Copy disabled (too large)
Download .txt
Showing preview only (47,460K chars total). Download the full file to get everything.
Repository: Tiiny-AI/PowerInfer
Branch: main
Commit: 59df17505d98
Files: 2271
Total size: 44.8 MB
Directory structure:
gitextract_pvz9t_lh/
├── .devops/
│ ├── cloud-v-pipeline
│ ├── full-cuda.Dockerfile
│ ├── full-rocm.Dockerfile
│ ├── full.Dockerfile
│ ├── llama-cpp-clblast.srpm.spec
│ ├── llama-cpp-cublas.srpm.spec
│ ├── llama-cpp.srpm.spec
│ ├── main-cuda.Dockerfile
│ ├── main-rocm.Dockerfile
│ ├── main.Dockerfile
│ └── tools.sh
├── .dockerignore
├── .ecrc
├── .editorconfig
├── .flake8
├── .github/
│ ├── ISSUE_TEMPLATE/
│ │ ├── bug.md
│ │ ├── enhancement.md
│ │ └── question.md
│ └── workflows/
│ ├── build.yml
│ ├── code-coverage.yml
│ ├── docker.yml
│ ├── editorconfig.yml
│ ├── gguf-publish.yml
│ ├── tidy-post.yml
│ ├── tidy-review.yml
│ └── zig-build.yml
├── .gitignore
├── .gitmodules
├── .pre-commit-config.yaml
├── CMakeLists.txt
├── LICENSE
├── Package.swift
├── README.md
├── SHA256SUMS
├── atomic_windows.h
├── build.zig
├── ci/
│ ├── README.md
│ └── run.sh
├── cmake/
│ └── FindSIMD.cmake
├── codecov.yml
├── common/
│ ├── CMakeLists.txt
│ ├── base64.hpp
│ ├── build-info.cpp.in
│ ├── common.cpp
│ ├── common.h
│ ├── console.cpp
│ ├── console.h
│ ├── grammar-parser.cpp
│ ├── grammar-parser.h
│ ├── log.h
│ ├── sampling.cpp
│ ├── sampling.h
│ ├── stb_image.h
│ ├── train.cpp
│ └── train.h
├── convert-dense.py
├── convert-hf-to-powerinfer-gguf.py
├── convert.py
├── docs/
│ ├── BLIS.md
│ └── token_generation_performance_tips.md
├── examples/
│ ├── CMakeLists.txt
│ ├── Miku.sh
│ ├── alpaca.sh
│ ├── baby-llama/
│ │ ├── CMakeLists.txt
│ │ └── baby-llama.cpp
│ ├── batched/
│ │ ├── CMakeLists.txt
│ │ ├── README.md
│ │ └── batched.cpp
│ ├── batched-bench/
│ │ ├── CMakeLists.txt
│ │ ├── README.md
│ │ └── batched-bench.cpp
│ ├── batched.swift/
│ │ ├── .gitignore
│ │ ├── Makefile
│ │ ├── Package.swift
│ │ ├── README.md
│ │ └── Sources/
│ │ └── main.swift
│ ├── beam-search/
│ │ ├── CMakeLists.txt
│ │ └── beam-search.cpp
│ ├── benchmark/
│ │ ├── CMakeLists.txt
│ │ └── benchmark-matmult.cpp
│ ├── chat-13B.sh
│ ├── chat-persistent.sh
│ ├── chat-vicuna.sh
│ ├── chat.sh
│ ├── convert-llama2c-to-ggml/
│ │ ├── CMakeLists.txt
│ │ ├── README.md
│ │ └── convert-llama2c-to-ggml.cpp
│ ├── embedding/
│ │ ├── CMakeLists.txt
│ │ ├── README.md
│ │ └── embedding.cpp
│ ├── export-lora/
│ │ ├── CMakeLists.txt
│ │ ├── README.md
│ │ └── export-lora.cpp
│ ├── finetune/
│ │ ├── CMakeLists.txt
│ │ ├── README.md
│ │ ├── convert-finetune-checkpoint-to-gguf.py
│ │ ├── finetune.cpp
│ │ └── finetune.sh
│ ├── gguf/
│ │ ├── CMakeLists.txt
│ │ └── gguf.cpp
│ ├── gpt4all.sh
│ ├── infill/
│ │ ├── CMakeLists.txt
│ │ ├── README.md
│ │ └── infill.cpp
│ ├── jeopardy/
│ │ ├── README.md
│ │ ├── graph.py
│ │ ├── jeopardy.sh
│ │ ├── qasheet.csv
│ │ └── questions.txt
│ ├── json-schema-to-grammar.py
│ ├── llama-bench/
│ │ ├── CMakeLists.txt
│ │ ├── README.md
│ │ └── llama-bench.cpp
│ ├── llama.vim
│ ├── llama2-13b.sh
│ ├── llama2.sh
│ ├── llava/
│ │ ├── CMakeLists.txt
│ │ ├── README.md
│ │ ├── clip.cpp
│ │ ├── clip.h
│ │ ├── convert-image-encoder-to-gguf.py
│ │ ├── llava-cli.cpp
│ │ ├── llava-surgery.py
│ │ ├── llava.cpp
│ │ └── llava.h
│ ├── llm.vim
│ ├── main/
│ │ ├── CMakeLists.txt
│ │ ├── README.md
│ │ └── main.cpp
│ ├── main-cmake-pkg/
│ │ ├── .gitignore
│ │ ├── CMakeLists.txt
│ │ └── README.md
│ ├── make-ggml.py
│ ├── metal/
│ │ ├── CMakeLists.txt
│ │ └── metal.cpp
│ ├── parallel/
│ │ ├── CMakeLists.txt
│ │ ├── README.md
│ │ └── parallel.cpp
│ ├── perplexity/
│ │ ├── CMakeLists.txt
│ │ ├── README.md
│ │ └── perplexity.cpp
│ ├── quantize/
│ │ ├── CMakeLists.txt
│ │ ├── README.md
│ │ └── quantize.cpp
│ ├── quantize-stats/
│ │ ├── CMakeLists.txt
│ │ └── quantize-stats.cpp
│ ├── reason-act.sh
│ ├── save-load-state/
│ │ ├── CMakeLists.txt
│ │ └── save-load-state.cpp
│ ├── server/
│ │ ├── CMakeLists.txt
│ │ ├── README.md
│ │ ├── api_like_OAI.py
│ │ ├── chat-llama2.sh
│ │ ├── chat.mjs
│ │ ├── chat.sh
│ │ ├── completion.js.hpp
│ │ ├── deps.sh
│ │ ├── httplib.h
│ │ ├── index.html.hpp
│ │ ├── index.js.hpp
│ │ ├── json-schema-to-grammar.mjs.hpp
│ │ ├── json.hpp
│ │ ├── public/
│ │ │ ├── completion.js
│ │ │ ├── index.html
│ │ │ ├── index.js
│ │ │ └── json-schema-to-grammar.mjs
│ │ └── server.cpp
│ ├── server-llama2-13B.sh
│ ├── simple/
│ │ ├── CMakeLists.txt
│ │ ├── README.md
│ │ └── simple.cpp
│ ├── speculative/
│ │ ├── CMakeLists.txt
│ │ └── speculative.cpp
│ └── train-text-from-scratch/
│ ├── CMakeLists.txt
│ ├── README.md
│ ├── convert-train-checkpoint-to-gguf.py
│ └── train-text-from-scratch.cpp
├── flake.nix
├── ggml-alloc.c
├── ggml-alloc.h
├── ggml-backend-impl.h
├── ggml-backend.c
├── ggml-backend.h
├── ggml-cuda.cu
├── ggml-cuda.h
├── ggml-impl.h
├── ggml-metal.h
├── ggml-metal.m
├── ggml-metal.metal
├── ggml-mpi.c
├── ggml-mpi.h
├── ggml-opencl.cpp
├── ggml-opencl.h
├── ggml-quants.c
├── ggml-quants.h
├── ggml.c
├── ggml.h
├── gguf-py/
│ ├── LICENSE
│ ├── README.md
│ ├── examples/
│ │ └── writer.py
│ ├── gguf/
│ │ ├── __init__.py
│ │ ├── constants.py
│ │ ├── gguf.py
│ │ ├── gguf_reader.py
│ │ ├── gguf_writer.py
│ │ ├── py.typed
│ │ ├── tensor_mapping.py
│ │ └── vocab.py
│ ├── pyproject.toml
│ ├── scripts/
│ │ ├── __init__.py
│ │ ├── gguf-convert-endian.py
│ │ ├── gguf-dump.py
│ │ └── gguf-set-metadata.py
│ └── tests/
│ └── test_gguf.py
├── grammars/
│ ├── README.md
│ ├── arithmetic.gbnf
│ ├── c.gbnf
│ ├── chess.gbnf
│ ├── japanese.gbnf
│ ├── json.gbnf
│ ├── json_arr.gbnf
│ └── list.gbnf
├── llama.cpp
├── llama.h
├── mypy.ini
├── pocs/
│ ├── CMakeLists.txt
│ └── vdot/
│ ├── CMakeLists.txt
│ ├── q8dot.cpp
│ └── vdot.cpp
├── powerinfer-py/
│ ├── powerinfer/
│ │ ├── __init__.py
│ │ ├── __main__.py
│ │ ├── export_split.py
│ │ └── solver.py
│ └── pyproject.toml
├── prompts/
│ ├── LLM-questions.txt
│ ├── alpaca.txt
│ ├── assistant.txt
│ ├── chat-with-baichuan.txt
│ ├── chat-with-bob.txt
│ ├── chat-with-vicuna-v0.txt
│ ├── chat-with-vicuna-v1.txt
│ ├── chat.txt
│ ├── dan-modified.txt
│ ├── dan.txt
│ ├── mnemonics.txt
│ ├── parallel-questions.txt
│ └── reason-act.txt
├── requirements.txt
├── run_with_preset.py
├── scripts/
│ ├── LlamaConfig.cmake.in
│ ├── build-info.cmake
│ ├── build-info.sh
│ ├── convert-gg.sh
│ ├── get-wikitext-2.sh
│ ├── qnt-all.sh
│ ├── run-all-perf.sh
│ ├── run-all-ppl.sh
│ ├── server-llm.sh
│ ├── sync-ggml.sh
│ └── verify-checksum-models.py
├── smallthinker/
│ ├── AUTHORS
│ ├── CMakeLists.txt
│ ├── CMakePresets.json
│ ├── CODEOWNERS
│ ├── CONTRIBUTING.md
│ ├── LICENSE
│ ├── Makefile
│ ├── README.md
│ ├── SECURITY.md
│ ├── build-xcframework.sh
│ ├── ci/
│ │ ├── README.md
│ │ └── run.sh
│ ├── cmake/
│ │ ├── arm64-apple-clang.cmake
│ │ ├── arm64-windows-llvm.cmake
│ │ ├── build-info.cmake
│ │ ├── common.cmake
│ │ ├── git-vars.cmake
│ │ ├── llama-config.cmake.in
│ │ ├── llama.pc.in
│ │ └── x64-windows-llvm.cmake
│ ├── common/
│ │ ├── CMakeLists.txt
│ │ ├── arg.cpp
│ │ ├── arg.h
│ │ ├── base64.hpp
│ │ ├── build-info.cpp.in
│ │ ├── chat-parser.cpp
│ │ ├── chat-parser.h
│ │ ├── chat.cpp
│ │ ├── chat.h
│ │ ├── cmake/
│ │ │ └── build-info-gen-cpp.cmake
│ │ ├── common.cpp
│ │ ├── common.h
│ │ ├── console.cpp
│ │ ├── console.h
│ │ ├── json-partial.cpp
│ │ ├── json-partial.h
│ │ ├── json-schema-to-grammar.cpp
│ │ ├── json-schema-to-grammar.h
│ │ ├── llguidance.cpp
│ │ ├── log.cpp
│ │ ├── log.h
│ │ ├── ngram-cache.cpp
│ │ ├── ngram-cache.h
│ │ ├── regex-partial.cpp
│ │ ├── regex-partial.h
│ │ ├── sampling.cpp
│ │ ├── sampling.h
│ │ ├── speculative.cpp
│ │ └── speculative.h
│ ├── convert_hf_to_gguf.py
│ ├── convert_hf_to_gguf_update.py
│ ├── convert_llama_ggml_to_gguf.py
│ ├── convert_lora_to_gguf.py
│ ├── docs/
│ │ ├── android.md
│ │ ├── backend/
│ │ │ ├── BLIS.md
│ │ │ ├── CANN.md
│ │ │ ├── CUDA-FEDORA.md
│ │ │ ├── OPENCL.md
│ │ │ └── SYCL.md
│ │ ├── build.md
│ │ ├── development/
│ │ │ ├── HOWTO-add-model.md
│ │ │ ├── debugging-tests.md
│ │ │ ├── llama-star/
│ │ │ │ └── idea-arch.key
│ │ │ └── token_generation_performance_tips.md
│ │ ├── docker.md
│ │ ├── function-calling.md
│ │ ├── install.md
│ │ ├── llguidance.md
│ │ ├── multimodal/
│ │ │ ├── MobileVLM.md
│ │ │ ├── gemma3.md
│ │ │ ├── glmedge.md
│ │ │ ├── granitevision.md
│ │ │ ├── llava.md
│ │ │ ├── minicpmo2.6.md
│ │ │ ├── minicpmv2.5.md
│ │ │ └── minicpmv2.6.md
│ │ └── multimodal.md
│ ├── examples/
│ │ ├── CMakeLists.txt
│ │ ├── Miku.sh
│ │ ├── batched/
│ │ │ ├── CMakeLists.txt
│ │ │ ├── README.md
│ │ │ └── batched.cpp
│ │ ├── batched.swift/
│ │ │ ├── .gitignore
│ │ │ ├── Makefile
│ │ │ ├── Package.swift
│ │ │ ├── README.md
│ │ │ └── Sources/
│ │ │ └── main.swift
│ │ ├── chat-13B.sh
│ │ ├── chat-persistent.sh
│ │ ├── chat-vicuna.sh
│ │ ├── chat.sh
│ │ ├── convert-llama2c-to-ggml/
│ │ │ ├── CMakeLists.txt
│ │ │ ├── README.md
│ │ │ └── convert-llama2c-to-ggml.cpp
│ │ ├── convert_legacy_llama.py
│ │ ├── deprecation-warning/
│ │ │ ├── README.md
│ │ │ └── deprecation-warning.cpp
│ │ ├── embedding/
│ │ │ ├── CMakeLists.txt
│ │ │ ├── README.md
│ │ │ └── embedding.cpp
│ │ ├── eval-callback/
│ │ │ ├── CMakeLists.txt
│ │ │ ├── README.md
│ │ │ └── eval-callback.cpp
│ │ ├── gen-docs/
│ │ │ ├── CMakeLists.txt
│ │ │ └── gen-docs.cpp
│ │ ├── gguf/
│ │ │ ├── CMakeLists.txt
│ │ │ └── gguf.cpp
│ │ ├── gguf-hash/
│ │ │ ├── CMakeLists.txt
│ │ │ ├── README.md
│ │ │ ├── deps/
│ │ │ │ ├── rotate-bits/
│ │ │ │ │ ├── package.json
│ │ │ │ │ └── rotate-bits.h
│ │ │ │ ├── sha1/
│ │ │ │ │ ├── package.json
│ │ │ │ │ ├── sha1.c
│ │ │ │ │ └── sha1.h
│ │ │ │ ├── sha256/
│ │ │ │ │ ├── package.json
│ │ │ │ │ ├── sha256.c
│ │ │ │ │ └── sha256.h
│ │ │ │ └── xxhash/
│ │ │ │ ├── clib.json
│ │ │ │ ├── xxhash.c
│ │ │ │ └── xxhash.h
│ │ │ └── gguf-hash.cpp
│ │ ├── gritlm/
│ │ │ ├── CMakeLists.txt
│ │ │ ├── README.md
│ │ │ └── gritlm.cpp
│ │ ├── jeopardy/
│ │ │ ├── README.md
│ │ │ ├── graph.py
│ │ │ ├── jeopardy.sh
│ │ │ ├── qasheet.csv
│ │ │ └── questions.txt
│ │ ├── json_schema_pydantic_example.py
│ │ ├── json_schema_to_grammar.py
│ │ ├── llama.android/
│ │ │ ├── .gitignore
│ │ │ ├── README.md
│ │ │ ├── app/
│ │ │ │ ├── .gitignore
│ │ │ │ ├── build.gradle.kts
│ │ │ │ ├── proguard-rules.pro
│ │ │ │ └── src/
│ │ │ │ └── main/
│ │ │ │ ├── AndroidManifest.xml
│ │ │ │ ├── java/
│ │ │ │ │ └── com/
│ │ │ │ │ └── example/
│ │ │ │ │ └── llama/
│ │ │ │ │ ├── Downloadable.kt
│ │ │ │ │ ├── MainActivity.kt
│ │ │ │ │ ├── MainViewModel.kt
│ │ │ │ │ └── ui/
│ │ │ │ │ └── theme/
│ │ │ │ │ ├── Color.kt
│ │ │ │ │ ├── Theme.kt
│ │ │ │ │ └── Type.kt
│ │ │ │ └── res/
│ │ │ │ ├── drawable/
│ │ │ │ │ ├── ic_launcher_background.xml
│ │ │ │ │ └── ic_launcher_foreground.xml
│ │ │ │ ├── mipmap-anydpi/
│ │ │ │ │ ├── ic_launcher.xml
│ │ │ │ │ └── ic_launcher_round.xml
│ │ │ │ ├── values/
│ │ │ │ │ ├── colors.xml
│ │ │ │ │ ├── strings.xml
│ │ │ │ │ └── themes.xml
│ │ │ │ └── xml/
│ │ │ │ ├── backup_rules.xml
│ │ │ │ └── data_extraction_rules.xml
│ │ │ ├── build.gradle.kts
│ │ │ ├── gradle/
│ │ │ │ └── wrapper/
│ │ │ │ ├── gradle-wrapper.jar
│ │ │ │ └── gradle-wrapper.properties
│ │ │ ├── gradle.properties
│ │ │ ├── gradlew
│ │ │ ├── llama/
│ │ │ │ ├── .gitignore
│ │ │ │ ├── build.gradle.kts
│ │ │ │ ├── consumer-rules.pro
│ │ │ │ ├── proguard-rules.pro
│ │ │ │ └── src/
│ │ │ │ ├── androidTest/
│ │ │ │ │ └── java/
│ │ │ │ │ └── android/
│ │ │ │ │ └── llama/
│ │ │ │ │ └── cpp/
│ │ │ │ │ └── ExampleInstrumentedTest.kt
│ │ │ │ ├── main/
│ │ │ │ │ ├── AndroidManifest.xml
│ │ │ │ │ ├── cpp/
│ │ │ │ │ │ ├── CMakeLists.txt
│ │ │ │ │ │ └── llama-android.cpp
│ │ │ │ │ └── java/
│ │ │ │ │ └── android/
│ │ │ │ │ └── llama/
│ │ │ │ │ └── cpp/
│ │ │ │ │ └── LLamaAndroid.kt
│ │ │ │ └── test/
│ │ │ │ └── java/
│ │ │ │ └── android/
│ │ │ │ └── llama/
│ │ │ │ └── cpp/
│ │ │ │ └── ExampleUnitTest.kt
│ │ │ └── settings.gradle.kts
│ │ ├── llama.swiftui/
│ │ │ ├── .gitignore
│ │ │ ├── README.md
│ │ │ ├── llama.cpp.swift/
│ │ │ │ └── LibLlama.swift
│ │ │ ├── llama.swiftui/
│ │ │ │ ├── Assets.xcassets/
│ │ │ │ │ ├── AppIcon.appiconset/
│ │ │ │ │ │ └── Contents.json
│ │ │ │ │ └── Contents.json
│ │ │ │ ├── Models/
│ │ │ │ │ └── LlamaState.swift
│ │ │ │ ├── Resources/
│ │ │ │ │ └── models/
│ │ │ │ │ └── .gitignore
│ │ │ │ ├── UI/
│ │ │ │ │ ├── ContentView.swift
│ │ │ │ │ ├── DownloadButton.swift
│ │ │ │ │ ├── InputButton.swift
│ │ │ │ │ └── LoadCustomButton.swift
│ │ │ │ └── llama_swiftuiApp.swift
│ │ │ └── llama.swiftui.xcodeproj/
│ │ │ ├── project.pbxproj
│ │ │ └── project.xcworkspace/
│ │ │ └── contents.xcworkspacedata
│ │ ├── llama.vim
│ │ ├── llm.vim
│ │ ├── lookahead/
│ │ │ ├── CMakeLists.txt
│ │ │ ├── README.md
│ │ │ └── lookahead.cpp
│ │ ├── lookup/
│ │ │ ├── CMakeLists.txt
│ │ │ ├── README.md
│ │ │ ├── lookup-create.cpp
│ │ │ ├── lookup-merge.cpp
│ │ │ ├── lookup-stats.cpp
│ │ │ └── lookup.cpp
│ │ ├── parallel/
│ │ │ ├── CMakeLists.txt
│ │ │ ├── README.md
│ │ │ └── parallel.cpp
│ │ ├── passkey/
│ │ │ ├── CMakeLists.txt
│ │ │ ├── README.md
│ │ │ └── passkey.cpp
│ │ ├── pydantic_models_to_grammar.py
│ │ ├── pydantic_models_to_grammar_examples.py
│ │ ├── reason-act.sh
│ │ ├── regex_to_grammar.py
│ │ ├── retrieval/
│ │ │ ├── CMakeLists.txt
│ │ │ ├── README.md
│ │ │ └── retrieval.cpp
│ │ ├── save-load-state/
│ │ │ ├── CMakeLists.txt
│ │ │ └── save-load-state.cpp
│ │ ├── server-llama2-13B.sh
│ │ ├── server_embd.py
│ │ ├── simple/
│ │ │ ├── CMakeLists.txt
│ │ │ ├── README.md
│ │ │ └── simple.cpp
│ │ ├── simple-chat/
│ │ │ ├── CMakeLists.txt
│ │ │ ├── README.md
│ │ │ └── simple-chat.cpp
│ │ ├── simple-cmake-pkg/
│ │ │ ├── .gitignore
│ │ │ ├── CMakeLists.txt
│ │ │ └── README.md
│ │ ├── speculative/
│ │ │ ├── CMakeLists.txt
│ │ │ ├── README.md
│ │ │ └── speculative.cpp
│ │ ├── speculative-simple/
│ │ │ ├── CMakeLists.txt
│ │ │ ├── README.md
│ │ │ └── speculative-simple.cpp
│ │ ├── sycl/
│ │ │ ├── CMakeLists.txt
│ │ │ ├── README.md
│ │ │ ├── build.sh
│ │ │ ├── ls-sycl-device.cpp
│ │ │ ├── run-llama2.sh
│ │ │ └── run-llama3.sh
│ │ ├── training/
│ │ │ ├── CMakeLists.txt
│ │ │ ├── README.md
│ │ │ └── finetune.cpp
│ │ └── ts-type-to-grammar.sh
│ ├── flake.nix
│ ├── get_no_moe_weights_ffn.py
│ ├── ggml/
│ │ ├── .gitignore
│ │ ├── CMakeLists.txt
│ │ ├── cmake/
│ │ │ ├── GitVars.cmake
│ │ │ ├── common.cmake
│ │ │ └── ggml-config.cmake.in
│ │ ├── include/
│ │ │ ├── .clang-format
│ │ │ ├── ggml-alloc.h
│ │ │ ├── ggml-backend.h
│ │ │ ├── ggml-blas.h
│ │ │ ├── ggml-cann.h
│ │ │ ├── ggml-cpp.h
│ │ │ ├── ggml-cpu.h
│ │ │ ├── ggml-cuda.h
│ │ │ ├── ggml-kompute.h
│ │ │ ├── ggml-metal.h
│ │ │ ├── ggml-opencl.h
│ │ │ ├── ggml-opt.h
│ │ │ ├── ggml-rpc.h
│ │ │ ├── ggml-sycl.h
│ │ │ ├── ggml-vulkan.h
│ │ │ ├── ggml.h
│ │ │ └── gguf.h
│ │ └── src/
│ │ ├── .clang-format
│ │ ├── CMakeLists.txt
│ │ ├── ggml-alloc.c
│ │ ├── ggml-backend-impl.h
│ │ ├── ggml-backend-reg.cpp
│ │ ├── ggml-backend.cpp
│ │ ├── ggml-blas/
│ │ │ ├── CMakeLists.txt
│ │ │ └── ggml-blas.cpp
│ │ ├── ggml-cann/
│ │ │ ├── CMakeLists.txt
│ │ │ ├── Doxyfile
│ │ │ ├── acl_tensor.cpp
│ │ │ ├── acl_tensor.h
│ │ │ ├── aclnn_ops.cpp
│ │ │ ├── aclnn_ops.h
│ │ │ ├── common.h
│ │ │ └── ggml-cann.cpp
│ │ ├── ggml-common.h
│ │ ├── ggml-cpu/
│ │ │ ├── CMakeLists.txt
│ │ │ ├── amx/
│ │ │ │ ├── amx.cpp
│ │ │ │ ├── amx.h
│ │ │ │ ├── common.h
│ │ │ │ ├── mmq.cpp
│ │ │ │ └── mmq.h
│ │ │ ├── binary-ops.cpp
│ │ │ ├── binary-ops.h
│ │ │ ├── cmake/
│ │ │ │ └── FindSIMD.cmake
│ │ │ ├── common.h
│ │ │ ├── cpu-feats-x86.cpp
│ │ │ ├── ggml-cpu-aarch64.cpp
│ │ │ ├── ggml-cpu-aarch64.h
│ │ │ ├── ggml-cpu-hbm.cpp
│ │ │ ├── ggml-cpu-hbm.h
│ │ │ ├── ggml-cpu-impl.h
│ │ │ ├── ggml-cpu-quants.c
│ │ │ ├── ggml-cpu-quants.h
│ │ │ ├── ggml-cpu-traits.cpp
│ │ │ ├── ggml-cpu-traits.h
│ │ │ ├── ggml-cpu.c
│ │ │ ├── ggml-cpu.cpp
│ │ │ ├── kleidiai/
│ │ │ │ ├── kernels.cpp
│ │ │ │ ├── kernels.h
│ │ │ │ ├── kleidiai.cpp
│ │ │ │ └── kleidiai.h
│ │ │ ├── llamafile/
│ │ │ │ ├── sgemm.cpp
│ │ │ │ └── sgemm.h
│ │ │ ├── ops.cpp
│ │ │ ├── ops.h
│ │ │ ├── simd-mappings.h
│ │ │ ├── unary-ops.cpp
│ │ │ ├── unary-ops.h
│ │ │ ├── vec.cpp
│ │ │ └── vec.h
│ │ ├── ggml-cuda/
│ │ │ ├── CMakeLists.txt
│ │ │ ├── acc.cu
│ │ │ ├── acc.cuh
│ │ │ ├── arange.cu
│ │ │ ├── arange.cuh
│ │ │ ├── argmax.cu
│ │ │ ├── argmax.cuh
│ │ │ ├── argsort.cu
│ │ │ ├── argsort.cuh
│ │ │ ├── binbcast.cu
│ │ │ ├── binbcast.cuh
│ │ │ ├── clamp.cu
│ │ │ ├── clamp.cuh
│ │ │ ├── common.cuh
│ │ │ ├── concat.cu
│ │ │ ├── concat.cuh
│ │ │ ├── conv-transpose-1d.cu
│ │ │ ├── conv-transpose-1d.cuh
│ │ │ ├── convert.cu
│ │ │ ├── convert.cuh
│ │ │ ├── count-equal.cu
│ │ │ ├── count-equal.cuh
│ │ │ ├── cp-async.cuh
│ │ │ ├── cpy.cu
│ │ │ ├── cpy.cuh
│ │ │ ├── cross-entropy-loss.cu
│ │ │ ├── cross-entropy-loss.cuh
│ │ │ ├── dequantize.cuh
│ │ │ ├── diagmask.cu
│ │ │ ├── diagmask.cuh
│ │ │ ├── fattn-common.cuh
│ │ │ ├── fattn-mma-f16.cuh
│ │ │ ├── fattn-tile-f16.cu
│ │ │ ├── fattn-tile-f16.cuh
│ │ │ ├── fattn-tile-f32.cu
│ │ │ ├── fattn-tile-f32.cuh
│ │ │ ├── fattn-vec-f16.cuh
│ │ │ ├── fattn-vec-f32.cuh
│ │ │ ├── fattn-wmma-f16.cu
│ │ │ ├── fattn-wmma-f16.cuh
│ │ │ ├── fattn.cu
│ │ │ ├── fattn.cuh
│ │ │ ├── getrows.cu
│ │ │ ├── getrows.cuh
│ │ │ ├── ggml-cuda.cu
│ │ │ ├── gla.cu
│ │ │ ├── gla.cuh
│ │ │ ├── im2col.cu
│ │ │ ├── im2col.cuh
│ │ │ ├── mma.cuh
│ │ │ ├── mmq.cu
│ │ │ ├── mmq.cuh
│ │ │ ├── mmv.cu
│ │ │ ├── mmv.cuh
│ │ │ ├── mmvq.cu
│ │ │ ├── mmvq.cuh
│ │ │ ├── norm.cu
│ │ │ ├── norm.cuh
│ │ │ ├── opt-step-adamw.cu
│ │ │ ├── opt-step-adamw.cuh
│ │ │ ├── out-prod.cu
│ │ │ ├── out-prod.cuh
│ │ │ ├── pad.cu
│ │ │ ├── pad.cuh
│ │ │ ├── pool2d.cu
│ │ │ ├── pool2d.cuh
│ │ │ ├── quantize.cu
│ │ │ ├── quantize.cuh
│ │ │ ├── rope.cu
│ │ │ ├── rope.cuh
│ │ │ ├── scale.cu
│ │ │ ├── scale.cuh
│ │ │ ├── softmax.cu
│ │ │ ├── softmax.cuh
│ │ │ ├── ssm-conv.cu
│ │ │ ├── ssm-conv.cuh
│ │ │ ├── ssm-scan.cu
│ │ │ ├── ssm-scan.cuh
│ │ │ ├── sum.cu
│ │ │ ├── sum.cuh
│ │ │ ├── sumrows.cu
│ │ │ ├── sumrows.cuh
│ │ │ ├── template-instances/
│ │ │ │ ├── fattn-mma-f16-instance-ncols1_1-ncols2_16.cu
│ │ │ │ ├── fattn-mma-f16-instance-ncols1_1-ncols2_8.cu
│ │ │ │ ├── fattn-mma-f16-instance-ncols1_16-ncols2_1.cu
│ │ │ │ ├── fattn-mma-f16-instance-ncols1_16-ncols2_2.cu
│ │ │ │ ├── fattn-mma-f16-instance-ncols1_16-ncols2_4.cu
│ │ │ │ ├── fattn-mma-f16-instance-ncols1_2-ncols2_16.cu
│ │ │ │ ├── fattn-mma-f16-instance-ncols1_2-ncols2_4.cu
│ │ │ │ ├── fattn-mma-f16-instance-ncols1_2-ncols2_8.cu
│ │ │ │ ├── fattn-mma-f16-instance-ncols1_32-ncols2_1.cu
│ │ │ │ ├── fattn-mma-f16-instance-ncols1_32-ncols2_2.cu
│ │ │ │ ├── fattn-mma-f16-instance-ncols1_4-ncols2_16.cu
│ │ │ │ ├── fattn-mma-f16-instance-ncols1_4-ncols2_2.cu
│ │ │ │ ├── fattn-mma-f16-instance-ncols1_4-ncols2_4.cu
│ │ │ │ ├── fattn-mma-f16-instance-ncols1_4-ncols2_8.cu
│ │ │ │ ├── fattn-mma-f16-instance-ncols1_64-ncols2_1.cu
│ │ │ │ ├── fattn-mma-f16-instance-ncols1_8-ncols2_1.cu
│ │ │ │ ├── fattn-mma-f16-instance-ncols1_8-ncols2_2.cu
│ │ │ │ ├── fattn-mma-f16-instance-ncols1_8-ncols2_4.cu
│ │ │ │ ├── fattn-mma-f16-instance-ncols1_8-ncols2_8.cu
│ │ │ │ ├── fattn-vec-f16-instance-hs128-f16-f16.cu
│ │ │ │ ├── fattn-vec-f16-instance-hs128-f16-q4_0.cu
│ │ │ │ ├── fattn-vec-f16-instance-hs128-f16-q4_1.cu
│ │ │ │ ├── fattn-vec-f16-instance-hs128-f16-q5_0.cu
│ │ │ │ ├── fattn-vec-f16-instance-hs128-f16-q5_1.cu
│ │ │ │ ├── fattn-vec-f16-instance-hs128-f16-q8_0.cu
│ │ │ │ ├── fattn-vec-f16-instance-hs128-q4_0-f16.cu
│ │ │ │ ├── fattn-vec-f16-instance-hs128-q4_0-q4_0.cu
│ │ │ │ ├── fattn-vec-f16-instance-hs128-q4_0-q4_1.cu
│ │ │ │ ├── fattn-vec-f16-instance-hs128-q4_0-q5_0.cu
│ │ │ │ ├── fattn-vec-f16-instance-hs128-q4_0-q5_1.cu
│ │ │ │ ├── fattn-vec-f16-instance-hs128-q4_0-q8_0.cu
│ │ │ │ ├── fattn-vec-f16-instance-hs128-q4_1-f16.cu
│ │ │ │ ├── fattn-vec-f16-instance-hs128-q4_1-q4_0.cu
│ │ │ │ ├── fattn-vec-f16-instance-hs128-q4_1-q4_1.cu
│ │ │ │ ├── fattn-vec-f16-instance-hs128-q4_1-q5_0.cu
│ │ │ │ ├── fattn-vec-f16-instance-hs128-q4_1-q5_1.cu
│ │ │ │ ├── fattn-vec-f16-instance-hs128-q4_1-q8_0.cu
│ │ │ │ ├── fattn-vec-f16-instance-hs128-q5_0-f16.cu
│ │ │ │ ├── fattn-vec-f16-instance-hs128-q5_0-q4_0.cu
│ │ │ │ ├── fattn-vec-f16-instance-hs128-q5_0-q4_1.cu
│ │ │ │ ├── fattn-vec-f16-instance-hs128-q5_0-q5_0.cu
│ │ │ │ ├── fattn-vec-f16-instance-hs128-q5_0-q5_1.cu
│ │ │ │ ├── fattn-vec-f16-instance-hs128-q5_0-q8_0.cu
│ │ │ │ ├── fattn-vec-f16-instance-hs128-q5_1-f16.cu
│ │ │ │ ├── fattn-vec-f16-instance-hs128-q5_1-q4_0.cu
│ │ │ │ ├── fattn-vec-f16-instance-hs128-q5_1-q4_1.cu
│ │ │ │ ├── fattn-vec-f16-instance-hs128-q5_1-q5_0.cu
│ │ │ │ ├── fattn-vec-f16-instance-hs128-q5_1-q5_1.cu
│ │ │ │ ├── fattn-vec-f16-instance-hs128-q5_1-q8_0.cu
│ │ │ │ ├── fattn-vec-f16-instance-hs128-q8_0-f16.cu
│ │ │ │ ├── fattn-vec-f16-instance-hs128-q8_0-q4_0.cu
│ │ │ │ ├── fattn-vec-f16-instance-hs128-q8_0-q4_1.cu
│ │ │ │ ├── fattn-vec-f16-instance-hs128-q8_0-q5_0.cu
│ │ │ │ ├── fattn-vec-f16-instance-hs128-q8_0-q5_1.cu
│ │ │ │ ├── fattn-vec-f16-instance-hs128-q8_0-q8_0.cu
│ │ │ │ ├── fattn-vec-f16-instance-hs256-f16-f16.cu
│ │ │ │ ├── fattn-vec-f16-instance-hs64-f16-f16.cu
│ │ │ │ ├── fattn-vec-f16-instance-hs64-f16-q4_0.cu
│ │ │ │ ├── fattn-vec-f16-instance-hs64-f16-q4_1.cu
│ │ │ │ ├── fattn-vec-f16-instance-hs64-f16-q5_0.cu
│ │ │ │ ├── fattn-vec-f16-instance-hs64-f16-q5_1.cu
│ │ │ │ ├── fattn-vec-f16-instance-hs64-f16-q8_0.cu
│ │ │ │ ├── fattn-vec-f32-instance-hs128-f16-f16.cu
│ │ │ │ ├── fattn-vec-f32-instance-hs128-f16-q4_0.cu
│ │ │ │ ├── fattn-vec-f32-instance-hs128-f16-q4_1.cu
│ │ │ │ ├── fattn-vec-f32-instance-hs128-f16-q5_0.cu
│ │ │ │ ├── fattn-vec-f32-instance-hs128-f16-q5_1.cu
│ │ │ │ ├── fattn-vec-f32-instance-hs128-f16-q8_0.cu
│ │ │ │ ├── fattn-vec-f32-instance-hs128-q4_0-f16.cu
│ │ │ │ ├── fattn-vec-f32-instance-hs128-q4_0-q4_0.cu
│ │ │ │ ├── fattn-vec-f32-instance-hs128-q4_0-q4_1.cu
│ │ │ │ ├── fattn-vec-f32-instance-hs128-q4_0-q5_0.cu
│ │ │ │ ├── fattn-vec-f32-instance-hs128-q4_0-q5_1.cu
│ │ │ │ ├── fattn-vec-f32-instance-hs128-q4_0-q8_0.cu
│ │ │ │ ├── fattn-vec-f32-instance-hs128-q4_1-f16.cu
│ │ │ │ ├── fattn-vec-f32-instance-hs128-q4_1-q4_0.cu
│ │ │ │ ├── fattn-vec-f32-instance-hs128-q4_1-q4_1.cu
│ │ │ │ ├── fattn-vec-f32-instance-hs128-q4_1-q5_0.cu
│ │ │ │ ├── fattn-vec-f32-instance-hs128-q4_1-q5_1.cu
│ │ │ │ ├── fattn-vec-f32-instance-hs128-q4_1-q8_0.cu
│ │ │ │ ├── fattn-vec-f32-instance-hs128-q5_0-f16.cu
│ │ │ │ ├── fattn-vec-f32-instance-hs128-q5_0-q4_0.cu
│ │ │ │ ├── fattn-vec-f32-instance-hs128-q5_0-q4_1.cu
│ │ │ │ ├── fattn-vec-f32-instance-hs128-q5_0-q5_0.cu
│ │ │ │ ├── fattn-vec-f32-instance-hs128-q5_0-q5_1.cu
│ │ │ │ ├── fattn-vec-f32-instance-hs128-q5_0-q8_0.cu
│ │ │ │ ├── fattn-vec-f32-instance-hs128-q5_1-f16.cu
│ │ │ │ ├── fattn-vec-f32-instance-hs128-q5_1-q4_0.cu
│ │ │ │ ├── fattn-vec-f32-instance-hs128-q5_1-q4_1.cu
│ │ │ │ ├── fattn-vec-f32-instance-hs128-q5_1-q5_0.cu
│ │ │ │ ├── fattn-vec-f32-instance-hs128-q5_1-q5_1.cu
│ │ │ │ ├── fattn-vec-f32-instance-hs128-q5_1-q8_0.cu
│ │ │ │ ├── fattn-vec-f32-instance-hs128-q8_0-f16.cu
│ │ │ │ ├── fattn-vec-f32-instance-hs128-q8_0-q4_0.cu
│ │ │ │ ├── fattn-vec-f32-instance-hs128-q8_0-q4_1.cu
│ │ │ │ ├── fattn-vec-f32-instance-hs128-q8_0-q5_0.cu
│ │ │ │ ├── fattn-vec-f32-instance-hs128-q8_0-q5_1.cu
│ │ │ │ ├── fattn-vec-f32-instance-hs128-q8_0-q8_0.cu
│ │ │ │ ├── fattn-vec-f32-instance-hs256-f16-f16.cu
│ │ │ │ ├── fattn-vec-f32-instance-hs64-f16-f16.cu
│ │ │ │ ├── fattn-vec-f32-instance-hs64-f16-q4_0.cu
│ │ │ │ ├── fattn-vec-f32-instance-hs64-f16-q4_1.cu
│ │ │ │ ├── fattn-vec-f32-instance-hs64-f16-q5_0.cu
│ │ │ │ ├── fattn-vec-f32-instance-hs64-f16-q5_1.cu
│ │ │ │ ├── fattn-vec-f32-instance-hs64-f16-q8_0.cu
│ │ │ │ ├── generate_cu_files.py
│ │ │ │ ├── mmq-instance-iq1_s.cu
│ │ │ │ ├── mmq-instance-iq2_s.cu
│ │ │ │ ├── mmq-instance-iq2_xs.cu
│ │ │ │ ├── mmq-instance-iq2_xxs.cu
│ │ │ │ ├── mmq-instance-iq3_s.cu
│ │ │ │ ├── mmq-instance-iq3_xxs.cu
│ │ │ │ ├── mmq-instance-iq4_nl.cu
│ │ │ │ ├── mmq-instance-iq4_xs.cu
│ │ │ │ ├── mmq-instance-q2_k.cu
│ │ │ │ ├── mmq-instance-q3_k.cu
│ │ │ │ ├── mmq-instance-q4_0.cu
│ │ │ │ ├── mmq-instance-q4_1.cu
│ │ │ │ ├── mmq-instance-q4_k.cu
│ │ │ │ ├── mmq-instance-q5_0.cu
│ │ │ │ ├── mmq-instance-q5_1.cu
│ │ │ │ ├── mmq-instance-q5_k.cu
│ │ │ │ ├── mmq-instance-q6_k.cu
│ │ │ │ └── mmq-instance-q8_0.cu
│ │ │ ├── tsembd.cu
│ │ │ ├── tsembd.cuh
│ │ │ ├── unary.cu
│ │ │ ├── unary.cuh
│ │ │ ├── upscale.cu
│ │ │ ├── upscale.cuh
│ │ │ ├── vecdotq.cuh
│ │ │ ├── vendors/
│ │ │ │ ├── cuda.h
│ │ │ │ ├── hip.h
│ │ │ │ └── musa.h
│ │ │ ├── wkv.cu
│ │ │ └── wkv.cuh
│ │ ├── ggml-hip/
│ │ │ └── CMakeLists.txt
│ │ ├── ggml-impl.h
│ │ ├── ggml-kompute/
│ │ │ ├── CMakeLists.txt
│ │ │ ├── ggml-kompute.cpp
│ │ │ └── kompute-shaders/
│ │ │ ├── common.comp
│ │ │ ├── op_add.comp
│ │ │ ├── op_addrow.comp
│ │ │ ├── op_cpy_f16_f16.comp
│ │ │ ├── op_cpy_f16_f32.comp
│ │ │ ├── op_cpy_f32_f16.comp
│ │ │ ├── op_cpy_f32_f32.comp
│ │ │ ├── op_diagmask.comp
│ │ │ ├── op_gelu.comp
│ │ │ ├── op_getrows.comp
│ │ │ ├── op_getrows_f16.comp
│ │ │ ├── op_getrows_f32.comp
│ │ │ ├── op_getrows_q4_0.comp
│ │ │ ├── op_getrows_q4_1.comp
│ │ │ ├── op_getrows_q6_k.comp
│ │ │ ├── op_mul.comp
│ │ │ ├── op_mul_mat_f16.comp
│ │ │ ├── op_mul_mat_mat_f32.comp
│ │ │ ├── op_mul_mat_q4_0.comp
│ │ │ ├── op_mul_mat_q4_1.comp
│ │ │ ├── op_mul_mat_q4_k.comp
│ │ │ ├── op_mul_mat_q6_k.comp
│ │ │ ├── op_mul_mat_q8_0.comp
│ │ │ ├── op_mul_mv_q_n.comp
│ │ │ ├── op_mul_mv_q_n_pre.comp
│ │ │ ├── op_norm.comp
│ │ │ ├── op_relu.comp
│ │ │ ├── op_rmsnorm.comp
│ │ │ ├── op_rope_neox_f16.comp
│ │ │ ├── op_rope_neox_f32.comp
│ │ │ ├── op_rope_norm_f16.comp
│ │ │ ├── op_rope_norm_f32.comp
│ │ │ ├── op_scale.comp
│ │ │ ├── op_scale_8.comp
│ │ │ ├── op_silu.comp
│ │ │ ├── op_softmax.comp
│ │ │ └── rope_common.comp
│ │ ├── ggml-metal/
│ │ │ ├── CMakeLists.txt
│ │ │ ├── ggml-metal-impl.h
│ │ │ ├── ggml-metal.m
│ │ │ └── ggml-metal.metal
│ │ ├── ggml-musa/
│ │ │ ├── CMakeLists.txt
│ │ │ ├── mudnn.cu
│ │ │ └── mudnn.cuh
│ │ ├── ggml-opencl/
│ │ │ ├── CMakeLists.txt
│ │ │ ├── ggml-opencl.cpp
│ │ │ └── kernels/
│ │ │ ├── add.cl
│ │ │ ├── argsort.cl
│ │ │ ├── clamp.cl
│ │ │ ├── concat.cl
│ │ │ ├── cpy.cl
│ │ │ ├── cvt.cl
│ │ │ ├── diag_mask_inf.cl
│ │ │ ├── div.cl
│ │ │ ├── embed_kernel.py
│ │ │ ├── gelu.cl
│ │ │ ├── gemv_noshuffle.cl
│ │ │ ├── gemv_noshuffle_general.cl
│ │ │ ├── get_rows.cl
│ │ │ ├── group_norm.cl
│ │ │ ├── im2col_f16.cl
│ │ │ ├── im2col_f32.cl
│ │ │ ├── mul.cl
│ │ │ ├── mul_mat_Ab_Bi_8x4.cl
│ │ │ ├── mul_mv_f16_f16.cl
│ │ │ ├── mul_mv_f16_f32.cl
│ │ │ ├── mul_mv_f16_f32_1row.cl
│ │ │ ├── mul_mv_f16_f32_l4.cl
│ │ │ ├── mul_mv_f32_f32.cl
│ │ │ ├── mul_mv_q4_0_f32.cl
│ │ │ ├── mul_mv_q4_0_f32_1d_16x_flat.cl
│ │ │ ├── mul_mv_q4_0_f32_1d_8x_flat.cl
│ │ │ ├── mul_mv_q4_0_f32_8x_flat.cl
│ │ │ ├── mul_mv_q4_0_f32_v.cl
│ │ │ ├── mul_mv_q6_k.cl
│ │ │ ├── norm.cl
│ │ │ ├── pad.cl
│ │ │ ├── relu.cl
│ │ │ ├── repeat.cl
│ │ │ ├── rms_norm.cl
│ │ │ ├── rope.cl
│ │ │ ├── scale.cl
│ │ │ ├── sigmoid.cl
│ │ │ ├── silu.cl
│ │ │ ├── softmax_4_f16.cl
│ │ │ ├── softmax_4_f32.cl
│ │ │ ├── softmax_f16.cl
│ │ │ ├── softmax_f32.cl
│ │ │ ├── sub.cl
│ │ │ ├── sum_rows.cl
│ │ │ ├── tanh.cl
│ │ │ ├── transpose.cl
│ │ │ ├── tsembd.cl
│ │ │ └── upscale.cl
│ │ ├── ggml-opt.cpp
│ │ ├── ggml-quants.c
│ │ ├── ggml-quants.h
│ │ ├── ggml-rpc/
│ │ │ ├── CMakeLists.txt
│ │ │ └── ggml-rpc.cpp
│ │ ├── ggml-sycl/
│ │ │ ├── CMakeLists.txt
│ │ │ ├── backend.hpp
│ │ │ ├── binbcast.cpp
│ │ │ ├── binbcast.hpp
│ │ │ ├── common.cpp
│ │ │ ├── common.hpp
│ │ │ ├── concat.cpp
│ │ │ ├── concat.hpp
│ │ │ ├── conv.cpp
│ │ │ ├── conv.hpp
│ │ │ ├── convert.cpp
│ │ │ ├── convert.hpp
│ │ │ ├── cpy.cpp
│ │ │ ├── cpy.hpp
│ │ │ ├── dequantize.hpp
│ │ │ ├── dmmv.cpp
│ │ │ ├── dmmv.hpp
│ │ │ ├── dpct/
│ │ │ │ └── helper.hpp
│ │ │ ├── element_wise.cpp
│ │ │ ├── element_wise.hpp
│ │ │ ├── gemm.hpp
│ │ │ ├── getrows.cpp
│ │ │ ├── getrows.hpp
│ │ │ ├── ggml-sycl.cpp
│ │ │ ├── gla.cpp
│ │ │ ├── gla.hpp
│ │ │ ├── im2col.cpp
│ │ │ ├── im2col.hpp
│ │ │ ├── mmq.cpp
│ │ │ ├── mmq.hpp
│ │ │ ├── mmvq.cpp
│ │ │ ├── mmvq.hpp
│ │ │ ├── norm.cpp
│ │ │ ├── norm.hpp
│ │ │ ├── outprod.cpp
│ │ │ ├── outprod.hpp
│ │ │ ├── presets.hpp
│ │ │ ├── quants.hpp
│ │ │ ├── rope.cpp
│ │ │ ├── rope.hpp
│ │ │ ├── softmax.cpp
│ │ │ ├── softmax.hpp
│ │ │ ├── sycl_hw.cpp
│ │ │ ├── sycl_hw.hpp
│ │ │ ├── tsembd.cpp
│ │ │ ├── tsembd.hpp
│ │ │ ├── vecdotq.hpp
│ │ │ ├── wkv.cpp
│ │ │ └── wkv.hpp
│ │ ├── ggml-threading.cpp
│ │ ├── ggml-threading.h
│ │ ├── ggml-vulkan/
│ │ │ ├── CMakeLists.txt
│ │ │ ├── cmake/
│ │ │ │ └── host-toolchain.cmake.in
│ │ │ ├── ggml-vulkan.cpp
│ │ │ └── vulkan-shaders/
│ │ │ ├── CMakeLists.txt
│ │ │ ├── acc.comp
│ │ │ ├── add.comp
│ │ │ ├── argmax.comp
│ │ │ ├── argsort.comp
│ │ │ ├── clamp.comp
│ │ │ ├── concat.comp
│ │ │ ├── contig_copy.comp
│ │ │ ├── conv2d_dw.comp
│ │ │ ├── copy.comp
│ │ │ ├── copy_from_quant.comp
│ │ │ ├── copy_to_quant.comp
│ │ │ ├── cos.comp
│ │ │ ├── count_equal.comp
│ │ │ ├── dequant_f32.comp
│ │ │ ├── dequant_funcs.comp
│ │ │ ├── dequant_funcs_cm2.comp
│ │ │ ├── dequant_head.comp
│ │ │ ├── dequant_iq1_m.comp
│ │ │ ├── dequant_iq1_s.comp
│ │ │ ├── dequant_iq2_s.comp
│ │ │ ├── dequant_iq2_xs.comp
│ │ │ ├── dequant_iq2_xxs.comp
│ │ │ ├── dequant_iq3_s.comp
│ │ │ ├── dequant_iq3_xxs.comp
│ │ │ ├── dequant_iq4_nl.comp
│ │ │ ├── dequant_iq4_xs.comp
│ │ │ ├── dequant_q2_k.comp
│ │ │ ├── dequant_q3_k.comp
│ │ │ ├── dequant_q4_0.comp
│ │ │ ├── dequant_q4_1.comp
│ │ │ ├── dequant_q4_k.comp
│ │ │ ├── dequant_q5_0.comp
│ │ │ ├── dequant_q5_1.comp
│ │ │ ├── dequant_q5_k.comp
│ │ │ ├── dequant_q6_k.comp
│ │ │ ├── dequant_q8_0.comp
│ │ │ ├── diag_mask_inf.comp
│ │ │ ├── div.comp
│ │ │ ├── flash_attn.comp
│ │ │ ├── flash_attn_base.comp
│ │ │ ├── flash_attn_cm1.comp
│ │ │ ├── flash_attn_cm2.comp
│ │ │ ├── flash_attn_split_k_reduce.comp
│ │ │ ├── gelu.comp
│ │ │ ├── gelu_quick.comp
│ │ │ ├── generic_binary_head.comp
│ │ │ ├── generic_head.comp
│ │ │ ├── generic_unary_head.comp
│ │ │ ├── get_rows.comp
│ │ │ ├── get_rows_quant.comp
│ │ │ ├── group_norm.comp
│ │ │ ├── im2col.comp
│ │ │ ├── l2_norm.comp
│ │ │ ├── leaky_relu.comp
│ │ │ ├── mul.comp
│ │ │ ├── mul_mat_split_k_reduce.comp
│ │ │ ├── mul_mat_vec.comp
│ │ │ ├── mul_mat_vec_base.comp
│ │ │ ├── mul_mat_vec_iq1_m.comp
│ │ │ ├── mul_mat_vec_iq1_s.comp
│ │ │ ├── mul_mat_vec_iq2_s.comp
│ │ │ ├── mul_mat_vec_iq2_xs.comp
│ │ │ ├── mul_mat_vec_iq2_xxs.comp
│ │ │ ├── mul_mat_vec_iq3_s.comp
│ │ │ ├── mul_mat_vec_iq3_xxs.comp
│ │ │ ├── mul_mat_vec_nc.comp
│ │ │ ├── mul_mat_vec_p021.comp
│ │ │ ├── mul_mat_vec_q2_k.comp
│ │ │ ├── mul_mat_vec_q3_k.comp
│ │ │ ├── mul_mat_vec_q4_k.comp
│ │ │ ├── mul_mat_vec_q5_k.comp
│ │ │ ├── mul_mat_vec_q6_k.comp
│ │ │ ├── mul_mm.comp
│ │ │ ├── mul_mm_cm2.comp
│ │ │ ├── mul_mmq.comp
│ │ │ ├── mul_mmq_funcs.comp
│ │ │ ├── norm.comp
│ │ │ ├── opt_step_adamw.comp
│ │ │ ├── pad.comp
│ │ │ ├── pool2d.comp
│ │ │ ├── quantize_q8_1.comp
│ │ │ ├── relu.comp
│ │ │ ├── repeat.comp
│ │ │ ├── repeat_back.comp
│ │ │ ├── rms_norm.comp
│ │ │ ├── rms_norm_back.comp
│ │ │ ├── rope_head.comp
│ │ │ ├── rope_multi.comp
│ │ │ ├── rope_neox.comp
│ │ │ ├── rope_norm.comp
│ │ │ ├── rope_vision.comp
│ │ │ ├── scale.comp
│ │ │ ├── sigmoid.comp
│ │ │ ├── silu.comp
│ │ │ ├── silu_back.comp
│ │ │ ├── sin.comp
│ │ │ ├── soft_max.comp
│ │ │ ├── soft_max_back.comp
│ │ │ ├── square.comp
│ │ │ ├── sub.comp
│ │ │ ├── sum_rows.comp
│ │ │ ├── tanh.comp
│ │ │ ├── test_bfloat16_support.comp
│ │ │ ├── test_coopmat2_support.comp
│ │ │ ├── test_coopmat_support.comp
│ │ │ ├── test_integer_dot_support.comp
│ │ │ ├── timestep_embedding.comp
│ │ │ ├── types.comp
│ │ │ ├── upscale.comp
│ │ │ ├── vulkan-shaders-gen.cpp
│ │ │ ├── wkv6.comp
│ │ │ └── wkv7.comp
│ │ ├── ggml.c
│ │ ├── ggml.cpp
│ │ └── gguf.cpp
│ ├── gguf-py/
│ │ ├── LICENSE
│ │ ├── README.md
│ │ ├── examples/
│ │ │ ├── reader.py
│ │ │ └── writer.py
│ │ ├── gguf/
│ │ │ ├── __init__.py
│ │ │ ├── constants.py
│ │ │ ├── gguf.py
│ │ │ ├── gguf_reader.py
│ │ │ ├── gguf_writer.py
│ │ │ ├── lazy.py
│ │ │ ├── metadata.py
│ │ │ ├── py.typed
│ │ │ ├── quants.py
│ │ │ ├── scripts/
│ │ │ │ ├── gguf_convert_endian.py
│ │ │ │ ├── gguf_dump.py
│ │ │ │ ├── gguf_editor_gui.py
│ │ │ │ ├── gguf_hash.py
│ │ │ │ ├── gguf_new_metadata.py
│ │ │ │ └── gguf_set_metadata.py
│ │ │ ├── tensor_mapping.py
│ │ │ ├── utility.py
│ │ │ └── vocab.py
│ │ ├── pyproject.toml
│ │ └── tests/
│ │ ├── __init__.py
│ │ ├── test_metadata.py
│ │ └── test_quants.py
│ ├── grammars/
│ │ ├── README.md
│ │ ├── arithmetic.gbnf
│ │ ├── c.gbnf
│ │ ├── chess.gbnf
│ │ ├── english.gbnf
│ │ ├── japanese.gbnf
│ │ ├── json.gbnf
│ │ ├── json_arr.gbnf
│ │ └── list.gbnf
│ ├── include/
│ │ ├── llama-cpp.h
│ │ └── llama.h
│ ├── licenses/
│ │ ├── LICENSE-curl
│ │ ├── LICENSE-httplib
│ │ ├── LICENSE-jsonhpp
│ │ └── LICENSE-linenoise
│ ├── models/
│ │ ├── .editorconfig
│ │ ├── ggml-vocab-bert-bge.gguf.inp
│ │ ├── ggml-vocab-bert-bge.gguf.out
│ │ ├── ggml-vocab-command-r.gguf.inp
│ │ ├── ggml-vocab-command-r.gguf.out
│ │ ├── ggml-vocab-deepseek-coder.gguf.inp
│ │ ├── ggml-vocab-deepseek-coder.gguf.out
│ │ ├── ggml-vocab-deepseek-llm.gguf.inp
│ │ ├── ggml-vocab-deepseek-llm.gguf.out
│ │ ├── ggml-vocab-falcon.gguf.inp
│ │ ├── ggml-vocab-falcon.gguf.out
│ │ ├── ggml-vocab-gpt-2.gguf.inp
│ │ ├── ggml-vocab-gpt-2.gguf.out
│ │ ├── ggml-vocab-llama-bpe.gguf.inp
│ │ ├── ggml-vocab-llama-bpe.gguf.out
│ │ ├── ggml-vocab-llama-spm.gguf.inp
│ │ ├── ggml-vocab-llama-spm.gguf.out
│ │ ├── ggml-vocab-mpt.gguf.inp
│ │ ├── ggml-vocab-mpt.gguf.out
│ │ ├── ggml-vocab-phi-3.gguf.inp
│ │ ├── ggml-vocab-phi-3.gguf.out
│ │ ├── ggml-vocab-qwen2.gguf.inp
│ │ ├── ggml-vocab-qwen2.gguf.out
│ │ ├── ggml-vocab-refact.gguf.inp
│ │ ├── ggml-vocab-refact.gguf.out
│ │ ├── ggml-vocab-starcoder.gguf.inp
│ │ ├── ggml-vocab-starcoder.gguf.out
│ │ └── templates/
│ │ ├── CohereForAI-c4ai-command-r-plus-tool_use.jinja
│ │ ├── CohereForAI-c4ai-command-r7b-12-2024-tool_use.jinja
│ │ ├── NousResearch-Hermes-2-Pro-Llama-3-8B-tool_use.jinja
│ │ ├── NousResearch-Hermes-3-Llama-3.1-8B-tool_use.jinja
│ │ ├── Qwen-QwQ-32B.jinja
│ │ ├── Qwen-Qwen2.5-7B-Instruct.jinja
│ │ ├── Qwen-Qwen3-0.6B.jinja
│ │ ├── README.md
│ │ ├── deepseek-ai-DeepSeek-R1-Distill-Llama-8B.jinja
│ │ ├── deepseek-ai-DeepSeek-R1-Distill-Qwen-32B.jinja
│ │ ├── fireworks-ai-llama-3-firefunction-v2.jinja
│ │ ├── google-gemma-2-2b-it.jinja
│ │ ├── llama-cpp-deepseek-r1.jinja
│ │ ├── meetkai-functionary-medium-v3.1.jinja
│ │ ├── meetkai-functionary-medium-v3.2.jinja
│ │ ├── meta-llama-Llama-3.1-8B-Instruct.jinja
│ │ ├── meta-llama-Llama-3.2-3B-Instruct.jinja
│ │ ├── meta-llama-Llama-3.3-70B-Instruct.jinja
│ │ ├── microsoft-Phi-3.5-mini-instruct.jinja
│ │ └── mistralai-Mistral-Nemo-Instruct-2407.jinja
│ ├── mypy.ini
│ ├── pocs/
│ │ ├── CMakeLists.txt
│ │ └── vdot/
│ │ ├── CMakeLists.txt
│ │ ├── q8dot.cpp
│ │ └── vdot.cpp
│ ├── powerinfer/
│ │ ├── .clang-format
│ │ ├── CMakeLists.txt
│ │ ├── cmake/
│ │ │ ├── Arch.cmake
│ │ │ └── FindSIMD.cmake
│ │ ├── fused_sparse_moe/
│ │ │ ├── CMakeLists.txt
│ │ │ ├── fused_sparse_moe/
│ │ │ │ └── fused_sparse_moe.hpp
│ │ │ └── fused_sparse_moe.cpp
│ │ ├── include/
│ │ │ ├── powerinfer-api.h
│ │ │ ├── powerinfer-az.h
│ │ │ ├── powerinfer-cpu.h
│ │ │ ├── powerinfer-error.h
│ │ │ ├── powerinfer-loader.h
│ │ │ ├── powerinfer-perf.h
│ │ │ ├── powerinfer-type.h
│ │ │ └── util/
│ │ │ └── hyper.h
│ │ ├── libaz/
│ │ │ ├── .clang-format
│ │ │ ├── .gitignore
│ │ │ ├── CMakeLists.txt
│ │ │ ├── README.md
│ │ │ ├── az/
│ │ │ │ ├── CMakeLists.txt
│ │ │ │ ├── assert.hpp
│ │ │ │ ├── common.hpp
│ │ │ │ ├── core/
│ │ │ │ │ ├── CMakeLists.txt
│ │ │ │ │ ├── aligned_alloc.cpp
│ │ │ │ │ ├── aligned_alloc.hpp
│ │ │ │ │ ├── bf16.hpp
│ │ │ │ │ ├── buf.cpp
│ │ │ │ │ ├── buf.hpp
│ │ │ │ │ ├── cpu_affinity.cpp
│ │ │ │ │ ├── cpu_affinity.hpp
│ │ │ │ │ ├── cpu_yield.cpp
│ │ │ │ │ ├── cpu_yield.hpp
│ │ │ │ │ ├── fp16.c
│ │ │ │ │ ├── fp16.h
│ │ │ │ │ ├── handle.cpp
│ │ │ │ │ ├── handle.hpp
│ │ │ │ │ ├── intrinsics.hpp
│ │ │ │ │ ├── layout.hpp
│ │ │ │ │ ├── list.hpp
│ │ │ │ │ ├── lru.cpp
│ │ │ │ │ ├── lru.hpp
│ │ │ │ │ ├── perfetto_trace.cpp
│ │ │ │ │ ├── perfetto_trace.h
│ │ │ │ │ ├── perfetto_trace.hpp
│ │ │ │ │ ├── spin_barrier.cpp
│ │ │ │ │ ├── spin_barrier.hpp
│ │ │ │ │ ├── spin_lock.hpp
│ │ │ │ │ ├── utils.cpp
│ │ │ │ │ ├── utils.hpp
│ │ │ │ │ └── worker_info.hpp
│ │ │ │ ├── cpu/
│ │ │ │ │ ├── CMakeLists.txt
│ │ │ │ │ ├── aarch64/
│ │ │ │ │ │ ├── gemv.cpp
│ │ │ │ │ │ └── gemv.hpp
│ │ │ │ │ ├── axpy.cpp
│ │ │ │ │ ├── axpy.hpp
│ │ │ │ │ ├── exp_lut.cpp
│ │ │ │ │ ├── exp_lut.hpp
│ │ │ │ │ ├── quant_types.cpp
│ │ │ │ │ ├── quant_types.hpp
│ │ │ │ │ ├── silu_lut.cpp
│ │ │ │ │ ├── silu_lut.hpp
│ │ │ │ │ ├── softmax.cpp
│ │ │ │ │ ├── softmax.hpp
│ │ │ │ │ ├── vdot.hpp
│ │ │ │ │ ├── vec_dot.cpp
│ │ │ │ │ └── vec_dot.hpp
│ │ │ │ ├── init.cpp
│ │ │ │ ├── init.hpp
│ │ │ │ └── pipeline/
│ │ │ │ ├── CMakeLists.txt
│ │ │ │ ├── pipeline.cpp
│ │ │ │ ├── pipeline.hpp
│ │ │ │ ├── task.cpp
│ │ │ │ ├── task.hpp
│ │ │ │ └── worker.hpp
│ │ │ ├── bin/
│ │ │ │ ├── CMakeLists.txt
│ │ │ │ ├── random_memtest.cpp
│ │ │ │ └── test_assert.cpp
│ │ │ ├── docs/
│ │ │ │ ├── compile_options.md
│ │ │ │ └── environment_variables.md
│ │ │ ├── external/
│ │ │ │ ├── .clang-format
│ │ │ │ ├── CMakeLists.txt
│ │ │ │ ├── cli11/
│ │ │ │ │ ├── .all-contributorsrc
│ │ │ │ │ ├── .ci/
│ │ │ │ │ │ ├── azure-build.yml
│ │ │ │ │ │ ├── azure-cmake-new.yml
│ │ │ │ │ │ ├── azure-cmake.yml
│ │ │ │ │ │ └── azure-test.yml
│ │ │ │ │ ├── .clang-format
│ │ │ │ │ ├── .cmake-format.yaml
│ │ │ │ │ ├── .codacy.yml
│ │ │ │ │ ├── .codecov.yml
│ │ │ │ │ ├── .editorconfig
│ │ │ │ │ ├── .github/
│ │ │ │ │ │ ├── CONTRIBUTING.md
│ │ │ │ │ │ ├── actions/
│ │ │ │ │ │ │ └── quick_cmake/
│ │ │ │ │ │ │ └── action.yml
│ │ │ │ │ │ ├── codecov.yml
│ │ │ │ │ │ ├── dependabot.yml
│ │ │ │ │ │ ├── labeler_merged.yml
│ │ │ │ │ │ └── workflows/
│ │ │ │ │ │ ├── docs.yml
│ │ │ │ │ │ ├── fuzz.yml
│ │ │ │ │ │ ├── pr_merged.yml
│ │ │ │ │ │ └── tests.yml
│ │ │ │ │ ├── .gitignore
│ │ │ │ │ ├── .pre-commit-config.yaml
│ │ │ │ │ ├── .remarkrc
│ │ │ │ │ ├── BUILD.bazel
│ │ │ │ │ ├── CHANGELOG.md
│ │ │ │ │ ├── CMakeLists.txt
│ │ │ │ │ ├── CPPLINT.cfg
│ │ │ │ │ ├── LICENSE
│ │ │ │ │ ├── MODULE.bazel
│ │ │ │ │ ├── README.md
│ │ │ │ │ ├── azure-pipelines.yml
│ │ │ │ │ ├── book/
│ │ │ │ │ │ ├── .gitignore
│ │ │ │ │ │ ├── CMakeLists.txt
│ │ │ │ │ │ ├── README.md
│ │ │ │ │ │ ├── SUMMARY.md
│ │ │ │ │ │ ├── book.json
│ │ │ │ │ │ ├── chapters/
│ │ │ │ │ │ │ ├── advanced-topics.md
│ │ │ │ │ │ │ ├── an-advanced-example.md
│ │ │ │ │ │ │ ├── basics.md
│ │ │ │ │ │ │ ├── config.md
│ │ │ │ │ │ │ ├── flags.md
│ │ │ │ │ │ │ ├── formatting.md
│ │ │ │ │ │ │ ├── installation.md
│ │ │ │ │ │ │ ├── internals.md
│ │ │ │ │ │ │ ├── options.md
│ │ │ │ │ │ │ ├── subcommands.md
│ │ │ │ │ │ │ ├── toolkits.md
│ │ │ │ │ │ │ └── validators.md
│ │ │ │ │ │ ├── code/
│ │ │ │ │ │ │ ├── CMakeLists.txt
│ │ │ │ │ │ │ ├── flags.cpp
│ │ │ │ │ │ │ ├── geet.cpp
│ │ │ │ │ │ │ ├── intro.cpp
│ │ │ │ │ │ │ └── simplest.cpp
│ │ │ │ │ │ └── package.json
│ │ │ │ │ ├── cmake/
│ │ │ │ │ │ ├── CLI11.pc.in
│ │ │ │ │ │ ├── CLI11ConfigVersion.cmake.in
│ │ │ │ │ │ ├── CLI11GeneratePkgConfig.cmake
│ │ │ │ │ │ ├── CLI11Warnings.cmake
│ │ │ │ │ │ ├── CLI11precompiled.pc.in
│ │ │ │ │ │ └── CodeCoverage.cmake
│ │ │ │ │ ├── docs/
│ │ │ │ │ │ ├── .gitignore
│ │ │ │ │ │ ├── CMakeLists.txt
│ │ │ │ │ │ ├── Doxyfile
│ │ │ │ │ │ └── mainpage.md
│ │ │ │ │ ├── examples/
│ │ │ │ │ │ ├── CMakeLists.txt
│ │ │ │ │ │ ├── arg_capture.cpp
│ │ │ │ │ │ ├── callback_passthrough.cpp
│ │ │ │ │ │ ├── config_app.cpp
│ │ │ │ │ │ ├── custom_parse.cpp
│ │ │ │ │ │ ├── digit_args.cpp
│ │ │ │ │ │ ├── enum.cpp
│ │ │ │ │ │ ├── enum_ostream.cpp
│ │ │ │ │ │ ├── formatter.cpp
│ │ │ │ │ │ ├── groups.cpp
│ │ │ │ │ │ ├── help_usage.cpp
│ │ │ │ │ │ ├── inter_argument_order.cpp
│ │ │ │ │ │ ├── json.cpp
│ │ │ │ │ │ ├── modhelp.cpp
│ │ │ │ │ │ ├── nested.cpp
│ │ │ │ │ │ ├── option_groups.cpp
│ │ │ │ │ │ ├── positional_arity.cpp
│ │ │ │ │ │ ├── positional_validation.cpp
│ │ │ │ │ │ ├── prefix_command.cpp
│ │ │ │ │ │ ├── ranges.cpp
│ │ │ │ │ │ ├── retired.cpp
│ │ │ │ │ │ ├── shapes.cpp
│ │ │ │ │ │ ├── simple.cpp
│ │ │ │ │ │ ├── subcom_help.cpp
│ │ │ │ │ │ ├── subcom_in_files/
│ │ │ │ │ │ │ ├── CMakeLists.txt
│ │ │ │ │ │ │ ├── subcommand_a.cpp
│ │ │ │ │ │ │ ├── subcommand_a.hpp
│ │ │ │ │ │ │ └── subcommand_main.cpp
│ │ │ │ │ │ ├── subcom_partitioned.cpp
│ │ │ │ │ │ ├── subcommands.cpp
│ │ │ │ │ │ ├── testEXE.cpp
│ │ │ │ │ │ └── validators.cpp
│ │ │ │ │ ├── fuzz/
│ │ │ │ │ │ ├── CMakeLists.txt
│ │ │ │ │ │ ├── cli11_app_fuzz.cpp
│ │ │ │ │ │ ├── cli11_file_fuzz.cpp
│ │ │ │ │ │ ├── fuzzApp.cpp
│ │ │ │ │ │ ├── fuzzApp.hpp
│ │ │ │ │ │ └── fuzzCommand.cpp
│ │ │ │ │ ├── include/
│ │ │ │ │ │ └── CLI/
│ │ │ │ │ │ ├── App.hpp
│ │ │ │ │ │ ├── Argv.hpp
│ │ │ │ │ │ ├── CLI.hpp
│ │ │ │ │ │ ├── Config.hpp
│ │ │ │ │ │ ├── ConfigFwd.hpp
│ │ │ │ │ │ ├── Encoding.hpp
│ │ │ │ │ │ ├── Error.hpp
│ │ │ │ │ │ ├── Formatter.hpp
│ │ │ │ │ │ ├── FormatterFwd.hpp
│ │ │ │ │ │ ├── Macros.hpp
│ │ │ │ │ │ ├── Option.hpp
│ │ │ │ │ │ ├── Split.hpp
│ │ │ │ │ │ ├── StringTools.hpp
│ │ │ │ │ │ ├── Timer.hpp
│ │ │ │ │ │ ├── TypeTools.hpp
│ │ │ │ │ │ ├── Validators.hpp
│ │ │ │ │ │ ├── Version.hpp
│ │ │ │ │ │ └── impl/
│ │ │ │ │ │ ├── App_inl.hpp
│ │ │ │ │ │ ├── Argv_inl.hpp
│ │ │ │ │ │ ├── Config_inl.hpp
│ │ │ │ │ │ ├── Encoding_inl.hpp
│ │ │ │ │ │ ├── Formatter_inl.hpp
│ │ │ │ │ │ ├── Option_inl.hpp
│ │ │ │ │ │ ├── Split_inl.hpp
│ │ │ │ │ │ ├── StringTools_inl.hpp
│ │ │ │ │ │ └── Validators_inl.hpp
│ │ │ │ │ ├── meson.build
│ │ │ │ │ ├── scripts/
│ │ │ │ │ │ ├── ExtractVersion.py
│ │ │ │ │ │ ├── MakeSingleHeader.py
│ │ │ │ │ │ ├── check_style.sh
│ │ │ │ │ │ ├── check_style_docker.sh
│ │ │ │ │ │ ├── clang-format-pre-commit
│ │ │ │ │ │ └── mdlint_style.rb
│ │ │ │ │ ├── single-include/
│ │ │ │ │ │ ├── CLI11.hpp.in
│ │ │ │ │ │ ├── CMakeLists.txt
│ │ │ │ │ │ └── meson.build
│ │ │ │ │ ├── src/
│ │ │ │ │ │ ├── CMakeLists.txt
│ │ │ │ │ │ └── Precompile.cpp
│ │ │ │ │ ├── subprojects/
│ │ │ │ │ │ └── catch2.wrap
│ │ │ │ │ └── tests/
│ │ │ │ │ ├── .syntastic_cpp_config
│ │ │ │ │ ├── AppTest.cpp
│ │ │ │ │ ├── BUILD.bazel
│ │ │ │ │ ├── BoostOptionTypeTest.cpp
│ │ │ │ │ ├── CMakeLists.txt
│ │ │ │ │ ├── ComplexTypeTest.cpp
│ │ │ │ │ ├── ConfigFileTest.cpp
│ │ │ │ │ ├── CreationTest.cpp
│ │ │ │ │ ├── DeprecatedTest.cpp
│ │ │ │ │ ├── EncodingTest.cpp
│ │ │ │ │ ├── FormatterTest.cpp
│ │ │ │ │ ├── FuzzFailTest.cpp
│ │ │ │ │ ├── HelpTest.cpp
│ │ │ │ │ ├── HelpersTest.cpp
│ │ │ │ │ ├── NewParseTest.cpp
│ │ │ │ │ ├── OptionGroupTest.cpp
│ │ │ │ │ ├── OptionTypeTest.cpp
│ │ │ │ │ ├── OptionalTest.cpp
│ │ │ │ │ ├── SetTest.cpp
│ │ │ │ │ ├── SimpleTest.cpp
│ │ │ │ │ ├── StringParseTest.cpp
│ │ │ │ │ ├── SubcommandTest.cpp
│ │ │ │ │ ├── TimerTest.cpp
│ │ │ │ │ ├── TransformTest.cpp
│ │ │ │ │ ├── TrueFalseTest.cpp
│ │ │ │ │ ├── WindowsTest.cpp
│ │ │ │ │ ├── app_helper.hpp
│ │ │ │ │ ├── applications/
│ │ │ │ │ │ ├── ensure_utf8.cpp
│ │ │ │ │ │ └── ensure_utf8_twice.cpp
│ │ │ │ │ ├── catch.hpp
│ │ │ │ │ ├── find_package_tests/
│ │ │ │ │ │ └── CMakeLists.txt
│ │ │ │ │ ├── fuzzFail/
│ │ │ │ │ │ ├── fuzz_app_fail1
│ │ │ │ │ │ ├── fuzz_app_fail2
│ │ │ │ │ │ ├── fuzz_app_fail3
│ │ │ │ │ │ ├── fuzz_app_file_fail1
│ │ │ │ │ │ ├── fuzz_app_file_fail10
│ │ │ │ │ │ ├── fuzz_app_file_fail11
│ │ │ │ │ │ ├── fuzz_app_file_fail12
│ │ │ │ │ │ ├── fuzz_app_file_fail13
│ │ │ │ │ │ ├── fuzz_app_file_fail14
│ │ │ │ │ │ ├── fuzz_app_file_fail15
│ │ │ │ │ │ ├── fuzz_app_file_fail16
│ │ │ │ │ │ ├── fuzz_app_file_fail17
│ │ │ │ │ │ ├── fuzz_app_file_fail18
│ │ │ │ │ │ ├── fuzz_app_file_fail19
│ │ │ │ │ │ ├── fuzz_app_file_fail2
│ │ │ │ │ │ ├── fuzz_app_file_fail20
│ │ │ │ │ │ ├── fuzz_app_file_fail21
│ │ │ │ │ │ ├── fuzz_app_file_fail22
│ │ │ │ │ │ ├── fuzz_app_file_fail23
│ │ │ │ │ │ ├── fuzz_app_file_fail24
│ │ │ │ │ │ ├── fuzz_app_file_fail25
│ │ │ │ │ │ ├── fuzz_app_file_fail26
│ │ │ │ │ │ ├── fuzz_app_file_fail27
│ │ │ │ │ │ ├── fuzz_app_file_fail28
│ │ │ │ │ │ ├── fuzz_app_file_fail29
│ │ │ │ │ │ ├── fuzz_app_file_fail3
│ │ │ │ │ │ ├── fuzz_app_file_fail30
│ │ │ │ │ │ ├── fuzz_app_file_fail31
│ │ │ │ │ │ ├── fuzz_app_file_fail32
│ │ │ │ │ │ ├── fuzz_app_file_fail33
│ │ │ │ │ │ ├── fuzz_app_file_fail34
│ │ │ │ │ │ ├── fuzz_app_file_fail35
│ │ │ │ │ │ ├── fuzz_app_file_fail36
│ │ │ │ │ │ ├── fuzz_app_file_fail37
│ │ │ │ │ │ ├── fuzz_app_file_fail38
│ │ │ │ │ │ ├── fuzz_app_file_fail39
│ │ │ │ │ │ ├── fuzz_app_file_fail4
│ │ │ │ │ │ ├── fuzz_app_file_fail40
│ │ │ │ │ │ ├── fuzz_app_file_fail5
│ │ │ │ │ │ ├── fuzz_app_file_fail6
│ │ │ │ │ │ ├── fuzz_app_file_fail7
│ │ │ │ │ │ ├── fuzz_app_file_fail8
│ │ │ │ │ │ ├── fuzz_app_file_fail9
│ │ │ │ │ │ ├── fuzz_file_fail1
│ │ │ │ │ │ ├── fuzz_file_fail2
│ │ │ │ │ │ ├── fuzz_file_fail3
│ │ │ │ │ │ ├── fuzz_file_fail4
│ │ │ │ │ │ ├── fuzz_file_fail5
│ │ │ │ │ │ ├── fuzz_file_fail6
│ │ │ │ │ │ ├── fuzz_file_fail7
│ │ │ │ │ │ ├── fuzz_file_fail8
│ │ │ │ │ │ ├── round_trip_custom1
│ │ │ │ │ │ ├── round_trip_custom2
│ │ │ │ │ │ ├── round_trip_custom3
│ │ │ │ │ │ ├── round_trip_fail1
│ │ │ │ │ │ ├── round_trip_fail2
│ │ │ │ │ │ ├── round_trip_fail3
│ │ │ │ │ │ ├── round_trip_fail4
│ │ │ │ │ │ └── round_trip_fail5
│ │ │ │ │ ├── informational.cpp
│ │ │ │ │ ├── link_test_1.cpp
│ │ │ │ │ ├── link_test_2.cpp
│ │ │ │ │ ├── main.cpp
│ │ │ │ │ ├── meson.build
│ │ │ │ │ ├── mesonTest/
│ │ │ │ │ │ ├── README.md
│ │ │ │ │ │ ├── main.cpp
│ │ │ │ │ │ └── meson.build
│ │ │ │ │ ├── package_config_tests/
│ │ │ │ │ │ └── CMakeLists.txt
│ │ │ │ │ └── tests/
│ │ │ │ │ └── .gitkeep
│ │ │ │ ├── fmt/
│ │ │ │ │ ├── .clang-format
│ │ │ │ │ ├── CMakeLists.txt
│ │ │ │ │ ├── CONTRIBUTING.md
│ │ │ │ │ ├── ChangeLog.md
│ │ │ │ │ ├── LICENSE
│ │ │ │ │ ├── README.md
│ │ │ │ │ ├── doc/
│ │ │ │ │ │ ├── ChangeLog-old.md
│ │ │ │ │ │ ├── api.md
│ │ │ │ │ │ ├── fmt.css
│ │ │ │ │ │ ├── fmt.js
│ │ │ │ │ │ ├── get-started.md
│ │ │ │ │ │ ├── index.md
│ │ │ │ │ │ └── syntax.md
│ │ │ │ │ ├── doc-html/
│ │ │ │ │ │ ├── 404.html
│ │ │ │ │ │ ├── api.html
│ │ │ │ │ │ ├── assets/
│ │ │ │ │ │ │ ├── _mkdocstrings.css
│ │ │ │ │ │ │ └── javascripts/
│ │ │ │ │ │ │ └── lunr/
│ │ │ │ │ │ │ ├── tinyseg.js
│ │ │ │ │ │ │ └── wordcut.js
│ │ │ │ │ │ ├── fmt.css
│ │ │ │ │ │ ├── fmt.js
│ │ │ │ │ │ ├── get-started.html
│ │ │ │ │ │ ├── index.html
│ │ │ │ │ │ ├── search/
│ │ │ │ │ │ │ └── search_index.json
│ │ │ │ │ │ ├── sitemap.xml
│ │ │ │ │ │ └── syntax.html
│ │ │ │ │ ├── include/
│ │ │ │ │ │ └── fmt/
│ │ │ │ │ │ ├── args.h
│ │ │ │ │ │ ├── base.h
│ │ │ │ │ │ ├── chrono.h
│ │ │ │ │ │ ├── color.h
│ │ │ │ │ │ ├── compile.h
│ │ │ │ │ │ ├── core.h
│ │ │ │ │ │ ├── format-inl.h
│ │ │ │ │ │ ├── format.h
│ │ │ │ │ │ ├── os.h
│ │ │ │ │ │ ├── ostream.h
│ │ │ │ │ │ ├── printf.h
│ │ │ │ │ │ ├── ranges.h
│ │ │ │ │ │ ├── std.h
│ │ │ │ │ │ └── xchar.h
│ │ │ │ │ ├── src/
│ │ │ │ │ │ ├── fmt.cc
│ │ │ │ │ │ ├── format.cc
│ │ │ │ │ │ └── os.cc
│ │ │ │ │ ├── support/
│ │ │ │ │ │ ├── Android.mk
│ │ │ │ │ │ ├── AndroidManifest.xml
│ │ │ │ │ │ ├── C++.sublime-syntax
│ │ │ │ │ │ ├── README
│ │ │ │ │ │ ├── Vagrantfile
│ │ │ │ │ │ ├── bazel/
│ │ │ │ │ │ │ ├── .bazelversion
│ │ │ │ │ │ │ ├── BUILD.bazel
│ │ │ │ │ │ │ ├── MODULE.bazel
│ │ │ │ │ │ │ ├── README.md
│ │ │ │ │ │ │ └── WORKSPACE.bazel
│ │ │ │ │ │ ├── check-commits
│ │ │ │ │ │ ├── cmake/
│ │ │ │ │ │ │ ├── FindSetEnv.cmake
│ │ │ │ │ │ │ ├── JoinPaths.cmake
│ │ │ │ │ │ │ ├── fmt-config.cmake.in
│ │ │ │ │ │ │ └── fmt.pc.in
│ │ │ │ │ │ ├── docopt.py
│ │ │ │ │ │ ├── mkdocs
│ │ │ │ │ │ ├── mkdocs.yml
│ │ │ │ │ │ ├── printable.py
│ │ │ │ │ │ ├── python/
│ │ │ │ │ │ │ └── mkdocstrings_handlers/
│ │ │ │ │ │ │ └── cxx/
│ │ │ │ │ │ │ ├── __init__.py
│ │ │ │ │ │ │ └── templates/
│ │ │ │ │ │ │ └── README
│ │ │ │ │ │ └── release.py
│ │ │ │ │ └── test/
│ │ │ │ │ ├── CMakeLists.txt
│ │ │ │ │ ├── add-subdirectory-test/
│ │ │ │ │ │ ├── CMakeLists.txt
│ │ │ │ │ │ └── main.cc
│ │ │ │ │ ├── args-test.cc
│ │ │ │ │ ├── assert-test.cc
│ │ │ │ │ ├── base-test.cc
│ │ │ │ │ ├── chrono-test.cc
│ │ │ │ │ ├── color-test.cc
│ │ │ │ │ ├── compile-error-test/
│ │ │ │ │ │ └── CMakeLists.txt
│ │ │ │ │ ├── compile-fp-test.cc
│ │ │ │ │ ├── compile-test.cc
│ │ │ │ │ ├── cuda-test/
│ │ │ │ │ │ ├── CMakeLists.txt
│ │ │ │ │ │ ├── cpp14.cc
│ │ │ │ │ │ └── cuda-cpp14.cu
│ │ │ │ │ ├── detect-stdfs.cc
│ │ │ │ │ ├── enforce-checks-test.cc
│ │ │ │ │ ├── find-package-test/
│ │ │ │ │ │ ├── CMakeLists.txt
│ │ │ │ │ │ └── main.cc
│ │ │ │ │ ├── format-impl-test.cc
│ │ │ │ │ ├── format-test.cc
│ │ │ │ │ ├── fuzzing/
│ │ │ │ │ │ ├── CMakeLists.txt
│ │ │ │ │ │ ├── README.md
│ │ │ │ │ │ ├── chrono-duration.cc
│ │ │ │ │ │ ├── chrono-timepoint.cc
│ │ │ │ │ │ ├── float.cc
│ │ │ │ │ │ ├── fuzzer-common.h
│ │ │ │ │ │ ├── main.cc
│ │ │ │ │ │ ├── named-arg.cc
│ │ │ │ │ │ ├── one-arg.cc
│ │ │ │ │ │ └── two-args.cc
│ │ │ │ │ ├── gtest/
│ │ │ │ │ │ ├── .clang-format
│ │ │ │ │ │ ├── CMakeLists.txt
│ │ │ │ │ │ ├── gmock/
│ │ │ │ │ │ │ └── gmock.h
│ │ │ │ │ │ ├── gmock-gtest-all.cc
│ │ │ │ │ │ └── gtest/
│ │ │ │ │ │ ├── gtest-spi.h
│ │ │ │ │ │ └── gtest.h
│ │ │ │ │ ├── gtest-extra-test.cc
│ │ │ │ │ ├── gtest-extra.cc
│ │ │ │ │ ├── gtest-extra.h
│ │ │ │ │ ├── header-only-test.cc
│ │ │ │ │ ├── mock-allocator.h
│ │ │ │ │ ├── module-test.cc
│ │ │ │ │ ├── no-builtin-types-test.cc
│ │ │ │ │ ├── noexception-test.cc
│ │ │ │ │ ├── os-test.cc
│ │ │ │ │ ├── ostream-test.cc
│ │ │ │ │ ├── perf-sanity.cc
│ │ │ │ │ ├── posix-mock-test.cc
│ │ │ │ │ ├── posix-mock.h
│ │ │ │ │ ├── printf-test.cc
│ │ │ │ │ ├── ranges-odr-test.cc
│ │ │ │ │ ├── ranges-test.cc
│ │ │ │ │ ├── scan-test.cc
│ │ │ │ │ ├── scan.h
│ │ │ │ │ ├── static-export-test/
│ │ │ │ │ │ ├── CMakeLists.txt
│ │ │ │ │ │ ├── library.cc
│ │ │ │ │ │ └── main.cc
│ │ │ │ │ ├── std-test.cc
│ │ │ │ │ ├── test-assert.h
│ │ │ │ │ ├── test-main.cc
│ │ │ │ │ ├── unicode-test.cc
│ │ │ │ │ ├── util.cc
│ │ │ │ │ ├── util.h
│ │ │ │ │ └── xchar-test.cc
│ │ │ │ ├── googletest/
│ │ │ │ │ ├── .clang-format
│ │ │ │ │ ├── .github/
│ │ │ │ │ │ └── ISSUE_TEMPLATE/
│ │ │ │ │ │ ├── 00-bug_report.yml
│ │ │ │ │ │ ├── 10-feature_request.yml
│ │ │ │ │ │ └── config.yml
│ │ │ │ │ ├── .gitignore
│ │ │ │ │ ├── BUILD.bazel
│ │ │ │ │ ├── CMakeLists.txt
│ │ │ │ │ ├── CONTRIBUTING.md
│ │ │ │ │ ├── CONTRIBUTORS
│ │ │ │ │ ├── LICENSE
│ │ │ │ │ ├── MODULE.bazel
│ │ │ │ │ ├── README.md
│ │ │ │ │ ├── WORKSPACE
│ │ │ │ │ ├── WORKSPACE.bzlmod
│ │ │ │ │ ├── ci/
│ │ │ │ │ │ ├── linux-presubmit.sh
│ │ │ │ │ │ └── macos-presubmit.sh
│ │ │ │ │ ├── docs/
│ │ │ │ │ │ ├── _config.yml
│ │ │ │ │ │ ├── _data/
│ │ │ │ │ │ │ └── navigation.yml
│ │ │ │ │ │ ├── _layouts/
│ │ │ │ │ │ │ └── default.html
│ │ │ │ │ │ ├── _sass/
│ │ │ │ │ │ │ └── main.scss
│ │ │ │ │ │ ├── advanced.md
│ │ │ │ │ │ ├── assets/
│ │ │ │ │ │ │ └── css/
│ │ │ │ │ │ │ └── style.scss
│ │ │ │ │ │ ├── community_created_documentation.md
│ │ │ │ │ │ ├── faq.md
│ │ │ │ │ │ ├── gmock_cheat_sheet.md
│ │ │ │ │ │ ├── gmock_cook_book.md
│ │ │ │ │ │ ├── gmock_faq.md
│ │ │ │ │ │ ├── gmock_for_dummies.md
│ │ │ │ │ │ ├── index.md
│ │ │ │ │ │ ├── pkgconfig.md
│ │ │ │ │ │ ├── platforms.md
│ │ │ │ │ │ ├── primer.md
│ │ │ │ │ │ ├── quickstart-bazel.md
│ │ │ │ │ │ ├── quickstart-cmake.md
│ │ │ │ │ │ ├── reference/
│ │ │ │ │ │ │ ├── actions.md
│ │ │ │ │ │ │ ├── assertions.md
│ │ │ │ │ │ │ ├── matchers.md
│ │ │ │ │ │ │ ├── mocking.md
│ │ │ │ │ │ │ └── testing.md
│ │ │ │ │ │ └── samples.md
│ │ │ │ │ ├── fake_fuchsia_sdk.bzl
│ │ │ │ │ ├── googlemock/
│ │ │ │ │ │ ├── CMakeLists.txt
│ │ │ │ │ │ ├── README.md
│ │ │ │ │ │ ├── cmake/
│ │ │ │ │ │ │ ├── gmock.pc.in
│ │ │ │ │ │ │ └── gmock_main.pc.in
│ │ │ │ │ │ ├── docs/
│ │ │ │ │ │ │ └── README.md
│ │ │ │ │ │ ├── include/
│ │ │ │ │ │ │ └── gmock/
│ │ │ │ │ │ │ ├── gmock-actions.h
│ │ │ │ │ │ │ ├── gmock-cardinalities.h
│ │ │ │ │ │ │ ├── gmock-function-mocker.h
│ │ │ │ │ │ │ ├── gmock-matchers.h
│ │ │ │ │ │ │ ├── gmock-more-actions.h
│ │ │ │ │ │ │ ├── gmock-more-matchers.h
│ │ │ │ │ │ │ ├── gmock-nice-strict.h
│ │ │ │ │ │ │ ├── gmock-spec-builders.h
│ │ │ │ │ │ │ ├── gmock.h
│ │ │ │ │ │ │ └── internal/
│ │ │ │ │ │ │ ├── custom/
│ │ │ │ │ │ │ │ ├── README.md
│ │ │ │ │ │ │ │ ├── gmock-generated-actions.h
│ │ │ │ │ │ │ │ ├── gmock-matchers.h
│ │ │ │ │ │ │ │ └── gmock-port.h
│ │ │ │ │ │ │ ├── gmock-internal-utils.h
│ │ │ │ │ │ │ ├── gmock-port.h
│ │ │ │ │ │ │ └── gmock-pp.h
│ │ │ │ │ │ ├── src/
│ │ │ │ │ │ │ ├── gmock-all.cc
│ │ │ │ │ │ │ ├── gmock-cardinalities.cc
│ │ │ │ │ │ │ ├── gmock-internal-utils.cc
│ │ │ │ │ │ │ ├── gmock-matchers.cc
│ │ │ │ │ │ │ ├── gmock-spec-builders.cc
│ │ │ │ │ │ │ ├── gmock.cc
│ │ │ │ │ │ │ └── gmock_main.cc
│ │ │ │ │ │ └── test/
│ │ │ │ │ │ ├── BUILD.bazel
│ │ │ │ │ │ ├── gmock-actions_test.cc
│ │ │ │ │ │ ├── gmock-cardinalities_test.cc
│ │ │ │ │ │ ├── gmock-function-mocker_test.cc
│ │ │ │ │ │ ├── gmock-internal-utils_test.cc
│ │ │ │ │ │ ├── gmock-matchers-arithmetic_test.cc
│ │ │ │ │ │ ├── gmock-matchers-comparisons_test.cc
│ │ │ │ │ │ ├── gmock-matchers-containers_test.cc
│ │ │ │ │ │ ├── gmock-matchers-misc_test.cc
│ │ │ │ │ │ ├── gmock-matchers_test.h
│ │ │ │ │ │ ├── gmock-more-actions_test.cc
│ │ │ │ │ │ ├── gmock-nice-strict_test.cc
│ │ │ │ │ │ ├── gmock-port_test.cc
│ │ │ │ │ │ ├── gmock-pp-string_test.cc
│ │ │ │ │ │ ├── gmock-pp_test.cc
│ │ │ │ │ │ ├── gmock-spec-builders_test.cc
│ │ │ │ │ │ ├── gmock_all_test.cc
│ │ │ │ │ │ ├── gmock_ex_test.cc
│ │ │ │ │ │ ├── gmock_leak_test.py
│ │ │ │ │ │ ├── gmock_leak_test_.cc
│ │ │ │ │ │ ├── gmock_link2_test.cc
│ │ │ │ │ │ ├── gmock_link_test.cc
│ │ │ │ │ │ ├── gmock_link_test.h
│ │ │ │ │ │ ├── gmock_output_test.py
│ │ │ │ │ │ ├── gmock_output_test_.cc
│ │ │ │ │ │ ├── gmock_stress_test.cc
│ │ │ │ │ │ ├── gmock_test.cc
│ │ │ │ │ │ └── gmock_test_utils.py
│ │ │ │ │ ├── googletest/
│ │ │ │ │ │ ├── CMakeLists.txt
│ │ │ │ │ │ ├── README.md
│ │ │ │ │ │ ├── cmake/
│ │ │ │ │ │ │ ├── Config.cmake.in
│ │ │ │ │ │ │ ├── gtest.pc.in
│ │ │ │ │ │ │ ├── gtest_main.pc.in
│ │ │ │ │ │ │ ├── internal_utils.cmake
│ │ │ │ │ │ │ └── libgtest.la.in
│ │ │ │ │ │ ├── docs/
│ │ │ │ │ │ │ └── README.md
│ │ │ │ │ │ ├── include/
│ │ │ │ │ │ │ └── gtest/
│ │ │ │ │ │ │ ├── gtest-assertion-result.h
│ │ │ │ │ │ │ ├── gtest-death-test.h
│ │ │ │ │ │ │ ├── gtest-matchers.h
│ │ │ │ │ │ │ ├── gtest-message.h
│ │ │ │ │ │ │ ├── gtest-param-test.h
│ │ │ │ │ │ │ ├── gtest-printers.h
│ │ │ │ │ │ │ ├── gtest-spi.h
│ │ │ │ │ │ │ ├── gtest-test-part.h
│ │ │ │ │ │ │ ├── gtest-typed-test.h
│ │ │ │ │ │ │ ├── gtest.h
│ │ │ │ │ │ │ ├── gtest_pred_impl.h
│ │ │ │ │ │ │ ├── gtest_prod.h
│ │ │ │ │ │ │ └── internal/
│ │ │ │ │ │ │ ├── custom/
│ │ │ │ │ │ │ │ ├── README.md
│ │ │ │ │ │ │ │ ├── gtest-port.h
│ │ │ │ │ │ │ │ ├── gtest-printers.h
│ │ │ │ │ │ │ │ └── gtest.h
│ │ │ │ │ │ │ ├── gtest-death-test-internal.h
│ │ │ │ │ │ │ ├── gtest-filepath.h
│ │ │ │ │ │ │ ├── gtest-internal.h
│ │ │ │ │ │ │ ├── gtest-param-util.h
│ │ │ │ │ │ │ ├── gtest-port-arch.h
│ │ │ │ │ │ │ ├── gtest-port.h
│ │ │ │ │ │ │ ├── gtest-string.h
│ │ │ │ │ │ │ └── gtest-type-util.h
│ │ │ │ │ │ ├── samples/
│ │ │ │ │ │ │ ├── prime_tables.h
│ │ │ │ │ │ │ ├── sample1.cc
│ │ │ │ │ │ │ ├── sample1.h
│ │ │ │ │ │ │ ├── sample10_unittest.cc
│ │ │ │ │ │ │ ├── sample1_unittest.cc
│ │ │ │ │ │ │ ├── sample2.cc
│ │ │ │ │ │ │ ├── sample2.h
│ │ │ │ │ │ │ ├── sample2_unittest.cc
│ │ │ │ │ │ │ ├── sample3-inl.h
│ │ │ │ │ │ │ ├── sample3_unittest.cc
│ │ │ │ │ │ │ ├── sample4.cc
│ │ │ │ │ │ │ ├── sample4.h
│ │ │ │ │ │ │ ├── sample4_unittest.cc
│ │ │ │ │ │ │ ├── sample5_unittest.cc
│ │ │ │ │ │ │ ├── sample6_unittest.cc
│ │ │ │ │ │ │ ├── sample7_unittest.cc
│ │ │ │ │ │ │ ├── sample8_unittest.cc
│ │ │ │ │ │ │ └── sample9_unittest.cc
│ │ │ │ │ │ ├── src/
│ │ │ │ │ │ │ ├── gtest-all.cc
│ │ │ │ │ │ │ ├── gtest-assertion-result.cc
│ │ │ │ │ │ │ ├── gtest-death-test.cc
│ │ │ │ │ │ │ ├── gtest-filepath.cc
│ │ │ │ │ │ │ ├── gtest-internal-inl.h
│ │ │ │ │ │ │ ├── gtest-matchers.cc
│ │ │ │ │ │ │ ├── gtest-port.cc
│ │ │ │ │ │ │ ├── gtest-printers.cc
│ │ │ │ │ │ │ ├── gtest-test-part.cc
│ │ │ │ │ │ │ ├── gtest-typed-test.cc
│ │ │ │ │ │ │ ├── gtest.cc
│ │ │ │ │ │ │ └── gtest_main.cc
│ │ │ │ │ │ └── test/
│ │ │ │ │ │ ├── BUILD.bazel
│ │ │ │ │ │ ├── googletest-break-on-failure-unittest.py
│ │ │ │ │ │ ├── googletest-break-on-failure-unittest_.cc
│ │ │ │ │ │ ├── googletest-catch-exceptions-test.py
│ │ │ │ │ │ ├── googletest-catch-exceptions-test_.cc
│ │ │ │ │ │ ├── googletest-color-test.py
│ │ │ │ │ │ ├── googletest-color-test_.cc
│ │ │ │ │ │ ├── googletest-death-test-test.cc
│ │ │ │ │ │ ├── googletest-death-test_ex_test.cc
│ │ │ │ │ │ ├── googletest-env-var-test.py
│ │ │ │ │ │ ├── googletest-env-var-test_.cc
│ │ │ │ │ │ ├── googletest-fail-if-no-test-linked-test-with-disabled-test_.cc
│ │ │ │ │ │ ├── googletest-fail-if-no-test-linked-test-with-enabled-test_.cc
│ │ │ │ │ │ ├── googletest-fail-if-no-test-linked-test.py
│ │ │ │ │ │ ├── googletest-failfast-unittest.py
│ │ │ │ │ │ ├── googletest-failfast-unittest_.cc
│ │ │ │ │ │ ├── googletest-filepath-test.cc
│ │ │ │ │ │ ├── googletest-filter-unittest.py
│ │ │ │ │ │ ├── googletest-filter-unittest_.cc
│ │ │ │ │ │ ├── googletest-global-environment-unittest.py
│ │ │ │ │ │ ├── googletest-global-environment-unittest_.cc
│ │ │ │ │ │ ├── googletest-json-outfiles-test.py
│ │ │ │ │ │ ├── googletest-json-output-unittest.py
│ │ │ │ │ │ ├── googletest-list-tests-unittest.py
│ │ │ │ │ │ ├── googletest-list-tests-unittest_.cc
│ │ │ │ │ │ ├── googletest-listener-test.cc
│ │ │ │ │ │ ├── googletest-message-test.cc
│ │ │ │ │ │ ├── googletest-options-test.cc
│ │ │ │ │ │ ├── googletest-output-test.py
│ │ │ │ │ │ ├── googletest-output-test_.cc
│ │ │ │ │ │ ├── googletest-param-test-invalid-name1-test.py
│ │ │ │ │ │ ├── googletest-param-test-invalid-name1-test_.cc
│ │ │ │ │ │ ├── googletest-param-test-invalid-name2-test.py
│ │ │ │ │ │ ├── googletest-param-test-invalid-name2-test_.cc
│ │ │ │ │ │ ├── googletest-param-test-test.cc
│ │ │ │ │ │ ├── googletest-param-test-test.h
│ │ │ │ │ │ ├── googletest-param-test2-test.cc
│ │ │ │ │ │ ├── googletest-port-test.cc
│ │ │ │ │ │ ├── googletest-printers-test.cc
│ │ │ │ │ │ ├── googletest-setuptestsuite-test.py
│ │ │ │ │ │ ├── googletest-setuptestsuite-test_.cc
│ │ │ │ │ │ ├── googletest-shuffle-test.py
│ │ │ │ │ │ ├── googletest-shuffle-test_.cc
│ │ │ │ │ │ ├── googletest-test-part-test.cc
│ │ │ │ │ │ ├── googletest-throw-on-failure-test.py
│ │ │ │ │ │ ├── googletest-throw-on-failure-test_.cc
│ │ │ │ │ │ ├── googletest-uninitialized-test.py
│ │ │ │ │ │ ├── googletest-uninitialized-test_.cc
│ │ │ │ │ │ ├── gtest-typed-test2_test.cc
│ │ │ │ │ │ ├── gtest-typed-test_test.cc
│ │ │ │ │ │ ├── gtest-typed-test_test.h
│ │ │ │ │ │ ├── gtest-unittest-api_test.cc
│ │ │ │ │ │ ├── gtest_all_test.cc
│ │ │ │ │ │ ├── gtest_assert_by_exception_test.cc
│ │ │ │ │ │ ├── gtest_dirs_test.cc
│ │ │ │ │ │ ├── gtest_environment_test.cc
│ │ │ │ │ │ ├── gtest_help_test.py
│ │ │ │ │ │ ├── gtest_help_test_.cc
│ │ │ │ │ │ ├── gtest_json_test_utils.py
│ │ │ │ │ │ ├── gtest_list_output_unittest.py
│ │ │ │ │ │ ├── gtest_list_output_unittest_.cc
│ │ │ │ │ │ ├── gtest_main_unittest.cc
│ │ │ │ │ │ ├── gtest_no_test_unittest.cc
│ │ │ │ │ │ ├── gtest_pred_impl_unittest.cc
│ │ │ │ │ │ ├── gtest_premature_exit_test.cc
│ │ │ │ │ │ ├── gtest_prod_test.cc
│ │ │ │ │ │ ├── gtest_repeat_test.cc
│ │ │ │ │ │ ├── gtest_skip_check_output_test.py
│ │ │ │ │ │ ├── gtest_skip_environment_check_output_test.py
│ │ │ │ │ │ ├── gtest_skip_in_environment_setup_test.cc
│ │ │ │ │ │ ├── gtest_skip_test.cc
│ │ │ │ │ │ ├── gtest_sole_header_test.cc
│ │ │ │ │ │ ├── gtest_stress_test.cc
│ │ │ │ │ │ ├── gtest_test_macro_stack_footprint_test.cc
│ │ │ │ │ │ ├── gtest_test_utils.py
│ │ │ │ │ │ ├── gtest_testbridge_test.py
│ │ │ │ │ │ ├── gtest_testbridge_test_.cc
│ │ │ │ │ │ ├── gtest_throw_on_failure_ex_test.cc
│ │ │ │ │ │ ├── gtest_unittest.cc
│ │ │ │ │ │ ├── gtest_xml_outfile1_test_.cc
│ │ │ │ │ │ ├── gtest_xml_outfile2_test_.cc
│ │ │ │ │ │ ├── gtest_xml_outfiles_test.py
│ │ │ │ │ │ ├── gtest_xml_output_unittest.py
│ │ │ │ │ │ ├── gtest_xml_output_unittest_.cc
│ │ │ │ │ │ ├── gtest_xml_test_utils.py
│ │ │ │ │ │ ├── production.cc
│ │ │ │ │ │ └── production.h
│ │ │ │ │ └── googletest_deps.bzl
│ │ │ │ └── perfetto/
│ │ │ │ ├── CMakeLists.txt
│ │ │ │ ├── perfetto.cc
│ │ │ │ └── perfetto.h
│ │ │ ├── tests/
│ │ │ │ ├── CMakeLists.txt
│ │ │ │ ├── core/
│ │ │ │ │ ├── CMakeLists.txt
│ │ │ │ │ ├── aligned_alloc.cpp
│ │ │ │ │ ├── buf.cpp
│ │ │ │ │ ├── distribute_items.cpp
│ │ │ │ │ ├── layout.cpp
│ │ │ │ │ ├── list.cpp
│ │ │ │ │ └── lru.cpp
│ │ │ │ └── test_main.cpp
│ │ │ └── tools/
│ │ │ └── set_pcie_speed.sh
│ │ ├── moe_sparse_pipeline/
│ │ │ ├── CMakeLists.txt
│ │ │ ├── expert_bundle.cpp
│ │ │ ├── expert_cache.cpp
│ │ │ ├── iou.cpp
│ │ │ ├── moe_sparse_pipeline/
│ │ │ │ ├── config.hpp
│ │ │ │ ├── expert_bundle.hpp
│ │ │ │ ├── expert_cache.hpp
│ │ │ │ ├── iou.hpp
│ │ │ │ ├── lockfree_queue.hpp
│ │ │ │ ├── object_pool.hpp
│ │ │ │ ├── packed_kernel.hpp
│ │ │ │ ├── pipeline.hpp
│ │ │ │ └── task.hpp
│ │ │ ├── packed_kernel.cpp
│ │ │ ├── pipeline.cpp
│ │ │ └── task.cpp
│ │ ├── powerinfer-common/
│ │ │ ├── CMakeLists.txt
│ │ │ └── include/
│ │ │ ├── powerinfer-exception.hpp
│ │ │ ├── powerinfer-log.hpp
│ │ │ ├── powerinfer-macro.hpp
│ │ │ ├── powerinfer-mem.hpp
│ │ │ ├── powerinfer-type.hpp
│ │ │ └── util.hpp
│ │ ├── powerinfer-cpu/
│ │ │ ├── CMakeLists.txt
│ │ │ ├── include/
│ │ │ │ ├── axpy.hpp
│ │ │ │ ├── chunked_vec_dot.hpp
│ │ │ │ ├── convert.hpp
│ │ │ │ ├── powerinfer-cpu-data.hpp
│ │ │ │ ├── powerinfer-cpu-exception.hpp
│ │ │ │ ├── powerinfer-cpu-param.hpp
│ │ │ │ ├── powerinfer-cpu-sgemm.hpp
│ │ │ │ ├── powerinfer-cpu.hpp
│ │ │ │ └── vdot.hpp
│ │ │ └── src/
│ │ │ ├── axpy.cpp
│ │ │ ├── common.cpp
│ │ │ ├── compare.hpp
│ │ │ ├── fused_sparse_ffn.cpp
│ │ │ ├── fused_sparse_ffn.hpp
│ │ │ ├── post_attn_layernorm.cpp
│ │ │ ├── powerinfer_cond_ffn.cpp
│ │ │ ├── powerinfer_cond_ffn.hpp
│ │ │ ├── rotary_embedding.cpp
│ │ │ ├── sgemm.cpp
│ │ │ ├── sparse_lmhead.cpp
│ │ │ ├── sparse_matmul.hpp
│ │ │ ├── sparse_moe_ffn.cpp
│ │ │ ├── sparse_moe_ffn.hpp
│ │ │ └── vec_dot.hpp
│ │ ├── powerinfer-disk/
│ │ │ ├── CMakeLists.txt
│ │ │ ├── include/
│ │ │ │ └── powerinfer-disk-queue.hpp
│ │ │ └── src/
│ │ │ ├── atomic-queue/
│ │ │ │ ├── defs.h
│ │ │ │ └── queue.h
│ │ │ └── powerinfer-queue.cpp
│ │ ├── powerinfer-perf/
│ │ │ ├── CMakeLists.txt
│ │ │ ├── include/
│ │ │ │ └── powerinfer-perf.hpp
│ │ │ └── src/
│ │ │ └── powerinfer-perf.cpp
│ │ ├── src/
│ │ │ ├── convert.hpp
│ │ │ ├── disk_buffer.hpp
│ │ │ ├── interface_az.cpp
│ │ │ ├── interface_host.cpp
│ │ │ └── interface_perf.cpp
│ │ ├── test/
│ │ │ ├── CMakeLists.txt
│ │ │ ├── benchmark/
│ │ │ │ ├── CMakeLists.txt
│ │ │ │ └── bench_example.cpp
│ │ │ └── unit_test/
│ │ │ └── CMakeLists.txt
│ │ └── third_part/
│ │ └── CMakeLists.txt
│ ├── pyproject.toml
│ ├── pyrightconfig.json
│ ├── requirements/
│ │ ├── requirements-all.txt
│ │ ├── requirements-compare-llama-bench.txt
│ │ ├── requirements-convert_hf_to_gguf.txt
│ │ ├── requirements-convert_hf_to_gguf_update.txt
│ │ ├── requirements-convert_legacy_llama.txt
│ │ ├── requirements-convert_llama_ggml_to_gguf.txt
│ │ ├── requirements-convert_lora_to_gguf.txt
│ │ ├── requirements-gguf_editor_gui.txt
│ │ ├── requirements-pydantic.txt
│ │ ├── requirements-test-tokenizer-random.txt
│ │ └── requirements-tool_bench.txt
│ ├── requirements.txt
│ ├── scripts/
│ │ ├── apple/
│ │ │ ├── validate-apps.sh
│ │ │ ├── validate-ios.sh
│ │ │ ├── validate-macos.sh
│ │ │ ├── validate-tvos.sh
│ │ │ └── validate-visionos.sh
│ │ ├── build-info.sh
│ │ ├── check-requirements.sh
│ │ ├── ci-run.sh
│ │ ├── compare-commits.sh
│ │ ├── compare-llama-bench.py
│ │ ├── debug-test.sh
│ │ ├── fetch_server_test_models.py
│ │ ├── gen-authors.sh
│ │ ├── gen-unicode-data.py
│ │ ├── get-flags.mk
│ │ ├── get-hellaswag.sh
│ │ ├── get-pg.sh
│ │ ├── get-wikitext-103.sh
│ │ ├── get-wikitext-2.sh
│ │ ├── get-winogrande.sh
│ │ ├── get_chat_template.py
│ │ ├── hf.sh
│ │ ├── qnt-all.sh
│ │ ├── run-all-perf.sh
│ │ ├── run-all-ppl.sh
│ │ ├── sync-ggml-am.sh
│ │ ├── sync-ggml.last
│ │ ├── sync-ggml.sh
│ │ ├── sync_vendor.py
│ │ ├── tool_bench.py
│ │ ├── tool_bench.sh
│ │ ├── verify-checksum-models.py
│ │ └── xxd.cmake
│ ├── src/
│ │ ├── .clang-format
│ │ ├── CMakeLists.txt
│ │ ├── llama-adapter.cpp
│ │ ├── llama-adapter.h
│ │ ├── llama-arch.cpp
│ │ ├── llama-arch.h
│ │ ├── llama-batch.cpp
│ │ ├── llama-batch.h
│ │ ├── llama-chat.cpp
│ │ ├── llama-chat.h
│ │ ├── llama-context.cpp
│ │ ├── llama-context.h
│ │ ├── llama-cparams.cpp
│ │ ├── llama-cparams.h
│ │ ├── llama-grammar.cpp
│ │ ├── llama-grammar.h
│ │ ├── llama-graph.cpp
│ │ ├── llama-graph.h
│ │ ├── llama-hparams.cpp
│ │ ├── llama-hparams.h
│ │ ├── llama-impl.cpp
│ │ ├── llama-impl.h
│ │ ├── llama-io.cpp
│ │ ├── llama-io.h
│ │ ├── llama-kv-cache-recurrent.cpp
│ │ ├── llama-kv-cache-recurrent.h
│ │ ├── llama-kv-cache-unified-iswa.cpp
│ │ ├── llama-kv-cache-unified-iswa.h
│ │ ├── llama-kv-cache-unified.cpp
│ │ ├── llama-kv-cache-unified.h
│ │ ├── llama-kv-cache.cpp
│ │ ├── llama-kv-cache.h
│ │ ├── llama-kv-cells.h
│ │ ├── llama-memory.cpp
│ │ ├── llama-memory.h
│ │ ├── llama-mmap.cpp
│ │ ├── llama-mmap.h
│ │ ├── llama-model-loader.cpp
│ │ ├── llama-model-loader.h
│ │ ├── llama-model-saver.cpp
│ │ ├── llama-model-saver.h
│ │ ├── llama-model.cpp
│ │ ├── llama-model.h
│ │ ├── llama-quant.cpp
│ │ ├── llama-quant.h
│ │ ├── llama-sampling.cpp
│ │ ├── llama-sampling.h
│ │ ├── llama-vocab.cpp
│ │ ├── llama-vocab.h
│ │ ├── llama.cpp
│ │ ├── unicode-data.cpp
│ │ ├── unicode-data.h
│ │ ├── unicode.cpp
│ │ └── unicode.h
│ ├── tests/
│ │ ├── .gitignore
│ │ ├── CMakeLists.txt
│ │ ├── get-model.cpp
│ │ ├── get-model.h
│ │ ├── run-json-schema-to-grammar.mjs
│ │ ├── test-arg-parser.cpp
│ │ ├── test-autorelease.cpp
│ │ ├── test-backend-ops.cpp
│ │ ├── test-barrier.cpp
│ │ ├── test-c.c
│ │ ├── test-chat-parser.cpp
│ │ ├── test-chat-template.cpp
│ │ ├── test-chat.cpp
│ │ ├── test-double-float.cpp
│ │ ├── test-gbnf-validator.cpp
│ │ ├── test-gguf.cpp
│ │ ├── test-grammar-integration.cpp
│ │ ├── test-grammar-llguidance.cpp
│ │ ├── test-grammar-parser.cpp
│ │ ├── test-json-partial.cpp
│ │ ├── test-json-schema-to-grammar.cpp
│ │ ├── test-llama-grammar.cpp
│ │ ├── test-log.cpp
│ │ ├── test-lora-conversion-inference.sh
│ │ ├── test-model-load-cancel.cpp
│ │ ├── test-mtmd-c-api.c
│ │ ├── test-opt.cpp
│ │ ├── test-quantize-fns.cpp
│ │ ├── test-quantize-perf.cpp
│ │ ├── test-quantize-stats.cpp
│ │ ├── test-regex-partial.cpp
│ │ ├── test-rope.cpp
│ │ ├── test-sampling.cpp
│ │ ├── test-tokenizer-0.cpp
│ │ ├── test-tokenizer-0.py
│ │ ├── test-tokenizer-0.sh
│ │ ├── test-tokenizer-1-bpe.cpp
│ │ ├── test-tokenizer-1-spm.cpp
│ │ └── test-tokenizer-random.py
│ ├── toolchains/
│ │ ├── aarch64-linux-gnu.cmake
│ │ ├── cross_compile.md
│ │ ├── raspi5.cmake
│ │ ├── rdkx5.cmake
│ │ ├── rk3566.cmake
│ │ ├── rk3576.cmake
│ │ └── rk3588.cmake
│ ├── tools/
│ │ ├── CMakeLists.txt
│ │ ├── batched-bench/
│ │ │ ├── CMakeLists.txt
│ │ │ ├── README.md
│ │ │ └── batched-bench.cpp
│ │ ├── cvector-generator/
│ │ │ ├── CMakeLists.txt
│ │ │ ├── README.md
│ │ │ ├── completions.txt
│ │ │ ├── cvector-generator.cpp
│ │ │ ├── mean.hpp
│ │ │ ├── negative.txt
│ │ │ ├── pca.hpp
│ │ │ └── positive.txt
│ │ ├── export-lora/
│ │ │ ├── CMakeLists.txt
│ │ │ ├── README.md
│ │ │ └── export-lora.cpp
│ │ ├── gguf-split/
│ │ │ ├── CMakeLists.txt
│ │ │ ├── README.md
│ │ │ ├── gguf-split.cpp
│ │ │ └── tests.sh
│ │ ├── imatrix/
│ │ │ ├── CMakeLists.txt
│ │ │ ├── README.md
│ │ │ └── imatrix.cpp
│ │ ├── llama-bench/
│ │ │ ├── CMakeLists.txt
│ │ │ ├── README.md
│ │ │ └── llama-bench.cpp
│ │ ├── main/
│ │ │ ├── CMakeLists.txt
│ │ │ ├── README.md
│ │ │ └── main.cpp
│ │ ├── mtmd/
│ │ │ ├── CMakeLists.txt
│ │ │ ├── README.md
│ │ │ ├── clip-impl.h
│ │ │ ├── clip.cpp
│ │ │ ├── clip.h
│ │ │ ├── deprecation-warning.cpp
│ │ │ ├── legacy-models/
│ │ │ │ ├── convert_image_encoder_to_gguf.py
│ │ │ │ ├── glmedge-convert-image-encoder-to-gguf.py
│ │ │ │ ├── glmedge-surgery.py
│ │ │ │ ├── llava_surgery.py
│ │ │ │ ├── llava_surgery_v2.py
│ │ │ │ ├── minicpmv-convert-image-encoder-to-gguf.py
│ │ │ │ └── minicpmv-surgery.py
│ │ │ ├── mtmd-audio.cpp
│ │ │ ├── mtmd-audio.h
│ │ │ ├── mtmd-cli.cpp
│ │ │ ├── mtmd-helper.cpp
│ │ │ ├── mtmd-helper.h
│ │ │ ├── mtmd.cpp
│ │ │ ├── mtmd.h
│ │ │ ├── requirements.txt
│ │ │ └── tests.sh
│ │ ├── perplexity/
│ │ │ ├── CMakeLists.txt
│ │ │ ├── README.md
│ │ │ └── perplexity.cpp
│ │ ├── quantize/
│ │ │ ├── CMakeLists.txt
│ │ │ ├── README.md
│ │ │ ├── quantize.cpp
│ │ │ └── tests.sh
│ │ ├── rpc/
│ │ │ ├── CMakeLists.txt
│ │ │ ├── README.md
│ │ │ └── rpc-server.cpp
│ │ ├── run/
│ │ │ ├── CMakeLists.txt
│ │ │ ├── README.md
│ │ │ ├── linenoise.cpp/
│ │ │ │ ├── linenoise.cpp
│ │ │ │ └── linenoise.h
│ │ │ └── run.cpp
│ │ ├── server/
│ │ │ ├── CMakeLists.txt
│ │ │ ├── README.md
│ │ │ ├── bench/
│ │ │ │ ├── README.md
│ │ │ │ ├── bench.py
│ │ │ │ ├── prometheus.yml
│ │ │ │ ├── requirements.txt
│ │ │ │ └── script.js
│ │ │ ├── chat-llama2.sh
│ │ │ ├── chat.mjs
│ │ │ ├── chat.sh
│ │ │ ├── public/
│ │ │ │ └── loading.html
│ │ │ ├── public_legacy/
│ │ │ │ ├── colorthemes.css
│ │ │ │ ├── completion.js
│ │ │ │ ├── index-new.html
│ │ │ │ ├── index.html
│ │ │ │ ├── index.js
│ │ │ │ ├── json-schema-to-grammar.mjs
│ │ │ │ ├── loading.html
│ │ │ │ ├── prompt-formats.js
│ │ │ │ ├── style.css
│ │ │ │ ├── system-prompts.js
│ │ │ │ ├── theme-beeninorder.css
│ │ │ │ ├── theme-ketivah.css
│ │ │ │ ├── theme-mangotango.css
│ │ │ │ ├── theme-playground.css
│ │ │ │ ├── theme-polarnight.css
│ │ │ │ └── theme-snowstorm.css
│ │ │ ├── public_simplechat/
│ │ │ │ ├── datautils.mjs
│ │ │ │ ├── index.html
│ │ │ │ ├── readme.md
│ │ │ │ ├── simplechat.css
│ │ │ │ ├── simplechat.js
│ │ │ │ └── ui.mjs
│ │ │ ├── server.cpp
│ │ │ ├── tests/
│ │ │ │ ├── .gitignore
│ │ │ │ ├── README.md
│ │ │ │ ├── conftest.py
│ │ │ │ ├── pytest.ini
│ │ │ │ ├── requirements.txt
│ │ │ │ ├── tests.sh
│ │ │ │ ├── unit/
│ │ │ │ │ ├── test_basic.py
│ │ │ │ │ ├── test_chat_completion.py
│ │ │ │ │ ├── test_completion.py
│ │ │ │ │ ├── test_ctx_shift.py
│ │ │ │ │ ├── test_embedding.py
│ │ │ │ │ ├── test_infill.py
│ │ │ │ │ ├── test_lora.py
│ │ │ │ │ ├── test_rerank.py
│ │ │ │ │ ├── test_security.py
│ │ │ │ │ ├── test_slot_save.py
│ │ │ │ │ ├── test_speculative.py
│ │ │ │ │ ├── test_template.py
│ │ │ │ │ ├── test_tokenize.py
│ │ │ │ │ ├── test_tool_call.py
│ │ │ │ │ └── test_vision_api.py
│ │ │ │ └── utils.py
│ │ │ ├── themes/
│ │ │ │ ├── README.md
│ │ │ │ ├── buttons-top/
│ │ │ │ │ ├── README.md
│ │ │ │ │ └── index.html
│ │ │ │ └── wild/
│ │ │ │ ├── README.md
│ │ │ │ └── index.html
│ │ │ ├── utils.hpp
│ │ │ └── webui/
│ │ │ ├── .gitignore
│ │ │ ├── .prettierignore
│ │ │ ├── eslint.config.js
│ │ │ ├── index.html
│ │ │ ├── package.json
│ │ │ ├── postcss.config.js
│ │ │ ├── public/
│ │ │ │ └── demo-conversation.json
│ │ │ ├── src/
│ │ │ │ ├── App.tsx
│ │ │ │ ├── Config.ts
│ │ │ │ ├── components/
│ │ │ │ │ ├── CanvasPyInterpreter.tsx
│ │ │ │ │ ├── ChatInputExtraContextItem.tsx
│ │ │ │ │ ├── ChatMessage.tsx
│ │ │ │ │ ├── ChatScreen.tsx
│ │ │ │ │ ├── Header.tsx
│ │ │ │ │ ├── MarkdownDisplay.tsx
│ │ │ │ │ ├── ModalProvider.tsx
│ │ │ │ │ ├── SettingDialog.tsx
│ │ │ │ │ ├── Sidebar.tsx
│ │ │ │ │ ├── useChatExtraContext.tsx
│ │ │ │ │ ├── useChatScroll.tsx
│ │ │ │ │ └── useChatTextarea.ts
│ │ │ │ ├── index.scss
│ │ │ │ ├── main.tsx
│ │ │ │ ├── utils/
│ │ │ │ │ ├── app.context.tsx
│ │ │ │ │ ├── common.tsx
│ │ │ │ │ ├── llama-vscode.ts
│ │ │ │ │ ├── misc.ts
│ │ │ │ │ ├── storage.ts
│ │ │ │ │ └── types.ts
│ │ │ │ └── vite-env.d.ts
│ │ │ ├── tailwind.config.js
│ │ │ ├── tsconfig.app.json
│ │ │ ├── tsconfig.json
│ │ │ ├── tsconfig.node.json
│ │ │ └── vite.config.ts
│ │ ├── tokenize/
│ │ │ ├── CMakeLists.txt
│ │ │ └── tokenize.cpp
│ │ └── tts/
│ │ ├── CMakeLists.txt
│ │ ├── README.md
│ │ ├── convert_pt_to_hf.py
│ │ ├── tts-outetts.py
│ │ └── tts.cpp
│ └── vendor/
│ ├── cpp-httplib/
│ │ └── httplib.h
│ ├── miniaudio/
│ │ └── miniaudio.h
│ ├── minja/
│ │ ├── chat-template.hpp
│ │ └── minja.hpp
│ ├── nlohmann/
│ │ ├── json.hpp
│ │ └── json_fwd.hpp
│ └── stb/
│ └── stb_image.h
├── tests/
│ ├── CMakeLists.txt
│ ├── test-c.c
│ ├── test-double-float.cpp
│ ├── test-grad0.cpp
│ ├── test-grammar-parser.cpp
│ ├── test-llama-grammar.cpp
│ ├── test-opt.cpp
│ ├── test-quantize-fns.cpp
│ ├── test-quantize-perf.cpp
│ ├── test-rope.cpp
│ ├── test-sampling.cpp
│ ├── test-tokenizer-0-falcon.cpp
│ ├── test-tokenizer-0-falcon.py
│ ├── test-tokenizer-0-llama.cpp
│ ├── test-tokenizer-0-llama.py
│ ├── test-tokenizer-1-bpe.cpp
│ └── test-tokenizer-1-llama.cpp
└── unicode.h
================================================
FILE CONTENTS
================================================
================================================
FILE: .devops/cloud-v-pipeline
================================================
node('x86_runner1'){ // Running on x86 runner containing latest vector qemu, latest vector gcc and all the necessary libraries
stage('Cleanup'){
cleanWs() // Cleaning previous CI build in workspace
}
stage('checkout repo'){
retry(5){ // Retry if the cloning fails due to some reason
checkout scm // Clone the repo on Runner
}
}
stage('Compiling llama.cpp'){
sh'''#!/bin/bash
make RISCV=1 RISCV_CROSS_COMPILE=1 # Compiling llama for RISC-V
'''
}
stage('Running llama.cpp'){
sh'''#!/bin/bash
module load gnu-bin2/0.1 # loading latest versions of vector qemu and vector gcc
qemu-riscv64 -L /softwares/gnu-bin2/sysroot -cpu rv64,v=true,vlen=256,elen=64,vext_spec=v1.0 ./main -m /home/alitariq/codellama-7b.Q4_K_M.gguf -p "Anything" -n 9 > llama_log.txt # Running llama.cpp on vector qemu-riscv64
cat llama_log.txt # Printing results
'''
}
}
================================================
FILE: .devops/full-cuda.Dockerfile
================================================
ARG UBUNTU_VERSION=22.04
# This needs to generally match the container host's environment.
ARG CUDA_VERSION=11.7.1
# Target the CUDA build image
ARG BASE_CUDA_DEV_CONTAINER=nvidia/cuda:${CUDA_VERSION}-devel-ubuntu${UBUNTU_VERSION}
FROM ${BASE_CUDA_DEV_CONTAINER} as build
# Unless otherwise specified, we make a fat build.
ARG CUDA_DOCKER_ARCH=all
RUN apt-get update && \
apt-get install -y build-essential python3 python3-pip git
COPY requirements.txt requirements.txt
RUN pip install --upgrade pip setuptools wheel \
&& pip install -r requirements.txt
WORKDIR /app
COPY . .
# Set nvcc architecture
ENV CUDA_DOCKER_ARCH=${CUDA_DOCKER_ARCH}
# Enable cuBLAS
ENV LLAMA_CUBLAS=1
RUN make
ENTRYPOINT ["/app/.devops/tools.sh"]
================================================
FILE: .devops/full-rocm.Dockerfile
================================================
ARG UBUNTU_VERSION=22.04
# This needs to generally match the container host's environment.
ARG ROCM_VERSION=5.6
# Target the CUDA build image
ARG BASE_ROCM_DEV_CONTAINER=rocm/dev-ubuntu-${UBUNTU_VERSION}:${ROCM_VERSION}-complete
FROM ${BASE_ROCM_DEV_CONTAINER} as build
# Unless otherwise specified, we make a fat build.
# List from https://github.com/ggerganov/llama.cpp/pull/1087#issuecomment-1682807878
# This is mostly tied to rocBLAS supported archs.
ARG ROCM_DOCKER_ARCH=\
gfx803 \
gfx900 \
gfx906 \
gfx908 \
gfx90a \
gfx1010 \
gfx1030 \
gfx1100 \
gfx1101 \
gfx1102
COPY requirements.txt requirements.txt
RUN pip install --upgrade pip setuptools wheel \
&& pip install -r requirements.txt
WORKDIR /app
COPY . .
# Set nvcc architecture
ENV GPU_TARGETS=${ROCM_DOCKER_ARCH}
# Enable ROCm
ENV LLAMA_HIPBLAS=1
ENV CC=/opt/rocm/llvm/bin/clang
ENV CXX=/opt/rocm/llvm/bin/clang++
RUN make
ENTRYPOINT ["/app/.devops/tools.sh"]
================================================
FILE: .devops/full.Dockerfile
================================================
ARG UBUNTU_VERSION=22.04
FROM ubuntu:$UBUNTU_VERSION as build
RUN apt-get update && \
apt-get install -y build-essential python3 python3-pip git
COPY requirements.txt requirements.txt
RUN pip install --upgrade pip setuptools wheel \
&& pip install -r requirements.txt
WORKDIR /app
COPY . .
RUN make
ENV LC_ALL=C.utf8
ENTRYPOINT ["/app/.devops/tools.sh"]
================================================
FILE: .devops/llama-cpp-clblast.srpm.spec
================================================
# SRPM for building from source and packaging an RPM for RPM-based distros.
# https://fedoraproject.org/wiki/How_to_create_an_RPM_package
# Built and maintained by John Boero - boeroboy@gmail.com
# In honor of Seth Vidal https://www.redhat.com/it/blog/thank-you-seth-vidal
# Notes for llama.cpp:
# 1. Tags are currently based on hash - which will not sort asciibetically.
# We need to declare standard versioning if people want to sort latest releases.
# 2. Builds for CUDA/OpenCL support are separate, with different depenedencies.
# 3. NVidia's developer repo must be enabled with nvcc, cublas, clblas, etc installed.
# Example: https://developer.download.nvidia.com/compute/cuda/repos/fedora37/x86_64/cuda-fedora37.repo
# 4. OpenCL/CLBLAST support simply requires the ICD loader and basic opencl libraries.
# It is up to the user to install the correct vendor-specific support.
Name: llama.cpp-clblast
Version: %( date "+%%Y%%m%%d" )
Release: 1%{?dist}
Summary: OpenCL Inference of LLaMA model in C/C++
License: MIT
Source0: https://github.com/ggerganov/llama.cpp/archive/refs/heads/master.tar.gz
BuildRequires: coreutils make gcc-c++ git mesa-libOpenCL-devel clblast-devel
Requires: clblast
URL: https://github.com/ggerganov/llama.cpp
%define debug_package %{nil}
%define source_date_epoch_from_changelog 0
%description
CPU inference for Meta's Lllama2 models using default options.
%prep
%setup -n llama.cpp-master
%build
make -j LLAMA_CLBLAST=1
%install
mkdir -p %{buildroot}%{_bindir}/
cp -p main %{buildroot}%{_bindir}/llamaclblast
cp -p server %{buildroot}%{_bindir}/llamaclblastserver
cp -p simple %{buildroot}%{_bindir}/llamaclblastsimple
mkdir -p %{buildroot}/usr/lib/systemd/system
%{__cat} <<EOF > %{buildroot}/usr/lib/systemd/system/llamaclblast.service
[Unit]
Description=Llama.cpp server, CPU only (no GPU support in this build).
After=syslog.target network.target local-fs.target remote-fs.target nss-lookup.target
[Service]
Type=simple
EnvironmentFile=/etc/sysconfig/llama
ExecStart=/usr/bin/llamaclblastserver $LLAMA_ARGS
ExecReload=/bin/kill -s HUP $MAINPID
Restart=never
[Install]
WantedBy=default.target
EOF
mkdir -p %{buildroot}/etc/sysconfig
%{__cat} <<EOF > %{buildroot}/etc/sysconfig/llama
LLAMA_ARGS="-m /opt/llama2/ggml-model-f32.bin"
EOF
%clean
rm -rf %{buildroot}
rm -rf %{_builddir}/*
%files
%{_bindir}/llamaclblast
%{_bindir}/llamaclblastserver
%{_bindir}/llamaclblastsimple
/usr/lib/systemd/system/llamaclblast.service
%config /etc/sysconfig/llama
%pre
%post
%preun
%postun
%changelog
================================================
FILE: .devops/llama-cpp-cublas.srpm.spec
================================================
# SRPM for building from source and packaging an RPM for RPM-based distros.
# https://fedoraproject.org/wiki/How_to_create_an_RPM_package
# Built and maintained by John Boero - boeroboy@gmail.com
# In honor of Seth Vidal https://www.redhat.com/it/blog/thank-you-seth-vidal
# Notes for llama.cpp:
# 1. Tags are currently based on hash - which will not sort asciibetically.
# We need to declare standard versioning if people want to sort latest releases.
# 2. Builds for CUDA/OpenCL support are separate, with different depenedencies.
# 3. NVidia's developer repo must be enabled with nvcc, cublas, clblas, etc installed.
# Example: https://developer.download.nvidia.com/compute/cuda/repos/fedora37/x86_64/cuda-fedora37.repo
# 4. OpenCL/CLBLAST support simply requires the ICD loader and basic opencl libraries.
# It is up to the user to install the correct vendor-specific support.
Name: llama.cpp-cublas
Version: %( date "+%%Y%%m%%d" )
Release: 1%{?dist}
Summary: CPU Inference of LLaMA model in pure C/C++ (no CUDA/OpenCL)
License: MIT
Source0: https://github.com/ggerganov/llama.cpp/archive/refs/heads/master.tar.gz
BuildRequires: coreutils make gcc-c++ git cuda-toolkit
Requires: cuda-toolkit
URL: https://github.com/ggerganov/llama.cpp
%define debug_package %{nil}
%define source_date_epoch_from_changelog 0
%description
CPU inference for Meta's Lllama2 models using default options.
%prep
%setup -n llama.cpp-master
%build
make -j LLAMA_CUBLAS=1
%install
mkdir -p %{buildroot}%{_bindir}/
cp -p main %{buildroot}%{_bindir}/llamacppcublas
cp -p server %{buildroot}%{_bindir}/llamacppcublasserver
cp -p simple %{buildroot}%{_bindir}/llamacppcublassimple
mkdir -p %{buildroot}/usr/lib/systemd/system
%{__cat} <<EOF > %{buildroot}/usr/lib/systemd/system/llamacublas.service
[Unit]
Description=Llama.cpp server, CPU only (no GPU support in this build).
After=syslog.target network.target local-fs.target remote-fs.target nss-lookup.target
[Service]
Type=simple
EnvironmentFile=/etc/sysconfig/llama
ExecStart=/usr/bin/llamacppcublasserver $LLAMA_ARGS
ExecReload=/bin/kill -s HUP $MAINPID
Restart=never
[Install]
WantedBy=default.target
EOF
mkdir -p %{buildroot}/etc/sysconfig
%{__cat} <<EOF > %{buildroot}/etc/sysconfig/llama
LLAMA_ARGS="-m /opt/llama2/ggml-model-f32.bin"
EOF
%clean
rm -rf %{buildroot}
rm -rf %{_builddir}/*
%files
%{_bindir}/llamacppcublas
%{_bindir}/llamacppcublasserver
%{_bindir}/llamacppcublassimple
/usr/lib/systemd/system/llamacublas.service
%config /etc/sysconfig/llama
%pre
%post
%preun
%postun
%changelog
================================================
FILE: .devops/llama-cpp.srpm.spec
================================================
# SRPM for building from source and packaging an RPM for RPM-based distros.
# https://fedoraproject.org/wiki/How_to_create_an_RPM_package
# Built and maintained by John Boero - boeroboy@gmail.com
# In honor of Seth Vidal https://www.redhat.com/it/blog/thank-you-seth-vidal
# Notes for llama.cpp:
# 1. Tags are currently based on hash - which will not sort asciibetically.
# We need to declare standard versioning if people want to sort latest releases.
# In the meantime, YYYYMMDD format will be used.
# 2. Builds for CUDA/OpenCL support are separate, with different depenedencies.
# 3. NVidia's developer repo must be enabled with nvcc, cublas, clblas, etc installed.
# Example: https://developer.download.nvidia.com/compute/cuda/repos/fedora37/x86_64/cuda-fedora37.repo
# 4. OpenCL/CLBLAST support simply requires the ICD loader and basic opencl libraries.
# It is up to the user to install the correct vendor-specific support.
Name: llama.cpp
Version: %( date "+%%Y%%m%%d" )
Release: 1%{?dist}
Summary: CPU Inference of LLaMA model in pure C/C++ (no CUDA/OpenCL)
License: MIT
Source0: https://github.com/ggerganov/llama.cpp/archive/refs/heads/master.tar.gz
BuildRequires: coreutils make gcc-c++ git libstdc++-devel
Requires: libstdc++
URL: https://github.com/ggerganov/llama.cpp
%define debug_package %{nil}
%define source_date_epoch_from_changelog 0
%description
CPU inference for Meta's Lllama2 models using default options.
Models are not included in this package and must be downloaded separately.
%prep
%setup -n llama.cpp-master
%build
make -j
%install
mkdir -p %{buildroot}%{_bindir}/
cp -p main %{buildroot}%{_bindir}/llama
cp -p server %{buildroot}%{_bindir}/llamaserver
cp -p simple %{buildroot}%{_bindir}/llamasimple
mkdir -p %{buildroot}/usr/lib/systemd/system
%{__cat} <<EOF > %{buildroot}/usr/lib/systemd/system/llama.service
[Unit]
Description=Llama.cpp server, CPU only (no GPU support in this build).
After=syslog.target network.target local-fs.target remote-fs.target nss-lookup.target
[Service]
Type=simple
EnvironmentFile=/etc/sysconfig/llama
ExecStart=/usr/bin/llamaserver $LLAMA_ARGS
ExecReload=/bin/kill -s HUP $MAINPID
Restart=never
[Install]
WantedBy=default.target
EOF
mkdir -p %{buildroot}/etc/sysconfig
%{__cat} <<EOF > %{buildroot}/etc/sysconfig/llama
LLAMA_ARGS="-m /opt/llama2/ggml-model-f32.bin"
EOF
%clean
rm -rf %{buildroot}
rm -rf %{_builddir}/*
%files
%{_bindir}/llama
%{_bindir}/llamaserver
%{_bindir}/llamasimple
/usr/lib/systemd/system/llama.service
%config /etc/sysconfig/llama
%pre
%post
%preun
%postun
%changelog
================================================
FILE: .devops/main-cuda.Dockerfile
================================================
ARG UBUNTU_VERSION=22.04
# This needs to generally match the container host's environment.
ARG CUDA_VERSION=11.7.1
# Target the CUDA build image
ARG BASE_CUDA_DEV_CONTAINER=nvidia/cuda:${CUDA_VERSION}-devel-ubuntu${UBUNTU_VERSION}
# Target the CUDA runtime image
ARG BASE_CUDA_RUN_CONTAINER=nvidia/cuda:${CUDA_VERSION}-runtime-ubuntu${UBUNTU_VERSION}
FROM ${BASE_CUDA_DEV_CONTAINER} as build
# Unless otherwise specified, we make a fat build.
ARG CUDA_DOCKER_ARCH=all
RUN apt-get update && \
apt-get install -y build-essential git
WORKDIR /app
COPY . .
# Set nvcc architecture
ENV CUDA_DOCKER_ARCH=${CUDA_DOCKER_ARCH}
# Enable cuBLAS
ENV LLAMA_CUBLAS=1
RUN make
FROM ${BASE_CUDA_RUN_CONTAINER} as runtime
COPY --from=build /app/main /main
ENTRYPOINT [ "/main" ]
================================================
FILE: .devops/main-rocm.Dockerfile
================================================
ARG UBUNTU_VERSION=22.04
# This needs to generally match the container host's environment.
ARG ROCM_VERSION=5.6
# Target the CUDA build image
ARG BASE_ROCM_DEV_CONTAINER=rocm/dev-ubuntu-${UBUNTU_VERSION}:${ROCM_VERSION}-complete
FROM ${BASE_ROCM_DEV_CONTAINER} as build
# Unless otherwise specified, we make a fat build.
# List from https://github.com/ggerganov/llama.cpp/pull/1087#issuecomment-1682807878
# This is mostly tied to rocBLAS supported archs.
ARG ROCM_DOCKER_ARCH=\
gfx803 \
gfx900 \
gfx906 \
gfx908 \
gfx90a \
gfx1010 \
gfx1030 \
gfx1100 \
gfx1101 \
gfx1102
COPY requirements.txt requirements.txt
RUN pip install --upgrade pip setuptools wheel \
&& pip install -r requirements.txt
WORKDIR /app
COPY . .
# Set nvcc architecture
ENV GPU_TARGETS=${ROCM_DOCKER_ARCH}
# Enable ROCm
ENV LLAMA_HIPBLAS=1
ENV CC=/opt/rocm/llvm/bin/clang
ENV CXX=/opt/rocm/llvm/bin/clang++
RUN make
ENTRYPOINT [ "/app/main" ]
================================================
FILE: .devops/main.Dockerfile
================================================
ARG UBUNTU_VERSION=22.04
FROM ubuntu:$UBUNTU_VERSION as build
RUN apt-get update && \
apt-get install -y build-essential git
WORKDIR /app
COPY . .
RUN make
FROM ubuntu:$UBUNTU_VERSION as runtime
COPY --from=build /app/main /main
ENV LC_ALL=C.utf8
ENTRYPOINT [ "/main" ]
================================================
FILE: .devops/tools.sh
================================================
#!/bin/bash
set -e
# Read the first argument into a variable
arg1="$1"
# Shift the arguments to remove the first one
shift
if [[ "$arg1" == '--convert' || "$arg1" == '-c' ]]; then
python3 ./convert.py "$@"
elif [[ "$arg1" == '--quantize' || "$arg1" == '-q' ]]; then
./quantize "$@"
elif [[ "$arg1" == '--run' || "$arg1" == '-r' ]]; then
./main "$@"
elif [[ "$arg1" == '--all-in-one' || "$arg1" == '-a' ]]; then
echo "Converting PTH to GGML..."
for i in `ls $1/$2/ggml-model-f16.bin*`; do
if [ -f "${i/f16/q4_0}" ]; then
echo "Skip model quantization, it already exists: ${i/f16/q4_0}"
else
echo "Converting PTH to GGML: $i into ${i/f16/q4_0}..."
./quantize "$i" "${i/f16/q4_0}" q4_0
fi
done
elif [[ "$arg1" == '--server' || "$arg1" == '-s' ]]; then
./server "$@"
else
echo "Unknown command: $arg1"
echo "Available commands: "
echo " --run (-r): Run a model previously converted into ggml"
echo " ex: -m /models/7B/ggml-model-q4_0.bin -p \"Building a website can be done in 10 simple steps:\" -n 512"
echo " --convert (-c): Convert a llama model into ggml"
echo " ex: --outtype f16 \"/models/7B/\" "
echo " --quantize (-q): Optimize with quantization process ggml"
echo " ex: \"/models/7B/ggml-model-f16.bin\" \"/models/7B/ggml-model-q4_0.bin\" 2"
echo " --all-in-one (-a): Execute --convert & --quantize"
echo " ex: \"/models/\" 7B"
echo " --server (-s): Run a model on the server"
echo " ex: -m /models/7B/ggml-model-q4_0.bin -c 2048 -ngl 43 -mg 1 --port 8080"
fi
================================================
FILE: .dockerignore
================================================
*.o
*.a
.cache/
.git/
.github/
.gitignore
.vs/
.vscode/
.DS_Store
build*/
models/*
/main
/quantize
arm_neon.h
compile_commands.json
Dockerfile
================================================
FILE: .ecrc
================================================
{
"Disable": {
"IndentSize": true
}
}
================================================
FILE: .editorconfig
================================================
# https://EditorConfig.org
# Top-most EditorConfig file
root = true
# Unix-style newlines with a newline ending every file, utf-8 charset
[*]
end_of_line = lf
insert_final_newline = true
trim_trailing_whitespace = true
charset = utf-8
indent_style = space
indent_size = 4
[Makefile]
indent_style = tab
[prompts/*.txt]
insert_final_newline = unset
[examples/server/public/*]
indent_size = 2
================================================
FILE: .flake8
================================================
[flake8]
max-line-length = 125
================================================
FILE: .github/ISSUE_TEMPLATE/bug.md
================================================
---
name: Bug template
about: Used to report bugs in PowerInfer
labels: ["bug-unconfirmed"]
assignees: ''
---
# Prerequisites
Before submitting your issue, please ensure the following:
- [ ] I am running the latest version of PowerInfer. Development is rapid, and as of now, there are no tagged versions.
- [ ] I have carefully read and followed the instructions in the [README.md](https://github.com/SJTU-IPADS/PowerInfer/blob/main/README.md).
- [ ] I [searched using keywords relevant to my issue](https://docs.github.com/en/issues/tracking-your-work-with-issues/filtering-and-searching-issues-and-pull-requests) to make sure that I am creating a new issue that is not already open (or closed).
# Expected Behavior
Please provide a detailed written description of what you were trying to do, and what you expected PowerInfer to do.
# Current Behavior
Please provide a detailed written description of what PowerInfer did, instead.
# Environment and Context
Please provide detailed information about your computer setup. This is important in case the issue is not reproducible except for under certain specific conditions.
* Physical (or virtual) hardware you are using, e.g. for Linux:
`$ lscpu`
* Operating System, e.g. for Linux:
`$ uname -a`
* SDK version, e.g. for Linux:
```
$ python3 --version
$ make --version
$ g++ --version
```
# Failure Information (for bugs)
Please help provide information about the failure / bug.
# Steps to Reproduce
Please provide detailed steps for reproducing the issue. We are not sitting in front of your screen, so the more detail the better.
1. step 1
2. step 2
3. step 3
4. etc.
# Failure Logs
Please include any relevant log snippets or files. If it works under one configuration but not under another, please provide logs for both configurations and their corresponding outputs so it is easy to see where behavior changes.
Also, please try to **avoid using screenshots** if at all possible. Instead, copy/paste the console output and use [Github's markdown](https://docs.github.com/en/get-started/writing-on-github/getting-started-with-writing-and-formatting-on-github/basic-writing-and-formatting-syntax) to cleanly format your logs for easy readability.
Example environment info:
```
llama.cpp$ git log | head -1
commit 2af23d30434a677c6416812eea52ccc0af65119c
llama.cpp$ lscpu | egrep "AMD|Flags"
Vendor ID: AuthenticAMD
Model name: AMD Ryzen Threadripper 1950X 16-Core Processor
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ht syscall nx mmxext fxsr_opt pdpe1gb rdtscp lm constant_tsc rep_good nopl nonstop_tsc cpuid extd_apicid amd_dcm aperfmperf rapl pni pclmulqdq monitor ssse3 fma cx16 sse4_1 sse4_2 movbe popcnt aes xsave avx f16c rdrand lahf_lm cmp_legacy svm extapic cr8_legacy abm sse4a misalignsse 3dnowprefetch osvw skinit wdt tce topoext perfctr_core perfctr_nb bpext perfctr_llc mwaitx cpb hw_pstate ssbd ibpb vmmcall fsgsbase bmi1 avx2 smep bmi2 rdseed adx smap clflushopt sha_ni xsaveopt xsavec xgetbv1 xsaves clzero irperf xsaveerptr arat npt lbrv svm_lock nrip_save tsc_scale vmcb_clean flushbyasid decodeassists pausefilter pfthreshold avic v_vmsave_vmload vgif overflow_recov succor smca sme sev
Virtualization: AMD-V
llama.cpp$ python3 --version
Python 3.10.9
llama.cpp$ pip list | egrep "torch|numpy|sentencepiece"
numpy 1.24.2
numpydoc 1.5.0
sentencepiece 0.1.97
torch 1.13.1
torchvision 0.14.1
llama.cpp$ make --version | head -1
GNU Make 4.3
$ md5sum ./models/65B/ggml-model-q4_0.bin
dbdd682cce80e2d6e93cefc7449df487 ./models/65B/ggml-model-q4_0.bin
```
Example run with the Linux command [perf](https://www.brendangregg.com/perf.html)
```
llama.cpp$ perf stat ./main -m ./models/65B/ggml-model-q4_0.bin -t 16 -n 1024 -p "Please close your issue when it has been answered."
main: seed = 1679149377
llama_model_load: loading model from './models/65B/ggml-model-q4_0.bin' - please wait ...
llama_model_load: n_vocab = 32000
llama_model_load: n_ctx = 512
llama_model_load: n_embd = 8192
llama_model_load: n_mult = 256
llama_model_load: n_head = 64
llama_model_load: n_layer = 80
llama_model_load: n_rot = 128
llama_model_load: f16 = 2
llama_model_load: n_ff = 22016
llama_model_load: n_parts = 8
llama_model_load: ggml ctx size = 41477.73 MB
llama_model_load: memory_size = 2560.00 MB, n_mem = 40960
llama_model_load: loading model part 1/8 from './models/65B/ggml-model-q4_0.bin'
llama_model_load: .......................................................................................... done
llama_model_load: model size = 4869.09 MB / num tensors = 723
llama_model_load: loading model part 2/8 from './models/65B/ggml-model-q4_0.bin.1'
llama_model_load: .......................................................................................... done
llama_model_load: model size = 4869.09 MB / num tensors = 723
llama_model_load: loading model part 3/8 from './models/65B/ggml-model-q4_0.bin.2'
llama_model_load: .......................................................................................... done
llama_model_load: model size = 4869.09 MB / num tensors = 723
llama_model_load: loading model part 4/8 from './models/65B/ggml-model-q4_0.bin.3'
llama_model_load: .......................................................................................... done
llama_model_load: model size = 4869.09 MB / num tensors = 723
llama_model_load: loading model part 5/8 from './models/65B/ggml-model-q4_0.bin.4'
llama_model_load: .......................................................................................... done
llama_model_load: model size = 4869.09 MB / num tensors = 723
llama_model_load: loading model part 6/8 from './models/65B/ggml-model-q4_0.bin.5'
llama_model_load: .......................................................................................... done
llama_model_load: model size = 4869.09 MB / num tensors = 723
llama_model_load: loading model part 7/8 from './models/65B/ggml-model-q4_0.bin.6'
llama_model_load: .......................................................................................... done
llama_model_load: model size = 4869.09 MB / num tensors = 723
llama_model_load: loading model part 8/8 from './models/65B/ggml-model-q4_0.bin.7'
llama_model_load: .......................................................................................... done
llama_model_load: model size = 4869.09 MB / num tensors = 723
system_info: n_threads = 16 / 32 | AVX = 1 | AVX2 = 1 | AVX512 = 0 | FMA = 1 | NEON = 0 | ARM_FMA = 0 | F16C = 1 | FP16_VA = 0 | WASM_SIMD = 0 | BLAS = 0 | SSE3 = 1 | VSX = 0 |
main: prompt: 'Please close your issue when it has been answered.'
main: number of tokens in prompt = 11
1 -> ''
12148 -> 'Please'
3802 -> ' close'
596 -> ' your'
2228 -> ' issue'
746 -> ' when'
372 -> ' it'
756 -> ' has'
1063 -> ' been'
7699 -> ' answered'
29889 -> '.'
sampling parameters: temp = 0.800000, top_k = 40, top_p = 0.950000, repeat_last_n = 64, repeat_penalty = 1.300000
Please close your issue when it has been answered.
@duncan-donut: I'm trying to figure out what kind of "support" you need for this script and why, exactly? Is there a question about how the code works that hasn't already been addressed in one or more comments below this ticket, or are we talking something else entirely like some sorta bugfixing job because your server setup is different from mine??
I can understand if your site needs to be running smoothly and you need help with a fix of sorts but there should really be nothing wrong here that the code itself could not handle. And given that I'm getting reports about how it works perfectly well on some other servers, what exactly are we talking? A detailed report will do wonders in helping us get this resolved for ya quickly so please take your time and describe the issue(s) you see as clearly & concisely as possible!!
@duncan-donut: I'm not sure if you have access to cPanel but you could try these instructions. It is worth a shot! Let me know how it goes (or what error message, exactly!) when/if ya give that code a go? [end of text]
main: mem per token = 71159620 bytes
main: load time = 19309.95 ms
main: sample time = 168.62 ms
main: predict time = 223895.61 ms / 888.47 ms per token
main: total time = 246406.42 ms
Performance counter stats for './main -m ./models/65B/ggml-model-q4_0.bin -t 16 -n 1024 -p Please close your issue when it has been answered.':
3636882.89 msec task-clock # 14.677 CPUs utilized
13509 context-switches # 3.714 /sec
2436 cpu-migrations # 0.670 /sec
10476679 page-faults # 2.881 K/sec
13133115082869 cycles # 3.611 GHz (16.77%)
29314462753 stalled-cycles-frontend # 0.22% frontend cycles idle (16.76%)
10294402631459 stalled-cycles-backend # 78.39% backend cycles idle (16.74%)
23479217109614 instructions # 1.79 insn per cycle
# 0.44 stalled cycles per insn (16.76%)
2353072268027 branches # 647.002 M/sec (16.77%)
1998682780 branch-misses # 0.08% of all branches (16.76%)
247.802177522 seconds time elapsed
3618.573072000 seconds user
18.491698000 seconds sys
```
================================================
FILE: .github/ISSUE_TEMPLATE/enhancement.md
================================================
---
name: Enhancement template
about: Used to request enhancements for PowerInfer
labels: ["enhancement"]
assignees: ''
---
# Prerequisites
Before submitting your issue, please ensure the following:
- [ ] I am running the latest version of PowerInfer. Development is rapid, and as of now, there are no tagged versions.
- [ ] I have carefully read and followed the instructions in the [README.md](https://github.com/SJTU-IPADS/PowerInfer/blob/main/README.md).
- [ ] I [searched using keywords relevant to my issue](https://docs.github.com/en/issues/tracking-your-work-with-issues/filtering-and-searching-issues-and-pull-requests) to make sure that I am creating a new issue that is not already open (or closed).
# Feature Description
Please provide a detailed written description of what you were trying to do, and what you expected PowerInfer to do as an enhancement.
# Motivation
Please provide a detailed written description of reasons why this feature is necessary and how it is useful to PowerInfer users.
# Possible Implementation
If you have an idea as to how it can be implemented, please write a detailed description. Feel free to give links to external sources or share visuals that might be helpful to understand the details better.
================================================
FILE: .github/ISSUE_TEMPLATE/question.md
================================================
---
name: Question template
about: Used for general questions and inquiries about PowerInfer
labels: ["question"]
assignees: ''
---
# Prerequisites
Before submitting your question, please ensure the following:
- [ ] I am running the latest version of PowerInfer. Development is rapid, and as of now, there are no tagged versions.
- [ ] I have carefully read and followed the instructions in the [README.md](https://github.com/SJTU-IPADS/PowerInfer/blob/main/README.md).
- [ ] I [searched using keywords relevant to my issue](https://docs.github.com/en/issues/tracking-your-work-with-issues/filtering-and-searching-issues-and-pull-requests) to make sure that I am creating a new issue that is not already open (or closed).
# Question Details
Please provide a clear and concise description of your question. If applicable, include steps to reproduce the issue or behaviors you've observed.
# Additional Context
Please provide any additional information that may be relevant to your question, such as specific system configurations, environment details, or any other context that could be helpful in addressing your inquiry.
================================================
FILE: .github/workflows/build.yml
================================================
name: CI
on:
workflow_dispatch: # allows manual triggering
inputs:
create_release:
description: 'Create new release'
required: true
type: boolean
push:
branches:
- master
paths: ['.github/workflows/**', '**/CMakeLists.txt', '**/Makefile', '**/*.h', '**/*.hpp', '**/*.c', '**/*.cpp', '**/*.cu', '**/*.swift', '**/*.m']
pull_request:
types: [opened, synchronize, reopened]
paths: ['**/CMakeLists.txt', '**/Makefile', '**/*.h', '**/*.hpp', '**/*.c', '**/*.cpp', '**/*.cu', '**/*.swift', '**/*.m']
env:
BRANCH_NAME: ${{ github.head_ref || github.ref_name }}
GGML_NLOOP: 3
GGML_N_THREADS: 1
jobs:
ubuntu-focal-make:
runs-on: ubuntu-20.04
steps:
- name: Clone
id: checkout
uses: actions/checkout@v3
- name: Dependencies
id: depends
run: |
sudo apt-get update
sudo apt-get install build-essential gcc-8
- name: Build
id: make_build
run: |
CC=gcc-8 make -j $(nproc)
- name: Test
id: make_test
run: |
CC=gcc-8 make tests -j $(nproc)
make test -j $(nproc)
ubuntu-latest-cmake:
runs-on: ubuntu-latest
steps:
- name: Clone
id: checkout
uses: actions/checkout@v3
- name: Dependencies
id: depends
run: |
sudo apt-get update
sudo apt-get install build-essential
- name: Build
id: cmake_build
run: |
mkdir build
cd build
cmake ..
cmake --build . --config Release -j $(nproc)
- name: Test
id: cmake_test
run: |
cd build
ctest --verbose --timeout 900
ubuntu-latest-cmake-sanitizer:
runs-on: ubuntu-latest
continue-on-error: true
strategy:
matrix:
sanitizer: [ADDRESS, THREAD, UNDEFINED]
build_type: [Debug, Release]
steps:
- name: Clone
id: checkout
uses: actions/checkout@v3
- name: Dependencies
id: depends
run: |
sudo apt-get update
sudo apt-get install build-essential
- name: Build
id: cmake_build
run: |
mkdir build
cd build
cmake .. -DLLAMA_SANITIZE_${{ matrix.sanitizer }}=ON -DCMAKE_BUILD_TYPE=${{ matrix.build_type }}
cmake --build . --config ${{ matrix.build_type }} -j $(nproc)
- name: Test
id: cmake_test
run: |
cd build
ctest --verbose --timeout 900
ubuntu-latest-cmake-mpi:
runs-on: ubuntu-latest
continue-on-error: true
strategy:
matrix:
mpi_library: [mpich, libopenmpi-dev]
steps:
- name: Clone
id: checkout
uses: actions/checkout@v3
- name: Dependencies
id: depends
run: |
sudo apt-get update
sudo apt-get install build-essential ${{ matrix.mpi_library }}
- name: Build
id: cmake_build
run: |
mkdir build
cd build
cmake -DLLAMA_MPI=ON ..
cmake --build . --config Release -j $(nproc)
- name: Test
id: cmake_test
run: |
cd build
ctest --verbose
macOS-latest-make:
runs-on: macos-latest
steps:
- name: Clone
id: checkout
uses: actions/checkout@v3
- name: Dependencies
id: depends
continue-on-error: true
run: |
brew update
- name: Build
id: make_build
run: |
make -j $(sysctl -n hw.logicalcpu)
- name: Test
id: make_test
run: |
make tests -j $(sysctl -n hw.logicalcpu)
make test -j $(sysctl -n hw.logicalcpu)
macOS-latest-cmake:
runs-on: macos-latest
steps:
- name: Clone
id: checkout
uses: actions/checkout@v3
- name: Dependencies
id: depends
continue-on-error: true
run: |
brew update
- name: Build
id: cmake_build
run: |
sysctl -a
mkdir build
cd build
cmake ..
cmake --build . --config Release -j $(sysctl -n hw.logicalcpu)
- name: Test
id: cmake_test
run: |
cd build
ctest --verbose --timeout 900
macOS-latest-cmake-ios:
runs-on: macos-latest
steps:
- name: Clone
id: checkout
uses: actions/checkout@v1
- name: Dependencies
id: depends
continue-on-error: true
run: |
brew update
- name: Build
id: cmake_build
run: |
sysctl -a
mkdir build
cd build
cmake -G Xcode .. \
-DLLAMA_BUILD_EXAMPLES=OFF \
-DLLAMA_BUILD_TESTS=OFF \
-DLLAMA_BUILD_SERVER=OFF \
-DCMAKE_SYSTEM_NAME=iOS \
-DCMAKE_OSX_DEPLOYMENT_TARGET=14.0
cmake --build . --config Release -j $(sysctl -n hw.logicalcpu)
macOS-latest-cmake-tvos:
runs-on: macos-latest
steps:
- name: Clone
id: checkout
uses: actions/checkout@v1
- name: Dependencies
id: depends
continue-on-error: true
run: |
brew update
- name: Build
id: cmake_build
run: |
sysctl -a
mkdir build
cd build
cmake -G Xcode .. \
-DLLAMA_BUILD_EXAMPLES=OFF \
-DLLAMA_BUILD_TESTS=OFF \
-DLLAMA_BUILD_SERVER=OFF \
-DCMAKE_SYSTEM_NAME=tvOS \
-DCMAKE_OSX_DEPLOYMENT_TARGET=14.0
cmake --build . --config Release -j $(sysctl -n hw.logicalcpu)
macOS-latest-swift:
runs-on: macos-latest
strategy:
matrix:
destination: ['generic/platform=macOS', 'generic/platform=iOS', 'generic/platform=tvOS']
steps:
- name: Clone
id: checkout
uses: actions/checkout@v1
- name: Dependencies
id: depends
continue-on-error: true
run: |
brew update
- name: xcodebuild for swift package
id: xcodebuild
run: |
xcodebuild -scheme llama -destination "${{ matrix.destination }}"
- name: Build Swift Example
id: make_build_swift_example
run: |
make swift
windows-latest-cmake:
runs-on: windows-latest
env:
OPENBLAS_VERSION: 0.3.23
OPENCL_VERSION: 2023.04.17
CLBLAST_VERSION: 1.6.0
SDE_VERSION: 9.21.1-2023-04-24
strategy:
matrix:
include:
- build: 'noavx'
defines: '-DLLAMA_NATIVE=OFF -DLLAMA_BUILD_SERVER=ON -DLLAMA_AVX=OFF -DLLAMA_AVX2=OFF -DLLAMA_FMA=OFF -DBUILD_SHARED_LIBS=ON'
- build: 'avx2'
defines: '-DLLAMA_NATIVE=OFF -DLLAMA_BUILD_SERVER=ON -DBUILD_SHARED_LIBS=ON'
- build: 'avx'
defines: '-DLLAMA_NATIVE=OFF -DLLAMA_BUILD_SERVER=ON -DLLAMA_AVX2=OFF -DBUILD_SHARED_LIBS=ON'
- build: 'avx512'
defines: '-DLLAMA_NATIVE=OFF -DLLAMA_BUILD_SERVER=ON -DLLAMA_AVX512=ON -DBUILD_SHARED_LIBS=ON'
- build: 'clblast'
defines: '-DLLAMA_NATIVE=OFF -DLLAMA_BUILD_SERVER=ON -DLLAMA_CLBLAST=ON -DBUILD_SHARED_LIBS=ON -DCMAKE_PREFIX_PATH="$env:RUNNER_TEMP/clblast"'
- build: 'openblas'
defines: '-DLLAMA_NATIVE=OFF -DLLAMA_BUILD_SERVER=ON -DLLAMA_BLAS=ON -DBUILD_SHARED_LIBS=ON -DLLAMA_BLAS_VENDOR=OpenBLAS -DBLAS_INCLUDE_DIRS="$env:RUNNER_TEMP/openblas/include" -DBLAS_LIBRARIES="$env:RUNNER_TEMP/openblas/lib/openblas.lib"'
steps:
- name: Clone
id: checkout
uses: actions/checkout@v3
with:
fetch-depth: 0
- name: Download OpenCL SDK
id: get_opencl
if: ${{ matrix.build == 'clblast' }}
run: |
curl.exe -o $env:RUNNER_TEMP/opencl.zip -L "https://github.com/KhronosGroup/OpenCL-SDK/releases/download/v${env:OPENCL_VERSION}/OpenCL-SDK-v${env:OPENCL_VERSION}-Win-x64.zip"
mkdir $env:RUNNER_TEMP/opencl
tar.exe -xvf $env:RUNNER_TEMP/opencl.zip --strip-components=1 -C $env:RUNNER_TEMP/opencl
- name: Download CLBlast
id: get_clblast
if: ${{ matrix.build == 'clblast' }}
run: |
curl.exe -o $env:RUNNER_TEMP/clblast.7z -L "https://github.com/CNugteren/CLBlast/releases/download/${env:CLBLAST_VERSION}/CLBlast-${env:CLBLAST_VERSION}-windows-x64.7z"
curl.exe -o $env:RUNNER_TEMP/CLBlast.LICENSE.txt -L "https://github.com/CNugteren/CLBlast/raw/${env:CLBLAST_VERSION}/LICENSE"
7z x "-o${env:RUNNER_TEMP}" $env:RUNNER_TEMP/clblast.7z
rename-item $env:RUNNER_TEMP/CLBlast-${env:CLBLAST_VERSION}-windows-x64 clblast
foreach ($f in (gci -Recurse -Path "$env:RUNNER_TEMP/clblast" -Filter '*.cmake')) {
$txt = Get-Content -Path $f -Raw
$txt.Replace('C:/vcpkg/packages/opencl_x64-windows/', "$($env:RUNNER_TEMP.Replace('\','/'))/opencl/") | Set-Content -Path $f -Encoding UTF8
}
- name: Download OpenBLAS
id: get_openblas
if: ${{ matrix.build == 'openblas' }}
run: |
curl.exe -o $env:RUNNER_TEMP/openblas.zip -L "https://github.com/xianyi/OpenBLAS/releases/download/v${env:OPENBLAS_VERSION}/OpenBLAS-${env:OPENBLAS_VERSION}-x64.zip"
curl.exe -o $env:RUNNER_TEMP/OpenBLAS.LICENSE.txt -L "https://github.com/xianyi/OpenBLAS/raw/v${env:OPENBLAS_VERSION}/LICENSE"
mkdir $env:RUNNER_TEMP/openblas
tar.exe -xvf $env:RUNNER_TEMP/openblas.zip -C $env:RUNNER_TEMP/openblas
$vcdir = $(vswhere -latest -products * -requires Microsoft.VisualStudio.Component.VC.Tools.x86.x64 -property installationPath)
$msvc = $(join-path $vcdir $('VC\Tools\MSVC\'+$(gc -raw $(join-path $vcdir 'VC\Auxiliary\Build\Microsoft.VCToolsVersion.default.txt')).Trim()))
$lib = $(join-path $msvc 'bin\Hostx64\x64\lib.exe')
& $lib /machine:x64 "/def:${env:RUNNER_TEMP}/openblas/lib/libopenblas.def" "/out:${env:RUNNER_TEMP}/openblas/lib/openblas.lib" /name:openblas.dll
- name: Build
id: cmake_build
run: |
mkdir build
cd build
cmake .. ${{ matrix.defines }}
cmake --build . --config Release -j ${env:NUMBER_OF_PROCESSORS}
- name: Add clblast.dll
id: add_clblast_dll
if: ${{ matrix.build == 'clblast' }}
run: |
cp $env:RUNNER_TEMP/clblast/lib/clblast.dll ./build/bin/Release
cp $env:RUNNER_TEMP/CLBlast.LICENSE.txt ./build/bin/Release/CLBlast-${env:CLBLAST_VERSION}.txt
- name: Add libopenblas.dll
id: add_libopenblas_dll
if: ${{ matrix.build == 'openblas' }}
run: |
cp $env:RUNNER_TEMP/openblas/bin/libopenblas.dll ./build/bin/Release/openblas.dll
cp $env:RUNNER_TEMP/OpenBLAS.LICENSE.txt ./build/bin/Release/OpenBLAS-${env:OPENBLAS_VERSION}.txt
- name: Check AVX512F support
id: check_avx512f
if: ${{ matrix.build == 'avx512' }}
continue-on-error: true
run: |
cd build
$vcdir = $(vswhere -latest -products * -requires Microsoft.VisualStudio.Component.VC.Tools.x86.x64 -property installationPath)
$msvc = $(join-path $vcdir $('VC\Tools\MSVC\'+$(gc -raw $(join-path $vcdir 'VC\Auxiliary\Build\Microsoft.VCToolsVersion.default.txt')).Trim()))
$cl = $(join-path $msvc 'bin\Hostx64\x64\cl.exe')
echo 'int main(void){unsigned int a[4];__cpuid(a,7);return !(a[1]&65536);}' >> avx512f.c
& $cl /O2 /GS- /kernel avx512f.c /link /nodefaultlib /entry:main
.\avx512f.exe && echo "AVX512F: YES" && ( echo HAS_AVX512F=1 >> $env:GITHUB_ENV ) || echo "AVX512F: NO"
- name: Test
id: cmake_test
if: ${{ matrix.build != 'clblast' && (matrix.build != 'avx512' || env.HAS_AVX512F == '1') }} # not all machines have native AVX-512
run: |
cd build
ctest -C Release --verbose --timeout 900
- name: Test (Intel SDE)
id: cmake_test_sde
if: ${{ matrix.build == 'avx512' && env.HAS_AVX512F == '0' }} # use Intel SDE for AVX-512 emulation
run: |
curl.exe -o $env:RUNNER_TEMP/sde.tar.xz -L "https://downloadmirror.intel.com/777395/sde-external-${env:SDE_VERSION}-win.tar.xz"
# for some weird reason windows tar doesn't like sde tar.xz
7z x "-o${env:RUNNER_TEMP}" $env:RUNNER_TEMP/sde.tar.xz
7z x "-o${env:RUNNER_TEMP}" $env:RUNNER_TEMP/sde.tar
$sde = $(join-path $env:RUNNER_TEMP sde-external-${env:SDE_VERSION}-win/sde.exe)
cd build
& $sde -future -- ctest -C Release --verbose --timeout 900
- name: Determine tag name
id: tag
shell: bash
run: |
BUILD_NUMBER="$(git rev-list --count HEAD)"
SHORT_HASH="$(git rev-parse --short=7 HEAD)"
if [[ "${{ env.BRANCH_NAME }}" == "master" ]]; then
echo "name=b${BUILD_NUMBER}" >> $GITHUB_OUTPUT
else
SAFE_NAME=$(echo "${{ env.BRANCH_NAME }}" | tr '/' '-')
echo "name=${SAFE_NAME}-b${BUILD_NUMBER}-${SHORT_HASH}" >> $GITHUB_OUTPUT
fi
- name: Pack artifacts
id: pack_artifacts
if: ${{ ( github.event_name == 'push' && github.ref == 'refs/heads/master' ) || github.event.inputs.create_release == 'true' }}
run: |
Copy-Item LICENSE .\build\bin\Release\llama.cpp.txt
7z a llama-${{ steps.tag.outputs.name }}-bin-win-${{ matrix.build }}-x64.zip .\build\bin\Release\*
- name: Upload artifacts
if: ${{ ( github.event_name == 'push' && github.ref == 'refs/heads/master' ) || github.event.inputs.create_release == 'true' }}
uses: actions/upload-artifact@v3
with:
path: |
llama-${{ steps.tag.outputs.name }}-bin-win-${{ matrix.build }}-x64.zip
windows-latest-cmake-cublas:
runs-on: windows-latest
strategy:
matrix:
cuda: ['12.2.0', '11.7.1']
build: ['cublas']
steps:
- name: Clone
id: checkout
uses: actions/checkout@v3
with:
fetch-depth: 0
- uses: Jimver/cuda-toolkit@v0.2.11
id: cuda-toolkit
with:
cuda: ${{ matrix.cuda }}
method: 'network'
sub-packages: '["nvcc", "cudart", "cublas", "cublas_dev", "thrust", "visual_studio_integration"]'
- name: Build
id: cmake_build
run: |
mkdir build
cd build
cmake .. -DLLAMA_NATIVE=OFF -DLLAMA_BUILD_SERVER=ON -DLLAMA_CUBLAS=ON -DBUILD_SHARED_LIBS=ON
cmake --build . --config Release -j ${env:NUMBER_OF_PROCESSORS}
- name: Determine tag name
id: tag
shell: bash
run: |
BUILD_NUMBER="$(git rev-list --count HEAD)"
SHORT_HASH="$(git rev-parse --short=7 HEAD)"
if [[ "${{ env.BRANCH_NAME }}" == "master" ]]; then
echo "name=b${BUILD_NUMBER}" >> $GITHUB_OUTPUT
else
SAFE_NAME=$(echo "${{ env.BRANCH_NAME }}" | tr '/' '-')
echo "name=${SAFE_NAME}-b${BUILD_NUMBER}-${SHORT_HASH}" >> $GITHUB_OUTPUT
fi
- name: Pack artifacts
id: pack_artifacts
if: ${{ ( github.event_name == 'push' && github.ref == 'refs/heads/master' ) || github.event.inputs.create_release == 'true' }}
run: |
7z a llama-${{ steps.tag.outputs.name }}-bin-win-${{ matrix.build }}-cu${{ matrix.cuda }}-x64.zip .\build\bin\Release\*
- name: Upload artifacts
if: ${{ ( github.event_name == 'push' && github.ref == 'refs/heads/master' ) || github.event.inputs.create_release == 'true' }}
uses: actions/upload-artifact@v3
with:
path: |
llama-${{ steps.tag.outputs.name }}-bin-win-${{ matrix.build }}-cu${{ matrix.cuda }}-x64.zip
- name: Copy and pack Cuda runtime
run: |
echo "Cuda install location: ${{steps.cuda-toolkit.outputs.CUDA_PATH}}"
$dst='.\build\bin\cudart\'
robocopy "${{steps.cuda-toolkit.outputs.CUDA_PATH}}\bin" $dst cudart64_*.dll cublas64_*.dll cublasLt64_*.dll
7z a cudart-llama-bin-win-cu${{ matrix.cuda }}-x64.zip $dst\*
- name: Upload Cuda runtime
if: ${{ ( github.event_name == 'push' && github.ref == 'refs/heads/master' ) || github.event.inputs.create_release == 'true' }}
uses: actions/upload-artifact@v3
with:
path: |
cudart-llama-bin-win-cu${{ matrix.cuda }}-x64.zip
# freeBSD-latest:
# runs-on: macos-12
# steps:
# - name: Clone
# uses: actions/checkout@v3
#
# - name: Build
# uses: cross-platform-actions/action@v0.19.0
# with:
# operating_system: freebsd
# version: '13.2'
# hypervisor: 'qemu'
# run: |
# sudo pkg update
# sudo pkg install -y gmake automake autoconf pkgconf llvm15 clinfo clover opencl clblast openblas
# gmake CC=/usr/local/bin/clang15 CXX=/usr/local/bin/clang++15 -j `sysctl -n hw.ncpu`
release:
if: ${{ ( github.event_name == 'push' && github.ref == 'refs/heads/master' ) || github.event.inputs.create_release == 'true' }}
runs-on: ubuntu-latest
needs:
- ubuntu-focal-make
- ubuntu-latest-cmake
- macOS-latest-make
- macOS-latest-cmake
- windows-latest-cmake
- windows-latest-cmake-cublas
steps:
- name: Clone
id: checkout
uses: actions/checkout@v3
with:
fetch-depth: 0
- name: Determine tag name
id: tag
shell: bash
run: |
BUILD_NUMBER="$(git rev-list --count HEAD)"
SHORT_HASH="$(git rev-parse --short=7 HEAD)"
if [[ "${{ env.BRANCH_NAME }}" == "master" ]]; then
echo "name=b${BUILD_NUMBER}" >> $GITHUB_OUTPUT
else
SAFE_NAME=$(echo "${{ env.BRANCH_NAME }}" | tr '/' '-')
echo "name=${SAFE_NAME}-b${BUILD_NUMBER}-${SHORT_HASH}" >> $GITHUB_OUTPUT
fi
- name: Download artifacts
id: download-artifact
uses: actions/download-artifact@v3
- name: Create release
id: create_release
uses: anzz1/action-create-release@v1
env:
GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }}
with:
tag_name: ${{ steps.tag.outputs.name }}
- name: Upload release
id: upload_release
uses: actions/github-script@v3
with:
github-token: ${{secrets.GITHUB_TOKEN}}
script: |
const path = require('path');
const fs = require('fs');
const release_id = '${{ steps.create_release.outputs.id }}';
for (let file of await fs.readdirSync('./artifact')) {
if (path.extname(file) === '.zip') {
console.log('uploadReleaseAsset', file);
await github.repos.uploadReleaseAsset({
owner: context.repo.owner,
repo: context.repo.repo,
release_id: release_id,
name: file,
data: await fs.readFileSync(`./artifact/${file}`)
});
}
}
# ubuntu-latest-gcc:
# runs-on: ubuntu-latest
#
# strategy:
# matrix:
# build: [Debug, Release]
#
# steps:
# - name: Clone
# uses: actions/checkout@v3
#
# - name: Dependencies
# run: |
# sudo apt-get update
# sudo apt-get install build-essential
# sudo apt-get install cmake
#
# - name: Configure
# run: cmake . -DCMAKE_BUILD_TYPE=${{ matrix.build }}
#
# - name: Build
# run: |
# make
#
# ubuntu-latest-clang:
# runs-on: ubuntu-latest
#
# strategy:
# matrix:
# build: [Debug, Release]
#
# steps:
# - name: Clone
# uses: actions/checkout@v3
#
# - name: Dependencies
# run: |
# sudo apt-get update
# sudo apt-get install build-essential
# sudo apt-get install cmake
#
# - name: Configure
# run: cmake . -DCMAKE_BUILD_TYPE=${{ matrix.build }} -DCMAKE_CXX_COMPILER=clang++ -DCMAKE_C_COMPILER=clang
#
# - name: Build
# run: |
# make
#
# ubuntu-latest-gcc-sanitized:
# runs-on: ubuntu-latest
#
# strategy:
# matrix:
# sanitizer: [ADDRESS, THREAD, UNDEFINED]
#
# steps:
# - name: Clone
# uses: actions/checkout@v3
#
# - name: Dependencies
# run: |
# sudo apt-get update
# sudo apt-get install build-essential
# sudo apt-get install cmake
#
# - name: Configure
# run: cmake . -DCMAKE_BUILD_TYPE=Debug -DLLAMA_SANITIZE_${{ matrix.sanitizer }}=ON
#
# - name: Build
# run: |
# make
#
# windows:
# runs-on: windows-latest
#
# strategy:
# matrix:
# build: [Release]
# arch: [Win32, x64]
# include:
# - arch: Win32
# s2arc: x86
# - arch: x64
# s2arc: x64
#
# steps:
# - name: Clone
# uses: actions/checkout@v3
#
# - name: Add msbuild to PATH
# uses: microsoft/setup-msbuild@v1
#
# - name: Configure
# run: >
# cmake -S . -B ./build -A ${{ matrix.arch }}
# -DCMAKE_BUILD_TYPE=${{ matrix.build }}
#
# - name: Build
# run: |
# cd ./build
# msbuild ALL_BUILD.vcxproj -t:build -p:configuration=${{ matrix.build }} -p:platform=${{ matrix.arch }}
#
# - name: Upload binaries
# uses: actions/upload-artifact@v1
# with:
# name: llama-bin-${{ matrix.arch }}
# path: build/bin/${{ matrix.build }}
#
# windows-blas:
# runs-on: windows-latest
#
# strategy:
# matrix:
# build: [Release]
# arch: [Win32, x64]
# blas: [ON]
# include:
# - arch: Win32
# obzip: https://github.com/xianyi/OpenBLAS/releases/download/v0.3.21/OpenBLAS-0.3.21-x86.zip
# s2arc: x86
# - arch: x64
# obzip: https://github.com/xianyi/OpenBLAS/releases/download/v0.3.21/OpenBLAS-0.3.21-x64.zip
# s2arc: x64
#
# steps:
# - name: Clone
# uses: actions/checkout@v3
#
# - name: Add msbuild to PATH
# uses: microsoft/setup-msbuild@v1
#
# - name: Fetch OpenBLAS
# if: matrix.blas == 'ON'
# run: |
# C:/msys64/usr/bin/wget.exe -qO blas.zip ${{ matrix.obzip }}
# 7z x blas.zip -oblas -y
# copy blas/include/cblas.h .
# copy blas/include/openblas_config.h .
# echo "blasdir=$env:GITHUB_WORKSPACE/blas" >> $env:GITHUB_ENV
#
# - name: Configure
# run: >
# cmake -S . -B ./build -A ${{ matrix.arch }}
# -DCMAKE_BUILD_TYPE=${{ matrix.build }}
# -DLLAMA_SUPPORT_OPENBLAS=${{ matrix.blas }}
# -DCMAKE_LIBRARY_PATH="$env:blasdir/lib"
#
# - name: Build
# run: |
# cd ./build
# msbuild ALL_BUILD.vcxproj -t:build -p:configuration=${{ matrix.build }} -p:platform=${{ matrix.arch }}
#
# - name: Copy libopenblas.dll
# if: matrix.blas == 'ON'
# run: copy "$env:blasdir/bin/libopenblas.dll" build/bin/${{ matrix.build }}
#
# - name: Upload binaries
# if: matrix.blas == 'ON'
# uses: actions/upload-artifact@v1
# with:
# name: llama-blas-bin-${{ matrix.arch }}
# path: build/bin/${{ matrix.build }}
#
# emscripten:
# runs-on: ubuntu-latest
#
# strategy:
# matrix:
# build: [Release]
#
# steps:
# - name: Clone
# uses: actions/checkout@v3
#
# - name: Dependencies
# run: |
# wget -q https://github.com/emscripten-core/emsdk/archive/master.tar.gz
# tar -xvf master.tar.gz
# emsdk-master/emsdk update
# emsdk-master/emsdk install latest
# emsdk-master/emsdk activate latest
#
# - name: Configure
# run: echo "tmp"
#
# - name: Build
# run: |
# pushd emsdk-master
# source ./emsdk_env.sh
# popd
# emcmake cmake . -DCMAKE_BUILD_TYPE=${{ matrix.build }}
# make
================================================
FILE: .github/workflows/code-coverage.yml
================================================
name: Code Coverage
on: [push, pull_request]
env:
GGML_NLOOP: 3
GGML_N_THREADS: 1
jobs:
run:
runs-on: ubuntu-20.04
steps:
- name: Checkout
uses: actions/checkout@v3
- name: Dependencies
run: |
sudo apt-get update
sudo apt-get install build-essential gcc-8 lcov
- name: Build
run: CC=gcc-8 make -j LLAMA_CODE_COVERAGE=1 tests
- name: Run tests
run: CC=gcc-8 make test
- name: Generate coverage report
run: |
make coverage
make lcov-report
- name: Upload coverage to Codecov
uses: codecov/codecov-action@v3
env:
CODECOV_TOKEN: ${{ secrets.CODECOV_TOKEN }}
with:
files: lcov-report/coverage.info
================================================
FILE: .github/workflows/docker.yml
================================================
# This workflow uses actions that are not certified by GitHub.
# They are provided by a third-party and are governed by
# separate terms of service, privacy policy, and support
# documentation.
# GitHub recommends pinning actions to a commit SHA.
# To get a newer version, you will need to update the SHA.
# You can also reference a tag or branch, but the action may change without warning.
name: Publish Docker image
on:
pull_request:
push:
branches:
- master
jobs:
push_to_registry:
name: Push Docker image to Docker Hub
if: github.event.pull_request.draft == false
runs-on: ubuntu-latest
env:
COMMIT_SHA: ${{ github.sha }}
strategy:
matrix:
config:
- { tag: "light", dockerfile: ".devops/main.Dockerfile", platforms: "linux/amd64,linux/arm64" }
- { tag: "full", dockerfile: ".devops/full.Dockerfile", platforms: "linux/amd64,linux/arm64" }
# NOTE(canardletter): The CUDA builds on arm64 are very slow, so I
# have disabled them for now until the reason why
# is understood.
- { tag: "light-cuda", dockerfile: ".devops/main-cuda.Dockerfile", platforms: "linux/amd64" }
- { tag: "full-cuda", dockerfile: ".devops/full-cuda.Dockerfile", platforms: "linux/amd64" }
- { tag: "light-rocm", dockerfile: ".devops/main-rocm.Dockerfile", platforms: "linux/amd64,linux/arm64" }
- { tag: "full-rocm", dockerfile: ".devops/full-rocm.Dockerfile", platforms: "linux/amd64,linux/arm64" }
steps:
- name: Check out the repo
uses: actions/checkout@v3
- name: Set up QEMU
uses: docker/setup-qemu-action@v2
- name: Set up Docker Buildx
uses: docker/setup-buildx-action@v2
- name: Log in to Docker Hub
uses: docker/login-action@v2
with:
registry: ghcr.io
username: ${{ github.repository_owner }}
password: ${{ secrets.GITHUB_TOKEN }}
- name: Build and push Docker image (versioned)
if: github.event_name == 'push'
uses: docker/build-push-action@v4
with:
context: .
push: true
platforms: ${{ matrix.config.platforms }}
tags: "ghcr.io/ggerganov/llama.cpp:${{ matrix.config.tag }}-${{ env.COMMIT_SHA }}"
file: ${{ matrix.config.dockerfile }}
- name: Build and push Docker image (tagged)
uses: docker/build-push-action@v4
with:
context: .
push: ${{ github.event_name == 'push' }}
platforms: ${{ matrix.config.platforms }}
tags: "ghcr.io/ggerganov/llama.cpp:${{ matrix.config.tag }}"
file: ${{ matrix.config.dockerfile }}
================================================
FILE: .github/workflows/editorconfig.yml
================================================
name: EditorConfig Checker
on:
push:
branches:
- master
pull_request:
branches:
- master
jobs:
editorconfig:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v3
- uses: editorconfig-checker/action-editorconfig-checker@main
- run: editorconfig-checker
================================================
FILE: .github/workflows/gguf-publish.yml
================================================
# This workflow will upload a Python Package using Twine when a GGUF release is created
# For more information see: https://help.github.com/en/actions/language-and-framework-guides/using-python-with-github-actions#publishing-to-package-registries
# See `gguf-py/README.md` for how to make a release.
# This workflow uses actions that are not certified by GitHub.
# They are provided by a third-party and are governed by
# separate terms of service, privacy policy, and support
# documentation.
name: Upload Python Package
on:
workflow_dispatch:
push:
# Pattern matched against refs/tags
tags:
- 'gguf-v*' # Push events to every version tag
jobs:
deploy:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v3
- name: Set up Python
uses: actions/setup-python@v2
with:
python-version: '3.9.x'
- name: Install dependencies
run: |
cd gguf-py
python -m pip install poetry
poetry install
- name: Build package
run: cd gguf-py && poetry build
- name: Publish package
uses: pypa/gh-action-pypi-publish@release/v1
with:
password: ${{ secrets.PYPI_API_TOKEN }}
packages-dir: gguf-py/dist
================================================
FILE: .github/workflows/tidy-post.yml
================================================
name: clang-tidy review post comments
on:
workflow_dispatch:
workflows: ["clang-tidy-review"]
types:
- completed
jobs:
build:
runs-on: ubuntu-latest
steps:
- uses: ZedThree/clang-tidy-review/post@v0.13.0
# lgtm_comment_body, max_comments, and annotations need to be set on the posting workflow in a split setup
with:
# adjust options as necessary
lgtm_comment_body: ''
annotations: false
max_comments: 25
================================================
FILE: .github/workflows/tidy-review.yml
================================================
name: clang-tidy-review
on:
pull_request:
branches:
- master
jobs:
clang-tidy-review:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v3
- uses: ZedThree/clang-tidy-review@v0.13.0
id: review
with:
lgtm_comment_body: ''
build_dir: build
cmake_command: cmake . -B build -DCMAKE_EXPORT_COMPILE_COMMANDS=on
split_workflow: true
- uses: ZedThree/clang-tidy-review/upload@v0.13.0
================================================
FILE: .github/workflows/zig-build.yml
================================================
name: Zig CI
on:
pull_request:
push:
branches:
- master
jobs:
build:
strategy:
fail-fast: false
matrix:
runs-on: [ubuntu-latest, macos-latest, windows-latest]
runs-on: ${{ matrix.runs-on }}
steps:
- uses: actions/checkout@v3
with:
submodules: recursive
fetch-depth: 0
- uses: goto-bus-stop/setup-zig@v2
with:
version: 0.11.0
- name: Build Summary
run: zig build --summary all -freference-trace
================================================
FILE: .gitignore
================================================
*.o
*.a
*.so
*.gguf
*.bin
*.exe
*.dll
*.log
*.gcov
*.gcno
*.gcda
*.dot
*.bat
*.metallib
.DS_Store
.build/
.cache/
.ccls-cache/
.direnv/
.envrc
.swiftpm
.venv
.clang-tidy
.vs/
.vscode/
lcov-report/
gcovr-report/
build*/
out/
tmp/
models/*
models-mnt
/Pipfile
/baby-llama
/beam-search
/benchmark-matmult
/convert-llama2c-to-ggml
/embd-input-test
/embedding
/gguf
/gguf-llama-simple
/infill
/libllama.so
/llama-bench
/llava-cli
/main
/metal
/perplexity
/q8dot
/quantize
/quantize-stats
/result
/save-load-state
/server
/simple
/batched
/batched-bench
/export-lora
/finetune
/speculative
/parallel
/train-text-from-scratch
/vdot
/common/build-info.cpp
arm_neon.h
compile_commands.json
CMakeSettings.json
__pycache__
dist
zig-out/
zig-cache/
ppl-*.txt
qnt-*.txt
perf-*.txt
examples/jeopardy/results.txt
poetry.lock
poetry.toml
# Test binaries
tests/test-grammar-parser
tests/test-llama-grammar
tests/test-double-float
tests/test-grad0
tests/test-opt
tests/test-quantize-fns
tests/test-quantize-perf
tests/test-sampling
tests/test-tokenizer-0-llama
tests/test-tokenizer-0-falcon
tests/test-tokenizer-1-llama
tests/test-tokenizer-1-bpe
build-info.h
================================================
FILE: .gitmodules
================================================
[submodule "smallthinker/ggml/src/ggml-kompute/kompute"]
path = smallthinker/ggml/src/ggml-kompute/kompute
url = https://github.com/nomic-ai/kompute.git
[submodule "smallthinker/powerinfer/third_part/perfetto"]
path = smallthinker/powerinfer/third_part/perfetto
url = https://github.com/google/perfetto.git
[submodule "smallthinker/powerinfer/third_part/benchmark"]
path = smallthinker/powerinfer/third_part/benchmark
url = https://github.com/google/benchmark.git
[submodule "smallthinker/powerinfer/third_part/googletest"]
path = smallthinker/powerinfer/third_part/googletest
url = https://github.com/google/googletest.git
[submodule "smallthinker/powerinfer/third_part/libaio"]
path = smallthinker/powerinfer/third_part/libaio
url = https://github.com/crossbuild/libaio.git
[submodule "smallthinker/powerinfer/third_part/liburing"]
path = smallthinker/powerinfer/third_part/liburing
url = https://github.com/axboe/liburing.git
[submodule "smallthinker/powerinfer/third_part/fmt"]
path = smallthinker/powerinfer/third_part/fmt
url = https://github.com/fmtlib/fmt.git
================================================
FILE: .pre-commit-config.yaml
================================================
# See https://pre-commit.com for more information
# See https://pre-commit.com/hooks.html for more hooks
exclude: prompts/.*.txt
repos:
- repo: https://github.com/pre-commit/pre-commit-hooks
rev: v3.2.0
hooks:
- id: trailing-whitespace
- id: end-of-file-fixer
- id: check-yaml
- id: check-added-large-files
- repo: https://github.com/PyCQA/flake8
rev: 6.0.0
hooks:
- id: flake8
================================================
FILE: CMakeLists.txt
================================================
cmake_minimum_required(VERSION 3.13) # for add_link_options
project("llama.cpp" C CXX)
set(CMAKE_EXPORT_COMPILE_COMMANDS ON)
if (NOT XCODE AND NOT MSVC AND NOT CMAKE_BUILD_TYPE)
set(CMAKE_BUILD_TYPE Release CACHE STRING "Build type" FORCE)
set_property(CACHE CMAKE_BUILD_TYPE PROPERTY STRINGS "Debug" "Release" "MinSizeRel" "RelWithDebInfo")
endif()
set(CMAKE_RUNTIME_OUTPUT_DIRECTORY ${CMAKE_BINARY_DIR}/bin)
if (CMAKE_SOURCE_DIR STREQUAL CMAKE_CURRENT_SOURCE_DIR)
set(LLAMA_STANDALONE ON)
# configure project version
# TODO
else()
set(LLAMA_STANDALONE OFF)
endif()
if (EMSCRIPTEN)
set(BUILD_SHARED_LIBS_DEFAULT OFF)
option(LLAMA_WASM_SINGLE_FILE "llama: embed WASM inside the generated llama.js" ON)
else()
if (MINGW)
set(BUILD_SHARED_LIBS_DEFAULT OFF)
else()
set(BUILD_SHARED_LIBS_DEFAULT ON)
endif()
endif()
#
# Option list
#
if (APPLE)
set(LLAMA_METAL_DEFAULT OFF) # metal has not been supported on Apple Silicon yet
else()
set(LLAMA_METAL_DEFAULT OFF)
endif()
# general
option(LLAMA_STATIC "llama: static link libraries" OFF)
option(LLAMA_NATIVE "llama: enable -march=native flag" ON)
option(LLAMA_LTO "llama: enable link time optimization" OFF)
# debug
option(LLAMA_ALL_WARNINGS "llama: enable all compiler warnings" ON)
option(LLAMA_ALL_WARNINGS_3RD_PARTY "llama: enable all compiler warnings in 3rd party libs" OFF)
option(LLAMA_GPROF "llama: enable gprof" OFF)
# sanitizers
option(LLAMA_SANITIZE_THREAD "llama: enable thread sanitizer" OFF)
option(LLAMA_SANITIZE_ADDRESS "llama: enable address sanitizer" OFF)
option(LLAMA_SANITIZE_UNDEFINED "llama: enable undefined sanitizer" OFF)
# instruction set specific
if (LLAMA_NATIVE)
set(INS_ENB OFF)
else()
set(INS_ENB ON)
endif()
option(LLAMA_AVX "llama: enable AVX" ${INS_ENB})
option(LLAMA_AVX2 "llama: enable AVX2" ${INS_ENB})
option(LLAMA_AVX512 "llama: enable AVX512" OFF)
option(LLAMA_AVX512_VBMI "llama: enable AVX512-VBMI" OFF)
option(LLAMA_AVX512_VNNI "llama: enable AVX512-VNNI" OFF)
option(LLAMA_FMA "llama: enable FMA" ${INS_ENB})
# in MSVC F16C is implied with AVX2/AVX512
if (NOT MSVC)
option(LLAMA_F16C "llama: enable F16C" ${INS_ENB})
endif()
# 3rd party libs
option(LLAMA_ACCELERATE "llama: enable Accelerate framework" ON)
option(LLAMA_BLAS "llama: use BLAS" OFF)
set(LLAMA_BLAS_VENDOR "Generic" CACHE STRING "llama: BLAS library vendor")
option(LLAMA_CUBLAS "llama: use CUDA" OFF)
#option(LLAMA_CUDA_CUBLAS "llama: use cuBLAS for prompt processing" OFF)
option(LLAMA_CUDA_FORCE_DMMV "llama: use dmmv instead of mmvq CUDA kernels" OFF)
option(LLAMA_CUDA_FORCE_MMQ "llama: use mmq kernels instead of cuBLAS" OFF)
set(LLAMA_CUDA_DMMV_X "32" CACHE STRING "llama: x stride for dmmv CUDA kernels")
set(LLAMA_CUDA_MMV_Y "1" CACHE STRING "llama: y block size for mmv CUDA kernels")
option(LLAMA_CUDA_F16 "llama: use 16 bit floats for some calculations" OFF)
set(LLAMA_CUDA_KQUANTS_ITER "2" CACHE STRING "llama: iters./thread per block for Q2_K/Q6_K")
set(LLAMA_CUDA_PEER_MAX_BATCH_SIZE "128" CACHE STRING
"llama: max. batch size for using peer access")
option(LLAMA_HIPBLAS "llama: use hipBLAS" OFF)
option(LLAMA_CLBLAST "llama: use CLBlast" OFF)
option(LLAMA_METAL "llama: use Metal" ${LLAMA_METAL_DEFAULT})
option(LLAMA_METAL_NDEBUG "llama: disable Metal debugging" OFF)
option(LLAMA_MPI "llama: use MPI" OFF)
option(LLAMA_QKK_64 "llama: use super-block size of 64 for k-quants" OFF)
option(LLAMA_BUILD_TESTS "llama: build tests" ${LLAMA_STANDALONE})
option(LLAMA_BUILD_EXAMPLES "llama: build examples" ${LLAMA_STANDALONE})
option(LLAMA_BUILD_SERVER "llama: build server example" ON)
#
# Compile flags
#
set(CMAKE_CXX_STANDARD 11)
set(CMAKE_CXX_STANDARD_REQUIRED true)
set(CMAKE_C_STANDARD 11)
set(CMAKE_C_STANDARD_REQUIRED true)
set(THREADS_PREFER_PTHREAD_FLAG ON)
find_package(Threads REQUIRED)
include(CheckCXXCompilerFlag)
if (NOT MSVC)
if (LLAMA_SANITIZE_THREAD)
add_compile_options(-fsanitize=thread)
link_libraries(-fsanitize=thread)
endif()
if (LLAMA_SANITIZE_ADDRESS)
add_compile_options(-fsanitize=address -fno-omit-frame-pointer)
link_libraries(-fsanitize=address)
endif()
if (LLAMA_SANITIZE_UNDEFINED)
add_compile_options(-fsanitize=undefined)
link_libraries(-fsanitize=undefined)
endif()
endif()
if (APPLE AND LLAMA_ACCELERATE)
find_library(ACCELERATE_FRAMEWORK Accelerate)
if (ACCELERATE_FRAMEWORK)
message(STATUS "Accelerate framework found")
add_compile_definitions(GGML_USE_ACCELERATE)
add_compile_definitions(ACCELERATE_NEW_LAPACK)
add_compile_definitions(ACCELERATE_LAPACK_ILP64)
set(LLAMA_EXTRA_LIBS ${LLAMA_EXTRA_LIBS} ${ACCELERATE_FRAMEWORK})
else()
message(WARNING "Accelerate framework not found")
endif()
endif()
if (LLAMA_METAL)
find_library(FOUNDATION_LIBRARY Foundation REQUIRED)
find_library(METAL_FRAMEWORK Metal REQUIRED)
find_library(METALKIT_FRAMEWORK MetalKit REQUIRED)
message(STATUS "Metal framework found")
set(GGML_HEADERS_METAL ggml-metal.h)
set(GGML_SOURCES_METAL ggml-metal.m)
add_compile_definitions(GGML_USE_METAL)
if (LLAMA_METAL_NDEBUG)
add_compile_definitions(GGML_METAL_NDEBUG)
endif()
# get full path to the file
#add_compile_definitions(GGML_METAL_DIR_KERNELS="${CMAKE_CURRENT_SOURCE_DIR}/")
# copy ggml-metal.metal to bin directory
configure_file(ggml-metal.metal bin/ggml-metal.metal COPYONLY)
set(LLAMA_EXTRA_LIBS ${LLAMA_EXTRA_LIBS}
${FOUNDATION_LIBRARY}
${METAL_FRAMEWORK}
${METALKIT_FRAMEWORK}
)
endif()
if (LLAMA_BLAS)
if (LLAMA_STATIC)
set(BLA_STATIC ON)
endif()
if ($(CMAKE_VERSION) VERSION_GREATER_EQUAL 3.22)
set(BLA_SIZEOF_INTEGER 8)
endif()
set(BLA_VENDOR ${LLAMA_BLAS_VENDOR})
find_package(BLAS)
if (BLAS_FOUND)
message(STATUS "BLAS found, Libraries: ${BLAS_LIBRARIES}")
if ("${BLAS_INCLUDE_DIRS}" STREQUAL "")
# BLAS_INCLUDE_DIRS is missing in FindBLAS.cmake.
# see https://gitlab.kitware.com/cmake/cmake/-/issues/20268
find_package(PkgConfig REQUIRED)
if (${LLAMA_BLAS_VENDOR} MATCHES "Generic")
pkg_check_modules(DepBLAS REQUIRED blas)
elseif (${LLAMA_BLAS_VENDOR} MATCHES "OpenBLAS")
pkg_check_modules(DepBLAS REQUIRED openblas)
elseif (${LLAMA_BLAS_VENDOR} MATCHES "FLAME")
pkg_check_modules(DepBLAS REQUIRED blis)
elseif (${LLAMA_BLAS_VENDOR} MATCHES "ATLAS")
pkg_check_modules(DepBLAS REQUIRED blas-atlas)
elseif (${LLAMA_BLAS_VENDOR} MATCHES "FlexiBLAS")
pkg_check_modules(DepBLAS REQUIRED flexiblas_api)
elseif (${LLAMA_BLAS_VENDOR} MATCHES "Intel")
# all Intel* libraries share the same include path
pkg_check_modules(DepBLAS REQUIRED mkl-sdl)
elseif (${LLAMA_BLAS_VENDOR} MATCHES "NVHPC")
# this doesn't provide pkg-config
# suggest to assign BLAS_INCLUDE_DIRS on your own
if ("${NVHPC_VERSION}" STREQUAL "")
message(WARNING "Better to set NVHPC_VERSION")
else()
set(DepBLAS_FOUND ON)
set(DepBLAS_INCLUDE_DIRS "/opt/nvidia/hpc_sdk/${CMAKE_SYSTEM_NAME}_${CMAKE_SYSTEM_PROCESSOR}/${NVHPC_VERSION}/math_libs/include")
endif()
endif()
if (DepBLAS_FOUND)
set(BLAS_INCLUDE_DIRS ${DepBLAS_INCLUDE_DIRS})
else()
message(WARNING "BLAS_INCLUDE_DIRS neither been provided nor been automatically"
" detected by pkgconfig, trying to find cblas.h from possible paths...")
find_path(BLAS_INCLUDE_DIRS
NAMES cblas.h
HINTS
/usr/include
/usr/local/include
/usr/include/openblas
/opt/homebrew/opt/openblas/include
/usr/local/opt/openblas/include
/usr/include/x86_64-linux-gnu/openblas/include
)
endif()
endif()
message(STATUS "BLAS found, Includes: ${BLAS_INCLUDE_DIRS}")
add_compile_options(${BLAS_LINKER_FLAGS})
add_compile_definitions(GGML_USE_OPENBLAS)
if (${BLAS_INCLUDE_DIRS} MATCHES "mkl" AND (${LLAMA_BLAS_VENDOR} MATCHES "Generic" OR ${LLAMA_BLAS_VENDOR} MATCHES "Intel"))
add_compile_definitions(GGML_BLAS_USE_MKL)
endif()
set(LLAMA_EXTRA_LIBS ${LLAMA_EXTRA_LIBS} ${BLAS_LIBRARIES})
set(LLAMA_EXTRA_INCLUDES ${LLAMA_EXTRA_INCLUDES} ${BLAS_INCLUDE_DIRS})
else()
message(WARNING "BLAS not found, please refer to "
"https://cmake.org/cmake/help/latest/module/FindBLAS.html#blas-lapack-vendors"
" to set correct LLAMA_BLAS_VENDOR")
endif()
endif()
if (LLAMA_QKK_64)
add_compile_definitions(GGML_QKK_64)
endif()
if (LLAMA_CUBLAS)
cmake_minimum_required(VERSION 3.17)
find_package(CUDAToolkit)
if (CUDAToolkit_FOUND)
message(STATUS "cuBLAS found")
enable_language(CUDA)
set(GGML_HEADERS_CUDA ggml-cuda.h)
set(GGML_SOURCES_CUDA ggml-cuda.cu)
add_compile_definitions(GGML_USE_CUBLAS)
# if (LLAMA_CUDA_CUBLAS)
# add_compile_definitions(GGML_CUDA_CUBLAS)
# endif()
if (LLAMA_CUDA_FORCE_DMMV)
add_compile_definitions(GGML_CUDA_FORCE_DMMV)
endif()
if (LLAMA_CUDA_FORCE_MMQ)
add_compile_definitions(GGML_CUDA_FORCE_MMQ)
endif()
add_compile_definitions(GGML_CUDA_DMMV_X=${LLAMA_CUDA_DMMV_X})
add_compile_definitions(GGML_CUDA_MMV_Y=${LLAMA_CUDA_MMV_Y})
if (DEFINED LLAMA_CUDA_DMMV_Y)
add_compile_definitions(GGML_CUDA_MMV_Y=${LLAMA_CUDA_DMMV_Y}) # for backwards compatibility
endif()
if (LLAMA_CUDA_F16 OR LLAMA_CUDA_DMMV_F16)
add_compile_definitions(GGML_CUDA_F16)
endif()
add_compile_definitions(K_QUANTS_PER_ITERATION=${LLAMA_CUDA_KQUANTS_ITER})
add_compile_definitions(GGML_CUDA_PEER_MAX_BATCH_SIZE=${LLAMA_CUDA_PEER_MAX_BATCH_SIZE})
if (LLAMA_STATIC)
set(LLAMA_EXTRA_LIBS ${LLAMA_EXTRA_LIBS} CUDA::cudart_static CUDA::cublas_static CUDA::cublasLt_static)
else()
set(LLAMA_EXTRA_LIBS ${LLAMA_EXTRA_LIBS} CUDA::cudart CUDA::cublas CUDA::cublasLt)
endif()
if (NOT DEFINED CMAKE_CUDA_ARCHITECTURES)
# 52 == lowest CUDA 12 standard
# 60 == f16 CUDA intrinsics
# 61 == integer CUDA intrinsics
# 70 == compute capability at which unrolling a loop in mul_mat_q kernels is faster
if (LLAMA_CUDA_F16 OR LLAMA_CUDA_DMMV_F16)
set(CMAKE_CUDA_ARCHITECTURES "60;61;70") # needed for f16 CUDA intrinsics
else()
set(CMAKE_CUDA_ARCHITECTURES "52;61;70") # lowest CUDA 12 standard + lowest for integer intrinsics
#set(CMAKE_CUDA_ARCHITECTURES "") # use this to compile much faster, but only F16 models work
endif()
endif()
message(STATUS "Using CUDA architectures: ${CMAKE_CUDA_ARCHITECTURES}")
else()
message(WARNING "cuBLAS not found")
endif()
endif()
if (LLAMA_MPI)
cmake_minimum_required(VERSION 3.10)
find_package(MPI)
if (MPI_C_FOUND)
message(STATUS "MPI found")
set(GGML_HEADERS_MPI ggml-mpi.h)
set(GGML_SOURCES_MPI ggml-mpi.c ggml-mpi.h)
add_compile_definitions(GGML_USE_MPI)
add_compile_definitions(${MPI_C_COMPILE_DEFINITIONS})
if (NOT MSVC)
add_compile_options(-Wno-cast-qual)
endif()
set(LLAMA_EXTRA_LIBS ${LLAMA_EXTRA_LIBS} ${MPI_C_LIBRARIES})
set(LLAMA_EXTRA_INCLUDES ${LLAMA_EXTRA_INCLUDES} ${MPI_C_INCLUDE_DIRS})
# Even if you're only using the C header, C++ programs may bring in MPI
# C++ functions, so more linkage is needed
if (MPI_CXX_FOUND)
set(LLAMA_EXTRA_LIBS ${LLAMA_EXTRA_LIBS} ${MPI_CXX_LIBRARIES})
endif()
else()
message(WARNING "MPI not found")
endif()
endif()
if (LLAMA_CLBLAST)
find_package(CLBlast)
if (CLBlast_FOUND)
message(STATUS "CLBlast found")
set(GGML_HEADERS_OPENCL ggml-opencl.h)
set(GGML_SOURCES_OPENCL ggml-opencl.cpp)
add_compile_definitions(GGML_USE_CLBLAST)
set(LLAMA_EXTRA_LIBS ${LLAMA_EXTRA_LIBS} clblast)
else()
message(WARNING "CLBlast not found")
endif()
endif()
if (LLAMA_HIPBLAS)
list(APPEND CMAKE_PREFIX_PATH /opt/rocm)
# enable fast atomic operation
add_compile_options(-munsafe-fp-atomics)
if (NOT ${CMAKE_C_COMPILER_ID} MATCHES "Clang")
message(WARNING "Only LLVM is supported for HIP, hint: CC=/opt/rocm/llvm/bin/clang")
endif()
if (NOT ${CMAKE_CXX_COMPILER_ID} MATCHES "Clang")
message(WARNING "Only LLVM is supported for HIP, hint: CXX=/opt/rocm/llvm/bin/clang++")
endif()
find_package(hip)
find_package(hipblas)
find_package(rocblas)
if (${hipblas_FOUND} AND ${hip_FOUND})
message(STATUS "HIP and hipBLAS found")
add_compile_definitions(GGML_USE_HIPBLAS GGML_USE_CUBLAS)
add_library(ggml-rocm OBJECT ggml-cuda.cu ggml-cuda.h)
if (BUILD_SHARED_LIBS)
set_target_properties(ggml-rocm PROPERTIES POSITION_INDEPENDENT_CODE ON)
endif()
if (LLAMA_CUDA_FORCE_DMMV)
target_compile_definitions(ggml-rocm PRIVATE GGML_CUDA_FORCE_DMMV)
endif()
if (LLAMA_CUDA_FORCE_MMQ)
target_compile_definitions(ggml-rocm PRIVATE GGML_CUDA_FORCE_MMQ)
endif()
target_compile_definitions(ggml-rocm PRIVATE GGML_CUDA_DMMV_X=${LLAMA_CUDA_DMMV_X})
target_compile_definitions(ggml-rocm PRIVATE GGML_CUDA_MMV_Y=${LLAMA_CUDA_MMV_Y})
target_compile_definitions(ggml-rocm PRIVATE K_QUANTS_PER_ITERATION=${LLAMA_CUDA_KQUANTS_ITER})
set_source_files_properties(ggml-cuda.cu PROPERTIES LANGUAGE CXX)
target_link_libraries(ggml-rocm PRIVATE hip::device PUBLIC hip::host roc::rocblas roc::hipblas)
if (LLAMA_STATIC)
message(FATAL_ERROR "Static linking not supported for HIP/ROCm")
endif()
set(LLAMA_EXTRA_LIBS ${LLAMA_EXTRA_LIBS} ggml-rocm)
else()
message(WARNING "hipBLAS or HIP not found. Try setting CMAKE_PREFIX_PATH=/opt/rocm")
endif()
endif()
if (LLAMA_ALL_WARNINGS)
if (NOT MSVC)
set(warning_flags -Wall -Wextra -Wpedantic -Wcast-qual -Wno-unused-function)
set(c_flags -Wshadow -Wstrict-prototypes -Wpointer-arith -Wmissing-prototypes -Werror=implicit-int -Werror=implicit-function-declaration)
set(cxx_flags -Wmissing-declarations -Wmissing-noreturn)
set(host_cxx_flags "")
if (CMAKE_C_COMPILER_ID MATCHES "Clang")
set(warning_flags ${warning_flags} -Wunreachable-code-break -Wunreachable-code-return)
set(host_cxx_flags ${host_cxx_flags} -Wmissing-prototypes -Wextra-semi)
if (
(CMAKE_C_COMPILER_ID STREQUAL "Clang" AND CMAKE_C_COMPILER_VERSION VERSION_GREATER_EQUAL 3.8.0) OR
(CMAKE_C_COMPILER_ID STREQUAL "AppleClang" AND CMAKE_C_COMPILER_VERSION VERSION_GREATER_EQUAL 7.3.0)
)
set(c_flags ${c_flags} -Wdouble-promotion)
endif()
elseif (CMAKE_C_COMPILER_ID STREQUAL "GNU")
set(c_flags ${c_flags} -Wdouble-promotion)
set(host_cxx_flags ${host_cxx_flags} -Wno-array-bounds)
if (CMAKE_CXX_COMPILER_VERSION VERSION_GREATER_EQUAL 7.1.0)
set(host_cxx_flags ${host_cxx_flags} -Wno-format-truncation)
endif()
if (CMAKE_CXX_COMPILER_VERSION VERSION_GREATER_EQUAL 8.1.0)
set(host_cxx_flags ${host_cxx_flags} -Wextra-semi)
endif()
endif()
else()
# todo : msvc
endif()
set(c_flags ${c_flags} ${warning_flags})
set(cxx_flags ${cxx_flags} ${warning_flags})
add_compile_options("$<$<COMPILE_LANGUAGE:C>:${c_flags}>"
"$<$<COMPILE_LANGUAGE:CXX>:${cxx_flags}>"
"$<$<COMPILE_LANGUAGE:CXX>:${host_cxx_flags}>")
endif()
if (NOT MSVC)
set(cuda_flags -Wno-pedantic)
endif()
set(cuda_flags ${cxx_flags} -use_fast_math ${cuda_flags})
list(JOIN host_cxx_flags " " cuda_host_flags) # pass host compiler flags as a single argument
if (NOT cuda_host_flags STREQUAL "")
set(cuda_flags -forward-unknown-to-host-compiler ${cuda_flags} -Xcompiler ${cuda_host_flags})
endif()
add_compile_options("$<$<COMPILE_LANGUAGE:CUDA>:${cuda_flags}>")
if (WIN32)
add_compile_definitions(_CRT_SECURE_NO_WARNINGS)
if (BUILD_SHARED_LIBS)
set(CMAKE_WINDOWS_EXPORT_ALL_SYMBOLS ON)
endif()
endif()
if (LLAMA_LTO)
include(CheckIPOSupported)
check_ipo_supported(RESULT result OUTPUT output)
if (result)
set(CMAKE_INTERPROCEDURAL_OPTIMIZATION TRUE)
else()
message(WARNING "IPO is not supported: ${output}")
endif()
endif()
# this version of Apple ld64 is buggy
execute_process(
COMMAND ${CMAKE_C_COMPILER} ${CMAKE_EXE_LINKER_FLAGS} -Wl,-v
ERROR_VARIABLE output
)
if (output MATCHES "dyld-1015\.7")
add_compile_definitions(HAVE_BUGGY_APPLE_LINKER)
endif()
# Architecture specific
# TODO: probably these flags need to be tweaked on some architectures
# feel free to update the Makefile for your architecture and send a pull request or issue
message(STATUS "CMAKE_SYSTEM_PROCESSOR: ${CMAKE_SYSTEM_PROCESSOR}")
if (MSVC)
string(TOLOWER "${CMAKE_GENERATOR_PLATFORM}" CMAKE_GENERATOR_PLATFORM_LWR)
message(STATUS "CMAKE_GENERATOR_PLATFORM: ${CMAKE_GENERATOR_PLATFORM}")
else ()
set(CMAKE_GENERATOR_PLATFORM_LWR "")
endif ()
if (NOT MSVC)
if (LLAMA_STATIC)
add_link_options(-static)
if (MINGW)
add_link_options(-static-libgcc -static-libstdc++)
endif()
endif()
if (LLAMA_GPROF)
add_compile_options(-pg)
endif()
endif()
if ((${CMAKE_SYSTEM_PROCESSOR} MATCHES "arm") OR (${CMAKE_SYSTEM_PROCESSOR} MATCHES "aarch64") OR ("${CMAKE_GENERATOR_PLATFORM_LWR}" MATCHES "arm64"))
message(STATUS "ARM detected")
if (MSVC)
add_compile_definitions(__ARM_NEON)
add_compile_definitions(__ARM_FEATURE_FMA)
add_compile_definitions(__ARM_FEATURE_DOTPROD)
# add_compile_definitions(__ARM_FEATURE_FP16_VECTOR_ARITHMETIC) # MSVC doesn't support vdupq_n_f16, vld1q_f16, vst1q_f16
add_compile_definitions(__aarch64__) # MSVC defines _M_ARM64 instead
else()
check_cxx_compiler_flag(-mfp16-format=ieee COMPILER_SUPPORTS_FP16_FORMAT_I3E)
if (NOT "${COMPILER_SUPPORTS_FP16_FORMAT_I3E}" STREQUAL "")
add_compile_options(-mfp16-format=ieee)
endif()
if (${CMAKE_SYSTEM_PROCESSOR} MATCHES "armv6")
# Raspberry Pi 1, Zero
add_compile_options(-mfpu=neon-fp-armv8 -mno-unaligned-access)
endif()
if (${CMAKE_SYSTEM_PROCESSOR} MATCHES "armv7")
# Raspberry Pi 2
add_compile_options(-mfpu=neon-fp-armv8 -mno-unaligned-access -funsafe-math-optimizations)
endif()
if (${CMAKE_SYSTEM_PROCESSOR} MATCHES "armv8")
# Raspberry Pi 3, 4, Zero 2 (32-bit)
add_compile_options(-mno-unaligned-access)
endif()
endif()
elseif (${CMAKE_SYSTEM_PROCESSOR} MATCHES "^(x86_64|i686|AMD64)$" OR "${CMAKE_GENERATOR_PLATFORM_LWR}" MATCHES "^(x86_64|i686|amd64|x64)$" )
message(STATUS "x86 detected")
if (MSVC)
# instruction set detection for MSVC only
if (LLAMA_NATIVE)
include(cmake/FindSIMD.cmake)
endif ()
if (LLAMA_AVX512)
add_compile_options($<$<COMPILE_LANGUAGE:C>:/arch:AVX512>)
add_compile_options($<$<COMPILE_LANGUAGE:CXX>:/arch:AVX512>)
# MSVC has no compile-time flags enabling specific
# AVX512 extensions, neither it defines the
# macros corresponding to the extensions.
# Do it manually.
if (LLAMA_AVX512_VBMI)
add_compile_definitions($<$<COMPILE_LANGUAGE:C>:__AVX512VBMI__>)
add_compile_definitions($<$<COMPILE_LANGUAGE:CXX>:__AVX512VBMI__>)
endif()
if (LLAMA_AVX512_VNNI)
add_compile_definitions($<$<COMPILE_LANGUAGE:C>:__AVX512VNNI__>)
add_compile_definitions($<$<COMPILE_LANGUAGE:CXX>:__AVX512VNNI__>)
endif()
elseif (LLAMA_AVX2)
add_compile_options($<$<COMPILE_LANGUAGE:C>:/arch:AVX2>)
add_compile_options($<$<COMPILE_LANGUAGE:CXX>:/arch:AVX2>)
elseif (LLAMA_AVX)
add_compile_options($<$<COMPILE_LANGUAGE:C>:/arch:AVX>)
add_compile_options($<$<COMPILE_LANGUAGE:CXX>:/arch:AVX>)
endif()
else()
if (LLAMA_NATIVE)
add_compile_options(-march=native)
endif()
if (LLAMA_F16C)
add_compile_options(-mf16c)
endif()
if (LLAMA_FMA)
add_compile_options(-mfma)
endif()
if (LLAMA_AVX)
add_compile_options(-mavx)
endif()
if (LLAMA_AVX2)
add_compile_options(-mavx2)
endif()
if (LLAMA_AVX512)
add_compile_options(-mavx512f)
add_compile_options(-mavx512bw)
endif()
if (LLAMA_AVX512_VBMI)
add_compile_options(-mavx512vbmi)
endif()
if (LLAMA_AVX512_VNNI)
add_compile_options(-mavx512vnni)
endif()
endif()
elseif (${CMAKE_SYSTEM_PROCESSOR} MATCHES "ppc64")
message(STATUS "PowerPC detected")
add_compile_options(-mcpu=native -mtune=native)
#TODO: Add targets for Power8/Power9 (Altivec/VSX) and Power10(MMA) and query for big endian systems (ppc64/le/be)
else()
message(STATUS "Unknown architecture")
endif()
#
# POSIX conformance
#
# clock_gettime came in POSIX.1b (1993)
# CLOCK_MONOTONIC came in POSIX.1-2001 / SUSv3 as optional
# posix_memalign came in POSIX.1-2001 / SUSv3
# M_PI is an XSI extension since POSIX.1-2001 / SUSv3, came in XPG1 (1985)
add_compile_definitions(_XOPEN_SOURCE=600)
# Somehow in OpenBSD whenever POSIX conformance is specified
# some string functions rely on locale_t availability,
# which was introduced in POSIX.1-2008, forcing us to go higher
if (CMAKE_SYSTEM_NAME MATCHES "OpenBSD")
remove_definitions(-D_XOPEN_SOURCE=600)
add_compile_definitions(_XOPEN_SOURCE=700)
endif()
# Data types, macros and functions related to controlling CPU affinity and
# some memory allocation are available on Linux through GNU extensions in libc
if (CMAKE_SYSTEM_NAME MATCHES "Linux")
add_compile_definitions(_GNU_SOURCE)
endif()
# RLIMIT_MEMLOCK came in BSD, is not specified in POSIX.1,
# and on macOS its availability depends on enabling Darwin extensions
# similarly on DragonFly, enabling BSD extensions is necessary
if (
CMAKE_SYSTEM_NAME MATCHES "Darwin" OR
CMAKE_SYSTEM_NAME MATCHES "iOS" OR
CMAKE_SYSTEM_NAME MATCHES "tvOS" OR
CMAKE_SYSTEM_NAME MATCHES "DragonFly"
)
add_compile_definitions(_DARWIN_C_SOURCE)
endif()
# alloca is a non-standard interface that is not visible on BSDs when
# POSIX conformance is specified, but not all of them provide a clean way
# to enable it in such cases
if (CMAKE_SYSTEM_NAME MATCHES "FreeBSD")
add_compile_definitions(__BSD_VISIBLE)
endif()
if (CMAKE_SYSTEM_NAME MATCHES "NetBSD")
add_compile_definitions(_NETBSD_SOURCE)
endif()
if (CMAKE_SYSTEM_NAME MATCHES "OpenBSD")
add_compile_definitions(_BSD_SOURCE)
endif()
#
# libraries
#
# ggml
if (GGML_USE_CPU_HBM)
add_definitions(-DGGML_USE_CPU_HBM)
find_library(memkind memkind REQUIRED)
endif()
add_library(ggml OBJECT
ggml.c
ggml.h
ggml-alloc.c
ggml-alloc.h
ggml-backend.c
ggml-backend.h
ggml-quants.c
ggml-quants.h
${GGML_SOURCES_CUDA} ${GGML_HEADERS_CUDA}
${GGML_SOURCES_OPENCL} ${GGML_HEADERS_OPENCL}
${GGML_SOURCES_METAL} ${GGML_HEADERS_METAL}
${GGML_SOURCES_MPI} ${GGML_HEADERS_MPI}
${GGML_SOURCES_EXTRA} ${GGML_HEADERS_EXTRA}
)
target_include_directories(ggml PUBLIC . ${LLAMA_EXTRA_INCLUDES})
target_compile_features(ggml PUBLIC c_std_11) # don't bump
target_link_libraries(ggml PUBLIC Threads::Threads ${LLAMA_EXTRA_LIBS})
if (GGML_USE_CPU_HBM)
target_link_libraries(ggml PUBLIC memkind)
endif()
add_library(ggml_static STATIC $<TARGET_OBJECTS:ggml>)
if (BUILD_SHARED_LIBS)
set_target_properties(ggml PROPERTIES POSITION_INDEPENDENT_CODE ON)
add_library(ggml_shared SHARED $<TARGET_OBJECTS:ggml>)
target_link_libraries(ggml_shared PUBLIC Threads::Threads ${LLAMA_EXTRA_LIBS})
install(TARGETS ggml_shared LIBRARY)
endif()
# llama
add_library(llama
llama.cpp
llama.h
)
target_include_directories(llama PUBLIC .)
target_compile_features(llama PUBLIC cxx_std_11) # don't bump
target_link_libraries(llama PRIVATE
ggml
${LLAMA_EXTRA_LIBS}
)
if (BUILD_SHARED_LIBS)
set_target_properties(llama PROPERTIES POSITION_INDEPENDENT_CODE ON)
target_compile_definitions(llama PRIVATE LLAMA_SHARED LLAMA_BUILD)
if (LLAMA_METAL)
set_target_properties(llama PROPERTIES RESOURCE "${CMAKE_CURRENT_SOURCE_DIR}/ggml-metal.metal")
endif()
endif()
#
# install
#
include(GNUInstallDirs)
include(CMakePackageConfigHelpers)
set(LLAMA_INCLUDE_INSTALL_DIR ${CMAKE_INSTALL_INCLUDEDIR}
CACHE PATH "Location of header files")
set(LLAMA_LIB_INSTALL_DIR ${CMAKE_INSTALL_LIBDIR}
CACHE PATH "Location of library files")
set(LLAMA_BIN_INSTALL_DIR ${CMAKE_INSTALL_BINDIR}
CACHE PATH "Location of binary files")
set(LLAMA_BUILD_NUMBER ${BUILD_NUMBER})
set(LLAMA_BUILD_COMMIT ${BUILD_COMMIT})
set(LLAMA_INSTALL_VERSION 0.0.${BUILD_NUMBER})
get_directory_property(LLAMA_TRANSIENT_DEFINES COMPILE_DEFINITIONS)
configure_package_config_file(
${CMAKE_CURRENT_SOURCE_DIR}/scripts/LlamaConfig.cmake.in
${CMAKE_CURRENT_BINARY_DIR}/LlamaConfig.cmake
INSTALL_DESTINATION ${CMAKE_INSTALL_LIBDIR}/cmake/Llama
PATH_VARS LLAMA_INCLUDE_INSTALL_DIR
LLAMA_LIB_INSTALL_DIR
LLAMA_BIN_INSTALL_DIR )
write_basic_package_version_file(
${CMAKE_CURRENT_BINARY_DIR}/LlamaConfigVersion.cmake
VERSION ${LLAMA_INSTALL_VERSION}
COMPATIBILITY SameMajorVersion)
install(FILES ${CMAKE_CURRENT_BINARY_DIR}/LlamaConfig.cmake
${CMAKE_CURRENT_BINARY_DIR}/LlamaConfigVersion.cmake
DESTINATION ${CMAKE_INSTALL_LIBDIR}/cmake/Llama)
set(GGML_PUBLIC_HEADERS "ggml.h"
"${GGML_HEADERS_CUDA}" "${GGML_HEADERS_OPENCL}"
"${GGML_HEADERS_METAL}" "${GGML_HEADERS_MPI}" "${GGML_HEADERS_EXTRA}")
set_target_properties(ggml PROPERTIES PUBLIC_HEADER "${GGML_PUBLIC_HEADERS}")
install(TARGETS ggml PUBLIC_HEADER)
set_target_properties(llama PROPERTIES PUBLIC_HEADER ${CMAKE_CURRENT_SOURCE_DIR}/llama.h)
install(TARGETS llama LIBRARY PUBLIC_HEADER)
install(
FILES convert.py
PERMISSIONS
OWNER_READ
OWNER_WRITE
OWNER_EXECUTE
GROUP_READ
GROUP_EXECUTE
WORLD_READ
WORLD_EXECUTE
DESTINATION ${CMAKE_INSTALL_BINDIR})
install(
FILES convert-hf-to-powerinfer-gguf.py
PERMISSIONS
OWNER_READ
OWNER_WRITE
OWNER_EXECUTE
GROUP_READ
GROUP_EXECUTE
WORLD_READ
WORLD_EXECUTE
DESTINATION ${CMAKE_INSTALL_BINDIR})
if (LLAMA_METAL)
install(
FILES ggml-metal.metal
PERMISSIONS
OWNER_READ
OWNER_WRITE
GROUP_READ
WORLD_READ
DESTINATION ${CMAKE_INSTALL_BINDIR})
endif()
#
# programs, examples and tests
#
add_subdirectory(common)
if (LLAMA_BUILD_TESTS AND NOT CMAKE_JS_VERSION)
include(CTest)
add_subdirectory(tests)
endif ()
if (LLAMA_BUILD_EXAMPLES)
add_subdirectory(examples)
add_subdirectory(pocs)
endif()
================================================
FILE: LICENSE
================================================
MIT License
Copyright (c) 2023 Georgi Gerganov
Copyright (c) 2023 SJTU-IPADS
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE.
================================================
FILE: Package.swift
================================================
// swift-tools-version:5.5
import PackageDescription
#if arch(arm) || arch(arm64)
let platforms: [SupportedPlatform]? = [
.macOS(.v12),
.iOS(.v14),
.watchOS(.v4),
.tvOS(.v14)
]
let exclude: [String] = []
let resources: [Resource] = [
.process("ggml-metal.metal")
]
let additionalSources: [String] = ["ggml-metal.m"]
let additionalSettings: [CSetting] = [
.unsafeFlags(["-fno-objc-arc"]),
.define("GGML_USE_METAL")
]
#else
let platforms: [SupportedPlatform]? = nil
let exclude: [String] = ["ggml-metal.metal"]
let resources: [Resource] = []
let additionalSources: [String] = []
let additionalSettings: [CSetting] = []
#endif
let package = Package(
name: "llama",
platforms: platforms,
products: [
.library(name: "llama", targets: ["llama"]),
],
targets: [
.target(
name: "llama",
path: ".",
exclude: exclude,
sources: [
"ggml.c",
"llama.cpp",
"ggml-alloc.c",
"ggml-backend.c",
"ggml-quants.c",
] + additionalSources,
resources: resources,
publicHeadersPath: "spm-headers",
cSettings: [
.unsafeFlags(["-Wno-shorten-64-to-32", "-O3", "-DNDEBUG"]),
.define("GGML_USE_ACCELERATE")
// NOTE: NEW_LAPACK will required iOS version 16.4+
// We should consider add this in the future when we drop support for iOS 14
// (ref: ref: https://developer.apple.com/documentation/accelerate/1513264-cblas_sgemm?language=objc)
// .define("ACCELERATE_NEW_LAPACK"),
// .define("ACCELERATE_LAPACK_ILP64")
] + additionalSettings,
linkerSettings: [
.linkedFramework("Accelerate")
]
)
],
cxxLanguageStandard: .cxx11
)
================================================
FILE: README.md
================================================
# PowerInfer: Fast Large Language Model Serving with a Consumer-grade GPU
## TL;DR
PowerInfer is a CPU/GPU LLM inference engine leveraging **activation locality** for your device.
<a href="https://trendshift.io/repositories/6186" target="_blank"><img src="https://trendshift.io/api/badge/repositories/6186" alt="SJTU-IPADS%2FPowerInfer | Trendshift" style="width: 250px; height: 55px;" width="250" height="55"/></a>
[](https://opensource.org/licenses/MIT)
[Project Kanban](https://github.com/orgs/SJTU-IPADS/projects/2/views/2)
## Latest News 🔥
- [2026/1/5] We released **[Tiiny AI Pocket Lab](https://tiiny.ai/)**, the world's first pocket-size supercomputer. It runs GPT-OSS-120B (int4) locally at **20 tokens/s**. Featured at CES 2026.
- [2025/7/27] We released [SmallThinker-21BA3B-Instruct](https://huggingface.co/PowerInfer/SmallThinker-21BA3B-Instruct) and [SmallThinker-4BA0.6B-Instruct](https://huggingface.co/PowerInfer/SmallThinker-4BA0.6B-Instruct). We also released a corresponding framework for efficient [on-device inference](./smallthinker/README.md).
- [2024/6/11] We are thrilled to introduce [PowerInfer-2](https://arxiv.org/abs/2406.06282), our highly optimized inference framework designed specifically for smartphones. With TurboSparse-Mixtral-47B, it achieves an impressive speed of 11.68 tokens per second, which is up to 22 times faster than other state-of-the-art frameworks.
- [2024/6/11] We are thrilled to present [Turbo Sparse](https://arxiv.org/abs/2406.05955), our TurboSparse models for fast inference. With just $0.1M, we sparsified the original Mistral and Mixtral model to nearly 90% sparsity while maintaining superior performance! For a Mixtral-level model, our TurboSparse-Mixtral activates only **4B** parameters!
- [2024/5/20] **Competition Recruitment: CCF-TCArch Customized Computing Challenge 2024**. The CCF TCARCH CCC is a national competition organized by the Technical Committee on Computer Architecture (TCARCH) of the China Computer Federation (CCF). This year's competition aims to optimize the PowerInfer inference engine using the open-source ROCm/HIP. More information about the competition can be found [here](https://ccf-tcarch-ccc.github.io/2024/).
- [2024/5/17] We now provide support for AMD devices with ROCm.
- [2024/3/28] We are trilled to present [Bamboo LLM](https://github.com/SJTU-IPADS/Bamboo) that achieves both top-level performance and unparalleled speed with PowerInfer! Experience it with Bamboo-7B [Base](https://huggingface.co/PowerInfer/Bamboo-base-v0.1-gguf) / [DPO](https://huggingface.co/PowerInfer/Bamboo-DPO-v0.1-gguf).
- [2024/3/14] We supported ProSparse Llama 2 ([7B](https://huggingface.co/SparseLLM/prosparse-llama-2-7b)/[13B](https://huggingface.co/SparseLLM/prosparse-llama-2-13b)), ReLU models with ~90% sparsity, matching original Llama 2's performance (Thanks THUNLP & ModelBest)!
- [2024/1/11] We supported Windows with GPU inference!
- [2023/12/24] We released an online [gradio demo](https://powerinfer-gradio.vercel.app/) for Falcon(ReLU)-40B-FP16!
- [2023/12/19] We officially released PowerInfer!
## Demo 🔥
https://github.com/SJTU-IPADS/PowerInfer/assets/34213478/fe441a42-5fce-448b-a3e5-ea4abb43ba23
PowerInfer v.s. llama.cpp on a single RTX 4090(24G) running Falcon(ReLU)-40B-FP16 with a 11x speedup!
<sub>Both PowerInfer and llama.cpp were running on the same hardware and fully utilized VRAM on RTX 4090.</sub>
> [!NOTE]
> **Live Demo Online⚡️**
>
> Try out our [Gradio server](https://powerinfer-gradio.vercel.app/) hosting Falcon(ReLU)-40B-FP16 on a RTX 4090!
>
> <sub>Experimental and without warranties 🚧</sub>
## Abstract
We introduce PowerInfer, a high-speed Large Language Model (LLM) inference engine on a personal computer (PC)
equipped with a single consumer-grade GPU. The key underlying the design of PowerInfer is exploiting the high **locality**
inherent in LLM inference, characterized by a power-law distribution in neuron activation.
This distribution indicates that a small subset of neurons, termed hot neurons, are consistently activated
across inputs, while the majority, cold neurons, vary based on specific inputs.
PowerInfer exploits such an insight to design a GPU-CPU hybrid inference engine:
hot-activated neurons are preloaded onto the GPU for fast access, while cold-activated neurons are computed
on the CPU, thus significantly reducing GPU memory demands and CPU-GPU data transfers.
PowerInfer further integrates adaptive predictors and neuron-aware sparse operators,
optimizing the efficiency of neuron activation and computational sparsity.
Evaluation shows that PowerInfer attains an average token generation rate of 13.20 tokens/s, with a peak of 29.08 tokens/s, across various LLMs (including OPT-175B) on a single NVIDIA RTX 4090 GPU,
only 18\% lower than that achieved by a top-tier server-grade A100 GPU.
This significantly outperforms llama.cpp by up to 11.69x while retaining model accuracy.
## Features
PowerInfer is a high-speed and easy-to-use inference engine for deploying LLMs locally.
PowerInfer is fast with:
- **Locality-centric design**: Utilizes sparse activation and 'hot'/'cold' neuron concept for efficient LLM inference, ensuring high speed with lower resource demands.
- **Hybrid CPU/GPU Utilization**: Seamlessly integrates memory/computation capabilities of CPU and GPU for a balanced workload and faster processing.
PowerInfer is flexible and easy to use with:
- **Easy Integration**: Compatible with popular [ReLU-sparse models](https://huggingface.co/SparseLLM).
- **Local Deployment Ease**: Designed and deeply optimized for local deployment on consumer-grade hardware, enabling low-latency LLM inference and serving on a single GPU.
- **Backward Compatibility**: While distinct from llama.cpp, you can make use of most of `examples/` the same way as llama.cpp such as server and batched generation. PowerInfer also supports inference with llama.cpp's model weights for compatibility purposes, but there will be no performance gain.
You can use these models with PowerInfer today:
- Falcon-40B
- Llama2 family
- ProSparse Llama2 family
- Bamboo-7B
We have tested PowerInfer on the following platforms:
- x86-64 CPUs with AVX2 instructions, with or without NVIDIA GPUs, under **Linux**.
- x86-64 CPUs with AVX2 instructions, with or without NVIDIA GPUs, under **Windows**.
- Apple M Chips (CPU only) on **macOS**. (As we do not optimize for Mac, the performance improvement is not significant now.)
And new features coming soon:
- Metal backend for sparse inference on macOS
Please kindly refer to our [Project Kanban](https://github.com/orgs/SJTU-IPADS/projects/2/views/2) for our current focus of development.
## Getting Started
- [Installation](#setup-and-installation)
- [Model Weights](#model-weights)
- [Inference](#inference)
## Setup and Installation
### Pre-requisites
PowerInfer requires the following dependencies:
- CMake (3.17+)
- Python (3.8+) and pip (19.3+), for converting model weights and automatic FFN offloading
### Get the Code
```bash
git clone https://github.com/Tiiny-AI/PowerInfer
cd PowerInfer
pip install -r requirements.txt # install Python helpers' dependencies
```
### Build
In order to build PowerInfer you have two different options. These commands are supposed to be run from the root directory of the project.
Using `CMake`(3.17+):
* If you have an NVIDIA GPU:
```bash
cmake -S . -B build -DLLAMA_CUBLAS=ON
cmake --build build --config Release
```
* If you have an AMD GPU:
```bash
# Replace '1100' to your card architecture name, you can get it by rocminfo
CC=/opt/rocm/llvm/bin/clang CXX=/opt/rocm/llvm/bin/clang++ cmake -S . -B build -DLLAMA_HIPBLAS=ON -DAMDGPU_TARGETS=gfx1100
cmake --build build --config Release
```
* If you have just CPU:
```bash
cmake -S . -B build
cmake --build build --config Release
```
## Model Weights
PowerInfer models are stored in a special format called *PowerInfer GGUF* based on GGUF format, consisting of both LLM weights and predictor weights.
### Download PowerInfer GGUF via Hugging Face
You can obtain PowerInfer GGUF weights at `*.powerinfer.gguf` as well as profiled model activation statistics for 'hot'-neuron offloading from each Hugging Face repo below.
| Base Model | PowerInfer GGUF |
| --------------------- | ------------------------------------------------------------------------------------------------------------- |
| LLaMA(ReLU)-2-7B | [PowerInfer/ReluLLaMA-7B-PowerInfer-GGUF](https://huggingface.co/PowerInfer/ReluLLaMA-7B-PowerInfer-GGUF) |
| LLaMA(ReLU)-2-13B | [PowerInfer/ReluLLaMA-13B-PowerInfer-GGUF](https://huggingface.co/PowerInfer/ReluLLaMA-13B-PowerInfer-GGUF) |
| Falcon(ReLU)-40B | [PowerInfer/ReluFalcon-40B-PowerInfer-GGUF](https://huggingface.co/PowerInfer/ReluFalcon-40B-PowerInfer-GGUF) |
| LLaMA(ReLU)-2-70B | [PowerInfer/ReluLLaMA-70B-PowerInfer-GGUF](https://huggingface.co/PowerInfer/ReluLLaMA-70B-PowerInfer-GGUF) |
| ProSparse-LLaMA-2-7B | [PowerInfer/ProSparse-LLaMA-2-7B-GGUF](https://huggingface.co/PowerInfer/prosparse-llama-2-7b-gguf) |
| ProSparse-LLaMA-2-13B | [PowerInfer/ProSparse-LLaMA-2-13B-GGUF](https://huggingface.co/PowerInfer/prosparse-llama-2-13b-gguf) |
| Bamboo-base-7B 🌟 | [PowerInfer/Bamboo-base-v0.1-gguf](https://huggingface.co/PowerInfer/Bamboo-base-v0.1-gguf) |
| Bamboo-DPO-7B 🌟 | [PowerInfer/Bamboo-DPO-v0.1-gguf](https://huggingface.co/PowerInfer/Bamboo-DPO-v0.1-gguf) |
We recommend using [`huggingface-cli`](https://huggingface.co/docs/huggingface_hub/guides/cli) to download the whole model repo. For example, the following command will download [PowerInfer/ReluLLaMA-7B-PowerInfer-GGUF](https://huggingface.co/PowerInfer/ReluLLaMA-7B-PowerInfer-GGUF) into the `./ReluLLaMA-7B` directory.
```shell
huggingface-cli download --resume-download --local-dir ReluLLaMA-7B --local-dir-use-symlinks False PowerInfer/ReluLLaMA-7B-PowerInfer-GGUF
```
As such, PowerInfer can automatically make use of the following directory structure for feature-complete model offloading:
```
.
├── *.powerinfer.gguf (Unquantized PowerInfer model)
├── *.q4.powerinfer.gguf (INT4 quantized PowerInfer model, if available)
├── activation (Profiled activation statistics for fine-grained FFN offloading)
│ ├── activation_x.pt (Profiled activation statistics for layer x)
│ └── ...
├── *.[q4].powerinfer.gguf.generated.gpuidx (Generated GPU index at runtime for corresponding model)
```
### Convert from Original Model Weights + Predictor Weights
Hugging Face limits single model weight to 50GiB. For unquantized models >= 40B, you can convert PowerInfer GGUF from the original model weights and predictor weights obtained from Hugging Face.
| Base Model | Original Model | Predictor |
| --------------------- | ----------------------------------------------------------------------------------------- | --------------------------------------------------------------------------------------------------------------- |
| LLaMA(ReLU)-2-7B | [SparseLLM/ReluLLaMA-7B](https://huggingface.co/SparseLLM/ReluLLaMA-7B) | [PowerInfer/ReluLLaMA-7B-Predictor](https://huggingface.co/PowerInfer/ReluLLaMA-7B-Predictor) |
| LLaMA(ReLU)-2-13B | [SparseLLM/ReluLLaMA-13B](https://huggingface.co/SparseLLM/ReluLLaMA-13B) | [PowerInfer/ReluLLaMA-13B-Predictor](https://huggingface.co/PowerInfer/ReluLLaMA-13B-Predictor) |
| Falcon(ReLU)-40B | [SparseLLM/ReluFalcon-40B](https://huggingface.co/SparseLLM/ReluFalcon-40B) | [PowerInfer/ReluFalcon-40B-Predictor](https://huggingface.co/PowerInfer/ReluFalcon-40B-Predictor) |
| LLaMA(ReLU)-2-70B | [SparseLLM/ReluLLaMA-70B](https://huggingface.co/SparseLLM/ReluLLaMA-70B) | [PowerInfer/ReluLLaMA-70B-Predictor](https://huggingface.co/PowerInfer/ReluLLaMA-70B-Predictor) |
| ProSparse-LLaMA-2-7B | [SparseLLM/ProSparse-LLaMA-2-7B](https://huggingface.co/SparseLLM/prosparse-llama-2-7b) | [PowerInfer/ProSparse-LLaMA-2-7B-Predictor](https://huggingface.co/PowerInfer/prosparse-llama-2-7b-predictor) |
| ProSparse-LLaMA-2-13B | [SparseLLM/ProSparse-LLaMA-2-13B](https://huggingface.co/SparseLLM/prosparse-llama-2-13b) | [PowerInfer/ProSparse-LLaMA-2-13B-Predictor](https://huggingface.co/PowerInfer/prosparse-llama-2-13b-predictor) |
| Bamboo-base-7B 🌟 | [PowerInfer/Bamboo-base-v0.1](https://huggingface.co/PowerInfer/Bamboo-base-v0_1) | [PowerInfer/Bamboo-base-v0.1-predictor](https://huggingface.co/PowerInfer/Bamboo-base-v0.1-predictor) |
| Bamboo-DPO-7B 🌟 | [PowerInfer/Bamboo-DPO-v0.1](https://huggingface.co/PowerInfer/Bamboo-DPO-v0_1) | [PowerInfer/Bamboo-DPO-v0.1-predictor](https://huggingface.co/PowerInfer/Bamboo-DPO-v0.1-predictor) |
You can use the following command to convert the original model weights and predictor weights to PowerInfer GGUF:
```bash
# make sure that you have done `pip install -r requirements.txt`
python convert.py --outfile /PATH/TO/POWERINFER/GGUF/REPO/MODELNAME.powerinfer.gguf /PATH/TO/ORIGINAL/MODEL /PATH/TO/PREDICTOR
# python convert.py --outfile ./ReluLLaMA-70B-PowerInfer-GGUF/llama-70b-relu.powerinfer.gguf ./SparseLLM/ReluLLaMA-70B ./PowerInfer/ReluLLaMA-70B-Predictor
```
For the same reason, we suggest keeping the same directory structure as PowerInfer GGUF repos after conversion.
<details>
<summary>Convert Original models into dense GGUF models(compatible with llama.cpp)</summary>
```bash
python convert-dense.py --outfile /PATH/TO/DENSE/GGUF/REPO/MODELNAME.gguf /PATH/TO/ORIGINAL/MODEL
# python convert-dense.py --outfile ./Bamboo-DPO-v0.1-gguf/bamboo-7b-dpo-v0.1.gguf --outtype f16 ./Bamboo-DPO-v0.1
```
Please note that the generated dense GGUF models might not work properly with llama.cpp, as we have altered activation functions (for ReluLLaMA and Prosparse models), or the model architecture (for Bamboo models). The dense GGUF models generated by convert-dense.py can be used for PowerInfer in dense inference mode, but might not work properly with llama.cpp.
</details>
## Inference
For CPU-only and CPU-GPU hybrid inference with all available VRAM, you can use the following instructions to run PowerInfer:
```bash
./build/bin/main -m /PATH/TO/MODEL -n $output_token_count -t $thread_num -p $prompt
# e.g.: ./build/bin/main -m ./ReluFalcon-40B-PowerInfer-GGUF/falcon-40b-relu.q4.powerinfer.gguf -n 128 -t 8 -p "Once upon a time"
# For Windows: .\build\bin\Release\main.exe -m .\ReluFalcon-40B-PowerInfer-GGUF\falcon-40b-relu.q4.powerinfer.gguf -n 128 -t 8 -p "Once upon a time"
```
If you want to limit the VRAM usage of GPU:
```bash
./build/bin/main -m /PATH/TO/MODEL -n $output_token_count -t $thread_num -p $prompt --vram-budget $vram_gb
# e.g.: ./build/bin/main -m ./ReluLLaMA-7B-PowerInfer-GGUF/llama-7b-relu.powerinfer.gguf -n 128 -t 8 -p "Once upon a time" --vram-budget 8
# For Windows: .\build\bin\Release\main.exe -m .\ReluLLaMA-7B-PowerInfer-GGUF\llama-7b-relu.powerinfer.gguf -n 128 -t 8 -p "Once upon a time" --vram-budget 8
```
Under CPU-GPU hybrid inference, PowerInfer will automatically offload all dense activation blocks to GPU, then split FFN and offload to GPU if possible.
<details>
<summary>Dense inference mode (limited support)</summary>
If you want to run PowerInfer to infer with the dense variants of the PowerInfer model family, you can use similarly as llama.cpp does:
```bash
./build/bin/main -m /PATH/TO/DENSE/MODEL -n $output_token_count -t $thread_num -p $prompt -ngl $num_gpu_layers
# e.g.: ./build/bin/main -m ./Bamboo-base-v0.1-gguf/bamboo-7b-v0.1.gguf -n 128 -t 8 -p "Once upon a time" -ngl 12
```
So is the case for other `examples/` like `server` and `batched_generation`. Please note that the dense inference mode is not a "compatible mode" for all models. We have altered activation functions (for ReluLLaMA and Prosparse models) in this mode to match with our model family.
</details>
## Serving, Perplexity Evaluation, and more applications
PowerInfer supports serving and batched generation with the same instructions as llama.cpp. Generally, you can use the same command as llama.cpp, except for `-ngl` argument which has been replaced by `--vram-budget` for PowerInfer. Please refer to the detailed instructions in each `examples/` directory. For example:
- [Serving](./examples/server/README.md)
- [Perplexity Evaluation](./examples/perplexity/README.md)
- [Batched Generation](./examples/batched/README.md)
## Quantization
PowerInfer has optimized quantization support for INT4(`Q4_0`) models. You can use the following instructions to quantize PowerInfer GGUF model:
```bash
./build/bin/quantize /PATH/TO/MODEL /PATH/TO/OUTPUT/QUANTIZED/MODEL Q4_0
# e.g.: ./build/bin/quantize ./ReluFalcon-40B-PowerInfer-GGUF/falcon-40b-relu.powerinfer.gguf ./ReluFalcon-40B-PowerInfer-GGUF/falcon-40b-relu.q4.powerinfer.gguf Q4_0
# For Windows: .\build\bin\Release\quantize.exe .\ReluFalcon-40B-PowerInfer-GGUF\falcon-40b-relu.powerinfer.gguf .\ReluFalcon-40B-PowerInfer-GGUF\falcon-40b-relu.q4.powerinfer.gguf Q4_0
```
Then you can use the quantized model for inference with PowerInfer with the same instructions as above.
## More Documentation
- [Performance troubleshooting](./docs/token_generation_performance_tips.md)
## Evaluation
We evaluated PowerInfer vs. llama.cpp on a single RTX 4090(24G) with a series of FP16 ReLU models under inputs of length 64, and the results are shown below. PowerInfer achieves up to 11x speedup on Falcon 40B and up to 3x speedup on Llama 2 70B.
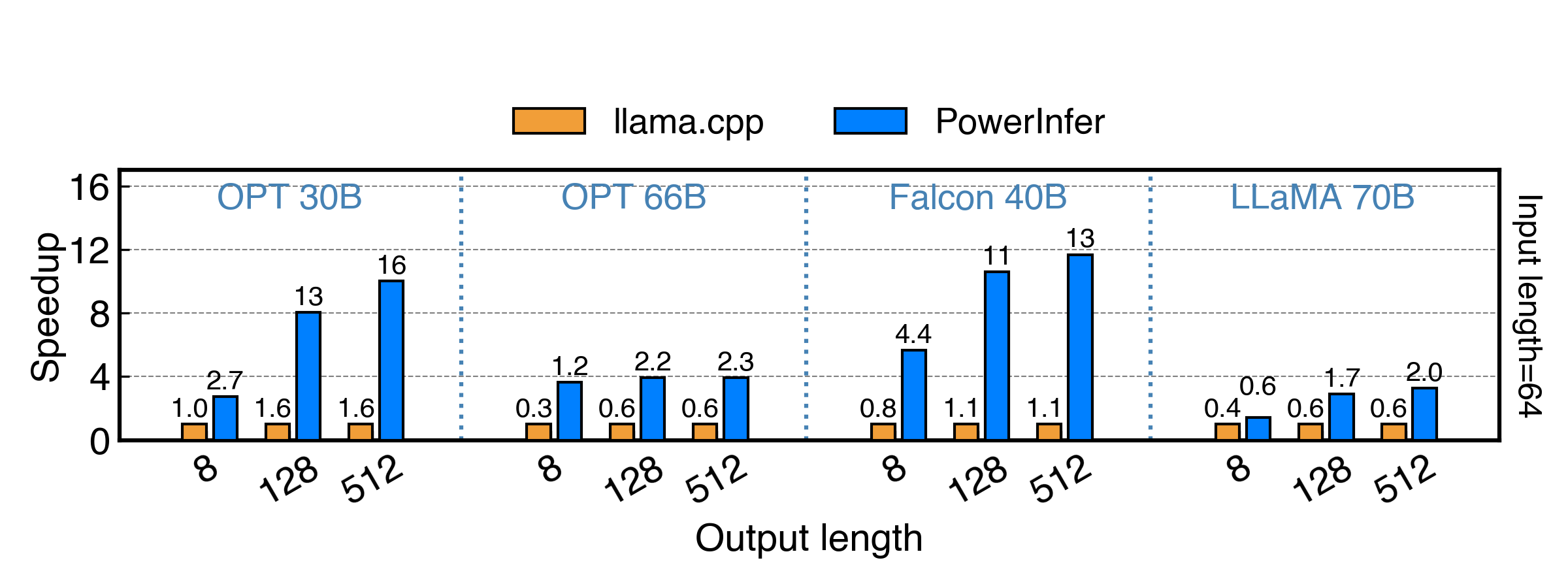
<sub>The X axis indicates the output length, and the Y axis represents the speedup compared with llama.cpp. The number above each bar indicates the end-to-end generation speed (total prompting + generation time / total tokens generated, in tokens/s).</sub>
We also evaluated PowerInfer on a single RTX 2080Ti(11G) with INT4 ReLU models under inputs of length 8, and the results are illustrated in the same way as above. PowerInfer achieves up to 8x speedup on Falcon 40B and up to 3x speedup on Llama 2 70B.
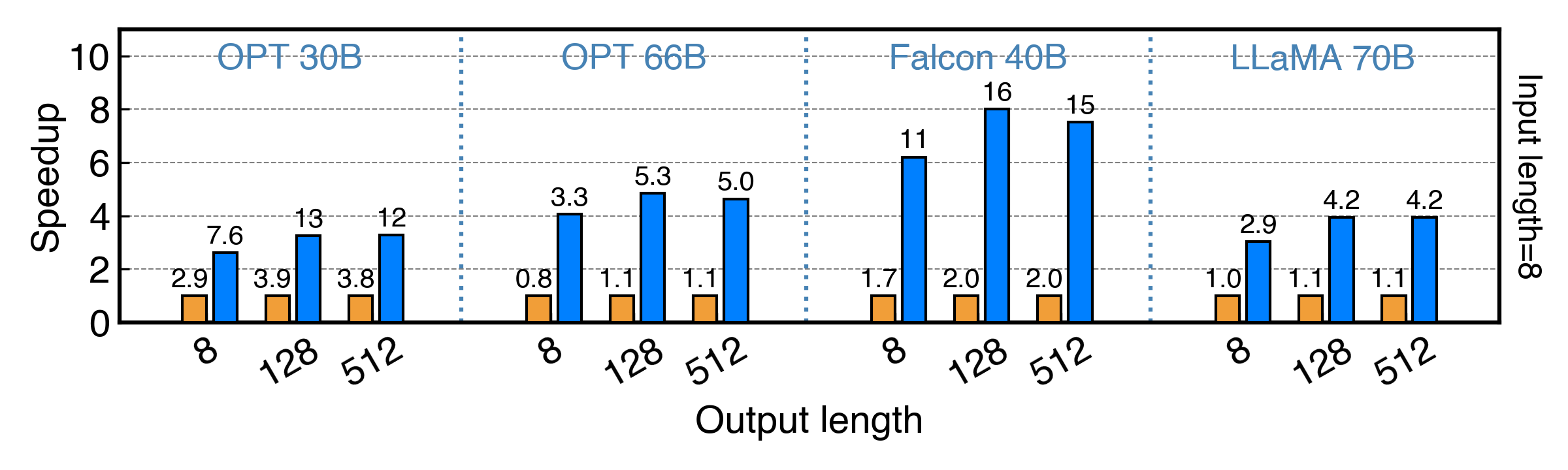
Please refer to our [paper](https://ipads.se.sjtu.edu.cn/_media/publications/powerinfer-20231219.pdf) for more evaluation details.
## FAQs
1. What if I encountered `CUDA_ERROR_OUT_OF_MEMORY`?
- You can try to run with `--reset-gpu-index` argument to rebuild the GPU index for this model to avoid any stale cache.
- Due to our current implementation, model offloading might not be as accurate as expected. You can try with `--vram-budget` with a slightly lower value or `--disable-gpu-index` to disable FFN offloading.
2. Does PowerInfer support mistral, original llama, Qwen, ...?
- Now we only support models with ReLU/ReGLU/Squared ReLU activation function. So we do not support these models now. It's worth mentioning that a [paper](https://arxiv.org/pdf/2310.04564.pdf) has demonstrated that using the ReLU/ReGLU activation function has a negligible impact on convergence and performance.
3. Why is there a noticeable downgrade in the performance metrics of our current ReLU model, particularly the 70B model?
- In contrast to the typical requirement of around 2T tokens for LLM training, our model's fine-tuning was conducted with only 5B tokens. This insufficient retraining has resulted in the model's inability to regain its original performance. We are actively working on updating to a more capable model, so please stay tuned.
4. What if...
- Issues are welcomed! Please feel free to open an issue and attach your running environment and running parameters. We will try our best to help you.
## TODOs
We will release the code and data in the following order, please stay tuned!
- [x] Release core code of PowerInfer, supporting Llama-2, Falcon-40B.
- [x] Support ~~Mistral-7B~~ (Bamboo-7B)
- [x] Support Windows
- [ ] Support text-generation-webui
- [x] Release perplexity evaluation code
- [ ] Support Metal for Mac
- [ ] Release code for OPT models
- [ ] Release predictor training code
- [x] Support online split for FFN network
- [ ] Support Multi-GPU
## Paper and Citation
More technical details can be found in our [paper](https://ipads.se.sjtu.edu.cn/_media/publications/powerinfer-20231219.pdf).
If you find PowerInfer useful or relevant to your project and research, please kindly cite our paper:
```bibtex
@misc{song2023powerinfer,
title={PowerInfer: Fast Large Language Model Serving with a Consumer-grade GPU},
author={Yixin Song and Zeyu Mi and Haotong Xie and Haibo Chen},
year={2023},
eprint={2312.12456},
archivePrefix={arXiv},
primaryClass={cs.LG}
}
```
## Acknowledgement
We are thankful for the easily modifiable operator library [ggml](https://github.com/ggerganov/ggml) and execution runtime provided by [llama.cpp](https://github.com/ggerganov/llama.cpp). We also extend our gratitude to [THUNLP](https://nlp.csai.tsinghua.edu.cn/) for their support of ReLU-based sparse models. We also appreciate the research of [Deja Vu](https://proceedings.mlr.press/v202/liu23am.html), which inspires PowerInfer.
================================================
FILE: SHA256SUMS
================================================
700df0d3013b703a806d2ae7f1bfb8e59814e3d06ae78be0c66368a50059f33d models/7B/consolidated.00.pth
666a4bb533b303bdaf89e1b6a3b6f93535d868de31d903afdc20983dc526c847 models/7B/ggml-model-f16.bin
ec2f2d1f0dfb73b72a4cbac7fa121abbe04c37ab327125a38248f930c0f09ddf models/7B/ggml-model-q4_0.bin
ffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffff models/7B/ggml-model-q4_1.bin
ffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffff models/7B/ggml-model-q5_0.bin
ffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffff models/7B/ggml-model-q5_1.bin
7e89e242ddc0dd6f060b43ca219ce8b3e8f08959a72cb3c0855df8bb04d46265 models/7B/params.json
745bf4e29a4dd6f411e72976d92b452da1b49168a4f41c951cfcc8051823cf08 models/13B/consolidated.00.pth
d5ccbcc465c71c0de439a5aeffebe8344c68a519bce70bc7f9f92654ee567085 models/13B/consolidated.01.pth
2b206e9b21fb1076f11cafc624e2af97c9e48ea09312a0962153acc20d45f808 models/13B/ggml-model-f16.bin
fad169e6f0f575402cf75945961cb4a8ecd824ba4da6be2af831f320c4348fa5 models/13B/ggml-model-q4_0.bin
ffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffff models/13B/ggml-model-q4_1.bin
ffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffff models/13B/ggml-model-q5_0.bin
ffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffff models/13B/ggml-model-q5_1.bin
4ab77bec4d4405ccb66a97b282574c89a94417e3c32e5f68f37e2876fc21322f models/13B/params.json
e23294a58552d8cdec5b7e8abb87993b97ea6eced4178ff2697c02472539d067 models/30B/consolidated.00.pth
4e077b7136c7ae2302e954860cf64930458d3076fcde9443f4d0e939e95903ff models/30B/consolidated.01.pth
24a87f01028cbd3a12de551dcedb712346c0b5cbdeff1454e0ddf2df9b675378 models/30B/consolidated.02.pth
1adfcef71420886119544949767f6a56cb6339b4d5fcde755d80fe68b49de93b models/30B/consolidated.03.pth
7e1b524061a9f4b27c22a12d6d2a5bf13b8ebbea73e99f218809351ed9cf7d37 models/30B/ggml-model-f16.bin
d2a441403944819492ec8c2002cc36fa38468149bfb4b7b4c52afc7bd9a7166d models/30B/ggml-model-q4_0.bin
ffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffff models/30B/ggml-model-q4_1.bin
ffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffff models/30B/ggml-model-q5_0.bin
ffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffff models/30B/ggml-model-q5_1.bin
2c07118ea98d69dbe7810d88520e30288fa994751b337f8fca02b171955f44cb models/30B/params.json
135c563f6b3938114458183afb01adc9a63bef3d8ff7cccc3977e5d3664ecafe models/65B/consolidated.00.pth
9a600b37b19d38c7e43809485f70d17d1dc12206c07efa83bc72bb498a568bde models/65B/consolidated.01.pth
e7babf7c5606f165a3756f527cb0fedc4f83e67ef1290391e52fb1cce5f26770 models/65B/consolidated.02.pth
73176ffb426b40482f2aa67ae1217ef79fbbd1fff5482bae5060cdc5a24ab70e models/65B/consolidated.03.pth
882e6431d0b08a8bc66261a0d3607da21cbaeafa96a24e7e59777632dbdac225 models/65B/consolidated.04.pth
a287c0dfe49081626567c7fe87f74cce5831f58e459b427b5e05567641f47b78 models/65B/consolidated.05.pth
72b4eba67a1a3b18cb67a85b70f8f1640caae9b40033ea943fb166bd80a7b36b models/65B/consolidated.06.pth
d27f5b0677d7ff129ceacd73fd461c4d06910ad7787cf217b249948c3f3bc638 models/65B/consolidated.07.pth
60758f2384d74e423dffddfd020ffed9d3bb186ebc54506f9c4a787d0f5367b0 models/65B/ggml-model-f16.bin
cde053439fa4910ae454407e2717cc46cc2c2b4995c00c93297a2b52e790fa92 models/65B/ggml-model-q4_0.bin
ffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffff models/65B/ggml-model-q4_1.bin
ffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffff models/65B/ggml-model-q5_0.bin
ffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffff models/65B/ggml-model-q5_1.bin
999ed1659b469ccc2a941714c0a9656fa571d17c9f7c8c7589817ca90edef51b models/65B/params.json
9e556afd44213b6bd1be2b850ebbbd98f5481437a8021afaf58ee7fb1818d347 models/tokenizer.model
================================================
FILE: atomic_windows.h
================================================
/*
* C11 <stdatomic.h> emulation header
*
* PLEASE LICENSE, (C) 2022, Michael Clark <michaeljclark@mac.com>
*
* All rights to this work are granted for all purposes, with exception of
* author's implied right of copyright to defend the free use of this work.
*
* THE SOFTWARE IS PROVIDED "AS IS" AND THE AUTHOR DISCLAIMS ALL WARRANTIES
* WITH REGARD TO THIS SOFTWARE INCLUDING ALL IMPLIED WARRANTIES OF
* MERCHANTABILITY AND FITNESS. IN NO EVENT SHALL THE AUTHOR BE LIABLE FOR
* ANY SPECIAL, DIRECT, INDIRECT, OR CONSEQUENTIAL DAMAGES OR ANY DAMAGES
* WHATSOEVER RESULTING FROM LOSS OF USE, DATA OR PROFITS, WHETHER IN AN
* ACTION OF CONTRACT, NEGLIGENCE OR OTHER TORTIOUS ACTION, ARISING OUT OF
* OR IN CONNECTION WITH THE USE OR PERFORMANCE OF THIS SOFTWARE.
*/
#ifdef _WIN32
/*
* C11 <stdatomic.h> emulation
*
* This header can be included from C and uses C11 _Generic selection.
* This header requires MSVC flags: "/O2 /TC /std:c11 /volatile:iso".
*
* Note: some primitives may be missing and some primitives may haver
* stronger ordering than is required thus not produce optimal code,
* and some primitives may be buggy.
*/
#include <windows.h>
#include "winnt.h"
#define __concat2(x,y) x ## y
#define __concat3(x,y,z) x ## y ## z
#if UINTPTR_MAX == 0xFFFFFFFFFFFFFFFFull
#define __intptr __int64
#define __ptr i64
#elif UINTPTR_MAX == 0xFFFFFFFFu
#define __intptr __int32
#define __ptr i32
#else
#error unable to determine pointer width
#endif
#define _Atomic volatile
#define ATOMIC_BOOL_LOCK_FREE 1
#define ATOMIC_CHAR_LOCK_FREE 1
#define ATOMIC_SHORT_LOCK_FREE 1
#define ATOMIC_INT_LOCK_FREE 1
#define ATOMIC_LONG_LOCK_FREE 1
#define ATOMIC_LLONG_LOCK_FREE 1
#define ATOMIC_POINTER_LOCK_FREE 1
#define ATOMIC_FLAG_INIT { 0 }
#define __ATOMIC_RELAXED 0
#define __ATOMIC_CONSUME 1
#define __ATOMIC_ACQUIRE 2
#define __ATOMIC_RELEASE 3
#define __ATOMIC_ACQ_REL 4
#define __ATOMIC_SEQ_CST 5
typedef enum memory_order {
memory_order_relaxed = __ATOMIC_RELAXED,
memory_order_consume = __ATOMIC_CONSUME,
memory_order_acquire = __ATOMIC_ACQUIRE,
memory_order_release = __ATOMIC_RELEASE,
memory_order_acq_rel = __ATOMIC_ACQ_REL,
memory_order_seq_cst = __ATOMIC_SEQ_CST
} memory_order;
typedef long long llong;
typedef unsigned char uchar;
typedef unsigned short ushort;
typedef unsigned int uint;
typedef unsigned long ulong;
typedef unsigned long long ullong;
typedef _Atomic _Bool atomic_bool;
typedef _Atomic char atomic_char;
typedef _Atomic unsigned char atomic_uchar;
typedef _Atomic short atomic_short;
typedef _Atomic unsigned short atomic_ushort;
typedef _Atomic int atomic_int;
typedef _Atomic unsigned int atomic_uint;
typedef _Atomic long atomic_long;
typedef _Atomic unsigned long atomic_ulong;
typedef _Atomic long long atomic_llong;
typedef _Atomic unsigned long long atomic_ullong;
typedef _Atomic intptr_t atomic_intptr_t;
typedef _Atomic uintptr_t atomic_uintptr_t;
typedef _Atomic size_t atomic_size_t;
typedef _Atomic ptrdiff_t atomic_ptrdiff_t;
typedef _Atomic intmax_t atomic_intmax_t;
typedef _Atomic uintmax_t atomic_uintmax_t;
typedef void* _Atomic atomic_ptr;
typedef struct atomic_flag { atomic_bool _Value; } atomic_flag;
static inline __int8 __msvc_xchg_i8(__int8 volatile* addr, __int8 val)
{
return _InterlockedExchange8(addr, val);
}
static inline __int16 __msvc_xchg_i16(__int16 volatile* addr, __int16 val)
{
return _InterlockedExchange16(addr, val);
}
static inline __int32 __msvc_xchg_i32(__int32 volatile* addr, __int32 val)
{
return _InterlockedExchange(addr, val);
}
static inline __int64 __msvc_xchg_i64(__int64 volatile* addr, __int64 val)
{
return _InterlockedExchange64(addr, val);
}
#define __msvc_xchg_ptr(ptr) __concat2(__msvc_xchg_,ptr)
static inline char __c11_atomic_exchange__atomic_char(atomic_char* obj, char desired)
{
return (char)__msvc_xchg_i8((__int8 volatile*)obj, (__int8)desired);
}
static inline short __c11_atomic_exchange__atomic_short(atomic_short* obj, short desired)
{
return (short)__msvc_xchg_i16((__int16 volatile*)obj, (__int16)desired);
}
static inline int __c11_atomic_exchange__atomic_int(atomic_int* obj, int desired)
{
return (int)__msvc_xchg_i32((__int32 volatile*)obj, (__int32)desired);
}
static inline long __c11_atomic_exchange__atomic_long(atomic_long* obj, long desired)
{
return (int)__msvc_xchg_i32((__int32 volatile*)obj, (__int32)desired);
}
static inline llong __c11_atomic_exchange__atomic_llong(atomic_llong* obj, llong desired)
{
return (llong)__msvc_xchg_i64((__int64 volatile*)obj, (__int64)desired);
}
static inline uchar __c11_atomic_exchange__atomic_uchar(atomic_uchar* obj, uchar desired)
{
return (char)__msvc_xchg_i8((__int8 volatile*)obj, (__int8)desired);
}
static inline ushort __c11_atomic_exchange__atomic_ushort(atomic_ushort* obj, ushort desired)
{
return (short)__msvc_xchg_i16((__int16 volatile*)obj, (__int16)desired);
}
static inline uint __c11_atomic_exchange__atomic_uint(atomic_uint* obj, uint desired)
{
return (int)__msvc_xchg_i32((__int32 volatile*)obj, (__int32)desired);
}
static inline ulong __c11_atomic_exchange__atomic_ulong(atomic_ulong* obj, ulong desired)
{
return (int)__msvc_xchg_i32((__int32 volatile*)obj, (__int32)desired);
}
static inline ullong __c11_atomic_exchange__atomic_ullong(atomic_ullong* obj, ullong desired)
{
return (llong)__msvc_xchg_i64((__int64 volatile*)obj, (__int64)desired);
}
static inline void* __c11_atomic_exchange__atomic_ptr(atomic_ptr* obj, void* desired)
{
return (void*)__msvc_xchg_ptr(__ptr)((__intptr volatile*)obj, (ptrdiff_t)desired);
}
#define __c11_atomic_exchange(obj,desired) \
_Generic((obj), \
atomic_char*: __c11_atomic_exchange__atomic_char, \
atomic_uchar*: __c11_atomic_exchange__atomic_uchar, \
atomic_short*: __c11_atomic_exchange__atomic_short, \
atomic_ushort*: __c11_atomic_exchange__atomic_ushort, \
atomic_int*: __c11_atomic_exchange__atomic_int, \
atomic_uint*: __c11_atomic_exchange__atomic_uint, \
atomic_long*: __c11_atomic_exchange__atomic_long, \
atomic_ulong*: __c11_atomic_exchange__atomic_ulong, \
atomic_llong*: __c11_atomic_exchange__atomic_llong, \
atomic_ullong*: __c11_atomic_exchange__atomic_ullong \
)(obj,desired)
#define atomic_exchange(obj,desired) __c11_atomic_exchange(obj,desired)
#define atomic_store(obj,desired) __c11_atomic_exchange(obj,desired)
#define atomic_exchange_explicit(obj,desired,mo) __c11_atomic_exchange(obj,desired)
#define atomic_store_explicit(obj,desired,mo) __c11_atomic_exchange(obj,desired)
static inline __int8 __msvc_cmpxchg_i8(__int8 volatile* addr, __int8 oldval, __int8 newval)
{
return _InterlockedCompareExchange8((__int8 volatile*)addr, newval, oldval);
}
static inline __int16 __msvc_cmpxchg_i16(__int16 volatile* addr, __int16 oldval, __int16 newval)
{
return _InterlockedCompareExchange16((__int16 volatile*)addr, newval, oldval);
}
static inline __int32 __msvc_cmpxchg_i32(__int32 volatile* addr, __int32 oldval, __int32 newval)
{
return _InterlockedCompareExchange((__int32 volatile*)addr, newval, oldval);
}
static inline __int64 __msvc_cmpxchg_i64(__int64 volatile* addr, __int64 oldval, __int64 newval)
{
return _InterlockedCompareExchange64((__int64 volatile*)addr, newval, oldval);
}
#define __msvc_cmpxchg_ptr(ptr) __concat2(__msvc_cmpxchg_,ptr)
static inline _Bool __c11_atomic_compare_exchange_strong__atomic_char(atomic_char* obj, char* expected, char desired)
{
char cmp = *expected, val = __msvc_cmpxchg_i8((__int8 volatile*)obj, (__int8)cmp, (__int8)desired); return val == cmp;
}
static inline _Bool __c11_atomic_compare_exchange_strong__atomic_short(atomic_short* obj, short* expected, short desired)
{
short cmp = *expected, val = __msvc_cmpxchg_i16((__int16 volatile*)obj, (__int16)cmp, (__int16)desired); return val == cmp;
}
static inline _Bool __c11_atomic_compare_exchange_strong__atomic_int(atomic_int* obj, int* expected, int desired)
{
int cmp = *expected, val = __msvc_cmpxchg_i32((__int32 volatile*)obj, (__int32)cmp, (__int32)desired); return val == cmp;
}
static inline _Bool __c11_atomic_compare_exchange_strong__atomic_long(atomic_long* obj, long* expected, long desired)
{
long cmp = *expected, val = __msvc_cmpxchg_i32((__int32 volatile*)obj, (__int32)cmp, (__int32)desired); return val == cmp;
}
static inline _Bool __c11_atomic_compare_exchange_strong__atomic_llong(atomic_llong* obj, llong* expected, llong desired)
{
llong cmp = *expected, val = __msvc_cmpxchg_i64((__int64 volatile*)obj, (__int64)cmp, (__int64)desired); return val == cmp;
}
static inline _Bool __c11_atomic_compare_exchange_strong__atomic_uchar(atomic_uchar* obj, uchar* expected, uchar desired)
{
uchar cmp = *expected, val = __msvc_cmpxchg_i8((__int8 volatile*)obj, (__int8)cmp, (__int8)desired); return val == cmp;
}
static inline _Bool __c11_atomic_compare_exchange_strong__atomic_ushort(atomic_ushort* obj, ushort* expected, ushort desired)
{
ushort cmp = *expected, val = __msvc_cmpxchg_i16((__int16 volatile*)obj, (__int16)cmp, (__int16)desired); return val == cmp;
}
static inline _Bool __c11_atomic_compare_exchange_strong__atomic_uint(atomic_uint* obj, uint* expected, uint desired)
{
uint cmp = *expected, val = __msvc_cmpxchg_i32((__int32 volatile*)obj, (__int32)cmp, (__int32)desired); return val == cmp;
}
static inline _Bool __c11_atomic_compare_exchange_strong__atomic_ulong(atomic_ulong* obj, ulong* expected, ulong desired)
{
ulong cmp = *expected, val = __msvc_cmpxchg_i32((__int32 volatile*)obj, (__int32)cmp, (__int32)desired); return val == cmp;
}
static inline _Bool __c11_atomic_compare_exchange_strong__atomic_ullong(atomic_ullong* obj, ullong* expected, ullong desired)
{
ullong cmp = *expected, val = __msvc_cmpxchg_i64((__int64 volatile*)obj, (__int64)cmp, (__int64)desired); return val == cmp;
}
static inline _Bool __c11_atomic_compare_exchange_strong__atomic_ptr(atomic_ptr* obj, void** expected, void* desired)
{
ptrdiff_t cmp = *(ptrdiff_t*)expected, val = __msvc_cmpxchg_ptr(__ptr)((__intptr volatile*)obj, (ptrdiff_t)cmp, (ptrdiff_t)desired); return (ptrdiff_t)val == cmp;
}
#define __c11_atomic_compare_exchange_strong(obj,expected,desired) \
_Generic((obj), \
atomic_char*: __c11_atomic_compare_exchange_strong__atomic_char, \
atomic_uchar*: __c11_atomic_compare_exchange_strong__atomic_uchar, \
atomic_short*: __c11_atomic_compare_exchange_strong__atomic_short, \
atomic_ushort*: __c11_atomic_compare_exchange_strong__atomic_ushort, \
atomic_int*: __c11_atomic_compare_exchange_strong__atomic_int, \
atomic_uint*: __c11_atomic_compare_exchange_strong__atomic_uint, \
atomic_long*: __c11_atomic_compare_exchange_strong__atomic_long, \
atomic_ulong*: __c11_atomic_compare_exchange_strong__atomic_ulong, \
atomic_llong*: __c11_atomic_compare_exchange_strong__atomic_llong, \
atomic_ullong*: __c11_atomic_compare_exchange_strong__atomic_ullong, \
atomic_ptr*: __c11_atomic_compare_exchange_strong__atomic_ptr \
)(obj,expected,desired)
#define atomic_compare_exchange_weak(obj,expected,desired) __c11_atomic_compare_exchange_strong(obj,expected,desired)
#define atomic_compare_exchange_strong(obj,expected,desired) __c11_atomic_compare_exchange_strong(obj,expected,desired)
#define atomic_compare_exchange_weak_explicit(obj,expected,desired,smo,fmo) __c11_atomic_compare_exchange_strong(obj,expected,desired)
#define atomic_compare_exchange_strong_explicit(obj,expected,desired,smo,fmo) __c11_atomic_compare_exchange_strong(obj,expected,desired)
#if !(defined __STDC_VERSION__ && __STDC_VERSION__ > 201710L)
#define ATOMIC_VAR_INIT(VALUE) (VALUE)
#endif
/*
* atomic_fetch_add
*/
static inline __int8 __msvc_xadd_i8(__int8 volatile* addr, __int8 val)
{
return _InterlockedExchangeAdd8(addr, val);
}
static inline __int16 __msvc_xadd_i16(__int16 volatile* addr, __int16 val)
{
return _InterlockedExchangeAdd16(addr, val);
}
static inline __int32 __msvc_xadd_i32(__int32 volatile* addr, __int32 val)
{
return _InterlockedExchangeAdd(addr, val);
}
static inline __int64 __msvc_xadd_i64(__int64 volatile* addr, __int64 val)
{
return _InterlockedExchangeAdd64(addr, val);
}
#define __msvc_xadd_ptr(ptr) __concat2(__msvc_xadd_,ptr)
static inline char __c11_atomic_fetch_add__atomic_char(atomic_char* obj, char arg)
{
return (char)__msvc_xadd_i8((__int8 volatile*)obj, (__int8)arg);
}
static inline short __c11_atomic_fetch_add__atomic_short(atomic_short* obj, short arg)
{
return (short)__msvc_xadd_i16((__int16 volatile*)obj, (__int16)arg);
}
static inline int __c11_atomic_fetch_add__atomic_int(atomic_int* obj, int arg)
{
return (int)__msvc_xadd_i32((__int32 volatile*)obj, (__int32)arg);
}
static inline long __c11_atomic_fetch_add__atomic_long(atomic_long* obj, long arg)
{
return (long)__msvc_xadd_i32((__int32 volatile*)obj, (__int32)arg);
}
static inline llong __c11_atomic_fetch_add__atomic_llong(atomic_llong* obj, llong arg)
{
return (llong)__msvc_xadd_i64((__int64 volatile*)obj, (__int64)arg);
}
static inline uchar __c11_atomic_fetch_add__atomic_uchar(atomic_uchar* obj, uchar arg)
{
return (uchar)__msvc_xadd_i8((__int8 volatile*)obj, (__int8)arg);
}
static inline ushort __c11_atomic_fetch_add__atomic_ushort(atomic_ushort* obj, ushort arg)
{
return (ushort)__msvc_xadd_i16((__int16 volatile*)obj, (__int16)arg);
}
static inline uint __c11_atomic_fetch_add__atomic_uint(atomic_uint* obj, uint arg)
{
return (uint)__msvc_xadd_i32((__int32 volatile*)obj, (__int32)arg);
}
static inline ulong __c11_atomic_fetch_add__atomic_ulong(atomic_ulong* obj, ulong arg)
{
return (ulong)__msvc_xadd_i32((__int32 volatile*)obj, (__int32)arg);
}
static inline ullong __c11_atomic_fetch_add__atomic_ullong(atomic_ullong* obj, ullong arg)
{
return (ullong)__msvc_xadd_i64((__int64 volatile*)obj, (__int64)arg);
}
static inline void* __c11_atomic_fetch_add__atomic_ptr(atomic_ptr* obj, void* arg)
{
return (void*)__msvc_xadd_ptr(__ptr)((__intptr volatile*)obj, (__intptr)arg);
}
#define __c11_atomic_fetch_add(obj,arg) \
_Generic((obj), \
atomic_char*: __c11_atomic_fetch_add__atomic_char, \
atomic_uchar*: __c11_atomic_fetch_add__atomic_uchar, \
atomic_short*: __c11_atomic_fetch_add__atomic_short, \
atomic_ushort*: __c11_atomic_fetch_add__atomic_ushort, \
atomic_int*: __c11_atomic_fetch_add__atomic_int, \
atomic_uint*: __c11_atomic_fetch_add__atomic_uint, \
atomic_long*: __c11_atomic_fetch_add__atomic_long, \
atomic_ulong*: __c11_atomic_fetch_add__atomic_ulong, \
atomic_llong*: __c11_atomic_fetch_add__atomic_llong, \
atomic_ullong*: __c11_atomic_fetch_add__atomic_ullong, \
atomic_ptr*: __c11_atomic_fetch_add__atomic_ptr \
)(obj,arg)
#define atomic_fetch_add(obj,arg) __c11_atomic_fetch_add(obj,arg)
#define atomic_fetch_sub(obj,arg) __c11_atomic_fetch_add(obj,-(arg))
#define atomic_fetch_add_explicit(obj,arg,mo) __c11_atomic_fetch_add(obj,arg)
#define atomic_fetch_sub_explicit(obj,arg,mo) __c11_atomic_fetch_add(obj,-(arg))
/*
* atomic_load
*/
static inline char __c11_atomic_load__atomic_char(atomic_char* obj)
{
char val; _ReadBarrier(); val = *obj; _ReadWriteBarrier(); return val;
}
static inline short __c11_atomic_load__atomic_short(atomic_short* obj)
{
short val; _ReadBarrier(); val = *obj; _ReadWriteBarrier(); return val;
}
static inline int __c11_atomic_load__atomic_int(atomic_int* obj)
{
int val; _ReadBarrier(); val = *obj; _ReadWriteBarrier(); return val;
}
static inline long __c11_atomic_load__atomic_long(atomic_long* obj)
{
long val; _ReadBarrier(); val = *obj; _ReadWriteBarrier(); return val;
}
static inline llong __c11_atomic_load__atomic_llong(atomic_llong* obj)
{
llong val; _ReadBarrier(); val = *obj; _ReadWriteBarrier(); return val;
}
static inline uchar __c11_atomic_load__atomic_uchar(atomic_uchar* obj)
{
uchar val; _ReadBarrier(); val = *obj; _ReadWriteBarrier(); return val;
}
static inline ushort __c11_atomic_load__atomic_ushort(atomic_ushort* obj)
{
ushort val; _ReadBarrier(); val = *obj; _ReadWriteBarrier(); return val;
}
static inline uint __c11_atomic_load__atomic_uint(atomic_uint* obj)
{
uint val; _ReadBarrier(); val = *obj; _ReadWriteBarrier(); return val;
}
static inline ulong __c11_atomic_load__atomic_ulong(atomic_ulong* obj)
{
ulong val; _ReadBarrier(); val = *obj; _ReadWriteBarrier(); return val;
}
static inline ullong __c11_atomic_load__atomic_ullong(atomic_ullong* obj)
{
ullong val; _ReadBarrier(); val = *obj; _ReadWriteBarrier(); return val;
}
static inline void* __c11_atomic_load__atomic_ptr(atomic_ptr* obj)
{
void* val; _ReadBarrier(); val = *obj; _ReadWriteBarrier(); return val;
}
#define __c11_atomic_load(obj) \
_Generic((obj), \
atomic_char*: __c11_atomic_load__atomic_char, \
atomic_uchar*: __c11_atomic_load__atomic_uchar, \
atomic_short*: __c11_atomic_load__atomic_short, \
atomic_ushort*: __c11_atomic_load__atomic_ushort, \
atomic_int*: __c11_atomic_load__atomic_int, \
atomic_uint*: __c11_atomic_load__atomic_uint, \
atomic_long*: __c11_atomic_load__atomic_long, \
atomic_ulong*: __c11_atomic_load__atomic_ulong, \
atomic_llong*: __c11_atomic_load__atomic_llong, \
atomic_ullong*: __c11_atomic_load__atomic_ullong, \
atomic_ptr*: __c11_atomic_load__atomic_ptr \
)(obj)
#define atomic_load(obj) __c11_atomic_load(obj)
#define atomic_load_explicit(obj,mo) __c11_atomic_load(obj)
/*
* atomic_fetch_{op} template for {and,or,xor} using atomic_compare_exchange
*/
#define __C11_ATOMIC_FETCH_OP_TEMPLATE(prefix,type,op) static inline type \
__concat3(prefix,atomic_,type)(__concat2(atomic_,type) *obj, type arg) { \
type oldval, newval; \
do { oldval = atomic_load(obj); newval = oldval op arg; } \
while (!atomic_compare_exchange_strong(obj, &oldval, newval)); \
return oldval; \
}
#define __C11_ATOMIC_FETCH_OP_POINTER_TEMPLATE(prefix,op) static inline void* \
__concat2(prefix,atomic_ptr)(atomic_ptr *obj, void* arg) { \
ptrdiff_t oldval, newval; \
do { oldval = (ptrdiff_t)atomic_load(obj); newval = oldval op (ptrdiff_t)arg; } \
while (!atomic_compare_exchange_strong(obj, (void**)&oldval, (void*)newval)); \
return (void*)oldval; \
}
/*
* atomic_fetch_and
*/
__C11_ATOMIC_FETCH_OP_TEMPLATE(__c11_atomic_fetch_and__, char, &)
__C11_ATOMIC_FETCH_OP_TEMPLATE(__c11_atomic_fetch_and__, short, &)
__C11_ATOMIC_FETCH_OP_TEMPLATE(__c11_atomic_fetch_and__, int, &)
__C11_ATOMIC_FETCH_OP_TEMPLATE(__c11_atomic_fetch_and__, long, &)
__C11_ATOMIC_FETCH_OP_TEMPLATE(__c11_atomic_fetch_and__, llong, &)
__C11_ATOMIC_FETCH_OP_TEMPLATE(__c11_atomic_fetch_and__, uchar, &)
__C11_ATOMIC_FETCH_OP_TEMPLATE(__c11_atomic_fetch_and__, ushort, &)
__C11_ATOMIC_FETCH_OP_TEMPLATE(__c11_atomic_fetch_and__, uint, &)
__C11_ATOMIC_FETCH_OP_TEMPLATE(__c11_atomic_fetch_and__, ulong, &)
__C11_ATOMIC_FETCH_OP_TEMPLATE(__c11_atomic_fetch_and__, ullong, &)
__C11_ATOMIC_FETCH_OP_POINTER_TEMPLATE(__c11_atomic_fetch_and__, &)
#define __c11_atomic_fetch_and(obj,arg) \
_Generic((obj), \
atomic_char*: __c11_atomic_fetch_and__atomic_char, \
atomic_uchar*: __c11_atomic_fetch_and__atomic_uchar, \
atomic_short*: __c11_atomic_fetch_and__atomic_short, \
atomic_ushort*: __c11_atomic_fetch_and__atomic_ushort, \
atomic_int*: __c11_atomic_fetch_and__atomic_int, \
atomic_uint*: __c11_atomic_fetch_and__atomic_uint, \
atomic_long*: __c11_atomic_fetch_and__atomic_long, \
atomic_ulong*: __c11_atomic_fetch_and__atomic_ulong, \
atomic_llong*: __c11_atomic_fetch_and__atomic_llong, \
atomic_ullong*: __c11_atomic_fetch_and__atomic_ullong, \
atomic_ptr*: __c11_atomic_fetch_and__atomic_ptr \
)(obj,arg)
#define atomic_fetch_and(obj,arg) __c11_atomic_fetch_and(obj,arg)
#define atomic_fetch_and_explicit(obj,arg,mo) __c11_atomic_fetch_and(obj,arg)
/*
* atomic_fetch_or
*/
__C11_ATOMIC_FETCH_OP_TEMPLATE(__c11_atomic_fetch_or__, char, | )
__C11_ATOMIC_FETCH_OP_TEMPLATE(__c11_atomic_fetch_or__, short, | )
__C11_ATOMIC_FETCH_OP_TEMPLATE(__c11_atomic_fetch_or__, int, | )
__C11_ATOMIC_FETCH_OP_TEMPLATE(__c11_atomic_fetch_or__, long, | )
__C11_ATOMIC_FETCH_OP_TEMPLATE(__c11_atomic_fetch_or__, llong, | )
__C11_ATOMIC_FETCH_OP_TEMPLATE(__c11_atomic_fetch_or__, uchar, | )
__C11_ATOMIC_FETCH_OP_TEMPLATE(__c11_atomic_fetch_or__, ushort, | )
__C11_ATOMIC_FETCH_OP_TEMPLATE(__c11_atomic_fetch_or__, uint, | )
__C11_ATOMIC_FETCH_OP_TEMPLATE(__c11_atomic_fetch_or__, ulong, | )
__C11_ATOMIC_FETCH_OP_TEMPLATE(__c11_atomic_fetch_or__, ullong, | )
__C11_ATOMIC_FETCH_OP_POINTER_TEMPLATE(__c11_atomic_fetch_or__, | )
#define __c11_atomic_fetch_or(obj,arg) \
_Generic((obj), \
atomic_char*: __c11_atomic_fetch_or__atomic_char, \
atomic_uchar*: __c11_atomic_fetch_or__atomic_uchar, \
atomic_short*: __c11_atomic_fetch_or__atomic_short, \
atomic_ushort*: __c11_atomic_fetch_or__atomic_ushort, \
atomic_int*: __c11_atomic_fetch_or__atomic_int, \
atomic_uint*: __c11_atomic_fetch_or__atomic_uint, \
atomic_long*: __c11_atomic_fetch_or__atomic_long, \
atomic_ulong*: __c11_atomic_fetch_or__atomic_ulong, \
atomic_llong*: __c11_atomic_fetch_or__atomic_llong, \
atomic_ullong*: __c11_atomic_fetch_or__atomic_ullong, \
atomic_ptr*: __c11_atomic_fetch_or__atomic_ptr \
)(obj,arg)
#define atomic_fetch_or(obj,arg) __c11_atomic_fetch_or(obj,arg)
#define atomic_fetch_or_explicit(obj,arg,mo) __c11_atomic_fetch_or(obj,arg)
/*
* atomic_fetch_xor
*/
__C11_ATOMIC_FETCH_OP_TEMPLATE(__c11_atomic_fetch_xor__, char, ^)
__C11_ATOMIC_FETCH_OP_TEMPLATE(__c11_atomic_fetch_xor__, short, ^)
__C11_ATOMIC_FETCH_OP_TEMPLATE(__c11_atomic_fetch_xor__, int, ^)
__C11_ATOMIC_FETCH_OP_TEMPLATE(__c11_atomic_fetch_xor__, long, ^)
__C11_ATOMIC_FETCH_OP_TEMPLATE(__c11_atomic_fetch_xor__, llong, ^)
__C11_ATOMIC_FETCH_OP_TEMPLATE(__c11_atomic_fetch_xor__, uchar, ^)
__C11_ATOMIC_FETCH_OP_TEMPLATE(__c11_atomic_fetch_xor__, ushort, ^)
__C11_ATOMIC_FETCH_OP_TEMPLATE(__c11_atomic_fetch_xor__, uint, ^)
__C11_ATOMIC_FETCH_OP_TEMPLATE(__c11_atomic_fetch_xor__, ulong, ^)
__C11_ATOMIC_FETCH_OP_TEMPLATE(__c11_atomic_fetch_xor__, ullong, ^)
__C11_ATOMIC_FETCH_OP_POINTER_TEMPLATE(__c11_atomic_fetch_xor__, ^)
#define __c11_atomic_fetch_xor(obj,arg) \
_Generic((obj), \
atomic_char*: __c11_atomic_fetch_xor__atomic_char, \
atomic_uchar*: __c11_atomic_fetch_xor__atomic_uchar, \
atomic_short*: __c11_atomic_fetch_xor__atomic_short, \
atomic_ushort*: __c11_atomic_fetch_xor__atomic_ushort, \
atomic_int*: __c11_atomic_fetch_xor__atomic_int, \
atomic_uint*: __c11_atomic_fetch_xor__atomic_uint, \
atomic_long*: __c11_atomic_fetch_xor__atomic_long, \
atomic_ulong*: __c11_atomic_fetch_xor__atomic_ulong, \
atomic_llong*: __c11_atomic_fetch_xor__atomic_llong, \
atomic_ullong*: __c11_atomic_fetch_xor__atomic_ullong, \
atomic_ptr*: __c11_atomic_fetch_xor__atomic_ptr \
)(obj,arg)
#define atomic_fetch_xor(obj,arg) __c11_atomic_fetch_xor(obj,arg)
#define atomic_fetch_xor_explicit(obj,arg,mo) __c11_atomic_fetch_xor(obj,arg)
/*
* atomic_flag_test_and_set, atomic_flag_clear
*/
static inline _Bool atomic_flag_test_and_set(volatile atomic_flag* obj)
{
char o = 0;
return atomic_compare_exchange_strong((atomic_char*)&obj->_Value, &o, 1) ? 0 : 1;
}
static inline void atomic_flag_clear(volatile atomic_flag* obj)
{
atomic_store_explicit((atomic_char*)&obj->_Value, 0, memory_order_release);
}
#define atomic_flag_test_and_set_explicit(obj,mo) atomic_flag_test_and_set(obj)
#define atomic_flag_clear_explicit(obj,mo) atomic_flag_clear(obj)
#endif
================================================
FILE: build.zig
================================================
// Compatible with Zig Version 0.11.0
const std = @import("std");
const ArrayList = std.ArrayList;
const Compile = std.Build.Step.Compile;
const ConfigHeader = std.Build.Step.ConfigHeader;
const Mode = std.builtin.Mode;
const CrossTarget = std.zig.CrossTarget;
const Maker = struct {
builder: *std.build.Builder,
target: CrossTarget,
optimize: Mode,
enable_lto: bool,
include_dirs: ArrayList([]const u8),
cflags: ArrayList([]const u8),
cxxflags: ArrayList([]const u8),
objs: ArrayList(*Compile),
fn addInclude(m: *Maker, dir: []const u8) !void {
try m.include_dirs.append(dir);
}
fn addProjectInclude(m: *Maker, path: []const []const u8) !void {
try m.addInclude(try m.builder.build_root.join(m.builder.allocator, path));
}
fn addCFlag(m: *Maker, flag: []const u8) !void {
try m.cflags.append(flag);
}
fn addCxxFlag(m: *Maker, flag: []const u8) !void {
try m.cxxflags.append(flag);
}
fn addFlag(m: *Maker, flag: []const u8) !void {
try m.addCFlag(flag);
try m.addCxxFlag(flag);
}
fn init(builder: *std.build.Builder) !Maker {
const target = builder.standardTargetOptions(.{});
const zig_version = @import("builtin").zig_version_string;
const commit_hash = try std.ChildProcess.exec(
.{ .allocator = builder.allocator, .argv = &.{ "git", "rev-parse", "HEAD" } },
);
try std.fs.cwd().writeFile("common/build-info.cpp", builder.fmt(
\\int LLAMA_BUILD_NUMBER = {};
\\char const *LLAMA_COMMIT = "{s}";
\\char const *LLAMA_COMPILER = "Zig {s}";
\\char const *LLAMA_BUILD_TARGET = "{s}";
\\
, .{ 0, commit_hash.stdout[0 .. commit_hash.stdout.len - 1], zig_version, try target.allocDescription(builder.allocator) }));
var m = Maker{
.builder = builder,
.target = target,
.optimize = builder.standardOptimizeOption(.{}),
.enable_lto = false,
.include_dirs = ArrayList([]const u8).init(builder.allocator),
.cflags = ArrayList([]const u8).init(builder.allocator),
.cxxflags = ArrayList([]const u8).init(builder.allocator),
.objs = ArrayList(*Compile).init(builder.allocator),
};
try m.addCFlag("-std=c11");
try m.addCxxFlag("-std=c++11");
try m.addProjectInclude(&.{});
try m.addProjectInclude(&.{"common"});
return m;
}
fn obj(m: *const Maker, name: []const u8, src: []const u8) *Compile {
const o = m.builder.addObject(.{ .name = name, .target = m.target, .optimize = m.optimize });
if (o.target.getAbi() != .msvc)
o.defineCMacro("_GNU_SOURCE", null);
if (std.mem.endsWith(u8, src, ".c")) {
o.addCSourceFiles(&.{src}, m.cflags.items);
o.linkLibC();
} else {
o.addCSourceFiles(&.{src}, m.cxxflags.items);
if (o.target.getAbi() == .msvc) {
o.linkLibC(); // need winsdk + crt
} else {
// linkLibCpp already add (libc++ + libunwind + libc)
o.linkLibCpp();
}
}
for (m.include_dirs.items) |i| o.addIncludePath(.{ .path = i });
o.want_lto = m.enable_lto;
return o;
}
fn exe(m: *const Maker, name: []const u8, src: []const u8, deps: []const *Compile) *Compile {
const e = m.builder.addExecutable(.{ .name = name, .target = m.target, .optimize = m.optimize });
e.addCSourceFiles(&.{src}, m.cxxflags.items);
for (deps) |d| e.addObject(d);
for (m.objs.items) |o| e.addObject(o);
for (m.include_dirs.items) |i| e.addIncludePath(.{ .path = i });
// https://github.com/ziglang/zig/issues/15448
if (e.target.getAbi() == .msvc) {
e.linkLibC(); // need winsdk + crt
} else {
// linkLibCpp already add (libc++ + libunwind + libc)
e.linkLibCpp();
}
m.builder.installArtifact(e);
e.want_lto = m.enable_lto;
return e;
}
};
pub fn build(b: *std.build.Builder) !void {
var make = try Maker.init(b);
make.enable_lto = b.option(bool, "lto", "Enable LTO optimization, (default: false)") orelse false;
const ggml = make.obj("ggml", "ggml.c");
const ggml_alloc = make.obj("ggml-alloc", "ggml-alloc.c");
const ggml_backend = make.obj("ggml-backend", "ggml-backend.c");
const ggml_quants = make.obj("ggml-quants", "ggml-quants.c");
const llama = make.obj("llama", "llama.cpp");
const buildinfo = make.obj("common", "common/build-info.cpp");
const common = make.obj("common", "common/common.cpp");
const console = make.obj("console", "common/console.cpp");
const sampling = make.obj("sampling", "common/sampling.cpp");
const grammar_parser = make.obj("grammar-parser", "common/grammar-parser.cpp");
const train = make.obj("train", "common/train.cpp");
const clip = make.obj("clip", "examples/llava/clip.cpp");
_ = make.exe("main", "examples/main/main.cpp", &.{ ggml, ggml_alloc, ggml_backend, ggml_quants, llama, common, buildinfo, sampling, console, grammar_parser });
_ = make.exe("quantize", "examples/quantize/quantize.cpp", &.{ ggml, ggml_alloc, ggml_backend, ggml_quants, llama, common, buildinfo });
_ = make.exe("perplexity", "examples/perplexity/perplexity.cpp", &.{ ggml, ggml_alloc, ggml_backend, ggml_quants, llama, common, buildinfo });
_ = make.exe("embedding", "examples/embedding/embedding.cpp", &.{ ggml, ggml_alloc, ggml_backend, ggml_quants, llama, common, buildinfo });
_ = make.exe("finetune", "examples/finetune/finetune.cpp", &.{ ggml, ggml_alloc, ggml_backend, ggml_quants, llama, common, buildinfo, train });
_ = make.exe("train-text-from-scratch", "examples/train-text-from-scratch/train-text-from-scratch.cpp", &.{ ggml, ggml_alloc, ggml_backend, ggml_quants, llama, common, buildinfo, train });
const server = make.exe("server", "examples/server/server.cpp", &.{ ggml, ggml_alloc, ggml_backend, ggml_quants, llama, common, buildinfo, sampling, grammar_parser, clip });
if (server.target.isWindows()) {
server.linkSystemLibrary("ws2_32");
}
}
================================================
FILE: ci/README.md
================================================
# CI
In addition to [Github Actions](https://github.com/ggerganov/llama.cpp/actions) `llama.cpp` uses a custom CI framework:
https://github.com/ggml-org/ci
It monitors the `master` branch for new commits and runs the
[ci/run.sh](https://github.com/ggerganov/llama.cpp/blob/master/ci/run.sh) script on dedicated cloud instances. This allows us
to execute heavier workloads compared to just using Github Actions. Also with time, the cloud instances will be scaled
to cover various hardware architectures, including GPU and Apple Silicon instances.
Collaborators can optionally trigger the CI run by adding the `ggml-ci` keyword to their commit message.
Only the branches of this repo are monitored for this keyword.
It is a good practice, before publishing changes to execute the full CI locally on your machine:
```bash
mkdir tmp
# CPU-only build
bash ./ci/run.sh ./tmp/results ./tmp/mnt
# with CUDA support
GG_BUILD_CUDA=1 bash ./ci/run.sh ./tmp/results ./tmp/mnt
```
================================================
FILE: ci/run.sh
================================================
#/bin/bash
#
# sample usage:
#
# mkdir tmp
#
# # CPU-only build
# bash ./ci/run.sh ./tmp/results ./tmp/mnt
#
# # with CUDA support
# GG_BUILD_CUDA=1 bash ./ci/run.sh ./tmp/results ./tmp/mnt
#
if [ -z "$2" ]; then
echo "usage: $0 <output-dir> <mnt-dir>"
exit 1
fi
mkdir -p "$1"
mkdir -p "$2"
OUT=$(realpath "$1")
MNT=$(realpath "$2")
rm -v $OUT/*.log
rm -v $OUT/*.exit
rm -v $OUT/*.md
sd=`dirname $0`
cd $sd/../
SRC=`pwd`
## helpers
# download a file if it does not exist or if it is outdated
function gg_wget {
local out=$1
local url=$2
local cwd=`pwd`
mkdir -p $out
cd $out
# should not re-download if file is the same
wget -nv -N $url
cd $cwd
}
function gg_printf {
printf -- "$@" >> $OUT/README.md
}
function gg_run {
ci=$1
set -o pipefail
set -x
gg_run_$ci | tee $OUT/$ci.log
cur=$?
echo "$cur" > $OUT/$ci.exit
set +x
set +o pipefail
gg_sum_$ci
ret=$((ret | cur))
}
## ci
# ctest_debug
function gg_run_ctest_debug {
cd ${SRC}
rm -rf build-ci-debug && mkdir build-ci-debug && cd build-ci-debug
set -e
(time cmake -DCMAKE_BUILD_TYPE=Debug .. ) 2>&1 | tee -a $OUT/${ci}-cmake.log
(time make -j ) 2>&1 | tee -a $OUT/${ci}-make.log
(time ctest --output-on-failure -E test-opt ) 2>&1 | tee -a $OUT/${ci}-ctest.log
set +e
}
function gg_sum_ctest_debug {
gg_printf '### %s\n\n' "${ci}"
gg_printf 'Runs ctest in debug mode\n'
gg_printf '- status: %s\n' "$(cat $OUT/${ci}.exit)"
gg_printf '```\n'
gg_printf '%s\n' "$(cat $OUT/${ci}-ctest.log)"
gg_printf '```\n'
gg_printf '\n'
}
# ctest_release
function gg_run_ctest_release {
cd ${SRC}
rm -rf build-ci-release && mkdir build-ci-release && cd build-ci-release
set -e
(time cmake -DCMAKE_BUILD_TYPE=Release .. ) 2>&1 | tee -a $OUT/${ci}-cmake.log
(time make -j ) 2>&1 | tee -a $OUT/${ci}-make.log
if [ -z ${GG_BUILD_LOW_PERF} ]; then
(time ctest --output-on-failure ) 2>&1 | tee -a $OUT/${ci}-ctest.log
else
(time ctest --output-on-failure -E test-opt ) 2>&1 | tee -a $OUT/${ci}-ctest.log
fi
set +e
}
function gg_sum_ctest_release {
gg_printf '### %s\n\n' "${ci}"
gg_printf 'Runs ctest in release mode\n'
gg_printf '- status: %s\n' "$(cat $OUT/${ci}.exit)"
gg_printf '```\n'
gg_printf '%s\n' "$(cat $OUT/${ci}-ctest.log)"
gg_printf '```\n'
}
# open_llama_3b_v2
function gg_run_open_llama_3b_v2 {
cd ${SRC}
gg_wget models-mnt/open-llama/3B-v2/ https://huggingface.co/openlm-research/open_llama_3b_v2/raw/main/config.json
gg_wget models-mnt/open-llama/3B-v2/ https://huggingface.co/openlm-research/open_llama_3b_v2/resolve/main/tokenizer.model
gg_wget models-mnt/open-llama/3B-v2/ https://huggingface.co/openlm-research/open_llama_3b_v2/raw/main/tokenizer_config.json
gg_wget models-mnt/open-llama/3B-v2/ https://huggingface.co/openlm-research/open_llama_3b_v2/raw/main/special_tokens_map.json
gg_wget models-mnt/open-llama/3B-v2/ https://huggingface.co/openlm-research/open_llama_3b_v2/resolve/main/pytorch_model.bin
gg_wget models-mnt/open-llama/3B-v2/ https://huggingface.co/openlm-research/open_llama_3b_v2/raw/main/generation_config.json
gg_wget models-mnt/wikitext/ https://s3.amazonaws.com/research.metamind.io/wikitext/wikitext-2-raw-v1.zip
unzip -o models-mnt/wikitext/wikitext-2-raw-v1.zip -d models-mnt/wikitext/
head -n 60 models-mnt/wikitext/wikitext-2-raw/wiki.test.raw > models-mnt/wikitext/wikitext-2-raw/wiki.test-60.raw
path_models="../models-mnt/open-llama/3B-v2"
path_wiki="../models-mnt/wikitext/wikitext-2-raw"
rm -rf build-ci-release && mkdir build-ci-release && cd build-ci-release
set -e
(time cmake -DCMAKE_BUILD_TYPE=Release -DLLAMA_QKK_64=1 .. ) 2>&1 | tee -a $OUT/${ci}-cmake.log
(time make -j ) 2>&1 | tee -a $OUT/${ci}-make.log
python3 ../convert.py ${path_models}
model_f16="${path_models}/ggml-model-f16.gguf"
model_q8_0="${path_models}/ggml-model-q8_0.gguf"
model_q4_0="${path_models}/ggml-model-q4_0.gguf"
model_q4_1="${path_models}/ggml-model-q4_1.gguf"
model_q5_0="${path_models}/ggml-model-q5_0.gguf"
model_q5_1="${path_models}/ggml-model-q5_1.gguf"
model_q2_k="${path_models}/ggml-model-q2_k.gguf"
model_q3_k="${path_models}/ggml-model-q3_k.gguf"
model_q4_k="${path_models}/ggml-model-q4_k.gguf"
model_q5_k="${path_models}/ggml-model-q5_k.gguf"
model_q6_k="${path_models}/ggml-model-q6_k.gguf"
wiki_test_60="${path_wiki}/wiki.test-60.raw"
./bin/quantize ${model_f16} ${model_q8_0} q8_0
./bin/quantize ${model_f16} ${model_q4_0} q4_0
./bin/quantize ${model_f16} ${model_q4_1} q4_1
./bin/quantize ${model_f16} ${model_q5_0} q5_0
./bin/quantize ${model_f16} ${model_q5_1} q5_1
./bin/quantize ${model_f16} ${model_q2_k} q2_k
./bin/quantize ${model_f16} ${model_q3_k} q3_k
./bin/quantize ${model_f16} ${model_q4_k} q4_k
./bin/quantize ${model_f16} ${model_q5_k} q5_k
./bin/quantize ${model_f16} ${model_q6_k} q6_k
(time ./bin/main --model ${model_f16} -s 1234 -n 64 --ignore-eos -p "I believe the meaning of life is" ) 2>&1 | tee -a $OUT/${ci}-tg-f16.log
(time ./bin/main --model ${model_q8_0} -s 1234 -n 64 --ignore-eos -p "I believe the meaning of life is" ) 2>&1 | tee -a $OUT/${ci}-tg-q8_0.log
(time ./bin/main --model ${model_q4_0} -s 1234 -n 64 --ignore-eos -p "I believe the meaning of life is" ) 2>&1 | tee -a $OUT/${ci}-tg-q4_0.log
(time ./bin/main --model ${model_q4_1} -s 1234 -n 64 --ignore-eos -p "I believe the meaning of life is" ) 2>&1 | tee -a $OUT/${ci}-tg-q4_1.log
(time ./bin/main --model ${model_q5_0} -s 1234 -n 64 --ignore-eos -p "I believe the meaning of life is" ) 2>&1 | tee -a $OUT/${ci}-tg-q5_0.log
(time ./bin/main --model ${model_q5_1} -s 1234 -n 64 --ignore-eos -p "I believe the meaning of life is" ) 2>&1 | tee -a $OUT/${ci}-tg-q5_1.log
(time ./bin/main --model ${model_q2_k} -s 1234 -n 64 --ignore-eos -p "I believe the meaning of life is" ) 2>&1 | tee -a $OUT/${ci}-tg-q2_k.log
(time ./bin/main --model ${model_q3_k} -s 1234 -n 64 --ignore-eos -p "I believe the meaning of life is" ) 2>&1 | tee -a $OUT/${ci}-tg-q3_k.log
(time ./bin/main --model ${model_q4_k} -s 1234 -n 64 --ignore-eos -p "I believe the meaning of life is" ) 2>&1 | tee -a $OUT/${ci}-tg-q4_k.log
(time ./bin/main --model ${model_q5_k} -s 1234 -n 64 --ignore-eos -p "I believe the meaning of life is" ) 2>&1 | tee -a $OUT/${ci}-tg-q5_k.log
(time ./bin/main --model ${model_q6_k} -s 1234 -n 64 --ignore-eos -p "I believe the meaning of life is" ) 2>&1 | tee -a $OUT/${ci}-tg-q6_k.log
(time ./bin/perplexity --model ${model_f16} -f ${wiki_test_60} -c 128 -b 128 --chunks 2 ) 2>&1 | tee -a $OUT/${ci}-tg-f16.log
(time ./bin/perplexity --model ${model_q8_0} -f ${wiki_test_60} -c 128 -b 128 --chunks 2 ) 2>&1 | tee -a $OUT/${ci}-tg-q8_0.log
(time ./bin/perplexity --model ${model_q4_0} -f ${wiki_test_60} -c 128 -b 128 --chunks 2 ) 2>&1 | tee -a $OUT/${ci}-tg-q4_0.log
(time ./bin/perplexity --model ${model_q4_1} -f ${wiki_test_60} -c 128 -b 128 --chunks 2 ) 2>&1 | tee -a $OUT/${ci}-tg-q4_1.log
(time ./bin/perplexity --model ${model_q5_0} -f ${wiki_test_60} -c 128 -b 128 --chunks 2 ) 2>&1 | tee -a $OUT/${ci}-tg-q5_0.log
(time ./bin/perplexity --model ${model_q5_1} -f ${wiki_test_60} -c 128 -b 128 --chunks 2 ) 2>&1 | tee -a $OUT/${ci}-tg-q5_1.log
(time ./bin/perplexity --model ${model_q2_k} -f ${wiki_test_60} -c 128 -b 128 --chunks 2 ) 2>&1 | tee -a $OUT/${ci}-tg-q2_k.log
(time ./bin/perplexity --model ${model_q3_k} -f ${wiki_test_60} -c 128 -b 128 --chunks 2 ) 2>&1 | tee -a $OUT/${ci}-tg-q3_k.log
(time ./bin/perplexity --model ${model_q4_k} -f ${wiki_test_60} -c 128 -b 128 --chunks 2 ) 2>&1 | tee -a $OUT/${ci}-tg-q4_k.log
(time ./bin/perplexity --model ${model_q5_k} -f ${wiki_test_60} -c 128 -b 128 --chunks 2 ) 2>&1 | tee -a $OUT/${ci}-tg-q5_k.log
(time ./bin/perplexity --model ${model_q6_k} -f ${wiki_test_60} -c 128 -b 128 --chunks 2 ) 2>&1 | tee -a $OUT/${ci}-tg-q6_k.log
(time ./bin/save-load-state --model ${model_q4_0} ) 2>&1 | tee -a $OUT/${ci}-save-load-state.log
function check_ppl {
qnt="$1"
ppl=$(echo "$2" | grep -oE "[0-9]+\.[0-9]+" | tail -n 1)
if [ $(echo "$ppl > 20.0" | bc) -eq 1 ]; then
printf ' - %s @ %s (FAIL: ppl > 20.0)\n' "$qnt" "$ppl"
return 20
fi
printf ' - %s @ %s OK\n' "$qnt" "$ppl"
return 0
}
check_ppl "f16" "$(cat $OUT/${ci}-tg-f16.log | grep "^\[1\]")" | tee -a $OUT/${ci}-ppl.log
check_ppl "q8_0" "$(cat $OUT/${ci}-tg-q8_0.log | grep "^\[1\]")" | tee -a $OUT/${ci}-ppl.log
check_ppl "q4_0" "$(cat $OUT/${ci}-tg-q4_0.log | grep "^\[1\]")" | tee -a $OUT/${ci}-ppl.log
check_ppl "q4_1" "$(cat $OUT/${ci}-tg-q4_1.log | grep "^\[1\]")" | tee -a $OUT/${ci}-ppl.log
check_ppl "q5_0" "$(cat $OUT/${ci}-tg-q5_0.log | grep "^\[1\]")" | tee -a $OUT/${ci}-ppl.log
check_ppl "q5_1" "$(cat $OUT/${ci}-tg-q5_1.log | grep "^\[1\]")" | tee -a $OUT/${ci}-ppl.log
check_ppl "q2_k" "$(cat $OUT/${ci}-tg-q2_k.log | grep "^\[1\]")" | tee -a $OUT/${ci}-ppl.log
check_ppl "q3_k" "$(cat $OUT/${ci}-tg-q3_k.log | grep "^\[1\]")" | tee -a $OUT/${ci}-ppl.log
check_ppl "q4_k" "$(cat $OUT/${ci}-tg-q4_k.log | grep "^\[1\]")" | tee -a $OUT/${ci}-ppl.log
check_ppl "q5_k" "$(cat $OUT/${ci}-tg-q5_k.log | grep "^\[1\]")" | tee -a $OUT/${ci}-ppl.log
check_ppl "q6_k" "$(cat $OUT/${ci}-tg-q6_k.log | grep "^\[1\]")" | tee -a $OUT/${ci}-ppl.log
# lora
function compare_ppl {
qnt="$1"
ppl1=$(echo "$2" | grep -oE "[0-9]+\.[0-9]+" | tail -n 1)
ppl2=$(echo "$3" | grep -oE "[0-9]+\.[0-9]+" | tail -n 1)
if [ $(echo "$ppl1 < $ppl2" | bc) -eq 1 ]; then
printf ' - %s @ %s (FAIL: %s > %s)\n' "$qnt" "$ppl" "$ppl1" "$ppl2"
return 20
fi
printf ' - %s @ %s %s OK\n' "$qnt" "$ppl1" "$ppl2"
return 0
}
path_lora="../models-mnt/open-llama/3B-v2/lora"
path_shakespeare="../models-mnt/shakespeare"
shakespeare="${path_shakespeare}/shakespeare.txt"
lora_shakespeare="${path_lora}/ggml-adapter-model.bin"
gg_wget ${path_lora} https://huggingface.co/slaren/open_llama_3b_v2_shakespeare_lora/resolve/main/adapter_config.json
gg_wget ${path_lora} https://huggingface.co/slaren/open_llama_3b_v2_shakespeare_lora/resolve/main/adapter_model.bin
gg_wget ${path_shakespeare} https://huggingface.co/slaren/open_llama_3b_v2_shakespeare_lora/resolve/main/shakespeare.txt
python3 ../convert-lora-to-ggml.py ${path_lora}
# f16
(time ./bin/perplexity --model ${model_f16} -f ${shakespeare} -c 128 -b 128 --chunks 2 ) 2>&1 | tee -a $OUT/${ci}-ppl-shakespeare-f16.log
(time ./bin/perplexity --model ${model_f16} -f ${shakespeare} --lora ${lora_shakespeare} -c 128 -b 128 --chunks 2 ) 2>&1 | tee -a $OUT/${ci}-ppl-shakespeare-lora-f16.log
compare_ppl "f16 shakespeare" "$(cat $OUT/${ci}-ppl-shakespeare-f16.log | grep "^\[1\]")" "$(cat $OUT/${ci}-ppl-shakespeare-lora-f16.log | grep "^\[1\]")" | tee -a $OUT/${ci}-lora-ppl.log
# q8_0
(time ./bin/perplexity --model ${model_q8_0} -f ${shakespeare} -c 128 -b 128 --chunks 2 ) 2>&1 | tee -a $OUT/${ci}-ppl-shakespeare-q8_0.log
(time ./bin/perplexity --model ${model_q8_0} -f ${shakespeare} --lora ${lora_shakespeare} -c 128 -b 128 --chunks 2 ) 2>&1 | tee -a $OUT/${ci}-ppl-shakespeare-lora-q8_0.log
compare_ppl "q8_0 shakespeare" "$(cat $OUT/${ci}-ppl-shakespeare-q8_0.log | grep "^\[1\]")" "$(cat $OUT/${ci}-ppl-shakespeare-lora-q8_0.log | grep "^\[1\]")" | tee -a $OUT/${ci}-lora-ppl.log
# q8_0 + f16 lora-base
(time ./bin/perplexity --model ${model_q8_0} -f ${shakespeare} --lora ${lora_shakespeare} --lora-base ${model_f16} -c 128 -b 128 --chunks 2 ) 2>&1 | tee -a $OUT/${ci}-ppl-shakespeare-lora-q8_0-f16.log
compare_ppl "q8_0 / f16 base shakespeare" "$(cat $OUT/${ci}-ppl-shakespeare-q8_0.log | grep "^\[1\]")" "$(cat $OUT/${ci}-ppl-shakespeare-lora-q8_0-f16.log | grep "^\[1\]")" | tee -a $OUT/${ci}-lora-ppl.log
set +e
}
function gg_sum_open_llama_3b_v2 {
gg_printf '### %s\n\n' "${ci}"
gg_printf 'OpenLLaMA 3B-v2:\n'
gg_printf '- status: %s\n' "$(cat $OUT/${ci}.exit)"
gg_printf '- perplexity:\n%s\n' "$(cat $OUT/${ci}-ppl.log)"
gg_printf '- lora:\n%s\n' "$(cat $OUT/${ci}-lora-ppl.log)"
gg_printf '- f16: \n```\n%s\n```\n' "$(cat $OUT/${ci}-tg-f16.log)"
gg_printf '- q8_0:\n```\n%s\n```\n' "$(cat $OUT/${ci}-tg-q8_0.log)"
gg_printf '- q4_0:\n```\n%s\n```\n' "$(cat $OUT/${ci}-tg-q4_0.log)"
gg_printf '- q4_1:\n```\n%s\n```\n' "$(cat $OUT/${ci}-tg-q4_1.log)"
gg_printf '- q5_0:\n```\n%s\n```\n' "$(cat $OUT/${ci}-tg-q5_0.log)"
gg_printf '- q5_1:\n```\n%s\n```\n' "$(cat $OUT/${ci}-tg-q5_1.log)"
gg_printf '- q2_k:\n```\n%s\n```\n' "$(cat $OUT/${ci}-tg-q2_k.log)"
gg_printf '- q3_k:\n```\n%s\n```\n' "$(cat $OUT/${ci}-tg-q3_k.log)"
gg_printf '- q4_k:\n```\n%s\n```\n' "$(cat $OUT/${ci}-tg-q4_k.log)"
gg_printf '- q5_k:\n```\n%s\n```\n' "$(cat $OUT/${ci}-tg-q5_k.log)"
gg_printf '- q6_k:\n```\n%s\n```\n' "$(cat $OUT/${ci}-tg-q6_k.log)"
gg_printf '- save-load-state: \n```\n%s\n```\n' "$(cat $OUT/${ci}-save-load-state.log)"
gg_printf '- shakespeare (f16):\n```\n%s\n```\n' "$(cat $OUT/${ci}-ppl-shakespeare-f16.log)"
gg_printf '- shakespeare (f16 lora):\n```\n%s\n```\n' "$(cat $OUT/${ci}-ppl-shakespeare-lora-f16.log)"
gg_printf '- shakespeare (q8_0):\n```\n%s\n```\n' "$(cat $OUT/${ci}-ppl-shakespeare-q8_0.log)"
gg_printf '- shakespeare (q8_0 lora):\n```\n%s\n```\n' "$(cat $OUT/${ci}-ppl-shakespeare-lora-q8_0.log)"
gg_printf '- shakespeare (q8_0 / f16 base lora):\n```\n%s\n```\n' "$(cat $OUT/${ci}-ppl-shakespeare-lora-q8_0-f16.log)"
}
# open_llama_7b_v2
# requires: GG_BUILD_CUDA
function gg_run_open_llama_7b_v2 {
cd ${SRC}
gg_wget models-mnt/open-llama/7B-v2/ https://huggingface.co/openlm-research/open_llama_7b_v2/raw/main/config.json
gg_wget models-mnt/open-llama/7B-v2/ https://huggingface.co/openlm-research/open_llama_7b_v2/resolve/main/tokenizer.model
gg_wget models-mnt/open-llama/7B-v2/ https://huggingface.co/openlm-research/open_llama_7b_v2/raw/main/tokenizer_config.json
gg_wget models-mnt/open-llama/7B-v2/ https://huggingface.co/openlm-research/open_llama_7b_v2/raw/main/special_tokens_map.json
gg_wget models-mnt/open-llama/7B-v2/ https://huggingface.co/openlm-research/open_llama_7b_v2/raw/main/pytorch_model.bin.index.json
gg_wget models-mnt/open-llama/7B-v2/ https://huggingface.co/openlm-research/open_llama_7b_v2/resolve/main/pytorch_model-00001-of-00002.bin
gg_wget models-mnt/open-llama/7B-v2/ https://huggingface.co/openlm-research/open_llama_7b_v2/resolve/main/pytorch_model-00002-of-00002.bin
gg_wget models-mnt/open-llama/7B-v2/ https://huggingface.co/openlm-research/open_llama_7b_v2/raw/main/generation_config.json
gg_wget models-mnt/wikitext/ https://s3.amazonaws.com/research.metamind.io/wikitext/wikitext-2-raw-v1.zip
unzip -o models-mnt/wikitext/wikitext-2-raw-v1.zip -d models-mnt/wikitext/
path_models="../models-mnt/open-llama/7B-v2"
path_wiki="../models-mnt/wikitext/wikitext-2-raw"
rm -rf build-ci-release && mkdir build-ci-release && cd build-ci-release
set -e
(time cmake -DCMAKE_BUILD_TYPE=Release -DLLAMA_CUBLAS=1 .. ) 2>&1 | tee -a $OUT/${ci}-cmake.log
(time make -j ) 2>&1 | tee -a $OUT/${ci}-make.log
python3 ../convert.py ${path_models}
model_f16="${path_models}/ggml-model-f16.gguf"
model_q8_0="${path_models}/ggml-model-q8_0.gguf"
model_q4_0="${path_models}/ggml-model-q4_0.gguf"
model_q4_1="${path_models}/ggml-model-q4_1.gguf"
model_q5_0="${path_models}/ggml-model-q5_0.gguf"
model_q5_1="${path_models}/ggml-model-q5_1.gguf"
model_q2_k="${path_models}/ggml-model-q2_k.gguf"
model_q3_k="${path_models}/ggml-model-q3_k.gguf"
model_q4_k="${path_models}/ggml-model-q4_k.gguf"
model_q5_k="${path_models}/ggml-model-q5_k.gguf"
model_q6_k="${path_models}/ggml-model-q6_k.gguf"
wiki_test="${path_wiki}/wiki.test.raw"
./bin/quantize ${model_f16} ${model_q8_0} q8_0
./bin/quantize ${model_f16} ${model_q4_0} q4_0
./bin/quantize ${model_f16} ${model_q4_1} q4_1
./bin/quantize ${model_f16} ${model_q5_0} q5_0
./bin/quantize ${model_f16} ${model_q5_1} q5_1
./bin/quantize ${model_f16} ${model_q2_k} q2_k
./bin/quantize ${model_f16} ${model_q3_k} q3_k
./bin/quantize ${model_f16} ${model_q4_k} q4_k
./bin/quantize ${model_f16} ${model_q5_k} q5_k
./bin/quantize ${model_f16} ${model_q6_k} q6_k
(time ./bin/main --model ${model_f16} -t 1 -ngl 999 -s 1234 -n 256 --ignore-eos -p "I believe the meaning of life is" ) 2>&1 | tee -a $OUT/${ci}-tg-f16.log
(time ./bin/main --model ${model_q8_0} -t 1 -ngl 999 -s 1234 -n 256 --ignore-eos -p "I believe the meaning of life is" ) 2>&1 | tee -a $OUT/${ci}-tg-q8_0.log
(time ./bin/main --model ${model_q4_0} -t 1 -ngl 999 -s 1234 -n 256 --ignore-eos -p "I believe the meaning of life is" ) 2>&1 | tee -a $OUT/${ci}-tg-q4_0.log
(time ./bin/main --model ${model_q4_1} -t 1 -ngl 999 -s 1234 -n 256 --ignore-eos -p "I believe the meaning of life is" ) 2>&1 | tee -a $OUT/${ci}-tg-q4_1.log
(time ./bin/main --model ${model_q5_0} -t 1 -ngl 999 -s 1234 -n 256 --ignore-eos -p "I believe the meaning of life is" ) 2>&1 | tee -a $OUT/${ci}-tg-q5_0.log
(time ./bin/main --model ${model_q5_1} -t 1 -ngl 999 -s 1234 -n 256 --ignore-eos -p "I believe the meaning of life is" ) 2>&1 | tee -a $OUT/${ci}-tg-q5_1.log
(time ./bin/main --model ${model_q2_k} -t 1 -ngl 999 -s 1234 -n 256 --ignore-eos -p "I believe the meaning of life is" ) 2>&1 | tee -a $OUT/${ci}-tg-q2_k.log
(time ./bin/main --model ${model_q3_k} -t 1 -ngl 999 -s 1234 -n 256 --ignore-eos -p "I believe the meaning of life is" ) 2>&1 | tee -a $OUT/${ci}-tg-q3_k.log
(time ./bin/main --model ${model_q4_k} -t 1 -ngl 999 -s 1234 -n 256 --ignore-eos -p "I believe the meaning of life is" ) 2>&1 | tee -a $OUT/${ci}-tg-q4_k.log
(time ./bin/main --model ${model_q5_k} -t 1 -ngl 999 -s 1234 -n 256 --ignore-eos -p "I believe the meaning of life is" ) 2>&1 | tee -a $OUT/${ci}-tg-q5_k.log
(time ./bin/main --model ${model_q6_k} -t 1 -ngl 999 -s 1234 -n 256 --ignore-eos -p "I believe the meaning of life is" ) 2>&1 | tee -a $OUT/${ci}-tg-q6_k.log
(time ./bin/perplexity --model ${model_f16} -f ${wiki_test} -t 1 -ngl 999 -c 2048 -b 512 --chunks 4 ) 2>&1 | tee -a $OUT/${ci}-tg-f16.log
(time ./bin/perplexity --model ${model_q8_0} -f ${wiki_test} -t 1 -ngl 999 -c 2048 -b 512 --chunks 4 ) 2>&1 | tee -a $OUT/${ci}-tg-q8_0.log
(time ./bin/perplexity --model ${model_q4_0} -f ${wiki_test} -t 1 -ngl 999 -c 2048 -b 512 --chunks 4 ) 2>&1 | tee -a $OUT/${ci}-tg-q4_0.log
(time ./bin/perplexity --model ${model_q4_1} -f ${wiki_test} -t 1 -ngl 999 -c 2048 -b 512 --chunks 4 ) 2>&1 | tee -a $OUT/${ci}-tg-q4_1.log
(time ./bin/perplexity --model ${model_q5_0} -f ${wiki_test} -t 1 -ngl 999 -c 2048 -b 512 --chunks 4 ) 2>&1 | tee -a $OUT/${ci}-tg-q5_0.log
(time ./bin/perplexity --model ${model_q5_1} -f ${wiki_test} -t 1 -ngl 999 -c 2048 -b 512 --chunks 4 ) 2>&1 | tee -a $OUT/${ci}-tg-q5_1.log
(time ./bin/perplexity --model ${model_q2_k} -f ${wiki_test} -t 1 -ngl 999 -c 2048 -b 512 --chunks 4 ) 2>&1 | tee -a $OUT/${ci}-tg-q2_k.log
(time ./bin/perplexity --model ${model_q3_k} -f ${wiki_test} -t 1 -ngl 999 -c 2048 -b 512 --chunks 4 ) 2>&1 | tee -a $OUT/${ci}-tg-q3_k.log
(time ./bin/perplexity --model ${model_q4_k} -f ${wiki_test} -t 1 -ngl 999 -c 2048 -b 512 --chunks 4 ) 2>&1 | tee -a $OUT/${ci}-tg-q4_k.log
(time ./bin/perplexity --model ${model_q5_k} -f ${wiki_test} -t 1 -ngl 999 -c 2048 -b 512 --chunks 4 ) 2>&1 | tee -a $OUT/${ci}-tg-q5_k.log
(time ./bin/perplexity --model ${model_q6_k} -f ${wiki_test} -t 1 -ngl 999 -c 2048 -b 512 --chunks 4 ) 2>&1 | tee -a $OUT/${ci}-tg-q6_k.log
(time ./bin/save-load-state --model ${model_q4_0} ) 2>&1 | tee -a $OUT/${ci}-save-load-state.log
function check_ppl {
qnt="$1"
ppl=$(echo "$2" | grep -oE "[0-9]+\.[0-9]+" | tail -n 1)
if [ $(echo "$ppl > 20.0" | bc) -eq 1 ]; then
printf ' - %s @ %s (FAIL: ppl > 20.0)\n' "$qnt" "$ppl"
return 20
fi
printf ' - %s @ %s OK\n' "$qnt" "$ppl"
return 0
}
check_ppl "f16" "$(cat $OUT/${ci}-tg-f16.log | grep "^\[1\]")" | tee -a $OUT/${ci}-ppl.log
check_ppl "q8_0" "$(cat $OUT/${ci}-tg-q8_0.log | grep "^\[1\]")" | tee -a $OUT/${ci}-ppl.log
check_ppl "q4_0" "$(cat $OUT/${ci}-tg-q4_0.log | grep "^\[1\]")" | tee -a $OUT/${ci}-ppl.log
check_ppl "q4_1" "$(cat $OUT/${ci}-tg-q4_1.log | grep "^\[1\]")" | tee -a $OUT/${ci}-ppl.log
check_ppl "q5_0" "$(cat $OUT/${ci}-tg-q5_0.log | grep "^\[1\]")" | tee -a $OUT/${ci}-ppl.log
check_ppl "q5_1" "$(cat $OUT/${ci}-tg-q5_1.log | grep "^\[1\]")" | tee -a $OUT/${ci}-ppl.log
check_ppl "q2_k" "$(cat $OUT/${ci}-tg-q2_k.log | grep "^\[1\]")" | tee -a $OUT/${ci}-ppl.log
check_ppl "q3_k" "$(cat $OUT/${ci}-tg-q3_k.log | grep "^\[1\]")" | tee -a $OUT/${ci}-ppl.log
check_ppl "q4_k" "$(cat $OUT/${ci}-tg-q4_k.log | grep "^\[1\]")" | tee -a $OUT/${ci}-ppl.log
check_ppl "q5_k" "$(cat $OUT/${ci}-tg-q5_k.log | grep "^\[1\]")" | tee -a $OUT/${ci}-ppl.log
check_ppl "q6_k" "$(cat $OUT/${ci}-tg-q6_k.log | grep "^\[1\]")" | tee -a $OUT/${ci}-ppl.log
# lora
function compare_ppl {
qnt="$1"
ppl1=$(echo "$2" | grep -oE "[0-9]+\.[0-9]+" | tail -n 1)
ppl2=$(echo "$3" | grep -oE "[0-9]+\.[0-9]+" | tail -n 1)
if [ $(echo "$ppl1 < $ppl2" | bc) -eq 1 ]; then
printf ' - %s @ %s (FAIL: %s > %s)\n' "$qnt" "$ppl" "$ppl1" "$ppl2"
return 20
fi
printf ' - %s @ %s %s OK\n' "$qnt" "$ppl1" "$ppl2"
return 0
}
path_lora="../models-mnt/open-llama/7B-v2/lora"
path_shakespeare="../models-mnt/shakespeare"
shakespeare="${path_shakespeare}/shakespeare.txt"
lora_shakespeare="${path_lora}/ggml-adapter-model.bin"
gg_wget ${path_lora} https://huggingface.co/slaren/open_llama_7b_v2_shakespeare_lora/resolve/main/adapter_config.json
gg_wget ${path_lora} https://huggingface.co/slaren/open_llama_7b_v2_shakespeare_lora/resolve/main/adapter_model.bin
gg_wget ${path_shakespeare} https://huggingface.co/slaren/open_llama_7b_v2_shakespeare_lora/resolve/main/shakespeare.txt
python3 ../convert-lora-to-ggml.py ${path_lora}
# f16
(time ./bin/perplexity --model ${model_f16} -f ${shakespeare} -t 1 -ngl 999 -c 2048 -b 512 --chunks 3 ) 2>&1 | tee -a $OUT/${ci}-ppl-shakespeare-f16.log
(time ./bin/perplexity --model ${model_f16} -f ${shakespeare} --lora ${lora_shakespeare} -t 1 -ngl 999 -c 2048 -b 512 --chunks 3 ) 2>&1 | tee -a $OUT/${ci}-ppl-shakespeare-lora-f16.log
compare_ppl "f16 shakespeare" "$(cat $OUT/${ci}-ppl-shakespeare-f16.log | grep "^\[1\]")" "$(cat $OUT/${ci}-ppl-shakespeare-lora-f16.log | grep "^\[1\]")" | tee -a $OUT/${ci}-lora-ppl.log
# currently not supported by the CUDA backend
# q8_0
#(time ./bin/perplexity --model ${model_q8_0} -f ${shakespeare} -t 1 -ngl 999 -c 2048 -b 512 --chunks 3 ) 2>&1 | tee -a $OUT/${ci}-ppl-shakespeare-q8_0.log
#(time ./bin/perplexity --model ${model_q8_0} -f ${shakespeare} --lora ${lora_shakespeare} -t 1 -ngl 999 -c 2048 -b 512 --chunks 3 ) 2>&1 | tee -a $OUT/${ci}-ppl-shakespeare-lora-q8_0.log
#compare_ppl "q8_0 shakespeare" "$(cat $OUT/${ci}-ppl-shakespeare-q8_0.log | grep "^\[1\]")" "$(cat $OUT/${ci}-ppl-shakespeare-lora-q8_0.log | grep "^\[1\]")" | tee -a $OUT/${ci}-lora-ppl.log
# q8_0 + f16 lora-base
#(time ./bin/perplexity --model ${model_q8_0} -f ${shakespeare} --lora ${lora_shakespeare} --lora-base ${model_f16} -t 1 -ngl 999 -c 2048 -b 512 --chunks 3 ) 2>&1 | tee -a $OUT/${ci}-ppl-shakespeare-lora-q8_0-f16.log
#compare_ppl "q8_0 / f16 shakespeare" "$(cat $OUT/${ci}-ppl-shakespeare-q8_0.log | grep "^\[1\]")" "$(cat $OUT/${ci}-ppl-shakespeare-lora-q8_0-f16.log | grep "^\[1\]")" | tee -a $OUT/${ci}-lora-ppl.log
set +e
}
function gg_sum_open_llama_7b_v2 {
gg_printf '### %s\n\n' "${ci}"
gg_printf 'OpenLLaMA 7B-v2:\n'
gg_printf '- status: %s\n' "$(cat $OUT/${ci}.exit)"
gg_printf '- perplexity:\n%s\n' "$(cat $OUT/${ci}-ppl.log)"
gg_printf '- lora:\n%s\n' "$(cat $OUT/${ci}-lora-ppl.log)"
gg_printf '- f16: \n```\n%s\n```\n' "$(cat $OUT/${ci}-tg-f16.log)"
gg_printf '- q8_0:\n```\n%s\n```\n' "$(cat $OUT/${ci}-tg-q8_0.log)"
gg_printf '- q4_0:\n```\n%s\n```\n' "$(cat $OUT/${ci}-tg-q4_0.log)"
gg_printf '- q4_1:\n```\n%s\n```\n' "$(cat $OUT/${ci}-tg-q4_1.log)"
gg_printf '- q5_0:\n```\n%s\n```\n' "$(cat $OUT/${ci}-tg-q5_0.log)"
gg_printf '- q5_1:\n```\n%s\n```\n' "$(cat $OUT/${ci}-tg-q5_1.log)"
gg_printf '- q2_k:\n```\n%s\n```\n' "$(cat $OUT/${ci}-tg-q2_k.log)"
gg_printf '- q3_k:\n```\n%s\n```\n' "$(cat $OUT/${ci}-tg-q3_k.log)"
gg_printf '- q4_k:\n```\n%s\n```\n' "$(cat $OUT/${ci}-tg-q4_k.log)"
gg_printf '- q5_k:\n```\n%s\n```\n' "$(cat $OUT/${ci}-tg-q5_k.log)"
gg_printf '- q6_k:\n```\n%s\n```\n' "$(cat $OUT/${ci}-tg-q6_k.log)"
gg_printf '- save-load-state: \n```\n%s\n```\n' "$(cat $OUT/${ci}-save-load-state.log)"
gg_printf '- shakespeare (f16):\n```\n%s\n```\n' "$(cat $OUT/${ci}-ppl-shakespeare-f16.log)"
gg_printf '- shakespeare (f16 lora):\n```\n%s\n```\n' "$(cat $OUT/${ci}-ppl-shakespeare-lora-f16.log)"
#gg_printf '- shakespeare (q8_0):\n```\n%s\n```\n' "$(cat $OUT/${ci}-ppl-shakespeare-q8_0.log)"
#gg_printf '- shakespeare (q8_0 lora):\n```\n%s\n```\n' "$(cat $OUT/${ci}-ppl-shakespeare-lora-q8_0.log)"
#gg_printf '- shakespeare (q8_0 / f16 base lora):\n```\n%s\n```\n' "$(cat $OUT/${ci}-ppl-shakespeare-lora-q8_0-f16.log)"
}
## main
if [ -z ${GG_BUILD_LOW_PERF} ]; then
rm -rf ${SRC}/models-mnt
mnt_models=${MNT}/models
mkdir -p ${mnt_models}
ln -sfn ${mnt_models} ${SRC}/models-mnt
python3 -m pip install -r ${SRC}/requirements.txt
python3 -m pip install --editable gguf-py
fi
ret=0
test $ret -eq 0 && gg_run ctest_debug
test $ret -eq 0 && gg_run ctest_release
if [ -z ${GG_BUILD_LOW_PERF} ]; then
if [ -z ${GG_BUILD_VRAM_GB} ] || [ ${GG_BUILD_VRAM_GB} -ge 8 ]; then
if [ -z ${GG_BUILD_CUDA} ]; then
test $ret -eq 0 && gg_run open_llama_3b_v2
else
test $ret -eq 0 && gg_run open_llama_7b_v2
fi
fi
fi
exit $ret
================================================
FILE: cmake/FindSIMD.cmake
================================================
include(CheckCSourceRuns)
set(AVX_CODE "
#include <immintrin.h>
int main()
{
__m256 a;
a = _mm256_set1_ps(0);
return 0;
}
")
set(AVX512_CODE "
#include <immintrin.h>
int main()
{
__m512i a = _mm512_set_epi8(0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0);
__m512i b = a;
__mmask64 equality_mask = _mm512_cmp_epi8_mask(a, b, _MM_CMPINT_EQ);
return 0;
}
")
set(AVX2_CODE "
#include <immintrin.h>
int main()
{
__m256i a = {0};
a = _mm256_abs_epi16(a);
__m256i x;
_mm256_extract_epi64(x, 0); // we rely on this in our AVX2 code
return 0;
}
")
set(FMA_CODE "
#include <immintrin.h>
int main()
{
__m256 acc = _mm256_setzero_ps();
const __m256 d = _mm256_setzero_ps();
const __m256 p = _mm256_setzero_ps();
acc = _mm256_fmadd_ps( d, p, acc );
return 0;
}
")
macro(check_sse type flags)
set(__FLAG_I 1)
set(CMAKE_REQUIRED_FLAGS_SAVE ${CMAKE_REQUIRED_FLAGS})
foreach (__FLAG ${flags})
if (NOT ${type}_FOUND)
set(CMAKE_REQUIRED_FLAGS ${__FLAG})
check_c_source_runs("${${type}_CODE}" HAS_${type}_${__FLAG_I})
if (HAS_${type}_${__FLAG_I})
set(${type}_FOUND TRUE CACHE BOOL "${type} support")
set(${type}_FLAGS "${__FLAG}" CACHE STRING "${type} flags")
endif()
math(EXPR __FLAG_I "${__FLAG_I}+1")
endif()
endforeach()
set(CMAKE_REQUIRED_FLAGS ${CMAKE_REQUIRED_FLAGS_SAVE})
if (NOT ${type}_FOUND)
set(${type}_FOUND FALSE CACHE BOOL "${type} support")
set(${type}_FLAGS "" CACHE STRING "${type} flags")
endif()
mark_as_advanced(${type}_FOUND ${type}_FLAGS)
endmacro()
# flags are for MSVC only!
check_sse("AVX" " ;/arch:AVX")
if (NOT ${AVX_FOUND})
set(LLAMA_AVX OFF)
else()
set(LLAMA_AVX ON)
endif()
check_sse("AVX2" " ;/arch:AVX2")
check_sse("FMA" " ;/arch:AVX2")
if ((NOT ${AVX2_FOUND}) OR (NOT ${FMA_FOUND}))
set(LLAMA_AVX2 OFF)
else()
set(LLAMA_AVX2 ON)
endif()
check_sse("AVX512" " ;/arch:AVX512")
if (NOT ${AVX512_FOUND})
set(LLAMA_AVX512 OFF)
else()
set(LLAMA_AVX512 ON)
endif()
================================================
FILE: codecov.yml
================================================
comment: off
coverage:
status:
project:
default:
target: auto
threshold: 0
base: auto
patch:
default:
target: auto
threshold: 0
base: auto
================================================
FILE: common/CMakeLists.txt
================================================
# common
# Build info header
#
if(EXISTS "${CMAKE_CURRENT_SOURCE_DIR}/../.git")
set(GIT_DIR "${CMAKE_CURRENT_SOURCE_DIR}/../.git")
# Is git submodule/worktree
if(NOT IS_DIRECTORY "${GIT_DIR}")
file(READ ${GIT_DIR} REAL_GIT_DIR_LINK)
string(REGEX REPLACE "gitdir: (.*)\n$" "\\1" REAL_GIT_DIR ${REAL_GIT_DIR_LINK})
set(GIT_DIR "${REAL_GIT_DIR}")
endif()
set(GIT_INDEX "${GIT_DIR}/index")
else()
message(WARNING "Git repository not found; to enable automatic generation of build info, make sure Git is installed and the project is a Git repository.")
set(GIT_INDEX "")
endif()
# Add a custom command to rebuild build-info.cpp when .git/index changes
add_custom_command(
OUTPUT "${CMAKE_CURRENT_SOURCE_DIR}/build-info.cpp"
COMMENT "Generating build details from Git"
COMMAND ${CMAKE_COMMAND} -DMSVC=${MSVC} -DCMAKE_C_COMPILER_VERSION=${CMAKE_C_COMPILER_VERSION}
-DCMAKE_C_COMPILER_ID=${CMAKE_C_COMPILER_ID} -DCMAKE_VS_PLATFORM_NAME=${CMAKE_VS_PLATFORM_NAME}
-DCMAKE_C_COMPILER=${CMAKE_C_COMPILER} -P "${CMAKE_CURRENT_SOURCE_DIR}/../scripts/build-info.cmake"
WORKING_DIRECTORY "${CMAKE_CURRENT_SOURCE_DIR}/.."
DEPENDS "${CMAKE_CURRENT_SOURCE_DIR}/build-info.cpp.in" ${GIT_INDEX}
VERBATIM
)
set(TARGET build_info)
add_library(${TARGET} OBJECT build-info.cpp)
if (BUILD_SHARED_LIBS)
set_target_properties(${TARGET} PROPERTIES POSITION_INDEPENDENT_CODE ON)
endif()
set(TARGET common)
add_library(${TARGET} STATIC
base64.hpp
common.h
common.cpp
sampling.h
sampling.cpp
console.h
console.cpp
grammar-parser.h
grammar-parser.cpp
train.h
train.cpp
)
if (BUILD_SHARED_LIBS)
set_target_properties(${TARGET} PROPERTIES POSITION_INDEPENDENT_CODE ON)
endif()
target_include_directories(${TARGET} PUBLIC .)
target_compile_features(${TARGET} PUBLIC cxx_std_11)
target_link_libraries(${TARGET} PRIVATE llama build_info)
================================================
FILE: common/base64.hpp
================================================
/*
This is free and unencumbered software released into the public domain.
Anyone is free to copy, modify, publish, use, compile, sell, or
distribute this software, either in source code form or as a compiled
binary, for any purpose, commercial or non-commercial, and by any
means.
In jurisdictions that recognize copyright laws, the author or authors
of this software dedicate any and all copyright interest in the
software to the public domain. We make this dedication for the benefit
of the public at large and to the detriment of our heirs and
successors. We intend this dedication to be an overt act of
relinquishment in perpetuity of all present and future rights to this
software under copyright law.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND,
EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF
MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT.
IN NO EVENT SHALL THE AUTHORS BE LIABLE FOR ANY CLAIM, DAMAGES OR
OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE,
ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR
OTHER DEALINGS IN THE SOFTWARE.
For more information, please refer to <http://unlicense.org>
*/
#ifndef PUBLIC_DOMAIN_BASE64_HPP_
#define PUBLIC_DOMAIN_BASE64_HPP_
#include <cstdint>
#include <iterator>
#include <stdexcept>
#include <string>
class base64_error : public std::runtime_error
{
public:
using std::runtime_error::runtime_error;
};
class base64
{
public:
enum class alphabet
{
/** the alphabet is detected automatically */
auto_,
/** the standard base64 alphabet is used */
standard,
/** like `standard` except that the characters `+` and `/` are replaced by `-` and `_` respectively*/
url_filename_safe
};
enum class decoding_behavior
{
/** if the input is not padded, the remaining bits are ignored */
moderate,
/** if a padding character is encounter decoding is finished */
loose
};
/**
Encodes all the elements from `in_begin` to `in_end` to `out`.
@warning The source and destination cannot overlap. The destination must be able to hold at least
`required_encode_size(std::distance(in_begin, in_end))`, otherwise the behavior depends on the output iterator.
@tparam Input_iterator the source; the returned elements are cast to `std::uint8_t` and should not be greater than
8 bits
@tparam Output_iterator the destination; the elements written to it are from the type `char`
@param in_begin the beginning of the source
@param in_end the ending of the source
@param out the destination iterator
@param alphabet which alphabet should be used
@returns the iterator to the next element past the last element copied
@throws see `Input_iterator` and `Output_iterator`
*/
template<typename Input_iterator, typename Output_iterator>
static Output_iterator encode(Input_iterator in_begin, Input_iterator in_end, Output_iterator out,
alphabet alphabet = alphabet::standard)
{
constexpr auto pad = '=';
const char* alpha = alphabet == alphabet::url_filename_safe
? "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789-_"
: "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/";
while (in_begin != in_end) {
std::uint8_t i0 = 0, i1 = 0, i2 = 0;
// first character
i0 = static_cast<std::uint8_t>(*in_begin);
++in_begin;
*out = alpha[i0 >> 2 & 0x3f];
++out;
// part of first character and second
if (in_begin != in_end) {
i1 = static_cast<std::uint8_t>(*in_begin);
++in_begin;
*out = alpha[((i0 & 0x3) << 4) | (i1 >> 4 & 0x0f)];
++out;
} else {
*out = alpha[(i0 & 0x3) << 4];
++out;
// last padding
*out = pad;
++out;
// last padding
*out = pad;
++out;
break;
}
// part of second character and third
if (in_begin != in_end) {
i2 = static_cast<std::uint8_t>(*in_begin);
++in_begin;
*out = alpha[((i1 & 0xf) << 2) | (i2 >> 6 & 0x03)];
++out;
} else {
*out = alpha[(i1 & 0xf) << 2];
++out;
// last padding
*out = pad;
++out;
break;
}
// rest of third
*out = alpha[i2 & 0x3f];
++out;
}
return out;
}
/**
Encodes a string.
@param str the string that should be encoded
@param alphabet which alphabet should be used
@returns the encoded base64 string
@throws see base64::encode()
*/
static std::string encode(const std::string& str, alphabet alphabet = alphabet::standard)
{
std::string result;
result.reserve(required_encode_size(str.length()) + 1);
encode(str.begin(), str.end(), std::back_inserter(result), alphabet);
return result;
}
/**
Encodes a char array.
@param buffer the char array
@param size the size of the array
@param alphabet which alphabet should be used
@returns the encoded string
*/
static std::string encode(const char* buffer, std::size_t size, alphabet alphabet = alphabet::standard)
{
std::string result;
result.reserve(required_encode_size(size) + 1);
encode(buffer, buffer + size, std::back_inserter(result), alphabet);
return result;
}
/**
Decodes all the elements from `in_begin` to `in_end` to `out`. `in_begin` may point to the same location as `out`,
in other words: inplace decoding is possible.
@warning The destination must be able to hold at least `required_decode_size(std::distance(in_begin, in_end))`,
otherwise the behavior depends on the output iterator.
@tparam Input_iterator the source; the returned elements are cast to `char`
@tparam Output_iterator the destination; the elements written to it are from the type `std::uint8_t`
@param in_begin the beginning of the source
@param in_end the ending of the source
@param out the destination iterator
@param alphabet which alphabet should be used
@param behavior the behavior when an error was detected
@returns the iterator to the next element past the last element copied
@throws base64_error depending on the set behavior
@throws see `Input_iterator` and `Output_iterator`
*/
template<typename Input_iterator, typename Output_iterator>
static Output_iterator decode(Input_iterator in_begin, Input_iterator in_end, Output_iterator out,
alphabet alphabet = alphabet::auto_,
decoding_behavior behavior = decoding_behavior::moderate)
{
//constexpr auto pad = '=';
std::uint8_t last = 0;
auto bits = 0;
while (in_begin != in_end) {
auto c = *in_begin;
++in_begin;
if (c == '=') {
break;
}
auto part = _base64_value(alphabet, c);
// enough bits for one byte
if (bits + 6 >= 8) {
*out = (last << (8 - bits)) | (part >> (bits - 2));
++out;
bits -= 2;
} else {
bits += 6;
}
last = part;
}
// check padding
if (behavior != decoding_behavior::loose) {
while (in_begin != in_end) {
auto c = *in_begin;
++in_begin;
if (c != '=') {
throw base64_error("invalid base64 character.");
}
}
}
return out;
}
/**
Decodes a string.
@param str the base64 encoded string
@param alphabet which alphabet should be used
@param behavior the behavior when an error was detected
@returns the decoded string
@throws see base64::decode()
*/
static std::string decode(const std::string& str, alphabet alphabet = alphabet::auto_,
decoding_behavior behavior = decoding_behavior::moderate)
{
std::string result;
result.reserve(max_decode_size(str.length()));
decode(str.begin(), str.end(), std::back_inserter(result), alphabet, behavior);
return result;
}
/**
Decodes a string.
@param buffer the base64 encoded buffer
@param size the size of the buffer
@param alphabet which alphabet should be used
@param behavior the behavior when an error was detected
@returns the decoded string
@throws see base64::decode()
*/
static std::string decode(const char* buffer, std::size_t size, alphabet alphabet = alphabet::auto_,
decoding_behavior behavior = decoding_behavior::moderate)
{
std::string result;
result.reserve(max_decode_size(size));
decode(buffer, buffer + size, std::back_inserter(result), alphabet, behavior);
return result;
}
/**
Decodes a string inplace.
@param[in,out] str the base64 encoded string
@param alphabet which alphabet should be used
@param behavior the behavior when an error was detected
@throws base64::decode_inplace()
*/
static void decode_inplace(std::string& str, alphabet alphabet = alphabet::auto_,
decoding_behavior behavior = decoding_behavior::moderate)
{
str.resize(decode(str.begin(), str.end(), str.begin(), alphabet, behavior) - str.begin());
}
/**
Decodes a char array inplace.
@param[in,out] str the string array
@param size the length of the array
@param alphabet which alphabet should be used
@param behavior the behavior when an error was detected
@returns the pointer to the next element past the last element decoded
@throws base64::decode_inplace()
*/
static char* decode_inplace(char* str, std::size_t size, alphabet alphabet = alphabet::auto_,
decoding_behavior behavior = decoding_behavior::moderate)
{
return decode(str, str + size, str, alphabet, behavior);
}
/**
Returns the required decoding size for a given size. The value is calculated with the following formula:
$$
\lceil \frac{size}{4} \rceil \cdot 3
$$
@param size the size of the encoded input
@returns the size of the resulting decoded buffer; this the absolute maximum
*/
static std::size_t max_decode_size(std::size_t size) noexcept
{
return (size / 4 + (size % 4 ? 1 : 0)) * 3;
}
/**
Returns the required encoding size for a given size. The value is calculated with the following formula:
$$
\lceil \frac{size}{3} \rceil \cdot 4
$
gitextract_pvz9t_lh/ ├── .devops/ │ ├── cloud-v-pipeline │ ├── full-cuda.Dockerfile │ ├── full-rocm.Dockerfile │ ├── full.Dockerfile │ ├── llama-cpp-clblast.srpm.spec │ ├── llama-cpp-cublas.srpm.spec │ ├── llama-cpp.srpm.spec │ ├── main-cuda.Dockerfile │ ├── main-rocm.Dockerfile │ ├── main.Dockerfile │ └── tools.sh ├── .dockerignore ├── .ecrc ├── .editorconfig ├── .flake8 ├── .github/ │ ├── ISSUE_TEMPLATE/ │ │ ├── bug.md │ │ ├── enhancement.md │ │ └── question.md │ └── workflows/ │ ├── build.yml │ ├── code-coverage.yml │ ├── docker.yml │ ├── editorconfig.yml │ ├── gguf-publish.yml │ ├── tidy-post.yml │ ├── tidy-review.yml │ └── zig-build.yml ├── .gitignore ├── .gitmodules ├── .pre-commit-config.yaml ├── CMakeLists.txt ├── LICENSE ├── Package.swift ├── README.md ├── SHA256SUMS ├── atomic_windows.h ├── build.zig ├── ci/ │ ├── README.md │ └── run.sh ├── cmake/ │ └── FindSIMD.cmake ├── codecov.yml ├── common/ │ ├── CMakeLists.txt │ ├── base64.hpp │ ├── build-info.cpp.in │ ├── common.cpp │ ├── common.h │ ├── console.cpp │ ├── console.h │ ├── grammar-parser.cpp │ ├── grammar-parser.h │ ├── log.h │ ├── sampling.cpp │ ├── sampling.h │ ├── stb_image.h │ ├── train.cpp │ └── train.h ├── convert-dense.py ├── convert-hf-to-powerinfer-gguf.py ├── convert.py ├── docs/ │ ├── BLIS.md │ └── token_generation_performance_tips.md ├── examples/ │ ├── CMakeLists.txt │ ├── Miku.sh │ ├── alpaca.sh │ ├── baby-llama/ │ │ ├── CMakeLists.txt │ │ └── baby-llama.cpp │ ├── batched/ │ │ ├── CMakeLists.txt │ │ ├── README.md │ │ └── batched.cpp │ ├── batched-bench/ │ │ ├── CMakeLists.txt │ │ ├── README.md │ │ └── batched-bench.cpp │ ├── batched.swift/ │ │ ├── .gitignore │ │ ├── Makefile │ │ ├── Package.swift │ │ ├── README.md │ │ └── Sources/ │ │ └── main.swift │ ├── beam-search/ │ │ ├── CMakeLists.txt │ │ └── beam-search.cpp │ ├── benchmark/ │ │ ├── CMakeLists.txt │ │ └── benchmark-matmult.cpp │ ├── chat-13B.sh │ ├── chat-persistent.sh │ ├── chat-vicuna.sh │ ├── chat.sh │ ├── convert-llama2c-to-ggml/ │ │ ├── CMakeLists.txt │ │ ├── README.md │ │ └── convert-llama2c-to-ggml.cpp │ ├── embedding/ │ │ ├── CMakeLists.txt │ │ ├── README.md │ │ └── embedding.cpp │ ├── export-lora/ │ │ ├── CMakeLists.txt │ │ ├── README.md │ │ └── export-lora.cpp │ ├── finetune/ │ │ ├── CMakeLists.txt │ │ ├── README.md │ │ ├── convert-finetune-checkpoint-to-gguf.py │ │ ├── finetune.cpp │ │ └── finetune.sh │ ├── gguf/ │ │ ├── CMakeLists.txt │ │ └── gguf.cpp │ ├── gpt4all.sh │ ├── infill/ │ │ ├── CMakeLists.txt │ │ ├── README.md │ │ └── infill.cpp │ ├── jeopardy/ │ │ ├── README.md │ │ ├── graph.py │ │ ├── jeopardy.sh │ │ ├── qasheet.csv │ │ └── questions.txt │ ├── json-schema-to-grammar.py │ ├── llama-bench/ │ │ ├── CMakeLists.txt │ │ ├── README.md │ │ └── llama-bench.cpp │ ├── llama.vim │ ├── llama2-13b.sh │ ├── llama2.sh │ ├── llava/ │ │ ├── CMakeLists.txt │ │ ├── README.md │ │ ├── clip.cpp │ │ ├── clip.h │ │ ├── convert-image-encoder-to-gguf.py │ │ ├── llava-cli.cpp │ │ ├── llava-surgery.py │ │ ├── llava.cpp │ │ └── llava.h │ ├── llm.vim │ ├── main/ │ │ ├── CMakeLists.txt │ │ ├── README.md │ │ └── main.cpp │ ├── main-cmake-pkg/ │ │ ├── .gitignore │ │ ├── CMakeLists.txt │ │ └── README.md │ ├── make-ggml.py │ ├── metal/ │ │ ├── CMakeLists.txt │ │ └── metal.cpp │ ├── parallel/ │ │ ├── CMakeLists.txt │ │ ├── README.md │ │ └── parallel.cpp │ ├── perplexity/ │ │ ├── CMakeLists.txt │ │ ├── README.md │ │ └── perplexity.cpp │ ├── quantize/ │ │ ├── CMakeLists.txt │ │ ├── README.md │ │ └── quantize.cpp │ ├── quantize-stats/ │ │ ├── CMakeLists.txt │ │ └── quantize-stats.cpp │ ├── reason-act.sh │ ├── save-load-state/ │ │ ├── CMakeLists.txt │ │ └── save-load-state.cpp │ ├── server/ │ │ ├── CMakeLists.txt │ │ ├── README.md │ │ ├── api_like_OAI.py │ │ ├── chat-llama2.sh │ │ ├── chat.mjs │ │ ├── chat.sh │ │ ├── completion.js.hpp │ │ ├── deps.sh │ │ ├── httplib.h │ │ ├── index.html.hpp │ │ ├── index.js.hpp │ │ ├── json-schema-to-grammar.mjs.hpp │ │ ├── json.hpp │ │ ├── public/ │ │ │ ├── completion.js │ │ │ ├── index.html │ │ │ ├── index.js │ │ │ └── json-schema-to-grammar.mjs │ │ └── server.cpp │ ├── server-llama2-13B.sh │ ├── simple/ │ │ ├── CMakeLists.txt │ │ ├── README.md │ │ └── simple.cpp │ ├── speculative/ │ │ ├── CMakeLists.txt │ │ └── speculative.cpp │ └── train-text-from-scratch/ │ ├── CMakeLists.txt │ ├── README.md │ ├── convert-train-checkpoint-to-gguf.py │ └── train-text-from-scratch.cpp ├── flake.nix ├── ggml-alloc.c ├── ggml-alloc.h ├── ggml-backend-impl.h ├── ggml-backend.c ├── ggml-backend.h ├── ggml-cuda.cu ├── ggml-cuda.h ├── ggml-impl.h ├── ggml-metal.h ├── ggml-metal.m ├── ggml-metal.metal ├── ggml-mpi.c ├── ggml-mpi.h ├── ggml-opencl.cpp ├── ggml-opencl.h ├── ggml-quants.c ├── ggml-quants.h ├── ggml.c ├── ggml.h ├── gguf-py/ │ ├── LICENSE │ ├── README.md │ ├── examples/ │ │ └── writer.py │ ├── gguf/ │ │ ├── __init__.py │ │ ├── constants.py │ │ ├── gguf.py │ │ ├── gguf_reader.py │ │ ├── gguf_writer.py │ │ ├── py.typed │ │ ├── tensor_mapping.py │ │ └── vocab.py │ ├── pyproject.toml │ ├── scripts/ │ │ ├── __init__.py │ │ ├── gguf-convert-endian.py │ │ ├── gguf-dump.py │ │ └── gguf-set-metadata.py │ └── tests/ │ └── test_gguf.py ├── grammars/ │ ├── README.md │ ├── arithmetic.gbnf │ ├── c.gbnf │ ├── chess.gbnf │ ├── japanese.gbnf │ ├── json.gbnf │ ├── json_arr.gbnf │ └── list.gbnf ├── llama.cpp ├── llama.h ├── mypy.ini ├── pocs/ │ ├── CMakeLists.txt │ └── vdot/ │ ├── CMakeLists.txt │ ├── q8dot.cpp │ └── vdot.cpp ├── powerinfer-py/ │ ├── powerinfer/ │ │ ├── __init__.py │ │ ├── __main__.py │ │ ├── export_split.py │ │ └── solver.py │ └── pyproject.toml ├── prompts/ │ ├── LLM-questions.txt │ ├── alpaca.txt │ ├── assistant.txt │ ├── chat-with-baichuan.txt │ ├── chat-with-bob.txt │ ├── chat-with-vicuna-v0.txt │ ├── chat-with-vicuna-v1.txt │ ├── chat.txt │ ├── dan-modified.txt │ ├── dan.txt │ ├── mnemonics.txt │ ├── parallel-questions.txt │ └── reason-act.txt ├── requirements.txt ├── run_with_preset.py ├── scripts/ │ ├── LlamaConfig.cmake.in │ ├── build-info.cmake │ ├── build-info.sh │ ├── convert-gg.sh │ ├── get-wikitext-2.sh │ ├── qnt-all.sh │ ├── run-all-perf.sh │ ├── run-all-ppl.sh │ ├── server-llm.sh │ ├── sync-ggml.sh │ └── verify-checksum-models.py ├── smallthinker/ │ ├── AUTHORS │ ├── CMakeLists.txt │ ├── CMakePresets.json │ ├── CODEOWNERS │ ├── CONTRIBUTING.md │ ├── LICENSE │ ├── Makefile │ ├── README.md │ ├── SECURITY.md │ ├── build-xcframework.sh │ ├── ci/ │ │ ├── README.md │ │ └── run.sh │ ├── cmake/ │ │ ├── arm64-apple-clang.cmake │ │ ├── arm64-windows-llvm.cmake │ │ ├── build-info.cmake │ │ ├── common.cmake │ │ ├── git-vars.cmake │ │ ├── llama-config.cmake.in │ │ ├── llama.pc.in │ │ └── x64-windows-llvm.cmake │ ├── common/ │ │ ├── CMakeLists.txt │ │ ├── arg.cpp │ │ ├── arg.h │ │ ├── base64.hpp │ │ ├── build-info.cpp.in │ │ ├── chat-parser.cpp │ │ ├── chat-parser.h │ │ ├── chat.cpp │ │ ├── chat.h │ │ ├── cmake/ │ │ │ └── build-info-gen-cpp.cmake │ │ ├── common.cpp │ │ ├── common.h │ │ ├── console.cpp │ │ ├── console.h │ │ ├── json-partial.cpp │ │ ├── json-partial.h │ │ ├── json-schema-to-grammar.cpp │ │ ├── json-schema-to-grammar.h │ │ ├── llguidance.cpp │ │ ├── log.cpp │ │ ├── log.h │ │ ├── ngram-cache.cpp │ │ ├── ngram-cache.h │ │ ├── regex-partial.cpp │ │ ├── regex-partial.h │ │ ├── sampling.cpp │ │ ├── sampling.h │ │ ├── speculative.cpp │ │ └── speculative.h │ ├── convert_hf_to_gguf.py │ ├── convert_hf_to_gguf_update.py │ ├── convert_llama_ggml_to_gguf.py │ ├── convert_lora_to_gguf.py │ ├── docs/ │ │ ├── android.md │ │ ├── backend/ │ │ │ ├── BLIS.md │ │ │ ├── CANN.md │ │ │ ├── CUDA-FEDORA.md │ │ │ ├── OPENCL.md │ │ │ └── SYCL.md │ │ ├── build.md │ │ ├── development/ │ │ │ ├── HOWTO-add-model.md │ │ │ ├── debugging-tests.md │ │ │ ├── llama-star/ │ │ │ │ └── idea-arch.key │ │ │ └── token_generation_performance_tips.md │ │ ├── docker.md │ │ ├── function-calling.md │ │ ├── install.md │ │ ├── llguidance.md │ │ ├── multimodal/ │ │ │ ├── MobileVLM.md │ │ │ ├── gemma3.md │ │ │ ├── glmedge.md │ │ │ ├── granitevision.md │ │ │ ├── llava.md │ │ │ ├── minicpmo2.6.md │ │ │ ├── minicpmv2.5.md │ │ │ └── minicpmv2.6.md │ │ └── multimodal.md │ ├── examples/ │ │ ├── CMakeLists.txt │ │ ├── Miku.sh │ │ ├── batched/ │ │ │ ├── CMakeLists.txt │ │ │ ├── README.md │ │ │ └── batched.cpp │ │ ├── batched.swift/ │ │ │ ├── .gitignore │ │ │ ├── Makefile │ │ │ ├── Package.swift │ │ │ ├── README.md │ │ │ └── Sources/ │ │ │ └── main.swift │ │ ├── chat-13B.sh │ │ ├── chat-persistent.sh │ │ ├── chat-vicuna.sh │ │ ├── chat.sh │ │ ├── convert-llama2c-to-ggml/ │ │ │ ├── CMakeLists.txt │ │ │ ├── README.md │ │ │ └── convert-llama2c-to-ggml.cpp │ │ ├── convert_legacy_llama.py │ │ ├── deprecation-warning/ │ │ │ ├── README.md │ │ │ └── deprecation-warning.cpp │ │ ├── embedding/ │ │ │ ├── CMakeLists.txt │ │ │ ├── README.md │ │ │ └── embedding.cpp │ │ ├── eval-callback/ │ │ │ ├── CMakeLists.txt │ │ │ ├── README.md │ │ │ └── eval-callback.cpp │ │ ├── gen-docs/ │ │ │ ├── CMakeLists.txt │ │ │ └── gen-docs.cpp │ │ ├── gguf/ │ │ │ ├── CMakeLists.txt │ │ │ └── gguf.cpp │ │ ├── gguf-hash/ │ │ │ ├── CMakeLists.txt │ │ │ ├── README.md │ │ │ ├── deps/ │ │ │ │ ├── rotate-bits/ │ │ │ │ │ ├── package.json │ │ │ │ │ └── rotate-bits.h │ │ │ │ ├── sha1/ │ │ │ │ │ ├── package.json │ │ │ │ │ ├── sha1.c │ │ │ │ │ └── sha1.h │ │ │ │ ├── sha256/ │ │ │ │ │ ├── package.json │ │ │ │ │ ├── sha256.c │ │ │ │ │ └── sha256.h │ │ │ │ └── xxhash/ │ │ │ │ ├── clib.json │ │ │ │ ├── xxhash.c │ │ │ │ └── xxhash.h │ │ │ └── gguf-hash.cpp │ │ ├── gritlm/ │ │ │ ├── CMakeLists.txt │ │ │ ├── README.md │ │ │ └── gritlm.cpp │ │ ├── jeopardy/ │ │ │ ├── README.md │ │ │ ├── graph.py │ │ │ ├── jeopardy.sh │ │ │ ├── qasheet.csv │ │ │ └── questions.txt │ │ ├── json_schema_pydantic_example.py │ │ ├── json_schema_to_grammar.py │ │ ├── llama.android/ │ │ │ ├── .gitignore │ │ │ ├── README.md │ │ │ ├── app/ │ │ │ │ ├── .gitignore │ │ │ │ ├── build.gradle.kts │ │ │ │ ├── proguard-rules.pro │ │ │ │ └── src/ │ │ │ │ └── main/ │ │ │ │ ├── AndroidManifest.xml │ │ │ │ ├── java/ │ │ │ │ │ └── com/ │ │ │ │ │ └── example/ │ │ │ │ │ └── llama/ │ │ │ │ │ ├── Downloadable.kt │ │ │ │ │ ├── MainActivity.kt │ │ │ │ │ ├── MainViewModel.kt │ │ │ │ │ └── ui/ │ │ │ │ │ └── theme/ │ │ │ │ │ ├── Color.kt │ │ │ │ │ ├── Theme.kt │ │ │ │ │ └── Type.kt │ │ │ │ └── res/ │ │ │ │ ├── drawable/ │ │ │ │ │ ├── ic_launcher_background.xml │ │ │ │ │ └── ic_launcher_foreground.xml │ │ │ │ ├── mipmap-anydpi/ │ │ │ │ │ ├── ic_launcher.xml │ │ │ │ │ └── ic_launcher_round.xml │ │ │ │ ├── values/ │ │ │ │ │ ├── colors.xml │ │ │ │ │ ├── strings.xml │ │ │ │ │ └── themes.xml │ │ │ │ └── xml/ │ │ │ │ ├── backup_rules.xml │ │ │ │ └── data_extraction_rules.xml │ │ │ ├── build.gradle.kts │ │ │ ├── gradle/ │ │ │ │ └── wrapper/ │ │ │ │ ├── gradle-wrapper.jar │ │ │ │ └── gradle-wrapper.properties │ │ │ ├── gradle.properties │ │ │ ├── gradlew │ │ │ ├── llama/ │ │ │ │ ├── .gitignore │ │ │ │ ├── build.gradle.kts │ │ │ │ ├── consumer-rules.pro │ │ │ │ ├── proguard-rules.pro │ │ │ │ └── src/ │ │ │ │ ├── androidTest/ │ │ │ │ │ └── java/ │ │ │ │ │ └── android/ │ │ │ │ │ └── llama/ │ │ │ │ │ └── cpp/ │ │ │ │ │ └── ExampleInstrumentedTest.kt │ │ │ │ ├── main/ │ │ │ │ │ ├── AndroidManifest.xml │ │ │ │ │ ├── cpp/ │ │ │ │ │ │ ├── CMakeLists.txt │ │ │ │ │ │ └── llama-android.cpp │ │ │ │ │ └── java/ │ │ │ │ │ └── android/ │ │ │ │ │ └── llama/ │ │ │ │ │ └── cpp/ │ │ │ │ │ └── LLamaAndroid.kt │ │ │ │ └── test/ │ │ │ │ └── java/ │ │ │ │ └── android/ │ │ │ │ └── llama/ │ │ │ │ └── cpp/ │ │ │ │ └── ExampleUnitTest.kt │ │ │ └── settings.gradle.kts │ │ ├── llama.swiftui/ │ │ │ ├── .gitignore │ │ │ ├── README.md │ │ │ ├── llama.cpp.swift/ │ │ │ │ └── LibLlama.swift │ │ │ ├── llama.swiftui/ │ │ │ │ ├── Assets.xcassets/ │ │ │ │ │ ├── AppIcon.appiconset/ │ │ │ │ │ │ └── Contents.json │ │ │ │ │ └── Contents.json │ │ │ │ ├── Models/ │ │ │ │ │ └── LlamaState.swift │ │ │ │ ├── Resources/ │ │ │ │ │ └── models/ │ │ │ │ │ └── .gitignore │ │ │ │ ├── UI/ │ │ │ │ │ ├── ContentView.swift │ │ │ │ │ ├── DownloadButton.swift │ │ │ │ │ ├── InputButton.swift │ │ │ │ │ └── LoadCustomButton.swift │ │ │ │ └── llama_swiftuiApp.swift │ │ │ └── llama.swiftui.xcodeproj/ │ │ │ ├── project.pbxproj │ │ │ └── project.xcworkspace/ │ │ │ └── contents.xcworkspacedata │ │ ├── llama.vim │ │ ├── llm.vim │ │ ├── lookahead/ │ │ │ ├── CMakeLists.txt │ │ │ ├── README.md │ │ │ └── lookahead.cpp │ │ ├── lookup/ │ │ │ ├── CMakeLists.txt │ │ │ ├── README.md │ │ │ ├── lookup-create.cpp │ │ │ ├── lookup-merge.cpp │ │ │ ├── lookup-stats.cpp │ │ │ └── lookup.cpp │ │ ├── parallel/ │ │ │ ├── CMakeLists.txt │ │ │ ├── README.md │ │ │ └── parallel.cpp │ │ ├── passkey/ │ │ │ ├── CMakeLists.txt │ │ │ ├── README.md │ │ │ └── passkey.cpp │ │ ├── pydantic_models_to_grammar.py │ │ ├── pydantic_models_to_grammar_examples.py │ │ ├── reason-act.sh │ │ ├── regex_to_grammar.py │ │ ├── retrieval/ │ │ │ ├── CMakeLists.txt │ │ │ ├── README.md │ │ │ └── retrieval.cpp │ │ ├── save-load-state/ │ │ │ ├── CMakeLists.txt │ │ │ └── save-load-state.cpp │ │ ├── server-llama2-13B.sh │ │ ├── server_embd.py │ │ ├── simple/ │ │ │ ├── CMakeLists.txt │ │ │ ├── README.md │ │ │ └── simple.cpp │ │ ├── simple-chat/ │ │ │ ├── CMakeLists.txt │ │ │ ├── README.md │ │ │ └── simple-chat.cpp │ │ ├── simple-cmake-pkg/ │ │ │ ├── .gitignore │ │ │ ├── CMakeLists.txt │ │ │ └── README.md │ │ ├── speculative/ │ │ │ ├── CMakeLists.txt │ │ │ ├── README.md │ │ │ └── speculative.cpp │ │ ├── speculative-simple/ │ │ │ ├── CMakeLists.txt │ │ │ ├── README.md │ │ │ └── speculative-simple.cpp │ │ ├── sycl/ │ │ │ ├── CMakeLists.txt │ │ │ ├── README.md │ │ │ ├── build.sh │ │ │ ├── ls-sycl-device.cpp │ │ │ ├── run-llama2.sh │ │ │ └── run-llama3.sh │ │ ├── training/ │ │ │ ├── CMakeLists.txt │ │ │ ├── README.md │ │ │ └── finetune.cpp │ │ └── ts-type-to-grammar.sh │ ├── flake.nix │ ├── get_no_moe_weights_ffn.py │ ├── ggml/ │ │ ├── .gitignore │ │ ├── CMakeLists.txt │ │ ├── cmake/ │ │ │ ├── GitVars.cmake │ │ │ ├── common.cmake │ │ │ └── ggml-config.cmake.in │ │ ├── include/ │ │ │ ├── .clang-format │ │ │ ├── ggml-alloc.h │ │ │ ├── ggml-backend.h │ │ │ ├── ggml-blas.h │ │ │ ├── ggml-cann.h │ │ │ ├── ggml-cpp.h │ │ │ ├── ggml-cpu.h │ │ │ ├── ggml-cuda.h │ │ │ ├── ggml-kompute.h │ │ │ ├── ggml-metal.h │ │ │ ├── ggml-opencl.h │ │ │ ├── ggml-opt.h │ │ │ ├── ggml-rpc.h │ │ │ ├── ggml-sycl.h │ │ │ ├── ggml-vulkan.h │ │ │ ├── ggml.h │ │ │ └── gguf.h │ │ └── src/ │ │ ├── .clang-format │ │ ├── CMakeLists.txt │ │ ├── ggml-alloc.c │ │ ├── ggml-backend-impl.h │ │ ├── ggml-backend-reg.cpp │ │ ├── ggml-backend.cpp │ │ ├── ggml-blas/ │ │ │ ├── CMakeLists.txt │ │ │ └── ggml-blas.cpp │ │ ├── ggml-cann/ │ │ │ ├── CMakeLists.txt │ │ │ ├── Doxyfile │ │ │ ├── acl_tensor.cpp │ │ │ ├── acl_tensor.h │ │ │ ├── aclnn_ops.cpp │ │ │ ├── aclnn_ops.h │ │ │ ├── common.h │ │ │ └── ggml-cann.cpp │ │ ├── ggml-common.h │ │ ├── ggml-cpu/ │ │ │ ├── CMakeLists.txt │ │ │ ├── amx/ │ │ │ │ ├── amx.cpp │ │ │ │ ├── amx.h │ │ │ │ ├── common.h │ │ │ │ ├── mmq.cpp │ │ │ │ └── mmq.h │ │ │ ├── binary-ops.cpp │ │ │ ├── binary-ops.h │ │ │ ├── cmake/ │ │ │ │ └── FindSIMD.cmake │ │ │ ├── common.h │ │ │ ├── cpu-feats-x86.cpp │ │ │ ├── ggml-cpu-aarch64.cpp │ │ │ ├── ggml-cpu-aarch64.h │ │ │ ├── ggml-cpu-hbm.cpp │ │ │ ├── ggml-cpu-hbm.h │ │ │ ├── ggml-cpu-impl.h │ │ │ ├── ggml-cpu-quants.c │ │ │ ├── ggml-cpu-quants.h │ │ │ ├── ggml-cpu-traits.cpp │ │ │ ├── ggml-cpu-traits.h │ │ │ ├── ggml-cpu.c │ │ │ ├── ggml-cpu.cpp │ │ │ ├── kleidiai/ │ │ │ │ ├── kernels.cpp │ │ │ │ ├── kernels.h │ │ │ │ ├── kleidiai.cpp │ │ │ │ └── kleidiai.h │ │ │ ├── llamafile/ │ │ │ │ ├── sgemm.cpp │ │ │ │ └── sgemm.h │ │ │ ├── ops.cpp │ │ │ ├── ops.h │ │ │ ├── simd-mappings.h │ │ │ ├── unary-ops.cpp │ │ │ ├── unary-ops.h │ │ │ ├── vec.cpp │ │ │ └── vec.h │ │ ├── ggml-cuda/ │ │ │ ├── CMakeLists.txt │ │ │ ├── acc.cu │ │ │ ├── acc.cuh │ │ │ ├── arange.cu │ │ │ ├── arange.cuh │ │ │ ├── argmax.cu │ │ │ ├── argmax.cuh │ │ │ ├── argsort.cu │ │ │ ├── argsort.cuh │ │ │ ├── binbcast.cu │ │ │ ├── binbcast.cuh │ │ │ ├── clamp.cu │ │ │ ├── clamp.cuh │ │ │ ├── common.cuh │ │ │ ├── concat.cu │ │ │ ├── concat.cuh │ │ │ ├── conv-transpose-1d.cu │ │ │ ├── conv-transpose-1d.cuh │ │ │ ├── convert.cu │ │ │ ├── convert.cuh │ │ │ ├── count-equal.cu │ │ │ ├── count-equal.cuh │ │ │ ├── cp-async.cuh │ │ │ ├── cpy.cu │ │ │ ├── cpy.cuh │ │ │ ├── cross-entropy-loss.cu │ │ │ ├── cross-entropy-loss.cuh │ │ │ ├── dequantize.cuh │ │ │ ├── diagmask.cu │ │ │ ├── diagmask.cuh │ │ │ ├── fattn-common.cuh │ │ │ ├── fattn-mma-f16.cuh │ │ │ ├── fattn-tile-f16.cu │ │ │ ├── fattn-tile-f16.cuh │ │ │ ├── fattn-tile-f32.cu │ │ │ ├── fattn-tile-f32.cuh │ │ │ ├── fattn-vec-f16.cuh │ │ │ ├── fattn-vec-f32.cuh │ │ │ ├── fattn-wmma-f16.cu │ │ │ ├── fattn-wmma-f16.cuh │ │ │ ├── fattn.cu │ │ │ ├── fattn.cuh │ │ │ ├── getrows.cu │ │ │ ├── getrows.cuh │ │ │ ├── ggml-cuda.cu │ │ │ ├── gla.cu │ │ │ ├── gla.cuh │ │ │ ├── im2col.cu │ │ │ ├── im2col.cuh │ │ │ ├── mma.cuh │ │ │ ├── mmq.cu │ │ │ ├── mmq.cuh │ │ │ ├── mmv.cu │ │ │ ├── mmv.cuh │ │ │ ├── mmvq.cu │ │ │ ├── mmvq.cuh │ │ │ ├── norm.cu │ │ │ ├── norm.cuh │ │ │ ├── opt-step-adamw.cu │ │ │ ├── opt-step-adamw.cuh │ │ │ ├── out-prod.cu │ │ │ ├── out-prod.cuh │ │ │ ├── pad.cu │ │ │ ├── pad.cuh │ │ │ ├── pool2d.cu │ │ │ ├── pool2d.cuh │ │ │ ├── quantize.cu │ │ │ ├── quantize.cuh │ │ │ ├── rope.cu │ │ │ ├── rope.cuh │ │ │ ├── scale.cu │ │ │ ├── scale.cuh │ │ │ ├── softmax.cu │ │ │ ├── softmax.cuh │ │ │ ├── ssm-conv.cu │ │ │ ├── ssm-conv.cuh │ │ │ ├── ssm-scan.cu │ │ │ ├── ssm-scan.cuh │ │ │ ├── sum.cu │ │ │ ├── sum.cuh │ │ │ ├── sumrows.cu │ │ │ ├── sumrows.cuh │ │ │ ├── template-instances/ │ │ │ │ ├── fattn-mma-f16-instance-ncols1_1-ncols2_16.cu │ │ │ │ ├── fattn-mma-f16-instance-ncols1_1-ncols2_8.cu │ │ │ │ ├── fattn-mma-f16-instance-ncols1_16-ncols2_1.cu │ │ │ │ ├── fattn-mma-f16-instance-ncols1_16-ncols2_2.cu │ │ │ │ ├── fattn-mma-f16-instance-ncols1_16-ncols2_4.cu │ │ │ │ ├── fattn-mma-f16-instance-ncols1_2-ncols2_16.cu │ │ │ │ ├── fattn-mma-f16-instance-ncols1_2-ncols2_4.cu │ │ │ │ ├── fattn-mma-f16-instance-ncols1_2-ncols2_8.cu │ │ │ │ ├── fattn-mma-f16-instance-ncols1_32-ncols2_1.cu │ │ │ │ ├── fattn-mma-f16-instance-ncols1_32-ncols2_2.cu │ │ │ │ ├── fattn-mma-f16-instance-ncols1_4-ncols2_16.cu │ │ │ │ ├── fattn-mma-f16-instance-ncols1_4-ncols2_2.cu │ │ │ │ ├── fattn-mma-f16-instance-ncols1_4-ncols2_4.cu │ │ │ │ ├── fattn-mma-f16-instance-ncols1_4-ncols2_8.cu │ │ │ │ ├── fattn-mma-f16-instance-ncols1_64-ncols2_1.cu │ │ │ │ ├── fattn-mma-f16-instance-ncols1_8-ncols2_1.cu │ │ │ │ ├── fattn-mma-f16-instance-ncols1_8-ncols2_2.cu │ │ │ │ ├── fattn-mma-f16-instance-ncols1_8-ncols2_4.cu │ │ │ │ ├── fattn-mma-f16-instance-ncols1_8-ncols2_8.cu │ │ │ │ ├── fattn-vec-f16-instance-hs128-f16-f16.cu │ │ │ │ ├── fattn-vec-f16-instance-hs128-f16-q4_0.cu │ │ │ │ ├── fattn-vec-f16-instance-hs128-f16-q4_1.cu │ │ │ │ ├── fattn-vec-f16-instance-hs128-f16-q5_0.cu │ │ │ │ ├── fattn-vec-f16-instance-hs128-f16-q5_1.cu │ │ │ │ ├── fattn-vec-f16-instance-hs128-f16-q8_0.cu │ │ │ │ ├── fattn-vec-f16-instance-hs128-q4_0-f16.cu │ │ │ │ ├── fattn-vec-f16-instance-hs128-q4_0-q4_0.cu │ │ │ │ ├── fattn-vec-f16-instance-hs128-q4_0-q4_1.cu │ │ │ │ ├── fattn-vec-f16-instance-hs128-q4_0-q5_0.cu │ │ │ │ ├── fattn-vec-f16-instance-hs128-q4_0-q5_1.cu │ │ │ │ ├── fattn-vec-f16-instance-hs128-q4_0-q8_0.cu │ │ │ │ ├── fattn-vec-f16-instance-hs128-q4_1-f16.cu │ │ │ │ ├── fattn-vec-f16-instance-hs128-q4_1-q4_0.cu │ │ │ │ ├── fattn-vec-f16-instance-hs128-q4_1-q4_1.cu │ │ │ │ ├── fattn-vec-f16-instance-hs128-q4_1-q5_0.cu │ │ │ │ ├── fattn-vec-f16-instance-hs128-q4_1-q5_1.cu │ │ │ │ ├── fattn-vec-f16-instance-hs128-q4_1-q8_0.cu │ │ │ │ ├── fattn-vec-f16-instance-hs128-q5_0-f16.cu │ │ │ │ ├── fattn-vec-f16-instance-hs128-q5_0-q4_0.cu │ │ │ │ ├── fattn-vec-f16-instance-hs128-q5_0-q4_1.cu │ │ │ │ ├── fattn-vec-f16-instance-hs128-q5_0-q5_0.cu │ │ │ │ ├── fattn-vec-f16-instance-hs128-q5_0-q5_1.cu │ │ │ │ ├── fattn-vec-f16-instance-hs128-q5_0-q8_0.cu │ │ │ │ ├── fattn-vec-f16-instance-hs128-q5_1-f16.cu │ │ │ │ ├── fattn-vec-f16-instance-hs128-q5_1-q4_0.cu │ │ │ │ ├── fattn-vec-f16-instance-hs128-q5_1-q4_1.cu │ │ │ │ ├── fattn-vec-f16-instance-hs128-q5_1-q5_0.cu │ │ │ │ ├── fattn-vec-f16-instance-hs128-q5_1-q5_1.cu │ │ │ │ ├── fattn-vec-f16-instance-hs128-q5_1-q8_0.cu │ │ │ │ ├── fattn-vec-f16-instance-hs128-q8_0-f16.cu │ │ │ │ ├── fattn-vec-f16-instance-hs128-q8_0-q4_0.cu │ │ │ │ ├── fattn-vec-f16-instance-hs128-q8_0-q4_1.cu │ │ │ │ ├── fattn-vec-f16-instance-hs128-q8_0-q5_0.cu │ │ │ │ ├── fattn-vec-f16-instance-hs128-q8_0-q5_1.cu │ │ │ │ ├── fattn-vec-f16-instance-hs128-q8_0-q8_0.cu │ │ │ │ ├── fattn-vec-f16-instance-hs256-f16-f16.cu │ │ │ │ ├── fattn-vec-f16-instance-hs64-f16-f16.cu │ │ │ │ ├── fattn-vec-f16-instance-hs64-f16-q4_0.cu │ │ │ │ ├── fattn-vec-f16-instance-hs64-f16-q4_1.cu │ │ │ │ ├── fattn-vec-f16-instance-hs64-f16-q5_0.cu │ │ │ │ ├── fattn-vec-f16-instance-hs64-f16-q5_1.cu │ │ │ │ ├── fattn-vec-f16-instance-hs64-f16-q8_0.cu │ │ │ │ ├── fattn-vec-f32-instance-hs128-f16-f16.cu │ │ │ │ ├── fattn-vec-f32-instance-hs128-f16-q4_0.cu │ │ │ │ ├── fattn-vec-f32-instance-hs128-f16-q4_1.cu │ │ │ │ ├── fattn-vec-f32-instance-hs128-f16-q5_0.cu │ │ │ │ ├── fattn-vec-f32-instance-hs128-f16-q5_1.cu │ │ │ │ ├── fattn-vec-f32-instance-hs128-f16-q8_0.cu │ │ │ │ ├── fattn-vec-f32-instance-hs128-q4_0-f16.cu │ │ │ │ ├── fattn-vec-f32-instance-hs128-q4_0-q4_0.cu │ │ │ │ ├── fattn-vec-f32-instance-hs128-q4_0-q4_1.cu │ │ │ │ ├── fattn-vec-f32-instance-hs128-q4_0-q5_0.cu │ │ │ │ ├── fattn-vec-f32-instance-hs128-q4_0-q5_1.cu │ │ │ │ ├── fattn-vec-f32-instance-hs128-q4_0-q8_0.cu │ │ │ │ ├── fattn-vec-f32-instance-hs128-q4_1-f16.cu │ │ │ │ ├── fattn-vec-f32-instance-hs128-q4_1-q4_0.cu │ │ │ │ ├── fattn-vec-f32-instance-hs128-q4_1-q4_1.cu │ │ │ │ ├── fattn-vec-f32-instance-hs128-q4_1-q5_0.cu │ │ │ │ ├── fattn-vec-f32-instance-hs128-q4_1-q5_1.cu │ │ │ │ ├── fattn-vec-f32-instance-hs128-q4_1-q8_0.cu │ │ │ │ ├── fattn-vec-f32-instance-hs128-q5_0-f16.cu │ │ │ │ ├── fattn-vec-f32-instance-hs128-q5_0-q4_0.cu │ │ │ │ ├── fattn-vec-f32-instance-hs128-q5_0-q4_1.cu │ │ │ │ ├── fattn-vec-f32-instance-hs128-q5_0-q5_0.cu │ │ │ │ ├── fattn-vec-f32-instance-hs128-q5_0-q5_1.cu │ │ │ │ ├── fattn-vec-f32-instance-hs128-q5_0-q8_0.cu │ │ │ │ ├── fattn-vec-f32-instance-hs128-q5_1-f16.cu │ │ │ │ ├── fattn-vec-f32-instance-hs128-q5_1-q4_0.cu │ │ │ │ ├── fattn-vec-f32-instance-hs128-q5_1-q4_1.cu │ │ │ │ ├── fattn-vec-f32-instance-hs128-q5_1-q5_0.cu │ │ │ │ ├── fattn-vec-f32-instance-hs128-q5_1-q5_1.cu │ │ │ │ ├── fattn-vec-f32-instance-hs128-q5_1-q8_0.cu │ │ │ │ ├── fattn-vec-f32-instance-hs128-q8_0-f16.cu │ │ │ │ ├── fattn-vec-f32-instance-hs128-q8_0-q4_0.cu │ │ │ │ ├── fattn-vec-f32-instance-hs128-q8_0-q4_1.cu │ │ │ │ ├── fattn-vec-f32-instance-hs128-q8_0-q5_0.cu │ │ │ │ ├── fattn-vec-f32-instance-hs128-q8_0-q5_1.cu │ │ │ │ ├── fattn-vec-f32-instance-hs128-q8_0-q8_0.cu │ │ │ │ ├── fattn-vec-f32-instance-hs256-f16-f16.cu │ │ │ │ ├── fattn-vec-f32-instance-hs64-f16-f16.cu │ │ │ │ ├── fattn-vec-f32-instance-hs64-f16-q4_0.cu │ │ │ │ ├── fattn-vec-f32-instance-hs64-f16-q4_1.cu │ │ │ │ ├── fattn-vec-f32-instance-hs64-f16-q5_0.cu │ │ │ │ ├── fattn-vec-f32-instance-hs64-f16-q5_1.cu │ │ │ │ ├── fattn-vec-f32-instance-hs64-f16-q8_0.cu │ │ │ │ ├── generate_cu_files.py │ │ │ │ ├── mmq-instance-iq1_s.cu │ │ │ │ ├── mmq-instance-iq2_s.cu │ │ │ │ ├── mmq-instance-iq2_xs.cu │ │ │ │ ├── mmq-instance-iq2_xxs.cu │ │ │ │ ├── mmq-instance-iq3_s.cu │ │ │ │ ├── mmq-instance-iq3_xxs.cu │ │ │ │ ├── mmq-instance-iq4_nl.cu │ │ │ │ ├── mmq-instance-iq4_xs.cu │ │ │ │ ├── mmq-instance-q2_k.cu │ │ │ │ ├── mmq-instance-q3_k.cu │ │ │ │ ├── mmq-instance-q4_0.cu │ │ │ │ ├── mmq-instance-q4_1.cu │ │ │ │ ├── mmq-instance-q4_k.cu │ │ │ │ ├── mmq-instance-q5_0.cu │ │ │ │ ├── mmq-instance-q5_1.cu │ │ │ │ ├── mmq-instance-q5_k.cu │ │ │ │ ├── mmq-instance-q6_k.cu │ │ │ │ └── mmq-instance-q8_0.cu │ │ │ ├── tsembd.cu │ │ │ ├── tsembd.cuh │ │ │ ├── unary.cu │ │ │ ├── unary.cuh │ │ │ ├── upscale.cu │ │ │ ├── upscale.cuh │ │ │ ├── vecdotq.cuh │ │ │ ├── vendors/ │ │ │ │ ├── cuda.h │ │ │ │ ├── hip.h │ │ │ │ └── musa.h │ │ │ ├── wkv.cu │ │ │ └── wkv.cuh │ │ ├── ggml-hip/ │ │ │ └── CMakeLists.txt │ │ ├── ggml-impl.h │ │ ├── ggml-kompute/ │ │ │ ├── CMakeLists.txt │ │ │ ├── ggml-kompute.cpp │ │ │ └── kompute-shaders/ │ │ │ ├── common.comp │ │ │ ├── op_add.comp │ │ │ ├── op_addrow.comp │ │ │ ├── op_cpy_f16_f16.comp │ │ │ ├── op_cpy_f16_f32.comp │ │ │ ├── op_cpy_f32_f16.comp │ │ │ ├── op_cpy_f32_f32.comp │ │ │ ├── op_diagmask.comp │ │ │ ├── op_gelu.comp │ │ │ ├── op_getrows.comp │ │ │ ├── op_getrows_f16.comp │ │ │ ├── op_getrows_f32.comp │ │ │ ├── op_getrows_q4_0.comp │ │ │ ├── op_getrows_q4_1.comp │ │ │ ├── op_getrows_q6_k.comp │ │ │ ├── op_mul.comp │ │ │ ├── op_mul_mat_f16.comp │ │ │ ├── op_mul_mat_mat_f32.comp │ │ │ ├── op_mul_mat_q4_0.comp │ │ │ ├── op_mul_mat_q4_1.comp │ │ │ ├── op_mul_mat_q4_k.comp │ │ │ ├── op_mul_mat_q6_k.comp │ │ │ ├── op_mul_mat_q8_0.comp │ │ │ ├── op_mul_mv_q_n.comp │ │ │ ├── op_mul_mv_q_n_pre.comp │ │ │ ├── op_norm.comp │ │ │ ├── op_relu.comp │ │ │ ├── op_rmsnorm.comp │ │ │ ├── op_rope_neox_f16.comp │ │ │ ├── op_rope_neox_f32.comp │ │ │ ├── op_rope_norm_f16.comp │ │ │ ├── op_rope_norm_f32.comp │ │ │ ├── op_scale.comp │ │ │ ├── op_scale_8.comp │ │ │ ├── op_silu.comp │ │ │ ├── op_softmax.comp │ │ │ └── rope_common.comp │ │ ├── ggml-metal/ │ │ │ ├── CMakeLists.txt │ │ │ ├── ggml-metal-impl.h │ │ │ ├── ggml-metal.m │ │ │ └── ggml-metal.metal │ │ ├── ggml-musa/ │ │ │ ├── CMakeLists.txt │ │ │ ├── mudnn.cu │ │ │ └── mudnn.cuh │ │ ├── ggml-opencl/ │ │ │ ├── CMakeLists.txt │ │ │ ├── ggml-opencl.cpp │ │ │ └── kernels/ │ │ │ ├── add.cl │ │ │ ├── argsort.cl │ │ │ ├── clamp.cl │ │ │ ├── concat.cl │ │ │ ├── cpy.cl │ │ │ ├── cvt.cl │ │ │ ├── diag_mask_inf.cl │ │ │ ├── div.cl │ │ │ ├── embed_kernel.py │ │ │ ├── gelu.cl │ │ │ ├── gemv_noshuffle.cl │ │ │ ├── gemv_noshuffle_general.cl │ │ │ ├── get_rows.cl │ │ │ ├── group_norm.cl │ │ │ ├── im2col_f16.cl │ │ │ ├── im2col_f32.cl │ │ │ ├── mul.cl │ │ │ ├── mul_mat_Ab_Bi_8x4.cl │ │ │ ├── mul_mv_f16_f16.cl │ │ │ ├── mul_mv_f16_f32.cl │ │ │ ├── mul_mv_f16_f32_1row.cl │ │ │ ├── mul_mv_f16_f32_l4.cl │ │ │ ├── mul_mv_f32_f32.cl │ │ │ ├── mul_mv_q4_0_f32.cl │ │ │ ├── mul_mv_q4_0_f32_1d_16x_flat.cl │ │ │ ├── mul_mv_q4_0_f32_1d_8x_flat.cl │ │ │ ├── mul_mv_q4_0_f32_8x_flat.cl │ │ │ ├── mul_mv_q4_0_f32_v.cl │ │ │ ├── mul_mv_q6_k.cl │ │ │ ├── norm.cl │ │ │ ├── pad.cl │ │ │ ├── relu.cl │ │ │ ├── repeat.cl │ │ │ ├── rms_norm.cl │ │ │ ├── rope.cl │ │ │ ├── scale.cl │ │ │ ├── sigmoid.cl │ │ │ ├── silu.cl │ │ │ ├── softmax_4_f16.cl │ │ │ ├── softmax_4_f32.cl │ │ │ ├── softmax_f16.cl │ │ │ ├── softmax_f32.cl │ │ │ ├── sub.cl │ │ │ ├── sum_rows.cl │ │ │ ├── tanh.cl │ │ │ ├── transpose.cl │ │ │ ├── tsembd.cl │ │ │ └── upscale.cl │ │ ├── ggml-opt.cpp │ │ ├── ggml-quants.c │ │ ├── ggml-quants.h │ │ ├── ggml-rpc/ │ │ │ ├── CMakeLists.txt │ │ │ └── ggml-rpc.cpp │ │ ├── ggml-sycl/ │ │ │ ├── CMakeLists.txt │ │ │ ├── backend.hpp │ │ │ ├── binbcast.cpp │ │ │ ├── binbcast.hpp │ │ │ ├── common.cpp │ │ │ ├── common.hpp │ │ │ ├── concat.cpp │ │ │ ├── concat.hpp │ │ │ ├── conv.cpp │ │ │ ├── conv.hpp │ │ │ ├── convert.cpp │ │ │ ├── convert.hpp │ │ │ ├── cpy.cpp │ │ │ ├── cpy.hpp │ │ │ ├── dequantize.hpp │ │ │ ├── dmmv.cpp │ │ │ ├── dmmv.hpp │ │ │ ├── dpct/ │ │ │ │ └── helper.hpp │ │ │ ├── element_wise.cpp │ │ │ ├── element_wise.hpp │ │ │ ├── gemm.hpp │ │ │ ├── getrows.cpp │ │ │ ├── getrows.hpp │ │ │ ├── ggml-sycl.cpp │ │ │ ├── gla.cpp │ │ │ ├── gla.hpp │ │ │ ├── im2col.cpp │ │ │ ├── im2col.hpp │ │ │ ├── mmq.cpp │ │ │ ├── mmq.hpp │ │ │ ├── mmvq.cpp │ │ │ ├── mmvq.hpp │ │ │ ├── norm.cpp │ │ │ ├── norm.hpp │ │ │ ├── outprod.cpp │ │ │ ├── outprod.hpp │ │ │ ├── presets.hpp │ │ │ ├── quants.hpp │ │ │ ├── rope.cpp │ │ │ ├── rope.hpp │ │ │ ├── softmax.cpp │ │ │ ├── softmax.hpp │ │ │ ├── sycl_hw.cpp │ │ │ ├── sycl_hw.hpp │ │ │ ├── tsembd.cpp │ │ │ ├── tsembd.hpp │ │ │ ├── vecdotq.hpp │ │ │ ├── wkv.cpp │ │ │ └── wkv.hpp │ │ ├── ggml-threading.cpp │ │ ├── ggml-threading.h │ │ ├── ggml-vulkan/ │ │ │ ├── CMakeLists.txt │ │ │ ├── cmake/ │ │ │ │ └── host-toolchain.cmake.in │ │ │ ├── ggml-vulkan.cpp │ │ │ └── vulkan-shaders/ │ │ │ ├── CMakeLists.txt │ │ │ ├── acc.comp │ │ │ ├── add.comp │ │ │ ├── argmax.comp │ │ │ ├── argsort.comp │ │ │ ├── clamp.comp │ │ │ ├── concat.comp │ │ │ ├── contig_copy.comp │ │ │ ├── conv2d_dw.comp │ │ │ ├── copy.comp │ │ │ ├── copy_from_quant.comp │ │ │ ├── copy_to_quant.comp │ │ │ ├── cos.comp │ │ │ ├── count_equal.comp │ │ │ ├── dequant_f32.comp │ │ │ ├── dequant_funcs.comp │ │ │ ├── dequant_funcs_cm2.comp │ │ │ ├── dequant_head.comp │ │ │ ├── dequant_iq1_m.comp │ │ │ ├── dequant_iq1_s.comp │ │ │ ├── dequant_iq2_s.comp │ │ │ ├── dequant_iq2_xs.comp │ │ │ ├── dequant_iq2_xxs.comp │ │ │ ├── dequant_iq3_s.comp │ │ │ ├── dequant_iq3_xxs.comp │ │ │ ├── dequant_iq4_nl.comp │ │ │ ├── dequant_iq4_xs.comp │ │ │ ├── dequant_q2_k.comp │ │ │ ├── dequant_q3_k.comp │ │ │ ├── dequant_q4_0.comp │ │ │ ├── dequant_q4_1.comp │ │ │ ├── dequant_q4_k.comp │ │ │ ├── dequant_q5_0.comp │ │ │ ├── dequant_q5_1.comp │ │ │ ├── dequant_q5_k.comp │ │ │ ├── dequant_q6_k.comp │ │ │ ├── dequant_q8_0.comp │ │ │ ├── diag_mask_inf.comp │ │ │ ├── div.comp │ │ │ ├── flash_attn.comp │ │ │ ├── flash_attn_base.comp │ │ │ ├── flash_attn_cm1.comp │ │ │ ├── flash_attn_cm2.comp │ │ │ ├── flash_attn_split_k_reduce.comp │ │ │ ├── gelu.comp │ │ │ ├── gelu_quick.comp │ │ │ ├── generic_binary_head.comp │ │ │ ├── generic_head.comp │ │ │ ├── generic_unary_head.comp │ │ │ ├── get_rows.comp │ │ │ ├── get_rows_quant.comp │ │ │ ├── group_norm.comp │ │ │ ├── im2col.comp │ │ │ ├── l2_norm.comp │ │ │ ├── leaky_relu.comp │ │ │ ├── mul.comp │ │ │ ├── mul_mat_split_k_reduce.comp │ │ │ ├── mul_mat_vec.comp │ │ │ ├── mul_mat_vec_base.comp │ │ │ ├── mul_mat_vec_iq1_m.comp │ │ │ ├── mul_mat_vec_iq1_s.comp │ │ │ ├── mul_mat_vec_iq2_s.comp │ │ │ ├── mul_mat_vec_iq2_xs.comp │ │ │ ├── mul_mat_vec_iq2_xxs.comp │ │ │ ├── mul_mat_vec_iq3_s.comp │ │ │ ├── mul_mat_vec_iq3_xxs.comp │ │ │ ├── mul_mat_vec_nc.comp │ │ │ ├── mul_mat_vec_p021.comp │ │ │ ├── mul_mat_vec_q2_k.comp │ │ │ ├── mul_mat_vec_q3_k.comp │ │ │ ├── mul_mat_vec_q4_k.comp │ │ │ ├── mul_mat_vec_q5_k.comp │ │ │ ├── mul_mat_vec_q6_k.comp │ │ │ ├── mul_mm.comp │ │ │ ├── mul_mm_cm2.comp │ │ │ ├── mul_mmq.comp │ │ │ ├── mul_mmq_funcs.comp │ │ │ ├── norm.comp │ │ │ ├── opt_step_adamw.comp │ │ │ ├── pad.comp │ │ │ ├── pool2d.comp │ │ │ ├── quantize_q8_1.comp │ │ │ ├── relu.comp │ │ │ ├── repeat.comp │ │ │ ├── repeat_back.comp │ │ │ ├── rms_norm.comp │ │ │ ├── rms_norm_back.comp │ │ │ ├── rope_head.comp │ │ │ ├── rope_multi.comp │ │ │ ├── rope_neox.comp │ │ │ ├── rope_norm.comp │ │ │ ├── rope_vision.comp │ │ │ ├── scale.comp │ │ │ ├── sigmoid.comp │ │ │ ├── silu.comp │ │ │ ├── silu_back.comp │ │ │ ├── sin.comp │ │ │ ├── soft_max.comp │ │ │ ├── soft_max_back.comp │ │ │ ├── square.comp │ │ │ ├── sub.comp │ │ │ ├── sum_rows.comp │ │ │ ├── tanh.comp │ │ │ ├── test_bfloat16_support.comp │ │ │ ├── test_coopmat2_support.comp │ │ │ ├── test_coopmat_support.comp │ │ │ ├── test_integer_dot_support.comp │ │ │ ├── timestep_embedding.comp │ │ │ ├── types.comp │ │ │ ├── upscale.comp │ │ │ ├── vulkan-shaders-gen.cpp │ │ │ ├── wkv6.comp │ │ │ └── wkv7.comp │ │ ├── ggml.c │ │ ├── ggml.cpp │ │ └── gguf.cpp │ ├── gguf-py/ │ │ ├── LICENSE │ │ ├── README.md │ │ ├── examples/ │ │ │ ├── reader.py │ │ │ └── writer.py │ │ ├── gguf/ │ │ │ ├── __init__.py │ │ │ ├── constants.py │ │ │ ├── gguf.py │ │ │ ├── gguf_reader.py │ │ │ ├── gguf_writer.py │ │ │ ├── lazy.py │ │ │ ├── metadata.py │ │ │ ├── py.typed │ │ │ ├── quants.py │ │ │ ├── scripts/ │ │ │ │ ├── gguf_convert_endian.py │ │ │ │ ├── gguf_dump.py │ │ │ │ ├── gguf_editor_gui.py │ │ │ │ ├── gguf_hash.py │ │ │ │ ├── gguf_new_metadata.py │ │ │ │ └── gguf_set_metadata.py │ │ │ ├── tensor_mapping.py │ │ │ ├── utility.py │ │ │ └── vocab.py │ │ ├── pyproject.toml │ │ └── tests/ │ │ ├── __init__.py │ │ ├── test_metadata.py │ │ └── test_quants.py │ ├── grammars/ │ │ ├── README.md │ │ ├── arithmetic.gbnf │ │ ├── c.gbnf │ │ ├── chess.gbnf │ │ ├── english.gbnf │ │ ├── japanese.gbnf │ │ ├── json.gbnf │ │ ├── json_arr.gbnf │ │ └── list.gbnf │ ├── include/ │ │ ├── llama-cpp.h │ │ └── llama.h │ ├── licenses/ │ │ ├── LICENSE-curl │ │ ├── LICENSE-httplib │ │ ├── LICENSE-jsonhpp │ │ └── LICENSE-linenoise │ ├── models/ │ │ ├── .editorconfig │ │ ├── ggml-vocab-bert-bge.gguf.inp │ │ ├── ggml-vocab-bert-bge.gguf.out │ │ ├── ggml-vocab-command-r.gguf.inp │ │ ├── ggml-vocab-command-r.gguf.out │ │ ├── ggml-vocab-deepseek-coder.gguf.inp │ │ ├── ggml-vocab-deepseek-coder.gguf.out │ │ ├── ggml-vocab-deepseek-llm.gguf.inp │ │ ├── ggml-vocab-deepseek-llm.gguf.out │ │ ├── ggml-vocab-falcon.gguf.inp │ │ ├── ggml-vocab-falcon.gguf.out │ │ ├── ggml-vocab-gpt-2.gguf.inp │ │ ├── ggml-vocab-gpt-2.gguf.out │ │ ├── ggml-vocab-llama-bpe.gguf.inp │ │ ├── ggml-vocab-llama-bpe.gguf.out │ │ ├── ggml-vocab-llama-spm.gguf.inp │ │ ├── ggml-vocab-llama-spm.gguf.out │ │ ├── ggml-vocab-mpt.gguf.inp │ │ ├── ggml-vocab-mpt.gguf.out │ │ ├── ggml-vocab-phi-3.gguf.inp │ │ ├── ggml-vocab-phi-3.gguf.out │ │ ├── ggml-vocab-qwen2.gguf.inp │ │ ├── ggml-vocab-qwen2.gguf.out │ │ ├── ggml-vocab-refact.gguf.inp │ │ ├── ggml-vocab-refact.gguf.out │ │ ├── ggml-vocab-starcoder.gguf.inp │ │ ├── ggml-vocab-starcoder.gguf.out │ │ └── templates/ │ │ ├── CohereForAI-c4ai-command-r-plus-tool_use.jinja │ │ ├── CohereForAI-c4ai-command-r7b-12-2024-tool_use.jinja │ │ ├── NousResearch-Hermes-2-Pro-Llama-3-8B-tool_use.jinja │ │ ├── NousResearch-Hermes-3-Llama-3.1-8B-tool_use.jinja │ │ ├── Qwen-QwQ-32B.jinja │ │ ├── Qwen-Qwen2.5-7B-Instruct.jinja │ │ ├── Qwen-Qwen3-0.6B.jinja │ │ ├── README.md │ │ ├── deepseek-ai-DeepSeek-R1-Distill-Llama-8B.jinja │ │ ├── deepseek-ai-DeepSeek-R1-Distill-Qwen-32B.jinja │ │ ├── fireworks-ai-llama-3-firefunction-v2.jinja │ │ ├── google-gemma-2-2b-it.jinja │ │ ├── llama-cpp-deepseek-r1.jinja │ │ ├── meetkai-functionary-medium-v3.1.jinja │ │ ├── meetkai-functionary-medium-v3.2.jinja │ │ ├── meta-llama-Llama-3.1-8B-Instruct.jinja │ │ ├── meta-llama-Llama-3.2-3B-Instruct.jinja │ │ ├── meta-llama-Llama-3.3-70B-Instruct.jinja │ │ ├── microsoft-Phi-3.5-mini-instruct.jinja │ │ └── mistralai-Mistral-Nemo-Instruct-2407.jinja │ ├── mypy.ini │ ├── pocs/ │ │ ├── CMakeLists.txt │ │ └── vdot/ │ │ ├── CMakeLists.txt │ │ ├── q8dot.cpp │ │ └── vdot.cpp │ ├── powerinfer/ │ │ ├── .clang-format │ │ ├── CMakeLists.txt │ │ ├── cmake/ │ │ │ ├── Arch.cmake │ │ │ └── FindSIMD.cmake │ │ ├── fused_sparse_moe/ │ │ │ ├── CMakeLists.txt │ │ │ ├── fused_sparse_moe/ │ │ │ │ └── fused_sparse_moe.hpp │ │ │ └── fused_sparse_moe.cpp │ │ ├── include/ │ │ │ ├── powerinfer-api.h │ │ │ ├── powerinfer-az.h │ │ │ ├── powerinfer-cpu.h │ │ │ ├── powerinfer-error.h │ │ │ ├── powerinfer-loader.h │ │ │ ├── powerinfer-perf.h │ │ │ ├── powerinfer-type.h │ │ │ └── util/ │ │ │ └── hyper.h │ │ ├── libaz/ │ │ │ ├── .clang-format │ │ │ ├── .gitignore │ │ │ ├── CMakeLists.txt │ │ │ ├── README.md │ │ │ ├── az/ │ │ │ │ ├── CMakeLists.txt │ │ │ │ ├── assert.hpp │ │ │ │ ├── common.hpp │ │ │ │ ├── core/ │ │ │ │ │ ├── CMakeLists.txt │ │ │ │ │ ├── aligned_alloc.cpp │ │ │ │ │ ├── aligned_alloc.hpp │ │ │ │ │ ├── bf16.hpp │ │ │ │ │ ├── buf.cpp │ │ │ │ │ ├── buf.hpp │ │ │ │ │ ├── cpu_affinity.cpp │ │ │ │ │ ├── cpu_affinity.hpp │ │ │ │ │ ├── cpu_yield.cpp │ │ │ │ │ ├── cpu_yield.hpp │ │ │ │ │ ├── fp16.c │ │ │ │ │ ├── fp16.h │ │ │ │ │ ├── handle.cpp │ │ │ │ │ ├── handle.hpp │ │ │ │ │ ├── intrinsics.hpp │ │ │ │ │ ├── layout.hpp │ │ │ │ │ ├── list.hpp │ │ │ │ │ ├── lru.cpp │ │ │ │ │ ├── lru.hpp │ │ │ │ │ ├── perfetto_trace.cpp │ │ │ │ │ ├── perfetto_trace.h │ │ │ │ │ ├── perfetto_trace.hpp │ │ │ │ │ ├── spin_barrier.cpp │ │ │ │ │ ├── spin_barrier.hpp │ │ │ │ │ ├── spin_lock.hpp │ │ │ │ │ ├── utils.cpp │ │ │ │ │ ├── utils.hpp │ │ │ │ │ └── worker_info.hpp │ │ │ │ ├── cpu/ │ │ │ │ │ ├── CMakeLists.txt │ │ │ │ │ ├── aarch64/ │ │ │ │ │ │ ├── gemv.cpp │ │ │ │ │ │ └── gemv.hpp │ │ │ │ │ ├── axpy.cpp │ │ │ │ │ ├── axpy.hpp │ │ │ │ │ ├── exp_lut.cpp │ │ │ │ │ ├── exp_lut.hpp │ │ │ │ │ ├── quant_types.cpp │ │ │ │ │ ├── quant_types.hpp │ │ │ │ │ ├── silu_lut.cpp │ │ │ │ │ ├── silu_lut.hpp │ │ │ │ │ ├── softmax.cpp │ │ │ │ │ ├── softmax.hpp │ │ │ │ │ ├── vdot.hpp │ │ │ │ │ ├── vec_dot.cpp │ │ │ │ │ └── vec_dot.hpp │ │ │ │ ├── init.cpp │ │ │ │ ├── init.hpp │ │ │ │ └── pipeline/ │ │ │ │ ├── CMakeLists.txt │ │ │ │ ├── pipeline.cpp │ │ │ │ ├── pipeline.hpp │ │ │ │ ├── task.cpp │ │ │ │ ├── task.hpp │ │ │ │ └── worker.hpp │ │ │ ├── bin/ │ │ │ │ ├── CMakeLists.txt │ │ │ │ ├── random_memtest.cpp │ │ │ │ └── test_assert.cpp │ │ │ ├── docs/ │ │ │ │ ├── compile_options.md │ │ │ │ └── environment_variables.md │ │ │ ├── external/ │ │ │ │ ├── .clang-format │ │ │ │ ├── CMakeLists.txt │ │ │ │ ├── cli11/ │ │ │ │ │ ├── .all-contributorsrc │ │ │ │ │ ├── .ci/ │ │ │ │ │ │ ├── azure-build.yml │ │ │ │ │ │ ├── azure-cmake-new.yml │ │ │ │ │ │ ├── azure-cmake.yml │ │ │ │ │ │ └── azure-test.yml │ │ │ │ │ ├── .clang-format │ │ │ │ │ ├── .cmake-format.yaml │ │ │ │ │ ├── .codacy.yml │ │ │ │ │ ├── .codecov.yml │ │ │ │ │ ├── .editorconfig │ │ │ │ │ ├── .github/ │ │ │ │ │ │ ├── CONTRIBUTING.md │ │ │ │ │ │ ├── actions/ │ │ │ │ │ │ │ └── quick_cmake/ │ │ │ │ │ │ │ └── action.yml │ │ │ │ │ │ ├── codecov.yml │ │ │ │ │ │ ├── dependabot.yml │ │ │ │ │ │ ├── labeler_merged.yml │ │ │ │ │ │ └── workflows/ │ │ │ │ │ │ ├── docs.yml │ │ │ │ │ │ ├── fuzz.yml │ │ │ │ │ │ ├── pr_merged.yml │ │ │ │ │ │ └── tests.yml │ │ │ │ │ ├── .gitignore │ │ │ │ │ ├── .pre-commit-config.yaml │ │ │ │ │ ├── .remarkrc │ │ │ │ │ ├── BUILD.bazel │ │ │ │ │ ├── CHANGELOG.md │ │ │ │ │ ├── CMakeLists.txt │ │ │ │ │ ├── CPPLINT.cfg │ │ │ │ │ ├── LICENSE │ │ │ │ │ ├── MODULE.bazel │ │ │ │ │ ├── README.md │ │ │ │ │ ├── azure-pipelines.yml │ │ │ │ │ ├── book/ │ │ │ │ │ │ ├── .gitignore │ │ │ │ │ │ ├── CMakeLists.txt │ │ │ │ │ │ ├── README.md │ │ │ │ │ │ ├── SUMMARY.md │ │ │ │ │ │ ├── book.json │ │ │ │ │ │ ├── chapters/ │ │ │ │ │ │ │ ├── advanced-topics.md │ │ │ │ │ │ │ ├── an-advanced-example.md │ │ │ │ │ │ │ ├── basics.md │ │ │ │ │ │ │ ├── config.md │ │ │ │ │ │ │ ├── flags.md │ │ │ │ │ │ │ ├── formatting.md │ │ │ │ │ │ │ ├── installation.md │ │ │ │ │ │ │ ├── internals.md │ │ │ │ │ │ │ ├── options.md │ │ │ │ │ │ │ ├── subcommands.md │ │ │ │ │ │ │ ├── toolkits.md │ │ │ │ │ │ │ └── validators.md │ │ │ │ │ │ ├── code/ │ │ │ │ │ │ │ ├── CMakeLists.txt │ │ │ │ │ │ │ ├── flags.cpp │ │ │ │ │ │ │ ├── geet.cpp │ │ │ │ │ │ │ ├── intro.cpp │ │ │ │ │ │ │ └── simplest.cpp │ │ │ │ │ │ └── package.json │ │ │ │ │ ├── cmake/ │ │ │ │ │ │ ├── CLI11.pc.in │ │ │ │ │ │ ├── CLI11ConfigVersion.cmake.in │ │ │ │ │ │ ├── CLI11GeneratePkgConfig.cmake │ │ │ │ │ │ ├── CLI11Warnings.cmake │ │ │ │ │ │ ├── CLI11precompiled.pc.in │ │ │ │ │ │ └── CodeCoverage.cmake │ │ │ │ │ ├── docs/ │ │ │ │ │ │ ├── .gitignore │ │ │ │ │ │ ├── CMakeLists.txt │ │ │ │ │ │ ├── Doxyfile │ │ │ │ │ │ └── mainpage.md │ │ │ │ │ ├── examples/ │ │ │ │ │ │ ├── CMakeLists.txt │ │ │ │ │ │ ├── arg_capture.cpp │ │ │ │ │ │ ├── callback_passthrough.cpp │ │ │ │ │ │ ├── config_app.cpp │ │ │ │ │ │ ├── custom_parse.cpp │ │ │ │ │ │ ├── digit_args.cpp │ │ │ │ │ │ ├── enum.cpp │ │ │ │ │ │ ├── enum_ostream.cpp │ │ │ │ │ │ ├── formatter.cpp │ │ │ │ │ │ ├── groups.cpp │ │ │ │ │ │ ├── help_usage.cpp │ │ │ │ │ │ ├── inter_argument_order.cpp │ │ │ │ │ │ ├── json.cpp │ │ │ │ │ │ ├── modhelp.cpp │ │ │ │ │ │ ├── nested.cpp │ │ │ │ │ │ ├── option_groups.cpp │ │ │ │ │ │ ├── positional_arity.cpp │ │ │ │ │ │ ├── positional_validation.cpp │ │ │ │ │ │ ├── prefix_command.cpp │ │ │ │ │ │ ├── ranges.cpp │ │ │ │ │ │ ├── retired.cpp │ │ │ │ │ │ ├── shapes.cpp │ │ │ │ │ │ ├── simple.cpp │ │ │ │ │ │ ├── subcom_help.cpp │ │ │ │ │ │ ├── subcom_in_files/ │ │ │ │ │ │ │ ├── CMakeLists.txt │ │ │ │ │ │ │ ├── subcommand_a.cpp │ │ │ │ │ │ │ ├── subcommand_a.hpp │ │ │ │ │ │ │ └── subcommand_main.cpp │ │ │ │ │ │ ├── subcom_partitioned.cpp │ │ │ │ │ │ ├── subcommands.cpp │ │ │ │ │ │ ├── testEXE.cpp │ │ │ │ │ │ └── validators.cpp │ │ │ │ │ ├── fuzz/ │ │ │ │ │ │ ├── CMakeLists.txt │ │ │ │ │ │ ├── cli11_app_fuzz.cpp │ │ │ │ │ │ ├── cli11_file_fuzz.cpp │ │ │ │ │ │ ├── fuzzApp.cpp │ │ │ │ │ │ ├── fuzzApp.hpp │ │ │ │ │ │ └── fuzzCommand.cpp │ │ │ │ │ ├── include/ │ │ │ │ │ │ └── CLI/ │ │ │ │ │ │ ├── App.hpp │ │ │ │ │ │ ├── Argv.hpp │ │ │ │ │ │ ├── CLI.hpp │ │ │ │ │ │ ├── Config.hpp │ │ │ │ │ │ ├── ConfigFwd.hpp │ │ │ │ │ │ ├── Encoding.hpp │ │ │ │ │ │ ├── Error.hpp │ │ │ │ │ │ ├── Formatter.hpp │ │ │ │ │ │ ├── FormatterFwd.hpp │ │ │ │ │ │ ├── Macros.hpp │ │ │ │ │ │ ├── Option.hpp │ │ │ │ │ │ ├── Split.hpp │ │ │ │ │ │ ├── StringTools.hpp │ │ │ │ │ │ ├── Timer.hpp │ │ │ │ │ │ ├── TypeTools.hpp │ │ │ │ │ │ ├── Validators.hpp │ │ │ │ │ │ ├── Version.hpp │ │ │ │ │ │ └── impl/ │ │ │ │ │ │ ├── App_inl.hpp │ │ │ │ │ │ ├── Argv_inl.hpp │ │ │ │ │ │ ├── Config_inl.hpp │ │ │ │ │ │ ├── Encoding_inl.hpp │ │ │ │ │ │ ├── Formatter_inl.hpp │ │ │ │ │ │ ├── Option_inl.hpp │ │ │ │ │ │ ├── Split_inl.hpp │ │ │ │ │ │ ├── StringTools_inl.hpp │ │ │ │ │ │ └── Validators_inl.hpp │ │ │ │ │ ├── meson.build │ │ │ │ │ ├── scripts/ │ │ │ │ │ │ ├── ExtractVersion.py │ │ │ │ │ │ ├── MakeSingleHeader.py │ │ │ │ │ │ ├── check_style.sh │ │ │ │ │ │ ├── check_style_docker.sh │ │ │ │ │ │ ├── clang-format-pre-commit │ │ │ │ │ │ └── mdlint_style.rb │ │ │ │ │ ├── single-include/ │ │ │ │ │ │ ├── CLI11.hpp.in │ │ │ │ │ │ ├── CMakeLists.txt │ │ │ │ │ │ └── meson.build │ │ │ │ │ ├── src/ │ │ │ │ │ │ ├── CMakeLists.txt │ │ │ │ │ │ └── Precompile.cpp │ │ │ │ │ ├── subprojects/ │ │ │ │ │ │ └── catch2.wrap │ │ │ │ │ └── tests/ │ │ │ │ │ ├── .syntastic_cpp_config │ │ │ │ │ ├── AppTest.cpp │ │ │ │ │ ├── BUILD.bazel │ │ │ │ │ ├── BoostOptionTypeTest.cpp │ │ │ │ │ ├── CMakeLists.txt │ │ │ │ │ ├── ComplexTypeTest.cpp │ │ │ │ │ ├── ConfigFileTest.cpp │ │ │ │ │ ├── CreationTest.cpp │ │ │ │ │ ├── DeprecatedTest.cpp │ │ │ │ │ ├── EncodingTest.cpp │ │ │ │ │ ├── FormatterTest.cpp │ │ │ │ │ ├── FuzzFailTest.cpp │ │ │ │ │ ├── HelpTest.cpp │ │ │ │ │ ├── HelpersTest.cpp │ │ │ │ │ ├── NewParseTest.cpp │ │ │ │ │ ├── OptionGroupTest.cpp │ │ │ │ │ ├── OptionTypeTest.cpp │ │ │ │ │ ├── OptionalTest.cpp │ │ │ │ │ ├── SetTest.cpp │ │ │ │ │ ├── SimpleTest.cpp │ │ │ │ │ ├── StringParseTest.cpp │ │ │ │ │ ├── SubcommandTest.cpp │ │ │ │ │ ├── TimerTest.cpp │ │ │ │ │ ├── TransformTest.cpp │ │ │ │ │ ├── TrueFalseTest.cpp │ │ │ │ │ ├── WindowsTest.cpp │ │ │ │ │ ├── app_helper.hpp │ │ │ │ │ ├── applications/ │ │ │ │ │ │ ├── ensure_utf8.cpp │ │ │ │ │ │ └── ensure_utf8_twice.cpp │ │ │ │ │ ├── catch.hpp │ │ │ │ │ ├── find_package_tests/ │ │ │ │ │ │ └── CMakeLists.txt │ │ │ │ │ ├── fuzzFail/ │ │ │ │ │ │ ├── fuzz_app_fail1 │ │ │ │ │ │ ├── fuzz_app_fail2 │ │ │ │ │ │ ├── fuzz_app_fail3 │ │ │ │ │ │ ├── fuzz_app_file_fail1 │ │ │ │ │ │ ├── fuzz_app_file_fail10 │ │ │ │ │ │ ├── fuzz_app_file_fail11 │ │ │ │ │ │ ├── fuzz_app_file_fail12 │ │ │ │ │ │ ├── fuzz_app_file_fail13 │ │ │ │ │ │ ├── fuzz_app_file_fail14 │ │ │ │ │ │ ├── fuzz_app_file_fail15 │ │ │ │ │ │ ├── fuzz_app_file_fail16 │ │ │ │ │ │ ├── fuzz_app_file_fail17 │ │ │ │ │ │ ├── fuzz_app_file_fail18 │ │ │ │ │ │ ├── fuzz_app_file_fail19 │ │ │ │ │ │ ├── fuzz_app_file_fail2 │ │ │ │ │ │ ├── fuzz_app_file_fail20 │ │ │ │ │ │ ├── fuzz_app_file_fail21 │ │ │ │ │ │ ├── fuzz_app_file_fail22 │ │ │ │ │ │ ├── fuzz_app_file_fail23 │ │ │ │ │ │ ├── fuzz_app_file_fail24 │ │ │ │ │ │ ├── fuzz_app_file_fail25 │ │ │ │ │ │ ├── fuzz_app_file_fail26 │ │ │ │ │ │ ├── fuzz_app_file_fail27 │ │ │ │ │ │ ├── fuzz_app_file_fail28 │ │ │ │ │ │ ├── fuzz_app_file_fail29 │ │ │ │ │ │ ├── fuzz_app_file_fail3 │ │ │ │ │ │ ├── fuzz_app_file_fail30 │ │ │ │ │ │ ├── fuzz_app_file_fail31 │ │ │ │ │ │ ├── fuzz_app_file_fail32 │ │ │ │ │ │ ├── fuzz_app_file_fail33 │ │ │ │ │ │ ├── fuzz_app_file_fail34 │ │ │ │ │ │ ├── fuzz_app_file_fail35 │ │ │ │ │ │ ├── fuzz_app_file_fail36 │ │ │ │ │ │ ├── fuzz_app_file_fail37 │ │ │ │ │ │ ├── fuzz_app_file_fail38 │ │ │ │ │ │ ├── fuzz_app_file_fail39 │ │ │ │ │ │ ├── fuzz_app_file_fail4 │ │ │ │ │ │ ├── fuzz_app_file_fail40 │ │ │ │ │ │ ├── fuzz_app_file_fail5 │ │ │ │ │ │ ├── fuzz_app_file_fail6 │ │ │ │ │ │ ├── fuzz_app_file_fail7 │ │ │ │ │ │ ├── fuzz_app_file_fail8 │ │ │ │ │ │ ├── fuzz_app_file_fail9 │ │ │ │ │ │ ├── fuzz_file_fail1 │ │ │ │ │ │ ├── fuzz_file_fail2 │ │ │ │ │ │ ├── fuzz_file_fail3 │ │ │ │ │ │ ├── fuzz_file_fail4 │ │ │ │ │ │ ├── fuzz_file_fail5 │ │ │ │ │ │ ├── fuzz_file_fail6 │ │ │ │ │ │ ├── fuzz_file_fail7 │ │ │ │ │ │ ├── fuzz_file_fail8 │ │ │ │ │ │ ├── round_trip_custom1 │ │ │ │ │ │ ├── round_trip_custom2 │ │ │ │ │ │ ├── round_trip_custom3 │ │ │ │ │ │ ├── round_trip_fail1 │ │ │ │ │ │ ├── round_trip_fail2 │ │ │ │ │ │ ├── round_trip_fail3 │ │ │ │ │ │ ├── round_trip_fail4 │ │ │ │ │ │ └── round_trip_fail5 │ │ │ │ │ ├── informational.cpp │ │ │ │ │ ├── link_test_1.cpp │ │ │ │ │ ├── link_test_2.cpp │ │ │ │ │ ├── main.cpp │ │ │ │ │ ├── meson.build │ │ │ │ │ ├── mesonTest/ │ │ │ │ │ │ ├── README.md │ │ │ │ │ │ ├── main.cpp │ │ │ │ │ │ └── meson.build │ │ │ │ │ ├── package_config_tests/ │ │ │ │ │ │ └── CMakeLists.txt │ │ │ │ │ └── tests/ │ │ │ │ │ └── .gitkeep │ │ │ │ ├── fmt/ │ │ │ │ │ ├── .clang-format │ │ │ │ │ ├── CMakeLists.txt │ │ │ │ │ ├── CONTRIBUTING.md │ │ │ │ │ ├── ChangeLog.md │ │ │ │ │ ├── LICENSE │ │ │ │ │ ├── README.md │ │ │ │ │ ├── doc/ │ │ │ │ │ │ ├── ChangeLog-old.md │ │ │ │ │ │ ├── api.md │ │ │ │ │ │ ├── fmt.css │ │ │ │ │ │ ├── fmt.js │ │ │ │ │ │ ├── get-started.md │ │ │ │ │ │ ├── index.md │ │ │ │ │ │ └── syntax.md │ │ │ │ │ ├── doc-html/ │ │ │ │ │ │ ├── 404.html │ │ │ │ │ │ ├── api.html │ │ │ │ │ │ ├── assets/ │ │ │ │ │ │ │ ├── _mkdocstrings.css │ │ │ │ │ │ │ └── javascripts/ │ │ │ │ │ │ │ └── lunr/ │ │ │ │ │ │ │ ├── tinyseg.js │ │ │ │ │ │ │ └── wordcut.js │ │ │ │ │ │ ├── fmt.css │ │ │ │ │ │ ├── fmt.js │ │ │ │ │ │ ├── get-started.html │ │ │ │ │ │ ├── index.html │ │ │ │ │ │ ├── search/ │ │ │ │ │ │ │ └── search_index.json │ │ │ │ │ │ ├── sitemap.xml │ │ │ │ │ │ └── syntax.html │ │ │ │ │ ├── include/ │ │ │ │ │ │ └── fmt/ │ │ │ │ │ │ ├── args.h │ │ │ │ │ │ ├── base.h │ │ │ │ │ │ ├── chrono.h │ │ │ │ │ │ ├── color.h │ │ │ │ │ │ ├── compile.h │ │ │ │ │ │ ├── core.h │ │ │ │ │ │ ├── format-inl.h │ │ │ │ │ │ ├── format.h │ │ │ │ │ │ ├── os.h │ │ │ │ │ │ ├── ostream.h │ │ │ │ │ │ ├── printf.h │ │ │ │ │ │ ├── ranges.h │ │ │ │ │ │ ├── std.h │ │ │ │ │ │ └── xchar.h │ │ │ │ │ ├── src/ │ │ │ │ │ │ ├── fmt.cc │ │ │ │ │ │ ├── format.cc │ │ │ │ │ │ └── os.cc │ │ │ │ │ ├── support/ │ │ │ │ │ │ ├── Android.mk │ │ │ │ │ │ ├── AndroidManifest.xml │ │ │ │ │ │ ├── C++.sublime-syntax │ │ │ │ │ │ ├── README │ │ │ │ │ │ ├── Vagrantfile │ │ │ │ │ │ ├── bazel/ │ │ │ │ │ │ │ ├── .bazelversion │ │ │ │ │ │ │ ├── BUILD.bazel │ │ │ │ │ │ │ ├── MODULE.bazel │ │ │ │ │ │ │ ├── README.md │ │ │ │ │ │ │ └── WORKSPACE.bazel │ │ │ │ │ │ ├── check-commits │ │ │ │ │ │ ├── cmake/ │ │ │ │ │ │ │ ├── FindSetEnv.cmake │ │ │ │ │ │ │ ├── JoinPaths.cmake │ │ │ │ │ │ │ ├── fmt-config.cmake.in │ │ │ │ │ │ │ └── fmt.pc.in │ │ │ │ │ │ ├── docopt.py │ │ │ │ │ │ ├── mkdocs │ │ │ │ │ │ ├── mkdocs.yml │ │ │ │ │ │ ├── printable.py │ │ │ │ │ │ ├── python/ │ │ │ │ │ │ │ └── mkdocstrings_handlers/ │ │ │ │ │ │ │ └── cxx/ │ │ │ │ │ │ │ ├── __init__.py │ │ │ │ │ │ │ └── templates/ │ │ │ │ │ │ │ └── README │ │ │ │ │ │ └── release.py │ │ │ │ │ └── test/ │ │ │ │ │ ├── CMakeLists.txt │ │ │ │ │ ├── add-subdirectory-test/ │ │ │ │ │ │ ├── CMakeLists.txt │ │ │ │ │ │ └── main.cc │ │ │ │ │ ├── args-test.cc │ │ │ │ │ ├── assert-test.cc │ │ │ │ │ ├── base-test.cc │ │ │ │ │ ├── chrono-test.cc │ │ │ │ │ ├── color-test.cc │ │ │ │ │ ├── compile-error-test/ │ │ │ │ │ │ └── CMakeLists.txt │ │ │ │ │ ├── compile-fp-test.cc │ │ │ │ │ ├── compile-test.cc │ │ │ │ │ ├── cuda-test/ │ │ │ │ │ │ ├── CMakeLists.txt │ │ │ │ │ │ ├── cpp14.cc │ │ │ │ │ │ └── cuda-cpp14.cu │ │ │ │ │ ├── detect-stdfs.cc │ │ │ │ │ ├── enforce-checks-test.cc │ │ │ │ │ ├── find-package-test/ │ │ │ │ │ │ ├── CMakeLists.txt │ │ │ │ │ │ └── main.cc │ │ │ │ │ ├── format-impl-test.cc │ │ │ │ │ ├── format-test.cc │ │ │ │ │ ├── fuzzing/ │ │ │ │ │ │ ├── CMakeLists.txt │ │ │ │ │ │ ├── README.md │ │ │ │ │ │ ├── chrono-duration.cc │ │ │ │ │ │ ├── chrono-timepoint.cc │ │ │ │ │ │ ├── float.cc │ │ │ │ │ │ ├── fuzzer-common.h │ │ │ │ │ │ ├── main.cc │ │ │ │ │ │ ├── named-arg.cc │ │ │ │ │ │ ├── one-arg.cc │ │ │ │ │ │ └── two-args.cc │ │ │ │ │ ├── gtest/ │ │ │ │ │ │ ├── .clang-format │ │ │ │ │ │ ├── CMakeLists.txt │ │ │ │ │ │ ├── gmock/ │ │ │ │ │ │ │ └── gmock.h │ │ │ │ │ │ ├── gmock-gtest-all.cc │ │ │ │ │ │ └── gtest/ │ │ │ │ │ │ ├── gtest-spi.h │ │ │ │ │ │ └── gtest.h │ │ │ │ │ ├── gtest-extra-test.cc │ │ │ │ │ ├── gtest-extra.cc │ │ │ │ │ ├── gtest-extra.h │ │ │ │ │ ├── header-only-test.cc │ │ │ │ │ ├── mock-allocator.h │ │ │ │ │ ├── module-test.cc │ │ │ │ │ ├── no-builtin-types-test.cc │ │ │ │ │ ├── noexception-test.cc │ │ │ │ │ ├── os-test.cc │ │ │ │ │ ├── ostream-test.cc │ │ │ │ │ ├── perf-sanity.cc │ │ │ │ │ ├── posix-mock-test.cc │ │ │ │ │ ├── posix-mock.h │ │ │ │ │ ├── printf-test.cc │ │ │ │ │ ├── ranges-odr-test.cc │ │ │ │ │ ├── ranges-test.cc │ │ │ │ │ ├── scan-test.cc │ │ │ │ │ ├── scan.h │ │ │ │ │ ├── static-export-test/ │ │ │ │ │ │ ├── CMakeLists.txt │ │ │ │ │ │ ├── library.cc │ │ │ │ │ │ └── main.cc │ │ │ │ │ ├── std-test.cc │ │ │ │ │ ├── test-assert.h │ │ │ │ │ ├── test-main.cc │ │ │ │ │ ├── unicode-test.cc │ │ │ │ │ ├── util.cc │ │ │ │ │ ├── util.h │ │ │ │ │ └── xchar-test.cc │ │ │ │ ├── googletest/ │ │ │ │ │ ├── .clang-format │ │ │ │ │ ├── .github/ │ │ │ │ │ │ └── ISSUE_TEMPLATE/ │ │ │ │ │ │ ├── 00-bug_report.yml │ │ │ │ │ │ ├── 10-feature_request.yml │ │ │ │ │ │ └── config.yml │ │ │ │ │ ├── .gitignore │ │ │ │ │ ├── BUILD.bazel │ │ │ │ │ ├── CMakeLists.txt │ │ │ │ │ ├── CONTRIBUTING.md │ │ │ │ │ ├── CONTRIBUTORS │ │ │ │ │ ├── LICENSE │ │ │ │ │ ├── MODULE.bazel │ │ │ │ │ ├── README.md │ │ │ │ │ ├── WORKSPACE │ │ │ │ │ ├── WORKSPACE.bzlmod │ │ │ │ │ ├── ci/ │ │ │ │ │ │ ├── linux-presubmit.sh │ │ │ │ │ │ └── macos-presubmit.sh │ │ │ │ │ ├── docs/ │ │ │ │ │ │ ├── _config.yml │ │ │ │ │ │ ├── _data/ │ │ │ │ │ │ │ └── navigation.yml │ │ │ │ │ │ ├── _layouts/ │ │ │ │ │ │ │ └── default.html │ │ │ │ │ │ ├── _sass/ │ │ │ │ │ │ │ └── main.scss │ │ │ │ │ │ ├── advanced.md │ │ │ │ │ │ ├── assets/ │ │ │ │ │ │ │ └── css/ │ │ │ │ │ │ │ └── style.scss │ │ │ │ │ │ ├── community_created_documentation.md │ │ │ │ │ │ ├── faq.md │ │ │ │ │ │ ├── gmock_cheat_sheet.md │ │ │ │ │ │ ├── gmock_cook_book.md │ │ │ │ │ │ ├── gmock_faq.md │ │ │ │ │ │ ├── gmock_for_dummies.md │ │ │ │ │ │ ├── index.md │ │ │ │ │ │ ├── pkgconfig.md │ │ │ │ │ │ ├── platforms.md │ │ │ │ │ │ ├── primer.md │ │ │ │ │ │ ├── quickstart-bazel.md │ │ │ │ │ │ ├── quickstart-cmake.md │ │ │ │ │ │ ├── reference/ │ │ │ │ │ │ │ ├── actions.md │ │ │ │ │ │ │ ├── assertions.md │ │ │ │ │ │ │ ├── matchers.md │ │ │ │ │ │ │ ├── mocking.md │ │ │ │ │ │ │ └── testing.md │ │ │ │ │ │ └── samples.md │ │ │ │ │ ├── fake_fuchsia_sdk.bzl │ │ │ │ │ ├── googlemock/ │ │ │ │ │ │ ├── CMakeLists.txt │ │ │ │ │ │ ├── README.md │ │ │ │ │ │ ├── cmake/ │ │ │ │ │ │ │ ├── gmock.pc.in │ │ │ │ │ │ │ └── gmock_main.pc.in │ │ │ │ │ │ ├── docs/ │ │ │ │ │ │ │ └── README.md │ │ │ │ │ │ ├── include/ │ │ │ │ │ │ │ └── gmock/ │ │ │ │ │ │ │ ├── gmock-actions.h │ │ │ │ │ │ │ ├── gmock-cardinalities.h │ │ │ │ │ │ │ ├── gmock-function-mocker.h │ │ │ │ │ │ │ ├── gmock-matchers.h │ │ │ │ │ │ │ ├── gmock-more-actions.h │ │ │ │ │ │ │ ├── gmock-more-matchers.h │ │ │ │ │ │ │ ├── gmock-nice-strict.h │ │ │ │ │ │ │ ├── gmock-spec-builders.h │ │ │ │ │ │ │ ├── gmock.h │ │ │ │ │ │ │ └── internal/ │ │ │ │ │ │ │ ├── custom/ │ │ │ │ │ │ │ │ ├── README.md │ │ │ │ │ │ │ │ ├── gmock-generated-actions.h │ │ │ │ │ │ │ │ ├── gmock-matchers.h │ │ │ │ │ │ │ │ └── gmock-port.h │ │ │ │ │ │ │ ├── gmock-internal-utils.h │ │ │ │ │ │ │ ├── gmock-port.h │ │ │ │ │ │ │ └── gmock-pp.h │ │ │ │ │ │ ├── src/ │ │ │ │ │ │ │ ├── gmock-all.cc │ │ │ │ │ │ │ ├── gmock-cardinalities.cc │ │ │ │ │ │ │ ├── gmock-internal-utils.cc │ │ │ │ │ │ │ ├── gmock-matchers.cc │ │ │ │ │ │ │ ├── gmock-spec-builders.cc │ │ │ │ │ │ │ ├── gmock.cc │ │ │ │ │ │ │ └── gmock_main.cc │ │ │ │ │ │ └── test/ │ │ │ │ │ │ ├── BUILD.bazel │ │ │ │ │ │ ├── gmock-actions_test.cc │ │ │ │ │ │ ├── gmock-cardinalities_test.cc │ │ │ │ │ │ ├── gmock-function-mocker_test.cc │ │ │ │ │ │ ├── gmock-internal-utils_test.cc │ │ │ │ │ │ ├── gmock-matchers-arithmetic_test.cc │ │ │ │ │ │ ├── gmock-matchers-comparisons_test.cc │ │ │ │ │ │ ├── gmock-matchers-containers_test.cc │ │ │ │ │ │ ├── gmock-matchers-misc_test.cc │ │ │ │ │ │ ├── gmock-matchers_test.h │ │ │ │ │ │ ├── gmock-more-actions_test.cc │ │ │ │ │ │ ├── gmock-nice-strict_test.cc │ │ │ │ │ │ ├── gmock-port_test.cc │ │ │ │ │ │ ├── gmock-pp-string_test.cc │ │ │ │ │ │ ├── gmock-pp_test.cc │ │ │ │ │ │ ├── gmock-spec-builders_test.cc │ │ │ │ │ │ ├── gmock_all_test.cc │ │ │ │ │ │ ├── gmock_ex_test.cc │ │ │ │ │ │ ├── gmock_leak_test.py │ │ │ │ │ │ ├── gmock_leak_test_.cc │ │ │ │ │ │ ├── gmock_link2_test.cc │ │ │ │ │ │ ├── gmock_link_test.cc │ │ │ │ │ │ ├── gmock_link_test.h │ │ │ │ │ │ ├── gmock_output_test.py │ │ │ │ │ │ ├── gmock_output_test_.cc │ │ │ │ │ │ ├── gmock_stress_test.cc │ │ │ │ │ │ ├── gmock_test.cc │ │ │ │ │ │ └── gmock_test_utils.py │ │ │ │ │ ├── googletest/ │ │ │ │ │ │ ├── CMakeLists.txt │ │ │ │ │ │ ├── README.md │ │ │ │ │ │ ├── cmake/ │ │ │ │ │ │ │ ├── Config.cmake.in │ │ │ │ │ │ │ ├── gtest.pc.in │ │ │ │ │ │ │ ├── gtest_main.pc.in │ │ │ │ │ │ │ ├── internal_utils.cmake │ │ │ │ │ │ │ └── libgtest.la.in │ │ │ │ │ │ ├── docs/ │ │ │ │ │ │ │ └── README.md │ │ │ │ │ │ ├── include/ │ │ │ │ │ │ │ └── gtest/ │ │ │ │ │ │ │ ├── gtest-assertion-result.h │ │ │ │ │ │ │ ├── gtest-death-test.h │ │ │ │ │ │ │ ├── gtest-matchers.h │ │ │ │ │ │ │ ├── gtest-message.h │ │ │ │ │ │ │ ├── gtest-param-test.h │ │ │ │ │ │ │ ├── gtest-printers.h │ │ │ │ │ │ │ ├── gtest-spi.h │ │ │ │ │ │ │ ├── gtest-test-part.h │ │ │ │ │ │ │ ├── gtest-typed-test.h │ │ │ │ │ │ │ ├── gtest.h │ │ │ │ │ │ │ ├── gtest_pred_impl.h │ │ │ │ │ │ │ ├── gtest_prod.h │ │ │ │ │ │ │ └── internal/ │ │ │ │ │ │ │ ├── custom/ │ │ │ │ │ │ │ │ ├── README.md │ │ │ │ │ │ │ │ ├── gtest-port.h │ │ │ │ │ │ │ │ ├── gtest-printers.h │ │ │ │ │ │ │ │ └── gtest.h │ │ │ │ │ │ │ ├── gtest-death-test-internal.h │ │ │ │ │ │ │ ├── gtest-filepath.h │ │ │ │ │ │ │ ├── gtest-internal.h │ │ │ │ │ │ │ ├── gtest-param-util.h │ │ │ │ │ │ │ ├── gtest-port-arch.h │ │ │ │ │ │ │ ├── gtest-port.h │ │ │ │ │ │ │ ├── gtest-string.h │ │ │ │ │ │ │ └── gtest-type-util.h │ │ │ │ │ │ ├── samples/ │ │ │ │ │ │ │ ├── prime_tables.h │ │ │ │ │ │ │ ├── sample1.cc │ │ │ │ │ │ │ ├── sample1.h │ │ │ │ │ │ │ ├── sample10_unittest.cc │ │ │ │ │ │ │ ├── sample1_unittest.cc │ │ │ │ │ │ │ ├── sample2.cc │ │ │ │ │ │ │ ├── sample2.h │ │ │ │ │ │ │ ├── sample2_unittest.cc │ │ │ │ │ │ │ ├── sample3-inl.h │ │ │ │ │ │ │ ├── sample3_unittest.cc │ │ │ │ │ │ │ ├── sample4.cc │ │ │ │ │ │ │ ├── sample4.h │ │ │ │ │ │ │ ├── sample4_unittest.cc │ │ │ │ │ │ │ ├── sample5_unittest.cc │ │ │ │ │ │ │ ├── sample6_unittest.cc │ │ │ │ │ │ │ ├── sample7_unittest.cc │ │ │ │ │ │ │ ├── sample8_unittest.cc │ │ │ │ │ │ │ └── sample9_unittest.cc │ │ │ │ │ │ ├── src/ │ │ │ │ │ │ │ ├── gtest-all.cc │ │ │ │ │ │ │ ├── gtest-assertion-result.cc │ │ │ │ │ │ │ ├── gtest-death-test.cc │ │ │ │ │ │ │ ├── gtest-filepath.cc │ │ │ │ │ │ │ ├── gtest-internal-inl.h │ │ │ │ │ │ │ ├── gtest-matchers.cc │ │ │ │ │ │ │ ├── gtest-port.cc │ │ │ │ │ │ │ ├── gtest-printers.cc │ │ │ │ │ │ │ ├── gtest-test-part.cc │ │ │ │ │ │ │ ├── gtest-typed-test.cc │ │ │ │ │ │ │ ├── gtest.cc │ │ │ │ │ │ │ └── gtest_main.cc │ │ │ │ │ │ └── test/ │ │ │ │ │ │ ├── BUILD.bazel │ │ │ │ │ │ ├── googletest-break-on-failure-unittest.py │ │ │ │ │ │ ├── googletest-break-on-failure-unittest_.cc │ │ │ │ │ │ ├── googletest-catch-exceptions-test.py │ │ │ │ │ │ ├── googletest-catch-exceptions-test_.cc │ │ │ │ │ │ ├── googletest-color-test.py │ │ │ │ │ │ ├── googletest-color-test_.cc │ │ │ │ │ │ ├── googletest-death-test-test.cc │ │ │ │ │ │ ├── googletest-death-test_ex_test.cc │ │ │ │ │ │ ├── googletest-env-var-test.py │ │ │ │ │ │ ├── googletest-env-var-test_.cc │ │ │ │ │ │ ├── googletest-fail-if-no-test-linked-test-with-disabled-test_.cc │ │ │ │ │ │ ├── googletest-fail-if-no-test-linked-test-with-enabled-test_.cc │ │ │ │ │ │ ├── googletest-fail-if-no-test-linked-test.py │ │ │ │ │ │ ├── googletest-failfast-unittest.py │ │ │ │ │ │ ├── googletest-failfast-unittest_.cc │ │ │ │ │ │ ├── googletest-filepath-test.cc │ │ │ │ │ │ ├── googletest-filter-unittest.py │ │ │ │ │ │ ├── googletest-filter-unittest_.cc │ │ │ │ │ │ ├── googletest-global-environment-unittest.py │ │ │ │ │ │ ├── googletest-global-environment-unittest_.cc │ │ │ │ │ │ ├── googletest-json-outfiles-test.py │ │ │ │ │ │ ├── googletest-json-output-unittest.py │ │ │ │ │ │ ├── googletest-list-tests-unittest.py │ │ │ │ │ │ ├── googletest-list-tests-unittest_.cc │ │ │ │ │ │ ├── googletest-listener-test.cc │ │ │ │ │ │ ├── googletest-message-test.cc │ │ │ │ │ │ ├── googletest-options-test.cc │ │ │ │ │ │ ├── googletest-output-test.py │ │ │ │ │ │ ├── googletest-output-test_.cc │ │ │ │ │ │ ├── googletest-param-test-invalid-name1-test.py │ │ │ │ │ │ ├── googletest-param-test-invalid-name1-test_.cc │ │ │ │ │ │ ├── googletest-param-test-invalid-name2-test.py │ │ │ │ │ │ ├── googletest-param-test-invalid-name2-test_.cc │ │ │ │ │ │ ├── googletest-param-test-test.cc │ │ │ │ │ │ ├── googletest-param-test-test.h │ │ │ │ │ │ ├── googletest-param-test2-test.cc │ │ │ │ │ │ ├── googletest-port-test.cc │ │ │ │ │ │ ├── googletest-printers-test.cc │ │ │ │ │ │ ├── googletest-setuptestsuite-test.py │ │ │ │ │ │ ├── googletest-setuptestsuite-test_.cc │ │ │ │ │ │ ├── googletest-shuffle-test.py │ │ │ │ │ │ ├── googletest-shuffle-test_.cc │ │ │ │ │ │ ├── googletest-test-part-test.cc │ │ │ │ │ │ ├── googletest-throw-on-failure-test.py │ │ │ │ │ │ ├── googletest-throw-on-failure-test_.cc │ │ │ │ │ │ ├── googletest-uninitialized-test.py │ │ │ │ │ │ ├── googletest-uninitialized-test_.cc │ │ │ │ │ │ ├── gtest-typed-test2_test.cc │ │ │ │ │ │ ├── gtest-typed-test_test.cc │ │ │ │ │ │ ├── gtest-typed-test_test.h │ │ │ │ │ │ ├── gtest-unittest-api_test.cc │ │ │ │ │ │ ├── gtest_all_test.cc │ │ │ │ │ │ ├── gtest_assert_by_exception_test.cc │ │ │ │ │ │ ├── gtest_dirs_test.cc │ │ │ │ │ │ ├── gtest_environment_test.cc │ │ │ │ │ │ ├── gtest_help_test.py │ │ │ │ │ │ ├── gtest_help_test_.cc │ │ │ │ │ │ ├── gtest_json_test_utils.py │ │ │ │ │ │ ├── gtest_list_output_unittest.py │ │ │ │ │ │ ├── gtest_list_output_unittest_.cc │ │ │ │ │ │ ├── gtest_main_unittest.cc │ │ │ │ │ │ ├── gtest_no_test_unittest.cc │ │ │ │ │ │ ├── gtest_pred_impl_unittest.cc │ │ │ │ │ │ ├── gtest_premature_exit_test.cc │ │ │ │ │ │ ├── gtest_prod_test.cc │ │ │ │ │ │ ├── gtest_repeat_test.cc │ │ │ │ │ │ ├── gtest_skip_check_output_test.py │ │ │ │ │ │ ├── gtest_skip_environment_check_output_test.py │ │ │ │ │ │ ├── gtest_skip_in_environment_setup_test.cc │ │ │ │ │ │ ├── gtest_skip_test.cc │ │ │ │ │ │ ├── gtest_sole_header_test.cc │ │ │ │ │ │ ├── gtest_stress_test.cc │ │ │ │ │ │ ├── gtest_test_macro_stack_footprint_test.cc │ │ │ │ │ │ ├── gtest_test_utils.py │ │ │ │ │ │ ├── gtest_testbridge_test.py │ │ │ │ │ │ ├── gtest_testbridge_test_.cc │ │ │ │ │ │ ├── gtest_throw_on_failure_ex_test.cc │ │ │ │ │ │ ├── gtest_unittest.cc │ │ │ │ │ │ ├── gtest_xml_outfile1_test_.cc │ │ │ │ │ │ ├── gtest_xml_outfile2_test_.cc │ │ │ │ │ │ ├── gtest_xml_outfiles_test.py │ │ │ │ │ │ ├── gtest_xml_output_unittest.py │ │ │ │ │ │ ├── gtest_xml_output_unittest_.cc │ │ │ │ │ │ ├── gtest_xml_test_utils.py │ │ │ │ │ │ ├── production.cc │ │ │ │ │ │ └── production.h │ │ │ │ │ └── googletest_deps.bzl │ │ │ │ └── perfetto/ │ │ │ │ ├── CMakeLists.txt │ │ │ │ ├── perfetto.cc │ │ │ │ └── perfetto.h │ │ │ ├── tests/ │ │ │ │ ├── CMakeLists.txt │ │ │ │ ├── core/ │ │ │ │ │ ├── CMakeLists.txt │ │ │ │ │ ├── aligned_alloc.cpp │ │ │ │ │ ├── buf.cpp │ │ │ │ │ ├── distribute_items.cpp │ │ │ │ │ ├── layout.cpp │ │ │ │ │ ├── list.cpp │ │ │ │ │ └── lru.cpp │ │ │ │ └── test_main.cpp │ │ │ └── tools/ │ │ │ └── set_pcie_speed.sh │ │ ├── moe_sparse_pipeline/ │ │ │ ├── CMakeLists.txt │ │ │ ├── expert_bundle.cpp │ │ │ ├── expert_cache.cpp │ │ │ ├── iou.cpp │ │ │ ├── moe_sparse_pipeline/ │ │ │ │ ├── config.hpp │ │ │ │ ├── expert_bundle.hpp │ │ │ │ ├── expert_cache.hpp │ │ │ │ ├── iou.hpp │ │ │ │ ├── lockfree_queue.hpp │ │ │ │ ├── object_pool.hpp │ │ │ │ ├── packed_kernel.hpp │ │ │ │ ├── pipeline.hpp │ │ │ │ └── task.hpp │ │ │ ├── packed_kernel.cpp │ │ │ ├── pipeline.cpp │ │ │ └── task.cpp │ │ ├── powerinfer-common/ │ │ │ ├── CMakeLists.txt │ │ │ └── include/ │ │ │ ├── powerinfer-exception.hpp │ │ │ ├── powerinfer-log.hpp │ │ │ ├── powerinfer-macro.hpp │ │ │ ├── powerinfer-mem.hpp │ │ │ ├── powerinfer-type.hpp │ │ │ └── util.hpp │ │ ├── powerinfer-cpu/ │ │ │ ├── CMakeLists.txt │ │ │ ├── include/ │ │ │ │ ├── axpy.hpp │ │ │ │ ├── chunked_vec_dot.hpp │ │ │ │ ├── convert.hpp │ │ │ │ ├── powerinfer-cpu-data.hpp │ │ │ │ ├── powerinfer-cpu-exception.hpp │ │ │ │ ├── powerinfer-cpu-param.hpp │ │ │ │ ├── powerinfer-cpu-sgemm.hpp │ │ │ │ ├── powerinfer-cpu.hpp │ │ │ │ └── vdot.hpp │ │ │ └── src/ │ │ │ ├── axpy.cpp │ │ │ ├── common.cpp │ │ │ ├── compare.hpp │ │ │ ├── fused_sparse_ffn.cpp │ │ │ ├── fused_sparse_ffn.hpp │ │ │ ├── post_attn_layernorm.cpp │ │ │ ├── powerinfer_cond_ffn.cpp │ │ │ ├── powerinfer_cond_ffn.hpp │ │ │ ├── rotary_embedding.cpp │ │ │ ├── sgemm.cpp │ │ │ ├── sparse_lmhead.cpp │ │ │ ├── sparse_matmul.hpp │ │ │ ├── sparse_moe_ffn.cpp │ │ │ ├── sparse_moe_ffn.hpp │ │ │ └── vec_dot.hpp │ │ ├── powerinfer-disk/ │ │ │ ├── CMakeLists.txt │ │ │ ├── include/ │ │ │ │ └── powerinfer-disk-queue.hpp │ │ │ └── src/ │ │ │ ├── atomic-queue/ │ │ │ │ ├── defs.h │ │ │ │ └── queue.h │ │ │ └── powerinfer-queue.cpp │ │ ├── powerinfer-perf/ │ │ │ ├── CMakeLists.txt │ │ │ ├── include/ │ │ │ │ └── powerinfer-perf.hpp │ │ │ └── src/ │ │ │ └── powerinfer-perf.cpp │ │ ├── src/ │ │ │ ├── convert.hpp │ │ │ ├── disk_buffer.hpp │ │ │ ├── interface_az.cpp │ │ │ ├── interface_host.cpp │ │ │ └── interface_perf.cpp │ │ ├── test/ │ │ │ ├── CMakeLists.txt │ │ │ ├── benchmark/ │ │ │ │ ├── CMakeLists.txt │ │ │ │ └── bench_example.cpp │ │ │ └── unit_test/ │ │ │ └── CMakeLists.txt │ │ └── third_part/ │ │ └── CMakeLists.txt │ ├── pyproject.toml │ ├── pyrightconfig.json │ ├── requirements/ │ │ ├── requirements-all.txt │ │ ├── requirements-compare-llama-bench.txt │ │ ├── requirements-convert_hf_to_gguf.txt │ │ ├── requirements-convert_hf_to_gguf_update.txt │ │ ├── requirements-convert_legacy_llama.txt │ │ ├── requirements-convert_llama_ggml_to_gguf.txt │ │ ├── requirements-convert_lora_to_gguf.txt │ │ ├── requirements-gguf_editor_gui.txt │ │ ├── requirements-pydantic.txt │ │ ├── requirements-test-tokenizer-random.txt │ │ └── requirements-tool_bench.txt │ ├── requirements.txt │ ├── scripts/ │ │ ├── apple/ │ │ │ ├── validate-apps.sh │ │ │ ├── validate-ios.sh │ │ │ ├── validate-macos.sh │ │ │ ├── validate-tvos.sh │ │ │ └── validate-visionos.sh │ │ ├── build-info.sh │ │ ├── check-requirements.sh │ │ ├── ci-run.sh │ │ ├── compare-commits.sh │ │ ├── compare-llama-bench.py │ │ ├── debug-test.sh │ │ ├── fetch_server_test_models.py │ │ ├── gen-authors.sh │ │ ├── gen-unicode-data.py │ │ ├── get-flags.mk │ │ ├── get-hellaswag.sh │ │ ├── get-pg.sh │ │ ├── get-wikitext-103.sh │ │ ├── get-wikitext-2.sh │ │ ├── get-winogrande.sh │ │ ├── get_chat_template.py │ │ ├── hf.sh │ │ ├── qnt-all.sh │ │ ├── run-all-perf.sh │ │ ├── run-all-ppl.sh │ │ ├── sync-ggml-am.sh │ │ ├── sync-ggml.last │ │ ├── sync-ggml.sh │ │ ├── sync_vendor.py │ │ ├── tool_bench.py │ │ ├── tool_bench.sh │ │ ├── verify-checksum-models.py │ │ └── xxd.cmake │ ├── src/ │ │ ├── .clang-format │ │ ├── CMakeLists.txt │ │ ├── llama-adapter.cpp │ │ ├── llama-adapter.h │ │ ├── llama-arch.cpp │ │ ├── llama-arch.h │ │ ├── llama-batch.cpp │ │ ├── llama-batch.h │ │ ├── llama-chat.cpp │ │ ├── llama-chat.h │ │ ├── llama-context.cpp │ │ ├── llama-context.h │ │ ├── llama-cparams.cpp │ │ ├── llama-cparams.h │ │ ├── llama-grammar.cpp │ │ ├── llama-grammar.h │ │ ├── llama-graph.cpp │ │ ├── llama-graph.h │ │ ├── llama-hparams.cpp │ │ ├── llama-hparams.h │ │ ├── llama-impl.cpp │ │ ├── llama-impl.h │ │ ├── llama-io.cpp │ │ ├── llama-io.h │ │ ├── llama-kv-cache-recurrent.cpp │ │ ├── llama-kv-cache-recurrent.h │ │ ├── llama-kv-cache-unified-iswa.cpp │ │ ├── llama-kv-cache-unified-iswa.h │ │ ├── llama-kv-cache-unified.cpp │ │ ├── llama-kv-cache-unified.h │ │ ├── llama-kv-cache.cpp │ │ ├── llama-kv-cache.h │ │ ├── llama-kv-cells.h │ │ ├── llama-memory.cpp │ │ ├── llama-memory.h │ │ ├── llama-mmap.cpp │ │ ├── llama-mmap.h │ │ ├── llama-model-loader.cpp │ │ ├── llama-model-loader.h │ │ ├── llama-model-saver.cpp │ │ ├── llama-model-saver.h │ │ ├── llama-model.cpp │ │ ├── llama-model.h │ │ ├── llama-quant.cpp │ │ ├── llama-quant.h │ │ ├── llama-sampling.cpp │ │ ├── llama-sampling.h │ │ ├── llama-vocab.cpp │ │ ├── llama-vocab.h │ │ ├── llama.cpp │ │ ├── unicode-data.cpp │ │ ├── unicode-data.h │ │ ├── unicode.cpp │ │ └── unicode.h │ ├── tests/ │ │ ├── .gitignore │ │ ├── CMakeLists.txt │ │ ├── get-model.cpp │ │ ├── get-model.h │ │ ├── run-json-schema-to-grammar.mjs │ │ ├── test-arg-parser.cpp │ │ ├── test-autorelease.cpp │ │ ├── test-backend-ops.cpp │ │ ├── test-barrier.cpp │ │ ├── test-c.c │ │ ├── test-chat-parser.cpp │ │ ├── test-chat-template.cpp │ │ ├── test-chat.cpp │ │ ├── test-double-float.cpp │ │ ├── test-gbnf-validator.cpp │ │ ├── test-gguf.cpp │ │ ├── test-grammar-integration.cpp │ │ ├── test-grammar-llguidance.cpp │ │ ├── test-grammar-parser.cpp │ │ ├── test-json-partial.cpp │ │ ├── test-json-schema-to-grammar.cpp │ │ ├── test-llama-grammar.cpp │ │ ├── test-log.cpp │ │ ├── test-lora-conversion-inference.sh │ │ ├── test-model-load-cancel.cpp │ │ ├── test-mtmd-c-api.c │ │ ├── test-opt.cpp │ │ ├── test-quantize-fns.cpp │ │ ├── test-quantize-perf.cpp │ │ ├── test-quantize-stats.cpp │ │ ├── test-regex-partial.cpp │ │ ├── test-rope.cpp │ │ ├── test-sampling.cpp │ │ ├── test-tokenizer-0.cpp │ │ ├── test-tokenizer-0.py │ │ ├── test-tokenizer-0.sh │ │ ├── test-tokenizer-1-bpe.cpp │ │ ├── test-tokenizer-1-spm.cpp │ │ └── test-tokenizer-random.py │ ├── toolchains/ │ │ ├── aarch64-linux-gnu.cmake │ │ ├── cross_compile.md │ │ ├── raspi5.cmake │ │ ├── rdkx5.cmake │ │ ├── rk3566.cmake │ │ ├── rk3576.cmake │ │ └── rk3588.cmake │ ├── tools/ │ │ ├── CMakeLists.txt │ │ ├── batched-bench/ │ │ │ ├── CMakeLists.txt │ │ │ ├── README.md │ │ │ └── batched-bench.cpp │ │ ├── cvector-generator/ │ │ │ ├── CMakeLists.txt │ │ │ ├── README.md │ │ │ ├── completions.txt │ │ │ ├── cvector-generator.cpp │ │ │ ├── mean.hpp │ │ │ ├── negative.txt │ │ │ ├── pca.hpp │ │ │ └── positive.txt │ │ ├── export-lora/ │ │ │ ├── CMakeLists.txt │ │ │ ├── README.md │ │ │ └── export-lora.cpp │ │ ├── gguf-split/ │ │ │ ├── CMakeLists.txt │ │ │ ├── README.md │ │ │ ├── gguf-split.cpp │ │ │ └── tests.sh │ │ ├── imatrix/ │ │ │ ├── CMakeLists.txt │ │ │ ├── README.md │ │ │ └── imatrix.cpp │ │ ├── llama-bench/ │ │ │ ├── CMakeLists.txt │ │ │ ├── README.md │ │ │ └── llama-bench.cpp │ │ ├── main/ │ │ │ ├── CMakeLists.txt │ │ │ ├── README.md │ │ │ └── main.cpp │ │ ├── mtmd/ │ │ │ ├── CMakeLists.txt │ │ │ ├── README.md │ │ │ ├── clip-impl.h │ │ │ ├── clip.cpp │ │ │ ├── clip.h │ │ │ ├── deprecation-warning.cpp │ │ │ ├── legacy-models/ │ │ │ │ ├── convert_image_encoder_to_gguf.py │ │ │ │ ├── glmedge-convert-image-encoder-to-gguf.py │ │ │ │ ├── glmedge-surgery.py │ │ │ │ ├── llava_surgery.py │ │ │ │ ├── llava_surgery_v2.py │ │ │ │ ├── minicpmv-convert-image-encoder-to-gguf.py │ │ │ │ └── minicpmv-surgery.py │ │ │ ├── mtmd-audio.cpp │ │ │ ├── mtmd-audio.h │ │ │ ├── mtmd-cli.cpp │ │ │ ├── mtmd-helper.cpp │ │ │ ├── mtmd-helper.h │ │ │ ├── mtmd.cpp │ │ │ ├── mtmd.h │ │ │ ├── requirements.txt │ │ │ └── tests.sh │ │ ├── perplexity/ │ │ │ ├── CMakeLists.txt │ │ │ ├── README.md │ │ │ └── perplexity.cpp │ │ ├── quantize/ │ │ │ ├── CMakeLists.txt │ │ │ ├── README.md │ │ │ ├── quantize.cpp │ │ │ └── tests.sh │ │ ├── rpc/ │ │ │ ├── CMakeLists.txt │ │ │ ├── README.md │ │ │ └── rpc-server.cpp │ │ ├── run/ │ │ │ ├── CMakeLists.txt │ │ │ ├── README.md │ │ │ ├── linenoise.cpp/ │ │ │ │ ├── linenoise.cpp │ │ │ │ └── linenoise.h │ │ │ └── run.cpp │ │ ├── server/ │ │ │ ├── CMakeLists.txt │ │ │ ├── README.md │ │ │ ├── bench/ │ │ │ │ ├── README.md │ │ │ │ ├── bench.py │ │ │ │ ├── prometheus.yml │ │ │ │ ├── requirements.txt │ │ │ │ └── script.js │ │ │ ├── chat-llama2.sh │ │ │ ├── chat.mjs │ │ │ ├── chat.sh │ │ │ ├── public/ │ │ │ │ └── loading.html │ │ │ ├── public_legacy/ │ │ │ │ ├── colorthemes.css │ │ │ │ ├── completion.js │ │ │ │ ├── index-new.html │ │ │ │ ├── index.html │ │ │ │ ├── index.js │ │ │ │ ├── json-schema-to-grammar.mjs │ │ │ │ ├── loading.html │ │ │ │ ├── prompt-formats.js │ │ │ │ ├── style.css │ │ │ │ ├── system-prompts.js │ │ │ │ ├── theme-beeninorder.css │ │ │ │ ├── theme-ketivah.css │ │ │ │ ├── theme-mangotango.css │ │ │ │ ├── theme-playground.css │ │ │ │ ├── theme-polarnight.css │ │ │ │ └── theme-snowstorm.css │ │ │ ├── public_simplechat/ │ │ │ │ ├── datautils.mjs │ │ │ │ ├── index.html │ │ │ │ ├── readme.md │ │ │ │ ├── simplechat.css │ │ │ │ ├── simplechat.js │ │ │ │ └── ui.mjs │ │ │ ├── server.cpp │ │ │ ├── tests/ │ │ │ │ ├── .gitignore │ │ │ │ ├── README.md │ │ │ │ ├── conftest.py │ │ │ │ ├── pytest.ini │ │ │ │ ├── requirements.txt │ │ │ │ ├── tests.sh │ │ │ │ ├── unit/ │ │ │ │ │ ├── test_basic.py │ │ │ │ │ ├── test_chat_completion.py │ │ │ │ │ ├── test_completion.py │ │ │ │ │ ├── test_ctx_shift.py │ │ │ │ │ ├── test_embedding.py │ │ │ │ │ ├── test_infill.py │ │ │ │ │ ├── test_lora.py │ │ │ │ │ ├── test_rerank.py │ │ │ │ │ ├── test_security.py │ │ │ │ │ ├── test_slot_save.py │ │ │ │ │ ├── test_speculative.py │ │ │ │ │ ├── test_template.py │ │ │ │ │ ├── test_tokenize.py │ │ │ │ │ ├── test_tool_call.py │ │ │ │ │ └── test_vision_api.py │ │ │ │ └── utils.py │ │ │ ├── themes/ │ │ │ │ ├── README.md │ │ │ │ ├── buttons-top/ │ │ │ │ │ ├── README.md │ │ │ │ │ └── index.html │ │ │ │ └── wild/ │ │ │ │ ├── README.md │ │ │ │ └── index.html │ │ │ ├── utils.hpp │ │ │ └── webui/ │ │ │ ├── .gitignore │ │ │ ├── .prettierignore │ │ │ ├── eslint.config.js │ │ │ ├── index.html │ │ │ ├── package.json │ │ │ ├── postcss.config.js │ │ │ ├── public/ │ │ │ │ └── demo-conversation.json │ │ │ ├── src/ │ │ │ │ ├── App.tsx │ │ │ │ ├── Config.ts │ │ │ │ ├── components/ │ │ │ │ │ ├── CanvasPyInterpreter.tsx │ │ │ │ │ ├── ChatInputExtraContextItem.tsx │ │ │ │ │ ├── ChatMessage.tsx │ │ │ │ │ ├── ChatScreen.tsx │ │ │ │ │ ├── Header.tsx │ │ │ │ │ ├── MarkdownDisplay.tsx │ │ │ │ │ ├── ModalProvider.tsx │ │ │ │ │ ├── SettingDialog.tsx │ │ │ │ │ ├── Sidebar.tsx │ │ │ │ │ ├── useChatExtraContext.tsx │ │ │ │ │ ├── useChatScroll.tsx │ │ │ │ │ └── useChatTextarea.ts │ │ │ │ ├── index.scss │ │ │ │ ├── main.tsx │ │ │ │ ├── utils/ │ │ │ │ │ ├── app.context.tsx │ │ │ │ │ ├── common.tsx │ │ │ │ │ ├── llama-vscode.ts │ │ │ │ │ ├── misc.ts │ │ │ │ │ ├── storage.ts │ │ │ │ │ └── types.ts │ │ │ │ └── vite-env.d.ts │ │ │ ├── tailwind.config.js │ │ │ ├── tsconfig.app.json │ │ │ ├── tsconfig.json │ │ │ ├── tsconfig.node.json │ │ │ └── vite.config.ts │ │ ├── tokenize/ │ │ │ ├── CMakeLists.txt │ │ │ └── tokenize.cpp │ │ └── tts/ │ │ ├── CMakeLists.txt │ │ ├── README.md │ │ ├── convert_pt_to_hf.py │ │ ├── tts-outetts.py │ │ └── tts.cpp │ └── vendor/ │ ├── cpp-httplib/ │ │ └── httplib.h │ ├── miniaudio/ │ │ └── miniaudio.h │ ├── minja/ │ │ ├── chat-template.hpp │ │ └── minja.hpp │ ├── nlohmann/ │ │ ├── json.hpp │ │ └── json_fwd.hpp │ └── stb/ │ └── stb_image.h ├── tests/ │ ├── CMakeLists.txt │ ├── test-c.c │ ├── test-double-float.cpp │ ├── test-grad0.cpp │ ├── test-grammar-parser.cpp │ ├── test-llama-grammar.cpp │ ├── test-opt.cpp │ ├── test-quantize-fns.cpp │ ├── test-quantize-perf.cpp │ ├── test-rope.cpp │ ├── test-sampling.cpp │ ├── test-tokenizer-0-falcon.cpp │ ├── test-tokenizer-0-falcon.py │ ├── test-tokenizer-0-llama.cpp │ ├── test-tokenizer-0-llama.py │ ├── test-tokenizer-1-bpe.cpp │ └── test-tokenizer-1-llama.cpp └── unicode.h
Copy disabled (too large)
Download .json
Condensed preview — 2271 files, each showing path, character count, and a content snippet. Download the .json file for the full structured content (48,679K chars).
[
{
"path": ".devops/cloud-v-pipeline",
"chars": 1072,
"preview": "node('x86_runner1'){ // Running on x86 runner containing latest vector qemu, latest vector gcc and all the ne"
},
{
"path": ".devops/full-cuda.Dockerfile",
"chars": 742,
"preview": "ARG UBUNTU_VERSION=22.04\n\n# This needs to generally match the container host's environment.\nARG CUDA_VERSION=11.7.1\n\n# T"
},
{
"path": ".devops/full-rocm.Dockerfile",
"chars": 979,
"preview": "ARG UBUNTU_VERSION=22.04\n\n# This needs to generally match the container host's environment.\nARG ROCM_VERSION=5.6\n\n# Targ"
},
{
"path": ".devops/full.Dockerfile",
"chars": 371,
"preview": "ARG UBUNTU_VERSION=22.04\n\nFROM ubuntu:$UBUNTU_VERSION as build\n\nRUN apt-get update && \\\n apt-get install -y build-ess"
},
{
"path": ".devops/llama-cpp-clblast.srpm.spec",
"chars": 2611,
"preview": "# SRPM for building from source and packaging an RPM for RPM-based distros.\n# https://fedoraproject.org/wiki/How_to_crea"
},
{
"path": ".devops/llama-cpp-cublas.srpm.spec",
"chars": 2622,
"preview": "# SRPM for building from source and packaging an RPM for RPM-based distros.\n# https://fedoraproject.org/wiki/How_to_crea"
},
{
"path": ".devops/llama-cpp.srpm.spec",
"chars": 2652,
"preview": "# SRPM for building from source and packaging an RPM for RPM-based distros.\n# https://fedoraproject.org/wiki/How_to_crea"
},
{
"path": ".devops/main-cuda.Dockerfile",
"chars": 776,
"preview": "ARG UBUNTU_VERSION=22.04\n# This needs to generally match the container host's environment.\nARG CUDA_VERSION=11.7.1\n# Tar"
},
{
"path": ".devops/main-rocm.Dockerfile",
"chars": 969,
"preview": "ARG UBUNTU_VERSION=22.04\n\n# This needs to generally match the container host's environment.\nARG ROCM_VERSION=5.6\n\n# Targ"
},
{
"path": ".devops/main.Dockerfile",
"chars": 283,
"preview": "ARG UBUNTU_VERSION=22.04\n\nFROM ubuntu:$UBUNTU_VERSION as build\n\nRUN apt-get update && \\\n apt-get install -y build-ess"
},
{
"path": ".devops/tools.sh",
"chars": 1674,
"preview": "#!/bin/bash\nset -e\n\n# Read the first argument into a variable\narg1=\"$1\"\n\n# Shift the arguments to remove the first one\ns"
},
{
"path": ".dockerignore",
"chars": 147,
"preview": "*.o\n*.a\n.cache/\n.git/\n.github/\n.gitignore\n.vs/\n.vscode/\n.DS_Store\n\nbuild*/\n\nmodels/*\n\n/main\n/quantize\n\narm_neon.h\ncompil"
},
{
"path": ".ecrc",
"chars": 46,
"preview": "{\n \"Disable\": {\n \"IndentSize\": true\n }\n}\n"
},
{
"path": ".editorconfig",
"chars": 395,
"preview": "# https://EditorConfig.org\n\n# Top-most EditorConfig file\nroot = true\n\n# Unix-style newlines with a newline ending every "
},
{
"path": ".flake8",
"chars": 31,
"preview": "[flake8]\nmax-line-length = 125\n"
},
{
"path": ".github/ISSUE_TEMPLATE/bug.md",
"chars": 9711,
"preview": "---\nname: Bug template\nabout: Used to report bugs in PowerInfer\nlabels: [\"bug-unconfirmed\"]\nassignees: ''\n\n---\n\n# Prereq"
},
{
"path": ".github/ISSUE_TEMPLATE/enhancement.md",
"chars": 1253,
"preview": "---\nname: Enhancement template\nabout: Used to request enhancements for PowerInfer\nlabels: [\"enhancement\"]\nassignees: ''\n"
},
{
"path": ".github/ISSUE_TEMPLATE/question.md",
"chars": 1130,
"preview": "---\nname: Question template\nabout: Used for general questions and inquiries about PowerInfer\nlabels: [\"question\"]\nassign"
},
{
"path": ".github/workflows/build.yml",
"chars": 24316,
"preview": "name: CI\n\non:\n workflow_dispatch: # allows manual triggering\n inputs:\n create_release:\n description: 'Cr"
},
{
"path": ".github/workflows/code-coverage.yml",
"chars": 775,
"preview": "name: Code Coverage\non: [push, pull_request]\n\nenv:\n GGML_NLOOP: 3\n GGML_N_THREADS: 1\n\njobs:\n run:\n runs-on: ubuntu"
},
{
"path": ".github/workflows/docker.yml",
"chars": 2744,
"preview": "# This workflow uses actions that are not certified by GitHub.\n# They are provided by a third-party and are governed by\n"
},
{
"path": ".github/workflows/editorconfig.yml",
"chars": 311,
"preview": "name: EditorConfig Checker\n\non:\n push:\n branches:\n - master\n pull_request:\n branches:\n - master\n\njobs:"
},
{
"path": ".github/workflows/gguf-publish.yml",
"chars": 1232,
"preview": "# This workflow will upload a Python Package using Twine when a GGUF release is created\n# For more information see: http"
},
{
"path": ".github/workflows/tidy-post.yml",
"chars": 496,
"preview": "name: clang-tidy review post comments\n\non:\n workflow_dispatch:\n workflows: [\"clang-tidy-review\"]\n types:\n - "
},
{
"path": ".github/workflows/tidy-review.yml",
"chars": 464,
"preview": "name: clang-tidy-review\n\non:\n pull_request:\n branches:\n - master\n\njobs:\n clang-tidy-review:\n runs-on: ubunt"
},
{
"path": ".github/workflows/zig-build.yml",
"chars": 516,
"preview": "name: Zig CI\n\non:\n pull_request:\n push:\n branches:\n - master\n\njobs:\n build:\n strategy:\n fail-fast: fa"
},
{
"path": ".gitignore",
"chars": 1153,
"preview": "*.o\n*.a\n*.so\n*.gguf\n*.bin\n*.exe\n*.dll\n*.log\n*.gcov\n*.gcno\n*.gcda\n*.dot\n*.bat\n*.metallib\n.DS_Store\n.build/\n.cache/\n.ccls-"
},
{
"path": ".gitmodules",
"chars": 1082,
"preview": "[submodule \"smallthinker/ggml/src/ggml-kompute/kompute\"]\n\tpath = smallthinker/ggml/src/ggml-kompute/kompute\n\turl = https"
},
{
"path": ".pre-commit-config.yaml",
"chars": 398,
"preview": "# See https://pre-commit.com for more information\n# See https://pre-commit.com/hooks.html for more hooks\nexclude: prompt"
},
{
"path": "CMakeLists.txt",
"chars": 29840,
"preview": "cmake_minimum_required(VERSION 3.13) # for add_link_options\nproject(\"llama.cpp\" C CXX)\n\nset(CMAKE_EXPORT_COMPILE_COMMAN"
},
{
"path": "LICENSE",
"chars": 1102,
"preview": "MIT License\n\nCopyright (c) 2023 Georgi Gerganov\nCopyright (c) 2023 SJTU-IPADS\n\nPermission is hereby granted, free of cha"
},
{
"path": "Package.swift",
"chars": 1915,
"preview": "// swift-tools-version:5.5\n\nimport PackageDescription\n\n#if arch(arm) || arch(arm64)\nlet platforms: [SupportedPlatform]? "
},
{
"path": "README.md",
"chars": 21766,
"preview": "# PowerInfer: Fast Large Language Model Serving with a Consumer-grade GPU\n\n## TL;DR\nPowerInfer is a CPU/GPU LLM inferenc"
},
{
"path": "SHA256SUMS",
"chars": 3829,
"preview": "700df0d3013b703a806d2ae7f1bfb8e59814e3d06ae78be0c66368a50059f33d models/7B/consolidated.00.pth\n666a4bb533b303bdaf89e1b6"
},
{
"path": "atomic_windows.h",
"chars": 24734,
"preview": "/*\n * C11 <stdatomic.h> emulation header\n *\n * PLEASE LICENSE, (C) 2022, Michael Clark <michaeljclark@mac.com>\n *\n * All"
},
{
"path": "build.zig",
"chars": 6287,
"preview": "// Compatible with Zig Version 0.11.0\nconst std = @import(\"std\");\nconst ArrayList = std.ArrayList;\nconst Compile = std.B"
},
{
"path": "ci/README.md",
"chars": 976,
"preview": "# CI\n\nIn addition to [Github Actions](https://github.com/ggerganov/llama.cpp/actions) `llama.cpp` uses a custom CI frame"
},
{
"path": "ci/run.sh",
"chars": 27079,
"preview": "#/bin/bash\n#\n# sample usage:\n#\n# mkdir tmp\n#\n# # CPU-only build\n# bash ./ci/run.sh ./tmp/results ./tmp/mnt\n#\n# # with CU"
},
{
"path": "cmake/FindSIMD.cmake",
"chars": 2657,
"preview": "include(CheckCSourceRuns)\n\nset(AVX_CODE \"\n #include <immintrin.h>\n int main()\n {\n __m256 a;\n a = "
},
{
"path": "codecov.yml",
"chars": 210,
"preview": "comment: off\n\ncoverage:\n status:\n project:\n default:\n target: auto\n threshold: 0\n base: au"
},
{
"path": "common/CMakeLists.txt",
"chars": 1967,
"preview": "# common\n\n\n# Build info header\n#\n\nif(EXISTS \"${CMAKE_CURRENT_SOURCE_DIR}/../.git\")\n set(GIT_DIR \"${CMAKE_CURRENT_SOUR"
},
{
"path": "common/base64.hpp",
"chars": 12878,
"preview": "/*\nThis is free and unencumbered software released into the public domain.\n\nAnyone is free to copy, modify, publish, use"
},
{
"path": "common/build-info.cpp.in",
"chars": 186,
"preview": "int LLAMA_BUILD_NUMBER = @BUILD_NUMBER@;\nchar const *LLAMA_COMMIT = \"@BUILD_COMMIT@\";\nchar const *LLAMA_COMPILER = \"@BUI"
},
{
"path": "common/common.cpp",
"chars": 60787,
"preview": "#include \"common.h\"\n#include \"llama.h\"\n\n#include <algorithm>\n#include <cassert>\n#include <cmath>\n#include <cstring>\n#inc"
},
{
"path": "common/common.h",
"chars": 10732,
"preview": "// Various helper functions and utilities\n\n#pragma once\n\n#include \"llama.h\"\n\n#include \"sampling.h\"\n\n#define LOG_NO_FILE_"
},
{
"path": "common/console.cpp",
"chars": 16237,
"preview": "#include \"console.h\"\n#include <vector>\n#include <iostream>\n\n#if defined(_WIN32)\n#define WIN32_LEAN_AND_MEAN\n#ifndef NOMI"
},
{
"path": "common/console.h",
"chars": 359,
"preview": "// Console functions\n\n#pragma once\n\n#include <string>\n\nnamespace console {\n enum display_t {\n reset = 0,\n "
},
{
"path": "common/grammar-parser.cpp",
"chars": 17695,
"preview": "#include \"grammar-parser.h\"\n#include <cstdint>\n#include <cwchar>\n#include <string>\n#include <utility>\n#include <stdexcep"
},
{
"path": "common/grammar-parser.h",
"chars": 874,
"preview": "// Implements a parser for an extended Backus-Naur form (BNF), producing the\n// binary context-free grammar format speci"
},
{
"path": "common/log.h",
"chars": 24418,
"preview": "#pragma once\n\n#include <chrono>\n#include <cstring>\n#include <sstream>\n#include <iostream>\n#include <thread>\n#include <ve"
},
{
"path": "common/sampling.cpp",
"chars": 8220,
"preview": "#include \"sampling.h\"\n\nstruct llama_sampling_context * llama_sampling_init(const struct llama_sampling_params & params) "
},
{
"path": "common/sampling.h",
"chars": 3976,
"preview": "#pragma once\n\n#include \"llama.h\"\n\n#include \"grammar-parser.h\"\n\n#include <string>\n#include <vector>\n#include <unordered_m"
},
{
"path": "common/stb_image.h",
"chars": 320946,
"preview": "/* stb_image - v2.28 - public domain image loader - http://nothings.org/stb\n no warrant"
},
{
"path": "common/train.cpp",
"chars": 65543,
"preview": "#include \"train.h\"\n#include \"common.h\"\n\n#include <random>\n#include <sstream>\n#include <functional>\n\nstruct random_normal"
},
{
"path": "common/train.h",
"chars": 7887,
"preview": "// Various helper functions and utilities for training\n\n#pragma once\n\n#include <string>\n#include <random>\n#include <vect"
},
{
"path": "convert-dense.py",
"chars": 50726,
"preview": "# SPDX-License-Identifier: MIT\n# Copyright (c) 2023 Georgi Gerganov\n# Based on code from https://github.com/ggerganov/ll"
},
{
"path": "convert-hf-to-powerinfer-gguf.py",
"chars": 25669,
"preview": "#!/usr/bin/env python3\n\nfrom __future__ import annotations\nfrom abc import ABC, abstractmethod\n\nimport argparse\nimport c"
},
{
"path": "convert.py",
"chars": 54761,
"preview": "#!/usr/bin/env python3\nfrom __future__ import annotations\n\nimport argparse\nimport concurrent.futures\nimport dataclasses\n"
},
{
"path": "docs/BLIS.md",
"chars": 1741,
"preview": "BLIS Installation Manual\n------------------------\n\nBLIS is a portable software framework for high-performance BLAS-like "
},
{
"path": "docs/token_generation_performance_tips.md",
"chars": 4948,
"preview": "# Token generation performance troubleshooting\n\n## Verifying that the model is running on the Nvidia GPU with cuBLAS\n\nMa"
},
{
"path": "examples/CMakeLists.txt",
"chars": 1006,
"preview": "# dependencies\n\nfind_package(Threads REQUIRED)\n\n# third-party\n\n# ...\n\n# examples\n\ninclude_directories(${CMAKE_CURRENT_SO"
},
{
"path": "examples/Miku.sh",
"chars": 2626,
"preview": "#!/bin/bash\nset -e\n\nAI_NAME=\"${AI_NAME:-Miku}\"\nMODEL=\"${MODEL:-./models/llama-2-7b-chat.ggmlv3.q4_K_M.bin}\"\nUSER_NAME=\"$"
},
{
"path": "examples/alpaca.sh",
"chars": 336,
"preview": "#!/bin/bash\n\n#\n# Temporary script - will be removed in the future\n#\n\ncd `dirname $0`\ncd ..\n\n./main -m ./models/alpaca.13"
},
{
"path": "examples/baby-llama/CMakeLists.txt",
"chars": 233,
"preview": "set(TARGET baby-llama)\nadd_executable(${TARGET} baby-llama.cpp)\ninstall(TARGETS ${TARGET} RUNTIME)\ntarget_link_libraries"
},
{
"path": "examples/baby-llama/baby-llama.cpp",
"chars": 62630,
"preview": "#include \"ggml.h\"\n#include \"train.h\"\n\n#include <vector>\n#include <cassert>\n#include <cstdlib>\n#include <cstring>\n#includ"
},
{
"path": "examples/batched/CMakeLists.txt",
"chars": 227,
"preview": "set(TARGET batched)\nadd_executable(${TARGET} batched.cpp)\ninstall(TARGETS ${TARGET} RUNTIME)\ntarget_link_libraries(${TAR"
},
{
"path": "examples/batched/README.md",
"chars": 1406,
"preview": "# llama.cpp/example/batched\n\nThe example demonstrates batched generation from a given prompt\n\n```bash\n./batched ./models"
},
{
"path": "examples/batched/batched.cpp",
"chars": 8326,
"preview": "#include \"common.h\"\n#include \"llama.h\"\n\n#include <algorithm>\n#include <cmath>\n#include <cstdio>\n#include <string>\n#inclu"
},
{
"path": "examples/batched-bench/CMakeLists.txt",
"chars": 239,
"preview": "set(TARGET batched-bench)\nadd_executable(${TARGET} batched-bench.cpp)\ninstall(TARGETS ${TARGET} RUNTIME)\ntarget_link_lib"
},
{
"path": "examples/batched-bench/README.md",
"chars": 2661,
"preview": "# llama.cpp/example/batched-bench\n\nBenchmark the batched decoding performance of `llama.cpp`\n\n## Usage\n\nThere are 2 mode"
},
{
"path": "examples/batched-bench/batched-bench.cpp",
"chars": 7318,
"preview": "#include \"common.h\"\n#include \"llama.h\"\n\n#include <algorithm>\n#include <cmath>\n#include <cstdio>\n#include <string>\n#inclu"
},
{
"path": "examples/batched.swift/.gitignore",
"chars": 173,
"preview": ".DS_Store\n/.build\n/Packages\nxcuserdata/\nDerivedData/\n.swiftpm/configuration/registries.json\n.swiftpm/xcode/package.xcwor"
},
{
"path": "examples/batched.swift/Makefile",
"chars": 206,
"preview": ".PHONY: build\n\nbuild:\n\txcodebuild -scheme batched_swift -destination \"generic/platform=macOS\" -derivedDataPath build\n\trm"
},
{
"path": "examples/batched.swift/Package.swift",
"chars": 754,
"preview": "// swift-tools-version: 5.5\n// The swift-tools-version declares the minimum version of Swift required to build this pack"
},
{
"path": "examples/batched.swift/README.md",
"chars": 98,
"preview": "This is a swift clone of `examples/batched`.\n\n$ `make`\n$ `./swift MODEL_PATH [PROMPT] [PARALLEL]`\n"
},
{
"path": "examples/batched.swift/Sources/main.swift",
"chars": 7722,
"preview": "import Foundation\nimport llama\n\nlet arguments = CommandLine.arguments\n\n// Check that we have at least one argument (the "
},
{
"path": "examples/beam-search/CMakeLists.txt",
"chars": 235,
"preview": "set(TARGET beam-search)\nadd_executable(${TARGET} beam-search.cpp)\ninstall(TARGETS ${TARGET} RUNTIME)\ntarget_link_librari"
},
{
"path": "examples/beam-search/beam-search.cpp",
"chars": 5904,
"preview": "#include \"common.h\"\n#include \"llama.h\"\n\n#include <cassert>\n#include <cinttypes>\n#include <cmath>\n#include <cstdio>\n#incl"
},
{
"path": "examples/benchmark/CMakeLists.txt",
"chars": 302,
"preview": "set(TARGET benchmark)\nadd_executable(${TARGET} benchmark-matmult.cpp)\ninstall(TARGETS ${TARGET} RUNTIME)\ntarget_link_lib"
},
{
"path": "examples/benchmark/benchmark-matmult.cpp",
"chars": 9853,
"preview": "#include \"common.h\"\n#include \"ggml.h\"\n\n#include <locale.h>\n#include <assert.h>\n#include <math.h>\n#include <cstring>\n#inc"
},
{
"path": "examples/chat-13B.sh",
"chars": 1339,
"preview": "#!/bin/bash\n\nset -e\n\ncd \"$(dirname \"$0\")/..\" || exit\n\nMODEL=\"${MODEL:-./models/13B/ggml-model-q4_0.bin}\"\nPROMPT_TEMPLATE"
},
{
"path": "examples/chat-persistent.sh",
"chars": 5028,
"preview": "#!/bin/bash\n\nset -euo pipefail\n\ncd \"$(dirname \"$0\")/..\" || exit\n\nif [[ -z \"${PROMPT_CACHE_FILE+x}\" || -z \"${CHAT_SAVE_DI"
},
{
"path": "examples/chat-vicuna.sh",
"chars": 1331,
"preview": "#!/bin/bash\n\nset -e\n\ncd \"$(dirname \"$0\")/..\" || exit\n\nMODEL=\"${MODEL:-./models/ggml-vic13b-uncensored-q5_0.bin}\"\nPROMPT_"
},
{
"path": "examples/chat.sh",
"chars": 344,
"preview": "#!/bin/bash\n\n#\n# Temporary script - will be removed in the future\n#\n\ncd `dirname $0`\ncd ..\n\n# Important:\n#\n# \"--keep 4"
},
{
"path": "examples/convert-llama2c-to-ggml/CMakeLists.txt",
"chars": 259,
"preview": "set(TARGET convert-llama2c-to-ggml)\nadd_executable(${TARGET} convert-llama2c-to-ggml.cpp)\ninstall(TARGETS ${TARGET} RUNT"
},
{
"path": "examples/convert-llama2c-to-ggml/README.md",
"chars": 1344,
"preview": "## Convert llama2.c model to ggml\n\nThis example reads weights from project [llama2.c](https://github.com/karpathy/llama2"
},
{
"path": "examples/convert-llama2c-to-ggml/convert-llama2c-to-ggml.cpp",
"chars": 36414,
"preview": "#include \"ggml.h\"\n#include \"llama.h\"\n#include \"common.h\"\n\n#include <unordered_map>\n#include <vector>\n#include <cassert>\n"
},
{
"path": "examples/embedding/CMakeLists.txt",
"chars": 231,
"preview": "set(TARGET embedding)\nadd_executable(${TARGET} embedding.cpp)\ninstall(TARGETS ${TARGET} RUNTIME)\ntarget_link_libraries($"
},
{
"path": "examples/embedding/README.md",
"chars": 564,
"preview": "# llama.cpp/example/embedding\n\nThis example demonstrates generate high-dimensional embedding vector of a given text with"
},
{
"path": "examples/embedding/embedding.cpp",
"chars": 2844,
"preview": "#include \"common.h\"\n#include \"llama.h\"\n\n#include <ctime>\n\n#if defined(_MSC_VER)\n#pragma warning(disable: 4244 4267) // p"
},
{
"path": "examples/export-lora/CMakeLists.txt",
"chars": 235,
"preview": "set(TARGET export-lora)\nadd_executable(${TARGET} export-lora.cpp)\ninstall(TARGETS ${TARGET} RUNTIME)\ntarget_link_librari"
},
{
"path": "examples/export-lora/README.md",
"chars": 914,
"preview": "# export-lora\n\nApply LORA adapters to base model and export the resulting model.\n\n```\nusage: export-lora [options]\n\nopti"
},
{
"path": "examples/export-lora/export-lora.cpp",
"chars": 15220,
"preview": "\n#include \"common.h\"\n#include \"ggml.h\"\n#include \"ggml-alloc.h\"\n\n#include <vector>\n#include <string>\n#include <thread>\n\ns"
},
{
"path": "examples/finetune/CMakeLists.txt",
"chars": 229,
"preview": "set(TARGET finetune)\nadd_executable(${TARGET} finetune.cpp)\ninstall(TARGETS ${TARGET} RUNTIME)\ntarget_link_libraries(${T"
},
{
"path": "examples/finetune/README.md",
"chars": 4548,
"preview": "# finetune\n\nBasic usage instructions:\n\n```bash\n# get training data\nwget https://raw.githubusercontent.com/brunoklein99/d"
},
{
"path": "examples/finetune/convert-finetune-checkpoint-to-gguf.py",
"chars": 27236,
"preview": "#!/usr/bin/env python3\n# finetune checkpoint --> gguf conversion\n\nimport argparse\nimport gguf\nimport os\nimport struct\nim"
},
{
"path": "examples/finetune/finetune.cpp",
"chars": 93880,
"preview": "#include \"ggml.h\"\n#include \"ggml-alloc.h\"\n#include \"llama.h\"\n#include \"common.h\"\n#include \"train.h\"\n#include <unordered_"
},
{
"path": "examples/finetune/finetune.sh",
"chars": 1084,
"preview": "#!/bin/bash\ncd `dirname $0`\ncd ../..\n\nEXE=\"./finetune\"\n\nif [[ ! $LLAMA_MODEL_DIR ]]; then LLAMA_MODEL_DIR=\"./models\"; fi"
},
{
"path": "examples/gguf/CMakeLists.txt",
"chars": 214,
"preview": "set(TARGET gguf)\nadd_executable(${TARGET} gguf.cpp)\ninstall(TARGETS ${TARGET} RUNTIME)\ntarget_link_libraries(${TARGET} P"
},
{
"path": "examples/gguf/gguf.cpp",
"chars": 7687,
"preview": "#include \"ggml.h\"\n#include \"llama.h\"\n\n#include <cstdio>\n#include <cinttypes>\n#include <string>\n#include <sstream>\n#inclu"
},
{
"path": "examples/gpt4all.sh",
"chars": 386,
"preview": "#!/bin/bash\n\n#\n# Temporary script - will be removed in the future\n#\n\ncd `dirname $0`\ncd ..\n\n./main --color --instruct --"
},
{
"path": "examples/infill/CMakeLists.txt",
"chars": 225,
"preview": "set(TARGET infill)\nadd_executable(${TARGET} infill.cpp)\ninstall(TARGETS ${TARGET} RUNTIME)\ntarget_link_libraries(${TARGE"
},
{
"path": "examples/infill/README.md",
"chars": 2362,
"preview": "# llama.cpp/example/infill\n\nThis example shows how to use the infill mode with Code Llama models supporting infill mode."
},
{
"path": "examples/infill/infill.cpp",
"chars": 28806,
"preview": "#include \"common.h\"\n\n#include \"console.h\"\n#include \"llama.h\"\n#include \"grammar-parser.h\"\n\n#include <cassert>\n#include <c"
},
{
"path": "examples/jeopardy/README.md",
"chars": 1024,
"preview": "# llama.cpp/example/jeopardy\n\nThis is pretty much just a straight port of aigoopy/llm-jeopardy/ with an added graph view"
},
{
"path": "examples/jeopardy/graph.py",
"chars": 1644,
"preview": "#!/usr/bin/env python3\nimport matplotlib.pyplot as plt\nimport os\nimport csv\n\nlabels = []\nnumbers = []\nnumEntries = 1\n\nro"
},
{
"path": "examples/jeopardy/jeopardy.sh",
"chars": 846,
"preview": "#!/bin/bash\nset -e\n\nMODEL=./models/ggml-vicuna-13b-1.1-q4_0.bin\nMODEL_NAME=Vicuna\n\n# exec options\nprefix=\"Human: \" # Ex."
},
{
"path": "examples/jeopardy/qasheet.csv",
"chars": 16613,
"preview": "Index,Original Category,Original Correct Question,Model Prompt\n1,The Oscars,Who is John Williams?,Which actor Born in 19"
},
{
"path": "examples/jeopardy/questions.txt",
"chars": 12296,
"preview": "Which man born in 1932 was the son of a percussionist in the CBS radio orchestra has been nominated for 53 Oscars?\nWhat "
},
{
"path": "examples/json-schema-to-grammar.py",
"chars": 4930,
"preview": "#!/usr/bin/env python3\nimport argparse\nimport json\nimport re\nimport sys\n\n# whitespace is constrained to a single space c"
},
{
"path": "examples/llama-bench/CMakeLists.txt",
"chars": 235,
"preview": "set(TARGET llama-bench)\nadd_executable(${TARGET} llama-bench.cpp)\ninstall(TARGETS ${TARGET} RUNTIME)\ntarget_link_librari"
},
{
"path": "examples/llama-bench/README.md",
"chars": 13675,
"preview": "# llama.cpp/example/llama-bench\n\nPerformance testing tool for llama.cpp.\n\n## Table of contents\n\n1. [Syntax](#syntax)\n2. "
},
{
"path": "examples/llama-bench/llama-bench.cpp",
"chars": 37018,
"preview": "#include <algorithm>\n#include <array>\n#include <cassert>\n#include <chrono>\n#include <cinttypes>\n#include <clocale>\n#incl"
},
{
"path": "examples/llama.vim",
"chars": 5023,
"preview": "\" Requires an already running llama.cpp server\n\" To install either copy or symlink to ~/.vim/autoload/llama.vim\n\" Then s"
},
{
"path": "examples/llama2-13b.sh",
"chars": 323,
"preview": "#!/bin/bash\n\n#\n# Temporary script - will be removed in the future\n#\n\ncd `dirname $0`\ncd ..\n\n./main -m models/available/L"
},
{
"path": "examples/llama2.sh",
"chars": 321,
"preview": "#!/bin/bash\n\n#\n# Temporary script - will be removed in the future\n#\n\ncd `dirname $0`\ncd ..\n\n./main -m models/available/L"
},
{
"path": "examples/llava/CMakeLists.txt",
"chars": 1214,
"preview": "add_library(llava OBJECT\n llava.cpp\n llava.h\n clip.cpp\n clip.h\n )"
},
{
"path": "examples/llava/README.md",
"chars": 1728,
"preview": "# LLaVA\n\nCurrently this implementation supports [llava-v1.5](https://huggingface.co/liuhaotian/llava-v1.5-7b) variants.\n"
},
{
"path": "examples/llava/clip.cpp",
"chars": 38719,
"preview": "// NOTE: This is modified from clip.cpp only for LLaVA,\n// so there might be still unnecessary artifacts hanging around\n"
},
{
"path": "examples/llava/clip.h",
"chars": 2551,
"preview": "#ifndef CLIP_H\n#define CLIP_H\n\n#include <stddef.h>\n#include <stdint.h>\n\n#ifdef LLAMA_SHARED\n# if defined(_WIN32) && !"
},
{
"path": "examples/llava/convert-image-encoder-to-gguf.py",
"chars": 9379,
"preview": "import argparse\nimport os\nimport json\n\nimport torch\nimport numpy as np\nfrom gguf import *\nfrom transformers import CLIPM"
},
{
"path": "examples/llava/llava-cli.cpp",
"chars": 12061,
"preview": "#include \"ggml.h\"\n#include \"common.h\"\n#include \"clip.h\"\n#include \"llava.h\"\n#include \"llama.h\"\n\n#include \"base64.hpp\"\n\n#i"
},
{
"path": "examples/llava/llava-surgery.py",
"chars": 1599,
"preview": "import argparse\nimport glob\nimport os\nimport torch\n\n\nap = argparse.ArgumentParser()\nap.add_argument(\"-m\", \"--model\", hel"
},
{
"path": "examples/llava/llava.cpp",
"chars": 5668,
"preview": "#include \"clip.h\"\n#include \"common.h\"\n#include \"llama.h\"\n#include \"llava.h\"\n\n#include <cstdio>\n#include <cstdlib>\n#inclu"
},
{
"path": "examples/llava/llava.h",
"chars": 1646,
"preview": "#ifndef LLAVA_H\n#define LLAVA_H\n\n#include \"ggml.h\"\n\n\n#ifdef LLAMA_SHARED\n# if defined(_WIN32) && !defined(__MINGW32__"
},
{
"path": "examples/llm.vim",
"chars": 921,
"preview": "\" Basic plugin example\n\nfunction! Llm()\n\n let url = \"http://127.0.0.1:8080/completion\"\n\n \" Get the content of the curr"
},
{
"path": "examples/main/CMakeLists.txt",
"chars": 221,
"preview": "set(TARGET main)\nadd_executable(${TARGET} main.cpp)\ninstall(TARGETS ${TARGET} RUNTIME)\ntarget_link_libraries(${TARGET} P"
},
{
"path": "examples/main/README.md",
"chars": 25788,
"preview": "# llama.cpp/example/main\n\nThis example program allows you to use various LLaMA language models in an easy and efficient "
},
{
"path": "examples/main/main.cpp",
"chars": 33399,
"preview": "#include \"common.h\"\n\n#include \"console.h\"\n#include \"llama.h\"\n\n#include <cassert>\n#include <cinttypes>\n#include <cmath>\n#"
},
{
"path": "examples/main-cmake-pkg/.gitignore",
"chars": 388,
"preview": "# Prerequisites\n*.d\n\n# Compiled Object files\n*.slo\n*.lo\n*.o\n*.obj\n\n# Precompiled Headers\n*.gch\n*.pch\n\n# Compiled Dynamic"
},
{
"path": "examples/main-cmake-pkg/CMakeLists.txt",
"chars": 1733,
"preview": "cmake_minimum_required(VERSION 3.12)\nproject(\"main-cmake-pkg\" C CXX)\nset(TARGET main-cmake-pkg)\n\nfind_package(Llama 0.0."
},
{
"path": "examples/main-cmake-pkg/README.md",
"chars": 1715,
"preview": "# llama.cpp/example/main-cmake-pkg\n\nThis program builds the [main](../main) application using a relocatable CMake packag"
},
{
"path": "examples/make-ggml.py",
"chars": 5105,
"preview": "#!/usr/bin/env python3\n\"\"\"\nThis script converts Hugging Face Llama, StarCoder, Falcon, Baichuan, and GPT-NeoX models to "
},
{
"path": "examples/metal/CMakeLists.txt",
"chars": 150,
"preview": "set(TEST_TARGET metal)\nadd_executable(${TEST_TARGET} metal.cpp)\ninstall(TARGETS ${TARGET} RUNTIME)\ntarget_link_libraries"
},
{
"path": "examples/metal/metal.cpp",
"chars": 2897,
"preview": "// Evaluate a statically exported ggml computation graph with Metal\n//\n// - First, export a LLaMA graph:\n//\n// $ ./bin/"
},
{
"path": "examples/parallel/CMakeLists.txt",
"chars": 229,
"preview": "set(TARGET parallel)\nadd_executable(${TARGET} parallel.cpp)\ninstall(TARGETS ${TARGET} RUNTIME)\ntarget_link_libraries(${T"
},
{
"path": "examples/parallel/README.md",
"chars": 93,
"preview": "# llama.cpp/example/parallel\n\nSimplified simulation of serving incoming requests in parallel\n"
},
{
"path": "examples/parallel/parallel.cpp",
"chars": 15266,
"preview": "// A basic application simulating a server with multiple clients.\n// The clients submite requests to the server and they"
},
{
"path": "examples/perplexity/CMakeLists.txt",
"chars": 233,
"preview": "set(TARGET perplexity)\nadd_executable(${TARGET} perplexity.cpp)\ninstall(TARGETS ${TARGET} RUNTIME)\ntarget_link_libraries"
},
{
"path": "examples/perplexity/README.md",
"chars": 526,
"preview": "# perplexity\n\nTODO\n\n## Llama 2 70B Scorechart\nQuantization | Model size (GiB) | Perplexity | Delta to fp16\n-- | -- | -- "
},
{
"path": "examples/perplexity/perplexity.cpp",
"chars": 28479,
"preview": "#include \"common.h\"\n#include \"llama.h\"\n\n#include <cmath>\n#include <cstdio>\n#include <cstring>\n#include <ctime>\n#include "
},
{
"path": "examples/quantize/CMakeLists.txt",
"chars": 292,
"preview": "set(TARGET quantize)\nadd_executable(${TARGET} quantize.cpp)\ninstall(TARGETS ${TARGET} RUNTIME)\ntarget_link_libraries(${T"
},
{
"path": "examples/quantize/README.md",
"chars": 566,
"preview": "# quantize\n\nTODO\n\n## Llama 2 7B\n\nQuantization | Bits per Weight (BPW)\n-- | --\nQ2_K | 3.35\nQ3_K_S | 3.50\nQ3_K_M | 3.91\nQ3"
},
{
"path": "examples/quantize/quantize.cpp",
"chars": 7053,
"preview": "#include \"common.h\"\n#include \"llama.h\"\n\n#include <cstdio>\n#include <cstring>\n#include <vector>\n#include <string>\n\nstruct"
},
{
"path": "examples/quantize-stats/CMakeLists.txt",
"chars": 304,
"preview": "set(TARGET quantize-stats)\nadd_executable(${TARGET} quantize-stats.cpp)\ninstall(TARGETS ${TARGET} RUNTIME)\ntarget_link_l"
},
{
"path": "examples/quantize-stats/quantize-stats.cpp",
"chars": 16048,
"preview": "#define LLAMA_API_INTERNAL\n#include \"common.h\"\n#include \"ggml.h\"\n#include \"llama.h\"\n\n#include <algorithm>\n#include <cass"
},
{
"path": "examples/reason-act.sh",
"chars": 350,
"preview": "#!/bin/bash\n\ncd `dirname $0`\ncd ..\n\n# get -m model parameter otherwise defer to default\nif [ \"$1\" == \"-m\" ]; then\n MODE"
},
{
"path": "examples/save-load-state/CMakeLists.txt",
"chars": 243,
"preview": "set(TARGET save-load-state)\nadd_executable(${TARGET} save-load-state.cpp)\ninstall(TARGETS ${TARGET} RUNTIME)\ntarget_link"
},
{
"path": "examples/save-load-state/save-load-state.cpp",
"chars": 4671,
"preview": "#include \"common.h\"\n#include \"llama.h\"\n\n#include <vector>\n#include <cstdio>\n#include <chrono>\n\nint main(int argc, char *"
},
{
"path": "examples/server/CMakeLists.txt",
"chars": 542,
"preview": "set(TARGET server)\noption(LLAMA_SERVER_VERBOSE \"Build verbose logging option for Server\" ON)\ninclude_directories(${CMAKE"
},
{
"path": "examples/server/README.md",
"chars": 16281,
"preview": "# llama.cpp/example/server\n\nThis example demonstrates a simple HTTP API server and a simple web front end to interact wi"
},
{
"path": "examples/server/api_like_OAI.py",
"chars": 9937,
"preview": "#!/usr/bin/env python3\nimport argparse\nfrom flask import Flask, jsonify, request, Response\nimport urllib.parse\nimport re"
},
{
"path": "examples/server/chat-llama2.sh",
"chars": 2516,
"preview": "#!/bin/bash\n\nAPI_URL=\"${API_URL:-http://127.0.0.1:8080}\"\n\nCHAT=(\n \"Hello, Assistant.\"\n \"Hello. How may I help you "
},
{
"path": "examples/server/chat.mjs",
"chars": 3773,
"preview": "import * as readline from 'node:readline'\nimport { stdin, stdout } from 'node:process'\nimport { readFileSync } from 'nod"
},
{
"path": "examples/server/chat.sh",
"chars": 1944,
"preview": "#!/bin/bash\n\nAPI_URL=\"${API_URL:-http://127.0.0.1:8080}\"\n\nCHAT=(\n \"Hello, Assistant.\"\n \"Hello. How may I help you "
},
{
"path": "examples/server/completion.js.hpp",
"chars": 31519,
"preview": "unsigned char completion_js[] = {\n 0x63, 0x6f, 0x6e, 0x73, 0x74, 0x20, 0x70, 0x61, 0x72, 0x61, 0x6d, 0x44,\n 0x65, 0x66"
},
{
"path": "examples/server/deps.sh",
"chars": 539,
"preview": "#!/bin/bash\n# Download and update deps for binary\n\n# get the directory of this script file\nDIR=\"$( cd \"$( dirname \"${BAS"
},
{
"path": "examples/server/httplib.h",
"chars": 288389,
"preview": "//\n// httplib.h\n//\n// Copyright (c) 2023 Yuji Hirose. All rights reserved.\n// MIT License\n//\n\n#ifndef CPPHTTPLIB_HTTP"
},
{
"path": "examples/server/index.html.hpp",
"chars": 204206,
"preview": "unsigned char index_html[] = {\n 0x3c, 0x68, 0x74, 0x6d, 0x6c, 0x3e, 0x0a, 0x0a, 0x3c, 0x68, 0x65, 0x61,\n 0x64, 0x3e, 0"
},
{
"path": "examples/server/index.js.hpp",
"chars": 138644,
"preview": "unsigned char index_js[] = {\n 0x66, 0x75, 0x6e, 0x63, 0x74, 0x69, 0x6f, 0x6e, 0x20, 0x74, 0x28, 0x29,\n 0x7b, 0x74, 0x6"
},
{
"path": "examples/server/json-schema-to-grammar.mjs.hpp",
"chars": 22887,
"preview": "unsigned char json_schema_to_grammar_mjs[] = {\n 0x63, 0x6f, 0x6e, 0x73, 0x74, 0x20, 0x53, 0x50, 0x41, 0x43, 0x45, 0x5f,"
},
{
"path": "examples/server/json.hpp",
"chars": 907857,
"preview": "// __ _____ _____ _____\n// __| | __| | | | JSON for Modern C++\n// | | |__ | | | | | | version 3.11"
},
{
"path": "examples/server/public/completion.js",
"chars": 5099,
"preview": "const paramDefaults = {\n stream: true,\n n_predict: 500,\n temperature: 0.2,\n stop: [\"</s>\"]\n};\n\nlet generation_settin"
},
{
"path": "examples/server/public/index.html",
"chars": 33103,
"preview": "<html>\n\n<head>\n <meta charset=\"UTF-8\">\n <meta name=\"viewport\" content=\"width=device-width, initial-scale=1, maximum-sc"
},
{
"path": "examples/server/public/index.js",
"chars": 22472,
"preview": "function t(){throw new Error(\"Cycle detected\")}function n(){if(u>1){u--;return}let t,n=!1;while(void 0!==_){let i=_;_=vo"
},
{
"path": "examples/server/public/json-schema-to-grammar.mjs",
"chars": 3695,
"preview": "const SPACE_RULE = '\" \"?';\n\nconst PRIMITIVE_RULES = {\n boolean: '(\"true\" | \"false\") space',\n number: '(\"-\"? ([0-9] | ["
},
{
"path": "examples/server/server.cpp",
"chars": 92823,
"preview": "#include \"common.h\"\n#include \"llama.h\"\n#include \"grammar-parser.h\"\n\n#include \"../llava/clip.h\"\n\n#include \"stb_image.h\"\n\n"
},
{
"path": "examples/server-llama2-13B.sh",
"chars": 784,
"preview": "#!/bin/bash\n\nset -e\n\ncd \"$(dirname \"$0\")/..\" || exit\n\n# Specify the model you want to use here:\nMODEL=\"${MODEL:-./models"
},
{
"path": "examples/simple/CMakeLists.txt",
"chars": 225,
"preview": "set(TARGET simple)\nadd_executable(${TARGET} simple.cpp)\ninstall(TARGETS ${TARGET} RUNTIME)\ntarget_link_libraries(${TARGE"
},
{
"path": "examples/simple/README.md",
"chars": 903,
"preview": "# llama.cpp/example/simple\n\nThe purpose of this example is to demonstrate a minimal usage of llama.cpp for generating te"
},
{
"path": "examples/simple/simple.cpp",
"chars": 5070,
"preview": "#include \"common.h\"\n#include \"llama.h\"\n\n#include <cmath>\n#include <cstdio>\n#include <string>\n#include <vector>\n\nint main"
},
{
"path": "examples/speculative/CMakeLists.txt",
"chars": 235,
"preview": "set(TARGET speculative)\nadd_executable(${TARGET} speculative.cpp)\ninstall(TARGETS ${TARGET} RUNTIME)\ntarget_link_librari"
},
{
"path": "examples/speculative/speculative.cpp",
"chars": 15888,
"preview": "#include \"common.h\"\n#include \"llama.h\"\n\n#include <cmath>\n#include <cstdio>\n#include <string>\n#include <vector>\n\n#define "
},
{
"path": "examples/train-text-from-scratch/CMakeLists.txt",
"chars": 259,
"preview": "set(TARGET train-text-from-scratch)\nadd_executable(${TARGET} train-text-from-scratch.cpp)\ninstall(TARGETS ${TARGET} RUNT"
},
{
"path": "examples/train-text-from-scratch/README.md",
"chars": 960,
"preview": "# train-text-from-scratch\n\nBasic usage instructions:\n\n```bash\n# get training data\nwget https://raw.githubusercontent.com"
},
{
"path": "examples/train-text-from-scratch/convert-train-checkpoint-to-gguf.py",
"chars": 26351,
"preview": "#!/usr/bin/env python3\n# train-text-from-scratch checkpoint --> gguf conversion\n\nimport argparse\nimport os\nimport struct"
},
{
"path": "examples/train-text-from-scratch/train-text-from-scratch.cpp",
"chars": 60099,
"preview": "#include \"ggml.h\"\n#include \"ggml-alloc.h\"\n#include \"common.h\"\n#include \"train.h\"\n#include \"llama.h\"\n#include <unordered_"
},
{
"path": "flake.nix",
"chars": 5761,
"preview": "{\n inputs = {\n nixpkgs.url = \"github:NixOS/nixpkgs/nixos-unstable\";\n flake-utils.url = \"github:numtide/flake-util"
},
{
"path": "ggml-alloc.c",
"chars": 27199,
"preview": "#include \"ggml-alloc.h\"\n#include \"ggml-backend-impl.h\"\n#include \"ggml.h\"\n#include \"ggml-impl.h\"\n#include <assert.h>\n#inc"
},
{
"path": "ggml-alloc.h",
"chars": 3465,
"preview": "#pragma once\n\n#include \"ggml.h\"\n\n#ifdef __cplusplus\nextern \"C\" {\n#endif\n\nstruct ggml_backend;\nstruct ggml_backend_buffe"
},
{
"path": "ggml-backend-impl.h",
"chars": 3265,
"preview": "#pragma once\n\n// ggml-backend internal header\n\n#include \"ggml-backend.h\"\n\n#ifdef __cplusplus\nextern \"C\" {\n#endif\n\n /"
},
{
"path": "ggml-backend.c",
"chars": 36282,
"preview": "#include \"ggml-backend-impl.h\"\n#include \"ggml-alloc.h\"\n#include \"ggml-impl.h\"\n\n#include <assert.h>\n#include <limits.h>\n#"
},
{
"path": "ggml-backend.h",
"chars": 5894,
"preview": "#pragma once\n\n#include \"ggml.h\"\n#include \"ggml-alloc.h\"\n\n#ifdef __cplusplus\nextern \"C\" {\n#endif\n\n //\n // Backend "
},
{
"path": "ggml-cuda.cu",
"chars": 366669,
"preview": "#include <algorithm>\n#include <cstddef>\n#include <cstdint>\n#include <limits>\n#include <stdint.h>\n#include <stdio.h>\n#inc"
},
{
"path": "ggml-cuda.h",
"chars": 2645,
"preview": "#pragma once\n\n#include \"ggml.h\"\n#include \"ggml-backend.h\"\n\n#ifdef GGML_USE_HIPBLAS\n#define GGML_CUDA_NAME \"ROCm\"\n#define"
},
{
"path": "ggml-impl.h",
"chars": 7382,
"preview": "#pragma once\n\n#include \"ggml.h\"\n\n// GGML internal header\n\n#include <assert.h>\n#include <stddef.h>\n#include <stdbool.h>\n#"
},
{
"path": "ggml-metal.h",
"chars": 3875,
"preview": "// An interface allowing to compute ggml_cgraph with Metal\n//\n// This is a fully functional interface that extends ggml "
},
{
"path": "ggml-metal.m",
"chars": 90604,
"preview": "#import \"ggml-metal.h\"\n\n#import \"ggml-backend-impl.h\"\n#import \"ggml.h\"\n\n#import <Foundation/Foundation.h>\n\n#import <Meta"
},
{
"path": "ggml-metal.metal",
"chars": 106747,
"preview": "#include <metal_stdlib>\n\nusing namespace metal;\n\n#define MAX(x, y) ((x) > (y) ? (x) : (y))\n\n#define QK4_0 32\n#define QR4"
},
{
"path": "ggml-mpi.c",
"chars": 6919,
"preview": "#include \"ggml-mpi.h\"\n\n#include \"ggml.h\"\n\n#include <mpi.h>\n\n#include <stdio.h>\n#include <stdlib.h>\n\n#define MIN(a, b) (("
},
{
"path": "ggml-mpi.h",
"chars": 911,
"preview": "#pragma once\n\nstruct ggml_context;\nstruct ggml_tensor;\nstruct ggml_cgraph;\n\n#ifdef __cplusplus\nextern \"C\" {\n#endif\n\nstru"
},
{
"path": "ggml-opencl.cpp",
"chars": 70992,
"preview": "#include \"ggml-opencl.h\"\n\n#include <array>\n#include <atomic>\n#include <sstream>\n#include <vector>\n#include <limits>\n\n#de"
},
{
"path": "ggml-opencl.h",
"chars": 845,
"preview": "#pragma once\n\n#include \"ggml.h\"\n\n#ifdef __cplusplus\nextern \"C\" {\n#endif\n\nvoid ggml_cl_init(void);\n\nvoid ggml_cl_mul(c"
},
{
"path": "ggml-quants.c",
"chars": 294468,
"preview": "#include \"ggml-quants.h\"\n#include \"ggml-impl.h\"\n\n#include <math.h>\n#include <string.h>\n#include <assert.h>\n#include <flo"
},
{
"path": "ggml-quants.h",
"chars": 10382,
"preview": "#pragma once\n\n#include \"ggml-impl.h\"\n\n// GGML internal header\n\n#include <stdint.h>\n#include <stddef.h>\n\n#define QK4_0 32"
},
{
"path": "ggml.c",
"chars": 679336,
"preview": "#define _CRT_SECURE_NO_DEPRECATE // Disables ridiculous \"unsafe\" warnigns on Windows\n#define _USE_MATH_DEFINES // For M_"
},
{
"path": "ggml.h",
"chars": 82077,
"preview": "#pragma once\n\n//\n// GGML Tensor Library\n//\n// This documentation is still a work in progress.\n// If you wish some specif"
},
{
"path": "gguf-py/LICENSE",
"chars": 1072,
"preview": "MIT License\n\nCopyright (c) 2023 Georgi Gerganov\n\nPermission is hereby granted, free of charge, to any person obtaining a"
},
{
"path": "gguf-py/README.md",
"chars": 2395,
"preview": "## gguf\n\nThis is a Python package for writing binary files in the [GGUF](https://github.com/ggerganov/ggml/pull/302)\n(GG"
},
{
"path": "gguf-py/examples/writer.py",
"chars": 1115,
"preview": "#!/usr/bin/env python3\nimport sys\nfrom pathlib import Path\n\nimport numpy as np\n\n# Necessary to load the local gguf packa"
}
]
// ... and 2071 more files (download for full content)
About this extraction
This page contains the full source code of the Tiiny-AI/PowerInfer GitHub repository, extracted and formatted as plain text for AI agents and large language models (LLMs). The extraction includes 2271 files (44.8 MB), approximately 11.9M tokens. Use this with OpenClaw, Claude, ChatGPT, Cursor, Windsurf, or any other AI tool that accepts text input. You can copy the full output to your clipboard or download it as a .txt file.
Extracted by GitExtract — free GitHub repo to text converter for AI. Built by Nikandr Surkov.