Repository: amusi/Deep-Learning-Interview-Book
Branch: master
Commit: 03fcd4431e9c
Files: 18
Total size: 208.7 KB
Directory structure:
gitextract_imlg91uk/
├── README.md
└── docs/
├── SLAM.md
├── 传统图像处理.md
├── 其它.md
├── 学习资料.md
├── 强化学习.md
├── 推荐算法.md
├── 数学.md
├── 数据结构与算法.md
├── 机器学习.md
├── 深度学习.md
├── 深度学习框架.md
├── 编程语言.md
├── 自我介绍.md
├── 自然语言处理.md
├── 计算机视觉.md
├── 面试技巧.md
└── 面试经验.md
================================================
FILE CONTENTS
================================================
================================================
FILE: README.md
================================================
# 深度学习面试宝典
**Deep Learning Interview Book**
- :star: [求职攻略](https://github.com/amusi/AI-Job-Notes)
- :smiley: [自我介绍](docs/自我介绍.md)
- :1234: [数学](docs/数学.md)
- :mortar_board: [机器学习](docs/机器学习.md)
- :closed_book: [深度学习](docs/深度学习.md)
- :green_book: [强化学习](docs/强化学习.md)
- :eyes: [计算机视觉](docs/计算机视觉.md)
- :camera: [传统图像处理](docs/传统图像处理.md)
- :mahjong: [自然语言处理](docs/自然语言处理.md)
- :surfer: [SLAM](docs/SLAM.md)
- :busts_in_silhouette: [推荐算法](docs/推荐算法.md)
- :bar_chart: [数据结构与算法](docs/数据结构与算法.md)
- :snake: [编程语言:C/C++/Python](docs/编程语言.md)
- :fireworks: [深度学习框架](docs/深度学习框架.md)
- :pencil2: [面试经验](docs/面试经验.md)
- :bulb: [面试技巧](docs/面试技巧.md)
- :mega: [其它(计算机网络/Linux等)](docs/其它.md)
- [2024年AI算法岗和开发岗求职群](https://mp.weixin.qq.com/s/sK_oSU1PmbUJ5ZGeMmY27A)
# 加入2024年AI算法岗和开发岗求职群方式
**价格:原价199元,限时立减50!特惠仅149元!(每天仅4毛钱)**
**时长:一年(从你加入的时刻算起)**
**加入方式:微信扫描下方二维码,即可加入AI算法岗和开发岗求职群(知识星球)**
> 建议:进群后,推荐下载知识星球APP使用,同时也可使用小程序或者知识星球公众号进行使用,可以发帖/提问/交流/回答,并可以快速访问群里的资源。


================================================
FILE: docs/SLAM.md
================================================
[TOC]
# SLAM
## 001 什么是回环检测?
随着路径的不断延伸,机器人在建图过程中会存在一些累计误差,除了利用局部优化、全局优化等来调整之外,还可以利用回环检测来优化位姿。
**什么是回环检测?**
回环检测,又称闭环检测,是指机器人识别曾到达某场景,使得地图闭环的能力。说的简单点,就是机器人在左转一下,右转一下建图的时候能意识到某个地方是“我”曾经来过的,然后把此刻生成的地图与刚刚生成的地图做匹配。

回环检测成功
回环检测之所以能成为一个难点,是因为:如果回环检测成功,可以显著地减小累积误差,帮助机器人更精准、快速的进行避障导航工作。而错误的检测结果可能使地图变得很糟糕。因此,回环检测在大面积、大场景地图构建上是非常有必要的 。

回环检测失败
**如何提升机器人回环检测能力?**
那么,怎么才能让机器人的回环检测能力得到一个质的提升呢?首先要有一个算法上的优化。
**基于图优化的SLAM算法**
基于图优化的SLAM 3.0 算是提升机器人回环检测能力的一大突破。
SLAM 3.0采用图优化的方式进行建图,进行了图片集成与优化处理,当机器人运动到已经探索过的原环境时,SLAM 3.0可依赖内部的拓扑图进行主动式的闭环检测。当发现了新的闭环信息后,SLAM 3.0使用Bundle Adjuestment(BA)等算法对原先的位姿拓扑地图进行修正(即进行图优化),从而能有效的进行闭环后地图的修正,实现更加可靠的环境建图。

**SLAM 3.0闭环检测**
SLAM 3.0环路闭合逻辑:先小闭环,后大闭环 ;选择特征丰富的点作为闭环点;多走重合之路,完善闭环细节。即使在超大场景下建图,也不慌。

超大场景下建图完整闭合过程
**词袋模型**
除了SLAM算法的升级和优化之外,现在还有很多系统采用成熟的词袋模型方法来帮助机器人完成闭环,说的简单点就是把帧与帧之间进行特征比配。
1、从每幅图像中提取特征点和特征描述,特征描述一般是一个多维向量,因此可以计算两个特征描述之间的距离;
2、将这些特征描述进行聚类(比如k-means),类别的个数就是词典的单词数,比如1000;也可以用Beyes、SVM等;
3、将这些词典组织成树的形式,方便搜索。

利用这个树,就可以将时间复杂度降低到对数级别,大大加速了特征匹配。
**相似度计算**
这种做法是从外观上根据两幅图像的相似性确定回环检测关系,那么,如何确定两个地图之间的相关性呢?
比如对于图像A和图像B,我们要计算它们之间的相似性评分:s(A,B)。如果单单用两幅图像相减然后取范数,即为: s(A,B)=||AB||s(A,B)=||AB||。但是由于一幅图像在不同角度或者不同光线下其结果会相差很多,所以不使用这个函数。而是使用相似度计算公式。
这里,我们提供一种方法叫TF-IDF。
TF的意思是:某特征在一幅图像中经常出现,它的区分度就越高。另一方面,IDF的思想是,某特征在字典中出现的频率越低,则分类图像时的区分度越高。
对于IDF部分,假设所有特征数量为n,某个节点的Wi所含的数量特征为Ni,那么该单词的IDF为:

TF是指某个特征在单副图像中出现的频率。假设图像A中单词Wi出现了N次,而一共出现的单词次数是n,那么TF为:

于是Wi的权重等于TF乘IDF之积,即:

考虑权重以后,对于某副图像,我们可以得到许多个单词,得到BOW:

(A表示某幅地图)
如何计算俩副图像相似度,这里使用了L1范数形式:

**深度学习及其他**
除了上面的几种方式之外,回环检测也可以建成一个模型识别问题,利用深度学习的方法帮助机器人完成回环检测。比如:决策树、SVM等。
……
最后,当回环出现以后,也不要急着就让机器人停止运动,要继续保持运动,多走重合的路,在已经完成闭合的路径上,进一步扫图完善细节。

继续走重合之路,完善闭环细节
所以,回环检测在SLAM中的作用也很重要哦。
**参考资料**
- [SLAM大法之回环检测](https://baijiahao.baidu.com/s?id=1627227355343777871)
## 002 常用的回环检测方法有哪些?
- [ ] TODO
## 003 介绍一下Gauss-Netwon和LM算法
- [ ] TODO
## 004 介绍一下Ceres优化库,比如你使用过里面哪些内容?
- [ ] TODO
## 005 描述(扩展)卡尔曼滤波与粒子滤波,你自己在用卡尔曼滤波时遇到什么问题没有?
- [ ] TODO
## 006 除了视觉传感,还用过其他传感吗?比如GPS,激光雷达
- [ ] TODO
## 007 什么是紧耦合、松耦合?优缺点
- [ ] TODO
## 008 你认为室内SLAM与自动驾驶SLAM有什么区别?
- [ ] TODO
## 009 地图点的构建方法有哪些?
TODO
## 010 如果对于一个3D点,我们在连续帧之间形成了2D特征点之间的匹配,但是这个匹配中可能存在错误的匹配。请问你如何去构建3D点?
- [ ] TODO
## 011 RANSAC在选择最佳模型的时候用的metric是什么?
- [ ] TODO
## 012 除了RANSAC之外,还有什么鲁棒估计的方法?

- [ ] TODO
## 013 有哪几种鲁棒核函数?
- [ ] TODO
## 014 3D地图点是怎么存储的?表达方式?
## 015 给你m相机n个点的bundle adjustment。当我们在仿真的时候,在迭代的时候,相机的位姿会很快的接近真值。而地图点却不能很快的收敛这是为什么呢?
- [ ] TODO
## 016 LM算法里面那个  是如何变化的呢?
- [ ] TODO
## 017 说一下3D空间的位姿如何去表达?
- [ ] TODO
## 018 介绍一下李群和李代数的关系
- [ ] TODO
## 019 写出单目相机的投影模型,畸变模型
- [ ] TODO
## 020 说一个自己熟悉的SLAM算法,Lidar/Visual slam,说优缺点
- [ ] TODO
## 021 读Maplab,设计室内服务机器人地图更新的方法、流程
- [ ] TODO
## 022 安装2D lidar的平台匀速旋转的时候,去激光数据畸变,写代码
- [ ] TODO
## 023 给两组已经匹配好的3D点,计算相对位姿变换。已知匹配的ICP问题,写代码。
- [ ] TODO
## 024 ORB-SLAM初始化的时候为什么要同时计算H矩阵和F矩阵?
- [ ] TODO
## 025 说一下Dog-Leg算法
- [ ] TODO
## 026 什么是边缘化?First Estimate Jacobian?一致性?可观性?
- [ ] TODO
## 027 说一下VINS-Mono的优缺点
- [ ] TODO
## 028 什么是Essential,Fundamental矩阵?
TODO
## 029 给定几个连续帧的带有位姿的帧,如何去测量车道线相对于世界坐标系的坐标。
- [ ] TODO
## 030 在给定一些有噪声的GPS信号的时候如何去精准的定位?
- [ ] TODO
## 031 如何标定IMU与相机之间的外参数?
- [ ] TODO
## 032 给你xx误差的GPS,给你xx误差的惯导你怎么得到一个cm级别的地图?
- [ ] TODO
## 033 计算H矩阵和F矩阵的时候有什么技巧呢?实际上在问归一化的操作
- [ ] TODO
## 034 给一组点云,从中提取平面
- [ ] TODO
## 035 给一张图片,知道相机与地面之间的相对关系,计算出图的俯视图
- [ ] TODO
## 036 RGB-D的SLAM和RGB的SLAM有什么区别?
- [ ] TODO
## 037 机器人从超市门口出发,前往3公里外的小区送货。请你设计一个定位系统,包括传感器的配置、算法的流程,用伪代码写出来
- [ ] TODO
## 038 什么是ORB特征,ORB特征的旋转不变性是如何做的,BRIEF算子是怎么提取的。
- [ ] TODO
## 039 如果把一张图像去畸变,写公式,流程
- [ ] TODO
## 040 ORB-SLAM中的特征是如何提取的?如何均匀化的?
- [ ] TODO
## 参考
- [SLAM、定位、建图求职分享](https://zhuanlan.zhihu.com/p/68858564)
================================================
FILE: docs/传统图像处理.md
================================================
[TOC]
# 传统图像处理
## 颜色空间
- **RGB**
- **HSI**
- **CMYK**
- **YUV**
OpenCV 读取图像存储的顺序为什么是 BGR,而不是 RGB?
- [ ] TODO
## 高斯滤波
> 先引入两个问题。
> 1.图像为什么要滤波?
> 答:a.消除图像在数字化过程中产生或者混入的噪声。
> b.提取图片对象的特征作为图像识别的特征模式。
> 2.滤波器该如何去理解?
> 答:滤波器可以想象成一个包含加权系数的窗口或者说一个镜片,当使用滤波器去平滑处理图像的时候,就是把通过这个窗口或者镜片去看这个图像。
滤波器分为很多种,有方框滤波、均值滤波、高斯滤波等。
**高斯滤波是一种线性平滑滤波,适用于消除高斯噪声。**所以在讲高斯滤波之前,先解释一下什么是高斯噪声?
**1 高斯噪声**
首先,**噪声**在图像当中常表现为一引起较强视觉效果的孤立像素点或像素块。简单来说,噪声的出现会给图像带来干扰,让图像变得不清楚。
**高斯噪声**就是它的概率密度函数服从高斯分布(即正态分布)的一类噪声。如果一个噪声,它的幅度分布服从高斯分布,而它的功率谱密度又是均匀分布的,则称它为高斯白噪声。高斯白噪声的二阶矩不相关,一阶矩为常数,是指先后信号在时间上的相关性。
**高斯滤波器是根据高斯函数的形状来选择权值的线性平滑滤波器**
所以接下来再讲解一下高斯函数和高斯核。
**2 高斯函数**

注:σ的大小决定了高斯函数的宽度。
**3 高斯核**
理论上,高斯分布在所有定义域上都有非负值,这就需要一个无限大的卷积核。实际上,仅需要取均值周围3倍标准差内的值,以外部份直接去掉即可。
**高斯滤波的重要两步就是先找到高斯模板然后再进行卷积**,模板(mask在查阅中有的地方也称作掩膜或者是高斯核)。所以这个时候需要知道它怎么来?又怎么用?
举个栗子:
假定中心点的坐标是(0,0),那么取距离它最近的8个点坐标,为了计算,需要设定σ的值。假定σ=1.5,则模糊半径为1的高斯模板就算如下

这个时候我们我们还要确保这九个点加起来为1(这个是高斯模板的特性),这9个点的权重总和等于0.4787147,因此上面9个值还要分别除以0.4787147,得到最终的高斯模板。

**4 高斯滤波计算**
有了高斯模板,那么高斯滤波的计算便顺风顺水了。
举个栗子:假设现有9个像素点,灰度值(0-255)的高斯滤波计算如下:

参考来源:(https://blog.csdn.net/nima1994/article/details/79776802)
将这9个值加起来,就是中心点的高斯滤波的值。
对所有点重复这个过程,就得到了高斯模糊后的图像。
**5 高斯滤波步骤**
综上可以总结一下步骤:
> (1)移动相关核的中心元素,使它位于输入图像待处理像素的正上方
> (2)将输入图像的像素值作为权重,乘以相关核
> (3)将上面各步得到的结果相加做为输出
> **简单来说就是根据高斯分布得到高斯模板然后做卷积相加的一个过程。**
**参考资料**
- [简单易懂的高斯滤波](https://www.jianshu.com/p/73e6ccbd8f3f)
- [图像滤波之高斯滤波介绍](https://www.cnblogs.com/qiqibaby/p/5289977.html)
## 腐蚀和膨胀
- [ ] TODO
## 开运算和闭运算
- [ ] TODO
## 如何求一张图片的均值?
- [ ] TODO
## 线性插值
- [ ] TODO
## 双线性插值
- [ ] TODO
## 仿射变换
- [ ] TODO
## 透视变换
- [ ] TODO
## 常见的边缘检测算子
- [ ] TODO
## Sobel 算法
- [ ] TODO
## Canny 算法
- [ ] TODO
## Hough 变换原理(直线和圆检测)
- [ ] TODO
## 找轮廓(findCountours)
- [ ] TODO
## 单应性(homography)原理
TODO
## 二维高斯滤波能否分解成一维操作
答:可以分解。
二维高斯滤波分解为两次一维高斯滤波,高斯二维公式可以推导为X轴与Y轴上的一维高斯公式。
即使用一维高斯核先对图像逐行滤波,再对中间结果逐列滤波。
**参考资料**
- [快速高斯滤波、高斯模糊、高斯平滑(二维卷积分步为一维卷积)](https://blog.csdn.net/qq_36359022/article/details/80188873)
## 图像去噪算法
- [ ] TODO
## HOG 算法
- [ ] TODO
## 高斯滤波
- [ ] TODO
## 均值滤波
- [ ] TODO
## 中值滤波
- [ ] TODO
## 双边滤波
- [ ] TODO
## 图像中的低频信息和高频信息
图像频率:图像中灰度变化剧烈程度的指标
- 低频信息(低频分量)表示图像中灰度值变化缓慢的区域,对应着图像中大块平坦的区域。
- 高频信息(高频分量)表示图像中灰度值变化剧烈的区域,对应着图像的边缘(轮廓)、噪声以及细节部分。
低频分量:主要对整幅图像强度的综合度量
高频分量:主要对图像边缘和轮廓的度量
从傅里叶变换的角度,将图像从灰度分布转化为频率分布。
**参考资料**
- [理解图像中的低频分量和高频分量](https://blog.csdn.net/Chaolei3/article/details/79443520)
## 引导滤波
**参考资料**
- [【拜小白opencv】33-平滑处理6——引导滤波/导向滤波(Guided Filter)](https://blog.csdn.net/sinat_36264666/article/details/77990790)
## 直方图均衡化
- [ ] TODO
## 相机标定方法与流程
- [ ] TODO
## 分水岭算法
- [ ] TODO
## RANSAC 算法
- [ ] TODO
## Bundle Adjustment(BA)算法
- [ ] TODO
## L-M 算法
- [ ] TODO
## SIFT 算法
- [ ] TODO
### SIFT 特征为什么能实现尺度不变性?
- [ ] TODO
### SIFT特征是如何保持旋转不变性的?
- [ ] TODO
## SURF 算法
- [ ] TODO
## ORB 算法
- [ ] TODO
## LSD 算法
- [ ] TODO
## LBP 算法
- [ ] TODO
## KCF 算法
- [ ] TODO
## TODO
================================================
FILE: docs/其它.md
================================================
[TOC]
# 其它
## TCP与UDP的区别
UDP 与 TCP 的主要区别在于 UDP 不一定提供可靠的数据传输,它不能保证数据准确无误地到达,不过UDP在许多方面非常有效。当程序是要尽快地传输尽可能多的信息时,可以使用 UDP。TCP它是通过三次握手建立的连接,它在两个服务之间始终保持一个连接状态,目的就是为了提供可靠的数据传输。许多程序使用单独的TCP连接和单独的UDP连接,比如重要的状态信息用可靠的TCP连接发送,而主数据流通过UDP发送。
TCP与UDP区别总结:
1、TCP面向连接(如打电话要先拨号建立连接);UDP是无连接的,即发送数据之前不需要建立连接
2、TCP提供可靠的服务。也就是说,通过TCP连接传送的数据,无差错,不丢失,不重复,且按序到达;UDP尽最大努力交付,即不保证可靠交付
3、TCP面向字节流,实际上是TCP把数据看成一连串无结构的字节流;UDP是面向报文的
## UDP没有拥塞控制,因此网络出现拥塞不会使源主机的发送速率降低(对实时应用很有用,如IP电话,实时视频会议等)
4、每一条TCP连接只能是点到点的;UDP支持一对一,一对多,多对一和多对多的交互通信
5、TCP首部开销20字节;UDP的首部开销小,只有8个字节
6、TCP的逻辑通信信道是全双工的可靠信道,UDP则是不可靠信道
一般面试官都会问TCP和UDP的区别,这个很好回答啊,TCP面向连接,可靠,基于字节流,而UDP不面向连接,不可靠,基于数据报。对于连接而言呢,其实真正的就不存在,TCP面向连接只不过三次握手在客户端和服务端之间初始化好了序列号。只要满足TCP的四元组+序列号,那客户端和服务端之间发送的消息就有效,可以正常接收。虽然说TCP可靠,但是可靠的背后却是lol无尽之刃的复杂和痛苦,滑动窗口,拥塞避免,四个超时定时器,还有什么慢启动啊,快恢复,快重传啊这里推荐大家看看(图解TCP/IP,这个简单容易,TCP卷123,大量的文字描述真是烦),所以什么都是相对呢,可靠性的实现也让TCP变的复杂,在网络的状况很差的时候,TCP的优势会变成。基于字节流什么意思呢?一句话就可以说明白,对于读写没有相对应的次数。UDP基于数据报就是每对应一个发,就要对应一个收。而TCP无所谓啊,现在应该懂了吧。对于UDP而言,不面向连接,不可靠,没有三次握手,我给你发送数据之前,不需要知道你在不在,不要你的同意,我只管把数据发送出去至于你收到不收到,从来和我没有半毛钱的关系。
对于可靠不可靠而言,没有绝对的说法,TCP可靠仅仅是在传输层实现了可靠,我也可以让UDP可靠啊,那么就要向上封装,在应该层实现可靠性。因此很多公司都不是直接用TCP和UDP,都是经过封装,满足业务的需要而已。说到这里的话,那就在提一下心跳包,在linux下有keep-alive系统自带的,但是默认时间很长,如果让想使用话可以setsockopt设置,我也可以在应用层实现一个简单心跳包,上次自己多开了一个线程来处理,还是包头解决。
上面解释完这个之后面试官可能问,那什么时候用TCP,什么时候用UDP呢?就是问应用场景,所以简历上的知识点自己应该提前做好准备应用场景,知识就是要用在显示场景中,废话真多。不管用TCP和UDP,应用只要看需求,对于TCP更加注重的是可靠性,而不是实时性,如果我发送的数据很重要一点也不能出错,有延迟无所谓的话,那就TCP啊。UDP更加注重是速度快,也就是实时性,对于可靠性要求不那么高,所以像斗鱼,熊猫这些在线直播网站应该在UDP基础是封装了其他协议,比如视频实时传输协议。而且UDP的支持多播,那就很符合这些直播网站了,有时候看直播视频卡顿,人飘逸那可能就是丢包了,但是你也只能往下看。
**参考资料**
- [TCP和UDP的优缺点及区别](https://www.cnblogs.com/xiaomayizoe/p/5258754.html)
- [关于面试中的TCP和UDP怎么用自己的话给面试官说](https://blog.csdn.net/lotluck/article/details/52688851)
## TCP三次握手
因为TCP是一个双向通讯协议,所以要三次握手才能建立:
第一次握手是客户端向服务端发送连接请求包(SYN=J),服务端接收到之后会给客户端发个确认标志(也就是两个包,一个是确认包ACK=J+1,另一个是连接询问请求包SYN=K),这是第二次握手。第三次握手就是客户端会再次给服务端发送消息确认标志ACK=K+1,表示能正常接收可以开始通信。第三次握手的目的是为了防止已经失效的连接请求突然又传送到了服务端,因为网络中有可能存在延迟的问题,如果采用二次握手就会让服务端误认为client是再次发出新的连接请求,然后server一直等待client发来数据,这样就浪费了很多资源。这三次握手是在connect,bind,listen和accept函数中完成的,这几个函数创建了比较可靠的连接通道。其实断开连接的四次握手是跟连接的时候一样的,唯一多了一步就是因为双方都处在连接的时候,而且有可能在传输数据,在服务端接收到客户端的关闭连接请求后它会给客户端确认,但是由于数据还没有传送完毕,此时会进入一个TIME_WAIT状态,所以在数据传送好之后会再次给客户端发消息,这就是多出来的那一步。
过程:
第一次
第一次握手:建立连接时,客户端发送syn包(syn=j)到服务器,并进入SYN_SENT状态,等待服务器确认;SYN:同步序列编号(Synchronize Sequence Numbers)。
此时客户端状态为:SYN_SENT,服务器为LISTEN。
第二次
第二次握手:服务器收到syn包,必须确认客户的SYN(ack=j+1),同时自己也发送一个SYN包(syn=k),即SYN+ACK包,此时服务器进入SYN_RECV状态;
此时客户端状态为ESTABLISHED,服务器为SYS_RCVD
第三次
第三次握手:客户端收到服务器的SYN+ACK包,向服务器发送确认包ACK(ack=k+1),此包发送完毕,客户端和服务器进入ESTABLISHED(TCP连接成功)状态,完成三次握手
此时客户端和服务器的状态都为ESTABLISHED。
完成三次握手,客户端与服务器开始传送数据。

必要性:
考虑一次的问题,首先tcp是面向连接,一次握手肯定建立不了连接,因为客户机给服务器发出请求信息却没有得到回应,客户机是没法判定是否发送成功然后建立连接的。
再看两次,假设只有两次握手,比如图中的1,2步,当A想要建立连接时发送一个SYN,然后等待ACK,结果这个SYN因为网络问题没有及时到达B,所以A在一段时间内没收到ACK后,再发送一个SYN,这次B顺利收到,接着A也收到ACK,这时A发送的第一个SYN终于到了B,对于B来说这是一个新连接请求,然后B又为这个连接申请资源,返回ACK,然而这个SYN是个无效的请求,A收到这个SYN的ACK后也并不会理会它,而B却不知道,B会一直为这个连接维持着资源,造成资源的浪费。
两次握手的问题在于服务器端不知道一个SYN是否是无效的,而三次握手机制因为客户端会给服务器回复第二次握手,也意味着服务器会等待客户端的第三次握手,如果第三次握手迟迟不来,服务器便会认为这个SYN是无效的,释放相关资源。但这时有个问题就是客户端完成第二次握手便认为连接已建立,而第三次握手可能在传输中丢失,服务端会认为连接是无效的,这时如果Client端向Server写数据,Server端将以RST包响应,这时便感知到Server的错误。
总之,三次握手可以保证任何一次握手的失败都是可感知的,不会浪费资源
## TCP四次挥手
对于一个已经建立的连接,TCP使用改进的三次握手来释放连接(使用一个带有FIN附加标记的报文段)。TCP关闭连接的步骤如下:
第一步,当主机A的应用程序通知TCP数据已经发送完毕时,TCP向主机B发送一个带有FIN附加标记的报文段(FIN表示英文finish)。
第二步,主机B收到这个FIN报文段之后,并不立即用FIN报文段回复主机A,而是先向主机A发送一个确认序号ACK,同时通知自己相应的应用程序:对方要求关闭连接(先发送ACK的目的是为了防止在这段时间内,对方重传FIN报文段)。
第三步,主机B的应用程序告诉TCP:我要彻底的关闭连接,TCP向主机A送一个FIN报文段。
第四步,主机A收到这个FIN报文段后,向主机B发送一个ACK表示连接彻底释放。

形象描述四次挥手:
假设Client端发起中断连接请求,也就是发送FIN报文。Server端接到FIN报文后,意思是说"我Client端没有数据要发给你了",但是如果你还有数据没有发送完成,则不必急着关闭Socket,可以继续发送数据。所以你先发送ACK,"告诉Client端,你的请求我收到了,但是我还没准备好,请继续你等我的消息"。这个时候Client端就进入FIN_WAIT状态,继续等待Server端的FIN报文。当Server端确定数据已发送完成,则向Client端发送FIN报文,"告诉Client端,好了,我这边数据发完了,准备好关闭连接了"。Client端收到FIN报文后,"就知道可以关闭连接了,但是他还是不相信网络,怕Server端不知道要关闭,所以发送ACK后进入TIME_WAIT状态,如果Server端没有收到ACK则可以重传。“,Server端收到ACK后,"就知道可以断开连接了"。Client端等待了2MSL后依然没有收到回复,则证明Server端已正常关闭,那好,我Client端也可以关闭连接了。Ok,TCP连接就这样关闭了!
需四次挥手原因:由于TCP的半关闭特性,TCP连接时双全工(即数据在两个方向上能同时传递),因此,每个方向必须单独的进行关闭。这个原则就是:当一方完成它的数据发送任务后就能发送一个FIN来终止这个方向上的连接。当一端收到一个FIN后,它必须通知应用层另一端已经终止了那个方向的数据传送。即收到一个FIN意味着在这一方向上没有数据流动了。
假设客户机A向服务器B请求释放TCP连接,则:
第一次挥手:主机A向主机B发送FIN包;A告诉B,我(A)发送给你(B)的数据大小是N,我发送完毕,请求断开A->B的连接。
第二次挥手:主机B收到了A发送的FIN包,并向主机A发送ACK包;B回答A,是的,我总共收到了你发给我N大小的数据,A->B的连接关闭。
第三次挥手:主机B向主机A发送FIN包;B告诉A,我(B)发送给你(A)的数据大小是M,我发送完毕,请求断开B->A的连接。
第四次挥手:主机A收到了B发送的FIN包,并向主机B发送ACK包;A回答B,是的,我收到了你发送给我的M大小的数据,B->A的连接关闭。
这里再系统性的介绍四次握手
当客户端和服务器通过三次握手建立了TCP连接以后,当数据传送完毕,肯定是要断开TCP连接的啊。那对于TCP的断开连接,这里就有了神秘的“四次挥手”。
1. 第一次挥手:主机1(可以使客户端,也可以是服务器端),设置Sequence Number和Acknowledgment Number,向主机2发送一个FIN报文段;此时,主机1进入FIN_WAIT_1状态;这表示主机1没有数据要发送给主机2了;
2. 第二次挥手:主机2收到了主机1发送的FIN报文段,向主机1回一个ACK报文段,Acknowledgment Number为Sequence Number加1;主机1进入FIN_WAIT_2状态;主机2告诉主机1,我“同意”你的关闭请求;
3. 第三次挥手:主机2向主机1发送FIN报文段,请求关闭连接,同时主机2进入LAST_ACK状态;
4. 第四次挥手:主机1收到主机2发送的FIN报文段,向主机2发送ACK报文段,然后主机1进入TIME_WAIT状态;主机2收到主机1的ACK报文段以后,就关闭连接;此时,主机1等待2MSL后依然没有收到回复,则证明Server端已正常关闭,那好,主机1也可以关闭连接了。
### 为什么要四次挥手?
那四次分手又是为何呢?TCP协议是一种面向连接的、可靠的、基于字节流的运输层通信协议。TCP是全双工模式,这就意味着,当主机1发出FIN报文段时,只是表示主机1已经没有数据要发送了,主机1告诉主机2,它的数据已经全部发送完毕了;但是,这个时候主机1还是可以接受来自主机2的数据;当主机2返回ACK报文段时,表示它已经知道主机1没有数据发送了,但是主机2还是可以发送数据到主机1的;当主机2也发送了FIN报文段时,这个时候就表示主机2也没有数据要发送了,就会告诉主机1,我也没有数据要发送了,之后彼此就会愉快的中断这次TCP连接。如果要正确的理解四次分手的原理,就需要了解四次分手过程中的状态变化。
- FIN_WAIT_1: 这个状态要好好解释一下,其实FIN_WAIT_1和FIN_WAIT_2状态的真正含义都是表示等待对方的FIN报文。而这两种状态的区别是:FIN_WAIT_1状态实际上是当SOCKET在ESTABLISHED状态时,它想主动关闭连接,向对方发送了FIN报文,此时该SOCKET即进入到FIN_WAIT_1状态。而当对方回应ACK报文后,则进入到FIN_WAIT_2状态,当然在实际的正常情况下,无论对方何种情况下,都应该马上回应ACK报文,所以FIN_WAIT_1状态一般是比较难见到的,而FIN_WAIT_2状态还有时常常可以用netstat看到。(主动方)
- FIN_WAIT_2:上面已经详细解释了这种状态,实际上FIN_WAIT_2状态下的SOCKET,表示半连接,也即有一方要求close连接,但另外还告诉对方,我暂时还有点数据需要传送给你(ACK信息),稍后再关闭连接。(主动方)
- CLOSE_WAIT:这种状态的含义其实是表示在等待关闭。怎么理解呢?当对方close一个SOCKET后发送FIN报文给自己,你系统毫无疑问地会回应一个ACK报文给对方,此时则进入到CLOSE_WAIT状态。接下来呢,实际上你真正需要考虑的事情是察看你是否还有数据发送给对方,如果没有的话,那么你也就可以 close这个SOCKET,发送FIN报文给对方,也即关闭连接。所以你在CLOSE_WAIT状态下,需要完成的事情是等待你去关闭连接。(被动方)
- LAST_ACK: 这个状态还是比较容易好理解的,它是被动关闭一方在发送FIN报文后,最后等待对方的ACK报文。当收到ACK报文后,也即可以进入到CLOSED可用状态了。(被动方)
- TIME_WAIT: 表示收到了对方的FIN报文,并发送出了ACK报文,就等2MSL后即可回到CLOSED可用状态了。如果FINWAIT1状态下,收到了对方同时带FIN标志和ACK标志的报文时,可以直接进入到TIME_WAIT状态,而无须经过FIN_WAIT_2状态。(主动方)
- CLOSED: 表示连接中断。
**参考资料**
- [三次握手](https://baike.baidu.com/item/%E4%B8%89%E6%AC%A1%E6%8F%A1%E6%89%8B/5111559)
- [tcp三次握手及其必要性](https://blog.csdn.net/u013344815/article/details/72134950)
- [c++面试题(网络通信篇)](https://blog.csdn.net/zhouchunyue/article/details/79271908)
- [tcp建立连接为什么需要三次握手](https://www.jianshu.com/p/e7f45779008a)
- [TCP相关面试题(转)](https://www.cnblogs.com/huajiezh/p/7492416.html)
### TCP四次挥手最后client端的状态是什么知道吗?
- [ ] TODO
## TCP连接的可靠性
TCP通过以下方式提供数据传输的可靠性:
(1)TCP在传输数据之前,都会把要传输的数据分割成TCP认为最合适的报文段大小。在TCP三次我握手的前两次握手中(也就是两个SYN报文段中),通过一个“协商”的方式来告知对方自己期待收到的最大报文段长度(MSS),结果使用通信双发较小的MSS最为最终的MSS。在SYN=1的报文段中,会在报文段的选项部分来指定MSS大小(相当于告知对方自己所能接收的最大报文段长度)。在后续通信双发发送应用层数据之前,如果发送数据超过MSS,会对数据进行分段。
(2)使用了超时重传机制。当发送一个TCP报文段后,发送发就会针对该发送的段启动一个定时器。如果在定时器规定时间内没有收到对该报文段的确认,发送方就认为发送的报文段丢失了要重新发送。
(3)确认机制。当通信双发的某一端收到另一个端发来的一个报文段时,就会返回对该报文段的确认报文。
(4)首部校验和。在TCP报文段首部中有16位的校验和字段,该字段用于校验整个TCP报文段(包括首部和数据部分)。IP数据报的首部校验和只对IP首部进行校验。TCP详细的校验过程如下,发送TCP报文段前求一个值放在校验位,接收端接受到数据后再求一个值,如果两次求值形同则说明传输过程中没有出错;如果两次求值不同,说明传输过程中发生错误,无条件丢弃该报文段引发超时重传。
(5)使用滑动窗口流量控制协议。
(6)由于在TCP发送端可能对数据分段,那么在接收端会对接收到的数据重新排序。
参考:[腾讯面试TCP连接相关问题](https://blog.csdn.net/bian_qing_quan11/article/details/74999463)
## TCP 面向字节流的体现
- [ ] TODO
## UDP 面向报文的体现
- [ ] TODO
## ISO的7层网络模型
口诀:应表会传网数物
- 应用层:处理网络应用
- 表示层:数据表示
- 会话层:互连主机通信
- 传输层:端到端连接
- 网络层:寻址和最短路径
- 数字链路层:接入介质
- 物理层:二进制传输
## DNS
DNS(Domain Name System,域名系统),万维网上作为域名和IP地址相互映射的一个分布式数据库,能够使用户更方便的访问互联网,而不用去记住能够被机器直接读取的IP数串。**通过域名,最终得到该域名对应的IP地址的过程叫做域名解析(或主机名解析)。DNS协议运行在UDP协议之上,使用端口号53**。在RFC文档中RFC 2181对DNS有规范说明,RFC 2136对DNS的动态更新进行说明,RFC 2308对DNS查询的反向缓存进行说明。
## DOS
Dos攻击在众多网络攻击技术中是一种简单有效并且具有很大危害性的攻击方法。它通过各种手段消耗网络带宽和系统资源,或者攻击系统缺陷,使正常系统的正常服务陷于瘫痪状态,不能对正常用户进行服务,从而实现拒绝正常用户访问服务。
DDOS攻击是基于DOS攻击的一种特殊形式。攻击者将多台受控制的计算机联合起来向目标计算机发起DOS攻击,它是一种大规模协作的攻击方式,主要瞄准比较大的商业站点,具有较大的破坏性。
如何防止DOS攻击?
1. 确保服务器的系统文件是最新的版本,并及时更新系统补丁。
2. 关闭不必要的服务。
3. 限制同时打开的SYN半连接数目。
4. 缩短SYN半连接的time out 时间。
5. 正确设置防火墙 禁止对主机的非开放服务的访问 限制特定IP地址的访问 启用防火墙的防DDoS的属性 严格限制对外开放的服务器的向外访问 运行端口映射程序祸端口扫描程序,要认真检查特权端口和非特权端口。
6. 认真检查网络设备和主机/服务器系统的日志。只要日志出现漏洞或是时间变更,那这台机器就可 能遭到了攻击。
7. 限制在防火墙外与网络文件共享。这样会给黑客截取系统文件的机会,主机的信息暴露给黑客,无疑是给了对方入侵的机会。
## 大小端模式
大端模式,是指数据的高字节保存在内存的低地址中,而数据的低字节保存在内存的高地址中,这样的存储模式有点儿类似于把数据当作字符串顺序处理:地址由小向大增加,而数据从高位往低位放;这和我们的阅读习惯一致。
小端模式,是指数据的高字节保存在内存的高地址中,而数据的低字节保存在内存的低地址中,这种存储模式将地址的高低和数据位权有效地结合起来,高地址部分权值高,低地址部分权值低。
比如现在有一块四个字节的内存,并且地址是从左往右递增的。为了方便,都置为 0
> 1000:1000 00 00 00 00
现有一个十六进制数 `0x12345678`,这个十六进制数刚好可以使用上面的那块内存去存放,因为它们都是32bits。
**大端序**
如果是大端序,内存表现将会是这样
> 1000:1000 12 34 56 78
可以发现,`12` 是原十六进制数 `0x12345678` 的高位,而这个 12 放在上面那块内存地址的最低单元中(因为前面说了,这块内存地址是从左往右递增的,所以左边是相对低位,右边是相对高位)。
这就是这段话的意思
> 大端模式,是指数据的高字节保存在内存的低地址中,而数据的低字节保存在内存的高地址中
**小端序**
如果是小端序,内存表现是这样的
> 1000:1000 78 56 34 12
可以发现,`78` 是原十六进制数 `0x12345678` 的低位,而此时它也放在了最低的内存单元中,这就是这段话的意思
> 小端模式,是指数据的高字节保存在内存的高地址中,而数据的低字节保存在内存的低地址中
另外,可以发现,大小端序对字节内容是没有影响的,`12` 还是 `12` 并没有变成 `21`
**参考资料**
- [百度百科:大小端模式](https://baike.baidu.com/item/%E5%A4%A7%E5%B0%8F%E7%AB%AF%E6%A8%A1%E5%BC%8F/6750542?fr=aladdin)
- [大小端模式](https://www.cnblogs.com/mconintet/p/4701790.html)
## 线程和进程的区别
根本区别:进程是操作系统资源分配的基本单位,而线程是任务调度和执行的基本单位
在开销方面:每个进程都有独立的代码和数据空间(程序上下文),程序之间的切换会有较大的开销;线程可以看做轻量级的进程,同一类线程共享代码和数据空间,每个线程都有自己独立的运行栈和程序计数器(PC),线程之间切换的开销小。
所处环境:在操作系统中能同时运行多个进程(程序);而在同一个进程(程序)中有多个线程同时执行(通过CPU调度,在每个时间片中只有一个线程执行)
内存分配方面:系统在运行的时候会为每个进程分配不同的内存空间;而对线程而言,除了CPU外,系统不会为线程分配内存(线程所使用的资源来自其所属进程的资源),线程组之间只能共享资源。
包含关系:没有线程的进程可以看做是单线程的,如果一个进程内有多个线程,则执行过程不是一条线的,而是多条线(线程)共同完成的;线程是进程的一部分,所以线程也被称为轻权进程或者轻量级进程。
**参考资料**
- [进程和线程的主要区别(总结)](https://blog.csdn.net/kuangsonghan/article/details/80674777)
- [线程和进程的区别](https://www.cnblogs.com/GodZhe/p/4887096.html)
## Linux 常见命令
- [ ] TODO
**参考资料**
- [Linux命令大全](https://man.linuxde.net/rm)
- [Linux常用命令大全(非常全!!!)](https://www.cnblogs.com/yjd_hycf_space/p/7730690.html)
## 操作系统加载流程?
- [ ] TODO
## 进程与线程的区别和联系?
- [ ] TODO
## 进程的常见状态?以及各种状态之间的转换条件?
- [ ] TODO
## 静态链接与动态链接的优缺点?
- [ ] TODO
## 死锁?死锁产生的条件?预防、避免死锁的方法?
- [ ] TODO
## 进程间通信的方式?各种方式的区别以及应用场景?
- [ ] TODO
## 线程同步的方式?各种方式的区别?
TODO
## 虚拟内存?使用虚拟内存的优点?
TODO
## Linux下进程的内存布局?
TODO
## 页面置换算法?LRU Cache算法?
- [ ] TODO
## Linux IO多路复用的机制:select,poll,epoll。三种复用机制的区别与联系?
- [ ] TODO
## OSI 7层网络模型中各层的名称及其作用?
- [ ] TODO
## TCP/IP 4层网络模型名称及其作用?
- [ ] TODO
## OSI 7层网络中各层的常见协议以及协议作用?
TODO
## OSI网络模型中工作在各个层次的物理设备以及其作用?
- [ ] TODO
## IP层功能?如何用int型变量保存一个IPv4地址?
- [ ] TODO
## UDP协议:头信息?使用场景?如何使用UDP建立可靠连接?
- [ ] TODO
## http协议:各个版本的区别?http请求头,响应头常用属性?常用状态码及其含义?
- [ ] TODO
## socket编程:服务端,客户端建立TCP连接调用那些函数?分别对应什么状态?
- [ ] TODO
## Linux 常用网络命令的原理:ping, traceroute
- [ ] TODO
## 浏览器中点击一个超链接到显示对应页面的全过程?
- [ ] TODO
## DNS的作用?什么时候使用TCP? 什么时候使用UDP?
- [ ] TODO
## TODO
================================================
FILE: docs/学习资料.md
================================================
深度学习:https://github.com/yoyoyo-yo/DeepLearningMugenKnock
图像处理:https://github.com/yoyoyo-yo/Gasyori100knock
# 目标检测
目标检测:从传统到深度学习
- [Object Detection for Dummies Part 1: Gradient Vector, HOG, and SS](https://lilianweng.github.io/lil-log/2017/10/29/object-recognition-for-dummies-part-1.html)
- [Object Detection for Dummies Part 2: CNN, DPM and Overfeat](https://lilianweng.github.io/lil-log/2017/12/15/object-recognition-for-dummies-part-2.html)
- [Object Detection for Dummies Part 3: R-CNN Family](https://lilianweng.github.io/lil-log/2017/12/31/object-recognition-for-dummies-part-3.html)
- [Object Detection Part 4: Fast Detection Models](https://lilianweng.github.io/lil-log/2018/12/27/object-detection-part-4.html)
================================================
FILE: docs/强化学习.md
================================================
[TOC]
# 强化学习
## 强化学习解决的是什么样的问题?
- [ ] TODO
## 举出强化学习与有监督学习的异同点。有监督学习靠样本标签训练模型,强化学习靠的是什么?
- [ ] TODO
## 强化学习的损失函数(loss function)是什么?
- [ ] TODO
## 写贝尔曼方程(Bellman Equation)
- [ ] TODO
**参考资料**
- [贝尔曼方程](https://blog.csdn.net/zbgzzz/article/details/80962645)
## 最优值函数和最优策略为什么等价?
- [ ] TODO
## 求解马尔科夫决策过程都有哪些方法?
- [ ] TODO
## 简述蒙特卡罗估计值函数的算法。
- [ ] TODO
## 简述时间差分算法
- [ ] TODO
## 介绍Q-Learning
- [ ] TODO
**参考资料**
- [Q-Learning](http://mnemstudio.org/path-finding-q-learning-tutorial.htm)
- [Q-learning算法](https://www.jianshu.com/p/eecb2230decf)
- [【强化学习】Q-Learning算法详解](https://blog.csdn.net/qq_30615903/article/details/80739243)
- [通过 Q-learning 深入理解强化学习](https://www.jiqizhixin.com/articles/2018-04-17-3)
## DQN 算法
### 基本原理
**参考资料**
- [【强化学习】Deep Q Network(DQN)算法详解](https://blog.csdn.net/qq_30615903/article/details/80744083)
- [强化学习—DQN算法原理详解](https://wanjun0511.github.io/2017/11/05/DQN/)
### DQN的两个关键trick分别是什么?
- [ ] TODO
### DQN 都有哪些变种?DQN有哪些改进方向?
- [ ] TODO
### 引入状态奖励的是哪种DQN?
- [ ] TODO
- Double -DQN
- 优先经验回放
- Dueling-DQN
### Dueling DQN和DQN有什么区别?
- [ ] TODO
## 介绍OpenAI用的PPO算法
- [ ] TODO
## 介绍TRPO算法
- [ ] TODO
## 为什么TRPO能保证新策略的回报函数单调不减?
- [ ] TODO
## 介绍DDPG算法
## 画出DDPG框架
## DDPG中的第二个D 为什么要确定?
- [ ] TODO
## 介绍A3C算法
- [ ] TODO
**参考资料**
- [一文读懂 深度强化学习算法 A3C (Actor-Critic Algorithm)](https://www.cnblogs.com/wangxiaocvpr/p/8110120.html)
- [深度强化学习——A3C](https://blog.csdn.net/u013236946/article/details/73195035/)
## A3C中优势函数意义
- [ ] TODO
## 强化学习如何用在推荐系统中?
- [ ] TODO
**参考资料**
- [ ] [用强化学习研究推荐系统的前景和难度怎么样?](https://www.zhihu.com/question/328133447)
- [ ] [深度强化学习如何和推荐系统结合起来?](https://www.zhihu.com/question/63037952)
- [ ] [ICML 2019 | 强化学习用于推荐系统,蚂蚁金服提出生成对抗用户模型](https://zhuanlan.zhihu.com/p/68029391)
- [ ] [最新!五大顶会2019必读的深度推荐系统与CTR预估相关的论文](https://zhuanlan.zhihu.com/p/69050253)
## 介绍Sarsa算法
- [ ] TODO
**参考资料**
- [AI学习笔记——Sarsa算法](https://www.jianshu.com/p/9bbe5aa3924b)
## Sarsa 和 Q-Learning区别
- [ ] TODO
**参考资料**
- [强化学习(五):Sarsa算法与Q-Learning算法](https://blog.csdn.net/liweibin1994/article/details/79119056)
- [强化学习中的Q-learning算法和Sarsa算法的区别](https://blog.csdn.net/wshixinshouaaa/article/details/80832415)
- [Bourne强化学习笔记2:彻底搞清楚什么是Q-learning与Sarsa](https://blog.csdn.net/linyijiong/article/details/81607691)
## 强化学习中有value-based 和 policy-based,这两种的优缺点分别是什么?应用场景分别是什么?
- [ ] TODO
## value-based方法学习的目标是什么?
- [ ] TODO
## 强化学习 DQN,DDQN,AC,DDPG 的区别
- [ ] TODO
## 参考资料
- [再励学习面试真题](https://zhuanlan.zhihu.com/p/33133828)
- [强化学习面经](https://zhuanlan.zhihu.com/p/44285282)
================================================
FILE: docs/推荐算法.md
================================================
[TOC]
# 推荐算法
## 常见的推荐算法有哪些?
- 协同过滤推荐算法(Collaborative Filtering Recommendation)
- 内容推荐算法(Content-based Recommendation)
- 相似性推荐算法(Similarity Recommendation)
- 关联规则推荐算法(Association Rule Based Recommendaion)
## 介绍 FM 和 DeepFM
- [https://www.hrwhisper.me/machine-learning-fm-ffm-deepfm-deepffm/ ]
## 介绍一下协同过滤的冷启动和原因
- [ ] TODO
## 基于内容的推荐算法优缺点
- [ ] TODO
## 你了解的 CTR 预估模型有哪些?
- [ ] TODO
## 推荐里面的低秩矩阵分解具体是怎么做的?
- [ ] TODO
## TODO
================================================
FILE: docs/数学.md
================================================
- [一、线性代数](#LA)
- [二、概率论](#Pro)
- [三、微积分](#Cal)
- [四、凸优化](#CO)
- [参考资料](#Reference)
# 一、线性代数
## 书籍&视频
- [李宏毅线性代数](http://speech.ee.ntu.edu.tw/~tlkagk/courses.html)
- [MIT Linear Algebra](https://ocw.mit.edu/courses/mathematics/18-06sc-linear-algebra-fall-2011/index.htm?utm_source=OCWDept&utm_medium=CarouselSm&utm_campaign=FeaturedCourse)
## 知识点
1)线性空间及线性变换
2)矩阵的基本概念
3)状态转移矩阵
4)特征向量
5)矩阵的相关乘法
6)矩阵的QR分解
7)对称矩阵、正交矩阵、正定矩阵
8)矩阵的SVD分解
9)矩阵的求导
10)矩阵映射/投影
11)矩阵的秩
12)矩阵的特征值和特征空间
# 二、概率论
## 书籍&视频
- [MIT Introduction to Probability and Statistics](https://ocw.mit.edu/courses/mathematics/18-05-introduction-to-probability-and-statistics-spring-2014/index.htm?utm_source=OCWDept&utm_medium=CarouselSm&utm_campaign=FeaturedCourse)
## 知识点
1)微积分与逼近论
2)极限、微分、积分基本概念
3)利用逼近的思想理解微分,利用积分的方式理解概率
4)概率论基础
5)古典模型
6)常见概率分布
7)大数定理和中心极限定理
8)协方差(矩阵)和相关系数
9)最大似然估计和最大后验估计
二项分布和泊松分布的区别和联系
**参考资料**
- [互联网公司 概率面试题整理](https://blog.csdn.net/bertdai/article/details/78070092)
- [面试中的概率题](https://www.cnblogs.com/fanling999/p/6777335.html)
- [2019 校园招聘算法面试概率题](https://zhuanlan.zhihu.com/p/46592195)
# 三、微积分
- [ ] TODO
# 四、凸优化
1)凸优化基本概念
2)凸集
3)凸函数
4)凸优化问题标准形式
5)凸优化之Lagerange对偶化
6)凸优化之牛顿法、梯度下降法求解
拉格朗日乘子法能否求解非凸的目标函数问题?
# 参考资料
- [如何看懂深度学习论文里的数学原理部分?](https://www.zhihu.com/question/266533669)
- [超级推荐!Mathematics for Machine Learning](https://zhuanlan.zhihu.com/p/35449496)
- [图解机器学习的数学基础专辑(完结)总结:who, why, what](https://zhuanlan.zhihu.com/p/36148930)
- [《深度学习》](https://github.com/exacity/deeplearningbook-chinese)圣经中有应用数学基础部分
- [优秀的程序员需要懂那些数学知识?](https://www.zhihu.com/question/21425201)
- [有什么深度学习数学基础书推荐?](https://www.zhihu.com/question/41459109)
- [机器学习理论篇1:机器学习的数学基础](https://zhuanlan.zhihu.com/p/25197792)
- [图像处理中的数学方法](http://bicmr.pku.edu.cn/~dongbin/Teaching_files/%E5%9B%BE%E5%83%8F%E5%A4%84%E7%90%86%E4%B8%AD%E7%9A%84%E6%95%B0%E5%AD%A6%E6%96%B9%E6%B3%95-18-19/index.html)
- [MIT数学课程](https://ocw.mit.edu/courses/mathematics/)
- [优秀的程序员需要懂那些数学知识?](https://www.zhihu.com/question/21425201/answer/632269759)
- [Free online math resources for Machine Learning](https://github.com/Machine-Learning-Tokyo/Math_resources)
================================================
FILE: docs/数据结构与算法.md
================================================
[TOC]
# 数据结构与算法
## 排序
**排序的定义**
假设含有n个记录的序列为{r1,r2,...,rn},其相应的关键字分别是{k1,k2,...,kn},需要确定1,2,...,n的一种排列p1,p2,...,pn,使其相应的关键字满足kp1<=kp2<=...<=kpn 非递减(或非递增)的关系,即使得序列成为一个按关键字有序的序列{rp1,rp2,...,rpn},这样的操作就称为排序[1]。
简单来说,排序就是使输入的序列变成符合一定规则(关键字)的有序序列(非递减或非递增)。大多数遇到的排序问题都是按数据元素值的大小规则进行排序的问题。所以本文为了方便起见,只讨论数据元素值大小比较的排序问题。
**排序的稳定性**
假设ki=kj(1<=i《=n,1<=j<=n,i!=j),且在排序前的序列中ri领先于rj(即i4,交换位置:{4,5,7,1,6,2}
第二次比较5和7,5
第三次比较7和1,7>1,交换位置:{4,5,1,7,6,2}
第四次比较7和6,7>6,交换位置:{4,5,1,6,7,2}
第五次比较7和2,7>2,交换位置:{4,5,1,6,2,7}
第一次循环完成结果:{4,5,1,6,2,7}
\----------------------------------------
第二次循环:
第一次比较4和5,4
第二次比较5和1,5>1,交换位置:{4,1,5,6,2,7}
第三次比较5和6,5
第四次比较6和2,6>2,交换位置:{4,1,5,2,6,7}
第五次比较6和7,6
第二次循环完成结果:{4,1,5,2,6,7}
\----------------------------------------
第三次循环:
第一次比较4和1,4>1,交换位置:{1,4,5,2,6,7}
第二次比较4和5,4
第三次比较5和2,5>2,交换位置:{1,4,2,5,6,7}
第四次比较5和6,5
第五次比较6和7,6
第三次循环完成结果:{1,4,2,5,6,7}
\----------------------------------------
第四次循环:
第一次比较1和4,1
第二次比较4和2,4>2,交换位置:{1,2,4,5,6,7}
第三次比较4和5,4
第四次比较5和6,5
第五次比较6和7,6
第三次循环完成结果:{1,2,4,5,6,7}
\----------------------------------------
第五次循环:
第一次比较1和2,1
第二次比较2和4,2
第三次比较4和5,4
第四次比较5和6,5
第五次比较6和7,6
第三次循环完成结果:{1,2,4,5,6,7}
相信看完上面的演示过程,你对冒泡排序过程及原理有了完全的理解,但是细心的朋友应该会发现其实在第四次循环就已经得到了最终的结果,这么来看第五次循环完全是多余的,于是就有冒泡排序的改进版本:当某一轮循环当中没有交换位置的操作,说明已经排好序了,就没必要再循环了,break退出循环即可。
**复杂度分析:**
- 时间复杂度:若给定的数组刚好是排好序的数组,采用改进后的冒泡排序算法,只需循环一次就行了,此时是最优时间复杂度:O(n),若给定的是倒序,此时是最差时间复杂度:O(n^2) ,因此综合平均时间复杂度为:O(n^2)
- 空间复杂度:因为每次只需开辟一个temp的空间,因此空间复杂度是:O(1)
**代码实现:**
-
- [bubble_sort.cpp](https://github.com/amusi/coding-note/blob/master/Data%20Structures%20and%20Algorithms/sort/code/bubble_sort.cpp)
```
/* Summary: 冒泡排序
* Author: Amusi
* Date: 208-05-27
*
* Reference:
* http://en.wikipedia.org/wiki/Bubble_sort
* https://github.com/xtaci/algorithms/blob/master/include/bubble_sort.h
* https://zhuanlan.zhihu.com/p/37077924
*
* 冒泡排序说明:比较相邻的两个元素,将值大的元素交换到右边(降序则相反)
*
*/
#include
// 冒泡函数
namespace alg{
template
static void BubbleSort(T list[], int length)
{
#if 1
// 版本1:两层for循环
for (int i = 0; i < length-1; ++i)
{
for (int j = 0; j < length - i -1; ++j)
{
// 两两相邻元素比较大小,从小到大排序
// if (list[j] < list[j + 1]) : 从大到小排序
if (list[j] > list[j + 1])
{
int temp = list[j + 1];
list[j + 1] = list[j];
list[j] = temp;
}
}
}
#else
// 版本2:while+一层for循环
bool swapped = false;
while (!swapped)
{
swapped = true;
for (int i = 0; i < length - 1; ++i)
{
// 两两相邻元素比较大小,从小到大排序
// if (list[j] < list[j + 1]) : 从大到小排序
if (list[i] > list[i + 1])
{
int temp = list[i + 1];
list[i + 1] = list[i];
list[i] = temp;
}
swapped = false;
}
length--;
}
#endif
}
}
using namespace std;
using namespace alg;
int main()
{
int a[8] = { 5, 2, 5, 7, 1, -3, 99, 56 };
BubbleSort(a, 8);
for (auto e : a)
std::cout << e << " ";
return 0;
}
```
- [bubble_sort.py](https://github.com/amusi/coding-note/blob/master/Data%20Structures%20and%20Algorithms/sort/code/bubble_sort.py)
```
''' Summary: 冒泡排序
* Author: Amusi
* Date: 208-05-27
*
* Reference:
* http://en.wikipedia.org/wiki/Bubble_sort
* https://github.com/xtaci/algorithms/blob/master/include/bubble_sort.h
* https://zhuanlan.zhihu.com/p/37077924
*
* 冒泡排序说明:比较相邻的两个元素,将值大的元素交换到右边(降序则相反)
*
'''
def BubbleSort(array):
lengths = len(array)
for i in range(lengths-1):
for j in range(lengths-1-i):
if array[j] > array[j+1]:
array[j+1], array[j] = array[j], array[j+1]
return array
array = [1,3,8,5,2,10,7,16,7,4,5]
print("Original array: ", array)
array = BubbleSort(array)
print("BubbleSort: ", array)
```
**参考:**
1 [经典排序算法之冒泡排序](http://baijiahao.baidu.com/s?id=1585931471155461767&wfr=spider&for=pc)
2 (图示版):[来、通俗聊聊冒泡排序](https://zhuanlan.zhihu.com/p/37077924)
### 选择排序(Selection Sort)
**基本思想**
首先在未排序序列中找到最小(大)元素,存放到排序序列的起始位置,然后,再从剩余未排序元素中继续寻找最小(大)元素,然后放到已排序序列的末尾。以此类推,直到所有元素均排序完毕。
**步骤**
n个记录的直接选择排序可经过n-1趟直接选择排序得到有序结果。具体算法描述如下:
- 初始状态:无序区为R[1..n],有序区为空;
- 第i趟排序(i=1,2,3…n-1)开始时,当前有序区和无序区分别为R[1..i-1]和R(i..n)。该趟排序从当前无序区中-选出关键字最小的记录 R[k],将它与无序区的第1个记录R交换,使R[1..i]和R[i+1..n)分别变为记录个数增加1个的新有序区和记录个数减少1个的新无序区;
- n-1趟结束,数组有序化了。
**动图演示**

**复杂度分析**
- 时间复杂度:O(n2)
注:无论什么数据进去,选择都是O(n2)的时间复杂度,所以若要使用它,建议数据规模越小越好。
- 空间复杂度:O(1)
**代码实现**
-
- [selection_sort.cpp](https://github.com/amusi/coding-note/blob/master/Data%20Structures%20and%20Algorithms/sort/code/selection_sort.cpp)
```
/* Summary: 选择排序
* Author: Amusi
* Date: 208-06-22
*
* Reference:
* https://en.wikipedia.org/wiki/Selection_sort
* https://github.com/xtaci/algorithms/blob/master/include/selection_sort.h
* 选择排序说明:首先在未排序序列中找到最小(大)元素,存放到排序序列的起始位置,然后,再从剩余未排序元素中继续寻找最小(大)元素,然后放到已排序序列的末尾。以此类推,直到所有元素均排序完毕。
*
*/
#include
// 选择排序函数
namespace alg{
template
static void SelectionSort(T list[], int length)
{
// 外循环: length-1次,因为当length-1个元素排序好后,第length个元素位置不再变化
for (int i = 0; i < length-1; ++i)
{
int minIndex = i;
// 从i的位置,进行遍历,因为前i-1个元素已经排序好
for (int j = i; j < length; ++j)
{
// 每次从未排序的数组中选出最小的值放入已排序的数组中,即从小到大排序
if (list[j] < list[minIndex])
{
minIndex = j;
}
}
int temp = list[minIndex];
list[minIndex] = list[i];
list[i] = temp;
}
}
}
using namespace std;
using namespace alg;
int main()
{
int a[8] = { 5, 2, 5, 7, 1, -3, 99, 56 };
SelectionSort(a, 8);
for (auto e : a)
std::cout << e << " ";
return 0;
}
```
- [selection_sort.py](https://github.com/amusi/coding-note/blob/master/Data%20Structures%20and%20Algorithms/sort/code/selection_sort.py)
```
''' Summary: 选择排序
* Author: Amusi
* Date: 208-06-22
*
* Reference:
* https://en.wikipedia.org/wiki/Selection_sort
*
* 选择排序说明:首先在未排序序列中找到最小(大)元素,存放到排序序列的起始位置,然后,再从剩余未排序元素中继续寻找最小(大)元素,然后放到已排序序列的末尾。以此类推,直到所有元素均排序完毕。
*
'''
def SelectionSort(array):
lengths = len(array)
for i in range(lengths-1):
min_index = i
for j in range(i, lengths):
if array[j] < array[min_index]:
min_index = j
array[i], array[min_index] = array[min_index], array[i]
return array
array = [1,3,8,5,2,10,7,16,7,4,5]
print("Original array: ", array)
array = SelectionSort(array)
print("SelectionSort: ", array)
```
### 插入排序(Insertion Sort)
**基本思想**
插入排序(insertion sort)又称直接插入排序(staright insertion sort),其是将未排序元素一个个插入到已排序列表中。对于未排序元素,在已排序序列中从后向前扫描,找到相应位置把它插进去;在从后向前扫描过程中,需要反复把已排序元素逐步向后挪,为新元素提供插入空间。
**步骤**
1. 从第一个元素开始,该元素可以认为已经被排序;
2. 取出下一个元素(未排序),在已经排序的元素序列中从后向前扫描;
3. 如果该元素(已排序)大于新元素,将该元素移到下一位置(往前移动);
4. 重复步骤3,直到找到已排序的元素小于或者等于新元素的位置;
5. 将新元素插入到该位置后;
6. 重复步骤2~5。
**动图演示**

**复杂度分析**
- 时间复杂度:最坏O(n2)、平均O(n2)、最好O(n)
- 空间复杂度:O(n1)
- 稳定性:稳定
举个例子(暴力手绘图)

**代码实现**
- [insertion_sort.cpp](https://github.com/amusi/coding-note/blob/master/Data%20Structures%20and%20Algorithms/sort/code/insertion_sort.cpp)
```
/* Summary: 插入排序(Insertion Sort)
* Author: Amusi
* Date: 2018-07-16
*
* Reference:
* https://en.wikipedia.org/wiki/Insertion_sort
*
* 插入排序(insertion sort)又称直接插入排序(staright insertion sort),其是将未排序元素一个个插入到已排序列表中。对于未排序元素,在已排序序列中从后向前扫描,找到相应位置把它插进去;在从后向前扫描过程中,需要反复把已排序元素逐步向后挪,为新元素提供插入空间。
*
*/
#include
// 插入排序函数
namespace alg{
template
static void InsertionSort(T list[], int length)
{
// 从索引为1的位置开始遍历
for (int i = 1; i < length; ++i)
{
T currentValue = list[i]; // 保存当前值
int preIndex = i - 1; // 前一个索引值
// 循环条件: 前一个索引值对应元素值大于当前值 && 前一个索引值大于等于0
while (list[preIndex] > currentValue && preIndex >= 0){
list[preIndex + 1] = list[preIndex];
preIndex--;
}
list[preIndex + 1] = currentValue;
}
}
}
using namespace std;
using namespace alg;
int main()
{
int a[8] = { 5, 2, 5, 7, 1, -3, 99, 56 };
InsertionSort(a, 8);
for (auto e : a)
std::cout << e << " ";
return 0;
}
```
- [insertion_sort.py](https://github.com/amusi/coding-note/blob/master/Data%20Structures%20and%20Algorithms/sort/code/insertion_sort.py)
```
''' Summary: 插入排序(Insertion Sort)
* Author: Amusi
* Date: 208-07-16
*
* Reference:
* https://en.wikipedia.org/wiki/Insertion_sort
* https://www.cnblogs.com/wujingqiao/articles/8961890.html
*
* 插入排序(insertion sort)又称直接插入排序(staright insertion sort),其是将未排序元素一个个插入到已排序列表中。对于未排序元素,在已排序序列中从后向前扫描,找到相应位置把它插进去;在从后向前扫描过程中,需要反复把已排序元素逐步向后挪,为新元素提供插入空间。
*
'''
def InsertionnSort(array):
lengths = len(array)
# 从索引位置1开始
for i in range(1, lengths):
currentValue = array[i] # 当前索引对应的元素数值
preIndex = i-1 # 前一个索引位置
# 循环条件: 前一个索引对应元素值大于当前值,前一个索引值大于等于0
while array[preIndex] > currentValue and preIndex>=0:
array[preIndex+1] = array[preIndex] # 前一个索引对应元素值赋值给当前值
preIndex -= 1 # 前一个索引位置-1
# preIndex+1,实现元素交换
array[preIndex+1] = currentValue
return array
array = [1,3,8,5,2,10,7,16,7,4,5]
print("Original array: ", array)
array = InsertionnSort(array)
print("InsertionnSort: ", array)
```
### 希尔排序(Shell Sort)
**基本思想**
设待排序元素序列有n个元素,首先取一个整数increment(小于n)作为间隔将全部元素分为increment个子序列,所有距离为increment的元素放在同一个子序列中,在每一个子序列中分别实行直接插入。
注:在[希尔排序算法](https://en.wikipedia.org/wiki/Shellsort)提出之前,排序算法的时间复杂度都为O(n^2),如冒泡排序、选择排序和插入排序。而希尔排序算法是突破这个时间复杂度的第一批算法之一。该复杂度为O(nlogn),其实直接插入排序算法的改进版,也称为缩小增量排序。**希尔排序是直接插入排序的一种改进,减少了其复制的次数,速度要快很多**。原因是,当n值很大时,数据项每一趟排序需要移动的个数很少,但数据项的距离很长;当n值减小时,每一趟需要移动的数据增多。正是因为这两种情况的结合才使得希尔排序效率比插入排序高很多。
**步骤**
先将整个待排序的记录序列分割成为若干子序列分别进行直接插入排序,具体算法描述:
- 选择一个增量序列t1,t2,…,tk
- 按增量序列个数k,对序列进行k 趟排序;
- 每趟排序,根据对应的增量ti,将待排序列分割成若干长度为m 的子序列,分别对各子表进行直接插入排序。仅增量因子为1 时,整个序列作为一个表来处理,表长度即为整个序列的长度。
注:增量的初始值一般为序列长度的一半,然后之后每次再自身减半。
**动图演示**
[](https://github.com/amusi/coding-note/blob/master/Data%20Structures%20and%20Algorithms/sort/images/shell_sort01.gif)
上图是不是很难理解,那么来看看这个!
[](https://github.com/amusi/coding-note/blob/master/Data%20Structures%20and%20Algorithms/sort/images/shell_sort02.png)
说实话,看了上面两个图,我还是有点不理解,不怕,我又找了下面这幅图像。
简单介绍一下:
对于[592, 401, 874, 141, 348, 72, 911, 887, 820, 283]序列,一共10个元素。
**第一次,设置增量为5=10/2**,所以有5个子序列:[592,72]、[401,911]、[874,887]、[141,820]和[348,283]。然后对每个子序列进行插入排序,结果是[72,592]、[401,911]、[874,887]、[141,820]和[283,348]。注意,这些元素在序列中的位置初始是不变的,只会随着部分子序列间元素的位置变化而变化,比如[592,72]在原来的序列中索引是[0,5],之后变成了[5,0];而[401,911]的序列索引是[1,6],第一次处理后,索引值不变。
总之,第一次处理的结果是将**[592, 401, 874, 141, 348, 72, 911, 887, 820, 283]—> [72, 401, 874, 141, 283, 592, 911, 887, 820, 348]**。
**第二次,设置增量为2=5/2**,所以有2个子序列:[72, 874, 283, 911, 820]和[401, 141, 592, 887, 348]。然后对每个子序列进行插入排序,[72, 874, 283, 911, 820]的结果是[72, 283, 820, 874, 911],而[401, 141, 292, 887, 348]的结果是[141, 292, 348, 401, 887]。
总之,第二次处理的结果是将 **[72, 401, 874, 141, 283, 592, 911, 887, 820, 348]—>[72, 141, 283, 292, 820, 348, 874, 401, 911, 997]**。
**第三次,设置增量为1=2/2**,所以有1个序列,就是上述生成的序列[72, 141, 283, 292, 820, 348, 874, 401, 911, 997]。然后进行插入排序,其结果为[72, 141, 283, 292, 348, 401, 820, 874, 911, 997]。
总之,第三次处理的结果是将 **[72, 141, 283, 292, 820, 348, 874, 401, 911, 997]—>[72, 141, 283, 292, 348, 401, 820, 874, 911, 997]**。
其实本质上还是利用了插入排序,但这里通过增量作用,相当于添加了预处理,减少插入排序中移动元素的次数,提高了效率。通过"增量"预处理,使得希尔排序算法时间复杂度降低。
[](https://github.com/amusi/coding-note/blob/master/Data%20Structures%20and%20Algorithms/sort/images/shell_sort03.jpg)
**复杂度分析**
希尔排序的时间复杂度与增量序列的选取有关。
时间复杂度:
- 平均:O(n^1.3)
- 最差:O(n2)
- 最好:O(n)
空间复杂度:O(1)
稳定性:不稳定
**代码实现**
[shell_sort.cpp](https://github.com/amusi/coding-note/blob/master/Data%20Structures%20and%20Algorithms/sort/code/shell_sort.cpp)
```
/* Summary: 希尔排序(Shell Sort)
* Author: Amusi
* Date: 2018-09-23
*
* Reference:
* https://en.wikipedia.org/wiki/Shellsort
* https://www.geeksforgeeks.org/shellsort/
* 希尔排序(shell sort):设待排序元素序列有n个元素,首先取一个整数increment(小于n)作为间隔将全部元素分为increment个子序列,所有距离为increment的元素放在同一个子序列中,在每一个子序列中分别实行直接插入。
*
*/
#include
// 希尔排序函数(基于快速插入排序)
namespace alg{
template
static void ShellSort(T list[], int n)
{
// 设置增量:以n/2为初始gap,然后逐渐减小gap(每次缩小为上次gap的一半)
for (int gap = n / 2; gap > 0; gap /= 2){
// 遍历当前趟,对每个子序列进行插入排序
for (int i = gap; i < n; i++){
int temp = list[i];
int j = 0;
// 遍历子序列
for (j = i; j >= gap && list[j - gap]>temp; j -= gap)
list[j] = list[j - gap];
list[j] = temp;
}
}
}
}
using namespace std;
using namespace alg;
int main()
{
int a[8] = { 5, 2, 5, 7, 1, -3, 99, 56 };
int n = sizeof(a) / sizeof(a[0]);
ShellSort(a, n);
for (auto e : a)
std::cout << e << " ";
return 0;
}
```
[shell_sort.py](https://github.com/amusi/coding-note/blob/master/Data%20Structures%20and%20Algorithms/sort/code/shell_sort.py)
```
'''
* Summary: 希尔排序(Shell Sort)
* Author: Amusi
* Date: 2018-09-23
*
* Reference:
* https://en.wikipedia.org/wiki/Shellsort
* https://www.geeksforgeeks.org/shellsort/
* 希尔排序(shell sort):设待排序元素序列有n个元素,首先取一个整数increment(小于n)作为间隔将全部元素分为increment个子序列,所有距离为increment的元素放在同一个子序列中,在每一个子序列中分别实行直接插入。
*
*
'''
def ShellSort(array):
lengths = len(array)
# 初始化gap
gap = lengths//2
# 减少增量,遍历子序列进行插入排序
while(gap > 0):
for i in range(gap, lengths):
#
temp = array[i]
j = i
# 子序列插入排序
while j>=gap and array[j-gap]>temp:
array[j] = array[j-gap]
j -= gap
array[j] = temp
gap = gap//2
return array
array = [1,3,8,5,2,10,7,16,7,4,5]
print("Original array: ", array)
array = ShellSort(array)
print("InsertionnSort: ", array)
```
参考:
- [Shell Sort](https://www.geeksforgeeks.org/shellsort/)
- [理解希尔排序的排序过程](https://blog.csdn.net/weixin_37818081/article/details/79202115)
- [图解排序算法(二)之希尔排序](https://www.cnblogs.com/chengxiao/p/6104371.html)
### 堆排序(Heap Sort)
**基本思想**
[堆排序(heap sort)](https://en.wikipedia.org/wiki/Heapsort):将待排序序列构造成一个大顶堆,此时,整个序列的最大值就是堆顶的根节点。将其与末尾元素进行交换,此时末尾就为最大值。然后将剩余n-1个元素重新构造成一个堆,这样会得到n个元素的次小值。如此反复执行,便能得到一个有序序列了。
注:堆排序是一种选择排序,指利用堆这种数据结构所设计的一种排序算法。堆积是一个近似完全二叉树的结构,并同时满足堆积的性质:即子结点的键值或索引总是小于(或者大于)它的父节点。
在介绍堆排序之前,先了解一下什么是**堆(heap)**?
**堆**
堆是具有以下性质的完全二叉树:每个结点的值都大于或等于其左右孩子结点的值,称为大顶堆;或者每个结点的值都小于或等于其左右孩子结点的值,称为小顶堆。如下图:
[](https://github.com/amusi/coding-note/blob/master/Data%20Structures%20and%20Algorithms/sort/images/heap.png)
同时,我们对堆的结点按层进行编号,将这种逻辑结构映射到数组中就是下面这个样子:
[](https://github.com/amusi/coding-note/blob/master/Data%20Structures%20and%20Algorithms/sort/images/heap2.png)
该数组从逻辑上讲就是一个堆结构,我们用简单的公式来描述一下堆的定义就是:
**大顶堆:arr[i] >= arr[2i+1] && arr[i] >= arr[2i+2] **
**小顶堆:arr[i] <= arr[2i+1] && arr[i] <= arr[2i+2] **
ok,了解了这些定义。接下来,我们来看看堆排序的基本思想及基本步骤:
**步骤**
- 将初始待排序关键字序列(R1,R2….Rn)构建成大顶堆,此堆为初始的无序区;
- 将堆顶元素R[1]与最后一个元素R[n]交换,此时得到新的无序区(R1,R2,……Rn-1)和新的有序区(Rn),且满足R[1,2…n-1]<=R[n];
- 由于交换后新的堆顶R[1]可能违反堆的性质,因此需要对当前无序区(R1,R2,……Rn-1)调整为新堆,然后再次将R[1]与无序区最后一个元素交换,得到新的无序区(R1,R2….Rn-2)和新的有序区(Rn-1,Rn)。不断重复此过程直到有序区的元素个数为n-1,则整个排序过程完成。
**动图演示**
[](https://github.com/amusi/coding-note/blob/master/Data%20Structures%20and%20Algorithms/sort/images/heap_sort.gif)
看到这里,你可能还是晕乎乎的,下面看个讲解示例:
**步骤一 构造初始堆。将给定无序序列构造成一个大顶堆(一般升序采用大顶堆,降序采用小顶堆)。**
a.假设给定无序序列结构如下
[](https://github.com/amusi/coding-note/blob/master/Data%20Structures%20and%20Algorithms/sort/images/heap_p1.png)
b.此时我们从最后一个非叶子结点开始(叶结点自然不用调整,第一个非叶子结点 arr.length/2-1=5/2-1=1,也就是下面的6结点),从左至右,从下至上进行调整。
[](https://github.com/amusi/coding-note/blob/master/Data%20Structures%20and%20Algorithms/sort/images/heap_p2.png)
c.找到第二个非叶节点4,由于[4,9,8]中9元素最大,4和9交换。
[](https://github.com/amusi/coding-note/blob/master/Data%20Structures%20and%20Algorithms/sort/images/heap_p3.png)
d.这时交换导致了子根[4,5,6]结构混乱,继续调整,[4,5,6]中6最大,交换4和6。
[](https://github.com/amusi/coding-note/blob/master/Data%20Structures%20and%20Algorithms/sort/images/heap_p4.png)
此时,我们就将一个无需序列构造成了一个大顶堆。
**步骤二 将堆顶元素与末尾元素进行交换,使末尾元素最大。然后继续调整堆,再将堆顶元素与末尾元素交换,得到第二大元素。如此反复进行交换、重建、交换。**
a.将堆顶元素9和末尾元素4进行交换
[](https://github.com/amusi/coding-note/blob/master/Data%20Structures%20and%20Algorithms/sort/images/heap_p5.png)
b.重新调整结构,使其继续满足堆定义
[](https://github.com/amusi/coding-note/blob/master/Data%20Structures%20and%20Algorithms/sort/images/heap_p6.png)
c.再将堆顶元素8与末尾元素5进行交换,得到第二大元素8.
[](https://github.com/amusi/coding-note/blob/master/Data%20Structures%20and%20Algorithms/sort/images/heap_p7.png)
后续过程,继续进行调整,交换,如此反复进行,最终使得整个序列有序
[](https://github.com/amusi/coding-note/blob/master/Data%20Structures%20and%20Algorithms/sort/images/heap_p8.png)
再简单总结下堆排序的基本思路:
**a.将无需序列构建成一个堆,根据升序降序需求选择大顶堆或小顶堆;**
**b.将堆顶元素与末尾元素交换,将最大元素"沉"到数组末端;**
**c.重新调整结构,使其满足堆定义,然后继续交换堆顶元素与当前末尾元素,反复执行调整+交换步骤,直到整个序列有序。**
**复杂度分析**
堆排序整体主要由构建初始堆+交换堆顶元素和末尾元素并重建堆两部分组成。其中构建初始堆经推导复杂度为O(n),在交换并重建堆的过程中,需交换n-1次,而重建堆的过程中,根据完全二叉树的性质,[log2(n-1),log2(n-2)...1]逐步递减,近似为nlogn。所以堆排序时间复杂度一般认为就是O(nlogn)级。
时间复杂度:
- 最差:O(nlogn)
- 平均:O(nlogn)
- 最优:O(nlogn)
空间复杂度:O(n)
稳定性:不稳定
**代码实现**
- TODO
参考:
- [图解排序算法(三)之堆排序](https://www.cnblogs.com/chengxiao/p/6129630.html)
- [heap-sort](https://www.geeksforgeeks.org/heap-sort/)
### 归并排序(Merge Sort)
**基本思想**
[归并排序(merge sort)](https://en.wikipedia.org/wiki/Merge_sort):
**步骤**
- [ ] TODO
### 快速排序(Quick Sort)
**基本思想**
[快速排序(quick sort)](https://en.wikipedia.org/wiki/Quicksort):通过一趟排序将待排列表分隔成独立的两部分,其中一部分的所有元素均比另一部分的所有元素小,则可分别对这两部分继续重复进行此操作,以达到整个序列有序。(这个过程,我们可以使用递归快速实现)
**步骤**
快速排序使用分治法来把一个串(list)分为两个子串(sub-lists)。具体算法描述如下:
- 从数列中挑出一个元素,称为 “基准”(pivot),这里我们通常都会选择第一个元素作为prvot;
- 重新排序数列,将比基准值小的所有元素放在基准前面,比基准值大的所有元素放在基准的后面(相同的数可以到任一边)。这样操作完成后,该基准就处于新数列的中间位置,即将数列分成了两部分。这个操作称为分区(partition)操作;
- 递归地(recursive)把小于基准值元素的子数列和大于基准值元素的子数按上述操作进行排序。这里的递归结束的条件是序列的大小为0或1。此时递归结束,排序就完成了。
**动图演示**
[](https://github.com/amusi/coding-note/blob/master/Data%20Structures%20and%20Algorithms/sort/images/quick_sort.gif)
**复杂度分析**
- 时间复杂度:
- 平均情况:O(nlogn)
- 最好情况:O(nlong)
- 最坏情况:O(n^2) 其实不难理解,快排的最坏情况就已经退化为冒泡排序了!所以大家深入理解就会发现各个排序算法是相通的,学习时间久了你就会发现它们的内在联系!是不是很神奇哈~
- 空间复杂度:
- 平均情况:O(logn)
- 最好情况:O(logn)
- 最坏情况:O(n)
- 稳定性:不稳定 (由于关键字的比较和交换是跳跃进行的,所以快速排序是一种不稳定的排序方法~)
举个例子(暴力手绘图)
[](https://github.com/amusi/coding-note/blob/master/Data%20Structures%20and%20Algorithms/sort/images/quick_sort.png)
**代码实现**
注:下面都是利用递归法实现快速排序。
[quick_sort.cpp](https://github.com/amusi/coding-note/blob/master/Data%20Structures%20and%20Algorithms/sort/code/quick_sort.cpp)
```
/* Summary: 快速排序(Quick Sort)
* Author: Amusi
* Date: 2018-07-28
*
* Reference:
* https://en.wikipedia.org/wiki/Quicksort
*
* 快速排序(quick sort):通过一趟排序将待排列表分隔成独立的两部分,其中一部分的所有元素均比另一部分的所有元素小,则可分别对这两部分继续重复进行此操作,以达到整个序列有序。(这个过程,我们可以使用递归快速实现)
*
*/
#include
// 快速排序函数(递归法)
namespace alg{
template
static void QuickSort(T list[], int start, int end)
{
int i = start;
int j = end;
// 结束排序(左右两索引值见面,即相等,或者左索引>右索引)
if (i >= j)
return;
// 保存首个数值(以首个数值作为基准)
// 这个位置很重要,一定要在if i >= j判断语句之后,否则就索引溢出了
T pivot = list[i];
// 一次排序,i和j的值不断的靠拢,然后最终停止,结束一次排序
while (i < j){
// 一层循环实现从左边起大于基准的值替换基准的位置,右边起小于基准的值位置替换从左起大于基准值的索引
//(从右往左)和最右边的比较,如果 >= pivot, 即满足要求,不需要交换,然后j - 1,慢慢左移,即拿基准值与前一个值比较; 如果值pivot,那么就交换位置
while (i < j && pivot >= list[i])
++i;
list[j] = list[i];
}
// 列表中索引i的位置为基准值,i左边序列都是小于基准值的,i右边序列都是大于基准值的,当前基准值的索引为i,之后不变
list[i] = pivot;
// 左边排序
QuickSort(list, start, i-1);
// 右边排序
QuickSort(list, i+1, end);
}
}
using namespace std;
using namespace alg;
int main()
{
int a[8] = { 5, 2, 5, 7, 1, -3, 99, 56 };
QuickSort(a, 0, sizeof(a)/sizeof(a[0]) - 1);
for (auto e : a)
std::cout << e << " ";
return 0;
}
```
[quick_sort.py](https://github.com/amusi/coding-note/blob/master/Data%20Structures%20and%20Algorithms/sort/code/quick_sort.py)
```python
''' Summary: 快速排序(Quick Sort)
* Author: Amusi
* Date: 208-07-28
*
* Reference:
* https://en.wikipedia.org/wiki/Quicksort
* https://www.cnblogs.com/wujingqiao/articles/8961890.html
* https://github.com/apachecn/LeetCode/blob/master/src/py3.x/sort/QuickSort.py
* 快速排序(quick sort):通过一趟排序将待排列表分隔成独立的两部分,其中一部分的所有元素均比另一部分的所有元素小,则可分别对这两部分继续重复进行此操作,以达到整个序列有序。(这个过程,我们可以使用递归快速实现)
*
'''
def QuickSort(array, start, end):
lengths = len(array)
i = start
j = end
# 结束排序(左右两索引值见面,即相等,或者左索引>右索引)
if i >= j:
return # 返回空即可
# 保存首个数值(以首个数值作为基准)
# 这个位置很重要,一定要在if i>=j判断语句之后,否则就索引溢出了
pivot = array[i]
# 一次排序,i和j的值不断的靠拢,然后最终停止,结束一次排序
while i < j:
# (从右往左)和最右边的比较,如果>=pivot,即满足要求,不需要交换,然后j-1,慢慢左移,即拿基准值与前一个值比较; 如果值pivot,那么就交换位置
while i < j and pivot >= array[i]:
# print(pivot, array[i], '*' * 30)
i += 1
array[j] = array[i]
# 列表中索引i的位置为基准值,i左边序列都是小于基准值的,i右边序列都是大于基准值的,当前基准值的索引为i,之后不变
array[i] = pivot
# 左边排序
QuickSort(array, start, i-1)
# 右边排序
QuickSort(array, i+1, end)
#return array
if __name__ == "__main__":
array = [1,3,8,5,2,10,7,16,7,4,5]
print("Original array: ", array)
#array = QuickSort(array, 0, len(array)-1)
# 因为python中的list对象是可变对象,所以在函数做"形参"时,是相当于按引用传递
# 所以不写成返回值的形式,也是OK的
QuickSort(array, 0, len(array)-1)
print("QuickSort: ", array)
```
## 查找
- [ ] TODO
### 二分查找
- [ ] TODO
### lower_bound
- [ ] TODO
### upper_bound
- [ ] TODO
## 分治与递归
- [ ] TODO
### 逆序对数
- [ ] TODO
### 大数相加
- [ ] TODO
### 大数相乘
- [ ] TODO
## 贪婪算法
- [ ] TODO
## 动态规划
### 背包问题
- [ ] TODO
### 找零钱问题
- [ ] TODO
### 最长公共子序列(LCS)
- [ ] TODO
## 字符串匹配算法
### KMP算法
- [ ] TODO
### BM算法
- [ ] TODO
### Sunday算法
- [ ] TODO
## 线性表
### 数组
- [ ] TODO
### 栈
- [ ] TODO
### 队列
- [ ] TODO
### 链表
- [ ] TODO
## 二叉树
### 二叉排序树/二叉查找树BST
- [ ] TODO
### 平衡二叉树
- [ ] TODO
### 求二叉树的最大高度
- [ ] TODO
### 二叉树的前序遍历
- [ ] TODO
### 二叉树打印出最右侧的节点
- [ ] TODO
### 非递归中序遍历二叉树
- [ ] TODO
### 求二叉树深度和宽度
- [ ] TODO
## 链表
### 找到链表倒数第k个结点
- [ ] TODO
### 如何判断单链表中是否有环?
- [ ] TODO
### 翻转链表
- [ ] TODO
### 手写双向链表
- [ ] TODO
## 堆
### 构建堆的复杂度
- [ ] TODO
### 堆找出第k大元素的复杂度
- [ ] TODO
## 打印螺旋矩阵
- [ ] TODO
## 找最小字串
- [ ] TODO
## 2-sum、3-sum和4-sum问题
N-sum就是从序列中找出N个数,使得N个数之和等于指定数值的问题。
**2-sum**
2-sum就是从序列中找出2个数,使得2个数之和等于0的问题,即a+b=sum。
下面的例子是规定指定数值为0:
```cpp
int sum_2()
{
int res = 0;
int n = data.size();
for(int i=0; i i)
res++;
}
return res;
}
```
**3-sum**
上述2-sum的解题思路适用于3-sum及4-sum问题,如求解a+b+c=0,可将其转换为求解a+b=-c,此就为2-sum问题。
为此将2-sum,3-sum,4-sum的求解方法以及相应的优化方法实现在如下所示的sum类中。
sum.h
```cpp
#ifndef SUM_H
#define SUM_H
#include
using std::vector;
class sum
{
private:
vector data;
public:
sum(){};
sum(const vector& a);
~sum(){};
int cal_sum_2() const;
int cal_sum_3() const;
int cal_sum_4() const;
int cal_sum_2_update() const;
int cal_sum_3_update() const;
int cal_sum_3_update2() const;
int cal_sum_4_update() const;
void sort(int low, int high);
void print() const;
friend int find(const sum& s, int target);
};
#endif
```
sum.cpp
```cpp
#include "Sum.h"
#include
using namespace std;
sum::sum(const vector& a)
{
data = a;
}
void sum::sort(int low, int high)
{
if(low >= high)
return;
int mid = (low+high)/2;
sort(low,mid);
sort(mid+1,high);
vector temp;
int l = low;
int h = mid+1;
while(l<=mid && h <=high)
{
if(data[l] > data[h])
temp.push_back(data[h++]);
else
temp.push_back(data[l++]);
}
while(l<=mid)
temp.push_back(data[l++]);
while(h<=high)
temp.push_back(data[h++]);
for(int i=low; i<=high; i++)
{
data[i] = temp[i-low];
}
}
void sum::print() const
{
for(int i=0; i target)
{
high = mid - 1;
}
else
{
return mid;
}
}
return -1;
}
int sum::cal_sum_2() const
{
int res = 0;
for(int i=0; i i)
res++;
}
return res;
}
int sum::cal_sum_3() const
{
int res = 0;
for(int i=0; i 0)
j--;
else if(data[i] + data[j] < 0)
i++;
else
{
res++;
j--;
i++;
}
}
return res;
}
int sum::cal_sum_3_update() const
{
int res = 0;
for(int i=0; i j)
res ++;
}
}
return res;
}
int sum::cal_sum_3_update2() const
{
int res = 0;
for(int i=0; i -data[i])
p--;
else
{
res++;
j++;
p--;
}
}
}
return res;
}
int sum::cal_sum_4_update() const
{
int res = 0;
for(int i=0; ip)
res++;
}
}
}
return res;
}
```
test.cpp
```cpp
#include "Sum.h"
#include
#include
#include
using namespace std;
void main()
{
ifstream in("1Kints.txt");
vector a;
while(!in.eof())
{
int temp;
in>>temp;
a.push_back(temp);
}
sum s(a);
s.sort(0,a.size()-1);
s.print();
cout<<"s.cal_sum_2() = "< 0.5 时,就将这个 x 归到 1 这一类,如果 y< 0.5 就将 x 归到 0 这一类。但是阈值是可以调整的,比如说一个比较保守的人,可能将阈值设为 0.9,也就是说有超过90%的把握,才相信这个x属于 1这一类。了解一个算法,最好的办法就是自己从头实现一次。下面是逻辑回归的具体实现。
**Regression 常规步骤**
1. 寻找h函数(即预测函数)
2. 构造J函数(损失函数)
3. 想办法(迭代)使得J函数最小并求得回归参数(θ)
函数h(x)的值有特殊的含义,它表示结果取1的概率,于是可以看成类1的后验估计。因此对于输入x分类结果为类别1和类别0的概率分别为:
P(y=1│x;θ)=hθ (x)
P(y=0│x;θ)=1-hθ (x)
**代价函数**
**逻辑回归一般使用交叉熵作为代价函数**。关于[代价函数](https://en.wikipedia.org/wiki/Loss_function)的具体细节,请参考[代价函数](http://www.cnblogs.com/Belter/p/6653773.html)。
交叉熵是对「出乎意料」(译者注:原文使用suprise)的度量。神经元的目标是去计算函数 y, 且 y = y(x)。但是我们让它取而代之计算函数 a, 且 a = a(x) 。假设我们把 a 当作 y 等于 1 的概率,1−a 是 y 等于 0 的概率。那么,交叉熵衡量的是我们在知道 y 的真实值时的平均「出乎意料」程度。当输出是我们期望的值,我们的「出乎意料」程度比较低;当输出不是我们期望的,我们的「出乎意料」程度就比较高。
交叉熵代价函数如下所示:
$$J(w)=-l(w)=-\sum_{i = 1}^n y^{(i)}ln(\phi(z^{(i)})) + (1 - y^{(i)})ln(1-\phi(z^{(i)}))$$
$$J(\phi(z),y;w)=-yln(\phi(z))-(1-y)ln(1-\phi(z))$$
注:为什么要使用交叉熵函数作为代价函数,而不是平方误差函数?请参考:[逻辑回归算法之交叉熵函数理解](https://blog.csdn.net/syyyy712/article/details/78252722)
**逻辑回归伪代码**
```
初始化线性函数参数为1
构造sigmoid函数
重复循环I次
计算数据集梯度
更新线性函数参数
确定最终的sigmoid函数
输入训练(测试)数据集
运用最终sigmoid函数求解分类
```
**逻辑回归算法之Python实现**
- [ ] TODO
**参考资料**
- [Logistic Regression](https://en.wikipedia.org/wiki/Logistic_regression)
- 《统计学习方法》 (蓝书) 第6章 P77页
- 《机器学习》 (西瓜书) 第3章 P57页
- [《Machine Learning》 吴恩达 Logistic Regression](https://d19vezwu8eufl6.cloudfront.net/ml/docs%2Fslides%2FLecture6.pdf)
- [逻辑回归 - 理论篇](https://blog.csdn.net/pakko/article/details/37878837)
- [逻辑回归(logistic regression)的本质——极大似然估计](https://blog.csdn.net/zjuPeco/article/details/77165974)
- [机器学习算法与Python实践之(七)逻辑回归(Logistic Regression)](https://www.cnblogs.com/zhizhan/p/4868555.html)
- [机器学习之Logistic回归与Python实现](https://blog.csdn.net/moxigandashu/article/details/72779856)
- [【机器学习】逻辑回归(Logistic Regression)](https://www.cnblogs.com/Belter/p/6128644.html)
- [机器学习算法--逻辑回归原理介绍](https://blog.csdn.net/chibangyuxun/article/details/53148005)
- [逻辑回归算法面经](https://zhuanlan.zhihu.com/p/46591702)
- [Logistic Regression 模型简介](https://tech.meituan.com/2015/05/08/intro-to-logistic-regression.html)
### 为什么 LR 要使用 sigmoid 函数?
1.广义模型推导所得
2.满足统计的最大熵模型
3.性质优秀,方便使用(Sigmoid函数是平滑的,而且任意阶可导,一阶二阶导数可以直接由函数值得到不用进行求导,这在实现中很实用)
**参考资料**
- [为什么逻辑回归 模型要使用 sigmoid 函数](https://blog.csdn.net/weixin_39881922/article/details/80366324)
### LR 可以用核函数么?
- [ ] TODO
### 为什么 LR 用交叉熵损失而不是平方损失?
- [ ] TODO
### LR 能否解决非线性分类问题?
- [ ] TODO
**参考资料**
- [逻辑斯蒂回归能否解决非线性分类问题?](https://www.zhihu.com/question/29385169)
### LR为什么要离散特征?
- [ ] TODO
### 逻辑回归是处理线性问题还是非线性问题的?
- [ ] TODO
## 线性回归
### 基本原理
- [ ] TODO
**参考资料**
- [通俗理解线性回归(一)](https://blog.csdn.net/alw_123/article/details/82193535)
### 线性回归与逻辑回归(LR)的区别
**参考资料**
- [线性回归和逻辑回归的比较](https://blog.csdn.net/ddydavie/article/details/82668141)
## 支持向量机(SVM)
### 基本原理
[支持向量机(supporr vector machine,SVM)](https://en.wikipedia.org/wiki/Support-vector_machine)是一种二类分类模型,该模型是定义在特征空间上的间隔最大的线性分类器。间隔最大使它有区别于感知机;支持向量机还包括核技巧,这使它成为实质上的非线性分类器。支持向量机的学习策略就是**间隔最大化**,可形式化为一个求解凸二次规划的最小化问题。
**知识点提炼:**
- SVM核函数
- 多项式核函数
- 高斯核函数
- 字符串核函数
- SMO
- SVM损失函数
支持向量机的学习算法是求解凸二次规划的最优化算法。
支持向量机学习方法包含构建由简至繁的模型:
- 线性可分支持向量机
- 线性支持向量机
- 非线性支持向量机(使用核函数)
当训练数据线性可分时,通过硬间隔最大化(hard margin maximization)学习一个线性的分类器,即线性可分支持向量机,又成为硬间隔支持向量机;
当训练数据近似线性可分时,通过软间隔最大化(soft margin maximization)也学习一个线性的分类器,即线性支持向量机,又称为软间隔支持向量机;
当训练数据不可分时,通过核技巧(kernel trick)及软间隔最大化,学习非线性支持向量机。
注:以上各SVM的数学推导应该熟悉:硬间隔最大化(几何间隔)---学习的对偶问题---软间隔最大化(引入松弛变量)---非线性支持向量机(核技巧)。
**SVM的主要特点**
(1)非线性映射-理论基础
(2)最大化分类边界-方法核心
(3)支持向量-计算结果
(4)小样本学习方法
(5)最终的决策函数只有少量支持向量决定,避免了“维数灾难”
(6)少数支持向量决定最终结果—->可“剔除”大量冗余样本+算法简单+具有鲁棒性(体现在3个方面)
(7)学习问题可表示为凸优化问题—->全局最小值
(8)可自动通过最大化边界控制模型,但需要用户指定核函数类型和引入松弛变量
(9)适合于小样本,优秀泛化能力(因为结构风险最小)
(10)泛化错误率低,分类速度快,结果易解释
**SVM为什么采用间隔最大化?**
当训练数据线性可分时,存在无穷个分离超平面可以将两类数据正确分开。
感知机利用误分类最小策略,求得分离超平面,不过此时的解有无穷多个。
线性可分支持向量机利用间隔最大化求得最优分离超平面,这时,解是唯一的。另一方面,此时的分隔超平面所产生的分类结果是最鲁棒的,对未知实例的泛化能力最强。
然后应该借此阐述,几何间隔,函数间隔,及从函数间隔—>求解最小化1/2 ||w||^2 时的w和b。即线性可分支持向量机学习算法—最大间隔法的由来。
**为什么要将求解SVM的原始问题转换为其对偶问题?**
1. 对偶问题往往更易求解(当我们寻找约束存在时的最优点的时候,约束的存在虽然减小了需要搜寻的范围,但是却使问题变得更加复杂。为了使问题变得易于处理,我们的方法是把目标函数和约束全部融入一个新的函数,即拉格朗日函数,再通过这个函数来寻找最优点。)
2. 自然引入核函数,进而推广到非线性分类问题
**为什么SVM要引入核函数?**
当样本在原始空间线性不可分时,可将样本从原始空间映射到一个更高维的特征空间,使得样本在这个特征空间内线性可分。
**SVM核函数有哪些?**
- 线性(Linear)核函数:主要用于线性可分的情形。参数少,速度快。
- 多项式核函数
- 高斯(RBF)核函数:主要用于线性不可分的情形。参数多,分类结果非常依赖于参数。
- Sigmoid核函数
- 拉普拉斯(Laplac)核函数
注:如果feature数量很大,跟样本数量差不多,建议使用LR或者Linear kernel的SVM。如果feature数量较少,样本数量一般,建议使用Gaussian Kernel的SVM。
**SVM如何处理多分类问题?**
一般有两种做法:
1. 直接法:直接在目标函数上修改,将多个分类面的参数求解合并到一个最优化问题里面。看似简单但是计算量却非常的大。
2. 间接法:对训练器进行组合。其中比较典型的有一对一,和一对多。
- 一对多:对每个类都训练出一个分类器,由svm是二分类,所以将此而分类器的两类设定为目标类为一类,其余类为另外一类。这样针对k个类可以训练出k个分类器,当有一个新的样本来的时候,用这k个分类器来测试,那个分类器的概率高,那么这个样本就属于哪一类。这种方法效果不太好,bias比较高。
- 一对一:针对任意两个类训练出一个分类器,如果有k类,一共训练出C(2,k) 个分类器,这样当有一个新的样本要来的时候,用这C(2,k) 个分类器来测试,每当被判定属于某一类的时候,该类就加一,最后票数最多的类别被认定为该样本的类。
**SVM中硬间隔和软间隔**
硬间隔分类即线性可分支持向量机,软间隔分类即线性不可分支持向量机,利用软间隔分类时是因为存在一些训练集样本不满足函数间隔(泛函间隔)大于等于1的条件,于是加入一个非负的参数 ζ (松弛变量),让得出的函数间隔加上 ζ 满足条件。于是软间隔分类法对应的拉格朗日方程对比于硬间隔分类法的方程就多了两个参数(一个ζ ,一个 β),但是当我们求出对偶问题的方程时惊奇的发现这两种情况下的方程是一致的。下面我说下自己对这个问题的理解。
我们可以先考虑软间隔分类法为什么会加入ζ 这个参数呢?硬间隔的分类法其结果容易受少数点的控制,这是很危险的,由于一定要满足函数间隔大于等于1的条件,而存在的少数离群点会让算法无法得到最优解,于是引入松弛变量,从字面就可以看出这个变量是为了缓和判定条件,所以当存在一些离群点时我们只要对应给他一个ζi,就可以在不变更最优分类超平面的情况下让这个离群点满足分类条件。
综上,我们可以看出来软间隔分类法加入ζ 参数,使得最优分类超平面不会受到离群点的影响,不会向离群点靠近或远离,相当于我们去求解排除了离群点之后,样本点已经线性可分的情况下的硬间隔分类问题,所以两者的对偶问题是一致的。
### 支持向量中的向量是指什么?
- [ ] TODO
### 手推SVM
**参考资料**
- [Support-vector machine](https://en.wikipedia.org/wiki/Support-vector_machine)
- [支持向量机通俗导论(理解SVM的三层境界)](https://blog.csdn.net/v_july_v/article/details/7624837)
- [数据挖掘(机器学习)面试--SVM面试常考问题](https://blog.csdn.net/szlcw1/article/details/52259668)
- [机器学习实战教程(八):支持向量机原理篇之手撕线性SVM](http://cuijiahua.com/blog/2017/11/ml_8_svm_1.html)
- [支持向量机(SVM)入门理解与推导](https://blog.csdn.net/sinat_20177327/article/details/79729551)
- [数据挖掘领域十大经典算法之—SVM算法(超详细附代码)](https://blog.csdn.net/fuqiuai/article/details/79483057)
### LR 与 SVM的区别和联系
**相同点**
第一,LR和SVM都是分类算法。
看到这里很多人就不会认同了,因为在很大一部分人眼里,LR是回归算法。我是非常不赞同这一点的,因为我认为判断一个算法是分类还是回归算法的唯一标准就是样本label的类型,如果label是离散的,就是分类算法,如果label是连续的,就是回归算法。很明显,LR的训练数据的label是“0或者1”,当然是分类算法。其实这样不重要啦,暂且迁就我认为它是分类算法吧,再说了,SVM也可以回归用呢。
第二,如果不考虑核函数,LR和SVM都是线性分类算法,也就是说他们的分类决策面都是线性的。
这里要先说明一点,那就是LR也是可以用核函数的,至于为什么通常在SVM中运用核函数而不在LR中运用,后面讲到他们之间区别的时候会重点分析。总之,原始的LR和SVM都是线性分类器,这也是为什么通常没人问你决策树和LR什么区别,决策树和SVM什么区别,你说一个非线性分类器和一个线性分类器有什么区别?
第三,LR和SVM都是监督学习算法。
这个就不赘述什么是监督学习,什么是半监督学习,什么是非监督学习了。
第四,LR和SVM都是判别模型。
判别模型会生成一个表示P(Y|X)的判别函数(或预测模型),而生成模型先计算联合概率p(Y,X)然后通过贝叶斯公式转化为条件概率。简单来说,在计算判别模型时,不会计算联合概率,而在计算生成模型时,必须先计算联合概率。或者这样理解:生成算法尝试去找到底这个数据是怎么生成的(产生的),然后再对一个信号进行分类。基于你的生成假设,那么那个类别最有可能产生这个信号,这个信号就属于那个类别。判别模型不关心数据是怎么生成的,它只关心信号之间的差别,然后用差别来简单对给定的一个信号进行分类。常见的判别模型有:KNN、SVM、LR,常见的生成模型有:朴素贝叶斯,隐马尔可夫模型。当然,这也是为什么很少有人问你朴素贝叶斯和LR以及朴素贝叶斯和SVM有什么区别(哈哈,废话是不是太多)。
**不同点**
第一,本质上是其损失函数(loss function)不同。
注:lr的损失函数是 cross entropy loss, adaboost的损失函数是 expotional loss ,svm是hinge loss,常见的回归模型通常用 均方误差 loss。
逻辑回归的损失函数

SVM的目标函数

不同的loss function代表了不同的假设前提,也就代表了不同的分类原理,也就代表了一切!!!简单来说,逻辑回归方法基于概率理论,假设样本为1的概率可以用sigmoid函数来表示,然后通过极大似然估计的方法估计出参数的值,具体细节参考[逻辑回归](http://blog.csdn.net/pakko/article/details/37878837)。支持向量机基于几何间隔最大化原理,认为存在最大几何间隔的分类面为最优分类面,具体细节参考[支持向量机通俗导论(理解SVM的三层境界)](http://blog.csdn.net/macyang/article/details/38782399)
第二,支持向量机只考虑局部的边界线附近的点,而逻辑回归考虑全局(远离的点对边界线的确定也起作用)。
当你读完上面两个网址的内容,深入了解了LR和SVM的原理过后,会发现影响SVM决策面的样本点只有少数的结构支持向量,当在支持向量外添加或减少任何样本点对分类决策面没有任何影响;而在LR中,每个样本点都会影响决策面的结果。用下图进行说明:
支持向量机改变非支持向量样本并不会引起决策面的变化

逻辑回归中改变任何样本都会引起决策面的变化

理解了这一点,有可能你会问,然后呢?有什么用呢?有什么意义吗?对使用两种算法有什么帮助么?一句话回答:
因为上面的原因,得知:线性SVM不直接依赖于数据分布,分类平面不受一类点影响;LR则受所有数据点的影响,如果数据不同类别strongly unbalance,一般需要先对数据做balancing。(引自http://www.zhihu.com/question/26768865/answer/34078149)
第三,在解决非线性问题时,支持向量机采用核函数的机制,而LR通常不采用核函数的方法。
这个问题理解起来非常简单。分类模型的结果就是计算决策面,模型训练的过程就是决策面的计算过程。通过上面的第二点不同点可以了解,在计算决策面时,SVM算法里只有少数几个代表支持向量的样本参与了计算,也就是只有少数几个样本需要参与核计算(即kernal machine解的系数是稀疏的)。然而,LR算法里,每个样本点都必须参与决策面的计算过程,也就是说,假设我们在LR里也运用核函数的原理,那么每个样本点都必须参与核计算,这带来的计算复杂度是相当高的。所以,在具体应用时,LR很少运用核函数机制。
第四,线性SVM依赖数据表达的距离测度,所以需要对数据先做normalization,LR不受其影响。(引自http://www.zhihu.com/question/26768865/answer/34078149)
一个机遇概率,一个机遇距离!
第五,SVM的损失函数就自带正则!!!(损失函数中的1/2||w||^2项),这就是为什么SVM是结构风险最小化算法的原因!!!而LR必须另外在损失函数上添加正则项!!!
以前一直不理解为什么SVM叫做结构风险最小化算法,**所谓结构风险最小化,意思就是在训练误差和模型复杂度之间寻求平衡,防止过拟合,从而达到真实误差的最小化**。未达到结构风险最小化的目的,最常用的方法就是添加正则项,后面的博客我会具体分析各种正则因子的不同,这里就不扯远了。但是,你发现没,SVM的目标函数里居然自带正则项!!!再看一下上面提到过的SVM目标函数:
SVM目标函数

有木有,那不就是L2正则项吗?
不用多说了,如果不明白看看L1正则与L2正则吧,参考http://www.mamicode.com/info-detail-517504.html
http://www.zhihu.com/question/26768865/answer/34078149
**快速理解LR和SVM的区别**
两种方法都是常见的分类算法,从目标函数来看,区别在于逻辑回归采用的是logistical loss,svm采用的是hinge loss。这两个损失函数的目的都是增加对分类影响较大的数据点的权重,减少与分类关系较小的数据点的权重。SVM的处理方法是只考虑support vectors,也就是和分类最相关的少数点,去学习分类器。而逻辑回归通过非线性映射,大大减小了离分类平面较远的点的权重,相对提升了与分类最相关的数据点的权重。两者的根本目的都是一样的。此外,根据需要,两个方法都可以增加不同的正则化项,如l1,l2等等。所以在很多实验中,两种算法的结果是很接近的。但是逻辑回归相对来说模型更简单,好理解,实现起来,特别是大规模线性分类时比较方便。而SVM的理解和优化相对来说复杂一些。但是SVM的理论基础更加牢固,有一套结构化风险最小化的理论基础,虽然一般使用的人不太会去关注。还有很重要的一点,SVM转化为对偶问题后,分类只需要计算与少数几个支持向量的距离,这个在进行复杂核函数计算时优势很明显,能够大大简化模型和计算量。
**SVM与LR的区别与联系**
联系:(1)分类(二分类) (2)可加入正则化项
区别:(1)LR–参数模型;SVM–非参数模型?(2)目标函数:LR—logistical loss;SVM–hinge loss (3)SVM–support vectors;LR–减少较远点的权重 (4)LR–模型简单,好理解,精度低,可能局部最优;SVM–理解、优化复杂,精度高,全局最优,转化为对偶问题—>简化模型和计算 (5)LR可以做的SVM可以做(线性可分),SVM能做的LR不一定能做(线性不可分)
**总结一下**
- Linear SVM和LR都是线性分类器
- Linear SVM不直接依赖数据分布,分类平面不受一类点影响;LR则受所有数据点的影响,如果数据不同类别strongly unbalance,一般需要对数据先做balancing。
- Linear SVM依赖数据表打对距离测度,所以需要对数据先做normalization;LR不受影响
- Linear SVM依赖penalty的系数,实验中需要做validation
- Linear SVM的LR的performance都会收到outlier的影响,就敏感程度而言,无法给出明确结论。
**参考资料**
- [LR与SVM的异同](https://www.cnblogs.com/zhizhan/p/5038747.html)
- [SVM和logistic回归分别在什么情况下使用?]()
- [Linear SVM 和 LR 有什么异同?](https://www.zhihu.com/question/26768865/answer/34078149)
### SVM 中有哪些核函数?
- [ ] TODO
**参考资料**
- [svm常用核函数及选择核函数的方法](https://blog.csdn.net/ningyanggege/article/details/84072842)
- [SVM由浅入深的尝试(五)核函数的理解](https://www.jianshu.com/p/e07932472257?utm_campaign)
### SVM 的对偶问题
- [ ] TODO
### SMO 算法原理
- [ ] TODO
SVM 为什么可以处理非线性问题?
- [ ] TODO
### SVM 中的优化技术有哪些?
- [ ] TODO
### SVM 的惩罚系数如何确定?
- [ ] TODO
### 正则化参数对支持向量数的影响
- [ ] TODO
### 如何解决线性不可分问题?
- [ ] TODO
### 软间隔和硬间隔
- [ ] TODO
### Hinge Loss
- [ ] TODO
## 梯度提升树(GBDT)
### 基本原理
下面关于GBDT的理解来自论文greedy function approximation: a gradient boosting machine
1. 损失函数的数值优化可以看成是在函数空间,而不是在参数空间。
2. 损失函数L(y,F)包含平方损失(y−F)2,绝对值损失|y−F|用于回归问题,负二项对数似然log(1+e−2yF),y∈{-1,1}用于分类。
3. 关注点是预测函数的加性扩展。
最关键的点在于损失函数的数值优化可以看成是在函数空间而不是参数空间。
GBDT对分类问题基学习器是二叉分类树,对回归问题基学习器是二叉决策树。
**参考资料**
- [简单易学的机器学习算法——梯度提升决策树GBDT](https://blog.csdn.net/google19890102/article/details/51746402/)
- [GBDT原理详解](https://www.cnblogs.com/ScorpioLu/p/8296994.html)
## AdaBoost
### 基本原理
Adaboost算法基本原理就是将多个弱分类器(弱分类器一般选用单层决策树)进行合理的结合,使其成为一个强分类器。
Adaboost采用迭代的思想,每次迭代只训练一个弱分类器,训练好的弱分类器将参与下一次迭代的使用。也就是说,在第N次迭代中,一共就有N个弱分类器,其中N-1个是以前训练好的,其各种参数都不再改变,本次训练第N个分类器。其中弱分类器的关系是第N个弱分类器更可能分对前N-1个弱分类器没分对的数据,最终分类输出要看这N个分类器的综合效果。
**参考资料**
- [Adaboost入门教程——最通俗易懂的原理介绍(图文实例)](https://blog.csdn.net/px_528/article/details/72963977)
- [AdaBoost原理详解](https://www.cnblogs.com/ScorpioLu/p/8295990.html)
- [数据挖掘领域十大经典算法之—AdaBoost算法(超详细附代码)](https://blog.csdn.net/fuqiuai/article/details/79482487)
- [聊聊Adaboost,从理念到硬核推导](https://zhuanlan.zhihu.com/p/62037189)
### GBDT 和 AdaBoost 区别
- [ ] TODO
## XGBoost
### 基本原理
**XGBoost全名叫(eXtreme Gradient Boosting)极端梯度提升**,经常被用在一些比赛中,其效果显著。它是大规模并行boosted tree的工具,它是目前最快最好的开源boosted tree工具包。下面我们将XGBoost的学习分为3步:
① 集成思想
② 损失函数分析
③ 求解
我们知道机器学习三要素:模型、策略、算法。对于集成思想的介绍,XGBoost算法本身就是以集成思想为基础的。所以理解清楚集成学习方法对XGBoost是必要的,它能让我们更好的理解其预测函数模型。在第二部分,我们将详细分析损失函数,这就是我们将要介绍策略。第三部分,对于目标损失函数求解,也就是算法了。
**参考资料**
- [XGBoost Documentation](https://xgboost.readthedocs.io/en/latest/)
- [通俗、有逻辑的写一篇说下Xgboost的原理,供讨论参考](https://blog.csdn.net/github_38414650/article/details/76061893)
- [xgboost的原理没你想像的那么难](https://www.jianshu.com/p/7467e616f227)
### XGBoost里处理缺失值的方法
- [ ] TODO
### XGBoost 和 GBDT 的区别
- 传统GBDT以CART作为基分类器,xgboost还支持线性分类器,这个时候xgboost相当于带L1和L2正则化项的逻辑斯蒂回归(分类问题)或者线性回归(回归问题)。
- 传统GBDT在优化时只用到一阶导数信息,xgboost则对代价函数进行了二阶泰勒展开,同时用到了一阶和二阶导数。顺便提一下,xgboost工具支持自定义代价函数,只要函数可一阶和二阶求导。
- xgboost在代价函数里加入了正则项,用于控制模型的复杂度。正则项里包含了树的叶子节点个数、每个叶子节点上输出的score的L2模的平方和。从Bias-variance tradeoff角度来讲,正则项降低了模型的variance,使学习出来的模型更加简单,防止过拟合,这也是xgboost优于传统GBDT的一个特性。
- Shrinkage(缩减),相当于学习速率(xgboost中的eta)。xgboost在进行完一次迭代后,会将叶子节点的权重乘上该系数,主要是为了削弱每棵树的影响,让后面有更大的学习空间。实际应用中,一般把eta设置得小一点,然后迭代次数设置得大一点。(补充:传统GBDT的实现也有学习速率)
- 列抽样(column subsampling)。xgboost借鉴了随机森林的做法,支持列抽样,不仅能降低过拟合,还能减少计算,这也是xgboost异于传统gbdt的一个特性。
- 对缺失值的处理。对于特征的值有缺失的样本,xgboost可以自动学习出它的分裂方向。
- xgboost工具支持并行。boosting不是一种串行的结构吗?怎么并行的?注意xgboost的并行不是tree粒度的并行,xgboost也是一次迭代完才能进行下一次迭代的(第t次迭代的代价函数里包含了前面t-1次迭代的预测值)。xgboost的并行是在特征粒度上的。我们知道,决策树的学习最耗时的一个步骤就是对特征的值进行排序(因为要确定最佳分割点),xgboost在训练之前,预先对数据进行了排序,然后保存为block结构,后面的迭代中重复地使用这个结构,大大减小计算量。这个block结构也使得并行成为了可能,在进行节点的分裂时,需要计算每个特征的增益,最终选增益最大的那个特征去做分裂,那么各个特征的增益计算就可以开多线程进行。
- 可并行的近似直方图算法。树节点在进行分裂时,我们需要计算每个特征的每个分割点对应的增益,即用贪心法枚举所有可能的分割点。当数据无法一次载入内存或者在分布式情况下,贪心算法效率就会变得很低,所以xgboost还提出了一种可并行的近似直方图算法,用于高效地生成候选的分割点。
### XGBoost 如何做到自定义损失函数?
- [ ] TODO
### XGBoost 如何防止过拟合?
- [ ] TODO
### XGBoost 为什么不用后剪枝?
- [ ] TODO
### XGBoost 是如何实现并行的?
- [ ] TODO
### XGBoost 有哪些参数,取指范围,各代表什么意思?
- [ ] TODO
**参考资料**
- [XGBoost——机器学习(理论+图解+安装方法+python代码)](https://blog.csdn.net/huacha__/article/details/81029680)
- [一文读懂机器学习大杀器 XGBoost 原理](http://blog.itpub.net/31542119/viewspace-2199549/)
### XGBoost 如何进行并行加速的?
- [ ] TODO
### 每次分裂叶子节点是怎么决定特征和分裂点的?
- [ ] TODO
### Adaboost、GBDT与XGBoost的区别
- [ ] TODO
**参考资料**
- [Adaboost、GBDT与XGBoost的区别](https://blog.csdn.net/hellozhxy/article/details/82143554)
## LightGBM
### 基本原理
- [ ] TODO
### LightGBM 与 XGBoost 的区别
- [ ] TODO
### GBDT、LightGBM 和 XGBoost 区别
- [ ] TODO
### 基本原理
1、KNN算法概述
kNN算法的核心思想是如果一个样本在特征空间中的k个最相邻的样本中的大多数属于某一个类别,则该样本也属于这个类别,并具有这个类别上样本的特性。该方法在确定分类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别。
2、KNN算法介绍
最简单最初级的分类器是将全部的训练数据所对应的类别都记录下来,当测试对象的属性和某个训练对象的属性完全匹配时,便可以对其进行分类。但是怎么可能所有测试对象都会找到与之完全匹配的训练对象呢,其次就是存在一个测试对象同时与多个训练对象匹配,导致一个训练对象被分到了多个类的问题,基于这些问题呢,就产生了KNN。
KNN是通过测量不同特征值之间的距离进行分类。它的的思路是:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。K通常是不大于20的整数。KNN算法中,所选择的邻居都是已经正确分类的对象。该方法在定类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别。
下面通过一个简单的例子说明一下:如下图,绿色圆要被决定赋予哪个类,是红色三角形还是蓝色四方形?如果K=3,由于红色三角形所占比例为2/3,绿色圆将被赋予红色三角形那个类,如果K=5,由于蓝色四方形比例为3/5,因此绿色圆被赋予蓝色四方形类。
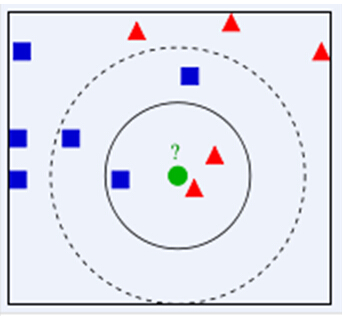
接下来对KNN算法的思想总结一下:就是在训练集中数据和标签已知的情况下,输入测试数据,将测试数据的特征与训练集中对应的特征进行相互比较,找到训练集中与之最为相似的前K个数据,则该测试数据对应的类别就是K个数据中出现次数最多的那个分类,其算法的描述为:
1)计算测试数据与各个训练数据之间的距离;
2)按照距离的递增关系进行排序;
3)选取距离最小的K个点;
4)确定前K个点所在类别的出现频率;
5)返回前K个点中出现频率最高的类别作为测试数据的预测分类。
**参考资料**
- [KNN算法原理及实现](https://www.cnblogs.com/sxron/p/5451923.html)
- [第2章 k-近邻算法](https://www.cnblogs.com/apachecnxy/p/7462628.html)
- [数据挖掘领域十大经典算法之—K-邻近算法/kNN(超详细附代码)](https://blog.csdn.net/fuqiuai/article/details/79458648)
## K-Means
### 基本原理
算法思想:
```
选择K个点作为初始质心
repeat
将每个点指派到最近的质心,形成K个簇
重新计算每个簇的质心
until 簇不发生变化或达到最大迭代次数
```
这里的重新计算每个簇的质心,如何计算的是根据目标函数得来的,因此在开始时我们要考虑距离度量和目标函数。
考虑欧几里得距离的数据,使用误差平方和(Sum of the Squared Error,SSE)作为聚类的目标函数,两次运行K均值产生的两个不同的簇集,我们更喜欢SSE最小的那个。
**参考资料**
- [深入理解K-Means聚类算法](https://blog.csdn.net/taoyanqi8932/article/details/53727841)
- [数据挖掘领域十大经典算法之—K-Means算法(超详细附代码)](https://blog.csdn.net/fuqiuai/article/details/79458331)
### 手撕 K-Means
- [ ] TODO
### K-Means 与 KNN 的区别
- [ ] TODO
**参考资料**
- [Kmeans算法与KNN算法的区别](https://www.cnblogs.com/peizhe123/p/4619066.html)
### K-Means 中的 K 怎么确定?
- [ ] TODO
### K-Means 的迭代循环停止条件
- [ ] TODO
### 评判聚类效果准则
- [ ] TODO
## Bagging
### 基本原理
- [ ] TODO
**参考资料**
- [集成算法中的Bagging](https://blog.csdn.net/fontthrone/article/details/79074296)
## Boosting
### 基本原理
- [ ] TODO
**参考资料**
- [机器学习 —— Boosting算法](https://blog.csdn.net/starter_____/article/details/79328749)
### Bagging 和 Boosting 的区别
1)样本选择上:
Bagging:训练集是在原始集中有放回选取的,从原始集中选出的各轮训练集之间是独立的.
Boosting:每一轮的训练集不变,只是训练集中每个样例在分类器中的权重发生变化.而权值是根据上一轮的分类结果进行调整.
2)样例权重:
Bagging:使用均匀取样,每个样例的权重相等
Boosting:根据错误率不断调整样例的权值,错误率越大则权重越大.
3)预测函数:
Bagging:所有预测函数的权重相等.
Boosting:每个弱分类器都有相应的权重,对于分类误差小的分类器会有更大的权重.
4)并行计算:
Bagging:各个预测函数可以并行生成
Boosting:各个预测函数只能顺序生成,因为后一个模型参数需要前一轮模型的结果.
**参考资料**
- [Bagging和Boosting的区别(面试准备)](https://www.cnblogs.com/earendil/p/8872001.html)
- [Bagging和Boosting 概念及区别](https://www.cnblogs.com/liuwu265/p/4690486.html)
- [Bagging和Boosting的概念与区别](https://www.cnblogs.com/onemorepoint/p/9264782.html)
## 朴素贝叶斯
### 基本原理
- [ ] TODO
**参考资料**
- [第4章 基于概率论的分类方法:朴素贝叶斯](https://www.cnblogs.com/apachecnxy/p/7471634.html)
- [数据挖掘领域十大经典算法之—朴素贝叶斯算法(超详细附代码)](https://blog.csdn.net/fuqiuai/article/details/79458943)
### 为什么朴素贝叶斯被称为“朴素”?
- [ ] TODO
## EM 算法
### 基本原理
- [ ] TODO
**参考资料**
- [数据挖掘领域十大经典算法之—EM算法](https://blog.csdn.net/fuqiuai/article/details/79484421)
### E 步和 M 步的具体步骤
- [ ] TODO
### E 中的期望是什么?
- [ ] TODO
## 决策树
### 基本原理
- [ ] TODO
### 决策树如何剪枝?
- [ ] TODO
### 决策树先剪枝还是后剪枝好?
- [ ] TODO
### 决策树能否有非数值型变量?
- [ ] TODO
### 决策树如何防止过拟合?
- [ ] TODO
**参考资料**
- [机器学习之-常见决策树算法(ID3、C4.5、CART)](https://shuwoom.com/?p=1452)
- [机器学习实战(三)——决策树](https://blog.csdn.net/jiaoyangwm/article/details/79525237)
- [决策树基本概念及算法优缺点](https://www.jianshu.com/p/655d8e555494)
### 决策树的ID3和C4.5介绍一下
- [ ] TODO
## 随机森林(RF)
### 基本原理
随机森林属于集成学习(Ensemble Learning)中的bagging算法。在集成学习中,主要分为bagging算法和boosting算法。我们先看看这两种方法的特点和区别。
**Bagging(套袋法)**
bagging的算法过程如下:
从原始样本集中使用Bootstraping方法随机抽取n个训练样本,共进行k轮抽取,得到k个训练集。(k个训练集之间相互独立,元素可以有重复)
对于k个训练集,我们训练k个模型(这k个模型可以根据具体问题而定,比如决策树,knn等)
对于分类问题:由投票表决产生分类结果;对于回归问题:由k个模型预测结果的均值作为最后预测结果。(所有模型的重要性相同)
**Boosting(提升法)**
boosting的算法过程如下:
对于训练集中的每个样本建立权值wi,表示对每个样本的关注度。当某个样本被误分类的概率很高时,需要加大对该样本的权值。
进行迭代的过程中,每一步迭代都是一个弱分类器。我们需要用某种策略将其组合,作为最终模型。(例如AdaBoost给每个弱分类器一个权值,将其线性组合最为最终分类器。误差越小的弱分类器,权值越大)
Bagging,Boosting的主要区别
样本选择上:Bagging采用的是Bootstrap随机有放回抽样;而Boosting每一轮的训练集是不变的,改变的只是每一个样本的权重。
样本权重:Bagging使用的是均匀取样,每个样本权重相等;Boosting根据错误率调整样本权重,错误率越大的样本权重越大。
预测函数:Bagging所有的预测函数的权重相等;Boosting中误差越小的预测函数其权重越大。
并行计算:Bagging各个预测函数可以并行生成;Boosting各个预测函数必须按顺序迭代生成。
下面是将决策树与这些算法框架进行结合所得到的新的算法:
1)Bagging + 决策树 = 随机森林
2)AdaBoost + 决策树 = 提升树
3)Gradient Boosting + 决策树 = GBDT
**决策树**
常用的决策树算法有ID3,C4.5,CART三种。3种算法的模型构建思想都十分类似,只是采用了不同的指标。决策树模型的构建过程大致如下:
**ID3,C4.5决策树的生成**
输入:训练集D,特征集A,阈值eps 输出:决策树T
若D中所有样本属于同一类Ck,则T为单节点树,将类Ck作为该结点的类标记,返回T
若A为空集,即没有特征作为划分依据,则T为单节点树,并将D中实例数最大的类Ck作为该结点的类标记,返回T
否则,计算A中各特征对D的信息增益(ID3)/信息增益比(C4.5),选择信息增益最大的特征Ag
若Ag的信息增益(比)小于阈值eps,则置T为单节点树,并将D中实例数最大的类Ck作为该结点的类标记,返回T
否则,依照特征Ag将D划分为若干非空子集Di,将Di中实例数最大的类作为标记,构建子节点,由结点及其子节点构成树T,返回T
对第i个子节点,以Di为训练集,以A-{Ag}为特征集,递归地调用1~5,得到子树Ti,返回Ti
**CART决策树的生成**
这里只简单介绍下CART与ID3和C4.5的区别。
CART树是二叉树,而ID3和C4.5可以是多叉树
CART在生成子树时,是选择一个特征一个取值作为切分点,生成两个子树
选择特征和切分点的依据是基尼指数,选择基尼指数最小的特征及切分点生成子树
**随机森林**
随机森林是一种重要的基于Bagging的集成学习方法,可以用来做分类、回归等问题。
随机森林有许多优点:
- 具有极高的准确率
- 随机性的引入,使得随机森林不容易过拟合
- 随机性的引入,使得随机森林有很好的抗噪声能力
- 能处理很高维度的数据,并且不用做特征选择
- 既能处理离散型数据,也能处理连续型数据,数据集无需规范化
- 训练速度快,可以得到变量重要性排序
- 容易实现并行化
**随机森林的缺点:**
当随机森林中的决策树个数很多时,训练时需要的空间和时间会较大
随机森林模型还有许多不好解释的地方,有点算个黑盒模型
与上面介绍的Bagging过程相似,随机森林的构建过程大致如下:
从原始训练集中使用Bootstraping方法随机有放回采样选出m个样本,共进行n_tree次采样,生成n_tree个训练集
对于n_tree个训练集,我们分别训练n_tree个决策树模型
对于单个决策树模型,假设训练样本特征的个数为n,那么每次分裂时根据信息增益/信息增益比/基尼指数选择最好的特征进行分裂
每棵树都一直这样分裂下去,直到该节点的所有训练样例都属于同一类。在决策树的分裂过程中不需要剪枝
将生成的多棵决策树组成随机森林。对于分类问题,按多棵树分类器投票决定最终分类结果;对于回归问题,由多棵树预测值的均值决定最终预测结果
**参考资料**
- [随机森林算法学习(Random Forest)](https://blog.csdn.net/qq547276542/article/details/78304454)
- [随机森林(Random Forest)算法原理](https://blog.csdn.net/edogawachia/article/details/79357844)
- [随机森林(Random Forest)](https://www.cnblogs.com/maybe2030/p/4585705.html)
- [机器学习算法之随机森林算法详解及工作原理图解](http://www.elecfans.com/d/647463.html)
### 随机森林中的“随机”指什么?
- [ ] TODO
### 随机森林处理缺失值的方法
- [ ] TODO
### 随机森林和 GBDT 的区别
- [ ] TODO
### 随机森林与决策树关系
- [ ] TODO
## CART回归树是怎么实现的?
- [ ] TODO
## CART分类树和ID3以及C4.5有什么区别?
- [ ] TODO
## 机器学习中的分类、回归和聚类模型有哪些?
分类:LR、SVM、KNN、决策树、RandomForest、GBDT
回归:non-Linear regression、SVR(支持向量回归-->可用线性或高斯核(RBF))、随机森林
聚类:Kmeans、层次聚类、GMM(高斯混合模型)、谱聚类
## 高斯混合模型(GMM)
- [ ] TODO
**参考资料**
- [深度理解高斯混合模型(GMM)](http://blog.sina.com.cn/s/blog_a36a563e0102y2ec.html)
- [高斯混合模型(GMM)](https://blog.csdn.net/m_buddy/article/details/80432384)
## 马尔科夫随机场(MRF)
### 基本原理
- [ ] TODO
**参考资料**
- [马尔可夫随机场 MRF](https://blog.csdn.net/pipisorry/article/details/78396503)
## 隐马尔科夫模型(HMM)
### 基本原理
- [ ] TODO
**参考资料**
- [一文搞懂HMM(隐马尔可夫模型)](https://www.cnblogs.com/skyme/p/4651331.html)
- [机器学习中的隐马尔科夫模型(HMM)详解](https://blog.csdn.net/baimafujinji/article/details/51285082)
### 发射概率和状态转移概率
- [ ] TODO
### 每层要记住所有路径吗?
- [ ] TODO
## 条件随机场(CRF)
### 基本原理
- [ ] TODO
### CRF 的损失函数是什么?
- [ ] TODO
**参考资料**
- [机器学习之条件随机场(CRF)](https://blog.csdn.net/wangyangzhizhou/article/details/78489593)
- [如何轻松愉快地理解条件随机场(CRF)?](https://www.jianshu.com/p/55755fc649b1)
- [一文理解条件随机场CRF](https://zhuanlan.zhihu.com/p/70067113)
### HMM、MEMM vs CRF 对比?
1)HMM是有向图模型,是生成模型;HMM有两个假设:一阶马尔科夫假设和观测独立性假设;但对于序列标注问题不仅和单个词相关,而且和观察序列的长度,单词的上下文,等等相关。
2)MEMM(最大熵马尔科夫模型)是有向图模型,是判别模型;MEMM打破了HMM的观测独立性假设,MEMM考虑到相邻状态之间依赖关系,且考虑整个观察序列,因此MEMM的表达能力更强;但MEMM会带来标注偏置问题:由于局部归一化问题,MEMM倾向于选择拥有更少转移的状态。这就是标记偏置问题。
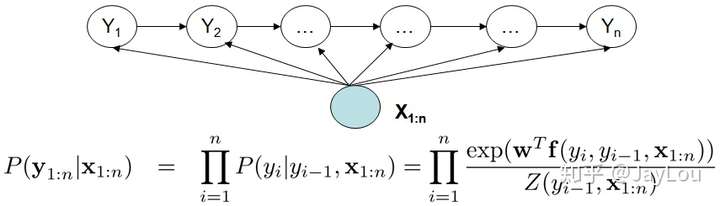最大熵模型(MEMM)
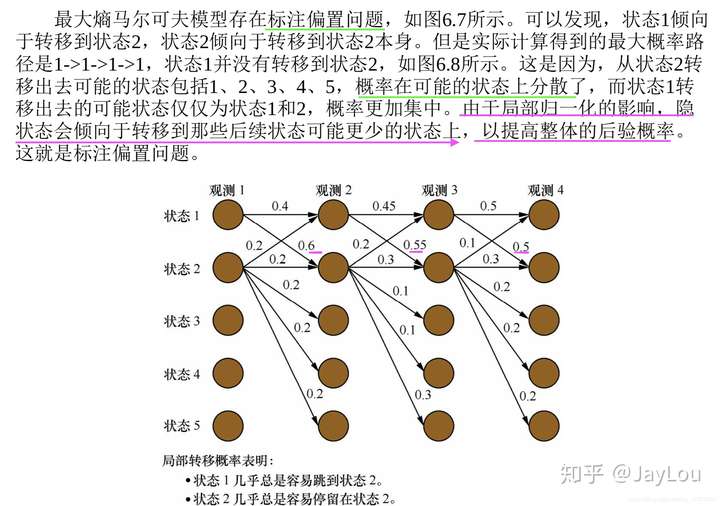
3)CRF模型解决了标注偏置问题,去除了HMM中两个不合理的假设,当然,模型相应得也变复杂了。
HMM、MEMM和CRF的优缺点比较:
a)与HMM比较。CRF没有HMM那样严格的独立性假设条件,因而可以容纳任意的上下文信息。特征设计灵活(与ME一样)
b)与MEMM比较。由于CRF计算全局最优输出节点的条件概率,它还克服了最大熵马尔可夫模型标记偏置(Label-bias)的缺点。
c)与ME比较。CRF是在给定需要标记的观察序列的条件下,计算整个标记序列的联合概率分布,而不是在给定当前状态条件下,定义下一个状态的状态分布.
> 首先,CRF,HMM(隐马模型),MEMM(最大熵隐马模型)都常用来做序列标注的建模,像分词、词性标注,以及命名实体标注
> 隐马模型一个最大的缺点就是由于其输出独立性假设,导致其不能考虑上下文的特征,限制了特征的选择
> 最大熵隐马模型则解决了隐马的问题,可以任意选择特征,但由于其在每一节点都要进行归一化,所以只能找到局部的最优值,同时也带来了标记偏见的问题,即凡是训练语料中未出现的情况全都忽略掉。
> 条件随机场则很好的解决了这一问题,他并不在每一个节点进行归一化,而是所有特征进行全局归一化,因此可以求得全局的最优值。
**参考资料**
- [HMM、MEMM vs CRF 对比?](https://zhuanlan.zhihu.com/p/57153934)
## 主成分分析(PCA)
### 基本原理
PCA(Principal Component Analysis)是一种常用的数据分析方法。PCA通过线性变换将原始数据变换为一组各维度线性无关的表示,可用于提取数据的主要特征分量,常用于高维数据的降维。网上关于PCA的文章有很多,但是大多数只描述了PCA的分析过程,而没有讲述其中的原理。这篇文章的目的是介绍PCA的基本数学原理,帮助读者了解PCA的工作机制是什么。
当然我并不打算把文章写成纯数学文章,而是希望用直观和易懂的方式叙述PCA的数学原理,所以整个文章不会引入严格的数学推导。希望读者在看完这篇文章后能更好的明白PCA的工作原理。
**参考资料**
- [PCA的数学原理](https://www.cnblogs.com/mikewolf2002/p/3429711.html)
- [PCA的数学原理(转)](https://zhuanlan.zhihu.com/p/21580949)
- [第13章 利用 PCA 来简化数据](https://www.cnblogs.com/apachecnxy/p/7640976.html)
- [PCA(主成分分析)原理推导](https://zhuanlan.zhihu.com/p/84946694)
## 线性判别分析(LDA)
TODO
**参考资料**
- [线性判别分析LDA原理总结](https://www.cnblogs.com/pinard/p/6244265.html)
- [LDA原理小结](https://blog.csdn.net/qq_16137569/article/details/82385050)
## 奇异值分解(SVD)
### 基本原理
- [ ] TODO
**参考资料**
- [Singular_value_decomposition](https://en.wikipedia.org/wiki/Singular_value_decomposition)
- [关于SVD(Singular Value Decomposition)的那些事儿](https://www.cnblogs.com/tgycoder/p/6266786.html)
- [奇异值分解(SVD)原理与在降维中的应用](https://www.cnblogs.com/pinard/p/6251584.html)
- [第14章 利用SVD简化数据](https://www.cnblogs.com/apachecnxy/p/7640987.html)
### 手撕 SVD
- [ ] TODO
### 特征值和SVD的区别
- [ ] TODO
**参考资料**
- [特征值和奇异值(svd)](https://blog.csdn.net/u012380663/article/details/36629951)
## 凸优化
### 基本原理
- [ ] TODO
**参考资料**
- [关于凸优化的一些简单概念](https://www.cnblogs.com/harvey888/p/7100815.html)
- [最优化理论与凸优化到底是干嘛的?](https://blog.csdn.net/qq_39422642/article/details/78816637)
- [深度学习/机器学习入门基础数学知识整理(三):凸优化,Hessian,牛顿法](https://blog.csdn.net/xbinworld/article/details/79113218)
## 神经网络
- [ ] TODO
注:建议放在深度学习中介绍,这里可以简单介绍
## Accuracy、Precision、Recall和 F1 Score
在学习机器学习、深度学习,甚至做自己项目的时候,经过看到上述名词。然而因为名词容易搞混,所以经常会忘记相关的含义。
这里做一次最全最清晰的介绍,若之后再次忘记相关知识点,本文可以帮助快速回顾。
首先,列出一个清单:
- TP(true positive,真正): 预测为正,实际为正
- FP(false positive,假正): 预测为正,实际为负
- TN(true negative,真负):预测为负,实际为负
- FN(false negative,假负): 预测为负,实际为正
- ACC(accuracy,准确率):ACC = (TP+TN)/(TP+TN+FN+FP)
- P(precision精确率、精准率、查准率P = TP/ (TP+FP)
- R(recall,召回率、查全率): R = TP/ (TP+FN)
- TPR(true positive rate,,真正类率同召回率、查全率):TPR = TP/ (TP+FN)
注:Recall = TPR
- FPR(false positive rate,假正类率):FPR =FP/ (FP+TN)
- F-Score: F-Score = (1+β^2) x (PxR) / (β^2x(P+R)) = 2xTP/(2xTP + FP + FN)
- 当β=1是,F1-score = 2xPxR/(P+R)
- P-R曲线(precision-recall,查准率-查全率曲线)
- ROC曲线(receiver operating characteristic,接收者操作特征曲线)
- AUC(area under curve)值
中文博大精深,为了不搞混,下面统一用英文全称或简称作为名词标识。
正式介绍一下前四个名词:
**True positives(TP,真正)** : 预测为正,实际为正
**True negatives(TN,真负)**:预测为负,实际为负
**False positives(FP,假正**): 预测为正,实际为负
**False negatives(FN,假负)**: 预测为负,实际为正
为了更好的理解,这里二元分类问题的例子:
假设,我们要对某一封邮件做出一个判定,判定这封邮件是垃圾邮件、还是这封邮件不是垃圾邮件?
如果判定是垃圾邮件,那就是做出(Positive)的判定;
如果判定不是垃圾邮件,那就做出(Negative)的判定。
True Positive(TP)意思表示做出Positive的判定,而且判定是正确的。
因此,TP的数值表示正确的Positive判定的个数。
同理,False Positive(TP)数值表示错误的Positive判定的个数。
依此,True Negative(TN)数值表示正确的Negative判定个数。
False Negative(FN)数值表示错误的Negative判定个数。
**TPR、FPR和TNR**
**TPR(true positive rate,真正类率)**
TPR = TP/(TP+FN)
真正类率TPR代表分类器预测的正类中实际正实例占所有正实例的比例。
**FPR(false positive rate,假正类率)**
FPR = FP/(FP+TN)
假正类率FPR代表分类器预测的正类中实际负实例占所有负实例的比例。
**TNR(ture negative rate,真负类率)**
TNR = TN/(FP+TN)
真负类率TNR代表分类器预测的负类中实际负实例占所有负实例的比例。
**Accuracy**
准确率(accuracy,ACC)
ACC = (TP+TN)/(TP+TN+FN+FP)
**Precision & Recall**
[Precision精确率](https://en.wikipedia.org/wiki/Precision_and_recall):
P = TP/(TP+FP)
表示当前划分到正样本类别中,被正确分类的比例(正确正样本所占比例)。
[Recall召回率](https://en.wikipedia.org/wiki/Precision_and_recall):
R = TP/(TP+FN)
表示当前划分到正样本类别中,真实正样本占所有正样本的比例。
**F-Score**
F-Score 是精确率Precision和召回率Recall的加权调和平均值。该值是为了综合衡量Precision和Recall而设定的。
F-Score = (1+β^2) x (PxR) / (β^2x(P+R)) = 2xTP/(2xTP + FP + FN)
当β=1时,F1-score = 2xPxR/(P+R)。这时,Precision和Recall都很重要,权重相同。
当有些情况下,我们认为Precision更重要,那就调整β的值小于1;如果我们认为Recall更加重要,那就调整β的值大于1。
一般来说,当F-Score或F1-score较高
**P-R曲线**
**ROC曲线**
横轴:负正类率(false postive rate FPR)
纵轴:真正类率(true postive rate TPR)

**AUC值**
上面都是理论,看起来很迷糊,这里举个真实应用的实例,加强理解。
对于那些不熟悉的人,我将解释精确度和召回率,对于那些熟悉的人,我将在比较精确召回曲线时解释文献中的一些混淆。
下面从图像分类的角度举个例子:
假设现在有这样一个测试集,测试集中的图片只由大雁和飞机两种图片组成,如下图所示:

假设你的分类系统最终的目的是:能取出测试集中所有飞机的图片,而不是大雁的图片。
现在做如下的定义:
True positives(TP,真正) : 飞机的图片被正确的识别成了飞机。
True negatives(TN,真负): 大雁的图片没有被识别出来,系统正确地认为它们是大雁。
False positives(FP,假正): 大雁的图片被错误地识别成了飞机。
False negatives(FN,假负): 飞机的图片没有被识别出来,系统错误地认为它们是大雁。
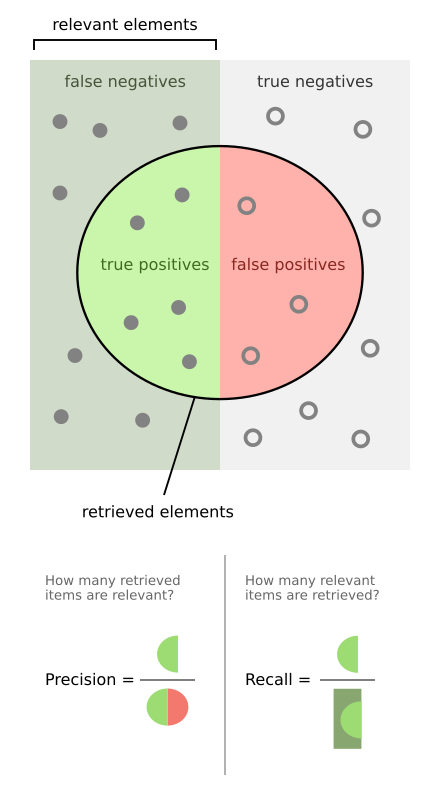
**实战**
```python
'''In binary classification settings'''
######### Create simple data ##########
from sklearn import svm, datasets
from sklearn.model_selection import train_test_split
import numpy as np
iris = datasets.load_iris()
X = iris.data
y = iris.target
# Add noisy features
random_state = np.random.RandomState(0)
n_samples, n_features = X.shape
X = np.c_[X, random_state.randn(n_samples, 200 * n_features)]
# Limit to the two first classes, and split into training and test
X_train, X_test, y_train, y_test = train_test_split(X[y < 2], y[y < 2],
test_size=.5,
random_state=random_state)
# Create a simple classifier
classifier = svm.LinearSVC(random_state=random_state)
classifier.fit(X_train, y_train)
y_score = classifier.decision_function(X_test)
######## Compute the average precision score ########
from sklearn.metrics import average_precision_score
average_precision = average_precision_score(y_test, y_score)
print('Average precision-recall score: {0:0.2f}'.format(
average_precision))
######## Plot the Precision-Recall curve ######
from sklearn.metrics import precision_recall_curve
import matplotlib.pyplot as plt
precision, recall, _ = precision_recall_curve(y_test, y_score)
plt.step(recall, precision, color='b', alpha=0.2,
where='post')
plt.fill_between(recall, precision, step='post', alpha=0.2,
color='b')
plt.xlabel('Recall')
plt.ylabel('Precision')
plt.ylim([0.0, 1.05])
plt.xlim([0.0, 1.0])
plt.title('2-class Precision-Recall curve: AP={0:0.2f}'.format(
average_precision))
plt.show()
```
**参考资料**
- [Accuracy, Precision, Recall & F1 Score: Interpretation of Performance Measures](http://blog.exsilio.com/all/accuracy-precision-recall-f1-score-interpretation-of-performance-measures/)
- [Precision and recall](https://en.wikipedia.org/wiki/Precision_and_recall)
- [average precision](https://sanchom.wordpress.com/tag/average-precision/)
- [Precision-Recall](http://scikit-learn.org/stable/auto_examples/model_selection/plot_precision_recall.html)
- [【YOLO学习】召回率(Recall),精确率(Precision),平均正确率(Average_precision(AP) ),交除并(Intersection-over-Union(IoU))](https://blog.csdn.net/hysteric314/article/details/54093734)
- [Precision,Recall,F1score,Accuracy的理解](https://blog.csdn.net/u014380165/article/details/77493978)
- [ROC、Precision、Recall、TPR、FPR理解](https://www.jianshu.com/p/be2e037900a1)
- [推荐系统评测指标—准确率(Precision)、召回率(Recall)、F值(F-Measure) ](http://bookshadow.com/weblog/2014/06/10/precision-recall-f-measure/)
- [机器学习之分类器性能指标之ROC曲线、AUC值](http://www.cnblogs.com/dlml/p/4403482.html)
## 正则化方法
- L1 范数
- L2 范数
- 数据集增广
- Dropout
- Batch Normaliztion
**参考资料**
- [[Deep Learning\] 正则化](https://www.cnblogs.com/maybe2030/p/9231231.html)
### L1和L2正则化
目的:降低损失函数
机器学习中几乎都可以看到损失函数后面会添加一个额外项,常用的额外项一般有两种,一般英文称作ℓ1-norm和ℓ2-norm,中文称作L1正则化和L2正则化,或者L1范数和L2范数。
L1正则化和L2正则化可以看做是损失函数的惩罚项。所谓『惩罚』是指对损失函数中的某些参数做一些限制。对于线性回归模型,使用L1正则化的模型建叫做Lasso回归,使用L2正则化的模型叫做Ridge回归(岭回归)。下图是Python中Lasso回归的损失函数,式中加号后面一项α||w||1即为L1正则化项。

下图是Python中Ridge回归的损失函数,式中加号后面一项即为L2正则化项。

一般回归分析中回归w表示特征的系数,从上式可以看到正则化项是对系数做了处理(限制)。L1正则化和L2正则化的说明如下:
- L1正则化是指权值向量w中各个元素的绝对值之和,通常表示为||w||1
- L2正则化是指权值向量w中各个元素的平方和然后再求平方根(可以看到Ridge回归的L2正则化项有平方符号),通常表示为||w||2
一般都会在正则化项之前添加一个系数,Python中用α表示,一些文章也用λ表示。这个系数需要用户指定。
那添加L1和L2正则化有什么用?下面是L1正则化和L2正则化的作用,这些表述可以在很多文章中找到。
- L1正则化可以产生稀疏权值矩阵,即产生一个稀疏模型,可以用于特征选择
- L2正则化可以防止模型过拟合(overfitting);一定程度上,L1也可以防止过拟合
**稀疏模型与特征选择**
上面提到L1正则化有助于生成一个稀疏权值矩阵,进而可以用于特征选择。为什么要生成一个稀疏矩阵?
稀疏矩阵指的是很多元素为0,只有少数元素是非零值的矩阵,即得到的线性回归模型的大部分系数都是0. 通常机器学习中特征数量很多,例如文本处理时,如果将一个词组(term)作为一个特征,那么特征数量会达到上万个(bigram)。在预测或分类时,那么多特征显然难以选择,但是如果代入这些特征得到的模型是一个稀疏模型,表示只有少数特征对这个模型有贡献,绝大部分特征是没有贡献的,或者贡献微小(因为它们前面的系数是0或者是很小的值,即使去掉对模型也没有什么影响),此时我们就可以只关注系数是非零值的特征。这就是稀疏模型与特征选择的关系。
**L1和L2正则化的直观理解**
这部分内容将解释为什么L1正则化可以产生稀疏模型(L1是怎么让系数等于零的),以及为什么L2正则化可以防止过拟合。
L1正则化和特征选择
假设有如下带L1正则化的损失函数:

其中J0是原始的损失函数,加号后面的一项是L1正则化项,α是正则化系数。注意到L1正则化是权值的绝对值之和,J是带有绝对值符号的函数,因此J是不完全可微的。机器学习的任务就是要通过一些方法(比如梯度下降)求出损失函数的最小值。当我们在原始损失函数J0后添加L1正则化项时,相当于对J0做了一个约束。令L=α∑w|w|,则J=J0+L,此时我们的任务变成在L约束下求出J0取最小值的解。考虑二维的情况,即只有两个权值w1和w2,此时L=|w1|+|w2|对于梯度下降法,求解J0的过程可以画出等值线,同时L1正则化的函数L也可以在w1w2的二维平面上画出来。如下图:

图1 L1正则化
图中等值线是J0的等值线,黑色方形是L函数的图形。在图中,当J0等值线与L图形首次相交的地方就是最优解。上图中J0与L在L的一个顶点处相交,这个顶点就是最优解。注意到这个顶点的值是(w1,w2)=(0,w)。可以直观想象,因为L函数有很多『突出的角』(二维情况下四个,多维情况下更多),J0与这些角接触的机率会远大于与L其它部位接触的机率,而在这些角上,会有很多权值等于0,这就是为什么L1正则化可以产生稀疏模型,进而可以用于特征选择。
而正则化前面的系数α,可以控制L图形的大小。α越小,L的图形越大(上图中的黑色方框);α越大,L的图形就越小,可以小到黑色方框只超出原点范围一点点,这是最优点的值(w1,w2)=(0,w)中的w可以取到很小的值。
类似,假设有如下带L2正则化的损失函数:

同样可以画出它们在二维平面上的图形,如下:

图2 L2正则化
二维平面下L2正则化的函数图形是个圆,与方形相比,被磨去了棱角。因此J0与L相交时使得w1或w2等于零的机率小了许多,这就是为什么L2正则化不具有稀疏性的原因。
注:以二维平面举例,借助可视化L1和L2,可知L1正则化具有稀疏性。
**L2正则化和过拟合**
拟合过程中通常都倾向于让权值尽可能小,最后构造一个所有参数都比较小的模型。因为一般认为参数值小的模型比较简单,能适应不同的数据集,也在一定程度上避免了过拟合现象。可以设想一下对于一个线性回归方程,若参数很大,那么只要数据偏移一点点,就会对结果造成很大的影响;但如果参数足够小,数据偏移得多一点也不会对结果造成什么影响,专业一点的说法是『抗扰动能力强』。
那为什么L2正则化可以获得值很小的参数?
以线性回归中的梯度下降法为例。假设要求的参数为θ,hθ(x)是我们的假设函数,那么线性回归的代价函数如下:

那么在梯度下降法中,最终用于迭代计算参数θ的迭代式为:

其中α是learning rate. 上式是没有添加L2正则化项的迭代公式,如果在原始代价函数之后添加L2正则化,则迭代公式会变成下面的样子:

其中λ就是正则化参数。从上式可以看到,与未添加L2正则化的迭代公式相比,每一次迭代,θj都要先乘以一个小于1的因子,从而使得θj不断减小,因此总得来看,θ是不断减小的。
最开始也提到L1正则化一定程度上也可以防止过拟合。之前做了解释,当L1的正则化系数很小时,得到的最优解会很小,可以达到和L2正则化类似的效果。
L2正则化参数
从上述公式可以看到,λ越大,θj衰减得越快。另一个理解可以参考图2,λ越大,L2圆的半径越小,最后求得代价函数最值时各参数也会变得很小。
### L1 和 L2 正则化的区别
- [ ] TODO
### 机器学习中常常提到的正则化到底是什么意思?
- [ ] TODO
**参考资料**
- [机器学习中常常提到的正则化到底是什么意思?](https://www.zhihu.com/question/20924039)
### 为什么 L2 正则化可以防止过拟合?
- [ ] TODO
## 过拟合和欠拟合
### 基本原理
**过拟合(Over-Fitting)**
高方差
在训练集上误差小,但在测试集上误差大,我们将这种情况称为高方差(high variance),也叫过拟合。
**欠拟合(Under-Fitting)**
在训练集上训练效果不好(测试集上也不好),准确率不高,我们将这种情况称为高偏差(high bias),也叫欠拟合。
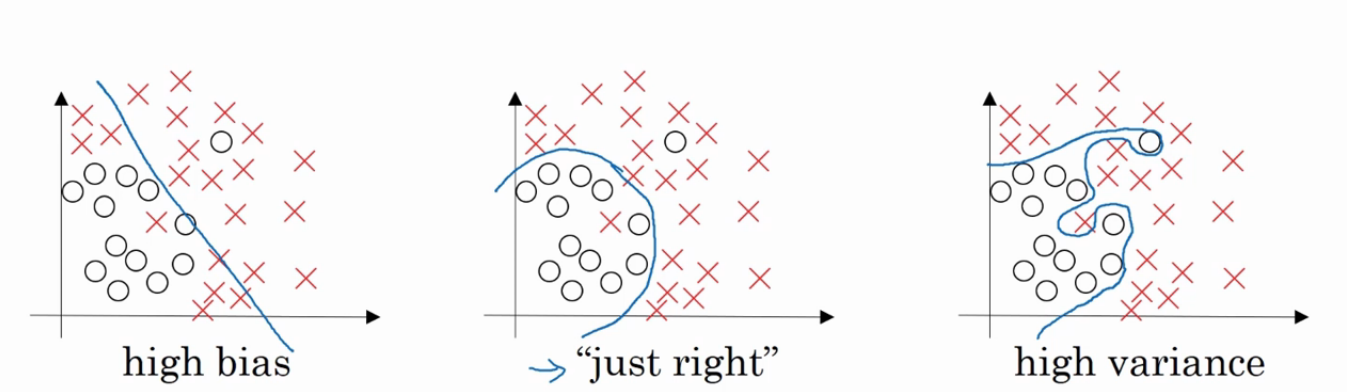
### 如何防止过拟合?
- 数据增广(Data Augmentation)
- 正则化(L0正则、L1正则和L2正则),也叫限制权值Weight-decay
- Dropout
- Early Stopping
- 简化模型
- 增加噪声
- Bagging
- 贝叶斯方法
- 决策树剪枝
- 集成方法,随机森林
- Batch Normalization
### 如何防止欠拟合?
- 添加新特征
- 添加多项式特征
- 减少正则化参数
- 增加网络复杂度
- 使用集成学习方法,如Bagging
## 精确率(Precision)和召回率(Recall)
- [ ] TODO
**参考资料**
- [如何解释召回率与精确率?](https://www.zhihu.com/question/19645541)
- [分类--精确率和召回率](https://www.cnblogs.com/taro/p/8643335.html)
## AUC 和 ROC
### 基本原理
- [ ] TODO
### 如何绘制ROC曲线?
- [ ] TODO
### ROC曲线下面积表示什么?
- [ ] TODO
### 手撕 AUC 曲面面积代码
- [ ] TODO
## 梯度弥散和梯度爆炸
- [ ] TODO
## 什么是参数范数惩罚?
- [ ] TODO
## 为什么要进行归一化?优点?
- [ ] TODO
## CCA和PCA的区别
- [ ] TODO
## Softmax
### 基本原理
- [ ] TODO
### Softmax是和什么loss function配合使用?
- [ ] TODO
### Softmax代码实现
- [ ] TODO
## 交叉熵损失函数
- [ ] TODO
## 通俗解释一下信息熵
- [ ] TODO
## 如何加快梯度下降收敛速度?
- [ ] TODO
## 如何解决正负样本数量不均衡?
- [ ] TODO
## 如何解决异常值问题?
- [ ] TODO
## 机器学习中使用正则化来防止过拟合是什么原理?
- [ ] TODO
**参考资料**
- [机器学习中使用正则化来防止过拟合是什么原理?](https://www.zhihu.com/question/20700829)
## 机器学习中常常提到的正则化到底是什么意思?
- [ ] TODO
**参考资料**
- [机器学习中常常提到的正则化到底是什么意思?](https://www.zhihu.com/question/20924039)
## 梯度下降陷入局部最优有什么解决办法
- [ ] TODO
## 聚类算法中的距离度量有哪些?
- [ ] TODO
常见的距离度量:欧氏距离、曼哈顿距离、夹角余弦、切比雪夫距离、汉明距离
## KL 散度和交叉熵的区别
- [ ] TODO
## 降维的方法都有哪些?
- [ ] TODO
## TODO
================================================
FILE: docs/深度学习.md
================================================
[TOC]
# 深度学习
## 神经网络中的Epoch、Iteration、Batchsize
神经网络中epoch与iteration是不相等的
- batchsize:中文翻译为批大小(批尺寸)。在深度学习中,一般采用SGD训练,即每次训练在训练集中取batchsize个样本训练;
- iteration:中文翻译为迭代,1个iteration等于使用batchsize个样本训练一次;一个迭代 = 一个正向通过+一个反向通过
- epoch:迭代次数,1个epoch等于使用训练集中的全部样本训练一次;一个epoch = 所有训练样本的一个正向传递和一个反向传递
举个例子,训练集有1000个样本,batchsize=10,那么:训练完整个样本集需要:100次iteration,1次epoch。

**参考资料**
- [神经网络中的Epoch、Iteration、Batchsize](https://zhuanlan.zhihu.com/p/67414365)
- [神经网络中epoch与iteration相等吗](https://zhidao.baidu.com/question/716300338908227765.html)
## 反向传播(BP)
- [ ] TODO
**参考资料**
- [一文搞懂反向传播算法](https://www.jianshu.com/p/964345dddb70)
## CNN本质和优势
局部卷积(提取局部特征)
权值共享(降低训练难度)
Pooling(降维,将低层次组合为高层次的特征)
多层次结构
## 鞍点的定义和特点?
- [ ] TODO
## 神经网络数据预处理方法有哪些?
- [ ] TODO
## 神经网络怎样进行参数初始化?
- [ ] TODO
## 卷积
- [ ] TODO
**参考资料**
- [Feature Extraction Using Convolution](http://ufldl.stanford.edu/tutorial/supervised/FeatureExtractionUsingConvolution/)
- [convolution](https://leonardoaraujosantos.gitbooks.io/artificial-inteligence/content/convolution.html)
- [理解图像卷积操作的意义](https://blog.csdn.net/chaipp0607/article/details/72236892?locationNum=9&fps=1)
- [关于深度学习中卷积核操作](https://www.cnblogs.com/Yu-FeiFei/p/6800519.html)
### 卷积的反向传播过程
- [ ] TODO
**参考资料**
- [Notes on Convolutional Neural Network](http://cogprints.org/5869/1/cnn_tutorial.pdf)
- [Deep Learning论文笔记之(四)CNN卷积神经网络推导和实现](https://blog.csdn.net/zouxy09/article/details/9993371)
- [反向传导算法](http://deeplearning.stanford.edu/wiki/index.php/%E5%8F%8D%E5%90%91%E4%BC%A0%E5%AF%BC%E7%AE%97%E6%B3%95)
- [Deep learning:五十一(CNN的反向求导及练习)](https://www.cnblogs.com/tornadomeet/p/3468450.html)
- [卷积神经网络(CNN)反向传播算法](https://www.cnblogs.com/pinard/p/6494810.html)
- [卷积神经网络(CNN)反向传播算法公式详细推导](https://blog.csdn.net/walegahaha/article/details/51945421)
- [全连接神经网络中反向传播算法数学推导](https://zhuanlan.zhihu.com/p/61863634)
- [卷积神经网络(CNN)反向传播算法推导](https://zhuanlan.zhihu.com/p/61898234)
## CNN 模型所需的计算力(flops)和参数(parameters)数量是怎么计算的?
对于一个卷积层,假设其大小为 (其中c为#input channel, n为#output channel),输出的feature map尺寸为 ,则该卷积层的
- paras =
- FLOPs = 
- [ ] TODO
**参考资料**
- [CNN 模型所需的计算力(flops)和参数(parameters)数量是怎么计算的?](https://www.zhihu.com/question/65305385/answer/256845252)
- [CNN中parameters和FLOPs计算](https://blog.csdn.net/sinat_34460960/article/details/84779219)
- [FLOPS理解](https://blog.csdn.net/smallhujiu/article/details/80876875)
- [PyTorch-OpCounter](https://github.com/Lyken17/pytorch-OpCounter)
## 池化(Pooling)
**平均池化(Mean Pooling)**
mean pooling的前向传播就是把一个patch中的值求取平均来做pooling,那么反向传播的过程也就是把某个元素的梯度等分为n份分配给前一层,这样就保证池化前后的梯度(残差)之和保持不变,还是比较理解的,图示如下
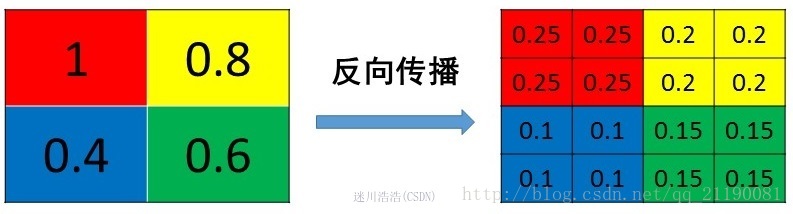
**最大池化(Max Pooling)**
max pooling也要满足梯度之和不变的原则,max pooling的前向传播是把patch中最大的值传递给后一层,而其他像素的值直接被舍弃掉。那么反向传播也就是把梯度直接传给前一层某一个像素,而其他像素不接受梯度,也就是为0。所以max pooling操作和mean pooling操作不同点在于需要记录下池化操作时到底哪个像素的值是最大,也就是max id,这个可以看caffe源码的pooling_layer.cpp,下面是caffe框架max pooling部分的源码
```python
// If max pooling, we will initialize the vector index part.
if (this->layer_param_.pooling_param().pool() == PoolingParameter_PoolMethod_MAX && top.size() == 1)
{
max_idx_.Reshape(bottom[0]->num(), channels_, pooled_height_,pooled_width_);
}
```
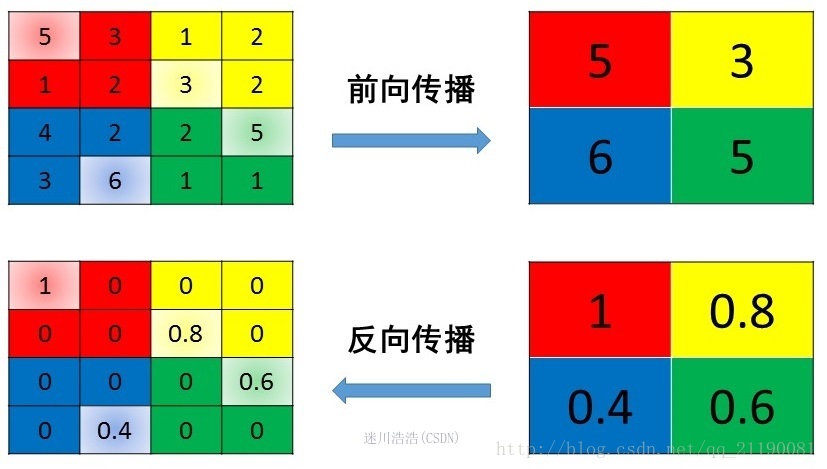
**参考资料**
- [如何理解CNN中的池化?](https://zhuanlan.zhihu.com/p/35769417)
- [深度学习笔记(3)——CNN中一些特殊环节的反向传播](https://blog.csdn.net/qq_21190081/article/details/72871704)
### 池化层怎么接收后面传过来的损失?
RF是感受野。N_RF和RF有点像,N代表 neighbour,指的是第n层的 a feature在n-1层的RF,记住N_RF只是一个中间变量,不要和RF混淆。 stride是步长,ksize是卷积核大小。
(N-1)_RF = f(N_RF, stride, kernel) = (N_RF - 1) * stride + kernel
第一层是3*3,第二层是7*7
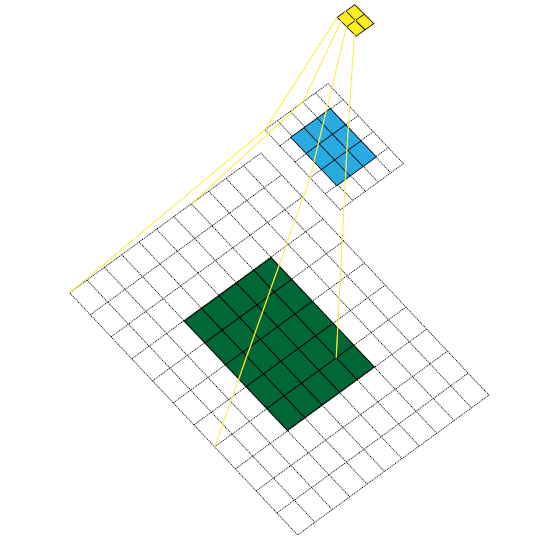
黄色feature map对应的感受野是7*7大小
### 平均池化(average pooling)
- [ ] TODO
### 最大池化(max pooling)
- [ ] TODO
## 感受野
感受野($Receptive$ $Field$)的定义是卷积神经网络每一层输出的特征图($feature$ $map$)上的像素点在**原始输入图片**上映射的区域大小。再通俗点的解释是,特征图上的一个点对应**原始输入图片**上的区域,如下图所示。

### 感受野的作用
(1)一般 $task$ 要求感受野越大越好,如图像分类中最后卷积层的感受野要大于输入图像,网络深度越深感受野越大性能越好;
(2)密集预测$task$要求输出像素的感受野足够的大,确保做出决策时没有忽略重要信息,一般也是越深越好;
(3)目标检测$task$中设置$anchor$要严格对应感受野,$anchor$太大或偏离感受野都会严重影响检测性能。
### 感受野计算
在计算感受野时有下面几点需要说明:
(1)第一层卷积层的输出特征图像素的感受野的大小等于卷积核的大小。
(2)深层卷积层的感受野大小和它之前所有层的滤波器大小和步长有关系。
(3)计算感受野大小时,忽略了图像边缘的影响,即不考虑padding的大小。
下面给出计算感受野大小的计算公式:
$$
RF_{l+1} = (RF_{l}-1)*stide + kernel
$$
其中$RF_{l+1}$为当前特征图对应的感受野的大小,也就是要计算的目标感受野,$RF_{l}$为上一层特征图对应的感受野大小,$f_{l+1}$为当前卷积层卷积核的大小,累乘项$strides$表示当前卷积层之前所有卷积层的步长乘积。
举一个例子,7 * 7的输入图经过三层卷积核为3 * 3的卷积操作后得到$Out3$的感受野为7 * 7,也就是$Out3$中的值是由$Input$所有区域的值经过卷积计算得到,其中卷积核($filter$)的步长($stride$)为1、$padding$为0,,如下图所示:

以上面举的$sample$为例:
$Out1$层由于是第一层卷积输出,即其感受野等于其卷积核的大小,**即第一层卷积层输出的特征图的感受野为3**,$RF1$=3;
$Out2$层的感受野$RF2$ = 3 + (3 - 1) * 1 = 5,**即第二层卷积层输出的特征图的感受野为5**;
$Out3$层的感受野$RF3$ = 3 + (5 - 1) * 1 = 7,**即第三层卷积层输出的特征图的感受野为7**;
**参考资料**
- [卷积神经网络物体检测之感受野大小计算](https://www.cnblogs.com/objectDetect/p/5947169.html)
- [如何计算感受野(Receptive Field)——原理](https://zhuanlan.zhihu.com/p/31004121)
- [Computing Receptive Fields of Convolutional Neural Networks](https://distill.pub/2019/computing-receptive-fields/)
### 卷积神经网络的感受野
- [ ] TODO
**参考资料**
- [卷积神经网络的感受野](https://zhuanlan.zhihu.com/p/44106492)
## 权重初始化方法
- [ ] TODO
### Xavier
- [ ] TODO
## 正则化方法
1. [参数范数惩罚](https://baike.baidu.com/item/%E6%AD%A3%E5%88%99%E5%8C%96%E6%96%B9%E6%B3%95/19145625?fr=aladdin#1)
2. [L2参数正则化](https://baike.baidu.com/item/%E6%AD%A3%E5%88%99%E5%8C%96%E6%96%B9%E6%B3%95/19145625?fr=aladdin#2)
3. [L1参数正则化](https://baike.baidu.com/item/%E6%AD%A3%E5%88%99%E5%8C%96%E6%96%B9%E6%B3%95/19145625?fr=aladdin#3)
4. [L1正则化和L2正则化的区别](https://baike.baidu.com/item/%E6%AD%A3%E5%88%99%E5%8C%96%E6%96%B9%E6%B3%95/19145625?fr=aladdin#4)
5. [数据集增强](https://baike.baidu.com/item/%E6%AD%A3%E5%88%99%E5%8C%96%E6%96%B9%E6%B3%95/19145625?fr=aladdin#5)
6. [噪音的鲁棒性](https://baike.baidu.com/item/%E6%AD%A3%E5%88%99%E5%8C%96%E6%96%B9%E6%B3%95/19145625?fr=aladdin#6)
7. [向输出目标注入噪声](https://baike.baidu.com/item/%E6%AD%A3%E5%88%99%E5%8C%96%E6%96%B9%E6%B3%95/19145625?fr=aladdin#7)
8. [半监督学习](https://baike.baidu.com/item/%E6%AD%A3%E5%88%99%E5%8C%96%E6%96%B9%E6%B3%95/19145625?fr=aladdin#8)
9. [多任务学习](https://baike.baidu.com/item/%E6%AD%A3%E5%88%99%E5%8C%96%E6%96%B9%E6%B3%95/19145625?fr=aladdin#9)
10. [提前终止](https://baike.baidu.com/item/%E6%AD%A3%E5%88%99%E5%8C%96%E6%96%B9%E6%B3%95/19145625?fr=aladdin#10)
11. [参数绑定和共享](https://baike.baidu.com/item/%E6%AD%A3%E5%88%99%E5%8C%96%E6%96%B9%E6%B3%95/19145625?fr=aladdin#11)
12. [稀疏表示](https://baike.baidu.com/item/%E6%AD%A3%E5%88%99%E5%8C%96%E6%96%B9%E6%B3%95/19145625?fr=aladdin#12)
13. [集成化方法](https://baike.baidu.com/item/%E6%AD%A3%E5%88%99%E5%8C%96%E6%96%B9%E6%B3%95/19145625?fr=aladdin#13)
**参考资料**
- [ ] [正则化方法](https://baike.baidu.com/item/%E6%AD%A3%E5%88%99%E5%8C%96%E6%96%B9%E6%B3%95/19145625?fr=aladdin)
- [ ] [你够全面了解L1与L2正则吗?](https://mp.weixin.qq.com/s?__biz=MzkzNDIxMzE1NQ==&mid=2247486609&idx=1&sn=76fc19df55a2d7f605b8203ccd5f101c&chksm=c241efddf53666cb70ebb3b44a40154778c94c2a2c2fda74418ce994805b99bd2ee644becf68&scene=178&cur_album_id=1860258784426672132#rd)
## Batch Normalization(BN)
### BN 原理
> 为了解决 ICS 的问题,(但是有人求证过了,ICS 的问题并不能完全解决),BN启发于白化操作。
因为深层神经网络在做非线性变换前的激活输入值(就是那个x=WU+B,U是输入)随着网络深度加深或者在训练过程中,其分布逐渐发生偏移或者变动,之所以训练收敛慢,所以这导致反向传播时低层神经网络的梯度消失,这是训练深层神经网络收敛越来越慢的.
BN就是通过一定的规范化手段,把每层神经网络任意神经元这个输入值的分布强行拉回到均值为0方差为1的标准正态分布 ,其实就是把越来越偏的分布强制拉回比较标准的分布,这样使得激活输入值落在非线性函数对输入比较敏感的区域,这样输入的小变化就会导致损失函数较大的变化,
上面记不住没关系,记住“保持数据同分布”即可
**参考资料**
- [Batch Normalization原理与实战](https://zhuanlan.zhihu.com/p/34879333)
### 手写 BN
的简单计算步骤为:
- 沿着通道计算每个batch的均值$\mu=\frac{1}{m} \sum_{i=1}^{m} x_{i}$。
- 沿着通道计算每个$batch$的方差$\delta^{2}=\frac{1}{m} \sum_{i=1}^{m}\left(x_{i}-\mu_{\mathcal{B}}\right)^{2}$。
- 对x做归一化, 
- 加入缩放和平移变量$\gamma$和$\beta$ ,归一化后的值,$y_{i} \leftarrow \gamma \widehat{x}_{i}+\beta$
$BN$适用于判别模型中,比如图片分类模型。因为$BN$注重对每个$batch$进行归一化,从而保证数据分布的一致性,而判别模型的结果正是取决于数据整体分布。但是$BN$对$batchsize$的大小比较敏感,由于每次计算均值和方差是在一个$batch$上,所以如果$batchsize$太小,则计算的均值、方差不足以代表整个数据分布。
### BN 的作用?
- $BN$加快网络的训练与收敛的速度
在深度神经网络中中,如果每层的数据分布都不一样的话,将会导致网络非常难收敛和训练。如果把每层的数据都在转换在均值为零,方差为1 的状态下,这样每层数据的分布都是一样的训练会比较容易收敛。
- 控制梯度爆炸防止梯度消失
以$sigmoid$函数为例,$sigmoid$函数使得输出在$[0,1]$之间,实际上当 输入过大或者过小,经过sigmoid函数后输出范围就会变得很小,而且反向传播时的梯度也会非常小,从而导致梯度消失,同时也会导致网络学习速率过慢;同时由于网络的前端比后端求梯度需要进行更多次的求导运算,最终会出现网络后端一直学习,而前端几乎不学习的情况。Batch Normalization (BN) 通常被添加在每一个全连接和激励函数之间,使数据在进入激活函数之前集中分布在0值附近,大部分激活函数输入在0周围时输出会有加大变化。
同样,使用了$BN$之后,可以使得权值不会很大,不会有梯度爆炸的问题。
- 防止过拟合
在网络的训练中,BN的使用使得一个$minibatch$中所有样本都被关联在了一起,因此网络不会从某一个训练样本中生成确定的结果,即同样一个样本的输出不再仅仅取决于样本的本身,也取决于跟这个样本同属一个$batch$的其他样本,而每次网络都是随机取$batch$,比较多样,可以在一定程度上避免了过拟合。
### BN 有哪些参数?
γ和β两个尺度变化系数
### BN 的反向传播推导

下面来一个背诵版本:

### BN 在训练和测试的区别?

- [推理时 cnn bn 折叠;基于KWS项目](https://blog.csdn.net/weixin_37598106/article/details/106825799)
### BN 是放在激活前面还是后面?
一般是放在激活层前面,但是自己做了一些实验,和网上有大佬的说法结合,放在前后的差别并不大,我做的实验是语音唤醒,非 CV 实验。但是一般使用的时候都是放在前面的。
## Weight Normalization(WN)
- [ ] TODO
## Layer Normalization(LN)
- [ ] TODO
## Instance Normalization(IN)
- [ ] TODO
## Group Normalization(GN)
- [ ] TODO
### BN、LN、WN、IN和GN的区别
**主要且常用**的归一化操作有**BN,LN,IN,GN**,示意图如图所示。

图中的蓝色部分,表示需要归一化的部分。其中两维$C$和$N$分别表示$channel$和$batch$ $size$,第三维表示$H$,$W$,可以理解为该维度大小是$H*W$,也就是拉长成一维,这样总体就可以用三维图形来表示。可以看出$BN$的计算和$batch$ $size$相关(蓝色区域为计算均值和方差的单元),而$LN$、$BN$和$GN$的计算和$batch$ $size$无关。同时$LN$和$IN$都可以看作是$GN$的特殊情况($LN$是$group$=1时候的$GN$,$IN$是$group=C$时候的$GN$)。
**参考资料**
- [深度学习中的五种归一化(BN、LN、IN、GN和SN)方法简介](https://blog.csdn.net/u013289254/article/details/99690730)
- [BatchNormalization、LayerNormalization、InstanceNorm、GroupNorm、SwitchableNorm总结](https://blog.csdn.net/liuxiao214/article/details/81037416)
## 优化算法
- 随机梯度下降(SGD)
- Mini-Batch
- 动量(Momentum)
- Nesterov 动量
- AdaGrad
- AdaDelta
- RMSProp
- Adam
- Adamax
- Nadam
- [AMSGrad](http://ruder.io/optimizing-gradient-descent/index.html#amsgrad)
- AdaBound
**参考资料**
- [《Deep Learning》第八章:深度模型中的优化](https://exacity.github.io/deeplearningbook-chinese/Chapter8_optimization_for_training_deep_models/)
- [从 SGD 到 Adam —— 深度学习优化算法概览(一)](https://zhuanlan.zhihu.com/p/32626442)
- [Adam 究竟还有什么问题 —— 深度学习优化算法概览(二)](https://zhuanlan.zhihu.com/p/37269222)
- [An overview of gradient descent optimization algorithms](http://ruder.io/optimizing-gradient-descent/)
## 011 梯度下降法
梯度下降的**本质**:是一种使用梯度去迭代更新权重参数使目标函数最小化的方法。
缺点:
1. 不保证全局最优
2. 到极小值附近收敛速度变慢
3. 可能出现“之”字型下降
- [温故知新——梯度下降(Gradient Descent)](https://zhuanlan.zhihu.com/p/72374201)
=======
### 梯度下降法
- [ ] TODO
### mini-batch梯度下降法
小批量梯度下降算法是折中方案,选取训练集中一个小批量样本(一般是2的倍数,如32,64,128等)计算,这样可以保证训练过程更稳定,而且采用批量训练方法也可以利用矩阵计算的优势。这是目前最常用的梯度下降算法。
> 批量梯度下降算法
> 对于批量梯度下降算法,其损失函数是在整个训练集上计算的,如果数据集比较大,可能会面临内存不足问题,而且其收敛速度一般比较慢。
区别点在于:**整个训练集**做一次损失函数计算还是**一个小批量样本**做一次损失函数计算
### 随机梯度下降法(SGD)
#### SGD每步做什么,为什么能online learning?
随机梯度下降算法是另外一个极端,损失函数是针对训练集中的一个训练样本计算的,又称为在线学习,即得到了一个样本,就可以执行一次参数更新。所以其收敛速度会快一些,但是有可能出现目标函数值震荡现象,因为高频率的参数更新导致了高方差。
区别点在于:**训练集中的一个训练样本**做一次损失函数计算
### 动量梯度下降法(Momentum)
引入一个指数加权平均的知识点。也就是下图中的前两行公式。使用这个公式,可以将之前的dW和db都联系起来,不再是每一次梯度都是独立的情况。

---
**参考资料**
- [简述动量Momentum梯度下降](https://blog.csdn.net/yinruiyang94/article/details/77944338)
### RMSprop
$$
S_{dW}=\beta S_{dW}+\left ( 1-\beta \right )dW^{2}
$$
$$
S_{db}=\beta S_{db}+\left ( 1-\beta \right )db^{2}
$$
$$
W=W-\alpha\frac{dW}{\sqrt{S_{dW}}}, b=b-\alpha\frac{db}{\sqrt{S_{db}}}
$$
更新权重的时候,使用除根号的方法,可以使较大的梯度大幅度变小,而较小的梯度小幅度变小,这样就可以使较大梯度方向上的波动小下来,那么整个梯度下降的过程中摆动就会比较小
### Adagrad
- [ ] TODO
### Adam
Adam算法结合了Momentum和RMSprop梯度下降法,是一种极其常见的学习算法,被证明能有效适用于不同神经网络,适用于广泛的结构。
$$
v_{dW}=\beta_{1} v_{dW}+\left ( 1-\beta_{1} \right )dW
$$
$$
v_{db}=\beta_{1} v_{db}+\left ( 1-\beta_{1} \right )db
$$
$$
S_{dW}=\beta_{2} S_{dW}+\left ( 1-\beta_{2} \right )dW^{2}
$$
$$
S_{db}=\beta_{2} S_{db}+\left ( 1-\beta_{2} \right )db^{2}
$$
$$
v_{dW}^{corrected}=\frac{v_{dW}}{1-\beta_{1}^{t}}
$$
$$
v_{db}^{corrected}=\frac{v_{db}}{1-\beta_{1}^{t}}
$$
$$
S_{dW}^{corrected}=\frac{S_{dW}}{1-\beta_{2}^{t}}
$$
$$
S_{db}^{corrected}=\frac{S_{db}}{1-\beta_{2}^{t}}
$$
$$
W:=W-\frac{av_{dW}^{corrected}}{\sqrt{S_{dW}^{corrected}}+\varepsilon }
$$
超参数:
$$
\alpha ,\beta _{1},\beta_{2},\varepsilon
$$
t是迭代次数
- [ ] TODO
## 017 常见的激活函数及其特点
- Sigmod
=======
#### Adam 优化器的迭代公式
- [ ] TODO
## 激活函数
- Tanh
- ReLU
---
- [常见的激活函数总结](https://blog.csdn.net/colourful_sky/article/details/79164720)
## 018 ReLU及其变体
- Leaky ReLU
=======
**参考资料**
- [What is activate function?](https://yogayu.github.io/DeepLearningCourse/03/ActivateFunction.html)
- [资源 | 从ReLU到Sinc,26种神经网络激活函数可视化](https://mp.weixin.qq.com/s/7DgiXCNBS5vb07WIKTFYRQ)
### Sigmoid
- [ ] TODO
#### Sigmoid用作激活函数时,分类为什么要用交叉熵损失,而不用均方损失?
- [ ] TODO
### tanh
- [ ] TODO
### ReLU
- [ ] TODO
ReLU 相关变体
#### ReLU 激活函数为什么比sigmoid和tanh好?
- PReLU
- RReLU
- ELU
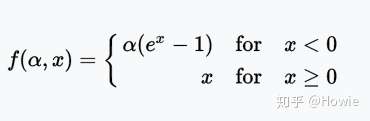
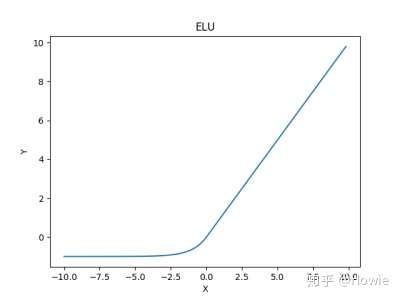
---
- [激活函数综述](https://zhuanlan.zhihu.com/p/56210226)
#### ReLU 激活函数为什么能解决梯度消失问题?
- [ ] TODO
#### ReLU 有哪些变体?
- [ ] TODO
## Dropout
### Dropout 基本原理
- [ ] TODO
**参考资料**
- [理解dropout](https://blog.csdn.net/stdcoutzyx/article/details/49022443)
### Dropout 如何实现?
- [ ] TODO
### Drop 在训练和测试的区别
- [ ] TODO
## 损失函数(Loss)
- [ ] TODO
### Cross Entropy Loss(CE)
- [ ] TODO
### Hinge Loss
- [ ] TODO
### Focal Loss
- [ ] TODO
## 1*1 卷积有什么作用?
- [ ] TODO
## AlexNet
- 使用ReLU激活函数
- Dropout
- 数据增广
先给出AlexNet的一些参数和结构图:
卷积层:5层
全连接层:3层
深度:8层
参数个数:60M
神经元个数:650k
分类数目:1000类
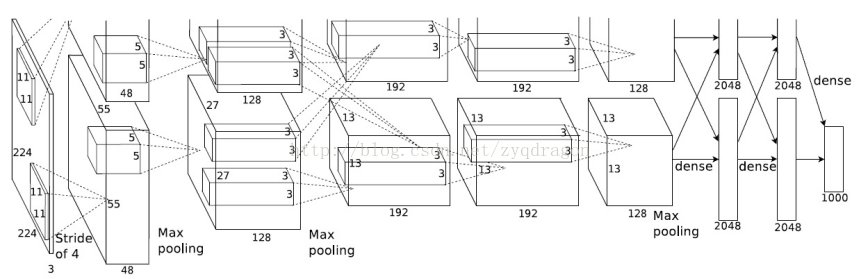
**参考资料**
[AlexNet](https://dgschwend.github.io/netscope/#/preset/alexnet)
## VGG
**《Very Deep Convolutional Networks for Large-Scale Image Recognition》**
- arXiv:https://arxiv.org/abs/1409.1556
- intro:ICLR 2015
- homepage:http://www.robots.ox.ac.uk/~vgg/research/very_deep/
[VGG](https://arxiv.org/abs/1409.1556) 是Oxford的**V**isual **G**eometry **G**roup的组提出的(大家应该能看出VGG名字的由来了)。该网络是在ILSVRC 2014上的相关工作,主要工作是证明了增加网络的深度能够在一定程度上影响网络最终的性能。VGG有两种结构,分别是VGG16和VGG19,两者并没有本质上的区别,只是网络深度不一样。
VGG16相比AlexNet的一个改进是采用**连续的几个3x3的卷积核代替AlexNet中的较大卷积核(11x11,7x7,5x5)**。对于给定的感受野(与输出有关的输入图片的局部大小),**采用堆积的小卷积核是优于采用大的卷积核,因为多层非线性层可以增加网络深度来保证学习更复杂的模式,而且代价还比较小(参数更少)**。
简单来说,在VGG中,使用了3个3x3卷积核来代替7x7卷积核,使用了2个3x3卷积核来代替5*5卷积核,这样做的主要目的是在保证具有**相同感知野的条件下,提升了网络的深度**,在一定程度上提升了神经网络的效果。
比如,3个步长为1的3x3卷积核的一层层叠加作用可看成一个大小为7的感受野(其实就表示3个3x3连续卷积相当于一个7x7卷积),其参数总量为 3x(9xC^2) ,如果直接使用7x7卷积核,其参数总量为 49xC^2 ,这里 C 指的是输入和输出的通道数。很明显,27xC^2小于49xC^2,即减少了参数;而且3x3卷积核有利于更好地保持图像性质。
这里解释一下为什么使用2个3x3卷积核可以来代替5*5卷积核:
5x5卷积看做一个小的全连接网络在5x5区域滑动,我们可以先用一个3x3的卷积滤波器卷积,然后再用一个全连接层连接这个3x3卷积输出,这个全连接层我们也可以看做一个3x3卷积层。这样我们就可以用两个3x3卷积级联(叠加)起来代替一个 5x5卷积。
具体如下图所示:

至于为什么使用3个3x3卷积核可以来代替7*7卷积核,推导过程与上述类似,大家可以自行绘图理解。
下面是VGG网络的结构(VGG16和VGG19都在):

- VGG16包含了16个隐藏层(13个卷积层和3个全连接层),如上图中的D列所示
- VGG19包含了19个隐藏层(16个卷积层和3个全连接层),如上图中的E列所示
VGG网络的结构非常一致,从头到尾全部使用的是3x3的卷积和2x2的max pooling。
如果你想看到更加形象化的VGG网络,可以使用[经典卷积神经网络(CNN)结构可视化工具](https://mp.weixin.qq.com/s/gktWxh1p2rR2Jz-A7rs_UQ)来查看高清无码的[VGG网络](https://dgschwend.github.io/netscope/#/preset/vgg-16)。
**VGG优点:**
- VGGNet的结构非常简洁,整个网络都使用了同样大小的卷积核尺寸(3x3)和最大池化尺寸(2x2)。
- 几个小滤波器(3x3)卷积层的组合比一个大滤波器(5x5或7x7)卷积层好:
- 验证了通过不断加深网络结构可以提升性能。
**VGG缺点**:
VGG耗费更多计算资源,并且使用了更多的参数(这里不是3x3卷积的锅),导致更多的内存占用(140M)。其中绝大多数的参数都是来自于第一个全连接层。VGG可是有3个全连接层啊!
PS:有的文章称:发现这些全连接层即使被去除,对于性能也没有什么影响,这样就显著降低了参数数量。
注:很多pretrained的方法就是使用VGG的model(主要是16和19),VGG相对其他的方法,参数空间很大,最终的model有500多m,AlexNet只有200m,GoogLeNet更少,所以train一个vgg模型通常要花费更长的时间,所幸有公开的pretrained model让我们很方便的使用。
关于感受野:
假设你一层一层地重叠了3个3x3的卷积层(层与层之间有非线性激活函数)。在这个排列下,第一个卷积层中的每个神经元都对输入数据体有一个3x3的视野。
**代码篇:VGG训练与测试**
这里推荐两个开源库,训练请参考[tensorflow-vgg](https://github.com/machrisaa/tensorflow-vgg),快速测试请参考[VGG-in TensorFlow](https://www.cs.toronto.edu/~frossard/post/vgg16/)。
代码我就不介绍了,其实跟上述内容一致,跟着原理看code应该会很快。我快速跑了一下[VGG-in TensorFlow](https://www.cs.toronto.edu/~frossard/post/vgg16/),代码亲测可用,效果很nice,就是model下载比较烦。
贴心的Amusi已经为你准备好了[VGG-in TensorFlow](https://www.cs.toronto.edu/~frossard/post/vgg16/)的测试代码、model和图像。需要的同学可以关注CVer微信公众号,后台回复:VGG。
天道酬勤,还有很多知识要学,想想都刺激~Fighting!
**参考资料**
- [《Very Deep Convolutional Networks for Large-Scale Image Recognition》](https://arxiv.org/abs/1409.1556)
- [深度网络VGG理解](https://blog.csdn.net/wcy12341189/article/details/56281618)
- [深度学习经典卷积神经网络之VGGNet](https://blog.csdn.net/marsjhao/article/details/72955935)
- [VGG16 结构可视化](https://dgschwend.github.io/netscope/#/preset/vgg-16)
- [tensorflow-vgg](https://github.com/machrisaa/tensorflow-vgg)
- [VGG-in TensorFlow](https://www.cs.toronto.edu/~frossard/post/vgg16/)
- [机器学习进阶笔记之五 | 深入理解VGG\Residual Network](https://zhuanlan.zhihu.com/p/23518167)
## ResNet
**1.ResNet意义**
随着网络的加深,出现了训练集准确率下降的现象,我们可以确定这不是由于Overfit过拟合造成的(过拟合的情况训练集应该准确率很高);所以作者针对这个问题提出了一种全新的网络,叫深度残差网络,它允许网络尽可能的加深,其中引入了全新的结构如图1;
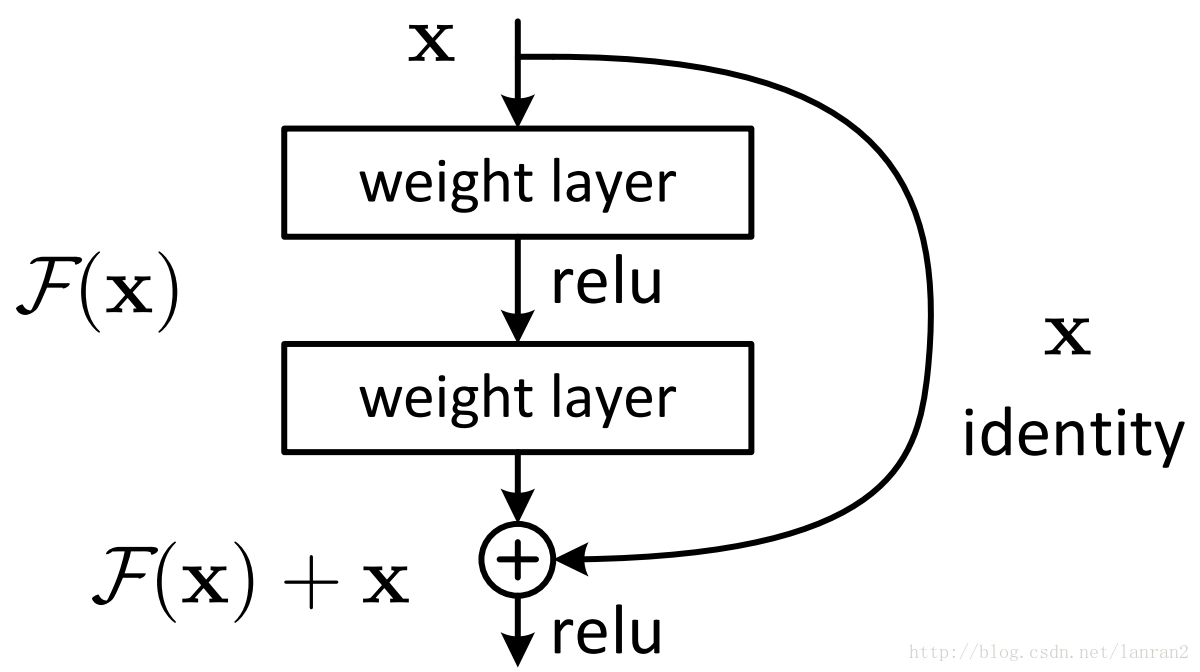
*图1 Shortcut Connection*
这里问大家一个问题,残差指的是什么?
其中ResNet提出了两种mapping:
一种是identity mapping,指的就是图1中”弯弯的曲线”,另一种residual mapping,指的就是除了”弯弯的曲线“那部分,所以最后的输出是 y=F(x)+x
identity mapping顾名思义,就是指本身,也就是公式中的x,而residual mapping指的是“差”,也就是y−x,所以残差指的就是F(x)部分。
为什么ResNet可以解决“随着网络加深,准确率不下降”的问题?
理论上,对于“随着网络加深,准确率下降”的问题,Resnet提供了两种选择方式,也就是identity mapping和residual mapping,如果网络已经到达最优,继续加深网络,residual mapping将被push为0,只剩下identity mapping,这样理论上网络一直处于最优状态了,网络的性能也就不会随着深度增加而降低了。
**2.ResNet结构**
它使用了一种连接方式叫做“shortcut connection”,顾名思义,shortcut就是“抄近道”的意思,看下图我们就能大致理解:

**ResNet的F(x)究竟长什么样子?**
残差的思想都是去掉相同的主体部分,从而突出微小的变化
> F是求和前网络映射,H是从输入到求和后的网络映射。比如把5映射到5.1,那么引入残差前是F'(5)=5.1,引入残差后是H(5)=5.1, H(5)=F(5)+5, F(5)=0.1。这里的F'和F都表示网络参数映射,引入残差后的映射对输出的变化更敏感。比如s输出从5.1变到5.2,映射F'的输出增加了1/51=2%,而对于残差结构输出从5.1到5.2,映射F是从0.1到0.2,增加了100%。明显后者输出变化对权重的调整作用更大,所以效果更好。
关于H(x) F(x) x 三者之间的关系:
> 网络输入是x,网络的输出是F(x),网络要拟合的目标是H(x),
传统网络的训练目标是F(x)=H(x)。
残差网络,则是把传统网络的输出F(x)处理一下,加上输入,将F(x)+x作为最终的输出,训练目标是F(x)=H(x)-x,因此得名残差网络。
现在我们要训练一个深层的网络,它可能过深,假设存在一个性能最强的完美网络N,与它相比我们的网络中必定有一些层是多余的,那么这些多余的层的训练目标是恒等变换,只有达到这个目标我们的网络性能才能跟N一样。
对于这些需要实现恒等变换的多余的层,要拟合的目标就成了H(x)=x,在传统网络中,网络的输出目标是F(x)=x,这比较困难,而在残差网络中,拟合的目标成了x-x=0,网络的输出目标为F(x)=0,这比前者要容易得多。
>
> 作者:王殊
> 链接:https://www.zhihu.com/question/53224378/answer/343061012
**参考资料**
- [ResNet解析](https://blog.csdn.net/lanran2/article/details/79057994)
- [ResNet论文笔记](https://blog.csdn.net/wspba/article/details/56019373)
- [残差网络ResNet笔记](https://www.jianshu.com/p/e58437f39f65)
- [An Overview of ResNet and its Variants](https://towardsdatascience.com/an-overview-of-resnet-and-its-variants-5281e2f56035)
- [译文](https://www.jianshu.com/p/46d76bd56766)
- [Understanding and Implementing Architectures of ResNet and ResNeXt for state-of-the-art Image Classification: From Microsoft to Facebook [Part 1]](https://medium.com/@14prakash/understanding-and-implementing-architectures-of-resnet-and-resnext-for-state-of-the-art-image-cf51669e1624)
- [给妹纸的深度学习教学(4)——同Residual玩耍](https://zhuanlan.zhihu.com/p/28413039)
- [Residual Networks 理解](https://zhuanlan.zhihu.com/p/32173684)
- [Identity Mapping in ResNet](https://zhuanlan.zhihu.com/p/32206896)
- [resnet(残差网络)的F(x)究竟长什么样子?](https://www.zhihu.com/question/53224378)
- [ResNet到底在解决一个什么问题呢?](https://www.zhihu.com/question/64494691)
### ResNet为什么不用Dropout?
### **YOLOv1**
(1) 给一个输入图像,首先将图像划分成7 * 7的网格。
- [ ] TODO
**参考资料**
-
- https://zhuanlan.zhihu.com/p/60923972
### 为什么 ResNet 不在一开始就使用residual block,而是使用一个7×7的卷积?
先上一下paper里的图例:
YOLO检测网络包含24个卷积层(用来提取特征)和2个全联接层(用来预测图像位置和类类别置信度),并且使用了大量的1x1的卷积用来降低上一层的layer到下一层的特征空间。

YOLO将输入图像分成SxS个格子,每个格子负责检测‘落入’该格子的物体。若某个物体的中心位置的坐标落入到某个格子,那么这个格子就负责检测出这个物体。如下图所示,图中物体狗的中心点(红色原点)落入第5行、第2列的格子内,所以这个格子负责预测图像中的物体狗。


这样的结果是针对每一个 bbox 而言的目标类别概率分布的置信值,这个置信值同时表达了 2 样东西,一个是目标是某个类别的概率,一个是预测的 bbox 离真实的 bbox 有多远。
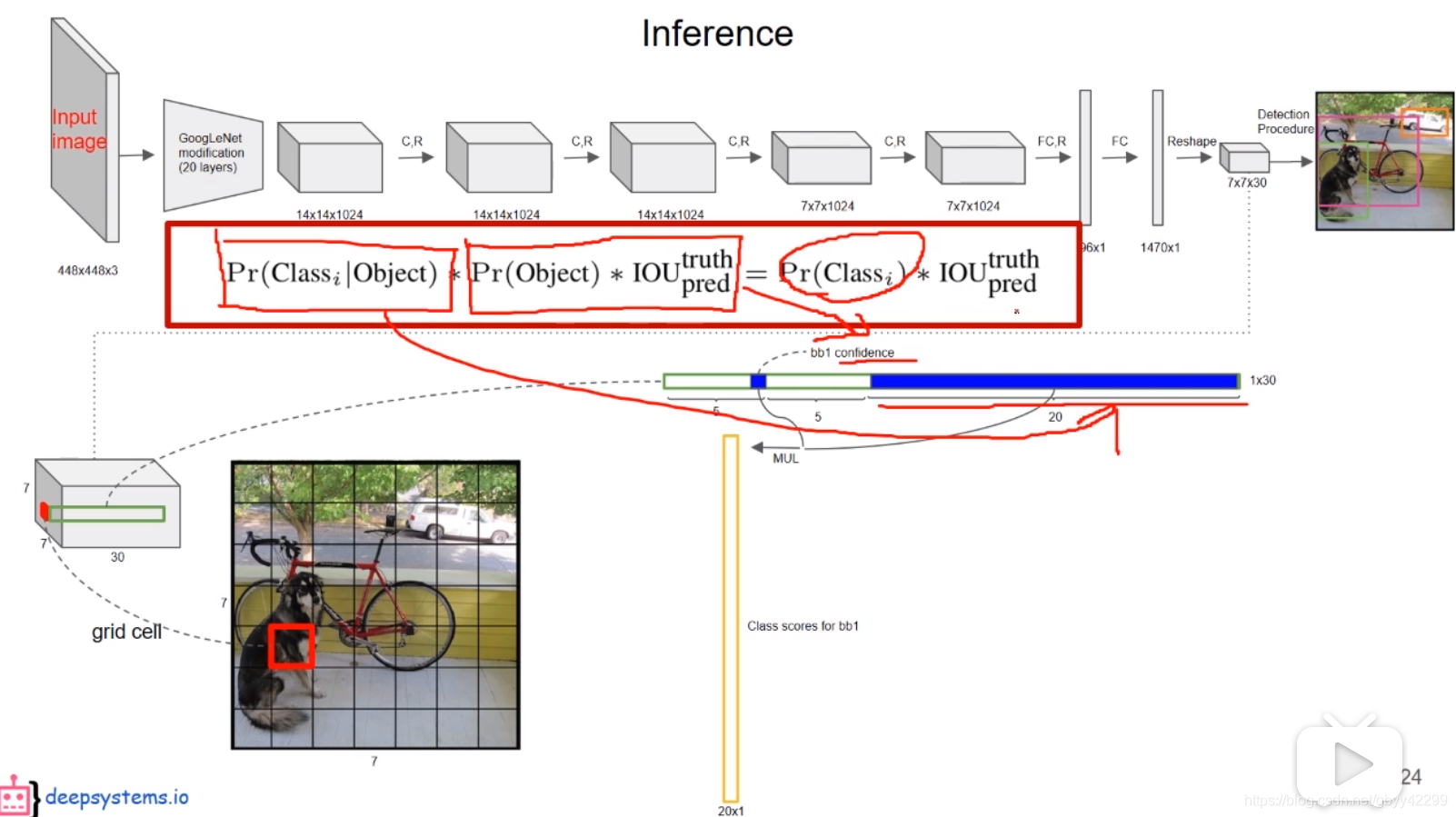
总结:
YOLO v1 也有和当年其它杰出的目标检测系统做对比,但在今天来看,这个并不十分重要,重要的是我们需要理解 YOLO 快的原因。
- YOLO 就是一个撒渔网的捕鱼过程,一次性搞定所有的目标定位。
- YOLO 快的原因在于比较粗的粒度将输入图片划分网格,然后做预测。
- YOLO 的算法精髓都体现在它的 Loss 设计上及作者如何针对问题改进 Loss,这种思考问题的方式才是最值得我们学习的。
缺馅:
- 输入尺寸固定:由于输出层为全连接层,因此在检测时,YOLO训练模型只支持与训练图像相同的输入分辨率。其它分辨率需要缩放成改分辨率.
- 占比较小的目标检测效果不好.虽然每个格子可以预测B个bounding box,但是最终只选择只选择IOU最高的bounding box作为物体检测输出,即每个格子最多只预测出一个物体。当物体占画面比例较小,如图像中包含畜群或鸟群时,每个格子包含多个物体,但却只能检测出其中一个。
**参考资料**
[YOLO V1全网最详细的解读](https://blog.csdn.net/gbyy42299/article/details/88869766)
[目标检测算法 YOLO 最耐心细致的讲解](https://blog.csdn.net/briblue/article/details/84794511 )
[yolo回归型的物体检测](https://blog.csdn.net/Jinlong_Xu/article/details/77888100)
[目标检测网络之 YOLOv3](https://www.cnblogs.com/makefile/p/YOLOv3.html)
---
NMS图解(IOU略过):
NMS主要就是通过迭代的形式,不断的以最大得分的框去与其他框做IoU操作,并过滤那些IoU较大(即交集较大)的框。如图 3图 4所示NMS的计算过程。
1、根据候选框的类别分类概率做排序,假如有4个 BBox ,其置信度A>B>C>D。
2、先标记最大概率矩形框A是算法要保留的BBox;
3、从最大概率矩形框A开始,分别判断ABC与D的重叠度IOU(两框的交并比)是否大于某个设定的阈值(0.5),假设D与A的重叠度超过阈值,那么就舍弃D;
4、从剩下的矩形框BC中,选择概率最大的B,标记为保留,然后判读C与B的重叠度,扔掉重叠度超过设定阈值的矩形框;
5、一直重复进行,标记完所有要保留下来的矩形框。
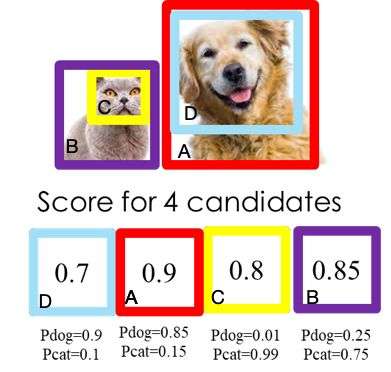
图3 猫和狗两类目标检测
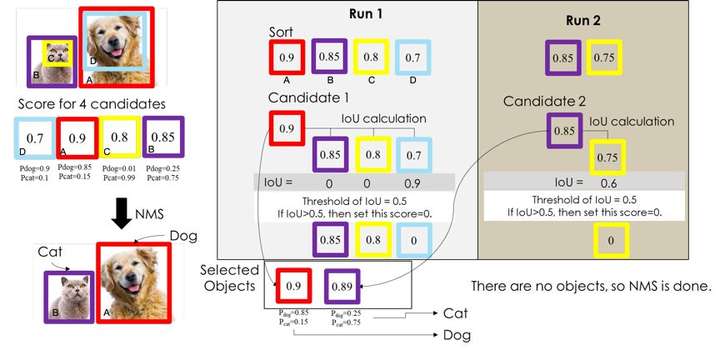
图4 NMS算法过程
---
### **YOLOv2**
=======

原因: 7x7卷积实际上是用来直接对**输入图片**降采样(early downsampling), 注意像7x7这样的大卷积核一般只出现在**input layer**
**目的是:** 尽可能**保留原始图像的信息,** 而不需要增加channels数.
**本质上是:** 多channels的非线性激活层是非常昂贵的, 在**input laye**r用**big kernel**换多channels是划算的

>【Tips】BN层的作用:
> (1)加速收敛 //数据同分布,缓解了ICS现象,并且可使用更大的学习率和更多的激活函数。
> (2)控制过拟合,可以少用或不用Dropout和正则 //引用均值和方差,增加数据噪声,即数据增强
> (3)允许使用较大的学习率 // 数据同分布
> 在使用BN前,减小学习率、小心的权重初始化的目的是:使其输出的数据分布不要发生太大的变化。
High Resolution Classifier
=======
注意一下, resnet接入residual block前pixel为56x56的layer, channels数才**64**, 但是同样大小的layer, 在vgg-19里已经有**256**个channels了.
这里要强调一下, 只有在input layer层, 也就是**最靠近输入图片**的那层, 才用大卷积, 原因如下:
深度学习领域, 有一种广泛的直觉,即更大的卷积更好,但更昂贵。输入层中的特征数量(224x224)是如此之小(相对于隐藏层),第一卷积可以非常大而不会大幅增加实际的权重数。**如果你想在某个地方进行大卷积,第一层通常是唯一的选择**。
我认为神经网络的第一层是最基本的,因为它基本上只是将数据嵌入到一个新的更大的向量空间中。ResNet在第二层之前没有开始其特征层跳过,所以看起来作者想要在开始整花里胡哨的layers之前尽可能保留图像里更多的primary features.
题外话, 同时期的GoogLeNet也在input layer用到了7x7大卷积, 所以resnet作者的灵感来源于GoogLeNet也说不定, 至于非要追问为啥这么用, 也许最直接的理由就是"深度学习就像炼丹, 因为这样网络工作得更好, 所以作者就这么用了".
之前的YOLO利用全连接层的数据完成边框的预测,导致丢失较多的空间信息,定位不准。作者在这一版本中借鉴了Faster R-CNN中的anchor思想,回顾一下,anchor是RNP网络中的一个关键步骤,说的是在卷积特征图上进行滑窗操作,每一个中心可以预测9种不同大小的建议框。看到YOLOv2的这一借鉴,我只能说SSD的作者是有先见之明的。
为了引入anchor boxes来预测bounding boxes,作者在网络中果断去掉了全连接层。剩下的具体怎么操作呢?首先,作者去掉了后面的一个池化层以确保输出的卷积特征图有更高的分辨率。然后,通过缩减网络,让图片输入分辨率为416 * 416,这一步的目的是为了让后面产生的卷积特征图宽高都为奇数,这样就可以产生一个center cell。作者观察到,大物体通常占据了图像的中间位置, 就可以只用中心的一个cell来预测这些物体的位置,否则就要用中间的4个cell来进行预测,这个技巧可稍稍提升效率。最后,YOLOv2使用了卷积层降采样(factor为32),使得输入卷积网络的416 * 416图片最终得到13 * 13的卷积特征图(416/32=13)。
再说个有趣的例子, resnet模型是实验先于理论, 实验证明有效, 后面才陆续有人研究为啥有效, 比如[The Shattered Gradients Problem: If resnets are the answer, then what is the question?](https://link.zhihu.com/?target=https%3A//arxiv.org/abs/1702.08591) 可不就是炼丹么?
**参考资料**
- [为什么resnet不在一开始就使用residual block,而是使用一个7×7的卷积?](https://www.zhihu.com/question/330735327/answer/725695411)
### 什么是Bottlenet layer?
- [ ] TODO
### ResNet如何解决梯度消失?
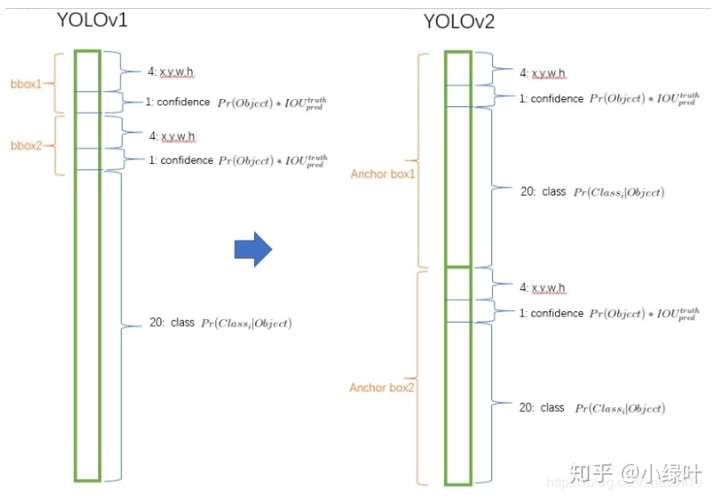
=======
- [ ] TODO
### ResNet网络越来越深,准确率会不会提升?
- [ ] TODO
## ResNet v2

---
**参考资料**
- [《Identity Mappings in Deep Residual Networks》](https://arxiv.org/abs/1603.05027)
- [Feature Extractor[ResNet v2]](https://www.cnblogs.com/shouhuxianjian/p/7770658.html)
- [ResNetV2:ResNet深度解析](https://blog.csdn.net/lanran2/article/details/80247515)
- [ResNet v2论文笔记](https://blog.csdn.net/u014061630/article/details/80558661)
- [[ResNet系] 002 ResNet-v2](https://segmentfault.com/a/1190000011228906)
### ResNet v1 与 ResNet v2的区别
ResNet V2和 ResNet V1 的主要区别在于,作者通过研究 ResNet 残差学习单元的传播公式,发现前馈和反馈信息可以直接传输,因此 skip connection 的非线性激活函数(如ReLU)替换为 Identity Mappings(y = x)。同时,ResNet V2在每一层中都使用了Batch Normalization。这样处理之后,新的残差学习单元将比以前更容易训练且泛化性更强。
- [tensorflow学习笔记——ResNet](https://www.cnblogs.com/wj-1314/p/11519663.html)
### ResNet v2 的 ReLU 激活函数有什么不同?
- [ ] TODO
## ResNeXt
在`ResNet`提出`deeper`可以带来网络性质提高的同时,`WideResNet`则认为`Wider`也可以带来深度网络性能的改善。为了打破或`deeper`,或`wider`的常规思路,ResNeXt则认为可以引入一个新维度,称之为`cardinality`。

- [ResNeXt算法详解](https://blog.csdn.net/u014380165/article/details/71667916)
- ResNet 的其他变种:WRNS(Wide Residual Networks)、Res2Net、ReXNet
## Inception系列(V1-V4)
### InceptionV1
- [ ] TODO
### InceptionV2
- [ ] TODO
[YOLO升级版:YOLOv2和YOLO9000解析](https://zhuanlan.zhihu.com/p/25052190)
## 023 R-CNN系列
### InceptionV3
- [ ] TODO
### InceptionV4
- [ ] TODO
**参考资料**
- [一文概览Inception家族的「奋斗史」](https://baijiahao.baidu.com/s?id=1601882944953788623&wfr=spider&for=pc)
- [inception-v1,v2,v3,v4----论文笔记](https://blog.csdn.net/weixin_39953502/article/details/80966046)
## DenseNet
在以往的网络都是从
- 要么深(比如`ResNet`,解决了网络深时候的梯度消失问题)
- 要么宽(比如`GoogleNet`的`Inception`)的网络,
而作者则是从`feature`入手,通过对`feature`的极致利用达到更好的效果和更少的参数。
`DenseNet`网络有以下优点:
- 由于密集连接方式,DenseNet提升了梯度的反向传播,**使得网络更容易训练**。
- **参数更小且计算更高效**,这有点违反直觉,由于DenseNet是通过concat特征来实现短路连接,实现了特征重用,并且采用较小的growth rate,每个层所独有的特征图是比较小的;
- 由于**特征复用**,最后的分类器使用了低级特征。
为了解决随着网络深度的增加,网络梯度消失的问题,在`ResNet`网络 之后,科研界把研究重心放在通过更有效的跳跃连接的方法上。`DenseNet`系列网络延续这个思路,并做到了一个极致,就是直接将所有层都连接起来。`DenseNet`层连接方法示意图如图所示。

### 为什么 DenseNet 比 ResNet 好?
- [ ] TODO
### 为什么 DenseNet 比 ResNet 更耗显存?
- [ ] TODO
## SE-Net
- [ ] TODO
### Squeeze-Excitation结构是怎么实现的?
TODO
## FCN
一句话概括就是:FCN将传统网络后面的全连接层换成了卷积层,这样网络输出不再是类别而是 heatmap;同时为了解决因为卷积和池化对图像尺寸的影响,提出使用上采样的方式恢复。
作者的FCN主要使用了三种技术:
- 卷积化(Convolutional)
- 上采样(Upsample)
- 跳跃结构(Skip Layer)
卷积化
卷积化即是将普通的分类网络,比如VGG16,ResNet50/101等网络丢弃全连接层,换上对应的卷积层即可。
上采样
此处的上采样即是反卷积(Deconvolution)。当然关于这个名字不同框架不同,Caffe和Kera里叫Deconvolution,而tensorflow里叫conv_transpose。CS231n这门课中说,叫conv_transpose更为合适。
众所诸知,普通的池化(为什么这儿是普通的池化请看后文)会缩小图片的尺寸,比如VGG16 五次池化后图片被缩小了32倍。为了得到和原图等大的分割图,我们需要上采样/反卷积。
反卷积和卷积类似,都是相乘相加的运算。只不过后者是多对一,前者是一对多。而反卷积的前向和后向传播,只用颠倒卷积的前后向传播即可。所以无论优化还是后向传播算法都是没有问题。
跳跃结构(Skip Layers)
(这个奇怪的名字是我翻译的,好像一般叫忽略连接结构)这个结构的作用就在于优化结果,因为如果将全卷积之后的结果直接上采样得到的结果是很粗糙的,所以作者将不同池化层的结果进行上采样之后来优化输出。
上采样获得与输入一样的尺寸
文章采用的网络经过5次卷积+池化后,图像尺寸依次缩小了 2、4、8、16、32倍,对最后一层做32倍上采样,就可以得到与原图一样的大小
作者发现,仅对第5层做32倍反卷积(deconvolution),得到的结果不太精确。于是将第 4 层和第 3 层的输出也依次反卷积(图5)
**参考资料**
[【总结】图像语义分割之FCN和CRF](https://zhuanlan.zhihu.com/p/22308032)
[图像语义分割(1)- FCN](https://blog.csdn.net/zizi7/article/details/77093447)
[全卷积网络 FCN 详解](https://www.cnblogs.com/gujianhan/p/6030639.html)
## U-Net
本文介绍一种编码器-解码器结构。编码器逐渐减少池化层的空间维度,解码器逐步修复物体的细节和空间维度。编码器和解码器之间通常存在快捷连接,因此能帮助解码器更好地修复目标的细节。U-Net 是这种方法中最常用的结构。
fcn(fully convolutional natwork)的思想是:修改一个普通的逐层收缩的网络,用上采样(up sampling)(??反卷积)操作代替网络后部的池化(pooling)操作。因此,这些层增加了输出的分辨率。为了使用局部的信息,在网络收缩过程(路径)中产生的高分辨率特征(high resolution features) ,被连接到了修改后网络的上采样的结果上。在此之后,一个卷积层基于这些信息综合得到更精确的结果。
与fcn(fully convolutional natwork)不同的是,我们的网络在上采样部分依然有大量的特征通道(feature channels),这使得网络可以将环境信息向更高的分辨率层(higher resolution layers)传播。结果是,扩张路径基本对称于收缩路径。网络不存在任何全连接层(fully connected layers),并且,只使用每个卷积的有效部分,例如,分割图(segmentation map)只包含这样一些像素点,这些像素点的完整上下文都出现在输入图像中。为了预测图像边界区域的像素点,我们采用镜像图像的方式补全缺失的环境像素。这个tiling方法在使用网络分割大图像时是非常有用的,因为如果不这么做,GPU显存会限制图像分辨率。
我们的训练数据太少,因此我们采用弹性形变的方式增加数据。这可以让模型学习得到形变不变性。这对医学图像分割是非常重要的,因为组织的形变是非常常见的情况,并且计算机可以很有效的模拟真实的形变。在[3]中指出了在无监督特征学习中,增加数据以获取不变性的重要性。
**参考资料**
- [U-net翻译](https://blog.csdn.net/natsuka/article/details/78565229)
## DeepLab 系列
- [ ] TODO
**参考资料**
- [Semantic Segmentation --DeepLab(1,2,3)系列总结](https://blog.csdn.net/u011974639/article/details/79148719)
## 边框回顾(Bounding-Box Regression)
如下图所示,绿色的框表示真实值Ground Truth, 红色的框为Selective Search提取的候选区域/框Region Proposal。那么即便红色的框被分类器识别为飞机,但是由于红色的框定位不准(IoU<0.5), 这张图也相当于没有正确的检测出飞机。

如果我们能对红色的框进行微调fine-tuning,使得经过微调后的窗口跟Ground Truth 更接近, 这样岂不是定位会更准确。 而Bounding-box regression 就是用来微调这个窗口的。
边框回归是什么?
对于窗口一般使用四维向量(x,y,w,h)(x,y,w,h) 来表示, 分别表示窗口的中心点坐标和宽高。 对于图2, 红色的框 P 代表原始的Proposal, 绿色的框 G 代表目标的 Ground Truth, 我们的目标是寻找一种关系使得输入原始的窗口 P 经过映射得到一个跟真实窗口 G 更接近的回归窗口G^。

所以,边框回归的目的即是:给定(Px,Py,Pw,Ph)寻找一种映射f, 使得f(Px,Py,Pw,Ph)=(Gx^,Gy^,Gw^,Gh^)并且(Gx^,Gy^,Gw^,Gh^)≈(Gx,Gy,Gw,Gh)
边框回归怎么做的?
那么经过何种变换才能从图2中的窗口 P 变为窗口G^呢? 比较简单的思路就是: 平移+尺度放缩
先做平移(Δx,Δy),Δx=Pwdx(P),Δy=Phdy(P)这是R-CNN论文的:
G^x=Pwdx(P)+Px,(1)
G^y=Phdy(P)+Py,(2)
然后再做尺度缩放(Sw,Sh), Sw=exp(dw(P)),Sh=exp(dh(P)),对应论文中:
G^w=Pwexp(dw(P)),(3)
G^h=Phexp(dh(P)),(4)
观察(1)-(4)我们发现, 边框回归学习就是dx(P),dy(P),dw(P),dh(P)这四个变换。
下一步就是设计算法那得到这四个映射。
线性回归就是给定输入的特征向量 X, 学习一组参数 W, 使得经过线性回归后的值跟真实值 Y(Ground Truth)非常接近. 即Y≈WX。 那么 Bounding-box 中我们的输入以及输出分别是什么呢?
Input:
RegionProposal→P=(Px,Py,Pw,Ph)这个是什么? 输入就是这四个数值吗?其实真正的输入是这个窗口对应的 CNN 特征,也就是 R-CNN 中的 Pool5 feature(特征向量)。 (注:训练阶段输入还包括 Ground Truth, 也就是下边提到的t∗=(tx,ty,tw,th))
Output:
需要进行的平移变换和尺度缩放 dx(P),dy(P),dw(P),dh(P),或者说是Δx,Δy,Sw,Sh。我们的最终输出不应该是 Ground Truth 吗? 是的, 但是有了这四个变换我们就可以直接得到 Ground Truth。
这里还有个问题, 根据(1)~(4)我们可以知道, P 经过 dx(P),dy(P),dw(P),dh(P)得到的并不是真实值 G,而是预测值G^。的确,这四个值应该是经过 Ground Truth 和 Proposal 计算得到的真正需要的平移量(tx,ty)和尺度缩放(tw,th)。
这也就是 R-CNN 中的(6)~(9):
tx=(Gx−Px)/Pw,(6)
ty=(Gy−Py)/Ph,(7)
tw=log(Gw/Pw),(8)
th=log(Gh/Ph),(9)
那么目标函数可以表示为 d∗(P)=wT∗Φ5(P),Φ5(P)是输入 Proposal 的特征向量,w∗是要学习的参数(*表示 x,y,w,h, 也就是每一个变换对应一个目标函数) , d∗(P) 是得到的预测值。
我们要让预测值跟真实值t∗=(tx,ty,tw,th)差距最小, 得到损失函数为:
Loss=∑iN(ti∗−w^T∗ϕ5(Pi))2
函数优化目标为:
W∗=argminw∗∑iN(ti∗−w^T∗ϕ5(Pi))2+λ||w^∗||2
利用梯度下降法或者最小二乘法就可以得到 w∗。
**参考资料**
- [bounding box regression](http://caffecn.cn/?/question/160)
- [边框回归(Bounding Box Regression)详解](https://blog.csdn.net/zijin0802034/article/details/77685438)
- [什么是边框回归Bounding-Box regression,以及为什么要做、怎么做](https://www.julyedu.com/question/big/kp_id/26/ques_id/2139)
## 反卷积(deconv)/转置卷积(trans)
**参考资料**
- [反卷积(Deconvolution)、上采样(UNSampling)与上池化(UnPooling)](https://blog.csdn.net/a_a_ron/article/details/79181108)
- [Transposed Convolution, Fractionally Strided Convolution or Deconvolution](https://buptldy.github.io/2016/10/29/2016-10-29-deconv/)
## 空洞卷积(dilated/Atrous conv)
- [ ] TODO
**参考资料**
- [如何理解空洞卷积(dilated convolution)?]()
## Pooling层原理
- [ ] TODO
## depthwise卷积加速比推导
- [ ] TODO
## 为什么降采用使用max pooling,而分类使用average pooling
- [ ] TODO
## max pooling如何反向传播
- [ ] TODO
## 反卷积
TODO
## 组卷积(group convolution)
- [ ] TODO
在说明分组卷积之前我们用一张图来体会一下一般的卷积操作。

从上图可以看出,一般的卷积会对输入数据的整体一起做卷积操作,即输入数据:H1×W1×C1;而卷积核大小为h1×w1,通道为C1,一共有C2个,然后卷积得到的输出数据就是H2×W2×C2。这里我们假设输出和输出的分辨率是不变的。主要看这个过程是一气呵成的,这对于存储器的容量提出了更高的要求。
但是分组卷积明显就没有那么多的参数。先用图片直观地感受一下分组卷积的过程。对于上面所说的同样的一个问题,分组卷积就如下图所示。

可以看到,图中将输入数据分成了2组(组数为g),需要注意的是,这种分组只是在深度上进行划分,即某几个通道编为一组,这个具体的数量由(C1/g)决定。因为输出数据的改变,相应的,卷积核也需要做出同样的改变。即每组中卷积核的深度也就变成了(C1/g),而卷积核的大小是不需要改变的,此时每组的卷积核的个数就变成了(C2/g)个,而不是原来的C2了。然后用每组的卷积核同它们对应组内的输入数据卷积,得到了输出数据以后,再用concatenate的方式组合起来,最终的输出数据的通道仍旧是C2。也就是说,分组数g决定以后,那么我们将并行的运算g个相同的卷积过程,每个过程里(每组),输入数据为H1×W1×C1/g,卷积核大小为h1×w1×C1/g,一共有C2/g个,输出数据为H2×W2×C2/g。
举个例子:
Group conv本身就极大地减少了参数。比如当输入通道为256,输出通道也为256,kernel size为3×3,不做Group conv参数为256×3×3×256。实施分组卷积时,若group为8,每个group的input channel和output channel均为32,参数为8×32×3×3×32,是原来的八分之一。而Group conv最后每一组输出的feature maps应该是以concatenate的方式组合。
Alex认为group conv的方式能够增加 filter之间的对角相关性,而且能够减少训练参数,不容易过拟合,这类似于正则的效果。
**参考资料**
- [A Tutorial on Filter Groups (Grouped Convolution)](https://blog.yani.io/filter-group-tutorial/)
- [深度可分离卷积、分组卷积、扩张卷积、转置卷积(反卷积)的理解](https://blog.csdn.net/chaolei3/article/details/79374563)
## 交错组卷积(Interleaved group convolutions,IGC)
**参考资料**
- [学界 | MSRA王井东详解ICCV 2017入选论文:通用卷积神经网络交错组卷积](https://www.sohu.com/a/161110049_465975)
- [视频:基于交错组卷积的高效深度神经网络](https://edu.csdn.net/course/play/8320/171433?s=1)
## 空洞/扩张卷积(Dilated/Atrous Convolution)
Dilated convolution/Atrous convolution可以叫空洞卷积或者扩张卷积。
背景:语义分割中pooling 和 up-sampling layer层。pooling会降低图像尺寸的同时增大感受野,而up-sampling操作扩大图像尺寸,这样虽然恢复了大小,但很多细节被池化操作丢失了。
需求:能不能设计一种新的操作,不通过pooling也能有较大的感受野看到更多的信息呢?
目的:替代pooling和up-sampling运算,既增大感受野又不减小图像大小。
简述:在标准的 convolution map 里注入空洞,以此来增加 reception field。相比原来的正常convolution,dilated convolution 多了一个 hyper-parameter 称之为 dilation rate 指的是kernel的间隔数量(e.g. 正常的 convolution 是 dilatation rate 1)。
空洞卷积诞生于图像分割领域,图像输入到网络中经过CNN提取特征,再经过pooling降低图像尺度的同时增大感受野。由于图像分割是pixel−wise预测输出,所以还需要通过upsampling将变小的图像恢复到原始大小。upsampling通常是通过deconv(转置卷积)完成。因此图像分割FCN有两个关键步骤:池化操作增大感受野,upsampling操作扩大图像尺寸。这儿有个问题,就是虽然图像经过upsampling操作恢复了大小,但是很多细节还是被池化操作丢失了。那么有没有办法既增大了感受野又不减小图像大小呢?Dilated conv横空出世。

注意事项:
1.为什么不直接使用5x5或者7x7的卷积核?这不也增加了感受野么?
答:增大卷积核能增大感受野,但是只是线性增长,参考答案里的那个公式,(kernel-1)*layer,并不能达到空洞卷积的指数增长。
2.2-dilated要在1-dilated的基础上才能达到7的感受野(如上图a、b所示)
关于空洞卷积的另一种概括:
Dilated Convolution问题的引出,是因为down-sample之后的为了让input和output的尺寸一致。我们需要up-sample,但是up-sample会丢失信息。如果不采用pooling,就无需下采样和上采样步骤了。但是这样会导致kernel 的感受野变小,导致预测不精确。。如果采用大的kernel话,一来训练的参数变大。二来没有小的kernel叠加的正则作用,所以kernel size变大行不通。
由此Dilated Convolution是在不改变kernel size的条件下,增大感受野。
**参考资料**
- [《Multi-Scale Context Aggregation by Dilated Convolutions》](https://arxiv.org/abs/1511.07122)
- [《Rethinking Atrous Convolution for Semantic Image Segmentation》](https://arxiv.org/abs/1706.05587)
- [如何理解空洞卷积(dilated convolution)?](https://www.zhihu.com/question/54149221)
- [Dilated/Atrous conv 空洞卷积/多孔卷积](https://blog.csdn.net/silence2015/article/details/79748729)
- [Multi-Scale Context Aggregation by Dilated Convolution 对空洞卷积(扩张卷积)、感受野的理解](https://blog.csdn.net/guvcolie/article/details/77884530?locationNum=10&fps=1)
- [对深度可分离卷积、分组卷积、扩张卷积、转置卷积(反卷积)的理解](https://blog.csdn.net/chaolei3/article/details/79374563)
- [tf.nn.atrous_conv2d](https://tensorflow.google.cn/api_docs/python/tf/nn/atrous_conv2d)
## 转置卷积(Transposed Convolutions/deconvlution)
转置卷积(transposed Convolutions)又名反卷积(deconvolution)或是分数步长卷积(fractially straced convolutions)。反卷积(Transposed Convolution, Fractionally Strided Convolution or Deconvolution)的概念第一次出现是 Zeiler 在2010年发表的论文 Deconvolutional networks 中。
**转置卷积和反卷积的区别**
那什么是反卷积?从字面上理解就是卷积的逆过程。值得注意的反卷积虽然存在,但是在深度学习中并不常用。而转置卷积虽然又名反卷积,却不是真正意义上的反卷积。因为根据反卷积的数学含义,通过反卷积可以将通过卷积的输出信号,完全还原输入信号。而事实是,转置卷积只能还原shape大小,而不能还原value。你可以理解成,至少在数值方面上,转置卷积不能实现卷积操作的逆过程。所以说转置卷积与真正的反卷积有点相似,因为两者产生了相同的空间分辨率。但是又名反卷积(deconvolutions)的这种叫法是不合适的,因为它不符合反卷积的概念。
简单来说,转置矩阵就是一种上采样过程。
正常卷积过程如下,利用3x3的卷积核对4x4的输入进行卷积,输出结果为2x2
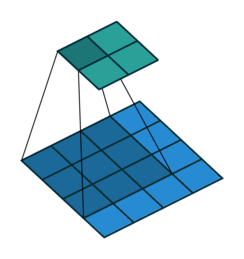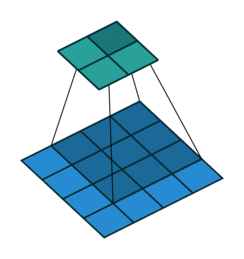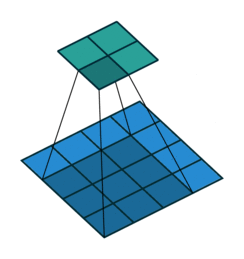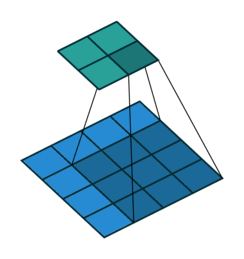
转置卷积过程如下,利用3x3的卷积核对"做了补0"的2x2输入进行卷积,输出结果为4x4。
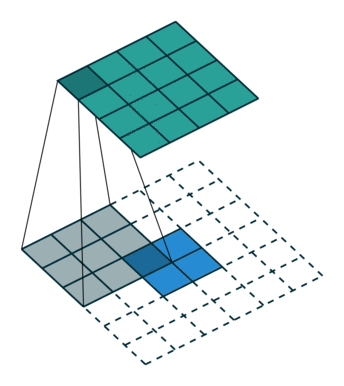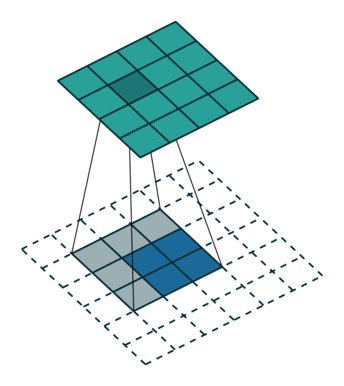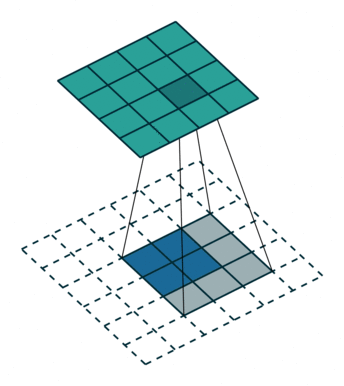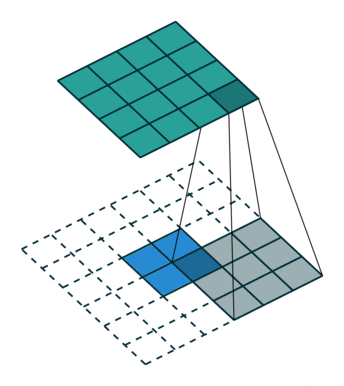
上述的卷积运算和转置卷积是"尺寸"对应的,卷积的输入大小与转置卷积的输出大小一致,分别可以看成下采样和上采样操作。
**参考资料**
- [Transposed Convolution, Fractionally Strided Convolution or Deconvolution](https://buptldy.github.io/2016/10/29/2016-10-29-deconv/)
- [深度学习 | 反卷积/转置卷积 的理解 transposed conv/deconv](https://blog.csdn.net/u014722627/article/details/60574260)
## Group Normalization
- [ ]
## Xception
- [ ] TODO
## SENet
**SENet**
论文:《Squeeze-and-Excitation Networks》
论文链接:https://arxiv.org/abs/1709.01507
代码地址:https://github.com/hujie-frank/SENet
论文的动机是从特征通道之间的关系入手,希望显式地建模特征通道之间的相互依赖关系。另外,没有引入一个新的空间维度来进行特征通道间的融合,而是采用了一种全新的“特征重标定”策略。具体来说,就是通过学习的方式来自动获取到每个特征通道的重要程度,然后依照这个重要程度去增强有用的特征并抑制对当前任务用处不大的特征,通俗来讲,就是让网络利用全局信息有选择的增强有益feature通道并抑制无用feature通道,从而能实现feature通道自适应校准。

**参考资料**
- [SENet学习笔记](https://blog.csdn.net/xjz18298268521/article/details/79078551)
## SKNet
- [ ] TODO
**参考资料**
- [SKNet——SENet孪生兄弟篇](https://zhuanlan.zhihu.com/p/59690223)
- [后ResNet时代:SENet与SKNet](https://zhuanlan.zhihu.com/p/60187262)
## GCNet
- [ ] TODO
**参考资料**
- [GCNet:当Non-local遇见SENet](https://zhuanlan.zhihu.com/p/64988633)
- [2019 GCNet(attention机制,目标检测backbone性能提升)论文阅读笔记](https://zhuanlan.zhihu.com/p/65776424)
## Octave Convolution
- [ ] TODO
**参考资料**
- [如何评价最新的Octave Convolution?](https://www.zhihu.com/question/320462422/)
## MobileNet 系列(V1-V3)
- [ ] TODO
### MobileNetV1
**参考资料**
- [深度解读谷歌MobileNet](https://blog.csdn.net/t800ghb/article/details/78879612)
### MobileNetV2
- [ ] TODO
### MobileNetV3
- [ ] TODO
- [如何评价google Searching for MobileNetV3?](https://www.zhihu.com/question/323419310)
### MobileNet系列为什么快?各有多少层?多少参数?
- [ ] TODO
### MobileNetV1、MobileNetV2和MobileNetV3有什么区别
MobileNetv1:在depthwise separable convolutions(参考Xception)方法的基础上提供了高校模型设计的两个选择:宽度因子(width multiplie)和分辨率因子(resolution multiplier)。深度可分离卷积depthwise separable convolutions(参考Xception)的本质是冗余信息更小的稀疏化表达。
下面介绍两幅Xception中 depthwise separable convolution的图示:


深度可分离卷积的过程是①用16个3×3大小的卷积核(1通道)分别与输入的16通道的数据做卷积(这里使用了16个1通道的卷积核,输入数据的每个通道用1个3×3的卷积核卷积),得到了16个通道的特征图,我们说该步操作是depthwise(逐层)的,在叠加16个特征图之前,②接着用32个1×1大小的卷积核(16通道)在这16个特征图进行卷积运算,将16个通道的信息进行融合(用1×1的卷积进行不同通道间的信息融合),我们说该步操作是pointwise(逐像素)的。这样我们可以算出整个过程使用了3×3×16+(1×1×16)×32 =656个参数。
注:上述描述与标准的卷积非常的不同,第一点在于使用非1x1卷积核时,是单channel的(可以说是1通道),即上一层输出的每个channel都有与之对应的卷积核。而标准的卷积过程,卷积核是多channel的。第二点在于使用1x1卷积核实现多channel的融合,并利用多个1x1卷积核生成多channel。表达的可能不是很清楚,但结合图示其实就容易明白了。
一般卷积核的channel也常称为深度(depth),所以叫做深度可分离,即原来为多channel组合,现在变成了单channel分离。
**参考资料**
- [深度解读谷歌MobileNet](https://blog.csdn.net/t800ghb/article/details/78879612)
- [对深度可分离卷积、分组卷积、扩张卷积、转置卷积(反卷积)的理解](https://blog.csdn.net/chaolei3/article/details/79374563)
### MobileNetv2为什么会加shotcut?
- [ ] TODO
### MobileNet V2中的Residual结构最先是哪个网络提出来的?
- [ ] TODO
## ShuffleNet 系列(V1-V2++)
- [ ] TODO
### ShuffleNetV1
- [ ] TODO
- [轻量级网络--ShuffleNet论文解读](https://blog.csdn.net/u011974639/article/details/79200559)
- [轻量级网络ShuffleNet v1](https://www.jianshu.com/p/29f4ec483b96)
- [CNN模型之ShuffleNet](https://zhuanlan.zhihu.com/p/32304419)
### ShuffleNetV2
- [ ] TODO
**参考资料**
- [ShuffleNetV2:轻量级CNN网络中的桂冠](https://zhuanlan.zhihu.com/p/48261931)
- [轻量级神经网络“巡礼”(一)—— ShuffleNetV2](https://zhuanlan.zhihu.com/p/67009992)
- [ShufflenetV2_高效网络的4条实用准则](https://zhuanlan.zhihu.com/p/42288448)
- [ShuffNet v1 和 ShuffleNet v2](https://zhuanlan.zhihu.com/p/51566209)
## IGC 系列(V1-V3)
- [ ] TODO
**参考资料**
- [微软资深研究员详解基于交错组卷积的高效DNN | 公开课笔记](https://mp.weixin.qq.com/s/ZLIL9A3RS0jj8knbXP9uFQ)
## 深度可分离网络(Depth separable convolution)
- [ ] TODO
## 学习率如何调整
- [ ] TODO
## 神经网络的深度和宽度作用
- [ ] TODO
## 网络压缩与量化
- [ ] TODO
**参考资料**
- [网络压缩-量化方法对比](https://blog.csdn.net/shuzfan/article/details/51678499)
## Batch Size
- [ ] TODO
**参考资料**
- [怎么选取训练神经网络时的Batch size?](https://www.zhihu.com/question/61607442)
- [谈谈深度学习中的 Batch_Size](https://blog.csdn.net/lien0906/article/details/79166196)
## BN和Dropout在训练和测试时的差别
- [ ] TODO
**参考资料**
- [BN和Dropout在训练和测试时的差别](https://zhuanlan.zhihu.com/p/61725100)
## 深度学习调参有哪些技巧?
**参考资料**
-
## 为什么深度学习中的模型基本用3x3和5x5的卷积(奇数),而不是2x2和4x4的卷积(偶数)?
**参考资料**
-
## 深度学习训练中是否有必要使用L1获得稀疏解?
- [ ] TODO
**参考资料**
-
## EfficientNet
- [ ] TODO
**参考资料**
- [如何评价谷歌大脑的EfficientNet?](https://www.zhihu.com/question/326833457)
- [EfficientNet-可能是迄今为止最好的CNN网络](https://zhuanlan.zhihu.com/p/67834114)
- [EfficientNet论文解读](https://zhuanlan.zhihu.com/p/70369784)
- [EfficientNet:调参侠的福音(ICML 2019)](https://zhuanlan.zhihu.com/p/69349360)
## 如何理解归一化(Normalization)对于神经网络(深度学习)的帮助?
BN最早被认为通过降低所谓**Internal Covariate Shift**,这种想法的出处可考至[Understanding the difficulty of training deep feedforward neural networks](https://link.zhihu.com/?target=http%3A//proceedings.mlr.press/v9/glorot10a/glorot10a.pdf),想必这也是batch norm作者这么设计的初衷。但是这种想法并没有过多实验支持,比如说去年NeurlPS这篇paper作者做了实验,在batch norm之后加上一些随机扰动(non-zero mean and non-unit variance,人为引入covariate shift),发现效果仍然比不加好很多。为什么放在batch norm layer之后而不是之前?因为为了证伪batch norm通过forward pass这一步降低covariate shift来提升网络训练效率的。这样说来故事就变得很有趣了,也就是说我们大概都理解一些BN对BN层之前网络噪音的好处,那么能不能研究一下它对它后面layer的影响?所以这些研究从优化的角度,有如下几种观点。
1. BN通过修改loss function, 可以令loss的和loss的梯度均满足更强的Lipschitzness性质(即函数f满足L-Lipschitz和 ![[公式]](https://www.zhihu.com/equation?tex=%5Cbeta) -smooth,令L和 ![[公式]](https://www.zhihu.com/equation?tex=%5Cbeta) 更小,后者其实等同于f Hessian的eigenvalue小于 ![[公式]](https://www.zhihu.com/equation?tex=%5Cbeta) ,可以作为光滑程度的度量,其实吧我觉得,一般convex optimization里拿这个度量算convergence rate是神器,对于non-convex optimization,不懂鸭,paper里好像也没写的样子),这么做的好处是当步子迈得大的时候,我们可以更自信地告诉自己计算出来的梯度可以更好地近似实际的梯度,因此也不容易让优化掉进小坑里。有意思的地方来了,是不是我在某些地方插入一个1/1000 layer,把梯度的L-Lipschitz变成1/1000L-Lipschitz就能让函数优化的更好了呢?其实不是的,因为单纯除以函数会改变整个优化问题,而BN做了不仅仅rescale这件事情,还让原来近似最优的点在做完变化之后,仍然保留在原来不远的位置。这也就是这篇文章的核心论点,BN做的是问题reparametrization而不是简单的scaling。 [1]
2. BN把优化这件事情分解成了优化参数的方向和长度两个任务,这么做呢可以解耦层与层之间的dependency因此会让curvature结构更易于优化。这篇证了convergence rate,但由于没有认真读,所以感觉没太多资格评价。[2]
归一化手段是否殊途同归?很可能是的,在[1]的3.3作者也尝试了Lp normalization,也得到了和BN差不多的效果。至于Layer norm还是weight norm,可能都可以顺着这个思路进行研究鸭,无论是通过[1]还是[2],可能今年的paper里就见分晓了,let's see。
1. [How Does Batch Normalization Help Optimization?](https://link.zhihu.com/?target=https%3A//arxiv.org/abs/1805.11604)
2. [Exponential convergence rates for Batch Normalization: The power of length-direction decoupling in non-convex optimization](https://link.zhihu.com/?target=https%3A//arxiv.org/abs/1805.10694)
**参考资料**
- [如何理解归一化(Normalization)对于神经网络(深度学习)的帮助?](https://www.zhihu.com/question/326034346/answer/708331566)
## 多标签分类怎么解决?
- [ ] TODO
## TODO
================================================
FILE: docs/深度学习框架.md
================================================
[TOC]
# 深度学习框架
## 001 深度学习框架有哪些?各有什么特点?



- [ ] TODO
**参考资料**
- [深度学习框架有哪些?各有什么特点?](https://www.zhihu.com/question/330766768/answer/724694967)
## 002 介绍一下TensorFlow常用的Optimizer
- [ ] TODO
## 003 Caffe的depthwise为什么慢,怎么解决
- [ ] TODO
## 004 比较小米MACE和腾讯NCNN框架
- [ ] TODO
## 005 MACE和NCNN加速原理
- [ ] TODO
## 006 TensorRT原理
- [ ] TODO
## 007 Caffe新加一层需要哪些操作
- [ ] TODO
## TODO
================================================
FILE: docs/编程语言.md
================================================
[TOC]
# 编程语言
## 一、C/C++
### C 与 C++ 的区别(面向对象的特点)
- [ ] TODO
### C++ 与 Python的区别
- [ ] TODO
### 判断struct的字节数
一般使用sizeof判断struct所占的字节数,那么计算规则是什么呢?
关键词:
1.变量的起始地址和变量自身的字节数
2.以最大变量字节数进行字节对齐(倍数关系)。
注:这里介绍的原则都是在没有#pragma pack宏的情况下
先举个例子:
```cpp
struct A
{
char a[5];
int b;
short int c;
}struct A;
```
在上例中,要计算 sizeof(a) 是多少?
有两个原则:
1)各成员变量存放的起始地址相对于结构的起始地址的偏移量必须为该变量的类型所占用的字节数的倍数
即当 A中的a占用了5个字节后,b需要占用四个字节,此时如果b直接放在a后,则b的起始地址是5,不是sizeof(int)的整数倍,所以
需要在a后面补充3个空字节,使得b的起始地址为8. 当放完b后,总空间为5+3+4 = 12. 接着放c,此时为 12 + 2 = 14.
2)为了确保结构的大小为结构的字节边界数(即该结构中占用最大空间的类型所占用的字节数)的倍数,
所以在为最后一个成员变量申请空间后,还会根据需要自动填充空缺的字节。
这是说A中占用最大空间的类型,就是int型了,占用了4个字节,那么规定A占用的空间必须是4的整数倍。本来计算出来占用的空间为14,
不是4的整数倍,因此需要在最后补充2个字节。最终导致A占用的空间为16个字节。
再举个例子:
```cpp
struct B
{
char *d;
short int e;
long long f;
char c[1];
}b;
void test2() {
printf("%d\n", sizeof(b));
}
```
对于此题,需要注意的一点是:windows系统对long long是按照8字节进行对齐的,但是Linux系统对long long则是按照4字节对齐的。
因此:
d占用4字节(因为d是指针)
e占用2字节
f占用8字节,但是其起始地址为为6,不是4的整数倍(对于Linux系统),或不是8的整数倍(对于Windows系统),因此对e之后进行字节补齐,在这里不管对于Linux还是Windows都是补充2个字节,因此 f 的起始地址是8,占用8个字节。
对于c,它占用了1个字节,起始地址是16,也是1的整数倍。
最后,在c之后需要对整个B结构体占用的空间进行补齐,目前占用空间是16+1 = 17个字节。
对于Linux,按4字节补齐(long long 是按4字节补齐的),因此补充了3位空字节,最后占用空间是 17 + 3 = 20字节。
对于Windows系统,是按8字节补齐的,因此就补充了7个字节,最后占用的空间是24字节。
**参考资料**
- [【C++】计算struct结构体占用的长度](https://blog.csdn.net/nisxiya/article/details/22456283?utm_source=copy )
### static 作用
**什么是static?**
static 是C++中很常用的修饰符,它被用来控制变量的存储方式和可见性。
**为什么要引入static?**
函数内部定义的变量,在程序执行到它的定义处时,编译器为它在栈上分配空间,大家知道,函数在栈上分配的空间在此函数执行结束时会释放掉,这样就产生了一个问题: 如果想将函数中此变量的值保存至下一次调用时,如何实现? 最容易想到的方法是定义一个全局的变量,但定义为一个全局变量有许多缺点,最明显的缺点是破坏了此变量的访问范围(使得在此函数中定义的变量,不仅仅受此函数控制)。
**static的作用**
第一个作用是限定作用域(隐藏);第二个作用是保持变量内容持久化;
- 函数体内static变量的作用范围为该函数体,不同于auto变量,该变量的内存只被分配一次,因此其值在下次调用时仍维持上次的值。
举个例子
```
#include
using namespace std;
int main(){
for(int i=0; i<10; ++i){
int a = 0;
static int b = 0;
cout<<"a: "<< a++ <)
- [NLP Interview Questions](https://medium.com/modern-nlp/nlp-interview-questions-f062040f32f7) [百度云链接](https://pan.baidu.com/s/1fY8HXiswGA1rbCnuGG5TXA) 提取码:h9k8
- https://github.com/songyingxin/NLPer-Interview
- [Transformer面试题总结101道题](https://zhuanlan.zhihu.com/p/438625445)
- [transformer面试题的简单回答](https://zhuanlan.zhihu.com/p/363466672)
- [史上最全Transformer面试题系列(一):灵魂20问帮你彻底搞定Transformer-干货!](https://zhuanlan.zhihu.com/p/148656446)
================================================
FILE: docs/计算机视觉.md
================================================
[TOC]
# 计算机视觉
## IoU
IoU(Intersection over Union),又称重叠度/交并比。
**1 NMS**:当在图像中预测多个proposals、pred bboxes时,由于预测的结果间可能存在高冗余(即同一个目标可能被预测多个矩形框),因此可以过滤掉一些彼此间高重合度的结果;具体操作就是根据各个bbox的score降序排序,剔除与高score bbox有较高重合度的低score bbox,那么重合度的度量指标就是IoU;
**2 mAP**:得到检测算法的预测结果后,需要对pred bbox与gt bbox一起评估检测算法的性能,涉及到的评估指标为mAP,那么当一个pred bbox与gt bbox的重合度较高(如IoU score > 0.5),且分类结果也正确时,就可以认为是该pred bbox预测正确,这里也同样涉及到IoU的概念;
提到IoU,大家都知道怎么回事,讲起来也都头头是道,我拿两个图示意下(以下两张图都不是本人绘制):
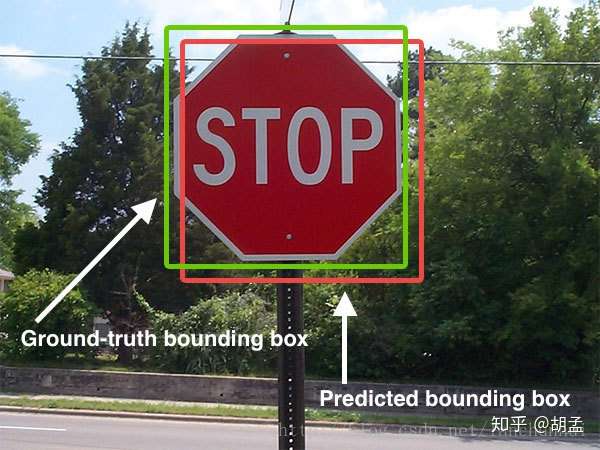
绿框:gt bbox;
红框:pred bbox;
那么IoU的计算如下:
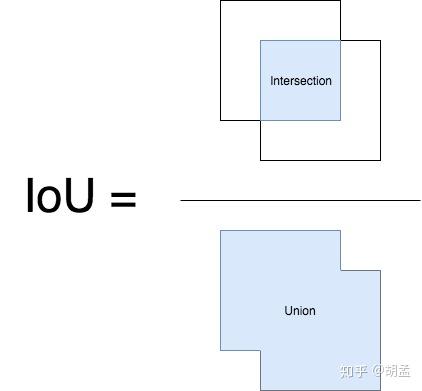
简单点说,就是**gt bbox、pred bbox交集的面积 / 二者并集的面积**;
好了,现在理解IoU的原理和计算方法了,就应该思考如何函数实现了,这也是我写本笔记的原因;
有次面试实习生的时候,一位同学讲各类目标检测算法头头是道,说到自己复现某某算法的mAP高达多少多少,问完他做的各种改进后,觉得小伙子还是挺不错的;
后来我是想着问问mAP的概念吧,但又觉得有点太复杂,不容易一下讲清楚细节,那就问问IoU吧,结果那位小朋友像傻逼一样看着我,说就是两个bbox的交并比啊,我说那要不你写段伪代码实现下吧,既然简单的话,应该实现起来还是很快的(一般我们也都会有这么个写伪代码的面试步骤,考考动手能力和思考能力吧);然后那位自信满满的小伙子就立马下手开始写了,一般听完题目直接写代码的面试者,有两种可能性:
1 确实写过类似的代码,已经知道里面有哪些坑了,直接信手拈来;
2 没写过类似的代码,且把问题考虑简单化了;
我说你不用着急写,可以先想想两个bbox出现交集的各种情况,如两个bbox如何摆放,位置,以及二者不存在交集的情况等等(看到IoU的具体代码后,你会发现虽然只有寥寥几行代码,但其实已经处理好此类情况了),然后他画了几个图,瞬间表情严肃起来,然后我继续说你还得考虑一个bbox包围另一个bbox;两bbox并不是边角相交,而是两条边相交的特殊情况等等(说到这里我觉得自己也坏坏滴,故意把人家往歪路上牵。。。但主要是看得出来他确实不熟悉IoU的实现了),他就又画了若干种情况,最后开始写代码,刚开始还ok,写了十几行,后来越加越多,草稿纸上也涂涂改改越来越夸张,脸也越胀越红;我看了下他的代码,觉得他思路还行,考虑的还挺周全的,就给了他一个提示:你有没有考虑到你列举的这些情况,有一些可以合并的?他看了下,觉得是可以合并一些情况,就删减了部分代码,稿纸上就更乱了,然后又问他:可不可以继续合并;他就又继续思考了。。。大概是后来越想越复杂,就给我说这个原理他懂的,代码也看过,但现在确实是没能写出来;然后我安慰他,说如果没写过的话,确实是会把问题考虑简单化 / 复杂化,不过我并不是专门考个题目刁难你,而是因为你一直都在做目标检测,所以以为IoU的原理、实现你应该会比较熟悉的,写起代码也应该没问题的;而且你的思路也挺好的,先考虑各种复杂情况,再慢慢合并一些情况,先从1到N,再回到1就行,只不过可能到了N,没考虑到如何再回到1了;
再后来,也面试过其他实习生同学,问到了IoU的实现,很可惜,好像还没有一位同学能圆满写出来的。。。当然了,可能是我有时候过于抠细节了,不利于他们的发挥吧。。。
好了,以上都是废话,看看如何实现吧;
```python
# -*- coding: utf-8 -*-
#
# This is the python code for calculating bbox IoU,
# By running the script, we can get the IoU score between pred / gt bboxes
#
# Author: hzhumeng01 2018-10-19
# copyright @ netease, AI group
from __future__ import print_function, absolute_import
import numpy as np
def get_IoU(pred_bbox, gt_bbox):
"""
return iou score between pred / gt bboxes
:param pred_bbox: predict bbox coordinate
:param gt_bbox: ground truth bbox coordinate
:return: iou score
"""
# bbox should be valid, actually we should add more judgements, just ignore here...
# assert ((abs(pred_bbox[2] - pred_bbox[0]) > 0) and
# (abs(pred_bbox[3] - pred_bbox[1]) > 0))
# assert ((abs(gt_bbox[2] - gt_bbox[0]) > 0) and
# (abs(gt_bbox[3] - gt_bbox[1]) > 0))
# -----0---- get coordinates of inters
ixmin = max(pred_bbox[0], gt_bbox[0])
iymin = max(pred_bbox[1], gt_bbox[1])
ixmax = min(pred_bbox[2], gt_bbox[2])
iymax = min(pred_bbox[3], gt_bbox[3])
iw = np.maximum(ixmax - ixmin + 1., 0.)
ih = np.maximum(iymax - iymin + 1., 0.)
# -----1----- intersection
inters = iw * ih
# -----2----- union, uni = S1 + S2 - inters
uni = ((pred_bbox[2] - pred_bbox[0] + 1.) * (pred_bbox[3] - pred_bbox[1] + 1.) +
(gt_bbox[2] - gt_bbox[0] + 1.) * (gt_bbox[3] - gt_bbox[1] + 1.) -
inters)
# -----3----- iou
overlaps = inters / uni
return overlaps
def get_max_IoU(pred_bboxes, gt_bbox):
"""
given 1 gt bbox, >1 pred bboxes, return max iou score for the given gt bbox and pred_bboxes
:param pred_bbox: predict bboxes coordinates, we need to find the max iou score with gt bbox for these pred bboxes
:param gt_bbox: ground truth bbox coordinate
:return: max iou score
"""
# bbox should be valid, actually we should add more judgements, just ignore here...
# assert ((abs(gt_bbox[2] - gt_bbox[0]) > 0) and
# (abs(gt_bbox[3] - gt_bbox[1]) > 0))
if pred_bboxes.shape[0] > 0:
# -----0---- get coordinates of inters, but with multiple predict bboxes
ixmin = np.maximum(pred_bboxes[:, 0], gt_bbox[0])
iymin = np.maximum(pred_bboxes[:, 1], gt_bbox[1])
ixmax = np.minimum(pred_bboxes[:, 2], gt_bbox[2])
iymax = np.minimum(pred_bboxes[:, 3], gt_bbox[3])
iw = np.maximum(ixmax - ixmin + 1., 0.)
ih = np.maximum(iymax - iymin + 1., 0.)
# -----1----- intersection
inters = iw * ih
# -----2----- union, uni = S1 + S2 - inters
uni = ((gt_bbox[2] - gt_bbox[0] + 1.) * (gt_bbox[3] - gt_bbox[1] + 1.) +
(pred_bboxes[:, 2] - pred_bboxes[:, 0] + 1.) * (pred_bboxes[:, 3] - pred_bboxes[:, 1] + 1.) -
inters)
# -----3----- iou, get max score and max iou index
overlaps = inters / uni
ovmax = np.max(overlaps)
jmax = np.argmax(overlaps)
return overlaps, ovmax, jmax
if __name__ == "__main__":
# test1
pred_bbox = np.array([50, 50, 90, 100]) # top-left: <50, 50>, bottom-down: <90, 100>,
gt_bbox = np.array([70, 80, 120, 150])
print (get_IoU(pred_bbox, gt_bbox))
# test2
pred_bboxes = np.array([[15, 18, 47, 60],
[50, 50, 90, 100],
[70, 80, 120, 145],
[130, 160, 250, 280],
[25.6, 66.1, 113.3, 147.8]])
gt_bbox = np.array([70, 80, 120, 150])
print (get_max_IoU(pred_bboxes, gt_bbox))
```
其实计算bbox间IoU唯一的难点就在计算intersection,代码的实现很简单:
```python
ixmin = max(pred_bbox[0], gt_bbox[0])
iymin = max(pred_bbox[1], gt_bbox[1])
ixmax = min(pred_bbox[2], gt_bbox[2])
iymax = min(pred_bbox[3], gt_bbox[3])
iw = np.maximum(ixmax - ixmin + 1., 0.)
ih = np.maximum(iymax - iymin + 1., 0.)
```
比较厉害的就是,以上短短六行代码就可以囊括所有pred bbox与gt bbox间的关系,不管是bboxes间相交 / 不相交,各种相交形式等等;我们在画图分析两个bbox间的关系时,会考虑各种情况,动手实践时会发现很复杂,是因为我们**陷入了一种先入为主的思维**,就是pred bbox与gt bbox有一个先后顺序,即我们认定了pred bbox为画图中的第一个bbox,gt bbox为第二个,这样在二者有不同位置关系时,就得考虑各种坐标判断情况,但若此时交换二者位置,其实并不影响我们计算IoU;
以上六行代码也印证了这个观点,直接计算两个bbox的相交边框坐标即可,若不相交得到的结果中,必有ixmax < ixmin、iymax - iymin其一成立,此时iw、ih就为0了;
好了,以上就是IoU的计算,原理比较简单,具体分析比较复杂,实现却异常简单,但通过对问题的深入分析,也能加深我们对知识的理解;
代码我传到github上了,比较简单:[IoU_demo.py](https://github.com/humengdoudou/object_detection_mAP/blob/master/IoU_demo.py)
**参考资料**
- [目标检测番外篇(1)_IoU](https://zhuanlan.zhihu.com/p/47189358)
- [目标检测之 IoU]()
- [Detection基础模块之(一)IoU](https://zhuanlan.zhihu.com/p/70768666)
### 如何计算 mIoU?
Mean Intersection over Union(MIoU,均交并比),为语义分割的标准度量。其计算两个集合的交集和并集之比,在语义分割问题中,这两个集合为真实值(ground truth)和预测值(predicted segmentation)。这个比例可以变形为TP(交集)比上TP、FP、FN之和(并集)。在每个类上计算IoU,然后取平均。
$$
MIoU=\frac{1}{k+1}\sum^{k}_{i=0}{\frac{p_{ii}}{\sum_{j=0}^{k}{p_{ij}+\sum_{j=0}^{k}{p_{ji}-p_{ii}}}}}
$$
pij表示真实值为i,被预测为j的数量。
**直观理解**

红色圆代表真实值,黄色圆代表预测值。橙色部分为两圆交集部分。
- MPA(Mean Pixel Accuracy,均像素精度):计算橙色与红色圆的比例;
- MIoU:计算两圆交集(橙色部分)与两圆并集(红色+橙色+黄色)之间的比例,理想情况下两圆重合,比例为1。
**Tensorflow源码解析**
Tensorflow主要用`tf.metrics.mean_iou`来计算mIoU,下面解析源码:
**第一步:计算混淆矩阵**
混淆矩阵例子

```
# 主要代码
def confusion_matrix(labels, predictions, num_classes=None, dtype=dtypes.int32,
name=None, weights=None):
# 例子:labels = [0, 1, 2, 0, 3]
# predictions =[0, 1, 1, 3, 3]
if num_classes is None: # 不指定类别个数,就以labels或者predictions最大的指定,即4
num_classes = math_ops.maximum(math_ops.reduce_max(predictions),
math_ops.reduce_max(labels)) + 1
else:
num_classes_int64 = math_ops.cast(num_classes, dtypes.int64)
labels = control_flow_ops.with_dependencies(
[check_ops.assert_less(
labels, num_classes_int64, message='`labels` out of bound')],
labels)
predictions = control_flow_ops.with_dependencies(
[check_ops.assert_less(
predictions, num_classes_int64,
message='`predictions` out of bound')],
predictions)
if weights is not None:
predictions.get_shape().assert_is_compatible_with(weights.get_shape())
weights = math_ops.cast(weights, dtype)
shape = array_ops.stack([num_classes, num_classes])
indices = array_ops.stack([labels, predictions], axis=1)
# indices = [[0,0],[1,1],[2,1],[0,3],[3,3]]
values = (array_ops.ones_like(predictions, dtype)
if weights is None else weights)
# 对应位置的values,若不指定,则全为1
cm_sparse = sparse_tensor.SparseTensor(
indices=indices, values=values, dense_shape=math_ops.to_int64(shape))
# 稀疏张量,指定indices位置为指定value,其他位置为0
# 多次指定一个位置,value为多次相加的结果
zero_matrix = array_ops.zeros(math_ops.to_int32(shape), dtype)
return sparse_ops.sparse_add(zero_matrix, cm_sparse)
```
SparseTensor例子:
```python
import tensorflow as tf
a = tf.SparseTensor(indices=[[0,0], [1,2], [0, 0]], values=[1, 1, 1], dense_shape=[3, 4])
zero_m = array_ops.zeros(math_ops.to_int32([3,4]),dtype=tf.int32)
r = sparse_ops.sparse_add(zero_m, a)
sess = tf.Session(config=tf.ConfigProto(device_count={'cpu':0}))
sess.run(r)
# array([[2, 0, 0, 0],
# [0, 0, 1, 0],
# [0, 0, 0, 0]], dtype=int32)
```
**第二步:计算mIoU**
```python
def compute_mean_iou(total_cm, name):
"""Compute the mean intersection-over-union via the confusion matrix."""
sum_over_row = math_ops.to_float(math_ops.reduce_sum(total_cm, 0))
sum_over_col = math_ops.to_float(math_ops.reduce_sum(total_cm, 1))
cm_diag = math_ops.to_float(array_ops.diag_part(total_cm)) # 交集
denominator = sum_over_row + sum_over_col - cm_diag # 分母,即并集
# The mean is only computed over classes that appear in the
# label or prediction tensor. If the denominator is 0, we need to
# ignore the class.
num_valid_entries = math_ops.reduce_sum(
math_ops.cast(
math_ops.not_equal(denominator, 0), dtype=dtypes.float32)) # 类别个数
# If the value of the denominator is 0, set it to 1 to avoid
# zero division.
denominator = array_ops.where(
math_ops.greater(denominator, 0), denominator,
array_ops.ones_like(denominator))
iou = math_ops.div(cm_diag, denominator) # 各类IoU
# If the number of valid entries is 0 (no classes) we return 0.
result = array_ops.where(
math_ops.greater(num_valid_entries, 0),
math_ops.reduce_sum(iou, name=name) / num_valid_entries, 0) #mIoU
return result
```
通过`tf.metrics.mean_iou`的API可以得到mIoU,但并没有把各类IoU释放出来,为了计算各类IoU,可以修改上面的代码,获取IoU中间结果,也可以用weight的方式变相计算。
基本思路就是把只保留一类的IoU,其他类IoU置零,然后最后将`mIoU * num_classes`就可以了。
```python
tp_position = tf.equal(tf.to_int32(labels), tf.to_int32(predictions))
label_0_weight = tf.where((tp_position & tf.not_equal(labels, 0)), tf.zeros_like(labels),
tf.ones_like(labels))
## 混淆矩阵对角线上只保留一类非0,其他类都置0
metric_map['IOU/class_0_iou'] = tf.metrics.mean_iou(
predictions, labels, dataset.num_classes, weights=label_0_weight)
## 结果是0类IoU/num_classes
```
**Pytorch源码解析**
Pytorch基本计算思路和上面是一样的,代码很简洁,就不过多介绍了。
```python
class IOUMetric:
"""
Class to calculate mean-iou using fast_hist method
"""
def __init__(self, num_classes):
self.num_classes = num_classes
self.hist = np.zeros((num_classes, num_classes))
def _fast_hist(self, label_pred, label_true):
mask = (label_true >= 0) & (label_true < self.num_classes)
hist = np.bincount(
self.num_classes * label_true[mask].astype(int) +
label_pred[mask], minlength=self.num_classes ** 2).reshape(self.num_classes, self.num_classes)
return hist
def add_batch(self, predictions, gts):
for lp, lt in zip(predictions, gts):
self.hist += self._fast_hist(lp.flatten(), lt.flatten())
def evaluate(self):
acc = np.diag(self.hist).sum() / self.hist.sum()
acc_cls = np.diag(self.hist) / self.hist.sum(axis=1)
acc_cls = np.nanmean(acc_cls)
iu = np.diag(self.hist) / (self.hist.sum(axis=1) + self.hist.sum(axis=0) - np.diag(self.hist))
mean_iu = np.nanmean(iu)
freq = self.hist.sum(axis=1) / self.hist.sum()
fwavacc = (freq[freq > 0] * iu[freq > 0]).sum()
return acc, acc_cls, iu, mean_iu, fwavacc
```
**Python 简版实现**
```python
#RT:RightTop
#LB:LeftBottom
def IOU(rectangle A, rectangleB):
W = min(A.RT.x, B.RT.x) - max(A.LB.x, B.LB.x)
H = min(A.RT.y, B.RT.y) - max(A.LB.y, B.LB.y)
if W <= 0 or H <= 0:
return 0;
SA = (A.RT.x - A.LB.x) * (A.RT.y - A.LB.y)
SB = (B.RT.x - B.LB.x) * (B.RT.y - B.LB.y)
cross = W * H
return cross/(SA + SB - cross)
```
**参考资料**
-
- [mIoU(平均交并比)计算代码与逐行解析](https://blog.csdn.net/jiongnima/article/details/84750819)
-
- [mIoU源码解析](https://tianws.github.io/skill/2018/10/30/miou/)
## mAP
mAP定义及相关概念
- mAP: mean Average Precision, 即各类别AP的平均值
- AP: PR曲线下面积,后文会详细讲解
- PR曲线: Precision-Recall曲线
- Precision: TP / (TP + FP)
- Recall: TP / (TP + FN)
- TP: IoU>0.5的检测框数量(同一Ground Truth只计算一次)
- FP: IoU<=0.5的检测框,或者是检测到同一个GT的多余检测框的数量
- FN: 没有检测到的GT的数量
本笔记介绍目标检测的一个基本概念:AP、mAP(mean Average Precision),做目标检测的同学想必对这个词语耳熟能详了,不管是Pascal VOC,还是COCO,甚至是人脸检测的wider face数据集,都使用到了AP、mAP的评估方式,那么AP、mAP到底是什么?如何计算的?
如果希望一篇笔记讲明白目标检测中的mAP,感觉自己表达能力有限,可能搞不定,但如果希望一下能明白mAP含义的,可以参照引用链接;今天主要介绍下mAP的计算方式,假定前提为已经明白了precision、recall、tp、fp等概念,当然了,不明白也没关系,下一篇介绍Pascal VOC评估工具时会再详细介绍;
**1 图像检索mAP**
那么mAP到底是什么东西,如何计算?网上已经有了很多很多资料,但其实很多感觉都讲不清楚,我看到过一个在图像检索里面介绍得最好的示意图,我们先以图像检索中的mAP为例说明,其实目标检测中mAP与之几乎一样:
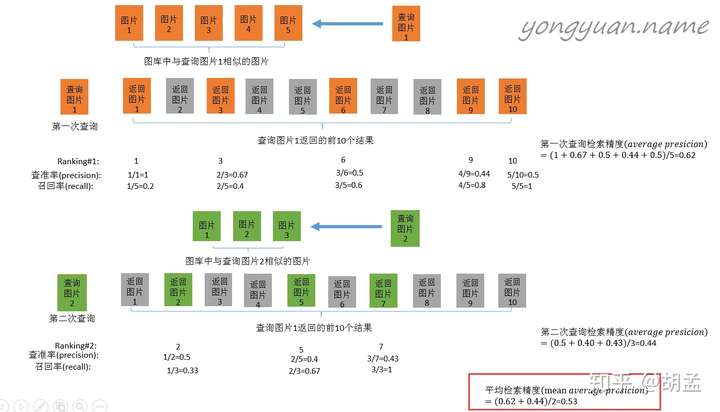
以上是图像检索中mAP的计算案例,简要说明下:
1 查询图片1在图像库中检索相似图像,假设图像库中有五张相似图像,表示为图片1、...、图片5,排名不分先后;
2 检索(过程略),返回了top-10图像,如上图第二行,橙色表示相似的图像,灰色为无关图像;
3 接下来就是precision、recall的计算过程了,结合上图比较容易理解;
以返回图片6的节点为例:
top-6中,有3张图像确实为相似图像,另三张图像为无关图像,因此precision = 3 / 6;同时,总共五张相似图像,top-6检索出来了三张,因此recall = 3 / 5;
4 然后计算AP,可以看右边的计算方式,可以发现是把列出来的查询率(precision)相加取平均,那么最关键的问题来了:为什么选择这几张图像的precision求平均?可惜图中并没有告诉我们原因;
但其实不难,一句话就是:**选择每个recall区间内对应的最高precision**;
举个栗子,以上图橙色检索案例为例,当我们只选择top-1作为检索结果返回(也即只返回一个检索结果)时,检索性能为:
```text
top-1:recall = 1 / 5、precision = 1 / 1;# 以下类推;
top-2:recall = 1 / 5、precision = 1 / 2;
top-3:recall = 2 / 5、precision = 2 / 3;
top-4:recall = 2 / 5、precision = 2 / 4;
top-5:recall = 2 / 5、precision = 2 / 5;
top-6:recall = 3 / 5、precision = 3 / 6;
top-7:recall = 3 / 5、precision = 3 / 7;
top-8:recall = 3 / 5、precision = 3 / 8;
top-9:recall = 4 / 5、precision = 4 / 9;
top-10:recall = 5 / 5、precision = 5 / 10;
```
结合上面清单,先找找recall = 1 / 5区间下的最高precision,对应着precision = 1 / 1;
同理,recall = 2 / 5区间下的最高precision,对应着precision = 2 / 3;
recall = 3 / 5区间下的最高precision,对应着precision = 3 / 6;依次类推;
这样AP = (1 / 1 + 2 / 3 + 3 / 6 + 4 / 9 + 5 / 10) / 5;
那么mAP是啥?计算所有检索图像返回的AP均值,对应上图就是橙、绿突图像计算AP求均值,对应红色框;
这样mAP就计算完毕啦~~~是不是很容易理解?目标检测的mAP也是类似操作了;
**2 目标检测中mAP计算流程**
这里面我引用的是一篇博文,以下内容大多参考该博文,做了一些小修改;
下面的例子也很容易理解,假设检测人脸吧,gt label表示1为人脸,0为bg,某张图像中共检出了20个pred bbox,id:1 ~ 20,并对应了confidence score,gt label也很容易获得,pred bbox与gt bbox算IoU,给定一个threshold,那么就**知道该pred bbox是否为正确的预测结果了,就对应了其gt label**;---- 其实下表不应该这么理解的,但我们还是先这么认为,忽略差异吧,先直捣黄龙,table 1:
接下来对confidence score排序,得到table 2:
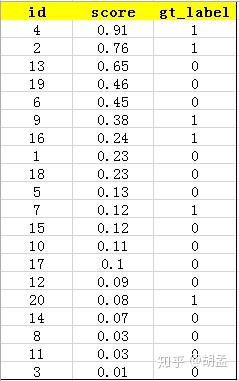
*这张表很重要,接下来的precision和recall都是依照这个表计算的,那么这里的confidence score其实就和图像检索中的相似度关联上了,具体地,就是如第一节的图像检索中,虽然我们计算mAP没在乎其检索返回的先后顺序,但top1肯定是与待检索图像最相似的,对应的similarity score最高,对人脸检测而言,pred bbox的confidence score最高,也说明该bbox最有可能是人脸;*
然后计算precision和recall,这两个标准的定义如下:
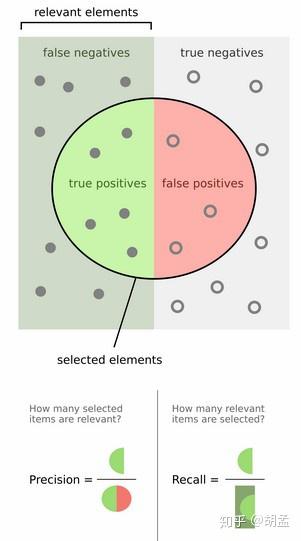
上面的图看看就行,能理解就理解,不理解可以参照第一节图像检索的例子来理解;
现以返回的top-5结果为例,如table 3:
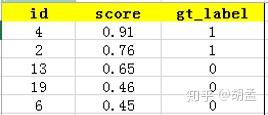
在这个例子中,true positives就是指id = 4、2的pred bbox,false positives就是指id = 13、19、6的pred bbox。方框内圆圈外的元素(false negatives + true negatives)是相对于方框内的元素而言,在这个例子中,是指confidence score排在top-5之外的元素,即table 4:
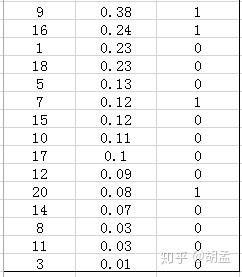
其中,false negatives是指id = 9、16、7、20的4个pred bbox,true negatives是指id = 1、18、5、15、10、17、12、14、8、11、3的11个pred bbox;
那么,这个例子中Precision = 2 / 5 = 40%,意思是对于人脸检测而言,我们选定了5 pred bbox,其中正确的有2个,即准确率为40%;Recall = 2 / 6 = 33%,意思是该图像中共有6个人脸,但是因为我们只召回了2个,所以召回率为33%;
实际的目标检测任务中,我们通常不满足只通过top-5来衡量一个模型的好坏,而是需要知道从top-1到top-N(N是所有pred bbox,本文中为20)对应的precision和recall;显然随着我们选定的pred bbox越来也多,recall一定会越来越高,而precision整体上会呈下降趋势;把recall当成横坐标,precision当成纵坐标,即可得到常用的precision-recall曲线,以上例子的precision-recall曲线如fig 1:
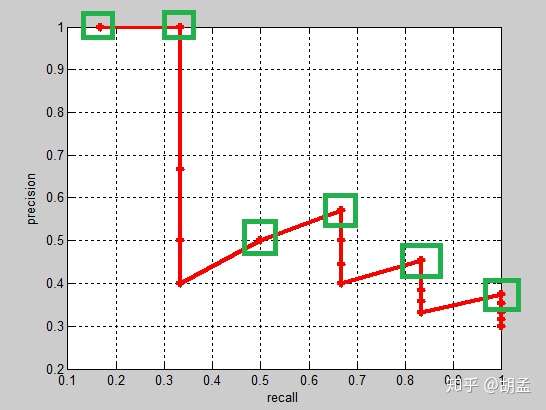
以上图像如何计算的?可以参照第一节图像检索中的栗子,还是比较容易理解的吧;
上面的每个红点,就相当于根据table 2,按照第一节中图像检索的方式计算出来的,也可以直接参照下面的table 5,自己心里算一算;
那么按照**选择每个recall区间内对应的最高precision**的计算方案,各个recall区间内对应的top-precision,就刚好如fig 1中的绿色框位置,可以进一步结合table 5中的绿色框理解;
好了,那么对这张图像而言,其AP = (1 / 1 + 2 / 2 + 3 / 6 + 4 / 7 + 5 / 11 + 6 / 16)/ 6;这是针对单张图像而言,所有图像也类似方式计算,那么就可以根据所有图像上的pred bbox,采用同样的方式,就计算出了所有图像上人脸这个类的AP;因为人脸检测只有一个类,如Pascal VOC这种20类的,每类都可以计算出一个AP,那么AP_total / 20,就是mAP啦;
但是等等,有没有发现table 5中,计算方式好像跟我们讲的有一点不一样?我们继续看看;
**3 Pascal VOC的两套mAP评估标准**
Pascal VOC中对mAP的计算经历了两次迭代,一种是VOC07的计算标准,对应绿色框:
首先设定一组阈值,T = [0、0.1、0.2、…、1],然后对于recall大于每一个阈值Ti(比如recall > 0.3),我们都会在该recall区间内得到一个对应的最大precision,这样我们就计算出了11个precision;----- 这里与上两节介绍的概念是一样的,只不过上面recall的区间是参照gt label来划分的,这里是我们人为划分的11个节点;
AP即为这11个precision的平均值,这种方法英文叫做11-point interpolated average precision;有了一个类的AP,所有类的AP均值即为mAP;
另一种是VOC10的计算标准,对应白色框:
新的计算方法假设N个pred bbox中有M个gt bbox,那么我们会得到M个recall节点(1 / M、2 / M、...、 M / M),对于**每个recall值 r,我们可以计算出对应(r' > r)的最大precision,然后对这M个precision值取平均即得到最后的AP值**,计算方法如table 5:
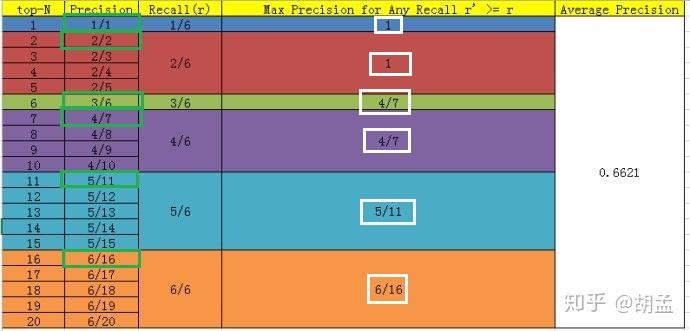
从VOC07的绿框、VOC10的白框对比可知,差异主要在recall = 3 / 6下的precision,可以发现VOC07找的top-precision是在该recall区间段内的,但**VOC10相当于是向后查找的,需确保该recall阈值以后的区间内,对应的是top-precision**,可知4 / 7 > 3 / 6,因此使用4 / 7替换了3 / 6,其他recall阈值下的操作方式类似;
**那么代码的实操中,就得从按照recall阈值从后往前计算了,这样就可以一遍就梭哈出所有结果,如果按recall从前往后计算,就有很多重复性计算(不断地重复向后recall区间内查找top-precision),然后呢,就可以使用到动态规划的方式做了,理论结合实践啊有木有~~~**
那么VOC10下,相应的Precision-Recall曲线如fig 2,可以发现这条曲线是单调递减的,剩下的AP计算方式就与VOC07相同了:
这里还需要继续一点,**VOC07是11点插值的AP方式,等于是卡了11个离散的点,划分10个区间来计算AP**,但VOC10是是**根据recall值变化的区间来计算的**,在这个栗子里,recall只变化了6次,但如果recall变化很多次,如100次、1000次、9999次等,就可以认为是**一种 “伪” 连续的方式计算**了;
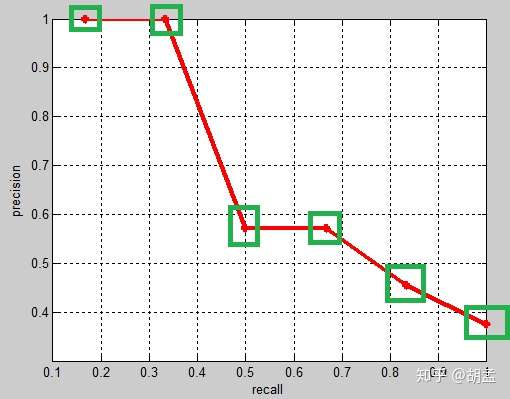
**总结**:
AP衡量的是模型在每个类别上的好坏,mAP衡量的是模型在所有类别上的好坏,得到AP后mAP的计算就变得很简单了,就是取所有类别AP的平均值。
**3 代码**
直接上代码吧,这个函数假设我们已经得到了排序好的precision、recall的list,对应上图fig 2,进一步可以参照第一节中的清单理解;
```python
# VOC-style mAP,分为两个计算方式,之所有两个计算方式,是因为2010年后VOC更新了评估方法,因此就有了07-metric和else...
def voc_ap(rec, prec, use_07_metric=False):
"""
average precision calculations
[precision integrated to recall]
:param rec: recall list
:param prec: precision list
:param use_07_metric: 2007 metric is 11-recall-point based AP
:return: average precision
"""
if use_07_metric:
# 11 point metric
ap = 0.
# VOC07是11点插值的AP方式,等于是卡了11个离散的点,划分10个区间来计算AP
for t in np.arange(0., 1.1, 0.1):
if np.sum(rec >= t) == 0:
p = 0 # recall卡的阈值到顶了,1.1
else:
p = np.max(prec[rec >= t]) # VOC07:选择每个recall区间内对应的最高precision的计算方案
ap = ap + p / 11. # 11-recall-point based AP
else:
# correct AP calculation
# first append sentinel values at the end
mrec = np.concatenate(([0.], rec, [1.]))
mpre = np.concatenate(([0.], prec, [0.]))
# compute the precision envelope
for i in range(mpre.size - 1, 0, -1):
mpre[i - 1] = np.maximum(mpre[i - 1], mpre[i]) # 这个是不是动态规划?从后往前找之前区间内的top-precision,多么优雅的代码呀~~~
# to calculate area under PR curve, look for points where X axis (recall) changes value
# 上面的英文,可以结合着fig 2的绿框理解,一目了然
# VOC10是是根据recall值变化的区间来计算的,如果recall变化很多次,就可以认为是一种 “伪” 连续的方式计算了,以下求的是recall的变化
i = np.where(mrec[1:] != mrec[:-1])[0]
# 计算AP,这个计算方式有点玄乎,是一个积分公式的简化,应该是对应的fig 2中红色曲线以下的面积,之前公式的推导我有看过,现在有点忘了,麻烦各位同学补充一下
# 现在理解了,不难,公式:sum (\Delta recall) * prec,其实结合fig2和下面的图,不就是算的积分么?如果recall划分得足够细,就可以当做连续数据,然后以下公式就是积分公式,算的precision、recall下面的面积了
ap = np.sum((mrec[i + 1] - mrec[i]) * mpre[i + 1])
return ap
```
通常VOC10标准下计算的mAP值会高于VOC07,原因如下,我就不详细介绍了:
> **Interpolated average precision**
> Some authors choose an alternate approximation that is called the *interpolated average precision*. Often, they still call it average precision. Instead of using *P(k)*, the precision at a retrieval cutoff of *k* images, the interpolated average precision uses:
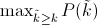
> In other words, instead of using the precision that was actually observed at cutoff *k*, the interpolated average precision uses the maximum precision observed across all cutoffs with higher recall. The full equation for computing the interpolated average precision is:
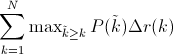
> Visually, here’s how the interpolated average precision compares to the approximated average precision (to show a more interesting plot, this one isn’t from the earlier example):
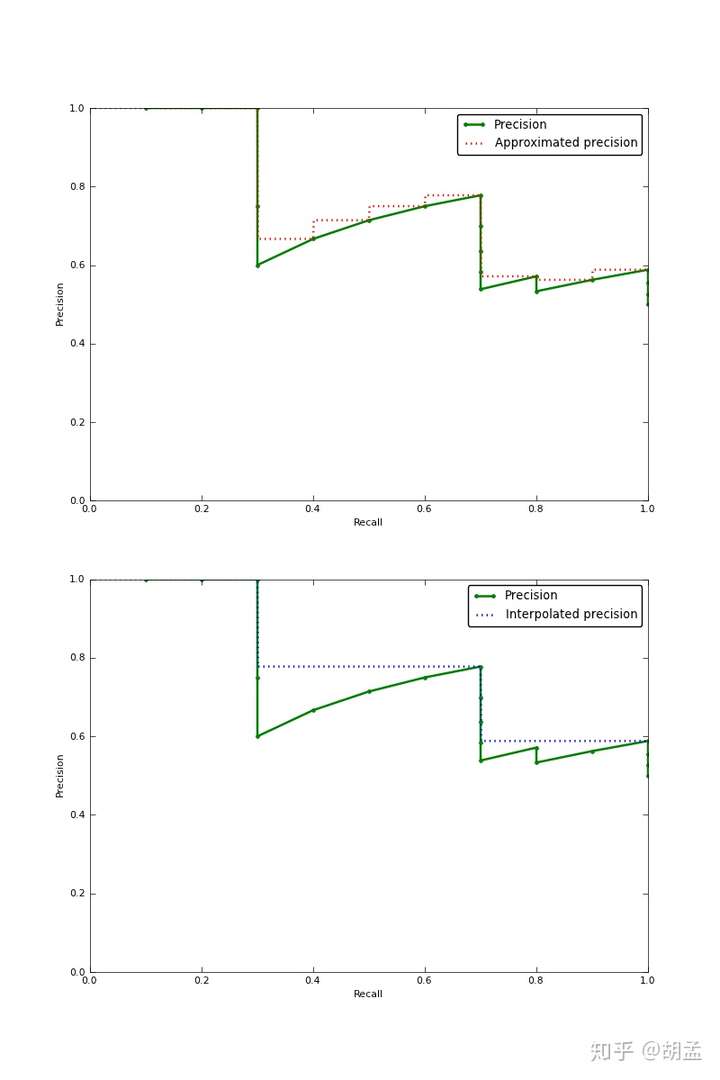
> *The approximated average precision closely hugs the actually observed curve. The interpolated average precision over estimates the precision at many points and produces a higher average precision value than the approximated average precision.*
>
> Further, there are variations on where to take the samples when computing the interpolated average precision. Some take samples at a fixed 11 points from 0 to 1: {0, 0.1, 0.2, …, 0.9, 1.0}. This is called the 11-point interpolated average precision. Others sample at every *k* where the recall changes.
**参考资料**
- [目标检测番外篇(2)_mAP](https://zhuanlan.zhihu.com/p/48992451)
- [目标检测中的mAP是什么含义?](https://www.zhihu.com/question/53405779)
- [Object-Detection-Metrics](https://github.com/rafaelpadilla/Object-Detection-Metrics)
- [【目标检测】VOC mAP](https://zhuanlan.zhihu.com/p/67279824)
- [白话mAP](https://zhuanlan.zhihu.com/p/60834912)
- [Detection基础模块之(二)mAP](https://zhuanlan.zhihu.com/p/60319755)
### 如何计算 mAP?
- [ ] TODO
**参考资料**
- https://github.com/Cartucho/mAP
-
- [【目标检测】VOC mAP](https://zhuanlan.zhihu.com/p/67279824)
## 目标检测度量标准
- mAP
- FPS
- [ ] TODO
**参考资料**
- [Object-Detection-Metrics](https://github.com/rafaelpadilla/Object-Detection-Metrics)
- [目标检测的性能评价指标](https://zhuanlan.zhihu.com/p/70306015)
- [【目标检测】基础知识:IoU、NMS、Bounding box regression](https://zhuanlan.zhihu.com/p/60794316)
## 图像分割度量标准
- [ ] TODO
- PA
- MP
- mIoU
- FWIoU
**参考资料**
- [《A Review on Deep Learning Techniques Applied to Semantic Segmentation》](https://arxiv.org/abs/1704.06857)
- [图像语义分割准确率度量方法总结](https://zhuanlan.zhihu.com/p/38236530)
- [论文笔记 | 基于深度学习的图像语义分割技术概述之5.1度量标准](https://blog.csdn.net/u014593748/article/details/71698246)
## 非极大值抑制NMS
- [ ] TODO
## 目标检测中的Anchor
- [ ]
**参考资料**
- [目标检测中的Anchor](https://zhuanlan.zhihu.com/p/55824651)
## 原始图片中的ROI如何映射到到feature map?
- [ ] TODO
**参考资料**
- https://zhuanlan.zhihu.com/p/24780433
- http://www.cnblogs.com/objectDetect/p/5947169.html
## 请问Faster R-CNN和SSD 中为什么用smooth l1 loss,和l2有什么区别?
- [ ]
**参考资料**
- [请问faster rcnn和ssd 中为什么用smooth l1 loss,和l2有什么区别?](https://www.zhihu.com/question/58200555/answer/621174180)
## 给定5个人脸关键点和5个对齐后的点,求怎么变换的?
- [ ] TODO
## Bounding boxes 回归原理/公式
- [ ] TODO
## U-Net 和 FCN的区别
- [ ] TODO
## 介绍KCF算法
- [ ] TODO
## 介绍MobileNet-SSD算法
- [ ] TODO
## 目标检测中的多尺度训练/测试?
- [ ] TODO
多尺度训练对全卷积网络有效,一般设置几种不同尺度的图片,训练时每隔一定iterations随机选取一种尺度训练。这样训练出来的模型鲁棒性强,其可以接受任意大小的图片作为输入,使用尺度小的图片测试速度会快些,但准确度低,用尺度大的图片测试速度慢,但是准确度高。
**参考资料**
- [目标检测中的多尺度训练/测试?](https://www.zhihu.com/question/271781123)
## 目标检测中的正负样本不平衡问题
- [OHEM](https://arxiv.org/abs/1604.03540)
- [Focal Loss](https://arxiv.org/abs/1708.02002)
- [GHM](https://arxiv.org/abs/1811.05181)
- [PISA](https://arxiv.org/abs/1904.04821)
- [AP-loss](https://arxiv.org/abs/1904.06373)
**参考资料**
- [样本贡献不均:Focal Loss和 Gradient Harmonizing Mechanism](https://zhuanlan.zhihu.com/p/55036597)
- [被忽略的Focal Loss变种](https://zhuanlan.zhihu.com/p/62314673)
- [Soft Sampling:探索更有效的采样策略](https://zhuanlan.zhihu.com/p/63954517):介绍了**Focal Loss**、**GHM**和**PISA**
## 目标检测中的类别漏检问题该怎么解决?
- [ ] TODO
**参考资料**
- [目标检测中的类别漏检问题该怎么解决?](https://www.zhihu.com/question/372208101)
## RPN
### RPN 的损失函数
- [ ] TODO
### RPN中的anchor box是怎么选取的?
- [ ] TODO
## RoI Pooling
- [ ] TODO
**参考资料**
- [你真的学会RoI Pooling了吗?](https://zhuanlan.zhihu.com/p/59692298)
- [IoUNet(5)源码 RoIPooling(1)](https://zhuanlan.zhihu.com/p/46927880)
## RoI Align
- [ ] TODO
**参考资料**
- [IoUNet(6) 源码 RoIAlign(1)](https://zhuanlan.zhihu.com/p/46928697)
## 为什么深度学习中的图像分割要先编码再解码?
- [ ] TODO
**参考资料**
- [为什么深度学习中的图像分割要先编码再解码?](https://www.zhihu.com/question/322191738)
## NMS
本笔记介绍目标检测的另一个基本概念:NMS(non-maximum suppression),做目标检测的同学想必对这个词语耳熟能详了;
在检测图像中的目标时,不可避免地会检出很多bboxes + cls scores,这些bbox之间有很多是冗余的,一个目标可能会被多个bboxes检出,如果所有bboxes都输出,就很影响体验和美观了(同一个目标输出100个bboxes,想想都后怕~~~),一种方案就是提升cls scores的阈值,减少bbox数量的输出;另一种方案就是使用NMS,将同一目标内的bboxes按照cls score + IoU阈值做筛选,剔除冗余地、低置信度的bbox;
可能又会问了:为什么目标检测时,会有这么多无效、冗余检测框呢?这个。。。我的理解,是因为图像中没有目标尺度、位置的先验知识,为保证对目标的高召回,就必须使用滑窗、anchor / default bbox密集采样的方式,尽管检测模型能对每个anchor / default bbox做出 cls + reg,可以一定程度上剔除误检,但没有结合检出bbox的cls score + IoU阈值做筛选,而NMS就可以做到这一点;
**1 NMS操作流程**
NMS用于剔除图像中检出的冗余bbox,标准NMS的具体做法为:
**step-1**:将所有检出的output_bbox按cls score划分(如pascal voc分20个类,也即将output_bbox按照其对应的cls score划分为21个集合,1个bg类,只不过bg类就没必要做NMS而已);
**step-2**:在每个集合内根据各个bbox的cls score做降序排列,得到一个降序的list_k;
**step-3**:从list_k中top1 cls score开始,计算该bbox_x与list中其他bbox_y的IoU,若IoU大于阈值T,则剔除该bbox_y,最终保留bbox_x,从list_k中取出;
**step-4**:选择list_k中top2 cls score(步骤3取出top 1 bbox_x后,原list_k中的top 2就相当于现list_k中的top 1了,但如果step-3中剔除的bbox_y刚好是原list_k中的top 2,就依次找top 3即可,理解这么个意思就行),重复step-3中的迭代操作,直至list_k中所有bbox都完成筛选;
**step-5**:对每个集合的list_k,重复step-3、4中的迭代操作,直至所有list_k都完成筛选;
以上操作写的有点绕,不过如果理解NMS操作流程的话,再结合下图,应该还是非常好理解的;

**2 代码学习**
**2.1 test_RFB.py**
我选择了RFBNet里的代码介绍NMS,因为里面的流程基本上就是按照我说的操作进行了;
先看看test_RFB.py中的片段,通过以下代码可以发现,其对应着step-1、step5操作,就是说NMS操作是逐类进行的,图像中检出的所有bboxes,按照 cls 做划分,再每个类的bbox进一步做NMS;
```python
out = net(x) # forward pass,这里相当于将图像 x 输入RFBNet,得到了pred cls + reg
boxes, scores = detector.forward(out,priors) # 结合priors,将pred reg(也即预测的offsets)解码成最终的pred bbox,如果理解anchor / default bbox操作流程,这个应该很好理解的;
boxes = boxes[0]
scores=scores[0]
# scale each detection back up to the image
boxes *= scale # (0,1)区间坐标的bbox做尺度反正则化
boxes = boxes.cpu().numpy()
scores = scores.cpu().numpy()
for j in range(1, num_classes): # 对每个类 j 的pred bbox单独做NMS,为什么index从1开始?因为0是bg,做NMS无意义
inds = np.where(scores[:, j] > thresh)[0] # 找到该类 j 下,所有cls score大于thresh的bbox,为什么选择大于thresh的bbox?因为score小于阈值的bbox,直接可以过滤掉,无需劳烦NMS
if len(inds) == 0: # 没有满足条件的bbox,返回空,跳过;
all_boxes[j][i] = np.empty([0, 5], dtype=np.float32)
continue
c_bboxes = boxes[inds]
c_scores = scores[inds, j] # 找到对应类 j 下的score即可
c_dets = np.hstack((c_bboxes, c_scores[:, np.newaxis])).astype(
np.float32, copy=False) # 将满足条件的bbox + cls score的bbox通过hstack完成合体
keep = nms(c_dets, 0.45, force_cpu=args.cpu) # NMS,返回需保存的bbox index:keep
c_dets = c_dets[keep, :]
all_boxes[j][i] = c_dets # i 对应每张图像,j 对应图像中类别 j 的bbox清单
```
介绍以上代码处理流程,**两个目的**:
1 test_RFB.py的处理流程非常清晰,也很方便我们的理解;
2 for j in range(1, num_classes)操作表明了,NMS是逐类进行的,也即参与NMS的bbox都属于同一类;
**2.2 py_cpu_nms.py**
代码同样来自于FRBNet,结合注释可以发现引自Fast R-CNN;
这个代码是最简版的nms,跟第一节中NMS处理流程一致,非常适合学习,可以作为baseline,我加了个简单的main函数做测试;
```python
# --------------------------------------------------------
# Fast R-CNN
# Copyright (c) 2015 Microsoft
# Licensed under The MIT License [see LICENSE for details]
# Written by Ross Girshick
# --------------------------------------------------------
import numpy as np
def py_cpu_nms(dets, thresh):
"""Pure Python NMS baseline."""
x1 = dets[:, 0] # pred bbox top_x
y1 = dets[:, 1] # pred bbox top_y
x2 = dets[:, 2] # pred bbox bottom_x
y2 = dets[:, 3] # pred bbox bottom_y
scores = dets[:, 4] # pred bbox cls score
areas = (x2 - x1 + 1) * (y2 - y1 + 1) # pred bbox areas
order = scores.argsort()[::-1] # 对pred bbox按score做降序排序,对应step-2
keep = [] # NMS后,保留的pred bbox
while order.size > 0:
i = order[0] # top-1 score bbox
keep.append(i) # top-1 score的话,自然就保留了
xx1 = np.maximum(x1[i], x1[order[1:]]) # top-1 bbox(score最大)与order中剩余bbox计算NMS
yy1 = np.maximum(y1[i], y1[order[1:]])
xx2 = np.minimum(x2[i], x2[order[1:]])
yy2 = np.minimum(y2[i], y2[order[1:]])
w = np.maximum(0.0, xx2 - xx1 + 1)
h = np.maximum(0.0, yy2 - yy1 + 1)
inter = w * h
ovr = inter / (areas[i] + areas[order[1:]] - inter) # 无处不在的IoU计算~~~
inds = np.where(ovr <= thresh)[0] # 这个操作可以对代码断点调试理解下,结合step-3,我们希望剔除所有与当前top-1 bbox IoU > thresh的冗余bbox,那么保留下来的bbox,自然就是ovr <= thresh的非冗余bbox,其inds保留下来,作进一步筛选
order = order[inds + 1] # 保留有效bbox,就是这轮NMS未被抑制掉的幸运儿,为什么 + 1?因为ind = 0就是这轮NMS的top-1,剩余有效bbox在IoU计算中与top-1做的计算,inds对应回原数组,自然要做 +1 的映射,接下来就是step-4的循环
return keep # 最终NMS结果返回
if __name__ == '__main__':
dets = np.array([[100,120,170,200,0.98],
[20,40,80,90,0.99],
[20,38,82,88,0.96],
[200,380,282,488,0.9],
[19,38,75,91, 0.8]])
py_cpu_nms(dets, 0.5)
```
**2.2 bbox_utils.py**
同样是RFBNet中的nms代码,用pytorch实现的,其实和2.1小节中的NMS操作完全一致;
```python
# Original author: Francisco Massa:
# https://github.com/fmassa/object-detection.torch
# Ported to PyTorch by Max deGroot (02/01/2017)
def nms(boxes, scores, overlap=0.5, top_k=200):
"""Apply non-maximum suppression at test time to avoid detecting too many
overlapping bounding boxes for a given object. ---- 这里面有一个细节,NMS仅用于测试阶段,为什么不用于训练阶段呢?可以评论留言下,我就不解释了,嘿嘿~~~
Args:
boxes: (tensor) The location preds for the img, Shape: [num_priors,4].
scores: (tensor) The class predscores for the img, Shape:[num_priors].
overlap: (float) The overlap thresh for suppressing unnecessary boxes.
top_k: (int) The Maximum number of box preds to consider.
Return:
The indices of the kept boxes with respect to num_priors.
"""
keep = torch.Tensor(scores.size(0)).fill_(0).long()
if boxes.numel() == 0:
return keep
x1 = boxes[:, 0]
y1 = boxes[:, 1]
x2 = boxes[:, 2]
y2 = boxes[:, 3]
area = torch.mul(x2 - x1, y2 - y1) # IoU初步准备
v, idx = scores.sort(0) # sort in ascending order,对应step-2,不过是升序操作,非降序
# I = I[v >= 0.01]
idx = idx[-top_k:] # indices of the top-k largest vals,依然是升序的结果
xx1 = boxes.new()
yy1 = boxes.new()
xx2 = boxes.new()
yy2 = boxes.new()
w = boxes.new()
h = boxes.new()
# keep = torch.Tensor()
count = 0
while idx.numel() > 0: # 对应step-4,若所有pred bbox都处理完毕,就可以结束循环啦~
i = idx[-1] # index of current largest val,top-1 score box,因为是升序的,所有返回index = -1的最后一个元素即可
# keep.append(i)
keep[count] = i
count += 1 # 不仅记数NMS保留的bbox个数,也作为index存储bbox
if idx.size(0) == 1:
break
idx = idx[:-1] # remove kept element from view,top-1已保存,不需要了~~~
# load bboxes of next highest vals
torch.index_select(x1, 0, idx, out=xx1)
torch.index_select(y1, 0, idx, out=yy1)
torch.index_select(x2, 0, idx, out=xx2)
torch.index_select(y2, 0, idx, out=yy2)
# store element-wise max with next highest score
xx1 = torch.clamp(xx1, min=x1[i]) # 对应 np.maximum(x1[i], x1[order[1:]])
yy1 = torch.clamp(yy1, min=y1[i])
xx2 = torch.clamp(xx2, max=x2[i])
yy2 = torch.clamp(yy2, max=y2[i])
w.resize_as_(xx2)
h.resize_as_(yy2)
w = xx2 - xx1
h = yy2 - yy1
# check sizes of xx1 and xx2.. after each iteration
w = torch.clamp(w, min=0.0) # clamp函数可以去查查,类似max、mini的操作
h = torch.clamp(h, min=0.0)
inter = w*h
# IoU = i / (area(a) + area(b) - i)
# 以下两步操作做了个优化,area已经计算好了,就可以直接根据idx读取结果了,area[i]同理,避免了不必要的冗余计算
rem_areas = torch.index_select(area, 0, idx) # load remaining areas)
union = (rem_areas - inter) + area[i] # 就是area(a) + area(b) - i
IoU = inter/union # store result in iou,# IoU来啦~~~
# keep only elements with an IoU <= overlap
idx = idx[IoU.le(overlap)] # 这一轮NMS操作,IoU阈值小于overlap的idx,就是需要保留的bbox,其他的就直接忽略吧,并进行下一轮计算
return keep, count
```
**2.2 cpu_nms.pyx**
同样在RGBNet项目中,下面就是优化后的NNS操作,以及soft-NMS操作,我就不细讲了~~~
```python
# --------------------------------------------------------
# Fast R-CNN
# Copyright (c) 2015 Microsoft
# Licensed under The MIT License [see LICENSE for details]
# Written by Ross Girshick
# --------------------------------------------------------
import numpy as np
cimport numpy as np
cdef inline np.float32_t max(np.float32_t a, np.float32_t b):
return a if a >= b else b
cdef inline np.float32_t min(np.float32_t a, np.float32_t b):
return a if a <= b else b
def cpu_nms(np.ndarray[np.float32_t, ndim=2] dets, np.float thresh):
cdef np.ndarray[np.float32_t, ndim=1] x1 = dets[:, 0]
cdef np.ndarray[np.float32_t, ndim=1] y1 = dets[:, 1]
cdef np.ndarray[np.float32_t, ndim=1] x2 = dets[:, 2]
cdef np.ndarray[np.float32_t, ndim=1] y2 = dets[:, 3]
cdef np.ndarray[np.float32_t, ndim=1] scores = dets[:, 4]
cdef np.ndarray[np.float32_t, ndim=1] areas = (x2 - x1 + 1) * (y2 - y1 + 1)
cdef np.ndarray[np.int_t, ndim=1] order = scores.argsort()[::-1]
cdef int ndets = dets.shape[0]
cdef np.ndarray[np.int_t, ndim=1] suppressed = \
np.zeros((ndets), dtype=np.int)
# nominal indices
cdef int _i, _j
# sorted indices
cdef int i, j
# temp variables for box i's (the box currently under consideration)
cdef np.float32_t ix1, iy1, ix2, iy2, iarea
# variables for computing overlap with box j (lower scoring box)
cdef np.float32_t xx1, yy1, xx2, yy2
cdef np.float32_t w, h
cdef np.float32_t inter, ovr
keep = []
for _i in range(ndets):
i = order[_i]
if suppressed[i] == 1:
continue
keep.append(i)
ix1 = x1[i]
iy1 = y1[i]
ix2 = x2[i]
iy2 = y2[i]
iarea = areas[i]
for _j in range(_i + 1, ndets):
j = order[_j]
if suppressed[j] == 1:
continue
xx1 = max(ix1, x1[j])
yy1 = max(iy1, y1[j])
xx2 = min(ix2, x2[j])
yy2 = min(iy2, y2[j])
w = max(0.0, xx2 - xx1 + 1)
h = max(0.0, yy2 - yy1 + 1)
inter = w * h
ovr = inter / (iarea + areas[j] - inter)
if ovr >= thresh:
suppressed[j] = 1
return keep
def cpu_soft_nms(np.ndarray[float, ndim=2] boxes, float sigma=0.5, float Nt=0.3, float threshold=0.001, unsigned int method=0):
cdef unsigned int N = boxes.shape[0]
cdef float iw, ih, box_area
cdef float ua
cdef int pos = 0
cdef float maxscore = 0
cdef int maxpos = 0
cdef float x1,x2,y1,y2,tx1,tx2,ty1,ty2,ts,area,weight,ov
for i in range(N):
maxscore = boxes[i, 4]
maxpos = i
tx1 = boxes[i,0]
ty1 = boxes[i,1]
tx2 = boxes[i,2]
ty2 = boxes[i,3]
ts = boxes[i,4]
pos = i + 1
# get max box
while pos < N:
if maxscore < boxes[pos, 4]:
maxscore = boxes[pos, 4]
maxpos = pos
pos = pos + 1
# add max box as a detection
boxes[i,0] = boxes[maxpos,0]
boxes[i,1] = boxes[maxpos,1]
boxes[i,2] = boxes[maxpos,2]
boxes[i,3] = boxes[maxpos,3]
boxes[i,4] = boxes[maxpos,4]
# swap ith box with position of max box
boxes[maxpos,0] = tx1
boxes[maxpos,1] = ty1
boxes[maxpos,2] = tx2
boxes[maxpos,3] = ty2
boxes[maxpos,4] = ts
tx1 = boxes[i,0]
ty1 = boxes[i,1]
tx2 = boxes[i,2]
ty2 = boxes[i,3]
ts = boxes[i,4]
pos = i + 1
# NMS iterations, note that N changes if detection boxes fall below threshold
while pos < N:
x1 = boxes[pos, 0]
y1 = boxes[pos, 1]
x2 = boxes[pos, 2]
y2 = boxes[pos, 3]
s = boxes[pos, 4]
area = (x2 - x1 + 1) * (y2 - y1 + 1)
iw = (min(tx2, x2) - max(tx1, x1) + 1)
if iw > 0:
ih = (min(ty2, y2) - max(ty1, y1) + 1)
if ih > 0:
ua = float((tx2 - tx1 + 1) * (ty2 - ty1 + 1) + area - iw * ih)
ov = iw * ih / ua #iou between max box and detection box
if method == 1: # linear
if ov > Nt:
weight = 1 - ov
else:
weight = 1
elif method == 2: # gaussian
weight = np.exp(-(ov * ov)/sigma)
else: # original NMS
if ov > Nt:
weight = 0
else:
weight = 1
boxes[pos, 4] = weight*boxes[pos, 4]
# if box score falls below threshold, discard the box by swapping with last box
# update N
if boxes[pos, 4] < threshold:
boxes[pos,0] = boxes[N-1, 0]
boxes[pos,1] = boxes[N-1, 1]
boxes[pos,2] = boxes[N-1, 2]
boxes[pos,3] = boxes[N-1, 3]
boxes[pos,4] = boxes[N-1, 4]
N = N - 1
pos = pos - 1
pos = pos + 1
keep = [i for i in range(N)]
return keep
```
**参考代码:**
[https://github.com/ruinmessi/RFBNet](https://link.zhihu.com/?target=https%3A//github.com/ruinmessi/RFBNet):RFBNet
[https://github.com/rbgirshick/py-faster-rcnn](https://link.zhihu.com/?target=https%3A//github.com/rbgirshick/py-faster-rcnn):学习一百遍都不为过的faster rcnn
NMS_demo.py:
**参考资料**
- [目标检测番外篇(3)_NMS](https://zhuanlan.zhihu.com/p/49481833)
- [浅谈NMS的多种实现](https://zhuanlan.zhihu.com/p/64423753)
## NMS及其变体
- NMS
- Soft-NMS
- Softer-NMS
- IoU-guided NMS
- ConvNMS
- Pure NMS
- Yes-Net
- LNMS
- INMS
- Polygon NMS
- MNMS
**参考资料**
- [Detection基础模块之(三)NMS及变体](https://zhuanlan.zhihu.com/p/70771042)
- [NMS也能玩出花样来……](https://zhuanlan.zhihu.com/p/28129034)
- [目标检测之非极大值抑制(NMS)各种变体](https://zhuanlan.zhihu.com/p/50126479)
## R-CNN 系列
### R-CNN
- [ ] TODO
### Fast R-CNN
- [ ] TODO
### Faster R-CNN
- [ ] TODO
#### Faster R-CNN 为什么用smooth l1 loss,和l2有什么区别?
- [ ] TODO
### Faster R-CNN的RPN网络
RPN结构说明:
1) 从基础网络提取的第五卷积层特征进入RPN后分为两个分支,其中一个分支进行针对feature map(上图conv-5-3共有512个feature-map)的每一个位置预测共(9*4=36)个参数,其中9代表的是每一个位置预设的9种形状的anchor-box,4对应的是每一个anchor-box的预测值(该预测值表示的是预设anchor-box到ground-truth-box之间的变换参数),上图中指向rpn-bbox-pred层的箭头上面的数字36即是代表了上述的36个参数,所以rpn-bbox-pred层的feature-map数量是36,而每一张feature-map的形状(大小)实际上跟conv5-3一模一样的;
2) 另一分支预测该anchor-box所框定的区域属于前景和背景的概率(网上很对博客说的是,指代该点属于前景背景的概率,那样是不对的,不然怎么会有18个feature-map输出呢?否则2个就足够了),前景背景的真值给定是根据当前像素(anchor-box中心)是否在ground-truth-box内;
3) 上图RPN-data(python)运算框内所进行的操作是读取图像信息(原始宽高),groun-truth boxes的信息(bounding-box的位置,形状,类别)等,作好相应的转换,输入到下面的层当中。
4) 要注意的是RPN内部有两个loss层,一个是BBox的loss,该loss通过减小ground-truth-box与预测的anchor-box之间的差异来进行参数学习,从而使RPN网络中的权重能够学习到预测box的能力。实现细节是每一个位置的anchor-box与ground-truth里面的box进行比较,选择IOU最大的一个作为该anchor-box的真值,若没有,则将之class设为背景(概率值0,否则1),这样背景的anchor-box的损失函数中每个box乘以其class的概率后就不会对bbox的损失函数造成影响。另一个loss是class-loss,该处的loss是指代的前景背景并不是实际的框中物体类别,它的存在可以使得在最后生成roi时能快速过滤掉预测值是背景的box。也可实现bbox的预测函数不受影响,使得anchor-box能(专注于)正确的学习前景框的预测,正如前所述。所以,综合来讲,整个RPN的作用就是替代了以前的selective-search方法,因为网络内的运算都是可GPU加速的,所以一下子提升了ROI生成的速度。可以将RPN理解为一个预测前景背景,并将前景框定的一个网络,并进行单独的训练,实际上论文里面就有一个分阶段训练的训练策略,实际上就是这个原因。
5) 最后经过非极大值抑制,RPN层产生的输出是一系列的ROI-data,它通过ROI的相对映射关系,将conv5-3中的特征已经存入ROI-data中,以供后面的分类网使用。
另外两个loss层的说明:
也许你注意到了,最后还有两个loss层,这里的class-loss指代的不再是前景背景loss,而是真正的类别loss了,这个应该就很好理解了。而bbox-loss则是因为rpn提取的只是前景背景的预测,往往很粗糙,这里其实是通过ROI-pooling后加上两层全连接实现更精细的box修正(这里其实是我猜的)。
ROI-Pooing的作用是为了将不同大小的Roi映射(重采样)成统一的大小输入到全连接层去。
以上。
**参考资料**
- [Faster-Rcnn中RPN(Region Proposal Network)的理解](https://blog.csdn.net/mllearnertj/article/details/53709766)
## SSD 算法
- [ ] TODO
**参考资料**
- [SSD 论文原文完整翻译](https://zhuanlan.zhihu.com/p/65484308)
## YOLO系列(V1-V8)
### YOLOV1
- [ ] TODO
### YOLOv2
- [ ] TODO
### YOLOv3
- [ ] TODO
### YOLOv4
**参考资料**
- [目标检测面试指南之YOLOV4](https://zhuanlan.zhihu.com/p/138824273)
### YOLOv5
- [ ] TODO
### YOLOv6
- [ ] TODO
### YOLOv7
- [ ] TODO
### YOLOv8
- [ ] TODO
### YOLOv1-YOLOv8的发展
- [ ] TODO
### YOLOv2和YOLOv3的损失函数区别
- [ ] TODO
**参考资料**
- [YOLOv1,YOLOv2,YOLOv3解读]()
###
## RetinaNet(Focal loss)
《Focal Loss for Dense Object Detection》
- arXiv:https://arxiv.org/abs/1708.02002
清华大学孔涛博士在知乎上这么写道:
目标的检测和定位中一个很困难的问题是,如何从数以万计的候选窗口中挑选包含目标物的物体。只有候选窗口足够多,才能保证模型的 Recall。
目前,目标检测框架主要有两种:
一种是 one-stage ,例如 YOLO、SSD 等,这一类方法速度很快,但识别精度没有 two-stage 的高,其中一个很重要的原因是,利用一个分类器很难既把负样本抑制掉,又把目标分类好。
另外一种目标检测框架是 two-stage ,以 Faster RCNN 为代表,这一类方法识别准确度和定位精度都很高,但存在着计算效率低,资源占用大的问题。
Focal Loss 从优化函数的角度上来解决这个问题,实验结果非常 solid,很赞的工作。
何恺明团队提出了用 Focal Loss 函数来训练。
因为,他在训练过程中发现,类别失衡是影响 one-stage 检测器准确度的主要原因。那么,如果能将“类别失衡”这个因素解决掉,one-stage 不就能达到比较高的识别精度了吗?
于是在研究中,何恺明团队采用 Focal Loss 函数来消除“类别失衡”这个主要障碍。
结果怎样呢?
为了评估该损失的有效性,该团队设计并训练了一个简单的密集目标检测器—RetinaNet。试验结果证明,当使用 Focal Loss 训练时,RetinaNet 不仅能赶上 one-stage 检测器的检测速度,而且还在准确度上超越了当前所有最先进的 two-stage 检测器。
**参考**
- [如何评价Kaiming的Focal Loss for Dense Object Detection?](https://www.zhihu.com/question/63581984)
- [首发 | 何恺明团队提出 Focal Loss,目标检测精度高达39.1AP,打破现有记录](https://zhuanlan.zhihu.com/p/28442066)
## FPN 特征金字塔网络
## ROI Pooling、ROI Align和ROI Warping对比
- [ ] TODO
**参考资料**
- [Mask-RCNN中的ROIAlign, ROIPooling及ROIWarp对比](https://blog.csdn.net/lanyuxuan100/article/details/71124596)
# Anchor-free目标检测系列
# DETR系列
## DeepLab系列(V1-V3+)
- [ ] TODO
## U-Net神经网络为什么会在医学图像分割表现好?
**参考资料**
- [U-Net神经网络为什么会在医学图像分割表现好?](https://www.zhihu.com/question/269914775)
## Scene Parsing和Semantic Segmentation有什么不同?
**参考资料**
- [Scene Parsing和Semantic Segmentation有什么不同?](https://www.zhihu.com/question/57726518)
## CenterNet
CornerNet介绍
### CornerPooling是怎么做的?
- [ ] TODO
# Transformer
**参考资料**
- [Transformer面试题总结101道题](https://zhuanlan.zhihu.com/p/438625445)
- [transformer面试题的简单回答](https://zhuanlan.zhihu.com/p/363466672)
- [史上最全Transformer面试题系列(一):灵魂20问帮你彻底搞定Transformer-干货!](https://zhuanlan.zhihu.com/p/148656446)
# 视觉Transformer
## ViT
## Swin
## PVT
## TODO
- [ ] 目标检测方向
- [ ] 图像分割方向
- [ ] 目标跟踪方向
- [ ] 人脸(检测&识别&关键点)
- [ ] OCR方向
- [ ] SLAM方向
- [ ] 超分辨率
- [ ] 医疗影响方向
- [ ] Re-ID
================================================
FILE: docs/面试技巧.md
================================================
[TOC]
# 面试技巧
## TODO
================================================
FILE: docs/面试经验.md
================================================
[TOC]
# 面试经验
- [经验总结](#Summary)
[HR 面](#HR)
- [2021届](#2021)
- [2020届](#2020)
- [2019届](#2019)
- [2018届](#2018)
## 经验总结
**经验一:**
1. **能内推尽量不走官网**。现在大厂的简历数量都非常吓人,可能几个算法岗位收到几百甚至上千的简历都不为过,那面试官怎么能从中捞出你的简历呢?一个有效的方法就是内推,内推意味着你能拿到正式员工的背书,有了这样的背书,相当于有了加分。内推还有一些好处,包括免笔试等(也有不免的,不绝对)。
2. **能投提前批尽量不等正式批**。HC(head count)就那么多,提前批发的差不多了,正式批的hc就少了,道理就是这么个简单的道理。另外如果部门有10个hc的时候,你水平差不多,招你一个问题不大,反正还有9个。但是只剩1个hc的时候,面试官就开始精挑细选,要求自然也就上来了。永远没有准备好的时候,有个60-80%的把握,其实就可以去面试了。你要问怎么算有60-80%的把握,把目标公司往年的面经拿出来,做模拟面试,如果60-80%的题目都能答出来,就差不多。
3. **能提前准备尽量别临时抱佛脚**。这是很多同学意识不到的,其实我们的秋招不止发生在这几个月,从你简历上第一段经历开始,已经是在为求职铺路了。学校,比赛,论文,其实这些都是面试的主要参考,如果能在更早的让简历变的丰富,让自己的编程和算法基本功变得扎实,将会在秋招中脱颖而出。
**经验二:**
1. 一定要有一门自己比较熟悉的语言。
我由于使用C++比较多,所以简历上只写了C++。C++的特性要了解,C++11要了解一些,还有STL。面试中常遇到的一些问题,手写代码实现一个string类,手写代码实现智能指针类,以及STL中的容器的实现机制,多态和继承,构造函数, 析构函数等。推荐看一下网易云课堂翁恺老师的C++的视频以及经典的几本书。
2. 一定要刷题
楼主主要刷了剑指offer以及leetcode上的easy,middle的题目。如果编程能力不是很强,推荐可以分类型进行刷题,按照tag来刷,对于某一类型的题目,可以先看一下该算法的核心思想,然后再刷题。楼主在求职的过程中,遇到好多跟leetcode上类似的题目,刷题的目的不是为了碰见原题,而是为了熟练算法。当然能够碰见原题最好不过啦。
3. 机器学习的一些建议
推荐西瓜书,以及李航老师的统计学方法。另外熟悉一种深度学习框架。学习计算机,一定要实战,毕竟只有在实战的过程中,才能懂得更透彻。可以多参加一些比赛,比如kaggle,天池,滴滴的一些比赛。这对找工作的用处很大。
4.能实习就尽量实习。
如果导师是学术大牛,可以带你发顶会的论文,并且自己对方向比较感兴趣,那可以在实验室待着好好搞科研。如果你研究生的研究方向跟你以后的求职方向不一致,建议早点出来实习,找个对口的实习,实习才能发现,实际工作和在学校学习的东西差距比较大。
**经验三:**
1. 实习!算法岗如果不是科班出身,实验室没有项目,一定要去大厂实习;
2. Coding!相较于前两年,编程能力在面试算法工程师过程中,所占比重越来越大,特别是百度、头条这些大厂;
3. 提前规划! 建议多看看面试经验,提前做好规划,按照计划去复习,尽量在提前批搞定;大厂在提前批名额会比较多,像阿里秋招HC已经很少了;
4. 找靠谱的人内推!
5. 找同样岗位的同学一起准确、相互监督。
**参考资料**
- [算法岗计算机视觉方向求职经验总结](https://www.nowcoder.com/discuss/61601)
- [一名渣渣C++程序员的心酸春招/秋招记【篇幅较长,慎入】](https://www.nowcoder.com/discuss/57942?type=0&order=0&pos=85&page=2)
- [机器学习/数据挖掘岗2019秋招总结 ](https://www.nowcoder.com/discuss/138721?type=0&order=0&pos=13&page=1)
- [你的2020秋招进展怎么样了?【Offer:快手,百度,字节,华为,大疆,旷视,地平线,第四范式,云从,Aibee。(4-SSP,4-SP,2-白菜)】](https://www.zhihu.com/question/315012080/answer/921230579)
- [ ] [写在20年初的校招面试心得与自学CS经验及找工作分享](https://zhuanlan.zhihu.com/p/108911948)
- [ ] [Google 面试技巧(来自一名谷歌面试官)](https://psc-g.github.io/interviews/google/2020/02/25/interviewing-at-google.html)
- [ ] [互联网算法工程师面试总结 - BATMD核心考题](https://zhuanlan.zhihu.com/p/103971049)
- [ ] [一个双非渣硕的自我救赎之路](https://www.nowcoder.com/discuss/328830)
- [ ] [秋招总结:非机器学习科班学生漫长的算法工程师上岸之旅](https://www.nowcoder.com/discuss/326300)
- [ ] [20校招AI算法岗(已获微软+BAT意向书)更新](https://www.nowcoder.com/discuss/216117)
- [ ] [算法上岸,特别回馈一下牛客上,发一波面经,祝各位前途似锦](https://www.nowcoder.com/discuss/302700)
- [ ] [转行渣硕的算法路,记录走过的坑和一些笔经面经给转行算法的同学](https://www.nowcoder.com/discuss/295287)
- [ ] [一个励志故事:从林学院本科到算法sp的四年](https://www.nowcoder.com/discuss/308026)
- [ ] [【算法小白出师记】我的秋招之路](https://www.nowcoder.com/discuss/225926)
- [ ] [技术道路分享|算法岗](https://www.nowcoder.com/discuss/146309)
- [ ] [本人18家算法面经,吐血整理](https://www.nowcoder.com/discuss/313143)
- [ ] [别让时间破碎了梦想,遇见未来不可思议的自己——秋招总结](https://www.nowcoder.com/discuss/331574)
- [ ] [总结一下自己的秋招吧 附带面经](https://www.nowcoder.com/discuss/337100)
- [ ] [2021届校招算法岗知识点总结](https://zhuanlan.zhihu.com/p/107911095)
## HR 面
1. 期望薪资
2. 你理想的工作是什么样的?
3. 关于你以后的工作打算,你有什么想法?
4. 职业规划
5. 做项目时遇到的困难及解决方法?
6. 做科研辛苦吗?
7. 对公司的看法?为什么应聘我们公司?
8. 你在同龄人中处于什么档次 和大牛的差距在哪?
9. 你跟同龄人相比有什么优势?
10. 你除了我们公司,还投了哪些公司?
11. 如果我们给你发offer,你还会继续秋招么?
12. 优缺点?
13. 介绍你一次最失败的一次经历?
14. 介绍你一次最成功的一次经历?
15. 这份工作你有想过会面对哪些困难吗?
16. 如果你发现上司做错了,你将怎么办?
17. 你觉得大学生活使你收获了什么?
18. 你对加班的看法?
**参考资料**
- [ ] [揭秘HR最常问的50个面试问题,你中枪了吗?](https://zhuanlan.zhihu.com/p/59444455)
## 2021届
> Date:2020-08-02
- [ ] [NLP算法面试必备!史上最全!PTMs:NLP预训练模型的全面总结](https://zhuanlan.zhihu.com/p/115014536)
- [ ] [字节跳动Ailab-NLP提前批四面面经](https://zhuanlan.zhihu.com/p/163261546)
- [ ] [一文梳理常见机器学习面试题](https://zhuanlan.zhihu.com/p/82105066)
- [ ] [2021届校招算法岗知识点总结](https://zhuanlan.zhihu.com/p/107911095)
- [ ] [Machine Learning Interview Questions](https://github.com/andrewekhalel/MLQuestions)
- [ ] [160+ Data Science Interview Questions](https://hackernoon.com/160-data-science-interview-questions-415s3y2a)
## 2020届
> Date:2019-12-31
- [ ] [2020届校招面试各类算法问题及个人理解的汇总](https://github.com/sladesha/Reflection_Summary)
- [ ] [2020算法岗面经集合](https://blog.nowcoder.net/n/6221a5d00a8d4c00bf66b2e403575151)
- [ ] [百度凤巢广告算法提前批三面面经(已发offer)](https://www.nowcoder.com/discuss/211954)
- [ ] [从0到1:终于告别0offer](https://www.nowcoder.com/discuss/136270)
- [ ] [深夜-作业帮NLP凉面](https://www.nowcoder.com/discuss/211426)
- [ ] [寒武纪服务器软件工程师面经](https://www.nowcoder.com/discuss/211983)
- [ ] [春招计算机视觉面经(阿里海康大华 华为腾讯、水晶光电、虹软)](https://www.nowcoder.com/discuss/190511)
- [ ] [美的提前批面试【数据挖掘】](https://www.nowcoder.com/discuss/203015)
- [ ] [银行笔试面试经验分享及资料分享](https://github.com/sty945/bank_interview)
- [x] [发个面经吧,bat加字节](https://www.nowcoder.com/discuss/198905)
- [x] [回馈牛客,字节算法三面许愿求offer](https://www.nowcoder.com/discuss/211763)
- [x] [字节跳动2020届提前批 AI Lab cv 三面视频面](https://www.nowcoder.com/discuss/210508)
- [x] [春招实习数分面经](https://www.nowcoder.com/discuss/189529)
- [x] [阿里算法面经](https://www.nowcoder.com/discuss/209306)
- [x] [菜鸡总结暑期实习求职经历(附部分面经)](https://www.nowcoder.com/discuss/205718)
- [x] [字节AiLab CV 面经,已经收到感谢信](https://www.nowcoder.com/discuss/211352)
- [x] [寒武纪加面,C++ 面经](https://www.nowcoder.com/discuss/210657)
- [x] [面试体验:Facebook 篇](https://www.nowcoder.com/discuss/211670)
- [x] [追一科技-视觉算法一面凉经](https://www.nowcoder.com/discuss/210063)
- [x] [百度 推荐架构部 后台开发 秋招面经](https://www.nowcoder.com/discuss/209462)
- [x] [商汤20校招CV算法研究员面经【三面+HR面】](https://www.nowcoder.com/discuss/209857)
- [x] [菜鸡总结暑期实习求职经历(附部分面经)](https://www.nowcoder.com/discuss/205718)
- [x] [头条机器学习算法岗面试记录](https://www.nowcoder.com/discuss/205260)
- [x] [京东提前批算法工程师电面面经](https://www.nowcoder.com/discuss/206186)
- [x] [字节跳动C++研发工程师(三面全通过)](https://www.nowcoder.com/discuss/208173)
- [x] [头条抖音互娱-图形图像一二三面](https://www.nowcoder.com/discuss/207369)
- [x] [字节跳动提前批算法工程师面经](https://www.nowcoder.com/discuss/207092)
- [x] [算法岗笔经面经记录(偏CV方向)](https://www.nowcoder.com/discuss/202732)
- [x] [Google面试经验](https://www.nowcoder.com/discuss/205633)
- [x] [铁牌退役ACM选手的春招实习日记(大数据方向)](https://www.nowcoder.com/discuss/154263)
- [x] [2019求职记录(定期更新,更新到7月现在)](https://www.nowcoder.com/discuss/202381)
- [x] [oppo提前批机器学习岗面经](https://www.nowcoder.com/discuss/205955)
- [x] [成都oppo机器学习算法工程师面经+还愿](https://www.nowcoder.com/discuss/205841)
- [x] [多益游戏研发工程师面经](https://www.nowcoder.com/discuss/205561)
- [x] [腾讯光子技术中心 日常实习CV方向面筋](https://www.nowcoder.com/discuss/206089)
- [x] [bigo 图像增强算法面试](https://www.nowcoder.com/discuss/202709)
- [x] [字节跳动提前批 大数据面经 = =](https://www.nowcoder.com/discuss/204677)
- [x] [字节跳动 成都效率工程后端C++提前批三面凉面](https://www.nowcoder.com/discuss/205353)
- [x] [渣渣的面试记录之OPPO提前批](https://www.nowcoder.com/discuss/205556)
- [x] [OPPO 视觉算法一二三面](https://www.nowcoder.com/discuss/205472)
- [x] [头条机器学习算法岗面试记录](https://www.nowcoder.com/discuss/205260)
- [x] [oppo 机器学习提前批面经](https://www.nowcoder.com/discuss/205464)
- [x] [多益面经(人工智能)](https://www.nowcoder.com/discuss/205251)
- [ ] [oppo c++面经](https://www.nowcoder.com/discuss/205493)
- [x] [2019.7.5百度生态搜索质量部 提前批 面试题回忆](https://www.nowcoder.com/discuss/203473)
- [x] [字节算法提前批一面凉经](https://www.nowcoder.com/discuss/203455)
- [x] [记一次十分惨烈的头条一面](https://www.nowcoder.com/discuss/203454)
- [x] [爱奇艺数据分析实习生面经](https://www.nowcoder.com/discuss/203036)
- [x] [中兴通讯2020届校园招聘提前批面经(算法工程师)](https://www.nowcoder.com/discuss/203584)
- [x] [浪潮提前批offer/ open day面经(AI相关)](https://www.nowcoder.com/discuss/203519)
- [ ] [84 Advanced Deep learning Interview questions and answers](https://onlinetutorials.today/deep-learning/deep-learning-interview-questions-and-answers/)
- [ ] [Top Deep Learning Interview Questions You Must Know](https://www.edureka.co/blog/interview-questions/deep-learning-interview-questions/?nsukey=n6BxpUwwiXRSAQ2Sv9V5eB9ZTB3P%2Bi%2BUXC2RBtSOQDXsXC2DPM%2BmBQx8jxTdSmmFhZNZiMp3vdJQSPsbs2VAduoPYVeGQzblJ0iAVOP3h6i678qyi0M%2BUsVYPxZYUa%2BphTX4MwUlFBw5FFdiQb1%2FVjoZ9xTEFtDcDHp6vpZlrY3gupLTH4wpZ1x7b088FBFeFLzWYleBjNEMLdPdic016g%3D%3D)
- [x] [【已拿offer】美的提前批数据挖掘工程师面经](https://www.nowcoder.com/discuss/200940)
- [x] [字节跳动大数据研发岗位实习生 已上岸](https://www.nowcoder.com/discuss/201086)
- [x] [攒人品的京东算法面经](https://www.nowcoder.com/discuss/199755)
- [x] [TP-LINK 提前批 算法岗面经](https://www.nowcoder.com/discuss/200260)
- [x] [VIVO杭州 NLP算法工程师面经](https://www.nowcoder.com/discuss/198376)
- [x] [百度机器学习实习三面](https://www.nowcoder.com/discuss/178148)
- [x] [2020届NLP小渣渣实习及秋招面试记录](https://zhuanlan.zhihu.com/p/62902811)
- [x] [字节跳动实习算法岗面经](https://www.nowcoder.com/discuss/174565)
- [x] ♥♥ [20届-视觉算法-暑期实习-菜鸡的心酸历程](https://www.nowcoder.com/discuss/173292)
- [x] [腾讯算法实习面试总结——论面试官虐我的一百种方式](https://www.nowcoder.com/discuss/163996)
- [x] [旷视(face++)算法实习生面经](https://zhuanlan.zhihu.com/p/61221469)
- [x] [我的春招实习结束了,详细算法面经](https://www.nowcoder.com/discuss/163388)
- [x] [字节跳动自然语言处理面经-半凉等offer](https://www.nowcoder.com/discuss/170907)
- [x] ♥ [算法春招上岸,心路历程(内含部分公司面经)](https://www.nowcoder.com/discuss/170673)
- [x] [360公司2018秋招算法精英面经分享~](https://www.nowcoder.com/discuss/154590)
- [x] [腾讯算法岗实习烫经](https://www.nowcoder.com/discuss/169896)
- [x] [海康威视 算法 一面面经](https://www.nowcoder.com/discuss/168907)
- [x] [旷视face++算法面经19.03](https://www.nowcoder.com/discuss/167336)
- [x] [格灵深瞳算法实习生电话面试凉经](https://www.nowcoder.com/discuss/167238)
- [x] [收到第一个实习offer,开心!](https://www.nowcoder.com/discuss/169201)
- [x] [字节跳动算法岗面经](https://zhuanlan.zhihu.com/p/60570461)
- [x] [华为算法实习生一面面经](https://www.nowcoder.com/discuss/166606)
- [x] [腾讯后台一面面经 + 更新二面面经](https://www.nowcoder.com/discuss/162246)
- [x] [蚂蚁金服机器学习实习生一面凉经](https://www.nowcoder.com/discuss/165483)
- [x] [腾讯数据分析实习生一面凉经](https://www.nowcoder.com/discuss/163386)
- [x] [阿里高德算法实习生一面面经](https://www.nowcoder.com/discuss/162232)
- [ ] [2018 年 LeetCode 高频算法面试题汇总](https://leetcode-cn.com/explore/interview/card/top-interview-quesitons-in-2018/)
- [ ] ♥♥ [互联网公司最常见的面试算法题有哪些?](https://www.zhihu.com/question/24964987/answer/586425979)
- [x] [C++后台开发学习路线(已签腾讯sp)](https://www.nowcoder.com/discuss/164781)
- [x] ♥ [【NLP/AI算法面试必备-1】学习NLP/AI,必须深入理解“神经网络及其优化问题”](https://zhuanlan.zhihu.com/p/56633392)
- [x] ♥♥ [【NLP/AI算法面试必备-2】NLP/AI面试全记录(持续更新)](https://zhuanlan.zhihu.com/p/57153934)
- [x] [腾讯应用研究-机器学习 一、二面面经](https://www.nowcoder.com/discuss/164635)
- [x] [腾讯计算机视觉方向暑期实习一面面筋](https://www.nowcoder.com/discuss/161590)
- [x] [【小米向】计算机视觉算法实习生一面伪凉经](https://www.nowcoder.com/discuss/158614)
- [x] [【小米向】计算机视觉算法实习生后续-二面面经](https://www.nowcoder.com/discuss/159018)
- [x] [字节跳动计算机视觉算法实习生视频面试](https://zhuanlan.zhihu.com/p/59270912)
- [x] [2020届计算机视觉实习生面试经验(腾讯/头条/商汤/旷视/达摩院等)](https://mp.weixin.qq.com/s/nPMit-VkuxsEfKW46Wvirw)
- [ ] [春招面试经验总结](https://www.nowcoder.com/discuss/160872)
- [ ] [字节跳动C++开发一二三面面经](https://www.nowcoder.com/discuss/158880)
- [ ] [我的C++后台/基础架构岗位学习路线(offer大多是ssp](https://www.nowcoder.com/discuss/147538)
## 2019届
- [ ] ♥♥ [送你一个励志故事——涵盖20多所互联网公司的校招C++面经](https://www.nowcoder.com/discuss/55353)
- [ ] ♥♥ [C++春招/秋招面经全记录](https://www.nowcoder.com/discuss/55004)
- [x] [渣硕C++秋招笔经面经全纪录](https://www.nowcoder.com/discuss/50209)
- [x] ♥♥ [C++开发的求职之路:坚持就是胜利](https://www.nowcoder.com/discuss/52132)
- [x] [平安科技CV岗面经](https://www.nowcoder.com/discuss/149300?type=0&order=0&pos=52&page=0)
- [x] [2018年秋招面试问题整理](https://www.nowcoder.com/discuss/148309?type=2)
- [x] [19校招阿里腾讯华为美团算法岗面经,均已拿offer](https://www.nowcoder.com/discuss/104930)
- [x] [简历上的哪些内容才是 HR 眼中的干货?](https://www.zhihu.com/question/39722495)
- [x] [有什么是你面试很多次都失败后才知道的?](https://www.zhihu.com/question/290543744)
- [x] [Top 10国际大厂人工智能岗位经典面试题精选](https://mp.weixin.qq.com/s/FUpPIZP0hzUWNXZobjGYPw)
- [x] [一些秋招面经 CV vs NLP](https://www.nowcoder.com/discuss/143458?type=0&order=0&pos=57&page=1)
- [x] ♥ [一个非科班普通211硕士如何拿到腾讯、百度等offer](https://www.nowcoder.com/discuss/142151?type=2&order=3&pos=11&page=1)
- [x] ♥♥ [秋招算法岗面经汇总](https://www.nowcoder.com/discuss/132540?type=0&order=0&pos=7&page=1)
- [x] [新鲜出炉的算法岗面经!!](https://www.nowcoder.com/discuss/139810?type=2&order=0&pos=8&page=1)
- [x] ♥ [我的 offer 选择心路历程](https://www.nowcoder.com/discuss/139622?type=0&order=0&pos=20&page=1)
- [x] ♥♥♥ [从ML零基础到斩获BAT offer ---我的秋招面经总结](https://www.nowcoder.com/discuss/138076?type=0&order=0&pos=6&page=1)
- [x] [机器学习/数据挖掘岗2019秋招总结 ](https://www.nowcoder.com/discuss/138721?type=0&order=0&pos=13&page=1)
- [x] [OPPO2019提前批计算机视觉算法开发工程师凉经](https://www.nowcoder.com/discuss/138577?type=0&order=0&pos=11&page=1)
- [x] [个人秋招算法岗总结、面经](https://www.nowcoder.com/discuss/137778?type=0&order=0&pos=27&page=1)
- [x] ♥♥ [技术面试需要掌握的基础知识整理](https://www.nowcoder.com/discuss/66985)
- [x] [2019届算法工程师秋招总结](https://www.nowcoder.com/discuss/138474)
- [x] [C++后台研发工程师2018年BAT华为网易等面经总结](https://www.nowcoder.com/discuss/103939?type=0&order=0&pos=41&page=1)
- [x] [一名985小硕的CV算法秋招面经和经历总结](https://www.nowcoder.com/discuss/122246?type=0&order=0&pos=23&page=1)
- [x] [算法岗面经(阿里头条网易爱奇艺等)](https://www.nowcoder.com/discuss/116512)
- [x] ♥♥♥ [C++面试题整理,量有点大,整整150页word文档](https://www.nowcoder.com/discuss/116903?type=0&order=0&pos=13&page=1)
- [ ] ♥♥ [面经记录](https://github.com/guanjunjian/Interview-Summary/blob/master/notes/interview/%E9%9D%A2%E8%AF%95%E8%AE%B0%E5%BD%95.md)
- [x] [有幸被菜鸟开奖,结束秋招,回馈牛油](https://www.nowcoder.com/discuss/110317)
- [ ] ♥♥♥ [大佬秋招算法面经](https://github.com/zslomo/2019-Autumn-recruitment-experience)
- [x] [海康威视提前批一面(电话面)(图像方向)](https://www.nowcoder.com/discuss/92896?type=0&order=0&pos=58&page=1)
- [x] ♥♥♥ [一名渣渣C++程序员的心酸春招/秋招记【篇幅较长,慎入】](https://www.nowcoder.com/discuss/57942?type=0&order=0&pos=85&page=2)
- [x] [百度一二三 + HR 面(机器学习)](https://www.nowcoder.com/discuss/105615?type=0&order=0&pos=18&page=1)
- [x] [海康威视上研院算法工程师4面面经,已拿到录用意向书](https://www.nowcoder.com/discuss/104874?type=0&order=0&pos=40&page=0)
- [x] [19届春招秋招面经-NLP方向](https://www.nowcoder.com/discuss/103406)
- [x] [上海杭州比较好的公司-算法NLP方向](https://www.nowcoder.com/discuss/103414?type=0&order=0&pos=26&page=1)
- [x] ♥♥ [牛客访谈|阿里腾讯美团华为,大佬如何斩获4大算法offer](https://zhuanlan.zhihu.com/p/43710339)
- [x] [渣硕秋招算法岗位面经](https://www.nowcoder.com/discuss/103047?type=0&order=0&pos=93&page=1)
- [x] [陌陌CV算法岗一面挂经](https://www.nowcoder.com/discuss/102492?type=0&order=0&pos=53&page=1)
- [x] [大华智能算法工程师一二凉面经](https://www.nowcoder.com/discuss/102369?type=0&order=0&pos=71&page=1)
- [x] [2019秋招算法面经](https://zhuanlan.zhihu.com/p/42936891)
- [x] [记录一下秋招内推凉凉的一些面经](https://www.nowcoder.com/discuss/97825?type=0&order=0&pos=48&page=1)
- [x] [2019秋招|阿里蚂蚁-机器学习算法工程师-共四面 面经](https://zhuanlan.zhihu.com/p/42705310)
- [x] [2018秋招算法岗面经与提问总结(蚂蚁/美图/宜信/滴滴)](https://www.nowcoder.com/discuss/93743)
- [x] [19校招AI算法面经(百度+京东+美团+地平线offer)](https://www.nowcoder.com/discuss/95895?type=0&order=0&pos=28&page=1)
- [x] [浙江大华 算法岗 1、2面面经](https://www.nowcoder.com/discuss/92585?type=0&order=0&pos=69&page=1)
- [x] [CVTE图形计算 面经(两面技术已过)](https://www.nowcoder.com/discuss/88069)
- [x] [阿里图像算法工程师内推电话面试记录](https://www.nowcoder.com/discuss/88050?type=2)
- [ ] [给正在备战春招/暑期实习的同学一些小建议](https://www.nowcoder.com/discuss/67028)
- [x] [整理了网易2018届的笔试面试题目,希望能给学弟学妹们帮助](https://www.nowcoder.com/discuss/87121?type=0&order=0&pos=37&page=1)
- [x] [DJI+阿里巴巴ICBU一面面经(后端C++)](https://www.nowcoder.com/discuss/87621?type=0&order=0&pos=10&page=1)
- [x] [深度学习&CV方向|腾讯优图、依图、百度面经分享](https://zhuanlan.zhihu.com/p/39334253)
- [x] [算法工程师(地平线/商汤/美团/华为) 面经精华帖](https://www.nowcoder.com/discuss/51522)
- [x] [非科班渣硕的校招季结束啦,写个算法面经回馈牛客了](https://www.nowcoder.com/discuss/51009)
- [x] [视觉算法岗秋招总结分享——教你如何准备](https://www.jianshu.com/p/604549f48904)
- [ ] [40+互联网企业2018校招笔试真题|秋招必备笔试攻略](https://zhuanlan.zhihu.com/p/38287889)
- [x] [即将入职蚂蚁金服的学长为你分享:秋招过来人的经验与建议](https://zhuanlan.zhihu.com/p/38460989)
- [ ] ♥♥♥ [2018校园招聘笔经面经合集:算法,机器学习,大数据方向](https://zhuanlan.zhihu.com/p/38067051)
- [x] ♥♥ [Linux后台C++学习之路 & 面经知识点收录](https://www.nowcoder.com/discuss/78222)
- [x] [写给准备参加秋招的童鞋的一点建议(1)](https://www.nowcoder.com/discuss/86179)
- [x] [写给准备参加校招的童鞋的一点建议(2)完 ](https://www.nowcoder.com/discuss/95852?type=0&order=0&pos=6&page=1)
- [x] ♥♥♥ [面试知识点总结-图像处理/CV/ML/DL到HR面](https://www.nowcoder.com/discuss/66115)
## 2018届
- [x] [2018秋招算法岗面经与提问总结(蚂蚁/美图/宜信/滴滴)](https://www.nowcoder.com/discuss/93743)
- [x] [牛客网平均水平的算法工程师面经分享](https://www.nowcoder.com/discuss/51529)
- [x] [非科班野路子的2018秋招机器学习面经:面试实录+人生经验](https://www.nowcoder.com/discuss/59687)
- [x] [做计算机视觉的你,如何拿到大厂的Offer的?可否分享下?](https://www.zhihu.com/question/272045026/answer/365719603)
- [x] [2017秋招面试总结-计算机视觉/深度学习算法](https://www.nowcoder.com/discuss/66114)
- [x] [计算机视觉岗渣硕秋招总结](https://www.nowcoder.com/discuss/59801)
- [x] ♥♥♥ [算法岗计算机视觉方向求职经验总结](https://www.nowcoder.com/discuss/61601)
- [x] [360公司 计算机视觉3面面试面经](https://www.nowcoder.com/discuss/37925)
- [x] [美图机器学习计算机视觉方向视频一面](https://www.nowcoder.com/discuss/37075)
- [x] [地平线机器人面经(已拿offer,算法岗,计算机视觉方向,)](https://www.nowcoder.com/discuss/23418)
- [x] [面试了10家公司,以下是一份机器学习面试内容总结](https://zhuanlan.zhihu.com/p/35814495)
- [x] [2017校招/社招总结(人工智能岗)](http://codewithzhangyi.com/2018/04/03/2017%E6%A0%A1%E6%8B%9B%E7%A4%BE%E6%8B%9B%E6%80%BB%E7%BB%93%EF%BC%88%E4%BA%BA%E5%B7%A5%E6%99%BA%E8%83%BD%E5%B2%97%EF%BC%89/)
- [x] [应届硕士毕业生如何拿到知名互联网公司深度学习 offer](https://www.zhihu.com/question/59683332/answer/281642849)
- [x] [在大疆公司 (DJI) 工作是怎样一番体验?](https://www.zhihu.com/question/24453944/answer/426577691)
- [x] [秋招总结(百度,阿里,好未来,腾讯,美团](http://m.nowcoder.com/discuss/43189?type=2&order=4&pos=8&page=2&utm_source=com.youdao.note&utm_medium=social)