Repository: TLYu0419/facebook_crawler
Branch: main
Commit: 82ec3ec46aa0
Files: 18
Total size: 131.1 KB
Directory structure:
gitextract_m2qqy_6g/
├── .github/
│ └── workflows/
│ └── pythonpublish.yml
├── .gitignore
├── LICENSE
├── README.md
├── main.py
├── paser.py
├── requester.py
├── requirements.txt
├── sample/
│ ├── 20221013_Sample.ipynb
│ ├── FansPages.ipynb
│ └── Group.ipynb
├── setup.py
├── tests/
│ ├── test_facebook_crawler.py
│ ├── test_page_parser.py
│ ├── test_post_parser.py
│ ├── test_requester.py
│ └── test_utils.py
└── utils.py
================================================
FILE CONTENTS
================================================
================================================
FILE: .github/workflows/pythonpublish.yml
================================================
name: Upload Python Package
on:
release:
types: [created]
jobs:
deploy:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v1
- name: Set up Python
uses: actions/setup-python@v1
with:
python-version: '3.x'
- name: Install dependencies
run: |
python -m pip install --upgrade pip
pip install setuptools wheel twine
- name: Build and publish
env:
TWINE_USERNAME: ${{ secrets.PYPI_USERNAME }}
TWINE_PASSWORD: ${{ secrets.PYPI_PASSWORD }}
run: |
python setup.py sdist bdist_wheel
twine upload dist/*
================================================
FILE: .gitignore
================================================
develop/
.ipynb_checkpoints/
.vscode/
*egg-info/
.idea/
venv2/
build/
dist/
__pycache__/
data/
================================================
FILE: LICENSE
================================================
MIT License
Copyright (c) 2021 tlyu0419
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE.
================================================
FILE: README.md
================================================
# Facebook_Crawler
[](https://pepy.tech/project/facebook-crawler)
[](https://pepy.tech/project/facebook-crawler)
[](https://pepy.tech/project/facebook-crawler)
## What's this?
This python package aims to help people who need to collect and analyze the public Fanspages or Groups data from Facebook with ease and efficiency.
Here are the three big points of this project:
1. Private: You don't need to log in to your account.
2. Easy: Just key in the link of Fanspage or group and the target date, and it will work.
3. Efficient: It collects the data through the requests package directly instead of opening another browser.
這個 Python 套件旨在幫助使用者輕鬆且快速的收集 Facebook 公開粉絲頁和公開社團的資料,藉以進行後續的分析。
以下是本專案的 3 個重點:
1. 隱私: 不需要登入你個人的帳號密碼
2. 簡單: 僅需輸入粉絲頁/社團的網址和停止的日期就可以開始執行程式
3. 高效: 透過 requests 直接向伺服器請求資料,不需另外開啟一個新的瀏覽器
## Quickstart
### Install
```pip
pip install -U facebook-crawler
```
### Usage
- Facebook Fanspage
```python
import facebook_crawler
pageurl= 'https://www.facebook.com/diudiu333'
facebook_crawler.Crawl_PagePosts(pageurl=pageurl, until_date='2021-01-01')
```
- Group
```python
import facebook_crawler
groupurl = 'https://www.facebook.com/groups/pythontw'
facebook_crawler.Crawl_GroupPosts(groupurl, until_date='2021-01-01')
```

## FAQ
- **How to get the comments or replies to the posts?**
> Please write an Email to me and tell me your project goal. Thanks!
- **How can I find out the post's link through the data?**
> You can add the string 'https://www.facebook.com' in front of the POSTID, and it's just its post link. So, for example, if the POSTID is 123456789, and its link is 'https://www.facebook.com/12345679'.
- **Can I directly collect the data in the specific time period?**
> No! This is the same as the behavior when we use Facebook. We need to collect the data from the newest posts to the older posts.
## License
[MIT License](https://github.com/TLYu0419/facebook_crawler/blob/main/LICENSE)
## Contribution
[](https://payment.ecpay.com.tw/QuickCollect/PayData?GcM4iJGUeCvhY%2fdFqqQ%2bFAyf3uA10KRo%2fqzP4DWtVcw%3d)
A donation is not the limitation to utilizing this package, but it would be great to have your support. Either donate, star or fork are good methods to support me keep maintaining and developing this project.
Thanks to these donors' help, due to their kind help, this project could keep maintained and developed.
**贊助不是使用這個套件的必要條件**,但如能獲得你的支持我將會非常感謝。不論是贊助、給予星星或分享都是很好的支持方式,幫助我繼續維護和開發這個專案
由於這些捐助者的幫助,由於他們的慷慨的幫助,這個項目才得以持續維護和發展
- Universities
- [Department of Social Work. The Chinese University of Hong Kong(香港中文大學社會工作學系)](https://web.swk.cuhk.edu.hk/zh-tw/)
- [Education, Graduate School of Curriculum and Instructional Communications Technology. National Taipei University.(國立台北教育大學課程與教學傳播科技研究所)](https://cict.ntue.edu.tw/?locale=zh_tw)
- [Department of Dusiness Administration. Chung Hua University.(中華大學企業管理學系)](https://ba.chu.edu.tw/?Lang=en)
## Contact Info
- Author: TENG-LIN YU
- Email: tlyu0419@gmail.com
- Facebook: https://www.facebook.com/tlyu0419
- PYPI: https://pypi.org/project/facebook-crawler/
- Github: https://github.com/TLYu0419/facebook_crawler
## Log
- 0.028: Modularized the crawler function.
- 0.0.26
1. Auto changes the cookie after it's expired to keep crawling data without changing IP.
================================================
FILE: main.py
================================================
from paser import _parse_category, _parse_pagename, _parse_creation_time, _parse_pagetype, _parse_likes, _parse_docid, _parse_pageurl
from paser import _parse_entryPoint, _parse_identifier, _parse_docid, _parse_composite_nojs, _parse_composite_graphql, _parse_relatedpages, _parse_pageinfo
from requester import _get_homepage, _get_posts, _get_headers
from utils import _init_request_vars
from bs4 import BeautifulSoup
import os
import re
import json
import time
import tqdm
import pandas as pd
import pickle
import datetime
import warnings
warnings.filterwarnings("ignore")
def Crawl_PagePosts(pageurl, until_date='2018-01-01', cursor=''):
# initial request variables
df, cursor, max_date, break_times = _init_request_vars(cursor)
# get headers
headers = _get_headers(pageurl)
# Get pageid, postid and entryPoint from homepage_response
homepage_response = _get_homepage(pageurl, headers)
entryPoint = _parse_entryPoint(homepage_response)
identifier = _parse_identifier(entryPoint, homepage_response)
docid = _parse_docid(entryPoint, homepage_response)
# Keep crawling post until reach the until_date
while max_date >= until_date:
try:
# Get posts by identifier, docid and entryPoint
resp = _get_posts(headers, identifier, entryPoint, docid, cursor)
if entryPoint == 'nojs':
ndf, max_date, cursor = _parse_composite_nojs(resp)
df.append(ndf)
else:
ndf, max_date, cursor = _parse_composite_graphql(resp)
df.append(ndf)
# Test
# print(ndf.shape[0])
break_times = 0
except:
# print(resp.json()[:3000])
try:
if resp.json()['data']['node']['timeline_feed_units']['page_info']['has_next_page'] == False:
print('The posts of the page has run over!')
break
except:
pass
print('Break Times {}: Something went wrong with this request. Sleep 20 seconds and send request again.'.format(
break_times))
print('REQUEST LOG >> pageid: {}, docid: {}, cursor: {}'.format(
identifier, docid, cursor))
print('RESPONSE LOG: ', resp.text[:3000])
print('================================================')
break_times += 1
if break_times > 15:
print('Please check your target page/group has up to date.')
print('If so, you can ignore this break time message, if not, please change your Internet IP and run this crawler again.')
break
time.sleep(20)
# Get new headers
headers = _get_headers(pageurl)
# Concat all dataframes
df = pd.concat(df, ignore_index=True)
df['UPDATETIME'] = datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S")
return df
def Crawl_GroupPosts(pageurl, until_date='2022-01-01'):
df = Crawl_PagePosts(pageurl, until_date)
return df
def Crawl_RelatedPages(seedpages, rounds):
# init
df = pd.DataFrame(data=[], columns=['SOURCE', 'TARGET', 'ROUND'])
pageurls = list(set(seedpages))
crawled_list = list(set(df['SOURCE']))
headers = _get_headers(pageurls[0])
for i in range(rounds):
print('Round {} started at: {}!'.format(
i, datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')))
for pageurl in tqdm(pageurls):
if pageurl not in crawled_list:
try:
homepage_response = _get_homepage(
pageurl=pageurl, headers=headers)
if 'Sorry, something went wrong.' not in homepage_response.text:
entryPoint = _parse_entryPoint(homepage_response)
identifier = _parse_identifier(
entryPoint, homepage_response)
relatedpages = _parse_relatedpages(
homepage_response, entryPoint, identifier)
ndf = pd.DataFrame({'SOURCE': homepage_response.url,
'TARGET': relatedpages,
'ROUND': i})
df = pd.concat([df, ndf], ignore_index=True)
except:
pass
# print('ERROE: {}'.format(pageurl))
pageurls = list(set(df['TARGET']))
crawled_list = list(set(df['SOURCE']))
return df
def Crawl_PageInfo(pagenum, pageurl):
break_times = 0
global headers
while True:
try:
homepage_response = _get_homepage(pageurl, headers)
pageinfo = _parse_pageinfo(homepage_response)
with open('data/pageinfo/' + str(pagenum) + '.pickle', "wb") as fp:
pickle.dump(pageinfo, fp)
break
except:
break_times = break_times + 1
if break_times >= 5:
break
time.sleep(5)
headers = _get_headers(pageurl=pageurl)
if __name__ == '__main__':
os.makedirs('data/', exist_ok=True)
# ===== fb_api_req_friendly_name: ProfileCometTimelineFeedRefetchQuery ====
pageurl = 'https://www.facebook.com/Gooaye' # 股癌 Gooaye: 30.4萬追蹤,
pageurl = 'https://www.facebook.com/StockOldBull' # 股海老牛: 16萬
pageurl = 'https://www.facebook.com/twherohan'
pageurl = 'https://www.facebook.com/diudiu333'
pageurl = 'https://www.facebook.com/chengwentsan'
pageurl = 'https://www.facebook.com/MaYingjeou'
pageurl = 'https://www.facebook.com/roberttawikofficial'
pageurl = 'https://www.facebook.com/NizamAbTitingan'
pageurl = 'https://www.facebook.com/joebiden'
# ==== fb_api_req_friendly_name: CometModernPageFeedPaginationQuery ====
pageurl = 'https://www.facebook.com/ebcmoney/' # 東森財經: 81萬追蹤
pageurl = 'https://www.facebook.com/moneyweekly.tw/' # 理財周刊: 36.3萬
pageurl = 'https://www.facebook.com/cmoneyapp/' # CMoney 理財寶: 84.2萬
pageurl = 'https://www.facebook.com/emily0806' # 艾蜜莉-自由之路: 20.9萬追蹤
pageurl = 'https://www.facebook.com/imoney889/' # 林恩如-飆股女王: 10.2萬
pageurl = 'https://www.facebook.com/wealth1974/' # 財訊: 17.5萬
pageurl = 'https://www.facebook.com/smart16888/' # 郭莉芳理財講堂: 1.6萬
pageurl = 'https://www.facebook.com/smartmonthly/' # Smart 智富月刊: 52.6萬
pageurl = 'https://www.facebook.com/ezmoney.tw/' # 統一投信: 1.5萬
pageurl = 'https://www.facebook.com/MoneyMoneyMeg/' # Money錢: 20.7萬
pageurl = 'https://www.facebook.com/imoneymagazine/' # iMoney 智富雜誌: 38萬
pageurl = 'https://www.facebook.com/edigest/' # 經濟一週 EDigest: 36.2萬
pageurl = 'https://www.facebook.com/BToday/' # 今周刊:107萬
pageurl = 'https://www.facebook.com/GreenHornFans/' # 綠角財經筆記: 25萬
pageurl = 'https://www.facebook.com/ec.ltn.tw/' # 自由時報財經頻道 42,656人在追蹤
pageurl = 'https://www.facebook.com/MoneyDJ' # MoneyDJ理財資訊 141,302人在追蹤
pageurl = 'https://www.facebook.com/YahooTWFinance/' # Yahoo奇摩股市理財 149,624人在追蹤
pageurl = 'https://www.facebook.com/win3105'
pageurl = 'https://www.facebook.com/Diss%E7%BA%8F%E7%B6%BF-111182238148502/'
# fb_api_req_friendly_name: CometUFICommentsProviderQuery
pageurl = 'https://www.facebook.com/anuetw/' # Anue鉅亨網財經新聞: 31.2萬追蹤
pageurl = 'https://www.facebook.com/wealtholic/' # 投資癮 Wealtholic: 2.萬
# fb_api_req_friendly_name: PresenceStatusProviderSubscription_ContactProfilesQuery
# fb_api_req_friendly_name: GroupsCometFeedRegularStoriesPaginationQuery
pageurl = 'https://www.facebook.com/groups/pythontw'
pageurl = 'https://www.facebook.com/groups/corollacrossclub/'
df = Crawl_PagePosts(pageurl, until_date='2022-08-10')
# df = Crawl_RelatedPages(seedpages=pageurls, rounds=10)
df = pd.read_csv(
'./data/relatedpages_edgetable.csv')[['SOURCE', 'TARGET', 'ROUND']]
headers = _get_headers(pageurl=pageurl)
for pagenum in tqdm(df['index']):
try:
Crawl_PageInfo(pagenum=pagenum, pageurl=df['pageurl'][pagenum])
except:
pass
homepage_response = _get_homepage(pageurl, headers)
pageinfo = _parse_pageinfo(homepage_response)
#
import pandas as pd
from main import Crawl_PagePosts
pageurl = 'https://www.facebook.com/hatendhu'
df = Crawl_PagePosts(pageurl, until_date='2014-11-01')
df
df.to_pickle('./data/20220926_hatendhu.pkl')
================================================
FILE: paser.py
================================================
import re
import json
import pandas as pd
from bs4 import BeautifulSoup
from utils import _extract_id, _init_request_vars
import datetime
from requester import _get_pageabout, _get_pagetransparency, _get_homepage, _get_posts, _get_headers
import requests
# Post-Paser
def _parse_edgelist(resp):
'''
Take edges from the response by graphql api
'''
edges = []
try:
edges = resp.json()['data']['node']['timeline_feed_units']['edges']
except:
for data in resp.text.split('\r\n', -1):
try:
edges.append(json.loads(data)[
'data']['node']['timeline_list_feed_units']['edges'][0])
except:
edges.append(json.loads(data)['data'])
return edges
def _parse_edge(edge):
'''
Parse edge to take informations, such as post name, id, message..., etc.
'''
comet_sections = edge['node']['comet_sections']
# name
name = comet_sections['context_layout']['story']['comet_sections']['actor_photo']['story']['actors'][0]['name']
# creation_time
creation_time = comet_sections['context_layout']['story']['comet_sections']['metadata'][0]['story']['creation_time']
# message
try:
message = comet_sections['content']['story']['comet_sections']['message']['story']['message']['text']
except:
try:
message = comet_sections['content']['story']['comet_sections']['message_container']['story']['message']['text']
except:
message = comet_sections['content']['story']['comet_sections']['message_container']
# postid
postid = comet_sections['feedback']['story']['feedback_context'][
'feedback_target_with_context']['ufi_renderer']['feedback']['subscription_target_id']
# actorid
pageid = comet_sections['context_layout']['story']['comet_sections']['actor_photo']['story']['actors'][0]['id']
# comment_count
comment_count = comet_sections['feedback']['story']['feedback_context'][
'feedback_target_with_context']['ufi_renderer']['feedback']['comment_count']['total_count']
# reaction_count
reaction_count = comet_sections['feedback']['story']['feedback_context']['feedback_target_with_context'][
'ufi_renderer']['feedback']['comet_ufi_summary_and_actions_renderer']['feedback']['reaction_count']['count']
# share_count
share_count = comet_sections['feedback']['story']['feedback_context']['feedback_target_with_context'][
'ufi_renderer']['feedback']['comet_ufi_summary_and_actions_renderer']['feedback']['share_count']['count']
# toplevel_comment_count
toplevel_comment_count = comet_sections['feedback']['story']['feedback_context'][
'feedback_target_with_context']['ufi_renderer']['feedback']['toplevel_comment_count']['count']
# top_reactions
top_reactions = comet_sections['feedback']['story']['feedback_context']['feedback_target_with_context']['ufi_renderer'][
'feedback']['comet_ufi_summary_and_actions_renderer']['feedback']['cannot_see_top_custom_reactions']['top_reactions']['edges']
# comet_footer_renderer for link
try:
comet_footer_renderer = comet_sections['content']['story']['attachments'][0]['comet_footer_renderer']
# attachment_title
attachment_title = comet_footer_renderer['attachment']['title_with_entities']['text']
# attachment_description
attachment_description = comet_footer_renderer['attachment']['description']['text']
except:
attachment_title = ''
attachment_description = ''
# all_subattachments for photos
try:
try:
media = comet_sections['content']['story']['attachments'][0]['styles']['attachment']['all_subattachments']['nodes']
attachments_photos = ', '.join(
[image['media']['viewer_image']['uri'] for image in media])
except:
media = comet_sections['content']['story']['attachments'][0]['styles']['attachment']
attachments_photos = media['media']['photo_image']['uri']
except:
attachments_photos = ''
# cursor
cursor = edge['cursor']
# actor url
actor_url = comet_sections['context_layout']['story']['comet_sections']['actor_photo']['story']['actors'][0]['url']
# post url
post_url = comet_sections['content']['story']['wwwURL']
return [name, pageid, postid, creation_time, message, reaction_count, comment_count, toplevel_comment_count, share_count, top_reactions, attachment_title, attachment_description, attachments_photos, cursor, actor_url, post_url]
def _parse_domops(resp):
'''
Take name, data id, time , message and page link from domops
'''
data = re.sub(r'for \(;;\);', '', resp.text)
data = json.loads(data)
domops = data['domops'][0][3]['__html']
cursor = re.findall(
'timeline_cursor%22%3A%22(.*?)%22%2C%22timeline_section_cursor', domops)[0]
content_list = []
soup = BeautifulSoup(domops, 'lxml')
for content in soup.findAll('div', {'class': 'userContentWrapper'}):
# name
name = content.find('img')['aria-label']
# id
dataid = content.find('div', {'data-testid': 'story-subtitle'})['id']
# actorid
pageid = _extract_id(dataid, 0)
# postid
postid = _extract_id(dataid, 1)
# time
time = content.find('abbr')['data-utime']
# message
message = content.find('div', {'data-testid': 'post_message'})
if message == None:
message = ''
else:
if len(message.findAll('p')) >= 1:
message = ''.join(p.text for p in message.findAll('p'))
elif len(message.select('span > span')) >= 2:
message = message.find('span').text
# attachment_title
try:
attachment_title = content.find(
'a', {'data-lynx-mode': 'hover'})['aria-label']
except:
attachment_title = ''
# attachment_description
try:
attachment_description = content.find(
'a', {'data-lynx-mode': 'hover'}).text
except:
attachment_description = ''
# actor_url
actor_url = content.find('a')['href'].split('?')[0]
# post_url
post_url = 'https://www.facebook.com/' + postid
content_list.append([name, pageid, postid, time, message, attachment_title,
attachment_description, cursor, actor_url, post_url])
return content_list, cursor
def _parse_jsmods(resp):
'''
Take postid, pageid, comment count , reaction count, sharecount, reactions and display_comments_count from jsmods
'''
data = re.sub(r'for \(;;\);', '', resp.text)
data = json.loads(data)
jsmods = data['jsmods']
requires_list = []
for requires in jsmods['pre_display_requires']:
try:
feedback = requires[3][1]['__bbox']['result']['data']['feedback']
# subscription_target_id ==> postid
subscription_target_id = feedback['subscription_target_id']
# owning_profile_id ==> pageid
owning_profile_id = feedback['owning_profile']['id']
# comment_count
comment_count = feedback['comment_count']['total_count']
# reaction_count
reaction_count = feedback['reaction_count']['count']
# share_count
share_count = feedback['share_count']['count']
# top_reactions
top_reactions = feedback['top_reactions']['edges']
# display_comments_count
display_comments_count = feedback['display_comments_count']['count']
# append data to list
requires_list.append([subscription_target_id, owning_profile_id, comment_count,
reaction_count, share_count, top_reactions, display_comments_count])
except:
pass
# reactions--video posts
for requires in jsmods['require']:
try:
# entidentifier ==> postid
entidentifier = requires[3][2]['feedbacktarget']['entidentifier']
# pageid
actorid = requires[3][2]['feedbacktarget']['actorid']
# comment count
commentcount = requires[3][2]['feedbacktarget']['commentcount']
# reaction count
likecount = requires[3][2]['feedbacktarget']['likecount']
# sharecount
sharecount = requires[3][2]['feedbacktarget']['sharecount']
# reactions
reactions = []
# display_comments_count
commentcount = requires[3][2]['feedbacktarget']['commentcount']
# append data to list
requires_list.append(
[entidentifier, actorid, commentcount, likecount, sharecount, reactions, commentcount])
except:
pass
return requires_list
def _parse_composite_graphql(resp):
edges = _parse_edgelist(resp)
df = []
for edge in edges:
try:
ndf = _parse_edge(edge)
df.append(ndf)
except:
pass
df = pd.DataFrame(df, columns=['NAME', 'PAGEID', 'POSTID', 'TIME', 'MESSAGE', 'REACTIONCOUNT', 'COMMENTCOUNT', 'DISPLAYCOMMENTCOUNT',
'SHARECOUNT', 'REACTIONS', 'ATTACHMENT_TITLE', 'ATTACHMENT_DESCRIPTION', 'ATTACHMENT_PHOTOS', 'CURSOR', 'ACTOR_URL', 'POST_URL'])
df = df[['NAME', 'PAGEID', 'POSTID', 'TIME', 'MESSAGE', 'ATTACHMENT_TITLE', 'ATTACHMENT_DESCRIPTION', 'ATTACHMENT_PHOTOS', 'REACTIONCOUNT',
'COMMENTCOUNT', 'DISPLAYCOMMENTCOUNT', 'SHARECOUNT', 'REACTIONS', 'CURSOR', 'ACTOR_URL', 'POST_URL']]
cursor = df['CURSOR'].to_list()[-1]
df['TIME'] = df['TIME'].apply(lambda x: datetime.datetime.fromtimestamp(
int(x)).strftime("%Y-%m-%d %H:%M:%S"))
max_date = df['TIME'].max()
print('The maximum date of these posts is: {}, keep crawling...'.format(max_date))
return df, max_date, cursor
def _parse_composite_nojs(resp):
domops, cursor = _parse_domops(resp)
domops = pd.DataFrame(domops, columns=['NAME', 'PAGEID', 'POSTID', 'TIME', 'MESSAGE',
'ATTACHMENT_TITLE', 'ATTACHMENT_DESCRIPTION', 'CURSOR', 'ACTOR_URL', 'POST_URL'])
domops['TIME'] = domops['TIME'].apply(
lambda x: datetime.datetime.fromtimestamp(int(x)).strftime("%Y-%m-%d %H:%M:%S"))
jsmods = _parse_jsmods(resp)
jsmods = pd.DataFrame(jsmods, columns=[
'POSTID', 'PAGEID', 'COMMENTCOUNT', 'REACTIONCOUNT', 'SHARECOUNT', 'REACTIONS', 'DISPLAYCOMMENTCOUNT'])
df = pd.merge(left=domops,
right=jsmods,
how='inner',
on=['PAGEID', 'POSTID'])
df = df[['NAME', 'PAGEID', 'POSTID', 'TIME', 'MESSAGE', 'ATTACHMENT_TITLE', 'ATTACHMENT_DESCRIPTION',
'REACTIONCOUNT', 'COMMENTCOUNT', 'DISPLAYCOMMENTCOUNT', 'SHARECOUNT', 'REACTIONS', 'CURSOR',
'ACTOR_URL', 'POST_URL']]
max_date = df['TIME'].max()
print('The maximum date of these posts is: {}, keep crawling...'.format(max_date))
return df, max_date, cursor
# Page paser
def _parse_pagetype(homepage_response):
if '/groups/' in homepage_response.url:
pagetype = 'Group'
else:
pagetype = 'Fanspage'
return pagetype
def _parse_pagename(homepage_response):
raw_json = homepage_response.text.encode('utf-8').decode('unicode_escape')
# pattern1
if len(re.findall(r'{"page":{"name":"(.*?)",', raw_json)) >= 1:
pagename = re.findall(r'{"page":{"name":"(.*?)",', raw_json)[0]
pagename = re.sub(r'\s\|\sFacebook', '', pagename)
return pagename
# pattern2
if len(re.findall('","name":"(.*?)","', raw_json)) >= 1:
pagename = re.findall('","name":"(.*?)","', raw_json)[0]
pagename = re.sub(r'\s\|\sFacebook', '', pagename)
return pagename
def _parse_entryPoint(homepage_response):
try:
entryPoint = re.findall(
'"entryPoint":{"__dr":"(.*?)"}}', homepage_response.text)[0]
except:
entryPoint = 'nojs'
return entryPoint
def _parse_identifier(entryPoint, homepage_response):
if entryPoint in ['ProfilePlusCometLoggedOutRouteRoot.entrypoint', 'CometGroupDiscussionRoot.entrypoint']:
# pattern 1
if len(re.findall('"identifier":"{0,1}([0-9]{5,})"{0,1},', homepage_response.text)) >= 1:
identifier = re.findall(
'"identifier":"{0,1}([0-9]{5,})"{0,1},', homepage_response.text)[0]
# pattern 2
elif len(re.findall('fb://profile/(.*?)"', homepage_response.text)) >= 1:
identifier = re.findall(
'fb://profile/(.*?)"', homepage_response.text)[0]
# pattern 3
elif len(re.findall('content="fb://group/([0-9]{1,})" />', homepage_response.text)) >= 1:
identifier = re.findall(
'content="fb://group/([0-9]{1,})" />', homepage_response.text)[0]
elif entryPoint in ['CometSinglePageHomeRoot.entrypoint', 'nojs']:
# pattern 1
if len(re.findall('"pageID":"{0,1}([0-9]{5,})"{0,1},', homepage_response.text)) >= 1:
identifier = re.findall(
'"pageID":"{0,1}([0-9]{5,})"{0,1},', homepage_response.text)[0]
return identifier
def _parse_docid(entryPoint, homepage_response):
soup = BeautifulSoup(homepage_response.text, 'lxml')
if entryPoint == 'nojs':
docid = 'NoDocid'
else:
for link in soup.findAll('link', {'rel': 'preload'}):
resp = requests.get(link['href'])
for line in resp.text.split('\n', -1):
if 'ProfileCometTimelineFeedRefetchQuery_' in line:
docid = re.findall('e.exports="([0-9]{1,})"', line)[0]
break
if 'CometModernPageFeedPaginationQuery_' in line:
docid = re.findall('e.exports="([0-9]{1,})"', line)[0]
break
if 'CometUFICommentsProviderQuery_' in line:
docid = re.findall('e.exports="([0-9]{1,})"', line)[0]
break
if 'GroupsCometFeedRegularStoriesPaginationQuery' in line:
docid = re.findall('e.exports="([0-9]{1,})"', line)[0]
break
if 'docid' in locals():
break
return docid
def _parse_likes(homepage_response, entryPoint, headers):
if entryPoint in ['CometGroupDiscussionRoot.entrypoint']:
pageabout = _get_pageabout(homepage_response, entryPoint, headers)
members = re.findall(
',"group_total_members_info_text":"(.*?) total members","', pageabout.text)[0]
members = re.sub(',', '', members)
return members
else:
# pattern 1
data = re.findall(
'"page_likers":{"global_likers_count":([0-9]{1,})},"', homepage_response.text)
if len(data) >= 1:
likes = data[0]
return likes
# pattern 2
data = re.findall(
' ([0-9]{0,},{0,}[0-9]{0,},{0,}[0-9]{0,},{0,}[0-9]{0,},{0,}[0-9]{0,},{0,}) likes', homepage_response.text)
if len(data) >= 1:
likes = data[0]
likes = re.sub(',', '', likes)
return likes
def _parse_creation_time(homepage_response, entryPoint, headers):
try:
if entryPoint in ['ProfilePlusCometLoggedOutRouteRoot.entrypoint']:
transparency_response = _get_pagetransparency(
homepage_response, entryPoint, headers)
transparency_info = re.findall(
'"field_section_type":"transparency","profile_fields":{"nodes":\[{"title":(.*?}),"field_type":"creation_date",', transparency_response.text)[0]
creation_time = json.loads(transparency_info)['text']
elif entryPoint in ['CometSinglePageHomeRoot.entrypoint']:
creation_time = re.findall(
',"page_creation_date":{"text":"Page created - (.*?)"},', homepage_response.text)[0]
elif entryPoint in ['nojs']:
if len(re.findall('<span>Page created - (.*?)</span>', homepage_response.text)) >= 1:
creation_time = re.findall(
'<span>Page created - (.*?)</span>', homepage_response.text)[0]
else:
creation_time = re.findall(
',"foundingDate":"(.*?)"}', homepage_response.text)[0][:10]
elif entryPoint in ['CometGroupDiscussionRoot.entrypoint']:
pageabout = _get_pageabout(homepage_response, entryPoint, headers)
creation_time = re.findall(
'"group_history_summary":{"text":"Group created on (.*?)"}},', pageabout.text)[0]
try:
creation_time = datetime.datetime.strptime(
creation_time, '%B %d, %Y')
except:
creation_time = creation_time + ', ' + datetime.datetime.now().year
creation_time = datetime.datetime.strptime(
creation_time, '%B %d, %Y')
creation_time = creation_time.strftime('%Y-%m-%d')
except:
creation_time = 'NotAvailable'
return creation_time
def _parse_category(homepage_response, entryPoint, headers):
pageabout = _get_pageabout(homepage_response, entryPoint, headers)
if entryPoint in ['ProfilePlusCometLoggedOutRouteRoot.entrypoint']:
if 'Page \\u00b7 Politician' in pageabout.text:
category = 'Politician'
if len(re.findall(r'"text":"Page \\u00b7 (.*?)"}', homepage_response.text)) >= 1:
category = re.findall(
r'"text":"Page \\u00b7 (.*?)"}', homepage_response.text)[0]
else:
soup = BeautifulSoup(pageabout.text)
for script in soup.findAll('script', {'type': 'application/ld+json'}):
if 'BreadcrumbList' in script.text:
data = script.text.encode('utf-8').decode('unicode_escape')
category = json.loads(data)['itemListElement']
category = ' / '.join([cate['name'] for cate in category])
elif entryPoint in ['CometSinglePageHomeRoot.entrypoint', 'nojs']:
if len(re.findall('","category_name":"(.*?)","', homepage_response.text)) >= 1:
category = re.findall(
'","category_name":"(.*?)","', homepage_response.text)
category = ' / '.join([cate for cate in category])
else:
soup = BeautifulSoup(homepage_response.text)
if len(soup.findAll('span', {'itemprop': 'itemListElement'})) >= 1:
category = [span.text for span in soup.findAll(
'span', {'itemprop': 'itemListElement'})]
category = ' / '.join(category)
else:
for script in soup.findAll('script', {'type': 'application/ld+json'}):
if 'BreadcrumbList' in script.text:
data = script.text.encode(
'utf-8').decode('unicode_escape')
category = json.loads(data)['itemListElement']
category = ' / '.join([cate['name']
for cate in category])
elif entryPoint in ['PagesCometAdminSelfViewAboutContainerRoot.entrypoint']:
category = eval(re.findall(
'"page_categories":(.*?),"addressEditable', homepage_response.text)[0])
category = ' / '.join([cate['text'] for cate in category])
elif entryPoint in ['CometGroupDiscussionRoot.entrypoint']:
category = 'Group'
try:
category = re.sub(r'\\/', '/', category)
except:
category = ''
return category
def _parse_pageurl(homepage_response):
pageurl = homepage_response.url
pageurl = re.sub('/$', '', pageurl)
return pageurl
def _parse_relatedpages(homepage_response, entryPoint, identifier):
relatedpages = []
if entryPoint in ['CometSinglePageHomeRoot.entrypoint']:
try:
data = re.findall(
r'"related_pages":\[(.*?)\],"view_signature"', homepage_response.text)[0]
data = re.sub('},{', '},,,,{', data)
for pages in data.split(',,,,', -1):
# print('id:', json.loads(pages)['id'])
# print('category_name:', json.loads(pages)['category_name'])
# print('name:', json.loads(pages)['name'])
url = json.loads(pages)['url']
url = url.split('?', -1)[0]
url = re.sub(r'/$', '', url)
# print('url:', url)
# print('========')
relatedpages.append(url)
except:
pass
elif entryPoint in ['nojs']:
soup = BeautifulSoup(homepage_response.text, 'lxml')
soup = soup.find(
'div', {'id': 'PageRelatedPagesSecondaryPagelet_{}'.format(identifier)})
for page in soup.select('ul > li > div'):
# print('name: ', page.find('img')['aria-label'])
url = page.find('a')['href']
url = url.split('?', -1)[0]
url = re.sub(r'/$', '', url)
# print('url:', url)
# print('===========')
relatedpages.append(url)
elif entryPoint in ['ProfilePlusCometLoggedOutRouteRoot.entrypoint', 'CometGroupDiscussionRoot.entrypoint']:
pass
# print('There\'s no related pages recommend.')
return relatedpages
def _parse_pageinfo(homepage_response):
'''
Parse the homepage response to get the page information, including id, docid and api_name.
'''
# pagetype
pagetype = _parse_pagetype(homepage_response)
# pagename
pagename = _parse_pagename(homepage_response)
# entryPoint
entryPoint = _parse_entryPoint(homepage_response)
# identifier
identifier = _parse_identifier(entryPoint, homepage_response)
# docid
docid = _parse_docid(entryPoint, homepage_response)
# likes / members
likes = _parse_likes(homepage_response, entryPoint, headers)
# creation time
creation_time = _parse_creation_time(
homepage_response, entryPoint, headers)
# category
category = _parse_category(homepage_response, entryPoint, headers)
# pageurl
pageurl = _parse_pageurl(homepage_response)
return [pagetype, pagename, identifier, likes, creation_time, category, pageurl]
if __name__ == '__main__':
# pageurls
pageurl = 'https://www.facebook.com/mohw.gov.tw'
pageurl = 'https://www.facebook.com/groups/pythontw'
pageurl = 'https://www.facebook.com/Gooaye'
pageurl = 'https://www.facebook.com/emily0806'
pageurl = 'https://www.facebook.com/anuetw/'
pageurl = 'https://www.facebook.com/wealtholic/'
pageurl = 'https://www.facebook.com/hatendhu'
headers = _get_headers(pageurl)
headers['Referer'] = 'https://www.facebook.com/hatendhu'
headers['Origin'] = 'https://www.facebook.com'
headers['Cookie'] = 'dpr=1.5; datr=rzIwY5yARwMzcR9H2GyqId_l'
homepage_response = _get_homepage(pageurl=pageurl, headers=headers)
entryPoint = _parse_entryPoint(homepage_response)
print(entryPoint)
identifier = _parse_identifier(entryPoint, homepage_response)
docid = _parse_docid(entryPoint, homepage_response)
df, cursor, max_date, break_times = _init_request_vars(cursor='')
cursor = 'AQHRlIMW9sczmHGnME47XeSdDNj6Jk9EcBOMlyxBdMNbZHM7dwd0rn8wsaxQxeXUsuhKVaMgVwPHb9YS9468INvb5yw2osoEmXd_sMXvj8rLhmBxeaJucMSPIDux_JuiHToC'
cursor = 'AQHRxSZTqUvlLpkXCnrOjdX0gZeyn-Q1cuJzn4SPJuZ5rkYi7nZFByE5pwy4AsBoUOtcmF28lNfXR_rqv7oO7545iURm_mx46aZLBDiYfPmgI2mjscHUTiVi5vv1vj5EXiF4'
resp = _get_posts(headers=headers, identifier=identifier,
entryPoint=entryPoint, docid=docid, cursor=cursor)
# graphql
edges = _parse_edgelist(resp)
print(len(edges))
_parse_edge(edges[0])
edges[0].keys()
edges[0]['node'].keys()
edges[0]['node']['comet_sections'].keys()
edges[0]['node']['comet_sections']
df, max_date, cursor = _parse_composite_graphql(resp)
df
# nojs
content_list, cursor = _parse_domops(resp)
df, max_date, cursor = _parse_composite_nojs(resp)
# page paser
pagename = _parse_pagename(homepage_response).encode('utf-8').decode()
likes = _parse_likes(homepage_response, entryPoint, headers)
creation_time = _parse_creation_time(
homepage_response=homepage_response, entryPoint=entryPoint, headers=headers)
category = _parse_category(homepage_response, entryPoint, headers)
pageurl = _parse_pageurl(homepage_response)
================================================
FILE: requester.py
================================================
import re
import requests
import time
from utils import _init_request_vars
def _get_headers(pageurl):
'''
Send a request to get cookieid as headers.
'''
pageurl = re.sub('www', 'm', pageurl)
resp = requests.get(pageurl)
headers = {'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'accept-language': 'en'}
headers['cookie'] = '; '.join(['{}={}'.format(cookieid, resp.cookies.get_dict()[
cookieid]) for cookieid in resp.cookies.get_dict()])
# headers['cookie'] = headers['cookie'] + '; locale=en_US'
return headers
def _get_homepage(pageurl, headers):
'''
Send a request to get the homepage response
'''
pageurl = re.sub('/$', '', pageurl)
timeout_cnt = 0
while True:
try:
homepage_response = requests.get(
pageurl, headers=headers, timeout=3)
return homepage_response
except:
time.sleep(5)
timeout_cnt = timeout_cnt + 1
if timeout_cnt > 20:
class homepage_response():
text = 'Sorry, something went wrong.'
return homepage_response
def _get_pageabout(homepage_response, entryPoint, headers):
'''
Send a request to get the about page response
'''
pageurl = re.sub('/$', '', homepage_response.url)
pageabout = requests.get(pageurl + '/about', headers=headers)
return pageabout
def _get_pagetransparency(homepage_response, entryPoint, headers):
'''
Send a request to get the transparency page response
'''
pageurl = re.sub('/$', '', homepage_response.url)
if entryPoint in ['ProfilePlusCometLoggedOutRouteRoot.entrypoint']:
transparency_response = requests.get(
pageurl + '/about_profile_transparency', headers=headers)
return transparency_response
def _get_posts(headers, identifier, entryPoint, docid, cursor):
'''
Send a request to get new posts from fanspage/group.
'''
if entryPoint in ['nojs']:
params = {'page_id': identifier,
'cursor': str({"timeline_cursor": cursor,
"timeline_section_cursor": '{}',
"has_next_page": 'true'}),
'surface': 'www_pages_posts',
'unit_count': 10,
'__a': '1'}
resp = requests.get(url='https://www.facebook.com/pages_reaction_units/more/',
params=params)
else: # entryPoint in ['CometSinglePageHomeRoot.entrypoint', 'ProfilePlusCometLoggedOutRouteRoot.entrypoint', 'CometGroupDiscussionRoot.entrypoint']
data = {'variables': str({'cursor': cursor,
'id': identifier,
'count': 3}),
'doc_id': docid}
resp = requests.post(url='https://www.facebook.com/api/graphql/',
data=data,
headers=headers)
return resp
if __name__ == '__main__':
pageurl = 'https://www.facebook.com/ec.ltn.tw/'
pageurl = 'https://www.facebook.com/Gooaye'
pageurl = 'https://www.facebook.com/groups/pythontw'
pageurl = 'https://www.facebook.com/hatendhu'
headers = _get_headers(pageurl)
homepage_response = _get_homepage(pageurl=pageurl, headers=headers)
df, cursor, max_date, break_times = _init_request_vars()
cursor = 'AQHRlIMW9sczmHGnME47XeSdDNj6Jk9EcBOMlyxBdMNbZHM7dwd0rn8wsaxQxeXUsuhKVaMgVwPHb9YS9468INvb5yw2osoEmXd_sMXvj8rLhmBxeaJucMSPIDux_JuiHToC'
cursor = 'AQHRixL5fPMA_nM-78jGg4LohG3M4a2-YQR6WSaWOTiqPRJ1dOGchYRzp1wdDtusNd-5FkCPXwByL_kZM2iyLIz1XHB8WIEzHYXTU3vQzviOI9GexNv__RPn1xnFJZddnjX3'
from paser import _parse_entryPoint, _parse_identifier, _parse_docid, _parse_composite_graphql
entryPoint = _parse_entryPoint(homepage_response)
identifier = _parse_identifier(entryPoint, homepage_response)
docid = _parse_docid(entryPoint, homepage_response)
df, cursor, max_date, break_times = _init_request_vars(cursor='')
resp = _get_posts(headers=headers, identifier=identifier,
entryPoint=entryPoint, docid=docid, cursor=cursor)
ndf, max_date, cursor = _parse_composite_graphql(resp)
resp.json()
ndf
max_date
cursor
# print(len(resp.text))
================================================
FILE: requirements.txt
================================================
requests==2.24.0
bs4==0.0.1
pandas==1.2.4
numpy==1.20.3
dicttoxml==1.7.4
lxml==4.9.2
================================================
FILE: sample/20221013_Sample.ipynb
================================================
{
"cells": [
{
"cell_type": "code",
"execution_count": 3,
"id": "7946c9a9-0a27-4de2-a32e-8de574f8d7fb",
"metadata": {
"execution": {
"iopub.execute_input": "2022-10-13T14:01:50.402181Z",
"iopub.status.busy": "2022-10-13T14:01:50.402181Z",
"iopub.status.idle": "2022-10-13T14:02:32.391460Z",
"shell.execute_reply": "2022-10-13T14:02:32.391460Z",
"shell.execute_reply.started": "2022-10-13T14:01:50.402181Z"
},
"tags": []
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"The maximum date of these posts is: 2022-10-13 01:06:00, keep crawling...\n",
"The maximum date of these posts is: 2022-10-12 19:47:59, keep crawling...\n",
"The maximum date of these posts is: 2022-10-12 19:47:37, keep crawling...\n",
"The maximum date of these posts is: 2022-10-12 19:47:19, keep crawling...\n",
"The maximum date of these posts is: 2022-10-12 02:37:08, keep crawling...\n",
"The maximum date of these posts is: 2022-10-12 02:36:56, keep crawling...\n",
"The maximum date of these posts is: 2022-10-12 02:36:50, keep crawling...\n",
"The maximum date of these posts is: 2022-10-10 23:07:48, keep crawling...\n",
"The maximum date of these posts is: 2022-10-10 18:18:13, keep crawling...\n",
"The maximum date of these posts is: 2022-10-09 22:47:33, keep crawling...\n",
"The maximum date of these posts is: 2022-10-08 23:59:35, keep crawling...\n",
"The maximum date of these posts is: 2022-10-08 16:27:26, keep crawling...\n",
"The maximum date of these posts is: 2022-10-07 21:05:48, keep crawling...\n",
"The maximum date of these posts is: 2022-10-07 21:05:34, keep crawling...\n",
"The maximum date of these posts is: 2022-10-07 21:05:14, keep crawling...\n",
"The maximum date of these posts is: 2022-10-07 21:04:46, keep crawling...\n",
"The maximum date of these posts is: 2022-10-07 21:04:17, keep crawling...\n",
"The maximum date of these posts is: 2022-10-07 00:58:39, keep crawling...\n",
"The maximum date of these posts is: 2022-10-06 23:56:05, keep crawling...\n",
"The maximum date of these posts is: 2022-10-06 22:25:05, keep crawling...\n",
"The maximum date of these posts is: 2022-10-06 22:24:57, keep crawling...\n",
"The maximum date of these posts is: 2022-10-06 22:24:48, keep crawling...\n",
"The maximum date of these posts is: 2022-10-06 22:24:39, keep crawling...\n",
"The maximum date of these posts is: 2022-10-06 22:24:31, keep crawling...\n",
"The maximum date of these posts is: 2022-10-06 22:24:19, keep crawling...\n",
"The maximum date of these posts is: 2022-10-05 21:33:20, keep crawling...\n",
"The maximum date of these posts is: 2022-10-05 21:33:12, keep crawling...\n",
"The maximum date of these posts is: 2022-10-05 21:33:05, keep crawling...\n",
"The maximum date of these posts is: 2022-10-05 21:32:59, keep crawling...\n",
"The maximum date of these posts is: 2022-10-04 23:21:34, keep crawling...\n",
"The maximum date of these posts is: 2022-10-04 23:21:14, keep crawling...\n",
"The maximum date of these posts is: 2022-10-04 23:20:37, keep crawling...\n",
"The maximum date of these posts is: 2022-10-04 23:19:57, keep crawling...\n",
"The maximum date of these posts is: 2022-10-04 23:19:33, keep crawling...\n",
"The maximum date of these posts is: 2022-10-03 22:40:18, keep crawling...\n",
"The maximum date of these posts is: 2022-10-01 06:49:51, keep crawling...\n",
"The maximum date of these posts is: 2022-10-01 06:49:39, keep crawling...\n",
"The maximum date of these posts is: 2022-10-01 06:49:32, keep crawling...\n",
"The maximum date of these posts is: 2022-09-30 00:28:37, keep crawling...\n"
]
},
{
"data": {
"text/html": [
"<div>\n",
"<style scoped>\n",
" .dataframe tbody tr th:only-of-type {\n",
" vertical-align: middle;\n",
" }\n",
"\n",
" .dataframe tbody tr th {\n",
" vertical-align: top;\n",
" }\n",
"\n",
" .dataframe thead th {\n",
" text-align: right;\n",
" }\n",
"</style>\n",
"<table border=\"1\" class=\"dataframe\">\n",
" <thead>\n",
" <tr style=\"text-align: right;\">\n",
" <th></th>\n",
" <th>NAME</th>\n",
" <th>PAGEID</th>\n",
" <th>POSTID</th>\n",
" <th>TIME</th>\n",
" <th>MESSAGE</th>\n",
" <th>ATTACHMENT_TITLE</th>\n",
" <th>ATTACHMENT_DESCRIPTION</th>\n",
" <th>ATTACHMENT_PHOTOS</th>\n",
" <th>REACTIONCOUNT</th>\n",
" <th>COMMENTCOUNT</th>\n",
" <th>DISPLAYCOMMENTCOUNT</th>\n",
" <th>SHARECOUNT</th>\n",
" <th>REACTIONS</th>\n",
" <th>CURSOR</th>\n",
" <th>ACTOR_URL</th>\n",
" <th>POST_URL</th>\n",
" <th>UPDATETIME</th>\n",
" </tr>\n",
" </thead>\n",
" <tbody>\n",
" <tr>\n",
" <th>0</th>\n",
" <td>黑特東華 NDHU Hate</td>\n",
" <td>100064708507691</td>\n",
" <td>476738834493063</td>\n",
" <td>2022-10-13 01:06:00</td>\n",
" <td>#52635\\n\\n志學街一堆店家把東華學生當搖錢樹,大家應該聯合抵制一下,盤子店通通給他倒...</td>\n",
" <td></td>\n",
" <td></td>\n",
" <td></td>\n",
" <td>166</td>\n",
" <td>25</td>\n",
" <td>15</td>\n",
" <td>2</td>\n",
" <td>[{'reaction_count': 138, 'node': {'id': '16358...</td>\n",
" <td>AQHRWkzldCEuXabhI1tJPZnVEn7FKGxga7nPHhIBgGzMmB...</td>\n",
" <td>https://www.facebook.com/people/%E9%BB%91%E7%8...</td>\n",
" <td>https://www.facebook.com/permalink.php?story_f...</td>\n",
" <td>2022-10-13 22:02:32</td>\n",
" </tr>\n",
" <tr>\n",
" <th>1</th>\n",
" <td>黑特東華 NDHU Hate</td>\n",
" <td>100064708507691</td>\n",
" <td>476738777826402</td>\n",
" <td>2022-10-13 01:05:58</td>\n",
" <td>#52634\\n\\n電音社第二次社課\\n\\n提醒各位這禮拜日為電音社第二次上課,不管是沒有參...</td>\n",
" <td></td>\n",
" <td></td>\n",
" <td>https://scontent.ftpe10-1.fna.fbcdn.net/v/t39....</td>\n",
" <td>3</td>\n",
" <td>0</td>\n",
" <td>0</td>\n",
" <td>0</td>\n",
" <td>[{'reaction_count': 2, 'node': {'id': '1635855...</td>\n",
" <td>AQHRRN-x6Hvn-AZ35SOZ2CNtJpaM3_9yYj9j9dTx5LxCWy...</td>\n",
" <td>https://www.facebook.com/people/%E9%BB%91%E7%8...</td>\n",
" <td>https://www.facebook.com/permalink.php?story_f...</td>\n",
" <td>2022-10-13 22:02:32</td>\n",
" </tr>\n",
" <tr>\n",
" <th>2</th>\n",
" <td>黑特東華 NDHU Hate</td>\n",
" <td>100064708507691</td>\n",
" <td>476533761180237</td>\n",
" <td>2022-10-12 19:48:11</td>\n",
" <td>#52633\\n\\n10/12晚上7.左右在理工停車場靠學活那側撿到BKS1(安全帽藍芽耳機...</td>\n",
" <td></td>\n",
" <td></td>\n",
" <td>https://scontent.ftpe10-1.fna.fbcdn.net/v/t39....</td>\n",
" <td>3</td>\n",
" <td>0</td>\n",
" <td>0</td>\n",
" <td>0</td>\n",
" <td>[{'reaction_count': 3, 'node': {'id': '1635855...</td>\n",
" <td>AQHRD6AVoPeV1kHsvTjT0XPsC42w8-nrRawALu9lBRlhH5...</td>\n",
" <td>https://www.facebook.com/people/%E9%BB%91%E7%8...</td>\n",
" <td>https://www.facebook.com/permalink.php?story_f...</td>\n",
" <td>2022-10-13 22:02:32</td>\n",
" </tr>\n",
" <tr>\n",
" <th>3</th>\n",
" <td>黑特東華 NDHU Hate</td>\n",
" <td>100064708507691</td>\n",
" <td>476533567846923</td>\n",
" <td>2022-10-12 19:47:59</td>\n",
" <td>#52632\\n\\n#非黑特\\nThis is 頌啦!浪‧人‧鬆‧餅👏👏👏\\n東華巡迴場10...</td>\n",
" <td></td>\n",
" <td></td>\n",
" <td>https://scontent.ftpe10-1.fna.fbcdn.net/v/t39....</td>\n",
" <td>16</td>\n",
" <td>0</td>\n",
" <td>0</td>\n",
" <td>1</td>\n",
" <td>[{'reaction_count': 16, 'node': {'id': '163585...</td>\n",
" <td>AQHRMe5o8KJIMTVYawF1o8Vd0cJzDc1dF1eum3VLMIYTpL...</td>\n",
" <td>https://www.facebook.com/people/%E9%BB%91%E7%8...</td>\n",
" <td>https://www.facebook.com/permalink.php?story_f...</td>\n",
" <td>2022-10-13 22:02:32</td>\n",
" </tr>\n",
" <tr>\n",
" <th>4</th>\n",
" <td>黑特東華 NDHU Hate</td>\n",
" <td>100064708507691</td>\n",
" <td>476533317846948</td>\n",
" <td>2022-10-12 19:47:47</td>\n",
" <td>#52631\\n\\n想問下 禮拜一晚上有上拳擊課的學生 \\n因為連假所以補課 想問是什麼時候...</td>\n",
" <td></td>\n",
" <td></td>\n",
" <td></td>\n",
" <td>9</td>\n",
" <td>9</td>\n",
" <td>4</td>\n",
" <td>0</td>\n",
" <td>[{'reaction_count': 9, 'node': {'id': '1635855...</td>\n",
" <td>AQHRppObbMGsrzRdDW6mI7HAOUiedMntD77Xe_-pnyteE3...</td>\n",
" <td>https://www.facebook.com/people/%E9%BB%91%E7%8...</td>\n",
" <td>https://www.facebook.com/permalink.php?story_f...</td>\n",
" <td>2022-10-13 22:02:32</td>\n",
" </tr>\n",
" <tr>\n",
" <th>...</th>\n",
" <td>...</td>\n",
" <td>...</td>\n",
" <td>...</td>\n",
" <td>...</td>\n",
" <td>...</td>\n",
" <td>...</td>\n",
" <td>...</td>\n",
" <td>...</td>\n",
" <td>...</td>\n",
" <td>...</td>\n",
" <td>...</td>\n",
" <td>...</td>\n",
" <td>...</td>\n",
" <td>...</td>\n",
" <td>...</td>\n",
" <td>...</td>\n",
" <td>...</td>\n",
" </tr>\n",
" <tr>\n",
" <th>112</th>\n",
" <td>黑特東華 NDHU Hate</td>\n",
" <td>100064708507691</td>\n",
" <td>466889638811316</td>\n",
" <td>2022-10-01 06:49:29</td>\n",
" <td>#52524\\n\\n29號接近午夜時分在外環拉轉按喇叭,後來一路騎進學人宿舍往舊宿去、還繼續...</td>\n",
" <td></td>\n",
" <td></td>\n",
" <td>https://scontent.ftpe10-1.fna.fbcdn.net/v/t39....</td>\n",
" <td>47</td>\n",
" <td>5</td>\n",
" <td>2</td>\n",
" <td>1</td>\n",
" <td>[{'reaction_count': 34, 'node': {'id': '163585...</td>\n",
" <td>AQHRsblILurBMfS7TsLUVyW3GVjCkGIVSJLXMn3lb0_a0P...</td>\n",
" <td>https://www.facebook.com/people/%E9%BB%91%E7%8...</td>\n",
" <td>https://www.facebook.com/permalink.php?story_f...</td>\n",
" <td>2022-10-13 22:02:32</td>\n",
" </tr>\n",
" <tr>\n",
" <th>113</th>\n",
" <td>黑特東華 NDHU Hate</td>\n",
" <td>100064708507691</td>\n",
" <td>465849725581974</td>\n",
" <td>2022-09-30 00:28:39</td>\n",
" <td>#52523\\n\\n向晴裝有買車停在宿舍旁的車主可不可以管好自己的車,常常半夜一直逼逼逼逼讓...</td>\n",
" <td></td>\n",
" <td></td>\n",
" <td></td>\n",
" <td>6</td>\n",
" <td>0</td>\n",
" <td>0</td>\n",
" <td>0</td>\n",
" <td>[{'reaction_count': 6, 'node': {'id': '1635855...</td>\n",
" <td>AQHRXXwiAQgdKEmnvEo3mUXyzuH6f-wXNQDeyzxZr2kEky...</td>\n",
" <td>https://www.facebook.com/people/%E9%BB%91%E7%8...</td>\n",
" <td>https://www.facebook.com/permalink.php?story_f...</td>\n",
" <td>2022-10-13 22:02:32</td>\n",
" </tr>\n",
" <tr>\n",
" <th>114</th>\n",
" <td>黑特東華 NDHU Hate</td>\n",
" <td>100064708507691</td>\n",
" <td>465849705581976</td>\n",
" <td>2022-09-30 00:28:37</td>\n",
" <td>#52522\\n\\n宿舍都知道要公告說晚上十點過後要小聲要安靜\\n然後擷雲宿委還可以快十一點...</td>\n",
" <td></td>\n",
" <td></td>\n",
" <td></td>\n",
" <td>27</td>\n",
" <td>6</td>\n",
" <td>5</td>\n",
" <td>0</td>\n",
" <td>[{'reaction_count': 21, 'node': {'id': '163585...</td>\n",
" <td>AQHRB_nYO_BnR2qBBs4LXzM6CPeLfOlTMiCE3ZR6Ed9uZB...</td>\n",
" <td>https://www.facebook.com/people/%E9%BB%91%E7%8...</td>\n",
" <td>https://www.facebook.com/permalink.php?story_f...</td>\n",
" <td>2022-10-13 22:02:32</td>\n",
" </tr>\n",
" <tr>\n",
" <th>115</th>\n",
" <td>黑特東華 NDHU Hate</td>\n",
" <td>100064708507691</td>\n",
" <td>465849682248645</td>\n",
" <td>2022-09-30 00:28:35</td>\n",
" <td>#52521\\n\\n*非黑特*\\n誠徵*日領* 兼職、打工、工讀, 10/3(一)3位Pm1...</td>\n",
" <td></td>\n",
" <td></td>\n",
" <td></td>\n",
" <td>8</td>\n",
" <td>1</td>\n",
" <td>1</td>\n",
" <td>0</td>\n",
" <td>[{'reaction_count': 8, 'node': {'id': '1635855...</td>\n",
" <td>AQHRQ11A6xsDyh3EgTdpIoAWmxFJQkoSXUrlVoeHXSDylA...</td>\n",
" <td>https://www.facebook.com/people/%E9%BB%91%E7%8...</td>\n",
" <td>https://www.facebook.com/permalink.php?story_f...</td>\n",
" <td>2022-10-13 22:02:32</td>\n",
" </tr>\n",
" <tr>\n",
" <th>116</th>\n",
" <td>黑特東華 NDHU Hate</td>\n",
" <td>100064708507691</td>\n",
" <td>465849665581980</td>\n",
" <td>2022-09-30 00:28:33</td>\n",
" <td>#52520\\n\\n同學你的便當🍱留在統冠(志學)\\n由於一直等不到你來拿\\n先幫你冰起來\\...</td>\n",
" <td></td>\n",
" <td></td>\n",
" <td>https://scontent.ftpe10-1.fna.fbcdn.net/v/t39....</td>\n",
" <td>11</td>\n",
" <td>0</td>\n",
" <td>0</td>\n",
" <td>0</td>\n",
" <td>[{'reaction_count': 8, 'node': {'id': '1635855...</td>\n",
" <td>AQHR5AKAESdSG7AYj3DfxnH6Gb8piuyeh9hP-f4Y9IFOdv...</td>\n",
" <td>https://www.facebook.com/people/%E9%BB%91%E7%8...</td>\n",
" <td>https://www.facebook.com/permalink.php?story_f...</td>\n",
" <td>2022-10-13 22:02:32</td>\n",
" </tr>\n",
" </tbody>\n",
"</table>\n",
"<p>117 rows × 17 columns</p>\n",
"</div>"
],
"text/plain": [
" NAME PAGEID POSTID TIME \\\n",
"0 黑特東華 NDHU Hate 100064708507691 476738834493063 2022-10-13 01:06:00 \n",
"1 黑特東華 NDHU Hate 100064708507691 476738777826402 2022-10-13 01:05:58 \n",
"2 黑特東華 NDHU Hate 100064708507691 476533761180237 2022-10-12 19:48:11 \n",
"3 黑特東華 NDHU Hate 100064708507691 476533567846923 2022-10-12 19:47:59 \n",
"4 黑特東華 NDHU Hate 100064708507691 476533317846948 2022-10-12 19:47:47 \n",
".. ... ... ... ... \n",
"112 黑特東華 NDHU Hate 100064708507691 466889638811316 2022-10-01 06:49:29 \n",
"113 黑特東華 NDHU Hate 100064708507691 465849725581974 2022-09-30 00:28:39 \n",
"114 黑特東華 NDHU Hate 100064708507691 465849705581976 2022-09-30 00:28:37 \n",
"115 黑特東華 NDHU Hate 100064708507691 465849682248645 2022-09-30 00:28:35 \n",
"116 黑特東華 NDHU Hate 100064708507691 465849665581980 2022-09-30 00:28:33 \n",
"\n",
" MESSAGE ATTACHMENT_TITLE \\\n",
"0 #52635\\n\\n志學街一堆店家把東華學生當搖錢樹,大家應該聯合抵制一下,盤子店通通給他倒... \n",
"1 #52634\\n\\n電音社第二次社課\\n\\n提醒各位這禮拜日為電音社第二次上課,不管是沒有參... \n",
"2 #52633\\n\\n10/12晚上7.左右在理工停車場靠學活那側撿到BKS1(安全帽藍芽耳機... \n",
"3 #52632\\n\\n#非黑特\\nThis is 頌啦!浪‧人‧鬆‧餅👏👏👏\\n東華巡迴場10... \n",
"4 #52631\\n\\n想問下 禮拜一晚上有上拳擊課的學生 \\n因為連假所以補課 想問是什麼時候... \n",
".. ... ... \n",
"112 #52524\\n\\n29號接近午夜時分在外環拉轉按喇叭,後來一路騎進學人宿舍往舊宿去、還繼續... \n",
"113 #52523\\n\\n向晴裝有買車停在宿舍旁的車主可不可以管好自己的車,常常半夜一直逼逼逼逼讓... \n",
"114 #52522\\n\\n宿舍都知道要公告說晚上十點過後要小聲要安靜\\n然後擷雲宿委還可以快十一點... \n",
"115 #52521\\n\\n*非黑特*\\n誠徵*日領* 兼職、打工、工讀, 10/3(一)3位Pm1... \n",
"116 #52520\\n\\n同學你的便當🍱留在統冠(志學)\\n由於一直等不到你來拿\\n先幫你冰起來\\... \n",
"\n",
" ATTACHMENT_DESCRIPTION ATTACHMENT_PHOTOS \\\n",
"0 \n",
"1 https://scontent.ftpe10-1.fna.fbcdn.net/v/t39.... \n",
"2 https://scontent.ftpe10-1.fna.fbcdn.net/v/t39.... \n",
"3 https://scontent.ftpe10-1.fna.fbcdn.net/v/t39.... \n",
"4 \n",
".. ... ... \n",
"112 https://scontent.ftpe10-1.fna.fbcdn.net/v/t39.... \n",
"113 \n",
"114 \n",
"115 \n",
"116 https://scontent.ftpe10-1.fna.fbcdn.net/v/t39.... \n",
"\n",
" REACTIONCOUNT COMMENTCOUNT DISPLAYCOMMENTCOUNT SHARECOUNT \\\n",
"0 166 25 15 2 \n",
"1 3 0 0 0 \n",
"2 3 0 0 0 \n",
"3 16 0 0 1 \n",
"4 9 9 4 0 \n",
".. ... ... ... ... \n",
"112 47 5 2 1 \n",
"113 6 0 0 0 \n",
"114 27 6 5 0 \n",
"115 8 1 1 0 \n",
"116 11 0 0 0 \n",
"\n",
" REACTIONS \\\n",
"0 [{'reaction_count': 138, 'node': {'id': '16358... \n",
"1 [{'reaction_count': 2, 'node': {'id': '1635855... \n",
"2 [{'reaction_count': 3, 'node': {'id': '1635855... \n",
"3 [{'reaction_count': 16, 'node': {'id': '163585... \n",
"4 [{'reaction_count': 9, 'node': {'id': '1635855... \n",
".. ... \n",
"112 [{'reaction_count': 34, 'node': {'id': '163585... \n",
"113 [{'reaction_count': 6, 'node': {'id': '1635855... \n",
"114 [{'reaction_count': 21, 'node': {'id': '163585... \n",
"115 [{'reaction_count': 8, 'node': {'id': '1635855... \n",
"116 [{'reaction_count': 8, 'node': {'id': '1635855... \n",
"\n",
" CURSOR \\\n",
"0 AQHRWkzldCEuXabhI1tJPZnVEn7FKGxga7nPHhIBgGzMmB... \n",
"1 AQHRRN-x6Hvn-AZ35SOZ2CNtJpaM3_9yYj9j9dTx5LxCWy... \n",
"2 AQHRD6AVoPeV1kHsvTjT0XPsC42w8-nrRawALu9lBRlhH5... \n",
"3 AQHRMe5o8KJIMTVYawF1o8Vd0cJzDc1dF1eum3VLMIYTpL... \n",
"4 AQHRppObbMGsrzRdDW6mI7HAOUiedMntD77Xe_-pnyteE3... \n",
".. ... \n",
"112 AQHRsblILurBMfS7TsLUVyW3GVjCkGIVSJLXMn3lb0_a0P... \n",
"113 AQHRXXwiAQgdKEmnvEo3mUXyzuH6f-wXNQDeyzxZr2kEky... \n",
"114 AQHRB_nYO_BnR2qBBs4LXzM6CPeLfOlTMiCE3ZR6Ed9uZB... \n",
"115 AQHRQ11A6xsDyh3EgTdpIoAWmxFJQkoSXUrlVoeHXSDylA... \n",
"116 AQHR5AKAESdSG7AYj3DfxnH6Gb8piuyeh9hP-f4Y9IFOdv... \n",
"\n",
" ACTOR_URL \\\n",
"0 https://www.facebook.com/people/%E9%BB%91%E7%8... \n",
"1 https://www.facebook.com/people/%E9%BB%91%E7%8... \n",
"2 https://www.facebook.com/people/%E9%BB%91%E7%8... \n",
"3 https://www.facebook.com/people/%E9%BB%91%E7%8... \n",
"4 https://www.facebook.com/people/%E9%BB%91%E7%8... \n",
".. ... \n",
"112 https://www.facebook.com/people/%E9%BB%91%E7%8... \n",
"113 https://www.facebook.com/people/%E9%BB%91%E7%8... \n",
"114 https://www.facebook.com/people/%E9%BB%91%E7%8... \n",
"115 https://www.facebook.com/people/%E9%BB%91%E7%8... \n",
"116 https://www.facebook.com/people/%E9%BB%91%E7%8... \n",
"\n",
" POST_URL UPDATETIME \n",
"0 https://www.facebook.com/permalink.php?story_f... 2022-10-13 22:02:32 \n",
"1 https://www.facebook.com/permalink.php?story_f... 2022-10-13 22:02:32 \n",
"2 https://www.facebook.com/permalink.php?story_f... 2022-10-13 22:02:32 \n",
"3 https://www.facebook.com/permalink.php?story_f... 2022-10-13 22:02:32 \n",
"4 https://www.facebook.com/permalink.php?story_f... 2022-10-13 22:02:32 \n",
".. ... ... \n",
"112 https://www.facebook.com/permalink.php?story_f... 2022-10-13 22:02:32 \n",
"113 https://www.facebook.com/permalink.php?story_f... 2022-10-13 22:02:32 \n",
"114 https://www.facebook.com/permalink.php?story_f... 2022-10-13 22:02:32 \n",
"115 https://www.facebook.com/permalink.php?story_f... 2022-10-13 22:02:32 \n",
"116 https://www.facebook.com/permalink.php?story_f... 2022-10-13 22:02:32 \n",
"\n",
"[117 rows x 17 columns]"
]
},
"execution_count": 3,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"import pandas as pd\n",
"from facebook_crawler import Crawl_PagePosts\n",
"pageurl = 'https://www.facebook.com/hatendhu'\n",
"df = Crawl_PagePosts(pageurl, until_date='2022-10-01')\n",
"df"
]
},
{
"cell_type": "code",
"execution_count": 4,
"id": "a7e18396-bfa1-4e9e-a507-162b2ae7b2d8",
"metadata": {
"execution": {
"iopub.execute_input": "2022-10-13T14:02:32.394376Z",
"iopub.status.busy": "2022-10-13T14:02:32.393376Z",
"iopub.status.idle": "2022-10-13T14:02:32.507986Z",
"shell.execute_reply": "2022-10-13T14:02:32.507986Z",
"shell.execute_reply.started": "2022-10-13T14:02:32.394376Z"
}
},
"outputs": [],
"source": [
"df.to_excel('./20221013_hatendhu.xlsx', index=False)"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "63e56913-ba96-4a21-b548-25ce27095430",
"metadata": {},
"outputs": [],
"source": []
}
],
"metadata": {
"kernelspec": {
"display_name": "Python 3 (ipykernel)",
"language": "python",
"name": "python3"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.10.5"
}
},
"nbformat": 4,
"nbformat_minor": 5
}
================================================
FILE: sample/FansPages.ipynb
================================================
{
"cells": [
{
"cell_type": "code",
"execution_count": 2,
"id": "37db8006-7e78-4d00-bfd2-862997b366c9",
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"Collecting facebook_crawler\n",
" Using cached facebook_crawler-0.0.25-py3-none-any.whl (7.0 kB)\n",
"Requirement already satisfied: pandas in /home/tlyu0419/github/envs/env/lib/python3.8/site-packages (from facebook_crawler) (1.3.4)\n",
"Requirement already satisfied: bs4 in /home/tlyu0419/github/envs/env/lib/python3.8/site-packages (from facebook_crawler) (0.0.1)\n",
"Requirement already satisfied: lxml in /home/tlyu0419/github/envs/env/lib/python3.8/site-packages (from facebook_crawler) (4.6.4)\n",
"Requirement already satisfied: requests in /home/tlyu0419/github/envs/env/lib/python3.8/site-packages (from facebook_crawler) (2.26.0)\n",
"Requirement already satisfied: numpy in /home/tlyu0419/github/envs/env/lib/python3.8/site-packages (from facebook_crawler) (1.21.4)\n",
"Requirement already satisfied: pytz>=2017.3 in /home/tlyu0419/github/envs/env/lib/python3.8/site-packages (from pandas->facebook_crawler) (2021.3)\n",
"Requirement already satisfied: python-dateutil>=2.7.3 in /home/tlyu0419/github/envs/env/lib/python3.8/site-packages (from pandas->facebook_crawler) (2.8.2)\n",
"Requirement already satisfied: beautifulsoup4 in /home/tlyu0419/github/envs/env/lib/python3.8/site-packages (from bs4->facebook_crawler) (4.10.0)\n",
"Requirement already satisfied: urllib3<1.27,>=1.21.1 in /home/tlyu0419/github/envs/env/lib/python3.8/site-packages (from requests->facebook_crawler) (1.26.7)\n",
"Requirement already satisfied: idna<4,>=2.5; python_version >= \"3\" in /home/tlyu0419/github/envs/env/lib/python3.8/site-packages (from requests->facebook_crawler) (3.3)\n",
"Requirement already satisfied: certifi>=2017.4.17 in /home/tlyu0419/github/envs/env/lib/python3.8/site-packages (from requests->facebook_crawler) (2021.10.8)\n",
"Requirement already satisfied: charset-normalizer~=2.0.0; python_version >= \"3\" in /home/tlyu0419/github/envs/env/lib/python3.8/site-packages (from requests->facebook_crawler) (2.0.9)\n",
"Requirement already satisfied: six>=1.5 in /home/tlyu0419/github/envs/env/lib/python3.8/site-packages (from python-dateutil>=2.7.3->pandas->facebook_crawler) (1.16.0)\n",
"Requirement already satisfied: soupsieve>1.2 in /home/tlyu0419/github/envs/env/lib/python3.8/site-packages (from beautifulsoup4->bs4->facebook_crawler) (2.3.1)\n",
"Installing collected packages: facebook-crawler\n",
"Successfully installed facebook-crawler-0.0.25\n"
]
}
],
"source": [
"!pip install facebook_crawler"
]
},
{
"cell_type": "code",
"execution_count": 3,
"id": "f421b324-f6a8-479a-8b63-c80d6543e12f",
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"TimeStamp: 2021-12-03.\n",
"TimeStamp: 2021-08-03.\n",
"TimeStamp: 2021-01-16.\n",
"TimeStamp: 2020-09-09.\n"
]
},
{
"data": {
"text/html": [
"<div>\n",
"<style scoped>\n",
" .dataframe tbody tr th:only-of-type {\n",
" vertical-align: middle;\n",
" }\n",
"\n",
" .dataframe tbody tr th {\n",
" vertical-align: top;\n",
" }\n",
"\n",
" .dataframe thead th {\n",
" text-align: right;\n",
" }\n",
"</style>\n",
"<table border=\"1\" class=\"dataframe\">\n",
" <thead>\n",
" <tr style=\"text-align: right;\">\n",
" <th></th>\n",
" <th>NAME</th>\n",
" <th>TIME</th>\n",
" <th>MESSAGE</th>\n",
" <th>LINK</th>\n",
" <th>PAGEID</th>\n",
" <th>POSTID</th>\n",
" <th>COMMENTCOUNT</th>\n",
" <th>REACTIONCOUNT</th>\n",
" <th>SHARECOUNT</th>\n",
" <th>DISPLAYCOMMENTCOUNT</th>\n",
" <th>ANGER</th>\n",
" <th>HAHA</th>\n",
" <th>LIKE</th>\n",
" <th>LOVE</th>\n",
" <th>SORRY</th>\n",
" <th>SUPPORT</th>\n",
" <th>WOW</th>\n",
" <th>UPDATETIME</th>\n",
" </tr>\n",
" </thead>\n",
" <tbody>\n",
" <tr>\n",
" <th>0</th>\n",
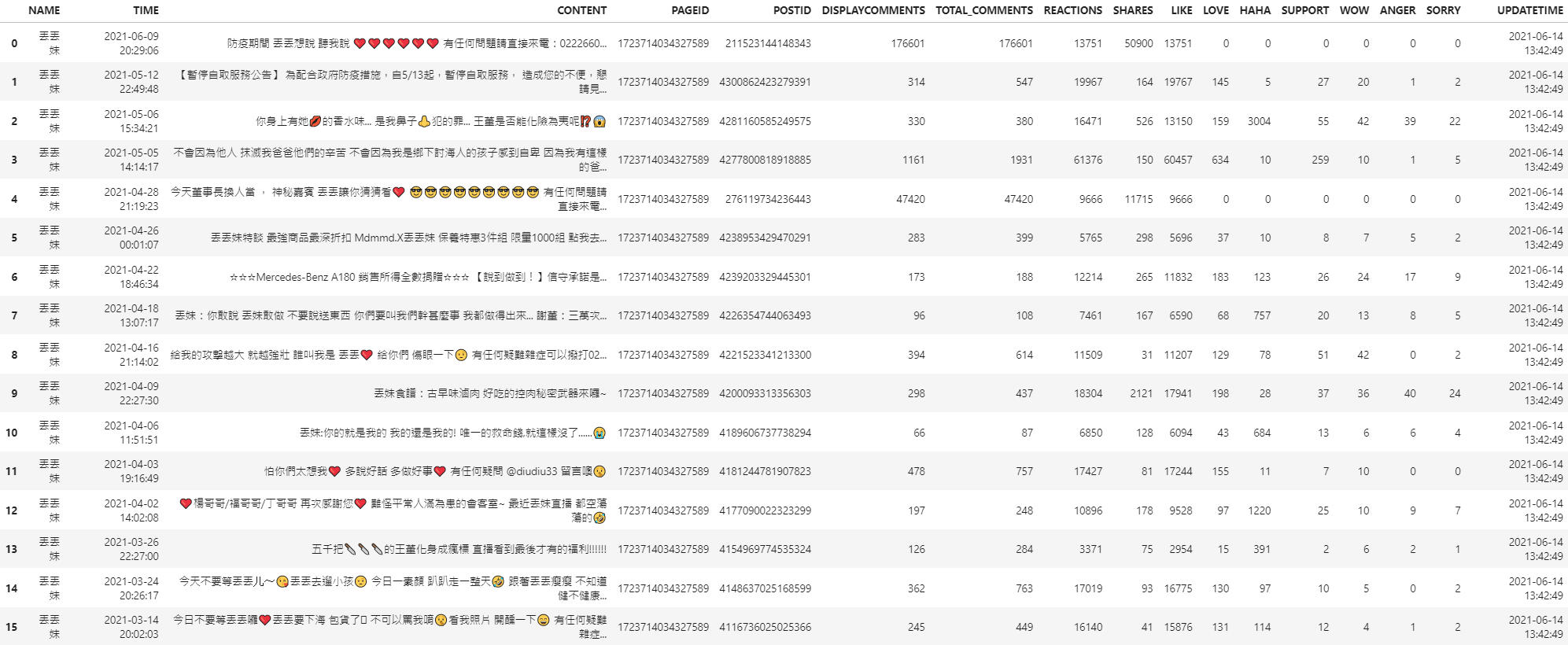
" <td>丟丟妹</td>\n",
" <td>2021-12-03 02:36:02</td>\n",
" <td>怎麼分不清 到底是誰帶壞誰XD 丟丟妹 和 Alizabeth 娘娘 根本姐妹淘🤣 互相「曉...</td>\n",
" <td>https://www.facebook.com/diudiu333</td>\n",
" <td>1723714034327589</td>\n",
" <td>4964611303571163</td>\n",
" <td>704.0</td>\n",
" <td>21797.0</td>\n",
" <td>546.0</td>\n",
" <td>572.0</td>\n",
" <td>6.0</td>\n",
" <td>5798.0</td>\n",
" <td>15841.0</td>\n",
" <td>108.0</td>\n",
" <td>6.0</td>\n",
" <td>17.0</td>\n",
" <td>21.0</td>\n",
" <td>2022-01-03 12:42:18</td>\n",
" </tr>\n",
" <tr>\n",
" <th>1</th>\n",
" <td>丟丟妹</td>\n",
" <td>2021-11-28 21:11:13</td>\n",
" <td>我喜歡這樣的陽光☀️ 開放留言 想要丟丟賣什麼? 遇到瓶頸了⋯⋯⋯😢 ❤️ #留起來</td>\n",
" <td>https://www.facebook.com/diudiu333</td>\n",
" <td>1723714034327589</td>\n",
" <td>4949186545113639</td>\n",
" <td>1675.0</td>\n",
" <td>12674.0</td>\n",
" <td>22.0</td>\n",
" <td>1142.0</td>\n",
" <td>1.0</td>\n",
" <td>7.0</td>\n",
" <td>12510.0</td>\n",
" <td>125.0</td>\n",
" <td>0.0</td>\n",
" <td>25.0</td>\n",
" <td>6.0</td>\n",
" <td>2022-01-03 12:42:18</td>\n",
" </tr>\n",
" <tr>\n",
" <th>2</th>\n",
" <td>丟丟妹</td>\n",
" <td>2021-11-19 18:02:56</td>\n",
" <td>人客啊 客倌們😆歡迎留言+1 2A頂級大閘蟹 (含繩6兩) 特價3088免運 (6隻一箱)最...</td>\n",
" <td>https://www.facebook.com/diudiu333</td>\n",
" <td>1723714034327589</td>\n",
" <td>4918431521522475</td>\n",
" <td>719.0</td>\n",
" <td>32242.0</td>\n",
" <td>65.0</td>\n",
" <td>543.0</td>\n",
" <td>1.0</td>\n",
" <td>31.0</td>\n",
" <td>31884.0</td>\n",
" <td>290.0</td>\n",
" <td>3.0</td>\n",
" <td>18.0</td>\n",
" <td>15.0</td>\n",
" <td>2022-01-03 12:42:18</td>\n",
" </tr>\n",
" <tr>\n",
" <th>3</th>\n",
" <td>丟丟妹</td>\n",
" <td>2021-11-12 22:35:08</td>\n",
" <td>丟丟妹 終於不用離婚🤣 這次直播半路認走 #乾哥哥:#郭丟丟! 叫買能力根本 #隔空遺傳?!...</td>\n",
" <td>https://www.facebook.com/diudiu333</td>\n",
" <td>1723714034327589</td>\n",
" <td>4894343770597917</td>\n",
" <td>477.0</td>\n",
" <td>18072.0</td>\n",
" <td>656.0</td>\n",
" <td>431.0</td>\n",
" <td>23.0</td>\n",
" <td>3495.0</td>\n",
" <td>14351.0</td>\n",
" <td>125.0</td>\n",
" <td>17.0</td>\n",
" <td>29.0</td>\n",
" <td>32.0</td>\n",
" <td>2022-01-03 12:42:18</td>\n",
" </tr>\n",
" <tr>\n",
" <th>4</th>\n",
" <td>丟丟妹</td>\n",
" <td>2021-11-10 21:00:52</td>\n",
" <td>各位親愛的帥哥美女們 由於訊息無限爆炸中 (已經快馬加鞭) 有留訊息就是 已接結單唷 造成...</td>\n",
" <td>https://www.facebook.com/diudiu333</td>\n",
" <td>1723714034327589</td>\n",
" <td>4887230927975868</td>\n",
" <td>352.0</td>\n",
" <td>9598.0</td>\n",
" <td>17.0</td>\n",
" <td>220.0</td>\n",
" <td>1.0</td>\n",
" <td>19.0</td>\n",
" <td>9476.0</td>\n",
" <td>59.0</td>\n",
" <td>0.0</td>\n",
" <td>34.0</td>\n",
" <td>9.0</td>\n",
" <td>2022-01-03 12:42:18</td>\n",
" </tr>\n",
" <tr>\n",
" <th>...</th>\n",
" <td>...</td>\n",
" <td>...</td>\n",
" <td>...</td>\n",
" <td>...</td>\n",
" <td>...</td>\n",
" <td>...</td>\n",
" <td>...</td>\n",
" <td>...</td>\n",
" <td>...</td>\n",
" <td>...</td>\n",
" <td>...</td>\n",
" <td>...</td>\n",
" <td>...</td>\n",
" <td>...</td>\n",
" <td>...</td>\n",
" <td>...</td>\n",
" <td>...</td>\n",
" <td>...</td>\n",
" </tr>\n",
" <tr>\n",
" <th>75</th>\n",
" <td>丟丟妹</td>\n",
" <td>2020-05-03 16:52:40</td>\n",
" <td>猜猜我在哪裡 陳冠霖牛仔部落格 連靜雯joanne lien</td>\n",
" <td>https://www.facebook.com/diudiu333</td>\n",
" <td>1723714034327589</td>\n",
" <td>184909892573719</td>\n",
" <td>2921.0</td>\n",
" <td>12355.0</td>\n",
" <td>851.0</td>\n",
" <td>2921.0</td>\n",
" <td>0.0</td>\n",
" <td>0.0</td>\n",
" <td>0.0</td>\n",
" <td>0.0</td>\n",
" <td>0.0</td>\n",
" <td>0.0</td>\n",
" <td>0.0</td>\n",
" <td>2022-01-03 12:42:18</td>\n",
" </tr>\n",
" <tr>\n",
" <th>76</th>\n",
" <td>丟丟妹</td>\n",
" <td>2020-04-30 13:36:40</td>\n",
" <td>踢爆娃娃機...</td>\n",
" <td>https://www.facebook.com/diudiu333</td>\n",
" <td>1723714034327589</td>\n",
" <td>3173673282664983</td>\n",
" <td>946.0</td>\n",
" <td>22357.0</td>\n",
" <td>1035.0</td>\n",
" <td>856.0</td>\n",
" <td>76.0</td>\n",
" <td>2661.0</td>\n",
" <td>19275.0</td>\n",
" <td>161.0</td>\n",
" <td>25.0</td>\n",
" <td>71.0</td>\n",
" <td>88.0</td>\n",
" <td>2022-01-03 12:42:18</td>\n",
" </tr>\n",
" <tr>\n",
" <th>77</th>\n",
" <td>丟丟妹</td>\n",
" <td>2020-04-29 21:51:13</td>\n",
" <td>今日直播暫停乙次 丟丟身體不舒服了😭 明天下午見 開播 要想我喲 嗚嗚😢</td>\n",
" <td>https://www.facebook.com/diudiu333</td>\n",
" <td>1723714034327589</td>\n",
" <td>3171969702835341</td>\n",
" <td>167.0</td>\n",
" <td>4123.0</td>\n",
" <td>8.0</td>\n",
" <td>164.0</td>\n",
" <td>0.0</td>\n",
" <td>3.0</td>\n",
" <td>3992.0</td>\n",
" <td>96.0</td>\n",
" <td>7.0</td>\n",
" <td>5.0</td>\n",
" <td>20.0</td>\n",
" <td>2022-01-03 12:42:18</td>\n",
" </tr>\n",
" <tr>\n",
" <th>78</th>\n",
" <td>丟丟妹</td>\n",
" <td>2020-04-17 19:46:50</td>\n",
" <td>帥哥美女今天星期五,丟妹偷懶去 明天下午二點 準時見❤️❤️😄有人會報到嗎 刷起來 😂</td>\n",
" <td>https://www.facebook.com/diudiu333</td>\n",
" <td>1723714034327589</td>\n",
" <td>3141849955847316</td>\n",
" <td>116.0</td>\n",
" <td>4804.0</td>\n",
" <td>20.0</td>\n",
" <td>114.0</td>\n",
" <td>0.0</td>\n",
" <td>6.0</td>\n",
" <td>4744.0</td>\n",
" <td>48.0</td>\n",
" <td>1.0</td>\n",
" <td>0.0</td>\n",
" <td>5.0</td>\n",
" <td>2022-01-03 12:42:18</td>\n",
" </tr>\n",
" <tr>\n",
" <th>79</th>\n",
" <td>丟丟妹</td>\n",
" <td>2020-04-15 20:48:08</td>\n",
" <td>丟丟 今天太累累了 😢 直播暫停乙次 王董想要替代丟丟當家 睡覺去 ~~ 可以 (到來...</td>\n",
" <td>https://www.facebook.com/diudiu333</td>\n",
" <td>1723714034327589</td>\n",
" <td>3136987929666852</td>\n",
" <td>145.0</td>\n",
" <td>6943.0</td>\n",
" <td>9.0</td>\n",
" <td>131.0</td>\n",
" <td>0.0</td>\n",
" <td>23.0</td>\n",
" <td>6847.0</td>\n",
" <td>59.0</td>\n",
" <td>0.0</td>\n",
" <td>0.0</td>\n",
" <td>14.0</td>\n",
" <td>2022-01-03 12:42:18</td>\n",
" </tr>\n",
" </tbody>\n",
"</table>\n",
"<p>80 rows × 18 columns</p>\n",
"</div>"
],
"text/plain": [
" NAME TIME \\\n",
"0 丟丟妹 2021-12-03 02:36:02 \n",
"1 丟丟妹 2021-11-28 21:11:13 \n",
"2 丟丟妹 2021-11-19 18:02:56 \n",
"3 丟丟妹 2021-11-12 22:35:08 \n",
"4 丟丟妹 2021-11-10 21:00:52 \n",
".. ... ... \n",
"75 丟丟妹 2020-05-03 16:52:40 \n",
"76 丟丟妹 2020-04-30 13:36:40 \n",
"77 丟丟妹 2020-04-29 21:51:13 \n",
"78 丟丟妹 2020-04-17 19:46:50 \n",
"79 丟丟妹 2020-04-15 20:48:08 \n",
"\n",
" MESSAGE \\\n",
"0 怎麼分不清 到底是誰帶壞誰XD 丟丟妹 和 Alizabeth 娘娘 根本姐妹淘🤣 互相「曉... \n",
"1 我喜歡這樣的陽光☀️ 開放留言 想要丟丟賣什麼? 遇到瓶頸了⋯⋯⋯😢 ❤️ #留起來 \n",
"2 人客啊 客倌們😆歡迎留言+1 2A頂級大閘蟹 (含繩6兩) 特價3088免運 (6隻一箱)最... \n",
"3 丟丟妹 終於不用離婚🤣 這次直播半路認走 #乾哥哥:#郭丟丟! 叫買能力根本 #隔空遺傳?!... \n",
"4 各位親愛的帥哥美女們 由於訊息無限爆炸中 (已經快馬加鞭) 有留訊息就是 已接結單唷 造成... \n",
".. ... \n",
"75 猜猜我在哪裡 陳冠霖牛仔部落格 連靜雯joanne lien \n",
"76 踢爆娃娃機... \n",
"77 今日直播暫停乙次 丟丟身體不舒服了😭 明天下午見 開播 要想我喲 嗚嗚😢 \n",
"78 帥哥美女今天星期五,丟妹偷懶去 明天下午二點 準時見❤️❤️😄有人會報到嗎 刷起來 😂 \n",
"79 丟丟 今天太累累了 😢 直播暫停乙次 王董想要替代丟丟當家 睡覺去 ~~ 可以 (到來... \n",
"\n",
" LINK PAGEID POSTID \\\n",
"0 https://www.facebook.com/diudiu333 1723714034327589 4964611303571163 \n",
"1 https://www.facebook.com/diudiu333 1723714034327589 4949186545113639 \n",
"2 https://www.facebook.com/diudiu333 1723714034327589 4918431521522475 \n",
"3 https://www.facebook.com/diudiu333 1723714034327589 4894343770597917 \n",
"4 https://www.facebook.com/diudiu333 1723714034327589 4887230927975868 \n",
".. ... ... ... \n",
"75 https://www.facebook.com/diudiu333 1723714034327589 184909892573719 \n",
"76 https://www.facebook.com/diudiu333 1723714034327589 3173673282664983 \n",
"77 https://www.facebook.com/diudiu333 1723714034327589 3171969702835341 \n",
"78 https://www.facebook.com/diudiu333 1723714034327589 3141849955847316 \n",
"79 https://www.facebook.com/diudiu333 1723714034327589 3136987929666852 \n",
"\n",
" COMMENTCOUNT REACTIONCOUNT SHARECOUNT DISPLAYCOMMENTCOUNT ANGER \\\n",
"0 704.0 21797.0 546.0 572.0 6.0 \n",
"1 1675.0 12674.0 22.0 1142.0 1.0 \n",
"2 719.0 32242.0 65.0 543.0 1.0 \n",
"3 477.0 18072.0 656.0 431.0 23.0 \n",
"4 352.0 9598.0 17.0 220.0 1.0 \n",
".. ... ... ... ... ... \n",
"75 2921.0 12355.0 851.0 2921.0 0.0 \n",
"76 946.0 22357.0 1035.0 856.0 76.0 \n",
"77 167.0 4123.0 8.0 164.0 0.0 \n",
"78 116.0 4804.0 20.0 114.0 0.0 \n",
"79 145.0 6943.0 9.0 131.0 0.0 \n",
"\n",
" HAHA LIKE LOVE SORRY SUPPORT WOW UPDATETIME \n",
"0 5798.0 15841.0 108.0 6.0 17.0 21.0 2022-01-03 12:42:18 \n",
"1 7.0 12510.0 125.0 0.0 25.0 6.0 2022-01-03 12:42:18 \n",
"2 31.0 31884.0 290.0 3.0 18.0 15.0 2022-01-03 12:42:18 \n",
"3 3495.0 14351.0 125.0 17.0 29.0 32.0 2022-01-03 12:42:18 \n",
"4 19.0 9476.0 59.0 0.0 34.0 9.0 2022-01-03 12:42:18 \n",
".. ... ... ... ... ... ... ... \n",
"75 0.0 0.0 0.0 0.0 0.0 0.0 2022-01-03 12:42:18 \n",
"76 2661.0 19275.0 161.0 25.0 71.0 88.0 2022-01-03 12:42:18 \n",
"77 3.0 3992.0 96.0 7.0 5.0 20.0 2022-01-03 12:42:18 \n",
"78 6.0 4744.0 48.0 1.0 0.0 5.0 2022-01-03 12:42:18 \n",
"79 23.0 6847.0 59.0 0.0 0.0 14.0 2022-01-03 12:42:18 \n",
"\n",
"[80 rows x 18 columns]"
]
},
"execution_count": 3,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"import facebook_crawler\n",
"pageurl= 'https://www.facebook.com/diudiu333'\n",
"facebook_crawler.Crawl_PagePosts(pageurl=pageurl, until_date='2021-01-01')"
]
},
{
"cell_type": "code",
"execution_count": 2,
"id": "0045bec9-db09-43c2-afd7-13439ab0c19d",
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"TimeStamp: 2022-01-01.\n",
"TimeStamp: 2021-06-04.\n",
"TimeStamp: 2021-03-08.\n",
"TimeStamp: 2020-12-11.\n",
"TimeStamp: 2020-10-07.\n",
"TimeStamp: 2020-07-19.\n",
"TimeStamp: 2020-05-10.\n",
"TimeStamp: 2020-02-14.\n",
"TimeStamp: 2019-12-25.\n",
"TimeStamp: 2019-11-16.\n",
"TimeStamp: 2019-08-23.\n",
"TimeStamp: 2019-06-06.\n",
"TimeStamp: 2019-03-20.\n",
"TimeStamp: 2018-12-27.\n",
"TimeStamp: 2018-09-01.\n",
"TimeStamp: 2017-12-29.\n",
"TimeStamp: 2017-06-26.\n",
"TimeStamp: 2016-12-11.\n",
"TimeStamp: 2016-05-15.\n",
"TimeStamp: 2016-04-05.\n",
"TimeStamp: 2016-03-12.\n",
"TimeStamp: 2016-02-06.\n",
"TimeStamp: 2016-01-03.\n",
"TimeStamp: 2015-11-28.\n"
]
},
{
"data": {
"text/html": [
"<div>\n",
"<style scoped>\n",
" .dataframe tbody tr th:only-of-type {\n",
" vertical-align: middle;\n",
" }\n",
"\n",
" .dataframe tbody tr th {\n",
" vertical-align: top;\n",
" }\n",
"\n",
" .dataframe thead th {\n",
" text-align: right;\n",
" }\n",
"</style>\n",
"<table border=\"1\" class=\"dataframe\">\n",
" <thead>\n",
" <tr style=\"text-align: right;\">\n",
" <th></th>\n",
" <th>NAME</th>\n",
" <th>TIME</th>\n",
" <th>MESSAGE</th>\n",
" <th>LINK</th>\n",
" <th>PAGEID</th>\n",
" <th>POSTID</th>\n",
" <th>COMMENTCOUNT</th>\n",
" <th>REACTIONCOUNT</th>\n",
" <th>SHARECOUNT</th>\n",
" <th>DISPLAYCOMMENTCOUNT</th>\n",
" <th>ANGER</th>\n",
" <th>DOROTHY</th>\n",
" <th>HAHA</th>\n",
" <th>LIKE</th>\n",
" <th>LOVE</th>\n",
" <th>SORRY</th>\n",
" <th>SUPPORT</th>\n",
" <th>TOTO</th>\n",
" <th>WOW</th>\n",
" <th>UPDATETIME</th>\n",
" </tr>\n",
" </thead>\n",
" <tbody>\n",
" <tr>\n",
" <th>0</th>\n",
" <td>馬英九</td>\n",
" <td>2022-01-01 08:00:56</td>\n",
" <td>今天是中華民國一百一十一年元旦,清晨的氣溫很低,看著國旗在空中飄揚,心中交集著感謝與感慨之情...</td>\n",
" <td>https://www.facebook.com/MaYingjeou/</td>\n",
" <td>118250504903757</td>\n",
" <td>4936286629766763</td>\n",
" <td>1243.0</td>\n",
" <td>38906.0</td>\n",
" <td>403.0</td>\n",
" <td>1022.0</td>\n",
" <td>5.0</td>\n",
" <td>NaN</td>\n",
" <td>22.0</td>\n",
" <td>38254.0</td>\n",
" <td>458.0</td>\n",
" <td>4.0</td>\n",
" <td>157.0</td>\n",
" <td>NaN</td>\n",
" <td>6.0</td>\n",
" <td>2022-01-05 23:16:30</td>\n",
" </tr>\n",
" <tr>\n",
" <th>1</th>\n",
" <td>馬英九</td>\n",
" <td>2021-12-21 17:05:14</td>\n",
" <td>冬至天氣冷颼颼,來一碗熱熱的燒湯圓 🤤 大家喜歡吃芝麻湯圓還是花生湯圓呢? #冬至 #吃湯圓...</td>\n",
" <td>https://www.facebook.com/MaYingjeou/</td>\n",
" <td>118250504903757</td>\n",
" <td>4893842230677870</td>\n",
" <td>1047.0</td>\n",
" <td>28432.0</td>\n",
" <td>179.0</td>\n",
" <td>844.0</td>\n",
" <td>15.0</td>\n",
" <td>NaN</td>\n",
" <td>64.0</td>\n",
" <td>27961.0</td>\n",
" <td>325.0</td>\n",
" <td>2.0</td>\n",
" <td>55.0</td>\n",
" <td>NaN</td>\n",
" <td>10.0</td>\n",
" <td>2022-01-05 23:16:30</td>\n",
" </tr>\n",
" <tr>\n",
" <th>2</th>\n",
" <td>馬英九</td>\n",
" <td>2021-12-17 17:00:00</td>\n",
" <td>公民投票是憲法賦予人民的權利 1218,穿得暖暖,出門投票! #四個都同意人民最有利 #返鄉...</td>\n",
" <td>https://www.facebook.com/MaYingjeou/</td>\n",
" <td>118250504903757</td>\n",
" <td>4874626962599397</td>\n",
" <td>1883.0</td>\n",
" <td>45037.0</td>\n",
" <td>519.0</td>\n",
" <td>1372.0</td>\n",
" <td>31.0</td>\n",
" <td>NaN</td>\n",
" <td>63.0</td>\n",
" <td>43941.0</td>\n",
" <td>336.0</td>\n",
" <td>16.0</td>\n",
" <td>634.0</td>\n",
" <td>NaN</td>\n",
" <td>16.0</td>\n",
" <td>2022-01-05 23:16:30</td>\n",
" </tr>\n",
" <tr>\n",
" <th>3</th>\n",
" <td>馬英九</td>\n",
" <td>2021-12-11 09:00:00</td>\n",
" <td>公投前最後一個周末,你收到投票通知單了嗎? 萊劑不是保健品 公投重新綁大選 三接興建傷藻礁⋯...</td>\n",
" <td>https://www.facebook.com/MaYingjeou/</td>\n",
" <td>118250504903757</td>\n",
" <td>4846491325412961</td>\n",
" <td>3254.0</td>\n",
" <td>39639.0</td>\n",
" <td>809.0</td>\n",
" <td>1742.0</td>\n",
" <td>60.0</td>\n",
" <td>NaN</td>\n",
" <td>78.0</td>\n",
" <td>38702.0</td>\n",
" <td>196.0</td>\n",
" <td>11.0</td>\n",
" <td>568.0</td>\n",
" <td>NaN</td>\n",
" <td>24.0</td>\n",
" <td>2022-01-05 23:16:30</td>\n",
" </tr>\n",
" <tr>\n",
" <th>4</th>\n",
" <td>馬英九</td>\n",
" <td>2021-11-14 13:52:11</td>\n",
" <td>鯉魚潭鐵三初體驗🏊♂️🚴♂️🏃♂️ 順利完賽💪💪💪 #2021年花蓮太平洋鐵人三項錦標...</td>\n",
" <td>https://www.facebook.com/MaYingjeou/</td>\n",
" <td>118250504903757</td>\n",
" <td>4764707240258037</td>\n",
" <td>2409.0</td>\n",
" <td>73538.0</td>\n",
" <td>501.0</td>\n",
" <td>2017.0</td>\n",
" <td>15.0</td>\n",
" <td>NaN</td>\n",
" <td>41.0</td>\n",
" <td>72407.0</td>\n",
" <td>557.0</td>\n",
" <td>4.0</td>\n",
" <td>292.0</td>\n",
" <td>NaN</td>\n",
" <td>222.0</td>\n",
" <td>2022-01-05 23:16:30</td>\n",
" </tr>\n",
" <tr>\n",
" <th>...</th>\n",
" <td>...</td>\n",
" <td>...</td>\n",
" <td>...</td>\n",
" <td>...</td>\n",
" <td>...</td>\n",
" <td>...</td>\n",
" <td>...</td>\n",
" <td>...</td>\n",
" <td>...</td>\n",
" <td>...</td>\n",
" <td>...</td>\n",
" <td>...</td>\n",
" <td>...</td>\n",
" <td>...</td>\n",
" <td>...</td>\n",
" <td>...</td>\n",
" <td>...</td>\n",
" <td>...</td>\n",
" <td>...</td>\n",
" <td>...</td>\n",
" </tr>\n",
" <tr>\n",
" <th>475</th>\n",
" <td>馬英九</td>\n",
" <td>2015-10-19 18:10:33</td>\n",
" <td>「六堆忠義祠」源於清康熙60年,六堆團練協助平定朱一貴起事,清廷興建了「西勢忠義亭」奉祀在戰...</td>\n",
" <td>https://www.facebook.com/MaYingjeou/</td>\n",
" <td>118250504903757</td>\n",
" <td>1050731538322311</td>\n",
" <td>1176.0</td>\n",
" <td>21803.0</td>\n",
" <td>316.0</td>\n",
" <td>705.0</td>\n",
" <td>0.0</td>\n",
" <td>NaN</td>\n",
" <td>0.0</td>\n",
" <td>21801.0</td>\n",
" <td>2.0</td>\n",
" <td>0.0</td>\n",
" <td>0.0</td>\n",
" <td>NaN</td>\n",
" <td>0.0</td>\n",
" <td>2022-01-05 23:16:30</td>\n",
" </tr>\n",
" <tr>\n",
" <th>476</th>\n",
" <td>馬英九</td>\n",
" <td>2015-10-12 18:07:34</td>\n",
" <td></td>\n",
" <td>https://www.facebook.com/MaYingjeou/</td>\n",
" <td>118250504903757</td>\n",
" <td>1047937641935034</td>\n",
" <td>NaN</td>\n",
" <td>NaN</td>\n",
" <td>NaN</td>\n",
" <td>NaN</td>\n",
" <td>0.0</td>\n",
" <td>NaN</td>\n",
" <td>0.0</td>\n",
" <td>0.0</td>\n",
" <td>0.0</td>\n",
" <td>0.0</td>\n",
" <td>0.0</td>\n",
" <td>NaN</td>\n",
" <td>0.0</td>\n",
" <td>2022-01-05 23:16:30</td>\n",
" </tr>\n",
" <tr>\n",
" <th>477</th>\n",
" <td>馬英九</td>\n",
" <td>2015-10-11 13:40:25</td>\n",
" <td></td>\n",
" <td>https://www.facebook.com/MaYingjeou/</td>\n",
" <td>118250504903757</td>\n",
" <td>1047435965318535</td>\n",
" <td>NaN</td>\n",
" <td>NaN</td>\n",
" <td>NaN</td>\n",
" <td>NaN</td>\n",
" <td>0.0</td>\n",
" <td>NaN</td>\n",
" <td>0.0</td>\n",
" <td>0.0</td>\n",
" <td>0.0</td>\n",
" <td>0.0</td>\n",
" <td>0.0</td>\n",
" <td>NaN</td>\n",
" <td>0.0</td>\n",
" <td>2022-01-05 23:16:30</td>\n",
" </tr>\n",
" <tr>\n",
" <th>478</th>\n",
" <td>馬英九</td>\n",
" <td>2015-10-10 14:08:46</td>\n",
" <td>今天是民國104年國慶日,讓我們一起祝中華民國生日快樂! 今年的國慶日,還有特別的意義。今年...</td>\n",
" <td>https://www.facebook.com/MaYingjeou/</td>\n",
" <td>118250504903757</td>\n",
" <td>1047031385358993</td>\n",
" <td>2219.0</td>\n",
" <td>36765.0</td>\n",
" <td>679.0</td>\n",
" <td>1357.0</td>\n",
" <td>3.0</td>\n",
" <td>NaN</td>\n",
" <td>1.0</td>\n",
" <td>36761.0</td>\n",
" <td>0.0</td>\n",
" <td>0.0</td>\n",
" <td>0.0</td>\n",
" <td>NaN</td>\n",
" <td>0.0</td>\n",
" <td>2022-01-05 23:16:30</td>\n",
" </tr>\n",
" <tr>\n",
" <th>479</th>\n",
" <td>馬英九</td>\n",
" <td>2015-10-09 19:58:31</td>\n",
" <td>故宮博物院於民國14年的國慶日成立,今年是它的90歲生日。故宮成立後幾經波折,對日抗戰爆發後...</td>\n",
" <td>https://www.facebook.com/MaYingjeou/</td>\n",
" <td>118250504903757</td>\n",
" <td>1046725805389551</td>\n",
" <td>993.0</td>\n",
" <td>14761.0</td>\n",
" <td>306.0</td>\n",
" <td>590.0</td>\n",
" <td>3.0</td>\n",
" <td>NaN</td>\n",
" <td>0.0</td>\n",
" <td>14757.0</td>\n",
" <td>1.0</td>\n",
" <td>0.0</td>\n",
" <td>0.0</td>\n",
" <td>NaN</td>\n",
" <td>0.0</td>\n",
" <td>2022-01-05 23:16:30</td>\n",
" </tr>\n",
" </tbody>\n",
"</table>\n",
"<p>480 rows × 20 columns</p>\n",
"</div>"
],
"text/plain": [
" NAME TIME \\\n",
"0 馬英九 2022-01-01 08:00:56 \n",
"1 馬英九 2021-12-21 17:05:14 \n",
"2 馬英九 2021-12-17 17:00:00 \n",
"3 馬英九 2021-12-11 09:00:00 \n",
"4 馬英九 2021-11-14 13:52:11 \n",
".. ... ... \n",
"475 馬英九 2015-10-19 18:10:33 \n",
"476 馬英九 2015-10-12 18:07:34 \n",
"477 馬英九 2015-10-11 13:40:25 \n",
"478 馬英九 2015-10-10 14:08:46 \n",
"479 馬英九 2015-10-09 19:58:31 \n",
"\n",
" MESSAGE \\\n",
"0 今天是中華民國一百一十一年元旦,清晨的氣溫很低,看著國旗在空中飄揚,心中交集著感謝與感慨之情... \n",
"1 冬至天氣冷颼颼,來一碗熱熱的燒湯圓 🤤 大家喜歡吃芝麻湯圓還是花生湯圓呢? #冬至 #吃湯圓... \n",
"2 公民投票是憲法賦予人民的權利 1218,穿得暖暖,出門投票! #四個都同意人民最有利 #返鄉... \n",
"3 公投前最後一個周末,你收到投票通知單了嗎? 萊劑不是保健品 公投重新綁大選 三接興建傷藻礁⋯... \n",
"4 鯉魚潭鐵三初體驗🏊♂️🚴♂️🏃♂️ 順利完賽💪💪💪 #2021年花蓮太平洋鐵人三項錦標... \n",
".. ... \n",
"475 「六堆忠義祠」源於清康熙60年,六堆團練協助平定朱一貴起事,清廷興建了「西勢忠義亭」奉祀在戰... \n",
"476 \n",
"477 \n",
"478 今天是民國104年國慶日,讓我們一起祝中華民國生日快樂! 今年的國慶日,還有特別的意義。今年... \n",
"479 故宮博物院於民國14年的國慶日成立,今年是它的90歲生日。故宮成立後幾經波折,對日抗戰爆發後... \n",
"\n",
" LINK PAGEID POSTID \\\n",
"0 https://www.facebook.com/MaYingjeou/ 118250504903757 4936286629766763 \n",
"1 https://www.facebook.com/MaYingjeou/ 118250504903757 4893842230677870 \n",
"2 https://www.facebook.com/MaYingjeou/ 118250504903757 4874626962599397 \n",
"3 https://www.facebook.com/MaYingjeou/ 118250504903757 4846491325412961 \n",
"4 https://www.facebook.com/MaYingjeou/ 118250504903757 4764707240258037 \n",
".. ... ... ... \n",
"475 https://www.facebook.com/MaYingjeou/ 118250504903757 1050731538322311 \n",
"476 https://www.facebook.com/MaYingjeou/ 118250504903757 1047937641935034 \n",
"477 https://www.facebook.com/MaYingjeou/ 118250504903757 1047435965318535 \n",
"478 https://www.facebook.com/MaYingjeou/ 118250504903757 1047031385358993 \n",
"479 https://www.facebook.com/MaYingjeou/ 118250504903757 1046725805389551 \n",
"\n",
" COMMENTCOUNT REACTIONCOUNT SHARECOUNT DISPLAYCOMMENTCOUNT ANGER \\\n",
"0 1243.0 38906.0 403.0 1022.0 5.0 \n",
"1 1047.0 28432.0 179.0 844.0 15.0 \n",
"2 1883.0 45037.0 519.0 1372.0 31.0 \n",
"3 3254.0 39639.0 809.0 1742.0 60.0 \n",
"4 2409.0 73538.0 501.0 2017.0 15.0 \n",
".. ... ... ... ... ... \n",
"475 1176.0 21803.0 316.0 705.0 0.0 \n",
"476 NaN NaN NaN NaN 0.0 \n",
"477 NaN NaN NaN NaN 0.0 \n",
"478 2219.0 36765.0 679.0 1357.0 3.0 \n",
"479 993.0 14761.0 306.0 590.0 3.0 \n",
"\n",
" DOROTHY HAHA LIKE LOVE SORRY SUPPORT TOTO WOW \\\n",
"0 NaN 22.0 38254.0 458.0 4.0 157.0 NaN 6.0 \n",
"1 NaN 64.0 27961.0 325.0 2.0 55.0 NaN 10.0 \n",
"2 NaN 63.0 43941.0 336.0 16.0 634.0 NaN 16.0 \n",
"3 NaN 78.0 38702.0 196.0 11.0 568.0 NaN 24.0 \n",
"4 NaN 41.0 72407.0 557.0 4.0 292.0 NaN 222.0 \n",
".. ... ... ... ... ... ... ... ... \n",
"475 NaN 0.0 21801.0 2.0 0.0 0.0 NaN 0.0 \n",
"476 NaN 0.0 0.0 0.0 0.0 0.0 NaN 0.0 \n",
"477 NaN 0.0 0.0 0.0 0.0 0.0 NaN 0.0 \n",
"478 NaN 1.0 36761.0 0.0 0.0 0.0 NaN 0.0 \n",
"479 NaN 0.0 14757.0 1.0 0.0 0.0 NaN 0.0 \n",
"\n",
" UPDATETIME \n",
"0 2022-01-05 23:16:30 \n",
"1 2022-01-05 23:16:30 \n",
"2 2022-01-05 23:16:30 \n",
"3 2022-01-05 23:16:30 \n",
"4 2022-01-05 23:16:30 \n",
".. ... \n",
"475 2022-01-05 23:16:30 \n",
"476 2022-01-05 23:16:30 \n",
"477 2022-01-05 23:16:30 \n",
"478 2022-01-05 23:16:30 \n",
"479 2022-01-05 23:16:30 \n",
"\n",
"[480 rows x 20 columns]"
]
},
"execution_count": 2,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"import facebook_crawler\n",
"pageurl= 'https://www.facebook.com/MaYingjeou'\n",
"df = facebook_crawler.Crawl_PagePosts(pageurl=pageurl, until_date='2016-01-01')\n",
"df"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "5696cdfc-8f3a-47cd-a936-97112f077db4",
"metadata": {},
"outputs": [],
"source": []
}
],
"metadata": {
"kernelspec": {
"display_name": "Python 3 (ipykernel)",
"language": "python",
"name": "python3"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.8.10"
}
},
"nbformat": 4,
"nbformat_minor": 5
}
================================================
FILE: sample/Group.ipynb
================================================
{
"cells": [
{
"cell_type": "code",
"execution_count": 2,
"id": "f31b5034-e3d4-40f4-b52a-8e4addba342d",
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"TimeStamp: 2022-01-05.\n",
"TimeStamp: 2022-01-02.\n",
"TimeStamp: 2021-12-28.\n",
"TimeStamp: 2021-12-26.\n",
"TimeStamp: 2021-12-21.\n",
"TimeStamp: 2021-12-17.\n",
"TimeStamp: 2021-12-14.\n",
"TimeStamp: 2021-12-12.\n",
"TimeStamp: 2021-12-08.\n",
"TimeStamp: 2021-12-07.\n",
"TimeStamp: 2021-12-04.\n",
"TimeStamp: 2021-11-30.\n",
"TimeStamp: 2021-11-28.\n",
"TimeStamp: 2021-11-25.\n",
"TimeStamp: 2021-11-22.\n",
"TimeStamp: 2021-11-19.\n",
"TimeStamp: 2021-11-18.\n",
"TimeStamp: 2021-11-15.\n",
"TimeStamp: 2021-11-14.\n",
"TimeStamp: 2021-11-11.\n",
"TimeStamp: 2021-11-09.\n",
"TimeStamp: 2021-11-07.\n",
"TimeStamp: 2021-11-05.\n",
"TimeStamp: 2021-11-03.\n",
"TimeStamp: 2021-11-02.\n",
"TimeStamp: 2021-10-31.\n",
"TimeStamp: 2021-10-28.\n",
"TimeStamp: 2021-10-26.\n",
"TimeStamp: 2021-10-24.\n",
"TimeStamp: 2021-10-22.\n",
"TimeStamp: 2021-10-20.\n",
"TimeStamp: 2021-10-18.\n",
"TimeStamp: 2021-10-17.\n",
"TimeStamp: 2021-10-15.\n",
"TimeStamp: 2021-10-13.\n",
"TimeStamp: 2021-10-11.\n",
"TimeStamp: 2021-10-09.\n",
"TimeStamp: 2021-10-07.\n",
"TimeStamp: 2021-10-05.\n",
"TimeStamp: 2021-10-03.\n",
"TimeStamp: 2021-10-01.\n",
"TimeStamp: 2021-09-30.\n",
"TimeStamp: 2021-09-28.\n",
"TimeStamp: 2021-09-25.\n",
"TimeStamp: 2021-09-23.\n",
"TimeStamp: 2021-09-21.\n",
"TimeStamp: 2021-09-19.\n",
"TimeStamp: 2021-09-18.\n",
"TimeStamp: 2021-09-16.\n",
"TimeStamp: 2021-09-15.\n",
"TimeStamp: 2021-09-13.\n",
"TimeStamp: 2021-09-11.\n",
"TimeStamp: 2021-09-09.\n",
"TimeStamp: 2021-09-08.\n",
"TimeStamp: 2021-09-06.\n",
"TimeStamp: 2021-09-05.\n",
"TimeStamp: 2021-09-03.\n",
"TimeStamp: 2021-09-02.\n",
"TimeStamp: 2021-09-01.\n",
"TimeStamp: 2021-08-29.\n",
"TimeStamp: 2021-08-27.\n",
"TimeStamp: 2021-08-25.\n",
"TimeStamp: 2021-08-23.\n",
"TimeStamp: 2021-08-22.\n",
"TimeStamp: 2021-08-20.\n",
"TimeStamp: 2021-08-18.\n",
"TimeStamp: 2021-08-17.\n",
"TimeStamp: 2021-08-15.\n",
"TimeStamp: 2021-08-14.\n",
"TimeStamp: 2021-08-12.\n",
"TimeStamp: 2021-08-11.\n",
"TimeStamp: 2021-08-10.\n",
"TimeStamp: 2021-08-08.\n",
"TimeStamp: 2021-08-06.\n",
"TimeStamp: 2021-08-04.\n",
"TimeStamp: 2021-08-02.\n",
"TimeStamp: 2021-07-31.\n",
"TimeStamp: 2021-07-29.\n",
"TimeStamp: 2021-07-28.\n",
"TimeStamp: 2021-07-26.\n",
"TimeStamp: 2021-07-24.\n",
"TimeStamp: 2021-07-22.\n",
"TimeStamp: 2021-07-21.\n",
"TimeStamp: 2021-07-19.\n",
"TimeStamp: 2021-07-18.\n",
"TimeStamp: 2021-07-17.\n",
"TimeStamp: 2021-07-16.\n",
"TimeStamp: 2021-07-14.\n",
"TimeStamp: 2021-07-12.\n",
"TimeStamp: 2021-07-10.\n",
"TimeStamp: 2021-07-09.\n",
"TimeStamp: 2021-07-07.\n",
"TimeStamp: 2021-07-04.\n",
"TimeStamp: 2021-07-03.\n",
"TimeStamp: 2021-07-02.\n",
"TimeStamp: 2021-06-30.\n",
"TimeStamp: 2021-06-28.\n",
"TimeStamp: 2021-06-26.\n",
"TimeStamp: 2021-06-25.\n",
"TimeStamp: 2021-06-22.\n",
"TimeStamp: 2021-06-21.\n",
"TimeStamp: 2021-06-19.\n",
"TimeStamp: 2021-06-18.\n",
"TimeStamp: 2021-06-16.\n",
"TimeStamp: 2021-06-14.\n",
"TimeStamp: 2021-06-12.\n",
"TimeStamp: 2021-06-11.\n",
"TimeStamp: 2021-06-10.\n",
"TimeStamp: 2021-06-08.\n",
"TimeStamp: 2021-06-06.\n",
"TimeStamp: 2021-06-06.\n",
"TimeStamp: 2021-06-04.\n",
"TimeStamp: 2021-06-02.\n",
"TimeStamp: 2021-05-31.\n",
"TimeStamp: 2021-05-29.\n",
"TimeStamp: 2021-05-26.\n",
"TimeStamp: 2021-05-25.\n",
"TimeStamp: 2021-05-23.\n",
"TimeStamp: 2021-05-21.\n",
"TimeStamp: 2021-05-19.\n",
"TimeStamp: 2021-05-17.\n",
"TimeStamp: 2021-05-13.\n",
"TimeStamp: 2021-05-11.\n",
"TimeStamp: 2021-05-09.\n",
"TimeStamp: 2021-05-07.\n",
"TimeStamp: 2021-05-05.\n",
"TimeStamp: 2021-05-04.\n",
"TimeStamp: 2021-05-03.\n",
"TimeStamp: 2021-04-30.\n",
"TimeStamp: 2021-04-29.\n",
"TimeStamp: 2021-04-28.\n",
"TimeStamp: 2021-04-27.\n",
"TimeStamp: 2021-04-26.\n",
"TimeStamp: 2021-04-24.\n",
"TimeStamp: 2021-04-22.\n",
"TimeStamp: 2021-04-20.\n",
"TimeStamp: 2021-04-19.\n",
"TimeStamp: 2021-04-17.\n",
"TimeStamp: 2021-04-16.\n",
"TimeStamp: 2021-04-14.\n",
"TimeStamp: 2021-04-12.\n",
"TimeStamp: 2021-04-11.\n",
"TimeStamp: 2021-04-08.\n",
"TimeStamp: 2021-04-07.\n",
"TimeStamp: 2021-04-06.\n",
"TimeStamp: 2021-04-04.\n",
"TimeStamp: 2021-04-03.\n",
"TimeStamp: 2021-04-01.\n",
"TimeStamp: 2021-03-30.\n",
"TimeStamp: 2021-03-29.\n",
"TimeStamp: 2021-03-27.\n",
"TimeStamp: 2021-03-26.\n",
"TimeStamp: 2021-03-25.\n",
"TimeStamp: 2021-03-24.\n",
"TimeStamp: 2021-03-21.\n",
"TimeStamp: 2021-03-19.\n",
"TimeStamp: 2021-03-18.\n",
"TimeStamp: 2021-03-16.\n",
"TimeStamp: 2021-03-14.\n",
"TimeStamp: 2021-03-12.\n",
"TimeStamp: 2021-03-11.\n",
"TimeStamp: 2021-03-09.\n",
"TimeStamp: 2021-03-08.\n",
"TimeStamp: 2021-03-06.\n",
"TimeStamp: 2021-03-05.\n",
"TimeStamp: 2021-03-04.\n",
"TimeStamp: 2021-03-02.\n",
"TimeStamp: 2021-02-28.\n",
"TimeStamp: 2021-02-27.\n",
"TimeStamp: 2021-02-25.\n",
"TimeStamp: 2021-02-23.\n",
"TimeStamp: 2021-02-20.\n",
"TimeStamp: 2021-02-18.\n",
"TimeStamp: 2021-02-16.\n",
"TimeStamp: 2021-02-14.\n",
"TimeStamp: 2021-02-11.\n",
"TimeStamp: 2021-02-09.\n",
"TimeStamp: 2021-02-07.\n",
"TimeStamp: 2021-02-05.\n",
"TimeStamp: 2021-02-03.\n",
"TimeStamp: 2021-02-01.\n",
"TimeStamp: 2021-01-31.\n",
"TimeStamp: 2021-01-29.\n",
"TimeStamp: 2021-01-27.\n",
"TimeStamp: 2021-01-25.\n",
"TimeStamp: 2021-01-23.\n",
"TimeStamp: 2021-01-21.\n",
"TimeStamp: 2021-01-20.\n",
"TimeStamp: 2021-01-18.\n",
"TimeStamp: 2021-01-15.\n",
"TimeStamp: 2021-01-13.\n",
"TimeStamp: 2021-01-11.\n",
"TimeStamp: 2021-01-09.\n",
"TimeStamp: 2021-01-07.\n",
"TimeStamp: 2021-01-06.\n",
"TimeStamp: 2021-01-03.\n",
"TimeStamp: 2020-12-30.\n"
]
},
{
"data": {
"text/html": [
"<div>\n",
"<style scoped>\n",
" .dataframe tbody tr th:only-of-type {\n",
" vertical-align: middle;\n",
" }\n",
"\n",
" .dataframe tbody tr th {\n",
" vertical-align: top;\n",
" }\n",
"\n",
" .dataframe thead th {\n",
" text-align: right;\n",
" }\n",
"</style>\n",
"<table border=\"1\" class=\"dataframe\">\n",
" <thead>\n",
" <tr style=\"text-align: right;\">\n",
" <th></th>\n",
" <th>ACTORID</th>\n",
" <th>NAME</th>\n",
" <th>GROUPID</th>\n",
" <th>POSTID</th>\n",
" <th>TIME</th>\n",
" <th>CONTENT</th>\n",
" <th>COMMENTCOUNT</th>\n",
" <th>SHARECOUNT</th>\n",
" <th>LIKECOUNT</th>\n",
" <th>UPDATETIME</th>\n",
" </tr>\n",
" </thead>\n",
" <tbody>\n",
" <tr>\n",
" <th>0</th>\n",
" <td>\"100008360976636\"</td>\n",
" <td>蔣忠祐</td>\n",
" <td>197223143437</td>\n",
" <td>10161825149923438</td>\n",
" <td>2022-01-04 19:28:20</td>\n",
" <td>小弟想問一下,因為本身只寫過python也只會ML其他的都不太熟悉。 如果我今天想要寫一個簡...</td>\n",
" <td>49</td>\n",
" <td>7</td>\n",
" <td>42</td>\n",
" <td>2022-01-05 22:47:28</td>\n",
" </tr>\n",
" <tr>\n",
" <th>1</th>\n",
" <td>1372450133</td>\n",
" <td>陳柏勳</td>\n",
" <td>197223143437</td>\n",
" <td>10161825076258438</td>\n",
" <td>2022-01-04 18:16:42</td>\n",
" <td>各位高手大大 小弟剛自學 python 我先在 Jupyter 寫一個檔案 並存檔為Hell...</td>\n",
" <td>14</td>\n",
" <td>0</td>\n",
" <td>10</td>\n",
" <td>2022-01-05 22:47:28</td>\n",
" </tr>\n",
" <tr>\n",
" <th>2</th>\n",
" <td>\"100029978773864\"</td>\n",
" <td>沈宗叡</td>\n",
" <td>197223143437</td>\n",
" <td>10161818603678438</td>\n",
" <td>2022-01-01 14:46:35</td>\n",
" <td>在練習網路上的題目: https://tioj.ck.tp.edu.tw/problems/...</td>\n",
" <td>15</td>\n",
" <td>3</td>\n",
" <td>3</td>\n",
" <td>2022-01-05 22:47:28</td>\n",
" </tr>\n",
" <tr>\n",
" <th>3</th>\n",
" <td>696780981</td>\n",
" <td>MaoYang Chien</td>\n",
" <td>197223143437</td>\n",
" <td>10161826718243438</td>\n",
" <td>2022-01-05 11:29:06</td>\n",
" <td>這個開源工具使用 python、flask 等技術開發 如果你用「專案管理」的方法來完成一堂...</td>\n",
" <td>0</td>\n",
" <td>9</td>\n",
" <td>24</td>\n",
" <td>2022-01-05 22:47:28</td>\n",
" </tr>\n",
" <tr>\n",
" <th>4</th>\n",
" <td>\"100006223006386\"</td>\n",
" <td>劉奕德</td>\n",
" <td>197223143437</td>\n",
" <td>10161816780833438</td>\n",
" <td>2021-12-31 23:20:43</td>\n",
" <td>想詢問版上各位大大 近期在做廠房的耗電量改善 想到python可以應用在建立模型及預測 請問...</td>\n",
" <td>37</td>\n",
" <td>2</td>\n",
" <td>29</td>\n",
" <td>2022-01-05 22:47:28</td>\n",
" </tr>\n",
" <tr>\n",
" <th>...</th>\n",
" <td>...</td>\n",
" <td>...</td>\n",
" <td>...</td>\n",
" <td>...</td>\n",
" <td>...</td>\n",
" <td>...</td>\n",
" <td>...</td>\n",
" <td>...</td>\n",
" <td>...</td>\n",
" <td>...</td>\n",
" </tr>\n",
" <tr>\n",
" <th>3935</th>\n",
" <td>\"105673814305452\"</td>\n",
" <td>用圖片高效學程式</td>\n",
" <td>105673814305452</td>\n",
" <td>10160837021273438</td>\n",
" <td>2020-12-27 13:00:34</td>\n",
" <td>【圖解演算法教學】Bubble Sort 大隊接力賽 這次首次嘗試以「動畫」形式,來演示Bu...</td>\n",
" <td>2</td>\n",
" <td>9</td>\n",
" <td>14</td>\n",
" <td>2022-01-05 22:47:28</td>\n",
" </tr>\n",
" <tr>\n",
" <th>3936</th>\n",
" <td>\"100051655785472\"</td>\n",
" <td>劉昶林</td>\n",
" <td>197223143437</td>\n",
" <td>10160814944163438</td>\n",
" <td>2020-12-19 23:56:39</td>\n",
" <td>嗨各位, 我現在有個問題,我想要將yolov4(darknet) 跟 Arduino做結合,...</td>\n",
" <td>34</td>\n",
" <td>13</td>\n",
" <td>72</td>\n",
" <td>2022-01-05 22:47:28</td>\n",
" </tr>\n",
" <tr>\n",
" <th>3937</th>\n",
" <td>\"100002220077374\"</td>\n",
" <td>Hugh LI</td>\n",
" <td>197223143437</td>\n",
" <td>10160840505808438</td>\n",
" <td>2020-12-28 20:01:25</td>\n",
" <td>想問一下各位一個蠻基礎的問題 (先撇開其他條件) c=s[a:b] c[::-1] 為甚麼...</td>\n",
" <td>10</td>\n",
" <td>1</td>\n",
" <td>12</td>\n",
" <td>2022-01-05 22:47:28</td>\n",
" </tr>\n",
" <tr>\n",
" <th>3938</th>\n",
" <td>504805657</td>\n",
" <td>Roy Hsu</td>\n",
" <td>197223143437</td>\n",
" <td>10160837961533438</td>\n",
" <td>2020-12-27 22:27:50</td>\n",
" <td>我想實現 用python 去更換 資料夾的icon ( windows ) 網路上看到這個 ...</td>\n",
" <td>6</td>\n",
" <td>1</td>\n",
" <td>3</td>\n",
" <td>2022-01-05 22:47:28</td>\n",
" </tr>\n",
" <tr>\n",
" <th>3939</th>\n",
" <td>\"100001849455014\"</td>\n",
" <td>Vivi Chen</td>\n",
" <td>197223143437</td>\n",
" <td>10160837910348438</td>\n",
" <td>2020-12-27 22:05:17</td>\n",
" <td>Test 的 SayHello 函式在初始化後, 就不用再輸入'Amy' 最終目的就是只要在...</td>\n",
" <td>6</td>\n",
" <td>1</td>\n",
" <td>9</td>\n",
" <td>2022-01-05 22:47:28</td>\n",
" </tr>\n",
" </tbody>\n",
"</table>\n",
"<p>3940 rows × 10 columns</p>\n",
"</div>"
],
"text/plain": [
" ACTORID NAME GROUPID POSTID \\\n",
"0 \"100008360976636\" 蔣忠祐 197223143437 10161825149923438 \n",
"1 1372450133 陳柏勳 197223143437 10161825076258438 \n",
"2 \"100029978773864\" 沈宗叡 197223143437 10161818603678438 \n",
"3 696780981 MaoYang Chien 197223143437 10161826718243438 \n",
"4 \"100006223006386\" 劉奕德 197223143437 10161816780833438 \n",
"... ... ... ... ... \n",
"3935 \"105673814305452\" 用圖片高效學程式 105673814305452 10160837021273438 \n",
"3936 \"100051655785472\" 劉昶林 197223143437 10160814944163438 \n",
"3937 \"100002220077374\" Hugh LI 197223143437 10160840505808438 \n",
"3938 504805657 Roy Hsu 197223143437 10160837961533438 \n",
"3939 \"100001849455014\" Vivi Chen 197223143437 10160837910348438 \n",
"\n",
" TIME CONTENT \\\n",
"0 2022-01-04 19:28:20 小弟想問一下,因為本身只寫過python也只會ML其他的都不太熟悉。 如果我今天想要寫一個簡... \n",
"1 2022-01-04 18:16:42 各位高手大大 小弟剛自學 python 我先在 Jupyter 寫一個檔案 並存檔為Hell... \n",
"2 2022-01-01 14:46:35 在練習網路上的題目: https://tioj.ck.tp.edu.tw/problems/... \n",
"3 2022-01-05 11:29:06 這個開源工具使用 python、flask 等技術開發 如果你用「專案管理」的方法來完成一堂... \n",
"4 2021-12-31 23:20:43 想詢問版上各位大大 近期在做廠房的耗電量改善 想到python可以應用在建立模型及預測 請問... \n",
"... ... ... \n",
"3935 2020-12-27 13:00:34 【圖解演算法教學】Bubble Sort 大隊接力賽 這次首次嘗試以「動畫」形式,來演示Bu... \n",
"3936 2020-12-19 23:56:39 嗨各位, 我現在有個問題,我想要將yolov4(darknet) 跟 Arduino做結合,... \n",
"3937 2020-12-28 20:01:25 想問一下各位一個蠻基礎的問題 (先撇開其他條件) c=s[a:b] c[::-1] 為甚麼... \n",
"3938 2020-12-27 22:27:50 我想實現 用python 去更換 資料夾的icon ( windows ) 網路上看到這個 ... \n",
"3939 2020-12-27 22:05:17 Test 的 SayHello 函式在初始化後, 就不用再輸入'Amy' 最終目的就是只要在... \n",
"\n",
" COMMENTCOUNT SHARECOUNT LIKECOUNT UPDATETIME \n",
"0 49 7 42 2022-01-05 22:47:28 \n",
"1 14 0 10 2022-01-05 22:47:28 \n",
"2 15 3 3 2022-01-05 22:47:28 \n",
"3 0 9 24 2022-01-05 22:47:28 \n",
"4 37 2 29 2022-01-05 22:47:28 \n",
"... ... ... ... ... \n",
"3935 2 9 14 2022-01-05 22:47:28 \n",
"3936 34 13 72 2022-01-05 22:47:28 \n",
"3937 10 1 12 2022-01-05 22:47:28 \n",
"3938 6 1 3 2022-01-05 22:47:28 \n",
"3939 6 1 9 2022-01-05 22:47:28 \n",
"\n",
"[3940 rows x 10 columns]"
]
},
"execution_count": 2,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"import facebook_crawler\n",
"groupurl = 'https://www.facebook.com/groups/pythontw'\n",
"facebook_crawler.Crawl_GroupPosts(groupurl, until_date='2021-01-01')"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "df297081-8a01-4a6c-9719-9b4dfa87410c",
"metadata": {},
"outputs": [],
"source": []
}
],
"metadata": {
"kernelspec": {
"display_name": "Python 3 (ipykernel)",
"language": "python",
"name": "python3"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.8.10"
}
},
"nbformat": 4,
"nbformat_minor": 5
}
================================================
FILE: setup.py
================================================
import setuptools
with open("README.md", "r") as fh:
long_description = fh.read()
setuptools.setup(
name="facebook_crawler",
version="0.0.28",
author="TENG-LIN YU",
author_email="tlyu0419@gmail.com",
description="Facebook crawler package can help you crawl the posts on public fanspages and groups from Facebook.",
long_description=long_description,
long_description_content_type="text/markdown",
url="https://github.com/TLYu0419/facebook_crawler",
packages=setuptools.find_packages(),
py_modules=['facebook_crawler'],
classifiers=[
"Programming Language :: Python :: 3",
"License :: OSI Approved :: Apache Software License",
"Operating System :: OS Independent",
],
python_requires=">=3.6",
install_requires=[
"requests",
"bs4",
"numpy",
"pandas",
"lxml"
],
)
================================================
FILE: tests/test_facebook_crawler.py
================================================
import pytest
@pytest.fixture
def pageurl():
return 'https://www.facebook.com/groups/pythontw'
@pytest.fixture
def until_date():
from datetime import datetime
from datetime import timedelta
return str(datetime.now() - timedelta(days=1))
def test_Crawl_PagePosts(pageurl, until_date):
from main import Crawl_PagePosts
df = Crawl_PagePosts(pageurl, until_date=until_date)
assert df
def test_Crawl_GroupPosts(pageurl, until_date):
from main import Crawl_GroupPosts
df = Crawl_GroupPosts(pageurl, until_date=until_date)
assert df
================================================
FILE: tests/test_page_parser.py
================================================
import pytest
from utils import _init_request_vars
@pytest.fixture
def pageurl():
return 'https://www.facebook.com/groups/pythontw'
@pytest.fixture
def headers(pageurl):
from requester import _get_headers
return _get_headers(pageurl)
@pytest.fixture
def homepage_response(pageurl, headers):
from requester import _get_homepage
return _get_homepage(pageurl=pageurl, headers=headers)
@pytest.fixture
def entryPoint(homepage_response):
from page_paser import _parse_entryPoint
return _parse_entryPoint(homepage_response)
@pytest.fixture
def identifier(entryPoint, homepage_response):
from page_paser import _parse_identifier
return _parse_identifier(entryPoint, homepage_response)
@pytest.fixture
def docid(entryPoint, homepage_response):
from page_paser import _parse_docid
return _parse_docid(entryPoint, homepage_response)
@pytest.fixture
def cursor():
_, cursor, _, _ = _init_request_vars()
return cursor
def test_parse_pagetype(homepage_response):
from page_paser import _parse_pagetype
page_type = _parse_pagetype(homepage_response)
assert page_type.lower() in ['group', 'fanspage']
def test_parse_pagename(homepage_response):
from page_paser import _parse_pagename
page_name = _parse_pagename(homepage_response)
assert page_name
def test_parse_entryPoint(homepage_response):
from page_paser import _parse_entryPoint
entryPoint = _parse_entryPoint(homepage_response)
assert entryPoint
def test_parse_identifier(entryPoint, homepage_response):
from page_paser import _parse_identifier
identifier = _parse_identifier(entryPoint, homepage_response)
assert identifier
def test_parse_docid(entryPoint, homepage_response):
from page_paser import _parse_docid
docid = _parse_docid(entryPoint, homepage_response)
assert docid
def test_parse_likes(homepage_response, entryPoint, headers):
from page_paser import _parse_likes
likes = _parse_likes(homepage_response, entryPoint, headers)
assert likes
def test_parse_creation_time(homepage_response, entryPoint, headers):
from page_paser import _parse_creation_time
creation_time = _parse_creation_time(homepage_response, entryPoint, headers)
assert creation_time
def test_parse_category(homepage_response, entryPoint, headers):
from page_paser import _parse_category
category = _parse_category(homepage_response, entryPoint, headers)
assert category
def test_parse_pageurl(homepage_response):
from page_paser import _parse_pageurl
pageurl = _parse_pageurl(homepage_response)
assert pageurl
================================================
FILE: tests/test_post_parser.py
================================================
import pytest
from post_paser import _parse_edgelist, _parse_edge, _parse_domops, _parse_jsmods, _parse_composite_graphql
from utils import _init_request_vars
@pytest.fixture
def pageurl():
return 'https://www.facebook.com/groups/pythontw'
@pytest.fixture
def headers(pageurl):
from requester import _get_headers
return _get_headers(pageurl)
@pytest.fixture
def homepage_response(pageurl, headers):
from requester import _get_homepage
return _get_homepage(pageurl=pageurl, headers=headers)
@pytest.fixture
def entryPoint(homepage_response):
from page_paser import _parse_entryPoint
return _parse_entryPoint(homepage_response)
@pytest.fixture
def identifier(entryPoint, homepage_response):
from page_paser import _parse_identifier
return _parse_identifier(entryPoint, homepage_response)
@pytest.fixture
def docid(entryPoint, homepage_response):
from page_paser import _parse_docid
return _parse_docid(entryPoint, homepage_response)
@pytest.fixture
def cursor():
_, cursor, _, _ = _init_request_vars()
return cursor
@pytest.fixture
def posts_response(headers, identifier, entryPoint, docid, cursor):
from requester import _get_posts
return _get_posts(headers=headers,
identifier=identifier,
entryPoint=entryPoint,
docid=docid,
cursor=cursor)
@pytest.fixture()
def edges(posts_response):
return _parse_edgelist(posts_response)
def test_parse_edgelist(posts_response):
edges = _parse_edgelist(posts_response)
assert len(edges) > 0
def test_parse_edge(edges):
for edge in edges:
result = _parse_edge(edge)
assert result
def test_parse_domops(posts_response):
content_list, cursor = _parse_domops(posts_response)
assert content_list is not None
assert cursor is not None
def test_parse_jsmods(posts_response):
_parse_jsmods(posts_response)
def test_parse_composite_graphql(posts_response):
df, max_date, cursor = _parse_composite_graphql(posts_response)
assert df is not None
assert max_date is not None
assert cursor is not None
def test_parse_composite_nojs(posts_response):
df, max_date, cursor = _parse_composite_graphql(posts_response)
assert df is not None
assert max_date is not None
assert cursor is not None
================================================
FILE: tests/test_requester.py
================================================
import pytest
from utils import _init_request_vars
@pytest.fixture
def pageurl():
return 'https://www.facebook.com/groups/pythontw'
@pytest.fixture
def headers(pageurl):
from requester import _get_headers
return _get_headers(pageurl)
@pytest.fixture
def homepage_response(pageurl, headers):
from requester import _get_homepage
return _get_homepage(pageurl=pageurl, headers=headers)
@pytest.fixture
def entryPoint(homepage_response):
from page_paser import _parse_entryPoint
return _parse_entryPoint(homepage_response)
@pytest.fixture
def identifier(entryPoint, homepage_response):
from page_paser import _parse_identifier
return _parse_identifier(entryPoint, homepage_response)
@pytest.fixture
def docid(entryPoint, homepage_response):
from page_paser import _parse_docid
return _parse_docid(entryPoint, homepage_response)
@pytest.fixture
def cursor():
_, cursor, _, _ = _init_request_vars()
return cursor
def test_get_homepage(pageurl, headers):
from requester import _get_homepage
homepage_response = _get_homepage(pageurl=pageurl, headers=headers)
assert homepage_response.status_code == 200
assert homepage_response.url == pageurl
def test_get_pageabout(homepage_response, entryPoint, headers):
from requester import _get_pageabout
pageabout = _get_pageabout(homepage_response, entryPoint, headers)
assert pageabout.status_code == 200
def test_get_posts(headers, identifier, entryPoint, docid, cursor):
from requester import _get_posts
resp = _get_posts(headers=headers,
identifier=identifier,
entryPoint=entryPoint,
docid=docid,
cursor=cursor)
assert resp.status_code == 200
================================================
FILE: tests/test_utils.py
================================================
import pytest
from utils import _extract_id, _extract_reactions
@pytest.fixture
def dataid():
return 'feed_subtitle_107207125979624;5762739400426340;;9'
def test_extract_pageid(dataid):
pageid = _extract_id(dataid, 0)
assert pageid == '107207125979624'
def test_extract_postid(dataid):
postid = _extract_id(dataid, 1)
assert postid == '5762739400426340'
# def test_extract_reactions(reactions, reaction_type):
# reactions = _extract_reactions(reactions, reaction_type)
# assert reactions is not None
================================================
FILE: utils.py
================================================
import sqlite3
import re
import datetime
import requests
def _connect_db():
conn = sqlite3.connect('./facebook_crawler.db', check_same_thread=False)
return conn
def _extract_id(string, num):
'''
Extract page and post id from the feed_subtitle infroamtion
'''
try:
return re.findall('[0-9]{5,}', string)[num]
except:
print('ERROR from extract {}'.froamt(string))
return string
def _extract_reactions(reactions, reaction_type):
'''
Extract reaction_type from reactions.
Possible reaction_type's value will be one of ['LIKE', 'HAHA', 'WOW', 'LOVE', 'SUPPORT', 'SORRY', 'ANGER']
'''
for reaction in reactions:
if reaction['node']['localized_name'].upper() == reaction_type.upper():
return reaction['reaction_count']
return 0
def _init_request_vars(cursor=''):
# init parameters
# cursor = ''
df = []
max_date = datetime.datetime.now().strftime('%Y-%m-%d')
break_times = 0
return df, cursor, max_date, break_times
def _download_images(link):
filename = link.split(r'?')[0].split(r'/')[-1]
resp = requests.get(link)
with open(f'data/photos/{filename}', 'wb') as f:
f.write(resp.content)
def parse_raw_json(string):
dic = {}
for line in string.split('\n'):
if line != '':
values = line.split(': ', -1)
dic[values[0]]= values[1]
return dic
if '__name__' == '__main__':
df, cursor, max_date, break_times = _init_request_vars(cursor='aa')
cursor
gitextract_m2qqy_6g/ ├── .github/ │ └── workflows/ │ └── pythonpublish.yml ├── .gitignore ├── LICENSE ├── README.md ├── main.py ├── paser.py ├── requester.py ├── requirements.txt ├── sample/ │ ├── 20221013_Sample.ipynb │ ├── FansPages.ipynb │ └── Group.ipynb ├── setup.py ├── tests/ │ ├── test_facebook_crawler.py │ ├── test_page_parser.py │ ├── test_post_parser.py │ ├── test_requester.py │ └── test_utils.py └── utils.py
SYMBOL INDEX (80 symbols across 9 files) FILE: main.py function Crawl_PagePosts (line 21) | def Crawl_PagePosts(pageurl, until_date='2018-01-01', cursor=''): function Crawl_GroupPosts (line 79) | def Crawl_GroupPosts(pageurl, until_date='2022-01-01'): function Crawl_RelatedPages (line 84) | def Crawl_RelatedPages(seedpages, rounds): function Crawl_PageInfo (line 116) | def Crawl_PageInfo(pagenum, pageurl): FILE: paser.py function _parse_edgelist (line 12) | def _parse_edgelist(resp): function _parse_edge (line 29) | def _parse_edge(edge): function _parse_domops (line 110) | def _parse_domops(resp): function _parse_jsmods (line 165) | def _parse_jsmods(resp): function _parse_composite_graphql (line 224) | def _parse_composite_graphql(resp): function _parse_composite_nojs (line 245) | def _parse_composite_nojs(resp): function _parse_pagetype (line 271) | def _parse_pagetype(homepage_response): function _parse_pagename (line 279) | def _parse_pagename(homepage_response): function _parse_entryPoint (line 293) | def _parse_entryPoint(homepage_response): function _parse_identifier (line 302) | def _parse_identifier(entryPoint, homepage_response): function _parse_docid (line 328) | def _parse_docid(entryPoint, homepage_response): function _parse_likes (line 356) | def _parse_likes(homepage_response, entryPoint, headers): function _parse_creation_time (line 379) | def _parse_creation_time(homepage_response, entryPoint, headers): function _parse_category (line 418) | def _parse_category(homepage_response, entryPoint, headers): function _parse_pageurl (line 465) | def _parse_pageurl(homepage_response): function _parse_relatedpages (line 471) | def _parse_relatedpages(homepage_response, entryPoint, identifier): function _parse_pageinfo (line 510) | def _parse_pageinfo(homepage_response): FILE: requester.py function _get_headers (line 7) | def _get_headers(pageurl): function _get_homepage (line 21) | def _get_homepage(pageurl, headers): function _get_pageabout (line 41) | def _get_pageabout(homepage_response, entryPoint, headers): function _get_pagetransparency (line 50) | def _get_pagetransparency(homepage_response, entryPoint, headers): function _get_posts (line 61) | def _get_posts(headers, identifier, entryPoint, docid, cursor): FILE: tests/test_facebook_crawler.py function pageurl (line 5) | def pageurl(): function until_date (line 10) | def until_date(): function test_Crawl_PagePosts (line 16) | def test_Crawl_PagePosts(pageurl, until_date): function test_Crawl_GroupPosts (line 22) | def test_Crawl_GroupPosts(pageurl, until_date): FILE: tests/test_page_parser.py function pageurl (line 7) | def pageurl(): function headers (line 12) | def headers(pageurl): function homepage_response (line 18) | def homepage_response(pageurl, headers): function entryPoint (line 24) | def entryPoint(homepage_response): function identifier (line 30) | def identifier(entryPoint, homepage_response): function docid (line 36) | def docid(entryPoint, homepage_response): function cursor (line 42) | def cursor(): function test_parse_pagetype (line 47) | def test_parse_pagetype(homepage_response): function test_parse_pagename (line 53) | def test_parse_pagename(homepage_response): function test_parse_entryPoint (line 59) | def test_parse_entryPoint(homepage_response): function test_parse_identifier (line 65) | def test_parse_identifier(entryPoint, homepage_response): function test_parse_docid (line 71) | def test_parse_docid(entryPoint, homepage_response): function test_parse_likes (line 77) | def test_parse_likes(homepage_response, entryPoint, headers): function test_parse_creation_time (line 83) | def test_parse_creation_time(homepage_response, entryPoint, headers): function test_parse_category (line 89) | def test_parse_category(homepage_response, entryPoint, headers): function test_parse_pageurl (line 95) | def test_parse_pageurl(homepage_response): FILE: tests/test_post_parser.py function pageurl (line 8) | def pageurl(): function headers (line 13) | def headers(pageurl): function homepage_response (line 19) | def homepage_response(pageurl, headers): function entryPoint (line 25) | def entryPoint(homepage_response): function identifier (line 31) | def identifier(entryPoint, homepage_response): function docid (line 37) | def docid(entryPoint, homepage_response): function cursor (line 43) | def cursor(): function posts_response (line 49) | def posts_response(headers, identifier, entryPoint, docid, cursor): function edges (line 59) | def edges(posts_response): function test_parse_edgelist (line 63) | def test_parse_edgelist(posts_response): function test_parse_edge (line 68) | def test_parse_edge(edges): function test_parse_domops (line 74) | def test_parse_domops(posts_response): function test_parse_jsmods (line 80) | def test_parse_jsmods(posts_response): function test_parse_composite_graphql (line 84) | def test_parse_composite_graphql(posts_response): function test_parse_composite_nojs (line 91) | def test_parse_composite_nojs(posts_response): FILE: tests/test_requester.py function pageurl (line 7) | def pageurl(): function headers (line 12) | def headers(pageurl): function homepage_response (line 18) | def homepage_response(pageurl, headers): function entryPoint (line 24) | def entryPoint(homepage_response): function identifier (line 30) | def identifier(entryPoint, homepage_response): function docid (line 36) | def docid(entryPoint, homepage_response): function cursor (line 42) | def cursor(): function test_get_homepage (line 47) | def test_get_homepage(pageurl, headers): function test_get_pageabout (line 54) | def test_get_pageabout(homepage_response, entryPoint, headers): function test_get_posts (line 60) | def test_get_posts(headers, identifier, entryPoint, docid, cursor): FILE: tests/test_utils.py function dataid (line 7) | def dataid(): function test_extract_pageid (line 11) | def test_extract_pageid(dataid): function test_extract_postid (line 16) | def test_extract_postid(dataid): FILE: utils.py function _connect_db (line 7) | def _connect_db(): function _extract_id (line 12) | def _extract_id(string, num): function _extract_reactions (line 23) | def _extract_reactions(reactions, reaction_type): function _init_request_vars (line 34) | def _init_request_vars(cursor=''): function _download_images (line 43) | def _download_images(link): function parse_raw_json (line 50) | def parse_raw_json(string):
Condensed preview — 18 files, each showing path, character count, and a content snippet. Download the .json file or copy for the full structured content (153K chars).
[
{
"path": ".github/workflows/pythonpublish.yml",
"chars": 645,
"preview": "name: Upload Python Package\r\n\r\non:\r\n release:\r\n types: [created]\r\n\r\njobs:\r\n deploy:\r\n runs-on: ubuntu-latest\r\n "
},
{
"path": ".gitignore",
"chars": 103,
"preview": "develop/\r\n.ipynb_checkpoints/\r\n.vscode/\r\n*egg-info/\r\n.idea/\r\nvenv2/\r\nbuild/\r\ndist/\r\n__pycache__/\r\ndata/"
},
{
"path": "LICENSE",
"chars": 1086,
"preview": "MIT License\r\n\r\nCopyright (c) 2021 tlyu0419\r\n\r\nPermission is hereby granted, free of charge, to any person obtaining a co"
},
{
"path": "README.md",
"chars": 3820,
"preview": "# Facebook_Crawler\n[](https://pepy.tech/project/facebook-crawler)\n"
},
{
"path": "main.py",
"chars": 8690,
"preview": "from paser import _parse_category, _parse_pagename, _parse_creation_time, _parse_pagetype, _parse_likes, _parse_docid, _"
},
{
"path": "paser.py",
"chars": 25248,
"preview": "import re\r\nimport json\r\nimport pandas as pd\r\nfrom bs4 import BeautifulSoup\r\nfrom utils import _extract_id, _init_request"
},
{
"path": "requester.py",
"chars": 4554,
"preview": "import re\r\nimport requests\r\nimport time\r\nfrom utils import _init_request_vars\r\n\r\n\r\ndef _get_headers(pageurl):\r\n '''\r\n"
},
{
"path": "requirements.txt",
"chars": 98,
"preview": "requests==2.24.0\r\nbs4==0.0.1\r\npandas==1.2.4 \r\nnumpy==1.20.3\r\ndicttoxml==1.7.4\r\nlxml==4.9.2"
},
{
"path": "sample/20221013_Sample.ipynb",
"chars": 25017,
"preview": "{\r\n \"cells\": [\r\n {\r\n \"cell_type\": \"code\",\r\n \"execution_count\": 3,\r\n \"id\": \"7946c9a9-0a27-4de2-a32e-8de574f8d7fb\","
},
{
"path": "sample/FansPages.ipynb",
"chars": 36305,
"preview": "{\r\n \"cells\": [\r\n {\r\n \"cell_type\": \"code\",\r\n \"execution_count\": 2,\r\n \"id\": \"37db8006-7e78-4d00-bfd2-862997b366c9\","
},
{
"path": "sample/Group.ipynb",
"chars": 18023,
"preview": "{\r\n \"cells\": [\r\n {\r\n \"cell_type\": \"code\",\r\n \"execution_count\": 2,\r\n \"id\": \"f31b5034-e3d4-40f4-b52a-8e4addba342d\","
},
{
"path": "setup.py",
"chars": 861,
"preview": "import setuptools\r\n\r\nwith open(\"README.md\", \"r\") as fh:\r\n long_description = fh.read()\r\n\r\nsetuptools.setup(\r\n name=\"fa"
},
{
"path": "tests/test_facebook_crawler.py",
"chars": 599,
"preview": "import pytest\r\n\r\n\r\n@pytest.fixture\r\ndef pageurl():\r\n return 'https://www.facebook.com/groups/pythontw'\r\n\r\n\r\n@pytest.f"
},
{
"path": "tests/test_page_parser.py",
"chars": 2723,
"preview": "import pytest\r\n\r\nfrom utils import _init_request_vars\r\n\r\n\r\n@pytest.fixture\r\ndef pageurl():\r\n return 'https://www.face"
},
{
"path": "tests/test_post_parser.py",
"chars": 2465,
"preview": "import pytest\r\n\r\nfrom post_paser import _parse_edgelist, _parse_edge, _parse_domops, _parse_jsmods, _parse_composite_gra"
},
{
"path": "tests/test_requester.py",
"chars": 1848,
"preview": "import pytest\r\n\r\nfrom utils import _init_request_vars\r\n\r\n\r\n@pytest.fixture\r\ndef pageurl():\r\n return 'https://www.face"
},
{
"path": "tests/test_utils.py",
"chars": 560,
"preview": "import pytest\r\n\r\nfrom utils import _extract_id, _extract_reactions\r\n\r\n\r\n@pytest.fixture\r\ndef dataid():\r\n return 'feed"
},
{
"path": "utils.py",
"chars": 1604,
"preview": "import sqlite3\r\nimport re\r\nimport datetime\r\nimport requests\r\n\r\n\r\ndef _connect_db():\r\n conn = sqlite3.connect('./faceb"
}
]
About this extraction
This page contains the full source code of the TLYu0419/facebook_crawler GitHub repository, extracted and formatted as plain text for AI agents and large language models (LLMs). The extraction includes 18 files (131.1 KB), approximately 45.3k tokens, and a symbol index with 80 extracted functions, classes, methods, constants, and types. Use this with OpenClaw, Claude, ChatGPT, Cursor, Windsurf, or any other AI tool that accepts text input. You can copy the full output to your clipboard or download it as a .txt file.
Extracted by GitExtract — free GitHub repo to text converter for AI. Built by Nikandr Surkov.