Repository: Vay-keen/Machine-learning-learning-notes
Branch: master
Commit: 7a79eb545e24
Files: 18
Total size: 81.7 KB
Directory structure:
gitextract_sl_2njny/
├── README.md
├── 周志华《Machine Learning》学习笔记(1)--绪论.md
├── 周志华《Machine Learning》学习笔记(10)--集成学习.md
├── 周志华《Machine Learning》学习笔记(11)--聚类.md
├── 周志华《Machine Learning》学习笔记(12)--降维与度量学习.md
├── 周志华《Machine Learning》学习笔记(13)--特征选择与稀疏学习.md
├── 周志华《Machine Learning》学习笔记(14)--计算学习理论.md
├── 周志华《Machine Learning》学习笔记(15)--半监督学习.md
├── 周志华《Machine Learning》学习笔记(16)--概率图模型.md
├── 周志华《Machine Learning》学习笔记(17)--强化学习.md
├── 周志华《Machine Learning》学习笔记(2)--性能度量.md
├── 周志华《Machine Learning》学习笔记(3)--假设检验&方差&偏差.md
├── 周志华《Machine Learning》学习笔记(4)--线性模型.md
├── 周志华《Machine Learning》学习笔记(5)--决策树.md
├── 周志华《Machine Learning》学习笔记(6)--神经网络.md
├── 周志华《Machine Learning》学习笔记(7)--支持向量机.md
├── 周志华《Machine Learning》学习笔记(8)--贝叶斯分类器.md
└── 周志华《Machine Learning》学习笔记(9)--EM算法.md
================================================
FILE CONTENTS
================================================
================================================
FILE: README.md
================================================
本文为周志华《机器学习》的学习笔记,记录了本人在学习这本书的过程中的理解思路以及一些有助于消化书内容的拓展知识,笔记中参考了许多网上的大牛经典博客以及李航《统计学习》的内容,向前辈们和知识致敬!
> 啃西瓜学习交流QQ群: 531701485, 遇到疑问可以随时在上面提问,并会不定期分享优质的机器/深度学习资料,欢迎各位机器学习爱好者的入群讨论学习!
> 作者目前在腾讯微信事业群从事大数据、机器学习、推荐系统工作,团队会定期输出:机器学习在实际业务领域的技术总结,欢迎大家关注学习,共同进步!
<img src="https://ftp.bmp.ovh/imgs/2021/07/022f98f41a401e3a.jpeg" width="250px" height="250px" />
================================================
FILE: 周志华《Machine Learning》学习笔记(1)--绪论.md
================================================
机器学习是目前信息技术中最激动人心的方向之一,其应用已经深入到生活的各个层面且与普通人的日常生活密切相关。本文为清华大学最新出版的《机器学习》教材的Learning Notes,书作者是南京大学周志华教授,多个大陆首位彰显其学术奢华。本篇主要介绍了该教材前两个章节的知识点以及自己一点浅陋的理解。
**1 绪论**
傍晚小街路面上沁出微雨后的湿润,和熙的细风吹来,抬头看看天边的晚霞,嗯,明天又是一个好天气。走到水果摊旁,挑了个根蒂蜷缩、敲起来声音浊响的青绿西瓜,一边满心期待着皮薄肉厚瓢甜的爽落感,一边愉快地想着,这学期狠下了工夫,基础概念弄得清清楚楚,算法作业也是信手拈来,这门课成绩一定差不了!哈哈,也希望自己这学期的machine learning课程取得一个好成绩!
**1.1 机器学习的定义**
正如我们根据过去的经验来判断明天的天气,吃货们希望从购买经验中挑选一个好瓜,那能不能让计算机帮助人类来实现这个呢?机器学习正是这样的一门学科,人的“经验”对应计算机中的“数据”,让计算机来学习这些经验数据,生成一个算法模型,在面对新的情况中,计算机便能作出有效的判断,这便是机器学习。
另一本经典教材的作者Mitchell给出了一个形式化的定义,假设:
- P:计算机程序在某任务类T上的性能。
- T:计算机程序希望实现的任务类。
- E:表示经验,即历史的数据集。
若该计算机程序通过利用经验E在任务T上获得了性能P的改善,则称该程序对E进行了学习。
**1.2 机器学习的一些基本术语**
假设我们收集了一批西瓜的数据,例如:(色泽=青绿;根蒂=蜷缩;敲声=浊响), (色泽=乌黑;根蒂=稍蜷;敲声=沉闷), (色泽=浅自;根蒂=硬挺;敲声=清脆)……每对括号内是一个西瓜的记录,定义:
- 所有记录的集合为:数据集。
- 每一条记录为:一个实例(instance)或样本(sample)。
- 例如:色泽或敲声,单个的特点为特征(feature)或属性(attribute)。
- 对于一条记录,如果在坐标轴上表示,每个西瓜都可以用坐标轴中的一个点表示,一个点也是一个向量,例如(青绿,蜷缩,浊响),即每个西瓜为:一个特征向量(feature vector)。
- 一个样本的特征数为:维数(dimensionality),该西瓜的例子维数为3,当维数非常大时,也就是现在说的“维数灾难”。
计算机程序学习经验数据生成算法模型的过程中,每一条记录称为一个“训练样本”,同时在训练好模型后,我们希望使用新的样本来测试模型的效果,则每一个新的样本称为一个“测试样本”。定义:
- 所有训练样本的集合为:训练集(trainning set),[特殊]。
- 所有测试样本的集合为:测试集(test set),[一般]。
- 机器学习出来的模型适用于新样本的能力为:泛化能力(generalization),即从特殊到一般。
西瓜的例子中,我们是想计算机通过学习西瓜的特征数据,训练出一个决策模型,来判断一个新的西瓜是否是好瓜。可以得知我们预测的是:西瓜是好是坏,即好瓜与差瓜两种,是离散值。同样地,也有通过历年的人口数据,来预测未来的人口数量,人口数量则是连续值。定义:
- 预测值为离散值的问题为:分类(classification)。
- 预测值为连续值的问题为:回归(regression)。
我们预测西瓜是否是好瓜的过程中,很明显对于训练集中的西瓜,我们事先已经知道了该瓜是否是好瓜,学习器通过学习这些好瓜或差瓜的特征,从而总结出规律,即训练集中的西瓜我们都做了标记,称为标记信息。但也有没有标记信息的情形,例如:我们想将一堆西瓜根据特征分成两个小堆,使得某一堆的西瓜尽可能相似,即都是好瓜或差瓜,对于这种问题,我们事先并不知道西瓜的好坏,样本没有标记信息。定义:
- 训练数据有标记信息的学习任务为:监督学习(supervised learning),容易知道上面所描述的分类和回归都是监督学习的范畴。
- 训练数据没有标记信息的学习任务为:无监督学习(unsupervised learning),常见的有聚类和关联规则。
**2 模型的评估与选择**
**2.1 误差与过拟合**
我们将学习器对样本的实际预测结果与样本的真实值之间的差异成为:误差(error)。定义:
- 在训练集上的误差称为训练误差(training error)或经验误差(empirical error)。
- 在测试集上的误差称为测试误差(test error)。
- 学习器在所有新样本上的误差称为泛化误差(generalization error)。
显然,我们希望得到的是在新样本上表现得很好的学习器,即泛化误差小的学习器。因此,我们应该让学习器尽可能地从训练集中学出普适性的“一般特征”,这样在遇到新样本时才能做出正确的判别。然而,当学习器把训练集学得“太好”的时候,即把一些训练样本的自身特点当做了普遍特征;同时也有学习能力不足的情况,即训练集的基本特征都没有学习出来。我们定义:
- 学习能力过强,以至于把训练样本所包含的不太一般的特性都学到了,称为:过拟合(overfitting)。
- 学习能太差,训练样本的一般性质尚未学好,称为:欠拟合(underfitting)。
可以得知:在过拟合问题中,训练误差十分小,但测试误差教大;在欠拟合问题中,训练误差和测试误差都比较大。目前,欠拟合问题比较容易克服,例如增加迭代次数等,但过拟合问题还没有十分好的解决方案,过拟合是机器学习面临的关键障碍。
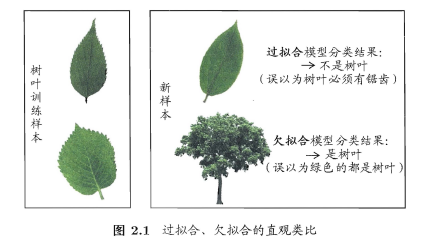
**2.2 评估方法**
在现实任务中,我们往往有多种算法可供选择,那么我们应该选择哪一个算法才是最适合的呢?如上所述,我们希望得到的是泛化误差小的学习器,理想的解决方案是对模型的泛化误差进行评估,然后选择泛化误差最小的那个学习器。但是,泛化误差指的是模型在所有新样本上的适用能力,我们无法直接获得泛化误差。
因此,通常我们采用一个“测试集”来测试学习器对新样本的判别能力,然后以“测试集”上的“测试误差”作为“泛化误差”的近似。显然:我们选取的测试集应尽可能与训练集互斥,下面用一个小故事来解释why:
假设老师出了10 道习题供同学们练习,考试时老师又用同样的这10道题作为试题,可能有的童鞋只会做这10 道题却能得高分,很明显:这个考试成绩并不能有效地反映出真实水平。回到我们的问题上来,我们希望得到泛化性能好的模型,好比希望同学们课程学得好并获得了对所学知识"举一反三"的能力;训练样本相当于给同学们练习的习题,测试过程则相当于考试。显然,若测试样本被用作训练了,则得到的将是过于"乐观"的估计结果。
**2.3 训练集与测试集的划分方法**
如上所述:我们希望用一个“测试集”的“测试误差”来作为“泛化误差”的近似,因此我们需要对初始数据集进行有效划分,划分出互斥的“训练集”和“测试集”。下面介绍几种常用的划分方法:
**2.3.1 留出法**
将数据集D划分为两个互斥的集合,一个作为训练集S,一个作为测试集T,满足D=S∪T且S∩T=∅,常见的划分为:大约2/3-4/5的样本用作训练,剩下的用作测试。需要注意的是:训练/测试集的划分要尽可能保持数据分布的一致性,以避免由于分布的差异引入额外的偏差,常见的做法是采取分层抽样。同时,由于划分的随机性,单次的留出法结果往往不够稳定,一般要采用若干次随机划分,重复实验取平均值的做法。
**2.3.2 交叉验证法**
将数据集D划分为k个大小相同的互斥子集,满足D=D1∪D2∪...∪Dk,Di∩Dj=∅(i≠j),同样地尽可能保持数据分布的一致性,即采用分层抽样的方法获得这些子集。交叉验证法的思想是:每次用k-1个子集的并集作为训练集,余下的那个子集作为测试集,这样就有K种训练集/测试集划分的情况,从而可进行k次训练和测试,最终返回k次测试结果的均值。交叉验证法也称“k折交叉验证”,k最常用的取值是10,下图给出了10折交叉验证的示意图。
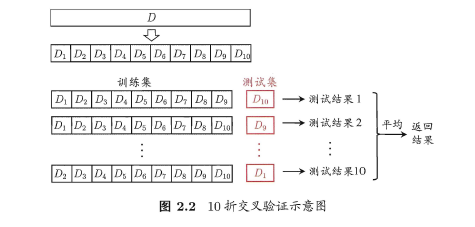
与留出法类似,将数据集D划分为K个子集的过程具有随机性,因此K折交叉验证通常也要重复p次,称为p次k折交叉验证,常见的是10次10折交叉验证,即进行了100次训练/测试。特殊地当划分的k个子集的每个子集中只有一个样本时,称为“留一法”,显然,留一法的评估结果比较准确,但对计算机的消耗也是巨大的。
**2.3.3 自助法**
我们希望评估的是用整个D训练出的模型。但在留出法和交叉验证法中,由于保留了一部分样本用于测试,因此实际评估的模型所使用的训练集比D小,这必然会引入一些因训练样本规模不同而导致的估计偏差。留一法受训练样本规模变化的影响较小,但计算复杂度又太高了。“自助法”正是解决了这样的问题。
自助法的基本思想是:给定包含m个样本的数据集D,每次随机从D 中挑选一个样本,将其拷贝放入D',然后再将该样本放回初始数据集D 中,使得该样本在下次采样时仍有可能被采到。重复执行m 次,就可以得到了包含m个样本的数据集D'。可以得知在m次采样中,样本始终不被采到的概率取极限为:
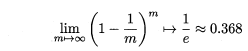
这样,通过自助采样,初始样本集D中大约有36.8%的样本没有出现在D'中,于是可以将D'作为训练集,D-D'作为测试集。自助法在数据集较小,难以有效划分训练集/测试集时很有用,但由于自助法产生的数据集(随机抽样)改变了初始数据集的分布,因此引入了估计偏差。在初始数据集足够时,留出法和交叉验证法更加常用。
**2.4 调参**
大多数学习算法都有些参数(parameter) 需要设定,参数配置不同,学得模型的性能往往有显著差别,这就是通常所说的"参数调节"或简称"调参" (parameter tuning)。
学习算法的很多参数是在实数范围内取值,因此,对每种参数取值都训练出模型来是不可行的。常用的做法是:对每个参数选定一个范围和步长λ,这样使得学习的过程变得可行。例如:假定算法有3 个参数,每个参数仅考虑5 个候选值,这样对每一组训练/测试集就有5*5*5= 125 个模型需考察,由此可见:拿下一个参数(即经验值)对于算法人员来说是有多么的happy。
最后需要注意的是:当选定好模型和调参完成后,我们需要使用初始的数据集D重新训练模型,即让最初划分出来用于评估的测试集也被模型学习,增强模型的学习效果。用上面考试的例子来比喻:就像高中时大家每次考试完,要将考卷的题目消化掉(大多数题目都还是之前没有见过的吧?),这样即使考差了也能开心的玩耍了~。
================================================
FILE: 周志华《Machine Learning》学习笔记(10)--集成学习.md
================================================
上篇主要介绍了鼎鼎大名的EM算法,从算法思想到数学公式推导(边际似然引入隐变量,Jensen不等式简化求导),EM算法实际上可以理解为一种坐标下降法,首先固定一个变量,接着求另外变量的最优解,通过其优美的“两步走”策略能较好地估计隐变量的值。本篇将继续讨论下一类经典算法--集成学习。
#**9、集成学习**
顾名思义,集成学习(ensemble learning)指的是将多个学习器进行有效地结合,组建一个“学习器委员会”,其中每个学习器担任委员会成员并行使投票表决权,使得委员会最后的决定更能够四方造福普度众生~...~,即其泛化性能要能优于其中任何一个学习器。
##**9.1 个体与集成**
集成学习的基本结构为:先产生一组个体学习器,再使用某种策略将它们结合在一起。集成模型如下图所示:
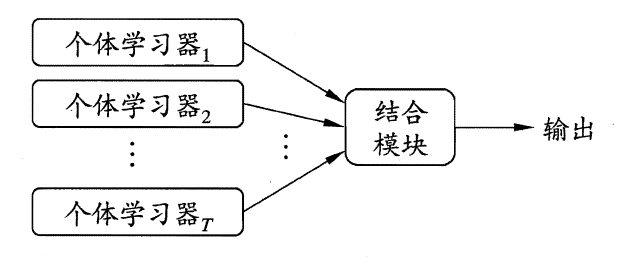
在上图的集成模型中,若个体学习器都属于同一类别,例如都是决策树或都是神经网络,则称该集成为同质的(homogeneous);若个体学习器包含多种类型的学习算法,例如既有决策树又有神经网络,则称该集成为异质的(heterogenous)。
> **同质集成**:个体学习器称为“基学习器”(base learner),对应的学习算法为“基学习算法”(base learning algorithm)。
> **异质集成**:个体学习器称为“组件学习器”(component learner)或直称为“个体学习器”。
上面我们已经提到要让集成起来的泛化性能比单个学习器都要好,虽说团结力量大但也有木桶短板理论调皮捣蛋,那如何做到呢?这就引出了集成学习的两个重要概念:**准确性**和**多样性**(diversity)。准确性指的是个体学习器不能太差,要有一定的准确度;多样性则是个体学习器之间的输出要具有差异性。通过下面的这三个例子可以很容易看出这一点,准确度较高,差异度也较高,可以较好地提升集成性能。

现在考虑二分类的简单情形,假设基分类器之间相互独立(能提供较高的差异度),且错误率相等为 ε,则可以将集成器的预测看做一个伯努利实验,易知当所有基分类器中不足一半预测正确的情况下,集成器预测错误,所以集成器的错误率可以计算为:

此时,集成器错误率随着基分类器的个数的增加呈指数下降,但前提是基分类器之间相互独立,在实际情形中显然是不可能的,假设训练有A和B两个分类器,对于某个测试样本,显然满足:P(A=1 | B=1)> P(A=1),因为A和B为了解决相同的问题而训练,因此在预测新样本时存在着很大的联系。因此,**个体学习器的“准确性”和“差异性”本身就是一对矛盾的变量**,准确性高意味着牺牲多样性,所以产生“**好而不同**”的个体学习器正是集成学习研究的核心。现阶段有三种主流的集成学习方法:Boosting、Bagging以及随机森林(Random Forest),接下来将进行逐一介绍。
##**9.2 Boosting**
Boosting是一种串行的工作机制,即个体学习器的训练存在依赖关系,必须一步一步序列化进行。其基本思想是:增加前一个基学习器在训练训练过程中预测错误样本的权重,使得后续基学习器更加关注这些打标错误的训练样本,尽可能纠正这些错误,一直向下串行直至产生需要的T个基学习器,Boosting最终对这T个学习器进行加权结合,产生学习器委员会。
Boosting族算法最著名、使用最为广泛的就是AdaBoost,因此下面主要是对AdaBoost算法进行介绍。AdaBoost使用的是**指数损失函数**,因此AdaBoost的权值与样本分布的更新都是围绕着最小化指数损失函数进行的。看到这里回想一下之前的机器学习算法,**不难发现机器学习的大部分带参模型只是改变了最优化目标中的损失函数**:如果是Square loss,那就是最小二乘了;如果是Hinge Loss,那就是著名的SVM了;如果是log-Loss,那就是Logistic Regression了。
定义基学习器的集成为加权结合,则有:
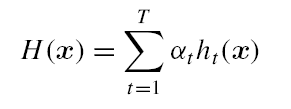
AdaBoost算法的指数损失函数定义为:
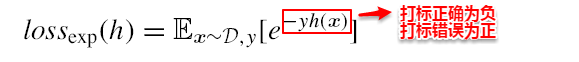
具体说来,整个Adaboost 迭代算法分为3步:
- 初始化训练数据的权值分布。如果有N个样本,则每一个训练样本最开始时都被赋予相同的权值:1/N。
- 训练弱分类器。具体训练过程中,如果某个样本点已经被准确地分类,那么在构造下一个训练集中,它的权值就被降低;相反,如果某个样本点没有被准确地分类,那么它的权值就得到提高。然后,权值更新过的样本集被用于训练下一个分类器,整个训练过程如此迭代地进行下去。
- 将各个训练得到的弱分类器组合成强分类器。各个弱分类器的训练过程结束后,加大分类误差率小的弱分类器的权重,使其在最终的分类函数中起着较大的决定作用,而降低分类误差率大的弱分类器的权重,使其在最终的分类函数中起着较小的决定作用。
整个AdaBoost的算法流程如下所示:

可以看出:**AdaBoost的核心步骤就是计算基学习器权重和样本权重分布**,那为何是上述的计算公式呢?这就涉及到了我们之前为什么说大部分带参机器学习算法只是改变了损失函数,就是因为**大部分模型的参数都是通过最优化损失函数(可能还加个规则项)而计算(梯度下降,坐标下降等)得到**,这里正是通过最优化指数损失函数从而得到这两个参数的计算公式,具体的推导过程此处不进行展开。
Boosting算法要求基学习器能对特定分布的数据进行学习,即每次都更新样本分布权重,这里书上提到了两种方法:“重赋权法”(re-weighting)和“重采样法”(re-sampling),书上的解释有些晦涩,这里进行展开一下:
> **重赋权法** : 对每个样本附加一个权重,这时涉及到样本属性与标签的计算,都需要乘上一个权值。
> **重采样法** : 对于一些无法接受带权样本的及学习算法,适合用“重采样法”进行处理。方法大致过程是,根据各个样本的权重,对训练数据进行重采样,初始时样本权重一样,每个样本被采样到的概率一致,每次从N个原始的训练样本中按照权重有放回采样N个样本作为训练集,然后计算训练集错误率,然后调整权重,重复采样,集成多个基学习器。
从偏差-方差分解来看:Boosting算法主要关注于降低偏差,每轮的迭代都关注于训练过程中预测错误的样本,将弱学习提升为强学习器。从AdaBoost的算法流程来看,标准的AdaBoost只适用于二分类问题。在此,当选为数据挖掘十大算法之一的AdaBoost介绍到这里,能够当选正是说明这个算法十分婀娜多姿,背后的数学证明和推导充分证明了这一点,限于篇幅不再继续展开。
##**9.3 Bagging与Random Forest**
相比之下,Bagging与随机森林算法就简洁了许多,上面已经提到产生“好而不同”的个体学习器是集成学习研究的核心,即在保证基学习器准确性的同时增加基学习器之间的多样性。而这两种算法的基本思(tao)想(lu)都是通过“自助采样”的方法来增加多样性。
###**9.3.1 Bagging**
Bagging是一种并行式的集成学习方法,即基学习器的训练之间没有前后顺序可以同时进行,Bagging使用“有放回”采样的方式选取训练集,对于包含m个样本的训练集,进行m次有放回的随机采样操作,从而得到m个样本的采样集,这样训练集中有接近36.8%的样本没有被采到。按照相同的方式重复进行,我们就可以采集到T个包含m个样本的数据集,从而训练出T个基学习器,最终对这T个基学习器的输出进行结合。
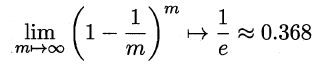
Bagging算法的流程如下所示:
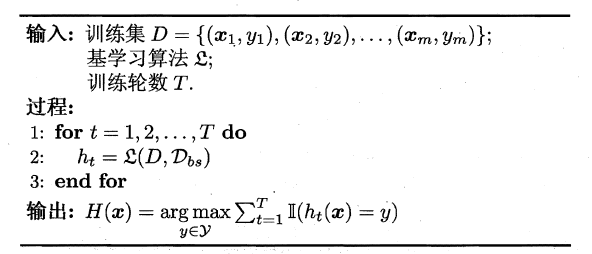
可以看出Bagging主要通过**样本的扰动**来增加基学习器之间的多样性,因此Bagging的基学习器应为那些对训练集十分敏感的不稳定学习算法,例如:神经网络与决策树等。从偏差-方差分解来看,Bagging算法主要关注于降低方差,即通过多次重复训练提高稳定性。不同于AdaBoost的是,Bagging可以十分简单地移植到多分类、回归等问题。总的说起来则是:**AdaBoost关注于降低偏差,而Bagging关注于降低方差。**
###**9.3.2 随机森林**
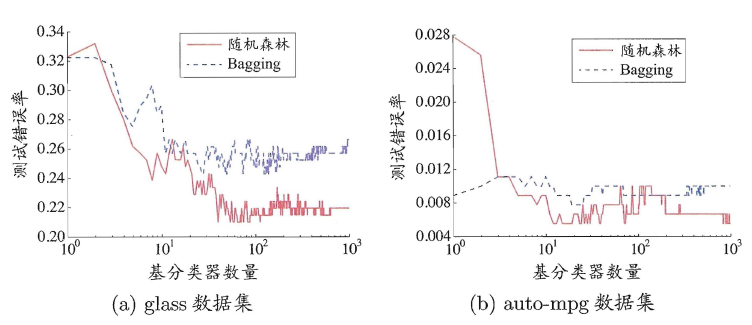
随机森林(Random Forest)是Bagging的一个拓展体,它的基学习器固定为决策树,多棵树也就组成了森林,而“随机”则在于选择划分属性的随机,随机森林在训练基学习器时,也采用有放回采样的方式添加样本扰动,同时它还引入了一种**属性扰动**,即在基决策树的训练过程中,在选择划分属性时,RF先从候选属性集中随机挑选出一个包含K个属性的子集,再从这个子集中选择最优划分属性,一般推荐K=log2(d)。
这样随机森林中基学习器的多样性不仅来自样本扰动,还来自属性扰动,从而进一步提升了基学习器之间的差异度。相比决策树的Bagging集成,随机森林的起始性能较差(由于属性扰动,基决策树的准确度有所下降),但随着基学习器数目的增多,随机森林往往会收敛到更低的泛化误差。同时不同于Bagging中决策树从所有属性集中选择最优划分属性,随机森林只在属性集的一个子集中选择划分属性,因此训练效率更高。
##**9.4 结合策略**
结合策略指的是在训练好基学习器后,如何将这些基学习器的输出结合起来产生集成模型的最终输出,下面将介绍一些常用的结合策略:
###**9.4.1 平均法(回归问题)**
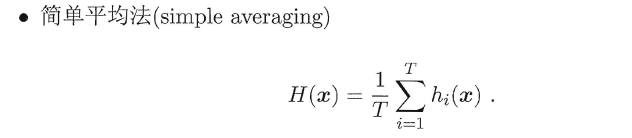
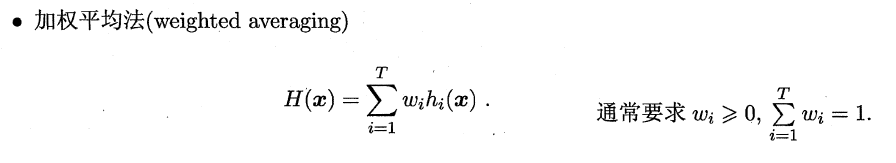
易知简单平均法是加权平均法的一种特例,加权平均法可以认为是集成学习研究的基本出发点。由于各个基学习器的权值在训练中得出,**一般而言,在个体学习器性能相差较大时宜使用加权平均法,在个体学习器性能相差较小时宜使用简单平均法**。
###**9.4.2 投票法(分类问题)**

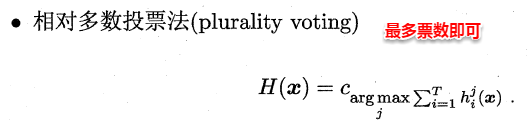
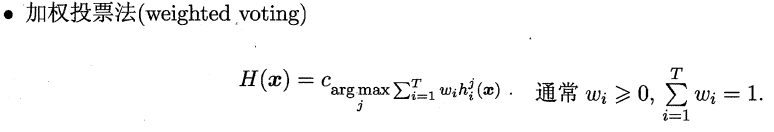
绝对多数投票法(majority voting)提供了拒绝选项,这在可靠性要求很高的学习任务中是一个很好的机制。同时,对于分类任务,各个基学习器的输出值有两种类型,分别为类标记和类概率。

一些在产生类别标记的同时也生成置信度的学习器,置信度可转化为类概率使用,**一般基于类概率进行结合往往比基于类标记进行结合的效果更好**,需要注意的是对于异质集成,其类概率不能直接进行比较,此时需要将类概率转化为类标记输出,然后再投票。
###**9.4.3 学习法**
学习法是一种更高级的结合策略,即学习出一种“投票”的学习器,Stacking是学习法的典型代表。Stacking的基本思想是:首先训练出T个基学习器,对于一个样本它们会产生T个输出,将这T个基学习器的输出与该样本的真实标记作为新的样本,m个样本就会产生一个m*T的样本集,来训练一个新的“投票”学习器。投票学习器的输入属性与学习算法对Stacking集成的泛化性能有很大的影响,书中已经提到:**投票学习器采用类概率作为输入属性,选用多响应线性回归(MLR)一般会产生较好的效果**。

##**9.5 多样性(diversity)**
在集成学习中,基学习器之间的多样性是影响集成器泛化性能的重要因素。因此增加多样性对于集成学习研究十分重要,一般的思路是在学习过程中引入随机性,常见的做法主要是对数据样本、输入属性、输出表示、算法参数进行扰动。
> **数据样本扰动**,即利用具有差异的数据集来训练不同的基学习器。例如:有放回自助采样法,但此类做法只对那些不稳定学习算法十分有效,例如:决策树和神经网络等,训练集的稍微改变能导致学习器的显著变动。
> **输入属性扰动**,即随机选取原空间的一个子空间来训练基学习器。例如:随机森林,从初始属性集中抽取子集,再基于每个子集来训练基学习器。但若训练集只包含少量属性,则不宜使用属性扰动。
> **输出表示扰动**,此类做法可对训练样本的类标稍作变动,或对基学习器的输出进行转化。
> **算法参数扰动**,通过随机设置不同的参数,例如:神经网络中,随机初始化权重与随机设置隐含层节点数。
在此,集成学习就介绍完毕,看到这里,大家也会发现集成学习实质上是一种通用框架,可以使用任何一种基学习器,从而改进单个学习器的泛化性能。据说数据挖掘竞赛KDDCup历年的冠军几乎都使用了集成学习,看来的确是个好东西~
================================================
FILE: 周志华《Machine Learning》学习笔记(11)--聚类.md
================================================
上篇主要介绍了一种机器学习的通用框架--集成学习方法,首先从准确性和差异性两个重要概念引出集成学习“**好而不同**”的四字真言,接着介绍了现阶段主流的三种集成学习方法:AdaBoost、Bagging及Random Forest,AdaBoost采用最小化指数损失函数迭代式更新样本分布权重和计算基学习器权重,Bagging通过自助采样引入样本扰动增加了基学习器之间的差异性,随机森林则进一步引入了属性扰动,最后简单概述了集成模型中的三类结合策略:平均法、投票法及学习法,其中Stacking是学习法的典型代表。本篇将讨论无监督学习中应用最为广泛的学习算法--聚类。
#**10、聚类算法**
聚类是一种经典的**无监督学习**方法,**无监督学习的目标是通过对无标记训练样本的学习,发掘和揭示数据集本身潜在的结构与规律**,即不依赖于训练数据集的类标记信息。聚类则是试图将数据集的样本划分为若干个互不相交的类簇,从而每个簇对应一个潜在的类别。
聚类直观上来说是将相似的样本聚在一起,从而形成一个**类簇(cluster)**。那首先的问题是如何来**度量相似性**(similarity measure)呢?这便是**距离度量**,在生活中我们说差别小则相似,对应到多维样本,每个样本可以对应于高维空间中的一个数据点,若它们的距离相近,我们便可以称它们相似。那接着如何来评价聚类结果的好坏呢?这便是**性能度量**,性能度量为评价聚类结果的好坏提供了一系列有效性指标。
##**10.1 距离度量**
谈及距离度量,最熟悉的莫过于欧式距离了,从年头一直用到年尾的距离计算公式:即对应属性之间相减的平方和再开根号。度量距离还有其它的很多经典方法,通常它们需要满足一些基本性质:

最常用的距离度量方法是**“闵可夫斯基距离”(Minkowski distance)**:
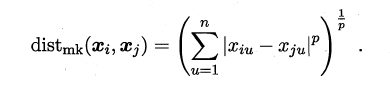
当p=1时,闵可夫斯基距离即**曼哈顿距离(Manhattan distance)**:
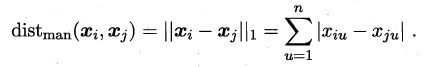
当p=2时,闵可夫斯基距离即**欧氏距离(Euclidean distance)**:
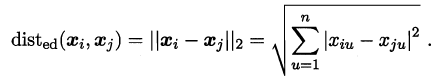
我们知道属性分为两种:**连续属性**和**离散属性**(有限个取值)。对于连续值的属性,一般都可以被学习器所用,有时会根据具体的情形作相应的预处理,例如:归一化等;而对于离散值的属性,需要作下面进一步的处理:
> 若属性值之间**存在序关系**,则可以将其转化为连续值,例如:身高属性“高”“中等”“矮”,可转化为{1, 0.5, 0}。
> 若属性值之间**不存在序关系**,则通常将其转化为向量的形式,例如:性别属性“男”“女”,可转化为{(1,0),(0,1)}。
在进行距离度量时,易知**连续属性和存在序关系的离散属性都可以直接参与计算**,因为它们都可以反映一种程度,我们称其为“**有序属性**”;而对于不存在序关系的离散属性,我们称其为:“**无序属性**”,显然无序属性再使用闵可夫斯基距离就行不通了。
**对于无序属性,我们一般采用VDM进行距离的计算**,例如:对于离散属性的两个取值a和b,定义:
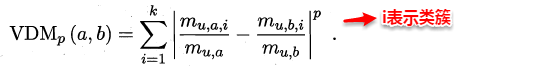
于是,在计算两个样本之间的距离时,我们可以将闵可夫斯基距离和VDM混合在一起进行计算:

若我们定义的距离计算方法是用来度量相似性,例如下面将要讨论的聚类问题,即距离越小,相似性越大,反之距离越大,相似性越小。这时距离的度量方法并不一定需要满足前面所说的四个基本性质,这样的方法称为:**非度量距离(non-metric distance)**。
##**10.2 性能度量**
由于聚类算法不依赖于样本的真实类标,就不能像监督学习的分类那般,通过计算分对分错(即精确度或错误率)来评价学习器的好坏或作为学习过程中的优化目标。一般聚类有两类性能度量指标:**外部指标**和**内部指标**。
###**10.2.1 外部指标**
即将聚类结果与某个参考模型的结果进行比较,**以参考模型的输出作为标准,来评价聚类好坏**。假设聚类给出的结果为λ,参考模型给出的结果是λ*,则我们将样本进行两两配对,定义:

显然a和b代表着聚类结果好坏的正能量,b和c则表示参考结果和聚类结果相矛盾,基于这四个值可以导出以下常用的外部评价指标:

###**10.2.2 内部指标**
内部指标即不依赖任何外部模型,直接对聚类的结果进行评估,聚类的目的是想将那些相似的样本尽可能聚在一起,不相似的样本尽可能分开,直观来说:**簇内高内聚紧紧抱团,簇间低耦合老死不相往来**。定义:

基于上面的四个距离,可以导出下面这些常用的内部评价指标:

##**10.3 原型聚类**
原型聚类即“**基于原型的聚类**”(prototype-based clustering),原型表示模板的意思,就是通过参考一个模板向量或模板分布的方式来完成聚类的过程,常见的K-Means便是基于簇中心来实现聚类,混合高斯聚类则是基于簇分布来实现聚类。
###**10.3.1 K-Means**
K-Means的思想十分简单,**首先随机指定类中心,根据样本与类中心的远近划分类簇,接着重新计算类中心,迭代直至收敛**。但是其中迭代的过程并不是主观地想象得出,事实上,若将样本的类别看做为“隐变量”(latent variable),类中心看作样本的分布参数,这一过程正是通过**EM算法**的两步走策略而计算出,其根本的目的是为了最小化平方误差函数E:
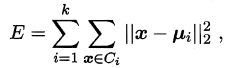
K-Means的算法流程如下所示:

###**10.3.2 学习向量量化(LVQ)**
LVQ也是基于原型的聚类算法,与K-Means不同的是,**LVQ使用样本真实类标记辅助聚类**,首先LVQ根据样本的类标记,从各类中分别随机选出一个样本作为该类簇的原型,从而组成了一个**原型特征向量组**,接着从样本集中随机挑选一个样本,计算其与原型向量组中每个向量的距离,并选取距离最小的原型向量所在的类簇作为它的划分结果,再与真实类标比较。
> **若划分结果正确,则对应原型向量向这个样本靠近一些**
> **若划分结果不正确,则对应原型向量向这个样本远离一些**
LVQ算法的流程如下所示:

###**10.3.3 高斯混合聚类**
现在可以看出K-Means与LVQ都试图以类中心作为原型指导聚类,高斯混合聚类则采用高斯分布来描述原型。现假设**每个类簇中的样本都服从一个多维高斯分布,那么空间中的样本可以看作由k个多维高斯分布混合而成**。
对于多维高斯分布,其概率密度函数如下所示:
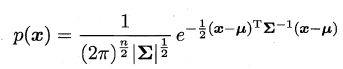
其中u表示均值向量,∑表示协方差矩阵,可以看出一个多维高斯分布完全由这两个参数所确定。接着定义高斯混合分布为:
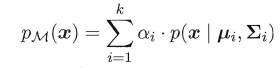
α称为混合系数,这样空间中样本的采集过程则可以抽象为:**(1)先选择一个类簇(高斯分布),(2)再根据对应高斯分布的密度函数进行采样**,这时候贝叶斯公式又能大展身手了:

此时只需要选择PM最大时的类簇并将该样本划分到其中,看到这里很容易发现:这和那个传说中的贝叶斯分类不是神似吗,都是通过贝叶斯公式展开,然后计算类先验概率和类条件概率。但遗憾的是:**这里没有真实类标信息,对于类条件概率,并不能像贝叶斯分类那样通过最大似然法美好地计算出来**,因为这里的样本可能属于所有的类簇,这里的似然函数变为:
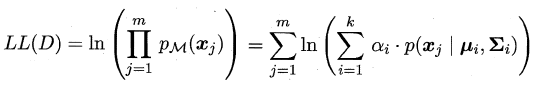
可以看出:简单的最大似然法根本无法求出所有的参数,这样PM也就没法计算。**这里就要召唤出之前的EM大法,首先对高斯分布的参数及混合系数进行随机初始化,计算出各个PM(即γji,第i个样本属于j类),再最大化似然函数(即LL(D)分别对α、u和∑求偏导 ),对参数进行迭代更新**。
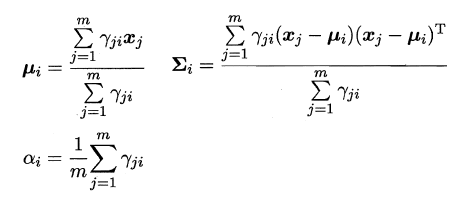
高斯混合聚类的算法流程如下图所示:

##**10.4 密度聚类**
密度聚类则是基于密度的聚类,它从样本分布的角度来考察样本之间的可连接性,并基于可连接性(密度可达)不断拓展疆域(类簇)。其中最著名的便是**DBSCAN**算法,首先定义以下概念:

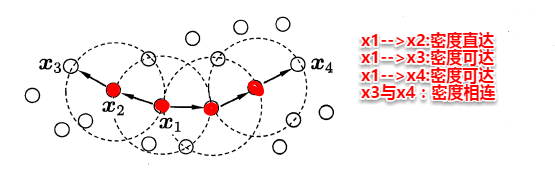
简单来理解DBSCAN便是:**找出一个核心对象所有密度可达的样本集合形成簇**。首先从数据集中任选一个核心对象A,找出所有A密度可达的样本集合,将这些样本形成一个密度相连的类簇,直到所有的核心对象都遍历完。DBSCAN算法的流程如下图所示:

##**10.5 层次聚类**
层次聚类是一种基于树形结构的聚类方法,常用的是**自底向上**的结合策略(**AGNES算法**)。假设有N个待聚类的样本,其基本步骤是:
> 1.初始化-->把每个样本归为一类,计算每两个类之间的距离,也就是样本与样本之间的相似度;
> 2.寻找各个类之间最近的两个类,把他们归为一类(这样类的总数就少了一个);
> 3.重新计算新生成的这个**类与各个旧类之间的相似度**;
> 4.重复2和3直到所有样本点都归为一类,结束。
可以看出其中最关键的一步就是**计算两个类簇的相似度**,这里有多种度量方法:
* 单链接(single-linkage):取类间最小距离。
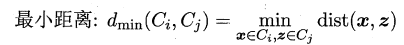
* 全链接(complete-linkage):取类间最大距离
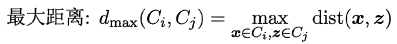
* 均链接(average-linkage):取类间两两的平均距离
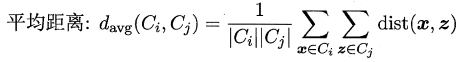
很容易看出:**单链接的包容性极强,稍微有点暧昧就当做是自己人了,全链接则是坚持到底,只要存在缺点就坚决不合并,均连接则是从全局出发顾全大局**。层次聚类法的算法流程如下所示:

> 在此聚类算法就介绍完毕,分类/聚类都是机器学习中最常见的任务,我实验室的大Boss也是靠着聚类起家,从此走上人生事业钱途...之巅峰,在书最后的阅读材料还看见Boss的名字,所以这章也是必读不可了...
================================================
FILE: 周志华《Machine Learning》学习笔记(12)--降维与度量学习.md
================================================
上篇主要介绍了几种常用的聚类算法,首先从距离度量与性能评估出发,列举了常见的距离计算公式与聚类评价指标,接着分别讨论了K-Means、LVQ、高斯混合聚类、密度聚类以及层次聚类算法。K-Means与LVQ都试图以类簇中心作为原型指导聚类,其中K-Means通过EM算法不断迭代直至收敛,LVQ使用真实类标辅助聚类;高斯混合聚类采用高斯分布来描述类簇原型;密度聚类则是将一个核心对象所有密度可达的样本形成类簇,直到所有核心对象都遍历完;最后层次聚类是一种自底向上的树形聚类方法,不断合并最相近的两个小类簇。本篇将讨论机器学习常用的方法--降维与度量学习。
#**11、降维与度量学习**
样本的特征数称为**维数**(dimensionality),当维数非常大时,也就是现在所说的“**维数灾难**”,具体表现在:在高维情形下,**数据样本将变得十分稀疏**,因为此时要满足训练样本为“**密采样**”的总体样本数目是一个触不可及的天文数字,谓可远观而不可亵玩焉...**训练样本的稀疏使得其代表总体分布的能力大大减弱,从而消减了学习器的泛化能力**;同时当维数很高时,**计算距离也变得十分复杂**,甚至连计算内积都不再容易,这也是为什么支持向量机(SVM)使用核函数**“低维计算,高维表现”**的原因。
缓解维数灾难的一个重要途径就是**降维,即通过某种数学变换将原始高维空间转变到一个低维的子空间**。在这个子空间中,样本的密度将大幅提高,同时距离计算也变得容易。这时也许会有疑问,这样降维之后不是会丢失原始数据的一部分信息吗?这是因为在很多实际的问题中,虽然训练数据是高维的,但是与学习任务相关也许仅仅是其中的一个低维子空间,也称为一个**低维嵌入**,例如:数据属性中存在噪声属性、相似属性或冗余属性等,**对高维数据进行降维能在一定程度上达到提炼低维优质属性或降噪的效果**。
##**11.1 K近邻学习**
k近邻算法简称**kNN(k-Nearest Neighbor)**,是一种经典的监督学习方法,同时也实力担当入选数据挖掘十大算法。其工作机制十分简单粗暴:给定某个测试样本,kNN基于某种**距离度量**在训练集中找出与其距离最近的k个带有真实标记的训练样本,然后给基于这k个邻居的真实标记来进行预测,类似于前面集成学习中所讲到的基学习器结合策略:分类任务采用投票法,回归任务则采用平均法。接下来本篇主要就kNN分类进行讨论。
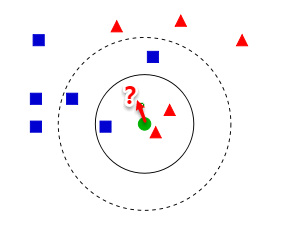
从上图【来自Wiki】中我们可以看到,图中有两种类型的样本,一类是蓝色正方形,另一类是红色三角形。而那个绿色圆形是我们待分类的样本。基于kNN算法的思路,我们很容易得到以下结论:
> 如果K=3,那么离绿色点最近的有2个红色三角形和1个蓝色的正方形,这3个点投票,于是绿色的这个待分类点属于红色的三角形。
> 如果K=5,那么离绿色点最近的有2个红色三角形和3个蓝色的正方形,这5个点投票,于是绿色的这个待分类点属于蓝色的正方形。
可以发现:**kNN虽然是一种监督学习方法,但是它却没有显式的训练过程**,而是当有新样本需要预测时,才来计算出最近的k个邻居,因此**kNN是一种典型的懒惰学习方法**,再来回想一下朴素贝叶斯的流程,训练的过程就是参数估计,因此朴素贝叶斯也可以懒惰式学习,此类技术在**训练阶段开销为零**,待收到测试样本后再进行计算。相应地我们称那些一有训练数据立马开工的算法为“**急切学习**”,可见前面我们学习的大部分算法都归属于急切学习。
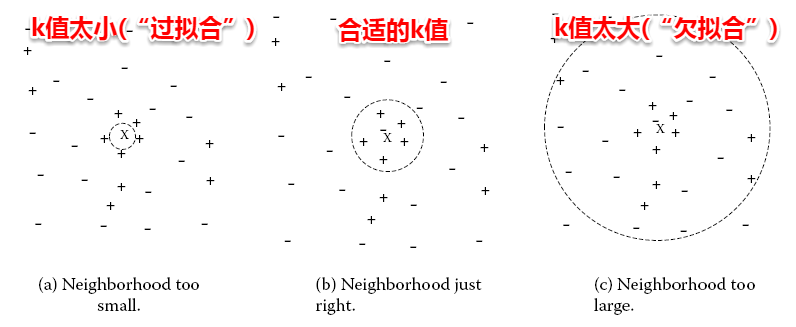
很容易看出:**kNN算法的核心在于k值的选取以及距离的度量**。k值选取太小,模型很容易受到噪声数据的干扰,例如:极端地取k=1,若待分类样本正好与一个噪声数据距离最近,就导致了分类错误;若k值太大, 则在更大的邻域内进行投票,此时模型的预测能力大大减弱,例如:极端取k=训练样本数,就相当于模型根本没有学习,所有测试样本的预测结果都是一样的。**一般地我们都通过交叉验证法来选取一个适当的k值**。
对于距离度量,**不同的度量方法得到的k个近邻不尽相同,从而对最终的投票结果产生了影响**,因此选择一个合适的距离度量方法也十分重要。在上一篇聚类算法中,在度量样本相似性时介绍了常用的几种距离计算方法,包括**闵可夫斯基距离,曼哈顿距离,VDM**等。在实际应用中,**kNN的距离度量函数一般根据样本的特性来选择合适的距离度量,同时应对数据进行去量纲/归一化处理来消除大量纲属性的强权政治影响**。
##**11.2 MDS算法**
不管是使用核函数升维还是对数据降维,我们都希望**原始空间样本点之间的距离在新空间中基本保持不变**,这样才不会使得原始空间样本之间的关系及总体分布发生较大的改变。**“多维缩放”(MDS)**正是基于这样的思想,**MDS要求原始空间样本之间的距离在降维后的低维空间中得以保持**。
假定m个样本在原始空间中任意两两样本之间的距离矩阵为D∈R(m*m),我们的目标便是获得样本在低维空间中的表示Z∈R(d'*m , d'< d),且任意两个样本在低维空间中的欧式距离等于原始空间中的距离,即||zi-zj||=Dist(ij)。因此接下来我们要做的就是根据已有的距离矩阵D来求解出降维后的坐标矩阵Z。

令降维后的样本坐标矩阵Z被中心化,**中心化是指将每个样本向量减去整个样本集的均值向量,故所有样本向量求和得到一个零向量**。这样易知:矩阵B的每一列以及每一列求和均为0,因为提取公因子后都有一项为所有样本向量的和向量。
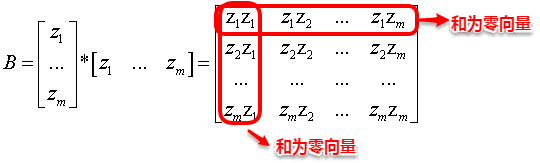
根据上面矩阵B的特征,我们很容易得到等式(2)、(3)以及(4):

这时根据(1)--(4)式我们便可以计算出bij,即**bij=(1)-(2)*(1/m)-(3)*(1/m)+(4)*(1/(m^2))**,再逐一地计算每个b(ij),就得到了降维后低维空间中的内积矩阵B(B=Z'*Z),只需对B进行特征值分解便可以得到Z。MDS的算法流程如下图所示:

##**11.3 主成分分析(PCA)**
不同于MDS采用距离保持的方法,**主成分分析(PCA)直接通过一个线性变换,将原始空间中的样本投影到新的低维空间中**。简单来理解这一过程便是:**PCA采用一组新的基来表示样本点,其中每一个基向量都是原来基向量的线性组合,通过使用尽可能少的新基向量来表出样本,从而达到降维的目的。**
假设使用d'个新基向量来表示原来样本,实质上是将样本投影到一个由d'个基向量确定的一个**超平面**上(**即舍弃了一些维度**),要用一个超平面对空间中所有高维样本进行恰当的表达,最理想的情形是:**若这些样本点都能在超平面上表出且这些表出在超平面上都能够很好地分散开来**。但是一般使用较原空间低一些维度的超平面来做到这两点十分不容易,因此我们退一步海阔天空,要求这个超平面应具有如下两个性质:
> **最近重构性**:样本点到超平面的距离足够近,即尽可能在超平面附近;
> **最大可分性**:样本点在超平面上的投影尽可能地分散开来,即投影后的坐标具有区分性。
这里十分神奇的是:**最近重构性与最大可分性虽然从不同的出发点来定义优化问题中的目标函数,但最终这两种特性得到了完全相同的优化问题**:
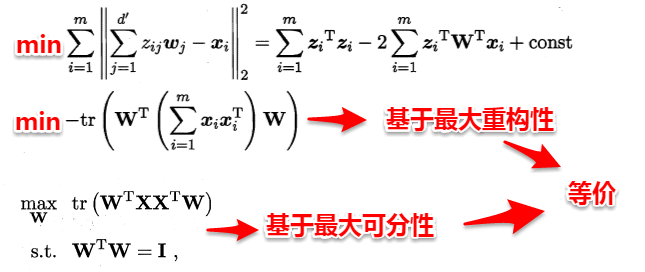
接着使用拉格朗日乘子法求解上面的优化问题,得到:

因此只需对协方差矩阵进行特征值分解即可求解出W,PCA算法的整个流程如下图所示:

另一篇博客给出更通俗更详细的理解:[主成分分析解析(基于最大方差理论)](http://blog.csdn.net/u011826404/article/details/57472730)
##**11.4 核化线性降维**
说起机器学习你中有我/我中有你/水乳相融...在这里能够得到很好的体现。正如SVM在处理非线性可分时,通过引入核函数将样本投影到高维特征空间,接着在高维空间再对样本点使用超平面划分。这里也是相同的问题:若我们的样本数据点本身就不是线性分布,那还如何使用一个超平面去近似表出呢?因此也就引入了核函数,**即先将样本映射到高维空间,再在高维空间中使用线性降维的方法**。下面主要介绍**核化主成分分析(KPCA)**的思想。
若核函数的形式已知,即我们知道如何将低维的坐标变换为高维坐标,这时我们只需先将数据映射到高维特征空间,再在高维空间中运用PCA即可。但是一般情况下,我们并不知道核函数具体的映射规则,例如:Sigmoid、高斯核等,我们只知道如何计算高维空间中的样本内积,这时就引出了KPCA的一个重要创新之处:**即空间中的任一向量,都可以由该空间中的所有样本线性表示**。证明过程也十分简单:

这样我们便可以将高维特征空间中的投影向量wi使用所有高维样本点线性表出,接着代入PCA的求解问题,得到:

化简到最后一步,发现结果十分的美妙,只需对核矩阵K进行特征分解,便可以得出投影向量wi对应的系数向量α,因此选取特征值前d'大对应的特征向量便是d'个系数向量。这时对于需要降维的样本点,只需按照以下步骤便可以求出其降维后的坐标。可以看出:KPCA在计算降维后的坐标表示时,需要与所有样本点计算核函数值并求和,因此该算法的计算开销十分大。

##**11.5 流形学习**
**流形学习(manifold learning)是一种借助拓扑流形概念的降维方法**,**流形是指在局部与欧式空间同胚的空间**,即在局部与欧式空间具有相同的性质,能用欧氏距离计算样本之间的距离。这样即使高维空间的分布十分复杂,但是在局部上依然满足欧式空间的性质,基于流形学习的降维正是这种**“邻域保持”**的思想。其中**等度量映射(Isomap)试图在降维前后保持邻域内样本之间的距离,而局部线性嵌入(LLE)则是保持邻域内样本之间的线性关系**,下面将分别对这两种著名的流行学习方法进行介绍。
###**11.5.1 等度量映射(Isomap)**
等度量映射的基本出发点是:高维空间中的直线距离具有误导性,因为有时高维空间中的直线距离在低维空间中是不可达的。**因此利用流形在局部上与欧式空间同胚的性质,可以使用近邻距离来逼近测地线距离**,即对于一个样本点,它与近邻内的样本点之间是可达的,且距离使用欧式距离计算,这样整个样本空间就形成了一张近邻图,高维空间中两个样本之间的距离就转为最短路径问题。可采用著名的**Dijkstra算法**或**Floyd算法**计算最短距离,得到高维空间中任意两点之间的距离后便可以使用MDS算法来其计算低维空间中的坐标。
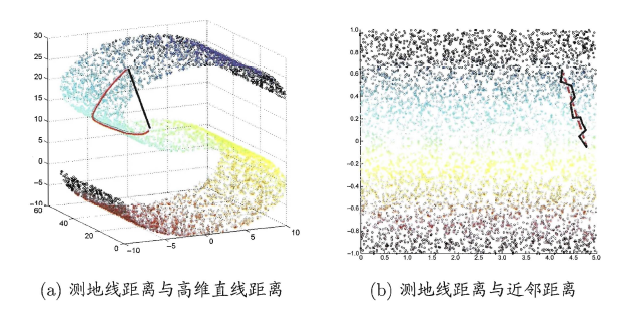
从MDS算法的描述中我们可以知道:MDS先求出了低维空间的内积矩阵B,接着使用特征值分解计算出了样本在低维空间中的坐标,但是并没有给出通用的投影向量w,因此对于需要降维的新样本无从下手,书中给出的权宜之计是利用已知高/低维坐标的样本作为训练集学习出一个“投影器”,便可以用高维坐标预测出低维坐标。Isomap算法流程如下图:

对于近邻图的构建,常用的有两种方法:**一种是指定近邻点个数**,像kNN一样选取k个最近的邻居;**另一种是指定邻域半径**,距离小于该阈值的被认为是它的近邻点。但两种方法均会出现下面的问题:
> 若**邻域范围指定过大,则会造成“短路问题”**,即本身距离很远却成了近邻,将距离近的那些样本扼杀在摇篮。
> 若**邻域范围指定过小,则会造成“断路问题”**,即有些样本点无法可达了,整个世界村被划分为互不可达的小部落。
###**11.5.2 局部线性嵌入(LLE)**
不同于Isomap算法去保持邻域距离,LLE算法试图去保持邻域内的线性关系,假定样本xi的坐标可以通过它的邻域样本线性表出:
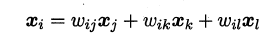
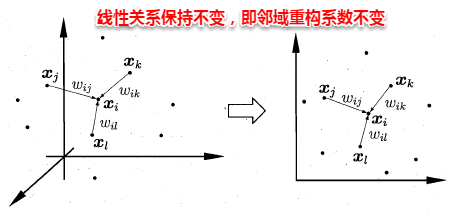
LLE算法分为两步走,**首先第一步根据近邻关系计算出所有样本的邻域重构系数w**:
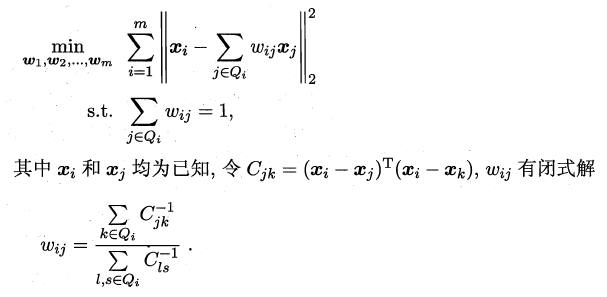
**接着根据邻域重构系数不变,去求解低维坐标**:
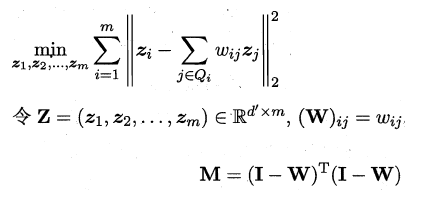
这样利用矩阵M,优化问题可以重写为:

M特征值分解后最小的d'个特征值对应的特征向量组成Z,LLE算法的具体流程如下图所示:

##**11.6 度量学习**
本篇一开始就提到维数灾难,即在高维空间进行机器学习任务遇到样本稀疏、距离难计算等诸多的问题,因此前面讨论的降维方法都试图将原空间投影到一个合适的低维空间中,接着在低维空间进行学习任务从而产生较好的性能。事实上,不管高维空间还是低维空间都潜在对应着一个距离度量,那可不可以直接学习出一个距离度量来等效降维呢?例如:**咋们就按照降维后的方式来进行距离的计算,这便是度量学习的初衷**。
**首先要学习出距离度量必须先定义一个合适的距离度量形式**。对两个样本xi与xj,它们之间的平方欧式距离为:
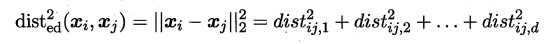
若各个属性重要程度不一样即都有一个权重,则得到加权的平方欧式距离:
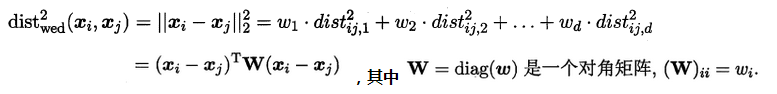
此时各个属性之间都是相互独立无关的,但现实中往往会存在属性之间有关联的情形,例如:身高和体重,一般人越高,体重也会重一些,他们之间存在较大的相关性。这样计算距离就不能分属性单独计算,于是就引入经典的**马氏距离(Mahalanobis distance)**:
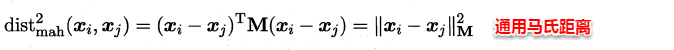
**标准的马氏距离中M是协方差矩阵的逆,马氏距离是一种考虑属性之间相关性且尺度无关(即无须去量纲)的距离度量**。
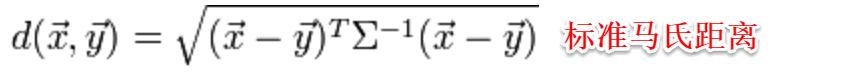
**矩阵M也称为“度量矩阵”,为保证距离度量的非负性与对称性,M必须为(半)正定对称矩阵**,这样就为度量学习定义好了距离度量的形式,换句话说:**度量学习便是对度量矩阵进行学习**。现在来回想一下前面我们接触的机器学习不难发现:**机器学习算法几乎都是在优化目标函数,从而求解目标函数中的参数**。同样对于度量学习,也需要设置一个优化目标,书中简要介绍了错误率和相似性两种优化目标,此处限于篇幅不进行展开。
在此,降维和度量学习就介绍完毕。**降维是将原高维空间嵌入到一个合适的低维子空间中,接着在低维空间中进行学习任务;度量学习则是试图去学习出一个距离度量来等效降维的效果**,两者都是为了解决维数灾难带来的诸多问题。也许大家最后心存疑惑,那kNN呢,为什么一开头就说了kNN算法,但是好像和后面没有半毛钱关系?正是因为在降维算法中,低维子空间的维数d'通常都由人为指定,因此我们需要使用一些低开销的学习器来选取合适的d',**kNN这家伙懒到家了根本无心学习,在训练阶段开销为零,测试阶段也只是遍历计算了距离,因此拿kNN来进行交叉验证就十分有优势了~同时降维后样本密度增大同时距离计算变易,更为kNN来展示它独特的十八般手艺提供了用武之地。**
================================================
FILE: 周志华《Machine Learning》学习笔记(13)--特征选择与稀疏学习.md
================================================
上篇主要介绍了经典的降维方法与度量学习,首先从“维数灾难”导致的样本稀疏以及距离难计算两大难题出发,引出了降维的概念,即通过某种数学变换将原始高维空间转变到一个低维的子空间,接着分别介绍了kNN、MDS、PCA、KPCA以及两种经典的流形学习方法,k近邻算法的核心在于k值的选取以及距离的度量,MDS要求原始空间样本之间的距离在降维后的低维空间中得以保持,主成分分析试图找到一个低维超平面来表出原空间样本点,核化主成分分析先将样本点映射到高维空间,再在高维空间中使用线性降维的方法,从而解决了原空间样本非线性分布的情形,基于流形学习的降维则是一种“邻域保持”的思想,最后度量学习试图去学习出一个距离度量来等效降维的效果。本篇将讨论另一种常用方法--特征选择与稀疏学习。
#**12、特征选择与稀疏学习**
最近在看论文的过程中,发现对于数据集行和列的叫法颇有不同,故在介绍本篇之前,决定先将最常用的术语罗列一二,以后再见到了不管它脚扑朔还是眼迷离就能一眼识破真身了~对于数据集中的一个对象及组成对象的零件元素:
> 统计学家常称它们为**观测**(**observation**)和**变量**(**variable**);
> 数据库分析师则称其为**记录**(**record**)和**字段**(**field**);
> 数据挖掘/机器学习学科的研究者则习惯把它们叫做**样本**/**示例**(**example**/**instance**)和**属性**/**特征**(**attribute**/**feature**)。
回归正题,在机器学习中特征选择是一个重要的“**数据预处理**”(**data** **preprocessing**)过程,即试图从数据集的所有特征中挑选出与当前学习任务相关的特征子集,接着再利用数据子集来训练学习器;稀疏学习则是围绕着稀疏矩阵的优良性质,来完成相应的学习任务。
##**12.1 子集搜索与评价**
一般地,我们可以用很多属性/特征来描述一个示例,例如对于一个人可以用性别、身高、体重、年龄、学历、专业、是否吃货等属性来描述,那现在想要训练出一个学习器来预测人的收入。根据生活经验易知:并不是所有的特征都与学习任务相关,例如年龄/学历/专业可能很大程度上影响了收入,身高/体重这些外貌属性也有较小的可能性影响收入,但像是否是一个地地道道的吃货这种属性就八杆子打不着了。因此我们只需要那些与学习任务紧密相关的特征,**特征选择便是从给定的特征集合中选出相关特征子集的过程**。
与上篇中降维技术有着异曲同工之处的是,特征选择也可以有效地解决维数灾难的难题。具体而言:**降维从一定程度起到了提炼优质低维属性和降噪的效果,特征选择则是直接剔除那些与学习任务无关的属性而选择出最佳特征子集**。若直接遍历所有特征子集,显然当维数过多时遭遇指数爆炸就行不通了;若采取从候选特征子集中不断迭代生成更优候选子集的方法,则时间复杂度大大减小。这时就涉及到了两个关键环节:**1.如何生成候选子集;2.如何评价候选子集的好坏**,这便是早期特征选择的常用方法。书本上介绍了贪心算法,分为三种策略:
> **前向搜索**:初始将每个特征当做一个候选特征子集,然后从当前所有的候选子集中选择出最佳的特征子集;接着在上一轮选出的特征子集中添加一个新的特征,同样地选出最佳特征子集;最后直至选不出比上一轮更好的特征子集。
> **后向搜索**:初始将所有特征作为一个候选特征子集;接着尝试去掉上一轮特征子集中的一个特征并选出当前最优的特征子集;最后直到选不出比上一轮更好的特征子集。
> **双向搜索**:将前向搜索与后向搜索结合起来,即在每一轮中既有添加操作也有剔除操作。
对于特征子集的评价,书中给出了一些想法及基于信息熵的方法。假设数据集的属性皆为离散属性,这样给定一个特征子集,便可以通过这个特征子集的取值将数据集合划分为V个子集。例如:A1={男,女},A2={本科,硕士}就可以将原数据集划分为2*2=4个子集,其中每个子集的取值完全相同。这时我们就可以像决策树选择划分属性那样,通过计算信息增益来评价该属性子集的好坏。

此时,信息增益越大表示该属性子集包含有助于分类的特征越多,使用上述这种**子集搜索与子集评价相结合的机制,便可以得到特征选择方法**。值得一提的是若将前向搜索策略与信息增益结合在一起,与前面我们讲到的ID3决策树十分地相似。事实上,决策树也可以用于特征选择,树节点划分属性组成的集合便是选择出的特征子集。
##**12.2 过滤式选择(Relief)**
过滤式方法是一种将特征选择与学习器训练相分离的特征选择技术,即首先将相关特征挑选出来,再使用选择出的数据子集来训练学习器。Relief是其中著名的代表性算法,它使用一个“**相关统计量**”来度量特征的重要性,该统计量是一个向量,其中每个分量代表着相应特征的重要性,因此我们最终可以根据这个统计量各个分量的大小来选择出合适的特征子集。
易知Relief算法的核心在于如何计算出该相关统计量。对于数据集中的每个样例xi,Relief首先找出与xi同类别的最近邻与不同类别的最近邻,分别称为**猜中近邻(near-hit)**与**猜错近邻(near-miss)**,接着便可以分别计算出相关统计量中的每个分量。对于j分量:
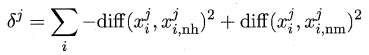
直观上理解:对于猜中近邻,两者j属性的距离越小越好,对于猜错近邻,j属性距离越大越好。更一般地,若xi为离散属性,diff取海明距离,即相同取0,不同取1;若xi为连续属性,则diff为曼哈顿距离,即取差的绝对值。分别计算每个分量,最终取平均便得到了整个相关统计量。
标准的Relief算法只用于二分类问题,后续产生的拓展变体Relief-F则解决了多分类问题。对于j分量,新的计算公式如下:
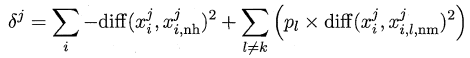
其中pl表示第l类样本在数据集中所占的比例,易知两者的不同之处在于:**标准Relief 只有一个猜错近邻,而Relief-F有多个猜错近邻**。
##**12.3 包裹式选择(LVW)**
与过滤式选择不同的是,包裹式选择将后续的学习器也考虑进来作为特征选择的评价准则。因此包裹式选择可以看作是为某种学习器**量身定做**的特征选择方法,由于在每一轮迭代中,包裹式选择都需要训练学习器,因此在获得较好性能的同时也产生了较大的开销。下面主要介绍一种经典的包裹式特征选择方法 --LVW(Las Vegas Wrapper),它在拉斯维加斯框架下使用随机策略来进行特征子集的搜索。拉斯维加斯?怎么听起来那么耳熟,不是那个声名显赫的赌场吗?歪果仁真会玩。怀着好奇科普一下,结果又顺带了一个赌场:
> **蒙特卡罗算法**:采样越多,越近似最优解,一定会给出解,但给出的解不一定是正确解;
> **拉斯维加斯算法**:采样越多,越有机会找到最优解,不一定会给出解,且给出的解一定是正确解。
举个例子,假如筐里有100个苹果,让我每次闭眼拿1个,挑出最大的。于是我随机拿1个,再随机拿1个跟它比,留下大的,再随机拿1个……我每拿一次,留下的苹果都至少不比上次的小。拿的次数越多,挑出的苹果就越大,但我除非拿100次,否则无法肯定挑出了最大的。这个挑苹果的算法,就属于蒙特卡罗算法——尽量找较好的,但不保证是最好的。
而拉斯维加斯算法,则是另一种情况。假如有一把锁,给我100把钥匙,只有1把是对的。于是我每次随机拿1把钥匙去试,打不开就再换1把。我试的次数越多,打开(正确解)的机会就越大,但在打开之前,那些错的钥匙都是没有用的。这个试钥匙的算法,就是拉斯维加斯的——尽量找最好的,但不保证能找到。
LVW算法的具体流程如下所示,其中比较特别的是停止条件参数T的设置,即在每一轮寻找最优特征子集的过程中,若随机T次仍没找到,算法就会停止,从而保证了算法运行时间的可行性。

##**12.4 嵌入式选择与正则化**
前面提到了的两种特征选择方法:**过滤式中特征选择与后续学习器完全分离,包裹式则是使用学习器作为特征选择的评价准则;嵌入式是一种将特征选择与学习器训练完全融合的特征选择方法,即将特征选择融入学习器的优化过程中**。在之前《经验风险与结构风险》中已经提到:经验风险指的是模型与训练数据的契合度,结构风险则是模型的复杂程度,机器学习的核心任务就是:**在模型简单的基础上保证模型的契合度**。例如:岭回归就是加上了L2范数的最小二乘法,有效地解决了奇异矩阵、过拟合等诸多问题,下面的嵌入式特征选择则是在损失函数后加上了L1范数。
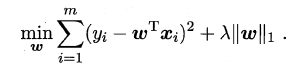
L1范数美名又约**Lasso Regularization**,指的是向量中每个元素的绝对值之和,这样在优化目标函数的过程中,就会使得w尽可能地小,在一定程度上起到了防止过拟合的作用,同时与L2范数(Ridge Regularization )不同的是,L1范数会使得部分w变为0, 从而达到了特征选择的效果。
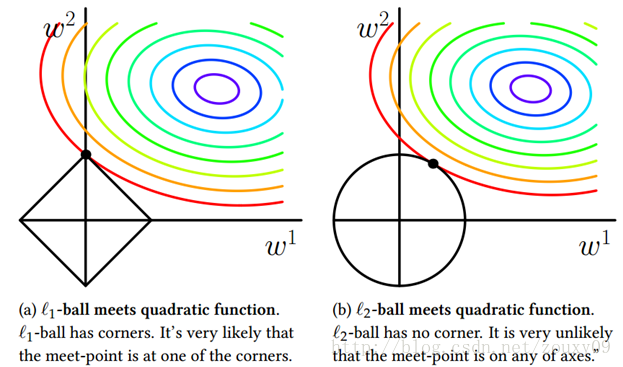
总的来说:**L1范数会趋向产生少量的特征,其他特征的权值都是0;L2会选择更多的特征,这些特征的权值都会接近于0**。这样L1范数在特征选择上就十分有用,而L2范数则具备较强的控制过拟合能力。可以从下面两个方面来理解:
(1)**下降速度**:L1范数按照绝对值函数来下降,L2范数按照二次函数来下降。因此在0附近,L1范数的下降速度大于L2范数,故L1范数能很快地下降到0,而L2范数在0附近的下降速度非常慢,因此较大可能收敛在0的附近。
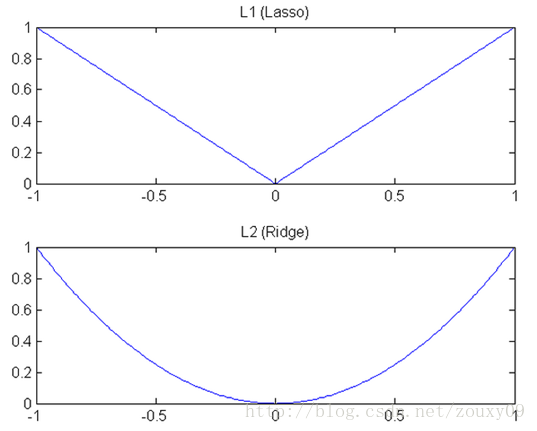
(2)**空间限制**:L1范数与L2范数都试图在最小化损失函数的同时,让权值W也尽可能地小。我们可以将原优化问题看做为下面的问题,即让后面的规则则都小于某个阈值。这样从图中可以看出:L1范数相比L2范数更容易得到稀疏解。
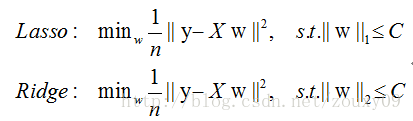
##**12.5 稀疏表示与字典学习**
当样本数据是一个稀疏矩阵时,对学习任务来说会有不少的好处,例如很多问题变得线性可分,储存更为高效等。这便是稀疏表示与字典学习的基本出发点。稀疏矩阵即矩阵的每一行/列中都包含了大量的零元素,且这些零元素没有出现在同一行/列,对于一个给定的稠密矩阵,若我们能**通过某种方法找到其合适的稀疏表示**,则可以使得学习任务更加简单高效,我们称之为**稀疏编码(sparse coding)**或**字典学习(dictionary learning)**。
给定一个数据集,字典学习/稀疏编码指的便是通过一个字典将原数据转化为稀疏表示,因此最终的目标就是求得字典矩阵B及稀疏表示α,书中使用变量交替优化的策略能较好地求得解,深感陷进去短时间无法自拔,故先不进行深入...

##**12.6 压缩感知**
压缩感知在前些年也是风风火火,与特征选择、稀疏表示不同的是:它关注的是通过欠采样信息来恢复全部信息。在实际问题中,为了方便传输和存储,我们一般将数字信息进行压缩,这样就有可能损失部分信息,如何根据已有的信息来重构出全部信号,这便是压缩感知的来历,压缩感知的前提是已知的信息具有稀疏表示。下面是关于压缩感知的一些背景:

在此,特征选择与稀疏学习就介绍完毕。在很多实际情形中,选了好的特征比选了好的模型更为重要,这也是为什么厉害的大牛能够很快地得出一些结论的原因,谓:吾昨晚夜观天象,星象云是否吃货乃无用也~
================================================
FILE: 周志华《Machine Learning》学习笔记(14)--计算学习理论.md
================================================
上篇主要介绍了常用的特征选择方法及稀疏学习。首先从相关/无关特征出发引出了特征选择的基本概念,接着分别介绍了子集搜索与评价、过滤式、包裹式以及嵌入式四种类型的特征选择方法。子集搜索与评价使用的是一种优中生优的贪婪算法,即每次从候选特征子集中选出最优子集;过滤式方法计算一个相关统计量来评判特征的重要程度;包裹式方法将学习器作为特征选择的评价准则;嵌入式方法则是通过L1正则项将特征选择融入到学习器参数优化的过程中。最后介绍了稀疏表示与压缩感知的核心思想:稀疏表示利用稀疏矩阵的优良性质,试图通过某种方法找到原始稠密矩阵的合适稀疏表示;压缩感知则试图利用可稀疏表示的欠采样信息来恢复全部信息。本篇将讨论一种为机器学习提供理论保证的学习方法--计算学习理论。
#**13、计算学习理论**
计算学习理论(computational learning theory)是通过“计算”来研究机器学习的理论,简而言之,其目的是分析学习任务的本质,例如:**在什么条件下可进行有效的学习,需要多少训练样本能获得较好的精度等,从而为机器学习算法提供理论保证**。
首先我们回归初心,再来谈谈经验误差和泛化误差。假设给定训练集D,其中所有的训练样本都服从一个未知的分布T,且它们都是在总体分布T中独立采样得到,即**独立同分布**(independent and identically distributed,i.i.d.),在《贝叶斯分类器》中我们已经提到:独立同分布是很多统计学习算法的基础假设,例如最大似然法,贝叶斯分类器,高斯混合聚类等,简单来理解独立同分布:每个样本都是从总体分布中独立采样得到,而没有拖泥带水。例如现在要进行问卷调查,要从总体人群中随机采样,看到一个美女你高兴地走过去,结果她男票突然冒了出来,说道:you jump,i jump,于是你本来只想调查一个人结果被强行撒了一把狗粮得到两份问卷,这样这两份问卷就不能称为独立同分布了,因为它们的出现具有强相关性。
回归正题,**泛化误差指的是学习器在总体上的预测误差,经验误差则是学习器在某个特定数据集D上的预测误差**。在实际问题中,往往我们并不能得到总体且数据集D是通过独立同分布采样得到的,因此我们常常使用经验误差作为泛化误差的近似。
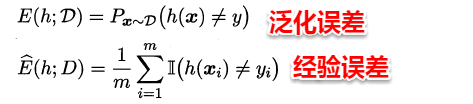
##**13.1 PAC学习**
在高中课本中,我们将**函数定义为:从自变量到因变量的一种映射;对于机器学习算法,学习器也正是为了寻找合适的映射规则**,即如何从条件属性得到目标属性。从样本空间到标记空间存在着很多的映射,我们将每个映射称之为**概念**(concept),定义:
> 若概念c对任何样本x满足c(x)=y,则称c为**目标概念**,即最理想的映射,所有的目标概念构成的集合称为**“概念类”**;
> 给定学习算法,它所有可能映射/概念的集合称为**“假设空间”**,其中单个的概念称为**“假设”**(hypothesis);
> 若一个算法的假设空间包含目标概念,则称该数据集对该算法是**可分**(separable)的,亦称**一致**(consistent)的;
> 若一个算法的假设空间不包含目标概念,则称该数据集对该算法是**不可分**(non-separable)的,或称**不一致**(non-consistent)的。
举个简单的例子:对于非线性分布的数据集,若使用一个线性分类器,则该线性分类器对应的假设空间就是空间中所有可能的超平面,显然假设空间不包含该数据集的目标概念,所以称数据集对该学习器是不可分的。给定一个数据集D,我们希望模型学得的假设h尽可能地与目标概念一致,这便是**概率近似正确** (Probably Approximately Correct,简称PAC)的来源,即以较大的概率学得模型满足误差的预设上限。




上述关于PAC的几个定义层层相扣:定义12.1表达的是对于某种学习算法,如果能以一个置信度学得假设满足泛化误差的预设上限,则称该算法能PAC辨识概念类,即该算法的输出假设已经十分地逼近目标概念。定义12.2则将样本数量考虑进来,当样本超过一定数量时,学习算法总是能PAC辨识概念类,则称概念类为PAC可学习的。定义12.3将学习器运行时间也考虑进来,若运行时间为多项式时间,则称PAC学习算法。
显然,PAC学习中的一个关键因素就是**假设空间的复杂度**,对于某个学习算法,**若假设空间越大,则其中包含目标概念的可能性也越大,但同时找到某个具体概念的难度也越大**,一般假设空间分为有限假设空间与无限假设空间。
##**13.2 有限假设空间**
###**13.2.1 可分情形**
可分或一致的情形指的是:**目标概念包含在算法的假设空间中**。对于目标概念,在训练集D中的经验误差一定为0,因此首先我们可以想到的是:不断地剔除那些出现预测错误的假设,直到找到经验误差为0的假设即为目标概念。但**由于样本集有限,可能会出现多个假设在D上的经验误差都为0,因此问题转化为:需要多大规模的数据集D才能让学习算法以置信度的概率从这些经验误差都为0的假设中找到目标概念的有效近似**。

通过上式可以得知:**对于可分情形的有限假设空间,目标概念都是PAC可学习的,即当样本数量满足上述条件之后,在与训练集一致的假设中总是可以在1-σ概率下找到目标概念的有效近似。**
###**13.2.2 不可分情形**
不可分或不一致的情形指的是:**目标概念不存在于假设空间中**,这时我们就不能像可分情形时那样从假设空间中寻找目标概念的近似。但**当假设空间给定时,必然存一个假设的泛化误差最小,若能找出此假设的有效近似也不失为一个好的目标,这便是不可知学习(agnostic learning)的来源。**

这时候便要用到**Hoeffding不等式**:
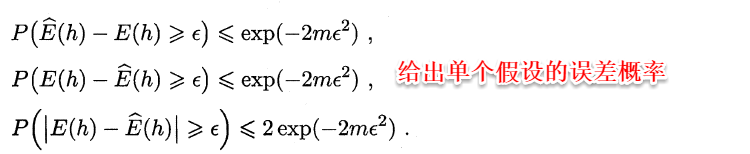
对于假设空间中的所有假设,出现泛化误差与经验误差之差大于e的概率和为:
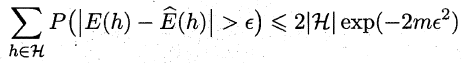
因此,可令不等式的右边小于(等于)σ,便可以求出满足泛化误差与经验误差相差小于e所需的最少样本数,同时也可以求出泛化误差界。
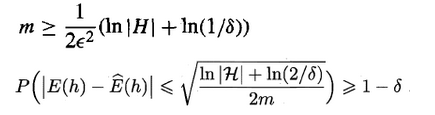
##**13.3 VC维**
现实中的学习任务通常都是无限假设空间,例如d维实数域空间中所有的超平面等,因此要对此种情形进行可学习研究,需要度量**假设空间的复杂度**。这便是**VC维**(Vapnik-Chervonenkis dimension)的来源。在介绍VC维之前,需要引入两个概念:
> **增长函数**:对于给定数据集D,假设空间中的每个假设都能对数据集的样本赋予标记,因此一个假设对应着一种打标结果,不同假设对D的打标结果可能是相同的,也可能是不同的。随着样本数量m的增大,假设空间对样本集D的打标结果也会增多,增长函数则表示假设空间对m个样本的数据集D打标的最大可能结果数,因此**增长函数描述了假设空间的表示能力与复杂度。**
>
> 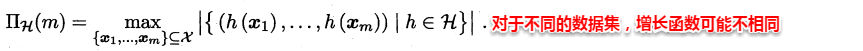
> **打散**:例如对二分类问题来说,m个样本最多有2^m个可能结果,每种可能结果称为一种**“对分”**,若假设空间能实现数据集D的所有对分,则称数据集能被该假设空间打散。
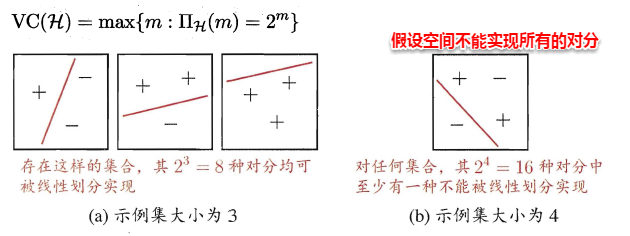
**因此尽管假设空间是无限的,但它对特定数据集打标的不同结果数是有限的,假设空间的VC维正是它能打散的最大数据集大小**。通常这样来计算假设空间的VC维:若存在大小为d的数据集能被假设空间打散,但不存在任何大小为d+1的数据集能被假设空间打散,则其VC维为d。
同时书中给出了假设空间VC维与增长函数的两个关系:
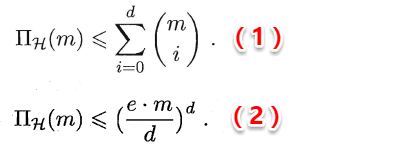
直观来理解(1)式也十分容易: 首先假设空间的VC维是d,说明当m<=d时,增长函数与2^m相等,例如:当m=d时,右边的组合数求和刚好等于2^d;而当m=d+1时,右边等于2^(d+1)-1,十分符合VC维的定义,同时也可以使用数学归纳法证明;(2)式则是由(1)式直接推导得出。
在有限假设空间中,根据Hoeffding不等式便可以推导得出学习算法的泛化误差界;但在无限假设空间中,由于假设空间的大小无法计算,只能通过增长函数来描述其复杂度,因此无限假设空间中的泛化误差界需要引入增长函数。


上式给出了基于VC维的泛化误差界,同时也可以计算出满足条件需要的样本数(样本复杂度)。若学习算法满足**经验风险最小化原则(ERM)**,即学习算法的输出假设h在数据集D上的经验误差最小,可证明:**任何VC维有限的假设空间都是(不可知)PAC可学习的,换而言之:若假设空间的最小泛化误差为0即目标概念包含在假设空间中,则是PAC可学习,若最小泛化误差不为0,则称为不可知PAC可学习。**
##**13.4 稳定性**
稳定性考察的是当算法的输入发生变化时,输出是否会随之发生较大的变化,输入的数据集D有以下两种变化:

若对数据集中的任何样本z,满足:
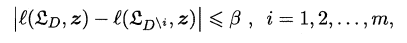
即原学习器和剔除一个样本后生成的学习器对z的损失之差保持β稳定,称学习器关于损失函数满足**β-均匀稳定性**。同时若损失函数有上界,即原学习器对任何样本的损失函数不超过M,则有如下定理:
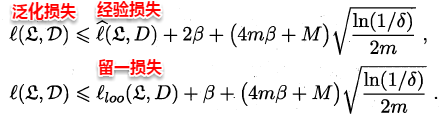
事实上,**若学习算法符合经验风险最小化原则(ERM)且满足β-均匀稳定性,则假设空间是可学习的**。稳定性通过损失函数与假设空间的可学习联系在了一起,区别在于:假设空间关注的是经验误差与泛化误差,需要考虑到所有可能的假设;而稳定性只关注当前的输出假设。
在此,计算学习理论就介绍完毕,一看这个名字就知道这一章比较偏底层理论了,最终还是咬着牙看完了它,这里引用一段小文字来梳理一下现在的心情:“孤岂欲卿治经为博士邪?但当涉猎,见往事耳”,就当扩充知识体系吧~
================================================
FILE: 周志华《Machine Learning》学习笔记(15)--半监督学习.md
================================================
上篇主要介绍了机器学习的理论基础,首先从独立同分布引入泛化误差与经验误差,接着介绍了PAC可学习的基本概念,即以较大的概率学习出与目标概念近似的假设(泛化误差满足预设上限),对于有限假设空间:(1)可分情形时,假设空间都是PAC可学习的,即当样本满足一定的数量之后,总是可以在与训练集一致的假设中找出目标概念的近似;(2)不可分情形时,假设空间都是不可知PAC可学习的,即以较大概率学习出与当前假设空间中泛化误差最小的假设的有效近似(Hoeffding不等式)。对于无限假设空间,通过增长函数与VC维来描述其复杂度,若学习算法满足经验风险最小化原则,则任何VC维有限的假设空间都是(不可知)PAC可学习的,同时也给出了泛化误差界与样本复杂度。稳定性则考察的是输入发生变化时输出的波动,稳定性通过损失函数与假设空间的可学习理论联系在了一起。本篇将讨论一种介于监督与非监督学习之间的学习算法--半监督学习。
#**14、半监督学习**
前面我们一直围绕的都是监督学习与无监督学习,监督学习指的是训练样本包含标记信息的学习任务,例如:常见的分类与回归算法;无监督学习则是训练样本不包含标记信息的学习任务,例如:聚类算法。在实际生活中,常常会出现一部分样本有标记和较多样本无标记的情形,例如:做网页推荐时需要让用户标记出感兴趣的网页,但是少有用户愿意花时间来提供标记。若直接丢弃掉无标记样本集,使用传统的监督学习方法,常常会由于训练样本的不充足,使得其刻画总体分布的能力减弱,从而影响了学习器泛化性能。那如何利用未标记的样本数据呢?
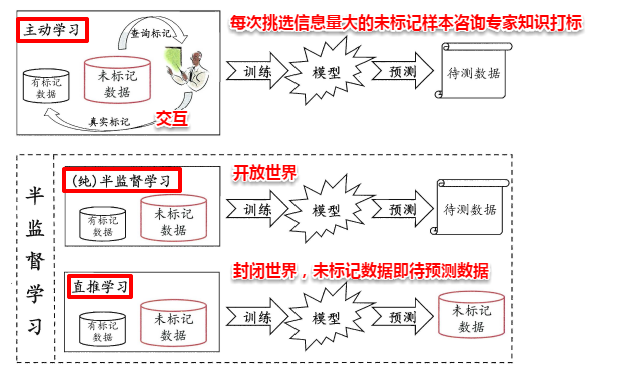
一种简单的做法是通过专家知识对这些未标记的样本进行打标,但随之而来的就是巨大的人力耗费。若我们先使用有标记的样本数据集训练出一个学习器,再基于该学习器对未标记的样本进行预测,从中**挑选出不确定性高或分类置信度低的样本来咨询专家并进行打标**,最后使用扩充后的训练集重新训练学习器,这样便能大幅度降低标记成本,这便是**主动学习**(active learning),其目标是**使用尽量少的/有价值的咨询来获得更好的性能**。
显然,**主动学习需要与外界进行交互/查询/打标,其本质上仍然属于一种监督学习**。事实上,无标记样本虽未包含标记信息,但它们与有标记样本一样都是从总体中独立同分布采样得到,因此**它们所包含的数据分布信息对学习器的训练大有裨益**。如何让学习过程不依赖外界的咨询交互,自动利用未标记样本所包含的分布信息的方法便是**半监督学习**(semi-supervised learning),**即训练集同时包含有标记样本数据和未标记样本数据**。
此外,半监督学习还可以进一步划分为**纯半监督学习**和**直推学习**,两者的区别在于:前者假定训练数据集中的未标记数据并非待预测数据,而后者假定学习过程中的未标记数据就是待预测数据。主动学习、纯半监督学习以及直推学习三者的概念如下图所示:
##**14.1 生成式方法**
**生成式方法**(generative methods)是基于生成式模型的方法,即先对联合分布P(x,c)建模,从而进一步求解 P(c | x),**此类方法假定样本数据服从一个潜在的分布,因此需要充分可靠的先验知识**。例如:前面已经接触到的贝叶斯分类器与高斯混合聚类,都属于生成式模型。现假定总体是一个高斯混合分布,即由多个高斯分布组合形成,从而一个子高斯分布就代表一个类簇(类别)。高斯混合分布的概率密度函数如下所示:

不失一般性,假设类簇与真实的类别按照顺序一一对应,即第i个类簇对应第i个高斯混合成分。与高斯混合聚类类似地,这里的主要任务也是估计出各个高斯混合成分的参数以及混合系数,不同的是:对于有标记样本,不再是可能属于每一个类簇,而是只能属于真实类标对应的特定类簇。

直观上来看,**基于半监督的高斯混合模型有机地整合了贝叶斯分类器与高斯混合聚类的核心思想**,有效地利用了未标记样本数据隐含的分布信息,从而使得参数的估计更加准确。同样地,这里也要召唤出之前的EM大法进行求解,首先对各个高斯混合成分的参数及混合系数进行随机初始化,计算出各个PM(即γji,第i个样本属于j类,有标记样本则直接属于特定类),再最大化似然函数(即LL(D)分别对α、u和∑求偏导 ),对参数进行迭代更新。
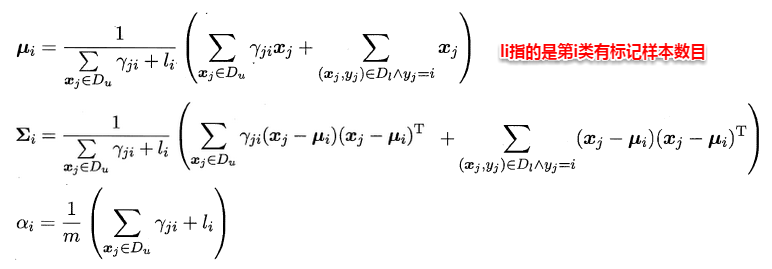
当参数迭代更新收敛后,对于待预测样本x,便可以像贝叶斯分类器那样计算出样本属于每个类簇的后验概率,接着找出概率最大的即可:
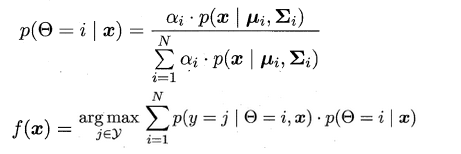
可以看出:基于生成式模型的方法十分依赖于对潜在数据分布的假设,即假设的分布要能和真实分布相吻合,否则利用未标记的样本数据反倒会在错误的道路上渐行渐远,从而降低学习器的泛化性能。因此,**此类方法要求极强的领域知识和掐指观天的本领**。
##**14.2 半监督SVM**
监督学习中的SVM试图找到一个划分超平面,使得两侧支持向量之间的间隔最大,即“**最大划分间隔**”思想。对于半监督学习,S3VM则考虑超平面需穿过数据低密度的区域。TSVM是半监督支持向量机中的最著名代表,其核心思想是:尝试为未标记样本找到合适的标记指派,使得超平面划分后的间隔最大化。TSVM采用局部搜索的策略来进行迭代求解,即首先使用有标记样本集训练出一个初始SVM,接着使用该学习器对未标记样本进行打标,这样所有样本都有了标记,并基于这些有标记的样本重新训练SVM,之后再寻找易出错样本不断调整。整个算法流程如下所示:
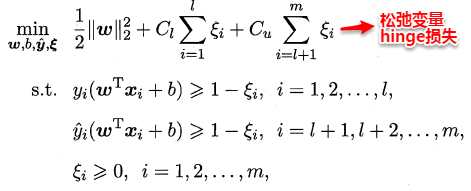

##**14.3 基于分歧的方法**
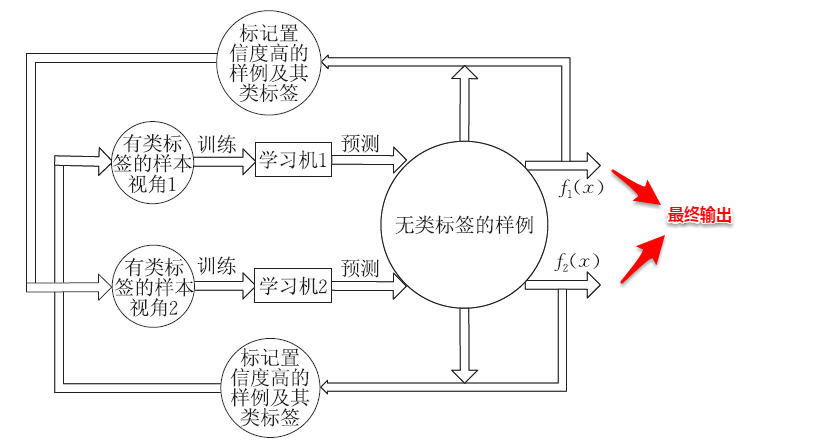
基于分歧的方法通过多个学习器之间的**分歧(disagreement)/多样性(diversity)**来利用未标记样本数据,协同训练就是其中的一种经典方法。**协同训练最初是针对于多视图(multi-view)数据而设计的,多视图数据指的是样本对象具有多个属性集,每个属性集则对应一个试图**。例如:电影数据中就包含画面类属性和声音类属性,这样画面类属性的集合就对应着一个视图。首先引入两个关于视图的重要性质:
> **相容性**:即使用单个视图数据训练出的学习器的输出空间是一致的。例如都是{好,坏}、{+1,-1}等。
> **互补性**:即不同视图所提供的信息是互补/相辅相成的,实质上这里体现的就是集成学习的思想。
协同训练正是很好地利用了多视图数据的“**相容互补性**”,其基本的思想是:首先基于有标记样本数据在每个视图上都训练一个初始分类器,然后让每个分类器去挑选分类置信度最高的样本并赋予标记,并将带有伪标记的样本数据传给另一个分类器去学习,从而**你依我侬/共同进步**。

##**14.4 半监督聚类**
前面提到的几种方法都是借助无标记样本数据来辅助监督学习的训练过程,从而使得学习更加充分/泛化性能得到提升;半监督聚类则是借助已有的监督信息来辅助聚类的过程。一般而言,监督信息大致有两种类型:
> **必连与勿连约束**:必连指的是两个样本必须在同一个类簇,勿连则是必不在同一个类簇。
> **标记信息**:少量的样本带有真实的标记。
下面主要介绍两种基于半监督的K-Means聚类算法:第一种是数据集包含一些必连与勿连关系,另外一种则是包含少量带有标记的样本。两种算法的基本思想都十分的简单:对于带有约束关系的k-均值算法,在迭代过程中对每个样本划分类簇时,需要**检测当前划分是否满足约束关系**,若不满足则会将该样本划分到距离次小对应的类簇中,再继续检测是否满足约束关系,直到完成所有样本的划分。算法流程如下图所示:

对于带有少量标记样本的k-均值算法,则可以**利用这些有标记样本进行类中心的指定,同时在对样本进行划分时,不需要改变这些有标记样本的簇隶属关系**,直接将其划分到对应类簇即可。算法流程如下所示:

在此,半监督学习就介绍完毕。十分有趣的是:半监督学习将前面许多知识模块联系在了一起,足以体现了作者编排的用心。结合本篇的新知识再来回想之前自己做过的一些研究,发现还是蹚了一些浑水,也许越是觉得过去的自己傻,越就是好的兆头吧~
================================================
FILE: 周志华《Machine Learning》学习笔记(16)--概率图模型.md
================================================
上篇主要介绍了半监督学习,首先从如何利用未标记样本所蕴含的分布信息出发,引入了半监督学习的基本概念,即训练数据同时包含有标记样本和未标记样本的学习方法;接着分别介绍了几种常见的半监督学习方法:生成式方法基于对数据分布的假设,利用未标记样本隐含的分布信息,使得对模型参数的估计更加准确;TSVM给未标记样本赋予伪标记,并通过不断调整易出错样本的标记得到最终输出;基于分歧的方法结合了集成学习的思想,通过多个学习器在不同视图上的协作,有效利用了未标记样本数据 ;最后半监督聚类则是借助已有的监督信息来辅助聚类的过程,带约束k-均值算法需检测当前样本划分是否满足约束关系,带标记k-均值算法则利用有标记样本指定初始类中心。本篇将讨论一种基于图的学习算法--概率图模型。
#**15、概率图模型**
现在再来谈谈机器学习的核心价值观,可以更通俗地理解为:**根据一些已观察到的证据来推断未知**,更具哲学性地可以阐述为:未来的发展总是遵循着历史的规律。其中**基于概率的模型将学习任务归结为计算变量的概率分布**,正如之前已经提到的:生成式模型先对联合分布进行建模,从而再来求解后验概率,例如:贝叶斯分类器先对联合分布进行最大似然估计,从而便可以计算类条件概率;判别式模型则是直接对条件分布进行建模。
**概率图模型**(probabilistic graphical model)是一类用**图结构**来表达各属性之间相关关系的概率模型,一般而言:**图中的一个结点表示一个或一组随机变量,结点之间的边则表示变量间的相关关系**,从而形成了一张“**变量关系图**”。若使用有向的边来表达变量之间的依赖关系,这样的有向关系图称为**贝叶斯网**(Bayesian nerwork)或有向图模型;若使用无向边,则称为**马尔可夫网**(Markov network)或无向图模型。
##**15.1 隐马尔可夫模型(HMM)**
隐马尔可夫模型(Hidden Markov Model,简称HMM)是结构最简单的一种贝叶斯网,在语音识别与自然语言处理领域上有着广泛的应用。HMM中的变量分为两组:**状态变量**与**观测变量**,其中状态变量一般是未知的,因此又称为“**隐变量**”,观测变量则是已知的输出值。在隐马尔可夫模型中,变量之间的依赖关系遵循如下两个规则:
> **1. 观测变量的取值仅依赖于状态变量**;
> **2. 下一个状态的取值仅依赖于当前状态**,通俗来讲:**现在决定未来,未来与过去无关**,这就是著名的**马尔可夫性**。
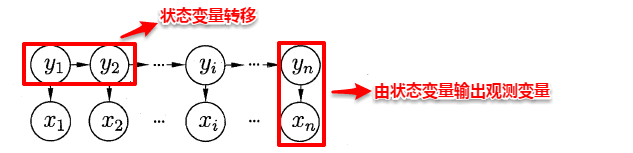
基于上述变量之间的依赖关系,我们很容易写出隐马尔可夫模型中所有变量的联合概率分布:
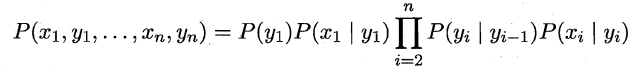
易知:**欲确定一个HMM模型需要以下三组参数**:

当确定了一个HMM模型的三个参数后,便按照下面的规则来生成观测值序列:

在实际应用中,HMM模型的发力点主要体现在下述三个问题上:

###**15.1.1 HMM评估问题**
HMM评估问题指的是:**给定了模型的三个参数与观测值序列,求该观测值序列出现的概率**。例如:对于赌场问题,便可以依据骰子掷出的结果序列来计算该结果序列出现的可能性,若小概率的事件发生了则可认为赌场的骰子有作弊的可能。解决该问题使用的是**前向算法**,即步步为营,自底向上的方式逐步增加序列的长度,直到获得目标概率值。在前向算法中,定义了一个**前向变量**,即给定观察值序列且t时刻的状态为Si的概率:
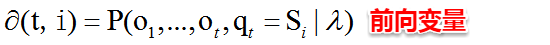
基于前向变量,很容易得到该问题的递推关系及终止条件:

因此可使用动态规划法,从最小的子问题开始,通过填表格的形式一步一步计算出目标结果。
###**15.1.2 HMM解码问题**
HMM解码问题指的是:**给定了模型的三个参数与观测值序列,求可能性最大的状态序列**。例如:在语音识别问题中,人说话形成的数字信号对应着观测值序列,对应的具体文字则是状态序列,从数字信号转化为文字正是对应着根据观测值序列推断最有可能的状态值序列。解决该问题使用的是**Viterbi算法**,与前向算法十分类似地,Viterbi算法定义了一个**Viterbi变量**,也是采用动态规划的方法,自底向上逐步求解。
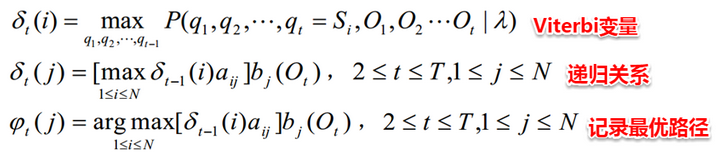
###**15.1.3 HMM学习问题**
HMM学习问题指的是:**给定观测值序列,如何调整模型的参数使得该序列出现的概率最大**。这便转化成了机器学习问题,即从给定的观测值序列中学习出一个HMM模型,**该问题正是EM算法的经典案例之一**。其思想也十分简单:对于给定的观测值序列,如果我们能够按照该序列潜在的规律来调整模型的三个参数,则可以使得该序列出现的可能性最大。假设状态值序列也已知,则很容易计算出与该序列最契合的模型参数:

但一般状态值序列都是不可观测的,且**即使给定观测值序列与模型参数,状态序列仍然遭遇组合爆炸**。因此上面这种简单的统计方法就行不通了,若将状态值序列看作为隐变量,这时便可以考虑使用EM算法来对该问题进行求解:
【1】首先对HMM模型的三个参数进行随机初始化;
【2】根据模型的参数与观测值序列,计算t时刻状态为i且t+1时刻状态为j的概率以及t时刻状态为i的概率。

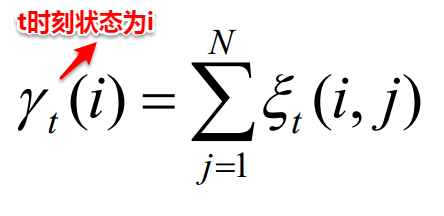
【3】接着便可以对模型的三个参数进行重新估计:

【4】重复步骤2-3,直至三个参数值收敛,便得到了最终的HMM模型。
##**15.2 马尔可夫随机场(MRF)**
马尔可夫随机场(Markov Random Field)是一种典型的马尔可夫网,即使用无向边来表达变量间的依赖关系。在马尔可夫随机场中,对于关系图中的一个子集,**若任意两结点间都有边连接,则称该子集为一个团;若再加一个结点便不能形成团,则称该子集为极大团**。MRF使用**势函数**来定义多个变量的概率分布函数,其中**每个(极大)团对应一个势函数**,一般团中的变量关系也体现在它所对应的极大团中,因此常常基于极大团来定义变量的联合概率分布函数。具体而言,若所有变量构成的极大团的集合为C,则MRF的联合概率函数可以定义为:

对于条件独立性,**马尔可夫随机场通过分离集来实现条件独立**,若A结点集必须经过C结点集才能到达B结点集,则称C为分离集。书上给出了一个简单情形下的条件独立证明过程,十分贴切易懂,此处不再展开。基于分离集的概念,得到了MRF的三个性质:
> **全局马尔可夫性**:给定两个变量子集的分离集,则这两个变量子集条件独立。
> **局部马尔可夫性**:给定某变量的邻接变量,则该变量与其它变量条件独立。
> **成对马尔可夫性**:给定所有其他变量,两个非邻接变量条件独立。
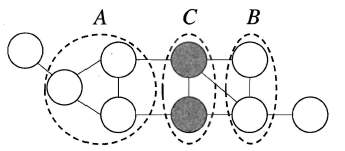
对于MRF中的势函数,势函数主要用于描述团中变量之间的相关关系,且要求为非负函数,直观来看:势函数需要在偏好的变量取值上函数值较大,例如:若x1与x2成正相关,则需要将这种关系反映在势函数的函数值中。一般我们常使用指数函数来定义势函数:

##**15.3 条件随机场(CRF)**
前面所讲到的**隐马尔可夫模型和马尔可夫随机场都属于生成式模型,即对联合概率进行建模,条件随机场则是对条件分布进行建模**。CRF试图在给定观测值序列后,对状态序列的概率分布进行建模,即P(y | x)。直观上看:CRF与HMM的解码问题十分类似,都是在给定观测值序列后,研究状态序列可能的取值。CRF可以有多种结构,只需保证状态序列满足马尔可夫性即可,一般我们常使用的是**链式条件随机场**:
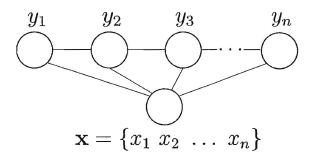
与马尔可夫随机场定义联合概率类似地,CRF也通过团以及势函数的概念来定义条件概率P(y | x)。在给定观测值序列的条件下,链式条件随机场主要包含两种团结构:单个状态团及相邻状态团,通过引入两类特征函数便可以定义出目标条件概率:
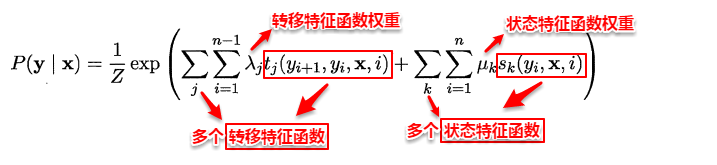
以词性标注为例,如何判断给出的一个标注序列靠谱不靠谱呢?**转移特征函数主要判定两个相邻的标注是否合理**,例如:动词+动词显然语法不通;**状态特征函数则判定观测值与对应的标注是否合理**,例如: ly结尾的词-->副词较合理。因此我们可以定义一个特征函数集合,用这个特征函数集合来为一个标注序列打分,并据此选出最靠谱的标注序列。也就是说,每一个特征函数(对应一种规则)都可以用来为一个标注序列评分,把集合中所有特征函数对同一个标注序列的评分综合起来,就是这个标注序列最终的评分值。可以看出:**特征函数是一些经验的特性**。
##**15.4 学习与推断**
对于生成式模型,通常我们都是先对变量的联合概率分布进行建模,接着再求出目标变量的**边际分布**(marginal distribution),那如何从联合概率得到边际分布呢?这便是学习与推断。下面主要介绍两种精确推断的方法:**变量消去**与**信念传播**。
###**15.4.1 变量消去**
变量消去利用条件独立性来消减计算目标概率值所需的计算量,它通过运用**乘法与加法的分配率**,将对变量的积的求和问题转化为对部分变量交替进行求积与求和的问题,从而将每次的**运算控制在局部**,达到简化运算的目的。
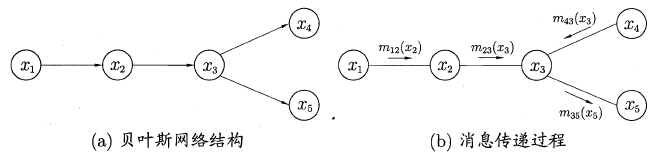
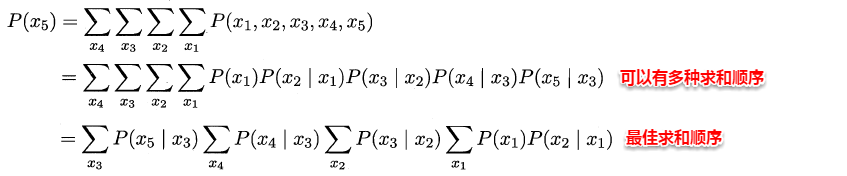
###**15.4.2 信念传播**
若将变量求和操作看作是一种消息的传递过程,信念传播可以理解成:**一个节点在接收到所有其它节点的消息后才向另一个节点发送消息**,同时当前节点的边际概率正比于他所接收的消息的乘积:
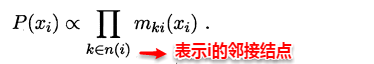
因此只需要经过下面两个步骤,便可以完成所有的消息传递过程。利用动态规划法的思想记录传递过程中的所有消息,当计算某个结点的边际概率分布时,只需直接取出传到该结点的消息即可,从而避免了计算多个边际分布时的冗余计算问题。
> 1.指定一个根节点,从所有的叶节点开始向根节点传递消息,直到根节点收到所有邻接结点的消息**(从叶到根)**;
> 2.从根节点开始向叶节点传递消息,直到所有叶节点均收到消息**(从根到叶)**。
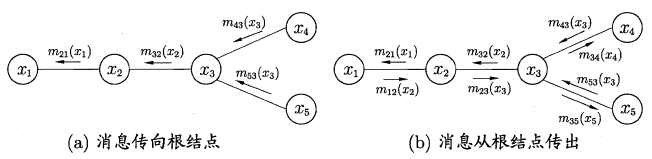
##**15.5 LDA话题模型**
话题模型主要用于处理文本类数据,其中**隐狄利克雷分配模型**(Latent Dirichlet Allocation,简称LDA)是话题模型的杰出代表。在话题模型中,有以下几个基本概念:词(word)、文档(document)、话题(topic)。
> **词**:最基本的离散单元;
> **文档**:由一组词组成,词在文档中不计顺序;
> **话题**:由一组特定的词组成,这组词具有较强的相关关系。
在现实任务中,一般我们可以得出一个文档的词频分布,但不知道该文档对应着哪些话题,LDA话题模型正是为了解决这个问题。具体来说:**LDA认为每篇文档包含多个话题,且其中每一个词都对应着一个话题**。因此可以假设文档是通过如下方式生成:

这样一个文档中的所有词都可以认为是通过话题模型来生成的,当已知一个文档的词频分布后(即一个N维向量,N为词库大小),则可以认为:**每一个词频元素都对应着一个话题,而话题对应的词频分布则影响着该词频元素的大小**。因此很容易写出LDA模型对应的联合概率函数:
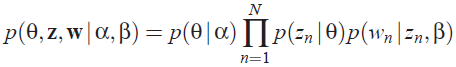
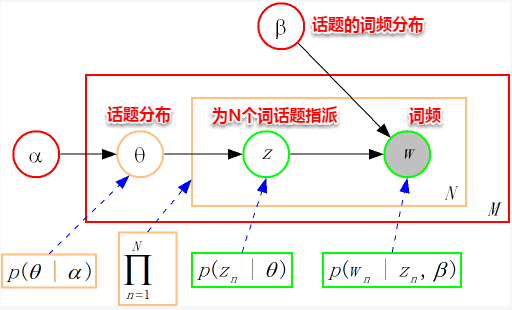
从上图可以看出,LDA的三个表示层被三种颜色表示出来:
> **corpus-level(红色):** α和β表示语料级别的参数,也就是每个文档都一样,因此生成过程只采样一次。
> **document-level(橙色):** θ是文档级别的变量,每个文档对应一个θ。
> **word-level(绿色):** z和w都是单词级别变量,z由θ生成,w由z和β共同生成,一个单词w对应一个主题z。
通过上面对LDA生成模型的讨论,可以知道**LDA模型主要是想从给定的输入语料中学习训练出两个控制参数α和β**,当学习出了这两个控制参数就确定了模型,便可以用来生成文档。其中α和β分别对应以下各个信息:
> **α**:分布p(θ)需要一个向量参数,即Dirichlet分布的参数,用于生成一个主题θ向量;
> **β**:各个主题对应的单词概率分布矩阵p(w|z)。
把w当做观察变量,θ和z当做隐藏变量,就可以通过EM算法学习出α和β,求解过程中遇到后验概率p(θ,z|w)无法直接求解,需要找一个似然函数下界来近似求解,原作者使用基于分解(factorization)假设的变分法(varialtional inference)进行计算,用到了EM算法。每次E-step输入α和β,计算似然函数,M-step最大化这个似然函数,算出α和β,不断迭代直到收敛。
在此,概率图模型就介绍完毕。上周受到协同训练的启发,让实验的小伙伴做了一个HMM的slides,结果扩充了好多知识,所以完成这篇笔记还是花费了不少功夫,还刚好赶上实验室没空调回到解放前的日子,可谓汗流之作...
================================================
FILE: 周志华《Machine Learning》学习笔记(17)--强化学习.md
================================================
上篇主要介绍了概率图模型,首先从生成式模型与判别式模型的定义出发,引出了概率图模型的基本概念,即利用图结构来表达变量之间的依赖关系;接着分别介绍了隐马尔可夫模型、马尔可夫随机场、条件随机场、精确推断方法以及LDA话题模型:HMM主要围绕着评估/解码/学习这三个实际问题展开论述;MRF基于团和势函数的概念来定义联合概率分布;CRF引入两种特征函数对状态序列进行评价打分;变量消去与信念传播在给定联合概率分布后计算特定变量的边际分布;LDA话题模型则试图去推断给定文档所蕴含的话题分布。本篇将介绍最后一种学习算法--强化学习。
#**16、强化学习**
**强化学习**(Reinforcement Learning,简称**RL**)是机器学习的一个重要分支,前段时间人机大战的主角AlphaGo正是以强化学习为核心技术。在强化学习中,包含两种基本的元素:**状态**与**动作**,**在某个状态下执行某种动作,这便是一种策略**,学习器要做的就是通过不断地探索学习,从而获得一个好的策略。例如:在围棋中,一种落棋的局面就是一种状态,若能知道每种局面下的最优落子动作,那就攻无不克/百战不殆了~
若将状态看作为属性,动作看作为标记,易知:**监督学习和强化学习都是在试图寻找一个映射,从已知属性/状态推断出标记/动作**,这样强化学习中的策略相当于监督学习中的分类/回归器。但在实际问题中,**强化学习并没有监督学习那样的标记信息**,通常都是在**尝试动作后才能获得结果**,因此强化学习是通过反馈的结果信息不断调整之前的策略,从而算法能够学习到:在什么样的状态下选择什么样的动作可以获得最好的结果。
##**16.1 基本要素**
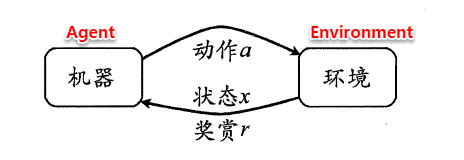
强化学习任务通常使用**马尔可夫决策过程**(Markov Decision Process,简称**MDP**)来描述,具体而言:机器处在一个环境中,每个状态为机器对当前环境的感知;机器只能通过动作来影响环境,当机器执行一个动作后,会使得环境按某种概率转移到另一个状态;同时,环境会根据潜在的奖赏函数反馈给机器一个奖赏。综合而言,强化学习主要包含四个要素:状态、动作、转移概率以及奖赏函数。
> **状态(X)**:机器对环境的感知,所有可能的状态称为状态空间;
> **动作(A)**:机器所采取的动作,所有能采取的动作构成动作空间;
> **转移概率(P)**:当执行某个动作后,当前状态会以某种概率转移到另一个状态;
> **奖赏函数(R)**:在状态转移的同时,环境给反馈给机器一个奖赏。
因此,**强化学习的主要任务就是通过在环境中不断地尝试,根据尝试获得的反馈信息调整策略,最终生成一个较好的策略π,机器根据这个策略便能知道在什么状态下应该执行什么动作**。常见的策略表示方法有以下两种:
> **确定性策略**:π(x)=a,即在状态x下执行a动作;
> **随机性策略**:P=π(x,a),即在状态x下执行a动作的概率。
**一个策略的优劣取决于长期执行这一策略后的累积奖赏**,换句话说:可以使用累积奖赏来评估策略的好坏,最优策略则表示在初始状态下一直执行该策略后,最后的累积奖赏值最高。长期累积奖赏通常使用下述两种计算方法:

##**16.2 K摇摆赌博机**
首先我们考虑强化学习最简单的情形:仅考虑一步操作,即在状态x下只需执行一次动作a便能观察到奖赏结果。易知:欲最大化单步奖赏,我们需要知道每个动作带来的期望奖赏值,这样便能选择奖赏值最大的动作来执行。若每个动作的奖赏值为确定值,则只需要将每个动作尝试一遍即可,但大多数情形下,一个动作的奖赏值来源于一个概率分布,因此需要进行多次的尝试。
单步强化学习实质上是**K-摇臂赌博机**(K-armed bandit)的原型,一般我们**尝试动作的次数是有限的**,那如何利用有限的次数进行有效地探索呢?这里有两种基本的想法:
> **仅探索法**:将尝试的机会平均分给每一个动作,即轮流执行,最终将每个动作的平均奖赏作为期望奖赏的近似值。
> **仅利用法**:将尝试的机会分给当前平均奖赏值最大的动作,隐含着让一部分人先富起来的思想。
可以看出:上述**两种方法是相互矛盾的**,仅探索法能较好地估算每个动作的期望奖赏,但是没能根据当前的反馈结果调整尝试策略;仅利用法在每次尝试之后都更新尝试策略,符合强化学习的思(tao)维(lu),但容易找不到最优动作。因此需要在这两者之间进行折中。
###**16.2.1 ε-贪心**
**ε-贪心法基于一个概率来对探索和利用进行折中**,具体而言:在每次尝试时,以ε的概率进行探索,即以均匀概率随机选择一个动作;以1-ε的概率进行利用,即选择当前最优的动作。ε-贪心法只需记录每个动作的当前平均奖赏值与被选中的次数,便可以增量式更新。

###**16.2.2 Softmax**
**Softmax算法则基于当前每个动作的平均奖赏值来对探索和利用进行折中,Softmax函数将一组值转化为一组概率**,值越大对应的概率也越高,因此当前平均奖赏值越高的动作被选中的几率也越大。Softmax函数如下所示:


##**16.3 有模型学习**
若学习任务中的四个要素都已知,即状态空间、动作空间、转移概率以及奖赏函数都已经给出,这样的情形称为“**有模型学习**”。假设状态空间和动作空间均为有限,即均为离散值,这样我们不用通过尝试便可以对某个策略进行评估。
###**16.3.1 策略评估**
前面提到:**在模型已知的前提下,我们可以对任意策略的进行评估**(后续会给出演算过程)。一般常使用以下两种值函数来评估某个策略的优劣:
> **状态值函数(V)**:V(x),即从状态x出发,使用π策略所带来的累积奖赏;
> **状态-动作值函数(Q)**:Q(x,a),即从状态x出发,执行动作a后再使用π策略所带来的累积奖赏。
根据累积奖赏的定义,我们可以引入T步累积奖赏与r折扣累积奖赏:
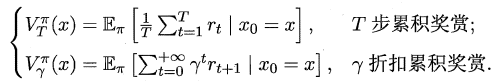
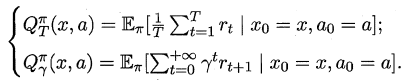
由于MDP具有马尔可夫性,即现在决定未来,将来和过去无关,我们很容易找到值函数的递归关系:

类似地,对于r折扣累积奖赏可以得到:
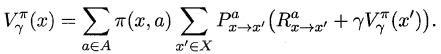
易知:**当模型已知时,策略的评估问题转化为一种动态规划问题**,即以填表格的形式自底向上,先求解每个状态的单步累积奖赏,再求解每个状态的两步累积奖赏,一直迭代逐步求解出每个状态的T步累积奖赏。算法流程如下所示:

对于状态-动作值函数,只需通过简单的转化便可得到:
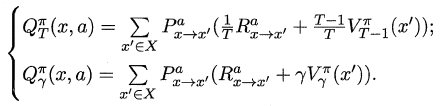
###**16.3.2 策略改进**
理想的策略应能使得每个状态的累积奖赏之和最大,简单来理解就是:不管处于什么状态,只要通过该策略执行动作,总能得到较好的结果。因此对于给定的某个策略,我们需要对其进行改进,从而得到**最优的值函数**。
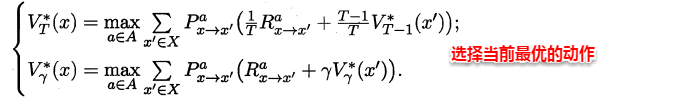
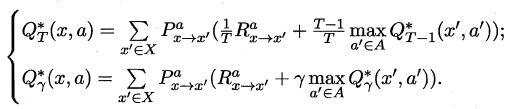
最优Bellman等式改进策略的方式为:**将策略选择的动作改为当前最优的动作**,而不是像之前那样对每种可能的动作进行求和。易知:选择当前最优动作相当于将所有的概率都赋给累积奖赏值最大的动作,因此每次改进都会使得值函数单调递增。
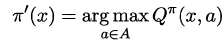
将策略评估与策略改进结合起来,我们便得到了生成最优策略的方法:先给定一个随机策略,现对该策略进行评估,然后再改进,接着再评估/改进一直到策略收敛、不再发生改变。这便是策略迭代算法,算法流程如下所示:

可以看出:策略迭代法在每次改进策略后都要对策略进行重新评估,因此比较耗时。若从最优化值函数的角度出发,即先迭代得到最优的值函数,再来计算如何改变策略,这便是值迭代算法,算法流程如下所示:

##**16.4 蒙特卡罗强化学习**
在现实的强化学习任务中,**环境的转移函数与奖赏函数往往很难得知**,因此我们需要考虑在不依赖于环境参数的条件下建立强化学习模型,这便是**免模型学习**。蒙特卡罗强化学习便是其中的一种经典方法。
由于模型参数未知,状态值函数不能像之前那样进行全概率展开,从而运用动态规划法求解。一种直接的方法便是通过采样来对策略进行评估/估算其值函数,**蒙特卡罗强化学习正是基于采样来估计状态-动作值函数**:对采样轨迹中的每一对状态-动作,记录其后的奖赏值之和,作为该状态-动作的一次累积奖赏,通过多次采样后,使用累积奖赏的平均作为状态-动作值的估计,并**引入ε-贪心策略保证采样的多样性**。

在上面的算法流程中,被评估和被改进的都是同一个策略,因此称为**同策略蒙特卡罗强化学习算法**。引入ε-贪心仅是为了便于采样评估,而在使用策略时并不需要ε-贪心,那能否仅在评估时使用ε-贪心策略,而在改进时使用原始策略呢?这便是**异策略蒙特卡罗强化学习算法**。

##**16.5 AlphaGo原理浅析**
本篇一开始便提到强化学习是AlphaGo的核心技术之一,刚好借着这个东风将AlphaGo的工作原理了解一番。正如人类下棋那般“**手下一步棋,心想三步棋**”,Alphago也正是这个思想,**当处于一个状态时,机器会暗地里进行多次的尝试/采样,并基于反馈回来的结果信息改进估值函数,从而最终通过增强版的估值函数来选择最优的落子动作。**
其中便涉及到了三个主要的问题:**(1)如何确定估值函数(2)如何进行采样(3)如何基于反馈信息改进估值函数**,这正对应着AlphaGo的三大核心模块:**深度学习**、**蒙特卡罗搜索树**、**强化学习**。
> **1.深度学习(拟合估值函数)**
由于围棋的状态空间巨大,像蒙特卡罗强化学习那样通过采样来确定值函数就行不通了。在围棋中,**状态值函数可以看作为一种局面函数,状态-动作值函数可以看作一种策略函数**,若我们能获得这两个估值函数,便可以根据这两个函数来完成:(1)衡量当前局面的价值;(2)选择当前最优的动作。那如何精确地估计这两个估值函数呢?**这就用到了深度学习,通过大量的对弈数据自动学习出特征,从而拟合出估值函数。**
> **2.蒙特卡罗搜索树(采样)**
蒙特卡罗树是一种经典的搜索框架,它通过反复地采样模拟对局来探索状态空间。具体表现在:从当前状态开始,利用策略函数尽可能选择当前最优的动作,同时也引入随机性来减小估值错误带来的负面影响,从而模拟棋局运行,使得棋盘达到终局或一定步数后停止。
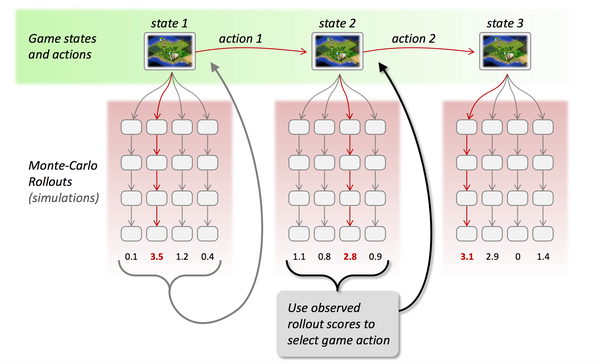
> **3.强化学习(调整估值函数)**
在使用蒙特卡罗搜索树进行多次采样后,每次采样都会反馈后续的局面信息(利用局面函数进行评价),根据反馈回来的结果信息自动调整两个估值函数的参数,这便是强化学习的核心思想,最后基于改进后的策略函数选择出当前最优的落子动作。
在此,强化学习就介绍完毕。同时也意味着大口小口地啃完了这个西瓜,十分记得去年双11之后立下这个Flag,现在回想起来,大半年的时间里在嚼瓜上还是花费了不少功夫。有人说:当你阐述的能让别人看懂才算是真的理解,有人说:在写的过程中能发现那些只看书发现不了的东西,自己最初的想法十分简单:当健忘症发作的时候,如果能看到之前按照自己思路写下的文字,回忆便会汹涌澎湃一些~
最后,感谢自己这大半年以来的坚持~Get busy living, or get busy dying!
================================================
FILE: 周志华《Machine Learning》学习笔记(2)--性能度量.md
================================================
本篇主要是对第二章剩余知识的理解,包括:性能度量、比较检验和偏差与方差。在上一篇中,我们解决了评估学习器泛化性能的方法,即用测试集的“测试误差”作为“泛化误差”的近似,当我们划分好训练/测试集后,那如何计算“测试误差”呢?这就是性能度量,例如:均方差,错误率等,即“测试误差”的一个评价标准。有了评估方法和性能度量,就可以计算出学习器的“测试误差”,但由于“测试误差”受到很多因素的影响,例如:算法随机性或测试集本身的选择,那如何对两个或多个学习器的性能度量结果做比较呢?这就是比较检验。最后偏差与方差是解释学习器泛化性能的一种重要工具。写到后面发现冗长之后读起来十分没有快感,故本篇主要知识点为性能度量。
**2.5 性能度量**
性能度量(performance measure)是衡量模型泛化能力的评价标准,在对比不同模型的能力时,使用不同的性能度量往往会导致不同的评判结果。本节除2.5.1外,其它主要介绍分类模型的性能度量。
**2.5.1 最常见的性能度量**
在回归任务中,即预测连续值的问题,最常用的性能度量是“均方误差”(mean squared error),很多的经典算法都是采用了MSE作为评价函数,想必大家都十分熟悉。

在分类任务中,即预测离散值的问题,最常用的是错误率和精度,错误率是分类错误的样本数占样本总数的比例,精度则是分类正确的样本数占样本总数的比例,易知:错误率+精度=1。
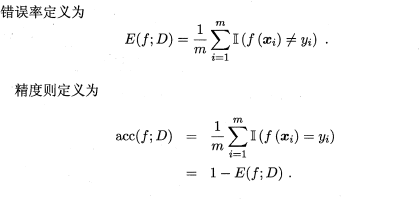

**2.5.2 查准率/查全率/F1**
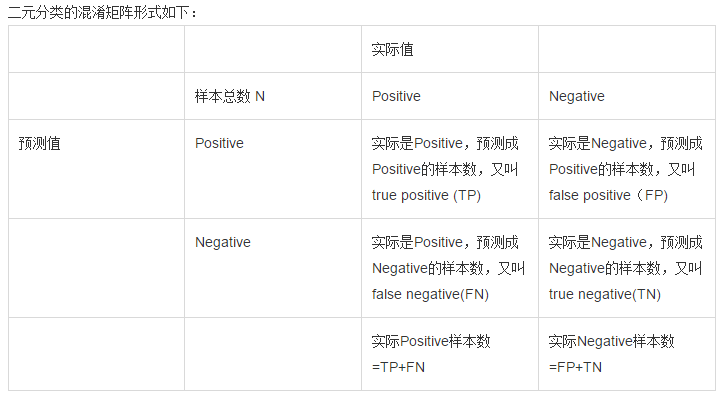
错误率和精度虽然常用,但不能满足所有的需求,例如:在推荐系统中,我们只关心推送给用户的内容用户是否感兴趣(即查准率),或者说所有用户感兴趣的内容我们推送出来了多少(即查全率)。因此,使用查准/查全率更适合描述这类问题。对于二分类问题,分类结果混淆矩阵与查准/查全率定义如下:

初次接触时,FN与FP很难正确的理解,按照惯性思维容易把FN理解成:False->Negtive,即将错的预测为错的,这样FN和TN就反了,后来找到一张图,描述得很详细,为方便理解,把这张图也贴在了下边:
正如天下没有免费的午餐,查准率和查全率是一对矛盾的度量。例如我们想让推送的内容尽可能用户全都感兴趣,那只能推送我们把握高的内容,这样就漏掉了一些用户感兴趣的内容,查全率就低了;如果想让用户感兴趣的内容都被推送,那只有将所有内容都推送上,宁可错杀一千,不可放过一个,这样查准率就很低了。
“P-R曲线”正是描述查准/查全率变化的曲线,P-R曲线定义如下:根据学习器的预测结果(一般为一个实值或概率)对测试样本进行排序,将最可能是“正例”的样本排在前面,最不可能是“正例”的排在后面,按此顺序逐个把样本作为“正例”进行预测,每次计算出当前的P值和R值,如下图所示:
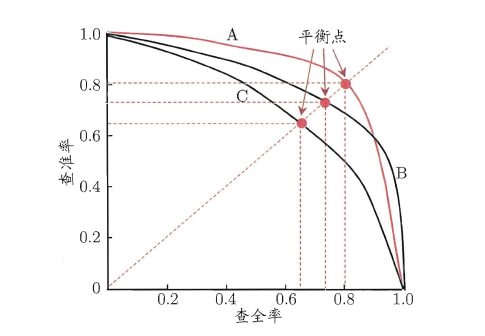
P-R曲线如何评估呢?若一个学习器A的P-R曲线被另一个学习器B的P-R曲线完全包住,则称:B的性能优于A。若A和B的曲线发生了交叉,则谁的曲线下的面积大,谁的性能更优。但一般来说,曲线下的面积是很难进行估算的,所以衍生出了“平衡点”(Break-Event Point,简称BEP),即当P=R时的取值,平衡点的取值越高,性能更优。
P和R指标有时会出现矛盾的情况,这样就需要综合考虑他们,最常见的方法就是F-Measure,又称F-Score。F-Measure是P和R的加权调和平均,即:
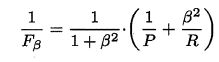
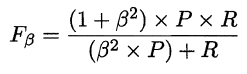
特别地,当β=1时,也就是常见的F1度量,是P和R的调和平均,当F1较高时,模型的性能越好。
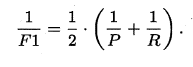

有时候我们会有多个二分类混淆矩阵,例如:多次训练或者在多个数据集上训练,那么估算全局性能的方法有两种,分为宏观和微观。简单理解,宏观就是先算出每个混淆矩阵的P值和R值,然后取得平均P值macro-P和平均R值macro-R,在算出Fβ或F1,而微观则是计算出混淆矩阵的平均TP、FP、TN、FN,接着进行计算P、R,进而求出Fβ或F1。
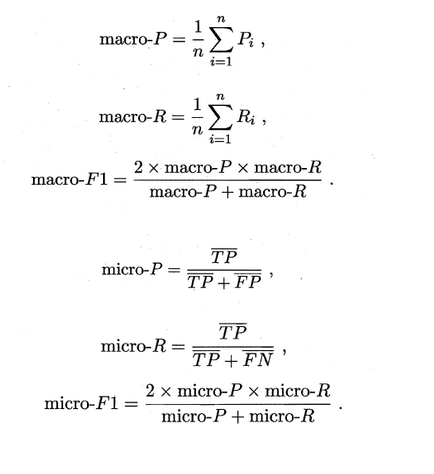
**2.5.3 ROC与AUC**
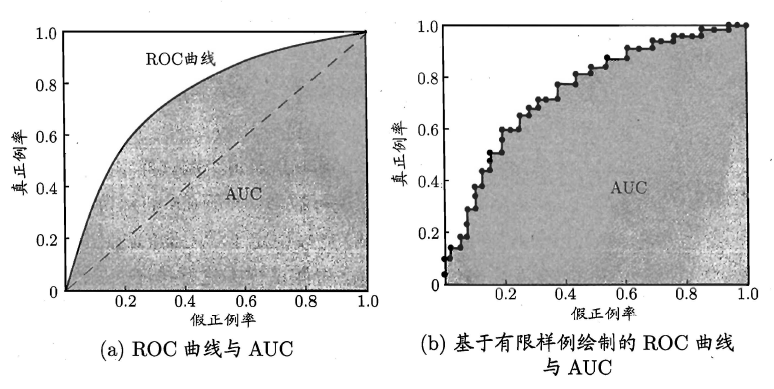
如上所述:学习器对测试样本的评估结果一般为一个实值或概率,设定一个阈值,大于阈值为正例,小于阈值为负例,因此这个实值的好坏直接决定了学习器的泛化性能,若将这些实值排序,则排序的好坏决定了学习器的性能高低。ROC曲线正是从这个角度出发来研究学习器的泛化性能,ROC曲线与P-R曲线十分类似,都是按照排序的顺序逐一按照正例预测,不同的是ROC曲线以“真正例率”(True Positive Rate,简称TPR)为横轴,纵轴为“假正例率”(False Positive Rate,简称FPR),ROC偏重研究基于测试样本评估值的排序好坏。

简单分析图像,可以得知:当FN=0时,TN也必须0,反之也成立,我们可以画一个队列,试着使用不同的截断点(即阈值)去分割队列,来分析曲线的形状,(0,0)表示将所有的样本预测为负例,(1,1)则表示将所有的样本预测为正例,(0,1)表示正例全部出现在负例之前的理想情况,(1,0)则表示负例全部出现在正例之前的最差情况。限于篇幅,这里不再论述。
现实中的任务通常都是有限个测试样本,因此只能绘制出近似ROC曲线。绘制方法:首先根据测试样本的评估值对测试样本排序,接着按照以下规则进行绘制。

同样地,进行模型的性能比较时,若一个学习器A的ROC曲线被另一个学习器B的ROC曲线完全包住,则称B的性能优于A。若A和B的曲线发生了交叉,则谁的曲线下的面积大,谁的性能更优。ROC曲线下的面积定义为AUC(Area Uder ROC Curve),不同于P-R的是,这里的AUC是可估算的,即AOC曲线下每一个小矩形的面积之和。易知:AUC越大,证明排序的质量越好,AUC为1时,证明所有正例排在了负例的前面,AUC为0时,所有的负例排在了正例的前面。
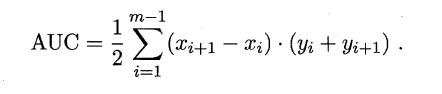
**2.5.4 代价敏感错误率与代价曲线**
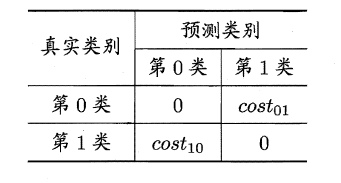
上面的方法中,将学习器的犯错同等对待,但在现实生活中,将正例预测成假例与将假例预测成正例的代价常常是不一样的,例如:将无疾病-->有疾病只是增多了检查,但有疾病-->无疾病却是增加了生命危险。以二分类为例,由此引入了“代价矩阵”(cost matrix)。
在非均等错误代价下,我们希望的是最小化“总体代价”,这样“代价敏感”的错误率(2.5.1节介绍)为:
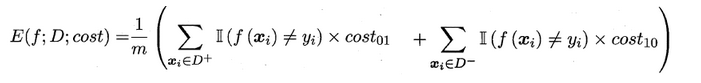
同样对于ROC曲线,在非均等错误代价下,演变成了“代价曲线”,代价曲线横轴是取值在[0,1]之间的正例概率代价,式中p表示正例的概率,纵轴是取值为[0,1]的归一化代价。
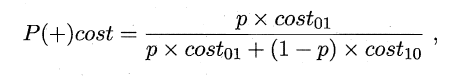
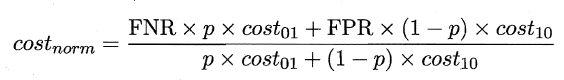
代价曲线的绘制很简单:设ROC曲线上一点的坐标为(TPR,FPR) ,则可相应计算出FNR,然后在代价平面上绘制一条从(0,FPR) 到(1,FNR) 的线段,线段下的面积即表示了该条件下的期望总体代价;如此将ROC 曲线土的每个点转化为代价平面上的一条线段,然后取所有线段的下界,围成的面积即为在所有条件下学习器的期望总体代价,如图所示:
在此模型的性能度量方法就介绍完了,以前一直以为均方误差和精准度就可以了,现在才发现天空如此广阔~
================================================
FILE: 周志华《Machine Learning》学习笔记(3)--假设检验&方差&偏差.md
================================================
在上两篇中,我们介绍了多种常见的评估方法和性能度量标准,这样我们就可以根据数据集以及模型任务的特征,选择出最合适的评估和性能度量方法来计算出学习器的“测试误差“。但由于“测试误差”受到很多因素的影响,例如:算法随机性(例如常见的K-Means)或测试集本身的选择,使得同一模型每次得到的结果不尽相同,同时测试误差是作为泛化误差的近似,并不能代表学习器真实的泛化性能,那如何对单个或多个学习器在不同或相同测试集上的性能度量结果做比较呢?这就是比较检验。最后偏差与方差是解释学习器泛化性能的一种重要工具。本篇延续上一篇的内容,主要讨论了比较检验、方差与偏差。
##**2.6 比较检验**
在比较学习器泛化性能的过程中,统计假设检验(hypothesis test)为学习器性能比较提供了重要依据,即若A在某测试集上的性能优于B,那A学习器比B好的把握有多大。 为方便论述,本篇中都是以“错误率”作为性能度量的标准。
###**2.6.1 假设检验**
“假设”指的是对样本总体的分布或已知分布中某个参数值的一种猜想,例如:假设总体服从泊松分布,或假设正态总体的期望u=u0。回到本篇中,我们可以通过测试获得测试错误率,但直观上测试错误率和泛化错误率相差不会太远,因此可以通过测试错误率来推测泛化错误率的分布,这就是一种假设检验。

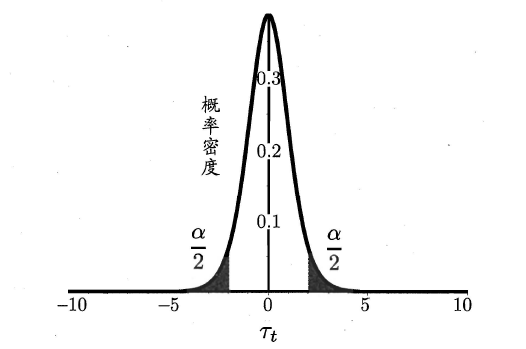
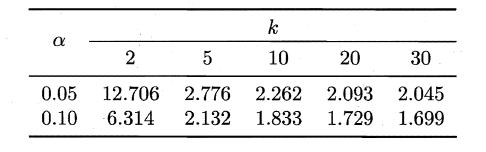
###**2.6.2 交叉验证t检验**

###**2.6.3 McNemar检验**
MaNemar主要用于二分类问题,与成对t检验一样也是用于比较两个学习器的性能大小。主要思想是:若两学习器的性能相同,则A预测正确B预测错误数应等于B预测错误A预测正确数,即e01=e10,且|e01-e10|服从N(1,e01+e10)分布。
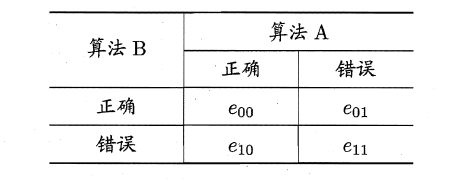
因此,如下所示的变量服从自由度为1的卡方分布,即服从标准正态分布N(0,1)的随机变量的平方和,下式只有一个变量,故自由度为1,检验的方法同上:做出假设-->求出满足显著度的临界点-->给出拒绝域-->验证假设。
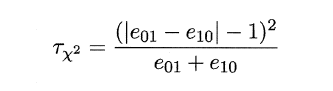
###**2.6.4 Friedman检验与Nemenyi后续检验**
上述的三种检验都只能在一组数据集上,F检验则可以在多组数据集进行多个学习器性能的比较,基本思想是在同一组数据集上,根据测试结果(例:测试错误率)对学习器的性能进行排序,赋予序值1,2,3...,相同则平分序值,如下图所示:

若学习器的性能相同,则它们的平均序值应该相同,且第i个算法的平均序值ri服从正态分布N((k+1)/2,(k+1)(k-1)/12),则有:

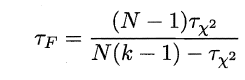
服从自由度为k-1和(k-1)(N-1)的F分布。下面是F检验常用的临界值:
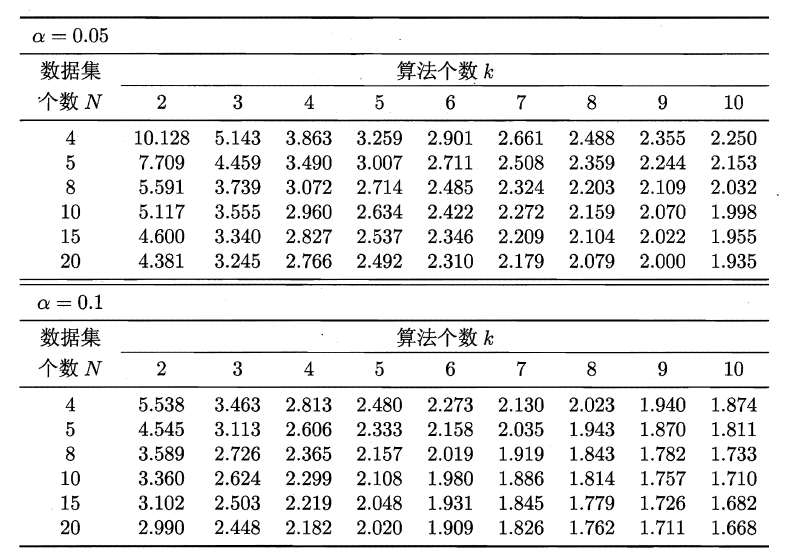
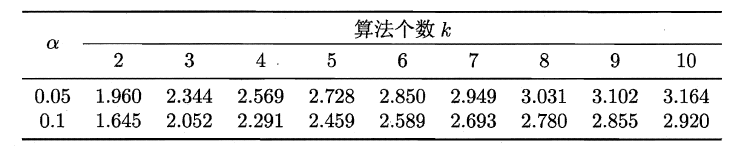
若“H0:所有算法的性能相同”这个假设被拒绝,则需要进行后续检验,来得到具体的算法之间的差异。常用的就是Nemenyi后续检验。Nemenyi检验计算出平均序值差别的临界值域,下表是常用的qa值,若两个算法的平均序值差超出了临界值域CD,则相应的置信度1-α拒绝“两个算法性能相同”的假设。
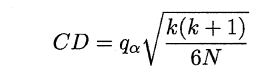
##**2.7 偏差与方差**
偏差-方差分解是解释学习器泛化性能的重要工具。在学习算法中,偏差指的是预测的期望值与真实值的偏差,方差则是每一次预测值与预测值得期望之间的差均方。实际上,偏差体现了学习器预测的准确度,而方差体现了学习器预测的稳定性。通过对泛化误差的进行分解,可以得到:
+ **期望泛化误差=方差+偏差**
+ **偏差刻画学习器的拟合能力**
+ **方差体现学习器的稳定性**
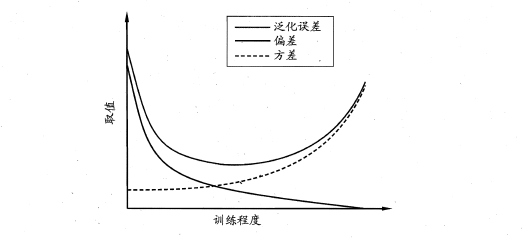
易知:方差和偏差具有矛盾性,这就是常说的偏差-方差窘境(bias-variance dilamma),随着训练程度的提升,期望预测值与真实值之间的差异越来越小,即偏差越来越小,但是另一方面,随着训练程度加大,学习算法对数据集的波动越来越敏感,方差值越来越大。换句话说:在欠拟合时,偏差主导泛化误差,而训练到一定程度后,偏差越来越小,方差主导了泛化误差。因此训练也不要贪杯,适度辄止。
================================================
FILE: 周志华《Machine Learning》学习笔记(4)--线性模型.md
================================================
笔记的前一部分主要是对机器学习预备知识的概括,包括机器学习的定义/术语、学习器性能的评估/度量以及比较,本篇之后将主要对具体的学习算法进行理解总结,本篇则主要是第3章的内容--线性模型。
#**3、线性模型**
谈及线性模型,其实我们很早就已经与它打过交道,还记得高中数学必修3课本中那个顽皮的“最小二乘法”吗?这就是线性模型的经典算法之一:根据给定的(x,y)点对,求出一条与这些点拟合效果最好的直线y=ax+b,之前我们利用下面的公式便可以计算出拟合直线的系数a,b(3.1中给出了具体的计算过程),从而对于一个新的x,可以预测它所对应的y值。前面我们提到:在机器学习的术语中,当预测值为连续值时,称为“回归问题”,离散值时为“分类问题”。本篇先从线性回归任务开始,接着讨论分类和多分类问题。
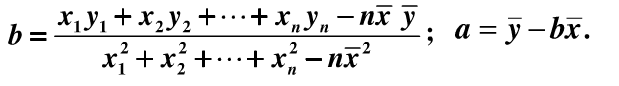
##**3.1 线性回归**
线性回归问题就是试图学到一个线性模型尽可能准确地预测新样本的输出值,例如:通过历年的人口数据预测2017年人口数量。在这类问题中,往往我们会先得到一系列的有标记数据,例如:2000-->13亿...2016-->15亿,这时输入的属性只有一个,即年份;也有输入多属性的情形,假设我们预测一个人的收入,这时输入的属性值就不止一个了,例如:(学历,年龄,性别,颜值,身高,体重)-->15k。
有时这些输入的属性值并不能直接被我们的学习模型所用,需要进行相应的处理,对于连续值的属性,一般都可以被学习器所用,有时会根据具体的情形作相应的预处理,例如:归一化等;对于离散值的属性,可作下面的处理:
- 若属性值之间存在“序关系”,则可以将其转化为连续值,例如:身高属性分为“高”“中等”“矮”,可转化为数值:{1, 0.5, 0}。
- 若属性值之间不存在“序关系”,则通常将其转化为向量的形式,例如:性别属性分为“男”“女”,可转化为二维向量:{(1,0),(0,1)}。
(1)当输入属性只有一个的时候,就是最简单的情形,也就是我们高中时最熟悉的“最小二乘法”(Euclidean distance),首先计算出每个样本预测值与真实值之间的误差并求和,通过最小化均方误差MSE,使用求偏导等于零的方法计算出拟合直线y=wx+b的两个参数w和b,计算过程如下图所示:

(2)当输入属性有多个的时候,例如对于一个样本有d个属性{(x1,x2...xd),y},则y=wx+b需要写成:
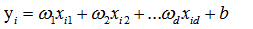
通常对于多元问题,常常使用矩阵的形式来表示数据。在本问题中,将具有m个样本的数据集表示成矩阵X,将系数w与b合并成一个列向量,这样每个样本的预测值以及所有样本的均方误差最小化就可以写成下面的形式:

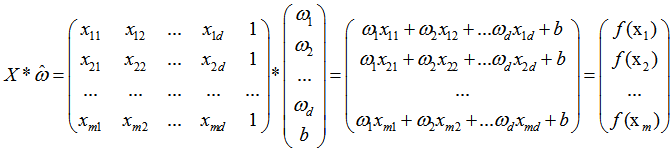
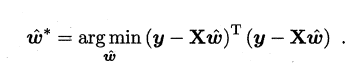
同样地,我们使用最小二乘法对w和b进行估计,令均方误差的求导等于0,需要注意的是,当一个矩阵的行列式不等于0时,我们才可能对其求逆,因此对于下式,我们需要考虑矩阵(X的转置*X)的行列式是否为0,若不为0,则可以求出其解,若为0,则需要使用其它的方法进行计算,书中提到了引入正则化,此处不进行深入。

另一方面,有时像上面这种原始的线性回归可能并不能满足需求,例如:y值并不是线性变化,而是在指数尺度上变化。这时我们可以采用线性模型来逼近y的衍生物,例如lny,这时衍生的线性模型如下所示,实际上就是相当于将指数曲线投影在一条直线上,如下图所示:
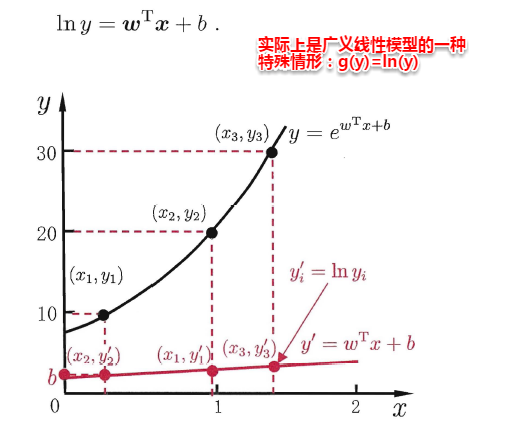
更一般地,考虑所有y的衍生物的情形,就得到了“广义的线性模型”(generalized linear model),其中,g(*)称为联系函数(link function)。
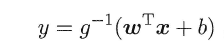
##**3.2 线性几率回归**
回归就是通过输入的属性值得到一个预测值,利用上述广义线性模型的特征,是否可以通过一个联系函数,将预测值转化为离散值从而进行分类呢?线性几率回归正是研究这样的问题。对数几率引入了一个对数几率函数(logistic function),将预测值投影到0-1之间,从而将线性回归问题转化为二分类问题。
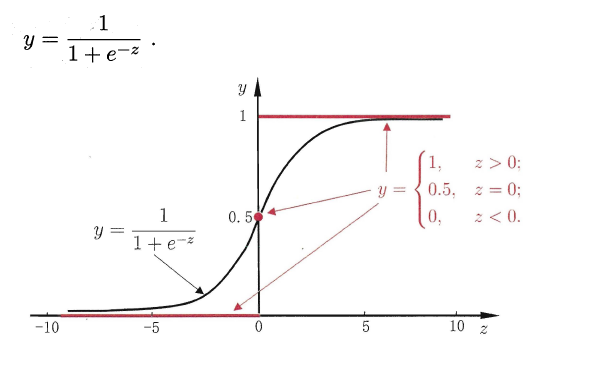

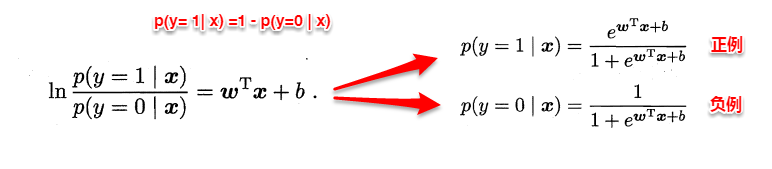
若将y看做样本为正例的概率,(1-y)看做样本为反例的概率,则上式实际上使用线性回归模型的预测结果器逼近真实标记的对数几率。因此这个模型称为“对数几率回归”(logistic regression),也有一些书籍称之为“逻辑回归”。下面使用最大似然估计的方法来计算出w和b两个参数的取值,下面只列出求解的思路,不列出具体的计算过程。

##**3.3 线性判别分析**
线性判别分析(Linear Discriminant Analysis,简称LDA),其基本思想是:将训练样本投影到一条直线上,使得同类的样例尽可能近,不同类的样例尽可能远。如图所示:
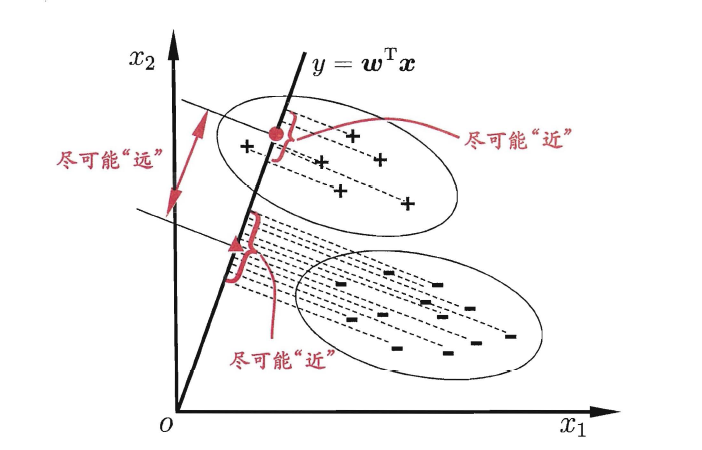
想让同类样本点的投影点尽可能接近,不同类样本点投影之间尽可能远,即:让各类的协方差之和尽可能小,不用类之间中心的距离尽可能大。基于这样的考虑,LDA定义了两个散度矩阵。
+ 类内散度矩阵(within-class scatter matrix)
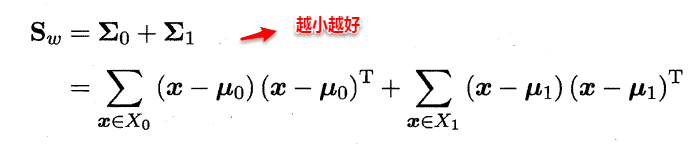
+ 类间散度矩阵(between-class scaltter matrix)
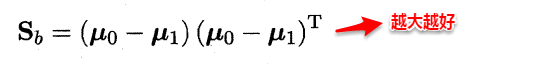
因此得到了LDA的最大化目标:“广义瑞利商”(generalized Rayleigh quotient)。
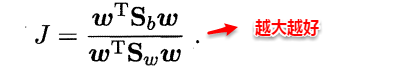
从而分类问题转化为最优化求解w的问题,当求解出w后,对新的样本进行分类时,只需将该样本点投影到这条直线上,根据与各个类别的中心值进行比较,从而判定出新样本与哪个类别距离最近。求解w的方法如下所示,使用的方法为λ乘子。

若将w看做一个投影矩阵,类似PCA的思想,则LDA可将样本投影到N-1维空间(N为类簇数),投影的过程使用了类别信息(标记信息),因此LDA也常被视为一种经典的监督降维技术。
##**3.4 多分类学习**
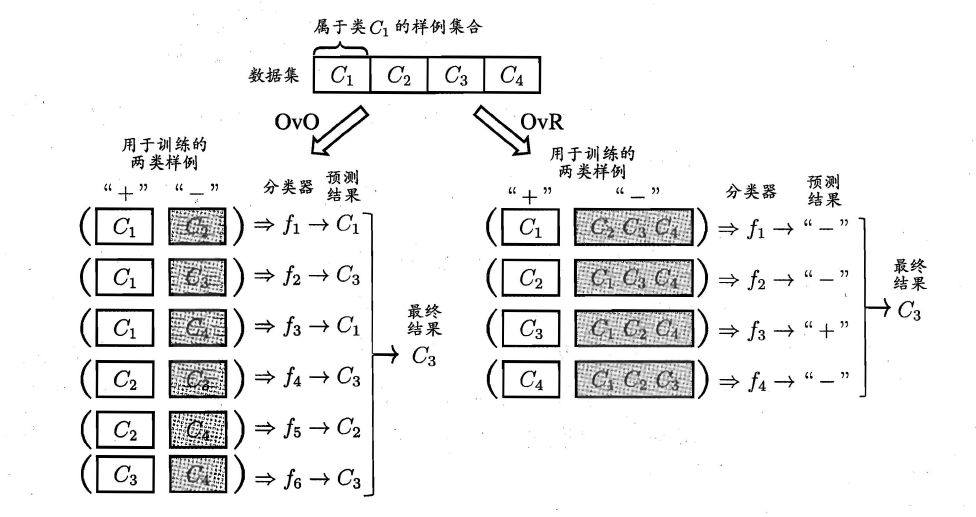
现实中我们经常遇到不只两个类别的分类问题,即多分类问题,在这种情形下,我们常常运用“拆分”的策略,通过多个二分类学习器来解决多分类问题,即将多分类问题拆解为多个二分类问题,训练出多个二分类学习器,最后将多个分类结果进行集成得出结论。最为经典的拆分策略有三种:“一对一”(OvO)、“一对其余”(OvR)和“多对多”(MvM),核心思想与示意图如下所示。
+ OvO:给定数据集D,假定其中有N个真实类别,将这N个类别进行两两配对(一个正类/一个反类),从而产生N(N-1)/2个二分类学习器,在测试阶段,将新样本放入所有的二分类学习器中测试,得出N(N-1)个结果,最终通过投票产生最终的分类结果。
+ OvM:给定数据集D,假定其中有N个真实类别,每次取出一个类作为正类,剩余的所有类别作为一个新的反类,从而产生N个二分类学习器,在测试阶段,得出N个结果,若仅有一个学习器预测为正类,则对应的类标作为最终分类结果。
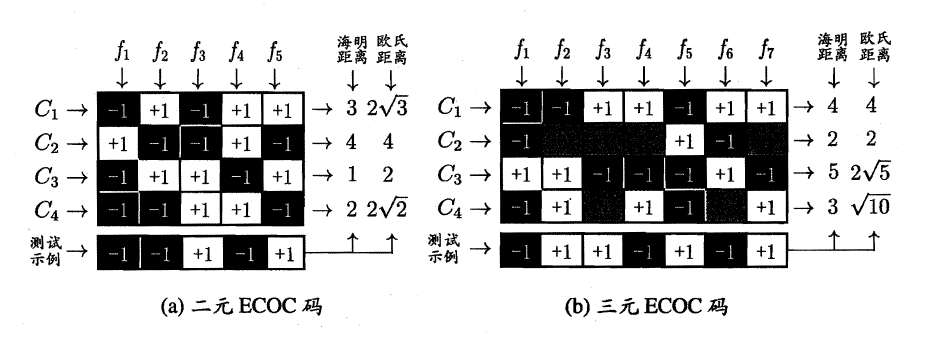
+ MvM:给定数据集D,假定其中有N个真实类别,每次取若干个类作为正类,若干个类作为反类(通过ECOC码给出,编码),若进行了M次划分,则生成了M个二分类学习器,在测试阶段(解码),得出M个结果组成一个新的码,最终通过计算海明/欧式距离选择距离最小的类别作为最终分类结果。
##**3.5 类别不平衡问题**
类别不平衡(class-imbanlance)就是指分类问题中不同类别的训练样本相差悬殊的情况,例如正例有900个,而反例只有100个,这个时候我们就需要进行相应的处理来平衡这个问题。常见的做法有三种:
1. 在训练样本较多的类别中进行“欠采样”(undersampling),比如从正例中采出100个,常见的算法有:EasyEnsemble。
2. 在训练样本较少的类别中进行“过采样”(oversampling),例如通过对反例中的数据进行插值,来产生额外的反例,常见的算法有SMOTE。
3. 直接基于原数据集进行学习,对预测值进行“再缩放”处理。其中再缩放也是代价敏感学习的基础。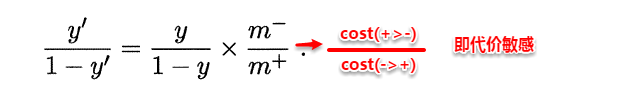
================================================
FILE: 周志华《Machine Learning》学习笔记(5)--决策树.md
================================================
上篇主要介绍和讨论了线性模型。首先从最简单的最小二乘法开始,讨论输入属性有一个和多个的情形,接着通过广义线性模型延伸开来,将预测连续值的回归问题转化为分类问题,从而引入了对数几率回归,最后线性判别分析LDA将样本点进行投影,多分类问题实质上通过划分的方法转化为多个二分类问题进行求解。本篇将讨论另一种被广泛使用的分类算法--决策树(Decision Tree)。
#**4、决策树**
##**4.1 决策树基本概念**
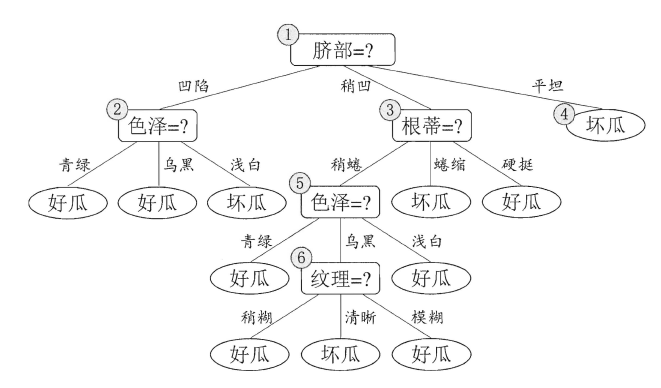
顾名思义,决策树是基于树结构来进行决策的,在网上看到一个例子十分有趣,放在这里正好合适。现想象一位捉急的母亲想要给自己的女娃介绍一个男朋友,于是有了下面的对话:
*****
女儿:多大年纪了?
母亲:26。
女儿:长的帅不帅?
母亲:挺帅的。
女儿:收入高不?
母亲:不算很高,中等情况。
女儿:是公务员不?
母亲:是,在税务局上班呢。
女儿:那好,我去见见。
*****
这个女孩的挑剔过程就是一个典型的决策树,即相当于通过年龄、长相、收入和是否公务员将男童鞋分为两个类别:见和不见。假设这个女孩对男人的要求是:30岁以下、长相中等以上并且是高收入者或中等以上收入的公务员,那么使用下图就能很好地表示女孩的决策逻辑(即一颗决策树)。
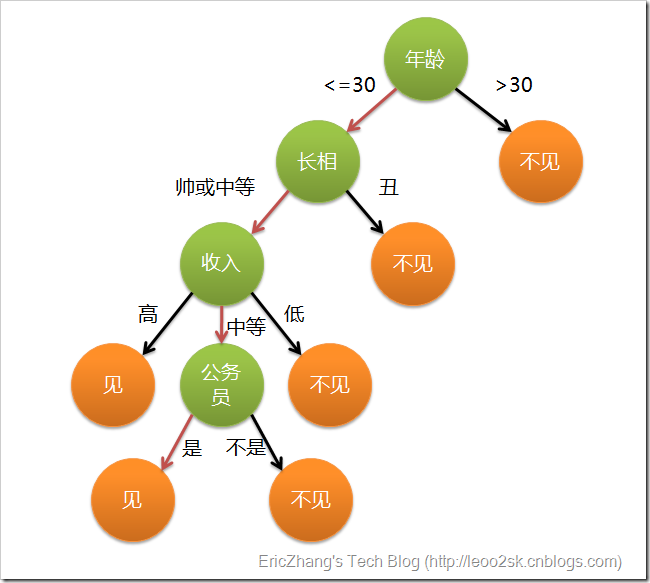
在上图的决策树中,决策过程的每一次判定都是对某一属性的“测试”,决策最终结论则对应最终的判定结果。一般一颗决策树包含:一个根节点、若干个内部节点和若干个叶子节点,易知:
* 每个非叶节点表示一个特征属性测试。
* 每个分支代表这个特征属性在某个值域上的输出。
* 每个叶子节点存放一个类别。
* 每个节点包含的样本集合通过属性测试被划分到子节点中,根节点包含样本全集。
##**4.2 决策树的构造**
决策树的构造是一个递归的过程,有三种情形会导致递归返回:(1) 当前结点包含的样本全属于同一类别,这时直接将该节点标记为叶节点,并设为相应的类别;(2) 当前属性集为空,或是所有样本在所有属性上取值相同,无法划分,这时将该节点标记为叶节点,并将其类别设为该节点所含样本最多的类别;(3) 当前结点包含的样本集合为空,不能划分,这时也将该节点标记为叶节点,并将其类别设为父节点中所含样本最多的类别。算法的基本流程如下图所示:

可以看出:决策树学习的关键在于如何选择划分属性,不同的划分属性得出不同的分支结构,从而影响整颗决策树的性能。属性划分的目标是让各个划分出来的子节点尽可能地“纯”,即属于同一类别。因此下面便是介绍量化纯度的具体方法,决策树最常用的算法有三种:ID3,C4.5和CART。
###**4.2.1 ID3算法**
ID3算法使用信息增益为准则来选择划分属性,“信息熵”(information entropy)是度量样本结合纯度的常用指标,假定当前样本集合D中第k类样本所占比例为pk,则样本集合D的信息熵定义为:

假定通过属性划分样本集D,产生了V个分支节点,v表示其中第v个分支节点,易知:分支节点包含的样本数越多,表示该分支节点的影响力越大。故可以计算出划分后相比原始数据集D获得的“信息增益”(information gain)。
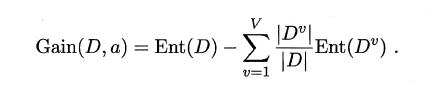
信息增益越大,表示使用该属性划分样本集D的效果越好,因此ID3算法在递归过程中,每次选择最大信息增益的属性作为当前的划分属性。
###**4.2.2 C4.5算法**
ID3算法存在一个问题,就是偏向于取值数目较多的属性,例如:如果存在一个唯一标识,这样样本集D将会被划分为|D|个分支,每个分支只有一个样本,这样划分后的信息熵为零,十分纯净,但是对分类毫无用处。因此C4.5算法使用了“增益率”(gain ratio)来选择划分属性,来避免这个问题带来的困扰。首先使用ID3算法计算出信息增益高于平均水平的候选属性,接着C4.5计算这些候选属性的增益率,增益率定义为:
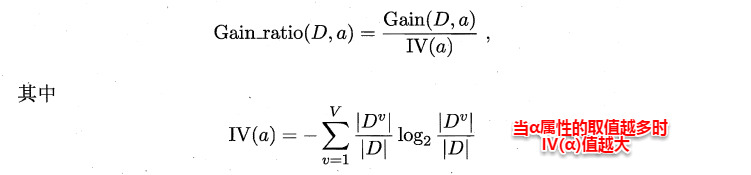
###**4.2.3 CART算法**
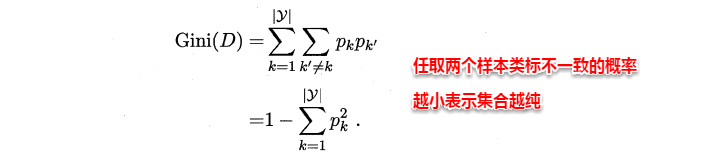
CART决策树使用“基尼指数”(Gini index)来选择划分属性,基尼指数反映的是从样本集D中随机抽取两个样本,其类别标记不一致的概率,因此Gini(D)越小越好,基尼指数定义如下:
进而,使用属性α划分后的基尼指数为:
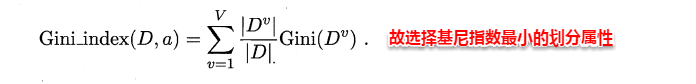
##**4.3 剪枝处理**
从决策树的构造流程中我们可以直观地看出:不管怎么样的训练集,决策树总是能很好地将各个类别分离开来,这时就会遇到之前提到过的问题:过拟合(overfitting),即太依赖于训练样本。剪枝(pruning)则是决策树算法对付过拟合的主要手段,剪枝的策略有两种如下:
* 预剪枝(prepruning):在构造的过程中先评估,再考虑是否分支。
* 后剪枝(post-pruning):在构造好一颗完整的决策树后,自底向上,评估分支的必要性。
评估指的是性能度量,即决策树的泛化性能。之前提到:可以使用测试集作为学习器泛化性能的近似,因此可以将数据集划分为训练集和测试集。预剪枝表示在构造数的过程中,对一个节点考虑是否分支时,首先计算决策树不分支时在测试集上的性能,再计算分支之后的性能,若分支对性能没有提升,则选择不分支(即剪枝)。后剪枝则表示在构造好一颗完整的决策树后,从最下面的节点开始,考虑该节点分支对模型的性能是否有提升,若无则剪枝,即将该节点标记为叶子节点,类别标记为其包含样本最多的类别。
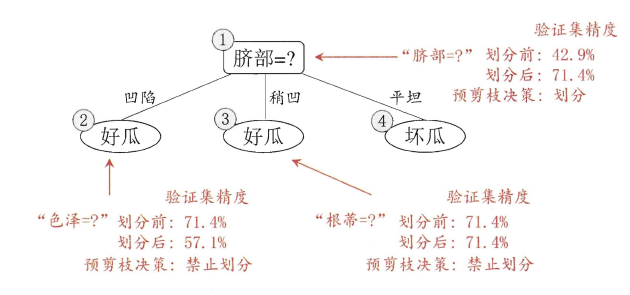
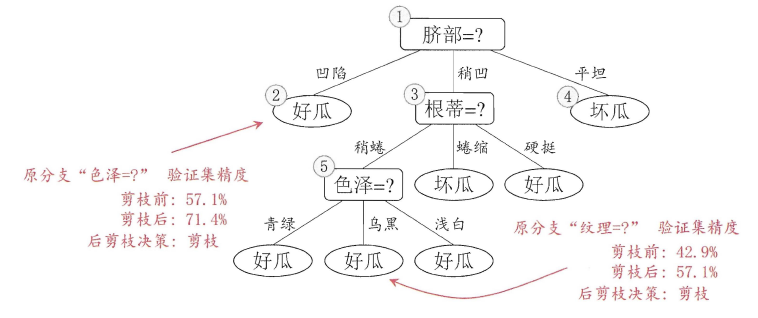
上图分别表示不剪枝处理的决策树、预剪枝决策树和后剪枝决策树。预剪枝处理使得决策树的很多分支被剪掉,因此大大降低了训练时间开销,同时降低了过拟合的风险,但另一方面由于剪枝同时剪掉了当前节点后续子节点的分支,因此预剪枝“贪心”的本质阻止了分支的展开,在一定程度上带来了欠拟合的风险。而后剪枝则通常保留了更多的分支,因此采用后剪枝策略的决策树性能往往优于预剪枝,但其自底向上遍历了所有节点,并计算性能,训练时间开销相比预剪枝大大提升。
##**4.4 连续值与缺失值处理**
对于连续值的属性,若每个取值作为一个分支则显得不可行,因此需要进行离散化处理,常用的方法为二分法,基本思想为:给定样本集D与连续属性α,二分法试图找到一个划分点t将样本集D在属性α上分为≤t与>t。
* 首先将α的所有取值按升序排列,所有相邻属性的均值作为候选划分点(n-1个,n为α所有的取值数目)。
* 计算每一个划分点划分集合D(即划分为两个分支)后的信息增益。
* 选择最大信息增益的划分点作为最优划分点。
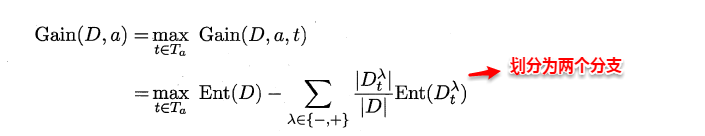
现实中常会遇到不完整的样本,即某些属性值缺失。有时若简单采取剔除,则会造成大量的信息浪费,因此在属性值缺失的情况下需要解决两个问题:(1)如何选择划分属性。(2)给定划分属性,若某样本在该属性上缺失值,如何划分到具体的分支上。假定为样本集中的每一个样本都赋予一个权重,根节点中的权重初始化为1,则定义:

对于(1):通过在样本集D中选取在属性α上没有缺失值的样本子集,计算在该样本子集上的信息增益,最终的信息增益等于该样本子集划分后信息增益乘以样本子集占样本集的比重。即:

对于(2):若该样本子集在属性α上的值缺失,则将该样本以不同的权重(即每个分支所含样本比例)划入到所有分支节点中。该样本在分支节点中的权重变为:

================================================
FILE: 周志华《Machine Learning》学习笔记(6)--神经网络.md
================================================
上篇主要讨论了决策树算法。首先从决策树的基本概念出发,引出决策树基于树形结构进行决策,进一步介绍了构造决策树的递归流程以及其递归终止条件,在递归的过程中,划分属性的选择起到了关键作用,因此紧接着讨论了三种评估属性划分效果的经典算法,介绍了剪枝策略来解决原生决策树容易产生的过拟合问题,最后简述了属性连续值/缺失值的处理方法。本篇将讨论现阶段十分热门的另一个经典监督学习算法--神经网络(neural network)。
#**5、神经网络**
在机器学习中,神经网络一般指的是“神经网络学习”,是机器学习与神经网络两个学科的交叉部分。所谓神经网络,目前用得最广泛的一个定义是“神经网络是由具有适应性的简单单元组成的广泛并行互连的网络,它的组织能够模拟生物神经系统对真实世界物体所做出的交互反应”。
##**5.1 神经元模型**
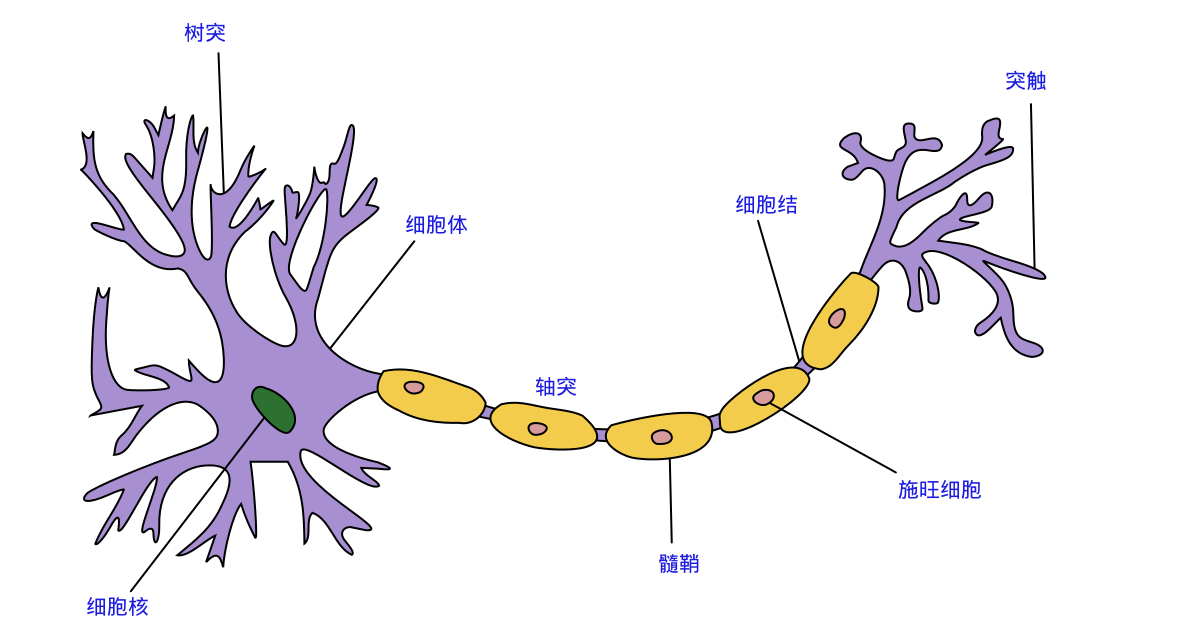
神经网络中最基本的单元是神经元模型(neuron)。在生物神经网络的原始机制中,每个神经元通常都有多个树突(dendrite),一个轴突(axon)和一个细胞体(cell body),树突短而多分支,轴突长而只有一个;在功能上,树突用于传入其它神经元传递的神经冲动,而轴突用于将神经冲动传出到其它神经元,当树突或细胞体传入的神经冲动使得神经元兴奋时,该神经元就会通过轴突向其它神经元传递兴奋。神经元的生物学结构如下图所示,不得不说高中的生化知识大学忘得可是真干净...
一直沿用至今的“M-P神经元模型”正是对这一结构进行了抽象,也称“阈值逻辑单元“,其中树突对应于输入部分,每个神经元收到n个其他神经元传递过来的输入信号,这些信号通过带权重的连接传递给细胞体,这些权重又称为连接权(connection weight)。细胞体分为两部分,前一部分计算总输入值(即输入信号的加权和,或者说累积电平),后一部分先计算总输入值与该神经元阈值的差值,然后通过激活函数(activation function)的处理,产生输出从轴突传送给其它神经元。M-P神经元模型如下图所示:
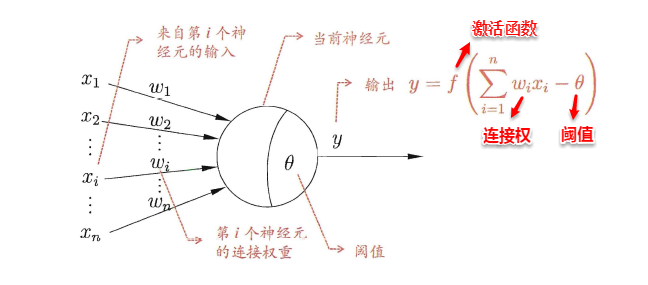
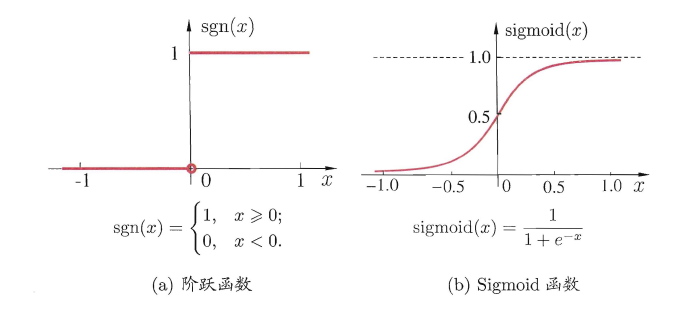
与线性分类十分相似,神经元模型最理想的激活函数也是阶跃函数,即将神经元输入值与阈值的差值映射为输出值1或0,若差值大于零输出1,对应兴奋;若差值小于零则输出0,对应抑制。但阶跃函数不连续,不光滑,故在M-P神经元模型中,也采用Sigmoid函数来近似, Sigmoid函数将较大范围内变化的输入值挤压到 (0,1) 输出值范围内,所以也称为挤压函数(squashing function)。
将多个神经元按一定的层次结构连接起来,就得到了神经网络。它是一种包含多个参数的模型,比方说10个神经元两两连接,则有100个参数需要学习(每个神经元有9个连接权以及1个阈值),若将每个神经元都看作一个函数,则整个神经网络就是由这些函数相互嵌套而成。
##**5.2 感知机与多层网络**
感知机(Perceptron)是由两层神经元组成的一个简单模型,但只有输出层是M-P神经元,即只有输出层神经元进行激活函数处理,也称为功能神经元(functional neuron);输入层只是接受外界信号(样本属性)并传递给输出层(输入层的神经元个数等于样本的属性数目),而没有激活函数。这样一来,感知机与之前线性模型中的对数几率回归的思想基本是一样的,都是通过对属性加权与另一个常数求和,再使用sigmoid函数将这个输出值压缩到0-1之间,从而解决分类问题。不同的是感知机的输出层应该可以有多个神经元,从而可以实现多分类问题,同时两个模型所用的参数估计方法十分不同。
给定训练集,则感知机的n+1个参数(n个权重+1个阈值)都可以通过学习得到。阈值Θ可以看作一个输入值固定为-1的哑结点的权重ωn+1,即假设有一个固定输入xn+1=-1的输入层神经元,其对应的权重为ωn+1,这样就把权重和阈值统一为权重的学习了。简单感知机的结构如下图所示:
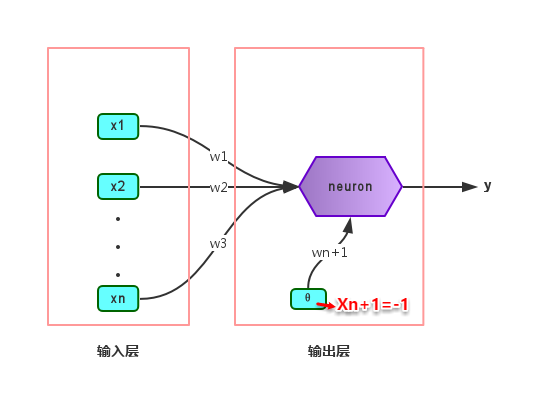
感知机权重的学习规则如下:对于训练样本(x,y),当该样本进入感知机学习后,会产生一个输出值,若该输出值与样本的真实标记不一致,则感知机会对权重进行调整,若激活函数为阶跃函数,则调整的方法为(基于梯度下降法):

其中 η∈(0,1)称为学习率,可以看出感知机是通过逐个样本输入来更新权重,首先设定好初始权重(一般为随机),逐个地输入样本数据,若输出值与真实标记相同则继续输入下一个样本,若不一致则更新权重,然后再重新逐个检验,直到每个样本数据的输出值都与真实标记相同。容易看出:感知机模型总是能将训练数据的每一个样本都预测正确,和决策树模型总是能将所有训练数据都分开一样,感知机模型很容易产生过拟合问题。
由于感知机模型只有一层功能神经元,因此其功能十分有限,只能处理线性可分的问题,对于这类问题,感知机的学习过程一定会收敛(converge),因此总是可以求出适当的权值。但是对于像书上提到的异或问题,只通过一层功能神经元往往不能解决,因此要解决非线性可分问题,需要考虑使用多层功能神经元,即神经网络。多层神经网络的拓扑结构如下图所示:
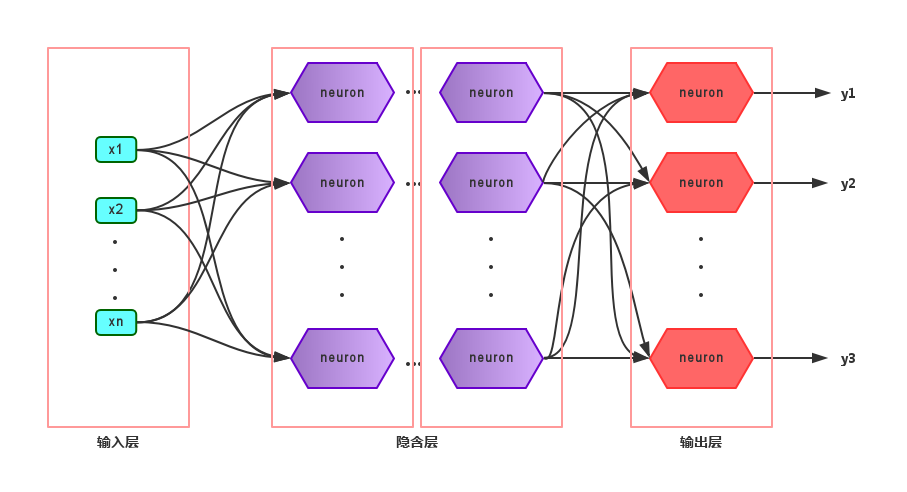
在神经网络中,输入层与输出层之间的层称为隐含层或隐层(hidden layer),隐层和输出层的神经元都是具有激活函数的功能神经元。只需包含一个隐层便可以称为多层神经网络,常用的神经网络称为“多层前馈神经网络”(multi-layer feedforward neural network),该结构满足以下几个特点:
* 每层神经元与下一层神经元之间完全互连
* 神经元之间不存在同层连接
* 神经元之间不存在跨层连接
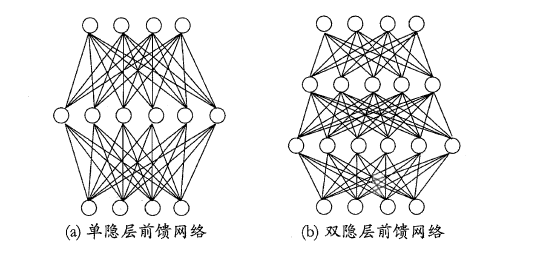
根据上面的特点可以得知:这里的“前馈”指的是网络拓扑结构中不存在环或回路,而不是指该网络只能向前传播而不能向后传播(下节中的BP神经网络正是基于前馈神经网络而增加了反馈调节机制)。神经网络的学习过程就是根据训练数据来调整神经元之间的“连接权”以及每个神经元的阈值,换句话说:神经网络所学习到的东西都蕴含在网络的连接权与阈值中。
##**5.3 BP神经网络算法**
由上面可以得知:神经网络的学习主要蕴含在权重和阈值中,多层网络使用上面简单感知机的权重调整规则显然不够用了,BP神经网络算法即误差逆传播算法(error BackPropagation)正是为学习多层前馈神经网络而设计,BP神经网络算法是迄今为止最成功的的神经网络学习算法。
一般而言,只需包含一个足够多神经元的隐层,就能以任意精度逼近任意复杂度的连续函数[Hornik et al.,1989],故下面以训练单隐层的前馈神经网络为例,介绍BP神经网络的算法思想。
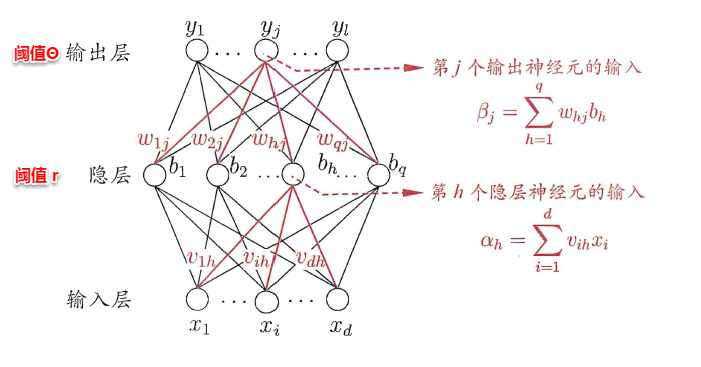
上图为一个单隐层前馈神经网络的拓扑结构,BP神经网络算法也使用梯度下降法(gradient descent),以单个样本的均方误差的负梯度方向对权重进行调节。可以看出:BP算法首先将误差反向传播给隐层神经元,调节隐层到输出层的连接权重与输出层神经元的阈值;接着根据隐含层神经元的均方误差,来调节输入层到隐含层的连接权值与隐含层神经元的阈值。BP算法基本的推导过程与感知机的推导过程原理是相同的,下面给出调整隐含层到输出层的权重调整规则的推导过程:

学习率η∈(0,1)控制着沿反梯度方向下降的步长,若步长太大则下降太快容易产生震荡,若步长太小则收敛速度太慢,一般地常把η设置为0.1,有时更新权重时会将输出层与隐含层设置为不同的学习率。BP算法的基本流程如下所示:

BP算法的更新规则是基于每个样本的预测值与真实类标的均方误差来进行权值调节,即BP算法每次更新只针对于单个样例。需要注意的是:BP算法的最终目标是要最小化整个训练集D上的累积误差,即:
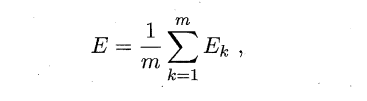
如果基于累积误差最小化的更新规则,则得到了累积误差逆传播算法(accumulated error backpropagation),即每次读取全部的数据集一遍,进行一轮学习,从而基于当前的累积误差进行权值调整,因此参数更新的频率相比标准BP算法低了很多,但在很多任务中,尤其是在数据量很大的时候,往往标准BP算法会获得较好的结果。另外对于如何设置隐层神经元个数的问题,至今仍然没有好的解决方案,常使用“试错法”进行调整。
前面提到,BP神经网络强大的学习能力常常容易造成过拟合问题,有以下两种策略来缓解BP网络的过拟合问题:
- 早停:将数据分为训练集与测试集,训练集用于学习,测试集用于评估性能,若在训练过程中,训练集的累积误差降低,而测试集的累积误差升高,则停止训练。
- 引入正则化(regularization):基本思想是在累积误差函数中增加一个用于描述网络复杂度的部分,例如所有权值与阈值的平方和,其中λ∈(0,1)用于对累积经验误差与网络复杂度这两项进行折中,常通过交叉验证法来估计。
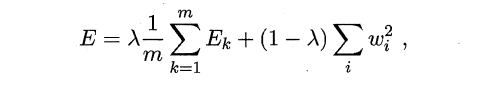
##**5.4 全局最小与局部最小**
模型学习的过程实质上就是一个寻找最优参数的过程,例如BP算法试图通过最速下降来寻找使得累积经验误差最小的权值与阈值,在谈到最优时,一般会提到局部极小(local minimum)和全局最小(global minimum)。
* 局部极小解:参数空间中的某个点,其邻域点的误差函数值均不小于该点的误差函数值。
* 全局最小解:参数空间中的某个点,所有其他点的误差函数值均不小于该点的误差函数值。
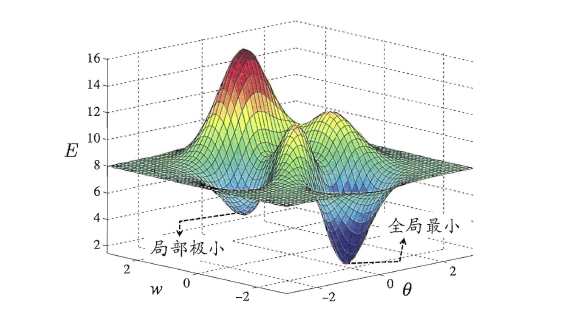
要成为局部极小点,只要满足该点在参数空间中的梯度为零。局部极小可以有多个,而全局最小只有一个。全局最小一定是局部极小,但局部最小却不一定是全局最小。显然在很多机器学习算法中,都试图找到目标函数的全局最小。梯度下降法的主要思想就是沿着负梯度方向去搜索最优解,负梯度方向是函数值下降最快的方向,若迭代到某处的梯度为0,则表示达到一个局部最小,参数更新停止。因此在现实任务中,通常使用以下策略尽可能地去接近全局最小。
* 以多组不同参数值初始化多个神经网络,按标准方法训练,迭代停止后,取其中误差最小的解作为最终参数。
* 使用“模拟退火”技术,这里不做具体介绍。
* 使用随机梯度下降,即在计算梯度时加入了随机因素,使得在局部最小时,计算的梯度仍可能不为0,从而迭代可以继续进行。
##**5.5 深度学习**
理论上,参数越多,模型复杂度就越高,容量(capability)就越大,从而能完成更复杂的学习任务。深度学习(deep learning)正是一种极其复杂而强大的模型。
怎么增大模型复杂度呢?两个办法,一是增加隐层的数目,二是增加隐层神经元的数目。前者更有效一些,因为它不仅增加了功能神经元的数量,还增加了激活函数嵌套的层数。但是对于多隐层神经网络,经典算法如标准BP算法往往会在误差逆传播时发散(diverge),无法收敛达到稳定状态。
那要怎么有效地训练多隐层神经网络呢?一般来说有以下两种方法:
- 无监督逐层训练(unsupervised layer-wise training):每次训练一层隐节点,把上一层隐节点的输出当作输入来训练,本层隐结点训练好后,输出再作为下一层的输入来训练,这称为预训练(pre-training)。全部预训练完成后,再对整个网络进行微调(fine-tuning)训练。一个典型例子就是深度信念网络(deep belief network,简称DBN)。这种做法其实可以视为把大量的参数进行分组,先找出每组较好的设置,再基于这些局部最优的结果来训练全局最优。
- 权共享(weight sharing):令同一层神经元使用完全相同的连接权,典型的例子是卷积神经网络(Convolutional Neural Network,简称CNN)。这样做可以大大减少需要训练的参数数目。
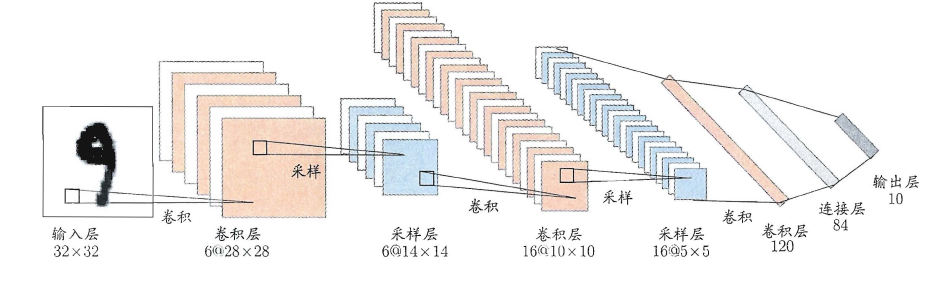
深度学习可以理解为一种特征学习(feature learning)或者表示学习(representation learning),无论是DBN还是CNN,都是通过多个隐层来把与输出目标联系不大的初始输入转化为与输出目标更加密切的表示,使原来只通过单层映射难以完成的任务变为可能。即通过多层处理,逐渐将初始的“低层”特征表示转化为“高层”特征表示,从而使得最后可以用简单的模型来完成复杂的学习任务。
传统任务中,样本的特征需要人类专家来设计,这称为特征工程(feature engineering)。特征好坏对泛化性能有至关重要的影响。而深度学习为全自动数据分析带来了可能,可以自动产生更好的特征。
================================================
FILE: 周志华《Machine Learning》学习笔记(7)--支持向量机.md
================================================
写在前面的话:距离上篇博客竟过去快一个月了,写完神经网络博客正式进入考试模式,几次考试+几篇报告下来弄得心颇不宁静了,今日定下来看到一句鸡血:Tomorrow is another due!也许生活就需要一些deadline~~
上篇主要介绍了神经网络。首先从生物学神经元出发,引出了它的数学抽象模型--MP神经元以及由两层神经元组成的感知机模型,并基于梯度下降的方法描述了感知机模型的权值调整规则。由于简单的感知机不能处理线性不可分的情形,因此接着引入了含隐层的前馈型神经网络,BP神经网络则是其中最为成功的一种学习方法,它使用误差逆传播的方法来逐层调节连接权。最后简单介绍了局部/全局最小以及目前十分火热的深度学习的概念。本篇围绕的核心则是曾经一度取代过神经网络的另一种监督学习算法--**支持向量机**(Support Vector Machine),简称**SVM**。
#**6、支持向量机**
支持向量机是一种经典的二分类模型,基本模型定义为特征空间中最大间隔的线性分类器,其学习的优化目标便是间隔最大化,因此支持向量机本身可以转化为一个凸二次规划求解的问题。
##**6.1 函数间隔与几何间隔**
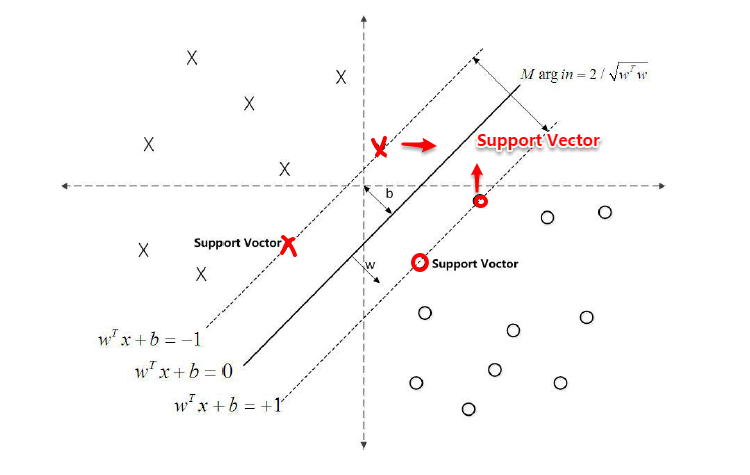
对于二分类学习,假设现在的数据是线性可分的,这时分类学习最基本的想法就是找到一个合适的超平面,该超平面能够将不同类别的样本分开,类似二维平面使用ax+by+c=0来表示,超平面实际上表示的就是高维的平面,如下图所示:
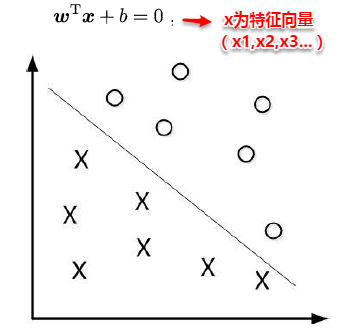
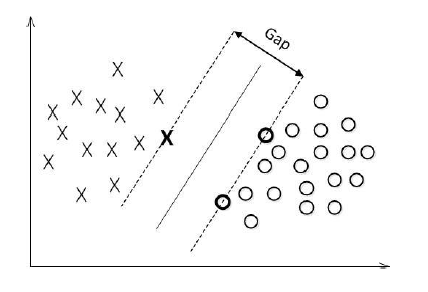
对数据点进行划分时,易知:当超平面距离与它最近的数据点的间隔越大,分类的鲁棒性越好,即当新的数据点加入时,超平面对这些点的适应性最强,出错的可能性最小。因此需要让所选择的超平面能够最大化这个间隔Gap(如下图所示), 常用的间隔定义有两种,一种称之为函数间隔,一种为几何间隔,下面将分别介绍这两种间隔,并对SVM为什么会选用几何间隔做了一些阐述。
###**6.1.1 函数间隔**
在超平面w'x+b=0确定的情况下,|w'x*+b|能够代表点x*距离超平面的远近,易知:当w'x*+b>0时,表示x*在超平面的一侧(正类,类标为1),而当w'x*+b<0时,则表示x*在超平面的另外一侧(负类,类别为-1),因此(w'x*+b)y* 的正负性恰能表示数据点x*是否被分类正确。于是便引出了**函数间隔**的定义(functional margin):
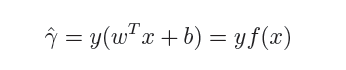
而超平面(w,b)关于所有样本点(Xi,Yi)的函数间隔最小值则为超平面在训练数据集T上的函数间隔:
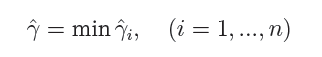
可以看出:这样定义的函数间隔在处理SVM上会有问题,当超平面的两个参数w和b同比例改变时,函数间隔也会跟着改变,但是实际上超平面还是原来的超平面,并没有变化。例如:w1x1+w2x2+w3x3+b=0其实等价于2w1x1+2w2x2+2w3x3+2b=0,但计算的函数间隔却翻了一倍。从而引出了能真正度量点到超平面距离的概念--几何间隔(geometrical margin)。
###**6.1.2 几何间隔**
**几何间隔**代表的则是数据点到超平面的真实距离,对于超平面w'x+b=0,w代表的是该超平面的法向量,设x*为超平面外一点x在法向量w方向上的投影点,x与超平面的距离为r,则有x*=x-r(w/||w||),又x*在超平面上,即w'x*+b=0,代入即可得:
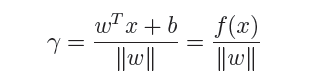
为了得到r的绝对值,令r呈上其对应的类别y,即可得到几何间隔的定义:
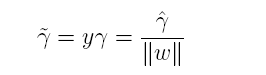
从上述函数间隔与几何间隔的定义可以看出:实质上函数间隔就是|w'x+b|,而几何间隔就是点到超平面的距离。
##**6.2 最大间隔与支持向量**
通过前面的分析可知:函数间隔不适合用来最大化间隔,因此这里我们要找的最大间隔指的是几何间隔,于是最大间隔分类器的目标函数定义为:
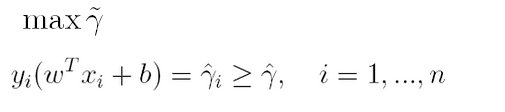
一般地,我们令r^为1(这样做的目的是为了方便推导和目标函数的优化),从而上述目标函数转化为:
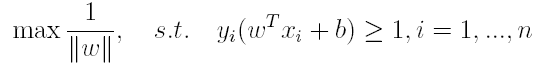
对于y(w'x+b)=1的数据点,即下图中位于w'x+b=1或w'x+b=-1上的数据点,我们称之为**支持向量**(support vector),易知:对于所有的支持向量,它们恰好满足y*(w'x*+b)=1,而所有不是支持向量的点,有y*(w'x*+b)>1。
##**6.3 从原始优化问题到对偶问题**
对于上述得到的目标函数,求1/||w||的最大值相当于求||w||^2的最小值,因此很容易将原来的目标函数转化为:
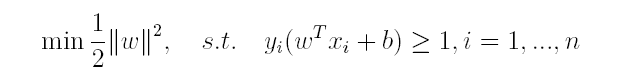
即变为了一个带约束的凸二次规划问题,按书上所说可以使用现成的优化计算包(QP优化包)求解,但由于SVM的特殊性,一般我们将原问题变换为它的**对偶问题**,接着再对其对偶问题进行求解。为什么通过对偶问题进行求解,有下面两个原因:
* 一是因为使用对偶问题更容易求解;
* 二是因为通过对偶问题求解出现了向量内积的形式,从而能更加自然地引出核函数。
对偶问题,顾名思义,可以理解成优化等价的问题,更一般地,是将一个原始目标函数的最小化转化为它的对偶函数最大化的问题。对于当前的优化问题,首先我们写出它的朗格朗日函数:
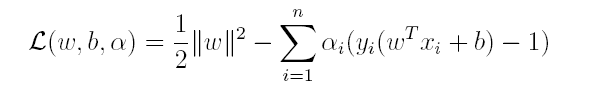
上式很容易验证:当其中有一个约束条件不满足时,L的最大值为 ∞(只需令其对应的α为 ∞即可);当所有约束条件都满足时,L的最大值为1/2||w||^2(此时令所有的α为0),因此实际上原问题等价于:
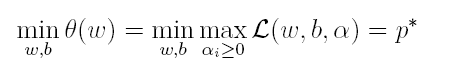
由于这个的求解问题不好做,因此一般我们将最小和最大的位置交换一下(需满足KKT条件) ,变成原问题的对偶问题:
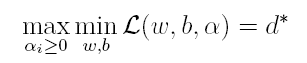
这样就将原问题的求最小变成了对偶问题求最大(用对偶这个词还是很形象),接下来便可以先求L对w和b的极小,再求L对α的极大。
(1)首先求L对w和b的极小,分别求L关于w和b的偏导,可以得出:
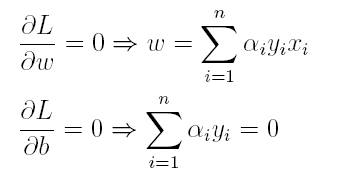
将上述结果代入L得到:
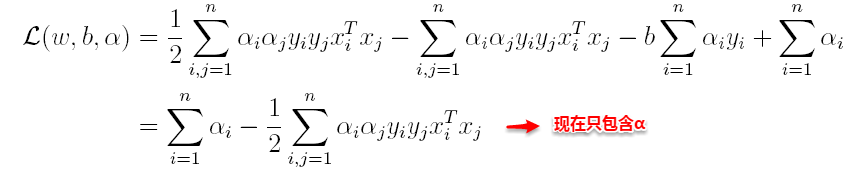
(2)接着L关于α极大求解α(通过SMO算法求解,此处不做深入)。
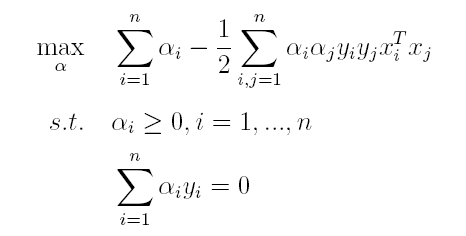
(3)最后便可以根据求解出的α,计算出w和b,从而得到分类超平面函数。
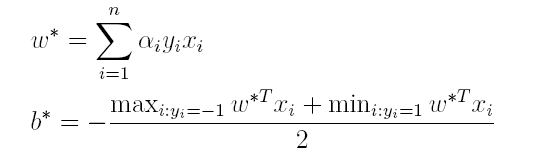
在对新的点进行预测时,实际上就是将数据点x*代入分类函数f(x)=w'x+b中,若f(x)>0,则为正类,f(x)<0,则为负类,根据前面推导得出的w与b,分类函数如下所示,此时便出现了上面所提到的内积形式。
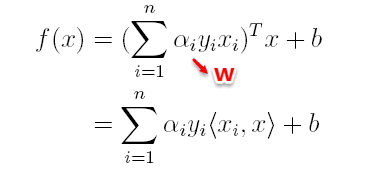
这里实际上只需计算新样本与支持向量的内积,因为对于非支持向量的数据点,其对应的拉格朗日乘子一定为0,根据最优化理论(K-T条件),对于不等式约束y(w'x+b)-1≥0,满足:
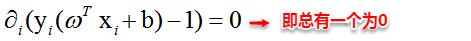
##**6.4 核函数**
由于上述的超平面只能解决线性可分的问题,对于线性不可分的问题,例如:异或问题,我们需要使用核函数将其进行推广。一般地,解决线性不可分问题时,常常采用**映射**的方式,将低维原始空间映射到高维特征空间,使得数据集在高维空间中变得线性可分,从而再使用线性学习器分类。如果原始空间为有限维,即属性数有限,那么总是存在一个高维特征空间使得样本线性可分。若∅代表一个映射,则在特征空间中的划分函数变为:
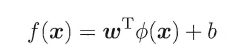
按照同样的方法,先写出新目标函数的拉格朗日函数,接着写出其对偶问题,求L关于w和b的极大,最后运用SOM求解α。可以得出:
(1)原对偶问题变为:
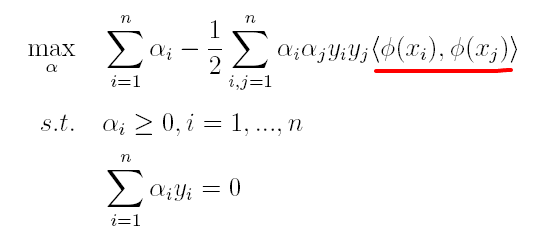
(2)原分类函数变为:
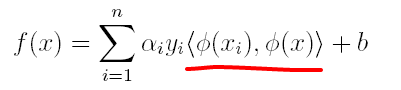
求解的过程中,只涉及到了高维特征空间中的内积运算,由于特征空间的维数可能会非常大,例如:若原始空间为二维,映射后的特征空间为5维,若原始空间为三维,映射后的特征空间将是19维,之后甚至可能出现无穷维,根本无法进行内积运算了,此时便引出了**核函数**(Kernel)的概念。

因此,核函数可以直接计算隐式映射到高维特征空间后的向量内积,而不需要显式地写出映射后的结果,它虽然完成了将特征从低维到高维的转换,但最终却是在低维空间中完成向量内积计算,与高维特征空间中的计算等效**(低维计算,高维表现)**,从而避免了直接在高维空间无法计算的问题。引入核函数后,原来的对偶问题与分类函数则变为:
(1)对偶问题:
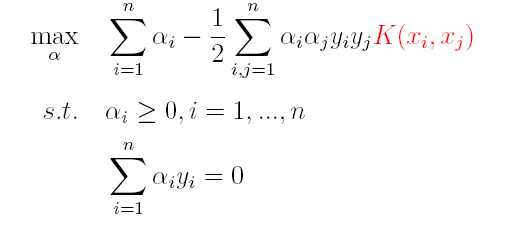
(2)分类函数:
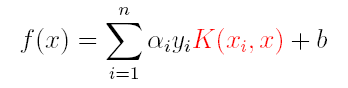
因此,在线性不可分问题中,核函数的选择成了支持向量机的最大变数,若选择了不合适的核函数,则意味着将样本映射到了一个不合适的特征空间,则极可能导致性能不佳。同时,核函数需要满足以下这个必要条件:

由于核函数的构造十分困难,通常我们都是从一些常用的核函数中选择,下面列出了几种常用的核函数:

##**6.5 软间隔支持向量机**
前面的讨论中,我们主要解决了两个问题:当数据线性可分时,直接使用最大间隔的超平面划分;当数据线性不可分时,则通过核函数将数据映射到高维特征空间,使之线性可分。然而在现实问题中,对于某些情形还是很难处理,例如数据中有**噪声**的情形,噪声数据(**outlier**)本身就偏离了正常位置,但是在前面的SVM模型中,我们要求所有的样本数据都必须满足约束,如果不要这些噪声数据还好,当加入这些outlier后导致划分超平面被挤歪了,如下图所示,对支持向量机的泛化性能造成很大的影响。
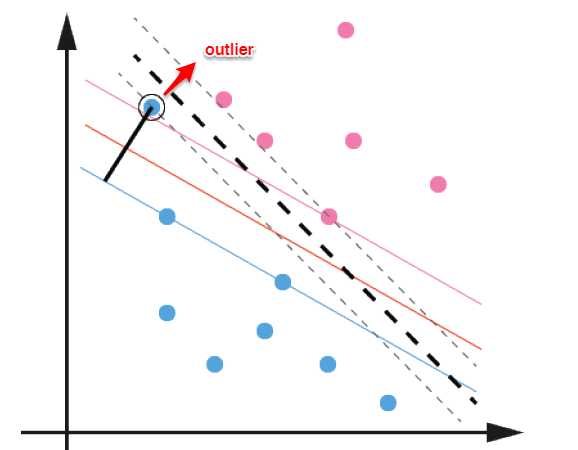
为了解决这一问题,我们需要允许某一些数据点不满足约束,即可以在一定程度上偏移超平面,同时使得不满足约束的数据点尽可能少,这便引出了**“软间隔”支持向量机**的概念
* 允许某些数据点不满足约束y(w'x+b)≥1;
* 同时又使得不满足约束的样本尽可能少。
这样优化目标变为:
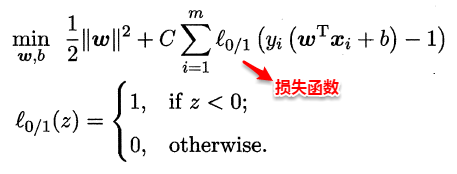
如同阶跃函数,0/1损失函数虽然表示效果最好,但是数学性质不佳。因此常用其它函数作为“替代损失函数”。
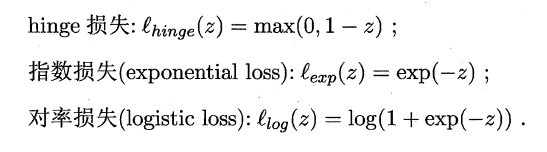
支持向量机中的损失函数为**hinge损失**,引入**“松弛变量”**,目标函数与约束条件可以写为:
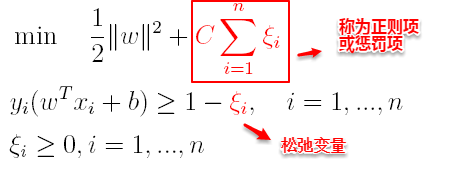
其中C为一个参数,控制着目标函数与新引入正则项之间的权重,这样显然每个样本数据都有一个对应的松弛变量,用以表示该样本不满足约束的程度,将新的目标函数转化为拉格朗日函数得到:
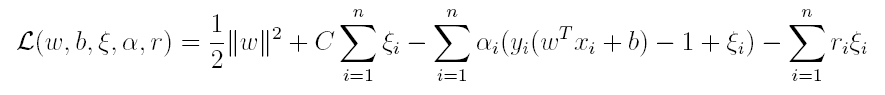
按照与之前相同的方法,先让L求关于w,b以及松弛变量的极小,再使用SMO求出α,有:
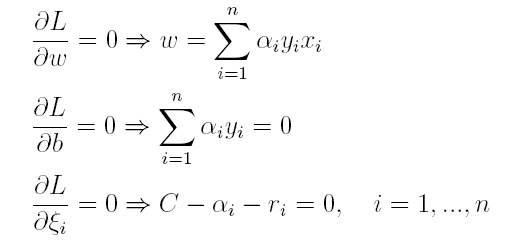
将w代入L化简,便得到其对偶问题:

将“软间隔”下产生的对偶问题与原对偶问题对比可以发现:新的对偶问题只是约束条件中的α多出了一个上限C,其它的完全相同,因此在引入核函数处理线性不可分问题时,便能使用与“硬间隔”支持向量机完全相同的方法。
----在此SVM就介绍完毕。
================================================
FILE: 周志华《Machine Learning》学习笔记(8)--贝叶斯分类器.md
================================================
上篇主要介绍和讨论了支持向量机。从最初的分类函数,通过最大化分类间隔,max(1/||w||),min(1/2||w||^2),凸二次规划,朗格朗日函数,对偶问题,一直到最后的SMO算法求解,都为寻找一个最优解。接着引入核函数将低维空间映射到高维特征空间,解决了非线性可分的情形。最后介绍了软间隔支持向量机,解决了outlier挤歪超平面的问题。本篇将讨论一个经典的统计学习算法--**贝叶斯分类器**。
#**7、贝叶斯分类器**
贝叶斯分类器是一种概率框架下的统计学习分类器,对分类任务而言,假设在相关概率都已知的情况下,贝叶斯分类器考虑如何基于这些概率为样本判定最优的类标。在开始介绍贝叶斯决策论之前,我们首先来回顾下概率论委员会常委--贝叶斯公式。

##**7.1 贝叶斯决策论**
若将上述定义中样本空间的划分Bi看做为类标,A看做为一个新的样本,则很容易将条件概率理解为样本A是类别Bi的概率。在机器学习训练模型的过程中,往往我们都试图去优化一个风险函数,因此在概率框架下我们也可以为贝叶斯定义“**条件风险**”(conditional risk)。
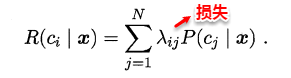
我们的任务就是寻找一个判定准则最小化所有样本的条件风险总和,因此就有了**贝叶斯判定准则**(Bayes decision rule):为最小化总体风险,只需在每个样本上选择那个使得条件风险最小的类标。
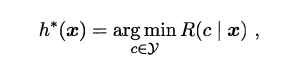
若损失函数λ取0-1损失,则有:
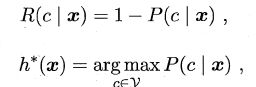
即对于每个样本x,选择其后验概率P(c | x)最大所对应的类标,能使得总体风险函数最小,从而将原问题转化为估计后验概率P(c | x)。一般这里有两种策略来对后验概率进行估计:
* 判别式模型:直接对 P(c | x)进行建模求解。例我们前面所介绍的决策树、神经网络、SVM都是属于判别式模型。
* 生成式模型:通过先对联合分布P(x,c)建模,从而进一步求解 P(c | x)。
贝叶斯分类器就属于生成式模型,基于贝叶斯公式对后验概率P(c | x) 进行一项神奇的变换,巴拉拉能量.... P(c | x)变身:
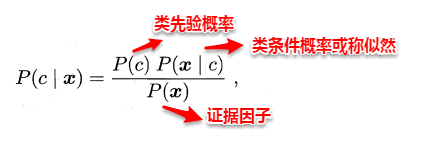
对于给定的样本x,P(x)与类标无关,P(c)称为类先验概率,p(x | c )称为类条件概率。这时估计后验概率P(c | x)就变成为估计类先验概率和类条件概率的问题。对于先验概率和后验概率,在看这章之前也是模糊了我好久,这里普及一下它们的基本概念。
* 先验概率: 根据以往经验和分析得到的概率。
* 后验概率:后验概率是基于新的信息,修正原来的先验概率后所获得的更接近实际情况的概率估计。
实际上先验概率就是在没有任何结果出来的情况下估计的概率,而后验概率则是在有一定依据后的重新估计,直观意义上后验概率就是条件概率。下面直接上Wiki上的一个例子,简单粗暴快速完事...

回归正题,对于类先验概率P(c),p(c)就是样本空间中各类样本所占的比例,根据大数定理(当样本足够多时,频率趋于稳定等于其概率),这样当训练样本充足时,p(c)可以使用各类出现的频率来代替。因此只剩下类条件概率p(x | c ),它表达的意思是在类别c中出现x的概率,它涉及到属性的联合概率问题,若只有一个离散属性还好,当属性多时采用频率估计起来就十分困难,因此这里一般采用极大似然法进行估计。
##**7.2 极大似然法**
极大似然估计(Maximum Likelihood Estimation,简称MLE),是一种根据数据采样来估计概率分布的经典方法。常用的策略是先假定总体具有某种确定的概率分布,再基于训练样本对概率分布的参数进行估计。运用到类条件概率p(x | c )中,假设p(x | c )服从一个参数为θ的分布,问题就变为根据已知的训练样本来估计θ。极大似然法的核心思想就是:估计出的参数使得已知样本出现的概率最大,即使得训练数据的似然最大。

所以,贝叶斯分类器的训练过程就是参数估计。总结最大似然法估计参数的过程,一般分为以下四个步骤:
* 1.写出似然函数;
* 2.对似然函数取对数,并整理;
* 3.求导数,令偏导数为0,得到似然方程组;
* 4.解似然方程组,得到所有参数即为所求。
例如:假设样本属性都是连续值,p(x | c )服从一个多维高斯分布,则通过MLE计算出的参数刚好分别为:
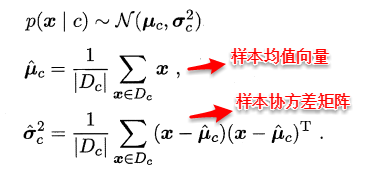
上述结果看起来十分合乎实际,但是采用最大似然法估计参数的效果很大程度上依赖于作出的假设是否合理,是否符合潜在的真实数据分布。这就需要大量的经验知识,搞统计越来越值钱也是这个道理,大牛们掐指一算比我们搬砖几天更有效果。
##**7.3 朴素贝叶斯分类器**
不难看出:原始的贝叶斯分类器最大的问题在于联合概率密度函数的估计,首先需要根据经验来假设联合概率分布,其次当属性很多时,训练样本往往覆盖不够,参数的估计会出现很大的偏差。为了避免这个问题,朴素贝叶斯分类器(naive Bayes classifier)采用了“属性条件独立性假设”,即样本数据的所有属性之间相互独立。这样类条件概率p(x | c )可以改写为:
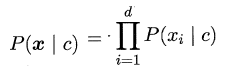
这样,为每个样本估计类条件概率变成为每个样本的每个属性估计类条件概率。

相比原始贝叶斯分类器,朴素贝叶斯分类器基于单个的属性计算类条件概率更加容易操作,需要注意的是:若某个属性值在训练集中和某个类别没有一起出现过,这样会抹掉其它的属性信息,因为该样本的类条件概率被计算为0。因此在估计概率值时,常常用进行平滑(smoothing)处理,拉普拉斯修正(Laplacian correction)就是其中的一种经典方法,具体计算方法如下:

当训练集越大时,拉普拉斯修正引入的影响越来越小。对于贝叶斯分类器,模型的训练就是参数估计,因此可以事先将所有的概率储存好,当有新样本需要判定时,直接查表计算即可。
针对朴素贝叶斯,人们觉得它too sample,sometimes too naive!因此又提出了半朴素的贝叶斯分类器,具体有SPODE、TAN、贝叶斯网络等来刻画属性之间的依赖关系,此处不进行深入,等哪天和贝叶斯邂逅了再回来讨论。在此鼎鼎大名的贝叶斯介绍完毕,下一篇将介绍这一章剩下的内容--EM算法,朴素贝叶斯和EM算法同为数据挖掘的十大经典算法,想着还是单独介绍吧~
================================================
FILE: 周志华《Machine Learning》学习笔记(9)--EM算法.md
================================================
上篇主要介绍了贝叶斯分类器,从贝叶斯公式到贝叶斯决策论,再到通过极大似然法估计类条件概率,贝叶斯分类器的训练就是参数估计的过程。朴素贝叶斯则是“属性条件独立性假设”下的特例,它避免了假设属性联合分布过于经验性和训练集不足引起参数估计较大偏差两个大问题,最后介绍的拉普拉斯修正将概率值进行平滑处理。本篇将介绍另一个当选为数据挖掘十大算法之一的**EM算法**。
#**8、EM算法**
EM(Expectation-Maximization)算法是一种常用的估计参数隐变量的利器,也称为“期望最大算法”,是数据挖掘的十大经典算法之一。EM算法主要应用于训练集样本不完整即存在隐变量时的情形(例如某个属性值未知),通过其独特的“两步走”策略能较好地估计出隐变量的值。
##**8.1 EM算法思想**
EM是一种迭代式的方法,它的基本思想就是:若样本服从的分布参数θ已知,则可以根据已观测到的训练样本推断出隐变量Z的期望值(E步),若Z的值已知则运用最大似然法估计出新的θ值(M步)。重复这个过程直到Z和θ值不再发生变化。
简单来讲:假设我们想估计A和B这两个参数,在开始状态下二者都是未知的,但如果知道了A的信息就可以得到B的信息,反过来知道了B也就得到了A。可以考虑首先赋予A某种初值,以此得到B的估计值,然后从B的当前值出发,重新估计A的取值,这个过程一直持续到收敛为止。

现在再来回想聚类的代表算法K-Means:【首先随机选择类中心=>将样本点划分到类簇中=>重新计算类中心=>不断迭代直至收敛】,不难发现这个过程和EM迭代的方法极其相似,事实上,若将样本的类别看做为“隐变量”(latent variable)Z,类中心看作样本的分布参数θ,K-Means就是通过EM算法来进行迭代的,与我们这里不同的是,K-Means的目标是最小化样本点到其对应类中心的距离和,上述为极大化似然函数。
##**8.2 EM算法数学推导**
在上篇极大似然法中,当样本属性值都已知时,我们很容易通过极大化对数似然,接着对每个参数求偏导计算出参数的值。但当存在隐变量时,就无法直接求解,此时我们通常最大化已观察数据的对数“边际似然”(marginal likelihood)。
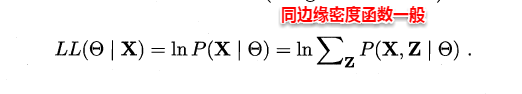
这时候,通过边缘似然将隐变量Z引入进来,对于参数估计,现在与最大似然不同的只是似然函数式中多了一个未知的变量Z,也就是说我们的目标是找到适合的θ和Z让L(θ)最大,这样我们也可以分别对未知的θ和Z求偏导,再令其等于0。
然而观察上式可以发现,和的对数(ln(x1+x2+x3))求导十分复杂,那能否通过变换上式得到一种求导简单的新表达式呢?这时候 Jensen不等式就派上用场了,先回顾一下高等数学凸函数的内容:
**Jensen's inequality**:过一个凸函数上任意两点所作割线一定在这两点间的函数图象的上方。理解起来也十分简单,对于凸函数f(x)''>0,即曲线的变化率是越来越大单调递增的,所以函数越到后面增长越厉害,这样在一个区间下,函数的均值就会大一些了。
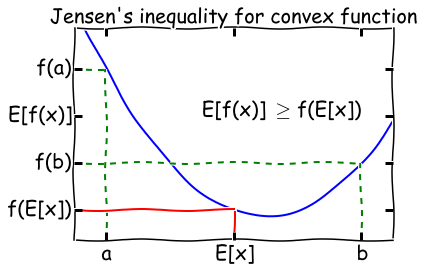
因为ln(*)函数为凹函数,故可以将上式“和的对数”变为“对数的和”,这样就很容易求导了。
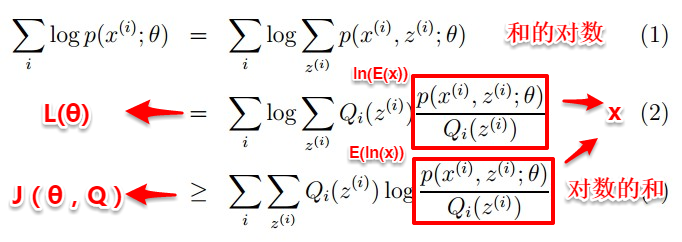
接着求解Qi和θ:首先固定θ(初始值),通过求解Qi使得J(θ,Q)在θ处与L(θ)相等,即求出L(θ)的下界;然后再固定Qi,调整θ,最大化下界J(θ,Q)。不断重复两个步骤直到稳定。通过jensen不等式的性质,Qi的计算公式实际上就是后验概率:
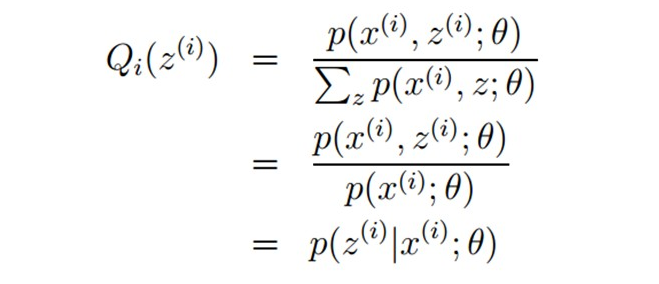
通过数学公式的推导,简单来理解这一过程:固定θ计算Q的过程就是在建立L(θ)的下界,即通过jenson不等式得到的下界(E步);固定Q计算θ则是使得下界极大化(M步),从而不断推高边缘似然L(θ)。从而循序渐进地计算出L(θ)取得极大值时隐变量Z的估计值。
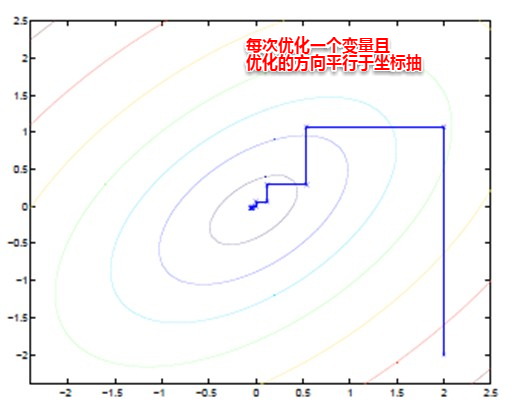
EM算法也可以看作一种“坐标下降法”,首先固定一个值,对另外一个值求极值,不断重复直到收敛。这时候也许大家就有疑问,问什么不直接这两个家伙求偏导用梯度下降呢?这时候就是坐标下降的优势,有些特殊的函数,例如曲线函数z=y^2+x^2+x^2y+xy+...,无法直接求导,这时如果先固定其中的一个变量,再对另一个变量求极值,则变得可行。
##**8.3 EM算法流程**
看完数学推导,算法的流程也就十分简单了,这里有两个版本,版本一来自西瓜书,周天使的介绍十分简洁;版本二来自于大牛的博客。结合着数学推导,自认为版本二更具有逻辑性,两者唯一的区别就在于版本二多出了红框的部分,这里我也没得到答案,欢迎骚扰讨论~
**版本一:**

**版本二:**

gitextract_sl_2njny/ ├── README.md ├── 周志华《Machine Learning》学习笔记(1)--绪论.md ├── 周志华《Machine Learning》学习笔记(10)--集成学习.md ├── 周志华《Machine Learning》学习笔记(11)--聚类.md ├── 周志华《Machine Learning》学习笔记(12)--降维与度量学习.md ├── 周志华《Machine Learning》学习笔记(13)--特征选择与稀疏学习.md ├── 周志华《Machine Learning》学习笔记(14)--计算学习理论.md ├── 周志华《Machine Learning》学习笔记(15)--半监督学习.md ├── 周志华《Machine Learning》学习笔记(16)--概率图模型.md ├── 周志华《Machine Learning》学习笔记(17)--强化学习.md ├── 周志华《Machine Learning》学习笔记(2)--性能度量.md ├── 周志华《Machine Learning》学习笔记(3)--假设检验&方差&偏差.md ├── 周志华《Machine Learning》学习笔记(4)--线性模型.md ├── 周志华《Machine Learning》学习笔记(5)--决策树.md ├── 周志华《Machine Learning》学习笔记(6)--神经网络.md ├── 周志华《Machine Learning》学习笔记(7)--支持向量机.md ├── 周志华《Machine Learning》学习笔记(8)--贝叶斯分类器.md └── 周志华《Machine Learning》学习笔记(9)--EM算法.md
Condensed preview — 18 files, each showing path, character count, and a content snippet. Download the .json file or copy for the full structured content (87K chars).
[
{
"path": "README.md",
"chars": 355,
"preview": "本文为周志华《机器学习》的学习笔记,记录了本人在学习这本书的过程中的理解思路以及一些有助于消化书内容的拓展知识,笔记中参考了许多网上的大牛经典博客以及李航《统计学习》的内容,向前辈们和知识致敬!\n\n\n\n> 啃西瓜学习交流QQ群: 53170"
},
{
"path": "周志华《Machine Learning》学习笔记(1)--绪论.md",
"chars": 4572,
"preview": "机器学习是目前信息技术中最激动人心的方向之一,其应用已经深入到生活的各个层面且与普通人的日常生活密切相关。本文为清华大学最新出版的《机器学习》教材的Learning Notes,书作者是南京大学周志华教授,多个大陆首位彰显其学术奢华。本篇主"
},
{
"path": "周志华《Machine Learning》学习笔记(10)--集成学习.md",
"chars": 6017,
"preview": "上篇主要介绍了鼎鼎大名的EM算法,从算法思想到数学公式推导(边际似然引入隐变量,Jensen不等式简化求导),EM算法实际上可以理解为一种坐标下降法,首先固定一个变量,接着求另外变量的最优解,通过其优美的“两步走”策略能较好地估计隐变量的值"
},
{
"path": "周志华《Machine Learning》学习笔记(11)--聚类.md",
"chars": 5557,
"preview": "上篇主要介绍了一种机器学习的通用框架--集成学习方法,首先从准确性和差异性两个重要概念引出集成学习“**好而不同**”的四字真言,接着介绍了现阶段主流的三种集成学习方法:AdaBoost、Bagging及Random Forest,AdaB"
},
{
"path": "周志华《Machine Learning》学习笔记(12)--降维与度量学习.md",
"chars": 7447,
"preview": "上篇主要介绍了几种常用的聚类算法,首先从距离度量与性能评估出发,列举了常见的距离计算公式与聚类评价指标,接着分别讨论了K-Means、LVQ、高斯混合聚类、密度聚类以及层次聚类算法。K-Means与LVQ都试图以类簇中心作为原型指导聚类,其"
},
{
"path": "周志华《Machine Learning》学习笔记(13)--特征选择与稀疏学习.md",
"chars": 5284,
"preview": "上篇主要介绍了经典的降维方法与度量学习,首先从“维数灾难”导致的样本稀疏以及距离难计算两大难题出发,引出了降维的概念,即通过某种数学变换将原始高维空间转变到一个低维的子空间,接着分别介绍了kNN、MDS、PCA、KPCA以及两种经典的流形学"
},
{
"path": "周志华《Machine Learning》学习笔记(14)--计算学习理论.md",
"chars": 5053,
"preview": "上篇主要介绍了常用的特征选择方法及稀疏学习。首先从相关/无关特征出发引出了特征选择的基本概念,接着分别介绍了子集搜索与评价、过滤式、包裹式以及嵌入式四种类型的特征选择方法。子集搜索与评价使用的是一种优中生优的贪婪算法,即每次从候选特征子集中"
},
{
"path": "周志华《Machine Learning》学习笔记(15)--半监督学习.md",
"chars": 4037,
"preview": "上篇主要介绍了机器学习的理论基础,首先从独立同分布引入泛化误差与经验误差,接着介绍了PAC可学习的基本概念,即以较大的概率学习出与目标概念近似的假设(泛化误差满足预设上限),对于有限假设空间:(1)可分情形时,假设空间都是PAC可学习的,即"
},
{
"path": "周志华《Machine Learning》学习笔记(16)--概率图模型.md",
"chars": 6641,
"preview": "上篇主要介绍了半监督学习,首先从如何利用未标记样本所蕴含的分布信息出发,引入了半监督学习的基本概念,即训练数据同时包含有标记样本和未标记样本的学习方法;接着分别介绍了几种常见的半监督学习方法:生成式方法基于对数据分布的假设,利用未标记样本隐"
},
{
"path": "周志华《Machine Learning》学习笔记(17)--强化学习.md",
"chars": 5789,
"preview": "上篇主要介绍了概率图模型,首先从生成式模型与判别式模型的定义出发,引出了概率图模型的基本概念,即利用图结构来表达变量之间的依赖关系;接着分别介绍了隐马尔可夫模型、马尔可夫随机场、条件随机场、精确推断方法以及LDA话题模型:HMM主要围绕着评"
},
{
"path": "周志华《Machine Learning》学习笔记(2)--性能度量.md",
"chars": 4097,
"preview": "本篇主要是对第二章剩余知识的理解,包括:性能度量、比较检验和偏差与方差。在上一篇中,我们解决了评估学习器泛化性能的方法,即用测试集的“测试误差”作为“泛化误差”的近似,当我们划分好训练/测试集后,那如何计算“测试误差”呢?这就是性能度量,例"
},
{
"path": "周志华《Machine Learning》学习笔记(3)--假设检验&方差&偏差.md",
"chars": 2426,
"preview": "在上两篇中,我们介绍了多种常见的评估方法和性能度量标准,这样我们就可以根据数据集以及模型任务的特征,选择出最合适的评估和性能度量方法来计算出学习器的“测试误差“。但由于“测试误差”受到很多因素的影响,例如:算法随机性(例如常见的K-Mean"
},
{
"path": "周志华《Machine Learning》学习笔记(4)--线性模型.md",
"chars": 4634,
"preview": "笔记的前一部分主要是对机器学习预备知识的概括,包括机器学习的定义/术语、学习器性能的评估/度量以及比较,本篇之后将主要对具体的学习算法进行理解总结,本篇则主要是第3章的内容--线性模型。\n\n#**3、线性模型**\n\n谈及线性模型,其实我们很"
},
{
"path": "周志华《Machine Learning》学习笔记(5)--决策树.md",
"chars": 3887,
"preview": "上篇主要介绍和讨论了线性模型。首先从最简单的最小二乘法开始,讨论输入属性有一个和多个的情形,接着通过广义线性模型延伸开来,将预测连续值的回归问题转化为分类问题,从而引入了对数几率回归,最后线性判别分析LDA将样本点进行投影,多分类问题实质上"
},
{
"path": "周志华《Machine Learning》学习笔记(6)--神经网络.md",
"chars": 5942,
"preview": "上篇主要讨论了决策树算法。首先从决策树的基本概念出发,引出决策树基于树形结构进行决策,进一步介绍了构造决策树的递归流程以及其递归终止条件,在递归的过程中,划分属性的选择起到了关键作用,因此紧接着讨论了三种评估属性划分效果的经典算法,介绍了剪"
},
{
"path": "周志华《Machine Learning》学习笔记(7)--支持向量机.md",
"chars": 6235,
"preview": "写在前面的话:距离上篇博客竟过去快一个月了,写完神经网络博客正式进入考试模式,几次考试+几篇报告下来弄得心颇不宁静了,今日定下来看到一句鸡血:Tomorrow is another due!也许生活就需要一些deadline~~\n\n上篇主要"
},
{
"path": "周志华《Machine Learning》学习笔记(8)--贝叶斯分类器.md",
"chars": 3259,
"preview": "上篇主要介绍和讨论了支持向量机。从最初的分类函数,通过最大化分类间隔,max(1/||w||),min(1/2||w||^2),凸二次规划,朗格朗日函数,对偶问题,一直到最后的SMO算法求解,都为寻找一个最优解。接着引入核函数将低维空间映射"
},
{
"path": "周志华《Machine Learning》学习笔记(9)--EM算法.md",
"chars": 2393,
"preview": "上篇主要介绍了贝叶斯分类器,从贝叶斯公式到贝叶斯决策论,再到通过极大似然法估计类条件概率,贝叶斯分类器的训练就是参数估计的过程。朴素贝叶斯则是“属性条件独立性假设”下的特例,它避免了假设属性联合分布过于经验性和训练集不足引起参数估计较大偏差"
}
]
About this extraction
This page contains the full source code of the Vay-keen/Machine-learning-learning-notes GitHub repository, extracted and formatted as plain text for AI agents and large language models (LLMs). The extraction includes 18 files (81.7 KB), approximately 55.5k tokens. Use this with OpenClaw, Claude, ChatGPT, Cursor, Windsurf, or any other AI tool that accepts text input. You can copy the full output to your clipboard or download it as a .txt file.
Extracted by GitExtract — free GitHub repo to text converter for AI. Built by Nikandr Surkov.