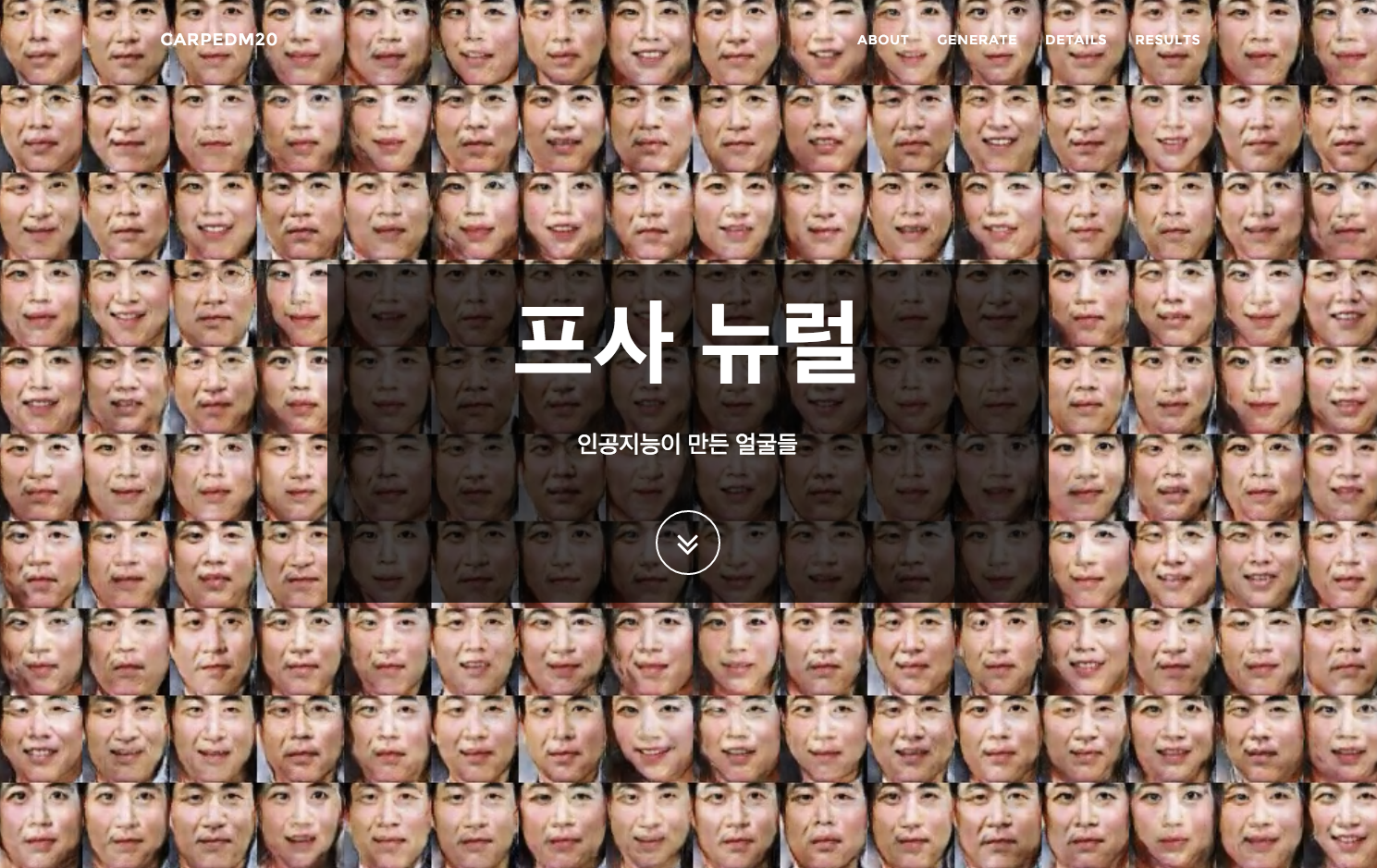
프사 뉴럴를 학습시키기 위해 인터넷에 10만 개 이상의 사진들을 모았고 이 사진들에서 얼굴 사진만 잘라서 얼굴 데이터 셋을 만들었습니다. 코드는 최근에 구글에서 공개한 TensorFlow로 구현했으며 GTX 980 Ti를 사용하여 이틀간 학습시켰습니다.
아래는 초기 학습 단계에서 프사 뉴럴이 정해진 z로 얼굴 사진을 만들어 가는 과정을 보여줍니다.
More than 100K images are crawled from online communities and those images are cropped by using openface which is a face recognition framework. Neural Face is implemented with TensorFlow and a GTX 980 Ti is used to train for two days.
Below is a series of images generated by Generator with a fixed z between the first and the fith epoch of training.
생성자가 사용하는 z는 -1에서 1 사이의 Gaussian Distribution을 따르는 확률 변수이며, 평균값인 0으로 이미지를 만들게 되면, 프사 뉴럴이 생각하는 평균적인 얼굴을 알 수 있습니다.
The vector z has real values from -1 to 1 and it follows the Gaussian Distribution. We can see the most common face that is interpreted by Neural Face using 0 as all values of z.
평균값 0에서 랜덤한 차원의 값을 조금씩 바꾸면 아래와 같은 변화를 볼 수 있습니다.
The below images are generated by changing the values of z continuously, starting from the average value (0) to -1 or 1.
아래의 사진들은 100차원의 z 값 중에서 임의의 차원들을 -1부터 1까지 바꾸면서 생성자 신경망에 넣은 결과이며, 점점 미소를 짓거나, 안경이 생기거나, 흑백 사진이 되거나, 성별이 바뀌는 등의 결과를 확인하실 수 있습니다.
The below images are generated by changing ten different values of z from -1 to 1. People in the images vary in characteristics such as smiling, wearing glasses, turning into black and white images, and changing into different sex.
 ](http://carpedm20.github.io/faces/)
[link](http://carpedm20.github.io/faces/)
## Prerequisites
- Python 2.7 or Python 3.3+
- [Tensorflow 0.12.1](https://github.com/tensorflow/tensorflow/tree/r0.12)
- [SciPy](http://www.scipy.org/install.html)
- [pillow](https://github.com/python-pillow/Pillow)
- [tqdm](https://pypi.org/project/tqdm/)
- (Optional) [moviepy](https://github.com/Zulko/moviepy) (for visualization)
- (Optional) [Align&Cropped Images.zip](http://mmlab.ie.cuhk.edu.hk/projects/CelebA.html) : Large-scale CelebFaces Dataset
## Usage
First, download dataset with:
$ python download.py mnist celebA
To train a model with downloaded dataset:
$ python main.py --dataset mnist --input_height=28 --output_height=28 --train
$ python main.py --dataset celebA --input_height=108 --train --crop
To test with an existing model:
$ python main.py --dataset mnist --input_height=28 --output_height=28
$ python main.py --dataset celebA --input_height=108 --crop
Or, you can use your own dataset (without central crop) by:
$ mkdir data/DATASET_NAME
... add images to data/DATASET_NAME ...
$ python main.py --dataset DATASET_NAME --train
$ python main.py --dataset DATASET_NAME
$ # example
$ python main.py --dataset=eyes --input_fname_pattern="*_cropped.png" --train
If your dataset is located in a different root directory:
$ python main.py --dataset DATASET_NAME --data_dir DATASET_ROOT_DIR --train
$ python main.py --dataset DATASET_NAME --data_dir DATASET_ROOT_DIR
$ # example
$ python main.py --dataset=eyes --data_dir ../datasets/ --input_fname_pattern="*_cropped.png" --train
## Results

### celebA
After 6th epoch:

After 10th epoch:

### Asian face dataset



### MNIST
MNIST codes are written by [@PhoenixDai](https://github.com/PhoenixDai).



More results can be found [here](./assets/) and [here](./web/img/).
## Training details
Details of the loss of Discriminator and Generator (with custom dataset not celebA).


Details of the histogram of true and fake result of discriminator (with custom dataset not celebA).


## Related works
- [BEGAN-tensorflow](https://github.com/carpedm20/BEGAN-tensorflow)
- [DiscoGAN-pytorch](https://github.com/carpedm20/DiscoGAN-pytorch)
- [simulated-unsupervised-tensorflow](https://github.com/carpedm20/simulated-unsupervised-tensorflow)
## Author
Taehoon Kim / [@carpedm20](http://carpedm20.github.io/)
================================================
FILE: download.py
================================================
"""
Modification of https://github.com/stanfordnlp/treelstm/blob/master/scripts/download.py
Downloads the following:
- Celeb-A dataset
- LSUN dataset
- MNIST dataset
"""
from __future__ import print_function
import os
import sys
import gzip
import json
import shutil
import zipfile
import argparse
import requests
import subprocess
from tqdm import tqdm
from six.moves import urllib
parser = argparse.ArgumentParser(description='Download dataset for DCGAN.')
parser.add_argument('datasets', metavar='N', type=str, nargs='+', choices=['celebA', 'lsun', 'mnist'],
help='name of dataset to download [celebA, lsun, mnist]')
def download(url, dirpath):
filename = url.split('/')[-1]
filepath = os.path.join(dirpath, filename)
u = urllib.request.urlopen(url)
f = open(filepath, 'wb')
filesize = int(u.headers["Content-Length"])
print("Downloading: %s Bytes: %s" % (filename, filesize))
downloaded = 0
block_sz = 8192
status_width = 70
while True:
buf = u.read(block_sz)
if not buf:
print('')
break
else:
print('', end='\r')
downloaded += len(buf)
f.write(buf)
status = (("[%-" + str(status_width + 1) + "s] %3.2f%%") %
('=' * int(float(downloaded) / filesize * status_width) + '>', downloaded * 100. / filesize))
print(status, end='')
sys.stdout.flush()
f.close()
return filepath
def download_file_from_google_drive(id, destination):
URL = "https://docs.google.com/uc?export=download"
session = requests.Session()
response = session.get(URL, params={ 'id': id }, stream=True)
token = get_confirm_token(response)
if token:
params = { 'id' : id, 'confirm' : token }
response = session.get(URL, params=params, stream=True)
save_response_content(response, destination)
def get_confirm_token(response):
for key, value in response.cookies.items():
if key.startswith('download_warning'):
return value
return None
def save_response_content(response, destination, chunk_size=32*1024):
total_size = int(response.headers.get('content-length', 0))
with open(destination, "wb") as f:
for chunk in tqdm(response.iter_content(chunk_size), total=total_size,
unit='B', unit_scale=True, desc=destination):
if chunk: # filter out keep-alive new chunks
f.write(chunk)
def unzip(filepath):
print("Extracting: " + filepath)
dirpath = os.path.dirname(filepath)
with zipfile.ZipFile(filepath) as zf:
zf.extractall(dirpath)
os.remove(filepath)
def download_celeb_a(dirpath):
data_dir = 'celebA'
if os.path.exists(os.path.join(dirpath, data_dir)):
print('Found Celeb-A - skip')
return
filename, drive_id = "img_align_celeba.zip", "0B7EVK8r0v71pZjFTYXZWM3FlRnM"
save_path = os.path.join(dirpath, filename)
if os.path.exists(save_path):
print('[*] {} already exists'.format(save_path))
else:
download_file_from_google_drive(drive_id, save_path)
zip_dir = ''
with zipfile.ZipFile(save_path) as zf:
zip_dir = zf.namelist()[0]
zf.extractall(dirpath)
os.remove(save_path)
os.rename(os.path.join(dirpath, zip_dir), os.path.join(dirpath, data_dir))
def _list_categories(tag):
url = 'http://lsun.cs.princeton.edu/htbin/list.cgi?tag=' + tag
f = urllib.request.urlopen(url)
return json.loads(f.read())
def _download_lsun(out_dir, category, set_name, tag):
url = 'http://lsun.cs.princeton.edu/htbin/download.cgi?tag={tag}' \
'&category={category}&set={set_name}'.format(**locals())
print(url)
if set_name == 'test':
out_name = 'test_lmdb.zip'
else:
out_name = '{category}_{set_name}_lmdb.zip'.format(**locals())
out_path = os.path.join(out_dir, out_name)
cmd = ['curl', url, '-o', out_path]
print('Downloading', category, set_name, 'set')
subprocess.call(cmd)
def download_lsun(dirpath):
data_dir = os.path.join(dirpath, 'lsun')
if os.path.exists(data_dir):
print('Found LSUN - skip')
return
else:
os.mkdir(data_dir)
tag = 'latest'
#categories = _list_categories(tag)
categories = ['bedroom']
for category in categories:
_download_lsun(data_dir, category, 'train', tag)
_download_lsun(data_dir, category, 'val', tag)
_download_lsun(data_dir, '', 'test', tag)
def download_mnist(dirpath):
data_dir = os.path.join(dirpath, 'mnist')
if os.path.exists(data_dir):
print('Found MNIST - skip')
return
else:
os.mkdir(data_dir)
url_base = 'http://yann.lecun.com/exdb/mnist/'
file_names = ['train-images-idx3-ubyte.gz',
'train-labels-idx1-ubyte.gz',
't10k-images-idx3-ubyte.gz',
't10k-labels-idx1-ubyte.gz']
for file_name in file_names:
url = (url_base+file_name).format(**locals())
print(url)
out_path = os.path.join(data_dir,file_name)
cmd = ['curl', url, '-o', out_path]
print('Downloading ', file_name)
subprocess.call(cmd)
cmd = ['gzip', '-d', out_path]
print('Decompressing ', file_name)
subprocess.call(cmd)
def prepare_data_dir(path = './data'):
if not os.path.exists(path):
os.mkdir(path)
if __name__ == '__main__':
args = parser.parse_args()
prepare_data_dir()
if any(name in args.datasets for name in ['CelebA', 'celebA', 'celebA']):
download_celeb_a('./data')
if 'lsun' in args.datasets:
download_lsun('./data')
if 'mnist' in args.datasets:
download_mnist('./data')
================================================
FILE: main.py
================================================
import os
import scipy.misc
import numpy as np
import json
from model import DCGAN
from utils import pp, visualize, to_json, show_all_variables, expand_path, timestamp
import tensorflow as tf
flags = tf.app.flags
flags.DEFINE_integer("epoch", 25, "Epoch to train [25]")
flags.DEFINE_float("learning_rate", 0.0002, "Learning rate of for adam [0.0002]")
flags.DEFINE_float("beta1", 0.5, "Momentum term of adam [0.5]")
flags.DEFINE_float("train_size", np.inf, "The size of train images [np.inf]")
flags.DEFINE_integer("batch_size", 64, "The size of batch images [64]")
flags.DEFINE_integer("input_height", 108, "The size of image to use (will be center cropped). [108]")
flags.DEFINE_integer("input_width", None, "The size of image to use (will be center cropped). If None, same value as input_height [None]")
flags.DEFINE_integer("output_height", 64, "The size of the output images to produce [64]")
flags.DEFINE_integer("output_width", None, "The size of the output images to produce. If None, same value as output_height [None]")
flags.DEFINE_string("dataset", "celebA", "The name of dataset [celebA, mnist, lsun]")
flags.DEFINE_string("input_fname_pattern", "*.jpg", "Glob pattern of filename of input images [*]")
flags.DEFINE_string("data_dir", "./data", "path to datasets [e.g. $HOME/data]")
flags.DEFINE_string("out_dir", "./out", "Root directory for outputs [e.g. $HOME/out]")
flags.DEFINE_string("out_name", "", "Folder (under out_root_dir) for all outputs. Generated automatically if left blank []")
flags.DEFINE_string("checkpoint_dir", "checkpoint", "Folder (under out_root_dir/out_name) to save checkpoints [checkpoint]")
flags.DEFINE_string("sample_dir", "samples", "Folder (under out_root_dir/out_name) to save samples [samples]")
flags.DEFINE_boolean("train", False, "True for training, False for testing [False]")
flags.DEFINE_boolean("crop", False, "True for training, False for testing [False]")
flags.DEFINE_boolean("visualize", False, "True for visualizing, False for nothing [False]")
flags.DEFINE_boolean("export", False, "True for exporting with new batch size")
flags.DEFINE_boolean("freeze", False, "True for exporting with new batch size")
flags.DEFINE_integer("max_to_keep", 1, "maximum number of checkpoints to keep")
flags.DEFINE_integer("sample_freq", 200, "sample every this many iterations")
flags.DEFINE_integer("ckpt_freq", 200, "save checkpoint every this many iterations")
flags.DEFINE_integer("z_dim", 100, "dimensions of z")
flags.DEFINE_string("z_dist", "uniform_signed", "'normal01' or 'uniform_unsigned' or uniform_signed")
flags.DEFINE_boolean("G_img_sum", False, "Save generator image summaries in log")
#flags.DEFINE_integer("generate_test_images", 100, "Number of images to generate during test. [100]")
FLAGS = flags.FLAGS
def main(_):
pp.pprint(flags.FLAGS.__flags)
# expand user name and environment variables
FLAGS.data_dir = expand_path(FLAGS.data_dir)
FLAGS.out_dir = expand_path(FLAGS.out_dir)
FLAGS.out_name = expand_path(FLAGS.out_name)
FLAGS.checkpoint_dir = expand_path(FLAGS.checkpoint_dir)
FLAGS.sample_dir = expand_path(FLAGS.sample_dir)
if FLAGS.output_height is None: FLAGS.output_height = FLAGS.input_height
if FLAGS.input_width is None: FLAGS.input_width = FLAGS.input_height
if FLAGS.output_width is None: FLAGS.output_width = FLAGS.output_height
# output folders
if FLAGS.out_name == "":
FLAGS.out_name = '{} - {} - {}'.format(timestamp(), FLAGS.data_dir.split('/')[-1], FLAGS.dataset) # penultimate folder of path
if FLAGS.train:
FLAGS.out_name += ' - x{}.z{}.{}.y{}.b{}'.format(FLAGS.input_width, FLAGS.z_dim, FLAGS.z_dist, FLAGS.output_width, FLAGS.batch_size)
FLAGS.out_dir = os.path.join(FLAGS.out_dir, FLAGS.out_name)
FLAGS.checkpoint_dir = os.path.join(FLAGS.out_dir, FLAGS.checkpoint_dir)
FLAGS.sample_dir = os.path.join(FLAGS.out_dir, FLAGS.sample_dir)
if not os.path.exists(FLAGS.checkpoint_dir): os.makedirs(FLAGS.checkpoint_dir)
if not os.path.exists(FLAGS.sample_dir): os.makedirs(FLAGS.sample_dir)
with open(os.path.join(FLAGS.out_dir, 'FLAGS.json'), 'w') as f:
flags_dict = {k:FLAGS[k].value for k in FLAGS}
json.dump(flags_dict, f, indent=4, sort_keys=True, ensure_ascii=False)
#gpu_options = tf.GPUOptions(per_process_gpu_memory_fraction=0.333)
run_config = tf.ConfigProto()
run_config.gpu_options.allow_growth=True
with tf.Session(config=run_config) as sess:
if FLAGS.dataset == 'mnist':
dcgan = DCGAN(
sess,
input_width=FLAGS.input_width,
input_height=FLAGS.input_height,
output_width=FLAGS.output_width,
output_height=FLAGS.output_height,
batch_size=FLAGS.batch_size,
sample_num=FLAGS.batch_size,
y_dim=10,
z_dim=FLAGS.z_dim,
dataset_name=FLAGS.dataset,
input_fname_pattern=FLAGS.input_fname_pattern,
crop=FLAGS.crop,
checkpoint_dir=FLAGS.checkpoint_dir,
sample_dir=FLAGS.sample_dir,
data_dir=FLAGS.data_dir,
out_dir=FLAGS.out_dir,
max_to_keep=FLAGS.max_to_keep)
else:
dcgan = DCGAN(
sess,
input_width=FLAGS.input_width,
input_height=FLAGS.input_height,
output_width=FLAGS.output_width,
output_height=FLAGS.output_height,
batch_size=FLAGS.batch_size,
sample_num=FLAGS.batch_size,
z_dim=FLAGS.z_dim,
dataset_name=FLAGS.dataset,
input_fname_pattern=FLAGS.input_fname_pattern,
crop=FLAGS.crop,
checkpoint_dir=FLAGS.checkpoint_dir,
sample_dir=FLAGS.sample_dir,
data_dir=FLAGS.data_dir,
out_dir=FLAGS.out_dir,
max_to_keep=FLAGS.max_to_keep)
show_all_variables()
if FLAGS.train:
dcgan.train(FLAGS)
else:
load_success, load_counter = dcgan.load(FLAGS.checkpoint_dir)
if not load_success:
raise Exception("Checkpoint not found in " + FLAGS.checkpoint_dir)
# to_json("./web/js/layers.js", [dcgan.h0_w, dcgan.h0_b, dcgan.g_bn0],
# [dcgan.h1_w, dcgan.h1_b, dcgan.g_bn1],
# [dcgan.h2_w, dcgan.h2_b, dcgan.g_bn2],
# [dcgan.h3_w, dcgan.h3_b, dcgan.g_bn3],
# [dcgan.h4_w, dcgan.h4_b, None])
# Below is codes for visualization
if FLAGS.export:
export_dir = os.path.join(FLAGS.checkpoint_dir, 'export_b'+str(FLAGS.batch_size))
dcgan.save(export_dir, load_counter, ckpt=True, frozen=False)
if FLAGS.freeze:
export_dir = os.path.join(FLAGS.checkpoint_dir, 'frozen_b'+str(FLAGS.batch_size))
dcgan.save(export_dir, load_counter, ckpt=False, frozen=True)
if FLAGS.visualize:
OPTION = 1
visualize(sess, dcgan, FLAGS, OPTION, FLAGS.sample_dir)
if __name__ == '__main__':
tf.app.run()
================================================
FILE: model.py
================================================
from __future__ import division
from __future__ import print_function
import os
import time
import math
from glob import glob
import tensorflow as tf
import numpy as np
from six.moves import xrange
from ops import *
from utils import *
def conv_out_size_same(size, stride):
return int(math.ceil(float(size) / float(stride)))
def gen_random(mode, size):
if mode=='normal01': return np.random.normal(0,1,size=size)
if mode=='uniform_signed': return np.random.uniform(-1,1,size=size)
if mode=='uniform_unsigned': return np.random.uniform(0,1,size=size)
class DCGAN(object):
def __init__(self, sess, input_height=108, input_width=108, crop=True,
batch_size=64, sample_num = 64, output_height=64, output_width=64,
y_dim=None, z_dim=100, gf_dim=64, df_dim=64,
gfc_dim=1024, dfc_dim=1024, c_dim=3, dataset_name='default',
max_to_keep=1,
input_fname_pattern='*.jpg', checkpoint_dir='ckpts', sample_dir='samples', out_dir='./out', data_dir='./data'):
"""
Args:
sess: TensorFlow session
batch_size: The size of batch. Should be specified before training.
y_dim: (optional) Dimension of dim for y. [None]
z_dim: (optional) Dimension of dim for Z. [100]
gf_dim: (optional) Dimension of gen filters in first conv layer. [64]
df_dim: (optional) Dimension of discrim filters in first conv layer. [64]
gfc_dim: (optional) Dimension of gen units for for fully connected layer. [1024]
dfc_dim: (optional) Dimension of discrim units for fully connected layer. [1024]
c_dim: (optional) Dimension of image color. For grayscale input, set to 1. [3]
"""
self.sess = sess
self.crop = crop
self.batch_size = batch_size
self.sample_num = sample_num
self.input_height = input_height
self.input_width = input_width
self.output_height = output_height
self.output_width = output_width
self.y_dim = y_dim
self.z_dim = z_dim
self.gf_dim = gf_dim
self.df_dim = df_dim
self.gfc_dim = gfc_dim
self.dfc_dim = dfc_dim
# batch normalization : deals with poor initialization helps gradient flow
self.d_bn1 = batch_norm(name='d_bn1')
self.d_bn2 = batch_norm(name='d_bn2')
if not self.y_dim:
self.d_bn3 = batch_norm(name='d_bn3')
self.g_bn0 = batch_norm(name='g_bn0')
self.g_bn1 = batch_norm(name='g_bn1')
self.g_bn2 = batch_norm(name='g_bn2')
if not self.y_dim:
self.g_bn3 = batch_norm(name='g_bn3')
self.dataset_name = dataset_name
self.input_fname_pattern = input_fname_pattern
self.checkpoint_dir = checkpoint_dir
self.data_dir = data_dir
self.out_dir = out_dir
self.max_to_keep = max_to_keep
if self.dataset_name == 'mnist':
self.data_X, self.data_y = self.load_mnist()
self.c_dim = self.data_X[0].shape[-1]
else:
data_path = os.path.join(self.data_dir, self.dataset_name, self.input_fname_pattern)
self.data = glob(data_path)
if len(self.data) == 0:
raise Exception("[!] No data found in '" + data_path + "'")
np.random.shuffle(self.data)
imreadImg = imread(self.data[0])
if len(imreadImg.shape) >= 3: #check if image is a non-grayscale image by checking channel number
self.c_dim = imread(self.data[0]).shape[-1]
else:
self.c_dim = 1
if len(self.data) < self.batch_size:
raise Exception("[!] Entire dataset size is less than the configured batch_size")
self.grayscale = (self.c_dim == 1)
self.build_model()
def build_model(self):
if self.y_dim:
self.y = tf.placeholder(tf.float32, [self.batch_size, self.y_dim], name='y')
else:
self.y = None
if self.crop:
image_dims = [self.output_height, self.output_width, self.c_dim]
else:
image_dims = [self.input_height, self.input_width, self.c_dim]
self.inputs = tf.placeholder(
tf.float32, [self.batch_size] + image_dims, name='real_images')
inputs = self.inputs
self.z = tf.placeholder(
tf.float32, [None, self.z_dim], name='z')
self.z_sum = histogram_summary("z", self.z)
self.G = self.generator(self.z, self.y)
self.D, self.D_logits = self.discriminator(inputs, self.y, reuse=False)
self.sampler = self.sampler(self.z, self.y)
self.D_, self.D_logits_ = self.discriminator(self.G, self.y, reuse=True)
self.d_sum = histogram_summary("d", self.D)
self.d__sum = histogram_summary("d_", self.D_)
self.G_sum = image_summary("G", self.G)
def sigmoid_cross_entropy_with_logits(x, y):
try:
return tf.nn.sigmoid_cross_entropy_with_logits(logits=x, labels=y)
except:
return tf.nn.sigmoid_cross_entropy_with_logits(logits=x, targets=y)
self.d_loss_real = tf.reduce_mean(
sigmoid_cross_entropy_with_logits(self.D_logits, tf.ones_like(self.D)))
self.d_loss_fake = tf.reduce_mean(
sigmoid_cross_entropy_with_logits(self.D_logits_, tf.zeros_like(self.D_)))
self.g_loss = tf.reduce_mean(
sigmoid_cross_entropy_with_logits(self.D_logits_, tf.ones_like(self.D_)))
self.d_loss_real_sum = scalar_summary("d_loss_real", self.d_loss_real)
self.d_loss_fake_sum = scalar_summary("d_loss_fake", self.d_loss_fake)
self.d_loss = self.d_loss_real + self.d_loss_fake
self.g_loss_sum = scalar_summary("g_loss", self.g_loss)
self.d_loss_sum = scalar_summary("d_loss", self.d_loss)
t_vars = tf.trainable_variables()
self.d_vars = [var for var in t_vars if 'd_' in var.name]
self.g_vars = [var for var in t_vars if 'g_' in var.name]
self.saver = tf.train.Saver(max_to_keep=self.max_to_keep)
def train(self, config):
d_optim = tf.train.AdamOptimizer(config.learning_rate, beta1=config.beta1) \
.minimize(self.d_loss, var_list=self.d_vars)
g_optim = tf.train.AdamOptimizer(config.learning_rate, beta1=config.beta1) \
.minimize(self.g_loss, var_list=self.g_vars)
try:
tf.global_variables_initializer().run()
except:
tf.initialize_all_variables().run()
if config.G_img_sum:
self.g_sum = merge_summary([self.z_sum, self.d__sum, self.G_sum, self.d_loss_fake_sum, self.g_loss_sum])
else:
self.g_sum = merge_summary([self.z_sum, self.d__sum, self.d_loss_fake_sum, self.g_loss_sum])
self.d_sum = merge_summary(
[self.z_sum, self.d_sum, self.d_loss_real_sum, self.d_loss_sum])
self.writer = SummaryWriter(os.path.join(self.out_dir, "logs"), self.sess.graph)
sample_z = gen_random(config.z_dist, size=(self.sample_num , self.z_dim))
if config.dataset == 'mnist':
sample_inputs = self.data_X[0:self.sample_num]
sample_labels = self.data_y[0:self.sample_num]
else:
sample_files = self.data[0:self.sample_num]
sample = [
get_image(sample_file,
input_height=self.input_height,
input_width=self.input_width,
resize_height=self.output_height,
resize_width=self.output_width,
crop=self.crop,
grayscale=self.grayscale) for sample_file in sample_files]
if (self.grayscale):
sample_inputs = np.array(sample).astype(np.float32)[:, :, :, None]
else:
sample_inputs = np.array(sample).astype(np.float32)
counter = 1
start_time = time.time()
could_load, checkpoint_counter = self.load(self.checkpoint_dir)
if could_load:
counter = checkpoint_counter
print(" [*] Load SUCCESS")
else:
print(" [!] Load failed...")
for epoch in xrange(config.epoch):
if config.dataset == 'mnist':
batch_idxs = min(len(self.data_X), config.train_size) // config.batch_size
else:
self.data = glob(os.path.join(
config.data_dir, config.dataset, self.input_fname_pattern))
np.random.shuffle(self.data)
batch_idxs = min(len(self.data), config.train_size) // config.batch_size
for idx in xrange(0, int(batch_idxs)):
if config.dataset == 'mnist':
batch_images = self.data_X[idx*config.batch_size:(idx+1)*config.batch_size]
batch_labels = self.data_y[idx*config.batch_size:(idx+1)*config.batch_size]
else:
batch_files = self.data[idx*config.batch_size:(idx+1)*config.batch_size]
batch = [
get_image(batch_file,
input_height=self.input_height,
input_width=self.input_width,
resize_height=self.output_height,
resize_width=self.output_width,
crop=self.crop,
grayscale=self.grayscale) for batch_file in batch_files]
if self.grayscale:
batch_images = np.array(batch).astype(np.float32)[:, :, :, None]
else:
batch_images = np.array(batch).astype(np.float32)
batch_z = gen_random(config.z_dist, size=[config.batch_size, self.z_dim]) \
.astype(np.float32)
if config.dataset == 'mnist':
# Update D network
_, summary_str = self.sess.run([d_optim, self.d_sum],
feed_dict={
self.inputs: batch_images,
self.z: batch_z,
self.y:batch_labels,
})
self.writer.add_summary(summary_str, counter)
# Update G network
_, summary_str = self.sess.run([g_optim, self.g_sum],
feed_dict={
self.z: batch_z,
self.y:batch_labels,
})
self.writer.add_summary(summary_str, counter)
# Run g_optim twice to make sure that d_loss does not go to zero (different from paper)
_, summary_str = self.sess.run([g_optim, self.g_sum],
feed_dict={ self.z: batch_z, self.y:batch_labels })
self.writer.add_summary(summary_str, counter)
errD_fake = self.d_loss_fake.eval({
self.z: batch_z,
self.y:batch_labels
})
errD_real = self.d_loss_real.eval({
self.inputs: batch_images,
self.y:batch_labels
})
errG = self.g_loss.eval({
self.z: batch_z,
self.y: batch_labels
})
else:
# Update D network
_, summary_str = self.sess.run([d_optim, self.d_sum],
feed_dict={ self.inputs: batch_images, self.z: batch_z })
self.writer.add_summary(summary_str, counter)
# Update G network
_, summary_str = self.sess.run([g_optim, self.g_sum],
feed_dict={ self.z: batch_z })
self.writer.add_summary(summary_str, counter)
# Run g_optim twice to make sure that d_loss does not go to zero (different from paper)
_, summary_str = self.sess.run([g_optim, self.g_sum],
feed_dict={ self.z: batch_z })
self.writer.add_summary(summary_str, counter)
errD_fake = self.d_loss_fake.eval({ self.z: batch_z })
errD_real = self.d_loss_real.eval({ self.inputs: batch_images })
errG = self.g_loss.eval({self.z: batch_z})
print("[%8d Epoch:[%2d/%2d] [%4d/%4d] time: %4.4f, d_loss: %.8f, g_loss: %.8f" \
% (counter, epoch, config.epoch, idx, batch_idxs,
time.time() - start_time, errD_fake+errD_real, errG))
if np.mod(counter, config.sample_freq) == 0:
if config.dataset == 'mnist':
samples, d_loss, g_loss = self.sess.run(
[self.sampler, self.d_loss, self.g_loss],
feed_dict={
self.z: sample_z,
self.inputs: sample_inputs,
self.y:sample_labels,
}
)
save_images(samples, image_manifold_size(samples.shape[0]),
'./{}/train_{:08d}.png'.format(config.sample_dir, counter))
print("[Sample] d_loss: %.8f, g_loss: %.8f" % (d_loss, g_loss))
else:
try:
samples, d_loss, g_loss = self.sess.run(
[self.sampler, self.d_loss, self.g_loss],
feed_dict={
self.z: sample_z,
self.inputs: sample_inputs,
},
)
save_images(samples, image_manifold_size(samples.shape[0]),
'./{}/train_{:08d}.png'.format(config.sample_dir, counter))
print("[Sample] d_loss: %.8f, g_loss: %.8f" % (d_loss, g_loss))
except:
print("one pic error!...")
if np.mod(counter, config.ckpt_freq) == 0:
self.save(config.checkpoint_dir, counter)
counter += 1
def discriminator(self, image, y=None, reuse=False):
with tf.variable_scope("discriminator") as scope:
if reuse:
scope.reuse_variables()
if not self.y_dim:
h0 = lrelu(conv2d(image, self.df_dim, name='d_h0_conv'))
h1 = lrelu(self.d_bn1(conv2d(h0, self.df_dim*2, name='d_h1_conv')))
h2 = lrelu(self.d_bn2(conv2d(h1, self.df_dim*4, name='d_h2_conv')))
h3 = lrelu(self.d_bn3(conv2d(h2, self.df_dim*8, name='d_h3_conv')))
h4 = linear(tf.reshape(h3, [self.batch_size, -1]), 1, 'd_h4_lin')
return tf.nn.sigmoid(h4), h4
else:
yb = tf.reshape(y, [self.batch_size, 1, 1, self.y_dim])
x = conv_cond_concat(image, yb)
h0 = lrelu(conv2d(x, self.c_dim + self.y_dim, name='d_h0_conv'))
h0 = conv_cond_concat(h0, yb)
h1 = lrelu(self.d_bn1(conv2d(h0, self.df_dim + self.y_dim, name='d_h1_conv')))
h1 = tf.reshape(h1, [self.batch_size, -1])
h1 = concat([h1, y], 1)
h2 = lrelu(self.d_bn2(linear(h1, self.dfc_dim, 'd_h2_lin')))
h2 = concat([h2, y], 1)
h3 = linear(h2, 1, 'd_h3_lin')
return tf.nn.sigmoid(h3), h3
def generator(self, z, y=None):
with tf.variable_scope("generator") as scope:
if not self.y_dim:
s_h, s_w = self.output_height, self.output_width
s_h2, s_w2 = conv_out_size_same(s_h, 2), conv_out_size_same(s_w, 2)
s_h4, s_w4 = conv_out_size_same(s_h2, 2), conv_out_size_same(s_w2, 2)
s_h8, s_w8 = conv_out_size_same(s_h4, 2), conv_out_size_same(s_w4, 2)
s_h16, s_w16 = conv_out_size_same(s_h8, 2), conv_out_size_same(s_w8, 2)
# project `z` and reshape
self.z_, self.h0_w, self.h0_b = linear(
z, self.gf_dim*8*s_h16*s_w16, 'g_h0_lin', with_w=True)
self.h0 = tf.reshape(
self.z_, [-1, s_h16, s_w16, self.gf_dim * 8])
h0 = tf.nn.relu(self.g_bn0(self.h0))
self.h1, self.h1_w, self.h1_b = deconv2d(
h0, [self.batch_size, s_h8, s_w8, self.gf_dim*4], name='g_h1', with_w=True)
h1 = tf.nn.relu(self.g_bn1(self.h1))
h2, self.h2_w, self.h2_b = deconv2d(
h1, [self.batch_size, s_h4, s_w4, self.gf_dim*2], name='g_h2', with_w=True)
h2 = tf.nn.relu(self.g_bn2(h2))
h3, self.h3_w, self.h3_b = deconv2d(
h2, [self.batch_size, s_h2, s_w2, self.gf_dim*1], name='g_h3', with_w=True)
h3 = tf.nn.relu(self.g_bn3(h3))
h4, self.h4_w, self.h4_b = deconv2d(
h3, [self.batch_size, s_h, s_w, self.c_dim], name='g_h4', with_w=True)
return tf.nn.tanh(h4)
else:
s_h, s_w = self.output_height, self.output_width
s_h2, s_h4 = int(s_h/2), int(s_h/4)
s_w2, s_w4 = int(s_w/2), int(s_w/4)
# yb = tf.expand_dims(tf.expand_dims(y, 1),2)
yb = tf.reshape(y, [self.batch_size, 1, 1, self.y_dim])
z = concat([z, y], 1)
h0 = tf.nn.relu(
self.g_bn0(linear(z, self.gfc_dim, 'g_h0_lin')))
h0 = concat([h0, y], 1)
h1 = tf.nn.relu(self.g_bn1(
linear(h0, self.gf_dim*2*s_h4*s_w4, 'g_h1_lin')))
h1 = tf.reshape(h1, [self.batch_size, s_h4, s_w4, self.gf_dim * 2])
h1 = conv_cond_concat(h1, yb)
h2 = tf.nn.relu(self.g_bn2(deconv2d(h1,
[self.batch_size, s_h2, s_w2, self.gf_dim * 2], name='g_h2')))
h2 = conv_cond_concat(h2, yb)
return tf.nn.sigmoid(
deconv2d(h2, [self.batch_size, s_h, s_w, self.c_dim], name='g_h3'))
def sampler(self, z, y=None):
with tf.variable_scope("generator") as scope:
scope.reuse_variables()
if not self.y_dim:
s_h, s_w = self.output_height, self.output_width
s_h2, s_w2 = conv_out_size_same(s_h, 2), conv_out_size_same(s_w, 2)
s_h4, s_w4 = conv_out_size_same(s_h2, 2), conv_out_size_same(s_w2, 2)
s_h8, s_w8 = conv_out_size_same(s_h4, 2), conv_out_size_same(s_w4, 2)
s_h16, s_w16 = conv_out_size_same(s_h8, 2), conv_out_size_same(s_w8, 2)
# project `z` and reshape
h0 = tf.reshape(
linear(z, self.gf_dim*8*s_h16*s_w16, 'g_h0_lin'),
[-1, s_h16, s_w16, self.gf_dim * 8])
h0 = tf.nn.relu(self.g_bn0(h0, train=False))
h1 = deconv2d(h0, [self.batch_size, s_h8, s_w8, self.gf_dim*4], name='g_h1')
h1 = tf.nn.relu(self.g_bn1(h1, train=False))
h2 = deconv2d(h1, [self.batch_size, s_h4, s_w4, self.gf_dim*2], name='g_h2')
h2 = tf.nn.relu(self.g_bn2(h2, train=False))
h3 = deconv2d(h2, [self.batch_size, s_h2, s_w2, self.gf_dim*1], name='g_h3')
h3 = tf.nn.relu(self.g_bn3(h3, train=False))
h4 = deconv2d(h3, [self.batch_size, s_h, s_w, self.c_dim], name='g_h4')
return tf.nn.tanh(h4)
else:
s_h, s_w = self.output_height, self.output_width
s_h2, s_h4 = int(s_h/2), int(s_h/4)
s_w2, s_w4 = int(s_w/2), int(s_w/4)
# yb = tf.reshape(y, [-1, 1, 1, self.y_dim])
yb = tf.reshape(y, [self.batch_size, 1, 1, self.y_dim])
z = concat([z, y], 1)
h0 = tf.nn.relu(self.g_bn0(linear(z, self.gfc_dim, 'g_h0_lin'), train=False))
h0 = concat([h0, y], 1)
h1 = tf.nn.relu(self.g_bn1(
linear(h0, self.gf_dim*2*s_h4*s_w4, 'g_h1_lin'), train=False))
h1 = tf.reshape(h1, [self.batch_size, s_h4, s_w4, self.gf_dim * 2])
h1 = conv_cond_concat(h1, yb)
h2 = tf.nn.relu(self.g_bn2(
deconv2d(h1, [self.batch_size, s_h2, s_w2, self.gf_dim * 2], name='g_h2'), train=False))
h2 = conv_cond_concat(h2, yb)
return tf.nn.sigmoid(deconv2d(h2, [self.batch_size, s_h, s_w, self.c_dim], name='g_h3'))
def load_mnist(self):
data_dir = os.path.join(self.data_dir, self.dataset_name)
fd = open(os.path.join(data_dir,'train-images-idx3-ubyte'))
loaded = np.fromfile(file=fd,dtype=np.uint8)
trX = loaded[16:].reshape((60000,28,28,1)).astype(np.float)
fd = open(os.path.join(data_dir,'train-labels-idx1-ubyte'))
loaded = np.fromfile(file=fd,dtype=np.uint8)
trY = loaded[8:].reshape((60000)).astype(np.float)
fd = open(os.path.join(data_dir,'t10k-images-idx3-ubyte'))
loaded = np.fromfile(file=fd,dtype=np.uint8)
teX = loaded[16:].reshape((10000,28,28,1)).astype(np.float)
fd = open(os.path.join(data_dir,'t10k-labels-idx1-ubyte'))
loaded = np.fromfile(file=fd,dtype=np.uint8)
teY = loaded[8:].reshape((10000)).astype(np.float)
trY = np.asarray(trY)
teY = np.asarray(teY)
X = np.concatenate((trX, teX), axis=0)
y = np.concatenate((trY, teY), axis=0).astype(np.int)
seed = 547
np.random.seed(seed)
np.random.shuffle(X)
np.random.seed(seed)
np.random.shuffle(y)
y_vec = np.zeros((len(y), self.y_dim), dtype=np.float)
for i, label in enumerate(y):
y_vec[i,y[i]] = 1.0
return X/255.,y_vec
@property
def model_dir(self):
return "{}_{}_{}_{}".format(
self.dataset_name, self.batch_size,
self.output_height, self.output_width)
def save(self, checkpoint_dir, step, filename='model', ckpt=True, frozen=False):
# model_name = "DCGAN.model"
# checkpoint_dir = os.path.join(checkpoint_dir, self.model_dir)
filename += '.b' + str(self.batch_size)
if not os.path.exists(checkpoint_dir):
os.makedirs(checkpoint_dir)
if ckpt:
self.saver.save(self.sess,
os.path.join(checkpoint_dir, filename),
global_step=step)
if frozen:
tf.train.write_graph(
tf.graph_util.convert_variables_to_constants(self.sess, self.sess.graph_def, ["generator_1/Tanh"]),
checkpoint_dir,
'{}-{:06d}_frz.pb'.format(filename, step),
as_text=False)
def load(self, checkpoint_dir):
#import re
print(" [*] Reading checkpoints...", checkpoint_dir)
# checkpoint_dir = os.path.join(checkpoint_dir, self.model_dir)
# print(" ->", checkpoint_dir)
ckpt = tf.train.get_checkpoint_state(checkpoint_dir)
if ckpt and ckpt.model_checkpoint_path:
ckpt_name = os.path.basename(ckpt.model_checkpoint_path)
self.saver.restore(self.sess, os.path.join(checkpoint_dir, ckpt_name))
#counter = int(next(re.finditer("(\d+)(?!.*\d)",ckpt_name)).group(0))
counter = int(ckpt_name.split('-')[-1])
print(" [*] Success to read {}".format(ckpt_name))
return True, counter
else:
print(" [*] Failed to find a checkpoint")
return False, 0
================================================
FILE: ops.py
================================================
import math
import numpy as np
import tensorflow as tf
from tensorflow.python.framework import ops
from utils import *
try:
image_summary = tf.image_summary
scalar_summary = tf.scalar_summary
histogram_summary = tf.histogram_summary
merge_summary = tf.merge_summary
SummaryWriter = tf.train.SummaryWriter
except:
image_summary = tf.summary.image
scalar_summary = tf.summary.scalar
histogram_summary = tf.summary.histogram
merge_summary = tf.summary.merge
SummaryWriter = tf.summary.FileWriter
if "concat_v2" in dir(tf):
def concat(tensors, axis, *args, **kwargs):
return tf.concat_v2(tensors, axis, *args, **kwargs)
else:
def concat(tensors, axis, *args, **kwargs):
return tf.concat(tensors, axis, *args, **kwargs)
class batch_norm(object):
def __init__(self, epsilon=1e-5, momentum = 0.9, name="batch_norm"):
with tf.variable_scope(name):
self.epsilon = epsilon
self.momentum = momentum
self.name = name
def __call__(self, x, train=True):
return tf.contrib.layers.batch_norm(x,
decay=self.momentum,
updates_collections=None,
epsilon=self.epsilon,
scale=True,
is_training=train,
scope=self.name)
def conv_cond_concat(x, y):
"""Concatenate conditioning vector on feature map axis."""
x_shapes = x.get_shape()
y_shapes = y.get_shape()
return concat([
x, y*tf.ones([x_shapes[0], x_shapes[1], x_shapes[2], y_shapes[3]])], 3)
def conv2d(input_, output_dim,
k_h=5, k_w=5, d_h=2, d_w=2, stddev=0.02,
name="conv2d"):
with tf.variable_scope(name):
w = tf.get_variable('w', [k_h, k_w, input_.get_shape()[-1], output_dim],
initializer=tf.truncated_normal_initializer(stddev=stddev))
conv = tf.nn.conv2d(input_, w, strides=[1, d_h, d_w, 1], padding='SAME')
biases = tf.get_variable('biases', [output_dim], initializer=tf.constant_initializer(0.0))
conv = tf.reshape(tf.nn.bias_add(conv, biases), conv.get_shape())
return conv
def deconv2d(input_, output_shape,
k_h=5, k_w=5, d_h=2, d_w=2, stddev=0.02,
name="deconv2d", with_w=False):
with tf.variable_scope(name):
# filter : [height, width, output_channels, in_channels]
w = tf.get_variable('w', [k_h, k_w, output_shape[-1], input_.get_shape()[-1]],
initializer=tf.random_normal_initializer(stddev=stddev))
try:
deconv = tf.nn.conv2d_transpose(input_, w, output_shape=output_shape,
strides=[1, d_h, d_w, 1])
# Support for verisons of TensorFlow before 0.7.0
except AttributeError:
deconv = tf.nn.deconv2d(input_, w, output_shape=output_shape,
strides=[1, d_h, d_w, 1])
biases = tf.get_variable('biases', [output_shape[-1]], initializer=tf.constant_initializer(0.0))
deconv = tf.reshape(tf.nn.bias_add(deconv, biases), deconv.get_shape())
if with_w:
return deconv, w, biases
else:
return deconv
def lrelu(x, leak=0.2, name="lrelu"):
return tf.maximum(x, leak*x)
def linear(input_, output_size, scope=None, stddev=0.02, bias_start=0.0, with_w=False):
shape = input_.get_shape().as_list()
with tf.variable_scope(scope or "Linear"):
try:
matrix = tf.get_variable("Matrix", [shape[1], output_size], tf.float32,
tf.random_normal_initializer(stddev=stddev))
except ValueError as err:
msg = "NOTE: Usually, this is due to an issue with the image dimensions. Did you correctly set '--crop' or '--input_height' or '--output_height'?"
err.args = err.args + (msg,)
raise
bias = tf.get_variable("bias", [output_size],
initializer=tf.constant_initializer(bias_start))
if with_w:
return tf.matmul(input_, matrix) + bias, matrix, bias
else:
return tf.matmul(input_, matrix) + bias
================================================
FILE: utils.py
================================================
"""
Some codes from https://github.com/Newmu/dcgan_code
"""
from __future__ import division
import math
import json
import random
import pprint
import scipy.misc
import cv2
import numpy as np
import os
import time
import datetime
from time import gmtime, strftime
from six.moves import xrange
from PIL import Image
import tensorflow as tf
import tensorflow.contrib.slim as slim
pp = pprint.PrettyPrinter()
get_stddev = lambda x, k_h, k_w: 1/math.sqrt(k_w*k_h*x.get_shape()[-1])
def expand_path(path):
return os.path.expanduser(os.path.expandvars(path))
def timestamp(s='%Y%m%d.%H%M%S', ts=None):
if not ts: ts = time.time()
st = datetime.datetime.fromtimestamp(ts).strftime(s)
return st
def show_all_variables():
model_vars = tf.trainable_variables()
slim.model_analyzer.analyze_vars(model_vars, print_info=True)
def get_image(image_path, input_height, input_width,
resize_height=64, resize_width=64,
crop=True, grayscale=False):
image = imread(image_path, grayscale)
return transform(image, input_height, input_width,
resize_height, resize_width, crop)
def save_images(images, size, image_path):
return imsave(inverse_transform(images), size, image_path)
def imread(path, grayscale = False):
if (grayscale):
return scipy.misc.imread(path, flatten = True).astype(np.float)
else:
# Reference: https://github.com/carpedm20/DCGAN-tensorflow/issues/162#issuecomment-315519747
img_bgr = cv2.imread(path)
# Reference: https://stackoverflow.com/a/15074748/
img_rgb = img_bgr[..., ::-1]
return img_rgb.astype(np.float)
def merge_images(images, size):
return inverse_transform(images)
def merge(images, size):
h, w = images.shape[1], images.shape[2]
if (images.shape[3] in (3,4)):
c = images.shape[3]
img = np.zeros((h * size[0], w * size[1], c))
for idx, image in enumerate(images):
i = idx % size[1]
j = idx // size[1]
img[j * h:j * h + h, i * w:i * w + w, :] = image
return img
elif images.shape[3]==1:
img = np.zeros((h * size[0], w * size[1]))
for idx, image in enumerate(images):
i = idx % size[1]
j = idx // size[1]
img[j * h:j * h + h, i * w:i * w + w] = image[:,:,0]
return img
else:
raise ValueError('in merge(images,size) images parameter '
'must have dimensions: HxW or HxWx3 or HxWx4')
def imsave(images, size, path):
image = np.squeeze(merge(images, size))
return scipy.misc.imsave(path, image)
def center_crop(x, crop_h, crop_w,
resize_h=64, resize_w=64):
if crop_w is None:
crop_w = crop_h
h, w = x.shape[:2]
j = int(round((h - crop_h)/2.))
i = int(round((w - crop_w)/2.))
im = Image.fromarray(x[j:j+crop_h, i:i+crop_w])
return np.array(im.resize([resize_h, resize_w]), PIL.Image.BILINEAR)
def transform(image, input_height, input_width,
resize_height=64, resize_width=64, crop=True):
if crop:
cropped_image = center_crop(
image, input_height, input_width,
resize_height, resize_width)
else:
im = Image.fromarray(image[j:j+crop_h, i:i+crop_w])
return np.array(im.resize([resize_h, resize_w]), PIL.Image.BILINEAR)/127.5 - 1.
def inverse_transform(images):
return (images+1.)/2.
def to_json(output_path, *layers):
with open(output_path, "w") as layer_f:
lines = ""
for w, b, bn in layers:
layer_idx = w.name.split('/')[0].split('h')[1]
B = b.eval()
if "lin/" in w.name:
W = w.eval()
depth = W.shape[1]
else:
W = np.rollaxis(w.eval(), 2, 0)
depth = W.shape[0]
biases = {"sy": 1, "sx": 1, "depth": depth, "w": ['%.2f' % elem for elem in list(B)]}
if bn != None:
gamma = bn.gamma.eval()
beta = bn.beta.eval()
gamma = {"sy": 1, "sx": 1, "depth": depth, "w": ['%.2f' % elem for elem in list(gamma)]}
beta = {"sy": 1, "sx": 1, "depth": depth, "w": ['%.2f' % elem for elem in list(beta)]}
else:
gamma = {"sy": 1, "sx": 1, "depth": 0, "w": []}
beta = {"sy": 1, "sx": 1, "depth": 0, "w": []}
if "lin/" in w.name:
fs = []
for w in W.T:
fs.append({"sy": 1, "sx": 1, "depth": W.shape[0], "w": ['%.2f' % elem for elem in list(w)]})
lines += """
var layer_%s = {
"layer_type": "fc",
"sy": 1, "sx": 1,
"out_sx": 1, "out_sy": 1,
"stride": 1, "pad": 0,
"out_depth": %s, "in_depth": %s,
"biases": %s,
"gamma": %s,
"beta": %s,
"filters": %s
};""" % (layer_idx.split('_')[0], W.shape[1], W.shape[0], biases, gamma, beta, fs)
else:
fs = []
for w_ in W:
fs.append({"sy": 5, "sx": 5, "depth": W.shape[3], "w": ['%.2f' % elem for elem in list(w_.flatten())]})
lines += """
var layer_%s = {
"layer_type": "deconv",
"sy": 5, "sx": 5,
"out_sx": %s, "out_sy": %s,
"stride": 2, "pad": 1,
"out_depth": %s, "in_depth": %s,
"biases": %s,
"gamma": %s,
"beta": %s,
"filters": %s
};""" % (layer_idx, 2**(int(layer_idx)+2), 2**(int(layer_idx)+2),
W.shape[0], W.shape[3], biases, gamma, beta, fs)
layer_f.write(" ".join(lines.replace("'","").split()))
def make_gif(images, fname, duration=2, true_image=False):
import moviepy.editor as mpy
def make_frame(t):
try:
x = images[int(len(images)/duration*t)]
except:
x = images[-1]
if true_image:
return x.astype(np.uint8)
else:
return ((x+1)/2*255).astype(np.uint8)
clip = mpy.VideoClip(make_frame, duration=duration)
clip.write_gif(fname, fps = len(images) / duration)
def visualize(sess, dcgan, config, option, sample_dir='samples'):
image_frame_dim = int(math.ceil(config.batch_size**.5))
if option == 0:
z_sample = np.random.uniform(-0.5, 0.5, size=(config.batch_size, dcgan.z_dim))
samples = sess.run(dcgan.sampler, feed_dict={dcgan.z: z_sample})
save_images(samples, [image_frame_dim, image_frame_dim], os.path.join(sample_dir, 'test_%s.png' % strftime("%Y%m%d%H%M%S", gmtime() )))
elif option == 1:
values = np.arange(0, 1, 1./config.batch_size)
for idx in xrange(dcgan.z_dim):
print(" [*] %d" % idx)
z_sample = np.random.uniform(-1, 1, size=(config.batch_size , dcgan.z_dim))
for kdx, z in enumerate(z_sample):
z[idx] = values[kdx]
if config.dataset == "mnist":
y = np.random.choice(10, config.batch_size)
y_one_hot = np.zeros((config.batch_size, 10))
y_one_hot[np.arange(config.batch_size), y] = 1
samples = sess.run(dcgan.sampler, feed_dict={dcgan.z: z_sample, dcgan.y: y_one_hot})
else:
samples = sess.run(dcgan.sampler, feed_dict={dcgan.z: z_sample})
save_images(samples, [image_frame_dim, image_frame_dim], os.path.join(sample_dir, 'test_arange_%s.png' % (idx)))
elif option == 2:
values = np.arange(0, 1, 1./config.batch_size)
for idx in [random.randint(0, dcgan.z_dim - 1) for _ in xrange(dcgan.z_dim)]:
print(" [*] %d" % idx)
z = np.random.uniform(-0.2, 0.2, size=(dcgan.z_dim))
z_sample = np.tile(z, (config.batch_size, 1))
#z_sample = np.zeros([config.batch_size, dcgan.z_dim])
for kdx, z in enumerate(z_sample):
z[idx] = values[kdx]
if config.dataset == "mnist":
y = np.random.choice(10, config.batch_size)
y_one_hot = np.zeros((config.batch_size, 10))
y_one_hot[np.arange(config.batch_size), y] = 1
samples = sess.run(dcgan.sampler, feed_dict={dcgan.z: z_sample, dcgan.y: y_one_hot})
else:
samples = sess.run(dcgan.sampler, feed_dict={dcgan.z: z_sample})
try:
make_gif(samples, './samples/test_gif_%s.gif' % (idx))
except:
save_images(samples, [image_frame_dim, image_frame_dim], os.path.join(sample_dir, 'test_%s.png' % strftime("%Y%m%d%H%M%S", gmtime() )))
elif option == 3:
values = np.arange(0, 1, 1./config.batch_size)
for idx in xrange(dcgan.z_dim):
print(" [*] %d" % idx)
z_sample = np.zeros([config.batch_size, dcgan.z_dim])
for kdx, z in enumerate(z_sample):
z[idx] = values[kdx]
samples = sess.run(dcgan.sampler, feed_dict={dcgan.z: z_sample})
make_gif(samples, os.path.join(sample_dir, 'test_gif_%s.gif' % (idx)))
elif option == 4:
image_set = []
values = np.arange(0, 1, 1./config.batch_size)
for idx in xrange(dcgan.z_dim):
print(" [*] %d" % idx)
z_sample = np.zeros([config.batch_size, dcgan.z_dim])
for kdx, z in enumerate(z_sample): z[idx] = values[kdx]
image_set.append(sess.run(dcgan.sampler, feed_dict={dcgan.z: z_sample}))
make_gif(image_set[-1], os.path.join(sample_dir, 'test_gif_%s.gif' % (idx)))
new_image_set = [merge(np.array([images[idx] for images in image_set]), [10, 10]) \
for idx in range(64) + range(63, -1, -1)]
make_gif(new_image_set, './samples/test_gif_merged.gif', duration=8)
def image_manifold_size(num_images):
manifold_h = int(np.floor(np.sqrt(num_images)))
manifold_w = int(np.ceil(np.sqrt(num_images)))
assert manifold_h * manifold_w == num_images
return manifold_h, manifold_w
================================================
FILE: web/app.py
================================================
from flask import Flask
from flask import render_template
app = Flask(__name__, template_folder="./", static_folder='./', static_url_path='')
@app.route('/')
def index():
return render_template('index.html')
if __name__ == '__main__':
app.debug=True
app.run(host='0.0.0.0')
================================================
FILE: web/css/fakeLoader.css
================================================
/**********************
*CSS Animations by:
*http://codepen.io/vivinantony
***********************/
.spinner1 {
width: 40px;
height: 40px;
position: relative;
}
.double-bounce1, .double-bounce2 {
width: 100%;
height: 100%;
border-radius: 50%;
background-color: #fff;
opacity: 0.6;
position: absolute;
top: 0;
left: 0;
-webkit-animation: bounce 2.0s infinite ease-in-out;
animation: bounce 2.0s infinite ease-in-out;
}
.double-bounce2 {
-webkit-animation-delay: -1.0s;
animation-delay: -1.0s;
}
@-webkit-keyframes bounce {
0%, 100% { -webkit-transform: scale(0.0) }
50% { -webkit-transform: scale(1.0) }
}
@keyframes bounce {
0%, 100% {
transform: scale(0.0);
-webkit-transform: scale(0.0);
} 50% {
transform: scale(1.0);
-webkit-transform: scale(1.0);
}
}
.spinner2 {
width: 40px;
height: 40px;
position: relative;
}
.container1 > div, .container2 > div, .container3 > div {
width: 6px;
height: 6px;
background-color: #fff;
border-radius: 100%;
position: absolute;
-webkit-animation: bouncedelay 1.2s infinite ease-in-out;
animation: bouncedelay 1.2s infinite ease-in-out;
/* Prevent first frame from flickering when animation starts */
-webkit-animation-fill-mode: both;
animation-fill-mode: both;
}
.spinner2 .spinner-container {
position: absolute;
width: 100%;
height: 100%;
}
.container2 {
-webkit-transform: rotateZ(45deg);
transform: rotateZ(45deg);
}
.container3 {
-webkit-transform: rotateZ(90deg);
transform: rotateZ(90deg);
}
.circle1 { top: 0; left: 0; }
.circle2 { top: 0; right: 0; }
.circle3 { right: 0; bottom: 0; }
.circle4 { left: 0; bottom: 0; }
.container2 .circle1 {
-webkit-animation-delay: -1.1s;
animation-delay: -1.1s;
}
.container3 .circle1 {
-webkit-animation-delay: -1.0s;
animation-delay: -1.0s;
}
.container1 .circle2 {
-webkit-animation-delay: -0.9s;
animation-delay: -0.9s;
}
.container2 .circle2 {
-webkit-animation-delay: -0.8s;
animation-delay: -0.8s;
}
.container3 .circle2 {
-webkit-animation-delay: -0.7s;
animation-delay: -0.7s;
}
.container1 .circle3 {
-webkit-animation-delay: -0.6s;
animation-delay: -0.6s;
}
.container2 .circle3 {
-webkit-animation-delay: -0.5s;
animation-delay: -0.5s;
}
.container3 .circle3 {
-webkit-animation-delay: -0.4s;
animation-delay: -0.4s;
}
.container1 .circle4 {
-webkit-animation-delay: -0.3s;
animation-delay: -0.3s;
}
.container2 .circle4 {
-webkit-animation-delay: -0.2s;
animation-delay: -0.2s;
}
.container3 .circle4 {
-webkit-animation-delay: -0.1s;
animation-delay: -0.1s;
}
@-webkit-keyframes bouncedelay {
0%, 80%, 100% { -webkit-transform: scale(0.0) }
40% { -webkit-transform: scale(1.0) }
}
@keyframes bouncedelay {
0%, 80%, 100% {
transform: scale(0.0);
-webkit-transform: scale(0.0);
} 40% {
transform: scale(1.0);
-webkit-transform: scale(1.0);
}
}
.spinner3 {
width: 40px;
height: 40px;
position: relative;
-webkit-animation: rotate 2.0s infinite linear;
animation: rotate 2.0s infinite linear;
}
.dot1, .dot2 {
width: 60%;
height: 60%;
display: inline-block;
position: absolute;
top: 0;
background-color: #fff;
border-radius: 100%;
-webkit-animation: bounce 2.0s infinite ease-in-out;
animation: bounce 2.0s infinite ease-in-out;
}
.dot2 {
top: auto;
bottom: 0px;
-webkit-animation-delay: -1.0s;
animation-delay: -1.0s;
}
@-webkit-keyframes rotate { 100% { -webkit-transform: rotate(360deg) }}
@keyframes rotate { 100% { transform: rotate(360deg); -webkit-transform: rotate(360deg) }}
@-webkit-keyframes bounce {
0%, 100% { -webkit-transform: scale(0.0) }
50% { -webkit-transform: scale(1.0) }
}
@keyframes bounce {
0%, 100% {
transform: scale(0.0);
-webkit-transform: scale(0.0);
} 50% {
transform: scale(1.0);
-webkit-transform: scale(1.0);
}
}
.spinner4 {
width: 30px;
height: 30px;
background-color: #fff;
-webkit-animation: rotateplane 1.2s infinite ease-in-out;
animation: rotateplane 1.2s infinite ease-in-out;
}
@-webkit-keyframes rotateplane {
0% { -webkit-transform: perspective(120px) }
50% { -webkit-transform: perspective(120px) rotateY(180deg) }
100% { -webkit-transform: perspective(120px) rotateY(180deg) rotateX(180deg) }
}
@keyframes rotateplane {
0% {
transform: perspective(120px) rotateX(0deg) rotateY(0deg);
-webkit-transform: perspective(120px) rotateX(0deg) rotateY(0deg)
} 50% {
transform: perspective(120px) rotateX(-180.1deg) rotateY(0deg);
-webkit-transform: perspective(120px) rotateX(-180.1deg) rotateY(0deg)
} 100% {
transform: perspective(120px) rotateX(-180deg) rotateY(-179.9deg);
-webkit-transform: perspective(120px) rotateX(-180deg) rotateY(-179.9deg);
}
}
@charset 'UTF-8';
/* Slider */
.slick-loading .slick-list
{
background: #fff url('./ajax-loader.gif') center center no-repeat;
}
/* Icons */
@font-face
{
font-family: 'slick';
font-weight: normal;
font-style: normal;
src: url('../fonts/slick.eot');
src: url('../fonts/slick.eot?#iefix') format('embedded-opentype'), url('../fonts/slick.woff') format('woff'), url('../fonts/slick.ttf') format('truetype'), url('../fonts/slick.svg#slick') format('svg');
}
/* Arrows */
.slick-prev,
.slick-next
{
font-size: 0;
line-height: 0;
position: absolute;
top: 50%;
display: block;
width: 20px;
height: 20px;
margin-top: -10px;
padding: 0;
cursor: pointer;
color: transparent;
border: none;
outline: none;
background: transparent;
}
.slick-prev:hover,
.slick-prev:focus,
.slick-next:hover,
.slick-next:focus
{
color: transparent;
outline: none;
background: transparent;
}
.slick-prev:hover:before,
.slick-prev:focus:before,
.slick-next:hover:before,
.slick-next:focus:before
{
opacity: 1;
}
.slick-prev.slick-disabled:before,
.slick-next.slick-disabled:before
{
opacity: .25;
}
.slick-prev:before,
.slick-next:before
{
font-family: 'slick';
font-size: 20px;
line-height: 1;
opacity: .75;
color: white;
-webkit-font-smoothing: antialiased;
-moz-osx-font-smoothing: grayscale;
}
.slick-prev
{
left: -25px;
}
[dir='rtl'] .slick-prev
{
right: -25px;
left: auto;
}
.slick-prev:before
{
content: '←';
}
[dir='rtl'] .slick-prev:before
{
content: '→';
}
.slick-next
{
right: -25px;
}
[dir='rtl'] .slick-next
{
right: auto;
left: -25px;
}
.slick-next:before
{
content: '→';
}
[dir='rtl'] .slick-next:before
{
content: '←';
}
/* Dots */
.slick-slider
{
margin-bottom: 30px;
}
.slick-dots
{
position: absolute;
bottom: -45px;
display: block;
width: 100%;
padding: 0;
list-style: none;
text-align: center;
}
.slick-dots li
{
position: relative;
display: inline-block;
width: 20px;
height: 20px;
margin: 0 5px;
padding: 0;
cursor: pointer;
}
.slick-dots li button
{
font-size: 0;
line-height: 0;
display: block;
width: 20px;
height: 20px;
padding: 5px;
cursor: pointer;
color: transparent;
border: 0;
outline: none;
background: transparent;
}
.slick-dots li button:hover,
.slick-dots li button:focus
{
outline: none;
}
.slick-dots li button:hover:before,
.slick-dots li button:focus:before
{
opacity: 1;
}
.slick-dots li button:before
{
font-family: 'slick';
font-size: 6px;
line-height: 20px;
position: absolute;
top: 0;
left: 0;
width: 20px;
height: 20px;
content: '•';
text-align: center;
opacity: .25;
color: white;
-webkit-font-smoothing: antialiased;
-moz-osx-font-smoothing: grayscale;
}
.slick-dots li.slick-active button:before
{
opacity: .75;
color: white;
}
================================================
FILE: web/css/main.css
================================================
canvas {
background-color: white;
}
#colors {
overflow: hidden;
width: 90px;
margin-left: 30px;
float: left;
}
#colors .color {
float: left;
width: 40px;
height: 40px;
}
#colors .color div {
width: 100%;
height: 100%;
cursor: pointer;
}
#colors .color #color_1::before { background-color: #000000; }
#colors .color #color_1::after { background-color: #000000; }
#colors .color #color_2::before { background-color: #444444; }
#colors .color #color_2::after { background-color: #303030; }
#colors .color #color_3::before { background-color: #000088; }
#colors .color #color_3::after { background-color: #00005f; }
#colors .color #color_4::before { background-color: #1111ff; }
#colors .color #color_4::after { background-color: #0000be; }
#colors .color #color_5::before { background-color: #008800; }
#colors .color #color_5::after { background-color: #005f00; }
#colors .color #color_6::before { background-color: #11ff11; }
#colors .color #color_6::after { background-color: #00be00; }
#colors .color #color_7::before { background-color: #008888; }
#colors .color #color_7::after { background-color: #005f5f; }
#colors .color #color_8::before { background-color: #11ffff; }
#colors .color #color_8::after { background-color: #00bebe; }
#colors .color #color_9::before { background-color: #880000; }
#colors .color #color_9::after { background-color: #5f0000; }
#colors .color #color_10::before { background-color: #ff1111; }
#colors .color #color_10::after { background-color: #be0000; }
#colors .color #color_11::before { background-color: #880088; }
#colors .color #color_11::after { background-color: #5f005f; }
#colors .color #color_12::before { background-color: #ff11ff; }
#colors .color #color_12::after { background-color: #be00be; }
#colors .color #color_13::before { background-color: #884400; }
#colors .color #color_13::after { background-color: #5f3000; }
#colors .color #color_14::before { background-color: #ffff11; }
#colors .color #color_14::after { background-color: #bebe00; }
#colors .color #color_15::before { background-color: #888888; }
#colors .color #color_15::after { background-color: #5f5f5f; }
#colors .color #color_16::before { background-color: #cccccc; }
#colors .color #color_16::after { background-color: #8f8f8f; }
#colors .color .isometric::after {
width: 40px;
height: 10px;
}
#colors .color .isometric::before {
width: 10px;
height: 40px;
}
#colors .color.active div {
top: 10px;
left: 10px;
}
/* CANVAS */
#canvas {
float: left;
cursor: crosshair;
width: 320px;
height: 320px;
margin: 0 auto;
}
#canvas.isometric::after {
width: 320px;
height: 10px;
}
#canvas.isometric::before {
width: 10px;
height: 320px;
}
/*!
* Start Bootstrap - Grayscale Bootstrap Theme (http://startbootstrap.com)
* Code licensed under the Apache License v2.0.
* For details, see http://www.apache.org/licenses/LICENSE-2.0.
*/
body {
width: 100%;
height: 100%;
font-family: Lora,"Helvetica Neue",Helvetica,Arial,sans-serif;
color: #fff;
background-color: #000;
}
html {
width: 100%;
height: 100%;
}
h1,
h2,
h3,
h4,
h5,
h6 {
margin: 0 0 35px;
text-transform: uppercase;
font-family: Montserrat,"Helvetica Neue",Helvetica,Arial,sans-serif;
font-weight: 700;
letter-spacing: 1px;
}
p {
margin: 0 0 25px;
font-size: 18px;
line-height: 1.5;
}
@media(min-width:768px) {
p {
margin: 0 0 35px;
font-size: 20px;
line-height: 1.6;
}
}
b {
color: #3A8BB2;
}
a {
color: #42dca3;
-webkit-transition: all .2s ease-in-out;
-moz-transition: all .2s ease-in-out;
transition: all .2s ease-in-out;
}
a:hover,
a:focus {
text-decoration: none;
color: #1d9b6c;
}
.light {
font-weight: 400;
}
.navbar-custom {
margin-bottom: 0;
border-bottom: 1px solid rgba(255,255,255,.3);
text-transform: uppercase;
font-family: Montserrat,"Helvetica Neue",Helvetica,Arial,sans-serif;
background-color: #000;
}
.navbar-custom .navbar-brand {
font-weight: 700;
}
.navbar-custom .navbar-brand:focus {
outline: 0;
}
.navbar-custom .navbar-brand .navbar-toggle {
padding: 4px 6px;
font-size: 16px;
color: #fff;
}
.navbar-custom .navbar-brand .navbar-toggle:focus,
.navbar-custom .navbar-brand .navbar-toggle:active {
outline: 0;
}
.navbar-custom a {
color: #fff;
}
.navbar-custom .nav li a {
-webkit-transition: background .3s ease-in-out;
-moz-transition: background .3s ease-in-out;
transition: background .3s ease-in-out;
}
.navbar-custom .nav li a:hover {
outline: 0;
color: rgba(255,255,255,.8);
background-color: transparent;
}
.navbar-custom .nav li a:focus,
.navbar-custom .nav li a:active {
outline: 0;
background-color: transparent;
}
.navbar-custom .nav li.active {
outline: 0;
}
.navbar-custom .nav li.active a {
background-color: rgba(255,255,255,.3);
}
.navbar-custom .nav li.active a:hover {
color: #fff;
}
@media(min-width:768px) {
.navbar-custom {
padding: 20px 0;
border-bottom: 0;
letter-spacing: 1px;
background: 0 0;
-webkit-transition: background .5s ease-in-out,padding .5s ease-in-out;
-moz-transition: background .5s ease-in-out,padding .5s ease-in-out;
transition: background .5s ease-in-out,padding .5s ease-in-out;
}
.navbar-custom.top-nav-collapse {
padding: 0;
border-bottom: 1px solid rgba(255,255,255,.3);
background: #000;
}
}
#background {
position: absolute;
top: 0;
left: 0;
min-width: 100%;
min-height: 100%;
width: auto;
height: auto;
}
.intro {
overflow: hidden;
position: relative;
display: table;
width: 100%;
height: auto;
min-height: 100%;
padding: 100px 0;
text-align: center;
color: #fff;
background-color: #000;
-webkit-background-size: cover;
-moz-background-size: cover;
background-size: cover;
-o-background-size: cover;
}
.intro .intro-body {
display: table-cell;
vertical-align: middle;
}
.intro .intro-body .brand-heading {
font-size: 40px;
}
.intro .intro-body .intro-text {
font-size: 18px;
}
@media(min-width:768px) {
.intro {
height: 100%;
padding: 0;
}
.intro .intro-body .brand-heading {
font-size: 100px;
}
.intro .intro-body .intro-text {
font-size: 26px;
}
}
.btn-circle {
width: 70px;
height: 70px;
margin-top: 15px;
padding: 7px 16px;
border: 2px solid #fff;
border-radius: 100%!important;
font-size: 40px;
color: #fff;
background: 0 0;
-webkit-transition: background .3s ease-in-out;
-moz-transition: background .3s ease-in-out;
transition: background .3s ease-in-out;
}
.btn-circle:hover,
.btn-circle:focus {
outline: 0;
color: #fff;
background: rgba(255,255,255,.1);
}
.btn-circle i.animated {
-webkit-transition-property: -webkit-transform;
-webkit-transition-duration: 1s;
-moz-transition-property: -moz-transform;
-moz-transition-duration: 1s;
}
.btn-circle:hover i.animated {
-webkit-animation-name: pulse;
-moz-animation-name: pulse;
-webkit-animation-duration: 1.5s;
-moz-animation-duration: 1.5s;
-webkit-animation-iteration-count: infinite;
-moz-animation-iteration-count: infinite;
-webkit-animation-timing-function: linear;
-moz-animation-timing-function: linear;
}
@-webkit-keyframes pulse {
0% {
-webkit-transform: scale(1);
transform: scale(1);
}
50% {
-webkit-transform: scale(1.2);
transform: scale(1.2);
}
100% {
-webkit-transform: scale(1);
transform: scale(1);
}
}
@-moz-keyframes pulse {
0% {
-moz-transform: scale(1);
transform: scale(1);
}
50% {
-moz-transform: scale(1.2);
transform: scale(1.2);
}
100% {
-moz-transform: scale(1);
transform: scale(1);
}
}
.content-section {
padding-top: 100px;
}
.download-section {
width: 100%;
padding: 50px 0;
color: #fff;
background: url(../img/downloads-bg.jpg) no-repeat center center scroll;
background-color: #000;
-webkit-background-size: cover;
-moz-background-size: cover;
background-size: cover;
-o-background-size: cover;
}
@media(min-width:767px) {
.content-section {
padding-top: 250px;
}
.download-section {
padding: 100px 0;
}
}
.btn {
border-radius: 0;
text-transform: uppercase;
font-family: Montserrat,"Helvetica Neue",Helvetica,Arial,sans-serif;
font-weight: 400;
-webkit-transition: all .3s ease-in-out;
-moz-transition: all .3s ease-in-out;
transition: all .3s ease-in-out;
}
.btn-default {
border: 1px solid #42dca3;
color: #42dca3;
background-color: transparent;
}
.btn-default:hover,
.btn-default:focus {
border: 1px solid #42dca3;
outline: 0;
color: #000;
background-color: #42dca3;
}
ul.banner-social-buttons {
margin-top: 0;
}
@media(max-width:1199px) {
ul.banner-social-buttons {
margin-top: 15px;
}
}
@media(max-width:767px) {
ul.banner-social-buttons li {
display: block;
margin-bottom: 20px;
padding: 0;
}
ul.banner-social-buttons li:last-child {
margin-bottom: 0;
}
}
footer {
padding: 50px 0;
}
footer p {
margin: 0;
}
::-moz-selection {
text-shadow: none;
background: #fcfcfc;
background: rgba(255,255,255,.2);
}
::selection {
text-shadow: none;
background: #fcfcfc;
background: rgba(255,255,255,.2);
}
img::selection {
background: 0 0;
}
img::-moz-selection {
background: 0 0;
}
body {
webkit-tap-highlight-color: rgba(255,255,255,.2);
}
.logo {
background-color: rgba(0,0,0,0.7);
padding: 30px;
}
.tooltip > .tooltip-inner { background-color: white; color: black; }
.tooltip > .tooltip-arrow { border-bottom-color: white; color: black; }
.tooltip {
opacity: 0.95 !important;
}
.pixel-tooltip {
padding: 0px !important;
background-color: transparent !important;
}
.fa-5 {
font-size: 40px !important;
}
.ico {
padding-right: 10px;
}
.sk-wave {
margin: 40px auto;
width: 50px;
height: 40px;
text-align: center;
font-size: 10px; }
.sk-wave .sk-rect {
background-color: #eeeeee;
height: 100%;
width: 6px;
display: inline-block;
-webkit-animation: sk-waveStretchDelay 1.2s infinite ease-in-out;
animation: sk-waveStretchDelay 1.2s infinite ease-in-out; }
.sk-wave .sk-rect1 {
-webkit-animation-delay: -1.2s;
animation-delay: -1.2s; }
.sk-wave .sk-rect2 {
-webkit-animation-delay: -1.1s;
animation-delay: -1.1s; }
.sk-wave .sk-rect3 {
-webkit-animation-delay: -1s;
animation-delay: -1s; }
.sk-wave .sk-rect4 {
-webkit-animation-delay: -0.9s;
animation-delay: -0.9s; }
.sk-wave .sk-rect5 {
-webkit-animation-delay: -0.8s;
animation-delay: -0.8s; }
@-webkit-keyframes sk-waveStretchDelay {
0%, 40%, 100% {
-webkit-transform: scaleY(0.4);
transform: scaleY(0.4); }
20% {
-webkit-transform: scaleY(1);
transform: scaleY(1); } }
@keyframes sk-waveStretchDelay {
0%, 40%, 100% {
-webkit-transform: scaleY(0.4);
transform: scaleY(0.4); }
20% {
-webkit-transform: scaleY(1);
transform: scaleY(1); } }
================================================
FILE: web/index.html
================================================
](http://carpedm20.github.io/faces/)
[link](http://carpedm20.github.io/faces/)
## Prerequisites
- Python 2.7 or Python 3.3+
- [Tensorflow 0.12.1](https://github.com/tensorflow/tensorflow/tree/r0.12)
- [SciPy](http://www.scipy.org/install.html)
- [pillow](https://github.com/python-pillow/Pillow)
- [tqdm](https://pypi.org/project/tqdm/)
- (Optional) [moviepy](https://github.com/Zulko/moviepy) (for visualization)
- (Optional) [Align&Cropped Images.zip](http://mmlab.ie.cuhk.edu.hk/projects/CelebA.html) : Large-scale CelebFaces Dataset
## Usage
First, download dataset with:
$ python download.py mnist celebA
To train a model with downloaded dataset:
$ python main.py --dataset mnist --input_height=28 --output_height=28 --train
$ python main.py --dataset celebA --input_height=108 --train --crop
To test with an existing model:
$ python main.py --dataset mnist --input_height=28 --output_height=28
$ python main.py --dataset celebA --input_height=108 --crop
Or, you can use your own dataset (without central crop) by:
$ mkdir data/DATASET_NAME
... add images to data/DATASET_NAME ...
$ python main.py --dataset DATASET_NAME --train
$ python main.py --dataset DATASET_NAME
$ # example
$ python main.py --dataset=eyes --input_fname_pattern="*_cropped.png" --train
If your dataset is located in a different root directory:
$ python main.py --dataset DATASET_NAME --data_dir DATASET_ROOT_DIR --train
$ python main.py --dataset DATASET_NAME --data_dir DATASET_ROOT_DIR
$ # example
$ python main.py --dataset=eyes --data_dir ../datasets/ --input_fname_pattern="*_cropped.png" --train
## Results

### celebA
After 6th epoch:

After 10th epoch:

### Asian face dataset



### MNIST
MNIST codes are written by [@PhoenixDai](https://github.com/PhoenixDai).



More results can be found [here](./assets/) and [here](./web/img/).
## Training details
Details of the loss of Discriminator and Generator (with custom dataset not celebA).


Details of the histogram of true and fake result of discriminator (with custom dataset not celebA).


## Related works
- [BEGAN-tensorflow](https://github.com/carpedm20/BEGAN-tensorflow)
- [DiscoGAN-pytorch](https://github.com/carpedm20/DiscoGAN-pytorch)
- [simulated-unsupervised-tensorflow](https://github.com/carpedm20/simulated-unsupervised-tensorflow)
## Author
Taehoon Kim / [@carpedm20](http://carpedm20.github.io/)
================================================
FILE: download.py
================================================
"""
Modification of https://github.com/stanfordnlp/treelstm/blob/master/scripts/download.py
Downloads the following:
- Celeb-A dataset
- LSUN dataset
- MNIST dataset
"""
from __future__ import print_function
import os
import sys
import gzip
import json
import shutil
import zipfile
import argparse
import requests
import subprocess
from tqdm import tqdm
from six.moves import urllib
parser = argparse.ArgumentParser(description='Download dataset for DCGAN.')
parser.add_argument('datasets', metavar='N', type=str, nargs='+', choices=['celebA', 'lsun', 'mnist'],
help='name of dataset to download [celebA, lsun, mnist]')
def download(url, dirpath):
filename = url.split('/')[-1]
filepath = os.path.join(dirpath, filename)
u = urllib.request.urlopen(url)
f = open(filepath, 'wb')
filesize = int(u.headers["Content-Length"])
print("Downloading: %s Bytes: %s" % (filename, filesize))
downloaded = 0
block_sz = 8192
status_width = 70
while True:
buf = u.read(block_sz)
if not buf:
print('')
break
else:
print('', end='\r')
downloaded += len(buf)
f.write(buf)
status = (("[%-" + str(status_width + 1) + "s] %3.2f%%") %
('=' * int(float(downloaded) / filesize * status_width) + '>', downloaded * 100. / filesize))
print(status, end='')
sys.stdout.flush()
f.close()
return filepath
def download_file_from_google_drive(id, destination):
URL = "https://docs.google.com/uc?export=download"
session = requests.Session()
response = session.get(URL, params={ 'id': id }, stream=True)
token = get_confirm_token(response)
if token:
params = { 'id' : id, 'confirm' : token }
response = session.get(URL, params=params, stream=True)
save_response_content(response, destination)
def get_confirm_token(response):
for key, value in response.cookies.items():
if key.startswith('download_warning'):
return value
return None
def save_response_content(response, destination, chunk_size=32*1024):
total_size = int(response.headers.get('content-length', 0))
with open(destination, "wb") as f:
for chunk in tqdm(response.iter_content(chunk_size), total=total_size,
unit='B', unit_scale=True, desc=destination):
if chunk: # filter out keep-alive new chunks
f.write(chunk)
def unzip(filepath):
print("Extracting: " + filepath)
dirpath = os.path.dirname(filepath)
with zipfile.ZipFile(filepath) as zf:
zf.extractall(dirpath)
os.remove(filepath)
def download_celeb_a(dirpath):
data_dir = 'celebA'
if os.path.exists(os.path.join(dirpath, data_dir)):
print('Found Celeb-A - skip')
return
filename, drive_id = "img_align_celeba.zip", "0B7EVK8r0v71pZjFTYXZWM3FlRnM"
save_path = os.path.join(dirpath, filename)
if os.path.exists(save_path):
print('[*] {} already exists'.format(save_path))
else:
download_file_from_google_drive(drive_id, save_path)
zip_dir = ''
with zipfile.ZipFile(save_path) as zf:
zip_dir = zf.namelist()[0]
zf.extractall(dirpath)
os.remove(save_path)
os.rename(os.path.join(dirpath, zip_dir), os.path.join(dirpath, data_dir))
def _list_categories(tag):
url = 'http://lsun.cs.princeton.edu/htbin/list.cgi?tag=' + tag
f = urllib.request.urlopen(url)
return json.loads(f.read())
def _download_lsun(out_dir, category, set_name, tag):
url = 'http://lsun.cs.princeton.edu/htbin/download.cgi?tag={tag}' \
'&category={category}&set={set_name}'.format(**locals())
print(url)
if set_name == 'test':
out_name = 'test_lmdb.zip'
else:
out_name = '{category}_{set_name}_lmdb.zip'.format(**locals())
out_path = os.path.join(out_dir, out_name)
cmd = ['curl', url, '-o', out_path]
print('Downloading', category, set_name, 'set')
subprocess.call(cmd)
def download_lsun(dirpath):
data_dir = os.path.join(dirpath, 'lsun')
if os.path.exists(data_dir):
print('Found LSUN - skip')
return
else:
os.mkdir(data_dir)
tag = 'latest'
#categories = _list_categories(tag)
categories = ['bedroom']
for category in categories:
_download_lsun(data_dir, category, 'train', tag)
_download_lsun(data_dir, category, 'val', tag)
_download_lsun(data_dir, '', 'test', tag)
def download_mnist(dirpath):
data_dir = os.path.join(dirpath, 'mnist')
if os.path.exists(data_dir):
print('Found MNIST - skip')
return
else:
os.mkdir(data_dir)
url_base = 'http://yann.lecun.com/exdb/mnist/'
file_names = ['train-images-idx3-ubyte.gz',
'train-labels-idx1-ubyte.gz',
't10k-images-idx3-ubyte.gz',
't10k-labels-idx1-ubyte.gz']
for file_name in file_names:
url = (url_base+file_name).format(**locals())
print(url)
out_path = os.path.join(data_dir,file_name)
cmd = ['curl', url, '-o', out_path]
print('Downloading ', file_name)
subprocess.call(cmd)
cmd = ['gzip', '-d', out_path]
print('Decompressing ', file_name)
subprocess.call(cmd)
def prepare_data_dir(path = './data'):
if not os.path.exists(path):
os.mkdir(path)
if __name__ == '__main__':
args = parser.parse_args()
prepare_data_dir()
if any(name in args.datasets for name in ['CelebA', 'celebA', 'celebA']):
download_celeb_a('./data')
if 'lsun' in args.datasets:
download_lsun('./data')
if 'mnist' in args.datasets:
download_mnist('./data')
================================================
FILE: main.py
================================================
import os
import scipy.misc
import numpy as np
import json
from model import DCGAN
from utils import pp, visualize, to_json, show_all_variables, expand_path, timestamp
import tensorflow as tf
flags = tf.app.flags
flags.DEFINE_integer("epoch", 25, "Epoch to train [25]")
flags.DEFINE_float("learning_rate", 0.0002, "Learning rate of for adam [0.0002]")
flags.DEFINE_float("beta1", 0.5, "Momentum term of adam [0.5]")
flags.DEFINE_float("train_size", np.inf, "The size of train images [np.inf]")
flags.DEFINE_integer("batch_size", 64, "The size of batch images [64]")
flags.DEFINE_integer("input_height", 108, "The size of image to use (will be center cropped). [108]")
flags.DEFINE_integer("input_width", None, "The size of image to use (will be center cropped). If None, same value as input_height [None]")
flags.DEFINE_integer("output_height", 64, "The size of the output images to produce [64]")
flags.DEFINE_integer("output_width", None, "The size of the output images to produce. If None, same value as output_height [None]")
flags.DEFINE_string("dataset", "celebA", "The name of dataset [celebA, mnist, lsun]")
flags.DEFINE_string("input_fname_pattern", "*.jpg", "Glob pattern of filename of input images [*]")
flags.DEFINE_string("data_dir", "./data", "path to datasets [e.g. $HOME/data]")
flags.DEFINE_string("out_dir", "./out", "Root directory for outputs [e.g. $HOME/out]")
flags.DEFINE_string("out_name", "", "Folder (under out_root_dir) for all outputs. Generated automatically if left blank []")
flags.DEFINE_string("checkpoint_dir", "checkpoint", "Folder (under out_root_dir/out_name) to save checkpoints [checkpoint]")
flags.DEFINE_string("sample_dir", "samples", "Folder (under out_root_dir/out_name) to save samples [samples]")
flags.DEFINE_boolean("train", False, "True for training, False for testing [False]")
flags.DEFINE_boolean("crop", False, "True for training, False for testing [False]")
flags.DEFINE_boolean("visualize", False, "True for visualizing, False for nothing [False]")
flags.DEFINE_boolean("export", False, "True for exporting with new batch size")
flags.DEFINE_boolean("freeze", False, "True for exporting with new batch size")
flags.DEFINE_integer("max_to_keep", 1, "maximum number of checkpoints to keep")
flags.DEFINE_integer("sample_freq", 200, "sample every this many iterations")
flags.DEFINE_integer("ckpt_freq", 200, "save checkpoint every this many iterations")
flags.DEFINE_integer("z_dim", 100, "dimensions of z")
flags.DEFINE_string("z_dist", "uniform_signed", "'normal01' or 'uniform_unsigned' or uniform_signed")
flags.DEFINE_boolean("G_img_sum", False, "Save generator image summaries in log")
#flags.DEFINE_integer("generate_test_images", 100, "Number of images to generate during test. [100]")
FLAGS = flags.FLAGS
def main(_):
pp.pprint(flags.FLAGS.__flags)
# expand user name and environment variables
FLAGS.data_dir = expand_path(FLAGS.data_dir)
FLAGS.out_dir = expand_path(FLAGS.out_dir)
FLAGS.out_name = expand_path(FLAGS.out_name)
FLAGS.checkpoint_dir = expand_path(FLAGS.checkpoint_dir)
FLAGS.sample_dir = expand_path(FLAGS.sample_dir)
if FLAGS.output_height is None: FLAGS.output_height = FLAGS.input_height
if FLAGS.input_width is None: FLAGS.input_width = FLAGS.input_height
if FLAGS.output_width is None: FLAGS.output_width = FLAGS.output_height
# output folders
if FLAGS.out_name == "":
FLAGS.out_name = '{} - {} - {}'.format(timestamp(), FLAGS.data_dir.split('/')[-1], FLAGS.dataset) # penultimate folder of path
if FLAGS.train:
FLAGS.out_name += ' - x{}.z{}.{}.y{}.b{}'.format(FLAGS.input_width, FLAGS.z_dim, FLAGS.z_dist, FLAGS.output_width, FLAGS.batch_size)
FLAGS.out_dir = os.path.join(FLAGS.out_dir, FLAGS.out_name)
FLAGS.checkpoint_dir = os.path.join(FLAGS.out_dir, FLAGS.checkpoint_dir)
FLAGS.sample_dir = os.path.join(FLAGS.out_dir, FLAGS.sample_dir)
if not os.path.exists(FLAGS.checkpoint_dir): os.makedirs(FLAGS.checkpoint_dir)
if not os.path.exists(FLAGS.sample_dir): os.makedirs(FLAGS.sample_dir)
with open(os.path.join(FLAGS.out_dir, 'FLAGS.json'), 'w') as f:
flags_dict = {k:FLAGS[k].value for k in FLAGS}
json.dump(flags_dict, f, indent=4, sort_keys=True, ensure_ascii=False)
#gpu_options = tf.GPUOptions(per_process_gpu_memory_fraction=0.333)
run_config = tf.ConfigProto()
run_config.gpu_options.allow_growth=True
with tf.Session(config=run_config) as sess:
if FLAGS.dataset == 'mnist':
dcgan = DCGAN(
sess,
input_width=FLAGS.input_width,
input_height=FLAGS.input_height,
output_width=FLAGS.output_width,
output_height=FLAGS.output_height,
batch_size=FLAGS.batch_size,
sample_num=FLAGS.batch_size,
y_dim=10,
z_dim=FLAGS.z_dim,
dataset_name=FLAGS.dataset,
input_fname_pattern=FLAGS.input_fname_pattern,
crop=FLAGS.crop,
checkpoint_dir=FLAGS.checkpoint_dir,
sample_dir=FLAGS.sample_dir,
data_dir=FLAGS.data_dir,
out_dir=FLAGS.out_dir,
max_to_keep=FLAGS.max_to_keep)
else:
dcgan = DCGAN(
sess,
input_width=FLAGS.input_width,
input_height=FLAGS.input_height,
output_width=FLAGS.output_width,
output_height=FLAGS.output_height,
batch_size=FLAGS.batch_size,
sample_num=FLAGS.batch_size,
z_dim=FLAGS.z_dim,
dataset_name=FLAGS.dataset,
input_fname_pattern=FLAGS.input_fname_pattern,
crop=FLAGS.crop,
checkpoint_dir=FLAGS.checkpoint_dir,
sample_dir=FLAGS.sample_dir,
data_dir=FLAGS.data_dir,
out_dir=FLAGS.out_dir,
max_to_keep=FLAGS.max_to_keep)
show_all_variables()
if FLAGS.train:
dcgan.train(FLAGS)
else:
load_success, load_counter = dcgan.load(FLAGS.checkpoint_dir)
if not load_success:
raise Exception("Checkpoint not found in " + FLAGS.checkpoint_dir)
# to_json("./web/js/layers.js", [dcgan.h0_w, dcgan.h0_b, dcgan.g_bn0],
# [dcgan.h1_w, dcgan.h1_b, dcgan.g_bn1],
# [dcgan.h2_w, dcgan.h2_b, dcgan.g_bn2],
# [dcgan.h3_w, dcgan.h3_b, dcgan.g_bn3],
# [dcgan.h4_w, dcgan.h4_b, None])
# Below is codes for visualization
if FLAGS.export:
export_dir = os.path.join(FLAGS.checkpoint_dir, 'export_b'+str(FLAGS.batch_size))
dcgan.save(export_dir, load_counter, ckpt=True, frozen=False)
if FLAGS.freeze:
export_dir = os.path.join(FLAGS.checkpoint_dir, 'frozen_b'+str(FLAGS.batch_size))
dcgan.save(export_dir, load_counter, ckpt=False, frozen=True)
if FLAGS.visualize:
OPTION = 1
visualize(sess, dcgan, FLAGS, OPTION, FLAGS.sample_dir)
if __name__ == '__main__':
tf.app.run()
================================================
FILE: model.py
================================================
from __future__ import division
from __future__ import print_function
import os
import time
import math
from glob import glob
import tensorflow as tf
import numpy as np
from six.moves import xrange
from ops import *
from utils import *
def conv_out_size_same(size, stride):
return int(math.ceil(float(size) / float(stride)))
def gen_random(mode, size):
if mode=='normal01': return np.random.normal(0,1,size=size)
if mode=='uniform_signed': return np.random.uniform(-1,1,size=size)
if mode=='uniform_unsigned': return np.random.uniform(0,1,size=size)
class DCGAN(object):
def __init__(self, sess, input_height=108, input_width=108, crop=True,
batch_size=64, sample_num = 64, output_height=64, output_width=64,
y_dim=None, z_dim=100, gf_dim=64, df_dim=64,
gfc_dim=1024, dfc_dim=1024, c_dim=3, dataset_name='default',
max_to_keep=1,
input_fname_pattern='*.jpg', checkpoint_dir='ckpts', sample_dir='samples', out_dir='./out', data_dir='./data'):
"""
Args:
sess: TensorFlow session
batch_size: The size of batch. Should be specified before training.
y_dim: (optional) Dimension of dim for y. [None]
z_dim: (optional) Dimension of dim for Z. [100]
gf_dim: (optional) Dimension of gen filters in first conv layer. [64]
df_dim: (optional) Dimension of discrim filters in first conv layer. [64]
gfc_dim: (optional) Dimension of gen units for for fully connected layer. [1024]
dfc_dim: (optional) Dimension of discrim units for fully connected layer. [1024]
c_dim: (optional) Dimension of image color. For grayscale input, set to 1. [3]
"""
self.sess = sess
self.crop = crop
self.batch_size = batch_size
self.sample_num = sample_num
self.input_height = input_height
self.input_width = input_width
self.output_height = output_height
self.output_width = output_width
self.y_dim = y_dim
self.z_dim = z_dim
self.gf_dim = gf_dim
self.df_dim = df_dim
self.gfc_dim = gfc_dim
self.dfc_dim = dfc_dim
# batch normalization : deals with poor initialization helps gradient flow
self.d_bn1 = batch_norm(name='d_bn1')
self.d_bn2 = batch_norm(name='d_bn2')
if not self.y_dim:
self.d_bn3 = batch_norm(name='d_bn3')
self.g_bn0 = batch_norm(name='g_bn0')
self.g_bn1 = batch_norm(name='g_bn1')
self.g_bn2 = batch_norm(name='g_bn2')
if not self.y_dim:
self.g_bn3 = batch_norm(name='g_bn3')
self.dataset_name = dataset_name
self.input_fname_pattern = input_fname_pattern
self.checkpoint_dir = checkpoint_dir
self.data_dir = data_dir
self.out_dir = out_dir
self.max_to_keep = max_to_keep
if self.dataset_name == 'mnist':
self.data_X, self.data_y = self.load_mnist()
self.c_dim = self.data_X[0].shape[-1]
else:
data_path = os.path.join(self.data_dir, self.dataset_name, self.input_fname_pattern)
self.data = glob(data_path)
if len(self.data) == 0:
raise Exception("[!] No data found in '" + data_path + "'")
np.random.shuffle(self.data)
imreadImg = imread(self.data[0])
if len(imreadImg.shape) >= 3: #check if image is a non-grayscale image by checking channel number
self.c_dim = imread(self.data[0]).shape[-1]
else:
self.c_dim = 1
if len(self.data) < self.batch_size:
raise Exception("[!] Entire dataset size is less than the configured batch_size")
self.grayscale = (self.c_dim == 1)
self.build_model()
def build_model(self):
if self.y_dim:
self.y = tf.placeholder(tf.float32, [self.batch_size, self.y_dim], name='y')
else:
self.y = None
if self.crop:
image_dims = [self.output_height, self.output_width, self.c_dim]
else:
image_dims = [self.input_height, self.input_width, self.c_dim]
self.inputs = tf.placeholder(
tf.float32, [self.batch_size] + image_dims, name='real_images')
inputs = self.inputs
self.z = tf.placeholder(
tf.float32, [None, self.z_dim], name='z')
self.z_sum = histogram_summary("z", self.z)
self.G = self.generator(self.z, self.y)
self.D, self.D_logits = self.discriminator(inputs, self.y, reuse=False)
self.sampler = self.sampler(self.z, self.y)
self.D_, self.D_logits_ = self.discriminator(self.G, self.y, reuse=True)
self.d_sum = histogram_summary("d", self.D)
self.d__sum = histogram_summary("d_", self.D_)
self.G_sum = image_summary("G", self.G)
def sigmoid_cross_entropy_with_logits(x, y):
try:
return tf.nn.sigmoid_cross_entropy_with_logits(logits=x, labels=y)
except:
return tf.nn.sigmoid_cross_entropy_with_logits(logits=x, targets=y)
self.d_loss_real = tf.reduce_mean(
sigmoid_cross_entropy_with_logits(self.D_logits, tf.ones_like(self.D)))
self.d_loss_fake = tf.reduce_mean(
sigmoid_cross_entropy_with_logits(self.D_logits_, tf.zeros_like(self.D_)))
self.g_loss = tf.reduce_mean(
sigmoid_cross_entropy_with_logits(self.D_logits_, tf.ones_like(self.D_)))
self.d_loss_real_sum = scalar_summary("d_loss_real", self.d_loss_real)
self.d_loss_fake_sum = scalar_summary("d_loss_fake", self.d_loss_fake)
self.d_loss = self.d_loss_real + self.d_loss_fake
self.g_loss_sum = scalar_summary("g_loss", self.g_loss)
self.d_loss_sum = scalar_summary("d_loss", self.d_loss)
t_vars = tf.trainable_variables()
self.d_vars = [var for var in t_vars if 'd_' in var.name]
self.g_vars = [var for var in t_vars if 'g_' in var.name]
self.saver = tf.train.Saver(max_to_keep=self.max_to_keep)
def train(self, config):
d_optim = tf.train.AdamOptimizer(config.learning_rate, beta1=config.beta1) \
.minimize(self.d_loss, var_list=self.d_vars)
g_optim = tf.train.AdamOptimizer(config.learning_rate, beta1=config.beta1) \
.minimize(self.g_loss, var_list=self.g_vars)
try:
tf.global_variables_initializer().run()
except:
tf.initialize_all_variables().run()
if config.G_img_sum:
self.g_sum = merge_summary([self.z_sum, self.d__sum, self.G_sum, self.d_loss_fake_sum, self.g_loss_sum])
else:
self.g_sum = merge_summary([self.z_sum, self.d__sum, self.d_loss_fake_sum, self.g_loss_sum])
self.d_sum = merge_summary(
[self.z_sum, self.d_sum, self.d_loss_real_sum, self.d_loss_sum])
self.writer = SummaryWriter(os.path.join(self.out_dir, "logs"), self.sess.graph)
sample_z = gen_random(config.z_dist, size=(self.sample_num , self.z_dim))
if config.dataset == 'mnist':
sample_inputs = self.data_X[0:self.sample_num]
sample_labels = self.data_y[0:self.sample_num]
else:
sample_files = self.data[0:self.sample_num]
sample = [
get_image(sample_file,
input_height=self.input_height,
input_width=self.input_width,
resize_height=self.output_height,
resize_width=self.output_width,
crop=self.crop,
grayscale=self.grayscale) for sample_file in sample_files]
if (self.grayscale):
sample_inputs = np.array(sample).astype(np.float32)[:, :, :, None]
else:
sample_inputs = np.array(sample).astype(np.float32)
counter = 1
start_time = time.time()
could_load, checkpoint_counter = self.load(self.checkpoint_dir)
if could_load:
counter = checkpoint_counter
print(" [*] Load SUCCESS")
else:
print(" [!] Load failed...")
for epoch in xrange(config.epoch):
if config.dataset == 'mnist':
batch_idxs = min(len(self.data_X), config.train_size) // config.batch_size
else:
self.data = glob(os.path.join(
config.data_dir, config.dataset, self.input_fname_pattern))
np.random.shuffle(self.data)
batch_idxs = min(len(self.data), config.train_size) // config.batch_size
for idx in xrange(0, int(batch_idxs)):
if config.dataset == 'mnist':
batch_images = self.data_X[idx*config.batch_size:(idx+1)*config.batch_size]
batch_labels = self.data_y[idx*config.batch_size:(idx+1)*config.batch_size]
else:
batch_files = self.data[idx*config.batch_size:(idx+1)*config.batch_size]
batch = [
get_image(batch_file,
input_height=self.input_height,
input_width=self.input_width,
resize_height=self.output_height,
resize_width=self.output_width,
crop=self.crop,
grayscale=self.grayscale) for batch_file in batch_files]
if self.grayscale:
batch_images = np.array(batch).astype(np.float32)[:, :, :, None]
else:
batch_images = np.array(batch).astype(np.float32)
batch_z = gen_random(config.z_dist, size=[config.batch_size, self.z_dim]) \
.astype(np.float32)
if config.dataset == 'mnist':
# Update D network
_, summary_str = self.sess.run([d_optim, self.d_sum],
feed_dict={
self.inputs: batch_images,
self.z: batch_z,
self.y:batch_labels,
})
self.writer.add_summary(summary_str, counter)
# Update G network
_, summary_str = self.sess.run([g_optim, self.g_sum],
feed_dict={
self.z: batch_z,
self.y:batch_labels,
})
self.writer.add_summary(summary_str, counter)
# Run g_optim twice to make sure that d_loss does not go to zero (different from paper)
_, summary_str = self.sess.run([g_optim, self.g_sum],
feed_dict={ self.z: batch_z, self.y:batch_labels })
self.writer.add_summary(summary_str, counter)
errD_fake = self.d_loss_fake.eval({
self.z: batch_z,
self.y:batch_labels
})
errD_real = self.d_loss_real.eval({
self.inputs: batch_images,
self.y:batch_labels
})
errG = self.g_loss.eval({
self.z: batch_z,
self.y: batch_labels
})
else:
# Update D network
_, summary_str = self.sess.run([d_optim, self.d_sum],
feed_dict={ self.inputs: batch_images, self.z: batch_z })
self.writer.add_summary(summary_str, counter)
# Update G network
_, summary_str = self.sess.run([g_optim, self.g_sum],
feed_dict={ self.z: batch_z })
self.writer.add_summary(summary_str, counter)
# Run g_optim twice to make sure that d_loss does not go to zero (different from paper)
_, summary_str = self.sess.run([g_optim, self.g_sum],
feed_dict={ self.z: batch_z })
self.writer.add_summary(summary_str, counter)
errD_fake = self.d_loss_fake.eval({ self.z: batch_z })
errD_real = self.d_loss_real.eval({ self.inputs: batch_images })
errG = self.g_loss.eval({self.z: batch_z})
print("[%8d Epoch:[%2d/%2d] [%4d/%4d] time: %4.4f, d_loss: %.8f, g_loss: %.8f" \
% (counter, epoch, config.epoch, idx, batch_idxs,
time.time() - start_time, errD_fake+errD_real, errG))
if np.mod(counter, config.sample_freq) == 0:
if config.dataset == 'mnist':
samples, d_loss, g_loss = self.sess.run(
[self.sampler, self.d_loss, self.g_loss],
feed_dict={
self.z: sample_z,
self.inputs: sample_inputs,
self.y:sample_labels,
}
)
save_images(samples, image_manifold_size(samples.shape[0]),
'./{}/train_{:08d}.png'.format(config.sample_dir, counter))
print("[Sample] d_loss: %.8f, g_loss: %.8f" % (d_loss, g_loss))
else:
try:
samples, d_loss, g_loss = self.sess.run(
[self.sampler, self.d_loss, self.g_loss],
feed_dict={
self.z: sample_z,
self.inputs: sample_inputs,
},
)
save_images(samples, image_manifold_size(samples.shape[0]),
'./{}/train_{:08d}.png'.format(config.sample_dir, counter))
print("[Sample] d_loss: %.8f, g_loss: %.8f" % (d_loss, g_loss))
except:
print("one pic error!...")
if np.mod(counter, config.ckpt_freq) == 0:
self.save(config.checkpoint_dir, counter)
counter += 1
def discriminator(self, image, y=None, reuse=False):
with tf.variable_scope("discriminator") as scope:
if reuse:
scope.reuse_variables()
if not self.y_dim:
h0 = lrelu(conv2d(image, self.df_dim, name='d_h0_conv'))
h1 = lrelu(self.d_bn1(conv2d(h0, self.df_dim*2, name='d_h1_conv')))
h2 = lrelu(self.d_bn2(conv2d(h1, self.df_dim*4, name='d_h2_conv')))
h3 = lrelu(self.d_bn3(conv2d(h2, self.df_dim*8, name='d_h3_conv')))
h4 = linear(tf.reshape(h3, [self.batch_size, -1]), 1, 'd_h4_lin')
return tf.nn.sigmoid(h4), h4
else:
yb = tf.reshape(y, [self.batch_size, 1, 1, self.y_dim])
x = conv_cond_concat(image, yb)
h0 = lrelu(conv2d(x, self.c_dim + self.y_dim, name='d_h0_conv'))
h0 = conv_cond_concat(h0, yb)
h1 = lrelu(self.d_bn1(conv2d(h0, self.df_dim + self.y_dim, name='d_h1_conv')))
h1 = tf.reshape(h1, [self.batch_size, -1])
h1 = concat([h1, y], 1)
h2 = lrelu(self.d_bn2(linear(h1, self.dfc_dim, 'd_h2_lin')))
h2 = concat([h2, y], 1)
h3 = linear(h2, 1, 'd_h3_lin')
return tf.nn.sigmoid(h3), h3
def generator(self, z, y=None):
with tf.variable_scope("generator") as scope:
if not self.y_dim:
s_h, s_w = self.output_height, self.output_width
s_h2, s_w2 = conv_out_size_same(s_h, 2), conv_out_size_same(s_w, 2)
s_h4, s_w4 = conv_out_size_same(s_h2, 2), conv_out_size_same(s_w2, 2)
s_h8, s_w8 = conv_out_size_same(s_h4, 2), conv_out_size_same(s_w4, 2)
s_h16, s_w16 = conv_out_size_same(s_h8, 2), conv_out_size_same(s_w8, 2)
# project `z` and reshape
self.z_, self.h0_w, self.h0_b = linear(
z, self.gf_dim*8*s_h16*s_w16, 'g_h0_lin', with_w=True)
self.h0 = tf.reshape(
self.z_, [-1, s_h16, s_w16, self.gf_dim * 8])
h0 = tf.nn.relu(self.g_bn0(self.h0))
self.h1, self.h1_w, self.h1_b = deconv2d(
h0, [self.batch_size, s_h8, s_w8, self.gf_dim*4], name='g_h1', with_w=True)
h1 = tf.nn.relu(self.g_bn1(self.h1))
h2, self.h2_w, self.h2_b = deconv2d(
h1, [self.batch_size, s_h4, s_w4, self.gf_dim*2], name='g_h2', with_w=True)
h2 = tf.nn.relu(self.g_bn2(h2))
h3, self.h3_w, self.h3_b = deconv2d(
h2, [self.batch_size, s_h2, s_w2, self.gf_dim*1], name='g_h3', with_w=True)
h3 = tf.nn.relu(self.g_bn3(h3))
h4, self.h4_w, self.h4_b = deconv2d(
h3, [self.batch_size, s_h, s_w, self.c_dim], name='g_h4', with_w=True)
return tf.nn.tanh(h4)
else:
s_h, s_w = self.output_height, self.output_width
s_h2, s_h4 = int(s_h/2), int(s_h/4)
s_w2, s_w4 = int(s_w/2), int(s_w/4)
# yb = tf.expand_dims(tf.expand_dims(y, 1),2)
yb = tf.reshape(y, [self.batch_size, 1, 1, self.y_dim])
z = concat([z, y], 1)
h0 = tf.nn.relu(
self.g_bn0(linear(z, self.gfc_dim, 'g_h0_lin')))
h0 = concat([h0, y], 1)
h1 = tf.nn.relu(self.g_bn1(
linear(h0, self.gf_dim*2*s_h4*s_w4, 'g_h1_lin')))
h1 = tf.reshape(h1, [self.batch_size, s_h4, s_w4, self.gf_dim * 2])
h1 = conv_cond_concat(h1, yb)
h2 = tf.nn.relu(self.g_bn2(deconv2d(h1,
[self.batch_size, s_h2, s_w2, self.gf_dim * 2], name='g_h2')))
h2 = conv_cond_concat(h2, yb)
return tf.nn.sigmoid(
deconv2d(h2, [self.batch_size, s_h, s_w, self.c_dim], name='g_h3'))
def sampler(self, z, y=None):
with tf.variable_scope("generator") as scope:
scope.reuse_variables()
if not self.y_dim:
s_h, s_w = self.output_height, self.output_width
s_h2, s_w2 = conv_out_size_same(s_h, 2), conv_out_size_same(s_w, 2)
s_h4, s_w4 = conv_out_size_same(s_h2, 2), conv_out_size_same(s_w2, 2)
s_h8, s_w8 = conv_out_size_same(s_h4, 2), conv_out_size_same(s_w4, 2)
s_h16, s_w16 = conv_out_size_same(s_h8, 2), conv_out_size_same(s_w8, 2)
# project `z` and reshape
h0 = tf.reshape(
linear(z, self.gf_dim*8*s_h16*s_w16, 'g_h0_lin'),
[-1, s_h16, s_w16, self.gf_dim * 8])
h0 = tf.nn.relu(self.g_bn0(h0, train=False))
h1 = deconv2d(h0, [self.batch_size, s_h8, s_w8, self.gf_dim*4], name='g_h1')
h1 = tf.nn.relu(self.g_bn1(h1, train=False))
h2 = deconv2d(h1, [self.batch_size, s_h4, s_w4, self.gf_dim*2], name='g_h2')
h2 = tf.nn.relu(self.g_bn2(h2, train=False))
h3 = deconv2d(h2, [self.batch_size, s_h2, s_w2, self.gf_dim*1], name='g_h3')
h3 = tf.nn.relu(self.g_bn3(h3, train=False))
h4 = deconv2d(h3, [self.batch_size, s_h, s_w, self.c_dim], name='g_h4')
return tf.nn.tanh(h4)
else:
s_h, s_w = self.output_height, self.output_width
s_h2, s_h4 = int(s_h/2), int(s_h/4)
s_w2, s_w4 = int(s_w/2), int(s_w/4)
# yb = tf.reshape(y, [-1, 1, 1, self.y_dim])
yb = tf.reshape(y, [self.batch_size, 1, 1, self.y_dim])
z = concat([z, y], 1)
h0 = tf.nn.relu(self.g_bn0(linear(z, self.gfc_dim, 'g_h0_lin'), train=False))
h0 = concat([h0, y], 1)
h1 = tf.nn.relu(self.g_bn1(
linear(h0, self.gf_dim*2*s_h4*s_w4, 'g_h1_lin'), train=False))
h1 = tf.reshape(h1, [self.batch_size, s_h4, s_w4, self.gf_dim * 2])
h1 = conv_cond_concat(h1, yb)
h2 = tf.nn.relu(self.g_bn2(
deconv2d(h1, [self.batch_size, s_h2, s_w2, self.gf_dim * 2], name='g_h2'), train=False))
h2 = conv_cond_concat(h2, yb)
return tf.nn.sigmoid(deconv2d(h2, [self.batch_size, s_h, s_w, self.c_dim], name='g_h3'))
def load_mnist(self):
data_dir = os.path.join(self.data_dir, self.dataset_name)
fd = open(os.path.join(data_dir,'train-images-idx3-ubyte'))
loaded = np.fromfile(file=fd,dtype=np.uint8)
trX = loaded[16:].reshape((60000,28,28,1)).astype(np.float)
fd = open(os.path.join(data_dir,'train-labels-idx1-ubyte'))
loaded = np.fromfile(file=fd,dtype=np.uint8)
trY = loaded[8:].reshape((60000)).astype(np.float)
fd = open(os.path.join(data_dir,'t10k-images-idx3-ubyte'))
loaded = np.fromfile(file=fd,dtype=np.uint8)
teX = loaded[16:].reshape((10000,28,28,1)).astype(np.float)
fd = open(os.path.join(data_dir,'t10k-labels-idx1-ubyte'))
loaded = np.fromfile(file=fd,dtype=np.uint8)
teY = loaded[8:].reshape((10000)).astype(np.float)
trY = np.asarray(trY)
teY = np.asarray(teY)
X = np.concatenate((trX, teX), axis=0)
y = np.concatenate((trY, teY), axis=0).astype(np.int)
seed = 547
np.random.seed(seed)
np.random.shuffle(X)
np.random.seed(seed)
np.random.shuffle(y)
y_vec = np.zeros((len(y), self.y_dim), dtype=np.float)
for i, label in enumerate(y):
y_vec[i,y[i]] = 1.0
return X/255.,y_vec
@property
def model_dir(self):
return "{}_{}_{}_{}".format(
self.dataset_name, self.batch_size,
self.output_height, self.output_width)
def save(self, checkpoint_dir, step, filename='model', ckpt=True, frozen=False):
# model_name = "DCGAN.model"
# checkpoint_dir = os.path.join(checkpoint_dir, self.model_dir)
filename += '.b' + str(self.batch_size)
if not os.path.exists(checkpoint_dir):
os.makedirs(checkpoint_dir)
if ckpt:
self.saver.save(self.sess,
os.path.join(checkpoint_dir, filename),
global_step=step)
if frozen:
tf.train.write_graph(
tf.graph_util.convert_variables_to_constants(self.sess, self.sess.graph_def, ["generator_1/Tanh"]),
checkpoint_dir,
'{}-{:06d}_frz.pb'.format(filename, step),
as_text=False)
def load(self, checkpoint_dir):
#import re
print(" [*] Reading checkpoints...", checkpoint_dir)
# checkpoint_dir = os.path.join(checkpoint_dir, self.model_dir)
# print(" ->", checkpoint_dir)
ckpt = tf.train.get_checkpoint_state(checkpoint_dir)
if ckpt and ckpt.model_checkpoint_path:
ckpt_name = os.path.basename(ckpt.model_checkpoint_path)
self.saver.restore(self.sess, os.path.join(checkpoint_dir, ckpt_name))
#counter = int(next(re.finditer("(\d+)(?!.*\d)",ckpt_name)).group(0))
counter = int(ckpt_name.split('-')[-1])
print(" [*] Success to read {}".format(ckpt_name))
return True, counter
else:
print(" [*] Failed to find a checkpoint")
return False, 0
================================================
FILE: ops.py
================================================
import math
import numpy as np
import tensorflow as tf
from tensorflow.python.framework import ops
from utils import *
try:
image_summary = tf.image_summary
scalar_summary = tf.scalar_summary
histogram_summary = tf.histogram_summary
merge_summary = tf.merge_summary
SummaryWriter = tf.train.SummaryWriter
except:
image_summary = tf.summary.image
scalar_summary = tf.summary.scalar
histogram_summary = tf.summary.histogram
merge_summary = tf.summary.merge
SummaryWriter = tf.summary.FileWriter
if "concat_v2" in dir(tf):
def concat(tensors, axis, *args, **kwargs):
return tf.concat_v2(tensors, axis, *args, **kwargs)
else:
def concat(tensors, axis, *args, **kwargs):
return tf.concat(tensors, axis, *args, **kwargs)
class batch_norm(object):
def __init__(self, epsilon=1e-5, momentum = 0.9, name="batch_norm"):
with tf.variable_scope(name):
self.epsilon = epsilon
self.momentum = momentum
self.name = name
def __call__(self, x, train=True):
return tf.contrib.layers.batch_norm(x,
decay=self.momentum,
updates_collections=None,
epsilon=self.epsilon,
scale=True,
is_training=train,
scope=self.name)
def conv_cond_concat(x, y):
"""Concatenate conditioning vector on feature map axis."""
x_shapes = x.get_shape()
y_shapes = y.get_shape()
return concat([
x, y*tf.ones([x_shapes[0], x_shapes[1], x_shapes[2], y_shapes[3]])], 3)
def conv2d(input_, output_dim,
k_h=5, k_w=5, d_h=2, d_w=2, stddev=0.02,
name="conv2d"):
with tf.variable_scope(name):
w = tf.get_variable('w', [k_h, k_w, input_.get_shape()[-1], output_dim],
initializer=tf.truncated_normal_initializer(stddev=stddev))
conv = tf.nn.conv2d(input_, w, strides=[1, d_h, d_w, 1], padding='SAME')
biases = tf.get_variable('biases', [output_dim], initializer=tf.constant_initializer(0.0))
conv = tf.reshape(tf.nn.bias_add(conv, biases), conv.get_shape())
return conv
def deconv2d(input_, output_shape,
k_h=5, k_w=5, d_h=2, d_w=2, stddev=0.02,
name="deconv2d", with_w=False):
with tf.variable_scope(name):
# filter : [height, width, output_channels, in_channels]
w = tf.get_variable('w', [k_h, k_w, output_shape[-1], input_.get_shape()[-1]],
initializer=tf.random_normal_initializer(stddev=stddev))
try:
deconv = tf.nn.conv2d_transpose(input_, w, output_shape=output_shape,
strides=[1, d_h, d_w, 1])
# Support for verisons of TensorFlow before 0.7.0
except AttributeError:
deconv = tf.nn.deconv2d(input_, w, output_shape=output_shape,
strides=[1, d_h, d_w, 1])
biases = tf.get_variable('biases', [output_shape[-1]], initializer=tf.constant_initializer(0.0))
deconv = tf.reshape(tf.nn.bias_add(deconv, biases), deconv.get_shape())
if with_w:
return deconv, w, biases
else:
return deconv
def lrelu(x, leak=0.2, name="lrelu"):
return tf.maximum(x, leak*x)
def linear(input_, output_size, scope=None, stddev=0.02, bias_start=0.0, with_w=False):
shape = input_.get_shape().as_list()
with tf.variable_scope(scope or "Linear"):
try:
matrix = tf.get_variable("Matrix", [shape[1], output_size], tf.float32,
tf.random_normal_initializer(stddev=stddev))
except ValueError as err:
msg = "NOTE: Usually, this is due to an issue with the image dimensions. Did you correctly set '--crop' or '--input_height' or '--output_height'?"
err.args = err.args + (msg,)
raise
bias = tf.get_variable("bias", [output_size],
initializer=tf.constant_initializer(bias_start))
if with_w:
return tf.matmul(input_, matrix) + bias, matrix, bias
else:
return tf.matmul(input_, matrix) + bias
================================================
FILE: utils.py
================================================
"""
Some codes from https://github.com/Newmu/dcgan_code
"""
from __future__ import division
import math
import json
import random
import pprint
import scipy.misc
import cv2
import numpy as np
import os
import time
import datetime
from time import gmtime, strftime
from six.moves import xrange
from PIL import Image
import tensorflow as tf
import tensorflow.contrib.slim as slim
pp = pprint.PrettyPrinter()
get_stddev = lambda x, k_h, k_w: 1/math.sqrt(k_w*k_h*x.get_shape()[-1])
def expand_path(path):
return os.path.expanduser(os.path.expandvars(path))
def timestamp(s='%Y%m%d.%H%M%S', ts=None):
if not ts: ts = time.time()
st = datetime.datetime.fromtimestamp(ts).strftime(s)
return st
def show_all_variables():
model_vars = tf.trainable_variables()
slim.model_analyzer.analyze_vars(model_vars, print_info=True)
def get_image(image_path, input_height, input_width,
resize_height=64, resize_width=64,
crop=True, grayscale=False):
image = imread(image_path, grayscale)
return transform(image, input_height, input_width,
resize_height, resize_width, crop)
def save_images(images, size, image_path):
return imsave(inverse_transform(images), size, image_path)
def imread(path, grayscale = False):
if (grayscale):
return scipy.misc.imread(path, flatten = True).astype(np.float)
else:
# Reference: https://github.com/carpedm20/DCGAN-tensorflow/issues/162#issuecomment-315519747
img_bgr = cv2.imread(path)
# Reference: https://stackoverflow.com/a/15074748/
img_rgb = img_bgr[..., ::-1]
return img_rgb.astype(np.float)
def merge_images(images, size):
return inverse_transform(images)
def merge(images, size):
h, w = images.shape[1], images.shape[2]
if (images.shape[3] in (3,4)):
c = images.shape[3]
img = np.zeros((h * size[0], w * size[1], c))
for idx, image in enumerate(images):
i = idx % size[1]
j = idx // size[1]
img[j * h:j * h + h, i * w:i * w + w, :] = image
return img
elif images.shape[3]==1:
img = np.zeros((h * size[0], w * size[1]))
for idx, image in enumerate(images):
i = idx % size[1]
j = idx // size[1]
img[j * h:j * h + h, i * w:i * w + w] = image[:,:,0]
return img
else:
raise ValueError('in merge(images,size) images parameter '
'must have dimensions: HxW or HxWx3 or HxWx4')
def imsave(images, size, path):
image = np.squeeze(merge(images, size))
return scipy.misc.imsave(path, image)
def center_crop(x, crop_h, crop_w,
resize_h=64, resize_w=64):
if crop_w is None:
crop_w = crop_h
h, w = x.shape[:2]
j = int(round((h - crop_h)/2.))
i = int(round((w - crop_w)/2.))
im = Image.fromarray(x[j:j+crop_h, i:i+crop_w])
return np.array(im.resize([resize_h, resize_w]), PIL.Image.BILINEAR)
def transform(image, input_height, input_width,
resize_height=64, resize_width=64, crop=True):
if crop:
cropped_image = center_crop(
image, input_height, input_width,
resize_height, resize_width)
else:
im = Image.fromarray(image[j:j+crop_h, i:i+crop_w])
return np.array(im.resize([resize_h, resize_w]), PIL.Image.BILINEAR)/127.5 - 1.
def inverse_transform(images):
return (images+1.)/2.
def to_json(output_path, *layers):
with open(output_path, "w") as layer_f:
lines = ""
for w, b, bn in layers:
layer_idx = w.name.split('/')[0].split('h')[1]
B = b.eval()
if "lin/" in w.name:
W = w.eval()
depth = W.shape[1]
else:
W = np.rollaxis(w.eval(), 2, 0)
depth = W.shape[0]
biases = {"sy": 1, "sx": 1, "depth": depth, "w": ['%.2f' % elem for elem in list(B)]}
if bn != None:
gamma = bn.gamma.eval()
beta = bn.beta.eval()
gamma = {"sy": 1, "sx": 1, "depth": depth, "w": ['%.2f' % elem for elem in list(gamma)]}
beta = {"sy": 1, "sx": 1, "depth": depth, "w": ['%.2f' % elem for elem in list(beta)]}
else:
gamma = {"sy": 1, "sx": 1, "depth": 0, "w": []}
beta = {"sy": 1, "sx": 1, "depth": 0, "w": []}
if "lin/" in w.name:
fs = []
for w in W.T:
fs.append({"sy": 1, "sx": 1, "depth": W.shape[0], "w": ['%.2f' % elem for elem in list(w)]})
lines += """
var layer_%s = {
"layer_type": "fc",
"sy": 1, "sx": 1,
"out_sx": 1, "out_sy": 1,
"stride": 1, "pad": 0,
"out_depth": %s, "in_depth": %s,
"biases": %s,
"gamma": %s,
"beta": %s,
"filters": %s
};""" % (layer_idx.split('_')[0], W.shape[1], W.shape[0], biases, gamma, beta, fs)
else:
fs = []
for w_ in W:
fs.append({"sy": 5, "sx": 5, "depth": W.shape[3], "w": ['%.2f' % elem for elem in list(w_.flatten())]})
lines += """
var layer_%s = {
"layer_type": "deconv",
"sy": 5, "sx": 5,
"out_sx": %s, "out_sy": %s,
"stride": 2, "pad": 1,
"out_depth": %s, "in_depth": %s,
"biases": %s,
"gamma": %s,
"beta": %s,
"filters": %s
};""" % (layer_idx, 2**(int(layer_idx)+2), 2**(int(layer_idx)+2),
W.shape[0], W.shape[3], biases, gamma, beta, fs)
layer_f.write(" ".join(lines.replace("'","").split()))
def make_gif(images, fname, duration=2, true_image=False):
import moviepy.editor as mpy
def make_frame(t):
try:
x = images[int(len(images)/duration*t)]
except:
x = images[-1]
if true_image:
return x.astype(np.uint8)
else:
return ((x+1)/2*255).astype(np.uint8)
clip = mpy.VideoClip(make_frame, duration=duration)
clip.write_gif(fname, fps = len(images) / duration)
def visualize(sess, dcgan, config, option, sample_dir='samples'):
image_frame_dim = int(math.ceil(config.batch_size**.5))
if option == 0:
z_sample = np.random.uniform(-0.5, 0.5, size=(config.batch_size, dcgan.z_dim))
samples = sess.run(dcgan.sampler, feed_dict={dcgan.z: z_sample})
save_images(samples, [image_frame_dim, image_frame_dim], os.path.join(sample_dir, 'test_%s.png' % strftime("%Y%m%d%H%M%S", gmtime() )))
elif option == 1:
values = np.arange(0, 1, 1./config.batch_size)
for idx in xrange(dcgan.z_dim):
print(" [*] %d" % idx)
z_sample = np.random.uniform(-1, 1, size=(config.batch_size , dcgan.z_dim))
for kdx, z in enumerate(z_sample):
z[idx] = values[kdx]
if config.dataset == "mnist":
y = np.random.choice(10, config.batch_size)
y_one_hot = np.zeros((config.batch_size, 10))
y_one_hot[np.arange(config.batch_size), y] = 1
samples = sess.run(dcgan.sampler, feed_dict={dcgan.z: z_sample, dcgan.y: y_one_hot})
else:
samples = sess.run(dcgan.sampler, feed_dict={dcgan.z: z_sample})
save_images(samples, [image_frame_dim, image_frame_dim], os.path.join(sample_dir, 'test_arange_%s.png' % (idx)))
elif option == 2:
values = np.arange(0, 1, 1./config.batch_size)
for idx in [random.randint(0, dcgan.z_dim - 1) for _ in xrange(dcgan.z_dim)]:
print(" [*] %d" % idx)
z = np.random.uniform(-0.2, 0.2, size=(dcgan.z_dim))
z_sample = np.tile(z, (config.batch_size, 1))
#z_sample = np.zeros([config.batch_size, dcgan.z_dim])
for kdx, z in enumerate(z_sample):
z[idx] = values[kdx]
if config.dataset == "mnist":
y = np.random.choice(10, config.batch_size)
y_one_hot = np.zeros((config.batch_size, 10))
y_one_hot[np.arange(config.batch_size), y] = 1
samples = sess.run(dcgan.sampler, feed_dict={dcgan.z: z_sample, dcgan.y: y_one_hot})
else:
samples = sess.run(dcgan.sampler, feed_dict={dcgan.z: z_sample})
try:
make_gif(samples, './samples/test_gif_%s.gif' % (idx))
except:
save_images(samples, [image_frame_dim, image_frame_dim], os.path.join(sample_dir, 'test_%s.png' % strftime("%Y%m%d%H%M%S", gmtime() )))
elif option == 3:
values = np.arange(0, 1, 1./config.batch_size)
for idx in xrange(dcgan.z_dim):
print(" [*] %d" % idx)
z_sample = np.zeros([config.batch_size, dcgan.z_dim])
for kdx, z in enumerate(z_sample):
z[idx] = values[kdx]
samples = sess.run(dcgan.sampler, feed_dict={dcgan.z: z_sample})
make_gif(samples, os.path.join(sample_dir, 'test_gif_%s.gif' % (idx)))
elif option == 4:
image_set = []
values = np.arange(0, 1, 1./config.batch_size)
for idx in xrange(dcgan.z_dim):
print(" [*] %d" % idx)
z_sample = np.zeros([config.batch_size, dcgan.z_dim])
for kdx, z in enumerate(z_sample): z[idx] = values[kdx]
image_set.append(sess.run(dcgan.sampler, feed_dict={dcgan.z: z_sample}))
make_gif(image_set[-1], os.path.join(sample_dir, 'test_gif_%s.gif' % (idx)))
new_image_set = [merge(np.array([images[idx] for images in image_set]), [10, 10]) \
for idx in range(64) + range(63, -1, -1)]
make_gif(new_image_set, './samples/test_gif_merged.gif', duration=8)
def image_manifold_size(num_images):
manifold_h = int(np.floor(np.sqrt(num_images)))
manifold_w = int(np.ceil(np.sqrt(num_images)))
assert manifold_h * manifold_w == num_images
return manifold_h, manifold_w
================================================
FILE: web/app.py
================================================
from flask import Flask
from flask import render_template
app = Flask(__name__, template_folder="./", static_folder='./', static_url_path='')
@app.route('/')
def index():
return render_template('index.html')
if __name__ == '__main__':
app.debug=True
app.run(host='0.0.0.0')
================================================
FILE: web/css/fakeLoader.css
================================================
/**********************
*CSS Animations by:
*http://codepen.io/vivinantony
***********************/
.spinner1 {
width: 40px;
height: 40px;
position: relative;
}
.double-bounce1, .double-bounce2 {
width: 100%;
height: 100%;
border-radius: 50%;
background-color: #fff;
opacity: 0.6;
position: absolute;
top: 0;
left: 0;
-webkit-animation: bounce 2.0s infinite ease-in-out;
animation: bounce 2.0s infinite ease-in-out;
}
.double-bounce2 {
-webkit-animation-delay: -1.0s;
animation-delay: -1.0s;
}
@-webkit-keyframes bounce {
0%, 100% { -webkit-transform: scale(0.0) }
50% { -webkit-transform: scale(1.0) }
}
@keyframes bounce {
0%, 100% {
transform: scale(0.0);
-webkit-transform: scale(0.0);
} 50% {
transform: scale(1.0);
-webkit-transform: scale(1.0);
}
}
.spinner2 {
width: 40px;
height: 40px;
position: relative;
}
.container1 > div, .container2 > div, .container3 > div {
width: 6px;
height: 6px;
background-color: #fff;
border-radius: 100%;
position: absolute;
-webkit-animation: bouncedelay 1.2s infinite ease-in-out;
animation: bouncedelay 1.2s infinite ease-in-out;
/* Prevent first frame from flickering when animation starts */
-webkit-animation-fill-mode: both;
animation-fill-mode: both;
}
.spinner2 .spinner-container {
position: absolute;
width: 100%;
height: 100%;
}
.container2 {
-webkit-transform: rotateZ(45deg);
transform: rotateZ(45deg);
}
.container3 {
-webkit-transform: rotateZ(90deg);
transform: rotateZ(90deg);
}
.circle1 { top: 0; left: 0; }
.circle2 { top: 0; right: 0; }
.circle3 { right: 0; bottom: 0; }
.circle4 { left: 0; bottom: 0; }
.container2 .circle1 {
-webkit-animation-delay: -1.1s;
animation-delay: -1.1s;
}
.container3 .circle1 {
-webkit-animation-delay: -1.0s;
animation-delay: -1.0s;
}
.container1 .circle2 {
-webkit-animation-delay: -0.9s;
animation-delay: -0.9s;
}
.container2 .circle2 {
-webkit-animation-delay: -0.8s;
animation-delay: -0.8s;
}
.container3 .circle2 {
-webkit-animation-delay: -0.7s;
animation-delay: -0.7s;
}
.container1 .circle3 {
-webkit-animation-delay: -0.6s;
animation-delay: -0.6s;
}
.container2 .circle3 {
-webkit-animation-delay: -0.5s;
animation-delay: -0.5s;
}
.container3 .circle3 {
-webkit-animation-delay: -0.4s;
animation-delay: -0.4s;
}
.container1 .circle4 {
-webkit-animation-delay: -0.3s;
animation-delay: -0.3s;
}
.container2 .circle4 {
-webkit-animation-delay: -0.2s;
animation-delay: -0.2s;
}
.container3 .circle4 {
-webkit-animation-delay: -0.1s;
animation-delay: -0.1s;
}
@-webkit-keyframes bouncedelay {
0%, 80%, 100% { -webkit-transform: scale(0.0) }
40% { -webkit-transform: scale(1.0) }
}
@keyframes bouncedelay {
0%, 80%, 100% {
transform: scale(0.0);
-webkit-transform: scale(0.0);
} 40% {
transform: scale(1.0);
-webkit-transform: scale(1.0);
}
}
.spinner3 {
width: 40px;
height: 40px;
position: relative;
-webkit-animation: rotate 2.0s infinite linear;
animation: rotate 2.0s infinite linear;
}
.dot1, .dot2 {
width: 60%;
height: 60%;
display: inline-block;
position: absolute;
top: 0;
background-color: #fff;
border-radius: 100%;
-webkit-animation: bounce 2.0s infinite ease-in-out;
animation: bounce 2.0s infinite ease-in-out;
}
.dot2 {
top: auto;
bottom: 0px;
-webkit-animation-delay: -1.0s;
animation-delay: -1.0s;
}
@-webkit-keyframes rotate { 100% { -webkit-transform: rotate(360deg) }}
@keyframes rotate { 100% { transform: rotate(360deg); -webkit-transform: rotate(360deg) }}
@-webkit-keyframes bounce {
0%, 100% { -webkit-transform: scale(0.0) }
50% { -webkit-transform: scale(1.0) }
}
@keyframes bounce {
0%, 100% {
transform: scale(0.0);
-webkit-transform: scale(0.0);
} 50% {
transform: scale(1.0);
-webkit-transform: scale(1.0);
}
}
.spinner4 {
width: 30px;
height: 30px;
background-color: #fff;
-webkit-animation: rotateplane 1.2s infinite ease-in-out;
animation: rotateplane 1.2s infinite ease-in-out;
}
@-webkit-keyframes rotateplane {
0% { -webkit-transform: perspective(120px) }
50% { -webkit-transform: perspective(120px) rotateY(180deg) }
100% { -webkit-transform: perspective(120px) rotateY(180deg) rotateX(180deg) }
}
@keyframes rotateplane {
0% {
transform: perspective(120px) rotateX(0deg) rotateY(0deg);
-webkit-transform: perspective(120px) rotateX(0deg) rotateY(0deg)
} 50% {
transform: perspective(120px) rotateX(-180.1deg) rotateY(0deg);
-webkit-transform: perspective(120px) rotateX(-180.1deg) rotateY(0deg)
} 100% {
transform: perspective(120px) rotateX(-180deg) rotateY(-179.9deg);
-webkit-transform: perspective(120px) rotateX(-180deg) rotateY(-179.9deg);
}
}
@charset 'UTF-8';
/* Slider */
.slick-loading .slick-list
{
background: #fff url('./ajax-loader.gif') center center no-repeat;
}
/* Icons */
@font-face
{
font-family: 'slick';
font-weight: normal;
font-style: normal;
src: url('../fonts/slick.eot');
src: url('../fonts/slick.eot?#iefix') format('embedded-opentype'), url('../fonts/slick.woff') format('woff'), url('../fonts/slick.ttf') format('truetype'), url('../fonts/slick.svg#slick') format('svg');
}
/* Arrows */
.slick-prev,
.slick-next
{
font-size: 0;
line-height: 0;
position: absolute;
top: 50%;
display: block;
width: 20px;
height: 20px;
margin-top: -10px;
padding: 0;
cursor: pointer;
color: transparent;
border: none;
outline: none;
background: transparent;
}
.slick-prev:hover,
.slick-prev:focus,
.slick-next:hover,
.slick-next:focus
{
color: transparent;
outline: none;
background: transparent;
}
.slick-prev:hover:before,
.slick-prev:focus:before,
.slick-next:hover:before,
.slick-next:focus:before
{
opacity: 1;
}
.slick-prev.slick-disabled:before,
.slick-next.slick-disabled:before
{
opacity: .25;
}
.slick-prev:before,
.slick-next:before
{
font-family: 'slick';
font-size: 20px;
line-height: 1;
opacity: .75;
color: white;
-webkit-font-smoothing: antialiased;
-moz-osx-font-smoothing: grayscale;
}
.slick-prev
{
left: -25px;
}
[dir='rtl'] .slick-prev
{
right: -25px;
left: auto;
}
.slick-prev:before
{
content: '←';
}
[dir='rtl'] .slick-prev:before
{
content: '→';
}
.slick-next
{
right: -25px;
}
[dir='rtl'] .slick-next
{
right: auto;
left: -25px;
}
.slick-next:before
{
content: '→';
}
[dir='rtl'] .slick-next:before
{
content: '←';
}
/* Dots */
.slick-slider
{
margin-bottom: 30px;
}
.slick-dots
{
position: absolute;
bottom: -45px;
display: block;
width: 100%;
padding: 0;
list-style: none;
text-align: center;
}
.slick-dots li
{
position: relative;
display: inline-block;
width: 20px;
height: 20px;
margin: 0 5px;
padding: 0;
cursor: pointer;
}
.slick-dots li button
{
font-size: 0;
line-height: 0;
display: block;
width: 20px;
height: 20px;
padding: 5px;
cursor: pointer;
color: transparent;
border: 0;
outline: none;
background: transparent;
}
.slick-dots li button:hover,
.slick-dots li button:focus
{
outline: none;
}
.slick-dots li button:hover:before,
.slick-dots li button:focus:before
{
opacity: 1;
}
.slick-dots li button:before
{
font-family: 'slick';
font-size: 6px;
line-height: 20px;
position: absolute;
top: 0;
left: 0;
width: 20px;
height: 20px;
content: '•';
text-align: center;
opacity: .25;
color: white;
-webkit-font-smoothing: antialiased;
-moz-osx-font-smoothing: grayscale;
}
.slick-dots li.slick-active button:before
{
opacity: .75;
color: white;
}
================================================
FILE: web/css/main.css
================================================
canvas {
background-color: white;
}
#colors {
overflow: hidden;
width: 90px;
margin-left: 30px;
float: left;
}
#colors .color {
float: left;
width: 40px;
height: 40px;
}
#colors .color div {
width: 100%;
height: 100%;
cursor: pointer;
}
#colors .color #color_1::before { background-color: #000000; }
#colors .color #color_1::after { background-color: #000000; }
#colors .color #color_2::before { background-color: #444444; }
#colors .color #color_2::after { background-color: #303030; }
#colors .color #color_3::before { background-color: #000088; }
#colors .color #color_3::after { background-color: #00005f; }
#colors .color #color_4::before { background-color: #1111ff; }
#colors .color #color_4::after { background-color: #0000be; }
#colors .color #color_5::before { background-color: #008800; }
#colors .color #color_5::after { background-color: #005f00; }
#colors .color #color_6::before { background-color: #11ff11; }
#colors .color #color_6::after { background-color: #00be00; }
#colors .color #color_7::before { background-color: #008888; }
#colors .color #color_7::after { background-color: #005f5f; }
#colors .color #color_8::before { background-color: #11ffff; }
#colors .color #color_8::after { background-color: #00bebe; }
#colors .color #color_9::before { background-color: #880000; }
#colors .color #color_9::after { background-color: #5f0000; }
#colors .color #color_10::before { background-color: #ff1111; }
#colors .color #color_10::after { background-color: #be0000; }
#colors .color #color_11::before { background-color: #880088; }
#colors .color #color_11::after { background-color: #5f005f; }
#colors .color #color_12::before { background-color: #ff11ff; }
#colors .color #color_12::after { background-color: #be00be; }
#colors .color #color_13::before { background-color: #884400; }
#colors .color #color_13::after { background-color: #5f3000; }
#colors .color #color_14::before { background-color: #ffff11; }
#colors .color #color_14::after { background-color: #bebe00; }
#colors .color #color_15::before { background-color: #888888; }
#colors .color #color_15::after { background-color: #5f5f5f; }
#colors .color #color_16::before { background-color: #cccccc; }
#colors .color #color_16::after { background-color: #8f8f8f; }
#colors .color .isometric::after {
width: 40px;
height: 10px;
}
#colors .color .isometric::before {
width: 10px;
height: 40px;
}
#colors .color.active div {
top: 10px;
left: 10px;
}
/* CANVAS */
#canvas {
float: left;
cursor: crosshair;
width: 320px;
height: 320px;
margin: 0 auto;
}
#canvas.isometric::after {
width: 320px;
height: 10px;
}
#canvas.isometric::before {
width: 10px;
height: 320px;
}
/*!
* Start Bootstrap - Grayscale Bootstrap Theme (http://startbootstrap.com)
* Code licensed under the Apache License v2.0.
* For details, see http://www.apache.org/licenses/LICENSE-2.0.
*/
body {
width: 100%;
height: 100%;
font-family: Lora,"Helvetica Neue",Helvetica,Arial,sans-serif;
color: #fff;
background-color: #000;
}
html {
width: 100%;
height: 100%;
}
h1,
h2,
h3,
h4,
h5,
h6 {
margin: 0 0 35px;
text-transform: uppercase;
font-family: Montserrat,"Helvetica Neue",Helvetica,Arial,sans-serif;
font-weight: 700;
letter-spacing: 1px;
}
p {
margin: 0 0 25px;
font-size: 18px;
line-height: 1.5;
}
@media(min-width:768px) {
p {
margin: 0 0 35px;
font-size: 20px;
line-height: 1.6;
}
}
b {
color: #3A8BB2;
}
a {
color: #42dca3;
-webkit-transition: all .2s ease-in-out;
-moz-transition: all .2s ease-in-out;
transition: all .2s ease-in-out;
}
a:hover,
a:focus {
text-decoration: none;
color: #1d9b6c;
}
.light {
font-weight: 400;
}
.navbar-custom {
margin-bottom: 0;
border-bottom: 1px solid rgba(255,255,255,.3);
text-transform: uppercase;
font-family: Montserrat,"Helvetica Neue",Helvetica,Arial,sans-serif;
background-color: #000;
}
.navbar-custom .navbar-brand {
font-weight: 700;
}
.navbar-custom .navbar-brand:focus {
outline: 0;
}
.navbar-custom .navbar-brand .navbar-toggle {
padding: 4px 6px;
font-size: 16px;
color: #fff;
}
.navbar-custom .navbar-brand .navbar-toggle:focus,
.navbar-custom .navbar-brand .navbar-toggle:active {
outline: 0;
}
.navbar-custom a {
color: #fff;
}
.navbar-custom .nav li a {
-webkit-transition: background .3s ease-in-out;
-moz-transition: background .3s ease-in-out;
transition: background .3s ease-in-out;
}
.navbar-custom .nav li a:hover {
outline: 0;
color: rgba(255,255,255,.8);
background-color: transparent;
}
.navbar-custom .nav li a:focus,
.navbar-custom .nav li a:active {
outline: 0;
background-color: transparent;
}
.navbar-custom .nav li.active {
outline: 0;
}
.navbar-custom .nav li.active a {
background-color: rgba(255,255,255,.3);
}
.navbar-custom .nav li.active a:hover {
color: #fff;
}
@media(min-width:768px) {
.navbar-custom {
padding: 20px 0;
border-bottom: 0;
letter-spacing: 1px;
background: 0 0;
-webkit-transition: background .5s ease-in-out,padding .5s ease-in-out;
-moz-transition: background .5s ease-in-out,padding .5s ease-in-out;
transition: background .5s ease-in-out,padding .5s ease-in-out;
}
.navbar-custom.top-nav-collapse {
padding: 0;
border-bottom: 1px solid rgba(255,255,255,.3);
background: #000;
}
}
#background {
position: absolute;
top: 0;
left: 0;
min-width: 100%;
min-height: 100%;
width: auto;
height: auto;
}
.intro {
overflow: hidden;
position: relative;
display: table;
width: 100%;
height: auto;
min-height: 100%;
padding: 100px 0;
text-align: center;
color: #fff;
background-color: #000;
-webkit-background-size: cover;
-moz-background-size: cover;
background-size: cover;
-o-background-size: cover;
}
.intro .intro-body {
display: table-cell;
vertical-align: middle;
}
.intro .intro-body .brand-heading {
font-size: 40px;
}
.intro .intro-body .intro-text {
font-size: 18px;
}
@media(min-width:768px) {
.intro {
height: 100%;
padding: 0;
}
.intro .intro-body .brand-heading {
font-size: 100px;
}
.intro .intro-body .intro-text {
font-size: 26px;
}
}
.btn-circle {
width: 70px;
height: 70px;
margin-top: 15px;
padding: 7px 16px;
border: 2px solid #fff;
border-radius: 100%!important;
font-size: 40px;
color: #fff;
background: 0 0;
-webkit-transition: background .3s ease-in-out;
-moz-transition: background .3s ease-in-out;
transition: background .3s ease-in-out;
}
.btn-circle:hover,
.btn-circle:focus {
outline: 0;
color: #fff;
background: rgba(255,255,255,.1);
}
.btn-circle i.animated {
-webkit-transition-property: -webkit-transform;
-webkit-transition-duration: 1s;
-moz-transition-property: -moz-transform;
-moz-transition-duration: 1s;
}
.btn-circle:hover i.animated {
-webkit-animation-name: pulse;
-moz-animation-name: pulse;
-webkit-animation-duration: 1.5s;
-moz-animation-duration: 1.5s;
-webkit-animation-iteration-count: infinite;
-moz-animation-iteration-count: infinite;
-webkit-animation-timing-function: linear;
-moz-animation-timing-function: linear;
}
@-webkit-keyframes pulse {
0% {
-webkit-transform: scale(1);
transform: scale(1);
}
50% {
-webkit-transform: scale(1.2);
transform: scale(1.2);
}
100% {
-webkit-transform: scale(1);
transform: scale(1);
}
}
@-moz-keyframes pulse {
0% {
-moz-transform: scale(1);
transform: scale(1);
}
50% {
-moz-transform: scale(1.2);
transform: scale(1.2);
}
100% {
-moz-transform: scale(1);
transform: scale(1);
}
}
.content-section {
padding-top: 100px;
}
.download-section {
width: 100%;
padding: 50px 0;
color: #fff;
background: url(../img/downloads-bg.jpg) no-repeat center center scroll;
background-color: #000;
-webkit-background-size: cover;
-moz-background-size: cover;
background-size: cover;
-o-background-size: cover;
}
@media(min-width:767px) {
.content-section {
padding-top: 250px;
}
.download-section {
padding: 100px 0;
}
}
.btn {
border-radius: 0;
text-transform: uppercase;
font-family: Montserrat,"Helvetica Neue",Helvetica,Arial,sans-serif;
font-weight: 400;
-webkit-transition: all .3s ease-in-out;
-moz-transition: all .3s ease-in-out;
transition: all .3s ease-in-out;
}
.btn-default {
border: 1px solid #42dca3;
color: #42dca3;
background-color: transparent;
}
.btn-default:hover,
.btn-default:focus {
border: 1px solid #42dca3;
outline: 0;
color: #000;
background-color: #42dca3;
}
ul.banner-social-buttons {
margin-top: 0;
}
@media(max-width:1199px) {
ul.banner-social-buttons {
margin-top: 15px;
}
}
@media(max-width:767px) {
ul.banner-social-buttons li {
display: block;
margin-bottom: 20px;
padding: 0;
}
ul.banner-social-buttons li:last-child {
margin-bottom: 0;
}
}
footer {
padding: 50px 0;
}
footer p {
margin: 0;
}
::-moz-selection {
text-shadow: none;
background: #fcfcfc;
background: rgba(255,255,255,.2);
}
::selection {
text-shadow: none;
background: #fcfcfc;
background: rgba(255,255,255,.2);
}
img::selection {
background: 0 0;
}
img::-moz-selection {
background: 0 0;
}
body {
webkit-tap-highlight-color: rgba(255,255,255,.2);
}
.logo {
background-color: rgba(0,0,0,0.7);
padding: 30px;
}
.tooltip > .tooltip-inner { background-color: white; color: black; }
.tooltip > .tooltip-arrow { border-bottom-color: white; color: black; }
.tooltip {
opacity: 0.95 !important;
}
.pixel-tooltip {
padding: 0px !important;
background-color: transparent !important;
}
.fa-5 {
font-size: 40px !important;
}
.ico {
padding-right: 10px;
}
.sk-wave {
margin: 40px auto;
width: 50px;
height: 40px;
text-align: center;
font-size: 10px; }
.sk-wave .sk-rect {
background-color: #eeeeee;
height: 100%;
width: 6px;
display: inline-block;
-webkit-animation: sk-waveStretchDelay 1.2s infinite ease-in-out;
animation: sk-waveStretchDelay 1.2s infinite ease-in-out; }
.sk-wave .sk-rect1 {
-webkit-animation-delay: -1.2s;
animation-delay: -1.2s; }
.sk-wave .sk-rect2 {
-webkit-animation-delay: -1.1s;
animation-delay: -1.1s; }
.sk-wave .sk-rect3 {
-webkit-animation-delay: -1s;
animation-delay: -1s; }
.sk-wave .sk-rect4 {
-webkit-animation-delay: -0.9s;
animation-delay: -0.9s; }
.sk-wave .sk-rect5 {
-webkit-animation-delay: -0.8s;
animation-delay: -0.8s; }
@-webkit-keyframes sk-waveStretchDelay {
0%, 40%, 100% {
-webkit-transform: scaleY(0.4);
transform: scaleY(0.4); }
20% {
-webkit-transform: scaleY(1);
transform: scaleY(1); } }
@keyframes sk-waveStretchDelay {
0%, 40%, 100% {
-webkit-transform: scaleY(0.4);
transform: scaleY(0.4); }
20% {
-webkit-transform: scaleY(1);
transform: scaleY(1); } }
================================================
FILE: web/index.html
================================================




































