Repository: bentoml/OpenLLM
Branch: main
Commit: 5725415eede5
Files: 39
Total size: 126.6 KB
Directory structure:
gitextract_cxwe9k92/
├── .editorconfig
├── .envrc.template
├── .git-blame-ignore-revs
├── .git_archival.txt
├── .gitattributes
├── .github/
│ ├── CODEOWNERS
│ ├── CODE_OF_CONDUCT.md
│ ├── ISSUE_TEMPLATE/
│ │ ├── bug_report.yml
│ │ ├── config.yml
│ │ └── feature_request.yml
│ ├── SECURITY.md
│ ├── dependabot.yml
│ └── workflows/
│ ├── create-releases.yml
│ └── dependabot-auto-merge.yml
├── .gitignore
├── .pre-commit-config.yaml
├── .python-version-default
├── .ruff.toml
├── CITATION.cff
├── DEVELOPMENT.md
├── LICENSE
├── README.md
├── README.md.tpl
├── gen_readme.py
├── pyproject.toml
├── pyrightconfig.json
├── release.sh
└── src/
└── openllm/
├── __init__.py
├── __main__.py
├── accelerator_spec.py
├── analytic.py
├── clean.py
├── cloud.py
├── common.py
├── local.py
├── model.py
├── py.typed
├── repo.py
└── venv.py
================================================
FILE CONTENTS
================================================
================================================
FILE: .editorconfig
================================================
root = true
[*]
end_of_line = lf
trim_trailing_whitespace = true
charset = utf-8
indent_style = space
indent_size = 2
[/node_modules/*]
indent_size = unset
indent_style = unset
[{package.json,.travis.yml,.eslintrc.json}]
indent_style = space
================================================
FILE: .envrc.template
================================================
export PAPERSPACE_API_KEY=
================================================
FILE: .git-blame-ignore-revs
================================================
# You can use this file with 'git config blame.ignoreRevsFile .git-blame-ignore-revs'
# 07/31/2023: Style guidelines
8c2867d26dfff8a4cf33bc59d5a8dee159f3256a
# 08/22/2023: Running yapf with guidelines
1488fbb167a0ae5b0770f33f50a7ee7f7b2223c9
eddbc063743b198d72c21bd7dced59dbd949b9f1
# 08/23/2023: Synchronize style guidelines
787ce1b3b63ecbacde371550f46fa7429f3e4db2
# 08/25/2023: Consistency between yapf and ruff
46c890480640294c3f34706d595559c7ea97dac5
# 08/26/2023: Add one blank space between top level definition to similar to Google Style Guide
806a663e4aa2b174969241f6e310e05762e233f0
# 08/30/2023: Update to google style
b545ad2ad1e3acbb69f6578d8a5ee03613867505
# 09/01/2023: ignore new line split on comma-separated item
7d893e6cd217ddfe845210503c8f2cf1667d16b6
# 11/09/2023: running ruff format preview
ac377fe490bd886cf76c3855e6a2a50fc0e03b51
# 11/26/2023: reduce line overhead
69aae34cf4e6995edf2e2dc1a669fc4bdecf959a
# 11/28/2023: compact
d04309188b8fccec6a3ff36a893099806f560551
# 12/14/2023: using ruff to 150 LL
c8c9663d06e49da327ed53a22bea79f78d808aa9
# 03/15/2024: ignore new ruff formatter
727361ced761c82351ff539fcafa7af62fb5e2f0
================================================
FILE: .git_archival.txt
================================================
node: $Format:%H$
node-date: $Format:%cI$
describe-name: $Format:%(describe:tags=true,match=*[0-9]*)$
ref-names: $Format:%D$
================================================
FILE: .gitattributes
================================================
* text=auto eol=lf
# Needed for setuptools-scm-git-archive
.git_archival.txt export-subst
================================================
FILE: .github/CODEOWNERS
================================================
* @aarnphm
================================================
FILE: .github/CODE_OF_CONDUCT.md
================================================
# Contributor Covenant Code of Conduct
## Our Pledge
We as members, contributors, and leaders pledge to make participation in our
community a harassment-free experience for everyone, regardless of age, body
size, visible or invisible disability, ethnicity, sex characteristics, gender
identity and expression, level of experience, education, socio-economic status,
nationality, personal appearance, race, religion, or sexual identity
and orientation.
We pledge to act and interact in ways that contribute to an open, welcoming,
diverse, inclusive, and healthy community.
## Our Standards
Examples of behavior that contributes to a positive environment for our
community include:
* Demonstrating empathy and kindness toward other people
* Being respectful of differing opinions, viewpoints, and experiences
* Giving and gracefully accepting constructive feedback
* Accepting responsibility and apologizing to those affected by our mistakes,
and learning from the experience
* Focusing on what is best not just for us as individuals, but for the
overall community
Examples of unacceptable behavior include:
* The use of sexualized language or imagery, and sexual attention or
advances of any kind
* Trolling, insulting or derogatory comments, and personal or political attacks
* Public or private harassment
* Publishing others' private information, such as a physical or email
address, without their explicit permission
* Other conduct which could reasonably be considered inappropriate in a
professional setting
## Enforcement Responsibilities
Community leaders are responsible for clarifying and enforcing our standards of
acceptable behavior and will take appropriate and fair corrective action in
response to any behavior that they deem inappropriate, threatening, offensive,
or harmful.
Community leaders have the right and responsibility to remove, edit, or reject
comments, commits, code, wiki edits, issues, and other contributions that are
not aligned to this Code of Conduct, and will communicate reasons for moderation
decisions when appropriate.
## Scope
This Code of Conduct applies within all community spaces, and also applies when
an individual is officially representing the community in public spaces.
Examples of representing our community include using an official e-mail address,
posting via an official social media account, or acting as an appointed
representative at an online or offline event.
## Enforcement
Instances of abusive, harassing, or otherwise unacceptable behavior may be
reported to the community leaders responsible for enforcement at
contact@bentoml.com.
All complaints will be reviewed and investigated promptly and fairly.
All community leaders are obligated to respect the privacy and security of the
reporter of any incident.
## Enforcement Guidelines
Community leaders will follow these Community Impact Guidelines in determining
the consequences for any action they deem in violation of this Code of Conduct:
### 1. Correction
**Community Impact**: Use of inappropriate language or other behavior deemed
unprofessional or unwelcome in the community.
**Consequence**: A private, written warning from community leaders, providing
clarity around the nature of the violation and an explanation of why the
behavior was inappropriate. A public apology may be requested.
### 2. Warning
**Community Impact**: A violation through a single incident or series
of actions.
**Consequence**: A warning with consequences for continued behavior. No
interaction with the people involved, including unsolicited interaction with
those enforcing the Code of Conduct, for a specified period of time. This
includes avoiding interactions in community spaces as well as external channels
like social media. Violating these terms may lead to a temporary or
permanent ban.
### 3. Temporary Ban
**Community Impact**: A serious violation of community standards, including
sustained inappropriate behavior.
**Consequence**: A temporary ban from any sort of interaction or public
communication with the community for a specified period of time. No public or
private interaction with the people involved, including unsolicited interaction
with those enforcing the Code of Conduct, is allowed during this period.
Violating these terms may lead to a permanent ban.
### 4. Permanent Ban
**Community Impact**: Demonstrating a pattern of violation of community
standards, including sustained inappropriate behavior, harassment of an
individual, or aggression toward or disparagement of classes of individuals.
**Consequence**: A permanent ban from any sort of public interaction within
the community.
## Attribution
This Code of Conduct is adapted from the [Contributor Covenant][homepage],
[version 2.0](https://www.contributor-covenant.org/version/2/0/code_of_conduct.html).
Community Impact Guidelines were inspired by [Mozilla's code of conduct
enforcement ladder](https://github.com/mozilla/diversity).
[homepage]: https://www.contributor-covenant.org
For answers to common questions about this code of conduct, see the [FAQ](https://www.contributor-covenant.org/faq). Translations are available
[here](https://www.contributor-covenant.org/translations)
================================================
FILE: .github/ISSUE_TEMPLATE/bug_report.yml
================================================
name: 🐛 Bug Report
description: Create a bug report on OpenLLM.
title: 'bug: '
labels: ['']
body:
- type: markdown
id: exists
attributes:
value: |
Please search to see if an issue already exists for the bug you encountered.
See [Searching Issues and Pull Requests](https://docs.github.com/en/search-github/searching-on-github/searching-issues-and-pull-requests) for how to use the GitHub search bar and filters.
- type: textarea
id: describe-the-bug
validations:
required: true
attributes:
label: Describe the bug
description: |
Please provide a clear and concise description of the problem you ran into.
placeholder: This happened when I...
- type: textarea
id: to-reproduce
validations:
required: false
attributes:
label: To reproduce
description: |
Please provide a code sample or a code snippet to reproduce said problem. If you have code snippets, error messages, stack trace please also provide them here.
**IMPORTANT**: make sure to use [code tag](https://docs.github.com/en/get-started/writing-on-github/working-with-advanced-formatting/creating-and-highlighting-code-blocks#syntax-highlighting) to correctly format your code. Screenshot is helpful but don't use it for code snippets as it doesn't allow others to copy-and-paste your code.
To give us more information for diagnosing the issue, it would be great if you can provide a minimal reproducible!
placeholder: |
Steps to reproduce the bug:
1. Provide '...'
2. Run '...'
3. See the error
- type: textarea
id: logs
attributes:
label: Logs
description: 'Please include the Python logs if you can.'
render: shell
- type: textarea
id: environment-info
attributes:
label: Environment
description: |
Please share your environment with us. You should run `bentoml env`, `transformers-cli env` and paste the result here.
placeholder: |
bentoml: ...
transformers: ...
python: ...
platform: ...
validations:
required: true
- type: textarea
id: system-info
attributes:
label: System information (Optional)
description: |
Please share your system information with us.
placeholder: |
memory: ...
platform: ...
architecture: ...
CPU: ...
GPU: ...
================================================
FILE: .github/ISSUE_TEMPLATE/config.yml
================================================
blank_issues_enabled: true
version: 2.1
contact_links:
- name: Blank issues
url: https://github.com/bentoml/openllm/issues/new
about: To create a blank issue
- name: BentoML Discussions
url: https://github.com/bentoml/openllm/discussions
about: Please ask general questions here.
================================================
FILE: .github/ISSUE_TEMPLATE/feature_request.yml
================================================
name: 🚀 Feature Request
description: Submit a proposal/request for new OpenLLM features.
title: 'feat: '
labels: ['']
body:
- type: textarea
id: feature-request
validations:
required: true
attributes:
label: Feature request
description: |
A clear and concise description of the feature request.
placeholder: |
I would like it if...
- type: textarea
id: motivation
validations:
required: false
attributes:
label: Motivation
description: |
Please outline the motivation for this feature request. Is your feature request related to a problem? e.g., I'm always frustrated when [...].
If this is related to another issue, please link here too.
If you have a current workaround, please also provide it here.
placeholder: |
This feature would solve ...
- type: textarea
id: other
attributes:
label: Other
description: |
Is there any way that you could help, e.g. by submitting a PR?
placeholder: |
I would love to contribute ...
================================================
FILE: .github/SECURITY.md
================================================
# Security Policy
## Supported Versions
We are following [semantic versioning](https://semver.org/) with strict
backward-compatibility policy. We can ensure that all minor and major version
are backward compatible. We are more lenient with patch as the development can
move quickly.
If you are just using public API, then feel free to always upgrade. Whenever
there is a breaking policies, it will be announced and will be broken.
> [!WARNING]
> Everything package under `openllm` that has an underscore prefixes
> are exempt from this. They are considered private API and can change at any
> time. However, you can ensure that all public API, classes and functions will
> be backward-compatible.
## Reporting a Vulnerability
To report a security vulnerability, please send us an
[email](contact@bentoml.com).
================================================
FILE: .github/dependabot.yml
================================================
version: 2
updates:
- package-ecosystem: github-actions
directory: '/'
schedule:
interval: 'weekly'
day: 'monday'
time: '09:00'
groups:
actions-dependencies:
applies-to: 'version-updates'
patterns:
- '*'
- package-ecosystem: pip
directory: '/'
schedule:
interval: 'weekly'
open-pull-requests-limit: 5
groups:
production-dependencies:
applies-to: 'version-updates'
patterns:
- '*'
================================================
FILE: .github/workflows/create-releases.yml
================================================
name: release
on:
push:
tags:
- "*"
jobs:
build:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@08c6903cd8c0fde910a37f88322edcfb5dd907a8 # ratchet:actions/checkout@v4
- name: Setup Python
uses: actions/setup-python@e797f83bcb11b83ae66e0230d6156d7c80228e7c # ratchet:actions/setup-python@v5
with:
python-version-file: .python-version-default
- name: Build
run: pipx run build
- name: Upload artifacts
uses: actions/upload-artifact@ea165f8d65b6e75b540449e92b4886f43607fa02 # ratchet:actions/upload-artifact@v4
with:
name: python-artefacts-openllm
path: dist/*
if-no-files-found: error
release:
if: github.repository_owner == 'bentoml'
needs:
- build
runs-on: ubuntu-latest
name: Release
permissions:
id-token: write
contents: write
steps:
- name: Download Python artifacts
uses: actions/download-artifact@634f93cb2916e3fdff6788551b99b062d0335ce0 # ratchet:actions/download-artifact@v4
with:
pattern: python-artefacts-*
merge-multiple: true
path: dist
- name: dry ls
run: ls -rthlaR
- name: Publish to PyPI
uses: pypa/gh-action-pypi-publish@ed0c53931b1dc9bd32cbe73a98c7f6766f8a527e # ratchet:pypa/gh-action-pypi-publish@release/v1
with:
print-hash: true
- name: Create release
uses: softprops/action-gh-release@6cbd405e2c4e67a21c47fa9e383d020e4e28b836 # ratchet:softprops/action-gh-release@v2
with:
# Use GH feature to populate the changelog automatically
generate_release_notes: true
fail_on_unmatched_files: true
files: |-
dist/*
================================================
FILE: .github/workflows/dependabot-auto-merge.yml
================================================
name: Dependabot Auto merge
on: pull_request
permissions:
contents: write
pull-requests: write
jobs:
dependabot:
runs-on: ubuntu-latest
if: github.event.pull_request.user.login == 'dependabot[bot]' && github.repository == 'bentoml/OpenLLM'
steps:
- name: Dependabot metadata
id: metadata
uses: dependabot/fetch-metadata@08eff52bf64351f401fb50d4972fa95b9f2c2d1b # ratchet:dependabot/fetch-metadata@v2.4.0
with:
github-token: "${{ secrets.GITHUB_TOKEN }}"
- name: Enable auto-merge for Dependabot PRs
if: steps.metadata.outputs.dependency-group == 'actions-dependencies' || steps.metadata.outputs.dependency-group == 'production-dependencies'
run: gh pr merge --auto --squash "$PR_URL"
env:
PR_URL: ${{github.event.pull_request.html_url}}
GH_TOKEN: ${{secrets.GITHUB_TOKEN}}
================================================
FILE: .gitignore
================================================
# Byte-compiled / optimized / DLL files
__pycache__/
*.py[cod]
*$py.class
# C extensions
*.so
# Distribution / packaging
.Python
build/
develop-eggs/
dist/
downloads/
eggs/
.eggs/
lib/
lib64/
parts/
sdist/
var/
wheels/
share/python-wheels/
*.egg-info/
.installed.cfg
*.egg
MANIFEST
# PyInstaller
# Usually these files are written by a python script from a template
# before PyInstaller builds the exe, so as to inject date/other infos into it.
*.manifest
*.spec
# Installer logs
pip-log.txt
pip-delete-this-directory.txt
# Unit test / coverage reports
htmlcov/
.tox/
.nox/
.coverage
.coverage.*
.cache
nosetests.xml
coverage.xml
*.cover
*.py,cover
.hypothesis/
.pytest_cache/
cover/
# Translations
*.mo
*.pot
# Django stuff:
*.log
local_settings.py
db.sqlite3
db.sqlite3-journal
# Flask stuff:
instance/
.webassets-cache
# Scrapy stuff:
.scrapy
# Sphinx documentation
docs/_build/
# PyBuilder
.pybuilder/
target/
# Jupyter Notebook
.ipynb_checkpoints
# IPython
profile_default/
ipython_config.py
# pyenv
# For a library or package, you might want to ignore these files since the code is
# intended to run in multiple environments; otherwise, check them in:
.python-version
# pipenv
# According to pypa/pipenv#598, it is recommended to include Pipfile.lock in version control.
# However, in case of collaboration, if having platform-specific dependencies or dependencies
# having no cross-platform support, pipenv may install dependencies that don't work, or not
# install all needed dependencies.
#Pipfile.lock
# poetry
# Similar to Pipfile.lock, it is generally recommended to include poetry.lock in version control.
# This is especially recommended for binary packages to ensure reproducibility, and is more
# commonly ignored for libraries.
# https://python-poetry.org/docs/basic-usage/#commit-your-poetrylock-file-to-version-control
#poetry.lock
# pdm
# Similar to Pipfile.lock, it is generally recommended to include pdm.lock in version control.
#pdm.lock
# pdm stores project-wide configurations in .pdm.toml, but it is recommended to not include it
# in version control.
# https://pdm.fming.dev/#use-with-ide
.pdm.toml
# PEP 582; used by e.g. github.com/David-OConnor/pyflow and github.com/pdm-project/pdm
__pypackages__/
# Celery stuff
celerybeat-schedule
celerybeat.pid
# SageMath parsed files
*.sage.py
# Environments
.env
.venv
env/
venv/
ENV/
env.bak/
venv.bak/
# Spyder project settings
.spyderproject
.spyproject
# Rope project settings
.ropeproject
# mkdocs documentation
/site
# mypy
.mypy_cache/
.dmypy.json
dmypy.json
# Pyre type checker
.pyre/
# pytype static type analyzer
.pytype/
# Cython debug symbols
cython_debug/
# PyCharm
# JetBrains specific template is maintained in a separate JetBrains.gitignore that can
# be found at https://github.com/github/gitignore/blob/main/Global/JetBrains.gitignore
# and can be added to the global gitignore or merged into this file. For a more nuclear
# option (not recommended) you can uncomment the following to ignore the entire idea folder.
#.idea/
*.whl
# Environments
venv/
.envrc
_version.py
.cursor
================================================
FILE: .pre-commit-config.yaml
================================================
ci:
autoupdate_schedule: weekly
autofix_commit_msg: "ci: auto fixes from pre-commit.ci\n\nFor more information, see https://pre-commit.ci"
autoupdate_commit_msg: "ci: pre-commit autoupdate [pre-commit.ci]"
autofix_prs: true
default_language_version:
python: python3.11 # NOTE: sync with .python-version-default
repos:
- repo: https://github.com/astral-sh/ruff-pre-commit
rev: "v0.12.12"
hooks:
- id: ruff
alias: r
verbose: true
args: [--exit-non-zero-on-fix, --show-fixes, --fix]
types_or: [python, pyi, jupyter]
- id: ruff-format
alias: rf
verbose: true
types_or: [python, pyi, jupyter]
- repo: https://github.com/pre-commit/mirrors-mypy
rev: "v1.17.1"
hooks:
- id: mypy
args: [--strict, --ignore-missing-imports]
additional_dependencies:
[pydantic, types-pyyaml, types-tabulate, types-psutil, typer]
- repo: https://github.com/editorconfig-checker/editorconfig-checker.python
rev: "3.4.0"
hooks:
- id: editorconfig-checker
verbose: true
alias: ec
types_or: [python]
- repo: meta
hooks:
- id: check-hooks-apply
- id: check-useless-excludes
- repo: https://github.com/pre-commit/pre-commit-hooks
rev: v6.0.0
hooks:
- id: trailing-whitespace
verbose: true
- id: end-of-file-fixer
verbose: true
- id: check-yaml
args: ["--unsafe"]
- id: check-toml
- id: check-docstring-first
- id: check-added-large-files
- id: debug-statements
- id: check-merge-conflict
================================================
FILE: .python-version-default
================================================
3.11
================================================
FILE: .ruff.toml
================================================
extend-include = ["*.ipynb"]
preview = true
line-length = 100
indent-width = 2
[format]
preview = true
quote-style = "single"
indent-style = "space"
skip-magic-trailing-comma = true
docstring-code-format = true
[lint]
ignore = [
"RUF012",
"ANN", # Mypy is better at this
"E722",
]
select = [
"F",
"G", # flake8-logging-format
"PERF", # perflint
"RUF", # Ruff-specific rules
"W6",
"E71",
"E72",
"E112",
"E113",
"E203",
"E272",
"E702",
"E703",
"E731",
"W191",
"W291",
"W293",
"UP039", # unnecessary-class-parentheses
]
[lint.pydocstyle]
convention = "google"
================================================
FILE: CITATION.cff
================================================
cff-version: 1.2.0
title: 'OpenLLM: Operating LLMs in production'
message: >-
If you use this software, please cite it using these
metadata.
type: software
authors:
- given-names: Aaron
family-names: Pham
email: aarnphm@bentoml.com
orcid: 'https://orcid.org/0009-0008-3180-5115'
- given-names: Chaoyu
family-names: Yang
email: chaoyu@bentoml.com
- given-names: Sean
family-names: Sheng
email: ssheng@bentoml.com
- given-names: Shenyang
family-names: Zhao
email: larme@bentoml.com
- given-names: Sauyon
family-names: Lee
email: sauyon@bentoml.com
- given-names: Bo
family-names: Jiang
email: jiang@bentoml.com
- given-names: Fog
family-names: Dong
email: fog@bentoml.com
- given-names: Xipeng
family-names: Guan
email: xipeng@bentoml.com
- given-names: Frost
family-names: Ming
email: frost@bentoml.com
repository-code: 'https://github.com/bentoml/OpenLLM'
url: 'https://bentoml.com/'
abstract: >-
OpenLLM is an open platform for operating large language
models (LLMs) in production. With OpenLLM, you can run
inference with any open-source large-language models,
deploy to the cloud or on-premises, and build powerful AI
apps. It has built-in support for a wide range of
open-source LLMs and model runtime, including StableLM,
Falcon, Dolly, Flan-T5, ChatGLM, StarCoder and more.
OpenLLM helps serve LLMs over RESTful API or gRPC with one
command or query via WebUI, CLI, our Python/Javascript
client, or any HTTP client. It provides first-class
support for LangChain, BentoML and Hugging Face that
allows you to easily create your own AI apps by composing
LLMs with other models and services. Last but not least,
it automatically generates LLM server OCI-compatible
Container Images or easily deploys as a serverless
endpoint via BentoCloud.
keywords:
- MLOps
- LLMOps
- LLM
- Infrastructure
- Transformers
- LLM Serving
- Model Serving
- Serverless Deployment
license: Apache-2.0
date-released: '2023-06-13'
================================================
FILE: DEVELOPMENT.md
================================================
# Developer Guide
This Developer Guide is designed to help you contribute to the OpenLLM project.
Follow these steps to set up your development environment and learn the process
of contributing to our open-source project.
Join our [Discord Channel](https://l.bentoml.com/join-openllm-discord) and reach
out to us if you have any question!
## Table of Contents
- [Developer Guide](#developer-guide)
- [Table of Contents](#table-of-contents)
- [Setting Up Your Development Environment](#setting-up-your-development-environment)
- [Development Workflow](#development-workflow)
- [Adding new models](#adding-new-models)
- [Adding bentos](#adding-new-models)
- [Adding repos](#adding-new-models)
## Setting Up Your Development Environment
Before you can start developing, you'll need to set up your environment:
1. Ensure you have [Git](https://git-scm.com/), and
[Python3.8+](https://www.python.org/downloads/) installed.
2. Fork the OpenLLM repository from GitHub.
3. Clone the forked repository from GitHub:
```bash
git clone git@github.com:username/OpenLLM.git && cd openllm
```
4. Add the OpenLLM upstream remote to your local OpenLLM clone:
```bash
git remote add upstream git@github.com:bentoml/OpenLLM.git
```
5. Configure git to pull from the upstream remote:
```bash
git switch main # ensure you're on the main branch
git fetch upstream --tags
git branch --set-upstream-to=upstream/main
```
6. (Optional) Link `.python-version-default` to `.python-version`:
```bash
ln .python-version-default .python-version
```
## Development Workflow
There are a few ways to contribute to the repository structure for OpenLLM:
### Adding new models
1. [recipe.yaml](./recipe.yaml) contains all related-metadata for generating new LLM-based bentos. To add a new LLM, the following structure should be adhere to:
```yaml
"<model_name>:<model_tag>":
project: vllm-chat
service_config:
name: phi3
traffic:
timeout: 300
resources:
gpu: 1
gpu_type: nvidia-tesla-l4
engine_config:
model: microsoft/Phi-3-mini-4k-instruct
max_model_len: 4096
dtype: half
chat_template: phi-3
```
- `<model_name>` represents the type of model to be supported. Currently supports `phi3`, `llama2`, `llama3`, `gemma`
- `<model_tag>` emphasizes the type of model and its related metadata. The convention would include `<model_size>-<model_type>-<precision>[-<quantization>]`
For example:
- `microsoft/Phi-3-mini-4k-instruct` should be represented as `3.8b-instruct-fp16`.
- `TheBloke/Llama-2-7B-Chat-AWQ` would be `7b-chat-awq-4bit`
- `project` would be used as the basis for the generated bento. Currently, most models should use `vllm-chat` as default.
- `service_config` entails all BentoML-related [configuration](https://docs.bentoml.com/en/latest/guides/configurations.html) to run this bento.
> [!NOTE]
>
> We recommend to include the following field for `service_config`:
>
> - `name` should be the same as `<model_name>`
> - `resources` includes the available accelerator that can run this models. See more [here](https://docs.bentoml.com/en/latest/guides/configurations.html#resources)
- `engine_config` are fields to be used for vLLM engine. See more supported arguments in [`AsyncEngineArgs`](https://github.com/vllm-project/vllm/blob/7cd2ebb0251fd1fd0eec5c93dac674603a22eddd/vllm/engine/arg_utils.py#L799). We recommend to always include `model`, `max_model_len`, `dtype` and `trust_remote_code`.
- If the model is a chat model, `chat_template` should be used. Add the appropriate `chat_template` under [chat_template directory](./vllm-chat/chat_templates/) should you decide to do so.
2. You can then run `BENTOML_HOME=$(openllm repo default)/bentoml/bentos python make.py <model_name>:<model_tag>` to generate the required bentos.
3. You can then submit a [Pull request](https://docs.github.com/en/pull-requests/collaborating-with-pull-requests/proposing-changes-to-your-work-with-pull-requests/creating-a-pull-request) to `openllm` with the recipe changes
### Adding bentos
OpenLLM now also manages a [generated bento repository](https://github.com/bentoml/openllm-models/tree/main). If you update and modify and generated bentos, make sure to update the recipe and added the generated bentos under `bentoml/bentos`.
### Adding repos
If you wish to create a your own managed git repo, you should follow the structure of [bentoml/openllm-models](https://github.com/bentoml/openllm-models/tree/main).
To add your custom repo, do `openllm repo add <repo_alias> <git_url>`
================================================
FILE: LICENSE
================================================
Apache License
Version 2.0, January 2004
http://www.apache.org/licenses/
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
1. Definitions.
"License" shall mean the terms and conditions for use, reproduction,
and distribution as defined by Sections 1 through 9 of this document.
"Licensor" shall mean the copyright owner or entity authorized by
the copyright owner that is granting the License.
"Legal Entity" shall mean the union of the acting entity and all
other entities that control, are controlled by, or are under common
control with that entity. For the purposes of this definition,
"control" means (i) the power, direct or indirect, to cause the
direction or management of such entity, whether by contract or
otherwise, or (ii) ownership of fifty percent (50%) or more of the
outstanding shares, or (iii) beneficial ownership of such entity.
"You" (or "Your") shall mean an individual or Legal Entity
exercising permissions granted by this License.
"Source" form shall mean the preferred form for making modifications,
including but not limited to software source code, documentation
source, and configuration files.
"Object" form shall mean any form resulting from mechanical
transformation or translation of a Source form, including but
not limited to compiled object code, generated documentation,
and conversions to other media types.
"Work" shall mean the work of authorship, whether in Source or
Object form, made available under the License, as indicated by a
copyright notice that is included in or attached to the work
(an example is provided in the Appendix below).
"Derivative Works" shall mean any work, whether in Source or Object
form, that is based on (or derived from) the Work and for which the
editorial revisions, annotations, elaborations, or other modifications
represent, as a whole, an original work of authorship. For the purposes
of this License, Derivative Works shall not include works that remain
separable from, or merely link (or bind by name) to the interfaces of,
the Work and Derivative Works thereof.
"Contribution" shall mean any work of authorship, including
the original version of the Work and any modifications or additions
to that Work or Derivative Works thereof, that is intentionally
submitted to Licensor for inclusion in the Work by the copyright owner
or by an individual or Legal Entity authorized to submit on behalf of
the copyright owner. For the purposes of this definition, "submitted"
means any form of electronic, verbal, or written communication sent
to the Licensor or its representatives, including but not limited to
communication on electronic mailing lists, source code control systems,
and issue tracking systems that are managed by, or on behalf of, the
Licensor for the purpose of discussing and improving the Work, but
excluding communication that is conspicuously marked or otherwise
designated in writing by the copyright owner as "Not a Contribution."
"Contributor" shall mean Licensor and any individual or Legal Entity
on behalf of whom a Contribution has been received by Licensor and
subsequently incorporated within the Work.
2. Grant of Copyright License. Subject to the terms and conditions of
this License, each Contributor hereby grants to You a perpetual,
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
copyright license to reproduce, prepare Derivative Works of,
publicly display, publicly perform, sublicense, and distribute the
Work and such Derivative Works in Source or Object form.
3. Grant of Patent License. Subject to the terms and conditions of
this License, each Contributor hereby grants to You a perpetual,
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
(except as stated in this section) patent license to make, have made,
use, offer to sell, sell, import, and otherwise transfer the Work,
where such license applies only to those patent claims licensable
by such Contributor that are necessarily infringed by their
Contribution(s) alone or by combination of their Contribution(s)
with the Work to which such Contribution(s) was submitted. If You
institute patent litigation against any entity (including a
cross-claim or counterclaim in a lawsuit) alleging that the Work
or a Contribution incorporated within the Work constitutes direct
or contributory patent infringement, then any patent licenses
granted to You under this License for that Work shall terminate
as of the date such litigation is filed.
4. Redistribution. You may reproduce and distribute copies of the
Work or Derivative Works thereof in any medium, with or without
modifications, and in Source or Object form, provided that You
meet the following conditions:
(a) You must give any other recipients of the Work or
Derivative Works a copy of this License; and
(b) You must cause any modified files to carry prominent notices
stating that You changed the files; and
(c) You must retain, in the Source form of any Derivative Works
that You distribute, all copyright, patent, trademark, and
attribution notices from the Source form of the Work,
excluding those notices that do not pertain to any part of
the Derivative Works; and
(d) If the Work includes a "NOTICE" text file as part of its
distribution, then any Derivative Works that You distribute must
include a readable copy of the attribution notices contained
within such NOTICE file, excluding those notices that do not
pertain to any part of the Derivative Works, in at least one
of the following places: within a NOTICE text file distributed
as part of the Derivative Works; within the Source form or
documentation, if provided along with the Derivative Works; or,
within a display generated by the Derivative Works, if and
wherever such third-party notices normally appear. The contents
of the NOTICE file are for informational purposes only and
do not modify the License. You may add Your own attribution
notices within Derivative Works that You distribute, alongside
or as an addendum to the NOTICE text from the Work, provided
that such additional attribution notices cannot be construed
as modifying the License.
You may add Your own copyright statement to Your modifications and
may provide additional or different license terms and conditions
for use, reproduction, or distribution of Your modifications, or
for any such Derivative Works as a whole, provided Your use,
reproduction, and distribution of the Work otherwise complies with
the conditions stated in this License.
5. Submission of Contributions. Unless You explicitly state otherwise,
any Contribution intentionally submitted for inclusion in the Work
by You to the Licensor shall be under the terms and conditions of
this License, without any additional terms or conditions.
Notwithstanding the above, nothing herein shall supersede or modify
the terms of any separate license agreement you may have executed
with Licensor regarding such Contributions.
6. Trademarks. This License does not grant permission to use the trade
names, trademarks, service marks, or product names of the Licensor,
except as required for reasonable and customary use in describing the
origin of the Work and reproducing the content of the NOTICE file.
7. Disclaimer of Warranty. Unless required by applicable law or
agreed to in writing, Licensor provides the Work (and each
Contributor provides its Contributions) on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
implied, including, without limitation, any warranties or conditions
of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
PARTICULAR PURPOSE. You are solely responsible for determining the
appropriateness of using or redistributing the Work and assume any
risks associated with Your exercise of permissions under this License.
8. Limitation of Liability. In no event and under no legal theory,
whether in tort (including negligence), contract, or otherwise,
unless required by applicable law (such as deliberate and grossly
negligent acts) or agreed to in writing, shall any Contributor be
liable to You for damages, including any direct, indirect, special,
incidental, or consequential damages of any character arising as a
result of this License or out of the use or inability to use the
Work (including but not limited to damages for loss of goodwill,
work stoppage, computer failure or malfunction, or any and all
other commercial damages or losses), even if such Contributor
has been advised of the possibility of such damages.
9. Accepting Warranty or Additional Liability. While redistributing
the Work or Derivative Works thereof, You may choose to offer,
and charge a fee for, acceptance of support, warranty, indemnity,
or other liability obligations and/or rights consistent with this
License. However, in accepting such obligations, You may act only
on Your own behalf and on Your sole responsibility, not on behalf
of any other Contributor, and only if You agree to indemnify,
defend, and hold each Contributor harmless for any liability
incurred by, or claims asserted against, such Contributor by reason
of your accepting any such warranty or additional liability.
END OF TERMS AND CONDITIONS
APPENDIX: How to apply the Apache License to your work.
To apply the Apache License to your work, attach the following
boilerplate notice, with the fields enclosed by brackets "[]"
replaced with your own identifying information. (Don't include
the brackets!) The text should be enclosed in the appropriate
comment syntax for the file format. We also recommend that a
file or class name and description of purpose be included on the
same "printed page" as the copyright notice for easier
identification within third-party archives.
Copyright [yyyy] [name of copyright owner]
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
================================================
FILE: README.md
================================================
<div align="center">
<h1>🦾 OpenLLM: Self-Hosting LLMs Made Easy</h1>
[](https://github.com/bentoml/OpenLLM/blob/main/LICENSE)
[](https://pypi.org/project/openllm)
[](https://results.pre-commit.ci/latest/github/bentoml/OpenLLM/main)
[](https://twitter.com/bentomlai)
[](https://l.bentoml.com/join-slack)
</div>
OpenLLM allows developers to run **any open-source LLMs** (Llama 3.3, Qwen2.5, Phi3 and [more](#supported-models)) or **custom models** as **OpenAI-compatible APIs** with a single command. It features a [built-in chat UI](#chat-ui), state-of-the-art inference backends, and a simplified workflow for creating enterprise-grade cloud deployment with Docker, Kubernetes, and [BentoCloud](#deploy-to-bentocloud).
Understand the [design philosophy of OpenLLM](https://www.bentoml.com/blog/from-ollama-to-openllm-running-llms-in-the-cloud).
## Get Started
Run the following commands to install OpenLLM and explore it interactively.
```bash
pip install openllm # or pip3 install openllm
openllm hello
```
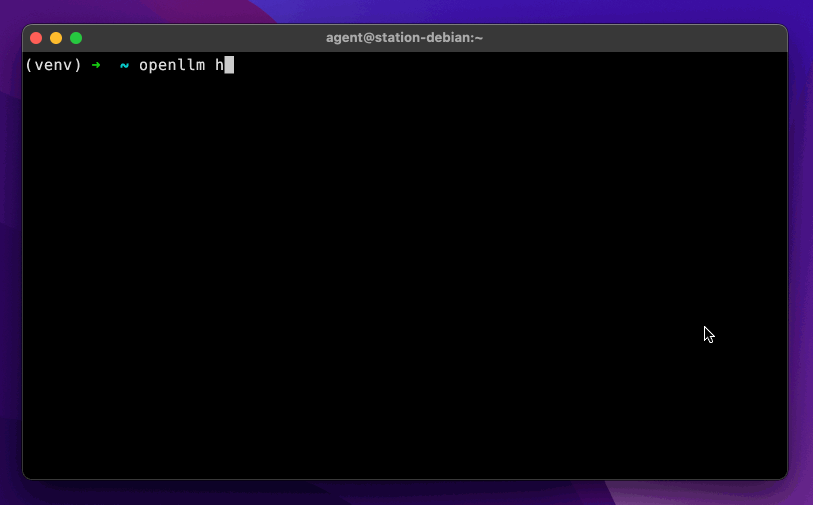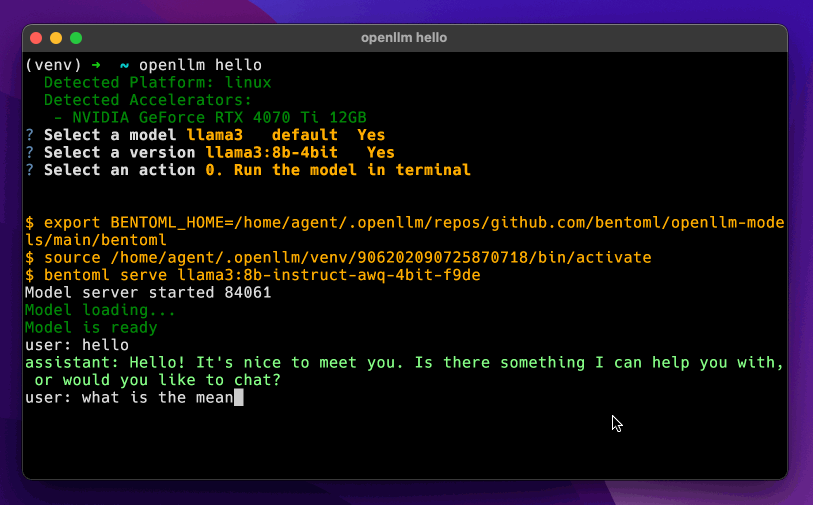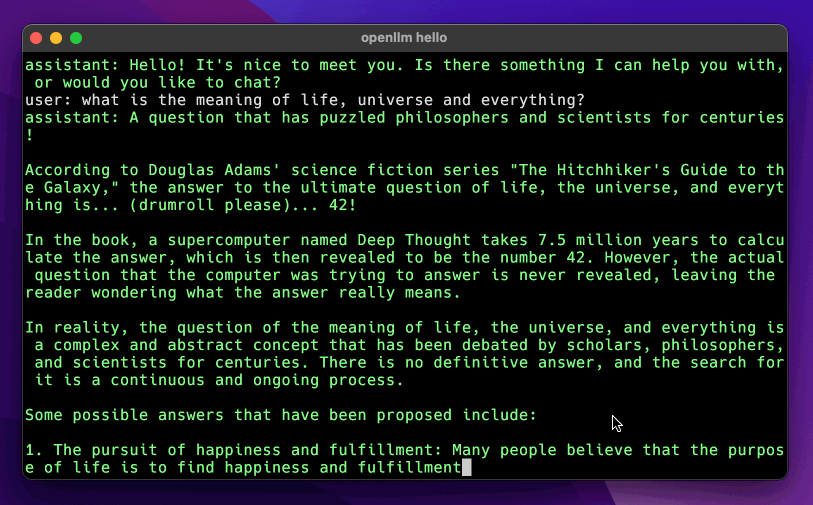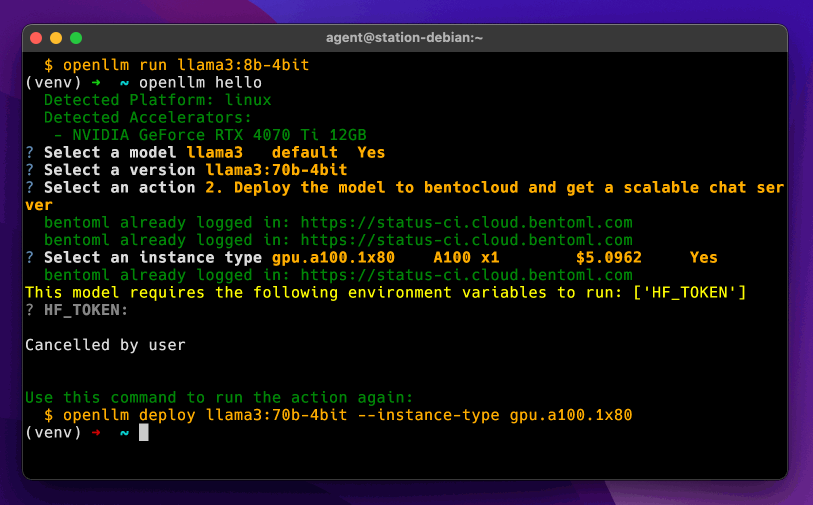
## Supported models
OpenLLM supports a wide range of state-of-the-art open-source LLMs. You can also add a [model repository to run custom models](#set-up-a-custom-repository) with OpenLLM.
<table>
<tr>
<th>Model</th>
<th>Parameters</th>
<th>Required GPU</th>
<th>Start a Server</th>
</tr>
<tr>
<td>deepseek</td>
<td>r1-671b</td>
<td>80Gx16</td>
<td><code>openllm serve deepseek:r1-671b</code></td>
</tr>
<tr>
<td>gemma2</td>
<td>2b</td>
<td>12G</td>
<td><code>openllm serve gemma2:2b</code></td>
</tr>
<tr>
<td>gemma3</td>
<td>3b</td>
<td>12G</td>
<td><code>openllm serve gemma3:3b</code></td>
</tr>
<tr>
<td>jamba1.5</td>
<td>mini-ff0a</td>
<td>80Gx2</td>
<td><code>openllm serve jamba1.5:mini-ff0a</code></td>
</tr>
<tr>
<td>llama3.1</td>
<td>8b</td>
<td>24G</td>
<td><code>openllm serve llama3.1:8b</code></td>
</tr>
<tr>
<td>llama3.2</td>
<td>1b</td>
<td>24G</td>
<td><code>openllm serve llama3.2:1b</code></td>
</tr>
<tr>
<td>llama3.3</td>
<td>70b</td>
<td>80Gx2</td>
<td><code>openllm serve llama3.3:70b</code></td>
</tr>
<tr>
<td>llama4</td>
<td>17b16e</td>
<td>80Gx8</td>
<td><code>openllm serve llama4:17b16e</code></td>
</tr>
<tr>
<td>mistral</td>
<td>8b-2410</td>
<td>24G</td>
<td><code>openllm serve mistral:8b-2410</code></td>
</tr>
<tr>
<td>mistral-large</td>
<td>123b-2407</td>
<td>80Gx4</td>
<td><code>openllm serve mistral-large:123b-2407</code></td>
</tr>
<tr>
<td>phi4</td>
<td>14b</td>
<td>80G</td>
<td><code>openllm serve phi4:14b</code></td>
</tr>
<tr>
<td>pixtral</td>
<td>12b-2409</td>
<td>80G</td>
<td><code>openllm serve pixtral:12b-2409</code></td>
</tr>
<tr>
<td>qwen2.5</td>
<td>7b</td>
<td>24G</td>
<td><code>openllm serve qwen2.5:7b</code></td>
</tr>
<tr>
<td>qwen2.5-coder</td>
<td>3b</td>
<td>24G</td>
<td><code>openllm serve qwen2.5-coder:3b</code></td>
</tr>
<tr>
<td>qwq</td>
<td>32b</td>
<td>80G</td>
<td><code>openllm serve qwq:32b</code></td>
</tr>
</table>
For the full model list, see the [OpenLLM models repository](https://github.com/bentoml/openllm-models).
## Start an LLM server
To start an LLM server locally, use the `openllm serve` command and specify the model version.
> [!NOTE]
> OpenLLM does not store model weights. A Hugging Face token (HF_TOKEN) is required for gated models.
>
> 1. Create your Hugging Face token [here](https://huggingface.co/settings/tokens).
> 2. Request access to the gated model, such as [meta-llama/Llama-3.2-1B-Instruct](https://huggingface.co/meta-llama/Llama-3.2-1B-Instruct).
> 3. Set your token as an environment variable by running:
> ```bash
> export HF_TOKEN=<your token>
> ```
```bash
openllm serve llama3.2:1b
```
The server will be accessible at [http://localhost:3000](http://localhost:3000/), providing OpenAI-compatible APIs for interaction. You can call the endpoints with different frameworks and tools that support OpenAI-compatible APIs. Typically, you may need to specify the following:
- **The API host address**: By default, the LLM is hosted at [http://localhost:3000](http://localhost:3000/).
- **The model name:** The name can be different depending on the tool you use.
- **The API key**: The API key used for client authentication. This is optional.
Here are some examples:
<details>
<summary>OpenAI Python client</summary>
```python
from openai import OpenAI
client = OpenAI(base_url='http://localhost:3000/v1', api_key='na')
# Use the following func to get the available models
# model_list = client.models.list()
# print(model_list)
chat_completion = client.chat.completions.create(
model="meta-llama/Llama-3.2-1B-Instruct",
messages=[
{
"role": "user",
"content": "Explain superconductors like I'm five years old"
}
],
stream=True,
)
for chunk in chat_completion:
print(chunk.choices[0].delta.content or "", end="")
```
</details>
<details>
<summary>LlamaIndex</summary>
```python
from llama_index.llms.openai import OpenAI
llm = OpenAI(api_bese="http://localhost:3000/v1", model="meta-llama/Llama-3.2-1B-Instruct", api_key="dummy")
...
```
</details>
## Chat UI
OpenLLM provides a chat UI at the `/chat` endpoint for the launched LLM server at http://localhost:3000/chat.
<img width="800" alt="openllm_ui" src="https://github.com/bentoml/OpenLLM/assets/5886138/8b426b2b-67da-4545-8b09-2dc96ff8a707">
## Chat with a model in the CLI
To start a chat conversation in the CLI, use the `openllm run` command and specify the model version.
```bash
openllm run llama3:8b
```
## Model repository
A model repository in OpenLLM represents a catalog of available LLMs that you can run. OpenLLM provides a default model repository that includes the latest open-source LLMs like Llama 3, Mistral, and Qwen2, hosted at [this GitHub repository](https://github.com/bentoml/openllm-models). To see all available models from the default and any added repository, use:
```bash
openllm model list
```
To ensure your local list of models is synchronized with the latest updates from all connected repositories, run:
```bash
openllm repo update
```
To review a model’s information, run:
```bash
openllm model get llama3.2:1b
```
### Add a model to the default model repository
You can contribute to the default model repository by adding new models that others can use. This involves creating and submitting a Bento of the LLM. For more information, check out this [example pull request](https://github.com/bentoml/openllm-models/pull/1).
### Set up a custom repository
You can add your own repository to OpenLLM with custom models. To do so, follow the format in the default OpenLLM model repository with a `bentos` directory to store custom LLMs. You need to [build your Bentos with BentoML](https://docs.bentoml.com/en/latest/guides/build-options.html) and submit them to your model repository.
First, prepare your custom models in a `bentos` directory following the guidelines provided by [BentoML to build Bentos](https://docs.bentoml.com/en/latest/guides/build-options.html). Check out the [default model repository](https://github.com/bentoml/openllm-repo) for an example and read the [Developer Guide](https://github.com/bentoml/OpenLLM/blob/main/DEVELOPMENT.md) for details.
Then, register your custom model repository with OpenLLM:
```bash
openllm repo add <repo-name> <repo-url>
```
**Note**: Currently, OpenLLM only supports adding public repositories.
## Deploy to BentoCloud
OpenLLM supports LLM cloud deployment via BentoML, the unified model serving framework, and BentoCloud, an AI inference platform for enterprise AI teams. BentoCloud provides fully-managed infrastructure optimized for LLM inference with autoscaling, model orchestration, observability, and many more, allowing you to run any AI model in the cloud.
[Sign up for BentoCloud](https://www.bentoml.com/) for free and [log in](https://docs.bentoml.com/en/latest/bentocloud/how-tos/manage-access-token.html). Then, run `openllm deploy` to deploy a model to BentoCloud:
```bash
openllm deploy llama3.2:1b --env HF_TOKEN
```
> [!NOTE]
> If you are deploying a gated model, make sure to set HF_TOKEN in enviroment variables.
Once the deployment is complete, you can run model inference on the BentoCloud console:
<img width="800" alt="bentocloud_ui" src="https://github.com/bentoml/OpenLLM/assets/65327072/4f7819d9-73ea-488a-a66c-f724e5d063e6">
## Community
OpenLLM is actively maintained by the BentoML team. Feel free to reach out and join us in our pursuit to make LLMs more accessible and easy to use 👉 [Join our Slack community!](https://l.bentoml.com/join-slack)
## Contributing
As an open-source project, we welcome contributions of all kinds, such as new features, bug fixes, and documentation. Here are some of the ways to contribute:
- Repost a bug by [creating a GitHub issue](https://github.com/bentoml/OpenLLM/issues/new/choose).
- [Submit a pull request](https://github.com/bentoml/OpenLLM/compare) or help review other developers’ [pull requests](https://github.com/bentoml/OpenLLM/pulls).
- Add an LLM to the OpenLLM default model repository so that other users can run your model. See the [pull request template](https://github.com/bentoml/openllm-models/pull/1).
- Check out the [Developer Guide](https://github.com/bentoml/OpenLLM/blob/main/DEVELOPMENT.md) to learn more.
## Acknowledgements
This project uses the following open-source projects:
- [bentoml/bentoml](https://github.com/bentoml/bentoml) for production level model serving
- [vllm-project/vllm](https://github.com/vllm-project/vllm) for production level LLM backend
- [blrchen/chatgpt-lite](https://github.com/blrchen/chatgpt-lite) for a fancy Web Chat UI
- [astral-sh/uv](https://github.com/astral-sh/uv) for blazing fast model requirements installing
We are grateful to the developers and contributors of these projects for their hard work and dedication.
================================================
FILE: README.md.tpl
================================================
<div align="center">
<h1>🦾 OpenLLM: Self-Hosting LLMs Made Easy</h1>
[](https://github.com/bentoml/OpenLLM/blob/main/LICENSE)
[](https://pypi.org/project/openllm)
[](https://results.pre-commit.ci/latest/github/bentoml/OpenLLM/main)
[](https://twitter.com/bentomlai)
[](https://l.bentoml.com/join-slack)
</div>
OpenLLM allows developers to run **any open-source LLMs** (Llama 3.3, Qwen2.5, Phi3 and [more](#supported-models)) or **custom models** as **OpenAI-compatible APIs** with a single command. It features a [built-in chat UI](#chat-ui), state-of-the-art inference backends, and a simplified workflow for creating enterprise-grade cloud deployment with Docker, Kubernetes, and [BentoCloud](#deploy-to-bentocloud).
Understand the [design philosophy of OpenLLM](https://www.bentoml.com/blog/from-ollama-to-openllm-running-llms-in-the-cloud).
## Get Started
Run the following commands to install OpenLLM and explore it interactively.
```bash
pip install openllm # or pip3 install openllm
openllm hello
```

## Supported models
OpenLLM supports a wide range of state-of-the-art open-source LLMs. You can also add a [model repository to run custom models](#set-up-a-custom-repository) with OpenLLM.
<table>
<tr>
<th>Model</th>
<th>Parameters</th>
<th>Required GPU</th>
<th>Start a Server</th>
</tr>
{%- for key, value in model_dict|items %}
<tr>
<td>{{key}}</td>
<td>{{value['version']}}</td>
<td>{{value['pretty_gpu']}}</td>
<td><code>{{value['command']}}</code></td>
</tr>
{%- endfor %}
</table>
For the full model list, see the [OpenLLM models repository](https://github.com/bentoml/openllm-models).
## Start an LLM server
To start an LLM server locally, use the `openllm serve` command and specify the model version.
> [!NOTE]
> OpenLLM does not store model weights. A Hugging Face token (HF_TOKEN) is required for gated models.
>
> 1. Create your Hugging Face token [here](https://huggingface.co/settings/tokens).
> 2. Request access to the gated model, such as [meta-llama/Llama-3.2-1B-Instruct](https://huggingface.co/meta-llama/Llama-3.2-1B-Instruct).
> 3. Set your token as an environment variable by running:
> ```bash
> export HF_TOKEN=<your token>
> ```
```bash
{{model_dict.get("llama3.2")["command"]}}
```
The server will be accessible at [http://localhost:3000](http://localhost:3000/), providing OpenAI-compatible APIs for interaction. You can call the endpoints with different frameworks and tools that support OpenAI-compatible APIs. Typically, you may need to specify the following:
- **The API host address**: By default, the LLM is hosted at [http://localhost:3000](http://localhost:3000/).
- **The model name:** The name can be different depending on the tool you use.
- **The API key**: The API key used for client authentication. This is optional.
Here are some examples:
<details>
<summary>OpenAI Python client</summary>
```python
from openai import OpenAI
client = OpenAI(base_url='http://localhost:3000/v1', api_key='na')
# Use the following func to get the available models
# model_list = client.models.list()
# print(model_list)
chat_completion = client.chat.completions.create(
model="meta-llama/Llama-3.2-1B-Instruct",
messages=[
{
"role": "user",
"content": "Explain superconductors like I'm five years old"
}
],
stream=True,
)
for chunk in chat_completion:
print(chunk.choices[0].delta.content or "", end="")
```
</details>
<details>
<summary>LlamaIndex</summary>
```python
from llama_index.llms.openai import OpenAI
llm = OpenAI(api_bese="http://localhost:3000/v1", model="meta-llama/Llama-3.2-1B-Instruct", api_key="dummy")
...
```
</details>
## Chat UI
OpenLLM provides a chat UI at the `/chat` endpoint for the launched LLM server at http://localhost:3000/chat.
<img width="800" alt="openllm_ui" src="https://github.com/bentoml/OpenLLM/assets/5886138/8b426b2b-67da-4545-8b09-2dc96ff8a707">
## Chat with a model in the CLI
To start a chat conversation in the CLI, use the `openllm run` command and specify the model version.
```bash
openllm run llama3:8b
```
## Model repository
A model repository in OpenLLM represents a catalog of available LLMs that you can run. OpenLLM provides a default model repository that includes the latest open-source LLMs like Llama 3, Mistral, and Qwen2, hosted at [this GitHub repository](https://github.com/bentoml/openllm-models). To see all available models from the default and any added repository, use:
```bash
openllm model list
```
To ensure your local list of models is synchronized with the latest updates from all connected repositories, run:
```bash
openllm repo update
```
To review a model’s information, run:
```bash
openllm model get {{model_dict.get("llama3.2")["tag"]}}
```
### Add a model to the default model repository
You can contribute to the default model repository by adding new models that others can use. This involves creating and submitting a Bento of the LLM. For more information, check out this [example pull request](https://github.com/bentoml/openllm-models/pull/1).
### Set up a custom repository
You can add your own repository to OpenLLM with custom models. To do so, follow the format in the default OpenLLM model repository with a `bentos` directory to store custom LLMs. You need to [build your Bentos with BentoML](https://docs.bentoml.com/en/latest/guides/build-options.html) and submit them to your model repository.
First, prepare your custom models in a `bentos` directory following the guidelines provided by [BentoML to build Bentos](https://docs.bentoml.com/en/latest/guides/build-options.html). Check out the [default model repository](https://github.com/bentoml/openllm-repo) for an example and read the [Developer Guide](https://github.com/bentoml/OpenLLM/blob/main/DEVELOPMENT.md) for details.
Then, register your custom model repository with OpenLLM:
```bash
openllm repo add <repo-name> <repo-url>
```
**Note**: Currently, OpenLLM only supports adding public repositories.
## Deploy to BentoCloud
OpenLLM supports LLM cloud deployment via BentoML, the unified model serving framework, and BentoCloud, an AI inference platform for enterprise AI teams. BentoCloud provides fully-managed infrastructure optimized for LLM inference with autoscaling, model orchestration, observability, and many more, allowing you to run any AI model in the cloud.
[Sign up for BentoCloud](https://www.bentoml.com/) for free and [log in](https://docs.bentoml.com/en/latest/bentocloud/how-tos/manage-access-token.html). Then, run `openllm deploy` to deploy a model to BentoCloud:
```bash
openllm deploy {{model_dict.get("llama3.2")["tag"]}}
```
> [!NOTE]
> If you are deploying a gated model, make sure to set HF_TOKEN in enviroment variables.
Once the deployment is complete, you can run model inference on the BentoCloud console:
<img width="800" alt="bentocloud_ui" src="https://github.com/bentoml/OpenLLM/assets/65327072/4f7819d9-73ea-488a-a66c-f724e5d063e6">
## Community
OpenLLM is actively maintained by the BentoML team. Feel free to reach out and join us in our pursuit to make LLMs more accessible and easy to use 👉 [Join our Slack community!](https://l.bentoml.com/join-slack)
## Contributing
As an open-source project, we welcome contributions of all kinds, such as new features, bug fixes, and documentation. Here are some of the ways to contribute:
- Repost a bug by [creating a GitHub issue](https://github.com/bentoml/OpenLLM/issues/new/choose).
- [Submit a pull request](https://github.com/bentoml/OpenLLM/compare) or help review other developers’ [pull requests](https://github.com/bentoml/OpenLLM/pulls).
- Add an LLM to the OpenLLM default model repository so that other users can run your model. See the [pull request template](https://github.com/bentoml/openllm-models/pull/1).
- Check out the [Developer Guide](https://github.com/bentoml/OpenLLM/blob/main/DEVELOPMENT.md) to learn more.
## Acknowledgements
This project uses the following open-source projects:
- [bentoml/bentoml](https://github.com/bentoml/bentoml) for production level model serving
- [vllm-project/vllm](https://github.com/vllm-project/vllm) for production level LLM backend
- [blrchen/chatgpt-lite](https://github.com/blrchen/chatgpt-lite) for a fancy Web Chat UI
- [astral-sh/uv](https://github.com/astral-sh/uv) for blazing fast model requirements installing
We are grateful to the developers and contributors of these projects for their hard work and dedication.
================================================
FILE: gen_readme.py
================================================
# /// script
# requires-python = ">=3.11"
# dependencies = [
# "jinja2",
# "pre-commit",
# "uv",
# ]
# ///
import subprocess, sys, pathlib, json, jinja2
if __name__ == '__main__':
with (pathlib.Path('.').parent / 'README.md').open('w') as f:
f.write(
jinja2.Environment(loader=jinja2.FileSystemLoader('.'))
.get_template('README.md.tpl')
.render(
model_dict=json.loads(
subprocess.run(
[
sys.executable,
'-m',
'uv',
'run',
'--with-editable',
'.',
'openllm',
'model',
'list',
'--output',
'readme',
],
text=True,
check=True,
capture_output=True,
).stdout.strip()
)
)
)
================================================
FILE: pyproject.toml
================================================
[project]
name = "openllm"
description = "OpenLLM: Self-hosting LLMs Made Easy."
readme = { file = "README.md", content-type = "text/markdown" }
authors = [{ name = "BentoML Team", email = "contact@bentoml.com" }]
dynamic = ["version"]
classifiers = [
"Development Status :: 5 - Production/Stable",
"Environment :: GPU :: NVIDIA CUDA",
"Environment :: GPU :: NVIDIA CUDA :: 12",
"Environment :: GPU :: NVIDIA CUDA :: 11.8",
"Environment :: GPU :: NVIDIA CUDA :: 11.7",
"License :: OSI Approved :: Apache Software License",
"Topic :: Scientific/Engineering :: Artificial Intelligence",
"Topic :: Software Development :: Libraries",
"Operating System :: OS Independent",
"Intended Audience :: Developers",
"Intended Audience :: Science/Research",
"Intended Audience :: System Administrators",
"Typing :: Typed",
"Programming Language :: Python",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3 :: Only",
"Programming Language :: Python :: 3.8",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: Implementation :: CPython",
"Programming Language :: Python :: Implementation :: PyPy",
]
dependencies = [
"bentoml==1.4.23",
"typer",
"questionary",
"pyaml",
"attrs",
"psutil",
"pip_requirements_parser",
"nvidia-ml-py",
"dulwich",
"tabulate",
"uv",
"openai==1.90.0",
"huggingface-hub",
"hf-xet",
"typing-extensions>=4.12.2",
]
keywords = [
"MLOps",
"AI",
"BentoML",
"Model Serving",
"Model Deployment",
"LLMOps",
"Falcon",
"Vicuna",
"Llama 2",
"Fine tuning",
"Serverless",
"Large Language Model",
"Generative AI",
"StableLM",
"Alpaca",
"PyTorch",
"Mistral",
"vLLM",
"Transformers",
]
license = "Apache-2.0"
requires-python = ">=3.9"
[project.scripts]
openllm = "openllm.__main__:app"
[project.urls]
Blog = "https://modelserving.com"
Documentation = "https://github.com/bentoml/OpenLLM#readme"
GitHub = "https://github.com/bentoml/OpenLLM"
Homepage = "https://bentoml.com"
Tracker = "https://github.com/bentoml/OpenLLM/issues"
Twitter = "https://twitter.com/bentomlai"
[tool.typer]
src-dir = "src/openllm"
[build-system]
requires = ["hatchling==1.27.0", "hatch-vcs==0.5.0"]
build-backend = 'hatchling.build'
[dependency-groups]
tests = ["pexpect>=4.9.0", "pytest>=8.3.5"]
[tool.hatch.version]
source = "vcs"
fallback-version = "0.0.0"
[tool.hatch.build.hooks.vcs]
version-file = "src/openllm/_version.py"
[tool.hatch.version.raw-options]
git_describe_command = [
"git",
"describe",
"--dirty",
"--tags",
"--long",
"--first-parent",
]
version_scheme = "post-release"
fallback_version = "0.0.0"
[tool.hatch.metadata]
allow-direct-references = true
[tool.hatch.build.targets.wheel]
only-include = ["src/openllm"]
sources = ["src"]
[tool.hatch.build.targets.sdist]
exclude = ["/.git_archival.txt", "/.python-version-default"]
================================================
FILE: pyrightconfig.json
================================================
{
"useLibraryCodeForTypes": true,
"verboseOutput": true,
"define": {
"MYPY": true
},
"venvPath": ".",
"venv": ".venv",
"pythonVersion": "3.9",
"enableExperimentalFeatures": true,
"reportMissingImports": "warning",
"reportMissingTypeStubs": false,
"reportPrivateUsage": "warning",
"reportUnknownArgumentType": "warning",
"reportUnsupportedDunderAll": "warning",
"reportWildcardImportFromLibrary": "warning"
}
================================================
FILE: release.sh
================================================
#!/usr/bin/env bash
set -e
# Function to print script usage
print_usage() {
echo "Usage: $0 [--release <major|minor|patch|alpha>]"
}
# Function to validate release argument
validate_release() {
local release=$1
if [[ $release == "major" || $release == "minor" || $release == "patch" || $release == "alpha" ]]; then
return 0
else
return 1
fi
}
# Check if release flag is provided
if [[ $1 == "--release" ]]; then
# Check if release argument is provided
if [[ -z $2 ]]; then
echo "Error: No release argument provided."
print_usage
exit 1
fi
release=$2
if ! validate_release "$release"; then
echo "Error: Invalid release argument. Only 'major', 'minor', 'patch', or 'alpha' are allowed."
print_usage
exit 1
fi
else
echo "Error: Unknown option or no option provided."
print_usage
exit 1
fi
# Get the current version and separate the alpha part if it exists
version="$(git describe --tags "$(git rev-list --tags --max-count=1)")"
VERSION="${version#v}"
# Initialize variables for alpha versioning
ALPHA=""
ALPHA_NUM=0
# Check if current version is an alpha version and split accordingly
if [[ $VERSION =~ -alpha ]]; then
IFS='-' read -r BASE_VERSION ALPHA <<<"$VERSION"
if [[ $ALPHA =~ [.] ]]; then
IFS='.' read -r ALPHA ALPHA_NUM <<<"$ALPHA"
fi
else
BASE_VERSION="$VERSION"
fi
# Save the current value of IFS to restore it later and split the base version
OLD_IFS=$IFS
IFS='.'
read -ra VERSION_BITS <<<"$BASE_VERSION"
IFS=$OLD_IFS
# Assign split version numbers
VNUM1=${VERSION_BITS[0]}
VNUM2=${VERSION_BITS[1]}
VNUM3=${VERSION_BITS[2]}
# Adjust the version numbers based on the release type
if [[ $release == 'major' ]]; then
VNUM1=$((VNUM1 + 1))
VNUM2=0
VNUM3=0
ALPHA="" # Reset alpha for major release
elif [[ $release == 'minor' ]]; then
if [[ -n $ALPHA ]]; then
ALPHA="" # Remove alpha suffix for minor release from an alpha version
else
VNUM2=$((VNUM2 + 1))
VNUM3=0
fi
elif [[ $release == 'patch' ]]; then
VNUM3=$((VNUM3 + 1))
ALPHA="" # Reset alpha for patch release
elif [[ $release == 'alpha' ]]; then
if [ -n "$ALPHA" ]; then
ALPHA_NUM=$((ALPHA_NUM + 1))
else
VNUM2=$((VNUM2 + 1))
VNUM3=0
ALPHA="alpha"
ALPHA_NUM=0
fi
fi
# Construct the new version string
if [ -n "$ALPHA" ]; then
if ((ALPHA_NUM > 0)); then
RELEASE_VERSION="$VNUM1.$VNUM2.$VNUM3-alpha.$ALPHA_NUM"
else
RELEASE_VERSION="$VNUM1.$VNUM2.$VNUM3-alpha"
fi
else
RELEASE_VERSION="$VNUM1.$VNUM2.$VNUM3"
fi
echo "Commit count: $(git rev-list --count HEAD)"
echo "Releasing tag ${RELEASE_VERSION}..." && git tag -a "v${RELEASE_VERSION}" -m "Release ${RELEASE_VERSION} [generated by GitHub Actions]"
git push origin "v${RELEASE_VERSION}"
echo "Finish releasing OpenLLM ${RELEASE_VERSION}"
================================================
FILE: src/openllm/__init__.py
================================================
================================================
FILE: src/openllm/__main__.py
================================================
from __future__ import annotations
import importlib.metadata, os, platform, random, sys, typing
import questionary, typer
from collections import defaultdict
from openllm.accelerator_spec import can_run, get_local_machine_spec
from openllm.analytic import DO_NOT_TRACK, OpenLLMTyper
from openllm.clean import app as clean_app
from openllm.cloud import deploy as cloud_deploy, get_cloud_machine_spec
from openllm.common import CHECKED, INTERACTIVE, VERBOSE_LEVEL, BentoInfo, output
from openllm.local import run as local_run, serve as local_serve
from openllm.model import app as model_app, ensure_bento, list_bento
from openllm.repo import app as repo_app, cmd_update
if typing.TYPE_CHECKING:
from openllm.common import DeploymentTarget
app = OpenLLMTyper(
help='`openllm hello` to get started. '
'OpenLLM is a CLI tool to manage and deploy open source LLMs and'
' get an OpenAI API compatible chat server in seconds.'
)
app.add_typer(repo_app, name='repo')
app.add_typer(model_app, name='model')
app.add_typer(clean_app, name='clean')
def _select_bento_name(models: list[BentoInfo], target: DeploymentTarget) -> tuple[str, str]:
from tabulate import tabulate
model_infos = [(model.repo.name, model.name, can_run(model, target)) for model in models]
model_name_groups: defaultdict[tuple[str, str], float] = defaultdict(lambda: 0.0)
for repo, name, score in model_infos:
model_name_groups[repo, name] += score
table_data = [
(name, repo, CHECKED if score > 0 else '') for (repo, name), score in model_name_groups.items()
]
if not table_data:
output('No model found', style='red')
raise typer.Exit(1)
table: list[str] = tabulate(table_data, headers=['model', 'repo', 'locally runnable']).split('\n')
selected: tuple[str, str] | None = questionary.select(
'Select a model',
[
questionary.Separator(f'{table[0]}\n {table[1]}'),
*[questionary.Choice(line, value=value[:2]) for value, line in zip(table_data, table[2:])],
],
use_search_filter=True,
use_jk_keys=False,
).ask()
if selected is None:
raise typer.Exit(1)
return selected
def _select_bento_version(
models: list[BentoInfo], target: DeploymentTarget | None, bento_name: str, repo: str
) -> tuple[BentoInfo, float]:
from tabulate import tabulate
model_infos: list[tuple[BentoInfo, float]] = [
(model, can_run(model, target))
for model in models
if model.name == bento_name and model.repo.name == repo
]
table_data = [
[model.tag, CHECKED if score > 0 else '']
for model, score in model_infos
if model.name == bento_name and model.repo.name == repo
]
if not table_data:
output(f'No model found for {bento_name} in {repo}', style='red')
raise typer.Exit(1)
table: list[str] = tabulate(table_data, headers=['version', 'locally runnable']).split('\n')
selected: tuple[BentoInfo, float] | None = questionary.select(
'Select a version',
[
questionary.Separator(f'{table[0]}\n {table[1]}'),
*[questionary.Choice(line, value=value[:2]) for value, line in zip(model_infos, table[2:])],
],
use_search_filter=True,
use_jk_keys=False,
).ask()
if selected is None:
raise typer.Exit(1)
return selected
def _select_target(bento: BentoInfo, targets: list[DeploymentTarget]) -> DeploymentTarget:
from tabulate import tabulate
targets.sort(key=lambda x: can_run(bento, x), reverse=True)
if not targets:
output('No available instance type, check your bentocloud account', style='red')
raise typer.Exit(1)
table = tabulate(
[
[
target.name,
target.accelerators_repr,
f'${target.price}',
CHECKED if can_run(bento, target) else 'insufficient res.',
]
for target in targets
],
headers=['instance type', 'accelerator', 'price/hr', 'deployable'],
).split('\n')
selected: DeploymentTarget | None = questionary.select(
'Select an instance type',
[
questionary.Separator(f'{table[0]}\n {table[1]}'),
*[questionary.Choice(f'{line}', value=target) for target, line in zip(targets, table[2:])],
],
use_search_filter=True,
use_jk_keys=False,
).ask()
if selected is None:
raise typer.Exit(1)
return selected
def _select_action(
bento: BentoInfo,
score: float,
context: typing.Optional[str] = None,
envs: typing.Optional[list[str]] = None,
arg: typing.Optional[list[str]] = None,
interactive: bool = False,
) -> None:
if score > 0:
options: list[typing.Any] = [
questionary.Separator('Available actions'),
questionary.Choice('0. Run the model in terminal', value='run', shortcut_key='0'),
questionary.Separator(f' $ openllm run {bento}'),
questionary.Separator(' '),
questionary.Choice(
'1. Serve the model locally and get a chat server', value='serve', shortcut_key='1'
),
questionary.Separator(f' $ openllm serve {bento}'),
questionary.Separator(' '),
questionary.Choice(
'2. Deploy the model to bentocloud and get a scalable chat server',
value='deploy',
shortcut_key='2',
),
questionary.Separator(f' $ openllm deploy {bento}'),
]
else:
options = [
questionary.Separator('Available actions'),
questionary.Choice(
'0. Run the model in terminal', value='run', disabled='insufficient res.', shortcut_key='0'
),
questionary.Separator(f' $ openllm run {bento}'),
questionary.Separator(' '),
questionary.Choice(
'1. Serve the model locally and get a chat server',
value='serve',
disabled='insufficient res.',
shortcut_key='1',
),
questionary.Separator(f' $ openllm serve {bento}'),
questionary.Separator(' '),
questionary.Choice(
'2. Deploy the model to bentocloud and get a scalable chat server',
value='deploy',
shortcut_key='2',
),
questionary.Separator(f' $ openllm deploy {bento}'),
]
action: str | None = questionary.select('Select an action', options).ask()
if action is None:
raise typer.Exit(1)
if action == 'run':
try:
port = random.randint(30000, 40000)
local_run(bento, port=port, cli_envs=envs, cli_args=arg)
finally:
output('\nUse this command to run the action again:', style='green')
output(f' $ openllm run {bento}', style='orange')
elif action == 'serve':
try:
local_serve(bento, cli_envs=envs, cli_args=arg)
finally:
output('\nUse this command to run the action again:', style='green')
output(f' $ openllm serve {bento}', style='orange')
elif action == 'deploy':
targets = get_cloud_machine_spec(context=context)
target = _select_target(bento, targets)
try:
cloud_deploy(
bento, target, cli_envs=envs, context=context, cli_args=arg, interactive=interactive
)
finally:
output('\nUse this command to run the action again:', style='green')
output(f' $ openllm deploy {bento} --instance-type {target.name}', style='orange')
@app.command(help='get started interactively')
def hello(
repo: typing.Optional[str] = None,
envs: typing.Optional[list[str]] = typer.Option(
None,
'--env',
help='Environment variables to pass to the deployment command. Format: NAME or NAME=value. Can be specified multiple times.',
),
arg: typing.Optional[list[str]] = typer.Option(
None,
'--arg',
help='Bento arguments in the form of key=value pairs. Can be specified multiple times.',
),
context: typing.Optional[str] = typer.Option(
None, '--context', help='BentoCloud context name to pass to the deployment command.'
),
) -> None:
cmd_update()
INTERACTIVE.set(True)
target = get_local_machine_spec()
output(f' Detected Platform: {target.platform}', style='green')
if target.accelerators:
output(' Detected Accelerators: ', style='green')
for a in target.accelerators:
output(f' - {a.model} {a.memory_size}GB', style='green')
else:
output(' Detected Accelerators: None', style='green')
models = list_bento(repo_name=repo)
if not models:
output('No model found, you probably need to update the model repo:', style='red')
output(' $ openllm repo update', style='orange')
raise typer.Exit(1)
bento_name, repo = _select_bento_name(models, target)
bento, score = _select_bento_version(models, target, bento_name, repo)
_select_action(bento, score, context=context, envs=envs, arg=arg, interactive=INTERACTIVE.get())
@app.command(help='start an OpenAI API compatible chat server and chat in browser')
def serve(
model: typing.Annotated[str, typer.Argument()],
repo: typing.Optional[str] = None,
port: int = 3000,
verbose: bool = False,
env: typing.Optional[list[str]] = typer.Option(
None,
'--env',
help='Environment variables to pass to the deployment command. Format: NAME or NAME=value. Can be specified multiple times.',
),
arg: typing.Optional[list[str]] = typer.Option(
None,
'--arg',
help='Bento arguments in the form of key=value pairs. Can be specified multiple times.',
),
) -> None:
cmd_update()
if verbose:
VERBOSE_LEVEL.set(20)
target = get_local_machine_spec()
bento = ensure_bento(model, target=target, repo_name=repo)
local_serve(bento, port=port, cli_envs=env, cli_args=arg)
@app.command(help='run the model and chat in terminal')
def run(
model: typing.Annotated[str, typer.Argument()] = '',
repo: typing.Optional[str] = None,
port: typing.Optional[int] = None,
timeout: int = 600,
verbose: bool = False,
env: typing.Optional[list[str]] = typer.Option(
None,
'--env',
help='Environment variables to pass to the deployment command. Format: NAME or NAME=value. Can be specified multiple times.',
),
arg: typing.Optional[list[str]] = typer.Option(
None,
'--arg',
help='Bento arguments in the form of key=value pairs. Can be specified multiple times.',
),
) -> None:
cmd_update()
if verbose:
VERBOSE_LEVEL.set(20)
target = get_local_machine_spec()
bento = ensure_bento(model, target=target, repo_name=repo)
if port is None:
port = random.randint(30000, 40000)
local_run(bento, port=port, timeout=timeout, cli_envs=env, cli_args=arg)
@app.command(help='deploy production-ready OpenAI API-compatible server to BentoCloud')
def deploy(
model: typing.Annotated[str, typer.Argument()] = '',
instance_type: typing.Optional[str] = None,
repo: typing.Optional[str] = None,
verbose: bool = False,
env: typing.Optional[list[str]] = typer.Option(
None,
'--env',
help='Environment variables to pass to the deployment command. Format: NAME or NAME=value. Can be specified multiple times.',
),
context: typing.Optional[str] = typer.Option(
None, '--context', help='BentoCloud context name to pass to the deployment command.'
),
arg: typing.Optional[list[str]] = typer.Option(
None,
'--arg',
help='Bento arguments in the form of key=value pairs. Can be specified multiple times.',
),
) -> None:
cmd_update()
if verbose:
VERBOSE_LEVEL.set(20)
bento = ensure_bento(model, repo_name=repo)
if instance_type is not None:
return cloud_deploy(
bento,
DeploymentTarget(accelerators=[], name=instance_type),
cli_envs=env,
context=context,
cli_args=arg,
interactive=INTERACTIVE.get(),
)
targets = get_cloud_machine_spec(context=context)
runnable_targets = sorted(
filter(lambda x: can_run(bento, x) > 0, targets), key=lambda x: can_run(bento, x), reverse=True
)
if not runnable_targets:
output('No available instance type, check your bentocloud account', style='red')
raise typer.Exit(1)
# Use questionary to select target when in interactive mode and no instance_type is provided
if INTERACTIVE.get() and instance_type is None:
target = _select_target(bento, targets)
else:
target = runnable_targets[0]
output(f'Recommended instance type: {target.name}', style='green')
cloud_deploy(
bento, target, cli_envs=env, context=context, cli_args=arg, interactive=INTERACTIVE.get()
)
@app.callback(invoke_without_command=True)
def typer_callback(
verbose: int = 0,
do_not_track: bool = typer.Option(
False, '--do-not-track', help='Whether to disable usage tracking', envvar=DO_NOT_TRACK
),
version: bool = typer.Option(False, '--version', '-v', help='Show version'),
) -> None:
if verbose:
VERBOSE_LEVEL.set(verbose)
if version:
output(
f'openllm, {importlib.metadata.version("openllm")}\nPython ({platform.python_implementation()}) {platform.python_version()}'
)
sys.exit(0)
if do_not_track:
os.environ[DO_NOT_TRACK] = str(True)
if __name__ == '__main__':
app()
================================================
FILE: src/openllm/accelerator_spec.py
================================================
from __future__ import annotations
import functools, math, re, typing
import psutil, pydantic
from pydantic import BeforeValidator
from typing_extensions import override
from openllm.common import BentoInfo, DeploymentTarget, output, Accelerator
def parse_memory_string(v: typing.Any) -> typing.Any:
"""Parse memory strings like "60Gi" into float."""
if isinstance(v, str):
match = re.match(r'(\d+(\.\d+)?)\s*Gi$', v, re.IGNORECASE)
if match:
return float(match.group(1))
# Pass other types (including numbers or other strings for standard float conversion) through
return v
class Resource(pydantic.BaseModel):
memory: typing.Annotated[float, BeforeValidator(parse_memory_string)] = 0.0
cpu: int = 0
gpu: int = 0
gpu_type: str = ''
@override
def __hash__(self) -> int:
return hash((self.cpu, self.memory, self.gpu, self.gpu_type))
def __bool__(self) -> bool:
return any(value is not None for value in self.__dict__.values())
ACCELERATOR_SPECS: dict[str, Accelerator] = {
'nvidia-gtx-1650': Accelerator(model='GTX 1650', memory_size=4.0),
'nvidia-gtx-1060': Accelerator(model='GTX 1060', memory_size=6.0),
'nvidia-gtx-1080-ti': Accelerator(model='GTX 1080 Ti', memory_size=11.0),
'nvidia-rtx-3060': Accelerator(model='RTX 3060', memory_size=12.0),
'nvidia-rtx-3060-ti': Accelerator(model='RTX 3060 Ti', memory_size=8.0),
'nvidia-rtx-3070-ti': Accelerator(model='RTX 3070 Ti', memory_size=8.0),
'nvidia-rtx-3080': Accelerator(model='RTX 3080', memory_size=10.0),
'nvidia-rtx-3080-ti': Accelerator(model='RTX 3080 Ti', memory_size=12.0),
'nvidia-rtx-3090': Accelerator(model='RTX 3090', memory_size=24.0),
'nvidia-rtx-4070-ti': Accelerator(model='RTX 4070 Ti', memory_size=12.0),
'nvidia-tesla-p4': Accelerator(model='P4', memory_size=8.0),
'nvidia-tesla-p100': Accelerator(model='P100', memory_size=16.0),
'nvidia-tesla-k80': Accelerator(model='K80', memory_size=12.0),
'nvidia-tesla-t4': Accelerator(model='T4', memory_size=16.0),
'nvidia-tesla-v100': Accelerator(model='V100', memory_size=16.0),
'nvidia-l4': Accelerator(model='L4', memory_size=24.0),
'nvidia-tesla-l4': Accelerator(model='L4', memory_size=24.0),
'nvidia-tesla-a10g': Accelerator(model='A10G', memory_size=24.0),
'nvidia-a100-80g': Accelerator(model='A100', memory_size=80.0),
'nvidia-a100-80gb': Accelerator(model='A100', memory_size=80.0),
'nvidia-tesla-a100': Accelerator(model='A100', memory_size=40.0),
'nvidia-tesla-h100': Accelerator(model='H100', memory_size=80.0),
'nvidia-h200-141gb': Accelerator(model='H200', memory_size=141.0),
'nvidia-blackwell-b100': Accelerator(model='B100', memory_size=192.0),
'nvidia-blackwell-gb200': Accelerator(model='GB200', memory_size=192.0),
}
@functools.lru_cache
def get_local_machine_spec() -> DeploymentTarget:
if psutil.MACOS:
return DeploymentTarget(accelerators=[], source='local', platform='macos')
if psutil.WINDOWS:
platform = 'windows'
elif psutil.LINUX:
platform = 'linux'
else:
raise NotImplementedError('Unsupported platform')
from pynvml import (
nvmlDeviceGetCount,
nvmlDeviceGetCudaComputeCapability,
nvmlDeviceGetHandleByIndex,
nvmlDeviceGetMemoryInfo,
nvmlDeviceGetName,
nvmlInit,
nvmlShutdown,
)
try:
nvmlInit()
device_count = nvmlDeviceGetCount()
accelerators: list[Accelerator] = []
for i in range(device_count):
handle = nvmlDeviceGetHandleByIndex(i)
name = nvmlDeviceGetName(handle)
memory_info = nvmlDeviceGetMemoryInfo(handle)
accelerators.append(
Accelerator(model=name, memory_size=math.ceil(int(memory_info.total) / 1024**3))
)
compute_capability = nvmlDeviceGetCudaComputeCapability(handle)
if compute_capability < (7, 5):
output(
f'GPU {name} with compute capability {compute_capability} '
'may not be supported, 7.5 or higher is recommended. check '
'https://developer.nvidia.com/cuda-gpus for more information',
style='yellow',
)
nvmlShutdown()
return DeploymentTarget(accelerators=accelerators, source='local', platform=platform)
except Exception as e:
output(
'Failed to get local GPU info. Ensure nvidia driver is installed to enable local GPU deployment',
style='yellow',
)
output(f'Error: {e}', style='red', level=20)
return DeploymentTarget(accelerators=[], source='local', platform=platform)
@functools.lru_cache(typed=True)
def can_run(bento: BentoInfo, target: DeploymentTarget | None = None) -> float:
"""
Calculate if the bento can be deployed on the target.
"""
if target is None:
target = get_local_machine_spec()
resource_spec = Resource(**(bento.bento_yaml['services'][0]['config'].get('resources', {})))
labels = bento.bento_yaml.get('labels', {})
platforms = labels.get('platforms', 'linux').split(',')
if target.platform not in platforms:
return 0.0
# return 1.0 if no resource is specified
if not resource_spec:
return 0.5
if resource_spec.gpu > 0:
required_gpu = ACCELERATOR_SPECS[resource_spec.gpu_type]
filtered_accelerators = [
ac for ac in target.accelerators if ac.memory_size >= required_gpu.memory_size
]
if resource_spec.gpu > len(filtered_accelerators):
return 0.0
return (
required_gpu.memory_size
* resource_spec.gpu
/ sum(ac.memory_size for ac in target.accelerators)
)
if target.accelerators:
return 0.01 / sum(ac.memory_size for ac in target.accelerators)
return 1.0
================================================
FILE: src/openllm/analytic.py
================================================
from __future__ import annotations
import functools, os, re, time, typing, abc
import attr, click, typer, typer.core
DO_NOT_TRACK = 'BENTOML_DO_NOT_TRACK'
class EventMeta(abc.ABC):
@property
def event_name(self) -> str:
# camel case to snake case
event_name = re.sub(r'(?<!^)(?=[A-Z])', '_', self.__class__.__name__).lower()
# remove "_event" suffix
suffix_to_remove = '_event'
if event_name.endswith(suffix_to_remove):
event_name = event_name[: -len(suffix_to_remove)]
return event_name
@attr.define
class CliEvent(EventMeta):
cmd_group: str
cmd_name: str
duration_in_ms: float = attr.field(default=0)
error_type: typing.Optional[str] = attr.field(default=None)
return_code: typing.Optional[int] = attr.field(default=None)
@attr.define
class OpenllmCliEvent(CliEvent):
pass
class OrderedCommands(typer.core.TyperGroup):
def list_commands(self, ctx: click.Context) -> list[str]:
return list(self.commands)
class OpenLLMTyper(typer.Typer):
def __init__(self, *args: typing.Any, **kwargs: typing.Any):
no_args_is_help: bool = kwargs.pop('no_args_is_help', True)
context_settings: dict[str, typing.Any] = kwargs.pop('context_settings', {})
if 'help_option_names' not in context_settings:
context_settings['help_option_names'] = ('-h', '--help')
if 'max_content_width' not in context_settings:
context_settings['max_content_width'] = int(os.environ.get('COLUMNS', str(120)))
klass = kwargs.pop('cls', OrderedCommands)
super().__init__(
*args, cls=klass, no_args_is_help=no_args_is_help, context_settings=context_settings, **kwargs
)
# NOTE: Since OpenLLMTyper only wraps command to add analytics, the default type-hint for @app.command
# does not change, hence the below hijacking.
if typing.TYPE_CHECKING:
command = typer.Typer.command
else:
def command(self, *args: typing.Any, **kwargs: typing.Any):
def decorator(f):
@functools.wraps(f)
@click.pass_context
def wrapped(ctx: click.Context, *args, **kwargs):
from bentoml._internal.utils.analytics import track
do_not_track = os.environ.get(DO_NOT_TRACK, str(False)).lower() == 'true'
# so we know that the root program is openllm
command_name = ctx.info_name
if ctx.parent.parent is not None:
# openllm model list
command_group = ctx.parent.info_name
elif ctx.parent.info_name == ctx.find_root().info_name:
# openllm run
command_group = 'openllm'
if do_not_track:
return f(*args, **kwargs)
start_time = time.time_ns()
try:
return_value = f(*args, **kwargs)
duration_in_ns = time.time_ns() - start_time
track(
OpenllmCliEvent(
cmd_group=command_group, cmd_name=command_name, duration_in_ms=duration_in_ns / 1e6
)
)
return return_value
except BaseException as e:
duration_in_ns = time.time_ns() - start_time
track(
OpenllmCliEvent(
cmd_group=command_group,
cmd_name=command_name,
duration_in_ms=duration_in_ns / 1e6,
error_type=type(e).__name__,
return_code=(2 if isinstance(e, KeyboardInterrupt) else 1),
)
)
raise
return typer.Typer.command(self, *args, **kwargs)(wrapped)
return decorator
================================================
FILE: src/openllm/clean.py
================================================
from __future__ import annotations
import os, pathlib, shutil
import questionary
from openllm.analytic import OpenLLMTyper
from openllm.common import CONFIG_FILE, REPO_DIR, VENV_DIR, VERBOSE_LEVEL, output
app = OpenLLMTyper(help='clean up and release disk space used by OpenLLM')
HUGGINGFACE_CACHE = pathlib.Path.home() / '.cache' / 'huggingface' / 'hub'
def _du(path: pathlib.Path) -> int:
seen_paths = set()
used_space = 0
for f in path.rglob('*'):
if os.name == 'nt': # Windows system
# On Windows, directly add file sizes without considering hard links
used_space += f.stat().st_size
else:
# On non-Windows systems, use inodes to avoid double counting
stat = f.stat()
if stat.st_ino not in seen_paths:
seen_paths.add(stat.st_ino)
used_space += stat.st_size
return used_space
@app.command(help='Clean up all the cached models from huggingface')
def model_cache(verbose: bool = False) -> None:
if verbose:
VERBOSE_LEVEL.set(20)
used_space = _du(HUGGINGFACE_CACHE)
sure = questionary.confirm(
f'This will remove all models cached by Huggingface (~{used_space / 1024 / 1024:.2f}MB), are you sure?'
).ask()
if not sure:
return
shutil.rmtree(HUGGINGFACE_CACHE, ignore_errors=True)
output('All models cached by Huggingface have been removed', style='green')
@app.command(help='Clean up all the virtual environments created by OpenLLM')
def venvs(verbose: bool = False) -> None:
if verbose:
VERBOSE_LEVEL.set(20)
used_space = _du(VENV_DIR)
sure = questionary.confirm(
f'This will remove all virtual environments created by OpenLLM (~{used_space / 1024 / 1024:.2f}MB), are you sure?'
).ask()
if not sure:
return
shutil.rmtree(VENV_DIR, ignore_errors=True)
output('All virtual environments have been removed', style='green')
@app.command(help='Clean up all the repositories cloned by OpenLLM')
def repos(verbose: bool = False) -> None:
if verbose:
VERBOSE_LEVEL.set(20)
shutil.rmtree(REPO_DIR, ignore_errors=True)
output('All repositories have been removed', style='green')
@app.command(help='Reset configurations to default')
def configs(verbose: bool = False) -> None:
if verbose:
VERBOSE_LEVEL.set(20)
shutil.rmtree(CONFIG_FILE, ignore_errors=True)
output('All configurations have been reset', style='green')
@app.command(name='all', help='Clean up all above and bring OpenLLM to a fresh start')
def all_cache(verbose: bool = False) -> None:
if verbose:
VERBOSE_LEVEL.set(20)
repos()
venvs()
model_cache()
configs()
================================================
FILE: src/openllm/cloud.py
================================================
from __future__ import annotations
import json, os, pathlib, shutil, subprocess, typing
import typer
from openllm.analytic import OpenLLMTyper
from openllm.accelerator_spec import ACCELERATOR_SPECS
from openllm.common import BentoInfo, DeploymentTarget, EnvVars, output, run_command, INTERACTIVE
app = OpenLLMTyper()
def resolve_cloud_config() -> pathlib.Path:
env = os.environ.get('BENTOML_HOME')
if env is not None:
return pathlib.Path(env) / '.yatai.yaml'
return pathlib.Path.home() / 'bentoml' / '.yatai.yaml'
def _get_deploy_cmd(
bento: BentoInfo,
target: typing.Optional[DeploymentTarget] = None,
cli_envs: typing.Optional[list[str]] = None,
context: typing.Optional[str] = None,
cli_args: typing.Optional[list[str]] = None,
) -> tuple[list[str], EnvVars]:
cmd = ['bentoml', 'deploy', bento.bentoml_tag]
if cli_args:
for arg in cli_args:
cmd += ['--arg', arg]
env = EnvVars({'BENTOML_HOME': f'{bento.repo.path}/bentoml'})
# Process CLI env vars first to determine overrides
explicit_envs: dict[str, str] = {}
if cli_envs:
for env_var in cli_envs:
if '=' in env_var:
name, value = env_var.split('=', 1)
explicit_envs[name] = value
else:
name = env_var
value = typing.cast(str, os.environ.get(name))
if value is None:
output(
f"Environment variable '{name}' specified via --env but not found in the current environment.",
style='red',
)
raise typer.Exit(1)
explicit_envs[name] = value
# Process envs defined in bento.yaml, skipping those overridden by CLI
required_envs = bento.bento_yaml.get('envs', [])
all_required_env_names = [env['name'] for env in required_envs if 'name' in env]
required_env_names = [
env['name']
for env in required_envs
if 'name' in env
and env['name'] not in explicit_envs
and not env.get('value')
and env['name'] not in os.environ
]
if required_env_names:
output(
f'This model requires the following environment variables to run (unless overridden via --env): {required_env_names!r}',
style='green',
)
for env_info in required_envs:
name = typing.cast(str, env_info.get('name'))
if not name or name in explicit_envs or env_info.get('value', ''):
continue
if os.environ.get(name):
default = os.environ[name]
elif 'value' in env_info:
default = env_info['value']
else:
default = ''
if INTERACTIVE.get():
import questionary
value = questionary.text(f'{name}: (from bento.yaml)', default=default).ask()
else:
if default == '':
output(
f'Environment variable {name} (from bento.yaml) is required but not provided', style='red'
)
raise typer.Exit(1)
else:
value = default
if value is None:
raise typer.Exit(1)
cmd += ['--env', f'{name}={value}']
# Add any required envs from os.environ that haven't been handled yet
for name in all_required_env_names:
if name in os.environ:
cmd += ['--env', f'{name}={os.environ.get(name)}']
# Add explicitly provided env vars from CLI
for name, value in explicit_envs.items():
cmd += ['--env', f'{name}={value}']
if target:
cmd += ['--instance-type', target.name]
if context:
cmd += ['--context', context]
base_config = resolve_cloud_config()
if not base_config.exists():
raise Exception('Cannot find cloud config.')
# remove before copy
if (bento.repo.path / 'bentoml' / '.yatai.yaml').exists():
(bento.repo.path / 'bentoml' / '.yatai.yaml').unlink()
shutil.copy(base_config, bento.repo.path / 'bentoml' / '.yatai.yaml')
return cmd, env
def get_current_context() -> str | None:
cmd = ['bentoml', 'cloud', 'current-context']
try:
result = subprocess.check_output(cmd, stderr=subprocess.DEVNULL)
return typing.cast(str, json.loads(result)['name'])
except subprocess.CalledProcessError:
return None
def ensure_cloud_context() -> None:
import questionary
cmd = ['bentoml', 'cloud', 'current-context']
try:
result = subprocess.check_output(cmd, stderr=subprocess.DEVNULL)
context = json.loads(result)
output(f' bentoml already logged in: {context["endpoint"]}', style='green', level=20)
except subprocess.CalledProcessError:
output(' bentoml not logged in', style='red')
if not INTERACTIVE.get():
output('\n get bentoml logged in by:')
output(' $ bentoml cloud login', style='orange')
output('')
output(
""" * you may need to visit https://cloud.bentoml.com to get an account. you can also bring your own bentoml cluster (BYOC) to your team from https://bentoml.com/contact""",
style='yellow',
)
raise typer.Exit(1)
else:
action = questionary.select(
'Choose an action:',
choices=['I have a BentoCloud account', 'get an account in two minutes'],
).ask()
if action is None:
raise typer.Exit(1)
elif action == 'get an account in two minutes':
output('Please visit https://cloud.bentoml.com to get your token', style='yellow')
endpoint = questionary.text(
'Enter the endpoint: (similar to https://my-org.cloud.bentoml.com)'
).ask()
if endpoint is None:
raise typer.Exit(1)
token = questionary.text('Enter your token: (similar to cniluaxxxxxxxx)').ask()
if token is None:
raise typer.Exit(1)
cmd = ['bentoml', 'cloud', 'login', '--api-token', token, '--endpoint', endpoint]
try:
result = subprocess.check_output(cmd)
output(' Logged in successfully', style='green')
except subprocess.CalledProcessError:
output(' Failed to login', style='red')
raise typer.Exit(1)
def get_cloud_machine_spec(context: typing.Optional[str] = None) -> list[DeploymentTarget]:
ensure_cloud_context()
cmd = ['bentoml', 'deployment', 'list-instance-types', '-o', 'json']
if context:
cmd += ['--context', context]
if context is None:
context = get_current_context()
try:
result = subprocess.check_output(cmd, stderr=subprocess.DEVNULL)
instance_types = json.loads(result)
return [
DeploymentTarget(
source='cloud',
name=it['name'],
price=it['price'],
platform='linux',
accelerators=(
[ACCELERATOR_SPECS[it['gpu_type']] for _ in range(int(it['gpu']))]
if it.get('gpu') and it['gpu_type'] in ACCELERATOR_SPECS
else []
),
)
for it in instance_types
]
except (subprocess.CalledProcessError, json.JSONDecodeError):
output(
f'Failed to get cloud instance types{"" if context is None else f" for context {context}"}',
style='red',
)
return []
def deploy(
bento: BentoInfo,
target: DeploymentTarget,
cli_envs: typing.Optional[list[str]] = None,
context: typing.Optional[str] = None,
cli_args: typing.Optional[list[str]] = None,
interactive: bool = False,
) -> None:
INTERACTIVE.set(interactive)
ensure_cloud_context()
cmd, env = _get_deploy_cmd(bento, target, cli_envs=cli_envs, context=context, cli_args=cli_args)
run_command(cmd, env=env, cwd=None)
================================================
FILE: src/openllm/common.py
================================================
from __future__ import annotations
import asyncio, asyncio.subprocess, functools, hashlib, io, json, os, pathlib, signal, subprocess, sys, sysconfig, typing, shlex
import typer, typer.core, pydantic, questionary, pyaml, yaml
from collections import UserDict
from contextlib import asynccontextmanager, contextmanager
from typing_extensions import override
from pydantic_core import core_schema
ERROR_STYLE = 'red'
SUCCESS_STYLE = 'green'
OPENLLM_HOME = pathlib.Path(os.getenv('OPENLLM_HOME', pathlib.Path.home() / '.openllm'))
REPO_DIR = OPENLLM_HOME / 'repos'
TEMP_DIR = OPENLLM_HOME / 'temp'
VENV_DIR = OPENLLM_HOME / 'venv'
REPO_DIR.mkdir(exist_ok=True, parents=True)
TEMP_DIR.mkdir(exist_ok=True, parents=True)
VENV_DIR.mkdir(exist_ok=True, parents=True)
CONFIG_FILE = OPENLLM_HOME / 'config.json'
CHECKED = 'Yes'
T = typing.TypeVar('T')
class ContextVar(typing.Generic[T]):
def __init__(self, default: T):
self._stack: list[T] = []
self._default = default
def get(self) -> T:
if self._stack:
return self._stack[-1]
return self._default
def set(self, value: T) -> None:
self._stack.append(value)
@contextmanager
def patch(self, value: T) -> typing.Iterator[None]:
self._stack.append(value)
try:
yield
finally:
self._stack.pop()
VERBOSE_LEVEL = ContextVar(0)
INTERACTIVE = ContextVar(False)
def output(
content: typing.Any, level: int = 0, style: str | None = None, end: str | None = None
) -> None:
if level > VERBOSE_LEVEL.get():
return
if not isinstance(content, str):
out = io.StringIO()
pyaml.pprint(content, dst=out, sort_dicts=False, sort_keys=False)
questionary.print(out.getvalue(), style=style, end='' if end is None else end)
out.close()
else:
questionary.print(content, style=style, end='\n' if end is None else end)
class Config(pydantic.BaseModel):
repos: dict[str, str] = pydantic.Field(
default_factory=lambda: {
'default': 'https://github.com/bentoml/openllm-models@main',
'nightly': 'https://github.com/bentoml/openllm-models@nightly',
}
)
default_repo: str = 'default'
def tolist(self) -> dict[str, typing.Any]:
return dict(repos=self.repos, default_repo=self.default_repo)
def load_config() -> Config:
if CONFIG_FILE.exists():
try:
with open(CONFIG_FILE) as f:
return Config(**json.load(f))
except json.JSONDecodeError:
return Config()
return Config()
def save_config(config: Config) -> None:
with open(CONFIG_FILE, 'w') as f:
json.dump(config.tolist(), f, indent=2)
class BentoMetadata(typing.TypedDict):
name: str
version: str
labels: dict[str, str]
envs: list[dict[str, str]]
services: list[dict[str, typing.Any]]
schema: dict[str, typing.Any]
class EnvVars(UserDict[str, str]):
"""
A dictionary-like object that sorted by key and only keeps the environment variables that have a value.
"""
@classmethod
def __get_pydantic_core_schema__(
cls: type[EnvVars], source_type: type[typing.Any], handler: typing.Callable[..., typing.Any]
) -> core_schema.DictSchema:
return core_schema.dict_schema(core_schema.str_schema(), core_schema.str_schema())
def __init__(self, data: typing.Mapping[str, str] | None = None):
super().__init__(data or {})
self.data = {k: v for k, v in sorted(self.data.items()) if v}
def __hash__(self) -> int:
return hash(tuple(sorted(self.data.items())))
class RepoInfo(pydantic.BaseModel):
name: str
path: pathlib.Path
url: str
server: str
owner: str
repo: str
branch: str
def tolist(self) -> str | dict[str, typing.Any] | None:
if VERBOSE_LEVEL.get() <= 0:
return f'{self.name} ({self.url}@{self.branch})'
if VERBOSE_LEVEL.get() <= 10:
return dict(name=self.name, url=f'{self.url}@{self.branch}', path=str(self.path))
if VERBOSE_LEVEL.get() <= 20:
return dict(
name=self.name,
url=f'{self.url}@{self.branch}',
path=str(self.path),
server=self.server,
owner=self.owner,
repo=self.repo,
)
return None
class BentoInfo(pydantic.BaseModel):
repo: RepoInfo
path: pathlib.Path
alias: str = ''
def __str__(self) -> str:
if self.repo.name == 'default':
return f'{self.tag}'
else:
return f'{self.repo.name}/{self.tag}'
@override
def __hash__(self) -> int:
return md5(str(self.path))
@property
def tag(self) -> str:
if self.alias:
return f'{self.path.parent.name}:{self.alias}'
return f'{self.path.parent.name}:{self.path.name}'
@property
def bentoml_tag(self) -> str:
return f'{self.path.parent.name}:{self.path.name}'
@property
def name(self) -> str:
return self.path.parent.name
@property
def version(self) -> str:
return self.path.name
@property
def labels(self) -> dict[str, str]:
return self.bento_yaml['labels']
@property
def envs(self) -> list[dict[str, str]]:
return self.bento_yaml['envs']
@functools.cached_property
def bento_yaml(self) -> BentoMetadata:
bento: BentoMetadata = yaml.safe_load((self.path / 'bento.yaml').read_text())
return bento
@functools.cached_property
def platforms(self) -> list[str]:
return self.bento_yaml['labels'].get('platforms', 'linux').split(',')
@functools.cached_property
def pretty_yaml(self) -> BentoMetadata | dict[str, typing.Any]:
def _pretty_routes(routes: list[dict[str, typing.Any]]) -> dict[str, typing.Any]:
return {
route['route']: {
'input': {k: v['type'] for k, v in route['input']['properties'].items()},
'output': route['output']['type'],
}
for route in routes
}
if len(self.bento_yaml['services']) == 1:
pretty_yaml: dict[str, typing.Any] = {
'apis': _pretty_routes(self.bento_yaml['schema']['routes']),
'resources': self.bento_yaml['services'][0]['config']['resources'],
'envs': self.bento_yaml['envs'],
'platforms': self.platforms,
}
return pretty_yaml
return self.bento_yaml
@functools.cached_property
def pretty_gpu(self) -> str:
from openllm.accelerator_spec import ACCELERATOR_SPECS
try:
resources = self.bento_yaml['services'][0]['config']['resources']
if resources['gpu'] > 1:
acc = ACCELERATOR_SPECS[resources['gpu_type']]
return f'{acc.memory_size:.0f}Gx{resources["gpu"]}'
elif resources['gpu'] > 0:
acc = ACCELERATOR_SPECS[resources['gpu_type']]
return f'{acc.memory_size:.0f}G'
except KeyError:
pass
return ''
def tolist(self) -> str | dict[str, typing.Any] | None:
verbose = VERBOSE_LEVEL.get()
if verbose <= 0:
return str(self)
if verbose <= 10:
return dict(
tag=self.tag, repo=self.repo.tolist(), path=str(self.path), model_card=self.pretty_yaml
)
if verbose <= 20:
return dict(
tag=self.tag, repo=self.repo.tolist(), path=str(self.path), bento_yaml=self.bento_yaml
)
return None
class VenvSpec(pydantic.BaseModel):
python_version: str
requirements_txt: str
envs: EnvVars
name_prefix: str = ''
@functools.cached_property
def normalized_requirements_txt(self) -> str:
parameter_lines: list[str] = []
dependency_lines: list[str] = []
comment_lines: list[str] = []
for line in self.requirements_txt.splitlines():
if not line.strip():
continue
elif line.strip().startswith('#'):
comment_lines.append(line.strip())
elif line.strip().startswith('-'):
parameter_lines.append(line.strip())
else:
dependency_lines.append(line.strip())
parameter_lines.sort()
dependency_lines.sort()
return '\n'.join(parameter_lines + dependency_lines).strip()
@functools.cached_property
def normalized_envs(self) -> str:
return '\n'.join(f'{k}={v}' for k, v in sorted(self.envs.items(), key=lambda x: x[0]) if not v)
@override
def __hash__(self) -> int:
return md5(self.normalized_requirements_txt, str(hash(self.normalized_envs)))
class Accelerator(pydantic.BaseModel):
model: str
memory_size: float
def __gt__(self, other: Accelerator) -> bool:
return self.memory_size > other.memory_size
def __eq__(self, other: object) -> bool:
if not isinstance(other, Accelerator):
return NotImplemented
return self.memory_size == other.memory_size
def __repr__(self) -> str:
return f'{self.model}({self.memory_size}GB)'
class DeploymentTarget(pydantic.BaseModel):
accelerators: list[Accelerator]
source: str = 'local'
name: str = 'local'
price: str = ''
platform: str = 'linux'
@override
def __hash__(self) -> int:
return hash(self.source)
@property
def accelerators_repr(self) -> str:
accs = {a.model for a in self.accelerators}
if len(accs) == 0:
return 'null'
if len(accs) == 1:
a = self.accelerators[0]
return f'{a.model} x{len(self.accelerators)}'
return ', '.join((f'{a.model}' for a in self.accelerators))
def run_command(
cmd: list[str],
cwd: str | None = None,
env: EnvVars | None = None,
copy_env: bool = True,
venv: pathlib.Path | None = None,
silent: bool = False,
) -> subprocess.CompletedProcess[typing.Any]:
env = env or EnvVars({})
cmd = [str(c) for c in cmd]
bin_dir = 'Scripts' if os.name == 'nt' else 'bin'
if not silent:
output('\n')
if cwd:
output(f'$ cd {cwd}', style='orange')
if env:
for k, v in env.items():
output(f'$ export {k}={shlex.quote(v)}', style='orange')
if venv:
output(f'$ source {venv / "bin" / "activate"}', style='orange')
output(f'$ {" ".join(cmd)}', style='orange')
if venv:
py = venv / bin_dir / f'python{sysconfig.get_config_var("EXE")}'
else:
py = pathlib.Path(sys.executable)
if copy_env:
env = EnvVars({**os.environ, **env})
if cmd and cmd[0] == 'bentoml':
cmd = [py.__fspath__(), '-m', 'bentoml', *cmd[1:]]
if cmd and cmd[0] == 'python':
cmd = [py.__fspath__(), *cmd[1:]]
try:
if silent:
return subprocess.run(
cmd, cwd=cwd, env=env, stdout=subprocess.DEVNULL, stderr=subprocess.DEVNULL, check=True
)
else:
return subprocess.run(cmd, cwd=cwd, env=env, check=True)
except Exception as e:
if VERBOSE_LEVEL.get() >= 20:
output(str(e), style='red')
raise typer.Exit(1)
async def stream_command_output(
stream: asyncio.streams.StreamReader | None, style: str = 'gray'
) -> None:
if stream:
async for line in stream:
output(line.decode(), style=style, end='')
@asynccontextmanager
async def async_run_command(
cmd: list[str],
cwd: str | None = None,
env: EnvVars | None = None,
copy_env: bool = True,
venv: pathlib.Path | None = None,
silent: bool = True,
) -> typing.AsyncGenerator[asyncio.subprocess.Process]:
env = env or EnvVars({})
cmd = [str(c) for c in cmd]
if not silent:
output('\n')
if cwd:
output(f'$ cd {cwd}', style='orange')
if env:
for k, v in env.items():
output(f'$ export {k}={shlex.quote(v)}', style='orange')
if venv:
output(f'$ source {venv / "bin" / "activate"}', style='orange')
output(f'$ {" ".join(cmd)}', style='orange')
if venv:
py = venv / 'bin' / 'python'
else:
py = pathlib.Path(sys.executable)
if copy_env:
env = EnvVars({**os.environ, **env})
if cmd and cmd[0] == 'bentoml':
cmd = [py.__fspath__(), '-m', 'bentoml', *cmd[1:]]
if cmd and cmd[0] == 'python':
cmd = [py.__fspath__(), *cmd[1:]]
proc = None
try:
proc = await asyncio.create_subprocess_shell(
' '.join(map(str, cmd)),
stdout=asyncio.subprocess.PIPE,
stderr=asyncio.subprocess.PIPE,
cwd=cwd,
env=env,
)
yield proc
except subprocess.CalledProcessError:
output('Command failed', style='red')
raise typer.Exit(1)
finally:
if proc:
proc.send_signal(signal.SIGINT)
await proc.wait()
def md5(*strings: str) -> int:
m = hashlib.md5()
for s in strings:
m.update(s.encode())
return int(m.hexdigest(), 16)
================================================
FILE: src/openllm/local.py
================================================
from __future__ import annotations
import asyncio, time, typing, os
import httpx, openai
from openai.types.chat import ChatCompletionAssistantMessageParam, ChatCompletionUserMessageParam
from openllm.common import (
BentoInfo,
EnvVars,
async_run_command,
output,
run_command,
stream_command_output,
)
from openllm.venv import ensure_venv
if typing.TYPE_CHECKING:
from openai.types.chat import ChatCompletionMessageParam
def prep_env_vars(bento: BentoInfo) -> None:
env_vars = bento.envs
for env_var in env_vars:
if not env_var.get('value'):
continue
key = env_var['name']
value = env_var['value']
os.environ[key] = value
def _get_serve_cmd(
bento: BentoInfo, port: int = 3000, cli_args: typing.Optional[list[str]] = None
) -> tuple[list[str], EnvVars]:
cmd = ['bentoml', 'serve', bento.bentoml_tag]
if port != 3000:
cmd += ['--port', str(port)]
# Add CLI arguments if provided
if cli_args:
for arg in cli_args:
cmd += ['--arg', arg]
return cmd, EnvVars({'BENTOML_HOME': f'{bento.repo.path}/bentoml'})
def serve(
bento: BentoInfo,
port: int = 3000,
cli_envs: typing.Optional[list[str]] = None,
cli_args: typing.Optional[list[str]] = None,
) -> None:
prep_env_vars(bento)
cmd, env = _get_serve_cmd(bento, port=port, cli_args=cli_args)
# Add CLI environment variables if provided
if cli_envs:
for env_var in cli_envs:
if '=' in env_var:
key, value = env_var.split('=', 1)
env[key] = value
else:
env[env_var] = os.environ.get(env_var, '')
venv = ensure_venv(bento, runtime_envs=env)
output(f'Access the Chat UI at http://localhost:{port}/chat (or with you IP)')
run_command(cmd, env=env, cwd=None, venv=venv)
async def _run_model(
bento: BentoInfo,
port: int = 3000,
timeout: int = 600,
cli_env: typing.Optional[dict[str, typing.Any]] = None,
cli_args: typing.Optional[list[str]] = None,
) -> None:
cmd, env = _get_serve_cmd(bento, port, cli_args=cli_args)
# Merge cli environment variables if provided
if cli_env:
env.update(cli_env)
venv = ensure_venv(bento, runtime_envs=env)
async with async_run_command(cmd, env=env, cwd=None, venv=venv, silent=False) as server_proc:
output(f'Model server started {server_proc.pid}')
stdout_streamer = None
stderr_streamer = None
start_time = time.time()
output('Model loading...', style='green')
for _ in range(timeout):
try:
resp = httpx.get(f'http://localhost:{port}/readyz', timeout=3)
if resp.status_code == 200:
break
except httpx.RequestError:
if time.time() - start_time > 30:
if not stdout_streamer:
stdout_streamer = asyncio.create_task(
stream_command_output(server_proc.stdout, style='gray')
)
if not stderr_streamer:
stderr_streamer = asyncio.create_task(
stream_command_output(server_proc.stderr, style='#BD2D0F')
)
await asyncio.sleep(1)
else:
output('Model failed to load', style='red')
server_proc.terminate()
return
if stdout_streamer:
stdout_streamer.cancel()
if stderr_streamer:
stderr_streamer.cancel()
output('Model is ready', style='green')
messages: list[ChatCompletionMessageParam] = []
client = openai.AsyncOpenAI(base_url=f'http://localhost:{port}/v1', api_key='local')
while True:
try:
message = input('user: ')
if message == '':
output('empty message, please enter something', style='yellow')
continue
messages.append(ChatCompletionUserMessageParam(role='user', content=message))
output('assistant: ', end='', style='lightgreen')
assistant_message = ''
stream = await client.chat.completions.create(
model=(await client.models.list()).data[0].id, messages=messages, stream=True
)
async for chunk in stream:
text = chunk.choices[0].delta.content or ''
assistant_message += text
output(text, end='', style='lightgreen')
messages.append(
ChatCompletionAssistantMessageParam(role='assistant', content=assistant_message)
)
output('')
except KeyboardInterrupt:
break
output('\nStopping model server...', style='green')
output('Stopped model server', style='green')
def run(
bento: BentoInfo,
port: int = 3000,
timeout: int = 600,
cli_envs: typing.Optional[list[str]] = None,
cli_args: typing.Optional[list[str]] = None,
) -> None:
prep_env_vars(bento)
# Add CLI environment variables to the process
env = {}
if cli_envs:
for env_var in cli_envs:
if '=' in env_var:
key, value = env_var.split('=', 1)
env[key] = value
else:
env[env_var] = os.environ.get(env_var, '')
asyncio.run(_run_model(bento, port=port, timeout=timeout, cli_env=env, cli_args=cli_args))
================================================
FILE: src/openllm/model.py
================================================
from __future__ import annotations
import re, typing, json
import tabulate, questionary, typer
from openllm.accelerator_spec import can_run
from openllm.common import DeploymentTarget
from openllm.analytic import OpenLLMTyper
from openllm.common import VERBOSE_LEVEL, BentoInfo, output as output_, load_config
from openllm.repo import ensure_repo_updated, list_repo
app = OpenLLMTyper(help='manage models')
@app.command(help='get model')
def get(tag: str, repo: typing.Optional[str] = None, verbose: bool = False) -> None:
if verbose:
VERBOSE_LEVEL.set(20)
bento_info = ensure_bento(tag, repo_name=repo)
if bento_info:
output_(bento_info)
@app.command(name='list', help='list available models')
def list_model(
tag: typing.Optional[str] = None,
repo: typing.Optional[str] = None,
verbose: bool = False,
output: typing.Optional[str] = typer.Option(None, hidden=True),
) -> None:
if verbose:
VERBOSE_LEVEL.set(20)
if repo is None:
repo = load_config().default_repo
bentos = list_bento(tag=tag, repo_name=repo)
bentos.sort(key=lambda x: x.name)
seen = set()
def is_seen(value: str) -> bool:
if value in seen:
return True
seen.add(value)
return False
if output == 'readme':
# Parse parameters from bento.tag (e.g. "model:671b-it" -> "671b", 'model:something-long-78b' -> '78b')
questionary.print(
json.dumps({
f'{bento.name}': dict(
tag=bento.tag,
version=bento.tag.split(':')[-1],
pretty_gpu=bento.pretty_gpu,
command=f'openllm serve {bento.tag}',
)
for bento in bentos
if not is_seen(bento.name)
})
)
return
table = tabulate.tabulate(
[
[
'' if is_seen(bento.name) else bento.name,
bento.tag,
bento.repo.name,
bento.pretty_gpu,
','.join(bento.platforms),
]
for bento in bentos
],
headers=['model', 'version', 'repo', 'required GPU RAM', 'platforms'],
)
output_(table)
def ensure_bento(
model: str,
target: typing.Optional[DeploymentTarget] = None,
repo_name: typing.Optional[str] = None,
) -> BentoInfo:
if repo_name is None:
from openllm.common import load_config
repo_name = load_config().default_repo
bentos = list_bento(model, repo_name=repo_name)
if len(bentos) == 0:
output_(f'No model found for {model}', style='red')
raise typer.Exit(1)
if len(bentos) == 1:
output_(f'Found model {bentos[0]}', style='green')
if target is not None and can_run(bentos[0], target) <= 0:
output_(
f'The machine({target.name}) with {target.accelerators_repr} does not appear to have sufficient '
f'resources to run model {bentos[0]}\n',
style='yellow',
)
return bentos[0]
# multiple models, pick one according to target
output_(f'Multiple models match {model}, did you mean one of these?', style='red')
list_model(model, repo=repo_name)
raise typer.Exit(1)
NUMBER_RE = re.compile(r'\d+')
def _extract_first_number(s: str) -> int:
match = NUMBER_RE.search(s)
if match:
return int(match.group())
else:
return 100
def list_bento(
tag: typing.Optional[str] = None,
repo_name: typing.Optional[str] = None,
include_alias: bool = False,
) -> typing.List[BentoInfo]:
ensure_repo_updated()
if repo_name is None and tag and '/' in tag:
repo_name, tag = tag.split('/', 1)
repo_list = list_repo(repo_name)
if repo_name is not None:
repo_map = {repo.name: repo for repo in repo_list}
if repo_name not in repo_map:
output_(f'Repo `{repo_name}` not found, did you mean one of these?')
for repo_name in repo_map:
output_(f' {repo_name}')
raise typer.Exit(1)
if not tag:
glob_pattern = 'bentoml/bentos/*/*'
elif ':' in tag:
bento_name, version = tag.split(':')
glob_pattern = f'bentoml/bentos/{bento_name}/{version}'
else:
glob_pattern = f'bentoml/bentos/{tag}/*'
model_list: list[BentoInfo] = []
repo_list = list_repo(repo_name)
for repo in repo_list:
paths = sorted(
repo.path.glob(glob_pattern),
key=lambda x: (x.parent.name, _extract_first_number(x.name), len(x.name), x.name),
)
for path in paths:
if path.is_dir() and (path / 'bento.yaml').exists():
model = BentoInfo(repo=repo, path=path)
elif path.is_file():
with open(path) as f:
origin_name = f.read().strip()
origin_path = path.parent / origin_name
model = BentoInfo(alias=path.name, repo=repo, path=origin_path)
else:
model = None
if model:
model_list.append(model)
if not include_alias:
seen: set[str] = set()
# we are calling side-effect in seen here.
model_list = [
x
for x in model_list
if not (
f'{x.bento_yaml["name"]}:{x.bento_yaml["version"]}' in seen
or seen.add(f'{x.bento_yaml["name"]}:{x.bento_yaml["version"]}') # type: ignore
)
]
return model_list
================================================
FILE: src/openllm/py.typed
================================================
================================================
FILE: src/openllm/repo.py
================================================
from __future__ import annotations
import datetime, subprocess, re, shutil, typing, os, pathlib
import pyaml, questionary, typer
from openllm.analytic import OpenLLMTyper
from openllm.common import (
INTERACTIVE,
REPO_DIR,
VERBOSE_LEVEL,
RepoInfo,
load_config,
output,
save_config,
)
UPDATE_INTERVAL = datetime.timedelta(days=3)
TEST_REPO = os.getenv('OPENLLM_TEST_REPO', None) # for testing
app = OpenLLMTyper(help='manage repos')
@app.command(name='list', help='list available repo')
def cmd_list(verbose: bool = False) -> None:
if verbose:
VERBOSE_LEVEL.set(20)
pyaml.pprint(list_repo(), sort_dicts=False, sort_keys=False)
@app.command(name='remove', help='remove given repo')
def cmd_remove(name: str) -> None:
if TEST_REPO:
return
config = load_config()
if name not in config.repos:
output(f'Repo {name} does not exist', style='red')
return
del config.repos[name]
save_config(config)
output(f'Repo {name} removed', style='green')
@app.command(name='update', help='update default repo')
def cmd_update() -> None:
if TEST_REPO:
return
repos_in_use = set()
for repo in list_repo():
# Show simplified output if not in verbose mode
if VERBOSE_LEVEL.get() <= 0:
output(f'updating repo {repo.name}', style='green')
repos_in_use.add((repo.server, repo.owner, repo.repo, repo.branch))
if repo.path.exists():
shutil.rmtree(repo.path, ignore_errors=True)
repo.path.parent.mkdir(parents=True, exist_ok=True)
try:
_clone_repo(repo)
if VERBOSE_LEVEL.get() > 0:
output('')
output(f'Repo `{repo.name}` updated', style='green')
except Exception as e:
shutil.rmtree(repo.path, ignore_errors=True)
if VERBOSE_LEVEL.get() > 0:
output(f'Failed to clone repo {repo.name}', style='red')
output(e)
for c in REPO_DIR.glob('*/*/*/*'):
repo_spec = tuple(c.parts[-4:])
if repo_spec not in repos_in_use:
shutil.rmtree(c, ignore_errors=True)
if VERBOSE_LEVEL.get() > 0:
output(f'Removed unused repo cache {c}')
with open(REPO_DIR / 'last_update', 'w') as f:
f.write(datetime.datetime.now().isoformat())
for repo in list_repo():
_complete_alias(repo.name)
@app.command(name='add', help='add new repo')
def cmd_add(name: str, repo: str) -> None:
if TEST_REPO:
return
name = name.lower()
if not name.isidentifier():
output(
f'Invalid repo name: {name}, should only contain letters, numbers and underscores',
style='red',
)
return
try:
parse_repo_url(repo)
except ValueError:
output(f'Invalid repo url: {repo}', style='red')
return
config = load_config()
if name in config.repos:
override = questionary.confirm(
f'Repo {name} already exists({config.repos[name]}), override?'
).ask()
if not override:
return
config.repos[name] = repo
save_config(config)
output(f'Repo {name} added', style='green')
@app.command(name='default', help='get default repo path')
def default() -> typing.Optional[pathlib.Path]:
if TEST_REPO:
return None
output((info := parse_repo_url(load_config().repos['default'], 'default')).path)
return info.path
def list_repo(repo_name: typing.Optional[str] = None) -> typing.List[RepoInfo]:
if TEST_REPO:
return [
RepoInfo(
name='default',
url='',
server='test',
owner='test',
repo='test',
branch='main',
path=pathlib.Path(TEST_REPO),
)
]
config = load_config()
repos = []
for _repo_name, repo_url in config.repos.items():
if repo_name is not None and _repo_name != repo_name:
continue
repo = parse_repo_url(repo_url, _repo_name)
repos.append(repo)
return repos
def _complete_alias(repo_name: str) -> None:
from openllm.model import list_bento
for bento in list_bento(repo_name=repo_name):
alias = bento.labels.get('aliases', '').strip()
if alias:
for a in alias.split(','):
with open(bento.path.parent / a, 'w') as f:
f.write(bento.version)
def _clone_repo(repo: RepoInfo) -> None:
try:
# Suppress output if verbosity level is low
if VERBOSE_LEVEL.get() <= 0:
subprocess.run(
['git', 'clone', '--depth=1', '-b', repo.branch, repo.url, str(repo.path)],
check=True,
stdout=subprocess.DEVNULL,
stderr=subprocess.DEVNULL,
)
else:
subprocess.run(
['git', 'clone', '--depth=1', '-b', repo.branch, repo.url, str(repo.path)], check=True
)
except (subprocess.CalledProcessError, FileNotFoundError):
import dulwich
import dulwich.porcelain
# Dulwich doesn't have easy output suppression, but we rarely get here
dulwich.porcelain.clone(repo.url, str(repo.path), checkout=True, depth=1, branch=repo.branch)
def ensure_repo_updated() -> None:
if TEST_REPO:
return
last_update_file = REPO_DIR / 'last_update'
if not last_update_file.exists():
if INTERACTIVE.get():
choice = questionary.confirm(
'The repo cache is never updated, do you want to update it to fetch the latest model list?'
).ask()
if choice:
cmd_update()
return
else:
output(
'The repo cache is never updated, please run `openllm repo update` to fetch the latest model list',
style='red',
)
raise typer.Exit(1)
last_update = datetime.datetime.fromisoformat(last_update_file.read_text().strip())
if datetime.datetime.now() - last_update > UPDATE_INTERVAL:
if INTERACTIVE.get():
choice = questionary.confirm(
'The repo cache is outdated, do you want to update it to fetch the latest model list?'
).ask()
if choice:
cmd_update()
else:
output(
'The repo cache is outdated, please run `openllm repo update` to fetch the latest model list',
style='yellow',
)
GIT_HTTP_RE = re.compile(
r'(?P<schema>git|ssh|http|https):\/\/(?P<server>[\.\w\d\-]+)\/(?P<owner>[\w\d\-]+)\/(?P<repo>[\w\d\-\_\.]+)(@(?P<branch>.+))?(\/)?$'
)
GIT_SSH_RE = re.compile(
r'git@(?P<server>[\.\w\d-]+):(?P<owner>[\w\d\-]+)\/(?P<repo>[\w\d\-\_\.]+)(@(?P<branch>.+))?(\/)?$'
)
def parse_repo_url(repo_url: str, repo_name: typing.Optional[str] = None) -> RepoInfo:
"""
parse the git repo url to server, owner, repo name, branch
>>> parse_repo_url('https://github.com/bentoml/bentovllm@main')
('github.com', 'bentoml', 'bentovllm', 'main')
>>> parse_repo_url('https://github.com/bentoml/bentovllm.git@main')
('github.com', 'bentoml', 'bentovllm', 'main')
>>> parse_repo_url('https://github.com/bentoml/bentovllm')
('github.com', 'bentoml', 'bentovllm', 'main')
>>> parse_repo_url('git@github.com:bentoml/openllm-models.git')
('github.com', 'bentoml', 'openllm-models', 'main')
"""
match = GIT_HTTP_RE.match(repo_url)
if match:
schema = match.group('schema')
else:
match = GIT_SSH_RE.match(repo_url)
if not match:
raise ValueError(f'Invalid git repo url: {repo_url}')
schema = None
if match.group('branch') is not None:
repo_url = repo_url[: match.start('branch') - 1]
server = match.group('server')
owner = match.group('owner')
repo = match.group('repo')
if repo.endswith('.git'):
repo = repo[:-4]
branch = match.group('branch') or 'main'
if schema is not None:
repo_url = f'{schema}://{server}/{owner}/{repo}'
else:
repo_url = f'git@{server}:{owner}/{repo}'
path = REPO_DIR / server / owner / repo / branch
return RepoInfo(
name=repo if repo_name is None else repo_name,
url=repo_url,
server=server,
owner=owner,
repo=repo,
branch=branch,
path=path,
)
if __name__ == '__main__':
app()
================================================
FILE: src/openllm/venv.py
================================================
from __future__ import annotations
import functools, os, pathlib, shutil
import typer, yaml
from openllm.common import (
VENV_DIR,
VERBOSE_LEVEL,
BentoInfo,
EnvVars,
VenvSpec,
output,
run_command,
)
@functools.lru_cache
def _resolve_bento_venv_spec(bento: BentoInfo, runtime_envs: EnvVars | None = None) -> VenvSpec:
lock_file = bento.path / 'env' / 'python' / 'requirements.lock.txt'
if not lock_file.exists():
lock_file = bento.path / 'env' / 'python' / 'requirements.txt'
reqs = lock_file.read_text().strip()
bentofile = bento.path / 'bento.yaml'
data = yaml.safe_load(bentofile.read_text())
bento_env_list = data.get('envs', [])
python_version = data.get('image', {})['python_version']
bento_envs = {e['name']: e.get('value') for e in bento_env_list}
envs = {k: runtime_envs.get(k, v) for k, v in bento_envs.items()} if runtime_envs else {}
return VenvSpec(
python_version=python_version,
requirements_txt=reqs,
name_prefix=f'{bento.tag.replace(":", "_")}-1-',
envs=EnvVars(envs),
)
def _ensure_venv(venv_spec: VenvSpec) -> pathlib.Path:
venv = VENV_DIR / str(hash(venv_spec))
if venv.exists() and not (venv / 'DONE').exists():
shutil.rmtree(venv, ignore_errors=True)
if not venv.exists():
output(f'Installing model dependencies({venv})...', style='green')
venv_py = venv / 'Scripts' / 'python.exe' if os.name == 'nt' else venv / 'bin' / 'python'
try:
run_command(
['python', '-m', 'uv', 'venv', venv.__fspath__(), '-p', venv_spec.python_version],
silent=VERBOSE_LEVEL.get() < 10,
)
run_command(
['python', '-m', 'uv', 'pip', 'install', '-p', str(venv_py), 'bentoml'],
silent=VERBOSE_LEVEL.get() < 10,
env=venv_spec.envs,
)
with open(venv / 'requirements.txt', 'w') as f:
f.write(venv_spec.normalized_requirements_txt)
run_command(
[
'python',
'-m',
'uv',
'pip',
'install',
'-p',
str(venv_py),
'-r',
(venv / 'requirements.txt').__fspath__(),
],
silent=VERBOSE_LEVEL.get() < 10,
env=venv_spec.envs,
)
with open(venv / 'DONE', 'w') as f:
f.write('DONE')
except Exception as e:
shutil.rmtree(venv, ignore_errors=True)
if VERBOSE_LEVEL.get() >= 10:
output(str(e), style='red')
output(f'Failed to install dependencies to {venv}. Cleaned up.', style='red')
raise typer.Exit(1)
output(f'Successfully installed dependencies to {venv}.', style='green')
return venv
else:
return venv
def ensure_venv(bento: BentoInfo, runtime_envs: EnvVars | None = None) -> pathlib.Path:
venv_spec = _resolve_bento_venv_spec(bento, runtime_envs=EnvVars(runtime_envs))
venv = _ensure_venv(venv_spec)
assert venv is not None
return venv
def check_venv(bento: BentoInfo) -> bool:
venv_spec = _resolve_bento_venv_spec(bento)
venv = VENV_DIR / str(hash(venv_spec))
if not venv.exists():
return False
if venv.exists() and not (venv / 'DONE').exists():
return False
return True
gitextract_cxwe9k92/
├── .editorconfig
├── .envrc.template
├── .git-blame-ignore-revs
├── .git_archival.txt
├── .gitattributes
├── .github/
│ ├── CODEOWNERS
│ ├── CODE_OF_CONDUCT.md
│ ├── ISSUE_TEMPLATE/
│ │ ├── bug_report.yml
│ │ ├── config.yml
│ │ └── feature_request.yml
│ ├── SECURITY.md
│ ├── dependabot.yml
│ └── workflows/
│ ├── create-releases.yml
│ └── dependabot-auto-merge.yml
├── .gitignore
├── .pre-commit-config.yaml
├── .python-version-default
├── .ruff.toml
├── CITATION.cff
├── DEVELOPMENT.md
├── LICENSE
├── README.md
├── README.md.tpl
├── gen_readme.py
├── pyproject.toml
├── pyrightconfig.json
├── release.sh
└── src/
└── openllm/
├── __init__.py
├── __main__.py
├── accelerator_spec.py
├── analytic.py
├── clean.py
├── cloud.py
├── common.py
├── local.py
├── model.py
├── py.typed
├── repo.py
└── venv.py
SYMBOL INDEX (106 symbols across 10 files)
FILE: src/openllm/__main__.py
function _select_bento_name (line 30) | def _select_bento_name(models: list[BentoInfo], target: DeploymentTarget...
function _select_bento_version (line 59) | def _select_bento_version(
function _select_target (line 94) | def _select_target(bento: BentoInfo, targets: list[DeploymentTarget]) ->...
function _select_action (line 129) | def _select_action(
function hello (line 207) | def hello(
function serve (line 247) | def serve(
function run (line 272) | def run(
function deploy (line 300) | def deploy(
function typer_callback (line 353) | def typer_callback(
FILE: src/openllm/accelerator_spec.py
function parse_memory_string (line 11) | def parse_memory_string(v: typing.Any) -> typing.Any:
class Resource (line 21) | class Resource(pydantic.BaseModel):
method __hash__ (line 28) | def __hash__(self) -> int:
method __bool__ (line 31) | def __bool__(self) -> bool:
function get_local_machine_spec (line 65) | def get_local_machine_spec() -> DeploymentTarget:
function can_run (line 117) | def can_run(bento: BentoInfo, target: DeploymentTarget | None = None) ->...
FILE: src/openllm/analytic.py
class EventMeta (line 9) | class EventMeta(abc.ABC):
method event_name (line 11) | def event_name(self) -> str:
class CliEvent (line 22) | class CliEvent(EventMeta):
class OpenllmCliEvent (line 31) | class OpenllmCliEvent(CliEvent):
class OrderedCommands (line 35) | class OrderedCommands(typer.core.TyperGroup):
method list_commands (line 36) | def list_commands(self, ctx: click.Context) -> list[str]:
class OpenLLMTyper (line 40) | class OpenLLMTyper(typer.Typer):
method __init__ (line 41) | def __init__(self, *args: typing.Any, **kwargs: typing.Any):
method command (line 60) | def command(self, *args: typing.Any, **kwargs: typing.Any):
FILE: src/openllm/clean.py
function _du (line 14) | def _du(path: pathlib.Path) -> int:
function model_cache (line 32) | def model_cache(verbose: bool = False) -> None:
function venvs (line 46) | def venvs(verbose: bool = False) -> None:
function repos (line 61) | def repos(verbose: bool = False) -> None:
function configs (line 69) | def configs(verbose: bool = False) -> None:
function all_cache (line 77) | def all_cache(verbose: bool = False) -> None:
FILE: src/openllm/cloud.py
function resolve_cloud_config (line 13) | def resolve_cloud_config() -> pathlib.Path:
function _get_deploy_cmd (line 20) | def _get_deploy_cmd(
function get_current_context (line 125) | def get_current_context() -> str | None:
function ensure_cloud_context (line 134) | def ensure_cloud_context() -> None:
function get_cloud_machine_spec (line 179) | def get_cloud_machine_spec(context: typing.Optional[str] = None) -> list...
function deploy (line 213) | def deploy(
FILE: src/openllm/common.py
class ContextVar (line 33) | class ContextVar(typing.Generic[T]):
method __init__ (line 34) | def __init__(self, default: T):
method get (line 38) | def get(self) -> T:
method set (line 43) | def set(self, value: T) -> None:
method patch (line 47) | def patch(self, value: T) -> typing.Iterator[None]:
function output (line 59) | def output(
class Config (line 74) | class Config(pydantic.BaseModel):
method tolist (line 83) | def tolist(self) -> dict[str, typing.Any]:
function load_config (line 87) | def load_config() -> Config:
function save_config (line 97) | def save_config(config: Config) -> None:
class BentoMetadata (line 102) | class BentoMetadata(typing.TypedDict):
class EnvVars (line 111) | class EnvVars(UserDict[str, str]):
method __get_pydantic_core_schema__ (line 117) | def __get_pydantic_core_schema__(
method __init__ (line 122) | def __init__(self, data: typing.Mapping[str, str] | None = None):
method __hash__ (line 126) | def __hash__(self) -> int:
class RepoInfo (line 130) | class RepoInfo(pydantic.BaseModel):
method tolist (line 139) | def tolist(self) -> str | dict[str, typing.Any] | None:
class BentoInfo (line 156) | class BentoInfo(pydantic.BaseModel):
method __str__ (line 161) | def __str__(self) -> str:
method __hash__ (line 168) | def __hash__(self) -> int:
method tag (line 172) | def tag(self) -> str:
method bentoml_tag (line 178) | def bentoml_tag(self) -> str:
method name (line 182) | def name(self) -> str:
method version (line 186) | def version(self) -> str:
method labels (line 190) | def labels(self) -> dict[str, str]:
method envs (line 194) | def envs(self) -> list[dict[str, str]]:
method bento_yaml (line 198) | def bento_yaml(self) -> BentoMetadata:
method platforms (line 203) | def platforms(self) -> list[str]:
method pretty_yaml (line 207) | def pretty_yaml(self) -> BentoMetadata | dict[str, typing.Any]:
method pretty_gpu (line 228) | def pretty_gpu(self) -> str:
method tolist (line 243) | def tolist(self) -> str | dict[str, typing.Any] | None:
class VenvSpec (line 258) | class VenvSpec(pydantic.BaseModel):
method normalized_requirements_txt (line 265) | def normalized_requirements_txt(self) -> str:
method normalized_envs (line 285) | def normalized_envs(self) -> str:
method __hash__ (line 289) | def __hash__(self) -> int:
class Accelerator (line 293) | class Accelerator(pydantic.BaseModel):
method __gt__ (line 297) | def __gt__(self, other: Accelerator) -> bool:
method __eq__ (line 300) | def __eq__(self, other: object) -> bool:
method __repr__ (line 305) | def __repr__(self) -> str:
class DeploymentTarget (line 309) | class DeploymentTarget(pydantic.BaseModel):
method __hash__ (line 317) | def __hash__(self) -> int:
method accelerators_repr (line 321) | def accelerators_repr(self) -> str:
function run_command (line 331) | def run_command(
function stream_command_output (line 379) | async def stream_command_output(
function async_run_command (line 388) | async def async_run_command(
function md5 (line 442) | def md5(*strings: str) -> int:
FILE: src/openllm/local.py
function prep_env_vars (line 21) | def prep_env_vars(bento: BentoInfo) -> None:
function _get_serve_cmd (line 31) | def _get_serve_cmd(
function serve (line 46) | def serve(
function _run_model (line 69) | async def _run_model(
function run (line 147) | def run(
FILE: src/openllm/model.py
function get (line 16) | def get(tag: str, repo: typing.Optional[str] = None, verbose: bool = Fal...
function list_model (line 25) | def list_model(
function ensure_bento (line 80) | def ensure_bento(
function _extract_first_number (line 114) | def _extract_first_number(s: str) -> int:
function list_bento (line 122) | def list_bento(
FILE: src/openllm/repo.py
function cmd_list (line 25) | def cmd_list(verbose: bool = False) -> None:
function cmd_remove (line 32) | def cmd_remove(name: str) -> None:
function cmd_update (line 46) | def cmd_update() -> None:
function cmd_add (line 83) | def cmd_add(name: str, repo: str) -> None:
function default (line 114) | def default() -> typing.Optional[pathlib.Path]:
function list_repo (line 121) | def list_repo(repo_name: typing.Optional[str] = None) -> typing.List[Rep...
function _complete_alias (line 144) | def _complete_alias(repo_name: str) -> None:
function _clone_repo (line 155) | def _clone_repo(repo: RepoInfo) -> None:
function ensure_repo_updated (line 177) | def ensure_repo_updated() -> None:
function parse_repo_url (line 218) | def parse_repo_url(repo_url: str, repo_name: typing.Optional[str] = None...
FILE: src/openllm/venv.py
function _resolve_bento_venv_spec (line 18) | def _resolve_bento_venv_spec(bento: BentoInfo, runtime_envs: EnvVars | N...
function _ensure_venv (line 39) | def _ensure_venv(venv_spec: VenvSpec) -> pathlib.Path:
function ensure_venv (line 88) | def ensure_venv(bento: BentoInfo, runtime_envs: EnvVars | None = None) -...
function check_venv (line 95) | def check_venv(bento: BentoInfo) -> bool:
Condensed preview — 39 files, each showing path, character count, and a content snippet. Download the .json file or copy for the full structured content (136K chars).
[
{
"path": ".editorconfig",
"chars": 245,
"preview": "root = true\n\n[*]\nend_of_line = lf\ntrim_trailing_whitespace = true\ncharset = utf-8\nindent_style = space\nindent_size = 2\n\n"
},
{
"path": ".envrc.template",
"chars": 27,
"preview": "export PAPERSPACE_API_KEY=\n"
},
{
"path": ".git-blame-ignore-revs",
"chars": 1151,
"preview": "# You can use this file with 'git config blame.ignoreRevsFile .git-blame-ignore-revs'\n# 07/31/2023: Style guidelines\n8c2"
},
{
"path": ".git_archival.txt",
"chars": 125,
"preview": "node: $Format:%H$\nnode-date: $Format:%cI$\ndescribe-name: $Format:%(describe:tags=true,match=*[0-9]*)$\nref-names: $Format"
},
{
"path": ".gitattributes",
"chars": 91,
"preview": "* text=auto eol=lf\n# Needed for setuptools-scm-git-archive\n.git_archival.txt export-subst\n"
},
{
"path": ".github/CODEOWNERS",
"chars": 11,
"preview": "* @aarnphm\n"
},
{
"path": ".github/CODE_OF_CONDUCT.md",
"chars": 5214,
"preview": "# Contributor Covenant Code of Conduct\n\n## Our Pledge\n\nWe as members, contributors, and leaders pledge to make participa"
},
{
"path": ".github/ISSUE_TEMPLATE/bug_report.yml",
"chars": 2461,
"preview": "name: 🐛 Bug Report\ndescription: Create a bug report on OpenLLM.\ntitle: 'bug: '\nlabels: ['']\nbody:\n - type: markdown\n "
},
{
"path": ".github/ISSUE_TEMPLATE/config.yml",
"chars": 300,
"preview": "blank_issues_enabled: true\nversion: 2.1\ncontact_links:\n - name: Blank issues\n url: https://github.com/bentoml/openll"
},
{
"path": ".github/ISSUE_TEMPLATE/feature_request.yml",
"chars": 1090,
"preview": "name: 🚀 Feature Request\ndescription: Submit a proposal/request for new OpenLLM features.\ntitle: 'feat: '\nlabels: ['']\nbo"
},
{
"path": ".github/SECURITY.md",
"chars": 816,
"preview": "# Security Policy\n\n## Supported Versions\n\nWe are following [semantic versioning](https://semver.org/) with strict\nbackwa"
},
{
"path": ".github/dependabot.yml",
"chars": 500,
"preview": "version: 2\nupdates:\n - package-ecosystem: github-actions\n directory: '/'\n schedule:\n interval: 'weekly'\n "
},
{
"path": ".github/workflows/create-releases.yml",
"chars": 1779,
"preview": "name: release\non:\n push:\n tags:\n - \"*\"\njobs:\n build:\n runs-on: ubuntu-latest\n steps:\n - uses: actio"
},
{
"path": ".github/workflows/dependabot-auto-merge.yml",
"chars": 883,
"preview": "name: Dependabot Auto merge\non: pull_request\n\npermissions:\n contents: write\n pull-requests: write\n\njobs:\n dependabot:"
},
{
"path": ".gitignore",
"chars": 3130,
"preview": "# Byte-compiled / optimized / DLL files\n__pycache__/\n*.py[cod]\n*$py.class\n\n# C extensions\n*.so\n\n# Distribution / packagi"
},
{
"path": ".pre-commit-config.yaml",
"chars": 1624,
"preview": "ci:\n autoupdate_schedule: weekly\n autofix_commit_msg: \"ci: auto fixes from pre-commit.ci\\n\\nFor more information, see "
},
{
"path": ".python-version-default",
"chars": 5,
"preview": "3.11\n"
},
{
"path": ".ruff.toml",
"chars": 612,
"preview": "extend-include = [\"*.ipynb\"]\npreview = true\nline-length = 100\nindent-width = 2\n\n[format]\npreview = true\nquote-style = \"s"
},
{
"path": "CITATION.cff",
"chars": 2056,
"preview": "cff-version: 1.2.0\ntitle: 'OpenLLM: Operating LLMs in production'\nmessage: >-\n If you use this software, please cite it"
},
{
"path": "DEVELOPMENT.md",
"chars": 4600,
"preview": "# Developer Guide\n\nThis Developer Guide is designed to help you contribute to the OpenLLM project.\nFollow these steps to"
},
{
"path": "LICENSE",
"chars": 11357,
"preview": " Apache License\n Version 2.0, January 2004\n "
},
{
"path": "README.md",
"chars": 10671,
"preview": "<div align=\"center\">\n\n<h1>🦾 OpenLLM: Self-Hosting LLMs Made Easy</h1>\n\n[ {\n echo \"Usage: $0 [--release <major|minor|"
},
{
"path": "src/openllm/__init__.py",
"chars": 0,
"preview": ""
},
{
"path": "src/openllm/__main__.py",
"chars": 12799,
"preview": "from __future__ import annotations\n\nimport importlib.metadata, os, platform, random, sys, typing\nimport questionary, typ"
},
{
"path": "src/openllm/accelerator_spec.py",
"chars": 5573,
"preview": "from __future__ import annotations\n\nimport functools, math, re, typing\nimport psutil, pydantic\n\nfrom pydantic import Bef"
},
{
"path": "src/openllm/analytic.py",
"chars": 3539,
"preview": "from __future__ import annotations\n\nimport functools, os, re, time, typing, abc\nimport attr, click, typer, typer.core\n\nD"
},
{
"path": "src/openllm/clean.py",
"chars": 2580,
"preview": "from __future__ import annotations\n\nimport os, pathlib, shutil\nimport questionary\n\nfrom openllm.analytic import OpenLLMT"
},
{
"path": "src/openllm/cloud.py",
"chars": 7256,
"preview": "from __future__ import annotations\n\nimport json, os, pathlib, shutil, subprocess, typing\nimport typer\n\nfrom openllm.anal"
},
{
"path": "src/openllm/common.py",
"chars": 12126,
"preview": "from __future__ import annotations\n\nimport asyncio, asyncio.subprocess, functools, hashlib, io, json, os, pathlib, signa"
},
{
"path": "src/openllm/local.py",
"chars": 4971,
"preview": "from __future__ import annotations\n\nimport asyncio, time, typing, os\nimport httpx, openai\n\nfrom openai.types.chat import"
},
{
"path": "src/openllm/model.py",
"chars": 5008,
"preview": "from __future__ import annotations\n\nimport re, typing, json\nimport tabulate, questionary, typer\n\nfrom openllm.accelerato"
},
{
"path": "src/openllm/py.typed",
"chars": 0,
"preview": ""
},
{
"path": "src/openllm/repo.py",
"chars": 7744,
"preview": "from __future__ import annotations\n\nimport datetime, subprocess, re, shutil, typing, os, pathlib\nimport pyaml, questiona"
},
{
"path": "src/openllm/venv.py",
"chars": 3142,
"preview": "from __future__ import annotations\n\nimport functools, os, pathlib, shutil\nimport typer, yaml\n\nfrom openllm.common import"
}
]
About this extraction
This page contains the full source code of the bentoml/OpenLLM GitHub repository, extracted and formatted as plain text for AI agents and large language models (LLMs). The extraction includes 39 files (126.6 KB), approximately 35.5k tokens, and a symbol index with 106 extracted functions, classes, methods, constants, and types. Use this with OpenClaw, Claude, ChatGPT, Cursor, Windsurf, or any other AI tool that accepts text input. You can copy the full output to your clipboard or download it as a .txt file.
Extracted by GitExtract — free GitHub repo to text converter for AI. Built by Nikandr Surkov.