Repository: ShomyLiu/Neu-Review-Rec
Branch: master
Commit: 6dfe4745c921
Files: 19
Total size: 67.3 KB
Directory structure:
gitextract_59dzc63p/
├── .gitignore
├── README.md
├── checkpoints/
│ └── .gitkeeper
├── config/
│ ├── __init__.py
│ └── config.py
├── dataset/
│ ├── __init__.py
│ └── data_review.py
├── framework/
│ ├── __init__.py
│ ├── fusion.py
│ ├── models.py
│ └── prediction.py
├── main.py
├── models/
│ ├── __init__.py
│ ├── d_attn.py
│ ├── daml.py
│ ├── deepconn.py
│ ├── mpcn.py
│ └── narre.py
└── pro_data/
└── data_pro.py
================================================
FILE CONTENTS
================================================
================================================
FILE: .gitignore
================================================
checkpoints/__pycache__
checkpoints/*pth
checkpoints/*ckpt
config/__pycache__
dataset/__pycache__
dataset/*_data
framework/__pycache__
models/__pycache__
pro_data/*json
*pyc
lightning_logs/
================================================
FILE: README.md
================================================
A Toolkit for Neural Review-based Recommendation models with Pytorch.
基于评论文本的深度推荐系统模型库 (Pytorch)
**Update: 2021.03.29**
Add a branch (PL) to use [PyTorch Lightning](https://github.com/PyTorchLightning/pytorch-lightning/) to wrap the framework for further distributed training.
```
git clone https://github.com/ShomyLiu/Neu-Review-Rec.git
git checkout pl
```
And the usage:
```
python3 pl_main.py run --use_ddp=True --gpu_id=2
# indicating that using ddp mode for distributed training with 2 gpus. refer `config/config.py`.
```
# Neural Review-based Recommendaton
In this repository, we reimplement some important review-based recommendation models, and provide an extensible framework **NRRec** with Pytorch.
Researchers can implement their own methodss easily in our framework (just in *models* folder).
## Introduction to Review-based Recommendaiton
E-commerce platforms allow users to post their reviews towards products, and the reviews may contain the opinions of users and the features of the items.
Hence, many works start to utilize the reviews to model user preference and item features.
Traditional methods always use topic modelling technology to capture the semantic informtion.
Recently, many deep learning based methods are proposed, such as DeepCoNN, D-Attn etc, which use the neural networks, attention mechanism to learn representations of users and items more comprehensively.
More details please refer to [my blog](http://shomy.top/2019/12/31/neu-review-rec/).
## Methods
>Note: since each user and each item would have multiple reviews, we categorize the existing methods into two kinds:
- document-level methods: concatenate all the reviews into a long document, and then learn representations from the doc, we denote as **Doc** feature.
- review-level methods: model each review seperately and then aggregate all reviews together as the user item latent feature.
Besides, the rating feature of users and items (i.e., ID embedding) is usefule when there are few reviews.
So there would be three features in all (i.e., document-level, review-level, ID).
We plan to follow the state-of-art review-based recommendation methods and involve them into this repo, the baseline methods are listed here:
| Method | Feature | Status|
| ---- | ---- | ---- |
| DeepCoNN(WSDM'17) | Doc | ✓ |
| D-Attn(RecSys'17) | Doc | ✓|
| ANR(CIKM'18) | Doc, ID | ☒|
|NARRE(WWW'18) | Review, ID | ✓ |
|MPCN(KDD'18) | Review |✓ |
|TARMF(WWW'18) | Review, ID | ☒|
| CARL(TOIS'19) | Doc, ID | ☒|
| CARP(SIGIR'19) | Doc, ID | ☒|
| DAML(KDD'19) | Doc, ID | ✓ |
We will release the rest unfinished baseline methods later.
### References
>
- Zheng L, Noroozi V, Yu P S. Joint deep modeling of users and items using reviews for recommendation[C]//Proceedings of the Tenth ACM International Conference on Web Search and Data Mining. ACM, 2017: 425-434.
- Sungyong Seo, Jing Huang, Hao Yang, and Yan Liu. 2017. Interpretable Convolutional Neural Networks with Dual Local and Global Attention for Review Rating Prediction. In Proceedings ofthe Eleventh ACMConference on Recommender Systems.
- Chin J Y, Zhao K, Joty S, et al. ANR: Aspect-based neural recommender[C]//Proceedings of the 27th ACM International Conference on Information and Knowledge Management. 2018: 147-156.
- Chen C, Zhang M, Liu Y, et al. Neural attentional rating regression with review-level explanations[C]//Proceedings of the 2018 World Wide Web Conference. 2018: 1583-1592.
- Tay Y, Luu A T, Hui S C. Multi-pointer co-attention networks for recommendation[C]//Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 2018: 2309-2318.
- Lu Y, Dong R, Smyth B. Coevolutionary recommendation model: Mutual learning between ratings and reviews[C]//Proceedings of the 2018 World Wide Web Conference. 2018: 773-782.
- Wu L, Quan C, Li C, et al. A context-aware user-item representation learning for item recommendation[J]. ACM Transactions on Information Systems (TOIS), 2019, 37(2): 1-29.
- Li C, Quan C, Peng L, et al. A capsule network for recommendation and explaining what you like and dislike[C]//Proceedings of the 42nd International ACM SIGIR Conference on Research and Development in Information Retrieval. 2019: 275-284.
- Liu D, Li J, Du B, et al. Daml: Dual attention mutual learning between ratings and reviews for item recommendation[C]//Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 2019: 344-352.
## Usage
**Requirements**
- Python >= 3.6
- Pytorch >= 1.0
- fire: commend line parameters (in `config/config.py`)
- numpy, gensim etc.
**Use the code**
- Preprocessing the origin Amazon or Yelp dataset via `pro_data/data_pro.py`, then some `npy` files will be generated in `dataset/`, including train, val, and test datset.
```
cd pro_data
python3 data_pro.py Digital_Music_5.json
# details in data_pro.py (e.g., the pretrained word2vec.bin path)
```
- Train the model. Take DeepCoNN and NARRE as examples, the command lines can be customized:
```
python3 main.py train --model=DeepCoNN --num_fea=1 --output=fm
python3 main.py train --model=NARRE --num_fea=2 --output=lfm
```
Note that the `num_fea (1,2,3)` corresponds how many features used in the methods, (ID feature, Review-level and Doc-level denoted above).
- Test the model using the saved pth file in `checkpoints` in the test datase: for example:
```
python3 main.py test --pth_path="./checkpoints/THE_PTH_PATH" --model=DeepCoNN
```
An output sample:
```
loading train data
loading val data
train data: 51764; test data: 6471
start training....
2020-07-28 12:27:58 Epoch 0...
train data: loss:107503.6215, mse: 2.0768;
evaluation reslut: mse: 1.2466; rmse: 1.1165; mae: 0.9691;
model save
******************************
2020-07-28 12:28:13 Epoch 1...
train data: loss:80552.2573, mse: 1.5561;
evaluation reslut: mse: 1.0296; rmse: 1.0147; mae: 0.8384;
model save
******************************
2020-07-28 12:28:29 Epoch 2...
train data: loss:70202.6199, mse: 1.3562;
evaluation reslut: mse: 0.9926; rmse: 0.9963; mae: 0.8146;
model save
******************************
```
## Framework Design
An overview of the package dir:
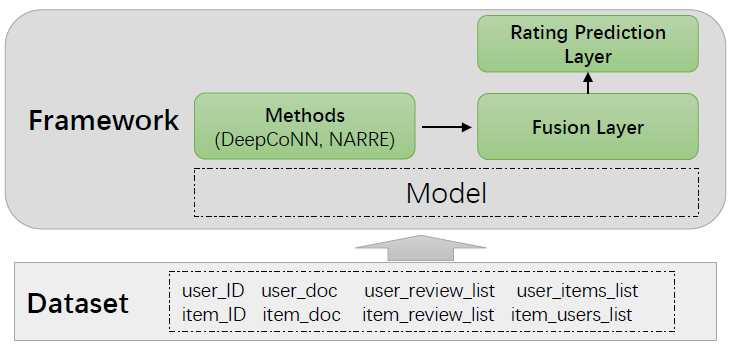
### Data Preprocessing
After data processing, one record of the training/validation/test dataset is:
```
user_id, item_id, ratings
```
For example the training data triples are stored as `Train.npy, Train_Score.npy` in `dataset/Digital_Music_data/train/`.
The review information of users and items are preprocessed in the following format:
- user_id
- user_doc: the word index sequence of the document of the user, `[w1, w2, ... wn]`
- user_reviews list: the list of all the review of the user, `[[w1,w2..], [w1,w2,..],...[w1,w2..]]`
- user_item2id: the item ids that the user have purchased, `[id1, id2,...]`
The same as the items. Hence in the code, we orgnize our batch data as:
```
uids, iids, user_reviews, item_reviews, user_item2id, item_user2id, user_doc, item_doc
```
This is all the information involved in review-based recommendation, researchers can utilize this data format to build own models.
Note that the review in validation/test dataset is excluded.
>Note that the review processing methods are usually different among these papers (e.g., the vocab, padding), which would influence their performance.
In this repo, to be fair, we adopt the same pre-poressing approach for all the methods.
Hence the performance may be not consistent with the origin papers.
### Model Details
In order to make our framework more extensible, we define three modules in our framework:
- User/Item Representation Learning Layer (in `models/*py`): the main part of most baseline methods, such as the CNN encoder in DeepCoNN.
- Fusion Layer in `framework/fusion.py`: combine the user/item different features (e.g., ID feature and review/doc feature), and then fuse the user and item feature into one feature vector, we pre-define the following methods:
- sum
- add
- concatenation
- self attention
- Prediction Layer in `framework/prediction.py`: prediction the score that user towards item (i.e., a regression layer), we pre-define the following rating prediction layers:
- (Neural) Factorization Machine
- Latent Factor Model
- MLP
Hence, researchers could build their models in user/item representation learning layer.
>Note that if you would like to add new method or datset, please remember to declare in the `__init__.py`
## Citation
If you use the code, please cite:
```
@inproceedings{liu2019nrpa,
title={NRPA: Neural Recommendation with Personalized Attention},
author={Liu, Hongtao and Wu, Fangzhao and Wang, Wenjun and Wang, Xianchen and Jiao, Pengfei and Wu, Chuhan and Xie, Xing},
booktitle={Proceedings of the 42nd International ACM SIGIR Conference on Research and Development in Information Retrieval},
pages={1233--1236},
year={2019}
}
```
================================================
FILE: checkpoints/.gitkeeper
================================================
================================================
FILE: config/__init__.py
================================================
# -*- coding: utf-8 -*-
from .config import DefaultConfig
# from .config import Office_Products_data_Config
# from .config import Gourmet_Food_data_Config
# from .config import Toys_and_Games_data_Config
# from .config import Sports_and_Outdoors_data_Config
# from .config import Clothing_Shoes_and_Jewelry_data_Config
# from .config import Toys_and_Games_data_Config
# from .config import Video_Games_data_Config
# from .config import Movies_and_TV_data_Config
# from .config import Kindle_Store_data_Config
# from .config import yelp2013_data_Config
# from .config import yelp2014_data_Config
# from .config import Musical_Instruments_data_Config
from .config import Digital_Music_data_Config
# from .config import yelp2016_data_Config
# from .config import Tools_Improvement_data_Config
# from .config import Automotive_data_Config
# from .config import Patio_Lawn_and_Garden_data_Config
================================================
FILE: config/config.py
================================================
# -*- coding: utf-8 -*-
import numpy as np
class DefaultConfig:
model = 'DeepCoNN'
dataset = 'Digital_Music_data'
# -------------base config-----------------------#
use_gpu = True
gpu_id = 1
multi_gpu = False
gpu_ids = []
seed = 2019
num_epochs = 20
num_workers = 0
optimizer = 'Adam'
weight_decay = 1e-3 # optimizer rameteri
lr = 2e-3
loss_method = 'mse'
drop_out = 0.5
use_word_embedding = True
id_emb_size = 32
query_mlp_size = 128
fc_dim = 32
doc_len = 500
filters_num = 100
kernel_size = 3
num_fea = 1 # id feature, review feature, doc feature
use_review = True
use_doc = True
self_att = False
r_id_merge = 'cat' # review and ID feature
ui_merge = 'cat' # cat/add/dot
output = 'lfm' # 'fm', 'lfm', 'other: sum the ui_feature'
fine_step = False # save mode in step level, defualt in epoch
pth_path = "" # the saved pth path for test
print_opt = 'default'
def set_path(self, name):
'''
specific
'''
self.data_root = f'./dataset/{name}'
prefix = f'{self.data_root}/train'
self.user_list_path = f'{prefix}/userReview2Index.npy'
self.item_list_path = f'{prefix}/itemReview2Index.npy'
self.user2itemid_path = f'{prefix}/user_item2id.npy'
self.item2userid_path = f'{prefix}/item_user2id.npy'
self.user_doc_path = f'{prefix}/userDoc2Index.npy'
self.item_doc_path = f'{prefix}/itemDoc2Index.npy'
self.w2v_path = f'{prefix}/w2v.npy'
def parse(self, kwargs):
'''
user can update the default hyperparamter
'''
print("load npy from dist...")
self.users_review_list = np.load(self.user_list_path, encoding='bytes')
self.items_review_list = np.load(self.item_list_path, encoding='bytes')
self.user2itemid_list = np.load(self.user2itemid_path, encoding='bytes')
self.item2userid_list = np.load(self.item2userid_path, encoding='bytes')
self.user_doc = np.load(self.user_doc_path, encoding='bytes')
self.item_doc = np.load(self.item_doc_path, encoding='bytes')
for k, v in kwargs.items():
if not hasattr(self, k):
raise Exception('opt has No key: {}'.format(k))
setattr(self, k, v)
print('*************************************************')
print('user config:')
for k, v in self.__class__.__dict__.items():
if not k.startswith('__') and k != 'user_list' and k != 'item_list':
print("{} => {}".format(k, getattr(self, k)))
print('*************************************************')
class Digital_Music_data_Config(DefaultConfig):
def __init__(self):
self.set_path('Digital_Music_data')
vocab_size = 50002
word_dim = 300
r_max_len = 202
u_max_r = 13
i_max_r = 24
train_data_size = 51764
test_data_size = 6471
val_data_size = 6471
user_num = 5541 + 2
item_num = 3568 + 2
batch_size = 128
print_step = 100
================================================
FILE: dataset/__init__.py
================================================
from .data_review import ReviewData
================================================
FILE: dataset/data_review.py
================================================
# -*- coding: utf-8 -*-
import os
import numpy as np
from torch.utils.data import Dataset
class ReviewData(Dataset):
def __init__(self, root_path, mode):
if mode == 'Train':
path = os.path.join(root_path, 'train/')
print('loading train data')
self.data = np.load(path + 'Train.npy', encoding='bytes')
self.scores = np.load(path + 'Train_Score.npy')
elif mode == 'Val':
path = os.path.join(root_path, 'val/')
print('loading val data')
self.data = np.load(path + 'Val.npy', encoding='bytes')
self.scores = np.load(path + 'Val_Score.npy')
else:
path = os.path.join(root_path, 'test/')
print('loading test data')
self.data = np.load(path + 'Test.npy', encoding='bytes')
self.scores = np.load(path + 'Test_Score.npy')
self.x = list(zip(self.data, self.scores))
def __getitem__(self, idx):
assert idx < len(self.x)
return self.x[idx]
def __len__(self):
return len(self.x)
================================================
FILE: framework/__init__.py
================================================
# -*- coding: utf-8 -*-
from .models import Model
================================================
FILE: framework/fusion.py
================================================
# -*- coding: utf-8 -*-
import torch
import torch.nn as nn
class FusionLayer(nn.Module):
'''
Fusion Layer for user feature and item feature
'''
def __init__(self, opt):
super(FusionLayer, self).__init__()
if opt.self_att:
self.attn = SelfAtt(opt.id_emb_size, opt.num_heads)
self.opt = opt
self.linear = nn.Linear(opt.feature_dim, opt.feature_dim)
self.drop_out = nn.Dropout(0.5)
nn.init.uniform_(self.linear.weight, -0.1, 0.1)
nn.init.constant_(self.linear.bias, 0.1)
def forward(self, u_out, i_out):
if self.opt.self_att:
out = self.attn(u_out, i_out)
s_u_out, s_i_out = torch.split(out, out.size(1)//2, 1)
u_out = u_out + s_u_out
i_out = i_out + s_i_out
if self.opt.r_id_merge == 'cat':
u_out = u_out.reshape(u_out.size(0), -1)
i_out = i_out.reshape(i_out.size(0), -1)
else:
u_out = u_out.sum(1)
i_out = i_out.sum(1)
if self.opt.ui_merge == 'cat':
out = torch.cat([u_out, i_out], 1)
elif self.opt.ui_merge == 'add':
out = u_out + i_out
else:
out = u_out * i_out
# out = self.drop_out(out)
# return F.relu(self.linear(out))
return out
class SelfAtt(nn.Module):
'''
self attention for interaction
'''
def __init__(self, dim, num_heads):
super(SelfAtt, self).__init__()
self.encoder_layer = nn.TransformerEncoderLayer(dim, num_heads, 128, 0.4)
self.encoder = nn.TransformerEncoder(self.encoder_layer, 1)
def forward(self, user_fea, item_fea):
fea = torch.cat([user_fea, item_fea], 1).permute(1, 0, 2) # batch * 6 * 64
out = self.encoder(fea)
return out.permute(1, 0, 2)
================================================
FILE: framework/models.py
================================================
# -*- coding: utf-8 -*-
import torch
import torch.nn as nn
import time
from .prediction import PredictionLayer
from .fusion import FusionLayer
class Model(nn.Module):
def __init__(self, opt, Net):
super(Model, self).__init__()
self.opt = opt
self.model_name = self.opt.model
self.net = Net(opt)
if self.opt.ui_merge == 'cat':
if self.opt.r_id_merge == 'cat':
feature_dim = self.opt.id_emb_size * self.opt.num_fea * 2
else:
feature_dim = self.opt.id_emb_size * 2
else:
if self.opt.r_id_merge == 'cat':
feature_dim = self.opt.id_emb_size * self.opt.num_fea
else:
feature_dim = self.opt.id_emb_size
self.opt.feature_dim = feature_dim
self.fusion_net = FusionLayer(opt)
self.predict_net = PredictionLayer(opt)
self.dropout = nn.Dropout(self.opt.drop_out)
def forward(self, datas):
user_reviews, item_reviews, uids, iids, user_item2id, item_user2id, user_doc, item_doc = datas
user_feature, item_feature = self.net(datas)
ui_feature = self.fusion_net(user_feature, item_feature)
ui_feature = self.dropout(ui_feature)
output = self.predict_net(ui_feature, uids, iids).squeeze(1)
return output
def load(self, path):
'''
加载指定模型
'''
self.load_state_dict(torch.load(path))
def save(self, epoch=None, name=None, opt=None):
'''
保存模型
'''
prefix = 'checkpoints/'
if name is None:
name = prefix + self.model_name + '_'
name = time.strftime(name + '%m%d_%H:%M:%S.pth')
else:
name = prefix + self.model_name + '_' + str(name) + '_' + str(opt) + '.pth'
torch.save(self.state_dict(), name)
return name
================================================
FILE: framework/prediction.py
================================================
# -*- coding: utf-8 -*-
import torch
import torch.nn as nn
import torch.nn.functional as F
class PredictionLayer(nn.Module):
'''
Rating Prediciton Methods
- LFM: Latent Factor Model
- (N)FM: (Neural) Factorization Machine
- MLP
- SUM
'''
def __init__(self, opt):
super(PredictionLayer, self).__init__()
self.output = opt.output
if opt.output == "fm":
self.model = FM(opt.feature_dim, opt.user_num, opt.item_num)
elif opt.output == "lfm":
self.model = LFM(opt.feature_dim, opt.user_num, opt.item_num)
elif opt.output == 'mlp':
self.model = MLP(opt.feature_dim)
elif opt.output == 'nfm':
self.model = NFM(opt.feature_dim)
else:
self.model = torch.sum
def forward(self, feature, uid, iid):
if self.output == "lfm" or "fm" or "nfm":
return self.model(feature, uid, iid)
else:
return self.model(feature, 1, keepdim=True)
class LFM(nn.Module):
def __init__(self, dim, user_num, item_num):
super(LFM, self).__init__()
# ---------------------------fc_linear------------------------------
self.fc = nn.Linear(dim, 1)
# -------------------------LFM-user/item-bias-----------------------
self.b_users = nn.Parameter(torch.randn(user_num, 1))
self.b_items = nn.Parameter(torch.randn(item_num, 1))
self.init_weight()
def init_weight(self):
nn.init.uniform_(self.fc.weight, a=-0.1, b=0.1)
nn.init.uniform_(self.fc.bias, a=0.5, b=1.5)
nn.init.uniform_(self.b_users, a=0.5, b=1.5)
nn.init.uniform_(self.b_users, a=0.5, b=1.5)
def rescale_sigmoid(self, score, a, b):
return a + torch.sigmoid(score) * (b - a)
def forward(self, feature, user_id, item_id):
# return self.rescale_sigmoid(self.fc(feature), 1.0, 5.0) + self.b_users[user_id] + self.b_items[item_id]
return self.fc(feature) + self.b_users[user_id] + self.b_items[item_id]
class NFM(nn.Module):
'''
Neural FM
'''
def __init__(self, dim):
super(NFM, self).__init__()
self.dim = dim
# ---------------------------fc_linear------------------------------
self.fc = nn.Linear(dim, 1)
# ------------------------------FM----------------------------------
self.fm_V = nn.Parameter(torch.randn(16, dim))
self.mlp = nn.Linear(16, 16)
self.h = nn.Linear(16, 1, bias=False)
self.drop_out = nn.Dropout(0.5)
self.init_weight()
def init_weight(self):
nn.init.uniform_(self.fc.weight, -0.1, 0.1)
nn.init.constant_(self.fc.bias, 0.1)
nn.init.uniform_(self.fm_V, -0.1, 0.1)
nn.init.uniform_(self.h.weight, -0.1, 0.1)
def forward(self, input_vec, *args):
fm_linear_part = self.fc(input_vec)
fm_interactions_1 = torch.mm(input_vec, self.fm_V.t())
fm_interactions_1 = torch.pow(fm_interactions_1, 2)
fm_interactions_2 = torch.mm(torch.pow(input_vec, 2), torch.pow(self.fm_V, 2).t())
bilinear = 0.5 * (fm_interactions_1 - fm_interactions_2)
out = F.relu(self.mlp(bilinear))
out = self.drop_out(out)
out = self.h(out) + fm_linear_part
return out
class FM(nn.Module):
def __init__(self, dim, user_num, item_num):
super(FM, self).__init__()
self.dim = dim
# ---------------------------fc_linear------------------------------
self.fc = nn.Linear(dim, 1)
# ------------------------------FM----------------------------------
self.fm_V = nn.Parameter(torch.randn(dim, 10))
self.b_users = nn.Parameter(torch.randn(user_num, 1))
self.b_items = nn.Parameter(torch.randn(item_num, 1))
self.init_weight()
def init_weight(self):
nn.init.uniform_(self.fc.weight, -0.05, 0.05)
nn.init.constant_(self.fc.bias, 0.0)
nn.init.uniform_(self.b_users, a=0, b=0.1)
nn.init.uniform_(self.b_items, a=0, b=0.1)
nn.init.uniform_(self.fm_V, -0.05, 0.05)
def build_fm(self, input_vec):
'''
y = w_0 + \sum {w_ix_i} + \sum_{i=1}\sum_{j=i+1}<v_i, v_j>x_ix_j
factorization machine layer
refer: https://github.com/vanzytay/KDD2018_MPCN/blob/master/tylib/lib
/compose_op.py#L13
'''
# linear part: first two items
fm_linear_part = self.fc(input_vec)
fm_interactions_1 = torch.mm(input_vec, self.fm_V)
fm_interactions_1 = torch.pow(fm_interactions_1, 2)
fm_interactions_2 = torch.mm(torch.pow(input_vec, 2),
torch.pow(self.fm_V, 2))
fm_output = 0.5 * torch.sum(fm_interactions_1 - fm_interactions_2, 1, keepdim=True) + fm_linear_part
return fm_output
def forward(self, feature, uids, iids):
fm_out = self.build_fm(feature)
return fm_out + self.b_users[uids] + self.b_items[iids]
class MLP(nn.Module):
def __init__(self, dim):
super(MLP, self).__init__()
self.dim = dim
# ---------------------------fc_linear------------------------------
self.fc = nn.Linear(dim, 1)
self.init_weight()
def init_weight(self):
nn.init.uniform_(self.fc.weight, 0.1, 0.1)
nn.init.uniform_(self.fc.bias, a=0, b=0.2)
def forward(self, feature, *args, **kwargs):
return F.relu(self.fc(feature))
================================================
FILE: main.py
================================================
# -*- encoding: utf-8 -*-
import time
import random
import math
import fire
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader
from dataset import ReviewData
from framework import Model
import models
import config
def now():
return str(time.strftime('%Y-%m-%d %H:%M:%S'))
def collate_fn(batch):
data, label = zip(*batch)
return data, label
def train(**kwargs):
if 'dataset' not in kwargs:
opt = getattr(config, 'Digital_Music_data_Config')()
else:
opt = getattr(config, kwargs['dataset'] + '_Config')()
opt.parse(kwargs)
random.seed(opt.seed)
np.random.seed(opt.seed)
torch.manual_seed(opt.seed)
if opt.use_gpu:
torch.cuda.manual_seed_all(opt.seed)
if len(opt.gpu_ids) == 0 and opt.use_gpu:
torch.cuda.set_device(opt.gpu_id)
model = Model(opt, getattr(models, opt.model))
if opt.use_gpu:
model.cuda()
if len(opt.gpu_ids) > 0:
model = nn.DataParallel(model, device_ids=opt.gpu_ids)
if model.net.num_fea != opt.num_fea:
raise ValueError(f"the num_fea of {opt.model} is error, please specific --num_fea={model.net.num_fea}")
# 3 data
train_data = ReviewData(opt.data_root, mode="Train")
train_data_loader = DataLoader(train_data, batch_size=opt.batch_size, shuffle=True, collate_fn=collate_fn)
val_data = ReviewData(opt.data_root, mode="Val")
val_data_loader = DataLoader(val_data, batch_size=opt.batch_size, shuffle=False, collate_fn=collate_fn)
print(f'train data: {len(train_data)}; test data: {len(val_data)}')
optimizer = optim.Adam(model.parameters(), lr=opt.lr, weight_decay=opt.weight_decay)
scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=5, gamma=0.8)
# training
print("start training....")
min_loss = 1e+10
best_res = 1e+10
mse_func = nn.MSELoss()
mae_func = nn.L1Loss()
smooth_mae_func = nn.SmoothL1Loss()
for epoch in range(opt.num_epochs):
total_loss = 0.0
total_maeloss = 0.0
model.train()
print(f"{now()} Epoch {epoch}...")
for idx, (train_datas, scores) in enumerate(train_data_loader):
if opt.use_gpu:
scores = torch.FloatTensor(scores).cuda()
else:
scores = torch.FloatTensor(scores)
train_datas = unpack_input(opt, train_datas)
optimizer.zero_grad()
output = model(train_datas)
mse_loss = mse_func(output, scores)
total_loss += mse_loss.item() * len(scores)
mae_loss = mae_func(output, scores)
total_maeloss += mae_loss.item()
smooth_mae_loss = smooth_mae_func(output, scores)
if opt.loss_method == 'mse':
loss = mse_loss
if opt.loss_method == 'rmse':
loss = torch.sqrt(mse_loss) / 2.0
if opt.loss_method == 'mae':
loss = mae_loss
if opt.loss_method == 'smooth_mae':
loss = smooth_mae_loss
loss.backward()
optimizer.step()
if opt.fine_step:
if idx % opt.print_step == 0 and idx > 0:
print("\t{}, {} step finised;".format(now(), idx))
val_loss, val_mse, val_mae = predict(model, val_data_loader, opt)
if val_loss < min_loss:
model.save(name=opt.dataset, opt=opt.print_opt)
min_loss = val_loss
print("\tmodel save")
if val_loss > min_loss:
best_res = min_loss
scheduler.step()
mse = total_loss * 1.0 / len(train_data)
print(f"\ttrain data: loss:{total_loss:.4f}, mse: {mse:.4f};")
val_loss, val_mse, val_mae = predict(model, val_data_loader, opt)
if val_loss < min_loss:
model.save(name=opt.dataset, opt=opt.print_opt)
min_loss = val_loss
print("model save")
if val_mse < best_res:
best_res = val_mse
print("*"*30)
print("----"*20)
print(f"{now()} {opt.dataset} {opt.print_opt} best_res: {best_res}")
print("----"*20)
def test(**kwargs):
if 'dataset' not in kwargs:
opt = getattr(config, 'Digital_Music_data_Config')()
else:
opt = getattr(config, kwargs['dataset'] + '_Config')()
opt.parse(kwargs)
assert(len(opt.pth_path) > 0)
random.seed(opt.seed)
np.random.seed(opt.seed)
torch.manual_seed(opt.seed)
if opt.use_gpu:
torch.cuda.manual_seed_all(opt.seed)
if len(opt.gpu_ids) == 0 and opt.use_gpu:
torch.cuda.set_device(opt.gpu_id)
model = Model(opt, getattr(models, opt.model))
if opt.use_gpu:
model.cuda()
if len(opt.gpu_ids) > 0:
model = nn.DataParallel(model, device_ids=opt.gpu_ids)
if model.net.num_fea != opt.num_fea:
raise ValueError(f"the num_fea of {opt.model} is error, please specific --num_fea={model.net.num_fea}")
model.load(opt.pth_path)
print(f"load model: {opt.pth_path}")
test_data = ReviewData(opt.data_root, mode="Test")
test_data_loader = DataLoader(test_data, batch_size=opt.batch_size, shuffle=False, collate_fn=collate_fn)
print(f"{now()}: test in the test datset")
predict_loss, test_mse, test_mae = predict(model, test_data_loader, opt)
def predict(model, data_loader, opt):
total_loss = 0.0
total_maeloss = 0.0
model.eval()
with torch.no_grad():
for idx, (test_data, scores) in enumerate(data_loader):
if opt.use_gpu:
scores = torch.FloatTensor(scores).cuda()
else:
scores = torch.FloatTensor(scores)
test_data = unpack_input(opt, test_data)
output = model(test_data)
mse_loss = torch.sum((output-scores)**2)
total_loss += mse_loss.item()
mae_loss = torch.sum(abs(output-scores))
total_maeloss += mae_loss.item()
data_len = len(data_loader.dataset)
mse = total_loss * 1.0 / data_len
mae = total_maeloss * 1.0 / data_len
print(f"\tevaluation reslut: mse: {mse:.4f}; rmse: {math.sqrt(mse):.4f}; mae: {mae:.4f};")
model.train()
return total_loss, mse, mae
def unpack_input(opt, x):
uids, iids = list(zip(*x))
uids = list(uids)
iids = list(iids)
user_reviews = opt.users_review_list[uids]
user_item2id = opt.user2itemid_list[uids] # 检索出该user对应的item id
user_doc = opt.user_doc[uids]
item_reviews = opt.items_review_list[iids]
item_user2id = opt.item2userid_list[iids] # 检索出该item对应的user id
item_doc = opt.item_doc[iids]
data = [user_reviews, item_reviews, uids, iids, user_item2id, item_user2id, user_doc, item_doc]
data = list(map(lambda x: torch.LongTensor(x).cuda(), data))
return data
if __name__ == "__main__":
fire.Fire()
================================================
FILE: models/__init__.py
================================================
# -*- coding: utf-8 -*-
# from .narre import NARRE
from .deepconn import DeepCoNN
from .daml import DAML
from .narre import NARRE
from .d_attn import D_ATTN
from .mpcn import MPCN
================================================
FILE: models/d_attn.py
================================================
# -*- coding: utf-8 -*-
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
class D_ATTN(nn.Module):
'''
Interpretable Convolutional Neural Networks with Dual Local and Global Attention for Review Rating Prediction
Rescys 2017
'''
def __init__(self, opt):
super(D_ATTN, self).__init__()
self.opt = opt
self.num_fea = 1 # Document
self.user_net = Net(opt, 'user')
self.item_net = Net(opt, 'item')
def forward(self, datas):
user_reviews, item_reviews, uids, iids, user_item2id, item_user2id, user_doc, item_doc = datas
u_fea = self.user_net(user_doc)
i_fea = self.item_net(item_doc)
return u_fea, i_fea
class Net(nn.Module):
def __init__(self, opt, uori='user'):
super(Net, self).__init__()
self.opt = opt
self.word_embs = nn.Embedding(self.opt.vocab_size, self.opt.word_dim) # vocab_size * 300
self.local_att = LocalAttention(opt.doc_len, win_size=5, emb_size=opt.word_dim, filters_num=opt.filters_num)
self.global_att = GlobalAttention(opt.doc_len, emb_size=opt.word_dim, filters_num=opt.filters_num)
fea_dim = opt.filters_num * 4
self.fc = nn.Sequential(
nn.Linear(fea_dim, fea_dim),
nn.Dropout(0.5),
nn.ReLU(),
nn.Linear(fea_dim, opt.id_emb_size),
)
self.dropout = nn.Dropout(self.opt.drop_out)
self.reset_para()
def forward(self, docs):
docs = self.word_embs(docs) # size * 300
local_fea = self.local_att(docs)
global_fea = self.global_att(docs)
r_fea = torch.cat([local_fea]+global_fea, 1)
r_fea = self.dropout(r_fea)
r_fea = self.fc(r_fea)
return torch.stack([r_fea], 1)
def reset_para(self):
cnns = [self.local_att.cnn, self.local_att.att_conv[0]]
for cnn in cnns:
nn.init.xavier_uniform_(cnn.weight, gain=1)
nn.init.uniform_(cnn.bias, -0.1, 0.1)
for cnn in self.global_att.convs:
nn.init.xavier_uniform_(cnn.weight, gain=1)
nn.init.uniform_(cnn.bias, -0.1, 0.1)
nn.init.uniform_(self.fc[0].weight, -0.1, 0.1)
nn.init.uniform_(self.fc[-1].weight, -0.1, 0.1)
if self.opt.use_word_embedding:
w2v = torch.from_numpy(np.load(self.opt.w2v_path))
if self.opt.use_gpu:
self.word_embs.weight.data.copy_(w2v.cuda())
else:
self.word_embs.weight.data.copy_(w2v)
else:
nn.init.xavier_normal_(self.word_embs.weight)
class LocalAttention(nn.Module):
def __init__(self, seq_len, win_size, emb_size, filters_num):
super(LocalAttention, self).__init__()
self.att_conv = nn.Sequential(
nn.Conv2d(1, 1, kernel_size=(win_size, emb_size), padding=((win_size-1)//2, 0)),
nn.Sigmoid()
)
self.cnn = nn.Conv2d(1, filters_num, kernel_size=(1, emb_size))
def forward(self, x):
score = self.att_conv(x.unsqueeze(1)).squeeze(1)
out = x.mul(score)
out = out.unsqueeze(1)
out = torch.tanh(self.cnn(out)).squeeze(3)
out = F.max_pool1d(out, out.size(2)).squeeze(2)
return out
class GlobalAttention(nn.Module):
def __init__(self, seq_len, emb_size, filters_size=[2, 3, 4], filters_num=100):
super(GlobalAttention, self).__init__()
self.att_conv = nn.Sequential(
nn.Conv2d(1, 1, kernel_size=(seq_len, emb_size)),
nn.Sigmoid()
)
self.convs = nn.ModuleList([nn.Conv2d(1, filters_num, (k, emb_size)) for k in filters_size])
def forward(self, x):
x = x.unsqueeze(1)
score = self.att_conv(x)
x = x.mul(score)
conv_outs = [torch.tanh(cnn(x).squeeze(3)) for cnn in self.convs]
conv_outs = [F.max_pool1d(out, out.size(2)).squeeze(2) for out in conv_outs]
return conv_outs
================================================
FILE: models/daml.py
================================================
# -*- coding: utf-8 -*-
import torch
import torch.nn as nn
import numpy as np
import torch.nn.functional as F
class DAML(nn.Module):
'''
KDD 2019 DAML
'''
def __init__(self, opt):
super(DAML, self).__init__()
self.opt = opt
self.num_fea = 2 # ID + DOC
self.user_word_embs = nn.Embedding(opt.vocab_size, opt.word_dim) # vocab_size * 300
self.item_word_embs = nn.Embedding(opt.vocab_size, opt.word_dim) # vocab_size * 300
# share
self.word_cnn = nn.Conv2d(1, 1, (5, opt.word_dim), padding=(2, 0))
# document-level cnn
self.user_doc_cnn = nn.Conv2d(1, opt.filters_num, (opt.kernel_size, opt.word_dim), padding=(1, 0))
self.item_doc_cnn = nn.Conv2d(1, opt.filters_num, (opt.kernel_size, opt.word_dim), padding=(1, 0))
# abstract-level cnn
self.user_abs_cnn = nn.Conv2d(1, opt.filters_num, (opt.kernel_size, opt.filters_num))
self.item_abs_cnn = nn.Conv2d(1, opt.filters_num, (opt.kernel_size, opt.filters_num))
self.unfold = nn.Unfold((3, opt.filters_num), padding=(1, 0))
# fc layer
self.user_fc = nn.Linear(opt.filters_num, opt.id_emb_size)
self.item_fc = nn.Linear(opt.filters_num, opt.id_emb_size)
self.uid_embedding = nn.Embedding(opt.user_num + 2, opt.id_emb_size)
self.iid_embedding = nn.Embedding(opt.item_num + 2, opt.id_emb_size)
self.reset_para()
def forward(self, datas):
'''
user_reviews, item_reviews, uids, iids, \
user_item2id, item_user2id, user_doc, item_doc = datas
'''
_, _, uids, iids, _, _, user_doc, item_doc = datas
# ------------------ review encoder ---------------------------------
user_word_embs = self.user_word_embs(user_doc)
item_word_embs = self.item_word_embs(item_doc)
# (BS, 100, DOC_LEN, 1)
user_local_fea = self.local_attention_cnn(user_word_embs, self.user_doc_cnn)
item_local_fea = self.local_attention_cnn(item_word_embs, self.item_doc_cnn)
# DOC_LEN * DOC_LEN
euclidean = (user_local_fea - item_local_fea.permute(0, 1, 3, 2)).pow(2).sum(1).sqrt()
attention_matrix = 1.0 / (1 + euclidean)
# (?, DOC_LEN)
user_attention = attention_matrix.sum(2)
item_attention = attention_matrix.sum(1)
# (?, 32)
user_doc_fea = self.local_pooling_cnn(user_local_fea, user_attention, self.user_abs_cnn, self.user_fc)
item_doc_fea = self.local_pooling_cnn(item_local_fea, item_attention, self.item_abs_cnn, self.item_fc)
# ------------------ id embedding ---------------------------------
uid_emb = self.uid_embedding(uids)
iid_emb = self.iid_embedding(iids)
use_fea = torch.stack([user_doc_fea, uid_emb], 1)
item_fea = torch.stack([item_doc_fea, iid_emb], 1)
return use_fea, item_fea
def local_attention_cnn(self, word_embs, doc_cnn):
'''
:Eq1 - Eq7
'''
local_att_words = self.word_cnn(word_embs.unsqueeze(1))
local_word_weight = torch.sigmoid(local_att_words.squeeze(1))
word_embs = word_embs * local_word_weight
d_fea = doc_cnn(word_embs.unsqueeze(1))
return d_fea
def local_pooling_cnn(self, feature, attention, cnn, fc):
'''
:Eq11 - Eq13
feature: (?, 100, DOC_LEN ,1)
attention: (?, DOC_LEN)
'''
bs, n_filters, doc_len, _ = feature.shape
feature = feature.permute(0, 3, 2, 1) # bs * 1 * doc_len * embed
attention = attention.reshape(bs, 1, doc_len, 1) # bs * doc
pools = feature * attention
pools = self.unfold(pools)
pools = pools.reshape(bs, 3, n_filters, doc_len)
pools = pools.sum(dim=1, keepdims=True) # bs * 1 * n_filters * doc_len
pools = pools.transpose(2, 3) # bs * 1 * doc_len * n_filters
abs_fea = cnn(pools).squeeze(3) # ? (DOC_LEN-2), 100
abs_fea = F.avg_pool1d(abs_fea, abs_fea.size(2)) # ? 100
abs_fea = F.relu(fc(abs_fea.squeeze(2))) # ? 32
return abs_fea
def reset_para(self):
cnns = [self.word_cnn, self.user_doc_cnn, self.item_doc_cnn, self.user_abs_cnn, self.item_abs_cnn]
for cnn in cnns:
nn.init.xavier_normal_(cnn.weight)
nn.init.uniform_(cnn.bias, -0.1, 0.1)
fcs = [self.user_fc, self.item_fc]
for fc in fcs:
nn.init.uniform_(fc.weight, -0.1, 0.1)
nn.init.constant_(fc.bias, 0.1)
nn.init.uniform_(self.uid_embedding.weight, -0.1, 0.1)
nn.init.uniform_(self.iid_embedding.weight, -0.1, 0.1)
w2v = torch.from_numpy(np.load(self.opt.w2v_path))
self.user_word_embs.weight.data.copy_(w2v.cuda())
self.item_word_embs.weight.data.copy_(w2v.cuda())
================================================
FILE: models/deepconn.py
================================================
# -*- coding: utf-8 -*-
import torch
import torch.nn as nn
import numpy as np
import torch.nn.functional as F
class DeepCoNN(nn.Module):
'''
deep conn 2017
'''
def __init__(self, opt, uori='user'):
super(DeepCoNN, self).__init__()
self.opt = opt
self.num_fea = 1 # DOC
self.user_word_embs = nn.Embedding(opt.vocab_size, opt.word_dim) # vocab_size * 300
self.item_word_embs = nn.Embedding(opt.vocab_size, opt.word_dim) # vocab_size * 300
self.user_cnn = nn.Conv2d(1, opt.filters_num, (opt.kernel_size, opt.word_dim))
self.item_cnn = nn.Conv2d(1, opt.filters_num, (opt.kernel_size, opt.word_dim))
self.user_fc_linear = nn.Linear(opt.filters_num, opt.fc_dim)
self.item_fc_linear = nn.Linear(opt.filters_num, opt.fc_dim)
self.dropout = nn.Dropout(self.opt.drop_out)
self.reset_para()
def forward(self, datas):
_, _, uids, iids, _, _, user_doc, item_doc = datas
user_doc = self.user_word_embs(user_doc)
item_doc = self.item_word_embs(item_doc)
u_fea = F.relu(self.user_cnn(user_doc.unsqueeze(1))).squeeze(3) # .permute(0, 2, 1)
i_fea = F.relu(self.item_cnn(item_doc.unsqueeze(1))).squeeze(3) # .permute(0, 2, 1)
u_fea = F.max_pool1d(u_fea, u_fea.size(2)).squeeze(2)
i_fea = F.max_pool1d(i_fea, i_fea.size(2)).squeeze(2)
u_fea = self.dropout(self.user_fc_linear(u_fea))
i_fea = self.dropout(self.item_fc_linear(i_fea))
return torch.stack([u_fea], 1), torch.stack([i_fea], 1)
def reset_para(self):
for cnn in [self.user_cnn, self.item_cnn]:
nn.init.xavier_normal_(cnn.weight)
nn.init.constant_(cnn.bias, 0.1)
for fc in [self.user_fc_linear, self.item_fc_linear]:
nn.init.uniform_(fc.weight, -0.1, 0.1)
nn.init.constant_(fc.bias, 0.1)
if self.opt.use_word_embedding:
w2v = torch.from_numpy(np.load(self.opt.w2v_path))
if self.opt.use_gpu:
self.user_word_embs.weight.data.copy_(w2v.cuda())
self.item_word_embs.weight.data.copy_(w2v.cuda())
else:
self.user_word_embs.weight.data.copy_(w2v)
self.item_word_embs.weight.data.copy_(w2v)
else:
nn.init.uniform_(self.user_word_embs.weight, -0.1, 0.1)
nn.init.uniform_(self.item_word_embs.weight, -0.1, 0.1)
================================================
FILE: models/mpcn.py
================================================
# -*- coding: utf-8 -*-
import torch
import torch.nn as nn
import numpy as np
import torch.nn.functional as F
class MPCN(nn.Module):
'''
Multi-Pointer Co-Attention Network for Recommendation
WWW 2018
'''
def __init__(self, opt, head=3):
'''
head: the number of pointers
'''
super(MPCN, self).__init__()
self.opt = opt
self.num_fea = 1 # ID + DOC
self.head = head
self.user_word_embs = nn.Embedding(opt.vocab_size, opt.word_dim) # vocab_size * 300
self.item_word_embs = nn.Embedding(opt.vocab_size, opt.word_dim) # vocab_size * 300
# review gate
self.fc_g1 = nn.Linear(opt.word_dim, opt.word_dim)
self.fc_g2 = nn.Linear(opt.word_dim, opt.word_dim)
# multi points
self.review_coatt = nn.ModuleList([Co_Attention(opt.word_dim, gumbel=True, pooling='max') for _ in range(head)])
self.word_coatt = nn.ModuleList([Co_Attention(opt.word_dim, gumbel=False, pooling='avg') for _ in range(head)])
# final fc
self.u_fc = self.fc_layer()
self.i_fc = self.fc_layer()
self.drop_out = nn.Dropout(opt.drop_out)
self.reset_para()
def fc_layer(self):
return nn.Sequential(
nn.Linear(self.opt.word_dim * self.head, self.opt.word_dim),
nn.ReLU(),
nn.Linear(self.opt.word_dim, self.opt.id_emb_size)
)
def forward(self, datas):
'''
user_reviews, item_reviews, uids, iids, \
user_item2id, item_user2id, user_doc, item_doc = datas
:user_reviews: B * L1 * N
:item_reviews: B * L2 * N
'''
user_reviews, item_reviews, _, _, _, _, _, _ = datas
# ------------------review-level co-attention ---------------------------------
u_word_embs = self.user_word_embs(user_reviews)
i_word_embs = self.item_word_embs(item_reviews)
u_reviews = self.review_gate(u_word_embs)
i_reviews = self.review_gate(i_word_embs)
u_fea = []
i_fea = []
for i in range(self.head):
r_coatt = self.review_coatt[i]
w_coatt = self.word_coatt[i]
# ------------------review-level co-attention ---------------------------------
p_u, p_i = r_coatt(u_reviews, i_reviews) # B * L1/2 * 1
# ------------------word-level co-attention ---------------------------------
u_r_words = user_reviews.permute(0, 2, 1).float().bmm(p_u) # (B * N * L1) X (B * L1 * 1)
i_r_words = item_reviews.permute(0, 2, 1).float().bmm(p_i) # (B * N * L2) X (B * L2 * 1)
u_words = self.user_word_embs(u_r_words.squeeze(2).long()) # B * N * d
i_words = self.item_word_embs(i_r_words.squeeze(2).long()) # B * N * d
p_u, p_i = w_coatt(u_words, i_words) # B * N * 1
u_w_fea = u_words.permute(0, 2, 1).bmm(p_u).squeeze(2)
i_w_fea = u_words.permute(0, 2, 1).bmm(p_i).squeeze(2)
u_fea.append(u_w_fea)
i_fea.append(i_w_fea)
u_fea = torch.cat(u_fea, 1)
i_fea = torch.cat(i_fea, 1)
u_fea = self.drop_out(self.u_fc(u_fea))
i_fea = self.drop_out(self.i_fc(i_fea))
return torch.stack([u_fea], 1), torch.stack([i_fea], 1)
def review_gate(self, reviews):
# Eq 1
reviews = reviews.sum(2)
return torch.sigmoid(self.fc_g1(reviews)) * torch.tanh(self.fc_g2(reviews))
def reset_para(self):
for fc in [self.fc_g1, self.fc_g2, self.u_fc[0], self.u_fc[-1], self.i_fc[0], self.i_fc[-1]]:
nn.init.uniform_(fc.weight, -0.1, 0.1)
nn.init.uniform_(fc.bias, -0.1, 0.1)
if self.opt.use_word_embedding:
w2v = torch.from_numpy(np.load(self.opt.w2v_path))
if self.opt.use_gpu:
self.user_word_embs.weight.data.copy_(w2v.cuda())
self.item_word_embs.weight.data.copy_(w2v.cuda())
else:
self.user_word_embs.weight.data.copy_(w2v)
self.item_word_embs.weight.data.copy_(w2v)
else:
nn.init.uniform_(self.user_word_embs.weight, -0.1, 0.1)
nn.init.uniform_(self.item_word_embs.weight, -0.1, 0.1)
class Co_Attention(nn.Module):
'''
review-level and word-level co-attention module
Eq (2,3, 10,11)
'''
def __init__(self, dim, gumbel, pooling):
super(Co_Attention, self).__init__()
self.gumbel = gumbel
self.pooling = pooling
self.M = nn.Parameter(torch.randn(dim, dim))
self.fc_u = nn.Linear(dim, dim)
self.fc_i = nn.Linear(dim, dim)
self.reset_para()
def reset_para(self):
nn.init.xavier_uniform_(self.M, gain=1)
nn.init.uniform_(self.fc_u.weight, -0.1, 0.1)
nn.init.uniform_(self.fc_u.bias, -0.1, 0.1)
nn.init.uniform_(self.fc_i.weight, -0.1, 0.1)
nn.init.uniform_(self.fc_i.bias, -0.1, 0.1)
def forward(self, u_fea, i_fea):
'''
u_fea: B * L1 * d
i_fea: B * L2 * d
return:
B * L1 * 1
B * L2 * 1
'''
u = self.fc_u(u_fea)
i = self.fc_i(i_fea)
S = u.matmul(self.M).bmm(i.permute(0, 2, 1)) # B * L1 * L2 Eq(2/10), we transport item instead user
if self.pooling == 'max':
u_score = S.max(2)[0] # B * L1
i_score = S.max(1)[0] # B * L2
else:
u_score = S.mean(2) # B * L1
i_score = S.mean(1) # B * L2
if self.gumbel:
p_u = F.gumbel_softmax(u_score, hard=True, dim=1)
p_i = F.gumbel_softmax(i_score, hard=True, dim=1)
else:
p_u = F.softmax(u_score, dim=1)
p_i = F.softmax(i_score, dim=1)
return p_u.unsqueeze(2), p_i.unsqueeze(2)
================================================
FILE: models/narre.py
================================================
# -*- coding: utf-8 -*-
import torch
import torch.nn as nn
import numpy as np
import torch.nn.functional as F
class NARRE(nn.Module):
'''
NARRE: WWW 2018
'''
def __init__(self, opt):
super(NARRE, self).__init__()
self.opt = opt
self.num_fea = 2 # ID + Review
self.user_net = Net(opt, 'user')
self.item_net = Net(opt, 'item')
def forward(self, datas):
user_reviews, item_reviews, uids, iids, user_item2id, item_user2id, user_doc, item_doc = datas
u_fea = self.user_net(user_reviews, uids, user_item2id)
i_fea = self.item_net(item_reviews, iids, item_user2id)
return u_fea, i_fea
class Net(nn.Module):
def __init__(self, opt, uori='user'):
super(Net, self).__init__()
self.opt = opt
if uori == 'user':
id_num = self.opt.user_num
ui_id_num = self.opt.item_num
else:
id_num = self.opt.item_num
ui_id_num = self.opt.user_num
self.id_embedding = nn.Embedding(id_num, self.opt.id_emb_size) # user/item num * 32
self.word_embs = nn.Embedding(self.opt.vocab_size, self.opt.word_dim) # vocab_size * 300
self.u_i_id_embedding = nn.Embedding(ui_id_num, self.opt.id_emb_size)
self.review_linear = nn.Linear(self.opt.filters_num, self.opt.id_emb_size)
self.id_linear = nn.Linear(self.opt.id_emb_size, self.opt.id_emb_size, bias=False)
self.attention_linear = nn.Linear(self.opt.id_emb_size, 1)
self.fc_layer = nn.Linear(self.opt.filters_num, self.opt.id_emb_size)
self.cnn = nn.Conv2d(1, opt.filters_num, (opt.kernel_size, opt.word_dim))
self.dropout = nn.Dropout(self.opt.drop_out)
self.reset_para()
def forward(self, reviews, ids, ids_list):
# --------------- word embedding ----------------------------------
reviews = self.word_embs(reviews) # size * 300
bs, r_num, r_len, wd = reviews.size()
reviews = reviews.view(-1, r_len, wd)
id_emb = self.id_embedding(ids)
u_i_id_emb = self.u_i_id_embedding(ids_list)
# --------cnn for review--------------------
fea = F.relu(self.cnn(reviews.unsqueeze(1))).squeeze(3) # .permute(0, 2, 1)
fea = F.max_pool1d(fea, fea.size(2)).squeeze(2)
fea = fea.view(-1, r_num, fea.size(1))
# ------------------linear attention-------------------------------
rs_mix = F.relu(self.review_linear(fea) + self.id_linear(F.relu(u_i_id_emb)))
att_score = self.attention_linear(rs_mix)
att_weight = F.softmax(att_score, 1)
r_fea = fea * att_weight
r_fea = r_fea.sum(1)
r_fea = self.dropout(r_fea)
return torch.stack([id_emb, self.fc_layer(r_fea)], 1)
def reset_para(self):
nn.init.xavier_normal_(self.cnn.weight)
nn.init.constant_(self.cnn.bias, 0.1)
nn.init.uniform_(self.id_linear.weight, -0.1, 0.1)
nn.init.uniform_(self.review_linear.weight, -0.1, 0.1)
nn.init.constant_(self.review_linear.bias, 0.1)
nn.init.uniform_(self.attention_linear.weight, -0.1, 0.1)
nn.init.constant_(self.attention_linear.bias, 0.1)
nn.init.uniform_(self.fc_layer.weight, -0.1, 0.1)
nn.init.constant_(self.fc_layer.bias, 0.1)
if self.opt.use_word_embedding:
w2v = torch.from_numpy(np.load(self.opt.w2v_path))
if self.opt.use_gpu:
self.word_embs.weight.data.copy_(w2v.cuda())
else:
self.word_embs.weight.data.copy_(w2v)
else:
nn.init.xavier_normal_(self.word_embs.weight)
nn.init.uniform_(self.id_embedding.weight, a=-0.1, b=0.1)
nn.init.uniform_(self.u_i_id_embedding.weight, a=-0.1, b=0.1)
================================================
FILE: pro_data/data_pro.py
================================================
# -*- coding: utf-8 -*-
import json
import pandas as pd
import re
import sys
import os
import numpy as np
import time
from sklearn.model_selection import train_test_split
from operator import itemgetter
import gensim
from collections import defaultdict
from sklearn.feature_extraction.text import TfidfVectorizer
P_REVIEW = 0.85
MAX_DF = 0.7
MAX_VOCAB = 50000
DOC_LEN = 500
PRE_W2V_BIN_PATH = "" # the pre-trained word2vec files
def now():
return str(time.strftime('%Y-%m-%d %H:%M:%S'))
def get_count(data, id):
ids = set(data[id].tolist())
return ids
def numerize(data):
uid = list(map(lambda x: user2id[x], data['user_id']))
iid = list(map(lambda x: item2id[x], data['item_id']))
data['user_id'] = uid
data['item_id'] = iid
return data
def clean_str(string):
string = re.sub(r"[^A-Za-z0-9]", " ", string)
string = re.sub(r"\'s", " \'s", string)
string = re.sub(r"\'ve", " \'ve", string)
string = re.sub(r"n\'t", " n\'t", string)
string = re.sub(r"\'re", " \'re", string)
string = re.sub(r"\'d", " \'d", string)
string = re.sub(r"\'ll", " \'ll", string)
string = re.sub(r",", " , ", string)
string = re.sub(r"!", " ! ", string)
string = re.sub(r"\(", " \( ", string)
string = re.sub(r"\)", " \) ", string)
string = re.sub(r"\?", " \? ", string)
string = re.sub(r"\s{2,}", " ", string)
string = re.sub(r"\s{2,}", " ", string)
string = re.sub(r"sssss ", " ", string)
return string.strip().lower()
def bulid_vocbulary(xDict):
rawReviews = []
for (id, text) in xDict.items():
rawReviews.append(' '.join(text))
return rawReviews
def build_doc(u_reviews_dict, i_reviews_dict):
'''
1. extract the vocab
2. fiter the reviews and documents of users and items
'''
u_reviews = []
for ind in range(len(u_reviews_dict)):
u_reviews.append(' <SEP> '.join(u_reviews_dict[ind]))
i_reviews = []
for ind in range(len(i_reviews_dict)):
i_reviews.append('<SEP>'.join(i_reviews_dict[ind]))
vectorizer = TfidfVectorizer(max_df=MAX_DF, max_features=MAX_VOCAB)
vectorizer.fit(u_reviews)
vocab = vectorizer.vocabulary_
vocab[MAX_VOCAB] = '<SEP>'
def clean_review(rDict):
new_dict = {}
for k, text in rDict.items():
new_reviews = []
for r in text:
words = ' '.join([w for w in r.split() if w in vocab])
new_reviews.append(words)
new_dict[k] = new_reviews
return new_dict
def clean_doc(raw):
new_raw = []
for line in raw:
review = [word for word in line.split() if word in vocab]
if len(review) > DOC_LEN:
review = review[:DOC_LEN]
new_raw.append(review)
return new_raw
u_reviews_dict = clean_review(u_reviews_dict)
i_reviews_dict = clean_review(i_reviews_dict)
u_doc = clean_doc(u_reviews)
i_doc = clean_doc(i_reviews)
return vocab, u_doc, i_doc, u_reviews_dict, i_reviews_dict
def countNum(xDict):
minNum = 100
maxNum = 0
sumNum = 0
maxSent = 0
minSent = 3000
# pSentLen = 0
ReviewLenList = []
SentLenList = []
for (i, text) in xDict.items():
sumNum = sumNum + len(text)
if len(text) < minNum:
minNum = len(text)
if len(text) > maxNum:
maxNum = len(text)
ReviewLenList.append(len(text))
for sent in text:
# SentLenList.append(len(sent))
if sent != "":
wordTokens = sent.split()
if len(wordTokens) > maxSent:
maxSent = len(wordTokens)
if len(wordTokens) < minSent:
minSent = len(wordTokens)
SentLenList.append(len(wordTokens))
averageNum = sumNum // (len(xDict))
x = np.sort(SentLenList)
xLen = len(x)
pSentLen = x[int(P_REVIEW * xLen) - 1]
x = np.sort(ReviewLenList)
xLen = len(x)
pReviewLen = x[int(P_REVIEW * xLen) - 1]
return minNum, maxNum, averageNum, maxSent, minSent, pReviewLen, pSentLen
if __name__ == '__main__':
start_time = time.time()
assert(len(sys.argv) >= 2)
filename = sys.argv[1]
yelp_data = False
if len(sys.argv) > 2 and sys.argv[2] == 'yelp':
# yelp dataset
yelp_data = True
save_folder = '../dataset/' + filename[:-3]+"_data"
else:
# amazon dataset
save_folder = '../dataset/' + filename[:-7]+"_data"
print(f"数据集名称:{save_folder}")
if not os.path.exists(save_folder + '/train'):
os.makedirs(save_folder + '/train')
if not os.path.exists(save_folder + '/val'):
os.makedirs(save_folder + '/val')
if not os.path.exists(save_folder + '/test'):
os.makedirs(save_folder + '/test')
if len(PRE_W2V_BIN_PATH) == 0:
print("Warning: the word embedding file is not provided, will be initialized randomly")
file = open(filename, errors='ignore')
print(f"{now()}: Step1: loading raw review datasets...")
users_id = []
items_id = []
ratings = []
reviews = []
if yelp_data:
for line in file:
value = line.split('\t')
reviews.append(value[2])
users_id.append(value[0])
items_id.append(value[1])
ratings.append(value[3])
else:
for line in file:
js = json.loads(line)
if str(js['reviewerID']) == 'unknown':
print("unknown user id")
continue
if str(js['asin']) == 'unknown':
print("unkown item id")
continue
try:
reviews.append(js['reviewText'])
users_id.append(str(js['reviewerID']))
items_id.append(str(js['asin']))
ratings.append(str(js['overall']))
except:
continue
data_frame = {'user_id': pd.Series(users_id), 'item_id': pd.Series(items_id),
'ratings': pd.Series(ratings), 'reviews': pd.Series(reviews)}
data = pd.DataFrame(data_frame) # [['user_id', 'item_id', 'ratings', 'reviews']]
del users_id, items_id, ratings, reviews
uidList, iidList = get_count(data, 'user_id'), get_count(data, 'item_id')
userNum_all = len(uidList)
itemNum_all = len(iidList)
print("===============Start:all rawData size======================")
print(f"dataNum: {data.shape[0]}")
print(f"userNum: {userNum_all}")
print(f"itemNum: {itemNum_all}")
print(f"data densiy: {data.shape[0]/float(userNum_all * itemNum_all):.4f}")
print("===============End: rawData size========================")
user2id = dict((uid, i) for(i, uid) in enumerate(uidList))
item2id = dict((iid, i) for(i, iid) in enumerate(iidList))
data = numerize(data)
print(f"-"*60)
print(f"{now()} Step2: split datsets into train/val/test, save into npy data")
data_train, data_test = train_test_split(data, test_size=0.2, random_state=1234)
uids_train, iids_train = get_count(data_train, 'user_id'), get_count(data_train, 'item_id')
userNum = len(uids_train)
itemNum = len(iids_train)
print("===============Start: no-preprocess: trainData size======================")
print("dataNum: {}".format(data_train.shape[0]))
print("userNum: {}".format(userNum))
print("itemNum: {}".format(itemNum))
print("===============End: no-preprocess: trainData size========================")
uidMiss = []
iidMiss = []
if userNum != userNum_all or itemNum != itemNum_all:
for uid in range(userNum_all):
if uid not in uids_train:
uidMiss.append(uid)
for iid in range(itemNum_all):
if iid not in iids_train:
iidMiss.append(iid)
uid_index = []
for uid in uidMiss:
index = data_test.index[data_test['user_id'] == uid].tolist()
uid_index.extend(index)
data_train = pd.concat([data_train, data_test.loc[uid_index]])
iid_index = []
for iid in iidMiss:
index = data_test.index[data_test['item_id'] == iid].tolist()
iid_index.extend(index)
data_train = pd.concat([data_train, data_test.loc[iid_index]])
all_index = list(set().union(uid_index, iid_index))
data_test = data_test.drop(all_index)
# split validate set aand test set
data_test, data_val = train_test_split(data_test, test_size=0.5, random_state=1234)
uidList_train, iidList_train = get_count(data_train, 'user_id'), get_count(data_train, 'item_id')
userNum = len(uidList_train)
itemNum = len(iidList_train)
print("===============Start--process finished: trainData size======================")
print("dataNum: {}".format(data_train.shape[0]))
print("userNum: {}".format(userNum))
print("itemNum: {}".format(itemNum))
print("===============End-process finished: trainData size========================")
def extract(data_dict):
x = []
y = []
for i in data_dict.values:
uid = i[0]
iid = i[1]
x.append([uid, iid])
y.append(float(i[2]))
return x, y
x_train, y_train = extract(data_train)
x_val, y_val = extract(data_val)
x_test, y_test = extract(data_test)
np.save(f"{save_folder}/train/Train.npy", x_train)
np.save(f"{save_folder}/train/Train_Score.npy", y_train)
np.save(f"{save_folder}/val/Val.npy", x_val)
np.save(f"{save_folder}/val/Val_Score.npy", y_val)
np.save(f"{save_folder}/test/Test.npy", x_test)
np.save(f"{save_folder}/test/Test_Score.npy", y_test)
print(now())
print(f"Train data size: {len(x_train)}")
print(f"Val data size: {len(x_val)}")
print(f"Test data size: {len(x_test)}")
print(f"-"*60)
print(f"{now()} Step3: Construct the vocab and user/item reviews from training set.")
# 2: build vocabulary only with train dataset
user_reviews_dict = {}
item_reviews_dict = {}
user_iid_dict = {}
item_uid_dict = {}
user_len = defaultdict(int)
item_len = defaultdict(int)
for i in data_train.values:
str_review = clean_str(i[3].encode('ascii', 'ignore').decode('ascii'))
if len(str_review.strip()) == 0:
str_review = "<unk>"
if i[0] in user_reviews_dict:
user_reviews_dict[i[0]].append(str_review)
user_iid_dict[i[0]].append(i[1])
else:
user_reviews_dict[i[0]] = [str_review]
user_iid_dict[i[0]] = [i[1]]
if i[1] in item_reviews_dict:
item_reviews_dict[i[1]].append(str_review)
item_uid_dict[i[1]].append(i[0])
else:
item_reviews_dict[i[1]] = [str_review]
item_uid_dict[i[1]] = [i[0]]
vocab, user_review2doc, item_review2doc, user_reviews_dict, item_reviews_dict = build_doc(user_reviews_dict, item_reviews_dict)
word_index = {}
word_index['<unk>'] = 0
for i, w in enumerate(vocab.keys(), 1):
word_index[w] = i
print(f"The vocab size: {len(word_index)}")
print(f"Average user document length: {sum([len(i) for i in user_review2doc])/len(user_review2doc)}")
print(f"Average item document length: {sum([len(i) for i in item_review2doc])/len(item_review2doc)}")
print(now())
u_minNum, u_maxNum, u_averageNum, u_maxSent, u_minSent, u_pReviewLen, u_pSentLen = countNum(user_reviews_dict)
print("用户最少有{}个评论,最多有{}个评论,平均有{}个评论, " \
"句子最大长度{},句子的最短长度{}," \
"设定用户评论个数为{}: 设定句子最大长度为{}".format(u_minNum, u_maxNum, u_averageNum, u_maxSent, u_minSent, u_pReviewLen, u_pSentLen))
i_minNum, i_maxNum, i_averageNum, i_maxSent, i_minSent, i_pReviewLen, i_pSentLen = countNum(item_reviews_dict)
print("商品最少有{}个评论,最多有{}个评论,平均有{}个评论," \
"句子最大长度{},句子的最短长度{}," \
",设定商品评论数目{}, 设定句子最大长度为{}".format(i_minNum, i_maxNum, i_averageNum, u_maxSent, i_minSent, i_pReviewLen, i_pSentLen))
print("最终设定句子最大长度为(取最大值):{}".format(max(u_pSentLen, i_pSentLen)))
# ########################################################################################################
maxSentLen = max(u_pSentLen, i_pSentLen)
minSentlen = 1
userReview2Index = []
userDoc2Index = []
user_iid_list = []
print(f"-"*60)
print(f"{now()} Step4: padding all the text and id lists and save into npy.")
def padding_text(textList, num):
new_textList = []
if len(textList) >= num:
new_textList = textList[:num]
else:
padding = [[0] * len(textList[0]) for _ in range(num - len(textList))]
new_textList = textList + padding
return new_textList
def padding_ids(iids, num, pad_id):
if len(iids) >= num:
new_iids = iids[:num]
else:
new_iids = iids + [pad_id] * (num - len(iids))
return new_iids
def padding_doc(doc):
pDocLen = DOC_LEN
new_doc = []
for d in doc:
if len(d) < pDocLen:
d = d + [0] * (pDocLen - len(d))
else:
d = d[:pDocLen]
new_doc.append(d)
return new_doc, pDocLen
for i in range(userNum):
count_user = 0
dataList = []
a_count = 0
textList = user_reviews_dict[i]
u_iids = user_iid_dict[i]
u_reviewList = []
user_iid_list.append(padding_ids(u_iids, u_pReviewLen, itemNum+1))
doc2index = [word_index[w] for w in user_review2doc[i]]
for text in textList:
text2index = []
wordTokens = text.strip().split()
if len(wordTokens) == 0:
wordTokens = ['<unk>']
text2index = [word_index[w] for w in wordTokens]
if len(text2index) < maxSentLen:
text2index = text2index + [0] * (maxSentLen - len(text2index))
else:
text2index = text2index[:maxSentLen]
u_reviewList.append(text2index)
userReview2Index.append(padding_text(u_reviewList, u_pReviewLen))
userDoc2Index.append(doc2index)
# userReview2Index = []
userDoc2Index, userDocLen = padding_doc(userDoc2Index)
print(f"user document length: {userDocLen}")
itemReview2Index = []
itemDoc2Index = []
item_uid_list = []
for i in range(itemNum):
count_item = 0
dataList = []
textList = item_reviews_dict[i]
i_uids = item_uid_dict[i]
i_reviewList = [] # 待添加
i_reviewLen = [] # 待添加
item_uid_list.append(padding_ids(i_uids, i_pReviewLen, userNum+1))
doc2index = [word_index[w] for w in item_review2doc[i]]
for text in textList:
text2index = []
wordTokens = text.strip().split()
if len(wordTokens) == 0:
wordTokens = ['<unk>']
text2index = [word_index[w] for w in wordTokens]
if len(text2index) < maxSentLen:
text2index = text2index + [0] * (maxSentLen - len(text2index))
else:
text2index = text2index[:maxSentLen]
if len(text2index) < maxSentLen:
text2index = text2index + [0] * (maxSentLen - len(text2index))
i_reviewList.append(text2index)
itemReview2Index.append(padding_text(i_reviewList, i_pReviewLen))
itemDoc2Index.append(doc2index)
itemDoc2Index, itemDocLen = padding_doc(itemDoc2Index)
print(f"item document length: {itemDocLen}")
print("-"*60)
print(f"{now()} start writing npy...")
np.save(f"{save_folder}/train/userReview2Index.npy", userReview2Index)
np.save(f"{save_folder}/train/user_item2id.npy", user_iid_list)
np.save(f"{save_folder}/train/userDoc2Index.npy", userDoc2Index)
np.save(f"{save_folder}/train/itemReview2Index.npy", itemReview2Index)
np.save(f"{save_folder}/train/item_user2id.npy", item_uid_list)
np.save(f"{save_folder}/train/itemDoc2Index.npy", itemDoc2Index)
print(f"{now()} write finised")
# #####################################################3,产生w2v############################################
print("-"*60)
print(f"{now()} Step5: start word embedding mapping...")
vocab_item = sorted(word_index.items(), key=itemgetter(1))
w2v = []
out = 0
if PRE_W2V_BIN_PATH:
pre_word2v = gensim.models.KeyedVectors.load_word2vec_format(PRE_W2V_BIN_PATH, binary=True)
else:
pre_word2v = {}
print(f"{now()} 开始提取embedding")
for word, key in vocab_item:
if word in pre_word2v:
w2v.append(pre_word2v[word])
else:
out += 1
w2v.append(np.random.uniform(-1.0, 1.0, (300,)))
print("############################")
print(f"out of vocab: {out}")
# print w2v[1000]
print(f"w2v size: {len(w2v)}")
print("############################")
w2vArray = np.array(w2v)
print(w2vArray.shape)
np.save(f"{save_folder}/train/w2v.npy", w2v)
end_time = time.time()
print(f"{now()} all steps finised, cost time: {end_time-start_time:.4f}s")
gitextract_59dzc63p/
├── .gitignore
├── README.md
├── checkpoints/
│ └── .gitkeeper
├── config/
│ ├── __init__.py
│ └── config.py
├── dataset/
│ ├── __init__.py
│ └── data_review.py
├── framework/
│ ├── __init__.py
│ ├── fusion.py
│ ├── models.py
│ └── prediction.py
├── main.py
├── models/
│ ├── __init__.py
│ ├── d_attn.py
│ ├── daml.py
│ ├── deepconn.py
│ ├── mpcn.py
│ └── narre.py
└── pro_data/
└── data_pro.py
SYMBOL INDEX (98 symbols across 12 files)
FILE: config/config.py
class DefaultConfig (line 6) | class DefaultConfig:
method set_path (line 50) | def set_path(self, name):
method parse (line 68) | def parse(self, kwargs):
class Digital_Music_data_Config (line 94) | class Digital_Music_data_Config(DefaultConfig):
method __init__ (line 96) | def __init__(self):
FILE: dataset/data_review.py
class ReviewData (line 8) | class ReviewData(Dataset):
method __init__ (line 10) | def __init__(self, root_path, mode):
method __getitem__ (line 28) | def __getitem__(self, idx):
method __len__ (line 32) | def __len__(self):
FILE: framework/fusion.py
class FusionLayer (line 7) | class FusionLayer(nn.Module):
method __init__ (line 11) | def __init__(self, opt):
method forward (line 21) | def forward(self, u_out, i_out):
class SelfAtt (line 45) | class SelfAtt(nn.Module):
method __init__ (line 49) | def __init__(self, dim, num_heads):
method forward (line 54) | def forward(self, user_fea, item_fea):
FILE: framework/models.py
class Model (line 11) | class Model(nn.Module):
method __init__ (line 13) | def __init__(self, opt, Net):
method forward (line 35) | def forward(self, datas):
method load (line 45) | def load(self, path):
method save (line 51) | def save(self, epoch=None, name=None, opt=None):
FILE: framework/prediction.py
class PredictionLayer (line 8) | class PredictionLayer(nn.Module):
method __init__ (line 16) | def __init__(self, opt):
method forward (line 30) | def forward(self, feature, uid, iid):
class LFM (line 37) | class LFM(nn.Module):
method __init__ (line 39) | def __init__(self, dim, user_num, item_num):
method init_weight (line 50) | def init_weight(self):
method rescale_sigmoid (line 56) | def rescale_sigmoid(self, score, a, b):
method forward (line 59) | def forward(self, feature, user_id, item_id):
class NFM (line 64) | class NFM(nn.Module):
method __init__ (line 68) | def __init__(self, dim):
method init_weight (line 80) | def init_weight(self):
method forward (line 86) | def forward(self, input_vec, *args):
class FM (line 100) | class FM(nn.Module):
method __init__ (line 102) | def __init__(self, dim, user_num, item_num):
method init_weight (line 114) | def init_weight(self):
method build_fm (line 121) | def build_fm(self, input_vec):
method forward (line 139) | def forward(self, feature, uids, iids):
class MLP (line 144) | class MLP(nn.Module):
method __init__ (line 146) | def __init__(self, dim):
method init_weight (line 153) | def init_weight(self):
method forward (line 157) | def forward(self, feature, *args, **kwargs):
FILE: main.py
function now (line 19) | def now():
function collate_fn (line 23) | def collate_fn(batch):
function train (line 28) | def train(**kwargs):
function test (line 131) | def test(**kwargs):
function predict (line 164) | def predict(model, data_loader, opt):
function unpack_input (line 191) | def unpack_input(opt, x):
FILE: models/d_attn.py
class D_ATTN (line 9) | class D_ATTN(nn.Module):
method __init__ (line 14) | def __init__(self, opt):
method forward (line 22) | def forward(self, datas):
class Net (line 29) | class Net(nn.Module):
method __init__ (line 30) | def __init__(self, opt, uori='user'):
method forward (line 48) | def forward(self, docs):
method reset_para (line 58) | def reset_para(self):
class LocalAttention (line 78) | class LocalAttention(nn.Module):
method __init__ (line 79) | def __init__(self, seq_len, win_size, emb_size, filters_num):
method forward (line 87) | def forward(self, x):
class GlobalAttention (line 96) | class GlobalAttention(nn.Module):
method __init__ (line 97) | def __init__(self, seq_len, emb_size, filters_size=[2, 3, 4], filters_...
method forward (line 105) | def forward(self, x):
FILE: models/daml.py
class DAML (line 9) | class DAML(nn.Module):
method __init__ (line 13) | def __init__(self, opt):
method forward (line 41) | def forward(self, datas):
method local_attention_cnn (line 75) | def local_attention_cnn(self, word_embs, doc_cnn):
method local_pooling_cnn (line 85) | def local_pooling_cnn(self, feature, attention, cnn, fc):
method reset_para (line 106) | def reset_para(self):
FILE: models/deepconn.py
class DeepCoNN (line 9) | class DeepCoNN(nn.Module):
method __init__ (line 13) | def __init__(self, opt, uori='user'):
method forward (line 30) | def forward(self, datas):
method reset_para (line 45) | def reset_para(self):
FILE: models/mpcn.py
class MPCN (line 9) | class MPCN(nn.Module):
method __init__ (line 14) | def __init__(self, opt, head=3):
method fc_layer (line 41) | def fc_layer(self):
method forward (line 48) | def forward(self, datas):
method review_gate (line 89) | def review_gate(self, reviews):
method reset_para (line 94) | def reset_para(self):
class Co_Attention (line 112) | class Co_Attention(nn.Module):
method __init__ (line 117) | def __init__(self, dim, gumbel, pooling):
method reset_para (line 127) | def reset_para(self):
method forward (line 134) | def forward(self, u_fea, i_fea):
FILE: models/narre.py
class NARRE (line 9) | class NARRE(nn.Module):
method __init__ (line 13) | def __init__(self, opt):
method forward (line 21) | def forward(self, datas):
class Net (line 28) | class Net(nn.Module):
method __init__ (line 29) | def __init__(self, opt, uori='user'):
method forward (line 54) | def forward(self, reviews, ids, ids_list):
method reset_para (line 79) | def reset_para(self):
FILE: pro_data/data_pro.py
function now (line 22) | def now():
function get_count (line 26) | def get_count(data, id):
function numerize (line 31) | def numerize(data):
function clean_str (line 39) | def clean_str(string):
function bulid_vocbulary (line 58) | def bulid_vocbulary(xDict):
function build_doc (line 65) | def build_doc(u_reviews_dict, i_reviews_dict):
function countNum (line 111) | def countNum(xDict):
function extract (line 272) | def extract(data_dict):
function padding_text (line 358) | def padding_text(textList, num):
function padding_ids (line 367) | def padding_ids(iids, num, pad_id):
function padding_doc (line 374) | def padding_doc(doc):
Condensed preview — 19 files, each showing path, character count, and a content snippet. Download the .json file or copy for the full structured content (72K chars).
[
{
"path": ".gitignore",
"chars": 190,
"preview": "checkpoints/__pycache__\ncheckpoints/*pth\ncheckpoints/*ckpt\nconfig/__pycache__\ndataset/__pycache__\ndataset/*_data\nframewo"
},
{
"path": "README.md",
"chars": 9104,
"preview": "A Toolkit for Neural Review-based Recommendation models with Pytorch.\n基于评论文本的深度推荐系统模型库 (Pytorch)\n\n**Update: 2021.03.29**"
},
{
"path": "checkpoints/.gitkeeper",
"chars": 0,
"preview": ""
},
{
"path": "config/__init__.py",
"chars": 892,
"preview": "# -*- coding: utf-8 -*-\n\nfrom .config import DefaultConfig\n# from .config import Office_Products_data_Config\n# from .con"
},
{
"path": "config/config.py",
"chars": 3108,
"preview": "# -*- coding: utf-8 -*-\n\nimport numpy as np\n\n\nclass DefaultConfig:\n\n model = 'DeepCoNN'\n dataset = 'Digital_Music_"
},
{
"path": "dataset/__init__.py",
"chars": 37,
"preview": "\nfrom .data_review import ReviewData\n"
},
{
"path": "dataset/data_review.py",
"chars": 1084,
"preview": "# -*- coding: utf-8 -*-\n\nimport os\nimport numpy as np\nfrom torch.utils.data import Dataset\n\n\nclass ReviewData(Dataset):\n"
},
{
"path": "framework/__init__.py",
"chars": 50,
"preview": "# -*- coding: utf-8 -*-\nfrom .models import Model\n"
},
{
"path": "framework/fusion.py",
"chars": 1839,
"preview": "# -*- coding: utf-8 -*-\n\nimport torch\nimport torch.nn as nn\n\n\nclass FusionLayer(nn.Module):\n '''\n Fusion Layer for"
},
{
"path": "framework/models.py",
"chars": 1883,
"preview": "# -*- coding: utf-8 -*-\n\nimport torch\nimport torch.nn as nn\nimport time\n\nfrom .prediction import PredictionLayer\nfrom .f"
},
{
"path": "framework/prediction.py",
"chars": 5509,
"preview": "# -*- coding: utf-8 -*-\n\nimport torch\nimport torch.nn as nn\nimport torch.nn.functional as F\n\n\nclass PredictionLayer(nn.M"
},
{
"path": "main.py",
"chars": 6997,
"preview": "# -*- encoding: utf-8 -*-\nimport time\nimport random\nimport math\nimport fire\n\nimport numpy as np\nimport torch\nimport torc"
},
{
"path": "models/__init__.py",
"chars": 181,
"preview": "# -*- coding: utf-8 -*-\n\n# from .narre import NARRE\nfrom .deepconn import DeepCoNN\nfrom .daml import DAML\nfrom .narre im"
},
{
"path": "models/d_attn.py",
"chars": 3991,
"preview": "# -*- coding: utf-8 -*-\n\nimport numpy as np\nimport torch\nimport torch.nn as nn\nimport torch.nn.functional as F\n\n\nclass D"
},
{
"path": "models/daml.py",
"chars": 4844,
"preview": "# -*- coding: utf-8 -*-\n\nimport torch\nimport torch.nn as nn\nimport numpy as np\nimport torch.nn.functional as F\n\n\nclass D"
},
{
"path": "models/deepconn.py",
"chars": 2456,
"preview": "# -*- coding: utf-8 -*-\n\nimport torch\nimport torch.nn as nn\nimport numpy as np\nimport torch.nn.functional as F\n\n\nclass D"
},
{
"path": "models/mpcn.py",
"chars": 5861,
"preview": "# -*- coding: utf-8 -*-\n\nimport torch\nimport torch.nn as nn\nimport numpy as np\nimport torch.nn.functional as F\n\n\nclass M"
},
{
"path": "models/narre.py",
"chars": 3800,
"preview": "# -*- coding: utf-8 -*-\n\nimport torch\nimport torch.nn as nn\nimport numpy as np\nimport torch.nn.functional as F\n\n\nclass N"
},
{
"path": "pro_data/data_pro.py",
"chars": 17081,
"preview": "# -*- coding: utf-8 -*-\nimport json\nimport pandas as pd\nimport re\nimport sys\nimport os\nimport numpy as np\nimport time\nfr"
}
]
About this extraction
This page contains the full source code of the ShomyLiu/Neu-Review-Rec GitHub repository, extracted and formatted as plain text for AI agents and large language models (LLMs). The extraction includes 19 files (67.3 KB), approximately 19.1k tokens, and a symbol index with 98 extracted functions, classes, methods, constants, and types. Use this with OpenClaw, Claude, ChatGPT, Cursor, Windsurf, or any other AI tool that accepts text input. You can copy the full output to your clipboard or download it as a .txt file.
Extracted by GitExtract — free GitHub repo to text converter for AI. Built by Nikandr Surkov.