Repository: bear-zd/ChaoXingReserveSeat
Branch: rebuild
Commit: 6fe851afe35c
Files: 8
Total size: 26.8 KB
Directory structure:
gitextract_1ir63j0f/
├── .github/
│ └── workflows/
│ └── reserve.yml
├── .gitignore
├── README.md
├── config.json
├── main.py
└── utils/
├── __init__.py
├── encrypt.py
└── reserve.py
================================================
FILE CONTENTS
================================================
================================================
FILE: .github/workflows/reserve.yml
================================================
# This is a basic workflow that is manually triggered
name: auto_Reserve
# Controls when the action will run. Workflow runs when manually triggered using the UI
# or API.
on:
schedule:
- cron: "59 21 * * 0,1,2,3,4" # 周一到周五每天早上5:59启动(防止github action过于高负载)
workflow_dispatch:
jobs:
build:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v2
- name: Set up Python 3.11
uses: actions/setup-python@v2
with:
python-version: 3.11
- name: install dependency
run: |
python -m pip install --upgrade pip
sudo apt-get install build-essential libssl-dev libffi-dev python3-dev -y
pip install cryptography requests opencv-python
- name: run script
env:
USERNAMES: ${{ secrets.USERNAMES }}
PASSWORDS: ${{ secrets.PASSWORDS }}
run: |
python main.py -m debug --action
================================================
FILE: .gitignore
================================================
# Byte-compiled / optimized / DLL files
__pycache__/
*.py[cod]
*$py.class
# C extensions
*.so
# Distribution / packaging
.Python
build/
develop-eggs/
dist/
downloads/
eggs/
.eggs/
lib/
lib64/
parts/
sdist/
var/
wheels/
pip-wheel-metadata/
share/python-wheels/
*.egg-info/
.installed.cfg
*.egg
MANIFEST
# PyInstaller
# Usually these files are written by a python script from a template
# before PyInstaller builds the exe, so as to inject date/other infos into it.
*.manifest
*.spec
# Installer logs
pip-log.txt
pip-delete-this-directory.txt
# Unit test / coverage reports
htmlcov/
.tox/
.nox/
.coverage
.coverage.*
.cache
nosetests.xml
coverage.xml
*.cover
*.py,cover
.hypothesis/
.pytest_cache/
# Translations
*.mo
*.pot
# Django stuff:
*.log
local_settings.py
db.sqlite3
db.sqlite3-journal
# Flask stuff:
instance/
.webassets-cache
# Scrapy stuff:
.scrapy
# Sphinx documentation
docs/_build/
# PyBuilder
target/
# Jupyter Notebook
.ipynb_checkpoints
# IPython
profile_default/
ipython_config.py
# pyenv
.python-version
# pipenv
# According to pypa/pipenv#598, it is recommended to include Pipfile.lock in version control.
# However, in case of collaboration, if having platform-specific dependencies or dependencies
# having no cross-platform support, pipenv may install dependencies that don't work, or not
# install all needed dependencies.
#Pipfile.lock
# PEP 582; used by e.g. github.com/David-OConnor/pyflow
__pypackages__/
# Celery stuff
celerybeat-schedule
celerybeat.pid
# SageMath parsed files
*.sage.py
# Environments
.env
.venv
env/
venv/
ENV/
env.bak/
venv.bak/
# Spyder project settings
.spyderproject
.spyproject
# Rope project settings
.ropeproject
# mkdocs documentation
/site
# mypy
.mypy_cache/
.dmypy.json
dmypy.json
# Pyre type checker
.pyre/
test.json
================================================
FILE: README.md
================================================
# ChaoXingServerSeat
超星图书馆座位预约脚本
(由于部分学校新增了点选式行为验证码导致原本的程序会显示验证失败,详细参见issue21[https://github.com/bear-zd/ChaoXingReserveSeat/issues/21])
## 注意
使用python消除了对js的依赖,请拉取最新版程序运行。
该版本试验性支持滑块验证,目前已经过测试可以使用,如果有滑块验证,请参考下面的**高级设置**部分
## 如何使用
### 本地部署方式
#### 1、安装依赖
运行脚本前先安装一个包
```bash
pip install cryptography
```
如果有滑块验证,则需要额外安装numpy和opencv-python
```bash
pip install numpy, opencv-python
```
#### 2、 获取roomid(图书馆id)和seatid(座位号)
在使用之前需要先在如下获取图书馆对应的id和座位号,下面的配置里已经提供了上海大学图书馆的id。对于不知道id的,可以通过如下方式进行:
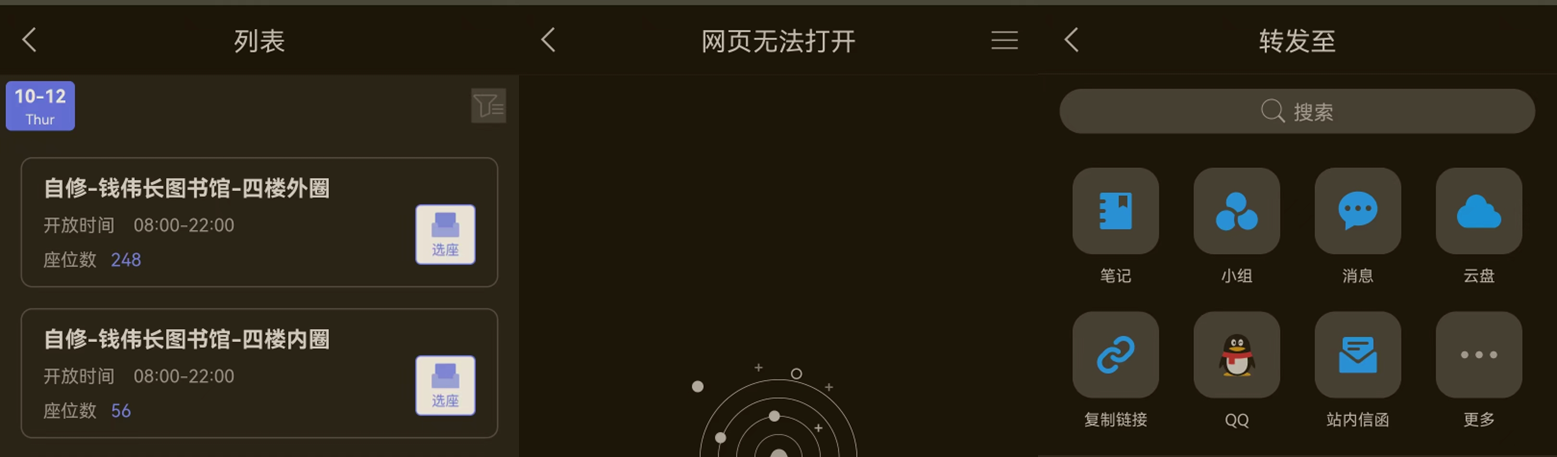
在进入预约图书馆列表界面时断开网络,点击你想预约的图书馆的`选座`按钮,会提示网页无法打开,此时点击`右上角的三条杠`,选择`复制链接`,会得到类似这样的链接:
> https://office.chaoxing.com/front/apps/seat/select?id=5483&day=2023-10-12&backLevel=2&pageToken=0f46f3acc7be4c60862cb9815870ddfd
其中的`id=5483`的5483即为对应图书馆的id,将其填写到config.json中,座位联网后自己挑即可(详细填写参见后面的setting)
#### 3、running
由于脚本是检测系统时间为7点时进行预约(在main.py 第16行),如果有特殊要求可以修改。通过 `python main.py` 运行脚本, 添加参数 `-u config.json` 来指明配置文件路径
运行`python main.py -m debug`可以立即运行查看配置是否正确。
关于运行的方式,现在提供了多种运行方式:
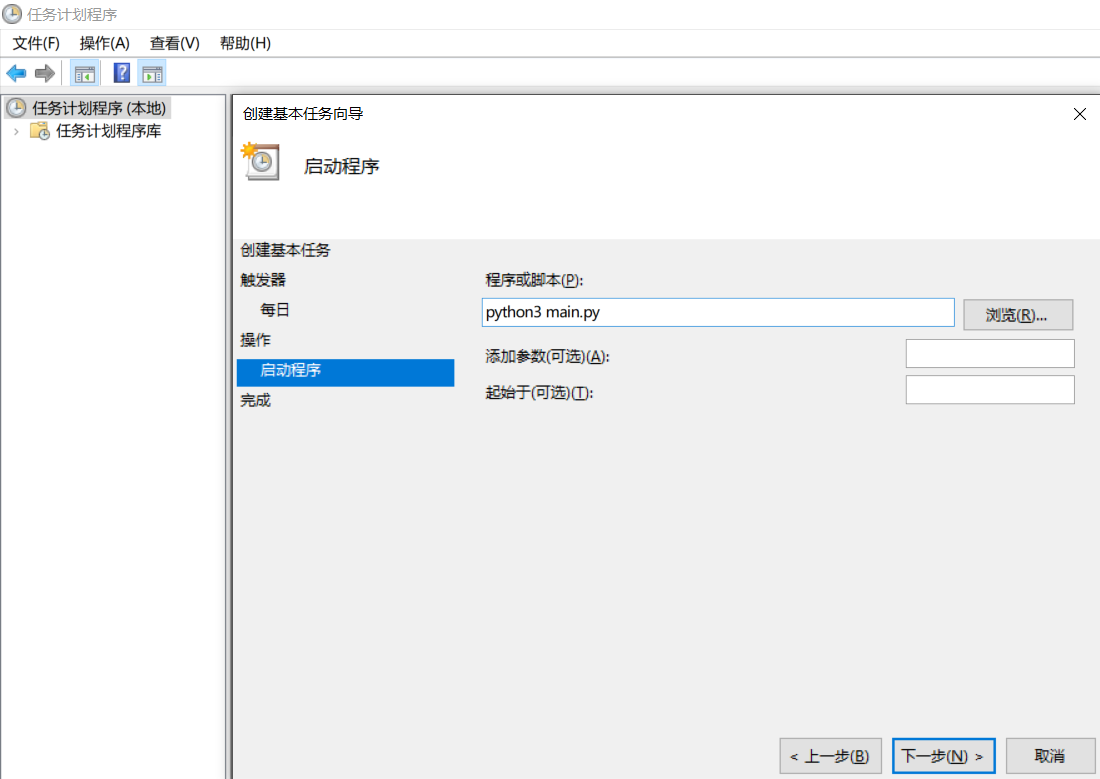
- Linux环境下:
在Linux下可以使用如下方式添加crontab , 运行:`crontab -e`添加指令 :`0 7 * * * python3 main.py`
- windows环境下:
windows下使用时间任务:
### github actions部署方式(目前应该没有问题了):
这种方式可以不需要在本地部署环境,只需要把fork该仓库并修改配置文件即可。
1.**fork该仓库**
2.**修改config.json**:这个仿照之前的方式进行修改即可,但是注意,username和password请留空或者随便填以防止泄漏个人账号密码。(具体的需要填写在自己repo的settings中)。时间什么也是需要修改(修改到仓库中)不要忘记。
3.**配置账号密码**:在settings->secrets and variables->Repository secrets 创建两个secret keys。名称分别为USERNAMES,PASSWORDS,填写自己的账号和密码即可。(如果有多个用户,请使用,(英文逗号)隔开,如果密码中有逗号可能会出现问题)。
```
xxxxxxx,xxxxxxx
```
4.**运行action**:在action -> auto_reserve -> run workflows 选择main分支即可。
## config配置
之后编辑config.json并填写座位预约相关信息即可
```json
{
"reserve": [
{"username": "XXXXXXXX", //https://passport2.chaoxing.com/mlogin?loginType=1&newversion=true&fid=& 在这个网站查看是否可以顺利登陆
"password": "XXXXXXXX",
"time": ["08:00","22:00"], // 预约的起始时间
"roomid":"2609", //2609:四楼外圈,5483:四楼内圈,2610:五楼外圈,5484:五楼内圈
"seatid":"002", // 注意要用0补全至3位数,例如6号座位应该填006
"daysofweek": ["Monday" , "Tuesday", "Wednesday", "Thursday", "Friday"]
},
{"username": "xxxxxxxxxx",
"password": "xxxxxxxxx",
"time": ["20:00","21:00"],
"roomid":"5483",
"seatid":["056"],
"daysofweek": ["Saturday" , "Sunday"]
}
}
```
参考前面的运行方式即可。
## 高级设置
在main.py中有四个参数可以选择
```python
SLEEPTIME = 0.2 # 每次抢座的间隔
ENDTIME = "07:01:00" # 根据学校的开始预约座位时间+1min即可
ENABLE_SLIDER = False # 是否有滑块验证,设置为True开启滑块验证
MAX_ATTEMPT = 4 # 最大尝试次数
```
可以直接进行修改,但是不建议把**SLEEPTIME**设置太小。
## 存在的问题
目前日志输出不是很人性化,如果出现了以下问题请提issue:
- 出现了代码逻辑的错误
- {当前人数过多,请等待5分钟后尝试}。这种是请求方式错误或者请求键值错误导致的,通常是由于学习通更新了预约导致的
- 以字典格式输出的其他错误,仔细查看用户名密码,roomid和seatid是否填写正确。如果问题不能解决请在github上提issue
- 滑块验证目前无法进行测试
### 无法预约情况debug方式
> 1、电脑端访问:"https://passport2.chaoxing.com/mlogin?loginType=1&newversion=true&fid=" 使用自己的用户名密码登录
> 2、电脑端访问:”https://office.chaoxing.com/front/third/apps/seat/code?id={图书馆id}&seatNum={座位id}“查看是否显示时间表
> 3、尝试预约看看是否会出现验证方式
目前无法实现跨单位座位预约。
================================================
FILE: config.json
================================================
{
"reserve": [
{"username": "xxxxxxxxxx",
"password": "xxxxxxxxx",
"time": ["21:00","22:00"],
"roomid":"3993",
"seatid":["111"],
"daysofweek": ["Monday" , "Tuesday", "Wednesday", "Thursday", "Friday"]
}
]
}
================================================
FILE: main.py
================================================
import json
import time
import argparse
import os
import logging
logging.basicConfig(
level=logging.INFO, format="%(asctime)s - %(levelname)s - %(message)s"
)
from utils import reserve, get_user_credentials
get_current_time = lambda action: (
time.strftime("%H:%M:%S", time.localtime(time.time() + 8 * 3600))
if action
else time.strftime("%H:%M:%S", time.localtime(time.time()))
)
get_current_dayofweek = lambda action: (
time.strftime("%A", time.localtime(time.time() + 8 * 3600))
if action
else time.strftime("%A", time.localtime(time.time()))
)
SLEEPTIME = 0.2 # 每次抢座的间隔
ENDTIME = "07:01:00" # 根据学校的预约座位时间+1min即可
ENABLE_SLIDER = True # 是否有滑块验证
MAX_ATTEMPT = 5 # 最大尝试次数
RESERVE_NEXT_DAY = False # 预约明天而不是今天的
def login_and_reserve(users, usernames, passwords, action, success_list=None):
logging.info(
f"Global settings: \nSLEEPTIME: {SLEEPTIME}\nENDTIME: {ENDTIME}\nENABLE_SLIDER: {ENABLE_SLIDER}\nRESERVE_NEXT_DAY: {RESERVE_NEXT_DAY}"
)
if action and len(usernames.split(",")) != len(users):
raise Exception("user number should match the number of config")
if success_list is None:
success_list = [False] * len(users)
current_dayofweek = get_current_dayofweek(action)
for index, user in enumerate(users):
username, password, times, roomid, seatid, daysofweek = user.values()
if action:
username, password = (
usernames.split(",")[index],
passwords.split(",")[index],
)
if current_dayofweek not in daysofweek:
logging.info("Today not set to reserve")
continue
if not success_list[index]:
logging.info(
f"----------- {username} -- {times} -- {seatid} try -----------"
)
s = reserve(
sleep_time=SLEEPTIME,
max_attempt=MAX_ATTEMPT,
enable_slider=ENABLE_SLIDER,
reserve_next_day=RESERVE_NEXT_DAY,
)
s.get_login_status()
s.login(username, password)
s.requests.headers.update({"Host": "office.chaoxing.com"})
suc = s.submit(times, roomid, seatid, action)
success_list[index] = suc
return success_list
def main(users, action=False):
current_time = get_current_time(action)
logging.info(f"start time {current_time}, action {'on' if action else 'off'}")
attempt_times = 0
usernames, passwords = None, None
if action:
usernames, passwords = get_user_credentials(action)
success_list = None
current_dayofweek = get_current_dayofweek(action)
today_reservation_num = sum(
1 for d in users if current_dayofweek in d.get("daysofweek")
)
while current_time < ENDTIME:
attempt_times += 1
# try:
success_list = login_and_reserve(
users, usernames, passwords, action, success_list
)
# except Exception as e:
# print(f"An error occurred: {e}")
print(
f"attempt time {attempt_times}, time now {current_time}, success list {success_list}"
)
current_time = get_current_time(action)
if sum(success_list) == today_reservation_num:
print(f"reserved successfully!")
return
def debug(users, action=False):
logging.info(
f"Global settings: \nSLEEPTIME: {SLEEPTIME}\nENDTIME: {ENDTIME}\nENABLE_SLIDER: {ENABLE_SLIDER}\nRESERVE_NEXT_DAY: {RESERVE_NEXT_DAY}"
)
suc = False
logging.info(f" Debug Mode start! , action {'on' if action else 'off'}")
if action:
usernames, passwords = get_user_credentials(action)
current_dayofweek = get_current_dayofweek(action)
for index, user in enumerate(users):
username, password, times, roomid, seatid, daysofweek = user.values()
if type(seatid) == str:
seatid = [seatid]
if action:
username, password = (
usernames.split(",")[index],
passwords.split(",")[index],
)
if current_dayofweek not in daysofweek:
logging.info("Today not set to reserve")
continue
logging.info(f"----------- {username} -- {times} -- {seatid} try -----------")
s = reserve(
sleep_time=SLEEPTIME,
max_attempt=MAX_ATTEMPT,
enable_slider=ENABLE_SLIDER,
reserve_next_day=RESERVE_NEXT_DAY,
)
s.get_login_status()
s.login(username, password)
s.requests.headers.update({"Host": "office.chaoxing.com"})
suc = s.submit(times, roomid, seatid, action)
if suc:
return
def get_roomid(args1, args2):
username = input("请输入用户名:")
password = input("请输入密码:")
s = reserve(
sleep_time=SLEEPTIME,
max_attempt=MAX_ATTEMPT,
enable_slider=ENABLE_SLIDER,
reserve_next_day=RESERVE_NEXT_DAY,
)
s.get_login_status()
s.login(username=username, password=password)
s.requests.headers.update({"Host": "office.chaoxing.com"})
encode = input("请输入deptldEnc:")
s.roomid(encode)
if __name__ == "__main__":
config_path = os.path.join(os.path.dirname(__file__), "config.json")
parser = argparse.ArgumentParser(prog="Chao Xing seat auto reserve")
parser.add_argument("-u", "--user", default=config_path, help="user config file")
parser.add_argument(
"-m",
"--method",
default="reserve",
choices=["reserve", "debug", "room"],
help="for debug",
)
parser.add_argument(
"-a",
"--action",
action="store_true",
help="use --action to enable in github action",
)
args = parser.parse_args()
func_dict = {"reserve": main, "debug": debug, "room": get_roomid}
with open(args.user, "r+") as data:
usersdata = json.load(data)["reserve"]
func_dict[args.method](usersdata, args.action)
================================================
FILE: utils/__init__.py
================================================
import os
from .encrypt import AES_Encrypt, generate_captcha_key, enc, verify_param
from .reserve import reserve
def _fetch_env_variables(env_name, action):
try:
return os.environ[env_name] if action else ""
except KeyError:
print(f"Environment variable {env_name} is not configured correctly.")
return None
def get_user_credentials(action):
usernames = _fetch_env_variables('USERNAMES', action)
passwords = _fetch_env_variables('PASSWORDS', action)
return usernames, passwords
================================================
FILE: utils/encrypt.py
================================================
from cryptography.hazmat.primitives import padding
from cryptography.hazmat.primitives.ciphers import Cipher, algorithms, modes
from cryptography.hazmat.backends import default_backend
import base64
from hashlib import md5
import random
from uuid import uuid1
import hashlib
def AES_Encrypt(data):
key = b"u2oh6Vu^HWe4_AES" # Convert to bytes
iv = b"u2oh6Vu^HWe4_AES" # Convert to bytes
padder = padding.PKCS7(128).padder()
padded_data = padder.update(data.encode("utf-8")) + padder.finalize()
cipher = Cipher(algorithms.AES(key), modes.CBC(iv), backend=default_backend())
encryptor = cipher.encryptor()
encrypted_data = encryptor.update(padded_data) + encryptor.finalize()
enctext = base64.b64encode(encrypted_data).decode("utf-8")
return enctext
def resort(submit_info):
return {key: submit_info[key] for key in sorted(submit_info.keys())}
def enc(submit_info):
add = lambda x, y: x + y
processed_info = resort(submit_info)
needed = [
add(add("[", key), "=" + value) + "]" for key, value in processed_info.items()
]
pattern = "%sd`~7^/>N4!Q#){''"
needed.append(add("[", pattern) + "]")
seq = "".join(needed)
return md5(seq.encode("utf-8")).hexdigest()
def generate_captcha_key(timestamp: int):
captcha_key = md5((str(timestamp) + str(uuid1())).encode("utf-8")).hexdigest()
encoded_timestamp = (
md5(
(
str(timestamp)
+ "42sxgHoTPTKbt0uZxPJ7ssOvtXr3ZgZ1"
+ "slide"
+ captcha_key
).encode("utf-8")
).hexdigest()
+ ":"
+ str(int(timestamp) + 0x493E0)
)
return [captcha_key, encoded_timestamp]
def sort_dict_by_keys(dictionary):
"""将字典按键排序并返回新字典"""
sorted_keys = sorted(dictionary.keys())
sorted_dict = {key: dictionary[key] for key in sorted_keys}
return sorted_dict
def verify_param(params, algorithm_value):
"""
生成参数的MD5验证哈希值
参数:
params: 要验证的参数字典
algorithm_value: 对应JavaScript中id为'algorithm'的元素值
返回:
计算得到的MD5哈希字符串
"""
# 对参数字典按键排序
sorted_params = sort_dict_by_keys(params)
# 构建哈希字符串列表
hash_list = []
# 遍历排序后的参数,构建格式为 [key=value] 的字符串
for key, value in sorted_params.items():
# 确保值转换为字符串,与JavaScript行为一致
hash_list.append(f"[{key}={str(value)}]")
# 添加algorithm值
hash_list.append(f"[{algorithm_value}]")
# 连接所有元素形成最终字符串
hash_string = "".join(hash_list)
# 计算MD5哈希值(注意:Python的hashlib返回bytes,需要转换为十六进制字符串)
md5_hash = hashlib.md5(hash_string.encode("utf-8")).hexdigest()
return md5_hash
================================================
FILE: utils/reserve.py
================================================
from utils import AES_Encrypt, enc, generate_captcha_key, verify_param
import json
import requests
import re
import time
import logging
import datetime
from urllib3.exceptions import InsecureRequestWarning
def get_date(day_offset: int = 0):
today = datetime.datetime.now().date()
offset_day = today + datetime.timedelta(days=day_offset)
tomorrow = offset_day.strftime("%Y-%m-%d")
return tomorrow
class reserve:
def __init__(
self,
sleep_time=0.2,
max_attempt=50,
enable_slider=False,
reserve_next_day=False,
):
self.login_page = (
"https://passport2.chaoxing.com/mlogin?loginType=1&newversion=true&fid="
)
self.url = (
"https://office.chaoxing.com/front/third/apps/seat/code?id={}&seatNum={}"
)
self.submit_url = "https://office.chaoxing.com/data/apps/seat/submit"
self.seat_url = "https://office.chaoxing.com/data/apps/seat/getusedtimes"
self.login_url = "https://passport2.chaoxing.com/fanyalogin"
self.token = ""
self.success_times = 0
self.fail_dict = []
self.submit_msg = []
self.requests = requests.session()
self.token_pattern = re.compile("token = '(.*?)'")
self.headers = {
"Referer": "https://office.chaoxing.com/",
"Host": "captcha.chaoxing.com",
"Pragma": "no-cache",
"Sec-Ch-Ua": '"Google Chrome";v="125", "Chromium";v="125", "Not.A/Brand";v="24"',
"Sec-Ch-Ua-Mobile": "?0",
"Sec-Ch-Ua-Platform": '"Linux"',
"Sec-Fetch-Dest": "document",
"Sec-Fetch-Mode": "navigate",
"Sec-Fetch-Site": "none",
"Sec-Fetch-User": "?1",
"Upgrade-Insecure-Requests": "1",
"User-Agent": "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/128.0.0.0 Safari/537.36",
}
self.login_headers = {
"Accept": "application/json, text/javascript, */*; q=0.01",
"accept-encoding": "gzip, deflate, br, zstd",
"cache-control": "no-cache",
"Connection": "keep-alive",
"Accept-Language": "zh-CN,zh;q=0.9,en-US;q=0.8,en;q=0.7",
"User-Agent": "Mozilla/5.0 (iPhone; CPU iPhone OS 10_3_1 like Mac OS X) AppleWebKit/603.1.3 (KHTML, like Gecko) Version/10.0 Mobile/14E304 Safari/602.1 wechatdevtools/1.05.2109131 MicroMessenger/8.0.5 Language/zh_CN webview/16364215743155638",
"X-Requested-With": "XMLHttpRequest",
"Content-Type": "application/x-www-form-urlencoded; charset=UTF-8",
"Host": "passport2.chaoxing.com",
}
self.sleep_time = sleep_time
self.max_attempt = max_attempt
self.enable_slider = enable_slider
self.reserve_next_day = reserve_next_day
requests.packages.urllib3.disable_warnings(InsecureRequestWarning)
# login and page token
def _get_page_token(self, url, require_value=False):
response = self.requests.get(url=url, verify=False)
html = response.content.decode("utf-8")
# matches = re.findall(r"token = \'(.*?)\'", html)
matches = re.findall(r'id="submit_enc"\s+value="(.*?)"', html)
value_matches = None
if require_value:
value_matches = re.findall(r'value="(.*?)"', html)
if not matches:
logging.error(f"Failed to get token from {url}")
return "", ""
if not value_matches:
logging.error(f"Failed to get submit value from {url}")
return matches[0], ""
return matches[0] if matches else "", value_matches[0] if value_matches else ""
def get_login_status(self):
self.requests.headers = self.login_headers
self.requests.get(url=self.login_page, verify=False)
def login(self, username, password):
username = AES_Encrypt(username)
password = AES_Encrypt(password)
parm = {
"fid": -1,
"uname": username,
"password": password,
"refer": "http%3A%2F%2Foffice.chaoxing.com%2Ffront%2Fthird%2Fapps%2Fseat%2Fcode%3Fid%3D4219%26seatNum%3D380",
"t": True,
}
jsons = self.requests.post(url=self.login_url, params=parm, verify=False)
obj = jsons.json()
if obj["status"]:
logging.info(f"User {username} login successfully")
return (True, "")
else:
logging.info(
f"User {username} login failed. Please check you password and username! "
)
return (False, obj["msg2"])
# extra: get roomid
def roomid(self, encode):
url = f"https://office.chaoxing.com/data/apps/seat/room/list?cpage=1&pageSize=100&firstLevelName=&secondLevelName=&thirdLevelName=&deptIdEnc={encode}"
json_data = self.requests.get(url=url).content.decode("utf-8")
ori_data = json.loads(json_data)
for i in ori_data["data"]["seatRoomList"]:
info = f'{i["firstLevelName"]}-{i["secondLevelName"]}-{i["thirdLevelName"]} id为:{i["id"]}'
print(info)
# solve captcha
def resolve_captcha(self):
logging.info(f"Start to resolve captcha token")
captcha_token, bg, tp = self.get_slide_captcha_data()
logging.info(f"Successfully get prepared captcha_token {captcha_token}")
logging.info(f"Captcha Image URL-small {tp}, URL-big {bg}")
x = self.x_distance(bg, tp)
logging.info(f"Successfully calculate the captcha distance {x}")
params = {
"callback": "jQuery33109180509737430778_1716381333117",
"captchaId": "42sxgHoTPTKbt0uZxPJ7ssOvtXr3ZgZ1",
"type": "slide",
"token": captcha_token,
"textClickArr": json.dumps([{"x": x}]),
"coordinate": json.dumps([]),
"runEnv": "10",
"version": "1.1.18",
"_": int(time.time() * 1000),
}
response = self.requests.get(
f"https://captcha.chaoxing.com/captcha/check/verification/result",
params=params,
headers=self.headers,
)
text = response.text.replace(
"jQuery33109180509737430778_1716381333117(", ""
).replace(")", "")
data = json.loads(text)
logging.info(f"Successfully resolve the captcha token {data}")
try:
validate_val = json.loads(data["extraData"])["validate"]
return validate_val
except KeyError as e:
logging.info("Can't load validate value. Maybe server return mistake.")
return ""
def get_slide_captcha_data(self):
url = "https://captcha.chaoxing.com/captcha/get/verification/image"
timestamp = int(time.time() * 1000)
capture_key, token = generate_captcha_key(timestamp)
referer = f"https://office.chaoxing.com/front/third/apps/seat/code?id=3993&seatNum=0199"
params = {
"callback": f"jQuery33107685004390294206_1716461324846",
"captchaId": "42sxgHoTPTKbt0uZxPJ7ssOvtXr3ZgZ1",
"type": "slide",
"version": "1.1.18",
"captchaKey": capture_key,
"token": token,
"referer": referer,
"_": timestamp,
"d": "a",
"b": "a",
}
response = self.requests.get(url=url, params=params, headers=self.headers)
content = response.text
data = content.replace(
"jQuery33107685004390294206_1716461324846(", ")"
).replace(")", "")
data = json.loads(data)
captcha_token = data["token"]
bg = data["imageVerificationVo"]["shadeImage"]
tp = data["imageVerificationVo"]["cutoutImage"]
return captcha_token, bg, tp
def x_distance(self, bg, tp):
import numpy as np
import cv2
def cut_slide(slide):
slider_array = np.frombuffer(slide, np.uint8)
slider_image = cv2.imdecode(slider_array, cv2.IMREAD_UNCHANGED)
slider_part = slider_image[:, :, :3]
mask = slider_image[:, :, 3]
mask[mask != 0] = 255
x, y, w, h = cv2.boundingRect(mask)
cropped_image = slider_part[y : y + h, x : x + w]
return cropped_image
c_captcha_headers = {
"Referer": "https://office.chaoxing.com/",
"Host": "captcha-b.chaoxing.com",
"Pragma": "no-cache",
"Sec-Ch-Ua": '"Google Chrome";v="125", "Chromium";v="125", "Not.A/Brand";v="24"',
"Sec-Ch-Ua-Mobile": "?0",
"Sec-Ch-Ua-Platform": '"Linux"',
"Sec-Fetch-Dest": "document",
"Sec-Fetch-Mode": "navigate",
"Sec-Fetch-Site": "none",
"Sec-Fetch-User": "?1",
"Upgrade-Insecure-Requests": "1",
"User-Agent": "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36",
}
bgc, tpc = self.requests.get(bg, headers=c_captcha_headers), self.requests.get(
tp, headers=c_captcha_headers
)
bg, tp = bgc.content, tpc.content
bg_img = cv2.imdecode(np.frombuffer(bg, np.uint8), cv2.IMREAD_COLOR)
tp_img = cut_slide(tp)
bg_edge = cv2.Canny(bg_img, 100, 200)
tp_edge = cv2.Canny(tp_img, 100, 200)
bg_pic = cv2.cvtColor(bg_edge, cv2.COLOR_GRAY2RGB)
tp_pic = cv2.cvtColor(tp_edge, cv2.COLOR_GRAY2RGB)
res = cv2.matchTemplate(bg_pic, tp_pic, cv2.TM_CCOEFF_NORMED)
_, _, _, max_loc = cv2.minMaxLoc(res)
tl = max_loc
return tl[0]
def submit(self, times, roomid, seatid, action):
for seat in seatid:
suc = False
while ~suc and self.max_attempt > 0:
token, value = self._get_page_token(
self.url.format(roomid, seat), require_value=True
)
logging.info(f"Get token: {token}")
captcha = self.resolve_captcha() if self.enable_slider else ""
logging.info(f"Captcha token {captcha}")
suc = self.get_submit(
self.submit_url,
times=times,
token=token,
roomid=roomid,
seatid=seat,
captcha=captcha,
action=action,
value=value,
)
if suc:
return suc
time.sleep(self.sleep_time)
self.max_attempt -= 1
return suc
def get_submit(
self, url, times, token, roomid, seatid, captcha="", action=False, value=""
):
delta_day = 1 if self.reserve_next_day else 0
day = datetime.date.today() + datetime.timedelta(
days=0 + delta_day
) # 预约今天,修改days=1表示预约明天
if action:
day = datetime.date.today() + datetime.timedelta(
days=1 + delta_day
) # 由于action时区问题导致其早+8区一天
parm = {
"roomId": roomid,
"startTime": times[0],
"endTime": times[1],
"day": str(day),
"seatNum": seatid,
"captcha": captcha,
"token": token,
"type": "1",
"verifyData": "1",
}
logging.info(f"submit parameter {parm} ")
# parm["enc"] = enc(parm)
parm["enc"] = verify_param(parm, value)
html = self.requests.post(url=url, params=parm, verify=True).content.decode(
"utf-8"
)
self.submit_msg.append(
times[0] + "~" + times[1] + ": " + str(json.loads(html))
)
logging.info(json.loads(html))
return json.loads(html)["success"]
gitextract_1ir63j0f/
├── .github/
│ └── workflows/
│ └── reserve.yml
├── .gitignore
├── README.md
├── config.json
├── main.py
└── utils/
├── __init__.py
├── encrypt.py
└── reserve.py
SYMBOL INDEX (24 symbols across 4 files)
FILE: main.py
function login_and_reserve (line 34) | def login_and_reserve(users, usernames, passwords, action, success_list=...
function main (line 71) | def main(users, action=False):
function debug (line 100) | def debug(users, action=False):
function get_roomid (line 136) | def get_roomid(args1, args2):
FILE: utils/__init__.py
function _fetch_env_variables (line 5) | def _fetch_env_variables(env_name, action):
function get_user_credentials (line 12) | def get_user_credentials(action):
FILE: utils/encrypt.py
function AES_Encrypt (line 11) | def AES_Encrypt(data):
function resort (line 23) | def resort(submit_info):
function enc (line 27) | def enc(submit_info):
function generate_captcha_key (line 39) | def generate_captcha_key(timestamp: int):
function sort_dict_by_keys (line 56) | def sort_dict_by_keys(dictionary):
function verify_param (line 63) | def verify_param(params, algorithm_value):
FILE: utils/reserve.py
function get_date (line 11) | def get_date(day_offset: int = 0):
class reserve (line 18) | class reserve:
method __init__ (line 19) | def __init__(
method _get_page_token (line 74) | def _get_page_token(self, url, require_value=False):
method get_login_status (line 90) | def get_login_status(self):
method login (line 94) | def login(self, username, password):
method roomid (line 116) | def roomid(self, encode):
method resolve_captcha (line 126) | def resolve_captcha(self):
method get_slide_captcha_data (line 162) | def get_slide_captcha_data(self):
method x_distance (line 191) | def x_distance(self, bg, tp):
method submit (line 234) | def submit(self, times, roomid, seatid, action):
method get_submit (line 260) | def get_submit(
Condensed preview — 8 files, each showing path, character count, and a content snippet. Download the .json file or copy for the full structured content (32K chars).
[
{
"path": ".github/workflows/reserve.yml",
"chars": 921,
"preview": "# This is a basic workflow that is manually triggered\n\nname: auto_Reserve\n\n# Controls when the action will run. Workflow"
},
{
"path": ".gitignore",
"chars": 1937,
"preview": "# Byte-compiled / optimized / DLL files\r\n__pycache__/\r\n*.py[cod]\r\n*$py.class\r\n\r\n# C extensions\r\n*.so\r\n\r\n# Distribution /"
},
{
"path": "README.md",
"chars": 3294,
"preview": "# ChaoXingServerSeat\r\n超星图书馆座位预约脚本\r\n\r\n(由于部分学校新增了点选式行为验证码导致原本的程序会显示验证失败,详细参见issue21[https://github.com/bear-zd/ChaoXingRes"
},
{
"path": "config.json",
"chars": 267,
"preview": "{\n \"reserve\": [\n {\"username\": \"xxxxxxxxxx\",\n \"password\": \"xxxxxxxxx\",\n \"time\": [\"21:00\",\"22:00\"]"
},
{
"path": "main.py",
"chars": 5984,
"preview": "import json\nimport time\nimport argparse\nimport os\nimport logging\n\nlogging.basicConfig(\n level=logging.INFO, format=\"%"
},
{
"path": "utils/__init__.py",
"chars": 524,
"preview": "import os \nfrom .encrypt import AES_Encrypt, generate_captcha_key, enc, verify_param\nfrom .reserve import reserve\n\ndef _"
},
{
"path": "utils/encrypt.py",
"chars": 2646,
"preview": "from cryptography.hazmat.primitives import padding\nfrom cryptography.hazmat.primitives.ciphers import Cipher, algorithms"
},
{
"path": "utils/reserve.py",
"chars": 11878,
"preview": "from utils import AES_Encrypt, enc, generate_captcha_key, verify_param\nimport json\nimport requests\nimport re\nimport time"
}
]
About this extraction
This page contains the full source code of the bear-zd/ChaoXingReserveSeat GitHub repository, extracted and formatted as plain text for AI agents and large language models (LLMs). The extraction includes 8 files (26.8 KB), approximately 7.9k tokens, and a symbol index with 24 extracted functions, classes, methods, constants, and types. Use this with OpenClaw, Claude, ChatGPT, Cursor, Windsurf, or any other AI tool that accepts text input. You can copy the full output to your clipboard or download it as a .txt file.
Extracted by GitExtract — free GitHub repo to text converter for AI. Built by Nikandr Surkov.