? P extends Promise ? MyAwaited : P
: never
```
如果 `Promise
` 取到的 `P` 还形如 `Promise`,就递归调用自己 `MyAwaited`。这里提到了递归,也就是 TS 类型处理可以是递归的,所以才有了后面版本做尾递归优化。
### [If](https://github.com/type-challenges/type-challenges/blob/main/questions/00268-easy-if/README.md)
实现类型 `If`,当 `C` 为 `true` 时返回 `T`,否则返回 `F`:
```ts
type A = If // expected to be 'a'
type B = If // expected to be 'b'
```
之前有提过,`extends` 还可以用来判定值,所以果断用 `extends true` 判断是否命中了 `true` 即可:
```ts
// 本题答案
type If = C extends true ? T : F
```
### [Concat](https://github.com/type-challenges/type-challenges/blob/main/questions/00533-easy-concat/README.md)
用类型系统实现 `Concat`,将两个数组类型连起来:
```ts
type Result = Concat<[1], [2]> // expected to be [1, 2]
```
由于 TS 支持数组解构语法,所以可以大胆的尝试这么写:
```ts
type Concat = [...P, ...Q]
```
考虑到 `Concat` 函数应该也能接收非数组类型,所以做一个判断,为了方便书写,把 `extends` 从泛型定义位置挪到 TS 类型推断的运行时:
```ts
// 本题答案
type Concat = [
...P extends any[] ? P : [P],
...Q extends any[] ? Q : [Q],
]
```
解决这题需要信念,相信 TS 可以像 JS 一样写逻辑。这些能力都是版本升级时渐进式提供的,所以需要不断阅读最新 TS 特性,快速将其理解为固化知识,其实还是有一定难度的。
### [Includes](https://github.com/type-challenges/type-challenges/blob/main/questions/00898-easy-includes/README.md)
用类型系统实现 `Includes` 函数:
```ts
type isPillarMen = Includes<['Kars', 'Esidisi', 'Wamuu', 'Santana'], 'Dio'> // expected to be `false`
```
由于之前的经验,很容易做下面的联想:
```ts
// 如果题目要求是这样
type isPillarMen = Includes<'Kars' | 'Esidisi' | 'Wamuu' | 'Santana', 'Dio'>
// 那我就能用 extends 轻松解决了
type Includes = K extends T ? true : false
```
可惜第一个输入是数组类型,`extends` 可不支持判定 “数组包含” 逻辑,此时要了解一个新知识点,即 TS 判断中的 `[number]` 下标。不仅这道题,以后很多困难题都需要它作为基础知识。
`[number]` 下标表示任意一项,而 `extends T[number]` 就可以实现数组包含的判定,因此下面的解法是有效的:
```ts
type Includes = K extends T[number] ? true : false
```
但翻答案后发现这并不是标准答案,还真找到一个反例:
```ts
type Includes = K extends T[number] ? true : false
type isPillarMen = Includes<[boolean], false> // true
```
原因很简单,`true`、`false` 都继承自 `boolean`,所以 `extends` 判断的界限太宽了,题目要求的是精确值匹配,故上面的答案理论上是错的。
标准答案是每次判断数组第一项,并递归(讲真觉得这不是 easy 题),分别有两个难点。
第一如何写 Equal 函数?比较流行的方案是这个:
```ts
type Equal =
(() => T extends X ? 1 : 2) extends
(() => T extends Y ? 1 : 2) ? true : false
```
关于如何写 Equal 函数还引发了一次 [小讨论](https://github.com/microsoft/TypeScript/issues/27024#issuecomment-421529650),上面的代码构造了两个函数,这两个函数内的 `T` 属于 deferred(延迟)判断的类型,该类型判断依赖于内部 `isTypeIdenticalTo` 函数完成判断。
有了 `Equal` 后就简单了,我们用解构 + `infer` + 递归的方式做就可以了:
```ts
// 本题答案
type Includes =
T extends [infer F, ...infer Rest] ?
Equal extends true ?
true
: Includes
: false
```
每次取数组第一个值判断 `Equal`,如果不匹配则拿剩余项递归判断。这个函数组合了不少 TS 知识,比如:
- 递归
- 解构
- `infer`
- `extends true`
可以发现,就为了解决 `true extends boolean` 为 `true` 的问题,我们绕了一大圈使用了更复杂的方式来实现,这在 TS 体操中也算是常态,解决问题需要耐心。
### [Push](https://github.com/type-challenges/type-challenges/blob/main/questions/03057-easy-push/README.md)
实现 `Push` 函数:
```ts
type Result = Push<[1, 2], '3'> // [1, 2, '3']
```
这道题真的很简单,用解构就行了:
```ts
// 本题答案
type Push = [...T, K]
```
可见,想要轻松解决一个 TS 简单问题,首先你需要能解决一些困难问题 😁。
### [Unshift](https://github.com/type-challenges/type-challenges/blob/main/questions/03060-easy-unshift/README.md)
实现 `Unshift` 函数:
```ts
type Result = Unshift<[1, 2], 0> // [0, 1, 2,]
```
在 `Push` 基础上改下顺序就行了:
```ts
// 本题答案
type Unshift = [K, ...T]
```
### [Parameters](https://github.com/type-challenges/type-challenges/blob/main/questions/03312-easy-parameters/README.md)
实现内置函数 `Parameters`:
`Parameters` 可以拿到函数的参数类型,直接用 `infer` 实现即可,也比较简单:
```ts
type Parameters = T extends (...args: infer P) => any ? P : []
```
`infer` 可以很方便从任何具体的位置取值,属于典型难懂易用的语法。
## 总结
学会 TS 基础语法后,活用才是关键。
> 讨论地址是:[精读《Pick, Awaited, If...》· Issue #422 · dt-fe/weekly](https://github.com/dt-fe/weekly/issues/422)
**如果你想参与讨论,请 [点击这里](https://github.com/dt-fe/weekly),每周都有新的主题,周末或周一发布。前端精读 - 帮你筛选靠谱的内容。**
> 关注 **前端精读微信公众号**
 > 版权声明:自由转载-非商用-非衍生-保持署名([创意共享 3.0 许可证](https://creativecommons.org/licenses/by-nc-nd/3.0/deed.zh))
================================================
FILE: TS 类型体操/244.精读《Get return type, Omit, ReadOnly...》.md
================================================
解决 TS 问题的最好办法就是多练,这次解读 [type-challenges](https://github.com/type-challenges/type-challenges) Medium 难度 1~8 题。
## 精读
### [Get Return Type](https://github.com/type-challenges/type-challenges/blob/main/questions/00002-medium-return-type/README.md)
实现非常经典的 `ReturnType`:
```ts
const fn = (v: boolean) => {
if (v)
return 1
else
return 2
}
type a = MyReturnType // should be "1 | 2"
```
首先不要被例子吓到了,觉得必须执行完代码才知道返回类型,其实 TS 已经帮我们推导好了返回类型,所以上面的函数 `fn` 的类型已经是这样了:
```ts
const fn = (v: boolean): 1 | 2 => { ... }
```
我们要做的就是把函数返回值从内部抽出来,这非常适合用 `infer` 实现:
```ts
// 本题答案
type MyReturnType = T extends (...args: any[]) => infer P ? P : never
```
`infer` 配合 `extends` 是解构复杂类型的神器,如果对上面代码不能一眼理解,说明对 `infer` 熟悉度还是不够,需要多看。
### [Omit](https://github.com/type-challenges/type-challenges/blob/main/questions/00003-medium-omit/README.md)
实现 `Omit`,作用恰好与 `Pick` 相反,排除对象 `T` 中的 `K` key:
```ts
interface Todo {
title: string
description: string
completed: boolean
}
type TodoPreview = MyOmit
const todo: TodoPreview = {
completed: false,
}
```
这道题比较容易尝试的方案是:
```ts
type MyOmit = {
[P in keyof T]: P extends K ? never : T[P]
}
```
其实仍然包含了 `description`、`title` 这两个 Key,只是这两个 Key 类型为 `never`,不符合要求。
所以只要 `P in keyof T` 写出来了,后面怎么写都无法将这个 Key 抹去,我们应该从 Key 下手:
```ts
type MyOmit = {
[P in (keyof T extends K ? never : keyof T)]: T[P]
}
```
但这样写仍然不对,我们思路正确,即把 `keyof T` 中归属于 `K` 的排除,但因为前后 `keyof T` 并没有关联,所以需要借助 `Exclude` 告诉 TS,前后 `keyof T` 是同一个指代(上一讲实现过 `Exclude`):
```ts
// 本题答案
type MyOmit = {
[P in Exclude]: T[P]
}
type Exclude = T extends U ? never : T
```
这样就正确了,掌握该题的核心是:
1. 三元判断还可以写在 Key 位置。
2. JS 抽不抽函数效果都一样,但 TS 需要推断,很多时候抽一个函数出来就是为了告诉 TS “是同一指代”。
当然既然都用上了 `Exclude`,我们不如再结合 `Pick`,写出更优雅的 `Omit` 实现:
```ts
// 本题优雅答案
type MyOmit = Pick>
```
### [Readonly 2](https://github.com/type-challenges/type-challenges/blob/main/questions/00008-medium-readonly-2/README.md)
实现 `MyReadonly2`,让指定的 Key `K` 成为 ReadOnly:
```ts
interface Todo {
title: string
description: string
completed: boolean
}
const todo: MyReadonly2 = {
title: "Hey",
description: "foobar",
completed: false,
}
todo.title = "Hello" // Error: cannot reassign a readonly property
todo.description = "barFoo" // Error: cannot reassign a readonly property
todo.completed = true // OK
```
该题乍一看蛮难的,因为 `readonly` 必须定义在 Key 位置,但我们又没法在这个位置做三元判断。其实利用之前我们自己做的 `Pick`、`Omit` 以及内置的 `Readonly` 组合一下就出来了:
```ts
// 本题答案
type MyReadonly2 = Readonly> & Omit
```
即我们可以将对象一分为二,先 `Pick` 出 `K` Key 部分设置为 Readonly,再用 `&` 合并上剩下的 Key,正好用到上一题的函数 `Omit`,完美。
### [Deep Readonly](https://github.com/type-challenges/type-challenges/blob/main/questions/00009-medium-deep-readonly/README.md)
实现 `DeepReadonly` 递归所有子元素:
```ts
type X = {
x: {
a: 1
b: 'hi'
}
y: 'hey'
}
type Expected = {
readonly x: {
readonly a: 1
readonly b: 'hi'
}
readonly y: 'hey'
}
type Todo = DeepReadonly // should be same as `Expected`
```
这肯定需要用类型递归实现了,既然要递归,肯定不能依赖内置 `Readonly` 函数,我们需要将函数展开手写:
```ts
// 本题答案
type DeepReadonly = {
readonly [K in keyof T]: T[K] extends Object> ? DeepReadonly : T[K]
}
```
这里 `Object` 也可以用 `Record` 代替。
### [Tuple to Union](https://github.com/type-challenges/type-challenges/blob/main/questions/00010-medium-tuple-to-union/README.md)
实现 `TupleToUnion` 返回元组所有值的集合:
```ts
type Arr = ['1', '2', '3']
type Test = TupleToUnion // expected to be '1' | '2' | '3'
```
该题将元组类型转换为其所有值的可能集合,也就是我们希望用所有下标访问这个数组,在 TS 里用 `[number]` 作为下标即可:
```ts
// 本题答案
type TupleToUnion = T[number]
```
### [Chainable Options](https://github.com/type-challenges/type-challenges/blob/main/questions/00012-medium-chainable-options/README.md)
直接看例子比较好懂:
```ts
declare const config: Chainable
const result = config
.option('foo', 123)
.option('name', 'type-challenges')
.option('bar', { value: 'Hello World' })
.get()
// expect the type of result to be:
interface Result {
foo: number
name: string
bar: {
value: string
}
}
```
也就是我们实现一个相对复杂的 `Chainable` 类型,拥有该类型的对象可以 `.option(key, value)` 一直链式调用下去,直到使用 `get()` 后拿到聚合了所有 `option` 的对象。
如果我们用 JS 实现该函数,肯定需要在当前闭包存储 Object 的值,然后提供 `get` 直接返回,或 `option` 递归并传入新的值。我们不妨用 Class 来实现:
```ts
class Chain {
constructor(previous = {}) {
this.obj = { ...previous }
}
obj: Object
get () {
return this.obj
}
option(key: string, value: any) {
return new Chain({
...this.obj,
[key]: value
})
}
}
const config = new Chain()
```
而本地要求用 TS 实现,这就比较有趣了,正好对比一下 JS 与 TS 的思维。先打个岔,该题用上面 JS 方式写出来后,其实类型也就出来了,但用 TS 完整实现类型也另有其用,特别在一些复杂函数场景,需要用 TS 系统描述类型,JS 真正实现时拿到 any 类型做纯运行时处理,将类型与运行时分离开。
好我们回到题目,我们先把 `Chainable` 的框架写出来:
```ts
type Chainable = {
option: (key: string, value: any) => any
get: () => any
}
```
问题来了,如何用类型描述 `option` 后还可以接 `option` 或 `get` 呢?还有更麻烦的,如何一步一步将类型传导下去,让 `get` 知道我此时拿的类型是什么呢?
`Chainable` 必须接收一个泛型,这个泛型默认值是个空对象,所以 `config.get()` 返回一个空对象也是合理的:
```ts
type Chainable = {
option: (key: string, value: any) => any
get: () => Result
}
```
上面的代码对于第一层是完全没问题的,直接调用 `get` 返回的就是空对象。
第二步解决递归问题:
```ts
// 本题答案
type Chainable = {
option: (key: K, value: V) => Chainable
get: () => Result
}
```
递归思维大家都懂就不赘述了。这里有个看似不值得一提,但确实容易坑人的地方,就是如何描述一个对象仅包含一个 Key 值,这个值为泛型 `K` 呢?
```ts
// 这是错的,因为描述了一大堆类型
{
[K] : V
}
// 这也是错的,这个 K 就是字面量 K,而非你希望的类型指代
{
K: V
}
```
所以必须使用 TS “习惯法” 的 `[K in keyof T]` 的套路描述,即便我们知道 `T` 只有一个固定的类型。可见 JS 与 TS 完全是两套思维方式,所以精通 JS 不必然精通 TS,TS 还是要大量刷题培养思维的。
### [Last of Array](https://github.com/type-challenges/type-challenges/blob/main/questions/00015-medium-last/README.md)
实现 `Last` 获取元组最后一项的类型:
```ts
type arr1 = ['a', 'b', 'c']
type arr2 = [3, 2, 1]
type tail1 = Last // expected to be 'c'
type tail2 = Last // expected to be 1
```
我们之前实现过 `First`,类似的,这里无非是解构时把最后一个描述成 `infer`:
```ts
// 本题答案
type Last = T extends [...infer Q, infer P] ? P : never
```
这里要注意,`infer Q` 有人第一次可能会写成:
```ts
type Last = T extends [...Others, infer P] ? P : never
```
发现报错,因为 TS 里不可能随便使用一个未定义的泛型,而如果把 Others 放在 `Last` 里,你又会面临一个 TS 大难题:
```ts
type Last = T extends [...Others, infer P] ? P : never
// 必然报错
Last
```
因为 `Last` 仅传入了一个参数,必然报错,但第一个参数是用户给的,第二个参数是我们推导出来的,这里既不能用默认值,又不能不写,无解了。
如果真的硬着头皮要这么写,必须借助 TS 还未通过的一项特性:[部分类型参数推断](https://github.com/microsoft/TypeScript/issues/26242),举个例子,很可能以后的语法是:
```ts
type Last = T extends [...Others, infer P] ? P : never
```
这样首先传参只需要一个了,而且还申明了第二个参数是一个推断类型。不过该提案还未支持,而且本质上和把 `infer` 写到表达式里面含义和效果也都一样,所以对这道题来说就不用折腾了。
### [Pop](https://github.com/type-challenges/type-challenges/blob/main/questions/00016-medium-pop/README.md)
实现 `Pop`,返回去掉元组最后一项之后的类型:
```ts
type arr1 = ['a', 'b', 'c', 'd']
type arr2 = [3, 2, 1]
type re1 = Pop // expected to be ['a', 'b', 'c']
type re2 = Pop // expected to be [3, 2]
```
这道题和 `Last` 几乎完全一样,返回第一个解构值就行了:
```ts
// 本题答案
type Pop = T extends [...infer Q, infer P] ? Q : never
```
## 总结
从题目中很明显能看出 TS 思维与 JS 思维有很大差异,想要真正掌握 TS,大量刷题是必须的。
> 讨论地址是:[精读《Get return type, Omit, ReadOnly...》· Issue #422 · dt-fe/weekly](https://github.com/dt-fe/weekly/issues/422)
**如果你想参与讨论,请 [点击这里](https://github.com/dt-fe/weekly),每周都有新的主题,周末或周一发布。前端精读 - 帮你筛选靠谱的内容。**
> 关注 **前端精读微信公众号**
> 版权声明:自由转载-非商用-非衍生-保持署名([创意共享 3.0 许可证](https://creativecommons.org/licenses/by-nc-nd/3.0/deed.zh))
================================================
FILE: TS 类型体操/245.精读《Promise.all, Replace, Type Lookup...》.md
================================================
解决 TS 问题的最好办法就是多练,这次解读 [type-challenges](https://github.com/type-challenges/type-challenges) Medium 难度 9~16 题。
## 精读
### [Promise.all](https://github.com/type-challenges/type-challenges/blob/main/questions/00020-medium-promise-all/README.md)
实现函数 `PromiseAll`,输入 PromiseLike,输出 `Promise`,其中 `T` 是输入的解析结果:
```ts
const promiseAllTest1 = PromiseAll([1, 2, 3] as const)
const promiseAllTest2 = PromiseAll([1, 2, Promise.resolve(3)] as const)
const promiseAllTest3 = PromiseAll([1, 2, Promise.resolve(3)])
```
该题难点不在 `Promise` 如何处理,而是在于 `{ [K in keyof T]: T[K] }` 在 TS 同样适用于描述数组,这是 JS 选手无论如何也想不到的:
```ts
// 本题答案
declare function PromiseAll(values: T): Promise<{
[K in keyof T]: T[K] extends Promise ? U : T[K]
}>
```
不知道是 bug 还是 feature,TS 的 `{ [K in keyof T]: T[K] }` 能同时兼容元组、数组与对象类型。
### [Type Lookup](https://github.com/type-challenges/type-challenges/blob/main/questions/00062-medium-type-lookup/README.md)
实现 `LookUp`,从联合类型 `T` 中查找 `type` 为 `P` 的项并返回:
```ts
interface Cat {
type: 'cat'
breeds: 'Abyssinian' | 'Shorthair' | 'Curl' | 'Bengal'
}
interface Dog {
type: 'dog'
breeds: 'Hound' | 'Brittany' | 'Bulldog' | 'Boxer'
color: 'brown' | 'white' | 'black'
}
type MyDog = LookUp // expected to be `Dog`
```
该题比较简单,只要学会灵活使用 `infer` 与 `extends` 即可:
```ts
// 本题答案
type LookUp = T extends {
type: infer U
} ? (
U extends P ? T : never
) : never
```
联合类型的判断是一个个来的,所以我们只要针对每一个单独写判断就行了。上面的解法中,我们先利用 `extend` + `infer` 锁定 `T` 的类型是包含 `type` key 的对象,且将 `infer U` 指向了 `type`,所以在内部再利用三元运算符判断 `U extends P ?` 就能将 `type` 命中的类型挑出来。
笔者翻了下答案,发现还有一种更高级的解法:
```ts
// 本题答案
type LookUp = U extends { type: T } ? U : never
```
该解法更简洁,更完备:
- 在泛型处利用 `extends { type: any }`、`extends U['type']` 直接锁定入参类型,让错误校验更早发生。
- `T extends U['type']` 精确缩小了参数 `T` 范围,可以学到的是,之前定义的泛型 `U` 可以直接被后面的新泛型使用。
- `U extends { type: T }` 是一种新的思考角度。在第一个答案中,我们的思维方式是 “找到对象中 `type` 值进行判断”,而第二个答案直接用整个对象结构 `{ type: T }` 判断,是更纯粹的 TS 思维。
### [Trim Left](https://github.com/type-challenges/type-challenges/blob/main/questions/00106-medium-trimleft/README.md)
实现 `TrimLeft`,将字符串左侧空格清空:
```ts
type trimed = TrimLeft<' Hello World '> // expected to be 'Hello World '
```
在 TS 处理这类问题只能用递归,不能用正则。比较容易想到的是下面的写法:
```ts
// 本题答案
type TrimLeft = T extends ` ${infer R}` ? TrimLeft : T
```
即如果字符串前面包含空格,就把空格去了继续递归,否则返回字符串本身。掌握该题的关键是 `infer` 也能用在字符串内进行推导。
### [Trim](https://github.com/type-challenges/type-challenges/blob/main/questions/00108-medium-trim/README.md)
实现 `Trim`,将字符串左右两侧空格清空:
```ts
type trimmed = Trim<' Hello World '> // expected to be 'Hello World'
```
这个问题简单的解法是,左右都 Trim 一下:
```ts
// 本题答案
type Trim = TrimLeft>
type TrimLeft = T extends ` ${infer R}` ? TrimLeft : T
type TrimRight = T extends `${infer R} ` ? TrimRight : T
```
这个成本很低,性能也不差,因为单写 `TrimLeft` 与 `TrimRight` 都很简单。
如果不采用先 Left 后 Right 的做法,想要一次性完成,就要有一些 TS 思维了。比较笨的思路是 “如果左边有空格就切分左边,或者右边有空格就切分右边”,最后写出来一个复杂的三元表达式。比较优秀的思路是利用 TS 联合类型:
```ts
// 本题答案
type Trim = T extends ` ${infer R}` | `${infer R} ` ? Trim : T
```
`extends` 后面还可以跟联合类型,这样任意一个匹配都会走到 `Trim` 递归里。这就是比较难说清楚的 TS 思维,如果没有它,你只能想到三元表达式,但一旦理解了联合类型还可以在 `extends` 里这么用,TS 帮你做了 N 元表达式的能力,那么写出来的代码就会非常清秀。
### [Capitalize](https://github.com/type-challenges/type-challenges/blob/main/questions/00110-medium-capitalize/README.md)
实现 `Capitalize` 将字符串第一个字母大写:
```ts
type capitalized = Capitalize<'hello world'> // expected to be 'Hello world'
```
如果这是一道 JS 题那就简单到爆,可题目是 TS 的,我们需要再度切换为 TS 思维。
首先要知道利用基础函数 `Uppercase` 将单个字母转化为大写,然后配合 `infer` 就不用多说了:
```ts
type MyCapitalize = T extends `${infer F}${infer U}` ? `${Uppercase}${U}` : T
```
### [Replace](https://github.com/type-challenges/type-challenges/blob/main/questions/00116-medium-replace/README.md)
实现 TS 版函数 `Replace`,将字符串 `From` 替换为 `To`:
```ts
type replaced = Replace<'types are fun!', 'fun', 'awesome'> // expected to be 'types are awesome!'
```
把 `From` 夹在字符串中间,前后用两个 `infer` 推导,最后输出时前后不变,把 `From` 换成 `To` 就行了:
```ts
// 本题答案
type Replace
> 版权声明:自由转载-非商用-非衍生-保持署名([创意共享 3.0 许可证](https://creativecommons.org/licenses/by-nc-nd/3.0/deed.zh))
================================================
FILE: TS 类型体操/244.精读《Get return type, Omit, ReadOnly...》.md
================================================
解决 TS 问题的最好办法就是多练,这次解读 [type-challenges](https://github.com/type-challenges/type-challenges) Medium 难度 1~8 题。
## 精读
### [Get Return Type](https://github.com/type-challenges/type-challenges/blob/main/questions/00002-medium-return-type/README.md)
实现非常经典的 `ReturnType`:
```ts
const fn = (v: boolean) => {
if (v)
return 1
else
return 2
}
type a = MyReturnType // should be "1 | 2"
```
首先不要被例子吓到了,觉得必须执行完代码才知道返回类型,其实 TS 已经帮我们推导好了返回类型,所以上面的函数 `fn` 的类型已经是这样了:
```ts
const fn = (v: boolean): 1 | 2 => { ... }
```
我们要做的就是把函数返回值从内部抽出来,这非常适合用 `infer` 实现:
```ts
// 本题答案
type MyReturnType = T extends (...args: any[]) => infer P ? P : never
```
`infer` 配合 `extends` 是解构复杂类型的神器,如果对上面代码不能一眼理解,说明对 `infer` 熟悉度还是不够,需要多看。
### [Omit](https://github.com/type-challenges/type-challenges/blob/main/questions/00003-medium-omit/README.md)
实现 `Omit`,作用恰好与 `Pick` 相反,排除对象 `T` 中的 `K` key:
```ts
interface Todo {
title: string
description: string
completed: boolean
}
type TodoPreview = MyOmit
const todo: TodoPreview = {
completed: false,
}
```
这道题比较容易尝试的方案是:
```ts
type MyOmit = {
[P in keyof T]: P extends K ? never : T[P]
}
```
其实仍然包含了 `description`、`title` 这两个 Key,只是这两个 Key 类型为 `never`,不符合要求。
所以只要 `P in keyof T` 写出来了,后面怎么写都无法将这个 Key 抹去,我们应该从 Key 下手:
```ts
type MyOmit = {
[P in (keyof T extends K ? never : keyof T)]: T[P]
}
```
但这样写仍然不对,我们思路正确,即把 `keyof T` 中归属于 `K` 的排除,但因为前后 `keyof T` 并没有关联,所以需要借助 `Exclude` 告诉 TS,前后 `keyof T` 是同一个指代(上一讲实现过 `Exclude`):
```ts
// 本题答案
type MyOmit = {
[P in Exclude]: T[P]
}
type Exclude = T extends U ? never : T
```
这样就正确了,掌握该题的核心是:
1. 三元判断还可以写在 Key 位置。
2. JS 抽不抽函数效果都一样,但 TS 需要推断,很多时候抽一个函数出来就是为了告诉 TS “是同一指代”。
当然既然都用上了 `Exclude`,我们不如再结合 `Pick`,写出更优雅的 `Omit` 实现:
```ts
// 本题优雅答案
type MyOmit = Pick>
```
### [Readonly 2](https://github.com/type-challenges/type-challenges/blob/main/questions/00008-medium-readonly-2/README.md)
实现 `MyReadonly2`,让指定的 Key `K` 成为 ReadOnly:
```ts
interface Todo {
title: string
description: string
completed: boolean
}
const todo: MyReadonly2 = {
title: "Hey",
description: "foobar",
completed: false,
}
todo.title = "Hello" // Error: cannot reassign a readonly property
todo.description = "barFoo" // Error: cannot reassign a readonly property
todo.completed = true // OK
```
该题乍一看蛮难的,因为 `readonly` 必须定义在 Key 位置,但我们又没法在这个位置做三元判断。其实利用之前我们自己做的 `Pick`、`Omit` 以及内置的 `Readonly` 组合一下就出来了:
```ts
// 本题答案
type MyReadonly2 = Readonly> & Omit
```
即我们可以将对象一分为二,先 `Pick` 出 `K` Key 部分设置为 Readonly,再用 `&` 合并上剩下的 Key,正好用到上一题的函数 `Omit`,完美。
### [Deep Readonly](https://github.com/type-challenges/type-challenges/blob/main/questions/00009-medium-deep-readonly/README.md)
实现 `DeepReadonly` 递归所有子元素:
```ts
type X = {
x: {
a: 1
b: 'hi'
}
y: 'hey'
}
type Expected = {
readonly x: {
readonly a: 1
readonly b: 'hi'
}
readonly y: 'hey'
}
type Todo = DeepReadonly // should be same as `Expected`
```
这肯定需要用类型递归实现了,既然要递归,肯定不能依赖内置 `Readonly` 函数,我们需要将函数展开手写:
```ts
// 本题答案
type DeepReadonly = {
readonly [K in keyof T]: T[K] extends Object> ? DeepReadonly : T[K]
}
```
这里 `Object` 也可以用 `Record` 代替。
### [Tuple to Union](https://github.com/type-challenges/type-challenges/blob/main/questions/00010-medium-tuple-to-union/README.md)
实现 `TupleToUnion` 返回元组所有值的集合:
```ts
type Arr = ['1', '2', '3']
type Test = TupleToUnion // expected to be '1' | '2' | '3'
```
该题将元组类型转换为其所有值的可能集合,也就是我们希望用所有下标访问这个数组,在 TS 里用 `[number]` 作为下标即可:
```ts
// 本题答案
type TupleToUnion = T[number]
```
### [Chainable Options](https://github.com/type-challenges/type-challenges/blob/main/questions/00012-medium-chainable-options/README.md)
直接看例子比较好懂:
```ts
declare const config: Chainable
const result = config
.option('foo', 123)
.option('name', 'type-challenges')
.option('bar', { value: 'Hello World' })
.get()
// expect the type of result to be:
interface Result {
foo: number
name: string
bar: {
value: string
}
}
```
也就是我们实现一个相对复杂的 `Chainable` 类型,拥有该类型的对象可以 `.option(key, value)` 一直链式调用下去,直到使用 `get()` 后拿到聚合了所有 `option` 的对象。
如果我们用 JS 实现该函数,肯定需要在当前闭包存储 Object 的值,然后提供 `get` 直接返回,或 `option` 递归并传入新的值。我们不妨用 Class 来实现:
```ts
class Chain {
constructor(previous = {}) {
this.obj = { ...previous }
}
obj: Object
get () {
return this.obj
}
option(key: string, value: any) {
return new Chain({
...this.obj,
[key]: value
})
}
}
const config = new Chain()
```
而本地要求用 TS 实现,这就比较有趣了,正好对比一下 JS 与 TS 的思维。先打个岔,该题用上面 JS 方式写出来后,其实类型也就出来了,但用 TS 完整实现类型也另有其用,特别在一些复杂函数场景,需要用 TS 系统描述类型,JS 真正实现时拿到 any 类型做纯运行时处理,将类型与运行时分离开。
好我们回到题目,我们先把 `Chainable` 的框架写出来:
```ts
type Chainable = {
option: (key: string, value: any) => any
get: () => any
}
```
问题来了,如何用类型描述 `option` 后还可以接 `option` 或 `get` 呢?还有更麻烦的,如何一步一步将类型传导下去,让 `get` 知道我此时拿的类型是什么呢?
`Chainable` 必须接收一个泛型,这个泛型默认值是个空对象,所以 `config.get()` 返回一个空对象也是合理的:
```ts
type Chainable = {
option: (key: string, value: any) => any
get: () => Result
}
```
上面的代码对于第一层是完全没问题的,直接调用 `get` 返回的就是空对象。
第二步解决递归问题:
```ts
// 本题答案
type Chainable = {
option: (key: K, value: V) => Chainable
get: () => Result
}
```
递归思维大家都懂就不赘述了。这里有个看似不值得一提,但确实容易坑人的地方,就是如何描述一个对象仅包含一个 Key 值,这个值为泛型 `K` 呢?
```ts
// 这是错的,因为描述了一大堆类型
{
[K] : V
}
// 这也是错的,这个 K 就是字面量 K,而非你希望的类型指代
{
K: V
}
```
所以必须使用 TS “习惯法” 的 `[K in keyof T]` 的套路描述,即便我们知道 `T` 只有一个固定的类型。可见 JS 与 TS 完全是两套思维方式,所以精通 JS 不必然精通 TS,TS 还是要大量刷题培养思维的。
### [Last of Array](https://github.com/type-challenges/type-challenges/blob/main/questions/00015-medium-last/README.md)
实现 `Last` 获取元组最后一项的类型:
```ts
type arr1 = ['a', 'b', 'c']
type arr2 = [3, 2, 1]
type tail1 = Last // expected to be 'c'
type tail2 = Last // expected to be 1
```
我们之前实现过 `First`,类似的,这里无非是解构时把最后一个描述成 `infer`:
```ts
// 本题答案
type Last = T extends [...infer Q, infer P] ? P : never
```
这里要注意,`infer Q` 有人第一次可能会写成:
```ts
type Last = T extends [...Others, infer P] ? P : never
```
发现报错,因为 TS 里不可能随便使用一个未定义的泛型,而如果把 Others 放在 `Last` 里,你又会面临一个 TS 大难题:
```ts
type Last = T extends [...Others, infer P] ? P : never
// 必然报错
Last
```
因为 `Last` 仅传入了一个参数,必然报错,但第一个参数是用户给的,第二个参数是我们推导出来的,这里既不能用默认值,又不能不写,无解了。
如果真的硬着头皮要这么写,必须借助 TS 还未通过的一项特性:[部分类型参数推断](https://github.com/microsoft/TypeScript/issues/26242),举个例子,很可能以后的语法是:
```ts
type Last = T extends [...Others, infer P] ? P : never
```
这样首先传参只需要一个了,而且还申明了第二个参数是一个推断类型。不过该提案还未支持,而且本质上和把 `infer` 写到表达式里面含义和效果也都一样,所以对这道题来说就不用折腾了。
### [Pop](https://github.com/type-challenges/type-challenges/blob/main/questions/00016-medium-pop/README.md)
实现 `Pop`,返回去掉元组最后一项之后的类型:
```ts
type arr1 = ['a', 'b', 'c', 'd']
type arr2 = [3, 2, 1]
type re1 = Pop // expected to be ['a', 'b', 'c']
type re2 = Pop // expected to be [3, 2]
```
这道题和 `Last` 几乎完全一样,返回第一个解构值就行了:
```ts
// 本题答案
type Pop = T extends [...infer Q, infer P] ? Q : never
```
## 总结
从题目中很明显能看出 TS 思维与 JS 思维有很大差异,想要真正掌握 TS,大量刷题是必须的。
> 讨论地址是:[精读《Get return type, Omit, ReadOnly...》· Issue #422 · dt-fe/weekly](https://github.com/dt-fe/weekly/issues/422)
**如果你想参与讨论,请 [点击这里](https://github.com/dt-fe/weekly),每周都有新的主题,周末或周一发布。前端精读 - 帮你筛选靠谱的内容。**
> 关注 **前端精读微信公众号**
> 版权声明:自由转载-非商用-非衍生-保持署名([创意共享 3.0 许可证](https://creativecommons.org/licenses/by-nc-nd/3.0/deed.zh))
================================================
FILE: TS 类型体操/245.精读《Promise.all, Replace, Type Lookup...》.md
================================================
解决 TS 问题的最好办法就是多练,这次解读 [type-challenges](https://github.com/type-challenges/type-challenges) Medium 难度 9~16 题。
## 精读
### [Promise.all](https://github.com/type-challenges/type-challenges/blob/main/questions/00020-medium-promise-all/README.md)
实现函数 `PromiseAll`,输入 PromiseLike,输出 `Promise`,其中 `T` 是输入的解析结果:
```ts
const promiseAllTest1 = PromiseAll([1, 2, 3] as const)
const promiseAllTest2 = PromiseAll([1, 2, Promise.resolve(3)] as const)
const promiseAllTest3 = PromiseAll([1, 2, Promise.resolve(3)])
```
该题难点不在 `Promise` 如何处理,而是在于 `{ [K in keyof T]: T[K] }` 在 TS 同样适用于描述数组,这是 JS 选手无论如何也想不到的:
```ts
// 本题答案
declare function PromiseAll(values: T): Promise<{
[K in keyof T]: T[K] extends Promise ? U : T[K]
}>
```
不知道是 bug 还是 feature,TS 的 `{ [K in keyof T]: T[K] }` 能同时兼容元组、数组与对象类型。
### [Type Lookup](https://github.com/type-challenges/type-challenges/blob/main/questions/00062-medium-type-lookup/README.md)
实现 `LookUp`,从联合类型 `T` 中查找 `type` 为 `P` 的项并返回:
```ts
interface Cat {
type: 'cat'
breeds: 'Abyssinian' | 'Shorthair' | 'Curl' | 'Bengal'
}
interface Dog {
type: 'dog'
breeds: 'Hound' | 'Brittany' | 'Bulldog' | 'Boxer'
color: 'brown' | 'white' | 'black'
}
type MyDog = LookUp // expected to be `Dog`
```
该题比较简单,只要学会灵活使用 `infer` 与 `extends` 即可:
```ts
// 本题答案
type LookUp = T extends {
type: infer U
} ? (
U extends P ? T : never
) : never
```
联合类型的判断是一个个来的,所以我们只要针对每一个单独写判断就行了。上面的解法中,我们先利用 `extend` + `infer` 锁定 `T` 的类型是包含 `type` key 的对象,且将 `infer U` 指向了 `type`,所以在内部再利用三元运算符判断 `U extends P ?` 就能将 `type` 命中的类型挑出来。
笔者翻了下答案,发现还有一种更高级的解法:
```ts
// 本题答案
type LookUp = U extends { type: T } ? U : never
```
该解法更简洁,更完备:
- 在泛型处利用 `extends { type: any }`、`extends U['type']` 直接锁定入参类型,让错误校验更早发生。
- `T extends U['type']` 精确缩小了参数 `T` 范围,可以学到的是,之前定义的泛型 `U` 可以直接被后面的新泛型使用。
- `U extends { type: T }` 是一种新的思考角度。在第一个答案中,我们的思维方式是 “找到对象中 `type` 值进行判断”,而第二个答案直接用整个对象结构 `{ type: T }` 判断,是更纯粹的 TS 思维。
### [Trim Left](https://github.com/type-challenges/type-challenges/blob/main/questions/00106-medium-trimleft/README.md)
实现 `TrimLeft`,将字符串左侧空格清空:
```ts
type trimed = TrimLeft<' Hello World '> // expected to be 'Hello World '
```
在 TS 处理这类问题只能用递归,不能用正则。比较容易想到的是下面的写法:
```ts
// 本题答案
type TrimLeft = T extends ` ${infer R}` ? TrimLeft : T
```
即如果字符串前面包含空格,就把空格去了继续递归,否则返回字符串本身。掌握该题的关键是 `infer` 也能用在字符串内进行推导。
### [Trim](https://github.com/type-challenges/type-challenges/blob/main/questions/00108-medium-trim/README.md)
实现 `Trim`,将字符串左右两侧空格清空:
```ts
type trimmed = Trim<' Hello World '> // expected to be 'Hello World'
```
这个问题简单的解法是,左右都 Trim 一下:
```ts
// 本题答案
type Trim = TrimLeft>
type TrimLeft = T extends ` ${infer R}` ? TrimLeft : T
type TrimRight = T extends `${infer R} ` ? TrimRight : T
```
这个成本很低,性能也不差,因为单写 `TrimLeft` 与 `TrimRight` 都很简单。
如果不采用先 Left 后 Right 的做法,想要一次性完成,就要有一些 TS 思维了。比较笨的思路是 “如果左边有空格就切分左边,或者右边有空格就切分右边”,最后写出来一个复杂的三元表达式。比较优秀的思路是利用 TS 联合类型:
```ts
// 本题答案
type Trim = T extends ` ${infer R}` | `${infer R} ` ? Trim : T
```
`extends` 后面还可以跟联合类型,这样任意一个匹配都会走到 `Trim` 递归里。这就是比较难说清楚的 TS 思维,如果没有它,你只能想到三元表达式,但一旦理解了联合类型还可以在 `extends` 里这么用,TS 帮你做了 N 元表达式的能力,那么写出来的代码就会非常清秀。
### [Capitalize](https://github.com/type-challenges/type-challenges/blob/main/questions/00110-medium-capitalize/README.md)
实现 `Capitalize` 将字符串第一个字母大写:
```ts
type capitalized = Capitalize<'hello world'> // expected to be 'Hello world'
```
如果这是一道 JS 题那就简单到爆,可题目是 TS 的,我们需要再度切换为 TS 思维。
首先要知道利用基础函数 `Uppercase` 将单个字母转化为大写,然后配合 `infer` 就不用多说了:
```ts
type MyCapitalize = T extends `${infer F}${infer U}` ? `${Uppercase}${U}` : T
```
### [Replace](https://github.com/type-challenges/type-challenges/blob/main/questions/00116-medium-replace/README.md)
实现 TS 版函数 `Replace`,将字符串 `From` 替换为 `To`:
```ts
type replaced = Replace<'types are fun!', 'fun', 'awesome'> // expected to be 'types are awesome!'
```
把 `From` 夹在字符串中间,前后用两个 `infer` 推导,最后输出时前后不变,把 `From` 换成 `To` 就行了:
```ts
// 本题答案
type Replace =
S extends `${infer A}${From}${infer B}` ? `${A}${To}${B}` : S
```
### [ReplaceAll](https://github.com/type-challenges/type-challenges/blob/main/questions/00119-medium-replaceall/README.md)
实现 `ReplaceAll`,将字符串 `From` 替换为 `To`:
```ts
type replaced = ReplaceAll<'t y p e s', ' ', ''> // expected to be 'types'
```
该题与上题不同之处在于替换全部,解法肯定是递归,关键是何时递归的判断条件是什么。经过一番思考,如果 `infer From` 能匹配到不就说明还可以递归吗?所以加一层三元判断 `From extends ''` 即可:
```ts
// 本题答案
type ReplaceAll =
From extends '' ? S : (
S extends `${infer A}${From}${infer B}` ? (
From extends '' ? `${A}${To}${B}` : `${A}${To}${ReplaceAll}`
) : S
)
```
补充一些细节:
1. 如果替换文本为空字符串需要跳过,否则会匹配第二个任意字符。
2. 为了防止替换完后结果可以再度匹配,对递归形式做一下调整,下次递归直接从剩余部分开始。
### [Append Argument](https://github.com/type-challenges/type-challenges/blob/main/questions/00191-medium-append-argument/README.md)
实现类型 `AppendArgument`,将函数参数拓展一个:
```ts
type Fn = (a: number, b: string) => number
type Result = AppendArgument
// expected be (a: number, b: string, x: boolean) => number
```
该题很简单,用 `infer` 就行了:
```ts
// 本题答案
type AppendArgument = F extends (...args: infer T) => infer R ? (...args: [...T, E]) => R : F
```
## 总结
这几道题都比较简单,主要考察对 `infer` 和递归的熟练使用。
> 讨论地址是:[精读《Promise.all, Replace, Type Lookup...》· Issue #425 · dt-fe/weekly](https://github.com/dt-fe/weekly/issues/425)
**如果你想参与讨论,请 [点击这里](https://github.com/dt-fe/weekly),每周都有新的主题,周末或周一发布。前端精读 - 帮你筛选靠谱的内容。**
> 关注 **前端精读微信公众号**
> 版权声明:自由转载-非商用-非衍生-保持署名([创意共享 3.0 许可证](https://creativecommons.org/licenses/by-nc-nd/3.0/deed.zh))
================================================
FILE: TS 类型体操/246.精读《Permutation, Flatten, Absolute...》.md
================================================
解决 TS 问题的最好办法就是多练,这次解读 [type-challenges](https://github.com/type-challenges/type-challenges) Medium 难度 17~24 题。
## 精读
### [Permutation](https://github.com/type-challenges/type-challenges/blob/main/questions/00296-medium-permutation/README.md)
实现 `Permutation` 类型,将联合类型替换为可能的全排列:
```ts
type perm = Permutation<'A' | 'B' | 'C'>; // ['A', 'B', 'C'] | ['A', 'C', 'B'] | ['B', 'A', 'C'] | ['B', 'C', 'A'] | ['C', 'A', 'B'] | ['C', 'B', 'A']
```
看到这题立马联想到 TS 对多个联合类型泛型处理是采用分配律的,在第一次做到 `Exclude` 题目时遇到过:
```ts
Exclude<'a' | 'b', 'a' | 'c'>
// 等价于
Exclude<'a', 'a' | 'c'> | Exclude<'b', 'a' | 'c'>
```
所以这题如果能 “递归触发联合类型分配率”,就有戏解决啊。但触发的条件必须存在两个泛型,而题目传入的只有一个,我们只好创造第二个泛型,使其默认值等于第一个:
```ts
type Permutation
```
这样对本题来说,会做如下展开:
```ts
Permutation<'A' | 'B' | 'C'>
// 等价于
Permutation<'A' | 'B' | 'C', 'A' | 'B' | 'C'>
// 等价于
Permutation<'A', 'A' | 'B' | 'C'> | Permutation<'B', 'A' | 'B' | 'C'> | Permutation<'C', 'A' | 'B' | 'C'>
```
对于 `Permutation<'A', 'A' | 'B' | 'C'>` 来说,排除掉对自身的组合,可形成 `'A', 'B'`,`'A', 'C'` 组合,之后只要再递归一次,再拼一次,把已有的排除掉,就形成了 `A` 的全排列,以此类推,形成所有字母的全排列。
这里要注意两点:
1. 如何排除掉自身?`Exclude` 正合适,该函数遇到 `T` 在联合类型 `P` 中时,会返回 `never`,否则返回 `T`。
2. 递归何时结束?每次递归时用 `Exclude` 留下没用过的组合,最后一次组合用完一定会剩下 `never`,此时终止递归。
```ts
// 本题答案
type Permutation = [T] extends [never] ? [] : T extends U ? [T, ...Permutation>] : []
```
验证一下答案,首先展开 `Permutation<'A', 'B', 'C'>`:
```ts
'A' extends 'A' | 'B' | 'C' ? ['A', ...Permutation<'B' | 'C'>] : []
'B' extends 'A' | 'B' | 'C' ? ['B', ...Permutation<'A' | 'C'>] : []
'C' extends 'A' | 'B' | 'C' ? ['C', ...Permutation<'A' | 'B'>] : []
```
我们再展开第一行 `Permutation<'B' | 'C'>`:
```ts
'B' extends 'B' | 'C' ? ['B', ...Permutation<'C'>] : []
'C' extends 'B' | 'C' ? ['C', ...Permutation<'B'>] : []
```
再展开第一行的 `Permutation<'C'>`:
```ts
'C' extends 'C' ? ['C', ...Permutation] : []
```
此时已经完成全排列,但我们还要处理一下 `Permutation`,使其返回 `[]` 并终止递归。那为什么要用 `[T] extends [never]` 而不是 `T extends never` 呢?
如果我们用 `T extends never` 代替本题答案,输出结果是 `never`,原因如下:
```ts
type X = never extends never ? 1 : 0 // 1
type Custom = T extends never ? 1 : 0
type Y = Custom // never
```
理论上相同的代码,为什么用泛型后输出就变成 `never` 了呢?原因是 TS 在做 `T extends never ?` 时,会对联合类型进行分配,此时有一个特例,即当 `T = never` 时,会跳过分配直接返回 `T` 本身,所以三元判断代码实际上没有执行。
`[T] extends [never]` 这种写法可以避免 TS 对联合类型进行分配,继而绕过上面的问题。
### [Length of String](https://github.com/type-challenges/type-challenges/blob/main/questions/00298-medium-length-of-string/README.md)
实现 `LengthOfString` 返回字符串 T 的长度:
```ts
LengthOfString<'abc'> // 3
```
破解此题你需要知道一个前提,即 TS 访问数组类型的 `[length]` 属性可以拿到长度值:
```ts
['a','b','c']['length'] // 3
```
也就是说,我们需要把 `'abc'` 转化为 `['a', 'b', 'c']`。
第二个需要了解的前置知识是,用 `infer` 指代字符串时,第一个指代指向第一个字母,第二个指向其余所有字母:
```ts
'abc' extends `${infer S}${infer E}` ? S : never // 'a'
```
那转换后的数组存在哪呢?类似 js,我们弄第二个默认值泛型存储即可:
```ts
// 本题答案
type LengthOfString = S extends `${infer S}${infer E}` ? LengthOfString : N['length']
```
思路就是,每次把字符串第一个字母拿出来放到数组 `N` 的第一项,直到字符串被取完,直接拿此时的数组长度。
### [Flatten](https://github.com/type-challenges/type-challenges/blob/main/questions/00459-medium-flatten/README.md)
实现类型 `Flatten`:
```ts
type flatten = Flatten<[1, 2, [3, 4], [[[5]]]]> // [1, 2, 3, 4, 5]
```
此题一看就需要递归:
```ts
// 本题答案
type Flatten = T extends [infer Start, ...infer Rest] ? (
Start extends any[] ? Flatten]> : Flatten
) : Result
```
这道题看似答案复杂,其实还是用到了上一题的套路:**递归时如果需要存储临时变量,用泛型默认值来存储**。
本题我们就用 `Result` 这个泛型存储打平后的结果,每次拿到数组第一个值,如果第一个值不是数组,则直接存进去继续递归,此时 `T` 自然是剩余的 `Rest`;如果第一个值是数组,则将其打平,此时有个精彩的地方,即 `...Start` 打平后依然可能是数组,比如 `[[5]]` 就套了两层,能不能想到 `...Flatten` 继续复用递归是解题关键。
### [Append to object](https://github.com/type-challenges/type-challenges/blob/main/questions/00527-medium-append-to-object/README.md)
实现 `AppendToObject`:
```ts
type Test = { id: '1' }
type Result = AppendToObject // expected to be { id: '1', value: 4 }
```
结合之前刷题的经验,该题解法很简单,注意 `K in Key` 可以给对象拓展某些指定 Key:
```ts
// 本题答案
type AppendToObject = Obj & {
[K in Key]: Value
}
```
当然也有不用 `Obj &` 的写法,即把原始对象和新 Key, Value 合在一起的描述方式:
```ts
// 本题答案
type AppendToObject = {
[key in (keyof T) | U]: key extends U ? V : T[Exclude]
}
```
### [Absolute](https://github.com/type-challenges/type-challenges/blob/main/questions/00529-medium-absolute/README.md)
实现 `Absolute` 将数字转成绝对值:
```ts
type Test = -100;
type Result = Absolute; // expected to be "100"
```
该题重点是把数字转成绝对值字符串,所以我们可以用字符串的方式进行匹配:
```ts
// 本题答案
type Absolute = `${T}` extends `-${infer R}` ? R : `${T}`
```
为什么不用 `T extends` 来判断呢?因为 `T` 是数字,这样写无法匹配符号的字符串描述。
### [String to Union](https://github.com/type-challenges/type-challenges/blob/main/questions/00531-medium-string-to-union/README.md)
实现 `StringToUnion` 将字符串转换为联合类型:
```ts
type Test = '123';
type Result = StringToUnion; // expected to be "1" | "2" | "3"
```
还是老套路,用一个新的泛型存储答案,递归即可:
```ts
// 本题答案
type StringToUnion = T extends `${infer F}${infer R}` ? StringToUnion : P
```
当然也可以不依托泛型存储答案,因为该题比较特殊,可以直接用 `|`:
```ts
// 本题答案
type StringToUnion = T extends `${infer F}${infer R}` ? F | StringToUnion : never
```
### [Merge](https://github.com/type-challenges/type-challenges/blob/main/questions/00599-medium-merge/README.md)
实现 `Merge` 合并两个对象,冲突时后者优先:
```ts
type foo = {
name: string;
age: string;
}
type coo = {
age: number;
sex: string
}
type Result = Merge; // expected to be {name: string, age: number, sex: string}
```
这道题答案甚至是之前题目的解题步骤,即用一个对象描述 + `keyof` 的思维:
```ts
// 本题答案
type Merge = {
[K in keyof A | keyof B] : K extends keyof B ? B[K] : (
K extends keyof A ? A[K] : never
)
}
```
只要知道 `in keyof` 支持元组,值部分用 `extends` 进行区分即可,很简单。
### [KebabCase](https://github.com/type-challenges/type-challenges/blob/main/questions/00612-medium-kebabcase/README.md)
实现驼峰转横线的函数 `KebabCase`:
```ts
KebabCase<'FooBarBaz'> // 'foo-bar-baz'
```
还是老套路,用第二个参数存储结果,用递归的方式遍历字符串,遇到大写字母就转成小写并添加上 `-`,最后把开头的 `-` 干掉就行了:
```ts
// 本题答案
type KebabCase = S extends `${infer F}${infer R}` ? (
Lowercase extends F ? KebabCase : KebabCase}`>
) : RemoveFirstHyphen
type RemoveFirstHyphen = S extends `-${infer Rest}` ? Rest : S
```
分开写就非常容易懂了,首先 `KebabCase` 每次递归取第一个字符,如何判断这个字符是大写呢?只要小写不等于原始值就是大写,所以判断条件就是 `Lowercase extends F` 的 false 分支。然后再写个函数 `RemoveFirstHyphen` 把字符串第一个 `-` 干掉即可。
## 总结
TS 是一门编程语言,而不是一门简单的描述或者修饰符,很多复杂类型问题要动用逻辑思维来实现,而不是查查语法就能简单实现。
> 讨论地址是:[精读《Permutation, Flatten, Absolute...》· Issue #426 · dt-fe/weekly](https://github.com/dt-fe/weekly/issues/426)
**如果你想参与讨论,请 [点击这里](https://github.com/dt-fe/weekly),每周都有新的主题,周末或周一发布。前端精读 - 帮你筛选靠谱的内容。**
> 关注 **前端精读微信公众号**
> 版权声明:自由转载-非商用-非衍生-保持署名([创意共享 3.0 许可证](https://creativecommons.org/licenses/by-nc-nd/3.0/deed.zh))
================================================
FILE: TS 类型体操/247.精读《Diff, AnyOf, IsUnion...》.md
================================================
解决 TS 问题的最好办法就是多练,这次解读 [type-challenges](https://github.com/type-challenges/type-challenges) Medium 难度 25~32 题。
## 精读
### [Diff](https://github.com/type-challenges/type-challenges/blob/main/questions/00645-medium-diff/README.md)
实现 `Diff`,返回一个新对象,类型为两个对象类型的 Diff:
```ts
type Foo = {
name: string
age: string
}
type Bar = {
name: string
age: string
gender: number
}
Equal // { gender: number }
```
首先要思考 Diff 的计算方式,A 与 B 的 Diff 是找到 A 存在 B 不存在,与 B 存在 A 不存在的值,那么正好可以利用 `Exclude` 函数,它可以得到存在于 `X` 不存在于 `Y` 的值,我们只要用 `keyof A`、`keyof B` 代替 `X` 与 `Y`,并交替 A、B 位置就能得到 Diff:
```ts
// 本题答案
type Diff = {
[K in Exclude | Exclude]:
K extends keyof A ? A[K] : (
K extends keyof B ? B[K]: never
)
}
```
Value 部分的小技巧我们之前也提到过,即需要用两套三元运算符保证访问的下标在对象中存在,即 `extends keyof` 的语法技巧。
### [AnyOf](https://github.com/type-challenges/type-challenges/blob/main/questions/00949-medium-anyof/README.md)
实现 `AnyOf` 函数,任意项为真则返回 `true`,否则返回 `false`,空数组返回 `false`:
```ts
type Sample1 = AnyOf<[1, '', false, [], {}]> // expected to be true.
type Sample2 = AnyOf<[0, '', false, [], {}]> // expected to be false.
```
本题有几个问题要思考:
第一是用何种判定思路?像这种判断数组内任意元素是否满足某个条件的题目,都可以用递归的方式解决,具体是先判断数组第一项,如果满足则继续递归判断剩余项,否则终止判断。这样能做但比较麻烦,还有种取巧的办法是利用 `extends Array<>` 的方式,让 TS 自动帮你遍历。
第二个是如何判断任意项为真?为真的情况很多,我们尝试枚举为假的 Case:`0` `undefined` `''` `undefined` `null` `never` `[]`。
结合上面两个思考,本题作如下解答不难想到:
```ts
type Falsy = '' | never | undefined | null | 0 | false | []
type AnyOf = T extends Falsy[] ? false : true
```
但会遇到这个测试用例没通过:
```ts
AnyOf<[0, '', false, [], {}]>
```
如果此时把 `{}` 补在 `Falsy` 里,会发现除了这个 case 外,其他判断都挂了,原因是 `{ a: 1 } extends {}` 结果为真,因为 `{}` 并不表示空对象,而是表示所有对象类型,所以我们要把它换成 `Record`,以锁定空对象:
```ts
// 本题答案
type Falsy = '' | never | undefined | null | 0 | false | [] | Record
type AnyOf = T extends Falsy[] ? false : true
```
### [IsNever](https://github.com/type-challenges/type-challenges/blob/main/questions/01042-medium-isnever/README.md)
实现 `IsNever` 判断值类型是否为 `never`:
```ts
type A = IsNever // expected to be true
type B = IsNever // expected to be false
type C = IsNever // expected to be false
type D = IsNever<[]> // expected to be false
type E = IsNever // expected to be false
```
首先我们可以毫不犹豫的写下一个错误答案:
```ts
type IsNever = T extends never ? true :false
```
这个错误答案离正确答案肯定是比较近的,但错在无法判断 `never` 上。在 `Permutation` 全排列题中我们就认识到了 `never` 在泛型中的特殊性,它不会触发 `extends` 判断,而是直接终结,致使判断无效。
而解法也很简单,只要绕过 `never` 这个特性即可,包一个数组:
```ts
// 本题答案
type IsNever = [T] extends [never] ? true :false
```
### [IsUnion](https://github.com/type-challenges/type-challenges/blob/main/questions/01097-medium-isunion/README.md)
实现 `IsUnion` 判断是否为联合类型:
```ts
type case1 = IsUnion // false
type case2 = IsUnion // true
type case3 = IsUnion<[string|number]> // false
```
这道题完全是脑筋急转弯了,因为 TS 肯定知道传入类型是否为联合类型,并且会对联合类型进行特殊处理,但并没有暴露联合类型的判断语法,所以我们只能对传入类型进行测试,推断是否为联合类型。
我们到现在能想到联合类型的特征只有两个:
1. 在 TS 处理泛型为联合类型时进行分发处理,即将联合类型拆解为独立项一一进行判定,最后再用 `|` 连接。
2. 用 `[]` 包裹联合类型可以规避分发的特性。
所以怎么判定传入泛型是联合类型呢?如果泛型进行了分发,就可以反推出它是联合类型。
难点就转移到了:如何判断泛型被分发了?首先分析一下,分发的效果是什么样:
```ts
A extends A
// 如果 A 是 1 | 2,分发结果是:
(1 extends 1 | 2) | (2 extends 1 | 2)
```
也就是这个表达式会被执行两次,第一个 `A` 在两次值分别为 `1` 与 `2`,而第二个 `A` 在两次执行中每次都是 `1 | 2`,但这两个表达式都是 `true`,无法体现分发的特殊性。
此时要利用包裹 `[]` 不分发的特性,即在分发后,由于在每次执行过程中,第一个 `A` 都是联合类型的某一项,因此用 `[]` 包裹后必然与原始值不相等,所以我们在 `extends` 分发过程中,再用 `[]` 包裹 `extends` 一次,如果此时匹配不上,说明产生了分发:
```ts
type IsUnion = A extends A ? (
[A] extends [A] ? false : true
) : false
```
但这段代码依然不正确,因为在第一个三元表达式括号内,`A` 已经被分发,所以 `[A] extends [A]` 即便对联合类型也是判定为真的,此时需要用原始值代替 `extends` 后面的 `[A]`,骚操作出现了:
```ts
type IsUnion = A extends A ? (
[B] extends [A] ? false : true
) : false
```
虽然我们申明了 `B = A`,但过程中因为 `A` 被分发了,所以运行时 `B` 是不等于 `A` 的,才使得我们达成目的。`[B]` 放 `extends` 前面是因为,`B` 是未被分发的,不可能被分发后的结果包含,所以分发时此条件必定为假。
最后因为测试用例有一个 `never` 情况,我们用刚才的 `IsNever` 函数提前判否即可:
```ts
// 本题答案
type IsUnion = IsNever extends true ? false : (
A extends A ? (
[B] extends [A] ? false : true
) : false
)
```
从该题我们可以深刻体会到 TS 的怪异之处,即 `type X = T extends ...` 中 `extends` 前面的 `T` 不一定是你看到传入的 `T`,如果是联合类型的话,会分发为单个类型分别处理。
### [ReplaceKeys](https://github.com/type-challenges/type-challenges/blob/main/questions/01130-medium-replacekeys/README.md)
实现 `ReplaceKeys` 将 `Obj` 中每个对象的 `Keys` Key 类型转化为符合 `Targets` 对象对应 Key 描述的类型,如果无法匹配到 `Targets` 则类型置为 `never`:
```ts
type NodeA = {
type: 'A'
name: string
flag: number
}
type NodeB = {
type: 'B'
id: number
flag: number
}
type NodeC = {
type: 'C'
name: string
flag: number
}
type Nodes = NodeA | NodeB | NodeC
type ReplacedNodes = ReplaceKeys // {type: 'A', name: number, flag: string} | {type: 'B', id: number, flag: string} | {type: 'C', name: number, flag: string} // would replace name from string to number, replace flag from number to string.
type ReplacedNotExistKeys = ReplaceKeys // {type: 'A', name: never, flag: number} | NodeB | {type: 'C', name: never, flag: number} // would replace name to never
```
本题别看描述很吓人,其实非常简单,思路:用 `K in keyof Obj` 遍历原始对象所有 Key,如果这个 Key 在描述的 `Keys` 中,且又在 `Targets` 中存在,则返回类型 `Targets[K]` 否则返回 `never`,如果不在描述的 `Keys` 中则用在对象里本来的类型:
```ts
// 本题答案
type ReplaceKeys = {
[K in keyof Obj] : K extends Keys ? (
K extends keyof Targets ? Targets[K] : never
) : Obj[K]
}
```
### [Remove Index Signature](https://github.com/type-challenges/type-challenges/blob/main/questions/01367-medium-remove-index-signature/README.md)
实现 `RemoveIndexSignature` 把对象 `` 中 Index 下标移除:
```ts
type Foo = {
[key: string]: any;
foo(): void;
}
type A = RemoveIndexSignature // expected { foo(): void }
```
该题思考的重点是如何将对象字符串 Key 识别出来,可以用 \`${infer P}\` 是否能识别到 `P` 来判断当前是否命中了字符串 Key:
```ts
// 本题答案
type RemoveIndexSignature = {
[K in keyof T as K extends `${infer P}` ? P : never]: T[K]
}
```
### [Percentage Parser](https://github.com/type-challenges/type-challenges/blob/main/questions/01978-medium-percentage-parser/README.md)
实现 `PercentageParser`,解析出百分比字符串的符号位与数字:
```ts
type PString1 = ''
type PString2 = '+85%'
type PString3 = '-85%'
type PString4 = '85%'
type PString5 = '85'
type R1 = PercentageParser // expected ['', '', '']
type R2 = PercentageParser // expected ["+", "85", "%"]
type R3 = PercentageParser // expected ["-", "85", "%"]
type R4 = PercentageParser // expected ["", "85", "%"]
type R5 = PercentageParser // expected ["", "85", ""]
```
这道题充分说明了 TS 没有正则能力,尽量还是不要做正则的事情 ^_^。
回到正题,如果非要用 TS 实现,我们只能枚举各种场景:
```ts
// 本题答案
type PercentageParser =
// +/-xxx%
A extends `${infer X extends '+' | '-'}${infer Y}%`? [X, Y, '%'] : (
// +/-xxx
A extends `${infer X extends '+' | '-'}${infer Y}` ? [X, Y, ''] : (
// xxx%
A extends `${infer X}%` ? ['', X, '%'] : (
// xxx 包括 ['100', '%', ''] 这三种情况
A extends `${infer X}` ? ['', X, '']: never
)
)
)
```
这道题运用了 `infer` 可以无限进行分支判断的知识。
### [Drop Char](https://github.com/type-challenges/type-challenges/blob/main/questions/02070-medium-drop-char/README.md)
实现 `DropChar` 从字符串中移除指定字符:
```ts
type Butterfly = DropChar<' b u t t e r f l y ! ', ' '> // 'butterfly!'
```
这道题和 `Replace` 很像,只要用递归不断把 `C` 排除掉即可:
```ts
// 本题答案
type DropChar = S extends `${infer A}${C}${infer B}` ?
`${A}${DropChar}` : S
```
## 总结
写到这,越发觉得 TS 虽然具备图灵完备性,但在逻辑处理上还是不如 JS 方便,很多设计计算逻辑的题目的解法都不是很优雅。
但是解决这类题目有助于强化对 TS 基础能力组合的理解与综合运用,在解决实际类型问题时又是必不可少的。
> 讨论地址是:[精读《Diff, AnyOf, IsUnion...》· Issue #429 · dt-fe/weekly](https://github.com/dt-fe/weekly/issues/429)
**如果你想参与讨论,请 [点击这里](https://github.com/dt-fe/weekly),每周都有新的主题,周末或周一发布。前端精读 - 帮你筛选靠谱的内容。**
> 关注 **前端精读微信公众号**
> 版权声明:自由转载-非商用-非衍生-保持署名([创意共享 3.0 许可证](https://creativecommons.org/licenses/by-nc-nd/3.0/deed.zh))
================================================
FILE: TS 类型体操/248.精读《MinusOne, PickByType, StartsWith...》.md
================================================
解决 TS 问题的最好办法就是多练,这次解读 [type-challenges](https://github.com/type-challenges/type-challenges) Medium 难度 33~40 题。
## 精读
### [MinusOne](https://github.com/type-challenges/type-challenges/blob/main/questions/02257-medium-minusone/README.md)
用 TS 实现 `MinusOne` 将一个数字减一:
```ts
type Zero = MinusOne<1> // 0
type FiftyFour = MinusOne<55> // 54
```
TS 没有 “普通” 的运算能力,但涉及数字却有一条生路,即 TS 可通过 `['length']` 访问数组长度,几乎所有数字计算都是通过它推导出来的。
这道题,我们只要构造一个长度为泛型长度 -1 的数组,获取其 `['length']` 属性即可,但该方案有一个硬伤,无法计算负值,因为数组长度不可能小于 0:
```ts
// 本题答案
type MinusOne = [
...arr,
''
]['length'] extends T
? arr['length']
: MinusOne
```
该方案的原理不是原数字 -1,而是从 0 开始不断加 1,一直加到目标数字减一。但该方案没有通过 `MinusOne<1101>` 测试,因为递归 1000 次就是上限了。
还有一种能打破递归的思路,即:
```ts
type Count = ['1', '1', '1'] extends [...infer T, '1'] ? T['length'] : 0 // 2
```
也就是把减一转化为 `extends [...infer T, '1']`,这样数组 `T` 的长度刚好等于答案。那么难点就变成了如何根据传入的数字构造一个等长的数组?即问题变成了如何实现 `CountTo` 生成一个长度为 `N`,每项均为 `1` 的数组,而且生成数组的递归效率也要高,否则还会遇到递归上限的问题。
网上有一个神仙解法,笔者自己想不到,但是可以拿出来给大家分析下:
```ts
type CountTo<
T extends string,
Count extends 1[] = []
> = T extends `${infer First}${infer Rest}`
? CountTo[keyof N & First]>
: Count
type N = {
'0': [...T, ...T, ...T, ...T, ...T, ...T, ...T, ...T, ...T, ...T]
'1': [...T, ...T, ...T, ...T, ...T, ...T, ...T, ...T, ...T, ...T, 1]
'2': [...T, ...T, ...T, ...T, ...T, ...T, ...T, ...T, ...T, ...T, 1, 1]
'3': [...T, ...T, ...T, ...T, ...T, ...T, ...T, ...T, ...T, ...T, 1, 1, 1]
'4': [...T, ...T, ...T, ...T, ...T, ...T, ...T, ...T, ...T, ...T, 1, 1, 1, 1]
'5': [
...T,
...T,
...T,
...T,
...T,
...T,
...T,
...T,
...T,
...T,
1,
1,
1,
1,
1
]
'6': [
...T,
...T,
...T,
...T,
...T,
...T,
...T,
...T,
...T,
...T,
1,
1,
1,
1,
1,
1
]
'7': [
...T,
...T,
...T,
...T,
...T,
...T,
...T,
...T,
...T,
...T,
1,
1,
1,
1,
1,
1,
1
]
'8': [
...T,
...T,
...T,
...T,
...T,
...T,
...T,
...T,
...T,
...T,
1,
1,
1,
1,
1,
1,
1,
1
]
'9': [
...T,
...T,
...T,
...T,
...T,
...T,
...T,
...T,
...T,
...T,
1,
1,
1,
1,
1,
1,
1,
1,
1
]
}
```
也就是该方法可以高效的实现 `CountTo<'1000'>` 产生长度为 1000,每项为 `1` 的数组,更具体一点,只需要遍历 `` 字符串长度次数,比如 `1000` 只要递归 4 次,而 `10000` 也只需要递归 5 次。
`CountTo` 函数体的逻辑是,如果字符串 `T` 非空,就拆为第一个字符 `First` 与剩余字符 `Rest`,然后拿剩余字符递归,但是把 `First` 一次性生成到了正确的长度。最核心的逻辑就是函数 `N` 了,它做的其实是把 `T` 的数组长度放大 10 倍再追加上当前数量的 1 在数组末尾。
而 `keyof N & First` 也是神来之笔,此处本意就是访问 `First` 下标,但 TS 不知道它是一个安全可访问的下标,而 `keyof N & First` 最终值还是 `First`,也可以被 TS 安全识别为下标。
拿 `CountTo<'123'>` 举例:
第一次执行 `First='1'`、`Rest='23'`:
```ts
CountTo<'23', N<[]>['1']>
// 展开时,...[] 还是 [],所以最终结果为 ['1']
```
第二次执行 `First='2'`、`Rest='3'`
```ts
CountTo<'3', N<['1']>['2']>
// 展开时,...[] 有 10 个,所以 ['1'] 变成了 10 个 1,追加上 N 映射表里的 2 个 1,现在一共有 12 个 1
```
第三次执行 `First='3'`、`Rest=''`
```ts
CountTo<'', N<['1', ...共 12 个]>['3']>
// 展开时,...[] 有 10 个,所以 12 个 1 变成 120 个,加上映射表中 3,一共有 123 个 1
```
总结一下,就是将数字 `T` 变成字符串,从最左侧开始获取,每次都把已经积累的数组数量乘以 10 再追加上当前值数量的 1,实现递归次数极大降低。
### [PickByType](https://github.com/type-challenges/type-challenges/blob/main/questions/02595-medium-pickbytype/README.md)
实现 `PickByType`,将对象 `P` 中类型为 `Q` 的 key 保留:
```ts
type OnlyBoolean = PickByType<
{
name: string
count: number
isReadonly: boolean
isEnable: boolean
},
boolean
> // { isReadonly: boolean; isEnable: boolean; }
```
本题很简单,因为之前碰到 Remove Index Signature 题目时,我们用了 `K in keyof P as xxx` 来对 Key 位置进行进一步判断,所以只要 `P[K] extends Q` 就保留,否则返回 `never` 即可:
```ts
// 本题答案
type PickByType = {
[K in keyof P as P[K] extends Q ? K : never]: P[K]
}
```
### [StartsWith](https://github.com/type-challenges/type-challenges/blob/main/questions/02688-medium-startswith/README.md)
实现 `StartsWith` 判断字符串 `T` 是否以 `U` 开头:
```ts
type a = StartsWith<'abc', 'ac'> // expected to be false
type b = StartsWith<'abc', 'ab'> // expected to be true
type c = StartsWith<'abc', 'abcd'> // expected to be false
```
本题也比较简单,用递归 + 首字符判等即可破解:
```ts
// 本题答案
type StartsWith<
T extends string,
U extends string
> = U extends `${infer US}${infer UE}`
? T extends `${infer TS}${infer TE}`
? TS extends US
? StartsWith
: false
: false
: true
```
思路是:
1. `U` 如果为空字符串则匹配一切场景,直接返回 `true`;否则 `U` 可以拆为以 `US`(U Start) 开头、`UE`(U End) 的字符串进行后续判定。
2. 接着上面的判定,如果 `T` 为空字符串则不可能被 `U` 匹配,直接返回 `false`;否则 `T` 可以拆为以 `TS`(T Start) 开头、`TE`(T End) 的字符串进行后续判定。
3. 接着上面的判定,如果 `TS extends US` 说明此次首字符匹配了,则递归匹配剩余字符 `StartsWith`,如果首字符不匹配提前返回 `false`。
笔者看了一些答案后发现还有一种降维打击方案:
```ts
// 本题答案
type StartsWith = T extends `${U}${string}`
? true
: false
```
没想到还可以用 `${string}` 匹配任意字符串进行 `extends` 判定,有点正则的意思了。当然 `${string}` 也可以被 `${infer X}` 代替,只是拿到的 `X` 不需要再用到了:
```ts
// 本题答案
type StartsWith = T extends `${U}${infer X}`
? true
: false
```
笔者还试了下面的答案在后缀 Diff 部分为 string like number 时也正确:
```ts
// 本题答案
type StartsWith = T extends `${U}${number}`
? true
: false
```
说明字符串模板最通用的指代是 `${infer X}` 或 `${string}`,如果要匹配特定的数字类字符串也可以混用 `${number}`。
### EndsWith
实现 `EndsWith` 判断字符串 `T` 是否以 `U` 结尾:
```ts
type a = EndsWith<'abc', 'bc'> // expected to be true
type b = EndsWith<'abc', 'abc'> // expected to be true
type c = EndsWith<'abc', 'd'> // expected to be false
```
有了上题的经验,这道题不要太简单:
```ts
// 本题答案
type EndsWith = T extends `${string}${U}`
? true
: false
```
这可以看出 TS 的技巧掌握了就非常简单,但不知道就几乎无解,或者用很笨的递归来解决。
### [PartialByKeys](https://github.com/type-challenges/type-challenges/blob/main/questions/02757-medium-partialbykeys/README.md)
实现 `PartialByKeys`,使 `K` 匹配的 Key 变成可选的定义,如果不传 `K` 效果与 `Partial` 一样:
```ts
interface User {
name: string
age: number
address: string
}
type UserPartialName = PartialByKeys // { name?:string; age:number; address:string }
```
看到题目要求是不传参数时和 `Partial` 行为一直,就应该能想到应该这么起头写个默认值:
```ts
type PartialByKeys = {}
```
我们得用可选与不可选分别描述两个对象拼起来,因为 TS 不支持同一个对象下用两个 `keyof` 描述,所以只能写成两个对象:
```ts
type PartialByKeys = {
[Q in keyof T as Q extends K ? Q : never]?: T[Q]
} & {
[Q in keyof T as Q extends K ? never : Q]: T[Q]
}
```
但不匹配测试用例,原因是最终类型正确,但因为分成了两个对象合并无法匹配成一个对象,所以需要用一点点 Magic 行为合并:
```ts
// 本题答案
type PartialByKeys = {
[Q in keyof T as Q extends K ? Q : never]?: T[Q]
} & {
[Q in keyof T as Q extends K ? never : Q]: T[Q]
} extends infer R
? {
[Q in keyof R]: R[Q]
}
: never
```
将一个对象 `extends infer R` 再重新展开一遍看似无意义,但确实让类型上合并成了一个对象,很有意思。我们也可以将其抽成一个函数 `Merge` 来使用。
本题还有一个函数组合的答案:
```ts
// 本题答案
type Merge = {
[K in keyof T]: T[K]
}
type PartialByKeys = Merge<
Partial & Omit
>
```
- 利用 `Partial & Omit` 来合并对象。
- 因为 `Omit` 中 `K` 有来自于 `keyof T` 的限制,而测试用例又包含 `unknown` 这种不存在的 Key 值,此时可以用 `extends PropertyKey` 处理此场景。
### [RequiredByKeys](https://github.com/type-challenges/type-challenges/blob/main/questions/02759-medium-requiredbykeys/README.md)
实现 `RequiredByKeys`,使 `K` 匹配的 Key 变成必选的定义,如果不传 `K` 效果与 `Required` 一样:
```ts
interface User {
name?: string
age?: number
address?: string
}
type UserRequiredName = RequiredByKeys // { name: string; age?: number; address?: string }
```
和上题正好相反,答案也呼之欲出了:
```ts
type Merge = {
[K in keyof T]: T[K]
}
type RequiredByKeys = Merge<
Required & Omit
>
```
等等,一个测试用例都没过,为啥呢?仔细想想发现确实暗藏玄机:
```ts
Merge<{
a: number
} & {
a?: number
}> // 结果是 { a: number }
```
也就是同一个 Key 可选与必选同时存在时,合并结果是必选。上一题因为将必选 `Omit` 掉了,所以可选不会被必选覆盖,但本题 `Merge & Omit>`,前面的 `Required` 必选优先级最高,后面的 `Omit` 虽然本身逻辑没错,但无法把必选覆盖为可选,因此测试用例都挂了。
解法就是破解这一特征,用原始对象 & 仅包含 `K` 的必选对象,使必选覆盖前面的可选 Key。后者可以 `Pick` 出来:
```ts
type Merge = {
[K in keyof T]: T[K]
}
type RequiredByKeys = Merge<
T & Required>
>
```
这样就剩一个单测没通过了:
```ts
Expect, UserRequiredName>>
```
我们还要兼容 `Pick` 访问不存在的 Key,用 `extends` 躲避一下即可:
```ts
// 本题答案
type Merge = {
[K in keyof T]: T[K]
}
type RequiredByKeys = Merge<
T & Required
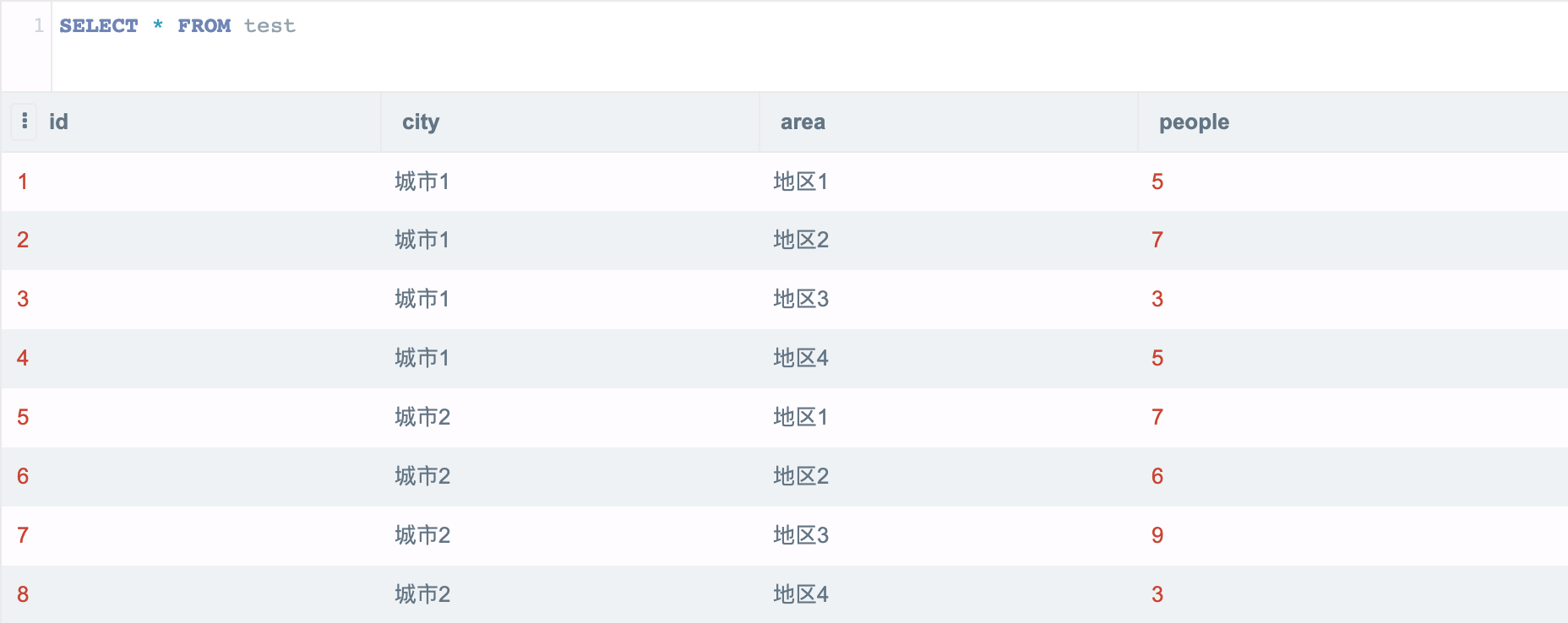 以上是示例底表,共有 8 条数据,城市1、城市2 两个城市,下面各有地区1~4,每条数据都有该数据的人口数。
## 分组排序
如果按照人口排序,`ORDER BY people` 就行了,但如果我们想在城市内排序怎么办?
此时就要用到窗口函数的分组排序能力:
以上是示例底表,共有 8 条数据,城市1、城市2 两个城市,下面各有地区1~4,每条数据都有该数据的人口数。
## 分组排序
如果按照人口排序,`ORDER BY people` 就行了,但如果我们想在城市内排序怎么办?
此时就要用到窗口函数的分组排序能力:
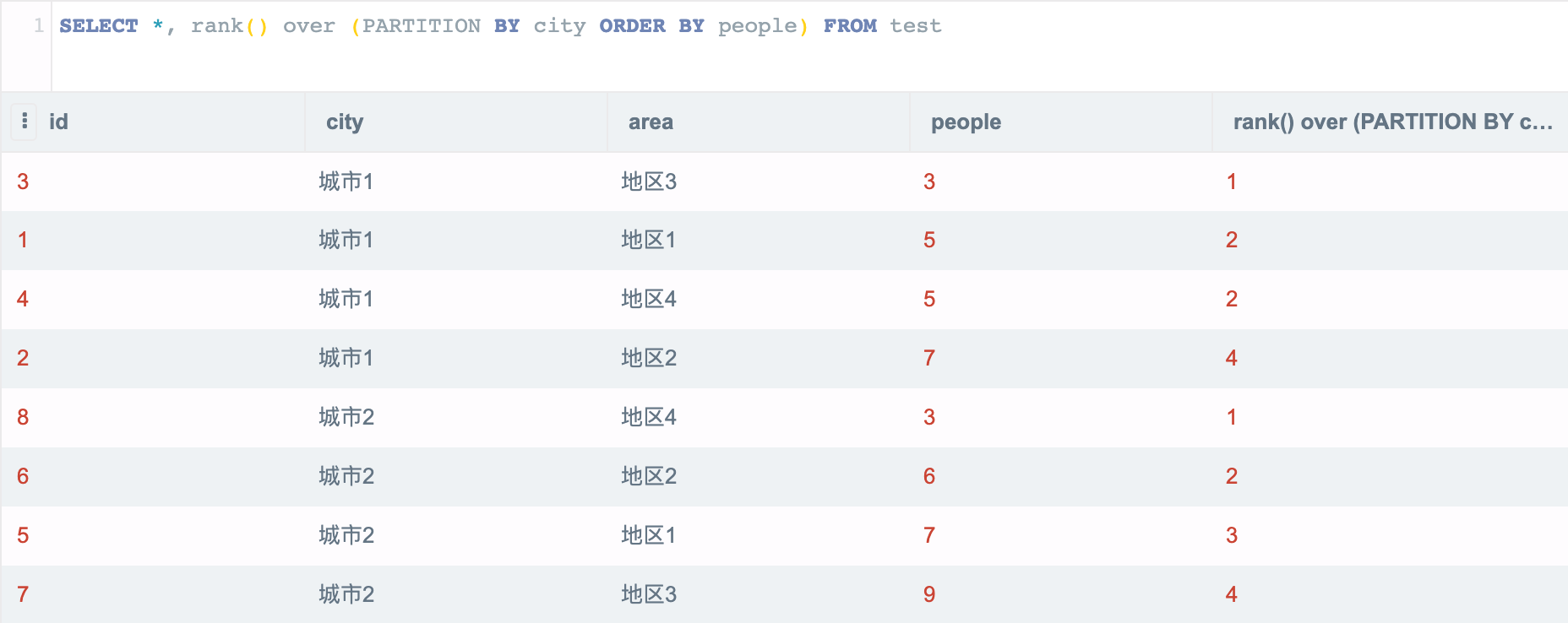 ```sql
SELECT *, rank() over (PARTITION BY city ORDER BY people) FROM test
```
该 SQL 表示在 city 组内按照 people 进行排序。
其实 PARTITION BY 也是可选的,如果我们忽略它:
```sql
SELECT *, rank() over (ORDER BY people) FROM test
```
也是生效的,但该语句与普通 ORDER BY 等价,因此利用窗口函数进行分组排序时,一般都会使用 PARTITION BY。
### 各分组排序函数的差异
我们将 `rank()` `dense_rank()` `row_number()` 的结果都打印出来:
```sql
SELECT *,
rank() over (PARTITION BY city ORDER BY people),
dense_rank() over (PARTITION BY city ORDER BY people),
row_number() over (PARTITION BY city ORDER BY people)
FROM test
```
```sql
SELECT *, rank() over (PARTITION BY city ORDER BY people) FROM test
```
该 SQL 表示在 city 组内按照 people 进行排序。
其实 PARTITION BY 也是可选的,如果我们忽略它:
```sql
SELECT *, rank() over (ORDER BY people) FROM test
```
也是生效的,但该语句与普通 ORDER BY 等价,因此利用窗口函数进行分组排序时,一般都会使用 PARTITION BY。
### 各分组排序函数的差异
我们将 `rank()` `dense_rank()` `row_number()` 的结果都打印出来:
```sql
SELECT *,
rank() over (PARTITION BY city ORDER BY people),
dense_rank() over (PARTITION BY city ORDER BY people),
row_number() over (PARTITION BY city ORDER BY people)
FROM test
```
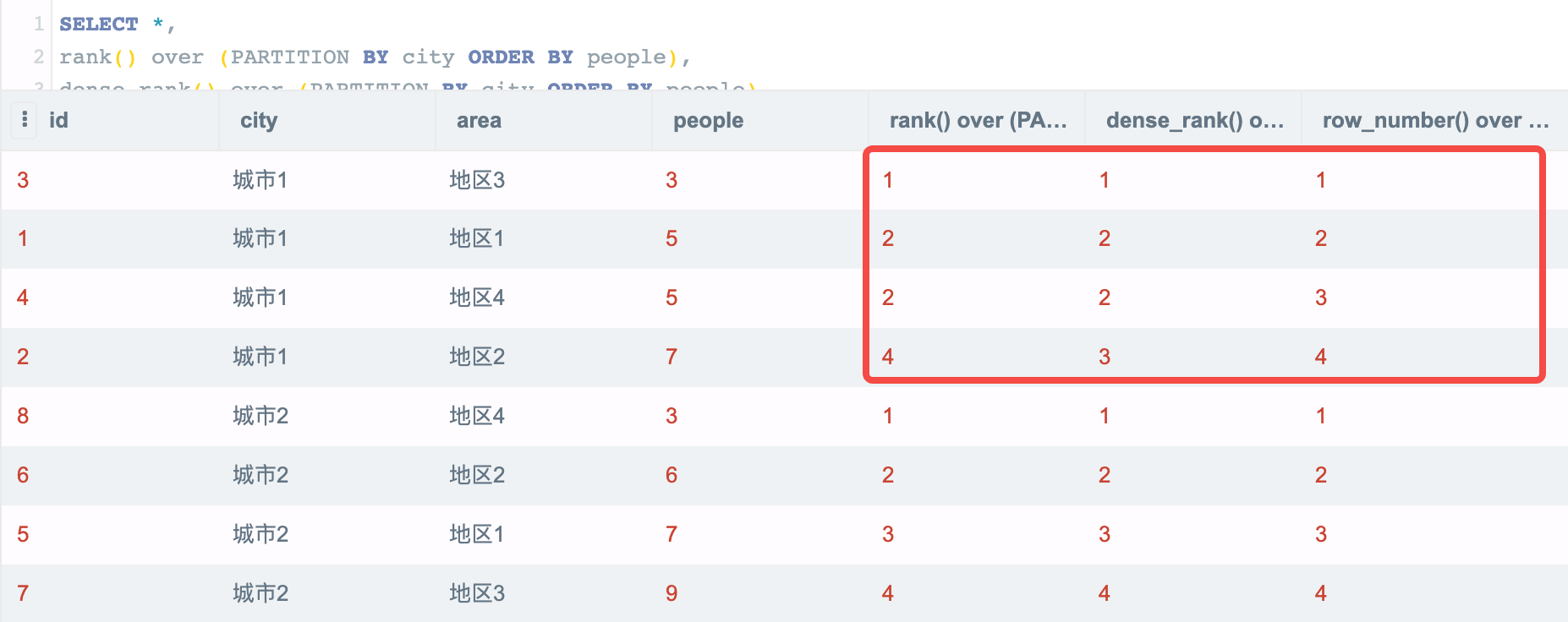 其实从结果就可以猜到,这三个函数在处理排序遇到相同值时,对排名统计逻辑有如下差异:
1. `rank()`: 值相同时排名相同,但占用排名数字。
2. `dense_rank()`: 值相同时排名相同,但不占用排名数字,整体排名更加紧凑。
3. `row_number()`: 无论值是否相同,都强制按照行号展示排名。
上面的例子可以优化一下,因为所有窗口逻辑都是相同的,我们可以利用 WINDOW AS 提取为一个变量:
```sql
SELECT *,
rank() over wd, dense_rank() over wd, row_number() over wd
FROM test
WINDOW wd as (PARTITION BY city ORDER BY people)
```
## 累计聚合
我们之前说过,凡事使用了聚合函数,都会让查询变成聚合模式。如果不用 GROUP BY,聚合后返回行数会压缩为一行,即使用了 GROUP BY,返回的行数一般也会大大减少,因为分组聚合了。
然而使用窗口函数的聚合却不会导致返回行数减少,那么这种聚合是怎么计算的呢?我们不如直接看下面的例子:
```sql
SELECT *,
sum(people) over (PARTITION BY city ORDER BY people)
FROM test
```
其实从结果就可以猜到,这三个函数在处理排序遇到相同值时,对排名统计逻辑有如下差异:
1. `rank()`: 值相同时排名相同,但占用排名数字。
2. `dense_rank()`: 值相同时排名相同,但不占用排名数字,整体排名更加紧凑。
3. `row_number()`: 无论值是否相同,都强制按照行号展示排名。
上面的例子可以优化一下,因为所有窗口逻辑都是相同的,我们可以利用 WINDOW AS 提取为一个变量:
```sql
SELECT *,
rank() over wd, dense_rank() over wd, row_number() over wd
FROM test
WINDOW wd as (PARTITION BY city ORDER BY people)
```
## 累计聚合
我们之前说过,凡事使用了聚合函数,都会让查询变成聚合模式。如果不用 GROUP BY,聚合后返回行数会压缩为一行,即使用了 GROUP BY,返回的行数一般也会大大减少,因为分组聚合了。
然而使用窗口函数的聚合却不会导致返回行数减少,那么这种聚合是怎么计算的呢?我们不如直接看下面的例子:
```sql
SELECT *,
sum(people) over (PARTITION BY city ORDER BY people)
FROM test
```
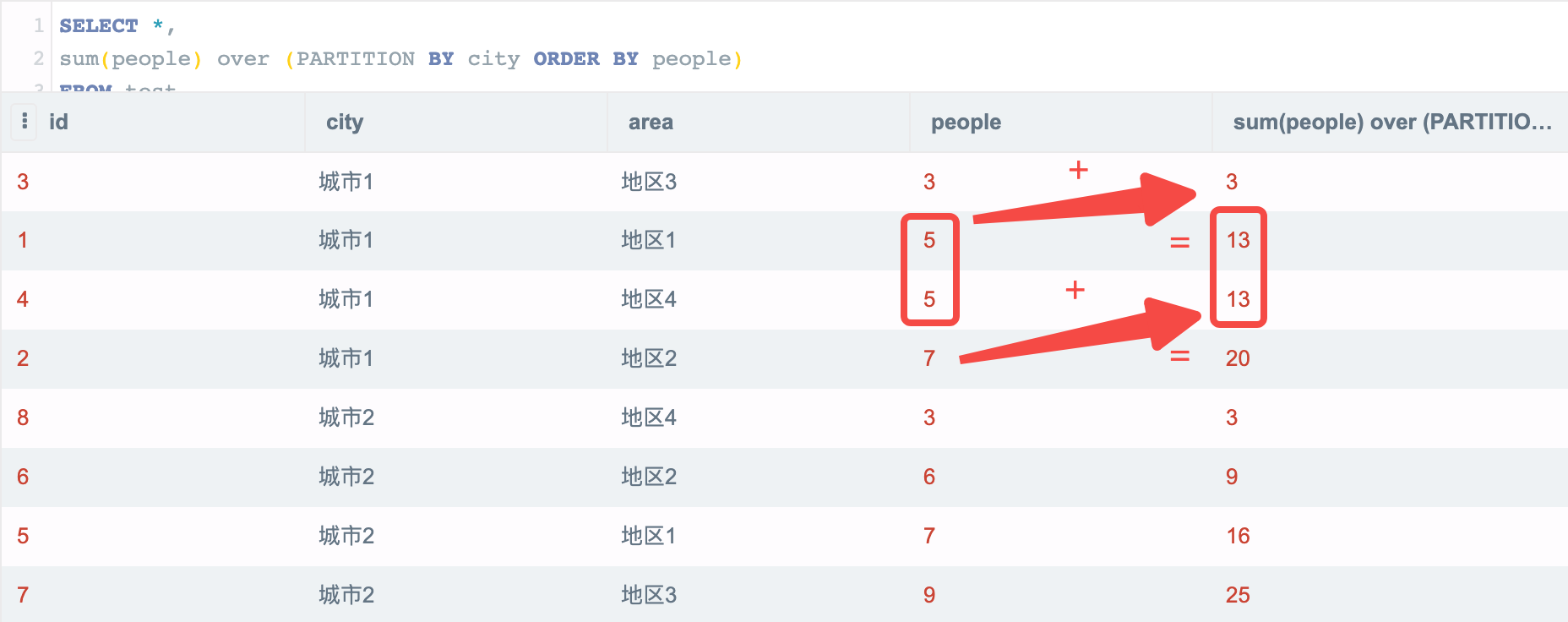 可以看到,在每个 city 分组内,按照 people 排序后进行了 **累加**(相同的值会合并在一起),这就是 BI 工具一般说的 RUNNGIN_SUM 的实现思路,当然一般我们排序规则使用绝对不会重复的日期,所以不会遇到第一个红框中合并计算的问题。
累计函数还有 `avg()` `min()` 等等,这些都一样可以作用于窗口函数,其逻辑可以按照下图理解:
可以看到,在每个 city 分组内,按照 people 排序后进行了 **累加**(相同的值会合并在一起),这就是 BI 工具一般说的 RUNNGIN_SUM 的实现思路,当然一般我们排序规则使用绝对不会重复的日期,所以不会遇到第一个红框中合并计算的问题。
累计函数还有 `avg()` `min()` 等等,这些都一样可以作用于窗口函数,其逻辑可以按照下图理解:
 你可能有疑问,直接 `sum(上一行结果,下一行)` 不是更方便吗?为了验证猜想,我们试试 `avg()` 的结果:
你可能有疑问,直接 `sum(上一行结果,下一行)` 不是更方便吗?为了验证猜想,我们试试 `avg()` 的结果:
 可见,如果直接利用上一行结果的缓存,那么 avg 结果必然是不准确的,所以窗口累计聚合是每行重新计算的。当然也不排除对于 sum、max、min 做额外性能优化的可能性,但 avg 只能每行重头计算。
### 与 GROUP BY 组合使用
窗口函数是可以与 GROUP BY 组合使用的,遵循的规则是,窗口范围对后面的查询结果生效,所以其实并不关心是否进行了 GROUP BY。我们看下面的例子:
可见,如果直接利用上一行结果的缓存,那么 avg 结果必然是不准确的,所以窗口累计聚合是每行重新计算的。当然也不排除对于 sum、max、min 做额外性能优化的可能性,但 avg 只能每行重头计算。
### 与 GROUP BY 组合使用
窗口函数是可以与 GROUP BY 组合使用的,遵循的规则是,窗口范围对后面的查询结果生效,所以其实并不关心是否进行了 GROUP BY。我们看下面的例子:
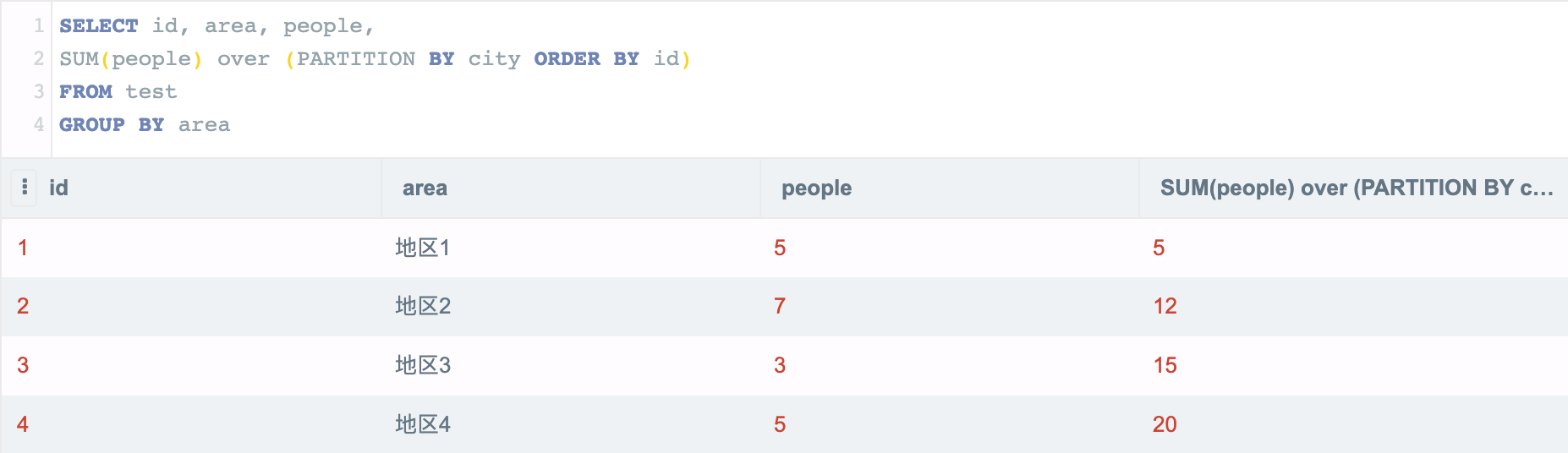 按照地区分组后进行累加聚合,是对 GROUP BY 后的数据行粒度进行的,而不是之前的明细行。
## 总结
窗口函数在计算组内排序或累计 GVM 等场景非常有用,我们只要牢记两个知识点就行了:
1. 分组排序要结合 PARTITION BY 才有意义。
2. 累计聚合作用于查询结果行粒度,支持所有聚合函数。
> 讨论地址是:[精读《SQL 窗口函数》· Issue #405 · ascoders/weekly](https://github.com/ascoders/weekly/issues/405)
**如果你想参与讨论,请 [点击这里](https://github.com/ascoders/weekly),每周都有新的主题,周末或周一发布。前端精读 - 帮你筛选靠谱的内容。**
> 关注 **前端精读微信公众号**
按照地区分组后进行累加聚合,是对 GROUP BY 后的数据行粒度进行的,而不是之前的明细行。
## 总结
窗口函数在计算组内排序或累计 GVM 等场景非常有用,我们只要牢记两个知识点就行了:
1. 分组排序要结合 PARTITION BY 才有意义。
2. 累计聚合作用于查询结果行粒度,支持所有聚合函数。
> 讨论地址是:[精读《SQL 窗口函数》· Issue #405 · ascoders/weekly](https://github.com/ascoders/weekly/issues/405)
**如果你想参与讨论,请 [点击这里](https://github.com/ascoders/weekly),每周都有新的主题,周末或周一发布。前端精读 - 帮你筛选靠谱的内容。**
> 关注 **前端精读微信公众号**
 但两条 select 语句聚合了两次,性能是一个不小的开销,因此 SQL 提供了 GROUPING SETS 语法解决这个问题。
## GROUPING SETS
GROUP BY GROUPING SETS 可以指定任意聚合项,比如我们要同时计算总计与分组合计,就要按照空内容进行 GROUP BY 进行一次 sum,再按照 city 进行 GROUP BY 再进行一次 sum,换成 GROUPING SETS 描述就是:
```sql
SELECT
city, area,
sum(people)
FROM test
GROUP BY GROUPING SETS((), (city, area))
```
其中 `GROUPING SETS((), (city, area))` 表示分别按照 `()`、`(city, area)` 聚合计算总计。返回结果是:
但两条 select 语句聚合了两次,性能是一个不小的开销,因此 SQL 提供了 GROUPING SETS 语法解决这个问题。
## GROUPING SETS
GROUP BY GROUPING SETS 可以指定任意聚合项,比如我们要同时计算总计与分组合计,就要按照空内容进行 GROUP BY 进行一次 sum,再按照 city 进行 GROUP BY 再进行一次 sum,换成 GROUPING SETS 描述就是:
```sql
SELECT
city, area,
sum(people)
FROM test
GROUP BY GROUPING SETS((), (city, area))
```
其中 `GROUPING SETS((), (city, area))` 表示分别按照 `()`、`(city, area)` 聚合计算总计。返回结果是:
 可以看到,值为 NULL 的行就是我们要的总计,其值是没有任何 GROUP BY 限制算出来的。
类似的,我们还可以写 `GROUPING SETS((), (city), (city, area), (area))` 等任意数量、任意组合的 GROUP BY 条件。
通过这种规则计算的数据我们称为 “超级分组记录”。我们发现 “超级分组记录” 产生的 NULL 值很容易和真正的 NULL 值弄混,所以 SQL 提供了 GROUPING 函数解决这个问题。
## 函数 GROUPING
对于超级分组记录产生的 NULL,是可以被 `GROUPING()` 函数识别为 1 的:
```sql
SELECT
GROUPING(city),
GROUPING(area),
sum(people)
FROM test
GROUP BY GROUPING SETS((), (city, area))
```
具体效果见下图:
可以看到,值为 NULL 的行就是我们要的总计,其值是没有任何 GROUP BY 限制算出来的。
类似的,我们还可以写 `GROUPING SETS((), (city), (city, area), (area))` 等任意数量、任意组合的 GROUP BY 条件。
通过这种规则计算的数据我们称为 “超级分组记录”。我们发现 “超级分组记录” 产生的 NULL 值很容易和真正的 NULL 值弄混,所以 SQL 提供了 GROUPING 函数解决这个问题。
## 函数 GROUPING
对于超级分组记录产生的 NULL,是可以被 `GROUPING()` 函数识别为 1 的:
```sql
SELECT
GROUPING(city),
GROUPING(area),
sum(people)
FROM test
GROUP BY GROUPING SETS((), (city, area))
```
具体效果见下图:
 可以看到,但凡是超级分组计算出来的字段都会识别为 1,我们利用之前学习的 [SQL CASE 表达式](https://github.com/ascoders/weekly/blob/master/SQL/234.SQL%20CASE%20%E8%A1%A8%E8%BE%BE%E5%BC%8F.md) 将其转换为总计、小计字样,就可以得出一张数据分析表了:
```sql
SELECT
CASE WHEN GROUPING(city) = 1 THEN '总计' ELSE city END,
CASE WHEN GROUPING(area) = 1 THEN '小计' ELSE area END,
sum(people)
FROM test
GROUP BY GROUPING SETS((), (city, area))
```
可以看到,但凡是超级分组计算出来的字段都会识别为 1,我们利用之前学习的 [SQL CASE 表达式](https://github.com/ascoders/weekly/blob/master/SQL/234.SQL%20CASE%20%E8%A1%A8%E8%BE%BE%E5%BC%8F.md) 将其转换为总计、小计字样,就可以得出一张数据分析表了:
```sql
SELECT
CASE WHEN GROUPING(city) = 1 THEN '总计' ELSE city END,
CASE WHEN GROUPING(area) = 1 THEN '小计' ELSE area END,
sum(people)
FROM test
GROUP BY GROUPING SETS((), (city, area))
```
 然后前端表格展示时,将第一行 “总计”、“小计” 单元格合并为 “总计”,就完成了总计这个 BI 可视化分析功能。
## ROLLUP
ROLLUP 是卷起的意思,是一种特定规则的 GROUPING SETS,以下两种写法是等价的:
```sql
SELECT sum(people) FROM test
GROUP BY ROLLUP(city)
-- 等价于
SELECT sum(people) FROM test
GROUP BY GROUPING SETS((), (city))
```
再看一组等价描述:
```sql
SELECT sum(people) FROM test
GROUP BY ROLLUP(city, area)
-- 等价于
SELECT sum(people) FROM test
GROUP BY GROUPING SETS((), (city), (city, area))
```
发现规律了吗?ROLLUP 会按顺序把 GROUP BY 内容 “一个个卷起来”。用 GROUPING 函数判断超级分组记录对 ROLLUP 同样适用。
## CUBE
CUBE 又有所不同,它对内容进行了所有可能性展开(所以叫 CUBE)。
类比上面的例子,我们再写两组等价的展开:
```sql
SELECT sum(people) FROM test
GROUP BY CUBE(city)
-- 等价于
SELECT sum(people) FROM test
GROUP BY GROUPING SETS((), (city))
```
上面的例子因为只有一项还看不出来,下面两项分组就能看出来了:
```sql
SELECT sum(people) FROM test
GROUP BY CUBE(city, area)
-- 等价于
SELECT sum(people) FROM test
GROUP BY GROUPING SETS((), (city), (area), (city, area))
```
所谓 CUBE,是一种多维形状的描述,二维时有 2^1 种展开,三维时有 2^2 种展开,四维、五维依此类推。可以想象,如果用 CUBE 描述了很多组合,复杂度会爆炸。
## 总结
学习了 GROUPING 语法,以后前端同学的你不会再纠结这个问题了吧:
> 产品开启了总计、小计,我们是额外取一次数还是放到一起获取啊?
这个问题的标准答案和原理都在这篇文章里了。PS:对于不支持 GROUPING 语法数据库,要想办法屏蔽,就像前端 polyfill 一样,是一种降级方案。至于如何屏蔽,参考文章开头提到的两个 SELECT + UNION。
> 讨论地址是:[精读《SQL grouping》· Issue #406 · ascoders/weekly](https://github.com/ascoders/weekly/issues/406)
**如果你想参与讨论,请 [点击这里](https://github.com/ascoders/weekly),每周都有新的主题,周末或周一发布。前端精读 - 帮你筛选靠谱的内容。**
> 关注 **前端精读微信公众号**
然后前端表格展示时,将第一行 “总计”、“小计” 单元格合并为 “总计”,就完成了总计这个 BI 可视化分析功能。
## ROLLUP
ROLLUP 是卷起的意思,是一种特定规则的 GROUPING SETS,以下两种写法是等价的:
```sql
SELECT sum(people) FROM test
GROUP BY ROLLUP(city)
-- 等价于
SELECT sum(people) FROM test
GROUP BY GROUPING SETS((), (city))
```
再看一组等价描述:
```sql
SELECT sum(people) FROM test
GROUP BY ROLLUP(city, area)
-- 等价于
SELECT sum(people) FROM test
GROUP BY GROUPING SETS((), (city), (city, area))
```
发现规律了吗?ROLLUP 会按顺序把 GROUP BY 内容 “一个个卷起来”。用 GROUPING 函数判断超级分组记录对 ROLLUP 同样适用。
## CUBE
CUBE 又有所不同,它对内容进行了所有可能性展开(所以叫 CUBE)。
类比上面的例子,我们再写两组等价的展开:
```sql
SELECT sum(people) FROM test
GROUP BY CUBE(city)
-- 等价于
SELECT sum(people) FROM test
GROUP BY GROUPING SETS((), (city))
```
上面的例子因为只有一项还看不出来,下面两项分组就能看出来了:
```sql
SELECT sum(people) FROM test
GROUP BY CUBE(city, area)
-- 等价于
SELECT sum(people) FROM test
GROUP BY GROUPING SETS((), (city), (area), (city, area))
```
所谓 CUBE,是一种多维形状的描述,二维时有 2^1 种展开,三维时有 2^2 种展开,四维、五维依此类推。可以想象,如果用 CUBE 描述了很多组合,复杂度会爆炸。
## 总结
学习了 GROUPING 语法,以后前端同学的你不会再纠结这个问题了吧:
> 产品开启了总计、小计,我们是额外取一次数还是放到一起获取啊?
这个问题的标准答案和原理都在这篇文章里了。PS:对于不支持 GROUPING 语法数据库,要想办法屏蔽,就像前端 polyfill 一样,是一种降级方案。至于如何屏蔽,参考文章开头提到的两个 SELECT + UNION。
> 讨论地址是:[精读《SQL grouping》· Issue #406 · ascoders/weekly](https://github.com/ascoders/weekly/issues/406)
**如果你想参与讨论,请 [点击这里](https://github.com/ascoders/weekly),每周都有新的主题,周末或周一发布。前端精读 - 帮你筛选靠谱的内容。**
> 关注 **前端精读微信公众号**