Repository: Skyellbin/neo4j-python-pandas-py2neo-v3
Branch: master
Commit: 35bc41cf638f
Files: 12
Total size: 18.3 KB
Directory structure:
gitextract_90xa6ih0/
├── Invoice_data_Demo.xls
├── README.md
├── __init__.py
├── dataToNeo4jClass/
│ ├── DataToNeo4jClass.py
│ └── __init__.py
├── invoice_neo4j.py
├── jieba_code/
│ ├── doubt.txt
│ ├── jieba_doubt.py
│ └── jieba_interface.py
├── neo4j_matrix.py
├── neo4j_to_dataframe.py
└── requirements.txt
================================================
FILE CONTENTS
================================================
================================================
FILE: README.md
================================================
# neo4j-python-pandas-py2neo-v3
Utilize pandas to extract data from Excel and load it into the Neo4j database in triplet form to construct a relevant knowledge graph.
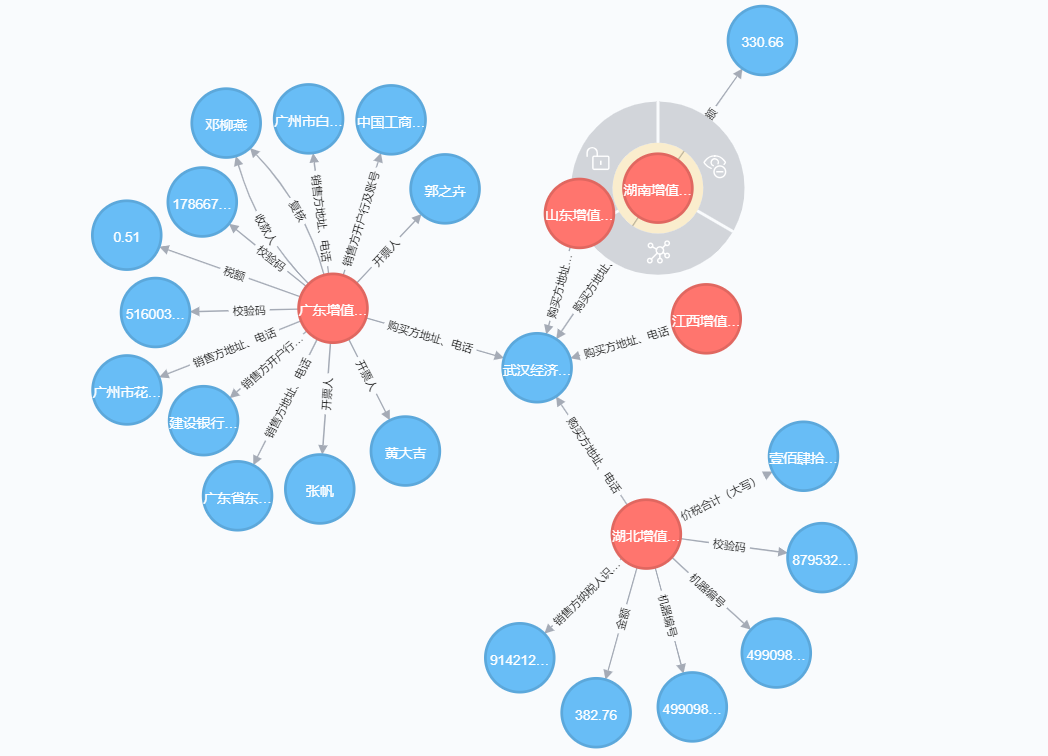
## Neo4j Knowledge Graph Construction
### 1. Running Environment:
python3.6.5
windows10
For specific package dependencies, refer to the requirements.txt file.
pip install -r requirements.txt
### 2. Pandas Extraction of Excel Data
The Excel data structure is as follows:
<img src="https://s1.ax1x.com/2018/11/13/iObTc8.png" width="800" hegiht="500" align=center />
The data_extraction and relation_extrantion functions are used to extract the node data and relationship data required for building the knowledge graph, respectively, to construct triplets.
Data extraction primarily uses pandas to convert Excel data into a DataFrame type.
invoice_neo4j.py
<img src="https://s1.ax1x.com/2018/11/13/iOb4ht.png" width="500" hegiht="313" align=center />
### 3. Establishing Node and Edge Data for the Knowledge Graph
DataToNeo4jClass.py
<img src="https://s1.ax1x.com/2018/11/13/iXk6iV.png" width="500" hegiht="313" align=center />
Update neo4j_matrix.py code to extract and convert knowledge graph data into a matrix, providing data for machine learning models.
### Related Projects
- [HappyHorseAI](https://happyhorseai.video/) — AI video generator for text-to-video and image-to-video creation, with 1080p output, native audio, and multi-shot storytelling.
- [HappyHorse20](https://www.happyhorse20.com/) — AI video creation platform for turning prompts and images into short videos for marketing, storytelling, and social content.
- [Seedance AI](https://seedance2ai.video/) — Professional AI video generator for creating cinematic videos from text and images, with native audio and advanced prompt control.
---
# neo4j-python-pandas-py2neo-v3
利用pandas将excel中数据抽取,以三元组形式加载到neo4j数据库中构建相关知识图谱
# Neo4j知识图谱构建

### 1.运行环境:
python3.6.5
windows10
具体包依赖可以参考文件requirements.txt
```
pip install -r requirements.txt
```
### 2.Pandas抽取excel数据
Excel数据结构如下
<img src="https://s1.ax1x.com/2018/11/13/iObTc8.png" width="800" hegiht="500" align=center />
通过函数data_extraction和函数relation_extrantion分别抽取构建知识图谱所需要的节点数据以及联系数据,构建三元组。
数据提取主要采用pandas将excel数据转换成dataframe类型
invoice_neo4j.py
<img src="https://s1.ax1x.com/2018/11/13/iOb4ht.png" width="500" hegiht="313" align=center />
### 3.建立知识图谱所需节点和边数据
DataToNeo4jClass.py
<img src="https://s1.ax1x.com/2018/11/13/iXk6iV.png" width="500" hegiht="313" align=center />
### 更新neo4j_matrix.py代码,将知识图谱中数据抽取转化成矩阵,为机器学习模型提供数据
================================================
FILE: __init__.py
================================================
from . import dataToNeo4jClass
================================================
FILE: dataToNeo4jClass/DataToNeo4jClass.py
================================================
# -*- coding: utf-8 -*-
from py2neo import Node, Graph, Relationship
class DataToNeo4j(object):
"""将excel中数据存入neo4j"""
def __init__(self):
"""建立连接"""
link = Graph("http://ip地址//:7474", username="xxx", password="xxx")
self.graph = link
# 定义label
self.invoice_name = '发票名称'
self.invoice_value = '发票值'
self.graph.delete_all()
def create_node(self, node_list_key, node_list_value):
"""建立节点"""
for name in node_list_key:
name_node = Node(self.invoice_name, name=name)
self.graph.create(name_node)
for name in node_list_value:
value_node = Node(self.invoice_value, name=name)
self.graph.create(value_node)
def create_relation(self, df_data):
"""建立联系"""
m = 0
for m in range(0, len(df_data)):
try:
rel = Relationship(self.graph.find_one(label=self.invoice_name, property_key='name', property_value=df_data['name'][m]),
df_data['relation'][m], self.graph.find_one(label=self.invoice_value, property_key='name',
property_value=df_data['name2'][m]))
self.graph.create(rel)
except AttributeError as e:
print(e, m)
================================================
FILE: dataToNeo4jClass/__init__.py
================================================
from . import DataToNeo4jClass
================================================
FILE: invoice_neo4j.py
================================================
# -*- coding: utf-8 -*-
from invoice_data.dataToNeo4jClass.DataToNeo4jClass import DataToNeo4j
import os
import pandas as pd
# 提取excel表格中数据,将其转换成dateframe类型
os.chdir('xxxx')
invoice_data = pd.read_excel('./Invoice_data_Demo.xls', header=0, encoding='utf8')
print(invoice_data)
def data_extraction():
"""节点数据抽取"""
# 取出发票名称到list
node_list_key = []
for i in range(0, len(invoice_data)):
node_list_key.append(invoice_data['发票名称'][i])
# 去除重复的发票名称
node_list_key = list(set(node_list_key))
# value抽出作node
node_list_value = []
for i in range(0, len(invoice_data)):
for n in range(1, len(invoice_data.columns)):
# 取出表头名称invoice_data.columns[i]
node_list_value.append(invoice_data[invoice_data.columns[n]][i])
# 去重
node_list_value = list(set(node_list_value))
# 将list中浮点及整数类型全部转成string类型
node_list_value = [str(i) for i in node_list_value]
return node_list_key, node_list_value
def relation_extraction():
"""联系数据抽取"""
links_dict = {}
name_list = []
relation_list = []
name2_list = []
for i in range(0, len(invoice_data)):
m = 0
name_node = invoice_data[invoice_data.columns[m]][i]
while m < len(invoice_data.columns)-1:
relation_list.append(invoice_data.columns[m+1])
name2_list.append(invoice_data[invoice_data.columns[m+1]][i])
name_list.append(name_node)
m += 1
# 将数据中int类型全部转成string
name_list = [str(i) for i in name_list]
name2_list = [str(i) for i in name2_list]
# 整合数据,将三个list整合成一个dict
links_dict['name'] = name_list
links_dict['relation'] = relation_list
links_dict['name2'] = name2_list
# 将数据转成DataFrame
df_data = pd.DataFrame(links_dict)
return df_data
# 实例化对象
data_extraction()
relation_extraction()
create_data = DataToNeo4j()
create_data.create_node(data_extraction()[0], data_extraction()[1])
create_data.create_relation(relation_extraction())
================================================
FILE: jieba_code/doubt.txt
================================================
'营业收入','营业成本','营业利润','利润总额','所得税费用','净利润','基本每股收益','货币资金','应收账款','存货','流动资产合计','固定资产净额','资产总计','流动负债合计','非流动负债合计','负债合计','所有者权益(或股东权益)合计','期初现金及现金等价物余额','经营活动产生的现金流量净额','投资活动产生的现金流量净额','筹资活动产生的现金流量净额','现金及现金等价物净增加额','期末现金及现金等价物余额','每股收益','每股净资产','每股未分配利润','每股资本公积金','每股经营性现金流','营业收入','营业成本','营业税金及附加','销售费用','管理费用','财务费用','资产减值损失','允许价值变动净收益','投资净收益','合营企业投资收益','汇兑净收益','营业外收入','营业外支出','非流动资产处置净损失','所得税','未确认的投资损失','少数股东损益','归属于母公司股东的净利润','基本每股收益','稀释每股收益','货币资金','交易性金融资产','应收票据','应收账款','预付账款','应收利息','应收股利','其他应收款','存货','消耗性生物资产','待摊费用','一年内到期的非流动资产','其他流动资产','影响流动资产其他科目','流动资产合计','流动资产','非流动资产','可供出售金融资产','持有至到期投资','投资性房地产','长期股权投资','长期应收款','固定资产','工程物资','在建工程','固定资产清理','生产性生物资产','油气资产','无形资产','开发支出','商誉','长期待摊费用','递延所得税资产','其他非流动资产','影响非流动资产其他科目','非流动资产合计','资产总计','流动负债','短期借款','交易性金融负债','应付票据','应付账款','预收账款','应付职工薪酬','应交税费','应付利息','应付股利','其他应付款','预提费用','预计负债','递延收益流动负债','一年内到期的非流动负债','应付短期债券','其他流动负债','影响流动负债其他科目','流动负债合计','非流动负债','长期借款','应付债券','长期应付款','专项应付款','递延所得税负债','递延收益非流动负债','其他非流动负债','影响非流动负债其他科目','非流动负债合计','负债合计','所有者权益','实收资本','资本公积金','盈余公积金','未分配利润','库存股','外币报表折算差额','未确认的投资损失','少数股东权益','归属于母公司股东权益合计','影响所有者权益其他科目','所有者权益合计','负债及所有者权益总计','销售商品提供劳务收到的现金','收到的税费返还','收到其他与经营活动有关的现金','购买商品接受劳务支付的现金','支付给职工以及为职工支付的现金','支付的各项税费','支付其他与经营活动有关的现金','经营活动现金流出小计','经营活动产生的现金流量净额','收回投资收到的现金','取得投资收益收到的现金','处置固定资产无形资产和其他长期','资产收回的现金净额','处置子公司及其他营业单位收到的现金净额','收到其他与投资活动有关的现金','投资活动现金流入小计','购建固定资产无形资产和其他长期资产支付的现金','投资支付的现金','取得子公司及其他营业单位支付的现金净额','支付其他与投资活动有关的现金','投资活动现金流出小计','投资活动产生的现金流量净额','汇率变动对现金的影响','现金及现金等价物净增加额','期初现金及现金等价物余额','期末现金及现金等价物余额','无形资产摊销','长期待摊费用摊销','待摊费用减少','预提费用增加','处置固定资产无形资产和其他长期资产的损失','固定资产报废损失','公允价值变动损失','财务费用','投资损失','递延所得税资产减少','递延所得税负债增加','存货的减少','经营性应收项目的减少','经营性应付项目的增加','未确认的投资损失','经营活动产生的现金流量净额','现金的期末余额','现金的期初余额','现金等价物的期末余额','现金等价物的期初余额','现金及现金等价物净增加额'
================================================
FILE: jieba_code/jieba_doubt.py
================================================
# -*- coding: utf-8 -*-
import jieba
import pymysql
# 连接数据库
conn = pymysql.connect(
host="xxx",
user="root",
passwd="xxx",
db="shenji",
charset='utf8')
# 创建游标
cursor = conn.cursor()
doubt_file = "select audit_dbt, audit_con, audit_rec from shenji_audit_doubt "
cursor.execute(doubt_file)
conn.commit()
cursor.close()
conn.close
result = list(cursor.fetchall())
# df = pd.DataFrame(result)
# print(df)
# userword = '''如果应付票据超过其付款期限,可能出现的问题包括利用“应付票据”账户,转移收入;购销双方存在经济纠纷;付款单位无力支付货款'''
f = open("./doubt.txt")
list_wordlist = f.readline().strip(" '").split("','")
# 列表去重
list_wordlist = list(set(list_wordlist))
# print(list_wordlist, len(list_wordlist))
'''
以三元组形式存入mysql中
1.jieba分词文本doubt.txt,找出关键词
2.遍历关键词是否与审计疑点文本有关联,找出相关的审计疑点关键词,存入列表doubt_list
3.审计疑点关键词与审计结论,审计建议建立关系映射(三元组)存入MySQL
'''
# 连接数据库
conn = pymysql.connect(
host="xxx",
user="root",
passwd="xxx",
db="invioce_info",
charset='utf8')
# 创建游标
cursor = conn.cursor()
for doubt in result:
# 疑点列表
doubt_list = []
for line in list_wordlist:
# 结巴分词,找出相关审计疑点
for word in jieba.lcut(line.strip().replace('\n', '').replace(' ', '')):
if word in doubt[0] and len(word) > 1:
doubt_list.append(line)
# 去重
doubt_list = list(set(doubt_list))
audit_map = []
for map in doubt_list:
audit_doubt = map
audit_con = doubt[1]
audit_rc = doubt[2]
# sql语句
sql = "insert into shenji_audit_map(audit_doubt, audit_con, audit_rc)" \
" values ('{}','{}','{}');" \
.format(audit_doubt, audit_con, audit_rc)
list_data = [audit_doubt, audit_con, audit_rc]
cursor.execute(sql)
# audit_map = [map, doubt[1], doubt[2]]
# print(audit_map)
# print(doubt_list, "\n", len(doubt_list))
conn.commit()
cursor.close()
conn.close
================================================
FILE: jieba_code/jieba_interface.py
================================================
# -*- coding: utf-8 -*-
import pymysql
# 连接数据库
conn = pymysql.connect(
host="115.xx.107.xx",
user="rootxxx",
passwd="rootxx",
db="shenji",
charset='utf8')
doubt_tag = '预提费用'
# 创建游标
cursor = conn.cursor()
sql = "select audit_con, audit_rc from shenji_audit_map where audit_doubt='"+doubt_tag+"'"
doubt_file = sql
print(doubt_file)
cursor.execute(doubt_file)
conn.commit()
cursor.close()
conn.close
result = list(cursor.fetchall())
print(result)
result_list = []
result_dict = {}
for line in result:
result_dict['审计建议'] = line[1]
result_dict['审计结论'] = line[0]
result_dict['审计疑点'] = doubt_tag
result_list.append(result_dict)
result_dict = {}
print(result_list)
================================================
FILE: neo4j_matrix.py
================================================
# -*- coding: utf-8 -*-
# @Time : 2019/2/13 13:29
# @Author : Skyell Wang
# @FileName: neo4j_matrix.py
from py2neo import Graph
import re
import pandas as pd
import numpy as np
class Neo4jToMatrix(object):
"""
知识图谱数据转换成矩阵类
1.主体-主体 邻接矩阵
2.主体-属性
"""
def __init__(self, select_name, label_name):
# 与neo4j服务器建立连接
self.graph = Graph("ip//:7474", username="xxxx", password="xxxx")
self.links = []
self.select_name = select_name
self.label_name = label_name
# 获取知识图谱中相关节点数据
links_data = self.graph.run("MATCH (n:" + self.label_name + "{name:'" + self.select_name + "'})-[r]-(b) return r").data()
# 获取知识图谱中关系数据
self.data_for_df = self.get_links(links_data)
def data_handle(self, name1, name2, flag_name):
"""
数据预处理
:param name1: 三元组中节点或关系
:param name2: 三元组中节点或关系
:param flag_name: 预处理流程标识,如果为'sub',处理主体-主体矩阵;如果为'att',处理主体-属性矩阵
:return: 预处理数据
"""
if flag_name == 'sub':
# 取出主体并去重
nod_list = []
for data in self.data_for_df:
nod_list.append(data[name1])
nod_list.append(data[name2])
# 去重
nod_list = list(set(nod_list))
return nod_list
elif flag_name == 'att':
name_list = []
nod_list = []
for data in self.data_for_df:
name_list.append(data[name1])
nod_list.append(data[name2])
name_list = list(set(name_list))
nod_list = list(set(nod_list))
return name_list, nod_list
else:
return
def sub_attrib(self):
"""
知识图谱三元组数据用户-属性矩阵
:return: 处理过后的数据
"""
# 取出数据
data_neo4j = self.data_handle('name', 'source', flag_name='att')
name_list = data_neo4j[0]
nod_list = data_neo4j[1]
print(nod_list)
print(name_list)
lation_list = []
mid_list = []
for name in name_list:
for i in range(0, len(nod_list)):
for lation in self.data_for_df:
if nod_list[i] != name:
if name in lation.values() and nod_list[i] in lation.values():
mid_list.append(lation['target'])
break
# 判断是否为最后一个列表元素,如果是最后一个,则赋值NaN,否则继续循环
if self.data_for_df.index(lation) == len(self.data_for_df) - 1:
mid_list.append('NaN')
lation_list.append(mid_list)
mid_list = []
print(lation_list)
# 用numpy将列表转成矩阵
matrix_data = np.array(lation_list).T
df = pd.DataFrame(matrix_data, columns=name_list, index=nod_list)
# 将矩阵写入csv格式的文件
df.to_csv('./data/neo4j_matrix_att.csv', encoding='gbk')
return df
def sub_to_sub(self):
"""
知识图谱三元组数据转邻接矩阵
:return: 主体-主体 邻接矩阵
"""
# 取出数据, flag_name:为判断数据初始化方式,如果为'sub',则为主体-主体;如果为'att',则为主体-属性
nod_list = self.data_handle('target', 'source', flag_name='sub')
# 抽取主体与主体间关系矩阵
lation_list = []
mid_list = []
for node_n in nod_list:
for i in range(0, len(nod_list)):
for lation in self.data_for_df:
# 判断行与列节点名称是否相等,如果不相等则继续
if nod_list[i] != node_n:
# 判断行列节点是否都在一个三元组中,如果同时存在将关系存入列表
if nod_list[i] in lation.values() and node_n in lation.values():
mid_list.append(lation['name'])
break
# 判断是否为最后一个列表元素,如果是最后一个,则赋值NaN,否则继续循环
if self.data_for_df.index(lation) == len(self.data_for_df) - 1:
mid_list.append('NaN')
lation_list.append(mid_list)
mid_list = []
print(lation_list)
# 用numpy将列表转成矩阵
matrix_data = np.array(lation_list)
print(matrix_data)
# 将列表转换成dataframe:columns index 指定行列名称;matrix_data 矩阵
df = pd.DataFrame(matrix_data, columns=nod_list, index=nod_list)
# 将矩阵写入csv格式的文件
df.to_csv('./data/neo4j_matrix.csv', encoding='gbk')
return df
def get_links(self, links_data):
"""
知识图谱关系数据获取
:param links_data: 知识图谱中数据
:return: 正则处理过的数据
"""
i = 1
dict = {}
# 匹配模式
pattern = '^\(|\{\}\]\-\>\(|\)\-\[\:|\)$'
for link in links_data:
# link_data样式:(南京审计大学) - [: 学校地址{}]->(江苏省南京市浦口区雨山西路86号)
link_data = str(link['r'])
# 正则,用split将string切成:['', '南京审计大学', '学校地址 ', '江苏省南京市浦口区雨山西路86号', '']
links_str = re.split(pattern, link_data)
for data in links_str:
if len(data) > 1:
if i == 1:
dict['source'] = data
elif i == 2:
dict['name'] = data
elif i == 3:
dict['target'] = data
self.links.append(dict)
dict = {}
i = 0
i += 1
return self.links
if __name__ == '__main__':
data_neo4j = Neo4jToMatrix('南京审计大学', '主体')
data_attribute = Neo4jToMatrix('南京审计大学', '主体')
print(data_attribute.sub_attrib())
# print(data_neo4j.sub_to_sub())
================================================
FILE: neo4j_to_dataframe.py
================================================
# -*- coding: utf-8 -*-
from py2neo import Graph
import re
from pandas import DataFrame
class Neo4jToJson(object):
"""知识图谱数据接口"""
# 与neo4j服务器建立连接
graph = Graph("http://IP//:7474", username="neo4j", password="xxxxxx")
links = []
nodes = []
def post(self):
"""与前端交互"""
# 前端传过来的数据
select_name = '南京审计大学'
label_name = '单位名称'
# 取出所有节点数据
nodes_data_all = self.graph.run("MATCH (n:" + label_name + ") RETURN n").data()
# node名存储
nodes_list = []
for node in nodes_data_all:
nodes_list.append(node['n']['name'])
# 根据前端的数据,判断搜索的关键字是否在nodes_list中存在,如果存在返回相应数据,否则返回全部数据
if select_name in nodes_list:
# 获取知识图谱中相关节点数据
links_data = self.graph.run("MATCH (n:" + label_name + "{name:'" + select_name + "'})-[r]-(b) return r").data()
else:
# 获取知识图谱中所有节点数据
links_data = self.graph.run("MATCH ()-[r]->() RETURN r").data()
data_for_df = self.get_links(links_data)
# 将列表转换成dataframe
df = DataFrame(data_for_df, columns=['source', 'name', 'target'])
return df
def get_links(self, links_data):
"""知识图谱关系数据获取"""
i = 1
dict = {}
# 匹配模式
pattern = '^\(|\{\}\]\-\>\(|\)\-\[\:|\)$'
for link in links_data:
# link_data样式:(南京审计大学) - [: 学校地址{}]->(江苏省南京市浦口区雨山西路86号)
link_data = str(link['r'])
# 正则,用split将string切成:['', '南京审计大学', '学校地址 ', '江苏省南京市浦口区雨山西路86号', '']
links_str = re.split(pattern, link_data)
for data in links_str:
if len(data) > 1:
if i == 1:
dict['source'] = data
elif i == 2:
dict['name'] = data
elif i == 3:
dict['target'] = data
self.links.append(dict)
dict = {}
i = 0
i += 1
return self.links
if __name__ == '__main__':
data_neo4j = Neo4jToJson()
print(data_neo4j.post())
================================================
FILE: requirements.txt
================================================
atomicwrites==1.2.1
attrs==18.2.0
backcall==0.1.0
certifi==2016.2.28
Click==7.0
colorama==0.4.0
decorator==4.3.0
ipykernel==5.1.0
ipython==7.1.1
ipython-genutils==0.2.0
jedi==0.13.1
jieba==0.39
jupyter-client==5.2.3
jupyter-console==6.0.0
jupyter-core==4.4.0
more-itertools==4.3.0
neo4j-driver==1.6.2
neobolt==1.7.0
neotime==1.7.1
numpy==1.15.3
pandas==0.23.4
parso==0.3.1
pickleshare==0.7.5
pluggy==0.8.0
prompt-toolkit==1.0.15
py==1.7.0
py2neo==3
Pygments==2.2.0
pytest==3.9.3
python-dateutil==2.7.5
pytz==2018.6
pyzmq==17.1.2
six==1.11.0
tornado==5.1.1
traitlets==4.3.2
urllib3==1.24
wcwidth==0.1.7
wincertstore==0.2
xlrd==1.1.0
gitextract_90xa6ih0/ ├── Invoice_data_Demo.xls ├── README.md ├── __init__.py ├── dataToNeo4jClass/ │ ├── DataToNeo4jClass.py │ └── __init__.py ├── invoice_neo4j.py ├── jieba_code/ │ ├── doubt.txt │ ├── jieba_doubt.py │ └── jieba_interface.py ├── neo4j_matrix.py ├── neo4j_to_dataframe.py └── requirements.txt
SYMBOL INDEX (15 symbols across 4 files)
FILE: dataToNeo4jClass/DataToNeo4jClass.py
class DataToNeo4j (line 5) | class DataToNeo4j(object):
method __init__ (line 8) | def __init__(self):
method create_node (line 17) | def create_node(self, node_list_key, node_list_value):
method create_relation (line 26) | def create_relation(self, df_data):
FILE: invoice_neo4j.py
function data_extraction (line 14) | def data_extraction():
function relation_extraction (line 39) | def relation_extraction():
FILE: neo4j_matrix.py
class Neo4jToMatrix (line 12) | class Neo4jToMatrix(object):
method __init__ (line 18) | def __init__(self, select_name, label_name):
method data_handle (line 30) | def data_handle(self, name1, name2, flag_name):
method sub_attrib (line 60) | def sub_attrib(self):
method sub_to_sub (line 103) | def sub_to_sub(self):
method get_links (line 144) | def get_links(self, links_data):
FILE: neo4j_to_dataframe.py
class Neo4jToJson (line 8) | class Neo4jToJson(object):
method post (line 16) | def post(self):
method get_links (line 41) | def get_links(self, links_data):
Condensed preview — 12 files, each showing path, character count, and a content snippet. Download the .json file or copy for the full structured content (25K chars).
[
{
"path": "README.md",
"chars": 2637,
"preview": "# neo4j-python-pandas-py2neo-v3\nUtilize pandas to extract data from Excel and load it into the Neo4j database in triplet"
},
{
"path": "__init__.py",
"chars": 30,
"preview": "from . import dataToNeo4jClass"
},
{
"path": "dataToNeo4jClass/DataToNeo4jClass.py",
"chars": 1319,
"preview": "# -*- coding: utf-8 -*-\nfrom py2neo import Node, Graph, Relationship\n\n\nclass DataToNeo4j(object):\n \"\"\"将excel中数据存入neo4"
},
{
"path": "dataToNeo4jClass/__init__.py",
"chars": 30,
"preview": "from . import DataToNeo4jClass"
},
{
"path": "invoice_neo4j.py",
"chars": 1998,
"preview": "# -*- coding: utf-8 -*-\nfrom invoice_data.dataToNeo4jClass.DataToNeo4jClass import DataToNeo4j\nimport os\nimport pandas a"
},
{
"path": "jieba_code/doubt.txt",
"chars": 1808,
"preview": "'营业收入','营业成本','营业利润','利润总额','所得税费用','净利润','基本每股收益','货币资金','应收账款','存货','流动资产合计','固定资产净额','资产总计','流动负债合计','非流动负债合计','负债合计'"
},
{
"path": "jieba_code/jieba_doubt.py",
"chars": 1876,
"preview": "# -*- coding: utf-8 -*-\nimport jieba\nimport pymysql\n\n\n# 连接数据库\nconn = pymysql.connect(\n host=\"xxx\",\n user=\"root\",\n "
},
{
"path": "jieba_code/jieba_interface.py",
"chars": 703,
"preview": "# -*- coding: utf-8 -*-\nimport pymysql\n\n# 连接数据库\nconn = pymysql.connect(\n host=\"115.xx.107.xx\",\n user=\"rootxxx\",\n "
},
{
"path": "neo4j_matrix.py",
"chars": 5512,
"preview": "# -*- coding: utf-8 -*-\n# @Time : 2019/2/13 13:29\n# @Author : Skyell Wang\n# @FileName: neo4j_matrix.py\n\nfrom py2neo "
},
{
"path": "neo4j_to_dataframe.py",
"chars": 2150,
"preview": "# -*- coding: utf-8 -*-\n\nfrom py2neo import Graph\nimport re\nfrom pandas import DataFrame\n\n\nclass Neo4jToJson(object):\n "
},
{
"path": "requirements.txt",
"chars": 632,
"preview": "atomicwrites==1.2.1\nattrs==18.2.0\nbackcall==0.1.0\ncertifi==2016.2.28\nClick==7.0\ncolorama==0.4.0\ndecorator==4.3.0\nipykern"
}
]
// ... and 1 more files (download for full content)
About this extraction
This page contains the full source code of the Skyellbin/neo4j-python-pandas-py2neo-v3 GitHub repository, extracted and formatted as plain text for AI agents and large language models (LLMs). The extraction includes 12 files (18.3 KB), approximately 6.5k tokens, and a symbol index with 15 extracted functions, classes, methods, constants, and types. Use this with OpenClaw, Claude, ChatGPT, Cursor, Windsurf, or any other AI tool that accepts text input. You can copy the full output to your clipboard or download it as a .txt file.
Extracted by GitExtract — free GitHub repo to text converter for AI. Built by Nikandr Surkov.