\n  \n
\n
\n\n## 项目介绍\n\n卡卡字幕助手(VideoCaptioner)操作简单且无需高配置,支持 API 和本地离线两种方式进行语音识别,利用大语言模型进行字幕智能断句、校正、翻译,字幕视频全流程一键处理。为视频配上效果惊艳的字幕。\n\n- 支持词级时间戳与 VAD 语音活动检测,识别准确率高\n- 基于 LLM 的语义理解,自动将逐字字幕重组为自然流畅的句子段落\n- 结合上下文的 AI 翻译,支持反思优化机制,译文地道专业\n- 支持批量视频字幕合成,提升处理效率\n- 直观的字幕编辑查看界面,支持实时预览和快捷编辑\n\n## 界面预览\n\n卡卡字幕助手
\nVideoCaptioner
\n一款基于大语言模型(LLM)的视频字幕处理助手,支持语音识别、字幕断句、优化、翻译全流程处理
\n\n简体中文 / [正體中文](./legacy-docs/README_TW.md) / [English](./legacy-docs/README_EN.md) / [日本語](./legacy-docs/README_JA.md)\n\n📚 **[在线文档](https://weifeng2333.github.io/VideoCaptioner/)** | 🚀 **[快速开始](https://weifeng2333.github.io/VideoCaptioner/guide/getting-started)** | ⚙️ **[配置指南](https://weifeng2333.github.io/VideoCaptioner/config/llm)**\n\n\n  \n
\n
\n\n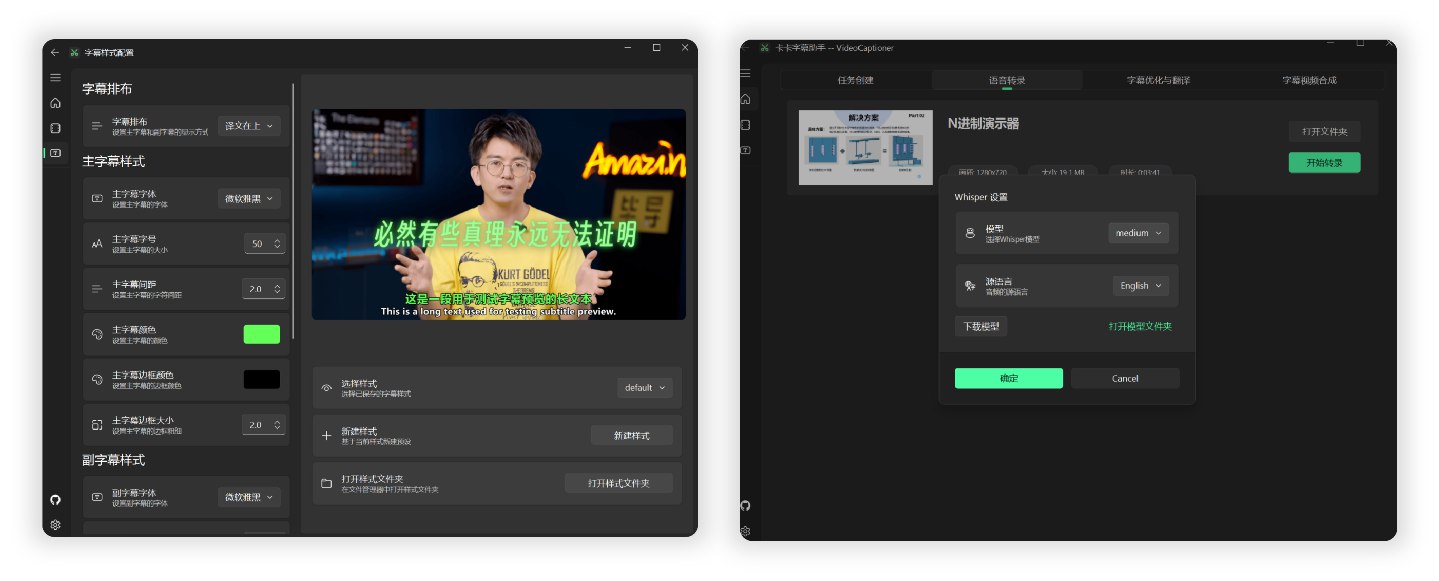\n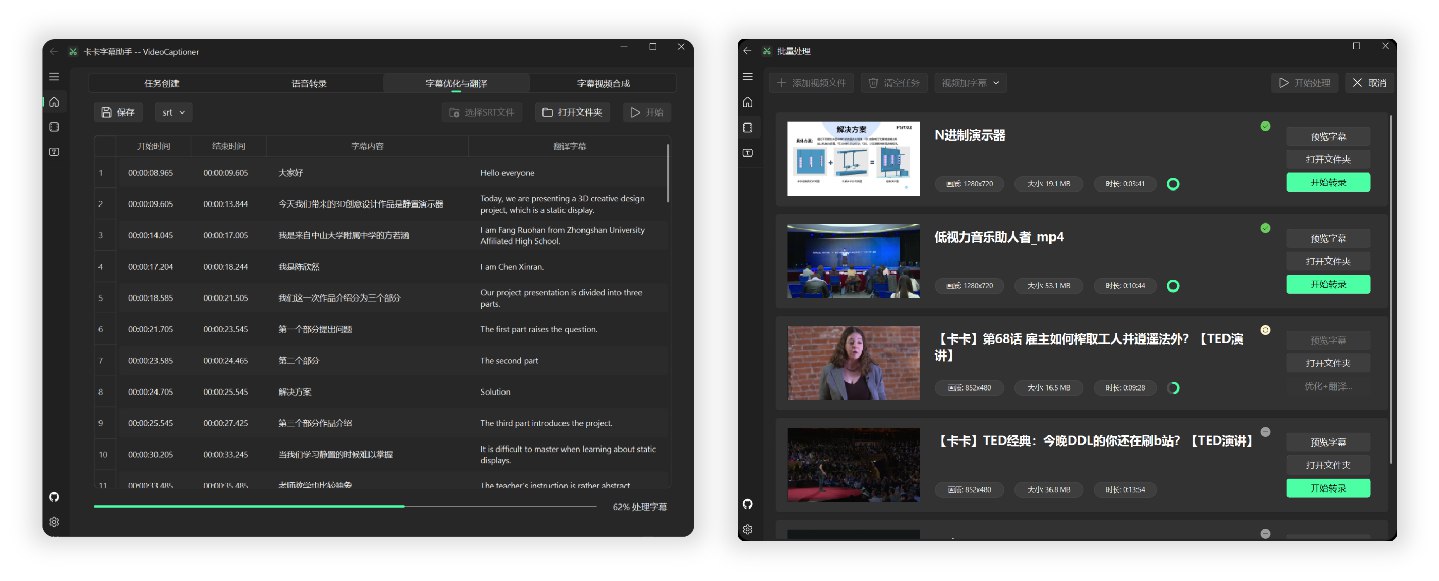\n\n## 测试\n\n全流程处理一个14分钟1080P的 [B站英文 TED 视频](https://www.bilibili.com/video/BV1jT411X7Dz),调用本地 Whisper 模型进行语音识别,使用 `gpt-5-mini` 模型优化和翻译为中文,总共消耗时间约 **4 分钟**。\n\n近后台计算,模型优化和翻译消耗费用不足 ¥0.01(以OpenAI官方价格为计算)\n\n具体字幕和视频合成的效果的测试结果图片,请参考 [TED视频测试](./legacy-docs/test.md)\n\n## 快速开始\n\n### Windows 用户\n\n#### 方式一:使用打包程序(推荐)\n\n软件较为轻量,打包大小不足 60M,已集成所有必要环境,下载后可直接运行。\n\n1. 从 [Release](https://github.com/WEIFENG2333/VideoCaptioner/releases) 页面下载最新版本的可执行程序。或者:[蓝奏盘下载](https://wwwm.lanzoue.com/ii14G2pdsbej)\n\n2. 打开安装包进行安装\n\n3. LLM API 配置,(用于字幕断句、校正),可使用[本项目的中转站](https://api.videocaptioner.cn)\n\n4. 翻译配置,选择是否启用翻译,翻译服务(默认使用微软翻译,质量一般,推荐配置自己的 API KEY 使用大模型翻译)\n\n5. 语音识别配置(默认使用B接口网络调用语音识别服务,中英以外的语言请使用本地转录)\n\n### macOS 用户\n\n#### 一键安装运行(推荐)\n\n```bash\n# 方式一:直接运行(自动安装 uv、克隆项目、安装相关依赖)\ncurl -fsSL https://raw.githubusercontent.com/WEIFENG2333/VideoCaptioner/main/scripts/run.sh | bash\n\n# 方式二:先克隆再运行\ngit clone https://github.com/WEIFENG2333/VideoCaptioner.git\ncd VideoCaptioner\n./scripts/run.sh\n```\n\n脚本会自动:\n\n1. 安装 [uv](https://docs.astral.sh/uv/) 包管理器(如果未安装)\n2. 克隆项目到 `~/VideoCaptioner`(如果不在项目目录中运行)\n3. 安装所有 Python 依赖\n4. 启动应用\n\n\n\n
\n\n### 开发者指南\n\n```bash\n# 安装依赖(包括开发依赖)\nuv sync\n\n# 运行应用\nuv run python main.py\n\n# 类型检查\nuv run pyright\n\n# 代码检查\nuv run ruff check .\n```\n\n## 基本配置\n\n### 1. LLM API 配置说明\n\nLLM 大模型是用来字幕段句、字幕优化、以及字幕翻译(如果选择了LLM 大模型翻译)。\n\n| 配置项 | 说明 |\n| -------------- | ------------------------------------------------------------------------------------------------------------------------------------------------- |\n| SiliconCloud | [SiliconCloud 官网](https://cloud.siliconflow.cn/i/onCHcaDx)配置方法请参考[配置文档](https://weifeng2333.github.io/VideoCaptioner/config/llm)手动安装步骤
\n\n#### 1. 安装 uv 包管理器\n\n```bash\ncurl -LsSf https://astral.sh/uv/install.sh | sh\n```\n\n#### 2. 安装系统依赖(macOS)\n\n```bash\nbrew install ffmpeg\n```\n\n#### 3. 克隆并运行\n\n```bash\ngit clone https://github.com/WEIFENG2333/VideoCaptioner.git\ncd VideoCaptioner\nuv sync # 安装依赖\nuv run python main.py # 运行\n```\n\n该并发较低,建议把线程设置为5以下。 |\n| DeepSeek | [DeepSeek 官网](https://platform.deepseek.com),建议使用 `deepseek-v3` 模型,
官方网站最近服务好像并不太稳定。 |\n| OpenAI兼容接口 | 如果有其他服务商的API,可直接在软件中填写。base_url 和api_key [VideoCaptioner API](https://api.videocaptioner.cn) |\n\n注:如果用的 API 服务商不支持高并发,请在软件设置中将“线程数”调低,避免请求错误。\n\n---\n\n如果希望高并发,或者希望在在软件内使用使用 OpenAI 或者 Claude 等优质大模型进行字幕校正和翻译。\n\n可使用本项目的✨LLM API中转站✨: [https://api.videocaptioner.cn](https://api.videocaptioner.cn)\n\n其支持高并发,性价比极高,且有国内外大量模型可挑选。\n\n注册获取key之后,设置中按照下面配置:\n\nBaseURL: `https://api.videocaptioner.cn/v1`\n\nAPI-key: `个人中心-API 令牌页面自行获取。`\n\n💡 模型选择建议 (本人在各质量层级中精选出的高性价比模型):\n\n- 高质量之选: `gemini-3-pro`、`claude-sonnet-4-5-20250929` (耗费比例:3)\n\n- 较高质量之选: `gpt-5-2025-08-07`、 `claude-haiku-4-5-20251001` (耗费比例:1.2)\n\n- 中质量之选: `gpt-5-mini`、`gemini-3-flash` (耗费比例:0.3)\n\n本站支持超高并发,软件中线程数直接拉满即可~ 处理速度非常快~\n\n更详细的API配置教程:[中转站配置](https://weifeng2333.github.io/VideoCaptioner/config/llm)\n\n---\n\n## 2. 翻译配置\n\n| 配置项 | 说明 |\n| -------------- | ----------------------------------------------------------------------------------------------------------------------------- |\n| LLM 大模型翻译 | 🌟 翻译质量最好的选择。使用 AI 大模型进行翻译,能更好理解上下文,翻译更自然。需要在设置中配置 LLM API(比如 OpenAI、DeepSeek 等) |\n| 微软翻译 | 使用微软的翻译服务, 速度非常快 |\n| 谷歌翻译 | 谷歌的翻译服务,速度快,但需要能访问谷歌的网络环境 |\n\n推荐使用 `LLM 大模型翻译` ,翻译质量最好。\n\n### 3. 语音识别接口说明\n\n| 接口名称 | 支持语言 | 运行方式 | 说明 |\n| ---------------- | -------------------------------------------------- | -------- | ----------------------------------------------------------------------------------------------------------------- |\n| B接口 | 仅支持中文、英文 | 在线 | 免费、速度较快 |\n| J接口 | 仅支持中文、英文 | 在线 | 免费、速度较快 |\n| WhisperCpp | 中文、日语、韩语、英文等 99 种语言,外语效果较好 | 本地 | (实际使用不稳定)需要下载转录模型
中文建议medium以上模型
英文等使用较小模型即可达到不错效果。 |\n| fasterWhisper 👍 | 中文、英文等多99种语言,外语效果优秀,时间轴更准确 | 本地 | (🌟推荐🌟)需要下载程序和转录模型
支持CUDA,速度更快,转录准确。
超级准确的时间戳字幕。
仅支持 window |\n\n### 4. 本地 Whisper 语音识别模型\n\nWhisper 版本有 WhisperCpp 和 fasterWhisper(推荐) 两种,后者效果更好,都需要自行在软件内下载模型。\n\n| 模型 | 磁盘空间 | 内存占用 | 说明 |\n| ----------- | -------- | -------- | ----------------------------------- |\n| Tiny | 75 MiB | ~273 MB | 转录很一般,仅用于测试 |\n| Small | 466 MiB | ~852 MB | 英文识别效果已经不错 |\n| Medium | 1.5 GiB | ~2.1 GB | 中文识别建议至少使用此版本 |\n| Large-v2 👍 | 2.9 GiB | ~3.9 GB | 效果好,配置允许情况推荐使用 |\n| Large-v3 | 2.9 GiB | ~3.9 GB | 社区反馈可能会出现幻觉/字幕重复问题 |\n\n推荐模型: `Large-v2` 稳定且质量较好。\n\n\n### 5. 文稿匹配\n\n- 在\"字幕优化与翻译\"页面,包含\"文稿匹配\"选项,支持以下**一种或者多种**内容,辅助校正字幕和翻译:\n\n| 类型 | 说明 | 填写示例 |\n| ---------- | ------------------------------------ | ------------------------------------------------------------------------------------------------------------------------------------------------------- |\n| 术语表 | 专业术语、人名、特定词语的修正对照表 | 机器学习->Machine Learning
马斯克->Elon Musk
打call -> 应援
图灵斑图
公交车悖论 |\n| 原字幕文稿 | 视频的原有文稿或相关内容 | 完整的演讲稿、课程讲义等 |\n| 修正要求 | 内容相关的具体修正要求 | 统一人称代词、规范专业术语等
填写**内容相关**的要求即可,[示例参考](https://github.com/WEIFENG2333/VideoCaptioner/issues/59#issuecomment-2495849752) |\n\n- 如果需要文稿进行字幕优化辅助,全流程处理时,先填写文稿信息,再进行开始任务处理\n- 注意: 使用上下文参数量不高的小型LLM模型时,建议控制文稿内容在1千字内,如果使用上下文较大的模型,则可以适当增加文稿内容。\n\n无特殊需求,可不填写。\n\n### 6. Cookie 配置说明\n\n如果使用URL下载功能时,如果遇到以下情况:\n\n1. 下载视频网站需要登录信息才可以下载;\n2. 只能下载较低分辨率的视频;\n3. 网络条件较差时需要验证;\n\n- 请参考 [Cookie 配置说明](https://weifeng2333.github.io/VideoCaptioner/guide/cookies-config) 获取Cookie信息,并将cookies.txt文件放置到软件安装目录的 `AppData` 目录下,即可正常下载高质量视频。\n\n## 软件流程介绍\n\n程序简单的处理流程如下:\n\n```\n语音识别转录 -> 字幕断句(可选) -> 字幕优化翻译(可选) -> 字幕视频合成\n```\n\n## 软件主要功能\n\n软件利用大语言模型(LLM)在理解上下文方面的优势,对语音识别生成的字幕进一步处理。有效修正错别字、统一专业术语,让字幕内容更加准确连贯,为用户带来出色的观看体验!\n\n#### 1. 多平台视频下载与处理\n\n- 支持国内外主流视频平台(B站、Youtube、小红书、TikTok、X、西瓜视频、抖音等)\n- 自动提取视频原有字幕处理\n\n#### 2. 专业的语音识别引擎\n\n- 提供多种接口在线识别,效果媲美剪映(免费、高速)\n- 支持本地Whisper模型(保护隐私、可离线)\n\n#### 3. 字幕智能纠错\n\n- 自动优化专业术语、代码片段和数学公式格式\n- 上下文进行断句优化,提升阅读体验\n- 支持文稿提示,使用原有文稿或者相关提示优化字幕断句\n\n#### 4. 高质量字幕翻译\n\n- 结合上下文的智能翻译,确保译文兼顾全文\n- 通过Prompt指导大模型反思翻译,提升翻译质量\n- 使用序列模糊匹配算法、保证时间轴完全一致\n\n#### 5. 字幕样式调整\n\n- 丰富的字幕样式模板(科普风、新闻风、番剧风等等)\n- 多种格式字幕视频(SRT、ASS、VTT、TXT)\n\n针对小白用户,对一些软件内的选项说明:\n\n#### 1. 语音转录页面\n\n- `VAD过滤`:开启后,VAD(语音活动检测)将过滤无人声的语音片段,从而减少幻觉现象。建议保持默认开启状态。如果不懂,其他VAD选项建议直接保持默认即可。\n\n- `音频分离`:开启后,使用MDX-Net进行降噪处理,能够有效分离人声和背景音乐,从而提升音频质量。建议只在嘈杂的视频中开启。\n\n#### 2. 字幕优化与翻译页面\n\n- `智能断句`:开启后,全流程处理时生成字级时间戳,然后通过LLM大模型进行断句,从而在视频有更完美的观看体验。有按照句子断句和按照语义断句两种模式。可根据自己的需求配置。\n\n- `字幕校正`:开启后,会通过LLM大模型对字幕内容进行校正(如:英文单词大小写、标点符号、错别字、数学公式和代码的格式等),提升字幕的质量。\n\n- `反思翻译`:开启后,会通过LLM大模型进行反思翻译,提升翻译的质量。相应的会增加请求的时间和消耗的Token。(选项在 设置页-LLM大模型翻译-反思翻译 中开启。)\n\n- `文稿提示`:填写后,这部分也将作为提示词发送给大模型,辅助字幕优化和翻译。\n\n#### 3. 字幕视频合成页面\n\n- `视频合成`:开启后,会根据合成字幕视频;关闭将跳过视频合成的流程。\n\n- `软字幕`:开启后,字幕不会烧录到视频中,处理速度极快。但是软字幕需要一些播放器(如PotPlayer)支持才可以进行显示播放。而且软字幕的样式不是软件内调整的字幕样式,而是播放器默认的白色样式。\n\n项目主要目录结构说明如下:\n\n```\nVideoCaptioner/\n├── app/ # 应用源代码目录\n│ ├── common/ # 公共模块(配置、信号总线)\n│ ├── components/ # UI 组件\n│ ├── core/ # 核心业务逻辑(ASR、翻译、优化等)\n│ ├── thread/ # 异步线程\n│ └── view/ # 界面视图\n├── resource/ # 资源文件目录\n│ ├── assets/ # 图标、Logo 等\n│ ├── bin/ # 二进制程序(FFmpeg、Whisper 等)\n│ ├── fonts/ # 字体文件\n│ ├── subtitle_style/ # 字幕样式模板\n│ └── translations/ # 多语言翻译文件\n├── work-dir/ # 工作目录(处理完成的视频和字幕)\n├── AppData/ # 应用数据目录\n│ ├── cache/ # 缓存目录(转录、LLM 请求)\n│ ├── models/ # Whisper 模型文件\n│ ├── logs/ # 日志文件\n│ └── settings.json # 用户设置\n├── scripts/ # 安装和运行脚本\n├── main.py # 程序入口\n└── pyproject.toml # 项目配置和依赖\n```\n\n## 📝 说明\n\n1. 字幕断句的质量对观看体验至关重要。软件能将逐字字幕智能重组为符合自然语言习惯的段落,并与视频画面完美同步。\n\n2. 在处理过程中,仅向大语言模型发送文本内容,不包含时间轴信息,这大大降低了处理开销。\n\n3. 在翻译环节,我们采用吴恩达提出的\"翻译-反思-翻译\"方法论。这种迭代优化的方式确保了翻译的准确性。\n\n4. 填入 YouTube 链接时进行处理时,会自动下载视频的字幕,从而省去转录步骤,极大地节省操作时间。\n\n## 🤝 贡献指南\n\n项目在不断完善中,如果在使用过程遇到的Bug,欢迎提交 [Issue](https://github.com/WEIFENG2333/VideoCaptioner/issues) 和 Pull Request 帮助改进项目。\n\n## 📝 更新日志\n\n查看完整的更新历史,请访问 [CHANGELOG.md](./CHANGELOG.md)\n\n## 💖 支持作者\n\n如果觉得项目对你有帮助,可以给项目点个Star!\n\n
\n
\n\n## ⭐ Star History\n\n[](https://star-history.com/#WEIFENG2333/VideoCaptioner&Date)\n"
},
{
"path": "app/__init__.py",
"content": ""
},
{
"path": "app/common/config.py",
"content": "# coding:utf-8\nfrom enum import Enum\n\nfrom PyQt5.QtCore import QLocale\nfrom PyQt5.QtGui import QColor\nfrom qfluentwidgets import (\n BoolValidator,\n ConfigItem,\n ConfigSerializer,\n EnumSerializer,\n FolderValidator,\n OptionsConfigItem,\n OptionsValidator,\n QConfig,\n RangeConfigItem,\n RangeValidator,\n Theme,\n qconfig,\n)\n\nfrom app.config import SETTINGS_PATH, WORK_PATH\nfrom app.core.utils.platform_utils import get_available_transcribe_models\n\nfrom ..core.entities import (\n FasterWhisperModelEnum,\n LLMServiceEnum,\n SubtitleLayoutEnum,\n SubtitleRenderModeEnum,\n TranscribeLanguageEnum,\n TranscribeModelEnum,\n TranscribeOutputFormatEnum,\n TranslatorServiceEnum,\n VadMethodEnum,\n VideoQualityEnum,\n WhisperModelEnum,\n)\nfrom ..core.translate.types import TargetLanguage\n\n\nclass Language(Enum):\n \"\"\"软件语言\"\"\"\n\n CHINESE_SIMPLIFIED = QLocale(QLocale.Chinese, QLocale.China)\n CHINESE_TRADITIONAL = QLocale(QLocale.Chinese, QLocale.HongKong)\n ENGLISH = QLocale(QLocale.English)\n AUTO = QLocale()\n\n\nclass LanguageSerializer(ConfigSerializer):\n \"\"\"Language serializer\"\"\"\n\n def serialize(self, language):\n return language.value.name() if language != Language.AUTO else \"Auto\"\n\n def deserialize(self, value: str):\n return Language(QLocale(value)) if value != \"Auto\" else Language.AUTO\n\n\nclass PlatformAwareTranscribeModelValidator(OptionsValidator):\n \"\"\"平台相关的转录模型验证器,在 macOS 上自动过滤掉 FasterWhisper\"\"\"\n\n def __init__(self):\n # 不调用父类的 __init__,因为我们要自定义 options\n self._options = get_available_transcribe_models()\n\n @property\n def options(self):\n return self._options\n\n def validate(self, value):\n return value in self._options\n\n def correct(self, value):\n return value if self.validate(value) else self._options[0]\n\n\nclass Config(QConfig):\n \"\"\"应用配置\"\"\"\n\n # LLM配置\n llm_service = OptionsConfigItem(\n \"LLM\",\n \"LLMService\",\n LLMServiceEnum.OPENAI,\n OptionsValidator(LLMServiceEnum),\n EnumSerializer(LLMServiceEnum),\n )\n\n openai_model = ConfigItem(\"LLM\", \"OpenAI_Model\", \"gpt-4o-mini\")\n openai_api_key = ConfigItem(\"LLM\", \"OpenAI_API_Key\", \"\")\n openai_api_base = ConfigItem(\"LLM\", \"OpenAI_API_Base\", \"https://api.openai.com/v1\")\n\n silicon_cloud_model = ConfigItem(\"LLM\", \"SiliconCloud_Model\", \"gpt-4o-mini\")\n silicon_cloud_api_key = ConfigItem(\"LLM\", \"SiliconCloud_API_Key\", \"\")\n silicon_cloud_api_base = ConfigItem(\n \"LLM\", \"SiliconCloud_API_Base\", \"https://api.siliconflow.cn/v1\"\n )\n\n deepseek_model = ConfigItem(\"LLM\", \"DeepSeek_Model\", \"deepseek-chat\")\n deepseek_api_key = ConfigItem(\"LLM\", \"DeepSeek_API_Key\", \"\")\n deepseek_api_base = ConfigItem(\n \"LLM\", \"DeepSeek_API_Base\", \"https://api.deepseek.com/v1\"\n )\n\n ollama_model = ConfigItem(\"LLM\", \"Ollama_Model\", \"llama2\")\n ollama_api_key = ConfigItem(\"LLM\", \"Ollama_API_Key\", \"ollama\")\n ollama_api_base = ConfigItem(\"LLM\", \"Ollama_API_Base\", \"http://localhost:11434/v1\")\n\n lm_studio_model = ConfigItem(\"LLM\", \"LmStudio_Model\", \"qwen2.5:7b\")\n lm_studio_api_key = ConfigItem(\"LLM\", \"LmStudio_API_Key\", \"lmstudio\")\n lm_studio_api_base = ConfigItem(\n \"LLM\", \"LmStudio_API_Base\", \"http://localhost:1234/v1\"\n )\n\n gemini_model = ConfigItem(\"LLM\", \"Gemini_Model\", \"gemini-pro\")\n gemini_api_key = ConfigItem(\"LLM\", \"Gemini_API_Key\", \"\")\n gemini_api_base = ConfigItem(\n \"LLM\",\n \"Gemini_API_Base\",\n \"https://generativelanguage.googleapis.com/v1beta/openai/\",\n )\n\n chatglm_model = ConfigItem(\"LLM\", \"ChatGLM_Model\", \"glm-4\")\n chatglm_api_key = ConfigItem(\"LLM\", \"ChatGLM_API_Key\", \"\")\n chatglm_api_base = ConfigItem(\n \"LLM\", \"ChatGLM_API_Base\", \"https://open.bigmodel.cn/api/paas/v4\"\n )\n\n # ------------------- 翻译配置 -------------------\n translator_service = OptionsConfigItem(\n \"Translate\",\n \"TranslatorServiceEnum\",\n TranslatorServiceEnum.BING,\n OptionsValidator(TranslatorServiceEnum),\n EnumSerializer(TranslatorServiceEnum),\n )\n need_reflect_translate = ConfigItem(\n \"Translate\", \"NeedReflectTranslate\", False, BoolValidator()\n )\n deeplx_endpoint = ConfigItem(\"Translate\", \"DeeplxEndpoint\", \"\")\n batch_size = RangeConfigItem(\"Translate\", \"BatchSize\", 10, RangeValidator(5, 50))\n thread_num = RangeConfigItem(\"Translate\", \"ThreadNum\", 10, RangeValidator(1, 50))\n\n # ------------------- 转录配置 -------------------\n transcribe_model = OptionsConfigItem(\n \"Transcribe\",\n \"TranscribeModel\",\n TranscribeModelEnum.BIJIAN,\n PlatformAwareTranscribeModelValidator(),\n EnumSerializer(TranscribeModelEnum),\n )\n transcribe_output_format = OptionsConfigItem(\n \"Transcribe\",\n \"OutputFormat\",\n TranscribeOutputFormatEnum.SRT,\n OptionsValidator(TranscribeOutputFormatEnum),\n EnumSerializer(TranscribeOutputFormatEnum),\n )\n transcribe_language = OptionsConfigItem(\n \"Transcribe\",\n \"TranscribeLanguage\",\n TranscribeLanguageEnum.AUTO,\n OptionsValidator(TranscribeLanguageEnum),\n EnumSerializer(TranscribeLanguageEnum),\n )\n\n # ------------------- Whisper Cpp 配置 -------------------\n whisper_model = OptionsConfigItem(\n \"Whisper\",\n \"WhisperModel\",\n WhisperModelEnum.TINY,\n OptionsValidator(WhisperModelEnum),\n EnumSerializer(WhisperModelEnum),\n )\n\n # ------------------- Faster Whisper 配置 -------------------\n faster_whisper_program = ConfigItem(\n \"FasterWhisper\",\n \"Program\",\n \"faster-whisper-xxl.exe\",\n )\n faster_whisper_model = OptionsConfigItem(\n \"FasterWhisper\",\n \"Model\",\n FasterWhisperModelEnum.TINY,\n OptionsValidator(FasterWhisperModelEnum),\n EnumSerializer(FasterWhisperModelEnum),\n )\n faster_whisper_model_dir = ConfigItem(\"FasterWhisper\", \"ModelDir\", \"\")\n faster_whisper_device = OptionsConfigItem(\n \"FasterWhisper\", \"Device\", \"cuda\", OptionsValidator([\"cuda\", \"cpu\"])\n )\n # VAD 参数\n faster_whisper_vad_filter = ConfigItem(\n \"FasterWhisper\", \"VadFilter\", True, BoolValidator()\n )\n faster_whisper_vad_threshold = RangeConfigItem(\n \"FasterWhisper\", \"VadThreshold\", 0.4, RangeValidator(0, 1)\n )\n faster_whisper_vad_method = OptionsConfigItem(\n \"FasterWhisper\",\n \"VadMethod\",\n VadMethodEnum.SILERO_V4,\n OptionsValidator(VadMethodEnum),\n EnumSerializer(VadMethodEnum),\n )\n # 人声提取\n faster_whisper_ff_mdx_kim2 = ConfigItem(\n \"FasterWhisper\", \"FfMdxKim2\", False, BoolValidator()\n )\n # 文本处理参数\n faster_whisper_one_word = ConfigItem(\n \"FasterWhisper\", \"OneWord\", True, BoolValidator()\n )\n # 提示词\n faster_whisper_prompt = ConfigItem(\"FasterWhisper\", \"Prompt\", \"\")\n\n # ------------------- Whisper API 配置 -------------------\n whisper_api_base = ConfigItem(\"WhisperAPI\", \"WhisperApiBase\", \"\")\n whisper_api_key = ConfigItem(\"WhisperAPI\", \"WhisperApiKey\", \"\")\n whisper_api_model = OptionsConfigItem(\"WhisperAPI\", \"WhisperApiModel\", \"\")\n whisper_api_prompt = ConfigItem(\"WhisperAPI\", \"WhisperApiPrompt\", \"\")\n\n # ------------------- 字幕配置 -------------------\n need_optimize = ConfigItem(\"Subtitle\", \"NeedOptimize\", False, BoolValidator())\n need_translate = ConfigItem(\"Subtitle\", \"NeedTranslate\", False, BoolValidator())\n need_split = ConfigItem(\"Subtitle\", \"NeedSplit\", False, BoolValidator())\n target_language = OptionsConfigItem(\n \"Subtitle\",\n \"TargetLanguage\",\n TargetLanguage.SIMPLIFIED_CHINESE,\n OptionsValidator(TargetLanguage),\n EnumSerializer(TargetLanguage),\n )\n max_word_count_cjk = ConfigItem(\n \"Subtitle\", \"MaxWordCountCJK\", 28, RangeValidator(8, 100)\n )\n max_word_count_english = ConfigItem(\n \"Subtitle\", \"MaxWordCountEnglish\", 20, RangeValidator(8, 100)\n )\n custom_prompt_text = ConfigItem(\"Subtitle\", \"CustomPromptText\", \"\")\n\n # ------------------- 字幕合成配置 -------------------\n soft_subtitle = ConfigItem(\"Video\", \"SoftSubtitle\", False, BoolValidator())\n need_video = ConfigItem(\"Video\", \"NeedVideo\", True, BoolValidator())\n video_quality = OptionsConfigItem(\n \"Video\",\n \"VideoQuality\",\n VideoQualityEnum.MEDIUM,\n OptionsValidator(VideoQualityEnum),\n EnumSerializer(VideoQualityEnum),\n )\n use_subtitle_style = ConfigItem(\"Video\", \"UseSubtitleStyle\", False, BoolValidator())\n\n # ------------------- 字幕样式配置 -------------------\n subtitle_style_name = ConfigItem(\"SubtitleStyle\", \"StyleName\", \"default\")\n subtitle_layout = OptionsConfigItem(\n \"SubtitleStyle\",\n \"Layout\",\n SubtitleLayoutEnum.TRANSLATE_ON_TOP,\n OptionsValidator(SubtitleLayoutEnum),\n EnumSerializer(SubtitleLayoutEnum),\n )\n subtitle_preview_image = ConfigItem(\"SubtitleStyle\", \"PreviewImage\", \"\")\n\n # 字幕渲染模式\n subtitle_render_mode = OptionsConfigItem(\n \"SubtitleStyle\",\n \"RenderMode\",\n SubtitleRenderModeEnum.ROUNDED_BG,\n OptionsValidator(SubtitleRenderModeEnum),\n EnumSerializer(SubtitleRenderModeEnum),\n )\n\n # 圆角背景模式配置\n rounded_bg_font_name = ConfigItem(\"RoundedBgStyle\", \"FontName\", \"LXGW WenKai\")\n rounded_bg_font_size = RangeConfigItem(\n \"RoundedBgStyle\", \"FontSize\", 52, RangeValidator(16, 120)\n )\n # 背景色:深灰半透明 (R=25, G=25, B=25, A=200)\n rounded_bg_color = ConfigItem(\"RoundedBgStyle\", \"BgColor\", \"#191919C8\")\n rounded_bg_text_color = ConfigItem(\"RoundedBgStyle\", \"TextColor\", \"#FFFFFF\")\n rounded_bg_corner_radius = RangeConfigItem(\n \"RoundedBgStyle\", \"CornerRadius\", 12, RangeValidator(0, 50)\n )\n rounded_bg_padding_h = RangeConfigItem(\n \"RoundedBgStyle\", \"PaddingH\", 28, RangeValidator(4, 100)\n )\n rounded_bg_padding_v = RangeConfigItem(\n \"RoundedBgStyle\", \"PaddingV\", 14, RangeValidator(4, 50)\n )\n rounded_bg_margin_bottom = RangeConfigItem(\n \"RoundedBgStyle\", \"MarginBottom\", 60, RangeValidator(20, 300)\n )\n rounded_bg_line_spacing = RangeConfigItem(\n \"RoundedBgStyle\", \"LineSpacing\", 10, RangeValidator(0, 50)\n )\n rounded_bg_letter_spacing = RangeConfigItem(\n \"RoundedBgStyle\", \"LetterSpacing\", 0, RangeValidator(0, 20)\n )\n\n # ------------------- 保存配置 -------------------\n work_dir = ConfigItem(\"Save\", \"Work_Dir\", WORK_PATH, FolderValidator())\n\n # ------------------- 软件页面配置 -------------------\n micaEnabled = ConfigItem(\"MainWindow\", \"MicaEnabled\", False, BoolValidator())\n dpiScale = OptionsConfigItem(\n \"MainWindow\",\n \"DpiScale\",\n \"Auto\",\n OptionsValidator([1, 1.25, 1.5, 1.75, 2, \"Auto\"]),\n restart=True,\n )\n language = OptionsConfigItem(\n \"MainWindow\",\n \"Language\",\n Language.AUTO,\n OptionsValidator(Language),\n LanguageSerializer(),\n restart=True,\n )\n\n # ------------------- 更新配置 -------------------\n checkUpdateAtStartUp = ConfigItem(\n \"Update\", \"CheckUpdateAtStartUp\", True, BoolValidator()\n )\n\n # ------------------- 缓存配置 -------------------\n cache_enabled = ConfigItem(\"Cache\", \"CacheEnabled\", True, BoolValidator())\n\n\ncfg = Config()\ncfg.themeMode.value = Theme.DARK\ncfg.themeColor.value = QColor(\"#ff28f08b\")\nqconfig.load(SETTINGS_PATH, cfg)\n"
},
{
"path": "app/common/signal_bus.py",
"content": "from PyQt5.QtCore import QObject, QUrl, pyqtSignal\n\n\nclass SignalBus(QObject):\n # 字幕排布信号\n subtitle_layout_changed = pyqtSignal(str)\n # 字幕优化信号\n subtitle_optimization_changed = pyqtSignal(bool)\n # 字幕翻译信号\n subtitle_translation_changed = pyqtSignal(bool)\n # 翻译语言\n target_language_changed = pyqtSignal(str)\n # 转录模型\n transcription_model_changed = pyqtSignal(str)\n # 软字幕信号\n soft_subtitle_changed = pyqtSignal(bool)\n # 视频合成信号\n need_video_changed = pyqtSignal(bool)\n # 视频质量信号\n video_quality_changed = pyqtSignal(str)\n # 使用样式信号\n use_subtitle_style_changed = pyqtSignal(bool)\n # 渲染模式变更信号\n subtitle_render_mode_changed = pyqtSignal(str)\n\n # 新增视频控制相关信号\n video_play = pyqtSignal() # 播放信号\n video_pause = pyqtSignal() # 暂停信号\n video_stop = pyqtSignal() # 停止信号\n video_source_changed = pyqtSignal(QUrl) # 视频源改变信号\n video_segment_play = pyqtSignal(int, int) # 播放片段信号,参数为开始和结束时间(ms)\n video_subtitle_added = pyqtSignal(str) # 添加字幕文件信号\n\n # 新增视频控制相关方法\n def play_video(self):\n \"\"\"触发视频播放\"\"\"\n self.video_play.emit()\n\n def pause_video(self):\n \"\"\"触发视频暂停\"\"\"\n self.video_pause.emit()\n\n def stop_video(self):\n \"\"\"触发视频停止\"\"\"\n self.video_stop.emit()\n\n def set_video_source(self, url: QUrl):\n \"\"\"设置视频源\n\n Args:\n url: 视频文件的URL\n \"\"\"\n self.video_source_changed.emit(url)\n\n def play_video_segment(self, start_time: int, end_time: int):\n \"\"\"播放指定时间段的视频\n\n Args:\n start_time: 开始时间(毫秒)\n end_time: 结束时间(毫秒)\n \"\"\"\n self.video_segment_play.emit(start_time, end_time)\n\n def add_subtitle(self, subtitle_file: str):\n \"\"\"添加字幕文件\n\n Args:\n subtitle_file: 字幕文件路径\n \"\"\"\n self.video_subtitle_added.emit(subtitle_file)\n\n\nsignalBus = SignalBus()\n"
},
{
"path": "app/components/DonateDialog.py",
"content": "import os\n\nfrom PyQt5.QtCore import Qt\nfrom PyQt5.QtGui import QPixmap\nfrom PyQt5.QtWidgets import QHBoxLayout, QLabel, QVBoxLayout\nfrom qfluentwidgets import BodyLabel, MessageBoxBase\n\nfrom app.config import ASSETS_PATH\n\n\nclass DonateDialog(MessageBoxBase):\n def __init__(self, parent=None):\n super().__init__(parent)\n # 定义二维码路径\n self.WECHAT_QR_PATH = os.path.join(ASSETS_PATH, \"donate_green.jpg\")\n self.ALIPAY_QR_PATH = os.path.join(ASSETS_PATH, \"donate_blue.jpg\")\n\n self.setup_ui()\n self.setWindowTitle(self.tr(\"支持作者\"))\n\n def setup_ui(self):\n # 创建标题标签\n self.titleLabel = BodyLabel(self.tr(\"感谢支持\"), self)\n\n # 创建说明文本\n self.descLabel = BodyLabel(\n self.tr(\n \"目前本人精力有限,您的支持让我有动力继续折腾这个项目!\\n感谢您对开源事业的热爱与支持!\"\n ),\n self,\n )\n self.descLabel.setAlignment(Qt.AlignCenter) # type: ignore\n\n # 创建水平布局放置两个二维码\n self.qrLayout = QHBoxLayout()\n\n # 创建支付宝二维码标签\n self.alipayContainer = QVBoxLayout()\n self.alipayQR = QLabel()\n self.alipayQR.setPixmap(\n QPixmap(self.ALIPAY_QR_PATH).scaled(\n 300,\n 300,\n Qt.AspectRatioMode.KeepAspectRatio,\n Qt.SmoothTransformation, # type: ignore\n )\n )\n self.alipayLabel = BodyLabel(self.tr(\"支付宝\"))\n self.alipayLabel.setAlignment(Qt.AlignCenter) # type: ignore\n self.alipayContainer.addWidget(self.alipayQR, alignment=Qt.AlignCenter) # type: ignore\n self.alipayContainer.addWidget(self.alipayLabel)\n\n # 创建微信二维码标签\n self.wechatContainer = QVBoxLayout()\n self.wechatQR = QLabel()\n self.wechatQR.setPixmap(\n QPixmap(self.WECHAT_QR_PATH).scaled(\n 300,\n 300,\n Qt.AspectRatioMode.KeepAspectRatio,\n Qt.SmoothTransformation, # type: ignore\n )\n )\n self.wechatLabel = BodyLabel(self.tr(\"微信\"))\n self.wechatLabel.setAlignment(Qt.AlignCenter) # type: ignore\n self.wechatContainer.addWidget(self.wechatQR, alignment=Qt.AlignCenter) # type: ignore\n self.wechatContainer.addWidget(self.wechatLabel)\n\n # 将二维码添加到水平布局\n self.qrLayout.addLayout(self.alipayContainer)\n self.qrLayout.addLayout(self.wechatContainer)\n\n self.viewLayout.setSpacing(30)\n # 添加到主布局\n self.viewLayout.addWidget(self.titleLabel)\n self.viewLayout.addWidget(self.descLabel)\n # 添加垂直间距\n self.viewLayout.addLayout(self.qrLayout)\n\n # 设置对话框最小宽度\n self.widget.setMinimumWidth(800)\n # 设置对话框最小高度\n self.widget.setMinimumHeight(500)\n\n # 隐藏是按钮,只显示取消按钮\n self.yesButton.hide()\n self.cancelButton.setText(self.tr(\"关闭\"))\n"
},
{
"path": "app/components/EditComboBoxSettingCard.py",
"content": "from typing import List, Optional, Union\n\nfrom PyQt5.QtCore import Qt, pyqtSignal\nfrom PyQt5.QtGui import QIcon\nfrom PyQt5.QtWidgets import QCompleter\nfrom qfluentwidgets import EditableComboBox, SettingCard\nfrom qfluentwidgets.common.config import ConfigItem, qconfig\n\n\nclass EditComboBoxSettingCard(SettingCard):\n \"\"\"可编辑的下拉框设置卡片\"\"\"\n\n currentTextChanged = pyqtSignal(str)\n\n def __init__(\n self,\n configItem: ConfigItem,\n icon: Union[str, QIcon],\n title: str,\n content: Optional[str] = None,\n items: Optional[List[str]] = None,\n parent=None,\n ):\n super().__init__(icon, title, content, parent)\n\n self.configItem = configItem\n self.items = items or []\n\n # 创建可编辑的组合框\n self.comboBox = EditableComboBox(self)\n for item in self.items:\n self.comboBox.addItem(item)\n\n # 设置搜索功能\n self._setupCompleter()\n\n # 设置布局\n self.hBoxLayout.addWidget(self.comboBox, 1, Qt.AlignRight) # type: ignore\n self.hBoxLayout.addSpacing(16)\n\n # 设置最小宽度\n self.comboBox.setMinimumWidth(280)\n\n # 设置初始值\n self.setValue(qconfig.get(configItem))\n\n # 连接信号\n self.comboBox.currentTextChanged.connect(self.__onTextChanged)\n configItem.valueChanged.connect(self.setValue)\n\n def _setupCompleter(self):\n \"\"\"设置搜索自动完成功能\"\"\"\n if not self.items:\n return\n\n completer = QCompleter(self.items, self)\n completer.setCaseSensitivity(Qt.CaseInsensitive) # type: ignore # 不区分大小写\n completer.setFilterMode(Qt.MatchContains) # type: ignore # 包含匹配\n self.comboBox.setCompleter(completer)\n\n def __onTextChanged(self, text: str):\n \"\"\"当文本改变时触发\"\"\"\n self.setValue(text)\n self.currentTextChanged.emit(text)\n\n def setValue(self, value: str):\n \"\"\"设置值\"\"\"\n qconfig.set(self.configItem, value)\n self.comboBox.setText(value)\n\n def addItems(self, items: List[str]):\n \"\"\"添加选项\"\"\"\n for item in items:\n self.comboBox.addItem(item)\n self.items.extend(items)\n self._setupCompleter()\n\n def setItems(self, items: List[str]):\n \"\"\"重新设置选项列表\"\"\"\n self.comboBox.clear()\n self.items = items\n for item in items:\n self.comboBox.addItem(item)\n self._setupCompleter()\n"
},
{
"path": "app/components/FasterWhisperSettingWidget.py",
"content": "import os\nimport subprocess\nfrom pathlib import Path\n\nfrom PyQt5.QtCore import Qt, QThread, pyqtSignal\nfrom PyQt5.QtGui import QShowEvent\nfrom PyQt5.QtWidgets import (\n QHBoxLayout,\n QHeaderView,\n QTableWidgetItem,\n QVBoxLayout,\n QWidget,\n)\nfrom qfluentwidgets import (\n BodyLabel,\n ComboBox,\n ComboBoxSettingCard,\n HyperlinkButton,\n HyperlinkCard,\n InfoBar,\n InfoBarPosition,\n MessageBoxBase,\n ProgressBar,\n PushButton,\n SettingCardGroup,\n SingleDirectionScrollArea,\n SubtitleLabel,\n SwitchSettingCard,\n TableItemDelegate,\n TableWidget,\n)\nfrom qfluentwidgets import FluentIcon as FIF\n\nfrom app.common.config import cfg\nfrom app.components.LineEditSettingCard import LineEditSettingCard\nfrom app.components.SpinBoxSettingCard import DoubleSpinBoxSettingCard\nfrom app.config import BIN_PATH, MODEL_PATH\nfrom app.core.entities import (\n FasterWhisperModelEnum,\n TranscribeLanguageEnum,\n VadMethodEnum,\n)\nfrom app.core.utils.platform_utils import open_folder\nfrom app.thread.file_download_thread import FileDownloadThread\nfrom app.thread.modelscope_download_thread import ModelscopeDownloadThread\n\n# 在文件开头添加常量定义\nFASTER_WHISPER_PROGRAMS = [\n {\n \"label\": \"GPU(cuda) + CPU 版本\",\n \"value\": \"faster-whisper-gpu.7z\",\n \"type\": \"GPU\",\n \"size\": \"1.35 GB\",\n \"downloadLink\": \"https://modelscope.cn/models/bkfengg/whisper-cpp/resolve/master/Faster-Whisper-XXL_r245.2_windows.7z\",\n },\n {\n \"label\": \"CPU版本\",\n \"value\": \"faster-whisper.exe\",\n \"type\": \"CPU\",\n \"size\": \"78.7 MB\",\n \"downloadLink\": \"https://modelscope.cn/models/bkfengg/whisper-cpp/resolve/master/whisper-faster.exe\",\n },\n]\n\nFASTER_WHISPER_MODELS = [\n {\n \"label\": \"Tiny\",\n \"value\": \"faster-whisper-tiny\",\n \"size\": \"77824\",\n \"downloadLink\": \"https://huggingface.co/Systran/faster-whisper-tiny\",\n \"modelScopeLink\": \"pengzhendong/faster-whisper-tiny\",\n },\n {\n \"label\": \"Base\",\n \"value\": \"faster-whisper-base\",\n \"size\": \"148480\",\n \"downloadLink\": \"https://huggingface.co/Systran/faster-whisper-base\",\n \"modelScopeLink\": \"pengzhendong/faster-whisper-base\",\n },\n {\n \"label\": \"Small\",\n \"value\": \"faster-whisper-small\",\n \"size\": \"495616\",\n \"downloadLink\": \"https://huggingface.co/Systran/faster-whisper-small\",\n \"modelScopeLink\": \"pengzhendong/faster-whisper-small\",\n },\n {\n \"label\": \"Medium\",\n \"value\": \"faster-whisper-medium\",\n \"size\": \"1572864\",\n \"downloadLink\": \"https://huggingface.co/Systran/faster-whisper-medium\",\n \"modelScopeLink\": \"pengzhendong/faster-whisper-medium\",\n },\n {\n \"label\": \"Large-v1\",\n \"value\": \"faster-whisper-large-v1\",\n \"size\": \"3145728\",\n \"downloadLink\": \"https://huggingface.co/Systran/faster-whisper-large-v1\",\n \"modelScopeLink\": \"pengzhendong/faster-whisper-large-v1\",\n },\n {\n \"label\": \"Large-v2\",\n \"value\": \"faster-whisper-large-v2\",\n \"size\": \"3145728\",\n \"downloadLink\": \"https://huggingface.co/Systran/faster-whisper-large-v2\",\n \"modelScopeLink\": \"pengzhendong/faster-whisper-large-v2\",\n },\n {\n \"label\": \"Large-v3\",\n \"value\": \"faster-whisper-large-v3\",\n \"size\": \"3145728\",\n \"downloadLink\": \"https://huggingface.co/Systran/faster-whisper-large-v3\",\n \"modelScopeLink\": \"pengzhendong/faster-whisper-large-v3\",\n },\n {\n \"label\": \"Large-v3-turbo\",\n \"value\": \"faster-whisper-large-v3-turbo\",\n \"size\": \"1720320\",\n \"downloadLink\": \"https://huggingface.co/Systran/faster-whisper-large-v3-turbo\",\n \"modelScopeLink\": \"pengzhendong/faster-whisper-large-v3-turbo\",\n },\n]\n\n\n# 在类外添加这个工具函数\ndef check_faster_whisper_exists() -> tuple[bool, list[str]]:\n \"\"\"检查 faster-whisper 程序是否存在\n\n 检查以下两种情况:\n 1. bin目录下是否有 faster-whisper.exe\n 2. bin目录下是否有 Faster-Whisper-XXL/faster-whisper-xxl.exe\n\n Returns:\n tuple[bool, list[str]]: (是否存在程序, 已安装的版本列表)\n \"\"\"\n bin_path = Path(BIN_PATH)\n installed_versions = []\n\n # 检查 faster-whisper.exe(CPU版本)\n if (bin_path / \"faster-whisper.exe\").exists():\n installed_versions.append(\"CPU\")\n\n # 检查 Faster-Whisper-XXL/faster-whisper-xxl.exe(GPU版本)\n xxl_path = bin_path / \"Faster-Whisper-XXL\" / \"faster-whisper-xxl.exe\"\n if xxl_path.exists():\n installed_versions.extend([\"GPU\", \"CPU\"])\n installed_versions = list(set(installed_versions))\n\n return bool(installed_versions), installed_versions\n\n\n# 添加新的解压线程类\nclass UnzipThread(QThread):\n \"\"\"7z解压线程\"\"\"\n\n finished = pyqtSignal() # 解压完成信号\n error = pyqtSignal(str) # 解压错误信号\n\n def __init__(self, zip_file, extract_path):\n super().__init__()\n self.zip_file = zip_file\n self.extract_path = extract_path\n\n def run(self):\n try:\n subprocess.run(\n [\"7z\", \"x\", self.zip_file, f\"-o{self.extract_path}\", \"-y\"],\n check=True,\n creationflags=subprocess.CREATE_NO_WINDOW if os.name == \"nt\" else 0,\n )\n # 删除压缩包\n os.remove(self.zip_file)\n self.finished.emit()\n except subprocess.CalledProcessError as e:\n self.error.emit(f\"解压失败: {str(e)}\")\n except Exception as e:\n self.error.emit(str(e))\n\n\nclass FasterWhisperDownloadDialog(MessageBoxBase):\n \"\"\"Faster Whisper 下载对话框\"\"\"\n\n # 添加类变量跟踪下载状态\n is_downloading = False\n\n def __init__(self, parent=None, setting_widget=None):\n super().__init__(parent)\n self.widget.setMinimumWidth(600)\n self.program_download_thread = None\n self.model_download_thread = None\n self._setup_ui()\n self._connect_signals()\n self.setting_widget = setting_widget\n\n def _setup_ui(self):\n \"\"\"设置UI\"\"\"\n layout = QVBoxLayout()\n self._setup_program_section(layout)\n layout.addSpacing(20)\n self._setup_model_section(layout)\n self._setup_progress_section(layout)\n\n self.viewLayout.addLayout(layout)\n self.cancelButton.setText(self.tr(\"关闭\"))\n self.yesButton.hide()\n\n def _setup_program_section(self, layout):\n \"\"\"设置程序下载部分UI\"\"\"\n # 标题和按钮的水平布局\n title_layout = QHBoxLayout()\n\n # 标题\n faster_whisper_title = SubtitleLabel(self.tr(\"Faster Whisper 下载\"), self)\n title_layout.addWidget(faster_whisper_title)\n\n # 添加打开文件夹按钮\n open_folder_btn = HyperlinkButton(\"\", self.tr(\"打开程序文件夹\"), parent=self)\n open_folder_btn.setIcon(FIF.FOLDER)\n open_folder_btn.clicked.connect(self._open_program_folder)\n title_layout.addStretch()\n title_layout.addWidget(open_folder_btn)\n\n layout.addLayout(title_layout)\n layout.addSpacing(8)\n\n # 检查已安装的版本\n has_program, installed_versions = check_faster_whisper_exists()\n\n if has_program:\n # 显示已安装版本\n versions_text = \" + \".join(installed_versions)\n program_status = BodyLabel(self.tr(f\"已安装版本: {versions_text}\"), self)\n program_status.setStyleSheet(\"color: green\")\n layout.addWidget(program_status)\n\n # 添加说明标签\n if len(installed_versions) == 1:\n desc_label = BodyLabel(self.tr(\"您可以继续下载其他版本:\"), self)\n layout.addWidget(desc_label)\n else:\n desc_label = BodyLabel(self.tr(\"未下载Faster Whisper 程序\"), self)\n layout.addWidget(desc_label)\n\n # 下载控件\n program_layout = QHBoxLayout()\n self.program_combo = ComboBox(self)\n self.program_combo.setFixedWidth(300)\n self.program_combo.hide()\n\n # 只显示未安装的版本\n for program in FASTER_WHISPER_PROGRAMS:\n version_type = program[\"type\"]\n if version_type not in installed_versions:\n self.program_combo.addItem(f\"{program['label']} ({program['size']})\")\n\n # 如果还有可下载的版本,显示下载控件\n if self.program_combo.count() > 0:\n self.program_combo.show()\n self.program_download_btn = PushButton(self.tr(\"下载程序\"), self)\n self.program_download_btn.clicked.connect(self._start_download)\n program_layout.addWidget(self.program_combo)\n program_layout.addWidget(self.program_download_btn)\n program_layout.addStretch()\n layout.addLayout(program_layout)\n\n def _setup_model_section(self, layout):\n \"\"\"设置模型下载部分UI\"\"\"\n # 标题和按钮的水平布局\n title_layout = QHBoxLayout()\n\n # 标题\n model_title = SubtitleLabel(self.tr(\"模型下载\"), self)\n title_layout.addWidget(model_title)\n\n # 添加打开文件夹按钮\n open_folder_btn = HyperlinkButton(\"\", self.tr(\"打开模型文件夹\"), parent=self)\n open_folder_btn.setIcon(FIF.FOLDER)\n open_folder_btn.clicked.connect(self._open_model_folder)\n title_layout.addStretch()\n title_layout.addWidget(open_folder_btn)\n\n layout.addLayout(title_layout)\n layout.addSpacing(8)\n\n # 模型表格\n self.model_table = self._create_model_table()\n self._populate_model_table()\n layout.addWidget(self.model_table)\n\n def _create_model_table(self):\n \"\"\"创建模型表格\"\"\"\n table = TableWidget(self)\n table.setEditTriggers(TableWidget.NoEditTriggers)\n table.setSelectionMode(TableWidget.NoSelection)\n table.setColumnCount(4)\n table.setHorizontalHeaderLabels(\n [self.tr(\"模型名称\"), self.tr(\"大小\"), self.tr(\"状态\"), self.tr(\"操作\")]\n )\n\n # 设置表格样式\n table.setBorderVisible(True)\n table.setBorderRadius(8)\n table.setItemDelegate(TableItemDelegate(table))\n\n # 设置列宽\n header = table.horizontalHeader()\n header.setSectionResizeMode(0, QHeaderView.Stretch)\n header.setSectionResizeMode(1, QHeaderView.Fixed)\n header.setSectionResizeMode(2, QHeaderView.Fixed)\n header.setSectionResizeMode(3, QHeaderView.Fixed)\n\n table.setColumnWidth(1, 100)\n table.setColumnWidth(2, 80)\n table.setColumnWidth(3, 150)\n\n # 设置行高\n row_height = 45\n table.verticalHeader().setDefaultSectionSize(row_height)\n\n # 设置表格高度\n header_height = 20\n max_visible_rows = 6\n table_height = row_height * max_visible_rows + header_height + 15\n table.setFixedHeight(table_height)\n\n return table\n\n def _setup_progress_section(self, layout):\n \"\"\"设置进度显示部分UI\"\"\"\n self.progress_bar = ProgressBar(self)\n self.progress_label = BodyLabel(\"\", self)\n self.progress_bar.hide()\n self.progress_label.hide()\n\n layout.addWidget(self.progress_bar)\n layout.addWidget(self.progress_label)\n\n def _populate_model_table(self):\n \"\"\"填充模型表格数据\"\"\"\n self.model_table.setRowCount(len(FASTER_WHISPER_MODELS))\n for i, model in enumerate(FASTER_WHISPER_MODELS):\n self._add_model_row(i, model)\n\n def _add_model_row(self, row, model):\n \"\"\"添加模型表格行\"\"\"\n # 模型名称\n name_item = QTableWidgetItem(model[\"label\"])\n name_item.setTextAlignment(Qt.AlignCenter) # type: ignore\n self.model_table.setItem(row, 0, name_item)\n\n # 大小\n size_item = QTableWidgetItem(f\"{int(model['size']) / 1024:.1f} MB\")\n size_item.setTextAlignment(Qt.AlignCenter) # type: ignore\n self.model_table.setItem(row, 1, size_item)\n\n # 状态 - 检查model.bin文件是否存在\n model_path = os.path.join(MODEL_PATH, model[\"value\"])\n model_bin_path = os.path.join(model_path, \"model.bin\")\n is_downloaded = os.path.exists(model_bin_path)\n\n status_item = QTableWidgetItem(\n self.tr(\"已下载\") if is_downloaded else self.tr(\"未下载\")\n )\n if is_downloaded:\n status_item.setForeground(Qt.green) # type: ignore\n status_item.setTextAlignment(Qt.AlignCenter) # type: ignore\n self.model_table.setItem(row, 2, status_item)\n\n # 下载按钮\n button_container = QWidget()\n button_layout = QHBoxLayout(button_container)\n button_layout.setContentsMargins(4, 4, 4, 4)\n\n download_btn = HyperlinkButton(\n \"\",\n self.tr(\"重新下载\") if is_downloaded else self.tr(\"下载\"),\n parent=self,\n )\n download_btn.setIcon(FIF.DOWNLOAD)\n download_btn.clicked.connect(lambda checked, r=row: self._download_model(r))\n\n button_layout.addStretch()\n button_layout.addWidget(download_btn)\n button_layout.addStretch()\n self.model_table.setCellWidget(row, 3, button_container)\n\n def _connect_signals(self):\n \"\"\"连接信号\"\"\"\n self.rejected.connect(self._on_dialog_reject)\n\n def _start_download(self):\n \"\"\"开始下载\"\"\"\n if FasterWhisperDownloadDialog.is_downloading:\n InfoBar.warning(\n self.tr(\"下载进行中\"),\n self.tr(\"请等待当前下载任务完成\"),\n duration=3000,\n parent=self,\n )\n return\n\n FasterWhisperDownloadDialog.is_downloading = True\n # 禁用所有下载按钮\n self._set_all_download_buttons_enabled(False)\n\n # 获取选中的文本\n selected_text = self.program_combo.currentText()\n\n # 从显示文本中提取程序标签\n selected_label = selected_text.split(\" (\")[0]\n\n # 根据标签找到对应的程序配置\n program = next(\n (p for p in FASTER_WHISPER_PROGRAMS if p[\"label\"] == selected_label), None\n )\n\n if not program:\n InfoBar.error(\n self.tr(\"下载错误\"),\n self.tr(\"未找到对应的程序配置\"),\n duration=3000,\n parent=self,\n )\n FasterWhisperDownloadDialog.is_downloading = False\n self._set_all_download_buttons_enabled(True)\n return\n\n # 确保 BIN_PATH 目录存在\n os.makedirs(BIN_PATH, exist_ok=True)\n\n self.progress_bar.show()\n self.progress_label.show()\n self.program_download_btn.setEnabled(False)\n self.program_combo.setEnabled(False)\n\n # 直接下载到bin目录\n save_path = os.path.join(BIN_PATH, program[\"value\"])\n\n self.program_download_thread = FileDownloadThread(\n program[\"downloadLink\"], save_path\n )\n self.program_download_thread.progress.connect(\n self._on_program_download_progress\n )\n self.program_download_thread.finished.connect(\n lambda: self._on_program_download_finished(save_path)\n )\n self.program_download_thread.error.connect(self._on_program_download_error)\n self.program_download_thread.start()\n\n def _on_program_download_progress(self, value, status_msg):\n \"\"\"更新程序下载进度\"\"\"\n self.progress_bar.setValue(int(value))\n self.progress_label.setText(status_msg)\n\n def _on_program_download_finished(self, save_path):\n \"\"\"程序下载完成处理\"\"\"\n try:\n # 检查是否是 CPU 版本的直接下载\n if save_path.endswith(\".exe\"):\n # 如果是exe文件,重命名为faster-whisper.exe\n os.rename(save_path, os.path.join(BIN_PATH, \"faster-whisper.exe\"))\n self._finish_program_installation()\n else:\n # GPU 版本需要解压\n self.progress_label.setText(self.tr(\"正在解压文件...\"))\n\n # 创建并启动解压线程\n self.unzip_thread = UnzipThread(save_path, BIN_PATH)\n self.unzip_thread.finished.connect(self._finish_program_installation)\n self.unzip_thread.error.connect(self._on_unzip_error)\n self.unzip_thread.start()\n return # 提前返回,等待解压完成\n\n except Exception as e:\n InfoBar.error(self.tr(\"安装失败\"), str(e), duration=3000, parent=self)\n self._cleanup_installation()\n\n def _on_program_download_error(self, error):\n \"\"\"程序下载错误处理\"\"\"\n InfoBar.error(self.tr(\"下载失败\"), error, duration=3000, parent=self)\n FasterWhisperDownloadDialog.is_downloading = False\n self._set_all_download_buttons_enabled(True)\n self.program_download_btn.setEnabled(True)\n self.program_combo.setEnabled(True)\n self.progress_bar.hide()\n self.progress_label.hide()\n\n def _on_dialog_reject(self):\n \"\"\"对话框关闭处理\"\"\"\n if self.program_download_thread and self.program_download_thread.isRunning():\n self.program_download_thread.stop()\n if self.model_download_thread and self.model_download_thread.isRunning():\n self.model_download_thread.terminate()\n FasterWhisperDownloadDialog.is_downloading = False\n self.reject()\n\n def closeEvent(self, event):\n \"\"\"窗口关闭事件处理\"\"\"\n self._on_dialog_reject()\n super().closeEvent(event)\n\n def _download_model(self, row):\n \"\"\"下载选中的模型\"\"\"\n if FasterWhisperDownloadDialog.is_downloading:\n InfoBar.warning(\n self.tr(\"下载进行中\"),\n self.tr(\"请等待当前下载任务完成\"),\n duration=3000,\n parent=self,\n )\n return\n\n FasterWhisperDownloadDialog.is_downloading = True\n self._set_all_download_buttons_enabled(False)\n\n model = FASTER_WHISPER_MODELS[row]\n self.progress_bar.show()\n self.progress_label.show()\n self.progress_label.setText(self.tr(f\"正在下载 {model['label']} 模型...\"))\n\n # 禁用当前行的下载按钮\n button_container = self.model_table.cellWidget(row, 3)\n download_btn = button_container.findChild(HyperlinkButton)\n if download_btn:\n download_btn.setEnabled(False)\n\n # 创建并启动下载线程,保存到类属性\n self.model_download_thread = ModelscopeDownloadThread(\n model[\"modelScopeLink\"], os.path.join(MODEL_PATH, model[\"value\"])\n )\n\n def _on_model_download_progress(value, msg):\n self.progress_bar.setValue(value)\n self.progress_label.setText(msg)\n\n def _on_model_download_finished():\n FasterWhisperDownloadDialog.is_downloading = False\n self._set_all_download_buttons_enabled(True)\n # 更新状态\n status_item = QTableWidgetItem(self.tr(\"已下载\"))\n status_item.setForeground(Qt.green) # type: ignore\n status_item.setTextAlignment(Qt.AlignCenter) # type: ignore\n self.model_table.setItem(row, 2, status_item)\n\n # 更新下载按钮文本\n if download_btn:\n download_btn.setText(self.tr(\"重新下载\"))\n download_btn.setEnabled(True)\n\n model = FASTER_WHISPER_MODELS[row]\n\n # 更新主设置对话框的模型选择\n if self.setting_widget:\n # 保存当前值并清空\n current_value = cfg.faster_whisper_model.value\n combo = self.setting_widget.model_card.comboBox\n combo.clear()\n\n # 找出已下载的模型\n available = []\n model_map = {\n m[\"label\"].lower(): m[\"value\"] for m in FASTER_WHISPER_MODELS\n }\n for enum_val in FasterWhisperModelEnum:\n if enum_val.value in model_map:\n if (MODEL_PATH / model_map[enum_val.value]).exists():\n available.append(enum_val)\n\n # 重建下拉框\n self.setting_widget.model_card.optionToText = {\n e: e.value for e in available\n }\n for enum_val in available:\n combo.addItem(enum_val.value, userData=enum_val)\n\n # 恢复选择\n if current_value in available:\n combo.setCurrentText(current_value.value)\n elif combo.count() > 0:\n combo.setCurrentIndex(0)\n\n InfoBar.success(\n self.tr(\"下载成功\"),\n self.tr(f\"{model['label']} 模型已下载完成\"),\n duration=3000,\n parent=self,\n )\n self.progress_bar.hide()\n self.progress_label.hide()\n\n def _on_model_download_error(error):\n FasterWhisperDownloadDialog.is_downloading = False\n self._set_all_download_buttons_enabled(True)\n if download_btn:\n download_btn.setEnabled(True)\n\n InfoBar.error(self.tr(\"下载失败\"), str(error), duration=3000, parent=self)\n self.progress_bar.hide()\n self.progress_label.hide()\n\n self.model_download_thread.progress.connect(_on_model_download_progress)\n self.model_download_thread.finished.connect(_on_model_download_finished)\n self.model_download_thread.error.connect(_on_model_download_error)\n self.model_download_thread.start()\n\n def _set_all_download_buttons_enabled(self, enabled: bool):\n \"\"\"设置所有下载按钮的启用状态\"\"\"\n # 设置程序下载按钮\n if hasattr(self, \"program_download_btn\"):\n self.program_download_btn.setEnabled(enabled)\n self.program_combo.setEnabled(enabled)\n\n # 设置所有模型下载按钮\n for row in range(self.model_table.rowCount()):\n button_container = self.model_table.cellWidget(row, 3)\n if button_container:\n download_btn = button_container.findChild(HyperlinkButton)\n if download_btn:\n download_btn.setEnabled(enabled)\n\n def _open_model_folder(self):\n \"\"\"打开模型文件夹\"\"\"\n if os.path.exists(MODEL_PATH):\n # 根据操作系统打开文件夹\n open_folder(str(MODEL_PATH))\n\n def _open_program_folder(self):\n \"\"\"打开程序文件夹\"\"\"\n if os.path.exists(BIN_PATH):\n # 根据操作系统打开文件夹\n open_folder(str(BIN_PATH))\n\n def _finish_program_installation(self):\n \"\"\"完成程序安装\"\"\"\n InfoBar.success(\n self.tr(\"安装完成\"),\n self.tr(\"Faster Whisper 程序已安装成功\"),\n duration=3000,\n parent=self,\n )\n self.accept()\n self._cleanup_installation()\n\n def _on_unzip_error(self, error_msg):\n \"\"\"处理解压错误\"\"\"\n InfoBar.error(self.tr(\"安装失败\"), error_msg, duration=3000, parent=self)\n self._cleanup_installation()\n\n def _cleanup_installation(self):\n \"\"\"清理安装状态\"\"\"\n FasterWhisperDownloadDialog.is_downloading = False\n self._set_all_download_buttons_enabled(True)\n self.progress_bar.hide()\n self.progress_label.hide()\n\n\nclass FasterWhisperSettingWidget(QWidget):\n def __init__(self, parent=None):\n super().__init__(parent)\n self.setup_ui()\n self._connect_signals()\n\n def showEvent(self, a0: QShowEvent) -> None:\n super().showEvent(a0)\n # 检查Faster Whisper模型是否存在\n is_faster_whisper_exists, _ = check_faster_whisper_exists()\n if not is_faster_whisper_exists:\n self.show_error_info(self.tr(\"Faster Whisper程序不存在,请先下载程序\"))\n self._show_model_manager()\n return\n\n def setup_ui(self):\n self.main_layout = QVBoxLayout(self)\n\n # 创建单向滚动区域和容器\n self.scrollArea = SingleDirectionScrollArea(orient=Qt.Vertical, parent=self) # type: ignore\n self.scrollArea.setStyleSheet(\n \"QScrollArea{background: transparent; border: none}\"\n )\n\n self.container = QWidget(self)\n self.container.setStyleSheet(\"QWidget{background: transparent}\")\n self.containerLayout = QVBoxLayout(self.container)\n\n self.setting_group = SettingCardGroup(\n self.tr(\"Faster Whisper 设置\"), self\n )\n\n # 模型选择\n self.model_card = ComboBoxSettingCard(\n cfg.faster_whisper_model,\n FIF.ROBOT,\n self.tr(\"模型\"),\n self.tr(\"选择 Faster Whisper 模型\"),\n [model.value for model in FasterWhisperModelEnum],\n self.setting_group,\n )\n\n # 检查未下载的模型并从下拉框中移除\n for i in range(self.model_card.comboBox.count() - 1, -1, -1):\n model_text = self.model_card.comboBox.itemText(i).lower()\n model_config = next(\n (\n model\n for model in FASTER_WHISPER_MODELS\n if model[\"label\"].lower() == model_text\n ),\n None,\n )\n if model_config:\n model_path = Path(MODEL_PATH) / model_config[\"value\"]\n model_bin_path = model_path / \"model.bin\"\n if model_bin_path.exists():\n continue\n self.model_card.comboBox.removeItem(i)\n\n # 创建管理模型卡片\n self.manage_model_card = HyperlinkCard(\n \"\", # 无链接\n self.tr(\"管理模型\"),\n FIF.DOWNLOAD, # 使用下载图标\n self.tr(\"模型管理\"),\n self.tr(\"下载或更新 Faster Whisper 模型\"),\n self.setting_group, # 添加到设置组\n )\n\n # 语言选择\n self.language_card = ComboBoxSettingCard(\n cfg.transcribe_language,\n FIF.LANGUAGE,\n self.tr(\"源语言\"),\n self.tr(\"音视频中说话的语言,默认根据前30秒自动识别\"),\n [lang.value for lang in TranscribeLanguageEnum],\n self.setting_group,\n )\n self.language_card.comboBox.setMaxVisibleItems(6)\n\n # 设备选择\n self.device_card = ComboBoxSettingCard(\n cfg.faster_whisper_device,\n FIF.IOT,\n self.tr(\"运行设备\"),\n self.tr(\"模型运行设备\"),\n [\"cuda\", \"cpu\"],\n self.setting_group,\n )\n # _, available_devices = check_faster_whisper_exists()\n # if \"GPU\" not in available_devices:\n # self.device_card.comboBox.removeItem(0)\n\n # VAD设置组\n self.vad_group = SettingCardGroup(self.tr(\"VAD设置\"), self)\n\n # VAD过滤开关\n self.vad_filter_card = SwitchSettingCard(\n FIF.CHECKBOX,\n self.tr(\"VAD过滤\"),\n self.tr(\"过滤无人声语音片断,减少幻觉\"),\n cfg.faster_whisper_vad_filter,\n self.vad_group,\n )\n\n # VAD阈值\n self.vad_threshold_card = DoubleSpinBoxSettingCard(\n cfg.faster_whisper_vad_threshold,\n FIF.VOLUME, # type: ignore\n self.tr(\"VAD阈值\"),\n self.tr(\"语音概率阈值,高于此值视为语音\"),\n minimum=0.00,\n maximum=1.00,\n decimals=2,\n step=0.05,\n )\n\n # VAD方法\n self.vad_method_card = ComboBoxSettingCard(\n cfg.faster_whisper_vad_method,\n FIF.MUSIC,\n self.tr(\"VAD方法\"),\n self.tr(\"选择VAD检测方法\"),\n [method.value for method in VadMethodEnum],\n self.vad_group,\n )\n\n # 其他设置组\n self.other_group = SettingCardGroup(self.tr(\"其他设置\"), self)\n\n # 音频降噪\n self.ff_mdx_kim2_card = SwitchSettingCard(\n FIF.MUSIC,\n self.tr(\"人声分离\"),\n self.tr(\"处理前使用MDX-Net降噪,分离人声和背景音乐\"),\n cfg.faster_whisper_ff_mdx_kim2,\n self.other_group,\n )\n\n # 单词时间戳\n self.one_word_card = SwitchSettingCard(\n FIF.UNIT,\n self.tr(\"单字时间戳\"),\n self.tr(\"开启生成单字级时间戳;关闭后使用原始分段断句\"),\n cfg.faster_whisper_one_word,\n self.other_group,\n )\n\n # 提示词\n self.prompt_card = LineEditSettingCard(\n cfg.faster_whisper_prompt,\n FIF.CHAT,\n self.tr(\"提示词\"),\n self.tr(\"可选的提示词,默认空\"),\n \"\",\n self.other_group,\n )\n\n # 添加模型设置组的卡片\n self.setting_group.addSettingCard(self.model_card)\n self.setting_group.addSettingCard(self.manage_model_card)\n self.setting_group.addSettingCard(self.device_card)\n self.setting_group.addSettingCard(self.language_card)\n\n # 添加VAD设置组的卡片\n self.vad_group.addSettingCard(self.vad_filter_card)\n self.vad_group.addSettingCard(self.vad_threshold_card)\n self.vad_group.addSettingCard(self.vad_method_card)\n\n # 添加其他设置的卡片\n self.other_group.addSettingCard(self.ff_mdx_kim2_card)\n self.other_group.addSettingCard(self.one_word_card)\n self.other_group.addSettingCard(self.prompt_card)\n\n # 将所有设置组添加到容器布局\n self.containerLayout.addWidget(self.setting_group)\n self.containerLayout.addWidget(self.vad_group)\n self.containerLayout.addWidget(self.other_group)\n self.containerLayout.addStretch(1)\n\n # 设置组件最小宽度\n self.model_card.comboBox.setMinimumWidth(200)\n self.device_card.comboBox.setMinimumWidth(200)\n self.language_card.comboBox.setMinimumWidth(200)\n self.vad_method_card.comboBox.setMinimumWidth(200)\n self.prompt_card.lineEdit.setMinimumWidth(200)\n\n # 设置滚动区域\n self.scrollArea.setWidget(self.container)\n self.scrollArea.setWidgetResizable(True)\n\n # 将滚动区域添加到主布局\n self.main_layout.addWidget(self.scrollArea)\n\n def _connect_signals(self):\n \"\"\"连接信号\"\"\"\n self.manage_model_card.linkButton.clicked.connect(self._show_model_manager)\n self.vad_filter_card.checkedChanged.connect(self._on_vad_filter_changed)\n\n def _on_vad_filter_changed(self, checked: bool):\n \"\"\"VAD过滤开关状态改变时的处理\"\"\"\n self.vad_threshold_card.setEnabled(checked)\n self.vad_method_card.setEnabled(checked)\n\n def _show_model_manager(self):\n \"\"\"显示模型管理对话框\"\"\"\n dialog = FasterWhisperDownloadDialog(self.window(), self)\n dialog.exec_()\n\n def show_error_info(self, error_msg):\n \"\"\"显示错误信息\"\"\"\n InfoBar.error(\n title=self.tr(\"错误\"),\n content=error_msg,\n parent=self.window(),\n duration=5000,\n position=InfoBarPosition.BOTTOM,\n )\n\n def check_faster_whisper_model(self):\n \"\"\"检查选定的Faster Whisper模型是否存在\n\n Returns:\n bool: 如果模型存在且配置正确返回True,否则返回False\n \"\"\"\n # 检查程序是否存在\n has_program, _ = check_faster_whisper_exists()\n if not has_program:\n self.show_error_info(self.tr(\"Faster Whisper程序不存在,请先下载程序\"))\n return False\n\n model_value = cfg.faster_whisper_model.value.value\n # 检查模型配置是否存在\n model_config = next(\n (\n m\n for m in FASTER_WHISPER_MODELS\n if m[\"label\"].lower() == model_value.lower()\n ),\n None,\n )\n if not model_config:\n self.show_error_info(self.tr(\"模型配置不存在\"))\n return False\n\n model_path = MODEL_PATH / model_config[\"value\"]\n model_files = model_path / \"model.bin\"\n # 检查模型文件是否存在\n if not model_path.exists() and not model_files.exists():\n self.show_error_info(self.tr(\"模型文件不存在: \") + model_value)\n return False\n return True\n"
},
{
"path": "app/components/LanguageSettingDialog.py",
"content": "from PyQt5.QtWidgets import QVBoxLayout\nfrom qfluentwidgets import (\n ComboBox,\n InfoBar,\n InfoBarPosition,\n MessageBoxBase,\n SettingCard,\n)\nfrom qfluentwidgets import FluentIcon as FIF\n\nfrom app.common.config import cfg\nfrom app.core.entities import (\n TranscribeLanguageEnum,\n TranscribeModelEnum,\n get_asr_language_capability,\n)\n\n\nclass LanguageSettingDialog(MessageBoxBase):\n \"\"\"语言设置对话框\"\"\"\n\n def __init__(self, model: TranscribeModelEnum, parent=None):\n self.model = model\n super().__init__(parent)\n self.widget.setMinimumWidth(500)\n self._setup_ui()\n self._connect_signals()\n\n def _get_available_languages(self) -> list[str]:\n \"\"\"获取当前模型支持的语言列表\"\"\"\n capability = get_asr_language_capability(self.model)\n languages = [lang.value for lang in capability.supported_languages]\n if capability.supports_auto:\n languages.insert(0, TranscribeLanguageEnum.AUTO.value)\n return languages\n\n def _setup_ui(self):\n \"\"\"设置UI\"\"\"\n self.yesButton.setText(self.tr(\"确定\"))\n self.cancelButton.setText(self.tr(\"取消\"))\n\n # 主布局\n layout = QVBoxLayout()\n\n # 使用自定义 SettingCard 代替 ComboBoxSettingCard(因为需要动态选项)\n self.language_card = SettingCard(\n FIF.LANGUAGE,\n self.tr(\"源语言\"),\n self.tr(\"音视频中说话的语言,默认根据前30秒自动识别\"),\n self,\n )\n\n # 创建 ComboBox\n self.language_combo = ComboBox(self)\n available_languages = self._get_available_languages()\n self.language_combo.addItems(available_languages)\n self.language_combo.setMaxVisibleItems(6)\n self.language_combo.setMinimumWidth(160)\n\n # 设置当前值\n current_lang = cfg.transcribe_language.value\n if current_lang.value in available_languages:\n self.language_combo.setCurrentText(current_lang.value)\n elif available_languages:\n # 当前选择的语言不在可选列表中,选择第一个\n self.language_combo.setCurrentIndex(0)\n\n # 添加 ComboBox 到卡片\n self.language_card.hBoxLayout.addWidget(self.language_combo)\n self.language_card.hBoxLayout.addSpacing(16)\n\n layout.addWidget(self.language_card)\n layout.addStretch(1)\n\n self.viewLayout.addLayout(layout)\n\n def _connect_signals(self):\n \"\"\"连接信号\"\"\"\n self.yesButton.clicked.connect(self.__onYesButtonClicked)\n\n def __onYesButtonClicked(self):\n # 保存选中的语言到配置\n selected_text = self.language_combo.currentText()\n for lang in TranscribeLanguageEnum:\n if lang.value == selected_text:\n cfg.set(cfg.transcribe_language, lang)\n break\n\n self.accept()\n InfoBar.success(\n self.tr(\"设置已保存\"),\n self.tr(\"语言设置已更新\"),\n duration=3000,\n parent=self.window(),\n position=InfoBarPosition.BOTTOM,\n )\n if cfg.transcribe_language.value == TranscribeLanguageEnum.JAPANESE:\n InfoBar.warning(\n self.tr(\"请注意身体!!\"),\n self.tr(\"小心肝儿,注意身体哦~\"),\n duration=2000,\n parent=self.window(),\n position=InfoBarPosition.BOTTOM,\n )\n"
},
{
"path": "app/components/LineEditSettingCard.py",
"content": "from typing import Optional\n\nfrom PyQt5.QtCore import Qt, pyqtSignal\nfrom qfluentwidgets import LineEdit, SettingCard\nfrom qfluentwidgets.common.config import ConfigItem, qconfig\n\n\nclass LineEditSettingCard(SettingCard):\n \"\"\"行输入卡片\"\"\"\n\n textChanged = pyqtSignal(str)\n\n def __init__(\n self,\n configItem: ConfigItem,\n icon,\n title: str,\n content: Optional[str] = None,\n placeholder: str = \"\",\n parent=None,\n ):\n super().__init__(icon, title, content, parent)\n\n self.configItem = configItem\n\n self.lineEdit = LineEdit(self)\n self.lineEdit.setPlaceholderText(placeholder)\n self.hBoxLayout.addWidget(self.lineEdit, 1, Qt.AlignRight) # type: ignore\n self.hBoxLayout.addSpacing(16)\n\n self.lineEdit.setMinimumWidth(280)\n\n self.setValue(qconfig.get(configItem))\n\n self.lineEdit.textChanged.connect(self.__onTextChanged)\n configItem.valueChanged.connect(self.setValue)\n\n def __onTextChanged(self, text: str):\n self.setValue(text)\n self.textChanged.emit(text)\n\n def setValue(self, value: str):\n qconfig.set(self.configItem, value)\n self.lineEdit.setText(value)\n"
},
{
"path": "app/components/MySettingCard.py",
"content": "# coding:utf-8\nfrom typing import List, Optional, Union\n\nfrom PyQt5.QtCore import Qt, pyqtSignal\nfrom PyQt5.QtGui import QColor, QIcon, QPainter\nfrom PyQt5.QtWidgets import QFrame, QHBoxLayout, QLabel, QToolButton, QVBoxLayout\nfrom qfluentwidgets import ColorDialog, ComboBox, CompactDoubleSpinBox, CompactSpinBox\nfrom qfluentwidgets.common.config import isDarkTheme\nfrom qfluentwidgets.common.icon import FluentIconBase, drawIcon\nfrom qfluentwidgets.common.style_sheet import FluentStyleSheet\nfrom qfluentwidgets.components.widgets.icon_widget import IconWidget\n\n\nclass SettingIconWidget(IconWidget):\n def paintEvent(self, e):\n painter = QPainter(self)\n\n if not self.isEnabled():\n painter.setOpacity(0.36)\n\n painter.setRenderHints(QPainter.Antialiasing | QPainter.SmoothPixmapTransform)\n drawIcon(self._icon, painter, self.rect())\n\n\nclass SettingCard(QFrame):\n \"\"\"Setting card\"\"\"\n\n def __init__(\n self, icon: Union[str, QIcon, FluentIconBase], title, content=None, parent=None\n ):\n \"\"\"\n Parameters\n ----------\n icon: str | QIcon | FluentIconBase\n the icon to be drawn\n\n title: str\n the title of card\n\n content: str\n the content of card\n\n parent: QWidget\n parent widget\n \"\"\"\n super().__init__(parent=parent)\n self.iconLabel = SettingIconWidget(icon, self)\n self.titleLabel = QLabel(title, self)\n self.contentLabel = QLabel(content or \"\", self)\n self.hBoxLayout = QHBoxLayout(self)\n self.vBoxLayout = QVBoxLayout()\n\n if not content:\n self.contentLabel.hide()\n\n self.setFixedHeight(70 if content else 50)\n self.iconLabel.setFixedSize(16, 16)\n\n # initialize layout\n self.hBoxLayout.setSpacing(0)\n self.hBoxLayout.setContentsMargins(16, 0, 0, 0)\n self.hBoxLayout.setAlignment(Qt.AlignVCenter) # type: ignore\n self.vBoxLayout.setSpacing(0)\n self.vBoxLayout.setContentsMargins(0, 0, 0, 0)\n self.vBoxLayout.setAlignment(Qt.AlignVCenter) # type: ignore\n\n self.hBoxLayout.addWidget(self.iconLabel, 0, Qt.AlignLeft) # type: ignore\n self.hBoxLayout.addSpacing(16)\n\n self.hBoxLayout.addLayout(self.vBoxLayout)\n self.vBoxLayout.addWidget(self.titleLabel, 0, Qt.AlignLeft) # type: ignore\n self.vBoxLayout.addWidget(self.contentLabel, 0, Qt.AlignLeft) # type: ignore\n\n self.hBoxLayout.addSpacing(16)\n self.hBoxLayout.addStretch(1)\n\n self.contentLabel.setObjectName(\"contentLabel\")\n FluentStyleSheet.SETTING_CARD.apply(self)\n\n def setTitle(self, title: str):\n \"\"\"set the title of card\"\"\"\n self.titleLabel.setText(title)\n\n def setContent(self, content: str):\n \"\"\"set the content of card\"\"\"\n self.contentLabel.setText(content)\n self.contentLabel.setVisible(bool(content))\n\n def setValue(self, value):\n \"\"\"set the value of config item\"\"\"\n pass\n\n def setIconSize(self, width: int, height: int):\n \"\"\"set the icon fixed size\"\"\"\n self.iconLabel.setFixedSize(width, height)\n\n def paintEvent(self, e):\n painter = QPainter(self)\n painter.setRenderHints(QPainter.Antialiasing)\n\n if isDarkTheme():\n painter.setBrush(QColor(255, 255, 255, 13))\n painter.setPen(QColor(0, 0, 0, 50))\n else:\n painter.setBrush(QColor(255, 255, 255, 170))\n painter.setPen(QColor(0, 0, 0, 19))\n\n painter.drawRoundedRect(self.rect().adjusted(1, 1, -1, -1), 6, 6)\n\n\nclass DoubleSpinBoxSettingCard(SettingCard):\n \"\"\"小数输入设置卡片\"\"\"\n\n valueChanged = pyqtSignal(float)\n\n def __init__(\n self,\n icon: Union[str, QIcon, FluentIconBase],\n title: str,\n content: Optional[str] = None,\n minimum: float = 0.0,\n maximum: float = 100.0,\n decimals: int = 1,\n parent=None,\n ):\n super().__init__(icon, title, content, parent)\n\n # 创建CompactDoubleSpinBox\n self.spinBox = CompactDoubleSpinBox(self)\n self.spinBox.setRange(minimum, maximum)\n self.spinBox.setDecimals(decimals)\n self.spinBox.setMinimumWidth(60)\n self.spinBox.setSingleStep(0.2) # 设置步长为0.1\n\n # 添加到布局\n self.hBoxLayout.addWidget(self.spinBox, 0, Qt.AlignRight) # type: ignore\n self.hBoxLayout.addSpacing(8)\n\n # 设置初始值和连接信号\n self.spinBox.valueChanged.connect(self.__onValueChanged)\n\n def __onValueChanged(self, value: float):\n \"\"\"数值改变时的槽函数\"\"\"\n self.setValue(value)\n self.valueChanged.emit(value)\n\n def setValue(self, value: float):\n \"\"\"设置数值\"\"\"\n self.spinBox.setValue(value)\n\n\nclass SpinBoxSettingCard(SettingCard):\n \"\"\"数值输入设置卡片\"\"\"\n\n valueChanged = pyqtSignal(int)\n\n def __init__(\n self,\n icon: Union[str, QIcon],\n title: str,\n content: Optional[str] = None,\n minimum: int = 0,\n maximum: int = 100,\n step: int = 2,\n parent=None,\n ):\n super().__init__(icon, title, content, parent)\n\n # 创建SpinBox\n self.spinBox = CompactSpinBox(self)\n self.spinBox.setRange(minimum, maximum)\n self.spinBox.setMinimumWidth(60)\n self.spinBox.setSingleStep(step)\n\n # 添加到布局\n self.hBoxLayout.addWidget(self.spinBox, 0, Qt.AlignRight) # type: ignore\n self.hBoxLayout.addSpacing(8)\n\n # 设置初始值和连接信号\n self.spinBox.valueChanged.connect(self.__onValueChanged)\n\n def __onValueChanged(self, value: int):\n \"\"\"数值改变时的槽函数\"\"\"\n self.setValue(value)\n self.valueChanged.emit(value)\n\n def setValue(self, value: int):\n \"\"\"设置数值\"\"\"\n self.spinBox.setValue(value)\n\n\nclass ComboBoxSettingCard(SettingCard):\n \"\"\"下拉框设置卡片\"\"\"\n\n currentTextChanged = pyqtSignal(str)\n currentIndexChanged = pyqtSignal(int)\n\n def __init__(\n self,\n icon: Union[str, QIcon],\n title: str,\n content: Optional[str] = None,\n texts: Optional[List[str]] = None,\n parent=None,\n ):\n super().__init__(icon, title, content, parent)\n\n # 创建ComboBox\n self.comboBox = ComboBox(self)\n self.hBoxLayout.addWidget(self.comboBox, 0, Qt.AlignRight) # type: ignore\n self.hBoxLayout.addSpacing(16)\n\n # 添加选项\n if texts:\n for text in texts:\n self.comboBox.addItem(text)\n\n # 连接信号\n self.comboBox.currentTextChanged.connect(self.__onCurrentTextChanged)\n self.comboBox.currentIndexChanged.connect(self.__onCurrentIndexChanged)\n\n def __onCurrentTextChanged(self, text: str):\n \"\"\"当前文本改变时的槽函数\"\"\"\n self.currentTextChanged.emit(text)\n\n def __onCurrentIndexChanged(self, index: int):\n \"\"\"当前索引改变时的槽函数\"\"\"\n self.currentIndexChanged.emit(index)\n\n def setCurrentText(self, text: str):\n \"\"\"设置当前文本\"\"\"\n self.comboBox.setCurrentText(text)\n\n def setCurrentIndex(self, index: int):\n \"\"\"设置当前索引\"\"\"\n self.comboBox.setCurrentIndex(index)\n\n def addItem(self, text: str):\n \"\"\"添加选项\"\"\"\n self.comboBox.addItem(text)\n\n def addItems(self, texts: List[str]):\n \"\"\"添加多个选项\"\"\"\n self.comboBox.addItems(texts)\n\n def clear(self):\n \"\"\"清空所有选项\"\"\"\n self.comboBox.clear()\n\n\nclass ColorSettingCard(SettingCard):\n \"\"\"带颜色选择器的设置卡片\"\"\"\n\n colorChanged = pyqtSignal(QColor)\n\n def __init__(\n self,\n color: QColor,\n icon: Union[str, QIcon, FluentIconBase],\n title: str,\n content: Optional[str] = None,\n parent=None,\n enableAlpha=False,\n ):\n \"\"\"\n 参数\n ----------\n color: QColor\n 初始颜色\n\n icon: str | QIcon | FluentIconBase\n 要绘制的图标\n\n title: str\n 卡片标题\n\n content: str\n 卡片内容\n\n parent: QWidget\n 父组件\n\n enableAlpha: bool\n 是否启用透明通道\n \"\"\"\n super().__init__(icon, title, content, parent)\n self.colorPicker = ColorPickerButton(color, title, self, enableAlpha)\n self.colorPicker.setFixedWidth(60)\n self.hBoxLayout.addWidget(self.colorPicker, 0, Qt.AlignRight) # type: ignore\n self.hBoxLayout.addSpacing(16)\n self.colorPicker.colorChanged.connect(self.__onColorChanged)\n\n def __onColorChanged(self, color: QColor):\n \"\"\"颜色改变时的槽函数\"\"\"\n self.colorChanged.emit(color)\n\n def setColor(self, color: QColor):\n \"\"\"设置颜色\"\"\"\n self.colorPicker.setColor(color)\n\n\nclass ColorPickerButton(QToolButton):\n \"\"\"Color picker button\"\"\"\n\n colorChanged = pyqtSignal(QColor)\n\n def __init__(self, color: QColor, title: str, parent=None, enableAlpha=False):\n super().__init__(parent=parent)\n self.title = title\n self.enableAlpha = enableAlpha\n self.setFixedSize(96, 32)\n self.setAttribute(Qt.WA_TranslucentBackground) # type: ignore\n\n self.setColor(color)\n self.setCursor(Qt.PointingHandCursor) # type: ignore\n self.clicked.connect(self.__showColorDialog)\n\n def __showColorDialog(self):\n \"\"\"show color dialog\"\"\"\n w = ColorDialog(\n self.color, self.tr(\"Choose \") + self.title, self.window(), self.enableAlpha\n )\n w.colorChanged.connect(self.__onColorChanged)\n w.exec()\n\n def __onColorChanged(self, color):\n \"\"\"color changed slot\"\"\"\n self.setColor(color)\n self.colorChanged.emit(color)\n\n def setColor(self, color):\n \"\"\"set color\"\"\"\n self.color = QColor(color)\n self.update()\n\n def paintEvent(self, e):\n painter = QPainter(self)\n painter.setRenderHints(QPainter.Antialiasing)\n pc = QColor(255, 255, 255, 10) if isDarkTheme() else QColor(234, 234, 234)\n painter.setPen(pc)\n\n color = QColor(self.color)\n if not self.enableAlpha:\n color.setAlpha(255)\n\n painter.setBrush(color)\n painter.drawRoundedRect(self.rect().adjusted(1, 1, -1, -1), 5, 5)\n"
},
{
"path": "app/components/MyVideoWidget.py",
"content": "# coding:utf-8\nimport sys\nfrom enum import Enum\nfrom pathlib import Path\nfrom typing import Optional\n\nimport vlc # type: ignore\nfrom PyQt5.QtCore import QObject, Qt, QTimer, QUrl, pyqtSignal\nfrom PyQt5.QtGui import QIcon\nfrom PyQt5.QtWidgets import QApplication, QHBoxLayout, QVBoxLayout, QWidget\n\n# from qfluentwidgets.multimedia.media_player import MediaPlayer, MediaPlayerBase\nfrom qfluentwidgets.common.icon import FluentIcon\nfrom qfluentwidgets.common.style_sheet import FluentStyleSheet\nfrom qfluentwidgets.components.widgets.label import CaptionLabel\nfrom qfluentwidgets.multimedia.media_play_bar import (\n MediaPlayBarBase,\n MediaPlayBarButton,\n)\n\nfrom app.common.signal_bus import signalBus\nfrom app.config import RESOURCE_PATH\n\n\nclass MediaStatus(Enum):\n NoMedia = 0\n LoadingMedia = 1\n LoadedMedia = 2\n BufferingMedia = 3\n BufferedMedia = 4\n EndOfMedia = 5\n InvalidMedia = 6\n UnknownMediaStatus = 7\n\n\nclass PlaybackState(Enum):\n StoppedState = 0\n PlayingState = 1\n PausedState = 2\n\n\nclass MediaPlayerBase(QObject):\n \"\"\"Media player base class\"\"\"\n\n mediaStatusChanged = pyqtSignal(MediaStatus)\n playbackRateChanged = pyqtSignal(float)\n positionChanged = pyqtSignal(int)\n durationChanged = pyqtSignal(int)\n sourceChanged = pyqtSignal(QUrl)\n volumeChanged = pyqtSignal(int)\n mutedChanged = pyqtSignal(bool)\n\n def __init__(self, parent=None):\n super().__init__(parent=parent)\n\n def isPlaying(self):\n \"\"\"Whether the media is playing\"\"\"\n raise NotImplementedError\n\n def mediaStatus(self) -> MediaStatus:\n \"\"\"Return the status of the current media stream\"\"\"\n raise NotImplementedError\n\n def playbackState(self) -> PlaybackState:\n \"\"\"Return the playback status of the current media stream\"\"\"\n raise NotImplementedError\n\n def duration(self):\n \"\"\"Returns the duration of the current media in ms\"\"\"\n raise NotImplementedError\n\n def position(self):\n \"\"\"Returns the current position inside the media being played back in ms\"\"\"\n raise NotImplementedError\n\n def volume(self):\n \"\"\"Return the volume of player\"\"\"\n raise NotImplementedError\n\n def source(self) -> QUrl:\n \"\"\"Return the active media source being used\"\"\"\n raise NotImplementedError\n\n def pause(self):\n \"\"\"Pause playing the current source\"\"\"\n raise NotImplementedError\n\n def play(self):\n \"\"\"Start or resume playing the current source\"\"\"\n raise NotImplementedError\n\n def stop(self):\n \"\"\"Stop playing, and reset the play position to the beginning\"\"\"\n raise NotImplementedError\n\n def playbackRate(self) -> float:\n \"\"\"Return the playback rate of the current media\"\"\"\n raise NotImplementedError\n\n def setPosition(self, position: int):\n \"\"\"Sets the position of media in ms\"\"\"\n raise NotImplementedError\n\n def setSource(self, media: QUrl):\n \"\"\"Sets the current source\"\"\"\n raise NotImplementedError\n\n def setPlaybackRate(self, rate: float):\n \"\"\"Sets the playback rate of player\"\"\"\n raise NotImplementedError\n\n def setVolume(self, volume: int):\n \"\"\"Sets the volume of player\"\"\"\n raise NotImplementedError\n\n def setMuted(self, isMuted: bool):\n raise NotImplementedError\n\n def videoOutput(self) -> QObject:\n \"\"\"Return the video output to be used by the media player\"\"\"\n raise NotImplementedError\n\n def setVideoOutput(self, output: QObject) -> None:\n \"\"\"Sets the video output to be used by the media player\"\"\"\n raise NotImplementedError\n\n\nclass MediaPlayer(MediaPlayerBase):\n def __init__(self, parent=None):\n # 确保在主线程中初始化\n if parent:\n super().__init__(parent)\n else:\n super().__init__()\n\n # 修改 VLC 参数以减少警告\n vlc_args = [\n \"--no-xlib\",\n \"--quiet\",\n ]\n\n # 在主线程中创建 VLC 实例\n self.moveToThread(QApplication.instance().thread())\n self.instance = vlc.Instance(vlc_args)\n self._player = self.instance.media_player_new()\n self._media = None\n self._source = None\n self._playback_rate = 1.0\n\n # 创建定时器用于更新状态\n self._update_timer = QTimer(self)\n self._update_timer.setInterval(100) # 100ms更新一次\n self._update_timer.timeout.connect(self._on_timer_update)\n self._update_timer.start()\n\n # 保存上一次的状态,用于检测变化\n self._last_position = 0\n self._last_duration = 0\n self._last_volume = 100\n\n def _on_timer_update(self):\n \"\"\"定时更新状态并发送信号\"\"\"\n if self._player:\n # 更新位置\n position = self._player.get_time()\n if position != self._last_position:\n self._last_position = position\n self.positionChanged.emit(position)\n\n # 更新时长\n duration = self._player.get_length()\n if duration != self._last_duration:\n self._last_duration = duration\n self.durationChanged.emit(duration)\n\n # 更新音量\n volume = self._player.audio_get_volume()\n if volume != self._last_volume:\n self._last_volume = volume\n self.volumeChanged.emit(volume)\n\n def isPlaying(self):\n return bool(self._player and self._player.is_playing())\n\n def mediaStatus(self) -> MediaStatus:\n if not self._player:\n return MediaStatus.NoMedia\n\n state = self._player.get_state()\n if state == vlc.State.NothingSpecial:\n return MediaStatus.NoMedia\n elif state == vlc.State.Opening:\n return MediaStatus.LoadingMedia\n elif state == vlc.State.Playing:\n return MediaStatus.BufferedMedia\n elif state == vlc.State.Paused:\n return MediaStatus.BufferedMedia\n elif state == vlc.State.Stopped:\n return MediaStatus.LoadedMedia\n elif state == vlc.State.Ended:\n return MediaStatus.EndOfMedia\n elif state == vlc.State.Error:\n return MediaStatus.InvalidMedia\n return MediaStatus.UnknownMediaStatus\n\n def playbackState(self) -> PlaybackState:\n if not self._player:\n return PlaybackState.StoppedState\n\n if self._player.is_playing():\n return PlaybackState.PlayingState\n elif self._player.get_state() == vlc.State.Paused:\n return PlaybackState.PausedState\n return PlaybackState.StoppedState\n\n def duration(self):\n return self._player.get_length() if self._player else 0\n\n def position(self):\n return self._player.get_time() if self._player else 0\n\n def volume(self):\n return self._player.audio_get_volume() if self._player else 0\n\n def source(self) -> QUrl:\n return self._source\n\n def get_subtitle(self):\n \"\"\"获取当前使用的字幕文件路径\n\n Returns:\n str: 当前字幕文件路径,如果没有字幕则返回 None\n \"\"\"\n if not self._player:\n return None\n\n try:\n # 获取当前字幕轨道ID\n current_spu = self._player.video_get_spu()\n if current_spu <= 0: # 0 表示禁用字幕,-1 表示错误\n return None\n\n # 获取字幕轨道描述信息\n spu_description = self._player.video_get_spu_description()\n if not spu_description:\n return None\n\n # 遍历查找当前使用的字幕轨道\n for spu in spu_description:\n if spu[0] == current_spu:\n # 返回字幕文件路径\n return spu[1].decode(\"utf-8\")\n\n return None\n except Exception:\n return None\n\n def pause(self):\n self._player.pause()\n\n def play(self):\n self._player.play()\n\n def stop(self):\n self._player.stop()\n\n def playbackRate(self) -> float:\n return self._playback_rate\n\n def setPosition(self, position: int):\n if self._player:\n self._player.set_time(position)\n self.positionChanged.emit(position)\n\n def setSource(self, media: QUrl):\n \"\"\"设置媒体源时重置状态\"\"\"\n path = media.toLocalFile() or media.toString()\n self._media = self.instance.media_new(path)\n self._player.set_media(self._media)\n self._source = media\n self.sourceChanged.emit(media)\n self.mediaStatusChanged.emit(self.mediaStatus())\n\n def setPlaybackRate(self, rate: float):\n if self._player:\n self._player.set_rate(rate)\n self._playback_rate = rate\n self.playbackRateChanged.emit(rate)\n\n def setVolume(self, volume: int):\n if self._player:\n self._player.audio_set_volume(volume)\n self.volumeChanged.emit(volume)\n\n def setMuted(self, isMuted: bool):\n if self._player:\n self._player.audio_set_mute(isMuted)\n self.mutedChanged.emit(isMuted)\n\n def videoOutput(self) -> Optional[QObject]:\n return None # VLC不需要这个\n\n def setVideoOutput(self, output: QObject) -> None:\n if isinstance(output, QWidget) and hasattr(output, \"winId\"): # type: ignore\n self._player.set_hwnd(output.winId())\n\n def hasMedia(self):\n \"\"\"检查是否有媒体文件加载\"\"\"\n return bool(self._media and self._player)\n\n def playSegment(self, start_time: int, end_time: int):\n \"\"\"播放指定时间段的视频片段\n\n Args:\n start_time: 开始时间(毫秒)\n end_time: 结束时间(毫秒)\n \"\"\"\n if not self._player or not self.hasMedia():\n return\n\n # 确保时间范围有效\n if start_time < 0 or end_time > self.duration() or start_time >= end_time:\n return\n\n # 创建事件管理器\n event_manager = self._player.event_manager()\n\n def on_time_changed(event):\n # 当播放位置到达结束时间时停止播放\n if self.position() >= end_time:\n self.pause()\n # 移除事件监听器\n event_manager.event_detach(vlc.EventType.MediaPlayerTimeChanged)\n\n # 注册时间变化事件\n event_manager.event_attach(\n vlc.EventType.MediaPlayerTimeChanged, on_time_changed\n )\n\n # 设置开始位置并播放\n self.setPosition(start_time)\n self.play()\n\n def add_subtitle(self, subtitle_file: str) -> bool:\n \"\"\"添加字幕文件\n\n Args:\n subtitle_file: 字幕文件的路径\n\n Returns:\n bool: 是否成功添加字幕\n \"\"\"\n if not self._player or not self.hasMedia():\n return False\n\n try:\n # 将路径转换为 URI 格式\n\n subtitle_uri = Path(subtitle_file).as_uri()\n\n # 添加字幕轨道\n result = self._player.add_slave(\n vlc.MediaSlaveType.subtitle, subtitle_uri, True\n )\n\n # 获取字幕轨道信息 (unused but potentially useful for debugging)\n # spu_description = self._player.video_get_spu_description()\n\n return result == 0\n except Exception:\n return False\n\n def get_subtitle_tracks(self) -> list:\n \"\"\"获取所有可用的字幕轨道\"\"\"\n if not self._player:\n return []\n\n tracks = []\n spu_count = self._player.video_get_spu_count()\n for i in range(spu_count):\n track_info = self._player.video_get_spu_description()[i]\n tracks.append(track_info)\n return tracks\n\n def set_subtitle_track(self, track_id: int):\n \"\"\"设置当前使用的字幕轨道\n\n Args:\n track_id: 字幕轨道ID,-1 表示禁用字幕\n \"\"\"\n if self._player:\n self._player.video_set_spu(track_id)\n\n\nclass StandardMediaPlayBar(MediaPlayBarBase):\n \"\"\"Standard media play bar\"\"\"\n\n def __init__(self, parent=None):\n super().__init__(parent)\n self.vBoxLayout = QVBoxLayout(self)\n self.timeLayout = QHBoxLayout()\n self.buttonLayout = QHBoxLayout()\n self.leftButtonContainer = QWidget()\n self.centerButtonContainer = QWidget()\n self.rightButtonContainer = QWidget()\n self.leftButtonLayout = QHBoxLayout(self.leftButtonContainer)\n self.centerButtonLayout = QHBoxLayout(self.centerButtonContainer)\n self.rightButtonLayout = QHBoxLayout(self.rightButtonContainer)\n\n self.skipBackButton = MediaPlayBarButton(FluentIcon.SKIP_BACK, self)\n self.skipForwardButton = MediaPlayBarButton(FluentIcon.SKIP_FORWARD, self)\n\n self.currentTimeLabel = CaptionLabel(\"0:00:00\", self)\n self.remainTimeLabel = CaptionLabel(\"0:00:00\", self)\n\n self.__initWidgets()\n\n def __initWidgets(self):\n self.setFixedHeight(102)\n self.vBoxLayout.setSpacing(6)\n self.vBoxLayout.setContentsMargins(5, 9, 5, 9)\n self.vBoxLayout.addWidget(self.progressSlider, 1, Qt.AlignTop) # type: ignore\n\n self.vBoxLayout.addLayout(self.timeLayout)\n self.timeLayout.setContentsMargins(10, 0, 10, 0)\n self.timeLayout.addWidget(self.currentTimeLabel, 0, Qt.AlignLeft) # type: ignore\n self.timeLayout.addWidget(self.remainTimeLabel, 0, Qt.AlignRight) # type: ignore\n\n self.vBoxLayout.addStretch(1)\n self.vBoxLayout.addLayout(self.buttonLayout, 1)\n self.buttonLayout.setContentsMargins(0, 0, 0, 0)\n self.leftButtonLayout.setContentsMargins(4, 0, 0, 0)\n self.centerButtonLayout.setContentsMargins(0, 0, 0, 0)\n self.rightButtonLayout.setContentsMargins(0, 0, 4, 0)\n\n self.leftButtonLayout.addWidget(self.volumeButton, 0, Qt.AlignLeft) # type: ignore\n self.centerButtonLayout.addWidget(self.skipBackButton)\n self.centerButtonLayout.addWidget(self.playButton)\n self.centerButtonLayout.addWidget(self.skipForwardButton)\n\n self.buttonLayout.addWidget(self.leftButtonContainer, 0, Qt.AlignLeft) # type: ignore\n self.buttonLayout.addWidget(self.centerButtonContainer, 0, Qt.AlignHCenter) # type: ignore\n self.buttonLayout.addWidget(self.rightButtonContainer, 0, Qt.AlignRight) # type: ignore\n\n self.skipBackButton.clicked.connect(lambda: self.skipBack(5000))\n self.skipForwardButton.clicked.connect(lambda: self.skipForward(5000))\n\n def skipBack(self, ms: int):\n \"\"\"Back up for specified milliseconds\"\"\"\n self.player.setPosition(self.player.position() - ms)\n\n def skipForward(self, ms: int):\n \"\"\"Fast forward specified milliseconds\"\"\"\n self.player.setPosition(self.player.position() + ms)\n\n def _onPositionChanged(self, position: int):\n super()._onPositionChanged(position)\n self.currentTimeLabel.setText(self._formatTime(position))\n self.remainTimeLabel.setText(\n self._formatTime(self.player.duration() - position)\n )\n\n def _formatTime(self, time: int):\n time = int(time / 1000)\n s = time % 60\n m = int(time / 60)\n h = int(time / 3600)\n return f\"{h}:{m:02}:{s:02}\"\n\n def closeEvent(self, event):\n self.release()\n super().closeEvent(event)\n\n\nclass MyVideoWidget(QWidget):\n \"\"\"Video widget\"\"\"\n\n def __init__(self, parent=None):\n super().__init__(parent)\n\n # 设置初始窗口大小\n self.resize(800, 600)\n self.setWindowTitle(\"VideoCaptioner\")\n self.setWindowIcon(QIcon(str(RESOURCE_PATH / \"assets\" / \"logo.png\")))\n\n # 创建一个专门用于视频输出的 widget\n self.videoWidget = QWidget(self)\n self.videoWidget.setStyleSheet(\"background-color: rgb(24, 24, 24);\")\n\n # 添加提示标签\n self.tipLabel = CaptionLabel(\"请拖入视频文件\", self.videoWidget)\n self.tipLabel.setStyleSheet(\n \"\"\"\n color: rgba(255, 255, 255, 0.5);\n font-size: 20px;\n font-weight: bold;\n letter-spacing: 2px;\n \"\"\"\n )\n\n # 创建布局使标签居中\n tipLayout = QVBoxLayout(self.videoWidget)\n tipLayout.addWidget(self.tipLabel, 0, Qt.AlignCenter) # type: ignore\n\n # 创建播放控制栏\n self.playBar = StandardMediaPlayBar(self)\n self.playBar.setAttribute(Qt.WA_TranslucentBackground) # type: ignore\n\n # 设置字幕文件\n self.subtitle_file = None\n\n # 创建垂直布局\n self.vBoxLayout = QVBoxLayout(self)\n self.vBoxLayout.setContentsMargins(0, 0, 0, 0)\n self.vBoxLayout.setSpacing(0)\n self.vBoxLayout.addWidget(self.videoWidget, 1)\n self.vBoxLayout.addWidget(self.playBar, 0)\n\n # 创建播放器并传入优化参数\n self.vlc_player = MediaPlayer(self)\n\n # 设置新的播放器\n self.playBar.setMediaPlayer(self.vlc_player) # type: ignore\n self.playBar.setVolume(80)\n self.vlc_player.setVideoOutput(self.videoWidget)\n FluentStyleSheet.MEDIA_PLAYER.apply(self)\n\n # 设置焦点和事件过滤\n self.setFocusPolicy(Qt.StrongFocus) # type: ignore\n self.videoWidget.setFocusPolicy(Qt.StrongFocus) # type: ignore\n\n # 安装事件过滤器\n self.videoWidget.installEventFilter(self)\n self.playBar.installEventFilter(self)\n\n FluentStyleSheet.MEDIA_PLAYER.apply(self)\n self.setAcceptDrops(True)\n\n # 连接 SignalBus 信号\n self._connectSignals()\n\n def _connectSignals(self):\n \"\"\"连接 SignalBus 的信号\"\"\"\n # 视频控制信号\n signalBus.video_play.connect(self.play)\n signalBus.video_pause.connect(self.pause)\n signalBus.video_stop.connect(self.stop)\n signalBus.video_source_changed.connect(self.setVideo)\n signalBus.video_segment_play.connect(self.playSegment)\n signalBus.video_subtitle_added.connect(self.addSubtitle)\n\n def addSubtitle(self, subtitle_file: str):\n \"\"\"添加字幕文件的内部方法\"\"\"\n self.subtitle_file = subtitle_file\n self.vlc_player.add_subtitle(subtitle_file)\n\n def setVideo(self, url: QUrl):\n \"\"\"设置视频源\n\n Args:\n url: 视频文件的 QUrl\n \"\"\"\n self.setWindowTitle(url.fileName())\n self.vlc_player.setSource(url)\n if self.subtitle_file:\n self.vlc_player.add_subtitle(self.subtitle_file)\n # 隐藏提示标签\n self.tipLabel.hide()\n\n def play(self):\n \"\"\"播放视频\"\"\"\n self.playBar.play()\n\n def pause(self):\n \"\"\"暂停视频\"\"\"\n self.playBar.pause()\n\n def stop(self):\n \"\"\"停止视频\"\"\"\n self.playBar.stop()\n\n def playSegment(self, start_time: int, end_time: int):\n \"\"\"播放指定时间段的视频\n\n Args:\n start_time: 开始时间(毫秒)\n end_time: 结束时间(毫秒)\n \"\"\"\n self.vlc_player.playSegment(start_time, end_time)\n\n def hideEvent(self, e):\n self.stop()\n e.accept()\n\n def wheelEvent(self, e):\n return\n\n def togglePlayState(self):\n \"\"\"toggle play state\"\"\"\n if self.vlc_player.isPlaying():\n self.pause()\n else:\n self.play()\n\n @property\n def player(self):\n return self.playBar.player\n\n def keyPressEvent(self, event):\n \"\"\"处理键盘事件\"\"\"\n if event.key() == Qt.Key_Space: # type: ignore\n self.playBar.togglePlayState()\n elif event.key() == Qt.Key_Left: # type: ignore\n self.playBar.skipBack(3000)\n elif event.key() == Qt.Key_Right: # type: ignore\n self.playBar.skipForward(3000)\n else:\n super().keyPressEvent(event)\n\n def dragEnterEvent(self, event):\n \"\"\"处理拖入事件\"\"\"\n if event.mimeData().hasUrls():\n urls = event.mimeData().urls()\n # 检查是否为视频文件或字幕文件\n if any(\n url.toLocalFile()\n .lower()\n .endswith(\n (\".mp4\", \".avi\", \".mkv\", \".mov\", \".wmv\", \".flv\", \".srt\", \".ass\")\n )\n for url in urls\n ):\n event.acceptProposedAction()\n\n def dropEvent(self, event):\n \"\"\"处理放下事件\"\"\"\n urls = event.mimeData().urls()\n for url in urls:\n file_path = url.toLocalFile().lower()\n if file_path.endswith((\".srt\", \".ass\")):\n # 处理字幕文件\n self.vlc_player.add_subtitle(url.toLocalFile())\n elif file_path.endswith((\".mp4\", \".avi\", \".mkv\", \".mov\", \".wmv\", \".flv\")):\n # 处理视频文件\n self.setVideo(url)\n self.play()\n break # 只处理第一个视频文件\n\n def eventFilter(self, obj, event):\n \"\"\"事件过滤器,用于捕获所有子部件的按键事件\"\"\"\n if event.type() == event.KeyPress:\n if event.key() in (Qt.Key_Left, Qt.Key_Right): # type: ignore\n self.keyPressEvent(event)\n return True\n return super().eventFilter(obj, event)\n\n def showEvent(self, event):\n \"\"\"窗口显示时设置焦点\"\"\"\n super().showEvent(event)\n self.setFocus()\n\n\nif __name__ == \"__main__\":\n app = QApplication(sys.argv)\n window = MyVideoWidget()\n # 设置视频源 - 请替换为您的测试视频路径\n # video_path = r\"path/to/your/test/video.mp4\"\n # window.setVideo(QUrl.fromLocalFile(video_path))\n\n # 确保窗口显示在屏幕中央\n window.show()\n window.activateWindow()\n window.raise_()\n\n # 开始播放视频\n # window.play()\n sys.exit(app.exec_())\n"
},
{
"path": "app/components/SimpleSettingCard.py",
"content": "from PyQt5.QtCore import pyqtSignal\nfrom PyQt5.QtWidgets import QHBoxLayout\nfrom qfluentwidgets import (\n CaptionLabel,\n CardWidget,\n ComboBox,\n SwitchButton,\n ToolTipFilter,\n ToolTipPosition,\n)\n\n\nclass SimpleSettingCard(CardWidget):\n \"\"\"基础设置卡片类\"\"\"\n\n def __init__(self, title, content, parent=None):\n super().__init__(parent)\n self.title = title\n self.content = content\n self.setup_ui()\n\n def setup_ui(self):\n self.hBoxLayout = QHBoxLayout(self)\n self.hBoxLayout.setContentsMargins(16, 10, 8, 10)\n self.hBoxLayout.setSpacing(8)\n\n self.label = CaptionLabel(self)\n self.label.setText(self.title)\n self.hBoxLayout.addWidget(self.label)\n\n self.hBoxLayout.addStretch(1)\n\n self.setToolTip(self.content)\n self.installEventFilter(ToolTipFilter(self, 100, ToolTipPosition.BOTTOM))\n\n\nclass ComboBoxSimpleSettingCard(SimpleSettingCard):\n \"\"\"下拉框设置卡片\"\"\"\n\n valueChanged = pyqtSignal(str)\n\n def __init__(self, title, content, items=None, parent=None):\n super().__init__(title, content, parent)\n self.items = items or []\n self.setup_combobox()\n\n def setup_combobox(self):\n self.comboBox = ComboBox(self)\n self.comboBox.addItems(self.items)\n self.comboBox.setMaxVisibleItems(6)\n self.comboBox.currentTextChanged.connect(self.valueChanged) # type: ignore\n self.hBoxLayout.addWidget(self.comboBox)\n\n def setValue(self, value):\n self.comboBox.setCurrentIndex(self.items.index(value))\n\n def value(self):\n return self.comboBox.currentText()\n\n\nclass SwitchButtonSimpleSettingCard(SimpleSettingCard):\n \"\"\"开关设置卡片\"\"\"\n\n checkedChanged = pyqtSignal(bool)\n\n def __init__(self, title, content, parent=None):\n super().__init__(title, content, parent)\n self.setup_switch()\n\n def setup_switch(self):\n self.switchButton = SwitchButton(self)\n self.switchButton.setOnText(\"开\")\n self.switchButton.setOffText(\"关\")\n self.switchButton.checkedChanged.connect(self.checkedChanged) # type: ignore\n self.hBoxLayout.addWidget(self.switchButton)\n\n self.clicked.connect( # type: ignore\n lambda: self.switchButton.setChecked(not self.switchButton.isChecked())\n )\n\n def setChecked(self, checked):\n self.switchButton.setChecked(checked)\n\n def isChecked(self):\n return self.switchButton.isChecked()\n"
},
{
"path": "app/components/SpinBoxSettingCard.py",
"content": "from typing import Optional, Union\n\nfrom PyQt5.QtCore import Qt, pyqtSignal\nfrom PyQt5.QtGui import QIcon\nfrom qfluentwidgets import CompactDoubleSpinBox, CompactSpinBox, SettingCard\nfrom qfluentwidgets.common.config import ConfigItem, qconfig\n\n\nclass DoubleSpinBoxSettingCard(SettingCard):\n \"\"\"小数输入设置卡片\"\"\"\n\n valueChanged = pyqtSignal(float)\n\n def __init__(\n self,\n configItem: ConfigItem,\n icon: Union[str, QIcon],\n title: str,\n content: Optional[str] = None,\n minimum: float = 0.0,\n maximum: float = 100.0,\n decimals: int = 1,\n step: float = 0.1,\n parent=None,\n ):\n super().__init__(icon, title, content, parent)\n\n self.configItem = configItem\n\n # 创建CompactDoubleSpinBox\n self.spinBox = CompactDoubleSpinBox(self)\n self.spinBox.setRange(minimum, maximum)\n self.spinBox.setDecimals(decimals)\n self.spinBox.setMinimumWidth(60)\n self.spinBox.setSingleStep(step) # 设置步长为0.2\n\n # 添加到布局\n self.hBoxLayout.addWidget(self.spinBox, 0, Qt.AlignRight) # type: ignore\n self.hBoxLayout.addSpacing(8)\n\n # 设置初始值和连接信号\n self.setValue(qconfig.get(configItem))\n self.spinBox.valueChanged.connect(self.__onValueChanged)\n configItem.valueChanged.connect(self.setValue)\n\n def __onValueChanged(self, value: float):\n \"\"\"数值改变时的槽函数\"\"\"\n self.setValue(value)\n self.valueChanged.emit(value)\n\n def setValue(self, value: float):\n \"\"\"设置数值\"\"\"\n qconfig.set(self.configItem, value)\n self.spinBox.setValue(value)\n\n\nclass SpinBoxSettingCard(SettingCard):\n \"\"\"数值输入设置卡片\"\"\"\n\n valueChanged = pyqtSignal(int)\n\n def __init__(\n self,\n configItem: ConfigItem,\n icon: Union[str, QIcon],\n title: str,\n content: Optional[str] = None,\n minimum: int = 0,\n maximum: int = 100,\n parent=None,\n ):\n super().__init__(icon, title, content, parent)\n\n self.configItem = configItem\n\n # 创建SpinBox\n self.spinBox = CompactSpinBox(self)\n self.spinBox.setRange(minimum, maximum)\n self.spinBox.setMinimumWidth(60)\n\n # 添加到布局\n self.hBoxLayout.addWidget(self.spinBox, 0, Qt.AlignRight) # type: ignore\n self.hBoxLayout.addSpacing(8)\n\n # 设置初始值和连接信号\n self.setValue(qconfig.get(configItem))\n self.spinBox.valueChanged.connect(self.__onValueChanged)\n configItem.valueChanged.connect(self.setValue)\n\n def __onValueChanged(self, value: int):\n \"\"\"数值改变时的槽函数\"\"\"\n self.setValue(value)\n self.valueChanged.emit(value)\n\n def setValue(self, value: int):\n \"\"\"设置数值\"\"\"\n qconfig.set(self.configItem, value)\n self.spinBox.setValue(value)\n"
},
{
"path": "app/components/SubtitleSettingDialog.py",
"content": "from qfluentwidgets import (\n BodyLabel,\n MessageBoxBase,\n SwitchSettingCard,\n)\nfrom qfluentwidgets import FluentIcon as FIF\n\nfrom app.common.config import cfg\nfrom app.components.SpinBoxSettingCard import SpinBoxSettingCard\n\n\nclass SubtitleSettingDialog(MessageBoxBase):\n \"\"\"字幕设置对话框\"\"\"\n\n def __init__(self, parent=None):\n super().__init__(parent)\n self.titleLabel = BodyLabel(self.tr(\"字幕设置\"), self)\n\n # 创建设置卡片\n self.split_card = SwitchSettingCard(\n FIF.ALIGNMENT,\n self.tr(\"字幕分割\"),\n self.tr(\"字幕是否使用大语言模型进行智能断句\"),\n cfg.need_split,\n self,\n )\n\n self.word_count_cjk_card = SpinBoxSettingCard(\n cfg.max_word_count_cjk,\n FIF.TILES, # type: ignore\n self.tr(\"中文最大字数\"),\n self.tr(\"单条字幕的最大字数 (对于中日韩等字符)\"),\n minimum=8,\n maximum=50,\n parent=self,\n )\n\n self.word_count_english_card = SpinBoxSettingCard(\n cfg.max_word_count_english,\n FIF.TILES, # type: ignore\n self.tr(\"英文最大单词数\"),\n self.tr(\"单条字幕的最大单词数 (英文)\"),\n minimum=8,\n maximum=50,\n parent=self,\n )\n\n # 添加到布局\n self.viewLayout.addWidget(self.titleLabel)\n self.viewLayout.addWidget(self.split_card)\n self.viewLayout.addWidget(self.word_count_cjk_card)\n self.viewLayout.addWidget(self.word_count_english_card)\n # 设置间距\n self.viewLayout.setSpacing(10)\n\n # 设置窗口标题和宽度\n self.setWindowTitle(self.tr(\"字幕设置\"))\n self.widget.setMinimumWidth(380)\n\n # 只显示取消按钮\n self.yesButton.hide()\n self.cancelButton.setText(self.tr(\"关闭\"))\n"
},
{
"path": "app/components/TranscriptionOutputDialog.py",
"content": "# -*- coding: utf-8 -*-\nfrom qfluentwidgets import (\n BodyLabel,\n ComboBoxSettingCard,\n MessageBoxBase,\n)\nfrom qfluentwidgets import FluentIcon as FIF\n\nfrom app.common.config import cfg\nfrom app.core.entities import TranscribeOutputFormatEnum\n\n\nclass TranscriptionSettingDialog(MessageBoxBase):\n \"\"\"转录设置对话框\"\"\"\n\n def __init__(self, parent=None):\n super().__init__(parent)\n self.titleLabel = BodyLabel(self.tr(\"转录设置\"), self)\n\n # 创建输出格式选择卡片\n self.output_format_card = ComboBoxSettingCard(\n cfg.transcribe_output_format,\n FIF.SAVE,\n self.tr(\"输出格式\"),\n self.tr(\"选择转录字幕的输出格式\"),\n texts=[fmt.value for fmt in TranscribeOutputFormatEnum],\n parent=self,\n )\n self.output_format_card.setMinimumWidth(420)\n\n # 添加到布局\n self.viewLayout.addWidget(self.titleLabel)\n self.viewLayout.addWidget(self.output_format_card)\n # 设置间距\n self.viewLayout.setSpacing(10)\n\n # 设置窗口标题\n self.setWindowTitle(self.tr(\"转录设置\"))\n\n # 只显示取消按钮\n self.yesButton.hide()\n self.cancelButton.setText(self.tr(\"关闭\"))\n\n"
},
{
"path": "app/components/TranscriptionSettingDialog.py",
"content": "# -*- coding: utf-8 -*-\nfrom qfluentwidgets import (\n BodyLabel,\n ComboBoxSettingCard,\n MessageBoxBase,\n)\nfrom qfluentwidgets import FluentIcon as FIF\n\nfrom app.common.config import cfg\nfrom app.core.entities import TranscribeOutputFormatEnum\n\n\nclass TranscriptionSettingDialog(MessageBoxBase):\n \"\"\"转录设置对话框\"\"\"\n\n def __init__(self, parent=None):\n super().__init__(parent)\n self.titleLabel = BodyLabel(self.tr(\"转录设置\"), self)\n\n # 创建输出格式选择卡片\n self.output_format_card = ComboBoxSettingCard(\n cfg.transcribe_output_format,\n FIF.SAVE,\n self.tr(\"输出格式\"),\n self.tr(\"选择转录字幕的输出格式\"),\n texts=[fmt.value for fmt in TranscribeOutputFormatEnum],\n parent=self,\n )\n\n # 添加到布局\n self.viewLayout.addWidget(self.titleLabel)\n self.viewLayout.addWidget(self.output_format_card)\n # 设置间距\n self.viewLayout.setSpacing(10)\n\n # 设置窗口标题和宽度\n self.setWindowTitle(self.tr(\"转录设置\"))\n self.widget.setMinimumWidth(380)\n\n # 只显示取消按钮\n self.yesButton.hide()\n self.cancelButton.setText(self.tr(\"关闭\"))\n\n"
},
{
"path": "app/components/WhisperAPISettingWidget.py",
"content": "from PyQt5.QtCore import Qt, QThread, pyqtSignal\nfrom PyQt5.QtWidgets import (\n QVBoxLayout,\n QWidget,\n)\nfrom qfluentwidgets import (\n ComboBoxSettingCard,\n InfoBar,\n InfoBarPosition,\n PushSettingCard,\n SettingCardGroup,\n SingleDirectionScrollArea,\n)\nfrom qfluentwidgets import FluentIcon as FIF\n\nfrom ..common.config import cfg\nfrom ..core.constant import INFOBAR_DURATION_ERROR, INFOBAR_DURATION_SUCCESS\nfrom ..core.entities import TranscribeLanguageEnum\nfrom ..core.llm import check_whisper_connection\nfrom .EditComboBoxSettingCard import EditComboBoxSettingCard\nfrom .LineEditSettingCard import LineEditSettingCard\n\n\nclass WhisperAPISettingWidget(QWidget):\n def __init__(self, parent=None):\n super().__init__(parent)\n self.setup_ui()\n\n def setup_ui(self):\n self.main_layout = QVBoxLayout(self)\n\n # 创建单向滚动区域和容器\n self.scrollArea = SingleDirectionScrollArea(orient=Qt.Vertical, parent=self) # type: ignore\n self.scrollArea.setStyleSheet(\n \"QScrollArea{background: transparent; border: none}\"\n )\n\n self.container = QWidget(self)\n self.container.setStyleSheet(\"QWidget{background: transparent}\")\n self.containerLayout = QVBoxLayout(self.container)\n\n self.setting_group = SettingCardGroup(self.tr(\"Whisper API 设置\"), self)\n\n # API Base URL\n self.base_url_card = LineEditSettingCard(\n cfg.whisper_api_base,\n FIF.LINK,\n self.tr(\"API Base URL\"),\n self.tr(\"输入 Whisper API Base URL\"),\n \"https://api.openai.com/v1\",\n self.setting_group,\n )\n\n # API Key\n self.api_key_card = LineEditSettingCard(\n cfg.whisper_api_key,\n FIF.FINGERPRINT,\n self.tr(\"API Key\"),\n self.tr(\"输入 Whisper API Key\"),\n \"sk-\",\n self.setting_group,\n )\n\n # Model\n self.model_card = EditComboBoxSettingCard(\n cfg.whisper_api_model,\n FIF.ROBOT, # type: ignore\n self.tr(\"Whisper 模型\"),\n self.tr(\"选择 Whisper 模型\"),\n [\"whisper-large-v3\", \"whisper-large-v3-turbo\", \"whisper-1\"],\n self.setting_group,\n )\n\n # 添加 Language 选择\n self.language_card = ComboBoxSettingCard(\n cfg.transcribe_language,\n FIF.LANGUAGE,\n self.tr(\"源语言\"),\n self.tr(\"音视频中说话的语言,默认根据前30秒自动识别\"),\n [lang.value for lang in TranscribeLanguageEnum],\n self.setting_group,\n )\n\n # 添加 Prompt\n self.prompt_card = LineEditSettingCard(\n cfg.whisper_api_prompt,\n FIF.CHAT,\n self.tr(\"提示词\"),\n self.tr(\"可选的提示词,默认空\"),\n \"\",\n self.setting_group,\n )\n\n # 添加测试连接按钮\n self.check_connection_card = PushSettingCard(\n self.tr(\"测试连接\"),\n FIF.CONNECT,\n self.tr(\"测试 Whisper API 连接\"),\n self.tr(\"点击测试 API 连接是否正常\"),\n self.setting_group,\n )\n\n # 设置最小宽度\n self.base_url_card.lineEdit.setMinimumWidth(200)\n self.api_key_card.lineEdit.setMinimumWidth(200)\n self.model_card.comboBox.setMinimumWidth(200)\n self.language_card.comboBox.setMinimumWidth(200)\n self.prompt_card.lineEdit.setMinimumWidth(200)\n\n # 使用 addSettingCard 添加所有卡片到组\n self.setting_group.addSettingCard(self.base_url_card)\n self.setting_group.addSettingCard(self.api_key_card)\n self.setting_group.addSettingCard(self.model_card)\n self.setting_group.addSettingCard(self.language_card)\n self.setting_group.addSettingCard(self.prompt_card)\n self.setting_group.addSettingCard(self.check_connection_card)\n\n # 连接测试按钮信号\n self.check_connection_card.clicked.connect(self.on_check_connection)\n\n # 将设置组添加到容器布局\n self.containerLayout.addWidget(self.setting_group)\n self.containerLayout.addStretch(1)\n\n # 设置滚动区域\n self.scrollArea.setWidget(self.container)\n self.scrollArea.setWidgetResizable(True)\n\n # 将滚动区域添加到主布局\n self.main_layout.addWidget(self.scrollArea)\n\n def on_check_connection(self):\n \"\"\"测试 Whisper API 连接\"\"\"\n # 获取配置\n base_url = self.base_url_card.lineEdit.text().strip()\n api_key = self.api_key_card.lineEdit.text().strip()\n model = self.model_card.comboBox.currentText().strip()\n\n # 验证必填字段\n if not base_url or not api_key or not model:\n InfoBar.warning(\n self.tr(\"配置不完整\"),\n self.tr(\"请输入 API Base URL、API Key 和 model\"),\n duration=INFOBAR_DURATION_ERROR,\n position=InfoBarPosition.TOP,\n parent=self.window(),\n )\n return\n\n # 禁用按钮,显示加载状态\n self.check_connection_card.button.setEnabled(False)\n self.check_connection_card.button.setText(self.tr(\"正在测试...\"))\n\n # 创建并启动测试线程\n self.connection_thread = WhisperConnectionThread(base_url, api_key, model)\n self.connection_thread.finished.connect(self.on_connection_check_finished)\n self.connection_thread.error.connect(self.on_connection_check_error)\n self.connection_thread.start()\n\n def on_connection_check_finished(self, success, result):\n \"\"\"处理连接检查完成事件\"\"\"\n # 恢复按钮状态\n self.check_connection_card.button.setEnabled(True)\n self.check_connection_card.button.setText(self.tr(\"测试连接\"))\n\n if success:\n InfoBar.success(\n self.tr(\"连接成功\"),\n self.tr(\"Whisper API 连接成功!\") + \"\\n\" + result,\n duration=INFOBAR_DURATION_SUCCESS,\n position=InfoBarPosition.BOTTOM,\n parent=self.window(),\n )\n else:\n InfoBar.error(\n self.tr(\"连接失败\"),\n self.tr(f\"Whisper API 连接失败!\\n{result}\"),\n duration=INFOBAR_DURATION_ERROR,\n position=InfoBarPosition.BOTTOM,\n parent=self.window(),\n )\n\n def on_connection_check_error(self, message):\n \"\"\"处理连接检查错误事件\"\"\"\n # 恢复按钮状态\n self.check_connection_card.button.setEnabled(True)\n self.check_connection_card.button.setText(self.tr(\"测试连接\"))\n InfoBar.error(\n self.tr(\"测试错误\"),\n message,\n duration=INFOBAR_DURATION_ERROR,\n position=InfoBarPosition.BOTTOM,\n parent=self.window(),\n )\n\n\nclass WhisperConnectionThread(QThread):\n \"\"\"Whisper API 连接测试线程\"\"\"\n\n finished = pyqtSignal(bool, str)\n error = pyqtSignal(str)\n\n def __init__(self, base_url, api_key, model):\n super().__init__()\n self.base_url = base_url\n self.api_key = api_key\n self.model = model\n\n def run(self):\n \"\"\"执行连接测试\"\"\"\n try:\n success, result = check_whisper_connection(\n self.base_url, self.api_key, self.model\n )\n self.finished.emit(success, result)\n except Exception as e:\n self.error.emit(str(e))\n"
},
{
"path": "app/components/WhisperCppSettingWidget.py",
"content": "import os\n\nfrom PyQt5.QtCore import Qt\nfrom PyQt5.QtWidgets import (\n QHBoxLayout,\n QHeaderView,\n QTableWidgetItem,\n QVBoxLayout,\n QWidget,\n)\nfrom qfluentwidgets import (\n BodyLabel,\n ComboBox,\n ComboBoxSettingCard,\n HyperlinkButton,\n HyperlinkCard,\n InfoBar,\n MessageBoxBase,\n ProgressBar,\n PushButton,\n SettingCardGroup,\n SingleDirectionScrollArea,\n SubtitleLabel,\n TableItemDelegate,\n TableWidget,\n)\nfrom qfluentwidgets import FluentIcon as FIF\n\nfrom app.common.config import cfg\nfrom app.config import MODEL_PATH\nfrom app.core.entities import (\n TranscribeLanguageEnum,\n WhisperModelEnum,\n)\nfrom app.core.utils.logger import setup_logger\nfrom app.core.utils.platform_utils import open_folder\nfrom app.thread.file_download_thread import FileDownloadThread\n\nlogger = setup_logger(\"whisper_download\")\n\n# 使用阿里云镜像定义模型配置\n# https://www.modelscope.cn/models/cjc1887415157/whisper.cpp/resolve/master/ggml-tiny.bin\n# \"mirrorLink\": \"https://hf-mirror.com/ggerganov/whisper.cpp/resolve/main/ggml-tiny.bin?download=true\"\n\n# 使用阿里云镜像定义模型配置\nWHISPER_CPP_MODELS = [\n {\n \"label\": \"Tiny\",\n \"value\": \"ggml-tiny.bin\",\n \"size\": \"77.7 MB\",\n \"downloadLink\": \"https://huggingface.co/ggerganov/whisper.cpp/resolve/main/ggml-tiny.bin\",\n \"mirrorLink\": \"https://www.modelscope.cn/models/cjc1887415157/whisper.cpp/resolve/master/ggml-tiny.bin\",\n \"sha\": \"bd577a113a864445d4c299885e0cb97d4ba92b5f\",\n },\n {\n \"label\": \"Base\",\n \"value\": \"ggml-base.bin\",\n \"size\": \"148 MB\",\n \"downloadLink\": \"https://huggingface.co/ggerganov/whisper.cpp/resolve/main/ggml-base.bin\",\n \"mirrorLink\": \"https://www.modelscope.cn/models/cjc1887415157/whisper.cpp/resolve/master/ggml-base.bin\",\n \"sha\": \"465707469ff3a37a2b9b8d8f89f2f99de7299dac\",\n },\n {\n \"label\": \"Small\",\n \"value\": \"ggml-small.bin\",\n \"size\": \"488 MB\",\n \"downloadLink\": \"https://huggingface.co/ggerganov/whisper.cpp/resolve/main/ggml-small.bin\",\n \"mirrorLink\": \"https://www.modelscope.cn/models/cjc1887415157/whisper.cpp/resolve/master/ggml-small.bin\",\n \"sha\": \"55356645c2b361a969dfd0ef2c5a50d530afd8d5\",\n },\n {\n \"label\": \"Medium\",\n \"value\": \"ggml-medium.bin\",\n \"size\": \"1.53 GB\",\n \"downloadLink\": \"https://huggingface.co/ggerganov/whisper.cpp/resolve/main/ggml-medium.bin\",\n \"mirrorLink\": \"https://www.modelscope.cn/models/cjc1887415157/whisper.cpp/resolve/master/ggml-medium.bin\",\n \"sha\": \"fd9727b6e1217c2f614f9b698455c4ffd82463b4\",\n },\n {\n \"label\": \"large-v1\",\n \"value\": \"ggml-large-v1.bin\",\n \"size\": \"3.09 GB\",\n \"downloadLink\": \"https://huggingface.co/ggerganov/whisper.cpp/resolve/main/ggml-large-v1.bin\",\n \"mirrorLink\": \"https://www.modelscope.cn/models/cjc1887415157/whisper.cpp/resolve/master/ggml-large-v1.bin\",\n \"sha\": \"b1caaf735c4cc1429223d5a74f0f4d0b9b59a299\",\n },\n {\n \"label\": \"large-v2\",\n \"value\": \"ggml-large-v2.bin\",\n \"size\": \"3.09 GB\",\n \"downloadLink\": \"https://huggingface.co/ggerganov/whisper.cpp/resolve/main/ggml-large-v2.bin\",\n \"mirrorLink\": \"https://www.modelscope.cn/models/cjc1887415157/whisper.cpp/resolve/master/ggml-large-v2.bin\",\n \"sha\": \"0f4c8e34f21cf1a914c59d8b3ce882345ad349d6\",\n },\n # {\n # \"label\": \"Large(v3)\",\n # \"value\": \"ggml-large-v3.bin\",\n # \"size\": \"3.09 GB\",\n # \"downloadLink\": \"https://huggingface.co/ggerganov/whisper.cpp/resolve/main/ggml-large-v3.bin\",\n # \"mirrorLink\": \"https://www.modelscope.cn/models/cjc1887415157/whisper.cpp/resolve/master/ggml-large-v3.bin\",\n # \"sha\": \"ad82bf6a9043ceed055076d0fd39f5f186ff8062\"\n # },\n # {\n # \"label\": \"Distil Large(v3)\",\n # \"value\": \"ggml-distil-large-v3.bin\",\n # \"size\": \"1.52 GB\",\n # \"downloadLink\": \"https://huggingface.co/distil-whisper/distil-large-v3-ggml/resolve/main/ggml-distil-large-v3.bin?download=true\",\n # \"mirrorLink\": \"https://www.modelscope.cn/models/cjc1887415157/whisper.cpp/resolve/master/ggml-distil-large-v3.bin\",\n # \"sha\": \"5e61e98bdcf3b9a78516c59bf7d1a10d64cae67a\"\n # }\n]\n\n\ndef check_whisper_cpp_exists():\n \"\"\"检查WhisperCpp程序是否存在\"\"\"\n return True, []\n\n\nclass DownloadDialog(MessageBoxBase):\n def __init__(self, parent=None):\n super().__init__(parent)\n self.setup_ui()\n self.setWindowTitle(self.tr(\"下载模型\"))\n self.download_thread = None\n\n def setup_ui(self):\n self.titleLabel = BodyLabel(self.tr(\"下载模型\"), self)\n\n # 添加模型选择下拉框\n self.model_combo = ComboBox(self)\n self.model_combo.setFixedWidth(300)\n for model in WHISPER_CPP_MODELS:\n # 检查模型是否已下载\n model_path = os.path.join(MODEL_PATH, model[\"value\"])\n downloaded = \"✓ \" if os.path.exists(model_path) else \" \"\n self.model_combo.addItem(f\"{downloaded}{model['label']} ({model['size']})\")\n\n # 进度条\n self.progress_bar = ProgressBar()\n self.progress_bar.hide()\n\n # 进度标签\n self.progress_label = BodyLabel()\n self.progress_label.hide()\n\n # 下载按钮\n self.download_button = PushButton(self.tr(\"下载\"), self)\n self.download_button.clicked.connect(self.start_download)\n\n # 添加到布局\n self.viewLayout.addWidget(self.titleLabel)\n self.viewLayout.addWidget(self.model_combo)\n self.viewLayout.addWidget(self.progress_bar)\n self.viewLayout.addWidget(self.progress_label)\n self.viewLayout.addWidget(self.download_button)\n # 设置间距\n self.viewLayout.setSpacing(10)\n\n # 只显示取消按钮\n self.yesButton.hide()\n self.cancelButton.setText(self.tr(\"关闭\"))\n\n def start_download(self):\n selected_index = self.model_combo.currentIndex()\n model = WHISPER_CPP_MODELS[selected_index]\n save_path = os.path.join(MODEL_PATH, model[\"value\"])\n\n # 检查模型文件是否已存在\n if os.path.exists(save_path):\n InfoBar.warning(\n title=self.tr(\"提示\"),\n content=self.tr(\"模型文件已存在,无需重复下载\"),\n parent=self.window(),\n duration=3000,\n )\n return\n\n self.progress_bar.show()\n self.progress_label.show()\n self.download_button.setEnabled(False)\n\n self.download_thread = FileDownloadThread(model[\"mirrorLink\"], save_path)\n self.download_thread.progress.connect(self.update_progress)\n self.download_thread.finished.connect(self.download_finished)\n self.download_thread.error.connect(self.download_error)\n self.download_thread.start()\n\n def update_progress(self, value, status_msg):\n self.progress_bar.setValue(int(value))\n self.progress_label.setText(status_msg)\n\n def download_finished(self):\n InfoBar.success(\n title=self.tr(\"完成\"),\n content=self.tr(\"模型下载完成!\"),\n parent=self.window(),\n duration=3000,\n )\n self.download_button.setEnabled(True)\n self.progress_label.setText(self.tr(\"下载完成\"))\n\n def download_error(self, error):\n InfoBar.error(\n title=self.tr(\"下载错误\"),\n content=error,\n parent=self.window(),\n duration=5000,\n )\n self.download_button.setEnabled(True)\n self.progress_label.hide()\n\n def reject(self):\n if self.download_thread and self.download_thread.isRunning():\n logger.info(\"关闭下载对话框,终止下载\")\n self.download_thread.stop()\n super().reject()\n\n\nclass WhisperCppDownloadDialog(MessageBoxBase):\n \"\"\"WhisperCpp 下载对话框\"\"\"\n\n # 添加类变量跟踪下载状态\n is_downloading = False\n\n def __init__(self, parent=None, setting_widget=None):\n super().__init__(parent)\n self.widget.setMinimumWidth(600)\n self.program_download_thread = None\n self.model_download_thread = None\n self._setup_ui()\n self.setting_widget = setting_widget\n\n def _setup_ui(self):\n \"\"\"设置UI\"\"\"\n layout = QVBoxLayout()\n self._setup_program_section(layout)\n layout.addSpacing(20)\n self._setup_model_section(layout)\n self._setup_progress_section(layout)\n\n self.viewLayout.addLayout(layout)\n self.cancelButton.setText(self.tr(\"关闭\"))\n self.yesButton.hide()\n\n def _setup_program_section(self, layout):\n \"\"\"设置程序下载部分UI\"\"\"\n # 标题\n whisper_cpp_title = SubtitleLabel(self.tr(\"WhisperCpp程序\"), self)\n layout.addWidget(whisper_cpp_title)\n layout.addSpacing(8)\n\n # 检查已安装的版本\n has_program, installed_versions = check_whisper_cpp_exists()\n\n if has_program:\n # 显示已安装版本\n versions_text = \" + \".join(installed_versions)\n program_status = BodyLabel(self.tr(f\"已安装版本: {versions_text}\"), self)\n program_status.setStyleSheet(\"color: green\")\n layout.addWidget(program_status)\n else:\n desc_label = BodyLabel(self.tr(\"未下载 WhisperCpp 程序\"), self)\n layout.addWidget(desc_label)\n\n def _setup_model_section(self, layout):\n \"\"\"设置模型下载部分UI\"\"\"\n # 标题和按钮的水平布局\n title_layout = QHBoxLayout()\n\n # 标题\n model_title = SubtitleLabel(self.tr(\"模型下载\"), self)\n title_layout.addWidget(model_title)\n\n # 添加打开文件夹按钮\n open_folder_btn = HyperlinkButton(\"\", self.tr(\"打开模型文件夹\"), parent=self)\n open_folder_btn.setIcon(FIF.FOLDER)\n open_folder_btn.clicked.connect(self._open_model_folder)\n title_layout.addStretch()\n title_layout.addWidget(open_folder_btn)\n\n layout.addLayout(title_layout)\n layout.addSpacing(8)\n\n # 模型表格\n self.model_table = self._create_model_table()\n self._populate_model_table()\n layout.addWidget(self.model_table)\n\n def _create_model_table(self):\n \"\"\"创建模型表格\"\"\"\n table = TableWidget(self)\n table.setEditTriggers(TableWidget.NoEditTriggers)\n table.setSelectionMode(TableWidget.NoSelection)\n table.setColumnCount(4)\n table.setHorizontalHeaderLabels(\n [self.tr(\"模型名称\"), self.tr(\"大小\"), self.tr(\"状态\"), self.tr(\"操作\")]\n )\n\n # 设置表格样式\n table.setBorderVisible(True)\n table.setBorderRadius(8)\n table.setItemDelegate(TableItemDelegate(table))\n\n # 设置列宽\n header = table.horizontalHeader()\n header.setSectionResizeMode(0, QHeaderView.Stretch)\n header.setSectionResizeMode(1, QHeaderView.Fixed)\n header.setSectionResizeMode(2, QHeaderView.Fixed)\n header.setSectionResizeMode(3, QHeaderView.Fixed)\n\n table.setColumnWidth(1, 100)\n table.setColumnWidth(2, 80)\n table.setColumnWidth(3, 150)\n\n # 设置行高\n row_height = 45\n table.verticalHeader().setDefaultSectionSize(row_height)\n\n # 设置表格高度\n header_height = 20\n max_visible_rows = 6\n table_height = row_height * max_visible_rows + header_height + 15\n table.setFixedHeight(table_height)\n\n return table\n\n def _setup_progress_section(self, layout):\n \"\"\"设置进度显示部分UI\"\"\"\n self.progress_bar = ProgressBar(self)\n self.progress_label = BodyLabel(\"\", self)\n self.progress_bar.hide()\n self.progress_label.hide()\n\n layout.addWidget(self.progress_bar)\n layout.addWidget(self.progress_label)\n\n def _populate_model_table(self):\n \"\"\"填充模型表格数据\"\"\"\n self.model_table.setRowCount(len(WHISPER_CPP_MODELS))\n for i, model in enumerate(WHISPER_CPP_MODELS):\n self._add_model_row(i, model)\n\n def _add_model_row(self, row, model):\n \"\"\"添加模型表格行\"\"\"\n # 模型名称\n name_item = QTableWidgetItem(model[\"label\"])\n name_item.setTextAlignment(Qt.AlignCenter) # type: ignore\n self.model_table.setItem(row, 0, name_item)\n\n # 大小\n size_item = QTableWidgetItem(f\"{model['size']}\")\n size_item.setTextAlignment(Qt.AlignCenter) # type: ignore\n self.model_table.setItem(row, 1, size_item)\n\n # 状态\n model_bin_path = os.path.join(MODEL_PATH, model[\"value\"])\n status_item = QTableWidgetItem(\n self.tr(\"已下载\") if os.path.exists(model_bin_path) else self.tr(\"未下载\")\n )\n if os.path.exists(model_bin_path):\n status_item.setForeground(Qt.green) # type: ignore\n status_item.setTextAlignment(Qt.AlignCenter) # type: ignore\n self.model_table.setItem(row, 2, status_item)\n\n # 下载按钮\n button_container = QWidget()\n button_layout = QHBoxLayout(button_container)\n button_layout.setContentsMargins(4, 4, 4, 4)\n\n download_btn = HyperlinkButton(\n \"\",\n self.tr(\"重新下载\") if os.path.exists(model_bin_path) else self.tr(\"下载\"),\n parent=self,\n )\n download_btn.setIcon(FIF.DOWNLOAD)\n download_btn.clicked.connect(lambda checked, r=row: self._download_model(r))\n\n button_layout.addStretch()\n button_layout.addWidget(download_btn)\n button_layout.addStretch()\n self.model_table.setCellWidget(row, 3, button_container)\n\n def _download_model(self, row):\n \"\"\"下载选中的模型\"\"\"\n if WhisperCppDownloadDialog.is_downloading:\n InfoBar.warning(\n self.tr(\"下载进行中\"),\n self.tr(\"请等待当前下载任务完成\"),\n duration=3000,\n parent=self,\n )\n return\n\n WhisperCppDownloadDialog.is_downloading = True\n self._set_all_download_buttons_enabled(False)\n\n model = WHISPER_CPP_MODELS[row]\n self.progress_bar.show()\n self.progress_label.show()\n self.progress_label.setText(self.tr(f\"正在下载 {model['label']} 模型...\"))\n\n # 禁用当前行的下载按钮\n button_container = self.model_table.cellWidget(row, 3)\n download_btn = button_container.findChild(HyperlinkButton)\n if download_btn:\n download_btn.setEnabled(False)\n\n def _on_model_download_progress(value, msg):\n self.progress_bar.setValue(int(value))\n self.progress_label.setText(msg)\n\n def _on_model_download_finished():\n WhisperCppDownloadDialog.is_downloading = False\n self._set_all_download_buttons_enabled(True)\n # 更新状态\n status_item = QTableWidgetItem(self.tr(\"已下载\"))\n status_item.setForeground(Qt.green) # type: ignore\n status_item.setTextAlignment(Qt.AlignCenter) # type: ignore\n self.model_table.setItem(row, 2, status_item)\n\n # 更新下载按钮文本\n if download_btn:\n download_btn.setText(self.tr(\"重新下载\"))\n download_btn.setEnabled(True)\n\n # 获取当前下载的模型信息\n model = WHISPER_CPP_MODELS[row]\n\n # 更新主设置对话框的模型选择\n if self.setting_widget:\n try:\n # 保存当前值并清空\n current_value = cfg.whisper_model.value\n combo = self.setting_widget.model_card.comboBox\n combo.clear()\n\n # 找出已下载的模型\n available = []\n model_map = {\n m[\"label\"].lower(): m[\"value\"] for m in WHISPER_CPP_MODELS\n }\n for enum_val in WhisperModelEnum:\n if enum_val.value in model_map:\n if (MODEL_PATH / model_map[enum_val.value]).exists():\n available.append(enum_val)\n\n # 重建下拉框\n self.setting_widget.model_card.optionToText = {\n e: e.value for e in available\n }\n for enum_val in available:\n combo.addItem(enum_val.value, userData=enum_val)\n\n # 恢复选择\n if current_value in available:\n combo.setCurrentText(current_value.value)\n elif combo.count() > 0:\n combo.setCurrentIndex(0)\n except Exception as e:\n logger.error(f\"更新模型选择失败: {e}\")\n\n InfoBar.success(\n self.tr(\"下载成功\"),\n self.tr(f\"{model['label']} 模型已下载完成\"),\n duration=3000,\n parent=self,\n )\n self.progress_bar.hide()\n self.progress_label.hide()\n\n def _on_model_download_error(error):\n WhisperCppDownloadDialog.is_downloading = False\n self._set_all_download_buttons_enabled(True)\n if download_btn:\n download_btn.setEnabled(True)\n\n InfoBar.error(self.tr(\"下载失败\"), str(error), duration=3000, parent=self)\n self.progress_bar.hide()\n self.progress_label.hide()\n\n self.model_download_thread = FileDownloadThread(\n model[\"mirrorLink\"], os.path.join(MODEL_PATH, model[\"value\"])\n )\n self.model_download_thread.progress.connect(_on_model_download_progress)\n self.model_download_thread.finished.connect(_on_model_download_finished)\n self.model_download_thread.error.connect(_on_model_download_error)\n self.model_download_thread.start()\n\n def _set_all_download_buttons_enabled(self, enabled: bool):\n \"\"\"设置所有下载按钮的启用状态\"\"\"\n # 设置程序下载按钮\n if hasattr(self, \"program_download_btn\"):\n self.program_download_btn.setEnabled(enabled)\n self.program_combo.setEnabled(enabled)\n\n # 设置所有模型下载按钮\n for row in range(self.model_table.rowCount()):\n button_container = self.model_table.cellWidget(row, 3)\n if button_container:\n download_btn = button_container.findChild(HyperlinkButton)\n if download_btn:\n download_btn.setEnabled(enabled)\n\n def _open_model_folder(self):\n \"\"\"打开模型文件夹\"\"\"\n if os.path.exists(MODEL_PATH):\n # 根据操作系统打开文件夹\n open_folder(str(MODEL_PATH))\n\n\nclass WhisperCppSettingWidget(QWidget):\n def __init__(self, parent=None):\n super().__init__(parent)\n self.setup_ui()\n self.setup_signals()\n\n def setup_ui(self):\n self.main_layout = QVBoxLayout(self)\n\n # 创建单向滚动区域和容器\n self.scrollArea = SingleDirectionScrollArea(orient=Qt.Vertical, parent=self) # type: ignore\n self.scrollArea.setStyleSheet(\n \"QScrollArea{background: transparent; border: none}\"\n )\n\n self.container = QWidget(self)\n self.container.setStyleSheet(\"QWidget{background: transparent}\")\n self.containerLayout = QVBoxLayout(self.container)\n\n self.setting_group = SettingCardGroup(self.tr(\"Whisper CPP 设置\"), self)\n\n # 模型选择\n self.model_card = ComboBoxSettingCard(\n cfg.whisper_model,\n FIF.ROBOT,\n self.tr(\"模型\"),\n self.tr(\"选择Whisper模型\"),\n [model.value for model in WhisperModelEnum],\n self.setting_group,\n )\n\n # 检查未下载的模型并从下拉框中移除\n for i in range(self.model_card.comboBox.count() - 1, -1, -1):\n model_text = self.model_card.comboBox.itemText(i).lower()\n model_configs = {\n model[\"label\"].lower(): model for model in WHISPER_CPP_MODELS\n }\n model_config = model_configs.get(model_text)\n if model_config and (MODEL_PATH / model_config[\"value\"]).exists():\n continue\n self.model_card.comboBox.removeItem(i)\n\n # 语言选择\n self.language_card = ComboBoxSettingCard(\n cfg.transcribe_language,\n FIF.LANGUAGE,\n self.tr(\"源语言\"),\n self.tr(\"音视频中说话的语言,默认根据前30秒自动识别\"),\n [language.value for language in TranscribeLanguageEnum],\n self.setting_group,\n )\n\n # 添加模型管理卡片\n self.manage_model_card = HyperlinkCard(\n \"\", # 无链接\n self.tr(\"管理模型\"),\n FIF.DOWNLOAD, # 使用下载图标\n self.tr(\"模型管理\"),\n self.tr(\"下载或更新 Whisper CPP 模型\"),\n self.setting_group, # 添加到设置组\n )\n\n # 添加 setMaxVisibleItems\n self.language_card.comboBox.setMaxVisibleItems(6)\n\n # 使用 addSettingCard 添加卡片到组\n self.setting_group.addSettingCard(self.model_card)\n self.setting_group.addSettingCard(self.language_card)\n self.setting_group.addSettingCard(self.manage_model_card)\n\n # 将设置组添加到容器布局\n self.containerLayout.addWidget(self.setting_group)\n self.containerLayout.addStretch(1)\n\n # 设置组件最小宽度\n self.model_card.comboBox.setMinimumWidth(200)\n self.language_card.comboBox.setMinimumWidth(200)\n\n # 设置滚动区域\n self.scrollArea.setWidget(self.container)\n self.scrollArea.setWidgetResizable(True)\n\n # 将滚动区域添加到主布局\n self.main_layout.addWidget(self.scrollArea)\n\n def setup_signals(self):\n self.manage_model_card.linkButton.clicked.connect(self.show_download_dialog)\n\n def show_download_dialog(self):\n \"\"\"显示下载对话框\"\"\"\n download_dialog = WhisperCppDownloadDialog(self.window(), self)\n download_dialog.show()\n"
},
{
"path": "app/components/transcription_setting_card.py",
"content": "from typing import Optional\n\nfrom PyQt5.QtWidgets import (\n QStackedWidget,\n QVBoxLayout,\n QWidget,\n)\n\nfrom ..core.entities import (\n TranscribeModelEnum,\n)\nfrom ..core.utils.platform_utils import is_macos\nfrom .FasterWhisperSettingWidget import FasterWhisperSettingWidget\nfrom .WhisperAPISettingWidget import WhisperAPISettingWidget\nfrom .WhisperCppSettingWidget import WhisperCppSettingWidget\n\n\nclass TranscriptionSettingCard(QWidget):\n def __init__(self, parent=None):\n super().__init__(parent)\n self.setup_ui()\n\n def setup_ui(self):\n self.main_layout = QVBoxLayout(self)\n self.main_layout.setContentsMargins(0, 0, 0, 0)\n\n # 设置界面堆叠\n self.stacked_widget = QStackedWidget(self)\n\n # 添加各个设置界面\n self.empty_widget = QWidget(self) # 添加空白页面作为默认显示\n self.whisper_cpp_widget = WhisperCppSettingWidget(self)\n self.whisper_api_widget = WhisperAPISettingWidget(self)\n\n # FasterWhisper 在 macOS 上不可用\n self.faster_whisper_widget: Optional[FasterWhisperSettingWidget] = None\n if not is_macos():\n self.faster_whisper_widget = FasterWhisperSettingWidget(self)\n\n self.stacked_widget.addWidget(self.empty_widget) # 添加空白页面\n self.stacked_widget.addWidget(self.whisper_cpp_widget)\n self.stacked_widget.addWidget(self.whisper_api_widget)\n if self.faster_whisper_widget is not None:\n self.stacked_widget.addWidget(self.faster_whisper_widget)\n\n self.main_layout.addWidget(self.stacked_widget)\n\n def on_model_changed(self, value):\n # 切换对应的设置界面\n if value == TranscribeModelEnum.WHISPER_CPP.value:\n self.stacked_widget.setCurrentWidget(self.whisper_cpp_widget)\n elif value == TranscribeModelEnum.WHISPER_API.value:\n self.stacked_widget.setCurrentWidget(self.whisper_api_widget)\n elif value == TranscribeModelEnum.FASTER_WHISPER.value:\n self.stacked_widget.setCurrentWidget(self.faster_whisper_widget)\n else:\n self.stacked_widget.setCurrentWidget(self.empty_widget)\n"
},
{
"path": "app/config.py",
"content": "import logging\nimport os\nfrom pathlib import Path\n\nVERSION = \"v1.4.0\"\nYEAR = 2025\nAPP_NAME = \"VideoCaptioner\"\nAUTHOR = \"Weifeng\"\n\nHELP_URL = \"https://github.com/WEIFENG2333/VideoCaptioner\"\nGITHUB_REPO_URL = \"https://github.com/WEIFENG2333/VideoCaptioner\"\nRELEASE_URL = \"https://github.com/WEIFENG2333/VideoCaptioner/releases/latest\"\nFEEDBACK_URL = \"https://github.com/WEIFENG2333/VideoCaptioner/issues\"\n\n# 路径\nROOT_PATH = Path(__file__).parent.parent\n\nRESOURCE_PATH = ROOT_PATH / \"resource\"\nAPPDATA_PATH = ROOT_PATH / \"AppData\"\nWORK_PATH = ROOT_PATH / \"work-dir\"\n\n\nBIN_PATH = RESOURCE_PATH / \"bin\"\nASSETS_PATH = RESOURCE_PATH / \"assets\"\nSUBTITLE_STYLE_PATH = RESOURCE_PATH / \"subtitle_style\"\nTRANSLATIONS_PATH = RESOURCE_PATH / \"translations\"\nFONTS_PATH = RESOURCE_PATH / \"fonts\"\n\nLOG_PATH = APPDATA_PATH / \"logs\"\nLLM_LOG_FILE = LOG_PATH / \"llm_requests.jsonl\"\nSETTINGS_PATH = APPDATA_PATH / \"settings.json\"\nCACHE_PATH = APPDATA_PATH / \"cache\"\nMODEL_PATH = APPDATA_PATH / \"models\"\n\nFASER_WHISPER_PATH = BIN_PATH / \"Faster-Whisper-XXL\"\n\n# 日志配置\nLOG_LEVEL = logging.INFO\nLOG_FORMAT = \"%(asctime)s - %(name)s - %(levelname)s - %(message)s\"\n\n# 环境变量添加 bin 路径,添加到PATH开头以优先使用\nos.environ[\"PATH\"] = str(FASER_WHISPER_PATH) + os.pathsep + os.environ[\"PATH\"]\nos.environ[\"PATH\"] = str(BIN_PATH) + os.pathsep + os.environ[\"PATH\"]\n\n# 添加 VLC 路径\nos.environ[\"PYTHON_VLC_MODULE_PATH\"] = str(BIN_PATH / \"vlc\")\n\n# 创建路径\nfor p in [CACHE_PATH, LOG_PATH, WORK_PATH, MODEL_PATH]:\n p.mkdir(parents=True, exist_ok=True)\n"
},
{
"path": "app/core/asr/__init__.py",
"content": "from .bcut import BcutASR\nfrom .chunked_asr import ChunkedASR\nfrom .faster_whisper import FasterWhisperASR\nfrom .jianying import JianYingASR\nfrom .status import ASRStatus\nfrom .transcribe import transcribe\nfrom .whisper_api import WhisperAPI\nfrom .whisper_cpp import WhisperCppASR\n\n__all__ = [\n \"BcutASR\",\n \"ChunkedASR\",\n \"FasterWhisperASR\",\n \"JianYingASR\",\n \"WhisperAPI\",\n \"WhisperCppASR\",\n \"transcribe\",\n \"ASRStatus\",\n]\n"
},
{
"path": "app/core/asr/asr_data.py",
"content": "import json\nimport math\nimport os\nimport platform\nimport re\nfrom pathlib import Path\nfrom typing import List, Optional, Tuple\n\nfrom langdetect import LangDetectException, detect\n\nfrom ..entities import SubtitleLayoutEnum\nfrom ..utils.text_utils import is_mainly_cjk\n\n# 多语言分词模式(支持词级和字符级语言)\n_WORD_SPLIT_PATTERN = (\n r\"[a-zA-Z\\u00c0-\\u00ff\\u0100-\\u017f']+\" # 拉丁字符(含扩展)\n r\"|[\\u0400-\\u04ff]+\" # 西里尔字母(俄文)\n r\"|[\\u0370-\\u03ff]+\" # 希腊字母\n r\"|[\\u0600-\\u06ff]+\" # 阿拉伯文\n r\"|[\\u0590-\\u05ff]+\" # 希伯来文\n r\"|\\d+\" # 数字\n r\"|[\\u4e00-\\u9fff]\" # 中文\n r\"|[\\u3040-\\u309f]\" # 日文平假名\n r\"|[\\u30a0-\\u30ff]\" # 日文片假名\n r\"|[\\uac00-\\ud7af]\" # 韩文\n r\"|[\\u0e00-\\u0e7f][\\u0e30-\\u0e3a\\u0e47-\\u0e4e]*\" # 泰文\n r\"|[\\u0900-\\u097f]\" # 天城文(印地语)\n r\"|[\\u0980-\\u09ff]\" # 孟加拉文\n r\"|[\\u0e80-\\u0eff]\" # 老挝文\n r\"|[\\u1000-\\u109f]\" # 缅甸文\n)\n\n\ndef handle_long_path(path: str) -> str:\n r\"\"\"Handle Windows long path limitation by adding \\\\?\\ prefix.\n\n Args:\n path: Original file path\n\n Returns:\n Path with \\\\?\\ prefix if needed (Windows only)\n \"\"\"\n if (\n platform.system() == \"Windows\"\n and len(path) > 260\n and not path.startswith(r\"\\\\?\\ \")\n ):\n return rf\"\\\\?\\{os.path.abspath(path)}\"\n return path\n\n\nclass ASRDataSeg:\n def __init__(\n self, text: str, start_time: int, end_time: int, translated_text: str = \"\"\n ):\n self.text = text\n self.translated_text = translated_text\n self.start_time = start_time\n self.end_time = end_time\n\n def to_srt_ts(self) -> str:\n \"\"\"Convert to SRT timestamp format\"\"\"\n return f\"{self._ms_to_srt_time(self.start_time)} --> {self._ms_to_srt_time(self.end_time)}\"\n\n def to_lrc_ts(self) -> str:\n \"\"\"Convert to LRC timestamp format\"\"\"\n return f\"[{self._ms_to_lrc_time(self.start_time)}]\"\n\n def to_ass_ts(self) -> Tuple[str, str]:\n \"\"\"Convert to ASS timestamp format\"\"\"\n return self._ms_to_ass_ts(self.start_time), self._ms_to_ass_ts(self.end_time)\n\n @staticmethod\n def _ms_to_lrc_time(ms: int) -> str:\n \"\"\"Convert milliseconds to LRC time format (MM:SS.cc)\"\"\"\n seconds = ms / 1000\n minutes, seconds = divmod(seconds, 60)\n return f\"{int(minutes):02}:{seconds:.2f}\"\n\n @staticmethod\n def _ms_to_srt_time(ms: int) -> str:\n \"\"\"Convert milliseconds to SRT time format (HH:MM:SS,mmm)\"\"\"\n total_seconds, milliseconds = divmod(ms, 1000)\n minutes, seconds = divmod(total_seconds, 60)\n hours, minutes = divmod(minutes, 60)\n return f\"{int(hours):02}:{int(minutes):02}:{int(seconds):02},{int(milliseconds):03}\"\n\n @staticmethod\n def _ms_to_ass_ts(ms: int) -> str:\n \"\"\"Convert milliseconds to ASS timestamp format (H:MM:SS.cc)\"\"\"\n total_seconds, milliseconds = divmod(ms, 1000)\n minutes, seconds = divmod(total_seconds, 60)\n hours, minutes = divmod(minutes, 60)\n centiseconds = int(milliseconds / 10)\n return f\"{int(hours):01}:{int(minutes):02}:{int(seconds):02}.{centiseconds:02}\"\n\n @property\n def transcript(self) -> str:\n \"\"\"Return segment text\"\"\"\n return self.text\n\n def __str__(self) -> str:\n return f\"ASRDataSeg({self.text}, {self.start_time}, {self.end_time})\"\n\n\nclass ASRData:\n def __init__(self, segments: List[ASRDataSeg]):\n filtered_segments = [seg for seg in segments if seg.text and seg.text.strip()]\n filtered_segments.sort(key=lambda x: x.start_time)\n self.segments = filtered_segments\n\n def __iter__(self):\n return iter(self.segments)\n\n def __len__(self) -> int:\n return len(self.segments)\n\n def has_data(self) -> bool:\n \"\"\"Check if there are any utterances\"\"\"\n return len(self.segments) > 0\n\n def _is_word_level_segment(self, segment: ASRDataSeg) -> bool:\n \"\"\"判断单个片段是否为词级\n\n Args:\n segment: 待判断的字幕片段\n\n Returns:\n True 如果片段符合词级模式\n \"\"\"\n text = segment.text.strip()\n\n # CJK语言:1-2个字符\n if is_mainly_cjk(text):\n return len(text) <= 2\n\n # 非CJK语言(如英文):单个单词\n words = text.split()\n return len(words) == 1\n\n def is_word_timestamp(self) -> bool:\n \"\"\"检查时间戳是否为词级(非句子级)\n\n 词级判定标准:\n - 英文: 单个单词\n - CJK/亚洲语言: 1-2个字符\n - 允许20%误差容忍\n\n Returns:\n True 如果80%+的片段符合词级模式\n \"\"\"\n if not self.segments:\n return False\n\n # 统计符合词级模式的片段数量\n word_level_count = sum(\n 1 for seg in self.segments if self._is_word_level_segment(seg)\n )\n\n WORD_LEVEL_THRESHOLD = 0.8\n word_level_ratio = word_level_count / len(self.segments)\n\n return word_level_ratio >= WORD_LEVEL_THRESHOLD\n\n def split_to_word_segments(self) -> \"ASRData\":\n \"\"\"将句子级字幕分割为词级字幕,并按音素估算分配时间戳\n\n 时间戳分配基于音素估算(每4个字符约1个音素)\n\n Returns:\n 修改后的ASRData实例\n \"\"\"\n CHARS_PER_PHONEME = 4\n new_segments = []\n\n for seg in self.segments:\n text = seg.text\n duration = seg.end_time - seg.start_time\n\n # 使用统一的多语言分词模式\n words_list = list(re.finditer(_WORD_SPLIT_PATTERN, text))\n\n if not words_list:\n continue\n\n # 计算总音素数\n total_phonemes = sum(\n math.ceil(len(w.group()) / CHARS_PER_PHONEME) for w in words_list\n )\n time_per_phoneme = duration / max(total_phonemes, 1)\n\n # 为每个词分配时间戳\n current_time = seg.start_time\n for word_match in words_list:\n word = word_match.group()\n word_phonemes = math.ceil(len(word) / CHARS_PER_PHONEME)\n word_duration = int(time_per_phoneme * word_phonemes)\n\n word_end_time = min(current_time + word_duration, seg.end_time)\n new_segments.append(\n ASRDataSeg(\n text=word, start_time=current_time, end_time=word_end_time\n )\n )\n current_time = word_end_time\n\n self.segments = new_segments\n return self\n\n def remove_punctuation(self) -> \"ASRData\":\n \"\"\"Remove trailing Chinese punctuation (comma, period) from segments.\"\"\"\n punctuation = r\"[,。]\"\n for seg in self.segments:\n seg.text = re.sub(f\"{punctuation}+$\", \"\", seg.text.strip())\n seg.translated_text = re.sub(\n f\"{punctuation}+$\", \"\", seg.translated_text.strip()\n )\n return self\n\n def save(\n self,\n save_path: str,\n ass_style: Optional[str] = None,\n layout: SubtitleLayoutEnum = SubtitleLayoutEnum.ORIGINAL_ON_TOP,\n ) -> None:\n \"\"\"Save ASRData to file in specified format.\n\n Args:\n save_path: Output file path\n ass_style: ASS style string (optional, uses default if None)\n layout: Subtitle layout mode\n \"\"\"\n save_path = handle_long_path(save_path)\n Path(save_path).parent.mkdir(parents=True, exist_ok=True)\n\n if save_path.endswith(\".srt\"):\n self.to_srt(save_path=save_path, layout=layout)\n elif save_path.endswith(\".txt\"):\n self.to_txt(save_path=save_path, layout=layout)\n elif save_path.endswith(\".json\"):\n with open(save_path, \"w\", encoding=\"utf-8\") as f:\n json.dump(self.to_json(), f, ensure_ascii=False)\n elif save_path.endswith(\".ass\"):\n self.to_ass(save_path=save_path, style_str=ass_style, layout=layout)\n else:\n raise ValueError(f\"Unsupported file extension: {save_path}\")\n\n def to_txt(\n self,\n save_path=None,\n layout: SubtitleLayoutEnum = SubtitleLayoutEnum.ORIGINAL_ON_TOP,\n ) -> str:\n \"\"\"Convert to plain text subtitle format (without timestamps)\"\"\"\n result = []\n for seg in self.segments:\n original = seg.text\n translated = seg.translated_text\n\n if layout == SubtitleLayoutEnum.ORIGINAL_ON_TOP:\n text = f\"{original}\\n{translated}\" if translated else original\n elif layout == SubtitleLayoutEnum.TRANSLATE_ON_TOP:\n text = f\"{translated}\\n{original}\" if translated else original\n elif layout == SubtitleLayoutEnum.ONLY_ORIGINAL:\n text = original\n else: # ONLY_TRANSLATE\n text = translated if translated else original\n result.append(text)\n text = \"\\n\".join(result)\n if save_path:\n save_path = handle_long_path(save_path)\n with open(save_path, \"w\", encoding=\"utf-8\") as f:\n f.write(\"\\n\".join(result))\n return text\n\n def to_srt(\n self,\n layout: SubtitleLayoutEnum = SubtitleLayoutEnum.ORIGINAL_ON_TOP,\n save_path=None,\n ) -> str:\n \"\"\"Convert to SRT subtitle format\"\"\"\n srt_lines = []\n for n, seg in enumerate(self.segments, 1):\n original = seg.text\n translated = seg.translated_text\n\n if layout == SubtitleLayoutEnum.ORIGINAL_ON_TOP:\n text = f\"{original}\\n{translated}\" if translated else original\n elif layout == SubtitleLayoutEnum.TRANSLATE_ON_TOP:\n text = f\"{translated}\\n{original}\" if translated else original\n elif layout == SubtitleLayoutEnum.ONLY_ORIGINAL:\n text = original\n else: # ONLY_TRANSLATE\n text = translated if translated else original\n\n srt_lines.append(f\"{n}\\n{seg.to_srt_ts()}\\n{text}\\n\")\n\n srt_text = \"\\n\".join(srt_lines)\n if save_path:\n save_path = handle_long_path(save_path)\n with open(save_path, \"w\", encoding=\"utf-8\") as f:\n f.write(srt_text)\n return srt_text\n\n def to_lrc(self, save_path=None) -> str:\n \"\"\"Convert to LRC subtitle format\"\"\"\n raise NotImplementedError(\"LRC format is not supported\")\n\n def to_json(self) -> dict:\n \"\"\"Convert to JSON format\"\"\"\n result_json = {}\n for i, segment in enumerate(self.segments, 1):\n result_json[str(i)] = {\n \"start_time\": segment.start_time,\n \"end_time\": segment.end_time,\n \"original_subtitle\": segment.text,\n \"translated_subtitle\": segment.translated_text,\n }\n return result_json\n\n def to_ass(\n self,\n style_str: Optional[str] = None,\n layout: SubtitleLayoutEnum = SubtitleLayoutEnum.ORIGINAL_ON_TOP,\n save_path: Optional[str] = None,\n video_width: int = 1280,\n video_height: int = 720,\n ) -> str:\n \"\"\"Convert to ASS subtitle format\n\n Args:\n style_str: ASS style string (optional, uses default if None)\n layout: Subtitle layout mode\n save_path: Save path for ASS file (optional)\n video_width: Video width (default 1280)\n video_height: Video height (default 720)\n\n Returns:\n ASS format subtitle content\n \"\"\"\n if not style_str:\n style_str = (\n \"[V4+ Styles]\\n\"\n \"Format: Name,Fontname,Fontsize,PrimaryColour,SecondaryColour,OutlineColour,BackColour,\"\n \"Bold,Italic,Underline,StrikeOut,ScaleX,ScaleY,Spacing,Angle,BorderStyle,Outline,Shadow,\"\n \"Alignment,MarginL,MarginR,MarginV,Encoding\\n\"\n \"Style: Default,MicrosoftYaHei-Bold,40,&H00FFFFFF,&H000000FF,&H00000000,&H00000000,-1,0,0,0,100,100,\"\n \"0,0,1,2,0,2,10,10,15,1\\n\"\n \"Style: Secondary,MicrosoftYaHei-Bold,30,&H00FFFFFF,&H000000FF,&H00000000,&H00000000,-1,0,0,0,100,100,\"\n \"0,0,1,2,0,2,10,10,15,1\"\n )\n\n ass_content = (\n \"[Script Info]\\n\"\n \"; Script generated by VideoCaptioner\\n\"\n \"; https://github.com/weifeng2333\\n\"\n \"ScriptType: v4.00+\\n\"\n f\"PlayResX: {video_width}\\n\"\n f\"PlayResY: {video_height}\\n\\n\"\n f\"{style_str}\\n\\n\"\n \"[Events]\\n\"\n \"Format: Layer, Start, End, Style, Name, MarginL, MarginR, MarginV, Effect, Text\\n\"\n )\n\n dialogue_template = \"Dialogue: 0,{},{},{},,0,0,0,,{}\\n\"\n for seg in self.segments:\n start_time, end_time = seg.to_ass_ts()\n original = seg.text\n translated = seg.translated_text\n has_translation = bool(translated and translated.strip())\n\n if layout == SubtitleLayoutEnum.TRANSLATE_ON_TOP:\n if has_translation:\n # 先写译文(Default)显示在上,后写原文(Secondary)显示在下\n ass_content += dialogue_template.format(\n start_time, end_time, \"Default\", translated\n )\n ass_content += dialogue_template.format(\n start_time, end_time, \"Secondary\", original\n )\n else:\n ass_content += dialogue_template.format(\n start_time, end_time, \"Default\", original\n )\n elif layout == SubtitleLayoutEnum.ORIGINAL_ON_TOP:\n if has_translation:\n # 先写原文(Default)显示在上,后写译文(Secondary)显示在下\n ass_content += dialogue_template.format(\n start_time, end_time, \"Default\", original\n )\n ass_content += dialogue_template.format(\n start_time, end_time, \"Secondary\", translated\n )\n else:\n ass_content += dialogue_template.format(\n start_time, end_time, \"Default\", original\n )\n elif layout == SubtitleLayoutEnum.ONLY_ORIGINAL:\n ass_content += dialogue_template.format(\n start_time, end_time, \"Default\", original\n )\n else: # ONLY_TRANSLATE\n text = translated if has_translation else original\n ass_content += dialogue_template.format(\n start_time, end_time, \"Default\", text\n )\n\n if save_path:\n save_path = handle_long_path(save_path)\n with open(save_path, \"w\", encoding=\"utf-8\") as f:\n f.write(ass_content)\n return ass_content\n\n def to_vtt(self, save_path=None) -> str:\n \"\"\"Convert to WebVTT subtitle format\n\n Args:\n save_path: Optional save path\n\n Returns:\n WebVTT format subtitle content\n \"\"\"\n raise NotImplementedError(\"WebVTT format is not supported\")\n # # WebVTT头部\n # vtt_lines = [\"WEBVTT\\n\"]\n\n # for n, seg in enumerate(self.segments, 1):\n # # 转换时间戳格式从毫秒到 HH:MM:SS.mmm\n # start_time = seg._ms_to_srt_time(seg.start_time).replace(\",\", \".\")\n # end_time = seg._ms_to_srt_time(seg.end_time).replace(\",\", \".\")\n\n # # 添加序号(可选)和时间戳\n # vtt_lines.append(f\"{n}\\n{start_time} --> {end_time}\\n{seg.transcript}\\n\")\n\n # vtt_text = \"\\n\".join(vtt_lines)\n\n # if save_path:\n # with open(save_path, \"w\", encoding=\"utf-8\") as f:\n # f.write(vtt_text)\n\n # return vtt_text\n\n def merge_segments(\n self, start_index: int, end_index: int, merged_text: Optional[str] = None\n ):\n \"\"\"Merge segments from start_index to end_index (inclusive).\"\"\"\n if (\n start_index < 0\n or end_index >= len(self.segments)\n or start_index > end_index\n ):\n raise IndexError(\"Invalid segment index\")\n merged_start_time = self.segments[start_index].start_time\n merged_end_time = self.segments[end_index].end_time\n if merged_text is None:\n merged_text = \"\".join(\n seg.text for seg in self.segments[start_index : end_index + 1]\n )\n merged_seg = ASRDataSeg(merged_text, merged_start_time, merged_end_time)\n self.segments[start_index : end_index + 1] = [merged_seg]\n\n def merge_with_next_segment(self, index: int) -> None:\n \"\"\"Merge segment at index with next segment.\"\"\"\n if index < 0 or index >= len(self.segments) - 1:\n raise IndexError(\"Index out of range or no next segment to merge\")\n current_seg = self.segments[index]\n next_seg = self.segments[index + 1]\n merged_text = f\"{current_seg.text} {next_seg.text}\"\n merged_seg = ASRDataSeg(merged_text, current_seg.start_time, next_seg.end_time)\n self.segments[index] = merged_seg\n del self.segments[index + 1]\n\n def optimize_timing(self, threshold_ms: int = 1000) -> \"ASRData\":\n \"\"\"Optimize subtitle display timing by adjusting adjacent segment boundaries.\n\n If gap between adjacent segments is below threshold, adjust the boundary\n to 3/4 point between them (reduces flicker).\n\n Args:\n threshold_ms: Time gap threshold in milliseconds (default 1000ms)\n\n Returns:\n Self for method chaining\n \"\"\"\n if self.is_word_timestamp() or not self.segments:\n return self\n\n for i in range(len(self.segments) - 1):\n current_seg = self.segments[i]\n next_seg = self.segments[i + 1]\n time_gap = next_seg.start_time - current_seg.end_time\n\n if time_gap < threshold_ms:\n mid_time = (\n current_seg.end_time + next_seg.start_time\n ) // 2 + time_gap // 4\n current_seg.end_time = mid_time\n next_seg.start_time = mid_time\n\n return self\n\n def __str__(self):\n return self.to_txt()\n\n @staticmethod\n def from_subtitle_file(file_path: str) -> \"ASRData\":\n \"\"\"Load ASRData from subtitle file.\n\n Args:\n file_path: Subtitle file path (supports .srt, .vtt, .ass, .json)\n\n Returns:\n Parsed ASRData instance\n\n Raises:\n FileNotFoundError: File does not exist\n ValueError: Unsupported file format\n \"\"\"\n file_path_obj = Path(file_path)\n if not file_path_obj.exists():\n raise FileNotFoundError(f\"File not found: {file_path_obj}\")\n\n try:\n content = file_path_obj.read_text(encoding=\"utf-8\")\n except UnicodeDecodeError:\n content = file_path_obj.read_text(encoding=\"gbk\")\n\n suffix = file_path_obj.suffix.lower()\n\n if suffix == \".srt\":\n return ASRData.from_srt(content)\n elif suffix == \".vtt\":\n if \"捐助支持
\n\n  \n
\n  \n
\n
\n\n \n(可在句内、句间灵活分段)\n2. 字数限制:\n - CJK语言(中文、日语、韩语等):每段≤ $max_word_count_cjk 字\n - 拉丁语言(英语、法语等):每段≤ $max_word_count_english 词\n3. 每段需包含完整语义,避免过短碎片\n4. 原文保持不变:不增删改,仅插入
\n5. 直接输出分段文本,无需解释\n
分隔,不要包含任何其他内容或解释。\n
(句号、逗号、分号等标点符号应出现的位置)\n2. 分割段的字数限制:\n - CJK语言(中文、日语、韩语等):每段≤ ${max_word_count_cjk} 字\n - 拉丁语言(英语、法语等):每段≤ ${max_word_count_english} 词\n3. 在遵循字数限制的同时,保持每个分句的意思完整\n4. 原文保持不变:不增删改,不要翻译,仅插入
\n5. 倒计时(每个数字进行分割)、关键信息揭示前及需要强调的位置需要进行适当分割\n
分隔,不要包含任何其他内容或解释。\n
tags to separate the following sentence:\\n{text}\"\n )\n\n messages = [\n {\"role\": \"system\", \"content\": system_prompt},\n {\"role\": \"user\", \"content\": user_prompt},\n ]\n\n last_result = None\n\n for step in range(MAX_STEPS):\n response = call_llm(\n messages=messages,\n model=model,\n temperature=0.1,\n )\n\n result_text = response.choices[0].message.content\n\n # 解析结果\n result_text_cleaned = re.sub(r\"\\n+\", \"\", result_text)\n split_result = [\n segment.strip()\n for segment in result_text_cleaned.split(\"
\")\n if segment.strip()\n ]\n last_result = split_result\n\n # 验证结果\n is_valid, error_message = _validate_split_result(\n original_text=text,\n split_result=split_result,\n max_word_count_cjk=max_word_count_cjk,\n max_word_count_english=max_word_count_english,\n )\n\n if is_valid:\n return split_result\n\n # 添加反馈到对话\n logger.warning(\n f\"模型输出错误,断句验证失败,频繁出现建议更换更智能的模型或者调整最大字数限制。开始反馈循环 (第{step + 1}次尝试):\\n {error_message}\\n\\n\"\n )\n messages.append({\"role\": \"assistant\", \"content\": result_text})\n messages.append(\n {\n \"role\": \"user\",\n \"content\": f\"Error: {error_message}\\nFix the errors above and output the COMPLETE corrected text with
tags (include ALL segments, not just the fixed ones), no explanation.\",\n }\n )\n\n return last_result if last_result else [text]\n\n\ndef _validate_split_result(\n original_text: str,\n split_result: List[str],\n max_word_count_cjk: int,\n max_word_count_english: int,\n) -> Tuple[bool, str]:\n \"\"\"验证断句结果:内容一致性、分段数量、长度限制\n\n 返回: (是否有效, 错误反馈)\n \"\"\"\n # 检查是否为空\n if not split_result:\n return False, \"No segments found. Split the text with
tags.\"\n\n # 检查内容是否被修改(使用difflib精确定位差异)\n original_cleaned = re.sub(r\"\\s+\", \" \", original_text)\n text_is_cjk = is_mainly_cjk(original_cleaned)\n\n merged_char = \"\" if text_is_cjk else \" \"\n merged = merged_char.join(split_result)\n merged_cleaned = re.sub(r\"\\s+\", \" \", merged)\n\n # 使用SequenceMatcher计算相似度和差异\n matcher = difflib.SequenceMatcher(None, original_cleaned, merged_cleaned)\n similarity_ratio = matcher.ratio()\n\n # 允许98%以上的相似度(容忍少量标点或空格差异)\n if similarity_ratio < 0.96:\n differences = []\n context_size = 5 if text_is_cjk else 20\n\n for opcode, a0, a1, b0, b1 in matcher.get_opcodes():\n if opcode == \"replace\":\n # 获取前后文\n before = original_cleaned[max(0, a0 - context_size) : a0]\n orig_part = original_cleaned[a0:a1]\n after = original_cleaned[a1 : a1 + context_size]\n\n new_part = merged_cleaned[b0:b1]\n\n if orig_part.isspace() or new_part.isspace():\n continue\n\n differences.append(\n f\"...{before}[{orig_part}]{after}... → changed to [{new_part}]\"\n )\n\n elif opcode == \"delete\":\n before = original_cleaned[max(0, a0 - context_size) : a0]\n deleted_part = original_cleaned[a0:a1]\n after = original_cleaned[a1 : a1 + context_size]\n\n if deleted_part.isspace():\n continue\n\n differences.append(f\"...{before}[{deleted_part}]{after}... → deleted\")\n\n elif opcode == \"insert\":\n # 对于插入,显示插入位置的上下文\n before = merged_cleaned[max(0, b0 - context_size) : b0]\n inserted_part = merged_cleaned[b0:b1]\n after = merged_cleaned[b1 : b1 + context_size]\n\n if inserted_part.isspace():\n continue\n\n differences.append(\n f\"Wrongly inserted [{inserted_part}] between '...{before}' and '{after}...'\"\n )\n\n if differences:\n error_msg = f\"Content modified (similarity: {similarity_ratio:.1%}):\\n\"\n error_msg += \"\\n\".join(f\"- {diff}\" for diff in differences)\n error_msg += (\n \"\\nKeep original text unchanged, only insert
between words.\"\n )\n return False, error_msg\n\n # 检查每段长度是否超限\n violations = []\n for i, segment in enumerate(split_result, 1):\n word_count = count_words(segment)\n\n max_allowed = max_word_count_cjk if text_is_cjk else max_word_count_english\n tolerance = max_allowed * 1 # 0容差\n\n if word_count > tolerance:\n segment_preview = segment[:40] + \"...\" if len(segment) > 40 else segment\n violations.append(\n f\"Segment {i} '{segment_preview}': {word_count} {'chars' if text_is_cjk else 'words'} > {max_allowed} limit\"\n )\n\n if violations:\n error_msg = \"Length violations:\\n\" + \"\\n\".join(f\"- {v}\" for v in violations)\n error_msg += \"\\n\\nSplit these long segments further with
, then output the COMPLETE text with ALL segments (not just the fixed ones).\"\n return False, error_msg\n\n return True, \"\"\n\n\nif __name__ == \"__main__\":\n sample_text = \"大家好我叫杨玉溪来自有着良好音乐氛围的福建厦门自记事起我眼中的世界就是朦胧的童话书是各色杂乱的线条电视机是颜色各异的雪花小伙伴是只听其声不便骑行的马赛克后来我才知道这是一种眼底黄斑疾病虽不至于失明但终身无法治愈\"\n sentences = split_by_llm(sample_text)\n print(f\"断句结果 ({len(sentences)} 段):\")\n for i, seg in enumerate(sentences, 1):\n print(f\" {i}. {seg}\")\n" }, { "path": "app/core/subtitle/README.md", "content": "# 字幕渲染模块\n\n提供两种字幕渲染方式:\n- **ASS 样式**:FFmpeg + libass 渲染(支持 CUDA 加速)\n- **圆角背景**:PIL 绘制现代风格字幕(带圆角矩形背景)\n\n## 模块结构\n\n```\napp/core/subtitle/\n├── __init__.py # 统一导出接口\n├── ass_renderer.py # ASS 渲染器(视频合成、预览)\n├── ass_utils.py # ASS 解析和处理(dataclass 化)\n├── rounded_renderer.py # 圆角背景渲染器\n├── styles.py # 样式配置(RoundedBgStyle)\n├── font_utils.py # 字体管理(内置/系统字体,LRU 缓存)\n└── text_utils.py # 文本处理(平衡换行算法)\n```\n\n## 快速使用\n\n### 1. ASS 解析\n\n```python\nfrom app.core.subtitle import parse_ass_info, auto_wrap_ass_file\n\n# 解析 ASS 文件(返回类型安全的 dataclass)\nass_info = parse_ass_info(ass_content)\nprint(f\"分辨率: {ass_info.video_width}x{ass_info.video_height}\")\nfor style in ass_info.styles.values():\n print(f\"{style.name}: {style.font_name} {style.font_size}px\")\n\n# 智能换行(基于实际字体渲染宽度)\nauto_wrap_ass_file(\"input.ass\", video_width=1920)\n```\n\n### 2. 圆角背景渲染\n\n```python\nfrom app.core.subtitle import render_rounded_video, RoundedBgStyle\n\nstyle = RoundedBgStyle(\n font_name=\"Noto Sans SC\",\n font_size=52,\n bg_color=\"#191919C8\", # 半透明深灰\n text_color=\"#FFFFFF\",\n corner_radius=12,\n letter_spacing=2, # 字符间距\n)\n\nrender_rounded_video(\n video_path=\"input.mp4\",\n asr_data=asr_data,\n output_path=\"output.mp4\",\n style=style,\n)\n```\n\n### 3. 字体和文本工具\n\n```python\nfrom app.core.subtitle import get_font, get_ass_to_pil_ratio, wrap_text\n\n# 获取字体(内置字体优先,系统字体后备)\nfont = get_font(52, \"Noto Sans SC\")\n\n# ASS 到 PIL 字体大小转换\nratio = get_ass_to_pil_ratio(\"Noto Sans SC\") # ≈ 1.448\npil_size = int(74 / ratio) # ASS 74px → PIL 51px\n\n# 平衡文本换行(每行长度更均衡)\nlines = wrap_text(text, font, max_width=1216)\n```\n\n## 核心特性\n\n### 精确换行\n- **实际渲染宽度**:使用 PIL 真实字体渲染,而非估算字符宽度\n- **平衡算法**:先计算最小行数,再平均分配字符,避免最后一行过短\n- **语言自适应**:CJK 按字符拆分,英文按单词拆分\n\n### 字体管理\n- **内置字体优先**:`resource/fonts/` 目录的字体优先加载\n- **系统字体后备**:自动检测 macOS/Windows/Linux 系统字体\n- **跨平台解析**:使用 `fontTools` 提取字体家族名\n- **LRU 缓存**:`@lru_cache` 装饰器优化性能\n\n### ASS 字体大小转换\n- **问题**:ASS 使用 Windows 行高(usWinAscent + usWinDescent),PIL 使用 em 方块(unitsPerEm)\n- **解决**:`get_ass_to_pil_ratio()` 自动读取字体度量,计算转换比例(通常 1.4-1.5)\n- **效果**:ASS 74px ≈ PIL 51px(Noto Sans SC),换行准确率显著提升\n\n## 技术难点与解决方案\n\n### 1. ASS 文本提前换行问题\n**现象**:直接用 ASS 字号加载 PIL 字体测量宽度,导致换行过早 \n**原因**:ASS 和 PIL 对 font size 的解释不同(单位不同) \n**方案**:\n- 从字体文件读取 `unitsPerEm` 和 Windows 行高\n- 计算转换比例:`ratio = (usWinAscent + usWinDescent) / unitsPerEm`\n- 使用转换后的字号:`pil_size = ass_size / ratio`\n\n### 2. 字幕行长度不均衡\n**现象**:贪心换行导致\"第1行很长,第2行很短\" \n**原因**:每行尽可能多地放字符,未考虑整体平衡 \n**方案**:\n- 先用贪心算法计算最小行数\n- 计算目标宽度:`target = total_width / num_lines`\n- 当前行达到 90% 目标宽度且下一个字符会超 110% 时提前换行\n- 平衡度从 50% 提升到 96%\n\n### 3. 类型安全与代码简洁\n**问题**:字典 + 元组 + 手动缓存导致代码复杂 \n**方案**:\n- 使用 `@dataclass` 替代字典和元组(`AssInfo`, `AssStyle`)\n- 使用 `@lru_cache` 替代手动缓存管理\n- 返回值类型明确(`AssInfo` 而非 `tuple[int, Dict[...]]`)\n\n## 注意事项\n\n1. **字体文件路径**:内置字体放在 `resource/fonts/`,优先级高于系统字体\n2. **ASS 样式换行**:使用 `\\q2` 禁用 libass 自动换行,完全由我们控制换行位置\n3. **文本宽度计算**:默认使用 95% 视频宽度(`video_width * 0.95`)作为最大文本宽度\n4. **字体度量缓存**:`get_ass_to_pil_ratio()` 结果已缓存,重复调用无性能损失\n5. **圆角背景字间距**:`letter_spacing > 0` 时逐字符绘制,`= 0` 时整体绘制(性能更好)\n" }, { "path": "app/core/subtitle/__init__.py", "content": "\"\"\"Subtitle rendering module (ASS and rounded background styles)\"\"\"\n\nfrom typing import Optional\n\nfrom app.config import SUBTITLE_STYLE_PATH\n\nfrom .ass_renderer import render_ass_preview, render_ass_video\nfrom .ass_utils import (\n AssInfo,\n AssStyle,\n auto_wrap_ass_file,\n parse_ass_info,\n wrap_ass_text,\n)\nfrom .font_utils import (\n FontType,\n clear_font_cache,\n get_ass_to_pil_ratio,\n get_builtin_fonts,\n get_font,\n)\nfrom .rounded_renderer import render_preview, render_rounded_video\nfrom .styles import RoundedBgStyle\nfrom .text_utils import hex_to_rgba, is_mainly_cjk, wrap_text\n\n\ndef get_subtitle_style(style_name: str) -> Optional[str]:\n \"\"\"Get subtitle style content\"\"\"\n style_path = SUBTITLE_STYLE_PATH / f\"{style_name}.txt\"\n if style_path.exists():\n return style_path.read_text(encoding=\"utf-8\")\n return None\n\n\n__all__ = [\n \"render_ass_video\",\n \"render_ass_preview\",\n \"auto_wrap_ass_file\",\n \"parse_ass_info\",\n \"wrap_ass_text\",\n \"AssInfo\",\n \"AssStyle\",\n \"render_preview\",\n \"render_rounded_video\",\n \"RoundedBgStyle\",\n \"get_subtitle_style\",\n \"FontType\",\n \"get_font\",\n \"get_ass_to_pil_ratio\",\n \"get_builtin_fonts\",\n \"clear_font_cache\",\n \"hex_to_rgba\",\n \"is_mainly_cjk\",\n \"wrap_text\",\n]\n" }, { "path": "app/core/subtitle/ass_renderer.py", "content": "\"\"\"ASS subtitle renderer\"\"\"\n\nimport os\nimport re\nimport subprocess\nimport tempfile\nfrom pathlib import Path\nfrom typing import TYPE_CHECKING, Callable, Optional, Tuple\n\nfrom PIL import Image\n\nfrom app.config import CACHE_PATH, FONTS_PATH, RESOURCE_PATH\nfrom app.core.entities import SubtitleLayoutEnum\nfrom app.core.utils.logger import setup_logger\n\nfrom .ass_utils import auto_wrap_ass_file\n\nif TYPE_CHECKING:\n from app.core.asr.asr_data import ASRData\n\nlogger = setup_logger(\"subtitle.ass\")\nASS_TEMPLATE = \"\"\"[Script Info]\n; Script generated by VideoCaptioner\nScriptType: v4.00+\nPlayResX: {video_width}\nPlayResY: {video_height}\n\n{style_str}\n\n[Events]\nFormat: Layer, Start, End, Style, Name, MarginL, MarginR, MarginV, Effect, Text\n{dialogue}\n\"\"\"\n\n\ndef _check_cuda_available() -> bool:\n \"\"\"检查 CUDA 是否可用\"\"\"\n try:\n # 检查 ffmpeg 是否支持 cuda\n result = subprocess.run(\n [\"ffmpeg\", \"-hwaccels\"],\n capture_output=True,\n text=True,\n creationflags=(\n getattr(subprocess, \"CREATE_NO_WINDOW\", 0) if os.name == \"nt\" else 0\n ),\n )\n if \"cuda\" not in result.stdout.lower():\n return False\n\n # 进一步检查 CUDA 设备信息\n result = subprocess.run(\n [\"ffmpeg\", \"-hide_banner\", \"-init_hw_device\", \"cuda\"],\n capture_output=True,\n text=True,\n creationflags=(\n getattr(subprocess, \"CREATE_NO_WINDOW\", 0) if os.name == \"nt\" else 0\n ),\n )\n\n # 如果 stderr 中包含错误信息,说明 CUDA 不可用\n if any(\n error in result.stderr.lower()\n for error in [\"cannot load cuda\", \"failed to load\", \"error\"]\n ):\n return False\n\n return True\n\n except Exception as e:\n logger.exception(f\"Check CUDA available error: {str(e)}\")\n return False\n\n\ndef _scale_ass_style(style_str: str, scale_factor: float) -> str:\n \"\"\"\n 缩放 ASS 样式中的数值参数\n\n Args:\n style_str: 原始 ASS 样式字符串(720P)\n scale_factor: 缩放因子\n\n Returns:\n 缩放后的 ASS 样式字符串\n \"\"\"\n if scale_factor == 1.0:\n return style_str\n\n lines = style_str.split(\"\\n\")\n scaled_lines = []\n\n for line in lines:\n if line.startswith(\"Style:\"):\n parts = line.split(\",\")\n if len(parts) >= 23:\n # parts[2]: Fontsize\n parts[2] = str(int(float(parts[2]) * scale_factor))\n # parts[13]: Spacing\n parts[13] = str(float(parts[13]) * scale_factor)\n # parts[16]: Outline\n parts[16] = str(float(parts[16]) * scale_factor)\n # parts[21]: MarginV (垂直间距)\n parts[21] = str(int(float(parts[21]) * scale_factor))\n line = \",\".join(parts)\n scaled_lines.append(line)\n\n return \"\\n\".join(scaled_lines)\n\n\ndef render_ass_preview(\n style_str: str,\n preview_text: Tuple[str, Optional[str]],\n bg_image_path: str,\n width: Optional[int] = None,\n height: Optional[int] = None,\n reference_height: int = 720,\n) -> str:\n \"\"\"\n 生成 ASS 样式字幕预览图\n\n Args:\n style_str: ASS 样式字符串(包含 PlayResY)\n preview_text: (原文, 译文) 元组,译文可以为 None\n bg_image_path: 背景图片路径\n width: 图片宽度(None=从bg_image_path自动获取)\n height: 图片高度(None=从bg_image_path自动获取)\n reference_height: 参考高度(固定720P)\n Returns:\n 生成的预览图路径\n \"\"\"\n # 自动获取图片尺寸\n if width is None or height is None:\n bg_path = Path(bg_image_path)\n if bg_path.exists():\n with Image.open(bg_path) as img:\n actual_width, actual_height = img.size\n width = width or actual_width\n height = height or actual_height\n else:\n width = width or 1920\n height = height or 1080\n\n original_text, translate_text = preview_text\n\n # 构建对话行\n if translate_text:\n dialogue = [\n f\"Dialogue: 0,0:00:00.00,0:00:01.00,Secondary,,0,0,0,,{translate_text}\",\n f\"Dialogue: 0,0:00:00.00,0:00:01.00,Default,,0,0,0,,{original_text}\",\n ]\n else:\n dialogue = [\n f\"Dialogue: 0,0:00:00.00,0:00:01.00,Default,,0,0,0,,{original_text}\"\n ]\n\n # 生成 ASS 内容\n ass_content = ASS_TEMPLATE.format(\n style_str=style_str,\n dialogue=os.linesep.join(dialogue),\n video_width=width,\n video_height=height,\n )\n\n # 从 ASS 内容中提取参考高度,根据图片高度自动缩放样式\n scale_factor = height / reference_height\n style_str = _scale_ass_style(style_str, scale_factor)\n\n # 重新生成缩放后的 ASS 内容\n ass_content = ASS_TEMPLATE.format(\n style_str=style_str,\n dialogue=os.linesep.join(dialogue),\n video_width=width,\n video_height=height,\n )\n\n # 创建临时 ASS 文件\n with tempfile.NamedTemporaryFile(\n mode=\"w\", suffix=\".ass\", delete=False, encoding=\"utf-8\"\n ) as f:\n f.write(ass_content)\n temp_ass_path = f.name\n\n processed_ass = temp_ass_path\n try:\n # 自动换行处理\n processed_ass = auto_wrap_ass_file(temp_ass_path)\n\n # 确保背景图片存在\n bg_path_obj = Path(bg_image_path)\n if not bg_path_obj.exists():\n # 使用默认黑色背景\n default_bg = RESOURCE_PATH / \"assets\" / \"default_bg.png\"\n if not default_bg.exists():\n default_bg.parent.mkdir(parents=True, exist_ok=True)\n # 生成黑色背景\n subprocess.run(\n [\n \"ffmpeg\",\n \"-f\",\n \"lavfi\",\n \"-i\",\n f\"color=c=black:s={width}x{height}\",\n \"-frames:v\",\n \"1\",\n str(default_bg),\n ],\n capture_output=True,\n creationflags=(\n getattr(subprocess, \"CREATE_NO_WINDOW\", 0)\n if os.name == \"nt\"\n else 0\n ),\n )\n bg_path_obj = default_bg\n\n # 生成预览图\n output_path = CACHE_PATH / \"ass_preview.png\"\n output_path.parent.mkdir(parents=True, exist_ok=True)\n\n # 处理 ASS 文件路径(Windows 兼容)\n ass_file_escaped = processed_ass.replace(\"\\\\\", \"/\").replace(\":\", r\"\\\\:\")\n\n # 添加内置字体目录支持\n fonts_dir_escaped = str(FONTS_PATH).replace(\"\\\\\", \"/\").replace(\":\", r\"\\\\:\")\n\n cmd = [\n \"ffmpeg\",\n \"-y\",\n \"-i\",\n str(bg_path_obj),\n \"-vf\",\n f\"ass={ass_file_escaped}:fontsdir={fonts_dir_escaped}\",\n \"-frames:v\",\n \"1\",\n str(output_path),\n ]\n\n result = subprocess.run(\n cmd,\n capture_output=True,\n creationflags=(\n getattr(subprocess, \"CREATE_NO_WINDOW\", 0) if os.name == \"nt\" else 0\n ),\n )\n\n if result.returncode != 0:\n logger.error(f\"FFmpeg 预览生成失败: {result.stderr}\")\n\n return str(output_path)\n\n finally:\n # 清理临时文件\n Path(temp_ass_path).unlink(missing_ok=True)\n if processed_ass != temp_ass_path:\n Path(processed_ass).unlink(missing_ok=True)\n\n\ndef _get_video_resolution(video_path: str) -> Tuple[int, int]:\n \"\"\"获取视频分辨率\"\"\"\n result = subprocess.run(\n [\"ffmpeg\", \"-i\", video_path],\n capture_output=True,\n text=True,\n creationflags=(\n getattr(subprocess, \"CREATE_NO_WINDOW\", 0) if os.name == \"nt\" else 0\n ),\n )\n\n # 从 ffmpeg 输出中解析分辨率\n pattern = r\"(\\d{2,5})x(\\d{2,5})\"\n match = re.search(pattern, result.stderr)\n if match:\n return int(match.group(1)), int(match.group(2))\n return 1920, 1080 # 默认返回 1080P\n\n\ndef render_ass_video(\n video_path: str,\n asr_data: \"ASRData\",\n output_path: str,\n style_str: str,\n layout: SubtitleLayoutEnum,\n crf: int = 23,\n preset: str = \"medium\",\n progress_callback: Optional[Callable] = None,\n reference_height: int = 720,\n) -> None:\n \"\"\"\n 渲染 ASS 样式字幕到视频(硬字幕)\n\n Args:\n video_path: 输入视频路径\n asr_data: 字幕数据\n output_path: 输出视频路径\n style_str: ASS 样式字符串(包含 PlayResY)\n layout: 字幕布局\n crf: 视频质量参数 (0-51,越小越好)\n preset: FFmpeg 编码预设\n progress_callback: 进度回调 (progress: str, message: str) -> None\n reference_height: 参考高度(固定720P)\n \"\"\"\n # 检查字幕数据是否为空\n if not asr_data or not asr_data.segments:\n raise ValueError(\"字幕数据为空,无法渲染视频\")\n\n # 获取视频分辨率\n width, height = _get_video_resolution(video_path)\n\n # 根据视频高度自动缩放样式\n scale_factor = height / reference_height\n style_str = _scale_ass_style(style_str, scale_factor)\n\n # 生成临时 ASS 文件(传入实际视频分辨率)\n with tempfile.NamedTemporaryFile(\n mode=\"w\", suffix=\".ass\", delete=False, encoding=\"utf-8\"\n ) as temp_file:\n ass_content = asr_data.to_ass(\n style_str=style_str,\n layout=layout,\n save_path=None,\n video_width=width,\n video_height=height,\n )\n temp_file.write(ass_content)\n temp_ass_path = temp_file.name\n\n processed_subtitle = temp_ass_path\n try:\n # 自动换行处理\n processed_subtitle = auto_wrap_ass_file(temp_ass_path)\n\n # 转义字幕路径\n subtitle_path_escaped = Path(processed_subtitle).as_posix().replace(\":\", r\"\\:\")\n\n # 构建 FFmpeg 命令\n vcodec = \"libx264\"\n if Path(output_path).suffix.lower() == \".webm\":\n vcodec = \"libvpx-vp9\"\n logger.info(\"WebM 格式视频,使用 libvpx-vp9 编码器\")\n\n # 添加内置字体目录支持\n fonts_dir_escaped = FONTS_PATH.as_posix().replace(\":\", r\"\\:\")\n\n # 统一使用 ass 滤镜\n vf = f\"ass='{subtitle_path_escaped}':fontsdir='{fonts_dir_escaped}'\"\n\n # 检查 CUDA 是否可用\n use_cuda = _check_cuda_available()\n cmd = [\"ffmpeg\"]\n if use_cuda:\n logger.info(\"使用 CUDA 加速\")\n cmd.extend([\"-hwaccel\", \"cuda\"])\n\n cmd.extend(\n [\n \"-i\",\n video_path,\n \"-acodec\",\n \"copy\",\n \"-vcodec\",\n vcodec,\n \"-crf\",\n str(crf),\n \"-preset\",\n preset,\n \"-vf\",\n vf,\n \"-y\",\n output_path,\n ]\n )\n\n cmd_str = subprocess.list2cmdline(cmd)\n logger.info(f\"添加字幕执行命令: {cmd_str}\")\n\n # 执行 FFmpeg\n process = None\n try:\n process = subprocess.Popen(\n cmd,\n stdout=subprocess.PIPE,\n stderr=subprocess.PIPE,\n text=True,\n encoding=\"utf-8\",\n errors=\"replace\",\n creationflags=(\n getattr(subprocess, \"CREATE_NO_WINDOW\", 0) if os.name == \"nt\" else 0\n ),\n )\n\n # 实时读取输出并调用回调\n total_duration = None\n current_time = 0\n\n while True:\n output_line = process.stderr.readline()\n if not output_line or (process.poll() is not None):\n break\n if not progress_callback:\n continue\n\n # 解析总时长\n if total_duration is None:\n duration_match = re.search(\n r\"Duration: (\\d{2}):(\\d{2}):(\\d{2}\\.\\d{2})\", output_line\n )\n if duration_match:\n h, m, s = map(float, duration_match.groups())\n total_duration = h * 3600 + m * 60 + s\n\n # 解析当前处理时间\n time_match = re.search(\n r\"time=(\\d{2}):(\\d{2}):(\\d{2}\\.\\d{2})\", output_line\n )\n if time_match:\n h, m, s = map(float, time_match.groups())\n current_time = h * 3600 + m * 60 + s\n\n # 计算进度百分比\n if total_duration:\n progress = (current_time / total_duration) * 100\n progress_callback(f\"{round(progress)}\", \"正在合成\")\n\n if progress_callback:\n progress_callback(\"100\", \"合成完成\")\n\n # 检查返回码\n return_code = process.wait()\n if return_code != 0:\n error_info = process.stderr.read()\n logger.error(\"== ffmpeg 渲染 ASS 字幕失败 ==\")\n logger.error(f\"返回码: {return_code}\")\n logger.error(f\"命令: {cmd_str}\")\n if error_info:\n logger.error(f\"错误信息: {error_info}\")\n raise Exception(f\"FFmpeg 返回码: {return_code}\")\n\n logger.info(\"ASS 字幕渲染完成\")\n\n except subprocess.SubprocessError as e:\n logger.error(\"== ffmpeg 进程执行异常 ==\")\n logger.error(f\"错误: {str(e)}\")\n if process and process.poll() is None:\n process.kill()\n raise\n except Exception as e:\n logger.error(f\"ASS 字幕渲染出错: {str(e)}\")\n if process and process.poll() is None:\n process.kill()\n raise\n\n finally:\n # 清理临时文件\n Path(temp_ass_path).unlink(missing_ok=True)\n if processed_subtitle != temp_ass_path:\n Path(processed_subtitle).unlink(missing_ok=True)\n" }, { "path": "app/core/subtitle/ass_utils.py", "content": "\"\"\"ASS subtitle utilities with accurate text width calculation\"\"\"\n\nimport re\nfrom dataclasses import dataclass\nfrom typing import Optional\n\nfrom .font_utils import get_ass_to_pil_ratio, get_font\nfrom .text_utils import is_mainly_cjk, wrap_text\n\n\n@dataclass\nclass AssStyle:\n \"\"\"ASS style information\"\"\"\n\n name: str # Style name\n font_name: str # Font family\n font_size: int # Font size\n primary_color: str = \"&H00FFFFFF\" # Primary text color\n secondary_color: str = \"&H000000FF\" # Secondary text color\n outline_color: str = \"&H00000000\" # Outline color\n back_color: str = \"&H00000000\" # Shadow color\n bold: int = 0 # Bold (-1 or 0)\n italic: int = 0 # Italic (-1 or 0)\n border_style: int = 1 # Border style (1 or 3)\n outline: float = 2.0 # Outline width\n shadow: float = 0.0 # Shadow depth\n alignment: int = 2 # Subtitle alignment (1-9)\n margin_l: int = 10 # Left margin\n margin_r: int = 10 # Right margin\n margin_v: int = 10 # Vertical margin\n spacing: float = 0.0 # Character spacing\n\n\n@dataclass\nclass AssInfo:\n \"\"\"ASS file information\"\"\"\n\n video_width: int # PlayResX\n video_height: int # PlayResY\n styles: dict[str, AssStyle] # {style_name: AssStyle}\n\n def get_style(self, style_name: str) -> AssStyle:\n \"\"\"Get style by name, fallback to Default\"\"\"\n default_style = AssStyle(\n name=\"Default\",\n font_name=\"Arial\",\n font_size=40,\n )\n return self.styles.get(style_name, self.styles.get(\"Default\", default_style))\n\n\ndef parse_ass_info(ass_content: str) -> AssInfo:\n \"\"\"\n Parse ASS file information including video resolution and styles\n\n Returns:\n AssInfo with video dimensions and all style definitions\n \"\"\"\n video_width = 1280\n video_height = 720\n styles = {}\n\n # 提取视频分辨率\n res_x_match = re.search(r\"PlayResX:\\s*(\\d+)\", ass_content)\n if res_x_match:\n video_width = int(res_x_match.group(1))\n\n res_y_match = re.search(r\"PlayResY:\\s*(\\d+)\", ass_content)\n if res_y_match:\n video_height = int(res_y_match.group(1))\n\n # 提取样式区块 [V4+ Styles]\n style_section = re.search(r\"\\[V4\\+ Styles\\].*?\\[\", ass_content, re.DOTALL)\n if style_section:\n style_content = style_section.group(0)\n\n # 解析 Format 行,建立字段名到索引的映射\n format_match = re.search(r\"Format:(.*?)$\", style_content, re.MULTILINE)\n\n if format_match:\n fields = [f.strip() for f in format_match.group(1).split(\",\")]\n field_map = {field: idx for idx, field in enumerate(fields)}\n\n # 逐行解析 Style 定义\n for style_line in re.finditer(r\"Style:(.*?)$\", style_content, re.MULTILINE):\n parts = [p.strip() for p in style_line.group(1).split(\",\")]\n\n try:\n style = AssStyle(\n name=parts[field_map[\"Name\"]],\n font_name=parts[field_map[\"Fontname\"]],\n font_size=int(parts[field_map[\"Fontsize\"]]),\n primary_color=(\n parts[field_map.get(\"PrimaryColour\", -1)]\n if \"PrimaryColour\" in field_map\n else \"&H00FFFFFF\"\n ),\n secondary_color=(\n parts[field_map.get(\"SecondaryColour\", -1)]\n if \"SecondaryColour\" in field_map\n else \"&H000000FF\"\n ),\n outline_color=(\n parts[field_map.get(\"OutlineColour\", -1)]\n if \"OutlineColour\" in field_map\n else \"&H00000000\"\n ),\n back_color=(\n parts[field_map.get(\"BackColour\", -1)]\n if \"BackColour\" in field_map\n else \"&H00000000\"\n ),\n bold=(\n int(parts[field_map.get(\"Bold\", -1)])\n if \"Bold\" in field_map\n else 0\n ),\n italic=(\n int(parts[field_map.get(\"Italic\", -1)])\n if \"Italic\" in field_map\n else 0\n ),\n border_style=(\n int(parts[field_map.get(\"BorderStyle\", -1)])\n if \"BorderStyle\" in field_map\n else 1\n ),\n outline=(\n float(parts[field_map.get(\"Outline\", -1)])\n if \"Outline\" in field_map\n else 2.0\n ),\n shadow=(\n float(parts[field_map.get(\"Shadow\", -1)])\n if \"Shadow\" in field_map\n else 0.0\n ),\n alignment=(\n int(parts[field_map.get(\"Alignment\", -1)])\n if \"Alignment\" in field_map\n else 2\n ),\n margin_l=(\n int(parts[field_map.get(\"MarginL\", -1)])\n if \"MarginL\" in field_map\n else 10\n ),\n margin_r=(\n int(parts[field_map.get(\"MarginR\", -1)])\n if \"MarginR\" in field_map\n else 10\n ),\n margin_v=(\n int(parts[field_map.get(\"MarginV\", -1)])\n if \"MarginV\" in field_map\n else 10\n ),\n spacing=(\n float(parts[field_map.get(\"Spacing\", -1)])\n if \"Spacing\" in field_map\n else 0.0\n ),\n )\n styles[style.name] = style\n except (ValueError, IndexError, KeyError):\n pass\n\n # 确保至少有一个 Default 样式\n if \"Default\" not in styles:\n styles[\"Default\"] = AssStyle(\n name=\"Default\",\n font_name=\"Arial\",\n font_size=40,\n )\n\n return AssInfo(video_width, video_height, styles)\n\n\ndef wrap_ass_text(\n text: str, max_width: int, font_name: str, font_size: int, spacing: float = 0.0\n) -> str:\n \"\"\"\n Wrap text using actual font rendering (accurate width calculation)\n\n Note: ASS font size is based on Windows line height, while PIL uses em square.\n We need to convert ASS font size to PIL font size for accurate measurement.\n\n For most fonts: PIL_size = ASS_size / ratio, where ratio ≈ 1.4-1.5\n\n Args:\n text: Text to wrap\n max_width: Maximum width in pixels\n font_name: Font name for rendering\n font_size: Font size (ASS font size, will be converted to PIL size)\n spacing: Character spacing in ASS (affects text width)\n\n Returns:\n Wrapped text with \\\\N line breaks\n \"\"\"\n # 已有换行符或空文本,直接返回\n if not text or \"\\\\N\" in text:\n return text\n\n # 只处理 CJK 文本(英文由 FFmpeg ASS 引擎自动换行)\n if not is_mainly_cjk(text):\n return text\n\n # Convert ASS font size to PIL font size\n # ASS uses Windows line height, PIL uses em square\n ratio = get_ass_to_pil_ratio(font_name)\n pil_font_size = int(round(font_size / ratio))\n\n # Load font with converted size and call wrap function\n # Pass spacing directly to wrap_text for accurate width calculation\n font = get_font(pil_font_size, font_name)\n lines = wrap_text(text, font, max_width, spacing=spacing)\n\n # 用 \\N 连接各行(ASS 格式的换行符)\n return \"\\\\N\".join(lines)\n\n\ndef auto_wrap_ass_file(\n input_file: str,\n output_file: Optional[str] = None,\n video_width: Optional[int] = None,\n video_height: Optional[int] = None,\n) -> str:\n \"\"\"\n Auto-wrap text in ASS file using accurate font rendering\n\n Args:\n input_file: Input ASS file path\n output_file: Output file path (overwrites input if None)\n video_width: Video width (overrides ASS settings if provided)\n video_height: Video height (not used, kept for compatibility)\n\n Returns:\n Output file path\n \"\"\"\n if output_file is None:\n output_file = input_file\n\n with open(input_file, \"r\", encoding=\"utf-8\") as f:\n ass_content = f.read()\n\n # 解析 ASS 文件信息\n ass_info = parse_ass_info(ass_content)\n\n if video_width is None:\n video_width = ass_info.video_width\n\n # 使用95%宽度作为最大文本宽度\n max_text_width = int(video_width * 0.95)\n\n def process_dialogue_line(match):\n \"\"\"处理每一行对话\"\"\"\n full_line = match.group(0)\n\n # 提取样式名称(Dialogue 行的第4个字段)\n style_pattern = r\"Dialogue:[^,]*,[^,]*,[^,]*,([^,]*),\"\n style_match = re.search(style_pattern, full_line)\n style_name = style_match.group(1).strip() if style_match else \"Default\"\n\n # 获取该样式对应的字体信息\n style = ass_info.get_style(style_name)\n text_part = match.group(1)\n\n # 使用实际字体渲染进行换行(考虑字符间距)\n wrapped_text = wrap_ass_text(\n text_part, max_text_width, style.font_name, style.font_size, style.spacing\n )\n\n return full_line.replace(text_part, wrapped_text)\n\n # 匹配所有对话行的文本部分(第10个字段)\n # Dialogue: Layer,Start,End,Style,Name,MarginL,MarginR,MarginV,Effect,Text\n pattern = r\"Dialogue:[^,]*(?:,[^,]*){8},(.*?)$\"\n processed_content = re.sub(\n pattern, process_dialogue_line, ass_content, flags=re.MULTILINE\n )\n\n # 写入处理后的文件\n with open(output_file, \"w\", encoding=\"utf-8\") as f:\n f.write(processed_content)\n\n return output_file\n" }, { "path": "app/core/subtitle/font_utils.py", "content": "\"\"\"Font discovery and loading utilities\"\"\"\n\nfrom functools import lru_cache\nfrom pathlib import Path\nfrom typing import Dict, Optional, Union\n\nfrom fontTools.ttLib import TTFont\nfrom PIL import ImageFont\n\nfrom app.config import FONTS_PATH\nfrom app.core.utils.logger import setup_logger\n\nFontType = Union[ImageFont.FreeTypeFont, ImageFont.ImageFont]\n\nlogger = setup_logger(\"subtitle.font\")\n\n\ndef _get_font_family_name(font_path: Path, font_index: int = 0) -> Optional[str]:\n \"\"\"Extract font family name from font file (cross-platform)\"\"\"\n try:\n font = TTFont(str(font_path), fontNumber=font_index)\n name_table = font.get(\"name\")\n if not name_table:\n return None\n\n # nameID 16: Typographic Family (preferred)\n # nameID 1: Font Family (fallback)\n for name_id in [16, 1]:\n for record in name_table.names:\n if record.nameID == name_id and record.platformID == 3:\n try:\n family_name = record.toUnicode()\n return family_name.split(\",\")[0].strip()\n except Exception:\n continue\n\n for name_id in [16, 1]:\n for record in name_table.names:\n if record.nameID == name_id:\n try:\n family_name = record.toUnicode()\n return family_name.split(\",\")[0].strip()\n except Exception:\n continue\n\n return None\n except Exception as e:\n logger.debug(f\"Failed to parse font {font_path.name} (index={font_index}): {e}\")\n return None\n\n\n@lru_cache(maxsize=1)\ndef get_builtin_fonts() -> tuple[Dict[str, str], ...]:\n \"\"\"Get built-in fonts list with actual family names\"\"\"\n builtin_fonts = []\n\n if FONTS_PATH.exists():\n for font_file in FONTS_PATH.glob(\"*.[ot]tf*\"):\n family_name = _get_font_family_name(font_file)\n if family_name:\n builtin_fonts.append({\"name\": family_name, \"path\": str(font_file)})\n logger.debug(f\"Built-in font: {font_file.name} -> {family_name}\")\n else:\n display_name = font_file.stem\n builtin_fonts.append({\"name\": display_name, \"path\": str(font_file)})\n logger.debug(\n f\"Cannot get family name for {font_file.name}, using filename\"\n )\n\n return tuple(builtin_fonts)\n\n\n@lru_cache(maxsize=64)\ndef get_font(size: int, font_name: str = \"\") -> FontType:\n \"\"\"Get font object (built-in fonts first, then system fonts)\"\"\"\n if font_name:\n builtin_fonts = get_builtin_fonts()\n for builtin in builtin_fonts:\n if builtin[\"name\"] == font_name:\n try:\n font = ImageFont.truetype(builtin[\"path\"], size)\n logger.debug(f\"Loaded built-in font: '{font_name}'\")\n return font\n except Exception as e:\n logger.warning(f\"Failed to load built-in font: {e}\")\n break\n\n try:\n font = ImageFont.truetype(font_name, size)\n logger.debug(f\"Loaded system font: '{font_name}'\")\n return font\n except (OSError, IOError):\n logger.warning(f\"Cannot load font '{font_name}', using fallback\")\n\n fallback_fonts = [f[\"name\"] for f in get_builtin_fonts()]\n fallback_fonts.extend(\n [\n \"PingFang SC\",\n \"Hiragino Sans GB\",\n \"Microsoft YaHei\",\n \"SimHei\",\n \"Arial Unicode MS\",\n \"Arial\",\n \"Helvetica\",\n ]\n )\n\n for fallback in fallback_fonts:\n try:\n font = ImageFont.truetype(fallback, size)\n logger.info(f\"Using fallback font: '{fallback}'\")\n return font\n except Exception:\n continue\n\n logger.warning(\"All fallback fonts failed, using default\")\n return ImageFont.load_default()\n\n\n@lru_cache(maxsize=128)\ndef get_ass_to_pil_ratio(font_name: str) -> float:\n \"\"\"\n Get ASS to PIL font size conversion ratio\n\n ASS uses Windows line height (usWinAscent + usWinDescent),\n PIL uses em square (unitsPerEm).\n\n For Noto Sans SC: ratio = 1.448\n This means: PIL_size = ASS_size / 1.448\n\n Returns:\n Conversion ratio (typically 1.4-1.5 for CJK fonts)\n \"\"\"\n # Find font file\n font_path = None\n for ext in [\".ttf\", \".otf\", \".ttc\"]:\n candidates = list(FONTS_PATH.glob(f\"**/{font_name}*{ext}\"))\n if candidates:\n font_path = candidates[0]\n break\n\n if not font_path:\n candidates = list(FONTS_PATH.glob(f\"**/*{font_name}*\"))\n if candidates:\n font_path = candidates[0]\n\n # Default ratio for most CJK fonts\n if not font_path:\n logger.debug(f\"Font file not found: {font_name}, using default ratio 1.448\")\n return 1.448\n\n try:\n font = TTFont(str(font_path))\n units_per_em = font[\"head\"].unitsPerEm # type: ignore\n win_ascent = font[\"OS/2\"].usWinAscent # type: ignore\n win_descent = font[\"OS/2\"].usWinDescent # type: ignore\n ratio = (win_ascent + win_descent) / units_per_em\n logger.debug(f\"Font metrics for {font_name}: ratio={ratio:.3f}\")\n return ratio\n except Exception as e:\n logger.warning(f\"Failed to read font metrics for {font_name}: {e}\")\n return 1.448\n\n\ndef clear_font_cache():\n \"\"\"Clear font cache\"\"\"\n get_builtin_fonts.cache_clear()\n get_font.cache_clear()\n get_ass_to_pil_ratio.cache_clear()\n logger.info(\"Font cache cleared\")\n" }, { "path": "app/core/subtitle/rounded_renderer.py", "content": "\"\"\"Rounded background subtitle renderer\"\"\"\n\nimport os\nimport re\nimport subprocess\nimport tempfile\nfrom dataclasses import replace\nfrom pathlib import Path\nfrom typing import TYPE_CHECKING, Callable, List, Optional, Tuple\n\nfrom PIL import Image, ImageDraw\n\nfrom app.core.entities import SubtitleLayoutEnum\nfrom app.core.utils.logger import setup_logger\n\nfrom .font_utils import FontType, get_font\nfrom .styles import RoundedBgStyle\nfrom .text_utils import hex_to_rgba, wrap_text\n\nif TYPE_CHECKING:\n from app.core.asr.asr_data import ASRData\n\nlogger = setup_logger(\"subtitle.rounded\")\n\n\ndef _get_video_info(video_path: str) -> Tuple[int, int, float]:\n \"\"\"获取视频分辨率和时长\"\"\"\n result = subprocess.run(\n [\"ffmpeg\", \"-i\", video_path],\n capture_output=True,\n text=True,\n encoding=\"utf-8\",\n errors=\"replace\",\n creationflags=(getattr(subprocess, \"CREATE_NO_WINDOW\", 0) if os.name == \"nt\" else 0),\n )\n\n # 解析分辨率\n width, height = 0, 0\n if match := re.search(r\"Stream.*Video:.* (\\d{2,5})x(\\d{2,5})\", result.stderr):\n width, height = int(match.group(1)), int(match.group(2))\n else:\n raise ValueError(f\"无法获取视频分辨率: {video_path}\")\n\n # 解析时长\n duration = 0.0\n if match := re.search(r\"Duration:\\s*(\\d+):(\\d+):(\\d+(?:\\.\\d+)?)\", result.stderr):\n h, m, s = match.groups()\n duration = int(h) * 3600 + int(m) * 60 + float(s)\n\n return width, height, duration\n\n\ndef render_text_block(\n draw: ImageDraw.ImageDraw,\n texts: List[str],\n font: FontType,\n center_x: int,\n top_y: float,\n style: RoundedBgStyle,\n) -> float:\n \"\"\"\n 渲染多行文本块(共享圆角背景)\n\n Args:\n draw: PIL ImageDraw 对象\n texts: 文本行列表\n font: 字体对象\n center_x: 水平中心位置\n top_y: 顶部 y 坐标\n style: 样式配置\n\n Returns:\n 背景框高度\n \"\"\"\n if not texts:\n return 0\n\n bg_color = hex_to_rgba(style.bg_color)\n text_color = hex_to_rgba(style.text_color)\n\n # 计算所有行的尺寸和垂直偏移\n line_sizes = []\n line_offsets = []\n for text in texts:\n bbox = font.getbbox(text)\n text_width = bbox[2] - bbox[0]\n # 如果有字符间距,需要加上额外的宽度\n if style.letter_spacing > 0 and len(text) > 1:\n text_width += style.letter_spacing * (len(text) - 1)\n line_sizes.append((text_width, bbox[3] - bbox[1]))\n line_offsets.append(bbox[1]) # 记录垂直偏移,用于居中对齐\n\n max_width = max(w for w, h in line_sizes)\n line_height = max(h for w, h in line_sizes)\n total_height = line_height * len(texts) + style.line_spacing * (len(texts) - 1)\n\n # 绘制共享背景\n bg_width = max_width + style.padding_h * 2\n bg_height = total_height + style.padding_v * 2\n bg_left = center_x - bg_width // 2\n bg_top = top_y\n\n draw.rounded_rectangle(\n [bg_left, bg_top, bg_left + bg_width, bg_top + bg_height],\n radius=style.corner_radius,\n fill=bg_color,\n )\n\n # 绘制文本(补偿字体垂直偏移)\n y = bg_top + style.padding_v\n for i, text in enumerate(texts):\n w, h = line_sizes[i]\n x = center_x - w // 2\n y_offset = line_offsets[i]\n text_y = y - y_offset # 补偿垂直偏移,使文本视觉居中\n\n # 如果有字符间距,逐字符绘制\n if style.letter_spacing > 0 and len(text) > 1:\n current_x = x\n for char in text:\n draw.text((current_x, text_y), char, font=font, fill=text_color)\n char_width = font.getbbox(char)[2] - font.getbbox(char)[0]\n current_x += char_width + style.letter_spacing\n else:\n # 无字符间距,一次性绘制(性能更好)\n draw.text((x, text_y), text, font=font, fill=text_color)\n\n y += line_height + style.line_spacing\n\n return bg_height\n\n\ndef render_subtitle_image(\n primary_text: str,\n secondary_text: str,\n width: int,\n height: int,\n style: RoundedBgStyle,\n) -> Image.Image:\n \"\"\"\n 渲染单帧字幕图像(透明背景)\n\n Args:\n primary_text: 主字幕文本\n secondary_text: 副字幕文本\n width: 图像宽度\n height: 图像高度\n style: 样式配置\n\n Returns:\n PIL Image 对象(RGBA 格式)\n \"\"\"\n image = Image.new(\"RGBA\", (width, height), (0, 0, 0, 0))\n draw = ImageDraw.Draw(image)\n font = get_font(style.font_size, style.font_name)\n\n # 换行处理(额外留 40px 边距防止文字贴边)\n extra_margin = int(width * 0.1)\n primary_lines = (\n wrap_text(primary_text, font, width, style.padding_h, extra_margin=extra_margin)\n if primary_text\n else []\n )\n secondary_lines = (\n wrap_text(secondary_text, font, width, style.padding_h, extra_margin=extra_margin)\n if secondary_text\n else []\n )\n\n center_x = width // 2\n\n # 计算总高度\n def calc_block_height(lines: List[str]) -> float:\n if not lines:\n return 0\n bbox = font.getbbox(\"测试Ag\")\n line_h = bbox[3] - bbox[1]\n return line_h * len(lines) + style.line_spacing * (len(lines) - 1) + style.padding_v * 2\n\n primary_height = calc_block_height(primary_lines)\n secondary_height = calc_block_height(secondary_lines)\n gap = style.line_spacing if primary_lines and secondary_lines else 0\n total_height = primary_height + gap + secondary_height\n\n # 从底部计算起始位置\n bottom_y = height - style.margin_bottom\n start_y = bottom_y - total_height\n\n # 渲染文本块\n current_y = start_y\n if primary_lines:\n h = render_text_block(draw, primary_lines, font, center_x, current_y, style)\n current_y += h + gap\n if secondary_lines:\n render_text_block(draw, secondary_lines, font, center_x, current_y, style)\n\n return image\n\n\ndef render_preview(\n primary_text: str,\n secondary_text: str = \"\",\n width: Optional[int] = None,\n height: Optional[int] = None,\n style: Optional[RoundedBgStyle] = None,\n bg_image_path: Optional[str] = None,\n reference_height: int = 720,\n) -> str:\n \"\"\"\n 渲染圆角背景字幕预览图\n\n Args:\n primary_text: 主字幕文本\n secondary_text: 副字幕文本\n width: 图片宽度(None=从bg_image_path自动获取)\n height: 图片高度(None=从bg_image_path自动获取)\n style: 圆角背景样式(包含reference_height,会根据height自动缩放)\n bg_image_path: 背景图片路径\n reference_height: 参考高度(固定720P)\n Returns:\n 生成的预览图路径\n \"\"\"\n if style is None:\n style = RoundedBgStyle()\n\n # 加载或创建背景\n if bg_image_path and Path(bg_image_path).exists():\n background = Image.open(bg_image_path).convert(\"RGB\")\n # 如果未提供尺寸,从图片获取\n if width is None or height is None:\n width, height = background.size\n else:\n # 没有背景图片,使用默认尺寸或提供的尺寸\n if width is None:\n width = 1920\n if height is None:\n height = 1080\n background = Image.new(\"RGB\", (width, height), (20, 20, 20))\n\n # 确保 width 和 height 不为 None(类型收窄)\n assert width is not None and height is not None\n\n # 从样式中获取参考高度,根据图片高度自动缩放样式\n scale_factor = height / reference_height\n\n if scale_factor != 1.0:\n style = replace(\n style,\n font_size=int(style.font_size * scale_factor),\n corner_radius=int(style.corner_radius * scale_factor),\n padding_h=int(style.padding_h * scale_factor),\n padding_v=int(style.padding_v * scale_factor),\n margin_bottom=int(style.margin_bottom * scale_factor),\n line_spacing=int(style.line_spacing * scale_factor),\n letter_spacing=int(style.letter_spacing * scale_factor),\n )\n\n # 渲染字幕并叠加\n subtitle_img = render_subtitle_image(primary_text, secondary_text, width, height, style)\n background.paste(subtitle_img, (0, 0), subtitle_img)\n\n # 保存到临时目录\n with tempfile.NamedTemporaryFile(mode=\"wb\", suffix=\".png\", delete=False) as tmp_file:\n background.save(tmp_file, \"PNG\")\n return tmp_file.name\n\n\ndef render_rounded_video(\n video_path: str,\n asr_data: \"ASRData\",\n output_path: str,\n rounded_style: Optional[dict] = None,\n layout: SubtitleLayoutEnum = SubtitleLayoutEnum.ONLY_ORIGINAL,\n crf: int = 23,\n preset: str = \"medium\",\n progress_callback: Optional[Callable] = None,\n reference_height: int = 720,\n) -> None:\n \"\"\"\n 渲染圆角背景字幕到视频(分批overlay方案)\n\n 核心流程:直接分批overlay字幕PNG到原视频\n 每批50个字幕,避免FFmpeg文件数量限制\n\n Args:\n video_path: 输入视频路径\n asr_data: 字幕数据\n output_path: 输出视频路径\n rounded_style: 圆角背景样式配置字典\n layout: 字幕布局\n crf: 视频质量参数\n preset: FFmpeg编码预设\n progress_callback: 进度回调 (progress: int, message: str)\n reference_height: 参考高度(固定720P)\n \"\"\"\n # 检查字幕数据\n if not asr_data or not asr_data.segments:\n raise ValueError(\"字幕数据为空,无法渲染视频\")\n\n # 检查布局合理性\n if layout == SubtitleLayoutEnum.ONLY_TRANSLATE:\n has_translation = any(\n seg.translated_text and seg.translated_text.strip() for seg in asr_data.segments\n )\n if not has_translation:\n layout = SubtitleLayoutEnum.ONLY_ORIGINAL\n elif (\n layout == SubtitleLayoutEnum.TRANSLATE_ON_TOP\n or layout == SubtitleLayoutEnum.ORIGINAL_ON_TOP\n ):\n has_translation = any(\n seg.translated_text and seg.translated_text.strip() for seg in asr_data.segments\n )\n if not has_translation:\n layout = SubtitleLayoutEnum.ONLY_ORIGINAL\n\n # 获取视频信息\n width, height, video_duration = _get_video_info(video_path)\n\n # 构建并缩放样式\n style_config = rounded_style or {}\n style_config[\"layout\"] = layout\n style = RoundedBgStyle(**style_config)\n\n scale_factor = height / reference_height\n if scale_factor != 1.0:\n style = replace(\n style,\n font_size=int(style.font_size * scale_factor),\n corner_radius=int(style.corner_radius * scale_factor),\n padding_h=int(style.padding_h * scale_factor),\n padding_v=int(style.padding_v * scale_factor),\n margin_bottom=int(style.margin_bottom * scale_factor),\n line_spacing=int(style.line_spacing * scale_factor),\n letter_spacing=int(style.letter_spacing * scale_factor),\n )\n\n with tempfile.TemporaryDirectory(prefix=\"rounded_subtitle_\") as temp_dir:\n temp_path = Path(temp_dir)\n\n # 步骤1: 生成所有字幕PNG (0-30%)\n logger.info(f\"生成字幕PNG图片(共{len(asr_data.segments)}个,布局:{layout.value})\")\n subtitle_frames = []\n\n for i, seg in enumerate(asr_data.segments):\n # 根据布局确定主副文本\n if layout == SubtitleLayoutEnum.ONLY_ORIGINAL:\n primary, secondary = seg.text, \"\"\n elif layout == SubtitleLayoutEnum.ONLY_TRANSLATE:\n primary, secondary = seg.translated_text or \"\", \"\"\n elif layout == SubtitleLayoutEnum.ORIGINAL_ON_TOP:\n primary, secondary = seg.text, seg.translated_text or \"\"\n else: # TRANSLATE_ON_TOP\n primary, secondary = seg.translated_text or \"\", seg.text\n\n # 渲染字幕图片\n img = render_subtitle_image(primary, secondary, width, height, style)\n png_path = temp_path / f\"subtitle_{i:06d}.png\"\n img.save(png_path, \"PNG\")\n\n # 记录时间戳\n start_time = seg.start_time / 1000.0\n end_time = seg.end_time / 1000.0\n subtitle_frames.append((start_time, end_time, png_path))\n\n # 进度回调\n if progress_callback:\n progress = int((i + 1) / len(asr_data.segments) * 30)\n progress_callback(progress, f\"生成字幕图片 {i + 1}/{len(asr_data.segments)}\")\n\n if not subtitle_frames:\n raise ValueError(\"没有生成任何有效的字幕图片\")\n\n # 步骤2: 分批overlay到视频 (30-100%)\n logger.info(\"分批叠加字幕到视频\")\n BATCH_SIZE = 50\n current_video = video_path\n total_batches = (len(subtitle_frames) + BATCH_SIZE - 1) // BATCH_SIZE\n\n for batch_idx in range(total_batches):\n start_idx = batch_idx * BATCH_SIZE\n end_idx = min((batch_idx + 1) * BATCH_SIZE, len(subtitle_frames))\n batch_frames = subtitle_frames[start_idx:end_idx]\n\n # 构建overlay滤镜链\n input_args = [\"-i\", current_video]\n filter_parts = []\n\n for local_idx, (start, end, png_path) in enumerate(batch_frames):\n input_args.extend([\"-i\", str(png_path)])\n prev = f\"[v{local_idx}]\" if local_idx > 0 else \"[0:v]\"\n curr = f\"[{local_idx + 1}:v]\"\n out = f\"[v{local_idx + 1}]\"\n filter_parts.append(\n f\"{prev}{curr}overlay=0:0:enable='between(t,{start},{end})'{out}\"\n )\n\n filter_complex = \";\".join(filter_parts)\n final_output = f\"[v{len(batch_frames)}]\"\n\n # 判断是否是最后一批\n is_last_batch = batch_idx == total_batches - 1\n batch_output = (\n output_path if is_last_batch else temp_path / f\"batch_{batch_idx:03d}.mp4\"\n )\n\n logger.info(f\"处理批次 {batch_idx + 1}/{total_batches}({len(batch_frames)}个字幕)\")\n # 构建 ffmpeg 命令\n # -t 参数强制保持原视频时长,防止因 overlay 结束而截断视频\n cmd = [\n \"ffmpeg\",\n \"-y\",\n *input_args,\n \"-filter_complex\",\n filter_complex,\n \"-map\",\n final_output,\n \"-map\",\n \"0:a?\",\n \"-t\",\n str(video_duration), # 强制保持原视频时长\n \"-c:v\",\n \"libx264\",\n \"-preset\",\n \"ultrafast\" if not is_last_batch else preset,\n \"-crf\",\n \"0\" if not is_last_batch else str(crf),\n \"-pix_fmt\",\n \"yuv420p\",\n \"-c:a\",\n \"copy\",\n str(batch_output),\n ]\n\n if batch_idx == 0 or is_last_batch:\n cmd_str = subprocess.list2cmdline(cmd)\n logger.info(f\"执行命令: {cmd_str}\")\n\n result = subprocess.run(\n cmd,\n capture_output=True,\n text=True,\n encoding=\"utf-8\",\n errors=\"replace\",\n creationflags=(\n getattr(subprocess, \"CREATE_NO_WINDOW\", 0) if os.name == \"nt\" else 0\n ),\n )\n\n if result.returncode != 0:\n logger.error(f\"批次 {batch_idx + 1} 失败: {result.stderr}\")\n raise RuntimeError(f\"字幕处理失败(批次 {batch_idx + 1})\")\n\n # 更新进度 (30-100%)\n if progress_callback:\n progress = 30 + int((batch_idx + 1) / total_batches * 70)\n progress_callback(progress, f\"合成视频 {batch_idx + 1}/{total_batches}\")\n\n # 更新当前视频\n current_video = str(batch_output)\n\n logger.info(\"视频合成完成\")\n" }, { "path": "app/core/subtitle/styles.py", "content": "\"\"\"Subtitle style configurations\"\"\"\n\nfrom dataclasses import dataclass\n\nfrom app.core.entities import SubtitleLayoutEnum\n\n\n@dataclass\nclass RoundedBgStyle:\n \"\"\"Rounded background subtitle style\"\"\"\n\n font_name: str = \"\"\n font_size: int = 52\n\n # 颜色配置(支持 hex 格式,如 #RRGGBB 或 #RRGGBBAA)\n bg_color: str = \"#191919C8\" # 背景颜色\n text_color: str = \"#FFFFFF\" # 文字颜色\n\n # 圆角和间距\n corner_radius: int = 12 # 圆角半径\n padding_h: int = 28 # 水平内边距\n padding_v: int = 14 # 垂直内边距\n margin_bottom: int = 60 # 底部外边距\n line_spacing: int = 10 # 行间距\n letter_spacing: int = 0 # 字符间距\n\n # 字幕布局\n layout: SubtitleLayoutEnum = SubtitleLayoutEnum.ONLY_ORIGINAL\n" }, { "path": "app/core/subtitle/text_utils.py", "content": "\"\"\"Text processing utilities\"\"\"\n\nimport re\nfrom typing import List, Tuple\n\nfrom .font_utils import FontType\n\n# CJK and Asian languages without spaces\n_NO_SPACE_LANGUAGES = r\"[\\u4e00-\\u9fff\\u3040-\\u309f\\u30a0-\\u30ff\\uac00-\\ud7af\\u0e00-\\u0eff\\u1000-\\u109f\\u1780-\\u17ff\\u0900-\\u0dff]\"\n\n\ndef is_mainly_cjk(text: str, threshold: float = 0.5) -> bool:\n \"\"\"Check if text is mainly CJK or Asian languages without spaces\"\"\"\n if not text:\n return False\n\n no_space_count = len(re.findall(_NO_SPACE_LANGUAGES, text))\n total_chars = len(\"\".join(text.split()))\n\n return no_space_count / total_chars > threshold if total_chars > 0 else False\n\n\ndef hex_to_rgba(hex_color: str) -> Tuple[int, int, int, int]:\n \"\"\"Convert hex color to RGBA tuple (#RRGGBB or #RRGGBBAA)\"\"\"\n hex_color = hex_color.lstrip(\"#\")\n if len(hex_color) == 6:\n r, g, b = (\n int(hex_color[0:2], 16),\n int(hex_color[2:4], 16),\n int(hex_color[4:6], 16),\n )\n return (r, g, b, 255)\n elif len(hex_color) == 8:\n r, g, b, a = (\n int(hex_color[0:2], 16),\n int(hex_color[2:4], 16),\n int(hex_color[4:6], 16),\n int(hex_color[6:8], 16),\n )\n return (r, g, b, a)\n return (0, 0, 0, 255)\n\n\ndef _calculate_text_width(text: str, font: FontType, spacing: float) -> int:\n \"\"\"\n Calculate text width including character spacing\n\n Args:\n text: Text to measure\n font: Font for measuring\n spacing: Character spacing (for N chars, adds spacing × (N-1) to width)\n\n Returns:\n Total width in pixels\n \"\"\"\n if not text:\n return 0\n bbox = font.getbbox(text)\n base_width = bbox[2] - bbox[0]\n # For N characters, there are N-1 spacing gaps\n spacing_width = spacing * (len(text) - 1) if len(text) > 1 else 0\n return int(base_width + spacing_width)\n\n\ndef wrap_text(\n text: str,\n font: FontType,\n max_width: int,\n horizontal_padding: int = 0,\n extra_margin: int = 0,\n spacing: float = 0.0,\n) -> List[str]:\n \"\"\"\n Wrap text to fit within max width with balanced line lengths\n\n Strategy:\n 1. Calculate minimum required lines using greedy algorithm\n 2. Calculate target width per line (total_width / num_lines)\n 3. Redistribute text to achieve balanced line lengths\n\n Args:\n text: Text to wrap\n font: Font for measuring text width\n max_width: Maximum width in pixels\n horizontal_padding: Left/right padding (reduces available width by 2x)\n extra_margin: Additional safety margin\n spacing: Character spacing (for N chars, adds spacing × (N-1) to width)\n \"\"\"\n available_width = max_width - horizontal_padding * 2 - extra_margin\n\n # 检测是否主要是 CJK 字符\n if is_mainly_cjk(text):\n return _wrap_cjk_balanced(text, font, available_width, spacing)\n else:\n return _wrap_english_balanced(text, font, available_width, spacing)\n\n\ndef _wrap_cjk_balanced(\n text: str, font: FontType, available_width: int, spacing: float = 0.0\n) -> List[str]:\n \"\"\"Wrap CJK text with balanced line lengths\"\"\"\n\n # Step 1: Calculate minimum required lines using greedy algorithm\n temp_lines = []\n current_line = \"\"\n for char in text:\n test_line = current_line + char\n if _calculate_text_width(test_line, font, spacing) <= available_width:\n current_line = test_line\n else:\n if current_line:\n temp_lines.append(current_line)\n current_line = char\n if current_line:\n temp_lines.append(current_line)\n\n if not temp_lines:\n return [text]\n\n # If only one line, no need to balance\n if len(temp_lines) == 1:\n return temp_lines\n\n # Step 2: Calculate total width and target width per line\n total_text_width = _calculate_text_width(text, font, spacing)\n num_lines = len(temp_lines)\n target_width = total_text_width / num_lines\n\n # Step 3: Redistribute text to achieve balanced lines\n # Important: Do not exceed the minimum line count from greedy algorithm\n lines = []\n current_line = \"\"\n for i, char in enumerate(text):\n test_line = current_line + char\n current_width = _calculate_text_width(test_line, font, spacing)\n\n # Check if we should break the line\n should_break = False\n\n if current_width > available_width:\n # Hard limit: must break\n should_break = True\n elif (\n len(lines) + 1 < num_lines\n and current_line\n and current_width >= target_width * 0.9\n ):\n # Only balance if we haven't reached the minimum line count yet\n # Close to target width (90% threshold)\n # Check if next char would significantly exceed target\n if i + 1 < len(text):\n next_test = test_line + text[i + 1]\n next_width = _calculate_text_width(next_test, font, spacing)\n if next_width > target_width * 1.1:\n should_break = True\n\n if should_break:\n if current_line:\n lines.append(current_line)\n current_line = char\n else:\n current_line = test_line\n else:\n current_line = test_line\n\n if current_line:\n lines.append(current_line)\n\n return lines if lines else [text]\n\n\ndef _wrap_english_balanced(\n text: str, font: FontType, available_width: int, spacing: float = 0.0\n) -> List[str]:\n \"\"\"Wrap English text with balanced line lengths\"\"\"\n\n words = text.split()\n if not words:\n return [text]\n\n # Step 1: Calculate minimum required lines\n temp_lines = []\n current_line = \"\"\n for word in words:\n test_line = f\"{current_line} {word}\".strip()\n if _calculate_text_width(test_line, font, spacing) <= available_width:\n current_line = test_line\n else:\n if current_line:\n temp_lines.append(current_line)\n current_line = word\n if current_line:\n temp_lines.append(current_line)\n\n if not temp_lines:\n return [text]\n\n # If only one line, no need to balance\n if len(temp_lines) == 1:\n return temp_lines\n\n # Step 2: Calculate target width\n total_text_width = _calculate_text_width(text, font, spacing)\n num_lines = len(temp_lines)\n target_width = total_text_width / num_lines\n\n # Step 3: Redistribute words to achieve balanced lines\n # Important: Do not exceed the minimum line count from greedy algorithm\n lines = []\n current_line = \"\"\n for i, word in enumerate(words):\n test_line = f\"{current_line} {word}\".strip()\n current_width = _calculate_text_width(test_line, font, spacing)\n\n should_break = False\n\n if current_width > available_width:\n # Hard limit: must break\n should_break = True\n elif (\n len(lines) + 1 < num_lines\n and current_line\n and current_width >= target_width * 0.9\n ):\n # Only balance if we haven't reached the minimum line count yet\n # Close to target width (90% threshold)\n # Check if next word would significantly exceed target\n if i + 1 < len(words):\n next_test = f\"{test_line} {words[i + 1]}\".strip()\n next_width = _calculate_text_width(next_test, font, spacing)\n if next_width > target_width * 1.1:\n should_break = True\n\n if should_break:\n if current_line:\n lines.append(current_line)\n current_line = word\n else:\n current_line = test_line\n else:\n current_line = test_line\n\n if current_line:\n lines.append(current_line)\n\n return lines if lines else [text]\n" }, { "path": "app/core/task_factory.py", "content": "import datetime\nfrom pathlib import Path\nfrom typing import Optional\n\nfrom app.common.config import cfg\nfrom app.config import MODEL_PATH, SUBTITLE_STYLE_PATH\nfrom app.core.entities import (\n LANGUAGES,\n FullProcessTask,\n LLMServiceEnum,\n SubtitleConfig,\n SubtitleTask,\n SynthesisConfig,\n SynthesisTask,\n TranscribeConfig,\n TranscribeTask,\n TranscriptAndSubtitleTask,\n)\n\n\nclass TaskFactory:\n \"\"\"任务工厂类,用于创建各种类型的任务\"\"\"\n\n @staticmethod\n def get_ass_style(style_name: str) -> str:\n \"\"\"获取 ASS 字幕样式内容\"\"\"\n style_path = SUBTITLE_STYLE_PATH / f\"{style_name}.txt\"\n if style_path.exists():\n return style_path.read_text(encoding=\"utf-8\")\n return \"\"\n\n @staticmethod\n def get_rounded_style() -> dict:\n \"\"\"获取圆角背景样式配置\"\"\"\n return {\n \"font_name\": cfg.rounded_bg_font_name.value,\n \"font_size\": cfg.rounded_bg_font_size.value,\n \"bg_color\": cfg.rounded_bg_color.value,\n \"text_color\": cfg.rounded_bg_text_color.value,\n \"corner_radius\": cfg.rounded_bg_corner_radius.value,\n \"padding_h\": cfg.rounded_bg_padding_h.value,\n \"padding_v\": cfg.rounded_bg_padding_v.value,\n \"margin_bottom\": cfg.rounded_bg_margin_bottom.value,\n \"line_spacing\": cfg.rounded_bg_line_spacing.value,\n \"letter_spacing\": cfg.rounded_bg_letter_spacing.value,\n }\n\n @staticmethod\n def create_transcribe_task(\n file_path: str,\n need_next_task: bool = False,\n task_id: Optional[str] = None,\n ) -> TranscribeTask:\n \"\"\"创建转录任务\"\"\"\n # 获取文件名\n file_name = Path(file_path).stem\n\n # 构建输出路径\n if need_next_task:\n need_word_time_stamp = cfg.need_split.value\n output_path = str(\n Path(cfg.work_dir.value)\n / file_name\n / \"subtitle\"\n / f\"【原始字幕】{file_name}-{cfg.transcribe_model.value.value}-{cfg.transcribe_language.value.value}.srt\"\n )\n else:\n need_word_time_stamp = False\n output_path = str(Path(file_path).parent / f\"{file_name}.srt\")\n\n config = TranscribeConfig(\n transcribe_model=cfg.transcribe_model.value,\n transcribe_language=LANGUAGES[cfg.transcribe_language.value.value],\n need_word_time_stamp=need_word_time_stamp,\n output_format=cfg.transcribe_output_format.value,\n # Whisper Cpp 配置\n whisper_model=cfg.whisper_model.value,\n # Whisper API 配置\n whisper_api_key=cfg.whisper_api_key.value,\n whisper_api_base=cfg.whisper_api_base.value,\n whisper_api_model=cfg.whisper_api_model.value,\n whisper_api_prompt=cfg.whisper_api_prompt.value,\n # Faster Whisper 配置\n faster_whisper_program=cfg.faster_whisper_program.value,\n faster_whisper_model=cfg.faster_whisper_model.value,\n faster_whisper_model_dir=str(MODEL_PATH),\n faster_whisper_device=cfg.faster_whisper_device.value,\n faster_whisper_vad_filter=cfg.faster_whisper_vad_filter.value,\n faster_whisper_vad_threshold=cfg.faster_whisper_vad_threshold.value,\n faster_whisper_vad_method=cfg.faster_whisper_vad_method.value,\n faster_whisper_ff_mdx_kim2=cfg.faster_whisper_ff_mdx_kim2.value,\n faster_whisper_one_word=cfg.faster_whisper_one_word.value,\n faster_whisper_prompt=cfg.faster_whisper_prompt.value,\n )\n\n task = TranscribeTask(\n queued_at=datetime.datetime.now(),\n file_path=file_path,\n output_path=output_path,\n transcribe_config=config,\n need_next_task=need_next_task,\n )\n if task_id:\n task.task_id = task_id\n return task\n\n @staticmethod\n def create_subtitle_task(\n file_path: str,\n video_path: Optional[str] = None,\n need_next_task: bool = False,\n task_id: Optional[str] = None,\n ) -> SubtitleTask:\n \"\"\"创建字幕任务\"\"\"\n output_name = (\n Path(file_path).stem.replace(\"【原始字幕】\", \"\").replace(\"【下载字幕】\", \"\")\n )\n # 只在需要翻译时添加翻译服务后缀\n suffix = (\n f\"-{cfg.translator_service.value.value}\" if cfg.need_translate.value else \"\"\n )\n\n if need_next_task:\n output_path = str(\n Path(file_path).parent / f\"【样式字幕】{output_name}{suffix}.ass\"\n )\n else:\n output_path = str(\n Path(file_path).parent / f\"【字幕】{output_name}{suffix}.srt\"\n )\n\n # 根据当前选择的LLM服务获取对应的配置\n current_service = cfg.llm_service.value\n if current_service == LLMServiceEnum.OPENAI:\n base_url = cfg.openai_api_base.value\n api_key = cfg.openai_api_key.value\n llm_model = cfg.openai_model.value\n elif current_service == LLMServiceEnum.SILICON_CLOUD:\n base_url = cfg.silicon_cloud_api_base.value\n api_key = cfg.silicon_cloud_api_key.value\n llm_model = cfg.silicon_cloud_model.value\n elif current_service == LLMServiceEnum.DEEPSEEK:\n base_url = cfg.deepseek_api_base.value\n api_key = cfg.deepseek_api_key.value\n llm_model = cfg.deepseek_model.value\n elif current_service == LLMServiceEnum.OLLAMA:\n base_url = cfg.ollama_api_base.value\n api_key = cfg.ollama_api_key.value\n llm_model = cfg.ollama_model.value\n elif current_service == LLMServiceEnum.LM_STUDIO:\n base_url = cfg.lm_studio_api_base.value\n api_key = cfg.lm_studio_api_key.value\n llm_model = cfg.lm_studio_model.value\n elif current_service == LLMServiceEnum.GEMINI:\n base_url = cfg.gemini_api_base.value\n api_key = cfg.gemini_api_key.value\n llm_model = cfg.gemini_model.value\n elif current_service == LLMServiceEnum.CHATGLM:\n base_url = cfg.chatglm_api_base.value\n api_key = cfg.chatglm_api_key.value\n llm_model = cfg.chatglm_model.value\n else:\n base_url = \"\"\n api_key = \"\"\n llm_model = \"\"\n\n config = SubtitleConfig(\n # 翻译配置\n base_url=base_url,\n api_key=api_key,\n llm_model=llm_model,\n deeplx_endpoint=cfg.deeplx_endpoint.value,\n # 翻译服务\n translator_service=cfg.translator_service.value,\n # 字幕处理\n need_reflect=cfg.need_reflect_translate.value,\n need_translate=cfg.need_translate.value,\n need_optimize=cfg.need_optimize.value,\n thread_num=cfg.thread_num.value,\n batch_size=cfg.batch_size.value,\n # 字幕布局、样式\n subtitle_layout=cfg.subtitle_layout.value, # Now returns SubtitleLayoutEnum\n subtitle_style=TaskFactory.get_ass_style(cfg.subtitle_style_name.value),\n # 字幕分割\n max_word_count_cjk=cfg.max_word_count_cjk.value,\n max_word_count_english=cfg.max_word_count_english.value,\n need_split=cfg.need_split.value,\n # 字幕翻译\n target_language=cfg.target_language.value,\n # 字幕提示\n custom_prompt_text=cfg.custom_prompt_text.value,\n )\n\n task = SubtitleTask(\n queued_at=datetime.datetime.now(),\n subtitle_path=file_path,\n video_path=video_path,\n output_path=output_path,\n subtitle_config=config,\n need_next_task=need_next_task,\n )\n if task_id:\n task.task_id = task_id\n return task\n\n @staticmethod\n def create_synthesis_task(\n video_path: str,\n subtitle_path: str,\n need_next_task: bool = False,\n task_id: Optional[str] = None,\n ) -> SynthesisTask:\n \"\"\"创建视频合成任务\"\"\"\n if need_next_task:\n output_path = str(\n Path(video_path).parent / f\"【卡卡】{Path(video_path).stem}.mp4\"\n )\n else:\n output_path = str(\n Path(video_path).parent / f\"【卡卡】{Path(video_path).stem}.mp4\"\n )\n\n # 只有启用样式时才传入样式配置\n use_style = cfg.use_subtitle_style.value\n config = SynthesisConfig(\n need_video=cfg.need_video.value,\n soft_subtitle=cfg.soft_subtitle.value,\n render_mode=cfg.subtitle_render_mode.value,\n video_quality=cfg.video_quality.value,\n subtitle_layout=cfg.subtitle_layout.value,\n ass_style=TaskFactory.get_ass_style(cfg.subtitle_style_name.value) if use_style else \"\",\n rounded_style=TaskFactory.get_rounded_style() if use_style else None,\n )\n\n task = SynthesisTask(\n queued_at=datetime.datetime.now(),\n video_path=video_path,\n subtitle_path=subtitle_path,\n output_path=output_path,\n synthesis_config=config,\n need_next_task=need_next_task,\n )\n if task_id:\n task.task_id = task_id\n return task\n\n @staticmethod\n def create_transcript_and_subtitle_task(\n file_path: str,\n output_path: Optional[str] = None,\n transcribe_config: Optional[TranscribeConfig] = None,\n subtitle_config: Optional[SubtitleConfig] = None,\n ) -> TranscriptAndSubtitleTask:\n \"\"\"创建转录和字幕任务\"\"\"\n if output_path is None:\n output_path = str(\n Path(file_path).parent / f\"{Path(file_path).stem}_processed.srt\"\n )\n\n return TranscriptAndSubtitleTask(\n queued_at=datetime.datetime.now(),\n file_path=file_path,\n output_path=output_path,\n )\n\n @staticmethod\n def create_full_process_task(\n file_path: str,\n output_path: Optional[str] = None,\n transcribe_config: Optional[TranscribeConfig] = None,\n subtitle_config: Optional[SubtitleConfig] = None,\n synthesis_config: Optional[SynthesisConfig] = None,\n ) -> FullProcessTask:\n \"\"\"创建完整处理任务(转录+字幕+合成)\"\"\"\n if output_path is None:\n output_path = str(\n Path(file_path).parent\n / f\"{Path(file_path).stem}_final{Path(file_path).suffix}\"\n )\n\n return FullProcessTask(\n queued_at=datetime.datetime.now(),\n file_path=file_path,\n output_path=output_path,\n )\n" }, { "path": "app/core/translate/__init__.py", "content": "\"\"\"\n翻译模块\n\n提供多种翻译服务:OpenAI LLM、Google、Bing、DeepLX\n\"\"\"\n\nfrom app.core.entities import SubtitleProcessData\nfrom app.core.translate.base import BaseTranslator\nfrom app.core.translate.bing_translator import BingTranslator\nfrom app.core.translate.deeplx_translator import DeepLXTranslator\nfrom app.core.translate.factory import TranslatorFactory\nfrom app.core.translate.google_translator import GoogleTranslator\nfrom app.core.translate.llm_translator import LLMTranslator\nfrom app.core.translate.types import TargetLanguage, TranslatorType\n\n__all__ = [\n \"BaseTranslator\",\n \"SubtitleProcessData\",\n \"TranslatorFactory\",\n \"TranslatorType\",\n \"TargetLanguage\",\n \"BingTranslator\",\n \"DeepLXTranslator\",\n \"GoogleTranslator\",\n \"LLMTranslator\",\n]\n" }, { "path": "app/core/translate/base.py", "content": "\"\"\"翻译器基类\"\"\"\n\nimport atexit\nfrom abc import ABC, abstractmethod\nfrom concurrent.futures import ThreadPoolExecutor, as_completed\nfrom typing import Callable, List, Optional\n\nfrom app.core.asr.asr_data import ASRData, ASRDataSeg\nfrom app.core.entities import SubtitleProcessData\nfrom app.core.translate.types import TargetLanguage\nfrom app.core.utils.cache import generate_cache_key, get_translate_cache\nfrom app.core.utils.logger import setup_logger\n\nlogger = setup_logger(\"subtitle_translator\")\n\n\nclass BaseTranslator(ABC):\n \"\"\"翻译器基类\"\"\"\n\n def __init__(\n self,\n thread_num: int,\n batch_num: int,\n target_language: TargetLanguage,\n update_callback: Optional[Callable],\n ):\n self.thread_num = thread_num\n self.batch_num = batch_num\n self.target_language = target_language\n self.is_running = True\n self.update_callback = update_callback\n self.executor = None\n self._cache = get_translate_cache()\n\n self._init_thread_pool()\n\n def _init_thread_pool(self):\n \"\"\"初始化线程池\"\"\"\n self.executor = ThreadPoolExecutor(max_workers=self.thread_num)\n atexit.register(self.stop)\n\n def translate_subtitle(self, subtitle_data: ASRData) -> ASRData:\n \"\"\"翻译字幕文件\"\"\"\n try:\n asr_data = subtitle_data\n\n # 将ASRData转换为SubtitleProcessData列表\n translate_data_list = [\n SubtitleProcessData(index=i, original_text=seg.text)\n for i, seg in enumerate(asr_data.segments, 1)\n ]\n\n # 分批处理字幕\n chunks = self._split_chunks(translate_data_list)\n\n # 多线程翻译\n translated_list = self._parallel_translate(chunks)\n\n # 设置字幕段的翻译文本\n new_segments = self._set_segments_translated_text(\n asr_data.segments, translated_list\n )\n\n return ASRData(new_segments)\n except Exception as e:\n logger.error(f\"翻译失败:{str(e)}\")\n raise RuntimeError(f\"翻译失败:{str(e)}\")\n\n def _split_chunks(\n self, translate_data_list: List[SubtitleProcessData]\n ) -> List[List[SubtitleProcessData]]:\n \"\"\"将字幕分割成块\"\"\"\n return [\n translate_data_list[i : i + self.batch_num]\n for i in range(0, len(translate_data_list), self.batch_num)\n ]\n\n def _parallel_translate(\n self, chunks: List[List[SubtitleProcessData]]\n ) -> List[SubtitleProcessData]:\n \"\"\"并行翻译所有块\"\"\"\n futures = []\n translated_list = []\n\n for chunk in chunks:\n future = self.executor.submit(self._safe_translate_chunk, chunk)\n futures.append(future)\n\n for future in as_completed(futures):\n if not self.is_running:\n break\n try:\n result = future.result()\n translated_list.extend(result)\n except Exception as e:\n logger.error(f\"翻译块失败:{str(e)}\")\n translated_list.extend(chunk)\n\n return translated_list\n\n def _get_cache_key(self, chunk: List[SubtitleProcessData]) -> str:\n \"\"\"生成缓存键\"\"\"\n class_name = self.__class__.__name__\n chunk_key = generate_cache_key(chunk)\n lang = self.target_language.value\n return f\"{class_name}:{chunk_key}:{lang}\"\n\n def _safe_translate_chunk(\n self, chunk: List[SubtitleProcessData]\n ) -> List[SubtitleProcessData]:\n \"\"\"安全的翻译块\"\"\"\n try:\n cache_key = self._get_cache_key(chunk)\n cached_result = self._cache.get(cache_key, default=None)\n if cached_result is not None:\n return cached_result\n\n result = self._translate_chunk(chunk)\n\n if self.update_callback:\n self.update_callback(result)\n\n self._cache.set(cache_key, result, expire=86400 * 7)\n return result\n\n except Exception as e:\n logger.exception(f\"翻译失败: {str(e)}\")\n raise\n\n @staticmethod\n def _set_segments_translated_text(\n original_segments: List[ASRDataSeg], translated_list: List[SubtitleProcessData]\n ) -> List[ASRDataSeg]:\n \"\"\"设置字幕段的翻译文本\"\"\"\n # 创建索引到翻译文本的映射\n translation_map = {data.index: data.translated_text for data in translated_list}\n\n for i, seg in enumerate(original_segments, 1):\n if i not in translation_map:\n logger.error(f\"字幕段 {i} 没有翻译\")\n continue\n seg.translated_text = translation_map[i]\n\n return original_segments\n\n @abstractmethod\n def _translate_chunk(\n self, subtitle_chunk: List[SubtitleProcessData]\n ) -> List[SubtitleProcessData]:\n \"\"\"翻译字幕块\"\"\"\n pass\n\n def stop(self):\n \"\"\"停止翻译器\"\"\"\n if not self.is_running:\n return\n\n self.is_running = False\n if hasattr(self, \"executor\") and self.executor is not None:\n try:\n self.executor.shutdown(wait=False, cancel_futures=True)\n except Exception as e:\n logger.error(f\"关闭线程池时出错:{str(e)}\")\n finally:\n self.executor = None\n" }, { "path": "app/core/translate/bing_translator.py", "content": "\"\"\"Bing 翻译器\"\"\"\n\nfrom typing import Callable, List, Optional\n\nimport requests\n\nfrom app.core.entities import SubtitleProcessData\nfrom app.core.translate.base import BaseTranslator, logger\nfrom app.core.translate.types import TargetLanguage, get_language_code\nfrom app.core.utils.cache import generate_cache_key\n\n\nclass BingTranslator(BaseTranslator):\n \"\"\"必应翻译器\"\"\"\n\n def __init__(\n self,\n thread_num: int,\n batch_num: int,\n target_language: TargetLanguage,\n update_callback: Optional[Callable],\n ):\n super().__init__(\n thread_num=thread_num,\n batch_num=batch_num,\n target_language=target_language,\n update_callback=update_callback,\n )\n self.timeout = 20\n self.session = requests.Session()\n self.auth_endpoint = \"https://edge.microsoft.com/translate/auth\"\n self.translate_endpoint = (\n \"https://api-edge.cognitive.microsofttranslator.com/translate\"\n )\n\n self.headers = {\n \"User-Agent\": \"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/131.0.0.0 Safari/537.36 Edg/131.0.0.0\",\n }\n self._init_session()\n\n def _init_session(self):\n \"\"\"初始化会话,获取必要的token\"\"\"\n try:\n response = self.session.get(self.auth_endpoint, timeout=self.timeout)\n response.raise_for_status()\n self.auth_token = response.text\n self.headers[\"authorization\"] = f\"Bearer {self.auth_token}\"\n except Exception as e:\n logger.error(f\"初始化必应翻译会话失败: {str(e)}\")\n raise RuntimeError(f\"初始化必应翻译会话失败: {str(e)}\")\n\n def _translate_chunk(\n self, subtitle_chunk: List[SubtitleProcessData]\n ) -> List[SubtitleProcessData]:\n \"\"\"翻译字幕块\"\"\"\n target_lang = get_language_code(self.target_language, \"bing\")\n\n # 准备批量翻译的数据\n texts_to_translate = [\n {\"Text\": data.original_text[:5000]} for data in subtitle_chunk\n ]\n\n if texts_to_translate:\n try:\n params = {\n \"to\": target_lang,\n \"api-version\": \"3.0\",\n \"includeSentenceLength\": \"true\",\n }\n\n response = self.session.post(\n self.translate_endpoint,\n params=params,\n headers=self.headers,\n json=texts_to_translate,\n timeout=self.timeout,\n )\n response.raise_for_status()\n translations = response.json()\n\n # 处理翻译结果\n for i, translation in enumerate(translations):\n subtitle_chunk[i].translated_text = translation[\"translations\"][0][\n \"text\"\n ]\n\n except Exception as e:\n logger.error(f\"必应翻译失败: {str(e)}\")\n if \"token\" in str(e).lower() or (\n hasattr(response, \"status_code\")\n and response.status_code in [401, 403]\n ):\n try:\n self._init_session()\n except Exception as e:\n logger.error(f\"重新初始化必应翻译会话失败: {str(e)}\")\n\n return subtitle_chunk\n\n def _get_cache_key(self, chunk: List[SubtitleProcessData]) -> str:\n \"\"\"生成缓存键\"\"\"\n class_name = self.__class__.__name__\n chunk_key = generate_cache_key(chunk)\n lang = self.target_language.value\n return f\"{class_name}:{chunk_key}:{lang}\"\n" }, { "path": "app/core/translate/deeplx_translator.py", "content": "\"\"\"DeepLX 翻译器\"\"\"\n\nimport os\nfrom typing import Callable, List, Optional\n\nimport requests\n\nfrom app.core.translate.base import BaseTranslator, SubtitleProcessData, logger\nfrom app.core.translate.types import TargetLanguage, get_language_code\nfrom app.core.utils.cache import generate_cache_key\n\n\nclass DeepLXTranslator(BaseTranslator):\n \"\"\"DeepLX翻译器\"\"\"\n\n def __init__(\n self,\n thread_num: int,\n batch_num: int,\n target_language: TargetLanguage,\n timeout: int,\n update_callback: Optional[Callable],\n ):\n super().__init__(\n thread_num=thread_num,\n batch_num=batch_num,\n target_language=target_language,\n update_callback=update_callback,\n )\n self.timeout = timeout\n self.session = requests.Session()\n self.endpoint = os.getenv(\"DEEPLX_ENDPOINT\", \"https://api.deeplx.org/translate\")\n\n def _translate_chunk(\n self, subtitle_chunk: List[SubtitleProcessData]\n ) -> List[SubtitleProcessData]:\n \"\"\"翻译字幕块\"\"\"\n target_lang = get_language_code(self.target_language, \"deeplx\")\n\n for data in subtitle_chunk:\n try:\n response = self.session.post(\n self.endpoint,\n json={\n \"text\": data.original_text,\n \"source_lang\": \"auto\",\n \"target_lang\": target_lang,\n },\n timeout=self.timeout,\n )\n response.raise_for_status()\n data.translated_text = response.json()[\"data\"]\n except Exception as e:\n logger.error(f\"DeepLX翻译失败 {data.index}: {str(e)}\")\n\n return subtitle_chunk\n\n def _get_cache_key(self, chunk: List[SubtitleProcessData]) -> str:\n \"\"\"生成缓存键\"\"\"\n class_name = self.__class__.__name__\n chunk_key = generate_cache_key(chunk)\n lang = self.target_language.value\n return f\"{class_name}:{chunk_key}:{lang}\"\n" }, { "path": "app/core/translate/factory.py", "content": "\"\"\"翻译器工厂\"\"\"\n\nfrom typing import Callable, Optional\n\nfrom app.core.translate.base import BaseTranslator\nfrom app.core.translate.bing_translator import BingTranslator\nfrom app.core.translate.deeplx_translator import DeepLXTranslator\nfrom app.core.translate.google_translator import GoogleTranslator\nfrom app.core.translate.llm_translator import LLMTranslator\nfrom app.core.translate.types import TargetLanguage, TranslatorType\nfrom app.core.utils.logger import setup_logger\n\nlogger = setup_logger(\"translator_factory\")\n\n\nclass TranslatorFactory:\n \"\"\"翻译器工厂类\"\"\"\n\n @staticmethod\n def create_translator(\n translator_type: TranslatorType,\n thread_num: int = 5,\n batch_num: int = 10,\n target_language: Optional[TargetLanguage] = None,\n model: str = \"gpt-4o-mini\",\n custom_prompt: str = \"\",\n is_reflect: bool = False,\n update_callback: Optional[Callable] = None,\n ) -> BaseTranslator:\n \"\"\"创建翻译器实例\"\"\"\n try:\n # 如果没有指定目标语言,使用默认值\n if target_language is None:\n target_language = TargetLanguage.SIMPLIFIED_CHINESE\n\n if translator_type == TranslatorType.OPENAI:\n return LLMTranslator(\n thread_num=thread_num,\n batch_num=batch_num,\n target_language=target_language,\n model=model,\n custom_prompt=custom_prompt,\n is_reflect=is_reflect,\n update_callback=update_callback,\n )\n elif translator_type == TranslatorType.GOOGLE:\n batch_num = 5\n return GoogleTranslator(\n thread_num=thread_num,\n batch_num=batch_num,\n target_language=target_language,\n timeout=20,\n update_callback=update_callback,\n )\n elif translator_type == TranslatorType.BING:\n batch_num = 10\n return BingTranslator(\n thread_num=thread_num,\n batch_num=batch_num,\n target_language=target_language,\n update_callback=update_callback,\n )\n elif translator_type == TranslatorType.DEEPLX:\n batch_num = 5\n return DeepLXTranslator(\n thread_num=thread_num,\n batch_num=batch_num,\n target_language=target_language,\n timeout=20,\n update_callback=update_callback,\n )\n except Exception as e:\n logger.error(f\"创建翻译器失败:{str(e)}\")\n raise\n" }, { "path": "app/core/translate/google_translator.py", "content": "\"\"\"Google 翻译器\"\"\"\n\nimport html\nimport re\nfrom typing import Callable, List, Optional\n\nimport requests\n\nfrom app.core.entities import SubtitleProcessData\nfrom app.core.translate.base import BaseTranslator, logger\nfrom app.core.translate.types import TargetLanguage, get_language_code\nfrom app.core.utils.cache import generate_cache_key\n\n\nclass GoogleTranslator(BaseTranslator):\n \"\"\"谷歌翻译器\"\"\"\n\n def __init__(\n self,\n thread_num: int,\n batch_num: int,\n target_language: TargetLanguage,\n timeout: int,\n update_callback: Optional[Callable],\n ):\n super().__init__(\n thread_num=thread_num,\n batch_num=batch_num,\n target_language=target_language,\n update_callback=update_callback,\n )\n self.timeout = timeout\n self.session = requests.Session()\n self.endpoint = \"http://translate.google.com/m\"\n self.headers = {\n \"User-Agent\": \"Mozilla/4.0 (compatible;MSIE 6.0;Windows NT 5.1;SV1;.NET CLR 1.1.4322;.NET CLR 2.0.50727;.NET CLR 3.0.04506.30)\"\n }\n\n def _translate_chunk(\n self, subtitle_chunk: List[SubtitleProcessData]\n ) -> List[SubtitleProcessData]:\n \"\"\"翻译字幕块\"\"\"\n target_lang = get_language_code(self.target_language, \"google\")\n\n for data in subtitle_chunk:\n try:\n text = data.original_text[:5000] # google translate max length\n response = self.session.get(\n self.endpoint,\n params={\"tl\": target_lang, \"sl\": \"auto\", \"q\": text},\n headers=self.headers,\n timeout=self.timeout,\n )\n\n if response.status_code == 400:\n logger.warning(f\"Google翻译返回400错误 {data.index}\")\n continue\n\n response.raise_for_status()\n re_result = re.findall(\n r'(?s)class=\"(?:t0|result-container)\">(.*?)<', response.text\n )\n if re_result:\n data.translated_text = html.unescape(re_result[0])\n data.translated_text = data.translated_text\n else:\n logger.warning(f\"无法从Google翻译响应中提取翻译结果: {data.index}\")\n except Exception as e:\n logger.error(f\"Google翻译失败 {data.index}: {str(e)}\")\n\n return subtitle_chunk\n\n def _get_cache_key(self, chunk: List[SubtitleProcessData]) -> str:\n \"\"\"生成缓存键\"\"\"\n class_name = self.__class__.__name__\n chunk_key = generate_cache_key(chunk)\n lang = self.target_language.value\n return f\"{class_name}:{chunk_key}:{lang}\"\n" }, { "path": "app/core/translate/llm_translator.py", "content": "\"\"\"LLM 翻译器(使用 OpenAI)\"\"\"\n\nimport json\nfrom typing import Any, Callable, Dict, List, Optional, Tuple\n\nimport json_repair\nimport openai\n\nfrom app.core.llm import call_llm\nfrom app.core.prompts import get_prompt\nfrom app.core.translate.base import BaseTranslator, SubtitleProcessData, logger\nfrom app.core.translate.types import TargetLanguage\nfrom app.core.utils.cache import generate_cache_key\n\n\nclass LLMTranslator(BaseTranslator):\n \"\"\"LLM 翻译器(OpenAI兼容API)\"\"\"\n\n MAX_STEPS = 3\n\n def __init__(\n self,\n thread_num: int,\n batch_num: int,\n target_language: TargetLanguage,\n model: str,\n custom_prompt: str,\n is_reflect: bool,\n update_callback: Optional[Callable],\n ):\n super().__init__(\n thread_num=thread_num,\n batch_num=batch_num,\n target_language=target_language,\n update_callback=update_callback,\n )\n\n self.model = model\n self.custom_prompt = custom_prompt\n self.is_reflect = is_reflect\n\n def _translate_chunk(\n self, subtitle_chunk: List[SubtitleProcessData]\n ) -> List[SubtitleProcessData]:\n \"\"\"翻译字幕块\"\"\"\n logger.info(\n f\"[+]正在翻译字幕:{subtitle_chunk[0].index} - {subtitle_chunk[-1].index}\"\n )\n\n # 转换为字典格式用于API调用\n subtitle_dict = {str(data.index): data.original_text for data in subtitle_chunk}\n\n # 获取提示词\n if self.is_reflect:\n prompt = get_prompt(\n \"translate/reflect\",\n target_language=self.target_language,\n custom_prompt=self.custom_prompt,\n )\n else:\n prompt = get_prompt(\n \"translate/standard\",\n target_language=self.target_language,\n custom_prompt=self.custom_prompt,\n )\n\n try:\n # 使用agent loop进行翻译,自动验证和修正\n result_dict = self._agent_loop(prompt, subtitle_dict)\n\n # 处理反思翻译模式的结果\n if self.is_reflect and isinstance(result_dict, dict):\n processed_result = {\n k: f\"{v.get('native_translation', v) if isinstance(v, dict) else v}\"\n for k, v in result_dict.items()\n }\n else:\n processed_result = {k: f\"{v}\" for k, v in result_dict.items()}\n\n # 将结果填充回SubtitleProcessData\n for data in subtitle_chunk:\n data.translated_text = processed_result.get(\n str(data.index), data.original_text\n )\n return subtitle_chunk\n except openai.RateLimitError as e:\n logger.error(f\"OpenAI Rate Limit Error: {str(e)}\")\n except openai.AuthenticationError as e:\n logger.error(f\"OpenAI Authentication Error: {str(e)}\")\n except openai.NotFoundError as e:\n logger.error(f\"OpenAI NotFound Error: {str(e)}\")\n except Exception as e:\n logger.exception(f\"Error: {str(e)}\")\n return self._translate_chunk_single(subtitle_chunk)\n\n def _agent_loop(\n self, system_prompt: str, subtitle_dict: Dict[str, str]\n ) -> Dict[str, str]:\n \"\"\"Agent loop翻译字幕块\"\"\"\n messages = [\n {\"role\": \"system\", \"content\": system_prompt},\n {\"role\": \"user\", \"content\": json.dumps(subtitle_dict, ensure_ascii=False)},\n ]\n last_response_dict = None\n # llm 反馈循环\n for _ in range(self.MAX_STEPS):\n response = call_llm(messages=messages, model=self.model)\n response_dict = json_repair.loads(\n response.choices[0].message.content.strip()\n )\n last_response_dict = response_dict\n is_valid, error_message = self._validate_llm_response(\n response_dict, subtitle_dict\n )\n if is_valid:\n return response_dict\n else:\n messages.append(\n {\n \"role\": \"assistant\",\n \"content\": json.dumps(response_dict, ensure_ascii=False),\n }\n )\n messages.append(\n {\n \"role\": \"user\",\n \"content\": f\"Error: {error_message}\\n\\nFix the errors above and output ONLY a valid JSON dictionary with ALL {len(subtitle_dict)} keys\",\n }\n )\n\n return last_response_dict\n\n def _validate_llm_response(\n self, response_dict: Any, subtitle_dict: Dict[str, str]\n ) -> Tuple[bool, str]:\n \"\"\"验证LLM翻译结果(支持普通和反思模式)\n\n 返回: (是否有效, 错误反馈)\n \"\"\"\n if not isinstance(response_dict, dict):\n return (\n False,\n f\"Output must be a dict, got {type(response_dict).__name__}. Use format: {{'0': 'text', '1': 'text'}}\",\n )\n\n expected_keys = set(subtitle_dict.keys())\n actual_keys = set(response_dict.keys())\n\n def sort_keys(keys):\n return sorted(keys, key=lambda x: int(x) if x.isdigit() else x)\n\n # 检查键是否匹配\n if expected_keys != actual_keys:\n missing = expected_keys - actual_keys\n extra = actual_keys - expected_keys\n error_parts = []\n\n if missing:\n error_parts.append(\n f\"Missing keys {sort_keys(missing)} - you must translate these items\"\n )\n if extra:\n error_parts.append(\n f\"Extra keys {sort_keys(extra)} - these keys are not in input, remove them\"\n )\n\n return (False, \"; \".join(error_parts))\n\n # 如果是反思模式,检查嵌套结构\n if self.is_reflect:\n for key, value in response_dict.items():\n if not isinstance(value, dict):\n return (\n False,\n f\"Key '{key}': value must be a dict with 'native_translation' field. Got {type(value).__name__}.\",\n )\n\n if \"native_translation\" not in value:\n available_keys = list(value.keys())\n return (\n False,\n f\"Key '{key}': missing 'native_translation' field. Found keys: {available_keys}. Must include 'native_translation'.\",\n )\n\n return True, \"\"\n\n def _translate_chunk_single(\n self, subtitle_chunk: List[SubtitleProcessData]\n ) -> List[SubtitleProcessData]:\n \"\"\"单条翻译模式\"\"\"\n single_prompt = get_prompt(\n \"translate/single\", target_language=self.target_language\n )\n\n for data in subtitle_chunk:\n try:\n response = call_llm(\n messages=[\n {\"role\": \"system\", \"content\": single_prompt},\n {\"role\": \"user\", \"content\": data.original_text},\n ],\n model=self.model,\n temperature=0.7,\n )\n translated_text = response.choices[0].message.content.strip()\n data.translated_text = translated_text\n except Exception as e:\n logger.error(f\"单条翻译失败 {data.index}: {str(e)}\")\n\n return subtitle_chunk\n\n def _get_cache_key(self, chunk: List[SubtitleProcessData]) -> str:\n \"\"\"生成缓存键\"\"\"\n class_name = self.__class__.__name__\n chunk_key = generate_cache_key(chunk)\n lang = self.target_language.value\n model = self.model\n return f\"{class_name}:{chunk_key}:{lang}:{model}\"\n" }, { "path": "app/core/translate/types.py", "content": "\"\"\"翻译器类型枚举\"\"\"\n\nfrom enum import Enum\n\n\nclass TranslatorType(Enum):\n \"\"\"翻译器类型\"\"\"\n\n OPENAI = \"openai\"\n GOOGLE = \"google\"\n BING = \"bing\"\n DEEPLX = \"deeplx\"\n\n\nclass TargetLanguage(Enum):\n \"\"\"目标语言枚举\"\"\"\n\n # 中文\n SIMPLIFIED_CHINESE = \"简体中文\"\n TRADITIONAL_CHINESE = \"繁体中文\"\n\n # 英语\n ENGLISH = \"英语\"\n ENGLISH_US = \"英语(美国)\"\n ENGLISH_UK = \"英语(英国)\"\n\n # 亚洲语言\n JAPANESE = \"日本語\"\n KOREAN = \"韩语\"\n CANTONESE = \"粤语\"\n THAI = \"泰语\"\n VIETNAMESE = \"越南语\"\n INDONESIAN = \"印尼语\"\n MALAY = \"马来语\"\n TAGALOG = \"菲律宾语\"\n\n # 欧洲语言\n FRENCH = \"法语\"\n GERMAN = \"德语\"\n SPANISH = \"西班牙语\"\n SPANISH_LATAM = \"西班牙语(拉丁美洲)\"\n RUSSIAN = \"俄语\"\n PORTUGUESE = \"葡萄牙语\"\n PORTUGUESE_BR = \"葡萄牙语(巴西)\"\n PORTUGUESE_PT = \"葡萄牙语(葡萄牙)\"\n ITALIAN = \"意大利语\"\n DUTCH = \"荷兰语\"\n POLISH = \"波兰语\"\n TURKISH = \"土耳其语\"\n GREEK = \"希腊语\"\n CZECH = \"捷克语\"\n SWEDISH = \"瑞典语\"\n DANISH = \"丹麦语\"\n FINNISH = \"芬兰语\"\n NORWEGIAN = \"挪威语\"\n HUNGARIAN = \"匈牙利语\"\n ROMANIAN = \"罗马尼亚语\"\n BULGARIAN = \"保加利亚语\"\n UKRAINIAN = \"乌克兰语\"\n\n # 中东语言\n ARABIC = \"阿拉伯语\"\n HEBREW = \"希伯来语\"\n PERSIAN = \"波斯语\"\n\n\n# Google Translate 语言代码映射\nGOOGLE_LANG_MAP = {\n # 中文\n TargetLanguage.SIMPLIFIED_CHINESE: \"zh-CN\",\n TargetLanguage.TRADITIONAL_CHINESE: \"zh-TW\",\n # 英语\n TargetLanguage.ENGLISH: \"en\",\n TargetLanguage.ENGLISH_US: \"en\",\n TargetLanguage.ENGLISH_UK: \"en\",\n # 亚洲语言\n TargetLanguage.JAPANESE: \"ja\",\n TargetLanguage.KOREAN: \"ko\",\n TargetLanguage.CANTONESE: \"yue\",\n TargetLanguage.THAI: \"th\",\n TargetLanguage.VIETNAMESE: \"vi\",\n TargetLanguage.INDONESIAN: \"id\",\n TargetLanguage.MALAY: \"ms\",\n TargetLanguage.TAGALOG: \"tl\",\n # 欧洲语言\n TargetLanguage.FRENCH: \"fr\",\n TargetLanguage.GERMAN: \"de\",\n TargetLanguage.SPANISH: \"es\",\n TargetLanguage.SPANISH_LATAM: \"es\",\n TargetLanguage.RUSSIAN: \"ru\",\n TargetLanguage.PORTUGUESE: \"pt\",\n TargetLanguage.PORTUGUESE_BR: \"pt\",\n TargetLanguage.PORTUGUESE_PT: \"pt\",\n TargetLanguage.ITALIAN: \"it\",\n TargetLanguage.DUTCH: \"nl\",\n TargetLanguage.POLISH: \"pl\",\n TargetLanguage.TURKISH: \"tr\",\n TargetLanguage.GREEK: \"el\",\n TargetLanguage.CZECH: \"cs\",\n TargetLanguage.SWEDISH: \"sv\",\n TargetLanguage.DANISH: \"da\",\n TargetLanguage.FINNISH: \"fi\",\n TargetLanguage.NORWEGIAN: \"no\",\n TargetLanguage.HUNGARIAN: \"hu\",\n TargetLanguage.ROMANIAN: \"ro\",\n TargetLanguage.BULGARIAN: \"bg\",\n TargetLanguage.UKRAINIAN: \"uk\",\n # 中东语言\n TargetLanguage.ARABIC: \"ar\",\n TargetLanguage.HEBREW: \"he\",\n TargetLanguage.PERSIAN: \"fa\",\n}\n\n# Bing Translator 语言代码映射\nBING_LANG_MAP = {\n # 中文\n TargetLanguage.SIMPLIFIED_CHINESE: \"zh-Hans\",\n TargetLanguage.TRADITIONAL_CHINESE: \"zh-Hant\",\n # 英语\n TargetLanguage.ENGLISH: \"en\",\n TargetLanguage.ENGLISH_US: \"en\",\n TargetLanguage.ENGLISH_UK: \"en\",\n # 亚洲语言\n TargetLanguage.JAPANESE: \"ja\",\n TargetLanguage.KOREAN: \"ko\",\n TargetLanguage.CANTONESE: \"yue\",\n TargetLanguage.THAI: \"th\",\n TargetLanguage.VIETNAMESE: \"vi\",\n TargetLanguage.INDONESIAN: \"id\",\n TargetLanguage.MALAY: \"ms\",\n TargetLanguage.TAGALOG: \"fil\",\n # 欧洲语言\n TargetLanguage.FRENCH: \"fr\",\n TargetLanguage.GERMAN: \"de\",\n TargetLanguage.SPANISH: \"es\",\n TargetLanguage.SPANISH_LATAM: \"es\",\n TargetLanguage.RUSSIAN: \"ru\",\n TargetLanguage.PORTUGUESE: \"pt\",\n TargetLanguage.PORTUGUESE_BR: \"pt\",\n TargetLanguage.PORTUGUESE_PT: \"pt-PT\",\n TargetLanguage.ITALIAN: \"it\",\n TargetLanguage.DUTCH: \"nl\",\n TargetLanguage.POLISH: \"pl\",\n TargetLanguage.TURKISH: \"tr\",\n TargetLanguage.GREEK: \"el\",\n TargetLanguage.CZECH: \"cs\",\n TargetLanguage.SWEDISH: \"sv\",\n TargetLanguage.DANISH: \"da\",\n TargetLanguage.FINNISH: \"fi\",\n TargetLanguage.NORWEGIAN: \"nb\",\n TargetLanguage.HUNGARIAN: \"hu\",\n TargetLanguage.ROMANIAN: \"ro\",\n TargetLanguage.BULGARIAN: \"bg\",\n TargetLanguage.UKRAINIAN: \"uk\",\n # 中东语言\n TargetLanguage.ARABIC: \"ar\",\n TargetLanguage.HEBREW: \"he\",\n TargetLanguage.PERSIAN: \"fa\",\n}\n\n# DeepL 语言代码映射\nDEEPL_LANG_MAP = {\n # 中文\n TargetLanguage.SIMPLIFIED_CHINESE: \"zh-Hans\",\n TargetLanguage.TRADITIONAL_CHINESE: \"zh-Hant\",\n # 英语\n TargetLanguage.ENGLISH: \"en\",\n TargetLanguage.ENGLISH_US: \"en-US\",\n TargetLanguage.ENGLISH_UK: \"en-GB\",\n # 亚洲语言\n TargetLanguage.JAPANESE: \"ja\",\n TargetLanguage.KOREAN: \"ko\",\n TargetLanguage.INDONESIAN: \"id\",\n # 欧洲语言\n TargetLanguage.FRENCH: \"fr\",\n TargetLanguage.GERMAN: \"de\",\n TargetLanguage.SPANISH: \"es\",\n TargetLanguage.RUSSIAN: \"ru\",\n TargetLanguage.PORTUGUESE: \"pt\",\n TargetLanguage.PORTUGUESE_BR: \"pt-BR\",\n TargetLanguage.PORTUGUESE_PT: \"pt-PT\",\n TargetLanguage.ITALIAN: \"it\",\n TargetLanguage.DUTCH: \"nl\",\n TargetLanguage.POLISH: \"pl\",\n TargetLanguage.TURKISH: \"tr\",\n TargetLanguage.GREEK: \"el\",\n TargetLanguage.CZECH: \"cs\",\n TargetLanguage.SWEDISH: \"sv\",\n TargetLanguage.DANISH: \"da\",\n TargetLanguage.FINNISH: \"fi\",\n TargetLanguage.NORWEGIAN: \"nb\",\n TargetLanguage.HUNGARIAN: \"hu\",\n TargetLanguage.ROMANIAN: \"ro\",\n TargetLanguage.BULGARIAN: \"bg\",\n TargetLanguage.UKRAINIAN: \"uk\",\n # 中东语言\n TargetLanguage.ARABIC: \"ar\",\n}\n\n\ndef get_language_code(target_language: TargetLanguage, translator_type: str) -> str:\n \"\"\"\n 获取翻译服务对应的语言代码\n\n Args:\n target_language: 目标语言枚举\n translator_type: 翻译器类型(google/bing/deeplx)\n\n Returns:\n 语言代码字符串\n \"\"\"\n lang_map = {\n \"google\": GOOGLE_LANG_MAP,\n \"bing\": BING_LANG_MAP,\n \"deeplx\": DEEPL_LANG_MAP,\n }\n\n # 获取对应的语言映射\n mapping = lang_map.get(translator_type, {})\n\n # 使用枚举的 value(中文名称)查找语言代码\n if target_language in mapping:\n return mapping[target_language]\n\n # 默认返回简体中文\n return mapping.get(TargetLanguage.SIMPLIFIED_CHINESE, \"zh-CN\")\n" }, { "path": "app/core/tts/__init__.py", "content": "\"\"\"TTS (Text-To-Speech) 模块\n\n提供多种 TTS 服务的统一接口\n\"\"\"\n\nfrom .base import BaseTTS\nfrom .openai_fm import OpenAIFmTTS\nfrom .openai_tts import OpenAITTS\nfrom .siliconflow import SiliconFlowTTS, VoiceCloneManager\nfrom .status import TTSStatus\nfrom .tts_data import TTSConfig, TTSData, TTSDataSeg\n\n__all__ = [\n \"BaseTTS\",\n \"OpenAITTS\",\n \"OpenAIFmTTS\",\n \"SiliconFlowTTS\",\n \"VoiceCloneManager\",\n \"TTSStatus\",\n \"TTSConfig\",\n \"TTSData\",\n \"TTSDataSeg\",\n]\n" }, { "path": "app/core/tts/base.py", "content": "\"\"\"TTS 基类 - 提供缓存、批量处理等通用功能\"\"\"\n\nimport hashlib\nfrom abc import ABC, abstractmethod\nfrom pathlib import Path\nfrom typing import Callable, Optional, cast\n\nfrom app.core.tts.status import TTSStatus\nfrom app.core.tts.tts_data import TTSConfig, TTSData, TTSDataSeg\nfrom app.core.utils.cache import get_tts_cache, is_cache_enabled\nfrom app.core.utils.logger import setup_logger\n\nlogger = setup_logger(\"tts\")\n\n\nclass BaseTTS(ABC):\n \"\"\"TTS 基类\n\n 提供通用功能:\n - 缓存机制(二进制数据缓存)\n - 批量处理(统一接口)\n - 配置管理\n \"\"\"\n\n def __init__(self, config: TTSConfig):\n \"\"\"初始化\n\n Args:\n config: TTS 配置\n \"\"\"\n self.config = config\n self.cache = get_tts_cache() # 总是初始化缓存实例\n\n def synthesize(\n self,\n tts_data: TTSData,\n output_dir: str,\n callback: Optional[Callable[[int, str], None]] = None,\n ) -> TTSData:\n \"\"\"合成语音(统一批量处理接口)\n\n Args:\n tts_data: TTS 数据(包含多个待合成的文本段)\n output_dir: 输出目录\n callback: 进度回调函数 callback(progress: int, message: str)\n\n Returns:\n TTS 数据(segments 已填充 audio_path 等信息)\n \"\"\"\n\n def _default_callback(progress: int, message: str):\n pass\n\n if callback is None:\n callback = _default_callback\n\n output_path = Path(output_dir)\n output_path.mkdir(parents=True, exist_ok=True)\n\n total = len(tts_data.segments)\n if total == 0:\n logger.warning(\"TTS 数据为空,无需合成\")\n return tts_data\n\n logger.info(f\"开始批量合成 {total} 条语音\")\n\n for idx, segment in enumerate(tts_data.segments):\n try:\n # 计算进度\n progress = int((idx / total) * 100)\n callback(progress, \"synthesizing\")\n\n # 生成音频文件名\n audio_filename = self._generate_filename(segment.text, idx)\n audio_path = output_path / audio_filename\n\n # 合成单条语音(带缓存)\n self._synthesize_segment(segment, str(audio_path))\n\n except Exception as e:\n logger.error(\n f\"TTS 失败 [{idx+1}/{total}]: {segment.text[:50]}... - {str(e)}\"\n )\n # 失败时保持 segment,但不设置 audio_path\n\n callback(*TTSStatus.COMPLETED.callback_tuple())\n success_count = sum(1 for seg in tts_data.segments if seg.audio_path)\n logger.info(f\"批量 TTS 完成: 成功 {success_count}/{total}\")\n return tts_data\n\n def _synthesize_segment(self, segment: TTSDataSeg, output_path: str) -> None:\n \"\"\"合成单个片段的语音(带缓存)\n\n Args:\n segment: TTS 数据段(会被修改,填充 audio_path 等)\n output_path: 输出音频路径\n \"\"\"\n # 生成缓存键(考虑声音克隆)\n cache_key = self._generate_cache_key_for_segment(segment)\n\n # 检查缓存\n if self.config.use_cache and is_cache_enabled():\n cached_audio_data = cast(Optional[bytes], self.cache.get(cache_key))\n\n if cached_audio_data:\n logger.info(f\"使用缓存: {segment.text[:50]}...\")\n # 将缓存的二进制数据写入文件\n Path(output_path).parent.mkdir(parents=True, exist_ok=True)\n with open(output_path, \"wb\") as f:\n f.write(cached_audio_data)\n\n # 更新 segment\n segment.audio_path = output_path\n # TODO: 从缓存元数据中获取 audio_duration\n return\n\n # 调用子类实现的核心方法\n self._synthesize(segment, output_path)\n\n # 保存二进制数据到缓存\n if self.config.use_cache and is_cache_enabled():\n try:\n with open(output_path, \"rb\") as f:\n audio_data = f.read()\n self.cache.set(cache_key, audio_data, expire=self.config.cache_ttl)\n except Exception as e:\n logger.warning(f\"缓存保存失败: {str(e)}\")\n\n @abstractmethod\n def _synthesize(self, segment: TTSDataSeg, output_path: str) -> None:\n \"\"\"合成语音的核心实现(子类必须实现)\n\n Args:\n segment: TTS 数据段(需要填充 audio_path, voice, clone_voice_uri 等字段)\n output_path: 输出音频路径\n \"\"\"\n pass\n\n def _generate_cache_key_for_segment(self, segment: TTSDataSeg) -> str:\n \"\"\"为 segment 生成缓存键(考虑声音克隆)\"\"\"\n content_parts = [\n segment.text,\n self.config.model,\n str(self.config.speed),\n str(self.config.gain),\n ]\n\n # 音色信息\n if segment.clone_audio_path and segment.clone_audio_text:\n # 声音克隆:使用参考音频的哈希\n try:\n with open(segment.clone_audio_path, \"rb\") as f:\n audio_hash = hashlib.md5(f.read()).hexdigest()[:12]\n content_parts.append(f\"clone_{audio_hash}\")\n except Exception:\n content_parts.append(f\"clone_{segment.clone_audio_path}\")\n elif segment.voice:\n # 指定音色\n content_parts.append(f\"voice_{segment.voice}\")\n elif self.config.voice:\n # 默认音色\n content_parts.append(f\"voice_{self.config.voice}\")\n\n content = \"_\".join(content_parts)\n return hashlib.md5(content.encode()).hexdigest()\n\n def _generate_filename(self, text: str, index: int) -> str:\n \"\"\"生成音频文件名\n\n Args:\n text: 文本内容\n index: 索引\n\n Returns:\n 文件名\n \"\"\"\n # 使用索引和文本哈希生成文件名\n text_hash = hashlib.md5(text.encode()).hexdigest()[:8]\n ext = self.config.response_format\n return f\"tts_{index:04d}_{text_hash}.{ext}\"\n" }, { "path": "app/core/tts/openai_fm.py", "content": "\"\"\"OpenAI.fm TTS 实现\n\nOpenAI.fm 是一个免费的 TTS 服务,提供多种音色和语音风格。\nAPI 文档: https://www.openai.fm/\n\"\"\"\n\nfrom urllib.parse import quote\n\nimport requests\n\nfrom app.core.tts.base import BaseTTS\nfrom app.core.tts.tts_data import TTSConfig, TTSDataSeg\nfrom app.core.utils.logger import setup_logger\n\nlogger = setup_logger(\"tts.openai_fm\")\n\n\nclass OpenAIFmTTS(BaseTTS):\n \"\"\"OpenAI.fm TTS API 实现\n\n 免费的云端 TTS 服务,支持多种音色和语音风格。\n \"\"\"\n\n # 预定义音色\n VOICES = {\n \"alloy\": \"alloy\",\n \"echo\": \"echo\",\n \"fable\": \"fable\",\n \"onyx\": \"onyx\",\n \"nova\": \"nova\",\n \"shimmer\": \"shimmer\",\n }\n\n # 预定义提示词模板\n PROMPT_TEMPLATES = {\n \"natural\": \"Natural and conversational voice with clear pronunciation.\",\n \"professional\": \"Professional and formal tone, suitable for business presentations.\",\n \"friendly\": \"Warm and friendly tone, like talking to a friend.\",\n \"storyteller\": \"Expressive and engaging, perfect for storytelling.\",\n \"news\": \"Clear and authoritative, like a news anchor.\",\n \"casual\": \"Relaxed and informal, everyday conversation style.\",\n }\n\n # API 端点(固定,不可配置)\n API_URL = \"https://www.openai.fm/api/generate\"\n\n def __init__(self, config: TTSConfig):\n \"\"\"初始化\n\n Args:\n config: TTS 配置\n - voice: 音色选择 (alloy, echo, fable, onyx, nova, shimmer)\n - 不需要 api_key 和 base_url\n \"\"\"\n super().__init__(config)\n\n # 默认音色\n if not config.voice:\n config.voice = \"fable\"\n\n def _synthesize(self, segment: TTSDataSeg, output_path: str) -> None:\n \"\"\"合成语音的核心实现\n\n Args:\n segment: TTS 数据段\n output_path: 输出音频路径\n \"\"\"\n # 构建提示词\n prompt = self._build_prompt()\n\n # 音色选择\n voice_to_use = segment.voice or self.config.voice or \"fable\"\n\n # 构建请求参数\n params = {\n \"input\": segment.text,\n \"prompt\": prompt,\n \"voice\": voice_to_use,\n }\n\n logger.info(\n f\"调用 OpenAI.fm TTS API: {segment.text[:50]}... (voice={voice_to_use})\"\n )\n\n # 发送请求(使用固定 API URL)\n response = requests.get(\n self.API_URL,\n params=params,\n timeout=self.config.timeout,\n )\n response.raise_for_status()\n\n # 保存音频文件\n with open(output_path, \"wb\") as f:\n f.write(response.content)\n\n logger.info(f\"TTS 成功: {output_path}\")\n\n # 更新 segment\n segment.audio_path = output_path\n segment.voice = voice_to_use\n\n def _build_prompt(self) -> str:\n \"\"\"构建提示词\n\n Returns:\n 提示词字符串\n \"\"\"\n # 如果配置中有自定义提示词,直接使用\n if self.config.custom_prompt:\n return self.config.custom_prompt\n\n # 使用默认提示词\n return self.PROMPT_TEMPLATES[\"natural\"]\n\n @staticmethod\n def get_available_voices():\n \"\"\"获取可用音色列表\n\n Returns:\n 音色列表\n \"\"\"\n return list(OpenAIFmTTS.VOICES.keys())\n\n @staticmethod\n def get_prompt_templates():\n \"\"\"获取预定义提示词模板\n\n Returns:\n 提示词模板字典\n \"\"\"\n return OpenAIFmTTS.PROMPT_TEMPLATES.copy()\n" }, { "path": "app/core/tts/openai_tts.py", "content": "\"\"\"OpenAI TTS 实现(支持 OpenAI 兼容接口)\"\"\"\n\nfrom openai import OpenAI\n\nfrom app.core.tts.base import BaseTTS\nfrom app.core.tts.tts_data import TTSConfig, TTSDataSeg\nfrom app.core.utils.logger import setup_logger\n\nlogger = setup_logger(\"tts.openai\")\n\n\nclass OpenAITTS(BaseTTS):\n \"\"\"OpenAI TTS API 实现\n\n 支持 OpenAI 及其兼容接口(如 SiliconFlow)\n \"\"\"\n\n def __init__(self, config: TTSConfig):\n \"\"\"初始化\n\n Args:\n config: TTS 配置\n \"\"\"\n super().__init__(config)\n if not config.api_key:\n raise ValueError(\"API key is required for OpenAI TTS\")\n\n # 初始化 OpenAI 客户端\n self.client = OpenAI(\n api_key=config.api_key,\n base_url=config.base_url,\n )\n\n def _synthesize(self, segment: TTSDataSeg, output_path: str) -> None:\n \"\"\"合成语音的核心实现\n\n Args:\n segment: TTS 数据段\n output_path: 输出音频路径\n \"\"\"\n logger.info(f\"调用 OpenAI TTS API: {segment.text[:50]}...\")\n\n # 音色选择\n voice_to_use = segment.voice or self.config.voice or \"alloy\"\n\n # 调用 OpenAI TTS API(流式响应)\n with self.client.audio.speech.with_streaming_response.create(\n model=self.config.model,\n voice=voice_to_use,\n input=segment.text,\n response_format=self.config.response_format,\n speed=self.config.speed,\n ) as response:\n response.stream_to_file(output_path)\n\n logger.info(f\"TTS 成功: {output_path}\")\n\n # 更新 segment\n segment.audio_path = output_path\n segment.voice = voice_to_use\n" }, { "path": "app/core/tts/siliconflow.py", "content": "\"\"\"SiliconFlow TTS 实现\"\"\"\n\nimport hashlib\nfrom pathlib import Path\n\nimport requests\n\nfrom app.core.tts.base import BaseTTS\nfrom app.core.tts.tts_data import TTSConfig, TTSDataSeg\nfrom app.core.utils.cache import get_tts_cache\nfrom app.core.utils.logger import setup_logger\n\nlogger = setup_logger(\"tts.siliconflow\")\n\n\nclass VoiceCloneManager:\n \"\"\"声音克隆管理器 - 处理音频上传和 URI 缓存\"\"\"\n\n def __init__(self, api_key: str, base_url: str):\n \"\"\"初始化\n\n Args:\n api_key: API 密钥\n base_url: API 基础 URL\n \"\"\"\n self.api_key = api_key\n self.base_url = base_url\n self.cache = get_tts_cache()\n\n def upload_voice(\n self,\n audio_path: str,\n text: str,\n model: str = \"FunAudioLLM/CosyVoice2-0.5B\",\n ) -> str:\n \"\"\"上传音频并获取声音克隆 URI\n\n Args:\n audio_path: 音频文件路径\n text: 对应文本内容\n model: 模型名称\n\n Returns:\n voice_uri: 形如 speech:your-voice-name:xxx:xxx 的 URI\n\n Raises:\n FileNotFoundError: 音频文件不存在\n ValueError: API 返回错误\n \"\"\"\n # 检查文件是否存在\n audio_file = Path(audio_path)\n if not audio_file.exists():\n raise FileNotFoundError(f\"音频文件不存在: {audio_path}\")\n\n # 检查缓存(避免重复上传)\n cache_key = self._generate_cache_key(audio_path, text, model)\n cached_uri = self.cache.get(cache_key)\n if cached_uri:\n logger.info(f\"使用缓存的声音克隆 URI: {cached_uri}\")\n return cached_uri\n\n logger.info(f\"上传声音克隆音频: {audio_path}, 对应文本: {text[:50]}...\")\n\n custom_name = \"video_captioner\"\n url = f\"{self.base_url}/uploads/audio/voice\"\n headers = {\"Authorization\": f\"Bearer {self.api_key}\"}\n\n with open(audio_path, \"rb\") as f:\n files = {\"file\": (audio_file.name, f, \"audio/mpeg\")}\n data = {\"model\": model, \"customName\": custom_name, \"text\": text}\n\n try:\n response = requests.post(\n url, headers=headers, files=files, data=data, timeout=60\n )\n response.raise_for_status()\n except requests.HTTPError as e:\n if e.response.status_code == 400:\n raise ValueError(f\"音频上传失败(参数错误): {e.response.text}\")\n elif e.response.status_code == 401:\n raise ValueError(\"API Key 无效\")\n else:\n raise ValueError(f\"音频上传失败: {e.response.text}\")\n\n result = response.json()\n voice_uri = result.get(\"uri\")\n if not voice_uri:\n raise ValueError(f\"API 未返回 URI: {result}\")\n\n logger.info(f\"获得声音克隆 URI: {voice_uri}\")\n\n # 缓存 URI\n self.cache.set(cache_key, voice_uri, expire=86400 * 2)\n\n return voice_uri\n\n def _generate_cache_key(self, audio_path: str, text: str, model: str) -> str:\n \"\"\"生成缓存键(基于文件内容哈希)\"\"\"\n with open(audio_path, \"rb\") as f:\n file_hash = hashlib.md5(f.read()).hexdigest()\n\n content = f\"voice_clone_{file_hash}_{text}_{model}\"\n return hashlib.md5(content.encode()).hexdigest()\n\n\nclass SiliconFlowTTS(BaseTTS):\n \"\"\"SiliconFlow TTS API 实现\n\n 使用硅基流动的云端 TTS 服务\n \"\"\"\n\n def __init__(self, config: TTSConfig):\n \"\"\"初始化\n\n Args:\n config: TTS 配置\n \"\"\"\n super().__init__(config)\n if not config.api_key:\n raise ValueError(\"API key is required for SiliconFlow TTS\")\n\n # 初始化声音克隆管理器\n self.voice_manager = VoiceCloneManager(config.api_key, config.base_url)\n\n def _synthesize(self, segment: TTSDataSeg, output_path: str) -> None:\n \"\"\"合成语音的核心实现\n\n Args:\n segment: TTS 数据段(需要填充 audio_path, voice, clone_voice_uri)\n output_path: 输出音频路径\n \"\"\"\n url = f\"{self.config.base_url}/audio/speech\"\n headers = {\n \"Authorization\": f\"Bearer {self.config.api_key}\",\n \"Content-Type\": \"application/json\",\n }\n\n # 构建请求数据\n payload = {\n \"model\": self.config.model,\n \"input\": segment.text,\n \"response_format\": self.config.response_format,\n \"sample_rate\": self.config.sample_rate,\n \"speed\": self.config.speed,\n \"gain\": self.config.gain,\n }\n\n # 音色选择(优先级:声音克隆 > segment指定 > 全局配置)\n voice_to_use = None\n\n if segment.clone_audio_path and segment.clone_audio_text:\n # 使用声音克隆\n logger.info(f\"上传声音克隆音频: {segment.clone_audio_path}\")\n voice_uri = self.voice_manager.upload_voice(\n audio_path=segment.clone_audio_path,\n text=segment.clone_audio_text,\n model=self.config.model,\n )\n voice_to_use = voice_uri\n segment.clone_voice_uri = voice_uri\n logger.info(f\"使用克隆音色: {voice_uri}\")\n\n elif segment.voice:\n # segment 指定了音色\n voice_to_use = segment.voice\n\n elif self.config.voice:\n # 使用全局配置的音色\n voice_to_use = self.config.voice\n\n if voice_to_use:\n payload[\"voice\"] = voice_to_use\n\n if self.config.stream:\n payload[\"stream\"] = self.config.stream\n\n # 发送请求\n response = requests.post(\n url,\n headers=headers,\n json=payload,\n timeout=self.config.timeout,\n )\n response.raise_for_status()\n\n # 保存音频文件\n with open(output_path, \"wb\") as f:\n f.write(response.content)\n\n logger.info(f\"TTS 成功: {output_path}\")\n\n # 更新 segment\n segment.audio_path = output_path\n segment.voice = voice_to_use\n # TODO: 获取实际音频时长\n # segment.audio_duration = get_audio_duration(output_path)\n" }, { "path": "app/core/tts/status.py", "content": "from enum import Enum\nfrom typing import Tuple\n\n\nclass TTSStatus(Enum):\n \"\"\"TTS processing status with progress percentage.\n\n Each status contains a tuple of (message, progress_percentage).\n Progress ranges from 0 to 100.\n \"\"\"\n\n # Initialization\n INITIALIZING = (\"initializing\", 0)\n PREPARING = (\"preparing\", 10)\n\n # Synthesis phase (20-90%)\n SYNTHESIZING = (\"synthesizing\", 30)\n PROCESSING = (\"processing\", 50)\n SAVING = (\"saving\", 70)\n\n # Completion phase (90-100%)\n FINALIZING = (\"finalizing\", 90)\n COMPLETED = (\"completed\", 100)\n\n @property\n def message(self) -> str:\n \"\"\"Get the status message.\"\"\"\n return self.value[0]\n\n @property\n def progress(self) -> int:\n \"\"\"Get the progress percentage (0-100).\"\"\"\n return self.value[1]\n\n def with_progress(self, progress: int) -> Tuple[int, str]:\n \"\"\"Create a callback tuple with custom progress.\n\n Args:\n progress: Progress percentage (0-100)\n\n Returns:\n Tuple of (progress, message) suitable for callback functions\n \"\"\"\n return (progress, self.message)\n\n def callback_tuple(self) -> Tuple[int, str]:\n \"\"\"Get the callback tuple (progress, message).\"\"\"\n return (self.progress, self.message)\n" }, { "path": "app/core/tts/tts_data.py", "content": "\"\"\"TTS 数据结构定义\"\"\"\n\nfrom dataclasses import dataclass\nfrom typing import List, Literal, Optional\n\n\n@dataclass\nclass TTSConfig:\n \"\"\"TTS 配置\"\"\"\n\n # 基础配置\n model: str\n api_key: str\n base_url: str\n\n # 音频参数\n voice: Optional[str] = None # 默认音色选择\n custom_prompt: Optional[str] = None # 自定义提示词(用于 OpenAI.fm 等)\n response_format: Literal[\"mp3\", \"opus\", \"aac\", \"flac\", \"wav\", \"pcm\"] = \"mp3\"\n sample_rate: int = 32000 # 采样率\n speed: float = 1.0 # 语速 0.25-4.0\n gain: int = 0 # 音量增益 -10 到 10\n\n # 处理参数\n stream: bool = False # 是否流式传输\n cache_ttl: int = 86400 * 2 # 缓存过期时间(秒),默认2天\n timeout: int = 60 # 超时时间(秒)\n use_cache: bool = True # 是否使用缓存\n\n\n@dataclass\nclass TTSDataSeg:\n \"\"\"TTS 数据段 - 单条文本转音频的片段\"\"\"\n\n text: str # 要合成的文本\n start_time: float = 0.0 # 开始时间(秒)\n end_time: float = 0.0 # 结束时间(秒)\n audio_path: str = \"\" # 生成的音频文件路径\n audio_duration: float = 0.0 # 实际音频时长(秒)\n voice: Optional[str] = None # 使用的音色\n\n # 声音克隆相关\n clone_audio_path: Optional[str] = None # 参考音频文件路径\n clone_audio_text: Optional[str] = None # 参考音频对应的文本\n clone_voice_uri: Optional[str] = None # 上传后获得的 URI\n\n def __str__(self) -> str:\n return f\"TTSDataSeg(text={self.text[:20]}..., audio_path={self.audio_path})\"\n\n\nclass TTSData:\n \"\"\"TTS 数据 - 包含多个 TTS 片段的容器(参考 ASRData 设计)\"\"\"\n\n def __init__(self, segments: Optional[List[TTSDataSeg]] = None):\n \"\"\"初始化 TTS 数据\n\n Args:\n segments: TTS 数据段列表\n \"\"\"\n if segments is None:\n segments = []\n # 过滤空文本,按时间排序\n filtered_segments = [seg for seg in segments if seg.text and seg.text.strip()]\n filtered_segments.sort(key=lambda x: x.start_time)\n self.segments = filtered_segments\n\n def __iter__(self):\n \"\"\"迭代器\"\"\"\n return iter(self.segments)\n\n def __len__(self) -> int:\n \"\"\"返回段落数量\"\"\"\n return len(self.segments)\n\n @classmethod\n def from_texts(\n cls,\n texts: List[str],\n clone_audio_path: Optional[str] = None,\n clone_audio_text: Optional[str] = None,\n ) -> \"TTSData\":\n \"\"\"从文本列表创建 TTSData\n\n Args:\n texts: 文本列表\n clone_audio_path: 统一的参考音频路径(可选)\n clone_audio_text: 统一的参考音频文本(可选)\n\n Returns:\n TTSData 实例\n \"\"\"\n segments = [\n TTSDataSeg(\n text=text,\n clone_audio_path=clone_audio_path,\n clone_audio_text=clone_audio_text,\n )\n for text in texts\n ]\n return cls(segments)\n" }, { "path": "app/core/utils/__init__.py", "content": "" }, { "path": "app/core/utils/cache.py", "content": "\"\"\"Disk cache utility for API responses and computation results.\n\nThis module provides a simple interface for caching using diskcache.\nCan be used by translation, ASR, and other modules that need caching.\n\"\"\"\n\nimport functools\nimport hashlib\nimport json\nfrom dataclasses import asdict, is_dataclass\nfrom typing import Any\n\nfrom diskcache import Cache\n\nfrom app.config import CACHE_PATH\n\n# Global cache switch\n_cache_enabled = True\n\n\ndef enable_cache() -> None:\n \"\"\"Enable caching globally.\"\"\"\n global _cache_enabled\n _cache_enabled = True\n\n\ndef disable_cache() -> None:\n \"\"\"Disable caching globally.\"\"\"\n global _cache_enabled\n _cache_enabled = False\n\n\ndef is_cache_enabled() -> bool:\n \"\"\"Check if caching is enabled.\"\"\"\n return _cache_enabled\n\n\n# Predefined cache instances for common use cases\n_llm_cache = Cache(str(CACHE_PATH / \"llm_translation\"))\n_asr_cache = Cache(str(CACHE_PATH / \"asr_results\"), tag_index=True)\n_tts_cache = Cache(str(CACHE_PATH / \"tts_audio\"))\n_translate_cache = Cache(str(CACHE_PATH / \"translate_results\"))\n_version_state_cache = Cache(str(CACHE_PATH / \"version_state\"))\n\n\ndef get_llm_cache() -> Cache:\n \"\"\"Get LLM translation cache instance.\"\"\"\n return _llm_cache\n\n\ndef get_asr_cache() -> Cache:\n \"\"\"Get ASR results cache instance.\"\"\"\n return _asr_cache\n\n\ndef get_translate_cache() -> Cache:\n \"\"\"Get translate cache instance.\"\"\"\n return _translate_cache\n\n\ndef get_tts_cache() -> Cache:\n \"\"\"Get TTS audio cache instance.\"\"\"\n return _tts_cache\n\n\ndef get_version_state_cache() -> Cache:\n \"\"\"Get version check state cache instance.\"\"\"\n return _version_state_cache\n\n\ndef memoize(cache_instance: Cache, **kwargs):\n \"\"\"Decorator to cache function results with global switch support.\n\n This is a thin wrapper around diskcache.Cache.memoize() that respects\n the global cache enable/disable setting.\n\n Args:\n cache_instance: Cache instance to use (from get_llm_cache(), etc.)\n **kwargs: Arguments passed to cache.memoize() (expire, typed, etc.)\n\n Returns:\n Decorated function\n\n Examples:\n @memoize(get_llm_cache(), expire=3600, typed=True)\n def call_api(prompt: str):\n response = client.chat.completions.create(...)\n if not response.choices:\n raise ValueError(\"Invalid response\") # Exceptions are not cached\n return response\n \"\"\"\n\n def decorator(func):\n memoized_func = cache_instance.memoize(**kwargs)(func)\n\n @functools.wraps(func)\n def wrapper(*args, **kw):\n if _cache_enabled:\n return memoized_func(*args, **kw)\n return func(*args, **kw)\n\n return wrapper\n\n return decorator\n\n\ndef generate_cache_key(data: Any) -> str:\n \"\"\"Generate cache key from data (supports dataclasses, dicts, lists).\n\n Args:\n data: Data to generate key from\n\n Returns:\n SHA256 hash of the data\n \"\"\"\n\n def _serialize(obj: Any) -> Any:\n \"\"\"Recursively serialize object to JSON-serializable format\"\"\"\n if is_dataclass(obj) and not isinstance(obj, type):\n return asdict(obj) # type: ignore\n elif isinstance(obj, list):\n return [_serialize(item) for item in obj]\n elif isinstance(obj, dict):\n return {k: _serialize(v) for k, v in obj.items()}\n else:\n return obj\n\n serialized_data = _serialize(data)\n data_str = json.dumps(serialized_data, ensure_ascii=False, sort_keys=True)\n return hashlib.sha256(data_str.encode()).hexdigest()\n" }, { "path": "app/core/utils/logger.py", "content": "import logging\nimport logging.handlers\nfrom pathlib import Path\n\nfrom ...config import LOG_LEVEL, LOG_PATH\n\n\ndef setup_logger(\n name: str,\n level: int = LOG_LEVEL,\n info_fmt: str = \"%(message)s\", # INFO级别使用简化格式\n default_fmt: str = \"%(asctime)s - %(name)s - %(levelname)s - %(message)s\", # 其他级别使用详细格式\n datefmt: str = \"%Y-%m-%d %H:%M:%S\",\n log_file: str = str(LOG_PATH / \"app.log\"),\n console_output: bool = True,\n) -> logging.Logger:\n \"\"\"\n 创建并配置一个日志记录器,INFO级别使用简化格式。\n\n 参数:\n - name: 日志记录器的名称\n - level: 日志级别\n - info_fmt: INFO级别的日志格式字符串\n - default_fmt: 其他级别的日志格式字符串\n - datefmt: 时间格式字符串\n - log_file: 日志文件路径\n \"\"\"\n\n logger = logging.getLogger(name)\n logger.setLevel(level)\n\n if not logger.handlers:\n # 创建级别特定的格式化器\n class LevelSpecificFormatter(logging.Formatter):\n def format(self, record):\n if record.levelno == logging.INFO:\n self._style._fmt = info_fmt\n else:\n self._style._fmt = default_fmt\n return super().format(record)\n\n level_formatter = LevelSpecificFormatter(default_fmt, datefmt=datefmt)\n\n # 只在console_output为True时添加控制台处理器\n if console_output:\n console_handler = logging.StreamHandler()\n console_handler.setLevel(level)\n console_handler.setFormatter(level_formatter)\n logger.addHandler(console_handler)\n\n # 文件处理器\n if log_file:\n Path(log_file).parent.mkdir(parents=True, exist_ok=True)\n file_handler = logging.handlers.RotatingFileHandler(\n log_file, maxBytes=10 * 1024 * 1024, backupCount=5, encoding=\"utf-8\"\n )\n file_handler.setLevel(level)\n file_handler.setFormatter(level_formatter)\n logger.addHandler(file_handler)\n\n # 设置特定库的日志级别为ERROR以减少日志噪音\n error_loggers = [\n \"urllib3\",\n \"requests\",\n \"openai\",\n \"httpx\",\n \"httpcore\",\n \"ssl\",\n \"certifi\",\n ]\n for lib in error_loggers:\n logging.getLogger(lib).setLevel(logging.ERROR)\n\n return logger\n" }, { "path": "app/core/utils/platform_utils.py", "content": "\"\"\"\n跨平台工具函数\n\"\"\"\n\nimport logging\nimport os\nimport platform\nimport subprocess\n\nfrom app.core.entities import TranscribeModelEnum\n\nlogger = logging.getLogger(__name__)\n\n\ndef open_folder(path):\n \"\"\"\n 跨平台打开文件夹\n\n Args:\n path: 要打开的文件夹路径\n \"\"\"\n system = platform.system()\n\n if system == \"Windows\":\n if hasattr(os, \"startfile\"):\n getattr(os, \"startfile\")(path)\n else:\n subprocess.Popen([\"explorer\", path])\n elif system == \"Darwin\": # macOS\n subprocess.Popen([\"open\", path])\n elif system == \"Linux\":\n subprocess.Popen([\"xdg-open\", path])\n else:\n # 其他系统,尝试使用默认方式\n try:\n subprocess.Popen([\"xdg-open\", path])\n except (OSError, subprocess.SubprocessError):\n logger.warning(f\"无法在当前系统打开文件夹: {path}\")\n\n\ndef open_file(path):\n \"\"\"\n 跨平台打开文件\n\n Args:\n path: 要打开的文件路径\n \"\"\"\n system = platform.system()\n\n if system == \"Windows\":\n if hasattr(os, \"startfile\"):\n getattr(os, \"startfile\")(path)\n else:\n subprocess.Popen([\"start\", path], shell=True)\n elif system == \"Darwin\": # macOS\n subprocess.Popen([\"open\", path])\n elif system == \"Linux\":\n subprocess.Popen([\"xdg-open\", path])\n else:\n # 其他系统,尝试使用默认方式\n try:\n subprocess.Popen([\"xdg-open\", path])\n except (OSError, subprocess.SubprocessError):\n logger.warning(f\"无法在当前系统打开文件: {path}\")\n\n\ndef get_subprocess_kwargs():\n \"\"\"\n 获取跨平台的subprocess参数\n\n Returns:\n dict: subprocess参数字典\n \"\"\"\n kwargs = {}\n\n # 仅在Windows上添加CREATE_NO_WINDOW标志\n if platform.system() == \"Windows\":\n if hasattr(subprocess, \"CREATE_NO_WINDOW\"):\n kwargs[\"creationflags\"] = getattr(subprocess, \"CREATE_NO_WINDOW\", 0)\n\n return kwargs\n\n\ndef is_macos() -> bool:\n \"\"\"\n 检测是否为 macOS 系统\n\n Returns:\n bool: 如果是 macOS 返回 True,否则返回 False\n \"\"\"\n return platform.system() == \"Darwin\"\n\n\ndef is_windows() -> bool:\n \"\"\"\n 检测是否为 Windows 系统\n\n Returns:\n bool: 如果是 Windows 返回 True,否则返回 False\n \"\"\"\n return platform.system() == \"Windows\"\n\n\ndef is_linux() -> bool:\n \"\"\"\n 检测是否为 Linux 系统\n\n Returns:\n bool: 如果是 Linux 返回 True,否则返回 False\n \"\"\"\n return platform.system() == \"Linux\"\n\n\ndef get_available_transcribe_models() -> list[TranscribeModelEnum]:\n \"\"\"\n 获取当前平台可用的转录模型列表\n\n macOS 上不支持 FasterWhisper,因为它依赖 CUDA/CuDNN\n\n Returns:\n list[TranscribeModelEnum]: 可用的转录模型列表\n \"\"\"\n all_models = list(TranscribeModelEnum)\n\n # macOS 上过滤掉 FasterWhisper\n if is_macos():\n return [\n model for model in all_models if model != TranscribeModelEnum.FASTER_WHISPER\n ]\n\n return all_models\n\n\ndef is_model_available(model: TranscribeModelEnum) -> bool:\n \"\"\"\n 检查指定模型是否在当前平台可用\n\n Args:\n model: 要检查的转录模型\n\n Returns:\n bool: 如果模型可用返回 True,否则返回 False\n \"\"\"\n # FasterWhisper 在 macOS 上不可用\n if is_macos() and model == TranscribeModelEnum.FASTER_WHISPER:\n return False\n\n return True\n" }, { "path": "app/core/utils/subprocess_helper.py", "content": "\"\"\"子进程输出流处理工具模块\"\"\"\n\nimport queue\nimport subprocess\nimport threading\nfrom typing import Callable, Optional, Tuple\n\nfrom ..utils.logger import setup_logger\n\nlogger = setup_logger(\"subprocess_helper\")\n\n\nclass StreamReader:\n \"\"\"通用的子进程输出流读取器\"\"\"\n\n def __init__(self, process: subprocess.Popen):\n \"\"\"\n 初始化流读取器\n\n Args:\n process: 子进程对象\n \"\"\"\n self.process = process\n self.output_queue = queue.Queue()\n self.threads = []\n\n def start_reading(self) -> None:\n \"\"\"启动异步读取stdout和stderr\"\"\"\n # 启动stdout读取线程\n if self.process.stdout:\n stdout_thread = threading.Thread(\n target=self._read_stream,\n args=(self.process.stdout, \"stdout\"),\n daemon=True,\n )\n stdout_thread.start()\n self.threads.append(stdout_thread)\n\n # 启动stderr读取线程\n if self.process.stderr:\n stderr_thread = threading.Thread(\n target=self._read_stream,\n args=(self.process.stderr, \"stderr\"),\n daemon=True,\n )\n stderr_thread.start()\n self.threads.append(stderr_thread)\n\n def _read_stream(self, stream, stream_name: str) -> None:\n \"\"\"读取流并放入队列\"\"\"\n try:\n for line in iter(stream.readline, \"\"):\n if line:\n self.output_queue.put((stream_name, line))\n except Exception as e:\n logger.debug(f\"读取 {stream_name} 结束: {e}\")\n finally:\n stream.close()\n\n def get_output(self, timeout: float = 0.1) -> Optional[Tuple[str, str]]:\n \"\"\"\n 获取输出\n\n Args:\n timeout: 等待超时时间\n\n Returns:\n (stream_name, line) 或 None\n \"\"\"\n try:\n return self.output_queue.get(timeout=timeout)\n except queue.Empty:\n return None\n\n def get_remaining_output(self) -> list:\n \"\"\"获取队列中剩余的所有输出\"\"\"\n output = []\n while not self.output_queue.empty():\n try:\n output.append(self.output_queue.get_nowait())\n except queue.Empty:\n break\n return output\n\n def is_empty(self) -> bool:\n \"\"\"检查队列是否为空\"\"\"\n return self.output_queue.empty()\n\n\ndef run_process_with_stream_reader(\n cmd: list,\n stdout_handler: Optional[Callable[[str], None]] = None,\n stderr_handler: Optional[Callable[[str], None]] = None,\n **popen_kwargs,\n) -> subprocess.Popen:\n \"\"\"\n 运行子进程并使用StreamReader处理输出\n\n Args:\n cmd: 命令列表\n stdout_handler: stdout行处理函数\n stderr_handler: stderr行处理函数\n **popen_kwargs: 传递给subprocess.Popen的额外参数\n\n Returns:\n 子进程对象\n\n Example:\n ```python\n def handle_stdout(line):\n print(f\"[stdout] {line.strip()}\")\n\n def handle_stderr(line):\n print(f\"[stderr] {line.strip()}\")\n\n process = run_process_with_stream_reader(\n [\"ls\", \"-la\"],\n stdout_handler=handle_stdout,\n stderr_handler=handle_stderr\n )\n process.wait()\n ```\n \"\"\"\n # 设置默认参数\n default_kwargs = {\n \"stdout\": subprocess.PIPE,\n \"stderr\": subprocess.PIPE,\n \"text\": True,\n \"encoding\": \"utf-8\",\n \"bufsize\": 1, # 行缓冲\n }\n default_kwargs.update(popen_kwargs)\n\n # 启动进程\n process = subprocess.Popen(cmd, **default_kwargs)\n\n # 创建流读取器\n reader = StreamReader(process)\n reader.start_reading()\n\n # 处理输出的线程\n def process_output():\n while True:\n # 检查进程状态\n if process.poll() is not None:\n # 进程已结束,读取剩余输出\n for stream_name, line in reader.get_remaining_output():\n if stream_name == \"stdout\" and stdout_handler:\n stdout_handler(line)\n elif stream_name == \"stderr\" and stderr_handler:\n stderr_handler(line)\n break\n\n # 读取输出\n output = reader.get_output()\n if output:\n stream_name, line = output\n if stream_name == \"stdout\" and stdout_handler:\n stdout_handler(line)\n elif stream_name == \"stderr\" and stderr_handler:\n stderr_handler(line)\n\n # 如果提供了处理函数,启动处理线程\n if stdout_handler or stderr_handler:\n handler_thread = threading.Thread(target=process_output, daemon=True)\n handler_thread.start()\n\n return process\n" }, { "path": "app/core/utils/text_utils.py", "content": "\"\"\"多语言文本处理工具\n\n统一的文本分析工具,支持CJK和世界多语言字符统计。\n\"\"\"\n\nimport re\n\n# ==================== Unicode 字符范围定义 ====================\n\n# 按字符计数的语言(不使用空格分词)\n# 包括:CJK(中日韩)+ 东南亚/南亚语言(泰文/缅甸文/高棉文/印地语等)\n_NO_SPACE_LANGUAGES = r\"[\\u4e00-\\u9fff\\u3040-\\u309f\\u30a0-\\u30ff\\uac00-\\ud7af\\u0e00-\\u0eff\\u1000-\\u109f\\u1780-\\u17ff\\u0900-\\u0dff]\"\n\n# 需要空格分隔的语言(按单词计数)\n# 包括:拉丁字母、西里尔字母、希腊字母、阿拉伯字母、希伯来字母、泰文\n_SPACE_SEPARATED_LANGUAGES = (\n r\"^[a-zA-Z0-9\\'\\u0400-\\u04ff\\u0370-\\u03ff\\u0600-\\u06ff\\u0590-\\u05ff\\u0e00-\\u0e7f]+$\"\n)\n\n\ndef is_pure_punctuation(text: str) -> bool:\n \"\"\"检查文本是否仅包含标点符号\"\"\"\n return not re.search(r\"\\w\", text, re.UNICODE)\n\n\ndef is_mainly_cjk(text: str, threshold: float = 0.5) -> bool:\n \"\"\"判断是否主要为不使用空格的亚洲语言文本\n\n 包括:中日韩、泰文、缅甸文、高棉文、印地语等\n\n Args:\n text: 待检测的文本\n threshold: 阈值比例(默认0.5,即超过50%)\n\n Returns:\n True表示主要为不使用空格的亚洲语言,False表示其他\n \"\"\"\n if not text:\n return False\n\n no_space_count = len(re.findall(_NO_SPACE_LANGUAGES, text))\n total_chars = len(\"\".join(text.split()))\n\n return no_space_count / total_chars > threshold if total_chars > 0 else False\n\n\ndef is_space_separated_language(text: str) -> bool:\n \"\"\"判断文本是否为需要空格分隔的语言\n\n 需要空格的语言包括:\n - 拉丁字母语言:英语、法语、德语、西班牙语等\n - 西里尔字母语言:俄语、乌克兰语、保加利亚语等\n - 希腊字母语言:希腊语\n - 阿拉伯字母语言:阿拉伯语、波斯语、乌尔都语等\n - 希伯来字母语言:希伯来语\n\n 不需要空格的语言(返回False):\n - 中文、日文、韩文(CJK)\n - 泰文、缅甸文、高棉文等\n\n Args:\n text: 待检测的文本\n\n Returns:\n True表示需要空格分隔,False表示不需要\n \"\"\"\n if not text:\n return False\n return bool(re.match(_SPACE_SEPARATED_LANGUAGES, text.strip()))\n\n\ndef count_words(text: str) -> int:\n \"\"\"统计文本字符/单词数\n\n 按字符计数的语言(不使用空格分词):\n - CJK (中文、日文、韩文)\n - 泰文、缅甸文、高棉文、印地语等\n\n 按单词计数的语言(使用空格分词):\n - 拉丁字母语言 (英语、法语、德语、西班牙语等)\n - 西里尔字母语言 (俄语、乌克兰语、保加利亚语等)\n - 希腊字母、阿拉伯字母、希伯来字母等\n\n 混合文本处理:\n - 按字符计数的语言统计字符数\n - 按单词计数的语言统计单词数\n - 返回总和\n\n Args:\n text: 待统计的文本\n\n Returns:\n 字符数 + 单词数\n \"\"\"\n if not text:\n return 0\n\n # 统计不使用空格的语言的字符数(CJK + 泰文/缅甸文等)\n char_count = len(re.findall(_NO_SPACE_LANGUAGES, text))\n\n # 移除不使用空格的字符后,统计使用空格的语言的单词数\n word_text = re.sub(_NO_SPACE_LANGUAGES, \" \", text)\n word_count = len(word_text.strip().split())\n\n return char_count + word_count\n" }, { "path": "app/core/utils/video_utils.py", "content": "import os\nimport re\nimport shutil\nimport subprocess\nimport tempfile\nfrom contextlib import contextmanager\nfrom pathlib import Path\nfrom typing import TYPE_CHECKING, Callable, Literal, Optional\n\nfrom ..entities import (\n AudioStreamInfo,\n SubtitleLayoutEnum,\n SubtitleRenderModeEnum,\n VideoInfo,\n)\nfrom ..subtitle.ass_renderer import render_ass_video\nfrom ..subtitle.ass_utils import auto_wrap_ass_file\nfrom ..subtitle.rounded_renderer import render_rounded_video\nfrom ..utils.logger import setup_logger\n\nif TYPE_CHECKING:\n from app.core.asr.asr_data import ASRData\n\n# FFmpeg preset 类型\nPresetType = Literal[\n \"ultrafast\",\n \"superfast\",\n \"veryfast\",\n \"faster\",\n \"fast\",\n \"medium\",\n \"slow\",\n \"slower\",\n \"veryslow\",\n]\n\nlogger = setup_logger(\"video_utils\")\n\n\n@contextmanager\ndef temporary_subtitle_file(subtitle_path: str):\n \"\"\"临时字幕文件上下文管理器\n\n 自动复制字幕文件到临时位置,使用后自动清理\n\n Args:\n subtitle_path: 原始字幕文件路径\n\n Yields:\n 临时字幕文件路径\n \"\"\"\n suffix = Path(subtitle_path).suffix.lower()\n temp_fd, temp_path = tempfile.mkstemp(\n suffix=suffix, prefix=\"VideoCaptioner_subtitle_\"\n )\n os.close(temp_fd)\n\n try:\n # 复制字幕到临时位置\n shutil.copy2(subtitle_path, temp_path)\n yield temp_path\n finally:\n # 自动清理临时文件\n Path(temp_path).unlink(missing_ok=True)\n\n\ndef video2audio(input_file: str, output: str = \"\", audio_track_index: int = 0) -> bool:\n \"\"\"使用 ffmpeg 将视频转换为音频\n\n Args:\n input_file: 输入视频文件路径\n output: 输出音频文件路径\n audio_track_index: 要提取的音轨索引,默认为 0(第一条音轨)\n\n Returns:\n 转换是否成功\n \"\"\"\n output_path = Path(output)\n output_path.parent.mkdir(parents=True, exist_ok=True)\n output = str(output_path)\n\n logger.info(f\"提取音轨索引 {audio_track_index}\")\n cmd = [\n \"ffmpeg\",\n \"-i\",\n input_file,\n \"-map\",\n f\"0:a:{audio_track_index}\",\n \"-vn\",\n \"-ac\",\n \"1\", # 单声道\n \"-ar\",\n \"16000\", # 采样率16kHz\n \"-y\",\n output,\n ]\n\n logger.info(f\"转换为音频执行命令: {' '.join(cmd)}\")\n\n try:\n result = subprocess.run(\n cmd,\n capture_output=True,\n check=True,\n encoding=\"utf-8\",\n errors=\"replace\",\n creationflags=(\n getattr(subprocess, \"CREATE_NO_WINDOW\", 0) if os.name == \"nt\" else 0\n ),\n )\n if result.returncode == 0 and Path(output).is_file():\n logger.info(\"音频转换成功\")\n return True\n else:\n logger.error(\"音频转换失败\")\n return False\n except subprocess.CalledProcessError as e:\n logger.error(\"== ffmpeg 执行失败 ==\")\n logger.error(f\"返回码: {e.returncode}\")\n logger.error(f\"命令: {' '.join(e.cmd)}\")\n if e.stdout:\n logger.error(f\"标准输出: {e.stdout}\")\n if e.stderr:\n logger.error(f\"标准错误: {e.stderr}\")\n return False\n except Exception as e:\n logger.exception(f\"音频转换出错: {str(e)}\")\n return False\n\n\ndef check_cuda_available() -> bool:\n \"\"\"检查CUDA是否可用\"\"\"\n logger.info(\"检查CUDA是否可用\")\n try:\n # 首先检查ffmpeg是否支持cuda\n result = subprocess.run(\n [\"ffmpeg\", \"-hwaccels\"],\n capture_output=True,\n text=True,\n creationflags=(\n getattr(subprocess, \"CREATE_NO_WINDOW\", 0) if os.name == \"nt\" else 0\n ),\n )\n if \"cuda\" not in result.stdout.lower():\n logger.info(\"CUDA不在支持的硬件加速器列表中\")\n return False\n\n # 进一步检查CUDA设备信息\n result = subprocess.run(\n [\"ffmpeg\", \"-hide_banner\", \"-init_hw_device\", \"cuda\"],\n capture_output=True,\n text=True,\n creationflags=(\n getattr(subprocess, \"CREATE_NO_WINDOW\", 0) if os.name == \"nt\" else 0\n ),\n )\n\n # 如果stderr中包含\"Cannot load cuda\" 或 \"Failed to load\"等错误信息,说明CUDA不可用\n if any(\n error in result.stderr.lower()\n for error in [\"cannot load cuda\", \"failed to load\", \"error\"]\n ):\n logger.info(\"CUDA设备初始化失败\")\n return False\n\n logger.info(\"CUDA可用\")\n return True\n\n except Exception as e:\n logger.exception(f\"检查CUDA出错: {str(e)}\")\n return False\n\n\ndef add_subtitles(\n input_file: str,\n subtitle_file: str,\n output: str,\n crf: int = 23,\n preset: Literal[\n \"ultrafast\",\n \"superfast\",\n \"veryfast\",\n \"faster\",\n \"fast\",\n \"medium\",\n \"slow\",\n \"slower\",\n \"veryslow\",\n ] = \"medium\",\n vcodec: str = \"libx264\",\n soft_subtitle: bool = False,\n progress_callback: Optional[Callable] = None,\n) -> None:\n assert Path(input_file).is_file(), \"输入文件不存在\"\n assert Path(subtitle_file).is_file(), \"字幕文件不存在\"\n\n # 使用临时文件上下文管理器处理字幕(自动清理)\n with temporary_subtitle_file(subtitle_file) as temp_subtitle_path:\n # 如果是 ASS 字幕,进行自动换行处理\n suffix = Path(subtitle_file).suffix.lower()\n processed_subtitle = temp_subtitle_path\n if suffix == \".ass\":\n processed_subtitle = auto_wrap_ass_file(temp_subtitle_path)\n\n # 如果是WebM格式,强制使用硬字幕\n if Path(output).suffix.lower() == \".webm\":\n soft_subtitle = False\n logger.info(\"WebM格式视频,强制使用硬字幕\")\n\n if soft_subtitle:\n # 添加软字幕\n cmd = [\n \"ffmpeg\",\n \"-i\",\n input_file,\n \"-i\",\n processed_subtitle,\n \"-c:v\",\n \"copy\",\n \"-c:a\",\n \"copy\",\n \"-c:s\",\n \"mov_text\",\n \"-y\",\n output,\n ]\n logger.info(f\"添加软字幕执行命令: {' '.join(cmd)}\")\n try:\n subprocess.run(\n cmd,\n capture_output=True,\n check=True,\n text=True,\n encoding=\"utf-8\",\n errors=\"replace\",\n creationflags=(\n getattr(subprocess, \"CREATE_NO_WINDOW\", 0)\n if os.name == \"nt\"\n else 0\n ),\n )\n logger.info(\"软字幕添加成功\")\n except subprocess.CalledProcessError as e:\n logger.error(\"== ffmpeg 添加软字幕失败 ==\")\n logger.error(f\"返回码: {e.returncode}\")\n logger.error(f\"命令: {' '.join(e.cmd)}\")\n if e.stdout:\n logger.error(f\"标准输出: {e.stdout}\")\n if e.stderr:\n logger.error(f\"标准错误: {e.stderr}\")\n raise\n else:\n # 使用硬字幕\n subtitle_path_escaped = (\n Path(processed_subtitle).as_posix().replace(\":\", r\"\\:\")\n )\n\n # 根据输出文件后缀决定vf参数\n if Path(output).suffix.lower() == \".ass\":\n vf = f\"ass='{subtitle_path_escaped}'\"\n else:\n vf = f\"subtitles='{subtitle_path_escaped}'\"\n\n if Path(output).suffix.lower() == \".webm\":\n vcodec = \"libvpx-vp9\"\n logger.info(\"WebM格式视频,使用libvpx-vp9编码器\")\n\n # 检查CUDA是否可用\n use_cuda = check_cuda_available()\n cmd = [\"ffmpeg\"]\n if use_cuda:\n logger.info(\"使用CUDA加速\")\n cmd.extend([\"-hwaccel\", \"cuda\"])\n cmd.extend(\n [\n \"-i\",\n input_file,\n \"-acodec\",\n \"copy\",\n \"-vcodec\",\n vcodec,\n \"-crf\",\n str(crf),\n \"-preset\",\n preset,\n \"-vf\",\n vf,\n \"-y\",\n output,\n ]\n )\n\n cmd_str = subprocess.list2cmdline(cmd)\n logger.info(f\"添加硬字幕执行命令: {cmd_str}\")\n\n process = None\n try:\n process = subprocess.Popen(\n cmd,\n stdout=subprocess.PIPE,\n stderr=subprocess.PIPE,\n text=True,\n encoding=\"utf-8\",\n errors=\"replace\",\n creationflags=(\n getattr(subprocess, \"CREATE_NO_WINDOW\", 0)\n if os.name == \"nt\"\n else 0\n ),\n )\n\n # 实时读取输出并调用回调函数\n total_duration = None\n current_time = 0\n\n while True:\n output_line = process.stderr.readline()\n if not output_line or (process.poll() is not None):\n break\n if not progress_callback:\n continue\n\n if total_duration is None:\n duration_match = re.search(\n r\"Duration: (\\d{2}):(\\d{2}):(\\d{2}\\.\\d{2})\", output_line\n )\n if duration_match:\n h, m, s = map(float, duration_match.groups())\n total_duration = h * 3600 + m * 60 + s\n logger.info(f\"视频总时长: {total_duration}秒\")\n\n # 解析当前处理时间\n time_match = re.search(\n r\"time=(\\d{2}):(\\d{2}):(\\d{2}\\.\\d{2})\", output_line\n )\n if time_match:\n h, m, s = map(float, time_match.groups())\n current_time = h * 3600 + m * 60 + s\n\n # 计算进度百分比\n if total_duration:\n progress = (current_time / total_duration) * 100\n progress_callback(f\"{round(progress)}\", \"正在合成\")\n\n if progress_callback:\n progress_callback(\"100\", \"合成完成\")\n\n # 检查进程的返回码\n return_code = process.wait()\n if return_code != 0:\n error_info = process.stderr.read()\n logger.error(\"== ffmpeg 添加硬字幕失败 ==\")\n logger.error(f\"返回码: {return_code}\")\n logger.error(f\"命令: {cmd_str}\")\n if error_info:\n logger.error(f\"错误信息: {error_info}\")\n raise Exception(f\"FFmpeg 返回码: {return_code}\")\n logger.info(\"视频合成完成\")\n\n except subprocess.SubprocessError as e:\n logger.error(\"== ffmpeg 进程执行异常 ==\")\n logger.error(f\"错误: {str(e)}\")\n if process and process.poll() is None:\n process.kill()\n raise\n except Exception as e:\n logger.error(f\"视频合成过程出错: {str(e)}\")\n if process and process.poll() is None:\n process.kill()\n raise\n\n\ndef get_video_info(\n file_path: str, thumbnail_path: Optional[str] = None\n) -> Optional[\"VideoInfo\"]:\n \"\"\"获取媒体文件信息(支持视频和音频文件)\n\n Args:\n file_path: 媒体文件路径(视频或音频)\n thumbnail_path: 缩略图保存路径(可选,仅对视频文件有效)\n\n Returns:\n VideoInfo 对象,失败返回 None\n 对于纯音频文件,视频相关字段(width/height/fps)将为 0\n \"\"\"\n try:\n # 执行 ffmpeg 获取视频信息\n result = subprocess.run(\n [\"ffmpeg\", \"-i\", file_path],\n capture_output=True,\n text=True,\n encoding=\"utf-8\",\n errors=\"replace\",\n creationflags=(\n getattr(subprocess, \"CREATE_NO_WINDOW\", 0) if os.name == \"nt\" else 0\n ),\n )\n info = result.stderr\n\n # 提取时长\n duration_seconds = 0.0\n if duration_match := re.search(r\"Duration: (\\d+):(\\d+):(\\d+\\.\\d+)\", info):\n hours, minutes, seconds = map(float, duration_match.groups())\n duration_seconds = hours * 3600 + minutes * 60 + seconds\n\n # 提取比特率\n bitrate_kbps = 0\n if bitrate_match := re.search(r\"bitrate: (\\d+) kb/s\", info):\n bitrate_kbps = int(bitrate_match.group(1))\n\n # 提取视频流信息\n width, height, fps, video_codec = 0, 0, 0.0, \"\"\n has_video_stream = False\n if video_stream_match := re.search(\n r\"Stream #.*?Video: (\\w+)(?:\\s*\\([^)]*\\))?.* (\\d+)x(\\d+).*?(?:(\\d+(?:\\.\\d+)?)\\s*(?:fps|tb[rn]))\",\n info,\n re.DOTALL,\n ):\n video_codec = video_stream_match.group(1)\n width = int(video_stream_match.group(2))\n height = int(video_stream_match.group(3))\n fps = float(video_stream_match.group(4))\n has_video_stream = True\n\n # 提取第一条音频流信息(用于兼容性)\n audio_codec, audio_sampling_rate = \"\", 0\n if audio_stream_match := re.search(\n r\"Stream #\\d+:\\d+.*Audio: (\\w+).* (\\d+) Hz\", info\n ):\n audio_codec = audio_stream_match.group(1)\n audio_sampling_rate = int(audio_stream_match.group(2))\n\n # 提取所有音频流信息(用于多音轨选择)\n audio_streams: list[AudioStreamInfo] = []\n for match in re.finditer(\n r\"Stream #\\d+:(\\d+)(?:\\[0x[0-9a-fA-F]+\\])?(?:\\(([a-z]{3})\\))?: Audio: (\\w+)\",\n info,\n ):\n audio_streams.append(\n AudioStreamInfo(\n index=int(match.group(1)),\n codec=match.group(3),\n language=match.group(2) or \"\",\n )\n )\n\n if audio_streams:\n logger.info(f\"检测到 {len(audio_streams)} 条音轨\")\n\n # 验证文件是否包含有效的媒体流\n if not has_video_stream and not audio_streams:\n logger.error(\"文件既没有视频流也没有音频流,可能不是有效的媒体文件\")\n return None\n\n # 提取缩略图(如果指定了路径且有视频流)\n final_thumbnail_path = \"\"\n if thumbnail_path and duration_seconds > 0 and has_video_stream:\n if _extract_thumbnail(file_path, duration_seconds * 0.3, thumbnail_path):\n final_thumbnail_path = thumbnail_path\n\n # 构造并返回 VideoInfo 对象\n return VideoInfo(\n file_name=Path(file_path).stem,\n file_path=file_path,\n width=width,\n height=height,\n fps=fps,\n duration_seconds=duration_seconds,\n bitrate_kbps=bitrate_kbps,\n video_codec=video_codec,\n audio_codec=audio_codec,\n audio_sampling_rate=audio_sampling_rate,\n thumbnail_path=final_thumbnail_path,\n audio_streams=audio_streams,\n )\n except Exception as e:\n logger.exception(f\"获取视频信息时出错: {str(e)}\")\n return None\n\n\ndef _extract_thumbnail(video_path: str, seek_time: float, thumbnail_path: str) -> bool:\n \"\"\"提取视频缩略图\n\n Args:\n video_path: 视频文件路径\n seek_time: 截取时间点(秒)\n thumbnail_path: 缩略图保存路径\n\n Returns:\n 是否成功\n \"\"\"\n if not Path(video_path).is_file():\n logger.error(f\"视频文件不存在: {video_path}\")\n return False\n\n try:\n timestamp = f\"{int(seek_time // 3600):02}:{int((seek_time % 3600) // 60):02}:{seek_time % 60:06.3f}\"\n Path(thumbnail_path).parent.mkdir(parents=True, exist_ok=True)\n\n result = subprocess.run(\n [\n \"ffmpeg\",\n \"-ss\",\n timestamp,\n \"-i\",\n Path(video_path).as_posix(),\n \"-vframes\",\n \"1\",\n \"-q:v\",\n \"2\",\n \"-y\",\n Path(thumbnail_path).as_posix(),\n ],\n capture_output=True,\n text=True,\n encoding=\"utf-8\",\n errors=\"replace\",\n creationflags=(\n getattr(subprocess, \"CREATE_NO_WINDOW\", 0) if os.name == \"nt\" else 0\n ),\n )\n return result.returncode == 0\n\n except Exception as e:\n logger.exception(f\"提取缩略图时出错: {str(e)}\")\n return False\n\n\ndef add_subtitles_with_style(\n video_path: str,\n asr_data: \"ASRData\",\n output_path: str,\n render_mode: SubtitleRenderModeEnum,\n subtitle_layout: SubtitleLayoutEnum,\n ass_style: str = \"\",\n rounded_style: Optional[dict] = None,\n crf: int = 23,\n preset: PresetType = \"medium\",\n progress_callback: Optional[Callable] = None,\n) -> None:\n \"\"\"\n 根据渲染模式选择合成方式\n\n Args:\n video_path: 输入视频路径\n asr_data: 字幕数据\n output_path: 输出视频路径\n render_mode: 渲染模式 (ASS_STYLE 或 ROUNDED_BG)\n subtitle_layout: 字幕布局\n ass_style: ASS 样式字符串 (仅 ASS_STYLE 模式使用)\n rounded_style: 圆角背景样式配置字典 (仅 ROUNDED_BG 模式使用)\n crf: 视频质量\n preset: FFmpeg 编码预设\n progress_callback: 进度回调\n \"\"\"\n\n if render_mode == SubtitleRenderModeEnum.ROUNDED_BG:\n # 圆角背景模式\n render_rounded_video(\n video_path=video_path,\n asr_data=asr_data,\n output_path=output_path,\n rounded_style=rounded_style,\n layout=subtitle_layout,\n crf=crf,\n preset=preset,\n progress_callback=progress_callback,\n )\n else:\n # ASS 样式模式\n render_ass_video(\n video_path=video_path,\n asr_data=asr_data,\n output_path=output_path,\n style_str=ass_style,\n layout=subtitle_layout,\n crf=crf,\n preset=preset,\n progress_callback=progress_callback,\n )\n" }, { "path": "app/thread/batch_process_thread.py", "content": "import queue\nimport time\nfrom functools import partial\nfrom typing import Dict, Optional\n\nfrom PyQt5.QtCore import QThread, pyqtSignal\n\nfrom app.core.entities import (\n BatchTaskStatus,\n BatchTaskType,\n TranscribeTask,\n)\nfrom app.core.task_factory import TaskFactory\nfrom app.core.utils.logger import setup_logger\nfrom app.thread.subtitle_thread import SubtitleThread\nfrom app.thread.transcript_thread import TranscriptThread\nfrom app.thread.video_synthesis_thread import VideoSynthesisThread\n\nlogger = setup_logger(\"batch_process_thread\")\n\n\nclass BatchTask:\n def __init__(self, file_path: str, task_type: BatchTaskType):\n self.file_path = file_path\n self.task_type = task_type\n self.status = BatchTaskStatus.WAITING\n self.progress = 0\n self.error_message = \"\"\n self.current_thread: Optional[QThread] = None\n\n\nclass BatchProcessThread(QThread):\n # 信号定义\n task_progress = pyqtSignal(str, int, str) # file_path, progress, status\n task_error = pyqtSignal(str, str) # file_path, error_message\n task_completed = pyqtSignal(str) # file_path\n\n def __init__(self):\n super().__init__()\n self.task_queue = queue.Queue()\n self.current_tasks: Dict[str, BatchTask] = {}\n self.max_concurrent_tasks = 1\n self.is_running = False\n self.factory = TaskFactory()\n self.threads = [] # 保存所有创建的线程\n\n def add_task(self, task: BatchTask):\n self.task_queue.put(task)\n self.current_tasks[task.file_path] = task\n if not self.isRunning():\n self.is_running = True\n self.start()\n\n def run(self):\n while self.is_running:\n # 检查是否有正在运行的任务数量是否达到上限\n running_tasks = sum(\n 1\n for task in self.current_tasks.values()\n if task.status == BatchTaskStatus.RUNNING\n )\n\n if running_tasks < self.max_concurrent_tasks:\n try:\n # 非阻塞方式获取任务\n task = self.task_queue.get_nowait()\n self._process_task(task)\n except queue.Empty:\n time.sleep(0.1) # 避免CPU过度使用\n else:\n time.sleep(0.1)\n\n def _process_task(self, batch_task: BatchTask):\n try:\n batch_task.status = BatchTaskStatus.RUNNING\n self.task_progress.emit(\n batch_task.file_path, 0, str(BatchTaskStatus.RUNNING)\n )\n\n if batch_task.task_type == BatchTaskType.TRANSCRIBE:\n self._handle_transcribe_task(batch_task)\n elif batch_task.task_type == BatchTaskType.SUBTITLE:\n self._handle_subtitle_task(batch_task)\n elif batch_task.task_type == BatchTaskType.TRANS_SUB:\n self._handle_trans_sub_task(batch_task)\n elif batch_task.task_type == BatchTaskType.FULL_PROCESS:\n self._handle_full_process_task(batch_task)\n\n except Exception as e:\n logger.exception(f\"处理任务失败: {str(e)}\")\n batch_task.status = BatchTaskStatus.FAILED\n batch_task.error_message = str(e)\n self.task_error.emit(batch_task.file_path, str(e))\n\n def _on_progress_wrapper(self, batch_task: BatchTask, progress: int, message: str):\n \"\"\"进度信号包装器\"\"\"\n self.task_progress.emit(batch_task.file_path, progress, message)\n\n def _on_error_wrapper(self, batch_task: BatchTask, error: str):\n \"\"\"错误信号包装器\"\"\"\n batch_task.status = BatchTaskStatus.FAILED\n batch_task.error_message = error\n self.task_error.emit(batch_task.file_path, error)\n\n def _on_finished_wrapper(self, batch_task: BatchTask, task=None):\n \"\"\"完成信号包装器\"\"\"\n batch_task.status = BatchTaskStatus.COMPLETED\n batch_task.progress = 100\n self.task_completed.emit(batch_task.file_path)\n if batch_task.current_thread in self.threads:\n self.threads.remove(batch_task.current_thread)\n\n def _handle_transcribe_task(self, batch_task: BatchTask):\n # self.max_concurrent_tasks = 3\n task = self.factory.create_transcribe_task(batch_task.file_path)\n thread = TranscriptThread(task)\n batch_task.current_thread = thread\n\n # 保存线程引用\n self.threads.append(thread)\n\n thread.progress.connect( # type: ignore\n partial(self._on_progress_wrapper, batch_task) # type: ignore\n )\n thread.error.connect( # type: ignore\n partial(self._on_error_wrapper, batch_task) # type: ignore\n )\n thread.finished.connect( # type: ignore\n partial(self._on_finished_wrapper, batch_task) # type: ignore\n )\n\n thread.start()\n\n def _handle_subtitle_task(self, batch_task: BatchTask):\n logger.info(f\"开始处理字幕任务: {batch_task.file_path}\")\n\n task = self.factory.create_subtitle_task(batch_task.file_path)\n thread = SubtitleThread(task)\n batch_task.current_thread = thread\n\n # 保存线程引用\n self.threads.append(thread)\n\n thread.progress.connect( # type: ignore\n partial(self._on_progress_wrapper, batch_task) # type: ignore\n )\n thread.error.connect( # type: ignore\n partial(self._on_error_wrapper, batch_task) # type: ignore\n )\n thread.finished.connect( # type: ignore\n partial(self._on_finished_wrapper, batch_task) # type: ignore\n )\n\n thread.start()\n\n def _handle_trans_sub_task(self, batch_task: BatchTask):\n trans_task = self.factory.create_transcribe_task(\n batch_task.file_path, need_next_task=True\n )\n thread = TranscriptThread(trans_task)\n batch_task.current_thread = thread\n self.current_tasks[batch_task.file_path] = batch_task\n\n # 保存线程引用\n self.threads.append(thread)\n\n thread.progress.connect(\n partial(self._on_trans_sub_progress_wrapper, batch_task)\n )\n thread.error.connect(partial(self._on_error_wrapper, batch_task))\n thread.finished.connect(\n partial(self._on_trans_sub_finished_wrapper, batch_task)\n )\n\n thread.start()\n\n def _on_trans_sub_progress_wrapper(\n self, batch_task: BatchTask, progress: int, message: str\n ):\n \"\"\"转录+字幕任务进度包装器\"\"\"\n progress = progress // 2 # 转录占50%进度\n self.task_progress.emit(batch_task.file_path, progress, message)\n\n def _on_trans_sub_finished_wrapper(\n self, batch_task: BatchTask, task: TranscribeTask\n ):\n \"\"\"转录+字幕任务转录完成包装器\"\"\"\n if batch_task.current_thread in self.threads:\n self.threads.remove(batch_task.current_thread)\n\n # 创建字幕任务\n if not task.output_path:\n raise ValueError(\"Task output_path is None\")\n subtitle_task = self.factory.create_subtitle_task(\n task.output_path, batch_task.file_path, need_next_task=True\n )\n thread = SubtitleThread(subtitle_task)\n batch_task.current_thread = thread\n self.current_tasks[batch_task.file_path] = batch_task\n\n # 保存线程引用\n self.threads.append(thread)\n\n thread.progress.connect(\n partial(self._on_trans_sub_subtitle_progress_wrapper, batch_task)\n )\n thread.error.connect(partial(self._on_error_wrapper, batch_task))\n thread.finished.connect(partial(self._on_finished_wrapper, batch_task))\n\n thread.start()\n\n def _on_trans_sub_subtitle_progress_wrapper(\n self, batch_task: BatchTask, progress: int, message: str\n ):\n \"\"\"转录+字幕任务字幕进度包装器\"\"\"\n progress = 50 + progress // 2 # 字幕处理占后50%进度\n self.task_progress.emit(batch_task.file_path, progress, message)\n\n def _handle_full_process_task(self, batch_task: BatchTask):\n # 首先创建转录任务\n trans_task = self.factory.create_transcribe_task(\n batch_task.file_path, need_next_task=True\n )\n thread = TranscriptThread(trans_task)\n batch_task.current_thread = thread\n\n # 保存线程引用\n self.threads.append(thread)\n\n thread.progress.connect(partial(self.on_full_process_progress, batch_task))\n thread.error.connect(partial(self._on_error_wrapper, batch_task))\n thread.finished.connect(partial(self.on_full_process_finished, batch_task))\n\n thread.start()\n\n def on_full_process_progress(\n self, batch_task: BatchTask, progress: int, message: str\n ):\n \"\"\"处理全流程任务的转录进度\"\"\"\n if batch_task.status == BatchTaskStatus.RUNNING:\n progress_value = progress // 3 # 转录占33%进度\n self.task_progress.emit(batch_task.file_path, progress_value, message)\n\n def on_full_process_finished(self, batch_task: BatchTask, task: TranscribeTask):\n \"\"\"处理转录完成后开始字幕任务\"\"\"\n if batch_task.current_thread in self.threads:\n self.threads.remove(batch_task.current_thread)\n\n # 转录完成后创建字幕任务\n if not task.output_path:\n raise ValueError(\"Task output_path is None\")\n subtitle_task = self.factory.create_subtitle_task(\n task.output_path,\n batch_task.file_path,\n need_next_task=True,\n )\n thread = SubtitleThread(subtitle_task)\n batch_task.current_thread = thread\n\n # 保存线程引用\n self.threads.append(thread)\n\n thread.progress.connect(\n partial(self.on_full_process_subtitle_progress, batch_task)\n )\n thread.error.connect(partial(self._on_error_wrapper, batch_task))\n thread.finished.connect(\n partial(self.on_full_process_subtitle_finished, batch_task)\n )\n\n thread.start()\n\n def on_full_process_subtitle_progress(\n self, batch_task: BatchTask, progress: int, message: str\n ):\n \"\"\"处理全流程任务中字幕部分的进度\"\"\"\n if batch_task.status == BatchTaskStatus.RUNNING:\n progress_value = 33 + progress // 3 # 字幕处理占中间33%进度\n self.task_progress.emit(batch_task.file_path, progress_value, message)\n\n def on_full_process_subtitle_finished(\n self, batch_task: BatchTask, video_path: str, subtitle_path: str\n ):\n \"\"\"处理字幕完成后开始视频合成任务\"\"\"\n if batch_task.current_thread in self.threads:\n self.threads.remove(batch_task.current_thread)\n\n # 字幕完成后创建视频合成任务\n synthesis_task = self.factory.create_synthesis_task(video_path, subtitle_path)\n thread = VideoSynthesisThread(synthesis_task)\n batch_task.current_thread = thread\n\n # 保存线程引用\n self.threads.append(thread)\n\n thread.progress.connect(\n partial(self.on_full_process_synthesis_progress, batch_task)\n )\n thread.error.connect(partial(self._on_error_wrapper, batch_task))\n thread.finished.connect(partial(self._on_finished_wrapper, batch_task))\n\n thread.start()\n\n def on_full_process_synthesis_progress(\n self, batch_task: BatchTask, progress: int, message: str\n ):\n \"\"\"处理全流程任务中视频合成部分的进度\"\"\"\n if batch_task.status == BatchTaskStatus.RUNNING:\n progress_value = 66 + progress // 3 # 视频合成占最后34%进度\n self.task_progress.emit(batch_task.file_path, progress_value, message)\n\n def stop_task(self, file_path: str):\n if file_path in self.current_tasks:\n task = self.current_tasks[file_path]\n if task.current_thread:\n if hasattr(task.current_thread, \"stop\"):\n task.current_thread.stop() # type: ignore\n del self.current_tasks[file_path]\n # 从队列中移除任务\n with self.task_queue.mutex:\n self.task_queue.queue.clear()\n\n def stop_all(self):\n self.is_running = False\n # 停止所有线程\n for thread in self.threads:\n if hasattr(thread, \"stop\"):\n thread.stop() # type: ignore\n thread.wait() # 等待线程结束\n self.threads.clear()\n self.current_tasks.clear()\n # 清空任务队列\n with self.task_queue.mutex:\n self.task_queue.queue.clear()\n" }, { "path": "app/thread/file_download_thread.py", "content": "import shutil\nimport subprocess\nfrom abc import ABC, abstractmethod\nfrom pathlib import Path\n\nimport requests\nfrom PyQt5.QtCore import QThread, pyqtSignal\n\nfrom app.config import CACHE_PATH\nfrom app.core.utils.logger import setup_logger\nfrom app.core.utils.platform_utils import get_subprocess_kwargs\n\nlogger = setup_logger(\"download_thread\")\n\n\nclass BaseDownloader(ABC):\n \"\"\"下载器基类\"\"\"\n\n def __init__(self, url: str, save_path: Path, progress_callback):\n self.url = url\n self.save_path = save_path\n self.progress_callback = progress_callback\n self._cancelled = False\n\n @abstractmethod\n def download(self) -> bool:\n \"\"\"执行下载,返回是否成功\"\"\"\n pass\n\n def cancel(self):\n \"\"\"取消下载\"\"\"\n self._cancelled = True\n\n\nclass Aria2Downloader(BaseDownloader):\n \"\"\"aria2c 多线程下载器\"\"\"\n\n def __init__(self, url: str, save_path: Path, progress_callback):\n super().__init__(url, save_path, progress_callback)\n self.process = None\n\n @staticmethod\n def is_available() -> bool:\n \"\"\"检查 aria2c 是否可用\"\"\"\n return shutil.which(\"aria2c\") is not None\n\n def download(self) -> bool:\n temp_dir = CACHE_PATH / \"download_cache\"\n temp_dir.mkdir(parents=True, exist_ok=True)\n temp_file = temp_dir / self.save_path.name\n\n cmd = [\n \"aria2c\",\n \"--no-conf\",\n \"--show-console-readout=false\",\n \"--summary-interval=1\",\n \"--max-connection-per-server=2\",\n \"--split=2\",\n \"--connect-timeout=10\",\n \"--timeout=10\",\n \"--max-tries=2\",\n \"--retry-wait=1\",\n \"--continue=true\",\n \"--auto-file-renaming=false\",\n \"--allow-overwrite=true\",\n \"--check-certificate=false\",\n f\"--dir={temp_dir}\",\n f\"--out={temp_file.name}\",\n self.url,\n ]\n\n subprocess_args = {\n \"stdout\": subprocess.PIPE,\n \"stderr\": subprocess.PIPE,\n \"universal_newlines\": True,\n \"encoding\": \"utf-8\",\n **get_subprocess_kwargs(),\n }\n\n logger.info(f\"使用 aria2c 下载: {self.url}\")\n self.process = subprocess.Popen(cmd, **subprocess_args)\n\n while True:\n if self._cancelled:\n self.process.terminate()\n return False\n\n if self.process.poll() is not None:\n break\n\n line = self.process.stdout.readline()\n self._parse_progress(line)\n\n if self.process.returncode == 0:\n self.save_path.parent.mkdir(parents=True, exist_ok=True)\n shutil.move(str(temp_file), self.save_path)\n return True\n else:\n error = self.process.stderr.read()\n logger.error(f\"aria2c 下载失败: {error}\")\n return False\n\n def _parse_progress(self, line: str):\n \"\"\"解析 aria2c 输出格式: [#40ca1b 2.4MiB/74MiB(3%) CN:2 DL:3.9MiB ETA:18s]\"\"\"\n if \"[#\" not in line or \"]\" not in line:\n return\n\n try:\n progress_part = line.split(\"(\")[1].split(\")\")[0]\n percent = float(progress_part.strip(\"%\"))\n\n speed = \"0\"\n eta = \"\"\n if \"DL:\" in line:\n speed = line.split(\"DL:\")[1].split()[0]\n if \"ETA:\" in line:\n eta = line.split(\"ETA:\")[1].split(\"]\")[0]\n\n status = f\"速度: {speed}/s, 剩余: {eta}\"\n self.progress_callback(percent, status)\n except Exception:\n pass\n\n def cancel(self):\n super().cancel()\n if self.process:\n self.process.terminate()\n self.process.wait()\n\n\nclass RequestsDownloader(BaseDownloader):\n \"\"\"Python requests 下载器(回退方案)\"\"\"\n\n CHUNK_SIZE = 8192\n\n def download(self) -> bool:\n logger.info(f\"使用 requests 下载: {self.url}\")\n self.progress_callback(0, \"正在连接...\")\n\n try:\n response = requests.get(self.url, stream=True, timeout=30)\n response.raise_for_status()\n\n total_size = int(response.headers.get(\"content-length\", 0))\n downloaded = 0\n\n self.save_path.parent.mkdir(parents=True, exist_ok=True)\n temp_file = self.save_path.with_suffix(\".tmp\")\n\n with open(temp_file, \"wb\") as f:\n for chunk in response.iter_content(chunk_size=self.CHUNK_SIZE):\n if self._cancelled:\n temp_file.unlink(missing_ok=True)\n return False\n\n f.write(chunk)\n downloaded += len(chunk)\n\n if total_size > 0:\n percent = (downloaded / total_size) * 100\n speed = self._format_size(downloaded)\n status = f\"已下载: {speed} / {self._format_size(total_size)}\"\n self.progress_callback(percent, status)\n\n # 下载完成后重命名\n shutil.move(str(temp_file), self.save_path)\n return True\n\n except requests.RequestException as e:\n logger.error(f\"requests 下载失败: {e}\")\n return False\n\n @staticmethod\n def _format_size(bytes_size: int) -> str:\n \"\"\"格式化文件大小\"\"\"\n size = float(bytes_size)\n for unit in [\"B\", \"KB\", \"MB\", \"GB\"]:\n if size < 1024:\n return f\"{size:.1f}{unit}\"\n size /= 1024\n return f\"{size:.1f}TB\"\n\n\nclass FileDownloadThread(QThread):\n \"\"\"文件下载线程\"\"\"\n\n progress = pyqtSignal(float, str)\n finished = pyqtSignal()\n error = pyqtSignal(str)\n\n def __init__(self, url: str, save_path: str):\n super().__init__()\n self.url = url\n self.save_path = Path(save_path)\n self.downloader: BaseDownloader | None = None\n\n def run(self):\n try:\n self.progress.emit(0, self.tr(\"正在连接...\"))\n\n # 选择下载器:优先 aria2c,否则回退到 requests\n if Aria2Downloader.is_available():\n self.downloader = Aria2Downloader(\n self.url, self.save_path, self._on_progress\n )\n else:\n logger.info(\"aria2c 不可用,使用 requests 下载\")\n self.downloader = RequestsDownloader(\n self.url, self.save_path, self._on_progress\n )\n\n success = self.downloader.download()\n\n if success:\n self.finished.emit()\n else:\n self.error.emit(self.tr(\"下载失败\"))\n\n except Exception as e:\n logger.exception(\"下载异常\")\n self.error.emit(str(e))\n\n def _on_progress(self, percent: float, status: str):\n \"\"\"进度回调\"\"\"\n self.progress.emit(percent, status)\n\n def stop(self):\n \"\"\"停止下载\"\"\"\n if self.downloader:\n self.downloader.cancel()\n" }, { "path": "app/thread/modelscope_download_thread.py", "content": "import io\nimport logging\nimport sys\nfrom typing import Callable\n\nfrom modelscope.hub.callback import ProgressCallback\nfrom modelscope.hub.snapshot_download import snapshot_download\nfrom PyQt5.QtCore import QThread, pyqtSignal\n\n\nclass SuppressOutput:\n \"\"\"上下文管理器:抑制 stdout/stderr 和 modelscope 日志\"\"\"\n\n def __enter__(self):\n self._stdout = sys.stdout\n self._stderr = sys.stderr\n sys.stdout = io.StringIO()\n sys.stderr = io.StringIO()\n self._loggers: dict[str, int] = {}\n for name in [\"modelscope\", \"tqdm\"]:\n logger = logging.getLogger(name)\n self._loggers[name] = logger.level\n logger.setLevel(logging.CRITICAL)\n return self\n\n def __exit__(self, *args):\n sys.stdout = self._stdout\n sys.stderr = self._stderr\n for name, level in self._loggers.items():\n logging.getLogger(name).setLevel(level)\n\n\ndef create_progress_callback_class(\n progress_callback: Callable[[int, str], None],\n) -> type[ProgressCallback]:\n \"\"\"创建一个自定义的 ProgressCallback 类,用于接收下载进度\"\"\"\n\n class CustomProgressCallback(ProgressCallback):\n def __init__(self, filename: str, file_size: int):\n super().__init__(filename, file_size)\n self.downloaded = 0\n\n def update(self, size: int):\n self.downloaded += size\n if self.file_size > 0:\n percentage = min(int(self.downloaded * 100 / self.file_size), 99)\n progress_callback(percentage, f\"{self.filename}: {percentage}%\")\n\n def end(self):\n pass\n\n return CustomProgressCallback\n\n\nclass ModelscopeDownloadThread(QThread):\n progress = pyqtSignal(int, str)\n error = pyqtSignal(str)\n\n def __init__(self, model_id: str, save_path: str):\n super().__init__()\n self.model_id = model_id\n self.save_path = save_path\n\n def run(self):\n try:\n self.progress.emit(0, self.tr(\"开始下载...\"))\n\n callback_class = create_progress_callback_class(self.progress.emit)\n\n with SuppressOutput():\n snapshot_download(\n self.model_id,\n local_dir=self.save_path,\n progress_callbacks=[callback_class],\n )\n\n self.progress.emit(100, self.tr(\"下载完成\"))\n\n except Exception as e:\n self.error.emit(str(e))\n\n\nif __name__ == \"__main__\":\n import sys\n\n from PyQt5.QtCore import QCoreApplication\n\n app = QCoreApplication(sys.argv)\n model_id = \"pengzhendong/faster-whisper-tiny\"\n save_path = r\"models/faster-whisper-tiny\"\n downloader = ModelscopeDownloadThread(model_id, save_path)\n\n def on_progress(percentage, message):\n print(f\"进度: {message}\")\n\n def on_error(error_msg):\n print(f\"错误: {error_msg}\")\n app.quit()\n\n def on_finished():\n print(\"下载完成!\")\n app.quit()\n\n downloader.progress.connect(on_progress)\n downloader.error.connect(on_error)\n downloader.finished.connect(on_finished)\n\n print(f\"开始下载模型 {model_id}\")\n downloader.start()\n\n sys.exit(app.exec_())\n" }, { "path": "app/thread/subtitle_pipeline_thread.py", "content": "import datetime\n\nfrom PyQt5.QtCore import QThread, pyqtSignal\n\nfrom app.core.entities import (\n FullProcessTask,\n SubtitleTask,\n SynthesisTask,\n TranscribeTask,\n)\nfrom app.core.utils.logger import setup_logger\n\nfrom .subtitle_thread import SubtitleThread\nfrom .transcript_thread import TranscriptThread\nfrom .video_synthesis_thread import VideoSynthesisThread\n\nlogger = setup_logger(\"subtitle_pipeline_thread\")\n\n\nclass SubtitlePipelineThread(QThread):\n \"\"\"字幕处理全流程线程,包含:\n 1. 转录生成字幕\n 2. 字幕优化/翻译\n 3. 视频合成\n \"\"\"\n\n progress = pyqtSignal(int, str) # 进度值, 进度描述\n finished = pyqtSignal(FullProcessTask)\n error = pyqtSignal(str)\n\n def __init__(self, task: FullProcessTask):\n super().__init__()\n self.task = task\n self.has_error = False\n\n def run(self):\n try:\n\n def handle_error(error_msg):\n logger.error(\"pipeline 发生错误: %s\", error_msg)\n self.has_error = True\n self.error.emit(error_msg)\n\n # 1. 转录生成字幕\n self.task.started_at = datetime.datetime.now()\n logger.info(f\"\\n{self.task.transcribe_config.print_config()}\")\n logger.info(f\"\\n{self.task.subtitle_config.print_config()}\")\n if self.task.synthesis_config:\n logger.info(f\"\\n{self.task.synthesis_config.print_config()}\")\n self.progress.emit(0, self.tr(\"开始转录\"))\n\n # 创建转录任务\n transcribe_task = TranscribeTask(\n file_path=self.task.file_path,\n transcribe_config=self.task.transcribe_config,\n need_next_task=True,\n queued_at=self.task.queued_at,\n started_at=self.task.started_at,\n completed_at=self.task.completed_at,\n )\n transcript_thread = TranscriptThread(transcribe_task)\n transcript_thread.progress.connect(\n lambda value, msg: self.progress.emit(int(value * 0.4), msg)\n )\n transcript_thread.error.connect(handle_error)\n transcript_thread.run()\n\n if self.has_error:\n logger.info(\"转录过程中发生错误,终止流程\")\n return\n\n # 2. 字幕优化/翻译\n # self.task.status = Task.Status.OPTIMIZING\n self.progress.emit(40, self.tr(\"开始优化字幕\"))\n\n # 创建字幕任务\n subtitle_task = SubtitleTask(\n subtitle_path=transcribe_task.output_path or \"\",\n video_path=self.task.file_path,\n output_path=self.task.output_path,\n subtitle_config=self.task.subtitle_config,\n need_next_task=True,\n queued_at=self.task.queued_at,\n started_at=self.task.started_at,\n completed_at=self.task.completed_at,\n )\n optimization_thread = SubtitleThread(subtitle_task)\n optimization_thread.progress.connect(\n lambda value, msg: self.progress.emit(int(40 + value * 0.2), msg)\n )\n optimization_thread.error.connect(handle_error)\n optimization_thread.run()\n\n if self.has_error:\n logger.info(\"字幕优化过程中发生错误,终止流程\")\n return\n\n # 3. 视频合成\n # self.task.status = Task.Status.GENERATING\n self.progress.emit(80, self.tr(\"开始合成视频\"))\n\n # 创建合成任务\n synthesis_task = SynthesisTask(\n video_path=self.task.file_path,\n subtitle_path=subtitle_task.output_path,\n output_path=self.task.output_path,\n synthesis_config=self.task.synthesis_config,\n queued_at=self.task.queued_at,\n started_at=self.task.started_at,\n completed_at=self.task.completed_at,\n )\n synthesis_thread = VideoSynthesisThread(synthesis_task)\n synthesis_thread.progress.connect(\n lambda value, msg: self.progress.emit(int(70 + value * 0.3), msg)\n )\n synthesis_thread.error.connect(handle_error)\n synthesis_thread.run()\n\n if self.has_error:\n logger.info(\"视频合成过程中发生错误,终止流程\")\n return\n\n # self.task.status = FullProcessTask.Status.COMPLETED # type: ignore\n logger.info(\"处理完成\")\n self.progress.emit(100, self.tr(\"处理完成\"))\n self.finished.emit(self.task)\n\n except Exception as e:\n # self.task.status = FullProcessTask.Status.FAILED # type: ignore\n logger.exception(\"处理失败: %s\", str(e))\n self.error.emit(str(e))\n" }, { "path": "app/thread/subtitle_thread.py", "content": "import os\nfrom pathlib import Path\nfrom typing import List, Optional\n\nfrom PyQt5.QtCore import QThread, pyqtSignal\n\nfrom app.core.asr.asr_data import ASRData\nfrom app.core.entities import (\n SubtitleConfig,\n SubtitleLayoutEnum,\n SubtitleProcessData,\n SubtitleTask,\n TranslatorServiceEnum,\n)\nfrom app.core.llm.check_llm import check_llm_connection\nfrom app.core.llm.context import clear_task_context, set_task_context, update_stage\nfrom app.core.optimize.optimize import SubtitleOptimizer\nfrom app.core.split.split import SubtitleSplitter\nfrom app.core.translate import (\n BingTranslator,\n DeepLXTranslator,\n GoogleTranslator,\n LLMTranslator,\n)\nfrom app.core.utils.logger import setup_logger\n\n# 配置日志\nlogger = setup_logger(\"subtitle_optimization_thread\")\n\n\nclass SubtitleThread(QThread):\n finished = pyqtSignal(str, str)\n progress = pyqtSignal(int, str)\n update = pyqtSignal(dict)\n update_all = pyqtSignal(dict)\n error = pyqtSignal(str)\n\n def __init__(self, task: SubtitleTask):\n super().__init__()\n self.task: SubtitleTask = task\n self.subtitle_length = 0\n self.finished_subtitle_length = 0\n self.custom_prompt_text = \"\"\n self.optimizer = None\n\n def set_custom_prompt_text(self, text: str):\n self.custom_prompt_text = text\n\n def _setup_llm_config(self) -> Optional[SubtitleConfig]:\n \"\"\"设置API配置,返回SubtitleConfig\"\"\"\n if (\n self.task.subtitle_config.base_url\n and self.task.subtitle_config.api_key\n and self.task.subtitle_config.llm_model\n ):\n success, message = check_llm_connection(\n self.task.subtitle_config.base_url,\n self.task.subtitle_config.api_key,\n self.task.subtitle_config.llm_model,\n )\n if not success:\n raise Exception(f\"{self.tr('LLM API 测试失败: ')}{message or ''}\")\n # 设置环境变量\n if self.task.subtitle_config.base_url:\n os.environ[\"OPENAI_BASE_URL\"] = self.task.subtitle_config.base_url\n if self.task.subtitle_config.api_key:\n os.environ[\"OPENAI_API_KEY\"] = self.task.subtitle_config.api_key\n return self.task.subtitle_config\n else:\n raise Exception(self.tr(\"LLM API 未配置, 请检查LLM配置\"))\n\n def run(self):\n # 设置任务上下文\n task_file = (\n Path(self.task.video_path) if self.task.video_path else Path(self.task.subtitle_path)\n )\n set_task_context(\n task_id=self.task.task_id,\n file_name=task_file.name,\n stage=\"subtitle\",\n )\n\n try:\n logger.info(f\"\\n{self.task.subtitle_config.print_config()}\")\n\n # 字幕文件路径检查、对断句字幕路径进行定义\n subtitle_path = self.task.subtitle_path\n assert subtitle_path is not None, self.tr(\"字幕文件路径为空\")\n\n subtitle_config = self.task.subtitle_config\n assert subtitle_config is not None, self.tr(\"字幕配置为空\")\n\n asr_data = ASRData.from_subtitle_file(subtitle_path)\n\n # 1. 分割成字词级时间戳(对于非断句字幕且开启分割选项)\n if subtitle_config.need_split and not asr_data.is_word_timestamp():\n asr_data.split_to_word_segments()\n self.update_all.emit(asr_data.to_json())\n\n # 验证 LLM 配置\n if self.need_llm(subtitle_config, asr_data):\n self.progress.emit(2, self.tr(\"开始验证 LLM 配置...\"))\n subtitle_config = self._setup_llm_config()\n\n # 2. 重新断句(对于字词级字幕)\n if asr_data.is_word_timestamp():\n update_stage(\"split\")\n self.progress.emit(5, self.tr(\"字幕断句...\"))\n logger.info(\"正在字幕断句...\")\n splitter = SubtitleSplitter(\n thread_num=subtitle_config.thread_num,\n model=subtitle_config.llm_model,\n max_word_count_cjk=subtitle_config.max_word_count_cjk,\n max_word_count_english=subtitle_config.max_word_count_english,\n )\n asr_data = splitter.split_subtitle(asr_data)\n self.update_all.emit(asr_data.to_json())\n\n # 3. 优化字幕\n context_info = f'The subtitles below are from a file named \"{task_file}\". Use this context to improve accuracy if needed.\\n'\n custom_prompt = context_info + (subtitle_config.custom_prompt_text or \"\") + \"\\n\"\n self.subtitle_length = len(asr_data.segments)\n\n if subtitle_config.need_optimize:\n update_stage(\"optimize\")\n self.progress.emit(0, self.tr(\"优化字幕...\"))\n logger.info(\"正在优化字幕...\")\n self.finished_subtitle_length = 0\n if not subtitle_config.llm_model:\n raise Exception(self.tr(\"LLM 模型未配置\"))\n optimizer = SubtitleOptimizer(\n thread_num=subtitle_config.thread_num,\n batch_num=subtitle_config.batch_size,\n model=subtitle_config.llm_model,\n custom_prompt=custom_prompt or \"\",\n update_callback=self.callback,\n )\n asr_data = optimizer.optimize_subtitle(asr_data)\n asr_data.remove_punctuation()\n self.update_all.emit(asr_data.to_json())\n\n # 4. 翻译字幕\n if subtitle_config.need_translate:\n update_stage(\"translate\")\n self.progress.emit(0, self.tr(\"翻译字幕...\"))\n logger.info(\"正在翻译字幕...\")\n self.finished_subtitle_length = 0\n translator_service = subtitle_config.translator_service\n\n if not subtitle_config.target_language:\n raise Exception(self.tr(\"目标语言未配置\"))\n\n if translator_service == TranslatorServiceEnum.OPENAI:\n if not subtitle_config.llm_model:\n raise Exception(self.tr(\"LLM 模型未配置\"))\n translator = LLMTranslator(\n thread_num=subtitle_config.thread_num,\n batch_num=subtitle_config.batch_size,\n target_language=subtitle_config.target_language,\n model=subtitle_config.llm_model,\n custom_prompt=custom_prompt or \"\",\n is_reflect=subtitle_config.need_reflect,\n update_callback=self.callback,\n )\n elif translator_service == TranslatorServiceEnum.GOOGLE:\n translator = GoogleTranslator(\n thread_num=subtitle_config.thread_num,\n batch_num=5,\n target_language=subtitle_config.target_language,\n timeout=20,\n update_callback=self.callback,\n )\n elif translator_service == TranslatorServiceEnum.BING:\n translator = BingTranslator(\n thread_num=subtitle_config.thread_num,\n batch_num=10,\n target_language=subtitle_config.target_language,\n update_callback=self.callback,\n )\n elif translator_service == TranslatorServiceEnum.DEEPLX:\n os.environ[\"DEEPLX_ENDPOINT\"] = subtitle_config.deeplx_endpoint or \"\"\n translator = DeepLXTranslator(\n thread_num=subtitle_config.thread_num,\n batch_num=5,\n target_language=subtitle_config.target_language,\n timeout=20,\n update_callback=self.callback,\n )\n else:\n raise Exception(self.tr(f\"不支持的翻译服务: {translator_service}\"))\n\n asr_data = translator.translate_subtitle(asr_data)\n\n # 移除末尾标点符号\n asr_data.remove_punctuation()\n self.update_all.emit(asr_data.to_json())\n\n # 保存翻译结果(单语、双语)\n if self.task.need_next_task and self.task.video_path:\n for layout in SubtitleLayoutEnum:\n save_path = str(\n Path(self.task.subtitle_path).parent\n / f\"{Path(self.task.video_path).stem}-{layout.value}.srt\"\n )\n asr_data.save(\n save_path=save_path,\n ass_style=subtitle_config.subtitle_style or \"\",\n layout=layout,\n )\n logger.info(f\"翻译字幕保存到:{save_path}\")\n\n # 5. 保存字幕\n asr_data.save(\n save_path=self.task.output_path or \"\",\n ass_style=subtitle_config.subtitle_style or \"\",\n layout=subtitle_config.subtitle_layout or SubtitleLayoutEnum.ONLY_TRANSLATE,\n )\n logger.info(f\"字幕保存到 {self.task.output_path}\")\n\n # 6. 文件移动与清理\n if self.task.need_next_task and self.task.video_path:\n # 保存srt/ass文件到视频目录(对于全流程任务)\n save_srt_path = (\n Path(self.task.video_path).parent / f\"{Path(self.task.video_path).stem}.srt\"\n )\n asr_data.to_srt(\n save_path=str(save_srt_path),\n layout=subtitle_config.subtitle_layout,\n )\n save_ass_path = (\n Path(self.task.video_path).parent / f\"{Path(self.task.video_path).stem}.ass\"\n )\n asr_data.to_ass(\n save_path=str(save_ass_path),\n layout=subtitle_config.subtitle_layout,\n style_str=subtitle_config.subtitle_style,\n )\n\n self.progress.emit(100, self.tr(\"优化完成\"))\n logger.info(\"优化完成\")\n self.finished.emit(self.task.video_path, self.task.output_path)\n\n except Exception as e:\n logger.exception(f\"字幕处理失败: {str(e)}\")\n self.error.emit(str(e))\n self.progress.emit(100, self.tr(\"字幕处理失败\"))\n finally:\n clear_task_context()\n\n def need_llm(self, subtitle_config: SubtitleConfig, asr_data: ASRData):\n return (\n subtitle_config.need_optimize\n or asr_data.is_word_timestamp()\n or (\n subtitle_config.need_translate\n and subtitle_config.translator_service\n not in [\n TranslatorServiceEnum.DEEPLX,\n TranslatorServiceEnum.BING,\n TranslatorServiceEnum.GOOGLE,\n ]\n )\n )\n\n def callback(self, result: List[SubtitleProcessData]):\n self.finished_subtitle_length += len(result)\n # 简单计算当前进度(0-100%)\n progress = min(int((self.finished_subtitle_length / self.subtitle_length) * 100), 100)\n self.progress.emit(progress, self.tr(\"{0}% 处理字幕\").format(progress))\n # 转换为字典格式供UI使用\n result_dict = {\n str(data.index): data.translated_text or data.optimized_text or data.original_text\n for data in result\n }\n self.update.emit(result_dict)\n\n def stop(self):\n \"\"\"停止所有处理\"\"\"\n try:\n # 先停止优化器\n if hasattr(self, \"optimizer\") and self.optimizer:\n try:\n self.optimizer.stop() # type: ignore\n except Exception as e:\n logger.error(f\"停止优化器时出错:{str(e)}\")\n\n # 终止线程\n self.terminate()\n # 等待最多3秒\n if not self.wait(3000):\n logger.warning(\"线程未能在3秒内正常停止\")\n\n # 发送进度信号\n self.progress.emit(100, self.tr(\"已终止\"))\n\n except Exception as e:\n logger.error(f\"停止线程时出错:{str(e)}\")\n self.progress.emit(100, self.tr(\"终止时发生错误\"))\n" }, { "path": "app/thread/transcript_thread.py", "content": "import datetime\nimport tempfile\nfrom pathlib import Path\n\nfrom PyQt5.QtCore import QThread, pyqtSignal\n\nfrom app.core.asr import transcribe\nfrom app.core.entities import TranscribeOutputFormatEnum, TranscribeTask\nfrom app.core.utils.logger import setup_logger\nfrom app.core.utils.video_utils import video2audio\n\nlogger = setup_logger(\"transcript_thread\")\n\n\nclass TranscriptThread(QThread):\n finished = pyqtSignal(TranscribeTask)\n progress = pyqtSignal(int, str)\n error = pyqtSignal(str)\n\n def __init__(self, task: TranscribeTask):\n super().__init__()\n self.task = task\n\n def run(self):\n try:\n self.task.started_at = datetime.datetime.now()\n logger.info(f\"\\n{self.task.transcribe_config.print_config()}\")\n\n self._validate_task()\n\n # 检查是否已下载字幕文件\n if self._check_downloaded_subtitle():\n return\n\n self._perform_transcription()\n\n except Exception as e:\n logger.exception(\"转录过程中发生错误: %s\", str(e))\n self.error.emit(str(e))\n self.progress.emit(100, self.tr(\"转录失败\"))\n\n def _validate_task(self):\n \"\"\"验证任务配置\"\"\"\n if not self.task.file_path:\n raise ValueError(self.tr(\"文件路径为空\"))\n\n video_path = Path(self.task.file_path)\n if not video_path.exists():\n logger.error(f\"视频文件不存在:{video_path}\")\n raise ValueError(self.tr(\"视频文件不存在\"))\n\n if not self.task.transcribe_config:\n raise ValueError(self.tr(\"转录配置为空\"))\n\n if not self.task.output_path:\n raise ValueError(self.tr(\"输出路径为空\"))\n\n def _check_downloaded_subtitle(self) -> bool:\n \"\"\"检查是否存在下载的字幕文件\"\"\"\n if not (self.task.need_next_task and self.task.file_path):\n return False\n\n subtitle_dir = Path(self.task.file_path).parent / \"subtitle\"\n if not subtitle_dir.exists():\n return False\n\n downloaded_subtitles = list(subtitle_dir.glob(\"【下载字幕】*\"))\n if not downloaded_subtitles:\n return False\n\n subtitle_file = downloaded_subtitles[0]\n self.task.output_path = str(subtitle_file)\n logger.info(f\"字幕文件已下载,跳过转录。找到下载的字幕文件:{subtitle_file}\")\n self.progress.emit(100, self.tr(\"字幕已下载\"))\n self.finished.emit(self.task)\n return True\n\n def _perform_transcription(self):\n \"\"\"执行转录流程\"\"\"\n assert self.task.file_path is not None\n assert self.task.transcribe_config is not None\n assert self.task.output_path is not None\n\n video_path = Path(self.task.file_path)\n\n self.progress.emit(5, self.tr(\"转换音频中\"))\n logger.info(\"开始转换音频\")\n\n # 创建临时音频文件(delete=False 避免 Windows 权限问题)\n temp_audio_file = tempfile.NamedTemporaryFile(suffix=\".wav\", delete=False)\n temp_audio_path = temp_audio_file.name\n temp_audio_file.close() # 立即关闭文件句柄,让 ffmpeg 可以写入\n\n try:\n # 转换音频文件\n # 获取选中的音轨索引(如果有)\n audio_track_index = self.task.selected_audio_track_index\n is_success = video2audio(\n str(video_path),\n output=temp_audio_path,\n audio_track_index=audio_track_index,\n )\n if not is_success:\n logger.error(\"音频转换失败\")\n raise RuntimeError(self.tr(\"音频转换失败\"))\n\n self.progress.emit(20, self.tr(\"语音转录中\"))\n logger.info(\"开始语音转录\")\n\n # 进行转录\n asr_data = transcribe(\n temp_audio_path,\n self.task.transcribe_config,\n callback=self.progress_callback,\n )\n\n # 保存字幕文件(根据配置的输出格式)\n output_path = Path(self.task.output_path)\n output_format_enum = self.task.transcribe_config.output_format\n base_path = output_path.with_suffix(\"\")\n \n # 根据选择的格式导出\n if output_format_enum == TranscribeOutputFormatEnum.ALL:\n formats_to_export = [\n fmt.value.lower() \n for fmt in TranscribeOutputFormatEnum \n if fmt != TranscribeOutputFormatEnum.ALL\n ]\n else:\n formats_to_export = [output_format_enum.value.lower()]\n \n if self.task.need_next_task:\n formats_to_export.append(TranscribeOutputFormatEnum.SRT.value.lower())\n formats_to_export = list(set(formats_to_export))\n \n # 保存字幕文件\n for fmt in formats_to_export:\n save_path = f\"{base_path}.{fmt}\"\n asr_data.save(save_path)\n logger.info(\"%s 字幕文件已保存到: %s\", fmt.upper(), save_path)\n\n self.progress.emit(100, self.tr(\"转录完成\"))\n self.finished.emit(self.task)\n finally:\n Path(temp_audio_path).unlink(missing_ok=True)\n\n def progress_callback(self, value, message):\n progress = min(20 + (value * 0.8), 100)\n self.progress.emit(int(progress), message)\n" }, { "path": "app/thread/version_checker_thread.py", "content": "# coding: utf-8\nimport hashlib\nfrom datetime import datetime\n\nimport requests\nfrom PyQt5.QtCore import QObject, QVersionNumber, pyqtSignal\n\nfrom app.config import VERSION\nfrom app.core.utils.cache import get_version_state_cache\nfrom app.core.utils.logger import setup_logger\n\nlogger = setup_logger(\"version_checker\")\n\n\nclass VersionChecker(QObject):\n \"\"\"Version checker\"\"\"\n\n newVersionAvailable = pyqtSignal(str, bool, str, str)\n announcementAvailable = pyqtSignal(str)\n checkCompleted = pyqtSignal()\n\n def __init__(self):\n super().__init__()\n self.current_version = VERSION\n self.latest_version = VERSION\n self.update_info = \"\"\n self.update_required = False\n self.download_url = \"\"\n self.announcement = {}\n\n self.cache = get_version_state_cache()\n\n def get_latest_version_info(self) -> dict:\n \"\"\"Get latest version information\"\"\"\n url = \"https://vc.bkfeng.top/api/version\"\n headers = {\"app_version\": VERSION}\n\n try:\n response = requests.get(url, timeout=10, headers=headers)\n response.raise_for_status()\n data = response.json()\n # data = {\n # \"latest_version\": \"v1.4.0\",\n # \"update_required\": True,\n # \"update_info\": \"更新内容\",\n # \"download_url\": \"https://github.com/WEIFENG2333/VideoCaptioner/releases/latest\",\n # \"announcement\": {\n # \"enabled\": True,\n # \"content\": \"公告内容211\",\n # \"start_date\": \"2025-01-01\",\n # \"end_date\": \"2025-12-30\",\n # },\n # }\n\n self.latest_version = data.get(\"latest_version\", self.current_version)\n self.update_required = data.get(\"update_required\", False)\n self.update_info = data.get(\"update_info\", \"\")\n self.download_url = data.get(\"download_url\", \"\")\n self.announcement = data.get(\"announcement\", {})\n\n logger.info(\"Successfully fetched version info: %s\", self.latest_version)\n return data\n\n except requests.RequestException:\n return {}\n\n def has_new_version(self) -> bool:\n \"\"\"Check if new version is available\"\"\"\n try:\n latest_ver = self.latest_version.lstrip(\"v\")\n current_ver = self.current_version.lstrip(\"v\")\n\n latest_ver_num = QVersionNumber.fromString(latest_ver)\n current_ver_num = QVersionNumber.fromString(current_ver)\n\n if latest_ver_num > current_ver_num:\n logger.info(\n \"New version found: %s (current: %s)\",\n self.latest_version,\n self.current_version,\n )\n self.newVersionAvailable.emit(\n self.latest_version,\n self.update_required,\n self.update_info,\n self.download_url,\n )\n return True\n\n except Exception as e:\n logger.error(\"Version comparison failed: %s\", str(e))\n\n return False\n\n def check_announcement(self) -> None:\n \"\"\"Check and show announcement\"\"\"\n ann = self.announcement\n if not ann.get(\"enabled\", False):\n return\n\n content = ann.get(\"content\", \"\")\n if not content:\n return\n\n announcement_id = (\n hashlib.sha256(content.encode(\"utf-8\")).hexdigest()\n + \"_\"\n + datetime.today().strftime(\"%Y-%m-%d\")\n )\n\n settings_key = f\"announcement/shown_{announcement_id}\"\n if self.cache.get(settings_key, default=False):\n return\n\n start_date_str = ann.get(\"start_date\")\n end_date_str = ann.get(\"end_date\")\n if not start_date_str or not end_date_str:\n return\n\n try:\n start_date = datetime.strptime(start_date_str, \"%Y-%m-%d\").date()\n end_date = datetime.strptime(end_date_str, \"%Y-%m-%d\").date()\n today = datetime.today().date()\n\n if start_date <= today <= end_date:\n self.cache.set(settings_key, True, expire=30 * 60 * 24)\n self.announcementAvailable.emit(content)\n\n except ValueError as e:\n logger.error(\"Announcement date format error: %s\", str(e))\n\n def check_new_version_announcement(self) -> None:\n \"\"\"Check new version announcement\"\"\"\n if self.latest_version != self.current_version:\n return\n\n version_key = f\"version/shown_{self.latest_version}\"\n\n if not self.cache.get(version_key, default=False):\n self.cache.set(version_key, True)\n\n update_announcement = (\n f\"Welcome to VideoCaptioner {self.current_version}\\n\\n\"\n f\"What's new:\\n{self.update_info}\"\n )\n self.announcementAvailable.emit(update_announcement)\n\n def perform_check(self) -> None:\n \"\"\"Perform version and announcement check\"\"\"\n try:\n version_data = self.get_latest_version_info()\n if not version_data:\n return\n self.has_new_version()\n self.check_new_version_announcement()\n self.check_announcement()\n self.checkCompleted.emit()\n except Exception:\n logger.exception(\"Version and announcement check failed\")\n" }, { "path": "app/thread/video_download_thread.py", "content": "import os\nimport re\nfrom pathlib import Path\n\nimport requests\nimport yt_dlp\nfrom PyQt5.QtCore import QThread, pyqtSignal\n\nfrom app.config import APPDATA_PATH\nfrom app.core.utils.logger import setup_logger\n\nlogger = setup_logger(\"video_download_thread\")\n\n\nclass VideoDownloadThread(QThread):\n \"\"\"视频下载线程类\"\"\"\n\n finished = pyqtSignal(\n str\n ) # 发送下载完成的信号(视频路径, 字幕路径, 缩略图路径, 视频信息)\n progress = pyqtSignal(int, str) # 发送下载进度的信号\n error = pyqtSignal(str) # 发送错误信息的信号\n\n def __init__(self, url: str, work_dir: str):\n super().__init__()\n self.url = url\n self.work_dir = work_dir\n\n def run(self):\n try:\n video_file_path, subtitle_file_path, thumbnail_file_path, info_dict = (\n self.download()\n )\n self.finished.emit(video_file_path)\n except Exception as e:\n logger.exception(\"下载视频失败: %s\", str(e))\n self.error.emit(str(e))\n\n def progress_hook(self, d):\n \"\"\"下载进度回调函数\"\"\"\n if d[\"status\"] == \"downloading\":\n percent = d[\"_percent_str\"]\n speed = d[\"_speed_str\"]\n\n # 提取百分比和速度的纯文本\n clean_percent = (\n percent.replace(\"\\x1b[0;94m\", \"\")\n .replace(\"\\x1b[0m\", \"\")\n .strip()\n .replace(\"%\", \"\")\n )\n clean_speed = speed.replace(\"\\x1b[0;32m\", \"\").replace(\"\\x1b[0m\", \"\").strip()\n\n self.progress.emit(\n int(float(clean_percent)),\n f\"下载进度: {clean_percent}% 速度: {clean_speed}\",\n )\n\n def sanitize_filename(self, name: str, replacement: str = \"_\") -> str:\n \"\"\"清理文件名中不允许的字符\"\"\"\n # 定义不允许的字符\n forbidden_chars = r'<>:\"/\\\\|?*'\n\n # 替换不允许的字符\n sanitized = re.sub(f\"[{re.escape(forbidden_chars)}]\", replacement, name)\n\n # 移除控制字符\n sanitized = re.sub(r\"[\\0-\\31]\", \"\", sanitized)\n\n # 去除文件名末尾的空格和点\n sanitized = sanitized.rstrip(\" .\")\n\n # 限制文件名长度\n max_length = 255\n if len(sanitized) > max_length:\n base, ext = os.path.splitext(sanitized)\n base_max_length = max_length - len(ext)\n sanitized = base[:base_max_length] + ext\n\n # 处理Windows保留名称\n windows_reserved_names = {\n \"CON\",\n \"PRN\",\n \"AUX\",\n \"NUL\",\n \"COM1\",\n \"COM2\",\n \"COM3\",\n \"COM4\",\n \"COM5\",\n \"COM6\",\n \"COM7\",\n \"COM8\",\n \"COM9\",\n \"LPT1\",\n \"LPT2\",\n \"LPT3\",\n \"LPT4\",\n \"LPT5\",\n \"LPT6\",\n \"LPT7\",\n \"LPT8\",\n \"LPT9\",\n }\n name_without_ext = os.path.splitext(sanitized)[0].upper()\n if name_without_ext in windows_reserved_names:\n sanitized = f\"{sanitized}_\"\n\n # 如果文件名为空,返回默认名称\n if not sanitized:\n sanitized = \"default_filename\"\n\n return sanitized\n\n def download(self, need_subtitle: bool = True, need_thumbnail: bool = False):\n \"\"\"下载视频\"\"\"\n logger.info(\"开始下载视频: %s\", self.url)\n\n # 初始化 ydl 选项\n initial_ydl_opts = {\n \"outtmpl\": {\n \"default\": \"%(title).200s.%(ext)s\", # 限制文件名最长200个字符\n \"subtitle\": \"【下载字幕】.%(ext)s\",\n \"thumbnail\": \"thumbnail\",\n },\n \"format\": \"bestvideo[ext=mp4]+bestaudio[ext=m4a]/best[ext=mp4]/best\", # 优先下载mp4格式\n \"progress_hooks\": [self.progress_hook], # 下载进度钩子\n \"quiet\": True, # 禁用日志输出\n \"no_warnings\": True, # 禁用警告信息\n \"noprogress\": True,\n \"writeautomaticsub\": need_subtitle, # 下载自动生成的字幕\n \"writethumbnail\": need_thumbnail, # 下载缩略图\n \"thumbnail_format\": \"jpg\", # 指定缩略图的格式\n }\n\n # 检查 cookies 文件\n cookiefile_path = APPDATA_PATH / \"cookies.txt\"\n if cookiefile_path.exists():\n logger.info(f\"使用cookiefile: {cookiefile_path}\")\n initial_ydl_opts[\"cookiefile\"] = str(cookiefile_path)\n\n with yt_dlp.YoutubeDL(initial_ydl_opts) as ydl:\n # 提取视频信息(不下载)\n info_dict = ydl.extract_info(self.url, download=False)\n\n # 设置动态下载文件夹为视频标题\n video_title = self.sanitize_filename(info_dict.get(\"title\", \"MyVideo\"))\n video_work_dir = Path(self.work_dir) / self.sanitize_filename(video_title)\n subtitle_language = info_dict.get(\"language\", None)\n if subtitle_language:\n subtitle_language = subtitle_language.lower().split(\"-\")[0]\n\n try:\n subtitle_download_link = None\n automatic_captions = info_dict.get(\"automatic_captions\")\n if automatic_captions and subtitle_language:\n for lang_code in automatic_captions:\n if lang_code.startswith(subtitle_language):\n subtitle_download_link = automatic_captions[lang_code][-1][\n \"url\"\n ]\n break\n except Exception:\n subtitle_download_link = None\n\n # 设置 yt-dlp 下载选项\n ydl_opts = {\n \"paths\": {\n \"home\": str(video_work_dir),\n \"subtitle\": str(video_work_dir / \"subtitle\"),\n \"thumbnail\": str(video_work_dir),\n },\n }\n # 更新 yt-dlp 的配置\n ydl.params.update(ydl_opts)\n\n # 使用 process_info 进行下载\n ydl.process_info(info_dict)\n\n # 获取视频文件路径\n video_file_path = Path(ydl.prepare_filename(info_dict))\n if video_file_path.exists():\n video_file_path = str(video_file_path)\n else:\n video_file_path = None\n\n # 获取字幕文件路径\n subtitle_file_path = None\n for file in video_work_dir.glob(\"**/【下载字幕】*\"):\n file_path = str(file)\n if subtitle_language and subtitle_language not in file_path:\n logger.info(\n \"字幕语言错误,重新下载字幕: %s\", subtitle_download_link\n )\n os.remove(file_path)\n if subtitle_download_link:\n response = requests.get(subtitle_download_link)\n file_path = (\n video_work_dir\n / \"subtitle\"\n / f\"【下载字幕】{subtitle_language}.vtt\"\n )\n if res := response.text:\n with open(file_path, \"w\", encoding=\"utf-8\") as f:\n f.write(res)\n subtitle_file_path = file_path\n else:\n subtitle_file_path = file_path\n break\n\n # 获取缩略图文件路径\n thumbnail_file_path = None\n for file in video_work_dir.glob(\"**/thumbnail*\"):\n thumbnail_file_path = str(file)\n break\n\n logger.info(f\"视频下载完成: {video_file_path}\")\n logger.info(f\"字幕文件路径: {subtitle_file_path}\")\n return video_file_path, subtitle_file_path, thumbnail_file_path, info_dict\n" }, { "path": "app/thread/video_info_thread.py", "content": "import tempfile\nfrom pathlib import Path\n\nfrom PyQt5.QtCore import QThread, pyqtSignal\n\nfrom app.core.entities import VideoInfo\nfrom app.core.utils.logger import setup_logger\nfrom app.core.utils.video_utils import get_video_info\n\nlogger = setup_logger(\"video_info_thread\")\n\n\nclass VideoInfoThread(QThread):\n finished = pyqtSignal(VideoInfo)\n error = pyqtSignal(str)\n\n def __init__(self, file_path):\n super().__init__()\n self.file_path = file_path\n\n def run(self):\n try:\n # 生成缩略图到临时文件\n temp_dir = tempfile.gettempdir()\n file_name = Path(self.file_path).stem\n thumbnail_path = f\"{temp_dir}/{file_name}_thumbnail.jpg\"\n\n # 使用统一的 get_video_info 函数\n video_info = get_video_info(self.file_path, thumbnail_path=thumbnail_path)\n\n if video_info:\n self.finished.emit(video_info)\n else:\n self.error.emit(\"无法获取媒体文件信息,请确保文件格式正确\")\n\n except Exception as e:\n logger.exception(\"获取视频信息时出错\")\n self.error.emit(str(e))\n" }, { "path": "app/thread/video_synthesis_thread.py", "content": "import datetime\nimport tempfile\nfrom pathlib import Path\n\nfrom PyQt5.QtCore import QThread, pyqtSignal\n\nfrom app.core.asr.asr_data import ASRData\nfrom app.core.entities import SynthesisTask\nfrom app.core.utils.logger import setup_logger\nfrom app.core.utils.video_utils import add_subtitles, add_subtitles_with_style\n\nlogger = setup_logger(\"video_synthesis_thread\")\n\n\nclass VideoSynthesisThread(QThread):\n finished = pyqtSignal(SynthesisTask)\n progress = pyqtSignal(int, str)\n error = pyqtSignal(str)\n\n def __init__(self, task: SynthesisTask):\n super().__init__()\n self.task = task\n logger.debug(f\"初始化 VideoSynthesisThread,任务: {self.task}\")\n\n def run(self):\n try:\n self.task.started_at = datetime.datetime.now()\n config = self.task.synthesis_config\n logger.info(f\"\\n{config.print_config()}\")\n\n video_file = self.task.video_path\n subtitle_file = self.task.subtitle_path\n output_path = self.task.output_path\n\n if not config.need_video:\n logger.info(\"不需要合成视频,跳过\")\n self.progress.emit(100, self.tr(\"合成完成\"))\n self.finished.emit(self.task)\n return\n\n logger.info(f\"开始合成视频: {video_file}\")\n self.progress.emit(5, self.tr(\"正在合成\"))\n\n if not video_file:\n raise ValueError(self.tr(\"视频路径为空\"))\n if not subtitle_file:\n raise ValueError(self.tr(\"字幕路径为空\"))\n if not output_path:\n raise ValueError(self.tr(\"输出路径为空\"))\n\n video_quality = config.video_quality\n crf = video_quality.get_crf()\n preset = video_quality.get_preset()\n\n # 读取字幕数据\n asr_data = ASRData.from_subtitle_file(subtitle_file)\n\n if config.soft_subtitle:\n # 软字幕:转为 SRT 后内嵌\n with tempfile.NamedTemporaryFile(\n mode=\"w\",\n suffix=\".srt\",\n delete=False,\n encoding=\"utf-8\",\n prefix=\"VideoCaptioner_soft_\",\n ) as f:\n srt_content = asr_data.to_srt(layout=config.subtitle_layout)\n f.write(srt_content)\n temp_srt_path = f.name\n\n try:\n add_subtitles(\n video_file,\n temp_srt_path,\n output_path,\n crf=crf,\n preset=preset,\n soft_subtitle=True,\n progress_callback=self.progress_callback,\n )\n finally:\n Path(temp_srt_path).unlink(missing_ok=True)\n\n else:\n # 硬字幕:使用样式配置渲染\n add_subtitles_with_style(\n video_path=video_file,\n asr_data=asr_data,\n output_path=output_path,\n render_mode=config.render_mode,\n subtitle_layout=config.subtitle_layout,\n ass_style=config.ass_style,\n rounded_style=config.rounded_style,\n crf=crf,\n preset=preset,\n progress_callback=self.progress_callback,\n )\n\n self.progress.emit(100, self.tr(\"合成完成\"))\n logger.info(f\"视频合成完成,保存路径: {output_path}\")\n self.finished.emit(self.task)\n\n except Exception as e:\n logger.exception(f\"视频合成失败: {e}\")\n self.error.emit(str(e))\n self.progress.emit(100, self.tr(\"视频合成失败\"))\n\n def progress_callback(self, value, message):\n progress = int(5 + int(value) / 100 * 95)\n logger.debug(f\"合成进度: {progress}% - {message}\")\n self.progress.emit(progress, str(progress) + \"% \" + message)\n" }, { "path": "app/view/batch_process_interface.py", "content": "import os\n\nfrom PyQt5.QtCore import Qt, QUrl\nfrom PyQt5.QtGui import QColor, QDesktopServices, QFont\nfrom PyQt5.QtWidgets import (\n QFileDialog,\n QHBoxLayout,\n QHeaderView,\n QSizePolicy,\n QTableWidget,\n QTableWidgetItem,\n QVBoxLayout,\n QWidget,\n)\nfrom qfluentwidgets import (\n Action,\n ComboBox,\n InfoBar,\n InfoBarPosition,\n ProgressBar,\n PushButton,\n RoundMenu,\n TableWidget,\n)\nfrom qfluentwidgets import (\n FluentIcon as FIF,\n)\n\nfrom app.core.constant import (\n INFOBAR_DURATION_INFO,\n INFOBAR_DURATION_SUCCESS,\n INFOBAR_DURATION_WARNING,\n)\nfrom app.core.entities import (\n BatchTaskStatus,\n BatchTaskType,\n SupportedAudioFormats,\n SupportedSubtitleFormats,\n SupportedVideoFormats,\n)\nfrom app.thread.batch_process_thread import (\n BatchProcessThread,\n BatchTask,\n)\n\n\nclass BatchProcessInterface(QWidget):\n def __init__(self, parent=None):\n super().__init__(parent=parent)\n self.setObjectName(\"batchProcessInterface\")\n self.setWindowTitle(self.tr(\"批量处理\"))\n self.setAcceptDrops(True)\n self.batch_thread = BatchProcessThread()\n\n self.init_ui()\n self.setup_connections()\n\n def init_ui(self):\n # 创建主布局\n main_layout = QVBoxLayout(self)\n main_layout.setContentsMargins(16, 16, 16, 16)\n main_layout.setSpacing(8)\n\n # 顶部控制区域\n top_layout = QHBoxLayout()\n top_layout.setSpacing(8)\n\n # 任务类型选择\n self.task_type_combo = ComboBox()\n self.task_type_combo.addItems([str(task_type) for task_type in BatchTaskType])\n self.task_type_combo.setCurrentText(str(BatchTaskType.FULL_PROCESS))\n\n # 任务类型说明\n self.task_type_descriptions = {\n str(BatchTaskType.TRANSCRIBE): self.tr(\"仅进行语音识别,生成字幕文件\"),\n str(BatchTaskType.SUBTITLE): self.tr(\"对已有字幕进行分割、优化或翻译\"),\n str(BatchTaskType.TRANS_SUB): self.tr(\"先转录再处理字幕,不合成视频\"),\n str(BatchTaskType.FULL_PROCESS): self.tr(\"转录 → 字幕处理 → 合成视频\"),\n }\n\n # 控制按钮\n self.add_file_btn = PushButton(self.tr(\"添加文件\"), icon=FIF.ADD)\n self.start_all_btn = PushButton(self.tr(\"开始处理\"), icon=FIF.PLAY)\n self.clear_btn = PushButton(self.tr(\"清空列表\"), icon=FIF.DELETE)\n\n # 添加到顶部布局\n top_layout.addWidget(self.task_type_combo)\n top_layout.addWidget(self.add_file_btn)\n top_layout.addWidget(self.clear_btn)\n\n top_layout.addStretch()\n top_layout.addWidget(self.start_all_btn)\n\n # 创建任务表格\n self.task_table = TableWidget()\n self.task_table.setColumnCount(3)\n self.task_table.setHorizontalHeaderLabels([\"文件名\", \"进度\", \"状态\"])\n\n # 设置表格样式\n self.task_table.horizontalHeader().setSectionResizeMode(0, QHeaderView.Stretch)\n self.task_table.horizontalHeader().setSectionResizeMode(1, QHeaderView.Fixed)\n self.task_table.horizontalHeader().setSectionResizeMode(2, QHeaderView.Fixed)\n self.task_table.setColumnWidth(1, 250) # 进度条列宽\n self.task_table.setColumnWidth(2, 160) # 状态列宽\n\n # 设置行高\n self.task_table.verticalHeader().setDefaultSectionSize(40) # 设置默认行高\n\n # 设置表格边框\n self.task_table.setBorderVisible(True)\n self.task_table.setBorderRadius(12)\n\n # 设置表格不可编辑\n self.task_table.setEditTriggers(QTableWidget.NoEditTriggers)\n\n # 设置表格大小策略\n self.task_table.setSizePolicy(QSizePolicy.Expanding, QSizePolicy.Expanding)\n self.task_table.setMinimumHeight(300) # 设置最小高度\n\n # 连接双击信号\n self.task_table.doubleClicked.connect(self.on_table_double_clicked)\n\n # 添加到主布局\n main_layout.addLayout(top_layout)\n main_layout.addWidget(self.task_table)\n\n # 连接信号\n self.add_file_btn.clicked.connect(self.on_add_file_clicked)\n self.start_all_btn.clicked.connect(self.start_all_tasks)\n self.clear_btn.clicked.connect(self.clear_tasks)\n self.task_type_combo.currentTextChanged.connect(self.on_task_type_changed)\n\n def setup_connections(self):\n # 批处理线程信号连接\n self.batch_thread.task_progress.connect(self.update_task_progress)\n self.batch_thread.task_error.connect(self.on_task_error)\n self.batch_thread.task_completed.connect(self.on_task_completed)\n\n # 表格右键菜单\n self.task_table.setContextMenuPolicy(Qt.CustomContextMenu) # type: ignore\n self.task_table.customContextMenuRequested.connect(self.show_context_menu)\n\n def on_add_file_clicked(self):\n task_type = self.task_type_combo.currentText()\n file_filter = \"\"\n if task_type in [\n BatchTaskType.TRANSCRIBE,\n BatchTaskType.TRANS_SUB,\n BatchTaskType.FULL_PROCESS,\n ]:\n # 获取所有支持的音视频格式\n audio_formats = [f\"*.{fmt.value}\" for fmt in SupportedAudioFormats]\n video_formats = [f\"*.{fmt.value}\" for fmt in SupportedVideoFormats]\n formats = audio_formats + video_formats\n file_filter = f\"音视频文件 ({' '.join(formats)})\"\n elif task_type == BatchTaskType.SUBTITLE:\n # 获取所有支持的字幕格式\n subtitle_formats = [f\"*.{fmt.value}\" for fmt in SupportedSubtitleFormats]\n file_filter = f\"字幕文件 ({' '.join(subtitle_formats)})\"\n\n files, _ = QFileDialog.getOpenFileNames(self, \"选择文件\", \"\", file_filter)\n if files:\n self.add_files(files)\n\n def dragEnterEvent(self, event):\n if event.mimeData().hasUrls():\n event.accept()\n else:\n event.ignore()\n\n def dropEvent(self, event):\n files = [url.toLocalFile() for url in event.mimeData().urls()]\n self.add_files(files)\n\n def add_files(self, file_paths):\n task_type = BatchTaskType(self.task_type_combo.currentText())\n\n # 检查文件是否存在并收集不存在的文件\n non_existent_files = []\n valid_files = []\n for file_path in file_paths:\n if not os.path.exists(file_path):\n non_existent_files.append(os.path.basename(file_path))\n else:\n valid_files.append(file_path)\n\n # 如果有不存在的文件,显示警告\n if non_existent_files:\n InfoBar.warning(\n title=\"文件不存在\",\n content=f\"以下文件不存在:\\n{', '.join(non_existent_files)}\",\n duration=INFOBAR_DURATION_WARNING,\n position=InfoBarPosition.TOP,\n parent=self,\n )\n\n # 如果没有有效文件,直接返回\n if not valid_files:\n return\n\n # 对有效文件按文件名排序\n valid_files.sort(key=lambda x: os.path.basename(x).lower())\n\n # 如果表格为空,自动检测文件类型并设置任务类型\n if self.task_table.rowCount() == 0 and self.task_type_combo.currentIndex() == 0:\n first_file = valid_files[0].lower()\n is_subtitle = any(\n first_file.endswith(f\".{fmt.value}\") for fmt in SupportedSubtitleFormats\n )\n if is_subtitle:\n self.task_type_combo.setCurrentText(str(BatchTaskType.SUBTITLE))\n task_type = BatchTaskType.SUBTITLE\n # elif is_media:\n # self.task_type_combo.setCurrentText(str(BatchTaskType.FULL_PROCESS))\n # task_type = BatchTaskType.FULL_PROCESS\n\n # 过滤文件类型\n valid_files = self.filter_files(valid_files, task_type)\n\n if not valid_files:\n InfoBar.warning(\n title=\"无效文件\",\n content=\"请选择正确的文件类型\",\n duration=INFOBAR_DURATION_WARNING,\n position=InfoBarPosition.TOP,\n parent=self,\n )\n return\n\n for file_path in valid_files:\n # 检查是否已存在相同任务\n exists = False\n for row in range(self.task_table.rowCount()):\n if self.task_table.item(row, 0).toolTip() == file_path:\n exists = True\n InfoBar.warning(\n title=\"任务已存在\",\n content=\"任务已存在\",\n duration=INFOBAR_DURATION_WARNING,\n position=InfoBarPosition.TOP_RIGHT,\n parent=self,\n )\n break\n\n if not exists:\n self.add_task_to_table(file_path)\n\n def filter_files(self, file_paths, task_type: BatchTaskType):\n valid_extensions = {}\n\n # 根据任务类型设置有效的扩展名\n if task_type in [\n BatchTaskType.TRANSCRIBE,\n BatchTaskType.TRANS_SUB,\n BatchTaskType.FULL_PROCESS,\n ]:\n valid_extensions = {f\".{fmt.value}\" for fmt in SupportedAudioFormats} | {\n f\".{fmt.value}\" for fmt in SupportedVideoFormats\n }\n elif task_type == BatchTaskType.SUBTITLE:\n valid_extensions = {f\".{fmt.value}\" for fmt in SupportedSubtitleFormats}\n\n return [\n f\n for f in file_paths\n if any(f.lower().endswith(ext) for ext in valid_extensions)\n ]\n\n def add_task_to_table(self, file_path):\n row = self.task_table.rowCount()\n self.task_table.insertRow(row)\n\n # 文件名\n file_name = QTableWidgetItem(os.path.basename(file_path))\n file_name.setToolTip(file_path)\n self.task_table.setItem(row, 0, file_name)\n\n # 进度条\n progress_bar = ProgressBar()\n progress_bar.setRange(0, 100)\n progress_bar.setValue(0)\n progress_bar.setFixedHeight(18)\n self.task_table.setCellWidget(row, 1, progress_bar)\n\n # 状态\n status = QTableWidgetItem(str(BatchTaskStatus.WAITING))\n status.setTextAlignment(Qt.AlignCenter) # type: ignore\n status.setForeground(Qt.gray) # type: ignore # 设置字体颜色为灰色\n font = QFont()\n font.setBold(True)\n status.setFont(font)\n self.task_table.setItem(row, 2, status)\n\n def show_context_menu(self, pos):\n row = self.task_table.rowAt(pos.y())\n if row < 0:\n return\n\n menu = RoundMenu(parent=self)\n file_path = self.task_table.item(row, 0).toolTip()\n status = self.task_table.item(row, 2).text()\n\n start_action = Action(FIF.PLAY, \"开始\")\n start_action.triggered.connect(lambda: self.start_task(file_path))\n menu.addAction(start_action)\n\n cancel_action = Action(FIF.CLOSE, \"取消\")\n cancel_action.triggered.connect(lambda: self.cancel_task(file_path))\n menu.addAction(cancel_action)\n\n menu.addSeparator()\n open_folder_action = Action(FIF.FOLDER, \"打开输出文件夹\")\n open_folder_action.triggered.connect(lambda: self.open_output_folder(file_path))\n menu.addAction(open_folder_action)\n\n if status != str(BatchTaskStatus.WAITING):\n start_action.setEnabled(False)\n\n menu.exec_(self.task_table.viewport().mapToGlobal(pos))\n\n def open_output_folder(self, file_path: str):\n # 根据任务类型和文件路径确定输出文件夹\n task_type = BatchTaskType(self.task_type_combo.currentText())\n file_dir = os.path.dirname(file_path)\n\n if task_type == BatchTaskType.FULL_PROCESS:\n # 对于全流程任务,输出在视频同目录下\n output_dir = file_dir\n else:\n # 其他任务输出在文件同目录下\n output_dir = file_dir\n\n # 打开文件夹\n QDesktopServices.openUrl(QUrl.fromLocalFile(output_dir))\n\n def update_task_progress(self, file_path: str, progress: int, status: str):\n for row in range(self.task_table.rowCount()):\n if self.task_table.item(row, 0).toolTip() == file_path:\n # 更新进度条\n progress_bar = self.task_table.cellWidget(row, 1)\n progress_bar.setValue(progress)\n # 更新状态\n self.task_table.item(row, 2).setText(status)\n break\n\n def on_task_error(self, file_path: str, error: str):\n for row in range(self.task_table.rowCount()):\n if self.task_table.item(row, 0).toolTip() == file_path:\n status_item = self.task_table.item(row, 2)\n status_item.setText(str(BatchTaskStatus.FAILED))\n status_item.setToolTip(error)\n break\n\n def on_task_completed(self, file_path: str):\n for row in range(self.task_table.rowCount()):\n if self.task_table.item(row, 0).toolTip() == file_path:\n self.task_table.item(row, 2).setText(str(BatchTaskStatus.COMPLETED))\n self.task_table.item(row, 2).setForeground(QColor(\"#13A10E\"))\n break\n\n def start_all_tasks(self):\n # 检查是否有任务\n if self.task_table.rowCount() == 0:\n InfoBar.warning(\n title=\"无任务\",\n content=\"请先添加需要处理的文件\",\n duration=INFOBAR_DURATION_WARNING,\n position=InfoBarPosition.TOP,\n parent=self,\n )\n return\n\n # 检查是否有等待处理的任务\n waiting_tasks = 0\n for row in range(self.task_table.rowCount()):\n if self.task_table.item(row, 2).text() == str(BatchTaskStatus.WAITING):\n waiting_tasks += 1\n\n if waiting_tasks == 0:\n InfoBar.warning(\n title=\"无待处理任务\",\n content=\"所有任务已经在处理或已完成\",\n duration=INFOBAR_DURATION_WARNING,\n position=InfoBarPosition.TOP,\n parent=self,\n )\n return\n\n # 显示开始处理的提示\n InfoBar.success(\n title=self.tr(\"开始处理\"),\n content=f\"开始处理 {waiting_tasks} 个任务\",\n duration=INFOBAR_DURATION_SUCCESS,\n position=InfoBarPosition.TOP,\n parent=self,\n )\n # 开始处理任务\n for row in range(self.task_table.rowCount()):\n file_path = self.task_table.item(row, 0).toolTip()\n status = self.task_table.item(row, 2).text()\n if status == str(BatchTaskStatus.WAITING):\n task_type = BatchTaskType(self.task_type_combo.currentText())\n batch_task = BatchTask(file_path, task_type)\n self.batch_thread.add_task(batch_task)\n\n def start_task(self, file_path: str):\n # 显示开始处理的提示\n file_name = os.path.basename(file_path)\n InfoBar.success(\n title=self.tr(\"开始处理\"),\n content=f\"开始处理文件:{file_name}\",\n duration=INFOBAR_DURATION_SUCCESS,\n position=InfoBarPosition.TOP,\n parent=self,\n )\n\n # 创建并添加单个任务\n task_type = BatchTaskType(self.task_type_combo.currentText())\n batch_task = BatchTask(file_path, task_type)\n self.batch_thread.add_task(batch_task)\n\n def cancel_task(self, file_path: str):\n self.batch_thread.stop_task(file_path)\n # 从表格中移除任务\n for row in range(self.task_table.rowCount()):\n if self.task_table.item(row, 0).toolTip() == file_path:\n self.task_table.removeRow(row)\n break\n\n def clear_tasks(self):\n self.batch_thread.stop_all()\n self.task_table.setRowCount(0)\n\n def on_task_type_changed(self, task_type: str):\n # 显示任务类型说明\n description = self.task_type_descriptions.get(task_type, \"\")\n if description:\n InfoBar.info(\n title=task_type,\n content=description,\n duration=INFOBAR_DURATION_INFO,\n position=InfoBarPosition.BOTTOM,\n parent=self,\n )\n # 清空当前任务列表\n self.clear_tasks()\n\n def closeEvent(self, event):\n self.batch_thread.stop_all()\n super().closeEvent(event)\n\n def on_table_double_clicked(self, index):\n \"\"\"处理表格双击事件\"\"\"\n row = index.row()\n file_path = self.task_table.item(row, 0).toolTip()\n self.open_output_folder(file_path)\n" }, { "path": "app/view/home_interface.py", "content": "from typing import Optional\n\nfrom PyQt5.QtWidgets import QSizePolicy, QStackedWidget, QVBoxLayout, QWidget\nfrom qfluentwidgets import SegmentedWidget\n\nfrom app.core.llm.context import generate_task_id\nfrom app.core.task_factory import TaskFactory\nfrom app.view.subtitle_interface import SubtitleInterface\nfrom app.view.task_creation_interface import TaskCreationInterface\nfrom app.view.transcription_interface import TranscriptionInterface\nfrom app.view.video_synthesis_interface import VideoSynthesisInterface\n\n\nclass HomeInterface(QWidget):\n def __init__(self, parent=None):\n super().__init__(parent)\n self._current_task_id: Optional[str] = None # 当前流程的任务 ID\n\n # 设置对象名称和样式\n self.setObjectName(\"HomeInterface\")\n self.setStyleSheet(\n \"\"\"\n HomeInterface{background: white}\n \"\"\"\n )\n\n # 创建分段控件和堆叠控件\n self.pivot = SegmentedWidget(self)\n self.pivot.setSizePolicy(QSizePolicy.Minimum, QSizePolicy.Fixed)\n\n self.stackedWidget = QStackedWidget(self)\n self.vBoxLayout = QVBoxLayout(self)\n\n # 添加子界面\n self.task_creation_interface = TaskCreationInterface(self)\n self.transcription_interface = TranscriptionInterface(self)\n self.subtitle_optimization_interface = SubtitleInterface(self)\n self.video_synthesis_interface = VideoSynthesisInterface(self)\n\n self.addSubInterface(\n self.task_creation_interface, \"TaskCreationInterface\", self.tr(\"任务创建\")\n )\n self.addSubInterface(\n self.transcription_interface, \"TranscriptionInterface\", self.tr(\"语音转录\")\n )\n self.addSubInterface(\n self.subtitle_optimization_interface,\n \"SubtitleInterface\",\n self.tr(\"字幕优化与翻译\"),\n )\n self.addSubInterface(\n self.video_synthesis_interface,\n \"VideoSynthesisInterface\",\n self.tr(\"字幕视频合成\"),\n )\n\n self.vBoxLayout.addWidget(self.pivot)\n self.vBoxLayout.addWidget(self.stackedWidget)\n self.vBoxLayout.setContentsMargins(30, 10, 30, 30)\n\n self.stackedWidget.currentChanged.connect(self.onCurrentIndexChanged)\n self.stackedWidget.setCurrentWidget(self.task_creation_interface)\n self.pivot.setCurrentItem(\"TaskCreationInterface\")\n\n self.task_creation_interface.finished.connect(self.switch_to_transcription)\n self.transcription_interface.finished.connect(\n self.switch_to_subtitle_optimization\n )\n self.subtitle_optimization_interface.finished.connect(\n self.switch_to_video_synthesis\n )\n\n def switch_to_transcription(self, file_path):\n # 流程开始,生成新的 task_id\n self._current_task_id = generate_task_id()\n\n transcribe_task = TaskFactory.create_transcribe_task(\n file_path, need_next_task=True, task_id=self._current_task_id\n )\n self.transcription_interface.set_task(transcribe_task)\n self.transcription_interface.process()\n self.stackedWidget.setCurrentWidget(self.transcription_interface)\n self.pivot.setCurrentItem(\"TranscriptionInterface\")\n\n def switch_to_subtitle_optimization(self, file_path, video_path):\n # 继续使用同一个 task_id\n subtitle_task = TaskFactory.create_subtitle_task(\n file_path, video_path, need_next_task=True, task_id=self._current_task_id\n )\n self.subtitle_optimization_interface.set_task(subtitle_task)\n self.subtitle_optimization_interface.process()\n self.stackedWidget.setCurrentWidget(self.subtitle_optimization_interface)\n self.pivot.setCurrentItem(\"SubtitleInterface\")\n\n def switch_to_video_synthesis(self, video_path, subtitle_path):\n # 继续使用同一个 task_id,流程结束后清空\n synthesis_task = TaskFactory.create_synthesis_task(\n video_path, subtitle_path, need_next_task=True, task_id=self._current_task_id\n )\n self._current_task_id = None # 流程结束\n self.video_synthesis_interface.set_task(synthesis_task)\n self.video_synthesis_interface.process()\n self.stackedWidget.setCurrentWidget(self.video_synthesis_interface)\n self.pivot.setCurrentItem(\"VideoSynthesisInterface\")\n\n def addSubInterface(self, widget, objectName, text):\n # 添加子界面到堆叠控件和分段控件\n widget.setObjectName(objectName)\n self.stackedWidget.addWidget(widget)\n self.pivot.addItem(\n routeKey=objectName,\n text=text,\n onClick=lambda: self.stackedWidget.setCurrentWidget(widget),\n )\n\n def onCurrentIndexChanged(self, index):\n # 当堆叠控件的当前索引改变时,更新分段控件的当前项\n widget = self.stackedWidget.widget(index)\n if widget:\n self.pivot.setCurrentItem(widget.objectName())\n\n def closeEvent(self, event):\n # 关闭事件,关闭所有子界面\n self.task_creation_interface.close()\n self.transcription_interface.close()\n self.subtitle_optimization_interface.close()\n self.video_synthesis_interface.close()\n super().closeEvent(event)\n" }, { "path": "app/view/llm_logs_interface.py", "content": "\"\"\"LLM 请求日志查看界面\"\"\"\n\nimport json\nfrom typing import Any, Dict, List\n\nfrom PyQt5.QtCore import QFileSystemWatcher, Qt\nfrom PyQt5.QtWidgets import (\n QApplication,\n QHBoxLayout,\n QHeaderView,\n QTableWidgetItem,\n QVBoxLayout,\n QWidget,\n)\nfrom qfluentwidgets import (\n BodyLabel,\n CaptionLabel,\n InfoBar,\n InfoBarPosition,\n MessageBox,\n MessageBoxBase,\n PillPushButton,\n PlainTextEdit,\n PushButton,\n SearchLineEdit,\n SubtitleLabel,\n TableWidget,\n ToolButton,\n setCustomStyleSheet,\n)\nfrom qfluentwidgets import FluentIcon as FIF\n\nfrom app.config import LLM_LOG_FILE, LOG_PATH\n\nPAGE_SIZE = 50\n\n\nclass LogDetailDialog(MessageBoxBase):\n \"\"\"日志详情对话框\"\"\"\n\n def __init__(self, log_entry: Dict[str, Any], parent=None):\n super().__init__(parent)\n self.log_entry = log_entry\n self._setup_ui()\n\n def _setup_ui(self):\n self.titleLabel = SubtitleLabel(self.tr(\"请求详情\"))\n self.viewLayout.addWidget(self.titleLabel)\n\n # 提取信息\n time_str = self.log_entry.get(\"time\", \"\")\n model = self.log_entry.get(\"request\", {}).get(\"model\", \"未知\")\n duration = self.log_entry.get(\"duration_ms\", 0) / 1000\n stage = self.log_entry.get(\"stage\", \"\") or \"-\"\n\n usage = self.log_entry.get(\"response\", {}).get(\"usage\", {})\n prompt_tokens = usage.get(\"prompt_tokens\", 0)\n completion_tokens = usage.get(\"completion_tokens\", 0)\n\n # 顶部信息栏\n info_row = QHBoxLayout()\n info_row.setSpacing(8)\n info_row.setContentsMargins(0, 0, 0, 8)\n\n # 用 PillPushButton 展示各项信息(禁用点击)\n items = [\n time_str,\n stage,\n model,\n f\"{duration:.1f}s\",\n f\"input token: {prompt_tokens}\",\n f\"output token: {completion_tokens}\",\n ]\n for text in items:\n if text:\n pill = PillPushButton(str(text))\n pill.setCheckable(False)\n pill.setEnabled(False)\n pill.setFixedHeight(24)\n info_row.addWidget(pill)\n\n info_row.addStretch()\n self.viewLayout.addLayout(info_row)\n\n # Request\n self.viewLayout.addWidget(SubtitleLabel(\"Request\"))\n self.request_edit = PlainTextEdit()\n self.request_edit.setReadOnly(True)\n self.request_edit.setMinimumHeight(180)\n request_text = json.dumps(\n self.log_entry.get(\"request\", {}), indent=2, ensure_ascii=False\n )\n self.request_edit.setPlainText(request_text)\n self.viewLayout.addWidget(self.request_edit)\n\n # Response\n self.viewLayout.addWidget(SubtitleLabel(\"Response\"))\n self.response_edit = PlainTextEdit()\n self.response_edit.setReadOnly(True)\n self.response_edit.setMinimumHeight(180)\n response_text = json.dumps(\n self.log_entry.get(\"response\", {}), indent=2, ensure_ascii=False\n )\n self.response_edit.setPlainText(response_text)\n self.viewLayout.addWidget(self.response_edit)\n\n # 底部按钮:替换默认按钮\n self.yesButton.setText(self.tr(\"关闭\"))\n self.cancelButton.hide() # type: ignore\n\n copy_req_btn = PushButton(FIF.COPY, self.tr(\"复制请求\"))\n copy_req_btn.clicked.connect(self._copy_request)\n self.buttonLayout.insertWidget(0, copy_req_btn) # type: ignore\n\n copy_resp_btn = PushButton(FIF.COPY, self.tr(\"复制响应\"))\n copy_resp_btn.clicked.connect(self._copy_response)\n self.buttonLayout.insertWidget(1, copy_resp_btn) # type: ignore\n\n self.widget.setMinimumWidth(700)\n\n def _copy_request(self):\n text = json.dumps(\n self.log_entry.get(\"request\", {}), indent=2, ensure_ascii=False\n )\n clipboard = QApplication.clipboard()\n if clipboard:\n clipboard.setText(text)\n InfoBar.success(\n title=\"\",\n content=self.tr(\"已复制\"),\n parent=self,\n position=InfoBarPosition.TOP,\n duration=1500,\n )\n\n def _copy_response(self):\n text = json.dumps(\n self.log_entry.get(\"response\", {}), indent=2, ensure_ascii=False\n )\n clipboard = QApplication.clipboard()\n if clipboard:\n clipboard.setText(text)\n InfoBar.success(\n title=\"\",\n content=self.tr(\"已复制\"),\n parent=self,\n position=InfoBarPosition.TOP,\n duration=1500,\n )\n\n\nclass LLMLogsInterface(QWidget):\n \"\"\"LLM 请求日志界面\"\"\"\n\n def __init__(self, parent=None):\n super().__init__(parent)\n self.setObjectName(\"llmLogsInterface\")\n self.setWindowTitle(self.tr(\"LLM 请求日志\"))\n\n self.all_logs: List[Dict[str, Any]] = []\n self.filtered_logs: List[Dict[str, Any]] = []\n self.current_page = 0\n\n self._setup_ui()\n self._connect_signals()\n self._load_logs()\n self._setup_file_watcher()\n\n def _setup_ui(self):\n self.main_layout = QVBoxLayout(self)\n self.main_layout.setContentsMargins(20, 20, 20, 20)\n self.main_layout.setSpacing(12)\n\n self._setup_toolbar()\n self._setup_table()\n self._setup_footer()\n\n def _setup_toolbar(self):\n toolbar = QHBoxLayout()\n toolbar.setSpacing(10)\n\n self.search_edit = SearchLineEdit()\n self.search_edit.setPlaceholderText(self.tr(\"搜索任务ID、文件名、模型...\"))\n self.search_edit.setFixedWidth(280)\n toolbar.addWidget(self.search_edit)\n\n toolbar.addStretch()\n\n self.refresh_btn = PushButton(FIF.SYNC, self.tr(\"刷新\"))\n toolbar.addWidget(self.refresh_btn)\n\n self.clear_btn = PushButton(FIF.DELETE, self.tr(\"清空日志\"))\n toolbar.addWidget(self.clear_btn)\n\n self.main_layout.addLayout(toolbar)\n\n def _setup_table(self):\n self.table = TableWidget()\n self.table.setColumnCount(7)\n self.table.setHorizontalHeaderLabels(\n [\n self.tr(\"时间\"),\n self.tr(\"任务ID\"),\n self.tr(\"文件\"),\n self.tr(\"阶段\"),\n self.tr(\"模型\"),\n self.tr(\"耗时\"),\n self.tr(\"Tokens\"),\n ]\n )\n\n header = self.table.horizontalHeader()\n if header:\n header.setSectionResizeMode(0, QHeaderView.Fixed)\n header.setSectionResizeMode(1, QHeaderView.Fixed)\n header.setSectionResizeMode(2, QHeaderView.Stretch) # 文件 - 自适应\n header.setSectionResizeMode(3, QHeaderView.Fixed)\n header.setSectionResizeMode(4, QHeaderView.Stretch) # 模型 - 自适应\n header.setSectionResizeMode(5, QHeaderView.Fixed)\n header.setSectionResizeMode(6, QHeaderView.Fixed)\n\n self.table.setColumnWidth(0, 130) # 时间\n self.table.setColumnWidth(1, 100) # 任务ID\n self.table.setColumnWidth(3, 90) # 阶段\n self.table.setColumnWidth(5, 70) # 耗时\n self.table.setColumnWidth(6, 70) # Tokens\n\n v_header = self.table.verticalHeader()\n if v_header:\n v_header.setVisible(False)\n\n self.table.setEditTriggers(self.table.NoEditTriggers)\n self.table.setSelectionBehavior(self.table.SelectRows)\n self.table.setSelectionMode(self.table.SingleSelection)\n self.table.setBorderVisible(True)\n self.table.setBorderRadius(8)\n\n # 减少单元格内边距,让文字显示更多\n qss = \"QTableView::item { padding-left: 8px; padding-right: 8px; }\"\n setCustomStyleSheet(self.table, qss, qss)\n\n self.main_layout.addWidget(self.table)\n\n def _setup_footer(self):\n \"\"\"底部:记录数 + 提示 + 分页\"\"\"\n footer = QHBoxLayout()\n footer.setSpacing(15)\n\n # 记录数\n self.status_label = BodyLabel(self.tr(\"共 0 条\"))\n footer.addWidget(self.status_label)\n\n # 双击提示\n hint_label = CaptionLabel(self.tr(\"双击查看详情\"))\n hint_label.setStyleSheet(\"color: gray;\")\n footer.addWidget(hint_label)\n\n footer.addStretch()\n\n # 右侧:分页\n self.prev_btn = ToolButton(FIF.LEFT_ARROW)\n self.prev_btn.setEnabled(False)\n footer.addWidget(self.prev_btn)\n\n self.page_label = BodyLabel(\"1 / 1\")\n footer.addWidget(self.page_label)\n\n self.next_btn = ToolButton(FIF.RIGHT_ARROW)\n self.next_btn.setEnabled(False)\n footer.addWidget(self.next_btn)\n\n self.main_layout.addLayout(footer)\n\n def _connect_signals(self):\n self.refresh_btn.clicked.connect(self._on_refresh_clicked)\n self.clear_btn.clicked.connect(self._clear_logs)\n self.search_edit.textChanged.connect(self._filter_logs)\n self.table.doubleClicked.connect(self._show_detail)\n self.prev_btn.clicked.connect(self._prev_page)\n self.next_btn.clicked.connect(self._next_page)\n\n def _setup_file_watcher(self):\n \"\"\"设置文件监控,日志文件变化时自动刷新\"\"\"\n self.file_watcher = QFileSystemWatcher(self)\n if LLM_LOG_FILE.exists():\n self.file_watcher.addPath(str(LLM_LOG_FILE))\n # 同时监控目录,以便检测文件创建\n self.file_watcher.addPath(str(LOG_PATH))\n self.file_watcher.fileChanged.connect(self._on_file_changed)\n self.file_watcher.directoryChanged.connect(self._on_dir_changed)\n\n def _on_file_changed(self, path: str):\n \"\"\"日志文件内容变化时自动刷新\"\"\"\n self._load_logs()\n # 文件变化后可能需要重新添加监控\n if LLM_LOG_FILE.exists() and str(LLM_LOG_FILE) not in self.file_watcher.files():\n self.file_watcher.addPath(str(LLM_LOG_FILE))\n\n def _on_dir_changed(self, path: str):\n \"\"\"目录变化时检查日志文件是否创建\"\"\"\n if LLM_LOG_FILE.exists() and str(LLM_LOG_FILE) not in self.file_watcher.files():\n self.file_watcher.addPath(str(LLM_LOG_FILE))\n self._load_logs()\n\n def _on_refresh_clicked(self):\n \"\"\"手动刷新按钮点击\"\"\"\n self._load_logs()\n InfoBar.success(\n title=\"\",\n content=self.tr(\"刷新成功\"),\n parent=self,\n position=InfoBarPosition.TOP,\n duration=1000,\n )\n\n def _load_logs(self):\n \"\"\"加载日志文件\"\"\"\n self.all_logs = []\n\n if not LLM_LOG_FILE.exists():\n self._update_table()\n return\n\n try:\n with open(LLM_LOG_FILE, \"r\", encoding=\"utf-8\") as f:\n for line in f:\n line = line.strip()\n if line:\n try:\n self.all_logs.append(json.loads(line))\n except json.JSONDecodeError:\n continue\n except Exception as e:\n InfoBar.error(\n title=self.tr(\"错误\"),\n content=str(e),\n parent=self,\n position=InfoBarPosition.TOP,\n duration=3000,\n )\n return\n\n self.all_logs.reverse()\n self._filter_logs()\n\n def _filter_logs(self):\n \"\"\"根据搜索词过滤日志\"\"\"\n search_text = self.search_edit.text().lower()\n\n if not search_text:\n self.filtered_logs = self.all_logs.copy()\n else:\n self.filtered_logs = []\n for log in self.all_logs:\n model = log.get(\"request\", {}).get(\"model\", \"\").lower()\n task_id = log.get(\"task_id\", \"\").lower()\n file_name = log.get(\"file_name\", \"\").lower()\n stage = log.get(\"stage\", \"\").lower()\n messages = json.dumps(log.get(\"request\", {}).get(\"messages\", []))\n response = json.dumps(log.get(\"response\", {}))\n\n if (\n search_text in model\n or search_text in task_id\n or search_text in file_name\n or search_text in stage\n or search_text in messages.lower()\n or search_text in response.lower()\n ):\n self.filtered_logs.append(log)\n\n self.current_page = 0\n self._update_table()\n\n def _update_table(self):\n \"\"\"更新表格显示\"\"\"\n self.table.setRowCount(0)\n\n total_pages = max(1, (len(self.filtered_logs) + PAGE_SIZE - 1) // PAGE_SIZE)\n start_idx = self.current_page * PAGE_SIZE\n end_idx = min(start_idx + PAGE_SIZE, len(self.filtered_logs))\n\n for log in self.filtered_logs[start_idx:end_idx]:\n row = self.table.rowCount()\n self.table.insertRow(row)\n\n # 时间(不显示年份:MM-DD HH:MM:SS)\n time_str = log.get(\"time\", \"\")\n if time_str and len(time_str) > 5:\n time_str = time_str[5:] # 去掉 \"YYYY-\"\n self.table.setItem(row, 0, self._create_item(time_str))\n\n # 任务ID\n task_id = log.get(\"task_id\", \"\") or \"-\"\n self.table.setItem(row, 1, self._create_item(task_id))\n\n # 文件\n file_name = log.get(\"file_name\", \"\") or \"-\"\n self.table.setItem(row, 2, self._create_item(file_name, align_left=True))\n\n # 阶段\n stage = log.get(\"stage\", \"\") or \"-\"\n self.table.setItem(row, 3, self._create_item(stage))\n\n # 模型\n model = log.get(\"request\", {}).get(\"model\", \"未知\")\n self.table.setItem(row, 4, self._create_item(model))\n\n # 耗时\n duration = log.get(\"duration_ms\", 0) / 1000\n self.table.setItem(row, 5, self._create_item(f\"{duration:.1f}s\"))\n\n # 总 Tokens\n usage = log.get(\"response\", {}).get(\"usage\", {})\n total_tokens = usage.get(\"total_tokens\", 0)\n if not total_tokens:\n total_tokens = usage.get(\"prompt_tokens\", 0) + usage.get(\n \"completion_tokens\", 0\n )\n self.table.setItem(row, 6, self._create_item(str(total_tokens)))\n\n # 更新分页和统计\n self.page_label.setText(f\"{self.current_page + 1} / {total_pages}\")\n self.prev_btn.setEnabled(self.current_page > 0)\n self.next_btn.setEnabled(self.current_page < total_pages - 1)\n self.status_label.setText(f\"共 {len(self.filtered_logs)} 条\")\n\n def _create_item(self, text: str, align_left: bool = False) -> QTableWidgetItem:\n \"\"\"创建表格项\"\"\"\n item = QTableWidgetItem(text)\n if align_left:\n item.setTextAlignment(Qt.AlignLeft | Qt.AlignVCenter) # type: ignore\n else:\n item.setTextAlignment(Qt.AlignCenter) # type: ignore\n return item\n\n def _show_detail(self, index):\n \"\"\"显示日志详情\"\"\"\n actual_idx = self.current_page * PAGE_SIZE + index.row()\n if 0 <= actual_idx < len(self.filtered_logs):\n dialog = LogDetailDialog(self.filtered_logs[actual_idx], self)\n dialog.exec()\n\n def _prev_page(self):\n if self.current_page > 0:\n self.current_page -= 1\n self._update_table()\n\n def _next_page(self):\n total_pages = (len(self.filtered_logs) + PAGE_SIZE - 1) // PAGE_SIZE\n if self.current_page < total_pages - 1:\n self.current_page += 1\n self._update_table()\n\n def _clear_logs(self):\n \"\"\"清空日志\"\"\"\n w = MessageBox(\n self.tr(\"确认清空\"),\n self.tr(\"确定要清空所有日志吗?此操作不可恢复。\"),\n self,\n )\n if w.exec():\n try:\n if LLM_LOG_FILE.exists():\n LLM_LOG_FILE.unlink()\n self.all_logs = []\n self.filtered_logs = []\n self._update_table()\n InfoBar.success(\n title=\"\",\n content=self.tr(\"日志已清空\"),\n parent=self,\n position=InfoBarPosition.TOP,\n duration=2000,\n )\n except Exception as e:\n InfoBar.error(\n title=self.tr(\"错误\"),\n content=str(e),\n parent=self,\n position=InfoBarPosition.TOP,\n duration=3000,\n )\n" }, { "path": "app/view/log_window.py", "content": "import os\nimport platform\nimport subprocess\n\nfrom PyQt5.QtCore import Qt, QTimer\nfrom PyQt5.QtGui import QTextCursor\nfrom PyQt5.QtWidgets import QHBoxLayout, QVBoxLayout, QWidget\nfrom qfluentwidgets import FluentStyleSheet, PushButton, TextEdit, isDarkTheme\n\nfrom app.config import LOG_PATH, RESOURCE_PATH\n\n\nclass LogWindow(QWidget):\n def __init__(self, parent=None):\n super().__init__(parent)\n self.setWindowTitle(\"日志查看器\")\n self.resize(800, 600)\n\n FluentStyleSheet.FLUENT_WINDOW.apply(self)\n\n theme = \"dark\" if isDarkTheme() else \"light\"\n with open(\n RESOURCE_PATH / \"assets\" / \"qss\" / theme / \"demo.qss\", encoding=\"utf-8\"\n ) as f:\n self.setStyleSheet(f.read())\n\n # 设置为非模态对话框\n self.setWindowModality(Qt.NonModal) # type: ignore\n # 设置窗口标志\n self.setWindowFlags(\n Qt.Window # type: ignore # 让窗口成为独立窗口\n | Qt.WindowCloseButtonHint # type: ignore # 添加关闭按钮\n | Qt.WindowMinMaxButtonsHint # type: ignore # 添加最小化最大化按钮\n )\n # 创建主布局\n layout = QVBoxLayout(self)\n\n # 创建顶部按钮布局\n top_layout = QHBoxLayout()\n self.open_folder_btn = PushButton(\"打开日志文件夹\", self)\n self.open_folder_btn.clicked.connect(self.open_log_folder)\n top_layout.addWidget(self.open_folder_btn)\n top_layout.addStretch()\n layout.addLayout(top_layout)\n\n # 创建文本编辑器用于显示日志\n self.log_text = TextEdit(self)\n self.log_text.setReadOnly(True)\n layout.addWidget(self.log_text)\n\n # 设置定时器用于更新日志\n self.timer = QTimer(self)\n self.timer.timeout.connect(self.update_log)\n self.timer.start(500) # 每2秒更新一次\n\n # 获取日志文件路径并打开文件\n self.log_path = LOG_PATH / \"app.log\"\n try:\n self.log_file = open(self.log_path, \"r\", encoding=\"utf-8\")\n self.load_last_lines(20480)\n self.log_text.moveCursor(QTextCursor.End)\n self.log_text.insertPlainText(f\"\\n{'=' * 25}以上是历史日志{'=' * 25}\\n\\n\")\n except Exception as e:\n self.log_file = None\n self.log_text.setPlainText(f\"打开日志文件失败: {str(e)}\")\n\n # 添加文件大小跟踪\n self.last_position = self.log_file.tell()\n self.max_lines = 100 # 最多显示100行\n\n self.auto_scroll = True # 添加自动滚动标志\n\n # 监听滚动条变化\n self.log_text.verticalScrollBar().valueChanged.connect(self.on_scroll_changed)\n\n # # 初始加载日志\n # self.update_log()\n\n def load_last_lines(self, read_size):\n \"\"\"加载文件最后的内容\n Args:\n read_size: 要读取的字节数,比如102400表示读取最后100KB\n \"\"\"\n try:\n # 移动到文件末尾\n self.log_file.seek(0, 2)\n file_size = self.log_file.tell()\n\n # 向前读取指定大小或整个文件\n read_size = min(read_size, file_size)\n\n # 从文件开头读取以确保不会破坏UTF-8编码\n self.log_file.seek(0)\n content = self.log_file.read()\n\n # 只保留最后一部分内容\n if len(content) > read_size:\n content = content[-read_size:]\n # 找到第一个完整的行\n newline_pos = content.find(\"\\n\")\n if newline_pos != -1:\n content = content[newline_pos + 1 :]\n\n self.last_position = self.log_file.tell()\n self.log_text.moveCursor(QTextCursor.End)\n self.log_text.setPlainText(content)\n\n # 滚动到底部\n self.log_text.verticalScrollBar().setValue(\n self.log_text.verticalScrollBar().maximum()\n )\n\n except Exception as e:\n self.log_text.setPlainText(f\"读取日志文件失败: {str(e)}\")\n\n # def closeEvent(self, event):\n # # 关闭窗口时同时关闭文件和定时器\n # self.timer.stop()\n # if self.log_file:\n # self.log_file.close()\n # event.accept()\n\n def on_scroll_changed(self, value):\n \"\"\"监听滚动条变化\"\"\"\n scrollbar = self.log_text.verticalScrollBar()\n max_value = scrollbar.maximum()\n self.auto_scroll = value <= max_value and value >= max_value * 0.85\n\n def update_log(self):\n \"\"\"更新日志内容\"\"\"\n if not self.log_file:\n return\n\n try:\n # 移动到上次读取的位置\n self.log_file.seek(self.last_position)\n new_content = self.log_file.read()\n\n if new_content:\n # 按行分割内容\n lines = new_content.splitlines(True) # keepends=True 保留换行符\n for line in lines:\n self.log_text.moveCursor(QTextCursor.End)\n self.log_text.insertPlainText(line)\n # time.sleep(0.02)\n self.log_text.repaint()\n\n self.last_position = self.log_file.tell()\n\n if self.auto_scroll:\n self.log_text.verticalScrollBar().setValue(\n self.log_text.verticalScrollBar().maximum()\n )\n\n except Exception as e:\n self.log_text.setPlainText(f\"读取日志文件出错: {str(e)}\")\n\n def open_log_folder(self):\n \"\"\"打开日志文件所在文件夹\"\"\"\n if platform.system() == \"Windows\":\n os.startfile(str(LOG_PATH)) # type: ignore\n elif platform.system() == \"Darwin\": # macOS\n subprocess.run([\"open\", str(LOG_PATH)])\n else: # Linux\n subprocess.run([\"xdg-open\", str(LOG_PATH)])\n" }, { "path": "app/view/main_window.py", "content": "import atexit\nimport os\nimport shutil\n\nimport psutil\nfrom PyQt5.QtCore import QSize, QThread, QUrl\nfrom PyQt5.QtGui import QDesktopServices, QIcon\nfrom PyQt5.QtWidgets import QApplication\nfrom qfluentwidgets import FluentIcon as FIF\nfrom qfluentwidgets import (\n FluentWindow,\n InfoBar,\n InfoBarPosition,\n MessageBox,\n NavigationItemPosition,\n SplashScreen,\n)\n\nfrom app.common.config import cfg\nfrom app.components.DonateDialog import DonateDialog\nfrom app.config import ASSETS_PATH, GITHUB_REPO_URL\nfrom app.core.constant import INFOBAR_DURATION_FOREVER\nfrom app.thread.version_checker_thread import VersionChecker\nfrom app.view.batch_process_interface import BatchProcessInterface\nfrom app.view.home_interface import HomeInterface\nfrom app.view.llm_logs_interface import LLMLogsInterface\nfrom app.view.setting_interface import SettingInterface\nfrom app.view.subtitle_style_interface import SubtitleStyleInterface\n\nLOGO_PATH = ASSETS_PATH / \"logo.png\"\n\n\nclass MainWindow(FluentWindow):\n def __init__(self):\n super().__init__()\n self.initWindow()\n\n # 创建子界面\n self.homeInterface = HomeInterface(self)\n self.settingInterface = SettingInterface(self)\n self.subtitleStyleInterface = SubtitleStyleInterface(self)\n self.batchProcessInterface = BatchProcessInterface(self)\n self.llmLogsInterface = LLMLogsInterface(self)\n\n # 初始化版本检查器\n self.versionChecker = VersionChecker()\n self.versionChecker.newVersionAvailable.connect(self.onNewVersion)\n self.versionChecker.announcementAvailable.connect(self.onAnnouncement)\n\n self.versionThread = QThread()\n self.versionChecker.moveToThread(self.versionThread)\n self.versionThread.started.connect(self.versionChecker.perform_check)\n self.versionThread.start()\n\n # 初始化导航界面\n self.initNavigation()\n self.splashScreen.finish()\n\n # 检查系统依赖\n self._check_ffmpeg()\n\n # 注册退出处理, 清理进程\n atexit.register(self.stop)\n\n def initNavigation(self):\n \"\"\"初始化导航栏\"\"\"\n # 添加导航项\n self.addSubInterface(self.homeInterface, FIF.HOME, self.tr(\"主页\"))\n self.addSubInterface(self.batchProcessInterface, FIF.VIDEO, self.tr(\"批量处理\"))\n self.addSubInterface(self.subtitleStyleInterface, FIF.FONT, self.tr(\"字幕样式\"))\n self.addSubInterface(self.llmLogsInterface, FIF.HISTORY, self.tr(\"请求日志\"))\n\n self.navigationInterface.addSeparator()\n\n # 在底部添加自定义小部件\n self.navigationInterface.addItem(\n routeKey=\"avatar\",\n text=\"GitHub\",\n icon=FIF.GITHUB,\n onClick=self.onGithubDialog,\n position=NavigationItemPosition.BOTTOM,\n )\n self.addSubInterface(\n self.settingInterface,\n FIF.SETTING,\n self.tr(\"Settings\"),\n NavigationItemPosition.BOTTOM,\n )\n\n # 设置默认界面\n self.switchTo(self.homeInterface)\n\n def switchTo(self, interface):\n if interface.windowTitle():\n self.setWindowTitle(interface.windowTitle())\n else:\n self.setWindowTitle(self.tr(\"卡卡字幕助手 -- VideoCaptioner\"))\n self.stackedWidget.setCurrentWidget(interface, popOut=False)\n\n def initWindow(self):\n \"\"\"初始化窗口\"\"\"\n self.resize(1050, 800)\n self.setMinimumWidth(700)\n self.setWindowIcon(QIcon(str(LOGO_PATH)))\n self.setWindowTitle(self.tr(\"卡卡字幕助手 -- VideoCaptioner\"))\n\n self.setMicaEffectEnabled(cfg.get(cfg.micaEnabled))\n\n # 创建启动画面\n self.splashScreen = SplashScreen(self.windowIcon(), self)\n self.splashScreen.setIconSize(QSize(106, 106))\n self.splashScreen.raise_()\n\n # 设置窗口位置, 居中\n desktop = QApplication.desktop().availableGeometry()\n w, h = desktop.width(), desktop.height()\n self.move(w // 2 - self.width() // 2, h // 2 - self.height() // 2)\n\n self.show()\n QApplication.processEvents()\n\n def onGithubDialog(self):\n \"\"\"打开GitHub\"\"\"\n w = MessageBox(\n self.tr(\"GitHub信息\"),\n self.tr(\n \"VideoCaptioner 由本人在课余时间独立开发完成,目前托管在GitHub上,欢迎Star和Fork。项目诚然还有很多地方需要完善,遇到软件的问题或者BUG欢迎提交Issue。\\n\\n https://github.com/WEIFENG2333/VideoCaptioner\"\n ),\n self,\n )\n w.yesButton.setText(self.tr(\"打开 GitHub\"))\n w.cancelButton.setText(self.tr(\"支持作者\"))\n if w.exec():\n QDesktopServices.openUrl(QUrl(GITHUB_REPO_URL))\n else:\n # 点击\"支持作者\"按钮时打开捐赠对话框\n donate_dialog = DonateDialog(self)\n donate_dialog.exec_()\n\n def onNewVersion(self, version, update_required, update_info, download_url):\n \"\"\"新版本提示\"\"\"\n if update_required:\n title = \"发现新版本, 需要更新\"\n content = f\"发现新版本 {version}\\n\\n\" f\"更新内容:\\n{update_info}\"\n else:\n title = \"发现新版本\"\n content = f\"发现新版本 {version}\\n\\n{update_info}\"\n\n w = MessageBox(title, content, self)\n w.yesButton.setText(\"立即更新\")\n w.cancelButton.setText(\"稍后再说\")\n\n if w.exec() or update_required:\n QDesktopServices.openUrl(QUrl(download_url))\n\n if update_required:\n self.homeInterface.setEnabled(False)\n self.batchProcessInterface.setEnabled(False)\n InfoBar.error(\n title=\"需要更新\",\n content=self.tr(\"当前版本部分功能已被禁用。请尽快更新。\"),\n isClosable=False,\n position=InfoBarPosition.BOTTOM,\n duration=-1,\n parent=self,\n )\n\n def onAnnouncement(self, content):\n \"\"\"显示公告\"\"\"\n w = MessageBox(\"公告\", content, self)\n w.yesButton.setText(\"我知道了\")\n w.cancelButton.hide()\n w.exec()\n\n def resizeEvent(self, e):\n super().resizeEvent(e)\n if hasattr(self, \"splashScreen\"):\n self.splashScreen.resize(self.size())\n\n def closeEvent(self, event):\n # 关闭所有子界面\n # self.homeInterface.close()\n # self.batchProcessInterface.close()\n # self.subtitleStyleInterface.close()\n # self.settingInterface.close()\n super().closeEvent(event)\n\n # 强制退出应用程序\n QApplication.quit()\n\n # 确保所有线程和进程都被终止 要是一些错误退出就不会处理了。\n # import os\n # os._exit(0)\n\n def stop(self):\n # 找到 FFmpeg 进程并关闭\n process = psutil.Process(os.getpid())\n for child in process.children(recursive=True):\n child.kill()\n\n def _check_ffmpeg(self):\n \"\"\"检查 FFmpeg 是否已安装\"\"\"\n if shutil.which(\"ffmpeg\") is None:\n InfoBar.warning(\n self.tr(\"FFmpeg 未安装\"),\n self.tr(\"软件处理音视频文件时需要 FFmpeg,请先安装\"),\n duration=INFOBAR_DURATION_FOREVER,\n position=InfoBarPosition.BOTTOM,\n parent=self,\n )\n" }, { "path": "app/view/setting_interface.py", "content": "import webbrowser\n\nfrom PyQt5.QtCore import Qt, QThread, QUrl, pyqtSignal\nfrom PyQt5.QtGui import QDesktopServices\nfrom PyQt5.QtWidgets import QFileDialog, QLabel, QWidget\nfrom qfluentwidgets import (\n ComboBoxSettingCard,\n CustomColorSettingCard,\n ExpandLayout,\n HyperlinkCard,\n InfoBar,\n OptionsSettingCard,\n PrimaryPushSettingCard,\n PushSettingCard,\n RangeSettingCard,\n ScrollArea,\n SettingCardGroup,\n SwitchSettingCard,\n setTheme,\n setThemeColor,\n)\nfrom qfluentwidgets import FluentIcon as FIF\n\nfrom app.common.config import cfg\nfrom app.common.signal_bus import signalBus\nfrom app.components.EditComboBoxSettingCard import EditComboBoxSettingCard\nfrom app.components.LineEditSettingCard import LineEditSettingCard\nfrom app.config import AUTHOR, FEEDBACK_URL, HELP_URL, RELEASE_URL, VERSION, YEAR\nfrom app.core.constant import (\n INFOBAR_DURATION_ERROR,\n INFOBAR_DURATION_SUCCESS,\n INFOBAR_DURATION_WARNING,\n)\nfrom app.core.entities import LLMServiceEnum, TranscribeModelEnum, TranslatorServiceEnum\nfrom app.core.llm import check_whisper_connection\nfrom app.core.llm.check_llm import check_llm_connection, get_available_models\nfrom app.core.utils.cache import disable_cache, enable_cache\n\n\nclass SettingInterface(ScrollArea):\n \"\"\"设置界面\"\"\"\n\n def __init__(self, parent=None):\n super().__init__(parent=parent)\n self.setWindowTitle(self.tr(\"设置\"))\n self.scrollWidget = QWidget()\n self.expandLayout = ExpandLayout(self.scrollWidget)\n self.settingLabel = QLabel(self.tr(\"设置\"), self)\n\n # 初始化所有设置组\n self.__initGroups()\n # 初始化所有配置卡片\n self.__initCards()\n # 初始化界面\n self.__initWidget()\n # 初始化布局\n self.__initLayout()\n # 连接信号和槽\n self.__connectSignalToSlot()\n\n def __initGroups(self):\n \"\"\"初始化所有设置组\"\"\"\n # 转录配置组\n self.transcribeGroup = SettingCardGroup(self.tr(\"转录配置\"), self.scrollWidget)\n # LLM配置组\n self.llmGroup = SettingCardGroup(self.tr(\"LLM配置\"), self.scrollWidget)\n # 翻译服务组\n self.translate_serviceGroup = SettingCardGroup(\n self.tr(\"翻译服务\"), self.scrollWidget\n )\n # 翻译与优化组\n self.translateGroup = SettingCardGroup(self.tr(\"翻译与优化\"), self.scrollWidget)\n # 字幕合成配置组\n self.subtitleGroup = SettingCardGroup(\n self.tr(\"字幕合成配置\"), self.scrollWidget\n )\n # 保存配置组\n self.saveGroup = SettingCardGroup(self.tr(\"保存配置\"), self.scrollWidget)\n # 个性化组\n self.personalGroup = SettingCardGroup(self.tr(\"个性化\"), self.scrollWidget)\n # 关于组\n self.aboutGroup = SettingCardGroup(self.tr(\"关于\"), self.scrollWidget)\n\n def __initCards(self):\n \"\"\"初始化所有配置卡片\"\"\"\n\n # ASR 服务配置卡片\n self.__createASRServiceCards()\n\n # LLM配置卡片\n self.__createLLMServiceCards()\n\n # 翻译配置卡片\n self.__createTranslateServiceCards()\n\n # 翻译与优化配置卡片\n self.subtitleCorrectCard = SwitchSettingCard(\n FIF.EDIT,\n self.tr(\"字幕校正\"),\n self.tr(\"字幕处理过程是否对生成的字幕错别字、名词等进行校正\"),\n cfg.need_optimize,\n self.translateGroup,\n )\n self.subtitleTranslateCard = SwitchSettingCard(\n FIF.LANGUAGE,\n self.tr(\"字幕翻译\"),\n self.tr(\"字幕处理过程是否对生成的字幕进行翻译\"),\n cfg.need_translate,\n self.translateGroup,\n )\n self.targetLanguageCard = ComboBoxSettingCard(\n cfg.target_language,\n FIF.LANGUAGE,\n self.tr(\"目标语言\"),\n self.tr(\"选择翻译字幕的目标语言\"),\n texts=[lang.value for lang in cfg.target_language.validator.options], # type: ignore\n parent=self.translateGroup,\n )\n\n # 字幕合成配置卡片\n self.subtitleStyleCard = HyperlinkCard(\n \"\",\n self.tr(\"修改\"),\n FIF.FONT,\n self.tr(\"字幕样式\"),\n self.tr(\"选择字幕的样式(颜色、大小、字体等)\"),\n self.subtitleGroup,\n )\n self.subtitleLayoutCard = HyperlinkCard(\n \"\",\n self.tr(\"修改\"),\n FIF.FONT,\n self.tr(\"字幕布局\"),\n self.tr(\"选择字幕的布局(单语、双语)\"),\n self.subtitleGroup,\n )\n self.needVideoCard = SwitchSettingCard(\n FIF.VIDEO,\n self.tr(\"需要合成视频\"),\n self.tr(\"开启时触发合成视频,关闭时跳过\"),\n cfg.need_video,\n self.subtitleGroup,\n )\n self.softSubtitleCard = SwitchSettingCard(\n FIF.FONT,\n self.tr(\"软字幕\"),\n self.tr(\"开启时字幕可在播放器中关闭或调整,关闭时字幕烧录到视频画面上\"),\n cfg.soft_subtitle,\n self.subtitleGroup,\n )\n self.videoQualityCard = ComboBoxSettingCard(\n cfg.video_quality,\n FIF.SPEED_HIGH,\n self.tr(\"视频合成质量\"),\n self.tr(\"硬字幕视频合成时的质量等级(质量越高文件越大,编码时间越长)\"),\n texts=[quality.value for quality in cfg.video_quality.validator.options], # type: ignore\n parent=self.subtitleGroup,\n )\n\n # 保存配置卡片\n self.savePathCard = PushSettingCard(\n self.tr(\"工作文件夹\"),\n FIF.SAVE,\n self.tr(\"工作目录路径\"),\n cfg.get(cfg.work_dir),\n self.saveGroup,\n )\n\n # 个性化配置卡片\n self.cacheEnabledCard = SwitchSettingCard(\n FIF.HISTORY,\n self.tr(\"启用缓存\"),\n self.tr(\"相同配置下会复用之前的 ASR 和 LLM 结果;关闭缓存后每次重新生成\"),\n cfg.cache_enabled,\n self.personalGroup,\n )\n self.themeCard = OptionsSettingCard(\n cfg.themeMode,\n FIF.BRUSH,\n self.tr(\"应用主题\"),\n self.tr(\"更改应用程序的外观\"),\n texts=[self.tr(\"浅色\"), self.tr(\"深色\"), self.tr(\"使用系统设置\")],\n parent=self.personalGroup,\n )\n self.themeColorCard = CustomColorSettingCard(\n cfg.themeColor,\n FIF.PALETTE,\n self.tr(\"主题颜色\"),\n self.tr(\"更改应用程序的主题颜色\"),\n self.personalGroup,\n )\n self.zoomCard = OptionsSettingCard(\n cfg.dpiScale,\n FIF.ZOOM,\n self.tr(\"界面缩放\"),\n self.tr(\"更改小部件和字体的大小\"),\n texts=[\"100%\", \"125%\", \"150%\", \"175%\", \"200%\", self.tr(\"使用系统设置\")],\n parent=self.personalGroup,\n )\n self.languageCard = ComboBoxSettingCard(\n cfg.language,\n FIF.LANGUAGE,\n self.tr(\"语言\"),\n self.tr(\"设置您偏好的界面语言\"),\n texts=[\"简体中文\", \"繁體中文\", \"English\", self.tr(\"使用系统设置\")],\n parent=self.personalGroup,\n )\n\n # 关于卡片\n self.helpCard = HyperlinkCard(\n HELP_URL,\n self.tr(\"打开帮助页面\"),\n FIF.HELP,\n self.tr(\"帮助\"),\n self.tr(\"发现新功能并了解有关VideoCaptioner的使用技巧\"),\n self.aboutGroup,\n )\n self.feedbackCard = PrimaryPushSettingCard(\n self.tr(\"提供反馈\"),\n FIF.FEEDBACK,\n self.tr(\"提供反馈\"),\n self.tr(\"提供反馈帮助我们改进VideoCaptioner\"),\n self.aboutGroup,\n )\n self.aboutCard = PrimaryPushSettingCard(\n self.tr(\"检查更新\"),\n FIF.INFO,\n self.tr(\"关于\"),\n \"© \"\n + self.tr(\"版权所有\")\n + f\" {YEAR}, {AUTHOR}. \"\n + self.tr(\"版本\")\n + \" \"\n + VERSION,\n self.aboutGroup,\n )\n\n # 添加卡片到对应的组\n self.translateGroup.addSettingCard(self.subtitleCorrectCard)\n self.translateGroup.addSettingCard(self.subtitleTranslateCard)\n self.translateGroup.addSettingCard(self.targetLanguageCard)\n\n self.subtitleGroup.addSettingCard(self.subtitleStyleCard)\n self.subtitleGroup.addSettingCard(self.subtitleLayoutCard)\n self.subtitleGroup.addSettingCard(self.needVideoCard)\n self.subtitleGroup.addSettingCard(self.softSubtitleCard)\n self.subtitleGroup.addSettingCard(self.videoQualityCard)\n\n self.saveGroup.addSettingCard(self.savePathCard)\n self.saveGroup.addSettingCard(self.cacheEnabledCard)\n\n self.personalGroup.addSettingCard(self.themeCard)\n self.personalGroup.addSettingCard(self.themeColorCard)\n self.personalGroup.addSettingCard(self.zoomCard)\n self.personalGroup.addSettingCard(self.languageCard)\n\n self.aboutGroup.addSettingCard(self.helpCard)\n self.aboutGroup.addSettingCard(self.feedbackCard)\n self.aboutGroup.addSettingCard(self.aboutCard)\n\n def __createLLMServiceCards(self):\n \"\"\"创建LLM服务相关的配置卡片\"\"\"\n # 服务选择卡片\n self.llmServiceCard = ComboBoxSettingCard(\n cfg.llm_service,\n FIF.ROBOT,\n self.tr(\"LLM 提供商\"),\n self.tr(\"选择大模型提供商,用于字幕断句、优化、翻译\"),\n texts=[service.value for service in cfg.llm_service.validator.options], # type: ignore\n parent=self.llmGroup,\n )\n self.llmServiceCard.comboBox.setMinimumWidth(150)\n\n # 创建OPENAI官方API链接卡片\n self.openaiOfficialApiCard = HyperlinkCard(\n \"https://api.videocaptioner.cn/register?aff=UrLB\",\n self.tr(\"访问\"),\n FIF.DEVELOPER_TOOLS,\n self.tr(\"VideoCaptioner 官方API\"),\n self.tr(\"集成多种大语言模型,支持高并发字幕优化、翻译\"),\n self.llmGroup,\n )\n # 默认隐藏\n self.openaiOfficialApiCard.setVisible(False)\n\n # 定义每个服务的配置\n service_configs = {\n LLMServiceEnum.OPENAI: {\n \"prefix\": \"openai\",\n \"api_key_cfg\": cfg.openai_api_key,\n \"api_base_cfg\": cfg.openai_api_base,\n \"model_cfg\": cfg.openai_model,\n \"default_base\": \"https://api.openai.com/v1\",\n \"default_models\": [\n \"gemini-2.5-pro\",\n \"gpt-5\",\n \"claude-sonnet-4-5-20250929\",\n \"gemini-2.5-flash\",\n \"claude-haiku-4-5-20251001\",\n ],\n },\n LLMServiceEnum.SILICON_CLOUD: {\n \"prefix\": \"silicon_cloud\",\n \"api_key_cfg\": cfg.silicon_cloud_api_key,\n \"api_base_cfg\": cfg.silicon_cloud_api_base,\n \"model_cfg\": cfg.silicon_cloud_model,\n \"default_base\": \"https://api.siliconflow.cn/v1\",\n \"default_models\": [\n \"moonshotai/Kimi-K2-Instruct-0905\",\n \"deepseek-ai/DeepSeek-V3\",\n ],\n },\n LLMServiceEnum.DEEPSEEK: {\n \"prefix\": \"deepseek\",\n \"api_key_cfg\": cfg.deepseek_api_key,\n \"api_base_cfg\": cfg.deepseek_api_base,\n \"model_cfg\": cfg.deepseek_model,\n \"default_base\": \"https://api.deepseek.com/v1\",\n \"default_models\": [\"deepseek-chat\", \"deepseek-reasoner\"],\n },\n LLMServiceEnum.OLLAMA: {\n \"prefix\": \"ollama\",\n \"api_key_cfg\": cfg.ollama_api_key,\n \"api_base_cfg\": cfg.ollama_api_base,\n \"model_cfg\": cfg.ollama_model,\n \"default_base\": \"http://localhost:11434/v1\",\n \"default_models\": [\"qwen3:8b\"],\n },\n LLMServiceEnum.LM_STUDIO: {\n \"prefix\": \"LM Studio\",\n \"api_key_cfg\": cfg.lm_studio_api_key,\n \"api_base_cfg\": cfg.lm_studio_api_base,\n \"model_cfg\": cfg.lm_studio_model,\n \"default_base\": \"http://localhost:1234/v1\",\n \"default_models\": [\"qwen3:8b\"],\n },\n LLMServiceEnum.GEMINI: {\n \"prefix\": \"gemini\",\n \"api_key_cfg\": cfg.gemini_api_key,\n \"api_base_cfg\": cfg.gemini_api_base,\n \"model_cfg\": cfg.gemini_model,\n \"default_base\": \"https://generativelanguage.googleapis.com/v1beta/openai/\",\n \"default_models\": [\n \"gemini-2.5-pro\",\n \"gemini-2.5-flash\",\n \"gemini-2.0-flash-lite\",\n ],\n },\n LLMServiceEnum.CHATGLM: {\n \"prefix\": \"chatglm\",\n \"api_key_cfg\": cfg.chatglm_api_key,\n \"api_base_cfg\": cfg.chatglm_api_base,\n \"model_cfg\": cfg.chatglm_model,\n \"default_base\": \"https://open.bigmodel.cn/api/paas/v4\",\n \"default_models\": [\"glm-4-plus\", \"glm-4-air-250414\", \"glm-4-flash\"],\n },\n }\n\n # 创建服务配置映射\n self.llm_service_configs = {}\n\n # 为每个服务创建配置卡片\n for service, config in service_configs.items():\n prefix = config[\"prefix\"]\n\n # 创建API Key卡片\n api_key_card = LineEditSettingCard(\n config[\"api_key_cfg\"],\n FIF.FINGERPRINT,\n self.tr(\"API Key\"),\n self.tr(f\"输入您的 {service.value} API Key\"),\n \"sk-\" if service != LLMServiceEnum.OLLAMA else \"\",\n self.llmGroup,\n )\n setattr(self, f\"{prefix}_api_key_card\", api_key_card)\n\n # 创建Base URL卡片\n api_base_card = LineEditSettingCard(\n config[\"api_base_cfg\"],\n FIF.LINK,\n self.tr(\"Base URL\"),\n self.tr(f\"输入 {service.value} Base URL\"),\n config[\"default_base\"],\n self.llmGroup,\n )\n setattr(self, f\"{prefix}_api_base_card\", api_base_card)\n\n # 设置只读状态:只有 OpenAI、Ollama、LM Studio 可以编辑 Base URL\n if service not in [\n LLMServiceEnum.OPENAI,\n LLMServiceEnum.OLLAMA,\n LLMServiceEnum.LM_STUDIO,\n ]:\n api_base_card.lineEdit.setReadOnly(True)\n\n # 创建模型选择卡片\n model_card = EditComboBoxSettingCard(\n config[\"model_cfg\"],\n FIF.ROBOT, # type: ignore\n self.tr(\"模型\"),\n self.tr(f\"选择 {service.value} 模型\"),\n config[\"default_models\"],\n self.llmGroup,\n )\n setattr(self, f\"{prefix}_model_card\", model_card)\n\n # 存储服务配置\n cards = [api_key_card, api_base_card, model_card]\n\n self.llm_service_configs[service] = {\n \"cards\": cards,\n \"api_base\": api_base_card,\n \"api_key\": api_key_card,\n \"model\": model_card,\n }\n\n # 创建检查连接卡片\n self.checkLLMConnectionCard = PushSettingCard(\n self.tr(\"检查连接\"),\n FIF.LINK,\n self.tr(\"检查 LLM 连接\"),\n self.tr(\"点击检查 API 连接是否正常,并获取模型列表\"),\n self.llmGroup,\n )\n\n # 初始化显示状态\n self.__onLLMServiceChanged(self.llmServiceCard.comboBox.currentText())\n\n def __createASRServiceCards(self):\n \"\"\"创建 Whisper API 配置卡片\"\"\"\n # 转录配置卡片\n self.transcribeModelCard = ComboBoxSettingCard(\n cfg.transcribe_model,\n FIF.MICROPHONE,\n self.tr(\"转录模型\"),\n self.tr(\"语音转换文字要使用的语音识别服务\"),\n texts=[model.value for model in cfg.transcribe_model.validator.options], # type: ignore\n parent=self.transcribeGroup,\n )\n self.transcribeModelCard.comboBox.setMinimumWidth(150)\n\n # API Base URL\n self.whisperApiBaseCard = LineEditSettingCard(\n cfg.whisper_api_base,\n FIF.LINK,\n self.tr(\"Whisper API Base URL\"),\n self.tr(\"输入 Whisper API Base URL\"),\n \"https://api.openai.com/v1\",\n self.transcribeGroup,\n )\n\n # API Key\n self.whisperApiKeyCard = LineEditSettingCard(\n cfg.whisper_api_key,\n FIF.FINGERPRINT,\n self.tr(\"Whisper API Key\"),\n self.tr(\"输入 Whisper API Key\"),\n \"sk-\",\n self.transcribeGroup,\n )\n\n # 模型选择\n self.whisperApiModelCard = EditComboBoxSettingCard(\n cfg.whisper_api_model,\n FIF.ROBOT, # type: ignore\n self.tr(\"Whisper 模型\"),\n self.tr(\"选择 Whisper 模型\"),\n [\n \"whisper-1\",\n \"whisper-large-v3-turbo\",\n ],\n self.transcribeGroup,\n )\n\n # 测试连接按钮\n self.checkWhisperConnectionCard = PushSettingCard(\n self.tr(\"测试 Whisper 连接\"),\n FIF.CONNECT,\n self.tr(\"测试 Whisper API 连接\"),\n self.tr(\"点击测试 API 连接是否正常\"),\n self.transcribeGroup,\n )\n\n # 默认隐藏 Whisper API 配置卡片(仅在选择 Whisper API 时显示)\n self.whisperApiBaseCard.setVisible(False)\n self.whisperApiKeyCard.setVisible(False)\n self.whisperApiModelCard.setVisible(False)\n self.checkWhisperConnectionCard.setVisible(False)\n\n def __createTranslateServiceCards(self):\n \"\"\"创建翻译服务相关的配置卡片\"\"\"\n # 翻译服务选择卡片\n self.translatorServiceCard = ComboBoxSettingCard(\n cfg.translator_service,\n FIF.ROBOT,\n self.tr(\"翻译服务\"),\n self.tr(\"选择翻译服务\"),\n texts=[\n service.value\n for service in cfg.translator_service.validator.options # type: ignore\n ],\n parent=self.translate_serviceGroup,\n )\n self.translatorServiceCard.comboBox.setMinimumWidth(150)\n\n # 反思翻译开关\n self.needReflectTranslateCard = SwitchSettingCard(\n FIF.EDIT,\n self.tr(\"需要反思翻译\"),\n self.tr(\"启用反思翻译可以提高翻译质量,但耗费更多时间和token\"),\n cfg.need_reflect_translate,\n self.translate_serviceGroup,\n )\n\n # DeepLx端点配置\n self.deeplxEndpointCard = LineEditSettingCard(\n cfg.deeplx_endpoint,\n FIF.LINK,\n self.tr(\"DeepLx 后端\"),\n self.tr(\"输入 DeepLx 的后端地址(开启deeplx翻译时必填)\"),\n \"https://api.deeplx.org/translate\",\n self.translate_serviceGroup,\n )\n\n # 批处理大小配置\n self.batchSizeCard = RangeSettingCard(\n cfg.batch_size,\n FIF.ALIGNMENT,\n self.tr(\"批处理大小\"),\n self.tr(\"每批处理字幕的数量,建议为 10 的倍数\"),\n parent=self.translate_serviceGroup,\n )\n\n # 线程数配置\n self.threadNumCard = RangeSettingCard(\n cfg.thread_num,\n FIF.SPEED_HIGH,\n self.tr(\"线程数\"),\n self.tr(\n \"请求并行处理的数量,模型服务商允许的情况下建议尽可能大,数值越大速度越快\"\n ),\n parent=self.translate_serviceGroup,\n )\n\n # 添加卡片到翻译服务组\n self.translate_serviceGroup.addSettingCard(self.translatorServiceCard)\n self.translate_serviceGroup.addSettingCard(self.needReflectTranslateCard)\n self.translate_serviceGroup.addSettingCard(self.deeplxEndpointCard)\n self.translate_serviceGroup.addSettingCard(self.batchSizeCard)\n self.translate_serviceGroup.addSettingCard(self.threadNumCard)\n\n # 初始化显示状态\n self.__onTranslatorServiceChanged(\n self.translatorServiceCard.comboBox.currentText()\n )\n\n def __initWidget(self):\n self.resize(1000, 800)\n self.setHorizontalScrollBarPolicy(Qt.ScrollBarAlwaysOff) # type: ignore\n self.setViewportMargins(0, 80, 0, 20)\n self.setWidget(self.scrollWidget)\n self.setWidgetResizable(True)\n self.setObjectName(\"settingInterface\")\n\n # 初始化样式表\n self.scrollWidget.setObjectName(\"scrollWidget\")\n self.settingLabel.setObjectName(\"settingLabel\")\n\n # 初始化转录模型配置卡片的显示状态\n self.__onTranscribeModelChanged(self.transcribeModelCard.comboBox.currentText())\n\n # 初始化翻译服务配置卡片的显示状态\n self.__onTranslatorServiceChanged(\n self.translatorServiceCard.comboBox.currentText()\n )\n\n self.setStyleSheet(\n \"\"\" \n SettingInterface, #scrollWidget {\n background-color: transparent;\n }\n QScrollArea {\n border: none;\n background-color: transparent;\n }\n QLabel#settingLabel {\n font: 33px 'Microsoft YaHei';\n background-color: transparent;\n color: white;\n }\n \"\"\"\n )\n\n def __initLayout(self):\n \"\"\"初始化布局\"\"\"\n self.settingLabel.move(36, 30)\n\n # 添加转录配置卡片\n self.transcribeGroup.addSettingCard(self.transcribeModelCard)\n # 添加 Whisper API 配置卡片\n self.transcribeGroup.addSettingCard(self.whisperApiBaseCard)\n self.transcribeGroup.addSettingCard(self.whisperApiKeyCard)\n self.transcribeGroup.addSettingCard(self.whisperApiModelCard)\n self.transcribeGroup.addSettingCard(self.checkWhisperConnectionCard)\n\n # 添加LLM配置卡片\n self.llmGroup.addSettingCard(self.llmServiceCard)\n # 添加OPENAI官方API链接卡片\n self.llmGroup.addSettingCard(self.openaiOfficialApiCard)\n for config in self.llm_service_configs.values():\n for card in config[\"cards\"]:\n self.llmGroup.addSettingCard(card)\n self.llmGroup.addSettingCard(self.checkLLMConnectionCard)\n\n # 将所有组添加到布局\n self.expandLayout.setSpacing(28)\n self.expandLayout.setContentsMargins(36, 10, 36, 0)\n self.expandLayout.addWidget(self.transcribeGroup)\n self.expandLayout.addWidget(self.llmGroup)\n self.expandLayout.addWidget(self.translate_serviceGroup)\n self.expandLayout.addWidget(self.translateGroup)\n self.expandLayout.addWidget(self.subtitleGroup)\n self.expandLayout.addWidget(self.saveGroup)\n self.expandLayout.addWidget(self.personalGroup)\n self.expandLayout.addWidget(self.aboutGroup)\n\n def __connectSignalToSlot(self):\n \"\"\"连接信号与槽\"\"\"\n cfg.appRestartSig.connect(self.__showRestartTooltip)\n\n # LLM服务切换\n self.llmServiceCard.comboBox.currentTextChanged.connect(\n self.__onLLMServiceChanged\n )\n\n # 翻译服务切换\n self.translatorServiceCard.comboBox.currentTextChanged.connect(\n self.__onTranslatorServiceChanged\n )\n\n # 转录模型切换\n self.transcribeModelCard.comboBox.currentTextChanged.connect(\n self.__onTranscribeModelChanged\n )\n\n # 检查 LLM 连接\n self.checkLLMConnectionCard.clicked.connect(self.checkLLMConnection)\n\n # 检查 Whisper 连接\n self.checkWhisperConnectionCard.clicked.connect(self.checkWhisperConnection)\n\n # 保存路径\n self.savePathCard.clicked.connect(self.__onsavePathCardClicked)\n\n # 字幕样式修改跳转\n self.subtitleStyleCard.linkButton.clicked.connect(\n lambda: self.window().switchTo(self.window().subtitleStyleInterface) # type: ignore\n )\n self.subtitleLayoutCard.linkButton.clicked.connect(\n lambda: self.window().switchTo(self.window().subtitleStyleInterface) # type: ignore\n )\n\n # 个性化\n self.cacheEnabledCard.checkedChanged.connect(self.__onCacheEnabledChanged)\n self.themeCard.optionChanged.connect(lambda ci: setTheme(cfg.get(ci)))\n self.themeColorCard.colorChanged.connect(setThemeColor)\n\n # 反馈\n self.feedbackCard.clicked.connect(\n lambda: QDesktopServices.openUrl(QUrl(FEEDBACK_URL)) # type: ignore\n )\n\n # 关于\n self.aboutCard.clicked.connect(self.checkUpdate)\n\n # 全局 signalBus\n self.transcribeModelCard.comboBox.currentTextChanged.connect(\n signalBus.transcription_model_changed\n )\n self.subtitleCorrectCard.checkedChanged.connect(\n signalBus.subtitle_optimization_changed\n )\n self.subtitleTranslateCard.checkedChanged.connect(\n signalBus.subtitle_translation_changed\n )\n self.targetLanguageCard.comboBox.currentTextChanged.connect(\n signalBus.target_language_changed\n )\n self.softSubtitleCard.checkedChanged.connect(signalBus.soft_subtitle_changed)\n self.needVideoCard.checkedChanged.connect(signalBus.need_video_changed)\n self.videoQualityCard.comboBox.currentTextChanged.connect(\n signalBus.video_quality_changed\n )\n\n def __showRestartTooltip(self):\n \"\"\"显示重启提示\"\"\"\n InfoBar.success(\n self.tr(\"更新成功\"),\n self.tr(\"配置将在重启后生效\"),\n duration=INFOBAR_DURATION_SUCCESS,\n parent=self,\n )\n\n def __onsavePathCardClicked(self):\n \"\"\"处理保存路径卡片点击事件\"\"\"\n folder = QFileDialog.getExistingDirectory(self, self.tr(\"选择文件夹\"), \"./\")\n if not folder or cfg.get(cfg.work_dir) == folder:\n return\n cfg.set(cfg.work_dir, folder)\n self.savePathCard.setContent(folder)\n\n def __onCacheEnabledChanged(self, is_enabled: bool):\n \"\"\"处理缓存开关变化\"\"\"\n if is_enabled:\n enable_cache()\n InfoBar.success(\n self.tr(\"缓存已启用\"),\n self.tr(\"ASR、翻译等操作将优先使用缓存\"),\n duration=INFOBAR_DURATION_SUCCESS,\n parent=self,\n )\n else:\n disable_cache()\n InfoBar.warning(\n self.tr(\"缓存已禁用\"),\n self.tr(\"所有操作将重新生成,不使用缓存(建议开启缓存)\"),\n duration=INFOBAR_DURATION_WARNING,\n parent=self,\n )\n\n def checkLLMConnection(self):\n \"\"\"检查 LLM 连接\"\"\"\n # 保存当前滚动位置\n scroll_position = self.verticalScrollBar().value()\n\n # 获取当前选中的服务\n current_service = LLMServiceEnum(self.llmServiceCard.comboBox.currentText())\n\n # 获取服务配置\n service_config = self.llm_service_configs.get(current_service)\n if not service_config:\n return\n\n api_base = (\n service_config[\"api_base\"].lineEdit.text()\n if service_config[\"api_base\"]\n else \"\"\n )\n api_key = (\n service_config[\"api_key\"].lineEdit.text()\n if service_config[\"api_key\"]\n else \"\"\n )\n model = (\n service_config[\"model\"].comboBox.currentText()\n if service_config[\"model\"]\n else \"\"\n )\n\n # 禁用检查按钮,显示加载状态\n self.checkLLMConnectionCard.button.setEnabled(False)\n self.checkLLMConnectionCard.button.setText(self.tr(\"正在检查...\"))\n\n # 立即恢复滚动位置(防止按钮状态改变导致的自动滚动)\n self.verticalScrollBar().setValue(scroll_position)\n\n # 创建并启动线程\n self.connection_thread = LLMConnectionThread(api_base, api_key, model)\n self.connection_thread.finished.connect(self.onConnectionCheckFinished)\n self.connection_thread.error.connect(self.onConnectionCheckError)\n self.connection_thread.start()\n\n def onConnectionCheckError(self, message):\n \"\"\"处理连接检查错误事件\"\"\"\n self.checkLLMConnectionCard.button.setEnabled(True)\n self.checkLLMConnectionCard.button.setText(self.tr(\"检查连接\"))\n InfoBar.error(\n self.tr(\"LLM 连接测试错误\"),\n message,\n duration=INFOBAR_DURATION_ERROR,\n parent=self,\n )\n\n def onConnectionCheckFinished(self, is_success, message, models):\n \"\"\"处理连接检查完成事件\"\"\"\n self.checkLLMConnectionCard.button.setEnabled(True)\n self.checkLLMConnectionCard.button.setText(self.tr(\"检查连接\"))\n\n # 获取当前服务\n current_service = LLMServiceEnum(self.llmServiceCard.comboBox.currentText())\n\n if models:\n # 更新当前服务的模型列表\n service_config = self.llm_service_configs.get(current_service)\n if service_config and service_config[\"model\"]:\n temp = service_config[\"model\"].comboBox.currentText()\n service_config[\"model\"].setItems(models)\n service_config[\"model\"].comboBox.setCurrentText(temp)\n\n InfoBar.success(\n self.tr(\"获取模型列表成功:\"),\n self.tr(\"一共\") + str(len(models)) + self.tr(\"个模型\"),\n duration=INFOBAR_DURATION_SUCCESS,\n parent=self,\n )\n if not is_success:\n InfoBar.error(\n self.tr(\"LLM 连接测试错误\"),\n message,\n duration=INFOBAR_DURATION_ERROR,\n parent=self,\n )\n else:\n InfoBar.success(\n self.tr(\"LLM 连接测试成功\"),\n message,\n duration=INFOBAR_DURATION_SUCCESS,\n parent=self,\n )\n\n def checkUpdate(self):\n webbrowser.open(RELEASE_URL)\n\n def __onLLMServiceChanged(self, service):\n \"\"\"处理LLM服务切换事件\"\"\"\n current_service = LLMServiceEnum(service)\n\n # 隐藏所有卡片\n for config in self.llm_service_configs.values():\n for card in config[\"cards\"]:\n card.setVisible(False)\n\n # 隐藏OPENAI官方API链接卡片\n self.openaiOfficialApiCard.setVisible(False)\n\n # 显示选中服务的卡片\n if current_service in self.llm_service_configs:\n for card in self.llm_service_configs[current_service][\"cards\"]:\n card.setVisible(True)\n\n # 为OLLAMA和LM_STUDIO设置默认API Key\n service_config = self.llm_service_configs[current_service]\n if current_service == LLMServiceEnum.OLLAMA and service_config[\"api_key\"]:\n # 如果API Key为空,设置默认值\"ollama\"\n if not service_config[\"api_key\"].lineEdit.text():\n service_config[\"api_key\"].lineEdit.setText(\"ollama\")\n if (\n current_service == LLMServiceEnum.LM_STUDIO\n and service_config[\"api_key\"]\n ):\n # 如果API Key为空,设置默认值 \"lm-studio\"\n if not service_config[\"api_key\"].lineEdit.text():\n service_config[\"api_key\"].lineEdit.setText(\"lm-studio\")\n\n # 如果是OPENAI服务,显示官方API链接卡片\n if current_service == LLMServiceEnum.OPENAI:\n self.openaiOfficialApiCard.setVisible(True)\n\n # 更新布局\n self.llmGroup.adjustSize()\n self.expandLayout.update()\n\n def __onTranslatorServiceChanged(self, service):\n openai_cards = [\n self.needReflectTranslateCard,\n self.batchSizeCard,\n ]\n deeplx_cards = [self.deeplxEndpointCard]\n\n all_cards = openai_cards + deeplx_cards\n for card in all_cards:\n card.setVisible(False)\n\n # 根据选择的服务显示相应的配置卡片\n if service in [TranslatorServiceEnum.DEEPLX.value]:\n for card in deeplx_cards:\n card.setVisible(True)\n elif service in [TranslatorServiceEnum.OPENAI.value]:\n for card in openai_cards:\n card.setVisible(True)\n\n # 更新布局\n self.translate_serviceGroup.adjustSize()\n self.expandLayout.update()\n\n def __onTranscribeModelChanged(self, model_name):\n \"\"\"处理转录模型切换事件\"\"\"\n # Whisper API 配置卡片\n whisper_api_cards = [\n self.whisperApiBaseCard,\n self.whisperApiKeyCard,\n self.whisperApiModelCard,\n self.checkWhisperConnectionCard,\n ]\n\n # 根据选择的模型显示/隐藏 Whisper API 配置\n is_whisper_api = model_name == TranscribeModelEnum.WHISPER_API.value\n for card in whisper_api_cards:\n card.setVisible(is_whisper_api)\n\n # 更新布局\n self.transcribeGroup.adjustSize()\n self.expandLayout.update()\n\n def checkWhisperConnection(self):\n \"\"\"检查 Whisper API 连接\"\"\"\n # 保存当前滚动位置\n scroll_position = self.verticalScrollBar().value()\n\n # 获取配置\n base_url = self.whisperApiBaseCard.lineEdit.text().strip()\n api_key = self.whisperApiKeyCard.lineEdit.text().strip()\n model = self.whisperApiModelCard.comboBox.currentText().strip()\n\n # 验证必填字段\n if not base_url:\n InfoBar.warning(\n self.tr(\"配置不完整\"),\n self.tr(\"请输入 Whisper API Base URL\"),\n duration=INFOBAR_DURATION_ERROR,\n parent=self,\n )\n return\n\n if not api_key:\n InfoBar.warning(\n self.tr(\"配置不完整\"),\n self.tr(\"请输入 Whisper API Key\"),\n duration=INFOBAR_DURATION_ERROR,\n parent=self,\n )\n return\n\n if not model:\n InfoBar.warning(\n self.tr(\"配置不完整\"),\n self.tr(\"请输入 Whisper 模型名称\"),\n duration=INFOBAR_DURATION_ERROR,\n parent=self,\n )\n return\n\n # 禁用按钮,显示加载状态\n self.checkWhisperConnectionCard.button.setEnabled(False)\n self.checkWhisperConnectionCard.button.setText(self.tr(\"正在测试...\"))\n\n # 立即恢复滚动位置(防止按钮状态改变导致的自动滚动)\n self.verticalScrollBar().setValue(scroll_position)\n\n # 创建并启动测试线程\n self.whisper_connection_thread = WhisperConnectionThread(\n base_url, api_key, model\n )\n self.whisper_connection_thread.finished.connect(\n self.onWhisperConnectionCheckFinished\n )\n self.whisper_connection_thread.error.connect(self.onWhisperConnectionCheckError)\n self.whisper_connection_thread.start()\n\n def onWhisperConnectionCheckFinished(self, success, result):\n \"\"\"处理 Whisper 连接检查完成事件\"\"\"\n # 恢复按钮状态\n self.checkWhisperConnectionCard.button.setEnabled(True)\n self.checkWhisperConnectionCard.button.setText(self.tr(\"测试 Whisper 连接\"))\n\n if success:\n InfoBar.success(\n self.tr(\"连接成功\"),\n self.tr(\"Whisper API 连接成功!\\n转录结果:\") + result,\n duration=INFOBAR_DURATION_SUCCESS,\n parent=self,\n )\n else:\n InfoBar.error(\n self.tr(\"连接失败\"),\n self.tr(f\"Whisper API 连接失败!\\n{result}\"),\n duration=INFOBAR_DURATION_ERROR,\n parent=self,\n )\n\n def onWhisperConnectionCheckError(self, message):\n \"\"\"处理 Whisper 连接检查错误事件\"\"\"\n # 恢复按钮状态\n self.checkWhisperConnectionCard.button.setEnabled(True)\n self.checkWhisperConnectionCard.button.setText(self.tr(\"测试 Whisper 连接\"))\n\n InfoBar.error(\n self.tr(\"测试错误\"),\n message,\n duration=INFOBAR_DURATION_ERROR,\n parent=self,\n )\n\n\nclass WhisperConnectionThread(QThread):\n \"\"\"Whisper API 连接测试线程\"\"\"\n\n finished = pyqtSignal(bool, str)\n error = pyqtSignal(str)\n\n def __init__(self, base_url, api_key, model):\n super().__init__()\n self.base_url = base_url\n self.api_key = api_key\n self.model = model\n\n def run(self):\n \"\"\"执行连接测试\"\"\"\n try:\n success, result = check_whisper_connection(\n self.base_url, self.api_key, self.model\n )\n self.finished.emit(success, result)\n except Exception as e:\n self.error.emit(str(e))\n\n\nclass LLMConnectionThread(QThread):\n finished = pyqtSignal(bool, str, list)\n error = pyqtSignal(str)\n\n def __init__(self, api_base, api_key, model):\n super().__init__()\n self.api_base = api_base\n self.api_key = api_key\n self.model = model\n\n def run(self):\n \"\"\"检查 LLM 连接并获取模型列表\"\"\"\n try:\n is_success, message = check_llm_connection(\n self.api_base, self.api_key, self.model\n )\n models = get_available_models(self.api_base, self.api_key)\n self.finished.emit(is_success, message, models)\n except Exception as e:\n self.error.emit(str(e))\n" }, { "path": "app/view/subtitle_interface.py", "content": "# -*- coding: utf-8 -*-\nimport json\nimport os\nimport sys\nimport tempfile\nfrom pathlib import Path\nfrom typing import Any, Dict, List, Optional, Union\n\nfrom PyQt5.QtCore import QAbstractTableModel, QModelIndex, Qt, QTime, pyqtSignal\nfrom PyQt5.QtGui import QCloseEvent, QColor, QDragEnterEvent, QDropEvent, QKeyEvent\nfrom PyQt5.QtWidgets import (\n QAbstractItemView,\n QApplication,\n QFileDialog,\n QHBoxLayout,\n QHeaderView,\n QVBoxLayout,\n QWidget,\n)\nfrom qfluentwidgets import (\n Action,\n BodyLabel,\n CommandBar,\n InfoBar,\n InfoBarPosition,\n MessageBoxBase,\n PrimaryPushButton,\n ProgressBar,\n PushButton,\n RoundMenu,\n TableView,\n TextEdit,\n TransparentDropDownPushButton,\n)\nfrom qfluentwidgets import FluentIcon as FIF\n\nfrom app.common.config import cfg\nfrom app.common.signal_bus import signalBus\nfrom app.components.SubtitleSettingDialog import SubtitleSettingDialog\nfrom app.config import SUBTITLE_STYLE_PATH\nfrom app.core.asr.asr_data import ASRData\nfrom app.core.constant import (\n INFOBAR_DURATION_ERROR,\n INFOBAR_DURATION_INFO,\n INFOBAR_DURATION_SUCCESS,\n INFOBAR_DURATION_WARNING,\n)\nfrom app.core.entities import (\n OutputSubtitleFormatEnum,\n SubtitleLayoutEnum,\n SubtitleTask,\n SupportedSubtitleFormats,\n)\nfrom app.core.subtitle import get_subtitle_style\nfrom app.core.task_factory import TaskFactory\nfrom app.core.translate.types import TargetLanguage\nfrom app.core.utils.platform_utils import open_folder\nfrom app.thread.subtitle_thread import SubtitleThread\n\n\nclass SubtitleTableModel(QAbstractTableModel):\n def __init__(self, data: Union[str, Dict[str, Any]] = \"\"):\n super().__init__()\n self._data: Dict[str, Any] = {}\n if isinstance(data, str):\n self.load_data(data)\n else:\n self._data = data\n\n def load_data(self, data: str):\n \"\"\"加载字幕数据\"\"\"\n try:\n self._data = json.loads(data)\n self.layoutChanged.emit()\n except json.JSONDecodeError:\n pass\n\n def data(self, index: QModelIndex, role: int = Qt.DisplayRole) -> Any: # type: ignore\n if not index.isValid() or not self._data:\n return None\n\n row = index.row()\n col = index.column()\n segment = self._data.get(str(row + 1))\n\n if not segment:\n return None\n\n if role == Qt.DisplayRole or role == Qt.EditRole: # type: ignore\n if col == 0:\n return (\n QTime(0, 0)\n .addMSecs(segment[\"start_time\"])\n .toString(\"hh:mm:ss.zzz\")[:-2]\n )\n elif col == 1:\n return (\n QTime(0, 0)\n .addMSecs(segment[\"end_time\"])\n .toString(\"hh:mm:ss.zzz\")[:-2]\n )\n elif col == 2:\n return segment[\"original_subtitle\"]\n elif col == 3:\n return segment[\"translated_subtitle\"]\n elif role == Qt.TextAlignmentRole: # type: ignore\n if col in [0, 1]:\n return Qt.AlignCenter # type: ignore\n return None\n\n def setData(self, index: QModelIndex, value: Any, role: int = Qt.EditRole) -> bool: # type: ignore\n if not index.isValid() or not self._data:\n return False\n\n if role == Qt.EditRole: # type: ignore\n row = index.row()\n col = index.column()\n segment = self._data.get(str(row + 1))\n\n if not segment:\n return False\n\n if col == 2:\n segment[\"original_subtitle\"] = value\n elif col == 3:\n segment[\"translated_subtitle\"] = value\n else:\n return False\n\n self.dataChanged.emit(index, index, [Qt.DisplayRole, Qt.EditRole]) # type: ignore\n return True\n return False\n\n def headerData(\n self,\n section: int,\n orientation: Qt.Orientation,\n role: int = Qt.DisplayRole, # type: ignore\n ) -> Any: # type: ignore\n if role == Qt.DisplayRole: # type: ignore\n if orientation == Qt.Horizontal: # type: ignore\n return [\n self.tr(\"开始时间\"),\n self.tr(\"结束时间\"),\n self.tr(\"字幕内容\"),\n (\n self.tr(\"翻译字幕\")\n if cfg.need_translate.value\n else self.tr(\"优化字幕\")\n ),\n ][section]\n elif orientation == Qt.Vertical: # type: ignore\n return str(section + 1) # 显示行号\n elif role == Qt.TextAlignmentRole: # type: ignore\n return Qt.AlignCenter # type: ignore # 居中对齐\n return None\n\n def rowCount(self, parent: Optional[QModelIndex] = None) -> int:\n return len(self._data)\n\n def columnCount(self, parent: Optional[QModelIndex] = None) -> int:\n return 4\n\n def flags(self, index: QModelIndex) -> Qt.ItemFlags:\n if not index.isValid():\n return Qt.NoItemFlags # type: ignore\n if index.column() in [2, 3]:\n return Qt.ItemIsEditable | Qt.ItemIsEnabled | Qt.ItemIsSelectable # type: ignore\n return Qt.ItemIsEnabled | Qt.ItemIsSelectable # type: ignore\n\n def update_data(self, new_data: Dict[str, str]) -> None:\n \"\"\"更新字幕数据\"\"\"\n updated_rows = set()\n\n # 更新内部数据\n for key, value in new_data.items():\n if key in self._data:\n self._data[key][\"translated_subtitle\"] = value\n row = list(self._data.keys()).index(key)\n updated_rows.add(row)\n\n # 如果有更新,发出dataChanged信号\n if updated_rows:\n min_row = min(updated_rows)\n max_row = max(updated_rows)\n top_left = self.index(min_row, 2)\n bottom_right = self.index(max_row, 3)\n self.dataChanged.emit(top_left, bottom_right, [Qt.DisplayRole, Qt.EditRole]) # type: ignore\n\n def update_all(self, data: Dict[str, Any]) -> None:\n \"\"\"更新所有数据\"\"\"\n self._data = data\n self.layoutChanged.emit()\n\n\nclass SubtitleInterface(QWidget):\n finished = pyqtSignal(str, str)\n\n def __init__(self, parent: Optional[QWidget] = None):\n super().__init__(parent)\n self.setAcceptDrops(True)\n self.task: Optional[SubtitleTask] = None\n self.subtitle_path: Optional[str] = None\n self.custom_prompt_text: str = cfg.custom_prompt_text.value\n self.setAttribute(Qt.WA_DeleteOnClose) # type: ignore\n self._init_ui()\n self._setup_signals()\n self._update_prompt_button_style()\n self.set_values()\n\n def _init_ui(self):\n self.main_layout = QVBoxLayout(self)\n self.main_layout.setObjectName(\"main_layout\")\n self.main_layout.setSpacing(20)\n\n self._setup_top_layout()\n self._setup_subtitle_table()\n self._setup_bottom_layout()\n\n def set_values(self):\n self.layout_button.setText(\n cfg.subtitle_layout.value.value\n ) # Get enum's string value\n self.translate_button.setChecked(cfg.need_translate.value)\n self.optimize_button.setChecked(cfg.need_optimize.value)\n self.target_language_button.setText(cfg.target_language.value.value)\n self.target_language_button.setEnabled(cfg.need_translate.value)\n\n def _setup_top_layout(self):\n # 创建水平布局\n top_layout = QHBoxLayout()\n\n # 创建命令栏\n self.command_bar = CommandBar(self)\n self.command_bar.setToolButtonStyle(\n Qt.ToolButtonTextBesideIcon # type: ignore\n ) # 设置图标和文字并排显示\n top_layout.addWidget(self.command_bar, 1) # 设置stretch为1,使其尽可能占用空间\n\n # 创建保存按钮的下拉菜单\n save_menu = RoundMenu(parent=self)\n save_menu.view.setMaxVisibleItems(8) # 设置菜单最大高度\n for format in OutputSubtitleFormatEnum:\n action = Action(text=format.value)\n action.triggered.connect(\n lambda checked, f=format.value: self.on_save_format_clicked(f)\n )\n save_menu.addAction(action)\n\n # 添加保存按钮(带下拉菜单)\n save_button = TransparentDropDownPushButton(self.tr(\"保存\"), self, FIF.SAVE)\n save_button.setMenu(save_menu)\n save_button.setFixedHeight(34)\n self.command_bar.addWidget(save_button)\n\n # 添加字幕排布下拉按钮\n self.layout_button = TransparentDropDownPushButton(\n self.tr(\"字幕排布\"), self, FIF.LAYOUT\n )\n self.layout_button.setFixedHeight(34)\n self.layout_button.setMinimumWidth(125)\n self.layout_menu = RoundMenu(parent=self)\n for layout in [\"译文在上\", \"原文在上\", \"仅译文\", \"仅原文\"]:\n action = Action(text=layout)\n action.triggered.connect(\n lambda checked, layout_value=layout: signalBus.subtitle_layout_changed.emit(\n layout_value\n )\n )\n self.layout_menu.addAction(action)\n self.layout_button.setMenu(self.layout_menu)\n self.command_bar.addWidget(self.layout_button)\n\n self.command_bar.addSeparator()\n\n # 添加字幕优化按钮\n self.optimize_button = Action(\n FIF.EDIT,\n self.tr(\"字幕校正\"),\n triggered=self.on_subtitle_optimization_changed,\n checkable=True,\n )\n self.command_bar.addAction(self.optimize_button)\n\n # 添加字幕翻译按钮\n self.translate_button = Action(\n FIF.LANGUAGE,\n self.tr(\"字幕翻译\"),\n triggered=self.on_subtitle_translation_changed,\n checkable=True,\n )\n self.command_bar.addAction(self.translate_button)\n\n # 添加翻译语言选择\n self.target_language_button = TransparentDropDownPushButton(\n self.tr(\"翻译语言\"), self, FIF.LANGUAGE\n )\n self.target_language_button.setFixedHeight(34)\n self.target_language_button.setMinimumWidth(125)\n self.target_language_menu = RoundMenu(parent=self)\n self.target_language_menu.setMaxVisibleItems(10)\n for lang in TargetLanguage:\n action = Action(text=lang.value)\n action.triggered.connect(\n lambda checked, lang_value=lang.value: signalBus.target_language_changed.emit(\n lang_value\n )\n )\n self.target_language_menu.addAction(action)\n self.target_language_button.setMenu(self.target_language_menu)\n\n self.command_bar.addWidget(self.target_language_button)\n\n self.command_bar.addSeparator()\n\n # 添加文稿提示按钮\n self.prompt_button = Action(\n FIF.DOCUMENT, self.tr(\"Prompt\"), triggered=self.show_prompt_dialog\n )\n self.command_bar.addAction(self.prompt_button)\n\n # 添加设置按钮\n self.command_bar.addAction(\n Action(FIF.SETTING, \"\", triggered=self.show_subtitle_settings)\n )\n\n # 添加视频播放按钮\n # self.command_bar.addAction(Action(FIF.VIDEO, \"\", triggered=self.show_video_player))\n\n # 添加打开文件夹按钮\n self.command_bar.addAction(\n Action(FIF.FOLDER, \"\", triggered=self.on_open_folder_clicked)\n )\n\n self.command_bar.addSeparator()\n\n # 添加文件选择按钮\n self.command_bar.addAction(\n Action(FIF.FOLDER_ADD, \"\", triggered=self.on_file_select)\n )\n\n # 添加开始按钮到水平布局\n self.start_button = PrimaryPushButton(self.tr(\"开始\"), self, icon=FIF.PLAY)\n self.start_button.clicked.connect(\n lambda: self.start_subtitle_optimization(need_create_task=True)\n )\n self.start_button.setFixedHeight(34)\n top_layout.addWidget(self.start_button)\n\n self.main_layout.addLayout(top_layout)\n\n def _setup_subtitle_table(self):\n self.subtitle_table = TableView(self)\n self.model = SubtitleTableModel(\"\")\n self.subtitle_table.setModel(self.model)\n self.subtitle_table.setBorderVisible(True)\n self.subtitle_table.setBorderRadius(8)\n self.subtitle_table.setWordWrap(True)\n self.subtitle_table.horizontalHeader().setSectionResizeMode(QHeaderView.Stretch)\n self.subtitle_table.horizontalHeader().setSectionResizeMode(\n 0, QHeaderView.Fixed\n )\n self.subtitle_table.horizontalHeader().setSectionResizeMode(\n 1, QHeaderView.Fixed\n )\n self.subtitle_table.setColumnWidth(0, 120)\n self.subtitle_table.setColumnWidth(1, 120)\n\n # 配置垂直表头\n self.subtitle_table.verticalHeader().setVisible(True) # 显示垂直表头\n self.subtitle_table.verticalHeader().setDefaultAlignment(\n Qt.AlignCenter # type: ignore\n ) # 居中对齐\n self.subtitle_table.verticalHeader().setDefaultSectionSize(50) # 行高\n self.subtitle_table.verticalHeader().setMinimumWidth(20) # 设置最小宽度\n\n self.subtitle_table.setEditTriggers(\n QAbstractItemView.DoubleClicked | QAbstractItemView.EditKeyPressed # type: ignore\n )\n self.subtitle_table.clicked.connect(self.on_subtitle_clicked)\n # 添加右键菜单支持\n self.subtitle_table.setContextMenuPolicy(Qt.CustomContextMenu) # type: ignore\n self.subtitle_table.customContextMenuRequested.connect(self.show_context_menu)\n self.main_layout.addWidget(self.subtitle_table)\n\n def _setup_bottom_layout(self):\n self.bottom_layout = QHBoxLayout()\n self.progress_bar = ProgressBar(self)\n self.status_label = BodyLabel(self.tr(\"请拖入字幕文件\"), self)\n self.status_label.setMinimumWidth(100)\n self.status_label.setAlignment(Qt.AlignCenter) # type: ignore\n\n # 添加取消按钮\n self.cancel_button = PushButton(self.tr(\"取消\"), self, icon=FIF.CANCEL)\n self.cancel_button.hide() # 初始隐藏\n self.cancel_button.clicked.connect(self.cancel_optimization)\n\n self.bottom_layout.addWidget(self.progress_bar, 1)\n self.bottom_layout.addWidget(self.status_label)\n self.bottom_layout.addWidget(self.cancel_button)\n self.main_layout.addLayout(self.bottom_layout)\n\n def _setup_signals(self) -> None:\n signalBus.subtitle_layout_changed.connect(self.on_subtitle_layout_changed)\n signalBus.target_language_changed.connect(self.on_target_language_changed)\n signalBus.subtitle_optimization_changed.connect(\n self.on_subtitle_optimization_changed\n )\n signalBus.subtitle_translation_changed.connect(\n self.on_subtitle_translation_changed\n )\n # self.subtitle_setting_button.clicked.connect(self.show_subtitle_settings)\n # self.video_player_button.clicked.connect(self.show_video_player)\n\n def show_prompt_dialog(self) -> None:\n dialog = PromptDialog(self)\n if dialog.exec_():\n self.custom_prompt_text = cfg.custom_prompt_text.value\n self._update_prompt_button_style()\n\n def _update_prompt_button_style(self) -> None:\n if self.custom_prompt_text.strip():\n green_icon = FIF.DOCUMENT.colored(\n QColor(76, 255, 165), QColor(76, 255, 165)\n )\n self.prompt_button.setIcon(green_icon)\n else:\n self.prompt_button.setIcon(FIF.DOCUMENT)\n\n def set_task(self, task: SubtitleTask) -> None:\n \"\"\"设置任务并更新UI\"\"\"\n if hasattr(self, \"subtitle_optimization_thread\"):\n self.subtitle_optimization_thread.stop() # type: ignore\n self.start_button.setEnabled(True)\n self.task = task\n self.subtitle_path = task.subtitle_path\n self.update_info(task)\n\n def update_info(self, task: SubtitleTask) -> None:\n \"\"\"更新页面信息\"\"\"\n if not self.task:\n return\n original_subtitle_save_path = Path(str(self.task.subtitle_path))\n asr_data = ASRData.from_subtitle_file(str(original_subtitle_save_path))\n self.model._data = asr_data.to_json()\n self.model.layoutChanged.emit()\n self.status_label.setText(self.tr(\"已加载文件\"))\n\n def start_subtitle_optimization(self, need_create_task: bool = True) -> None:\n # 检查是否有任务\n if not self.subtitle_path:\n InfoBar.warning(\n self.tr(\"警告\"),\n self.tr(\"请先加载字幕文件\"),\n duration=INFOBAR_DURATION_WARNING,\n parent=self,\n )\n return\n self.start_button.setEnabled(False)\n self.progress_bar.resume()\n self.progress_bar.reset()\n self.cancel_button.show()\n\n if need_create_task:\n self.task = TaskFactory.create_subtitle_task(file_path=self.subtitle_path)\n if self.task:\n self.subtitle_optimization_thread = SubtitleThread(self.task)\n self.subtitle_optimization_thread.finished.connect(\n self.on_subtitle_optimization_finished\n )\n self.subtitle_optimization_thread.progress.connect(\n self.on_subtitle_optimization_progress\n )\n self.subtitle_optimization_thread.update.connect(self.update_data)\n self.subtitle_optimization_thread.update_all.connect(self.update_all)\n self.subtitle_optimization_thread.error.connect(\n self.on_subtitle_optimization_error\n )\n self.subtitle_optimization_thread.set_custom_prompt_text(\n self.custom_prompt_text\n )\n self.subtitle_optimization_thread.start()\n InfoBar.info(\n self.tr(\"开始优化\"),\n self.tr(\"开始优化字幕\"),\n duration=INFOBAR_DURATION_INFO,\n parent=self,\n )\n\n def process(self) -> None:\n \"\"\"主处理函数\"\"\"\n # 检查是否有任务\n self.start_subtitle_optimization(need_create_task=False)\n\n def on_subtitle_optimization_finished(\n self, video_path: str, output_path: str\n ) -> None:\n self.start_button.setEnabled(True)\n self.cancel_button.hide()\n self.progress_bar.setValue(100)\n if self.task and self.task.need_next_task:\n self.finished.emit(video_path, output_path)\n InfoBar.success(\n self.tr(\"优化完成\"),\n self.tr(\"优化完成字幕...\"),\n duration=INFOBAR_DURATION_SUCCESS,\n position=InfoBarPosition.BOTTOM,\n parent=self.parent(),\n )\n\n def on_subtitle_optimization_error(self, error: str) -> None:\n self.start_button.setEnabled(True)\n self.cancel_button.hide() # 隐藏取消按钮\n self.progress_bar.error()\n InfoBar.error(\n self.tr(\"优化失败\"),\n self.tr(error),\n duration=INFOBAR_DURATION_ERROR,\n parent=self,\n )\n\n def on_subtitle_optimization_progress(self, value: int, status: str) -> None:\n self.progress_bar.setValue(value)\n self.status_label.setText(status)\n\n def update_data(self, data):\n self.model.update_data(data)\n\n def update_all(self, data):\n self.model.update_all(data)\n\n def remove_widget(self) -> None:\n \"\"\"隐藏顶部开始按钮和底部进度条\"\"\"\n self.start_button.hide()\n for i in range(self.bottom_layout.count()):\n item = self.bottom_layout.itemAt(i)\n if item:\n widget = item.widget()\n if widget:\n widget.hide()\n\n def on_file_select(self) -> None:\n # 构建文件过滤器\n subtitle_formats = \" \".join(\n f\"*.{fmt.value}\" for fmt in SupportedSubtitleFormats\n )\n filter_str = f\"{self.tr('字幕文件')} ({subtitle_formats})\"\n\n file_path, _ = QFileDialog.getOpenFileName(\n self, self.tr(\"选择字幕文件\"), \"\", filter_str\n )\n if file_path:\n self.subtitle_path = file_path\n self.load_subtitle_file(file_path)\n\n def on_save_format_clicked(self, format: str) -> None:\n \"\"\"处理保存格式的选择\"\"\"\n if not self.subtitle_path:\n InfoBar.warning(\n self.tr(\"警告\"),\n self.tr(\"请先加载字幕文件\"),\n duration=INFOBAR_DURATION_WARNING,\n parent=self,\n )\n return\n\n # 获取保存路径\n default_name = Path(self.subtitle_path).stem\n file_path, _ = QFileDialog.getSaveFileName(\n self,\n self.tr(\"保存字幕文件\"),\n default_name, # 使用原文件名作为默认名\n f\"{self.tr('字幕文件')} (*.{format})\",\n )\n if not file_path:\n return\n\n try:\n # 转换并保存字幕\n asr_data = ASRData.from_json(self.model._data)\n layout = cfg.subtitle_layout.value\n\n if file_path.endswith(\".ass\"):\n style_str = get_subtitle_style(cfg.subtitle_style_name.value)\n asr_data.to_ass(style_str, layout, file_path)\n else:\n asr_data.save(file_path, layout=layout)\n InfoBar.success(\n self.tr(\"保存成功\"),\n self.tr(\"字幕已保存至:\") + file_path,\n duration=INFOBAR_DURATION_SUCCESS,\n parent=self,\n )\n except Exception as e:\n InfoBar.error(\n self.tr(\"保存失败\"),\n self.tr(\"保存字幕文件失败: \") + str(e),\n duration=INFOBAR_DURATION_ERROR,\n parent=self,\n )\n\n def on_open_folder_clicked(self) -> None:\n \"\"\"打开文件夹按钮点击事件\"\"\"\n if not self.task:\n InfoBar.warning(\n self.tr(\"警告\"),\n self.tr(\"请先加载字幕文件\"),\n duration=INFOBAR_DURATION_WARNING,\n parent=self,\n )\n return\n if not self.task:\n return\n if self.task.output_path:\n output_path = Path(self.task.output_path)\n target_dir = str(\n output_path.parent\n if output_path.exists()\n else Path(self.task.subtitle_path).parent\n )\n else:\n target_dir = str(Path(self.task.subtitle_path).parent)\n open_folder(target_dir)\n\n def load_subtitle_file(self, file_path: str) -> None:\n self.subtitle_path = file_path\n asr_data = ASRData.from_subtitle_file(file_path)\n self.model._data = asr_data.to_json()\n self.model.layoutChanged.emit()\n self.status_label.setText(self.tr(\"已加载文件\"))\n\n def dragEnterEvent(self, event: QDragEnterEvent) -> None:\n event.accept() if event.mimeData().hasUrls() else event.ignore()\n\n def dropEvent(self, event: QDropEvent) -> None:\n files = [u.toLocalFile() for u in event.mimeData().urls()]\n for file_path in files:\n if not os.path.isfile(file_path):\n continue\n\n file_ext = os.path.splitext(file_path)[1][1:].lower()\n\n # 检查文件格式是否支持\n supported_formats = {fmt.value for fmt in SupportedSubtitleFormats}\n is_supported = file_ext in supported_formats\n\n if is_supported:\n self.load_subtitle_file(file_path)\n InfoBar.success(\n self.tr(\"导入成功\"),\n self.tr(\"成功导入\") + os.path.basename(file_path),\n duration=INFOBAR_DURATION_SUCCESS,\n position=InfoBarPosition.BOTTOM,\n parent=self,\n )\n break\n else:\n InfoBar.error(\n self.tr(\"格式错误\") + file_ext,\n self.tr(\"支持的字幕格式:\") + str(supported_formats),\n duration=INFOBAR_DURATION_ERROR,\n parent=self,\n )\n event.accept()\n\n def closeEvent(self, event: QCloseEvent) -> None:\n if hasattr(self, \"subtitle_optimization_thread\"):\n self.subtitle_optimization_thread.stop() # type: ignore\n super().closeEvent(event)\n\n def show_subtitle_settings(self) -> None:\n \"\"\"显示字幕设置对话框\"\"\"\n dialog = SubtitleSettingDialog(self.window())\n dialog.exec_()\n\n def show_video_player(self) -> None:\n \"\"\"显示视频播放器窗口\"\"\"\n # 创建视频播放器窗口(延迟导入,因为vlc是可选依赖)\n from app.components.MyVideoWidget import MyVideoWidget\n\n self.video_player = MyVideoWidget()\n self.video_player.resize(800, 600)\n\n def signal_update() -> None:\n if not self.model._data:\n return\n ass_style_name = cfg.subtitle_style_name.value\n ass_style_path = SUBTITLE_STYLE_PATH / f\"{ass_style_name}.txt\"\n if ass_style_path.exists():\n subtitle_style_srt = ass_style_path.read_text(encoding=\"utf-8\")\n else:\n subtitle_style_srt = None\n temp_srt_path = os.path.join(tempfile.gettempdir(), \"temp_subtitle.ass\")\n asr_data = ASRData.from_json(self.model._data)\n asr_data.save(\n temp_srt_path,\n layout=cfg.subtitle_layout.value,\n ass_style=subtitle_style_srt or \"\",\n )\n signalBus.add_subtitle(temp_srt_path)\n\n # 如果有字幕文件,则添加字幕\n signal_update()\n\n signalBus.subtitle_layout_changed.connect(signal_update)\n self.model.dataChanged.connect(signal_update)\n self.model.layoutChanged.connect(signal_update)\n\n # 如果有关联的视频文件,则自动加载\n # Note: SubtitleTask doesn't have file_path attribute\n # if self.task and hasattr(self.task, \"file_path\") and self.task.file_path:\n # self.video_player.setVideo(QUrl.fromLocalFile(self.task.file_path))\n\n self.video_player.show()\n self.video_player.play()\n\n def on_subtitle_clicked(self, index: QModelIndex) -> None:\n row = index.row()\n item = list(self.model._data.values())[row]\n start_time = item[\"start_time\"] # 毫秒\n end_time = (\n item[\"end_time\"] - 50\n if item[\"end_time\"] - 50 > start_time\n else item[\"end_time\"]\n )\n signalBus.play_video_segment(start_time, end_time)\n\n def show_context_menu(self, pos) -> None:\n \"\"\"显示右键菜单\"\"\"\n menu = RoundMenu(parent=self)\n\n # 获取选中的行\n indexes = self.subtitle_table.selectedIndexes()\n if not indexes:\n return\n\n # 获取唯一的行号\n rows = sorted(set(index.row() for index in indexes))\n if not rows:\n return\n\n # 添加菜单项\n # retranslate_action = Action(FIF.SYNC, self.tr(\"重新翻译\"))\n merge_action = Action(FIF.LINK, self.tr(\"合并\")) # 添加快捷键提示\n # menu.addAction(retranslate_action)\n menu.addAction(merge_action)\n merge_action.setShortcut(\"Ctrl+M\") # 设置快捷键\n\n # 设置动作状态\n # retranslate_action.setEnabled(cfg.need_translate.value)\n merge_action.setEnabled(len(rows) > 1)\n\n # 连接动作信号\n # retranslate_action.triggered.connect(lambda: self.retranslate_selected_rows(rows))\n merge_action.triggered.connect(lambda: self.merge_selected_rows(rows))\n\n # 显示菜单\n menu.exec(self.subtitle_table.viewport().mapToGlobal(pos))\n\n def merge_selected_rows(self, rows: List[int]) -> None:\n \"\"\"合并选中的字幕行\"\"\"\n if not rows or len(rows) < 2:\n return\n\n # 获取选中行的数据\n data = self.model._data\n data_list = list(data.values())\n\n # 获取第一行和最后一行的时间戳\n first_row = data_list[rows[0]]\n last_row = data_list[rows[-1]]\n start_time = first_row[\"start_time\"]\n end_time = last_row[\"end_time\"]\n\n # 合并字幕内容\n original_subtitles = []\n translated_subtitles = []\n for row in rows:\n item = data_list[row]\n original_subtitles.append(item[\"original_subtitle\"])\n translated_subtitles.append(item[\"translated_subtitle\"])\n\n merged_original = \" \".join(original_subtitles)\n merged_translated = \" \".join(translated_subtitles)\n\n # 创建新的合并后的字幕项\n merged_item = {\n \"start_time\": start_time,\n \"end_time\": end_time,\n \"original_subtitle\": merged_original,\n \"translated_subtitle\": merged_translated,\n }\n\n # 获取所有需要保留的键\n keys = list(data.keys())\n preserved_keys = keys[: rows[0]] + keys[rows[-1] + 1 :]\n\n # 创建新的数据字典\n new_data = {}\n for i, key in enumerate(preserved_keys):\n if i == rows[0]:\n new_key = f\"{len(new_data) + 1}\"\n new_data[new_key] = merged_item\n new_key = f\"{len(new_data) + 1}\"\n new_data[new_key] = data[key]\n\n # 如果合并的是最后几行,需要确保合并项被添加\n if rows[0] >= len(preserved_keys):\n new_key = f\"{len(new_data) + 1}\"\n new_data[new_key] = merged_item\n\n # 更新模型数据\n self.model.update_all(new_data)\n\n # 显示成功提示\n InfoBar.success(\n self.tr(\"合并成功\"),\n self.tr(\"已成功合并选中的字幕行\"),\n duration=INFOBAR_DURATION_SUCCESS,\n parent=self,\n )\n\n def keyPressEvent(self, event: QKeyEvent) -> None:\n \"\"\"处理键盘事件\"\"\"\n # 处理 Ctrl+M 快捷键\n if event.modifiers() == Qt.ControlModifier and event.key() == Qt.Key_M: # type: ignore\n indexes = self.subtitle_table.selectedIndexes()\n if indexes:\n rows = sorted(set(index.row() for index in indexes))\n if len(rows) > 1:\n self.merge_selected_rows(rows)\n event.accept()\n else:\n super().keyPressEvent(event)\n\n def cancel_optimization(self) -> None:\n \"\"\"取消字幕校正\"\"\"\n if hasattr(self, \"subtitle_optimization_thread\"):\n self.subtitle_optimization_thread.stop() # type: ignore\n self.start_button.setEnabled(True)\n self.cancel_button.hide()\n self.progress_bar.resume() # 恢复正常状态\n self.progress_bar.setValue(0)\n self.status_label.setText(self.tr(\"已取消校正\"))\n InfoBar.warning(\n self.tr(\"已取消\"),\n self.tr(\"字幕校正已取消\"),\n duration=INFOBAR_DURATION_WARNING,\n parent=self,\n )\n\n def on_target_language_changed(self, language: str) -> None:\n \"\"\"处理翻译语言变更\"\"\"\n for lang in TargetLanguage:\n if lang.value == language:\n self.target_language_button.setText(lang.value)\n cfg.set(cfg.target_language, lang)\n break\n\n def on_subtitle_optimization_changed(self, checked: bool) -> None:\n \"\"\"处理字幕优化开关变更\"\"\"\n cfg.set(cfg.need_optimize, checked)\n self.optimize_button.setChecked(checked)\n\n def on_subtitle_translation_changed(self, checked: bool) -> None:\n \"\"\"处理字幕翻译开关变更\"\"\"\n cfg.set(cfg.need_translate, checked)\n self.translate_button.setChecked(checked)\n # 控制翻译语言选择按钮的启用状态\n self.target_language_button.setEnabled(checked)\n\n def on_subtitle_layout_changed(self, layout: str) -> None:\n \"\"\"处理字幕排布变更\"\"\"\n layout_enum = SubtitleLayoutEnum(layout) # Convert string to enum\n cfg.set(cfg.subtitle_layout, layout_enum)\n self.layout_button.setText(layout)\n\n\nclass PromptDialog(MessageBoxBase):\n def __init__(self, parent: Optional[QWidget] = None):\n super().__init__(parent)\n self.setup_ui()\n self.setWindowTitle(self.tr(\"文稿提示\"))\n # 连接按钮点击事件\n self.yesButton.clicked.connect(self.save_prompt)\n\n def setup_ui(self) -> None:\n self.titleLabel = BodyLabel(self.tr(\"文稿提示\"), self)\n\n # 添加文本编辑框\n self.text_edit = TextEdit(self)\n self.text_edit.setPlaceholderText(\n self.tr(\n \"请输入文稿提示(辅助校正字幕和翻译)\\n\\n\"\n \"支持以下内容:\\n\"\n \"1. 术语表 - 专业术语、人名、特定词语的修正对照表\\n\"\n \"示例:\\n机器学习->Machine Learning\\n马斯克->Elon Musk\\n打call->应援\\n\\n\"\n \"2. 原字幕文稿 - 视频的原有文稿或相关内容\\n\"\n \"示例: 完整的演讲稿、课程讲义等\\n\\n\"\n \"3. 修正要求 - 内容相关的具体修正要求\\n\"\n \"示例: 统一人称代词、规范专业术语等\\n\\n\"\n \"注意: 使用小型LLM模型时建议控制文稿在1千字内。对于不同字幕文件,请使用与该字幕相关的文稿提示。\"\n )\n )\n self.text_edit.setText(cfg.custom_prompt_text.value)\n\n self.text_edit.setMinimumWidth(420)\n self.text_edit.setMinimumHeight(380)\n\n # 添加到布局\n self.viewLayout.addWidget(self.titleLabel)\n self.viewLayout.addWidget(self.text_edit)\n self.viewLayout.setSpacing(10)\n\n # 设置按钮文本\n self.yesButton.setText(self.tr(\"确定\"))\n self.cancelButton.setText(self.tr(\"取消\"))\n\n def get_prompt(self) -> str:\n return self.text_edit.toPlainText()\n\n def save_prompt(self) -> None:\n # 在点击确定按钮时保存提示文本到配置\n prompt_text = self.text_edit.toPlainText()\n cfg.set(cfg.custom_prompt_text, prompt_text)\n\n\nif __name__ == \"__main__\":\n QApplication.setHighDpiScaleFactorRoundingPolicy(\n Qt.HighDpiScaleFactorRoundingPolicy.PassThrough # type: ignore\n )\n QApplication.setAttribute(Qt.AA_EnableHighDpiScaling) # type: ignore\n QApplication.setAttribute(Qt.AA_UseHighDpiPixmaps) # type: ignore\n\n app = QApplication(sys.argv)\n window = SubtitleInterface()\n window.show()\n sys.exit(app.exec_())\n" }, { "path": "app/view/subtitle_style_interface.py", "content": "import json\nfrom pathlib import Path\nfrom typing import Optional, Tuple\n\nfrom PIL import ImageFont\nfrom PyQt5.QtCore import Qt, QThread, pyqtSignal\nfrom PyQt5.QtGui import QColor, QFontDatabase\nfrom PyQt5.QtWidgets import QFileDialog, QHBoxLayout, QVBoxLayout, QWidget\nfrom qfluentwidgets import (\n BodyLabel,\n CardWidget,\n ImageLabel,\n InfoBar,\n InfoBarPosition,\n LineEdit,\n MessageBoxBase,\n PushSettingCard,\n ScrollArea,\n SettingCardGroup,\n)\nfrom qfluentwidgets import FluentIcon as FIF\n\nfrom app.common.config import cfg\nfrom app.common.signal_bus import signalBus\nfrom app.components.MySettingCard import (\n ColorSettingCard,\n ComboBoxSettingCard,\n DoubleSpinBoxSettingCard,\n SpinBoxSettingCard,\n)\nfrom app.config import ASSETS_PATH, SUBTITLE_STYLE_PATH\nfrom app.core.constant import INFOBAR_DURATION_SUCCESS, INFOBAR_DURATION_WARNING\nfrom app.core.entities import SubtitleLayoutEnum, SubtitleRenderModeEnum\nfrom app.core.subtitle import get_builtin_fonts, render_ass_preview, render_preview\nfrom app.core.subtitle.styles import RoundedBgStyle\nfrom app.core.utils.platform_utils import open_folder\n\nPERVIEW_TEXTS = {\n \"长文本\": (\n \"This is a long text for testing subtitle preview, text wrapping, and style settings.\",\n \"这是一段用于测试字幕预览、自动换行以及样式设置的较长文本内容。\",\n ),\n \"中文本\": (\n \"Welcome to apply for the prestigious South China Normal University!\",\n \"欢迎报考百年名校华南师范大学\",\n ),\n \"短文本\": (\"Elementary school students know this\", \"小学二年级的都知道\"),\n}\n\nDEFAULT_BG_LANDSCAPE = {\n \"path\": ASSETS_PATH / \"default_bg_landscape.png\",\n \"width\": 1280,\n \"height\": 720,\n}\nDEFAULT_BG_PORTRAIT = {\n \"path\": ASSETS_PATH / \"default_bg_portrait.png\",\n \"width\": 480,\n \"height\": 852,\n}\n\n\nclass AssPreviewThread(QThread):\n \"\"\"ASS 样式预览线程\"\"\"\n\n previewReady = pyqtSignal(str)\n\n def __init__(\n self,\n preview_text: Tuple[str, Optional[str]],\n style_str: str,\n bg_image_path: str,\n width: Optional[int] = None,\n height: Optional[int] = None,\n ):\n super().__init__()\n self.preview_text = preview_text\n self.width = width\n self.height = height\n self.style_str = style_str\n self.bg_image_path = bg_image_path\n\n def run(self):\n preview_path = render_ass_preview(\n style_str=self.style_str,\n preview_text=self.preview_text,\n bg_image_path=self.bg_image_path,\n width=self.width,\n height=self.height,\n )\n self.previewReady.emit(preview_path)\n\n\nclass RoundedBgPreviewThread(QThread):\n \"\"\"圆角背景预览线程\"\"\"\n\n previewReady = pyqtSignal(str)\n\n def __init__(\n self,\n style: RoundedBgStyle,\n preview_text: Tuple[str, Optional[str]],\n width: Optional[int] = None,\n height: Optional[int] = None,\n bg_image_path: Optional[str] = None,\n ):\n super().__init__()\n self.primary_text = preview_text[0]\n self.secondary_text = preview_text[1] or \"\"\n self.width = width\n self.height = height\n self.style = style\n self.bg_image_path = bg_image_path\n\n def run(self):\n preview_path = render_preview(\n primary_text=self.primary_text,\n secondary_text=self.secondary_text,\n width=self.width,\n height=self.height,\n style=self.style,\n bg_image_path=self.bg_image_path,\n )\n self.previewReady.emit(preview_path)\n\n\nclass SubtitleStyleInterface(QWidget):\n def __init__(self, parent=None):\n super().__init__(parent=parent)\n self.setObjectName(\"SubtitleStyleInterface\")\n self.setWindowTitle(self.tr(\"字幕样式配置\"))\n self.setAcceptDrops(True) # 启用拖放功能\n\n # 创建主布局\n self.hBoxLayout = QHBoxLayout(self)\n\n # 初始化界面组件\n self._initSettingsArea()\n self._initPreviewArea()\n self._initSettingCards()\n self._initLayout()\n self._initStyle()\n\n # 控制是否触发样式变更回调(加载样式时禁用)\n self._loading_style = False\n\n # 设置初始值,加载样式\n self.__setValues()\n\n # 连接信号\n self.connectSignals()\n\n def _initSettingsArea(self):\n \"\"\"初始化左侧设置区域\"\"\"\n self.settingsScrollArea = ScrollArea()\n self.settingsScrollArea.setFixedWidth(350)\n self.settingsWidget = QWidget()\n self.settingsLayout = QVBoxLayout(self.settingsWidget)\n self.settingsScrollArea.setWidget(self.settingsWidget)\n self.settingsScrollArea.setWidgetResizable(True)\n\n # 创建设置组 - 通用\n self.layoutGroup = SettingCardGroup(self.tr(\"字幕排布\"), self.settingsWidget)\n\n # ASS 样式设置组\n self.assPrimaryGroup = SettingCardGroup(\n self.tr(\"主字幕样式\"), self.settingsWidget\n )\n self.assSecondaryGroup = SettingCardGroup(\n self.tr(\"副字幕样式\"), self.settingsWidget\n )\n\n # 圆角背景设置组\n self.roundedBgGroup = SettingCardGroup(\n self.tr(\"圆角背景样式\"), self.settingsWidget\n )\n\n # 预览设置组\n self.previewGroup = SettingCardGroup(self.tr(\"预览设置\"), self.settingsWidget)\n\n def _initPreviewArea(self):\n \"\"\"初始化右侧预览区域\"\"\"\n self.previewCard = CardWidget()\n self.previewLayout = QVBoxLayout(self.previewCard)\n self.previewLayout.setSpacing(16)\n\n # 顶部预览区域\n self.previewTopWidget = QWidget()\n self.previewTopWidget.setFixedHeight(430)\n self.previewTopLayout = QVBoxLayout(self.previewTopWidget)\n\n self.previewLabel = BodyLabel(self.tr(\"预览效果\"))\n self.previewImage = ImageLabel()\n self.previewImage.setAlignment(Qt.AlignCenter) # type: ignore\n self.previewTopLayout.addWidget(self.previewImage, 0, Qt.AlignCenter) # type: ignore\n self.previewTopLayout.setAlignment(Qt.AlignVCenter) # type: ignore\n\n # 底部控件区域\n self.previewBottomWidget = QWidget()\n self.previewBottomLayout = QVBoxLayout(self.previewBottomWidget)\n\n self.styleNameComboBox = ComboBoxSettingCard(\n FIF.VIEW, # type: ignore\n self.tr(\"选择样式\"),\n self.tr(\"选择已保存的字幕样式\"),\n texts=[], # type: ignore\n )\n\n self.newStyleButton = PushSettingCard(\n self.tr(\"新建样式\"),\n FIF.ADD,\n self.tr(\"新建样式\"),\n self.tr(\"基于当前样式新建预设\"),\n )\n\n self.openStyleFolderButton = PushSettingCard(\n self.tr(\"打开样式文件夹\"),\n FIF.FOLDER,\n self.tr(\"打开样式文件夹\"),\n self.tr(\"在文件管理器中打开样式文件夹\"),\n )\n\n self.previewBottomLayout.addWidget(self.styleNameComboBox)\n self.previewBottomLayout.addWidget(self.newStyleButton)\n self.previewBottomLayout.addWidget(self.openStyleFolderButton)\n\n self.previewLayout.addWidget(self.previewTopWidget)\n self.previewLayout.addWidget(self.previewBottomWidget)\n self.previewLayout.addStretch(1)\n\n def _initSettingCards(self):\n \"\"\"初始化所有设置卡片\"\"\"\n # 渲染模式切换\n self.renderModeCard = ComboBoxSettingCard(\n FIF.BRUSH, # type: ignore\n self.tr(\"渲染模式\"),\n self.tr(\"选择字幕渲染方式\"),\n texts=[e.value for e in SubtitleRenderModeEnum],\n )\n\n # 字幕排布设置\n self.layoutCard = ComboBoxSettingCard(\n FIF.ALIGNMENT, # type: ignore\n self.tr(\"字幕排布\"),\n self.tr(\"设置主字幕和副字幕的显示方式\"),\n texts=[\"译文在上\", \"原文在上\", \"仅译文\", \"仅原文\"],\n )\n\n # ASS 模式 - 垂直间距\n self.assVerticalSpacingCard = SpinBoxSettingCard(\n FIF.ALIGNMENT, # type: ignore\n self.tr(\"垂直间距\"),\n self.tr(\"设置字幕的垂直间距\"),\n minimum=8,\n maximum=10000,\n )\n\n # ASS 模式 - 主字幕样式\n self.assPrimaryFontCard = ComboBoxSettingCard(\n FIF.FONT, # type: ignore\n self.tr(\"主字幕字体\"),\n self.tr(\"设置主字幕的字体\"),\n )\n\n self.assPrimarySizeCard = SpinBoxSettingCard(\n FIF.FONT_SIZE, # type: ignore\n self.tr(\"主字幕字号\"),\n self.tr(\"设置主字幕的大小\"),\n minimum=8,\n maximum=1000,\n )\n\n self.assPrimarySpacingCard = DoubleSpinBoxSettingCard(\n FIF.ALIGNMENT, # type: ignore\n self.tr(\"主字幕间距\"),\n self.tr(\"设置主字幕的字符间距\"),\n minimum=0.0,\n maximum=10.0,\n decimals=1,\n )\n\n self.assPrimaryColorCard = ColorSettingCard(\n QColor(255, 255, 255),\n FIF.PALETTE, # type: ignore\n self.tr(\"主字幕颜色\"),\n self.tr(\"设置主字幕的颜色\"),\n )\n\n self.assPrimaryOutlineColorCard = ColorSettingCard(\n QColor(0, 0, 0),\n FIF.PALETTE, # type: ignore\n self.tr(\"主字幕边框颜色\"),\n self.tr(\"设置主字幕的边框颜色\"),\n )\n\n self.assPrimaryOutlineSizeCard = DoubleSpinBoxSettingCard(\n FIF.ZOOM, # type: ignore\n self.tr(\"主字幕边框大小\"),\n self.tr(\"设置主字幕的边框粗细\"),\n minimum=0.0,\n maximum=10.0,\n decimals=1,\n )\n\n # ASS 模式 - 副字幕样式\n self.assSecondaryFontCard = ComboBoxSettingCard(\n FIF.FONT, # type: ignore\n self.tr(\"副字幕字体\"),\n self.tr(\"设置副字幕的字体\"),\n )\n\n self.assSecondarySizeCard = SpinBoxSettingCard(\n FIF.FONT_SIZE, # type: ignore\n self.tr(\"副字幕字号\"),\n self.tr(\"设置副字幕的大小\"),\n minimum=8,\n maximum=1000,\n )\n\n self.assSecondarySpacingCard = DoubleSpinBoxSettingCard(\n FIF.ALIGNMENT, # type: ignore\n self.tr(\"副字幕间距\"),\n self.tr(\"设置副字幕的字符间距\"),\n minimum=0.0,\n maximum=50.0,\n decimals=1,\n )\n\n self.assSecondaryColorCard = ColorSettingCard(\n QColor(255, 255, 255),\n FIF.PALETTE, # type: ignore\n self.tr(\"副字幕颜色\"),\n self.tr(\"设置副字幕的颜色\"),\n )\n\n self.assSecondaryOutlineColorCard = ColorSettingCard(\n QColor(0, 0, 0),\n FIF.PALETTE, # type: ignore\n self.tr(\"副字幕边框颜色\"),\n self.tr(\"设置副字幕的边框颜色\"),\n )\n\n self.assSecondaryOutlineSizeCard = DoubleSpinBoxSettingCard(\n FIF.ZOOM, # type: ignore\n self.tr(\"副字幕边框大小\"),\n self.tr(\"设置副字幕的边框粗细\"),\n minimum=0.0,\n maximum=50.0,\n decimals=1,\n )\n\n # 圆角背景样式设置\n self.roundedFontCard = ComboBoxSettingCard(\n FIF.FONT, # type: ignore\n self.tr(\"字体\"),\n self.tr(\"设置字幕字体\"),\n )\n\n self.roundedFontSizeCard = SpinBoxSettingCard(\n FIF.FONT_SIZE, # type: ignore\n self.tr(\"字体大小\"),\n self.tr(\"设置字幕字体大小\"),\n minimum=16,\n maximum=120,\n )\n\n self.roundedTextColorCard = ColorSettingCard(\n QColor(255, 255, 255),\n FIF.PALETTE, # type: ignore\n self.tr(\"文字颜色\"),\n self.tr(\"设置字幕文字颜色\"),\n )\n\n self.roundedBgColorCard = ColorSettingCard(\n QColor(25, 25, 25, 200),\n FIF.PALETTE, # type: ignore\n self.tr(\"背景颜色\"),\n self.tr(\"设置圆角矩形背景颜色\"),\n enableAlpha=True,\n )\n\n self.roundedCornerRadiusCard = SpinBoxSettingCard(\n FIF.ZOOM, # type: ignore\n self.tr(\"圆角半径\"),\n self.tr(\"设置背景圆角大小\"),\n minimum=0,\n maximum=50,\n )\n\n self.roundedPaddingHCard = SpinBoxSettingCard(\n FIF.ALIGNMENT, # type: ignore\n self.tr(\"水平内边距\"),\n self.tr(\"文字与背景边缘的水平距离\"),\n minimum=4,\n maximum=100,\n )\n\n self.roundedPaddingVCard = SpinBoxSettingCard(\n FIF.ALIGNMENT, # type: ignore\n self.tr(\"垂直内边距\"),\n self.tr(\"文字与背景边缘的垂直距离\"),\n minimum=4,\n maximum=50,\n )\n\n self.roundedMarginBottomCard = SpinBoxSettingCard(\n FIF.ALIGNMENT, # type: ignore\n self.tr(\"底部边距\"),\n self.tr(\"字幕距视频底部的距离\"),\n minimum=20,\n maximum=300,\n )\n\n self.roundedLineSpacingCard = SpinBoxSettingCard(\n FIF.ALIGNMENT, # type: ignore\n self.tr(\"行间距\"),\n self.tr(\"双语字幕的行间距\"),\n minimum=0,\n maximum=50,\n )\n\n self.roundedLetterSpacingCard = SpinBoxSettingCard(\n FIF.FONT, # type: ignore\n self.tr(\"字符间距\"),\n self.tr(\"每个字符之间的额外间距\"),\n minimum=0,\n maximum=20,\n step=1,\n )\n\n # 预览设置\n self.previewTextCard = ComboBoxSettingCard(\n FIF.MESSAGE, # type: ignore\n self.tr(\"预览文字\"),\n self.tr(\"设置预览显示的文字内容\"),\n texts=list(PERVIEW_TEXTS.keys()),\n parent=self.previewGroup,\n )\n\n self.orientationCard = ComboBoxSettingCard(\n FIF.LAYOUT, # type: ignore\n self.tr(\"预览方向\"),\n self.tr(\"设置预览图片的显示方向\"),\n texts=[\"横屏\", \"竖屏\"],\n parent=self.previewGroup,\n )\n\n self.previewImageCard = PushSettingCard(\n self.tr(\"选择图片\"),\n FIF.PHOTO,\n self.tr(\"预览背景\"),\n self.tr(\"选择预览使用的背景图片\"),\n parent=self.previewGroup,\n )\n\n def _initLayout(self):\n \"\"\"初始化布局\"\"\"\n # 通用设置\n self.layoutGroup.addSettingCard(self.renderModeCard)\n self.layoutGroup.addSettingCard(self.layoutCard)\n self.layoutGroup.addSettingCard(self.assVerticalSpacingCard)\n\n # ASS 样式卡片\n self.assPrimaryGroup.addSettingCard(self.assPrimaryFontCard)\n self.assPrimaryGroup.addSettingCard(self.assPrimarySizeCard)\n self.assPrimaryGroup.addSettingCard(self.assPrimarySpacingCard)\n self.assPrimaryGroup.addSettingCard(self.assPrimaryColorCard)\n self.assPrimaryGroup.addSettingCard(self.assPrimaryOutlineColorCard)\n self.assPrimaryGroup.addSettingCard(self.assPrimaryOutlineSizeCard)\n\n self.assSecondaryGroup.addSettingCard(self.assSecondaryFontCard)\n self.assSecondaryGroup.addSettingCard(self.assSecondarySizeCard)\n self.assSecondaryGroup.addSettingCard(self.assSecondarySpacingCard)\n self.assSecondaryGroup.addSettingCard(self.assSecondaryColorCard)\n self.assSecondaryGroup.addSettingCard(self.assSecondaryOutlineColorCard)\n self.assSecondaryGroup.addSettingCard(self.assSecondaryOutlineSizeCard)\n\n # 圆角背景卡片\n self.roundedBgGroup.addSettingCard(self.roundedFontCard)\n self.roundedBgGroup.addSettingCard(self.roundedFontSizeCard)\n self.roundedBgGroup.addSettingCard(self.roundedTextColorCard)\n self.roundedBgGroup.addSettingCard(self.roundedBgColorCard)\n self.roundedBgGroup.addSettingCard(self.roundedCornerRadiusCard)\n self.roundedBgGroup.addSettingCard(self.roundedPaddingHCard)\n self.roundedBgGroup.addSettingCard(self.roundedPaddingVCard)\n self.roundedBgGroup.addSettingCard(self.roundedMarginBottomCard)\n self.roundedBgGroup.addSettingCard(self.roundedLineSpacingCard)\n self.roundedBgGroup.addSettingCard(self.roundedLetterSpacingCard)\n\n # 预览设置\n self.previewGroup.addSettingCard(self.previewTextCard)\n self.previewGroup.addSettingCard(self.orientationCard)\n self.previewGroup.addSettingCard(self.previewImageCard)\n\n # 添加组到布局\n self.settingsLayout.addWidget(self.layoutGroup)\n self.settingsLayout.addWidget(self.assPrimaryGroup)\n self.settingsLayout.addWidget(self.assSecondaryGroup)\n self.settingsLayout.addWidget(self.roundedBgGroup)\n self.settingsLayout.addWidget(self.previewGroup)\n self.settingsLayout.addStretch(1)\n\n # 添加左右两侧到主布局\n self.hBoxLayout.addWidget(self.settingsScrollArea)\n self.hBoxLayout.addWidget(self.previewCard)\n\n def _initStyle(self):\n \"\"\"初始化样式\"\"\"\n self.settingsWidget.setObjectName(\"settingsWidget\")\n self.setStyleSheet(\n \"\"\"\n SubtitleStyleInterface, #settingsWidget {\n background-color: transparent;\n }\n QScrollArea {\n border: none;\n background-color: transparent;\n }\n \"\"\"\n )\n\n def __setValues(self):\n \"\"\"设置初始值\"\"\"\n # 设置渲染模式\n self.renderModeCard.comboBox.setCurrentText(\n cfg.subtitle_render_mode.value.value\n )\n\n # 设置字幕排布\n self.layoutCard.comboBox.setCurrentText(cfg.subtitle_layout.value.value)\n\n # 设置字幕样式\n self.styleNameComboBox.comboBox.setCurrentText(cfg.get(cfg.subtitle_style_name))\n\n # 获取字体列表(内置字体 + 系统字体)\n builtin_fonts = get_builtin_fonts()\n builtin_font_names = [f[\"name\"] for f in builtin_fonts]\n\n fontDatabase = QFontDatabase()\n fontFamilies = fontDatabase.families()\n\n # 过滤系统字体:\n # 1. 排除私有字体(以 . 开头)\n # 2. 排除已有的内置字体\n # 3. 只保留 PIL 能实际加载的字体(用于圆角背景渲染)\n system_fonts = []\n for font_name in fontFamilies:\n if font_name.startswith(\".\") or font_name in builtin_font_names:\n continue\n # 测试 PIL 是否能加载此字体\n try:\n ImageFont.truetype(font_name, 12) # 测试用小尺寸\n system_fonts.append(font_name)\n except (OSError, IOError):\n # PIL 无法加载,跳过此字体\n pass\n\n # 合并字体列表:内置字体在最前面\n all_fonts = builtin_font_names + sorted(system_fonts)\n\n # ASS 模式字体\n self.assPrimaryFontCard.addItems(all_fonts)\n self.assSecondaryFontCard.addItems(all_fonts)\n self.assPrimaryFontCard.comboBox.setMaxVisibleItems(12)\n self.assSecondaryFontCard.comboBox.setMaxVisibleItems(12)\n\n # 圆角背景模式字体\n self.roundedFontCard.addItems(all_fonts)\n self.roundedFontCard.comboBox.setMaxVisibleItems(12)\n\n # 设置圆角背景模式的初始值\n self.roundedFontSizeCard.spinBox.setValue(cfg.get(cfg.rounded_bg_font_size))\n self.roundedCornerRadiusCard.spinBox.setValue(\n cfg.get(cfg.rounded_bg_corner_radius)\n )\n self.roundedPaddingHCard.spinBox.setValue(cfg.get(cfg.rounded_bg_padding_h))\n self.roundedPaddingVCard.spinBox.setValue(cfg.get(cfg.rounded_bg_padding_v))\n self.roundedMarginBottomCard.spinBox.setValue(\n cfg.get(cfg.rounded_bg_margin_bottom)\n )\n self.roundedLineSpacingCard.spinBox.setValue(\n cfg.get(cfg.rounded_bg_line_spacing)\n )\n self.roundedLetterSpacingCard.spinBox.setValue(\n cfg.get(cfg.rounded_bg_letter_spacing)\n )\n\n # 设置颜色\n text_color = cfg.get(cfg.rounded_bg_text_color)\n self.roundedTextColorCard.setColor(QColor(text_color))\n bg_color = cfg.get(cfg.rounded_bg_color)\n self.roundedBgColorCard.setColor(self._parseRgbaHex(bg_color))\n\n # 加载样式列表(根据当前模式)\n self._refreshStyleList()\n\n # 根据当前渲染模式显示/隐藏设置组\n self._updateVisibleGroups()\n\n def connectSignals(self):\n \"\"\"连接所有设置变更的信号到预览更新函数\"\"\"\n # 渲染模式切换\n self.renderModeCard.currentTextChanged.connect(self.onRenderModeChanged)\n\n # 字幕排布(通用设置)\n self.layoutCard.currentTextChanged.connect(self.updatePreview)\n self.layoutCard.currentTextChanged.connect(\n lambda: cfg.set(\n cfg.subtitle_layout,\n SubtitleLayoutEnum(self.layoutCard.comboBox.currentText()),\n )\n )\n # ASS 模式 - 垂直间距\n self.assVerticalSpacingCard.spinBox.valueChanged.connect(\n self.onAssSettingChanged\n )\n\n # ASS 模式 - 主字幕样式\n self.assPrimaryFontCard.currentTextChanged.connect(self.onAssSettingChanged)\n self.assPrimarySizeCard.spinBox.valueChanged.connect(self.onAssSettingChanged)\n self.assPrimarySpacingCard.spinBox.valueChanged.connect(\n self.onAssSettingChanged\n )\n self.assPrimaryColorCard.colorChanged.connect(self.onAssSettingChanged)\n self.assPrimaryOutlineColorCard.colorChanged.connect(self.onAssSettingChanged)\n self.assPrimaryOutlineSizeCard.spinBox.valueChanged.connect(\n self.onAssSettingChanged\n )\n\n # ASS 模式 - 副字幕样式\n self.assSecondaryFontCard.currentTextChanged.connect(self.onAssSettingChanged)\n self.assSecondarySizeCard.spinBox.valueChanged.connect(self.onAssSettingChanged)\n self.assSecondarySpacingCard.spinBox.valueChanged.connect(\n self.onAssSettingChanged\n )\n self.assSecondaryColorCard.colorChanged.connect(self.onAssSettingChanged)\n self.assSecondaryOutlineColorCard.colorChanged.connect(self.onAssSettingChanged)\n self.assSecondaryOutlineSizeCard.spinBox.valueChanged.connect(\n self.onAssSettingChanged\n )\n\n # 圆角背景样式信号\n self.roundedFontCard.currentTextChanged.connect(self.onRoundedBgSettingChanged)\n self.roundedFontSizeCard.spinBox.valueChanged.connect(\n self.onRoundedBgSettingChanged\n )\n self.roundedTextColorCard.colorChanged.connect(self.onRoundedBgSettingChanged)\n self.roundedBgColorCard.colorChanged.connect(self.onRoundedBgSettingChanged)\n self.roundedCornerRadiusCard.spinBox.valueChanged.connect(\n self.onRoundedBgSettingChanged\n )\n self.roundedPaddingHCard.spinBox.valueChanged.connect(\n self.onRoundedBgSettingChanged\n )\n self.roundedPaddingVCard.spinBox.valueChanged.connect(\n self.onRoundedBgSettingChanged\n )\n self.roundedMarginBottomCard.spinBox.valueChanged.connect(\n self.onRoundedBgSettingChanged\n )\n self.roundedLineSpacingCard.spinBox.valueChanged.connect(\n self.onRoundedBgSettingChanged\n )\n self.roundedLetterSpacingCard.spinBox.valueChanged.connect(\n self.onRoundedBgSettingChanged\n )\n\n # 预览设置(通用设置)\n self.previewTextCard.currentTextChanged.connect(self.updatePreview)\n self.orientationCard.currentTextChanged.connect(self.onOrientationChanged)\n self.previewImageCard.clicked.connect(self.selectPreviewImage)\n\n # 连接样式切换信号\n self.styleNameComboBox.currentTextChanged.connect(self.loadStyle)\n self.newStyleButton.clicked.connect(self.createNewStyle)\n self.openStyleFolderButton.clicked.connect(self.on_open_style_folder_clicked)\n\n # 连接字幕排布信号\n self.layoutCard.comboBox.currentTextChanged.connect(\n signalBus.subtitle_layout_changed\n )\n signalBus.subtitle_layout_changed.connect(self.on_subtitle_layout_changed)\n\n # 连接渲染模式信号(从视频合成界面同步)\n signalBus.subtitle_render_mode_changed.connect(self.on_render_mode_changed_external)\n\n def on_open_style_folder_clicked(self):\n \"\"\"打开样式文件夹\"\"\"\n open_folder(str(SUBTITLE_STYLE_PATH))\n\n def on_subtitle_layout_changed(self, layout: str):\n layout_enum = SubtitleLayoutEnum(layout)\n cfg.subtitle_layout.value = layout_enum\n self.layoutCard.setCurrentText(layout)\n\n def on_render_mode_changed_external(self, mode_text: str):\n \"\"\"处理外部渲染模式变更(从视频合成界面同步)\"\"\"\n # 避免信号循环:阻断信号后再更新\n self.renderModeCard.comboBox.blockSignals(True)\n self.renderModeCard.comboBox.setCurrentText(mode_text)\n self.renderModeCard.comboBox.blockSignals(False)\n # 手动触发 UI 更新\n self._updateVisibleGroups()\n self._refreshStyleList()\n self.updatePreview()\n\n def onRenderModeChanged(self):\n \"\"\"渲染模式切换(本界面触发)\"\"\"\n mode_text = self.renderModeCard.comboBox.currentText()\n mode = SubtitleRenderModeEnum(mode_text)\n cfg.set(cfg.subtitle_render_mode, mode)\n # 断开自身监听,避免信号回传导致重复执行\n signalBus.subtitle_render_mode_changed.disconnect(self.on_render_mode_changed_external)\n signalBus.subtitle_render_mode_changed.emit(mode_text)\n signalBus.subtitle_render_mode_changed.connect(self.on_render_mode_changed_external)\n self._updateVisibleGroups()\n self._refreshStyleList()\n self.updatePreview()\n\n def onRoundedBgSettingChanged(self):\n \"\"\"圆角背景设置变更\"\"\"\n if self._loading_style:\n return\n\n # 保存圆角背景配置\n cfg.set(cfg.rounded_bg_font_name, self.roundedFontCard.comboBox.currentText())\n cfg.set(cfg.rounded_bg_font_size, self.roundedFontSizeCard.spinBox.value())\n cfg.set(\n cfg.rounded_bg_corner_radius, self.roundedCornerRadiusCard.spinBox.value()\n )\n cfg.set(cfg.rounded_bg_padding_h, self.roundedPaddingHCard.spinBox.value())\n cfg.set(cfg.rounded_bg_padding_v, self.roundedPaddingVCard.spinBox.value())\n cfg.set(\n cfg.rounded_bg_margin_bottom, self.roundedMarginBottomCard.spinBox.value()\n )\n cfg.set(\n cfg.rounded_bg_line_spacing, self.roundedLineSpacingCard.spinBox.value()\n )\n cfg.set(\n cfg.rounded_bg_letter_spacing, self.roundedLetterSpacingCard.spinBox.value()\n )\n\n # 保存颜色\n text_color = self.roundedTextColorCard.colorPicker.color.name()\n cfg.set(cfg.rounded_bg_text_color, text_color)\n bg_color = self.roundedBgColorCard.colorPicker.color\n bg_color_hex = f\"#{bg_color.red():02x}{bg_color.green():02x}{bg_color.blue():02x}{bg_color.alpha():02x}\"\n cfg.set(cfg.rounded_bg_color, bg_color_hex)\n\n # 自动保存当前样式\n current_style = self.styleNameComboBox.comboBox.currentText()\n if current_style:\n self.saveStyle(current_style)\n\n self.updatePreview()\n\n def _updateVisibleGroups(self):\n \"\"\"根据渲染模式显示/隐藏设置组\"\"\"\n mode_text = self.renderModeCard.comboBox.currentText()\n is_ass_mode = mode_text == SubtitleRenderModeEnum.ASS_STYLE.value\n\n # ASS 样式设置组\n self.assVerticalSpacingCard.setVisible(is_ass_mode)\n self.assPrimaryGroup.setVisible(is_ass_mode)\n self.assSecondaryGroup.setVisible(is_ass_mode)\n\n # 圆角背景设置组\n self.roundedBgGroup.setVisible(not is_ass_mode)\n\n def _getStyleFileExtension(self) -> str:\n \"\"\"获取当前模式的样式文件扩展名\"\"\"\n mode = self._getCurrentRenderMode()\n return \".txt\" if mode == SubtitleRenderModeEnum.ASS_STYLE else \".json\"\n\n def _refreshStyleList(self):\n \"\"\"根据当前渲染模式刷新样式列表\"\"\"\n ext = self._getStyleFileExtension()\n pattern = f\"*{ext}\"\n\n # 阻断信号,避免 addItems/setCurrentText 重复触发 loadStyle\n self.styleNameComboBox.comboBox.blockSignals(True)\n\n # 清空现有列表\n self.styleNameComboBox.comboBox.clear()\n\n # 获取样式文件\n style_files = [f.stem for f in SUBTITLE_STYLE_PATH.glob(pattern)]\n\n # 确保有默认样式\n if \"default\" not in style_files:\n style_files.insert(0, \"default\")\n self.saveStyle(\"default\")\n else:\n style_files.insert(0, style_files.pop(style_files.index(\"default\")))\n\n self.styleNameComboBox.comboBox.addItems(style_files)\n\n # 加载默认样式或配置中保存的样式\n subtitle_style_name = cfg.get(cfg.subtitle_style_name)\n if subtitle_style_name in style_files:\n self.styleNameComboBox.comboBox.setCurrentText(subtitle_style_name)\n else:\n self.styleNameComboBox.comboBox.setCurrentText(style_files[0])\n subtitle_style_name = style_files[0]\n\n # 恢复信号\n self.styleNameComboBox.comboBox.blockSignals(False)\n\n # 只调用一次 loadStyle\n self.loadStyle(subtitle_style_name)\n\n def _getCurrentRenderMode(self) -> SubtitleRenderModeEnum:\n \"\"\"获取当前渲染模式\"\"\"\n mode_text = self.renderModeCard.comboBox.currentText()\n return SubtitleRenderModeEnum(mode_text)\n\n def _parseRgbaHex(self, hex_color: str) -> QColor:\n \"\"\"解析 #RRGGBBAA 格式的颜色\"\"\"\n hex_color = hex_color.lstrip(\"#\")\n if len(hex_color) == 8:\n r = int(hex_color[0:2], 16)\n g = int(hex_color[2:4], 16)\n b = int(hex_color[4:6], 16)\n a = int(hex_color[6:8], 16)\n return QColor(r, g, b, a)\n elif len(hex_color) == 6:\n return QColor(f\"#{hex_color}\")\n return QColor(25, 25, 25, 200) # 默认值\n\n def onOrientationChanged(self):\n \"\"\"当预览方向改变时调用\"\"\"\n orientation = self.orientationCard.comboBox.currentText()\n preview_image = (\n DEFAULT_BG_LANDSCAPE if orientation == \"横屏\" else DEFAULT_BG_PORTRAIT\n )\n cfg.set(cfg.subtitle_preview_image, str(Path(preview_image[\"path\"])))\n self.updatePreview()\n\n def onAssSettingChanged(self):\n \"\"\"ASS 样式设置变更\"\"\"\n if self._loading_style:\n return\n\n self.updatePreview()\n current_style = self.styleNameComboBox.comboBox.currentText()\n if current_style:\n self.saveStyle(current_style)\n else:\n self.saveStyle(\"default\")\n\n def selectPreviewImage(self):\n \"\"\"选择预览背景图片\"\"\"\n file_path, _ = QFileDialog.getOpenFileName(\n self,\n self.tr(\"选择背景图片\"),\n \"\",\n self.tr(\"图片文件\") + \" (*.png *.jpg *.jpeg)\",\n )\n if file_path:\n cfg.set(cfg.subtitle_preview_image, file_path)\n self.updatePreview()\n\n def generateAssStyles(self) -> str:\n \"\"\"生成 ASS 样式字符串(固定720P分辨率)\"\"\"\n style_format = \"Format: Name,Fontname,Fontsize,PrimaryColour,SecondaryColour,OutlineColour,BackColour,Bold,Italic,Underline,StrikeOut,ScaleX,ScaleY,Spacing,Angle,BorderStyle,Outline,Shadow,Alignment,MarginL,MarginR,MarginV,Encoding\"\n\n # 垂直间距\n vertical_spacing = self.assVerticalSpacingCard.spinBox.value()\n\n # 主字幕样式\n primary_font = self.assPrimaryFontCard.comboBox.currentText()\n primary_size = self.assPrimarySizeCard.spinBox.value()\n\n # 颜色转换为 ASS 格式 (AABBGGRR)\n primary_color_hex = self.assPrimaryColorCard.colorPicker.color.name()\n primary_outline_hex = self.assPrimaryOutlineColorCard.colorPicker.color.name()\n primary_color = f\"&H00{primary_color_hex[5:7]}{primary_color_hex[3:5]}{primary_color_hex[1:3]}\"\n primary_outline_color = f\"&H00{primary_outline_hex[5:7]}{primary_outline_hex[3:5]}{primary_outline_hex[1:3]}\"\n primary_spacing = self.assPrimarySpacingCard.spinBox.value()\n primary_outline_size = self.assPrimaryOutlineSizeCard.spinBox.value()\n\n # 副字幕样式\n secondary_font = self.assSecondaryFontCard.comboBox.currentText()\n secondary_size = self.assSecondarySizeCard.spinBox.value()\n\n secondary_color_hex = self.assSecondaryColorCard.colorPicker.color.name()\n secondary_outline_hex = (\n self.assSecondaryOutlineColorCard.colorPicker.color.name()\n )\n secondary_color = f\"&H00{secondary_color_hex[5:7]}{secondary_color_hex[3:5]}{secondary_color_hex[1:3]}\"\n secondary_outline_color = f\"&H00{secondary_outline_hex[5:7]}{secondary_outline_hex[3:5]}{secondary_outline_hex[1:3]}\"\n secondary_spacing = self.assSecondarySpacingCard.spinBox.value()\n secondary_outline_size = self.assSecondaryOutlineSizeCard.spinBox.value()\n\n # 生成样式字符串\n primary_style = f\"Style: Default,{primary_font},{primary_size},{primary_color},&H000000FF,{primary_outline_color},&H00000000,-1,0,0,0,100,100,{primary_spacing},0,1,{primary_outline_size},0,2,10,10,{vertical_spacing},1,\\\\q1\"\n secondary_style = f\"Style: Secondary,{secondary_font},{secondary_size},{secondary_color},&H000000FF,{secondary_outline_color},&H00000000,-1,0,0,0,100,100,{secondary_spacing},0,1,{secondary_outline_size},0,2,10,10,{vertical_spacing},1,\\\\q1\"\n\n return f\"[V4+ Styles]\\n{style_format}\\n{primary_style}\\n{secondary_style}\"\n\n def updatePreview(self):\n \"\"\"更新预览图片\"\"\"\n # 获取预览文本\n main_text, sub_text = PERVIEW_TEXTS[self.previewTextCard.comboBox.currentText()]\n\n # 字幕布局\n layout = self.layoutCard.comboBox.currentText()\n if layout == \"译文在上\":\n main_text, sub_text = sub_text, main_text\n elif layout == \"原文在上\":\n main_text, sub_text = main_text, sub_text\n elif layout == \"仅译文\":\n main_text, sub_text = sub_text, None\n elif layout == \"仅原文\":\n main_text, sub_text = main_text, None\n\n # 获取预览方向和背景\n orientation = self.orientationCard.comboBox.currentText()\n default_preview = (\n DEFAULT_BG_LANDSCAPE if orientation == \"横屏\" else DEFAULT_BG_PORTRAIT\n )\n\n # 获取背景图片路径\n user_bg_path = cfg.get(cfg.subtitle_preview_image)\n if user_bg_path and Path(user_bg_path).exists():\n path = user_bg_path\n else:\n path = default_preview[\"path\"]\n\n # 根据渲染模式创建不同的预览线程(不传入尺寸,由渲染层自动从图片获取)\n render_mode = self._getCurrentRenderMode()\n\n if render_mode == SubtitleRenderModeEnum.ROUNDED_BG:\n # 圆角背景模式(样式720P基准,由渲染层自动缩放)\n bg_color = self.roundedBgColorCard.colorPicker.color\n bg_color_hex = f\"#{bg_color.red():02x}{bg_color.green():02x}{bg_color.blue():02x}{bg_color.alpha():02x}\"\n\n style = RoundedBgStyle(\n font_name=self.roundedFontCard.comboBox.currentText(),\n font_size=self.roundedFontSizeCard.spinBox.value(),\n bg_color=bg_color_hex,\n text_color=self.roundedTextColorCard.colorPicker.color.name(),\n corner_radius=self.roundedCornerRadiusCard.spinBox.value(),\n padding_h=self.roundedPaddingHCard.spinBox.value(),\n padding_v=self.roundedPaddingVCard.spinBox.value(),\n margin_bottom=self.roundedMarginBottomCard.spinBox.value(),\n line_spacing=self.roundedLineSpacingCard.spinBox.value(),\n letter_spacing=self.roundedLetterSpacingCard.spinBox.value(),\n )\n\n self.preview_thread = RoundedBgPreviewThread(\n preview_text=(main_text, sub_text),\n style=style,\n bg_image_path=str(path),\n )\n else:\n # ASS 样式模式(样式720P基准,由渲染层自动缩放)\n style_str = self.generateAssStyles()\n self.preview_thread = AssPreviewThread(\n preview_text=(main_text, sub_text),\n style_str=style_str,\n bg_image_path=str(path),\n )\n\n self.preview_thread.previewReady.connect(self.onPreviewReady)\n self.preview_thread.start()\n\n def onPreviewReady(self, preview_path):\n \"\"\"预览图片生成完成的回调\"\"\"\n self.previewImage.setImage(preview_path)\n self.updatePreviewImage()\n\n def updatePreviewImage(self):\n \"\"\"更新预览图片\"\"\"\n height = int(self.previewTopWidget.height() * 0.98)\n width = int(self.previewTopWidget.width() * 0.98)\n self.previewImage.scaledToWidth(width)\n if self.previewImage.height() > height:\n self.previewImage.scaledToHeight(height)\n self.previewImage.setBorderRadius(8, 8, 8, 8)\n\n def resizeEvent(self, event):\n super().resizeEvent(event)\n self.updatePreviewImage()\n\n def showEvent(self, event):\n \"\"\"窗口显示事件\"\"\"\n super().showEvent(event)\n self.updatePreviewImage()\n\n def loadStyle(self, style_name):\n \"\"\"加载指定样式(根据当前渲染模式加载对应格式)\"\"\"\n ext = self._getStyleFileExtension()\n style_path = SUBTITLE_STYLE_PATH / f\"{style_name}{ext}\"\n\n if not style_path.exists():\n return\n\n self._loading_style = True\n\n mode = self._getCurrentRenderMode()\n if mode == SubtitleRenderModeEnum.ROUNDED_BG:\n self._loadRoundedBgStyle(style_path)\n else:\n self._loadAssStyle(style_path)\n\n cfg.set(cfg.subtitle_style_name, style_name)\n self._loading_style = False\n self.updatePreview()\n\n InfoBar.success(\n title=self.tr(\"成功\"),\n content=self.tr(\"已加载样式 \") + style_name,\n orient=Qt.Horizontal, # type: ignore\n isClosable=True,\n position=InfoBarPosition.TOP,\n duration=INFOBAR_DURATION_SUCCESS,\n parent=self,\n )\n\n def _loadAssStyle(self, style_path: Path):\n \"\"\"加载 ASS 样式 (.txt)\"\"\"\n with open(style_path, \"r\", encoding=\"utf-8\") as f:\n style_content = f.read()\n\n for line in style_content.split(\"\\n\"):\n if line.startswith(\"Style: Default\"):\n parts = line.split(\",\")\n self.assPrimaryFontCard.setCurrentText(parts[1])\n self.assPrimarySizeCard.spinBox.setValue(int(parts[2]))\n self.assVerticalSpacingCard.spinBox.setValue(int(parts[21]))\n\n primary_color = parts[3].strip()\n if primary_color.startswith(\"&H\"):\n color_hex = primary_color[2:]\n a, b, g, r = (\n int(color_hex[0:2], 16),\n int(color_hex[2:4], 16),\n int(color_hex[4:6], 16),\n int(color_hex[6:8], 16),\n )\n self.assPrimaryColorCard.setColor(QColor(r, g, b, a))\n\n outline_color = parts[5].strip()\n if outline_color.startswith(\"&H\"):\n color_hex = outline_color[2:]\n a, b, g, r = (\n int(color_hex[0:2], 16),\n int(color_hex[2:4], 16),\n int(color_hex[4:6], 16),\n int(color_hex[6:8], 16),\n )\n self.assPrimaryOutlineColorCard.setColor(QColor(r, g, b, a))\n\n self.assPrimarySpacingCard.spinBox.setValue(float(parts[13]))\n self.assPrimaryOutlineSizeCard.spinBox.setValue(float(parts[16]))\n\n elif line.startswith(\"Style: Secondary\"):\n parts = line.split(\",\")\n\n self.assSecondaryFontCard.setCurrentText(parts[1])\n self.assSecondarySizeCard.spinBox.setValue(int(parts[2]))\n\n secondary_color = parts[3].strip()\n if secondary_color.startswith(\"&H\"):\n color_hex = secondary_color[2:]\n a, b, g, r = (\n int(color_hex[0:2], 16),\n int(color_hex[2:4], 16),\n int(color_hex[4:6], 16),\n int(color_hex[6:8], 16),\n )\n self.assSecondaryColorCard.setColor(QColor(r, g, b, a))\n\n outline_color = parts[5].strip()\n if outline_color.startswith(\"&H\"):\n color_hex = outline_color[2:]\n a, b, g, r = (\n int(color_hex[0:2], 16),\n int(color_hex[2:4], 16),\n int(color_hex[4:6], 16),\n int(color_hex[6:8], 16),\n )\n self.assSecondaryOutlineColorCard.setColor(QColor(r, g, b, a))\n\n self.assSecondarySpacingCard.spinBox.setValue(float(parts[13]))\n self.assSecondaryOutlineSizeCard.spinBox.setValue(float(parts[16]))\n\n def _loadRoundedBgStyle(self, style_path: Path):\n \"\"\"加载圆角背景样式 (.json)\"\"\"\n with open(style_path, \"r\", encoding=\"utf-8\") as f:\n data = json.load(f)\n\n if \"font_name\" in data:\n self.roundedFontCard.setCurrentText(data[\"font_name\"])\n if \"font_size\" in data:\n self.roundedFontSizeCard.spinBox.setValue(data[\"font_size\"])\n if \"text_color\" in data:\n self.roundedTextColorCard.setColor(QColor(data[\"text_color\"]))\n if \"bg_color\" in data:\n self.roundedBgColorCard.setColor(self._parseRgbaHex(data[\"bg_color\"]))\n if \"corner_radius\" in data:\n self.roundedCornerRadiusCard.spinBox.setValue(data[\"corner_radius\"])\n if \"padding_h\" in data:\n self.roundedPaddingHCard.spinBox.setValue(data[\"padding_h\"])\n if \"padding_v\" in data:\n self.roundedPaddingVCard.spinBox.setValue(data[\"padding_v\"])\n if \"margin_bottom\" in data:\n self.roundedMarginBottomCard.spinBox.setValue(data[\"margin_bottom\"])\n if \"line_spacing\" in data:\n self.roundedLineSpacingCard.spinBox.setValue(data[\"line_spacing\"])\n if \"letter_spacing\" in data:\n self.roundedLetterSpacingCard.spinBox.setValue(data[\"letter_spacing\"])\n\n def createNewStyle(self):\n \"\"\"创建新样式\"\"\"\n dialog = StyleNameDialog(self)\n if dialog.exec():\n style_name = dialog.nameLineEdit.text().strip()\n if not style_name:\n return\n\n # 检查是否已存在同名样式\n ext = self._getStyleFileExtension()\n if (SUBTITLE_STYLE_PATH / f\"{style_name}{ext}\").exists():\n InfoBar.warning(\n title=self.tr(\"警告\"),\n content=self.tr(\"样式 \") + style_name + self.tr(\" 已存在\"),\n orient=Qt.Horizontal, # type: ignore\n isClosable=True,\n position=InfoBarPosition.TOP,\n duration=INFOBAR_DURATION_WARNING,\n parent=self,\n )\n return\n\n # 保存新样式\n self.saveStyle(style_name)\n\n # 更新样式列表并选中新样式\n self.styleNameComboBox.addItem(style_name)\n self.styleNameComboBox.comboBox.setCurrentText(style_name)\n\n InfoBar.success(\n title=self.tr(\"成功\"),\n content=self.tr(\"已创建新样式 \") + style_name,\n orient=Qt.Horizontal, # type: ignore\n isClosable=True,\n position=InfoBarPosition.TOP,\n duration=INFOBAR_DURATION_SUCCESS,\n parent=self,\n )\n\n def saveStyle(self, style_name):\n \"\"\"保存样式(根据当前渲染模式保存对应格式)\"\"\"\n SUBTITLE_STYLE_PATH.mkdir(parents=True, exist_ok=True)\n\n mode = self._getCurrentRenderMode()\n ext = self._getStyleFileExtension()\n style_path = SUBTITLE_STYLE_PATH / f\"{style_name}{ext}\"\n\n if mode == SubtitleRenderModeEnum.ROUNDED_BG:\n self._saveRoundedBgStyle(style_path)\n else:\n self._saveAssStyle(style_path)\n\n def _saveAssStyle(self, style_path: Path):\n \"\"\"保存 ASS 样式 (.txt)\"\"\"\n style_content = self.generateAssStyles()\n with open(style_path, \"w\", encoding=\"utf-8\") as f:\n f.write(style_content)\n\n def _saveRoundedBgStyle(self, style_path: Path):\n \"\"\"保存圆角背景样式 (.json)\"\"\"\n bg_color = self.roundedBgColorCard.colorPicker.color\n bg_color_hex = f\"#{bg_color.red():02x}{bg_color.green():02x}{bg_color.blue():02x}{bg_color.alpha():02x}\"\n\n data = {\n \"font_name\": self.roundedFontCard.comboBox.currentText(),\n \"font_size\": self.roundedFontSizeCard.spinBox.value(),\n \"text_color\": self.roundedTextColorCard.colorPicker.color.name(),\n \"bg_color\": bg_color_hex,\n \"corner_radius\": self.roundedCornerRadiusCard.spinBox.value(),\n \"padding_h\": self.roundedPaddingHCard.spinBox.value(),\n \"padding_v\": self.roundedPaddingVCard.spinBox.value(),\n \"margin_bottom\": self.roundedMarginBottomCard.spinBox.value(),\n \"line_spacing\": self.roundedLineSpacingCard.spinBox.value(),\n \"letter_spacing\": self.roundedLetterSpacingCard.spinBox.value(),\n }\n with open(style_path, \"w\", encoding=\"utf-8\") as f:\n json.dump(data, f, ensure_ascii=False, indent=2)\n\n def dragEnterEvent(self, event):\n \"\"\"拖入事件:检查是否为图片文件\"\"\"\n if event.mimeData().hasUrls():\n # 检查是否有图片文件\n for url in event.mimeData().urls():\n file_path = url.toLocalFile()\n if file_path.lower().endswith((\".png\", \".jpg\", \".jpeg\")):\n event.accept()\n return\n event.ignore()\n\n def dropEvent(self, event):\n \"\"\"放下事件:将图片设置为预览背景\"\"\"\n files = [u.toLocalFile() for u in event.mimeData().urls()]\n for file_path in files:\n # 检查是否为图片文件\n if file_path.lower().endswith((\".png\", \".jpg\", \".jpeg\")):\n # 设置为预览背景\n cfg.set(cfg.subtitle_preview_image, file_path)\n # 更新预览\n self.updatePreview()\n # 显示成功提示\n InfoBar.success(\n title=self.tr(\"成功\"),\n content=self.tr(\"已设置预览背景:\") + Path(file_path).name,\n orient=Qt.Horizontal, # type: ignore\n isClosable=True,\n position=InfoBarPosition.TOP,\n duration=INFOBAR_DURATION_SUCCESS,\n parent=self,\n )\n break # 只处理第一个图片文件\n\n\nclass StyleNameDialog(MessageBoxBase):\n \"\"\"样式名称输入对话框\"\"\"\n\n def __init__(self, parent=None):\n super().__init__(parent)\n self.titleLabel = BodyLabel(self.tr(\"新建样式\"), self)\n self.nameLineEdit = LineEdit(self)\n\n self.nameLineEdit.setPlaceholderText(self.tr(\"输入样式名称\"))\n self.nameLineEdit.setClearButtonEnabled(True)\n\n # 添加控件到布局\n self.viewLayout.addWidget(self.titleLabel)\n self.viewLayout.addWidget(self.nameLineEdit)\n\n # 设置按钮文本\n self.yesButton.setText(self.tr(\"确定\"))\n self.cancelButton.setText(self.tr(\"取消\"))\n\n self.widget.setMinimumWidth(350)\n self.yesButton.setDisabled(True)\n self.nameLineEdit.textChanged.connect(self._validateInput)\n\n def _validateInput(self, text):\n self.yesButton.setEnabled(bool(text.strip()))\n" }, { "path": "app/view/task_creation_interface.py", "content": "# -*- coding: utf-8 -*-\nimport os\nimport sys\nfrom urllib.parse import urlparse\n\nfrom PyQt5.QtCore import QStandardPaths, Qt, pyqtSignal\nfrom PyQt5.QtGui import QPixmap\nfrom PyQt5.QtWidgets import (\n QApplication,\n QFileDialog,\n QHBoxLayout,\n QLabel,\n QVBoxLayout,\n QWidget,\n)\nfrom qfluentwidgets import (\n BodyLabel,\n FluentIcon,\n HyperlinkButton,\n InfoBar,\n InfoBarPosition,\n LineEdit,\n ProgressBar,\n ToolButton,\n)\n\nfrom app.common.config import cfg\nfrom app.components.DonateDialog import DonateDialog\nfrom app.config import APPDATA_PATH, ASSETS_PATH, VERSION\nfrom app.core.constant import (\n INFOBAR_DURATION_ERROR,\n INFOBAR_DURATION_INFO,\n INFOBAR_DURATION_SUCCESS,\n INFOBAR_DURATION_WARNING,\n)\nfrom app.core.entities import (\n SupportedAudioFormats,\n SupportedVideoFormats,\n)\nfrom app.thread.video_download_thread import VideoDownloadThread\nfrom app.view.log_window import LogWindow\n\nLOGO_PATH = ASSETS_PATH / \"logo.png\"\n\n\nclass TaskCreationInterface(QWidget):\n \"\"\"\n 任务创建界面类,用于创建和配置任务。\n \"\"\"\n\n finished = pyqtSignal(str) # 该信号用于在任务创建完成后通知主窗口\n\n def __init__(self, parent=None):\n super().__init__(parent)\n self.task = None\n self.log_window = None\n\n self.setObjectName(\"TaskCreationInterface\")\n self.setAttribute(Qt.WA_StyledBackground, True) # type: ignore\n self.setAcceptDrops(True)\n\n self.setup_ui()\n self.setup_values()\n self.setup_signals()\n\n def setup_ui(self):\n self.main_layout = QVBoxLayout(self)\n self.main_layout.setObjectName(\"main_layout\")\n self.main_layout.setSpacing(50)\n self.main_layout.addSpacing(120)\n self.setup_logo()\n self.setup_search_layout()\n self.setup_status_layout()\n self.setup_info_label()\n\n def setup_logo(self):\n self.logo_label = QLabel(self)\n self.logo_pixmap = QPixmap(str(LOGO_PATH))\n self.logo_pixmap = self.logo_pixmap.scaled(\n 150,\n 150,\n Qt.AspectRatioMode.KeepAspectRatio,\n Qt.SmoothTransformation, # type: ignore\n )\n\n self.logo_label.setPixmap(self.logo_pixmap)\n self.logo_label.setAlignment(Qt.AlignCenter) # type: ignore\n self.main_layout.addWidget(self.logo_label)\n self.main_layout.addSpacing(10)\n\n def setup_search_layout(self):\n self.search_layout = QHBoxLayout()\n self.search_layout.setContentsMargins(80, 0, 80, 0)\n self.search_input = LineEdit(self)\n self.search_input.setPlaceholderText(self.tr(\"请拖拽文件或输入视频URL\"))\n self.search_input.setFixedHeight(40)\n self.search_input.setClearButtonEnabled(True)\n self.search_input.focusOutEvent = lambda e: super(\n LineEdit, self.search_input\n ).focusOutEvent(e)\n self.search_input.paintEvent = lambda e: super(\n LineEdit, self.search_input\n ).paintEvent(e)\n self.search_input.setStyleSheet(\n self.search_input.styleSheet()\n + \"\"\"\n QLineEdit {\n border-radius: 18px;\n padding: 0 20px;\n background-color: transparent;\n border: 1px solid rgba(255,255, 255, 0.08);\n }\n QLineEdit:focus[transparent=true] {\n border: 1px solid rgba(47,141, 99, 0.48);\n }\n \n \"\"\"\n )\n self.start_button = ToolButton(FluentIcon.FOLDER, self)\n self.start_button.setFixedSize(40, 40)\n self.start_button.setStyleSheet(\n self.start_button.styleSheet()\n + \"\"\"\n QToolButton {\n border-radius: 20px;\n background-color: #2F8D63;\n }\n QToolButton:hover {\n background-color: #2E805C;\n }\n QToolButton:pressed {\n background-color: #2E905C;\n }\n \"\"\"\n )\n self.search_layout.addWidget(self.search_input)\n self.search_layout.addWidget(self.start_button)\n self.search_layout.setSpacing(10)\n self.main_layout.addLayout(self.search_layout)\n self.main_layout.addSpacing(100)\n\n def setup_status_layout(self):\n self.status_layout = QVBoxLayout()\n self.status_layout.setContentsMargins(50, 0, 30, 5)\n self.status_layout.setAlignment(Qt.AlignBottom | Qt.AlignHCenter) # type: ignore\n self.status_label = BodyLabel(self.tr(\"准备就绪\"), self)\n self.status_label.setStyleSheet(\"font-size: 14px; color: #888888;\")\n self.status_layout.addWidget(self.status_label, 0, Qt.AlignCenter) # type: ignore\n self.progress_bar = ProgressBar(self)\n self.status_label.hide()\n self.progress_bar.hide()\n self.progress_bar.setFixedWidth(300)\n self.status_layout.addWidget(self.progress_bar, 0, Qt.AlignCenter) # type: ignore\n\n self.main_layout.addStretch(1)\n self.main_layout.addLayout(self.status_layout)\n\n def setup_info_label(self):\n # 创建底部容器\n bottom_container = QWidget()\n bottom_layout = QHBoxLayout(bottom_container)\n bottom_layout.setContentsMargins(0, 0, 0, 0)\n\n # 创建日志按钮\n self.log_button = HyperlinkButton(url=\"\", text=self.tr(\"查看日志\"), parent=self)\n self.log_button.setStyleSheet(\n self.log_button.styleSheet()\n + \"\"\"\n QPushButton {\n font-size: 12px;\n color: #2F8D63;\n text-decoration: underline;\n }\n \"\"\"\n )\n\n # 创建捐助按钮\n self.donate_button = HyperlinkButton(url=\"\", text=self.tr(\"捐助\"), parent=self)\n self.donate_button.setStyleSheet(\n self.donate_button.styleSheet()\n + \"\"\"\n QPushButton {\n font-size: 12px;\n color: #2F8D63;\n text-decoration: underline;\n }\n \"\"\"\n )\n\n # 添加版权信息标签\n self.info_label = BodyLabel(\n self.tr(f\"©VideoCaptioner {VERSION} • By Weifeng\"), self\n )\n self.info_label.setAlignment(Qt.AlignCenter) # type: ignore\n self.info_label.setStyleSheet(\"font-size: 12px; color: #888888;\")\n\n # 将组件添加到底部布局\n bottom_layout.addStretch()\n bottom_layout.addWidget(self.info_label)\n bottom_layout.addWidget(self.log_button)\n bottom_layout.addWidget(self.donate_button)\n bottom_layout.addStretch()\n\n self.main_layout.addStretch()\n self.main_layout.addWidget(bottom_container)\n\n def setup_signals(self):\n self.start_button.clicked.connect(self.on_start_clicked)\n self.search_input.textChanged.connect(self.on_search_input_changed)\n self.log_button.clicked.connect(self.show_log_window)\n self.donate_button.clicked.connect(self.show_donate_dialog)\n\n def setup_values(self):\n self.search_input.setText(\"\")\n\n def on_start_clicked(self):\n if self.start_button._icon == FluentIcon.FOLDER:\n desktop_path = QStandardPaths.writableLocation(\n QStandardPaths.DesktopLocation\n )\n file_dialog = QFileDialog()\n\n # 构建文件过滤器\n video_formats = \" \".join(f\"*.{fmt.value}\" for fmt in SupportedVideoFormats)\n audio_formats = \" \".join(f\"*.{fmt.value}\" for fmt in SupportedAudioFormats)\n filter_str = f\"{self.tr('媒体文件')} ({video_formats} {audio_formats});;{self.tr('视频文件')} ({video_formats});;{self.tr('音频文件')} ({audio_formats})\"\n\n file_path, _ = file_dialog.getOpenFileName(\n self, self.tr(\"选择媒体文件\"), desktop_path, filter_str\n )\n if file_path:\n self.search_input.setText(file_path)\n return\n\n self.process()\n\n def on_search_input_changed(self):\n if self.search_input.text():\n self.start_button.setIcon(FluentIcon.PLAY)\n else:\n self.start_button.setIcon(FluentIcon.FOLDER)\n\n def dragEnterEvent(self, event):\n event.accept() if event.mimeData().hasUrls() else event.ignore()\n\n def dropEvent(self, event):\n files = [u.toLocalFile() for u in event.mimeData().urls()]\n for file_path in files:\n if not os.path.isfile(file_path):\n continue\n\n file_ext = os.path.splitext(file_path)[1][1:].lower()\n\n # 检查文件格式是否支持\n supported_formats = {fmt.value for fmt in SupportedVideoFormats} | {\n fmt.value for fmt in SupportedAudioFormats\n }\n is_supported = file_ext in supported_formats\n\n if is_supported:\n self.search_input.setText(file_path)\n self.status_label.setText(self.tr(\"导入成功\"))\n InfoBar.success(\n self.tr(\"导入成功\"),\n self.tr(\"导入媒体文件成功\"),\n duration=INFOBAR_DURATION_SUCCESS,\n parent=self,\n )\n break\n else:\n InfoBar.error(\n self.tr(\"格式错误\") + file_ext,\n self.tr(\"不支持该文件格式\"),\n duration=INFOBAR_DURATION_ERROR,\n parent=self,\n )\n\n def create_task(self):\n search_input = self.search_input.text()\n if os.path.isfile(search_input):\n self._process_file(search_input)\n elif self._is_valid_url(search_input):\n self._process_url(search_input)\n else:\n InfoBar.error(\n self.tr(\"错误\"),\n self.tr(\"请输入有效的文件路径或视频URL\"),\n duration=INFOBAR_DURATION_ERROR,\n parent=self,\n )\n\n def _is_valid_url(self, url):\n try:\n result = urlparse(url)\n return result.scheme in (\"http\", \"https\") and bool(result.netloc)\n except ValueError:\n return False\n\n def _process_file(self, file_path):\n self.finished.emit(file_path)\n\n def _process_url(self, url):\n # 检测 cookies.txt 文件\n cookiefile_path = APPDATA_PATH / \"cookies.txt\"\n if not cookiefile_path.exists():\n InfoBar.warning(\n self.tr(\"警告\"),\n self.tr(\"建议根据文档配置cookies.txt文件,以可以下载高清视频\"),\n duration=INFOBAR_DURATION_WARNING,\n parent=self,\n )\n\n # 创建视频下载线程\n self.video_download_thread = VideoDownloadThread(url, str(cfg.work_dir.value))\n self.video_download_thread.finished.connect(self.on_video_download_finished)\n self.video_download_thread.progress.connect(self.on_create_task_progress)\n self.video_download_thread.error.connect(self.on_create_task_error)\n self.video_download_thread.start()\n\n InfoBar.info(\n self.tr(\"开始下载\"),\n self.tr(\"开始下载视频...\"),\n duration=INFOBAR_DURATION_INFO,\n parent=self,\n )\n\n def on_video_download_finished(self, video_file_path):\n \"\"\"视频下载完成的回调函数\"\"\"\n if video_file_path:\n self.finished.emit(video_file_path)\n InfoBar.success(\n self.tr(\"下载成功\"),\n self.tr(\"视频下载完成,开始自动处理...\"),\n duration=INFOBAR_DURATION_SUCCESS,\n position=InfoBarPosition.BOTTOM,\n parent=self.parent(),\n )\n else:\n InfoBar.error(\n self.tr(\"错误\"),\n self.tr(\"视频下载失败\"),\n duration=INFOBAR_DURATION_ERROR,\n parent=self,\n )\n\n def on_create_task_progress(self, value, status):\n self.progress_bar.show()\n self.status_label.show()\n self.progress_bar.setValue(value)\n self.status_label.setText(status)\n\n def on_create_task_error(self, error):\n InfoBar.error(\n self.tr(\"错误\"),\n self.tr(error),\n duration=INFOBAR_DURATION_ERROR,\n parent=self,\n )\n\n def set_task(self, task):\n self.task = task\n self.update_info()\n\n def update_info(self):\n if self.task:\n self.search_input.setText(self.task.file_path)\n\n def process(self):\n search_input = self.search_input.text()\n\n if os.path.isfile(search_input):\n self._process_file(search_input)\n elif self._is_valid_url(search_input):\n self._process_url(search_input)\n else:\n InfoBar.error(\n self.tr(\"错误\"),\n self.tr(\"请输入音视频文件路径或URL\"),\n duration=INFOBAR_DURATION_ERROR,\n parent=self,\n )\n\n def show_log_window(self):\n \"\"\"显示日志窗口\"\"\"\n if self.log_window is None:\n self.log_window = LogWindow()\n if self.log_window.isHidden():\n self.log_window.show()\n else:\n self.log_window.activateWindow()\n\n def show_donate_dialog(self):\n \"\"\"显示捐助窗口\"\"\"\n donate_dialog = DonateDialog(self)\n donate_dialog.exec_()\n\n\nif __name__ == \"__main__\":\n QApplication.setHighDpiScaleFactorRoundingPolicy(\n Qt.HighDpiScaleFactorRoundingPolicy.PassThrough\n )\n QApplication.setAttribute(Qt.AA_EnableHighDpiScaling) # type: ignore\n QApplication.setAttribute(Qt.AA_UseHighDpiPixmaps) # type: ignore\n\n app = QApplication(sys.argv)\n window = TaskCreationInterface()\n window.show()\n sys.exit(app.exec_())\n" }, { "path": "app/view/transcription_interface.py", "content": "# -*- coding: utf-8 -*-\n\nimport datetime\nimport os\nimport sys\nfrom pathlib import Path\nfrom typing import Optional\n\nfrom PyQt5.QtCore import QStandardPaths, Qt, pyqtSignal\nfrom PyQt5.QtGui import QFont, QPixmap\nfrom PyQt5.QtWidgets import (\n QApplication,\n QFileDialog,\n QHBoxLayout,\n QLabel,\n QVBoxLayout,\n QWidget,\n)\nfrom qfluentwidgets import (\n Action,\n BodyLabel,\n CardWidget,\n CommandBar,\n FluentIcon,\n InfoBar,\n InfoBarPosition,\n PillPushButton,\n PrimaryPushButton,\n ProgressRing,\n PushButton,\n RoundMenu,\n TransparentDropDownPushButton,\n setFont,\n)\n\nfrom app.common.config import cfg\nfrom app.common.signal_bus import signalBus\nfrom app.components.transcription_setting_card import TranscriptionSettingCard\nfrom app.components.TranscriptionSettingDialog import TranscriptionSettingDialog\nfrom app.config import RESOURCE_PATH\nfrom app.core.constant import (\n INFOBAR_DURATION_ERROR,\n INFOBAR_DURATION_SUCCESS,\n INFOBAR_DURATION_WARNING,\n)\nfrom app.core.entities import (\n SupportedAudioFormats,\n SupportedVideoFormats,\n TranscribeModelEnum,\n TranscribeTask,\n VideoInfo,\n)\nfrom app.core.task_factory import TaskFactory\nfrom app.core.utils.platform_utils import get_available_transcribe_models, open_folder\nfrom app.thread.transcript_thread import TranscriptThread\nfrom app.thread.video_info_thread import VideoInfoThread\n\nDEFAULT_THUMBNAIL_PATH = RESOURCE_PATH / \"assets\" / \"default_thumbnail.jpg\"\n\n\nclass VideoInfoCard(CardWidget):\n finished = pyqtSignal(TranscribeTask)\n\n def __init__(self, parent: Optional[QWidget] = None):\n super().__init__(parent)\n self.setup_ui()\n self.setup_signals()\n self.task: Optional[TranscribeTask] = None\n self.video_info: Optional[VideoInfo] = None\n self.transcription_interface = parent\n self.selected_audio_track_index = 0 # 默认选择第一条音轨\n\n def setup_ui(self) -> None:\n self.setFixedHeight(150)\n self.main_layout = QHBoxLayout(self)\n self.main_layout.setContentsMargins(20, 15, 20, 15)\n self.main_layout.setSpacing(20)\n\n self.setup_thumbnail()\n self.setup_info_layout()\n self.setup_button_layout()\n\n def setup_thumbnail(self) -> None:\n default_thumbnail_path = os.path.join(DEFAULT_THUMBNAIL_PATH)\n\n self.video_thumbnail = QLabel(self)\n self.video_thumbnail.setFixedSize(208, 117)\n self.video_thumbnail.setStyleSheet(\"background-color: #1E1F22;\")\n self.video_thumbnail.setAlignment(Qt.AlignCenter) # type: ignore\n pixmap = QPixmap(default_thumbnail_path).scaled(\n self.video_thumbnail.size(),\n Qt.AspectRatioMode.KeepAspectRatio,\n Qt.SmoothTransformation, # type: ignore\n )\n self.video_thumbnail.setPixmap(pixmap)\n self.main_layout.addWidget(self.video_thumbnail, 0, Qt.AlignLeft) # type: ignore\n\n def setup_info_layout(self) -> None:\n self.info_layout = QVBoxLayout()\n self.info_layout.setContentsMargins(3, 8, 3, 8)\n self.info_layout.setSpacing(10)\n\n self.video_title = BodyLabel(self.tr(\"请拖入音频或视频文件\"), self)\n self.video_title.setFont(QFont(\"Microsoft YaHei\", 14, QFont.Bold))\n self.video_title.setWordWrap(True)\n self.info_layout.addWidget(self.video_title, alignment=Qt.AlignTop) # type: ignore\n\n self.details_layout = QHBoxLayout()\n self.details_layout.setSpacing(15)\n\n self.resolution_info = self.create_pill_button(self.tr(\"画质\"), 110)\n self.file_size_info = self.create_pill_button(self.tr(\"文件大小\"), 110)\n self.duration_info = self.create_pill_button(self.tr(\"时长\"), 100)\n self.audio_track_button = self.create_pill_button(self.tr(\"音轨\"), 100)\n self.audio_track_button.hide() # 默认隐藏,只在多音轨时显示\n\n self.progress_ring = ProgressRing(self)\n self.progress_ring.setFixedSize(20, 20)\n self.progress_ring.setStrokeWidth(4)\n self.progress_ring.hide()\n\n self.details_layout.addWidget(self.resolution_info)\n self.details_layout.addWidget(self.file_size_info)\n self.details_layout.addWidget(self.duration_info)\n self.details_layout.addWidget(self.audio_track_button)\n self.details_layout.addWidget(self.progress_ring)\n self.details_layout.addStretch(1)\n self.info_layout.addLayout(self.details_layout)\n self.main_layout.addLayout(self.info_layout) # type: ignore\n\n def create_pill_button(self, text: str, width: int) -> PillPushButton:\n button = PillPushButton(text, self)\n button.setCheckable(False)\n setFont(button, 11)\n # button.setFixedWidth(width)\n button.setMinimumWidth(50)\n return button\n\n def setup_button_layout(self) -> None:\n self.button_layout = QVBoxLayout()\n self.open_folder_button = PushButton(self.tr(\"打开文件夹\"), self)\n self.start_button = PrimaryPushButton(self.tr(\"开始转录\"), self)\n self.button_layout.addWidget(self.open_folder_button)\n self.button_layout.addWidget(self.start_button)\n\n self.start_button.setDisabled(True)\n\n button_widget = QWidget()\n button_widget.setLayout(self.button_layout)\n button_widget.setFixedWidth(130)\n self.main_layout.addWidget(button_widget) # type: ignore\n\n def update_info(self, video_info: VideoInfo) -> None:\n \"\"\"更新视频信息显示\"\"\"\n self.reset_ui()\n self.video_info = video_info\n\n self.video_title.setText(video_info.file_name.rsplit(\".\", 1)[0])\n self.resolution_info.setText(\n self.tr(\"画质: \") + f\"{video_info.width}x{video_info.height}\"\n )\n file_size_mb = os.path.getsize(video_info.file_path) / 1024 / 1024\n self.file_size_info.setText(self.tr(\"大小: \") + f\"{file_size_mb:.1f} MB\")\n duration = datetime.timedelta(seconds=int(video_info.duration_seconds))\n self.duration_info.setText(self.tr(\"时长: \") + f\"{duration}\")\n\n # 更新音轨选择按钮\n self.update_audio_tracks(video_info)\n\n if self.transcription_interface and self.transcription_interface.is_processing: # type: ignore\n self.start_button.setEnabled(False)\n else:\n self.start_button.setEnabled(True)\n self.update_thumbnail(video_info.thumbnail_path)\n\n def update_audio_tracks(self, video_info: VideoInfo) -> None:\n \"\"\"更新音轨选择按钮\"\"\"\n audio_streams = video_info.audio_streams\n\n if len(audio_streams) > 1:\n # 多音轨,显示选择按钮,默认选择第一条音轨(数组索引0)\n self.selected_audio_track_index = 0\n self.update_audio_track_button_text(audio_streams, 0)\n\n # 创建下拉菜单\n menu = RoundMenu(parent=self)\n for i, stream in enumerate(audio_streams):\n lang = stream.language\n\n # 构建菜单项文本(使用序号 i+1)\n text = self.tr(\"音轨\") + str(i + 1)\n if lang:\n text += f\" ({lang})\"\n\n action = Action(text)\n action.triggered.connect(\n lambda checked, array_idx=i, streams=audio_streams: self.on_audio_track_selected(\n array_idx, streams\n )\n )\n menu.addAction(action)\n\n # 绑定菜单到按钮\n self.audio_track_button.clicked.connect(\n lambda: menu.exec(\n self.audio_track_button.mapToGlobal(\n self.audio_track_button.rect().bottomLeft()\n )\n )\n )\n self.audio_track_button.show()\n else:\n self.audio_track_button.hide()\n self.selected_audio_track_index = 0\n\n def update_audio_track_button_text(\n self, audio_streams: list, array_index: int\n ) -> None:\n \"\"\"更新音轨按钮显示文本\n\n Args:\n audio_streams: 音轨列表\n array_index: 数组索引(0, 1, 2...)\n \"\"\"\n if array_index < len(audio_streams):\n stream = audio_streams[array_index]\n lang = stream.language\n text = f\"{self.tr('音轨')} {array_index + 1}\"\n if lang:\n text += f\" ({lang})\"\n self.audio_track_button.setText(text)\n\n def on_audio_track_selected(self, array_index: int, audio_streams: list) -> None:\n \"\"\"音轨选择事件处理\n\n Args:\n array_index: 数组索引(0, 1, 2...),用于 UI 显示和 ffmpeg -map 0:a:N\n audio_streams: 音轨列表\n \"\"\"\n self.selected_audio_track_index = array_index # 保存数组索引,传给 ffmpeg\n self.update_audio_track_button_text(audio_streams, array_index)\n\n def update_thumbnail(self, thumbnail_path):\n \"\"\"更新视频缩略图\"\"\"\n if not Path(thumbnail_path).exists():\n thumbnail_path = RESOURCE_PATH / \"assets\" / \"audio-thumbnail.png\"\n\n pixmap = QPixmap(str(thumbnail_path)).scaled(\n self.video_thumbnail.size(),\n Qt.AspectRatioMode.KeepAspectRatio,\n Qt.SmoothTransformation, # type: ignore\n )\n self.video_thumbnail.setPixmap(pixmap)\n\n def setup_signals(self) -> None:\n self.start_button.clicked.connect(self.on_start_button_clicked)\n self.open_folder_button.clicked.connect(self.on_open_folder_clicked)\n\n def on_start_button_clicked(self):\n \"\"\"开始转录按钮点击事件\"\"\"\n self.progress_ring.setValue(0)\n self.progress_ring.show()\n self.start_button.setDisabled(True)\n self.start_transcription()\n\n def on_open_folder_clicked(self):\n \"\"\"打开文件夹按钮点击事件\"\"\"\n if self.task and self.task.output_path:\n original_subtitle_save_path = Path(str(self.task.output_path))\n target_dir = str(\n original_subtitle_save_path.parent\n if original_subtitle_save_path.exists()\n else Path(str(self.task.file_path)).parent\n )\n open_folder(target_dir)\n else:\n InfoBar.warning(\n self.tr(\"警告\"),\n self.tr(\"没有可用的字幕文件夹\"),\n duration=INFOBAR_DURATION_WARNING,\n parent=self,\n )\n\n def start_transcription(self, need_create_task=True):\n \"\"\"开始转录过程\"\"\"\n self.transcription_interface.is_processing = True # type: ignore\n self.start_button.setEnabled(False)\n\n if need_create_task:\n self.task = TaskFactory.create_transcribe_task(self.video_info.file_path)\n\n if not self.task:\n return\n\n # 将选中的音轨索引作为临时属性传递给 task\n self.task.selected_audio_track_index = self.selected_audio_track_index # type: ignore\n\n self.transcript_thread = TranscriptThread(self.task)\n self.transcript_thread.finished.connect(self.on_transcript_finished)\n self.transcript_thread.progress.connect(self.on_transcript_progress)\n self.transcript_thread.error.connect(self.on_transcript_error)\n self.transcript_thread.start()\n\n def on_transcript_progress(self, value, message):\n \"\"\"更新转录进度\"\"\"\n self.start_button.setText(message)\n self.progress_ring.setValue(value)\n\n def on_transcript_error(self, error):\n \"\"\"处理转录错误\"\"\"\n self.transcription_interface.is_processing = False # type: ignore\n self.start_button.setEnabled(True)\n self.start_button.setText(self.tr(\"重新转录\"))\n self.progress_ring.hide()\n InfoBar.error(\n self.tr(\"转录失败\"),\n self.tr(error),\n duration=INFOBAR_DURATION_ERROR,\n parent=self.parent().parent(),\n )\n\n def on_transcript_finished(self, task):\n \"\"\"转录完成处理\"\"\"\n self.start_button.setEnabled(True)\n self.start_button.setText(self.tr(\"转录完成\"))\n self.progress_ring.hide()\n self.finished.emit(task)\n\n def reset_ui(self):\n \"\"\"重置UI状态\"\"\"\n self.start_button.setDisabled(False)\n self.start_button.setText(self.tr(\"开始转录\"))\n self.progress_ring.setValue(0)\n self.progress_ring.hide()\n\n def set_task(self, task):\n \"\"\"设置任务并更新UI\"\"\"\n self.task = task\n self.reset_ui()\n\n def stop(self):\n if hasattr(self, \"transcript_thread\"):\n self.transcript_thread.terminate()\n\n\nclass TranscriptionInterface(QWidget):\n \"\"\"转录界面类,用于显示视频信息和转录进度\"\"\"\n\n finished = pyqtSignal(str, str)\n\n def __init__(self, parent: Optional[QWidget] = None):\n super().__init__(parent)\n self.setAttribute(Qt.WA_StyledBackground, True) # type: ignore\n self.setAcceptDrops(True)\n self.task: Optional[TranscribeTask] = None\n self.is_processing: bool = False\n\n self._init_ui()\n self._setup_signals()\n self._set_value()\n\n def _init_ui(self) -> None:\n \"\"\"初始化UI\"\"\"\n self.main_layout = QVBoxLayout(self)\n self.main_layout.setObjectName(\"main_layout\")\n self.main_layout.setSpacing(20)\n\n # 添加命令栏\n self._setup_command_bar()\n\n self.video_info_card = VideoInfoCard(self)\n self.main_layout.addWidget(self.video_info_card)\n\n # 添加转录设置卡片\n self.transcription_setting_card = TranscriptionSettingCard(self)\n self.main_layout.addWidget(self.transcription_setting_card)\n\n def _setup_command_bar(self):\n \"\"\"设置命令栏\"\"\"\n self.command_bar = CommandBar(self)\n self.command_bar.setToolButtonStyle(Qt.ToolButtonTextBesideIcon) # type: ignore\n self.command_bar.setFixedHeight(40)\n\n # 添加打开文件按钮\n self.open_file_action = Action(FluentIcon.FOLDER, self.tr(\"打开文件\"))\n self.open_file_action.triggered.connect(self._on_file_select)\n self.command_bar.addAction(self.open_file_action)\n\n self.command_bar.addSeparator()\n\n # 添加转录模型选择按钮\n self.model_button = TransparentDropDownPushButton(\n self.tr(\"转录模型\"), self, FluentIcon.MICROPHONE\n )\n self.model_button.setFixedHeight(34)\n self.model_button.setMinimumWidth(180)\n\n self.model_menu = RoundMenu(parent=self)\n # 只显示当前平台可用的模型(macOS 上不显示 FasterWhisper)\n available_models = get_available_transcribe_models()\n for model in available_models:\n if (\n model == TranscribeModelEnum.WHISPER_API\n or model == TranscribeModelEnum.BIJIAN\n or model == TranscribeModelEnum.JIANYING\n ):\n self.model_menu.addActions(\n [\n Action(FluentIcon.GLOBE, model.value),\n ]\n )\n else:\n self.model_menu.addActions(\n [\n Action(FluentIcon.ROBOT, model.value),\n ]\n )\n self.model_button.setMenu(self.model_menu)\n self.command_bar.addWidget(self.model_button)\n\n self.command_bar.addSeparator()\n\n # 添加输出设置按钮\n self.command_bar.addAction(\n Action(FluentIcon.SETTING, \"\", triggered=self._show_output_settings)\n )\n\n self.main_layout.addWidget(self.command_bar)\n\n def _setup_signals(self) -> None:\n \"\"\"设置信号连接\"\"\"\n self.video_info_card.finished.connect(self._on_transcript_finished)\n\n # 设置模型选择菜单的信号连接\n for action in self.model_menu.actions():\n action.triggered.connect(\n lambda checked, text=action.text(): self.on_transcription_model_changed(\n text\n )\n )\n\n # 全局信号连接\n signalBus.transcription_model_changed.connect(\n self.on_transcription_model_changed\n )\n\n def _show_output_settings(self):\n \"\"\"显示转录设置对话框\"\"\"\n dialog = TranscriptionSettingDialog(self.window())\n dialog.exec_()\n\n def _set_value(self) -> None:\n \"\"\"设置转录模型\"\"\"\n model_name = cfg.get(cfg.transcribe_model).value\n # self.model_button.setText(self.tr(model_name))\n self.on_transcription_model_changed(model_name)\n\n def on_transcription_model_changed(self, model_name: str):\n \"\"\"处理转录模型改变\"\"\"\n self.model_button.setText(self.tr(model_name))\n self.transcription_setting_card.on_model_changed(model_name)\n for model in TranscribeModelEnum:\n if model.value == model_name:\n cfg.set(cfg.transcribe_model, model)\n break\n\n def _on_transcript_finished(self, task: TranscribeTask):\n \"\"\"转录完成处理\"\"\"\n self.is_processing = False\n if task.need_next_task:\n self.finished.emit(task.output_path, task.file_path)\n\n InfoBar.success(\n self.tr(\"转录完成\"),\n self.tr(\"开始字幕优化...\"),\n duration=INFOBAR_DURATION_SUCCESS,\n position=InfoBarPosition.BOTTOM,\n parent=self.parent(),\n )\n\n def _on_file_select(self):\n \"\"\"文件选择处理\"\"\"\n desktop_path = QStandardPaths.writableLocation(QStandardPaths.DesktopLocation)\n file_dialog = QFileDialog()\n\n video_formats = \" \".join(f\"*.{fmt.value}\" for fmt in SupportedVideoFormats)\n audio_formats = \" \".join(f\"*.{fmt.value}\" for fmt in SupportedAudioFormats)\n filter_str = f\"{self.tr('媒体文件')} ({video_formats} {audio_formats});;{self.tr('视频文件')} ({video_formats});;{self.tr('音频文件')} ({audio_formats})\"\n\n file_path, _ = file_dialog.getOpenFileName(\n self, self.tr(\"选择媒体文件\"), desktop_path, filter_str\n )\n if file_path:\n self.update_info(file_path)\n\n def update_info(self, file_path):\n \"\"\"设置UI\"\"\"\n self.video_info_thread = VideoInfoThread(file_path)\n self.video_info_thread.finished.connect(self.video_info_card.update_info)\n self.video_info_thread.error.connect(self._on_video_info_error)\n self.video_info_thread.start()\n\n def _on_video_info_error(self, error_msg):\n \"\"\"处理视频信息提取错误\"\"\"\n self.is_processing = False\n InfoBar.error(\n self.tr(\"错误\"),\n self.tr(error_msg),\n duration=INFOBAR_DURATION_ERROR,\n parent=self,\n )\n\n def set_task(self, task: TranscribeTask) -> None:\n \"\"\"设置任务并更新UI\"\"\"\n self.task = task\n self.video_info_card.set_task(self.task)\n self.update_info(self.task.file_path)\n\n def process(self):\n \"\"\"主处理函数\"\"\"\n self.is_processing = True\n self.video_info_card.start_transcription(need_create_task=False)\n\n def dragEnterEvent(self, event):\n \"\"\"拖拽进入事件处理\"\"\"\n event.accept() if event.mimeData().hasUrls() else event.ignore()\n\n def dropEvent(self, event):\n \"\"\"拖拽放下事件处理\"\"\"\n if self.is_processing:\n InfoBar.warning(\n self.tr(\"警告\"),\n self.tr(\"正在处理中,请等待当前任务完成\"),\n duration=INFOBAR_DURATION_WARNING,\n parent=self,\n )\n return\n\n files = [u.toLocalFile() for u in event.mimeData().urls()]\n for file_path in files:\n if not os.path.isfile(file_path):\n continue\n\n file_ext = os.path.splitext(file_path)[1][1:].lower()\n\n # 检查文件格式是否支持\n supported_formats = {fmt.value for fmt in SupportedVideoFormats} | {\n fmt.value for fmt in SupportedAudioFormats\n }\n is_supported = file_ext in supported_formats\n\n if is_supported:\n self.update_info(file_path)\n InfoBar.success(\n self.tr(\"导入成功\"),\n self.tr(\"开始语音转文字\"),\n duration=INFOBAR_DURATION_SUCCESS,\n parent=self,\n )\n break\n else:\n InfoBar.error(\n self.tr(\"格式错误\") + file_ext,\n self.tr(\"请拖入音频或视频文件\"),\n duration=INFOBAR_DURATION_ERROR,\n parent=self,\n )\n\n def closeEvent(self, event):\n self.video_info_card.stop()\n super().closeEvent(event)\n\n\nif __name__ == \"__main__\":\n QApplication.setHighDpiScaleFactorRoundingPolicy(\n Qt.HighDpiScaleFactorRoundingPolicy.PassThrough\n )\n QApplication.setAttribute(Qt.AA_EnableHighDpiScaling) # type: ignore\n QApplication.setAttribute(Qt.AA_UseHighDpiPixmaps) # type: ignore\n\n app = QApplication(sys.argv)\n window = TranscriptionInterface()\n window.show()\n sys.exit(app.exec_())\n" }, { "path": "app/view/video_synthesis_interface.py", "content": "# -*- coding: utf-8 -*-\n\nimport os\nimport sys\nfrom pathlib import Path\n\nfrom PyQt5.QtCore import Qt, pyqtSignal\nfrom PyQt5.QtGui import QDropEvent\nfrom PyQt5.QtWidgets import QApplication, QFileDialog, QHBoxLayout, QVBoxLayout, QWidget\nfrom qfluentwidgets import (\n Action,\n BodyLabel,\n CardWidget,\n CommandBar,\n InfoBar,\n InfoBarPosition,\n LineEdit,\n PrimaryPushButton,\n ProgressBar,\n PushButton,\n RoundMenu,\n ToolTipFilter,\n ToolTipPosition,\n TransparentDropDownPushButton,\n)\nfrom qfluentwidgets import FluentIcon as FIF\n\nfrom app.common.config import cfg\nfrom app.common.signal_bus import signalBus\nfrom app.core.constant import (\n INFOBAR_DURATION_ERROR,\n INFOBAR_DURATION_SUCCESS,\n INFOBAR_DURATION_WARNING,\n)\nfrom app.core.entities import (\n SubtitleRenderModeEnum,\n SupportedSubtitleFormats,\n SupportedVideoFormats,\n SynthesisTask,\n VideoQualityEnum,\n)\nfrom app.core.task_factory import TaskFactory\nfrom app.core.utils.platform_utils import open_folder\nfrom app.thread.video_synthesis_thread import VideoSynthesisThread\n\n\nclass VideoSynthesisInterface(QWidget):\n finished = pyqtSignal()\n\n def __init__(self, parent=None):\n super().__init__(parent)\n self.setObjectName(\"VideoSynthesisInterface\")\n self.setAttribute(Qt.WA_StyledBackground, True) # type: ignore\n self.setAcceptDrops(True) # 启用拖放功能\n self.setup_ui()\n self.setup_style()\n self.set_value()\n self.setup_signals()\n self.task = None\n\n self.installEventFilter(ToolTipFilter(self, 100, ToolTipPosition.BOTTOM))\n\n def setup_ui(self):\n self.main_layout = QVBoxLayout(self)\n self.main_layout.setSpacing(20)\n\n # 创建顶部布局\n top_layout = QHBoxLayout()\n\n # 添加顶部命令栏\n self.command_bar = CommandBar(self)\n self.command_bar.setToolButtonStyle(Qt.ToolButtonTextBesideIcon) # type: ignore\n top_layout.addWidget(self.command_bar, 1) # 设置stretch为1,使其尽可能占用空间\n\n # 设置命令栏\n self._setup_command_bar()\n\n # 添加开始合成按钮到水平布局\n self.synthesize_button = PrimaryPushButton(\n self.tr(\"开始合成\"), self, icon=FIF.PLAY\n )\n self.synthesize_button.setFixedHeight(34)\n top_layout.addWidget(self.synthesize_button)\n\n self.main_layout.addLayout(top_layout)\n\n # 配置卡片\n self.config_card = CardWidget(self)\n self.config_layout = QVBoxLayout(self.config_card)\n self.config_layout.setContentsMargins(20, 20, 20, 20)\n self.config_layout.setSpacing(20)\n\n # 字幕文件选择\n self.subtitle_layout = QHBoxLayout()\n self.subtitle_layout.setSpacing(15)\n self.subtitle_label = BodyLabel(self.tr(\"字幕文件\"), self)\n self.subtitle_input = LineEdit(self)\n self.subtitle_input.setPlaceholderText(self.tr(\"选择或者拖拽字幕文件\"))\n self.subtitle_input.setAcceptDrops(True) # 启用拖放\n self.subtitle_button = PushButton(self.tr(\"浏览\"))\n self.subtitle_layout.addWidget(self.subtitle_label)\n self.subtitle_layout.addWidget(self.subtitle_input)\n self.subtitle_layout.addWidget(self.subtitle_button)\n self.config_layout.addLayout(self.subtitle_layout)\n\n # 视频文件选择\n self.video_layout = QHBoxLayout()\n self.video_layout.setSpacing(15)\n self.video_label = BodyLabel(self.tr(\"视频文件\"), self)\n self.video_input = LineEdit(self)\n self.video_input.setPlaceholderText(self.tr(\"选择或者拖拽视频文件\"))\n self.video_input.setAcceptDrops(True) # 启用拖放\n self.video_button = PushButton(self.tr(\"浏览\"))\n self.video_layout.addWidget(self.video_label)\n self.video_layout.addWidget(self.video_input)\n self.video_layout.addWidget(self.video_button)\n self.config_layout.addLayout(self.video_layout)\n\n self.main_layout.addWidget(self.config_card)\n\n self.main_layout.addStretch(1)\n\n # 底部进度条和状态信息\n self.bottom_layout = QHBoxLayout()\n self.progress_bar = ProgressBar(self)\n self.status_label = BodyLabel(self.tr(\"就绪\"), self)\n self.status_label.setMinimumWidth(100) # 设置最小宽度\n self.status_label.setAlignment(Qt.AlignCenter) # type: ignore # 设置文本居中对齐\n self.bottom_layout.addWidget(self.progress_bar, 1) # 进度条使用剩余空间\n self.bottom_layout.addWidget(self.status_label) # 状态标签使用固定宽度\n self.main_layout.addLayout(self.bottom_layout)\n\n def _setup_command_bar(self):\n \"\"\"设置顶部命令栏\"\"\"\n # 添加软字幕选项\n self.soft_subtitle_action = Action(\n FIF.FONT,\n self.tr(\"软字幕\"),\n triggered=self.on_soft_subtitle_action_triggered,\n checkable=True,\n )\n self.soft_subtitle_action.setToolTip(self.tr(\"使用软字幕嵌入视频\"))\n self.command_bar.addAction(self.soft_subtitle_action)\n\n # 添加分隔符\n self.command_bar.addSeparator()\n\n # 添加使用样式开关\n self.use_style_action = Action(\n FIF.PALETTE,\n self.tr(\"使用样式\"),\n triggered=self.on_use_style_action_triggered,\n checkable=True,\n )\n self.use_style_action.setToolTip(self.tr(\"启用字幕样式渲染\"))\n self.command_bar.addAction(self.use_style_action)\n\n self.command_bar.addSeparator()\n\n # 添加渲染模式下拉按钮\n self.render_mode_button = TransparentDropDownPushButton(\n self.tr(\"渲染模式\"), self, FIF.FONT_SIZE\n )\n self.render_mode_button.setFixedHeight(34)\n self.render_mode_button.setMinimumWidth(140)\n self.render_mode_menu = RoundMenu(parent=self)\n for mode in SubtitleRenderModeEnum:\n action = Action(text=mode.value)\n action.triggered.connect(\n lambda checked, m=mode.value: self.on_render_mode_changed(m)\n )\n self.render_mode_menu.addAction(action)\n self.render_mode_button.setMenu(self.render_mode_menu)\n self.command_bar.addWidget(self.render_mode_button)\n\n self.command_bar.addSeparator()\n\n # 添加视频质量选择下拉按钮\n self.video_quality_button = TransparentDropDownPushButton(\n self.tr(\"视频质量\"), self, FIF.SPEED_HIGH\n )\n self.video_quality_button.setFixedHeight(34)\n self.video_quality_button.setMinimumWidth(125)\n self.video_quality_menu = RoundMenu(parent=self)\n for quality in VideoQualityEnum:\n action = Action(text=quality.value)\n action.triggered.connect(\n lambda checked, q=quality.value: self.on_video_quality_action_changed(q)\n )\n self.video_quality_menu.addAction(action)\n self.video_quality_button.setMenu(self.video_quality_menu)\n self.command_bar.addWidget(self.video_quality_button)\n\n # 添加分隔符\n self.command_bar.addSeparator()\n\n # 添加是否合成视频选项\n self.need_video_action = Action(\n FIF.VIDEO,\n self.tr(\"合成视频\"),\n triggered=self.on_need_video_action_triggered,\n checkable=True,\n )\n self.need_video_action.setToolTip(self.tr(\"是否生成新的视频文件\"))\n self.command_bar.addAction(self.need_video_action)\n\n self.command_bar.addSeparator()\n\n # 添加打开文件夹按钮\n folder_action = Action(FIF.FOLDER, \"\", triggered=self.open_video_folder)\n folder_action.setToolTip(self.tr(\"打开输出文件夹\"))\n self.command_bar.addAction(folder_action)\n\n def setup_style(self):\n self.subtitle_input.focusOutEvent = lambda e: super(\n LineEdit, self.subtitle_input\n ).focusOutEvent(e)\n self.subtitle_input.paintEvent = lambda e: super(\n LineEdit, self.subtitle_input\n ).paintEvent(e)\n self.subtitle_input.setStyleSheet(\n self.subtitle_input.styleSheet()\n + \"\"\"\n QLineEdit {\n border-radius: 15px;\n padding: 0 20px;\n background-color: transparent;\n border: 1px solid rgba(255,255, 255, 0.08);\n }\n QLineEdit:focus[transparent=true] {\n border: 1px solid rgba(47,141, 99, 0.48);\n }\n \"\"\"\n )\n\n self.video_input.focusOutEvent = lambda e: super(\n LineEdit, self.video_input\n ).focusOutEvent(e)\n self.video_input.paintEvent = lambda e: super(\n LineEdit, self.video_input\n ).paintEvent(e)\n self.video_input.setStyleSheet(\n self.video_input.styleSheet()\n + \"\"\"\n QLineEdit {\n border-radius: 15px;\n padding: 0 20px;\n background-color: transparent;\n border: 1px solid rgba(255,255, 255, 0.08);\n }\n QLineEdit:focus[transparent=true] {\n border: 1px solid rgba(47,141, 99, 0.48);\n }\n \"\"\"\n )\n\n def setup_signals(self):\n # 文件选择相关信号\n self.subtitle_button.clicked.connect(self.choose_subtitle_file)\n self.video_button.clicked.connect(self.choose_video_file)\n\n # 合成和文件夹相关信号\n self.synthesize_button.clicked.connect(\n lambda: self.start_video_synthesis(need_create_task=True)\n )\n\n # 全局 signalBus\n signalBus.soft_subtitle_changed.connect(self.on_soft_subtitle_changed)\n signalBus.need_video_changed.connect(self.on_need_video_changed)\n signalBus.video_quality_changed.connect(self.on_video_quality_changed)\n signalBus.use_subtitle_style_changed.connect(self.on_use_style_changed)\n signalBus.subtitle_render_mode_changed.connect(self.on_render_mode_changed_external)\n\n def set_value(self):\n \"\"\"设置初始值\"\"\"\n self.soft_subtitle_action.setChecked(cfg.soft_subtitle.value)\n self.need_video_action.setChecked(cfg.need_video.value)\n self.video_quality_button.setText(cfg.video_quality.value.value)\n\n # 设置样式相关初始值\n self.use_style_action.setChecked(cfg.use_subtitle_style.value)\n self.render_mode_button.setText(cfg.subtitle_render_mode.value.value)\n self._update_synthesis_controls_state()\n\n def on_soft_subtitle_action_triggered(self, checked: bool):\n \"\"\"处理软字幕按钮点击(更新配置+显示InfoBar)\"\"\"\n cfg.set(cfg.soft_subtitle, checked)\n\n # 显示说明信息\n if checked:\n # 开启软字幕时自动关闭使用样式\n if self.use_style_action.isChecked():\n self.use_style_action.setChecked(False)\n cfg.set(cfg.use_subtitle_style, False)\n self._update_style_controls_state()\n InfoBar.info(\n self.tr(\"开启软字幕\"),\n self.tr(\"字幕作为独立轨道嵌入视频,不包含字幕样式\"),\n duration=3000,\n position=InfoBarPosition.BOTTOM,\n parent=self,\n )\n else:\n InfoBar.info(\n self.tr(\"开启硬烧录字幕\"),\n self.tr(\"字幕直接烧录到视频画面中,包含字幕样式\"),\n duration=3000,\n position=InfoBarPosition.BOTTOM,\n parent=self,\n )\n\n def on_soft_subtitle_changed(self, checked: bool):\n \"\"\"处理外部软字幕配置变更(仅更新UI状态)\"\"\"\n self.soft_subtitle_action.setChecked(checked)\n\n def on_need_video_action_triggered(self, checked: bool):\n \"\"\"处理视频合成按钮点击(更新配置+显示InfoBar)\"\"\"\n cfg.set(cfg.need_video, checked)\n self._update_synthesis_controls_state()\n\n # 显示说明信息\n if checked:\n InfoBar.info(\n self.tr(\"开启视频合成\"),\n self.tr(\"将进行视频与字幕的合成操作\"),\n duration=3000,\n position=InfoBarPosition.BOTTOM,\n parent=self,\n )\n else:\n InfoBar.info(\n self.tr(\"关闭视频合成\"),\n self.tr(\"仅生成字幕文件,不生成新的视频文件\"),\n duration=3000,\n position=InfoBarPosition.BOTTOM,\n parent=self,\n )\n\n def on_need_video_changed(self, checked: bool):\n \"\"\"处理外部视频合成配置变更(仅更新UI状态)\"\"\"\n self.need_video_action.setChecked(checked)\n self._update_synthesis_controls_state()\n\n def on_video_quality_action_changed(self, quality_text: str):\n \"\"\"处理质量选择\"\"\"\n # 根据文本找到对应的枚举\n quality_enum = None\n for e in VideoQualityEnum:\n if e.value == quality_text:\n quality_enum = e\n break\n\n if quality_enum is None:\n return\n\n cfg.set(cfg.video_quality, quality_enum)\n self.video_quality_button.setText(quality_text)\n\n def on_video_quality_changed(self, quality_text: str):\n \"\"\"处理外部质量配置变更(仅更新UI状态)\"\"\"\n self.video_quality_button.setText(quality_text)\n\n def on_use_style_action_triggered(self, checked: bool):\n \"\"\"处理使用样式开关点击\"\"\"\n cfg.set(cfg.use_subtitle_style, checked)\n self._update_style_controls_state()\n\n if checked:\n # 启用样式时自动关闭软字幕\n if self.soft_subtitle_action.isChecked():\n self.soft_subtitle_action.setChecked(False)\n cfg.set(cfg.soft_subtitle, False)\n InfoBar.info(\n self.tr(\"启用字幕样式\"),\n self.tr(\"已自动切换为硬字幕渲染\"),\n duration=3000,\n position=InfoBarPosition.BOTTOM,\n parent=self,\n )\n else:\n InfoBar.info(\n self.tr(\"关闭字幕样式\"),\n self.tr(\"将使用默认字幕渲染\"),\n duration=3000,\n position=InfoBarPosition.BOTTOM,\n parent=self,\n )\n\n def on_use_style_changed(self, checked: bool):\n \"\"\"处理外部使用样式配置变更(仅更新 UI)\"\"\"\n self.use_style_action.setChecked(checked)\n self._update_style_controls_state()\n\n def on_render_mode_changed(self, mode_text: str):\n \"\"\"处理渲染模式选择(本界面触发)\"\"\"\n mode_enum = None\n for e in SubtitleRenderModeEnum:\n if e.value == mode_text:\n mode_enum = e\n break\n if mode_enum:\n cfg.set(cfg.subtitle_render_mode, mode_enum)\n self.render_mode_button.setText(mode_text)\n signalBus.subtitle_render_mode_changed.emit(mode_text)\n\n def on_render_mode_changed_external(self, mode_text: str):\n \"\"\"处理外部渲染模式变更(仅更新 UI)\"\"\"\n self.render_mode_button.setText(mode_text)\n\n def _update_synthesis_controls_state(self):\n \"\"\"更新所有合成相关控件的启用/禁用状态\"\"\"\n need_video = self.need_video_action.isChecked()\n\n # 合成视频关闭时,禁用所有相关选项\n self.soft_subtitle_action.setEnabled(need_video)\n self.use_style_action.setEnabled(need_video)\n self.video_quality_button.setEnabled(need_video)\n\n # 渲染模式按钮需要同时满足:合成视频开启 且 使用样式开启\n self._update_style_controls_state()\n\n def _update_style_controls_state(self):\n \"\"\"更新样式相关控件的启用/禁用状态\"\"\"\n need_video = self.need_video_action.isChecked()\n use_style = self.use_style_action.isChecked()\n # 渲染模式按钮:需要合成视频开启 且 使用样式开启\n self.render_mode_button.setEnabled(need_video and use_style)\n\n def choose_subtitle_file(self):\n # 构建文件过滤器\n subtitle_formats = \" \".join(\n f\"*.{fmt.value}\" for fmt in SupportedSubtitleFormats\n )\n filter_str = f\"{self.tr('字幕文件')} ({subtitle_formats})\"\n\n file_path, _ = QFileDialog.getOpenFileName(\n self, self.tr(\"选择字幕文件\"), \"\", filter_str\n )\n if file_path:\n self.subtitle_input.setText(file_path)\n\n def choose_video_file(self):\n # 构建文件过滤器\n video_formats = \" \".join(f\"*.{fmt.value}\" for fmt in SupportedVideoFormats)\n filter_str = f\"{self.tr('视频文件')} ({video_formats})\"\n\n file_path, _ = QFileDialog.getOpenFileName(\n self, self.tr(\"选择视频文件\"), \"\", filter_str\n )\n if file_path:\n self.video_input.setText(file_path)\n\n def create_task(self):\n subtitle_file = self.subtitle_input.text()\n video_file = self.video_input.text()\n if not subtitle_file or not video_file:\n InfoBar.error(\n self.tr(\"错误\"),\n self.tr(\"请选择字幕文件和视频文件\"),\n duration=INFOBAR_DURATION_ERROR,\n position=InfoBarPosition.TOP,\n parent=self,\n )\n return None\n return TaskFactory.create_synthesis_task(video_file, subtitle_file)\n\n def set_task(self, task: SynthesisTask):\n self.task = task\n self.update_info()\n\n def update_info(self):\n if self.task:\n self.video_input.setText(self.task.video_path)\n self.subtitle_input.setText(self.task.subtitle_path)\n\n def start_video_synthesis(self, need_create_task=True):\n self.synthesize_button.setEnabled(False)\n self.progress_bar.resume()\n self.progress_bar.reset()\n if need_create_task:\n self.task = self.create_task()\n\n if self.task:\n self.video_synthesis_thread = VideoSynthesisThread(self.task)\n self.video_synthesis_thread.finished.connect(\n self.on_video_synthesis_finished\n )\n self.video_synthesis_thread.progress.connect(\n self.on_video_synthesis_progress\n )\n self.video_synthesis_thread.error.connect(self.on_video_synthesis_error)\n self.video_synthesis_thread.start()\n else:\n self.synthesize_button.setEnabled(True)\n\n def process(self):\n self.start_video_synthesis(need_create_task=False)\n\n def on_video_synthesis_finished(self, task):\n self.synthesize_button.setEnabled(True)\n self.progress_bar.setValue(100)\n self.open_video_folder()\n InfoBar.success(\n self.tr(\"成功\"),\n self.tr(\"视频合成已完成\"),\n duration=INFOBAR_DURATION_SUCCESS,\n position=InfoBarPosition.TOP,\n parent=self,\n )\n\n def on_video_synthesis_progress(self, progress, message):\n self.progress_bar.setValue(progress)\n self.status_label.setText(message)\n\n def on_video_synthesis_error(self, error):\n self.synthesize_button.setEnabled(True)\n self.progress_bar.error()\n InfoBar.error(\n self.tr(\"错误\"),\n str(error),\n duration=INFOBAR_DURATION_ERROR,\n position=InfoBarPosition.TOP,\n parent=self,\n )\n\n def open_video_folder(self):\n if self.task and self.task.output_path:\n file_path = Path(self.task.output_path)\n target_dir = str(\n file_path.parent\n if file_path.exists()\n else (\n Path(str(self.task.video_path)).parent\n if self.task.video_path\n else file_path.parent\n )\n )\n # Cross-platform folder opening\n open_folder(target_dir)\n else:\n InfoBar.warning(\n self.tr(\"警告\"),\n self.tr(\"没有可用的视频文件夹\"),\n duration=INFOBAR_DURATION_WARNING,\n position=InfoBarPosition.TOP,\n parent=self,\n )\n\n def dragEnterEvent(self, event):\n \"\"\"拖拽进入事件处理\"\"\"\n event.accept() if event.mimeData().hasUrls() else event.ignore()\n\n def dropEvent(self, event: QDropEvent):\n \"\"\"拖拽放下事件处理\"\"\"\n files = [u.toLocalFile() for u in event.mimeData().urls()]\n for file_path in files:\n if not os.path.isfile(file_path):\n continue\n\n file_ext = os.path.splitext(file_path)[1][1:].lower()\n\n # 检查文件格式是否支持\n if file_ext in {fmt.value for fmt in SupportedSubtitleFormats}:\n self.subtitle_input.setText(file_path)\n InfoBar.success(\n self.tr(\"导入成功\"),\n self.tr(\"字幕文件已放入输入框\"),\n duration=INFOBAR_DURATION_SUCCESS,\n parent=self,\n )\n break\n elif file_ext in {fmt.value for fmt in SupportedVideoFormats}:\n self.video_input.setText(file_path)\n InfoBar.success(\n self.tr(\"导入成功\"),\n self.tr(\"视频文件已输入框\"),\n duration=INFOBAR_DURATION_SUCCESS,\n parent=self,\n )\n break\n else:\n InfoBar.error(\n self.tr(\"格式错误\") + file_ext,\n self.tr(\"请拖入视频或者字幕文件\"),\n duration=INFOBAR_DURATION_ERROR,\n parent=self,\n )\n\n\nif __name__ == \"__main__\":\n QApplication.setHighDpiScaleFactorRoundingPolicy(\n Qt.HighDpiScaleFactorRoundingPolicy.PassThrough\n )\n QApplication.setAttribute(Qt.AA_EnableHighDpiScaling) # type: ignore\n QApplication.setAttribute(Qt.AA_UseHighDpiPixmaps) # type: ignore\n\n app = QApplication(sys.argv)\n window = VideoSynthesisInterface()\n window.resize(600, 400) # 设置窗口大小\n window.show()\n sys.exit(app.exec_())\n" }, { "path": "docs/.vitepress/config.mts", "content": "import { defineConfig } from 'vitepress'\n\nexport default defineConfig({\n title: 'VideoCaptioner',\n description: '基于大语言模型(LLM)的视频字幕处理助手,支持语音识别、字幕断句、优化、翻译全流程处理',\n titleTemplate: ':title - VideoCaptioner',\n\n lastUpdated: true,\n cleanUrls: true,\n ignoreDeadLinks: true,\n\n // 多语言替代链接配置\n transformHead({ pageData }) {\n const canonicalUrl = `https://weifeng2333.github.io/VideoCaptioner/${pageData.relativePath}`\n .replace(/index\\.md$/, '')\n .replace(/\\.md$/, '')\n\n const head: [string, Record
\n \n \n \n \n\n \n \n \n\n \n \n \n\n \n \n \n
\n\n\n\n\n\n"
},
{
"path": "docs/.vitepress/theme/custom.css",
"content": "/**\n * VideoCaptioner Custom Theme\n * Inspired by Anthropic's modern, elegant design\n */\n\n/* ===== Color Variables ===== */\n:root {\n /* Primary Brand Colors - Purple Gradient */\n --vc-c-brand-1: #667eea;\n --vc-c-brand-2: #764ba2;\n --vc-c-brand-3: #5a67d8;\n\n /* Accent Colors */\n --vc-c-accent: #d97757;\n --vc-c-success: #43e97b;\n --vc-c-info: #4facfe;\n\n /* Light Theme */\n --vp-c-brand-1: var(--vc-c-brand-1);\n --vp-c-brand-2: var(--vc-c-brand-2);\n --vp-c-brand-3: var(--vc-c-brand-3);\n\n /* Refined spacing */\n --vc-spacing-xs: 0.5rem;\n --vc-spacing-sm: 1rem;\n --vc-spacing-md: 2rem;\n --vc-spacing-lg: 4rem;\n --vc-spacing-xl: 6rem;\n\n /* Smooth transitions */\n --vc-transition-fast: 0.15s cubic-bezier(0.16, 1, 0.3, 1);\n --vc-transition-base: 0.3s cubic-bezier(0.16, 1, 0.3, 1);\n --vc-transition-slow: 0.5s cubic-bezier(0.16, 1, 0.3, 1);\n\n /* Shadows */\n --vc-shadow-sm: 0 2px 8px rgba(102, 126, 234, 0.08);\n --vc-shadow-md: 0 8px 24px rgba(102, 126, 234, 0.12);\n --vc-shadow-lg: 0 16px 48px rgba(102, 126, 234, 0.16);\n --vc-shadow-xl: 0 24px 64px rgba(102, 126, 234, 0.2);\n}\n\n.dark {\n --vc-shadow-sm: 0 2px 8px rgba(0, 0, 0, 0.3);\n --vc-shadow-md: 0 8px 24px rgba(0, 0, 0, 0.4);\n --vc-shadow-lg: 0 16px 48px rgba(0, 0, 0, 0.5);\n --vc-shadow-xl: 0 24px 64px rgba(0, 0, 0, 0.6);\n}\n\n/* ===== Hero Section - Anthropic Style ===== */\n.VPHero {\n padding-top: var(--vc-spacing-xl) !important;\n padding-bottom: var(--vc-spacing-xl) !important;\n}\n\n.VPHero .container {\n max-width: 1280px;\n}\n\n.VPHero .name {\n font-size: clamp(2.5rem, 5vw, 4rem) !important;\n font-weight: 800 !important;\n letter-spacing: -0.02em !important;\n line-height: 1.1 !important;\n background: linear-gradient(\n 135deg,\n var(--vc-c-brand-1) 0%,\n var(--vc-c-brand-2) 100%\n );\n -webkit-background-clip: text;\n -webkit-text-fill-color: transparent;\n background-clip: text;\n animation: fadeInUp 0.8s var(--vc-transition-base) backwards;\n}\n\n.VPHero .text {\n font-size: clamp(1.5rem, 3vw, 2.5rem) !important;\n font-weight: 600 !important;\n letter-spacing: -0.01em !important;\n line-height: 1.3 !important;\n margin-top: var(--vc-spacing-sm) !important;\n animation: fadeInUp 0.8s 0.1s var(--vc-transition-base) backwards;\n}\n\n.VPHero .tagline {\n font-size: clamp(1rem, 2vw, 1.25rem) !important;\n line-height: 1.6 !important;\n margin-top: var(--vc-spacing-md) !important;\n opacity: 0.8;\n max-width: 800px;\n animation: fadeInUp 0.8s 0.2s var(--vc-transition-base) backwards;\n}\n\n.VPHero .actions {\n margin-top: var(--vc-spacing-md) !important;\n animation: fadeInUp 0.8s 0.3s var(--vc-transition-base) backwards;\n}\n\n/* Hero Image Animation */\n.VPHero .VPImage {\n animation:\n float 6s ease-in-out infinite,\n fadeIn 1s var(--vc-transition-base);\n}\n\n@keyframes float {\n 0%,\n 100% {\n transform: translateY(0) rotate(0deg);\n }\n 50% {\n transform: translateY(-20px) rotate(2deg);\n }\n}\n\n@keyframes fadeInUp {\n from {\n opacity: 0;\n transform: translateY(30px);\n }\n to {\n opacity: 1;\n transform: translateY(0);\n }\n}\n\n@keyframes fadeIn {\n from {\n opacity: 0;\n }\n to {\n opacity: 1;\n }\n}\n\n/* ===== Buttons - Modern Style ===== */\n.VPButton {\n font-weight: 600 !important;\n padding: 0.875rem 2rem !important;\n font-size: 1.0625rem !important;\n border-radius: 12px !important;\n transition: all var(--vc-transition-base) !important;\n border: none !important;\n position: relative;\n overflow: hidden;\n}\n\n.VPButton.brand {\n background: linear-gradient(\n 135deg,\n var(--vc-c-brand-1) 0%,\n var(--vc-c-brand-2) 100%\n ) !important;\n box-shadow: var(--vc-shadow-sm);\n}\n\n.VPButton.brand:hover {\n transform: translateY(-2px);\n box-shadow: var(--vc-shadow-md);\n}\n\n.VPButton.brand:active {\n transform: translateY(0);\n}\n\n.VPButton.alt {\n background: transparent !important;\n border: 2px solid var(--vc-c-brand-1) !important;\n color: var(--vc-c-brand-1) !important;\n}\n\n.VPButton.alt:hover {\n background: rgba(102, 126, 234, 0.08) !important;\n transform: translateY(-2px);\n}\n\n/* ===== Features - Card Grid ===== */\n.VPFeatures {\n padding: var(--vc-spacing-xl) 0 !important;\n}\n\n.VPFeature {\n border-radius: 16px !important;\n border: 1px solid transparent !important;\n padding: var(--vc-spacing-md) !important;\n transition: all var(--vc-transition-base) !important;\n background: var(--vp-c-bg-soft);\n position: relative;\n overflow: hidden;\n}\n\n.VPFeature::before {\n content: \"\";\n position: absolute;\n top: 0;\n left: 0;\n right: 0;\n height: 3px;\n background: linear-gradient(90deg, var(--vc-c-brand-1), var(--vc-c-brand-2));\n opacity: 0;\n transition: opacity var(--vc-transition-base);\n}\n\n.VPFeature:hover {\n transform: translateY(-8px);\n box-shadow: var(--vc-shadow-lg);\n border-color: rgba(102, 126, 234, 0.2) !important;\n}\n\n.VPFeature:hover::before {\n opacity: 1;\n}\n\n.VPFeature .icon {\n font-size: 2.5rem !important;\n line-height: 1 !important;\n margin-bottom: var(--vc-spacing-sm) !important;\n display: inline-block;\n transition: transform var(--vc-transition-base);\n}\n\n.VPFeature:hover .icon {\n transform: scale(1.1) rotate(5deg);\n}\n\n.VPFeature .title {\n font-size: 1.25rem !important;\n font-weight: 700 !important;\n line-height: 1.4 !important;\n margin-bottom: var(--vc-spacing-xs) !important;\n}\n\n.VPFeature .details {\n font-size: 0.9375rem !important;\n line-height: 1.7 !important;\n opacity: 0.85;\n}\n\n/* ===== Content Area ===== */\n.vp-doc {\n font-size: 1.0625rem;\n line-height: 1.75;\n}\n\n.vp-doc h1,\n.vp-doc h2,\n.vp-doc h3 {\n font-weight: 700;\n letter-spacing: -0.01em;\n line-height: 1.3;\n position: relative;\n}\n\n.vp-doc h2 {\n font-size: clamp(1.75rem, 3vw, 2.25rem);\n margin-top: var(--vc-spacing-lg);\n padding-top: var(--vc-spacing-md);\n border-top: 1px solid var(--vp-c-divider);\n}\n\n.vp-doc h3 {\n font-size: clamp(1.375rem, 2.5vw, 1.75rem);\n margin-top: var(--vc-spacing-md);\n}\n\n/* ===== Links ===== */\n.vp-doc a {\n color: var(--vc-c-brand-1);\n text-decoration: none;\n border-bottom: 1px solid transparent;\n transition: all var(--vc-transition-fast);\n font-weight: 500;\n}\n\n.vp-doc a:hover {\n border-bottom-color: var(--vc-c-brand-1);\n opacity: 0.85;\n}\n\n/* ===== Tables - Elegant Style ===== */\n.vp-doc table {\n border-radius: 12px;\n overflow: hidden;\n box-shadow: var(--vc-shadow-sm);\n border: 1px solid var(--vp-c-divider);\n}\n\n.vp-doc thead {\n background: linear-gradient(\n 135deg,\n rgba(102, 126, 234, 0.08),\n rgba(118, 75, 162, 0.08)\n );\n}\n\n.vp-doc th {\n font-weight: 700;\n text-align: left;\n padding: 1rem 1.5rem !important;\n font-size: 0.9375rem;\n letter-spacing: 0.01em;\n}\n\n.vp-doc td {\n padding: 1rem 1.5rem !important;\n}\n\n.vp-doc tbody tr {\n transition: background-color var(--vc-transition-fast);\n}\n\n.vp-doc tbody tr:hover {\n background-color: rgba(102, 126, 234, 0.03);\n}\n\n/* ===== Code Blocks ===== */\n.vp-doc div[class*=\"language-\"] {\n border-radius: 12px;\n box-shadow: var(--vc-shadow-sm);\n margin: var(--vc-spacing-md) 0;\n overflow: hidden;\n}\n\n.vp-doc div[class*=\"language-\"]:hover {\n box-shadow: var(--vc-shadow-md);\n}\n\n/* ===== Images ===== */\n.vp-doc img {\n border-radius: 12px;\n transition: all var(--vc-transition-base);\n}\n\n.vp-doc img:hover {\n transform: scale(1.01);\n box-shadow: var(--vc-shadow-lg) !important;\n}\n\n/* ===== Mermaid Diagrams ===== */\n.vp-doc .mermaid {\n background: linear-gradient(\n 135deg,\n rgba(102, 126, 234, 0.03),\n rgba(118, 75, 162, 0.03)\n );\n border-radius: 16px;\n padding: var(--vc-spacing-md);\n margin: var(--vc-spacing-md) 0;\n border: 1px solid rgba(102, 126, 234, 0.1);\n}\n\n/* ===== Scrollbar ===== */\n::-webkit-scrollbar {\n width: 10px;\n height: 10px;\n}\n\n::-webkit-scrollbar-track {\n background: var(--vp-c-bg);\n}\n\n::-webkit-scrollbar-thumb {\n background: linear-gradient(135deg, var(--vc-c-brand-1), var(--vc-c-brand-2));\n border-radius: 5px;\n}\n\n::-webkit-scrollbar-thumb:hover {\n opacity: 0.8;\n}\n\n/* ===== Responsive Optimizations ===== */\n@media (max-width: 768px) {\n .VPHero {\n padding-top: var(--vc-spacing-lg) !important;\n padding-bottom: var(--vc-spacing-lg) !important;\n }\n\n .VPFeature {\n padding: var(--vc-spacing-sm) !important;\n }\n\n .vp-doc h2 {\n margin-top: var(--vc-spacing-md);\n padding-top: var(--vc-spacing-sm);\n }\n}\n\n/* ===== Accessibility ===== */\n@media (prefers-reduced-motion: reduce) {\n *,\n *::before,\n *::after {\n animation-duration: 0.01ms !important;\n animation-iteration-count: 1 !important;\n transition-duration: 0.01ms !important;\n }\n\n .VPHero .VPImage {\n animation: none !important;\n }\n}\n\n/* ===== Focus States ===== */\n.VPButton:focus-visible {\n outline: 3px solid var(--vc-c-brand-1);\n outline-offset: 3px;\n}\n\n.vp-doc a:focus-visible {\n outline: 2px solid var(--vc-c-brand-1);\n outline-offset: 2px;\n border-radius: 3px;\n}\n"
},
{
"path": "docs/.vitepress/theme/index.ts",
"content": "import DefaultTheme from \"vitepress/theme\";\nimport CustomHome from \"./CustomHome.vue\";\nimport \"./custom.css\";\n\nexport default {\n extends: DefaultTheme,\n enhanceApp({ app }) {\n app.component(\"CustomHome\", CustomHome);\n },\n};\n"
},
{
"path": "docs/README.md",
"content": "# VideoCaptioner 文档\n\n这是 VideoCaptioner 项目的文档源文件,使用 [VitePress](https://vitepress.dev/) 构建。\n\n## 📚 在线查看\n\n文档已自动部署到 GitHub Pages:\n\n**[https://weifeng2333.github.io/VideoCaptioner/](https://weifeng2333.github.io/VideoCaptioner/)**\n\n## 🚀 本地开发\n\n### 安装依赖\n\n```bash\nnpm install\n```\n\n### 启动开发服务器\n\n```bash\nnpm run docs:dev\n```\n\n访问 http://localhost:5173 查看文档\n\n### 构建文档\n\n```bash\nnpm run docs:build\n```\n\n构建产物位于 `docs/.vitepress/dist/`\n\n### 预览构建结果\n\n```bash\nnpm run docs:preview\n```\n\n## 📁 目录结构\n\n```\ndocs/\n├── .vitepress/\n│ ├── config.mts # VitePress 配置文件(含 SEO 优化)\n│ └── theme/ # 自定义主题(可选)\n├── public/ # 静态资源(图片、Logo、robots.txt)\n├── guide/ # 中文使用指南\n│ ├── getting-started.md\n│ ├── configuration.md\n│ └── ...\n├── config/ # 中文配置文档\n│ ├── llm.md\n│ ├── asr.md\n│ └── ...\n├── dev/ # 中文开发者文档\n│ ├── architecture.md\n│ └── ...\n├── en/ # 英文文档(镜像中文结构)\n│ ├── guide/\n│ ├── config/\n│ └── dev/\n└── index.md # 中文首页\n```\n\n## ✍️ 贡献文档\n\n### 添加新页面\n\n1. 在对应目录下创建 Markdown 文件\n2. **添加 Frontmatter SEO 优化**(重要!):\n\n```markdown\n---\ntitle: 页面标题 - VideoCaptioner\ndescription: 页面描述,包含关键词\nhead:\n - - meta\n - name: keywords\n content: 关键词1,关键词2,关键词3\n---\n\n# 页面标题\n\n内容...\n```\n\n3. 在 `.vitepress/config.mts` 的 `sidebar` 中添加链接\n4. 提交 PR\n\n### 编辑现有页面\n\n直接编辑 Markdown 文件即可,支持:\n\n- **Markdown 扩展语法**:表格、代码块、提示框等\n- **Vue 组件**:可在 Markdown 中使用 Vue 组件\n- **自定义容器**:`::: tip`, `::: warning`, `::: danger`\n\n示例:\n\n```md\n::: tip 提示\n这是一个提示框\n:::\n\n::: warning 注意\n这是一个警告框\n:::\n\n::: danger 危险\n这是一个危险警告框\n:::\n```\n\n### 文档规范\n\n- **文件名**:使用小写字母和连字符(如 `getting-started.md`)\n- **标题**:使用清晰的层级结构(# → ## → ###)\n- **代码块**:标注语言类型以启用语法高亮\n- **图片**:放在 `public/` 目录,使用 `/image.png` 引用\n- **链接**:内部链接使用相对路径(如 `/guide/getting-started`)\n- **SEO**:每个页面都应添加 title、description 和 keywords\n\n## 🔍 SEO 优化\n\n本文档系统已经过全面 SEO 优化,详情请查看 [SEO_OPTIMIZATION.md](../SEO_OPTIMIZATION.md)。\n\n### 已实施的 SEO 功能\n\n✅ **基础 SEO**\n\n- Title 标签优化\n- Meta Description 和 Keywords\n- Open Graph(社交媒体卡片)\n- Twitter Card\n- JSON-LD 结构化数据\n- Sitemap 自动生成\n- robots.txt\n- Canonical URL\n\n✅ **技术 SEO**\n\n- 响应式设计\n- Clean URLs\n- 快速加载(Vite 优化)\n- HTTPS(GitHub Pages)\n\n### 提交到搜索引擎\n\n部署后需要手动提交到搜索引擎:\n\n1. **Google Search Console**\n - 访问 https://search.google.com/search-console\n - 添加网站并验证\n - 提交 sitemap: `https://weifeng2333.github.io/VideoCaptioner/sitemap.xml`\n\n2. **Bing Webmaster Tools**\n - 访问 https://www.bing.com/webmasters\n - 添加网站并验证\n - 提交 sitemap\n\n3. **百度站长平台**\n - 访问 https://ziyuan.baidu.com/\n - 添加网站并验证\n - 提交 sitemap\n\n### SEO 检查工具\n\n- [Google PageSpeed Insights](https://pagespeed.web.dev/)\n- [Google Rich Results Test](https://search.google.com/test/rich-results)\n- [Open Graph Debugger](https://developers.facebook.com/tools/debug/)\n- [Twitter Card Validator](https://cards-dev.twitter.com/validator)\n\n## 🌐 多语言支持\n\n文档支持中英双语:\n\n- **中文**:`docs/` 根目录\n- **英文**:`docs/en/` 目录\n\n添加新语言:\n\n1. 在 `docs/` 下创建语言目录(如 `ja/`)\n2. 在 `.vitepress/config.mts` 中添加 locale 配置\n3. 复制文档结构并翻译内容\n\n## 🔧 技术栈\n\n- **VitePress**: 基于 Vite 的静态站点生成器\n- **Vue 3**: 组件化开发\n- **TypeScript**: 类型安全的配置\n\n## 📝 更新文档\n\n文档更新会自动触发 GitHub Actions 部署:\n\n1. 提交文档修改到 `docs/` 目录\n2. 推送到 `master` 或 `main` 分支\n3. GitHub Actions 自动构建并部署\n4. 约 2-3 分钟后更新生效\n\n## ❓ 常见问题\n\n### 本地开发时看不到样式?\n\n确保已安装依赖:\n\n```bash\nnpm install\n```\n\n### 如何添加自定义样式?\n\n在 `docs/.vitepress/theme/` 目录下创建自定义主题:\n\n```ts\n// docs/.vitepress/theme/index.ts\nimport DefaultTheme from \"vitepress/theme\";\nimport \"./custom.css\";\n\nexport default DefaultTheme;\n```\n\n### 如何配置搜索功能?\n\nVitePress 默认提供本地搜索,已在 `config.mts` 中配置。\n\n### 如何优化图片?\n\n1. 使用图片压缩工具(如 TinyPNG)\n2. 考虑使用 WebP 格式\n3. 添加 `loading=\"lazy\"` 属性\n\n### 如何添加 Google Analytics?\n\n在 `config.mts` 的 `head` 中添加:\n\n```typescript\n([\n \"script\",\n {\n async: true,\n src: \"https://www.googletagmanager.com/gtag/js?id=G-XXXXXXXXXX\",\n },\n],\n [\n \"script\",\n {},\n `\n window.dataLayer = window.dataLayer || [];\n function gtag(){dataLayer.push(arguments);}\n gtag('js', new Date());\n gtag('config', 'G-XXXXXXXXXX');\n`,\n ]);\n```\n\n---\n\n更多 VitePress 使用方法请参考 [官方文档](https://vitepress.dev/)。\n\n更多 SEO 优化细节请查看 [SEO_OPTIMIZATION.md](../SEO_OPTIMIZATION.md)。\n"
},
{
"path": "docs/config/asr.md",
"content": "# ASR 配置指南\n\n语音识别(ASR)配置详解。\n\n## 支持的 ASR 引擎\n\n| 引擎 | 特点 | 推荐场景 |\n|------|------|---------|\n| **FasterWhisper** | 准确度高,支持GPU | 推荐使用 |\n| **WhisperCpp** | 轻量级 | CPU环境 |\n| **Whisper API** | 云端服务 | 无需本地模型 |\n| **B接口/J接口** | 免费在线 | 快速测试 |\n\n## 模型下载\n\n待补充...\n\n## 配置参数\n\n待补充...\n\n---\n\n相关文档:\n- [快速开始](/guide/getting-started)\n- [LLM 配置](/config/llm)\n"
},
{
"path": "docs/config/cookies.md",
"content": "# Cookie 配置指南\n\n配置 Cookie 以下载高清视频。\n\n## 何时需要配置 Cookie?\n\n在以下情况下需要配置 Cookie:\n\n1. 下载视频网站需要登录信息\n2. 只能下载较低分辨率的视频\n3. 网络条件较差时需要验证\n\n## 获取 Cookie\n\n待补充...\n\n## 配置方法\n\n1. 获取 `cookies.txt` 文件\n2. 放置到 `AppData/` 目录\n3. 重启软件\n\n---\n\n相关文档:\n- [快速开始](/guide/getting-started)\n"
},
{
"path": "docs/config/llm.md",
"content": "---\ntitle: LLM 配置指南 - VideoCaptioner\ndescription: 详细的 LLM API 配置教程,支持 OpenAI、DeepSeek、SiliconCloud、Gemini、Ollama 等多种服务商。包含费用估算和优化建议。\nhead:\n - - meta\n - name: keywords\n content: LLM配置,OpenAI API,DeepSeek,Gemini API,Ollama,字幕优化,AI翻译,大语言模型配置\n---\n\n# LLM 配置指南\n\nLLM(大语言模型)是 VideoCaptioner 的核心功能之一,用于字幕断句、优化和翻译。本指南将帮助你配置 LLM API。\n\n## 为什么需要配置 LLM?\n\n- **字幕断句**:使用 LLM 进行语义分析,生成自然流畅的字幕分段\n- **字幕优化**:自动修正错别字、统一专业术语、优化格式\n- **字幕翻译**:结合上下文的高质量翻译\n\n::: tip 提示\n软件内置了基础 LLM 模型可供测试使用,但配置自己的 API 可以获得:\n\n- ✅ 更稳定的服务\n- ✅ 更高的并发能力\n- ✅ 更好的处理质量\n :::\n\n## 支持的 LLM 服务商\n\nVideoCaptioner 支持多种 LLM 服务商,你可以根据自己的需求选择:\n\n| 服务商 | 特点 | 推荐场景 |\n| ---------------- | ----------------------- | ------------ |\n| **OpenAI** | 质量最好,API 稳定 | 追求极致质量 |\n| **DeepSeek** | 性价比高,中文优秀 | 中文内容处理 |\n| **SiliconCloud** | 国内可用,模型丰富 | 国内用户 |\n| **Gemini** | Google 出品,免费额度大 | 预算有限 |\n| **Ollama** | 完全本地运行,免费 | 隐私敏感场景 |\n| **LM Studio** | 本地运行,图形化界面 | 本地部署 |\n| **ChatGLM** | 国产模型 | 国内用户 |\n\n## 配置方法\n\n### 方式一:使用 SiliconCloud(推荐国内用户)\n\n[SiliconCloud](https://cloud.siliconflow.cn) 集成了国内多家大模型厂商,使用方便。\n\n**步骤:**\n\n1. **注册账号**\n\n 访问 [SiliconCloud](https://cloud.siliconflow.cn/i/onCHcaDx) 注册账号(通过链接注册可获得额外额度)\n\n2. **获取 API Key**\n\n 登录后,在 [设置页面](https://cloud.siliconflow.cn/account/ak) 获取 API Key\n\n \n\n3. **在 VideoCaptioner 中配置**\n\n 打开 VideoCaptioner,进入 **设置 → LLM 配置**:\n - **LLM 服务**: 选择 `SiliconCloud`\n - **API Base URL**: `https://api.siliconflow.cn/v1`\n - **API Key**: 粘贴你的 API Key\n - 点击 **\"检查连接\"** 测试配置\n - **模型选择**: 推荐 `Qwen/Qwen2.5-72B-Instruct` 或 `deepseek-ai/DeepSeek-V3`\n\n \n\n4. **配置线程数**\n\n SiliconCloud 并发能力有限,建议设置:\n - **线程数**: 5 或更少\n\n::: warning 注意\n自 2025 年 2 月 6 日起,未实名用户每日最多请求 DeepSeek-V3 模型 100 次。如不想实名,可考虑使用其他中转站或模型。\n:::\n\n### 方式二:使用 OpenAI\n\n如果你有 OpenAI 账号和 API Key:\n\n1. 访问 [OpenAI Platform](https://platform.openai.com) 获取 API Key\n\n2. 在 VideoCaptioner 中配置:\n - **LLM 服务**: 选择 `OpenAI`\n - **API Base URL**: `https://api.openai.com/v1`\n - **API Key**: 你的 OpenAI API Key\n - **模型选择**:\n - 经济实惠:`gpt-4o-mini`\n - 高质量:`gpt-4o` 或 `gpt-4-turbo`\n\n3. **线程数配置**:\n - OpenAI API 支持较高并发,可设置 10-20 个线程\n\n### 方式三:使用 DeepSeek\n\n[DeepSeek](https://platform.deepseek.com) 是一个性价比极高的国产 LLM。\n\n1. 访问 [DeepSeek 平台](https://platform.deepseek.com) 注册并获取 API Key\n\n2. 在 VideoCaptioner 中配置:\n - **LLM 服务**: 选择 `DeepSeek`\n - **API Base URL**: `https://api.deepseek.com/v1`\n - **API Key**: 你的 DeepSeek API Key\n - **模型选择**: `deepseek-chat` 或 `deepseek-coder`\n\n3. **线程数配置**:\n - 建议 5-10 个线程\n\n### 方式四:使用本项目中转站(推荐)⭐\n\n本项目提供了高性价比的 LLM API 中转站,支持多种优质模型和高并发。\n\n**特点:**\n\n- ✅ 支持 OpenAI、Claude、Gemini 等优质模型\n- ✅ 超高并发能力,处理速度极快\n- ✅ 稳定可靠,专为本项目优化\n- ✅ 国内可直接访问\n\n**配置步骤:**\n\n1. **注册账号**\n\n 访问 [https://api.videocaptioner.cn/register](https://api.videocaptioner.cn/register?aff=UrLB) 注册(通过链接注册赠送 $0.4 测试余额)\n\n2. **获取 API Key**\n\n 登录后访问 [Token 页面](https://api.videocaptioner.cn/token) 获取 API Key\n\n3. **在 VideoCaptioner 中配置**\n - **LLM 服务**: 选择 `OpenAI`(兼容模式)\n - **API Base URL**: `https://api.videocaptioner.cn/v1`\n - **API Key**: 你获取的 API Key\n - 点击 **\"检查连接\"** 测试\n\n \n\n4. **模型选择建议**\n\n 根据预算和质量需求选择:\n\n | 质量层级 | 推荐模型 | 耗费比例 | 适用场景 |\n | ------------ | ------------------------------------------------------ | -------- | -------------------- |\n | **高质量** | `gemini-2.0-flash-exp`\n
\n \n \n 给你的视频
\n
\n \n 🎬\n 开源免费 · 用心打造\n
\n \n 给你的视频
\n 一副好字幕\n
\n \n 不只是转录文字,更懂语义和语境
\n 让 AI 帮你把字幕做得像人工精修一样好\n
\n ⚡ 4分钟处理14分钟视频\n ·\n 💰 成本不足 ¥0.01\n ·\n 🌍 支持99种语言\n
\n \n \n 立即开始\n →\n \n \n \n 看看源码\n \n
\n \n
\n \n \n \n
\n \n 实时预览
\n \n
\n \n
\n \n
\n 95%+
\n 识别准确度
\n \n
\n 99
\n 支持语言
\n \n
\n 4min
\n 处理14分钟视频
\n \n
\n ¥0.01
\n 单视频成本
\n \n
\n \n
\n 我们在乎的事情
\n这些功能,都是为了让你更轻松
\n\n
\n \n \n
\n 快,真的快
\n14分钟视频只需4分钟处理。你去泡杯咖啡的功夫,字幕就好了
\n\n \n
\n 懂语义,不只是转录
\nLLM 会帮你智能断句、纠正错别字、统一专业术语。就像有个助手在帮你
\n\n \n
\n 全球化不是梦
\n99种语言识别,37种语言翻译。你的内容可以触达全世界
\n\n \n
\n 完全免费,永久开源
\nMIT 协议,代码透明。你的数据在本地,隐私完全掌控在自己手里
\n\n \n
\n 老电脑也能用
\n不需要昂贵的显卡。有 CPU 就能跑,有 GPU 更快。云端和本地随你选
\n\n \n
\n 样式随心调
\n科普风、新闻风、番剧风...各种模板任你挑。支持 SRT、ASS、VTT 格式
\n\n
\n \n
\n ✨
\n 试试看?不用担心,完全免费
\n\n 下载或者直接从源码运行都可以
\n 有问题随时在 GitHub 提 Issue,社区会帮你\n
`claude-sonnet-4.5-20250929` | 3 | 重要内容、专业翻译 |\n | **较高质量** | `gpt-4o-2024-08-07`
`claude-haiku-4-5-20251001` | 1.2 | 日常使用、高质量需求 |\n | **中质量** | `gpt-4o-mini`
`gemini-2.0-flash-exp` | 0.3 | 快速处理、预算有限 |\n\n5. **线程数配置**\n\n 中转站支持超高并发,可以直接拉满:\n - **线程数**: 20-50(根据你的网络和机器性能)\n\n::: tip 推荐配置\n\n- **日常使用**: `gpt-4o-mini` + 30 线程\n- **追求质量**: `claude-sonnet-4.5` + 20 线程\n- **预算有限**: `gemini-2.0-flash-exp` + 50 线程\n :::\n\n### 方式五:本地部署 Ollama\n\n如果你希望完全本地运行,保护隐私:\n\n1. **安装 Ollama**\n\n 访问 [Ollama 官网](https://ollama.com) 下载并安装\n\n2. **下载模型**\n\n ```bash\n # 下载推荐模型\n ollama pull llama3.1:8b\n\n # 或下载更大的模型\n ollama pull qwen2.5:14b\n ```\n\n3. **启动 Ollama 服务**\n\n ```bash\n ollama serve\n ```\n\n4. **在 VideoCaptioner 中配置**\n - **LLM 服务**: 选择 `Ollama`\n - **API Base URL**: `http://localhost:11434/v1`\n - **API Key**: 留空或填写任意值\n - **模型选择**: 你下载的模型名称(如 `llama3.1:8b`)\n\n5. **线程数配置**\n\n 根据你的硬件配置:\n - **CPU**: 2-4 个线程\n - **GPU**: 4-8 个线程\n\n::: warning 注意\n本地模型的质量通常不如云端 API,建议使用 14B 以上参数的模型。\n:::\n\n## 高级配置\n\n### 自定义提示词\n\n在字幕优化和翻译时,你可以添加自定义提示词来改善输出质量:\n\n**示例:**\n\n```\n请注意以下专业术语:\n- 机器学习 -> Machine Learning\n- 深度学习 -> Deep Learning\n- 神经网络 -> Neural Network\n\n请保持技术术语的准确性,不要过度意译。\n```\n\n在 **字幕优化与翻译** 页面的 **\"文稿提示\"** 输入框中填写。\n\n### 并发线程数调优\n\n线程数影响处理速度和成本:\n\n| API 类型 | 推荐线程数 | 说明 |\n| ------------ | ---------- | -------------- |\n| OpenAI | 10-20 | 支持高并发 |\n| 中转站 | 20-50 | 专为高并发优化 |\n| DeepSeek | 5-10 | 有一定并发限制 |\n| SiliconCloud | 3-5 | 并发能力较弱 |\n| Ollama 本地 | 2-8 | 取决于硬件性能 |\n\n::: tip 提示\n如果遇到 **请求超时** 或 **429 错误**,说明并发过高,需要降低线程数。\n:::\n\n### 温度参数(Temperature)\n\n温度参数控制模型输出的随机性:\n\n- **0.1-0.3**:输出更稳定、保守(推荐用于字幕优化)\n- **0.5-0.7**:输出更自然、灵活(推荐用于翻译)\n- **0.8-1.0**:输出更有创意(不推荐)\n\n默认值 `0.3` 适用于大多数场景。\n\n## 费用估算\n\n使用 LLM API 会产生一定费用,以下是参考估算:\n\n**示例:处理 14 分钟视频**\n\n- **转录字数**:约 2000 字\n- **使用模型**:`gpt-4o-mini`\n- **处理流程**:断句 + 优化 + 翻译\n- **总费用**:< ¥0.01\n\n::: info 说明\n\n- LLM 仅处理文本内容,不包含时间轴信息,Token 消耗很少\n- 翻译采用 \"翻译-反思-翻译\" 方法,费用会相应增加\n- 使用批量处理时,费用基本按视频数量线性增长\n :::\n\n## 常见问题\n\n### 连接测试失败\n\n::: details 解决方案\n\n1. **检查 API Key 格式**\n - OpenAI: 以 `sk-` 开头\n - 其他服务商可能有不同格式\n\n2. **检查 Base URL**\n - 必须包含 `/v1` 后缀\n - 不要有多余的斜杠\n\n3. **检查网络连接**\n - 某些服务商需要科学上网\n - 检查防火墙设置\n\n4. **查看详细错误**\n - 在 **设置 → 日志** 中查看详细错误信息\n :::\n\n### 请求频繁失败\n\n::: details 解决方案\n\n1. **降低线程数**\n - 从 20 降低到 10 或 5\n\n2. **检查 API 额度**\n - 登录服务商平台查看余额\n\n3. **更换服务商**\n - 尝试使用本项目中转站\n\n4. **检查模型可用性**\n - 某些模型可能有地区限制\n :::\n\n### 输出质量不佳\n\n::: details 解决方案\n\n1. **更换更好的模型**\n - `gpt-4o-mini` → `gpt-4o`\n - `gemini-1.5-flash` → `gemini-2.0-flash-exp`\n\n2. **调整温度参数**\n - 降低温度(如 0.3 → 0.1)获得更稳定输出\n\n3. **添加文稿提示**\n - 在文稿提示中添加术语表和修正要求\n\n4. **使用反思翻译**\n - 在翻译设置中启用 \"反思翻译\"\n :::\n\n## 推荐配置方案\n\n### 新手推荐\n\n```\n服务商: 本项目中转站\n模型: gpt-4o-mini\n线程数: 20\n温度: 0.3\n```\n\n### 追求质量\n\n```\n服务商: 本项目中转站\n模型: claude-sonnet-4.5\n线程数: 15\n温度: 0.3\n反思翻译: 开启\n```\n\n### 预算有限\n\n```\n服务商: SiliconCloud\n模型: Qwen/Qwen2.5-72B-Instruct\n线程数: 5\n温度: 0.3\n```\n\n### 隐私优先\n\n```\n服务商: Ollama(本地)\n模型: qwen2.5:14b\n线程数: 4\n温度: 0.5\n```\n\n---\n\n如果还有其他问题,欢迎在 [GitHub Issues](https://github.com/WEIFENG2333/VideoCaptioner/issues) 提问。\n" }, { "path": "docs/config/translator.md", "content": "# 翻译配置指南\n\n字幕翻译配置详解。\n\n## 支持的翻译服务\n\n| 服务 | 特点 | 推荐场景 |\n|------|------|---------|\n| **LLM 翻译** | 质量最好 | 追求质量 |\n| **Bing 翻译** | 速度快,免费 | 快速翻译 |\n| **Google 翻译** | 质量好 | 英语翻译 |\n| **DeepLX** | 专业翻译 | 自建服务 |\n\n## 配置方法\n\n待补充...\n\n## 支持的目标语言\n\n待补充...\n\n---\n\n相关文档:\n- [LLM 配置](/config/llm)\n- [快速开始](/guide/getting-started)\n" }, { "path": "docs/dev/api.md", "content": "# API 文档\n\n核心 API 接口文档。\n\n## ASR API\n\n### `transcribe()`\n\n```python\nfrom app.core.asr import transcribe\n\nresult = transcribe(\n audio_path=\"video.mp4\",\n config=TranscribeConfig(...)\n)\n```\n\n## 字幕处理 API\n\n待补充...\n\n## 翻译 API\n\n待补充...\n\n---\n\n详细 API 说明请参考源代码和 `CLAUDE.md` 文档。\n\n相关文档:\n- [架构设计](/dev/architecture)\n- [贡献指南](/dev/contributing)\n" }, { "path": "docs/dev/architecture.md", "content": "# 架构设计\n\nVideoCaptioner 的系统架构设计。\n\n## 技术栈\n\n- **UI 框架**: PyQt5 + QFluentWidgets\n- **ASR 引擎**: Whisper (FasterWhisper/WhisperCpp)\n- **LLM 集成**: OpenAI/DeepSeek/Gemini/Ollama 等\n- **视频处理**: FFmpeg\n\n## 核心模块\n\n### 1. ASR 模块 (`app/core/asr/`)\n\n语音识别模块,支持多种 ASR 引擎。\n\n### 2. 字幕处理模块 (`app/core/split/`, `app/core/optimize/`)\n\n字幕分割和优化模块,使用 LLM 进行智能处理。\n\n### 3. 翻译模块 (`app/core/translate/`)\n\n字幕翻译模块,支持多种翻译服务。\n\n### 4. UI 模块 (`app/view/`)\n\nPyQt5 用户界面模块。\n\n## 数据流\n\n```\n视频/音频 → ASR → ASRData → 分割 → 优化 → 翻译 → 字幕文件 → 视频合成\n```\n\n详细架构说明请参考 `CLAUDE.md` 文件。\n\n---\n\n相关文档:\n- [API 文档](/dev/api)\n- [贡献指南](/dev/contributing)\n" }, { "path": "docs/dev/asr-chunk-merger.md", "content": "# ChunkMerger 使用指南\n\n## 概述\n\n`ChunkMerger` 用于合并多个音频分块的 ASR(语音识别)结果。当处理长音频时,通常需要将音频分割成多个片段分别识别,然后合并结果。本模块使用精确文本匹配算法(基于 Groq API Cookbook)来智能处理重叠区域。\n\n## 核心特性\n\n- ✅ **精确文本匹配**:使用滑动窗口找最长公共序列,不使用模糊相似度\n- ✅ **自动时间戳调整**:正确处理每个 chunk 的时间偏移\n- ✅ **重叠区域智能处理**:自动检测和去除重复的识别内容\n- ✅ **多语言支持**:支持中文、英文、混合文本等\n- ✅ **词级/句子级时间戳**:两种时间戳类型均可正确处理\n\n## 基本用法\n\n### 示例 1:合并两个有重叠的音频片段\n\n```python\nfrom app.core.asr.chunk_merger import ChunkMerger\nfrom app.core.asr.asr_data import ASRData, ASRDataSeg\n\n# 创建合并器\nmerger = ChunkMerger(min_match_count=2)\n\n# Chunk 1: 0-30s 的识别结果\nchunk1_segments = [\n ASRDataSeg(\"Hello\", 0, 1000),\n ASRDataSeg(\"world\", 1000, 2000),\n ASRDataSeg(\"this\", 2000, 3000),\n # ... 更多片段\n]\nchunk1 = ASRData(chunk1_segments)\n\n# Chunk 2: 20-50s 的识别结果(重叠 10s)\nchunk2_segments = [\n ASRDataSeg(\"this\", 0, 1000), # 实际时间 20-21s\n ASRDataSeg(\"is\", 1000, 2000), # 实际时间 21-22s\n ASRDataSeg(\"test\", 2000, 3000), # 实际时间 22-23s\n # ... 更多片段\n]\nchunk2 = ASRData(chunk2_segments)\n\n# 合并\nmerged = merger.merge_chunks(\n chunks=[chunk1, chunk2],\n chunk_offsets=[0, 20000], # chunk2 实际从 20s 开始\n overlap_duration=10000 # 10s 重叠\n)\n\nprint(f\"合并后片段数: {len(merged.segments)}\")\n```\n\n### 示例 2:合并多个音频片段\n\n```python\n# 模拟长音频:3 个 30s 的片段,每个重叠 10s\nchunk1 = ASRData([...]) # 0-30s\nchunk2 = ASRData([...]) # 20-50s\nchunk3 = ASRData([...]) # 40-70s\n\n# 一次性合并所有片段\nmerged = merger.merge_chunks(\n chunks=[chunk1, chunk2, chunk3],\n chunk_offsets=[0, 20000, 40000],\n overlap_duration=10000\n)\n```\n\n### 示例 3:自动推断时间偏移\n\n```python\n# 如果不提供 chunk_offsets,会自动推断\nmerged = merger.merge_chunks(\n chunks=[chunk1, chunk2, chunk3],\n overlap_duration=10000 # 只需指定重叠时长\n)\n```\n\n## 参数说明\n\n### ChunkMerger 构造函数\n\n```python\nChunkMerger(min_match_count: int = 2)\n```\n\n- `min_match_count`: 最小匹配词数阈值,低于此值视为无效匹配(默认 2)\n\n### merge_chunks 方法\n\n```python\nmerge_chunks(\n chunks: List[ASRData],\n chunk_offsets: Optional[List[int]] = None,\n overlap_duration: int = 10000\n) -> ASRData\n```\n\n**参数**:\n\n- `chunks`: ASRData 对象列表(必需)\n- `chunk_offsets`: 每个 chunk 的起始时间(毫秒),如为 None 则自动推断\n- `overlap_duration`: 重叠时长(毫秒),默认 10 秒\n\n**返回**:\n\n- 合并后的 `ASRData` 对象\n\n## 算法原理\n\n### 1. 精确文本匹配\n\n使用滑动窗口遍历所有可能的对齐方式,计算每个位置的精确匹配词数(要求连续匹配):\n\n```\nChunk1 末尾: [\"and\", \"we\", \"need\", \"to\", \"find\", \"the\", \"best\"]\nChunk2 开头: [\"need\", \"to\", \"find\", \"the\", \"best\", \"solution\"]\n\n最佳匹配: [\"need\", \"to\", \"find\", \"the\", \"best\"] (5个词)\n```\n\n### 2. 时间戳调整\n\n```python\n# Chunk2 的时间戳加上偏移量\nadjusted_time = original_time + chunk_offset\n```\n\n### 3. 合并策略\n\n- **有匹配**:保留 chunk1 的重叠部分,丢弃 chunk2 的重叠部分\n- **无匹配**:使用时间边界切分\n\n## 实际应用场景\n\n### 场景 1:长视频字幕生成\n\n```python\n# 60 分钟视频,每 30 秒一个片段,重叠 10 秒\nchunks = []\noffsets = []\n\nfor i in range(0, 3600, 20): # 每 20s 一个起点(30s 片段 - 10s 重叠)\n audio_chunk = extract_audio(video_path, start=i, duration=30)\n asr_result = transcribe(audio_chunk)\n chunks.append(asr_result)\n offsets.append(i * 1000) # 转换为毫秒\n\n# 合并所有片段\nfinal_result = merger.merge_chunks(\n chunks=chunks,\n chunk_offsets=offsets,\n overlap_duration=10000\n)\n\n# 保存字幕\nfinal_result.save(\"output.srt\")\n```\n\n### 场景 2:在线流式识别\n\n```python\nclass StreamingASR:\n def __init__(self):\n self.merger = ChunkMerger()\n self.chunks = []\n self.offsets = []\n\n def on_chunk_received(self, chunk_audio, timestamp):\n # 识别当前片段\n asr_result = transcribe(chunk_audio)\n self.chunks.append(asr_result)\n self.offsets.append(timestamp)\n\n # 实时合并\n if len(self.chunks) >= 2:\n merged = self.merger.merge_chunks(\n chunks=self.chunks,\n chunk_offsets=self.offsets,\n overlap_duration=5000 # 5s 重叠\n )\n return merged\n```\n\n## 注意事项\n\n### 1. 重叠时长建议\n\n- **推荐**:10 秒重叠(足以捕获句子边界)\n- **最小**:3-5 秒(太短可能匹配失败)\n- **最大**:不超过 chunk 长度的 1/3\n\n### 2. 匹配阈值\n\n```python\n# 对于短句子,可以降低阈值\nmerger = ChunkMerger(min_match_count=1)\n\n# 对于长句子,可以提高阈值以提高准确性\nmerger = ChunkMerger(min_match_count=3)\n```\n\n### 3. 时间戳连续性\n\n合并后,请验证时间戳的连续性:\n\n```python\n# 验证时间戳\nfor i in range(len(merged.segments) - 1):\n seg1 = merged.segments[i]\n seg2 = merged.segments[i + 1]\n gap = seg2.start_time - seg1.end_time\n if gap > 2000: # 间隔超过 2s\n print(f\"警告: 片段 {i} 和 {i+1} 之间有 {gap}ms 间隔\")\n```\n\n## 测试\n\n运行测试套件:\n\n```bash\n# 运行所有测试\nuv run pytest tests/test_asr/test_chunk_merger.py -v\n\n# 运行特定测试\nuv run pytest tests/test_asr/test_chunk_merger.py::TestChunkMergerBasic -v\n```\n\n## 常见问题\n\n### Q1: 合并后丢失了部分内容?\n\n**A**: 检查重叠区域是否足够长,确保 `overlap_duration` 至少为 5 秒。\n\n### Q2: 匹配失败,使用了时间边界切分?\n\n**A**: 可能是重叠区域的文本差异太大(识别错误)。可以:\n\n1. 降低 `min_match_count` 阈值\n2. 增加重叠时长\n3. 检查 ASR 质量\n\n### Q3: 时间戳不连续?\n\n**A**: 检查 `chunk_offsets` 是否正确,应该准确反映每个 chunk 的实际起始时间。\n\n## 相关文档\n\n- [ASRData 数据结构](../asr_data.py)\n- [Groq Audio Chunking Tutorial](https://github.com/groq/groq-api-cookbook/blob/main/tutorials/audio-chunking/audio_chunking_tutorial.ipynb)\n" }, { "path": "docs/dev/asr-chunked-usage.md", "content": "# ChunkedASR 使用指南\n\n## 概述\n\n`ChunkedASR` 是一个装饰器类,为任何 `BaseASR` 实现添加音频分块转录能力。适用于长音频(>20分钟)的分块转录,避免 API 超时或内存溢出。\n\n## 核心特性\n\n- ✅ **装饰器模式** - 关注点分离,不污染 BaseASR\n- ✅ **并发转录** - 使用 ThreadPoolExecutor 并发处理多个块\n- ✅ **智能合并** - 使用 ChunkMerger 消除重叠区域的重复内容\n- ✅ **进度回调** - 支持细粒度的进度追踪\n- ✅ **自动判断** - 短音频自动跳过分块,直接转录\n\n## 快速开始\n\n### 基本用法\n\n```python\nfrom app.core.asr import BcutASR, ChunkedASR\n\n# 1. 创建基础 ASR 实例\nbase_asr = BcutASR(audio_path, need_word_time_stamp=True)\n\n# 2. 用 ChunkedASR 包装\nchunked_asr = ChunkedASR(\n base_asr,\n chunk_length=1200, # 20 分钟/块\n chunk_overlap=10, # 10 秒重叠\n chunk_concurrency=3 # 3 个并发\n)\n\n# 3. 运行转录\nresult = chunked_asr.run(callback=my_callback)\n```\n\n### 在 transcribe() 中自动使用\n\n`transcribe()` 函数已经自动为 `BIJIAN` 和 `JIANYING` 启用了分块:\n\n```python\nfrom app.core.asr import transcribe\nfrom app.core.entities import TranscribeConfig, TranscribeModelEnum\n\nconfig = TranscribeConfig(\n transcribe_model=TranscribeModelEnum.BIJIAN,\n need_word_time_stamp=True\n)\n\n# 自动使用 ChunkedASR 包装(20 分钟/块)\nresult = transcribe(audio_path, config, callback)\n```\n\n## 参数说明\n\n### `ChunkedASR.__init__`\n\n| 参数 | 类型 | 默认值 | 说明 |\n| ------------------- | ------- | -------- | -------------------- |\n| `base_asr` | BaseASR | **必需** | 底层 ASR 实例 |\n| `chunk_length` | int | 1200 | 每块长度(秒) |\n| `chunk_overlap` | int | 10 | 块之间重叠时长(秒) |\n| `chunk_concurrency` | int | 3 | 并发转录数量 |\n\n### 参数选择建议\n\n**chunk_length(分块长度)**\n\n- **公益 API(BIJIAN/JIANYING)**: 1200 秒(20 分钟)- 避免超时\n- **付费 API(Whisper API)**: 可更长,如 3600 秒(1 小时)\n- **本地转录(FasterWhisper)**: 通常不需要分块\n\n**chunk_overlap(重叠时长)**\n\n- **推荐值**: 10 秒\n- **作用**: 提供足够的上下文用于合并,避免丢失边界内容\n- **注意**: 过长会增加计算量,过短可能导致合并不准确\n\n**chunk_concurrency(并发数)**\n\n- **公益 API**: 2-3(避免触发限流)\n- **付费 API**: 5-10(根据账户配额调整)\n- **本地转录**: 根据 CPU/GPU 资源调整\n\n## 工作流程\n\n```\n┌──────────────┐\n│ 长音频文件 │\n└──────┬───────┘\n │\n ▼\n┌──────────────────────────────┐\n│ 1. _split_audio() │\n│ - 使用 pydub 切割音频 │\n│ - 每块 20 分钟,重叠 10 秒 │\n└──────┬───────────────────────┘\n │\n ▼\n┌──────────────────────────────┐\n│ 2. _transcribe_chunks() │\n│ - ThreadPoolExecutor 并发 │\n│ - 每块独立调用 base_asr.run()│\n└──────┬───────────────────────┘\n │\n ▼\n┌──────────────────────────────┐\n│ 3. _merge_results() │\n│ - ChunkMerger 合并结果 │\n│ - 消除重叠区域的重复内容 │\n└──────┬───────────────────────┘\n │\n ▼\n┌──────────────┐\n│ ASRData 结果 │\n└──────────────┘\n```\n\n## 高级用法\n\n### 自定义进度回调\n\n```python\ndef progress_callback(progress: int, message: str):\n print(f\"[{progress}%] {message}\")\n # 可以更新 UI 进度条、发送通知等\n\nchunked_asr = ChunkedASR(base_asr)\nresult = chunked_asr.run(callback=progress_callback)\n```\n\n输出示例:\n\n```\n[5%] Chunk 1/5: uploading\n[25%] Chunk 1/5: transcribing\n[30%] Chunk 2/5: uploading\n[50%] Chunk 2/5: transcribing\n...\n```\n\n### 为其他 ASR 添加分块能力\n\n```python\n# 为 FasterWhisper 添加分块(处理超长音频)\nfrom app.core.asr import FasterWhisperASR, ChunkedASR\n\nbase_asr = FasterWhisperASR(\n audio_path,\n whisper_model=\"large-v3\",\n language=\"zh\"\n)\n\n# 用于处理 2 小时的音频\nchunked_asr = ChunkedASR(\n base_asr,\n chunk_length=3600, # 1 小时/块\n chunk_overlap=30, # 30 秒重叠\n chunk_concurrency=2 # 2 个并发(避免显存不足)\n)\n\nresult = chunked_asr.run()\n```\n\n## 注意事项\n\n### 1. 音频格式要求\n\n- ChunkedASR 依赖 `pydub` 进行音频切割\n- 确保安装了 `ffmpeg`(pydub 的依赖)\n- 支持所有 pydub 支持的格式(mp3, wav, m4a, flac 等)\n\n### 2. 内存管理\n\n- 每个并发块会临时占用内存\n- `chunk_concurrency=3` 时,同时会有 3 个音频块在内存中\n- 对于超大文件,适当降低并发数\n\n### 3. 缓存行为\n\n- ChunkedASR 本身不处理缓存\n- 缓存由底层 `base_asr` 的 `run()` 方法处理\n- 每个块会独立缓存(如果 `use_cache=True`)\n\n### 4. 错误处理\n\n- 如果某个块转录失败,整个任务会抛出异常\n- 建议在外层捕获异常并进行重试\n\n## 性能优化建议\n\n### 1. 合理设置并发数\n\n```python\n# ❌ 不推荐:并发过高导致限流\nchunked_asr = ChunkedASR(base_asr, chunk_concurrency=10)\n\n# ✅ 推荐:根据 API 限制调整\nchunked_asr = ChunkedASR(base_asr, chunk_concurrency=3)\n```\n\n### 2. 根据音频长度调整分块大小\n\n```python\n# 短音频(< 20 分钟)- 不使用分块\nif audio_duration < 1200:\n result = base_asr.run()\nelse:\n # 长音频 - 使用分块\n result = ChunkedASR(base_asr).run()\n```\n\n### 3. 启用缓存避免重复转录\n\n```python\n# 为底层 ASR 启用缓存\nbase_asr = BcutASR(audio_path, use_cache=True)\nchunked_asr = ChunkedASR(base_asr)\n\n# 第一次转录会缓存每个块\nresult1 = chunked_asr.run() # 调用 API\n\n# 第二次转录直接读取缓存\nresult2 = chunked_asr.run() # 从缓存读取\n```\n\n## 测试\n\n运行测试验证 ChunkedASR 功能:\n\n```bash\n# 测试 BcutASR 和 JianYingASR(已自动使用 ChunkedASR)\nuv run pytest tests/test_asr/test_bcut_asr.py -v\nuv run pytest tests/test_asr/test_jianying_asr.py -v\n\n# 测试分块相关功能\nuv run pytest tests/test_asr/test_chunking.py -v\nuv run pytest tests/test_asr/test_chunk_merger.py -v\n```\n\n## 常见问题\n\n**Q: 短音频会被分块吗?**\nA: 不会。ChunkedASR 会自动判断,如果音频短于 `chunk_length`,会直接调用 `base_asr.run()` 而不分块。\n\n**Q: 分块会丢失内容吗?**\nA: 不会。通过 `chunk_overlap` 保证块之间有重叠,ChunkMerger 会智能合并重叠区域,不会丢失内容。\n\n**Q: 如何调试分块问题?**\nA: 查看日志输出:\n\n```python\nimport logging\nlogging.getLogger(\"chunked_asr\").setLevel(logging.DEBUG)\n```\n\n**Q: 可以为本地 ASR 使用分块吗?**\nA: 可以,但通常不推荐。本地 ASR(如 FasterWhisper)通常足够快,不需要分块。仅在处理超长音频(>2 小时)或显存不足时使用。\n\n## 相关文档\n\n- [ChunkMerger 使用指南](./CHUNK_MERGER_USAGE.md)\n- [ASR 模块开发指南](./README.md)\n- [测试指南](../../tests/test_asr/TEST_GUIDE.md)\n" }, { "path": "docs/dev/contributing.md", "content": "# 贡献指南\n\n感谢你对 VideoCaptioner 的贡献!\n\n## 开发环境设置\n\n1. Fork 本仓库\n2. 克隆你的 Fork\n3. 安装开发依赖\n\n```bash\ngit clone https://github.com/YOUR_USERNAME/VideoCaptioner.git\ncd VideoCaptioner\npip install -r requirements.txt\n```\n\n## 代码规范\n\n- 使用 `pyright` 进行类型检查\n- 使用 `ruff` 进行代码格式化\n\n```bash\n# 类型检查\nuv run pyright\n\n# 代码格式化\nuv run ruff check --select I --fix .\n```\n\n## 提交 Pull Request\n\n1. 创建新分支\n2. 提交你的修改\n3. 推送到你的 Fork\n4. 创建 Pull Request\n\n## 注释要求\n\n保持简洁清晰,只需要必要的注释即可。\n\n---\n\n相关文档:\n- [架构设计](/dev/architecture)\n- [API 文档](/dev/api)\n\n更多信息请参考 [GitHub Issues](https://github.com/WEIFENG2333/VideoCaptioner/issues)。\n" }, { "path": "docs/dev/translate-module.md", "content": "# 翻译模块 (Translate Module)\n\n多语言字幕翻译模块,支持多种翻译服务。\n\n## 模块结构\n\n```\napp/core/translate/\n├── __init__.py # 模块导出\n├── types.py # 翻译器类型枚举\n├── base.py # 翻译器基类\n├── llm_translator.py # LLM 翻译器(使用 litellm)\n├── google_translator.py # Google 翻译器\n├── bing_translator.py # Bing 翻译器\n├── deeplx_translator.py # DeepLX 翻译器\n└── factory.py # 翻译器工厂\n```\n\n## 支持的翻译服务\n\n### 1. LLM 翻译器 (OpenAI 兼容)\n\n- 使用 `litellm` 直接调用 OpenAI 兼容 API\n- 支持批量翻译和单条翻译\n- 内置缓存机制\n- 支持 Reflect 模式(反思优化翻译)\n- 支持自定义 Prompt\n\n### 2. Google 翻译器\n\n- 免费翻译服务\n- 支持多种语言\n- 适合日常使用\n\n### 3. Bing 翻译器\n\n- Microsoft 翻译服务\n- 批量翻译支持\n- 自动 Token 管理\n\n### 4. DeepLX 翻译器\n\n- DeepL 的免费接口\n- 高质量翻译\n- 可自定义端点\n\n## 使用示例\n\n### 基础使用\n\n```python\nfrom app.core.translate import TranslatorFactory, TranslatorType\n\n# 创建 LLM 翻译器\ntranslator = TranslatorFactory.create_translator(\n translator_type=TranslatorType.OPENAI,\n model=\"gpt-4o-mini\",\n target_language=\"Chinese\",\n temperature=0.7,\n)\n\n# 翻译字幕\nresult = translator.translate_subtitle(\"subtitle.srt\")\n```\n\n### 使用 Google 翻译\n\n```python\ntranslator = TranslatorFactory.create_translator(\n translator_type=TranslatorType.GOOGLE,\n target_language=\"简体中文\",\n)\n\nresult = translator.translate_subtitle(\"subtitle.srt\")\n```\n\n### 使用 Bing 翻译\n\n```python\ntranslator = TranslatorFactory.create_translator(\n translator_type=TranslatorType.BING,\n target_language=\"Chinese\",\n)\n\nresult = translator.translate_subtitle(\"subtitle.srt\")\n```\n\n### 使用 DeepLX 翻译\n\n```python\nimport os\n\n# 设置 DeepLX 端点(可选)\nos.environ[\"DEEPLX_ENDPOINT\"] = \"https://your-deeplx-endpoint.com/translate\"\n\ntranslator = TranslatorFactory.create_translator(\n translator_type=TranslatorType.DEEPLX,\n target_language=\"Chinese\",\n)\n\nresult = translator.translate_subtitle(\"subtitle.srt\")\n```\n\n## 环境变量配置\n\n### LLM 翻译器\n\n```bash\nexport OPENAI_API_KEY=\"your-api-key\"\nexport OPENAI_BASE_URL=\"https://api.openai.com/v1\"\n```\n\n### DeepLX 翻译器\n\n```bash\nexport DEEPLX_ENDPOINT=\"https://api.deeplx.org/translate\"\n```\n\n## 高级功能\n\n### 并发翻译\n\n```python\ntranslator = TranslatorFactory.create_translator(\n translator_type=TranslatorType.OPENAI,\n thread_num=10, # 并发线程数\n batch_num=20, # 每批处理数量\n)\n```\n\n### 自定义 Prompt\n\n```python\ntranslator = TranslatorFactory.create_translator(\n translator_type=TranslatorType.OPENAI,\n custom_prompt=\"请保持原文的语气和风格\",\n)\n```\n\n### 进度回调\n\n```python\ndef on_progress(result):\n print(f\"翻译进度: {result}\")\n\ntranslator = TranslatorFactory.create_translator(\n translator_type=TranslatorType.OPENAI,\n update_callback=on_progress,\n)\n```\n\n### Reflect 模式(反思优化)\n\n```python\ntranslator = TranslatorFactory.create_translator(\n translator_type=TranslatorType.OPENAI,\n is_reflect=True, # 启用反思模式\n)\n```\n\n## 缓存机制\n\n所有翻译器都内置了缓存支持:\n\n- **LLM 翻译器**: 使用 `CacheManager` 缓存翻译结果\n- **Google/Bing/DeepLX**: 使用 `CacheManager` 缓存翻译结果\n\n缓存基于:\n\n- 原文内容\n- 目标语言\n- 模型参数(LLM)\n- Prompt 哈希(LLM)\n\n## 扩展新的翻译器\n\n1. 继承 `BaseTranslator`\n2. 实现 `_translate_chunk` 方法\n3. 在 `factory.py` 中注册\n\n```python\nfrom app.core.translate.base import BaseTranslator\n\nclass MyTranslator(BaseTranslator):\n def _translate_chunk(self, subtitle_chunk: Dict[str, str]) -> Dict[str, str]:\n # 实现翻译逻辑\n result = {}\n for idx, text in subtitle_chunk.items():\n result[idx] = my_translate_function(text)\n return result\n```\n\n## 注意事项\n\n1. **LLM 翻译器**需要设置 `OPENAI_API_KEY` 和 `OPENAI_BASE_URL`\n2. **批量大小**会影响翻译效率和 API 成本\n3. **并发数量**应根据网络和 API 限制调整\n4. 所有翻译器都支持 **停止**操作:`translator.stop()`\n5. 翻译结果会自动保存到 `ASRData` 的 `translated_text` 字段\n\n## 性能优化建议\n\n- 使用缓存避免重复翻译\n- 合理设置 `batch_num` 减少 API 调用\n- 调整 `thread_num` 提高并发效率\n- 对于大量字幕,使用 Google/Bing 等免费服务\n- 对于高质量要求,使用 LLM 或 DeepLX\n" }, { "path": "docs/dev/view-structure.md", "content": "view/ 目录结构:用户界面 (UI) 模块 \n\n下面是本软件的一个主要页面结构,方便开发者查看和修改。\n\n\n```\n├── main_window.py ------------------ 主窗口 (应用程序框架)\n│ │\n│ └── \n│ ├── home_interface.py -------- 主页窗口 (程序主界面,包含核心功能)\n│ │ │\n│ │ └── 包含以下子功能模块:\n│ │ ├── task_creation_interface.py - 任务创建窗口\n│ │ ├── transcription_interface.py - 语音转录窗口\n│ │ ├── subtitle_interface.py -------- 字幕优化窗口\n│ │ └── video_synthesis_interface.py - 视频合成窗口\n│ │\n│ ├── batch_process_interface.py ------- 批量处理窗口\n│ ├── subtitle_style_interface.py ------ 字幕样式窗口\n│ └── setting_interface.py -------------- 设置窗口\n│\n├── log_window.py -------------------- 日志窗口 (独立窗口,集成在 home_interface)\n\n```" }, { "path": "docs/en/config/asr.md", "content": "" }, { "path": "docs/en/config/cookies.md", "content": "" }, { "path": "docs/en/config/llm.md", "content": "" }, { "path": "docs/en/config/translator.md", "content": "" }, { "path": "docs/en/dev/api.md", "content": "" }, { "path": "docs/en/dev/architecture.md", "content": "" }, { "path": "docs/en/dev/contributing.md", "content": "" }, { "path": "docs/en/guide/batch-processing.md", "content": "" }, { "path": "docs/en/guide/configuration.md", "content": "# Configuration\n\nEnglish documentation coming soon...\n" }, { "path": "docs/en/guide/faq.md", "content": "# FAQ\n\nEnglish documentation coming soon...\n" }, { "path": "docs/en/guide/getting-started.md", "content": "# Getting Started\n\nEnglish documentation coming soon...\n\nPlease refer to the Chinese version for now.\n" }, { "path": "docs/en/guide/manuscript.md", "content": "" }, { "path": "docs/en/guide/subtitle-style.md", "content": "" }, { "path": "docs/en/guide/workflow.md", "content": "# Workflow\n\nEnglish documentation coming soon...\n" }, { "path": "docs/en/index.md", "content": "---\nlayout: home\ntitle: VideoCaptioner - AI Video Subtitle Tool | Free & Open Source\ntitleTemplate: false\ndescription: Free and open-source AI-powered video subtitle tool. Supports Whisper speech recognition, LLM intelligent segmentation, subtitle optimization, and 99-language translation. Perfect for YouTube, Bilibili, and more.\n\nhead:\n - - meta\n - name: keywords\n content: VideoCaptioner,video subtitle generator,AI automatic subtitles,Whisper subtitles,LLM subtitle translation,free subtitle tool,open source caption software,video transcription,speech to text,subtitle maker,YouTube subtitle tool,multilingual subtitles,automatic caption generator,subtitle editing software,video captioning,AI subtitle creator,subtitle optimization,video to text converter\n - - meta\n - property: og:title\n content: VideoCaptioner - AI Video Subtitle Tool | Free & Open Source\n - - meta\n - property: og:description\n content: Free & open-source AI subtitle tool powered by Whisper & LLM. Supports 99 languages with intelligent segmentation, professional translation, and one-click processing. Perfect for content creators on YouTube, Bilibili, and other platforms.\n - - meta\n - property: og:url\n content: https://weifeng2333.github.io/VideoCaptioner/en/\n - - meta\n - property: og:locale\n content: en_US\n - - meta\n - property: og:type\n content: website\n - - meta\n - property: article:published_time\n content: 2024-01-01T00:00:00Z\n - - meta\n - property: article:modified_time\n content: 2025-01-25T00:00:00Z\n - - meta\n - name: twitter:title\n content: VideoCaptioner - AI Video Subtitle Tool | Free & Open Source\n - - meta\n - name: twitter:description\n content: Free AI-powered subtitle tool with Whisper & LLM. Supports 99 languages, intelligent segmentation, and professional translation. Perfect for content creators.\n\nhero:\n name: VideoCaptioner\n text: Professional Video Subtitle Processing\n tagline: Open Source · LLM-Powered · Process 14-minute video in 4 minutes, cost less than $0.002\n image:\n src: /logo.png\n alt: VideoCaptioner\n actions:\n - theme: brand\n text: Get Started\n link: /en/guide/getting-started\n - theme: alt\n text: GitHub Repository\n link: https://github.com/WEIFENG2333/VideoCaptioner\n\nfeatures:\n - icon: ⚡\n title: Lightning Fast, Ultra Low Cost\n details: Process 14-minute video in just 4 minutes, cost less than $0.002. Powered by Whisper + LLM stack for quality and speed.\n\n - icon: 🧠\n title: LLM-Powered Intelligence\n details: Beyond speech recognition. LLM semantic segmentation, auto error correction, terminology unification, expression optimization for professional results.\n\n - icon: 🌐\n title: Multilingual Support\n details: Recognize 99 languages, translate to 37 languages. Reflection translation mechanism ensures quality with precise timeline alignment.\n\n - icon: 📖\n title: Fully Open Source & Free\n details: MIT license, no hidden fees. Run locally for complete data privacy control. Community-driven continuous improvement.\n\n - icon: 💻\n title: No High-End Hardware\n details: Run Whisper on CPU, optional GPU acceleration. Choose between cloud API or local offline processing.\n\n - icon: 📦\n title: Batch Processing\n details: Drag and drop videos for automatic processing with batch queue support. From recognition to translation to synthesis, zero manual intervention.\n\n - icon: 🎨\n title: Professional Subtitle Styles\n details: Built-in style templates. Support hard/soft subtitles with SRT/ASS/VTT multi-format output.\n\n - icon: 🔧\n title: Advanced Features\n details: VAD voice detection, vocal separation, word-level timestamps, manuscript matching, custom prompts, and more.\n\n - icon: 🖥️\n title: Cross-Platform Desktop App\n details: Windows/macOS/Linux installers available. Modern PyQt5 interface with real-time preview and quick editing.\n---\n\n## Interface Preview\n\n
\n \n
\n\n## Quick Experience\n\n::: code-group\n\n```bash [Windows]\n# Download and run the installer directly\n# Or run from source\ngit clone https://github.com/WEIFENG2333/VideoCaptioner.git\ncd VideoCaptioner\nrun.bat\n```\n\n```bash [macOS/Linux]\n# Use automatic installation script\ngit clone https://github.com/WEIFENG2333/VideoCaptioner.git\ncd VideoCaptioner\nchmod +x run.sh\n./run.sh\n```\n\n:::\n\n## Why Choose VideoCaptioner?\n\n- **🎯 Efficient Processing**: Full processing of a 14-minute video takes only about 4 minutes, costing less than ¥0.01\n- **🌟 Quality Assurance**: Uses advanced Whisper models and large language models to ensure subtitle quality\n- **💡 Intelligent Optimization**: Automatically corrects typos, unifies terminology, optimizes expressions\n- **🚀 Easy to Use**: Drag and drop videos for fully automatic processing, no complex configuration needed\n\n## Core Features\n\n### Speech Recognition & Transcription\n\n- Supports Whisper API, FasterWhisper, WhisperCpp, and other engines\n- Supports 99 language recognition\n- Supports VAD (Voice Activity Detection)\n- Supports vocal separation\n\n### Intelligent Subtitle Processing\n\n- LLM semantic segmentation for smoother reading\n- Automatically optimizes terminology, code snippets, mathematical formulas\n- Supports manuscript matching to improve accuracy\n- Precise subtitle timeline alignment\n\n### High-Quality Translation\n\n- Supports LLM translation, Google Translate, Bing Translate, DeepLX\n- Reflection translation mechanism improves translation quality\n- Maintains complete timeline consistency\n- Supports 37 target languages\n\n### Video Synthesis\n\n- Supports hard subtitles and soft subtitles\n- Rich subtitle style templates\n- Supports multiple subtitle formats (SRT, ASS, VTT, TXT)\n- Supports batch video processing\n\n## Get Started\n\nReady to begin? Check out the [Getting Started Guide](/en/guide/getting-started) to learn how to use VideoCaptioner.\n\n\n"
},
{
"path": "docs/guide/configuration.md",
"content": "# 配置指南\n\n详细的配置选项说明。\n\n## 全局配置\n\n待补充...\n\n## 高级配置\n\n待补充...\n\n---\n\n更多配置细节,请参考:\n- [LLM 配置](/config/llm)\n- [ASR 配置](/config/asr)\n- [翻译配置](/config/translator)\n"
},
{
"path": "docs/guide/cookies-config.md",
"content": "# Cookie 配置指南\n\n本指南将帮助你配置浏览器 Cookie,以便下载需要登录才能访问的视频。\n\n## 为什么需要配置 Cookie?\n\n在使用 VideoCaptioner 下载视频时,你可能会遇到以下错误:\n\n\n\n这通常是因为:\n\n1. **某些视频平台**(如 B 站、YouTube)需要用户登录才能获取高质量视频\n2. **网络条件较差**时,部分网站需要验证用户身份才能下载\n3. **地区限制**的内容需要特定账号权限\n\n:::tip 何时需要配置\n只有当你看到上述错误提示时才需要配置 Cookie。大多数情况下,VideoCaptioner 可以直接下载视频。\n:::\n\n---\n\n## 配置步骤\n\n### 1. 安装浏览器扩展\n\n根据你使用的浏览器选择对应的扩展:\n\n| 浏览器 | 扩展名称 | 下载链接 |\n| ----------- | --------------------- | ----------------------------------------------------------------------------------------------------------------------- |\n| **Chrome** | Get CookieTxt Locally | [Chrome 应用店](https://chromewebstore.google.com/detail/get-cookiestxt-locally/cclelndahbckbenkjhflpdbgdldlbecc) |\n| **Edge** | Export Cookies File | [Edge 插件商店](https://microsoftedge.microsoft.com/addons/detail/export-cookies-file/hbglikhfdcfhdfikmocdflffaecbnedo) |\n| **Firefox** | cookies.txt | [Firefox 附加组件](https://addons.mozilla.org/zh-CN/firefox/addon/cookies-txt/) |\n\n:::info 其他浏览器\n如果你使用其他浏览器(如 Safari、Opera),可以搜索类似的 \"Export Cookies\" 扩展。\n:::\n\n### 2. 导出 Cookie 文件\n\n安装扩展后,按以下步骤操作:\n\n#### 步骤一:登录目标网站\n\n打开需要下载视频的网站(如 B 站、YouTube),**确保你已登录账号**。\n\n#### 步骤二:导出 Cookie\n\n1. 在该网站页面点击浏览器扩展图标\n2. 选择 **\"Export Cookies\"** 或类似选项\n3. 扩展会自动下载一个 `cookies.txt` 文件\n\n\n\n:::warning 注意事项\n\n- 确保在**目标网站的页面**上导出 Cookie(不是在其他网站)\n- 某些扩展可能默认导出为 `cookies.json`,请重命名为 `cookies.txt`\n :::\n\n### 3. 放置 Cookie 文件\n\n将导出的 `cookies.txt` 文件移动到 VideoCaptioner 的 **AppData** 目录下。\n\n#### AppData 目录位置\n\nVideoCaptioner 的 AppData 目录通常位于:\n\n```\nVideoCaptioner/\n├─ app/\n├─ resource/\n├─ AppData/ # Cookie 文件放这里\n│ ├─ cache/\n│ ├─ logs/\n│ ├─ models/\n│ ├─ cookies.txt # ← 将文件放在这里\n│ └─ settings.json\n└─ work-dir/\n```\n\n:::tip 快速定位\n在 VideoCaptioner 中点击 **设置 → 打开日志文件夹**,然后返回上一级目录即可看到 `AppData` 文件夹。\n:::\n\n### 4. 验证配置\n\n配置完成后:\n\n1. 重启 VideoCaptioner\n2. 再次尝试下载视频\n3. 如果仍然失败,请检查 Cookie 文件是否正确放置\n\n---\n\n## 常见问题\n\n### Cookie 文件格式不正确\n\n**问题**:提示 \"Cookie 文件格式错误\"\n\n**解决方法**:\n\n- 确保文件名为 `cookies.txt`(不是 `cookies.json` 或其他)\n- 使用文本编辑器打开文件,检查是否为 Netscape Cookie 格式\n- 重新导出 Cookie,确保选择正确的格式\n\n### 下载仍然失败\n\n**问题**:配置 Cookie 后仍然无法下载\n\n**可能原因**:\n\n1. **Cookie 已过期** - 重新登录网站并导出新的 Cookie\n2. **账号权限不足** - 确认你的账号能否在浏览器中正常观看该视频\n3. **地区限制** - 视频可能仅限特定地区访问\n\n### 需要为每个网站单独配置吗?\n\n**答案**:不需要。\n\n- 一个 `cookies.txt` 文件可以包含多个网站的 Cookie\n- 浏览器扩展通常会导出**所有已登录网站**的 Cookie\n- 建议在常用的视频网站(B 站、YouTube 等)都登录后再导出\n\n### Cookie 安全吗?\n\n**安全建议**:\n\n- Cookie 文件包含你的登录信息,**不要分享给他人**\n- 定期更新 Cookie(每月导出一次)\n- 如果担心安全,可以使用**小号**登录并导出 Cookie\n\n### 支持哪些视频网站?\n\nVideoCaptioner 使用 [yt-dlp](https://github.com/yt-dlp/yt-dlp) 作为下载引擎,支持 1000+ 个视频网站,包括:\n\n- 🎬 YouTube、Bilibili、抖音、快手\n- 📺 爱奇艺、腾讯视频、优酷\n- 🎓 Coursera、Udemy、Khan Academy\n- 🐦 Twitter、Facebook、Instagram\n- ...以及更多\n\n完整列表请查看 [yt-dlp 支持列表](https://github.com/yt-dlp/yt-dlp/blob/master/supportedsites.md)\n\n---\n\n## 下一步\n\n配置完成后,你可以:\n\n- 查看 [快速开始指南](./getting-started.md) 下载并处理视频\n- 了解 [批量处理功能](./batch-processing.md) 处理多个视频\n- 探索 [视频下载技巧](./video-download.md)\n"
},
{
"path": "docs/guide/faq.md",
"content": "# 常见问题\n\n常见问题解答。\n\n## 安装问题\n\n### Q: 如何安装依赖?\n\nA: 参考[快速开始](/guide/getting-started)中的安装步骤。\n\n## 使用问题\n\n### Q: 转录时出现幻觉或重复怎么办?\n\nA: \n- 启用 VAD 过滤\n- 更换更大的模型\n- 尝试 Large-v2 而不是 Large-v3\n- 在嘈杂环境中启用音频分离\n\n### Q: LLM 请求失败怎么办?\n\nA:\n- 检查 API Key 是否正确\n- 检查 Base URL 是否正确\n- 降低线程数\n- 检查网络连接\n- 查看日志文件获取详细错误信息\n\n更多问题,请访问 [GitHub Issues](https://github.com/WEIFENG2333/VideoCaptioner/issues)。\n"
},
{
"path": "docs/guide/getting-started.md",
"content": "---\ntitle: 快速开始 - VideoCaptioner\ndescription: 快速安装和配置 VideoCaptioner,5分钟开始处理你的第一个视频字幕。支持 Windows、macOS、Linux 多平台。\nhead:\n - - meta\n - name: keywords\n content: VideoCaptioner安装,快速开始,视频字幕教程,Whisper安装,LLM配置,字幕处理入门\n---\n\n# 快速开始\n\n本指南将帮助你快速上手 VideoCaptioner,开始处理你的第一个视频字幕。\n\n## 系统要求\n\n- **Windows**: Windows 10/11 (64位)\n- **macOS**: macOS 10.15 或更高版本\n- **Linux**: Ubuntu 20.04+ / Debian 11+ / Fedora 35+\n- **Python**: Python 3.10 或更高版本(源码运行时需要)\n- **内存**: 建议 4GB 以上(使用本地 Whisper 需要 8GB+)\n\n## 安装方式\n\n### Windows 用户(推荐使用打包版本)\n\n软件较为轻量,打包大小不足 60M,已集成所有必要环境,下载后可直接运行。\n\n1. 从 [Release](https://github.com/WEIFENG2333/VideoCaptioner/releases) 页面下载最新版本的可执行程序\n\n 或者:[蓝奏盘下载](https://wwwm.lanzoue.com/ii14G2pdsbej)\n\n2. 双击打开安装包进行安装\n\n3. 首次运行会自动检测环境,无需额外配置\n\n### macOS / Linux 用户\n\n#### 使用自动安装脚本(推荐)\n\n```bash\n# 1. 克隆项目\ngit clone https://github.com/WEIFENG2333/VideoCaptioner.git\ncd VideoCaptioner\n\n# 2. 运行安装脚本\nchmod +x run.sh\n./run.sh\n```\n\n脚本会自动:\n\n- 检测 Python 环境\n- 创建虚拟环境并安装依赖\n- 检测系统工具(ffmpeg、aria2)\n- 启动应用程序\n\n::: tip 提示\nmacOS 用户需要先安装 [Homebrew](https://brew.sh/)\n:::\n\n#### 手动安装\n\n\n\n
\n\n### Docker 部署(实验性)\n\n::: warning 注意\nDocker 版本目前还比较基础,欢迎提交 PR 改进。\n:::\n\n```bash\n# 1. 构建镜像\ndocker build -t video-captioner .\n\n# 2. 运行容器\ndocker run -d \\\n -p 8501:8501 \\\n -v $(pwd)/temp:/app/temp \\\n -e OPENAI_BASE_URL=\"Your API address\" \\\n -e OPENAI_API_KEY=\"Your API key\" \\\n --name video-captioner \\\n video-captioner\n\n# 3. 访问应用\n# 打开浏览器访问 http://localhost:8501\n```\n\n## 基础配置\n\n在开始处理视频之前,建议先完成以下基础配置:\n\n### 1. LLM API 配置(可选但推荐)\n\nLLM 用于字幕断句、优化和翻译。软件内置了基础模型,但配置自己的 API 可以获得更好的效果。\n\n打开 **设置 → LLM 配置**,选择以下任一服务:\n\n| 服务商 | 特点 | 推荐模型 |\n| ---------------- | ------------------ | --------------------------------------- |\n| **OpenAI** | 质量最好 | `gpt-4o-mini` (经济), `gpt-4o` (高质量) |\n| **DeepSeek** | 性价比高 | `deepseek-chat` |\n| **SiliconCloud** | 国内可用,并发较低 | `Qwen/Qwen2.5-72B-Instruct` |\n| **Ollama** | 本地运行,完全免费 | `llama3.1:8b` |\n\n::: tip 推荐\n如果需要高并发和优质模型,可使用本项目的 [LLM API 中转站](https://api.videocaptioner.cn)\n\n配置方式:\n\n- Base URL: `https://api.videocaptioner.cn/v1`\n- API Key: 注册后在个人中心获取\n\n推荐模型:\n\n- 高质量:`gemini-2.0-flash-exp`、`claude-sonnet-4.5`\n- 经济实惠:`gpt-4o-mini`、`gemini-2.0-flash-exp`\n :::\n\n详细配置方法请查看 [LLM 配置指南](/config/llm)。\n\n### 2. 语音识别配置\n\n打开 **设置 → 转录配置**,选择语音识别引擎:\n\n| 引擎 | 支持语言 | 运行方式 | 推荐场景 |\n| -------------------- | -------- | -------- | ----------------------------- |\n| **FasterWhisper** ⭐ | 99种语言 | 本地 | 最推荐,准确度高,支持GPU加速 |\n| **B接口** | 中英文 | 在线 | 快速测试,无需下载模型 |\n| **J接口** | 中英文 | 在线 | 备用选项 |\n| **WhisperCpp** | 99种语言 | 本地 | 轻量级本地方案 |\n| **Whisper API** | 99种语言 | 在线 | 使用 OpenAI API |\n\n::: tip 推荐配置\n\n- **中文视频**: FasterWhisper + Medium 模型或以上\n- **英文视频**: FasterWhisper + Small 模型即可\n- **其他语言**: FasterWhisper + Large-v2 模型\n\n首次使用需要在软件内下载模型,国内网络可直接下载。\n:::\n\n详细配置方法请查看 [ASR 配置指南](/config/asr)。\n\n### 3. 翻译配置(可选)\n\n如果需要翻译字幕,打开 **设置 → 翻译配置**:\n\n| 翻译服务 | 特点 | 推荐场景 |\n| --------------- | -------------------- | ------------ |\n| **LLM 翻译** ⭐ | 质量最好,理解上下文 | 追求翻译质量 |\n| **Bing 翻译** | 速度快,免费 | 快速翻译 |\n| **Google 翻译** | 速度快,需要科学上网 | 英语翻译 |\n| **DeepLX** | 质量好,需要自建服务 | 专业翻译 |\n\n详细配置方法请查看 [翻译配置指南](/config/translator)。\n\n## 开始处理视频\n\n### 全流程处理(最简单)\n\n这是最简单的方式,一键完成所有步骤:\n\n1. 在主界面点击 **\"任务创建\"** 标签\n2. 拖拽视频文件到窗口,或点击选择文件\n - 也可以输入 YouTube、B站等视频链接\n3. 点击 **\"开始全流程处理\"** 按钮\n4. 等待处理完成,输出文件保存在 `work-dir/` 目录\n\n::: info 处理流程\n全流程会依次执行:\n\n1. 语音识别转录\n2. 字幕智能断句(可选)\n3. 字幕优化(可选)\n4. 字幕翻译(可选)\n5. 视频合成\n :::\n\n### 分步处理\n\n如果你需要更精细的控制,可以分步处理:\n\n#### 步骤 1:语音识别转录\n\n1. 切换到 **\"语音转录\"** 标签\n2. 选择视频或音频文件\n3. 配置转录参数:\n - 转录语言(自动检测或手动指定)\n - VAD 方法(建议保持默认)\n - 是否启用音频分离(嘈杂环境推荐)\n4. 点击 **\"开始转录\"**\n5. 转录完成后会生成字幕文件\n\n#### 步骤 2:字幕优化与翻译\n\n1. 切换到 **\"字幕优化与翻译\"** 标签\n2. 加载字幕文件(自动加载或手动选择)\n3. 配置处理选项:\n - **智能断句**:重新分段,阅读更流畅\n - **字幕校正**:修正错别字、优化格式\n - **字幕翻译**:翻译为目标语言\n4. (可选)填写文稿提示,提升准确度\n5. 点击 **\"开始处理\"**\n6. 处理完成后可以实时预览和编辑\n\n#### 步骤 3:字幕视频合成\n\n1. 切换到 **\"字幕视频合成\"** 标签\n2. 选择字幕样式(科普风、新闻风等)\n3. 选择合成方式:\n - **硬字幕**:烧录到视频中\n - **软字幕**:内嵌字幕轨道(需要播放器支持)\n4. 点击 **\"开始合成\"**\n5. 输出视频保存在 `work-dir/` 目录\n\n## 实用技巧\n\n### 1. 提升字幕质量\n\n- ✅ 使用 FasterWhisper Large-v2 模型\n- ✅ 启用 VAD 过滤,减少幻觉\n- ✅ 在嘈杂环境中启用音频分离\n- ✅ 使用智能断句(语义分段)\n- ✅ 填写文稿提示(术语表、原文稿等)\n\n### 2. 加快处理速度\n\n- ✅ 使用在线 ASR(B接口/J接口)跳过模型下载\n- ✅ 提高 LLM 并发线程数(如果 API 支持)\n- ✅ 使用软字幕合成(速度极快)\n- ✅ 关闭不需要的功能(如翻译、优化)\n\n### 3. 批量处理\n\n如果需要处理多个视频:\n\n1. 切换到 **\"批量处理\"** 标签\n2. 选择处理类型(批量转录/字幕处理/视频合成)\n3. 添加视频文件到队列\n4. 点击 **\"开始批量处理\"**\n\n详细说明请查看 [批量处理指南](/guide/batch-processing)。\n\n## 常见问题\n\n### 转录时出现幻觉或重复\n\n::: details 解决方案\n\n- 启用 VAD 过滤\n- 更换更大的模型(如 Medium → Large)\n- 尝试 Large-v2 而不是 Large-v3\n- 在嘈杂环境中启用音频分离\n :::\n\n### LLM 请求失败\n\n::: details 解决方案\n\n- 检查 API Key 是否正确\n- 检查 Base URL 是否正确\n- 降低线程数(某些服务商限制并发)\n- 检查网络连接\n- 查看日志文件获取详细错误信息\n :::\n\n### 字幕时间轴不准确\n\n::: details 解决方案\n\n- 使用 FasterWhisper(时间轴最准确)\n- 启用智能断句时使用语义分段模式\n- 手动在字幕编辑界面调整\n :::\n\n更多问题请查看 [常见问题解答](/guide/faq)。\n\n## 下一步\n\n- 📖 了解 [工作流程](/guide/workflow)\n- ⚙️ 查看 [详细配置指南](/guide/configuration)\n- 🎨 自定义 [字幕样式](/guide/subtitle-style)\n- 📝 使用 [文稿匹配](/guide/manuscript) 提升准确度\n\n---\n\n如果在使用过程中遇到问题,欢迎提交 [Issue](https://github.com/WEIFENG2333/VideoCaptioner/issues) 或加入社区讨论。\n"
},
{
"path": "docs/guide/llm-config.md",
"content": "# LLM API 配置指南\n\n本指南将帮助你配置大语言模型(LLM)API,用于字幕的智能断句、优化和翻译。\n\n## 为什么需要配置 LLM?\n\nVideoCaptioner 使用 LLM 提供以下核心功能:\n\n- **智能断句** - 根据语义自动分割字幕,而不是简单按时长切割\n- **字幕优化** - 纠正语音识别的错误,统一专业术语\n- **高质量翻译** - 提供符合语境的翻译,而不是机器直译\n\n:::tip 费用说明\n处理一个 14 分钟的视频,使用 `gpt-4o-mini` 模型,总费用约为 **¥0.01**(不到一分钱)\n:::\n\n## 配置方式\n\n目前有两种主流配置方式:\n\n1. [国内 API 服务商](#国内-api-服务商)(推荐新手)\n2. [OpenAI 官方或中转站](#openai-官方或中转站)\n\n---\n\n## 国内 API 服务商\n\n### 使用 SiliconCloud\n\n[SiliconCloud](https://cloud.siliconflow.cn/i/onCHcaDx) 集成了国内多家大模型厂商,注册即送测试额度。\n\n#### 1. 注册并获取 API Key\n\n访问 [SiliconCloud 设置页面](https://cloud.siliconflow.cn/account/ak) 获取 API Key\n\n\n\n#### 2. 在软件中配置\n\n打开 VideoCaptioner,进入 **设置 → LLM 服务配置**\n\n填写以下信息:\n\n| 配置项 | 值 |\n| ---------------- | -------------------------------- |\n| **API 接口地址** | `https://api.siliconflow.cn/v1` |\n| **API Key** | 粘贴你从 SiliconCloud 获取的密钥 |\n| **模型** | 推荐 `deepseek-ai/DeepSeek-V3` |\n\n\n\n#### 3. 验证连接\n\n点击 **检查连接** 按钮,如果配置正确:\n\n- 软件会自动填充所有支持的模型名称\n- 你可以从下拉菜单中选择需要的模型\n\n:::warning 并发限制\nSiliconCloud 对并发请求有限制,建议将 **线程数** 设置为 **5 或以下**\n:::\n\n:::info 实名要求\n自 2025 年 2 月 6 日起,DeepSeek-V3 模型要求实名认证才能获得更多调用次数。未实名用户每日最多请求 100 次。\n:::\n\n---\n\n## OpenAI 官方或中转站\n\n### 使用项目推荐的中转站\n\n如果你需要使用 OpenAI、Claude 或 Gemini 模型,可以使用中转服务。\n\n#### 1. 注册账号\n\n访问 [本项目的中转站](https://api.videocaptioner.cn/register?aff=UrLB),通过此链接注册默认赠送 **$0.4** 测试余额。\n\n#### 2. 获取 API Key\n\n登录后访问 [https://api.videocaptioner.cn/token](https://api.videocaptioner.cn/token) 获取你的 API Key\n\n#### 3. 在软件中配置\n\n打开 VideoCaptioner,进入 **设置 → LLM 服务配置**\n\n填写以下信息:\n\n| 配置项 | 值 |\n| ---------------- | ---------------------------------- |\n| **API 接口地址** | `https://api.videocaptioner.cn/v1` |\n| **API Key** | 粘贴你获取的密钥 |\n| **模型** | 见下方推荐 |\n\n\n\n#### 4. 模型选择建议\n\n根据质量和成本需求选择:\n\n| 质量层级 | 推荐模型 | 成本比例 | 适用场景 |\n| --------------- | ------------------------------------- | -------- | ---------------------- |\n| 🏆 **高质量** | `claude-3-5-sonnet-20241022` | 3 | 专业内容、重要视频 |\n| ⭐ **较高质量** | `gemini-2.0-flash`点击展开手动安装步骤
\n\n**1. 安装系统依赖**\n\n::: code-group\n\n```bash [macOS]\nbrew install ffmpeg aria2 python@3.11\n```\n\n```bash [Ubuntu/Debian]\nsudo apt update\nsudo apt install ffmpeg aria2 python3.11 python3.11-venv python3-pip\n```\n\n```bash [Fedora]\nsudo dnf install ffmpeg aria2 python3.11\n```\n\n:::\n\n**2. 克隆项目并安装 Python 依赖**\n\n```bash\ngit clone https://github.com/WEIFENG2333/VideoCaptioner.git\ncd VideoCaptioner\n\n# 创建虚拟环境\npython3.11 -m venv venv\n\n# 激活虚拟环境\nsource venv/bin/activate # macOS/Linux\n# 或\n.\\venv\\Scripts\\activate # Windows\n\n# 安装依赖\npip install -r requirements.txt\n```\n\n**3. 运行程序**\n\n```bash\npython main.py\n```\n\n`deepseek-chat` | 1 | 日常使用、质量要求较高 |\n| 💰 **性价比** | `gpt-4o-mini`
`gemini-1.5-flash` | 0.15 | 大量视频、成本敏感 |\n\n:::tip 性能优势\n本中转站支持超高并发,软件中 **线程数可以拉满**,处理速度非常快!\n:::\n\n:::info 成本建议\n如果条件有限,直接使用 `gpt-4o-mini` 即可。这个模型便宜且速度快,处理一个视频只需几分钱,**建议不要折腾本地部署了**。\n:::\n\n---\n\n## 使用 OpenAI 官方 API\n\n如果你有 OpenAI 官方账号,可以直接使用官方 API。\n\n#### 1. 获取 API Key\n\n访问 [OpenAI API Keys](https://platform.openai.com/api-keys) 创建 API Key\n\n#### 2. 在软件中配置\n\n| 配置项 | 值 |\n| ---------------- | --------------------------- |\n| **API 接口地址** | `https://api.openai.com/v1` |\n| **API Key** | 粘贴你的 OpenAI API Key |\n| **模型** | `gpt-4o-mini` 或 `gpt-4o` |\n\n---\n\n## 常见问题\n\n### 如何选择线程数?\n\n**线程数**决定了并发处理字幕的速度:\n\n- **SiliconCloud**: 建议 5 或以下(有并发限制)\n- **中转站**: 可以拉满(支持高并发)\n- **OpenAI 官方**: 建议 10-20(取决于账号等级)\n\n### 如何降低成本?\n\n1. 选择更便宜的模型(如 `gpt-4o-mini`)\n2. 禁用字幕优化功能(只保留翻译)\n3. 使用本地 Whisper 模型进行转录,只用 LLM 做翻译\n\n### API Key 安全吗?\n\n- 所有 API Key 都保存在本地 `AppData/settings.json` 文件中\n- 不会上传到任何服务器\n- 建议定期轮换 API Key\n\n### 连接失败怎么办?\n\n检查以下几点:\n\n1. API 接口地址是否正确(注意末尾的 `/v1`)\n2. API Key 是否正确复制(没有多余空格)\n3. 网络是否能访问 API 服务器\n4. 账号余额是否充足\n\n---\n\n## 下一步\n\n配置完成后,你可以:\n\n- 查看 [快速开始指南](./getting-started.md) 处理你的第一个视频\n- 了解 [字幕优化功能](./subtitle-optimization.md)\n- 探索 [批量处理功能](./batch-processing.md)\n" }, { "path": "docs/guide/quick-example.md", "content": "# 快速示例教程\n\n通过一个 TED 演讲视频的完整处理流程,快速了解 VideoCaptioner 的强大功能。\n\n:::tip 示例视频信息\n\n- 视频时长:14 分钟\n- 原始语言:英语\n- 目标语言:简体中文\n- 总处理时间:约 4 分钟\n- LLM 费用:¥0.01\n :::\n\n---\n\n## 处理流程总览\n\n```mermaid\ngraph LR\n A[导入视频] --> B[Whisper 转录]\n B --> C[LLM 智能断句]\n C --> D[LLM 优化翻译]\n D --> E[视频合成]\n E --> F[完成]\n```\n\n---\n\n## 步骤 1:语音转录\n\n### 转录设置\n\n\n\n| 配置项 | 选择 |\n| ------------ | ----------------------- |\n| **转录模型** | Faster Whisper Large-v2 |\n| **语言** | English(自动检测) |\n| **VAD 方法** | Silero V4 |\n\n### 转录结果\n\n转录完成后生成的原始字幕:\n\n```srt{1,3,6,9}\n1\n00:00:02,080 --> 00:00:08,600\nSo in college, I was a government major,\n\n2\n00:00:08,600 --> 00:00:11,080\nwhich means I had to write a lot of papers.\n\n3\n00:00:11,080 --> 00:00:12,600\nNow, when a normal student writes a paper,\n\n4\n00:00:12,600 --> 00:00:15,460\nthey might spread the work out a little like this.\n\n5\n00:00:15,460 --> 00:00:16,300\nSo you know.\n\n6\n00:00:16,300 --> 00:00:20,040\nYou get started maybe a little slowly,\n\n7\n00:00:20,040 --> 00:00:21,600\nbut you get enough done in the first week\n\n8\n00:00:21,600 --> 00:00:24,000\nthat with some heavier days later on,\n\n9\n00:00:24,000 --> 00:00:26,200\neverything gets done and things stay civil.\n```\n\n:::info 初步观察\n\n- ✅ 语音识别准确度高\n- ⚠️ 断句较为机械,按固定时长切割\n- ⚠️ 标点符号简单,只有逗号和句号\n :::\n\n---\n\n## 步骤 2:智能断句与优化\n\n### 开启优化选项\n\n- ✅ **智能断句** - 语义分段模式\n- ✅ **字幕优化** - LLM 纠错和标点优化\n- ✅ **字幕翻译** - 简体中文\n- ✅ **反思翻译** - 提升译文质量\n\n### 优化后的双语字幕\n\n```srt{1,3-4,7-8,11-12}\n1\n00:00:02,080 --> 00:00:08,597\n所以在大学时,我是政府专业的学生\nSo in college, I was a government major.\n\n2\n00:00:08,600 --> 00:00:11,078\n这意味着我得写很多论文\nWhich means I had to write a lot of papers.\n\n3\n00:00:11,080 --> 00:00:12,596\n现在,普通学生写论文时\nNow when a normal student writes a paper,\n\n4\n00:00:12,600 --> 00:00:15,460\n他们可能会这样分散工作\nThey might spread the work out a little like this.\n\n5\n00:00:15,460 --> 00:00:20,040\n所以你知道,你可能会稍微慢一些开始\nSo you know, you get started maybe a little slowly,\n\n6\n00:00:20,040 --> 00:00:21,593\n但你在第一周能够完成足够的工作\nBut you get enough done in the first week.\n\n7\n00:00:21,600 --> 00:00:23,996\n这样之后的一些繁忙日子\nThat with some heavier days later on.\n\n8\n00:00:24,000 --> 00:00:26,200\n一切都能完成,事情保持得当\nEverything gets done and things stay civil.\n```\n\n:::tip 优化效果\n\n- ✨ 断句更自然,根据语义重新分段\n- ✨ 中文翻译流畅,符合中文表达习惯\n- ✨ 保留原文,方便对照学习\n :::\n\n---\n\n## 步骤 3:查看翻译细节\n\nVideoCaptioner 使用**反思翻译**技术,每句字幕都经过两次优化:\n\n### 翻译对比示例\n\n#### 示例 1:优化冗余词汇\n\n```log{2-3}\n原字幕:So in college, I was a government major.\n翻译后字幕:所以在大学时,我是一个政府专业的学生。\n反思后字幕:所以在大学时,我是政府专业的学生。\n```\n\n**改进点**:删除不必要的\"一个\",使译文更简洁\n\n#### 示例 2:自然化表达\n\n```log{2-3}\n原字幕:Which means I had to write a lot of papers.\n翻译后字幕:这意味着我必须写很多论文。\n反思后字幕:这意味着我得写很多论文。\n```\n\n**改进点**:\"必须\" → \"得\",更符合口语表达\n\n#### 示例 3:精简句式\n\n```log{2-3}\n原字幕:Now when a normal student writes a paper,\n翻译后字幕:现在,当一个普通学生写论文时,\n反思后字幕:现在,普通学生写论文时,\n```\n\n**改进点**:删除\"当\"和\"一个\",句式更紧凑\n\n#### 示例 4:优化动词选择\n\n```log{2-3}\n原字幕:They might spread the work out a little like this.\n翻译后字幕:他们可能会像这样分散工作。\n反思后字幕:他们可能会这样分散工作。\n```\n\n**改进点**:\"像这样\" → \"这样\",更自然\n\n#### 示例 5:调整语序\n\n```log{2-3}\n原字幕:So you know, you get started maybe a little slowly,\n翻译后字幕:所以你知道,你可能会开始得有点慢,\n反思后字幕:所以你知道,你可能会稍微慢一些开始,\n```\n\n**改进点**:调整语序和用词,更符合中文习惯\n\n---\n\n## 步骤 4:视频合成\n\n### 合成设置\n\n| 配置项 | 选择 |\n| ------------ | -------------------- |\n| **字幕样式** | 科普风格 |\n| **字幕布局** | 双语字幕(中文在上) |\n| **合成方式** | 硬字幕(烧录到视频) |\n\n### 最终效果\n\n#### 效果图 1:Hero Section\n\n\n\n#### 效果图 2:中段内容\n\n\n\n#### 效果图 3:结尾部分\n\n\n\n:::tip 字幕特点\n\n- 双语对照,学习更方便\n- 字体清晰,阅读体验好\n- 位置合理,不遮挡画面重点\n :::\n\n---\n\n## 步骤 5:查看成本统计\n\n处理完成后,可以在 LLM 服务商后台查看调用情况:\n\n\n\n### 费用明细\n\n| 项目 | 数值 |\n| -------------- | ------------------------------ |\n| **视频时长** | 14 分钟 |\n| **字幕段数** | ~50 段 |\n| **使用模型** | gpt-4o-mini |\n| **处理类型** | 断句 + 优化 + 翻译(反思模式) |\n| **Token 消耗** | ~5,000 tokens |\n| **总费用** | **¥0.01** |\n\n:::info 成本分析\n\n- 使用 `gpt-4o-mini` 模型,性价比极高\n- 即使开启反思翻译,费用依然不到一分钱\n- 处理 100 个类似视频,总费用约 ¥1\n :::\n\n---\n\n## 性能总结\n\n### 时间统计\n\n| 步骤 | 耗时 |\n| ------------ | ------------- |\n| **语音转录** | ~2 分钟 |\n| **智能断句** | ~30 秒 |\n| **优化翻译** | ~1 分钟 |\n| **视频合成** | ~30 秒 |\n| **总计** | **约 4 分钟** |\n\n:::tip 速度优势\n处理 14 分钟视频只需 4 分钟,效率远超人工处理!\n:::\n\n### 质量对比\n\n| 对比项 | 原始转录 | 优化后 |\n| ------------ | --------------- | ------------------- |\n| **断句质量** | ⭐⭐⭐ 机械切割 | ⭐⭐⭐⭐⭐ 语义分段 |\n| **标点符号** | ⭐⭐ 仅基础标点 | ⭐⭐⭐⭐⭐ 完整标点 |\n| **翻译质量** | - | ⭐⭐⭐⭐⭐ 反思优化 |\n| **阅读体验** | ⭐⭐⭐ 可用 | ⭐⭐⭐⭐⭐ 接近专业 |\n\n---\n\n## 适用场景\n\n通过这个示例,VideoCaptioner 特别适合:\n\n### 1. 教育学习\n\n- 📚 为英文课程添加中文字幕\n- 🎓 制作双语学习材料\n- 📝 提取视频文字稿用于笔记\n\n### 2. 内容创作\n\n- 🎬 YouTube 视频搬运到 B 站\n- 🌍 为自己的视频制作多语言版本\n- 📺 字幕组快速打轴和翻译\n\n### 3. 商业用途\n\n- 💼 会议录音转文字稿\n- 🎤 演讲视频添加字幕\n- 🌐 企业宣传片多语言化\n\n---\n\n## 下一步\n\n掌握了基本流程后,你可以:\n\n- 🎨 [自定义字幕样式](./subtitle-style.md) - 打造独特风格\n- ⚙️ [调整高级参数](./advanced-settings.md) - 进一步提升质量\n- 🚀 [批量处理视频](./batch-processing.md) - 提高工作效率\n- 📖 [查看完整文档](./getting-started.md) - 了解所有功能\n\n---\n\n## 常见问题\n\n### 为什么我的翻译质量不如示例?\n\n可能原因:\n\n- 使用的模型质量较低(如 Qwen 小模型)\n- 没有启用反思翻译\n- 线程数过高导致 API 限流\n\n**建议**:使用 `gpt-4o-mini` 或 `gemini-2.0-flash`,启用反思翻译\n\n### 处理速度慢怎么办?\n\n**加速技巧**:\n\n- 使用在线 ASR(B 接口/J 接口)跳过模型下载\n- 提高 LLM 线程数(如果服务商支持高并发)\n- 使用软字幕合成(速度极快)\n\n### 如何降低成本?\n\n**省钱技巧**:\n\n- 选择更便宜的模型(`gpt-4o-mini` 已经很便宜)\n- 关闭字幕优化,只保留翻译\n- 使用本地 Whisper,不用 API\n\n---\n\n需要帮助?欢迎在 [GitHub Issues](https://github.com/WEIFENG2333/VideoCaptioner/issues) 提问!\n" }, { "path": "docs/guide/workflow.md", "content": "# 工作流程\n\n了解 VideoCaptioner 的完整工作流程。\n\n## 处理流程图\n\n```\n视频输入 → 语音识别 → 字幕分割 → 字幕优化 → 字幕翻译 → 视频合成\n```\n\n## 详细说明\n\n待补充...\n\n---\n\n相关文档:\n- [快速开始](/guide/getting-started)\n- [配置指南](/guide/configuration)\n" }, { "path": "docs/index.md", "content": "---\nlayout: page\ntitle: VideoCaptioner - 基于LLM的智能视频字幕处理工具\ntitleTemplate: false\ndescription: 免费开源的AI视频字幕处理助手,支持Whisper语音识别、LLM智能断句、字幕优化和99种语言翻译。一键生成高质量字幕,适用于YouTube、B站等平台。\n\nhead:\n - - meta\n - name: keywords\n content: VideoCaptioner,卡卡字幕助手,视频字幕生成器,AI自动字幕,Whisper中文字幕,LLM字幕翻译,免费字幕工具,开源字幕软件,视频转文字,语音识别字幕,B站字幕生成,YouTube字幕工具,多语言字幕,字幕断句优化,视频字幕处理,自动生成字幕,字幕制作软件,视频配字幕\n - - meta\n - property: og:title\n content: VideoCaptioner - 基于LLM的智能视频字幕处理工具 | 免费开源\n - - meta\n - property: og:description\n content: 免费开源的AI视频字幕处理助手。支持Whisper语音识别、LLM智能断句与翻译、多语言字幕生成。适用于YouTube、B站等平台,支持99种语言。一键处理,专业质量。\n - - meta\n - property: og:url\n content: https://weifeng2333.github.io/VideoCaptioner/\n - - meta\n - property: og:type\n content: website\n - - meta\n - property: article:published_time\n content: 2024-01-01T00:00:00+08:00\n - - meta\n - property: article:modified_time\n content: 2025-01-25T00:00:00+08:00\n - - meta\n - name: twitter:title\n content: VideoCaptioner - AI Video Subtitle Tool | Free & Open Source\n - - meta\n - name: twitter:description\n content: Free AI-powered subtitle tool with Whisper & LLM. Supports 99 languages, intelligent segmentation, and professional translation.\n---\n\n
\n  \n
\n
\n\n## 📖 Introduction\n\nKaka Subtitle Assistant (VideoCaptioner) is easy to operate and doesn't require high-end hardware. It supports both online API calls and local offline processing (with GPU support) for speech recognition. It leverages Large Language Models (LLMs) for intelligent subtitle segmentation, correction, and translation. It offers a one-click solution for the entire video subtitle workflow! Add stunning subtitles to your videos.\n\n- Support for word-level timestamps and VAD voice activity detection with high recognition accuracy\n- LLM-based semantic understanding to automatically reorganize word-by-word subtitles into natural, fluent sentence paragraphs\n- Context-aware AI translation with reflection optimization mechanism for idiomatic and professional translations\n- Batch video subtitle synthesis support to improve processing efficiency\n- Intuitive subtitle editing and viewing interface with real-time preview and quick editing\n\n## 📸 Interface Preview\n\nKaka Subtitle Assistant
\nVideoCaptioner
\nAn LLM-powered video subtitle processing assistant, supporting speech recognition, subtitle segmentation, optimization, and translation.
\n\n [简体中文](../README.md) / [正體中文](./README_TW.md) / English / [日本語](./README_JA.md)\n\n\n \n
\n\n\n\n\n\n## 🧪 Testing\n\nProcessing a 14-minute 1080P [English TED video from Bilibili](https://www.bilibili.com/video/BV1jT411X7Dz) end-to-end, using the local Whisper model for speech recognition and the `gpt-5-mini` model for optimization and translation into Chinese, took approximately **4 minutes**.\n\nBased on backend calculations, the cost for model optimization and translation was less than ¥0.01 (calculated using OpenAI's official pricing).\n\nFor detailed results of subtitle and video synthesis, please refer to the [TED Video Test](./test.md).\n\n\n## 🚀 Quick Start\n\n### For Windows Users\n\nThe software is lightweight, with a package size of less than 60MB, and includes all necessary environments. Download and run directly.\n\n1. Download the latest version of the executable from the [Release](https://github.com/WEIFENG2333/VideoCaptioner/releases) page. Or: [Lanzou Cloud Download](https://wwwm.lanzoue.com/ii14G2pdsbej)\n\n2. Open the installer to install.\n\n3. LLM API Configuration (for subtitle segmentation and correction), you can use [this project's API relay](https://api.videocaptioner.cn)\n\n4. Translation configuration, choose whether to enable translation (default uses Microsoft Translator, average quality, recommend configuring your own API KEY for LLM translation)\n\n5. Speech recognition configuration (default uses B interface for online speech recognition, use local transcription for languages other than Chinese and English)\n\n### For macOS Users\n\n#### One-Click Install & Run (Recommended)\n\n```bash\n# Method 1: Direct run (auto-installs uv, clones project, installs dependencies)\ncurl -fsSL https://raw.githubusercontent.com/WEIFENG2333/VideoCaptioner/main/scripts/run.sh | bash\n\n# Method 2: Clone first, then run\ngit clone https://github.com/WEIFENG2333/VideoCaptioner.git\ncd VideoCaptioner\n./scripts/run.sh\n```\n\nThe script will automatically:\n\n1. Install the [uv](https://docs.astral.sh/uv/) package manager (if not installed)\n2. Clone the project to `~/VideoCaptioner` (if not running from project directory)\n3. Install all Python dependencies\n4. Launch the application\n\n\n\n
\n\n### Developer Guide\n\n```bash\n# Install dependencies (including dev dependencies)\nuv sync\n\n# Run application\nuv run python main.py\n\n# Type checking\nuv run pyright\n\n# Code linting\nuv run ruff check .\n```\n\n## ✨ Main Features\n\nThe software fully utilizes the advantages of Large Language Models (LLMs) in understanding context to further process subtitles generated by speech recognition. It effectively corrects typos, unifies terminology, and makes the subtitle content more accurate and coherent, providing users with an excellent viewing experience!\n\n#### 1. Multi-platform Video Download and Processing\n- Supports mainstream video platforms (Bilibili, YouTube, TikTok, X, etc.)\n- Automatically extracts and processes the original subtitles of the video.\n\n#### 2. Professional Speech Recognition Engine\n- Provides multiple online recognition interfaces with effects comparable to Jianying (free, high-speed).\n- Supports local Whisper model (privacy protection, offline).\n\n#### 3. Intelligent Subtitle Correction\n- Automatically optimizes the format of terminology, code snippets, and mathematical formulas.\n- Contextual sentence segmentation optimization to improve reading experience.\n- Supports manuscript prompts, using original manuscripts or related prompts to optimize subtitle segmentation.\n\n#### 4. High-Quality Subtitle Translation\n- Context-aware intelligent translation ensures that the translation takes the entire text into account.\n- Guides the large model to reflect on the translation through prompts, improving translation quality.\n- Uses a sequence fuzzy matching algorithm to ensure complete consistency of the timeline.\n\n#### 5. Subtitle Style Adjustment\n- Rich subtitle style templates (popular science style, news style, anime style, etc.).\n- Multiple subtitle video formats (SRT, ASS, VTT, TXT).\n\n\n## ⚙️ Basic Configuration\n\n### 1. LLM API Configuration Instructions\n\nLLM is used for subtitle segmentation, optimization, and translation (if LLM translation is selected).\n\n| Configuration Item | Description |\n|--------|------|\n| SiliconCloud | [SiliconCloud Official](https://cloud.siliconflow.cn/i/onCHcaDx), for configuration see [online docs](https://weifeng2333.github.io/VideoCaptioner/config/llm)Manual Installation Steps
\n\n#### 1. Install uv package manager\n\n```bash\ncurl -LsSf https://astral.sh/uv/install.sh | sh\n```\n\n#### 2. Install system dependencies (macOS)\n\n```bash\nbrew install ffmpeg\n```\n\n#### 3. Clone and run\n\n```bash\ngit clone https://github.com/WEIFENG2333/VideoCaptioner.git\ncd VideoCaptioner\nuv sync # Install dependencies\nuv run python main.py # Run\n```\n\nLow concurrency, recommend setting threads below 5. |\n| DeepSeek | [DeepSeek Official](https://platform.deepseek.com), recommend using `deepseek-v3` model. |\n| OpenAI Compatible | If you have API from other providers, fill in directly. base_url and api_key [VideoCaptioner API](https://api.videocaptioner.cn) |\n\nNote: If your API provider doesn't support high concurrency, lower the \"thread count\" in settings to avoid request errors.\n\n---\n\nFor high concurrency, or to use quality models like OpenAI or Claude for subtitle correction and translation:\n\nUse this project's ✨LLM API Relay✨: [https://api.videocaptioner.cn](https://api.videocaptioner.cn)\n\nSupports high concurrency, excellent value, with many domestic and international models available.\n\nAfter registering and getting your key, configure settings as follows:\n\nBaseURL: `https://api.videocaptioner.cn/v1`\n\nAPI-key: `Get from Personal Center - API Token page.`\n\n💡 Model Selection Recommendations (high-value models selected at each quality tier):\n\n- High quality: `gemini-3-pro`, `claude-sonnet-4-5-20250929` (cost ratio: 3)\n\n- Higher quality: `gpt-5-2025-08-07`, `claude-haiku-4-5-20251001` (cost ratio: 1.2)\n\n- Medium quality: `gpt-5-mini`, `gemini-3-flash` (cost ratio: 0.3)\n\nThis site supports ultra-high concurrency, max out the thread count in the software~ Processing speed is very fast~\n\nFor more detailed API configuration tutorial: [API Configuration](https://weifeng2333.github.io/VideoCaptioner/config/llm)\n\n---\n\n### 2. Translation Configuration\n\n| Configuration Item | Description |\n| -------------- | ----------------------------------------------------------------------------------------------------------------------------- |\n| LLM Translation | 🌟 Best translation quality. Uses AI large models for translation, better context understanding, more natural translations. Requires LLM API configuration (e.g., OpenAI, DeepSeek, etc.) |\n| Microsoft Translator | Uses Microsoft's translation service, very fast |\n| Google Translate | Google's translation service, fast, but requires access to Google's network |\n\nRecommended: `LLM Translation` for the best translation quality.\n\n### 3. Speech Recognition Interface Description\n\n| Interface Name | Supported Languages | Running Mode | Description |\n|---------|---------|---------|------|\n| Interface B | Chinese, English only | Online | Free, fast |\n| Interface J | Chinese, English only | Online | Free, fast |\n| WhisperCpp | Chinese, Japanese, Korean, English, and 99 other languages. Good performance for foreign languages. | Local | (Actual use is unstable) Requires downloading transcription models.
Chinese: Medium or larger model recommended.
English, etc.: Smaller models can achieve good results. |\n| fasterWhisper 👍 | Chinese, English, and 99 other languages. Excellent performance for foreign languages, more accurate timeline. | Local | (🌟Recommended🌟) Requires downloading the program and transcription models.
Supports CUDA, faster, accurate transcription.
Super accurate timestamp subtitles.
Windows only |\n\n\n### 4. Local Whisper Speech Recognition Configuration (Requires download within the software)\n\nThere are two Whisper versions: WhisperCpp and fasterWhisper (recommended). The latter has better performance and both require downloading models within the software.\n\n| Model | Disk Space | RAM Usage | Description |\n|------|----------|----------|------|\n| Tiny | 75 MiB | ~273 MB | Transcription is mediocre, for testing only. |\n| Small | 466 MiB | ~852 MB | English recognition is already good. |\n| Medium | 1.5 GiB | ~2.1 GB | This version is recommended as the minimum for Chinese recognition. |\n| Large-v2 👍 | 2.9 GiB | ~3.9 GB | Good performance, recommended if your configuration allows. |\n| Large-v3 | 2.9 GiB | ~3.9 GB | Community feedback suggests potential hallucination/subtitle repetition issues. |\n\nRecommended model: `Large-v2` is stable and of good quality.\n\n\n### 5. Manuscript Matching\n\n- On the \"Subtitle Optimization and Translation\" page, there is a \"Manuscript Matching\" option, which supports the following **one or more** types of content to assist in subtitle correction and translation:\n\n| Type | Description | Example |\n|------|------|------|\n| Glossary | Correction table for terminology, names, and specific words. | Machine Learning->机器学习
Elon Musk->马斯克
Turing patterns
Bus paradox |\n| Original Subtitle Text | The original manuscript or related content of the video. | Complete speech scripts, lecture notes, etc. |\n| Correction Requirements | Specific correction requirements related to the content. | Unify personal pronouns, standardize terminology, etc.
Fill in requirements **related to the content**, [example reference](https://github.com/WEIFENG2333/VideoCaptioner/issues/59#issuecomment-2495849752) |\n\n- If you need manuscript assistance for subtitle optimization, fill in the manuscript information first, then start the task processing.\n- Note: When using small LLM models with limited context, it is recommended to keep the manuscript content within 1000 words. If using a model with a larger context window, you can appropriately increase the manuscript content.\n\n\n### 6. Cookie Configuration Instructions\n\nIf you encounter the following situations when using the URL download function:\n1. The video website requires login information to download.\n2. Only lower resolution videos can be downloaded.\n3. Verification is required when network conditions are poor.\n\n- Please refer to the [Cookie Configuration Instructions](https://weifeng2333.github.io/VideoCaptioner/guide/cookies-config) to obtain cookie information and place the `cookies.txt` file in the `AppData` directory of the software installation directory to download high-quality videos normally.\n\n## 💡 Software Process Introduction\n\nThe simple processing flow of the program is as follows:\n```\nSpeech Recognition -> Subtitle Segmentation (optional) -> Subtitle Optimization & Translation (optional) -> Subtitle & Video Synthesis\n```\n\nThe main directory structure of the project is as follows:\n```\nVideoCaptioner/\n├── app/ # Application source code directory\n│ ├── common/ # Common modules (config, signal bus)\n│ ├── components/ # UI components\n│ ├── core/ # Core business logic (ASR, translation, optimization, etc.)\n│ ├── thread/ # Async threads\n│ └── view/ # Interface views\n├── resource/ # Resource file directory\n│ ├── assets/ # Icons, Logo, etc.\n│ ├── bin/ # Binary programs (FFmpeg, Whisper, etc.)\n│ ├── fonts/ # Font files\n│ ├── subtitle_style/ # Subtitle style templates\n│ └── translations/ # Multi-language translation files\n├── work-dir/ # Working directory (processed videos and subtitles)\n├── AppData/ # Application data directory\n│ ├── cache/ # Cache directory (transcription, LLM requests)\n│ ├── models/ # Whisper model files\n│ ├── logs/ # Log files\n│ └── settings.json # User settings\n├── scripts/ # Installation and run scripts\n├── main.py # Program entry\n└── pyproject.toml # Project configuration and dependencies\n```\n\n## 📝 Notes\n\n1. The quality of subtitle segmentation is crucial for the viewing experience. The software can intelligently reorganize word-by-word subtitles into paragraphs that conform to natural language habits and perfectly synchronize with the video frames.\n\n2. During processing, only the text content is sent to the large language model, without timeline information, which greatly reduces processing overhead.\n\n3. In the translation stage, we adopt the \"translate-reflect-translate\" methodology proposed by Andrew Ng. This iterative optimization method ensures the accuracy of the translation.\n\n4. When processing YouTube links, video subtitles are automatically downloaded, saving the transcription step and significantly reducing operation time.\n\n## 🤝 Contribution Guidelines\n\nThe project is constantly being improved. If you encounter any bugs during use, please feel free to submit [Issues](https://github.com/WEIFENG2333/VideoCaptioner/issues) and Pull Requests to help improve the project.\n\n## 📝 Changelog\n\nView the complete update history at [CHANGELOG.md](../CHANGELOG.md)\n\n## ⭐ Star History\n\n[](https://star-history.com/#WEIFENG2333/VideoCaptioner&Date)\n\n## 💖 Support the Author\n\nIf you find this project helpful, please give it a Star!\n\n
\n
\n"
},
{
"path": "legacy-docs/README_JA.md",
"content": "Donation Support
\n\n  \n
\n  \n
\n
\n\n \n\n  \n
\n
\n\n## 📖 はじめに\n\nKaka 字幕アシスタント(VideoCaptioner)は操作が簡単で、高性能なハードウェアを必要としません。音声認識のためのオンラインAPI呼び出しとローカルオフライン処理(GPUサポートあり)の両方をサポートしています。大規模言語モデル(LLM)を活用して、インテリジェントな字幕のセグメンテーション、修正、翻訳を行います。ビデオ字幕のワークフロー全体をワンクリックで解決します!あなたのビデオに素晴らしい字幕を追加しましょう。\n\n- 単語レベルのタイムスタンプとVAD音声活動検出をサポートし、高い認識精度を実現\n- LLMベースの意味理解により、単語ごとの字幕を自然で流暢な文章段落に自動再構成\n- 文脈を考慮したAI翻訳、反映最適化メカニズムにより、慣用的でプロフェッショナルな翻訳を実現\n- バッチビデオ字幕合成をサポートし、処理効率を向上\n- 直感的な字幕編集と表示インターフェース、リアルタイムプレビューとクイック編集をサポート\n\n## 📸 インターフェースプレビュー\n\nKaka カカ字幕アシスタント
\nVideoCaptioner
\n音声認識、字幕のセグメンテーション、最適化、翻訳をサポートするLLM駆動のビデオ字幕処理アシスタント。
\n\n [简体中文](../README.md) / [正體中文](./README_TW.md) / [English](./README_EN.md) / 日本語\n\n\n \n
\n\n\n\n\n## 🧪 テスト\n\n14分の1080P [Bilibiliの英語TEDビデオ](https://www.bilibili.com/video/BV1jT411X7Dz)をエンドツーエンドで処理し、ローカルWhisperモデルを使用して音声認識を行い、`gpt-5-mini`モデルを使用して中国語に最適化および翻訳するのに約**4分**かかりました。\n\nバックエンドの計算に基づくと、モデルの最適化と翻訳のコストは¥0.01未満でした(OpenAIの公式価格を使用して計算)。\n\n字幕とビデオ合成の詳細な結果については、[TEDビデオテスト](./test.md)を参照してください。\n\n\n## 🚀 クイックスタート\n\n### Windowsユーザー向け\n\nこのソフトウェアは軽量で、パッケージサイズは60MB未満であり、必要な環境がすべて含まれています。ダウンロードして直接実行できます。\n\n1. [リリースページ](https://github.com/WEIFENG2333/VideoCaptioner/releases)から最新バージョンの実行ファイルをダウンロードします。または:[Lanzou Cloud Download](https://wwwm.lanzoue.com/ii14G2pdsbej)\n\n2. インストーラーを開いてインストールします。\n\n3. LLM API設定(字幕のセグメンテーションと修正用)、[このプロジェクトのAPIリレー](https://api.videocaptioner.cn)を使用できます\n\n4. 翻訳設定、翻訳を有効にするかどうかを選択(デフォルトはMicrosoft翻訳、品質は普通、LLM翻訳用に自分のAPI KEYを設定することを推奨)\n\n5. 音声認識設定(デフォルトはBインターフェースでオンライン音声認識、中国語と英語以外の言語にはローカル文字起こしを使用)\n\n### macOSユーザー向け\n\n#### ワンクリックインストール&実行(推奨)\n\n```bash\n# 方法1:直接実行(自動的にuv、プロジェクトのクローン、依存関係のインストール)\ncurl -fsSL https://raw.githubusercontent.com/WEIFENG2333/VideoCaptioner/main/scripts/run.sh | bash\n\n# 方法2:先にクローンしてから実行\ngit clone https://github.com/WEIFENG2333/VideoCaptioner.git\ncd VideoCaptioner\n./scripts/run.sh\n```\n\nスクリプトは自動的に:\n\n1. [uv](https://docs.astral.sh/uv/)パッケージマネージャーをインストール(未インストールの場合)\n2. プロジェクトを`~/VideoCaptioner`にクローン(プロジェクトディレクトリから実行していない場合)\n3. すべてのPython依存関係をインストール\n4. アプリケーションを起動\n\n\n\n
\n\n### 開発者ガイド\n\n```bash\n# 依存関係をインストール(開発依存関係を含む)\nuv sync\n\n# アプリケーションを実行\nuv run python main.py\n\n# 型チェック\nuv run pyright\n\n# コードリンティング\nuv run ruff check .\n```\n\n## ✨ 主要機能\n\nこのソフトウェアは、大規模言語モデル(LLM)の文脈理解の利点を最大限に活用し、音声認識で生成された字幕をさらに処理します。誤字を効果的に修正し、用語を統一し、字幕の内容をより正確で一貫性のあるものにし、ユーザーに優れた視聴体験を提供します!\n\n#### 1. マルチプラットフォーム動画ダウンロードと処理\n- 国内外の主流のビデオプラットフォーム(Bilibili、YouTube、TikTok、Xなど)をサポート\n- ビデオの元の字幕を自動的に抽出して処理します。\n\n#### 2. プロフェッショナルな音声認識エンジン\n- Jianyingに匹敵する効果を持つ複数のオンライン認識インターフェースを提供(無料、高速)。\n- ローカルWhisperモデルをサポート(プライバシー保護、オフライン)。\n\n#### 3. 字幕のスマート修正\n- 用語、コードスニペット、数式のフォーマットを自動的に最適化。\n- 読みやすさを向上させるための文脈的な文の分割最適化。\n- 原稿プロンプトをサポートし、元の原稿や関連するプロンプトを使用して字幕のセグメンテーションを最適化。\n\n#### 4. 高品質な字幕翻訳\n- 文脈を考慮したインテリジェントな翻訳により、翻訳が全体のテキストを考慮することを保証。\n- プロンプトを通じて大規模モデルに翻訳を反映させ、翻訳の質を向上。\n- シーケンスのあいまい一致アルゴリズムを使用して、タイムラインの完全な一貫性を保証。\n\n#### 5. 字幕スタイル調整\n- 豊富な字幕スタイルテンプレート(科学スタイル、ニューススタイル、アニメスタイルなど)。\n- 複数の字幕ビデオ形式(SRT、ASS、VTT、TXT)。\n\n## ⚙️ 基本設定\n\n### 1. LLM API設定手順\n\nLLMは字幕のセグメンテーション、最適化、翻訳(LLM翻訳を選択した場合)に使用されます。\n\n| 設定項目 | 説明 |\n|--------|------|\n| SiliconCloud | [SiliconCloud公式](https://cloud.siliconflow.cn/i/onCHcaDx)、設定については[オンラインドキュメント](https://weifeng2333.github.io/VideoCaptioner/config/llm)を参照手動インストール手順
\n\n#### 1. uvパッケージマネージャーをインストール\n\n```bash\ncurl -LsSf https://astral.sh/uv/install.sh | sh\n```\n\n#### 2. システム依存関係をインストール(macOS)\n\n```bash\nbrew install ffmpeg\n```\n\n#### 3. クローンして実行\n\n```bash\ngit clone https://github.com/WEIFENG2333/VideoCaptioner.git\ncd VideoCaptioner\nuv sync # 依存関係をインストール\nuv run python main.py # 実行\n```\n\n並行性が低いため、スレッド数を5以下に設定することを推奨。 |\n| DeepSeek | [DeepSeek公式](https://platform.deepseek.com)、`deepseek-v3`モデルの使用を推奨。 |\n| OpenAI互換 | 他のプロバイダーからのAPIがある場合は、直接入力してください。base_urlとapi_key [VideoCaptioner API](https://api.videocaptioner.cn) |\n\n注意:APIプロバイダーが高並行性をサポートしていない場合は、設定で「スレッド数」を下げてリクエストエラーを回避してください。\n\n---\n\n高並行性、またはOpenAIやClaudeなどの高品質モデルを字幕修正と翻訳に使用する場合:\n\nこのプロジェクトの✨LLM APIリレー✨を使用:[https://api.videocaptioner.cn](https://api.videocaptioner.cn)\n\n高並行性をサポートし、優れた価値を提供し、国内外の多くのモデルが利用可能です。\n\n登録してキーを取得後、以下のように設定を構成します:\n\nBaseURL: `https://api.videocaptioner.cn/v1`\n\nAPI-key: `個人センター - APIトークンページから取得。`\n\n💡 モデル選択の推奨(各品質層で選ばれた高価値モデル):\n\n- 高品質:`gemini-3-pro`、`claude-sonnet-4-5-20250929`(コスト比:3)\n\n- より高品質:`gpt-5-2025-08-07`、`claude-haiku-4-5-20251001`(コスト比:1.2)\n\n- 中品質:`gpt-5-mini`、`gemini-3-flash`(コスト比:0.3)\n\nこのサイトは超高並行性をサポートしています。ソフトウェアのスレッド数を最大にしてください~処理速度は非常に速いです~\n\n詳細なAPI設定チュートリアル:[API設定](https://weifeng2333.github.io/VideoCaptioner/config/llm)\n\n---\n\n### 2. 翻訳設定\n\n| 設定項目 | 説明 |\n| -------------- | ----------------------------------------------------------------------------------------------------------------------------- |\n| LLM翻訳 | 🌟 最高の翻訳品質。AI大規模モデルを使用した翻訳、より良い文脈理解、より自然な翻訳。LLM API設定が必要(例:OpenAI、DeepSeekなど) |\n| Microsoft翻訳 | Microsoftの翻訳サービスを使用、非常に高速 |\n| Google翻訳 | Googleの翻訳サービス、高速、ただしGoogleのネットワークへのアクセスが必要 |\n\n推奨:最高の翻訳品質には`LLM翻訳`。\n\n### 3. 音声認識インターフェースの説明\n\n| インターフェース名 | 対応言語 | 実行方式 | 説明 |\n|---------|---------|---------|------|\n| インターフェースB | 中国語、英語のみ | オンライン | 無料、高速 |\n| インターフェースJ | 中国語、英語のみ | オンライン | 無料、高速 |\n| WhisperCpp | 中国語、日本語、韓国語、英語、その他99の言語。外国語に対して良好なパフォーマンス。 | ローカル | (実際の使用は不安定)トランスクリプションモデルのダウンロードが必要。
中国語:中型以上のモデルを推奨。
英語など:小型モデルでも良好な結果が得られます。 |\n| fasterWhisper 👍 | 中国語、英語、その他99の言語。外国語に対して優れたパフォーマンス、より正確なタイムライン。 | ローカル | (🌟推奨🌟)プログラムとトランスクリプションモデルのダウンロードが必要。
CUDAをサポートし、より高速で正確なトランスクリプション。
非常に正確なタイムスタンプ字幕。
Windowsのみ |\n\n### 4. ローカルWhisper音声認識設定(ソフトウェア内でダウンロードが必要)\n\nWhisperには2つのバージョンがあります:WhisperCppとfasterWhisper(推奨)。後者はより良いパフォーマンスを持ち、どちらもソフトウェア内でモデルをダウンロードする必要があります。\n\n| モデル | ディスク容量 | メモリ使用量 | 説明 |\n|------|----------|----------|------|\n| Tiny | 75 MiB | ~273 MB | トランスクリプションは平均的で、テストのみを目的としています。 |\n| Small | 466 MiB | ~852 MB | 英語の認識はすでに良好です。 |\n| Medium | 1.5 GiB | ~2.1 GB | 中国語の認識にはこのバージョンが最低限推奨されます。 |\n| Large-v2 👍 | 2.9 GiB | ~3.9 GB | 良好なパフォーマンスを持ち、設定が許すなら推奨されます。 |\n| Large-v3 | 2.9 GiB | ~3.9 GB | コミュニティのフィードバックによると、幻覚/字幕の繰り返しの問題がある可能性があります。 |\n\n推奨モデル:`Large-v2`は安定しており、品質が良好です。\n\n\n### 5. 原稿マッチング\n\n- 「字幕の最適化と翻訳」ページには「原稿マッチング」オプションがあり、以下の**1つ以上**のタイプのコンテンツをサポートして字幕の修正と翻訳を支援します:\n\n| タイプ | 説明 | 例 |\n|------|------|------|\n| 用語集 | 用語、名前、特定の単語の修正表。 | Machine Learning->机器学习
Elon Musk->马斯克
Turing patterns
Bus paradox |\n| 元の字幕テキスト | ビデオの元の原稿または関連するコンテンツ。 | 完全なスピーチスクリプト、講義ノートなど。 |\n| 修正要件 | コンテンツに関連する特定の修正要件。 | 人称代名詞の統一、用語の標準化など。
**コンテンツに関連する**要件を記入してください。[例の参照](https://github.com/WEIFENG2333/VideoCaptioner/issues/59#issuecomment-2495849752) |\n\n- 字幕の最適化に原稿の支援が必要な場合は、まず原稿情報を記入し、タスク処理を開始してください。\n- 注意:コンテキストが限られている小さなLLMモデルを使用する場合、原稿の内容は1000語以内にすることをお勧めします。より大きなコンテキストウィンドウを持つモデルを使用する場合は、原稿の内容を適切に増やすことができます。\n\n### 6. Cookie設定手順\n\nURLダウンロード機能を使用する際に以下の状況に遭遇した場合:\n1. ビデオサイトがダウンロードにログイン情報を要求する。\n2. 低解像度のビデオしかダウンロードできない。\n3. ネットワーク状況が悪いときに認証が必要。\n\n- [Cookie設定手順](https://weifeng2333.github.io/VideoCaptioner/guide/cookies-config)を参照して、cookie情報を取得し、`cookies.txt`ファイルをソフトウェアのインストールディレクトリの`AppData`ディレクトリに配置して、高品質のビデオを通常通りダウンロードしてください。\n\n## 💡 ソフトウェアプロセスの紹介\n\nプログラムの簡単な処理フローは以下の通りです:\n```\n音声認識 -> 字幕セグメンテーション(オプション) -> 字幕の最適化と翻訳(オプション) -> 字幕とビデオの合成\n```\n\nプロジェクトの主なディレクトリ構造は以下の通りです:\n```\nVideoCaptioner/\n├── app/ # アプリケーションソースコードディレクトリ\n│ ├── common/ # 共通モジュール(設定、シグナルバス)\n│ ├── components/ # UIコンポーネント\n│ ├── core/ # コアビジネスロジック(ASR、翻訳、最適化など)\n│ ├── thread/ # 非同期スレッド\n│ └── view/ # インターフェースビュー\n├── resource/ # リソースファイルディレクトリ\n│ ├── assets/ # アイコン、ロゴなど\n│ ├── bin/ # バイナリプログラム(FFmpeg、Whisperなど)\n│ ├── fonts/ # フォントファイル\n│ ├── subtitle_style/ # 字幕スタイルテンプレート\n│ └── translations/ # 多言語翻訳ファイル\n├── work-dir/ # 作業ディレクトリ(処理されたビデオと字幕)\n├── AppData/ # アプリケーションデータディレクトリ\n│ ├── cache/ # キャッシュディレクトリ(トランスクリプション、LLMリクエスト)\n│ ├── models/ # Whisperモデルファイル\n│ ├── logs/ # ログファイル\n│ └── settings.json # ユーザー設定\n├── scripts/ # インストールと実行スクリプト\n├── main.py # プログラムエントリー\n└── pyproject.toml # プロジェクト設定と依存関係\n```\n\n## 📝 注意事項\n\n1. 字幕セグメンテーションの品質は視聴体験にとって非常に重要です。ソフトウェアは単語ごとの字幕を自然言語の習慣に従って段落に再編成し、ビデオフレームと完全に同期させることができます。\n\n2. 処理中、タイムライン情報なしでテキストコンテンツのみが大規模言語モデルに送信され、処理のオーバーヘッドが大幅に削減されます。\n\n3. 翻訳段階では、Andrew Ngが提案した「翻訳-反映-翻訳」手法を採用しています。この反復的な最適化方法は、翻訳の正確性を保証します。\n\n4. YouTubeリンクを処理する際、ビデオ字幕が自動的にダウンロードされ、トランスクリプションステップが省略され、操作時間が大幅に短縮されます。\n\n## 🤝 貢献ガイドライン\n\nプロジェクトは継続的に改善中で、使用中にバグに遭遇した場合は、[Issue](https://github.com/WEIFENG2333/VideoCaptioner/issues)の提出とPull Requestによるプロジェクト改善へのご協力をお願いします。\n\n## 📝 更新履歴\n\n完全な更新履歴は[CHANGELOG.md](../CHANGELOG.md)をご覧ください。\n\n## ⭐ Star History\n\n[](https://star-history.com/#WEIFENG2333/VideoCaptioner&Date)\n\n## 💖 作者を支援する\n\nこのプロジェクトがお役に立てましたら、Starを付けていただけると幸いです!\n\n
\n
\n"
},
{
"path": "legacy-docs/README_TW.md",
"content": "寄付サポート
\n\n \n \n
\n\n \n\n \n
\n\n## 📖 項目介紹\n\n卡卡字幕助手(VideoCaptioner)操作簡單且無需高配置,支持 API 和本地離線兩種方式進行語音識別,利用大語言模型進行字幕智能斷句、校正、翻譯,字幕視頻全流程一鍵處理。為視頻配上效果驚艷的字幕。\n\n- 支持詞級時間戳與 VAD 語音活動檢測,識別準確率高\n- 基於 LLM 的語義理解,自動將逐字字幕重組為自然流暢的句子段落\n- 結合上下文的 AI 翻譯,支持反思優化機制,譯文地道專業\n- 支持批量視頻字幕合成,提升處理效率\n- 直觀的字幕編輯查看介面,支持即時預覽和快捷編輯\n\n## 📸 介面預覽\n\n卡卡字幕助手
\nVideoCaptioner
\n一款基於大語言模型(LLM)的視頻字幕處理助手,支持語音識別、字幕斷句、優化、翻譯全流程處理
\n\n [简体中文](../README.md) / 正體中文 / [English](./README_EN.md) / [日本語](./README_JA.md)\n\n📚 **[線上文檔](https://weifeng2333.github.io/VideoCaptioner/)** | 🚀 **[快速開始](https://weifeng2333.github.io/VideoCaptioner/guide/getting-started)** | ⚙️ **[配置指南](https://weifeng2333.github.io/VideoCaptioner/config/llm)**\n\n\n \n
\n\n\n\n\n## 🧪 測試\n\n全流程處理一個 14 分鐘 1080P 的 [B站英文 TED 視頻](https://www.bilibili.com/video/BV1jT411X7Dz),調用本地 Whisper 模型進行語音識別,使用 `gpt-5-mini` 模型優化和翻譯為中文,總共消耗時間約 **4 分鐘**。\n\n根據後台計算,模型優化和翻譯消耗費用不足 ¥0.01(以 OpenAI 官方價格計算)\n\n具體字幕和視頻合成效果的測試結果圖片,請參考 [TED 視頻測試](./test.md)\n\n## 🚀 快速開始\n\n### Windows 用戶\n\n#### 方式一:使用打包程式(推薦)\n\n軟體較為輕量,打包大小不足 60M,已集成所有必要環境,下載後可直接運行。\n\n1. 從 [Release](https://github.com/WEIFENG2333/VideoCaptioner/releases) 頁面下載最新版本的可執行程式。或者:[藍奏盤下載](https://wwwm.lanzoue.com/ii14G2pdsbej)\n\n2. 打開安裝包進行安裝\n\n3. LLM API 配置(用於字幕斷句、校正),可使用[本項目的中轉站](https://api.videocaptioner.cn)\n\n4. 翻譯配置,選擇是否啟用翻譯,翻譯服務(預設使用微軟翻譯,質量一般,推薦配置自己的 API KEY 使用大模型翻譯)\n\n5. 語音識別配置(預設使用B介面網路調用語音識別服務,中英以外的語言請使用本地轉錄)\n\n### macOS 用戶\n\n#### 一鍵安裝運行(推薦)\n\n```bash\n# 方式一:直接運行(自動安裝 uv、克隆項目、安裝相關依賴)\ncurl -fsSL https://raw.githubusercontent.com/WEIFENG2333/VideoCaptioner/main/scripts/run.sh | bash\n\n# 方式二:先克隆再運行\ngit clone https://github.com/WEIFENG2333/VideoCaptioner.git\ncd VideoCaptioner\n./scripts/run.sh\n```\n\n腳本會自動:\n\n1. 安裝 [uv](https://docs.astral.sh/uv/) 套件管理器(如果未安裝)\n2. 克隆項目到 `~/VideoCaptioner`(如果不在項目目錄中運行)\n3. 安裝所有 Python 依賴\n4. 啟動應用\n\n\n\n
\n\n### 開發者指南\n\n```bash\n# 安裝依賴(包括開發依賴)\nuv sync\n\n# 運行應用\nuv run python main.py\n\n# 類型檢查\nuv run pyright\n\n# 代碼檢查\nuv run ruff check .\n```\n\n## 基本配置\n\n### 1. LLM API 配置說明\n\nLLM 大模型是用來字幕斷句、字幕優化、以及字幕翻譯(如果選擇了LLM 大模型翻譯)。\n\n| 配置項 | 說明 |\n| -------------- | ------------------------------------------------------------------------------------------------------------------------------------------------- |\n| SiliconCloud | [SiliconCloud 官網](https://cloud.siliconflow.cn/i/onCHcaDx)配置方法請參考[配置文檔](https://weifeng2333.github.io/VideoCaptioner/config/llm)手動安裝步驟
\n\n#### 1. 安裝 uv 套件管理器\n\n```bash\ncurl -LsSf https://astral.sh/uv/install.sh | sh\n```\n\n#### 2. 安裝系統依賴(macOS)\n\n```bash\nbrew install ffmpeg\n```\n\n#### 3. 克隆並運行\n\n```bash\ngit clone https://github.com/WEIFENG2333/VideoCaptioner.git\ncd VideoCaptioner\nuv sync # 安裝依賴\nuv run python main.py # 運行\n```\n\n該並發較低,建議把線程設置為5以下。 |\n| DeepSeek | [DeepSeek 官網](https://platform.deepseek.com),建議使用 `deepseek-v3` 模型。 |\n| OpenAI兼容介面 | 如果有其他服務商的API,可直接在軟體中填寫。base_url 和api_key [VideoCaptioner API](https://api.videocaptioner.cn) |\n\n注:如果用的 API 服務商不支持高並發,請在軟體設置中將「線程數」調低,避免請求錯誤。\n\n---\n\n如果希望高並發,或者希望在軟體內使用 OpenAI 或者 Claude 等優質大模型進行字幕校正和翻譯。\n\n可使用本項目的✨LLM API中轉站✨: [https://api.videocaptioner.cn](https://api.videocaptioner.cn)\n\n其支持高並發,性價比極高,且有國內外大量模型可挑選。\n\n註冊獲取key之後,設置中按照下面配置:\n\nBaseURL: `https://api.videocaptioner.cn/v1`\n\nAPI-key: `個人中心-API 令牌頁面自行獲取。`\n\n💡 模型選擇建議 (本人在各質量層級中精選出的高性價比模型):\n\n- 高質量之選: `gemini-3-pro`、`claude-sonnet-4-5-20250929` (耗費比例:3)\n\n- 較高質量之選: `gpt-5-2025-08-07`、 `claude-haiku-4-5-20251001` (耗費比例:1.2)\n\n- 中質量之選: `gpt-5-mini`、`gemini-3-flash` (耗費比例:0.3)\n\n本站支持超高並發,軟體中線程數直接拉滿即可~ 處理速度非常快~\n\n更詳細的API配置教程:[中轉站配置](https://weifeng2333.github.io/VideoCaptioner/config/llm)\n\n---\n\n## 2. 翻譯配置\n\n| 配置項 | 說明 |\n| -------------- | ----------------------------------------------------------------------------------------------------------------------------- |\n| LLM 大模型翻譯 | 🌟 翻譯質量最好的選擇。使用 AI 大模型進行翻譯,能更好理解上下文,翻譯更自然。需要在設置中配置 LLM API(比如 OpenAI、DeepSeek 等) |\n| 微軟翻譯 | 使用微軟的翻譯服務,速度非常快 |\n| 谷歌翻譯 | 谷歌的翻譯服務,速度快,但需要能訪問谷歌的網路環境 |\n\n推薦使用 `LLM 大模型翻譯` ,翻譯質量最好。\n\n### 3. 語音識別介面說明\n\n| 介面名稱 | 支持語言 | 運行方式 | 說明 |\n| ---------------- | -------------------------------------------------- | -------- | ----------------------------------------------------------------------------------------------------------------- |\n| B介面 | 僅支持中文、英文 | 線上 | 免費、速度較快 |\n| J介面 | 僅支持中文、英文 | 線上 | 免費、速度較快 |\n| WhisperCpp | 中文、日語、韓語、英文等 99 種語言,外語效果較好 | 本地 | (實際使用不穩定)需要下載轉錄模型
中文建議medium以上模型
英文等使用較小模型即可達到不錯效果。 |\n| fasterWhisper 👍 | 中文、英文等多99種語言,外語效果優秀,時間軸更準確 | 本地 | (🌟推薦🌟)需要下載程式和轉錄模型
支持CUDA,速度更快,轉錄準確。
超級準確的時間戳字幕。
僅支持 Windows |\n\n### 4. 本地 Whisper 語音識別模型\n\nWhisper 版本有 WhisperCpp 和 fasterWhisper(推薦) 兩種,後者效果更好,都需要自行在軟體內下載模型。\n\n| 模型 | 磁碟空間 | 記憶體佔用 | 說明 |\n| ----------- | -------- | -------- | ----------------------------------- |\n| Tiny | 75 MiB | ~273 MB | 轉錄很一般,僅用於測試 |\n| Small | 466 MiB | ~852 MB | 英文識別效果已經不錯 |\n| Medium | 1.5 GiB | ~2.1 GB | 中文識別建議至少使用此版本 |\n| Large-v2 👍 | 2.9 GiB | ~3.9 GB | 效果好,配置允許情況推薦使用 |\n| Large-v3 | 2.9 GiB | ~3.9 GB | 社區反饋可能會出現幻覺/字幕重複問題 |\n\n推薦模型: `Large-v2` 穩定且質量較好。\n\n\n### 5. 文稿匹配\n\n- 在「字幕優化與翻譯」頁面,包含「文稿匹配」選項,支持以下**一種或者多種**內容,輔助校正字幕和翻譯:\n\n| 類型 | 說明 | 填寫示例 |\n| ---------- | ------------------------------------ | ------------------------------------------------------------------------------------------------------------------------------------------------------- |\n| 術語表 | 專業術語、人名、特定詞語的修正對照表 | 機器學習->Machine Learning
馬斯克->Elon Musk
打call -> 應援
圖靈斑圖
公車悖論 |\n| 原字幕文稿 | 視頻的原有文稿或相關內容 | 完整的演講稿、課程講義等 |\n| 修正要求 | 內容相關的具體修正要求 | 統一人稱代詞、規範專業術語等
填寫**內容相關**的要求即可,[示例參考](https://github.com/WEIFENG2333/VideoCaptioner/issues/59#issuecomment-2495849752) |\n\n- 如果需要文稿進行字幕優化輔助,全流程處理時,先填寫文稿資訊,再進行開始任務處理\n- 注意: 使用上下文參數量不高的小型LLM模型時,建議控制文稿內容在1千字內,如果使用上下文較大的模型,則可以適當增加文稿內容。\n\n無特殊需求,可不填寫。\n\n### 6. Cookie 配置說明\n\n如果使用URL下載功能時,如果遇到以下情況:\n\n1. 下載視頻網站需要登入資訊才可以下載;\n2. 只能下載較低解析度的視頻;\n3. 網路條件較差時需要驗證;\n\n- 請參考 [Cookie 配置說明](https://weifeng2333.github.io/VideoCaptioner/guide/cookies-config) 獲取Cookie資訊,並將cookies.txt檔案放置到軟體安裝目錄的 `AppData` 目錄下,即可正常下載高質量視頻。\n\n## 軟體流程介紹\n\n程式簡單的處理流程如下:\n\n```\n語音識別轉錄 -> 字幕斷句(可選) -> 字幕優化翻譯(可選) -> 字幕視頻合成\n```\n\n## 軟體主要功能\n\n軟體利用大語言模型(LLM)在理解上下文方面的優勢,對語音識別生成的字幕進一步處理。有效修正錯別字、統一專業術語,讓字幕內容更加準確連貫,為用戶帶來出色的觀看體驗!\n\n#### 1. 多平台視頻下載與處理\n\n- 支持國內外主流視頻平台(B站、Youtube、小紅書、TikTok、X、西瓜視頻、抖音等)\n- 自動提取視頻原有字幕處理\n\n#### 2. 專業的語音識別引擎\n\n- 提供多種介面線上識別,效果媲美剪映(免費、高速)\n- 支持本地Whisper模型(保護隱私、可離線)\n\n#### 3. 字幕智能糾錯\n\n- 自動優化專業術語、代碼片段和數學公式格式\n- 上下文進行斷句優化,提升閱讀體驗\n- 支持文稿提示,使用原有文稿或者相關提示優化字幕斷句\n\n#### 4. 高質量字幕翻譯\n\n- 結合上下文的智能翻譯,確保譯文兼顧全文\n- 透過Prompt指導大模型反思翻譯,提升翻譯質量\n- 使用序列模糊匹配算法、保證時間軸完全一致\n\n#### 5. 字幕樣式調整\n\n- 豐富的字幕樣式模板(科普風、新聞風、番劇風等等)\n- 多種格式字幕視頻(SRT、ASS、VTT、TXT)\n\n項目主要目錄結構說明如下:\n\n```\nVideoCaptioner/\n├── app/ # 應用源代碼目錄\n│ ├── common/ # 公共模組(配置、信號匯流排)\n│ ├── components/ # UI 元件\n│ ├── core/ # 核心業務邏輯(ASR、翻譯、優化等)\n│ ├── thread/ # 異步線程\n│ └── view/ # 介面視圖\n├── resource/ # 資源檔案目錄\n│ ├── assets/ # 圖示、Logo 等\n│ ├── bin/ # 二進制程式(FFmpeg、Whisper 等)\n│ ├── fonts/ # 字體檔案\n│ ├── subtitle_style/ # 字幕樣式模板\n│ └── translations/ # 多語言翻譯檔案\n├── work-dir/ # 工作目錄(處理完成的視頻和字幕)\n├── AppData/ # 應用資料目錄\n│ ├── cache/ # 快取目錄(轉錄、LLM 請求)\n│ ├── models/ # Whisper 模型檔案\n│ ├── logs/ # 日誌檔案\n│ └── settings.json # 用戶設置\n├── scripts/ # 安裝和運行腳本\n├── main.py # 程式入口\n└── pyproject.toml # 項目配置和依賴\n```\n\n## 📝 說明\n\n1. 字幕斷句的質量對觀看體驗至關重要。軟體能將逐字字幕智能重組為符合自然語言習慣的段落,並與視頻畫面完美同步。\n\n2. 在處理過程中,僅向大語言模型發送文本內容,不包含時間軸資訊,這大大降低了處理開銷。\n\n3. 在翻譯環節,我們採用吳恩達提出的「翻譯-反思-翻譯」方法論。這種迭代優化的方式確保了翻譯的準確性。\n\n4. 填入 YouTube 連結時進行處理時,會自動下載視頻的字幕,從而省去轉錄步驟,極大地節省操作時間。\n\n## 🤝 貢獻指南\n\n項目在不斷完善中,如果在使用過程遇到的Bug,歡迎提交 [Issue](https://github.com/WEIFENG2333/VideoCaptioner/issues) 和 Pull Request 幫助改進項目。\n\n## 📝 更新日誌\n\n查看完整的更新歷史,請訪問 [CHANGELOG.md](../CHANGELOG.md)\n\n## ⭐ Star History\n\n[](https://star-history.com/#WEIFENG2333/VideoCaptioner&Date)\n\n## 💖 支持作者\n\n如果覺得項目對你有幫助,可以給項目點個Star!\n\n
\n
\n"
},
{
"path": "legacy-docs/about_chunk_merge.md",
"content": "\nhttps://github.com/groq/groq-api-cookbook/blob/main/tutorials/audio-chunking/audio_chunking_tutorial.ipynb"
},
{
"path": "legacy-docs/get_cookies.md",
"content": "# Cookie 配置说明\n\n## 问题说明\n在使用软件下载视频时,可能会遇到以下错误提示:\n\n\n\n这是因为:\n1. 某些视频平台(如B站)需要用户登录信息才能获取高质量视频\n2. 部分网站(如YouTube)在网络条件较差时需要验证用户身份\n\n## 解决方法\n\n### 1. 安装浏览器扩展\n根据你使用的浏览器选择安装:\n\n- Chrome浏览器: [Get CookieTxt Locally](https://chromewebstore.google.com/detail/get-cookiestxt-locally/cclelndahbckbenkjhflpdbgdldlbecc)\n- Edge浏览器: [Export Cookies File](https://microsoftedge.microsoft.com/addons/detail/export-cookies-file/hbglikhfdcfhdfikmocdflffaecbnedo)\n\n### 2. 导出Cookie文件\n1. 登录需要下载视频的网站(如B站、YouTube等)\n2. 点击浏览器扩展图标\n3. 选择\"Export Cookies\"选项\n4. 将导出的cookies.txt文件保存到软件的AppData目录下\n\n\n\n### 3. 确认文件位置\n完成后的目录结构应如下:\n\n```\n├─AppData\n│ ├─cache\n│ ├─logs\n│ ├─models\n│ ├─cookies.txt # Cookie文件\n│ └─settings.json\n \n```\n"
},
{
"path": "legacy-docs/llm_config.md",
"content": "\n目前国内多家大模型厂商都提供了API接口,可以自行申请。也可以使用中转站,使用 OpenAI 或 Claude的API。\n\n本教程以两种配置方式为例进行说明:\n\n[SiliconFlow-API 配置](./llm_config.md#SiliconFlow-API-配置)\n\n[中转站配置](./llm_config.md#中转站配置)\n\n\n# SiliconFlow-API 配置\n\n1. 申请大模型API\n\n这里以国内的 [SiliconCloud](https://cloud.siliconflow.cn/i/onCHcaDx) 的 API 为例子,其已经集合国内多家大模型厂商。(注意以上是我的推广链接,通过此可以获得14元额度,介意就百度自行搜索注册,非广告)\n\n\n\n注册后,在[设置](https://cloud.siliconflow.cn/account/ak)中获取API Key。\n\n\n\nAPI 接口地址: https://api.siliconflow.cn/v1 (需要添加 /v1)\n\nAPI Key: 将 SiliconCloud 平台的密钥粘贴到此处。\n\n点击检查连接,“模型”设置栏会自动填充所有支持的模型名称。\n\n选择需要的模型名称,推荐:deepseek-ai/DeepSeek-V3\n\n> 2025 年 2 月 6 日起,未实名用户每日最多请求此模型 100 次\n\n根据官方要求该模型需要实名才能获取更多的调用次数。不想实名可以考虑使用其他中转站。\n\n`线程数 (Thread Count)`: SiliconCloud 并发有限,推荐只设置 5 个线程或以下。\n\n\n# 中转站配置\n\n1. 先在 [本项目的中转站](https://api.videocaptioner.cn/register?aff=UrLB) 注册账号\n,通过此链接注册默认赠送 $0.4 测试余额。\n\n2. 然后获取 API Key: [https://api.videocaptioner.cn/token](https://api.videocaptioner.cn/token)\n\n3. 在软件设置中配置 API Key 和 API 接口地址, 如下图:\n\n\n\nBaseURL: `https://api.videocaptioner.cn/v1`\n\nAPI-key: `上面获取的API Key`\n\n💡 模型选择建议 (本人在各质量层级中选出的高性价比模型): \n\n - 高质量之选: `claude-3-5-sonnet-20241022` (耗费比例:3) \n\n - 较高质量之选: `gemini-2.0-flash`、`deepseek-chat` (耗费比例:1) \n\n - 中质量之选: `gpt-4o-mini`、`gemini-1.5-flash` (耗费比例:0.15) \n\n`线程数 (Thread Count)`: 本站支持超高并发,软件中线程数直接拉满即可~ 处理速度非常快~\n\n> PS: 条件差一点的可直接使用 `gpt-4o-mini`, 便宜且速度快。这个模型也花不了几个钱的,建议不要折腾本地部署了。\n\n\n\n\n"
},
{
"path": "legacy-docs/test.md",
"content": "### 使用 Whisper 转录\n\n\n### 转录成功以后的字幕\n```\n1\n00:00:02,080 --> 00:00:08,600\nSo in college, I was a government major,\n\n2\n00:00:08,600 --> 00:00:11,080\nwhich means I had to write a lot of papers.\n\n3\n00:00:11,080 --> 00:00:12,600\nNow, when a normal student writes a paper,\n\n4\n00:00:12,600 --> 00:00:15,460\nthey might spread the work out a little like this.\n\n5\n00:00:15,460 --> 00:00:16,300\nSo you know.\n\n6\n00:00:16,300 --> 00:00:20,040\nYou get started maybe a little slowly,\n\n7\n00:00:20,040 --> 00:00:21,600\nbut you get enough done in the first week\n\n8\n00:00:21,600 --> 00:00:24,000\nthat with some heavier days later on,\n\n9\n00:00:24,000 --> 00:00:26,200\neverything gets done and things stay civil.\n\n10\n00:00:26,200 --> 00:00:29,840\nAnd I would wanna do that like that.\n\n11\n00:00:29,840 --> 00:00:30,840\nThat would be the plan.\n\n12\n00:00:30,840 --> 00:00:33,580\nI would have it all ready to go,\n\n13\n00:00:33,580 --> 00:00:36,120\nbut then actually the paper would come along\n\n14\n00:00:36,120 --> 00:00:37,720\nand then I would kinda do this.\n\n15\n00:00:40,480 --> 00:00:43,280\nAnd that would happen to every single paper.\n\n16\n00:00:43,280 --> 00:00:47,240\nBut then came my 90 page senior thesis,\n\n17\n00:00:47,240 --> 00:00:49,580\na paper you're supposed to spend a year on.\n\n18\n00:00:49,580 --> 00:00:52,320\nI knew for a paper like that, my normal workflow\n\n19\n00:00:52,320 --> 00:00:54,580\nwas not an option, it was way too big a project.\n\n20\n00:00:54,580 --> 00:00:56,580\nSo I planned things out and I decided\n\n21\n00:00:56,580 --> 00:00:59,520\nI kinda had to go something like this.\n\n```\n\n### 进行断句与字幕的优化翻译\n```\n1\n00:00:02,080 --> 00:00:08,597\n所以在大学时,我是政府专业的学生\nSo in college, I was a government major.\n\n2\n00:00:08,600 --> 00:00:11,078\n这意味着我得写很多论文\nWhich means I had to write a lot of papers.\n\n3\n00:00:11,080 --> 00:00:12,596\n现在,普通学生写论文时\nNow when a normal student writes a paper,\n\n4\n00:00:12,600 --> 00:00:15,460\n他们可能会这样分散工作\nThey might spread the work out a little like this.\n\n5\n00:00:15,460 --> 00:00:20,040\n所以你知道,你可能会稍微慢一些开始\nSo you know, you get started maybe a little slowly,\n\n6\n00:00:20,040 --> 00:00:21,593\n但你在第一周能够完成足够的工作\nBut you get enough done in the first week.\n\n7\n00:00:21,600 --> 00:00:23,996\n这样之后的一些繁忙日子\nThat with some heavier days later on.\n\n8\n00:00:24,000 --> 00:00:26,200\n一切都能完成,事情保持得当\nEverything gets done and things stay civil.\n\n9\n00:00:26,200 --> 00:00:29,840\n我也希望那样去做\nAnd I would wanna do that like that.\n\n10\n00:00:29,840 --> 00:00:31,936\n那将是我的计划\nThat would be the plan I would have.\n\n11\n00:00:31,936 --> 00:00:35,059\n一切都准备好了,但实际上论文却并没有完成\nIt was all ready to go, but then actually the paper\n\n```\n\n### 最终合成视频\n\n\n\n\n\n\n### 查看日志\n```\n原字幕:So in college, I was a government major.\n翻译后字幕:所以在大学时,我是一个政府专业的学生。\n反思后字幕:所以在大学时,我是政府专业的学生。\n===========\n原字幕:Which means I had to write a lot of papers.\n翻译后字幕:这意味着我必须写很多论文。\n反思后字幕:这意味着我得写很多论文。\n===========\n原字幕:Now when a normal student writes a paper,\n翻译后字幕:现在,当一个普通学生写论文时,\n反思后字幕:现在,普通学生写论文时,\n===========\n原字幕:They might spread the work out a little like this.\n翻译后字幕:他们可能会像这样分散工作。\n反思后字幕:他们可能会这样分散工作。\n===========\n原字幕:So you know, you get started maybe a little slowly,\n翻译后字幕:所以你知道,你可能会开始得有点慢,\n反思后字幕:所以你知道,你可能会稍微慢一些开始,\n===========\n原字幕:But you get enough done in the first week,\n翻译后字幕:但你在第一周能完成足够的工作,\n反思后字幕:但你在第一周能够完成足够的工作,\n===========\n原字幕:That with some heavier days later on,\n翻译后字幕:这样之后几天会比较忙,\n反思后字幕:这样之后的一些繁忙日子,\n===========\n原字幕:Everything gets done and things stay civil.\n翻译后字幕:所有事情都能完成,事情保持得体。\n反思后字幕:一切都能完成,事情保持得当。\n===========\n原字幕:And I would wanna do that like that.\n翻译后字幕:而我想要那样做。\n反思后字幕:我也希望那样去做。\n===========\n原字幕:That would be the plan I would have.\n翻译后字幕:那是我会有的计划。\n反思后字幕:那将是我的计划。\n\n```\n\n### 查看大模型调用情况\n\n本次字幕的优化翻译调用了大模型,进入服务商后台查看\n\n调用花费的Tokens很少,消耗金额仅仅 ¥0.01 (OpenAI 官方价格计费,使用一些中转站的逆向模型花费更少)\n\n\n"
},
{
"path": "main.py",
"content": "\"\"\"\nCopyright (c) 2024 [VideoCaptioner]\nAll rights reserved.\n\nAuthor: Weifeng\n\"\"\"\n\nimport os\nimport platform\nimport sys\nimport traceback\n\nfrom app.config import TRANSLATIONS_PATH\n\n# Add project root directory to Python path\nproject_root = os.path.dirname(os.path.abspath(__file__))\nsys.path.append(project_root)\n\n# Use appropriate library folder name based on OS\nlib_folder = \"Lib\" if platform.system() == \"Windows\" else \"lib\"\nplugin_path = os.path.join(\n sys.prefix, lib_folder, \"site-packages\", \"PyQt5\", \"Qt5\", \"plugins\"\n)\nos.environ[\"QT_QPA_PLATFORM_PLUGIN_PATH\"] = plugin_path\n\n# Delete pyd files app*.pyd\nfor file in os.listdir():\n if file.startswith(\"app\") and file.endswith(\".pyd\"):\n os.remove(file)\n\n# Now import the modules that depend on the setup above\nfrom PyQt5.QtCore import Qt, QTranslator # noqa: E402\nfrom PyQt5.QtWidgets import QApplication # noqa: E402\nfrom qfluentwidgets import FluentTranslator # noqa: E402\n\nfrom app.common.config import cfg # noqa: E402\nfrom app.config import RESOURCE_PATH # noqa: E402\nfrom app.core.utils.cache import disable_cache, enable_cache # noqa: E402\nfrom app.core.utils.logger import setup_logger # noqa: E402\nfrom app.view.main_window import MainWindow # noqa: E402\n\nlogger_instance = setup_logger(\"VideoCaptioner\")\n\n\ndef exception_hook(exctype, value, tb):\n logger_instance.error(\"\".join(traceback.format_exception(exctype, value, tb)))\n sys.__excepthook__(exctype, value, tb) # 调用默认的异常处理\n\n\nsys.excepthook = exception_hook\n\n# 应用缓存配置\nif cfg.get(cfg.cache_enabled):\n enable_cache()\nelse:\n disable_cache()\n\n\n# Enable DPI Scale\nif cfg.get(cfg.dpiScale) == \"Auto\":\n QApplication.setHighDpiScaleFactorRoundingPolicy(\n Qt.HighDpiScaleFactorRoundingPolicy.PassThrough # type: ignore\n )\n QApplication.setAttribute(Qt.AA_EnableHighDpiScaling, True) # type: ignore\nelse:\n os.environ[\"QT_ENABLE_HIGHDPI_SCALING\"] = \"0\"\n os.environ[\"QT_SCALE_FACTOR\"] = str(cfg.get(cfg.dpiScale))\nQApplication.setAttribute(Qt.AA_UseHighDpiPixmaps, True) # type: ignore\n\napp = QApplication(sys.argv)\napp.setAttribute(Qt.AA_DontCreateNativeWidgetSiblings, True) # type: ignore\n\n# Internationalization\nlocale = cfg.get(cfg.language).value\ntranslator = FluentTranslator(locale)\nmyTranslator = QTranslator()\ntranslations_path = TRANSLATIONS_PATH / f\"VideoCaptioner_{locale.name()}.qm\"\nmyTranslator.load(str(translations_path))\napp.installTranslator(translator)\napp.installTranslator(myTranslator)\n\n\ndef main():\n w = MainWindow()\n w.show()\n sys.exit(app.exec_())\n\n\nif __name__ == \"__main__\":\n main()\n"
},
{
"path": "pyproject.toml",
"content": "[project]\nname = \"videocaptioner\"\nversion = \"1.3.3\"\ndescription = \"AI-powered video captioning tool based on LLM\"\nreadme = \"README.md\"\nlicense = { text = \"GPL-3.0\" }\nauthors = [{ name = \"Weifeng\" }]\nrequires-python = \">=3.10,<3.13\"\nkeywords = [\"video\", \"caption\", \"subtitle\", \"asr\", \"llm\", \"translation\"]\nclassifiers = [\n \"Development Status :: 4 - Beta\",\n \"Environment :: X11 Applications :: Qt\",\n \"Intended Audience :: End Users/Desktop\",\n \"License :: OSI Approved :: GNU General Public License v3 (GPLv3)\",\n \"Operating System :: OS Independent\",\n \"Programming Language :: Python :: 3\",\n \"Programming Language :: Python :: 3.10\",\n \"Programming Language :: Python :: 3.11\",\n \"Programming Language :: Python :: 3.12\",\n \"Topic :: Multimedia :: Video\",\n]\ndependencies = [\n \"requests>=2.32.4\",\n \"openai>=1.97.1\",\n \"diskcache>=5.6.3\",\n \"PyQt5==5.15.11\",\n \"PyQt-Fluent-Widgets==1.8.4\",\n \"yt-dlp>=2025.7.21\",\n \"modelscope>=1.32.0\",\n \"psutil>=7.0.0\",\n \"json-repair>=0.49.0\",\n \"langdetect>=1.0.9\",\n \"pydub>=0.25.1\",\n \"tenacity>=8.2.0\",\n \"GPUtil>=1.4.0\",\n \"pillow>=12.0.0\",\n \"fonttools>=4.61.1\",\n]\n\n[project.urls]\nHomepage = \"https://github.com/WEIFENG2333/VideoCaptioner\"\nRepository = \"https://github.com/WEIFENG2333/VideoCaptioner\"\nIssues = \"https://github.com/WEIFENG2333/VideoCaptioner/issues\"\n\n[project.scripts]\nvideocaptioner = \"main:main\"\n\n[build-system]\nrequires = [\"hatchling\"]\nbuild-backend = \"hatchling.build\"\n\n[tool.hatch.build.targets.wheel]\npackages = [\"app\"]\n\n[tool.uv]\n# 为不同平台分别解析依赖(PyQt5-Qt5 版本因平台而异)\nenvironments = [\n \"sys_platform == 'win32'\",\n \"sys_platform == 'darwin'\",\n \"sys_platform == 'linux'\",\n]\n# 覆盖 PyQt5-Qt5 版本:Windows 用 5.15.2,其他平台用最新版\noverride-dependencies = [\n \"PyQt5-Qt5==5.15.2; sys_platform == 'win32'\",\n \"PyQt5-Qt5>=5.15.11; sys_platform != 'win32'\",\n]\ndev-dependencies = [\n \"pyright>=1.1.0\",\n \"ruff>=0.4.0\",\n \"pytest>=8.0.0\",\n]\n\n[tool.pyright]\nvenvPath = \".\"\nvenv = \".venv\"\npythonVersion = \"3.12\"\ntypeCheckingMode = \"basic\"\ninclude = [\"app\", \"main.py\"]\nexclude = [\n \"**/__pycache__\",\n \"**/.pytest_cache\",\n \".venv\",\n \"venv\",\n \"build\",\n \"dist\",\n \"work-dir\",\n \"AppData\",\n \"resource\",\n \"**/node_modules\"\n]\n# 导入相关\nreportMissingImports = \"warning\"\nreportMissingTypeStubs = false\n# 类型检查级别(降低严格度)\nreportGeneralTypeIssues = false\nreportOptionalOperand = \"warning\"\nreportOptionalMemberAccess = false\nreportArgumentType = \"warning\"\n# 禁用的检查\nreportCallIssue = false\nreportUnknownMemberType = false\nreportUnknownArgumentType = false\nreportUnknownVariableType = false\nreportUnknownParameterType = false\nreportUnusedImport = \"warning\"\nreportUnusedVariable = \"warning\"\n\n[tool.pytest.ini_options]\ntestpaths = [\"tests\"]\npython_files = [\"test_*.py\"]\npython_classes = [\"Test*\"]\npython_functions = [\"test_*\"]\naddopts = \"-v --strict-markers --tb=short --disable-warnings\"\nmarkers = [\n \"integration: Integration tests that require external services\",\n \"slow: Slow running tests\",\n \"llm: Tests that require LLM API access\",\n \"translator: Tests for translation modules\",\n]\nlog_cli = true\nlog_cli_level = \"INFO\"\nlog_cli_format = \"%(asctime)s [%(levelname)8s] %(message)s\"\nlog_cli_date_format = \"%Y-%m-%d %H:%M:%S\"\n\n[tool.ruff]\nline-length = 100\ntarget-version = \"py310\"\n\n[tool.ruff.lint]\nselect = [\"E\", \"F\", \"I\", \"W\"]\nignore = [\"E501\"]\n"
},
{
"path": "resource/assets/qss/dark/demo.qss",
"content": "QWidget {\n border: 1px solid rgb(29, 29, 29);\n border-right: none;\n border-bottom: none;\n border-top-left-radius: 10px;\n background-color: rgb(39, 39, 39);\n}\n\nWindow {\n background-color: rgb(32, 32, 32);\n}"
},
{
"path": "resource/assets/qss/light/demo.qss",
"content": "Widget > QLabel {\n font: 24px 'Segoe UI', 'Microsoft YaHei';\n}\n\nWidget {\n border: 1px solid rgb(229, 229, 229);\n border-right: none;\n border-bottom: none;\n border-top-left-radius: 10px;\n background-color: rgb(249, 249, 249);\n}\n\nWindow {\n background-color: rgb(243, 243, 243);\n}\n\n"
},
{
"path": "resource/subtitle_style/default.json",
"content": "{\n \"font_name\": \"LXGW WenKai\",\n \"font_size\": 32,\n \"text_color\": \"#000000\",\n \"bg_color\": \"#0de3ffe5\",\n \"corner_radius\": 14,\n \"padding_h\": 24,\n \"padding_v\": 18,\n \"margin_bottom\": 40,\n \"line_spacing\": 12,\n \"letter_spacing\": 1\n}"
},
{
"path": "resource/subtitle_style/default.txt",
"content": "[V4+ Styles]\nFormat: Name,Fontname,Fontsize,PrimaryColour,SecondaryColour,OutlineColour,BackColour,Bold,Italic,Underline,StrikeOut,ScaleX,ScaleY,Spacing,Angle,BorderStyle,Outline,Shadow,Alignment,MarginL,MarginR,MarginV,Encoding\nStyle: Default,Arial,42,&H005aff65,&H000000FF,&H00000000,&H00000000,-1,0,0,0,100,100,3.2,0,1,2.0,0,2,10,10,30,1,\\q1\nStyle: Secondary,Arial,30,&H00ffffff,&H000000FF,&H00000000,&H00000000,-1,0,0,0,100,100,0.8,0,1,2.0,0,2,10,10,30,1,\\q1"
},
{
"path": "resource/subtitle_style/毕导科普风.txt",
"content": "[V4+ Styles]\nFormat: Name,Fontname,Fontsize,PrimaryColour,SecondaryColour,OutlineColour,BackColour,Bold,Italic,Underline,StrikeOut,ScaleX,ScaleY,Spacing,Angle,BorderStyle,Outline,Shadow,Alignment,MarginL,MarginR,MarginV,Encoding\nStyle: Default,微软雅黑,44,&H00e6e8f1,&H000000FF,&H00060606,&H00000000,-1,0,0,0,100,100,3.0,0,1,2.2,0,2,10,10,32,1,\\q1\nStyle: Secondary,微软雅黑,28,&H00ffffff,&H000000FF,&H00000000,&H00000000,-1,0,0,0,100,100,0.2,0,1,2.0,0,2,10,10,32,1,\\q1"
},
{
"path": "resource/subtitle_style/番剧可爱风.txt",
"content": "[V4+ Styles]\nFormat: Name,Fontname,Fontsize,PrimaryColour,SecondaryColour,OutlineColour,BackColour,Bold,Italic,Underline,StrikeOut,ScaleX,ScaleY,Spacing,Angle,BorderStyle,Outline,Shadow,Alignment,MarginL,MarginR,MarginV,Encoding\nStyle: Default,微软雅黑,46,&H00e6e8f1,&H000000FF,&H000987f5,&H00000000,-1,0,0,0,100,100,2.6,0,1,2.6,0,2,10,10,20,1,\\q1\nStyle: Secondary,微软雅黑,26,&H00ffffff,&H000000FF,&H000987f5,&H00000000,-1,0,0,0,100,100,0.0,0,1,2.0,0,2,10,10,20,1,\\q1"
},
{
"path": "resource/subtitle_style/竖屏.txt",
"content": "[V4+ Styles]\nFormat: Name,Fontname,Fontsize,PrimaryColour,SecondaryColour,OutlineColour,BackColour,Bold,Italic,Underline,StrikeOut,ScaleX,ScaleY,Spacing,Angle,BorderStyle,Outline,Shadow,Alignment,MarginL,MarginR,MarginV,Encoding\nStyle: Default,微软雅黑,34,&H005aff65,&H000000FF,&H00000000,&H00000000,-1,0,0,0,100,100,4.0,0,1,2.0,0,2,10,10,182,1,\\q1\nStyle: Secondary,微软雅黑,18,&H00ffffff,&H000000FF,&H00000000,&H00000000,-1,0,0,0,100,100,0.8,0,1,2.0,0,2,10,10,182,1,\\q1"
},
{
"path": "resource/translations/VideoCaptioner_en_US.ts",
"content": "\n捐助支持
\n\n \n \n
\n\n \n\" in user_content or \"separate\" in user_content.lower():\n # Split request - return text with
tags\n text_to_split = user_content.split(\"sentence:\\n\")[-1].strip()\n\n # Extract max length from system prompt\n import re\n\n max_cjk = 18 # default\n max_eng = 12 # default\n if \"max\" in system_content.lower():\n cjk_match = re.search(r\"中文.*?(\\d+)\", system_content)\n if cjk_match:\n max_cjk = int(cjk_match.group(1))\n eng_match = re.search(r\"英文.*?(\\d+)\", system_content)\n if eng_match:\n max_eng = int(eng_match.group(1))\n\n # Split by punctuation first\n sentences = re.split(r\"([。!?\\.!?])\", text_to_split)\n initial_parts = []\n for i in range(0, len(sentences) - 1, 2):\n if i + 1 < len(sentences):\n initial_parts.append(sentences[i] + sentences[i + 1])\n if len(sentences) % 2 == 1 and sentences[-1].strip():\n initial_parts.append(sentences[-1])\n\n # Further split long segments\n from app.core.utils.text_utils import count_words, is_mainly_cjk\n\n result_parts = []\n for part in initial_parts:\n part = part.strip()\n if not part:\n continue\n\n word_count = count_words(part)\n max_limit = max_cjk if is_mainly_cjk(part) else max_eng\n\n if word_count <= max_limit:\n result_parts.append(part)\n else:\n # Split long part into smaller chunks\n words = list(part) if is_mainly_cjk(part) else part.split()\n chunk = []\n for word in words:\n chunk.append(word)\n if (\n count_words(\n \"\".join(chunk)\n if is_mainly_cjk(part)\n else \" \".join(chunk)\n )\n >= max_limit\n ):\n result_parts.append(\n \"\".join(chunk)\n if is_mainly_cjk(part)\n else \" \".join(chunk)\n )\n chunk = []\n if chunk:\n result_parts.append(\n \"\".join(chunk) if is_mainly_cjk(part) else \" \".join(chunk)\n )\n\n response_text = \"
\".join(p for p in result_parts if p)\n elif \"translate\" in system_content.lower() or \"翻译\" in system_content.lower():\n # Translation request - parse JSON input and return translated JSON\n import json\n\n import json_repair\n\n try:\n # Try to parse JSON from user content\n input_dict = json_repair.loads(user_content)\n\n # Create mock translations\n translated_dict = {}\n for key, value in input_dict.items():\n # Simple mock translation: add \"[译]\" prefix\n if (\n \"简体中文\" in system_content\n or \"Simplified Chinese\" in system_content\n ):\n translated_dict[key] = f\"[中文]{value}\"\n elif \"日本語\" in system_content or \"Japanese\" in system_content:\n translated_dict[key] = f\"[日]{value}\"\n else:\n translated_dict[key] = f\"[译]{value}\"\n\n response_text = json.dumps(translated_dict, ensure_ascii=False)\n except Exception:\n # Fallback to simple response\n response_text = '{\"1\": \"Mocked translation\"}'\n elif \"correct\" in system_content.lower() or \"优化\" in system_content.lower():\n # Optimization request - parse JSON input and return optimized JSON\n import json\n\n import json_repair\n\n try:\n # Extract input from user content\n if \"