Repository: ben-hayes/neural-waveshaping-synthesis
Branch: main
Commit: cb7aaea0412c
Files: 46
Total size: 71.9 KB
Directory structure:
gitextract_i3m08itl/
├── .gitignore
├── LICENSE
├── README.md
├── checkpoints/
│ └── nws/
│ ├── fl/
│ │ ├── data_mean.npy
│ │ ├── data_std.npy
│ │ ├── epoch=4992-step=119831.ckpt
│ │ └── last.ckpt
│ ├── tpt/
│ │ ├── data_mean.npy
│ │ ├── data_std.npy
│ │ ├── epoch=358-step=24052.ckpt
│ │ └── last.ckpt
│ └── vn/
│ ├── data_mean.npy
│ ├── data_std.npy
│ ├── epoch=526-step=102237.ckpt
│ └── last.ckpt
├── gin/
│ ├── data/
│ │ └── urmp_4second_crepe.gin
│ ├── models/
│ │ └── newt.gin
│ └── train/
│ └── train_newt.gin
├── neural_waveshaping_synthesis/
│ ├── __init__.py
│ ├── data/
│ │ ├── __init__.py
│ │ ├── general.py
│ │ ├── urmp.py
│ │ └── utils/
│ │ ├── __init__.py
│ │ ├── create_dataset.py
│ │ ├── f0_extraction.py
│ │ ├── loudness_extraction.py
│ │ ├── mfcc_extraction.py
│ │ ├── preprocess_audio.py
│ │ └── upsampling.py
│ ├── models/
│ │ ├── __init__.py
│ │ ├── modules/
│ │ │ ├── __init__.py
│ │ │ ├── dynamic.py
│ │ │ ├── generators.py
│ │ │ └── shaping.py
│ │ └── neural_waveshaping.py
│ └── utils/
│ ├── __init__.py
│ ├── seed_all.py
│ └── utils.py
├── requirements.txt
├── scripts/
│ ├── create_dataset.py
│ ├── create_urmp_dataset.py
│ ├── resynthesise_dataset.py
│ ├── time_buffer_sizes.py
│ ├── time_forward_pass.py
│ └── train.py
└── setup.py
================================================
FILE CONTENTS
================================================
================================================
FILE: .gitignore
================================================
# Created by https://www.toptal.com/developers/gitignore/api/python,jupyternotebooks,vscode
# Edit at https://www.toptal.com/developers/gitignore?templates=python,jupyternotebooks,vscode
### JupyterNotebooks ###
# gitignore template for Jupyter Notebooks
# website: http://jupyter.org/
.ipynb_checkpoints
*/.ipynb_checkpoints/*
# IPython
profile_default/
ipython_config.py
# Remove previous ipynb_checkpoints
# git rm -r .ipynb_checkpoints/
### Python ###
# Byte-compiled / optimized / DLL files
__pycache__/
*.py[cod]
*$py.class
# C extensions
*.so
# Distribution / packaging
.Python
build/
develop-eggs/
dist/
downloads/
eggs/
.eggs/
lib/
lib64/
parts/
sdist/
var/
wheels/
pip-wheel-metadata/
share/python-wheels/
*.egg-info/
.installed.cfg
*.egg
MANIFEST
# PyInstaller
# Usually these files are written by a python script from a template
# before PyInstaller builds the exe, so as to inject date/other infos into it.
*.manifest
*.spec
# Installer logs
pip-log.txt
pip-delete-this-directory.txt
# Unit test / coverage reports
htmlcov/
.tox/
.nox/
.coverage
.coverage.*
.cache
nosetests.xml
coverage.xml
*.cover
*.py,cover
.hypothesis/
.pytest_cache/
pytestdebug.log
# Translations
*.mo
*.pot
# Django stuff:
*.log
local_settings.py
db.sqlite3
db.sqlite3-journal
# Flask stuff:
instance/
.webassets-cache
# Scrapy stuff:
.scrapy
# Sphinx documentation
docs/_build/
doc/_build/
# PyBuilder
target/
# Jupyter Notebook
# IPython
# pyenv
.python-version
# pipenv
# According to pypa/pipenv#598, it is recommended to include Pipfile.lock in version control.
# However, in case of collaboration, if having platform-specific dependencies or dependencies
# having no cross-platform support, pipenv may install dependencies that don't work, or not
# install all needed dependencies.
#Pipfile.lock
# PEP 582; used by e.g. github.com/David-OConnor/pyflow
__pypackages__/
# Celery stuff
celerybeat-schedule
celerybeat.pid
# SageMath parsed files
*.sage.py
# Environments
.env
.venv
env/
venv/
ENV/
env.bak/
venv.bak/
pythonenv*
# Spyder project settings
.spyderproject
.spyproject
# Rope project settings
.ropeproject
# mkdocs documentation
/site
# mypy
.mypy_cache/
.dmypy.json
dmypy.json
# Pyre type checker
.pyre/
# pytype static type analyzer
.pytype/
# profiling data
.prof
### vscode ###
.vscode/*
# End of https://www.toptal.com/developers/gitignore/api/python,jupyternotebooks,vscode
.DS_Store
test_audio
wandb
wandb/*
lightning_logs
lightning_logs/*
*.ipynb
*.wav
neural-timbre-shaping
*.webm
================================================
FILE: LICENSE
================================================
Mozilla Public License Version 2.0
==================================
1. Definitions
--------------
1.1. "Contributor"
means each individual or legal entity that creates, contributes to
the creation of, or owns Covered Software.
1.2. "Contributor Version"
means the combination of the Contributions of others (if any) used
by a Contributor and that particular Contributor's Contribution.
1.3. "Contribution"
means Covered Software of a particular Contributor.
1.4. "Covered Software"
means Source Code Form to which the initial Contributor has attached
the notice in Exhibit A, the Executable Form of such Source Code
Form, and Modifications of such Source Code Form, in each case
including portions thereof.
1.5. "Incompatible With Secondary Licenses"
means
(a) that the initial Contributor has attached the notice described
in Exhibit B to the Covered Software; or
(b) that the Covered Software was made available under the terms of
version 1.1 or earlier of the License, but not also under the
terms of a Secondary License.
1.6. "Executable Form"
means any form of the work other than Source Code Form.
1.7. "Larger Work"
means a work that combines Covered Software with other material, in
a separate file or files, that is not Covered Software.
1.8. "License"
means this document.
1.9. "Licensable"
means having the right to grant, to the maximum extent possible,
whether at the time of the initial grant or subsequently, any and
all of the rights conveyed by this License.
1.10. "Modifications"
means any of the following:
(a) any file in Source Code Form that results from an addition to,
deletion from, or modification of the contents of Covered
Software; or
(b) any new file in Source Code Form that contains any Covered
Software.
1.11. "Patent Claims" of a Contributor
means any patent claim(s), including without limitation, method,
process, and apparatus claims, in any patent Licensable by such
Contributor that would be infringed, but for the grant of the
License, by the making, using, selling, offering for sale, having
made, import, or transfer of either its Contributions or its
Contributor Version.
1.12. "Secondary License"
means either the GNU General Public License, Version 2.0, the GNU
Lesser General Public License, Version 2.1, the GNU Affero General
Public License, Version 3.0, or any later versions of those
licenses.
1.13. "Source Code Form"
means the form of the work preferred for making modifications.
1.14. "You" (or "Your")
means an individual or a legal entity exercising rights under this
License. For legal entities, "You" includes any entity that
controls, is controlled by, or is under common control with You. For
purposes of this definition, "control" means (a) the power, direct
or indirect, to cause the direction or management of such entity,
whether by contract or otherwise, or (b) ownership of more than
fifty percent (50%) of the outstanding shares or beneficial
ownership of such entity.
2. License Grants and Conditions
--------------------------------
2.1. Grants
Each Contributor hereby grants You a world-wide, royalty-free,
non-exclusive license:
(a) under intellectual property rights (other than patent or trademark)
Licensable by such Contributor to use, reproduce, make available,
modify, display, perform, distribute, and otherwise exploit its
Contributions, either on an unmodified basis, with Modifications, or
as part of a Larger Work; and
(b) under Patent Claims of such Contributor to make, use, sell, offer
for sale, have made, import, and otherwise transfer either its
Contributions or its Contributor Version.
2.2. Effective Date
The licenses granted in Section 2.1 with respect to any Contribution
become effective for each Contribution on the date the Contributor first
distributes such Contribution.
2.3. Limitations on Grant Scope
The licenses granted in this Section 2 are the only rights granted under
this License. No additional rights or licenses will be implied from the
distribution or licensing of Covered Software under this License.
Notwithstanding Section 2.1(b) above, no patent license is granted by a
Contributor:
(a) for any code that a Contributor has removed from Covered Software;
or
(b) for infringements caused by: (i) Your and any other third party's
modifications of Covered Software, or (ii) the combination of its
Contributions with other software (except as part of its Contributor
Version); or
(c) under Patent Claims infringed by Covered Software in the absence of
its Contributions.
This License does not grant any rights in the trademarks, service marks,
or logos of any Contributor (except as may be necessary to comply with
the notice requirements in Section 3.4).
2.4. Subsequent Licenses
No Contributor makes additional grants as a result of Your choice to
distribute the Covered Software under a subsequent version of this
License (see Section 10.2) or under the terms of a Secondary License (if
permitted under the terms of Section 3.3).
2.5. Representation
Each Contributor represents that the Contributor believes its
Contributions are its original creation(s) or it has sufficient rights
to grant the rights to its Contributions conveyed by this License.
2.6. Fair Use
This License is not intended to limit any rights You have under
applicable copyright doctrines of fair use, fair dealing, or other
equivalents.
2.7. Conditions
Sections 3.1, 3.2, 3.3, and 3.4 are conditions of the licenses granted
in Section 2.1.
3. Responsibilities
-------------------
3.1. Distribution of Source Form
All distribution of Covered Software in Source Code Form, including any
Modifications that You create or to which You contribute, must be under
the terms of this License. You must inform recipients that the Source
Code Form of the Covered Software is governed by the terms of this
License, and how they can obtain a copy of this License. You may not
attempt to alter or restrict the recipients' rights in the Source Code
Form.
3.2. Distribution of Executable Form
If You distribute Covered Software in Executable Form then:
(a) such Covered Software must also be made available in Source Code
Form, as described in Section 3.1, and You must inform recipients of
the Executable Form how they can obtain a copy of such Source Code
Form by reasonable means in a timely manner, at a charge no more
than the cost of distribution to the recipient; and
(b) You may distribute such Executable Form under the terms of this
License, or sublicense it under different terms, provided that the
license for the Executable Form does not attempt to limit or alter
the recipients' rights in the Source Code Form under this License.
3.3. Distribution of a Larger Work
You may create and distribute a Larger Work under terms of Your choice,
provided that You also comply with the requirements of this License for
the Covered Software. If the Larger Work is a combination of Covered
Software with a work governed by one or more Secondary Licenses, and the
Covered Software is not Incompatible With Secondary Licenses, this
License permits You to additionally distribute such Covered Software
under the terms of such Secondary License(s), so that the recipient of
the Larger Work may, at their option, further distribute the Covered
Software under the terms of either this License or such Secondary
License(s).
3.4. Notices
You may not remove or alter the substance of any license notices
(including copyright notices, patent notices, disclaimers of warranty,
or limitations of liability) contained within the Source Code Form of
the Covered Software, except that You may alter any license notices to
the extent required to remedy known factual inaccuracies.
3.5. Application of Additional Terms
You may choose to offer, and to charge a fee for, warranty, support,
indemnity or liability obligations to one or more recipients of Covered
Software. However, You may do so only on Your own behalf, and not on
behalf of any Contributor. You must make it absolutely clear that any
such warranty, support, indemnity, or liability obligation is offered by
You alone, and You hereby agree to indemnify every Contributor for any
liability incurred by such Contributor as a result of warranty, support,
indemnity or liability terms You offer. You may include additional
disclaimers of warranty and limitations of liability specific to any
jurisdiction.
4. Inability to Comply Due to Statute or Regulation
---------------------------------------------------
If it is impossible for You to comply with any of the terms of this
License with respect to some or all of the Covered Software due to
statute, judicial order, or regulation then You must: (a) comply with
the terms of this License to the maximum extent possible; and (b)
describe the limitations and the code they affect. Such description must
be placed in a text file included with all distributions of the Covered
Software under this License. Except to the extent prohibited by statute
or regulation, such description must be sufficiently detailed for a
recipient of ordinary skill to be able to understand it.
5. Termination
--------------
5.1. The rights granted under this License will terminate automatically
if You fail to comply with any of its terms. However, if You become
compliant, then the rights granted under this License from a particular
Contributor are reinstated (a) provisionally, unless and until such
Contributor explicitly and finally terminates Your grants, and (b) on an
ongoing basis, if such Contributor fails to notify You of the
non-compliance by some reasonable means prior to 60 days after You have
come back into compliance. Moreover, Your grants from a particular
Contributor are reinstated on an ongoing basis if such Contributor
notifies You of the non-compliance by some reasonable means, this is the
first time You have received notice of non-compliance with this License
from such Contributor, and You become compliant prior to 30 days after
Your receipt of the notice.
5.2. If You initiate litigation against any entity by asserting a patent
infringement claim (excluding declaratory judgment actions,
counter-claims, and cross-claims) alleging that a Contributor Version
directly or indirectly infringes any patent, then the rights granted to
You by any and all Contributors for the Covered Software under Section
2.1 of this License shall terminate.
5.3. In the event of termination under Sections 5.1 or 5.2 above, all
end user license agreements (excluding distributors and resellers) which
have been validly granted by You or Your distributors under this License
prior to termination shall survive termination.
************************************************************************
* *
* 6. Disclaimer of Warranty *
* ------------------------- *
* *
* Covered Software is provided under this License on an "as is" *
* basis, without warranty of any kind, either expressed, implied, or *
* statutory, including, without limitation, warranties that the *
* Covered Software is free of defects, merchantable, fit for a *
* particular purpose or non-infringing. The entire risk as to the *
* quality and performance of the Covered Software is with You. *
* Should any Covered Software prove defective in any respect, You *
* (not any Contributor) assume the cost of any necessary servicing, *
* repair, or correction. This disclaimer of warranty constitutes an *
* essential part of this License. No use of any Covered Software is *
* authorized under this License except under this disclaimer. *
* *
************************************************************************
************************************************************************
* *
* 7. Limitation of Liability *
* -------------------------- *
* *
* Under no circumstances and under no legal theory, whether tort *
* (including negligence), contract, or otherwise, shall any *
* Contributor, or anyone who distributes Covered Software as *
* permitted above, be liable to You for any direct, indirect, *
* special, incidental, or consequential damages of any character *
* including, without limitation, damages for lost profits, loss of *
* goodwill, work stoppage, computer failure or malfunction, or any *
* and all other commercial damages or losses, even if such party *
* shall have been informed of the possibility of such damages. This *
* limitation of liability shall not apply to liability for death or *
* personal injury resulting from such party's negligence to the *
* extent applicable law prohibits such limitation. Some *
* jurisdictions do not allow the exclusion or limitation of *
* incidental or consequential damages, so this exclusion and *
* limitation may not apply to You. *
* *
************************************************************************
8. Litigation
-------------
Any litigation relating to this License may be brought only in the
courts of a jurisdiction where the defendant maintains its principal
place of business and such litigation shall be governed by laws of that
jurisdiction, without reference to its conflict-of-law provisions.
Nothing in this Section shall prevent a party's ability to bring
cross-claims or counter-claims.
9. Miscellaneous
----------------
This License represents the complete agreement concerning the subject
matter hereof. If any provision of this License is held to be
unenforceable, such provision shall be reformed only to the extent
necessary to make it enforceable. Any law or regulation which provides
that the language of a contract shall be construed against the drafter
shall not be used to construe this License against a Contributor.
10. Versions of the License
---------------------------
10.1. New Versions
Mozilla Foundation is the license steward. Except as provided in Section
10.3, no one other than the license steward has the right to modify or
publish new versions of this License. Each version will be given a
distinguishing version number.
10.2. Effect of New Versions
You may distribute the Covered Software under the terms of the version
of the License under which You originally received the Covered Software,
or under the terms of any subsequent version published by the license
steward.
10.3. Modified Versions
If you create software not governed by this License, and you want to
create a new license for such software, you may create and use a
modified version of this License if you rename the license and remove
any references to the name of the license steward (except to note that
such modified license differs from this License).
10.4. Distributing Source Code Form that is Incompatible With Secondary
Licenses
If You choose to distribute Source Code Form that is Incompatible With
Secondary Licenses under the terms of this version of the License, the
notice described in Exhibit B of this License must be attached.
Exhibit A - Source Code Form License Notice
-------------------------------------------
This Source Code Form is subject to the terms of the Mozilla Public
License, v. 2.0. If a copy of the MPL was not distributed with this
file, You can obtain one at http://mozilla.org/MPL/2.0/.
If it is not possible or desirable to put the notice in a particular
file, then You may include the notice in a location (such as a LICENSE
file in a relevant directory) where a recipient would be likely to look
for such a notice.
You may add additional accurate notices of copyright ownership.
Exhibit B - "Incompatible With Secondary Licenses" Notice
---------------------------------------------------------
This Source Code Form is "Incompatible With Secondary Licenses", as
defined by the Mozilla Public License, v. 2.0.
================================================
FILE: README.md
================================================
neural waveshaping synthesis
real-time neural audio synthesis in the waveform domain
by Ben Hayes, Charalampos Saitis, György Fazekas
This repository is the official implementation of [Neural Waveshaping Synthesis](https://benhayes.net/projects/nws/).
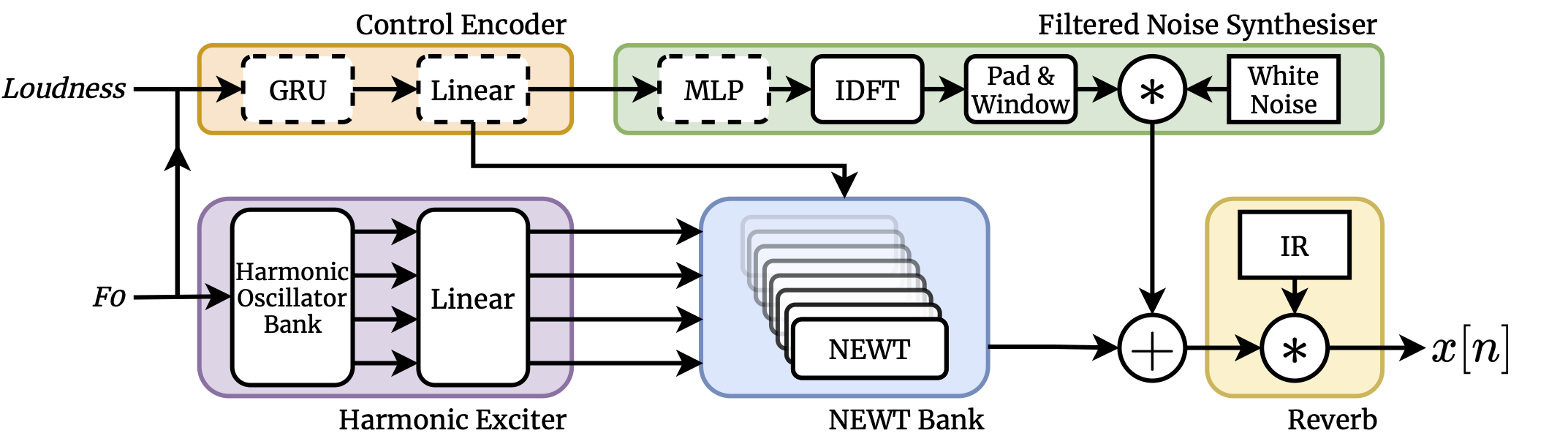
## Model Architecture
## Requirements
To install:
```setup
pip install -r requirements.txt
pip install -e .
```
We recommend installing in a virtual environment.
## Data
We trained our checkpoints on the [URMP](http://www2.ece.rochester.edu/projects/air/projects/URMP.html) dataset.
Once downloaded, the dataset can be preprocessed using `scripts/create_urmp_dataset.py`.
This will consolidate recordings of each instrument within the dataset and preprocess them according to the pipeline in the paper.
```bash
python scripts/create_urmp_dataset.py \
--gin-file gin/data/urmp_4second_crepe.gin \
--data-directory /path/to/urmp \
--output-directory /path/to/output \
--device cuda:0 # torch device string for CREPE model
```
Alternatively, you can supply your own dataset and use the general `create_dataset.py` script:
```bash
python scripts/create_dataset.py \
--gin-file gin/data/urmp_4second_crepe.gin \
--data-directory /path/to/dataset \
--output-directory /path/to/output \
--device cuda:0 # torch device string for CREPE model
```
## Training
To train a model on the URMP dataset, use this command:
```bash
python scripts/train.py \
--gin-file gin/train/train_newt.gin \
--dataset-path /path/to/processed/urmp \
--urmp \
--instrument vn \ # select URMP instrument with abbreviated string
--load-data-to-memory
```
Or to use a non-URMP dataset:
```bash
python scripts/train.py \
--gin-file gin/train/train_newt.gin \
--dataset-path /path/to/processed/data \
--load-data-to-memory
```
================================================
FILE: gin/data/urmp_4second_crepe.gin
================================================
sample_rate = 16000
interpolation = None
control_hop = 128
extract_f0_with_crepe.sample_rate = %sample_rate
extract_f0_with_crepe.device = %device
extract_f0_with_crepe.full_model = True
extract_f0_with_crepe.interpolate_fn = %interpolation
extract_f0_with_crepe.hop_length = %control_hop
extract_perceptual_loudness.sample_rate = %sample_rate
extract_perceptual_loudness.interpolate_fn = %interpolation
extract_perceptual_loudness.n_fft = 1024
extract_perceptual_loudness.hop_length = %control_hop
extract_mfcc.sample_rate = %sample_rate
extract_mfcc.n_fft = 1024
extract_mfcc.hop_length = 128
extract_mfcc.n_mfcc = 16
preprocess_audio.target_sr = %sample_rate
preprocess_audio.f0_extractor = @extract_f0_with_crepe
preprocess_audio.loudness_extractor = @extract_perceptual_loudness
preprocess_audio.segment_length_in_seconds = 4
preprocess_audio.hop_length_in_seconds = 4
preprocess_audio.normalise_audio = True
preprocess_audio.control_decimation_factor = %control_hop
================================================
FILE: gin/models/newt.gin
================================================
sample_rate = 16000
control_embedding_size = 128
n_waveshapers = 64
control_hop = 128
HarmonicOscillator.n_harmonics = 101
HarmonicOscillator.sample_rate = %sample_rate
NEWT.n_waveshapers = %n_waveshapers
NEWT.control_embedding_size = %control_embedding_size
NEWT.shaping_fn_size = 8
NEWT.out_channels = 1
TrainableNonlinearity.depth = 4
ControlModule.control_size = 2
ControlModule.hidden_size = 128
ControlModule.embedding_size = %control_embedding_size
noise_synth/TimeDistributedMLP.in_size = %control_embedding_size
noise_synth/TimeDistributedMLP.hidden_size = %control_embedding_size
noise_synth/TimeDistributedMLP.out_size = 129
noise_synth/TimeDistributedMLP.depth = 4
noise_synth/FIRNoiseSynth.ir_length = 256
noise_synth/FIRNoiseSynth.hop_length = %control_hop
Reverb.length_in_seconds = 2
Reverb.sr = %sample_rate
NeuralWaveshaping.n_waveshapers = %n_waveshapers
NeuralWaveshaping.control_hop = %control_hop
NeuralWaveshaping.sample_rate = %sample_rate
================================================
FILE: gin/train/train_newt.gin
================================================
get_model.model = @NeuralWaveshaping
include 'gin/models/newt.gin'
URMPDataModule.batch_size = 8
NeuralWaveshaping.learning_rate = 0.001
NeuralWaveshaping.lr_decay = 0.9
NeuralWaveshaping.lr_decay_interval = 10000
trainer_kwargs.max_steps = 120000
trainer_kwargs.gradient_clip_val = 2.0
trainer_kwargs.accelerator = 'dp'
================================================
FILE: neural_waveshaping_synthesis/__init__.py
================================================
================================================
FILE: neural_waveshaping_synthesis/data/__init__.py
================================================
================================================
FILE: neural_waveshaping_synthesis/data/general.py
================================================
import os
import gin
import numpy as np
import pytorch_lightning as pl
import torch
class GeneralDataset(torch.utils.data.Dataset):
def __init__(self, path: str, split: str = "train", load_to_memory: bool = True):
super().__init__()
# split = "train"
self.load_to_memory = load_to_memory
self.split_path = os.path.join(path, split)
self.data_list = [
f.replace("audio_", "")
for f in os.listdir(os.path.join(self.split_path, "audio"))
if f[-4:] == ".npy"
]
if load_to_memory:
self.audio = [
np.load(os.path.join(self.split_path, "audio", "audio_%s" % name))
for name in self.data_list
]
self.control = [
np.load(os.path.join(self.split_path, "control", "control_%s" % name))
for name in self.data_list
]
self.data_mean = np.load(os.path.join(path, "data_mean.npy"))
self.data_std = np.load(os.path.join(path, "data_std.npy"))
def __len__(self):
return len(self.data_list)
def __getitem__(self, idx):
# idx = 10
name = self.data_list[idx]
if self.load_to_memory:
audio = self.audio[idx]
control = self.control[idx]
else:
audio_name = "audio_%s" % name
control_name = "control_%s" % name
audio = np.load(os.path.join(self.split_path, "audio", audio_name))
control = np.load(os.path.join(self.split_path, "control", control_name))
denormalised_control = (control * self.data_std) + self.data_mean
return {
"audio": audio,
"f0": denormalised_control[0:1, :],
"amp": denormalised_control[1:2, :],
"control": control,
"name": os.path.splitext(os.path.basename(name))[0],
}
@gin.configurable
class GeneralDataModule(pl.LightningDataModule):
def __init__(
self,
data_root: str,
batch_size: int = 16,
load_to_memory: bool = True,
**dataloader_args
):
super().__init__()
self.data_dir = data_root
self.batch_size = batch_size
self.dataloader_args = dataloader_args
self.load_to_memory = load_to_memory
def prepare_data(self):
pass
def setup(self, stage: str = None):
if stage == "fit":
self.urmp_train = GeneralDataset(self.data_dir, "train", self.load_to_memory)
self.urmp_val = GeneralDataset(self.data_dir, "val", self.load_to_memory)
elif stage == "test" or stage is None:
self.urmp_test = GeneralDataset(self.data_dir, "test", self.load_to_memory)
def _make_dataloader(self, dataset):
return torch.utils.data.DataLoader(
dataset, self.batch_size, **self.dataloader_args
)
def train_dataloader(self):
return self._make_dataloader(self.urmp_train)
def val_dataloader(self):
return self._make_dataloader(self.urmp_val)
def test_dataloader(self):
return self._make_dataloader(self.urmp_test)
================================================
FILE: neural_waveshaping_synthesis/data/urmp.py
================================================
import os
import gin
from .general import GeneralDataModule
@gin.configurable
class URMPDataModule(GeneralDataModule):
def __init__(
self,
urmp_root: str,
instrument: str,
batch_size: int = 16,
load_to_memory: bool = True,
**dataloader_args
):
super().__init__(
os.path.join(urmp_root, instrument),
batch_size,
load_to_memory,
**dataloader_args
)
================================================
FILE: neural_waveshaping_synthesis/data/utils/__init__.py
================================================
================================================
FILE: neural_waveshaping_synthesis/data/utils/create_dataset.py
================================================
import os
import shutil
from typing import Sequence
import gin
import numpy as np
from sklearn.model_selection import train_test_split
from .preprocess_audio import preprocess_audio
from ...utils import seed_all
def create_directory(path):
if not os.path.isdir(path):
try:
os.mkdir(path)
except OSError:
print("Failed to create directory %s" % path)
else:
print("Created directory %s..." % path)
else:
print("Directory %s already exists. Skipping..." % path)
def create_directories(target_root, names):
create_directory(target_root)
for name in names:
create_directory(os.path.join(target_root, name))
def make_splits(
audio_list: Sequence[str],
control_list: Sequence[str],
splits: Sequence[str],
split_proportions: Sequence[float],
):
assert len(splits) == len(
split_proportions
), "Length of splits and split_proportions must be equal"
train_size = split_proportions[0] / np.sum(split_proportions)
audio_0, audio_1, control_0, control_1 = train_test_split(
audio_list, control_list, train_size=train_size
)
if len(splits) == 2:
return {
splits[0]: {
"audio": audio_0,
"control": control_0,
},
splits[1]: {
"audio": audio_1,
"control": control_1,
},
}
elif len(splits) > 2:
return {
splits[0]: {
"audio": audio_0,
"control": control_0,
},
**make_splits(audio_1, control_1, splits[1:], split_proportions[1:]),
}
elif len(splits) == 1:
return {
splits[0]: {
"audio": audio_list,
"control": control_list,
}
}
def lazy_create_dataset(
files: Sequence[str],
output_directory: str,
splits: Sequence[str],
split_proportions: Sequence[float],
):
audio_files = []
control_files = []
audio_max = 1e-5
means = []
stds = []
lengths = []
control_mean = 0
control_std = 1
for i, (all_audio, all_f0, all_confidence, all_loudness, all_mfcc) in enumerate(
preprocess_audio(files)
):
file = os.path.split(files[i])[-1].replace(".wav", "")
for j, (audio, f0, confidence, loudness, mfcc) in enumerate(
zip(all_audio, all_f0, all_confidence, all_loudness, all_mfcc)
):
audio_file_name = "audio_%s_%d.npy" % (file, j)
control_file_name = "control_%s_%d.npy" % (file, j)
max_sample = np.abs(audio).max()
if max_sample > audio_max:
audio_max = max_sample
np.save(
os.path.join(output_directory, "temp", "audio", audio_file_name),
audio,
)
control = np.stack((f0, loudness, confidence), axis=0)
control = np.concatenate((control, mfcc), axis=0)
np.save(
os.path.join(output_directory, "temp", "control", control_file_name),
control,
)
audio_files.append(audio_file_name)
control_files.append(control_file_name)
means.append(control.mean(axis=-1))
stds.append(control.std(axis=-1))
lengths.append(control.shape[-1])
if len(audio_files) == 0:
print("No datapoints to split. Skipping...")
return
data_mean = np.mean(np.stack(means, axis=-1), axis=-1)[:, np.newaxis]
lengths = np.stack(lengths)[np.newaxis, :]
stds = np.stack(stds, axis=-1)
data_std = np.sqrt(np.sum(lengths * stds ** 2, axis=-1) / np.sum(lengths))[
:, np.newaxis
]
print("Saving dataset stats...")
np.save(os.path.join(output_directory, "data_mean.npy"), data_mean)
np.save(os.path.join(output_directory, "data_std.npy"), data_std)
splits = make_splits(audio_files, control_files, splits, split_proportions)
for split in splits:
for audio_file in splits[split]["audio"]:
audio = np.load(os.path.join(output_directory, "temp", "audio", audio_file))
audio = audio / audio_max
np.save(os.path.join(output_directory, split, "audio", audio_file), audio)
for control_file in splits[split]["control"]:
control = np.load(
os.path.join(output_directory, "temp", "control", control_file)
)
control = (control - data_mean) / data_std
np.save(
os.path.join(output_directory, split, "control", control_file), control
)
@gin.configurable
def create_dataset(
files: Sequence[str],
output_directory: str,
splits: Sequence[str] = ("train", "val", "test"),
split_proportions: Sequence[float] = (0.8, 0.1, 0.1),
lazy: bool = True,
):
create_directories(output_directory, (*splits, "temp"))
for split in (*splits, "temp"):
create_directories(os.path.join(output_directory, split), ("audio", "control"))
if lazy:
lazy_create_dataset(files, output_directory, splits, split_proportions)
shutil.rmtree(os.path.join(output_directory, "temp"))
================================================
FILE: neural_waveshaping_synthesis/data/utils/f0_extraction.py
================================================
from functools import partial
from typing import Callable, Optional, Sequence, Union
import gin
import librosa
import numpy as np
import torch
import torchcrepe
from .upsampling import linear_interpolation
from ...utils import apply
CREPE_WINDOW_LENGTH = 1024
@gin.configurable
def extract_f0_with_crepe(
audio: np.ndarray,
sample_rate: float,
hop_length: int = 128,
minimum_frequency: float = 50.0,
maximum_frequency: float = 2000.0,
full_model: bool = True,
batch_size: int = 2048,
device: Union[str, torch.device] = "cpu",
interpolate_fn: Optional[Callable] = linear_interpolation,
):
# convert to torch tensor with channel dimension (necessary for CREPE)
audio = torch.tensor(audio).unsqueeze(0)
f0, confidence = torchcrepe.predict(
audio,
sample_rate,
hop_length,
minimum_frequency,
maximum_frequency,
"full" if full_model else "tiny",
batch_size=batch_size,
device=device,
decoder=torchcrepe.decode.viterbi,
# decoder=torchcrepe.decode.weighted_argmax,
return_harmonicity=True,
)
f0, confidence = f0.squeeze().numpy(), confidence.squeeze().numpy()
if interpolate_fn:
f0 = interpolate_fn(
f0, CREPE_WINDOW_LENGTH, hop_length, original_length=audio.shape[-1]
)
confidence = interpolate_fn(
confidence,
CREPE_WINDOW_LENGTH,
hop_length,
original_length=audio.shape[-1],
)
return f0, confidence
@gin.configurable
def extract_f0_with_pyin(
audio: np.ndarray,
sample_rate: float,
minimum_frequency: float = 65.0, # recommended minimum freq from librosa docs
maximum_frequency: float = 2093.0, # recommended maximum freq from librosa docs
frame_length: int = 1024,
hop_length: int = 128,
fill_na: Optional[float] = None,
interpolate_fn: Optional[Callable] = linear_interpolation,
):
f0, _, voiced_prob = librosa.pyin(
audio,
sr=sample_rate,
fmin=minimum_frequency,
fmax=maximum_frequency,
frame_length=frame_length,
hop_length=hop_length,
fill_na=fill_na,
)
if interpolate_fn:
f0 = interpolate_fn(
f0, frame_length, hop_length, original_length=audio.shape[-1]
)
voiced_prob = interpolate_fn(
voiced_prob,
frame_length,
hop_length,
original_length=audio.shape[-1],
)
return f0, voiced_prob
================================================
FILE: neural_waveshaping_synthesis/data/utils/loudness_extraction.py
================================================
from typing import Callable, Optional
import warnings
import gin
import librosa
import numpy as np
from .upsampling import linear_interpolation
def compute_power_spectrogram(
audio: np.ndarray,
n_fft: int,
hop_length: int,
window: str,
epsilon: float,
):
spectrogram = librosa.stft(audio, n_fft=n_fft, hop_length=hop_length, window=window)
magnitude_spectrogram = np.abs(spectrogram)
power_spectrogram = librosa.amplitude_to_db(
magnitude_spectrogram, ref=np.max, amin=epsilon
)
return power_spectrogram
def perform_perceptual_weighting(
power_spectrogram_in_db: np.ndarray, sample_rate: float, n_fft: int
):
centre_frequencies = librosa.fft_frequencies(sample_rate, n_fft)
# We know that we will get a log(0) warning here due to the DC component -- we can
# safely ignore as it is clipped to the default min dB value of -80.0 dB
with warnings.catch_warnings():
warnings.simplefilter("ignore")
weights = librosa.A_weighting(centre_frequencies)
weights = np.expand_dims(weights, axis=1)
weighted_spectrogram = power_spectrogram_in_db # + weights
return weighted_spectrogram
@gin.configurable
def extract_perceptual_loudness(
audio: np.ndarray,
sample_rate: float = 16000,
n_fft: int = 2048,
hop_length: int = 512,
window: str = "hann",
epsilon: float = 1e-5,
interpolate_fn: Optional[Callable] = linear_interpolation,
normalise: bool = True,
):
power_spectrogram = compute_power_spectrogram(
audio, n_fft=n_fft, hop_length=hop_length, window=window, epsilon=epsilon
)
perceptually_weighted_spectrogram = perform_perceptual_weighting(
power_spectrogram, sample_rate=sample_rate, n_fft=n_fft
)
loudness = np.mean(perceptually_weighted_spectrogram, axis=0)
if interpolate_fn:
loudness = interpolate_fn(
loudness, n_fft, hop_length, original_length=audio.size
)
if normalise:
loudness = (loudness + 80) / 80
return loudness
@gin.configurable
def extract_rms(
audio: np.ndarray,
window_size: int = 2048,
hop_length: int = 512,
sample_rate: Optional[float] = 16000.0,
interpolate_fn: Optional[Callable] = linear_interpolation,
):
# pad audio to centre frames
padded_audio = np.pad(audio, (window_size // 2, window_size // 2))
frames = librosa.util.frame(padded_audio, window_size, hop_length)
squared = frames ** 2
mean = np.mean(squared, axis=0)
root = np.sqrt(mean)
if interpolate_fn:
assert sample_rate is not None, "Must provide sample rate if upsampling"
root = interpolate_fn(root, window_size, hop_length, original_length=audio.size)
return root
================================================
FILE: neural_waveshaping_synthesis/data/utils/mfcc_extraction.py
================================================
import gin
import librosa
import numpy as np
@gin.configurable
def extract_mfcc(
audio: np.ndarray, sample_rate: float, n_fft: int, hop_length: int, n_mfcc: int
):
mfcc = librosa.feature.mfcc(
audio, sr=sample_rate, n_mfcc=n_mfcc, n_fft=n_fft, hop_length=hop_length
)
return mfcc
================================================
FILE: neural_waveshaping_synthesis/data/utils/preprocess_audio.py
================================================
from functools import partial
from typing import Callable, Sequence, Union
import gin
import librosa
import numpy as np
import resampy
import scipy.io.wavfile as wavfile
from .f0_extraction import extract_f0_with_crepe, extract_f0_with_pyin
from .loudness_extraction import extract_perceptual_loudness, extract_rms
from .mfcc_extraction import extract_mfcc
from ...utils import apply, apply_unpack, unzip
def read_audio_files(files: list):
rates_and_audios = apply(wavfile.read, files)
return unzip(rates_and_audios)
def convert_to_float32_audio(audio: np.ndarray):
if audio.dtype == np.float32:
return audio
max_sample_value = np.iinfo(audio.dtype).max
floating_point_audio = audio / max_sample_value
return floating_point_audio.astype(np.float32)
def make_monophonic(audio: np.ndarray, strategy: str = "keep_left"):
# deal with non stereo array formats
if len(audio.shape) == 1:
return audio
elif len(audio.shape) != 2:
raise ValueError("Unknown audio array format.")
# deal with single audio channel
if audio.shape[0] == 1:
return audio[0]
elif audio.shape[1] == 1:
return audio[:, 0]
# deal with more than two channels
elif audio.shape[0] != 2 and audio.shape[1] != 2:
raise ValueError("Expected stereo input audio but got too many channels.")
# put channel first
if audio.shape[1] == 2:
audio = audio.T
# make stereo audio monophonic
if strategy == "keep_left":
return audio[0]
elif strategy == "keep_right":
return audio[1]
elif strategy == "sum":
return np.mean(audio, axis=0)
elif strategy == "diff":
return audio[0] - audio[1]
def normalise_signal(audio: np.ndarray, factor: float):
return audio / factor
def resample_audio(audio: np.ndarray, original_sr: float, target_sr: float):
return resampy.resample(audio, original_sr, target_sr)
def segment_signal(
signal: np.ndarray,
sample_rate: float,
segment_length_in_seconds: float,
hop_length_in_seconds: float,
):
segment_length_in_samples = int(sample_rate * segment_length_in_seconds)
hop_length_in_samples = int(sample_rate * hop_length_in_seconds)
segments = librosa.util.frame(
signal, segment_length_in_samples, hop_length_in_samples
)
return segments
def filter_segments(
threshold: float,
key_segments: np.ndarray,
segments: Sequence[np.ndarray],
):
mean_keys = key_segments.mean(axis=0)
mask = mean_keys > threshold
filtered_segments = apply(
lambda x: x[:, mask] if len(x.shape) == 2 else x[:, :, mask], segments
)
return filtered_segments
def preprocess_single_audio_file(
file: str,
control_decimation_factor: float,
target_sr: float = 16000.0,
segment_length_in_seconds: float = 4.0,
hop_length_in_seconds: float = 2.0,
confidence_threshold: float = 0.85,
f0_extractor: Callable = extract_f0_with_crepe,
loudness_extractor: Callable = extract_perceptual_loudness,
mfcc_extractor: Callable = extract_mfcc,
normalisation_factor: Union[float, None] = None,
):
print("Loading audio file: %s..." % file)
original_sr, audio = wavfile.read(file)
audio = convert_to_float32_audio(audio)
audio = make_monophonic(audio)
if normalisation_factor:
audio = normalise_signal(audio, normalisation_factor)
print("Resampling audio file: %s..." % file)
audio = resample_audio(audio, original_sr, target_sr)
print("Extracting f0 with extractor '%s': %s..." % (f0_extractor.__name__, file))
f0, confidence = f0_extractor(audio)
print(
"Extracting loudness with extractor '%s': %s..."
% (loudness_extractor.__name__, file)
)
loudness = loudness_extractor(audio)
print(
"Extracting MFCC with extractor '%s': %s..." % (mfcc_extractor.__name__, file)
)
mfcc = mfcc_extractor(audio)
print("Segmenting audio file: %s..." % file)
segmented_audio = segment_signal(
audio, target_sr, segment_length_in_seconds, hop_length_in_seconds
)
print("Segmenting control signals: %s..." % file)
segmented_f0 = segment_signal(
f0,
target_sr / (control_decimation_factor or 1),
segment_length_in_seconds,
hop_length_in_seconds,
)
segmented_confidence = segment_signal(
confidence,
target_sr / (control_decimation_factor or 1),
segment_length_in_seconds,
hop_length_in_seconds,
)
segmented_loudness = segment_signal(
loudness,
target_sr / (control_decimation_factor or 1),
segment_length_in_seconds,
hop_length_in_seconds,
)
segmented_mfcc = segment_signal(
mfcc,
target_sr / (control_decimation_factor or 1),
segment_length_in_seconds,
hop_length_in_seconds,
)
(
filtered_audio,
filtered_f0,
filtered_confidence,
filtered_loudness,
filtered_mfcc,
) = filter_segments(
confidence_threshold,
segmented_confidence,
(
segmented_audio,
segmented_f0,
segmented_confidence,
segmented_loudness,
segmented_mfcc,
),
)
if filtered_audio.shape[-1] == 0:
print("No segments exceeding confidence threshold...")
audio_split, f0_split, confidence_split, loudness_split, mfcc_split = (
[],
[],
[],
[],
[],
)
else:
split = lambda x: [e.squeeze() for e in np.split(x, x.shape[-1], -1)]
audio_split = split(filtered_audio)
f0_split = split(filtered_f0)
confidence_split = split(filtered_confidence)
loudness_split = split(filtered_loudness)
mfcc_split = split(filtered_mfcc)
return audio_split, f0_split, confidence_split, loudness_split, mfcc_split
@gin.configurable
def preprocess_audio(
files: list,
control_decimation_factor: float,
target_sr: float = 16000,
segment_length_in_seconds: float = 4.0,
hop_length_in_seconds: float = 2.0,
confidence_threshold: float = 0.85,
f0_extractor: Callable = extract_f0_with_crepe,
loudness_extractor: Callable = extract_perceptual_loudness,
normalise_audio: bool = False,
):
if normalise_audio:
print("Finding normalisation factor...")
normalisation_factor = 0
for file in files:
_, audio = wavfile.read(file)
audio = convert_to_float32_audio(audio)
audio = make_monophonic(audio)
max_value = np.abs(audio).max()
normalisation_factor = (
max_value if max_value > normalisation_factor else normalisation_factor
)
processor = partial(
preprocess_single_audio_file,
control_decimation_factor=control_decimation_factor,
target_sr=target_sr,
segment_length_in_seconds=segment_length_in_seconds,
hop_length_in_seconds=hop_length_in_seconds,
f0_extractor=f0_extractor,
loudness_extractor=loudness_extractor,
normalisation_factor=None if not normalise_audio else normalisation_factor,
)
for file in files:
yield processor(file)
================================================
FILE: neural_waveshaping_synthesis/data/utils/upsampling.py
================================================
from typing import Optional
import gin
import numpy as np
import scipy.interpolate
import scipy.signal.windows
def get_padded_length(frames: int, window_length: int, hop_length: int):
return frames * hop_length + window_length - hop_length
def get_source_target_axes(frames: int, window_length: int, hop_length: int):
padded_length = get_padded_length(frames, window_length, hop_length)
source_x = np.linspace(0, frames - 1, frames)
target_x = np.linspace(0, frames - 1, padded_length)
return source_x, target_x
@gin.configurable
def linear_interpolation(
signal: np.ndarray,
window_length: int,
hop_length: int,
original_length: Optional[int] = None,
):
source_x, target_x = get_source_target_axes(signal.size, window_length, hop_length)
interpolated = np.interp(target_x, source_x, signal)
if original_length:
interpolated = interpolated[window_length // 2 :]
interpolated = interpolated[:original_length]
return interpolated
@gin.configurable
def cubic_spline_interpolation(
signal: np.ndarray,
window_length: int,
hop_length: int,
original_length: Optional[int] = None,
):
source_x, target_x = get_source_target_axes(signal.size, window_length, hop_length)
interpolant = scipy.interpolate.interp1d(source_x, signal, kind="cubic")
interpolated = interpolant(target_x)
if original_length:
interpolated = interpolated[window_length // 2 :]
interpolated = interpolated[:original_length]
return interpolated
@gin.configurable
def overlap_add_upsample(
signal: np.ndarray,
window_length: int,
hop_length: int,
window_fn: str = "hann",
window_scale: int = 2,
original_length: Optional[int] = None,
):
window = scipy.signal.windows.get_window(window_fn, hop_length * window_scale)
padded_length = get_padded_length(signal.size, window_length, hop_length)
padded_output = np.zeros(padded_length)
for i, value in enumerate(signal):
window_start = i * hop_length
window_end = window_start + hop_length * window_scale
padded_output[window_start:window_end] += window * value
if original_length:
output = padded_output[(padded_length - original_length) // 2:]
output = output[:original_length]
else:
output = padded_output
return output
================================================
FILE: neural_waveshaping_synthesis/models/__init__.py
================================================
================================================
FILE: neural_waveshaping_synthesis/models/modules/__init__.py
================================================
================================================
FILE: neural_waveshaping_synthesis/models/modules/dynamic.py
================================================
import gin
import torch.nn as nn
import torch.nn.functional as F
class FiLM(nn.Module):
def forward(self, x, gamma, beta):
return gamma * x + beta
class TimeDistributedLayerNorm(nn.Module):
def __init__(self, size: int):
super().__init__()
self.layer_norm = nn.LayerNorm(size)
def forward(self, x):
return self.layer_norm(x.transpose(1, 2)).transpose(1, 2)
@gin.configurable
class TimeDistributedMLP(nn.Module):
def __init__(self, in_size: int, hidden_size: int, out_size: int, depth: int = 3):
super().__init__()
assert depth >= 3, "Depth must be at least 3"
layers = []
for i in range(depth):
layers.append(
nn.Conv1d(
in_size if i == 0 else hidden_size,
hidden_size if i < depth - 1 else out_size,
1,
)
)
if i < depth - 1:
layers.append(TimeDistributedLayerNorm(hidden_size))
layers.append(nn.LeakyReLU())
self.net = nn.Sequential(*layers)
def forward(self, x):
return self.net(x)
================================================
FILE: neural_waveshaping_synthesis/models/modules/generators.py
================================================
import math
from typing import Callable
import gin
import torch
import torch.fft
import torch.nn as nn
import torch.nn.functional as F
@gin.configurable
class FIRNoiseSynth(nn.Module):
def __init__(
self, ir_length: int, hop_length: int, window_fn: Callable = torch.hann_window
):
super().__init__()
self.ir_length = ir_length
self.hop_length = hop_length
self.register_buffer("window", window_fn(ir_length))
def forward(self, H_re):
H_im = torch.zeros_like(H_re)
H_z = torch.complex(H_re, H_im)
h = torch.fft.irfft(H_z.transpose(1, 2))
h = h.roll(self.ir_length // 2, -1)
h = h * self.window.view(1, 1, -1)
H = torch.fft.rfft(h)
noise = torch.rand(self.hop_length * H_re.shape[-1] - 1, device=H_re.device)
X = torch.stft(noise, self.ir_length, self.hop_length, return_complex=True)
X = X.unsqueeze(0)
Y = X * H.transpose(1, 2)
y = torch.istft(Y, self.ir_length, self.hop_length, center=False)
return y.unsqueeze(1)[:, :, : H_re.shape[-1] * self.hop_length]
@gin.configurable
class HarmonicOscillator(nn.Module):
def __init__(self, n_harmonics, sample_rate):
super().__init__()
self.sample_rate = sample_rate
self.n_harmonics = n_harmonics
self.register_buffer("harmonic_axis", self._create_harmonic_axis(n_harmonics))
self.register_buffer("rand_phase", torch.ones(1, n_harmonics, 1) * math.tau)
def _create_harmonic_axis(self, n_harmonics):
return torch.arange(1, n_harmonics + 1).view(1, -1, 1)
def _create_antialias_mask(self, f0):
freqs = f0.unsqueeze(1) * self.harmonic_axis
return freqs < (self.sample_rate / 2)
def _create_phase_shift(self, n_harmonics):
shift = torch.rand_like(self.rand_phase) * self.rand_phase - math.pi
return shift
def forward(self, f0):
phase = math.tau * f0.cumsum(-1) / self.sample_rate
harmonic_phase = self.harmonic_axis * phase.unsqueeze(1)
harmonic_phase = harmonic_phase + self._create_phase_shift(self.n_harmonics)
antialias_mask = self._create_antialias_mask(f0)
output = torch.sin(harmonic_phase) * antialias_mask
return output
================================================
FILE: neural_waveshaping_synthesis/models/modules/shaping.py
================================================
import gin
import torch
import torch.fft
import torch.nn as nn
import torch.nn.functional as F
from .dynamic import FiLM, TimeDistributedMLP
class Sine(nn.Module):
def forward(self, x: torch.Tensor):
return torch.sin(x)
@gin.configurable
class TrainableNonlinearity(nn.Module):
def __init__(
self, channels, width, nonlinearity=nn.ReLU, final_nonlinearity=Sine, depth=3
):
super().__init__()
self.input_scale = nn.Parameter(torch.randn(1, channels, 1) * 10)
layers = []
for i in range(depth):
layers.append(
nn.Conv1d(
channels if i == 0 else channels * width,
channels * width if i < depth - 1 else channels,
1,
groups=channels,
)
)
layers.append(nonlinearity() if i < depth - 1 else final_nonlinearity())
self.net = nn.Sequential(*layers)
def forward(self, x):
return self.net(self.input_scale * x)
@gin.configurable
class NEWT(nn.Module):
def __init__(
self,
n_waveshapers: int,
control_embedding_size: int,
shaping_fn_size: int = 16,
out_channels: int = 1,
):
super().__init__()
self.n_waveshapers = n_waveshapers
self.mlp = TimeDistributedMLP(
control_embedding_size, control_embedding_size, n_waveshapers * 4, depth=4
)
self.waveshaping_index = FiLM()
self.shaping_fn = TrainableNonlinearity(
n_waveshapers, shaping_fn_size, nonlinearity=Sine
)
self.normalising_coeff = FiLM()
self.mixer = nn.Sequential(
nn.Conv1d(n_waveshapers, out_channels, 1),
)
def forward(self, exciter, control_embedding):
film_params = self.mlp(control_embedding)
film_params = F.upsample(film_params, exciter.shape[-1], mode="linear")
gamma_index, beta_index, gamma_norm, beta_norm = torch.split(
film_params, self.n_waveshapers, 1
)
x = self.waveshaping_index(exciter, gamma_index, beta_index)
x = self.shaping_fn(x)
x = self.normalising_coeff(x, gamma_norm, beta_norm)
# return x
return self.mixer(x)
class FastNEWT(NEWT):
def __init__(
self,
newt: NEWT,
table_size: int = 4096,
table_min: float = -3.0,
table_max: float = 3.0,
):
super().__init__()
self.table_size = table_size
self.table_min = table_min
self.table_max = table_max
self.n_waveshapers = newt.n_waveshapers
self.mlp = newt.mlp
self.waveshaping_index = newt.waveshaping_index
self.normalising_coeff = newt.normalising_coeff
self.mixer = newt.mixer
self.lookup_table = self._init_lookup_table(
newt, table_size, self.n_waveshapers, table_min, table_max
)
self.to(next(iter(newt.parameters())).device)
def _init_lookup_table(
self,
newt: NEWT,
table_size: int,
n_waveshapers: int,
table_min: float,
table_max: float,
):
sample_values = torch.linspace(table_min, table_max, table_size, device=next(iter(newt.parameters())).device).expand(
1, n_waveshapers, table_size
)
lookup_table = newt.shaping_fn(sample_values)[0]
return nn.Parameter(lookup_table)
def _lookup(self, idx):
return torch.stack(
[
torch.stack(
[
self.lookup_table[shaper, idx[batch, shaper]]
for shaper in range(idx.shape[1])
],
dim=0,
)
for batch in range(idx.shape[0])
],
dim=0,
)
def shaping_fn(self, x):
idx = self.table_size * (x - self.table_min) / (self.table_max - self.table_min)
lower = torch.floor(idx).long()
lower[lower < 0] = 0
lower[lower >= self.table_size] = self.table_size - 1
upper = lower + 1
upper[upper >= self.table_size] = self.table_size - 1
fract = idx - lower
lower_v = self._lookup(lower)
upper_v = self._lookup(upper)
output = (upper_v - lower_v) * fract + lower_v
return output
@gin.configurable
class Reverb(nn.Module):
def __init__(self, length_in_seconds, sr):
super().__init__()
self.ir = nn.Parameter(torch.randn(1, sr * length_in_seconds - 1) * 1e-6)
self.register_buffer("initial_zero", torch.zeros(1, 1))
def forward(self, x):
ir_ = torch.cat((self.initial_zero, self.ir), dim=-1)
if x.shape[-1] > ir_.shape[-1]:
ir_ = F.pad(ir_, (0, x.shape[-1] - ir_.shape[-1]))
x_ = x
else:
x_ = F.pad(x, (0, ir_.shape[-1] - x.shape[-1]))
return (
x
+ torch.fft.irfft(torch.fft.rfft(x_) * torch.fft.rfft(ir_))[
..., : x.shape[-1]
]
)
================================================
FILE: neural_waveshaping_synthesis/models/neural_waveshaping.py
================================================
import auraloss
import gin
import pytorch_lightning as pl
import torch
import torch.nn as nn
import torch.nn.functional as F
import wandb
from .modules.dynamic import TimeDistributedMLP
from .modules.generators import FIRNoiseSynth, HarmonicOscillator
from .modules.shaping import NEWT, Reverb
gin.external_configurable(nn.GRU, module="torch.nn")
gin.external_configurable(nn.Conv1d, module="torch.nn")
@gin.configurable
class ControlModule(nn.Module):
def __init__(self, control_size: int, hidden_size: int, embedding_size: int):
super().__init__()
self.gru = nn.GRU(control_size, hidden_size, batch_first=True)
self.proj = nn.Conv1d(hidden_size, embedding_size, 1)
def forward(self, x):
x, _ = self.gru(x.transpose(1, 2))
return self.proj(x.transpose(1, 2))
@gin.configurable
class NeuralWaveshaping(pl.LightningModule):
def __init__(
self,
n_waveshapers: int,
control_hop: int,
sample_rate: float = 16000,
learning_rate: float = 1e-3,
lr_decay: float = 0.9,
lr_decay_interval: int = 10000,
log_audio: bool = False,
):
super().__init__()
self.save_hyperparameters()
self.learning_rate = learning_rate
self.lr_decay = lr_decay
self.lr_decay_interval = lr_decay_interval
self.control_hop = control_hop
self.log_audio = log_audio
self.sample_rate = sample_rate
self.embedding = ControlModule()
self.osc = HarmonicOscillator()
self.harmonic_mixer = nn.Conv1d(self.osc.n_harmonics, n_waveshapers, 1)
self.newt = NEWT()
with gin.config_scope("noise_synth"):
self.h_generator = TimeDistributedMLP()
self.noise_synth = FIRNoiseSynth()
self.reverb = Reverb()
def render_exciter(self, f0):
sig = self.osc(f0[:, 0])
sig = self.harmonic_mixer(sig)
return sig
def get_embedding(self, control):
f0, other = control[:, 0:1], control[:, 1:2]
control = torch.cat((f0, other), dim=1)
return self.embedding(control)
def forward(self, f0, control):
f0_upsampled = F.upsample(f0, f0.shape[-1] * self.control_hop, mode="linear")
x = self.render_exciter(f0_upsampled)
control_embedding = self.get_embedding(control)
x = self.newt(x, control_embedding)
H = self.h_generator(control_embedding)
noise = self.noise_synth(H)
x = torch.cat((x, noise), dim=1)
x = x.sum(1)
x = self.reverb(x)
return x
def configure_optimizers(self):
self.stft_loss = auraloss.freq.MultiResolutionSTFTLoss()
optimizer = torch.optim.Adam(self.parameters(), lr=self.learning_rate)
scheduler = torch.optim.lr_scheduler.StepLR(
optimizer, self.lr_decay_interval, self.lr_decay
)
return {
"optimizer": optimizer,
"lr_scheduler": {"scheduler": scheduler, "interval": "step"},
}
def _run_step(self, batch):
audio = batch["audio"].float()
f0 = batch["f0"].float()
control = batch["control"].float()
recon = self(f0, control)
loss = self.stft_loss(recon, audio)
return loss, recon, audio
def _log_audio(self, name, audio):
wandb.log(
{
"audio/%s"
% name: wandb.Audio(audio, sample_rate=self.sample_rate, caption=name)
},
commit=False,
)
def training_step(self, batch, batch_idx):
loss, _, _ = self._run_step(batch)
self.log(
"train/loss",
loss.item(),
on_step=False,
on_epoch=True,
prog_bar=True,
logger=True,
sync_dist=True,
)
return loss
def validation_step(self, batch, batch_idx):
loss, recon, audio = self._run_step(batch)
self.log(
"val/loss",
loss.item(),
on_step=False,
on_epoch=True,
prog_bar=True,
logger=True,
sync_dist=True,
)
if batch_idx == 0 and self.log_audio:
self._log_audio("original", audio[0].detach().cpu().squeeze())
self._log_audio("recon", recon[0].detach().cpu().squeeze())
return loss
def test_step(self, batch, batch_idx):
loss, recon, audio = self._run_step(batch)
self.log(
"test/loss",
loss.item(),
on_step=False,
on_epoch=True,
prog_bar=True,
logger=True,
sync_dist=True,
)
if batch_idx == 0:
self._log_audio("original", audio[0].detach().cpu().squeeze())
self._log_audio("recon", recon[0].detach().cpu().squeeze())
================================================
FILE: neural_waveshaping_synthesis/utils/__init__.py
================================================
from .utils import *
from .seed_all import *
================================================
FILE: neural_waveshaping_synthesis/utils/seed_all.py
================================================
import numpy as np
import os
import random
import torch
def seed_all(seed):
np.random.seed(seed)
os.environ['PYTHONHASHSEED'] = str(seed)
random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
torch.backends.cudnn.deterministic = True
================================================
FILE: neural_waveshaping_synthesis/utils/utils.py
================================================
import os
from typing import Callable, Sequence
def apply(fn: Callable[[any], any], x: Sequence[any]):
if type(x) not in (tuple, list):
raise TypeError("x must be a tuple or list.")
return type(x)([fn(element) for element in x])
def apply_unpack(fn: Callable[[any], any], x: Sequence[Sequence[any]]):
if type(x) not in (tuple, list):
raise TypeError("x must be a tuple or list.")
return type(x)([fn(*element) for element in x])
def unzip(x: Sequence[any]):
return list(zip(*x))
def make_dir_if_not_exists(path):
if not os.path.exists(path):
os.makedirs(path, exist_ok=True)
================================================
FILE: requirements.txt
================================================
auraloss==0.2.1
black==20.8b1
click==7.1.2
gin-config==0.4.0
librosa==0.8.0
numpy==1.20.1
pytorch_lightning==1.1.2
resampy==0.2.2
scipy==1.6.1
torch==1.7.1
torchcrepe==0.0.12
================================================
FILE: scripts/create_dataset.py
================================================
import os
import click
import gin
from neural_waveshaping_synthesis.data.utils.create_dataset import create_dataset
from neural_waveshaping_synthesis.utils import seed_all
def get_filenames(directory):
return [os.path.join(directory, f) for f in os.listdir(directory) if ".wav" in f]
@click.command()
@click.option("--gin-file", prompt="Gin config file")
@click.option("--data-directory", prompt="Data directory")
@click.option("--output-directory", prompt="Output directory")
@click.option("--seed", default=0)
@click.option("--device", default="cpu")
def main(gin_file, data_directory, output_directory, seed=0, device="cpu"):
gin.constant("device", device)
gin.parse_config_file(gin_file)
seed_all(seed)
files = get_filenames(data_directory)
create_dataset(files, output_directory)
if __name__ == "__main__":
main()
================================================
FILE: scripts/create_urmp_dataset.py
================================================
import os
from pathlib import Path
import click
import gin
from neural_waveshaping_synthesis.data.utils.create_dataset import create_dataset
from neural_waveshaping_synthesis.utils import seed_all
INSTRUMENTS = (
"vn",
"vc",
"fl",
"cl",
"tpt",
"sax",
"tbn",
"ob",
"va",
"bn",
"hn",
"db",
)
def get_instrument_file_list(instrument_string, directory):
return [
str(f)
for f in Path(directory).glob(
"**/*_%s_*/AuSep*_%s_*.wav" % (instrument_string, instrument_string)
)
]
@click.command()
@click.option("--gin-file", prompt="Gin config file")
@click.option("--data-directory", prompt="Data directory")
@click.option("--output-directory", prompt="Output directory")
@click.option("--seed", default=0)
@click.option("--device", default="cpu")
def main(gin_file, data_directory, output_directory, seed=0, device="cpu"):
gin.constant("device", device)
gin.parse_config_file(gin_file)
seed_all(seed)
file_lists = {
instrument: get_instrument_file_list(instrument, data_directory)
for instrument in INSTRUMENTS
}
for instrument in file_lists:
create_dataset(
file_lists[instrument], os.path.join(output_directory, instrument)
)
if __name__ == "__main__":
main()
================================================
FILE: scripts/resynthesise_dataset.py
================================================
import os
import click
import gin
from scipy.io import wavfile
from tqdm import tqdm
import torch
from neural_waveshaping_synthesis.data.urmp import URMPDataset
from neural_waveshaping_synthesis.models.modules.shaping import FastNEWT
from neural_waveshaping_synthesis.models.neural_waveshaping import NeuralWaveshaping
from neural_waveshaping_synthesis.utils import make_dir_if_not_exists
@click.command()
@click.option("--model-gin", prompt="Model .gin file")
@click.option("--model-checkpoint", prompt="Model checkpoint")
@click.option("--dataset-root", prompt="Dataset root directory")
@click.option("--dataset-split", default="test")
@click.option("--output-path", default="audio_output")
@click.option("--load-data-to-memory", default=False)
@click.option("--device", default="cuda:0")
@click.option("--batch-size", default=8)
@click.option("--num_workers", default=16)
@click.option("--use-fastnewt", is_flag=True)
def main(
model_gin,
model_checkpoint,
dataset_root,
dataset_split,
output_path,
load_data_to_memory,
device,
batch_size,
num_workers,
use_fastnewt
):
gin.parse_config_file(model_gin)
make_dir_if_not_exists(output_path)
data = URMPDataset(dataset_root, dataset_split, load_data_to_memory)
data_loader = torch.utils.data.DataLoader(
data, batch_size=batch_size, num_workers=num_workers
)
device = torch.device(device)
model = NeuralWaveshaping.load_from_checkpoint(model_checkpoint)
model.eval()
if use_fastnewt:
model.newt = FastNEWT(model.newt)
model = model.to(device)
for i, batch in enumerate(tqdm(data_loader)):
with torch.no_grad():
f0 = batch["f0"].float().to(device)
control = batch["control"].float().to(device)
output = model(f0, control)
target_audio = batch["audio"].float().numpy()
output_audio = output.cpu().numpy()
for j in range(output_audio.shape[0]):
name = batch["name"][j]
target_name = "%s.target.wav" % name
output_name = "%s.output.wav" % name
wavfile.write(
os.path.join(output_path, target_name),
model.sample_rate,
target_audio[j],
)
wavfile.write(
os.path.join(output_path, output_name),
model.sample_rate,
output_audio[j],
)
if __name__ == "__main__":
main()
================================================
FILE: scripts/time_buffer_sizes.py
================================================
import time
import click
import gin
import numpy as np
import pandas as pd
import torch
from tqdm import trange
from neural_waveshaping_synthesis.models.neural_waveshaping import NeuralWaveshaping
from neural_waveshaping_synthesis.models.modules.shaping import FastNEWT
BUFFER_SIZES = [256, 512, 1024, 2048, 4096, 8192, 16384, 32768]
@click.command()
@click.option("--gin-file", prompt="Model config gin file")
@click.option("--output-file", prompt="output file")
@click.option("--num-iters", default=100)
@click.option("--batch-size", default=1)
@click.option("--device", default="cpu")
@click.option("--length-in-seconds", default=4)
@click.option("--use-fast-newt", is_flag=True)
@click.option("--model-name", default="ours")
def main(
gin_file,
output_file,
num_iters,
batch_size,
device,
length_in_seconds,
use_fast_newt,
model_name,
):
gin.parse_config_file(gin_file)
model = NeuralWaveshaping()
if use_fast_newt:
model.newt = FastNEWT(model.newt)
model.eval()
model = model.to(device)
# eliminate any lazy init costs
with torch.no_grad():
for i in range(10):
model(
torch.rand(4, 1, 250, device=device),
torch.rand(4, 2, 250, device=device),
)
times = []
with torch.no_grad():
for bs in BUFFER_SIZES:
dummy_control = torch.rand(
batch_size,
2,
bs // 128,
device=device,
requires_grad=False,
)
dummy_f0 = torch.rand(
batch_size,
1,
bs // 128,
device=device,
requires_grad=False,
)
for i in trange(num_iters):
start_time = time.time()
model(dummy_f0, dummy_control)
time_elapsed = time.time() - start_time
times.append(
[model_name, device if device == "cpu" else "gpu", bs, time_elapsed]
)
df = pd.DataFrame(times)
df.to_csv(output_file)
if __name__ == "__main__":
main()
================================================
FILE: scripts/time_forward_pass.py
================================================
import time
import click
import gin
import numpy as np
from scipy.stats import describe
import torch
from tqdm import trange
from neural_waveshaping_synthesis.models.neural_waveshaping import NeuralWaveshaping
from neural_waveshaping_synthesis.models.modules.shaping import FastNEWT
@click.command()
@click.option("--gin-file", prompt="Model config gin file")
@click.option("--num-iters", default=100)
@click.option("--batch-size", default=1)
@click.option("--device", default="cpu")
@click.option("--length-in-seconds", default=4)
@click.option("--sample-rate", default=16000)
@click.option("--control-hop", default=128)
@click.option("--use-fast-newt", is_flag=True)
def main(
gin_file, num_iters, batch_size, device, length_in_seconds, sample_rate, control_hop, use_fast_newt
):
gin.parse_config_file(gin_file)
dummy_control = torch.rand(
batch_size,
2,
sample_rate * length_in_seconds // control_hop,
device=device,
requires_grad=False,
)
dummy_f0 = torch.rand(
batch_size,
1,
sample_rate * length_in_seconds // control_hop,
device=device,
requires_grad=False,
)
model = NeuralWaveshaping()
if use_fast_newt:
model.newt = FastNEWT(model.newt)
model.eval()
model = model.to(device)
times = []
with torch.no_grad():
for i in trange(num_iters):
start_time = time.time()
model(dummy_f0, dummy_control)
time_elapsed = time.time() - start_time
times.append(time_elapsed)
print(describe(times))
rtfs = np.array(times) / length_in_seconds
print("Mean RTF: %.4f" % np.mean(rtfs))
print("90th percentile RTF: %.4f" % np.percentile(rtfs, 90))
if __name__ == "__main__":
main()
================================================
FILE: scripts/train.py
================================================
import click
import gin
import pytorch_lightning as pl
from neural_waveshaping_synthesis.data.general import GeneralDataModule
from neural_waveshaping_synthesis.data.urmp import URMPDataModule
from neural_waveshaping_synthesis.models.neural_waveshaping import NeuralWaveshaping
@gin.configurable
def get_model(model, with_wandb):
return model(log_audio=with_wandb)
@gin.configurable
def trainer_kwargs(**kwargs):
return kwargs
@click.command()
@click.option("--gin-file", prompt="Gin config file")
@click.option("--dataset-path", prompt="Dataset root")
@click.option("--urmp", is_flag=True)
@click.option("--device", default="0")
@click.option("--instrument", default="vn")
@click.option("--load-data-to-memory", is_flag=True)
@click.option("--with-wandb", is_flag=True)
@click.option("--restore-checkpoint", default="")
def main(
gin_file,
dataset_path,
urmp,
device,
instrument,
load_data_to_memory,
with_wandb,
restore_checkpoint,
):
gin.parse_config_file(gin_file)
model = get_model(with_wandb=with_wandb)
if urmp:
data = URMPDataModule(
dataset_path,
instrument,
load_to_memory=load_data_to_memory,
num_workers=16,
shuffle=True,
)
else:
data = GeneralDataModule(
dataset_path,
load_to_memory=load_data_to_memory,
num_workers=16,
shuffle=True,
)
checkpointing = pl.callbacks.ModelCheckpoint(
monitor="val/loss", save_top_k=1, save_last=True
)
callbacks = [checkpointing]
if with_wandb:
lr_logger = pl.callbacks.LearningRateMonitor(logging_interval="epoch")
callbacks.append(lr_logger)
logger = pl.loggers.WandbLogger(project="neural-waveshaping-synthesis")
logger.watch(model, log="parameters")
kwargs = trainer_kwargs()
trainer = pl.Trainer(
logger=logger if with_wandb else None,
callbacks=callbacks,
gpus=device,
resume_from_checkpoint=restore_checkpoint if restore_checkpoint != "" else None,
**kwargs
)
trainer.fit(model, data)
if __name__ == "__main__":
main()
================================================
FILE: setup.py
================================================
from setuptools import setup, find_packages
setup(name="neural_waveshaping_synthesis", version="0.0.1", packages=find_packages())