Copy disabled (too large)
Download .txt
Showing preview only (19,758K chars total). Download the full file to get everything.
Repository: TencentARC/AudioStory
Branch: main
Commit: ed38aba2cd80
Files: 157
Total size: 18.0 MB
Directory structure:
gitextract_mqsl_z9m/
├── .gitignore
├── README.md
├── configs/
│ └── audiostory_llm_qwen25_3b_lora.yaml
├── envs/
│ └── peft/
│ ├── .github/
│ │ ├── ISSUE_TEMPLATE/
│ │ │ ├── bug-report.yml
│ │ │ └── feature-request.yml
│ │ └── workflows/
│ │ ├── build_docker_images.yml
│ │ ├── build_documentation.yml
│ │ ├── build_pr_documentation.yml
│ │ ├── delete_doc_comment.yml
│ │ ├── delete_doc_comment_trigger.yml
│ │ ├── nightly.yml
│ │ ├── stale.yml
│ │ ├── tests.yml
│ │ └── upload_pr_documentation.yml
│ ├── .gitignore
│ ├── LICENSE
│ ├── Makefile
│ ├── README.md
│ ├── docker/
│ │ ├── peft-cpu/
│ │ │ └── Dockerfile
│ │ └── peft-gpu/
│ │ └── Dockerfile
│ ├── docs/
│ │ ├── Makefile
│ │ ├── README.md
│ │ └── source/
│ │ ├── _config.py
│ │ ├── _toctree.yml
│ │ ├── accelerate/
│ │ │ ├── deepspeed-zero3-offload.mdx
│ │ │ └── fsdp.mdx
│ │ ├── conceptual_guides/
│ │ │ ├── ia3.mdx
│ │ │ ├── lora.mdx
│ │ │ └── prompting.mdx
│ │ ├── index.mdx
│ │ ├── install.mdx
│ │ ├── package_reference/
│ │ │ ├── config.mdx
│ │ │ ├── peft_model.mdx
│ │ │ └── tuners.mdx
│ │ ├── quicktour.mdx
│ │ └── task_guides/
│ │ ├── clm-prompt-tuning.mdx
│ │ ├── dreambooth_lora.mdx
│ │ ├── image_classification_lora.mdx
│ │ ├── int8-asr.mdx
│ │ ├── ptuning-seq-classification.mdx
│ │ ├── semantic-similarity-lora.md
│ │ ├── semantic_segmentation_lora.mdx
│ │ ├── seq2seq-prefix-tuning.mdx
│ │ └── token-classification-lora.mdx
│ ├── examples/
│ │ ├── causal_language_modeling/
│ │ │ ├── accelerate_ds_zero3_cpu_offload_config.yaml
│ │ │ ├── peft_lora_clm_accelerate_big_model_inference.ipynb
│ │ │ ├── peft_lora_clm_accelerate_ds_zero3_offload.py
│ │ │ ├── peft_prefix_tuning_clm.ipynb
│ │ │ ├── peft_prompt_tuning_clm.ipynb
│ │ │ └── requirements.txt
│ │ ├── conditional_generation/
│ │ │ ├── accelerate_ds_zero3_cpu_offload_config.yaml
│ │ │ ├── peft_adalora_seq2seq.py
│ │ │ ├── peft_ia3_seq2seq.ipynb
│ │ │ ├── peft_lora_seq2seq.ipynb
│ │ │ ├── peft_lora_seq2seq_accelerate_big_model_inference.ipynb
│ │ │ ├── peft_lora_seq2seq_accelerate_ds_zero3_offload.py
│ │ │ ├── peft_lora_seq2seq_accelerate_fsdp.py
│ │ │ ├── peft_prefix_tuning_seq2seq.ipynb
│ │ │ ├── peft_prompt_tuning_seq2seq.ipynb
│ │ │ ├── peft_prompt_tuning_seq2seq_with_generate.ipynb
│ │ │ └── requirements.txt
│ │ ├── feature_extraction/
│ │ │ ├── peft_lora_embedding_semantic_search.py
│ │ │ ├── peft_lora_embedding_semantic_similarity_inference.ipynb
│ │ │ └── requirements.txt
│ │ ├── fp4_finetuning/
│ │ │ └── finetune_fp4_opt_bnb_peft.py
│ │ ├── image_classification/
│ │ │ ├── README.md
│ │ │ └── image_classification_peft_lora.ipynb
│ │ ├── int8_training/
│ │ │ ├── Finetune_flan_t5_large_bnb_peft.ipynb
│ │ │ ├── Finetune_opt_bnb_peft.ipynb
│ │ │ ├── fine_tune_blip2_int8.py
│ │ │ ├── peft_adalora_whisper_large_training.py
│ │ │ ├── peft_bnb_whisper_large_v2_training.ipynb
│ │ │ └── run_adalora_whisper_int8.sh
│ │ ├── lora_dreambooth/
│ │ │ ├── colab_notebook.ipynb
│ │ │ ├── convert_kohya_ss_sd_lora_to_peft.py
│ │ │ ├── convert_peft_sd_lora_to_kohya_ss.py
│ │ │ ├── lora_dreambooth_inference.ipynb
│ │ │ ├── requirements.txt
│ │ │ └── train_dreambooth.py
│ │ ├── multi_adapter_examples/
│ │ │ └── PEFT_Multi_LoRA_Inference.ipynb
│ │ ├── semantic_segmentation/
│ │ │ ├── README.md
│ │ │ └── semantic_segmentation_peft_lora.ipynb
│ │ ├── sequence_classification/
│ │ │ ├── IA3.ipynb
│ │ │ ├── LoRA.ipynb
│ │ │ ├── P_Tuning.ipynb
│ │ │ ├── Prompt_Tuning.ipynb
│ │ │ ├── peft_no_lora_accelerate.py
│ │ │ ├── prefix_tuning.ipynb
│ │ │ └── requirements.txt
│ │ └── token_classification/
│ │ ├── peft_lora_token_cls.ipynb
│ │ └── requirements.txt
│ ├── pyproject.toml
│ ├── scripts/
│ │ ├── log_reports.py
│ │ └── stale.py
│ ├── setup.py
│ ├── src/
│ │ └── peft/
│ │ ├── __init__.py
│ │ ├── auto.py
│ │ ├── import_utils.py
│ │ ├── mapping.py
│ │ ├── peft_model.py
│ │ ├── py.typed
│ │ ├── tuners/
│ │ │ ├── __init__.py
│ │ │ ├── adalora.py
│ │ │ ├── adaption_prompt.py
│ │ │ ├── ia3.py
│ │ │ ├── lora.py
│ │ │ ├── p_tuning.py
│ │ │ ├── prefix_tuning.py
│ │ │ └── prompt_tuning.py
│ │ └── utils/
│ │ ├── __init__.py
│ │ ├── config.py
│ │ ├── hub_utils.py
│ │ ├── other.py
│ │ └── save_and_load.py
│ └── tests/
│ ├── __init__.py
│ ├── test_adaption_prompt.py
│ ├── test_auto.py
│ ├── test_common_gpu.py
│ ├── test_config.py
│ ├── test_custom_models.py
│ ├── test_decoder_models.py
│ ├── test_encoder_decoder_models.py
│ ├── test_feature_extraction_models.py
│ ├── test_gpu_examples.py
│ ├── test_stablediffusion.py
│ ├── testing_common.py
│ └── testing_utils.py
├── evaluate/
│ ├── demo_gradio_video_dubbing.py
│ ├── evaluate_long_audio.py
│ ├── evaluate_long_audio.sh
│ └── inference.py
├── install_audiostory.sh
├── src/
│ ├── models/
│ │ ├── detokenizer/
│ │ │ ├── __init__.py
│ │ │ ├── modeling_flux.py
│ │ │ └── resampler.py
│ │ ├── detokenizer_cotrain/
│ │ │ └── modeling_flux_cotrain.py
│ │ ├── mllm/
│ │ │ ├── __init__.py
│ │ │ ├── generation.py
│ │ │ ├── load_qwenvl_llm.py
│ │ │ ├── modeling_audiostory_llm.py
│ │ │ ├── modeling_audiostory_unified.py
│ │ │ ├── modeling_llama_xformer.py
│ │ │ ├── peft_models.py
│ │ │ └── utils.py
│ │ └── tokenizer/
│ │ ├── __init__.py
│ │ ├── init_qwen_tokenizer.py
│ │ ├── init_qwen_tokenizer_special_token.py
│ │ ├── modeling_tangoflux.py
│ │ ├── modeling_whisper.py
│ │ ├── modeling_whisper_inference.py
│ │ └── qwen_visual.py
│ └── processer/
│ ├── tokenizer.py
│ └── transforms.py
└── tokenizer/
├── added_tokens.json
├── tokenizer.json
├── tokenizer_config.json
└── vocab.json
================================================
FILE CONTENTS
================================================
================================================
FILE: .gitignore
================================================
ckpt
ckpt/*
ckpt_upload/*
output/*
__pycache__
.vscode/
.vscode
*.pyc
.DS_Store
*.pt
*.pth
*.ckpt
*.safetensors
*.ptl
*.ptl.tar
*.ptl.tar.gz
*.ptl.tar.bz2
*.ptl.tar.xz
*.ptl.tar.lzma
*.ptl.tar.7z
*.wav
================================================
FILE: README.md
================================================
# AudioStory: Generating Long-Form Narrative Audio with Large Language Models
**[Yuxin Guo<sup>1,2</sup>](https://scholar.google.com/citations?user=x_0spxgAAAAJ&hl=en),
[Teng Wang<sup>2,✉</sup>](http://ttengwang.com/),
[Yuying Ge<sup>2</sup>](https://geyuying.github.io/),
[Shijie Ma<sup>1,2</sup>](https://mashijie1028.github.io/),
[Yixiao Ge<sup>2</sup>](https://geyixiao.com/),
[Wei Zou<sup>1</sup>](https://people.ucas.ac.cn/~zouwei),
[Ying Shan<sup>2</sup>](https://scholar.google.com/citations?user=4oXBp9UAAAAJ&hl=en)**
<br>
<sup>1</sup>Institute of Automation, CAS
<sup>2</sup>ARC Lab, Tencent PCG
<br>
✨ TL; DR: We propose a model for long-form narrative audio generation built upon a unified understanding–generation framework, capable of handling video dubbing, audio continuation, and long-form narrative audio synthesis.
<div align="center">
<a href="https://www.youtube.com/watch?v=mySEYHryYwY" target="_blank">
<img src="https://img.youtube.com/vi/mySEYHryYwY/maxresdefault.jpg" alt="AudioStory Demo Video" width="600" style="border-radius: 10px; box-shadow: 0 4px 8px rgba(0,0,0,0.1);"/>
<br>
<strong>🎥 Watch Full Demo on YouTube</strong>
</a>
</div>
## 📖 Release
[2025/09/02] 🔥🔥 Text-to-long audio checkpoint released!
<br>
[2025/08/28] 🔥🔥 We release the inference code!
<br>
[2025/08/28] 🔥🔥 We release our demo videos!
## 🔎 Introduction

Recent advances in text-to-audio (TTA) generation excel at synthesizing short audio clips but struggle with long-form narrative audio, which requires temporal coherence and compositional reasoning. To address this gap, we propose AudioStory, a unified framework that integrates large language models (LLMs) with TTA systems to generate structured, long-form audio narratives. AudioStory possesses strong instruction-following reasoning generation capabilities. It employs LLMs to decompose complex narrative queries into temporally ordered sub-tasks with contextual cues, enabling coherent scene transitions and emotional tone consistency. AudioStory has two appealing features:
1) Decoupled bridging mechanism: AudioStory disentangles LLM-diffuser collaboration into two specialized components—a bridging query for intra-event semantic alignment and a consistency query for cross-event coherence preservation.
2) End-to-end training: By unifying instruction comprehension and audio generation within a single end-to-end framework, AudioStory eliminates the need for modular training pipelines while enhancing synergy between components.
Furthermore, we establish a benchmark AudioStory-10K, encompassing diverse domains such as animated soundscapes and natural sound narratives.
Extensive experiments show the superiority of AudioStory on both single-audio generation and narrative audio generation, surpassing prior TTA baselines in both instruction-following ability and audio fidelity.
## ⭐ Demos
### 1. Video Dubbing (Tom & Jerry style)
> Dubbing is achieved using AudioStory (trained on Tom & Jerry) with visual captions extracted from videos.
<table class="center">
<td><video src="https://github.com/user-attachments/assets/f06b5999-6649-44d3-af38-63fdcecd833c"></video></td>
<td><video src="https://github.com/user-attachments/assets/17727c2a-bfea-4252-9aa8-48fc9ac33500"></video></td>
<td><video src="https://github.com/user-attachments/assets/09589d82-62c9-47a6-838a-5a62319f35e2"></video></td>
<tr>
</table >
### 2. Cross-domain Video Dubbing (Tom & Jerry style)
<table class="center">
<td><video src="https://github.com/user-attachments/assets/4089493c-2a26-4093-9709-0827c6dafcde"></video></td>
<td><video src="https://github.com/user-attachments/assets/67fafed1-2547-49ba-afaa-75fc7f9d58ca"></video></td>
<td><video src="https://github.com/user-attachments/assets/abbc9192-894c-49a2-9b55-8cc4852483c2"></video></td>
<tr>
<td><video src="https://github.com/user-attachments/assets/e62d0c09-cdf0-4e51-b550-0a2c23f8d68d"></video></td>
<td><video src="https://github.com/user-attachments/assets/38339d5b-b96a-4ffd-8607-c94eb254beb6"></video></td>
<td><video src="https://github.com/user-attachments/assets/f2f7c94c-7f72-4cc0-8edc-290910980b04"></video></td>
<tr>
<td><video src="https://github.com/user-attachments/assets/d3e58dd4-31ae-4e32-aef1-03f1e649cb0c"></video></td>
<td><video src="https://github.com/user-attachments/assets/ab7e46d5-f42c-472e-b66e-df786b658210"></video></td>
<td><video src="https://github.com/user-attachments/assets/062236c3-1d26-4622-b843-cc0cd0c58053"></video></td>
<tr>
<td><video src="https://github.com/user-attachments/assets/8931f428-dd4d-430f-9927-068f2912dd36"></video></td>
<td><video src="https://github.com/user-attachments/assets/4f68199f-e48a-4be7-b6dc-1acb8d377a6e"></video></td>
<td><video src="https://github.com/user-attachments/assets/736d22ca-6636-4ef0-99f3-768e4dfb112a"></video></td>
<tr>
</table >
### 3. Text-to-Long Audio (Natural sound)
<table class="center">
<td style="text-align:center;" width="480">Instruction: "Develop a comprehensive audio that fully represents jake shimabukuro performs a complex ukulele piece in a studio, receives applause, and discusses his career in an interview. The total duration is 49.9 seconds."</td>
<td><video src="https://github.com/user-attachments/assets/461e8a34-4217-454e-87b3-e4285f36ec43"></video></td>
<tr>
<td style="text-align:center;" width="480">Instruction: "Develop a comprehensive audio that fully represents a fire truck leaves the station with sirens blaring, signaling an emergency response, and drives away. The total duration is 35.1 seconds."</td>
<td><video src="https://github.com/user-attachments/assets/aac0243f-5d12-480e-9850-a7f6720e4f9c"></video></td>
<tr>
<td style="text-align:center;" width="480">Instruction: "Understand the input audio, infer the subsequent events, and generate the continued audio of the coach giving basketball lessons to the players. The total duration is 36.6 seconds."</td>
<td><video src="https://github.com/user-attachments/assets/c4ed306a-651e-43d6-aeea-ee159542418a"></video></td>
<tr>
</table >
## 🔎 Methods

To achieve effective instruction-following audio generation, the ability to understand the input instruction or audio stream and reason about relevant audio sub-events is essential. To this end, AudioStory adopts a unified understanding-generation framework (Fig.). Specifically, given textual instruction or audio input, the LLM analyzes and decomposes it into structured audio sub-events with context. Based on the inferred sub-events, the LLM performs **interleaved reasoning generation**, sequentially producing captions, semantic tokens, and residual tokens for each audio clip. These two types of tokens are fused and passed to the DiT, effectively bridging the LLM with the audio generator. Through progressive training, AudioStory ultimately achieves both strong instruction comprehension and high-quality audio generation.
## 🔩 Installation
### Dependencies
* Python >= 3.10 (Recommend to use [Anaconda](https://www.anaconda.com/download/#linux))
* [PyTorch >=2.1.0](https://pytorch.org/)
* NVIDIA GPU + [CUDA](https://developer.nvidia.com/cuda-downloads)
### Installation
```
git clone https://github.com/TencentARC/AudioStory.git
cd AudioStory
conda create -n audiostory python=3.10 -y
conda activate audiostory
bash install_audiostory.sh
```
## 📊 Evaluation
Download model checkpoint from [Huggingface Models](https://huggingface.co/TencentARC/AudioStory-3B).
### Inference
```bash
python evaluate/inference.py \
--model_path ckpt/audiostory-3B \
--guidance 4.0 \
--save_folder_name audiostory \
--total_duration 50
```
## 🔋 Acknowledgement
When building the codebase of continuous denosiers, we refer to [SEED-X](https://github.com/AILab-CVC/SEED-X) and [TangoFlux](https://github.com/declare-lab/TangoFlux). Thanks for their wonderful projects.
## 📆 TO DO
- [ ] Release our gradio demo.
- [x] 💾 Release AudioStory model checkpoints
- [ ] Release AudioStory-10k dataset.
- [ ] Release training codes of all three stages.
## 📜 License
This repository is under the [Apache 2 License](https://github.com/mashijie1028/Gen4Rep/blob/main/LICENSE).
## 📚 BibTeX
```
@misc{guo2025audiostory,
title={AudioStory: Generating Long-Form Narrative Audio with Large Language Models},
author={Yuxin Guo and Teng Wang and Yuying Ge and Shijie Ma and Yixiao Ge and Wei Zou and Ying Shan},
year={2025},
eprint={2508.20088},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2508.20088},
}
```
## 📧 Contact
If you have further questions, feel free to contact me: guoyuxin2021@ia.ac.cn
Discussions and potential collaborations are also welcome.
================================================
FILE: configs/audiostory_llm_qwen25_3b_lora.yaml
================================================
_target_: src.models.mllm.peft_models.get_peft_model_with_resize_embedding
model:
_target_: transformers.AutoModelForCausalLM.from_pretrained
pretrained_model_name_or_path: ckpt/Qwen2.5-3B-Instruct
peft_config:
_target_: peft.LoraConfig
_convert_: object
r: 32
lora_alpha: 32
modules_to_save:
- input_layernorm
- post_attention_layernorm
- norm
target_modules:
- q_proj
- v_proj
- k_proj
- o_proj
- gate_proj
- down_proj
- up_proj
task_type: CAUSAL_LM
lora_dropout: 0.05
vocab_size: 152277
================================================
FILE: envs/peft/.github/ISSUE_TEMPLATE/bug-report.yml
================================================
name: "\U0001F41B Bug Report"
description: Submit a bug report to help us improve the library
body:
- type: textarea
id: system-info
attributes:
label: System Info
description: Please share your relevant system information with us
placeholder: peft & accelerate & transformers version, platform, python version, ...
validations:
required: true
- type: textarea
id: who-can-help
attributes:
label: Who can help?
description: |
Your issue will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
All issues are read by one of the core maintainers, so if you don't know who to tag, just leave this blank and
a core maintainer will ping the right person.
Please tag fewer than 3 people.
Library: @pacman100 @younesbelkada @sayakpaul
Documentation: @stevhliu and @MKhalusova
placeholder: "@Username ..."
- type: checkboxes
id: information-scripts-examples
attributes:
label: Information
description: 'The problem arises when using:'
options:
- label: "The official example scripts"
- label: "My own modified scripts"
- type: checkboxes
id: information-tasks
attributes:
label: Tasks
description: "The tasks I am working on are:"
options:
- label: "An officially supported task in the `examples` folder"
- label: "My own task or dataset (give details below)"
- type: textarea
id: reproduction
validations:
required: true
attributes:
label: Reproduction
description: |
Please provide a code sample that reproduces the problem you ran into. It can be a Colab link or just a code snippet.
Please provide the simplest reproducer as possible so that we can quickly fix the issue.
placeholder: |
Reproducer:
- type: textarea
id: expected-behavior
validations:
required: true
attributes:
label: Expected behavior
description: "A clear and concise description of what you would expect to happen."
================================================
FILE: envs/peft/.github/ISSUE_TEMPLATE/feature-request.yml
================================================
name: "\U0001F680 Feature request"
description: Submit a proposal/request for a new feature
labels: [ "feature" ]
body:
- type: textarea
id: feature-request
validations:
required: true
attributes:
label: Feature request
description: |
A clear and concise description of the feature proposal. Please provide a link to the paper and code in case they exist.
- type: textarea
id: motivation
validations:
required: true
attributes:
label: Motivation
description: |
Please outline the motivation for the proposal. Is your feature request related to a problem?
- type: textarea
id: contribution
validations:
required: true
attributes:
label: Your contribution
description: |
Is there any way that you could help, e.g. by submitting a PR?
================================================
FILE: envs/peft/.github/workflows/build_docker_images.yml
================================================
name: Build Docker images (scheduled)
on:
workflow_dispatch:
workflow_call:
schedule:
- cron: "0 1 * * *"
concurrency:
group: docker-image-builds
cancel-in-progress: false
jobs:
latest-cpu:
name: "Latest Peft CPU [dev]"
runs-on: ubuntu-latest
steps:
- name: Cleanup disk
run: |
sudo ls -l /usr/local/lib/
sudo ls -l /usr/share/
sudo du -sh /usr/local/lib/
sudo du -sh /usr/share/
sudo rm -rf /usr/local/lib/android
sudo rm -rf /usr/share/dotnet
sudo du -sh /usr/local/lib/
sudo du -sh /usr/share/
- name: Set up Docker Buildx
uses: docker/setup-buildx-action@v1
- name: Check out code
uses: actions/checkout@v2
- name: Login to DockerHub
uses: docker/login-action@v2
with:
username: ${{ secrets.DOCKERHUB_USERNAME }}
password: ${{ secrets.DOCKERHUB_PASSWORD }}
- name: Build and Push CPU
uses: docker/build-push-action@v4
with:
context: ./docker/peft-cpu
push: true
tags: huggingface/peft-cpu
latest-cuda:
name: "Latest Peft GPU [dev]"
runs-on: ubuntu-latest
steps:
- name: Cleanup disk
run: |
sudo ls -l /usr/local/lib/
sudo ls -l /usr/share/
sudo du -sh /usr/local/lib/
sudo du -sh /usr/share/
sudo rm -rf /usr/local/lib/android
sudo rm -rf /usr/share/dotnet
sudo du -sh /usr/local/lib/
sudo du -sh /usr/share/
- name: Set up Docker Buildx
uses: docker/setup-buildx-action@v1
- name: Check out code
uses: actions/checkout@v2
- name: Login to DockerHub
uses: docker/login-action@v1
with:
username: ${{ secrets.DOCKERHUB_USERNAME }}
password: ${{ secrets.DOCKERHUB_PASSWORD }}
- name: Build and Push GPU
uses: docker/build-push-action@v2
with:
context: ./docker/peft-gpu
push: true
tags: huggingface/peft-gpu
================================================
FILE: envs/peft/.github/workflows/build_documentation.yml
================================================
name: Build documentation
on:
push:
branches:
- main
- doc-builder*
- v*-release
jobs:
build:
uses: huggingface/doc-builder/.github/workflows/build_main_documentation.yml@main
with:
commit_sha: ${{ github.sha }}
package: peft
notebook_folder: peft_docs
secrets:
token: ${{ secrets.HUGGINGFACE_PUSH }}
hf_token: ${{ secrets.HF_DOC_BUILD_PUSH }}
================================================
FILE: envs/peft/.github/workflows/build_pr_documentation.yml
================================================
name: Build PR Documentation
on:
pull_request:
concurrency:
group: ${{ github.workflow }}-${{ github.head_ref || github.run_id }}
cancel-in-progress: true
jobs:
build:
uses: huggingface/doc-builder/.github/workflows/build_pr_documentation.yml@main
with:
commit_sha: ${{ github.event.pull_request.head.sha }}
pr_number: ${{ github.event.number }}
package: peft
================================================
FILE: envs/peft/.github/workflows/delete_doc_comment.yml
================================================
name: Delete doc comment
on:
workflow_run:
workflows: ["Delete doc comment trigger"]
types:
- completed
jobs:
delete:
uses: huggingface/doc-builder/.github/workflows/delete_doc_comment.yml@main
secrets:
comment_bot_token: ${{ secrets.COMMENT_BOT_TOKEN }}
================================================
FILE: envs/peft/.github/workflows/delete_doc_comment_trigger.yml
================================================
name: Delete doc comment trigger
on:
pull_request:
types: [ closed ]
jobs:
delete:
uses: huggingface/doc-builder/.github/workflows/delete_doc_comment_trigger.yml@main
with:
pr_number: ${{ github.event.number }}
================================================
FILE: envs/peft/.github/workflows/nightly.yml
================================================
name: Self-hosted runner with slow tests (scheduled)
on:
workflow_dispatch:
schedule:
- cron: "0 2 * * *"
env:
RUN_SLOW: "yes"
IS_GITHUB_CI: "1"
SLACK_API_TOKEN: ${{ secrets.SLACK_API_TOKEN }}
jobs:
run_all_tests_single_gpu:
runs-on: [self-hosted, docker-gpu, multi-gpu]
env:
CUDA_VISIBLE_DEVICES: "0"
TEST_TYPE: "single_gpu"
container:
image: huggingface/peft-gpu:latest
options: --gpus all --shm-size "16gb"
defaults:
run:
working-directory: peft/
shell: bash
steps:
- name: Update clone & pip install
run: |
source activate peft
git config --global --add safe.directory '*'
git fetch && git checkout ${{ github.sha }}
pip install -e . --no-deps
pip install pytest-reportlog
- name: Run common tests on single GPU
run: |
source activate peft
make tests_common_gpu
- name: Run examples on single GPU
run: |
source activate peft
make tests_examples_single_gpu
- name: Run core tests on single GPU
run: |
source activate peft
make tests_core_single_gpu
- name: Generate Report
if: always()
run: |
pip install slack_sdk tabulate
python scripts/log_reports.py >> $GITHUB_STEP_SUMMARY
run_all_tests_multi_gpu:
runs-on: [self-hosted, docker-gpu, multi-gpu]
env:
CUDA_VISIBLE_DEVICES: "0,1"
TEST_TYPE: "multi_gpu"
container:
image: huggingface/peft-gpu:latest
options: --gpus all --shm-size "16gb"
defaults:
run:
working-directory: peft/
shell: bash
steps:
- name: Update clone
run: |
source activate peft
git config --global --add safe.directory '*'
git fetch && git checkout ${{ github.sha }}
pip install -e . --no-deps
pip install pytest-reportlog
- name: Run core GPU tests on multi-gpu
run: |
source activate peft
- name: Run common tests on multi GPU
run: |
source activate peft
make tests_common_gpu
- name: Run examples on multi GPU
run: |
source activate peft
make tests_examples_multi_gpu
- name: Run core tests on multi GPU
run: |
source activate peft
make tests_core_multi_gpu
- name: Generate Report
if: always()
run: |
pip install slack_sdk tabulate
python scripts/log_reports.py >> $GITHUB_STEP_SUMMARY
================================================
FILE: envs/peft/.github/workflows/stale.yml
================================================
name: Stale Bot
on:
schedule:
- cron: "0 15 * * *"
jobs:
close_stale_issues:
name: Close Stale Issues
if: github.repository == 'huggingface/peft'
runs-on: ubuntu-latest
env:
GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }}
steps:
- uses: actions/checkout@v3
- name: Setup Python
uses: actions/setup-python@v4
with:
python-version: 3.8
- name: Install requirements
run: |
pip install PyGithub
- name: Close stale issues
run: |
python scripts/stale.py
================================================
FILE: envs/peft/.github/workflows/tests.yml
================================================
name: tests
on:
push:
branches: [main]
pull_request:
jobs:
check_code_quality:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v3
- name: Set up Python
uses: actions/setup-python@v4
with:
python-version: "3.8"
cache: "pip"
cache-dependency-path: "setup.py"
- name: Install dependencies
run: |
python -m pip install --upgrade pip
pip install .[dev]
- name: Check quality
run: |
make quality
tests:
needs: check_code_quality
strategy:
matrix:
python-version: ["3.8", "3.9", "3.10"]
os: ["ubuntu-latest", "macos-latest", "windows-latest"]
runs-on: ${{ matrix.os }}
steps:
- uses: actions/checkout@v3
- name: Set up Python ${{ matrix.python-version }}
uses: actions/setup-python@v4
with:
python-version: ${{ matrix.python-version }}
cache: "pip"
cache-dependency-path: "setup.py"
- name: Install dependencies
run: |
python -m pip install --upgrade pip
# cpu version of pytorch
pip install -e .[test]
- name: Test with pytest
run: |
make test
================================================
FILE: envs/peft/.github/workflows/upload_pr_documentation.yml
================================================
name: Upload PR Documentation
on:
workflow_run:
workflows: ["Build PR Documentation"]
types:
- completed
jobs:
build:
uses: huggingface/doc-builder/.github/workflows/upload_pr_documentation.yml@main
with:
package_name: peft
secrets:
hf_token: ${{ secrets.HF_DOC_BUILD_PUSH }}
comment_bot_token: ${{ secrets.COMMENT_BOT_TOKEN }}
================================================
FILE: envs/peft/.gitignore
================================================
# Byte-compiled / optimized / DLL files
__pycache__/
*.py[cod]
*$py.class
# C extensions
*.so
# Distribution / packaging
.Python
build/
develop-eggs/
dist/
downloads/
eggs/
.eggs/
lib/
lib64/
parts/
sdist/
var/
wheels/
pip-wheel-metadata/
share/python-wheels/
*.egg-info/
.installed.cfg
*.egg
MANIFEST
# PyInstaller
# Usually these files are written by a python script from a template
# before PyInstaller builds the exe, so as to inject date/other infos into it.
*.manifest
*.spec
# Installer logs
pip-log.txt
pip-delete-this-directory.txt
# Unit test / coverage reports
htmlcov/
.tox/
.nox/
.coverage
.coverage.*
.cache
nosetests.xml
coverage.xml
*.cover
*.py,cover
.hypothesis/
.pytest_cache/
# Translations
*.mo
*.pot
# Django stuff:
*.log
local_settings.py
db.sqlite3
db.sqlite3-journal
# Flask stuff:
instance/
.webassets-cache
# Scrapy stuff:
.scrapy
# Sphinx documentation
docs/_build/
# PyBuilder
target/
# Jupyter Notebook
.ipynb_checkpoints
# IPython
profile_default/
ipython_config.py
# pyenv
.python-version
# pipenv
# According to pypa/pipenv#598, it is recommended to include Pipfile.lock in version control.
# However, in case of collaboration, if having platform-specific dependencies or dependencies
# having no cross-platform support, pipenv may install dependencies that don't work, or not
# install all needed dependencies.
#Pipfile.lock
# PEP 582; used by e.g. github.com/David-OConnor/pyflow
__pypackages__/
# Celery stuff
celerybeat-schedule
celerybeat.pid
# SageMath parsed files
*.sage.py
# Environments
.env
.venv
env/
venv/
ENV/
env.bak/
venv.bak/
# Spyder project settings
.spyderproject
.spyproject
# Rope project settings
.ropeproject
# mkdocs documentation
/site
# mypy
.mypy_cache/
.dmypy.json
dmypy.json
# Pyre type checker
.pyre/
# VSCode
.vscode
# IntelliJ
.idea
# Mac .DS_Store
.DS_Store
# More test things
wandb
================================================
FILE: envs/peft/LICENSE
================================================
Apache License
Version 2.0, January 2004
http://www.apache.org/licenses/
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
1. Definitions.
"License" shall mean the terms and conditions for use, reproduction,
and distribution as defined by Sections 1 through 9 of this document.
"Licensor" shall mean the copyright owner or entity authorized by
the copyright owner that is granting the License.
"Legal Entity" shall mean the union of the acting entity and all
other entities that control, are controlled by, or are under common
control with that entity. For the purposes of this definition,
"control" means (i) the power, direct or indirect, to cause the
direction or management of such entity, whether by contract or
otherwise, or (ii) ownership of fifty percent (50%) or more of the
outstanding shares, or (iii) beneficial ownership of such entity.
"You" (or "Your") shall mean an individual or Legal Entity
exercising permissions granted by this License.
"Source" form shall mean the preferred form for making modifications,
including but not limited to software source code, documentation
source, and configuration files.
"Object" form shall mean any form resulting from mechanical
transformation or translation of a Source form, including but
not limited to compiled object code, generated documentation,
and conversions to other media types.
"Work" shall mean the work of authorship, whether in Source or
Object form, made available under the License, as indicated by a
copyright notice that is included in or attached to the work
(an example is provided in the Appendix below).
"Derivative Works" shall mean any work, whether in Source or Object
form, that is based on (or derived from) the Work and for which the
editorial revisions, annotations, elaborations, or other modifications
represent, as a whole, an original work of authorship. For the purposes
of this License, Derivative Works shall not include works that remain
separable from, or merely link (or bind by name) to the interfaces of,
the Work and Derivative Works thereof.
"Contribution" shall mean any work of authorship, including
the original version of the Work and any modifications or additions
to that Work or Derivative Works thereof, that is intentionally
submitted to Licensor for inclusion in the Work by the copyright owner
or by an individual or Legal Entity authorized to submit on behalf of
the copyright owner. For the purposes of this definition, "submitted"
means any form of electronic, verbal, or written communication sent
to the Licensor or its representatives, including but not limited to
communication on electronic mailing lists, source code control systems,
and issue tracking systems that are managed by, or on behalf of, the
Licensor for the purpose of discussing and improving the Work, but
excluding communication that is conspicuously marked or otherwise
designated in writing by the copyright owner as "Not a Contribution."
"Contributor" shall mean Licensor and any individual or Legal Entity
on behalf of whom a Contribution has been received by Licensor and
subsequently incorporated within the Work.
2. Grant of Copyright License. Subject to the terms and conditions of
this License, each Contributor hereby grants to You a perpetual,
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
copyright license to reproduce, prepare Derivative Works of,
publicly display, publicly perform, sublicense, and distribute the
Work and such Derivative Works in Source or Object form.
3. Grant of Patent License. Subject to the terms and conditions of
this License, each Contributor hereby grants to You a perpetual,
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
(except as stated in this section) patent license to make, have made,
use, offer to sell, sell, import, and otherwise transfer the Work,
where such license applies only to those patent claims licensable
by such Contributor that are necessarily infringed by their
Contribution(s) alone or by combination of their Contribution(s)
with the Work to which such Contribution(s) was submitted. If You
institute patent litigation against any entity (including a
cross-claim or counterclaim in a lawsuit) alleging that the Work
or a Contribution incorporated within the Work constitutes direct
or contributory patent infringement, then any patent licenses
granted to You under this License for that Work shall terminate
as of the date such litigation is filed.
4. Redistribution. You may reproduce and distribute copies of the
Work or Derivative Works thereof in any medium, with or without
modifications, and in Source or Object form, provided that You
meet the following conditions:
(a) You must give any other recipients of the Work or
Derivative Works a copy of this License; and
(b) You must cause any modified files to carry prominent notices
stating that You changed the files; and
(c) You must retain, in the Source form of any Derivative Works
that You distribute, all copyright, patent, trademark, and
attribution notices from the Source form of the Work,
excluding those notices that do not pertain to any part of
the Derivative Works; and
(d) If the Work includes a "NOTICE" text file as part of its
distribution, then any Derivative Works that You distribute must
include a readable copy of the attribution notices contained
within such NOTICE file, excluding those notices that do not
pertain to any part of the Derivative Works, in at least one
of the following places: within a NOTICE text file distributed
as part of the Derivative Works; within the Source form or
documentation, if provided along with the Derivative Works; or,
within a display generated by the Derivative Works, if and
wherever such third-party notices normally appear. The contents
of the NOTICE file are for informational purposes only and
do not modify the License. You may add Your own attribution
notices within Derivative Works that You distribute, alongside
or as an addendum to the NOTICE text from the Work, provided
that such additional attribution notices cannot be construed
as modifying the License.
You may add Your own copyright statement to Your modifications and
may provide additional or different license terms and conditions
for use, reproduction, or distribution of Your modifications, or
for any such Derivative Works as a whole, provided Your use,
reproduction, and distribution of the Work otherwise complies with
the conditions stated in this License.
5. Submission of Contributions. Unless You explicitly state otherwise,
any Contribution intentionally submitted for inclusion in the Work
by You to the Licensor shall be under the terms and conditions of
this License, without any additional terms or conditions.
Notwithstanding the above, nothing herein shall supersede or modify
the terms of any separate license agreement you may have executed
with Licensor regarding such Contributions.
6. Trademarks. This License does not grant permission to use the trade
names, trademarks, service marks, or product names of the Licensor,
except as required for reasonable and customary use in describing the
origin of the Work and reproducing the content of the NOTICE file.
7. Disclaimer of Warranty. Unless required by applicable law or
agreed to in writing, Licensor provides the Work (and each
Contributor provides its Contributions) on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
implied, including, without limitation, any warranties or conditions
of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
PARTICULAR PURPOSE. You are solely responsible for determining the
appropriateness of using or redistributing the Work and assume any
risks associated with Your exercise of permissions under this License.
8. Limitation of Liability. In no event and under no legal theory,
whether in tort (including negligence), contract, or otherwise,
unless required by applicable law (such as deliberate and grossly
negligent acts) or agreed to in writing, shall any Contributor be
liable to You for damages, including any direct, indirect, special,
incidental, or consequential damages of any character arising as a
result of this License or out of the use or inability to use the
Work (including but not limited to damages for loss of goodwill,
work stoppage, computer failure or malfunction, or any and all
other commercial damages or losses), even if such Contributor
has been advised of the possibility of such damages.
9. Accepting Warranty or Additional Liability. While redistributing
the Work or Derivative Works thereof, You may choose to offer,
and charge a fee for, acceptance of support, warranty, indemnity,
or other liability obligations and/or rights consistent with this
License. However, in accepting such obligations, You may act only
on Your own behalf and on Your sole responsibility, not on behalf
of any other Contributor, and only if You agree to indemnify,
defend, and hold each Contributor harmless for any liability
incurred by, or claims asserted against, such Contributor by reason
of your accepting any such warranty or additional liability.
END OF TERMS AND CONDITIONS
APPENDIX: How to apply the Apache License to your work.
To apply the Apache License to your work, attach the following
boilerplate notice, with the fields enclosed by brackets "[]"
replaced with your own identifying information. (Don't include
the brackets!) The text should be enclosed in the appropriate
comment syntax for the file format. We also recommend that a
file or class name and description of purpose be included on the
same "printed page" as the copyright notice for easier
identification within third-party archives.
Copyright [yyyy] [name of copyright owner]
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
================================================
FILE: envs/peft/Makefile
================================================
.PHONY: quality style test docs
check_dirs := src tests examples docs
# Check that source code meets quality standards
# this target runs checks on all files
quality:
black --check $(check_dirs)
ruff $(check_dirs)
doc-builder style src/peft tests docs/source --max_len 119 --check_only
# Format source code automatically and check is there are any problems left that need manual fixing
style:
black $(check_dirs)
ruff $(check_dirs) --fix
doc-builder style src/peft tests docs/source --max_len 119
test:
python -m pytest -n 3 tests/ $(if $(IS_GITHUB_CI),--report-log "ci_tests.log",)
tests_examples_multi_gpu:
python -m pytest -m multi_gpu_tests tests/test_gpu_examples.py $(if $(IS_GITHUB_CI),--report-log "multi_gpu_examples.log",)
tests_examples_single_gpu:
python -m pytest -m single_gpu_tests tests/test_gpu_examples.py $(if $(IS_GITHUB_CI),--report-log "single_gpu_examples.log",)
tests_core_multi_gpu:
python -m pytest -m multi_gpu_tests tests/test_common_gpu.py $(if $(IS_GITHUB_CI),--report-log "core_multi_gpu.log",)
tests_core_single_gpu:
python -m pytest -m single_gpu_tests tests/test_common_gpu.py $(if $(IS_GITHUB_CI),--report-log "core_single_gpu.log",)
tests_common_gpu:
python -m pytest tests/test_decoder_models.py $(if $(IS_GITHUB_CI),--report-log "common_decoder.log",)
python -m pytest tests/test_encoder_decoder_models.py $(if $(IS_GITHUB_CI),--report-log "common_encoder_decoder.log",)
================================================
FILE: envs/peft/README.md
================================================
<!---
Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
-->
<h1 align="center"> <p>🤗 PEFT</p></h1>
<h3 align="center">
<p>State-of-the-art Parameter-Efficient Fine-Tuning (PEFT) methods</p>
</h3>
Parameter-Efficient Fine-Tuning (PEFT) methods enable efficient adaptation of pre-trained language models (PLMs) to various downstream applications without fine-tuning all the model's parameters. Fine-tuning large-scale PLMs is often prohibitively costly. In this regard, PEFT methods only fine-tune a small number of (extra) model parameters, thereby greatly decreasing the computational and storage costs. Recent State-of-the-Art PEFT techniques achieve performance comparable to that of full fine-tuning.
Seamlessly integrated with 🤗 Accelerate for large scale models leveraging DeepSpeed and Big Model Inference.
Supported methods:
1. LoRA: [LORA: LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS](https://arxiv.org/abs/2106.09685)
2. Prefix Tuning: [Prefix-Tuning: Optimizing Continuous Prompts for Generation](https://aclanthology.org/2021.acl-long.353/), [P-Tuning v2: Prompt Tuning Can Be Comparable to Fine-tuning Universally Across Scales and Tasks](https://arxiv.org/pdf/2110.07602.pdf)
3. P-Tuning: [GPT Understands, Too](https://arxiv.org/abs/2103.10385)
4. Prompt Tuning: [The Power of Scale for Parameter-Efficient Prompt Tuning](https://arxiv.org/abs/2104.08691)
5. AdaLoRA: [Adaptive Budget Allocation for Parameter-Efficient Fine-Tuning](https://arxiv.org/abs/2303.10512)
6. $(IA)^3$ : [Infused Adapter by Inhibiting and Amplifying Inner Activations](https://arxiv.org/abs/2205.05638)
## Getting started
```python
from transformers import AutoModelForSeq2SeqLM
from peft import get_peft_config, get_peft_model, LoraConfig, TaskType
model_name_or_path = "bigscience/mt0-large"
tokenizer_name_or_path = "bigscience/mt0-large"
peft_config = LoraConfig(
task_type=TaskType.SEQ_2_SEQ_LM, inference_mode=False, r=8, lora_alpha=32, lora_dropout=0.1
)
model = AutoModelForSeq2SeqLM.from_pretrained(model_name_or_path)
model = get_peft_model(model, peft_config)
model.print_trainable_parameters()
# output: trainable params: 2359296 || all params: 1231940608 || trainable%: 0.19151053100118282
```
## Use Cases
### Get comparable performance to full finetuning by adapting LLMs to downstream tasks using consumer hardware
GPU memory required for adapting LLMs on the few-shot dataset [`ought/raft/twitter_complaints`](https://huggingface.co/datasets/ought/raft/viewer/twitter_complaints). Here, settings considered
are full finetuning, PEFT-LoRA using plain PyTorch and PEFT-LoRA using DeepSpeed with CPU Offloading.
Hardware: Single A100 80GB GPU with CPU RAM above 64GB
| Model | Full Finetuning | PEFT-LoRA PyTorch | PEFT-LoRA DeepSpeed with CPU Offloading |
| --------- | ---- | ---- | ---- |
| bigscience/T0_3B (3B params) | 47.14GB GPU / 2.96GB CPU | 14.4GB GPU / 2.96GB CPU | 9.8GB GPU / 17.8GB CPU |
| bigscience/mt0-xxl (12B params) | OOM GPU | 56GB GPU / 3GB CPU | 22GB GPU / 52GB CPU |
| bigscience/bloomz-7b1 (7B params) | OOM GPU | 32GB GPU / 3.8GB CPU | 18.1GB GPU / 35GB CPU |
Performance of PEFT-LoRA tuned [`bigscience/T0_3B`](https://huggingface.co/bigscience/T0_3B) on [`ought/raft/twitter_complaints`](https://huggingface.co/datasets/ought/raft/viewer/twitter_complaints) leaderboard.
A point to note is that we didn't try to squeeze performance by playing around with input instruction templates, LoRA hyperparams and other training related hyperparams. Also, we didn't use the larger 13B [mt0-xxl](https://huggingface.co/bigscience/mt0-xxl) model.
So, we are already seeing comparable performance to SoTA with parameter efficient tuning. Also, the final checkpoint size is just `19MB` in comparison to `11GB` size of the backbone [`bigscience/T0_3B`](https://huggingface.co/bigscience/T0_3B) model.
| Submission Name | Accuracy |
| --------- | ---- |
| Human baseline (crowdsourced) | 0.897 |
| Flan-T5 | 0.892 |
| lora-t0-3b | 0.863 |
**Therefore, we can see that performance comparable to SoTA is achievable by PEFT methods with consumer hardware such as 16GB and 24GB GPUs.**
An insightful blogpost explaining the advantages of using PEFT for fine-tuning FlanT5-XXL: [https://www.philschmid.de/fine-tune-flan-t5-peft](https://www.philschmid.de/fine-tune-flan-t5-peft)
### Parameter Efficient Tuning of Diffusion Models
GPU memory required by different settings during training is given below. The final checkpoint size is `8.8 MB`.
Hardware: Single A100 80GB GPU with CPU RAM above 64GB
| Model | Full Finetuning | PEFT-LoRA | PEFT-LoRA with Gradient Checkpointing |
| --------- | ---- | ---- | ---- |
| CompVis/stable-diffusion-v1-4 | 27.5GB GPU / 3.97GB CPU | 15.5GB GPU / 3.84GB CPU | 8.12GB GPU / 3.77GB CPU |
**Training**
An example of using LoRA for parameter efficient dreambooth training is given in [`examples/lora_dreambooth/train_dreambooth.py`](examples/lora_dreambooth/train_dreambooth.py)
```bash
export MODEL_NAME= "CompVis/stable-diffusion-v1-4" #"stabilityai/stable-diffusion-2-1"
export INSTANCE_DIR="path-to-instance-images"
export CLASS_DIR="path-to-class-images"
export OUTPUT_DIR="path-to-save-model"
accelerate launch train_dreambooth.py \
--pretrained_model_name_or_path=$MODEL_NAME \
--instance_data_dir=$INSTANCE_DIR \
--class_data_dir=$CLASS_DIR \
--output_dir=$OUTPUT_DIR \
--train_text_encoder \
--with_prior_preservation --prior_loss_weight=1.0 \
--instance_prompt="a photo of sks dog" \
--class_prompt="a photo of dog" \
--resolution=512 \
--train_batch_size=1 \
--lr_scheduler="constant" \
--lr_warmup_steps=0 \
--num_class_images=200 \
--use_lora \
--lora_r 16 \
--lora_alpha 27 \
--lora_text_encoder_r 16 \
--lora_text_encoder_alpha 17 \
--learning_rate=1e-4 \
--gradient_accumulation_steps=1 \
--gradient_checkpointing \
--max_train_steps=800
```
Try out the 🤗 Gradio Space which should run seamlessly on a T4 instance:
[smangrul/peft-lora-sd-dreambooth](https://huggingface.co/spaces/smangrul/peft-lora-sd-dreambooth).
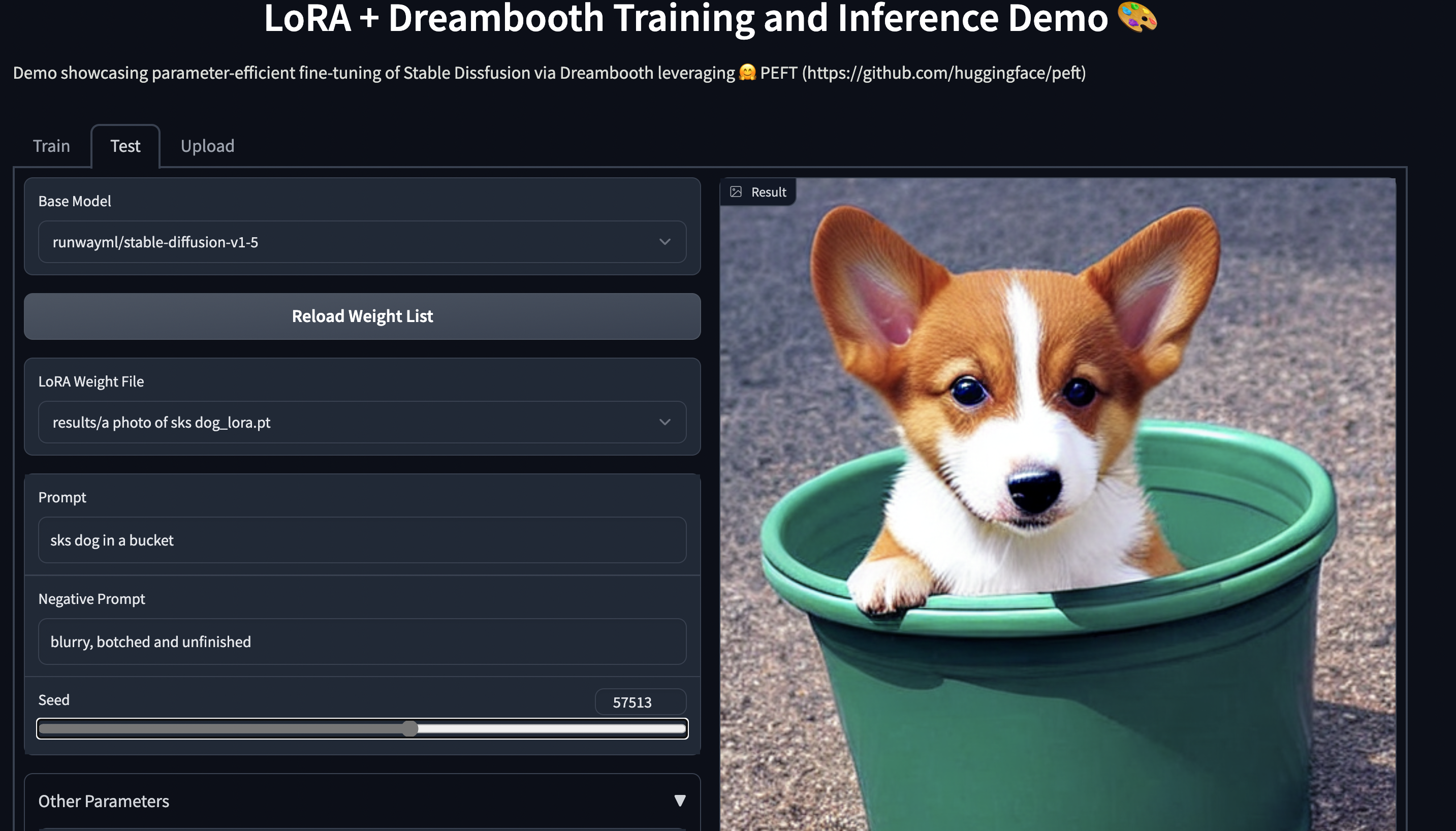
**NEW** ✨ Multi Adapter support and combining multiple LoRA adapters in a weighted combination

### Parameter Efficient Tuning of LLMs for RLHF components such as Ranker and Policy
- Here is an example in [trl](https://github.com/lvwerra/trl) library using PEFT+INT8 for tuning policy model: [gpt2-sentiment_peft.py](https://github.com/lvwerra/trl/blob/main/examples/sentiment/scripts/gpt2-sentiment_peft.py) and corresponding [Blog](https://huggingface.co/blog/trl-peft)
- Example using PEFT for Instrction finetuning, reward model and policy : [stack_llama](https://github.com/lvwerra/trl/tree/main/examples/stack_llama/scripts) and corresponding [Blog](https://huggingface.co/blog/stackllama)
### INT8 training of large models in Colab using PEFT LoRA and bits_and_bytes
- Here is now a demo on how to fine tune [OPT-6.7b](https://huggingface.co/facebook/opt-6.7b) (14GB in fp16) in a Google Colab: [](https://colab.research.google.com/drive/1jCkpikz0J2o20FBQmYmAGdiKmJGOMo-o?usp=sharing)
- Here is now a demo on how to fine tune [whisper-large](https://huggingface.co/openai/whisper-large-v2) (1.5B params) (14GB in fp16) in a Google Colab: [](https://colab.research.google.com/drive/1DOkD_5OUjFa0r5Ik3SgywJLJtEo2qLxO?usp=sharing) and [](https://colab.research.google.com/drive/1vhF8yueFqha3Y3CpTHN6q9EVcII9EYzs?usp=sharing)
### Save compute and storage even for medium and small models
Save storage by avoiding full finetuning of models on each of the downstream tasks/datasets,
With PEFT methods, users only need to store tiny checkpoints in the order of `MBs` all the while retaining
performance comparable to full finetuning.
An example of using LoRA for the task of adapting `LayoutLMForTokenClassification` on `FUNSD` dataset is given in `~examples/token_classification/PEFT_LoRA_LayoutLMForTokenClassification_on_FUNSD.py`. We can observe that with only `0.62 %` of parameters being trainable, we achieve performance (F1 0.777) comparable to full finetuning (F1 0.786) (without any hyerparam tuning runs for extracting more performance), and the checkpoint of this is only `2.8MB`. Now, if there are `N` such datasets, just have these PEFT models one for each dataset and save a lot of storage without having to worry about the problem of catastrophic forgetting or overfitting of backbone/base model.
Another example is fine-tuning [`roberta-large`](https://huggingface.co/roberta-large) on [`MRPC` GLUE](https://huggingface.co/datasets/glue/viewer/mrpc) dataset using different PEFT methods. The notebooks are given in `~examples/sequence_classification`.
## PEFT + 🤗 Accelerate
PEFT models work with 🤗 Accelerate out of the box. Use 🤗 Accelerate for Distributed training on various hardware such as GPUs, Apple Silicon devices, etc during training.
Use 🤗 Accelerate for inferencing on consumer hardware with small resources.
### Example of PEFT model training using 🤗 Accelerate's DeepSpeed integration
DeepSpeed version required `v0.8.0`. An example is provided in `~examples/conditional_generation/peft_lora_seq2seq_accelerate_ds_zero3_offload.py`.
a. First, run `accelerate config --config_file ds_zero3_cpu.yaml` and answer the questionnaire.
Below are the contents of the config file.
```yaml
compute_environment: LOCAL_MACHINE
deepspeed_config:
gradient_accumulation_steps: 1
gradient_clipping: 1.0
offload_optimizer_device: cpu
offload_param_device: cpu
zero3_init_flag: true
zero3_save_16bit_model: true
zero_stage: 3
distributed_type: DEEPSPEED
downcast_bf16: 'no'
dynamo_backend: 'NO'
fsdp_config: {}
machine_rank: 0
main_training_function: main
megatron_lm_config: {}
mixed_precision: 'no'
num_machines: 1
num_processes: 1
rdzv_backend: static
same_network: true
use_cpu: false
```
b. run the below command to launch the example script
```bash
accelerate launch --config_file ds_zero3_cpu.yaml examples/peft_lora_seq2seq_accelerate_ds_zero3_offload.py
```
c. output logs:
```bash
GPU Memory before entering the train : 1916
GPU Memory consumed at the end of the train (end-begin): 66
GPU Peak Memory consumed during the train (max-begin): 7488
GPU Total Peak Memory consumed during the train (max): 9404
CPU Memory before entering the train : 19411
CPU Memory consumed at the end of the train (end-begin): 0
CPU Peak Memory consumed during the train (max-begin): 0
CPU Total Peak Memory consumed during the train (max): 19411
epoch=4: train_ppl=tensor(1.0705, device='cuda:0') train_epoch_loss=tensor(0.0681, device='cuda:0')
100%|████████████████████████████████████████████████████████████████████████████████████████████| 7/7 [00:27<00:00, 3.92s/it]
GPU Memory before entering the eval : 1982
GPU Memory consumed at the end of the eval (end-begin): -66
GPU Peak Memory consumed during the eval (max-begin): 672
GPU Total Peak Memory consumed during the eval (max): 2654
CPU Memory before entering the eval : 19411
CPU Memory consumed at the end of the eval (end-begin): 0
CPU Peak Memory consumed during the eval (max-begin): 0
CPU Total Peak Memory consumed during the eval (max): 19411
accuracy=100.0
eval_preds[:10]=['no complaint', 'no complaint', 'complaint', 'complaint', 'no complaint', 'no complaint', 'no complaint', 'complaint', 'complaint', 'no complaint']
dataset['train'][label_column][:10]=['no complaint', 'no complaint', 'complaint', 'complaint', 'no complaint', 'no complaint', 'no complaint', 'complaint', 'complaint', 'no complaint']
```
### Example of PEFT model inference using 🤗 Accelerate's Big Model Inferencing capabilities
An example is provided in `~examples/causal_language_modeling/peft_lora_clm_accelerate_big_model_inference.ipynb`.
## Models support matrix
### Causal Language Modeling
| Model | LoRA | Prefix Tuning | P-Tuning | Prompt Tuning | IA3 |
|--------------| ---- | ---- | ---- | ---- | ---- |
| GPT-2 | ✅ | ✅ | ✅ | ✅ | ✅ |
| Bloom | ✅ | ✅ | ✅ | ✅ | ✅ |
| OPT | ✅ | ✅ | ✅ | ✅ | ✅ |
| GPT-Neo | ✅ | ✅ | ✅ | ✅ | ✅ |
| GPT-J | ✅ | ✅ | ✅ | ✅ | ✅ |
| GPT-NeoX-20B | ✅ | ✅ | ✅ | ✅ | ✅ |
| LLaMA | ✅ | ✅ | ✅ | ✅ | ✅ |
| ChatGLM | ✅ | ✅ | ✅ | ✅ | ✅ |
### Conditional Generation
| Model | LoRA | Prefix Tuning | P-Tuning | Prompt Tuning | IA3 |
| --------- | ---- | ---- | ---- | ---- | ---- |
| T5 | ✅ | ✅ | ✅ | ✅ | ✅ |
| BART | ✅ | ✅ | ✅ | ✅ | ✅ |
### Sequence Classification
| Model | LoRA | Prefix Tuning | P-Tuning | Prompt Tuning | IA3 |
| --------- | ---- | ---- | ---- | ---- | ---- |
| BERT | ✅ | ✅ | ✅ | ✅ | ✅ |
| RoBERTa | ✅ | ✅ | ✅ | ✅ | ✅ |
| GPT-2 | ✅ | ✅ | ✅ | ✅ | |
| Bloom | ✅ | ✅ | ✅ | ✅ | |
| OPT | ✅ | ✅ | ✅ | ✅ | |
| GPT-Neo | ✅ | ✅ | ✅ | ✅ | |
| GPT-J | ✅ | ✅ | ✅ | ✅ | |
| Deberta | ✅ | | ✅ | ✅ | |
| Deberta-v2 | ✅ | | ✅ | ✅ | |
### Token Classification
| Model | LoRA | Prefix Tuning | P-Tuning | Prompt Tuning | IA3 |
| --------- | ---- | ---- | ---- | ---- | ---- |
| BERT | ✅ | ✅ | | | |
| RoBERTa | ✅ | ✅ | | | |
| GPT-2 | ✅ | ✅ | | | |
| Bloom | ✅ | ✅ | | | |
| OPT | ✅ | ✅ | | | |
| GPT-Neo | ✅ | ✅ | | | |
| GPT-J | ✅ | ✅ | | | |
| Deberta | ✅ | | | | |
| Deberta-v2 | ✅ | | | | |
### Text-to-Image Generation
| Model | LoRA | Prefix Tuning | P-Tuning | Prompt Tuning | IA3 |
| --------- | ---- | ---- | ---- | ---- | ---- |
| Stable Diffusion | ✅ | | | | |
### Image Classification
| Model | LoRA | Prefix Tuning | P-Tuning | Prompt Tuning | IA3 |
| --------- | ---- | ---- | ---- | ---- | ---- |
| ViT | ✅ | | | | |
| Swin | ✅ | | | | |
### Image to text (Multi-modal models)
| Model | LoRA | Prefix Tuning | P-Tuning | Prompt Tuning | IA3
| --------- | ---- | ---- | ---- | ---- | ---- |
| Blip-2 | ✅ | | | | |
___Note that we have tested LoRA for [ViT](https://huggingface.co/docs/transformers/model_doc/vit) and [Swin](https://huggingface.co/docs/transformers/model_doc/swin) for fine-tuning on image classification. However, it should be possible to use LoRA for any compatible model [provided](https://huggingface.co/models?pipeline_tag=image-classification&sort=downloads&search=vit) by 🤗 Transformers. Check out the respective
examples to learn more. If you run into problems, please open an issue.___
The same principle applies to our [segmentation models](https://huggingface.co/models?pipeline_tag=image-segmentation&sort=downloads) as well.
### Semantic Segmentation
| Model | LoRA | Prefix Tuning | P-Tuning | Prompt Tuning | IA3 |
| --------- | ---- | ---- | ---- | ---- | ---- |
| SegFormer | ✅ | | | | |
## Caveats:
1. Below is an example of using PyTorch FSDP for training. However, it doesn't lead to
any GPU memory savings. Please refer issue [[FSDP] FSDP with CPU offload consumes 1.65X more GPU memory when training models with most of the params frozen](https://github.com/pytorch/pytorch/issues/91165).
```python
from peft.utils.other import fsdp_auto_wrap_policy
...
if os.environ.get("ACCELERATE_USE_FSDP", None) is not None:
accelerator.state.fsdp_plugin.auto_wrap_policy = fsdp_auto_wrap_policy(model)
model = accelerator.prepare(model)
```
Example of parameter efficient tuning with [`mt0-xxl`](https://huggingface.co/bigscience/mt0-xxl) base model using 🤗 Accelerate is provided in `~examples/conditional_generation/peft_lora_seq2seq_accelerate_fsdp.py`.
a. First, run `accelerate config --config_file fsdp_config.yaml` and answer the questionnaire.
Below are the contents of the config file.
```yaml
command_file: null
commands: null
compute_environment: LOCAL_MACHINE
deepspeed_config: {}
distributed_type: FSDP
downcast_bf16: 'no'
dynamo_backend: 'NO'
fsdp_config:
fsdp_auto_wrap_policy: TRANSFORMER_BASED_WRAP
fsdp_backward_prefetch_policy: BACKWARD_PRE
fsdp_offload_params: true
fsdp_sharding_strategy: 1
fsdp_state_dict_type: FULL_STATE_DICT
fsdp_transformer_layer_cls_to_wrap: T5Block
gpu_ids: null
machine_rank: 0
main_process_ip: null
main_process_port: null
main_training_function: main
megatron_lm_config: {}
mixed_precision: 'no'
num_machines: 1
num_processes: 2
rdzv_backend: static
same_network: true
tpu_name: null
tpu_zone: null
use_cpu: false
```
b. run the below command to launch the example script
```bash
accelerate launch --config_file fsdp_config.yaml examples/peft_lora_seq2seq_accelerate_fsdp.py
```
2. When using ZeRO3 with zero3_init_flag=True, if you find the gpu memory increase with training steps. we might need to update deepspeed after [deepspeed commit 42858a9891422abc](https://github.com/microsoft/DeepSpeed/commit/42858a9891422abcecaa12c1bd432d28d33eb0d4) . The related issue is [[BUG] Peft Training with Zero.Init() and Zero3 will increase GPU memory every forward step ](https://github.com/microsoft/DeepSpeed/issues/3002)
## Backlog:
- [x] Add tests
- [x] Multi Adapter training and inference support
- [x] Add more use cases and examples
- [x] Integrate`(IA)^3`, `AdaptionPrompt`
- [ ] Explore and possibly integrate methods like `Bottleneck Adapters`, ...
## Citing 🤗 PEFT
If you use 🤗 PEFT in your publication, please cite it by using the following BibTeX entry.
```bibtex
@Misc{peft,
title = {PEFT: State-of-the-art Parameter-Efficient Fine-Tuning methods},
author = {Sourab Mangrulkar and Sylvain Gugger and Lysandre Debut and Younes Belkada and Sayak Paul},
howpublished = {\url{https://github.com/huggingface/peft}},
year = {2022}
}
```
================================================
FILE: envs/peft/docker/peft-cpu/Dockerfile
================================================
# Builds GPU docker image of PyTorch
# Uses multi-staged approach to reduce size
# Stage 1
# Use base conda image to reduce time
FROM continuumio/miniconda3:latest AS compile-image
# Specify py version
ENV PYTHON_VERSION=3.8
# Install apt libs - copied from https://github.com/huggingface/accelerate/blob/main/docker/accelerate-gpu/Dockerfile
RUN apt-get update && \
apt-get install -y curl git wget software-properties-common git-lfs && \
apt-get clean && \
rm -rf /var/lib/apt/lists*
# Install audio-related libraries
RUN apt-get update && \
apt install -y ffmpeg
RUN apt install -y libsndfile1-dev
RUN git lfs install
# Create our conda env - copied from https://github.com/huggingface/accelerate/blob/main/docker/accelerate-gpu/Dockerfile
RUN conda create --name peft python=${PYTHON_VERSION} ipython jupyter pip
RUN python3 -m pip install --no-cache-dir --upgrade pip
# Below is copied from https://github.com/huggingface/accelerate/blob/main/docker/accelerate-gpu/Dockerfile
# We don't install pytorch here yet since CUDA isn't available
# instead we use the direct torch wheel
ENV PATH /opt/conda/envs/peft/bin:$PATH
# Activate our bash shell
RUN chsh -s /bin/bash
SHELL ["/bin/bash", "-c"]
# Activate the conda env and install transformers + accelerate from source
RUN source activate peft && \
python3 -m pip install --no-cache-dir \
librosa \
"soundfile>=0.12.1" \
scipy \
git+https://github.com/huggingface/transformers \
git+https://github.com/huggingface/accelerate \
peft[test]@git+https://github.com/huggingface/peft
# Install apt libs
RUN apt-get update && \
apt-get install -y curl git wget && \
apt-get clean && \
rm -rf /var/lib/apt/lists*
RUN echo "source activate peft" >> ~/.profile
# Activate the virtualenv
CMD ["/bin/bash"]
================================================
FILE: envs/peft/docker/peft-gpu/Dockerfile
================================================
# Builds GPU docker image of PyTorch
# Uses multi-staged approach to reduce size
# Stage 1
# Use base conda image to reduce time
FROM continuumio/miniconda3:latest AS compile-image
# Specify py version
ENV PYTHON_VERSION=3.8
# Install apt libs - copied from https://github.com/huggingface/accelerate/blob/main/docker/accelerate-gpu/Dockerfile
RUN apt-get update && \
apt-get install -y curl git wget software-properties-common git-lfs && \
apt-get clean && \
rm -rf /var/lib/apt/lists*
# Install audio-related libraries
RUN apt-get update && \
apt install -y ffmpeg
RUN apt install -y libsndfile1-dev
RUN git lfs install
# Create our conda env - copied from https://github.com/huggingface/accelerate/blob/main/docker/accelerate-gpu/Dockerfile
RUN conda create --name peft python=${PYTHON_VERSION} ipython jupyter pip
RUN python3 -m pip install --no-cache-dir --upgrade pip
# Below is copied from https://github.com/huggingface/accelerate/blob/main/docker/accelerate-gpu/Dockerfile
# We don't install pytorch here yet since CUDA isn't available
# instead we use the direct torch wheel
ENV PATH /opt/conda/envs/peft/bin:$PATH
# Activate our bash shell
RUN chsh -s /bin/bash
SHELL ["/bin/bash", "-c"]
# Activate the conda env and install transformers + accelerate from source
RUN source activate peft && \
python3 -m pip install --no-cache-dir \
librosa \
"soundfile>=0.12.1" \
scipy \
git+https://github.com/huggingface/transformers \
git+https://github.com/huggingface/accelerate \
peft[test]@git+https://github.com/huggingface/peft
RUN python3 -m pip install --no-cache-dir bitsandbytes
# Stage 2
FROM nvidia/cuda:11.3.1-devel-ubuntu20.04 AS build-image
COPY --from=compile-image /opt/conda /opt/conda
ENV PATH /opt/conda/bin:$PATH
# Install apt libs
RUN apt-get update && \
apt-get install -y curl git wget && \
apt-get clean && \
rm -rf /var/lib/apt/lists*
RUN echo "source activate peft" >> ~/.profile
# Activate the virtualenv
CMD ["/bin/bash"]
================================================
FILE: envs/peft/docs/Makefile
================================================
# Minimal makefile for Sphinx documentation
#
# You can set these variables from the command line.
SPHINXOPTS =
SPHINXBUILD = sphinx-build
SOURCEDIR = source
BUILDDIR = _build
# Put it first so that "make" without argument is like "make help".
help:
@$(SPHINXBUILD) -M help "$(SOURCEDIR)" "$(BUILDDIR)" $(SPHINXOPTS) $(O)
.PHONY: help Makefile
# Catch-all target: route all unknown targets to Sphinx using the new
# "make mode" option. $(O) is meant as a shortcut for $(SPHINXOPTS).
%: Makefile
@$(SPHINXBUILD) -M $@ "$(SOURCEDIR)" "$(BUILDDIR)" $(SPHINXOPTS) $(O)
================================================
FILE: envs/peft/docs/README.md
================================================
<!---
Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
-->
# Generating the documentation
To generate the documentation, you first have to build it. Several packages are necessary to build the doc,
you can install them with the following command, at the root of the code repository:
```bash
pip install -e ".[docs]"
```
Then you need to install our special tool that builds the documentation:
```bash
pip install git+https://github.com/huggingface/doc-builder
```
---
**NOTE**
You only need to generate the documentation to inspect it locally (if you're planning changes and want to
check how they look before committing for instance). You don't have to commit the built documentation.
---
## Building the documentation
Once you have setup the `doc-builder` and additional packages, you can generate the documentation by
typing the following command:
```bash
doc-builder build peft docs/source/ --build_dir ~/tmp/test-build
```
You can adapt the `--build_dir` to set any temporary folder that you prefer. This command will create it and generate
the MDX files that will be rendered as the documentation on the main website. You can inspect them in your favorite
Markdown editor.
## Previewing the documentation
To preview the docs, first install the `watchdog` module with:
```bash
pip install watchdog
```
Then run the following command:
```bash
doc-builder preview {package_name} {path_to_docs}
```
For example:
```bash
doc-builder preview peft docs/source
```
The docs will be viewable at [http://localhost:3000](http://localhost:3000). You can also preview the docs once you have opened a PR. You will see a bot add a comment to a link where the documentation with your changes lives.
---
**NOTE**
The `preview` command only works with existing doc files. When you add a completely new file, you need to update `_toctree.yml` & restart `preview` command (`ctrl-c` to stop it & call `doc-builder preview ...` again).
---
## Adding a new element to the navigation bar
Accepted files are Markdown (.md or .mdx).
Create a file with its extension and put it in the source directory. You can then link it to the toc-tree by putting
the filename without the extension in the [`_toctree.yml`](https://github.com/huggingface/peft/blob/main/docs/source/_toctree.yml) file.
## Renaming section headers and moving sections
It helps to keep the old links working when renaming the section header and/or moving sections from one document to another. This is because the old links are likely to be used in Issues, Forums, and Social media and it'd make for a much more superior user experience if users reading those months later could still easily navigate to the originally intended information.
Therefore, we simply keep a little map of moved sections at the end of the document where the original section was. The key is to preserve the original anchor.
So if you renamed a section from: "Section A" to "Section B", then you can add at the end of the file:
```
Sections that were moved:
[ <a href="#section-b">Section A</a><a id="section-a"></a> ]
```
and of course, if you moved it to another file, then:
```
Sections that were moved:
[ <a href="../new-file#section-b">Section A</a><a id="section-a"></a> ]
```
Use the relative style to link to the new file so that the versioned docs continue to work.
## Writing Documentation - Specification
The `huggingface/peft` documentation follows the
[Google documentation](https://sphinxcontrib-napoleon.readthedocs.io/en/latest/example_google.html) style for docstrings,
although we can write them directly in Markdown.
### Adding a new tutorial
Adding a new tutorial or section is done in two steps:
- Add a new file under `./source`. This file can either be ReStructuredText (.rst) or Markdown (.md).
- Link that file in `./source/_toctree.yml` on the correct toc-tree.
Make sure to put your new file under the proper section. It's unlikely to go in the first section (*Get Started*), so
depending on the intended targets (beginners, more advanced users, or researchers) it should go in sections two, three, or
four.
### Writing source documentation
Values that should be put in `code` should either be surrounded by backticks: \`like so\`. Note that argument names
and objects like True, None, or any strings should usually be put in `code`.
When mentioning a class, function, or method, it is recommended to use our syntax for internal links so that our tool
adds a link to its documentation with this syntax: \[\`XXXClass\`\] or \[\`function\`\]. This requires the class or
function to be in the main package.
If you want to create a link to some internal class or function, you need to
provide its path. For instance: \[\`utils.gather\`\]. This will be converted into a link with
`utils.gather` in the description. To get rid of the path and only keep the name of the object you are
linking to in the description, add a ~: \[\`~utils.gather\`\] will generate a link with `gather` in the description.
The same works for methods so you can either use \[\`XXXClass.method\`\] or \[~\`XXXClass.method\`\].
#### Defining arguments in a method
Arguments should be defined with the `Args:` (or `Arguments:` or `Parameters:`) prefix, followed by a line return and
an indentation. The argument should be followed by its type, with its shape if it is a tensor, a colon, and its
description:
```
Args:
n_layers (`int`): The number of layers of the model.
```
If the description is too long to fit in one line (more than 119 characters in total), another indentation is necessary
before writing the description after the argument.
Finally, to maintain uniformity if any *one* description is too long to fit on one line, the
rest of the parameters should follow suit and have an indention before their description.
Here's an example showcasing everything so far:
```
Args:
gradient_accumulation_steps (`int`, *optional*, default to 1):
The number of steps that should pass before gradients are accumulated. A number > 1 should be combined with `Accelerator.accumulate`.
cpu (`bool`, *optional*):
Whether or not to force the script to execute on CPU. Will ignore GPU available if set to `True` and force the execution on one process only.
```
For optional arguments or arguments with defaults we follow the following syntax: imagine we have a function with the
following signature:
```
def my_function(x: str = None, a: float = 1):
```
then its documentation should look like this:
```
Args:
x (`str`, *optional*):
This argument controls ... and has a description longer than 119 chars.
a (`float`, *optional*, defaults to 1):
This argument is used to ... and has a description longer than 119 chars.
```
Note that we always omit the "defaults to \`None\`" when None is the default for any argument. Also note that even
if the first line describing your argument type and its default gets long, you can't break it on several lines. You can
however write as many lines as you want in the indented description (see the example above with `input_ids`).
#### Writing a multi-line code block
Multi-line code blocks can be useful for displaying examples. They are done between two lines of three backticks as usual in Markdown:
````
```python
# first line of code
# second line
# etc
```
````
#### Writing a return block
The return block should be introduced with the `Returns:` prefix, followed by a line return and an indentation.
The first line should be the type of the return, followed by a line return. No need to indent further for the elements
building the return.
Here's an example of a single value return:
```
Returns:
`List[int]`: A list of integers in the range [0, 1] --- 1 for a special token, 0 for a sequence token.
```
Here's an example of a tuple return, comprising several objects:
```
Returns:
`tuple(torch.FloatTensor)` comprising various elements depending on the configuration ([`BertConfig`]) and inputs:
- ** loss** (*optional*, returned when `masked_lm_labels` is provided) `torch.FloatTensor` of shape `(1,)` --
Total loss is the sum of the masked language modeling loss and the next sequence prediction (classification) loss.
- **prediction_scores** (`torch.FloatTensor` of shape `(batch_size, sequence_length, config.vocab_size)`) --
Prediction scores of the language modeling head (scores for each vocabulary token before SoftMax).
```
## Styling the docstring
We have an automatic script running with the `make style` comment that will make sure that:
- the docstrings fully take advantage of the line width
- all code examples are formatted using black, like the code of the Transformers library
This script may have some weird failures if you made a syntax mistake or if you uncover a bug. Therefore, it's
recommended to commit your changes before running `make style`, so you can revert the changes done by that script
easily.
## Writing documentation examples
The syntax for Example docstrings can look as follows:
```
Example:
```python
>>> import time
>>> from accelerate import Accelerator
>>> accelerator = Accelerator()
>>> if accelerator.is_main_process:
... time.sleep(2)
>>> else:
... print("I'm waiting for the main process to finish its sleep...")
>>> accelerator.wait_for_everyone()
>>> # Should print on every process at the same time
>>> print("Everyone is here")
```
```
The docstring should give a minimal, clear example of how the respective function
is to be used in inference and also include the expected (ideally sensible)
output.
Often, readers will try out the example before even going through the function
or class definitions. Therefore, it is of utmost importance that the example
works as expected.
================================================
FILE: envs/peft/docs/source/_config.py
================================================
# docstyle-ignore
INSTALL_CONTENT = """
# PEFT installation
! pip install peft accelerate transformers
# To install from source instead of the last release, comment the command above and uncomment the following one.
# ! pip install git+https://github.com/huggingface/peft.git
"""
================================================
FILE: envs/peft/docs/source/_toctree.yml
================================================
- title: Get started
sections:
- local: index
title: 🤗 PEFT
- local: quicktour
title: Quicktour
- local: install
title: Installation
- title: Task guides
sections:
- local: task_guides/image_classification_lora
title: Image classification using LoRA
- local: task_guides/seq2seq-prefix-tuning
title: Prefix tuning for conditional generation
- local: task_guides/clm-prompt-tuning
title: Prompt tuning for causal language modeling
- local: task_guides/semantic_segmentation_lora
title: Semantic segmentation using LoRA
- local: task_guides/ptuning-seq-classification
title: P-tuning for sequence classification
- local: task_guides/dreambooth_lora
title: Dreambooth fine-tuning with LoRA
- local: task_guides/token-classification-lora
title: LoRA for token classification
- local: task_guides/int8-asr
title: int8 training for automatic speech recognition
- local: task_guides/semantic-similarity-lora
title: semantic similairty with peft
- title: 🤗 Accelerate integrations
sections:
- local: accelerate/deepspeed-zero3-offload
title: DeepSpeed
- local: accelerate/fsdp
title: Fully Sharded Data Parallel
- title: Conceptual guides
sections:
- local: conceptual_guides/lora
title: LoRA
- local: conceptual_guides/prompting
title: Prompting
- local: conceptual_guides/ia3
title: IA3
- title: Reference
sections:
- local: package_reference/peft_model
title: PEFT model
- local: package_reference/config
title: Configuration
- local: package_reference/tuners
title: Tuners
================================================
FILE: envs/peft/docs/source/accelerate/deepspeed-zero3-offload.mdx
================================================
# DeepSpeed
[DeepSpeed](https://www.deepspeed.ai/) is a library designed for speed and scale for distributed training of large models with billions of parameters. At its core is the Zero Redundancy Optimizer (ZeRO) that shards optimizer states (ZeRO-1), gradients (ZeRO-2), and parameters (ZeRO-3) across data parallel processes. This drastically reduces memory usage, allowing you to scale your training to billion parameter models. To unlock even more memory efficiency, ZeRO-Offload reduces GPU compute and memory by leveraging CPU resources during optimization.
Both of these features are supported in 🤗 Accelerate, and you can use them with 🤗 PEFT. This guide will help you learn how to use our DeepSpeed [training script](https://github.com/huggingface/peft/blob/main/examples/conditional_generation/peft_lora_seq2seq_accelerate_ds_zero3_offload.py). You'll configure the script to train a large model for conditional generation with ZeRO-3 and ZeRO-Offload.
<Tip>
💡 To help you get started, check out our example training scripts for [causal language modeling](https://github.com/huggingface/peft/blob/main/examples/causal_language_modeling/peft_lora_clm_accelerate_ds_zero3_offload.py) and [conditional generation](https://github.com/huggingface/peft/blob/main/examples/conditional_generation/peft_lora_seq2seq_accelerate_ds_zero3_offload.py). You can adapt these scripts for your own applications or even use them out of the box if your task is similar to the one in the scripts.
</Tip>
## Configuration
Start by running the following command to [create a DeepSpeed configuration file](https://huggingface.co/docs/accelerate/quicktour#launching-your-distributed-script) with 🤗 Accelerate. The `--config_file` flag allows you to save the configuration file to a specific location, otherwise it is saved as a `default_config.yaml` file in the 🤗 Accelerate cache.
The configuration file is used to set the default options when you launch the training script.
```bash
accelerate config --config_file ds_zero3_cpu.yaml
```
You'll be asked a few questions about your setup, and configure the following arguments. In this example, you'll use ZeRO-3 and ZeRO-Offload so make sure you pick those options.
```bash
`zero_stage`: [0] Disabled, [1] optimizer state partitioning, [2] optimizer+gradient state partitioning and [3] optimizer+gradient+parameter partitioning
`gradient_accumulation_steps`: Number of training steps to accumulate gradients before averaging and applying them.
`gradient_clipping`: Enable gradient clipping with value.
`offload_optimizer_device`: [none] Disable optimizer offloading, [cpu] offload optimizer to CPU, [nvme] offload optimizer to NVMe SSD. Only applicable with ZeRO >= Stage-2.
`offload_param_device`: [none] Disable parameter offloading, [cpu] offload parameters to CPU, [nvme] offload parameters to NVMe SSD. Only applicable with ZeRO Stage-3.
`zero3_init_flag`: Decides whether to enable `deepspeed.zero.Init` for constructing massive models. Only applicable with ZeRO Stage-3.
`zero3_save_16bit_model`: Decides whether to save 16-bit model weights when using ZeRO Stage-3.
`mixed_precision`: `no` for FP32 training, `fp16` for FP16 mixed-precision training and `bf16` for BF16 mixed-precision training.
```
An example [configuration file](https://github.com/huggingface/peft/blob/main/examples/conditional_generation/accelerate_ds_zero3_cpu_offload_config.yaml) might look like the following. The most important thing to notice is that `zero_stage` is set to `3`, and `offload_optimizer_device` and `offload_param_device` are set to the `cpu`.
```yml
compute_environment: LOCAL_MACHINE
deepspeed_config:
gradient_accumulation_steps: 1
gradient_clipping: 1.0
offload_optimizer_device: cpu
offload_param_device: cpu
zero3_init_flag: true
zero3_save_16bit_model: true
zero_stage: 3
distributed_type: DEEPSPEED
downcast_bf16: 'no'
dynamo_backend: 'NO'
fsdp_config: {}
machine_rank: 0
main_training_function: main
megatron_lm_config: {}
mixed_precision: 'no'
num_machines: 1
num_processes: 1
rdzv_backend: static
same_network: true
use_cpu: false
```
## The important parts
Let's dive a little deeper into the script so you can see what's going on, and understand how it works.
Within the [`main`](https://github.com/huggingface/peft/blob/2822398fbe896f25d4dac5e468624dc5fd65a51b/examples/conditional_generation/peft_lora_seq2seq_accelerate_ds_zero3_offload.py#L103) function, the script creates an [`~accelerate.Accelerator`] class to initialize all the necessary requirements for distributed training.
<Tip>
💡 Feel free to change the model and dataset inside the `main` function. If your dataset format is different from the one in the script, you may also need to write your own preprocessing function.
</Tip>
The script also creates a configuration for the 🤗 PEFT method you're using, which in this case, is LoRA. The [`LoraConfig`] specifies the task type and important parameters such as the dimension of the low-rank matrices, the matrices scaling factor, and the dropout probability of the LoRA layers. If you want to use a different 🤗 PEFT method, make sure you replace `LoraConfig` with the appropriate [class](../package_reference/tuners).
```diff
def main():
+ accelerator = Accelerator()
model_name_or_path = "facebook/bart-large"
dataset_name = "twitter_complaints"
+ peft_config = LoraConfig(
task_type=TaskType.SEQ_2_SEQ_LM, inference_mode=False, r=8, lora_alpha=32, lora_dropout=0.1
)
```
Throughout the script, you'll see the [`~accelerate.Accelerator.main_process_first`] and [`~accelerate.Accelerator.wait_for_everyone`] functions which help control and synchronize when processes are executed.
The [`get_peft_model`] function takes a base model and the [`peft_config`] you prepared earlier to create a [`PeftModel`]:
```diff
model = AutoModelForSeq2SeqLM.from_pretrained(model_name_or_path)
+ model = get_peft_model(model, peft_config)
```
Pass all the relevant training objects to 🤗 Accelerate's [`~accelerate.Accelerator.prepare`] which makes sure everything is ready for training:
```py
model, train_dataloader, eval_dataloader, test_dataloader, optimizer, lr_scheduler = accelerator.prepare(
model, train_dataloader, eval_dataloader, test_dataloader, optimizer, lr_scheduler
)
```
The next bit of code checks whether the DeepSpeed plugin is used in the `Accelerator`, and if the plugin exists, then the `Accelerator` uses ZeRO-3 as specified in the configuration file:
```py
is_ds_zero_3 = False
if getattr(accelerator.state, "deepspeed_plugin", None):
is_ds_zero_3 = accelerator.state.deepspeed_plugin.zero_stage == 3
```
Inside the training loop, the usual `loss.backward()` is replaced by 🤗 Accelerate's [`~accelerate.Accelerator.backward`] which uses the correct `backward()` method based on your configuration:
```diff
for epoch in range(num_epochs):
with TorchTracemalloc() as tracemalloc:
model.train()
total_loss = 0
for step, batch in enumerate(tqdm(train_dataloader)):
outputs = model(**batch)
loss = outputs.loss
total_loss += loss.detach().float()
+ accelerator.backward(loss)
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad()
```
That is all! The rest of the script handles the training loop, evaluation, and even pushes it to the Hub for you.
## Train
Run the following command to launch the training script. Earlier, you saved the configuration file to `ds_zero3_cpu.yaml`, so you'll need to pass the path to the launcher with the `--config_file` argument like this:
```bash
accelerate launch --config_file ds_zero3_cpu.yaml examples/peft_lora_seq2seq_accelerate_ds_zero3_offload.py
```
You'll see some output logs that track memory usage during training, and once it's completed, the script returns the accuracy and compares the predictions to the labels:
```bash
GPU Memory before entering the train : 1916
GPU Memory consumed at the end of the train (end-begin): 66
GPU Peak Memory consumed during the train (max-begin): 7488
GPU Total Peak Memory consumed during the train (max): 9404
CPU Memory before entering the train : 19411
CPU Memory consumed at the end of the train (end-begin): 0
CPU Peak Memory consumed during the train (max-begin): 0
CPU Total Peak Memory consumed during the train (max): 19411
epoch=4: train_ppl=tensor(1.0705, device='cuda:0') train_epoch_loss=tensor(0.0681, device='cuda:0')
100%|████████████████████████████████████████████████████████████████████████████████████████████| 7/7 [00:27<00:00, 3.92s/it]
GPU Memory before entering the eval : 1982
GPU Memory consumed at the end of the eval (end-begin): -66
GPU Peak Memory consumed during the eval (max-begin): 672
GPU Total Peak Memory consumed during the eval (max): 2654
CPU Memory before entering the eval : 19411
CPU Memory consumed at the end of the eval (end-begin): 0
CPU Peak Memory consumed during the eval (max-begin): 0
CPU Total Peak Memory consumed during the eval (max): 19411
accuracy=100.0
eval_preds[:10]=['no complaint', 'no complaint', 'complaint', 'complaint', 'no complaint', 'no complaint', 'no complaint', 'complaint', 'complaint', 'no complaint']
dataset['train'][label_column][:10]=['no complaint', 'no complaint', 'complaint', 'complaint', 'no complaint', 'no complaint', 'no complaint', 'complaint', 'complaint', 'no complaint']
```
================================================
FILE: envs/peft/docs/source/accelerate/fsdp.mdx
================================================
# Fully Sharded Data Parallel
[Fully sharded data parallel](https://pytorch.org/docs/stable/fsdp.html) (FSDP) is developed for distributed training of large pretrained models up to 1T parameters. FSDP achieves this by sharding the model parameters, gradients, and optimizer states across data parallel processes and it can also offload sharded model parameters to a CPU. The memory efficiency afforded by FSDP allows you to scale training to larger batch or model sizes.
<Tip warning={true}>
Currently, FSDP does not confer any reduction in GPU memory usage and FSDP with CPU offload actually consumes 1.65x more GPU memory during training. You can track this PyTorch [issue](https://github.com/pytorch/pytorch/issues/91165) for any updates.
</Tip>
FSDP is supported in 🤗 Accelerate, and you can use it with 🤗 PEFT. This guide will help you learn how to use our FSDP [training script](https://github.com/huggingface/peft/blob/main/examples/conditional_generation/peft_lora_seq2seq_accelerate_fsdp.py). You'll configure the script to train a large model for conditional generation.
## Configuration
Begin by running the following command to [create a FSDP configuration file](https://huggingface.co/docs/accelerate/main/en/usage_guides/fsdp) with 🤗 Accelerate. Use the `--config_file` flag to save the configuration file to a specific location, otherwise it is saved as a `default_config.yaml` file in the 🤗 Accelerate cache.
The configuration file is used to set the default options when you launch the training script.
```bash
accelerate config --config_file fsdp_config.yaml
```
You'll be asked a few questions about your setup, and configure the following arguments. For this example, make sure you fully shard the model parameters, gradients, optimizer states, leverage the CPU for offloading, and wrap model layers based on the Transformer layer class name.
```bash
`Sharding Strategy`: [1] FULL_SHARD (shards optimizer states, gradients and parameters), [2] SHARD_GRAD_OP (shards optimizer states and gradients), [3] NO_SHARD
`Offload Params`: Decides Whether to offload parameters and gradients to CPU
`Auto Wrap Policy`: [1] TRANSFORMER_BASED_WRAP, [2] SIZE_BASED_WRAP, [3] NO_WRAP
`Transformer Layer Class to Wrap`: When using `TRANSFORMER_BASED_WRAP`, user specifies comma-separated string of transformer layer class names (case-sensitive) to wrap ,e.g,
`BertLayer`, `GPTJBlock`, `T5Block`, `BertLayer,BertEmbeddings,BertSelfOutput`...
`Min Num Params`: minimum number of parameters when using `SIZE_BASED_WRAP`
`Backward Prefetch`: [1] BACKWARD_PRE, [2] BACKWARD_POST, [3] NO_PREFETCH
`State Dict Type`: [1] FULL_STATE_DICT, [2] LOCAL_STATE_DICT, [3] SHARDED_STATE_DICT
```
For example, your FSDP configuration file may look like the following:
```yaml
command_file: null
commands: null
compute_environment: LOCAL_MACHINE
deepspeed_config: {}
distributed_type: FSDP
downcast_bf16: 'no'
dynamo_backend: 'NO'
fsdp_config:
fsdp_auto_wrap_policy: TRANSFORMER_BASED_WRAP
fsdp_backward_prefetch_policy: BACKWARD_PRE
fsdp_offload_params: true
fsdp_sharding_strategy: 1
fsdp_state_dict_type: FULL_STATE_DICT
fsdp_transformer_layer_cls_to_wrap: T5Block
gpu_ids: null
machine_rank: 0
main_process_ip: null
main_process_port: null
main_training_function: main
megatron_lm_config: {}
mixed_precision: 'no'
num_machines: 1
num_processes: 2
rdzv_backend: static
same_network: true
tpu_name: null
tpu_zone: null
use_cpu: false
```
## The important parts
Let's dig a bit deeper into the training script to understand how it works.
The [`main()`](https://github.com/huggingface/peft/blob/2822398fbe896f25d4dac5e468624dc5fd65a51b/examples/conditional_generation/peft_lora_seq2seq_accelerate_fsdp.py#L14) function begins with initializing an [`~accelerate.Accelerator`] class which handles everything for distributed training, such as automatically detecting your training environment.
<Tip>
💡 Feel free to change the model and dataset inside the `main` function. If your dataset format is different from the one in the script, you may also need to write your own preprocessing function.
</Tip>
The script also creates a configuration corresponding to the 🤗 PEFT method you're using. For LoRA, you'll use [`LoraConfig`] to specify the task type, and several other important parameters such as the dimension of the low-rank matrices, the matrices scaling factor, and the dropout probability of the LoRA layers. If you want to use a different 🤗 PEFT method, replace `LoraConfig` with the appropriate [class](../package_reference/tuners).
Next, the script wraps the base model and `peft_config` with the [`get_peft_model`] function to create a [`PeftModel`].
```diff
def main():
+ accelerator = Accelerator()
model_name_or_path = "t5-base"
base_path = "temp/data/FinancialPhraseBank-v1.0"
+ peft_config = LoraConfig(
task_type=TaskType.SEQ_2_SEQ_LM, inference_mode=False, r=8, lora_alpha=32, lora_dropout=0.1
)
model = AutoModelForSeq2SeqLM.from_pretrained(model_name_or_path)
+ model = get_peft_model(model, peft_config)
```
Throughout the script, you'll see the [`~accelerate.Accelerator.main_process_first`] and [`~accelerate.Accelerator.wait_for_everyone`] functions which help control and synchronize when processes are executed.
After your dataset is prepared, and all the necessary training components are loaded, the script checks if you're using the `fsdp_plugin`. PyTorch offers two ways for wrapping model layers in FSDP, automatically or manually. The simplest method is to allow FSDP to automatically recursively wrap model layers without changing any other code. You can choose to wrap the model layers based on the layer name or on the size (number of parameters). In the FSDP configuration file, it uses the `TRANSFORMER_BASED_WRAP` option to wrap the [`T5Block`] layer.
```py
if getattr(accelerator.state, "fsdp_plugin", None) is not None:
accelerator.state.fsdp_plugin.auto_wrap_policy = fsdp_auto_wrap_policy(model)
```
Next, use 🤗 Accelerate's [`~accelerate.Accelerator.prepare`] function to prepare the model, datasets, optimizer, and scheduler for training.
```py
model, train_dataloader, eval_dataloader, optimizer, lr_scheduler = accelerator.prepare(
model, train_dataloader, eval_dataloader, optimizer, lr_scheduler
)
```
From here, the remainder of the script handles the training loop, evaluation, and sharing your model to the Hub.
## Train
Run the following command to launch the training script. Earlier, you saved the configuration file to `fsdp_config.yaml`, so you'll need to pass the path to the launcher with the `--config_file` argument like this:
```bash
accelerate launch --config_file fsdp_config.yaml examples/peft_lora_seq2seq_accelerate_fsdp.py
```
Once training is complete, the script returns the accuracy and compares the predictions to the labels.
================================================
FILE: envs/peft/docs/source/conceptual_guides/ia3.mdx
================================================
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# IA3
This conceptual guide gives a brief overview of [IA3](https://arxiv.org/abs/2205.05638), a parameter-efficient fine tuning technique that is
intended to improve over [LoRA](./lora).
To make fine-tuning more efficient, IA3 (Infused Adapter by Inhibiting and Amplifying Inner Activations)
rescales inner activations with learned vectors. These learned vectors are injected in the attention and feedforward modules
in a typical transformer-based architecture. These learned vectors are the only trainable parameters during fine-tuning, and thus the original
weights remain frozen. Dealing with learned vectors (as opposed to learned low-rank updates to a weight matrix like LoRA)
keeps the number of trainable parameters much smaller.
Being similar to LoRA, IA3 carries many of the same advantages:
* IA3 makes fine-tuning more efficient by drastically reducing the number of trainable parameters. (For T0, an IA3 model only has about 0.01% trainable parameters, while even LoRA has > 0.1%)
* The original pre-trained weights are kept frozen, which means you can have multiple lightweight and portable IA3 models for various downstream tasks built on top of them.
* Performance of models fine-tuned using IA3 is comparable to the performance of fully fine-tuned models.
* IA3 does not add any inference latency because adapter weights can be merged with the base model.
In principle, IA3 can be applied to any subset of weight matrices in a neural network to reduce the number of trainable
parameters. Following the authors' implementation, IA3 weights are added to the key, value and feedforward layers
of a Transformer model. Given the target layers for injecting IA3 parameters, the number of trainable parameters
can be determined based on the size of the weight matrices.
## Common IA3 parameters in PEFT
As with other methods supported by PEFT, to fine-tune a model using IA3, you need to:
1. Instantiate a base model.
2. Create a configuration (`IA3Config`) where you define IA3-specific parameters.
3. Wrap the base model with `get_peft_model()` to get a trainable `PeftModel`.
4. Train the `PeftModel` as you normally would train the base model.
`IA3Config` allows you to control how IA3 is applied to the base model through the following parameters:
- `target_modules`: The modules (for example, attention blocks) to apply the IA3 vectors.
- `feedforward_modules`: The list of modules to be treated as feedforward layers in `target_modules`. While learned vectors are multiplied with
the output activation for attention blocks, the vectors are multiplied with the input for classic feedforward layers.
- `modules_to_save`: List of modules apart from IA3 layers to be set as trainable and saved in the final checkpoint. These typically include model's custom head that is randomly initialized for the fine-tuning task.
================================================
FILE: envs/peft/docs/source/conceptual_guides/lora.mdx
================================================
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# LoRA
This conceptual guide gives a brief overview of [LoRA](https://arxiv.org/abs/2106.09685), a technique that accelerates
the fine-tuning of large models while consuming less memory.
To make fine-tuning more efficient, LoRA's approach is to represent the weight updates with two smaller
matrices (called **update matrices**) through low-rank decomposition. These new matrices can be trained to adapt to the
new data while keeping the overall number of changes low. The original weight matrix remains frozen and doesn't receive
any further adjustments. To produce the final results, both the original and the adapted weights are combined.
This approach has a number of advantages:
* LoRA makes fine-tuning more efficient by drastically reducing the number of trainable parameters.
* The original pre-trained weights are kept frozen, which means you can have multiple lightweight and portable LoRA models for various downstream tasks built on top of them.
* LoRA is orthogonal to many other parameter-efficient methods and can be combined with many of them.
* Performance of models fine-tuned using LoRA is comparable to the performance of fully fine-tuned models.
* LoRA does not add any inference latency because adapter weights can be merged with the base model.
In principle, LoRA can be applied to any subset of weight matrices in a neural network to reduce the number of trainable
parameters. However, for simplicity and further parameter efficiency, in Transformer models LoRA is typically applied to
attention blocks only. The resulting number of trainable parameters in a LoRA model depends on the size of the low-rank
update matrices, which is determined mainly by the rank `r` and the shape of the original weight matrix.
## Merge LoRA weights into the base model
While LoRA is significantly smaller and faster to train, you may encounter latency issues during inference due to separately loading the base model and the LoRA model. To eliminate latency, use the [`~LoraModel.merge_and_unload`] function to merge the adapter weights with the base model which allows you to effectively use the newly merged model as a standalone model.
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/peft/lora_diagram.png"/>
</div>
This works because during training, the smaller weight matrices (*A* and *B* in the diagram above) are separate. But once training is complete, the weights can actually be merged into a new weight matrix that is identical.
## Utils for LoRA
Use [`~LoraModel.merge_adapter`] to merge the LoRa layers into the base model while retaining the PeftModel.
This will help in later unmerging, deleting, loading different adapters and so on.
Use [`~LoraModel.unmerge_adapter`] to unmerge the LoRa layers from the base model while retaining the PeftModel.
This will help in later merging, deleting, loading different adapters and so on.
Use [`~LoraModel.unload`] to get back the base model without the merging of the active lora modules.
This will help when you want to get back the pretrained base model in some applications when you want to reset the model to its original state.
For example, in Stable Diffusion WebUi, when the user wants to infer with base model post trying out LoRAs.
Use [`~LoraModel.delete_adapter`] to delete an existing adapter.
Use [`~LoraModel.add_weighted_adapter`] to combine multiple LoRAs into a new adapter based on the user provided weighing scheme.
## Common LoRA parameters in PEFT
As with other methods supported by PEFT, to fine-tune a model using LoRA, you need to:
1. Instantiate a base model.
2. Create a configuration (`LoraConfig`) where you define LoRA-specific parameters.
3. Wrap the base model with `get_peft_model()` to get a trainable `PeftModel`.
4. Train the `PeftModel` as you normally would train the base model.
`LoraConfig` allows you to control how LoRA is applied to the base model through the following parameters:
- `r`: the rank of the update matrices, expressed in `int`. Lower rank results in smaller update matrices with fewer trainable parameters.
- `target_modules`: The modules (for example, attention blocks) to apply the LoRA update matrices.
- `alpha`: LoRA scaling factor.
- `bias`: Specifies if the `bias` parameters should be trained. Can be `'none'`, `'all'` or `'lora_only'`.
- `modules_to_save`: List of modules apart from LoRA layers to be set as trainable and saved in the final checkpoint. These typically include model's custom head that is randomly initialized for the fine-tuning task.
- `layers_to_transform`: List of layers to be transformed by LoRA. If not specified, all layers in `target_modules` are transformed.
- `layers_pattern`: Pattern to match layer names in `target_modules`, if `layers_to_transform` is specified. By default `PeftModel` will look at common layer pattern (`layers`, `h`, `blocks`, etc.), use it for exotic and custom models.
## LoRA examples
For an example of LoRA method application to various downstream tasks, please refer to the following guides:
* [Image classification using LoRA](../task_guides/image_classification_lora)
* [Semantic segmentation](../task_guides/semantic_segmentation_lora)
While the original paper focuses on language models, the technique can be applied to any dense layers in deep learning
models. As such, you can leverage this technique with diffusion models. See [Dreambooth fine-tuning with LoRA](../task_guides/task_guides/dreambooth_lora) task guide for an example.
================================================
FILE: envs/peft/docs/source/conceptual_guides/prompting.mdx
================================================
# Prompting
Training large pretrained language models is very time-consuming and compute-intensive. As they continue to grow in size, there is increasing interest in more efficient training methods such as *prompting*. Prompting primes a frozen pretrained model for a specific downstream task by including a text prompt that describes the task or even demonstrates an example of the task. With prompting, you can avoid fully training a separate model for each downstream task, and use the same frozen pretrained model instead. This is a lot easier because you can use the same model for several different tasks, and it is significantly more efficient to train and store a smaller set of prompt parameters than to train all the model's parameters.
There are two categories of prompting methods:
- hard prompts are manually handcrafted text prompts with discrete input tokens; the downside is that it requires a lot of effort to create a good prompt
- soft prompts are learnable tensors concatenated with the input embeddings that can be optimized to a dataset; the downside is that they aren't human readable because you aren't matching these "virtual tokens" to the embeddings of a real word
This conceptual guide provides a brief overview of the soft prompt methods included in 🤗 PEFT: prompt tuning, prefix tuning, and P-tuning.
## Prompt tuning
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/peft/prompt-tuning.png"/>
</div>
<small>Only train and store a significantly smaller set of task-specific prompt parameters <a href="https://arxiv.org/abs/2104.08691">(image source)</a>.</small>
Prompt tuning was developed for text classification tasks on T5 models, and all downstream tasks are cast as a text generation task. For example, sequence classification usually assigns a single class label to a sequence of text. By casting it as a text generation task, the tokens that make up the class label are *generated*. Prompts are added to the input as a series of tokens. Typically, the model parameters are fixed which means the prompt tokens are also fixed by the model parameters.
The key idea behind prompt tuning is that prompt tokens have their own parameters that are updated independently. This means you can keep the pretrained model's parameters frozen, and only update the gradients of the prompt token embeddings. The results are comparable to the traditional method of training the entire model, and prompt tuning performance scales as model size increases.
Take a look at [Prompt tuning for causal language modeling](../task_guides/clm-prompt-tuning) for a step-by-step guide on how to train a model with prompt tuning.
## Prefix tuning
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/peft/prefix-tuning.png"/>
</div>
<small>Optimize the prefix parameters for each task <a href="https://arxiv.org/abs/2101.00190">(image source)</a>.</small>
Prefix tuning was designed for natural language generation (NLG) tasks on GPT models. It is very similar to prompt tuning; prefix tuning also prepends a sequence of task-specific vectors to the input that can be trained and updated while keeping the rest of the pretrained model's parameters frozen.
The main difference is that the prefix parameters are inserted in **all** of the model layers, whereas prompt tuning only adds the prompt parameters to the model input embeddings. The prefix parameters are also optimized by a separate feed-forward network (FFN) instead of training directly on the soft prompts because it causes instability and hurts performance. The FFN is discarded after updating the soft prompts.
As a result, the authors found that prefix tuning demonstrates comparable performance to fully finetuning a model, despite having 1000x fewer parameters, and it performs even better in low-data settings.
Take a look at [Prefix tuning for conditional generation](../task_guides/seq2seq-prefix-tuning) for a step-by-step guide on how to train a model with prefix tuning.
## P-tuning
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/peft/p-tuning.png"/>
</div>
<small>Prompt tokens can be inserted anywhere in the input sequence, and they are optimized by a prompt encoder <a href="https://arxiv.org/abs/2103.10385">(image source)</a>.</small>
P-tuning is designed for natural language understanding (NLU) tasks and all language models.
It is another variation of a soft prompt method; P-tuning also adds a trainable embedding tensor that can be optimized to find better prompts, and it uses a prompt encoder (a bidirectional long-short term memory network or LSTM) to optimize the prompt parameters. Unlike prefix tuning though:
- the prompt tokens can be inserted anywhere in the input sequence, and it isn't restricted to only the beginning
- the prompt tokens are only added to the input instead of adding them to every layer of the model
- introducing *anchor* tokens can improve performance because they indicate characteristics of a component in the input sequence
The results suggest that P-tuning is more efficient than manually crafting prompts, and it enables GPT-like models to compete with BERT-like models on NLU tasks.
Take a look at [P-tuning for sequence classification](../task_guides/ptuning-seq-classification) for a step-by-step guide on how to train a model with P-tuning.
================================================
FILE: envs/peft/docs/source/index.mdx
================================================
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# PEFT
🤗 PEFT, or Parameter-Efficient Fine-Tuning (PEFT), is a library for efficiently adapting pre-trained language models (PLMs) to various downstream applications without fine-tuning all the model's parameters.
PEFT methods only fine-tune a small number of (extra) model parameters, significantly decreasing computational and storage costs because fine-tuning large-scale PLMs is prohibitively costly.
Recent state-of-the-art PEFT techniques achieve performance comparable to that of full fine-tuning.
PEFT is seamlessly integrated with 🤗 Accelerate for large-scale models leveraging DeepSpeed and [Big Model Inference](https://huggingface.co/docs/accelerate/usage_guides/big_modeling).
<div class="mt-10">
<div class="w-full flex flex-col space-y-4 md:space-y-0 md:grid md:grid-cols-2 md:gap-y-4 md:gap-x-5">
<a class="!no-underline border dark:border-gray-700 p-5 rounded-lg shadow hover:shadow-lg" href="quicktour"
><div class="w-full text-center bg-gradient-to-br from-blue-400 to-blue-500 rounded-lg py-1.5 font-semibold mb-5 text-white text-lg leading-relaxed">Get started</div>
<p class="text-gray-700">Start here if you're new to 🤗 PEFT to get an overview of the library's main features, and how to train a model with a PEFT method.</p>
</a>
<a class="!no-underline border dark:border-gray-700 p-5 rounded-lg shadow hover:shadow-lg" href="./task_guides/image_classification_lora"
><div class="w-full text-center bg-gradient-to-br from-indigo-400 to-indigo-500 rounded-lg py-1.5 font-semibold mb-5 text-white text-lg leading-relaxed">How-to guides</div>
<p class="text-gray-700">Practical guides demonstrating how to apply various PEFT methods across different types of tasks like image classification, causal language modeling, automatic speech recognition, and more. Learn how to use 🤗 PEFT with the DeepSpeed and Fully Sharded Data Parallel scripts.</p>
</a>
<a class="!no-underline border dark:border-gray-700 p-5 rounded-lg shadow hover:shadow-lg" href="./conceptual_guides/lora"
><div class="w-full text-center bg-gradient-to-br from-pink-400 to-pink-500 rounded-lg py-1.5 font-semibold mb-5 text-white text-lg leading-relaxed">Conceptual guides</div>
<p class="text-gray-700">Get a better theoretical understanding of how LoRA and various soft prompting methods help reduce the number of trainable parameters to make training more efficient.</p>
</a>
<a class="!no-underline border dark:border-gray-700 p-5 rounded-lg shadow hover:shadow-lg" href="./package_reference/config"
><div class="w-full text-center bg-gradient-to-br from-purple-400 to-purple-500 rounded-lg py-1.5 font-semibold mb-5 text-white text-lg leading-relaxed">Reference</div>
<p class="text-gray-700">Technical descriptions of how 🤗 PEFT classes and methods work.</p>
</a>
</div>
</div>
## Supported methods
1. LoRA: [LORA: LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS](https://arxiv.org/pdf/2106.09685.pdf)
2. Prefix Tuning: [Prefix-Tuning: Optimizing Continuous Prompts for Generation](https://aclanthology.org/2021.acl-long.353/), [P-Tuning v2: Prompt Tuning Can Be Comparable to Fine-tuning Universally Across Scales and Tasks](https://arxiv.org/pdf/2110.07602.pdf)
3. P-Tuning: [GPT Understands, Too](https://arxiv.org/pdf/2103.10385.pdf)
4. Prompt Tuning: [The Power of Scale for Parameter-Efficient Prompt Tuning](https://arxiv.org/pdf/2104.08691.pdf)
5. AdaLoRA: [Adaptive Budget Allocation for Parameter-Efficient Fine-Tuning](https://arxiv.org/abs/2303.10512)
6. [LLaMA-Adapter: Efficient Fine-tuning of Language Models with Zero-init Attention](https://github.com/ZrrSkywalker/LLaMA-Adapter)
7. IA3: [Infused Adapter by Inhibiting and Amplifying Inner Activations](https://arxiv.org/abs/2205.05638)
## Supported models
The tables provided below list the PEFT methods and models supported for each task. To apply a particular PEFT method for
a task, please refer to the corresponding Task guides.
### Causal Language Modeling
| Model | LoRA | Prefix Tuning | P-Tuning | Prompt Tuning | IA3 |
|--------------| ---- | ---- | ---- | ---- | ---- |
| GPT-2 | ✅ | ✅ | ✅ | ✅ | ✅ |
| Bloom | ✅ | ✅ | ✅ | ✅ | ✅ |
| OPT | ✅ | ✅ | ✅ | ✅ | ✅ |
| GPT-Neo | ✅ | ✅ | ✅ | ✅ | ✅ |
| GPT-J | ✅ | ✅ | ✅ | ✅ | ✅ |
| GPT-NeoX-20B | ✅ | ✅ | ✅ | ✅ | ✅ |
| LLaMA | ✅ | ✅ | ✅ | ✅ | ✅ |
| ChatGLM | ✅ | ✅ | ✅ | ✅ | ✅ |
### Conditional Generation
| Model | LoRA | Prefix Tuning | P-Tuning | Prompt Tuning | IA3 |
| --------- | ---- | ---- | ---- | ---- | ---- |
| T5 | ✅ | ✅ | ✅ | ✅ | ✅ |
| BART | ✅ | ✅ | ✅ | ✅ | ✅ |
### Sequence Classification
| Model | LoRA | Prefix Tuning | P-Tuning | Prompt Tuning | IA3 |
| --------- | ---- | ---- | ---- | ---- | ---- |
| BERT | ✅ | ✅ | ✅ | ✅ | ✅ |
| RoBERTa | ✅ | ✅ | ✅ | ✅ | ✅ |
| GPT-2 | ✅ | ✅ | ✅ | ✅ | |
| Bloom | ✅ | ✅ | ✅ | ✅ | |
| OPT | ✅ | ✅ | ✅ | ✅ | |
| GPT-Neo | ✅ | ✅ | ✅ | ✅ | |
| GPT-J | ✅ | ✅ | ✅ | ✅ | |
| Deberta | ✅ | | ✅ | ✅ | |
| Deberta-v2 | ✅ | | ✅ | ✅ | |
### Token Classification
| Model | LoRA | Prefix Tuning | P-Tuning | Prompt Tuning | IA3 |
| --------- | ---- | ---- | ---- | ---- | --- |
| BERT | ✅ | ✅ | | | |
| RoBERTa | ✅ | ✅ | | | |
| GPT-2 | ✅ | ✅ | | | |
| Bloom | ✅ | ✅ | | | |
| OPT | ✅ | ✅ | | | |
| GPT-Neo | ✅ | ✅ | | | |
| GPT-J | ✅ | ✅ | | | |
| Deberta | ✅ | | | | |
| Deberta-v2 | ✅ | | | | |
### Text-to-Image Generation
| Model | LoRA | Prefix Tuning | P-Tuning | Prompt Tuning | IA3 |
| --------- | ---- | ---- | ---- | ---- | ---- |
| Stable Diffusion | ✅ | | | | |
### Image Classification
| Model | LoRA | Prefix Tuning | P-Tuning | Prompt Tuning | IA3 |
| --------- | ---- | ---- | ---- | ---- | ---- | ---- |
| ViT | ✅ | | | | |
| Swin | ✅ | | | | |
### Image to text (Multi-modal models)
We have tested LoRA for [ViT](https://huggingface.co/docs/transformers/model_doc/vit) and [Swin](https://huggingface.co/docs/transformers/model_doc/swin) for fine-tuning on image classification.
However, it should be possible to use LoRA for any [ViT-based model](https://huggingface.co/models?pipeline_tag=image-classification&sort=downloads&search=vit) from 🤗 Transformers.
Check out the [Image classification](/task_guides/image_classification_lora) task guide to learn more. If you run into problems, please open an issue.
| Model | LoRA | Prefix Tuning | P-Tuning | Prompt Tuning | IA3 |
| --------- | ---- | ---- | ---- | ---- | ---- |
| Blip-2 | ✅ | | | | |
### Semantic Segmentation
As with image-to-text models, you should be able to apply LoRA to any of the [segmentation models](https://huggingface.co/models?pipeline_tag=image-segmentation&sort=downloads).
It's worth noting that we haven't tested this with every architecture yet. Therefore, if you come across any issues, kindly create an issue report.
| Model | LoRA | Prefix Tuning | P-Tuning | Prompt Tuning | IA3 |
| --------- | ---- | ---- | ---- | ---- | ---- |
| SegFormer | ✅ | | | | |
================================================
FILE: envs/peft/docs/source/install.mdx
================================================
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# Installation
Before you start, you will need to setup your environment, install the appropriate packages, and configure 🤗 PEFT. 🤗 PEFT is tested on **Python 3.8+**.
🤗 PEFT is available on PyPI, as well as GitHub:
## PyPI
To install 🤗 PEFT from PyPI:
```bash
pip install peft
```
## Source
New features that haven't been released yet are added every day, which also means there may be some bugs. To try them out, install from the GitHub repository:
```bash
pip install git+https://github.com/huggingface/peft
```
If you're working on contributing to the library or wish to play with the source code and see live
results as you run the code, an editable version can be installed from a locally-cloned version of the
repository:
```bash
git clone https://github.com/huggingface/peft
cd peft
pip install -e .
```
================================================
FILE: envs/peft/docs/source/package_reference/config.mdx
================================================
# Configuration
The configuration classes stores the configuration of a [`PeftModel`], PEFT adapter models, and the configurations of [`PrefixTuning`], [`PromptTuning`], and [`PromptEncoder`]. They contain methods for saving and loading model configurations from the Hub, specifying the PEFT method to use, type of task to perform, and model configurations like number of layers and number of attention heads.
## PeftConfigMixin
[[autodoc]] utils.config.PeftConfigMixin
- all
## PeftConfig
[[autodoc]] PeftConfig
- all
## PromptLearningConfig
[[autodoc]] PromptLearningConfig
- all
================================================
FILE: envs/peft/docs/source/package_reference/peft_model.mdx
================================================
# Models
[`PeftModel`] is the base model class for specifying the base Transformer model and configuration to apply a PEFT method to. The base `PeftModel` contains methods for loading and saving models from the Hub, and supports the [`PromptEncoder`] for prompt learning.
## PeftModel
[[autodoc]] PeftModel
- all
## PeftModelForSequenceClassification
A `PeftModel` for sequence classification tasks.
[[autodoc]] PeftModelForSequenceClassification
- all
## PeftModelForTokenClassification
A `PeftModel` for token classification tasks.
[[autodoc]] PeftModelForTokenClassification
- all
## PeftModelForCausalLM
A `PeftModel` for causal language modeling.
[[autodoc]] PeftModelForCausalLM
- all
## PeftModelForSeq2SeqLM
A `PeftModel` for sequence-to-sequence language modeling.
[[autodoc]] PeftModelForSeq2SeqLM
- all
## PeftModelForQuestionAnswering
A `PeftModel` for question answering.
[[autodoc]] PeftModelForQuestionAnswering
- all
## PeftModelForFeatureExtraction
A `PeftModel` for getting extracting features/embeddings from transformer models.
[[autodoc]] PeftModelForFeatureExtraction
- all
================================================
FILE: envs/peft/docs/source/package_reference/tuners.mdx
================================================
# Tuners
Each tuner (or PEFT method) has a configuration and model.
## LoRA
For finetuning a model with LoRA.
[[autodoc]] LoraConfig
[[autodoc]] LoraModel
[[autodoc]] tuners.lora.LoraLayer
[[autodoc]] tuners.lora.Linear
## P-tuning
[[autodoc]] tuners.p_tuning.PromptEncoderConfig
[[autodoc]] tuners.p_tuning.PromptEncoder
## Prefix tuning
[[autodoc]] tuners.prefix_tuning.PrefixTuningConfig
[[autodoc]] tuners.prefix_tuning.PrefixEncoder
## Prompt tuning
[[autodoc]] tuners.prompt_tuning.PromptTuningConfig
[[autodoc]] tuners.prompt_tuning.PromptEmbedding
## IA3
[[autodoc]] tuners.ia3.IA3Config
[[autodoc]] tuners.ia3.IA3Model
================================================
FILE: envs/peft/docs/source/quicktour.mdx
================================================
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# Quicktour
🤗 PEFT contains parameter-efficient finetuning methods for training large pretrained models. The traditional paradigm is to finetune all of a model's parameters for each downstream task, but this is becoming exceedingly costly and impractical because of the enormous number of parameters in models today. Instead, it is more efficient to train a smaller number of prompt parameters or use a reparametrization method like low-rank adaptation (LoRA) to reduce the number of trainable parameters.
This quicktour will show you 🤗 PEFT's main features and help you train large pretrained models that would typically be inaccessible on consumer devices. You'll see how to train the 1.2B parameter [`bigscience/mt0-large`](https://huggingface.co/bigscience/mt0-large) model with LoRA to generate a classification label and use it for inference.
## PeftConfig
Each 🤗 PEFT method is defined by a [`PeftConfig`] class that stores all the important parameters for building a [`PeftModel`].
Because you're going to use LoRA, you'll need to load and create a [`LoraConfig`] class. Within `LoraConfig`, specify the following parameters:
- the `task_type`, or sequence-to-sequence language modeling in this case
- `inference_mode`, whether you're using the model for inference or not
- `r`, the dimension of the low-rank matrices
- `lora_alpha`, the scaling factor for the low-rank matrices
- `lora_dropout`, the dropout probability of the LoRA layers
```python
from peft import LoraConfig, TaskType
peft_config = LoraConfig(task_type=TaskType.SEQ_2_SEQ_LM, inference_mode=False, r=8, lora_alpha=32, lora_dropout=0.1)
```
<Tip>
💡 See the [`LoraConfig`] reference for more details about other parameters you can adjust.
</Tip>
## PeftModel
A [`PeftModel`] is created by the [`get_peft_model`] function. It takes a base model - which you can load from the 🤗 Transformers library - and the [`PeftConfig`] containing the instructions for how to configure a model for a specific 🤗 PEFT method.
Start by loading the base model you want to finetune.
```python
from transformers import AutoModelForSeq2SeqLM
model_name_or_path = "bigscience/mt0-large"
tokenizer_name_or_path = "bigscience/mt0-large"
model = AutoModelForSeq2SeqLM.from_pretrained(model_name_or_path)
```
Wrap your base model and `peft_config` with the `get_peft_model` function to create a [`PeftModel`]. To get a sense of the number of trainable parameters in your model, use the [`print_trainable_parameters`] method. In this case, you're only training 0.19% of the model's parameters! 🤏
```python
from peft import get_peft_model
model = get_peft_model(model, peft_config)
model.print_trainable_parameters()
"output: trainable params: 2359296 || all params: 1231940608 || trainable%: 0.19151053100118282"
```
That is it 🎉! Now you can train the model using the 🤗 Transformers [`~transformers.Trainer`], 🤗 Accelerate, or any custom PyTorch training loop.
## Save and load a model
After your model is finished training, you can save your model to a directory using the [`~transformers.PreTrainedModel.save_pretrained`] function. You can also save your model to the Hub (make sure you log in to your Hugging Face account first) with the [`~transformers.PreTrainedModel.push_to_hub`] function.
```python
model.save_pretrained("output_dir")
# if pushing to Hub
from huggingface_hub import notebook_login
notebook_login()
model.push_to_hub("my_awesome_peft_model")
```
This only saves the incremental 🤗 PEFT weights that were trained, meaning it is super efficient to store, transfer, and load. For example, this [`bigscience/T0_3B`](https://huggingface.co/smangrul/twitter_complaints_bigscience_T0_3B_LORA_SEQ_2_SEQ_LM) model trained with LoRA on the [`twitter_complaints`](https://huggingface.co/datasets/ought/raft/viewer/twitter_complaints/train) subset of the RAFT [dataset](https://huggingface.co/datasets/ought/raft) only contains two files: `adapter_config.json` and `adapter_model.bin`. The latter file is just 19MB!
Easily load your model for inference using the [`~transformers.PreTrainedModel.from_pretrained`] function:
```diff
from transformers import AutoModelForSeq2SeqLM
+ from peft import PeftModel, PeftConfig
+ peft_model_id = "smangrul/twitter_complaints_bigscience_T0_3B_LORA_SEQ_2_SEQ_LM"
+ config = PeftConfig.from_pretrained(peft_model_id)
model = AutoModelForSeq2SeqLM.from_pretrained(config.base_model_name_or_path)
+ model = PeftModel.from_pretrained(model, peft_model_id)
tokenizer = AutoTokenizer.from_pretrained(config.base_model_name_or_path)
model = model.to(device)
model.eval()
inputs = tokenizer("Tweet text : @HondaCustSvc Your customer service has been horrible during the recall process. I will never purchase a Honda again. Label :", return_tensors="pt")
with torch.no_grad():
outputs = model.generate(input_ids=inputs["input_ids"].to("cuda"), max_new_tokens=10)
print(tokenizer.batch_decode(outputs.detach().cpu().numpy(), skip_special_tokens=True)[0])
'complaint'
```
## Easy loading with Auto classes
If you have saved your adapter locally or on the Hub, you can leverage the `AutoPeftModelForxxx` classes and load any PEFT model with a single line of code:
```diff
- from peft import PeftConfig, PeftModel
- from transformers import AutoModelForCausalLM
+ from peft import AutoPeftModelForCausalLM
- peft_config = PeftConfig.from_pretrained("ybelkada/opt-350m-lora")
- base_model_path = peft_config.base_model_name_or_path
- transformers_model = AutoModelForCausalLM.from_pretrained(base_model_path)
- peft_model = PeftModel.from_pretrained(transformers_model, peft_config)
+ peft_model = AutoPeftModelForCausalLM.from_pretrained("ybelkada/opt-350m-lora")
```
Currently, supported auto classes are: `AutoPeftModelForCausalLM`, `AutoPeftModelForSequenceClassification`, `AutoPeftModelForSeq2SeqLM`, `AutoPeftModelForTokenClassification`, `AutoPeftModelForQuestionAnswering` and `AutoPeftModelForFeatureExtraction`. For other tasks (e.g. Whisper, StableDiffusion), you can load the model with:
```diff
- from peft import PeftModel, PeftConfig, AutoPeftModel
+ from peft import AutoPeftModel
- from transformers import WhisperForConditionalGeneration
- model_id = "smangrul/openai-whisper-large-v2-LORA-colab"
peft_model_id = "smangrul/openai-whisper-large-v2-LORA-colab"
- peft_config = PeftConfig.from_pretrained(peft_model_id)
- model = WhisperForConditionalGeneration.from_pretrained(
- peft_config.base_model_name_or_path, load_in_8bit=True, device_map="auto"
- )
- model = PeftModel.from_pretrained(model, peft_model_id)
+ model = AutoPeftModel.from_pretrained(peft_model_id)
```
## Next steps
Now that you've seen how to train a model with one of the 🤗 PEFT methods, we encourage you to try out some of the other methods like prompt tuning. The steps are very similar to the ones shown in this quickstart; prepare a [`PeftConfig`] for a 🤗 PEFT method, and use the `get_peft_model` to create a [`PeftModel`] from the configuration and base model. Then you can train it however you like!
Feel free to also take a look at the task guides if you're interested in training a model with a 🤗 PEFT method for a specific task such as semantic segmentation, multilingual automatic speech recognition, DreamBooth, and token classification.
================================================
FILE: envs/peft/docs/source/task_guides/clm-prompt-tuning.mdx
================================================
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# Prompt tuning for causal language modeling
[[open-in-colab]]
Prompting helps guide language model behavior by adding some input text specific to a task. Prompt tuning is an additive method for only training and updating the newly added prompt tokens to a pretrained model. This way, you can use one pretrained model whose weights are frozen, and train and update a smaller set of prompt parameters for each downstream task instead of fully finetuning a separate model. As models grow larger and larger, prompt tuning can be more efficient, and results are even better as model parameters scale.
<Tip>
💡 Read [The Power of Scale for Parameter-Efficient Prompt Tuning](https://arxiv.org/abs/2104.08691) to learn more about prompt tuning.
</Tip>
This guide will show you how to apply prompt tuning to train a [`bloomz-560m`](https://huggingface.co/bigscience/bloomz-560m) model on the `twitter_complaints` subset of the [RAFT](https://huggingface.co/datasets/ought/raft) dataset.
Before you begin, make sure you have all the necessary libraries installed:
```bash
!pip install -q peft transformers datasets
```
## Setup
Start by defining the model and tokenizer, the dataset and the dataset columns to train on, some training hyperparameters, and the [`PromptTuningConfig`]. The [`PromptTuningConfig`] contains information about the task type, the text to initialize the prompt embedding, the number of virtual tokens, and the tokenizer to use:
```py
from transformers import AutoModelForCausalLM, AutoTokenizer, default_data_collator, get_linear_schedule_with_warmup
from peft import get_peft_config, get_peft_model, PromptTuningInit, PromptTuningConfig, TaskType, PeftType
import torch
from datasets import load_dataset
import os
from torch.utils.data import DataLoader
from tqdm import tqdm
device = "cuda"
model_name_or_path = "bigscience/bloomz-560m"
tokenizer_name_or_path = "bigscience/bloomz-560m"
peft_config = PromptTuningConfig(
task_type=TaskType.CAUSAL_LM,
prompt_tuning_init=PromptTuningInit.TEXT,
num_virtual_tokens=8,
prompt_tuning_init_text="Classify if the tweet is a complaint or not:",
tokenizer_name_or_path=model_name_or_path,
)
dataset_name = "twitter_complaints"
checkpoint_name = f"{dataset_name}_{model_name_or_path}_{peft_config.peft_type}_{peft_config.task_type}_v1.pt".replace(
"/", "_"
)
text_column = "Tweet text"
label_column = "text_label"
max_length = 64
lr = 3e-2
num_epochs = 50
batch_size = 8
```
## Load dataset
For this guide, you'll load the `twitter_complaints` subset of the [RAFT](https://huggingface.co/datasets/ought/raft) dataset. This subset contains tweets that are labeled either `complaint` or `no complaint`:
```py
dataset = load_dataset("ought/raft", dataset_name)
dataset["train"][0]
{"Tweet text": "@HMRCcustomers No this is my first job", "ID": 0, "Label": 2}
```
To make the `Label` column more readable, replace the `Label` value with the corresponding label text and store them in a `text_label` column. You can use the [`~datasets.Dataset.map`] function to apply this change over the entire dataset in one step:
```py
classes = [k.replace("_", " ") for k in dataset["train"].features["Label"].names]
dataset = dataset.map(
lambda x: {"text_label": [classes[label] for label in x["Label"]]},
batched=True,
num_proc=1,
)
dataset["train"][0]
{"Tweet text": "@HMRCcustomers No this is my first job", "ID": 0, "Label": 2, "text_label": "no complaint"}
```
## Preprocess dataset
Next, you'll setup a tokenizer; configure the appropriate padding token to use for padding sequences, and determine the maximum length of the tokenized labels:
```py
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path)
if tokenizer.pad_token_id is None:
tokenizer.pad_token_id = tokenizer.eos_token_id
target_max_length = max([len(tokenizer(class_label)["input_ids"]) for class_label in classes])
print(target_max_length)
3
```
Create a `preprocess_function` to:
1. Tokenize the input text and labels.
2. For each example in a batch, pad the labels with the tokenizers `pad_token_id`.
3. Concatenate the input text and labels into the `model_inputs`.
4. Create a separate attention mask for `labels` and `model_inputs`.
5. Loop through each example in the batch again to pad the input ids, labels, and attention mask to the `max_length` and convert them to PyTorch tensors.
```py
def preprocess_function(examples):
batch_size = len(examples[text_column])
inputs = [f"{text_column} : {x} Label : " for x in examples[text_column]]
targets = [str(x) for x in examples[label_column]]
model_inputs = tokenizer(inputs)
labels = tokenizer(targets)
for i in range(batch_size):
sample_input_ids = model_inputs["input_ids"][i]
label_input_ids = labels["input_ids"][i] + [tokenizer.pad_token_id]
# print(i, sample_input_ids, label_input_ids)
model_inputs["input_ids"][i] = sample_input_ids + label_input_ids
labels["input_ids"][i] = [-100] * len(sample_input_ids) + label_input_ids
model_inputs["attention_mask"][i] = [1] * len(model_inputs["input_ids"][i])
# print(model_inputs)
for i in range(batch_size):
sample_input_ids = model_inputs["input_ids"][i]
label_input_ids = labels["input_ids"][i]
model_inputs["input_ids"][i] = [tokenizer.pad_token_id] * (
max_length - len(sample_input_ids)
) + sample_input_ids
model_inputs["attention_mask"][i] = [0] * (max_length - len(sample_input_ids)) + model_inputs[
"attention_mask"
][i]
labels["input_ids"][i] = [-100] * (max_length - len(sample_input_ids)) + label_input_ids
model_inputs["input_ids"][i] = torch.tensor(model_inputs["input_ids"][i][:max_length])
model_inputs["attention_mask"][i] = torch.tensor(model_inputs["attention_mask"][i][:max_length])
labels["input_ids"][i] = torch.tensor(labels["input_ids"][i][:max_length])
model_inputs["labels"] = labels["input_ids"]
return model_inputs
```
Use the [`~datasets.Dataset.map`] function to apply the `preprocess_function` to the entire dataset. You can remove the unprocessed columns since the model won't need them:
```py
processed_datasets = dataset.map(
preprocess_function,
batched=True,
num_proc=1,
remove_columns=dataset["train"].column_names,
load_from_cache_file=False,
desc="Running tokenizer on dataset",
)
```
Create a [`DataLoader`](https://pytorch.org/docs/stable/data.html#torch.utils.data.DataLoader) from the `train` and `eval` datasets. Set `pin_memory=True` to speed up the data transfer to the GPU during training if the samples in your dataset are on a CPU.
```py
train_dataset = processed_datasets["train"]
eval_dataset = processed_datasets["test"]
train_dataloader = DataLoader(
train_dataset, shuffle=True, collate_fn=default_data_collator, batch_size=batch_size, pin_memory=True
)
eval_dataloader = DataLoader(eval_dataset, collate_fn=default_data_collator, batch_size=batch_size, pin_memory=True)
```
## Train
You're almost ready to setup your model and start training!
Initialize a base model from [`~transformers.AutoModelForCausalLM`], and pass it and `peft_config` to the [`get_peft_model`] function to create a [`PeftModel`]. You can print the new [`PeftModel`]'s trainable parameters to see how much more efficient it is than training the full parameters of the original model!
```py
model = AutoModelForCausalLM.from_pretrained(model_name_or_path)
model = get_peft_model(model, peft_config)
print(model.print_trainable_parameters())
"trainable params: 8192 || all params: 559222784 || trainable%: 0.0014648902430985358"
```
Setup an optimizer and learning rate scheduler:
```py
optimizer = torch.optim.AdamW(model.parameters(), lr=lr)
lr_scheduler = get_linear_schedule_with_warmup(
optimizer=optimizer,
num_warmup_steps=0,
num_training_steps=(len(train_dataloader) * num_epochs),
)
```
Move the model to the GPU, then write a training loop to start training!
```py
model = model.to(device)
for epoch in range(num_epochs):
model.train()
total_loss = 0
for step, batch in enumerate(tqdm(train_dataloader)):
batch = {k: v.to(device) for k, v in batch.items()}
outputs = model(**batch)
loss = outputs.loss
total_loss += loss.detach().float()
loss.backward()
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad()
model.eval()
eval_loss = 0
eval_preds = []
for step, batch in enumerate(tqdm(eval_dataloader)):
batch = {k: v.to(device) for k, v in batch.items()}
with torch.no_grad():
outputs = model(**batch)
loss = outputs.loss
eval_loss += loss.detach().float()
eval_preds.extend(
tokenizer.batch_decode(torch.argmax(outputs.logits, -1).detach().cpu().numpy(), skip_special_tokens=True)
)
eval_epoch_loss = eval_loss / len(eval_dataloader)
eval_ppl = torch.exp(eval_epoch_loss)
train_epoch_loss = total_loss / len(train_dataloader)
train_ppl = torch.exp(train_epoch_loss)
print(f"{epoch=}: {train_ppl=} {train_epoch_loss=} {eval_ppl=} {eval_epoch_loss=}")
```
## Share model
You can store and share your model on the Hub if you'd like. Log in to your Hugging Face account and enter your token when prompted:
```py
from huggingface_hub import notebook_login
notebook_login()
```
Use the [`~transformers.PreTrainedModel.push_to_hub`] function to upload your model to a model repository on the Hub:
```py
peft_model_id = "your-name/bloomz-560m_PROMPT_TUNING_CAUSAL_LM"
model.push_to_hub("your-name/bloomz-560m_PROMPT_TUNING_CAUSAL_LM", use_auth_token=True)
```
Once the model is uploaded, you'll see the model file size is only 33.5kB! 🤏
## Inference
Let's try the model on a sample input for inference. If you look at the repository you uploaded the model to, you'll see a `adapter_config.json` file. Load this file into [`PeftConfig`] to specify the `peft_type` and `task_type`. Then you can load the prompt tuned model weights, and the configuration into [`~PeftModel.from_pretrained`] to create the [`PeftModel`]:
```py
from peft import PeftModel, PeftConfig
peft_model_id = "stevhliu/bloomz-560m_PROMPT_TUNING_CAUSAL_LM"
config = PeftConfig.from_pretrained(peft_model_id)
model = AutoModelForCausalLM.from_pretrained(config.base_model_name_or_path)
model = PeftModel.from_pretrained(model, peft_model_id)
```
Grab a tweet and tokenize it:
```py
inputs = tokenizer(
f'{text_column} : {"@nationalgridus I have no water and the bill is current and paid. Can you do something about this?"} Label : ',
return_tensors="pt",
)
```
Put the model on a GPU and *generate* the predicted label:
```py
model.to(device)
with torch.no_grad():
inputs = {k: v.to(device) for k, v in inputs.items()}
outputs = model.generate(
input_ids=inputs["input_ids"], attention_mask=inputs["attention_mask"], max_new_tokens=10, eos_token_id=3
)
print(tokenizer.batch_decode(outputs.detach().cpu().numpy(), skip_special_tokens=True))
[
"Tweet text : @nationalgridus I have no water and the bill is current and paid. Can you do something about this? Label : complaint"
]
```
================================================
FILE: envs/peft/docs/source/task_guides/dreambooth_lora.mdx
================================================
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# DreamBooth fine-tuning with LoRA
This guide demonstrates how to use LoRA, a low-rank approximation technique, to fine-tune DreamBooth with the
`CompVis/stable-diffusion-v1-4` model.
Although LoRA was initially designed as a technique for reducing the number of trainable parameters in
large-language models, the technique can also be applied to diffusion models. Performing a complete model fine-tuning
of diffusion models is a time-consuming task, which is why lightweight techniques like DreamBooth or Textual Inversion
gained popularity. With the introduction of LoRA, customizing and fine-tuning a model on a specific dataset has become
even faster.
In this guide we'll be using a DreamBooth fine-tuning script that is available in
[PEFT's GitHub repo](https://github.com/huggingface/peft/tree/main/examples/lora_dreambooth). Feel free to explore it and
learn how things work.
## Set up your environment
Start by cloning the PEFT repository:
```bash
git clone https://github.com/huggingface/peft
```
Navigate to the directory containing the training scripts for fine-tuning Dreambooth with LoRA:
```bash
cd peft/examples/lora_dreambooth
```
Set up your environment: install PEFT, and all the required libraries. At the time of writing this guide we recommend
installing PEFT from source.
```bash
pip install -r requirements.txt
pip install git+https://github.com/huggingface/peft
```
## Fine-tuning DreamBooth
Prepare the images that you will use for fine-tuning the model. Set up a few environment variables:
```bash
export MODEL_NAME="CompVis/stable-diffusion-v1-4"
export INSTANCE_DIR="path-to-instance-images"
export CLASS_DIR="path-to-class-images"
export OUTPUT_DIR="path-to-save-model"
```
Here:
- `INSTANCE_DIR`: The directory containing the images that you intend to use for training your model.
- `CLASS_DIR`: The directory containing class-specific images. In this example, we use prior preservation to avoid overfitting and language-drift. For prior preservation, you need other images of the same class as part of the training process. However, these images can be generated and the training script will save them to a local path you specify here.
- `OUTPUT_DIR`: The destination folder for storing the trained model's weights.
To learn more about DreamBooth fine-tuning with prior-preserving loss, check out the [Diffusers documentation](https://huggingface.co/docs/diffusers/training/dreambooth#finetuning-with-priorpreserving-loss).
Launch the training script with `accelerate` and pass hyperparameters, as well as LoRa-specific arguments to it such as:
- `use_lora`: Enables LoRa in the training script.
- `lora_r`: The dimension used by the LoRA update matrices.
- `lora_alpha`: Scaling factor.
- `lora_text_encoder_r`: LoRA rank for text encoder.
- `lora_text_encoder_alpha`: LoRA alpha (scaling factor) for text encoder.
Here's what the full set of script arguments may look like:
```bash
accelerate launch train_dreambooth.py \
--pretrained_model_name_or_path=$MODEL_NAME \
--instance_data_dir=$INSTANCE_DIR \
--class_data_dir=$CLASS_DIR \
--output_dir=$OUTPUT_DIR \
--train_text_encoder \
--with_prior_preservation --prior_loss_weight=1.0 \
--instance_prompt="a photo of sks dog" \
--class_prompt="a photo of dog" \
--resolution=512 \
--train_batch_size=1 \
--lr_scheduler="constant" \
--lr_warmup_steps=0 \
--num_class_images=200 \
--use_lora \
--lora_r 16 \
--lora_alpha 27 \
--lora_text_encoder_r 16 \
--lora_text_encoder_alpha 17 \
--learning_rate=1e-4 \
--gradient_accumulation_steps=1 \
--gradient_checkpointing \
--max_train_steps=800
```
## Inference with a single adapter
To run inference with the fine-tuned model, first specify the base model with which the fine-tuned LoRA weights will be combined:
```python
import os
import torch
from diffusers import StableDiffusionPipeline
from peft import PeftModel, LoraConfig
MODEL_NAME = "CompVis/stable-diffusion-v1-4"
```
Next, add a function that will create a Stable Diffusion pipeline for image generation. It will combine the weights of
the base model with the fine-tuned LoRA weights using `LoraConfig`.
```python
def get_lora_sd_pipeline(
ckpt_dir, base_model_name_or_path=None, dtype=torch.float16, device="cuda", adapter_name="default"
):
unet_sub_dir = os.path.join(ckpt_dir, "unet")
text_encoder_sub_dir = os.path.join(ckpt_dir, "text_encoder")
if os.path.exists(text_encoder_sub_dir) and base_model_name_or_path is None:
config = LoraConfig.from_pretrained(text_encoder_sub_dir)
base_model_name_or_path = config.base_model_name_or_path
if base_model_name_or_path is None:
raise ValueError("Please specify the base model name or path")
pipe = StableDiffusionPipeline.from_pretrained(base_model_name_or_path, torch_dtype=dtype).to(device)
pipe.unet = PeftModel.from_pretrained(pipe.unet, unet_sub_dir, adapter_name=adapter_name)
if os.path.exists(text_encoder_sub_dir):
pipe.text_encoder = PeftModel.from_pretrained(
pipe.text_encoder, text_encoder_sub_dir, adapter_name=adapter_name
)
if dtype in (torch.float16, torch.bfloat16):
pipe.unet.half()
pipe.text_encoder.half()
pipe.to(device)
return pipe
```
Now you can use the function above to create a Stable Diffusion pipeline using the LoRA weights that you have created during the fine-tuning step.
Note, if you're running inference on the same machine, the path you specify here will be the same as `OUTPUT_DIR`.
```python
pipe = get_lora_sd_pipeline(Path("path-to-saved-model"), adapter_name="dog")
```
Once you have the pipeline with your fine-tuned model, you can use it to generate images:
```python
prompt = "sks dog playing fetch in the park"
negative_prompt = "low quality, blurry, unfinished"
image = pipe(prompt, num_inference_steps=50, guidance_scale=7, negative_prompt=negative_prompt).images[0]
image.save("DESTINATION_PATH_FOR_THE_IMAGE")
```
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/peft/lora_dreambooth_dog_park.png" alt="Generated image of a dog in a park"/>
</div>
## Multi-adapter inference
With PEFT you can combine multiple adapters for inference. In the previous example you have fine-tuned Stable Diffusion on
some dog images. The pipeline created based on these weights got a name - `adapter_name="dog`. Now, suppose you also fine-tuned
this base model on images of a crochet toy. Let's see how we can use both adapters.
First, you'll need to perform all the steps as in the single adapter inference example:
1. Specify the base model.
2. Add a function that creates a Stable Diffusion pipeline for image generation uses LoRA weights.
3. Create a `pipe` with `adapter_name="dog"` based on the model fine-tuned on dog images.
Next, you're going to need a few more helper functions.
To load another adapter, create a `load_adapter()` function that leverages `load_adapter()` method of `PeftModel` (e.g. `pipe.unet.load_adapter(peft_model_path, adapter_name)`):
```python
def load_adapter(pipe, ckpt_dir, adapter_name):
unet_sub_dir = os.path.join(ckpt_dir, "unet")
text_encoder_sub_dir = os.path.join(ckpt_dir, "text_encoder")
pipe.unet.load_adapter(unet_sub_dir, adapter_name=adapter_name)
if os.path.exists(text_encoder_sub_dir):
pipe.text_encoder.load_adapter(text_encoder_sub_dir, adapter_name=adapter_name)
```
To switch between adapters, write a function that uses `set_adapter()` method of `PeftModel` (see `pipe.unet.set_adapter(adapter_name)`)
```python
def set_adapter(pipe, adapter_name):
pipe.unet.set_adapter(adapter_name)
if isinstance(pipe.text_encoder, PeftModel):
pipe.text_encoder.set_adapter(adapter_name)
```
Finally, add a function to create weighted LoRA adapter.
```python
def create_weighted_lora_adapter(pipe, adapters, weights, adapter_name="default"):
pipe.unet.add_weighted_adapter(adapters, weights, adapter_name)
if isinstance(pipe.text_encoder, PeftModel):
pipe.text_encoder.add_weighted_adapter(adapters, weights, adapter_name)
return pipe
```
Let's load the second adapter from the model fine-tuned on images of a crochet toy, and give it a unique name:
```python
load_adapter(pipe, Path("path-to-the-second-saved-model"), adapter_name="crochet")
```
Create a pipeline using weighted adapters:
```python
pipe = create_weighted_lora_adapter(pipe, ["crochet", "dog"], [1.0, 1.05], adapter_name="crochet_dog")
```
Now you can switch between adapters. If you'd like to generate more dog images, set the adapter to `"dog"`:
```python
set_adapter(pipe, adapter_name="dog")
prompt = "sks dog in a supermarket isle"
negative_prompt = "low quality, blurry, unfinished"
image = pipe(prompt, num_inference_steps=50, guidance_scale=7, negative_prompt=negative_prompt).images[0]
image
```
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/peft/lora_dreambooth_dog_supermarket.png" alt="Generated image of a dog in a supermarket"/>
</div>
In the same way, you can switch to the second adapter:
```python
set_adapter(pipe, adapter_name="crochet")
prompt = "a fish rendered in the style of <1>"
negative_prompt = "low quality, blurry, unfinished"
image = pipe(prompt, num_inference_steps=50, guidance_scale=7, negative_prompt=negative_prompt).images[0]
image
```
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/peft/lora_dreambooth_fish.png" alt="Generated image of a crochet fish"/>
</div>
Finally, you can use combined weighted adapters:
```python
set_adapter(pipe, adapter_name="crochet_dog")
prompt = "sks dog rendered in the style of <1>, close up portrait, 4K HD"
negative_prompt = "low quality, blurry, unfinished"
image = pipe(prompt, num_inference_steps=50, guidance_scale=7, negative_prompt=negative_prompt).images[0]
image
```
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/peft/lora_dreambooth_crochet_dog.png" alt="Generated image of a crochet dog"/>
</div>
================================================
FILE: envs/peft/docs/source/task_guides/image_classification_lora.mdx
================================================
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# Image classification using LoRA
This guide demonstrates how to use LoRA, a low-rank approximation technique, to fine-tune an image classification model.
By using LoRA from 🤗 PEFT, we can reduce the number of trainable parameters in the model to only 0.77% of the original.
LoRA achieves this reduction by adding low-rank "update matrices" to specific blocks of the model, such as the attention
blocks. During fine-tuning, only these matrices are trained, while the original model parameters are left unchanged.
At inference time, the update matrices are merged with the original model parameters to produce the final classification result.
For more information on LoRA, please refer to the [original LoRA paper](https://arxiv.org/abs/2106.09685).
## Install dependencies
Install the libraries required for model training:
```bash
!pip install transformers accelerate evaluate datasets peft -q
```
Check the versions of all required libraries to make sure you are up to date:
```python
import transformers
import accelerate
import peft
print(f"Transformers version: {transformers.__version__}")
print(f"Accelerate version: {accelerate.__version__}")
print(f"PEFT version: {peft.__version__}")
"Transformers version: 4.27.4"
"Accelerate version: 0.18.0"
"PEFT version: 0.2.0"
```
## Authenticate to share your model
To share the fine-tuned model at the end of the training with the community, authenticate using your 🤗 token.
You can obtain your token from your [account settings](https://huggingface.co/settings/token).
```python
from huggingface_hub import notebook_login
notebook_login()
```
## Select a model checkpoint to fine-tune
Choose a model checkpoint from any of the model architectures supported for [image classification](https://huggingface.co/models?pipeline_tag=image-classification&sort=downloads). When in doubt, refer to
the [image classification task guide](https://huggingface.co/docs/transformers/v4.27.2/en/tasks/image_classification) in
🤗 Transformers documentation.
```python
model_checkpoint = "google/vit-base-patch16-224-in21k"
```
## Load a dataset
To keep this example's runtime short, let's only load the first 5000 instances from the training set of the [Food-101 dataset](https://huggingface.co/datasets/food101):
```python
from datasets import load_dataset
dataset = load_dataset("food101", split="train[:5000]")
```
## Dataset preparation
To prepare the dataset for training and evaluation, create `label2id` and `id2label` dictionaries. These will come in
handy when performing inference and for metadata information:
```python
labels = dataset.features["label"].names
label2id, id2label = dict(), dict()
for i, label in enumerate(labels):
label2id[label] = i
id2label[i] = label
id2label[2]
"baklava"
```
Next, load the image processor of the model you're fine-tuning:
```python
from transformers import AutoImageProcessor
image_processor = AutoImageProcessor.from_pretrained(model_checkpoint)
```
The `image_processor` contains useful information on which size the training and evaluation images should be resized
to, as well as values that should be used to normalize the pixel values. Using the `image_processor`, prepare transformation
functions for the datasets. These functions will include data augmentation and pixel scaling:
```python
from torchvision.transforms import (
CenterCrop,
Compose,
Normalize,
RandomHorizontalFlip,
RandomResizedCrop,
Resize,
ToTensor,
)
normalize = Normalize(mean=image_processor.image_mean, std=image_processor.image_std)
train_transforms = Compose(
[
RandomResizedCrop(image_processor.size["height"]),
RandomHorizontalFlip(),
ToTensor(),
normalize,
]
)
val_transforms = Compose(
[
Resize(image_processor.size["height"]),
CenterCrop(image_processor.size["height"]),
ToTensor(),
normalize,
]
)
def preprocess_train(example_batch):
"""Apply train_transforms across a batch."""
example_batch["pixel_values"] = [train_transforms(image.convert("RGB")) for image in example_batch["image"]]
return example_batch
def preprocess_val(example_batch):
"""Apply val_transforms across a batch."""
example_batch["pixel_values"] = [val_transforms(image.convert("RGB")) for image in example_batch["image"]]
return example_batch
```
Split the dataset into training and validation sets:
```python
splits = dataset.train_test_split(test_size=0.1)
train_ds = splits["train"]
val_ds = splits["test"]
```
Finally, set the transformation functions for the datasets accordingly:
```python
train_ds.set_transform(preprocess_train)
val_ds.set_transform(preprocess_val)
```
## Load and prepare a model
Before loading the model, let's define a helper function to check the total number of parameters a model has, as well
as how many of them are trainable.
```python
def print_trainable_parameters(model):
trainable_params = 0
all_param = 0
for _, param in model.named_parameters():
all_param += param.numel()
if param.requires_grad:
trainable_params += param.numel()
print(
f"trainable params: {trainable_params} || all params: {all_param} || trainable%: {100 * trainable_params / all_param:.2f}"
)
```
It's important to initialize the original model correctly as it will be used as a base to create the `PeftModel` you'll
actually fine-tune. Specify the `label2id` and `id2label` so that [`~transformers.AutoModelForImageClassification`] can append a classification
head to the underlying model, adapted for this dataset. You should see the following output:
```
Some weights of ViTForImageClassification were not initialized from the model checkpoint at google/vit-base-patch16-224-in21k and are newly initialized: ['classifier.weight', 'classifier.bias']
```
```python
from transformers import AutoModelForImageClassification, TrainingArguments, Trainer
model = AutoModelForImageClassification.from_pretrained(
model_checkpoint,
label2id=label2id,
id2label=id2label,
ignore_mismatched_sizes=True, # provide this in case you're planning to fine-tune an already fine-tuned checkpoint
)
```
Before creating a `PeftModel`, you can check the number of trainable parameters in the original model:
```python
print_trainable_parameters(model)
"trainable params: 85876325 || all params: 85876325 || trainable%: 100.00"
```
Next, use `get_peft_model` to wrap the base model so that "update" matrices are added to the respective places.
```python
from peft import LoraConfig, get_peft_model
config = LoraConfig(
r=16,
lora_alpha=16,
target_modules=["query", "value"],
lora_dropout=0.1,
bias="none",
modules_to_save=["classifier"],
)
lora_model = get_peft_model(model, config)
print_trainable_parameters(lora_model)
"trainable params: 667493 || all params: 86466149 || trainable%: 0.77"
```
Let's unpack what's going on here.
To use LoRA, you need to specify the target modules in `LoraConfig` so that `get_peft_model()` knows which modules
inside our model need to be amended with LoRA matrices. In this example, we're only interested in targeting the query and
value matrices of the attention blocks of the base model. Since the parameters corresponding to these matrices are "named"
"query" and "value" respectively, we specify them accordingly in the `target_modules` argument of `LoraConfig`.
We also specify `modules_to_save`. After wrapping the base model with `get_peft_model()` along with the `config`, we get
a new model where only the LoRA parameters are trainable (so-called "update matrices") while the pre-trained parameters
are kept frozen. However, we want the classifier parameters to be trained too when fine-tuning the base model on our
custom dataset. To ensure that the classifier parameters are also trained, we specify `modules_to_save`. This also
ensures that these modules are serialized alongside the LoRA trainable parameters when using utilities like `save_pretrained()`
and `push_to_hub()`.
Here's what the other parameters mean:
- `r`: The dimension used by the LoRA update matrices.
- `alpha`: Scaling factor.
- `bias`: Specifies if the `bias` parameters should be trained. `None` denotes none of the `bias` parameters will be trained.
`r` and `alpha` together control the total number of final trainable parameters when using LoRA, giving you the flexibility
to balance a trade-off between end performance and compute efficiency.
By looking at the number of trainable parameters, you can see how many parameters we're actually training. Since the goal is
to achieve parameter-efficient fine-tuning, you should expect to see fewer trainable parameters in the `lora_model`
in comparison to the original model, which is indeed the case here.
## Define training arguments
For model fine-tuning, use [`~transformers.Trainer`]. It accepts
several arguments which you can wrap using [`~transformers.TrainingArguments`].
```python
from transformers import TrainingArguments, Trainer
model_name = model_checkpoint.split("/")[-1]
batch_size = 128
args = TrainingArguments(
f"{model_name}-finetuned-lora-food101",
remove_unused_columns=False,
evaluation_strategy="epoch",
save_strategy="epoch",
learning_rate=5e-3,
per_device_train_batch_size=batch_size,
gradient_accumulation_steps=4,
per_device_eval_batch_size=batch_size,
fp16=True,
num_train_epochs=5,
logging_steps=10,
load_best_model_at_end=True,
metric_for_best_model="accuracy",
push_to_hub=True,
label_names=["labels"],
)
```
Compared to non-PEFT methods, you can use a larger batch size since there are fewer parameters to train.
You can also set a larger learning rate than the normal (1e-5 for example).
This can potentially also reduce the need to conduct expensive hyperparameter tuning experiments.
## Prepare evaluation metric
```python
import numpy as np
import evaluate
metric = evaluate.load("accuracy")
def compute_metrics(eval_pred):
"""Computes accuracy on a batch of predictions"""
predictions = np.argmax(eval_pred.predictions, axis=1)
return metric.compute(predictions=predictions, references=eval_pred.label_ids)
```
The `compute_metrics` function takes a named tuple as input: `predictions`, which are the logits of the model as Numpy arrays,
and `label_ids`, which are the ground-truth labels as Numpy arrays.
## Define collation function
A collation function is used by [`~transformers.Trainer`] to gather a batch of training and evaluation examples and prepare them in a
format that is acceptable by the underlying model.
```python
import torch
def collate_fn(examples):
pixel_values = torch.stack([example["pixel_values"] for example in examples])
labels = torch.tensor([example["label"] for example in examples])
return {"pixel_values": pixel_values, "labels": labels}
```
## Train and evaluate
Bring everything together - model, training arguments, data, collation function, etc. Then, start the training!
```python
trainer = Trainer(
lora_model,
args,
train_dataset=train_ds,
eval_dataset=val_ds,
tokenizer=image_processor,
compute_metrics=compute_metrics,
data_collator=collate_fn,
)
train_results = trainer.train()
```
In just a few minutes, the fine-tuned model shows 96% validation accuracy even on this small
subset of the training dataset.
```python
trainer.evaluate(val_ds)
{
"eval_loss": 0.14475855231285095,
"eval_accuracy": 0.96,
"eval_runtime": 3.5725,
"eval_samples_per_second": 139.958,
"eval_steps_per_second": 1.12,
"epoch": 5.0,
}
```
## Share your model and run inference
Once the fine-tuning is done, share the LoRA parameters with the community like so:
```python
repo_name = f"sayakpaul/{model_name}-finetuned-lora-food101"
lora_model.push_to_hub(repo_name)
```
When calling [`~transformers.PreTrainedModel.push_to_hub`] on the `lora_model`, only the LoRA parameters along with any modules specified in `modules_to_save`
are saved. Take a look at the [trained LoRA parameters](https://huggingface.co/sayakpaul/vit-base-patch16-224-in21k-finetuned-lora-food101/blob/main/adapter_model.bin).
You'll see that it's only 2.6 MB! This greatly helps with portability, especially when using a very large model to fine-tune (such as [BLOOM](https://huggingface.co/bigscience/bloom)).
Next, let's see how to load the LoRA updated parameters along with our base model for inference. When you wrap a base model
with `PeftModel`, modifications are done *in-place*. To mitigate any concerns that might stem from in-place modifications,
initialize the base model just like you did earlier and construct the inference model.
```python
from peft import PeftConfig, PeftModel
config = PeftConfig.from_pretrained(repo_name)
model = AutoModelForImageClassification.from_pretrained(
config.base_model_name_or_path,
label2id=label2id,
id2label=id2label,
ignore_mismatched_sizes=True, # provide this in case you're planning to fine-tune an already fine-tuned checkpoint
)
# Load the LoRA model
inference_model = PeftModel.from_pretrained(model, repo_name)
```
Let's now fetch an example image for inference.
```python
from PIL import Image
import requests
url = "https://huggingface.co/datasets/sayakpaul/sample-datasets/resolve/main/beignets.jpeg"
image = Image.open(requests.get(url, stream=True).raw)
image
```
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/sayakpaul/sample-datasets/resolve/main/beignets.jpeg" alt="image of beignets"/>
</div>
First, instantiate an `image_processor` from the underlying model repo.
```python
image_processor = AutoImageProcessor.from_pretrained(repo_name)
```
Then, prepare the example for inference.
```python
encoding = image_processor(image.convert("RGB"), return_tensors="pt")
```
Finally, run inference!
```python
with torch.no_grad():
outputs = inference_model(**encoding)
logits = outputs.logits
predicted_class_idx = logits.argmax(-1).item()
print("Predicted class:", inference_model.config.id2label[predicted_class_idx])
"Predicted class: beignets"
```
================================================
FILE: envs/peft/docs/source/task_guides/int8-asr.mdx
================================================
# int8 training for automatic speech recognition
Quantization reduces the precision of floating point data types, decreasing the memory required to store model weights. However, quantization degrades inference performance because you lose information when you reduce the precision. 8-bit or `int8` quantization uses only a quarter precision, but it does not degrade performance because it doesn't just drop the bits or data. Instead, `int8` quantization *rounds* from one data type to another.
<Tip>
💡 Read the [LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale](https://arxiv.org/abs/2208.07339) paper to learn more, or you can take a look at the corresponding [blog post](https://huggingface.co/blog/hf-bitsandbytes-integration) for a gentler introduction.
</Tip>
This guide will show you how to train a [`openai/whisper-large-v2`](https://huggingface.co/openai/whisper-large-v2) model for multilingual automatic speech recognition (ASR) using a combination of `int8` quantization and LoRA. You'll train Whisper for multilingual ASR on Marathi from the [Common Voice 11.0](https://huggingface.co/datasets/mozilla-foundation/common_voice_11_0) dataset.
Before you start, make sure you have all the necessary libraries installed:
```bash
!pip install -q peft transformers datasets accelerate evaluate jiwer bitsandbytes
```
## Setup
Let's take care of some of the setup first so you can start training faster later. Set the `CUDA_VISIBLE_DEVICES` to `0` to use the first GPU on your machine. Then you can specify the model name (either a Hub model repository id or a path to a directory containing the model), language and language abbreviation to train on, the task type, and the dataset name:
```py
import os
os.environ["CUDA_VISIBLE_DEVICES"] = "0"
model_name_or_path = "openai/whisper-large-v2"
language = "Marathi"
language_abbr = "mr"
task = "transcribe"
dataset_name = "mozilla-foundation/common_voice_11_0"
```
You can also log in to your Hugging Face account to save and share your trained model on the Hub if you'd like:
```py
from huggingface_hub import notebook_login
notebook_login()
```
## Load dataset and metric
The [Common Voice 11.0](https://huggingface.co/datasets/mozilla-foundation/common_voice_11_0) dataset contains many hours of recorded speech in many different languages. This guide uses the [Marathi](https://huggingface.co/datasets/mozilla-foundation/common_voice_11_0/viewer/mr/train) language as an example, but feel free to use any other language you're interested in.
Initialize a [`~datasets.DatasetDict`] structure, and load the [`train`] (load both the `train+validation` split into `train`) and [`test`] splits from the dataset into it:
```py
from datasets import load_dataset
from datasets import load_dataset, DatasetDict
common_voice = DatasetDict()
common_voice["train"] = load_dataset(dataset_name, language_abbr, split="train+validation", use_auth_token=True)
common_voice["test"] = load_dataset(dataset_name, language_abbr, split="test", use_auth_token=True)
common_voice["train"][0]
```
## Preprocess dataset
Let's prepare the dataset for training. Load a feature extractor, tokenizer, and processor. You should also pass the language and task to the tokenizer and processor so they know how to process the inputs:
```py
from transformers import AutoFeatureExtractor, AutoTokenizer, AutoProcessor
feature_extractor = AutoFeatureExtractor.from_pretrained(model_name_or_path)
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, language=language, task=task)
processor = AutoProcessor.from_pretrained(model_name_or_path, language=language, task=task)
```
You'll only be training on the `sentence` and `audio` columns, so you can remove the rest of the metadata with [`~datasets.Dataset.remove_columns`]:
```py
common_voice = common_voice.remove_columns(
["accent", "age", "client_id", "down_votes", "gender", "locale", "path", "segment", "up_votes"]
)
common_voice["train"][0]
{
"audio": {
"path": "/root/.cache/huggingface/datasets/downloads/extracted/f7e1ef6a2d14f20194999aad5040c5d4bb3ead1377de3e1bbc6e9dba34d18a8a/common_voice_mr_30585613.mp3",
"array": array(
[1.13686838e-13, -1.42108547e-13, -1.98951966e-13, ..., 4.83472422e-06, 3.54798703e-06, 1.63231743e-06]
),
"sampling_rate": 48000,
},
"sentence": "आईचे आजारपण वाढत चालले, तसतशी मथीही नीट खातपीतनाशी झाली.",
}
```
If you look at the `sampling_rate`, you'll see the audio was sampled at 48kHz. The Whisper model was pretrained on audio inputs at 16kHZ which means you'll need to downsample the audio inputs to match what the model was pretrained on. Downsample the audio by using the [`~datasets.Dataset.cast_column`] method on the `audio` column, and set the `sampling_rate` to 16kHz. The audio input is resampled on the fly the next time you call it:
```py
from datasets import Audio
common_voice = common_voice.cast_column("audio", Audio(sampling_rate=16000))
common_voice["train"][0]
{
"audio": {
"path": "/root/.cache/huggingface/datasets/downloads/extracted/f7e1ef6a2d14f20194999aad5040c5d4bb3ead1377de3e1bbc6e9dba34d18a8a/common_voice_mr_30585613.mp3",
"array": array(
[-3.06954462e-12, -3.63797881e-12, -4.54747351e-12, ..., -7.74800901e-06, -1.74738125e-06, 4.36312439e-06]
),
"sampling_rate": 16000,
},
"sentence": "आईचे आजारपण वाढत चालले, तसतशी मथीही नीट खातपीतनाशी झाली.",
}
```
Once you've cleaned up the dataset, you can write a function to generate the correct model inputs. The function should:
1. Resample the audio inputs to 16kHZ by loading the `audio` column.
2. Compute the input features from the audio `array` using the feature extractor.
3. Tokenize the `sentence` column to the input labels.
```py
def prepare_dataset(batch):
audio = batch["audio"]
batch["input_features"] = feature_extractor(audio["array"], sampling_rate=audio["sampling_rate"]).input_features[0]
batch["labels"] = tokenizer(batch["sentence"]).input_ids
return batch
```
Apply the `prepare_dataset` function to the dataset with the [`~datasets.Dataset.map`] function, and set the `num_proc` argument to `2` to enable multiprocessing (if `map` hangs, then set `num_proc=1`):
```py
common_voice = common_voice.map(prepare_dataset, remove_columns=common_voice.column_names["train"], num_proc=2)
```
Finally, create a `DataCollator` class to pad the labels in each batch to the maximum length, and replace padding with `-100` so they're ignored by the loss function. Then initialize an instance of the data collator:
```py
import torch
from dataclasses import dataclass
from typing import Any, Dict, List, Union
@dataclass
class DataCollatorSpeechSeq2SeqWithPadding:
processor: Any
def __call__(self, features: List[Dict[str, Union[List[int], torch.Tensor]]]) -> Dict[str, torch.Tensor]:
input_features = [{"input_features": feature["input_features"]} for feature in features]
batch = self.processor.feature_extractor.pad(input_features, return_tensors="pt")
label_features = [{"input_ids": feature["labels"]} for feature in features]
labels_batch = self.processor.tokenizer.pad(label_features, return_tensors="pt")
labels = labels_batch["input_ids"].masked_fill(labels_batch.attention_mask.ne(1), -100)
if (labels[:, 0] == self.processor.tokenizer.bos_token_id).all().cpu().item():
labels = labels[:, 1:]
batch["labels"] = labels
return batch
data_collator = DataCollatorSpeechSeq2SeqWithPadding(processor=processor)
```
## Train
Now that the dataset is ready, you can turn your attention to the model. Start by loading the pretrained [`openai/whisper-large-v2`]() model from [`~transformers.AutoModelForSpeechSeq2Seq`], and make sure to set the [`~transformers.BitsAndBytesConfig.load_in_8bit`] argument to `True` to enable `int8` quantization. The `device_map=auto` argument automatically determines how to load and store the model weights:
```py
from transformers import AutoModelForSpeechSeq2Seq
model = AutoModelForSpeechSeq2Seq.from_pretrained(model_name_or_path, load_in_8bit=True, device_map="auto")
```
You should configure `forced_decoder_ids=None` because no tokens are used before sampling, and you won't need to suppress any tokens during generation either:
```py
model.config.forced_decoder_ids = None
model.config.suppress_tokens = []
```
To get the model ready for `int8` quantization, use the utility function [`prepare_model_for_int8_training`](https://github.com/huggingface/peft/blob/34027fe813756897767b9a6f19ae7f1c4c7b418c/src/peft/utils/other.py#L35) to handle the following:
- casts all the non `int8` modules to full precision (`fp32`) for stability
- adds a forward hook to the input embedding layer to calculate the gradients of the input hidden states
- enables gradient checkpointing for more memory-efficient training
```py
from peft import prepare_model_for_int8_training
model = prepare_model_for_int8_training(model)
```
Let's also apply LoRA to the training to make it even more efficient. Load a [`~peft.LoraConfig`] and configure the following parameters:
- `r`, the dimension of the low-rank matrices
- `lora_alpha`, scaling factor for the weight matrices
- `target_modules`, the name of the attention matrices to apply LoRA to (`q_proj` and `v_proj`, or query and value in this case)
- `lora_dropout`, dropout probability of the LoRA layers
- `bias`, set to `none`
<Tip>
💡 The weight matrix is scaled by `lora_alpha/r`, and a higher `lora_alpha` value assigns more weight to the LoRA activations. For performance, we recommend setting bias to `None` first, and then `lora_only`, before trying `all`.
</Tip>
```py
from peft import LoraConfig, PeftModel, LoraModel, LoraConfig, get_peft_model
config = LoraConfig(r=32, lora_alpha=64, target_modules=["q_proj", "v_proj"], lora_dropout=0.05, bias="none")
```
After you set up the [`~peft.LoraConfig`], wrap it and the base model with the [`get_peft_model`] function to create a [`PeftModel`]. Print out the number of trainable parameters to see how much more efficient LoRA is compared to fully training the model!
```py
model = get_peft_model(model, config)
model.print_trainable_parameters()
"trainable params: 15728640 || all params: 1559033600 || trainable%: 1.0088711365810203"
```
Now you're ready to define some training hyperparameters in the [`~transformers.Seq2SeqTrainingArguments`] class, such as where to save the model to, batch size, learning rate, and number of epochs to train for. The [`PeftModel`] doesn't have the same signature as the base model, so you'll need to explicitly set `remove_unused_columns=False` and `label_names=["labels"]`.
```py
from transformers import Seq2SeqTrainingArguments
training_args = Seq2SeqTrainingArguments(
output_dir="your-name/int8-whisper-large-v2-asr",
per_device_train_batch_size=8,
gradient_accumulation_steps=1,
learning_rate=1e-3,
warmup_steps=50,
num_train_epochs=3,
evaluation_strategy="epoch",
fp16=True,
per_device_eval_batch_size=8,
generation_max_length=128,
logging_steps=25,
remove_unused_columns=False,
label_names=["labels"],
)
```
It is also a good idea to write a custom [`~transformers.TrainerCallback`] to save model checkpoints during training:
```py
from transformers.trainer_utils import PREFIX_CHECKPOINT_DIR
class SavePeftModelCallback(TrainerCallback):
def on_save(
self,
args: TrainingArguments,
state: TrainerState,
control: TrainerControl,
**kwargs,
):
checkpoint_folder = os.path.join(args.output_dir, f"{PREFIX_CHECKPOINT_DIR}-{state.global_step}")
peft_model_path = os.path.join(checkpoint_folder, "adapter_model")
kwargs["model"].save_pretrained(peft_model_path)
pytorch_model_path = os.path.join(checkpoint_folder, "pytorch_model.bin")
if os.path.exists(pytorch_model_path):
os.remove(pytorch_model_path)
return control
```
Pass the `Seq2SeqTrainingArguments`, model, datasets, data collator, tokenizer, and callback to the [`~transformers.Seq2SeqTrainer`]. You can optionally set `model.config.use_cache = False` to silence any warnings. Once everything is ready, call [`~transformers.Trainer.train`] to start training!
```py
from transformers import Seq2SeqTrainer, TrainerCallback, Seq2SeqTrainingArguments, TrainerState, TrainerControl
trainer = Seq2SeqTrainer(
args=training_args,
model=model,
train_dataset=common_voice["train"],
eval_dataset=common_voice["test"],
data_collator=data_collator,
tokenizer=processor.feature_extractor,
callbacks=[SavePeftModelCallback],
)
model.config.use_cache = False
trainer.train()
```
## Evaluate
[Word error rate](https://huggingface.co/spaces/evaluate-metric/wer) (WER) is a common metric for evaluating ASR models. Load the WER metric from 🤗 Evaluate:
```py
import evaluate
metric = evaluate.load("wer")
```
Write a loop to evaluate the model performance. Set the model to evaluation mode first, and write the loop with [`torch.cuda.amp.autocast()`](https://pytorch.org/docs/stable/amp.html) because `int8` training requires autocasting. Then, pass a batch of examples to the model to evaluate. Get the decoded predictions and labels, and add them as a batch to the WER metric before calling `compute` to get the final WER score:
```py
from torch.utils.data import DataLoader
from tqdm import tqdm
import numpy as np
import gc
eval_dataloader = DataLoader(common_voice["test"], batch_size=8, collate_fn=data_collator)
model.eval()
for step, batch in enumerate(tqdm(eval_dataloader)):
with torch.cuda.amp.autocast():
with torch.no_grad():
generated_tokens = (
model.generate(
input_features=batch["input_features"].to("cuda"),
decoder_input_ids=batch["labels"][:, :4].to("cuda"),
max_new_tokens=255,
)
.cpu()
.numpy()
)
labels = batch["labels"].cpu().numpy()
labels = np.where(labels != -100, labels, tokenizer.pad_token_id)
decoded_preds = tokenizer.batch_decode(generated_tokens, skip_special_tokens=True)
decoded_labels = tokenizer.batch_decode(labels, skip_special_tokens=True)
metric.add_batch(
predictions=decoded_preds,
references=decoded_labels,
)
del generated_tokens, labels, batch
gc.collect()
wer = 100 * metric.compute()
print(f"{wer=}")
```
## Share model
Once you're happy with your results, you can upload your model to the Hub with the [`~transformers.PreTrainedModel.push_to_hub`] method:
```py
model.push_to_hub("your-name/int8-whisper-large-v2-asr")
```
## Inference
Let's test the model out now!
Instantiate the model configuration from [`PeftConfig`], and from here, you can use the configuration to load the base and [`PeftModel`], tokenizer, processor, and feature extractor. Remember to define the `language` and `task` in the tokenizer, processor, and `forced_decoder_ids`:
```py
from peft import PeftModel, PeftConfig
peft_model_id = "smangrul/openai-whisper-large-v2-LORA-colab"
language = "Marathi"
task = "transcribe"
peft_config = PeftConfig.from_pretrained(peft_model_id)
model = WhisperForConditionalGeneration.from_pretrained(
peft_config.base_model_name_or_path, load_in_8bit=True, device_map="auto"
)
model = PeftModel.from_pretrained(model, peft_model_id)
tokenizer = WhisperTokenizer.from_pretrained(peft_config.base_model_name_or_path, language=language, task=task)
processor = WhisperProcessor.from_pretrained(peft_config.base_model_name_or_path, language=language, task=task)
feature_extractor = processor.feature_extractor
forced_decoder_ids = processor.get_decoder_prompt_ids(language=language, task=task)
```
Load an audio sample (you can listen to it in the [Dataset Preview](https://huggingface.co/datasets/stevhliu/dummy)) to transcribe, and the [`~transformers.AutomaticSpeechRecognitionPipeline`]:
```py
from transformers import AutomaticSpeechRecognitionPipeline
audio = "https://huggingface.co/datasets/stevhliu/dummy/resolve/main/mrt_01523_00028548203.wav"
pipeline = AutomaticSpeechRecognitionPipeline(model=model, tokenizer=tokenizer, feature_extractor=feature_extractor)
```
Then use the pipeline with autocast as a context manager on the audio sample:
```py
with torch.cuda.amp.autocast():
text = pipe(audio, generate_kwargs={"forced_decoder_ids": forced_decoder_ids}, max_new_tokens=255)["text"]
text
"मी तुमच्यासाठी काही करू शकतो का?"
```
================================================
FILE: envs/peft/docs/source/task_guides/ptuning-seq-classification.mdx
================================================
# P-tuning for sequence classification
It is challenging to finetune large language models for downstream tasks because they have so many parameters. To work around this, you can use *prompts* to steer the model toward a particular downstream task without fully finetuning a model. Typically, these prompts are handcrafted, which may be impractical because you need very large validation sets to find the best prompts. *P-tuning* is a method for automatically searching and optimizing for better prompts in a continuous space.
<Tip>
💡 Read [GPT Understands, Too](https://arxiv.org/abs/2103.10385) to learn more about p-tuning.
</Tip>
This guide will show you how to train a [`roberta-large`](https://huggingface.co/roberta-large) model (but you can also use any of the GPT, OPT, or BLOOM models) with p-tuning on the `mrpc` configuration of the [GLUE](https://huggingface.co/datasets/glue) benchmark.
Before you begin, make sure you have all the necessary libraries installed:
```bash
!pip install -q peft transformers datasets evaluate
```
## Setup
To get started, import 🤗 Transformers to create the base model, 🤗 Datasets to load a dataset, 🤗 Evaluate to load an evaluation metric, and 🤗 PEFT to create a [`PeftModel`] and setup the configuration for p-tuning.
Define the model, dataset, and some basic training hyperparameters:
```py
from transformers import (
AutoModelForSequenceClassification,
AutoTokenizer,
DataCollatorWithPadding,
TrainingArguments,
Trainer,
)
from peft import (
get_peft_config,
get_peft_model,
get_peft_model_state_dict,
set_peft_model_state_dict,
PeftType,
PromptEncoderConfig,
)
from datasets import load_dataset
import evaluate
import torch
model_name_or_path = "roberta-large"
task = "mrpc"
num_epochs = 20
lr = 1e-3
batch_size = 32
```
## Load dataset and metric
Next, load the `mrpc` configuration - a corpus of sentence pairs labeled according to whether they're semantically equivalent or not - from the [GLUE](https://huggingface.co/datasets/glue) benchmark:
```py
dataset = load_dataset("glue", task)
dataset["train"][0]
{
"sentence1": 'Amrozi accused his brother , whom he called " the witness " , of deliberately distorting his evidence .',
"sentence2": 'Referring to him as only " the witness " , Amrozi accused his brother of deliberately distorting his evidence .',
"label": 1,
"idx": 0,
}
```
From 🤗 Evaluate, load a metric for evaluating the model's performance. The evaluation module returns the accuracy and F1 scores associated with this specific task.
```py
metric = evaluate.load("glue", task)
```
Now you can use the `metric` to write a function that computes the accuracy and F1 scores. The `compute_metric` function calculates the scores from the model predictions and labels:
```py
import numpy as np
def compute_metrics(eval_pred):
predictions, labels = eval_pred
predictions = np.argmax(predictions, axis=1)
return metric.compute(predictions=predictions, references=labels)
```
## Preprocess dataset
Initialize the tokenizer and configure the padding token to use. If you're using a GPT, OPT, or BLOOM model, you should set the `padding_side` to the left; otherwise it'll be set to the right. Tokenize the sentence pairs and truncate them to the maximum length.
```py
if any(k in model_name_or_path for k in ("gpt", "opt", "bloom")):
padding_side = "left"
else:
padding_side = "right"
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, padding_side=padding_side)
if getattr(tokenizer, "pad_token_id") is None:
tokenizer.pad_token_id = tokenizer.eos_token_id
def tokenize_function(examples):
# max_length=None => use the model max length (it's actually the default)
outputs = tokenizer(examples["sentence1"], examples["sentence2"], truncation=True, max_length=None)
return outputs
```
Use [`~datasets.Dataset.map`] to apply the `tokenize_function` to the dataset, and remove the unprocessed columns because the model won't need those. You should also rename the `label` column to `labels` because that is the expected name for the labels by models in the 🤗 Transformers library.
```py
tokenized_datasets = dataset.map(
tokenize_function,
batched=True,
remove_columns=["idx", "sentence1", "sentence2"],
)
tokenized_datasets = tokenized_datasets.rename_column("label", "labels")
```
Create a collator function with [`~transformers.DataCollatorWithPadding`] to pad the examples in the batches to the `longest` sequence in the batch:
```py
data_collator = DataCollatorWithPadding(tokenizer=tokenizer, padding="longest")
```
## Train
P-tuning uses a prompt encoder to optimize the prompt parameters, so you'll need to initialize the [`PromptEncoderConfig`] with several arguments:
- `task_type`: the type of task you're training on, in this case it is sequence classification or `SEQ_CLS`
- `num_virtual_tokens`: the number of virtual tokens to use, or in other words, the prompt
- `encoder_hidden_size`: the hidden size of the encoder used to optimize the prompt parameters
```py
peft_config = PromptEncoderConfig(task_type="SEQ_CLS", num_virtual_tokens=20, encoder_hidden_size=128)
```
Create the base `roberta-large` model from [`~transformers.AutoModelForSequenceClassification`], and then wrap the base model and `peft_config` with [`get_peft_model`] to create a [`PeftModel`]. If you're curious to see how many parameters you're actually training compared to training on all the model parameters, you can print it out with [`~peft.PeftModel.print_trainable_parameters`]:
```py
model = AutoModelForSequenceClassification.from_pretrained(model_name_or_path, return_dict=True)
model = get_peft_model(model, peft_config)
model.print_trainable_parameters()
"trainable params: 1351938 || all params: 355662082 || trainable%: 0.38011867680626127"
```
From the 🤗 Transformers library, set up the [`~transformers.TrainingArguments`] class with where you want to save the model to, the training hyperparameters, how to evaluate the model, and when to save the checkpoints:
```py
training_args = TrainingArguments(
output_dir="your-name/roberta-large-peft-p-tuning",
learning_rate=1e-3,
per_device_train_batch_size=32,
per_device_eval_batch_size=32,
num_train_epochs=2,
weight_decay=0.01,
evaluation_strategy="epoch",
save_strategy="epoch",
load_best_model_at_end=True,
)
```
Then pass the model, `TrainingArguments`, datasets, tokenizer, data collator, and evaluation function to the [`~transformers.Trainer`] class, which'll handle the entire training loop for you. Once you're ready, call [`~transformers.Trainer.train`] to start training!
```py
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_datasets["train"],
eval_dataset=tokenized_datasets["test"],
tokenizer=tokenizer,
data_collator=data_collator,
compute_metrics=compute_metrics,
)
trainer.train()
```
## Share model
You can store and share your model on the Hub if you'd like. Log in to your Hugging Face account and enter your token when prompted:
```py
from huggingface_hub import notebook_login
notebook_login()
```
Upload the model to a specifc model repository on the Hub with the [`~transformers.PreTrainedModel.push_to_hub`] function:
```py
model.push_to_hub("your-name/roberta-large-peft-p-tuning", use_auth_token=True)
```
## Inference
Once the model has been uploaded to the Hub, anyone can easily use it for inference. Load the configuration and model:
```py
import torch
from peft import PeftModel, PeftConfig
from transformers import AutoModelForCausalLM, AutoTokenizer
peft_model_id = "smangrul/roberta-large-peft-p-tuning"
config = PeftConfig.from_pretrained(peft_model_id)
inference_model = AutoModelForSequenceClassification.from_pretrained(config.base_model_name_or_path)
tokenizer = AutoTokenizer.from_pretrained(config.base_model_name_or_path)
model = PeftModel.from_pretrained(inference_model, peft_model_id)
```
Get some text and tokenize it:
```py
classes = ["not equivalent", "equivalent"]
sentence1 = "Coast redwood trees are the tallest trees on the planet and can grow over 300 feet tall."
sentence2 = "The coast redwood trees, which can attain a height of over 300 feet, are the tallest trees on earth."
inputs = tokenizer(sentence1, sentence2, truncation=True, padding="longest", return_tensors="pt")
```
Pass the inputs to the model to classify the sentences:
```py
with torch.no_grad():
outputs = model(**inputs).logits
print(outputs)
paraphrased_text = torch.softmax(outputs, dim=1).tolist()[0]
for i in range(len(classes)):
print(f"{classes[i]}: {int(round(paraphrased_text[i] * 100))}%")
"not equivalent: 4%"
"equivalent: 96%"
```
================================================
FILE: envs/peft/docs/source/task_guides/semantic-similarity-lora.md
================================================
# LoRA for semantic similarity tasks
Low-Rank Adaptation (LoRA) is a reparametrization method that aims to reduce the number of trainable parameters with low-rank representations. The weight matrix is broken down into low-rank matrices that are trained and updated. All the pretrained model parameters remain frozen. After training, the low-rank matrices are added back to the original weights. This makes it more efficient to store and train a LoRA model because there are significantly fewer parameters.
<Tip>
💡 Read [LoRA: Low-Rank Adaptation of Large Language Models](https://arxiv.org/abs/2106.09685) to learn more about LoRA.
</Tip>
In this guide, we'll be using a LoRA [script](https://github.com/huggingface/peft/tree/main/examples/lora_dreambooth) to fine-tune a [`intfloat/e5-large-v2`](https://huggingface.co/intfloat/e5-large-v2) model on the [`smangrul/amazon_esci`](https://huggingface.co/datasets/smangrul/amazon_esci) dataset for semantic similarity tasks. Feel free to explore the script to learn how things work in greater detail!
## Setup
Start by installing 🤗 PEFT from [source](https://github.com/huggingface/peft), and then navigate to the directory containing the training scripts for fine-tuning DreamBooth with LoRA:
```bash
cd peft/examples/feature_extraction
```
Install all the necessary required libraries with:
```bash
pip install -r requirements.txt
```
## Setup
Let's start by importing all the necessary libraries you'll need:
- 🤗 Transformers for loading the `intfloat/e5-large-v2` model and tokenizer
- 🤗 Accelerate for the training loop
- 🤗 Datasets for loading and preparing the `smangrul/amazon_esci` dataset for training and inference
- 🤗 Evaluate for evaluating the model's performance
- 🤗 PEFT for setting up the LoRA configuration and creating the PEFT model
- 🤗 huggingface_hub for uploading the trained model to HF hub
- hnswlib for creating the search index and doing fast approximate nearest neighbor search
<Tip>
It is assumed that PyTorch with CUDA support is already installed.
</Tip>
## Train
Launch the training script with `accelerate launch` and pass your hyperparameters along with the `--use_peft` argument to enable LoRA.
This guide uses the following [`LoraConfig`]:
```py
peft_config = LoraConfig(
r=8,
lora_alpha=16,
bias="none",
task_type=TaskType.FEATURE_EXTRACTION,
target_modules=["key", "query", "value"],
)
```
Here's what a full set of script arguments may look like when running in Colab on a V100 GPU with standard RAM:
```bash
accelerate launch \
--mixed_precision="fp16" \
peft_lora_embedding_semantic_search.py \
--dataset_name="smangrul/amazon_esci" \
--max_length=70 --model_name_or_path="intfloat/e5-large-v2" \
--per_device_train_batch_size=64 \
--per_device_eval_batch_size=128 \
--learning_rate=5e-4 \
--weight_decay=0.0 \
--num_train_epochs 3 \
--gradient_accumulation_steps=1 \
--output_dir="results/peft_lora_e5_ecommerce_semantic_search_colab" \
--seed=42 \
--push_to_hub \
--hub_model_id="smangrul/peft_lora_e5_ecommerce_semantic_search_colab" \
--with_tracking \
--report_to="wandb" \
--use_peft \
--checkpointing_steps "epoch"
```
## Dataset for semantic similarity
The dataset we'll be using is a small subset of the [esci-data](https://github.com/amazon-science/esci-data.git) dataset (it can be found on Hub at [smangrul/amazon_esci](https://huggingface.co/datasets/smangrul/amazon_esci)).
Each sample contains a tuple of `(query, product_title, relevance_label)` where `relevance_label` is `1` if the product matches the intent of the `query`, otherwise it is `0`.
Our task is to build an embedding model that can retrieve semantically similar products given a product query.
This is usually the first stage in building a product search engine to retrieve all the potentially relevant products of a given query.
Typically, this involves using Bi-Encoder models to cross-join the query and millions of products which could blow up quickly.
Instead, you can use a Transformer model to retrieve the top K nearest similar products for a given query by
embedding the query and products in the same latent embedding space.
The millions of products are embedded offline to create a search index.
At run time, only the query is embedded by the model, and products are retrieved from the search index with a
fast approximate nearest neighbor search library such as [FAISS](https://github.com/facebookresearch/faiss) or [HNSWlib](https://github.com/nmslib/hnswlib).
The next stage involves reranking the retrieved list of products to return the most relevant ones;
this stage can utilize cross-encoder based models as the cross-join between the query and a limited set of retrieved products.
The diagram below from [awesome-semantic-search](https://github.com/rom1504/awesome-semantic-search) outlines a rough semantic search pipeline:
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/peft/semantic_search_pipeline.png"
alt="Semantic Search Pipeline"/>
</div>
For this task guide, we will explore the first stage of training an embedding model to predict semantically similar products
given a product query.
## Training script deep dive
We finetune [e5-large-v2](https://huggingface.co/intfloat/e5-large-v2) which tops the [MTEB benchmark](https://huggingface.co/spaces/mteb/leaderboard) using PEFT-LoRA.
[`AutoModelForSentenceEmbedding`] returns the query and product embeddings, and the `mean_pooling` function pools them across the sequence dimension and normalizes them:
```py
class AutoModelForSentenceEmbedding(nn.Module):
def __init__(self, model_name, tokenizer, normalize=True):
super(AutoModelForSentenceEmbedding, self).__init__()
self.model = AutoModel.from_pretrained(model_name)
self.normalize = normalize
self.tokenizer = tokenizer
def forward(self, **kwargs):
model_output = self.model(**kwargs)
embeddings = self.mean_pooling(model_output, kwargs["attention_mask"])
if self.normalize:
embeddings = torch.nn.functional.normalize(embeddings, p=2, dim=1)
return embeddings
def mean_pooling(self, model_output, attention_mask):
token_embeddings = model_output[0] # First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
def __getattr__(self, name: str):
"""Forward missing attributes to the wrapped module."""
try:
return super().__getattr__(name) # defer to nn.Module's logic
except AttributeError:
return getattr(self.model, name)
def get_cosine_embeddings(query_embs, product_embs):
return torch.sum(query_embs * product_embs, axis=1)
def get_loss(cosine_score, labels):
return torch.mean(torch.square(labels * (1 - cosine_score) + torch.clamp((1 - labels) * cosine_score, min=0.0)))
```
The `get_cosine_embeddings` function computes the cosine similarity and the `get_loss` function computes the loss. The loss enables the model to learn that a cosine score of `1` for query and product pairs is relevant, and a cosine score of `0` or below is irrelevant.
Define the [`PeftConfig`] with your LoRA hyperparameters, and create a [`PeftModel`]. We use 🤗 Accelerate for handling all device management, mixed precision training, gradient accumulation, WandB tracking, and saving/loading utilities.
## Results
The table below compares the training time, the batch size that could be fit in Colab, and the best ROC-AUC scores between a PEFT model and a fully fine-tuned model:
| Training Type | Training time per epoch (Hrs) | Batch Size that fits | ROC-AUC score (higher is better) |
| ----------------- | ------------- | ---------- |
gitextract_mqsl_z9m/
├── .gitignore
├── README.md
├── configs/
│ └── audiostory_llm_qwen25_3b_lora.yaml
├── envs/
│ └── peft/
│ ├── .github/
│ │ ├── ISSUE_TEMPLATE/
│ │ │ ├── bug-report.yml
│ │ │ └── feature-request.yml
│ │ └── workflows/
│ │ ├── build_docker_images.yml
│ │ ├── build_documentation.yml
│ │ ├── build_pr_documentation.yml
│ │ ├── delete_doc_comment.yml
│ │ ├── delete_doc_comment_trigger.yml
│ │ ├── nightly.yml
│ │ ├── stale.yml
│ │ ├── tests.yml
│ │ └── upload_pr_documentation.yml
│ ├── .gitignore
│ ├── LICENSE
│ ├── Makefile
│ ├── README.md
│ ├── docker/
│ │ ├── peft-cpu/
│ │ │ └── Dockerfile
│ │ └── peft-gpu/
│ │ └── Dockerfile
│ ├── docs/
│ │ ├── Makefile
│ │ ├── README.md
│ │ └── source/
│ │ ├── _config.py
│ │ ├── _toctree.yml
│ │ ├── accelerate/
│ │ │ ├── deepspeed-zero3-offload.mdx
│ │ │ └── fsdp.mdx
│ │ ├── conceptual_guides/
│ │ │ ├── ia3.mdx
│ │ │ ├── lora.mdx
│ │ │ └── prompting.mdx
│ │ ├── index.mdx
│ │ ├── install.mdx
│ │ ├── package_reference/
│ │ │ ├── config.mdx
│ │ │ ├── peft_model.mdx
│ │ │ └── tuners.mdx
│ │ ├── quicktour.mdx
│ │ └── task_guides/
│ │ ├── clm-prompt-tuning.mdx
│ │ ├── dreambooth_lora.mdx
│ │ ├── image_classification_lora.mdx
│ │ ├── int8-asr.mdx
│ │ ├── ptuning-seq-classification.mdx
│ │ ├── semantic-similarity-lora.md
│ │ ├── semantic_segmentation_lora.mdx
│ │ ├── seq2seq-prefix-tuning.mdx
│ │ └── token-classification-lora.mdx
│ ├── examples/
│ │ ├── causal_language_modeling/
│ │ │ ├── accelerate_ds_zero3_cpu_offload_config.yaml
│ │ │ ├── peft_lora_clm_accelerate_big_model_inference.ipynb
│ │ │ ├── peft_lora_clm_accelerate_ds_zero3_offload.py
│ │ │ ├── peft_prefix_tuning_clm.ipynb
│ │ │ ├── peft_prompt_tuning_clm.ipynb
│ │ │ └── requirements.txt
│ │ ├── conditional_generation/
│ │ │ ├── accelerate_ds_zero3_cpu_offload_config.yaml
│ │ │ ├── peft_adalora_seq2seq.py
│ │ │ ├── peft_ia3_seq2seq.ipynb
│ │ │ ├── peft_lora_seq2seq.ipynb
│ │ │ ├── peft_lora_seq2seq_accelerate_big_model_inference.ipynb
│ │ │ ├── peft_lora_seq2seq_accelerate_ds_zero3_offload.py
│ │ │ ├── peft_lora_seq2seq_accelerate_fsdp.py
│ │ │ ├── peft_prefix_tuning_seq2seq.ipynb
│ │ │ ├── peft_prompt_tuning_seq2seq.ipynb
│ │ │ ├── peft_prompt_tuning_seq2seq_with_generate.ipynb
│ │ │ └── requirements.txt
│ │ ├── feature_extraction/
│ │ │ ├── peft_lora_embedding_semantic_search.py
│ │ │ ├── peft_lora_embedding_semantic_similarity_inference.ipynb
│ │ │ └── requirements.txt
│ │ ├── fp4_finetuning/
│ │ │ └── finetune_fp4_opt_bnb_peft.py
│ │ ├── image_classification/
│ │ │ ├── README.md
│ │ │ └── image_classification_peft_lora.ipynb
│ │ ├── int8_training/
│ │ │ ├── Finetune_flan_t5_large_bnb_peft.ipynb
│ │ │ ├── Finetune_opt_bnb_peft.ipynb
│ │ │ ├── fine_tune_blip2_int8.py
│ │ │ ├── peft_adalora_whisper_large_training.py
│ │ │ ├── peft_bnb_whisper_large_v2_training.ipynb
│ │ │ └── run_adalora_whisper_int8.sh
│ │ ├── lora_dreambooth/
│ │ │ ├── colab_notebook.ipynb
│ │ │ ├── convert_kohya_ss_sd_lora_to_peft.py
│ │ │ ├── convert_peft_sd_lora_to_kohya_ss.py
│ │ │ ├── lora_dreambooth_inference.ipynb
│ │ │ ├── requirements.txt
│ │ │ └── train_dreambooth.py
│ │ ├── multi_adapter_examples/
│ │ │ └── PEFT_Multi_LoRA_Inference.ipynb
│ │ ├── semantic_segmentation/
│ │ │ ├── README.md
│ │ │ └── semantic_segmentation_peft_lora.ipynb
│ │ ├── sequence_classification/
│ │ │ ├── IA3.ipynb
│ │ │ ├── LoRA.ipynb
│ │ │ ├── P_Tuning.ipynb
│ │ │ ├── Prompt_Tuning.ipynb
│ │ │ ├── peft_no_lora_accelerate.py
│ │ │ ├── prefix_tuning.ipynb
│ │ │ └── requirements.txt
│ │ └── token_classification/
│ │ ├── peft_lora_token_cls.ipynb
│ │ └── requirements.txt
│ ├── pyproject.toml
│ ├── scripts/
│ │ ├── log_reports.py
│ │ └── stale.py
│ ├── setup.py
│ ├── src/
│ │ └── peft/
│ │ ├── __init__.py
│ │ ├── auto.py
│ │ ├── import_utils.py
│ │ ├── mapping.py
│ │ ├── peft_model.py
│ │ ├── py.typed
│ │ ├── tuners/
│ │ │ ├── __init__.py
│ │ │ ├── adalora.py
│ │ │ ├── adaption_prompt.py
│ │ │ ├── ia3.py
│ │ │ ├── lora.py
│ │ │ ├── p_tuning.py
│ │ │ ├── prefix_tuning.py
│ │ │ └── prompt_tuning.py
│ │ └── utils/
│ │ ├── __init__.py
│ │ ├── config.py
│ │ ├── hub_utils.py
│ │ ├── other.py
│ │ └── save_and_load.py
│ └── tests/
│ ├── __init__.py
│ ├── test_adaption_prompt.py
│ ├── test_auto.py
│ ├── test_common_gpu.py
│ ├── test_config.py
│ ├── test_custom_models.py
│ ├── test_decoder_models.py
│ ├── test_encoder_decoder_models.py
│ ├── test_feature_extraction_models.py
│ ├── test_gpu_examples.py
│ ├── test_stablediffusion.py
│ ├── testing_common.py
│ └── testing_utils.py
├── evaluate/
│ ├── demo_gradio_video_dubbing.py
│ ├── evaluate_long_audio.py
│ ├── evaluate_long_audio.sh
│ └── inference.py
├── install_audiostory.sh
├── src/
│ ├── models/
│ │ ├── detokenizer/
│ │ │ ├── __init__.py
│ │ │ ├── modeling_flux.py
│ │ │ └── resampler.py
│ │ ├── detokenizer_cotrain/
│ │ │ └── modeling_flux_cotrain.py
│ │ ├── mllm/
│ │ │ ├── __init__.py
│ │ │ ├── generation.py
│ │ │ ├── load_qwenvl_llm.py
│ │ │ ├── modeling_audiostory_llm.py
│ │ │ ├── modeling_audiostory_unified.py
│ │ │ ├── modeling_llama_xformer.py
│ │ │ ├── peft_models.py
│ │ │ └── utils.py
│ │ └── tokenizer/
│ │ ├── __init__.py
│ │ ├── init_qwen_tokenizer.py
│ │ ├── init_qwen_tokenizer_special_token.py
│ │ ├── modeling_tangoflux.py
│ │ ├── modeling_whisper.py
│ │ ├── modeling_whisper_inference.py
│ │ └── qwen_visual.py
│ └── processer/
│ ├── tokenizer.py
│ └── transforms.py
└── tokenizer/
├── added_tokens.json
├── tokenizer.json
├── tokenizer_config.json
└── vocab.json
SYMBOL INDEX (860 symbols across 61 files)
FILE: envs/peft/examples/causal_language_modeling/peft_lora_clm_accelerate_ds_zero3_offload.py
function levenshtein_distance (line 24) | def levenshtein_distance(str1, str2):
function get_closest_label (line 45) | def get_closest_label(eval_pred, classes):
function b2mb (line 57) | def b2mb(x):
class TorchTracemalloc (line 62) | class TorchTracemalloc:
method __enter__ (line 63) | def __enter__(self):
method cpu_mem_used (line 77) | def cpu_mem_used(self):
method peak_monitor_func (line 81) | def peak_monitor_func(self):
method __exit__ (line 93) | def __exit__(self, *exc):
function main (line 109) | def main():
FILE: envs/peft/examples/conditional_generation/peft_adalora_seq2seq.py
function preprocess_function (line 65) | def preprocess_function(examples):
FILE: envs/peft/examples/conditional_generation/peft_lora_seq2seq_accelerate_ds_zero3_offload.py
function levenshtein_distance (line 18) | def levenshtein_distance(str1, str2):
function get_closest_label (line 39) | def get_closest_label(eval_pred, classes):
function b2mb (line 51) | def b2mb(x):
class TorchTracemalloc (line 56) | class TorchTracemalloc:
method __enter__ (line 57) | def __enter__(self):
method cpu_mem_used (line 71) | def cpu_mem_used(self):
method peak_monitor_func (line 75) | def peak_monitor_func(self):
method __exit__ (line 87) | def __exit__(self, *exc):
function main (line 103) | def main():
FILE: envs/peft/examples/conditional_generation/peft_lora_seq2seq_accelerate_fsdp.py
function main (line 14) | def main():
FILE: envs/peft/examples/feature_extraction/peft_lora_embedding_semantic_search.py
function parse_args (line 44) | def parse_args():
function save_model_hook (line 156) | def save_model_hook(models, weights, output_dir):
function load_model_hook (line 163) | def load_model_hook(models, input_dir):
class AutoModelForSentenceEmbedding (line 171) | class AutoModelForSentenceEmbedding(nn.Module):
method __init__ (line 172) | def __init__(self, model_name, tokenizer, normalize=True):
method forward (line 179) | def forward(self, **kwargs):
method mean_pooling (line 187) | def mean_pooling(self, model_output, attention_mask):
method __getattr__ (line 192) | def __getattr__(self, name: str):
function get_cosing_embeddings (line 200) | def get_cosing_embeddings(query_embs, product_embs):
function get_loss (line 204) | def get_loss(cosine_score, labels):
function main (line 208) | def main():
FILE: envs/peft/examples/fp4_finetuning/finetune_fp4_opt_bnb_peft.py
class CastOutputToFloat (line 79) | class CastOutputToFloat(nn.Sequential):
method forward (line 80) | def forward(self, x):
function print_trainable_parameters (line 92) | def print_trainable_parameters(model):
FILE: envs/peft/examples/int8_training/fine_tune_blip2_int8.py
class ImageCaptioningDataset (line 43) | class ImageCaptioningDataset(Dataset):
method __init__ (line 44) | def __init__(self, dataset, processor):
method __len__ (line 48) | def __len__(self):
method __getitem__ (line 51) | def __getitem__(self, idx):
function collator (line 60) | def collator(batch):
FILE: envs/peft/examples/int8_training/peft_adalora_whisper_large_training.py
function parse_args (line 49) | def parse_args():
function load_streaming_dataset (line 280) | def load_streaming_dataset(dataset_name, dataset_config_name, split, **k...
function prepare_dataset_wrapper (line 296) | def prepare_dataset_wrapper(do_lower_case, do_remove_punctuation, proces...
function save_model_hook (line 322) | def save_model_hook(models, weights, output_dir):
function load_model_hook (line 329) | def load_model_hook(models, input_dir):
class DataCollatorSpeechSeq2SeqWithPadding (line 337) | class DataCollatorSpeechSeq2SeqWithPadding:
method __call__ (line 340) | def __call__(self, features: List[Dict[str, Union[List[int], torch.Ten...
function get_audio_length_processor (line 364) | def get_audio_length_processor(max_input_length):
function evaluation_loop (line 371) | def evaluation_loop(model, eval_dataloader, processor, normalizer, metri...
function main (line 422) | def main():
FILE: envs/peft/examples/lora_dreambooth/convert_kohya_ss_sd_lora_to_peft.py
function get_modules_names (line 24) | def get_modules_names(
function get_rank_alpha (line 53) | def get_rank_alpha(
FILE: envs/peft/examples/lora_dreambooth/convert_peft_sd_lora_to_kohya_ss.py
function get_module_kohya_state_dict (line 20) | def get_module_kohya_state_dict(
FILE: envs/peft/examples/lora_dreambooth/train_dreambooth.py
function import_model_class_from_model_name_or_path (line 53) | def import_model_class_from_model_name_or_path(pretrained_model_name_or_...
function parse_args (line 73) | def parse_args(input_args=None):
function b2mb (line 395) | def b2mb(x):
class TorchTracemalloc (line 400) | class TorchTracemalloc:
method __enter__ (line 401) | def __enter__(self):
method cpu_mem_used (line 415) | def cpu_mem_used(self):
method peak_monitor_func (line 419) | def peak_monitor_func(self):
method __exit__ (line 431) | def __exit__(self, *exc):
class DreamBoothDataset (line 447) | class DreamBoothDataset(Dataset):
method __init__ (line 453) | def __init__(
method __len__ (line 495) | def __len__(self):
method __getitem__ (line 498) | def __getitem__(self, index):
function collate_fn (line 528) | def collate_fn(examples, with_prior_preservation=False):
class PromptDataset (line 550) | class PromptDataset(Dataset):
method __init__ (line 553) | def __init__(self, prompt, num_samples):
method __len__ (line 557) | def __len__(self):
method __getitem__ (line 560) | def __getitem__(self, index):
function get_full_repo_name (line 567) | def get_full_repo_name(model_id: str, organization: Optional[str] = None...
function main (line 577) | def main(args):
FILE: envs/peft/examples/sequence_classification/peft_no_lora_accelerate.py
function parse_args (line 21) | def parse_args():
function main (line 79) | def main():
FILE: envs/peft/scripts/stale.py
function main (line 35) | def main():
FILE: envs/peft/src/peft/auto.py
class _BaseAutoPeftModel (line 43) | class _BaseAutoPeftModel:
method __init__ (line 47) | def __init__(self, *args, **kwargs):
method from_pretrained (line 56) | def from_pretrained(
class AutoPeftModel (line 113) | class AutoPeftModel(_BaseAutoPeftModel):
class AutoPeftModelForCausalLM (line 118) | class AutoPeftModelForCausalLM(_BaseAutoPeftModel):
class AutoPeftModelForSeq2SeqLM (line 123) | class AutoPeftModelForSeq2SeqLM(_BaseAutoPeftModel):
class AutoPeftModelForSequenceClassification (line 128) | class AutoPeftModelForSequenceClassification(_BaseAutoPeftModel):
class AutoPeftModelForTokenClassification (line 133) | class AutoPeftModelForTokenClassification(_BaseAutoPeftModel):
class AutoPeftModelForQuestionAnswering (line 138) | class AutoPeftModelForQuestionAnswering(_BaseAutoPeftModel):
class AutoPeftModelForFeatureExtraction (line 143) | class AutoPeftModelForFeatureExtraction(_BaseAutoPeftModel):
FILE: envs/peft/src/peft/import_utils.py
function is_bnb_available (line 18) | def is_bnb_available():
function is_bnb_4bit_available (line 22) | def is_bnb_4bit_available():
FILE: envs/peft/src/peft/mapping.py
function get_peft_config (line 67) | def get_peft_config(config_dict: Dict[str, Any]):
function get_peft_model (line 78) | def get_peft_model(model: PreTrainedModel, peft_config: PeftConfig, adap...
FILE: envs/peft/src/peft/peft_model.py
class PeftModel (line 78) | class PeftModel(PushToHubMixin, torch.nn.Module):
method __init__ (line 102) | def __init__(self, model: PreTrainedModel, peft_config: PeftConfig, ad...
method save_pretrained (line 122) | def save_pretrained(
method from_pretrained (line 205) | def from_pretrained(
method _setup_prompt_encoder (line 274) | def _setup_prompt_encoder(self, adapter_name: str):
method _prepare_model_for_gradient_checkpointing (line 314) | def _prepare_model_for_gradient_checkpointing(self, model: PreTrainedM...
method get_prompt_embedding_to_save (line 329) | def get_prompt_embedding_to_save(self, adapter_name: str):
method get_prompt (line 343) | def get_prompt(self, batch_size: int):
method print_trainable_parameters (line 386) | def print_trainable_parameters(self):
method __getattr__ (line 405) | def __getattr__(self, name: str):
method forward (line 412) | def forward(self, *args: Any, **kwargs: Any):
method _get_base_model_class (line 418) | def _get_base_model_class(self, is_prompt_tuning=False):
method disable_adapter (line 427) | def disable_adapter(self):
method get_base_model (line 449) | def get_base_model(self):
method add_adapter (line 455) | def add_adapter(self, adapter_name: str, peft_config: PeftConfig):
method set_additional_trainable_modules (line 475) | def set_additional_trainable_modules(self, peft_config, adapter_name):
method _split_kwargs (line 484) | def _split_kwargs(cls, kwargs: Dict[str, Any]):
method load_adapter (line 497) | def load_adapter(self, model_id: str, adapter_name: str, is_trainable:...
method set_adapter (line 607) | def set_adapter(self, adapter_name: str):
method base_model_torch_dtype (line 619) | def base_model_torch_dtype(self):
method active_peft_config (line 623) | def active_peft_config(self):
method create_or_update_model_card (line 626) | def create_or_update_model_card(self, output_dir: str):
class PeftModelForSequenceClassification (line 667) | class PeftModelForSequenceClassification(PeftModel):
method __init__ (line 707) | def __init__(self, model, peft_config: PeftConfig, adapter_name="defau...
method forward (line 722) | def forward(
method _prefix_tuning_forward (line 783) | def _prefix_tuning_forward(
class PeftModelForCausalLM (line 855) | class PeftModelForCausalLM(PeftModel):
method __init__ (line 892) | def __init__(self, model, peft_config: PeftConfig, adapter_name="defau...
method forward (line 896) | def forward(
method generate (line 970) | def generate(self, **kwargs):
method prepare_inputs_for_generation (line 985) | def prepare_inputs_for_generation(self, *args, **kwargs):
class PeftModelForSeq2SeqLM (line 1021) | class PeftModelForSeq2SeqLM(PeftModel):
method __init__ (line 1057) | def __init__(self, model, peft_config: PeftConfig, adapter_name="defau...
method forward (line 1064) | def forward(
method generate (line 1184) | def generate(self, **kwargs):
method prepare_inputs_for_generation (line 1249) | def prepare_inputs_for_generation(self, *args, **kwargs):
class PeftModelForTokenClassification (line 1260) | class PeftModelForTokenClassification(PeftModel):
method __init__ (line 1300) | def __init__(self, model, peft_config: PeftConfig = None, adapter_name...
method forward (line 1315) | def forward(
method _prefix_tuning_forward (line 1377) | def _prefix_tuning_forward(
class PeftModelForQuestionAnswering (line 1432) | class PeftModelForQuestionAnswering(PeftModel):
method __init__ (line 1470) | def __init__(self, model, peft_config: PeftConfig = None, adapter_name...
method forward (line 1485) | def forward(
method _prefix_tuning_forward (line 1552) | def _prefix_tuning_forward(
class PeftModelForFeatureExtraction (line 1624) | class PeftModelForFeatureExtraction(PeftModel):
method __init__ (line 1659) | def __init__(self, model, peft_config: PeftConfig = None, adapter_name...
method forward (line 1662) | def forward(
FILE: envs/peft/src/peft/tuners/adalora.py
class AdaLoraConfig (line 32) | class AdaLoraConfig(LoraConfig):
method __post_init__ (line 60) | def __post_init__(self):
class AdaLoraModel (line 64) | class AdaLoraModel(LoraModel):
method __init__ (line 90) | def __init__(self, model, config, adapter_name):
method add_adapter (line 96) | def add_adapter(self, adapter_name, config=None):
method _find_and_replace (line 124) | def _find_and_replace(self, adapter_name):
method __getattr__ (line 219) | def __getattr__(self, name: str):
method forward (line 226) | def forward(self, *args, **kwargs):
method resize_modules_by_rank_pattern (line 250) | def resize_modules_by_rank_pattern(self, rank_pattern, adapter_name):
method resize_state_dict_by_rank_pattern (line 281) | def resize_state_dict_by_rank_pattern(self, rank_pattern, state_dict, ...
method update_and_allocate (line 297) | def update_and_allocate(self, global_step):
method _prepare_adalora_config (line 320) | def _prepare_adalora_config(peft_config, model_config):
class AdaLoraLayer (line 330) | class AdaLoraLayer(LoraLayer):
method __init__ (line 331) | def __init__(
method update_layer (line 342) | def update_layer(self, adapter_name, r, lora_alpha, lora_dropout, init...
method reset_lora_parameters (line 369) | def reset_lora_parameters(self, adapter_name):
class SVDLinear (line 376) | class SVDLinear(nn.Linear, AdaLoraLayer):
method __init__ (line 378) | def __init__(
method merge (line 403) | def merge(self):
method unmerge (line 421) | def unmerge(self):
method forward (line 438) | def forward(self, x: torch.Tensor):
class SVDLinear8bitLt (line 463) | class SVDLinear8bitLt(bnb.nn.Linear8bitLt, AdaLoraLayer):
method __init__ (line 465) | def __init__(
method forward (line 493) | def forward(self, x: torch.Tensor):
class SVDLinear4bit (line 529) | class SVDLinear4bit(bnb.nn.Linear4bit, AdaLoraLayer):
method __init__ (line 531) | def __init__(
method forward (line 558) | def forward(self, x: torch.Tensor):
class RankAllocator (line 592) | class RankAllocator(object):
method __init__ (line 602) | def __init__(self, model, peft_config, adapter_name):
method set_total_step (line 613) | def set_total_step(self, total_step):
method reset_ipt (line 616) | def reset_ipt(self):
method _set_budget_scheduler (line 621) | def _set_budget_scheduler(self, model):
method budget_schedule (line 632) | def budget_schedule(self, step: int):
method update_ipt (line 651) | def update_ipt(self, model):
method _element_score (line 668) | def _element_score(self, n):
method _combine_ipt (line 671) | def _combine_ipt(self, ipt_E, ipt_AB):
method mask_to_budget (line 676) | def mask_to_budget(self, model, budget):
method update_and_allocate (line 728) | def update_and_allocate(self, model, global_step, force_mask=False):
method mask_using_rank_pattern (line 740) | def mask_using_rank_pattern(self, model, rank_pattern):
FILE: envs/peft/src/peft/tuners/adaption_prompt.py
function llama_rotate_half (line 29) | def llama_rotate_half(x: torch.Tensor) -> torch.Tensor:
function llama_apply_rotary_pos_emb (line 44) | def llama_apply_rotary_pos_emb(q, cos, sin, position_ids):
function llama_compute_query_states (line 61) | def llama_compute_query_states(model: nn.Module, **kwargs) -> torch.Tensor:
function is_adaption_prompt_trainable (line 99) | def is_adaption_prompt_trainable(params: str) -> bool:
class AdaptionPromptConfig (line 105) | class AdaptionPromptConfig(PeftConfig):
method __post_init__ (line 114) | def __post_init__(self):
function prepare_config (line 118) | def prepare_config(
class AdaptionPromptModel (line 134) | class AdaptionPromptModel(nn.Module):
method __init__ (line 151) | def __init__(self, model, configs: Dict, adapter_name: str):
method add_adapter (line 169) | def add_adapter(self, adapter_name: str, config: AdaptionPromptConfig)...
method set_adapter (line 205) | def set_adapter(self, adapter_name: str) -> None:
method enable_adapter_layers (line 218) | def enable_adapter_layers(self):
method disable_adapter_layers (line 223) | def disable_adapter_layers(self):
method _create_adapted_attentions (line 228) | def _create_adapted_attentions(self, config: AdaptionPromptConfig, par...
method _set_adapted_attentions (line 238) | def _set_adapted_attentions(self, adapter_name: str) -> None:
method _remove_adapted_attentions (line 246) | def _remove_adapted_attentions(self, adapter_name: str) -> None:
method _mark_only_adaption_prompts_as_trainable (line 256) | def _mark_only_adaption_prompts_as_trainable(self) -> None:
method __getattr__ (line 262) | def __getattr__(self, name: str):
class AdaptedAttention (line 272) | class AdaptedAttention(nn.Module):
method __init__ (line 275) | def __init__(self, model_type: str, adapter_len: int, model):
method forward (line 305) | def forward(self, **kwargs):
FILE: envs/peft/src/peft/tuners/ia3.py
class IA3Config (line 44) | class IA3Config(PeftConfig):
method __post_init__ (line 90) | def __post_init__(self):
class IA3Model (line 94) | class IA3Model(torch.nn.Module):
method __init__ (line 128) | def __init__(self, model, config, adapter_name):
method add_adapter (line 135) | def add_adapter(self, adapter_name, config=None):
method _check_quantization_dependency (line 146) | def _check_quantization_dependency(self):
method _create_new_module (line 159) | def _create_new_module(self, ia3_config, adapter_name, target, is_feed...
method _check_target_module_exists (line 216) | def _check_target_module_exists(self, ia3_config, key):
method _find_and_replace (line 225) | def _find_and_replace(self, adapter_name):
method _is_valid_match (line 261) | def _is_valid_match(key: str, target_key: str):
method _replace_module (line 272) | def _replace_module(self, parent_module, child_name, new_module, old_m...
method __getattr__ (line 286) | def __getattr__(self, name: str):
method get_peft_config_as_dict (line 293) | def get_peft_config_as_dict(self, inference: bool = False):
method _set_adapter_layers (line 302) | def _set_adapter_layers(self, enabled=True):
method enable_adapter_layers (line 307) | def enable_adapter_layers(self):
method disable_adapter_layers (line 310) | def disable_adapter_layers(self):
method set_adapter (line 313) | def set_adapter(self, adapter_name):
method _prepare_ia3_config (line 322) | def _prepare_ia3_config(peft_config, model_config):
method merge_and_unload (line 335) | def merge_and_unload(self):
function mark_only_ia3_as_trainable (line 375) | def mark_only_ia3_as_trainable(model: nn.Module) -> None:
class IA3Layer (line 381) | class IA3Layer:
method __init__ (line 382) | def __init__(
method update_layer (line 397) | def update_layer(self, adapter_name, init_ia3_weights):
method reset_ia3_parameters (line 408) | def reset_ia3_parameters(self, adapter_name):
class Linear (line 414) | class Linear(nn.Linear, IA3Layer):
method __init__ (line 416) | def __init__(
method merge (line 442) | def merge(self):
method unmerge (line 455) | def unmerge(self):
method forward (line 470) | def forward(self, x: torch.Tensor):
class Linear8bitLt (line 502) | class Linear8bitLt(bnb.nn.Linear8bitLt, IA3Layer):
method __init__ (line 504) | def __init__(
method forward (line 532) | def forward(self, x: torch.Tensor):
FILE: envs/peft/src/peft/tuners/lora.py
class LoraConfig (line 46) | class LoraConfig(PeftConfig):
method __post_init__ (line 114) | def __post_init__(self):
class LoraModel (line 118) | class LoraModel(torch.nn.Module):
method __init__ (line 175) | def __init__(self, model, config, adapter_name):
method add_adapter (line 186) | def add_adapter(self, adapter_name, config=None):
method _check_quantization_dependency (line 203) | def _check_quantization_dependency(self):
method _check_target_module_exists (line 212) | def _check_target_module_exists(self, lora_config, key):
method _create_new_module (line 238) | def _create_new_module(self, lora_config, adapter_name, target):
method _find_and_replace (line 313) | def _find_and_replace(self, adapter_name):
method _replace_module (line 361) | def _replace_module(self, parent_module, child_name, new_module, old_m...
method __getattr__ (line 379) | def __getattr__(self, name: str):
method get_peft_config_as_dict (line 386) | def get_peft_config_as_dict(self, inference: bool = False):
method _set_adapter_layers (line 395) | def _set_adapter_layers(self, enabled=True):
method enable_adapter_layers (line 400) | def enable_adapter_layers(self):
method disable_adapter_layers (line 403) | def disable_adapter_layers(self):
method set_adapter (line 406) | def set_adapter(self, adapter_name):
method merge_adapter (line 414) | def merge_adapter(self):
method unmerge_adapter (line 422) | def unmerge_adapter(self):
method _prepare_lora_config (line 431) | def _prepare_lora_config(peft_config, model_config):
method _unload_and_optionally_merge (line 438) | def _unload_and_optionally_merge(self, merge=True):
method add_weighted_adapter (line 476) | def add_weighted_adapter(self, adapters, weights, adapter_name, combin...
method _svd_weighted_adapter (line 538) | def _svd_weighted_adapter(self, adapters, weights, new_rank, target, t...
method delete_adapter (line 568) | def delete_adapter(self, adapter_name):
method merge_and_unload (line 601) | def merge_and_unload(self):
method unload (line 620) | def unload(self):
function mark_only_lora_as_trainable (line 639) | def mark_only_lora_as_trainable(model: nn.Module, bias: str = "none") ->...
class LoraLayer (line 657) | class LoraLayer:
method __init__ (line 658) | def __init__(self, in_features: int, out_features: int, **kwargs):
method update_layer (line 675) | def update_layer(self, adapter_name, r, lora_alpha, lora_dropout, init...
method update_layer_conv2d (line 693) | def update_layer_conv2d(self, adapter_name, r, lora_alpha, lora_dropou...
method update_layer_embedding (line 718) | def update_layer_embedding(self, adapter_name, r, lora_alpha, lora_dro...
method reset_lora_parameters (line 738) | def reset_lora_parameters(self, adapter_name):
class Linear (line 749) | class Linear(nn.Linear, LoraLayer):
method __init__ (line 751) | def __init__(
method merge (line 779) | def merge(self):
method unmerge (line 789) | def unmerge(self):
method get_delta_weight (line 799) | def get_delta_weight(self, adapter):
method forward (line 808) | def forward(self, x: torch.Tensor):
class Embedding (line 835) | class Embedding(nn.Embedding, LoraLayer):
method __init__ (line 837) | def __init__(
method unmerge (line 858) | def unmerge(self):
method merge (line 866) | def merge(self):
method get_delta_weight (line 874) | def get_delta_weight(self, adapter):
method forward (line 877) | def forward(self, x: torch.Tensor):
class Conv2d (line 901) | class Conv2d(nn.Conv2d, LoraLayer):
method __init__ (line 903) | def __init__(
method merge (line 934) | def merge(self):
method unmerge (line 944) | def unmerge(self):
method get_delta_weight (line 954) | def get_delta_weight(self, adapter):
method forward (line 971) | def forward(self, x: torch.Tensor):
class Linear8bitLt (line 1033) | class Linear8bitLt(bnb.nn.Linear8bitLt, LoraLayer):
method __init__ (line 1035) | def __init__(
method forward (line 1063) | def forward(self, x: torch.Tensor):
class Linear4bit (line 1092) | class Linear4bit(bnb.nn.Linear4bit, LoraLayer):
method __init__ (line 1094) | def __init__(
method forward (line 1122) | def forward(self, x: torch.Tensor):
FILE: envs/peft/src/peft/tuners/p_tuning.py
class PromptEncoderReparameterizationType (line 26) | class PromptEncoderReparameterizationType(str, enum.Enum):
class PromptEncoderConfig (line 32) | class PromptEncoderConfig(PromptLearningConfig):
method __post_init__ (line 61) | def __post_init__(self):
class PromptEncoder (line 67) | class PromptEncoder(torch.nn.Module):
method __init__ (line 114) | def __init__(self, config):
method forward (line 161) | def forward(self, indices):
FILE: envs/peft/src/peft/tuners/prefix_tuning.py
class PrefixTuningConfig (line 25) | class PrefixTuningConfig(PromptLearningConfig):
method __post_init__ (line 43) | def __post_init__(self):
class PrefixEncoder (line 49) | class PrefixEncoder(torch.nn.Module):
method __init__ (line 85) | def __init__(self, config):
method forward (line 103) | def forward(self, prefix: torch.Tensor):
FILE: envs/peft/src/peft/tuners/prompt_tuning.py
class PromptTuningInit (line 26) | class PromptTuningInit(str, enum.Enum):
class PromptTuningConfig (line 32) | class PromptTuningConfig(PromptLearningConfig):
method __post_init__ (line 61) | def __post_init__(self):
class PromptEmbedding (line 65) | class PromptEmbedding(torch.nn.Module):
method __init__ (line 103) | def __init__(self, config, word_embeddings):
method forward (line 127) | def forward(self, indices):
FILE: envs/peft/src/peft/utils/config.py
class PeftType (line 28) | class PeftType(str, enum.Enum):
class TaskType (line 38) | class TaskType(str, enum.Enum):
class PeftConfigMixin (line 48) | class PeftConfigMixin(PushToHubMixin):
method to_dict (line 63) | def to_dict(self):
method save_pretrained (line 66) | def save_pretrained(self, save_directory, **kwargs):
method from_pretrained (line 95) | def from_pretrained(cls, pretrained_model_name_or_path, subfolder=None...
method from_json_file (line 134) | def from_json_file(cls, path_json_file, **kwargs):
method _split_kwargs (line 148) | def _split_kwargs(cls, kwargs):
method _get_peft_type (line 164) | def _get_peft_type(
class PeftConfig (line 190) | class PeftConfig(PeftConfigMixin):
class PromptLearningConfig (line 208) | class PromptLearningConfig(PeftConfig):
FILE: envs/peft/src/peft/utils/hub_utils.py
function hub_file_exists (line 20) | def hub_file_exists(repo_id: str, filename: str, revision: str = None, r...
FILE: envs/peft/src/peft/utils/other.py
function add_library_to_model_card (line 37) | def add_library_to_model_card(output_dir):
function bloom_model_postprocess_past_key_value (line 62) | def bloom_model_postprocess_past_key_value(past_key_values):
function prepare_model_for_kbit_training (line 75) | def prepare_model_for_kbit_training(model, use_gradient_checkpointing=Tr...
function prepare_model_for_int8_training (line 114) | def prepare_model_for_int8_training(*args, **kwargs):
function shift_tokens_right (line 123) | def shift_tokens_right(input_ids: torch.Tensor, pad_token_id: int, decod...
class ModulesToSaveWrapper (line 144) | class ModulesToSaveWrapper(torch.nn.Module):
method __init__ (line 145) | def __init__(self, module_to_save, adapter_name):
method update (line 152) | def update(self, adapter_name):
method forward (line 188) | def forward(self, *args, **kwargs):
function _get_submodules (line 194) | def _get_submodules(model, key):
function _freeze_adapter (line 201) | def _freeze_adapter(model, adapter_name):
function _set_trainable (line 207) | def _set_trainable(model, adapter_name):
function _set_adapter (line 221) | def _set_adapter(model, adapter_name):
function _prepare_prompt_learning_config (line 227) | def _prepare_prompt_learning_config(peft_config, model_config):
function fsdp_auto_wrap_policy (line 269) | def fsdp_auto_wrap_policy(model):
function transpose (line 304) | def transpose(weight, fan_in_fan_out):
FILE: envs/peft/src/peft/utils/save_and_load.py
function get_peft_model_state_dict (line 19) | def get_peft_model_state_dict(model, state_dict=None, adapter_name="defa...
function set_peft_model_state_dict (line 82) | def set_peft_model_state_dict(model, peft_model_state_dict, adapter_name...
FILE: envs/peft/tests/test_adaption_prompt.py
function is_llama_available (line 33) | def is_llama_available() -> bool:
class AdaptionPromptTester (line 47) | class AdaptionPromptTester(TestCase, PeftCommonTester):
method setUp (line 55) | def setUp(self):
method _create_test_llama_config (line 61) | def _create_test_llama_config():
method test_attributes (line 72) | def test_attributes(self) -> None:
method test_prepare_for_training (line 81) | def test_prepare_for_training(self) -> None:
method test_prepare_for_int8_training (line 92) | def test_prepare_for_int8_training(self) -> None:
method test_save_pretrained (line 118) | def test_save_pretrained(self) -> None:
method test_save_pretrained_selected_adapters (line 163) | def test_save_pretrained_selected_adapters(self) -> None:
method test_generate (line 213) | def test_generate(self) -> None:
method test_sequence_adapter_ops (line 229) | def test_sequence_adapter_ops(self) -> None:
method test_add_and_set_while_disabled (line 298) | def test_add_and_set_while_disabled(self):
method test_use_cache (line 343) | def test_use_cache(self) -> None:
method test_bf16_inference (line 367) | def test_bf16_inference(self) -> None:
method test_disable_adapter (line 380) | def test_disable_adapter(self):
FILE: envs/peft/tests/test_auto.py
class PeftAutoModelTester (line 38) | class PeftAutoModelTester(unittest.TestCase):
method test_peft_causal_lm (line 39) | def test_peft_causal_lm(self):
method test_peft_seq2seq_lm (line 60) | def test_peft_seq2seq_lm(self):
method test_peft_sequence_cls (line 81) | def test_peft_sequence_cls(self):
method test_peft_token_classification (line 104) | def test_peft_token_classification(self):
method test_peft_question_answering (line 127) | def test_peft_question_answering(self):
method test_peft_feature_extraction (line 150) | def test_peft_feature_extraction(self):
method test_peft_whisper (line 173) | def test_peft_whisper(self):
FILE: envs/peft/tests/test_common_gpu.py
class PeftGPUCommonTests (line 42) | class PeftGPUCommonTests(unittest.TestCase):
method setUp (line 47) | def setUp(self):
method tearDown (line 53) | def tearDown(self):
method test_lora_bnb_8bit_quantization (line 65) | def test_lora_bnb_8bit_quantization(self):
method test_lora_bnb_4bit_quantization_from_pretrained_safetensors (line 116) | def test_lora_bnb_4bit_quantization_from_pretrained_safetensors(self):
method test_lora_bnb_4bit_quantization (line 131) | def test_lora_bnb_4bit_quantization(self):
method test_lora_causal_lm_mutli_gpu_inference (line 179) | def test_lora_causal_lm_mutli_gpu_inference(self):
method test_lora_seq2seq_lm_mutli_gpu_inference (line 209) | def test_lora_seq2seq_lm_mutli_gpu_inference(self):
method test_adaption_prompt_8bit (line 235) | def test_adaption_prompt_8bit(self):
method test_adaption_prompt_4bit (line 258) | def test_adaption_prompt_4bit(self):
FILE: envs/peft/tests/test_config.py
class PeftConfigTestMixin (line 35) | class PeftConfigTestMixin:
class PeftConfigTester (line 46) | class PeftConfigTester(unittest.TestCase, PeftConfigTestMixin):
method test_methods (line 47) | def test_methods(self):
method test_task_type (line 63) | def test_task_type(self):
method test_from_pretrained (line 68) | def test_from_pretrained(self):
method test_save_pretrained (line 78) | def test_save_pretrained(self):
method test_from_json_file (line 91) | def test_from_json_file(self):
method test_to_dict (line 100) | def test_to_dict(self):
method test_from_pretrained_cache_dir (line 109) | def test_from_pretrained_cache_dir(self):
method test_from_pretrained_cache_dir_remote (line 119) | def test_from_pretrained_cache_dir_remote(self):
method test_set_attributes (line 127) | def test_set_attributes(self):
method test_config_copy (line 139) | def test_config_copy(self):
method test_config_deepcopy (line 146) | def test_config_deepcopy(self):
method test_config_pickle_roundtrip (line 153) | def test_config_pickle_roundtrip(self):
FILE: envs/peft/tests/test_custom_models.py
class MLP (line 46) | class MLP(nn.Module):
method __init__ (line 47) | def __init__(self):
method forward (line 55) | def forward(self, X):
class ModelEmbConv1D (line 65) | class ModelEmbConv1D(nn.Module):
method __init__ (line 66) | def __init__(self):
method forward (line 74) | def forward(self, X):
class ModelConv2D (line 83) | class ModelConv2D(nn.Module):
method __init__ (line 84) | def __init__(self):
method forward (line 91) | def forward(self, X):
class MockTransformerWrapper (line 100) | class MockTransformerWrapper:
method from_pretrained (line 108) | def from_pretrained(cls, model_id):
class PeftCustomModelTester (line 124) | class PeftCustomModelTester(unittest.TestCase, PeftCommonTester):
method prepare_inputs_for_testing (line 129) | def prepare_inputs_for_testing(self):
method test_attributes_parametrized (line 134) | def test_attributes_parametrized(self, test_name, model_id, config_cls...
method test_adapter_name (line 138) | def test_adapter_name(self, test_name, model_id, config_cls, config_kw...
method test_prepare_for_training_parametrized (line 142) | def test_prepare_for_training_parametrized(self, test_name, model_id, ...
method test_save_pretrained (line 150) | def test_save_pretrained(self, test_name, model_id, config_cls, config...
method test_from_pretrained_config_construction (line 154) | def test_from_pretrained_config_construction(self, test_name, model_id...
method test_merge_layers (line 158) | def test_merge_layers(self, test_name, model_id, config_cls, config_kw...
method test_generate (line 169) | def test_generate(self, test_name, model_id, config_cls, config_kwargs):
method test_generate_half_prec (line 174) | def test_generate_half_prec(self, test_name, model_id, config_cls, con...
method test_training_customs (line 179) | def test_training_customs(self, test_name, model_id, config_cls, confi...
method test_training_customs_layer_indexing (line 183) | def test_training_customs_layer_indexing(self, test_name, model_id, co...
method test_training_customs_gradient_checkpointing (line 189) | def test_training_customs_gradient_checkpointing(self, test_name, mode...
method test_inference_safetensors (line 193) | def test_inference_safetensors(self, test_name, model_id, config_cls, ...
method test_peft_model_device_map (line 197) | def test_peft_model_device_map(self, test_name, model_id, config_cls, ...
method test_only_params_are_updated (line 201) | def test_only_params_are_updated(self, test_name, model_id, config_cls...
method test_disable_adapters (line 236) | def test_disable_adapters(self, test_name, model_id, config_cls, confi...
FILE: envs/peft/tests/test_decoder_models.py
function skip_non_pt_mqa (line 41) | def skip_non_pt_mqa(test_list):
class PeftDecoderModelTester (line 48) | class PeftDecoderModelTester(unittest.TestCase, PeftCommonTester):
method prepare_inputs_for_testing (line 57) | def prepare_inputs_for_testing(self):
method test_attributes_parametrized (line 69) | def test_attributes_parametrized(self, test_name, model_id, config_cls...
method test_adapter_name (line 73) | def test_adapter_name(self, test_name, model_id, config_cls, config_kw...
method test_prepare_for_training_parametrized (line 77) | def test_prepare_for_training_parametrized(self, test_name, model_id, ...
method test_save_pretrained (line 81) | def test_save_pretrained(self, test_name, model_id, config_cls, config...
method test_save_pretrained_selected_adapters (line 85) | def test_save_pretrained_selected_adapters(self, test_name, model_id, ...
method test_from_pretrained_config_construction (line 89) | def test_from_pretrained_config_construction(self, test_name, model_id...
method test_merge_layers (line 102) | def test_merge_layers(self, test_name, model_id, config_cls, config_kw...
method test_generate (line 106) | def test_generate(self, test_name, model_id, config_cls, config_kwargs):
method test_generate_half_prec (line 110) | def test_generate_half_prec(self, test_name, model_id, config_cls, con...
method test_prefix_tuning_half_prec_conversion (line 114) | def test_prefix_tuning_half_prec_conversion(self, test_name, model_id,...
method test_training_decoders (line 118) | def test_training_decoders(self, test_name, model_id, config_cls, conf...
method test_training_decoders_layer_indexing (line 122) | def test_training_decoders_layer_indexing(self, test_name, model_id, c...
method test_training_decoders_gradient_checkpointing (line 126) | def test_training_decoders_gradient_checkpointing(self, test_name, mod...
method test_inference_safetensors (line 130) | def test_inference_safetensors(self, test_name, model_id, config_cls, ...
method test_peft_model_device_map (line 134) | def test_peft_model_device_map(self, test_name, model_id, config_cls, ...
method test_delete_adapter (line 138) | def test_delete_adapter(self, test_name, model_id, config_cls, config_...
method test_unload_adapter (line 150) | def test_unload_adapter(self, test_name, model_id, config_cls, config_...
method test_weighted_combination_of_adapters (line 162) | def test_weighted_combination_of_adapters(self, test_name, model_id, c...
method test_training_prompt_learning_tasks (line 166) | def test_training_prompt_learning_tasks(self, test_name, model_id, con...
method test_disable_adapter (line 180) | def test_disable_adapter(self, test_name, model_id, config_cls, config...
FILE: envs/peft/tests/test_encoder_decoder_models.py
class PeftEncoderDecoderModelTester (line 32) | class PeftEncoderDecoderModelTester(unittest.TestCase, PeftCommonTester):
method prepare_inputs_for_testing (line 41) | def prepare_inputs_for_testing(self):
method test_attributes_parametrized (line 55) | def test_attributes_parametrized(self, test_name, model_id, config_cls...
method test_adapter_name (line 59) | def test_adapter_name(self, test_name, model_id, config_cls, config_kw...
method test_prepare_for_training_parametrized (line 63) | def test_prepare_for_training_parametrized(self, test_name, model_id, ...
method test_save_pretrained (line 67) | def test_save_pretrained(self, test_name, model_id, config_cls, config...
method test_save_pretrained_selected_adapters (line 71) | def test_save_pretrained_selected_adapters(self, test_name, model_id, ...
method test_from_pretrained_config_construction (line 75) | def test_from_pretrained_config_construction(self, test_name, model_id...
method test_merge_layers (line 88) | def test_merge_layers(self, test_name, model_id, config_cls, config_kw...
method test_generate (line 93) | def test_generate(self, test_name, model_id, config_cls, config_kwargs):
method test_generate_half_prec (line 97) | def test_generate_half_prec(self, test_name, model_id, config_cls, con...
method test_prefix_tuning_half_prec_conversion (line 101) | def test_prefix_tuning_half_prec_conversion(self, test_name, model_id,...
method test_training_encoder_decoders (line 105) | def test_training_encoder_decoders(self, test_name, model_id, config_c...
method test_training_encoder_decoders_layer_indexing (line 109) | def test_training_encoder_decoders_layer_indexing(self, test_name, mod...
method test_training_encoder_decoders_gradient_checkpointing (line 113) | def test_training_encoder_decoders_gradient_checkpointing(self, test_n...
method test_inference_safetensors (line 117) | def test_inference_safetensors(self, test_name, model_id, config_cls, ...
method test_peft_model_device_map (line 121) | def test_peft_model_device_map(self, test_name, model_id, config_cls, ...
method test_delete_adapter (line 125) | def test_delete_adapter(self, test_name, model_id, config_cls, config_...
method test_unload_adapter (line 138) | def test_unload_adapter(self, test_name, model_id, config_cls, config_...
method test_weighted_combination_of_adapters (line 150) | def test_weighted_combination_of_adapters(self, test_name, model_id, c...
method test_training_prompt_learning_tasks (line 154) | def test_training_prompt_learning_tasks(self, test_name, model_id, con...
method test_disable_adapter (line 167) | def test_disable_adapter(self, test_name, model_id, config_cls, config...
FILE: envs/peft/tests/test_feature_extraction_models.py
function skip_deberta_lora_tests (line 37) | def skip_deberta_lora_tests(test_list):
function skip_deberta_pt_tests (line 44) | def skip_deberta_pt_tests(test_list):
class PeftFeatureExtractionModelTester (line 51) | class PeftFeatureExtractionModelTester(unittest.TestCase, PeftCommonTest...
method prepare_inputs_for_testing (line 60) | def prepare_inputs_for_testing(self):
method test_attributes_parametrized (line 72) | def test_attributes_parametrized(self, test_name, model_id, config_cls...
method test_adapter_name (line 76) | def test_adapter_name(self, test_name, model_id, config_cls, config_kw...
method test_prepare_for_training_parametrized (line 80) | def test_prepare_for_training_parametrized(self, test_name, model_id, ...
method test_save_pretrained (line 84) | def test_save_pretrained(self, test_name, model_id, config_cls, config...
method test_save_pretrained_selected_adapters (line 88) | def test_save_pretrained_selected_adapters(self, test_name, model_id, ...
method test_from_pretrained_config_construction (line 92) | def test_from_pretrained_config_construction(self, test_name, model_id...
method test_merge_layers (line 105) | def test_merge_layers(self, test_name, model_id, config_cls, config_kw...
method test_training (line 109) | def test_training(self, test_name, model_id, config_cls, config_kwargs):
method test_training_prompt_learning_tasks (line 115) | def test_training_prompt_learning_tasks(self, test_name, model_id, con...
method test_training_layer_indexing (line 119) | def test_training_layer_indexing(self, test_name, model_id, config_cls...
method test_training_gradient_checkpointing (line 125) | def test_training_gradient_checkpointing(self, test_name, model_id, co...
method test_inference_safetensors (line 129) | def test_inference_safetensors(self, test_name, model_id, config_cls, ...
method test_peft_model_device_map (line 133) | def test_peft_model_device_map(self, test_name, model_id, config_cls, ...
method test_delete_adapter (line 137) | def test_delete_adapter(self, test_name, model_id, config_cls, config_...
method test_unload_adapter (line 149) | def test_unload_adapter(self, test_name, model_id, config_cls, config_...
method test_weighted_combination_of_adapters (line 161) | def test_weighted_combination_of_adapters(self, test_name, model_id, c...
FILE: envs/peft/tests/test_gpu_examples.py
class DataCollatorSpeechSeq2SeqWithPadding (line 56) | class DataCollatorSpeechSeq2SeqWithPadding:
method __call__ (line 63) | def __call__(self, features: List[Dict[str, Union[List[int], torch.Ten...
class PeftBnbGPUExampleTests (line 89) | class PeftBnbGPUExampleTests(unittest.TestCase):
method setUp (line 105) | def setUp(self):
method tearDown (line 110) | def tearDown(self):
method test_causal_lm_training (line 120) | def test_causal_lm_training(self):
method test_4bit_adalora_causalLM (line 179) | def test_4bit_adalora_causalLM(self):
method test_causal_lm_training_mutli_gpu (line 240) | def test_causal_lm_training_mutli_gpu(self):
method test_seq2seq_lm_training_single_gpu (line 303) | def test_seq2seq_lm_training_single_gpu(self):
method test_seq2seq_lm_training_mutli_gpu (line 364) | def test_seq2seq_lm_training_mutli_gpu(self):
method test_audio_model_training (line 424) | def test_audio_model_training(self):
FILE: envs/peft/tests/test_stablediffusion.py
class StableDiffusionModelTester (line 56) | class StableDiffusionModelTester(TestCase, PeftCommonTester):
method instantiate_sd_peft (line 63) | def instantiate_sd_peft(self, model_id, config_cls, config_kwargs):
method prepare_inputs_for_testing (line 88) | def prepare_inputs_for_testing(self):
method test_merge_layers (line 102) | def test_merge_layers(self, test_name, model_id, config_cls, config_kw...
method test_add_weighted_adapter_base_unchanged (line 130) | def test_add_weighted_adapter_base_unchanged(self, test_name, model_id...
method test_disable_adapter (line 158) | def test_disable_adapter(self, test_name, model_id, config_cls, config...
FILE: envs/peft/tests/testing_common.py
class ClassInstantier (line 81) | class ClassInstantier(OrderedDict):
method __getitem__ (line 82) | def __getitem__(self, key, *args, **kwargs):
method get_grid_parameters (line 91) | def get_grid_parameters(self, grid_parameters, filter_params_func=None):
class PeftCommonTester (line 145) | class PeftCommonTester:
method prepare_inputs_for_common (line 158) | def prepare_inputs_for_common(self):
method _test_model_attr (line 161) | def _test_model_attr(self, model_id, config_cls, config_kwargs):
method _test_adapter_name (line 173) | def _test_adapter_name(self, model_id, config_cls, config_kwargs):
method _test_prepare_for_training (line 188) | def _test_prepare_for_training(self, model_id, config_cls, config_kwar...
method _test_save_pretrained (line 229) | def _test_save_pretrained(self, model_id, config_cls, config_kwargs):
method _test_save_pretrained_selected_adapters (line 271) | def _test_save_pretrained_selected_adapters(self, model_id, config_cls...
method _test_from_pretrained_config_construction (line 331) | def _test_from_pretrained_config_construction(self, model_id, config_c...
method _test_merge_layers (line 348) | def _test_merge_layers(self, model_id, config_cls, config_kwargs):
method _test_generate (line 395) | def _test_generate(self, model_id, config_cls, config_kwargs):
method _test_generate_half_prec (line 413) | def _test_generate_half_prec(self, model_id, config_cls, config_kwargs):
method _test_prefix_tuning_half_prec_conversion (line 435) | def _test_prefix_tuning_half_prec_conversion(self, model_id, config_cl...
method _test_training (line 450) | def _test_training(self, model_id, config_cls, config_kwargs):
method _test_inference_safetensors (line 475) | def _test_inference_safetensors(self, model_id, config_cls, config_kwa...
method _test_training_layer_indexing (line 511) | def _test_training_layer_indexing(self, model_id, config_cls, config_k...
method _test_training_gradient_checkpointing (line 565) | def _test_training_gradient_checkpointing(self, model_id, config_cls, ...
method _test_peft_model_device_map (line 597) | def _test_peft_model_device_map(self, model_id, config_cls, config_kwa...
method _test_training_prompt_learning_tasks (line 619) | def _test_training_prompt_learning_tasks(self, model_id, config_cls, c...
method _test_delete_adapter (line 642) | def _test_delete_adapter(self, model_id, config_cls, config_kwargs):
method _test_unload_adapter (line 676) | def _test_unload_adapter(self, model_id, config_cls, config_kwargs):
method _test_weighted_combination_of_adapters (line 702) | def _test_weighted_combination_of_adapters(self, model_id, config_cls,...
method _test_disable_adapter (line 767) | def _test_disable_adapter(self, model_id, config_cls, config_kwargs):
FILE: envs/peft/tests/testing_utils.py
function require_torch_gpu (line 22) | def require_torch_gpu(test_case):
function require_torch_multi_gpu (line 32) | def require_torch_multi_gpu(test_case):
function require_bitsandbytes (line 42) | def require_bitsandbytes(test_case):
function temp_seed (line 55) | def temp_seed(seed: int):
FILE: evaluate/demo_gradio_video_dubbing.py
function resize_video (line 87) | def resize_video(video_path, output_path, max_size=448):
function chat_with_multi_modal (line 114) | def chat_with_multi_modal(model: str, prompt: str, bucket_name: str, vid...
function smooth_concatenate (line 155) | def smooth_concatenate(audio_tensors: List[torch.Tensor], sample_rate: i...
function process_and_save_audio (line 188) | def process_and_save_audio(audio_tensors: List[torch.Tensor],
function merge_audio_video (line 200) | def merge_audio_video(audio_path: str,
class PrintToLog (line 219) | class PrintToLog:
method write (line 220) | def write(self, message):
method flush (line 224) | def flush(self):
function init_audiostory (line 229) | def init_audiostory():
function video_dubbing (line 258) | def video_dubbing(video_path: str, guidance: float, step: int):
function generate_video (line 363) | def generate_video(steps, guidance_scale, video_input):
function clear_all (line 421) | def clear_all():
FILE: evaluate/evaluate_long_audio.py
function extract_content_and_duration (line 69) | def extract_content_and_duration(text: str) -> Tuple[str, float | None]:
function smooth_concatenate (line 95) | def smooth_concatenate(
function process_and_save_audio (line 148) | def process_and_save_audio(
function wav2fbank (line 179) | def wav2fbank(filename: str) -> torch.Tensor:
function norm_fbank (line 211) | def norm_fbank(fbank: torch.Tensor) -> torch.Tensor:
function prepare_one_fbank (line 216) | def prepare_one_fbank(wav_path: str, cuda_enabled: bool = True) -> Dict[...
FILE: evaluate/inference.py
function smooth_concatenate (line 93) | def smooth_concatenate(
function process_and_prepare_concat (line 146) | def process_and_prepare_concat(
function wav2fbank (line 170) | def wav2fbank(filename: str) -> torch.Tensor:
function norm_fbank (line 203) | def norm_fbank(fbank: torch.Tensor) -> torch.Tensor:
function prepare_one_fbank (line 208) | def prepare_one_fbank(wav_path: str, cuda_enabled: bool = True) -> Dict[...
function extract_content_and_duration (line 226) | def extract_content_and_duration(text: str) -> Tuple[str, Optional[float]]:
function parse_args (line 256) | def parse_args() -> argparse.Namespace:
function main (line 301) | def main() -> None:
FILE: src/models/detokenizer/modeling_flux.py
class StableAudioPositionalEmbedding (line 21) | class StableAudioPositionalEmbedding(nn.Module):
method __init__ (line 26) | def __init__(self, dim: int):
method forward (line 32) | def forward(self, times: torch.Tensor) -> torch.Tensor:
class DurationEmbedder (line 40) | class DurationEmbedder(nn.Module):
method __init__ (line 58) | def __init__(
method forward (line 76) | def forward(
function retrieve_timesteps (line 96) | def retrieve_timesteps(
class Flux_T5 (line 139) | class Flux_T5(nn.Module):
method __init__ (line 141) | def __init__(self, config, text_encoder_dir=None, initialize_reference...
method get_sigmas (line 189) | def get_sigmas(self, timesteps, n_dim=3, dtype=torch.float32):
method encode_text_classifier_free (line 202) | def encode_text_classifier_free(self, prompt: List[str], T5_tokens_see...
method encode_text (line 273) | def encode_text(self, prompt):
method encode_duration (line 294) | def encode_duration(self, duration):
method inference_flow (line 298) | def inference_flow(
method encode_text_classifier_free_padding (line 421) | def encode_text_classifier_free_padding(self, prompt: List[str], T5_to...
method inference_flow_padding (line 493) | def inference_flow_padding(
method encode_text_classifier_free_full_tokens (line 616) | def encode_text_classifier_free_full_tokens(self, T5_tokens_seedx, num...
method inference_flow_full_tokens (line 669) | def inference_flow_full_tokens(
method forward (line 789) | def forward(self, latents, t5_tokens, duration=torch.tensor([10]), sft...
FILE: src/models/detokenizer/resampler.py
function FeedForward (line 9) | def FeedForward(dim, mult=4):
function reshape_tensor (line 19) | def reshape_tensor(x, heads):
class PerceiverAttention (line 30) | class PerceiverAttention(nn.Module):
method __init__ (line 32) | def __init__(self, *, dim, dim_head=64, heads=8):
method forward (line 46) | def forward(self, x, latents):
class AttentionPool2d (line 78) | class AttentionPool2d(nn.Module):
method __init__ (line 80) | def __init__(self, seq_len: int, embed_dim: int, num_heads: int, outpu...
method forward (line 89) | def forward(self, x, return_all_tokens=False):
class Resampler (line 119) | class Resampler(nn.Module):
method __init__ (line 121) | def __init__(
method forward (line 152) | def forward(self, x):
class ResamplerXL (line 168) | class ResamplerXL(nn.Module):
method __init__ (line 170) | def __init__(
method forward (line 206) | def forward(self, x):
class ResamplerXLV2 (line 226) | class ResamplerXLV2(nn.Module):
method __init__ (line 228) | def __init__(
method forward (line 266) | def forward(self, x,pooled_text_embeds=None):
class ResamplerXLIdentity (line 288) | class ResamplerXLIdentity(nn.Module):
method __init__ (line 289) | def __init__(self) -> None:
method forward (line 292) | def forward(self, x, pooled_text_embeds=None):
FILE: src/models/detokenizer_cotrain/modeling_flux_cotrain.py
class StableAudioPositionalEmbedding (line 20) | class StableAudioPositionalEmbedding(nn.Module):
method __init__ (line 25) | def __init__(self, dim: int):
method forward (line 31) | def forward(self, times: torch.Tensor) -> torch.Tensor:
class DurationEmbedder (line 39) | class DurationEmbedder(nn.Module):
method __init__ (line 57) | def __init__(
method forward (line 75) | def forward(
function retrieve_timesteps (line 95) | def retrieve_timesteps(
class Flux_T5_cotrain (line 138) | class Flux_T5_cotrain(nn.Module):
method __init__ (line 140) | def __init__(self, config, text_encoder_dir=None, initialize_reference...
method get_sigmas (line 188) | def get_sigmas(self, timesteps, n_dim=3, dtype=torch.float32):
method encode_text_classifier_free (line 201) | def encode_text_classifier_free(self, prompt: List[str], T5_tokens_see...
method encode_text (line 272) | def encode_text(self, prompt):
method encode_duration (line 293) | def encode_duration(self, duration):
method inference_flow (line 297) | def inference_flow(
method encode_text_classifier_free_padding (line 419) | def encode_text_classifier_free_padding(self, prompt: List[str], T5_to...
method inference_flow_padding (line 491) | def inference_flow_padding(
method encode_text_classifier_free_full_tokens (line 613) | def encode_text_classifier_free_full_tokens(self, T5_tokens_seedx, num...
method inference_flow_full_tokens (line 666) | def inference_flow_full_tokens(
method forward (line 790) | def forward(self, latents, t5_tokens, duration=torch.tensor([10]), sft...
method forward_fake (line 943) | def forward_fake(self, latents, t5_tokens, duration=torch.tensor([10])...
FILE: src/models/mllm/generation.py
class AutoAudioTokenGenerationProcessor (line 9) | class AutoAudioTokenGenerationProcessor(LogitsProcessor):
method __init__ (line 11) | def __init__(self, tokenizer, num_aud_gen_tokens=32) -> None:
method __call__ (line 19) | def __call__(self, input_ids, scores):
class AutoT5TokenGenerationProcessor (line 39) | class AutoT5TokenGenerationProcessor(LogitsProcessor):
method __init__ (line 41) | def __init__(self, tokenizer, num_t5_gen_tokens=64) -> None:
method __call__ (line 49) | def __call__(self, input_ids, scores):
FILE: src/models/mllm/load_qwenvl_llm.py
function load_checkpoint (line 8) | def load_checkpoint(source_model, target_model):
FILE: src/models/mllm/modeling_audiostory_llm.py
function cosine_loss (line 40) | def cosine_loss(rec, target):
function get_2d_sincos_pos_embed (line 47) | def get_2d_sincos_pos_embed(embed_dim, h_size, w_size, cls_token=False):
function get_2d_sincos_pos_embed_from_grid (line 65) | def get_2d_sincos_pos_embed_from_grid(embed_dim, grid):
function get_1d_sincos_pos_embed_from_grid (line 75) | def get_1d_sincos_pos_embed_from_grid(embed_dim, pos):
function get_abs_pos (line 96) | def get_abs_pos(abs_pos, tgt_size):
class AudioStory_llm (line 116) | class AudioStory_llm(nn.Module):
method __init__ (line 118) | def __init__(self, llm, input_resampler, output_resampler, whisper_res...
method _init_weights (line 166) | def _init_weights(self, m):
method build_audio_projector (line 176) | def build_audio_projector(self, projector_type, hidden_size, target_hi...
method forward (line 196) | def forward(self, input_ids, attention_mask, labels, image_embeds, aud...
method get_last_hidden_states (line 241) | def get_last_hidden_states(self, input_ids, attention_mask, labels, im...
method generate_T5_audtoken_attn_multi_audio (line 298) | def generate_T5_audtoken_attn_multi_audio(self,
method from_pretrained (line 415) | def from_pretrained(cls, llm, input_resampler, output_resampler, whisp...
FILE: src/models/mllm/modeling_audiostory_unified.py
function cosine_loss (line 40) | def cosine_loss(rec: torch.Tensor, target: torch.Tensor) -> torch.Tensor:
class AudioStory_unified (line 55) | class AudioStory_unified(nn.Module):
method __init__ (line 69) | def __init__(
method build_audio_projector_layernorm (line 95) | def build_audio_projector_layernorm(
method forward (line 109) | def forward(
method inference_audiostory_tta (line 189) | def inference_audiostory_tta(
method from_pretrained (line 233) | def from_pretrained(
FILE: src/models/mllm/modeling_llama_xformer.py
function _make_causal_mask (line 51) | def _make_causal_mask(
function _expand_mask (line 82) | def _expand_mask(mask: torch.Tensor, dtype: torch.dtype, tgt_len: Option...
class LlamaRotaryEmbedding (line 97) | class LlamaRotaryEmbedding(torch.nn.Module):
method __init__ (line 99) | def __init__(self, dim, max_position_embeddings=2048, base=10000, devi...
method forward (line 117) | def forward(self, x, seq_len=None):
function rotate_half (line 134) | def rotate_half(x):
function apply_rotary_pos_emb (line 141) | def apply_rotary_pos_emb(q, k, cos, sin, position_ids):
class LlamaMLP (line 152) | class LlamaMLP(nn.Module):
method __init__ (line 154) | def __init__(
method forward (line 166) | def forward(self, x):
class LlamaAttention (line 170) | class LlamaAttention(nn.Module):
method __init__ (line 173) | def __init__(self, config: LlamaConfig):
method _shape (line 190) | def _shape(self, tensor: torch.Tensor, seq_len: int, bsz: int):
method forward (line 193) | def forward(
class LlamaDecoderLayer (line 247) | class LlamaDecoderLayer(nn.Module):
method __init__ (line 249) | def __init__(self, config: LlamaConfig):
method forward (line 261) | def forward(
class LlamaPreTrainedModel (line 337) | class LlamaPreTrainedModel(PreTrainedModel):
method _init_weights (line 344) | def _init_weights(self, module):
method _set_gradient_checkpointing (line 355) | def _set_gradient_checkpointing(self, module, value=False):
class LlamaModel (line 428) | class LlamaModel(LlamaPreTrainedModel):
method __init__ (line 436) | def __init__(self, config: LlamaConfig):
method get_input_embeddings (line 449) | def get_input_embeddings(self):
method set_input_embeddings (line 452) | def set_input_embeddings(self, value):
method _prepare_decoder_attention_mask (line 456) | def _prepare_decoder_attention_mask(self, attention_mask, input_shape,...
method forward (line 477) | def forward(
class LlamaForCausalLM (line 612) | class LlamaForCausalLM(LlamaPreTrainedModel):
method __init__ (line 614) | def __init__(self, config):
method get_input_embeddings (line 623) | def get_input_embeddings(self):
method set_input_embeddings (line 626) | def set_input_embeddings(self, value):
method get_output_embeddings (line 629) | def get_output_embeddings(self):
method set_output_embeddings (line 632) | def set_output_embeddings(self, new_embeddings):
method set_decoder (line 635) | def set_decoder(self, decoder):
method get_decoder (line 638) | def get_decoder(self):
method forward (line 643) | def forward(
method prepare_inputs_for_generation (line 748) | def prepare_inputs_for_generation(
method _reorder_cache (line 782) | def _reorder_cache(past_key_values, beam_idx):
class LlamaForSequenceClassification (line 804) | class LlamaForSequenceClassification(LlamaPreTrainedModel):
method __init__ (line 807) | def __init__(self, config):
method get_input_embeddings (line 816) | def get_input_embeddings(self):
method set_input_embeddings (line 819) | def set_input_embeddings(self, value):
method forward (line 823) | def forward(
FILE: src/models/mllm/peft_models.py
function get_peft_model_with_resize_embedding (line 29) | def get_peft_model_with_resize_embedding(model, peft_config=None, model_...
function get_model_with_resize_embedding (line 117) | def get_model_with_resize_embedding(model, vocab_size=None, torch_dtype=...
function get_full_model_with_resize_embedding (line 162) | def get_full_model_with_resize_embedding(model, vocab_size=None, torch_d...
FILE: src/models/mllm/utils.py
function remove_mismatched_weights (line 9) | def remove_mismatched_weights(model, pretrained_state_dict):
function load_zero3_checkpoint (line 28) | def load_zero3_checkpoint(module: nn.Module, state_dict, prefix="", erro...
FILE: src/models/tokenizer/init_qwen_tokenizer.py
function init_tokenizer (line 6) | def init_tokenizer(pretrained_model_path, add_tokens_path=None):
FILE: src/models/tokenizer/init_qwen_tokenizer_special_token.py
function init_tokenizer (line 6) | def init_tokenizer(pretrained_model_path, add_tokens_path=None):
FILE: src/models/tokenizer/modeling_tangoflux.py
class StableAudioPositionalEmbedding (line 19) | class StableAudioPositionalEmbedding(nn.Module):
method __init__ (line 24) | def __init__(self, dim: int):
method forward (line 30) | def forward(self, times: torch.Tensor) -> torch.Tensor:
class DurationEmbedder (line 38) | class DurationEmbedder(nn.Module):
method __init__ (line 56) | def __init__(
method forward (line 74) | def forward(
function retrieve_timesteps (line 94) | def retrieve_timesteps(
class TangoFlux (line 137) | class TangoFlux(nn.Module):
method __init__ (line 139) | def __init__(self, config, text_encoder_dir=None, initialize_reference...
method get_sigmas (line 185) | def get_sigmas(self, timesteps, n_dim=3, dtype=torch.float32):
method encode_text_classifier_free (line 198) | def encode_text_classifier_free(self, prompt: List[str], num_samples_p...
method encode_text (line 255) | def encode_text(self, prompt):
method encode_duration (line 276) | def encode_duration(self, duration):
method inference_flow (line 280) | def inference_flow(
method inference_text_prompt_tokens (line 398) | def inference_text_prompt_tokens(
method forward (line 454) | def forward(self, latents, prompt, duration=torch.tensor([10]), sft=Tr...
FILE: src/models/tokenizer/modeling_whisper.py
function shift_tokens_right (line 44) | def shift_tokens_right(input_ids: torch.Tensor, pad_token_id: int, decod...
function _make_causal_mask (line 61) | def _make_causal_mask(
function _expand_mask (line 79) | def _expand_mask(mask: torch.Tensor, dtype: torch.dtype, tgt_len: Option...
function _compute_mask_indices (line 94) | def _compute_mask_indices(
class WhisperPositionalEmbedding (line 213) | class WhisperPositionalEmbedding(nn.Embedding):
method __init__ (line 214) | def __init__(self, num_positions: int, embedding_dim: int, padding_idx...
method forward (line 217) | def forward(self, input_ids, past_key_values_length=0):
class WhisperAttention (line 221) | class WhisperAttention(nn.Module):
method __init__ (line 224) | def __init__(
method _shape (line 252) | def _shape(self, tensor: torch.Tensor, seq_len: int, bsz: int):
method forward (line 256) | def forward(
class WhisperEncoderLayer (line 378) | class WhisperEncoderLayer(nn.Module):
method __init__ (line 379) | def __init__(self, config: WhisperConfig):
method forward (line 395) | def forward(
class WhisperDecoderLayer (line 447) | class WhisperDecoderLayer(nn.Module):
method __init__ (line 448) | def __init__(self, config: WhisperConfig):
method forward (line 474) | def forward(
class WhisperPreTrainedModel (line 564) | class WhisperPreTrainedModel(PreTrainedModel):
method _init_weights (line 571) | def _init_weights(self, module):
method _set_gradient_checkpointing (line 582) | def _set_gradient_checkpointing(self, module, value=False):
method _get_feat_extract_output_lengths (line 586) | def _get_feat_extract_output_lengths(self, input_lengths: torch.LongTe...
class WhisperEncoder (line 724) | class WhisperEncoder(WhisperPreTrainedModel):
method __init__ (line 733) | def __init__(self, config: WhisperConfig):
method _freeze_parameters (line 759) | def _freeze_parameters(self):
method get_input_embeddings (line 764) | def get_input_embeddings(self) -> nn.Module:
method set_input_embeddings (line 767) | def set_input_embeddings(self, value: nn.Module):
method forward (line 770) | def forward(
class WhisperDecoder (line 876) | class WhisperDecoder(WhisperPreTrainedModel):
method __init__ (line 884) | def __init__(self, config: WhisperConfig):
method get_input_embeddings (line 904) | def get_input_embeddings(self):
method set_input_embeddings (line 907) | def set_input_embeddings(self, value):
method _prepare_decoder_attention_mask (line 910) | def _prepare_decoder_attention_mask(self, attention_mask, input_shape,...
method forward (line 932) | def forward(
class WhisperModel (line 1137) | class WhisperModel(WhisperPreTrainedModel):
method __init__ (line 1140) | def __init__(self, config: WhisperConfig):
method get_input_embeddings (line 1148) | def get_input_embeddings(self):
method set_input_embeddings (line 1151) | def set_input_embeddings(self, value):
method get_encoder (line 1154) | def get_encoder(self):
method get_decoder (line 1157) | def get_decoder(self):
method freeze_encoder (line 1160) | def freeze_encoder(self):
method _mask_input_features (line 1167) | def _mask_input_features(
method forward (line 1212) | def forward(
class WhisperForConditionalGeneration (line 1323) | class WhisperForConditionalGeneration(WhisperPreTrainedModel):
method __init__ (line 1334) | def __init__(self, config: WhisperConfig):
method get_encoder (line 1342) | def get_encoder(self):
method get_decoder (line 1345) | def get_decoder(self):
method resize_token_embeddings (line 1348) | def resize_token_embeddings(self, new_num_tokens: int) -> nn.Embedding:
method get_output_embeddings (line 1352) | def get_output_embeddings(self):
method set_output_embeddings (line 1355) | def set_output_embeddings(self, new_embeddings):
method get_input_embeddings (line 1358) | def get_input_embeddings(self) -> nn.Module:
method freeze_encoder (line 1361) | def freeze_encoder(self):
method forward (line 1370) | def forward(
method generate (line 1466) | def generate(
method prepare_inputs_for_generation (line 1638) | def prepare_inputs_for_generation(
method _reorder_cache (line 1661) | def _reorder_cache(past_key_values, beam_idx):
class WhisperForAudioClassification (line 1675) | class WhisperForAudioClassification(WhisperPreTrainedModel):
method __init__ (line 1676) | def __init__(self, config):
method freeze_encoder (line 1689) | def freeze_encoder(self):
method get_input_embeddings (line 1696) | def get_input_embeddings(self) -> nn.Module:
method set_input_embeddings (line 1699) | def set_input_embeddings(self, value: nn.Module):
method forward (line 1704) | def forward(
class Whisper_Resampler_llava (line 1797) | class Whisper_Resampler_llava(nn.Module):
method __init__ (line 1798) | def __init__(self, token_num, ori_embed_dim, tgt_embed_dim):
method _init_weights (line 1816) | def _init_weights(self, m):
method forward (line 1825) | def forward(self, x: torch.Tensor) -> torch.Tensor:
class Whisper_Resampler_llava_old (line 1837) | class Whisper_Resampler_llava_old(nn.Module):
method __init__ (line 1838) | def __init__(self, window_size, ori_embed_dim, tgt_embed_dim):
method _init_weights (line 1853) | def _init_weights(self, m):
method forward (line 1862) | def forward(self, x: torch.Tensor) -> torch.Tensor:
FILE: src/models/tokenizer/modeling_whisper_inference.py
function shift_tokens_right (line 44) | def shift_tokens_right(input_ids: torch.Tensor, pad_token_id: int, decod...
function _make_causal_mask (line 61) | def _make_causal_mask(
function _expand_mask (line 79) | def _expand_mask(mask: torch.Tensor, dtype: torch.dtype, tgt_len: Option...
function _compute_mask_indices (line 94) | def _compute_mask_indices(
class WhisperPositionalEmbedding (line 213) | class WhisperPositionalEmbedding(nn.Embedding):
method __init__ (line 214) | def __init__(self, num_positions: int, embedding_dim: int, padding_idx...
method forward (line 217) | def forward(self, input_ids, past_key_values_length=0):
class WhisperAttention (line 221) | class WhisperAttention(nn.Module):
method __init__ (line 224) | def __init__(
method _shape (line 252) | def _shape(self, tensor: torch.Tensor, seq_len: int, bsz: int):
method forward (line 256) | def forward(
class WhisperEncoderLayer (line 378) | class WhisperEncoderLayer(nn.Module):
method __init__ (line 379) | def __init__(self, config: WhisperConfig):
method forward (line 395) | def forward(
class WhisperDecoderLayer (line 447) | class WhisperDecoderLayer(nn.Module):
method __init__ (line 448) | def __init__(self, config: WhisperConfig):
method forward (line 474) | def forward(
class WhisperPreTrainedModel (line 564) | class WhisperPreTrainedModel(PreTrainedModel):
method _init_weights (line 571) | def _init_weights(self, module):
method _set_gradient_checkpointing (line 582) | def _set_gradient_checkpointing(self, module, value=False):
method _get_feat_extract_output_lengths (line 586) | def _get_feat_extract_output_lengths(self, input_lengths: torch.LongTe...
class WhisperEncoder (line 724) | class WhisperEncoder(WhisperPreTrainedModel):
method __init__ (line 733) | def __init__(self, config: WhisperConfig):
method _freeze_parameters (line 756) | def _freeze_parameters(self):
method get_input_embeddings (line 761) | def get_input_embeddings(self) -> nn.Module:
method set_input_embeddings (line 764) | def set_input_embeddings(self, value: nn.Module):
method forward (line 767) | def forward(
class WhisperDecoder (line 871) | class WhisperDecoder(WhisperPreTrainedModel):
method __init__ (line 879) | def __init__(self, config: WhisperConfig):
method get_input_embeddings (line 899) | def get_input_embeddings(self):
method set_input_embeddings (line 902) | def set_input_embeddings(self, value):
method _prepare_decoder_attention_mask (line 905) | def _prepare_decoder_attention_mask(self, attention_mask, input_shape,...
method forward (line 927) | def forward(
class WhisperModel (line 1132) | class WhisperModel(WhisperPreTrainedModel):
method __init__ (line 1135) | def __init__(self, config: WhisperConfig):
method get_input_embeddings (line 1143) | def get_input_embeddings(self):
method set_input_embeddings (line 1146) | def set_input_embeddings(self, value):
method get_encoder (line 1149) | def get_encoder(self):
method get_decoder (line 1152) | def get_decoder(self):
method freeze_encoder (line 1155) | def freeze_encoder(self):
method _mask_input_features (line 1162) | def _mask_input_features(
method forward (line 1207) | def forward(
class WhisperForConditionalGeneration (line 1302) | class WhisperForConditionalGeneration(WhisperPreTrainedModel):
method __init__ (line 1313) | def __init__(self, config: WhisperConfig):
method get_encoder (line 1321) | def get_encoder(self):
method get_decoder (line 1324) | def get_decoder(self):
method resize_token_embeddings (line 1327) | def resize_token_embeddings(self, new_num_tokens: int) -> nn.Embedding:
method get_output_embeddings (line 1331) | def get_output_embeddings(self):
method set_output_embeddings (line 1334) | def set_output_embeddings(self, new_embeddings):
method get_input_embeddings (line 1337) | def get_input_embeddings(self) -> nn.Module:
method freeze_encoder (line 1340) | def freeze_encoder(self):
method forward (line 1349) | def forward(
method generate (line 1445) | def generate(
method prepare_inputs_for_generation (line 1617) | def prepare_inputs_for_generation(
method _reorder_cache (line 1640) | def _reorder_cache(past_key_values, beam_idx):
class WhisperForAudioClassification (line 1654) | class WhisperForAudioClassification(WhisperPreTrainedModel):
method __init__ (line 1655) | def __init__(self, config):
method freeze_encoder (line 1668) | def freeze_encoder(self):
method get_input_embeddings (line 1675) | def get_input_embeddings(self) -> nn.Module:
method set_input_embeddings (line 1678) | def set_input_embeddings(self, value: nn.Module):
method forward (line 1683) | def forward(
FILE: src/models/tokenizer/qwen_visual.py
function get_abs_pos (line 24) | def get_abs_pos(abs_pos, tgt_size):
function get_2d_sincos_pos_embed (line 44) | def get_2d_sincos_pos_embed(embed_dim, grid_size, cls_token=False):
function get_2d_sincos_pos_embed_from_grid (line 62) | def get_2d_sincos_pos_embed_from_grid(embed_dim, grid):
function get_1d_sincos_pos_embed_from_grid (line 73) | def get_1d_sincos_pos_embed_from_grid(embed_dim, pos):
class Resampler (line 94) | class Resampler(nn.Module):
method __init__ (line 102) | def __init__(self, grid_size, embed_dim, num_heads, kv_dim=None, norm_...
method _init_weights (line 132) | def _init_weights(self, m):
method forward (line 141) | def forward(self, x, attn_mask=None):
method _repeat (line 153) | def _repeat(self, query, N: int):
method __init__ (line 165) | def __init__(self, grid_size, embed_dim, num_heads, kv_dim=None, norm_...
method _init_weights (line 195) | def _init_weights(self, m):
method forward (line 204) | def forward(self, x, attn_mask=None):
method _repeat (line 216) | def _repeat(self, query, N: int):
class Resampler (line 157) | class Resampler(nn.Module):
method __init__ (line 102) | def __init__(self, grid_size, embed_dim, num_heads, kv_dim=None, norm_...
method _init_weights (line 132) | def _init_weights(self, m):
method forward (line 141) | def forward(self, x, attn_mask=None):
method _repeat (line 153) | def _repeat(self, query, N: int):
method __init__ (line 165) | def __init__(self, grid_size, embed_dim, num_heads, kv_dim=None, norm_...
method _init_weights (line 195) | def _init_weights(self, m):
method forward (line 204) | def forward(self, x, attn_mask=None):
method _repeat (line 216) | def _repeat(self, query, N: int):
class VisualAttention (line 220) | class VisualAttention(nn.Module):
method __init__ (line 227) | def __init__(self, embed_dim, num_heads, bias=True, kdim=None, vdim=No...
method forward (line 248) | def forward(self, query, key, value, attn_mask=None):
class VisualAttentionBlock (line 301) | class VisualAttentionBlock(nn.Module):
method __init__ (line 303) | def __init__(
method attention (line 325) | def attention(
method forward (line 338) | def forward(
class TransformerBlock (line 353) | class TransformerBlock(nn.Module):
method __init__ (line 355) | def __init__(
method get_cast_dtype (line 371) | def get_cast_dtype(self) -> torch.dtype:
method get_cast_device (line 374) | def get_cast_device(self) -> torch.device:
method forward (line 377) | def forward(self, x: torch.Tensor, attn_mask: Optional[torch.Tensor] =...
class VisionTransformerWithAttnPool (line 393) | class VisionTransformerWithAttnPool(nn.Module):
method __init__ (line 395) | def __init__(self,
method forward (line 455) | def forward(self, x: torch.Tensor, patch_positions: Optional[torch.Ten...
method encode (line 487) | def encode(self, image_paths: List[str]):
method from_pretrained (line 500) | def from_pretrained(cls, pretrained_model_path=None, **kwargs):
class VisionTransformer (line 530) | class VisionTransformer(nn.Module):
method __init__ (line 532) | def __init__(self,
method forward (line 575) | def forward(self, x: torch.Tensor):
method encode (line 596) | def encode(self, image_paths: List[str]):
FILE: src/processer/tokenizer.py
function bert_tokenizer (line 4) | def bert_tokenizer(pretrained_model_name_or_path):
FILE: src/processer/transforms.py
function get_transform (line 5) | def get_transform(type='clip', keep_ratio=True, image_size=224):
Copy disabled (too large)
Download .json
Condensed preview — 157 files, each showing path, character count, and a content snippet. Download the .json file for the full structured content (21,833K chars).
[
{
"path": ".gitignore",
"chars": 201,
"preview": "ckpt\nckpt/*\nckpt_upload/*\noutput/*\n__pycache__\n.vscode/\n.vscode\n*.pyc\n.DS_Store\n*.pt\n*.pth\n*.ckpt\n*.safetensors\n*.ptl\n*."
},
{
"path": "README.md",
"chars": 8894,
"preview": "# AudioStory: Generating Long-Form Narrative Audio with Large Language Models\n\n**[Yuxin Guo<sup>1,2</sup>](https://schol"
},
{
"path": "configs/audiostory_llm_qwen25_3b_lora.yaml",
"chars": 558,
"preview": "_target_: src.models.mllm.peft_models.get_peft_model_with_resize_embedding\nmodel:\n _target_: transformers.AutoModelForC"
},
{
"path": "envs/peft/.github/ISSUE_TEMPLATE/bug-report.yml",
"chars": 2291,
"preview": "name: \"\\U0001F41B Bug Report\"\ndescription: Submit a bug report to help us improve the library\nbody:\n - type: textarea\n "
},
{
"path": "envs/peft/.github/ISSUE_TEMPLATE/feature-request.yml",
"chars": 855,
"preview": "name: \"\\U0001F680 Feature request\"\ndescription: Submit a proposal/request for a new feature\nlabels: [ \"feature\" ]\nbody:\n"
},
{
"path": "envs/peft/.github/workflows/build_docker_images.yml",
"chars": 2088,
"preview": "name: Build Docker images (scheduled)\n\non:\n workflow_dispatch:\n workflow_call:\n schedule:\n - cron: \"0 1 * * *\"\n\nco"
},
{
"path": "envs/peft/.github/workflows/build_documentation.yml",
"chars": 414,
"preview": "name: Build documentation\n\non:\n push:\n branches:\n - main\n - doc-builder*\n - v*-release\n\njobs:\n buil"
},
{
"path": "envs/peft/.github/workflows/build_pr_documentation.yml",
"chars": 397,
"preview": "name: Build PR Documentation\n\non:\n pull_request:\n\nconcurrency:\n group: ${{ github.workflow }}-${{ github.head_ref || g"
},
{
"path": "envs/peft/.github/workflows/delete_doc_comment.yml",
"chars": 289,
"preview": "name: Delete doc comment\n\non:\n workflow_run:\n workflows: [\"Delete doc comment trigger\"]\n types:\n - completed"
},
{
"path": "envs/peft/.github/workflows/delete_doc_comment_trigger.yml",
"chars": 236,
"preview": "name: Delete doc comment trigger\n\non:\n pull_request:\n types: [ closed ]\n\n\njobs:\n delete:\n uses: huggingface/doc-"
},
{
"path": "envs/peft/.github/workflows/nightly.yml",
"chars": 2673,
"preview": "name: Self-hosted runner with slow tests (scheduled)\n\non:\n workflow_dispatch:\n schedule:\n - cron: \"0 2 * * *\"\n\nenv:"
},
{
"path": "envs/peft/.github/workflows/stale.yml",
"chars": 544,
"preview": "name: Stale Bot\n\non:\n schedule:\n - cron: \"0 15 * * *\"\n\njobs:\n close_stale_issues:\n name: Close Stale Issues\n "
},
{
"path": "envs/peft/.github/workflows/tests.yml",
"chars": 1248,
"preview": "name: tests\n\non:\n push:\n branches: [main]\n pull_request:\n\njobs:\n check_code_quality:\n runs-on: ubuntu-latest\n "
},
{
"path": "envs/peft/.github/workflows/upload_pr_documentation.yml",
"chars": 377,
"preview": "name: Upload PR Documentation\n\non:\n workflow_run:\n workflows: [\"Build PR Documentation\"]\n types:\n - complete"
},
{
"path": "envs/peft/.gitignore",
"chars": 1887,
"preview": "# Byte-compiled / optimized / DLL files\n__pycache__/\n*.py[cod]\n*$py.class\n\n# C extensions\n*.so\n\n# Distribution / packagi"
},
{
"path": "envs/peft/LICENSE",
"chars": 11357,
"preview": " Apache License\n Version 2.0, January 2004\n "
},
{
"path": "envs/peft/Makefile",
"chars": 1432,
"preview": ".PHONY: quality style test docs\n\ncheck_dirs := src tests examples docs\n\n# Check that source code meets quality standards"
},
{
"path": "envs/peft/README.md",
"chars": 19216,
"preview": "<!---\nCopyright 2023 The HuggingFace Team. All rights reserved.\n\nLicensed under the Apache License, Version 2.0 (the \"Li"
},
{
"path": "envs/peft/docker/peft-cpu/Dockerfile",
"chars": 1812,
"preview": "# Builds GPU docker image of PyTorch\n# Uses multi-staged approach to reduce size\n# Stage 1\n# Use base conda image to red"
},
{
"path": "envs/peft/docker/peft-gpu/Dockerfile",
"chars": 2015,
"preview": "# Builds GPU docker image of PyTorch\n# Uses multi-staged approach to reduce size\n# Stage 1\n# Use base conda image to red"
},
{
"path": "envs/peft/docs/Makefile",
"chars": 585,
"preview": "# Minimal makefile for Sphinx documentation\n#\n\n# You can set these variables from the command line.\nSPHINXOPTS =\nSPHI"
},
{
"path": "envs/peft/docs/README.md",
"chars": 10424,
"preview": "<!---\nCopyright 2023 The HuggingFace Team. All rights reserved.\n\nLicensed under the Apache License, Version 2.0 (the \"Li"
},
{
"path": "envs/peft/docs/source/_config.py",
"chars": 280,
"preview": "# docstyle-ignore\nINSTALL_CONTENT = \"\"\"\n# PEFT installation\n! pip install peft accelerate transformers\n# To install from"
},
{
"path": "envs/peft/docs/source/_toctree.yml",
"chars": 1603,
"preview": "- title: Get started\n sections:\n - local: index\n title: 🤗 PEFT\n - local: quicktour\n title: Quicktour\n - local:"
},
{
"path": "envs/peft/docs/source/accelerate/deepspeed-zero3-offload.mdx",
"chars": 9456,
"preview": "# DeepSpeed\n\n[DeepSpeed](https://www.deepspeed.ai/) is a library designed for speed and scale for distributed training o"
},
{
"path": "envs/peft/docs/source/accelerate/fsdp.mdx",
"chars": 6877,
"preview": "# Fully Sharded Data Parallel\n\n[Fully sharded data parallel](https://pytorch.org/docs/stable/fsdp.html) (FSDP) is develo"
},
{
"path": "envs/peft/docs/source/conceptual_guides/ia3.mdx",
"chars": 3444,
"preview": "<!--Copyright 2023 The HuggingFace Team. All rights reserved.\n\nLicensed under the Apache License, Version 2.0 (the \"Lice"
},
{
"path": "envs/peft/docs/source/conceptual_guides/lora.mdx",
"chars": 6130,
"preview": "<!--Copyright 2023 The HuggingFace Team. All rights reserved.\n\nLicensed under the Apache License, Version 2.0 (the \"Lice"
},
{
"path": "envs/peft/docs/source/conceptual_guides/prompting.mdx",
"chars": 5521,
"preview": "# Prompting\n\nTraining large pretrained language models is very time-consuming and compute-intensive. As they continue to"
},
{
"path": "envs/peft/docs/source/index.mdx",
"chars": 8137,
"preview": "<!--Copyright 2023 The HuggingFace Team. All rights reserved.\n\nLicensed under the Apache License, Version 2.0 (the \"Lice"
},
{
"path": "envs/peft/docs/source/install.mdx",
"chars": 1411,
"preview": "<!--Copyright 2023 The HuggingFace Team. All rights reserved.\n\nLicensed under the Apache License, Version 2.0 (the \"Lice"
},
{
"path": "envs/peft/docs/source/package_reference/config.mdx",
"chars": 601,
"preview": "# Configuration\n\nThe configuration classes stores the configuration of a [`PeftModel`], PEFT adapter models, and the con"
},
{
"path": "envs/peft/docs/source/package_reference/peft_model.mdx",
"chars": 1145,
"preview": "# Models\n\n[`PeftModel`] is the base model class for specifying the base Transformer model and configuration to apply a P"
},
{
"path": "envs/peft/docs/source/package_reference/tuners.mdx",
"chars": 646,
"preview": "# Tuners\n\nEach tuner (or PEFT method) has a configuration and model.\n\n## LoRA\n\nFor finetuning a model with LoRA.\n\n[[auto"
},
{
"path": "envs/peft/docs/source/quicktour.mdx",
"chars": 7892,
"preview": "<!--Copyright 2023 The HuggingFace Team. All rights reserved.\n\nLicensed under the Apache License, Version 2.0 (the \"Lice"
},
{
"path": "envs/peft/docs/source/task_guides/clm-prompt-tuning.mdx",
"chars": 11850,
"preview": "<!--Copyright 2023 The HuggingFace Team. All rights reserved.\n\nLicensed under the Apache License, Version 2.0 (the \"Lice"
},
{
"path": "envs/peft/docs/source/task_guides/dreambooth_lora.mdx",
"chars": 10877,
"preview": "<!--Copyright 2023 The HuggingFace Team. All rights reserved.\n\nLicensed under the Apache License, Version 2.0 (the \"Lice"
},
{
"path": "envs/peft/docs/source/task_guides/image_classification_lora.mdx",
"chars": 14766,
"preview": "<!--Copyright 2023 The HuggingFace Team. All rights reserved.\n\nLicensed under the Apache License, Version 2.0 (the \"Lice"
},
{
"path": "envs/peft/docs/source/task_guides/int8-asr.mdx",
"chars": 16716,
"preview": "# int8 training for automatic speech recognition\n\nQuantization reduces the precision of floating point data types, decre"
},
{
"path": "envs/peft/docs/source/task_guides/ptuning-seq-classification.mdx",
"chars": 8754,
"preview": "# P-tuning for sequence classification\n\nIt is challenging to finetune large language models for downstream tasks because"
},
{
"path": "envs/peft/docs/source/task_guides/semantic-similarity-lora.md",
"chars": 15016,
"preview": "# LoRA for semantic similarity tasks\n\nLow-Rank Adaptation (LoRA) is a reparametrization method that aims to reduce the n"
},
{
"path": "envs/peft/docs/source/task_guides/semantic_segmentation_lora.mdx",
"chars": 17371,
"preview": "<!--Copyright 2023 The HuggingFace Team. All rights reserved.\n\nLicensed under the Apache License, Version 2.0 (the \"Lice"
},
{
"path": "envs/peft/docs/source/task_guides/seq2seq-prefix-tuning.mdx",
"chars": 9667,
"preview": "# Prefix tuning for conditional generation\n\n[[open-in-colab]]\n\nPrefix tuning is an additive method where only a sequence"
},
{
"path": "envs/peft/docs/source/task_guides/token-classification-lora.mdx",
"chars": 11228,
"preview": "# LoRA for token classification\n\nLow-Rank Adaptation (LoRA) is a reparametrization method that aims to reduce the number"
},
{
"path": "envs/peft/examples/causal_language_modeling/accelerate_ds_zero3_cpu_offload_config.yaml",
"chars": 506,
"preview": "compute_environment: LOCAL_MACHINE\ndeepspeed_config:\n gradient_accumulation_steps: 1\n gradient_clipping: 1.0\n offload"
},
{
"path": "envs/peft/examples/causal_language_modeling/peft_lora_clm_accelerate_big_model_inference.ipynb",
"chars": 17139,
"preview": "{\n \"cells\": [\n {\n \"cell_type\": \"code\",\n \"execution_count\": 1,\n \"id\": \"71fbfca2\",\n \"metadata\": {},\n \"outputs\":"
},
{
"path": "envs/peft/examples/causal_language_modeling/peft_lora_clm_accelerate_ds_zero3_offload.py",
"chars": 14871,
"preview": "import gc\nimport os\nimport sys\nimport threading\n\nimport numpy as np\nimport psutil\nimport torch\nfrom accelerate import Ac"
},
{
"path": "envs/peft/examples/causal_language_modeling/peft_prefix_tuning_clm.ipynb",
"chars": 52456,
"preview": "{\n \"cells\": [\n {\n \"cell_type\": \"code\",\n \"execution_count\": 2,\n \"id\": \"71fbfca2\",\n \"metadata\": {},\n \"outputs\":"
},
{
"path": "envs/peft/examples/causal_language_modeling/peft_prompt_tuning_clm.ipynb",
"chars": 48967,
"preview": "{\n \"cells\": [\n {\n \"cell_type\": \"code\",\n \"execution_count\": null,\n \"id\": \"71fbfca2\",\n \"metadata\": {},\n \"output"
},
{
"path": "envs/peft/examples/causal_language_modeling/requirements.txt",
"chars": 56,
"preview": "transformers\naccelerate\nevaluate\ndeepspeed\ntqdm\ndatasets"
},
{
"path": "envs/peft/examples/conditional_generation/accelerate_ds_zero3_cpu_offload_config.yaml",
"chars": 506,
"preview": "compute_environment: LOCAL_MACHINE\ndeepspeed_config:\n gradient_accumulation_steps: 1\n gradient_clipping: 1.0\n offload"
},
{
"path": "envs/peft/examples/conditional_generation/peft_adalora_seq2seq.py",
"chars": 5536,
"preview": "import os\n\nimport torch\nfrom datasets import load_dataset\nfrom torch.utils.data import DataLoader\nfrom tqdm import tqdm\n"
},
{
"path": "envs/peft/examples/conditional_generation/peft_ia3_seq2seq.ipynb",
"chars": 91180,
"preview": "{\n \"cells\": [\n {\n \"cell_type\": \"code\",\n \"execution_count\": 12,\n \"metadata\": {\n \"id\": \"5f93b7d1\"\n },\n \"outp"
},
{
"path": "envs/peft/examples/conditional_generation/peft_lora_seq2seq.ipynb",
"chars": 15812,
"preview": "{\n \"cells\": [\n {\n \"cell_type\": \"code\",\n \"execution_count\": 1,\n \"id\": \"5f93b7d1\",\n \"metadata\": {},\n \"outputs\":"
},
{
"path": "envs/peft/examples/conditional_generation/peft_lora_seq2seq_accelerate_big_model_inference.ipynb",
"chars": 9149,
"preview": "{\n \"cells\": [\n {\n \"cell_type\": \"code\",\n \"execution_count\": null,\n \"id\": \"71fbfca2\",\n \"metadata\": {},\n \"output"
},
{
"path": "envs/peft/examples/conditional_generation/peft_lora_seq2seq_accelerate_ds_zero3_offload.py",
"chars": 12438,
"preview": "import gc\nimport os\nimport sys\nimport threading\n\nimport numpy as np\nimport psutil\nimport torch\nfrom accelerate import Ac"
},
{
"path": "envs/peft/examples/conditional_generation/peft_lora_seq2seq_accelerate_fsdp.py",
"chars": 5091,
"preview": "import os\n\nimport torch\nfrom accelerate import Accelerator\nfrom datasets import load_dataset\nfrom torch.utils.data impor"
},
{
"path": "envs/peft/examples/conditional_generation/peft_prefix_tuning_seq2seq.ipynb",
"chars": 17977,
"preview": "{\n \"cells\": [\n {\n \"cell_type\": \"code\",\n \"execution_count\": 1,\n \"id\": \"5f93b7d1\",\n \"metadata\": {},\n \"outputs\":"
},
{
"path": "envs/peft/examples/conditional_generation/peft_prompt_tuning_seq2seq.ipynb",
"chars": 31377,
"preview": "{\n \"cells\": [\n {\n \"cell_type\": \"code\",\n \"execution_count\": 1,\n \"id\": \"5f93b7d1\",\n \"metadata\": {\n \"ExecuteTim"
},
{
"path": "envs/peft/examples/conditional_generation/peft_prompt_tuning_seq2seq_with_generate.ipynb",
"chars": 64556,
"preview": "{\n \"cells\": [\n {\n \"cell_type\": \"code\",\n \"execution_count\": 1,\n \"id\": \"5f93b7d1\",\n \"metadata\": {\n \"ExecuteTim"
},
{
"path": "envs/peft/examples/conditional_generation/requirements.txt",
"chars": 56,
"preview": "transformers\naccelerate\nevaluate\ndeepspeed\ntqdm\ndatasets"
},
{
"path": "envs/peft/examples/feature_extraction/peft_lora_embedding_semantic_search.py",
"chars": 20717,
"preview": "# coding=utf-8\n# Copyright 2023-present the HuggingFace Inc. team.\n#\n# Licensed under the Apache License, Version 2.0 (t"
},
{
"path": "envs/peft/examples/feature_extraction/peft_lora_embedding_semantic_similarity_inference.ipynb",
"chars": 173760,
"preview": "{\n \"cells\": [\n {\n \"cell_type\": \"code\",\n \"execution_count\": 1,\n \"id\": \"3e7b6247\",\n \"metadata\": {},\n \"outputs\":"
},
{
"path": "envs/peft/examples/feature_extraction/requirements.txt",
"chars": 193,
"preview": "git+https://github.com/huggingface/peft\ngit+https://github.com/huggingface/accelerate\ngit+https://github.com/huggingface"
},
{
"path": "envs/peft/examples/fp4_finetuning/finetune_fp4_opt_bnb_peft.py",
"chars": 6417,
"preview": "import os\n\nimport torch\nimport torch.nn as nn\nimport transformers\nfrom datasets import load_dataset\nfrom transformers im"
},
{
"path": "envs/peft/examples/image_classification/README.md",
"chars": 883,
"preview": "# Fine-tuning for image classification using LoRA and 🤗 PEFT\n\n[\n\n# ===== Standard libs =====\nimport os\nimport re\nimport json\nimport ti"
},
{
"path": "evaluate/evaluate_long_audio.py",
"chars": 16368,
"preview": "#!/usr/bin/env python3\n# -*- coding: utf-8 -*-\n\n\"\"\"\nMulti-clip audio generation and smooth concatenation.\n\n- Load config"
},
{
"path": "evaluate/evaluate_long_audio.sh",
"chars": 1064,
"preview": "#!/bin/bash\n\necho $ENV_VENUS_PROXY\nexport NO_PROXY=localhost,.woa.com,.oa.com,.tencent.com\nexport HTTP_PROXY=$ENV_VENUS_"
},
{
"path": "evaluate/inference.py",
"chars": 16554,
"preview": "#!/usr/bin/env python3\n# -*- coding: utf-8 -*-\n\n\"\"\"\nLong-form audio generation inference code.\n\n- Load configs via Hydra"
},
{
"path": "install_audiostory.sh",
"chars": 1172,
"preview": "#!/bin/bash\n\npip install torch==2.1.0 torchvision==0.16.0 torchaudio==2.1.0 --index-url https://download.pytorch.org/whl"
},
{
"path": "src/models/detokenizer/__init__.py",
"chars": 1,
"preview": "\n"
},
{
"path": "src/models/detokenizer/modeling_flux.py",
"chars": 34702,
"preview": "from transformers import T5EncoderModel, T5TokenizerFast\nimport torch\nfrom diffusers import FluxTransformer2DModel\nfrom "
},
{
"path": "src/models/detokenizer/resampler.py",
"chars": 10341,
"preview": "# modified from https://github.com/mlfoundations/open_flamingo/blob/main/open_flamingo/src/helpers.py\nimport math\nimport"
},
{
"path": "src/models/detokenizer_cotrain/modeling_flux_cotrain.py",
"chars": 39638,
"preview": "from transformers import T5EncoderModel, T5TokenizerFast\nimport torch\nfrom diffusers import FluxTransformer2DModel\nfrom "
},
{
"path": "src/models/mllm/__init__.py",
"chars": 0,
"preview": ""
},
{
"path": "src/models/mllm/generation.py",
"chars": 2292,
"preview": "import torch\nfrom transformers import LogitsProcessor\n\n\nBOA_TOKEN = '<aud>'\nEOA_TOKEN = '</aud>'\nAUD_TOKEN = '<aud_{:05d"
},
{
"path": "src/models/mllm/load_qwenvl_llm.py",
"chars": 396,
"preview": "import os\nimport torch\nimport transformers\nfrom transformers import Qwen2ForCausalLM\nimport torch\n\n\ndef load_checkpoint("
},
{
"path": "src/models/mllm/modeling_audiostory_llm.py",
"chars": 16241,
"preview": "# --------------------------------------------------------\n# AudioStory: Generating Long-Form Narrative Audio with Large"
},
{
"path": "src/models/mllm/modeling_audiostory_unified.py",
"chars": 8500,
"preview": "# --------------------------------------------------------\n# AudioStory: Generating Long-Form Narrative Audio with Large"
},
{
"path": "src/models/mllm/modeling_llama_xformer.py",
"chars": 39430,
"preview": "# coding=utf-8\n# Copyright 2023 EleutherAI and the HuggingFace Inc. team. All rights reserved.\n#\n# This code is based on"
},
{
"path": "src/models/mllm/peft_models.py",
"chars": 7874,
"preview": "import sys\nsys.path.append('envs/peft/src')\n\nimport os\nfrom peft import (\n LoraConfig,\n PeftModel,\n LoraModel,\n"
},
{
"path": "src/models/mllm/utils.py",
"chars": 3926,
"preview": "import deepspeed\nfrom transformers import AutoConfig\nfrom transformers.integrations.deepspeed import is_deepspeed_zero3_"
},
{
"path": "src/models/tokenizer/__init__.py",
"chars": 0,
"preview": ""
},
{
"path": "src/models/tokenizer/init_qwen_tokenizer.py",
"chars": 453,
"preview": "from transformers import AutoModelForCausalLM, AutoTokenizer\nimport torch\nimport json\n\n\ndef init_tokenizer(pretrained_mo"
},
{
"path": "src/models/tokenizer/init_qwen_tokenizer_special_token.py",
"chars": 688,
"preview": "from transformers import AutoModelForCausalLM, AutoTokenizer, AddedToken\nimport torch\nimport json\n\n\ndef init_tokenizer(p"
},
{
"path": "src/models/tokenizer/modeling_tangoflux.py",
"chars": 22714,
"preview": "from transformers import T5EncoderModel, T5TokenizerFast\nimport torch\nfrom diffusers import FluxTransformer2DModel\nfrom "
},
{
"path": "src/models/tokenizer/modeling_whisper.py",
"chars": 88720,
"preview": "# This script is based on https://github.com/huggingface/transformers/blob/v4.29.1/src/transformers/models/whisper/model"
},
{
"path": "src/models/tokenizer/modeling_whisper_inference.py",
"chars": 84955,
"preview": "# This script is based on https://github.com/huggingface/transformers/blob/v4.29.1/src/transformers/models/whisper/model"
},
{
"path": "src/models/tokenizer/qwen_visual.py",
"chars": 21729,
"preview": "# Tongyi Qianwen is licensed under the Tongyi Qianwen \n# LICENSE AGREEMENT, Copyright (c) Alibaba Cloud. \n# All Rights R"
},
{
"path": "src/processer/tokenizer.py",
"chars": 350,
"preview": "from transformers import BertTokenizer\n\n\ndef bert_tokenizer(pretrained_model_name_or_path):\n tokenizer = BertTokenize"
},
{
"path": "src/processer/transforms.py",
"chars": 3160,
"preview": "from torchvision import transforms\nfrom PIL import Image\n\n\ndef get_transform(type='clip', keep_ratio=True, image_size=22"
},
{
"path": "tokenizer/added_tokens.json",
"chars": 16397,
"preview": "{\n \"</t5>\": 151937,\n \"<video_padding>\": 151939,\n \"<timestamp>\": 152165,\n \"</timestamp>\": 152164,\n \"<t5>\":"
},
{
"path": "tokenizer/tokenizer.json",
"chars": 6244779,
"preview": "{\n \"version\": \"1.0\",\n \"truncation\": null,\n \"padding\": null,\n \"added_tokens\": [\n {\n \"id\": 151643,\n \"cont"
},
{
"path": "tokenizer/tokenizer_config.json",
"chars": 7305,
"preview": "{\n \"add_bos_token\": false,\n \"add_prefix_space\": false,\n \"added_tokens_decoder\": {\n \"151643\": {\n \"content\": \"<"
},
{
"path": "tokenizer/vocab.json",
"chars": 5282650,
"preview": "{\n \"</img>\": 151937,\n \"</patch>\": 151939,\n \"<box_end>\": 152165,\n \"<box_start>\": 152164,\n \"<img>\": 151936,"
}
]
About this extraction
This page contains the full source code of the TencentARC/AudioStory GitHub repository, extracted and formatted as plain text for AI agents and large language models (LLMs). The extraction includes 157 files (18.0 MB), approximately 4.7M tokens, and a symbol index with 860 extracted functions, classes, methods, constants, and types. Use this with OpenClaw, Claude, ChatGPT, Cursor, Windsurf, or any other AI tool that accepts text input. You can copy the full output to your clipboard or download it as a .txt file.
Extracted by GitExtract — free GitHub repo to text converter for AI. Built by Nikandr Surkov.