recommendation/popularity/__init__.py
================================================
from .popularity import PopularityModel
================================================
FILE: crslab/model/recommendation/popularity/popularity.py
================================================
# @Time : 2020/12/16
# @Author : Yuanhang Zhou
# @Email : sdzyh002@gmail.com
# UPDATE
# @Time : 2020/12/29, 2021/1/4
# @Author : Xiaolei Wang, Yuanhang Zhou
# @email : wxl1999@foxmail.com, sdzyh002@gmail.com
r"""
Popularity
==========
"""
from collections import defaultdict
import torch
from loguru import logger
from crslab.model.base import BaseModel
class PopularityModel(BaseModel):
"""
Attributes:
item_size: A integer indicating the number of items.
"""
def __init__(self, opt, device, vocab, side_data):
"""
Args:
opt (dict): A dictionary record the hyper parameters.
device (torch.device): A variable indicating which device to place the data and model.
vocab (dict): A dictionary record the vocabulary information.
side_data (dict): A dictionary record the side data.
"""
self.item_size = vocab['n_entity']
super(PopularityModel, self).__init__(opt, device)
def build_model(self):
self.item_frequency = defaultdict(int)
logger.debug('[Finish build rec layer]')
def forward(self, batch, mode):
context, mask, input_ids, target_pos, input_mask, sample_negs, y = batch
if mode == 'train':
for ids in input_ids:
for id in ids:
self.item_frequency[id.item()] += 1
bs = input_ids.shape[0]
rec_score = [self.item_frequency.get(item_id, 0) for item_id in range(self.item_size)]
rec_scores = torch.tensor([rec_score] * bs, dtype=torch.long)
loss = torch.zeros(1, requires_grad=True)
return loss, rec_scores
================================================
FILE: crslab/model/recommendation/sasrec/__init__.py
================================================
from .sasrec import SASRECModel
================================================
FILE: crslab/model/recommendation/sasrec/modules.py
================================================
# @Time : 2020/12/13
# @Author : Kun Zhou
# @Email : wxl1999@foxmail.com
# UPDATE
# @Time : 2020/12/13, 2021/1/4
# @Author : Xiaolei Wang, Yuanhang Zhou
# @email : wxl1999@foxmail.com, sdzyh002@gmail.com
import copy
import math
import torch
import torch.nn as nn
import torch.nn.functional as F
class SASRec(nn.Module):
def __init__(self, hidden_dropout_prob, device, initializer_range,
hidden_size, max_seq_length, item_size, num_attention_heads,
attention_probs_dropout_prob, hidden_act, num_hidden_layers):
super(SASRec, self).__init__()
self.hidden_dropout_prob = hidden_dropout_prob
self.device = device
self.initializer_range = initializer_range
self.hidden_size = hidden_size
self.max_seq_length = max_seq_length
self.item_size = item_size
self.num_attention_heads = num_attention_heads
self.attention_probs_dropout_prob = attention_probs_dropout_prob
self.hidden_act = hidden_act
self.num_hidden_layers = num_hidden_layers
self.build_model()
self.init_model()
def build_model(self):
self.embeddings = Embeddings(self.item_size, self.hidden_size,
self.max_seq_length,
self.hidden_dropout_prob)
self.encoder = Encoder(self.num_hidden_layers, self.hidden_size,
self.num_attention_heads,
self.hidden_dropout_prob, self.hidden_act,
self.attention_probs_dropout_prob)
self.act = nn.Tanh()
self.dropout = nn.Dropout(p=self.hidden_dropout_prob)
def init_model(self):
self.apply(self.init_sas_weights)
def forward(self,
input_ids,
attention_mask=None,
output_all_encoded_layers=True):
if attention_mask is None:
attention_mask = torch.ones_like(input_ids) # (bs, seq_len)
# We create a 3D attention mask from a 2D tensor mask.
# Sizes are [batch_size, 1, 1, to_seq_length]
# So we can broadcast to [batch_size, num_heads, from_seq_length, to_seq_length]
# this attention mask is more simple than the triangular masking of causal attention
# used in OpenAI GPT, we just need to prepare the broadcast dimension here.
extended_attention_mask = attention_mask.unsqueeze(1).unsqueeze(
2) # torch.int64, (bs, 1, 1, seq_len)
# 添加mask 只关注前几个物品进行推荐
max_len = attention_mask.size(-1)
attn_shape = (1, max_len, max_len)
subsequent_mask = torch.triu(torch.ones(attn_shape),
diagonal=1) # torch.uint8
subsequent_mask = (subsequent_mask == 0).unsqueeze(1)
subsequent_mask = subsequent_mask.long().to(self.device)
extended_attention_mask = extended_attention_mask * subsequent_mask
# Since attention_mask is 1.0 for positions we want to attend and 0.0 for
# masked positions, this operation will create a tensor which is 0.0 for
# positions we want to attend and -10000.0 for masked positions.
# Since we are adding it to the raw scores before the softmax, this is
# effectively the same as removing these entirely.
# extended_attention_mask = extended_attention_mask.to(
# dtype=next(self.parameters()).dtype) # fp16 compatibility
extended_attention_mask = (1.0 - extended_attention_mask) * -10000.0
embedding = self.embeddings(input_ids)
encoded_layers = self.encoder(
embedding,
extended_attention_mask,
output_all_encoded_layers=output_all_encoded_layers)
# [B L H]
sequence_output = encoded_layers[-1]
return sequence_output
def init_sas_weights(self, module):
""" Initialize the weights.
"""
if isinstance(module, (nn.Linear, nn.Embedding)):
# Slightly different from the TF version which uses truncated_normal for initialization
# cf https://github.com/pytorch/pytorch/pull/5617
module.weight.data.normal_(mean=0.0, std=self.initializer_range)
elif isinstance(module, LayerNorm):
module.bias.data.zero_()
module.weight.data.fill_(1.0)
if isinstance(module, nn.Linear) and module.bias is not None:
module.bias.data.zero_()
def save_model(self, file_name):
torch.save(self.cpu().state_dict(), file_name)
self.to(self.device)
def load_model(self, path):
load_states = torch.load(path, map_location=self.device)
load_states_keys = set(load_states.keys())
this_states_keys = set(self.state_dict().keys())
assert this_states_keys.issubset(this_states_keys)
key_not_used = load_states_keys - this_states_keys
for key in key_not_used:
del load_states[key]
self.load_state_dict(load_states)
def compute_loss(self, y_pred, y, subset='test'):
pass
def cross_entropy(self, seq_out, pos_ids, neg_ids):
# [batch seq_len hidden_size]
pos_emb = self.embeddings.item_embeddings(pos_ids)
neg_emb = self.embeddings.item_embeddings(neg_ids)
# [batch*seq_len hidden_size]
pos = pos_emb.view(-1, pos_emb.size(2))
neg = neg_emb.view(-1, neg_emb.size(2))
# [batch*seq_len hidden_size]
seq_emb = seq_out.view(-1, self.hidden_size)
# [batch*seq_len]
pos_logits = torch.sum(pos * seq_emb, -1)
neg_logits = torch.sum(neg * seq_emb, -1)
# [batch*seq_len]
istarget = (pos_ids > 0).view(-1).float()
loss = torch.sum(-torch.log(torch.sigmoid(pos_logits) + 1e-24) *
istarget -
torch.log(1 - torch.sigmoid(neg_logits) + 1e-24) *
istarget) / torch.sum(istarget)
return loss
def gelu(x):
"""Implementation of the gelu activation function.
For information: OpenAI GPT's gelu is slightly different
(and gives slightly different results):
0.5 * x * (1 + torch.tanh(math.sqrt(2 / math.pi) *
(x + 0.044715 * torch.pow(x, 3))))
Also see https://arxiv.org/abs/1606.08415
"""
return x * 0.5 * (1.0 + torch.erf(x / math.sqrt(2.0)))
def swish(x):
return x * torch.sigmoid(x)
ACT2FN = {"gelu": gelu, "relu": F.relu, "swish": swish}
class LayerNorm(nn.Module):
def __init__(self, hidden_size, eps=1e-12):
"""Construct a layernorm module in the TF style (epsilon inside the square root)."""
super(LayerNorm, self).__init__()
self.weight = nn.Parameter(torch.ones(hidden_size), requires_grad=True)
self.bias = nn.Parameter(torch.zeros(hidden_size), requires_grad=True)
self.variance_epsilon = eps
def forward(self, x):
u = x.mean(-1, keepdim=True)
s = (x - u).pow(2).mean(-1, keepdim=True)
x = (x - u) / torch.sqrt(s + self.variance_epsilon)
return self.weight * x + self.bias
class Embeddings(nn.Module):
"""Construct the embeddings from item, position, attribute."""
def __init__(self, item_size, hidden_size, max_seq_length,
hidden_dropout_prob):
super(Embeddings, self).__init__()
self.item_embeddings = nn.Embedding(item_size, hidden_size)
self.position_embeddings = nn.Embedding(max_seq_length, hidden_size)
self.LayerNorm = LayerNorm(hidden_size, eps=1e-12)
self.dropout = nn.Dropout(hidden_dropout_prob)
def forward(self, input_ids):
seq_length = input_ids.size(1)
position_ids = torch.arange(seq_length,
dtype=torch.long,
device=input_ids.device)
position_ids = position_ids.unsqueeze(0).expand_as(input_ids)
items_embeddings = self.item_embeddings(input_ids)
position_embeddings = self.position_embeddings(position_ids)
embeddings = items_embeddings + position_embeddings
embeddings = self.LayerNorm(embeddings)
embeddings = self.dropout(embeddings)
return embeddings
class SelfAttention(nn.Module):
def __init__(self, hidden_size, num_attention_heads, hidden_dropout_prob,
attention_probs_dropout_prob):
super(SelfAttention, self).__init__()
if hidden_size % num_attention_heads != 0:
raise ValueError(
"The hidden size (%d) is not a multiple of the number of attention "
"heads (%d)" % (hidden_size, num_attention_heads))
self.num_attention_heads = num_attention_heads
self.attention_head_size = int(hidden_size / num_attention_heads)
self.all_head_size = self.num_attention_heads * self.attention_head_size
self.query = nn.Linear(hidden_size, self.all_head_size)
self.key = nn.Linear(hidden_size, self.all_head_size)
self.value = nn.Linear(hidden_size, self.all_head_size)
self.attn_dropout = nn.Dropout(attention_probs_dropout_prob)
self.dense = nn.Linear(hidden_size, hidden_size)
self.LayerNorm = LayerNorm(hidden_size, eps=1e-12)
self.out_dropout = nn.Dropout(hidden_dropout_prob)
def transpose_for_scores(self, x):
"""
Args:
x: (bs, seq_len, all_head_size)
Returns:
x.permute(0, 2, 1, 3), (bs, num_heads, seq_len, head_size)
"""
new_x_shape = x.size()[:-1] + (self.num_attention_heads,
self.attention_head_size)
x = x.view(*new_x_shape)
return x.permute(0, 2, 1, 3)
def forward(self, input_tensor, attention_mask):
mixed_query_layer = self.query(input_tensor)
mixed_key_layer = self.key(input_tensor)
mixed_value_layer = self.value(input_tensor)
query_layer = self.transpose_for_scores(mixed_query_layer)
key_layer = self.transpose_for_scores(mixed_key_layer)
value_layer = self.transpose_for_scores(mixed_value_layer)
# Take the dot product between "query" and "key" to get the raw attention scores.
attention_scores = torch.matmul(query_layer, key_layer.transpose(
-1, -2)) # (bs, num_heads, seq_len, seq_len)
attention_scores = attention_scores / math.sqrt(
self.attention_head_size)
# Apply the attention mask is (precomputed for all layers in BertModel forward() function)
# [batch_size heads seq_len seq_len] scores
# [batch_size 1 1 seq_len]
attention_scores = attention_scores + attention_mask
# Normalize the attention scores to probabilities.
attention_probs = nn.Softmax(dim=-1)(attention_scores)
# This is actually dropping out entire tokens to attend to, which might
# seem a bit unusual, but is taken from the original Transformer paper.
attention_probs = self.attn_dropout(attention_probs)
context_layer = torch.matmul(attention_probs, value_layer)
context_layer = context_layer.permute(0, 2, 1, 3).contiguous()
new_context_layer_shape = context_layer.size()[:-2] + (
self.all_head_size,)
context_layer = context_layer.view(*new_context_layer_shape)
hidden_states = self.dense(context_layer)
hidden_states = self.out_dropout(hidden_states)
hidden_states = self.LayerNorm(hidden_states + input_tensor)
return hidden_states
class Intermediate(nn.Module):
def __init__(self, hidden_size, hidden_act, hidden_dropout_prob):
super(Intermediate, self).__init__()
self.dense_1 = nn.Linear(hidden_size, hidden_size * 4)
if isinstance(hidden_act, str):
self.intermediate_act_fn = ACT2FN[hidden_act]
else:
self.intermediate_act_fn = hidden_act
self.dense_2 = nn.Linear(hidden_size * 4, hidden_size)
self.LayerNorm = LayerNorm(hidden_size, eps=1e-12)
self.dropout = nn.Dropout(hidden_dropout_prob)
def forward(self, input_tensor):
hidden_states = self.dense_1(input_tensor)
hidden_states = self.intermediate_act_fn(hidden_states)
hidden_states = self.dense_2(hidden_states)
hidden_states = self.dropout(hidden_states)
hidden_states = self.LayerNorm(hidden_states + input_tensor)
return hidden_states
class Layer(nn.Module):
def __init__(self, hidden_size, num_attention_heads, hidden_dropout_prob,
hidden_act, attention_probs_dropout_prob):
super(Layer, self).__init__()
self.attention = SelfAttention(hidden_size, num_attention_heads,
hidden_dropout_prob,
attention_probs_dropout_prob)
self.intermediate = Intermediate(hidden_size, hidden_act, hidden_dropout_prob)
def forward(self, hidden_states, attention_mask):
attention_output = self.attention(hidden_states, attention_mask)
intermediate_output = self.intermediate(attention_output)
return intermediate_output
class Encoder(nn.Module):
def __init__(self, num_hidden_layers, hidden_size, num_attention_heads,
hidden_dropout_prob, hidden_act,
attention_probs_dropout_prob):
super(Encoder, self).__init__()
layer = Layer(hidden_size, num_attention_heads, hidden_dropout_prob,
hidden_act, attention_probs_dropout_prob)
self.layer = nn.ModuleList(
[copy.deepcopy(layer) for _ in range(num_hidden_layers)])
def forward(self,
hidden_states,
attention_mask,
output_all_encoded_layers=True):
all_encoder_layers = []
for layer_module in self.layer:
hidden_states = layer_module(hidden_states, attention_mask)
if output_all_encoded_layers:
all_encoder_layers.append(hidden_states)
if not output_all_encoded_layers:
all_encoder_layers.append(hidden_states)
return all_encoder_layers
================================================
FILE: crslab/model/recommendation/sasrec/sasrec.py
================================================
# @Time : 2020/12/16
# @Author : Yuanhang Zhou
# @Email : sdzyh002@gmail.com
# UPDATE
# @Time : 2020/12/29, 2021/1/4
# @Author : Xiaolei Wang, Yuanhang Zhou
# @email : wxl1999@foxmail.com, sdzyh002@gmail.com
r"""
SASREC
======
References:
Kang, Wang-Cheng, and Julian McAuley. `"Self-attentive sequential recommendation."`_ in ICDM 2018.
.. _`"Self-attentive sequential recommendation."`:
https://ieeexplore.ieee.org/abstract/document/8594844
"""
import torch
from loguru import logger
from torch import nn
from crslab.model.base import BaseModel
from crslab.model.recommendation.sasrec.modules import SASRec
class SASRECModel(BaseModel):
"""
Attributes:
hidden_dropout_prob: A float indicating the dropout rate to dropout hidden state in SASRec.
initializer_range: A float indicating the range of parameters initiation in SASRec.
hidden_size: A integer indicating the size of hidden state in SASRec.
max_seq_length: A integer indicating the max interaction history length.
item_size: A integer indicating the number of items.
num_attention_heads: A integer indicating the head number in SASRec.
attention_probs_dropout_prob: A float indicating the dropout rate in attention layers.
hidden_act: A string indicating the activation function type in SASRec.
num_hidden_layers: A integer indicating the number of hidden layers in SASRec.
"""
def __init__(self, opt, device, vocab, side_data):
"""
Args:
opt (dict): A dictionary record the hyper parameters.
device (torch.device): A variable indicating which device to place the data and model.
vocab (dict): A dictionary record the vocabulary information.
side_data (dict): A dictionary record the side data.
"""
self.hidden_dropout_prob = opt['hidden_dropout_prob']
self.initializer_range = opt['initializer_range']
self.hidden_size = opt['hidden_size']
self.max_seq_length = opt['max_history_items']
self.item_size = vocab['n_entity'] + 1
self.num_attention_heads = opt['num_attention_heads']
self.attention_probs_dropout_prob = opt['attention_probs_dropout_prob']
self.hidden_act = opt['hidden_act']
self.num_hidden_layers = opt['num_hidden_layers']
super(SASRECModel, self).__init__(opt, device)
def build_model(self):
# build BERT layer, give the architecture, load pretrained parameters
self.SASREC = SASRec(self.hidden_dropout_prob, self.device,
self.initializer_range, self.hidden_size,
self.max_seq_length, self.item_size,
self.num_attention_heads,
self.attention_probs_dropout_prob,
self.hidden_act, self.num_hidden_layers)
# this loss may conduct to some weakness
self.rec_loss = nn.CrossEntropyLoss()
logger.debug('[Finish build rec layer]')
def forward(self, batch, mode):
context, mask, input_ids, target_pos, input_mask, sample_negs, y = batch
# print(input_ids.shape)
sequence_output = self.SASREC(input_ids, input_mask) # bs, max_len, hidden_size2
logit = sequence_output[:, -1:, :]
rec_scores = torch.matmul(logit, self.SASREC.embeddings.item_embeddings.weight.data.T)
rec_scores = rec_scores.squeeze(1)
# print('rec_scores.shape', rec_scores.shape)
rec_loss = self.SASREC.cross_entropy(sequence_output, target_pos,
sample_negs)
return rec_loss, rec_scores
================================================
FILE: crslab/model/recommendation/textcnn/__init__.py
================================================
from .textcnn import TextCNNModel
================================================
FILE: crslab/model/recommendation/textcnn/textcnn.py
================================================
# @Time : 2020/12/16
# @Author : Yuanhang Zhou
# @Email : sdzyh002@gmail.com
# UPDATE
# @Time : 2020/12/29, 2021/1/4
# @Author : Xiaolei Wang, Yuanhang Zhou
# @email : wxl1999@foxmail.com, sdzyh002@gmail.com
r"""
TextCNN
=======
References:
Kim, Yoon. `"Convolutional Neural Networks for Sentence Classification."`_ in EMNLP 2014.
.. _`"Convolutional Neural Networks for Sentence Classification."`:
https://www.aclweb.org/anthology/D14-1181/
"""
import torch
import torch.nn.functional as F
from loguru import logger
from torch import nn
from crslab.model.base import BaseModel
class TextCNNModel(BaseModel):
"""
Attributes:
movie_num: A integer indicating the number of items.
num_filters: A string indicating the number of filter in CNN.
embed: A integer indicating the size of embedding layer.
filter_sizes: A string indicating the size of filter in CNN.
dropout: A float indicating the dropout rate.
"""
def __init__(self, opt, device, vocab, side_data):
"""
Args:
opt (dict): A dictionary record the hyper parameters.
device (torch.device): A variable indicating which device to place the data and model.
vocab (dict): A dictionary record the vocabulary information.
side_data (dict): A dictionary record the side data.
"""
self.movie_num = vocab['n_entity']
self.num_filters = opt['num_filters']
self.embed = opt['embed']
self.filter_sizes = eval(opt['filter_sizes'])
self.dropout = opt['dropout']
super(TextCNNModel, self).__init__(opt, device)
def conv_and_pool(self, x, conv):
x = F.relu(conv(x)).squeeze(3)
x = F.max_pool1d(x, x.size(2)).squeeze(2)
return x
def build_model(self):
self.embedding = nn.Embedding(self.movie_num, self.embed)
self.convs = nn.ModuleList(
[nn.Conv2d(1, self.num_filters, (k, self.embed)) for k in self.filter_sizes])
self.dropout = nn.Dropout(self.dropout)
self.fc = nn.Linear(self.num_filters * len(self.filter_sizes), self.movie_num)
# this loss may conduct to some weakness
self.rec_loss = nn.CrossEntropyLoss()
logger.debug('[Finish build rec layer]')
def forward(self, batch, mode):
context, mask, input_ids, target_pos, input_mask, sample_negs, y = batch
out = self.embedding(context)
out = out.unsqueeze(1)
out = torch.cat([self.conv_and_pool(out, conv) for conv in self.convs], 1)
out = self.dropout(out)
out = self.fc(out)
rec_scores = out
rec_loss = self.rec_loss(out, y)
return rec_loss, rec_scores
================================================
FILE: crslab/model/utils/__init__.py
================================================
================================================
FILE: crslab/model/utils/functions.py
================================================
# -*- encoding: utf-8 -*-
# @Time : 2020/11/26
# @Author : Xiaolei Wang
# @email : wxl1999@foxmail.com
# UPDATE
# @Time : 2020/11/16
# @Author : Xiaolei Wang
# @email : wxl1999@foxmail.com
import torch
def edge_to_pyg_format(edge, type='RGCN'):
if type == 'RGCN':
edge_sets = torch.as_tensor(edge, dtype=torch.long)
edge_idx = edge_sets[:, :2].t()
edge_type = edge_sets[:, 2]
return edge_idx, edge_type
elif type == 'GCN':
edge_set = [[co[0] for co in edge], [co[1] for co in edge]]
return torch.as_tensor(edge_set, dtype=torch.long)
else:
raise NotImplementedError('type {} has not been implemented', type)
def sort_for_packed_sequence(lengths: torch.Tensor):
"""
:param lengths: 1D array of lengths
:return: sorted_lengths (lengths in descending order), sorted_idx (indices to sort), rev_idx (indices to retrieve original order)
"""
sorted_idx = torch.argsort(lengths, descending=True) # idx to sort by length
rev_idx = torch.argsort(sorted_idx) # idx to retrieve original order
sorted_lengths = lengths[sorted_idx]
return sorted_lengths, sorted_idx, rev_idx
================================================
FILE: crslab/model/utils/modules/__init__.py
================================================
================================================
FILE: crslab/model/utils/modules/attention.py
================================================
# -*- coding: utf-8 -*-
# @Time : 2020/11/22
# @Author : Kun Zhou
# @Email : francis_kun_zhou@163.com
# UPDATE:
# @Time : 2020/11/24
# @Author : Kun Zhou
# @Email : francis_kun_zhou@163.com
import torch
import torch.nn as nn
import torch.nn.functional as F
class SelfAttentionBatch(nn.Module):
def __init__(self, dim, da, alpha=0.2, dropout=0.5):
super(SelfAttentionBatch, self).__init__()
self.dim = dim
self.da = da
self.alpha = alpha
self.dropout = dropout
self.a = nn.Parameter(torch.zeros(size=(self.dim, self.da)), requires_grad=True)
self.b = nn.Parameter(torch.zeros(size=(self.da, 1)), requires_grad=True)
nn.init.xavier_uniform_(self.a.data, gain=1.414)
nn.init.xavier_uniform_(self.b.data, gain=1.414)
def forward(self, h):
# h: (N, dim)
e = torch.matmul(torch.tanh(torch.matmul(h, self.a)), self.b).squeeze(dim=1)
attention = F.softmax(e, dim=0) # (N)
return torch.matmul(attention, h) # (dim)
class SelfAttentionSeq(nn.Module):
def __init__(self, dim, da, alpha=0.2, dropout=0.5):
super(SelfAttentionSeq, self).__init__()
self.dim = dim
self.da = da
self.alpha = alpha
self.dropout = dropout
self.a = nn.Parameter(torch.zeros(size=(self.dim, self.da)), requires_grad=True)
self.b = nn.Parameter(torch.zeros(size=(self.da, 1)), requires_grad=True)
nn.init.xavier_uniform_(self.a.data, gain=1.414)
nn.init.xavier_uniform_(self.b.data, gain=1.414)
def forward(self, h, mask=None, return_logits=False):
"""
For the padding tokens, its corresponding mask is True
if mask==[1, 1, 1, ...]
"""
# h: (batch, seq_len, dim), mask: (batch, seq_len)
e = torch.matmul(torch.tanh(torch.matmul(h, self.a)), self.b) # (batch, seq_len, 1)
if mask is not None:
full_mask = -1e30 * mask.float()
batch_mask = torch.sum((mask == False), -1).bool().float().unsqueeze(-1) # for all padding one, the mask=0
mask = full_mask * batch_mask
e += mask.unsqueeze(-1)
attention = F.softmax(e, dim=1) # (batch, seq_len, 1)
# (batch, dim)
if return_logits:
return torch.matmul(torch.transpose(attention, 1, 2), h).squeeze(1), attention.squeeze(-1)
else:
return torch.matmul(torch.transpose(attention, 1, 2), h).squeeze(1)
================================================
FILE: crslab/model/utils/modules/transformer.py
================================================
# @Time : 2020/11/22
# @Author : Kun Zhou
# @Email : francis_kun_zhou@163.com
# UPDATE:
# @Time : 2020/11/24
# @Author : Kun Zhou
# @Email : francis_kun_zhou@163.com
import math
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
"""Near infinity, useful as a large penalty for scoring when inf is bad."""
NEAR_INF = 1e20
NEAR_INF_FP16 = 65504
def neginf(dtype):
"""Returns a representable finite number near -inf for a dtype."""
if dtype is torch.float16:
return -NEAR_INF_FP16
else:
return -NEAR_INF
def _create_selfattn_mask(x):
# figure out how many timestamps we need
bsz = x.size(0)
time = x.size(1)
# make sure that we don't look into the future
mask = torch.tril(x.new(time, time).fill_(1))
# broadcast across batch
mask = mask.unsqueeze(0).expand(bsz, -1, -1)
return mask
def create_position_codes(n_pos, dim, out):
position_enc = np.array([
[pos / np.power(10000, 2 * j / dim) for j in range(dim // 2)]
for pos in range(n_pos)
])
out.data[:, 0::2] = torch.as_tensor(np.sin(position_enc))
out.data[:, 1::2] = torch.as_tensor(np.cos(position_enc))
out.detach_()
out.requires_grad = False
def _normalize(tensor, norm_layer):
"""Broadcast layer norm"""
size = tensor.size()
return norm_layer(tensor.view(-1, size[-1])).view(size)
class MultiHeadAttention(nn.Module):
def __init__(self, n_heads, dim, dropout=.0):
super(MultiHeadAttention, self).__init__()
self.n_heads = n_heads
self.dim = dim
self.attn_dropout = nn.Dropout(p=dropout) # --attention-dropout
self.q_lin = nn.Linear(dim, dim)
self.k_lin = nn.Linear(dim, dim)
self.v_lin = nn.Linear(dim, dim)
# TODO: merge for the initialization step
nn.init.xavier_normal_(self.q_lin.weight)
nn.init.xavier_normal_(self.k_lin.weight)
nn.init.xavier_normal_(self.v_lin.weight)
# and set biases to 0
self.out_lin = nn.Linear(dim, dim)
nn.init.xavier_normal_(self.out_lin.weight)
def forward(self, query, key=None, value=None, mask=None):
# Input is [B, query_len, dim]
# Mask is [B, key_len] (selfattn) or [B, key_len, key_len] (enc attn)
batch_size, query_len, dim = query.size()
assert dim == self.dim, \
f'Dimensions do not match: {dim} query vs {self.dim} configured'
assert mask is not None, 'Mask is None, please specify a mask'
n_heads = self.n_heads
dim_per_head = dim // n_heads
scale = math.sqrt(dim_per_head)
def prepare_head(tensor):
# input is [batch_size, seq_len, n_heads * dim_per_head]
# output is [batch_size * n_heads, seq_len, dim_per_head]
bsz, seq_len, _ = tensor.size()
tensor = tensor.view(batch_size, tensor.size(1), n_heads, dim_per_head)
tensor = tensor.transpose(1, 2).contiguous().view(
batch_size * n_heads,
seq_len,
dim_per_head
)
return tensor
# q, k, v are the transformed values
if key is None and value is None:
# self attention
key = value = query
elif value is None:
# key and value are the same, but query differs
# self attention
value = key
_, key_len, dim = key.size()
q = prepare_head(self.q_lin(query))
k = prepare_head(self.k_lin(key))
v = prepare_head(self.v_lin(value))
dot_prod = q.div_(scale).bmm(k.transpose(1, 2))
# [B * n_heads, query_len, key_len]
attn_mask = (
(mask == 0)
.view(batch_size, 1, -1, key_len)
.repeat(1, n_heads, 1, 1)
.expand(batch_size, n_heads, query_len, key_len)
.view(batch_size * n_heads, query_len, key_len)
)
assert attn_mask.shape == dot_prod.shape
dot_prod.masked_fill_(attn_mask, neginf(dot_prod.dtype))
attn_weights = F.softmax(dot_prod, dim=-1).type_as(query)
attn_weights = self.attn_dropout(attn_weights) # --attention-dropout
attentioned = attn_weights.bmm(v)
attentioned = (
attentioned.type_as(query)
.view(batch_size, n_heads, query_len, dim_per_head)
.transpose(1, 2).contiguous()
.view(batch_size, query_len, dim)
)
out = self.out_lin(attentioned)
return out
class TransformerFFN(nn.Module):
def __init__(self, dim, dim_hidden, relu_dropout=.0):
super(TransformerFFN, self).__init__()
self.relu_dropout = nn.Dropout(p=relu_dropout)
self.lin1 = nn.Linear(dim, dim_hidden)
self.lin2 = nn.Linear(dim_hidden, dim)
nn.init.xavier_uniform_(self.lin1.weight)
nn.init.xavier_uniform_(self.lin2.weight)
# TODO: initialize biases to 0
def forward(self, x):
x = F.relu(self.lin1(x))
x = self.relu_dropout(x) # --relu-dropout
x = self.lin2(x)
return x
class TransformerEncoderLayer(nn.Module):
def __init__(
self,
n_heads,
embedding_size,
ffn_size,
attention_dropout=0.0,
relu_dropout=0.0,
dropout=0.0,
):
super().__init__()
self.dim = embedding_size
self.ffn_dim = ffn_size
self.attention = MultiHeadAttention(
n_heads, embedding_size,
dropout=attention_dropout, # --attention-dropout
)
self.norm1 = nn.LayerNorm(embedding_size)
self.ffn = TransformerFFN(embedding_size, ffn_size, relu_dropout=relu_dropout)
self.norm2 = nn.LayerNorm(embedding_size)
self.dropout = nn.Dropout(p=dropout)
def forward(self, tensor, mask):
tensor = tensor + self.dropout(self.attention(tensor, mask=mask))
tensor = _normalize(tensor, self.norm1)
tensor = tensor + self.dropout(self.ffn(tensor))
tensor = _normalize(tensor, self.norm2)
tensor *= mask.unsqueeze(-1).type_as(tensor)
return tensor
class TransformerEncoder(nn.Module):
"""
Transformer encoder module.
:param int n_heads: the number of multihead attention heads.
:param int n_layers: number of transformer layers.
:param int embedding_size: the embedding sizes. Must be a multiple of n_heads.
:param int ffn_size: the size of the hidden layer in the FFN
:param embedding: an embedding matrix for the bottom layer of the transformer.
If none, one is created for this encoder.
:param float dropout: Dropout used around embeddings and before layer
layer normalizations. This is used in Vaswani 2017 and works well on
large datasets.
:param float attention_dropout: Dropout performed after the multhead attention
softmax. This is not used in Vaswani 2017.
:param float relu_dropout: Dropout used after the ReLU in the FFN. Not used
in Vaswani 2017, but used in Tensor2Tensor.
:param int padding_idx: Reserved padding index in the embeddings matrix.
:param bool learn_positional_embeddings: If off, sinusoidal embeddings are
used. If on, position embeddings are learned from scratch.
:param bool embeddings_scale: Scale embeddings relative to their dimensionality.
Found useful in fairseq.
:param bool reduction: If true, returns the mean vector for the entire encoding
sequence.
:param int n_positions: Size of the position embeddings matrix.
"""
def __init__(
self,
n_heads,
n_layers,
embedding_size,
ffn_size,
vocabulary_size,
embedding=None,
dropout=0.0,
attention_dropout=0.0,
relu_dropout=0.0,
padding_idx=0,
learn_positional_embeddings=False,
embeddings_scale=False,
reduction=True,
n_positions=1024
):
super(TransformerEncoder, self).__init__()
self.embedding_size = embedding_size
self.ffn_size = ffn_size
self.n_layers = n_layers
self.n_heads = n_heads
self.dim = embedding_size
self.embeddings_scale = embeddings_scale
self.reduction = reduction
self.padding_idx = padding_idx
# this is --dropout, not --relu-dropout or --attention-dropout
self.dropout = nn.Dropout(dropout)
self.out_dim = embedding_size
assert embedding_size % n_heads == 0, \
'Transformer embedding size must be a multiple of n_heads'
# check input formats:
if embedding is not None:
assert (
embedding_size is None or embedding_size == embedding.weight.shape[1]
), "Embedding dim must match the embedding size."
if embedding is not None:
self.embeddings = embedding
else:
assert False
assert padding_idx is not None
self.embeddings = nn.Embedding(
vocabulary_size, embedding_size, padding_idx=padding_idx
)
nn.init.normal_(self.embeddings.weight, 0, embedding_size ** -0.5)
# create the positional embeddings
self.position_embeddings = nn.Embedding(n_positions, embedding_size)
if not learn_positional_embeddings:
create_position_codes(
n_positions, embedding_size, out=self.position_embeddings.weight
)
else:
nn.init.normal_(self.position_embeddings.weight, 0, embedding_size ** -0.5)
# build the model
self.layers = nn.ModuleList()
for _ in range(self.n_layers):
self.layers.append(TransformerEncoderLayer(
n_heads, embedding_size, ffn_size,
attention_dropout=attention_dropout,
relu_dropout=relu_dropout,
dropout=dropout,
))
def forward(self, input):
"""
input data is a FloatTensor of shape [batch, seq_len, dim]
mask is a ByteTensor of shape [batch, seq_len], filled with 1 when
inside the sequence and 0 outside.
"""
mask = input != self.padding_idx
positions = (mask.cumsum(dim=1, dtype=torch.int64) - 1).clamp_(min=0)
tensor = self.embeddings(input)
if self.embeddings_scale:
tensor = tensor * np.sqrt(self.dim)
tensor = tensor + self.position_embeddings(positions).expand_as(tensor)
# --dropout on the embeddings
tensor = self.dropout(tensor)
tensor *= mask.unsqueeze(-1).type_as(tensor)
for i in range(self.n_layers):
tensor = self.layers[i](tensor, mask)
if self.reduction:
divisor = mask.type_as(tensor).sum(dim=1).unsqueeze(-1).clamp(min=1e-7)
output = tensor.sum(dim=1) / divisor
return output
else:
output = tensor
return output, mask
class TransformerDecoderLayer(nn.Module):
def __init__(
self,
n_heads,
embedding_size,
ffn_size,
attention_dropout=0.0,
relu_dropout=0.0,
dropout=0.0,
):
super().__init__()
self.dim = embedding_size
self.ffn_dim = ffn_size
self.dropout = nn.Dropout(p=dropout)
self.self_attention = MultiHeadAttention(
n_heads, embedding_size, dropout=attention_dropout
)
self.norm1 = nn.LayerNorm(embedding_size)
self.encoder_attention = MultiHeadAttention(
n_heads, embedding_size, dropout=attention_dropout
)
self.norm2 = nn.LayerNorm(embedding_size)
self.ffn = TransformerFFN(embedding_size, ffn_size, relu_dropout=relu_dropout)
self.norm3 = nn.LayerNorm(embedding_size)
def forward(self, x, encoder_output, encoder_mask):
decoder_mask = self._create_selfattn_mask(x)
# first self attn
residual = x
# don't peak into the future!
x = self.self_attention(query=x, mask=decoder_mask)
x = self.dropout(x) # --dropout
x = x + residual
x = _normalize(x, self.norm1)
residual = x
x = self.encoder_attention(
query=x,
key=encoder_output,
value=encoder_output,
mask=encoder_mask
)
x = self.dropout(x) # --dropout
x = residual + x
x = _normalize(x, self.norm2)
# finally the ffn
residual = x
x = self.ffn(x)
x = self.dropout(x) # --dropout
x = residual + x
x = _normalize(x, self.norm3)
return x
def _create_selfattn_mask(self, x):
# figure out how many timestamps we need
bsz = x.size(0)
time = x.size(1)
# make sure that we don't look into the future
mask = torch.tril(x.new(time, time).fill_(1))
# broadcast across batch
mask = mask.unsqueeze(0).expand(bsz, -1, -1)
return mask
class TransformerDecoder(nn.Module):
"""
Transformer Decoder layer.
:param int n_heads: the number of multihead attention heads.
:param int n_layers: number of transformer layers.
:param int embedding_size: the embedding sizes. Must be a multiple of n_heads.
:param int ffn_size: the size of the hidden layer in the FFN
:param embedding: an embedding matrix for the bottom layer of the transformer.
If none, one is created for this encoder.
:param float dropout: Dropout used around embeddings and before layer
layer normalizations. This is used in Vaswani 2017 and works well on
large datasets.
:param float attention_dropout: Dropout performed after the multhead attention
softmax. This is not used in Vaswani 2017.
:param int padding_idx: Reserved padding index in the embeddings matrix.
:param bool learn_positional_embeddings: If off, sinusoidal embeddings are
used. If on, position embeddings are learned from scratch.
:param bool embeddings_scale: Scale embeddings relative to their dimensionality.
Found useful in fairseq.
:param int n_positions: Size of the position embeddings matrix.
"""
def __init__(
self,
n_heads,
n_layers,
embedding_size,
ffn_size,
vocabulary_size,
embedding=None,
dropout=0.0,
attention_dropout=0.0,
relu_dropout=0.0,
embeddings_scale=True,
learn_positional_embeddings=False,
padding_idx=None,
n_positions=1024,
):
super().__init__()
self.embedding_size = embedding_size
self.ffn_size = ffn_size
self.n_layers = n_layers
self.n_heads = n_heads
self.dim = embedding_size
self.embeddings_scale = embeddings_scale
self.dropout = nn.Dropout(p=dropout) # --dropout
self.out_dim = embedding_size
assert embedding_size % n_heads == 0, \
'Transformer embedding size must be a multiple of n_heads'
self.embeddings = embedding
# create the positional embeddings
self.position_embeddings = nn.Embedding(n_positions, embedding_size)
if not learn_positional_embeddings:
create_position_codes(
n_positions, embedding_size, out=self.position_embeddings.weight
)
else:
nn.init.normal_(self.position_embeddings.weight, 0, embedding_size ** -0.5)
# build the model
self.layers = nn.ModuleList()
for _ in range(self.n_layers):
self.layers.append(TransformerDecoderLayer(
n_heads, embedding_size, ffn_size,
attention_dropout=attention_dropout,
relu_dropout=relu_dropout,
dropout=dropout,
))
def forward(self, input, encoder_state, incr_state=None):
encoder_output, encoder_mask = encoder_state
seq_len = input.shape[1]
positions = input.new_empty(seq_len).long()
positions = torch.arange(seq_len, out=positions).unsqueeze(0) # (batch, seq_len)
tensor = self.embeddings(input)
if self.embeddings_scale:
tensor = tensor * np.sqrt(self.dim)
tensor = tensor + self.position_embeddings(positions).expand_as(tensor)
tensor = self.dropout(tensor) # --dropout
for layer in self.layers:
tensor = layer(tensor, encoder_output, encoder_mask)
return tensor, None
================================================
FILE: crslab/quick_start/__init__.py
================================================
from .quick_start import run_crslab
================================================
FILE: crslab/quick_start/quick_start.py
================================================
# -*- encoding: utf-8 -*-
# @Time : 2021/1/8
# @Author : Xiaolei Wang
# @email : wxl1999@foxmail.com
# UPDATE
# @Time : 2021/1/9
# @Author : Xiaolei Wang
# @email : wxl1999@foxmail.com
from crslab.config import Config
from crslab.data import get_dataset, get_dataloader
from crslab.system import get_system
def run_crslab(config, save_data=False, restore_data=False, save_system=False, restore_system=False,
interact=False, debug=False, tensorboard=False):
"""A fast running api, which includes the complete process of training and testing models on specified datasets.
Args:
config (Config or str): an instance of ``Config`` or path to the config file,
which should be in ``yaml`` format. You can use default config provided in the `Github repo`_,
or write it by yourself.
save_data (bool): whether to save data. Defaults to False.
restore_data (bool): whether to restore data. Defaults to False.
save_system (bool): whether to save system. Defaults to False.
restore_system (bool): whether to restore system. Defaults to False.
interact (bool): whether to interact with the system. Defaults to False.
debug (bool): whether to debug the system. Defaults to False.
.. _Github repo:
https://github.com/RUCAIBox/CRSLab
"""
# dataset & dataloader
if isinstance(config['tokenize'], str):
CRS_dataset = get_dataset(config, config['tokenize'], restore_data, save_data)
side_data = CRS_dataset.side_data
vocab = CRS_dataset.vocab
train_dataloader = get_dataloader(config, CRS_dataset.train_data, vocab)
valid_dataloader = get_dataloader(config, CRS_dataset.valid_data, vocab)
test_dataloader = get_dataloader(config, CRS_dataset.test_data, vocab)
else:
tokenized_dataset = {}
train_dataloader = {}
valid_dataloader = {}
test_dataloader = {}
vocab = {}
side_data = {}
for task, tokenize in config['tokenize'].items():
if tokenize in tokenized_dataset:
dataset = tokenized_dataset[tokenize]
else:
dataset = get_dataset(config, tokenize, restore_data, save_data)
tokenized_dataset[tokenize] = dataset
train_data = dataset.train_data
valid_data = dataset.valid_data
test_data = dataset.test_data
side_data[task] = dataset.side_data
vocab[task] = dataset.vocab
train_dataloader[task] = get_dataloader(config, train_data, vocab[task])
valid_dataloader[task] = get_dataloader(config, valid_data, vocab[task])
test_dataloader[task] = get_dataloader(config, test_data, vocab[task])
# system
CRS = get_system(config, train_dataloader, valid_dataloader, test_dataloader, vocab, side_data, restore_system,
interact, debug, tensorboard)
if interact:
CRS.interact()
else:
CRS.fit()
if save_system:
CRS.save_model()
================================================
FILE: crslab/system/__init__.py
================================================
# @Time : 2020/11/22
# @Author : Kun Zhou
# @Email : francis_kun_zhou@163.com
# UPDATE:
# @Time : 2020/11/24, 2020/12/29
# @Author : Kun Zhou, Xiaolei Wang
# @Email : francis_kun_zhou@163.com, wxl1999@foxmail.com
# @Time : 2021/10/6
# @Author : Zhipeng Zhao
# @email : oran_official@outlook.com
from loguru import logger
from .inspired import InspiredSystem
from .kbrd import KBRDSystem
from .kgsf import KGSFSystem
from .redial import ReDialSystem
from .ntrd import NTRDSystem
from .tgredial import TGReDialSystem
system_register_table = {
'ReDialRec_ReDialConv': ReDialSystem,
'KBRD': KBRDSystem,
'KGSF': KGSFSystem,
'TGRec_TGConv': TGReDialSystem,
'TGRec_TGConv_TGPolicy': TGReDialSystem,
'InspiredRec_InspiredConv': InspiredSystem,
'GPT2': TGReDialSystem,
'Transformer': TGReDialSystem,
'ConvBERT': TGReDialSystem,
'ProfileBERT': TGReDialSystem,
'TopicBERT': TGReDialSystem,
'PMI': TGReDialSystem,
'MGCG': TGReDialSystem,
'BERT': TGReDialSystem,
'SASREC': TGReDialSystem,
'GRU4REC': TGReDialSystem,
'Popularity': TGReDialSystem,
'TextCNN': TGReDialSystem,
'NTRD': NTRDSystem
}
def get_system(opt, train_dataloader, valid_dataloader, test_dataloader, vocab, side_data, restore_system=False,
interact=False, debug=False, tensorboard=False):
"""
return the system class
"""
model_name = opt['model_name']
if model_name in system_register_table:
system = system_register_table[model_name](opt, train_dataloader, valid_dataloader, test_dataloader, vocab,
side_data, restore_system, interact, debug, tensorboard)
logger.info(f'[Build system {model_name}]')
return system
else:
raise NotImplementedError('The system with model [{}] in dataset [{}] has not been implemented'.
format(model_name, opt['dataset']))
================================================
FILE: crslab/system/base.py
================================================
# @Time : 2020/11/22
# @Author : Kun Zhou
# @Email : francis_kun_zhou@163.com
# UPDATE:
# @Time : 2020/11/24, 2021/1/9
# @Author : Kun Zhou, Xiaolei Wang
# @Email : francis_kun_zhou@163.com, wxl1999@foxmail.com
# UPDATE:
# @Time : 2021/11/5
# @Author : Zhipeng Zhao
# @Email : oran_official@outlook.com
import os
from abc import ABC, abstractmethod
import numpy as np
import random
import nltk
import torch
from fuzzywuzzy.process import extractOne
from loguru import logger
from nltk import word_tokenize
from torch import optim
from transformers import AdamW, Adafactor
from crslab.config import SAVE_PATH
from crslab.evaluator import get_evaluator
from crslab.evaluator.metrics.base import AverageMetric
from crslab.model import get_model
from crslab.system.utils import lr_scheduler
from crslab.system.utils.functions import compute_grad_norm
optim_class = {}
optim_class.update({k: v for k, v in optim.__dict__.items() if not k.startswith('__') and k[0].isupper()})
optim_class.update({'AdamW': AdamW, 'Adafactor': Adafactor})
lr_scheduler_class = {k: v for k, v in lr_scheduler.__dict__.items() if not k.startswith('__') and k[0].isupper()}
transformers_tokenizer = ('bert', 'gpt2')
class BaseSystem(ABC):
"""Base class for all system"""
def __init__(self, opt, train_dataloader, valid_dataloader, test_dataloader, vocab, side_data, restore_system=False,
interact=False, debug=False, tensorboard=False):
"""
Args:
opt (dict): Indicating the hyper parameters.
train_dataloader (BaseDataLoader): Indicating the train dataloader of corresponding dataset.
valid_dataloader (BaseDataLoader): Indicating the valid dataloader of corresponding dataset.
test_dataloader (BaseDataLoader): Indicating the test dataloader of corresponding dataset.
vocab (dict): Indicating the vocabulary.
side_data (dict): Indicating the side data.
restore_system (bool, optional): Indicating if we store system after training. Defaults to False.
interact (bool, optional): Indicating if we interact with system. Defaults to False.
debug (bool, optional): Indicating if we train in debug mode. Defaults to False.
tensorboard (bool, optional) Indicating if we monitor the training performance in tensorboard. Defaults to False.
"""
self.opt = opt
if opt["gpu"] == [-1]:
self.device = torch.device('cpu')
elif len(opt["gpu"]) == 1:
self.device = torch.device('cuda')
else:
self.device = torch.device('cuda')
# seed
if 'seed' in opt:
seed = int(opt['seed'])
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
logger.info(f'[Set seed] {seed}')
# data
if debug:
self.train_dataloader = valid_dataloader
self.valid_dataloader = valid_dataloader
self.test_dataloader = test_dataloader
else:
self.train_dataloader = train_dataloader
self.valid_dataloader = valid_dataloader
self.test_dataloader = test_dataloader
self.vocab = vocab
self.side_data = side_data
# model
if 'model' in opt:
self.model = get_model(opt, opt['model'], self.device, vocab, side_data).to(self.device)
else:
if 'rec_model' in opt:
self.rec_model = get_model(opt, opt['rec_model'], self.device, vocab['rec'], side_data['rec']).to(
self.device)
if 'conv_model' in opt:
self.conv_model = get_model(opt, opt['conv_model'], self.device, vocab['conv'], side_data['conv']).to(
self.device)
if 'policy_model' in opt:
self.policy_model = get_model(opt, opt['policy_model'], self.device, vocab['policy'],
side_data['policy']).to(self.device)
model_file_name = opt.get('model_file', f'{opt["model_name"]}.pth')
self.model_file = os.path.join(SAVE_PATH, model_file_name)
if restore_system:
self.restore_model()
if not interact:
self.evaluator = get_evaluator(opt.get('evaluator', 'standard'), opt['dataset'], tensorboard)
def init_optim(self, opt, parameters):
self.optim_opt = opt
parameters = list(parameters)
if isinstance(parameters[0], dict):
for i, d in enumerate(parameters):
parameters[i]['params'] = list(d['params'])
# gradient acumulation
self.update_freq = opt.get('update_freq', 1)
self._number_grad_accum = 0
self.gradient_clip = opt.get('gradient_clip', -1)
self.build_optimizer(parameters)
self.build_lr_scheduler()
if isinstance(parameters[0], dict):
self.parameters = []
for d in parameters:
self.parameters.extend(d['params'])
else:
self.parameters = parameters
# early stop
self.need_early_stop = self.optim_opt.get('early_stop', False)
if self.need_early_stop:
logger.debug('[Enable early stop]')
self.reset_early_stop_state()
def build_optimizer(self, parameters):
optimizer_opt = self.optim_opt['optimizer']
optimizer = optimizer_opt.pop('name')
self.optimizer = optim_class[optimizer](parameters, **optimizer_opt)
logger.info(f"[Build optimizer: {optimizer}]")
def build_lr_scheduler(self):
"""
Create the learning rate scheduler, and assign it to self.scheduler. This
scheduler will be updated upon a call to receive_metrics. May also create
self.warmup_scheduler, if appropriate.
:param state_dict states: Possible state_dict provided by model
checkpoint, for restoring LR state
:param bool hard_reset: If true, the LR scheduler should ignore the
state dictionary.
"""
if self.optim_opt.get('lr_scheduler', None):
lr_scheduler_opt = self.optim_opt['lr_scheduler']
lr_scheduler = lr_scheduler_opt.pop('name')
self.scheduler = lr_scheduler_class[lr_scheduler](self.optimizer, **lr_scheduler_opt)
logger.info(f"[Build scheduler {lr_scheduler}]")
def reset_early_stop_state(self):
self.best_valid = None
self.drop_cnt = 0
self.impatience = self.optim_opt.get('impatience', 3)
if self.optim_opt['stop_mode'] == 'max':
self.stop_mode = 1
elif self.optim_opt['stop_mode'] == 'min':
self.stop_mode = -1
else:
raise
logger.debug('[Reset early stop state]')
@abstractmethod
def fit(self):
"""fit the whole system"""
pass
@abstractmethod
def step(self, batch, stage, mode):
"""calculate loss and prediction for batch data under certrain stage and mode
Args:
batch (dict or tuple): batch data
stage (str): recommendation/policy/conversation etc.
mode (str): train/valid/test
"""
pass
def backward(self, loss):
"""empty grad, backward loss and update params
Args:
loss (torch.Tensor):
"""
self._zero_grad()
if self.update_freq > 1:
self._number_grad_accum = (self._number_grad_accum + 1) % self.update_freq
loss /= self.update_freq
loss.backward(loss.clone().detach())
self._update_params()
def _zero_grad(self):
if self._number_grad_accum != 0:
# if we're accumulating gradients, don't actually zero things out yet.
return
self.optimizer.zero_grad()
def _update_params(self):
if self.update_freq > 1:
# we're doing gradient accumulation, so we don't only want to step
# every N updates instead
# self._number_grad_accum is updated in backward function
if self._number_grad_accum != 0:
return
if self.gradient_clip > 0:
grad_norm = torch.nn.utils.clip_grad_norm_(
self.parameters, self.gradient_clip
)
self.evaluator.optim_metrics.add('grad norm', AverageMetric(grad_norm))
self.evaluator.optim_metrics.add(
'grad clip ratio',
AverageMetric(float(grad_norm > self.gradient_clip)),
)
else:
grad_norm = compute_grad_norm(self.parameters)
self.evaluator.optim_metrics.add('grad norm', AverageMetric(grad_norm))
self.optimizer.step()
if hasattr(self, 'scheduler'):
self.scheduler.train_step()
def adjust_lr(self, metric=None):
"""adjust learning rate w/o metric by scheduler
Args:
metric (optional): Defaults to None.
"""
if not hasattr(self, 'scheduler') or self.scheduler is None:
return
self.scheduler.valid_step(metric)
logger.debug('[Adjust learning rate after valid epoch]')
def early_stop(self, metric):
if not self.need_early_stop:
return False
if self.best_valid is None or metric * self.stop_mode > self.best_valid * self.stop_mode:
self.best_valid = metric
self.drop_cnt = 0
logger.info('[Get new best model]')
return False
else:
self.drop_cnt += 1
if self.drop_cnt >= self.impatience:
logger.info('[Early stop]')
return True
def save_model(self):
r"""Store the model parameters."""
state = {}
if hasattr(self, 'model'):
state['model_state_dict'] = self.model.state_dict()
if hasattr(self, 'rec_model'):
state['rec_state_dict'] = self.rec_model.state_dict()
if hasattr(self, 'conv_model'):
state['conv_state_dict'] = self.conv_model.state_dict()
if hasattr(self, 'policy_model'):
state['policy_state_dict'] = self.policy_model.state_dict()
os.makedirs(SAVE_PATH, exist_ok=True)
torch.save(state, self.model_file)
logger.info(f'[Save model into {self.model_file}]')
def restore_model(self):
r"""Store the model parameters."""
if not os.path.exists(self.model_file):
raise ValueError(f'Saved model [{self.model_file}] does not exist')
checkpoint = torch.load(self.model_file, map_location=self.device)
if hasattr(self, 'model'):
self.model.load_state_dict(checkpoint['model_state_dict'])
if hasattr(self, 'rec_model'):
self.rec_model.load_state_dict(checkpoint['rec_state_dict'])
if hasattr(self, 'conv_model'):
self.conv_model.load_state_dict(checkpoint['conv_state_dict'])
if hasattr(self, 'policy_model'):
self.policy_model.load_state_dict(checkpoint['policy_state_dict'])
logger.info(f'[Restore model from {self.model_file}]')
@abstractmethod
def interact(self):
pass
def init_interact(self):
self.finished = False
self.context = {
'rec': {},
'conv': {}
}
for key in self.context:
self.context[key]['context_tokens'] = []
self.context[key]['context_entities'] = []
self.context[key]['context_words'] = []
self.context[key]['context_items'] = []
self.context[key]['user_profile'] = []
self.context[key]['interaction_history'] = []
self.context[key]['entity_set'] = set()
self.context[key]['word_set'] = set()
def update_context(self, stage, token_ids=None, entity_ids=None, item_ids=None, word_ids=None):
if token_ids is not None:
self.context[stage]['context_tokens'].append(token_ids)
if item_ids is not None:
self.context[stage]['context_items'] += item_ids
if entity_ids is not None:
for entity_id in entity_ids:
if entity_id not in self.context[stage]['entity_set']:
self.context[stage]['entity_set'].add(entity_id)
self.context[stage]['context_entities'].append(entity_id)
if word_ids is not None:
for word_id in word_ids:
if word_id not in self.context[stage]['word_set']:
self.context[stage]['word_set'].add(word_id)
self.context[stage]['context_words'].append(word_id)
def get_input(self, language):
print("Enter [EXIT] if you want to quit.")
if language == 'zh':
language = 'chinese'
elif language == 'en':
language = 'english'
else:
raise
text = input(f"Enter Your Message in {language}: ")
if '[EXIT]' in text:
self.finished = True
return text
def tokenize(self, text, tokenizer, path=None):
tokenize_fun = getattr(self, tokenizer + '_tokenize')
if path is not None:
return tokenize_fun(text, path)
else:
return tokenize_fun(text)
def nltk_tokenize(self, text):
nltk.download('punkt')
return word_tokenize(text)
def bert_tokenize(self, text, path):
if not hasattr(self, 'bert_tokenizer'):
from transformers import AutoTokenizer
self.bert_tokenizer = AutoTokenizer.from_pretrained(path)
return self.bert_tokenizer.tokenize(text)
def gpt2_tokenize(self, text, path):
if not hasattr(self, 'gpt2_tokenizer'):
from transformers import AutoTokenizer
self.gpt2_tokenizer = AutoTokenizer.from_pretrained(path)
return self.gpt2_tokenizer.tokenize(text)
def pkuseg_tokenize(self, text):
if not hasattr(self, 'pkuseg_tokenizer'):
import pkuseg
self.pkuseg_tokenizer = pkuseg.pkuseg()
return self.pkuseg_tokenizer.cut(text)
def link(self, tokens, entities):
linked_entities = []
for token in tokens:
entity = extractOne(token, entities, score_cutoff=90)
if entity:
linked_entities.append(entity[0])
return linked_entities
================================================
FILE: crslab/system/inspired.py
================================================
# @Time : 2021/3/1
# @Author : Beichen Zhang
# @Email : zhangbeichen724@gmail.com
import torch
from loguru import logger
from math import floor
from crslab.data import dataset_language_map
from crslab.evaluator.metrics.base import AverageMetric
from crslab.evaluator.metrics.gen import PPLMetric
from crslab.system.base import BaseSystem
from crslab.system.utils.functions import ind2txt
class InspiredSystem(BaseSystem):
"""This is the system for Inspired model"""
def __init__(self, opt, train_dataloader, valid_dataloader, test_dataloader, vocab, side_data, restore_system=False,
interact=False, debug=False, tensorboard=False):
"""
Args:
opt (dict): Indicating the hyper parameters.
train_dataloader (BaseDataLoader): Indicating the train dataloader of corresponding dataset.
valid_dataloader (BaseDataLoader): Indicating the valid dataloader of corresponding dataset.
test_dataloader (BaseDataLoader): Indicating the test dataloader of corresponding dataset.
vocab (dict): Indicating the vocabulary.
side_data (dict): Indicating the side data.
restore_system (bool, optional): Indicating if we store system after training. Defaults to False.
interact (bool, optional): Indicating if we interact with system. Defaults to False.
debug (bool, optional): Indicating if we train in debug mode. Defaults to False.
tensorboard (bool, optional) Indicating if we monitor the training performance in tensorboard. Defaults to False.
"""
super(InspiredSystem, self).__init__(opt, train_dataloader, valid_dataloader,
test_dataloader, vocab, side_data, restore_system, interact, debug,
tensorboard)
if hasattr(self, 'conv_model'):
self.ind2tok = vocab['conv']['ind2tok']
self.end_token_idx = vocab['conv']['end']
if hasattr(self, 'rec_model'):
self.item_ids = side_data['rec']['item_entity_ids']
self.id2entity = vocab['rec']['id2entity']
if hasattr(self, 'rec_model'):
self.rec_optim_opt = self.opt['rec']
self.rec_epoch = self.rec_optim_opt['epoch']
self.rec_batch_size = self.rec_optim_opt['batch_size']
if hasattr(self, 'conv_model'):
self.conv_optim_opt = self.opt['conv']
self.conv_epoch = self.conv_optim_opt['epoch']
self.conv_batch_size = self.conv_optim_opt['batch_size']
if self.conv_optim_opt.get('lr_scheduler', None) and 'Transformers' in self.conv_optim_opt['lr_scheduler'][
'name']:
batch_num = 0
for _ in self.train_dataloader['conv'].get_conv_data(batch_size=self.conv_batch_size, shuffle=False):
batch_num += 1
conv_training_steps = self.conv_epoch * floor(batch_num / self.conv_optim_opt.get('update_freq', 1))
self.conv_optim_opt['lr_scheduler']['training_steps'] = conv_training_steps
self.language = dataset_language_map[self.opt['dataset']]
def rec_evaluate(self, rec_predict, item_label):
rec_predict = rec_predict.cpu()
rec_predict = rec_predict[:, self.item_ids]
_, rec_ranks = torch.topk(rec_predict, 50, dim=-1)
rec_ranks = rec_ranks.tolist()
item_label = item_label.tolist()
for rec_rank, item in zip(rec_ranks, item_label):
item = self.item_ids.index(item)
self.evaluator.rec_evaluate(rec_rank, item)
def conv_evaluate(self, prediction, response):
"""
Args:
prediction: torch.LongTensor, shape=(bs, response_truncate-1)
response: (torch.LongTensor, torch.LongTensor), shape=((bs, response_truncate), (bs, response_truncate))
the first token in response is <|endoftext|>, it is not in prediction
"""
prediction = prediction.tolist()
response = response.tolist()
for p, r in zip(prediction, response):
p_str = ind2txt(p, self.ind2tok, self.end_token_idx)
r_str = ind2txt(r[1:], self.ind2tok, self.end_token_idx)
self.evaluator.gen_evaluate(p_str, [r_str])
def step(self, batch, stage, mode):
"""
stage: ['policy', 'rec', 'conv']
mode: ['train', 'val', 'test]
"""
batch = [ele.to(self.device) for ele in batch]
if stage == 'rec':
if mode == 'train':
self.rec_model.train()
else:
self.rec_model.eval()
rec_loss, rec_predict = self.rec_model.recommend(batch, mode)
if mode == "train":
self.backward(rec_loss)
else:
self.rec_evaluate(rec_predict, batch[-1])
rec_loss = rec_loss.item()
self.evaluator.optim_metrics.add("rec_loss",
AverageMetric(rec_loss))
elif stage == "conv":
if mode != "test":
# train + valid: need to compute ppl
gen_loss, pred = self.conv_model.converse(batch, mode)
if mode == 'train':
self.conv_model.train()
self.backward(gen_loss)
else:
self.conv_model.eval()
self.conv_evaluate(pred, batch[-1])
gen_loss = gen_loss.item()
self.evaluator.optim_metrics.add("gen_loss",
AverageMetric(gen_loss))
self.evaluator.gen_metrics.add("ppl", PPLMetric(gen_loss))
else:
# generate response in conv_model.step
pred = self.conv_model.converse(batch, mode)
self.conv_evaluate(pred, batch[-1])
else:
raise
def train_recommender(self):
if hasattr(self.rec_model, 'bert'):
bert_param = list(self.rec_model.bert.named_parameters())
bert_param_name = ['bert.' + n for n, p in bert_param]
else:
bert_param = []
bert_param_name = []
other_param = [
name_param for name_param in self.rec_model.named_parameters()
if name_param[0] not in bert_param_name
]
params = [{'params': [p for n, p in bert_param], 'lr': self.rec_optim_opt['lr_bert']},
{'params': [p for n, p in other_param]}]
self.init_optim(self.rec_optim_opt, params)
for epoch in range(self.rec_epoch):
self.evaluator.reset_metrics()
logger.info(f'[Recommendation epoch {str(epoch)}]')
for batch in self.train_dataloader['rec'].get_rec_data(self.rec_batch_size,
shuffle=True):
self.step(batch, stage='rec', mode='train')
self.evaluator.report(epoch=epoch, mode='train')
# val
with torch.no_grad():
self.evaluator.reset_metrics()
for batch in self.valid_dataloader['rec'].get_rec_data(
self.rec_batch_size, shuffle=False):
self.step(batch, stage='rec', mode='val')
self.evaluator.report(epoch=epoch, mode='val')
# early stop
metric = self.evaluator.rec_metrics['hit@1'] + self.evaluator.rec_metrics['hit@50']
if self.early_stop(metric):
break
# test
with torch.no_grad():
self.evaluator.reset_metrics()
for batch in self.test_dataloader['rec'].get_rec_data(self.rec_batch_size,
shuffle=False):
self.step(batch, stage='rec', mode='test')
self.evaluator.report(mode='test')
def train_conversation(self):
self.init_optim(self.conv_optim_opt, self.conv_model.parameters())
for epoch in range(self.conv_epoch):
self.evaluator.reset_metrics()
logger.info(f'[Conversation epoch {str(epoch)}]')
for batch in self.train_dataloader['conv'].get_conv_data(
batch_size=self.conv_batch_size, shuffle=True):
self.step(batch, stage='conv', mode='train')
self.evaluator.report(epoch=epoch, mode='train')
# val
with torch.no_grad():
self.evaluator.reset_metrics()
for batch in self.valid_dataloader['conv'].get_conv_data(
batch_size=self.conv_batch_size, shuffle=False):
self.step((batch), stage='conv', mode='val')
self.evaluator.report(epoch=epoch, mode='val')
# early stop
metric = self.evaluator.gen_metrics['ppl']
if self.early_stop(metric):
break
# test
with torch.no_grad():
self.evaluator.reset_metrics()
for batch in self.test_dataloader['conv'].get_conv_data(
batch_size=self.conv_batch_size, shuffle=False):
self.step((batch), stage='conv', mode='test')
self.evaluator.report(mode='test')
def fit(self):
if hasattr(self, 'rec_model'):
self.train_recommender()
if hasattr(self, 'conv_model'):
self.train_conversation()
def interact(self):
pass
================================================
FILE: crslab/system/kbrd.py
================================================
# -*- encoding: utf-8 -*-
# @Time : 2020/12/4
# @Author : Xiaolei Wang
# @email : wxl1999@foxmail.com
# UPDATE
# @Time : 2021/1/3
# @Author : Xiaolei Wang
# @email : wxl1999@foxmail.com
import os
import torch
from loguru import logger
from crslab.evaluator.metrics.base import AverageMetric
from crslab.evaluator.metrics.gen import PPLMetric
from crslab.system.base import BaseSystem
from crslab.system.utils.functions import ind2txt
class KBRDSystem(BaseSystem):
"""This is the system for KBRD model"""
def __init__(self, opt, train_dataloader, valid_dataloader, test_dataloader, vocab, side_data, restore_system=False,
interact=False, debug=False, tensorboard=False):
"""
Args:
opt (dict): Indicating the hyper parameters.
train_dataloader (BaseDataLoader): Indicating the train dataloader of corresponding dataset.
valid_dataloader (BaseDataLoader): Indicating the valid dataloader of corresponding dataset.
test_dataloader (BaseDataLoader): Indicating the test dataloader of corresponding dataset.
vocab (dict): Indicating the vocabulary.
side_data (dict): Indicating the side data.
restore_system (bool, optional): Indicating if we store system after training. Defaults to False.
interact (bool, optional): Indicating if we interact with system. Defaults to False.
debug (bool, optional): Indicating if we train in debug mode. Defaults to False.
tensorboard (bool, optional) Indicating if we monitor the training performance in tensorboard. Defaults to False.
"""
super(KBRDSystem, self).__init__(opt, train_dataloader, valid_dataloader, test_dataloader, vocab, side_data,
restore_system, interact, debug, tensorboard)
self.ind2tok = vocab['ind2tok']
self.end_token_idx = vocab['end']
self.item_ids = side_data['item_entity_ids']
self.rec_optim_opt = opt['rec']
self.conv_optim_opt = opt['conv']
self.rec_epoch = self.rec_optim_opt['epoch']
self.conv_epoch = self.conv_optim_opt['epoch']
self.rec_batch_size = self.rec_optim_opt['batch_size']
self.conv_batch_size = self.conv_optim_opt['batch_size']
def rec_evaluate(self, rec_predict, item_label):
rec_predict = rec_predict.cpu()
rec_predict = rec_predict[:, self.item_ids]
_, rec_ranks = torch.topk(rec_predict, 50, dim=-1)
rec_ranks = rec_ranks.tolist()
item_label = item_label.tolist()
for rec_rank, label in zip(rec_ranks, item_label):
label = self.item_ids.index(label)
self.evaluator.rec_evaluate(rec_rank, label)
def conv_evaluate(self, prediction, response):
prediction = prediction.tolist()
response = response.tolist()
for p, r in zip(prediction, response):
p_str = ind2txt(p, self.ind2tok, self.end_token_idx)
r_str = ind2txt(r, self.ind2tok, self.end_token_idx)
self.evaluator.gen_evaluate(p_str, [r_str])
def step(self, batch, stage, mode):
assert stage in ('rec', 'conv')
assert mode in ('train', 'valid', 'test')
for k, v in batch.items():
if isinstance(v, torch.Tensor):
batch[k] = v.to(self.device)
if stage == 'rec':
rec_loss, rec_scores = self.model.forward(batch, mode, stage)
rec_loss = rec_loss.sum()
if mode == 'train':
self.backward(rec_loss)
else:
self.rec_evaluate(rec_scores, batch['item'])
rec_loss = rec_loss.item()
self.evaluator.optim_metrics.add("rec_loss", AverageMetric(rec_loss))
else:
if mode != 'test':
gen_loss, preds = self.model.forward(batch, mode, stage)
if mode == 'train':
self.backward(gen_loss)
else:
self.conv_evaluate(preds, batch['response'])
gen_loss = gen_loss.item()
self.evaluator.optim_metrics.add('gen_loss', AverageMetric(gen_loss))
self.evaluator.gen_metrics.add("ppl", PPLMetric(gen_loss))
else:
preds = self.model.forward(batch, mode, stage)
self.conv_evaluate(preds, batch['response'])
def train_recommender(self):
self.init_optim(self.rec_optim_opt, self.model.parameters())
for epoch in range(self.rec_epoch):
self.evaluator.reset_metrics()
logger.info(f'[Recommendation epoch {str(epoch)}]')
logger.info('[Train]')
for batch in self.train_dataloader.get_rec_data(self.rec_batch_size):
self.step(batch, stage='rec', mode='train')
self.evaluator.report(epoch=epoch, mode='train')
# val
logger.info('[Valid]')
with torch.no_grad():
self.evaluator.reset_metrics()
for batch in self.valid_dataloader.get_rec_data(self.rec_batch_size, shuffle=False):
self.step(batch, stage='rec', mode='valid')
self.evaluator.report(epoch=epoch, mode='valid')
# early stop
metric = self.evaluator.optim_metrics['rec_loss']
if self.early_stop(metric):
break
# test
logger.info('[Test]')
with torch.no_grad():
self.evaluator.reset_metrics()
for batch in self.test_dataloader.get_rec_data(self.rec_batch_size, shuffle=False):
self.step(batch, stage='rec', mode='test')
self.evaluator.report(mode='test')
def train_conversation(self):
if os.environ["CUDA_VISIBLE_DEVICES"] == '-1':
self.model.freeze_parameters()
elif len(os.environ["CUDA_VISIBLE_DEVICES"]) == 1:
self.model.freeze_parameters()
else:
self.model.module.freeze_parameters()
self.init_optim(self.conv_optim_opt, self.model.parameters())
for epoch in range(self.conv_epoch):
self.evaluator.reset_metrics()
logger.info(f'[Conversation epoch {str(epoch)}]')
logger.info('[Train]')
for batch in self.train_dataloader.get_conv_data(batch_size=self.conv_batch_size):
self.step(batch, stage='conv', mode='train')
self.evaluator.report(epoch=epoch, mode='train')
# val
logger.info('[Valid]')
with torch.no_grad():
self.evaluator.reset_metrics()
for batch in self.valid_dataloader.get_conv_data(batch_size=self.conv_batch_size, shuffle=False):
self.step(batch, stage='conv', mode='valid')
self.evaluator.report(epoch=epoch, mode='valid')
# early stop
metric = self.evaluator.optim_metrics['gen_loss']
if self.early_stop(metric):
break
# test
logger.info('[Test]')
with torch.no_grad():
self.evaluator.reset_metrics()
for batch in self.test_dataloader.get_conv_data(batch_size=self.conv_batch_size, shuffle=False):
self.step(batch, stage='conv', mode='test')
self.evaluator.report(mode='test')
def fit(self):
self.train_recommender()
self.train_conversation()
def interact(self):
pass
================================================
FILE: crslab/system/kgsf.py
================================================
# @Time : 2020/11/22
# @Author : Kun Zhou
# @Email : francis_kun_zhou@163.com
# UPDATE:
# @Time : 2020/11/24, 2021/1/3
# @Author : Kun Zhou, Xiaolei Wang
# @Email : francis_kun_zhou@163.com, wxl1999@foxmail.com
import os
import torch
from loguru import logger
from crslab.evaluator.metrics.base import AverageMetric
from crslab.evaluator.metrics.gen import PPLMetric
from crslab.system.base import BaseSystem
from crslab.system.utils.functions import ind2txt
class KGSFSystem(BaseSystem):
"""This is the system for KGSF model"""
def __init__(self, opt, train_dataloader, valid_dataloader, test_dataloader, vocab, side_data, restore_system=False,
interact=False, debug=False, tensorboard=False):
"""
Args:
opt (dict): Indicating the hyper parameters.
train_dataloader (BaseDataLoader): Indicating the train dataloader of corresponding dataset.
valid_dataloader (BaseDataLoader): Indicating the valid dataloader of corresponding dataset.
test_dataloader (BaseDataLoader): Indicating the test dataloader of corresponding dataset.
vocab (dict): Indicating the vocabulary.
side_data (dict): Indicating the side data.
restore_system (bool, optional): Indicating if we store system after training. Defaults to False.
interact (bool, optional): Indicating if we interact with system. Defaults to False.
debug (bool, optional): Indicating if we train in debug mode. Defaults to False.
tensorboard (bool, optional) Indicating if we monitor the training performance in tensorboard. Defaults to False.
"""
super(KGSFSystem, self).__init__(opt, train_dataloader, valid_dataloader, test_dataloader, vocab, side_data,
restore_system, interact, debug, tensorboard)
self.ind2tok = vocab['ind2tok']
self.end_token_idx = vocab['end']
self.item_ids = side_data['item_entity_ids']
self.pretrain_optim_opt = self.opt['pretrain']
self.rec_optim_opt = self.opt['rec']
self.conv_optim_opt = self.opt['conv']
self.pretrain_epoch = self.pretrain_optim_opt['epoch']
self.rec_epoch = self.rec_optim_opt['epoch']
self.conv_epoch = self.conv_optim_opt['epoch']
self.pretrain_batch_size = self.pretrain_optim_opt['batch_size']
self.rec_batch_size = self.rec_optim_opt['batch_size']
self.conv_batch_size = self.conv_optim_opt['batch_size']
def rec_evaluate(self, rec_predict, item_label):
rec_predict = rec_predict.cpu()
rec_predict = rec_predict[:, self.item_ids]
_, rec_ranks = torch.topk(rec_predict, 50, dim=-1)
rec_ranks = rec_ranks.tolist()
item_label = item_label.tolist()
for rec_rank, item in zip(rec_ranks, item_label):
item = self.item_ids.index(item)
self.evaluator.rec_evaluate(rec_rank, item)
def conv_evaluate(self, prediction, response):
prediction = prediction.tolist()
response = response.tolist()
for p, r in zip(prediction, response):
p_str = ind2txt(p, self.ind2tok, self.end_token_idx)
r_str = ind2txt(r, self.ind2tok, self.end_token_idx)
self.evaluator.gen_evaluate(p_str, [r_str])
def step(self, batch, stage, mode):
batch = [ele.to(self.device) for ele in batch]
if stage == 'pretrain':
info_loss = self.model.forward(batch, stage, mode)
if info_loss is not None:
self.backward(info_loss.sum())
info_loss = info_loss.sum().item()
self.evaluator.optim_metrics.add("info_loss", AverageMetric(info_loss))
elif stage == 'rec':
rec_loss, info_loss, rec_predict = self.model.forward(batch, stage, mode)
if info_loss:
loss = rec_loss + 0.025 * info_loss
else:
loss = rec_loss
if mode == "train":
self.backward(loss.sum())
else:
self.rec_evaluate(rec_predict, batch[-1])
rec_loss = rec_loss.sum().item()
self.evaluator.optim_metrics.add("rec_loss", AverageMetric(rec_loss))
if info_loss:
info_loss = info_loss.sum().item()
self.evaluator.optim_metrics.add("info_loss", AverageMetric(info_loss))
elif stage == "conv":
if mode != "test":
gen_loss, pred = self.model.forward(batch, stage, mode)
if mode == 'train':
self.backward(gen_loss.sum())
else:
self.conv_evaluate(pred, batch[-1])
gen_loss = gen_loss.sum().item()
self.evaluator.optim_metrics.add("gen_loss", AverageMetric(gen_loss))
self.evaluator.gen_metrics.add("ppl", PPLMetric(gen_loss))
else:
pred = self.model.forward(batch, stage, mode)
self.conv_evaluate(pred, batch[-1])
else:
raise
def pretrain(self):
self.init_optim(self.pretrain_optim_opt, self.model.parameters())
for epoch in range(self.pretrain_epoch):
self.evaluator.reset_metrics()
logger.info(f'[Pretrain epoch {str(epoch)}]')
for batch in self.train_dataloader.get_pretrain_data(self.pretrain_batch_size, shuffle=False):
self.step(batch, stage="pretrain", mode='train')
self.evaluator.report()
def train_recommender(self):
self.init_optim(self.rec_optim_opt, self.model.parameters())
for epoch in range(self.rec_epoch):
self.evaluator.reset_metrics()
logger.info(f'[Recommendation epoch {str(epoch)}]')
logger.info('[Train]')
for batch in self.train_dataloader.get_rec_data(self.rec_batch_size, shuffle=False):
self.step(batch, stage='rec', mode='train')
self.evaluator.report(epoch=epoch, mode='train')
# val
logger.info('[Valid]')
with torch.no_grad():
self.evaluator.reset_metrics()
for batch in self.valid_dataloader.get_rec_data(self.rec_batch_size, shuffle=False):
self.step(batch, stage='rec', mode='val')
self.evaluator.report(epoch=epoch, mode='val')
# early stop
metric = self.evaluator.rec_metrics['hit@1'] + self.evaluator.rec_metrics['hit@50']
if self.early_stop(metric):
break
# test
logger.info('[Test]')
with torch.no_grad():
self.evaluator.reset_metrics()
for batch in self.test_dataloader.get_rec_data(self.rec_batch_size, shuffle=False):
self.step(batch, stage='rec', mode='test')
self.evaluator.report(mode='test')
def train_conversation(self):
if os.environ["CUDA_VISIBLE_DEVICES"] == '-1':
self.model.freeze_parameters()
else:
self.model.module.freeze_parameters()
self.init_optim(self.conv_optim_opt, self.model.parameters())
for epoch in range(self.conv_epoch):
self.evaluator.reset_metrics()
logger.info(f'[Conversation epoch {str(epoch)}]')
logger.info('[Train]')
for batch in self.train_dataloader.get_conv_data(batch_size=self.conv_batch_size, shuffle=False):
self.step(batch, stage='conv', mode='train')
self.evaluator.report(epoch=epoch, mode='train')
# val
logger.info('[Valid]')
with torch.no_grad():
self.evaluator.reset_metrics()
for batch in self.valid_dataloader.get_conv_data(batch_size=self.conv_batch_size, shuffle=False):
self.step(batch, stage='conv', mode='val')
self.evaluator.report(epoch=epoch, mode='val')
# test
logger.info('[Test]')
with torch.no_grad():
self.evaluator.reset_metrics()
for batch in self.test_dataloader.get_conv_data(batch_size=self.conv_batch_size, shuffle=False):
self.step(batch, stage='conv', mode='test')
self.evaluator.report(mode='test')
def fit(self):
self.pretrain()
self.train_recommender()
self.train_conversation()
def interact(self):
pass
================================================
FILE: crslab/system/ntrd.py
================================================
# @Time : 2021/10/05
# @Author : Zhipeng Zhao
# @Email : oran_official@outlook.com
import os
from crslab.evaluator.metrics import gen
from numpy.core.numeric import NaN
import torch
from loguru import logger
from crslab.evaluator.metrics.base import AverageMetric
from crslab.evaluator.metrics.gen import PPLMetric
from crslab.system.base import BaseSystem
from crslab.system.utils.functions import ind2slot,ind2txt_with_slots
class NTRDSystem(BaseSystem):
"""This is the system for NTRD model"""
def __init__(self, opt, train_dataloader, valid_dataloader, test_dataloader, vocab, side_data, restore_system=False,
interact=False, debug=False, tensorboard=False):
super(NTRDSystem, self).__init__(opt, train_dataloader, valid_dataloader, test_dataloader, vocab, side_data,
restore_system, interact, debug, tensorboard)
self.ind2tok = vocab['ind2tok']
self.ind2movie = vocab['id2entity']
self.end_token_idx = vocab['end']
self.item_ids = side_data['item_entity_ids']
self.pretrain_optim_opt = self.opt['pretrain']
self.rec_optim_opt = self.opt['rec']
self.conv_optim_opt = self.opt['conv']
self.pretrain_epoch = self.pretrain_optim_opt['epoch']
self.rec_epoch = self.rec_optim_opt['epoch']
self.conv_epoch = self.conv_optim_opt['epoch']
self.pretrain_batch_size = self.pretrain_optim_opt['batch_size']
self.rec_batch_size = self.rec_optim_opt['batch_size']
self.conv_batch_size = self.conv_optim_opt['batch_size']
# loss weight
self.gen_loss_weight = self.opt['gen_loss_weight']
def rec_evaluate(self, rec_predict, item_label):
rec_predict = rec_predict.cpu()
rec_predict = rec_predict[:, self.item_ids]
_, rec_ranks = torch.topk(rec_predict, 50, dim=-1)
rec_ranks = rec_ranks.tolist()
item_label = item_label.tolist()
for rec_rank, item in zip(rec_ranks, item_label):
item = self.item_ids.index(item)
self.evaluator.rec_evaluate(rec_rank, item)
def conv_evaluate(self, prediction,movie_prediction,response,movie_response):
prediction = prediction.tolist()
response = response.tolist()
if movie_prediction != None:
movie_prediction = movie_prediction * (movie_prediction!=-1)
movie_prediction = torch.masked_select(movie_prediction,(movie_prediction!=0))
movie_prediction = movie_prediction.tolist()
movie_prediction = ind2slot(movie_prediction,self.ind2movie)
if movie_response != None:
movie_response = movie_response * (movie_response!=-1)
movie_response = torch.masked_select(movie_response,(movie_response!=0))
movie_response = movie_response.tolist()
movie_response = ind2slot(movie_response,self.ind2movie)
for p, r in zip(prediction,response):
p_str = ind2txt_with_slots(p, movie_prediction, self.ind2tok, self.end_token_idx)
p_str = p_str[1:]
r_str = ind2txt_with_slots(r, movie_response, self.ind2tok, self.end_token_idx)
self.evaluator.gen_evaluate(p_str, [r_str])
def step(self, batch, stage, mode):
'''
converse:
context_tokens, context_entities, context_words, response,all_movies = batch
recommend
context_entities, context_words, entities, movie = batch
'''
batch = [ele.to(self.device) for ele in batch]
if stage == 'pretrain':
info_loss = self.model.forward(batch, stage, mode)
if info_loss is not None:
self.backward(info_loss.sum())
info_loss = info_loss.sum().item()
self.evaluator.optim_metrics.add("info_loss", AverageMetric(info_loss))
elif stage == 'rec':
rec_loss, info_loss, rec_predict = self.model.forward(batch, stage, mode)
if info_loss:
loss = rec_loss + 0.025 * info_loss
else:
loss = rec_loss
if mode == "train":
self.backward(loss.sum())
else:
self.rec_evaluate(rec_predict, batch[-1])
rec_loss = rec_loss.sum().item()
self.evaluator.optim_metrics.add("rec_loss", AverageMetric(rec_loss))
if info_loss:
info_loss = info_loss.sum().item()
self.evaluator.optim_metrics.add("info_loss", AverageMetric(info_loss))
elif stage == "conv":
if mode != "test":
gen_loss,selection_loss,pred = self.model.forward(batch, stage, mode)
if mode == 'train':
loss = self.gen_loss_weight * gen_loss + selection_loss
self.backward(loss.sum())
loss = loss.sum().item()
self.evaluator.optim_metrics.add("gen_total_loss", AverageMetric(loss))
gen_loss = gen_loss.sum().item()
self.evaluator.optim_metrics.add("gen_loss", AverageMetric(gen_loss))
self.evaluator.gen_metrics.add("ppl", PPLMetric(gen_loss))
selection_loss = selection_loss.sum().item()
self.evaluator.optim_metrics.add('sel_loss',AverageMetric(selection_loss))
else:
pred,matching_pred,matching_logist = self.model.forward(batch, stage, mode)
self.conv_evaluate(pred,matching_pred,batch[-2],batch[-1])
else:
raise
def pretrain(self):
self.init_optim(self.pretrain_optim_opt, self.model.parameters())
for epoch in range(self.pretrain_epoch):
self.evaluator.reset_metrics()
logger.info(f'[Pretrain epoch {str(epoch)}]')
for batch in self.train_dataloader.get_pretrain_data(self.pretrain_batch_size, shuffle=False):
self.step(batch, stage="pretrain", mode='train')
self.evaluator.report()
def train_recommender(self):
self.init_optim(self.rec_optim_opt, self.model.parameters())
for epoch in range(self.rec_epoch):
self.evaluator.reset_metrics()
logger.info(f'[Recommendation epoch {str(epoch)}]')
logger.info('[Train]')
for batch in self.train_dataloader.get_rec_data(self.rec_batch_size, shuffle=False):
self.step(batch, stage='rec', mode='train')
self.evaluator.report(epoch=epoch, mode='train')
# val
logger.info('[Valid]')
with torch.no_grad():
self.evaluator.reset_metrics()
for batch in self.valid_dataloader.get_rec_data(self.rec_batch_size, shuffle=False):
self.step(batch, stage='rec', mode='val')
self.evaluator.report(epoch=epoch, mode='val')
# early stop
metric = self.evaluator.rec_metrics['hit@1'] + self.evaluator.rec_metrics['hit@50']
if self.early_stop(metric):
break
# test
logger.info('[Test]')
with torch.no_grad():
self.evaluator.reset_metrics()
for batch in self.test_dataloader.get_rec_data(self.rec_batch_size, shuffle=False):
self.step(batch, stage='rec', mode='test')
self.evaluator.report(mode='test')
def train_conversation(self):
if os.environ["CUDA_VISIBLE_DEVICES"] == '-1':
self.model.freeze_parameters()
else:
self.model.module.freeze_parameters()
self.init_optim(self.conv_optim_opt, self.model.parameters())
for epoch in range(self.conv_epoch):
self.evaluator.reset_metrics()
logger.info(f'[Conversation epoch {str(epoch)}]')
logger.info('[Train]')
for batch in self.train_dataloader.get_conv_data(batch_size=self.conv_batch_size, shuffle=False):
self.step(batch, stage='conv', mode='train')
self.evaluator.report(epoch=epoch, mode='train')
# val
logger.info('[Valid]')
with torch.no_grad():
self.evaluator.reset_metrics()
for batch in self.valid_dataloader.get_conv_data(batch_size=self.conv_batch_size, shuffle=False):
self.step(batch, stage='conv', mode='val')
self.evaluator.report(epoch=epoch, mode='val')
# test
logger.info('[Test]')
with torch.no_grad():
self.evaluator.reset_metrics()
for batch in self.test_dataloader.get_conv_data(batch_size=self.conv_batch_size, shuffle=False):
self.step(batch, stage='conv', mode='test')
self.evaluator.report(mode='test')
def fit(self):
self.pretrain()
self.train_recommender()
self.train_conversation()
def interact(self):
pass
================================================
FILE: crslab/system/redial.py
================================================
# @Time : 2020/12/4
# @Author : Chenzhan Shang
# @Email : czshang@outlook.com
# UPDATE
# @Time : 2021/1/3
# @Author : Xiaolei Wang
# @email : wxl1999@foxmail.com
import torch
from loguru import logger
from crslab.data import dataset_language_map
from crslab.evaluator.metrics.base import AverageMetric
from crslab.evaluator.metrics.gen import PPLMetric
from crslab.system.base import BaseSystem
from crslab.system.utils.functions import ind2txt
class ReDialSystem(BaseSystem):
"""This is the system for KGSF model"""
def __init__(self, opt, train_dataloader, valid_dataloader, test_dataloader, vocab, side_data, restore_system=False,
interact=False, debug=False, tensorboard=False):
"""
Args:
opt (dict): Indicating the hyper parameters.
train_dataloader (BaseDataLoader): Indicating the train dataloader of corresponding dataset.
valid_dataloader (BaseDataLoader): Indicating the valid dataloader of corresponding dataset.
test_dataloader (BaseDataLoader): Indicating the test dataloader of corresponding dataset.
vocab (dict): Indicating the vocabulary.
side_data (dict): Indicating the side data.
restore_system (bool, optional): Indicating if we store system after training. Defaults to False.
interact (bool, optional): Indicating if we interact with system. Defaults to False.
debug (bool, optional): Indicating if we train in debug mode. Defaults to False.
tensorboard (bool, optional) Indicating if we monitor the training performance in tensorboard. Defaults to False.
"""
super(ReDialSystem, self).__init__(opt, train_dataloader, valid_dataloader, test_dataloader, vocab, side_data,
restore_system, interact, debug, tensorboard)
self.ind2tok = vocab['conv']['ind2tok']
self.end_token_idx = vocab['conv']['end']
self.item_ids = side_data['rec']['item_entity_ids']
self.id2entity = vocab['rec']['id2entity']
self.rec_optim_opt = opt['rec']
self.conv_optim_opt = opt['conv']
self.rec_epoch = self.rec_optim_opt['epoch']
self.conv_epoch = self.conv_optim_opt['epoch']
self.rec_batch_size = self.rec_optim_opt['batch_size']
self.conv_batch_size = self.conv_optim_opt['batch_size']
self.language = dataset_language_map[self.opt['dataset']]
def rec_evaluate(self, rec_predict, item_label):
rec_predict = rec_predict.cpu()
rec_predict = rec_predict[:, self.item_ids]
_, rec_ranks = torch.topk(rec_predict, 50, dim=-1)
rec_ranks = rec_ranks.tolist()
item_label = item_label.tolist()
for rec_rank, item in zip(rec_ranks, item_label):
item = self.item_ids.index(item)
self.evaluator.rec_evaluate(rec_rank, item)
def conv_evaluate(self, prediction, response):
prediction = prediction.tolist()
response = response.tolist()
for p, r in zip(prediction, response):
p_str = ind2txt(p, self.ind2tok, self.end_token_idx)
r_str = ind2txt(r, self.ind2tok, self.end_token_idx)
self.evaluator.gen_evaluate(p_str, [r_str])
def step(self, batch, stage, mode):
assert stage in ('rec', 'conv')
assert mode in ('train', 'valid', 'test')
for k, v in batch.items():
if isinstance(v, torch.Tensor):
batch[k] = v.to(self.device)
if stage == 'rec':
rec_loss, rec_scores = self.rec_model.forward(batch, mode=mode)
rec_loss = rec_loss.sum()
if mode == 'train':
self.backward(rec_loss)
else:
self.rec_evaluate(rec_scores, batch['item'])
rec_loss = rec_loss.item()
self.evaluator.optim_metrics.add("rec_loss", AverageMetric(rec_loss))
else:
gen_loss, preds = self.conv_model.forward(batch, mode=mode)
gen_loss = gen_loss.sum()
if mode == 'train':
self.backward(gen_loss)
else:
self.conv_evaluate(preds, batch['response'])
gen_loss = gen_loss.item()
self.evaluator.optim_metrics.add('gen_loss', AverageMetric(gen_loss))
self.evaluator.gen_metrics.add('ppl', PPLMetric(gen_loss))
def train_recommender(self):
self.init_optim(self.rec_optim_opt, self.rec_model.parameters())
for epoch in range(self.rec_epoch):
self.evaluator.reset_metrics()
logger.info(f'[Recommendation epoch {str(epoch)}]')
logger.info('[Train]')
for batch in self.train_dataloader['rec'].get_rec_data(batch_size=self.rec_batch_size):
self.step(batch, stage='rec', mode='train')
self.evaluator.report(epoch=epoch, mode='train') # report train loss
# val
logger.info('[Valid]')
with torch.no_grad():
self.evaluator.reset_metrics()
for batch in self.valid_dataloader['rec'].get_rec_data(batch_size=self.rec_batch_size, shuffle=False):
self.step(batch, stage='rec', mode='valid')
self.evaluator.report(epoch=epoch, mode='valid') # report valid loss
# early stop
metric = self.evaluator.optim_metrics['rec_loss']
if self.early_stop(metric):
break
# test
logger.info('[Test]')
with torch.no_grad():
self.evaluator.reset_metrics()
for batch in self.test_dataloader['rec'].get_rec_data(batch_size=self.rec_batch_size, shuffle=False):
self.step(batch, stage='rec', mode='test')
self.evaluator.report(mode='test')
def train_conversation(self):
self.init_optim(self.conv_optim_opt, self.conv_model.parameters())
for epoch in range(self.conv_epoch):
self.evaluator.reset_metrics()
logger.info(f'[Conversation epoch {str(epoch)}]')
logger.info('[Train]')
for batch in self.train_dataloader['conv'].get_conv_data(batch_size=self.conv_batch_size):
self.step(batch, stage='conv', mode='train')
self.evaluator.report(epoch=epoch, mode='train')
# val
logger.info('[Valid]')
with torch.no_grad():
self.evaluator.reset_metrics()
for batch in self.valid_dataloader['conv'].get_conv_data(batch_size=self.conv_batch_size,
shuffle=False):
self.step(batch, stage='conv', mode='valid')
self.evaluator.report(epoch=epoch, mode='valid')
metric = self.evaluator.optim_metrics['gen_loss']
if self.early_stop(metric):
break
# test
logger.info('[Test]')
with torch.no_grad():
self.evaluator.reset_metrics()
for batch in self.test_dataloader['conv'].get_conv_data(batch_size=self.conv_batch_size, shuffle=False):
self.step(batch, stage='conv', mode='test')
self.evaluator.report(mode='test')
def fit(self):
self.train_recommender()
self.train_conversation()
def interact(self):
pass
================================================
FILE: crslab/system/tgredial.py
================================================
# @Time : 2020/12/9
# @Author : Yuanhang Zhou
# @Email : sdzyh002@gmail.com
# UPDATE:
# @Time : 2021/1/3
# @Author : Xiaolei Wang
# @Email : wxl1999@foxmail.com
import os
import torch
from loguru import logger
from math import floor
from crslab.config import PRETRAIN_PATH
from crslab.data import get_dataloader, dataset_language_map
from crslab.evaluator.metrics.base import AverageMetric
from crslab.evaluator.metrics.gen import PPLMetric
from crslab.system.base import BaseSystem
from crslab.system.utils.functions import ind2txt
class TGReDialSystem(BaseSystem):
"""This is the system for TGReDial model"""
def __init__(self, opt, train_dataloader, valid_dataloader, test_dataloader, vocab, side_data, restore_system=False,
interact=False, debug=False, tensorboard=False):
"""
Args:
opt (dict): Indicating the hyper parameters.
train_dataloader (BaseDataLoader): Indicating the train dataloader of corresponding dataset.
valid_dataloader (BaseDataLoader): Indicating the valid dataloader of corresponding dataset.
test_dataloader (BaseDataLoader): Indicating the test dataloader of corresponding dataset.
vocab (dict): Indicating the vocabulary.
side_data (dict): Indicating the side data.
restore_system (bool, optional): Indicating if we store system after training. Defaults to False.
interact (bool, optional): Indicating if we interact with system. Defaults to False.
debug (bool, optional): Indicating if we train in debug mode. Defaults to False.
tensorboard (bool, optional) Indicating if we monitor the training performance in tensorboard. Defaults to False.
"""
super(TGReDialSystem, self).__init__(opt, train_dataloader, valid_dataloader,
test_dataloader, vocab, side_data, restore_system, interact, debug,
tensorboard)
if hasattr(self, 'conv_model'):
self.ind2tok = vocab['conv']['ind2tok']
self.end_token_idx = vocab['conv']['end']
if hasattr(self, 'rec_model'):
self.item_ids = side_data['rec']['item_entity_ids']
self.id2entity = vocab['rec']['id2entity']
if hasattr(self, 'rec_model'):
self.rec_optim_opt = self.opt['rec']
self.rec_epoch = self.rec_optim_opt['epoch']
self.rec_batch_size = self.rec_optim_opt['batch_size']
if hasattr(self, 'conv_model'):
self.conv_optim_opt = self.opt['conv']
self.conv_epoch = self.conv_optim_opt['epoch']
self.conv_batch_size = self.conv_optim_opt['batch_size']
if self.conv_optim_opt.get('lr_scheduler', None) and 'Transformers' in self.conv_optim_opt['lr_scheduler'][
'name']:
batch_num = 0
for _ in self.train_dataloader['conv'].get_conv_data(batch_size=self.conv_batch_size, shuffle=False):
batch_num += 1
conv_training_steps = self.conv_epoch * floor(batch_num / self.conv_optim_opt.get('update_freq', 1))
self.conv_optim_opt['lr_scheduler']['training_steps'] = conv_training_steps
if hasattr(self, 'policy_model'):
self.policy_optim_opt = self.opt['policy']
self.policy_epoch = self.policy_optim_opt['epoch']
self.policy_batch_size = self.policy_optim_opt['batch_size']
self.language = dataset_language_map[self.opt['dataset']]
def rec_evaluate(self, rec_predict, item_label):
rec_predict = rec_predict.cpu()
rec_predict = rec_predict[:, self.item_ids]
_, rec_ranks = torch.topk(rec_predict, 50, dim=-1)
rec_ranks = rec_ranks.tolist()
item_label = item_label.tolist()
for rec_rank, item in zip(rec_ranks, item_label):
item = self.item_ids.index(item)
self.evaluator.rec_evaluate(rec_rank, item)
def policy_evaluate(self, rec_predict, movie_label):
rec_predict = rec_predict.cpu()
_, rec_ranks = torch.topk(rec_predict, 50, dim=-1)
rec_ranks = rec_ranks.tolist()
movie_label = movie_label.tolist()
for rec_rank, movie in zip(rec_ranks, movie_label):
self.evaluator.rec_evaluate(rec_rank, movie)
def conv_evaluate(self, prediction, response):
"""
Args:
prediction: torch.LongTensor, shape=(bs, response_truncate-1)
response: torch.LongTensor, shape=(bs, response_truncate)
the first token in response is <|endoftext|>, it is not in prediction
"""
prediction = prediction.tolist()
response = response.tolist()
for p, r in zip(prediction, response):
p_str = ind2txt(p, self.ind2tok, self.end_token_idx)
r_str = ind2txt(r[1:], self.ind2tok, self.end_token_idx)
self.evaluator.gen_evaluate(p_str, [r_str])
def step(self, batch, stage, mode):
"""
stage: ['policy', 'rec', 'conv']
mode: ['train', 'val', 'test]
"""
batch = [ele.to(self.device) for ele in batch]
if stage == 'policy':
if mode == 'train':
self.policy_model.train()
else:
self.policy_model.eval()
policy_loss, policy_predict = self.policy_model.forward(batch, mode)
if mode == "train" and policy_loss is not None:
policy_loss = policy_loss.sum()
self.backward(policy_loss)
else:
self.policy_evaluate(policy_predict, batch[-1])
if isinstance(policy_loss, torch.Tensor):
policy_loss = policy_loss.item()
self.evaluator.optim_metrics.add("policy_loss",
AverageMetric(policy_loss))
elif stage == 'rec':
if mode == 'train':
self.rec_model.train()
else:
self.rec_model.eval()
rec_loss, rec_predict = self.rec_model.forward(batch, mode)
rec_loss = rec_loss.sum()
if mode == "train":
self.backward(rec_loss)
else:
self.rec_evaluate(rec_predict, batch[-1])
rec_loss = rec_loss.item()
self.evaluator.optim_metrics.add("rec_loss",
AverageMetric(rec_loss))
elif stage == "conv":
if mode != "test":
# train + valid: need to compute ppl
gen_loss, pred = self.conv_model.forward(batch, mode)
gen_loss = gen_loss.sum()
if mode == 'train':
self.backward(gen_loss)
else:
self.conv_evaluate(pred, batch[-1])
gen_loss = gen_loss.item()
self.evaluator.optim_metrics.add("gen_loss",
AverageMetric(gen_loss))
self.evaluator.gen_metrics.add("ppl", PPLMetric(gen_loss))
else:
# generate response in conv_model.step
pred = self.conv_model.forward(batch, mode)
self.conv_evaluate(pred, batch[-1])
else:
raise
def train_recommender(self):
if hasattr(self.rec_model, 'bert'):
if os.environ["CUDA_VISIBLE_DEVICES"] == '-1':
bert_param = list(self.rec_model.bert.named_parameters())
else:
bert_param = list(self.rec_model.module.bert.named_parameters())
bert_param_name = ['bert.' + n for n, p in bert_param]
else:
bert_param = []
bert_param_name = []
other_param = [
name_param for name_param in self.rec_model.named_parameters()
if name_param[0] not in bert_param_name
]
params = [{'params': [p for n, p in bert_param], 'lr': self.rec_optim_opt['lr_bert']},
{'params': [p for n, p in other_param]}]
self.init_optim(self.rec_optim_opt, params)
for epoch in range(self.rec_epoch):
self.evaluator.reset_metrics()
logger.info(f'[Recommendation epoch {str(epoch)}]')
for batch in self.train_dataloader['rec'].get_rec_data(self.rec_batch_size,
shuffle=True):
self.step(batch, stage='rec', mode='train')
self.evaluator.report(epoch=epoch, mode='train')
# val
with torch.no_grad():
self.evaluator.reset_metrics()
for batch in self.valid_dataloader['rec'].get_rec_data(
self.rec_batch_size, shuffle=False):
self.step(batch, stage='rec', mode='val')
self.evaluator.report(epoch=epoch, mode='val')
# early stop
metric = self.evaluator.rec_metrics['hit@1'] + self.evaluator.rec_metrics['hit@50']
if self.early_stop(metric):
break
# test
with torch.no_grad():
self.evaluator.reset_metrics()
for batch in self.test_dataloader['rec'].get_rec_data(self.rec_batch_size,
shuffle=False):
self.step(batch, stage='rec', mode='test')
self.evaluator.report(mode='test')
def train_conversation(self):
self.init_optim(self.conv_optim_opt, self.conv_model.parameters())
for epoch in range(self.conv_epoch):
self.evaluator.reset_metrics()
logger.info(f'[Conversation epoch {str(epoch)}]')
for batch in self.train_dataloader['conv'].get_conv_data(
batch_size=self.conv_batch_size, shuffle=True):
self.step(batch, stage='conv', mode='train')
self.evaluator.report(epoch=epoch, mode='train')
# val
with torch.no_grad():
self.evaluator.reset_metrics()
for batch in self.valid_dataloader['conv'].get_conv_data(
batch_size=self.conv_batch_size, shuffle=False):
self.step(batch, stage='conv', mode='val')
self.evaluator.report(epoch=epoch, mode='val')
# early stop
metric = self.evaluator.gen_metrics['ppl']
if self.early_stop(metric):
break
# test
with torch.no_grad():
self.evaluator.reset_metrics()
for batch in self.test_dataloader['conv'].get_conv_data(
batch_size=self.conv_batch_size, shuffle=False):
self.step(batch, stage='conv', mode='test')
self.evaluator.report(mode='test')
def train_policy(self):
policy_params = list(self.policy_model.named_parameters())
no_decay = ['bias', 'LayerNorm.bias', 'LayerNorm.weight']
params = [{
'params': [
p for n, p in policy_params
if not any(nd in n for nd in no_decay)
],
'weight_decay':
self.policy_optim_opt['weight_decay']
}, {
'params': [
p for n, p in policy_params
if any(nd in n for nd in no_decay)
],
}]
self.init_optim(self.policy_optim_opt, params)
for epoch in range(self.policy_epoch):
self.evaluator.reset_metrics()
logger.info(f'[Policy epoch {str(epoch)}]')
# change the shuffle to True
for batch in self.train_dataloader['policy'].get_policy_data(
self.policy_batch_size, shuffle=True):
self.step(batch, stage='policy', mode='train')
self.evaluator.report(epoch=epoch, mode='train')
# val
with torch.no_grad():
self.evaluator.reset_metrics()
for batch in self.valid_dataloader['policy'].get_policy_data(
self.policy_batch_size, shuffle=False):
self.step(batch, stage='policy', mode='val')
self.evaluator.report(epoch=epoch, mode='val')
# early stop
metric = self.evaluator.rec_metrics['hit@1'] + self.evaluator.rec_metrics['hit@50']
if self.early_stop(metric):
break
# test
with torch.no_grad():
self.evaluator.reset_metrics()
for batch in self.test_dataloader['policy'].get_policy_data(
self.policy_batch_size, shuffle=False):
self.step(batch, stage='policy', mode='test')
self.evaluator.report(mode='test')
def fit(self):
if hasattr(self, 'rec_model'):
self.train_recommender()
if hasattr(self, 'policy_model'):
self.train_policy()
if hasattr(self, 'conv_model'):
self.train_conversation()
def interact(self):
self.init_interact()
input_text = self.get_input(self.language)
while not self.finished:
# rec
if hasattr(self, 'rec_model'):
rec_input = self.process_input(input_text, 'rec')
scores = self.rec_model.forward(rec_input, 'infer')
scores = scores.cpu()[0]
scores = scores[self.item_ids]
_, rank = torch.topk(scores, 10, dim=-1)
item_ids = []
for r in rank.tolist():
item_ids.append(self.item_ids[r])
first_item_id = item_ids[:1]
self.update_context('rec', entity_ids=first_item_id, item_ids=first_item_id)
print(f"[Recommend]:")
for item_id in item_ids:
if item_id in self.id2entity:
print(self.id2entity[item_id])
# conv
if hasattr(self, 'conv_model'):
conv_input = self.process_input(input_text, 'conv')
preds = self.conv_model.forward(conv_input, 'infer').tolist()[0]
p_str = ind2txt(preds, self.ind2tok, self.end_token_idx)
token_ids, entity_ids, movie_ids, word_ids = self.convert_to_id(p_str, 'conv')
self.update_context('conv', token_ids, entity_ids, movie_ids, word_ids)
print(f"[Response]:\n{p_str}")
# input
input_text = self.get_input(self.language)
def process_input(self, input_text, stage):
token_ids, entity_ids, movie_ids, word_ids = self.convert_to_id(input_text, stage)
self.update_context(stage, token_ids, entity_ids, movie_ids, word_ids)
data = {'role': 'Seeker', 'context_tokens': self.context[stage]['context_tokens'],
'context_entities': self.context[stage]['context_entities'],
'context_words': self.context[stage]['context_words'],
'context_items': self.context[stage]['context_items'],
'user_profile': self.context[stage]['user_profile'],
'interaction_history': self.context[stage]['interaction_history']}
dataloader = get_dataloader(self.opt, data, self.vocab[stage])
if stage == 'rec':
data = dataloader.rec_interact(data)
elif stage == 'conv':
data = dataloader.conv_interact(data)
data = [ele.to(self.device) if isinstance(ele, torch.Tensor) else ele for ele in data]
return data
def convert_to_id(self, text, stage):
if self.language == 'zh':
tokens = self.tokenize(text, 'pkuseg')
elif self.language == 'en':
tokens = self.tokenize(text, 'nltk')
else:
raise
entities = self.link(tokens, self.side_data[stage]['entity_kg']['entity'])
words = self.link(tokens, self.side_data[stage]['word_kg']['entity'])
if self.opt['tokenize'][stage] in ('gpt2', 'bert'):
language = dataset_language_map[self.opt['dataset']]
path = os.path.join(PRETRAIN_PATH, self.opt['tokenize'][stage], language)
tokens = self.tokenize(text, 'bert', path)
token_ids = [self.vocab[stage]['tok2ind'].get(token, self.vocab[stage]['unk']) for token in tokens]
entity_ids = [self.vocab[stage]['entity2id'][entity] for entity in entities if
entity in self.vocab[stage]['entity2id']]
movie_ids = [entity_id for entity_id in entity_ids if entity_id in self.item_ids]
word_ids = [self.vocab[stage]['word2id'][word] for word in words if word in self.vocab[stage]['word2id']]
return token_ids, entity_ids, movie_ids, word_ids
================================================
FILE: crslab/system/utils/__init__.py
================================================
================================================
FILE: crslab/system/utils/functions.py
================================================
# @Time : 2020/11/22
# @Author : Kun Zhou
# @Email : francis_kun_zhou@163.com
# UPDATE:
# @Time : 2020/11/24, 2020/12/18
# @Author : Kun Zhou, Xiaolei Wang
# @Email : francis_kun_zhou@163.com, wxl1999@foxmail.com
# UPDATE:
# @Time : 2021/10/05
# @Author : Zhipeng Zhao
# @email : oran_official@outlook.com
import torch
def compute_grad_norm(parameters, norm_type=2.0):
"""
Compute norm over gradients of model parameters.
:param parameters:
the model parameters for gradient norm calculation. Iterable of
Tensors or single Tensor
:param norm_type:
type of p-norm to use
:returns:
the computed gradient norm
"""
if isinstance(parameters, torch.Tensor):
parameters = [parameters]
parameters = [p for p in parameters if p is not None and p.grad is not None]
total_norm = 0
for p in parameters:
param_norm = p.grad.data.norm(norm_type)
total_norm += param_norm.item() ** norm_type
return total_norm ** (1.0 / norm_type)
def ind2txt(inds, ind2tok, end_token_idx=None, unk_token='unk'):
sentence = []
for ind in inds:
if isinstance(ind, torch.Tensor):
ind = ind.item()
if end_token_idx and ind == end_token_idx:
break
sentence.append(ind2tok.get(ind, unk_token))
return ' '.join(sentence)
def ind2txt_with_slots(inds,slots,ind2tok, end_token_idx=None, unk_token='unk',slot_token='[ITEM]'):
sentence = []
for ind in inds:
if isinstance(ind, torch.Tensor):
ind = ind.item()
if end_token_idx and ind == end_token_idx:
break
token = ind2tok.get(ind, unk_token)
if token == slot_token:
token = slots[0]
slots = slots[1:]
sentence.append(token)
return ' '.join(sentence)
def ind2slot(inds,ind2slot):
return [ ind2slot[ind] for ind in inds]
================================================
FILE: crslab/system/utils/lr_scheduler.py
================================================
# @Time : 2020/12/1
# @Author : Xiaolei Wang
# @Email : wxl1999@foxmail.com
from abc import abstractmethod, ABC
# UPDATE:
# @Time : 2020/12/14
# @Author : Xiaolei Wang
# @Email : wxl1999@foxmail.com
import math
import numpy as np
import torch
from loguru import logger
from torch import optim
class LRScheduler(ABC):
"""
Class for LR Schedulers.
Includes some basic functionality by default - setting up the warmup
scheduler, passing the correct number of steps to train_step, loading and
saving states.
Subclasses must implement abstract methods train_step() and valid_step().
Schedulers should be initialized with lr_scheduler_factory().
__init__() should not be called directly.
"""
def __init__(self, optimizer, warmup_steps: int = 0):
"""
Initialize warmup scheduler. Specific main schedulers should be initialized in
the subclasses. Do not invoke this method diretly.
:param optimizer optimizer:
Optimizer being used for training. May be wrapped in
fp16_optimizer_wrapper depending on whether fp16 is used.
:param int warmup_steps:
Number of training step updates warmup scheduler should take.
"""
self._number_training_updates = 0
self.warmup_steps = warmup_steps
self._init_warmup_scheduler(optimizer)
def _warmup_lr(self, step):
"""
Return lr multiplier (on initial lr) for warmup scheduler.
"""
return float(step) / float(max(1, self.warmup_steps))
def _init_warmup_scheduler(self, optimizer):
if self.warmup_steps > 0:
self.warmup_scheduler = optim.lr_scheduler.LambdaLR(optimizer, self._warmup_lr)
else:
self.warmup_scheduler = None
def _is_lr_warming_up(self):
"""
Check if we're warming up the learning rate.
"""
return (
hasattr(self, 'warmup_scheduler')
and self.warmup_scheduler is not None
and self._number_training_updates <= self.warmup_steps
)
def train_step(self):
"""
Use the number of train steps to adjust the warmup scheduler or the main
scheduler, depending on where in training we are.
Override this method to override the behavior for training schedulers.
"""
self._number_training_updates += 1
if self._is_lr_warming_up():
self.warmup_scheduler.step()
else:
self.train_adjust()
def valid_step(self, metric=None):
if self._is_lr_warming_up():
# we're not done warming up, so don't start using validation
# metrics to adjust schedule
return
self.valid_adjust(metric)
@abstractmethod
def train_adjust(self):
"""
Use the number of train steps to decide when to adjust LR schedule.
Override this method to override the behavior for training schedulers.
"""
pass
@abstractmethod
def valid_adjust(self, metric):
"""
Use the metrics to decide when to adjust LR schedule.
This uses the loss as the validation metric if present, if not this
function does nothing. Note that the model must be reporting loss for
this to work.
Override this method to override the behavior for validation schedulers.
"""
pass
class ReduceLROnPlateau(LRScheduler):
"""
Scheduler that decays by a multiplicative rate when valid loss plateaus.
"""
def __init__(self, optimizer, mode='min', factor=0.1, patience=10, verbose=False, threshold=0.0001,
threshold_mode='rel', cooldown=0, min_lr=0, eps=1e-08, warmup_steps=0):
super(ReduceLROnPlateau, self).__init__(optimizer, warmup_steps)
self.scheduler = optim.lr_scheduler.ReduceLROnPlateau(optimizer=optimizer, mode=mode, factor=factor,
patience=patience, verbose=verbose, threshold=threshold,
threshold_mode=threshold_mode, cooldown=cooldown,
min_lr=min_lr, eps=eps)
def train_adjust(self):
pass
def valid_adjust(self, metric):
self.scheduler.step(metric)
class StepLR(LRScheduler):
"""
Scheduler that decays by a fixed multiplicative rate at each valid step.
"""
def __init__(self, optimizer, step_size, gamma=0.1, last_epoch=-1, warmup_steps=0):
super(StepLR, self).__init__(optimizer, warmup_steps)
self.scheduler = optim.lr_scheduler.StepLR(optimizer, step_size, gamma, last_epoch)
def train_adjust(self):
pass
def valid_adjust(self, metric=None):
self.scheduler.step()
class ConstantLR(LRScheduler):
def __init__(self, optimizer, warmup_steps=0):
super(ConstantLR, self).__init__(optimizer, warmup_steps)
def train_adjust(self):
pass
def valid_adjust(self, metric):
pass
class InvSqrtLR(LRScheduler):
"""
Scheduler that decays at an inverse square root rate.
"""
def __init__(self, optimizer, invsqrt_lr_decay_gamma=-1, last_epoch=-1, warmup_steps=0):
"""
invsqrt_lr_decay_gamma determines the cycle length of the inverse square root
scheduler.
When steps taken == invsqrt_lr_decay_gamma, the lr multiplier is 1
"""
super(InvSqrtLR, self).__init__(optimizer, warmup_steps)
self.invsqrt_lr_decay_gamma = invsqrt_lr_decay_gamma
if invsqrt_lr_decay_gamma <= 0:
logger.warning(
'--lr-scheduler invsqrt requires a value for '
'--invsqrt-lr-decay-gamma. Defaulting to set gamma to '
'--warmup-updates value for backwards compatibility.'
)
self.invsqrt_lr_decay_gamma = self.warmup_steps
self.decay_factor = np.sqrt(max(1, self.invsqrt_lr_decay_gamma))
self.scheduler = torch.optim.lr_scheduler.LambdaLR(optimizer, self._invsqrt_lr, last_epoch)
def _invsqrt_lr(self, step):
return self.decay_factor / np.sqrt(max(1, self.invsqrt_lr_decay_gamma + step))
def train_adjust(self):
self.scheduler.step()
def valid_adjust(self, metric):
# this is a training step lr scheduler, nothing to adjust in validation
pass
class CosineAnnealingLR(LRScheduler):
"""
Scheduler that decays by a cosine function.
"""
def __init__(self, optimizer, T_max, eta_min=0, last_epoch=-1, warmup_steps=0):
"""
training_steps determines the cycle length of the cosine annealing.
It indicates the number of steps from 1.0 multiplier to 0.0, which corresponds
to going from cos(0) to cos(pi)
"""
super(CosineAnnealingLR, self).__init__(optimizer, warmup_steps)
self.scheduler = optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max, eta_min, last_epoch)
def train_adjust(self):
self.scheduler.step()
def valid_adjust(self, metric):
pass
class CosineAnnealingWarmRestartsLR(LRScheduler):
def __init__(self, optimizer, T_0, T_mult=1, eta_min=0, last_epoch=-1, warmup_steps=0):
super(CosineAnnealingWarmRestartsLR, self).__init__(optimizer, warmup_steps)
self.scheduler = optim.lr_scheduler.CosineAnnealingWarmRestarts(optimizer, T_0, T_mult, eta_min, last_epoch)
def train_adjust(self):
self.scheduler.step()
def valid_adjust(self, metric):
pass
class TransformersLinearLR(LRScheduler):
"""
Scheduler that decays linearly.
"""
def __init__(self, optimizer, training_steps, warmup_steps=0):
"""
training_steps determines the cycle length of the linear annealing.
It indicates the number of steps from 1.0 multiplier to 0.0
"""
super(TransformersLinearLR, self).__init__(optimizer, warmup_steps)
self.training_steps = training_steps - warmup_steps
self.scheduler = torch.optim.lr_scheduler.LambdaLR(optimizer, self._linear_lr)
def _linear_lr(self, step):
return max(0.0, float(self.training_steps - step) / float(max(1, self.training_steps)))
def train_adjust(self):
self.scheduler.step()
def valid_adjust(self, metric):
pass
class TransformersCosineLR(LRScheduler):
def __init__(self, optimizer, training_steps: int, num_cycles: float = 0.5, last_epoch: int = -1,
warmup_steps: int = 0):
super(TransformersCosineLR, self).__init__(optimizer, warmup_steps)
self.training_steps = training_steps - warmup_steps
self.num_cycles = num_cycles
self.scheduler = torch.optim.lr_scheduler.LambdaLR(optimizer, self._cosine_lr, last_epoch)
def _cosine_lr(self, step):
progress = float(step) / float(max(1, self.training_steps))
return max(0.0, 0.5 * (1.0 + math.cos(math.pi * float(self.num_cycles) * 2.0 * progress)))
def train_adjust(self):
self.scheduler.step()
def valid_adjust(self, metric):
pass
class TransformersCosineWithHardRestartsLR(LRScheduler):
def __init__(self, optimizer, training_steps: int, num_cycles: int = 1, last_epoch: int = -1,
warmup_steps: int = 0):
super(TransformersCosineWithHardRestartsLR, self).__init__(optimizer, warmup_steps)
self.training_steps = training_steps - warmup_steps
self.num_cycles = num_cycles
self.scheduler = torch.optim.lr_scheduler.LambdaLR(optimizer, self._cosine_with_hard_restarts_lr, last_epoch)
def _cosine_with_hard_restarts_lr(self, step):
progress = float(step) / float(max(1, self.training_steps))
if progress >= 1.0:
return 0.0
return max(0.0, 0.5 * (1.0 + math.cos(math.pi * ((float(self.num_cycles) * progress) % 1.0))))
def train_adjust(self):
self.scheduler.step()
def valid_adjust(self, metric):
pass
class TransformersPolynomialDecayLR(LRScheduler):
def __init__(self, optimizer, training_steps, lr_end=1e-7, power=1.0, last_epoch=-1, warmup_steps=0):
super(TransformersPolynomialDecayLR, self).__init__(optimizer, warmup_steps)
self.training_steps = training_steps - warmup_steps
self.lr_init = optimizer.defaults["lr"]
self.lr_end = lr_end
assert self.lr_init > lr_end, f"lr_end ({lr_end}) must be be smaller than initial lr ({self.lr_init})"
self.power = power
self.scheduler = torch.optim.lr_scheduler.LambdaLR(optimizer, self._polynomial_decay_lr, last_epoch)
def _polynomial_decay_lr(self, step):
if step > self.training_steps:
return self.lr_end / self.lr_init # as LambdaLR multiplies by lr_init
else:
lr_range = self.lr_init - self.lr_end
decay_steps = self.training_steps
pct_remaining = 1 - step / decay_steps
decay = lr_range * pct_remaining ** self.power + self.lr_end
return decay / self.lr_init # as LambdaLR multiplies by lr_init
def train_adjust(self):
self.scheduler.step()
def valid_adjust(self, metric):
pass
================================================
FILE: docs/Makefile
================================================
# Minimal makefile for Sphinx documentation
#
# You can set these variables from the command line, and also
# from the environment for the first two.
SPHINXOPTS ?=
SPHINXBUILD ?= sphinx-build
SOURCEDIR = source
BUILDDIR = build
# Put it first so that "make" without argument is like "make help".
help:
@$(SPHINXBUILD) -M help "$(SOURCEDIR)" "$(BUILDDIR)" $(SPHINXOPTS) $(O)
.PHONY: help Makefile
# Catch-all target: route all unknown targets to Sphinx using the new
# "make mode" option. $(O) is meant as a shortcut for $(SPHINXOPTS).
%: Makefile
@$(SPHINXBUILD) -M $@ "$(SOURCEDIR)" "$(BUILDDIR)" $(SPHINXOPTS) $(O)
================================================
FILE: docs/make.bat
================================================
@ECHO OFF
pushd %~dp0
REM Command file for Sphinx documentation
if "%SPHINXBUILD%" == "" (
set SPHINXBUILD=sphinx-build
)
set SOURCEDIR=source
set BUILDDIR=build
if "%1" == "" goto help
%SPHINXBUILD% >NUL 2>NUL
if errorlevel 9009 (
echo.
echo.The 'sphinx-build' command was not found. Make sure you have Sphinx
echo.installed, then set the SPHINXBUILD environment variable to point
echo.to the full path of the 'sphinx-build' executable. Alternatively you
echo.may add the Sphinx directory to PATH.
echo.
echo.If you don't have Sphinx installed, grab it from
echo.http://sphinx-doc.org/
exit /b 1
)
%SPHINXBUILD% -M %1 %SOURCEDIR% %BUILDDIR% %SPHINXOPTS% %O%
goto end
:help
%SPHINXBUILD% -M help %SOURCEDIR% %BUILDDIR% %SPHINXOPTS% %O%
:end
popd
================================================
FILE: docs/requirements.txt
================================================
numpy~=1.19.4
sentencepiece<0.1.92
dataclasses~=0.7
transformers~=4.1.1
fasttext~=0.9.2
pkuseg~=0.0.25
pyyaml~=5.4
tqdm~=4.55.0
loguru~=0.5.3
nltk~=3.4.4
requests~=2.25.1
scikit-learn~=0.24.0
fuzzywuzzy~=0.18.0
================================================
FILE: docs/requirements_geometric.txt
================================================
-f https://pytorch-geometric.com/whl/torch-1.4.0+cpu.html
torch-cluster==1.5.4
torch-scatter==2.0.4
torch-sparse==0.6.1
torch-spline-conv==1.2.0
torch-geometric~=1.6.3
================================================
FILE: docs/requirements_sphinx.txt
================================================
sphinx~=3.4.1
sphinx_rtd_theme~=0.5.0
recommonmark~=0.7.1
================================================
FILE: docs/requirements_torch.txt
================================================
-f https://download.pytorch.org/whl/torch_stable.html
torch==1.4.0+cpu
torchvision==0.5.0+cpu
================================================
FILE: docs/source/api/crslab.config.rst
================================================
crslab.config package
=====================
Submodules
----------
.. automodule:: crslab.config.config
:members:
:undoc-members:
:show-inheritance:
Module contents
---------------
.. automodule:: crslab.config
:members:
:undoc-members:
:show-inheritance:
================================================
FILE: docs/source/api/crslab.data.dataloader.rst
================================================
crslab.data.dataloader package
==============================
Submodules
----------
.. automodule:: crslab.data.dataloader.base
:members:
:undoc-members:
:show-inheritance:
.. automodule:: crslab.data.dataloader.kbrd
:members:
:undoc-members:
:show-inheritance:
.. automodule:: crslab.data.dataloader.kgsf
:members:
:undoc-members:
:show-inheritance:
.. automodule:: crslab.data.dataloader.redial
:members:
:undoc-members:
:show-inheritance:
.. automodule:: crslab.data.dataloader.tgredial
:members:
:undoc-members:
:show-inheritance:
.. automodule:: crslab.data.dataloader.utils
:members:
:undoc-members:
:show-inheritance:
Module contents
---------------
.. automodule:: crslab.data.dataloader
:members:
:undoc-members:
:show-inheritance:
================================================
FILE: docs/source/api/crslab.data.dataset.durecdial.rst
================================================
crslab.data.dataset.durecdial package
=====================================
Submodules
----------
.. automodule:: crslab.data.dataset.durecdial.durecdial
:members:
:undoc-members:
:show-inheritance:
.. automodule:: crslab.data.dataset.durecdial.resources
:members:
:undoc-members:
:show-inheritance:
Module contents
---------------
.. automodule:: crslab.data.dataset.durecdial
:members:
:undoc-members:
:show-inheritance:
================================================
FILE: docs/source/api/crslab.data.dataset.gorecdial.rst
================================================
crslab.data.dataset.gorecdial package
=====================================
Submodules
----------
.. automodule:: crslab.data.dataset.gorecdial.gorecdial
:members:
:undoc-members:
:show-inheritance:
.. automodule:: crslab.data.dataset.gorecdial.resources
:members:
:undoc-members:
:show-inheritance:
Module contents
---------------
.. automodule:: crslab.data.dataset.gorecdial
:members:
:undoc-members:
:show-inheritance:
================================================
FILE: docs/source/api/crslab.data.dataset.inspired.rst
================================================
crslab.data.dataset.inspired package
====================================
Submodules
----------
.. automodule:: crslab.data.dataset.inspired.inspired
:members:
:undoc-members:
:show-inheritance:
.. automodule:: crslab.data.dataset.inspired.resources
:members:
:undoc-members:
:show-inheritance:
Module contents
---------------
.. automodule:: crslab.data.dataset.inspired
:members:
:undoc-members:
:show-inheritance:
================================================
FILE: docs/source/api/crslab.data.dataset.opendialkg.rst
================================================
crslab.data.dataset.opendialkg package
======================================
Submodules
----------
.. automodule:: crslab.data.dataset.opendialkg.opendialkg
:members:
:undoc-members:
:show-inheritance:
.. automodule:: crslab.data.dataset.opendialkg.resources
:members:
:undoc-members:
:show-inheritance:
Module contents
---------------
.. automodule:: crslab.data.dataset.opendialkg
:members:
:undoc-members:
:show-inheritance:
================================================
FILE: docs/source/api/crslab.data.dataset.redial.rst
================================================
crslab.data.dataset.redial package
==================================
Submodules
----------
.. automodule:: crslab.data.dataset.redial.redial
:members:
:undoc-members:
:show-inheritance:
.. automodule:: crslab.data.dataset.redial.resources
:members:
:undoc-members:
:show-inheritance:
Module contents
---------------
.. automodule:: crslab.data.dataset.redial
:members:
:undoc-members:
:show-inheritance:
================================================
FILE: docs/source/api/crslab.data.dataset.rst
================================================
crslab.data.dataset package
===========================
Subpackages
-----------
.. toctree::
:maxdepth: 1
crslab.data.dataset.durecdial
crslab.data.dataset.gorecdial
crslab.data.dataset.inspired
crslab.data.dataset.opendialkg
crslab.data.dataset.redial
crslab.data.dataset.tgredial
Submodules
----------
.. automodule:: crslab.data.dataset.base_dataset
:members:
:undoc-members:
:show-inheritance:
Module contents
---------------
.. automodule:: crslab.data.dataset
:members:
:undoc-members:
:show-inheritance:
================================================
FILE: docs/source/api/crslab.data.dataset.tgredial.rst
================================================
crslab.data.dataset.tgredial package
====================================
Submodules
----------
.. automodule:: crslab.data.dataset.tgredial.resources
:members:
:undoc-members:
:show-inheritance:
.. automodule:: crslab.data.dataset.tgredial.tgredial
:members:
:undoc-members:
:show-inheritance:
Module contents
---------------
.. automodule:: crslab.data.dataset.tgredial
:members:
:undoc-members:
:show-inheritance:
================================================
FILE: docs/source/api/crslab.data.rst
================================================
crslab.data package
===================
Subpackages
-----------
.. toctree::
:maxdepth: 1
crslab.data.dataloader
crslab.data.dataset
Module contents
---------------
.. automodule:: crslab.data
:members:
:undoc-members:
:show-inheritance:
================================================
FILE: docs/source/api/crslab.evaluator.metrics.rst
================================================
crslab.evaluator.metrics package
================================
Submodules
----------
.. automodule:: crslab.evaluator.metrics.base
:members:
:undoc-members:
:show-inheritance:
.. automodule:: crslab.evaluator.metrics.gen
:members:
:undoc-members:
:show-inheritance:
.. automodule:: crslab.evaluator.metrics.rec
:members:
:undoc-members:
:show-inheritance:
Module contents
---------------
.. automodule:: crslab.evaluator.metrics
:members:
:undoc-members:
:show-inheritance:
================================================
FILE: docs/source/api/crslab.evaluator.rst
================================================
crslab.evaluator package
========================
Subpackages
-----------
.. toctree::
:maxdepth: 1
crslab.evaluator.metrics
Submodules
----------
.. automodule:: crslab.evaluator.base
:members:
:undoc-members:
:show-inheritance:
.. automodule:: crslab.evaluator.conv
:members:
:undoc-members:
:show-inheritance:
.. automodule:: crslab.evaluator.embeddings
:members:
:undoc-members:
:show-inheritance:
.. automodule:: crslab.evaluator.end2end
:members:
:undoc-members:
:show-inheritance:
.. automodule:: crslab.evaluator.rec
:members:
:undoc-members:
:show-inheritance:
.. automodule:: crslab.evaluator.standard
:members:
:undoc-members:
:show-inheritance:
.. automodule:: crslab.evaluator.utils
:members:
:undoc-members:
:show-inheritance:
Module contents
---------------
.. automodule:: crslab.evaluator
:members:
:undoc-members:
:show-inheritance:
================================================
FILE: docs/source/api/crslab.model.conversation.gpt2.rst
================================================
crslab.model.conversation.gpt2 package
======================================
Submodules
----------
.. automodule:: crslab.model.conversation.gpt2.gpt2
:members:
:undoc-members:
:show-inheritance:
Module contents
---------------
.. automodule:: crslab.model.conversation.gpt2
:members:
:undoc-members:
:show-inheritance:
================================================
FILE: docs/source/api/crslab.model.conversation.rst
================================================
crslab.model.conversation package
=================================
Subpackages
-----------
.. toctree::
:maxdepth: 1
crslab.model.conversation.gpt2
crslab.model.conversation.transformer
Module contents
---------------
.. automodule:: crslab.model.conversation
:members:
:undoc-members:
:show-inheritance:
================================================
FILE: docs/source/api/crslab.model.conversation.transformer.rst
================================================
crslab.model.conversation.transformer package
=============================================
Submodules
----------
.. automodule:: crslab.model.conversation.transformer.transformer
:members:
:undoc-members:
:show-inheritance:
Module contents
---------------
.. automodule:: crslab.model.conversation.transformer
:members:
:undoc-members:
:show-inheritance:
================================================
FILE: docs/source/api/crslab.model.crs.kbrd.rst
================================================
crslab.model.crs.kbrd package
=============================
Submodules
----------
.. automodule:: crslab.model.crs.kbrd.kbrd
:members:
:undoc-members:
:show-inheritance:
Module contents
---------------
.. automodule:: crslab.model.crs.kbrd
:members:
:undoc-members:
:show-inheritance:
================================================
FILE: docs/source/api/crslab.model.crs.kgsf.rst
================================================
crslab.model.crs.kgsf package
=============================
Submodules
----------
.. automodule:: crslab.model.crs.kgsf.kgsf
:members:
:undoc-members:
:show-inheritance:
.. automodule:: crslab.model.crs.kgsf.modules
:members:
:undoc-members:
:show-inheritance:
.. automodule:: crslab.model.crs.kgsf.resources
:members:
:undoc-members:
:show-inheritance:
Module contents
---------------
.. automodule:: crslab.model.crs.kgsf
:members:
:undoc-members:
:show-inheritance:
================================================
FILE: docs/source/api/crslab.model.crs.redial.rst
================================================
crslab.model.crs.redial package
===============================
Submodules
----------
.. automodule:: crslab.model.crs.redial.modules
:members:
:undoc-members:
:show-inheritance:
.. automodule:: crslab.model.crs.redial.redial_conv
:members:
:undoc-members:
:show-inheritance:
.. automodule:: crslab.model.crs.redial.redial_rec
:members:
:undoc-members:
:show-inheritance:
Module contents
---------------
.. automodule:: crslab.model.crs.redial
:members:
:undoc-members:
:show-inheritance:
================================================
FILE: docs/source/api/crslab.model.crs.rst
================================================
crslab.model.crs package
========================
Subpackages
-----------
.. toctree::
:maxdepth: 1
crslab.model.crs.kbrd
crslab.model.crs.kgsf
crslab.model.crs.redial
crslab.model.crs.tgredial
Module contents
---------------
.. automodule:: crslab.model.crs
:members:
:undoc-members:
:show-inheritance:
================================================
FILE: docs/source/api/crslab.model.crs.tgredial.rst
================================================
crslab.model.crs.tgredial package
=================================
Submodules
----------
.. automodule:: crslab.model.crs.tgredial.tg_conv
:members:
:undoc-members:
:show-inheritance:
.. automodule:: crslab.model.crs.tgredial.tg_policy
:members:
:undoc-members:
:show-inheritance:
.. automodule:: crslab.model.crs.tgredial.tg_rec
:members:
:undoc-members:
:show-inheritance:
Module contents
---------------
.. automodule:: crslab.model.crs.tgredial
:members:
:undoc-members:
:show-inheritance:
================================================
FILE: docs/source/api/crslab.model.policy.conv_bert.rst
================================================
crslab.model.policy.conv\_bert package
======================================
Submodules
----------
.. automodule:: crslab.model.policy.conv_bert.conv_bert
:members:
:undoc-members:
:show-inheritance:
Module contents
---------------
.. automodule:: crslab.model.policy.conv_bert
:members:
:undoc-members:
:show-inheritance:
================================================
FILE: docs/source/api/crslab.model.policy.mgcg.rst
================================================
crslab.model.policy.mgcg package
================================
Submodules
----------
.. automodule:: crslab.model.policy.mgcg.mgcg
:members:
:undoc-members:
:show-inheritance:
Module contents
---------------
.. automodule:: crslab.model.policy.mgcg
:members:
:undoc-members:
:show-inheritance:
================================================
FILE: docs/source/api/crslab.model.policy.pmi.rst
================================================
crslab.model.policy.pmi package
===============================
Submodules
----------
.. automodule:: crslab.model.policy.pmi.pmi
:members:
:undoc-members:
:show-inheritance:
Module contents
---------------
.. automodule:: crslab.model.policy.pmi
:members:
:undoc-members:
:show-inheritance:
================================================
FILE: docs/source/api/crslab.model.policy.profile_bert.rst
================================================
crslab.model.policy.profile\_bert package
=========================================
Submodules
----------
.. automodule:: crslab.model.policy.profile_bert.profile_bert
:members:
:undoc-members:
:show-inheritance:
Module contents
---------------
.. automodule:: crslab.model.policy.profile_bert
:members:
:undoc-members:
:show-inheritance:
================================================
FILE: docs/source/api/crslab.model.policy.rst
================================================
crslab.model.policy package
===========================
Subpackages
-----------
.. toctree::
:maxdepth: 1
crslab.model.policy.conv_bert
crslab.model.policy.mgcg
crslab.model.policy.pmi
crslab.model.policy.profile_bert
crslab.model.policy.topic_bert
Module contents
---------------
.. automodule:: crslab.model.policy
:members:
:undoc-members:
:show-inheritance:
================================================
FILE: docs/source/api/crslab.model.policy.topic_bert.rst
================================================
crslab.model.policy.topic\_bert package
=======================================
Submodules
----------
.. automodule:: crslab.model.policy.topic_bert.topic_bert
:members:
:undoc-members:
:show-inheritance:
Module contents
---------------
.. automodule:: crslab.model.policy.topic_bert
:members:
:undoc-members:
:show-inheritance:
================================================
FILE: docs/source/api/crslab.model.recommendation.bert.rst
================================================
crslab.model.recommendation.bert package
========================================
Submodules
----------
.. automodule:: crslab.model.recommendation.bert.bert
:members:
:undoc-members:
:show-inheritance:
Module contents
---------------
.. automodule:: crslab.model.recommendation.bert
:members:
:undoc-members:
:show-inheritance:
================================================
FILE: docs/source/api/crslab.model.recommendation.gru4rec.rst
================================================
crslab.model.recommendation.gru4rec package
===========================================
Submodules
----------
.. automodule:: crslab.model.recommendation.gru4rec.gru4rec
:members:
:undoc-members:
:show-inheritance:
Module contents
---------------
.. automodule:: crslab.model.recommendation.gru4rec
:members:
:undoc-members:
:show-inheritance:
================================================
FILE: docs/source/api/crslab.model.recommendation.popularity.rst
================================================
crslab.model.recommendation.popularity package
==============================================
Submodules
----------
.. automodule:: crslab.model.recommendation.popularity.popularity
:members:
:undoc-members:
:show-inheritance:
Module contents
---------------
.. automodule:: crslab.model.recommendation.popularity
:members:
:undoc-members:
:show-inheritance:
================================================
FILE: docs/source/api/crslab.model.recommendation.rst
================================================
crslab.model.recommendation package
===================================
Subpackages
-----------
.. toctree::
:maxdepth: 1
crslab.model.recommendation.bert
crslab.model.recommendation.gru4rec
crslab.model.recommendation.popularity
crslab.model.recommendation.sasrec
crslab.model.recommendation.textcnn
Module contents
---------------
.. automodule:: crslab.model.recommendation
:members:
:undoc-members:
:show-inheritance:
================================================
FILE: docs/source/api/crslab.model.recommendation.sasrec.rst
================================================
crslab.model.recommendation.sasrec package
==========================================
Submodules
----------
.. automodule:: crslab.model.recommendation.sasrec.modules
:members:
:undoc-members:
:show-inheritance:
.. automodule:: crslab.model.recommendation.sasrec.sasrec
:members:
:undoc-members:
:show-inheritance:
Module contents
---------------
.. automodule:: crslab.model.recommendation.sasrec
:members:
:undoc-members:
:show-inheritance:
================================================
FILE: docs/source/api/crslab.model.recommendation.textcnn.rst
================================================
crslab.model.recommendation.textcnn package
===========================================
Submodules
----------
.. automodule:: crslab.model.recommendation.textcnn.textcnn
:members:
:undoc-members:
:show-inheritance:
Module contents
---------------
.. automodule:: crslab.model.recommendation.textcnn
:members:
:undoc-members:
:show-inheritance:
================================================
FILE: docs/source/api/crslab.model.rst
================================================
crslab.model package
====================
Subpackages
-----------
.. toctree::
:maxdepth: 1
crslab.model.conversation
crslab.model.crs
crslab.model.policy
crslab.model.recommendation
crslab.model.utils
Submodules
----------
.. automodule:: crslab.model.base
:members:
:undoc-members:
:show-inheritance:
.. automodule:: crslab.model.pretrain_models
:members:
:undoc-members:
:show-inheritance:
Module contents
---------------
.. automodule:: crslab.model
:members:
:undoc-members:
:show-inheritance:
================================================
FILE: docs/source/api/crslab.model.utils.modules.rst
================================================
crslab.model.utils.modules package
==================================
Submodules
----------
.. automodule:: crslab.model.utils.modules.attention
:members:
:undoc-members:
:show-inheritance:
.. automodule:: crslab.model.utils.modules.transformer
:members:
:undoc-members:
:show-inheritance:
Module contents
---------------
.. automodule:: crslab.model.utils.modules
:members:
:undoc-members:
:show-inheritance:
================================================
FILE: docs/source/api/crslab.model.utils.rst
================================================
crslab.model.utils package
==========================
Subpackages
-----------
.. toctree::
:maxdepth: 1
crslab.model.utils.modules
Submodules
----------
.. automodule:: crslab.model.utils.functions
:members:
:undoc-members:
:show-inheritance:
Module contents
---------------
.. automodule:: crslab.model.utils
:members:
:undoc-members:
:show-inheritance:
================================================
FILE: docs/source/api/crslab.quick_start.rst
================================================
crslab.quick\_start package
===========================
Submodules
----------
.. automodule:: crslab.quick_start.quick_start
:members:
:undoc-members:
:show-inheritance:
Module contents
---------------
.. automodule:: crslab.quick_start
:members:
:undoc-members:
:show-inheritance:
================================================
FILE: docs/source/api/crslab.rst
================================================
crslab package
==============
Subpackages
-----------
.. toctree::
:maxdepth: 1
crslab.config
crslab.data
crslab.evaluator
crslab.model
crslab.quick_start
crslab.system
Submodules
----------
.. automodule:: crslab.download
:members:
:undoc-members:
:show-inheritance:
Module contents
---------------
.. automodule:: crslab
:members:
:undoc-members:
:show-inheritance:
================================================
FILE: docs/source/api/crslab.system.rst
================================================
crslab.system package
=====================
Submodules
----------
.. automodule:: crslab.system.base
:members:
:undoc-members:
:show-inheritance:
.. automodule:: crslab.system.kbrd
:members:
:undoc-members:
:show-inheritance:
.. automodule:: crslab.system.kgsf
:members:
:undoc-members:
:show-inheritance:
.. automodule:: crslab.system.lr_scheduler
:members:
:undoc-members:
:show-inheritance:
.. automodule:: crslab.system.redial
:members:
:undoc-members:
:show-inheritance:
.. automodule:: crslab.system.tgredial
:members:
:undoc-members:
:show-inheritance:
.. automodule:: crslab.system.utils
:members:
:undoc-members:
:show-inheritance:
Module contents
---------------
.. automodule:: crslab.system
:members:
:undoc-members:
:show-inheritance:
================================================
FILE: docs/source/api/modules.rst
================================================
crslab
======
.. toctree::
:maxdepth: 1
crslab
================================================
FILE: docs/source/conf.py
================================================
# Configuration file for the Sphinx documentation builder.
#
# This file only contains a selection of the most common options. For a full
# list see the documentation:
# https://www.sphinx-doc.org/en/master/usage/configuration.html
# -- Path setup --------------------------------------------------------------
# If extensions (or modules to document with autodoc) are in another directory,
# add these directories to sys.path here. If the directory is relative to the
# documentation root, use os.path.abspath to make it absolute, like shown here.
#
import os
import sys
sys.path.insert(0, os.path.abspath('../../'))
from recommonmark.transform import AutoStructify
# -- Project information -----------------------------------------------------
project = 'CRSLab'
copyright = '2021, RUC AIBox'
author = 'RUC AIBox'
# The full version, including alpha/beta/rc tags
release = '0.1.1'
# -- General configuration ---------------------------------------------------
# Add any Sphinx extension module names here, as strings. They can be
# extensions coming with Sphinx (named 'sphinx.ext.*') or your custom
# ones.
extensions = [
'sphinx.ext.napoleon',
'sphinx.ext.autodoc',
'sphinx.ext.doctest',
'sphinx.ext.intersphinx',
'sphinx.ext.todo',
'sphinx.ext.coverage',
'sphinx.ext.mathjax',
'sphinx.ext.viewcode',
'recommonmark'
]
source_suffix = ['.rst', '.md']
autoclass_content = "both"
# napoleon
napoleon_include_private_with_doc = True
napoleon_use_admonition_for_examples = True
napoleon_use_admonition_for_notes = True
napoleon_use_admonition_for_references = True
# Add any paths that contain templates here, relative to this directory.
templates_path = ['_templates']
# List of patterns, relative to source directory, that match files and
# directories to ignore when looking for source files.
# This pattern also affects html_static_path and html_extra_path.
exclude_patterns = []
# -- Options for HTML output -------------------------------------------------
# The theme to use for HTML and HTML Help pages. See the documentation for
# a list of builtin themes.
#
html_theme = 'sphinx_rtd_theme'
# Add any paths that contain custom static files (such as style sheets) here,
# relative to this directory. They are copied after the builtin static files,
# so a file named "default.css" will overwrite the builtin "default.css".
html_static_path = ['_static']
def setup(app):
app.add_config_value('recommonmark_config', {
'auto_toc_tree_section': 'Contents',
}, True)
app.add_transform(AutoStructify)
================================================
FILE: docs/source/index.md
================================================
# CRSLab
```eval_rst
.. image:: https://img.shields.io/pypi/v/crslab
:target: https://pypi.org/project/crslab
.. image:: https://img.shields.io/github/v/release/rucaibox/crslab.svg
:target: https://github.com/rucaibox/crslab/releases
.. image:: https://img.shields.io/badge/License-MIT-blue.svg
:target: ../../../LICENSE
.. image:: https://img.shields.io/badge/arXiv-CRSLab-%23B21B1B
:target: https://arxiv.org/abs/2101.00939
.. toctree::
:maxdepth: 1
:caption: API REFERENCE
api/crslab.quick_start
api/crslab.config
api/crslab.data
api/crslab.evaluator
api/crslab.model
api/crslab.system
Indices and tables
==================
* :ref:`genindex`
* :ref:`modindex`
* :ref:`search`
```
================================================
FILE: requirements.txt
================================================
numpy~=1.19.4
sentencepiece<0.1.92
dataclasses~=0.7; python_version<'3.7'
transformers~=4.1.1
fasttext~=0.9.2
pkuseg~=0.0.25
pyyaml~=5.4
tqdm~=4.55.0
loguru~=0.5.3
nltk~=3.4.4
requests~=2.25.1
scikit-learn~=0.24.0
fuzzywuzzy~=0.18.0
tensorboard~=2.4.1
================================================
FILE: run_crslab.py
================================================
# @Time : 2020/11/22
# @Author : Kun Zhou
# @Email : francis_kun_zhou@163.com
# UPDATE:
# @Time : 2020/11/24, 2021/1/9
# @Author : Kun Zhou, Xiaolei Wang
# @Email : francis_kun_zhou@163.com, wxl1999@foxmail.com
import argparse
import warnings
from crslab.config import Config
warnings.filterwarnings('ignore')
if __name__ == '__main__':
# parse args
parser = argparse.ArgumentParser()
parser.add_argument('-c', '--config', type=str,
default='config/crs/tgredial/tgredial.yaml', help='config file(yaml) path')
parser.add_argument('-g', '--gpu', type=str, default='-1',
help='specify GPU id(s) to use, we now support multiple GPUs. Defaults to CPU(-1).')
parser.add_argument('-sd', '--save_data', action='store_true',
help='save processed dataset')
parser.add_argument('-rd', '--restore_data', action='store_true',
help='restore processed dataset')
parser.add_argument('-ss', '--save_system', action='store_true',
help='save trained system')
parser.add_argument('-rs', '--restore_system', action='store_true',
help='restore trained system')
parser.add_argument('-d', '--debug', action='store_true',
help='use valid dataset to debug your system')
parser.add_argument('-i', '--interact', action='store_true',
help='interact with your system instead of training')
parser.add_argument('-tb', '--tensorboard', action='store_true',
help='enable tensorboard to monitor train performance')
args, _ = parser.parse_known_args()
config = Config(args.config, args.gpu, args.debug)
from crslab.quick_start import run_crslab
run_crslab(config, args.save_data, args.restore_data, args.save_system, args.restore_system, args.interact,
args.debug, args.tensorboard)
================================================
FILE: setup.py
================================================
from setuptools import setup, find_packages
try:
import torch
import torch_geometric
except Exception:
raise Exception('Please install PyTorch and PyTorch Geometric manually first.\n' +
'View CRSLab GitHub page for more information: https://github.com/RUCAIBox/CRSLab')
setup_requires = []
install_requires = [
'numpy~=1.19.4',
'sentencepiece<0.1.92',
"dataclasses~=0.7;python_version<'3.7'",
'transformers~=4.1.1',
'fasttext~=0.9.2',
'pkuseg~=0.0.25',
'pyyaml~=5.4',
'tqdm~=4.55.0',
'loguru~=0.5.3',
'nltk~=3.4.4',
'requests~=2.25.1',
'scikit-learn~=0.24.0',
'fuzzywuzzy~=0.18.0',
'tensorboard~=2.4.1',
]
classifiers = [
"Programming Language :: Python :: 3",
"License :: OSI Approved :: MIT License",
"Topic :: Scientific/Engineering :: Artificial Intelligence",
"Topic :: Scientific/Engineering :: Human Machine Interfaces"
]
with open("README.md", "r", encoding="utf-8") as f:
long_description = f.read()
setup(
name='crslab',
version='0.1.1', # please remember to edit crslab/__init__.py in response, once updating the version
author='CRSLabTeam',
author_email='francis_kun_zhou@163.com',
description='An Open-Source Toolkit for Building Conversational Recommender System(CRS)',
long_description=long_description,
long_description_content_type="text/markdown",
url='https://github.com/RUCAIBox/CRSLab',
packages=[
package for package in find_packages()
if package.startswith('crslab')
],
classifiers=classifiers,
install_requires=install_requires,
setup_requires=setup_requires,
python_requires='>=3.6',
)