Showing preview only (933K chars total). Download the full file or copy to clipboard to get everything.
Repository: YelpArchive/elastalert
Branch: master
Commit: e0bbcb5b71e9
Files: 84
Total size: 897.8 KB
Directory structure:
gitextract_1pot3uo0/
├── .editorconfig
├── .gitignore
├── .pre-commit-config.yaml
├── .secrets.baseline
├── .travis.yml
├── Dockerfile-test
├── LICENSE
├── Makefile
├── README.md
├── changelog.md
├── config.yaml.example
├── docker-compose.yml
├── docs/
│ ├── Makefile
│ └── source/
│ ├── _static/
│ │ └── .gitkeep
│ ├── conf.py
│ ├── elastalert.rst
│ ├── elastalert_status.rst
│ ├── index.rst
│ ├── recipes/
│ │ ├── adding_alerts.rst
│ │ ├── adding_enhancements.rst
│ │ ├── adding_loaders.rst
│ │ ├── adding_rules.rst
│ │ ├── signing_requests.rst
│ │ └── writing_filters.rst
│ ├── ruletypes.rst
│ └── running_elastalert.rst
├── elastalert/
│ ├── __init__.py
│ ├── alerts.py
│ ├── auth.py
│ ├── config.py
│ ├── create_index.py
│ ├── elastalert.py
│ ├── enhancements.py
│ ├── es_mappings/
│ │ ├── 5/
│ │ │ ├── elastalert.json
│ │ │ ├── elastalert_error.json
│ │ │ ├── elastalert_status.json
│ │ │ ├── past_elastalert.json
│ │ │ └── silence.json
│ │ └── 6/
│ │ ├── elastalert.json
│ │ ├── elastalert_error.json
│ │ ├── elastalert_status.json
│ │ ├── past_elastalert.json
│ │ └── silence.json
│ ├── kibana.py
│ ├── kibana_discover.py
│ ├── loaders.py
│ ├── opsgenie.py
│ ├── rule_from_kibana.py
│ ├── ruletypes.py
│ ├── schema.yaml
│ ├── test_rule.py
│ ├── util.py
│ └── zabbix.py
├── example_rules/
│ ├── example_cardinality.yaml
│ ├── example_change.yaml
│ ├── example_frequency.yaml
│ ├── example_new_term.yaml
│ ├── example_opsgenie_frequency.yaml
│ ├── example_percentage_match.yaml
│ ├── example_single_metric_agg.yaml
│ ├── example_spike.yaml
│ ├── example_spike_single_metric_agg.yaml
│ ├── jira_acct.txt
│ ├── ssh-repeat-offender.yaml
│ └── ssh.yaml
├── pytest.ini
├── requirements-dev.txt
├── requirements.txt
├── setup.cfg
├── setup.py
├── supervisord.conf.example
├── tests/
│ ├── __init__.py
│ ├── alerts_test.py
│ ├── auth_test.py
│ ├── base_test.py
│ ├── conftest.py
│ ├── create_index_test.py
│ ├── elasticsearch_test.py
│ ├── kibana_discover_test.py
│ ├── kibana_test.py
│ ├── loaders_test.py
│ ├── rules_test.py
│ └── util_test.py
└── tox.ini
================================================
FILE CONTENTS
================================================
================================================
FILE: .editorconfig
================================================
root = true
[*]
end_of_line = lf
insert_final_newline = true
charset = utf-8
[*.py]
indent_style = space
indent_size = 4
[Makefile]
indent_style = tab
[{*.json,*.yml,*.yaml}]
indent_style = space
indent_size = 2
================================================
FILE: .gitignore
================================================
config.yaml
.tox/
.coverage
.idea/*
.cache/
__pycache__/
*.pyc
virtualenv_run/
*.egg-info/
dist/
venv/
env/
docs/build/
build/
.pytest_cache/
my_rules
*.swp
*~
================================================
FILE: .pre-commit-config.yaml
================================================
repos:
- repo: git://github.com/pre-commit/pre-commit-hooks
sha: v1.1.1
hooks:
- id: trailing-whitespace
- id: end-of-file-fixer
- id: autopep8-wrapper
args:
- -i
- --ignore=E265,E309,E501
- id: flake8
- id: check-yaml
- id: debug-statements
- id: requirements-txt-fixer
- id: name-tests-test
- repo: git://github.com/asottile/reorder_python_imports
sha: v0.3.5
hooks:
- id: reorder-python-imports
- repo: git://github.com/Yelp/detect-secrets
sha: 0.9.1
hooks:
- id: detect-secrets
args: ['--baseline', '.secrets.baseline']
exclude: .*tests/.*|.*yelp/testing/.*|\.pre-commit-config\.yaml
================================================
FILE: .secrets.baseline
================================================
{
"exclude_regex": ".*tests/.*|.*yelp/testing/.*|\\.pre-commit-config\\.yaml",
"generated_at": "2018-07-06T22:54:22Z",
"plugins_used": [
{
"base64_limit": 4.5,
"name": "Base64HighEntropyString"
},
{
"hex_limit": 3,
"name": "HexHighEntropyString"
},
{
"name": "PrivateKeyDetector"
}
],
"results": {
".travis.yml": [
{
"hashed_secret": "4f7a1ea04dafcbfee994ee1d08857b8aaedf8065",
"line_number": 14,
"type": "Base64 High Entropy String"
}
]
},
"version": "0.9.1"
}
================================================
FILE: .travis.yml
================================================
language: python
python:
- '3.6'
env:
- TOXENV=docs
- TOXENV=py36
install:
- pip install tox
- >
if [[ -n "${ES_VERSION}" ]] ; then
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-${ES_VERSION}.tar.gz
mkdir elasticsearch-${ES_VERSION} && tar -xzf elasticsearch-${ES_VERSION}.tar.gz -C elasticsearch-${ES_VERSION} --strip-components=1
./elasticsearch-${ES_VERSION}/bin/elasticsearch &
fi
script:
- >
if [[ -n "${ES_VERSION}" ]] ; then
wget -q --waitretry=1 --retry-connrefused --tries=30 -O - http://127.0.0.1:9200
make test-elasticsearch
else
make test
fi
jobs:
include:
- stage: 'Elasticsearch test'
env: TOXENV=py36 ES_VERSION=7.0.0-linux-x86_64
- env: TOXENV=py36 ES_VERSION=6.6.2
- env: TOXENV=py36 ES_VERSION=6.3.2
- env: TOXENV=py36 ES_VERSION=6.2.4
- env: TOXENV=py36 ES_VERSION=6.0.1
- env: TOXENV=py36 ES_VERSION=5.6.16
deploy:
provider: pypi
user: yelplabs
password:
secure: TpSTlFu89tciZzboIfitHhU5NhAB1L1/rI35eQTXstiqzYg2mweOuip+MPNx9AlX3Swg7MhaFYnSUvRqPljuoLjLD0EQ7BHLVSBFl92ukkAMTeKvM6LbB9HnGOwzmAvTR5coegk8IHiegudODWvnhIj4hp7/0EA+gVX7E55kEAw=
on:
tags: true
distributions: sdist bdist_wheel
repo: Yelp/elastalert
branch: master
================================================
FILE: Dockerfile-test
================================================
FROM ubuntu:latest
RUN apt-get update && apt-get upgrade -y
RUN apt-get -y install build-essential python3.6 python3.6-dev python3-pip libssl-dev git
WORKDIR /home/elastalert
ADD requirements*.txt ./
RUN pip3 install -r requirements-dev.txt
================================================
FILE: LICENSE
================================================
Apache License
Version 2.0, January 2004
http://www.apache.org/licenses/
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
1. Definitions.
"License" shall mean the terms and conditions for use, reproduction,
and distribution as defined by Sections 1 through 9 of this document.
"Licensor" shall mean the copyright owner or entity authorized by
the copyright owner that is granting the License.
"Legal Entity" shall mean the union of the acting entity and all
other entities that control, are controlled by, or are under common
control with that entity. For the purposes of this definition,
"control" means (i) the power, direct or indirect, to cause the
direction or management of such entity, whether by contract or
otherwise, or (ii) ownership of fifty percent (50%) or more of the
outstanding shares, or (iii) beneficial ownership of such entity.
"You" (or "Your") shall mean an individual or Legal Entity
exercising permissions granted by this License.
"Source" form shall mean the preferred form for making modifications,
including but not limited to software source code, documentation
source, and configuration files.
"Object" form shall mean any form resulting from mechanical
transformation or translation of a Source form, including but
not limited to compiled object code, generated documentation,
and conversions to other media types.
"Work" shall mean the work of authorship, whether in Source or
Object form, made available under the License, as indicated by a
copyright notice that is included in or attached to the work
(an example is provided in the Appendix below).
"Derivative Works" shall mean any work, whether in Source or Object
form, that is based on (or derived from) the Work and for which the
editorial revisions, annotations, elaborations, or other modifications
represent, as a whole, an original work of authorship. For the purposes
of this License, Derivative Works shall not include works that remain
separable from, or merely link (or bind by name) to the interfaces of,
the Work and Derivative Works thereof.
"Contribution" shall mean any work of authorship, including
the original version of the Work and any modifications or additions
to that Work or Derivative Works thereof, that is intentionally
submitted to Licensor for inclusion in the Work by the copyright owner
or by an individual or Legal Entity authorized to submit on behalf of
the copyright owner. For the purposes of this definition, "submitted"
means any form of electronic, verbal, or written communication sent
to the Licensor or its representatives, including but not limited to
communication on electronic mailing lists, source code control systems,
and issue tracking systems that are managed by, or on behalf of, the
Licensor for the purpose of discussing and improving the Work, but
excluding communication that is conspicuously marked or otherwise
designated in writing by the copyright owner as "Not a Contribution."
"Contributor" shall mean Licensor and any individual or Legal Entity
on behalf of whom a Contribution has been received by Licensor and
subsequently incorporated within the Work.
2. Grant of Copyright License. Subject to the terms and conditions of
this License, each Contributor hereby grants to You a perpetual,
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
copyright license to reproduce, prepare Derivative Works of,
publicly display, publicly perform, sublicense, and distribute the
Work and such Derivative Works in Source or Object form.
3. Grant of Patent License. Subject to the terms and conditions of
this License, each Contributor hereby grants to You a perpetual,
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
(except as stated in this section) patent license to make, have made,
use, offer to sell, sell, import, and otherwise transfer the Work,
where such license applies only to those patent claims licensable
by such Contributor that are necessarily infringed by their
Contribution(s) alone or by combination of their Contribution(s)
with the Work to which such Contribution(s) was submitted. If You
institute patent litigation against any entity (including a
cross-claim or counterclaim in a lawsuit) alleging that the Work
or a Contribution incorporated within the Work constitutes direct
or contributory patent infringement, then any patent licenses
granted to You under this License for that Work shall terminate
as of the date such litigation is filed.
4. Redistribution. You may reproduce and distribute copies of the
Work or Derivative Works thereof in any medium, with or without
modifications, and in Source or Object form, provided that You
meet the following conditions:
(a) You must give any other recipients of the Work or
Derivative Works a copy of this License; and
(b) You must cause any modified files to carry prominent notices
stating that You changed the files; and
(c) You must retain, in the Source form of any Derivative Works
that You distribute, all copyright, patent, trademark, and
attribution notices from the Source form of the Work,
excluding those notices that do not pertain to any part of
the Derivative Works; and
(d) If the Work includes a "NOTICE" text file as part of its
distribution, then any Derivative Works that You distribute must
include a readable copy of the attribution notices contained
within such NOTICE file, excluding those notices that do not
pertain to any part of the Derivative Works, in at least one
of the following places: within a NOTICE text file distributed
as part of the Derivative Works; within the Source form or
documentation, if provided along with the Derivative Works; or,
within a display generated by the Derivative Works, if and
wherever such third-party notices normally appear. The contents
of the NOTICE file are for informational purposes only and
do not modify the License. You may add Your own attribution
notices within Derivative Works that You distribute, alongside
or as an addendum to the NOTICE text from the Work, provided
that such additional attribution notices cannot be construed
as modifying the License.
You may add Your own copyright statement to Your modifications and
may provide additional or different license terms and conditions
for use, reproduction, or distribution of Your modifications, or
for any such Derivative Works as a whole, provided Your use,
reproduction, and distribution of the Work otherwise complies with
the conditions stated in this License.
5. Submission of Contributions. Unless You explicitly state otherwise,
any Contribution intentionally submitted for inclusion in the Work
by You to the Licensor shall be under the terms and conditions of
this License, without any additional terms or conditions.
Notwithstanding the above, nothing herein shall supersede or modify
the terms of any separate license agreement you may have executed
with Licensor regarding such Contributions.
6. Trademarks. This License does not grant permission to use the trade
names, trademarks, service marks, or product names of the Licensor,
except as required for reasonable and customary use in describing the
origin of the Work and reproducing the content of the NOTICE file.
7. Disclaimer of Warranty. Unless required by applicable law or
agreed to in writing, Licensor provides the Work (and each
Contributor provides its Contributions) on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
implied, including, without limitation, any warranties or conditions
of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
PARTICULAR PURPOSE. You are solely responsible for determining the
appropriateness of using or redistributing the Work and assume any
risks associated with Your exercise of permissions under this License.
8. Limitation of Liability. In no event and under no legal theory,
whether in tort (including negligence), contract, or otherwise,
unless required by applicable law (such as deliberate and grossly
negligent acts) or agreed to in writing, shall any Contributor be
liable to You for damages, including any direct, indirect, special,
incidental, or consequential damages of any character arising as a
result of this License or out of the use or inability to use the
Work (including but not limited to damages for loss of goodwill,
work stoppage, computer failure or malfunction, or any and all
other commercial damages or losses), even if such Contributor
has been advised of the possibility of such damages.
9. Accepting Warranty or Additional Liability. While redistributing
the Work or Derivative Works thereof, You may choose to offer,
and charge a fee for, acceptance of support, warranty, indemnity,
or other liability obligations and/or rights consistent with this
License. However, in accepting such obligations, You may act only
on Your own behalf and on Your sole responsibility, not on behalf
of any other Contributor, and only if You agree to indemnify,
defend, and hold each Contributor harmless for any liability
incurred by, or claims asserted against, such Contributor by reason
of your accepting any such warranty or additional liability.
END OF TERMS AND CONDITIONS
APPENDIX: How to apply the Apache License to your work.
To apply the Apache License to your work, attach the following
boilerplate notice, with the fields enclosed by brackets "[]"
replaced with your own identifying information. (Don't include
the brackets!) The text should be enclosed in the appropriate
comment syntax for the file format. We also recommend that a
file or class name and description of purpose be included on the
same "printed page" as the copyright notice for easier
identification within third-party archives.
Copyright [yyyy] [name of copyright owner]
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
================================================
FILE: Makefile
================================================
.PHONY: all production test docs clean
all: production
production:
@true
docs:
tox -e docs
dev: $(LOCAL_CONFIG_DIR) $(LOGS_DIR) install-hooks
install-hooks:
pre-commit install -f --install-hooks
test:
tox
test-elasticsearch:
tox -- --runelasticsearch
test-docker:
docker-compose --project-name elastalert build tox
docker-compose --project-name elastalert run tox
clean:
make -C docs clean
find . -name '*.pyc' -delete
find . -name '__pycache__' -delete
rm -rf virtualenv_run .tox .coverage *.egg-info build
================================================
FILE: README.md
================================================
**ElastAlert is no longer maintained. Please use [ElastAlert2](https://github.com/jertel/elastalert2) instead.**
[](https://travis-ci.org/Yelp/elastalert)
[](https://gitter.im/Yelp/elastalert?utm_source=badge&utm_medium=badge&utm_campaign=pr-badge&utm_content=badge)
## ElastAlert - [Read the Docs](http://elastalert.readthedocs.org).
### Easy & Flexible Alerting With Elasticsearch
ElastAlert is a simple framework for alerting on anomalies, spikes, or other patterns of interest from data in Elasticsearch.
ElastAlert works with all versions of Elasticsearch.
At Yelp, we use Elasticsearch, Logstash and Kibana for managing our ever increasing amount of data and logs.
Kibana is great for visualizing and querying data, but we quickly realized that it needed a companion tool for alerting
on inconsistencies in our data. Out of this need, ElastAlert was created.
If you have data being written into Elasticsearch in near real time and want to be alerted when that data matches certain patterns, ElastAlert is the tool for you. If you can see it in Kibana, ElastAlert can alert on it.
## Overview
We designed ElastAlert to be reliable, highly modular, and easy to set up and configure.
It works by combining Elasticsearch with two types of components, rule types and alerts.
Elasticsearch is periodically queried and the data is passed to the rule type, which determines when
a match is found. When a match occurs, it is given to one or more alerts, which take action based on the match.
This is configured by a set of rules, each of which defines a query, a rule type, and a set of alerts.
Several rule types with common monitoring paradigms are included with ElastAlert:
- Match where there are at least X events in Y time" (``frequency`` type)
- Match when the rate of events increases or decreases" (``spike`` type)
- Match when there are less than X events in Y time" (``flatline`` type)
- Match when a certain field matches a blacklist/whitelist" (``blacklist`` and ``whitelist`` type)
- Match on any event matching a given filter" (``any`` type)
- Match when a field has two different values within some time" (``change`` type)
- Match when a never before seen term appears in a field" (``new_term`` type)
- Match when the number of unique values for a field is above or below a threshold (``cardinality`` type)
Currently, we have built-in support for the following alert types:
- Email
- JIRA
- OpsGenie
- Commands
- HipChat
- MS Teams
- Slack
- Telegram
- GoogleChat
- AWS SNS
- VictorOps
- PagerDuty
- PagerTree
- Exotel
- Twilio
- Gitter
- Line Notify
- Zabbix
Additional rule types and alerts can be easily imported or written.
In addition to this basic usage, there are many other features that make alerts more useful:
- Alerts link to Kibana dashboards
- Aggregate counts for arbitrary fields
- Combine alerts into periodic reports
- Separate alerts by using a unique key field
- Intercept and enhance match data
To get started, check out `Running ElastAlert For The First Time` in the [documentation](http://elastalert.readthedocs.org).
## Running ElastAlert
You can either install the latest released version of ElastAlert using pip:
```pip install elastalert```
or you can clone the ElastAlert repository for the most recent changes:
```git clone https://github.com/Yelp/elastalert.git```
Install the module:
```pip install "setuptools>=11.3"```
```python setup.py install```
The following invocation can be used to run ElastAlert after installing
``$ elastalert [--debug] [--verbose] [--start <timestamp>] [--end <timestamp>] [--rule <filename.yaml>] [--config <filename.yaml>]``
``--debug`` will print additional information to the screen as well as suppresses alerts and instead prints the alert body. Not compatible with `--verbose`.
``--verbose`` will print additional information without suppressing alerts. Not compatible with `--debug.`
``--start`` will begin querying at the given timestamp. By default, ElastAlert will begin querying from the present.
Timestamp format is ``YYYY-MM-DDTHH-MM-SS[-/+HH:MM]`` (Note the T between date and hour).
Eg: ``--start 2014-09-26T12:00:00`` (UTC) or ``--start 2014-10-01T07:30:00-05:00``
``--end`` will cause ElastAlert to stop querying at the given timestamp. By default, ElastAlert will continue
to query indefinitely.
``--rule`` will allow you to run only one rule. It must still be in the rules folder.
Eg: ``--rule this_rule.yaml``
``--config`` allows you to specify the location of the configuration. By default, it is will look for config.yaml in the current directory.
## Third Party Tools And Extras
### Kibana plugin
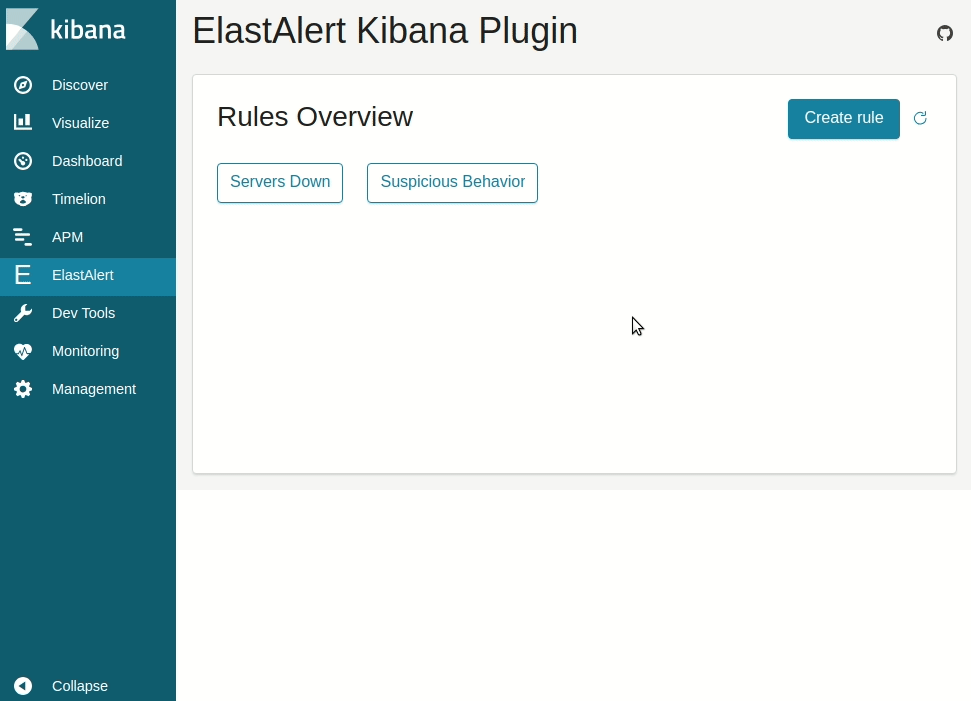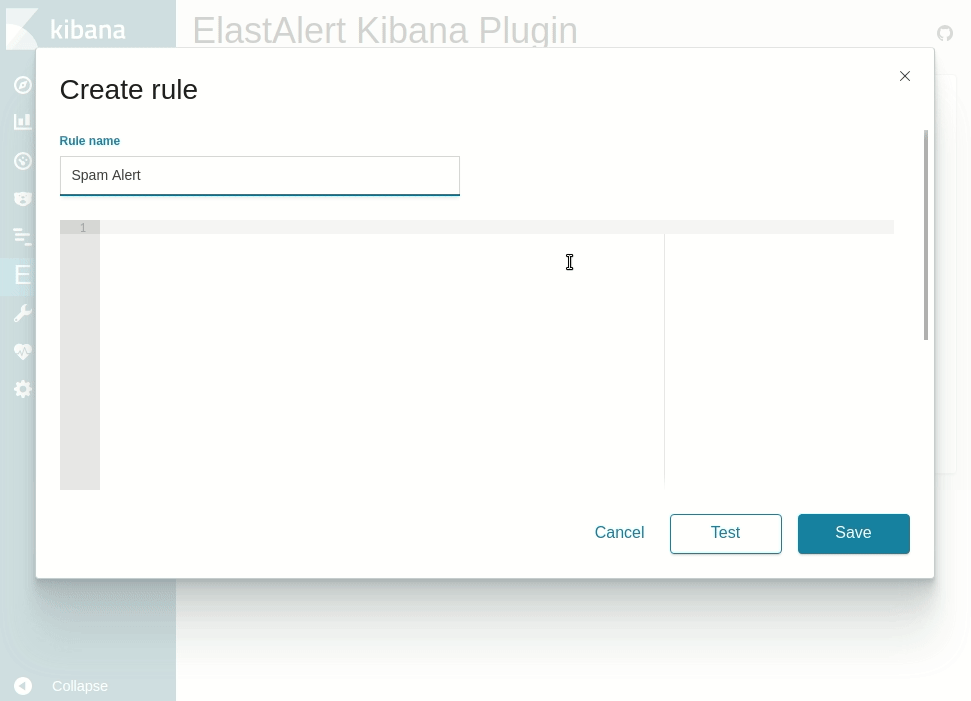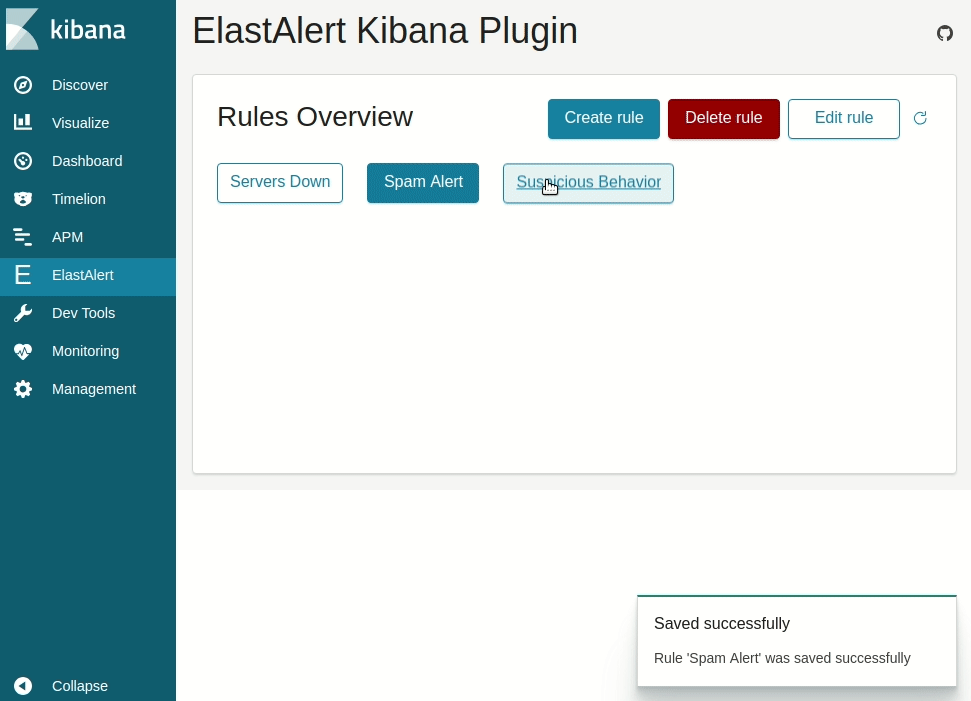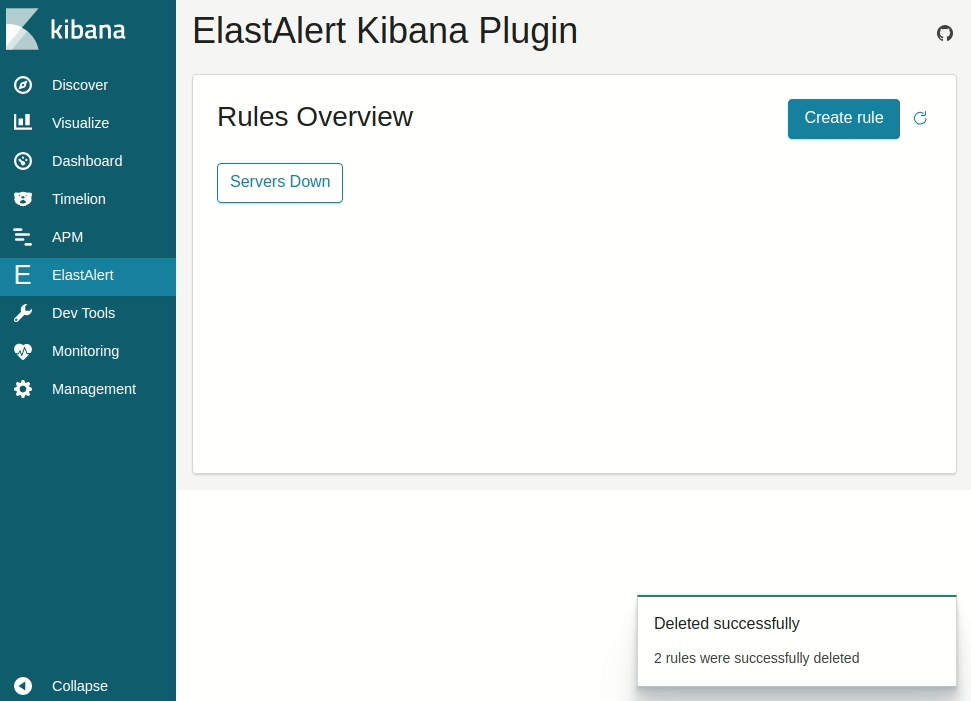
Available at the [ElastAlert Kibana plugin repository](https://github.com/bitsensor/elastalert-kibana-plugin).
### Docker
A [Dockerized version](https://github.com/bitsensor/elastalert) of ElastAlert including a REST api is build from `master` to `bitsensor/elastalert:latest`.
```bash
git clone https://github.com/bitsensor/elastalert.git; cd elastalert
docker run -d -p 3030:3030 \
-v `pwd`/config/elastalert.yaml:/opt/elastalert/config.yaml \
-v `pwd`/config/config.json:/opt/elastalert-server/config/config.json \
-v `pwd`/rules:/opt/elastalert/rules \
-v `pwd`/rule_templates:/opt/elastalert/rule_templates \
--net="host" \
--name elastalert bitsensor/elastalert:latest
```
## Documentation
Read the documentation at [Read the Docs](http://elastalert.readthedocs.org).
To build a html version of the docs locally
```
pip install sphinx_rtd_theme sphinx
cd docs
make html
```
View in browser at build/html/index.html
## Configuration
See config.yaml.example for details on configuration.
## Example rules
Examples of different types of rules can be found in example_rules/.
- ``example_spike.yaml`` is an example of the "spike" rule type, which allows you to alert when the rate of events, averaged over a time period,
increases by a given factor. This example will send an email alert when there are 3 times more events matching a filter occurring within the
last 2 hours than the number of events in the previous 2 hours.
- ``example_frequency.yaml`` is an example of the "frequency" rule type, which will alert when there are a given number of events occuring
within a time period. This example will send an email when 50 documents matching a given filter occur within a 4 hour timeframe.
- ``example_change.yaml`` is an example of the "change" rule type, which will alert when a certain field in two documents changes. In this example,
the alert email is sent when two documents with the same 'username' field but a different value of the 'country_name' field occur within 24 hours
of each other.
- ``example_new_term.yaml`` is an example of the "new term" rule type, which alerts when a new value appears in a field or fields. In this example,
an email is sent when a new value of ("username", "computer") is encountered in example login logs.
## Frequently Asked Questions
### My rule is not getting any hits?
So you've managed to set up ElastAlert, write a rule, and run it, but nothing happens, or it says ``0 query hits``. First of all, we recommend using the command ``elastalert-test-rule rule.yaml`` to debug. It will show you how many documents match your filters for the last 24 hours (or more, see ``--help``), and then shows you if any alerts would have fired. If you have a filter in your rule, remove it and try again. This will show you if the index is correct and that you have at least some documents. If you have a filter in Kibana and want to recreate it in ElastAlert, you probably want to use a query string. Your filter will look like
```
filter:
- query:
query_string:
query: "foo: bar AND baz: abc*"
```
If you receive an error that Elasticsearch is unable to parse it, it's likely the YAML is not spaced correctly, and the filter is not in the right format. If you are using other types of filters, like ``term``, a common pitfall is not realizing that you may need to use the analyzed token. This is the default if you are using Logstash. For example,
```
filter:
- term:
foo: "Test Document"
```
will not match even if the original value for ``foo`` was exactly "Test Document". Instead, you want to use ``foo.raw``. If you are still having trouble troubleshooting why your documents do not match, try running ElastAlert with ``--es_debug_trace /path/to/file.log``. This will log the queries made to Elasticsearch in full so that you can see exactly what is happening.
### I got hits, why didn't I get an alert?
If you got logs that had ``X query hits, 0 matches, 0 alerts sent``, it depends on the ``type`` why you didn't get any alerts. If ``type: any``, a match will occur for every hit. If you are using ``type: frequency``, ``num_events`` must occur within ``timeframe`` of each other for a match to occur. Different rules apply for different rule types.
If you see ``X matches, 0 alerts sent``, this may occur for several reasons. If you set ``aggregation``, the alert will not be sent until after that time has elapsed. If you have gotten an alert for this same rule before, that rule may be silenced for a period of time. The default is one minute between alerts. If a rule is silenced, you will see ``Ignoring match for silenced rule`` in the logs.
If you see ``X alerts sent`` but didn't get any alert, it's probably related to the alert configuration. If you are using the ``--debug`` flag, you will not receive any alerts. Instead, the alert text will be written to the console. Use ``--verbose`` to achieve the same affects without preventing alerts. If you are using email alert, make sure you have it configured for an SMTP server. By default, it will connect to localhost on port 25. It will also use the word "elastalert" as the "From:" address. Some SMTP servers will reject this because it does not have a domain while others will add their own domain automatically. See the email section in the documentation for how to configure this.
### Why did I only get one alert when I expected to get several?
There is a setting called ``realert`` which is the minimum time between two alerts for the same rule. Any alert that occurs within this time will simply be dropped. The default value for this is one minute. If you want to receive an alert for every single match, even if they occur right after each other, use
```
realert:
minutes: 0
```
You can of course set it higher as well.
### How can I prevent duplicate alerts?
By setting ``realert``, you will prevent the same rule from alerting twice in an amount of time.
```
realert:
days: 1
```
You can also prevent duplicates based on a certain field by using ``query_key``. For example, to prevent multiple alerts for the same user, you might use
```
realert:
hours: 8
query_key: user
```
Note that this will also affect the way many rule types work. If you are using ``type: frequency`` for example, ``num_events`` for a single value of ``query_key`` must occur before an alert will be sent. You can also use a compound of multiple fields for this key. For example, if you only wanted to receieve an alert once for a specific error and hostname, you could use
```
query_key: [error, hostname]
```
Internally, this works by creating a new field for each document called ``field1,field2`` with a value of ``value1,value2`` and using that as the ``query_key``.
The data for when an alert will fire again is stored in Elasticsearch in the ``elastalert_status`` index, with a ``_type`` of ``silence`` and also cached in memory.
### How can I change what's in the alert?
You can use the field ``alert_text`` to add custom text to an alert. By setting ``alert_text_type: alert_text_only``, it will be the entirety of the alert. You can also add different fields from the alert by using Python style string formatting and ``alert_text_args``. For example
```
alert_text: "Something happened with {0} at {1}"
alert_text_type: alert_text_only
alert_text_args: ["username", "@timestamp"]
```
You can also limit the alert to only containing certain fields from the document by using ``include``.
```
include: ["ip_address", "hostname", "status"]
```
### My alert only contains data for one event, how can I see more?
If you are using ``type: frequency``, you can set the option ``attach_related: true`` and every document will be included in the alert. An alternative, which works for every type, is ``top_count_keys``. This will show the top counts for each value for certain fields. For example, if you have
```
top_count_keys: ["ip_address", "status"]
```
and 10 documents matched your alert, it may contain something like
```
ip_address:
127.0.0.1: 7
10.0.0.1: 2
192.168.0.1: 1
status:
200: 9
500: 1
```
### How can I make the alert come at a certain time?
The ``aggregation`` feature will take every alert that has occured over a period of time and send them together in one alert. You can use cron style syntax to send all alerts that have occured since the last once by using
```
aggregation:
schedule: '2 4 * * mon,fri'
```
### I have lots of documents and it's really slow, how can I speed it up?
There are several ways to potentially speed up queries. If you are using ``index: logstash-*``, Elasticsearch will query all shards, even if they do not possibly contain data with the correct timestamp. Instead, you can use Python time format strings and set ``use_strftime_index``
```
index: logstash-%Y.%m
use_strftime_index: true
```
Another thing you could change is ``buffer_time``. By default, ElastAlert will query large overlapping windows in order to ensure that it does not miss any events, even if they are indexed in real time. In config.yaml, you can adjust ``buffer_time`` to a smaller number to only query the most recent few minutes.
```
buffer_time:
minutes: 5
```
By default, ElastAlert will download every document in full before processing them. Instead, you can have ElastAlert simply get a count of the number of documents that have occured in between each query. To do this, set ``use_count_query: true``. This cannot be used if you use ``query_key``, because ElastAlert will not know the contents of each documents, just the total number of them. This also reduces the precision of alerts, because all events that occur between each query will be rounded to a single timestamp.
If you are using ``query_key`` (a single key, not multiple keys) you can use ``use_terms_query``. This will make ElastAlert perform a terms aggregation to get the counts for each value of a certain field. Both ``use_terms_query`` and ``use_count_query`` also require ``doc_type`` to be set to the ``_type`` of the documents. They may not be compatible with all rule types.
### Can I perform aggregations?
The only aggregation supported currently is a terms aggregation, by setting ``use_terms_query``.
### I'm not using @timestamp, what do I do?
You can use ``timestamp_field`` to change which field ElastAlert will use as the timestamp. You can use ``timestamp_type`` to change it between ISO 8601 and unix timestamps. You must have some kind of timestamp for ElastAlert to work. If your events are not in real time, you can use ``query_delay`` and ``buffer_time`` to adjust when ElastAlert will look for documents.
### I'm using flatline but I don't see any alerts
When using ``type: flatline``, ElastAlert must see at least one document before it will alert you that it has stopped seeing them.
### How can I get a "resolve" event?
ElastAlert does not currently support stateful alerts or resolve events.
### Can I set a warning threshold?
Currently, the only way to set a warning threshold is by creating a second rule with a lower threshold.
## License
ElastAlert is licensed under the Apache License, Version 2.0: http://www.apache.org/licenses/LICENSE-2.0
### Read the documentation at [Read the Docs](http://elastalert.readthedocs.org).
### Questions? Drop by #elastalert on Freenode IRC.
================================================
FILE: changelog.md
================================================
# Change Log
# v0.2.4
### Added
- Added back customFields support for The Hive
# v0.2.3
### Added
- Added back TheHive alerter without TheHive4py library
# v0.2.2
### Added
- Integration with Kibana Discover app
- Addied ability to specify opsgenie alert details
### Fixed
- Fix some encoding issues with command alerter
- Better error messages for missing config file
- Fixed an issue with run_every not applying per-rule
- Fixed an issue with rules not being removed
- Fixed an issue with top count keys and nested query keys
- Various documentation fixes
- Fixed an issue with not being able to use spike aggregation
### Removed
- Remove The Hive alerter
# v0.2.1
### Fixed
- Fixed an AttributeError introduced in 0.2.0
# v0.2.0
- Switched to Python 3
### Added
- Add rule loader class for customized rule loading
- Added thread based rules and limit_execution
- Run_every can now be customized per rule
### Fixed
- Various small fixes
# v0.1.39
### Added
- Added spike alerts for metric aggregations
- Allow SSL connections for Stomp
- Allow limits on alert text length
- Add optional min doc count for terms queries
- Add ability to index into arrays for alert_text_args, etc
### Fixed
- Fixed bug involving --config flag with create-index
- Fixed some settings not being inherited from the config properly
- Some fixes for Hive alerter
- Close SMTP connections properly
- Fix timestamps in Pagerduty v2 payload
- Fixed an bug causing aggregated alerts to mix up
# v0.1.38
### Added
- Added PagerTree alerter
- Added Line alerter
- Added more customizable logging
- Added new logic in test-rule to detemine the default timeframe
### Fixed
- Fixed an issue causing buffer_time to sometimes be ignored
# v0.1.37
### Added
- Added more options for Opsgenie alerter
- Added more pagerduty options
- Added ability to add metadata to elastalert logs
### Fixed
- Fixed some documentation to be more clear
- Stop requiring doc_type for metric aggregations
- No longer puts quotes around regex terms in blacklists or whitelists
# v0.1.36
### Added
- Added a prefix "metric_" to the key used for metric aggregations to avoid possible conflicts
- Added option to skip Alerta certificate validation
### Fixed
- Fixed a typo in the documentation for spike rule
# v0.1.35
### Fixed
- Fixed an issue preventing new term rule from working with terms query
# v0.1.34
### Added
- Added prefix/suffix support for summary table
- Added support for ignoring SSL validation in Slack
- More visible exceptions during query parse failures
### Fixed
- Fixed top_count_keys when using compound query_key
- Fixed num_hits sometimes being reported too low
- Fixed an issue with setting ES_USERNAME via env
- Fixed an issue when using test script with custom timestamps
- Fixed a unicode error when using Telegram
- Fixed an issue with jsonschema version conflict
- Fixed an issue with nested timestamps in cardinality type
# v0.1.33
### Added
- Added ability to pipe alert text to a command
- Add --start and --end support for elastalert-test-rule
- Added ability to turn blacklist/whitelist files into queries for better performance
- Allow setting of OpsGenie priority
- Add ability to query the adjacent index if timestamp_field not used for index timestamping
- Add support for pagerduty v2
- Add option to turn off .raw/.keyword field postfixing in new term rule
- Added --use-downloaded feature for elastalert-test-rule
### Fixed
- Fixed a bug that caused num_hits in matches to sometimes be erroneously small
- Fixed an issue with HTTP Post alerter that could cause it to hang indefinitely
- Fixed some issues with string formatting for various alerters
- Fixed a couple of incorrect parts of the documentation
# v0.1.32
### Added
- Add support for setting ES url prefix via environment var
- Add support for using native Slack fields in alerts
### Fixed
- Fixed a bug that would could scrolling queries to sometimes terminate early
# v0.1.31
### Added
- Added ability to add start date to new term rule
### Fixed
- Fixed a bug in create_index which would try to delete a nonexistent index
- Apply filters to new term rule all terms query
- Support Elasticsearch 6 for new term rule
- Fixed is_enabled not working on rule changes
# v0.1.30
### Added
- Alerta alerter
- Added support for transitioning JIRA issues
- Option to recreate index in elastalert-create-index
### Fixed
- Update jira_ custom fields before each alert if they were modified
- Use json instead of simplejson
- Allow for relative path for smtp_auth_file
- Fixed some grammar issues
- Better code formatting of index mappings
- Better formatting and size limit for HipChat HTML
- Fixed gif link in readme for kibana plugin
- Fixed elastalert-test-rule with Elasticsearch > 4
- Added documentation for is_enabled option
## v0.1.29
### Added
- Added a feature forget_keys to prevent realerting when using flatline with query_key
- Added a new alert_text_type, aggregation_summary_only
### Fixed
- Fixed incorrect documentation about es_conn_timeout default
## v0.1.28
### Added
- Added support for Stride formatting of simple HTML tags
- Added support for custom titles in Opsgenie alerts
- Added a denominator to percentage match based alerts
### Fixed
- Fixed a bug with Stomp alerter connections
- Removed escaping of some characaters in Slack messages
## v0.1.27
# Added
- Added support for a value other than <MISSING VALUE> in formatted alerts
### Fixed
- Fixed a failed creation of elastalert indicies when using Elasticsearch 6
- Truncate Telegram alerts to avoid API errors
## v0.1.26
### Added
- Added support for Elasticsearch 6
- Added support for mentions in Hipchat
### Fixed
- Fixed an issue where a nested field lookup would crash if one of the intermediate fields was null
## v0.1.25
### Fixed
- Fixed a bug causing new term rule to break unless you passed a start time
- Add a slight clarification on the localhost:9200 reported in es_debug_trace
## v0.1.24
### Fixed
- Pinned pytest
- create-index reads index name from config.yaml
- top_count_keys now works for context on a flatline rule type
- Fixed JIRA behavior for issues with statuses that have spaces in the name
## v0.1.22
### Added
- Added Stride alerter
- Allow custom string formatters for aggregation percentage
- Added a field to disable rules from config
- Added support for subaggregations for the metric rule type
### Fixed
- Fixed a bug causing create-index to fail if missing config.yaml
- Fixed a bug when using ES5 with query_key and top_count_keys
- Allow enhancements to set and clear arbitrary JIRA fields
- Fixed a bug causing timestamps to be formatted in scientific notation
- Stop attempting to initialize alerters in debug mode
- Changed default alert ordering so that JIRA tickets end up in other alerts
- Fixed a bug when using Stomp alerter with complex query_key
- Fixed a bug preventing hipchat room ID from being an integer
- Fixed a bug causing duplicate alerts when using spike with alert_on_new_data
- Minor fixes to summary table formatting
- Fixed elastalert-test-rule when using new term rule type
## v0.1.21
### Fixed
- Fixed an incomplete bug fix for preventing duplicate enhancement runs
## v0.1.20
### Added
- Added support for client TLS keys
### Fixed
- Fixed the formatting of summary tables in Slack
- Fixed ES_USE_SSL env variable
- Fixed the unique value count printed by new_term rule type
- Jira alerter no longer uses the non-existent json code formatter
## v0.1.19
### Added
- Added support for populating JIRA fields via fields in the match
- Added support for using a TLS certificate file for SMTP connections
- Allow a custom suffix for non-analyzed Elasticsearch fields, like ".raw" or ".keyword"
- Added match_time to Elastalert alert documents in Elasticsearch
### Fixed
- Fixed an error in the documentation for rule importing
- Prevent enhancements from re-running on retried alerts
- Fixed a bug when using custom timestamp formats and new term rule
- Lowered jira_bump_after_inactivity default to 0 days
## v0.1.18
### Added
- Added a new alerter "post" based on "simple" which makes POSTS JSON to HTTP endpoints
- Added an option jira_bump_after_inacitivty to prevent ElastAlert commenting on active JIRA tickets
### Removed
- Removed "simple" alerter, replaced by "post"
## v0.1.17
### Added
- Added a --patience flag to allow Elastalert to wait for Elasticsearch to become available
- Allow custom PagerDuty alert titles via alert_subject
## v0.1.16
### Fixed
- Fixed a bug where JIRA titles might not use query_key values
- Fixed a bug where flatline alerts don't respect query_key for realert
- Fixed a typo "twilio_accout_sid"
### Added
- Added support for env variables in kibana4 dashboard links
- Added ca_certs option for custom CA support
## v0.1.15
### Fixed
- Fixed a bug where Elastalert would crash on connection error during startup
- Fixed some typos in documentation
- Fixed a bug in metric bucket offset calculation
- Fixed a TypeError in Service Now alerter
### Added
- Added support for compound compare key in change rules
- Added support for absolute paths in rule config imports
- Added Microsoft Teams alerter
- Added support for markdown in Slack alerts
- Added error codes to test script
- Added support for lists in email_from_field
## v0.1.14 - 2017-05-11
### Fixed
- Twilio alerter uses the from number appropriately
- Fixed a TypeError in SNS alerter
- Some changes to requirements.txt and setup.py
- Fixed a TypeError in new term rule
### Added
- Set a custom pagerduty incident key
- Preserve traceback in most exceptions
## v0.1.12 - 2017-04-21
### Fixed
- Fixed a bug causing filters to be ignored when using Elasticsearch 5
## v0.1.11 - 2017-04-19
### Fixed
- Fixed an issue that would cause filters starting with "query" to sometimes throw errors in ES5
- Fixed a bug with multiple versions of ES on different rules
- Fixed a possible KeyError when using use_terms_query with ES5
## v0.1.10 - 2017-04-17
### Fixed
- Fixed an AttributeError occuring with older versions of Elasticsearch library
- Made example rules more consistent and with unique names
- Fixed an error caused by a typo when es_username is used
## v0.1.9 - 2017-04-14
### Added
- Added a changelog
- Added metric aggregation rule type
- Added percentage match rule type
- Added default doc style and improved the instructions
- Rule names will default to the filename
- Added import keyword in rules to include sections from other files
- Added email_from_field option to derive the recipient from a field in the match
- Added simple HTTP alerter
- Added Exotel SMS alerter
- Added a readme link to third party Kibana plugin
- Added option to use env variables to configure some settings
- Added duplicate hits count in log line
### Fixed
- Fixed a bug in change rule where a boolean false would be ignored
- Clarify documentation on format of alert_text_args and alert_text_kw
- Fixed a bug preventing new silence stashes from being loaded after a rule has previous alerted
- Changed the default es_host in elastalert-test-rule to localhost
- Fixed a bug preventing ES <5.0 formatted queries working in elastalert-test-rule
- Fixed top_count_keys adding .raw on ES >5.0, uses .keyword instead
- Fixed a bug causing compound aggregation keys not to work
- Better error reporting for the Jira alerter
- AWS request signing now refreshes credentials, uses boto3
- Support multiple ES versions on different rules
- Added documentation for percentage match rule type
### Removed
- Removed a feature that would disable writeback_es on errors, causing various issues
================================================
FILE: config.yaml.example
================================================
# This is the folder that contains the rule yaml files
# Any .yaml file will be loaded as a rule
rules_folder: example_rules
# How often ElastAlert will query Elasticsearch
# The unit can be anything from weeks to seconds
run_every:
minutes: 1
# ElastAlert will buffer results from the most recent
# period of time, in case some log sources are not in real time
buffer_time:
minutes: 15
# The Elasticsearch hostname for metadata writeback
# Note that every rule can have its own Elasticsearch host
es_host: elasticsearch.example.com
# The Elasticsearch port
es_port: 9200
# The AWS region to use. Set this when using AWS-managed elasticsearch
#aws_region: us-east-1
# The AWS profile to use. Use this if you are using an aws-cli profile.
# See http://docs.aws.amazon.com/cli/latest/userguide/cli-chap-getting-started.html
# for details
#profile: test
# Optional URL prefix for Elasticsearch
#es_url_prefix: elasticsearch
# Connect with TLS to Elasticsearch
#use_ssl: True
# Verify TLS certificates
#verify_certs: True
# GET request with body is the default option for Elasticsearch.
# If it fails for some reason, you can pass 'GET', 'POST' or 'source'.
# See http://elasticsearch-py.readthedocs.io/en/master/connection.html?highlight=send_get_body_as#transport
# for details
#es_send_get_body_as: GET
# Option basic-auth username and password for Elasticsearch
#es_username: someusername
#es_password: somepassword
# Use SSL authentication with client certificates client_cert must be
# a pem file containing both cert and key for client
#verify_certs: True
#ca_certs: /path/to/cacert.pem
#client_cert: /path/to/client_cert.pem
#client_key: /path/to/client_key.key
# The index on es_host which is used for metadata storage
# This can be a unmapped index, but it is recommended that you run
# elastalert-create-index to set a mapping
writeback_index: elastalert_status
writeback_alias: elastalert_alerts
# If an alert fails for some reason, ElastAlert will retry
# sending the alert until this time period has elapsed
alert_time_limit:
days: 2
# Custom logging configuration
# If you want to setup your own logging configuration to log into
# files as well or to Logstash and/or modify log levels, use
# the configuration below and adjust to your needs.
# Note: if you run ElastAlert with --verbose/--debug, the log level of
# the "elastalert" logger is changed to INFO, if not already INFO/DEBUG.
#logging:
# version: 1
# incremental: false
# disable_existing_loggers: false
# formatters:
# logline:
# format: '%(asctime)s %(levelname)+8s %(name)+20s %(message)s'
#
# handlers:
# console:
# class: logging.StreamHandler
# formatter: logline
# level: DEBUG
# stream: ext://sys.stderr
#
# file:
# class : logging.FileHandler
# formatter: logline
# level: DEBUG
# filename: elastalert.log
#
# loggers:
# elastalert:
# level: WARN
# handlers: []
# propagate: true
#
# elasticsearch:
# level: WARN
# handlers: []
# propagate: true
#
# elasticsearch.trace:
# level: WARN
# handlers: []
# propagate: true
#
# '': # root logger
# level: WARN
# handlers:
# - console
# - file
# propagate: false
================================================
FILE: docker-compose.yml
================================================
version: '2'
services:
tox:
build:
context: ./
dockerfile: Dockerfile-test
command: tox
container_name: elastalert_tox
working_dir: /home/elastalert
volumes:
- ./:/home/elastalert/
================================================
FILE: docs/Makefile
================================================
# Makefile for Sphinx documentation
#
# You can set these variables from the command line.
SPHINXOPTS =
SPHINXBUILD = sphinx-build
PAPER =
BUILDDIR = build
# Internal variables.
PAPEROPT_a4 = -D latex_paper_size=a4
PAPEROPT_letter = -D latex_paper_size=letter
ALLSPHINXOPTS = -d $(BUILDDIR)/doctrees $(PAPEROPT_$(PAPER)) $(SPHINXOPTS) source
.PHONY: help clean html dirhtml pickle json htmlhelp qthelp latex changes linkcheck doctest
help:
@echo "Please use \`make <target>' where <target> is one of"
@echo " html to make standalone HTML files"
@echo " dirhtml to make HTML files named index.html in directories"
@echo " pickle to make pickle files"
@echo " json to make JSON files"
@echo " htmlhelp to make HTML files and a HTML help project"
@echo " qthelp to make HTML files and a qthelp project"
@echo " latex to make LaTeX files, you can set PAPER=a4 or PAPER=letter"
@echo " changes to make an overview of all changed/added/deprecated items"
@echo " linkcheck to check all external links for integrity"
@echo " doctest to run all doctests embedded in the documentation (if enabled)"
clean:
-rm -rf $(BUILDDIR)/*
html:
$(SPHINXBUILD) -b html $(ALLSPHINXOPTS) $(BUILDDIR)/html
@echo
@echo "Build finished. The HTML pages are in $(BUILDDIR)/html."
dirhtml:
$(SPHINXBUILD) -b dirhtml $(ALLSPHINXOPTS) $(BUILDDIR)/dirhtml
@echo
@echo "Build finished. The HTML pages are in $(BUILDDIR)/dirhtml."
pickle:
$(SPHINXBUILD) -b pickle $(ALLSPHINXOPTS) $(BUILDDIR)/pickle
@echo
@echo "Build finished; now you can process the pickle files."
json:
$(SPHINXBUILD) -b json $(ALLSPHINXOPTS) $(BUILDDIR)/json
@echo
@echo "Build finished; now you can process the JSON files."
htmlhelp:
$(SPHINXBUILD) -b htmlhelp $(ALLSPHINXOPTS) $(BUILDDIR)/htmlhelp
@echo
@echo "Build finished; now you can run HTML Help Workshop with the" \
".hhp project file in $(BUILDDIR)/htmlhelp."
qthelp:
$(SPHINXBUILD) -b qthelp $(ALLSPHINXOPTS) $(BUILDDIR)/qthelp
@echo
@echo "Build finished; now you can run "qcollectiongenerator" with the" \
".qhcp project file in $(BUILDDIR)/qthelp, like this:"
@echo "# qcollectiongenerator $(BUILDDIR)/qthelp/monitor.qhcp"
@echo "To view the help file:"
@echo "# assistant -collectionFile $(BUILDDIR)/qthelp/monitor.qhc"
latex:
$(SPHINXBUILD) -b latex $(ALLSPHINXOPTS) $(BUILDDIR)/latex
@echo
@echo "Build finished; the LaTeX files are in $(BUILDDIR)/latex."
@echo "Run \`make all-pdf' or \`make all-ps' in that directory to" \
"run these through (pdf)latex."
changes:
$(SPHINXBUILD) -b changes $(ALLSPHINXOPTS) $(BUILDDIR)/changes
@echo
@echo "The overview file is in $(BUILDDIR)/changes."
linkcheck:
$(SPHINXBUILD) -b linkcheck $(ALLSPHINXOPTS) $(BUILDDIR)/linkcheck
@echo
@echo "Link check complete; look for any errors in the above output " \
"or in $(BUILDDIR)/linkcheck/output.txt."
doctest:
$(SPHINXBUILD) -b doctest $(ALLSPHINXOPTS) $(BUILDDIR)/doctest
@echo "Testing of doctests in the sources finished, look at the " \
"results in $(BUILDDIR)/doctest/output.txt."
================================================
FILE: docs/source/_static/.gitkeep
================================================
================================================
FILE: docs/source/conf.py
================================================
import sphinx_rtd_theme
# -*- coding: utf-8 -*-
#
# ElastAlert documentation build configuration file, created by
# sphinx-quickstart on Thu Jul 11 15:45:31 2013.
#
# This file is execfile()d with the current directory set to its containing dir.
#
# Note that not all possible configuration values are present in this
# autogenerated file.
#
# All configuration values have a default; values that are commented out
# serve to show the default.
# If extensions (or modules to document with autodoc) are in another directory,
# add these directories to sys.path here. If the directory is relative to the
# documentation root, use os.path.abspath to make it absolute, like shown here.
# sys.path.append(os.path.abspath('.'))
# -- General configuration -----------------------------------------------------
# Add any Sphinx extension module names here, as strings. They can be extensions
# coming with Sphinx (named 'sphinx.ext.*') or your custom ones.
extensions = []
# Add any paths that contain templates here, relative to this directory.
templates_path = ['_templates']
# The suffix of source filenames.
source_suffix = '.rst'
# The encoding of source files.
# source_encoding = 'utf-8'
# The master toctree document.
master_doc = 'index'
# General information about the project.
project = u'ElastAlert'
copyright = u'2014, Yelp'
# The version info for the project you're documenting, acts as replacement for
# |version| and |release|, also used in various other places throughout the
# built documents.
#
# The short X.Y version.
version = '0.0.1'
# The full version, including alpha/beta/rc tags.
release = '0.0.1'
# The language for content autogenerated by Sphinx. Refer to documentation
# for a list of supported languages.
# language = None
# There are two options for replacing |today|: either, you set today to some
# non-false value, then it is used:
# today = ''
# Else, today_fmt is used as the format for a strftime call.
# today_fmt = '%B %d, %Y'
# List of documents that shouldn't be included in the build.
# unused_docs = []
# List of directories, relative to source directory, that shouldn't be searched
# for source files.
exclude_trees = []
# The reST default role (used for this markup: `text`) to use for all documents.
# default_role = None
# If true, '()' will be appended to :func: etc. cross-reference text.
# add_function_parentheses = True
# If true, the current module name will be prepended to all description
# unit titles (such as .. function::).
# add_module_names = True
# If true, sectionauthor and moduleauthor directives will be shown in the
# output. They are ignored by default.
# show_authors = False
# The name of the Pygments (syntax highlighting) style to use.
pygments_style = 'sphinx'
# A list of ignored prefixes for module index sorting.
# modindex_common_prefix = []
# -- Options for HTML output ---------------------------------------------------
# The theme to use for HTML and HTML Help pages. Major themes that come with
# Sphinx are currently 'default' and 'sphinxdoc'.
html_theme = 'sphinx_rtd_theme'
# Theme options are theme-specific and customize the look and feel of a theme
# further. For a list of options available for each theme, see the
# documentation.
# html_theme_options = {}
# Add any paths that contain custom themes here, relative to this directory.
html_theme_path = [sphinx_rtd_theme.get_html_theme_path()]
# html_theme_path = []
# The name for this set of Sphinx documents. If None, it defaults to
# "<project> v<release> documentation".
# html_title = None
# A shorter title for the navigation bar. Default is the same as html_title.
# html_short_title = None
# The name of an image file (relative to this directory) to place at the top
# of the sidebar.
# html_logo = None
# The name of an image file (within the static path) to use as favicon of the
# docs. This file should be a Windows icon file (.ico) being 16x16 or 32x32
# pixels large.
# html_favicon = None
# Add any paths that contain custom static files (such as style sheets) here,
# relative to this directory. They are copied after the builtin static files,
# so a file named "default.css" will overwrite the builtin "default.css".
html_static_path = ['_static']
# If not '', a 'Last updated on:' timestamp is inserted at every page bottom,
# using the given strftime format.
# html_last_updated_fmt = '%b %d, %Y'
# If true, SmartyPants will be used to convert quotes and dashes to
# typographically correct entities.
# html_use_smartypants = True
# Custom sidebar templates, maps document names to template names.
# html_sidebars = {}
# Additional templates that should be rendered to pages, maps page names to
# template names.
# html_additional_pages = {}
# If false, no module index is generated.
# html_use_modindex = True
# If false, no index is generated.
# html_use_index = True
# If true, the index is split into individual pages for each letter.
# html_split_index = False
# If true, links to the reST sources are added to the pages.
# html_show_sourcelink = True
# If true, an OpenSearch description file will be output, and all pages will
# contain a <link> tag referring to it. The value of this option must be the
# base URL from which the finished HTML is served.
# html_use_opensearch = ''
# If nonempty, this is the file name suffix for HTML files (e.g. ".xhtml").
# html_file_suffix = ''
# Output file base name for HTML help builder.
htmlhelp_basename = 'elastalertdoc'
# -- Options for LaTeX output --------------------------------------------------
# The paper size ('letter' or 'a4').
# latex_paper_size = 'letter'
# The font size ('10pt', '11pt' or '12pt').
# latex_font_size = '10pt'
# Grouping the document tree into LaTeX files. List of tuples
# (source start file, target name, title, author, documentclass [howto/manual]).
latex_documents = [
('index', 'elastalert.tex', u'ElastAlert Documentation',
u'Quentin Long', 'manual'),
]
# The name of an image file (relative to this directory) to place at the top of
# the title page.
# latex_logo = None
# For "manual" documents, if this is true, then toplevel headings are parts,
# not chapters.
# latex_use_parts = False
# Additional stuff for the LaTeX preamble.
# latex_preamble = ''
# Documents to append as an appendix to all manuals.
# latex_appendices = []
# If false, no module index is generated.
# latex_use_modindex = True
================================================
FILE: docs/source/elastalert.rst
================================================
ElastAlert - Easy & Flexible Alerting With Elasticsearch
********************************************************
ElastAlert is a simple framework for alerting on anomalies, spikes, or other patterns of interest from data in Elasticsearch.
At Yelp, we use Elasticsearch, Logstash and Kibana for managing our ever increasing amount of data and logs.
Kibana is great for visualizing and querying data, but we quickly realized that it needed a companion tool for alerting
on inconsistencies in our data. Out of this need, ElastAlert was created.
If you have data being written into Elasticsearch in near real time and want to be alerted when that data matches certain patterns, ElastAlert is the tool for you.
Overview
========
We designed ElastAlert to be :ref:`reliable <reliability>`, highly :ref:`modular <modularity>`, and easy to :ref:`set up <tutorial>` and :ref:`configure <configuration>`.
It works by combining Elasticsearch with two types of components, rule types and alerts.
Elasticsearch is periodically queried and the data is passed to the rule type, which determines when
a match is found. When a match occurs, it is given to one or more alerts, which take action based on the match.
This is configured by a set of rules, each of which defines a query, a rule type, and a set of alerts.
Several rule types with common monitoring paradigms are included with ElastAlert:
- "Match where there are X events in Y time" (``frequency`` type)
- "Match when the rate of events increases or decreases" (``spike`` type)
- "Match when there are less than X events in Y time" (``flatline`` type)
- "Match when a certain field matches a blacklist/whitelist" (``blacklist`` and ``whitelist`` type)
- "Match on any event matching a given filter" (``any`` type)
- "Match when a field has two different values within some time" (``change`` type)
Currently, we have support built in for these alert types:
- Command
- Email
- JIRA
- OpsGenie
- SNS
- HipChat
- Slack
- Telegram
- GoogleChat
- Debug
- Stomp
- TheHive
Additional rule types and alerts can be easily imported or written. (See :ref:`Writing rule types <writingrules>` and :ref:`Writing alerts <writingalerts>`)
In addition to this basic usage, there are many other features that make alerts more useful:
- Alerts link to Kibana dashboards
- Aggregate counts for arbitrary fields
- Combine alerts into periodic reports
- Separate alerts by using a unique key field
- Intercept and enhance match data
To get started, check out :ref:`Running ElastAlert For The First Time <tutorial>`.
.. _reliability:
Reliability
===========
ElastAlert has several features to make it more reliable in the event of restarts or Elasticsearch unavailability:
- ElastAlert :ref:`saves its state to Elasticsearch <metadata>` and, when started, will resume where previously stopped
- If Elasticsearch is unresponsive, ElastAlert will wait until it recovers before continuing
- Alerts which throw errors may be automatically retried for a period of time
.. _modularity:
Modularity
==========
ElastAlert has three main components that may be imported as a module or customized:
Rule types
----------
The rule type is responsible for processing the data returned from Elasticsearch. It is initialized with the rule configuration, passed data
that is returned from querying Elasticsearch with the rule's filters, and outputs matches based on this data. See :ref:`Writing rule types <writingrules>`
for more information.
Alerts
------
Alerts are responsible for taking action based on a match. A match is generally a dictionary containing values from a document in Elasticsearch,
but may contain arbitrary data added by the rule type. See :ref:`Writing alerts <writingalerts>` for more information.
Enhancements
------------
Enhancements are a way of intercepting an alert and modifying or enhancing it in some way. They are passed the match dictionary before it is given
to the alerter. See :ref:`Enhancements` for more information.
.. _configuration:
Configuration
=============
ElastAlert has a global configuration file, ``config.yaml``, which defines several aspects of its operation:
``buffer_time``: ElastAlert will continuously query against a window from the present to ``buffer_time`` ago.
This way, logs can be back filled up to a certain extent and ElastAlert will still process the events. This
may be overridden by individual rules. This option is ignored for rules where ``use_count_query`` or ``use_terms_query``
is set to true. Note that back filled data may not always trigger count based alerts as if it was queried in real time.
``es_host``: The host name of the Elasticsearch cluster where ElastAlert records metadata about its searches.
When ElastAlert is started, it will query for information about the time that it was last run. This way,
even if ElastAlert is stopped and restarted, it will never miss data or look at the same events twice. It will also specify the default cluster for each rule to run on.
The environment variable ``ES_HOST`` will override this field.
``es_port``: The port corresponding to ``es_host``. The environment variable ``ES_PORT`` will override this field.
``use_ssl``: Optional; whether or not to connect to ``es_host`` using TLS; set to ``True`` or ``False``.
The environment variable ``ES_USE_SSL`` will override this field.
``verify_certs``: Optional; whether or not to verify TLS certificates; set to ``True`` or ``False``. The default is ``True``.
``client_cert``: Optional; path to a PEM certificate to use as the client certificate.
``client_key``: Optional; path to a private key file to use as the client key.
``ca_certs``: Optional; path to a CA cert bundle to use to verify SSL connections
``es_username``: Optional; basic-auth username for connecting to ``es_host``. The environment variable ``ES_USERNAME`` will override this field.
``es_password``: Optional; basic-auth password for connecting to ``es_host``. The environment variable ``ES_PASSWORD`` will override this field.
``es_url_prefix``: Optional; URL prefix for the Elasticsearch endpoint. The environment variable ``ES_URL_PREFIX`` will override this field.
``es_send_get_body_as``: Optional; Method for querying Elasticsearch - ``GET``, ``POST`` or ``source``. The default is ``GET``
``es_conn_timeout``: Optional; sets timeout for connecting to and reading from ``es_host``; defaults to ``20``.
``rules_loader``: Optional; sets the loader class to be used by ElastAlert to retrieve rules and hashes.
Defaults to ``FileRulesLoader`` if not set.
``rules_folder``: The name of the folder which contains rule configuration files. ElastAlert will load all
files in this folder, and all subdirectories, that end in .yaml. If the contents of this folder change, ElastAlert will load, reload
or remove rules based on their respective config files. (only required when using ``FileRulesLoader``).
``scan_subdirectories``: Optional; Sets whether or not ElastAlert should recursively descend the rules directory - ``true`` or ``false``. The default is ``true``
``run_every``: How often ElastAlert should query Elasticsearch. ElastAlert will remember the last time
it ran the query for a given rule, and periodically query from that time until the present. The format of
this field is a nested unit of time, such as ``minutes: 5``. This is how time is defined in every ElastAlert
configuration.
``writeback_index``: The index on ``es_host`` to use.
``max_query_size``: The maximum number of documents that will be downloaded from Elasticsearch in a single query. The
default is 10,000, and if you expect to get near this number, consider using ``use_count_query`` for the rule. If this
limit is reached, ElastAlert will `scroll <https://www.elastic.co/guide/en/elasticsearch/reference/current/search-request-scroll.html>`_
using the size of ``max_query_size`` through the set amount of pages, when ``max_scrolling_count`` is set or until processing all results.
``max_scrolling_count``: The maximum amount of pages to scroll through. The default is ``0``, which means the scrolling has no limit.
For example if this value is set to ``5`` and the ``max_query_size`` is set to ``10000`` then ``50000`` documents will be downloaded at most.
``scroll_keepalive``: The maximum time (formatted in `Time Units <https://www.elastic.co/guide/en/elasticsearch/reference/current/common-options.html#time-units>`_) the scrolling context should be kept alive. Avoid using high values as it abuses resources in Elasticsearch, but be mindful to allow sufficient time to finish processing all the results.
``max_aggregation``: The maximum number of alerts to aggregate together. If a rule has ``aggregation`` set, all
alerts occuring within a timeframe will be sent together. The default is 10,000.
``old_query_limit``: The maximum time between queries for ElastAlert to start at the most recently run query.
When ElastAlert starts, for each rule, it will search ``elastalert_metadata`` for the most recently run query and start
from that time, unless it is older than ``old_query_limit``, in which case it will start from the present time. The default is one week.
``disable_rules_on_error``: If true, ElastAlert will disable rules which throw uncaught (not EAException) exceptions. It
will upload a traceback message to ``elastalert_metadata`` and if ``notify_email`` is set, send an email notification. The
rule will no longer be run until either ElastAlert restarts or the rule file has been modified. This defaults to True.
``show_disabled_rules``: If true, ElastAlert show the disable rules' list when finishes the execution. This defaults to True.
``notify_email``: An email address, or list of email addresses, to which notification emails will be sent. Currently,
only an uncaught exception will send a notification email. The from address, SMTP host, and reply-to header can be set
using ``from_addr``, ``smtp_host``, and ``email_reply_to`` options, respectively. By default, no emails will be sent.
``from_addr``: The address to use as the from header in email notifications.
This value will be used for email alerts as well, unless overwritten in the rule config. The default value
is "ElastAlert".
``smtp_host``: The SMTP host used to send email notifications. This value will be used for email alerts as well,
unless overwritten in the rule config. The default is "localhost".
``email_reply_to``: This sets the Reply-To header in emails. The default is the recipient address.
``aws_region``: This makes ElastAlert to sign HTTP requests when using Amazon Elasticsearch Service. It'll use instance role keys to sign the requests.
The environment variable ``AWS_DEFAULT_REGION`` will override this field.
``boto_profile``: Deprecated! Boto profile to use when signing requests to Amazon Elasticsearch Service, if you don't want to use the instance role keys.
``profile``: AWS profile to use when signing requests to Amazon Elasticsearch Service, if you don't want to use the instance role keys.
The environment variable ``AWS_DEFAULT_PROFILE`` will override this field.
``replace_dots_in_field_names``: If ``True``, ElastAlert replaces any dots in field names with an underscore before writing documents to Elasticsearch.
The default value is ``False``. Elasticsearch 2.0 - 2.3 does not support dots in field names.
``string_multi_field_name``: If set, the suffix to use for the subfield for string multi-fields in Elasticsearch.
The default value is ``.raw`` for Elasticsearch 2 and ``.keyword`` for Elasticsearch 5.
``add_metadata_alert``: If set, alerts will include metadata described in rules (``category``, ``description``, ``owner`` and ``priority``); set to ``True`` or ``False``. The default is ``False``.
``skip_invalid``: If ``True``, skip invalid files instead of exiting.
Logging
-------
By default, ElastAlert uses a simple basic logging configuration to print log messages to standard error.
You can change the log level to ``INFO`` messages by using the ``--verbose`` or ``--debug`` command line options.
If you need a more sophisticated logging configuration, you can provide a full logging configuration
in the config file. This way you can also configure logging to a file, to Logstash and
adjust the logging format.
For details, see the end of ``config.yaml.example`` where you can find an example logging
configuration.
.. _runningelastalert:
Running ElastAlert
==================
``$ python elastalert/elastalert.py``
Several arguments are available when running ElastAlert:
``--config`` will specify the configuration file to use. The default is ``config.yaml``.
``--debug`` will run ElastAlert in debug mode. This will increase the logging verboseness, change
all alerts to ``DebugAlerter``, which prints alerts and suppresses their normal action, and skips writing
search and alert metadata back to Elasticsearch. Not compatible with `--verbose`.
``--verbose`` will increase the logging verboseness, which allows you to see information about the state
of queries. Not compatible with `--debug`.
``--start <timestamp>`` will force ElastAlert to begin querying from the given time, instead of the default,
querying from the present. The timestamp should be ISO8601, e.g. ``YYYY-MM-DDTHH:MM:SS`` (UTC) or with timezone
``YYYY-MM-DDTHH:MM:SS-08:00`` (PST). Note that if querying over a large date range, no alerts will be
sent until that rule has finished querying over the entire time period. To force querying from the current time, use "NOW".
``--end <timestamp>`` will cause ElastAlert to stop querying at the specified timestamp. By default, ElastAlert
will periodically query until the present indefinitely.
``--rule <rule.yaml>`` will only run the given rule. The rule file may be a complete file path or a filename in ``rules_folder``
or its subdirectories.
``--silence <unit>=<number>`` will silence the alerts for a given rule for a period of time. The rule must be specified using
``--rule``. <unit> is one of days, weeks, hours, minutes or seconds. <number> is an integer. For example,
``--rule noisy_rule.yaml --silence hours=4`` will stop noisy_rule from generating any alerts for 4 hours.
``--es_debug`` will enable logging for all queries made to Elasticsearch.
``--es_debug_trace <trace.log>`` will enable logging curl commands for all queries made to Elasticsearch to the
specified log file. ``--es_debug_trace`` is passed through to `elasticsearch.py
<http://elasticsearch-py.readthedocs.io/en/master/index.html#logging>`_ which logs `localhost:9200`
instead of the actual ``es_host``:``es_port``.
``--end <timestamp>`` will force ElastAlert to stop querying after the given time, instead of the default,
querying to the present time. This really only makes sense when running standalone. The timestamp is formatted
as ``YYYY-MM-DDTHH:MM:SS`` (UTC) or with timezone ``YYYY-MM-DDTHH:MM:SS-XX:00`` (UTC-XX).
``--pin_rules`` will stop ElastAlert from loading, reloading or removing rules based on changes to their config files.
================================================
FILE: docs/source/elastalert_status.rst
================================================
.. _metadata:
ElastAlert Metadata Index
=========================
ElastAlert uses Elasticsearch to store various information about its state. This not only allows for some
level of auditing and debugging of ElastAlert's operation, but also to avoid loss of data or duplication of alerts
when ElastAlert is shut down, restarted, or crashes. This cluster and index information is defined
in the global config file with ``es_host``, ``es_port`` and ``writeback_index``. ElastAlert must be able
to write to this index. The script, ``elastalert-create-index`` will create the index with the correct mapping
for you, and optionally copy the documents from an existing ElastAlert writeback index. Run it and it will
prompt you for the cluster information.
ElastAlert will create three different types of documents in the writeback index:
elastalert_status
~~~~~~~~~~~~~~~~~
``elastalert_status`` is a log of the queries performed for a given rule and contains:
- ``@timestamp``: The time when the document was uploaded to Elasticsearch. This is after a query has been run and the results have been processed.
- ``rule_name``: The name of the corresponding rule.
- ``starttime``: The beginning of the timestamp range the query searched.
- ``endtime``: The end of the timestamp range the query searched.
- ``hits``: The number of results from the query.
- ``matches``: The number of matches that the rule returned after processing the hits. Note that this does not necessarily mean that alerts were triggered.
- ``time_taken``: The number of seconds it took for this query to run.
``elastalert_status`` is what ElastAlert will use to determine what time range to query when it first starts to avoid duplicating queries.
For each rule, it will start querying from the most recent endtime. If ElastAlert is running in debug mode, it will still attempt to base
its start time by looking for the most recent search performed, but it will not write the results of any query back to Elasticsearch.
elastalert
~~~~~~~~~~
``elastalert`` is a log of information about every alert triggered and contains:
- ``@timestamp``: The time when the document was uploaded to Elasticsearch. This is not the same as when the alert was sent, but rather when the rule outputs a match.
- ``rule_name``: The name of the corresponding rule.
- ``alert_info``: This contains the output of Alert.get_info, a function that alerts implement to give some relevant context to the alert type. This may contain alert_info.type, alert_info.recipient, or any number of other sub fields.
- ``alert_sent``: A boolean value as to whether this alert was actually sent or not. It may be false in the case of an exception or if it is part of an aggregated alert.
- ``alert_time``: The time that the alert was or will be sent. Usually, this is the same as @timestamp, but may be some time in the future, indicating when an aggregated alert will be sent.
- ``match_body``: This is the contents of the match dictionary that is used to create the alert. The subfields may include a number of things containing information about the alert.
- ``alert_exception``: This field is only present when the alert failed because of an exception occurring, and will contain the exception information.
- ``aggregate_id``: This field is only present when the rule is configured to use aggregation. The first alert of the aggregation period will contain an alert_time set to the aggregation time into the future, and subsequent alerts will contain the document ID of the first. When the alert_time is reached, all alerts with that aggregate_id will be sent together.
elastalert_error
~~~~~~~~~~~~~~~~
When an error occurs in ElastAlert, it is written to both Elasticsearch and to stderr. The ``elastalert_error`` type contains:
- ``@timestamp``: The time when the error occurred.
- ``message``: The error or exception message.
- ``traceback``: The traceback from when the error occurred.
- ``data``: Extra information about the error. This often contains the name of the rule which caused the error.
silence
~~~~~~~
``silence`` is a record of when alerts for a given rule will be suppressed, either because of a ``realert`` setting or from using --silence. When
an alert with ``realert`` is triggered, a ``silence`` record will be written with ``until`` set to the alert time plus ``realert``.
- ``@timestamp``: The time when the document was uploaded to Elasticsearch.
- ``rule_name``: The name of the corresponding rule.
- ``until``: The timestamp when alerts will begin being sent again.
- ``exponent``: The exponential factor which multiplies ``realert``. The length of this silence is equal to ``realert`` * 2**exponent. This will
be 0 unless ``exponential_realert`` is set.
Whenever an alert is triggered, ElastAlert will check for a matching ``silence`` document, and if the ``until`` timestamp is in the future, it will ignore
the alert completely. See the :ref:`Running ElastAlert <runningelastalert>` section for information on how to silence an alert.
================================================
FILE: docs/source/index.rst
================================================
.. ElastAlert documentation master file, created by
sphinx-quickstart on Thu Jul 11 15:45:31 2013.
You can adapt this file completely to your liking, but it should at least
contain the root `toctree` directive.
ElastAlert - Easy & Flexible Alerting With Elasticsearch
========================================================
Contents:
.. toctree::
:maxdepth: 2
elastalert
running_elastalert
ruletypes
elastalert_status
recipes/adding_rules
recipes/adding_alerts
recipes/writing_filters
recipes/adding_enhancements
recipes/adding_loaders
recipes/signing_requests
Indices and Tables
==================
* :ref:`genindex`
* :ref:`modindex`
* :ref:`search`
================================================
FILE: docs/source/recipes/adding_alerts.rst
================================================
.. _writingalerts:
Adding a New Alerter
====================
Alerters are subclasses of ``Alerter``, found in ``elastalert/alerts.py``. They are given matches
and perform some action based on that. Your alerter needs to implement two member functions, and will look
something like this:
.. code-block:: python
class AwesomeNewAlerter(Alerter):
required_options = set(['some_config_option'])
def alert(self, matches):
...
def get_info(self):
...
You can import alert types by specifying the type as ``module.file.AlertName``, where module is the name of a python module,
and file is the name of the python file containing a ``Alerter`` subclass named ``AlertName``.
Basics
------
The alerter class will be instantiated when ElastAlert starts, and be periodically passed
matches through the ``alert`` method. ElastAlert also writes back info about the alert into
Elasticsearch that it obtains through ``get_info``. Several important member properties:
``self.required_options``: This is a set containing names of configuration options that must be
present. ElastAlert will not instantiate the alert if any are missing.
``self.rule``: The dictionary containing the rule configuration. All options specific to the alert
should be in the rule configuration file and can be accessed here.
``self.pipeline``: This is a dictionary object that serves to transfer information between alerts. When an alert is triggered,
a new empty pipeline object will be created and each alerter can add or receive information from it. Note that alerters
are called in the order they are defined in the rule file. For example, the JIRA alerter will add its ticket number
to the pipeline and the email alerter will add that link if it's present in the pipeline.
alert(self, match):
-------------------
ElastAlert will call this function to send an alert. ``matches`` is a list of dictionary objects with
information about the match. You can get a nice string representation of the match by calling
``self.rule['type'].get_match_str(match, self.rule)``. If this method raises an exception, it will
be caught by ElastAlert and the alert will be marked as unsent and saved for later.
get_info(self):
---------------
This function is called to get information about the alert to save back to Elasticsearch. It should
return a dictionary, which is uploaded directly to Elasticsearch, and should contain useful information
about the alert such as the type, recipients, parameters, etc.
Tutorial
--------
Let's create a new alert that will write alerts to a local output file. First,
create a modules folder in the base ElastAlert folder:
.. code-block:: console
$ mkdir elastalert_modules
$ cd elastalert_modules
$ touch __init__.py
Now, in a file named ``my_alerts.py``, add
.. code-block:: python
from elastalert.alerts import Alerter, BasicMatchString
class AwesomeNewAlerter(Alerter):
# By setting required_options to a set of strings
# You can ensure that the rule config file specifies all
# of the options. Otherwise, ElastAlert will throw an exception
# when trying to load the rule.
required_options = set(['output_file_path'])
# Alert is called
def alert(self, matches):
# Matches is a list of match dictionaries.
# It contains more than one match when the alert has
# the aggregation option set
for match in matches:
# Config options can be accessed with self.rule
with open(self.rule['output_file_path'], "a") as output_file:
# basic_match_string will transform the match into the default
# human readable string format
match_string = str(BasicMatchString(self.rule, match))
output_file.write(match_string)
# get_info is called after an alert is sent to get data that is written back
# to Elasticsearch in the field "alert_info"
# It should return a dict of information relevant to what the alert does
def get_info(self):
return {'type': 'Awesome Alerter',
'output_file': self.rule['output_file_path']}
In the rule configuration file, we are going to specify the alert by writing
.. code-block:: yaml
alert: "elastalert_modules.my_alerts.AwesomeNewAlerter"
output_file_path: "/tmp/alerts.log"
ElastAlert will attempt to import the alert with ``from elastalert_modules.my_alerts import AwesomeNewAlerter``.
This means that the folder must be in a location where it can be imported as a python module.
================================================
FILE: docs/source/recipes/adding_enhancements.rst
================================================
.. _enhancements:
Enhancements
============
Enhancements are modules which let you modify a match before an alert is sent. They should subclass ``BaseEnhancement``, found in ``elastalert/enhancements.py``.
They can be added to rules using the ``match_enhancements`` option::
match_enhancements:
- module.file.MyEnhancement
where module is the name of a Python module, or folder containing ``__init__.py``,
and file is the name of the Python file containing a ``BaseEnhancement`` subclass named ``MyEnhancement``.
A special exception class ```DropMatchException``` can be used in enhancements to drop matches if custom conditions are met. For example:
.. code-block:: python
class MyEnhancement(BaseEnhancement):
def process(self, match):
# Drops a match if "field_1" == "field_2"
if match['field_1'] == match['field_2']:
raise DropMatchException()
Example
-------
As an example enhancement, let's add a link to a whois website. The match must contain a field named domain and it will
add an entry named domain_whois_link. First, create a modules folder for the enhancement in the ElastAlert directory.
.. code-block:: console
$ mkdir elastalert_modules
$ cd elastalert_modules
$ touch __init__.py
Now, in a file named ``my_enhancements.py``, add
.. code-block:: python
from elastalert.enhancements import BaseEnhancement
class MyEnhancement(BaseEnhancement):
# The enhancement is run against every match
# The match is passed to the process function where it can be modified in any way
# ElastAlert will do this for each enhancement linked to a rule
def process(self, match):
if 'domain' in match:
url = "http://who.is/whois/%s" % (match['domain'])
match['domain_whois_link'] = url
Enhancements will not automatically be run. Inside the rule configuration file, you need to point it to the enhancement(s) that it should run
by setting the ``match_enhancements`` option::
match_enhancements:
- "elastalert_modules.my_enhancements.MyEnhancement"
================================================
FILE: docs/source/recipes/adding_loaders.rst
================================================
.. _loaders:
Rules Loaders
========================
RulesLoaders are subclasses of ``RulesLoader``, found in ``elastalert/loaders.py``. They are used to
gather rules for a particular source. Your RulesLoader needs to implement three member functions, and
will look something like this:
.. code-block:: python
class AwesomeNewRulesLoader(RulesLoader):
def get_names(self, conf, use_rule=None):
...
def get_hashes(self, conf, use_rule=None):
...
def get_yaml(self, rule):
...
You can import loaders by specifying the type as ``module.file.RulesLoaderName``, where module is the name of a
python module, and file is the name of the python file containing a ``RulesLoader`` subclass named ``RulesLoaderName``.
Example
-------
As an example loader, let's retrieve rules from a database rather than from the local file system. First, create a
modules folder for the loader in the ElastAlert directory.
.. code-block:: console
$ mkdir elastalert_modules
$ cd elastalert_modules
$ touch __init__.py
Now, in a file named ``mongo_loader.py``, add
.. code-block:: python
from pymongo import MongoClient
from elastalert.loaders import RulesLoader
import yaml
class MongoRulesLoader(RulesLoader):
def __init__(self, conf):
super(MongoRulesLoader, self).__init__(conf)
self.client = MongoClient(conf['mongo_url'])
self.db = self.client[conf['mongo_db']]
self.cache = {}
def get_names(self, conf, use_rule=None):
if use_rule:
return [use_rule]
rules = []
self.cache = {}
for rule in self.db.rules.find():
self.cache[rule['name']] = yaml.load(rule['yaml'])
rules.append(rule['name'])
return rules
def get_hashes(self, conf, use_rule=None):
if use_rule:
return [use_rule]
hashes = {}
self.cache = {}
for rule in self.db.rules.find():
self.cache[rule['name']] = rule['yaml']
hashes[rule['name']] = rule['hash']
return hashes
def get_yaml(self, rule):
if rule in self.cache:
return self.cache[rule]
self.cache[rule] = yaml.load(self.db.rules.find_one({'name': rule})['yaml'])
return self.cache[rule]
Finally, you need to specify in your ElastAlert configuration file that MongoRulesLoader should be used instead of the
default FileRulesLoader, so in your ``elastalert.conf`` file::
rules_loader: "elastalert_modules.mongo_loader.MongoRulesLoader"
================================================
FILE: docs/source/recipes/adding_rules.rst
================================================
.. _writingrules:
Adding a New Rule Type
======================
This document describes how to create a new rule type. Built in rule types live in ``elastalert/ruletypes.py``
and are subclasses of ``RuleType``. At the minimum, your rule needs to implement ``add_data``.
Your class may implement several functions from ``RuleType``:
.. code-block:: python
class AwesomeNewRule(RuleType):
# ...
def add_data(self, data):
# ...
def get_match_str(self, match):
# ...
def garbage_collect(self, timestamp):
# ...
You can import new rule types by specifying the type as ``module.file.RuleName``, where module is the name of a Python module, or folder
containing ``__init__.py``, and file is the name of the Python file containing a ``RuleType`` subclass named ``RuleName``.
Basics
------
The ``RuleType`` instance remains in memory while ElastAlert is running, receives data, keeps track of its state,
and generates matches. Several important member properties are created in the ``__init__`` method of ``RuleType``:
``self.rules``: This dictionary is loaded from the rule configuration file. If there is a ``timeframe`` configuration
option, this will be automatically converted to a ``datetime.timedelta`` object when the rules are loaded.
``self.matches``: This is where ElastAlert checks for matches from the rule. Whatever information is relevant to the match
(generally coming from the fields in Elasticsearch) should be put into a dictionary object and
added to ``self.matches``. ElastAlert will pop items out periodically and send alerts based on these objects. It is
recommended that you use ``self.add_match(match)`` to add matches. In addition to appending to ``self.matches``,
``self.add_match`` will convert the datetime ``@timestamp`` back into an ISO8601 timestamp.
``self.required_options``: This is a set of options that must exist in the configuration file. ElastAlert will
ensure that all of these fields exist before trying to instantiate a ``RuleType`` instance.
add_data(self, data):
---------------------
When ElastAlert queries Elasticsearch, it will pass all of the hits to the rule type by calling ``add_data``.
``data`` is a list of dictionary objects which contain all of the fields in ``include``, ``query_key`` and ``compare_key``
if they exist, and ``@timestamp`` as a datetime object. They will always come in chronological order sorted by '@timestamp'.
get_match_str(self, match):
---------------------------
Alerts will call this function to get a human readable string about a match for an alert. Match will be the same
object that was added to ``self.matches``, and ``rules`` the same as ``self.rules``. The ``RuleType`` base implementation
will return an empty string. Note that by default, the alert text will already contain the key-value pairs from the match. This
should return a string that gives some information about the match in the context of this specific RuleType.
garbage_collect(self, timestamp):
---------------------------------
This will be called after ElastAlert has run over a time period ending in ``timestamp`` and should be used
to clear any state that may be obsolete as of ``timestamp``. ``timestamp`` is a datetime object.
Tutorial
--------
As an example, we are going to create a rule type for detecting suspicious logins. Let's imagine the data we are querying is login
events that contains IP address, username and a timestamp. Our configuration will take a list of usernames and a time range
and alert if a login occurs in the time range. First, let's create a modules folder in the base ElastAlert folder:
.. code-block:: console
$ mkdir elastalert_modules
$ cd elastalert_modules
$ touch __init__.py
Now, in a file named ``my_rules.py``, add
.. code-block:: python
import dateutil.parser
from elastalert.ruletypes import RuleType
# elastalert.util includes useful utility functions
# such as converting from timestamp to datetime obj
from elastalert.util import ts_to_dt
class AwesomeRule(RuleType):
# By setting required_options to a set of strings
# You can ensure that the rule config file specifies all
# of the options. Otherwise, ElastAlert will throw an exception
# when trying to load the rule.
required_options = set(['time_start', 'time_end', 'usernames'])
# add_data will be called each time Elasticsearch is queried.
# data is a list of documents from Elasticsearch, sorted by timestamp,
# including all the fields that the config specifies with "include"
def add_data(self, data):
for document in data:
# To access config options, use self.rules
if document['username'] in self.rules['usernames']:
# Convert the timestamp to a time object
login_time = document['@timestamp'].time()
# Convert time_start and time_end to time objects
time_start = dateutil.parser.parse(self.rules['time_start']).time()
time_end = dateutil.parser.parse(self.rules['time_end']).time()
# If the time falls between start and end
if login_time > time_start and login_time < time_end:
# To add a match, use self.add_match
self.add_match(document)
# The results of get_match_str will appear in the alert text
def get_match_str(self, match):
return "%s logged in between %s and %s" % (match['username'],
self.rules['time_start'],
self.rules['time_end'])
# garbage_collect is called indicating that ElastAlert has already been run up to timestamp
# It is useful for knowing that there were no query results from Elasticsearch because
# add_data will not be called with an empty list
def garbage_collect(self, timestamp):
pass
In the rule configuration file, ``example_rules/example_login_rule.yaml``, we are going to specify this rule by writing
.. code-block:: yaml
name: "Example login rule"
es_host: elasticsearch.example.com
es_port: 14900
type: "elastalert_modules.my_rules.AwesomeRule"
# Alert if admin, userXYZ or foobaz log in between 8 PM and midnight
time_start: "20:00"
time_end: "24:00"
usernames:
- "admin"
- "userXYZ"
- "foobaz"
# We require the username field from documents
include:
- "username"
alert:
- debug
ElastAlert will attempt to import the rule with ``from elastalert_modules.my_rules import AwesomeRule``.
This means that the folder must be in a location where it can be imported as a Python module.
An alert from this rule will look something like::
Example login rule
userXYZ logged in between 20:00 and 24:00
@timestamp: 2015-03-02T22:23:24Z
username: userXYZ
================================================
FILE: docs/source/recipes/signing_requests.rst
================================================
.. _signingrequests:
Signing requests to Amazon Elasticsearch service
================================================
When using Amazon Elasticsearch service, you need to secure your Elasticsearch
from the outside. Currently, there is no way to secure your Elasticsearch using
network firewall rules, so the only way is to signing the requests using the
access key and secret key for a role or user with permissions on the
Elasticsearch service.
You can sign requests to AWS using any of the standard AWS methods of providing
credentials.
- Environment Variables, ``AWS_ACCESS_KEY_ID`` and ``AWS_SECRET_ACCESS_KEY``
- AWS Config or Credential Files, ``~/.aws/config`` and ``~/.aws/credentials``
- AWS Instance Profiles, uses the EC2 Metadata service
Using an Instance Profile
-------------------------
Typically, you'll deploy ElastAlert on a running EC2 instance on AWS. You can
assign a role to this instance that gives it permissions to read from and write
to the Elasticsearch service. When using an Instance Profile, you will need to
specify the ``aws_region`` in the configuration file or set the
``AWS_DEFAULT_REGION`` environment variable.
Using AWS profiles
------------------
You can also create a user with permissions on the Elasticsearch service and
tell ElastAlert to authenticate itself using that user. First, create an AWS
profile in the machine where you'd like to run ElastAlert for the user with
permissions.
You can use the environment variables ``AWS_DEFAULT_PROFILE`` and
``AWS_DEFAULT_REGION`` or add two options to the configuration file:
- ``aws_region``: The AWS region where you want to operate.
- ``profile``: The name of the AWS profile to use to sign the requests.
================================================
FILE: docs/source/recipes/writing_filters.rst
================================================
.. _writingfilters:
Writing Filters For Rules
=========================
This document describes how to create a filter section for your rule config file.
The filters used in rules are part of the Elasticsearch query DSL, further documentation for which can be found at
https://www.elastic.co/guide/en/elasticsearch/reference/current/query-dsl.html
This document contains a small subset of particularly useful filters.
The filter section is passed to Elasticsearch exactly as follows::
filter:
and:
filters:
- [filters from rule.yaml]
Every result that matches these filters will be passed to the rule for processing.
Common Filter Types:
--------------------
query_string
************
The query_string type follows the Lucene query format and can be used for partial or full matches to multiple fields.
See http://lucene.apache.org/core/2_9_4/queryparsersyntax.html for more information::
filter:
- query:
query_string:
query: "username: bob"
- query:
query_string:
query: "_type: login_logs"
- query:
query_string:
query: "field: value OR otherfield: othervalue"
- query:
query_string:
query: "this: that AND these: those"
term
****
The term type allows for exact field matches::
filter:
- term:
name_field: "bob"
- term:
_type: "login_logs"
Note that a term query may not behave as expected if a field is analyzed. By default, many string fields will be tokenized by whitespace, and a term query for "foo bar" may not match
a field that appears to have the value "foo bar", unless it is not analyzed. Conversely, a term query for "foo" will match analyzed strings "foo bar" and "foo baz". For full text
matching on analyzed fields, use query_string. See https://www.elastic.co/guide/en/elasticsearch/guide/current/term-vs-full-text.html
`terms <https://www.elastic.co/guide/en/elasticsearch/reference/current/query-dsl-terms-query.html>`_
*****************************************************************************************************
Terms allows for easy combination of multiple term filters::
filter:
- terms:
field: ["value1", "value2"] # value1 OR value2
You can also match on multiple fields::
- terms:
fieldX: ["value1", "value2"]
fieldY: ["something", "something_else"]
fieldZ: ["foo", "bar", "baz"]
wildcard
********
For wildcard matches::
filter:
- query:
wildcard:
field: "foo*bar"
range
*****
For ranges on fields::
filter:
- range:
status_code:
from: 500
to: 599
Negation, and, or
*****************
For Elasticsearch 2.X, any of the filters can be embedded in ``not``, ``and``, and ``or``::
filter:
- or:
- term:
field: "value"
- wildcard:
field: "foo*bar"
- and:
- not:
term:
field: "value"
- not:
term:
_type: "something"
For Elasticsearch 5.x, this will not work and to implement boolean logic use query strings::
filter:
- query:
query_string:
query: "somefield: somevalue OR foo: bar"
Loading Filters Directly From Kibana 3
--------------------------------------
There are two ways to load filters directly from a Kibana 3 dashboard. You can set your filter to::
filter:
download_dashboard: "My Dashboard Name"
and when ElastAlert starts, it will download the dashboard schema from Elasticsearch and use the filters from that.
However, if the dashboard name changes or if there is connectivity problems when ElastAlert starts, the rule will not load and
ElastAlert will exit with an error like "Could not download filters for .."
The second way is to generate a config file once using the Kibana dashboard. To do this, run ``elastalert-rule-from-kibana``.
.. code-block:: console
$ elastalert-rule-from-kibana
Elasticsearch host: elasticsearch.example.com
Elasticsearch port: 14900
Dashboard name: My Dashboard
Partial Config file
-----------
name: My Dashboard
es_host: elasticsearch.example.com
es_port: 14900
filter:
- query:
query_string: {query: '_exists_:log.message'}
- query:
query_string: {query: 'some_field:12345'}
================================================
FILE: docs/source/ruletypes.rst
================================================
Rule Types and Configuration Options
************************************
Examples of several types of rule configuration can be found in the example_rules folder.
.. _commonconfig:
.. note:: All "time" formats are of the form ``unit: X`` where unit is one of weeks, days, hours, minutes or seconds.
Such as ``minutes: 15`` or ``hours: 1``.
Rule Configuration Cheat Sheet
==============================
+--------------------------------------------------------------------------+
| FOR ALL RULES |
+==============================================================+===========+
| ``es_host`` (string) | Required |
+--------------------------------------------------------------+ |
| ``es_port`` (number) | |
+--------------------------------------------------------------+ |
| ``index`` (string) | |
+--------------------------------------------------------------+ |
| ``type`` (string) | |
+--------------------------------------------------------------+ |
| ``alert`` (string or list) | |
+--------------------------------------------------------------+-----------+
| ``name`` (string, defaults to the filename) | |
+--------------------------------------------------------------+ |
| ``use_strftime_index`` (boolean, default False) | Optional |
+--------------------------------------------------------------+ |
| ``use_ssl`` (boolean, default False) | |
+--------------------------------------------------------------+ |
| ``verify_certs`` (boolean, default True) | |
+--------------------------------------------------------------+ |
| ``es_username`` (string, no default) | |
+--------------------------------------------------------------+ |
| ``es_password`` (string, no default) | |
+--------------------------------------------------------------+ |
| ``es_url_prefix`` (string, no default) | |
+--------------------------------------------------------------+ |
| ``es_send_get_body_as`` (string, default "GET") | |
+--------------------------------------------------------------+ |
| ``aggregation`` (time, no default) | |
+--------------------------------------------------------------+ |
| ``description`` (string, default empty string) | |
+--------------------------------------------------------------+ |
| ``generate_kibana_link`` (boolean, default False) | |
+--------------------------------------------------------------+ |
| ``use_kibana_dashboard`` (string, no default) | |
+--------------------------------------------------------------+ |
| ``kibana_url`` (string, default from es_host) | |
+--------------------------------------------------------------+ |
| ``use_kibana4_dashboard`` (string, no default) | |
+--------------------------------------------------------------+ |
| ``kibana4_start_timedelta`` (time, default: 10 min) | |
+--------------------------------------------------------------+ |
| ``kibana4_end_timedelta`` (time, default: 10 min) | |
+--------------------------------------------------------------+ |
| ``generate_kibana_discover_url`` (boolean, default False) | |
+--------------------------------------------------------------+ |
| ``kibana_discover_app_url`` (string, no default) | |
+--------------------------------------------------------------+ |
| ``kibana_discover_version`` (string, no default) | |
+--------------------------------------------------------------+ |
| ``kibana_discover_index_pattern_id`` (string, no default) | |
+--------------------------------------------------------------+ |
| ``kibana_discover_columns`` (list of strs, default _source) | |
+--------------------------------------------------------------+ |
| ``kibana_discover_from_timedelta`` (time, default: 10 min) | |
+--------------------------------------------------------------+ |
| ``kibana_discover_to_timedelta`` (time, default: 10 min) | |
+--------------------------------------------------------------+ |
| ``use_local_time`` (boolean, default True) | |
+--------------------------------------------------------------+ |
| ``realert`` (time, default: 1 min) | |
+--------------------------------------------------------------+ |
| ``exponential_realert`` (time, no default) | |
+--------------------------------------------------------------+ |
| ``match_enhancements`` (list of strs, no default) | |
+--------------------------------------------------------------+ |
| ``top_count_number`` (int, default 5) | |
+--------------------------------------------------------------+ |
| ``top_count_keys`` (list of strs) | |
+--------------------------------------------------------------+ |
| ``raw_count_keys`` (boolean, default True) | |
+--------------------------------------------------------------+ |
| ``include`` (list of strs, default ["*"]) | |
+--------------------------------------------------------------+ |
| ``filter`` (ES filter DSL, no default) | |
+--------------------------------------------------------------+ |
| ``max_query_size`` (int, default global max_query_size) | |
+--------------------------------------------------------------+ |
| ``query_delay`` (time, default 0 min) | |
+--------------------------------------------------------------+ |
| ``owner`` (string, default empty string) | |
+--------------------------------------------------------------+ |
| ``priority`` (int, default 2) | |
+--------------------------------------------------------------+ |
| ``category`` (string, default empty string) | |
+--------------------------------------------------------------+ |
| ``scan_entire_timeframe`` (bool, default False) | |
+--------------------------------------------------------------+ |
| ``import`` (string) | |
| | |
| IGNORED IF ``use_count_query`` or ``use_terms_query`` is true| |
+--------------------------------------------------------------+ +
| ``buffer_time`` (time, default from config.yaml) | |
+--------------------------------------------------------------+ |
| ``timestamp_type`` (string, default iso) | |
+--------------------------------------------------------------+ |
| ``timestamp_format`` (string, default "%Y-%m-%dT%H:%M:%SZ") | |
+--------------------------------------------------------------+ |
| ``timestamp_format_expr`` (string, no default ) | |
+--------------------------------------------------------------+ |
| ``_source_enabled`` (boolean, default True) | |
+--------------------------------------------------------------+ |
| ``alert_text_args`` (array of strs) | |
+--------------------------------------------------------------+ |
| ``alert_text_kw`` (object) | |
+--------------------------------------------------------------+ |
| ``alert_missing_value`` (string, default "<MISSING VALUE>") | |
+--------------------------------------------------------------+ |
| ``is_enabled`` (boolean, default True) | |
+--------------------------------------------------------------+-----------+
| ``search_extra_index`` (boolean, default False) | |
+--------------------------------------------------------------+-----------+
|
+----------------------------------------------------+--------+-----------+-----------+--------+-----------+-------+----------+--------+-----------+
| RULE TYPE | Any | Blacklist | Whitelist | Change | Frequency | Spike | Flatline |New_term|Cardinality|
+====================================================+========+===========+===========+========+===========+=======+==========+========+===========+
| ``compare_key`` (list of strs, no default) | | Req | Req | Req | | | | | |
+----------------------------------------------------+--------+-----------+-----------+--------+-----------+-------+----------+--------+-----------+
|``blacklist`` (list of strs, no default) | | Req | | | | | | | |
+----------------------------------------------------+--------+-----------+-----------+--------+-----------+-------+----------+--------+-----------+
|``whitelist`` (list of strs, no default) | | | Req | | | | | | |
+----------------------------------------------------+--------+-----------+-----------+--------+-----------+-------+----------+--------+-----------+
| ``ignore_null`` (boolean, no default) | | | Req | Req | | | | | |
+----------------------------------------------------+--------+-----------+-----------+--------+-----------+-------+----------+--------+-----------+
| ``query_key`` (string, no default) | Opt | | | Req | Opt | Opt | Opt | Req | Opt |
+----------------------------------------------------+--------+-----------+-----------+--------+-----------+-------+----------+--------+-----------+
| ``aggregation_key`` (string, no default) | Opt | | | | | | | | |
+----------------------------------------------------+--------+-----------+-----------+--------+-----------+-------+----------+--------+-----------+
| ``summary_table_fields`` (list, no default) | Opt | | | | | | | | |
+----------------------------------------------------+--------+-----------+-----------+--------+-----------+-------+----------+--------+-----------+
| ``timeframe`` (time, no default) | | | | Opt | Req | Req | Req | | Req |
+----------------------------------------------------+--------+-----------+-----------+--------+-----------+-------+----------+--------+-----------+
| ``num_events`` (int, no default) | | | | | Req | | | | |
+----------------------------------------------------+--------+-----------+-----------+--------+-----------+-------+----------+--------+-----------+
| ``attach_related`` (boolean, no default) | | | | | Opt | | | | |
+----------------------------------------------------+--------+-----------+-----------+--------+-----------+-------+----------+--------+-----------+
|``use_count_query`` (boolean, no default) | | | | | Opt | Opt | Opt | | |
| | | | | | | | | | |
|``doc_type`` (string, no default) | | | | | | | | | |
+----------------------------------------------------+--------+-----------+-----------+--------+-----------+-------+----------+--------+-----------+
|``use_terms_query`` (boolean, no default) | | | | | Opt | Opt | | Opt | |
| | | | | | | | | | |
|``doc_type`` (string, no default) | | | | | | | | | |
| | | | | | | | | | |
|``query_key`` (string, no default) | | | | | | | | | |
| | | | | | | | | | |
|``terms_size`` (int, default 50) | | | | | | | | | |
+----------------------------------------------------+--------+-----------+-----------+--------+-----------+-------+----------+--------+-----------+
| ``spike_height`` (int, no default) | | | | | | Req | | | |
+----------------------------------------------------+--------+-----------+-----------+--------+-----------+-------+----------+--------+-----------+
|``spike_type`` ([up|down|both], no default) | | | | | | Req | | | |
+----------------------------------------------------+--------+-----------+-----------+--------+-----------+-------+----------+--------+-----------+
|``alert_on_new_data`` (boolean, default False) | | | | | | Opt | | | |
+----------------------------------------------------+--------+-----------+-----------+--------+-----------+-------+----------+--------+-----------+
|``threshold_ref`` (int, no default) | | | | | | Opt | | | |
+----------------------------------------------------+--------+-----------+-----------+--------+-----------+-------+----------+--------+-----------+
|``threshold_cur`` (int, no default) | | | | | | Opt | | | |
+----------------------------------------------------+--------+-----------+-----------+--------+-----------+-------+----------+--------+-----------+
|``threshold`` (int, no default) | | | | | | | Req | | |
+----------------------------------------------------+--------+-----------+-----------+--------+-----------+-------+----------+--------+-----------+
|``fields`` (string or list, no default) | | | | | | | | Req | |
+----------------------------------------------------+--------+-----------+-----------+--------+-----------+-------+----------+--------+-----------+
|``terms_window_size`` (time, default 30 days) | | | | | | | | Opt | |
+----------------------------------------------------+--------+-----------+-----------+--------+-----------+-------+----------+--------+-----------+
|``window_step_size`` (time, default 1 day) | | | | | | | | Opt | |
+----------------------------------------------------+--------+-----------+-----------+--------+-----------+-------+----------+--------+-----------+
|``alert_on_missing_fields`` (boolean, default False)| | | | | | | | Opt | |
+----------------------------------------------------+--------+-----------+-----------+--------+-----------+-------+----------+--------+-----------+
|``cardinality_field`` (string, no default) | | | | | | | | | Req |
+----------------------------------------------------+--------+-----------+-----------+--------+-----------+-------+----------+--------+-----------+
|``max_cardinality`` (boolean, no default) | | | | | | | | | Opt |
+----------------------------------------------------+--------+-----------+-----------+--------+-----------+-------+----------+--------+-----------+
|``min_cardinality`` (boolean, no default) | | | | | | | | | Opt |
+----------------------------------------------------+--------+-----------+-----------+--------+-----------+-------+----------+--------+-----------+
Common Configuration Options
============================
Every file that ends in ``.yaml`` in the ``rules_folder`` will be run by default.
The following configuration settings are common to all types of rules.
Required Settings
~~~~~~~~~~~~~~~~~
es_host
^^^^^^^
``es_host``: The hostname of the Elasticsearch cluster the rule will use to query. (Required, string, no default)
The environment variable ``ES_HOST`` will override this field.
es_port
^^^^^^^
``es_port``: The port of the Elasticsearch cluster. (Required, number, no default)
The environment variable ``ES_PORT`` will override this field.
index
^^^^^
``index``: The name of the index that will be searched. Wildcards can be used here, such as:
``index: my-index-*`` which will match ``my-index-2014-10-05``. You can also use a format string containing
``%Y`` for year, ``%m`` for month, and ``%d`` for day. To use this, you must also set ``use_strftime_index`` to true. (Required, string, no default)
name
^^^^
``name``: The name of the rule. This must be unique across all rules. The name will be used in
alerts and used as a key when writing and reading search metadata back from Elasticsearch. (Required, string, no default)
type
^^^^
``type``: The ``RuleType`` to use. This may either be one of the built in rule types, see :ref:`Rule Types <ruletypes>` section below for more information,
or loaded from a module. For loading from a module, the type should be specified as ``module.file.RuleName``. (Required, string, no default)
alert
^^^^^
``alert``: The ``Alerter`` type to use. This may be one or more of the built in alerts, see :ref:`Alert Types <alerts>` section below for more information,
or loaded from a module. For loading from a module, the alert should be specified as ``module.file.AlertName``. (Required, string or list, no default)
Optional Settings
~~~~~~~~~~~~~~~~~
import
^^^^^^
``import``: If specified includes all the settings from this yaml file. This allows common config options to be shared. Note that imported files that aren't
complete rules should not have a ``.yml`` or ``.yaml`` suffix so that ElastAlert doesn't treat them as rules. Filters in imported files are merged (ANDed)
with any filters in the rule. You can only have one import per rule, though the imported file can import another file, recursively. The filename
can be an absolute path or relative to the rules directory. (Optional, string, no default)
use_ssl
^^^^^^^
``use_ssl``: Whether or not to connect to ``es_host`` using TLS. (Optional, boolean, default False)
The environment variable ``ES_USE_SSL`` will override this field.
verify_certs
^^^^^^^^^^^^
``verify_certs``: Whether or not to verify TLS certificates. (Optional, boolean, default True)
client_cert
^^^^^^^^^^^
``client_cert``: Path to a PEM certificate to use as the client certificate (Optional, string, no default)
client_key
^^^^^^^^^^^
``client_key``: Path to a private key file to use as the client key (Optional, string, no default)
ca_certs
^^^^^^^^
``ca_certs``: Path to a CA cert bundle to use to verify SSL connections (Optional, string, no default)
es_username
^^^^^^^^^^^
``es_username``: basic-auth username for connecting to ``es_host``. (Optional, string, no default) The environment variable ``ES_USERNAME`` will override this field.
es_password
^^^^^^^^^^^
``es_password``: basic-auth password for connecting to ``es_host``. (Optional, string, no default) The environment variable ``ES_PASSWORD`` will override this field.
es_url_prefix
^^^^^^^^^^^^^
``es_url_prefix``: URL prefix for the Elasticsearch endpoint. (Optional, string, no default)
es_send_get_body_as
^^^^^^^^^^^^^^^^^^^
``es_send_get_body_as``: Method for querying Elasticsearch. (Optional, string, default "GET")
use_strftime_index
^^^^^^^^^^^^^^^^^^
``use_strftime_index``: If this is true, ElastAlert will format the index using datetime.strftime for each query.
See https://docs.python.org/2/library/datetime.html#strftime-strptime-behavior for more details.
If a query spans multiple days, the formatted indexes will be concatenated with commas. This is useful
as narrowing the number of indexes searched, compared to using a wildcard, may be significantly faster. For example, if ``index`` is
``logstash-%Y.%m.%d``, the query url will be similar to ``elasticsearch.example.com/logstash-2015.02.03/...`` or
``elasticsearch.example.com/logstash-2015.02.03,logstash-2015.02.04/...``.
search_extra_index
^^^^^^^^^^^^^^^^^^
``search_extra_index``: If this is true, ElastAlert will add an extra index on the early side onto each search. For example, if it's querying
completely within 2018-06-28, it will actually use 2018-06-27,2018-06-28. This can be useful if your timestamp_field is not what's being used
to generate the index names. If that's the case, sometimes a query would not have been using the right index.
aggregation
^^^^^^^^^^^
``aggregation``: This option allows you to aggregate multiple matches together into one alert. Every time a match is found,
ElastAlert will wait for the ``aggregation`` period, and send all of the matches that have occurred in that time for a particular
rule together.
For example::
aggregation:
hours: 2
means that if one match occurred at 12:00, another at 1:00, and a third at 2:30, one
alert would be sent at 2:00, containing the first two matches, and another at 4:30, containing the third match plus any additional matches
occurring before 4:30. This can be very useful if you expect a large number of matches and only want a periodic report. (Optional, time, default none)
If you wish to aggregate all your alerts and send them on a recurring interval, you can do that using the ``schedule`` field.
For example, if you wish to receive alerts every Monday and Friday::
aggregation:
schedule: '2 4 * * mon,fri'
This uses Cron syntax, which you can read more about `here <http://www.nncron.ru/help/EN/working/cron-format.htm>`_. Make sure to `only` include either a schedule field or standard datetime fields (such as ``hours``, ``minutes``, ``days``), not both.
By default, all events that occur during an aggregation window are grouped together. However, if your rule has the ``aggregation_key`` field set, then each event sharing a common key value will be grouped together. A separate aggregation window will be made for each newly encountered key value.
For example, if you wish to receive alerts that are grouped by the user who triggered the event, you can set::
aggregation_key: 'my_data.username'
Then, assuming an aggregation window of 10 minutes, if you receive the following data points::
{'my_data': {'username': 'alice', 'event_type': 'login'}, '@timestamp': '2016-09-20T00:00:00'}
{'my_data': {'username': 'bob', 'event_type': 'something'}, '@timestamp': '2016-09-20T00:05:00'}
{'my_data': {'username': 'alice', 'event_type': 'something else'}, '@timestamp': '2016-09-20T00:06:00'}
This should result in 2 alerts: One containing alice's two events, sent at ``2016-09-20T00:10:00`` and one containing bob's one event sent at ``2016-09-20T00:16:00``
For aggregations, there can sometimes be a large number of documents present in the viewing medium (email, jira ticket, etc..). If you set the ``summary_table_fields`` field, Elastalert will provide a summary of the specified fields from all the results.
For example, if you wish to summarize the usernames and event_types that appear in the documents so that you can see the most relevant fields at a quick glance, you can set::
summary_table_fields:
- my_data.username
- my_data.event_type
Then, for the same sample data shown above listing alice and bob's events, Elastalert will provide the following summary table in the alert medium::
+------------------+--------------------+
| my_data.username | my_data.event_type |
+------------------+--------------------+
| alice | login |
| bob | something |
| alice | something else |
+------------------+--------------------+
.. note::
By default, aggregation time is relative to the current system time, not the time of the match. This means that running elastalert over
past events will result in different alerts than if elastalert had been running while those events occured. This behavior can be changed
by setting ``aggregate_by_match_time``.
aggregate_by_match_time
^^^^^^^^^^^^^^^^^^^^^^^
Setting this to true will cause aggregations to be created relative to the timestamp of the first event, rather than the current time. This
is useful for querying over historic data or if using a very large buffer_time and you want multiple aggregations to occur from a single query.
realert
^^^^^^^
``realert``: This option allows you to ignore repeating alerts for a period of time. If the rule uses a ``query_key``, this option
will be applied on a per key basis. All matches for a given rule, or for matches with the same ``query_key``, will be ignored for
the given time. All matches with a missing ``query_key`` will be grouped together using a value of ``_missing``.
This is applied to the time the alert is sent, not to the time of the event. It defaults to one minute, which means
that if ElastAlert is run over a large time period which triggers many matches, only the first alert will be sent by default. If you want
every alert, set realert to 0 minutes. (Optional, time, default 1 minute)
exponential_realert
^^^^^^^^^^^^^^^^^^^
``exponential_realert``: This option causes the value of ``realert`` to exponentially increase while alerts continue to fire. If set,
the value of ``exponential_realert`` is the maximum ``realert`` will increase to. If the time between alerts is less than twice ``realert``,
``realert`` will double. For example, if ``realert: minutes: 10`` and ``exponential_realert: hours: 1``, an alerts fires at 1:00 and another
at 1:15, the next alert will not be until at least 1:35. If another alert fires between 1:35 and 2:15, ``realert`` will increase to the
1 hour maximum. If more than 2 hours elapse before the next alert, ``realert`` will go back down. Note that alerts that are ignored (e.g.
one that occurred at 1:05) would not change ``realert``. (Optional, time, no default)
buffer_time
^^^^^^^^^^^
``buffer_time``: This options allows the rule to override the ``buffer_time`` global setting defined in config.yaml. This value is ignored if
``use_count_query`` or ``use_terms_query`` is true. (Optional, time)
query_delay
^^^^^^^^^^^
``query_delay``: This option will cause ElastAlert to subtract a time delta from every query, causing the rule to run with a delay.
This is useful if the data is Elasticsearch doesn't get indexed immediately. (Optional, time)
owner
^^^^^
``owner``: This value will be used to identify the stakeholder of the alert. Optionally, this field can be included in any alert type. (Optional, string)
priority
^^^^^^^^
``priority``: This value will be used to identify the relative priority of the alert. Optionally, this field can be included in any alert type (e.g. for use in email subject/body text). (Optional, int, default 2)
category
^^^^^^^^
``category``: This value will be used to identify the category of the alert. Optionally, this field can be included in any alert type (e.g. for use in email subject/body text). (Optional, string, default empty string)
max_query_size
^^^^^^^^^^^^^^
``max_query_size``: The maximum number of documents that will be downloaded from Elasticsearch in a single query. If you
expect a large number of results, consider using ``use_count_query`` for the rule. If this
limit is reached, a warning will be logged but ElastAlert will continue without downloading more results. This setting will
override a global ``max_query_size``. (Optional, int, default value of global ``max_query_size``)
filter
^^^^^^
``filter``: A list of Elasticsearch query DSL filters that is used to query Elasticsearch. ElastAlert will query Elasticsearch using the format
``{'filter': {'bool': {'must': [config.filter]}}}`` with an additional timestamp range filter.
All of the results of querying with these filters are passed to the ``RuleType`` for analysis.
For more information writing filters, see :ref:`Writing Filters <writingfilters>`. (Required, Elasticsearch query DSL, no default)
include
^^^^^^^
``include``: A list of terms that should be included in query results and passed to rule types and alerts. When set, only those
fields, along with '@timestamp', ``query_key``, ``compare_key``, and ``top_count_keys`` are included, if present.
(Optional, list of strings, default all fields)
top_count_keys
^^^^^^^^^^^^^^
``top_count_keys``: A list of fields. ElastAlert will perform a terms query for the top X most common values for each of the fields,
where X is 5 by default, or ``top_count_number`` if it exists.
For example, if ``num_events`` is 100, and ``top_count_keys`` is ``- "username"``, the alert will say how many of the 100 events
have each username, for the top 5 usernames. When this is computed, the time range used is from ``timeframe`` before the most recent event
to 10 minutes past the most recent event. Because ElastAlert uses an aggregation query to compute this, it will attempt to use the
field name plus ".raw" to count unanalyzed terms. To turn this off, set ``raw_count_keys`` to false.
top_count_number
^^^^^^^^^^^^^^^^
``top_count_number``: The number of terms to list if ``top_count_keys`` is set. (Optional, integer, default 5)
raw_count_keys
^^^^^^^^^^^^^^
``raw_count_keys``: If true, all fields in ``top_count_keys`` will have ``.raw`` appended to them. (Optional, boolean, default true)
description
^^^^^^^^^^^
``description``: text describing the purpose of rule. (Optional, string, default empty string)
Can be referenced in custom alerters to provide context as to why a rule might trigger.
generate_kibana_link
^^^^^^^^^^^^^^^^^^^^
``generate_kibana_link``: This option is for Kibana 3 only.
If true, ElastAlert will generate a temporary Kibana dashboard and include a link to it in alerts. The dashboard
consists of an events over time graph and a table with ``include`` fields selected in the table. If the rule uses ``query_key``, the
dashboard will also contain a filter for the ``query_key`` of the alert. The dashboard schema will
be uploaded to the kibana-int index as a temporary dashboard. (Optional, boolean, default False)
kibana_url
^^^^^^^^^^
``kibana_url``: The url to access Kibana. This will be used if ``generate_kibana_link`` or
``use_kibana_dashboard`` is true. If not specified, a URL will be constructed using ``es_host`` and ``es_port``.
(Optional, string, default ``http://<es_host>:<es_port>/_plugin/kibana/``)
use_kibana_dashboard
^^^^^^^^^^^^^^^^^^^^
``use_kibana_dashboard``: The name of a Kibana 3 dashboard to link to. Instead of generating a dashboard from a template,
ElastAlert can use an existing dashboard. It will set the time range on the dashboard to around the match time,
upload it as a temporary dashboard, add a filter to the ``query_key`` of the alert if applicable,
and put the url to the dashboard in the alert. (Optional, string, no default)
use_kibana4_dashboard
^^^^^^^^^^^^^^^^^^^^^
``use_kibana4_dashboard``: A link to a Kibana 4 dashboard. For example, "https://kibana.example.com/#/dashboard/My-Dashboard".
This will set the time setting on the dashboard from the match time minus the timeframe, to 10 minutes after the match time.
Note that this does not support filtering by ``query_key`` like Kibana 3. This value can use `$VAR` and `${VAR}` references
to expand environment variables.
kibana4_start_timedelta
^^^^^^^^^^^^^^^^^^^^^^^
``kibana4_start_timedelta``: Defaults to 10 minutes. This option allows you to specify the start time for the generated kibana4 dashboard.
This value is added in front of the event. For example,
``kibana4_start_timedelta: minutes: 2``
kibana4_end_timedelta
^^^^^^^^^^^^^^^^^^^^^
``kibana4_end_timedelta``: Defaults to 10 minutes. This option allows you to specify the end time for the generated kibana4 dashboard.
This value is added in back of the event. For example,
``kibana4_end_timedelta: minutes: 2``
generate_kibana_discover_url
^^^^^^^^^^^^^^^^^^^^^^^^^^^^
``generate_kibana_discover_url``: Enables the generation of the ``kibana_discover_url`` variable for the Kibana Discover application.
This setting requires the following settings are also configured:
- ``kibana_discover_app_url``
- ``kibana_discover_version``
- ``kibana_discover_index_pattern_id``
``generate_kibana_discover_url: true``
kibana_discover_app_url
^^^^^^^^^^^^^^^^^^^^^^^
``kibana_discover_app_url``: The url of the Kibana Discover application used to generate the ``kibana_discover_url`` variable.
This value can use `$VAR` and `${VAR}` references to expand environment variables.
``kibana_discover_app_url: http://kibana:5601/#/discover``
kibana_discover_version
^^^^^^^^^^^^^^^^^^^^^^^
``kibana_discover_version``: Specifies the version of the Kibana Discover application.
The currently supported versions of Kibana Discover are:
- `5.6`
- `6.0`, `6.1`, `6.2`, `6.3`, `6.4`, `6.5`, `6.6`, `6.7`, `6.8`
- `7.0`, `7.1`, `7.2`, `7.3`
``kibana_discover_version: '7.3'``
kibana_discover_index_pattern_id
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
``kibana_discover_index_pattern_id``: The id of the index pattern to link to in the Kibana Discover application.
These ids are usually generated and can be found in url of the index pattern management page, or by exporting its saved object.
Example export of an index pattern's saved object:
.. code-block:: text
[
{
"_id": "4e97d188-8a45-4418-8a37-07ed69b4d34c",
"_type": "index-pattern",
"_source": { ... }
}
]
You can modify an index pattern's id by exporting the saved object, modifying the ``_id`` field, and re-importing.
``kibana_discover_index_pattern_id: 4e97d188-8a45-4418-8a37-07ed69b4d34c``
kibana_discover_columns
^^^^^^^^^^^^^^^^^^^^^^^
``kibana_discover_columns``: The columns to display in the generated Kibana Discover application link.
Defaults to the ``_source`` column.
``kibana_discover_columns: [ timestamp, message ]``
kibana_discover_from_timedelta
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
``kibana_discover_from_timedelta``: The offset to the `from` time of the Kibana Discover link's time range.
The `from` time is calculated by subtracting this timedelta from the event time. Defaults to 10 minutes.
``kibana_discover_from_timedelta: minutes: 2``
kibana_discover_to_timedelta
^^^^^^^^^^^^^^^^^^^^^^^^^^^^
``kibana_discover_to_timedelta``: The offset to the `to` time of the Kibana Discover link's time range.
The `to` time is calculated by adding this timedelta to the event time. Defaults to 10 minutes.
``kibana_discover_to_timedelta: minutes: 2``
use_local_time
^^^^^^^^^^^^^^
``use_local_time``: Whether to convert timestamps to the local time zone in alerts. If false, timestamps will
be converted to UTC, which is what ElastAlert uses internally. (Optional, boolean, default true)
match_enhancements
^^^^^^^^^^^^^^^^^^
``match_enhancements``: A list of enhancement modules to use with this rule. An enhancement module is a subclass of enhancements.BaseEnhancement
that will be given the match dictionary and can modify it before it is passed to the alerter. The enhancements will be run after silence and realert
is calculated and in the case of aggregated alerts, right before the alert is sent. This can be changed by setting ``run_enhancements_first``.
The enhancements should be specified as
``module.file.EnhancementName``. See :ref:`Enhancements` for more information. (Optional, list of strings, no default)
run_enhancements_first
^^^^^^^^^^^^^^^^^^^^^^
``run_enhancements_first``: If set to true, enhancements will be run as soon as a match is found. This means that they can be changed
or dropped before affecting realert or being added to an aggregation. Silence stashes will still be created before the
enhancement runs, meaning even if a ``DropMatchException`` is raised, the rule will still be silenced. (Optional, boolean, default false)
query_key
^^^^^^^^^
``query_key``: Having a query key means that realert time will be counted separately for each unique value of ``query_key``. For rule types which
count documents, such as spike, frequency and flatline, it also means that these counts will be independent for each unique value of ``query_key``.
For example, if ``query_key`` is set to ``username`` and ``realert`` is set, and an alert triggers on a document with ``{'username': 'bob'}``,
additional alerts for ``{'username': 'bob'}`` will be ignored while other usernames will trigger alerts. Documents which are missing the
``query_key`` will be grouped together. A list of fields may also be used, which will create a compound query key. This compound key is
treated as if it were a single field whose value is the component values, or "None", joined by commas. A new field with the key
"field1,field2,etc" will be created in each document and may conflict with existing fields of the same name.
aggregation_key
^^^^^^^^^^^^^^^
``aggregation_key``: Having an aggregation key in conjunction with an aggregation will make it so that each new value encountered for the aggregation_key field will result in a new, separate aggregation window.
summary_table_fields
^^^^^^^^^^^^^^^^^^^^
``summary_table_fields``: Specifying the summmary_table_fields in conjunction with an aggregation will make it so that each aggregated alert will contain a table summarizing the values for the specified fields in all the matches that were aggregated together.
timestamp_type
^^^^^^^^^^^^^^
``timestamp_type``: One of ``iso``, ``unix``, ``unix_ms``, ``custom``. This option will set the type of ``@timestamp`` (or ``timestamp_field``)
used to query Elasticsearch. ``iso`` will use ISO8601 timestamps, which will work with most Elasticsearch date type field. ``unix`` will
query using an integer unix (seconds since 1/1/1970) timestamp. ``unix_ms`` will use milliseconds unix timestamp. ``custom`` allows you to define
your own ``timestamp_format``. The default is ``iso``.
(Optional, string enum, default iso).
timestamp_format
^^^^^^^^^^^^^^^^
``timestamp_format``: In case Elasticsearch used custom date format for date type field, this option provides a way to define custom timestamp
format to match the type used for Elastisearch date type field. This option is only valid if ``timestamp_type`` set to ``custom``.
(Optional, string, default '%Y-%m-%dT%H:%M:%SZ').
timestamp_format_expr
^^^^^^^^^^^^^^^^^^^^^
``timestamp_format_expr``: In case Elasticsearch used custom date format for date type field, this option provides a way to adapt the
value obtained converting a datetime through ``timestamp_format``, when the format cannot match perfectly what defined in Elastisearch.
When set, this option is evaluated as a Python expression along with a *globals* dictionary containing the original datetime instance
named ``dt`` and the timestamp to be refined, named ``ts``. The returned value becomes the timestamp obtained from the datetime.
For example, when the date type field in Elasticsearch uses milliseconds (``yyyy-MM-dd'T'HH:mm:ss.SSS'Z'``) and ``timestamp_format``
option is ``'%Y-%m-%dT%H:%M:%S.%fZ'``, Elasticsearch would fail to parse query terms as they contain microsecond values - that is
it gets 6 digits instead of 3 - since the ``%f`` placeholder stands for microseconds for Python *strftime* method calls.
Setting ``timestamp_format_expr: 'ts[:23] + ts[26:]'`` will truncate the value to milliseconds granting Elasticsearch compatibility.
This option is only valid if ``timestamp_type`` set to ``custom``.
(Optional, string, no default).
_source_enabled
^^^^^^^^^^^^^^^
``_source_enabled``: If true, ElastAlert will use _source to retrieve fields from documents in Elasticsearch. If false,
ElastAlert will use ``fields`` to retrieve stored fields. Both of these are represented internally as if they came from ``_source``.
See https://www.elastic.co/guide/en/elasticsearch/reference/current/mapping-fields.html for more details. The fields used come from ``include``,
see above for more details. (Optional, boolean, default True)
scan_entire_timeframe
^^^^^^^^^^^^^^^^^^^^^
``scan_entire_timeframe``: If true, when ElastAlert starts, it will always start querying at the current time minus the timeframe.
``timeframe`` must exist in the rule. This may be useful, for example, if you are using a flatline rule type with a large timeframe,
and you want to be sure that if ElastAlert restarts, you can still get alerts. This may cause duplicate alerts for some rule types,
for example, Frequency can alert multiple times in a single timeframe, and if ElastAlert were to restart with this setting, it may
scan the same range again, triggering duplicate alerts.
Some rules and alerts require additional options, which also go in the top level of the rule configuration file.
.. _testing :
Testing Your Rule
=================
Once you've written a rule configuration, you will want to validate it. To do so, you can either run ElastAlert in debug mode,
or use ``elastalert-test-rule``, which is a script that makes various aspects of testing easier.
It can:
- Check that the configuration file loaded successfully.
- Check that the Elasticsearch filter parses.
- Run against the last X day(s) and the show the number of hits that match your filter.
- Show the available terms in one of the results.
- Save documents returned to a JSON file.
- Run ElastAlert using either a JSON file or actual results from Elasticsearch.
- Print out debug alerts or trigger real alerts.
- Check that, if they exist, the primary_key, compare_key and include terms are in the results.
- Show what metadata documents would be written to ``elastalert_status``.
Without any optional arguments, it will run ElastAlert over the last 24 hours and print out any alerts that would have occurred.
Here is an example test run which triggered an alert:
.. code-block:: console
$ elastalert-test-rule my_rules/rule1.yaml
Successfully Loaded Example rule1
Got 105 hits from the last 1 day
Available terms in first hit:
@timestamp
field1
field2
...
Included term this_field_doesnt_exist may be missing or null
INFO:root:Queried rule Example rule1 from 6-16 15:21 PDT to 6-17 15:21 PDT: 105 hits
INFO:root:Alert for Example rule1 at 2015-06-16T23:53:12Z:
INFO:root:Example rule1
At least 50 events occurred between 6-16 18:30 PDT and 6-16 20:30 PDT
field1:
value1: 25
value2: 25
@timestamp: 2015-06-16T20:30:04-07:00
field1: value1
field2: something
Would have written the following documents to elastalert_status:
silence - {'rule_name': 'Example rule1', '@timestamp': datetime.datetime( ... ), 'exponent': 0, 'until':
datetime.datetime( ... )}
elastalert_status - {'hits': 105, 'matches': 1, '@timestamp': datetime.datetime( ... ), 'rule_name': 'Example rule1',
'starttime': datetime.datetime( ... ), 'endtime': datetime.datetime( ... ), 'time_taken': 3.1415926}
Note that everything between "Alert for Example rule1 at ..." and "Would have written the following ..." is the exact text body that an alert would have.
See the section below on alert content for more details.
Also note that datetime objects are converted to ISO8601 timestamps when uploaded to Elasticsearch. See :ref:`the section on metadata <metadata>` for more details.
Other options include:
``--schema-only``: Only perform schema validation on the file. It will not load modules or query Elasticsearch. This may catch invalid YAML
and missing or misconfigured fields.
``--count-only``: Only find the number of matching documents and list available fields. ElastAlert will not be run and documents will not be downloaded.
``--days N``: Instead of the default 1 day, query N days. For selecting more specific time ranges, you must run ElastAlert itself and use ``--start``
and ``--end``.
``--save-json FILE``: Save all documents downloaded to a file as JSON. This is useful if you wish to modify data while testing or do offline
testing in conjunction with ``--data FILE``. A maximum of 10,000 documents will be downloaded.
``--data FILE``: Use a JSON file as a data source instead of Elasticsearch. The file should be a single list containing objects,
rather than objects on separate lines. Note than this uses mock functions which mimic some Elasticsearch query methods and is not
guaranteed to have the exact same results as with Elasticsearch. For example, analyzed string fields may behave differently.
``--alert``: Trigger real alerts instead of the debug (logging text) alert.
``--formatted-output``: Output results in formatted JSON.
.. note::
Results from running this script may not always be the same as if an actual ElastAlert instance was running. Some rule types, such as spike
and flatline require a minimum elapsed time before they begin alerting, based on their timeframe. In addition, use_count_query and
use_terms_query rely on run_every to determine their resolution. This script uses a fixed 5 minute window, which is the same as the default.
.. _ruletypes:
Rule Types
==========
The various ``RuleType`` classes, defined in ``elastalert/ruletypes.py``, form the main logic behind ElastAlert. An instance
is held in memory for each rule, passed all of the data returned by querying Elasticsearch with a given filter, and generates
matches based on that data.
To select a rule type, set the ``type`` option to the name of the rule type in the rule configuration file:
``type: <rule type>``
Any
~~~
``any``: The any rule will match everything. Every hit that the query returns will generate an alert.
Blacklist
~~~~~~~~~
``blacklist``: The blacklist rule will check a certain field against a blacklist, and match if it is in the blacklist.
This rule requires two additional options:
``compare_key``: The name of the field to use to compare to the blacklist. If the field is null, those events will be ignored.
``blacklist``: A list of blacklisted values, and/or a list of paths to flat files which contain the blacklisted values using ``- "!file /path/to/file"``; for example::
blacklist:
- value1
- value2
- "!file /tmp/blacklist1.txt"
- "!file /tmp/blacklist2.txt"
It is possible to mix between blacklist value definitions, or use either one. The ``compare_key`` term must be equal to one of these values for it to match.
Whitelist
~~~~~~~~~
``whitelist``: Similar to ``blacklist``, this rule will compare a certain field to a whitelist, and match if the list does not contain
the term.
This rule requires three additional options:
``compare_key``: The name of the field to use to compare to the whitelist.
``ignore_null``: If true, events without a ``compare_key`` field will not match.
``whitelist``: A list of whitelisted values, and/or a list of paths to flat files which contain the whitelisted values using ``- "!file /path/to/file"``; for example::
whitelist:
- value1
- value2
- "!file /tmp/whitelist1.txt"
- "!file /tmp/whitelist2.txt"
It is possible to mix between whitelisted value definitions, or use either one. The ``compare_key`` term must be in this list or else it will match.
Change
~~~~~~
For an example configuration file using this rule type, look at ``example_rules/example_change.yaml``.
``change``: This rule will monitor a certain field and match if that field changes. The field
must change with respect to the last event with the same ``query_key``.
This rule requires three additional options:
``compare_key``: The names of the field to monitor for changes. Since this is a list of strings, we can
have multiple keys. An alert will trigger if any of the fields change.
``ignore_null``: If true, events without a ``compare_key`` field will not count as changed. Currently this checks for all the fields in ``compare_key``
``query_key``: This rule is applied on a per-``query_key`` basis. This field must be present in all of
the events that are checked.
There is also an optional field:
``timeframe``: The maximum time between changes. After this time period, ElastAlert will forget the old value
of the ``compare_key`` field.
Frequency
~~~~~~~~~
For an example configuration file using this rule type, look at ``example_rules/example_frequency.yaml``.
``frequency``: This rule matches when there are at least a certain number of events in a given time frame. This
may be counted on a per-``query_key`` basis.
This rule requires two additional options:
``num_events``: The number of events which will trigger an alert, inclusive.
``timeframe``: The time that ``num_events`` must occur within.
Optional:
``use_count_query``: If true, ElastAlert will poll Elasticsearch using the count api, and not download all of the matching documents. This is
useful is you care only about numbers and not the actual data. It should also be used if you expect a large number of query hits, in the order
of tens of thousands or more. ``doc_type`` must be set to use this.
``doc_type``: Specify the ``_type`` of document to search for. This must be present if ``use_count_query`` or ``use_terms_query`` is set.
``use_terms_query``: If true, ElastAlert will make an aggregation query against Elasticsearch to get counts of documents matching
each unique value of ``query_key``. This must be used with ``query_key`` and ``doc_type``. This will only return a maximum of ``terms_size``,
default 50, unique terms.
``terms_size``: When used with ``use_terms_query``, this is the maximum number of terms returned per query. Default is 50.
``query_key``: Counts of documents will be stored independently for each value of ``query_key``. Only ``num_events`` documents,
all with the same value of ``query_key``, will trigger an alert.
``attach_related``: Will attach all the related events to the event that triggered the frequency alert. For example in an alert triggered with ``num_events``: 3,
the 3rd event will trigger the alert on itself and add the other 2 events in a key named ``related_events`` that can be accessed in the alerter.
Spike
~~~~~
``spike``: This rule matches when the volume of events during a given time period is ``spike_height`` times larger or smaller
than during the previous time period. It uses two sliding windows to compare the current and reference frequency
of events. We will call this two windows "reference" and "current".
This rule requires three additional options:
``spike_height``: The ratio of number of events in the last ``timeframe`` to the previous ``timeframe`` that when hit
will trigger an alert.
``spike_type``: Either 'up', 'down' or 'both'. 'Up' meaning the rule will only match when the number of events is ``spike_height`` times
higher. 'Down' meaning the reference number is ``spike_height`` higher than the current number. 'Both' will match either.
``timeframe``: The rule will average out the rate of events over this time period. For example, ``hours: 1`` means that the 'current'
window will span from present to one hour ago, and the 'reference' window will span from one hour ago to two hours ago. The rule
will not be active until the time elapsed from the first event is at least two timeframes. This is to prevent an alert being triggered
before a baseline rate has been established. This can be overridden using ``alert_on_new_data``.
Optional:
``field_value``: When set, uses the value of the field in the document and not the number of matching documents.
This is useful to monitor for example a temperature sensor and raise an alarm if the temperature grows too fast.
Note that the means of the field on the reference and current windows are used to determine if the ``spike_height`` value is reached.
Note also that the threshold parameters are ignored in this smode.
``threshold_ref``: The minimum number of events that must exist in the reference window for an alert to trigger. For example, if
``spike_height: 3`` and ``threshold_ref: 10``, then the 'reference' window must contain at least 10 events and the 'current' window at
least three times that for an alert to be triggered.
``threshold_cur``: The minimum number of events that must exist in the current window for an alert to trigger. For example, if
``spike_height: 3`` and ``threshold_cur: 60``, then an alert will occur if the current window has more than 60 events and
the reference window has less than a third as many.
To illustrate the use of ``threshold_ref``, ``threshold_cur``, ``alert_on_new_data``, ``timeframe`` and ``spike_height`` together,
consider the following examples::
" Alert if at least 15 events occur within two hours and less than a quarter of that number occurred within the previous two hours. "
timeframe: hours: 2
spike_height: 4
spike_type: up
threshold_cur: 15
hour1: 5 events (ref: 0, cur: 5) - No alert because (a) threshold_cur not met, (b) ref window not filled
hour2: 5 events (ref: 0, cur: 10) - No alert because (a) threshold_cur not met, (b) ref window not filled
hour3: 10 events (ref: 5, cur: 15) - No alert because (a) spike_height not met, (b) ref window not filled
hour4: 35 events (ref: 10, cur: 45) - Alert because (a) spike_height met, (b) threshold_cur met, (c) ref window filled
hour1: 20 events (ref: 0, cur: 20) - No alert because ref window not filled
hour2: 21 events (ref: 0, cur: 41) - No alert because ref window not filled
hour3: 19 events (ref: 20, cur: 40) - No alert because (a) spike_height not met, (b) ref window not filled
hour4: 23 events (ref: 41, cur: 42) - No alert because spike_height not met
hour1: 10 events (ref: 0, cur: 10) - No alert because (a) threshold_cur not met, (b) ref window not filled
hour2: 0 events (ref: 0, cur: 10) - No alert because (a) threshold_cur not met, (b) ref window not filled
hour3: 0 events (ref: 10, cur: 0) - No alert because (a) threshold_cur not met, (b) ref window not filled, (c) spike_height not met
hour4: 30 events (ref: 10, cur: 30) - No alert because spike_height not met
hour5: 5 events (ref: 0, cur: 35) - Alert because (a) spike_height met, (b) threshold_cur met, (c) ref window filled
" Alert if at least 5 events occur within two hours, and twice as many events occur within the next two hours. "
timeframe: hours: 2
spike_height: 2
spike_type: up
threshold_ref: 5
hour1: 20 events (ref: 0, cur: 20) - No alert because (a) threshold_ref not met, (b) ref window not filled
hour2: 100 events (ref: 0, cur: 120) - No alert because (a) threshold_ref not met, (b) ref window not filled
hour3: 100 events (ref: 20, cur: 200) - No alert because ref window not filled
hour4: 100 events (ref: 120, cur: 200) - No alert because spike_height not met
hour1: 0 events (ref: 0, cur: 0) - No alert because (a) threshold_ref not met, (b) ref window not filled
hour2: 20 events (ref: 0, cur: 20) - No alert because (a) threshold_ref not met, (b) ref window not filled
hour3: 100 events (ref: 0, cur: 120) - No alert because (a) threshold_ref not met, (b) ref window not filled
hour4: 100 events (ref: 20, cur: 200) - Alert because (a) spike_height met, (b) threshold_ref met, (c) ref window filled
hour1: 1 events (ref: 0, cur: 1) - No alert because (a) threshold_ref not met, (b) ref window not filled
hour2: 2 events (ref: 0, cur: 3) - No alert because (a) threshold_ref not met, (b) ref window not filled
hour3: 2 events (ref: 1, cur: 4) - No alert because (a) threshold_ref not met, (b) ref window not filled
hour4: 1000 events (ref: 3, cur: 1002) - No alert because threshold_ref not met
hour5: 2 events (ref: 4, cur: 1002) - No alert because threshold_ref not met
hour6: 4 events: (ref: 1002, cur: 6) - No alert because spike_height not met
hour1: 1000 events (ref: 0, cur: 1000) - No alert because (a) threshold_ref not met, (b) ref window not filled
hour2: 0 events (ref: 0, cur: 1000) - No alert because (a) threshold_ref not met, (b) ref window not filled
hour3: 0 events (ref: 1000, cur: 0) - No alert because (a) spike_height not met, (b) ref window not filled
hour4: 0 events (ref: 1000, cur: 0) - No alert because spike_height not met
hour5: 1000 events (ref: 0, cur: 1000) - No alert because threshold_ref not met
hour6: 1050 events (ref: 0, cur: 2050)- No alert because threshold_ref not met
hour7: 1075 events (ref: 1000, cur: 2125) Alert because (a) spike_height met, (b) threshold_ref met, (c) ref window filled
" Alert if at least 100 events occur within two hours and less than a fifth of that number occurred in the previous two hours. "
timeframe: hours: 2
spike_height: 5
spike_type: up
threshold_cur: 100
hour1: 1000 events (ref: 0, cur: 1000) - No alert because ref window not filled
hour1: 2 events (ref: 0, cur: 2) - No alert because (a) threshold_cur not met, (b) ref window not filled
hour2: 1 events (ref: 0, cur: 3) - No alert because (a) threshold_cur not met, (b) ref window not filled
hour3: 20 events (ref: 2, cur: 21) - No alert because (a) threshold_cur not met, (b) ref window not filled
hour4: 81 events (ref: 3, cur: 101) - Alert because (a) spike_height met, (b) threshold_cur met, (c) ref window filled
hour1: 10 events (ref: 0, cur: 10) - No alert because (a) threshold_cur not met, (b) ref window not filled
hour2: 20 events (ref: 0, cur: 30) - No alert because (a) threshold_cur not met, (b) ref window not filled
hour3: 40 events (ref: 10, cur: 60) - No alert because (a) threshold_cur not met, (b) ref window not filled
hour4: 80 events (ref: 30, cur: 120) - No alert because spike_height not met
hour5: 200 events (ref: 60, cur: 280) - No alert because spike_height not met
``alert_on_new_data``: This option is only used if ``query_key`` is set. When this is set to true, any new ``query_key`` encountered may
trigger an immediate alert. When set to false, baseline must be established for each new ``query_key`` value, and then subsequent spikes may
cause alerts. Baseline is established after ``timeframe`` has elapsed twice since first occurrence.
``use_count_query``: If true, ElastAlert will poll Elasticsearch using the count api, and not download all of the matching documents. This is
useful is you care only about numbers and not the actual data. It should also be used if you expect a large number of query hits, in the order
of tens of thousands or more. ``doc_type`` must be set to use this.
``doc_type``: Specify the ``_type`` of document to search for. This must be present if ``use_count_query`` or ``use_terms_query`` is set.
``use_terms_query``: If true, ElastAlert will make an aggregation query against Elasticsearch to get counts of documents matching
each unique value of ``query_key``. This must be used with ``query_key`` and ``doc_type``. This will only return a maximum of ``terms_size``,
default 50, unique terms.
``terms_size``: When used with ``use_terms_query``, this is the maximum number of terms returned per query. Default is 50.
``query_key``: Counts of documents will be stored independently for each value of ``query_key``.
Flatline
~~~~~~~~
``flatline``: This rule matches when the total number of events is under a given ``threshold`` for a time period.
This rule requires two additional options:
``threshold``: The minimum number of events for an alert not to be triggered.
``timeframe``: The time period that must contain less than ``threshold`` events.
Optional:
``use_count_query``: If true, ElastAlert will poll Elasticsearch using the count api, and not download all of the matching documents. This is
useful is you care only about numbers and not the actual data. It should also be used if you expect a large number of query hits, in the order
of tens of thousands or more. ``doc_type`` must be set to use this.
``doc_type``: Specify the ``_type`` of document to search for. This must be present if ``use_count_query`` or ``use_terms_query`` is set.
``use_terms_query``: If true, ElastAlert will make an aggregation query against Elasticsearch to get counts of documents matching
each unique value of ``query_key``. This must be used with ``query_key`` and ``doc_type``. This will only return a maximum of ``terms_size``,
default 50, unique terms.
``terms_size``: When used with ``use_terms_query``, this is the maximum number of terms returned per query. Default is 50.
``query_key``: With flatline rule, ``query_key`` means that an alert will be triggered if any value of ``query_key`` has been seen at least once
and then falls below the threshold.
``forget_keys``: Only valid when used with ``query_key``. If this is set to true, ElastAlert will "forget" about the ``query_key`` value that
triggers an alert, therefore preventing any more alerts for it until it's seen again.
New Term
~~~~~~~~
``new_term``: This rule matches when a new value appears in a field that has never been seen before. When ElastAlert starts, it will
use an aggregation query to gather all known terms for a list of fields.
This rule requires one additional option:
``fields``: A list of fields to monitor for new terms. ``query_key`` will be used if ``fields`` is not set. Each entry in the
list of fields can itself be a list. If a field entry is provided as a list, it will be interpreted as a set of fields
that compose a composite key used for the ElasticSearch query.
.. note::
The composite fields may only refer to primitive types, otherwise the initial ElasticSearch query will not properly return
the aggregation results, thus causing alerts to fire every time the ElastAlert service initially launches with the rule.
A warning will be logged to the console if this scenario is encountered. However, future alerts will actually work as
expected after the initial flurry.
Optional:
``terms_window_size``: The amount of time used for the initial query to find existing terms. No term that has occurred within this time frame
will trigger an alert. The default is 30 days.
``window_step_size``: When querying for existing terms, split up the time range into steps of this size. For example, using the default
30 day window size, and the default 1 day step size, 30 invidivdual queries will be made. This helps to avoid timeouts for very
expensive aggregation queries. The default is 1 day.
``alert_on_missing_field``: Whether or not to alert when a field is missing from a document. The default is false.
``use_terms_query``: If true, ElastAlert will use aggregation queries to get terms instead of regular search queries. This is faster
than regular searching if there is a large number of documents. If this is used, you may only specify a single field, and must also set
``query_key`` to that field. Also, note that ``terms_size`` (the number of buckets returned per query) defaults to 50. This means
that if a new term appears but there are at least 50 terms which appear more frequently, it will not be found.
.. note::
When using use_terms_query, make sure that the field you are using is not analyzed. If it is, the results of each terms
query may return tokens rather than full values. ElastAlert will by default turn on use_keyword_postfix, which attempts
to use the non-analyzed version (.keyword or .raw) to gather initial terms. These will not match the partial values and
result in false positives.
``use_keyword_postfix``: If true, ElastAlert will automatically try to add .keyword (ES5+) or .raw to the fields when making an
initial query. These are non-analyzed fields added by Logstash. If the field used is analyzed, the initial query will return
only the tokenized values, potentially causing false positives. Defaults to true.
Cardinality
~~~~~~~~~~~
``cardinality``: This rule matches when a the total number of unique values for a certain field within a time frame is higher or lower
than a threshold.
This rule requires:
``timeframe``: The time period in which the number of unique values will be counted.
``cardinality_field``: Which field to count the cardinality for.
This rule requires one of the two following options:
``max_cardinality``: If the cardinality of the data is greater than this number, an alert will be triggered. Each new event that
raises the cardinality will trigger an alert.
``min_cardinality``: If the cardinality of the data is lower than this number, an alert will be triggered. The ``timeframe`` must
have elapsed since the first event before any alerts will be sent. When a match occurs, the ``timeframe`` will be reset and must elapse
again before additional alerts.
Optional:
``query_key``: Group cardinality counts by this field. For each unique value of the ``query_key`` field, cardinality will be counted separately.
Metric Aggregation
~~~~~~~~~~~~~~~~~~
``metric_aggregation``: This rule matches when the value of a metric within the calculation window is higher or lower than a threshold. By
default this is ``buffer_time``.
This rule requires:
``metric_agg_key``: This is the name of the field over which the metric value will be calculated. The underlying type of this field must be
supported by the specified aggregation type.
``metric_agg_type``: The type of metric aggregation to perform on the ``metric_agg_key`` field. This must be one of 'min', 'max', 'avg',
'sum', 'cardinality', 'value_count'.
``doc_type``: Specify the ``_type`` of document to search for.
This rule also requires at least one of the two following options:
``max_threshold``: If the calculated metric value is greater than this number, an alert will be triggered. This threshold is exclusive.
``min_threshold``: If the calculated metric value is less than this number, an alert will be triggered. This threshold is exclusive.
Optional:
``query_key``: Group metric calculations by this field. For each unique value of the ``query_key`` field, the metric will be calculated and
evaluated separately against the threshold(s).
``min_doc_count``: The minimum number of events in the current window needed for an alert to trigger. Used in conjunction with ``query_key``,
this will only consider terms which in their last ``buffer_time`` had at least ``min_doc_count`` records. Default 1.
``use_run_every_query_size``: By default the metric value is calculated over a ``buffer_time`` sized window. If this parameter is true
the rule will use ``run_every`` as the calculation window.
``allow_buffer_time_overlap``: This setting will only have an effect if ``use_run_every_query_size`` is false and ``buffer_time`` is greater
than ``run_every``. If true will allow the start of the metric calculation window to overlap the end time of a previous run. By default the
start and end times will not overlap, so if the time elapsed since the last run is less than the metric calculation window size, rule execution
will be skipped (to avoid calculations on partial data).
``bucket_interval``: If present this will divide the metric calculation window into ``bucket_interval`` sized segments. The metric value will
be calculated and evaluated against the threshold(s) for each segment. If ``bucket_interval`` is specified then ``buffer_time`` must be a
multiple of ``bucket_interval``. (Or ``run_every`` if ``use_run_every_query_size`` is true).
``sync_bucket_interval``: This only has an effect if ``bucket_interval`` is present. If true it will sync the start and end times of the metric
calculation window to the keys (timestamps) of the underlying date_histogram buckets. Because of the way elasticsearch calculates date_histogram
bucket keys these usually round evenly to nearest minute, hour, day etc (depending on the bucket size). By default the bucket keys are offset to
allign with the time elastalert runs, (This both avoid calculations on partial data, and ensures the very latest documents are included).
See: https://www.elastic.co/guide/en/elasticsearch/reference/current/search-aggregations-bucket-datehistogram-aggregation.html#_offset for a
more comprehensive explaination.
Spike Aggregation
~~~~~~~~~~~~~~~~~~
``spike_aggregation``: This rule matches when the value of a metric within the calculation window is ``spike_height`` times larger or smaller
than during the previous time period. It uses two sliding windows to compare the current and reference metric values.
We will call these two windows "reference" and "current".
This rule requires:
``metric_agg_key``: This is the name of the field over which the metric value will be calculated. The underlying type of this field must be
supported by the specified aggregation type. If using a scripted field via ``metric_agg_script``, this is the name for your scripted field
``metric_agg_type``: The type of metric aggregation to perform on the ``metric_agg_key`` field. This must be one of 'min', 'max', 'avg',
'sum', 'cardinality', 'value_count'.
``spike_height``: The ratio of the metric value in the last ``timeframe`` to the previous ``timeframe`` that when hit
will trigger an alert.
``spike_type``: Either 'up', 'down' or 'both'. 'Up' meaning the rule will only match when the metric value is ``spike_height`` times
higher. 'Down' meaning the reference metric value is ``spike_height`` higher than the current metric value. 'Both' will match either.
``buffer_time``: The rule will average out the rate of events over this time period. For example, ``hours: 1`` means that the 'current'
window will span from present to one hour ago, and the 'reference' window will span from one hour ago to two hours ago. The rule
will not be active until the time elapsed from the first event is at least two timeframes. This is to prevent an alert being triggered
before a baseline rate has been established. This can be overridden using ``alert_on_new_data``.
Optional:
``query_key``: Group metric calculations by this field. For each unique value of the ``query_key`` field, the metric will be calculated and
evaluated separately against the 'reference'/'current' metric value and ``spike height``.
``metric_agg_script``: A `Painless` formatted script describing how to calculate your metric on-the-fly::
metric_agg_key: myScriptedMetric
metric_agg_script:
script: doc['field1'].value * doc['field2'].value
``threshold_ref``: The minimum value of the metric in the reference window for an alert to trigger. For example, if
``spike_height: 3`` and ``threshold_ref: 10``, then the 'reference' window must have a metric value of 10 and the 'current' window at
least three times that for an alert to be triggered.
``threshold_cur``: The minimum value of the metric in the current window for an alert to trigger. For example, if
``spike_height: 3`` and ``threshold_cur: 60``, then an alert will occur if the current window has a metric value greater than 60 and
the reference window is less than a third of that value.
``min_doc_count``: The minimum number of events in the current window needed for an alert to trigger. Used in conjunction with ``query_key``,
this will only consider terms which in their last ``buffer_time`` had at least ``min_doc_count`` records. Default 1.
Percentage Match
~~~~~~~~~~~~~~~~
``percentage_match``: This rule matches when the percentage of document in the match bucket within a calculation window is higher or lower
than a threshold. By default the calculation window is ``buffer_time``.
This rule requires:
``match_bucket_filter``: ES filter DSL. This defines a filter for the match bucket, which should match a subset of the documents returned by the
main query filter.
``doc_type``: Specify the ``_type`` of document to search for.
This rule also requires at least one of the two following options:
``min_percentage``: If the percentage of matching documents is less than this number, an alert will be triggered.
``max_percentage``: If the percentage of matching documents is greater than this number, an alert will be triggered.
Optional:
``query_key``: Group percentage by this field. For each unique value of the ``query_key`` field, the percentage will be calculated and
evaluated separately against the threshold(s).
``use_run_every_query_size``: See ``use_run_every_query_size`` in Metric Aggregation rule
``allow_buffer_time_overlap``: See ``allow_buffer_time_overlap`` in Metric Aggregation rule
``bucket_interval``: See ``bucket_interval`` in Metric Aggregation rule
``sync_bucket_interval``: See ``sync_bucket_interval`` in Metric Aggregation rule
``percentage_format_string``: An optional format string to apply to the percentage value in the alert match text. Must be a valid python format string.
For example, "%.2f" will round it to 2 decimal places.
See: https://docs.python.org/3.4/library/string.html#format-specification-mini-language
``min_denominator``: Minimum number of documents on which percentage calculation will apply. Default is 0.
.. _alerts:
Alerts
======
Each rule may have any number of alerts attached to it. Alerts are subclasses of ``Alerter`` and are passed
a dictionary, or list of dictionaries, from ElastAlert which contain relevant information. They are configured
in the rule configuration file similarly to rule types.
To set the alerts for a rule, set the ``alert`` option to the name of the alert, or a list of the names of alerts:
``alert: email``
or
.. code-block:: yaml
alert:
- email
- jira
Options for each alerter can either defined at the top level of the YAML file, or nested within the alert name, allowing for different settings
for multiple of the same alerter. For example, consider sending multiple emails, but with different 'To' and 'From' fields:
.. code-block:: yaml
alert:
- email
from_addr: "no-reply@example.com"
email: "customer@example.com"
versus
.. code-block:: yaml
alert:
- email:
from_addr: "no-reply@example.com"
email: "customer@example.com"
- email:
from_addr: "elastalert@example.com""
email: "devs@example.com"
If multiple of the same alerter type are used, top level settings will be used as the default and inline settings will override those
for each alerter.
Alert Subject
~~~~~~~~~~~~~
E-mail subjects, JIRA issue summaries, PagerDuty alerts, or any alerter that has a "subject" can be customized by adding an ``alert_subject``
that contains a custom summary.
It can be further formatted using standard Python formatting syntax::
alert_subject: "Issue {0} occurred at {1}"
The arguments for the formatter will be fed from the matched objects related to the alert.
The field names whose values will be used as the arguments can be passed with ``alert_subject_args``::
alert_subject_args:
- issue.name
- "@timestamp"
It is mandatory to enclose the ``@timestamp`` field in quotes since in YAML format a token cannot begin with the ``@`` character. Not using the quotation marks will trigger a YAML parse error.
In case the rule matches multiple objects in the index, only the first match is used to populate the arguments for the formatter.
If the field(s) mentioned in the arguments list are missing, the email alert will have the text ``alert_missing_value`` in place of its expected value. This will also occur if ``use_count_query`` is set to true.
Alert Content
~~~~~~~~~~~~~
There are several ways to format the body text of the various types of events. In EBNF::
rule_name = name
alert_text = alert_text
ruletype_text = Depends on type
top_counts_header = top_count_key, ":"
top_counts_value = Value, ": ", Count
top_counts = top_counts_header, LF, top_counts_value
field_values = Field, ": ", Value
Similarly to ``alert_subject``, ``alert_text`` can be further formatted using standard Python formatting syntax.
The field names whose values will be used as the arguments can be passed with ``alert_text_args`` or ``alert_text_kw``.
You may also refer to any top-level rule property in the ``alert_subject_args``, ``alert_text_args``, ``alert_missing_value``, and ``alert_text_kw fields``. However, if the matched document has a key with the same name, that will take preference over the rule property.
By default::
body = rule_name
[alert_text]
ruletype_text
{top_counts}
{field_values}
With ``alert_text_type: alert_text_only``::
body = rule_name
alert_text
With ``alert_text_type: exclude_fields``::
body = rule_name
[alert_text]
ruletype_text
{top_counts}
With ``alert_text_type: aggregation_summary_only``::
body = rule_name
aggregation_summary
ruletype_text is the string returned by RuleType.get_match_str.
field_values will contain every key value pair included in the results from Elasticsearch. These fields include "@timestamp" (or the value of ``timestamp_field``),
every key in ``include``, every key in ``top_count_keys``, ``query_key``, and ``compare_key``. If the alert spans multiple events, these values may
come from an individual event, usually the one which triggers the alert.
When using ``alert_text_args``, you can access nested fields and index into arrays. For example, if your match was ``{"data": {"ips": ["127.0.0.1", "12.34.56.78"]}}``, then by using ``"data.ips[1]"`` in ``alert_text_args``, it would replace value with ``"12.34.56.78"``. This can go arbitrarily deep into fields and will still work on keys that contain dots themselves.
Command
~~~~~~~
The command alert allows you to execute an arbitrary command and pass arguments or stdin from the match. Arguments to the command can use
Python format string syntax to access parts of the match. The alerter will open a subprocess and optionally pass the match, or matches
in the case of an aggregated alert, as a JSON array, to the stdin of the process.
This alert requires one option:
``command``: A list of arguments to execute or a string to execute. If in list format, the first argument is the name of the program to execute. If passed a
string, the command is executed through the shell.
Strings can be formatted using the old-style format (``%``) or the new-style format (``.format()``). When the old-style format is used, fields are accessed
using ``%(field_name)s``, or ``%(field.subfield)s``. When the new-style format is used, fields are accessed using ``{field_name}``. New-style formatting allows accessing nested
fields (e.g., ``{field_1[subfield]}``).
In an aggregated alert, these fields come from the first match.
Optional:
``pipe_match_json``: If true, the match will be converted to JSON and passed to stdin of the command. Note that this will cause ElastAlert to block
until the command exits or sends an EOF to stdout.
``pipe_alert_text``: If true, the standard alert body text will be passed to stdin of the command. Note that this will cause ElastAlert to block
until the command exits or sends an EOF to stdout. It cannot be used at the same time as ``pipe_match_json``.
Example usage using old-style format::
alert:
- command
command: ["/bin/send_alert", "--username", "%(username)s"]
.. warning::
Executing commmands with untrusted data can make it vulnerable to shell injection! If you use formatted data in
your command, it is highly recommended that you use a args list format instead of a shell string.
Example usage using new-style format::
alert:
- command
command: ["/bin/send_alert", "--username", "{match[username]}"]
Email
~~~~~
This alert will send an email. It connects to an smtp server located at ``smtp_host``, or localhost by default.
If available, it will use STARTTLS.
This alert requires one additional option:
``email``: An address or list of addresses to sent the alert to.
Optional:
``email_from_field``: Use a field from the document that triggered the alert as the recipient. If the field cannot be found,
the ``email`` value will be used as a default. Note that this field will not be available in every rule type, for example, if
you have ``use_count_query`` or if it's ``type: flatline``. You can optionally add a domain suffix to the field to generate the
address using ``email_add_domain``. It can be a single recipient or list of recipients. For example, with the following settings::
email_from_field: "data.user"
email_add_domain: "@example.com"
and a match ``{"@timestamp": "2017", "data": {"foo": "bar", "user": "qlo"}}``
an email would be sent to ``qlo@example.com``
``smtp_host``: The SMTP host to use, defaults to localhost.
``smtp_port``: The port to use. Default is 25.
``smtp_ssl``: Connect the SMTP host using TLS, defaults to ``false``. If ``smtp_ssl`` is not used, ElastAlert will still attempt
STARTTLS.
``smtp_auth_file``: The path to a file which contains SMTP authentication credentials. The path can be either absolute or relative
to the given rule. It should be YAML formatted and contain two fields, ``user`` and ``password``. If this is not present,
no authentication will be attempted.
``smtp_cert_file``: Connect the SMTP host using the given path to a TLS certificate file, default to ``None``.
``smtp_key_file``: Connect the SMTP host using the given path to a TLS key file, default to ``None``.
``email_reply_to``: This sets the Reply-To header in the email. By default, the from address is ElastAlert@ and the domain will be set
by the smtp server.
``from_addr``: This sets the From header in the email. By default, the from address is ElastAlert@ and the domain will be set
by the smtp server.
``cc``: This adds the CC emails to the list of recipients. By default, this is left empty.
``bcc``: This adds the BCC emails to the list of recipients but does not show up in the email message. By default, this is left empty.
``email_format``: If set to ``html``, the email's MIME type will be set to HTML, and HTML content should correctly render. If you use this,
you need to put your own HTML into ``alert_text`` and use ``alert_text_type: alert_text_only``.
Jira
~~~~
The JIRA alerter will open a ticket on jira whenever an alert is triggered. You must have a service account for ElastAlert to connect with.
The credentials of the service account are loaded from a separate file. The ticket number will be written to the alert pipeline, and if it
is followed by an email alerter, a link will be included in the email.
This alert requires four additional options:
``jira_server``: The hostname of the JIRA server.
``jira_project``: The project to open the ticket under.
``jira_issuetype``: The type of issue that the ticket will be filed as. Note that this is case sensitive.
``jira_account_file``: The path to the file which contains JIRA account credentials.
For an example JIRA account file, see ``example_rules/jira_acct.yaml``. The account file is also yaml formatted and must contain two fields:
``user``: The username.
``password``: The password.
Optional:
``jira_component``: The name of the component or components to set the ticket to. This can be a single string or a list of strings. This is provided for backwards compatibility and will eventually be deprecated. It is preferable to use the plural ``jira_components`` instead.
``jira_components``: The name of the component or components to set the ticket to. This can be a single string or a list of strings.
``jira_description``: Similar to ``alert_text``, this text is prepended to the JIRA description.
``jira_label``: The label or labels to add to the JIRA ticket. This can be a single string or a list of strings. This is provided for backwards compatibility and will eventually be deprecated. It is preferable to use the plural ``jira_labels`` instead.
``jira_labels``: The label or labels to add to the JIRA ticket. This can be a single string or a list of strings.
``jira_priority``: The index of the priority to set the issue to. In the JIRA dropdown for priorities, 0 would represent the first priority,
1 the 2nd, etc.
``jira_watchers``: A list of user names to add as watchers on a JIRA ticket. This can be a single string or a list of strings.
``jira_bump_tickets``: If true, ElastAlert search for existing tickets newer than ``jira_max_age`` and comment on the ticket with
information about the alert instead of opening another ticket. ElastAlert finds the existing ticket by searching by summary. If the
summary has changed or contains special characters, it may fail to find the ticket. If you are using a custom ``alert_subject``,
the two summaries must be exact matches, except by setting ``jira_ignore_in_title``, you can ignore the value of a field when searching.
For example, if the custom subject is "foo occured at bar", and "foo" is the value field X in the match, you can set ``jira_ignore_in_title``
to "X" and it will only bump tickets with "bar" in the subject. Defaults to false.
``jira_ignore_in_title``: ElastAlert will attempt to remove the value for this field from the JIRA subject when searching for tickets to bump.
See ``jira_bump_tickets`` description above for an example.
``jira_max_age``: If ``jira_bump_tickets`` is true, the maximum age of a ticket, in days, such that ElastAlert will comment on the ticket
instead of opening a new one. Default is 30 days.
``jira_bump_not_in_statuses``: If ``jira_bump_tickets`` is true, a list of statuses the ticket must **not** be in for ElastAlert to comment on
the ticket instead of opening a new one. For example, to prevent comments being added to resolved or closed tickets, set this to 'Resolved'
and 'Closed'. This option should not be set if the ``jira_bump_in_statuses`` option is set.
Example usage::
jira_bump_not_in_statuses:
- Resolved
- Closed
``jira_bump_in_statuses``: If ``jira_bump_tickets`` is true, a list of statuses the ticket *must be in* for ElastAlert to comment on
the ticket instead of opening a new one. For example, to only comment on 'Open' tickets -- and thus not 'In Progress', 'Analyzing',
'Resolved', etc. tickets -- set this to 'Open'. This option should not be set if the ``jira_bump_not_in_statuses`` option is set.
Example usage::
jira_bump_in_statuses:
- Open
``jira_bump_only``: Only update if a ticket is found to bump. This skips ticket creation for rules where you only want to affect existing tickets.
Example usage::
jira_bump_only: true
``jira_transition_to``: If ``jira_bump_tickets`` is true, Transition this ticket to the given Status when bumping. Must match the text of your JIRA implementation's Status field.
Example usage::
jira_transition_to: 'Fixed'
``jira_bump_after_inactivity``: If this is set, ElastAlert will only comment on tickets that have been inactive for at least this many days.
It only applies if ``jira_bump_tickets`` is true. Default is 0 days.
Arbitrary Jira fields:
ElastAlert supports setting any arbitrary JIRA field that your jira issue supports. For example, if you had a custom field, called "Affected User", you can set it by providing that field name in ``snake_case`` prefixed with ``jira_``. These fields can contain primitive strings or arrays of strings. Note that when you create a custom field in your JIRA server, internally, the field is represented as ``customfield_1111``. In elastalert, you may refer to either the public facing name OR the internal representation.
In addition, if you would like to use a field in the alert as the value for a custom JIRA field, use the field name plus a # symbol in front. For example, if you wanted to set a custom JIRA field called "user" to the value of the field "username" from the match, you would use the following.
Example::
jira_user: "#username"
Example usage::
jira_arbitrary_singular_field: My Name
jira_arbitrary_multivalue_field:
- Name 1
- Name 2
jira_customfield_12345: My Custom Value
jira_customfield_9999:
- My Custom Value 1
- My Custom Value 2
OpsGenie
~~~~~~~~
OpsGenie alerter will create an alert which can be used to notify Operations people of issues or log information. An OpsGenie ``API``
integration must be created in order to acquire the necessary ``opsgenie_key`` rule variable. Currently the OpsGenieAlerter only creates
an alert, however it could be extended to update or close existing alerts.
It is necessary for the user to create an OpsGenie Rest HTTPS API `integration page <https://app.opsgenie.com/integration>`_ in order to create alerts.
The OpsGenie alert requires one option:
``opsgenie_key``: The randomly generated API Integration key created by OpsGenie.
Optional:
``opsgenie_account``: The OpsGenie account to integrate with.
``opsgenie_recipients``: A list OpsGenie recipients who will be notified by the alert.
``opsgenie_recipients_args``: Map of arguments used to format opsgenie_recipients.
``opsgenie_default_recipients``: List of default recipients to notify when the formatting of opsgenie_recipients is unsuccesful.
``opsgenie_teams``: A list of OpsGenie teams to notify (useful for schedules with escalation).
``opsgenie_teams_args``: Map of arguments used to format opsgenie_teams (useful for assigning the alerts to teams based on some data)
``opsgenie_default_teams``: List of default teams to notify when the formatting of opsgenie_teams is unsuccesful.
``opsgenie_tags``: A list of tags for this alert.
``opsgenie_message``: Set the OpsGenie message to something other than the rule name. The message can be formatted with fields from the first match e.g. "Error occurred for {app_name} at {timestamp}.".
``opsgenie_alias``: Set the OpsGenie alias. The alias can be formatted with fields from the first match e.g "{app_name} error".
``opsgenie_subject``: A string used to create the title of the OpsGenie alert. Can use Python string formatting.
``opsgenie_subject_args``: A list of fields to use to format ``opsgenie_subject`` if it contains formaters.
``opsgenie_priority``: Set the OpsGenie priority level. Possible values are P1, P2, P3, P4, P5.
``opsgenie_details``: Map of custom key/value pairs to include in the alert's details. The value can sourced from either fields in the first match, environment variables, or a constant value.
Example usage::
opsgenie_details:
Author: 'Bob Smith' # constant value
Environment: '$VAR' # environment variable
Message: { field: message } # field in the first match
SNS
~~~
The SNS alerter will send an SNS notification. The body of the notification is formatted the same as with other alerters.
The SNS alerter uses boto3 and can use credentials in the rule yaml, in a standard AWS credential and config files, or
via environment variables. See http://docs.aws.amazon.com/cli/latest/userguide/cli-chap-getting-started.html for details.
SNS requires one option:
``sns_topic_arn``: The SNS topic's ARN. For example, ``arn:aws:sns:us-east-1:123456789:somesnstopic``
Optional:
``aws_access_key``: An access key to connect to SNS with.
``aws_secret_key``: The secret key associated with the access key.
``aws_region``: The AWS region in which the SNS resource is located. Default is us-east-1
``profile``: The AWS profile to use. If none specified, the default will be used.
HipChat
~~~~~~~
HipChat alerter will send a notification to a predefined HipChat room. The body of the notification is formatted the same as with other alerters.
The alerter requires the following two options:
``hipchat_auth_token``: The randomly generated notification token created by HipChat. Go to https://XXXXX.hipchat.com/account/api and use
'Create new token' section, choosing 'Send notification' in Scopes list.
``hipchat_room_id``: The id associated with the HipChat room you want to send the alert to. Go to https://XXXXX.hipchat.com/rooms and choose
the room you want to post to. The room ID will be the numeric part of the URL.
``hipchat_msg_color``: The color of the message background that is sent to HipChat. May be set to green, yellow or red. Default is red.
``hipchat_domain``: The custom domain in case you have HipChat own server deployment. Default is api.hipchat.com.
``hipchat_ignore_ssl_errors``: Ignore TLS errors (self-signed certificates, etc.). Default is false.
``hipchat_proxy``: By default ElastAlert will not use a network proxy to send notifications to HipChat. Set this option using ``hostname:port`` if you need to use a proxy.
``hipchat_notify``: When set to true, triggers a hipchat bell as if it were a user. Default is true.
``hipchat_from``: When humans report to hipchat, a timestamp appears next to their name. For bots, the name is the name of the token. The from, instead of a timestamp, defaults to empty unless set, which you can do here. This is optional.
``hipchat_message_format``: Determines how the message is treated by HipChat and rendered inside HipChat applications
html - Message is rendered as HTML and receives no special treatment. Must be valid HTML and entities must be escaped (e.g.: '&' instead of '&'). May contain basic tags: a, b, i, strong, em, br, img, pre, code, lists, tables.
text - Message is treated just like a message sent by a user. Can include @mentions, emoticons, pastes, and auto-detected URLs (Twitter, YouTube, images, etc).
Valid values: html, text.
Defaults to 'html'.
``hipchat_mentions``: When using a ``html`` message format, it's not possible to mentions specific users using the ``@user`` syntax.
In that case, you can set ``hipchat_mentions`` to a list of users which will be first mentioned using a single text message, then the normal ElastAlert message will be sent to Hipchat.
If set, it will mention the users, no matter if the original message format is set to HTML or text.
Valid values: list of strings.
Defaults to ``[]``.
Stride
~~~~~~~
Stride alerter will send a notification to a predefined Stride room. The body of the notification is formatted the same as with other alerters.
Simple HTML such as <a> and <b> tags will be parsed into a format that Stride can consume.
The alerter requires the following two options:
``stride_access_token``: The randomly generated notification token created by Stride.
``stride_cloud_id``: The site_id associated with the Stride site you want to send the alert to.
``stride_conversation_id``: The conversation_id associated with the Stride conversation you want to send the alert to.
``stride_ignore_ssl_errors``: Ignore TLS errors (self-signed certificates, etc.). Default is false.
``stride_proxy``: By default ElastAlert will not use a network proxy to send notifications to Stride. Set this option using ``hostname:port`` if you need to use a proxy.
MS Teams
~~~~~~~~
MS Teams alert
gitextract_1pot3uo0/ ├── .editorconfig ├── .gitignore ├── .pre-commit-config.yaml ├── .secrets.baseline ├── .travis.yml ├── Dockerfile-test ├── LICENSE ├── Makefile ├── README.md ├── changelog.md ├── config.yaml.example ├── docker-compose.yml ├── docs/ │ ├── Makefile │ └── source/ │ ├── _static/ │ │ └── .gitkeep │ ├── conf.py │ ├── elastalert.rst │ ├── elastalert_status.rst │ ├── index.rst │ ├── recipes/ │ │ ├── adding_alerts.rst │ │ ├── adding_enhancements.rst │ │ ├── adding_loaders.rst │ │ ├── adding_rules.rst │ │ ├── signing_requests.rst │ │ └── writing_filters.rst │ ├── ruletypes.rst │ └── running_elastalert.rst ├── elastalert/ │ ├── __init__.py │ ├── alerts.py │ ├── auth.py │ ├── config.py │ ├── create_index.py │ ├── elastalert.py │ ├── enhancements.py │ ├── es_mappings/ │ │ ├── 5/ │ │ │ ├── elastalert.json │ │ │ ├── elastalert_error.json │ │ │ ├── elastalert_status.json │ │ │ ├── past_elastalert.json │ │ │ └── silence.json │ │ └── 6/ │ │ ├── elastalert.json │ │ ├── elastalert_error.json │ │ ├── elastalert_status.json │ │ ├── past_elastalert.json │ │ └── silence.json │ ├── kibana.py │ ├── kibana_discover.py │ ├── loaders.py │ ├── opsgenie.py │ ├── rule_from_kibana.py │ ├── ruletypes.py │ ├── schema.yaml │ ├── test_rule.py │ ├── util.py │ └── zabbix.py ├── example_rules/ │ ├── example_cardinality.yaml │ ├── example_change.yaml │ ├── example_frequency.yaml │ ├── example_new_term.yaml │ ├── example_opsgenie_frequency.yaml │ ├── example_percentage_match.yaml │ ├── example_single_metric_agg.yaml │ ├── example_spike.yaml │ ├── example_spike_single_metric_agg.yaml │ ├── jira_acct.txt │ ├── ssh-repeat-offender.yaml │ └── ssh.yaml ├── pytest.ini ├── requirements-dev.txt ├── requirements.txt ├── setup.cfg ├── setup.py ├── supervisord.conf.example ├── tests/ │ ├── __init__.py │ ├── alerts_test.py │ ├── auth_test.py │ ├── base_test.py │ ├── conftest.py │ ├── create_index_test.py │ ├── elasticsearch_test.py │ ├── kibana_discover_test.py │ ├── kibana_test.py │ ├── loaders_test.py │ ├── rules_test.py │ └── util_test.py └── tox.ini
SYMBOL INDEX (701 symbols across 27 files)
FILE: elastalert/__init__.py
class ElasticSearchClient (line 12) | class ElasticSearchClient(Elasticsearch):
method __init__ (line 15) | def __init__(self, conf):
method conf (line 35) | def conf(self):
method es_version (line 42) | def es_version(self):
method is_atleastfive (line 57) | def is_atleastfive(self):
method is_atleastsix (line 63) | def is_atleastsix(self):
method is_atleastsixtwo (line 69) | def is_atleastsixtwo(self):
method is_atleastsixsix (line 76) | def is_atleastsixsix(self):
method is_atleastseven (line 83) | def is_atleastseven(self):
method resolve_writeback_index (line 89) | def resolve_writeback_index(self, writeback_index, doc_type):
method deprecated_search (line 149) | def deprecated_search(self, index=None, doc_type=None, body=None, para...
FILE: elastalert/alerts.py
class DateTimeEncoder (line 44) | class DateTimeEncoder(json.JSONEncoder):
method default (line 45) | def default(self, obj):
class BasicMatchString (line 52) | class BasicMatchString(object):
method __init__ (line 55) | def __init__(self, rule, match):
method _ensure_new_line (line 59) | def _ensure_new_line(self):
method _add_custom_alert_text (line 63) | def _add_custom_alert_text(self):
method _add_rule_text (line 97) | def _add_rule_text(self):
method _add_top_counts (line 100) | def _add_top_counts(self):
method _add_match_items (line 115) | def _add_match_items(self):
method _pretty_print_as_json (line 131) | def _pretty_print_as_json(self, blob):
method __str__ (line 138) | def __str__(self):
class JiraFormattedMatchString (line 155) | class JiraFormattedMatchString(BasicMatchString):
method _add_match_items (line 156) | def _add_match_items(self):
class Alerter (line 163) | class Alerter(object):
method __init__ (line 170) | def __init__(self, rule):
method resolve_rule_references (line 177) | def resolve_rule_references(self, root):
method resolve_rule_reference (line 194) | def resolve_rule_reference(self, value):
method alert (line 204) | def alert(self, match):
method get_info (line 211) | def get_info(self):
method create_title (line 216) | def create_title(self, matches):
method create_custom_title (line 226) | def create_custom_title(self, matches):
method create_alert_body (line 252) | def create_alert_body(self, matches):
method get_aggregation_summary_text__maximum_width (line 262) | def get_aggregation_summary_text__maximum_width(self):
method get_aggregation_summary_text (line 266) | def get_aggregation_summary_text(self, matches):
method create_default_title (line 297) | def create_default_title(self, matches):
method get_account (line 300) | def get_account(self, account_file):
class StompAlerter (line 317) | class StompAlerter(Alerter):
method alert (line 322) | def alert(self, matches):
method get_info (line 381) | def get_info(self):
class DebugAlerter (line 385) | class DebugAlerter(Alerter):
method alert (line 388) | def alert(self, matches):
method get_info (line 398) | def get_info(self):
class EmailAlerter (line 402) | class EmailAlerter(Alerter):
method __init__ (line 406) | def __init__(self, *args):
method alert (line 432) | def alert(self, matches):
method create_default_title (line 492) | def create_default_title(self, matches):
method get_info (line 503) | def get_info(self):
class JiraAlerter (line 508) | class JiraAlerter(Alerter):
method __init__ (line 549) | def __init__(self, rule):
method set_priority (line 604) | def set_priority(self):
method reset_jira_args (line 611) | def reset_jira_args(self):
method set_jira_arg (line 635) | def set_jira_arg(self, jira_field, value, fields):
method get_arbitrary_fields (line 699) | def get_arbitrary_fields(self):
method get_priorities (line 712) | def get_priorities(self):
method set_assignee (line 719) | def set_assignee(self, assignee):
method find_existing_ticket (line 726) | def find_existing_ticket(self, matches):
method comment_on_ticket (line 758) | def comment_on_ticket(self, ticket, match):
method transition_ticket (line 764) | def transition_ticket(self, ticket):
method alert (line 770) | def alert(self, matches):
method create_alert_body (line 844) | def create_alert_body(self, matches):
method get_aggregation_summary_text (line 854) | def get_aggregation_summary_text(self, matches):
method create_default_title (line 860) | def create_default_title(self, matches, for_search=False):
method get_info (line 882) | def get_info(self):
class CommandAlerter (line 886) | class CommandAlerter(Alerter):
method __init__ (line 889) | def __init__(self, *args):
method alert (line 905) | def alert(self, matches):
method get_info (line 928) | def get_info(self):
class SnsAlerter (line 933) | class SnsAlerter(Alerter):
method __init__ (line 937) | def __init__(self, *args):
method create_default_title (line 946) | def create_default_title(self, matches):
method alert (line 950) | def alert(self, matches):
class HipChatAlerter (line 968) | class HipChatAlerter(Alerter):
method __init__ (line 972) | def __init__(self, rule):
method create_alert_body (line 986) | def create_alert_body(self, matches):
method alert (line 1006) | def alert(self, matches):
method get_info (line 1049) | def get_info(self):
class MsTeamsAlerter (line 1054) | class MsTeamsAlerter(Alerter):
method __init__ (line 1058) | def __init__(self, rule):
method format_body (line 1068) | def format_body(self, body):
method alert (line 1074) | def alert(self, matches):
method get_info (line 1100) | def get_info(self):
class SlackAlerter (line 1105) | class SlackAlerter(Alerter):
method __init__ (line 1109) | def __init__(self, rule):
method format_body (line 1134) | def format_body(self, body):
method get_aggregation_summary_text__maximum_width (line 1138) | def get_aggregation_summary_text__maximum_width(self):
method get_aggregation_summary_text (line 1143) | def get_aggregation_summary_text(self, matches):
method populate_fields (line 1149) | def populate_fields(self, matches):
method alert (line 1157) | def alert(self, matches):
method get_info (line 1225) | def get_info(self):
class MattermostAlerter (line 1230) | class MattermostAlerter(Alerter):
method __init__ (line 1234) | def __init__(self, rule):
method get_aggregation_summary_text__maximum_width (line 1254) | def get_aggregation_summary_text__maximum_width(self):
method get_aggregation_summary_text (line 1259) | def get_aggregation_summary_text(self, matches):
method populate_fields (line 1265) | def populate_fields(self, matches):
method alert (line 1280) | def alert(self, matches):
method get_info (line 1333) | def get_info(self):
class PagerDutyAlerter (line 1339) | class PagerDutyAlerter(Alerter):
method __init__ (line 1343) | def __init__(self, rule):
method alert (line 1368) | def alert(self, matches):
method resolve_formatted_key (line 1434) | def resolve_formatted_key(self, key, args, matches):
method get_incident_key (line 1451) | def get_incident_key(self, matches):
method get_info (line 1468) | def get_info(self):
class PagerTreeAlerter (line 1473) | class PagerTreeAlerter(Alerter):
method __init__ (line 1477) | def __init__(self, rule):
method alert (line 1482) | def alert(self, matches):
method get_info (line 1501) | def get_info(self):
class ExotelAlerter (line 1506) | class ExotelAlerter(Alerter):
method __init__ (line 1509) | def __init__(self, rule):
method alert (line 1517) | def alert(self, matches):
method get_info (line 1529) | def get_info(self):
class TwilioAlerter (line 1533) | class TwilioAlerter(Alerter):
method __init__ (line 1536) | def __init__(self, rule):
method alert (line 1543) | def alert(self, matches):
method get_info (line 1556) | def get_info(self):
class VictorOpsAlerter (line 1561) | class VictorOpsAlerter(Alerter):
method __init__ (line 1565) | def __init__(self, rule):
method alert (line 1576) | def alert(self, matches):
method get_info (line 1599) | def get_info(self):
class TelegramAlerter (line 1604) | class TelegramAlerter(Alerter):
method __init__ (line 1608) | def __init__(self, rule):
method alert (line 1618) | def alert(self, matches):
method get_info (line 1650) | def get_info(self):
class GoogleChatAlerter (line 1655) | class GoogleChatAlerter(Alerter):
method __init__ (line 1659) | def __init__(self, rule):
method create_header (line 1670) | def create_header(self):
method create_footer (line 1680) | def create_footer(self):
method create_card (line 1698) | def create_card(self, matches):
method create_basic (line 1718) | def create_basic(self, matches):
method alert (line 1722) | def alert(self, matches):
method get_info (line 1739) | def get_info(self):
class GitterAlerter (line 1744) | class GitterAlerter(Alerter):
method __init__ (line 1748) | def __init__(self, rule):
method alert (line 1754) | def alert(self, matches):
method get_info (line 1773) | def get_info(self):
class ServiceNowAlerter (line 1778) | class ServiceNowAlerter(Alerter):
method __init__ (line 1793) | def __init__(self, rule):
method alert (line 1798) | def alert(self, matches):
method get_info (line 1832) | def get_info(self):
class AlertaAlerter (line 1837) | class AlertaAlerter(Alerter):
method __init__ (line 1841) | def __init__(self, rule):
method alert (line 1869) | def alert(self, matches):
method create_default_title (line 1886) | def create_default_title(self, matches):
method get_info (line 1895) | def get_info(self):
method get_json_payload (line 1899) | def get_json_payload(self, match):
class HTTPPostAlerter (line 1947) | class HTTPPostAlerter(Alerter):
method __init__ (line 1950) | def __init__(self, rule):
method alert (line 1963) | def alert(self, matches):
method get_info (line 1985) | def get_info(self):
class StrideHTMLParser (line 1990) | class StrideHTMLParser(HTMLParser):
method __init__ (line 1993) | def __init__(self):
method handle_starttag (line 2001) | def handle_starttag(self, tag, attrs):
method handle_endtag (line 2010) | def handle_endtag(self, tag):
method handle_data (line 2014) | def handle_data(self, data):
class StrideAlerter (line 2022) | class StrideAlerter(Alerter):
method __init__ (line 2028) | def __init__(self, rule):
method alert (line 2039) | def alert(self, matches):
method get_info (line 2077) | def get_info(self):
class LineNotifyAlerter (line 2083) | class LineNotifyAlerter(Alerter):
method __init__ (line 2087) | def __init__(self, rule):
method alert (line 2091) | def alert(self, matches):
method get_info (line 2108) | def get_info(self):
class HiveAlerter (line 2112) | class HiveAlerter(Alerter):
method alert (line 2119) | def alert(self, matches):
method get_info (line 2181) | def get_info(self):
FILE: elastalert/auth.py
class RefeshableAWSRequestsAuth (line 7) | class RefeshableAWSRequestsAuth(AWSRequestsAuth):
method __init__ (line 12) | def __init__(self,
method aws_access_key (line 27) | def aws_access_key(self):
method aws_secret_access_key (line 31) | def aws_secret_access_key(self):
method aws_token (line 35) | def aws_token(self):
class Auth (line 39) | class Auth(object):
method __call__ (line 41) | def __call__(self, host, username, password, aws_region, profile_name):
FILE: elastalert/config.py
function load_conf (line 34) | def load_conf(args, defaults=None, overwrites=None):
function configure_logging (line 107) | def configure_logging(args, conf):
FILE: elastalert/create_index.py
function create_index_mappings (line 22) | def create_index_mappings(es_client, ea_index, recreate=False, old_ea_in...
function read_es_index_mappings (line 116) | def read_es_index_mappings(es_version=6):
function read_es_index_mapping (line 127) | def read_es_index_mapping(mapping, es_version=6):
function is_atleastsix (line 136) | def is_atleastsix(es_version):
function is_atleastsixtwo (line 140) | def is_atleastsixtwo(es_version):
function is_atleastseven (line 145) | def is_atleastseven(es_version):
function main (line 149) | def main():
FILE: elastalert/elastalert.py
class ElastAlerter (line 58) | class ElastAlerter(object):
method parse_args (line 73) | def parse_args(self, args):
method __init__ (line 110) | def __init__(self, args):
method get_index (line 181) | def get_index(rule, starttime=None, endtime=None):
method get_query (line 200) | def get_query(filters, starttime=None, endtime=None, sort=True, timest...
method get_terms_query (line 226) | def get_terms_query(self, query, rule, size, field, five=False):
method get_aggregation_query (line 243) | def get_aggregation_query(self, query, rule, query_key, terms_size, ti...
method get_index_start (line 279) | def get_index_start(self, index, timestamp_field='@timestamp'):
method process_hits (line 302) | def process_hits(rule, hits):
method get_hits (line 347) | def get_hits(self, rule, starttime, endtime, index, scroll=False):
method get_hits_count (line 434) | def get_hits_count(self, rule, starttime, endtime, index):
method get_hits_terms (line 471) | def get_hits_terms(self, rule, starttime, endtime, index, key, qk=None...
method get_hits_aggregation (line 541) | def get_hits_aggregation(self, rule, starttime, endtime, index, query_...
method remove_duplicate_events (line 586) | def remove_duplicate_events(self, data, rule):
method remove_old_events (line 598) | def remove_old_events(self, rule):
method run_query (line 610) | def run_query(self, rule, start=None, end=None, scroll=False):
method get_starttime (line 670) | def get_starttime(self, rule):
method set_starttime (line 706) | def set_starttime(self, rule, endtime):
method adjust_start_time_for_overlapping_agg_query (line 748) | def adjust_start_time_for_overlapping_agg_query(self, rule):
method adjust_start_time_for_interval_sync (line 755) | def adjust_start_time_for_interval_sync(self, rule, endtime):
method get_segment_size (line 771) | def get_segment_size(self, rule):
method get_query_key_value (line 784) | def get_query_key_value(self, rule, match):
method get_aggregation_key_value (line 791) | def get_aggregation_key_value(self, rule, match):
method get_named_key_value (line 795) | def get_named_key_value(self, rule, match, key_name):
method enhance_filter (line 813) | def enhance_filter(self, rule):
method run_rule (line 849) | def run_rule(self, rule, endtime, starttime=None):
method init_rule (line 969) | def init_rule(self, new_rule, new=True):
method modify_rule_for_ES5 (line 1044) | def modify_rule_for_ES5(new_rule):
method load_rule_changes (line 1062) | def load_rule_changes(self):
method start (line 1143) | def start(self):
method wait_until_responsive (line 1186) | def wait_until_responsive(self, timeout, clock=timeit.default_timer):
method run_all_rules (line 1220) | def run_all_rules(self):
method handle_pending_alerts (line 1229) | def handle_pending_alerts(self):
method handle_config_change (line 1235) | def handle_config_change(self):
method handle_rule_execution (line 1240) | def handle_rule_execution(self, rule):
method reset_rule_schedule (line 1302) | def reset_rule_schedule(self, rule):
method stop (line 1312) | def stop(self):
method get_disabled_rules (line 1316) | def get_disabled_rules(self):
method sleep_for (line 1320) | def sleep_for(self, duration):
method generate_kibana4_db (line 1325) | def generate_kibana4_db(self, rule, match):
method generate_kibana_db (line 1338) | def generate_kibana_db(self, rule, match):
method upload_dashboard (line 1359) | def upload_dashboard(self, db, rule, match):
method get_dashboard (line 1406) | def get_dashboard(self, rule, db_name):
method use_kibana_link (line 1423) | def use_kibana_link(self, rule, match):
method filters_from_kibana (line 1438) | def filters_from_kibana(self, rule, db_name):
method alert (line 1449) | def alert(self, matches, rule, alert_time=None, retried=False):
method send_alert (line 1456) | def send_alert(self, matches, rule, alert_time=None, retried=False):
method get_alert_body (line 1565) | def get_alert_body(self, match, rule, alert_sent, alert_time, alert_ex...
method writeback (line 1594) | def writeback(self, doc_type, body, rule=None, match_body=None):
method find_recent_pending_alerts (line 1623) | def find_recent_pending_alerts(self, time_limit):
method send_pending_alerts (line 1652) | def send_pending_alerts(self):
method get_aggregated_matches (line 1723) | def get_aggregated_matches(self, _id):
method find_pending_aggregate_alert (line 1746) | def find_pending_aggregate_alert(self, rule, aggregation_key_value=None):
method add_aggregated_alert (line 1769) | def add_aggregated_alert(self, match, rule):
method silence (line 1846) | def silence(self, silence_cache_key=None):
method set_realert (line 1872) | def set_realert(self, silence_cache_key, timestamp, exponent):
method is_silenced (line 1882) | def is_silenced(self, rule_name):
method handle_error (line 1926) | def handle_error(self, message, data=None):
method handle_uncaught_exception (line 1936) | def handle_uncaught_exception(self, exception, rule):
method send_notification_email (line 1948) | def send_notification_email(self, text='', exception=None, rule=None, ...
method get_top_counts (line 1986) | def get_top_counts(self, rule, starttime, endtime, keys, number=None, ...
method next_alert_time (line 2015) | def next_alert_time(self, rule, name, timestamp):
function handle_signal (line 2041) | def handle_signal(signal, frame):
function main (line 2047) | def main(args=None):
FILE: elastalert/enhancements.py
class BaseEnhancement (line 5) | class BaseEnhancement(object):
method __init__ (line 10) | def __init__(self, rule):
method process (line 13) | def process(self, match):
class TimeEnhancement (line 18) | class TimeEnhancement(BaseEnhancement):
method process (line 19) | def process(self, match):
class DropMatchException (line 23) | class DropMatchException(Exception):
FILE: elastalert/kibana.py
function set_time (line 178) | def set_time(dashboard, start, end):
function set_index_name (line 183) | def set_index_name(dashboard, name):
function set_timestamp_field (line 187) | def set_timestamp_field(dashboard, field):
function add_filter (line 200) | def add_filter(dashboard, es_filter):
function set_name (line 244) | def set_name(dashboard, name):
function set_included_fields (line 248) | def set_included_fields(dashboard, fields):
function filters_from_dashboard (line 252) | def filters_from_dashboard(db):
function kibana4_dashboard_link (line 284) | def kibana4_dashboard_link(dashboard, starttime, endtime):
FILE: elastalert/kibana_discover.py
function generate_kibana_discover_url (line 19) | def generate_kibana_discover_url(rule, match):
function kibana6_disover_global_state (line 88) | def kibana6_disover_global_state(from_time, to_time):
function kibana7_disover_global_state (line 102) | def kibana7_disover_global_state(from_time, to_time):
function kibana_discover_app_state (line 116) | def kibana_discover_app_state(index, columns, filters, query_keys, match):
FILE: elastalert/loaders.py
class RulesLoader (line 30) | class RulesLoader(object):
method __init__ (line 92) | def __init__(self, conf):
method load (line 99) | def load(self, conf, args=None):
method get_names (line 133) | def get_names(self, conf, use_rule=None):
method get_hashes (line 143) | def get_hashes(self, conf, use_rule=None):
method get_yaml (line 153) | def get_yaml(self, filename):
method get_import_rule (line 162) | def get_import_rule(self, rule):
method load_configuration (line 171) | def load_configuration(self, filename, conf, args=None):
method load_yaml (line 184) | def load_yaml(self, filename):
method load_options (line 219) | def load_options(self, rule, conf, filename, args=None):
method load_modules (line 404) | def load_modules(self, rule, args=None):
method load_alerts (line 441) | def load_alerts(self, rule, alert_field):
method adjust_deprecated_values (line 480) | def adjust_deprecated_values(rule):
class FileRulesLoader (line 492) | class FileRulesLoader(RulesLoader):
method get_names (line 497) | def get_names(self, conf, use_rule=None):
method get_hashes (line 517) | def get_hashes(self, conf, use_rule=None):
method get_yaml (line 524) | def get_yaml(self, filename):
method get_import_rule (line 530) | def get_import_rule(self, rule):
method get_rule_file_hash (line 542) | def get_rule_file_hash(self, rule_file):
method is_yaml (line 552) | def is_yaml(filename):
FILE: elastalert/opsgenie.py
class OpsGenieAlerter (line 14) | class OpsGenieAlerter(Alerter):
method __init__ (line 18) | def __init__(self, *args):
method _parse_responders (line 38) | def _parse_responders(self, responders, responder_args, matches, defau...
method _fill_responders (line 60) | def _fill_responders(self, responders, type_):
method alert (line 63) | def alert(self, matches):
method create_default_title (line 126) | def create_default_title(self, matches):
method create_title (line 137) | def create_title(self, matches):
method create_custom_title (line 144) | def create_custom_title(self, matches):
method get_info (line 161) | def get_info(self):
method get_details (line 171) | def get_details(self, matches):
FILE: elastalert/rule_from_kibana.py
function main (line 11) | def main():
FILE: elastalert/ruletypes.py
class RuleType (line 23) | class RuleType(object):
method __init__ (line 31) | def __init__(self, rules, args=None):
method add_data (line 40) | def add_data(self, data):
method add_match (line 48) | def add_match(self, event):
method get_match_str (line 63) | def get_match_str(self, match):
method garbage_collect (line 71) | def garbage_collect(self, timestamp):
method add_count_data (line 79) | def add_count_data(self, counts):
method add_terms_data (line 86) | def add_terms_data(self, terms):
method add_aggregation_data (line 92) | def add_aggregation_data(self, payload):
class CompareRule (line 98) | class CompareRule(RuleType):
method expand_entries (line 102) | def expand_entries(self, list_type):
method compare (line 117) | def compare(self, event):
method add_data (line 121) | def add_data(self, data):
class BlacklistRule (line 128) | class BlacklistRule(CompareRule):
method __init__ (line 132) | def __init__(self, rules, args=None):
method compare (line 136) | def compare(self, event):
class WhitelistRule (line 143) | class WhitelistRule(CompareRule):
method __init__ (line 147) | def __init__(self, rules, args=None):
method compare (line 151) | def compare(self, event):
class ChangeRule (line 160) | class ChangeRule(CompareRule):
method compare (line 166) | def compare(self, event):
method add_match (line 200) | def add_match(self, match):
class FrequencyRule (line 213) | class FrequencyRule(RuleType):
method __init__ (line 217) | def __init__(self, *args):
method add_count_data (line 223) | def add_count_data(self, data):
method add_terms_data (line 234) | def add_terms_data(self, terms):
method add_data (line 242) | def add_data(self, data):
method check_for_match (line 264) | def check_for_match(self, key, end=False):
method garbage_collect (line 275) | def garbage_collect(self, timestamp):
method get_match_str (line 283) | def get_match_str(self, match):
class AnyRule (line 294) | class AnyRule(RuleType):
method add_data (line 297) | def add_data(self, data):
class EventWindow (line 302) | class EventWindow(object):
method __init__ (line 305) | def __init__(self, timeframe, onRemoved=None, getTimestamp=new_get_eve...
method clear (line 312) | def clear(self):
method append (line 316) | def append(self, event):
method duration (line 329) | def duration(self):
method count (line 335) | def count(self):
method mean (line 339) | def mean(self):
method __iter__ (line 354) | def __iter__(self):
method append_middle (line 357) | def append_middle(self, event):
class SpikeRule (line 381) | class SpikeRule(RuleType):
method __init__ (line 385) | def __init__(self, *args):
method add_count_data (line 401) | def add_count_data(self, data):
method add_terms_data (line 408) | def add_terms_data(self, terms):
method add_data (line 417) | def add_data(self, data):
method clear_windows (line 436) | def clear_windows(self, qk, event):
method handle_event (line 442) | def handle_event(self, event, count, qk='all'):
method add_match (line 482) | def add_match(self, match, qk):
method find_matches (line 497) | def find_matches(self, ref, cur):
method get_match_str (line 518) | def get_match_str(self, match):
method garbage_collect (line 536) | def garbage_collect(self, ts):
class FlatlineRule (line 552) | class FlatlineRule(FrequencyRule):
method __init__ (line 556) | def __init__(self, *args):
method check_for_match (line 563) | def check_for_match(self, key, end=True):
method get_match_str (line 597) | def get_match_str(self, match):
method garbage_collect (line 608) | def garbage_collect(self, ts):
class NewTermsRule (line 623) | class NewTermsRule(RuleType):
method __init__ (line 626) | def __init__(self, rule, args=None):
method get_all_terms (line 656) | def get_all_terms(self, args):
method flatten_aggregation_hierarchy (line 751) | def flatten_aggregation_hierarchy(self, root, hierarchy_tuple=()):
method add_data (line 854) | def add_data(self, data):
method add_terms_data (line 880) | def add_terms_data(self, terms):
method is_five_or_above (line 893) | def is_five_or_above(self):
class CardinalityRule (line 898) | class CardinalityRule(RuleType):
method __init__ (line 902) | def __init__(self, *args):
method add_data (line 912) | def add_data(self, data):
method check_for_match (line 928) | def check_for_match(self, key, event, gc=True):
method garbage_collect (line 943) | def garbage_collect(self, timestamp):
method get_match_str (line 957) | def get_match_str(self, match):
class BaseAggregationRule (line 972) | class BaseAggregationRule(RuleType):
method __init__ (line 973) | def __init__(self, *args):
method generate_aggregation_query (line 997) | def generate_aggregation_query(self):
method add_aggregation_data (line 1000) | def add_aggregation_data(self, payload):
method unwrap_interval_buckets (line 1009) | def unwrap_interval_buckets(self, timestamp, query_key, interval_bucke...
method unwrap_term_buckets (line 1014) | def unwrap_term_buckets(self, timestamp, term_buckets):
method check_matches (line 1021) | def check_matches(self, timestamp, query_key, aggregation_data):
class MetricAggregationRule (line 1025) | class MetricAggregationRule(BaseAggregationRule):
method __init__ (line 1030) | def __init__(self, *args):
method get_match_str (line 1043) | def get_match_str(self, match):
method generate_aggregation_query (line 1053) | def generate_aggregation_query(self):
method check_matches (line 1056) | def check_matches(self, timestamp, query_key, aggregation_data):
method check_matches_recursive (line 1069) | def check_matches_recursive(self, timestamp, query_key, aggregation_da...
method crossed_thresholds (line 1095) | def crossed_thresholds(self, metric_value):
class SpikeMetricAggregationRule (line 1105) | class SpikeMetricAggregationRule(BaseAggregationRule, SpikeRule):
method __init__ (line 1110) | def __init__(self, *args):
method generate_aggregation_query (line 1125) | def generate_aggregation_query(self):
method add_aggregation_data (line 1131) | def add_aggregation_data(self, payload):
method unwrap_term_buckets (line 1147) | def unwrap_term_buckets(self, timestamp, term_buckets, qk=[]):
method get_match_str (line 1173) | def get_match_str(self, match):
class PercentageMatchRule (line 1187) | class PercentageMatchRule(BaseAggregationRule):
method __init__ (line 1190) | def __init__(self, *args):
method get_match_str (line 1200) | def get_match_str(self, match):
method generate_aggregation_query (line 1210) | def generate_aggregation_query(self):
method check_matches (line 1226) | def check_matches(self, timestamp, query_key, aggregation_data):
method percentage_violation (line 1244) | def percentage_violation(self, match_percentage):
FILE: elastalert/test_rule.py
function print_terms (line 35) | def print_terms(terms, parent):
class MockElastAlerter (line 44) | class MockElastAlerter(object):
method __init__ (line 45) | def __init__(self):
method test_file (line 49) | def test_file(self, conf, args):
method mock_count (line 169) | def mock_count(self, rule, start, end, index):
method mock_hits (line 177) | def mock_hits(self, rule, start, end, index, scroll=False):
method mock_terms (line 199) | def mock_terms(self, rule, start, end, index, key, qk=None, size=None):
method mock_elastalert (line 218) | def mock_elastalert(self, elastalert):
method run_elastalert (line 225) | def run_elastalert(self, rule, conf, args):
method run_rule_test (line 339) | def run_rule_test(self):
function main (line 443) | def main():
FILE: elastalert/util.py
function get_module (line 20) | def get_module(module_name):
function new_get_event_ts (line 34) | def new_get_event_ts(ts_field):
function _find_es_dict_by_key (line 44) | def _find_es_dict_by_key(lookup_dict, term):
function set_es_key (line 122) | def set_es_key(lookup_dict, term, value):
function lookup_es_key (line 135) | def lookup_es_key(lookup_dict, term):
function ts_to_dt (line 143) | def ts_to_dt(timestamp):
function dt_to_ts (line 153) | def dt_to_ts(dt):
function ts_to_dt_with_format (line 167) | def ts_to_dt_with_format(timestamp, ts_format):
function dt_to_ts_with_format (line 177) | def dt_to_ts_with_format(dt, ts_format):
function ts_now (line 185) | def ts_now():
function inc_ts (line 189) | def inc_ts(timestamp, milliseconds=1):
function pretty_ts (line 196) | def pretty_ts(timestamp, tz=True):
function ts_add (line 208) | def ts_add(ts, td):
function hashable (line 213) | def hashable(obj):
function format_index (line 222) | def format_index(index, start, end, add_extra=False):
class EAException (line 244) | class EAException(Exception):
function seconds (line 248) | def seconds(td):
function total_seconds (line 252) | def total_seconds(dt):
function dt_to_int (line 262) | def dt_to_int(dt):
function unixms_to_dt (line 267) | def unixms_to_dt(ts):
function unix_to_dt (line 271) | def unix_to_dt(ts):
function dt_to_unix (line 277) | def dt_to_unix(dt):
function dt_to_unixms (line 281) | def dt_to_unixms(dt):
function cronite_datetime_to_timestamp (line 285) | def cronite_datetime_to_timestamp(self, d):
function add_raw_postfix (line 295) | def add_raw_postfix(field, is_five_or_above):
function replace_dots_in_field_names (line 305) | def replace_dots_in_field_names(document):
function elasticsearch_client (line 317) | def elasticsearch_client(conf):
function build_es_conn_config (line 330) | def build_es_conn_config(conf):
function pytzfy (line 391) | def pytzfy(dt):
function parse_duration (line 400) | def parse_duration(value):
function parse_deadline (line 406) | def parse_deadline(value):
function flatten_dict (line 412) | def flatten_dict(dct, delim='.', prefix=''):
function resolve_string (line 422) | def resolve_string(string, match, missing_text='<MISSING VALUE>'):
function should_scrolling_continue (line 452) | def should_scrolling_continue(rule_conf):
FILE: elastalert/zabbix.py
class ZabbixClient (line 8) | class ZabbixClient(ZabbixAPI):
method __init__ (line 10) | def __init__(self, url='http://localhost', use_authenticate=False, use...
method send_metric (line 21) | def send_metric(self, hostname, key, data):
class ZabbixAlerter (line 42) | class ZabbixAlerter(Alerter):
method __init__ (line 50) | def __init__(self, *args):
method alert (line 59) | def alert(self, matches):
method get_info (line 74) | def get_info(self):
FILE: tests/alerts_test.py
class mock_rule (line 30) | class mock_rule:
method get_match_str (line 31) | def get_match_str(self, event):
function test_basic_match_string (line 35) | def test_basic_match_string(ea):
function test_jira_formatted_match_string (line 79) | def test_jira_formatted_match_string(ea):
function test_email (line 95) | def test_email():
function test_email_from_field (line 120) | def test_email_from_field():
function test_email_with_unicode_strings (line 160) | def test_email_with_unicode_strings():
function test_email_with_auth (line 185) | def test_email_with_auth():
function test_email_with_cert_key (line 207) | def test_email_with_cert_key():
function test_email_with_cc (line 229) | def test_email_with_cc():
function test_email_with_bcc (line 254) | def test_email_with_bcc():
function test_email_with_cc_and_bcc (line 279) | def test_email_with_cc_and_bcc():
function test_email_with_args (line 314) | def test_email_with_args():
function test_email_query_key_in_subject (line 355) | def test_email_query_key_in_subject():
function test_opsgenie_basic (line 375) | def test_opsgenie_basic():
function test_opsgenie_frequency (line 396) | def test_opsgenie_frequency():
function test_opsgenie_alert_routing (line 423) | def test_opsgenie_alert_routing():
function test_opsgenie_default_alert_routing (line 440) | def test_opsgenie_default_alert_routing():
function test_opsgenie_details_with_constant_value (line 459) | def test_opsgenie_details_with_constant_value():
function test_opsgenie_details_with_field (line 498) | def test_opsgenie_details_with_field():
function test_opsgenie_details_with_nested_field (line 538) | def test_opsgenie_details_with_nested_field():
function test_opsgenie_details_with_non_string_field (line 580) | def test_opsgenie_details_with_non_string_field():
function test_opsgenie_details_with_missing_field (line 629) | def test_opsgenie_details_with_missing_field():
function test_opsgenie_details_with_environment_variable_replacement (line 672) | def test_opsgenie_details_with_environment_variable_replacement(environ):
function test_jira (line 714) | def test_jira():
function test_jira_arbitrary_field_support (line 879) | def test_jira_arbitrary_field_support():
function test_kibana (line 1012) | def test_kibana(ea):
function test_command (line 1050) | def test_command():
function test_ms_teams (line 1131) | def test_ms_teams():
function test_ms_teams_uses_color_and_fixed_width_text (line 1166) | def test_ms_teams_uses_color_and_fixed_width_text():
function test_slack_uses_custom_title (line 1206) | def test_slack_uses_custom_title():
function test_slack_uses_custom_timeout (line 1251) | def test_slack_uses_custom_timeout():
function test_slack_uses_rule_name_when_custom_title_is_not_provided (line 1297) | def test_slack_uses_rule_name_when_custom_title_is_not_provided():
function test_slack_uses_custom_slack_channel (line 1341) | def test_slack_uses_custom_slack_channel():
function test_slack_uses_list_of_custom_slack_channel (line 1386) | def test_slack_uses_list_of_custom_slack_channel():
function test_slack_attach_kibana_discover_url_when_generated (line 1448) | def test_slack_attach_kibana_discover_url_when_generated():
function test_slack_attach_kibana_discover_url_when_not_generated (line 1499) | def test_slack_attach_kibana_discover_url_when_not_generated():
function test_slack_kibana_discover_title (line 1544) | def test_slack_kibana_discover_title():
function test_slack_kibana_discover_color (line 1596) | def test_slack_kibana_discover_color():
function test_http_alerter_with_payload (line 1648) | def test_http_alerter_with_payload():
function test_http_alerter_with_payload_all_values (line 1680) | def test_http_alerter_with_payload_all_values():
function test_http_alerter_without_payload (line 1715) | def test_http_alerter_without_payload():
function test_pagerduty_alerter (line 1747) | def test_pagerduty_alerter():
function test_pagerduty_alerter_v2 (line 1779) | def test_pagerduty_alerter_v2():
function test_pagerduty_alerter_custom_incident_key (line 1825) | def test_pagerduty_alerter_custom_incident_key():
function test_pagerduty_alerter_custom_incident_key_with_args (line 1857) | def test_pagerduty_alerter_custom_incident_key_with_args():
function test_pagerduty_alerter_custom_alert_subject (line 1890) | def test_pagerduty_alerter_custom_alert_subject():
function test_pagerduty_alerter_custom_alert_subject_with_args (line 1924) | def test_pagerduty_alerter_custom_alert_subject_with_args():
function test_pagerduty_alerter_custom_alert_subject_with_args_specifying_trigger (line 1960) | def test_pagerduty_alerter_custom_alert_subject_with_args_specifying_tri...
function test_alert_text_kw (line 1997) | def test_alert_text_kw(ea):
function test_alert_text_global_substitution (line 2010) | def test_alert_text_global_substitution(ea):
function test_alert_text_kw_global_substitution (line 2032) | def test_alert_text_kw_global_substitution(ea):
function test_resolving_rule_references (line 2058) | def test_resolving_rule_references(ea):
function test_stride_plain_text (line 2089) | def test_stride_plain_text():
function test_stride_underline_text (line 2133) | def test_stride_underline_text():
function test_stride_bold_text (line 2179) | def test_stride_bold_text():
function test_stride_strong_text (line 2225) | def test_stride_strong_text():
function test_stride_hyperlink (line 2271) | def test_stride_hyperlink():
function test_stride_html (line 2317) | def test_stride_html():
function test_hipchat_body_size_limit_text (line 2366) | def test_hipchat_body_size_limit_text():
function test_hipchat_body_size_limit_html (line 2394) | def test_hipchat_body_size_limit_html():
function test_alerta_no_auth (line 2423) | def test_alerta_no_auth(ea):
function test_alerta_auth (line 2488) | def test_alerta_auth(ea):
function test_alerta_new_style (line 2522) | def test_alerta_new_style(ea):
function test_alert_subject_size_limit_no_args (line 2587) | def test_alert_subject_size_limit_no_args(ea):
function test_alert_subject_size_limit_with_args (line 2601) | def test_alert_subject_size_limit_with_args(ea):
FILE: tests/auth_test.py
function test_auth_none (line 5) | def test_auth_none():
function test_auth_username_password (line 18) | def test_auth_username_password():
function test_auth_aws_region (line 31) | def test_auth_aws_region():
FILE: tests/base_test.py
function _set_hits (line 30) | def _set_hits(ea_inst, hits):
function generate_hits (line 35) | def generate_hits(timestamps, **kwargs):
function assert_alerts (line 51) | def assert_alerts(ea_inst, calls):
function test_starttime (line 59) | def test_starttime(ea):
function test_init_rule (line 68) | def test_init_rule(ea):
function test_query (line 93) | def test_query(ea):
function test_query_sixsix (line 104) | def test_query_sixsix(ea_sixsix):
function test_query_with_fields (line 115) | def test_query_with_fields(ea):
function test_query_sixsix_with_fields (line 126) | def test_query_sixsix_with_fields(ea_sixsix):
function test_query_with_unix (line 138) | def test_query_with_unix(ea):
function test_query_sixsix_with_unix (line 153) | def test_query_sixsix_with_unix(ea_sixsix):
function test_query_with_unixms (line 168) | def test_query_with_unixms(ea):
function test_query_sixsix_with_unixms (line 183) | def test_query_sixsix_with_unixms(ea_sixsix):
function test_no_hits (line 198) | def test_no_hits(ea):
function test_no_terms_hits (line 204) | def test_no_terms_hits(ea):
function test_some_hits (line 213) | def test_some_hits(ea):
function test_some_hits_unix (line 222) | def test_some_hits_unix(ea):
function _duplicate_hits_generator (line 234) | def _duplicate_hits_generator(timestamps, **kwargs):
function test_duplicate_timestamps (line 241) | def test_duplicate_timestamps(ea):
function test_match (line 253) | def test_match(ea):
function test_run_rule_calls_garbage_collect (line 264) | def test_run_rule_calls_garbage_collect(ea):
function run_rule_query_exception (line 282) | def run_rule_query_exception(ea, mock_es):
function test_query_exception (line 295) | def test_query_exception(ea):
function test_query_exception_count_query (line 301) | def test_query_exception_count_query(ea):
function test_match_with_module (line 309) | def test_match_with_module(ea):
function test_match_with_module_from_pending (line 317) | def test_match_with_module_from_pending(ea):
function test_match_with_module_with_agg (line 340) | def test_match_with_module_with_agg(ea):
function test_match_with_enhancements_first (line 353) | def test_match_with_enhancements_first(ea):
function test_agg_matchtime (line 378) | def test_agg_matchtime(ea):
function test_agg_not_matchtime (line 435) | def test_agg_not_matchtime(ea):
function test_agg_cron (line 465) | def test_agg_cron(ea):
function test_agg_no_writeback_connectivity (line 502) | def test_agg_no_writeback_connectivity(ea):
function test_agg_with_aggregation_key (line 532) | def test_agg_with_aggregation_key(ea):
function test_silence (line 604) | def test_silence(ea):
function test_compound_query_key (line 628) | def test_compound_query_key(ea):
function test_silence_query_key (line 639) | def test_silence_query_key(ea):
function test_realert (line 671) | def test_realert(ea):
function test_realert_with_query_key (line 699) | def test_realert_with_query_key(ea):
function test_realert_with_nested_query_key (line 739) | def test_realert_with_nested_query_key(ea):
function test_count (line 758) | def test_count(ea):
function run_and_assert_segmented_queries (line 778) | def run_and_assert_segmented_queries(ea, start, end, segment_size):
function test_query_segmenting_reset_num_hits (line 797) | def test_query_segmenting_reset_num_hits(ea):
function test_query_segmenting (line 808) | def test_query_segmenting(ea):
function test_get_starttime (line 843) | def test_get_starttime(ea):
function test_set_starttime (line 861) | def test_set_starttime(ea):
function test_kibana_dashboard (line 947) | def test_kibana_dashboard(ea):
function test_rule_changes (line 994) | def test_rule_changes(ea):
function test_strf_index (line 1073) | def test_strf_index(ea):
function test_count_keys (line 1093) | def test_count_keys(ea):
function test_exponential_realert (line 1112) | def test_exponential_realert(ea):
function test_wait_until_responsive (line 1140) | def test_wait_until_responsive(ea):
function test_wait_until_responsive_timeout_es_not_available (line 1162) | def test_wait_until_responsive_timeout_es_not_available(ea, capsys):
function test_wait_until_responsive_timeout_index_does_not_exist (line 1189) | def test_wait_until_responsive_timeout_index_does_not_exist(ea, capsys):
function test_stop (line 1216) | def test_stop(ea):
function test_notify_email (line 1245) | def test_notify_email(ea):
function test_uncaught_exceptions (line 1271) | def test_uncaught_exceptions(ea):
function test_get_top_counts_handles_no_hits_returned (line 1304) | def test_get_top_counts_handles_no_hits_returned(ea):
function test_remove_old_events (line 1317) | def test_remove_old_events(ea):
function test_query_with_whitelist_filter_es (line 1337) | def test_query_with_whitelist_filter_es(ea):
function test_query_with_whitelist_filter_es_five (line 1349) | def test_query_with_whitelist_filter_es_five(ea_sixsix):
function test_query_with_blacklist_filter_es (line 1360) | def test_query_with_blacklist_filter_es(ea):
function test_query_with_blacklist_filter_es_five (line 1371) | def test_query_with_blacklist_filter_es_five(ea_sixsix):
FILE: tests/conftest.py
function pytest_addoption (line 17) | def pytest_addoption(parser):
function pytest_collection_modifyitems (line 23) | def pytest_collection_modifyitems(config, items):
function reset_loggers (line 39) | def reset_loggers():
class mock_es_indices_client (line 55) | class mock_es_indices_client(object):
method __init__ (line 56) | def __init__(self):
class mock_es_client (line 60) | class mock_es_client(object):
method __init__ (line 61) | def __init__(self, host='es', port=14900):
class mock_es_sixsix_client (line 82) | class mock_es_sixsix_client(object):
method __init__ (line 83) | def __init__(self, host='es', port=14900):
class mock_rule_loader (line 116) | class mock_rule_loader(object):
method __init__ (line 117) | def __init__(self, conf):
class mock_ruletype (line 124) | class mock_ruletype(object):
method __init__ (line 125) | def __init__(self):
class mock_alert (line 135) | class mock_alert(object):
method __init__ (line 136) | def __init__(self):
method get_info (line 139) | def get_info(self):
function ea (line 144) | def ea():
function ea_sixsix (line 198) | def ea_sixsix():
function environ (line 249) | def environ():
FILE: tests/create_index_test.py
function test_read_default_index_mapping (line 18) | def test_read_default_index_mapping(es_mapping):
function test_read_es_5_index_mapping (line 25) | def test_read_es_5_index_mapping(es_mapping):
function test_read_es_6_index_mapping (line 32) | def test_read_es_6_index_mapping(es_mapping):
function test_read_default_index_mappings (line 38) | def test_read_default_index_mappings():
function test_read_es_5_index_mappings (line 44) | def test_read_es_5_index_mappings():
function test_read_es_6_index_mappings (line 50) | def test_read_es_6_index_mappings():
FILE: tests/elasticsearch_test.py
function es_client (line 23) | def es_client():
class TestElasticsearch (line 29) | class TestElasticsearch(object):
method test_create_indices (line 34) | def test_create_indices(self, es_client):
method test_aggregated_alert (line 54) | def test_aggregated_alert(self, ea, es_client): # noqa: F811
method test_silenced (line 74) | def test_silenced(self, ea, es_client): # noqa: F811
method test_get_hits (line 91) | def test_get_hits(self, ea, es_client): # noqa: F811
FILE: tests/kibana_discover_test.py
function test_generate_kibana_discover_url_with_kibana_5x_and_6x (line 9) | def test_generate_kibana_discover_url_with_kibana_5x_and_6x(kibana_versi...
function test_generate_kibana_discover_url_with_kibana_7x (line 42) | def test_generate_kibana_discover_url_with_kibana_7x(kibana_version):
function test_generate_kibana_discover_url_with_missing_kibana_discover_version (line 74) | def test_generate_kibana_discover_url_with_missing_kibana_discover_versi...
function test_generate_kibana_discover_url_with_missing_kibana_discover_app_url (line 89) | def test_generate_kibana_discover_url_with_missing_kibana_discover_app_u...
function test_generate_kibana_discover_url_with_missing_kibana_discover_index_pattern_id (line 104) | def test_generate_kibana_discover_url_with_missing_kibana_discover_index...
function test_generate_kibana_discover_url_with_invalid_kibana_version (line 119) | def test_generate_kibana_discover_url_with_invalid_kibana_version():
function test_generate_kibana_discover_url_with_kibana_discover_app_url_env_substitution (line 134) | def test_generate_kibana_discover_url_with_kibana_discover_app_url_env_s...
function test_generate_kibana_discover_url_with_from_timedelta (line 170) | def test_generate_kibana_discover_url_with_from_timedelta():
function test_generate_kibana_discover_url_with_from_timedelta_and_timeframe (line 203) | def test_generate_kibana_discover_url_with_from_timedelta_and_timeframe():
function test_generate_kibana_discover_url_with_to_timedelta (line 237) | def test_generate_kibana_discover_url_with_to_timedelta():
function test_generate_kibana_discover_url_with_to_timedelta_and_timeframe (line 270) | def test_generate_kibana_discover_url_with_to_timedelta_and_timeframe():
function test_generate_kibana_discover_url_with_timeframe (line 304) | def test_generate_kibana_discover_url_with_timeframe():
function test_generate_kibana_discover_url_with_custom_columns (line 337) | def test_generate_kibana_discover_url_with_custom_columns():
function test_generate_kibana_discover_url_with_single_filter (line 370) | def test_generate_kibana_discover_url_with_single_filter():
function test_generate_kibana_discover_url_with_multiple_filters (line 421) | def test_generate_kibana_discover_url_with_multiple_filters():
function test_generate_kibana_discover_url_with_int_query_key (line 475) | def test_generate_kibana_discover_url_with_int_query_key():
function test_generate_kibana_discover_url_with_str_query_key (line 535) | def test_generate_kibana_discover_url_with_str_query_key():
function test_generate_kibana_discover_url_with_null_query_key_value (line 597) | def test_generate_kibana_discover_url_with_null_query_key_value():
function test_generate_kibana_discover_url_with_missing_query_key_value (line 647) | def test_generate_kibana_discover_url_with_missing_query_key_value():
function test_generate_kibana_discover_url_with_compound_query_key (line 696) | def test_generate_kibana_discover_url_with_compound_query_key():
function test_generate_kibana_discover_url_with_filter_and_query_key (line 784) | def test_generate_kibana_discover_url_with_filter_and_query_key():
FILE: tests/kibana_test.py
function test_filters_from_dashboard (line 55) | def test_filters_from_dashboard():
function test_add_filter (line 61) | def test_add_filter():
function test_url_encoded (line 89) | def test_url_encoded():
function test_url_env_substitution (line 94) | def test_url_env_substitution(environ):
FILE: tests/loaders_test.py
function test_import_rules (line 48) | def test_import_rules():
function test_import_import (line 73) | def test_import_import():
function test_import_absolute_import (line 100) | def test_import_absolute_import():
function test_import_filter (line 124) | def test_import_filter():
function test_load_inline_alert_rule (line 144) | def test_load_inline_alert_rule():
function test_file_rules_loader_get_names_recursive (line 169) | def test_file_rules_loader_get_names_recursive():
function test_file_rules_loader_get_names (line 188) | def test_file_rules_loader_get_names():
function test_load_rules (line 207) | def test_load_rules():
function test_load_default_host_port (line 231) | def test_load_default_host_port():
function test_load_ssl_env_false (line 251) | def test_load_ssl_env_false():
function test_load_ssl_env_true (line 270) | def test_load_ssl_env_true():
function test_load_url_prefix_env (line 289) | def test_load_url_prefix_env():
function test_load_disabled_rules (line 308) | def test_load_disabled_rules():
function test_raises_on_missing_config (line 325) | def test_raises_on_missing_config():
function test_compound_query_key (line 348) | def test_compound_query_key():
function test_query_key_with_single_value (line 361) | def test_query_key_with_single_value():
function test_query_key_with_no_values (line 373) | def test_query_key_with_no_values():
function test_name_inference (line 384) | def test_name_inference():
function test_raises_on_bad_generate_kibana_filters (line 393) | def test_raises_on_bad_generate_kibana_filters():
function test_kibana_discover_from_timedelta (line 423) | def test_kibana_discover_from_timedelta():
function test_kibana_discover_to_timedelta (line 433) | def test_kibana_discover_to_timedelta():
FILE: tests/rules_test.py
function hits (line 27) | def hits(size, **kwargs):
function create_event (line 37) | def create_event(timestamp, timestamp_field='@timestamp', **kwargs):
function create_bucket_aggregation (line 43) | def create_bucket_aggregation(agg_name, buckets):
function create_percentage_match_agg (line 48) | def create_percentage_match_agg(match_count, other_count):
function assert_matches_have (line 62) | def assert_matches_have(matches, terms):
function test_any (line 71) | def test_any():
function test_freq (line 78) | def test_freq():
function test_freq_count (line 107) | def test_freq_count():
function test_freq_out_of_order (line 136) | def test_freq_out_of_order():
function test_freq_terms (line 160) | def test_freq_terms():
function test_eventwindow (line 187) | def test_eventwindow():
function test_spike_count (line 208) | def test_spike_count():
function test_spike_deep_key (line 234) | def test_spike_deep_key():
function test_spike (line 246) | def test_spike():
function test_spike_query_key (line 313) | def test_spike_query_key():
function test_spike_terms (line 348) | def test_spike_terms():
function test_spike_terms_query_key_alert_on_new_data (line 410) | def test_spike_terms_query_key_alert_on_new_data():
function test_blacklist (line 462) | def test_blacklist():
function test_whitelist (line 476) | def test_whitelist():
function test_whitelist_dont_ignore_nulls (line 491) | def test_whitelist_dont_ignore_nulls():
function test_change (line 507) | def test_change():
function test_new_term (line 550) | def test_new_term():
function test_new_term_nested_field (line 620) | def test_new_term_nested_field():
function test_new_term_with_terms (line 644) | def test_new_term_with_terms():
function test_new_term_with_composite_fields (line 682) | def test_new_term_with_composite_fields():
function test_flatline (line 772) | def test_flatline():
function test_flatline_no_data (line 813) | def test_flatline_no_data():
function test_flatline_count (line 831) | def test_flatline_count():
function test_flatline_query_key (line 846) | def test_flatline_query_key():
function test_flatline_forget_query_key (line 881) | def test_flatline_forget_query_key():
function test_cardinality_max (line 909) | def test_cardinality_max():
function test_cardinality_min (line 945) | def test_cardinality_min():
function test_cardinality_qk (line 976) | def test_cardinality_qk():
function test_cardinality_nested_cardinality_field (line 1005) | def test_cardinality_nested_cardinality_field():
function test_base_aggregation_constructor (line 1047) | def test_base_aggregation_constructor():
function test_base_aggregation_payloads (line 1089) | def test_base_aggregation_payloads():
function test_metric_aggregation (line 1126) | def test_metric_aggregation():
function test_metric_aggregation_complex_query_key (line 1163) | def test_metric_aggregation_complex_query_key():
function test_percentage_match (line 1187) | def test_percentage_match():
FILE: tests/util_test.py
function test_parse_duration (line 25) | def test_parse_duration(spec, expected_delta):
function test_parse_deadline (line 35) | def test_parse_deadline(spec, expected_deadline):
function test_setting_keys (line 48) | def test_setting_keys(ea):
function test_looking_up_missing_keys (line 66) | def test_looking_up_missing_keys(ea):
function test_looking_up_nested_keys (line 81) | def test_looking_up_nested_keys(ea):
function test_looking_up_nested_composite_keys (line 95) | def test_looking_up_nested_composite_keys(ea):
function test_looking_up_arrays (line 109) | def test_looking_up_arrays(ea):
function test_add_raw_postfix (line 127) | def test_add_raw_postfix(ea):
function test_replace_dots_in_field_names (line 136) | def test_replace_dots_in_field_names(ea):
function test_resolve_string (line 169) | def test_resolve_string(ea):
function test_format_index (line 206) | def test_format_index():
function test_should_scrolling_continue (line 219) | def test_should_scrolling_continue():
Condensed preview — 84 files, each showing path, character count, and a content snippet. Download the .json file or copy for the full structured content (950K chars).
[
{
"path": ".editorconfig",
"chars": 216,
"preview": "root = true\n\n[*]\nend_of_line = lf\ninsert_final_newline = true\ncharset = utf-8\n\n[*.py]\nindent_style = space\nindent_size ="
},
{
"path": ".gitignore",
"chars": 160,
"preview": "config.yaml\n.tox/\n.coverage\n.idea/*\n.cache/\n__pycache__/\n*.pyc\nvirtualenv_run/\n*.egg-info/\ndist/\nvenv/\nenv/\ndocs/build/\n"
},
{
"path": ".pre-commit-config.yaml",
"chars": 718,
"preview": "repos:\n- repo: git://github.com/pre-commit/pre-commit-hooks\n sha: v1.1.1\n hooks:\n - id: trailing-whitespace"
},
{
"path": ".secrets.baseline",
"chars": 574,
"preview": "{\n \"exclude_regex\": \".*tests/.*|.*yelp/testing/.*|\\\\.pre-commit-config\\\\.yaml\",\n \"generated_at\": \"2018-07-06T22:54:22Z"
},
{
"path": ".travis.yml",
"chars": 1262,
"preview": "language: python\npython:\n- '3.6'\nenv:\n- TOXENV=docs\n- TOXENV=py36\ninstall:\n- pip install tox\n- >\n if [[ -n \"${ES_VERSIO"
},
{
"path": "Dockerfile-test",
"chars": 244,
"preview": "FROM ubuntu:latest\n\nRUN apt-get update && apt-get upgrade -y\nRUN apt-get -y install build-essential python3.6 python3.6-"
},
{
"path": "LICENSE",
"chars": 11359,
"preview": "\n Apache License\n Version 2.0, January 2004\n "
},
{
"path": "Makefile",
"chars": 528,
"preview": ".PHONY: all production test docs clean\n\nall: production\n\nproduction:\n\t@true\n\ndocs:\n\ttox -e docs\n\ndev: $(LOCAL_CONFIG_DIR"
},
{
"path": "README.md",
"chars": 16197,
"preview": "**ElastAlert is no longer maintained. Please use [ElastAlert2](https://github.com/jertel/elastalert2) instead.**\n\n\n[![Bu"
},
{
"path": "changelog.md",
"chars": 11648,
"preview": "# Change Log\n\n# v0.2.4\n\n### Added\n- Added back customFields support for The Hive\n\n# v0.2.3\n\n### Added\n- Added back TheHi"
},
{
"path": "config.yaml.example",
"chars": 3321,
"preview": "# This is the folder that contains the rule yaml files\n# Any .yaml file will be loaded as a rule\nrules_folder: example_r"
},
{
"path": "docker-compose.yml",
"chars": 261,
"preview": "version: '2'\nservices:\n tox:\n build:\n context: ./\n dockerfile: Dockerfile-test\n c"
},
{
"path": "docs/Makefile",
"chars": 3132,
"preview": "# Makefile for Sphinx documentation\n#\n\n# You can set these variables from the command line.\nSPHINXOPTS =\nSPHINXBUILD "
},
{
"path": "docs/source/_static/.gitkeep",
"chars": 0,
"preview": ""
},
{
"path": "docs/source/conf.py",
"chars": 6406,
"preview": "import sphinx_rtd_theme\n\n# -*- coding: utf-8 -*-\n#\n# ElastAlert documentation build configuration file, created by\n# sph"
},
{
"path": "docs/source/elastalert.rst",
"chars": 14996,
"preview": "ElastAlert - Easy & Flexible Alerting With Elasticsearch\n********************************************************\n\nElast"
},
{
"path": "docs/source/elastalert_status.rst",
"chars": 5012,
"preview": ".. _metadata:\n\nElastAlert Metadata Index\n=========================\n\nElastAlert uses Elasticsearch to store various infor"
},
{
"path": "docs/source/index.rst",
"chars": 700,
"preview": ".. ElastAlert documentation master file, created by\n sphinx-quickstart on Thu Jul 11 15:45:31 2013.\n You can adapt t"
},
{
"path": "docs/source/recipes/adding_alerts.rst",
"chars": 4674,
"preview": ".. _writingalerts:\n\nAdding a New Alerter\n====================\n\nAlerters are subclasses of ``Alerter``, found in ``elasta"
},
{
"path": "docs/source/recipes/adding_enhancements.rst",
"chars": 2129,
"preview": ".. _enhancements:\n\nEnhancements\n============\n\nEnhancements are modules which let you modify a match before an alert is s"
},
{
"path": "docs/source/recipes/adding_loaders.rst",
"chars": 2696,
"preview": ".. _loaders:\n\nRules Loaders\n========================\n\nRulesLoaders are subclasses of ``RulesLoader``, found in ``elastal"
},
{
"path": "docs/source/recipes/adding_rules.rst",
"chars": 7056,
"preview": ".. _writingrules:\n\nAdding a New Rule Type\n======================\n\nThis document describes how to create a new rule type."
},
{
"path": "docs/source/recipes/signing_requests.rst",
"chars": 1706,
"preview": ".. _signingrequests:\n\nSigning requests to Amazon Elasticsearch service\n================================================\n"
},
{
"path": "docs/source/recipes/writing_filters.rst",
"chars": 4414,
"preview": ".. _writingfilters:\n\nWriting Filters For Rules\n=========================\n\nThis document describes how to create a filter"
},
{
"path": "docs/source/ruletypes.rst",
"chars": 121886,
"preview": "Rule Types and Configuration Options\n************************************\n\nExamples of several types of rule configurati"
},
{
"path": "docs/source/running_elastalert.rst",
"chars": 10769,
"preview": ".. _tutorial:\n\nRunning ElastAlert for the First Time\n=====================================\n\nRequirements\n------------\n\n-"
},
{
"path": "elastalert/__init__.py",
"chars": 11791,
"preview": "# -*- coding: utf-8 -*-\nimport copy\nimport time\n\nfrom elasticsearch import Elasticsearch\nfrom elasticsearch import Reque"
},
{
"path": "elastalert/alerts.py",
"chars": 97025,
"preview": "# -*- coding: utf-8 -*-\nimport copy\nimport datetime\nimport json\nimport logging\nimport os\nimport re\nimport subprocess\nimp"
},
{
"path": "elastalert/auth.py",
"chars": 2118,
"preview": "# -*- coding: utf-8 -*-\nimport os\nimport boto3\nfrom aws_requests_auth.aws_auth import AWSRequestsAuth\n\n\nclass Refeshable"
},
{
"path": "elastalert/config.py",
"chars": 5197,
"preview": "# -*- coding: utf-8 -*-\nimport datetime\nimport logging\nimport logging.config\n\nfrom envparse import Env\nfrom staticconf.l"
},
{
"path": "elastalert/create_index.py",
"chars": 13210,
"preview": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\nimport argparse\nimport getpass\nimport json\nimport os\nimport time\n\nimport e"
},
{
"path": "elastalert/elastalert.py",
"chars": 93965,
"preview": "# -*- coding: utf-8 -*-\nimport argparse\nimport copy\nimport datetime\nimport json\nimport logging\nimport os\nimport random\ni"
},
{
"path": "elastalert/enhancements.py",
"chars": 822,
"preview": "# -*- coding: utf-8 -*-\nfrom .util import pretty_ts\n\n\nclass BaseEnhancement(object):\n \"\"\" Enhancements take a match d"
},
{
"path": "elastalert/es_mappings/5/elastalert.json",
"chars": 590,
"preview": "{\n \"elastalert\": {\n \"properties\": {\n \"rule_name\": {\n \"index\": \"not_analyzed\",\n \"type\": \"string\"\n "
},
{
"path": "elastalert/es_mappings/5/elastalert_error.json",
"chars": 227,
"preview": "{\n \"elastalert_error\": {\n \"properties\": {\n \"data\": {\n \"type\": \"object\",\n \"enabled\": \"false\"\n "
},
{
"path": "elastalert/es_mappings/5/elastalert_status.json",
"chars": 238,
"preview": "{\n \"elastalert_status\": {\n \"properties\": {\n \"rule_name\": {\n \"index\": \"not_analyzed\",\n \"type\": \"st"
},
{
"path": "elastalert/es_mappings/5/past_elastalert.json",
"chars": 411,
"preview": "{\n \"past_elastalert\": {\n \"properties\": {\n \"rule_name\": {\n \"index\": \"not_analyzed\",\n \"type\": \"stri"
},
{
"path": "elastalert/es_mappings/5/silence.json",
"chars": 315,
"preview": "{\n \"silence\": {\n \"properties\": {\n \"rule_name\": {\n \"index\": \"not_analyzed\",\n \"type\": \"string\"\n "
},
{
"path": "elastalert/es_mappings/6/elastalert.json",
"chars": 697,
"preview": "{\n \"numeric_detection\": true,\n \"date_detection\": false,\n \"dynamic_templates\": [\n {\n \"strings_as_keyword\": {\n "
},
{
"path": "elastalert/es_mappings/6/elastalert_error.json",
"chars": 179,
"preview": "{\n \"properties\": {\n \"data\": {\n \"type\": \"object\",\n \"enabled\": \"false\"\n },\n \"@timestamp\": {\n \"typ"
},
{
"path": "elastalert/es_mappings/6/elastalert_status.json",
"chars": 159,
"preview": "{\n \"properties\": {\n \"rule_name\": {\n \"type\": \"keyword\"\n },\n \"@timestamp\": {\n \"type\": \"date\",\n \"f"
},
{
"path": "elastalert/es_mappings/6/past_elastalert.json",
"chars": 288,
"preview": "{\n \"properties\": {\n \"rule_name\": {\n \"type\": \"keyword\"\n },\n \"match_body\": {\n \"type\": \"object\",\n "
},
{
"path": "elastalert/es_mappings/6/silence.json",
"chars": 238,
"preview": "{\n \"properties\": {\n \"rule_name\": {\n \"type\": \"keyword\"\n },\n \"until\": {\n \"type\": \"date\",\n \"format"
},
{
"path": "elastalert/kibana.py",
"chars": 13475,
"preview": "# -*- coding: utf-8 -*-\n# flake8: noqa\nimport os.path\nimport urllib.error\nimport urllib.parse\nimport urllib.request\n\nfro"
},
{
"path": "elastalert/kibana_discover.py",
"chars": 5644,
"preview": "# -*- coding: utf-8 -*-\n# flake8: noqa\nimport datetime\nimport logging\nimport json\nimport os.path\nimport prison\nimport ur"
},
{
"path": "elastalert/loaders.py",
"chars": 23700,
"preview": "# -*- coding: utf-8 -*-\nimport copy\nimport datetime\nimport hashlib\nimport logging\nimport os\nimport sys\n\nimport jsonschem"
},
{
"path": "elastalert/opsgenie.py",
"chars": 7765,
"preview": "# -*- coding: utf-8 -*-\nimport json\nimport logging\nimport os.path\nimport requests\n\nfrom .alerts import Alerter\nfrom .ale"
},
{
"path": "elastalert/rule_from_kibana.py",
"chars": 1464,
"preview": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\nimport json\n\nimport yaml\n\nfrom elastalert.kibana import filters_from_dashb"
},
{
"path": "elastalert/ruletypes.py",
"chars": 57843,
"preview": "# -*- coding: utf-8 -*-\nimport copy\nimport datetime\nimport sys\n\nfrom blist import sortedlist\n\nfrom .util import add_raw_"
},
{
"path": "elastalert/schema.yaml",
"chars": 12098,
"preview": "$schema: http://json-schema.org/draft-07/schema#\ndefinitions:\n\n # Either a single string OR an array of strings\n array"
},
{
"path": "elastalert/test_rule.py",
"chars": 18279,
"preview": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\nimport argparse\nimport copy\nimport datetime\nimport json\nimport logging\nimp"
},
{
"path": "elastalert/util.py",
"chars": 15420,
"preview": "# -*- coding: utf-8 -*-\nimport collections\nimport datetime\nimport logging\nimport os\nimport re\nimport sys\n\nimport dateuti"
},
{
"path": "elastalert/zabbix.py",
"chars": 3179,
"preview": "from alerts import Alerter # , BasicMatchString\nimport logging\nfrom pyzabbix.api import ZabbixAPI\nfrom pyzabbix import "
},
{
"path": "example_rules/example_cardinality.yaml",
"chars": 1453,
"preview": "# Alert when the rate of events exceeds a threshold\n\n# (Optional)\n# Elasticsearch host\n# es_host: elasticsearch.example."
},
{
"path": "example_rules/example_change.yaml",
"chars": 1944,
"preview": "# Alert when some field changes between documents\n# This rule would alert on documents similar to the following:\n# {'use"
},
{
"path": "example_rules/example_frequency.yaml",
"chars": 1346,
"preview": "# Alert when the rate of events exceeds a threshold\n\n# (Optional)\n# Elasticsearch host\n# es_host: elasticsearch.example."
},
{
"path": "example_rules/example_new_term.yaml",
"chars": 1667,
"preview": "# Alert when a login event is detected for user \"admin\" never before seen IP\n# In this example, \"login\" logs contain whi"
},
{
"path": "example_rules/example_opsgenie_frequency.yaml",
"chars": 1920,
"preview": "# Alert when the rate of events exceeds a threshold\n\n# (Optional)\n# Elasticsearch host\n#es_host: localhost\n\n# (Optional)"
},
{
"path": "example_rules/example_percentage_match.yaml",
"chars": 602,
"preview": "name: Example Percentage Match\ntype: percentage_match\n\n#es_host: localhost\n#es_port: 9200\n\nindex: logstash-http-request-"
},
{
"path": "example_rules/example_single_metric_agg.yaml",
"chars": 524,
"preview": "name: Metricbeat CPU Spike Rule\ntype: metric_aggregation\n\n#es_host: localhost\n#es_port: 9200\n\nindex: metricbeat-*\n\nbuffe"
},
{
"path": "example_rules/example_spike.yaml",
"chars": 2070,
"preview": "# Alert when there is a sudden spike in the volume of events\n\n# (Optional)\n# Elasticsearch host\n# es_host: elasticsearch"
},
{
"path": "example_rules/example_spike_single_metric_agg.yaml",
"chars": 1478,
"preview": "name: Metricbeat Average CPU Spike Rule\ntype: spike_aggregation\n\n#es_host: localhost\n#es_port: 9200\n\nindex: metricbeat-*"
},
{
"path": "example_rules/jira_acct.txt",
"chars": 226,
"preview": "# Example jira_account information file\n# You should make sure that this file is not globally readable or version contro"
},
{
"path": "example_rules/ssh-repeat-offender.yaml",
"chars": 1542,
"preview": "# Rule name, must be unique\nname: SSH abuse - reapeat offender\n\n# Alert on x events in y seconds\ntype: frequency\n\n# Aler"
},
{
"path": "example_rules/ssh.yaml",
"chars": 1527,
"preview": "# Rule name, must be unique\n name: SSH abuse (ElastAlert 3.0.1) - 2\n\n# Alert on x events in y seconds\ntype: frequency\n\n"
},
{
"path": "pytest.ini",
"chars": 74,
"preview": "[pytest]\nmarkers =\n elasticsearch: mark a test as using elasticsearch.\n"
},
{
"path": "requirements-dev.txt",
"chars": 114,
"preview": "-r requirements.txt\ncoverage==4.5.4\nflake8\npre-commit\npylint<1.4\npytest<3.3.0\nsetuptools\nsphinx_rtd_theme\ntox<2.0\n"
},
{
"path": "requirements.txt",
"chars": 389,
"preview": "apscheduler>=3.3.0\naws-requests-auth>=0.3.0\nblist>=1.3.6\nboto3>=1.4.4\ncffi>=1.11.5\nconfigparser>=3.5.0\ncroniter>=0.3.16\n"
},
{
"path": "setup.cfg",
"chars": 100,
"preview": "[flake8]\nexclude = .git,__pycache__,.tox,docs,virtualenv_run,modules,venv,env\nmax-line-length = 140\n"
},
{
"path": "setup.py",
"chars": 1659,
"preview": "# -*- coding: utf-8 -*-\nimport os\n\nfrom setuptools import find_packages\nfrom setuptools import setup\n\n\nbase_dir = os.pat"
},
{
"path": "supervisord.conf.example",
"chars": 780,
"preview": "[unix_http_server]\nfile=/var/run/elastalert_supervisor.sock\n\n[supervisord]\nlogfile=/var/log/elastalert_supervisord.log\nl"
},
{
"path": "tests/__init__.py",
"chars": 0,
"preview": ""
},
{
"path": "tests/alerts_test.py",
"chars": 96298,
"preview": "# -*- coding: utf-8 -*-\nimport base64\nimport datetime\nimport json\nimport subprocess\n\nimport mock\nimport pytest\nfrom jira"
},
{
"path": "tests/auth_test.py",
"chars": 803,
"preview": "# -*- coding: utf-8 -*-\nfrom elastalert.auth import Auth, RefeshableAWSRequestsAuth\n\n\ndef test_auth_none():\n\n auth = "
},
{
"path": "tests/base_test.py",
"chars": 63597,
"preview": "# -*- coding: utf-8 -*-\nimport copy\nimport datetime\nimport json\nimport threading\n\nimport elasticsearch\nimport mock\nimpor"
},
{
"path": "tests/conftest.py",
"chars": 9824,
"preview": "# -*- coding: utf-8 -*-\nimport datetime\nimport logging\nimport os\n\nimport mock\nimport pytest\n\nimport elastalert.elastaler"
},
{
"path": "tests/create_index_test.py",
"chars": 1548,
"preview": "# -*- coding: utf-8 -*-\nimport json\n\nimport pytest\n\nimport elastalert.create_index\n\nes_mappings = [\n 'elastalert',\n "
},
{
"path": "tests/elasticsearch_test.py",
"chars": 4195,
"preview": "# -*- coding: utf-8 -*-\nimport datetime\nimport json\nimport time\n\nimport dateutil\nimport pytest\n\nimport elastalert.create"
},
{
"path": "tests/kibana_discover_test.py",
"chars": 28926,
"preview": "# -*- coding: utf-8 -*-\nfrom datetime import timedelta\nimport pytest\n\nfrom elastalert.kibana_discover import generate_ki"
},
{
"path": "tests/kibana_test.py",
"chars": 2703,
"preview": "import copy\nimport json\n\nfrom elastalert.kibana import add_filter\nfrom elastalert.kibana import dashboard_temp\nfrom elas"
},
{
"path": "tests/loaders_test.py",
"chars": 18593,
"preview": "# -*- coding: utf-8 -*-\nimport copy\nimport datetime\nimport os\n\nimport mock\nimport pytest\n\nimport elastalert.alerts\nimpor"
},
{
"path": "tests/rules_test.py",
"chars": 46723,
"preview": "# -*- coding: utf-8 -*-\nimport copy\nimport datetime\n\nimport mock\nimport pytest\n\nfrom elastalert.ruletypes import AnyRule"
},
{
"path": "tests/util_test.py",
"chars": 7699,
"preview": "# -*- coding: utf-8 -*-\nfrom datetime import datetime\nfrom datetime import timedelta\n\nimport mock\nimport pytest\nfrom dat"
},
{
"path": "tox.ini",
"chars": 609,
"preview": "[tox]\nproject = elastalert\nenvlist = py36,docs\n\n[testenv]\ndeps = -rrequirements-dev.txt\ncommands =\n coverage run --so"
}
]
About this extraction
This page contains the full source code of the YelpArchive/elastalert GitHub repository, extracted and formatted as plain text for AI agents and large language models (LLMs). The extraction includes 84 files (897.8 KB), approximately 219.9k tokens, and a symbol index with 701 extracted functions, classes, methods, constants, and types. Use this with OpenClaw, Claude, ChatGPT, Cursor, Windsurf, or any other AI tool that accepts text input. You can copy the full output to your clipboard or download it as a .txt file.
Extracted by GitExtract — free GitHub repo to text converter for AI. Built by Nikandr Surkov.