Showing preview only (544K chars total). Download the full file or copy to clipboard to get everything.
Repository: chefyuan/algorithm-base
Branch: main
Commit: 64a0a4c2370a
Files: 116
Total size: 511.1 KB
Directory structure:
gitextract_xq6x2zva/
├── .gitattributes
├── .github/
│ └── workflows/
│ ├── check_dead_links.yml
│ └── restructure_files.yml
├── LICENSE
├── README.md
└── animation-simulation/
├── Leetcode常用类和函数.md
├── 一些分享/
│ ├── 区块链详解.md
│ ├── 厨子的2020.md
│ ├── 学习.md
│ ├── 考研分享.md
│ └── 软件分享.md
├── 二分查找及其变种/
│ ├── leetcode 81不完全有序查找目标元素(包含重复值) .md
│ ├── leetcode153搜索旋转数组的最小值.md
│ ├── leetcode33不完全有序查找目标元素(不包含重复值).md
│ ├── leetcode34查找第一个位置和最后一个位置.md
│ ├── leetcode35搜索插入位置.md
│ ├── 二分查找详解.md
│ ├── 二维数组的二分查找.md
│ └── 找出第一个大于或小于目标的索引.md
├── 二叉树/
│ ├── 二叉树中序遍历(Morris).md
│ ├── 二叉树中序遍历(迭代).md
│ ├── 二叉树基础.md
│ ├── 二叉树的前序遍历(Morris).md
│ ├── 二叉树的前序遍历(栈).md
│ ├── 二叉树的后续遍历 (迭代).md
│ ├── 二叉树的后续遍历(Morris).md
│ └── 前序序列和中序构建二叉树.md
├── 位运算/
│ └── 空.md
├── 写写水文/
│ ├── 书单.md
│ ├── 如何学习.md
│ ├── 学弟问了我一个问题.md
│ ├── 常看的UP主.md
│ └── 送书.md
├── 分治/
│ └── 空.md
├── 前缀和/
│ ├── leetcode1248寻找优美子数组.md
│ ├── leetcode523连续的子数组和.md
│ ├── leetcode560和为K的子数组.md
│ ├── leetcode724寻找数组的中心索引.md
│ └── leetcode974和可被K整除的子数组.md
├── 剑指offer/
│ └── 1的个数.md
├── 动态规划/
│ └── 空.md
├── 单调队列单调栈/
│ ├── leetcode739每日温度.md
│ ├── 剑指offer59队列的最大值.md
│ ├── 接雨水.md
│ ├── 最小栈.md
│ └── 滑动窗口的最大值.md
├── 哈希表篇/
│ └── 空.md
├── 回溯/
│ └── 空.md
├── 并查集/
│ └── 空.md
├── 数据结构和算法/
│ ├── BF算法.md
│ ├── BM.md
│ ├── Hash表的那些事.md
│ ├── KMP.md
│ ├── read.md
│ ├── 关于栈和队列的那些事.md
│ ├── 关于链表的那些事.md
│ ├── 冒泡排序.md
│ ├── 合成.md
│ ├── 基数排序.md
│ ├── 堆排序.md
│ ├── 字符串匹配算法.md
│ ├── 希尔排序.md
│ ├── 归并排序.md
│ ├── 快速排序.md
│ ├── 桶排序.md
│ ├── 直接插入排序.md
│ ├── 简单选择排序.md
│ ├── 翻转对.md
│ ├── 荷兰国旗.md
│ ├── 计数排序.md
│ └── 逆序对问题.md
├── 数组篇/
│ ├── leetcode1052爱生气的书店老板.md
│ ├── leetcode1438绝对值不超过限制的最长子数组.md
│ ├── leetcode1两数之和.md
│ ├── leetcode219数组中重复元素2.md
│ ├── leetcode27移除元素.md
│ ├── leetcode41缺失的第一个正数.md
│ ├── leetcode485最大连续1的个数.md
│ ├── leetcode54螺旋矩阵.md
│ ├── leetcode560和为K的子数组.md
│ ├── leetcode59螺旋矩阵2.md
│ ├── leetcode66加一.md
│ ├── leetcode75颜色分类.md
│ ├── 剑指offer3数组中重复的数.md
│ └── 长度最小的子数组.md
├── 栈和队列/
│ ├── 225.用队列实现栈.md
│ ├── leetcode1047 删除字符串中的所有相邻重复项.md
│ ├── leetcode20有效的括号.md
│ ├── leetcode402移掉K位数字.md
│ └── 剑指Offer09用两个栈实现队列.md
├── 求和问题/
│ ├── 三数之和.md
│ ├── 两数之和.md
│ └── 四数之和.md
├── 求次数问题/
│ ├── 只出现一次的数.md
│ ├── 只出现一次的数2.md
│ └── 只出现一次的数3.md
├── 滑动窗口/
│ └── 空.md
├── 缓存淘汰算法/
│ ├── LFU.md
│ └── LRU.md
├── 设计/
│ └── LRU.md
├── 贪心/
│ └── 空.md
├── 递归/
│ └── 空.md
└── 链表篇/
├── 234. 回文链表.md
├── leetcode141环形链表.md
├── leetcode142环形链表2.md
├── leetcode147对链表进行插入排序.md
├── leetcode206反转链表.md
├── leetcode328奇偶链表.md
├── leetcode82删除排序链表中的重复元素II.md
├── leetcode86分隔链表.md
├── leetcode92反转链表2.md
├── 剑指Offer25合并两个排序的链表.md
├── 剑指Offer52两个链表的第一个公共节点.md
├── 剑指offer22倒数第k个节点.md
├── 面试题 02.03. 链表中间节点.md
└── 面试题 02.05. 链表求和.md
================================================
FILE CONTENTS
================================================
================================================
FILE: .gitattributes
================================================
*.md text=auto
================================================
FILE: .github/workflows/check_dead_links.yml
================================================
name: Check Markdown links
on:
push:
branches: [ main ]
pull_request:
branches: [ main ]
workflow_dispatch:
jobs:
test-and-build:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v2
with:
persist-credentials: false
fetch-depth: 0
- uses: gaurav-nelson/github-action-markdown-link-check@v1
with:
use-quiet-mode: 'yes'
================================================
FILE: .github/workflows/restructure_files.yml
================================================
name: Restructure files
on:
push:
branches: [ main ]
workflow_dispatch:
jobs:
test-and-build:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v2
with:
persist-credentials: false
fetch-depth: 0
- name: Install Prettier
run: npm install --save-dev --save-exact prettier
- name: Restructure files
run: node_modules/.bin/prettier --write README.md animation-simulation/
- name: Commit files
run: |
git config --local user.email "41898282+github-actions[bot]@users.noreply.github.com"
git config --local user.name "github-actions[bot]"
git diff-index --quiet HEAD -- || git commit -am "代码重构 【Github Actions】"
- name: Push changes
uses: ad-m/github-push-action@master
with:
github_token: ${{ secrets.GITHUB_TOKEN }}
branch: ${{ github.ref }}
================================================
FILE: LICENSE
================================================
MIT License
Copyright (c) 2021 算法基地
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE.
================================================
FILE: README.md
================================================
# **algorithm-base**
<div align="left"> <a href = "https://www.zhihu.com/people/suan-fa-ji-di"><img src="https://img.shields.io/badge/Zhihu-知乎-blue" width = "80px" hight = "50px"/></a><span style="font-size:12px"> @程序厨</span>    
<a href = "https://mp.weixin.qq.com/s/TJ_U9B3ttghwz_vWNdAjXw"><img src="https://img.shields.io/badge/WX-公众号-green" width = "80px" hight = "50px"/></a><span style="font-size:12px"> @程序厨</span>
    
<a href = "https://github.com/chefyuan/algorithm-base"><img src="https://img.shields.io/badge/GitHub-仓库-red" width = "80px" hight = "50px"/></a><span style="font-size:12px">  @算法基地</span>
</div>
### **❤️ 致各位题友的一封信(使用仓库前必读)**
推荐在线阅读,更稳定[www.chengxuchu.com](https://www.chengxuchu.com)
如果想要贡献代码的大佬可以添加我的微信 **[iamchuzi](https://cdn.jsdelivr.net/gh/tan45du/test@master/美化.1kdnk85ce5c0.png)** 备注贡献仓库即可。
在这里先替所有使用仓库的同学,谢谢各位贡献者啦。
如果老哥觉得仓库很用心的话,麻烦大佬帮忙点个 star ,这也是我们一直更新下去的动力。
感谢支持,该仓库会一直维护,希望对各位有一丢丢帮助.
如果你需要加入**刷题/秋招小队**的话,可以扫描下方二维码,点击与我联系/交流小队,该小队永不收费,也不会有人发广告,仅仅用作交流,但是希望大家进入时,可以备注自身情况,并做一个简短的自我介绍。
<div align="center"> <img src="https://cdn.jsdelivr.net/gh/tan45du/test@master/美化.1kdnk85ce5c0.png" width = "150px" hight = "150px"/> </div>
## 另外如果你需要 C++ 项目的话,可以看下这些项目介绍 [www.chengxuchu.com/cppcamp.html](https://www.chengxuchu.com/cppcamp.html)
### 📢 数据结构(前置知识)
- [【动画模拟】哈希表详解,万字长文](https://github.com/chefyuan/algorithm-base/blob/main/animation-simulation/%E6%95%B0%E6%8D%AE%E7%BB%93%E6%9E%84%E5%92%8C%E7%AE%97%E6%B3%95/Hash%E8%A1%A8%E7%9A%84%E9%82%A3%E4%BA%9B%E4%BA%8B.md)
- [【动画模拟】栈和队列详解](https://github.com/chefyuan/algorithm-base/blob/main/animation-simulation/%E6%95%B0%E6%8D%AE%E7%BB%93%E6%9E%84%E5%92%8C%E7%AE%97%E6%B3%95/%E5%85%B3%E4%BA%8E%E6%A0%88%E5%92%8C%E9%98%9F%E5%88%97%E7%9A%84%E9%82%A3%E4%BA%9B%E4%BA%8B.md)
- [【绘图解析】链表详解](https://github.com/chefyuan/algorithm-base/blob/main/animation-simulation/%E6%95%B0%E6%8D%AE%E7%BB%93%E6%9E%84%E5%92%8C%E7%AE%97%E6%B3%95/%E5%85%B3%E4%BA%8E%E9%93%BE%E8%A1%A8%E7%9A%84%E9%82%A3%E4%BA%9B%E4%BA%8B.md)
- [【绘图描述】递归详解](https://mp.weixin.qq.com/s/A4xG9IbQUjFwQoy9YcneCw)
- [【动画模拟】树](https://github.com/chefyuan/algorithm-base/blob/main/animation-simulation/%E4%BA%8C%E5%8F%89%E6%A0%91/%E4%BA%8C%E5%8F%89%E6%A0%91%E5%9F%BA%E7%A1%80.md)
### 🔋 字符串匹配算法
- [【动画模拟】字符串匹配 BF 算法](https://github.com/chefyuan/algorithm-base/blob/main/animation-simulation/%E6%95%B0%E6%8D%AE%E7%BB%93%E6%9E%84%E5%92%8C%E7%AE%97%E6%B3%95/BF%E7%AE%97%E6%B3%95.md)
- [【动画模拟】字符串匹配 BM 算法](https://github.com/chefyuan/algorithm-base/blob/main/animation-simulation/%E6%95%B0%E6%8D%AE%E7%BB%93%E6%9E%84%E5%92%8C%E7%AE%97%E6%B3%95/BM.md)
- [【动画模拟】字符串匹配 KMP 算法](https://github.com/chefyuan/algorithm-base/blob/main/animation-simulation/%E6%95%B0%E6%8D%AE%E7%BB%93%E6%9E%84%E5%92%8C%E7%AE%97%E6%B3%95/KMP.md)
### 🧮 排序算法
- [【动画模拟】冒泡排序](https://github.com/chefyuan/algorithm-base/blob/main/animation-simulation/%E6%95%B0%E6%8D%AE%E7%BB%93%E6%9E%84%E5%92%8C%E7%AE%97%E6%B3%95/%E5%86%92%E6%B3%A1%E6%8E%92%E5%BA%8F.md)
- [【动画模拟】简单选择排序](https://github.com/chefyuan/algorithm-base/blob/main/animation-simulation/%E6%95%B0%E6%8D%AE%E7%BB%93%E6%9E%84%E5%92%8C%E7%AE%97%E6%B3%95/%E7%AE%80%E5%8D%95%E9%80%89%E6%8B%A9%E6%8E%92%E5%BA%8F.md)
- [【动画模拟】插入排序](https://github.com/chefyuan/algorithm-base/blob/main/animation-simulation/%E6%95%B0%E6%8D%AE%E7%BB%93%E6%9E%84%E5%92%8C%E7%AE%97%E6%B3%95/%E7%9B%B4%E6%8E%A5%E6%8F%92%E5%85%A5%E6%8E%92%E5%BA%8F.md)
- [【动画模拟】希尔排序](https://github.com/chefyuan/algorithm-base/blob/main/animation-simulation/%E6%95%B0%E6%8D%AE%E7%BB%93%E6%9E%84%E5%92%8C%E7%AE%97%E6%B3%95/%E5%B8%8C%E5%B0%94%E6%8E%92%E5%BA%8F.md)
- [【动画模拟】归并排序](https://github.com/chefyuan/algorithm-base/blob/main/animation-simulation/%E6%95%B0%E6%8D%AE%E7%BB%93%E6%9E%84%E5%92%8C%E7%AE%97%E6%B3%95/%E5%BD%92%E5%B9%B6%E6%8E%92%E5%BA%8F.md)
- [【动画模拟】快速排序](https://github.com/chefyuan/algorithm-base/blob/main/animation-simulation/%E6%95%B0%E6%8D%AE%E7%BB%93%E6%9E%84%E5%92%8C%E7%AE%97%E6%B3%95/%E5%BF%AB%E9%80%9F%E6%8E%92%E5%BA%8F.md)
- [【动画模拟】堆排序](https://github.com/chefyuan/algorithm-base/blob/main/animation-simulation/%E6%95%B0%E6%8D%AE%E7%BB%93%E6%9E%84%E5%92%8C%E7%AE%97%E6%B3%95/%E5%A0%86%E6%8E%92%E5%BA%8F.md)
- [【动画模拟】计数排序](https://github.com/chefyuan/algorithm-base/blob/main/animation-simulation/%E6%95%B0%E6%8D%AE%E7%BB%93%E6%9E%84%E5%92%8C%E7%AE%97%E6%B3%95/%E8%AE%A1%E6%95%B0%E6%8E%92%E5%BA%8F.md)
### 🍺 二叉树
- [【动画模拟】前序遍历(迭代)](<https://github.com/chefyuan/algorithm-base/blob/main/animation-simulation/%E4%BA%8C%E5%8F%89%E6%A0%91/%E4%BA%8C%E5%8F%89%E6%A0%91%E7%9A%84%E5%89%8D%E5%BA%8F%E9%81%8D%E5%8E%86(%E6%A0%88).md>)
- [【动画模拟】前序遍历(Morris)](<https://github.com/chefyuan/algorithm-base/blob/main/animation-simulation/%E4%BA%8C%E5%8F%89%E6%A0%91/%E4%BA%8C%E5%8F%89%E6%A0%91%E7%9A%84%E5%89%8D%E5%BA%8F%E9%81%8D%E5%8E%86(Morris).md>)
- [【动画模拟】中序遍历(迭代)](https://github.com/chefyuan/algorithm-base/blob/main/animation-simulation/%E4%BA%8C%E5%8F%89%E6%A0%91/%E4%BA%8C%E5%8F%89%E6%A0%91%E4%B8%AD%E5%BA%8F%E9%81%8D%E5%8E%86%EF%BC%88%E8%BF%AD%E4%BB%A3%EF%BC%89.md)
- [【动画模拟】中序遍历(Morris)](https://github.com/chefyuan/algorithm-base/blob/main/animation-simulation/%E4%BA%8C%E5%8F%89%E6%A0%91/%E4%BA%8C%E5%8F%89%E6%A0%91%E4%B8%AD%E5%BA%8F%E9%81%8D%E5%8E%86%EF%BC%88Morris%EF%BC%89.md)
- [【动画模拟】后序遍历(迭代)](<https://github.com/chefyuan/algorithm-base/blob/main/animation-simulation/%E4%BA%8C%E5%8F%89%E6%A0%91/%E4%BA%8C%E5%8F%89%E6%A0%91%E7%9A%84%E5%90%8E%E7%BB%AD%E9%81%8D%E5%8E%86%20(%E8%BF%AD%E4%BB%A3).md>)
- [【动画模拟】后序遍历(Morris)](https://github.com/chefyuan/algorithm-base/blob/main/animation-simulation/%E4%BA%8C%E5%8F%89%E6%A0%91/%E4%BA%8C%E5%8F%89%E6%A0%91%E7%9A%84%E5%90%8E%E7%BB%AD%E9%81%8D%E5%8E%86%EF%BC%88Morris%EF%BC%89.md)
### 🍗 排序算法秒杀题目
- [【动画模拟】荷兰国旗](https://github.com/chefyuan/algorithm-base/blob/main/animation-simulation/%E6%95%B0%E6%8D%AE%E7%BB%93%E6%9E%84%E5%92%8C%E7%AE%97%E6%B3%95/%E8%8D%B7%E5%85%B0%E5%9B%BD%E6%97%97.md)
- [【反证解决】数组合成最小的数,最大数](https://github.com/chefyuan/algorithm-base/blob/main/animation-simulation/%E6%95%B0%E6%8D%AE%E7%BB%93%E6%9E%84%E5%92%8C%E7%AE%97%E6%B3%95/%E5%90%88%E6%88%90.md)
- [【动画模拟】逆序对问题](https://github.com/chefyuan/algorithm-base/blob/main/animation-simulation/%E6%95%B0%E6%8D%AE%E7%BB%93%E6%9E%84%E5%92%8C%E7%AE%97%E6%B3%95/%E9%80%86%E5%BA%8F%E5%AF%B9%E9%97%AE%E9%A2%98.md)
- [【动画模拟】翻转对问题](https://github.com/chefyuan/algorithm-base/blob/main/animation-simulation/%E6%95%B0%E6%8D%AE%E7%BB%93%E6%9E%84%E5%92%8C%E7%AE%97%E6%B3%95/%E7%BF%BB%E8%BD%AC%E5%AF%B9.md)
- [【动画模拟】链表插入排序](https://github.com/chefyuan/algorithm-base/blob/main/animation-simulation/%E9%93%BE%E8%A1%A8%E7%AF%87/leetcode147%E5%AF%B9%E9%93%BE%E8%A1%A8%E8%BF%9B%E8%A1%8C%E6%8F%92%E5%85%A5%E6%8E%92%E5%BA%8F.md)
### 🍖 数组篇
- [【动画模拟】leetcode 1 两数之和](https://github.com/chefyuan/algorithm-base/blob/main/animation-simulation/%E6%95%B0%E7%BB%84%E7%AF%87/leetcode1%E4%B8%A4%E6%95%B0%E4%B9%8B%E5%92%8C.md)
- [【动画模拟】leetcode 27 移除元素](https://github.com/chefyuan/algorithm-base/blob/main/animation-simulation/%E6%95%B0%E7%BB%84%E7%AF%87/leetcode27%E7%A7%BB%E9%99%A4%E5%85%83%E7%B4%A0.md)
- [【动画模拟】leetcode 41 缺失的第一个正数](https://github.com/chefyuan/algorithm-base/blob/main/animation-simulation/%E6%95%B0%E7%BB%84%E7%AF%87/leetcode41%E7%BC%BA%E5%A4%B1%E7%9A%84%E7%AC%AC%E4%B8%80%E4%B8%AA%E6%AD%A3%E6%95%B0.md)
- [【动画模拟】leetcode 485 最大连续 1 的个数](https://github.com/chefyuan/algorithm-base/blob/main/animation-simulation/%E6%95%B0%E7%BB%84%E7%AF%87/leetcode485%E6%9C%80%E5%A4%A7%E8%BF%9E%E7%BB%AD1%E7%9A%84%E4%B8%AA%E6%95%B0.md)
- [【绘图描述】leetcode 1052 爱生气的书店老板](https://github.com/chefyuan/algorithm-base/blob/main/animation-simulation/%E6%95%B0%E7%BB%84%E7%AF%87/leetcode1052%E7%88%B1%E7%94%9F%E6%B0%94%E7%9A%84%E4%B9%A6%E5%BA%97%E8%80%81%E6%9D%BF.md)
- [【动画模拟】剑指 offer 3 数组中重复的数字](https://github.com/chefyuan/algorithm-base/blob/main/animation-simulation/%E6%95%B0%E7%BB%84%E7%AF%87/%E5%89%91%E6%8C%87offer3%E6%95%B0%E7%BB%84%E4%B8%AD%E9%87%8D%E5%A4%8D%E7%9A%84%E6%95%B0.md)
- [【动画模拟】leetcode 219 数组中重复元素 2](https://github.com/chefyuan/algorithm-base/blob/main/animation-simulation/%E6%95%B0%E7%BB%84%E7%AF%87/leetcode219%E6%95%B0%E7%BB%84%E4%B8%AD%E9%87%8D%E5%A4%8D%E5%85%83%E7%B4%A02.md)
- [【动画模拟】leetcode 560 和为 K 的子数组](https://github.com/chefyuan/algorithm-base/blob/main/animation-simulation/%E6%95%B0%E7%BB%84%E7%AF%87/leetcode560%E5%92%8C%E4%B8%BAK%E7%9A%84%E5%AD%90%E6%95%B0%E7%BB%84.md)
- [【绘图描述】leetcode 66 加一](https://github.com/chefyuan/algorithm-base/blob/main/animation-simulation/%E6%95%B0%E7%BB%84%E7%AF%87/leetcode66%E5%8A%A0%E4%B8%80.md)
- [【动画模拟】leetcode 75 颜色分类](https://github.com/chefyuan/algorithm-base/blob/main/animation-simulation/%E6%95%B0%E7%BB%84%E7%AF%87/leetcode75%E9%A2%9C%E8%89%B2%E5%88%86%E7%B1%BB.md)
- [【动画模拟】leetcode 54 螺旋矩阵](https://github.com/chefyuan/algorithm-base/blob/main/animation-simulation/%E6%95%B0%E7%BB%84%E7%AF%87/leetcode54%E8%9E%BA%E6%97%8B%E7%9F%A9%E9%98%B5.md)
- [【动画模拟】leetcode 59 螺旋矩阵 2](https://github.com/chefyuan/algorithm-base/blob/main/animation-simulation/%E6%95%B0%E7%BB%84%E7%AF%87/leetcode59%E8%9E%BA%E6%97%8B%E7%9F%A9%E9%98%B52.md)
- [【动画模拟】leetcode 233 数字 1 的个数](https://github.com/chefyuan/algorithm-base/blob/main/animation-simulation/%E5%89%91%E6%8C%87offer/1%E7%9A%84%E4%B8%AA%E6%95%B0.md)
### 🦞 求和问题
- [【动画模拟】leetcode 01 两数之和](https://github.com/chefyuan/algorithm-base/blob/main/animation-simulation/%E6%B1%82%E5%92%8C%E9%97%AE%E9%A2%98/%E4%B8%A4%E6%95%B0%E4%B9%8B%E5%92%8C.md)
- [【动画模拟】leetcode 15 三数之和](https://github.com/chefyuan/algorithm-base/blob/main/animation-simulation/%E6%B1%82%E5%92%8C%E9%97%AE%E9%A2%98/%E4%B8%89%E6%95%B0%E4%B9%8B%E5%92%8C.md)
- [【动画模拟】leetcode 18 四数之和](https://github.com/chefyuan/algorithm-base/blob/main/animation-simulation/%E6%B1%82%E5%92%8C%E9%97%AE%E9%A2%98/%E5%9B%9B%E6%95%B0%E4%B9%8B%E5%92%8C.md)
### 🍓 求次数问题
- [【动画模拟】leetcode 136 只出现一次的数](https://github.com/chefyuan/algorithm-base/blob/main/animation-simulation/%E6%B1%82%E6%AC%A1%E6%95%B0%E9%97%AE%E9%A2%98/%E5%8F%AA%E5%87%BA%E7%8E%B0%E4%B8%80%E6%AC%A1%E7%9A%84%E6%95%B0.md)
- [【动画模拟】leetcode 137 只出现一次的数字 II](https://github.com/chefyuan/algorithm-base/blob/main/animation-simulation/%E6%B1%82%E6%AC%A1%E6%95%B0%E9%97%AE%E9%A2%98/%E5%8F%AA%E5%87%BA%E7%8E%B0%E4%B8%80%E6%AC%A1%E7%9A%84%E6%95%B02.md)
- [【动画模拟】leetcode 260 只出现一次的数字 III](https://github.com/chefyuan/algorithm-base/blob/main/animation-simulation/%E6%B1%82%E6%AC%A1%E6%95%B0%E9%97%AE%E9%A2%98/%E5%8F%AA%E5%87%BA%E7%8E%B0%E4%B8%80%E6%AC%A1%E7%9A%84%E6%95%B03.md)
### 🍅 链表篇
- [【动画模拟】剑指 offer 22 倒数第 k 个节点](https://github.com/chefyuan/algorithm-base/blob/main/animation-simulation/%E9%93%BE%E8%A1%A8%E7%AF%87/%E5%89%91%E6%8C%87offer22%E5%80%92%E6%95%B0%E7%AC%ACk%E4%B8%AA%E8%8A%82%E7%82%B9.md)
- [【动画模拟】面试题 02.03. 链表中间节点](https://github.com/chefyuan/algorithm-base/blob/main/animation-simulation/%E9%93%BE%E8%A1%A8%E7%AF%87/%E9%9D%A2%E8%AF%95%E9%A2%98%2002.03.%20%E9%93%BE%E8%A1%A8%E4%B8%AD%E9%97%B4%E8%8A%82%E7%82%B9.md)
- [【动画模拟】剑指 offer 52 两个链表的第一个公共节点 & leetcode 160 相交链表](https://github.com/chefyuan/algorithm-base/blob/main/animation-simulation/%E9%93%BE%E8%A1%A8%E7%AF%87/%E5%89%91%E6%8C%87Offer52%E4%B8%A4%E4%B8%AA%E9%93%BE%E8%A1%A8%E7%9A%84%E7%AC%AC%E4%B8%80%E4%B8%AA%E5%85%AC%E5%85%B1%E8%8A%82%E7%82%B9.md)
- [【动画模拟】leetcode 234 回文链表](https://github.com/chefyuan/algorithm-base/blob/main/animation-simulation/%E9%93%BE%E8%A1%A8%E7%AF%87/234.%20%E5%9B%9E%E6%96%87%E9%93%BE%E8%A1%A8.md)
- [【动画模拟】leetcode 206 反转链表](https://github.com/chefyuan/algorithm-base/blob/main/animation-simulation/%E9%93%BE%E8%A1%A8%E7%AF%87/leetcode206%E5%8F%8D%E8%BD%AC%E9%93%BE%E8%A1%A8.md)
- [【动画模拟】leetcode 92 反转链表 2](https://github.com/chefyuan/algorithm-base/blob/main/animation-simulation/%E9%93%BE%E8%A1%A8%E7%AF%87/leetcode92%E5%8F%8D%E8%BD%AC%E9%93%BE%E8%A1%A82.md)
- [【动画模拟】leetcode 141 环形链表](https://github.com/chefyuan/algorithm-base/blob/main/animation-simulation/%E9%93%BE%E8%A1%A8%E7%AF%87/leetcode141%E7%8E%AF%E5%BD%A2%E9%93%BE%E8%A1%A8.md)
- [【动画模拟】leetcode 142 环形链表 2](https://github.com/chefyuan/algorithm-base/blob/main/animation-simulation/%E9%93%BE%E8%A1%A8%E7%AF%87/leetcode142%E7%8E%AF%E5%BD%A2%E9%93%BE%E8%A1%A82.md)
- [【动画模拟】leetcode 86 分隔链表](https://github.com/chefyuan/algorithm-base/blob/main/animation-simulation/%E9%93%BE%E8%A1%A8%E7%AF%87/leetcode86%E5%88%86%E9%9A%94%E9%93%BE%E8%A1%A8.md)
- [【动画模拟】leetcode 328 奇偶链表](https://github.com/chefyuan/algorithm-base/blob/main/animation-simulation/%E9%93%BE%E8%A1%A8%E7%AF%87/leetcode328%E5%A5%87%E5%81%B6%E9%93%BE%E8%A1%A8.md)
- [【动画模拟】剑指 offer 25 合并两个排序链表](https://github.com/chefyuan/algorithm-base/blob/main/animation-simulation/%E9%93%BE%E8%A1%A8%E7%AF%87/%E5%89%91%E6%8C%87Offer25%E5%90%88%E5%B9%B6%E4%B8%A4%E4%B8%AA%E6%8E%92%E5%BA%8F%E7%9A%84%E9%93%BE%E8%A1%A8.md)
- [【动画模拟】leetcode 82 删除排序链表的重复元素 2](https://github.com/chefyuan/algorithm-base/blob/main/animation-simulation/%E9%93%BE%E8%A1%A8%E7%AF%87/leetcode82%E5%88%A0%E9%99%A4%E6%8E%92%E5%BA%8F%E9%93%BE%E8%A1%A8%E4%B8%AD%E7%9A%84%E9%87%8D%E5%A4%8D%E5%85%83%E7%B4%A0II.md)
- [【动画模拟】leetcode 147 对链表进行插入排序](https://github.com/chefyuan/algorithm-base/blob/main/animation-simulation/%E9%93%BE%E8%A1%A8%E7%AF%87/leetcode147%E5%AF%B9%E9%93%BE%E8%A1%A8%E8%BF%9B%E8%A1%8C%E6%8F%92%E5%85%A5%E6%8E%92%E5%BA%8F.md)
- [【动画模拟】面试题 02.05 链表求和](https://github.com/chefyuan/algorithm-base/blob/main/animation-simulation/%E9%93%BE%E8%A1%A8%E7%AF%87/%E9%9D%A2%E8%AF%95%E9%A2%98%2002.05.%20%E9%93%BE%E8%A1%A8%E6%B1%82%E5%92%8C.md)
### 🚁 双指针
- [【动画模拟】二分查找详解](https://github.com/chefyuan/algorithm-base/blob/main/animation-simulation/%E4%BA%8C%E5%88%86%E6%9F%A5%E6%89%BE%E5%8F%8A%E5%85%B6%E5%8F%98%E7%A7%8D/%E4%BA%8C%E5%88%86%E6%9F%A5%E6%89%BE%E8%AF%A6%E8%A7%A3.md)
- [【动画模拟】leetcode 35 搜索插入位置](https://github.com/chefyuan/algorithm-base/blob/main/animation-simulation/%E4%BA%8C%E5%88%86%E6%9F%A5%E6%89%BE%E5%8F%8A%E5%85%B6%E5%8F%98%E7%A7%8D/leetcode35%E6%90%9C%E7%B4%A2%E6%8F%92%E5%85%A5%E4%BD%8D%E7%BD%AE.md)
- [【动画模拟】leetcode 27 移除元素](https://github.com/chefyuan/algorithm-base/blob/main/animation-simulation/%E6%95%B0%E7%BB%84%E7%AF%87/leetcode27%E7%A7%BB%E9%99%A4%E5%85%83%E7%B4%A0.md)
- [【动画模拟】leetcode 209 长度最小的子数组](https://github.com/chefyuan/algorithm-base/blob/main/animation-simulation/%E6%95%B0%E7%BB%84%E7%AF%87/%E9%95%BF%E5%BA%A6%E6%9C%80%E5%B0%8F%E7%9A%84%E5%AD%90%E6%95%B0%E7%BB%84.md)
- [【动画模拟】leetcode 141 环形链表](https://github.com/chefyuan/algorithm-base/blob/main/animation-simulation/%E9%93%BE%E8%A1%A8%E7%AF%87/leetcode141%E7%8E%AF%E5%BD%A2%E9%93%BE%E8%A1%A8.md)
- [【动画模拟】剑指 offer 52 两个链表的第一个公共节点 & leetcode 160 相交链表](https://github.com/chefyuan/algorithm-base/blob/main/animation-simulation/%E9%93%BE%E8%A1%A8%E7%AF%87/%E5%89%91%E6%8C%87Offer52%E4%B8%A4%E4%B8%AA%E9%93%BE%E8%A1%A8%E7%9A%84%E7%AC%AC%E4%B8%80%E4%B8%AA%E5%85%AC%E5%85%B1%E8%8A%82%E7%82%B9.md)
- [【动画模拟】leetcode 328 奇偶链表](https://github.com/chefyuan/algorithm-base/blob/main/animation-simulation/%E9%93%BE%E8%A1%A8%E7%AF%87/leetcode328%E5%A5%87%E5%81%B6%E9%93%BE%E8%A1%A8.md)
### 🏳🌈 栈和队列
- [【动画模拟】leetcode 225 队列实现栈](https://github.com/chefyuan/algorithm-base/blob/main/animation-simulation/%E6%A0%88%E5%92%8C%E9%98%9F%E5%88%97/225.%E7%94%A8%E9%98%9F%E5%88%97%E5%AE%9E%E7%8E%B0%E6%A0%88.md)
- [【动画模拟】剑指 Offer 09. 用两个栈实现队列](https://github.com/chefyuan/algorithm-base/blob/main/animation-simulation/%E6%A0%88%E5%92%8C%E9%98%9F%E5%88%97/%E5%89%91%E6%8C%87Offer09%E7%94%A8%E4%B8%A4%E4%B8%AA%E6%A0%88%E5%AE%9E%E7%8E%B0%E9%98%9F%E5%88%97.md)
- [【动画模拟】leetcode 20 有效的括号](https://github.com/chefyuan/algorithm-base/blob/main/animation-simulation/%E6%A0%88%E5%92%8C%E9%98%9F%E5%88%97/leetcode20%E6%9C%89%E6%95%88%E7%9A%84%E6%8B%AC%E5%8F%B7.md)
- [【动画模拟】leetcode1047 删除字符串中的所有相邻重复项](https://github.com/chefyuan/algorithm-base/blob/main/animation-simulation/%E6%A0%88%E5%92%8C%E9%98%9F%E5%88%97/leetcode1047%20%E5%88%A0%E9%99%A4%E5%AD%97%E7%AC%A6%E4%B8%B2%E4%B8%AD%E7%9A%84%E6%89%80%E6%9C%89%E7%9B%B8%E9%82%BB%E9%87%8D%E5%A4%8D%E9%A1%B9.md)
- [【动画模拟】leetcode 402 移掉 K 位数字](https://github.com/chefyuan/algorithm-base/blob/main/animation-simulation/%E6%A0%88%E5%92%8C%E9%98%9F%E5%88%97/leetcode402%E7%A7%BB%E6%8E%89K%E4%BD%8D%E6%95%B0%E5%AD%97.md)
### 🏬 二分查找及其变种
- [【动画模拟】二分查找详解](https://github.com/chefyuan/algorithm-base/blob/main/animation-simulation/%E4%BA%8C%E5%88%86%E6%9F%A5%E6%89%BE%E5%8F%8A%E5%85%B6%E5%8F%98%E7%A7%8D/%E4%BA%8C%E5%88%86%E6%9F%A5%E6%89%BE%E8%AF%A6%E8%A7%A3.md)
- [【动画模拟】leetcode 35 搜索插入位置](https://github.com/chefyuan/algorithm-base/blob/main/animation-simulation/%E4%BA%8C%E5%88%86%E6%9F%A5%E6%89%BE%E5%8F%8A%E5%85%B6%E5%8F%98%E7%A7%8D/leetcode35%E6%90%9C%E7%B4%A2%E6%8F%92%E5%85%A5%E4%BD%8D%E7%BD%AE.md)
- [【动画模拟】leetcode 34 查找元素的第一个位置和最后一个位置](https://github.com/chefyuan/algorithm-base/blob/main/animation-simulation/%E4%BA%8C%E5%88%86%E6%9F%A5%E6%89%BE%E5%8F%8A%E5%85%B6%E5%8F%98%E7%A7%8D/leetcode34%E6%9F%A5%E6%89%BE%E7%AC%AC%E4%B8%80%E4%B8%AA%E4%BD%8D%E7%BD%AE%E5%92%8C%E6%9C%80%E5%90%8E%E4%B8%80%E4%B8%AA%E4%BD%8D%E7%BD%AE.md)
- [【绘图描述】找出第一个大于或小于目标元素的索引](https://github.com/chefyuan/algorithm-base/blob/main/animation-simulation/%E4%BA%8C%E5%88%86%E6%9F%A5%E6%89%BE%E5%8F%8A%E5%85%B6%E5%8F%98%E7%A7%8D/%E6%89%BE%E5%87%BA%E7%AC%AC%E4%B8%80%E4%B8%AA%E5%A4%A7%E4%BA%8E%E6%88%96%E5%B0%8F%E4%BA%8E%E7%9B%AE%E6%A0%87%E7%9A%84%E7%B4%A2%E5%BC%95.md)
- [【动画模拟】leetcode 33 旋转数组中查找目标元素(不含重复元素)](<https://github.com/chefyuan/algorithm-base/blob/main/animation-simulation/%E4%BA%8C%E5%88%86%E6%9F%A5%E6%89%BE%E5%8F%8A%E5%85%B6%E5%8F%98%E7%A7%8D/leetcode33%E4%B8%8D%E5%AE%8C%E5%85%A8%E6%9C%89%E5%BA%8F%E6%9F%A5%E6%89%BE%E7%9B%AE%E6%A0%87%E5%85%83%E7%B4%A0(%E4%B8%8D%E5%8C%85%E5%90%AB%E9%87%8D%E5%A4%8D%E5%80%BC).md>)
- [【绘图描述】leetcode 81 旋转数组中查找目标元素(包含重复元素)](<https://github.com/chefyuan/algorithm-base/blob/main/animation-simulation/%E4%BA%8C%E5%88%86%E6%9F%A5%E6%89%BE%E5%8F%8A%E5%85%B6%E5%8F%98%E7%A7%8D/leetcode%2081%E4%B8%8D%E5%AE%8C%E5%85%A8%E6%9C%89%E5%BA%8F%E6%9F%A5%E6%89%BE%E7%9B%AE%E6%A0%87%E5%85%83%E7%B4%A0(%E5%8C%85%E5%90%AB%E9%87%8D%E5%A4%8D%E5%80%BC)%20.md>)
- [【绘图描述】leetcode 153 寻找旋转数组中的最小值](https://github.com/chefyuan/algorithm-base/blob/main/animation-simulation/%E4%BA%8C%E5%88%86%E6%9F%A5%E6%89%BE%E5%8F%8A%E5%85%B6%E5%8F%98%E7%A7%8D/leetcode153%E6%90%9C%E7%B4%A2%E6%97%8B%E8%BD%AC%E6%95%B0%E7%BB%84%E7%9A%84%E6%9C%80%E5%B0%8F%E5%80%BC.md)
- [【动画模拟】leetcode 74 二维数组的二分查找](https://github.com/chefyuan/algorithm-base/blob/main/animation-simulation/%E4%BA%8C%E5%88%86%E6%9F%A5%E6%89%BE%E5%8F%8A%E5%85%B6%E5%8F%98%E7%A7%8D/%E4%BA%8C%E7%BB%B4%E6%95%B0%E7%BB%84%E7%9A%84%E4%BA%8C%E5%88%86%E6%9F%A5%E6%89%BE.md)
### 💒 单调队列单调栈
- [【动画模拟】剑指 Offer 59 - II. 队列的最大值](https://github.com/chefyuan/algorithm-base/blob/main/animation-simulation/%E5%8D%95%E8%B0%83%E9%98%9F%E5%88%97%E5%8D%95%E8%B0%83%E6%A0%88/%E5%89%91%E6%8C%87offer59%E9%98%9F%E5%88%97%E7%9A%84%E6%9C%80%E5%A4%A7%E5%80%BC.md)
- [【动画模拟】剑指 Offer 59 - I. 滑动窗口的最大值](https://github.com/chefyuan/algorithm-base/blob/main/animation-simulation/%E5%8D%95%E8%B0%83%E9%98%9F%E5%88%97%E5%8D%95%E8%B0%83%E6%A0%88/%E6%BB%91%E5%8A%A8%E7%AA%97%E5%8F%A3%E7%9A%84%E6%9C%80%E5%A4%A7%E5%80%BC.md)
- [【动画模拟】leetcode 1438 绝对值不超过限制的最长子数组](https://github.com/chefyuan/algorithm-base/blob/main/animation-simulation/%E6%95%B0%E7%BB%84%E7%AF%87/leetcode1438%E7%BB%9D%E5%AF%B9%E5%80%BC%E4%B8%8D%E8%B6%85%E8%BF%87%E9%99%90%E5%88%B6%E7%9A%84%E6%9C%80%E9%95%BF%E5%AD%90%E6%95%B0%E7%BB%84.md)
- [【动画模拟】leetcode 155 最小栈](https://github.com/chefyuan/algorithm-base/blob/main/animation-simulation/%E5%8D%95%E8%B0%83%E9%98%9F%E5%88%97%E5%8D%95%E8%B0%83%E6%A0%88/%E6%9C%80%E5%B0%8F%E6%A0%88.md)
- [【动画模拟】leetcode 739 每日温度](https://github.com/chefyuan/algorithm-base/blob/main/animation-simulation/%E5%8D%95%E8%B0%83%E9%98%9F%E5%88%97%E5%8D%95%E8%B0%83%E6%A0%88/leetcode739%E6%AF%8F%E6%97%A5%E6%B8%A9%E5%BA%A6.md)
- [【动画模拟】leetcode 42 接雨水](https://github.com/chefyuan/algorithm-base/blob/main/animation-simulation/%E5%8D%95%E8%B0%83%E9%98%9F%E5%88%97%E5%8D%95%E8%B0%83%E6%A0%88/%E6%8E%A5%E9%9B%A8%E6%B0%B4.md)
### 🛳 前缀和
- [【动画模拟】leetcode 724 寻找数组的中心索引](https://github.com/chefyuan/algorithm-base/blob/main/animation-simulation/%E5%89%8D%E7%BC%80%E5%92%8C/leetcode724%E5%AF%BB%E6%89%BE%E6%95%B0%E7%BB%84%E7%9A%84%E4%B8%AD%E5%BF%83%E7%B4%A2%E5%BC%95.md)
- [【动画模拟】leetcode 523 连续的子数组和](https://github.com/chefyuan/algorithm-base/blob/main/animation-simulation/%E5%89%8D%E7%BC%80%E5%92%8C/leetcode523%E8%BF%9E%E7%BB%AD%E7%9A%84%E5%AD%90%E6%95%B0%E7%BB%84%E5%92%8C.md)
- [【动画模拟】leetcode 560 和为 K 的子数组](https://github.com/chefyuan/algorithm-base/blob/main/animation-simulation/%E5%89%8D%E7%BC%80%E5%92%8C/leetcode560%E5%92%8C%E4%B8%BAK%E7%9A%84%E5%AD%90%E6%95%B0%E7%BB%84.md)
- [【绘图描述】leetcode1248 统计「优美子数组」](https://github.com/chefyuan/algorithm-base/blob/main/animation-simulation/%E5%89%8D%E7%BC%80%E5%92%8C/leetcode1248%E5%AF%BB%E6%89%BE%E4%BC%98%E7%BE%8E%E5%AD%90%E6%95%B0%E7%BB%84.md)
- [【绘图描述】leetcode 974 和可被 K 整除的子数组](https://github.com/chefyuan/algorithm-base/blob/main/animation-simulation/%E5%89%8D%E7%BC%80%E5%92%8C/leetcode974%E5%92%8C%E5%8F%AF%E8%A2%ABK%E6%95%B4%E9%99%A4%E7%9A%84%E5%AD%90%E6%95%B0%E7%BB%84.md)
### 🥥 递归
- 敬请期待。。。
### 🍒 贪心
- 敬请期待。。。
### 🚃 回溯
- 敬请期待。。。
### 🌆 分治
- 敬请期待。。。
### 🧭 动态规划
- 敬请期待。。。
### 🌋 并查集
- 敬请期待。。。
> > > > > > >
---
<div align="center"> <img src="https://cdn.jsdelivr.net/gh/tan45du/photobed@master/赞赏码.2mrhxsmxexa0.png" width = "200px" hight = "200px"/> </div>
================================================
FILE: animation-simulation/Leetcode常用类和函数.md
================================================
# Leetcode 常用函数
## 链表篇
一些节点,除了最后一个节点以外的每一个节点都存储着下一个节点的地址,依据这种方法依次连接, 构成一个链式结构。
### ListNode
```java
ListNode list=new ListNode(0)
```
初始化一个值为 0 的空节点,提倡的写法
### HashSet
HashSet 基于 HashMap 来实现的,是一个不允许有重复元素的集合但是允许有 null 值,HashSet 是无序的,即不会记录插入的顺序。HashSet 不是线程安全的, 如果多个线程尝试同时修改 HashSet,则最终结果是不确定的。 您必须在多线程访问时显式同步对 HashSet 的并发访问。
```java
HashSet<String> sites = new HashSet<String>();
```
#### add()
往 HashSet 里添加元素
```
sites.add("我是袁厨,大家快快关注我吧");
```
#### size()
#### remove()
remover()size()也是会用到的函数,具体用法和 ArrayList 一样
#### contains()
判断元素是否存在
```
System.out.println(sites.contains("我是袁厨,大家快快关注我吧"));
```
> 输出:true;
## 数组篇
### length
该函数是用来得到数组长度的函数,这里需要注意的是 length 后面没有括号
### sort()
该函数用于给数组进行排序,这两个函数用的比较多
### Arrays.fill()
用于填充数组
一共有四个参数,分别是数组,开始索引,结束索引,填充数值。
```
Arrays.fill(nums, 0, 2, 0);
for(int x:nums){
System.out.println(x);
}
```
> 输出:0,0
### Arrays.sort()
给数组排序,也可以做到部分排序 ,在括号中添加索引即可
```
int[] array = {1,6,3,4};
Arrays.sort(array);
return array;
```
> array : 1,3,4,6;
### Arrays.copyOfRange()
将一个原始的数组,从下标 0 开始复制,复制到上标 2,生成一个新的数组
```
int[] array = {1,2,3,4};
int[] ar= Arrays.copyOfRange(intersection, 0, 2);
return ar;
```
> array2: 1 , 2 ;
### System.arraycopy();
```java
System.arraycopy(targetnums,beganindex, newnums, newindex, length);
```
targetnums:目标数组,想要复制的数组
beganindex:目标数组开始索引
newsnums:复制到的新数组
newindex:开始索引
length:想要复制的长度
```java
int[] array = {1,2,3,4};
int[] newarray = new int[2];
System.arraycopy(array,0,newarray,0,2);
for(int x : newarray){
System.out.println(x)
}
```
> 输出:1,2
### 逻辑运算符
#### x | 0
得到的仍然是他本身,
例:1001|0000=1001;或运算代表的是如果两位其中有一个 1 则返回 1,否则为 0;
```java
public static void main(String[] args) {
int x =10 ;
System.out.println(x|0);
}
```
> 输出:10
#### x & 0
无论任何数都会输出 0,这个也很好理解。
例:1001&0000=0000;两位都为 1 才能返回 1
```
public static void main(String[] args) {
int x =10 ;
System.out.println(x&0);
}
```
> 输出:0
#### x ^ 0
得到的还是他本身,这个也很好理解,异或的含义就是如果相同输出 0,如果不同输出 1
例:0111^0000=0111 第一位相同,其余位不同
```java
public static void main(String[] args) {
int x =-10 ;
System.out.println(x^0);
}
```
> 输出:-10
#### x | 1
如果是奇数的话,还是它本身,偶数的话则加 1;
```java
int x =-9 ;
int y = -10;
System.out.println(x|1);
System.out.println(y|1);
```
> 输出:-9,-9
#### x ^ 1
如果是偶数则加 1,如果是奇数则减 1;
```java
int x =-9 ;
int y = -10;
System.out.println(x^1);
System.out.println(y^1);
```
> 输出:-10,-9
#### x & 1
得出最后一位是 0 还是 1,通常会用来判断奇偶
```java
int x =-9 ;
int y = -10;
System.out.println(x&1);
System.out.println(y&1);
```
> 输出:1,0
#### 1<<3
代表的含义是将 1 左移 3 位,即 0001 ---->1000 则为 2^3 为 8
```java
System.out.println(1<<3);
```
> 输出:8
#### HashMap
创建一个 HashMap,两种数据类型
```
HashMap<Integer,Integer> map = new HashMap<Integer,Integer>();
```
往 hashmap 里面插入数据
```java
for (int num : arr){
map.put(num, map.getOrDefault(num, 0) + 1);//如果没有则添加,如果有则加1
}
```
遍历 Hashmap,查询值为 k 的元素
```
for (int k : hashmap.keySet())
if (hashmap.get(k) == 1) return k;
```
遍历 HashSet
```
set.iterator().next();//迭代器
```
## 树篇
### ArrayList<List<对象类型>>
```java
List<List<Integer>> arr = new ArrayList<List<Integer>>();
```
用来创建二维的动态数组,层次遍历用到这个。
### ArrayList
```java
List<Integer> array = new ArrayList<>();
```
ArrayList 类是一个可以动态修改的数组,与普通数组的区别就是它是没有固定大小的限制,我们可以添加或删除元素。<>代表的数组类型
#### add()元素,括号内为需要添加的元素
```java
public class Test {
public static void main(String[] args) {
List<String> array = new ArrayList<>();
array.add("大家好我是袁厨");
System.out.println(array);
}
}
```
> 输出:大家好我是袁厨
#### get()
get()函数用于获取动态数组的元素,括号内为索引值
```java
public class Test {
public static void main(String[] args) {
List<String> array = new ArrayList<>();
array.add("大家好我是袁厨");
System.out.println(array.get(0));//获取第一个元素
}
}
```
> 输出:大家好我是袁厨
#### set()
set()用于修改元素,括号内为索引值
```
public class Test {
public static void main(String[] args) {
List<String> array = new ArrayList<>();
array.add("大家好我是袁厨");
array.set(0,"祝大家天天开心")
System.out.println(array.get(0));//获取第一个元素
}
}
```
> 输出:祝大家天天开心
#### remove()
用来删除数组内的元素
```
public class Test {
public static void main(String[] args) {
List<String> array = new ArrayList<>();
array.add("大家好我是袁厨");
array.add("祝大家天天开心");
array.remove(0);
System.out.println(array);//获取第一个元素
}
}
```
> 输出:祝大家天天开心
#### isEmpty()
isEmpty()函数判断是否为空,这个函数用到的地方很多,队列和栈的时候总会用。总是会在 while 循环中使用
while(!queue.isEmpty()){
//用来判断队列是否为空的情况
}
```
public class Test {
public static void main(String[] args) {
List<String> array = new ArrayList<>();
array.add("大家好我是袁厨");
array.add("祝大家天天开心");
array.remove(0);
System.out.println(array.isEmpty());//获取第一个元素
}
}
```
输出:false
#### clear()
该函数用来清空动态数组
```
ArrayList<String> sites = new ArrayList<>();
sites.add("袁厨不帅");
sites.add("袁厨不帅");
sites.add("袁厨不帅");
System.out.println(sites);
// 删除所有元素
sites.clear();
System.out.println(sites);
```
> ```
> 删除前:[袁厨不帅,袁厨不帅,袁厨不帅]删除后:[]
> ```
#### sort()
该函数用来给动态数组排序,这个有时也会用到。
```
public class leetcode {
public static void main(String[] args) {
int[] arr = {4,5,1,3,6};
Arrays.sort(arr);
for(int x : arr){
System.out.println(x);
}
}
}
```
> 输出:1,3,4,5,6
## 字符串篇
### StringBuffer
StringBuilder 类在 Java 5 中被提出,它和 StringBuffer 之间的最大不同在于 StringBuilder 的方法不是线程安全的(不能同步访问)。由于 StringBuilder 相较于 StringBuffer 有速度优势,所以多数情况下建议使用 StringBuilder 类。然而在应用程序要求线程安全的情况下,则必须使用 StringBuffer 类。
```Java
public class Test{
public static void main(String args[]){
StringBuffer sBuffer = new StringBuffer("我的");
sBuffer.append("名字");
sBuffer.append("是");
sBuffer.append("袁厨");
sBuffer.append("大家点个关注吧");
System.out.println(sBuffer);
}
}
```
> 输出:我的名字是袁厨大家点个关注吧
String 中的字符串是不允许修改的,这个 StringBuffer 可以进行修改,做字符串的题目时会经常用到,树的题目中也偶尔会遇到
### charAt(i)
charAt() 方法用于返回指定索引处的字符。索引范围为从 0 到 length() - 1。
```java
public class Test {
public static void main(String[] args) {
String s = "大家好我是袁厨,点个关注哦";
char result = s.charAt(6);
System.out.println(result);
}
}
```
> 输出:厨
这个函数的用法,就跟我们根据数组的索引输出值一样。在字符串题目中也比较常用。
### s.charAt(index)-'0'
这个函数的用途是将字符串索引值变成 int 型。知道这个可以大大提高刷题效率。大家可以掌握一下。
```java
public class Test {
public static String getType(Object test) {
return test.getClass().getName();
}
public static void main(String[] args) {
String s = "祝大家永不脱发,点个关注哦";
System.out.println(getType(s.charAt(6)-'0'));
}
}
```
> 输出:java.lang.Integer
### Integer.toString()
该函数用于将 int 型变为 string 型,比如这个**第 9 题求回文数**的题目,我们就是先将 x 变为字符串,然后再遍历字符串
```java
class Solution {
public boolean isPalindrome(int x) {
if(x<0){
return false;
}
//将int型变成string型,然后遍历字符串,不再需要使用额外数组进行存储
String t = Integer.toString(x);
int i = 0;
int j = t.length()-1;
//双指针遍历
while(i<j){
if(t.charAt(i)!=t.charAt(j)){
return false;
}
else{
i++;
j--;
}
}
return true;
}
}
```
### substring()
substring() 方法返回字符串的子字符串
```java
public String substring(int beginIndex);
public String substring(int beginIndex, int endIndex);
```
表示两种情况,一种是从 beginIndex 到结尾,一种是从 beginIndex ->endIndex;
```
String Str = new String("程序员爱做饭");
System.out.println(Str.substring(3) );
System.out.println(Str.substring(4, 5) );
```
> 输出:爱做饭,做
### equals()
equals() 方法用于判断 Number 对象与方法的参数和类型是否相等。
```
public static void main(String args[]){
Integer x = 5;
Integer y = 10;
Integer z =5;
Short a = 5;
System.out.println(x.equals(y));
System.out.println(x.equals(z));
System.out.println(x.equals(a));
}
```
> 输出:false,true,false
### toCharArray()
```java
String num = "12345";
char[] s = num.toCharArray();//将字符串变为char数组
System.out.println(s);
```
> 输出:12345
### char 数组变为 String
```java
String newstr = new String (arr2,start,end);
```
### indexOf
- **int indexOf(String str):** 返回指定字符在字符串中第一次出现处的索引,如果此字符串中没有这样的字符,则返回 -1。
- **int indexOf(String str, int fromIndex):** 返回从 fromIndex 位置开始查找指定字符在字符串中第一次出现处的索引,如果此字符串中没有这样的字符,则返回 -1
```
String s = "LkLLAAAOOO";
return s.indexOf("LLL");
```
> 返回-1
## 栈(Stack)
#### 创建栈
```
Stack<TreeNode> stack = new Stack<TreeNode>();//创建栈
```
上面的是创建新栈,栈的变量类型为 TreeNode,我们用深度优先遍历树来举例
#### push()
把项压入栈顶部
```
stack.push(root);//将根节点入栈
```
#### pop()
移除堆栈顶部的对象,并作为此函数的值返回该对象。
```java
TreeNode temp = stack.pop();//将栈顶元素出栈,赋值TreeNode变量temp
```
peek()
查看栈顶元素但是不移除它
```java
stack.push(root);
TreeNode temp2 = stack.peek();
System.out.println(temp2.val);
```
#### 出栈操作
```
StringBuilder str = new StringBuilder();
//遍历栈
while(!stack.isEmpty()){
str.append(stack.pop());
}
//反转并变为字符串
return str.reverse().toString();
```
================================================
FILE: animation-simulation/一些分享/区块链详解.md
================================================
最近总是能在一些网站上看到比特币大涨的消息,诺,这不都涨破 20000 美元啦。
最近比特币涨势喜人,牵动着每一位股民的心,持有的老哥后悔说当时我咋就没多买点呢,不然明天早饭又能多加个鸡蛋啦,没持有的呢,就在懊恼后悔当时为啥就没买入呢?这不我女朋友也看到新闻了,说比特币最近涨那么厉害,咱们要不买两个呀!然后这个总是听到的比特币到底是什么东西呀?
你说那个比特币呀,我也不是很懂,知道一点点,我给你讲一下我知道的吧。
**注:本文和股票无关,单纯的介绍一下比特币原理,投资有风险,入场需谨慎**
> 关键词 :比特币,去中心化,挖矿,区块链,双重支付,最长链原则,工作量证明
我先给你说一下比特币的历史吧。
> 2008 年爆发全球金融危机,同年 11 月 1 日,一个自称中本聪(Satoshi Nakamoto)的人在 P2P foundation 网站上发布了比特币白皮书《比特币:一种点对点的电子现金系统》 陈述了他对电子货币的新设想——比特币就此面世。2009 年 1 月 3 日,比特币创世区块诞生。
你平时不是会把每天的收入和支出记在自己的小本本上,我们称之为记账。我们平常在消费的时候,银行也会为我们记录这条交易记录及交易后银行卡里的余额。然后我们会通过银行卡里数字来评估自己拥有的财富。所以我们拥有多少财富都通过银行的记账本来决定的。
**中本聪**在**2008**年提出,其实我们可以不需要一个**中心化**的记账系统,不需要以某个人或者机构为中心来帮我们记账,我们可以**去中心化**,每一个人的账本都是透明公开的,这就叫做**去中心化电子记账系统**。下面我们通过一个例子来进行描述。
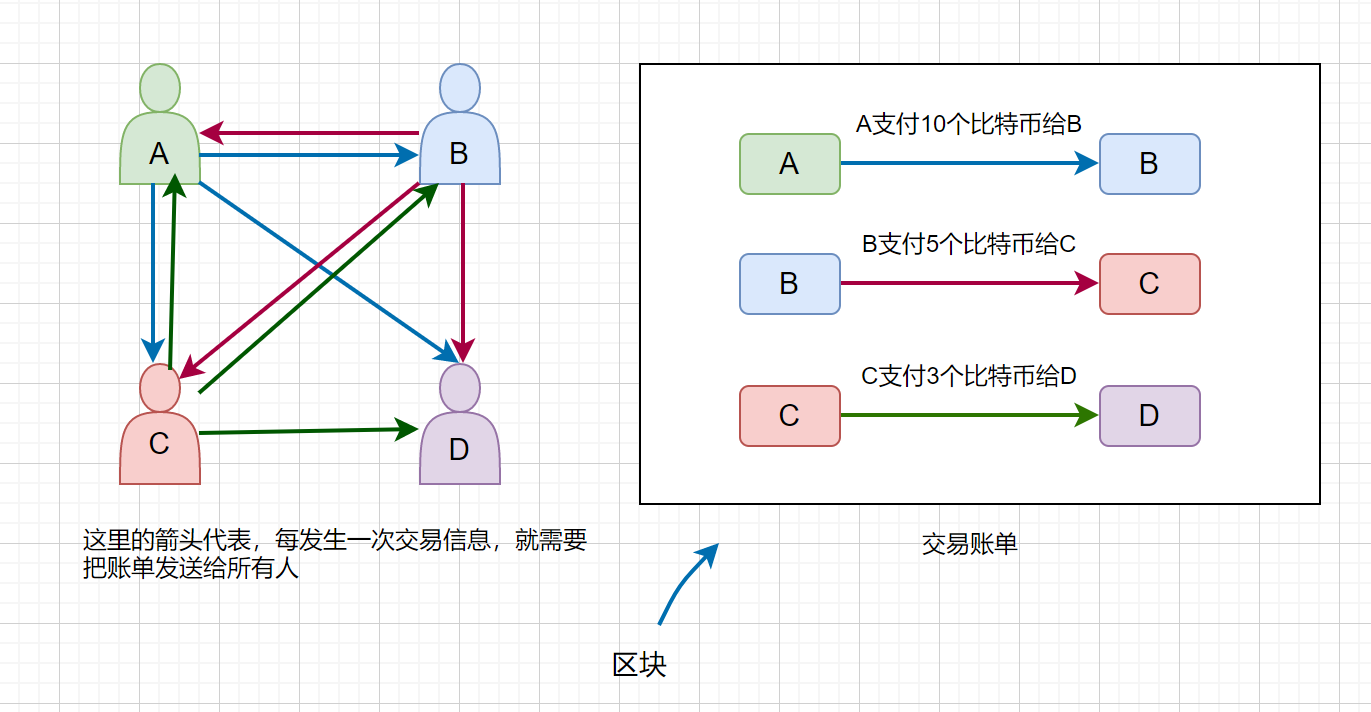
### 1.那你说的那个区块链到底是什么东西呀,我不是很懂哎?
我们对上图进行解析,A,B,C,D,四个小伙伴进行交易,首先 A 支付 5 个比特币给 B,那么他需要将这条交易信息发送给每位小伙伴,同理 B 和 C,C 和 D 的交易也要传送给所有的小伙伴,用户会将这些交易信息记录下来,并打包成块,我们称之为**区块**,(区块大小约为 1M,约 4000 条左右交易记录),当块存满时我们将这个块接到以前的交易记录上,形成一条链,过一段时间再把新的块接到它后面,我们称这条链为**区块链**,如下图。
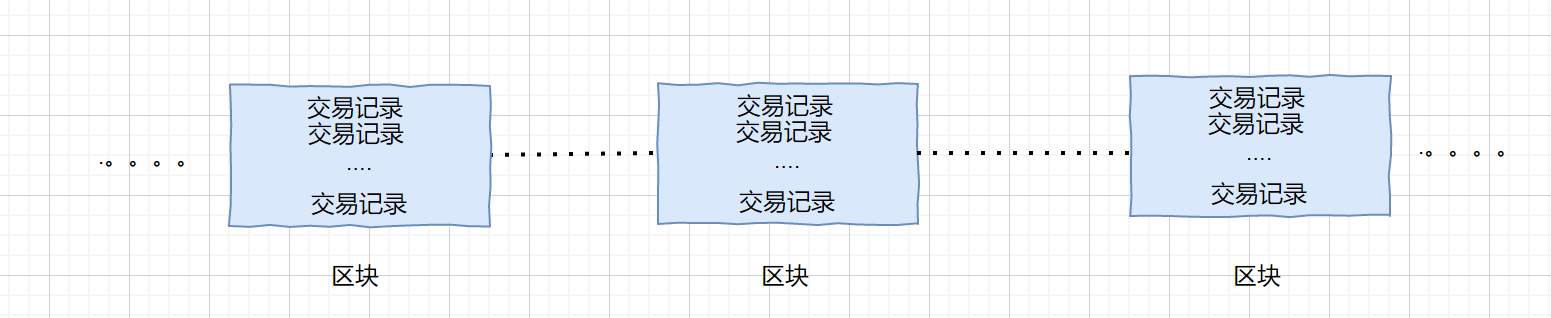
好啦,我们大概了解什么是区块链了。
### 2.好啦我知道什么是区块链了,但是那些用户为什么要记录交易信息呢?
记账奖励:每个用户都可以去记账,如果某个用户进行记帐则会奖励他一些手续费,比如 A 和 B 交易 10 个比特币,A 就需要多支出一点点给为其记录的人。其实现实生活中,我们使用银行卡时也会有手续费,这里的手续费是支付给银行。
打包(将交易记录打包成块)奖励:打包者只能有一位,完成打包的那一位能够获得**打包奖励**,
### 3.哦,知道了,那打包一次能获得多少奖励呢?
2008 年刚提出这个系统时,奖励方案如下
每十分钟打一个包,最开始的时候,每打一个包会奖励打包者 50 个比特币,过了四年之后,每打一个包奖励 25 个比特币,再过四年的则奖励 12.5 个比特币,以此类推。
### 4.哇,那么多,那世界上一共有多少个比特币呢?
一个包奖励 50 个比特币,一个小时 6 个包,一天 24 小时,一年 365 天 ,每隔四年减半,则计算公式如下
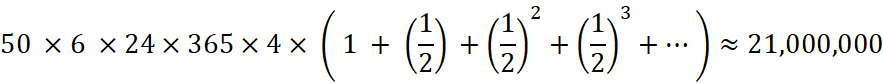
总数大概为 2100 万个比特币。
### 5.因为我们有手续费和打包费的奖励机制,所以大家都抢着打包,但是打包者只能有一个人,那么我们应该让谁打包呢?
中本聪提出了一个**工作量证明**的办法,说白了就是想打包的用户都要去做一个很难的数学题,谁先做出来,谁就能获得这个打包的权力。打包者就能够获得奖励,但是这个题目很特别,就是我们任何人都不能用脑子把他做出来,我们只能一个数一个数的去尝试,直到你把这个数尝试出来,那么你就获得了奖励,这个过程就是我们经常说的挖矿。
### 6.你说的那个挖矿的原理是怎样的呢,我想不通?
刚才我们说挖矿的原理其实是让我们做一道数学题,谁先做出来算谁的,这个题目还不拼智商,需要我们一个一个的试,取决于咱们 CPU 的运行速度。那么具体原理是什么呢?
**这里可以选择性阅读,不感兴趣可以直接跳到第 8 个问题**
介绍原理之前,我们先来了解一下哈希函数,大家可以去看一下我之前之前的文章《[学生物的女朋友都能看懂的哈希表总结!](http://mp.weixin.qq.com/s?__biz=Mzg3NDQ2NDY3MA==&mid=2247486429&idx=1&sn=449b0482f89a4b2778cbd5c5d6dcc67f&chksm=ced11f2cf9a6963ab9ce6331c4bec69775e347ef03e4bae46e93113f6e99d18c83f45359a04c&scene=21#wechat_redirect)》,里面对哈希函数做出了简要描述。下面我们再来了解一下数字摘要。
数字摘要就是采用**单向 Hash 函数**将需要加密的明文“摘要”成一串固定长度的密文这一串密文又称为数字指纹,它有固定的长度,而且不同的明文摘要成密文,其结果总是不同的,而同样的明文其摘要必定一致。
通俗点说就是,一个字符串,我们通过 hash 函数计算,得到一个固定长度的密文,不同的字符串得到的密文不同,哪怕仅仅是两个字符串相差一个 0 最后的得到的密文也可能完全不同,相同的字符串会得到相同的密文。通过明文得到密文很容易,我们通过特定的哈希函数就可以,但是反过来是极其难的。
下面我们简单描述一下 著名的哈希函数 SHA256 的生成摘要的过程
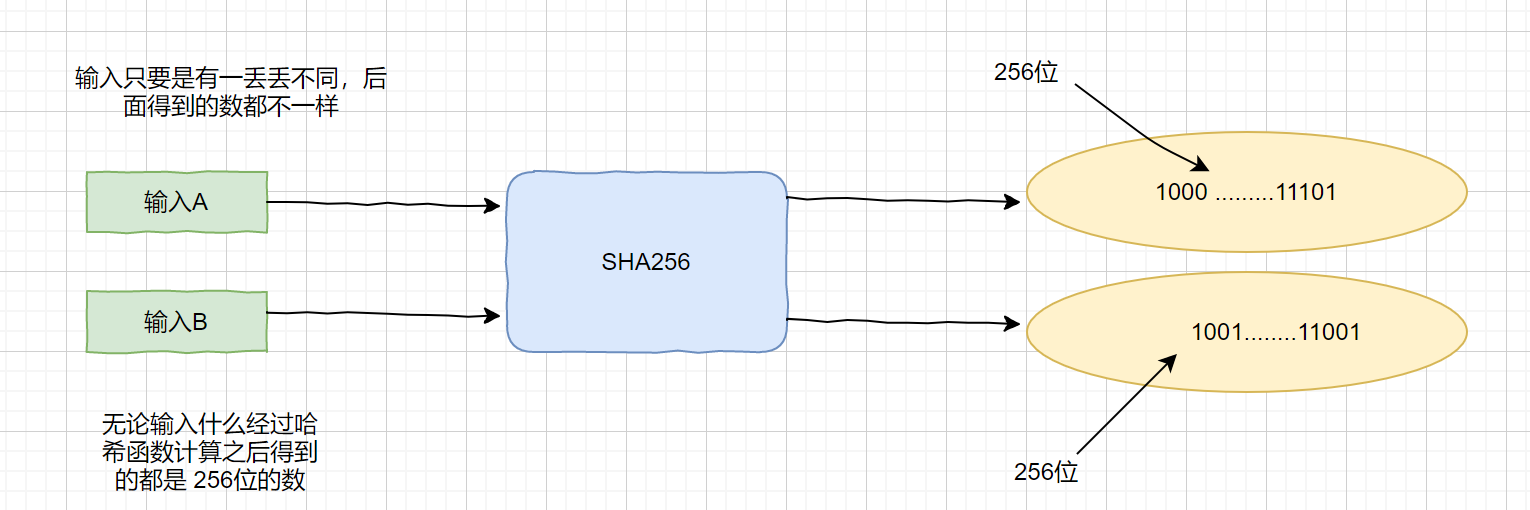
我们已经了解了生成摘要的过程,那么挖矿的具体原理是什么样呢?
刚才我们说到,区块链其实是一大堆交易信息,其实我们的区块里面不只有交易信息,还有头部。目前有很多人记录了系统的交易信息,然后想把自己记录的交易信息打包成块,并连接到区块链上,获得打包费。那么多人想打包,但是只能有一个人可以获得打包权,那么具体是解决了怎样的数学问题获得打包权的呢?
刚才我们描述了生成密文过程,那么我们的明文,也就是输入字符串,在这里主要由什么组成呢?
字符串 :**前块头部 + 账单的信息 + 时间 + 随机数**
主要有以上信息组成,前块的头部,你所记录的账单信息,时间戳,随机数组成。那么我们看,这里的组成部分对于所用用户来说,只有前块头部是固定的,账单信息因为每个人记录顺序不同也是不固定的,每个人开始的时间不一样,那么时间也是不固定的,随机数也不固定,那么既然我们的输入都是不固定的,那这个题应该怎么答呀,那怎么保证公平呢?主要通过以下方法
刚才我们也说了,经过 SHA256 加密之后会得到一个 256 位的二进制数。
获得打包权的那个难题就是让我们把字符串经过两次 SHA256 运算之后得到一个哈希值,哈希值要求**前 n 位**为 0,意思就是谁先算出那个前 n 位为 0 的哈希值,谁就能获得打包权。
因为每个人的输入是不固定的,但是对于个人来说,他开始运算的时间是固定的,头部也是固定的,他所记录内容也是固定的,所以他只能依靠调整**随机数**来修改最后的哈希值,只能挨个试,但是如果人品爆发可能试的第一个数就能得到符合要求的哈希值,但是总的来说还是一个考察算力的题目。
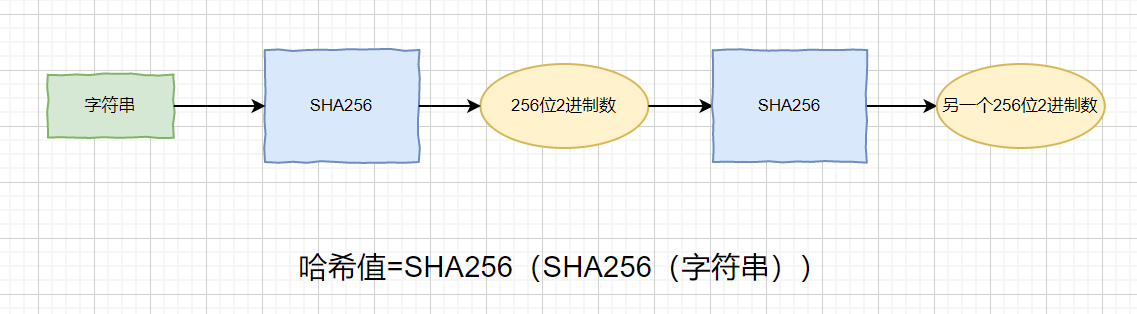
### 7.那哈希值前 n 位为 0 ,这个 n 是依据什么决定的呢?
这个 n 越大计算难度就越大,因为我们不能反算,只能挨个去试,每一位上出现 0 或 1 的概率都为 1/2,那么我们获得前 n 位为 0 的哈希值概率也就是 1/2 的 n 次方。
当时中本聪在设计时,为了保证每十分钟出一个块,所以就会适当的调整 n, 比特币系统每过 2016 个区块之后,就会自动调整一次难度目标。如果上一个难度目标调整周期(也就是之前 2016 个区块),平均出块时间大于 10 分钟,说明挖矿难度偏高,需要降低挖矿难度;反之,前一个难度目标调整周期,平均出块时间小于 10 分钟,说明挖矿难度偏低,需要提高挖矿难度。难度目标上调和下调的范围都有 4 倍的限制。
所以这个 n 是根据挖矿难度(算力)进行调整的,也就是我们矿机的算力和矿机数量等进行调整。
### 8.哦,我懂了,那如果有人冒充咱们咋办,偷偷花咱们的比特币!
这个问题问的好
说到防止假冒,我们先来说一下身份认证,身份验证又称“验证”、“鉴权”,是指通过一定的手段,完成对用户身份的确认。指纹,人脸,签名等都是传统的认证手段,另外我们说一下比特币系统的电子签名。
比特币用户在注册时会生成一个随机数,通过随机数会产生一个私钥的字符串,这个私钥又可以产生一个公钥字符串和地址,私钥和公钥是对应的,并且私钥是保密的,别人向你交易时,你只需要把你的地址发过去即可,如果你给别人交易时,则需要将你的公钥和地址一起发过去。流程图如下
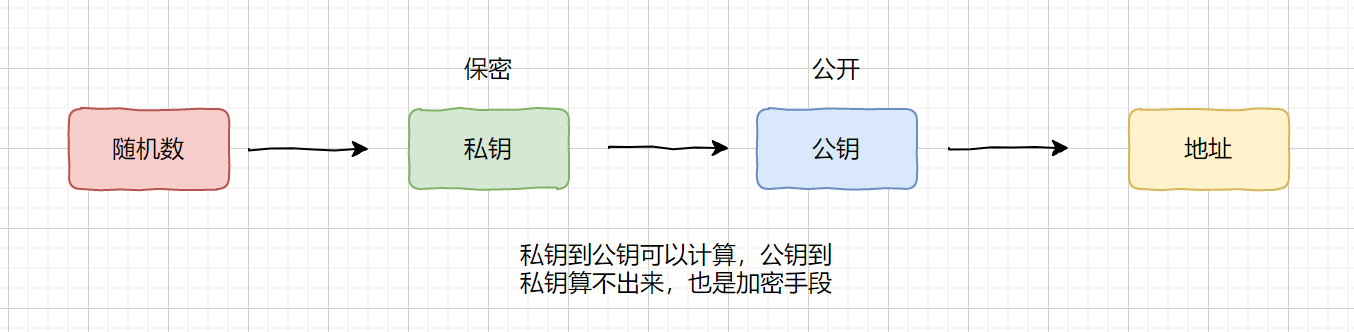
我们在传输记录时通过私钥加密,然后通过公钥解密,加密和解密的钥匙不一样,所以我们称之为非对称加密
具体交易流程如下,例 A 支付 5 个比特币给 B
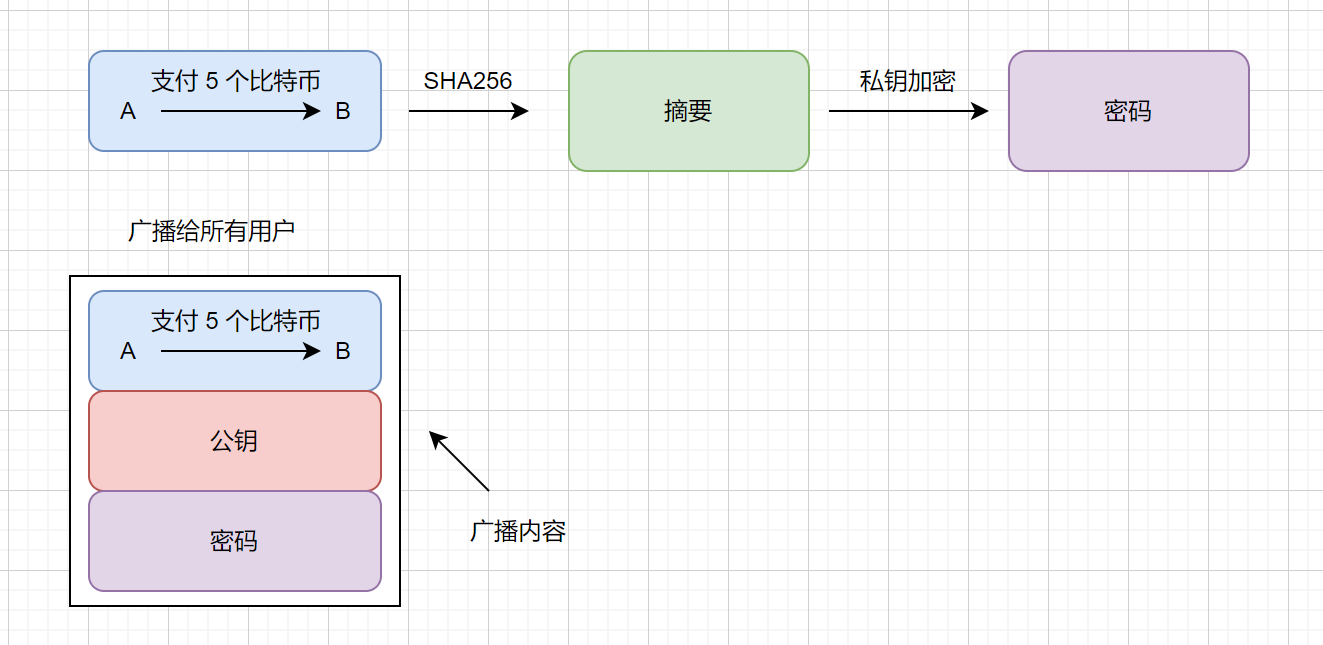
我们其他用户接收到了这个支付消息,那其他用户怎么判断这条信息是不是 A 发出的呢?不是他人冒充 A 发的呢?具体流程如下
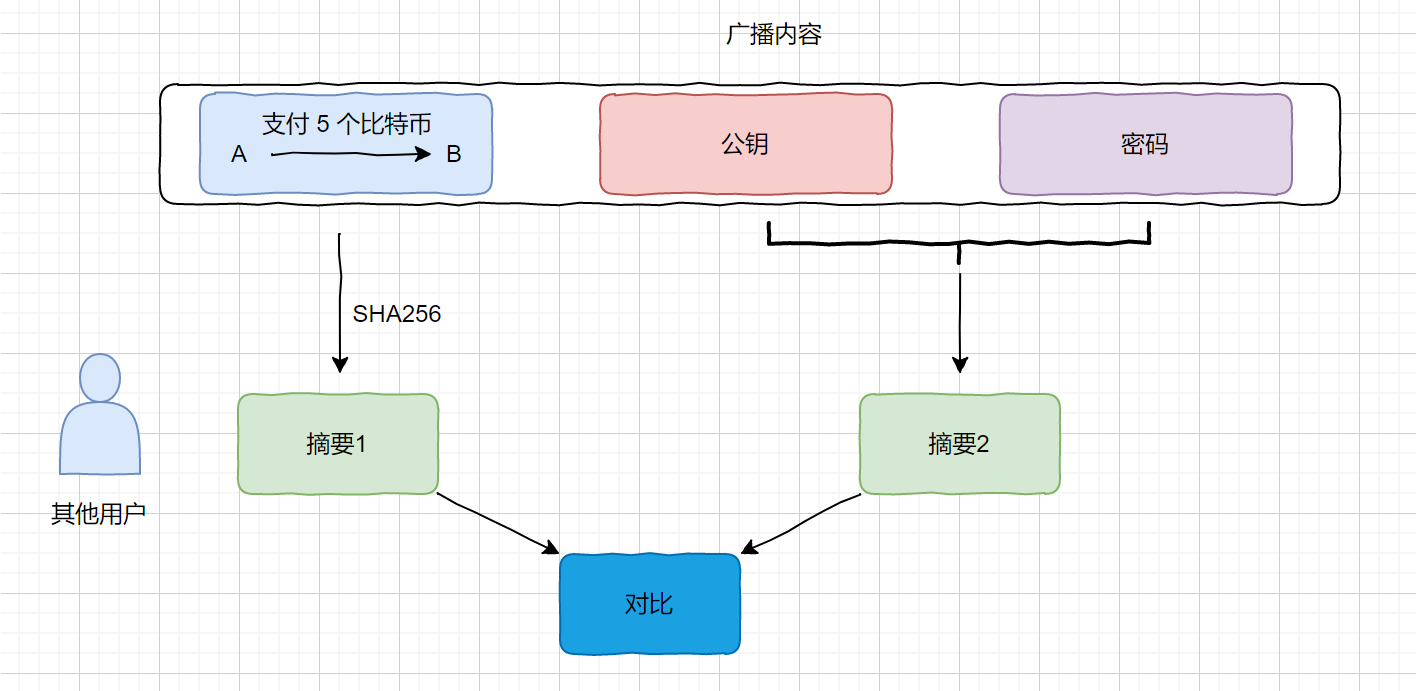
其他用户进行对比,如果一致则认可这条消息是 A 发的,不一致则认为是别人冒充,所有用户则会拒绝这条消息。这里可能会不明白了,公钥和私钥你都发出来了解密肯定的呀,刚才我们说公钥的公开的,但是公钥是由私钥加密得到的,私钥是私密的唯一的,只有 A 用户知道自己的私钥。
### 9.哇,好神奇啊,我知道了,那要是我只有 5 个比特币,同时支付给两个人咋办,每个人五个,那我岂不是赚了呀。
厉害呀,这你都能想到,但是你想多啦。
比如 A 只有五个比特币,他同时发了两个消息,分别是给 B 五个比特币,给 C 五个比特币,但是他总数只有 5 个,这样显然是不行的,我们称之为**双重支付**。
那么我们如何解决呢?
##### 余额检查
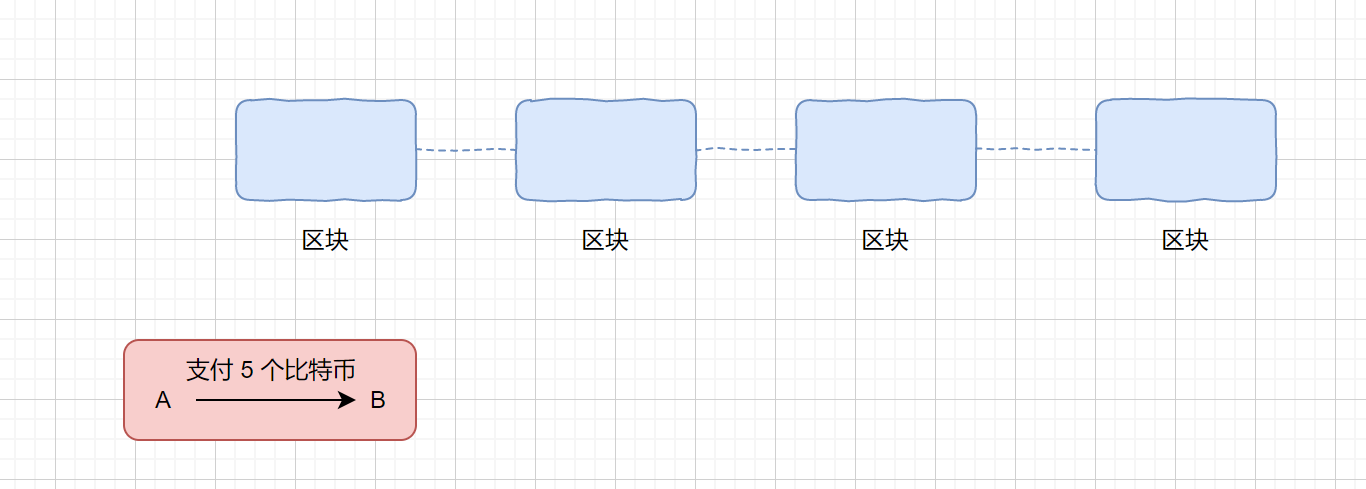追溯
用户在接收到这个消息时,会先从区块链里,进行查询 A 的交易记录,得出 A 的余额是否大于交易数额,如果大于则接收,反之则拒绝。
##### 解决双重支付
首先我们来了解下什么是双重支付,打个比方哈,袁记菜馆第 963 家分店因为店长经营不善,要进行出售,出售的时候店长将这个房子同时卖给了两个人,但是只有一个房子,这就是**双重支付**。
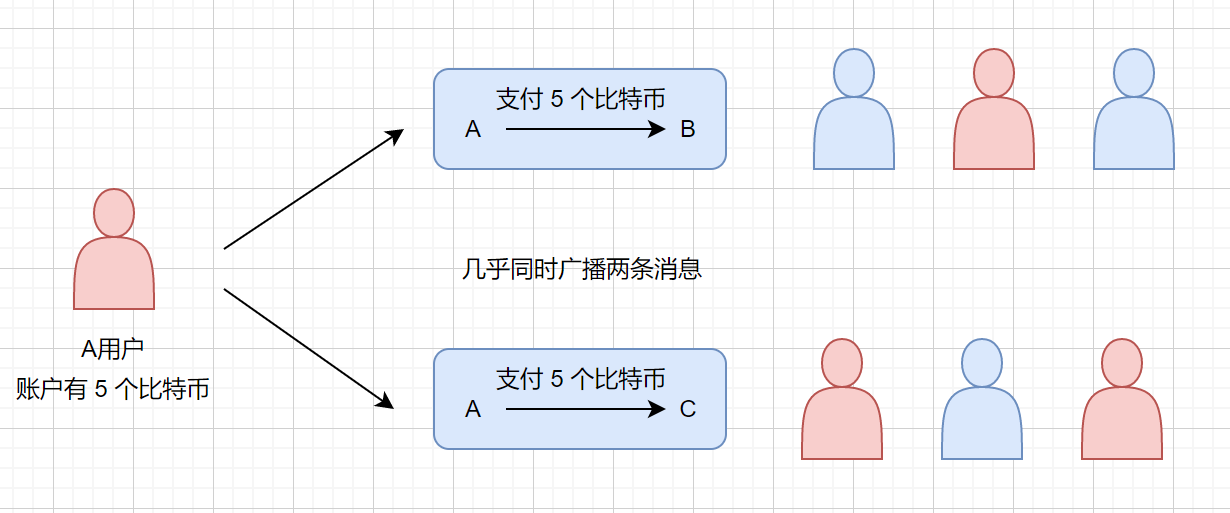双重支付
在比特币系统中是如何解决双重支付问题的呢?我们 A 用户只有 5 个比特币,但是他几乎同时发布了两条广播,此时有些用户会先接收到第一条广播,然后进行追溯,发现 A 只有 5 个比特币,则会拒绝第二条。同理先接收到第二条广播的用户也会如此。就好比形成了两个阵营,然后两个阵营的用户进行答题,然后获得了打包权,则会将自己打的包接到区块链上,那么他所接收到的那条消息则会被整个系统认可。另一条则会放弃。
比如用户 D 先接收到了第二条广播 ,A 支付给 C,然后 D 用户获得了打包权,则 D 将包接到链上,那么其余用户则会放弃自己的包,全部都认可 D 所记录的交易信息。所以此时 C 收入 5 个比特币,B 没有收入。所以我们接收到别人交易消息时,不能认为当时已经到账,要等新的块已经形成,消息被记录到主链上才可以。
### 10.那如果有人偷偷篡改交易信息,那他不就成比特币最多的人了吗?
想的挺全面呀,厉害呀你
我们考虑一下这种情况,A 已经支付给了 B 五个比特币,但是他想把这个记录删掉,伪造一下记录。有这种可能吗?
说之前我们先来描述一下比特币系统遵循的**最长链原则**,那什么是最长链原则呢?
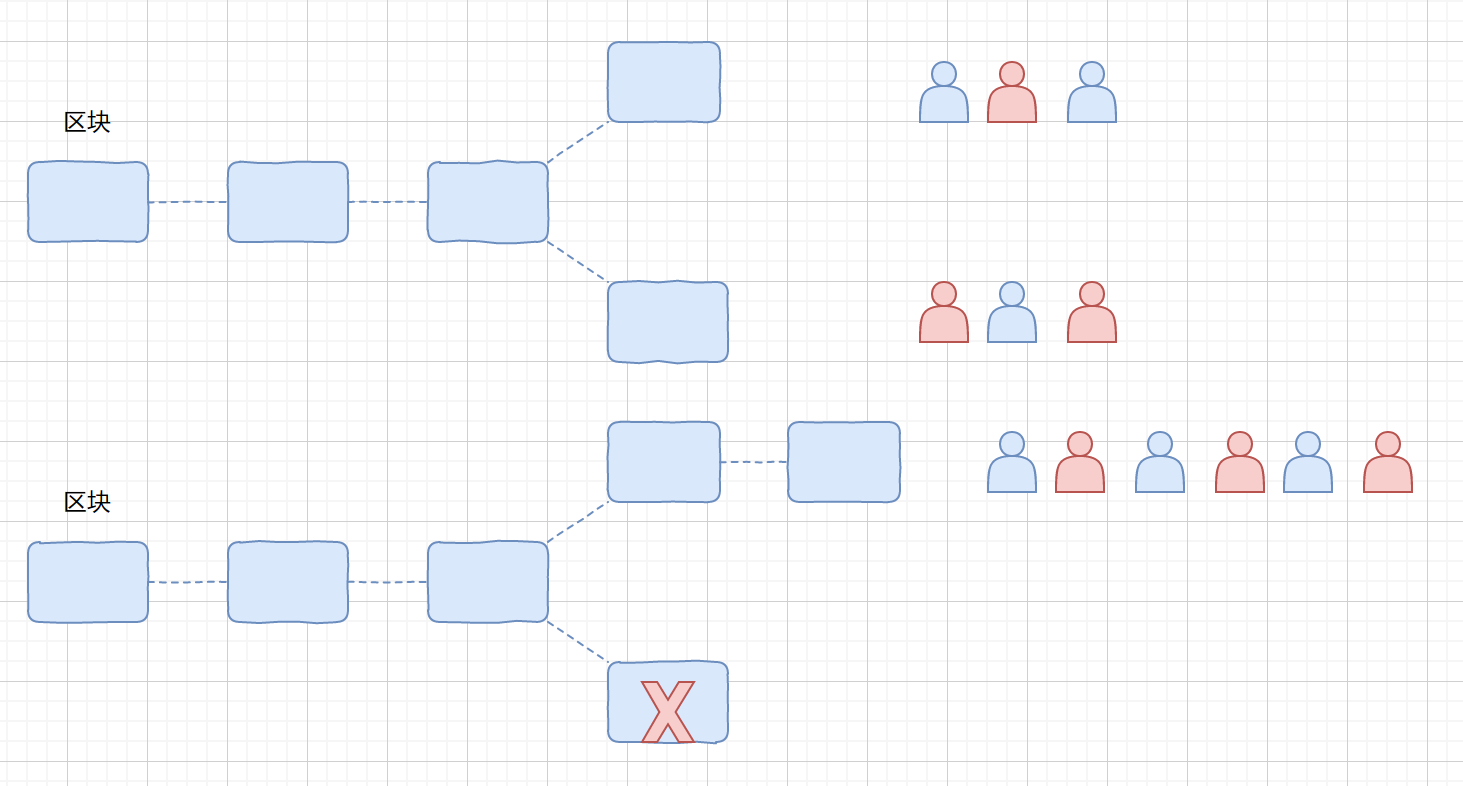最长链
比如上图,我们同时有两个块接到了链上,那么会有两拨人,他们都会以第一个接收到的块为准,然后两拨人继续运算,当某一拨中的某个人获得打包权之后则会将新块接到他接收的块后面,那么此时他的这个链是整个系统最长的链,则会被所有人认可,另一拨人也会来到这个最长链下面继续打包。之前的那个分支则会废弃。如果说某个人他就不想转移阵容,非得死守那个相对短的链,这样也是可以的,只要你一己之力可以对抗所有人,把你这个链变成最长链,大家则会都认可你这条链。
那么我们来说一下,如何防止篡改
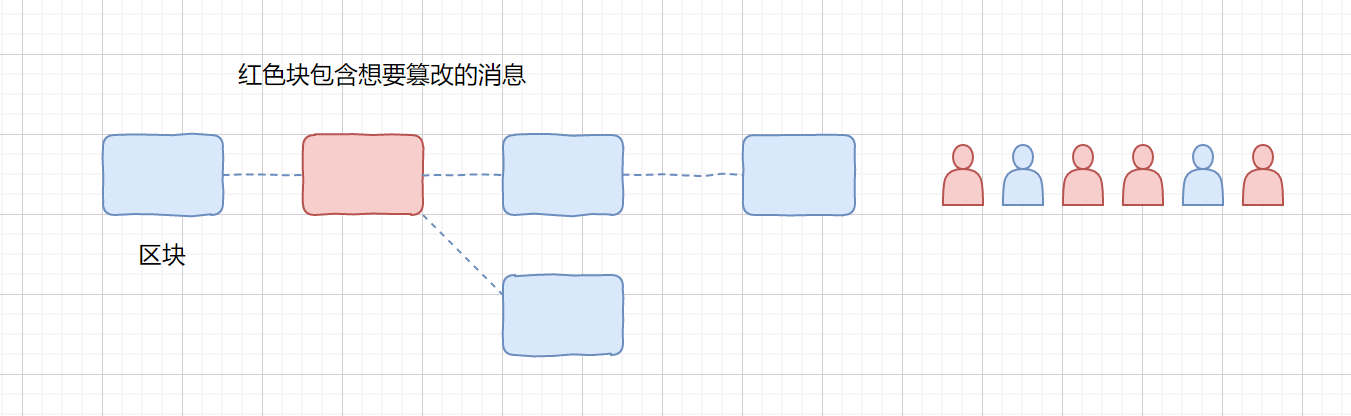
A 此时想要修改红色块里的交易记录,则 A 需要重新计算重新打包,创造出一个支链来,但是大家不会承认你这个支链,因为这个支链不是最长的,所以不会承认你伪造的信息,如果你非要继续往下算,什么时候你自己创造的支链长度大于世界上所有人的打包的链的长度,那么恭喜你,你伪造成功了,大家都认可你的伪造信息了,所以说理论上是可以篡改的,但是你改了之后不会被大家承认,除非你的计算能力超过了世界上其余所有的人。大家试想一下一个掌握全世界一半以上算力的人,会去干这种无聊的事吗?
这下我全都懂了,那咱们快去买两个吧!
你看看现在一个多少钱啦,买不起呀咱们。
<u></u>
另外给大家建了一个寒假刷题互相监督群,需要的可以联系我,公众号内点击一起刷题即可,为了防止广告党进入,大家记得备注【刷题】,目前人数大概有 200 来人。大家可以自行组成小队,也可以一起商量题目。多个人一起走,才能走得更远
================================================
FILE: animation-simulation/一些分享/厨子的2020.md
================================================
## 我的那些牛 X 的事
在火车上无聊,写下了这篇随笔,2020 年已经过去了一段时间,这篇年度总结好像来的略微晚了一些,因为实在不知道写些什么,感觉这一年没有特别突出的成绩,也没有特别大的突破,平平淡淡。下面我试着说一下我的 2020,希望不会浪费你们的这几分钟。
### **2020 印象最难忘的一件事**
印象最深的一件事,应该是我疫情期间参加志愿者吧,做一些很简单的工作,站岗,登记,测温,消毒,宣传抗疫知识,虽没有什么技术含量,但也要细心严谨。
参加志愿者的时间是在一月下旬,算是疫情最严重的时候,爸妈虽然担心,但还算支持,就这样安然无恙的工作了两个多星期,但是某天晚上睡觉前,总感觉身体不舒服,当时心想,我去,该不是发烧了吧,
我就拿起体温计,测了一下体温,37.8!不对不对,肯定是温度计整错了,再来。我就又测了一遍,38.1!坏了,我该不会被感染了吧!说实话,当时我真以为我被感染了,真的把自己吓坏了。
那天的夜格外漫长,一夜无眠,思考了很多,在半梦半醒度过了忐忑的一夜。现在想想当时可真幼稚啊。哈哈
第二天一大早,我就全副武装,把自己包的严严的,来到医院后,医生问了我各种信息之后开始验血,检验科的医生一听我 38.1,着实吓了一跳,抽血时,手止不住的发抖,两次才抽血成功,
抽完之后,地上湿了一小片,不是我的血,是因为医生额头上豆大的汗珠滴落在地。(没有夸张,因为我们是先在小医院初检,所以医生的心理素质没有那么高)我当时的心情却格外平静,(可能该吓得都吓完了)之后又做了一些别的检查,最后发现我没有被传染,而是得了水痘。
就是那种小朋友容易得的小水泡,我也想不明白我 20 多岁的大小伙子,咋就得了水痘了。不过万幸没有被传染。然后在家休息了两个星期,痊愈之后,又继续干了一段时间的志愿者,直到解封。
这件事算是给我上了一课,现在想想当时真的太幼稚啦,不过也算是给我的 2020 增添了一些别样的色彩。
### **2020 最正确的一件事**
最正确的事应该是学会书写,在此之前我是以读者的角度思考问题,想方设法将别人的知识搞懂,搞懂之后也就不在理会。
现在的我想方设法的让别人弄懂,努力将一些不是特别容易理解的问题,包装加工,让其变的生动活泼,尽全力让其变的通俗易懂。在这个过程中我的收获是巨大的,让我对问题的理解更加透彻,注意到了之前忽略掉的一些细节。
写文章从来不是一件容易的事情,把文章写好更是如此,这是之前的我没有体会到的。每次写完一篇文章,都会给自己带来满满的自豪感,就好像辛苦拉扯大了一个孩子。
前辈们的每一次转载,读者的每一次点赞,都会让我感觉到努力得到了认可,促使我更加积极,用心的去输出,所以希望读者以后遇到对你们有帮助的文章(不仅仅是我的),不要吝啬你的点赞,多多鼓励一下他们。借用小林的一句话,利他必利己。
### **2020 最遗憾的一件事**
2020 最遗憾的事,是自己没有利用好疫情居家期间那段可以自由支配的时间,没有那时候就开始写作。
在家里学习的效率是很低的,没有很强的自制力,只是按部就班的上网课,写实验报告,做课设。因为上半学期有一门课考的很差劲,所以下半学期就需要使劲学,去填那一门的坑。
虽然最后如愿获得了奖学金和评优资格。但是技术上的东西学的很少,很是后悔。开学后,时间开始不受自己控制,看论文,做展板,开组会,汇报实验进度,那些不是我喜欢的,却是我不得不去做的,写东西是我喜欢做的,甚至可以在图书馆连续写 6,7 个小时,期间不看一次手机。即使这样仍感觉十分有趣。
不过人成长的标志就是开始学着“身不由己”,做一些自己不是那么想做,甚至说有点讨厌的事。所以希望我以后可以合理利用我能利用的时间。控制好我所能控制的事。
以上就是我的 2020,在你们看来或许都是很平常的事,但做为亲身经历者的我而言,就是我的那些牛 X 的事。
### **2021 想要做的一些事**
多打打球,自从写了公众号之后,把运动和娱乐的时间都用到了写作上,虽然体 型变化不大,但是明显感觉到了打球时的体力下降。
- 2021 保证一周打两次球。
- 和女朋友毕业后能在同一座城市找到满意的工作。
- 坚持写作,希望 2021 可以完成 70 篇高质量原创。
- 理财收益 2020 大概百分之 27,希望 2021 可以继续保持。
- 完成一次半马,一直想参加,但还没有参加过,希望今年可以实现
好啦,就这么些吧,多了我也完成不了,感谢各位阅读,拜了个拜。
================================================
FILE: animation-simulation/一些分享/学习.md
================================================
不知道各位有没有遇到过下面这种情况
每天早上醒来,先给自己打个气,今天我一定要好好学习。打完气之后,就开始躺在床上玩手机。吃了睡,睡了吃,好不容易打开电脑学个习,看了半个小时就再次倒下。
还有的时候呢?2:45 啦,我再玩一会吧,凑个整,到 3 点再学习,玩着玩着,那边你妈喊你吃晚饭了。
晚上,躺在床上,再一次给自己打气,我明天一定要早起好好学习,然后一个没忍住继续玩手机,第二天又睡过头了,继续复制昨天的生活。
相信大家放假之前都有在假期里大干一场的想法,可谁知回到家之后,身体开始不受控制,总想躺着。给大家总结了一波小技巧,希望对大家有一丢丢帮助。
**拒绝舒适**
**换掉睡衣**,或许我们不能好好学习的**罪魁祸首之一**就是身上的睡衣,行为影响态度,如果我们穿着睡衣葛优躺在沙发上的时候,我们就倾向于刷刷视频,找朋友开开黑,做一些放松的活动。但是如果你**穿上上学的衣服**,甚至说穿上校服,你离学习就更近一些,**更容易进入到类似于学校的学习状态**,**成为一个没有感情的学习机器。**
**欺骗自己**
有的时候我们好不容易坐到电脑前,然后我们开始纠结,翻两下书又开始背单词,事情太多,先做哪个呢?
要不还是先看会手机吧,总的来说就是**计划太多,无从下手,犹豫太久,啥也没有**。**重要的不是学什么,而是学。**
对我们来说更难的不是继续做,而是开始做。就比如我们**离开舒适区**,进入书房,坐在电脑前敲下第一行代码的过程,往往比我们已经开始,继续行动,要难很多很多,所以**我们可以欺骗自己,我就学十分钟,只听一节网课,只做一道算法题,总的来说就是先开始再说。**
**然后刚开始学习时我们可以先做些简单的工作,提高我们的学习积极性,**帮助我们进入学习状态,**循序渐进**。如果刚一开始就做些困难工作,我们内心会对其抗拒,渐渐失去对学习的耐心。
**整齐的学习环境**
一个整齐的学习环境能让你。。。算了,这个我也没做到,不说了,反正还是整洁一点好。
**学会休息**
个人认为这一点格外重要,在家里同样需要管理好作息,管理作息不一定非要起的特别早来学习,而是**保持一个较规律的作息习惯**。你可以给自己**设定一个睡觉时间和起床时间**,完全按照这个时间执行。这样你前一天做好的规划就不会被打乱。
告诉大家一个我经常用的小窍门,那就是**不躺在床上玩手机,看手机的时候坐在桌子旁,到了睡觉时间,则把手机放在桌子上,躺到床上迅速入睡**。那么你的起床时间和睡觉时间就能得到保证。因为我们**晚睡晚起的大多数情况都是赖床玩手机。**
我们被闹钟吵醒之后肯定还是很困,可能会关掉桌子上的闹钟继续睡觉,这时我们可以**做几个俯卧撑,听听音乐**,就会让你困意全无。起床成功。
**制定任务清单**
在前一天晚上**按照轻重缓急**制定第二天的任务清单,第二天我们就可以直接按照任务清单进行工作,这样能让你快速进入学习状态。
另外我建议大家尽量将**任务拆解细化**,因为我们大脑在面对庞大的工作时内心是拒绝的,**任务量越大,我们越难开始行动**,所以我们**将任务拆解细化之后,更容易让我们开始做**。其实很多时候我们迷惑的不是怎样继续当下的学习任务,而是怎样开始当下的学习任务。
**不要用时间做计划**
因为我们是在家里学习,**没有学校那么严格的束缚**,这时我们该想着那我得自己约束自己呀,今天我要学习六个小时,明天七个,后天八个。但是结果是这样的吗?
**帕金森定理:只要还有时间,工作就会自动地占满所有可用的时间;如果你给自己安排了充裕的时间从事一项活动,你会放慢你的节奏以使用掉所有分配的时间。**
当我们给我们的某一项工作规划了固定的时间之后,我们可能会出现两种情况
1.拖延反正还有那么多时间可以用,先玩会手机等会再做吧。
2.痛苦比如我们给自己规划了今天要学 6 个小时,这时我们可能就在想,哇,今天还有六个小时要学,好煎熬,这样或许就**会打击我们学习的积极性**,总之我们不要低估我们拖延的能力,你会发现自己真的很牛批。
更好的方法是**用学习量来做规划**,比如今天刷几道题,记几个单词,看几页书等,**一个清晰明确的目标或许会让我们事半功倍。**
既然都读到了这里,还不赶快行动起来,**快去学习吧**。
好啦,现在我们坐到桌子前准备学习啦,那么我们有没有遇到过这种情况呢?
我们学习的时候**总会走神**,一会转转笔,一会抠抠手,刷刷手机,大家**不要太自责**,这不是我们一个人的问题《单核工作法》的作者说,这是人的生理本能惹的货,**大脑会鼓励我们走神**,每次我们走神之后,大脑就会获得一份多巴胺奖励,让你爽一下。
那么有没有什么办法帮助提升学习时的专注力呢?下面是一些小技巧希望能够帮到大家。
**舒缓音乐**
个人习惯会在工作时**听一些舒缓的音乐**,帮助我**提高专注度**,但是不一定适用所有人,大家可以试一下,另外这个歌单的名字是清华大学自习室歌单,不知道真假,俺也没去过清华,不过歌是真不错,大家可以去听一下。
<img src="https://pic2.zhimg.com/80/v2-ed02d6887fa21ee94815240a7c40cd9d_1440w.jpeg" alt="img" style="zoom: 25%;" />
**动手实践**
动手实践在结合我们手和脑方面非常有效,我们可以使用这种方法让自己专注,**边看书,边实践**可以带动我们的思考。比起只看书可以更好的集中我们的注意力,当我们**接受知识的速度和处理知识的速度是趋同的时候**,我们就会**忘记时间,超级专注**。
为啥我们看电视的时候可以一看看几个小时,忘记时间,是因为我们接收剧情的速度和大脑处理的速度是趋同的,看的时候不用思考,越看越上瘾。
**巧用工具**
大家不要排斥利用软件帮助我们学习,毕竟人都是有惰性的,我们不能控制住自己的时候,可以**使用一些工具来帮助我们**,下面我给大家介绍几个我之前读大学的时候用过的软件,个人认为是有一些帮助的。
<img src="https://pic4.zhimg.com/80/v2-74e41ddace28ffe7449da82bf329ae95_1440w.jpeg" alt="img" style="zoom:25%;" />
**软件名称:达目标**
这是一款**设定目标的软件**,我们可以在上面设定我们想要完成的目标,然后我们每天打卡,如果**忘记打卡的次数超过我们设定的休假天数,则会挑战失败**。失败的代价是金钱。是的,我们就失去了我们的挑战金。所以这个软件可以让我们强制打卡,毕竟钱没了还是很心疼的。我们还可以围观别人的目标,**监督别人打卡,如果他挑战失败则可以分得他的挑战金。**
<img src="https://pic2.zhimg.com/80/v2-cd03cec563095eb03e74880ff3bf936b_1440w.jpeg" alt="img" style="zoom:25%;" />
**软件名称:番茄 ToDo**
这是一款锁机软件,我们可以用它来**强制锁机,只保留通话功能,**设定好锁机时间之后,手机就变成了一块板砖,只有等到时间结束之后,才能使用手机。如果手机**没有禅定模式**的话,则可以用这个软件代替
<img src="https://pic1.zhimg.com/80/v2-41cbd40c65ee96ac81768b757f024f58_1440w.jpeg" alt="img" style="zoom:25%;" />
**软件名称:Forest**
这也是一款能够**帮助我们自律**的软件,我们可以设定学习时长,**如果期间玩手机,则会让你的小树枯萎,完成目标则会让小树长大**,有点类似养成型游戏。这是同学推荐的,他经常用,听说效果还不错,感兴趣的同学可以试试。
好啦,我知道的大概就这么多啦,希望大家可以利用好寒假,冲冲冲!
================================================
FILE: animation-simulation/一些分享/考研分享.md
================================================
## 终于轮到我了,关于计算机考研的一点点经验
之前有虎扑老哥让我写一下考研经验分享,但是距离我考研已经好几年了,记忆有些模糊,所以就请了一位跨考浙大计算机并成功上岸的学弟为大家分享。希望对准备考研的学弟学妹有一丢丢帮助。
下面是学弟的分享
---
先说明一下自己的情况,南开材料跨考浙大计算机学硕,初试 411 分,已经拟录取,接受算法基地老哥的邀请,分享一下自己关于考研的一点点经验
主要分三个部分来说吧,择校,初试科目复习以及整个过程中的心态。
## 择校
说来惭愧,择校这个事情,我好像真没什么经验可以分享,知道了自己平时成绩不够保研,然后对于本科材料学科也不是很感兴趣,
加上从小就对计算机很有兴趣,高中时候也参加过一段时间的信息竞赛,所以决定跨考计算机专业,
但刚开始定的目标是本校的计算机学院,六月份返校之后深入了解发现本校计算机招生人数很少(一年就两三个),感觉风险还挺大的,于是和山大计算机本科的高中同学询问,知道浙大计算机每年招收考研生挺多。
自己是南方人也对浙大印象挺好,于是便决定了报考浙大。(马后炮:希望大家不要学我,现在回想起来还是觉得有点悬,信息收集的太少会让自己整个复习过程都有压力)。
**信息收集对于考研来说是非常重要的,大家考研之前要充分调查自己的目标院校,主要途径,该校的师兄师姐,论坛,官网,官方公众号,考研群等。**

## 初试科目复习
我的初试科目是政治、英语一、数学一、408
因为疫情,去年上半年直接在家里,而我又是一个在家里从来不学的人,一本张宇的基础三十讲,从过年到六月份看了十二章,
408 也是只买了王道的课压根就没打开,在家里每天就是打游戏和吃东西,等到 6.8 号返校开始全面复习时,才发现自己的进度非常的慢,
导致一直都有一点点担心自己的进度(但是也不要一味的赶进度,我还是踏踏实实的学,后来的结果也没有很差)开始全面复习之后作息就比较规律了。
早上七点二十起床,八点钟开始上午自习,十二点结束自习,开始吃饭午休,下午两点开始自习,六点吃饭,休息,七点开始晚上的自习,一直到晚上十一点,一天十二个小时,从六月八号到十二月二十五号,每天雷打不动。
### 政治
关于具体的每个学科的复习,首先,政治,我的政治很差,一千题刷了两遍,知识点精讲精练也过了三遍,但是最后客观题还是扣了十五分,导致只有 67,不过主要是错在时政的选择题(我个人属于有点喜欢钻牛角尖的,所以会纠结一些很奇怪的方面),
虽然我政治考的很差,但我觉得 **1000 题和肖四肖八 **还是很重要的,毕竟大题接近于进场默写,时政方面我确实没有去管于是也在这里吃了亏。

### 英语
然后就是英语一,我的英语很烂,虽然高考的时候有 137 分,但是就属于那种,短时间的应试,并不是自己语言能力的提高,四级四百多分,六级考了两遍最终也是四百九十多分,英语就死抓着真题硬啃就够了,再搭配上单词的背记。
但我太懒了,单词背了一遍就没背了最终也是吃了亏,刚开始刷真题的时候,一套题客观题基本就拿个二十几分,那段时间每天做完英语对答案就会心慌,害怕自己因为英语拖后腿考不上研究生,我是两天一个周期,第一天做完对答案,第二天整张卷子翻译并且找出生词。
刚开始从一张卷子有一两百个不认识的慢慢的到几十个到最后基本都认识,可以感受到自己对于考研词汇的掌握是在不断提升的。
第二轮刷真题就不怎么在意选项是啥了,毕竟题都背的下来,主要就是看自己能否顺畅在心中翻译理解卷子中的文章,再有就是分析阅读题出题逻辑的角度,其实如果文章意思能读懂,每个人会出错的方面基本不会变,多分析自己错的题,找出自己逻辑与正确答案逻辑的差异,并且让自己的逻辑往正确答案靠,养成试卷的思维,我认为是很重要的。
我把 97 年到 15 年的英语真题都刷了两边,最后冲刺刷 16 到 20 的卷子每张卷子客观题都只错了十分之内,不过今年的题还是给我上了一课 hhhh,惩罚了我不去背单词,搞得自己阅读题很多都没有看懂,最终拿了 70 分也算是很一般了,大家一定可以做的比我更好。

### 数学
接下来就是数学,我高中的数学倒是学的挺不错,但是上了大学数学完全没有学,开始复习数学的时候,啥都忘了,连三角函数的基本值那些都已经忘了,于是花了很长一段的时间看基础的高数视频和高数基础教程。
哦对了,关于考研跟哪位数学老师,我觉得这是很个人的事情,市面上比较有名的老师教学肯定都是没问题的,得看你自己喜欢什么样的风格,我最终选择了张宇,因为他讲课很有意思,不会让我打瞌睡,我从六月份开始花了一个半月把基础课程看完。
这期间跟着视频做例题和书上的习题,然后第二轮看提高的教材和提高的视频,这期间除了做提高的教材,还搭配刷配套的 1000 题,关于题集的选择也是很个人的,我刚开始选的是 1800 题,但是做的太不顺了,后来换成了 1000 题,1000 题刚开始只做 AB,最后冲刺的时候才做的 C。
第三轮就是开始刷真题和模拟卷以及开始收集错题,因为我的基础太差了,导致我的数学进度一直很赶,最后半个月才把错题整理完,导致我线代复习的还不是很好,最后也确实错了一个选择题和线代大题的第二问,真题我从 87 年还是多少年开始刷的,一直刷到 20 年,一天一套,做完就对答案然后整理错题,整理错题是很重要的一环.
我觉得对于应试数学的提高还是很有效的,毕竟题是做不完的,但是题型只有这么多,如果能做到做一题而通一类,对于数学分数的提高还是很有作用的,模拟题我做了李林和张宇的模拟题,但是还有其他的模拟题比如**合工大**,但我实在是时间太赶了,所以就没有再做,最后的结果 141 也算还不错。

### 专业课
最后是 408,408 我也是从六月份开始复习的,刚开始拿着王道的教材和王道的视频过一遍,做王道书上的选择题,因为 408 的知识很系统,所以刚开始做题痛苦的一比,一章错一半是常有,第二轮自己细读教材,把知识点自己提炼写在笔记本上.
同时二刷选择题然后把王道书上的大题过一遍,最后第三轮的时候刷 408 真题和王道的模拟题,我觉得 408 很像理综,数据结构和计组像物理,有思维逻辑思考的过程,操作系统和计网就和化学生物一样,一定要基础的知识稳固才能做出题,对了,如果时间充裕,基础教材也是很重要的.
我就因为完全没看过基础教材,搞得今年那些很基础很基础的概念题错了,408 只要选择题不出问题,大题基本上不会错多少分,最多是数据结构的算法题有一些障碍,但直接用暴力算法也只会扣几分无伤大雅,最终我错了六个选择题 ORZ,大家不要学习我基础薄弱,最后 133 分也算不错。
噢对了,如果目标院校有机试的兄弟,机试也是很重要的一部分,建议尽早复习,机试复习对于数据结构的复习帮助也是很大的。
而关于复习时的时间安排,我是完全按照考试时间来的,**所有的上午都是用来复习数学,下午用来复习 408,晚上则前期安排英语卷子,后面就是政治背记和写题(晚上经常因为数学学不完被挪用时间写数学)所以我觉得大伙可以比我更早开始,比如四月五月,也不至于像我一样到最后手忙脚乱。**

## 心态
第三点就是整个过程中的心态,我觉得考研比起高考难顶的最重要的一点就是考研属于盲人摸象。
你永远不知道自己到底是什么水平,只要做题时哪个地方出现瑕疵,心理就会紧张,就会想自己的竞争对手是不是会完美的做出这一题,而且长时间高强度的学习对于身心都是很大的挑战。
我在考研期间压力很大老是想吃宵夜导致现在重了二十斤,而且会有无数次想要给自己放松一下,复习考研的时候正常情况不会像高考一样一直有人督促,所以自己如果想偷懒,一下一天就被荒废了,所以我觉得自己内心的渴望必须要十分强烈,才能够真的咬牙撑下这一段孤独旅程。

其实整个复习过程我也不是完完全全没有放松,初期我每周日都会有一个半天啥事不干就放松,而且中间有段时间压力实在太大,晚上十二点多躺下来还在床上看火影忍者看到一两点。
但是却没有缺席任何一个我计划中学习的半天,风雨无阻,当时我给自己心里说的就是“尽人事,听天命”,我不想之后再来后悔,所以我想做到能利用的每一秒钟都把握住,最后发生什么结果也都接受,每个人调节的方式都不太一样,我抛砖引玉仅供大家参考。
考前一个月其实压力已经很大了,经常自己一个人在食堂吃早饭啃着个包子眼泪就止不住的往下掉,和家里人电话的时候,只要他们一问自己累不累就会哽咽,但是这些都是必经的,既然自己选择了目标,就应该为之付出应有的努力,才配得上能够实现目标。
之前复习的时候还 yy 如果上岸了,该怎么来装逼,到了现在只想说,考研确实挺辛苦的,但做出选择就得有所行动,对于年级还低的兄弟,我的建议只有一个,好好学习,争取保研,考研太苦了,我这辈子不想再体验一次这样的备考,就这么多了,祝福各位心想事成,早日上岸!
---
厨子寄语:考研备考的过程真的很苦,深有体会,尽人事,听天命,你越渴望,机会越大。愿努力考研的你们,都能成功上岸心仪的院校。
================================================
FILE: animation-simulation/一些分享/软件分享.md
================================================
这两天读者让我介绍一下写东西用到的工具,那咱们就来看看我都用了什么工具吧。
PS:这期很多利器,大家不要错过哈,总有一款适合你。
---
## **Typora**
这个大家肯定都不陌生,我的所有文章都是用这个软件写出来的,非常喜欢这个软件,界面简洁,功能强大。
是一款 markdown 神器,支持代码、表格、公式插入,支持导出各种格式文件 pdf,doc 等。
img
上面就是软件实况,大家可以试一下,是不是看起来很不错,另外还有一些我没用过的功能,欢迎大家尝试,下面为官方网站
https://www.typora.io/
另外还有 notion 也是贼好用的软件,我哥们一直在用,我也早就下载了,一直放着没用,得抽空学学,真的很不错。
还有一个国产软件 wolai,是读者推荐的,功能和 notion 差不多,也非常不错,大家可以都试一下,挑选适合自己的。
推荐指数:⭐⭐⭐⭐⭐
---
## draw.io
这个也是我写东西的主力军,从林总那里知道的,非常牛批,原来我还用 PPT 和 Process 画图,自从有了这个,其他的再也没用过了,
画的图贼好看,这也是你们问的最多的,呐,大家快拿去用吧,具体功能我就不介绍啦,大家一看便知。
我平常画图都是在这个网站上,真的很不错,强烈推荐。
https://app.diagrams.net/
大家也可以试试 Process ,之前也一直用它,也是一个很不错的在线画图网站。
推荐指数:⭐⭐⭐⭐⭐
---
## picx
我是用的 GitHub 当的图床,所以这个神器可帮了我大忙了,是一款贼好用的图床神器,
图片外链使用 jsDelivr 进行 CDN 加速。不用下载和安装,只需要一个 Github 账号,打开 PicX 官网即可配置使用
img
刚开始用的时候才几百位小伙伴使用,当时还怕用的人太少,管理员不再继续维护,现在看来担心是多余的,越来越多的人发现这个网站啦,大家也可以试试,真的不错,大家如果有更好的可以在评论区说一下呀。
picx.xpoet.cn
GitHub 配置图床大家可以搜索一哈,跟着做就行啦,很简单的。
推荐指数:⭐⭐⭐⭐⭐
---
## mdnice
这个网站也帮助到我很多,我主要用它来排版,在 typora 编辑好文章之后,导入到 mdnice ,然后一键复制到公众号,省掉了排版的时间, mdnice 和 draw.io 算是号主们必备网站,站如其名真的很 nice。

算是我的排版主力,一个免费好使的网站
www.mdnice.com
另外还有另一个排版网站 http://md.aclickall.com/ 大家可以选择自己喜欢的。
推荐指数:⭐⭐⭐⭐⭐
---
## carbon
这个网站我刚开始用的贼多,可以把代码转化成图片,大家可以不用滑动,就能看清所有代码,但是代码比较小,后来吴师兄建议我换成代码形式,要照顾下电脑阅读的读者,图片的话大家也不好复制,后面就没有再使用了,
大家可以先收藏一哈,后面需要的话就就拿出来用用,很多主题,都挺好看。
carbon.now.sh
推荐指数:⭐⭐⭐⭐
---
## **Free Video to GIF Converter**
这时一款将视频转为 gif 图的软件,比如上面的动画我就是先录屏然后再将视频转化为 gif,平常用的也比较多,另外还有一款可以直接录屏保存为 gif 的软件 ScreenToGif,不过这个用的不太多。

这个软件的使用率也挺高,也是一块免费的软件,用着很顺手,需要的老哥可以试一哈。
推荐指数:⭐⭐⭐⭐
好啦,上面的软件我都给留下了网站,大家可以自己下载或者在线使用,另外我给大家打包了一份,
大家可以自己下载,拜了个拜。
链接:https://pan.baidu.com/s/1oQi1OECYagZyCjKtxPog9A
提取码:jrnb
================================================
FILE: animation-simulation/二分查找及其变种/leetcode 81不完全有序查找目标元素(包含重复值) .md
================================================
> 如果阅读时,发现错误,或者动画不可以显示的问题可以添加我微信好友 **[tan45du_one](https://raw.githubusercontent.com/tan45du/tan45du.github.io/master/个人微信.15egrcgqd94w.jpg)** ,备注 github + 题目 + 问题 向我反馈
>
> 感谢支持,该仓库会一直维护,希望对各位有一丢丢帮助。
>
> 另外希望手机阅读的同学可以来我的 <u>[**公众号:程序厨**](https://raw.githubusercontent.com/tan45du/test/master/微信图片_20210320152235.2pthdebvh1c0.png)</u> 两个平台同步,想要和题友一起刷题,互相监督的同学,可以在我的小屋点击<u>[**刷题小队**](https://raw.githubusercontent.com/tan45du/test/master/微信图片_20210320152235.2pthdebvh1c0.png)</u>进入。
## **查找目标元素(含重复元素)**
我们通过刚才的例子了解了,如果在不完全有序的数组中查找目标元素,但是我们的不完全有序数组中是不包含重复元素的,那如果我们的数组中包含重复元素我们应该怎么做呢?见下图
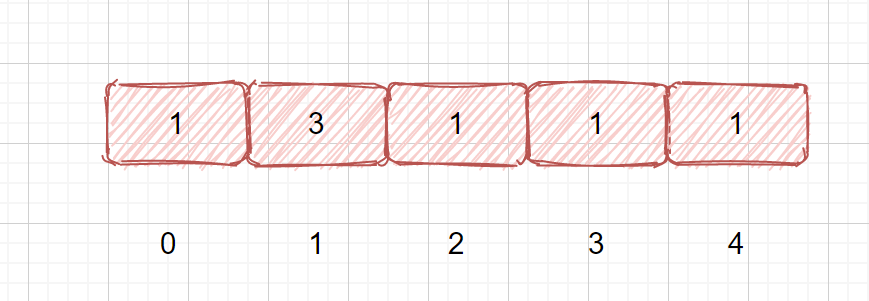
如上图,如果我们继续使用刚才的代码,则会报错这是为什么呢?我们来分析一下。
所以我们需要对其进行改进,我们只需将重复元素去掉即可,当我们的 nums[left] == nums[mid] 时,让 left ++ 即可,比如 1,3,1,1,1 此时 nums[mid] == nums[left] 则 left ++,那我们此时会不会错过目标值呢?其实并不会,只是去掉了某些重复元素,如果此时我们的目标元素是 3,则我们 left++,之后情况就变为了上题中的情况。
#### [81. 搜索旋转排序数组 II](https://leetcode-cn.com/problems/search-in-rotated-sorted-array-ii/)
#### **题目描述**
假设按照升序排序的数组在预先未知的某个点上进行了旋转。
( 例如,数组 [0,0,1,2,2,5,6] 可能变为 [2,5,6,0,0,1,2] )。
编写一个函数来判断给定的目标值是否存在于数组中。若存在返回 true,否则返回 false。
示例 1:
> 输入:nums = [2,5,6,0,0,1,2], target = 0 输出:true
示例 2:
> 输入:nums = [2,5,6,0,0,1,2], target = 3 输出:false
#### **题目解析**
这个题目就比刚才的不含重复元素的题目多了一个去除某些重复元素的情况,当 nums[mid] == nums[left] 时,让 left++,并退出本次循环,其余部分完全相同,大家可以结合代码和图片进行理解。
#### **题目代码**
Java Code:
```java
class Solution {
public boolean search(int[] nums, int target) {
int left = 0;
int right = nums.length - 1;
while (left <= right) {
int mid = left+((right-left)>>1);
if (nums[mid] == target) {
return true;
}
if (nums[mid] == nums[left]) {
left++;
continue;
}
if (nums[mid] > nums[left]) {
if (nums[mid] > target && target >= nums[left]) {
right = mid - 1;
} else if (target > nums[mid] || target < nums[left]) {
left = mid + 1;
}
}else if (nums[mid] < nums[left]) {
if (nums[mid] < target && target <= nums[right]) {
left = mid + 1;
} else if (target < nums[mid] || target > nums[right]) {
right = mid - 1;
}
}
}
return false;
}
}
```
================================================
FILE: animation-simulation/二分查找及其变种/leetcode153搜索旋转数组的最小值.md
================================================
> 如果阅读时,发现错误,或者动画不可以显示的问题可以添加我微信好友 **[tan45du_one](https://raw.githubusercontent.com/tan45du/tan45du.github.io/master/个人微信.15egrcgqd94w.jpg)** ,备注 github + 题目 + 问题 向我反馈
>
> 感谢支持,该仓库会一直维护,希望对各位有一丢丢帮助。
>
> 另外希望手机阅读的同学可以来我的 <u>[**公众号:程序厨**](https://raw.githubusercontent.com/tan45du/test/master/微信图片_20210320152235.2pthdebvh1c0.png)</u> 两个平台同步,想要和题友一起刷题,互相监督的同学,可以在我的小屋点击<u>[**刷题小队**](https://raw.githubusercontent.com/tan45du/test/master/微信图片_20210320152235.2pthdebvh1c0.png)</u>进入。
## **寻找最小值**
这种情况也很容易处理,和咱们的 leetcode33 搜索旋转排序数组,题目类似,只不过一个需要搜索目标元素,一个搜索最小值,我们搜索目标元素很容易处理,但是我们搜索最小值应该怎么整呢?见下图
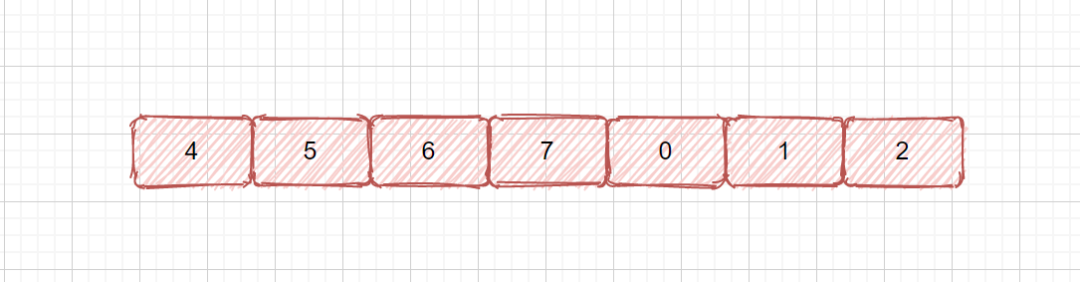
我们需要在一个旋转数组中,查找其中的最小值,如果我们数组是完全有序的很容易,我们只需要返回第一个元素即可,但是此时我们是旋转过的数组。
我们需要考虑以下情况
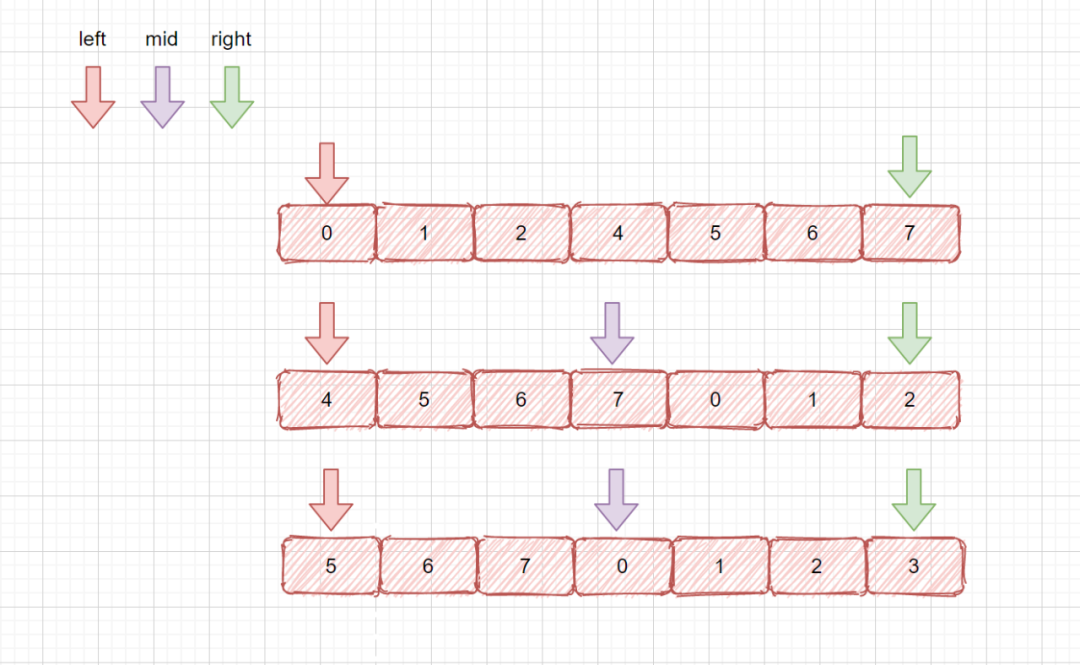
我们见上图,我们需要考虑的情况是
- 数组完全有序 nums[left] < nums[right],此时返回 nums[left] 即可
- left 和 mid 在一个都在前半部分,单调递增区间内,所以需要移动 left,继续查找,left = mid + 1;
- left 在前半部分,mid 在后半部分,则最小值必在 left 和 mid 之间(见下图)。则需要移动 right ,right = mid,我们见上图,如果我们 right = mid - 1,则会漏掉我们的最小值,因为此时 mid 指向的可能就是我们的最小值。所以应该是 right = mid 。
#### [153. 寻找旋转排序数组中的最小值](https://leetcode-cn.com/problems/find-minimum-in-rotated-sorted-array/)
#### **题目描述**
假设按照升序排序的数组在预先未知的某个点上进行了旋转。例如,数组 [0,1,2,4,5,6,7] 可能变为 [4,5,6,7,0,1,2] 。
请找出其中最小的元素。
示例 1:
> 输入:nums = [3,4,5,1,2]输出:1
示例 2:
> 输入:nums = [4,5,6,7,0,1,2] 输出:0
示例 3:
> 输入:nums = [1] 输出:1
#### **题目解析**
我们在上面的描述中已经和大家分析过几种情况,下面我们一起来看一下,[5,6,7,0,1,2,3]的执行过程,相信通过这个例子,大家就能把这个题目整透了。
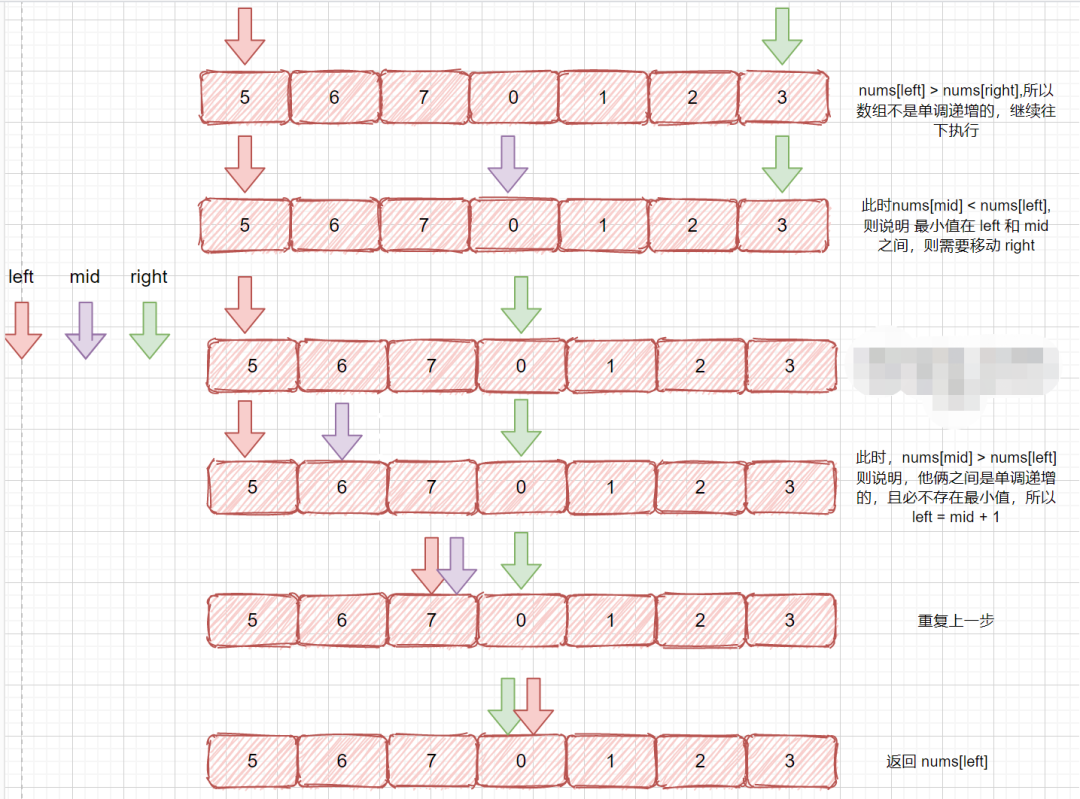
**题目代码**
Java Code:
```java
class Solution {
public int findMin(int[] nums) {
int left = 0;
int right = nums.length - 1;
while (left < right) {
if (nums[left] < nums[right]) {
return nums[left];
}
int mid = left + ((right - left) >> 1);
if (nums[left] > nums[mid]) {
right = mid;
} else {
left = mid + 1;
}
}
return nums[left];
}
}
```
C++ Code:
```cpp
class Solution {
public:
int findMin(vector <int> & nums) {
int left = 0;
int right = nums.size() - 1;
while (left < right) {
if (nums[left] < nums[right]) {
return nums[left];
}
int mid = left + ((right - left) >> 1);
if (nums[left] > nums[mid]) {
right = mid;
} else {
left = mid + 1;
}
}
return nums[left];
}
};
```
================================================
FILE: animation-simulation/二分查找及其变种/leetcode33不完全有序查找目标元素(不包含重复值).md
================================================
> 如果阅读时,发现错误,或者动画不可以显示的问题可以添加我微信好友 **[tan45du_one](https://raw.githubusercontent.com/tan45du/tan45du.github.io/master/个人微信.15egrcgqd94w.jpg)** ,备注 github + 题目 + 问题 向我反馈
>
> 感谢支持,该仓库会一直维护,希望对各位有一丢丢帮助。
>
> 另外希望手机阅读的同学可以来我的 <u>[**公众号:程序厨**](https://raw.githubusercontent.com/tan45du/test/master/微信图片_20210320152235.2pthdebvh1c0.png)</u> 两个平台同步,想要和题友一起刷题,互相监督的同学,可以在我的小屋点击<u>[**刷题小队**](https://raw.githubusercontent.com/tan45du/test/master/微信图片_20210320152235.2pthdebvh1c0.png)</u>进入。
# **不完全有序**
## **查找目标元素(不含重复元素)**
之前我们说二分查找需要在完全有序的数组里使用,那么不完全有序时可以用吗?
例:
上面的新数组虽然不是完全有序,但是也可以看成是由一个完全有序的数组翻折得到的。或者可以理解成两个有序数组,且第二个数组的最大值小于第一的最小值,我们将其拼接,拼接成了一个不完全有序的数组,在这个数组中我们需要找到 target ,找到后返回其索引,如果没有找到则返回 -1;
我们第一次看到这种题目时,可能会想到,我们只需要挨个遍历就好啦,发现后返回索引即可,这样做当然是可以滴,那么我们可不可以使用二分查找呢?
下面我们看一下解决该题的具体思路。
首先我们设想一下 mid 值会落到哪里,我们一起来想一下。
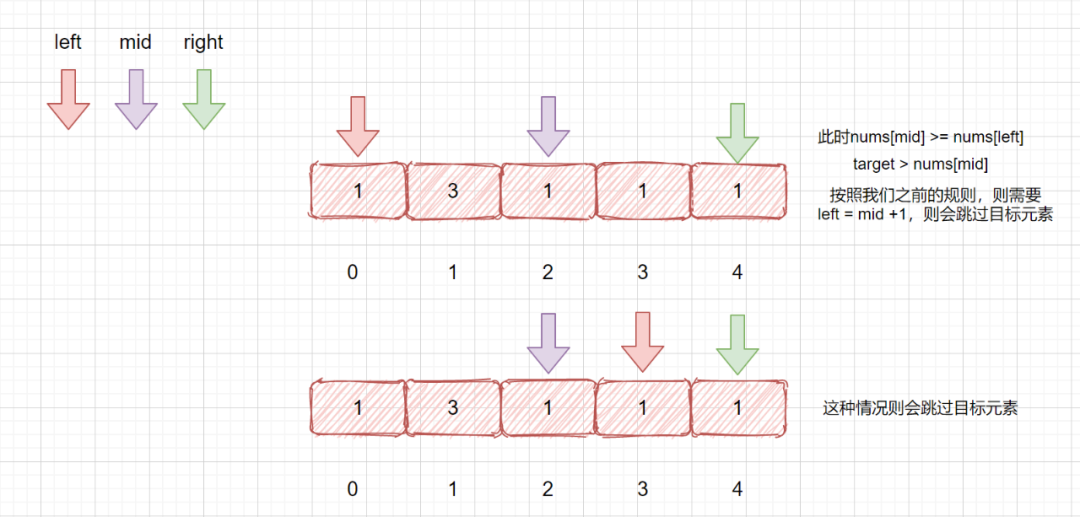
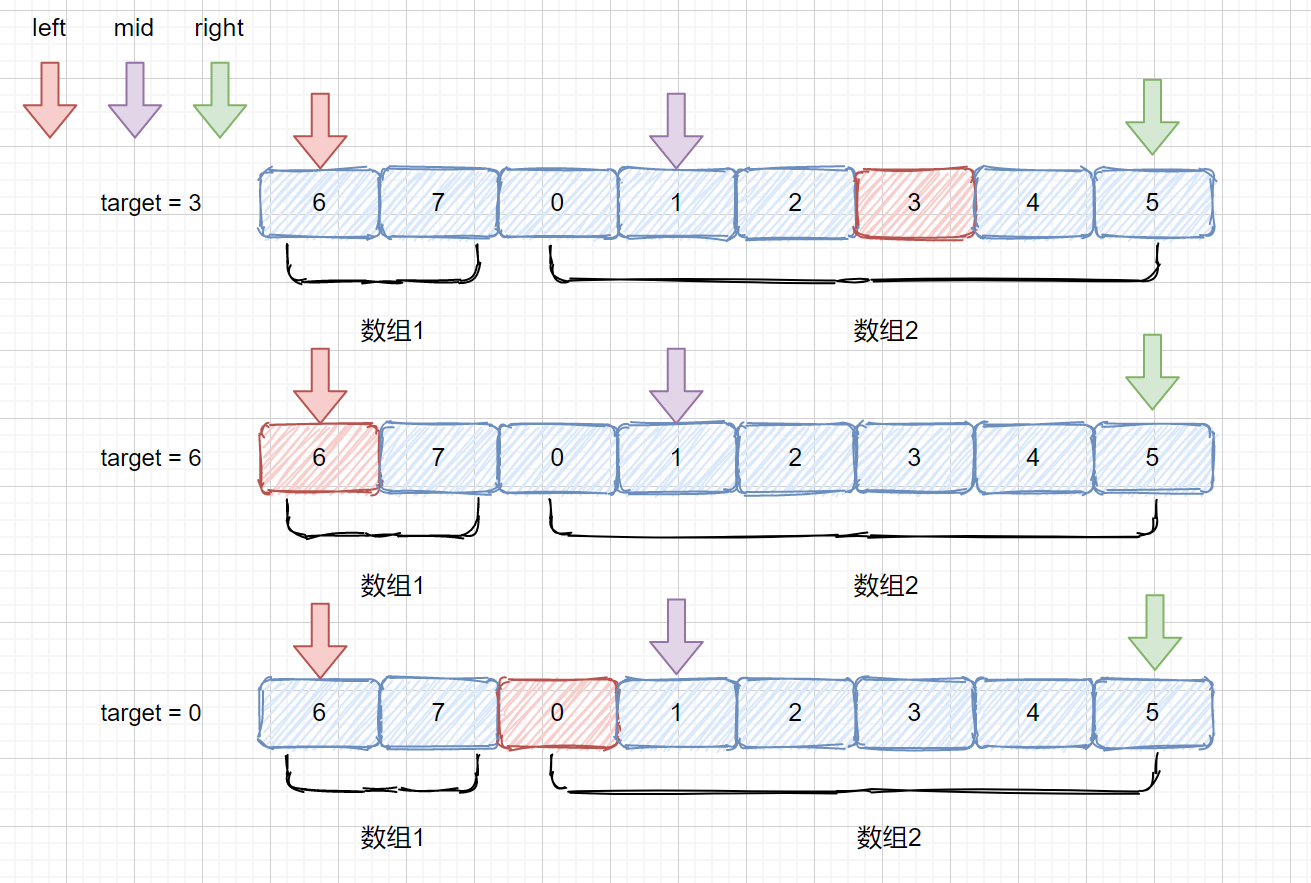
是不是只有两种情况,和 left 在一个数组,同时落在 数组 1 或同时在 数组 2,或者不在一个数组, left 在数组 1,mid 在数组 2。想到这里咱们这个题目已经完成一半了。
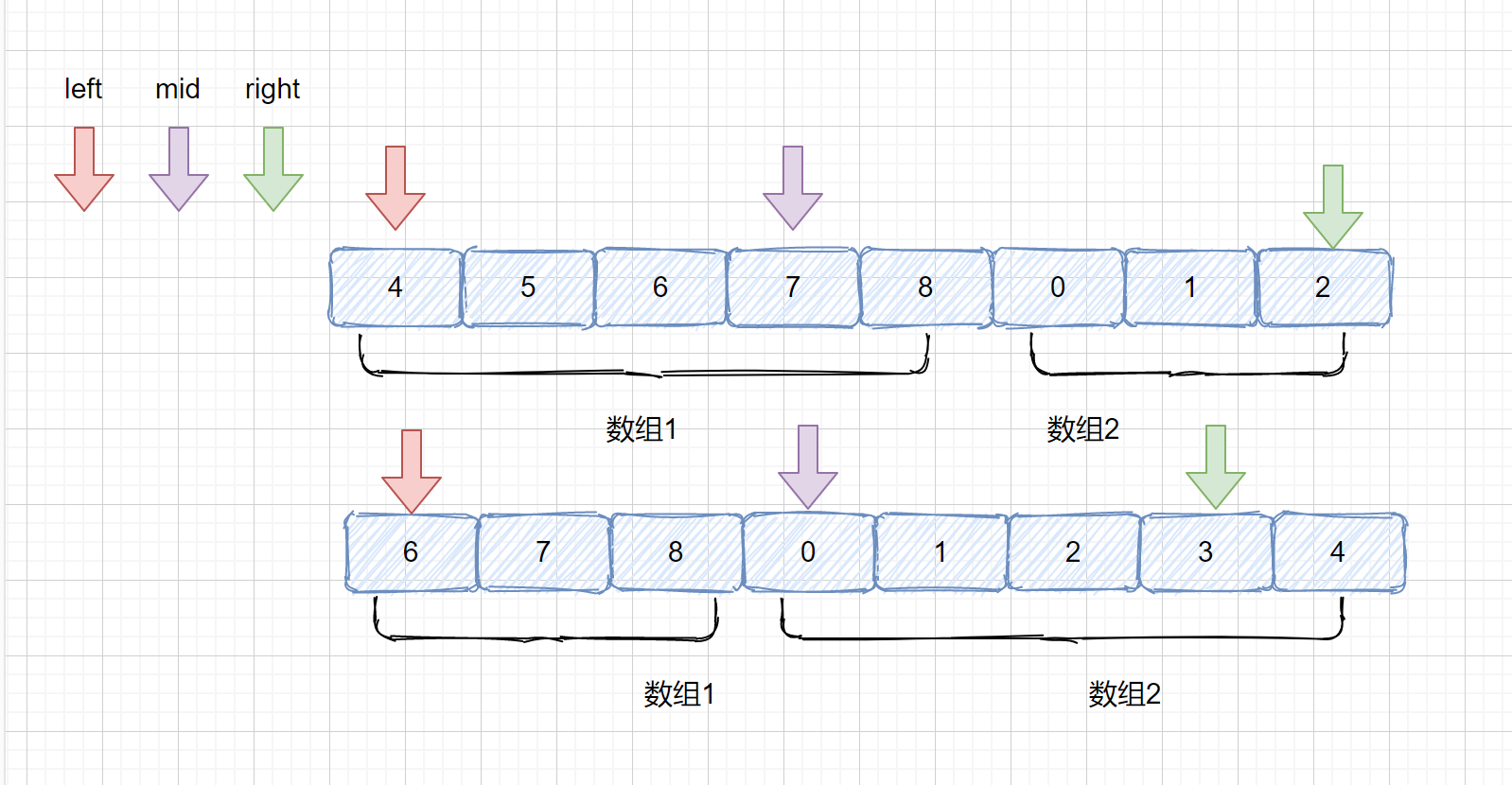
那么我们先来思考一下,?我们可以根据 nums[mid] 和 nums[left] 判断,是因为我们的 mid 一定是会落在 left 和 right 之间,那如果 nums[mid] >= nums[left] 时,说明他俩落在一个数组里了,如果 nums[mid] < nums[left] 时,说明他俩落在了不同的数组,此时 left 在数组 1 mid 在数组 2.
注:left 和 mid 落在同一数组时,不能是 left 在 数组 2 ,mid 在 数组 1 呢?因为咱们的 mid 是通过 left 和 right 的下标求得,所以应该在 left 和 right 中间
如果我们的 mid 和 left 在同一个数组内时?咱们的 target 会有几种情况呢?我们通过都落在 数组 1 举例。
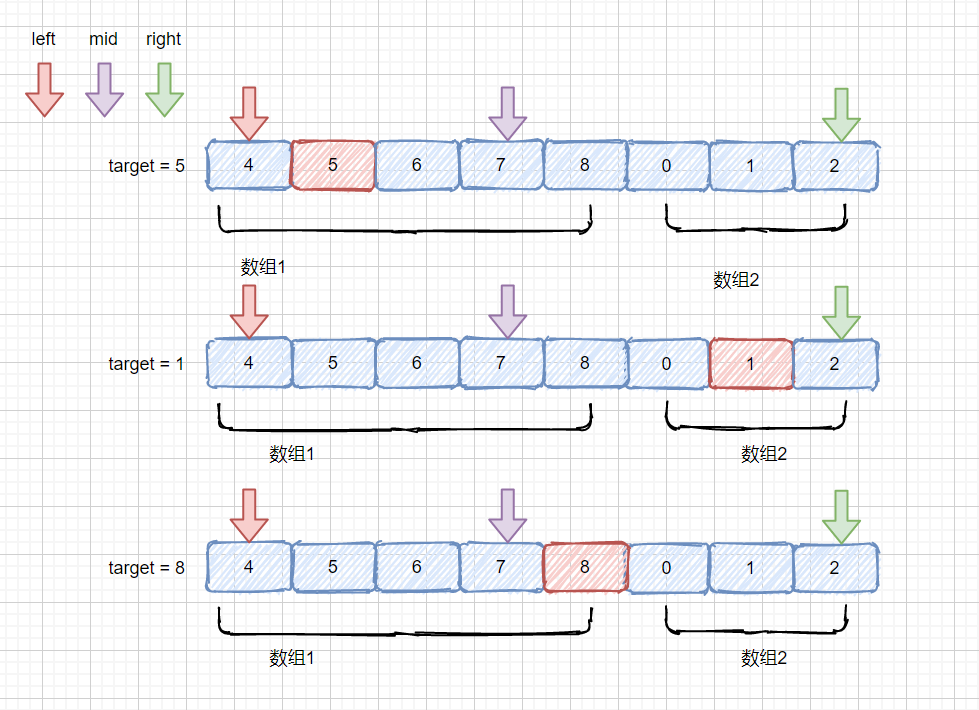
无非也是两种情况,用我们上面的例子来说,
1.**落在 mid 的左边**,当前例子中 情况是落在 [4,7)区间内,即 4 <= target < 7 ,也就是 target >= nums[left] && target < nums[mid],此时我们让 right = mid -1,让 left 和 right 都落到数组 1 中,下次查找我们就是在数组 1 中进行了,完全有序,
2.**落在 mid 的右边**,此时例子中 target 不落在 [4,7)区间内,那就 target = 8 或 0 <= target <= 2 (此时我们的 target 均小于 nums[left]) 两种情况,也就是 target > nums[mid] || target < nums[left] 此时我们让 left = mid + 1 即可,也是为了慢慢将 left 和 right 指针赶到一个有序数组内。
那我们在来思考一下当 mid 值落在 **数组 2** 中时,target 会有几种情况呢?其实和上面的例子思路一致,情况相反而已。
1. target <= nums[right] && target > nums[mid]
> 这里和上面的对应,此时的情况就是整个落在右半部分,我们下次就可以在数组 2 内进行查找。
2. target > nums[right] || target < nums[mid]
> 这里就是和上面的第二种情况对应,落在 mid 的左半部分,我们尽量将两个指针赶到一起
希望我的表达能够让大家对这个变种理解透彻,如果没能让各位理解,或者有表达不当的地方欢迎各位批评指导。然后我们一起来做一下 leetcode 33 题吧。
#### [33. 搜索旋转排序数组](https://leetcode-cn.com/problems/search-in-rotated-sorted-array/)
#### 题目描述
给你一个整数数组 nums ,和一个整数 target 。
该整数数组原本是按升序排列,但输入时在预先未知的某个点上进行了旋转。(例如,数组 [0,1,2,4,5,6,7] 可能变为 [4,5,6,7,0,1,2] )。
请你在数组中搜索 target ,如果数组中存在这个目标值,则返回它的索引,否则返回 -1 。
示例 1:
> 输入:nums = [4,5,6,7,0,1,2], target = 0
> 输出:4
示例 2:
> 输入:nums = [4,5,6,7,0,1,2], target = 3
> 输出:-1
示例 3:
> 输入:nums = [1], target = 0
> 输出:-1
#### 题目解析
这个题目的解答方法,咱们在上面已经有所描述,下面我们来看一下下面这个例子的代码执行过程吧.
> 输入 nums = [4,5,6,7,8,0,1,2] target = 8
下面我们看题目代码吧,如果还没有完全理解的同学,可以仔细阅读 if ,else if 里面的语句,还有注释,一定可以整透的。
#### 题目代码
Java Code:
```java
class Solution {
public int search(int[] nums, int target) {
//左右指针
int left = 0;
int right = nums.length - 1;
while (left <= right) {
int mid = left+((right-left)>>1);
if (nums[mid] == target) {
return mid;
}
//落在同一数组的情况,同时落在数组1 或 数组2
if (nums[mid] >= nums[left]) {
//target 落在 left 和 mid 之间,则移动我们的right,完全有序的一个区间内查找
if (nums[mid] > target && target >= nums[left]) {
right = mid - 1;
// target 落在right和 mid 之间,有可能在数组1, 也有可能在数组2
} else if (target > nums[mid] || target < nums[left]) {
left = mid + 1;
}
//不落在同一数组的情况,left 在数组1, mid 落在 数组2
}else if (nums[mid] < nums[left]) {
//有序的一段区间,target 在 mid 和 right 之间
if (nums[mid] < target && target <= nums[right]) {
left = mid + 1;
// 两种情况,target 在left 和 mid 之间
} else if (target < nums[mid] || target > nums[right]) {
right = mid - 1;
}
}
}
//没有查找到
return -1;
}
}
```
================================================
FILE: animation-simulation/二分查找及其变种/leetcode34查找第一个位置和最后一个位置.md
================================================
> 如果阅读时,发现错误,或者动画不可以显示的问题可以添加我微信好友 **[tan45du_one](https://raw.githubusercontent.com/tan45du/tan45du.github.io/master/个人微信.15egrcgqd94w.jpg)** ,备注 github + 题目 + 问题 向我反馈
>
> 感谢支持,该仓库会一直维护,希望对各位有一丢丢帮助。
>
> 另外希望手机阅读的同学可以来我的 <u>[**公众号:程序厨**](https://raw.githubusercontent.com/tan45du/test/master/微信图片_20210320152235.2pthdebvh1c0.png)</u> 两个平台同步,想要和题友一起刷题,互相监督的同学,可以在我的小屋点击<u>[**刷题小队**](https://raw.githubusercontent.com/tan45du/test/master/微信图片_20210320152235.2pthdebvh1c0.png)</u>进入。
## 查找元素第一个位置和最后一个位置
上面我们说了如何使用二分查找在数组或区间里查出特定值的索引位置。但是我们刚才数组里面都没有重复值,查到返回即可,那么我们思考一下下面这种情况
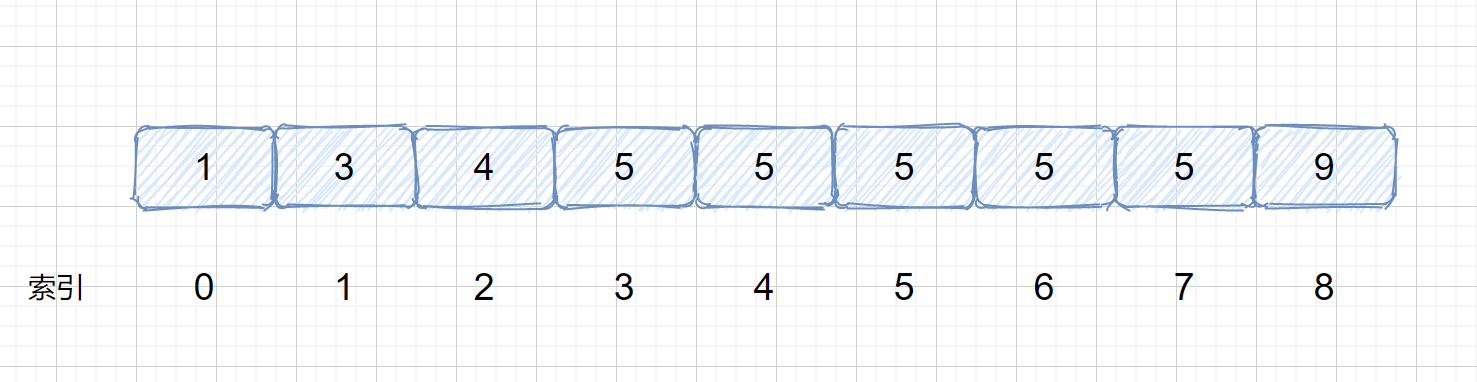
此时我们数组里含有多个 5 ,我们查询是否含有 5 可以很容易查到,但是我们想获取第一个 5 和 最后一个 5 的位置应该怎么实现呢?哦!我们可以使用遍历,当查询到第一个 5 时,我们设立一个指针进行定位,然后到达最后一个 5 时返回,这样我们就能求的第一个和最后一个五了?因为我们这个文章的主题就是二分查找,我们可不可以用二分查找来实现呢?当然是可以的。
#### [34. 在排序数组中查找元素的第一个和最后一个位置](https://leetcode-cn.com/problems/find-first-and-last-position-of-element-in-sorted-array/)
#### 题目描述
> 给定一个按照升序排列的整数数组 nums,和一个目标值 target。找出给定目标值在数组中的开始位置和结束位置。
>
> 如果数组中不存在目标值 target,返回 [-1, -1]。
示例 1:
> 输入:nums = [5,7,7,8,8,10], target = 8
> 输出:[3,4]
示例 2:
> 输入:nums = [5,7,7,8,8,10], target = 6
> 输出:[-1,-1]
示例 3:
> 输入:nums = [], target = 0
> 输出:[-1,-1]
#### 题目解析
这个题目很容易理解,我们在上面说了如何使用遍历解决该题,但是这个题目的目的就是让我们使用二分查找,我们来逐个分析,先找出目标元素的下边界,那么我们如何找到目标元素的下边界呢?
我们来重点分析一下刚才二分查找中的这段代码
```java
if (nums[mid] == target) {
return mid;
}else if (nums[mid] < target) {
//这里需要注意,移动左指针
left = mid + 1;
}else if (nums[mid] > target) {
//这里需要注意,移动右指针
right = mid - 1;
}
```
我们只需在这段代码中修改即可,我们再来剖析一下这块代码,nums[mid] == target 时则返回,nums[mid] < target 时则移动左指针,在右区间进行查找, nums[mid] > target 时则移动右指针,在左区间内进行查找。
那么我们思考一下,如果此时我们的 nums[mid] = target ,但是我们不能确定 mid 是否为该目标数的左边界,所以此时我们不可以返回下标。例如下面这种情况。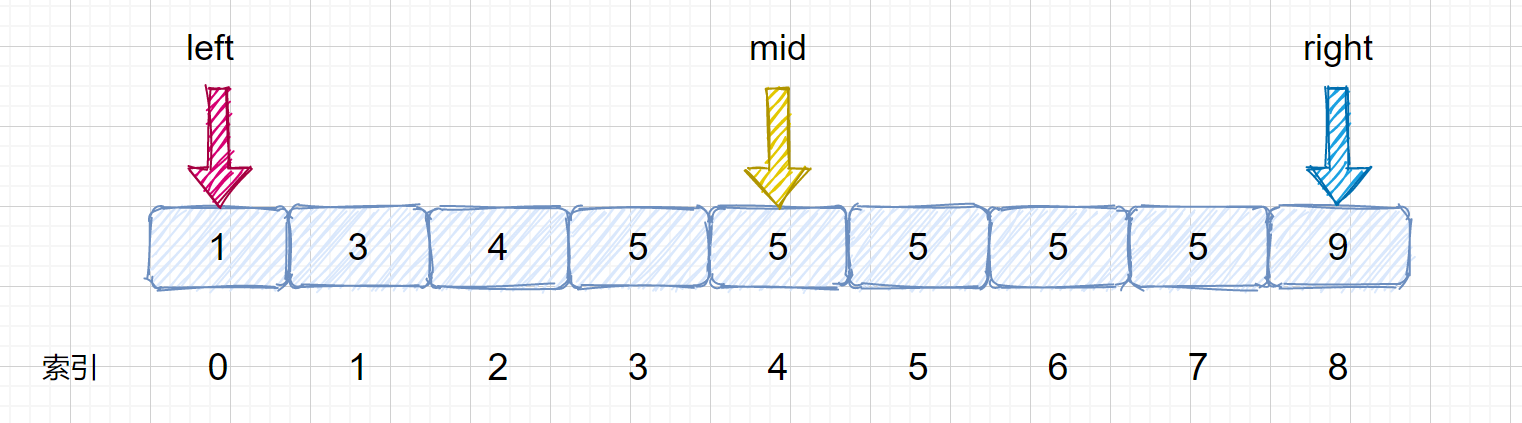
此时 mid = 4 ,nums[mid] = 5,但是此时的 mid 指向的并不是第一个 5,所以我们需要继续查找 ,因为我们要找
的是数的下边界,所以我们需要在 mid 的值的左区间继续寻找 5 ,那我们应该怎么做呢?我们只需在
target <= nums[mid] 时,让 right = mid - 1 即可,这样我们就可以继续在 mid 的左区间继续找 5 。是不是听着有点绕,我们通过下面这组图进行描述。
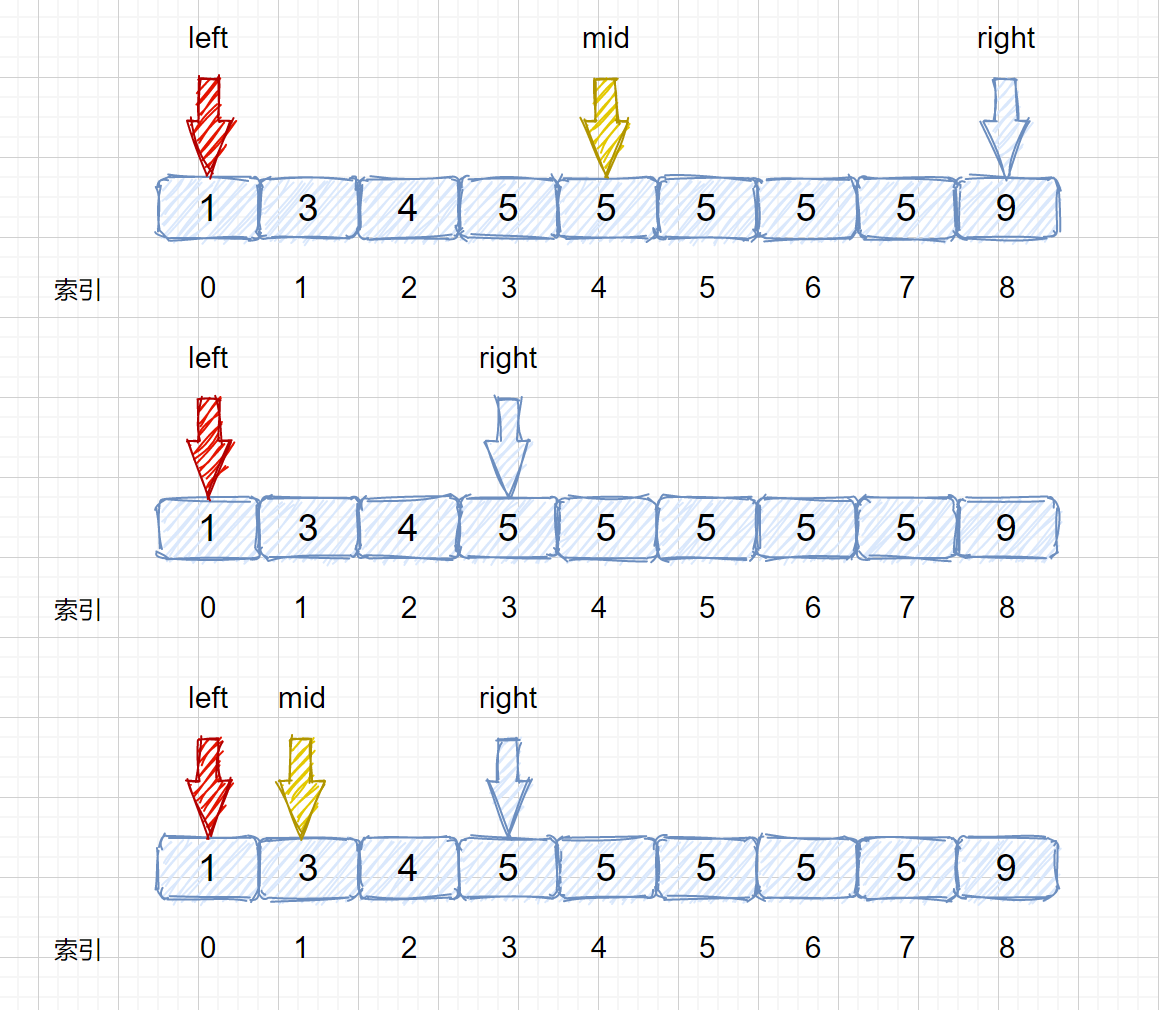
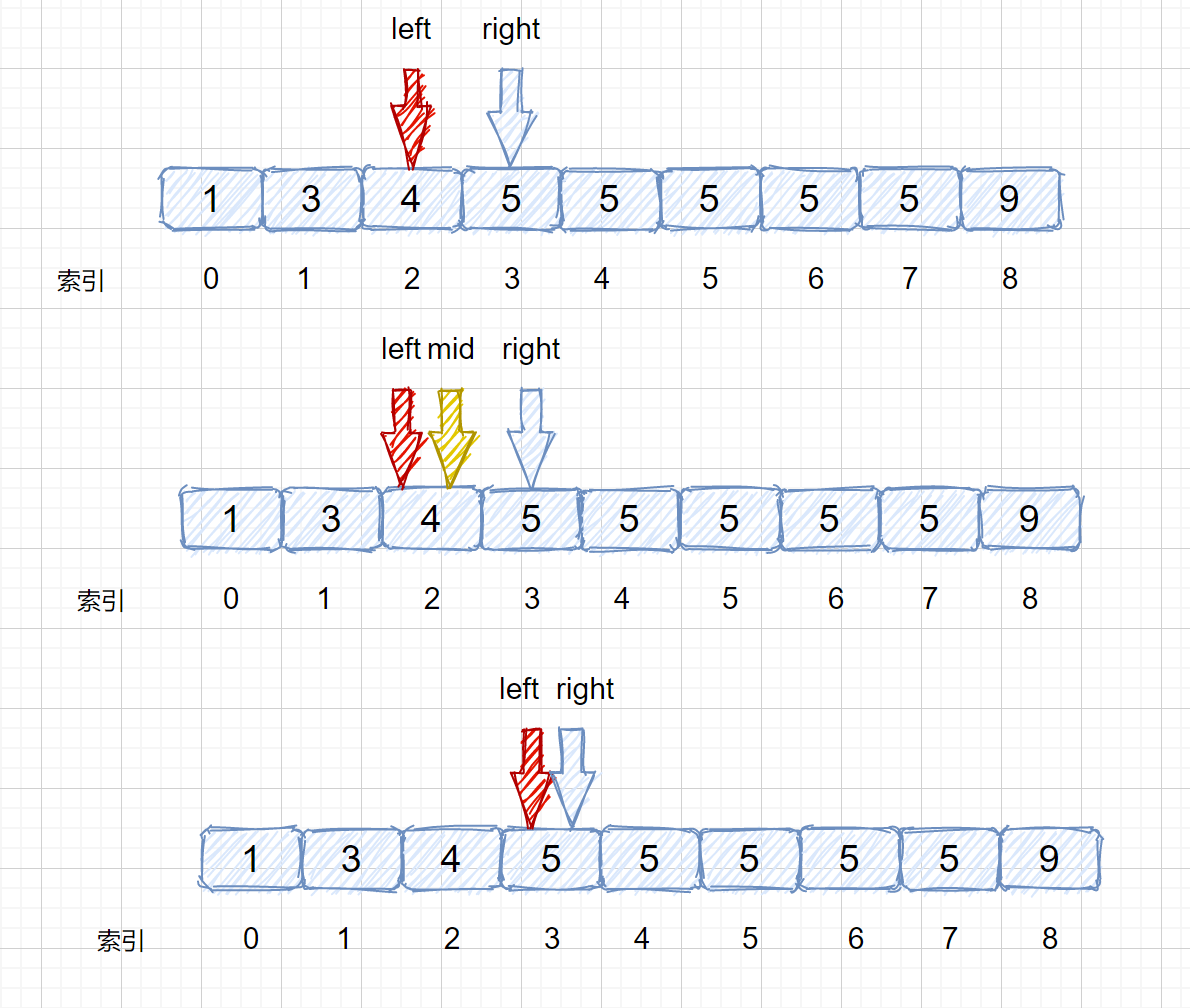
其实原理很简单,就是我们将小于和等于合并在一起处理,当 target <= nums[mid] 时,我们都移动右指针,也就是 right = mid -1,还有一个需要注意的就是,我们计算下边界时最后的返回值为 left ,当上图结束循环时,left = 3,right = 2,返回 left 刚好时我们的下边界。我们来看一下求下边界的具体执行过程。
**动图解析**
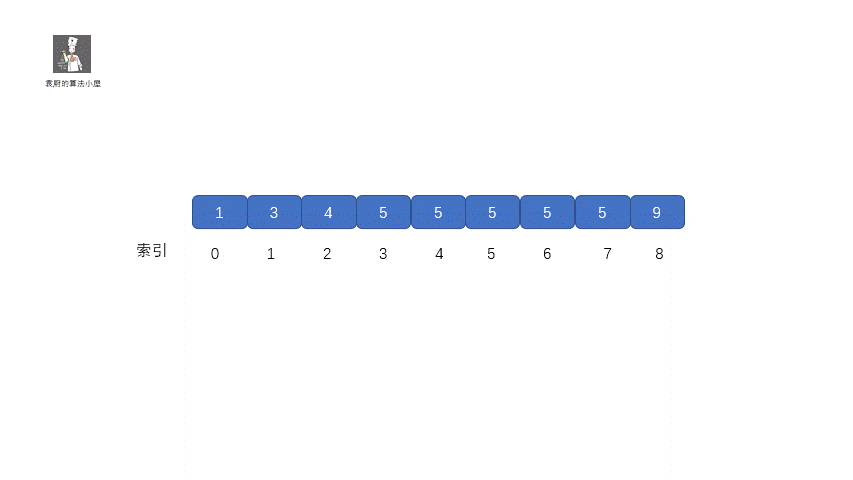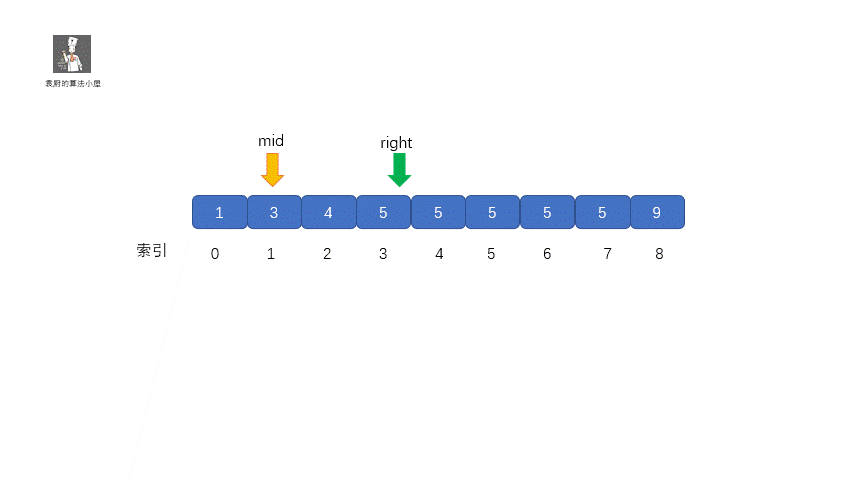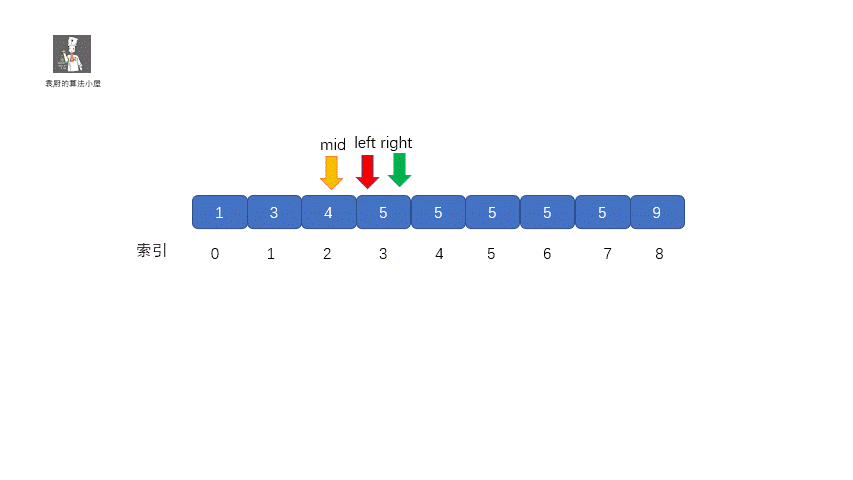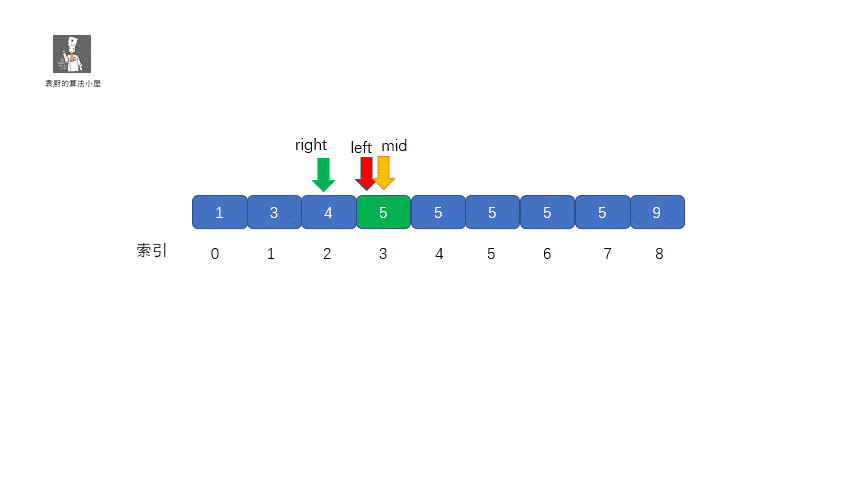
```java
int lowerBound(int[] nums, int target) {
int left = 0, right = nums.length - 1;
while (left <= right) {
//这里需要注意,计算mid
int mid = left + ((right - left) >> 1);
if (target <= nums[mid]) {
//当目标值小于等于nums[mid]时,继续在左区间检索,找到第一个数
right = mid - 1;
}else if (target > nums[mid]) {
//目标值大于nums[mid]时,则在右区间继续检索,找到第一个等于目标值的数
left = mid + 1;
}
}
return left;
}
```
计算上边界时算是和计算上边界时条件相反,
计算下边界时,当 target <= nums[mid] 时,right = mid -1;target > nums[mid] 时,left = mid + 1;
计算上边界时,当 target < nums[mid] 时,right = mid -1; target >= nums[mid] 时 left = mid + 1;刚好和计算下边界时条件相反,返回 right。
**计算上边界代码**
```java
int upperBound(int[] nums, int target) {
int left = 0, right = nums.length - 1;
while (left <= right) {
//求mid
int mid = left + ((right - left) >> 1);
//移动左指针情况
if (target >= nums[mid]) {
left = mid + 1;
//移动右指针情况
}else if (target < nums[mid]) {
right = mid - 1;
}
}
return left;
}
```
#### **题目完整代码**
Java Code:
```java
class Solution {
public int[] searchRange (int[] nums, int target) {
int upper = upperBound(nums,target);
int low = lowerBound(nums,target);
//不存在情况
if (upper < low) {
return new int[]{-1,-1};
}
return new int[]{low,upper};
}
//计算下边界
int lowerBound(int[] nums, int target) {
int left = 0, right = nums.length - 1;
while (left <= right) {
//这里需要注意,计算mid
int mid = left + ((right - left) >> 1);
if (target <= nums[mid]) {
//当目标值小于等于nums[mid]时,继续在左区间检索,找到第一个数
right = mid - 1;
}else if (target > nums[mid]) {
//目标值大于nums[mid]时,则在右区间继续检索,找到第一个等于目标值的数
left = mid + 1;
}
}
return left;
}
//计算上边界
int upperBound(int[] nums, int target) {
int left = 0, right = nums.length - 1;
while (left <= right) {
int mid = left + ((right - left) >> 1);
if (target >= nums[mid]) {
left = mid + 1;
}else if (target < nums[mid]) {
right = mid - 1;
}
}
return right;
}
}
```
================================================
FILE: animation-simulation/二分查找及其变种/leetcode35搜索插入位置.md
================================================
> 如果阅读时,发现错误,或者动画不可以显示的问题可以添加我微信好友 **[tan45du_one](https://raw.githubusercontent.com/tan45du/tan45du.github.io/master/个人微信.15egrcgqd94w.jpg)** ,备注 github + 题目 + 问题 向我反馈
>
> 感谢支持,该仓库会一直维护,希望对各位有一丢丢帮助。
>
> 另外希望手机阅读的同学可以来我的 <u>[**公众号:程序厨**](https://raw.githubusercontent.com/tan45du/test/master/微信图片_20210320152235.2pthdebvh1c0.png)</u> 两个平台同步,想要和题友一起刷题,互相监督的同学,可以在我的小屋点击<u>[**刷题小队**](https://raw.githubusercontent.com/tan45du/test/master/微信图片_20210320152235.2pthdebvh1c0.png)</u>进入。
#### [35. 搜索插入位置](https://leetcode-cn.com/problems/search-insert-position/)
#### 题目描述
> 给定一个排序数组和一个目标值,在数组中找到目标值,并返回其索引。如果目标值不存在于数组中,返回它将会被按顺序插入的位置。
>
> 你可以假设数组中无重复元素。
示例 1:
> 输入: [1,3,5,6], 5
> 输出: 2
示例 2:
> 输入: [1,3,5,6], 2
> 输出: 1
示例 3:
> 输入: [1,3,5,6], 7
> 输出: 4
示例 4:
> 输入: [1,3,5,6], 0
> 输出: 0
#### 题目解析
这个题目完全就和咱们的二分查找一样,只不过有了一点改写,那就是将咱们的返回值改成了 left,具体实现过程见下图
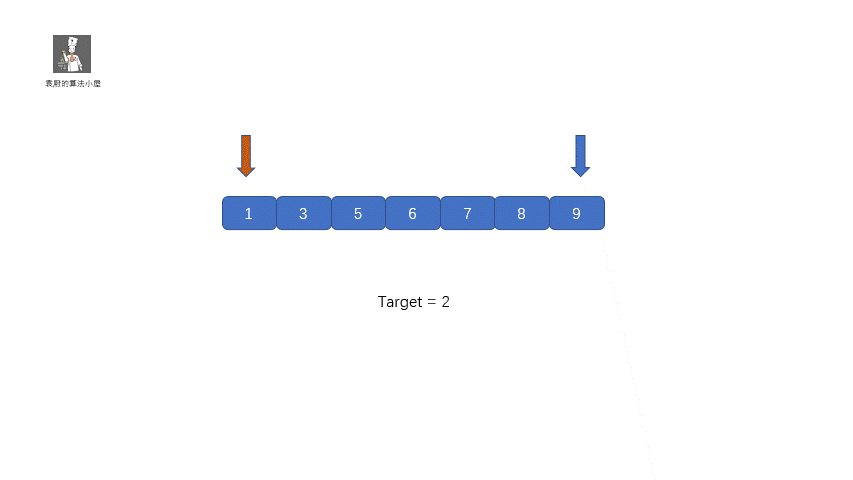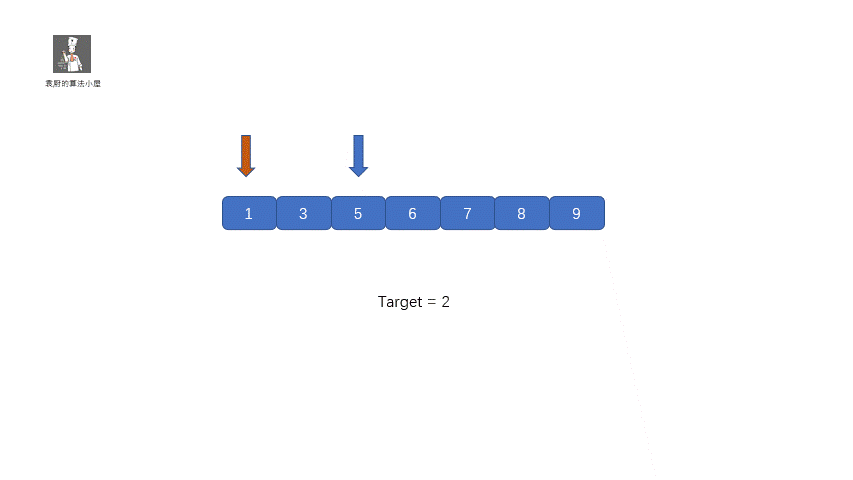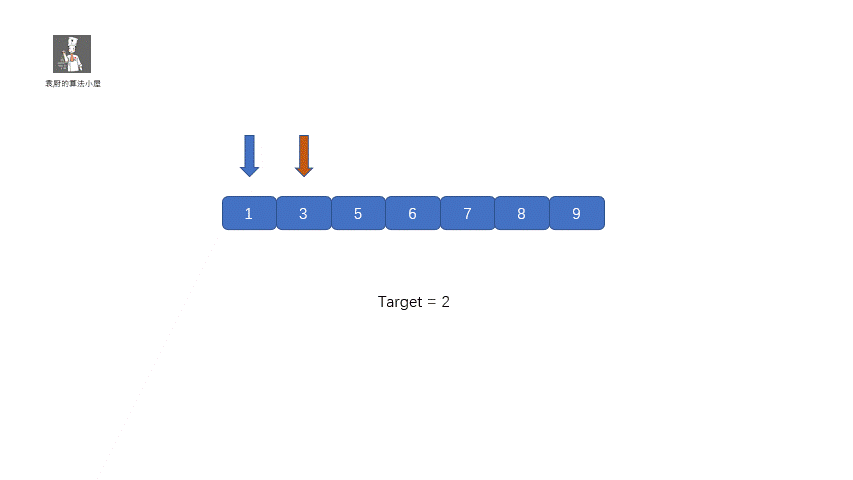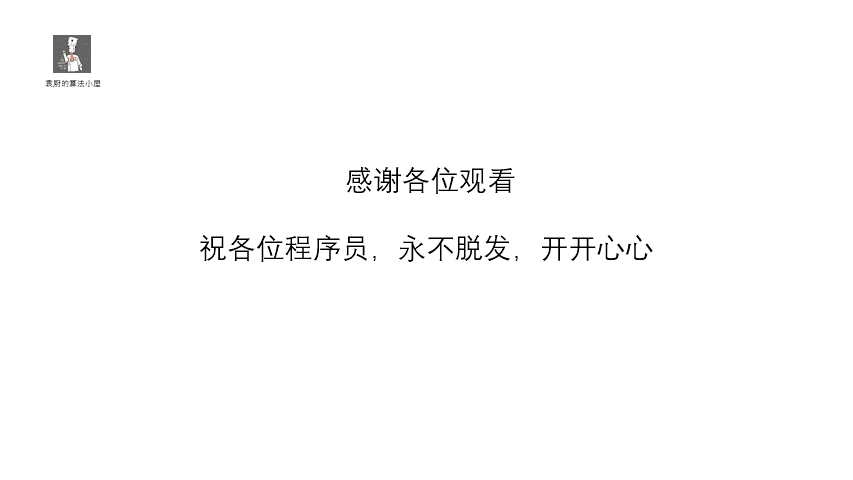
#### 题目代码
Java Code:
```java
class Solution {
public int searchInsert(int[] nums, int target) {
int left = 0, right = nums.length-1;
//注意循环条件
while (left <= right) {
//求mid
int mid = left + ((right - left ) >> 1);
//查询成功
if (target == nums[mid]) {
return mid;
//右区间
} else if (nums[mid] < target) {
left = mid + 1;
//左区间
} else if (nums[mid] > target) {
right = mid - 1;
}
}
//返回插入位置
return left;
}
}
```
Go Code:
================================================
FILE: animation-simulation/二分查找及其变种/二分查找详解.md
================================================
> 如果阅读时,发现错误,或者动画不可以显示的问题可以添加我微信好友 **[tan45du_one](https://raw.githubusercontent.com/tan45du/tan45du.github.io/master/个人微信.15egrcgqd94w.jpg)** ,备注 github + 题目 + 问题 向我反馈
>
> 感谢支持,该仓库会一直维护,希望对各位有一丢丢帮助。
>
> 另外希望手机阅读的同学可以来我的 <u>[**公众号:程序厨**](https://raw.githubusercontent.com/tan45du/test/master/微信图片_20210320152235.2pthdebvh1c0.png)</u> 两个平台同步,想要和题友一起刷题,互相监督的同学,可以在我的小屋点击<u>[**刷题小队**](https://raw.githubusercontent.com/tan45du/test/master/微信图片_20210320152235.2pthdebvh1c0.png)</u>进入。
### 什么是二分?
废话不多说,让导演帮我们把镜头切到袁记菜馆吧!
袁记菜馆内。。。。
> 店小二:掌柜的,您进货回来了呀,哟!今天您买这鱼挺大呀!
>
> 袁厨:那是,这是我今天从咱们江边买的,之前一直去菜市场买,那里的老贵了,你猜猜我今天买的多少钱一条。
>
> 店小二:之前的鱼,30 个铜板一条,今天的我猜 26 个铜板。
>
> 袁厨:贵了。
>
> 店小二:还贵呀!那我猜 20 个铜板!
>
> 袁厨:还是贵了。
>
> 店小二:15 个铜板。
>
> 袁厨:便宜了
>
> 店小二:18 个铜板
>
> 袁厨:恭喜你猜对了
上面的例子就用到了我们的二分查找思想,如果你玩过类似的游戏,那二分查找理解起来肯定很轻松啦,下面我们一起征服二分查找吧!
# **完全有序**
## 二分查找
> 二分查找也称折半查找(Binary Search),是一种在有序数组中查找某一特定元素的搜索算法。我们可以从定义可知,运用二分搜索的前提是数组必须是有序的,这里需要注意的是,我们的输入不一定是数组,也可以是数组中某一区间的起始位置和终止位置
通过上面二分查找的定义,我们知道了二分查找算法的作用及要求,那么该算法的具体执行过程是怎样的呢?
下面我们通过一个例子来帮助我们理解。我们需要在 nums 数组中,查询元素 8 的索引
```java
int[ ] nums = {1,3,4,5,6,8,12,14,16}; target = 8
```
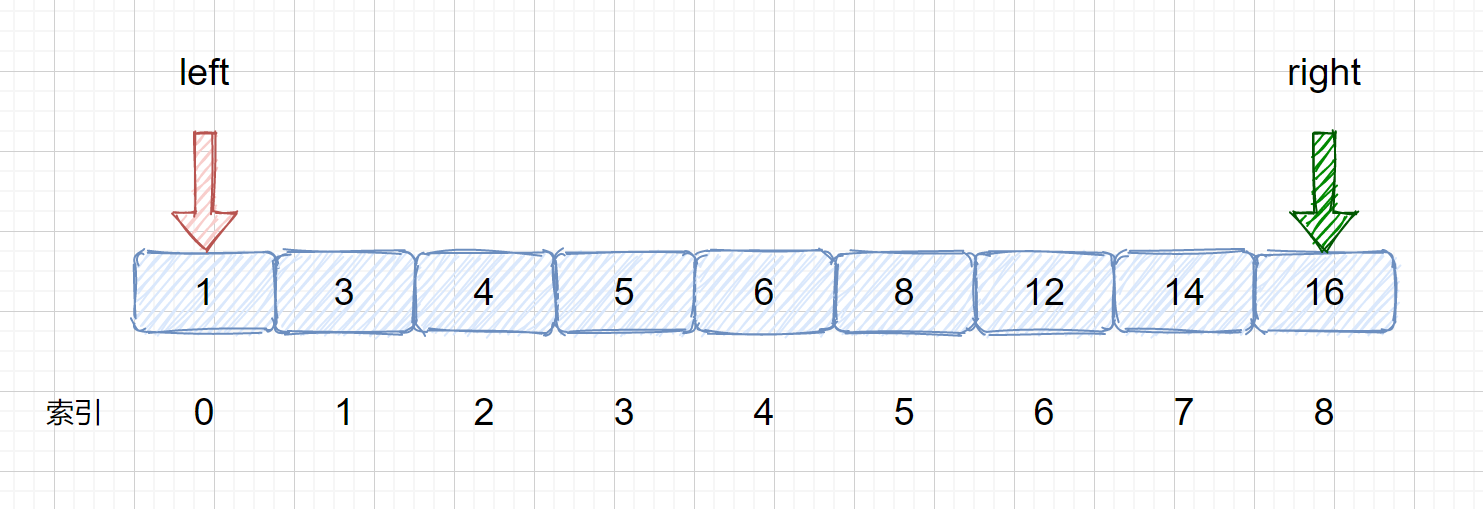
> (1)我们需要定义两个指针分别指向数组的头部及尾部,这是我们在整个数组中查询的情况,当我们在数组
>
> 某一区间进行查询时,可以输入数组,起始位置,终止位置进行查询。
> (2)找出 mid,该索引为 mid =(left + right)/ 2,但是这样写有可能溢出,所以我们需要改进一下写成
>
> mid = left +(right - left)/ 2 或者 left + ((right - left ) >> 1) 两者作用是一样的,都是为了找到两指针的中
>
> 间索引,使用位运算的速度更快。那么此时的 mid = 0 + (8-0) / 2 = 4
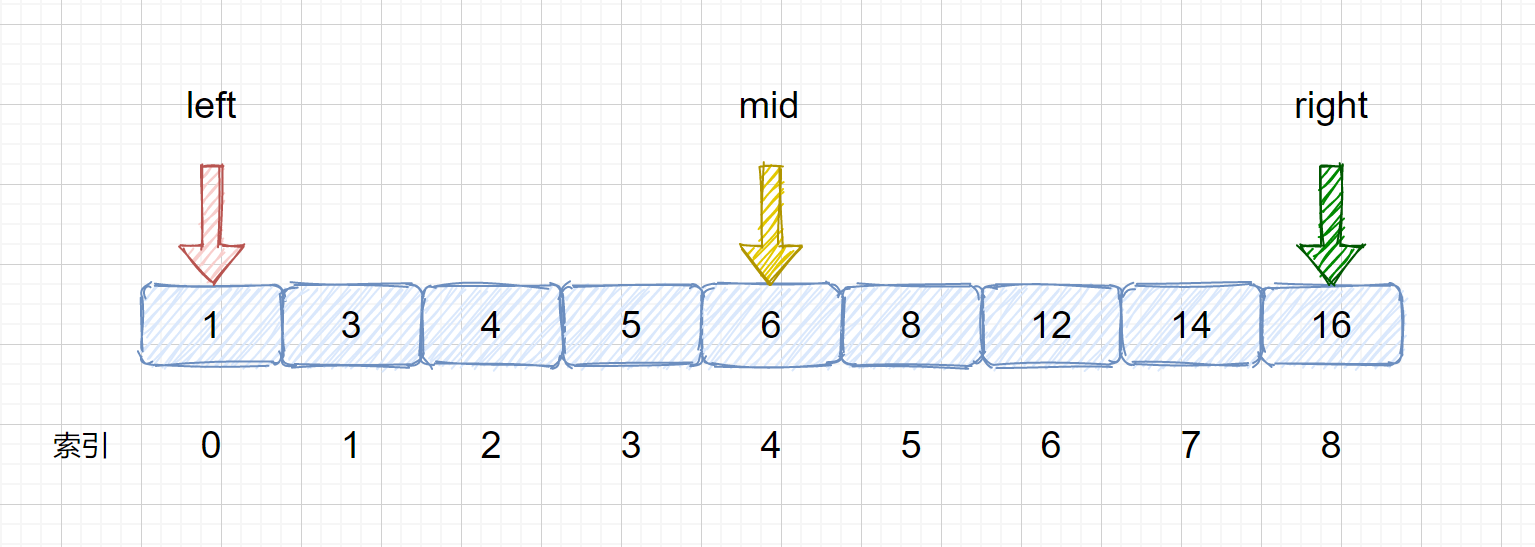
> (3)此时我们的 mid = 4,nums[mid] = 6 < target,那么我们需要移动我们的 left 指针,让 left = mid + 1,下次则可以在新的 left 和 right 区间内搜索目标值,下图为移动前和移动后
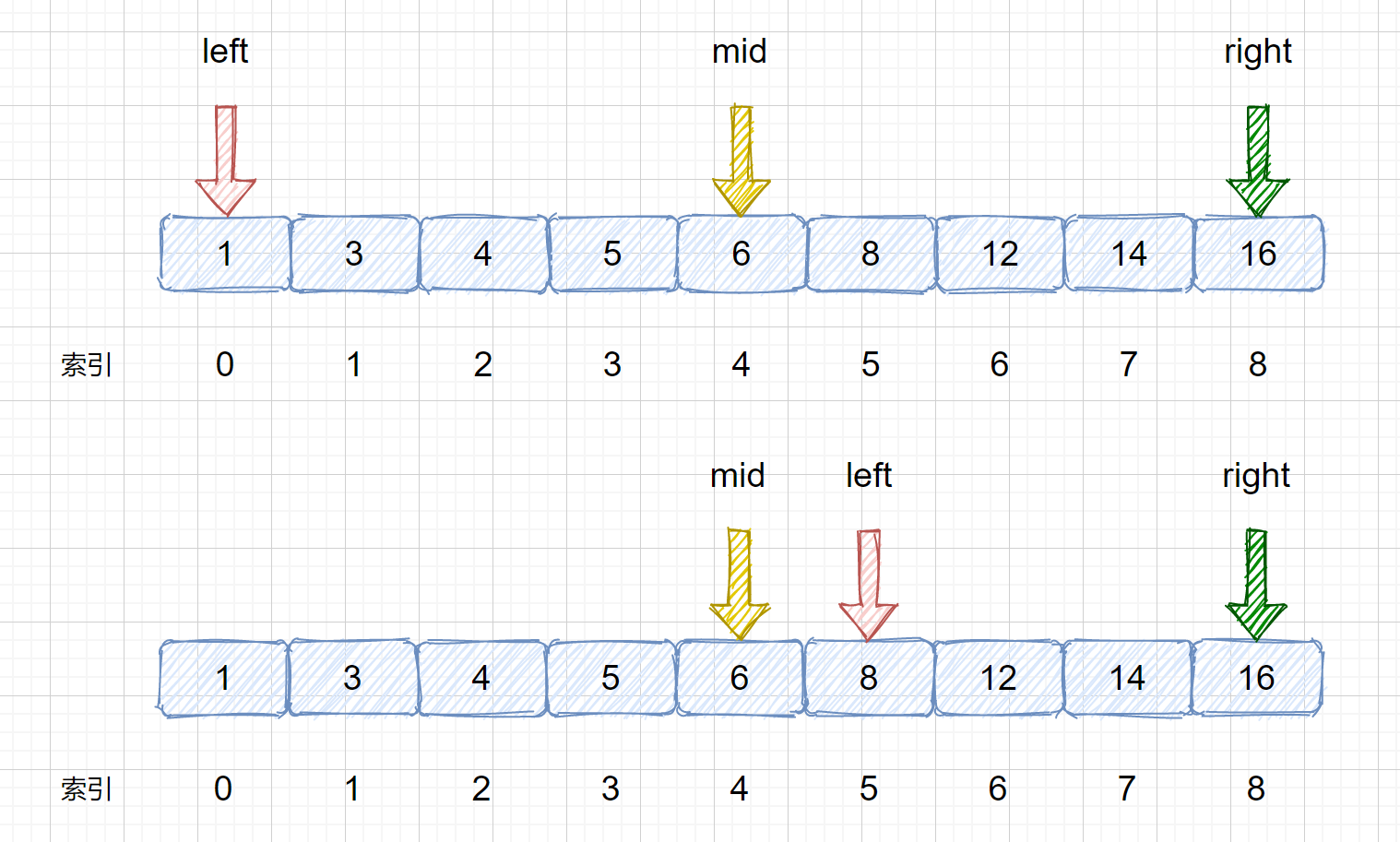
> (4)我们需要在 left 和 right 之间计算 mid 值,mid = 5 + (8 - 5)/ 2 = 6 然后将 nums[mid] 与 target 继续比较,进而决定下次移动 left 指针还是 right 指针,见下图
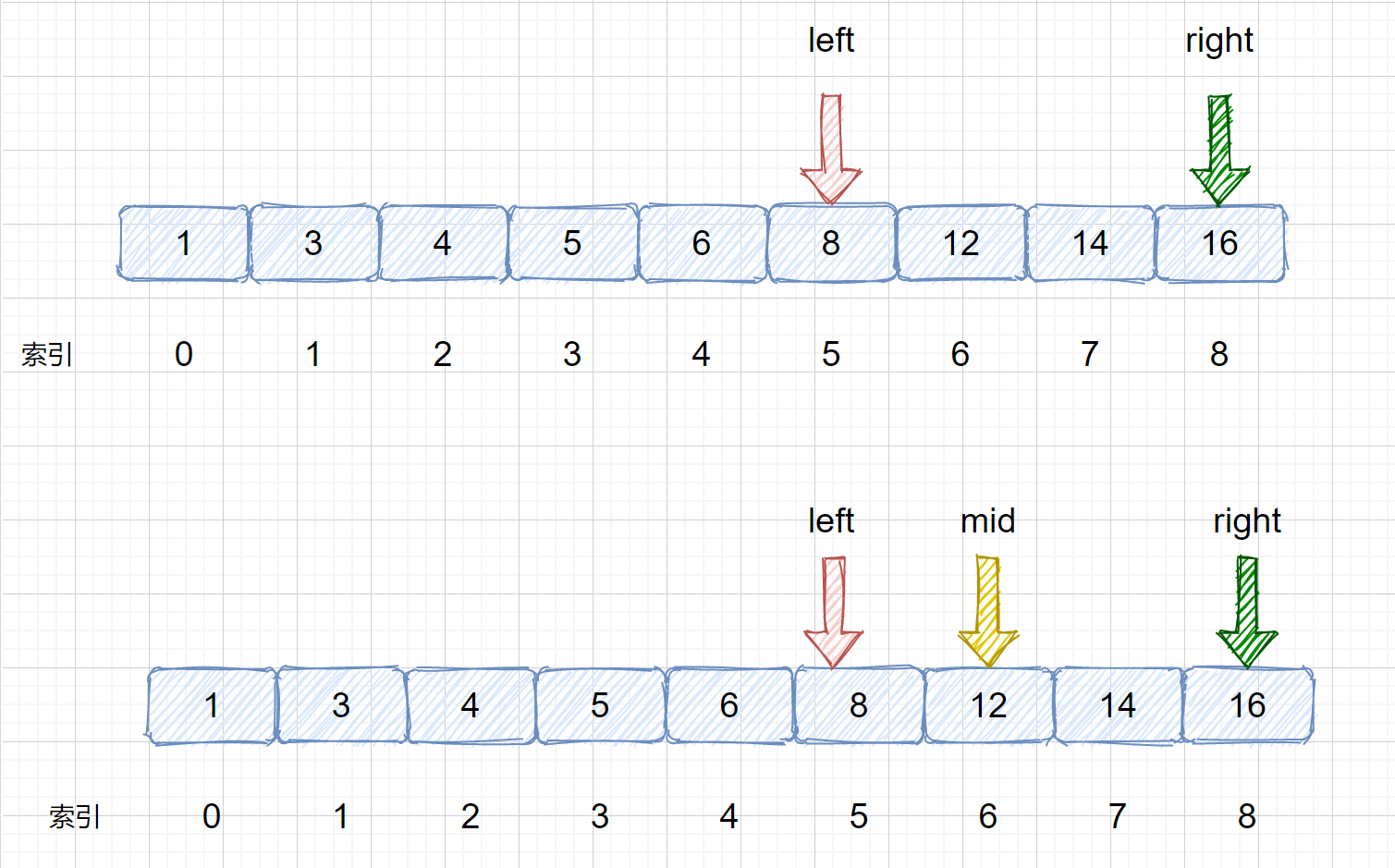
> (5)我们发现 nums[mid] > target,则需要移动我们的 right 指针, 则 right = mid - 1;则移动过后我们的 left 和 right 会重合,这里是我们的一个重点大家需要注意一下,后面会对此做详细叙述。
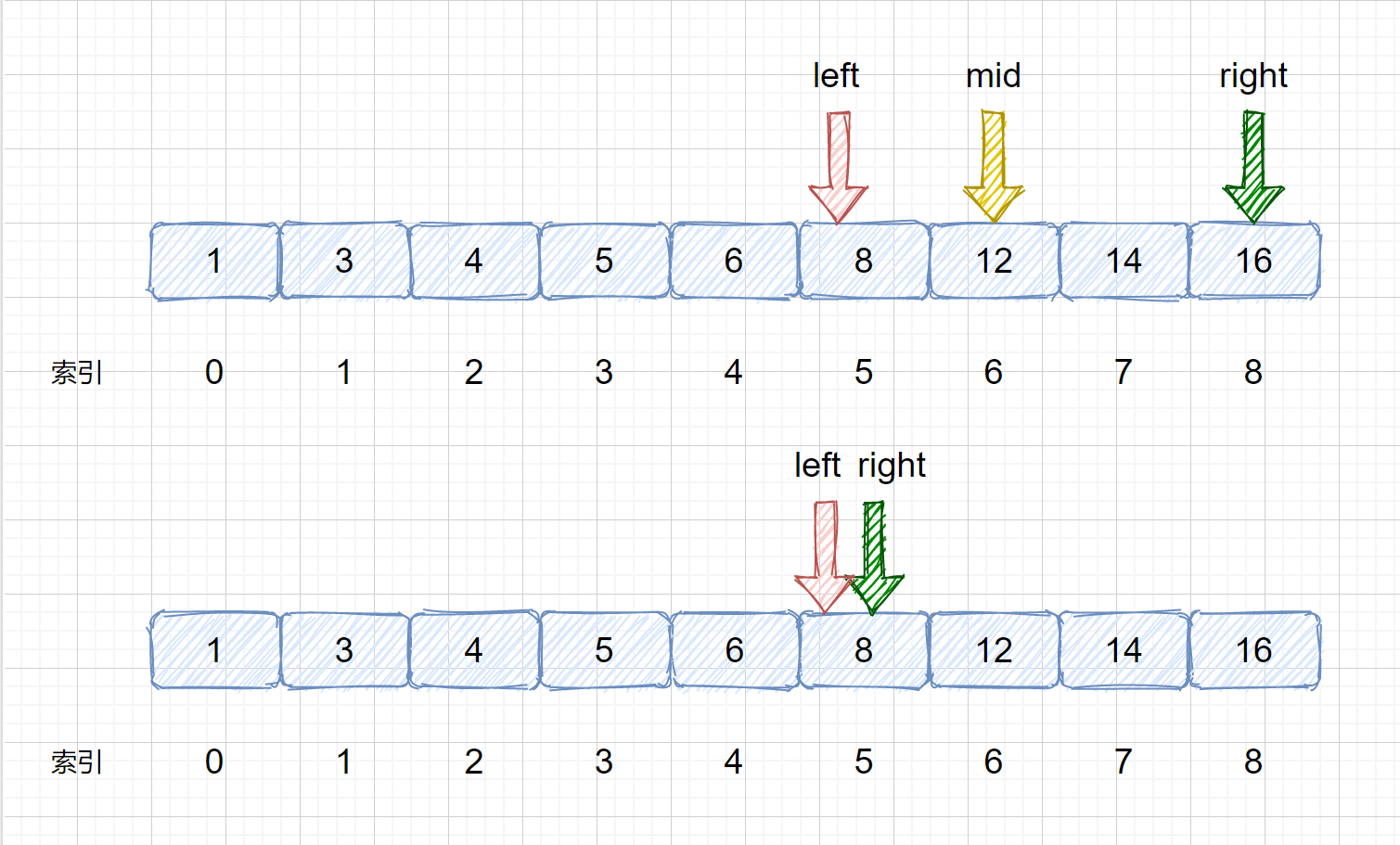
> (6)我们需要在 left 和 right 之间继续计算 mid 值,则 mid = 5 +(5 - 5)/ 2 = 5 ,见下图,此时我们将 nums[mid] 和 target 比较,则发现两值相等,返回 mid 即可 ,如果不相等则跳出循环,返回 -1。

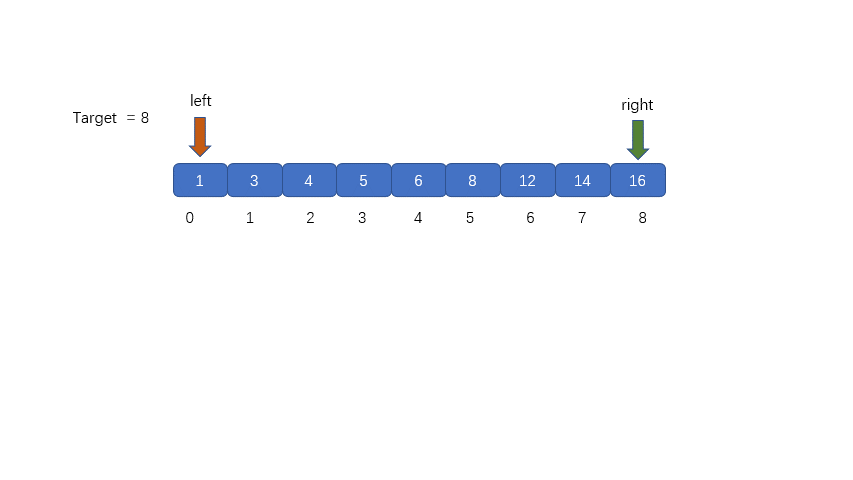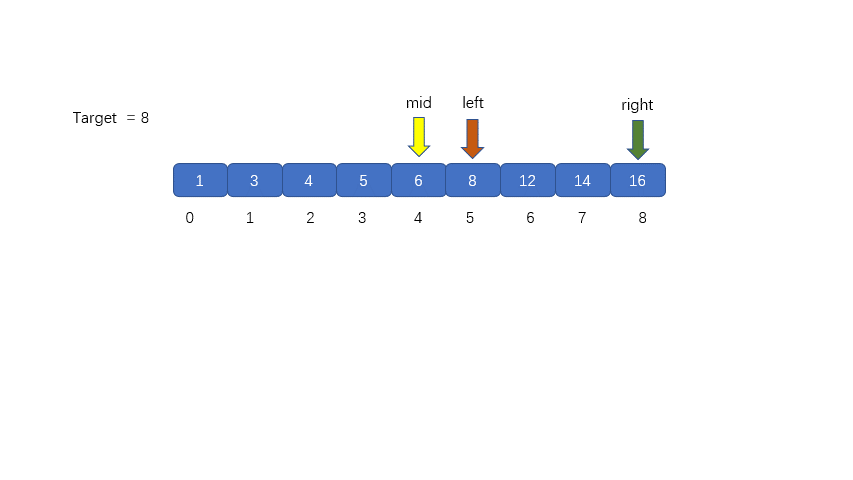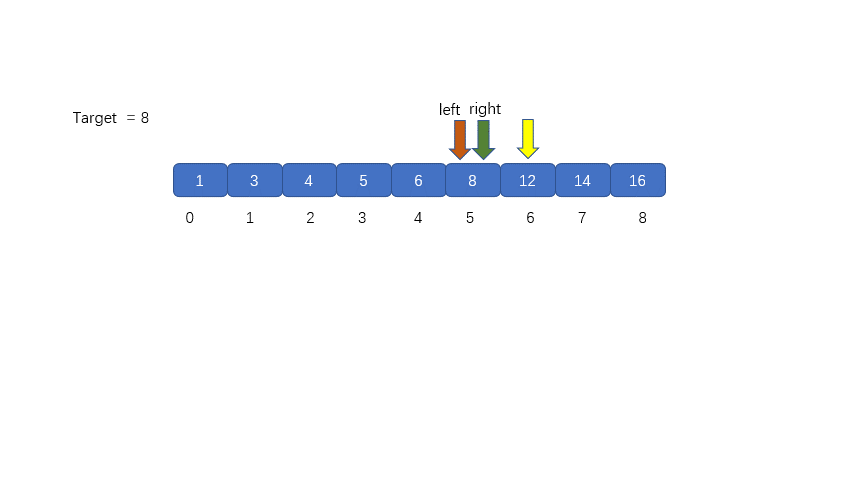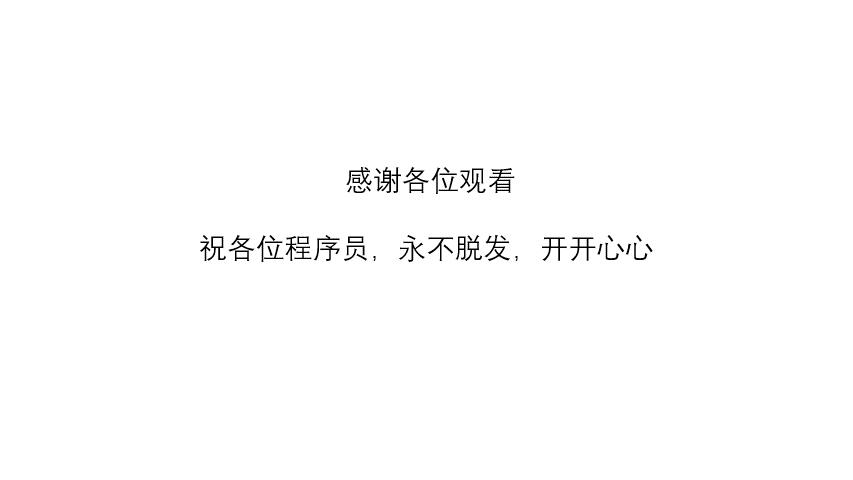
二分查找的执行过程如下
1.从已经排好序的数组或区间中,取出中间位置的元素,将其与我们的目标值进行比较,判断是否相等,如果相等
则返回。
2.如果 nums[mid] 和 target 不相等,则对 nums[mid] 和 target 值进行比较大小,通过比较结果决定是从 mid
的左半部分还是右半部分继续搜索。如果 target > nums[mid] 则右半区间继续进行搜索,即 left = mid + 1; 若
target < nums[mid] 则在左半区间继续进行搜索,即 right = mid -1;
**动图解析**
下面我们来看一下二分查找的代码,可以认真思考一下 if 语句的条件,每个都没有简写。
Java Code:
```java
public static int binarySearch(int[] nums,int target,int left, int right) {
//这里需要注意,循环条件
while (left <= right) {
//这里需要注意,计算mid
int mid = left + ((right - left) >> 1);
if (nums[mid] == target) {
return mid;
}else if (nums[mid] < target) {
//这里需要注意,移动左指针
left = mid + 1;
}else if (nums[mid] > target) {
//这里需要注意,移动右指针
right = mid - 1;
}
}
//没有找到该元素,返回 -1
return -1;
}
```
Go Code:
```go
func binarySearch(nums []int, target, left, right int) int {
//这里需要注意,循环条件
for left <= right {
//这里需要注意,计算mid
mid := left + ((right - left) >> 1)
if nums[mid] == target {
return mid
} else if nums[mid] < target {
//这里需要注意,移动左指针
left = mid + 1
} else if nums[mid] > target {
//这里需要注意,移动右指针
right = mid - 1
}
}
//没有找到该元素,返回 -1
return -1
}
```
二分查找的思路及代码已经理解了,那么我们来看一下实现时容易出错的地方
1.计算 mid 时 ,不能使用 (left + right )/ 2,否则有可能会导致溢出
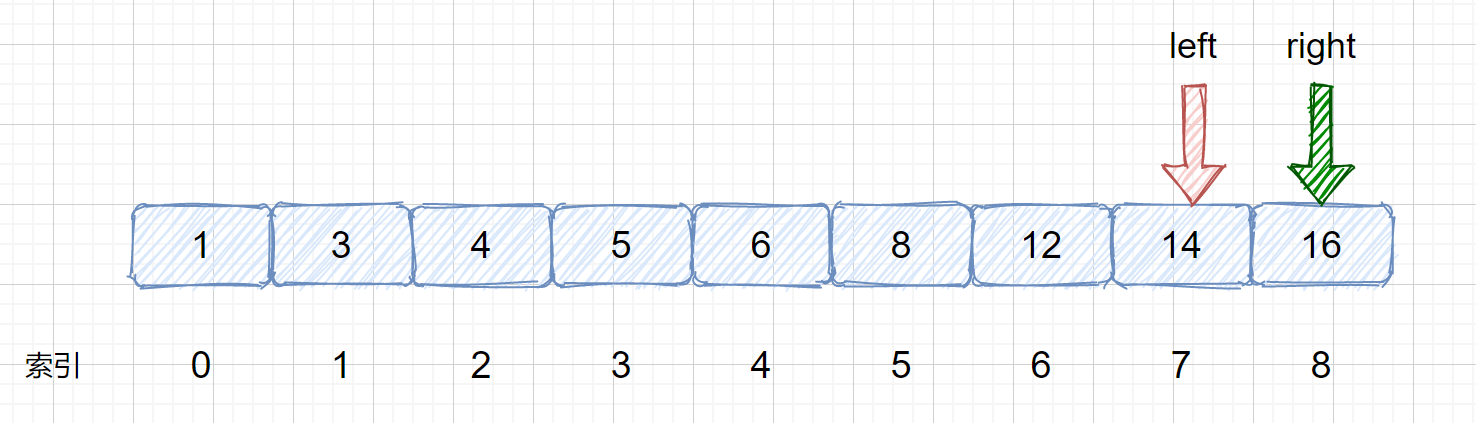
2.while (left < = right) { } 注意括号内为 left <= right ,而不是 left < right ,我们继续回顾刚才的例子,如果我们设置条件为 left < right 则当我们执行到最后一步时,则我们的 left 和 right 重叠时,则会跳出循环,返回 -1,区间内不存在该元素,但是不是这样的,我们的 left 和 right 此时指向的就是我们的目标元素 ,但是此时 left = right 跳出循环
3. left = mid + 1,right = mid - 1 而不是 left = mid 和 right = mid。我们思考一下这种情况,见下图,当我们的 target 元素为 16 时,然后我们此时 left = 7 ,right = 8,mid = left + (right - left) = 7 + (8-7) = 7,那如果设置 left = mid 的话,则会进入死循环,mid 值一直为 7 。
下面我们来看一下二分查找的递归写法
Java Code:
```java
public static int binarySearch(int[] nums,int target,int left, int right) {
if (left <= right) {
int mid = left + ((right - left) >> 1);
if (nums[mid] == target) {
//查找成功
return mid;
}else if (nums[mid] > target) {
//新的区间,左半区间
return binarySearch(nums,target,left,mid-1);
}else if (nums[mid] < target) {
//新的区间,右半区间
return binarySearch(nums,target,mid+1,right);
}
}
//不存在返回-1
return -1;
}
```
Go Code:
```go
func binarySearch(nums []int, target, left, right int) int {
if left <= right {
mid := left + ((right - left) >> 1)
if nums[mid] == target {
//查找成功
return mid
} else if nums[mid] > target {
//新的区间,左半区间
return binarySearch(nums, target, left, mid-1)
} else if nums[mid] < target {
//新的区间,右半区间
return binarySearch(nums, target, mid+1, right)
}
}
//不存在返回-1
return -1
}
```
================================================
FILE: animation-simulation/二分查找及其变种/二维数组的二分查找.md
================================================
> 如果阅读时,发现错误,或者动画不可以显示的问题可以添加我微信好友 **[tan45du_one](https://raw.githubusercontent.com/tan45du/tan45du.github.io/master/个人微信.15egrcgqd94w.jpg)** ,备注 github + 题目 + 问题 向我反馈
>
> 感谢支持,该仓库会一直维护,希望对各位有一丢丢帮助。
>
> 另外希望手机阅读的同学可以来我的 <u>[**公众号:程序厨**](https://raw.githubusercontent.com/tan45du/test/master/微信图片_20210320152235.2pthdebvh1c0.png)</u> 两个平台同步,想要和题友一起刷题,互相监督的同学,可以在我的小屋点击<u>[**刷题小队**](https://raw.githubusercontent.com/tan45du/test/master/微信图片_20210320152235.2pthdebvh1c0.png)</u>进入。
#### [74. 搜索二维矩阵](https://leetcode-cn.com/problems/search-a-2d-matrix/)\*\*\*\*
下面我们来看一下另外一种变体,如何在二维矩阵里使用二分查找呢?
其实这个很简单,只要学会了二分查找,这个完全可以解决,我们先来看一个例子
我们需要从一个二维矩阵中,搜索是否含有元素 7,我们如何使用二分查找呢?其实我们可以完全将二维矩阵想象成一个有序的一维数组,然后用二分,,比如我们的二维矩阵中,共有 9 个元素,那定义我们的 left = 0,right = 9 - 1= 8,是不是和一维数组定义相同,然后我们求我们的 mid 值, mid = left +((right - left) >> 1)此时 mid = 4 ,但是我们的二维矩阵下标最大是,nums[2,2]呀,你这求了一个 4 ,让我们怎么整呀。如果我们理解了二分查找,那么这个题目考察我们的应该是如何将一维数组的下标,变为 二维坐标。其实也很简单,咱们看哈,此时咱们的 mid = 4,咱们的二维矩阵共有 3 行, 3 列,那我们 mid =4,肯定在第二行,那么这个应该怎么求得呢?
我们可以直接用 (mid/列数),即可,因为我们 mid = 4,4 /3 = 1,说明在 在第二行,那如果 mid = 7 ,7/3=2,在第三行,我们第几行知道了,那么我们如何知道第几列呢?我们可以直接根据 (mid % 列数 )来求得呀,比如我们此时 mid = 7,7%3 = 1,那么在我们一维数组索引为 7 的元素,其处于二维数组的第 2 列,大家看看下图是不是呀!
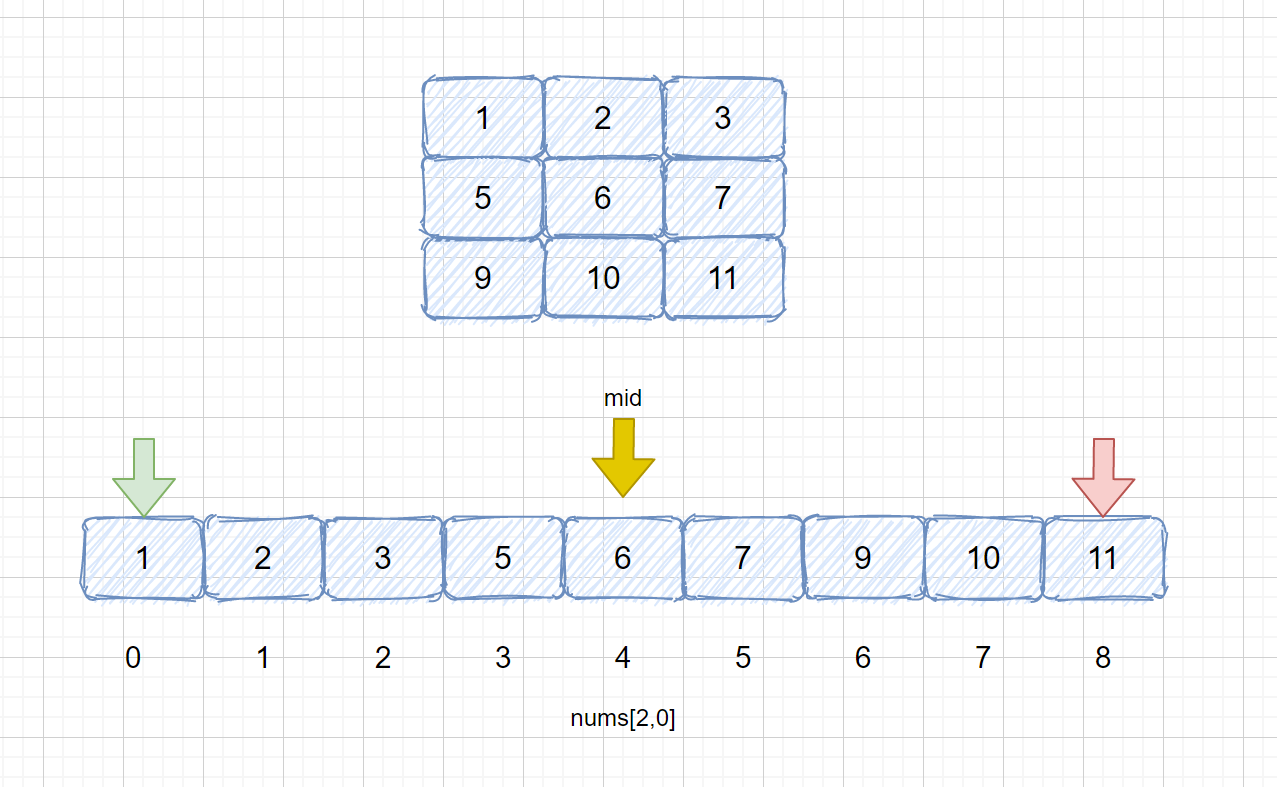
下面我们来看一下 leetcode 74 题,让我们给他整个通透
### 搜索二维矩阵
#### 题目描述
编写一个高效的算法来判断 m x n 矩阵中,是否存在一个目标值。该矩阵具有如下特性:
每行中的整数从左到右按升序排列。
每行的第一个整数大于前一行的最后一个整数。
示例 1
> 输入:matrix = [[1,3,5,7],[10,11,16,20],[23,30,34,50]], target = 3
> 输出:true
示例 2
> 输入:matrix = [[1,3,5,7],[10,11,16,20],[23,30,34,50]], target = 13
> 输出:false
示例 3
> 输入:matrix = [], target = 0
> 输出:false
#### 题目解析
在上面我们已经解释了如何在二维矩阵中进行搜索,这里我们再对其进行一个总结,就是我们凭空想象一个一维数组,这个数组是有二维数组一层一层拼接来的,也是完全有序,然后我们定义两个指针一个指向一维数组头部,一个指向尾部,我们求得 mid 值然后将 mid 变成二维坐标,然后和 target 进行比较,如果大于则移动 left ,如果小于则移动 right 。
动图解析
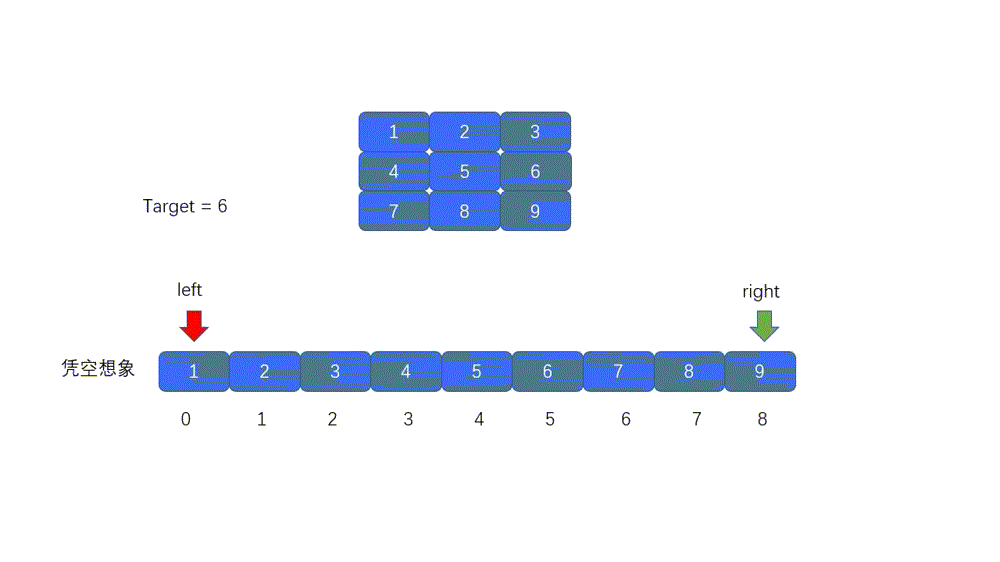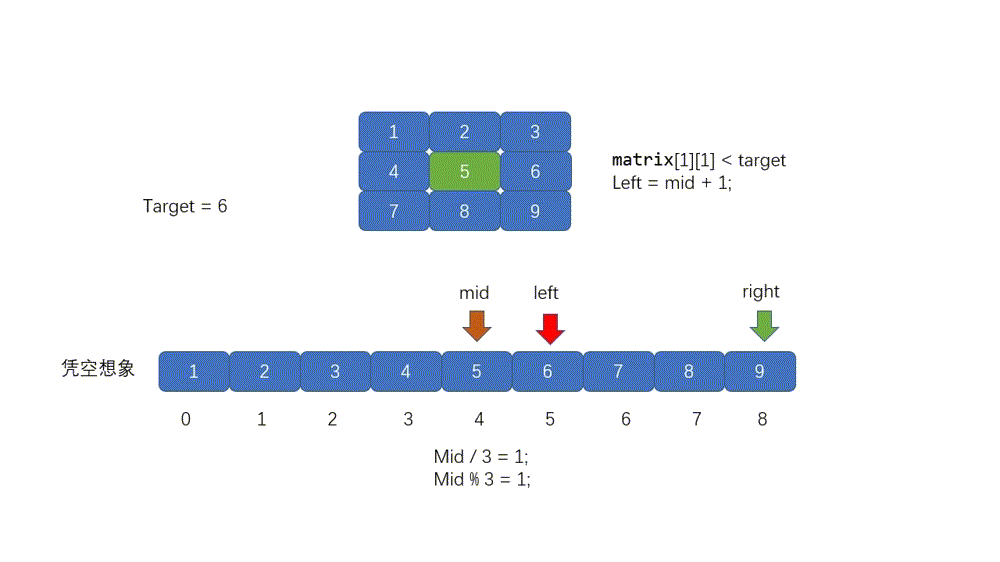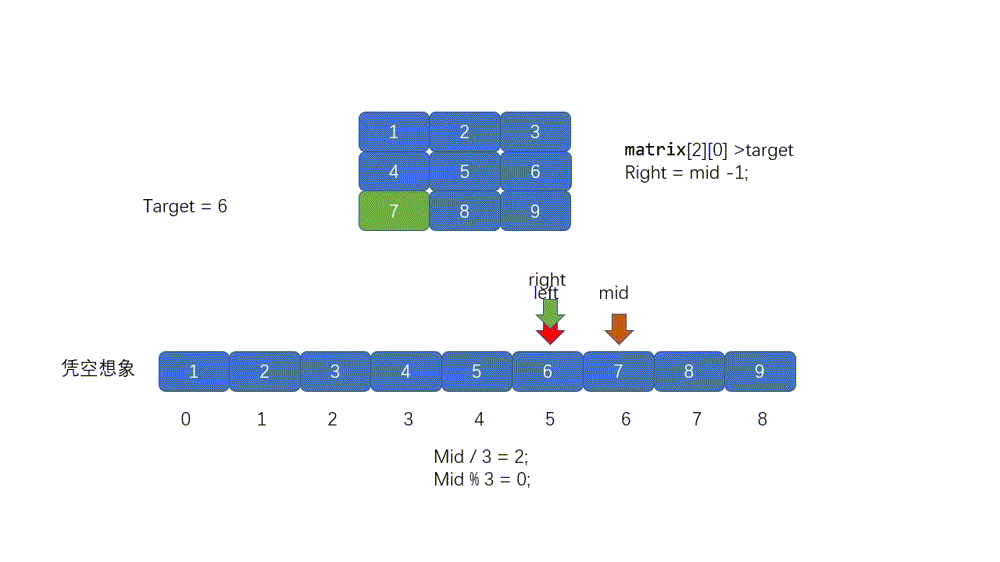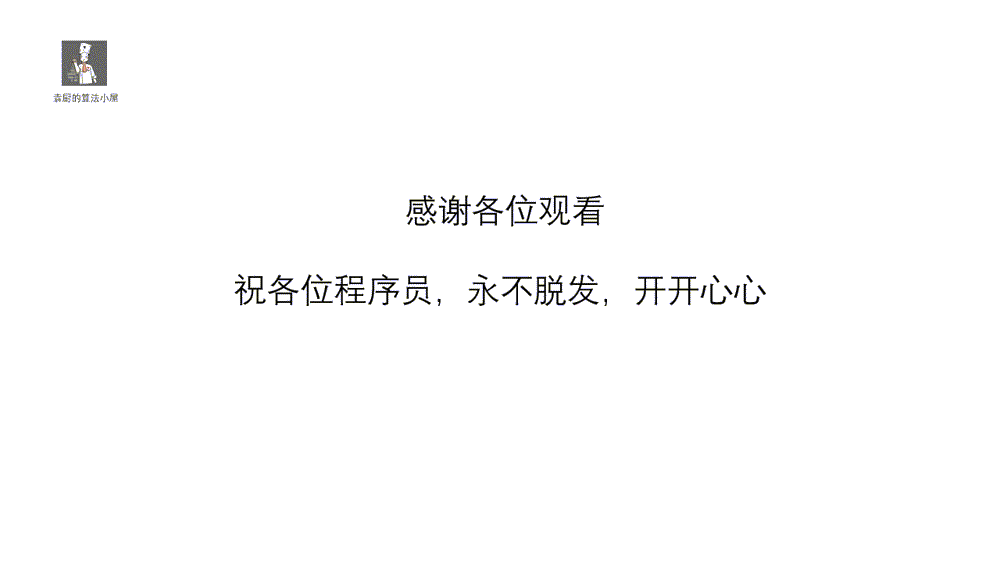
#### 题目代码
Java Code:
```java
class Solution {
public boolean searchMatrix(int[][] matrix, int target) {
if (matrix.length == 0) {
return false;
}
//行数
int row = matrix.length;
//列数
int col = matrix[0].length;
int left = 0;
//行数乘列数 - 1,右指针
int right = row * col - 1;
while (left <= right) {
int mid = left+ ((right-left) >> 1);
//将一维坐标变为二维坐标
int rownum = mid / col;
int colnum = mid % col;
if (matrix[rownum][colnum] == target) {
return true;
} else if (matrix[rownum][colnum] > target) {
right = mid - 1;
} else if (matrix[rownum][colnum] < target) {
left = mid + 1;
}
}
return false;
}
}
```
================================================
FILE: animation-simulation/二分查找及其变种/找出第一个大于或小于目标的索引.md
================================================
> 如果阅读时,发现错误,或者动画不可以显示的问题可以添加我微信好友 **[tan45du_one](https://raw.githubusercontent.com/tan45du/tan45du.github.io/master/个人微信.15egrcgqd94w.jpg)** ,备注 github + 题目 + 问题 向我反馈
>
> 感谢支持,该仓库会一直维护,希望对各位有一丢丢帮助。
>
> 另外希望手机阅读的同学可以来我的 <u>[**公众号:程序厨**](https://raw.githubusercontent.com/tan45du/test/master/微信图片_20210320152235.2pthdebvh1c0.png)</u> 两个平台同步,想要和题友一起刷题,互相监督的同学,可以在我的小屋点击<u>[**刷题小队**](https://raw.githubusercontent.com/tan45du/test/master/微信图片_20210320152235.2pthdebvh1c0.png)</u>进入。
## 找出第一个大于目标元素的索引
我们在上面的变种中,描述了如何找出目标元素在数组中的上下边界,然后我们下面来看一个新的变种,如何从数组或区间中找出第一个大于或最后一个小于目标元素的数的索引,例 nums = {1,3,5,5,6,6,8,9,11} 我们希望找出第一个大于 5 的元素的索引,那我们需要返回 4 ,因为 5 的后面为 6,第一个 6 的索引为 4,如果希望找出最后一个小于 6 的元素,那我们则会返回 3 ,因为 6 的前面为 5 最后一个 5 的索引为 3。好啦题目我们已经了解,下面我们先来看一下如何在数组或区间中找出第一个大于目标元素的数吧。
找出第一个大于目标元素的数,大概有以下几种情况
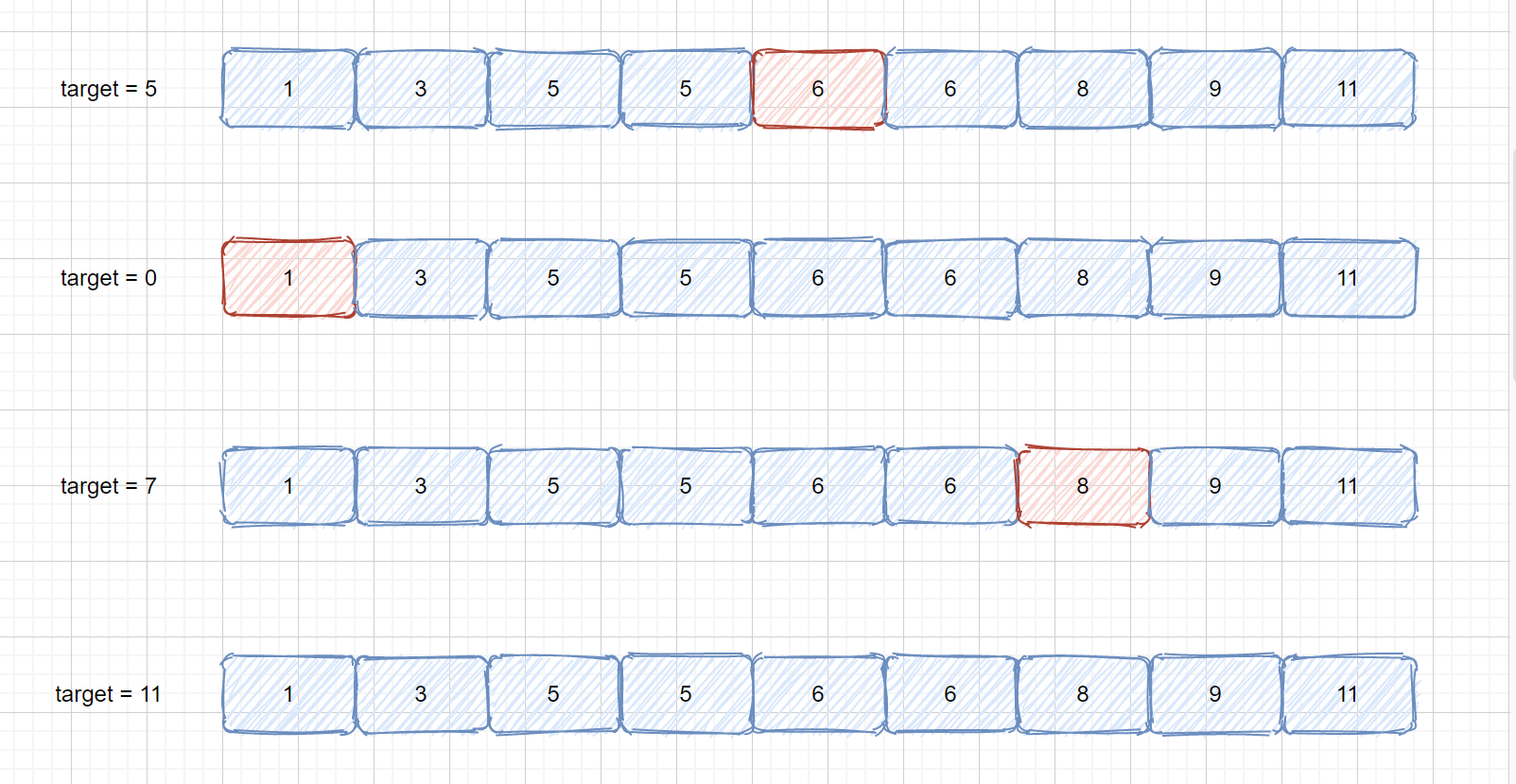
1.数组包含目标元素,找出在他后面的第一个元素
2.目标元素不在数组中,数组内的部分元素大于它,此时我们需要返回第一个大于他的元素
3.目标元素不在数组中,且数组中的所有元素都大于它,那么我们此时返回数组的第一个元素即可
4.目标元素不在数组中,且数组中的所有元素都小于它,那么我们此时没有查询到,返回 -1 即可。
既然我们已经分析完所有情况,那么这个题目对咱们就没有难度了,下面我们描述一下案例的执行过程
> nums = {1,3,5,5,6,6,8,9,11} target = 7
上面的例子中,我们需要找出第一个大于 7 的数,那么我们的程序是如何执行的呢?
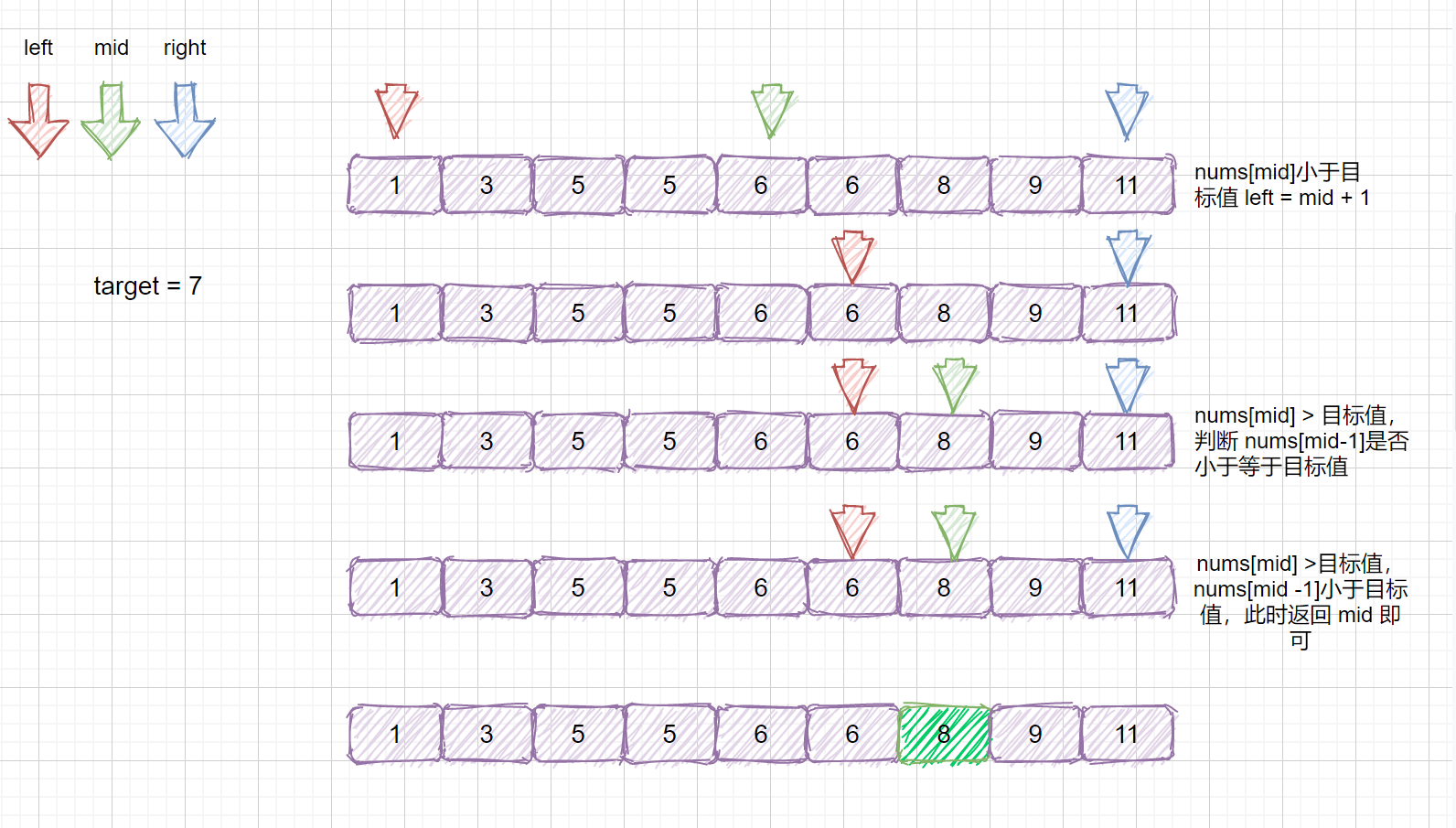
上面的例子我们已经弄懂了,那么我们看一下,当 target = 0 时,程序应该怎么执行呢?
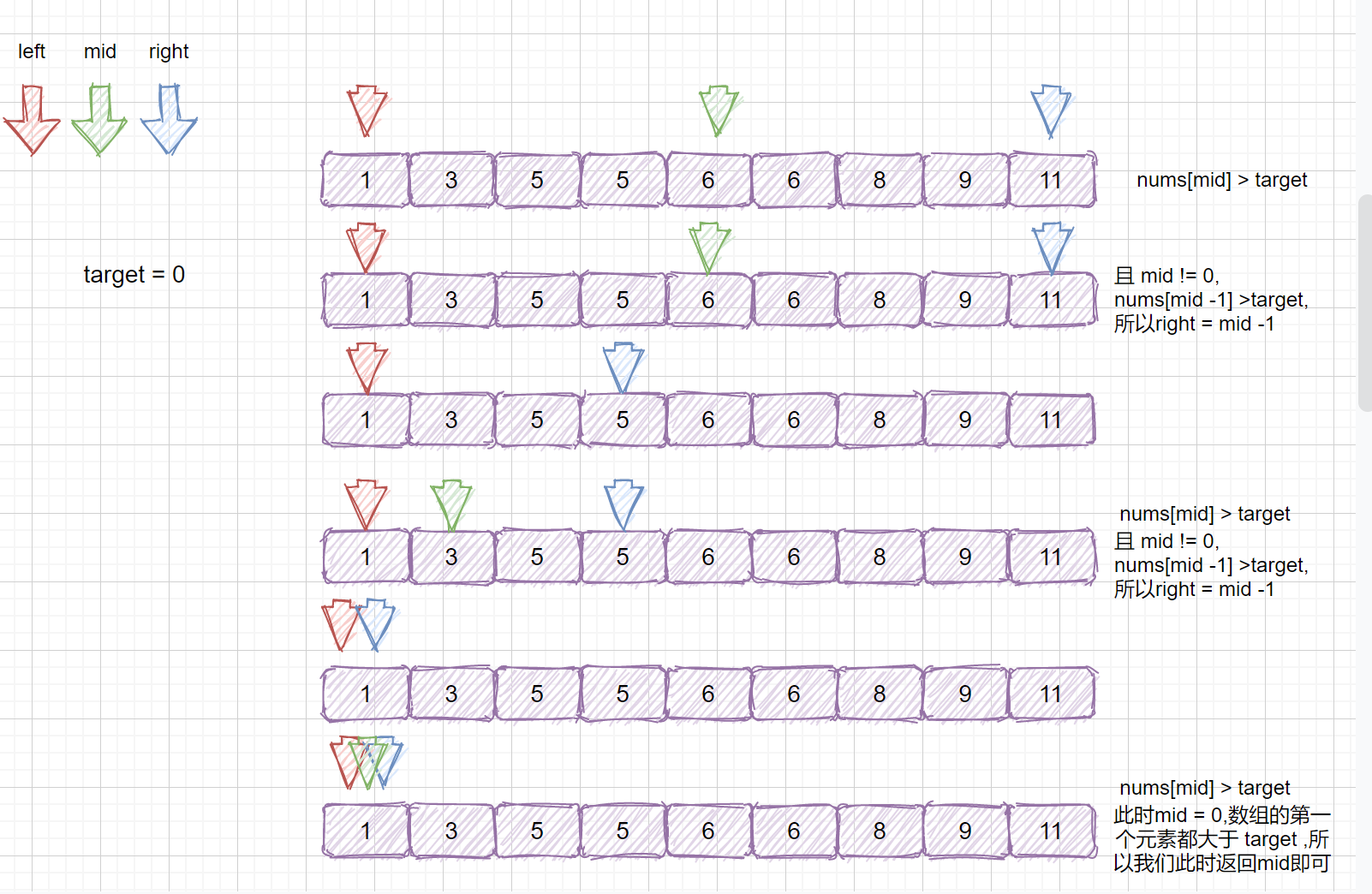
OK!我们到这一步就能把这个变种给整的明明白白的了,下面我们看一哈程序代码吧,也是非常简单的。
Java Code:
```java
public static int lowBoundnum(int[] nums,int target,int left, int right) {
while (left <= right) {
//求中间值
int mid = left + ((right - left) >> 1);
//大于目标值的情况
if (nums[mid] > target) {
//返回 mid
if (mid == 0 || nums[mid-1] <= target) {
return mid;
}
else{
right = mid -1;
}
} else if (nums[mid] <= target){
left = mid + 1;
}
}
//所有元素都小于目标元素
return -1;
}
```
Go Code:
```go
func lowBoundnum(nums []int, target, left, right int) int {
for (left <= right) {
//求中间值
mid := left + ((right - left) >> 1);
//大于目标值的情况
if (nums[mid] > target) {
//返回 mid
if (mid == 0 || nums[mid-1] <= target) {
return mid
}else{
right = mid -1
}
} else if (nums[mid] <= target){
left = mid + 1
}
}
//所有元素都小于目标元素
return -1
}
```
## **找出最后一个小于目标元素的索引**
通过上面的例子我们应该可以完全理解了那个变种,下面我们继续来看以下这种情况,那就是如何找到最后一个小于目标数的元素。还是上面那个例子
> nums = {1,3,5,5,6,6,8,9,11} target = 7
查找最后一个小于目标数的元素,比如我们的目标数为 7 ,此时他前面的数为 6,最后一个 6 的索引为 5,此时我们返回 5 即可,如果目标数元素为 12,那么我们最后一个元素为 11,仍小于目标数,那么我们此时返回 8,即可。这个变种其实算是上面变种的相反情况,上面的会了,这个也完全可以搞定了,下面我们看一下代码吧。
Java Code:
```java
public static int upperBoundnum(int[] nums,int target,int left, int right) {
while (left <= right) {
int mid = left + ((right - left) >> 1);
//小于目标值
if (nums[mid] < target) {
//看看是不是当前区间的最后一位,如果当前小于,后面一位大于,返回当前值即可
if (mid == right || nums[mid+1] >= target) {
return mid;
}
else{
left = mid + 1;
}
} else if (nums[mid] >= target){
right = mid - 1;
}
}
//没有查询到的情况
return -1;
}
```
Go Code:
```go
func upperBoundnum(nums []int, target, left, right int) int {
for left <= right {
mid := left + ((right - left) >> 1)
//小于目标值
if nums[mid] < target {
//看看是不是当前区间的最后一位,如果当前小于,后面一位大于,返回当前值即可
if mid == right || nums[mid+1] >= target {
return mid
} else {
left = mid + 1
}
} else if nums[mid] >= target {
right = mid - 1
}
}
//没有查询到的情况
return -1
}
```
================================================
FILE: animation-simulation/二叉树/二叉树中序遍历(Morris).md
================================================
### **Morris**
我们之前说过,前序遍历的 Morris 方法,如果已经掌握,今天中序遍历的 Morris 方法也就没有什么难度,仅仅修改了一丢丢。
我们先来回顾一下前序遍历 Morris 方法的代码部分。
**前序遍历 Morris 代码**
```java
class Solution {
public List<Integer> preorderTraversal(TreeNode root) {
List<Integer> list = new ArrayList<>();
if (root == null) {
return list;
}
TreeNode p1 = root; TreeNode p2 = null;
while (p1 != null) {
p2 = p1.left;
if (p2 != null) {
//找到左子树的最右叶子节点
while (p2.right != null && p2.right != p1) {
p2 = p2.right;
}
//添加 right 指针,对应 right 指针为 null 的情况
//标注 1
if (p2.right == null) {
list.add(p1.val);
p2.right = p1;
p1 = p1.left;
continue;
}
//对应 right 指针存在的情况,则去掉 right 指针
p2.right = null;
//标注2
} else {
list.add(p1.val);
}
//移动 p1
p1 = p1.right;
}
return list;
}
}
```
我们先来看标注 1 的部分,这里的含义是,当找到 p1 指向节点的左子树中的最右子节点时。也就是下图中的情况,此时我们需要将 p1 指向的节点值,存入 list。
上述为前序遍历时的情况,那么中序遍历应该如何操作嘞。
前序遍历我们需要移动 p1 指针,`p1 = p1.left` 这样做的原因和上述迭代法原理一致,找到我们当前需要遍历的那个节点。
我们还需要修改哪里呢?见下图
我们在前序遍历时,遇到 `p2.right == p1`的情况时,则会执行 `p2.right == null` 并让 `p1 = p1.right`,这样做是因为,我们此时 p1 指向的值已经遍历完毕,为了防止重复遍历。
但是呢,在我们的中序 Morris 中我们遇到`p2.right == p1`此时 p1 还未遍历,所以我们需要在上面两条代码之间添加一行代码`list.add(p1.val);`
好啦,到这里我们就基本上就搞定了中序遍历的 Morris 方法,下面我们通过动画来加深一下印象吧,当然我也会把前序遍历的动画放在这里,大家可以看一下哪里有所不同。
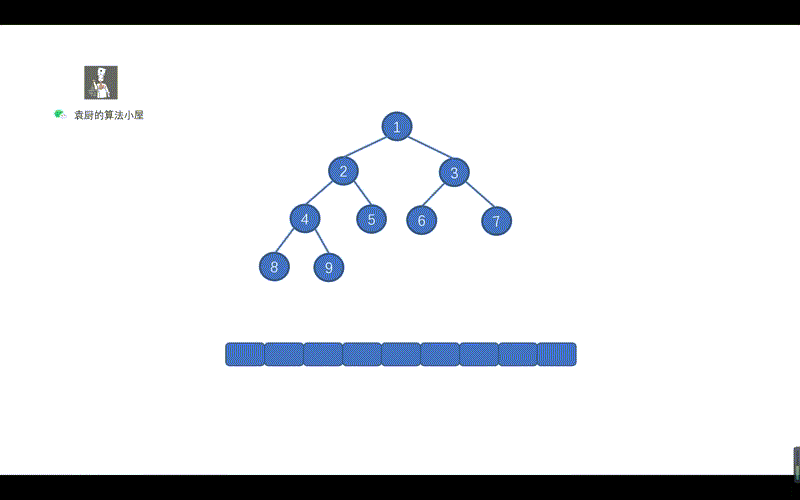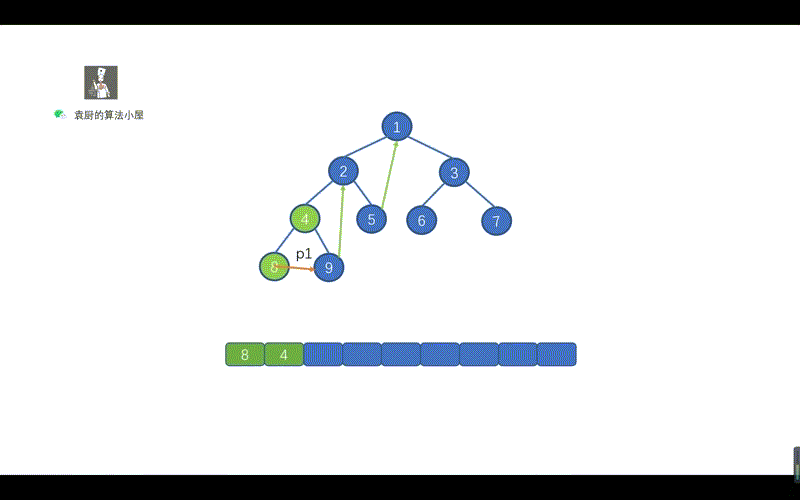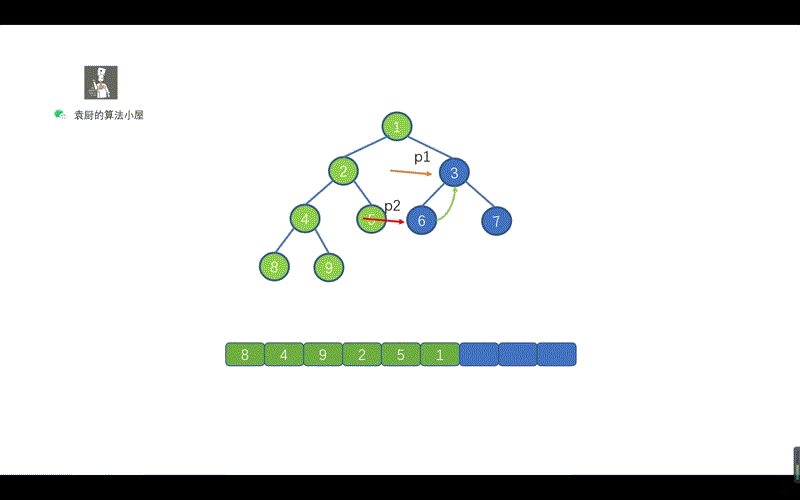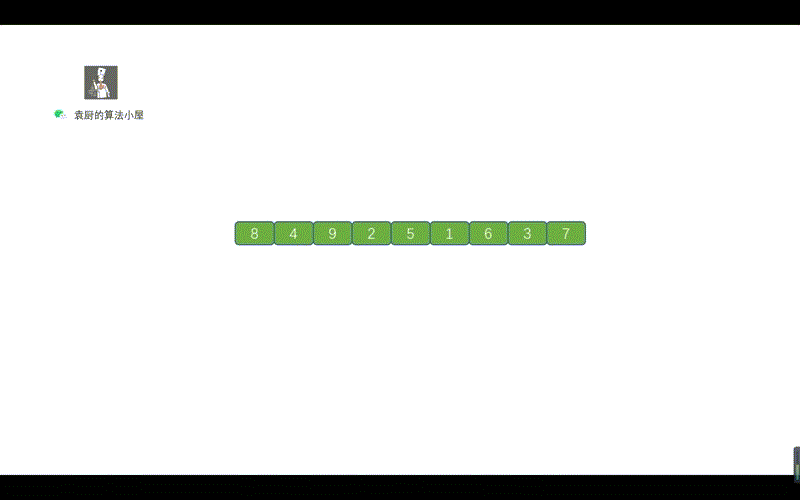
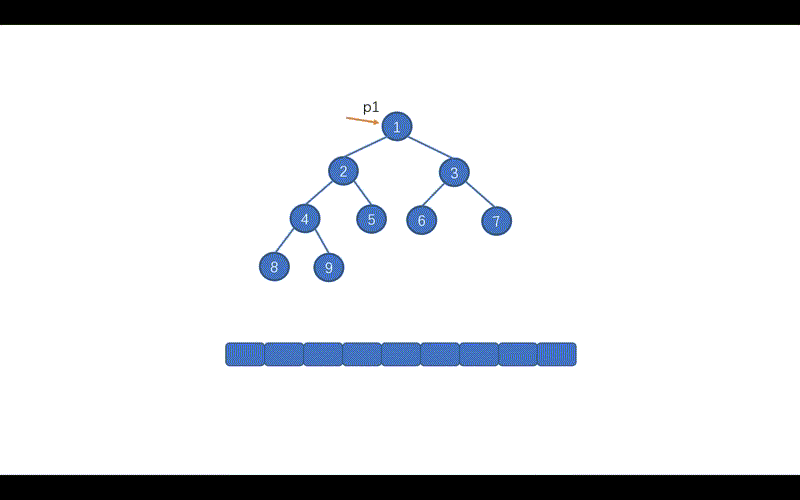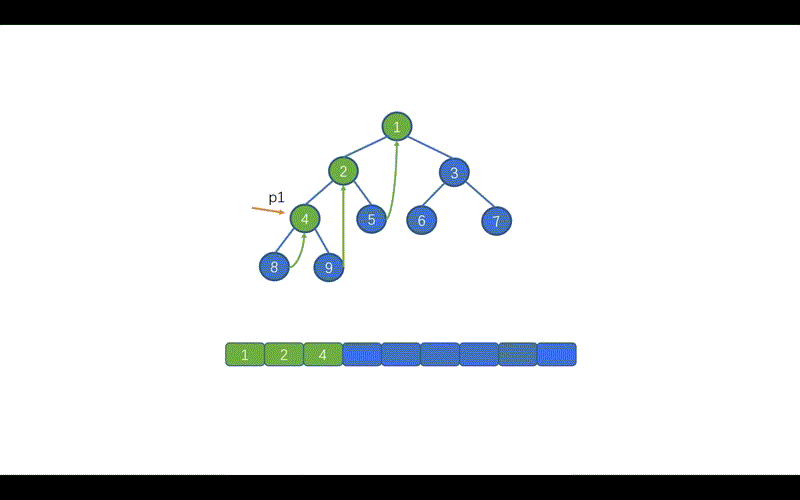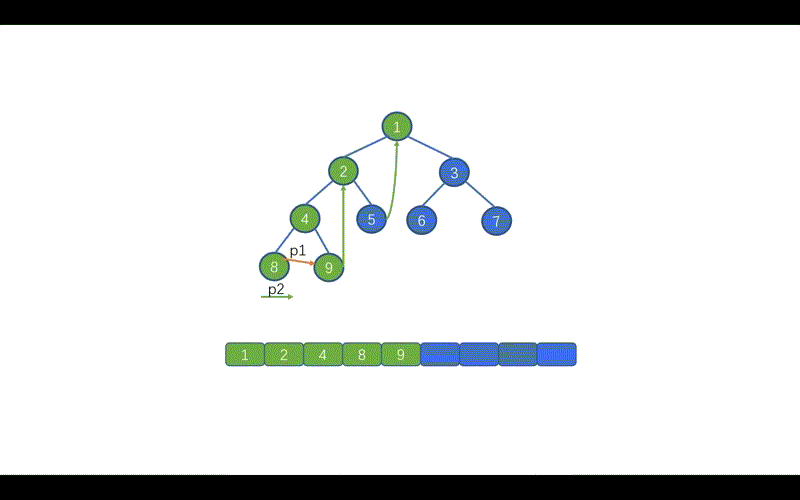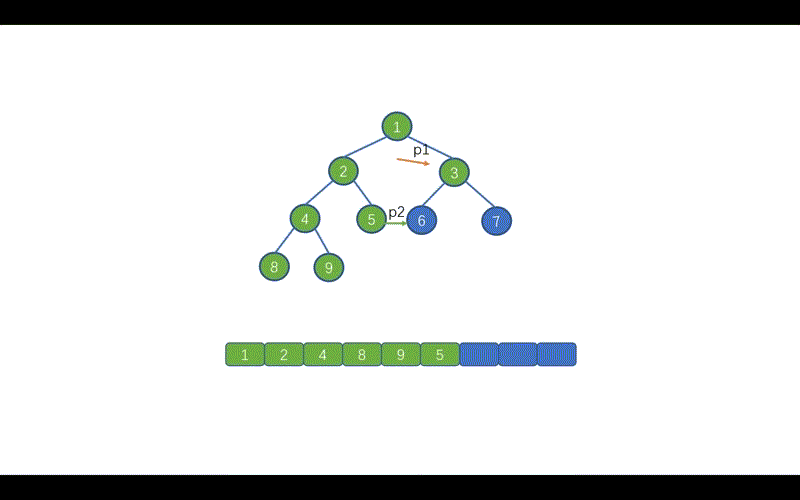
**参考代码:**
```java
//中序 Morris
class Solution {
public List<Integer> inorderTraversal(TreeNode root) {
List<Integer> list = new ArrayList<Integer>();
if (root == null) {
return list;
}
TreeNode p1 = root;
TreeNode p2 = null;
while (p1 != null) {
p2 = p1.left;
if (p2 != null) {
while (p2.right != null && p2.right != p1) {
p2 = p2.right;
}
if (p2.right == null) {
p2.right = p1;
p1 = p1.left;
continue;
} else {
p2.right = null;
}
}
list.add(p1.val);
p1 = p1.right;
}
return list;
}
}
```
Swift Code:
```swift
class Solution {
func inorderTraversal(_ root: TreeNode?) -> [Int] {
var list:[Int] = []
guard root != nil else {
return list
}
var p1 = root, p2: TreeNode?
while p1 != nil {
p2 = p1!.left
if p2 != nil {
while p2!.right != nil && p2!.right !== p1 {
p2 = p2!.right
}
if p2!.right == nil {
p2!.right = p1
p1 = p1!.left
continue
} else {
p2!.right = nil
}
}
list.append(p1!.val)
p1 = p1!.right
}
return list
}
}
```
================================================
FILE: animation-simulation/二叉树/二叉树中序遍历(迭代).md
================================================
哈喽大家好,我是厨子,之前我们说了二叉树前序遍历的迭代法和 Morris,今天咱们写一下中序遍历的迭代法和 Morris。
> 注:数据结构掌握不熟练的同学,阅读该文章之前,可以先阅读这两篇文章,二叉树基础,前序遍历另外喜欢电脑阅读的同学,可以在小屋后台回复仓库地址,获取 Github 链接进行阅读。
中序遍历的顺序是, `对于树中的某节点,先遍历该节点的左子树, 然后再遍历该节点, 最后遍历其右子树`。老规矩,上动画,我们先通过动画回忆一下二叉树的中序遍历。
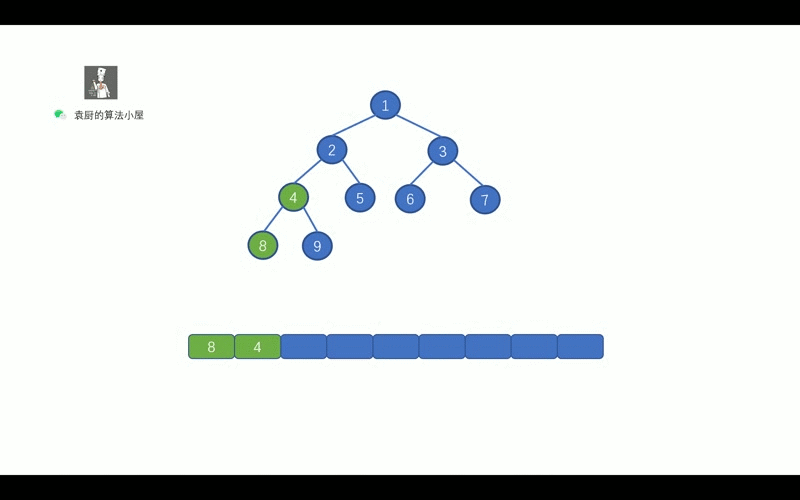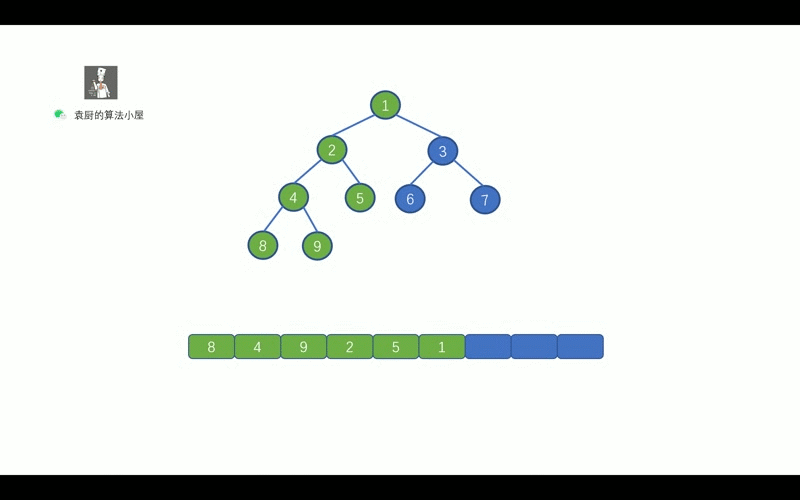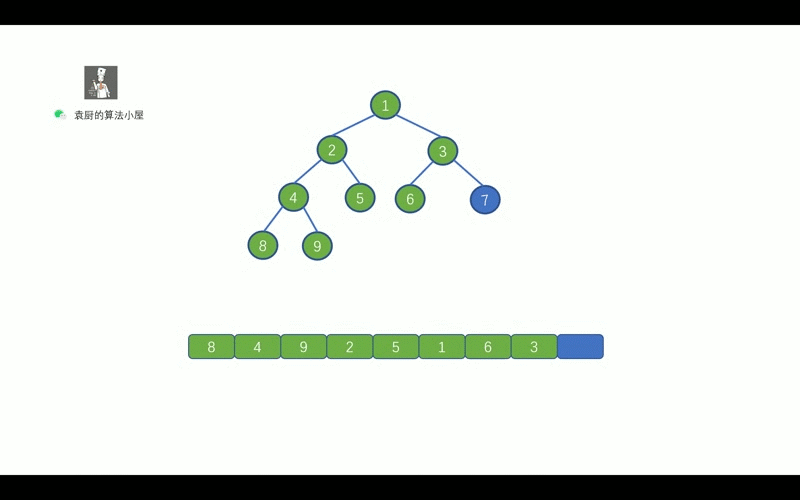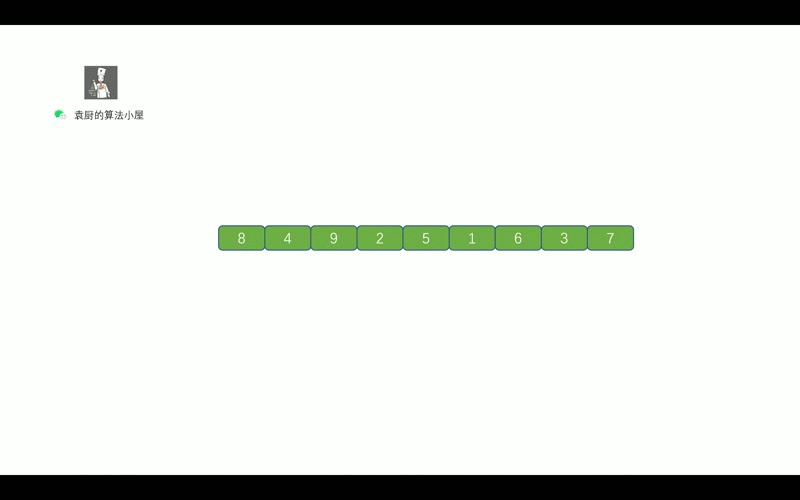
注:二叉树基础总结大家可以阅读这篇文章,点我。
## 迭代法
我们二叉树的中序遍历迭代法和前序遍历是一样的,都是借助栈来帮助我们完成。
我们结合动画思考一下,该如何借助栈来实现呢?
我们来看下面这个动画。
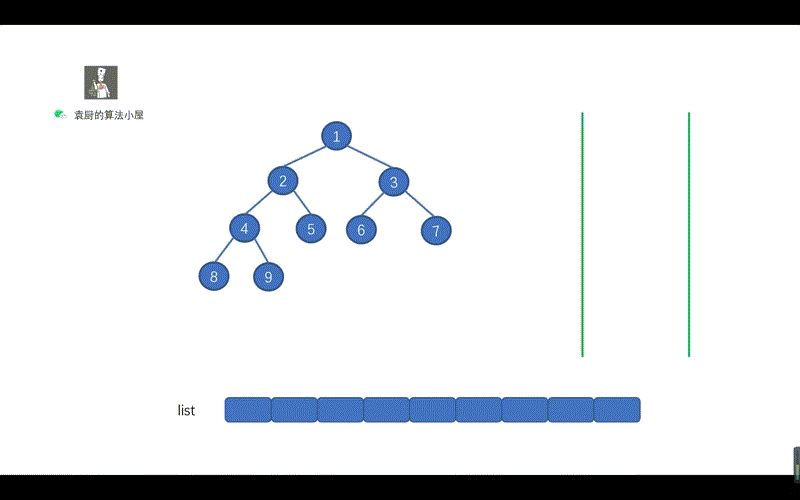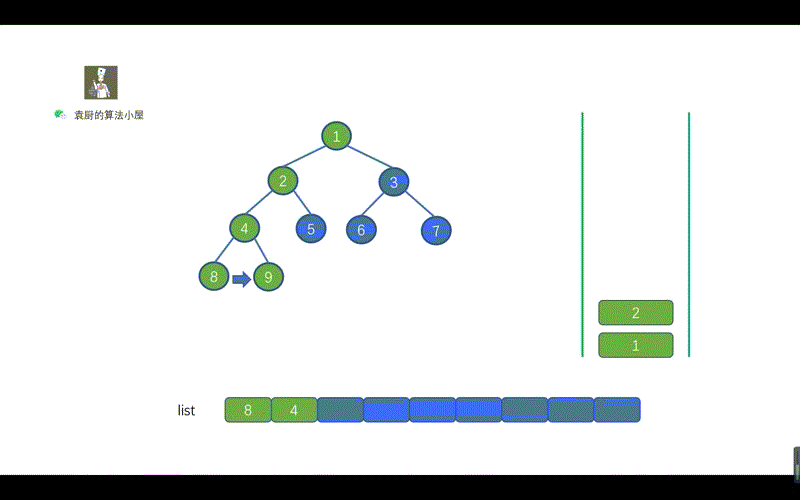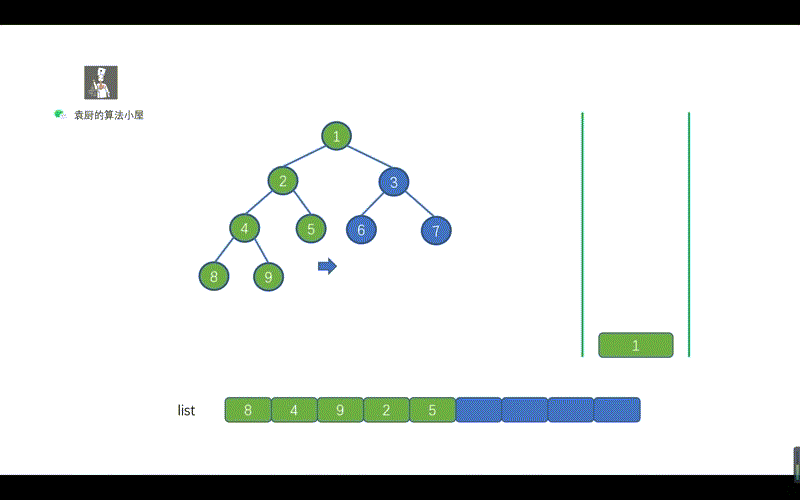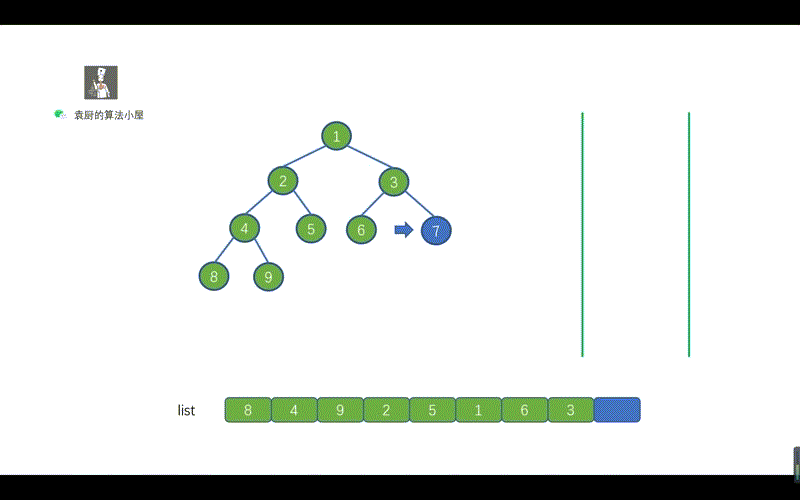
用栈实现的二叉树的中序遍历有两个关键的地方。
- 指针不断向节点的左孩子移动,为了找到我们当前需要遍历的节点。途中不断执行入栈操作
- 当指针为空时,则开始出栈,并将指针指向出栈节点的右孩子。
这两个关键点也很容易理解,指针不断向左孩子移动,是为了找到我们此时需要节点。然后当指针指向空时,则说明我们此时已经找到该节点,执行出栈操作,并将其值存入 list 即可,另外我们需要将指针指向出栈节点的右孩子,迭代执行上诉操作。
大家是不是已经知道怎么写啦,下面我们看代码吧。
```java
class Solution {
public List<Integer> inorderTraversal(TreeNode root) {
List<Integer> arr = new ArrayList<>();
TreeNode cur = new TreeNode(-1);
cur = root;
Stack<TreeNode> stack = new Stack<>();
while (!stack.isEmpty() || cur != null) {
//找到当前应该遍历的那个节点
while (cur != null) {
stack.push(cur);
cur = cur.left;
}
//此时指针指向空,也就是没有左子节点,则开始执行出栈操作
TreeNode temp = stack.pop();
arr.add(temp.val);
//指向右子节点
cur = temp.right;
}
return arr;
}
}
```
Swift Code:
```swift
class Solution {
func inorderTraversal(_ root: TreeNode?) -> [Int] {
var arr:[Int] = []
var cur = root
var stack:[TreeNode] = []
while !stack.isEmpty || cur != nil {
//找到当前应该遍历的那个节点
while cur != nil {
stack.append(cur!)
cur = cur!.left
}
//此时指针指向空,也就是没有左子节点,则开始执行出栈操作
if let temp = stack.popLast() {
arr.append(temp.val)
//指向右子节点
cur = temp.right
}
}
return arr
}
}
```
Go Code:
```go
func inorderTraversal(root *TreeNode) []int {
res := []int{}
if root == nil {
return res
}
stk := []*TreeNode{}
cur := root
for len(stk) != 0 || cur != nil {
// 找到当前应该遍历的那个节点,并且把左子节点都入栈
for cur != nil {
stk = append(stk, cur)
cur = cur.Left
}
// 没有左子节点,则开始执行出栈操作
temp := stk[len(stk) - 1]
stk = stk[: len(stk) - 1]
res = append(res, temp.Val)
cur = temp.Right
}
return res
}
```
###
================================================
FILE: animation-simulation/二叉树/二叉树基础.md
================================================
> 如果阅读时,发现错误,或者动画不可以显示的问题可以添加我微信好友 **[tan45du_one](https://raw.githubusercontent.com/tan45du/tan45du.github.io/master/个人微信.15egrcgqd94w.jpg)** ,备注 github + 题目 + 问题 向我反馈
>
> 感谢支持,该仓库会一直维护,希望对各位有一丢丢帮助。
>
> 另外希望手机阅读的同学可以来我的 <u>[**公众号:程序厨**](https://raw.githubusercontent.com/tan45du/test/master/微信图片_20210320152235.2pthdebvh1c0.png)</u> 两个平台同步,想要和题友一起刷题,互相监督的同学,可以在我的小屋点击<u>[**刷题小队**](https://raw.githubusercontent.com/tan45du/test/master/微信图片_20210320152235.2pthdebvh1c0.png)</u>进入。
这假期咋就唰的一下就没啦,昨天还跟放假第一天似的,今天就开始上班了。
既然开工了,那咱们就随遇而安呗,继续努力搬砖吧。
下面我们将镜头切到袁记菜馆。
小二:掌柜的,最近大家都在忙着种树,说是要保护环境。
老板娘:树 ? 咱们店有呀,前几年种的那棵葡萄树,不是都结果子了吗?就数你吃的最多。
小儿:这.......。
大家应该猜到,咱们今天要唠啥了。
之前给大家介绍了`链表`,`栈`,`哈希表` 等数据结构
今天咱们来看一种新的数据结构,树。
PS:本篇文章内容较基础,对于没有学过数据结构的同学会有一些帮助,如果你已经学过的话,也可以复习一下,查缺补漏,后面会继续更新这个系列。
**文章大纲**
> 注:可能有的同学不喜欢手机阅读,所以将这篇同步在了我的仓库,大家可以去 Github 进行阅读,点击文章最下方的阅读原文即可
## 树
我们先来看下百度百科对树的定义
> 树是 n (n >= 0) 个节点的有限集。 n = 0 时 我们称之为空树, 空树是树的特例。
在`任意一棵非空树`中:
- 有且仅有一个特定的节点称为根(Root)的节点
- 当 n > 1 时,其余节点可分为 m (m > 0)个`互不相交的有限集` T1、T2、........Tm,其中每一个集合本身又是一棵树,并且称为根的子树。
我们一起来拆解一下上面的两句话,到底什么是子树呢?见下图
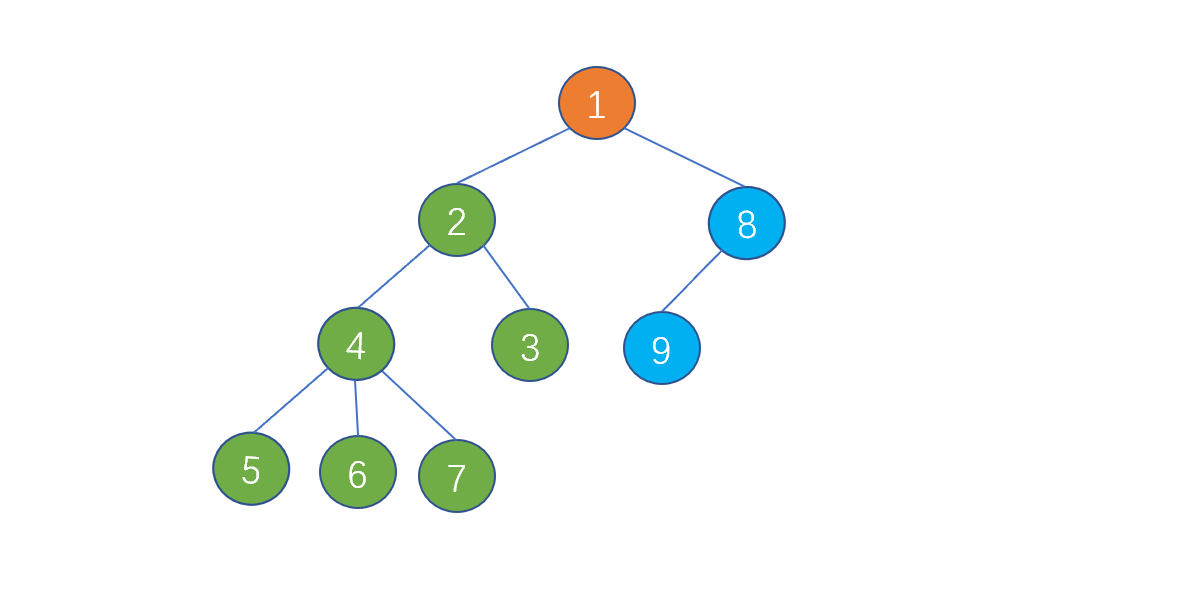
例如在上面的图中
有且仅有一个特定的节点称为根节点,也就是上图中的`橙色节点`。
当节点数目大于 1 时,除根节点以外的节点,可分为 m 个`互不相交`的有限集 T1,T2........Tm。
例如上图中,我们将根节点以外的节点,分为了 T1 (2,3,4,5,6,7),T2(8,9)两个有限集。
那么 T1 (绿色节点)和 T2(蓝色节点)就是根节点(橙色节点)的子树。
我们拆解之后发现,我们上图中的例子符合树的要求,另外不知道大家有没有注意到这个地方。
除根节点以外的节点,可分为 m 个`互不相交`的有限集。
那么这个互不相交又是什么含义呢?见下图。
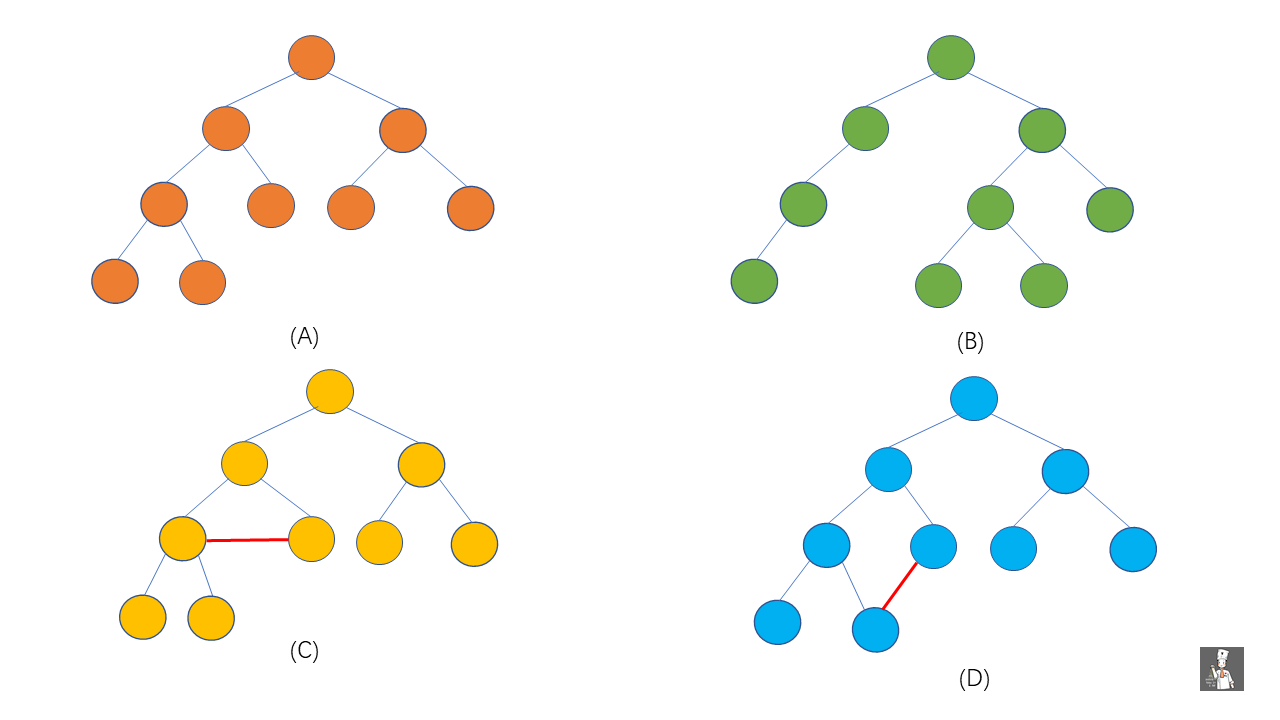
我们将 (A) , (B) , (C) , (D) 代入上方定义中发现,(A) , (B) 符合树的定义,(C), (D) 不符合,这是因为 (C) , (D) 它们都有相交的子树。
好啦,到这里我们知道如何辨别树啦,下面我们通过下面两张图再来深入了解一下树。
主要从节点类型,节点间的关系下手。
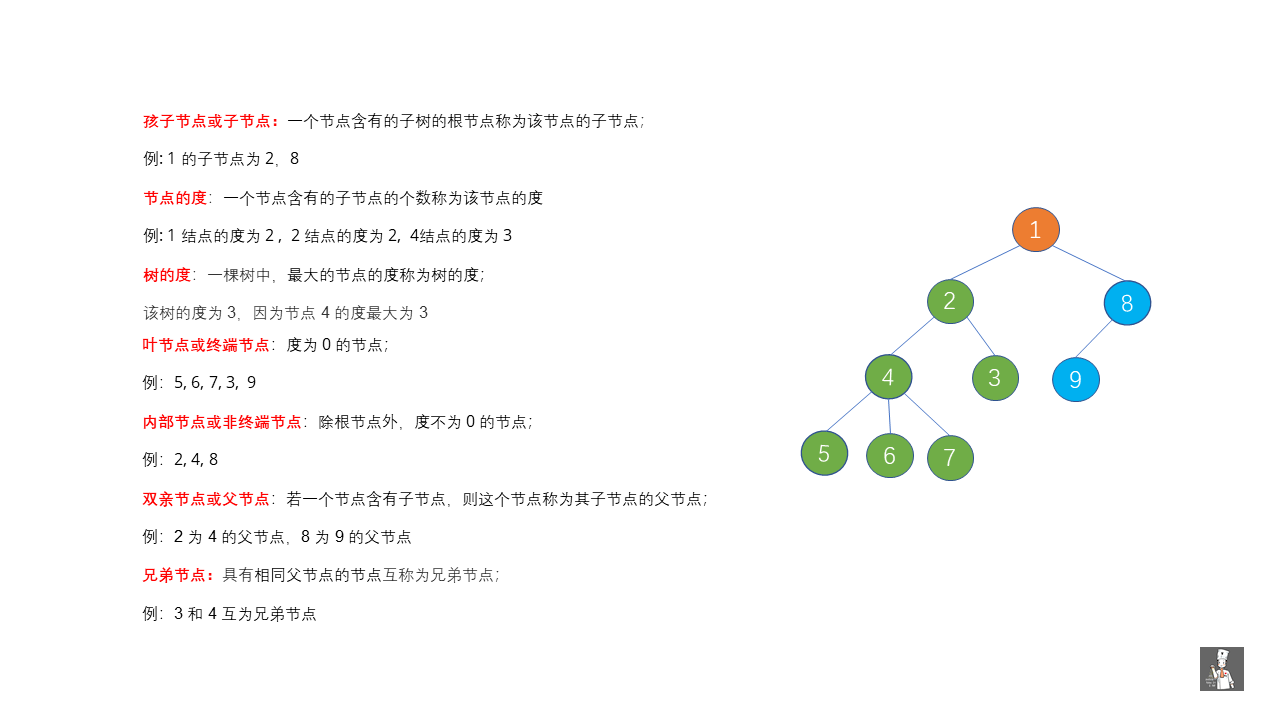
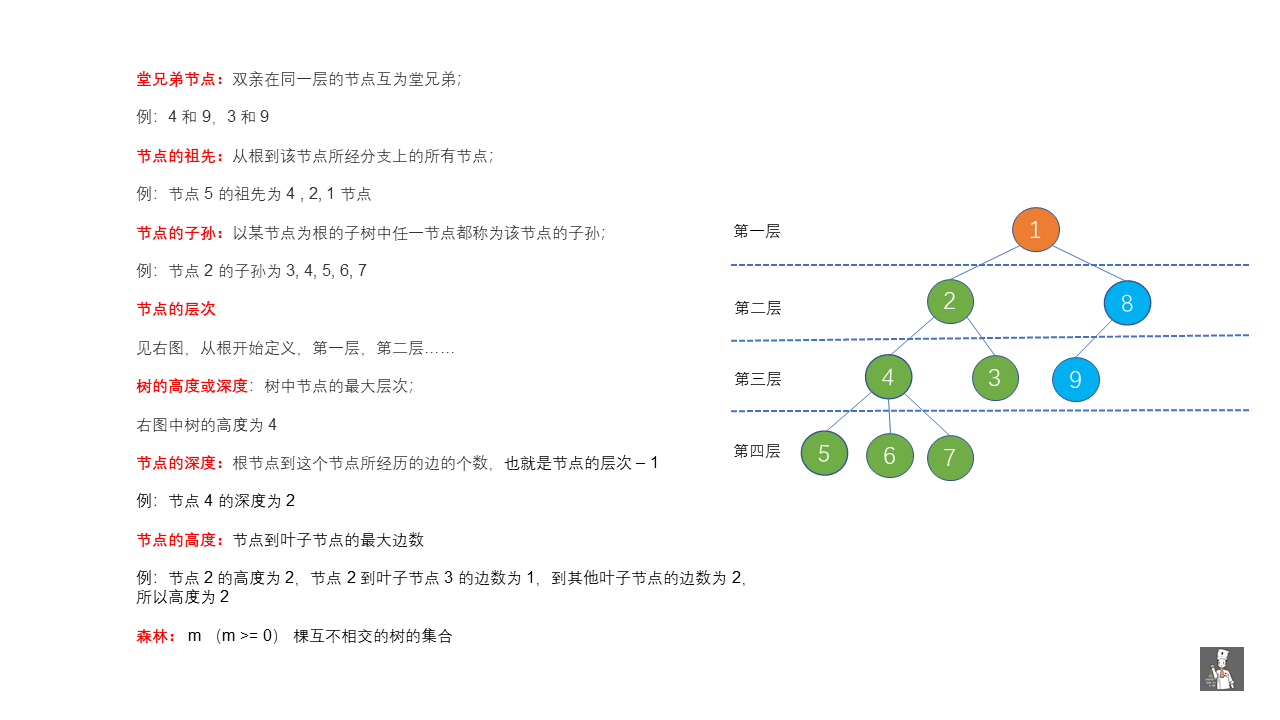
这里节点的高度和深度可能容易记混,我们代入到现实即可。
我们求深度时,从上往下测量,求高度时,从下往上测量,节点的高度和深度也是如此。
## 二叉树
我们刷题时遇到的就是二叉树啦,下面我们一起来了解一下二叉树
二叉树前提是一棵树,也就是`需要满足我们树的定义的同时`,还需要满足以下要求
每个节点`最多`有两个子节点,分别是左子节点和右子节点。
注意我们这里提到的是`最多`,所以二叉树并不是`必须要求每个节点都有两个子节点`,也可以有的仅有一个左子节点,有的节点仅有一个右子节点。
下面我们来总结一下二叉树的特点
- 每个节点最多有两棵子树,也就是说二叉树中不存在度大于 2 的节点,节点的度可以为 0,1,2。
- 左子树和右子树是有顺序的,有左右之分。
- 假如只有一棵子树 ,也要区分它是左子树还是右子树
好啦,我们已经了解了二叉树的特点,那我们分析一下,下图中的树是否满足二叉树定义,共有几种二叉树。
上图共为 5 种不同的二叉树,在二叉树的定义中提到,二叉树的左子树和右子树是有顺序的,所以 B,C 是两个不同的二叉树,故上图为 5 种不同的二叉树。
## 特殊的二叉树
下面我们来说几种比较特殊的二叉树,可以`帮助我们刷题时,考虑到特殊情况`。
### 满二叉树
满二叉树:在一棵二叉树中,`所有分支节点都存在左子树和右子树`,并且`所有的叶子都在同一层`,这种树我们称之为满二叉树.见下图
我们发现只有 (B) 符合满二叉树的定义,我们发现其实满二叉树也为完全二叉树的一种。
### 完全二叉树
完全二叉树:叶子结点只能出现在最下层和次下层,且最下层的叶子结点集中在树的左部。
哦!我们可以这样理解,除了最后一层,其他层的节点个数都是满的,而且最后一层的叶子节点必须靠左。
下面我们来看一下这几个例子
上面的几个例子中,(A)(B)为完全二叉树,(C)(D)不是完全二叉树
### 斜二叉树
这个就很好理解啦,斜二叉树也就是斜的二叉树,所有的节点只有左子树的称为左斜树,所有节点只有右子树的二叉树称为右斜树.
诺,下面这俩就是.
另外还有 一些二叉树的性质, 比如第 i 层至多有多少节点,通过叶子节点求度为 2 的节点, 通过节点树求二叉树的深度等, 这些是考研常考的知识, 就不在这里进行赘述,需要的同学可以看一下王道或者天勤的数据结构, 上面描述的很具体, 并附有证明过程.
好啦,我们已经了解了二叉树,那么二叉树如何存储呢?
## 如何存储二叉树
二叉树多采用两种方法进行存储,基于数组的顺序存储法和基于指针的二叉链式存储法
我们在之前说过的堆排序中,其中对堆的存储采用的则是顺序存储法,具体细节可以看这篇文章
**一个破堆排我搞了 4 个动画?**
这里我们再来回顾一下如何用数组存储完全二叉树.
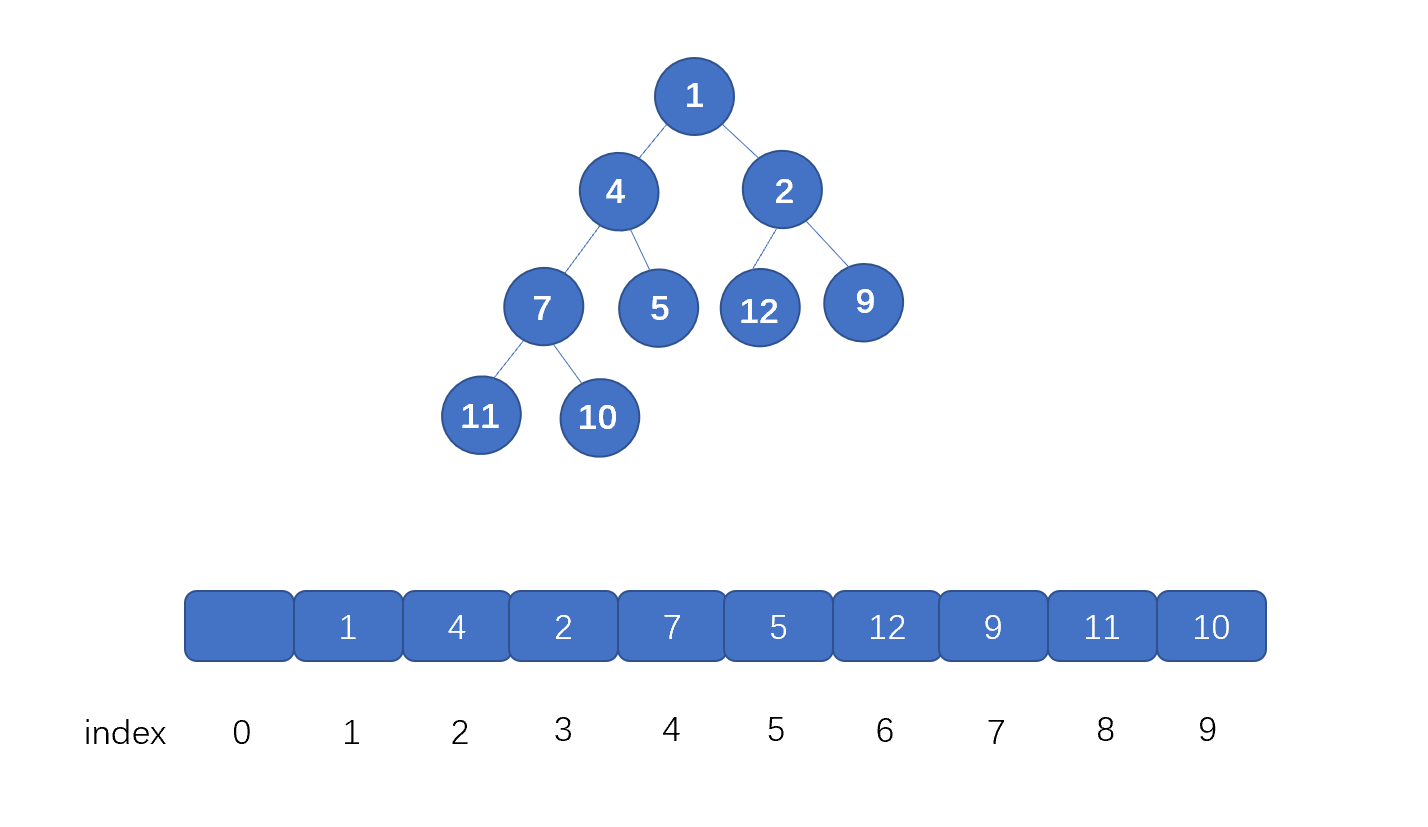
我们首先看根节点,也就是值为 1 的节点,它在数组中的下标为 1 ,它的左子节点,也就是值为 4 的节点,此时索引为 2,右子节点也就是值为 2 的节点,它的索引为 3。
我们发现其中的关系了吗?
数组中,某节点(非叶子节点)的下标为 i , 那么其`左子节点下标为 2*i `(这里可以直接通过相乘得到左孩子, 也就是为什么空出第一个位置, 如果从 0 开始存,则需要 2*i+1 才行), 右子节点为 2*i+1,其父节点为 i/2 。既然我们完全可以根据索引找到某节点的 `左子节点` 和` 右子节点`,那么我们用数组存储是完全没有问题的。
但是,我们再考虑一下这种情景,如果我们用数组存储`斜树`时会出现什么情况?
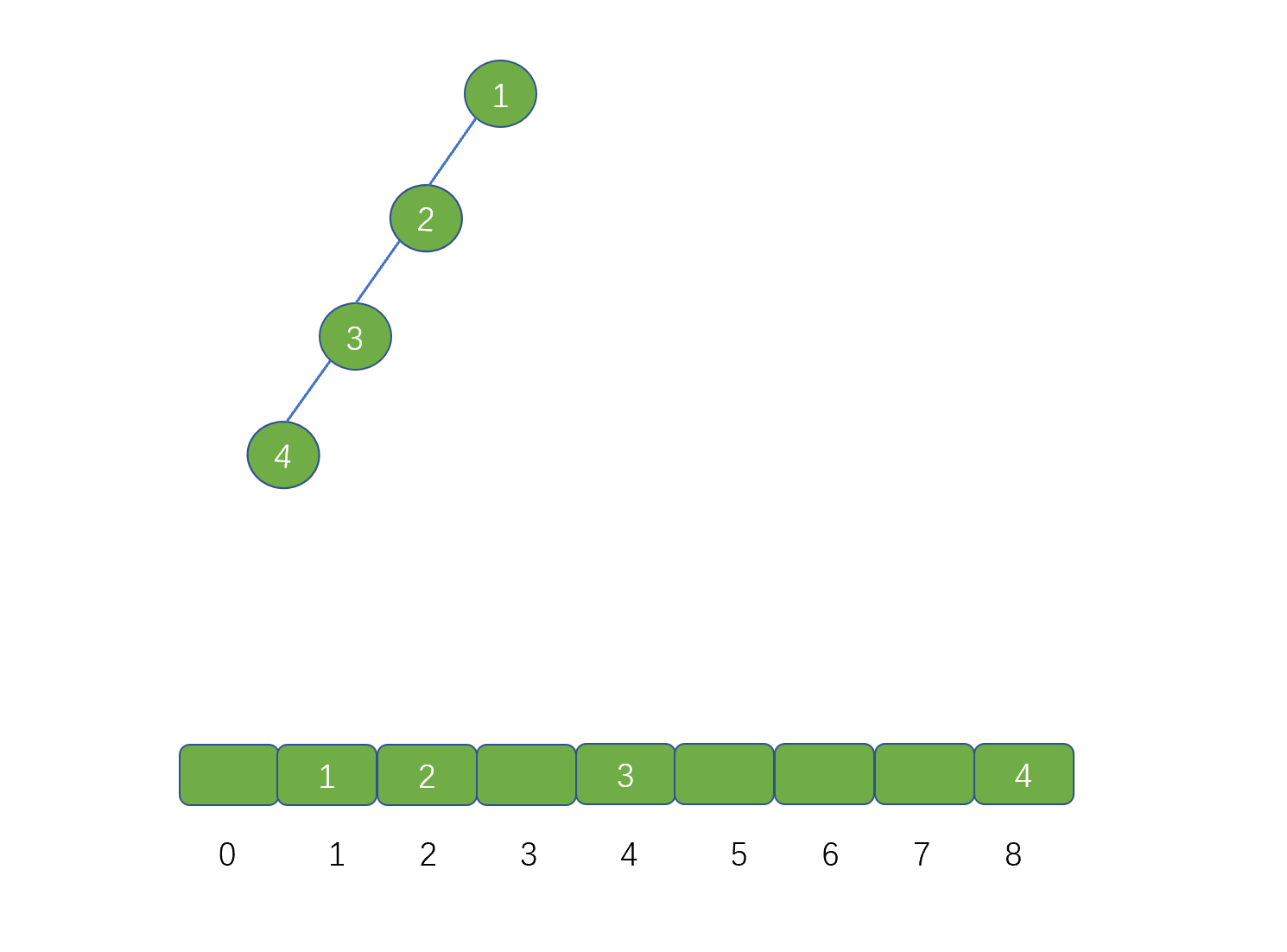
通过 2\*i 进行存储左子节点的话,如果遇到斜树时,则会浪费很多的存储空间,这样显然是不合适的,
所以说当存储完全二叉树时,我们用数组存储,无疑是最省内存的,但是存储斜树时,则就不太合适。
所以我们下面介绍一下另一种存储结构,链式存储结构.
因为二叉树的每个节点, 最多有两个孩子, 所以我们只需为每个节点定义一个数据域,两个指针域即可
val 为节点的值, left 指向左子节点, right 指向右子节点.

下面我们对树 1, 2, 3, 4, 5, 6, 7 使用链式存储结构进行存储,即为下面这种情况.
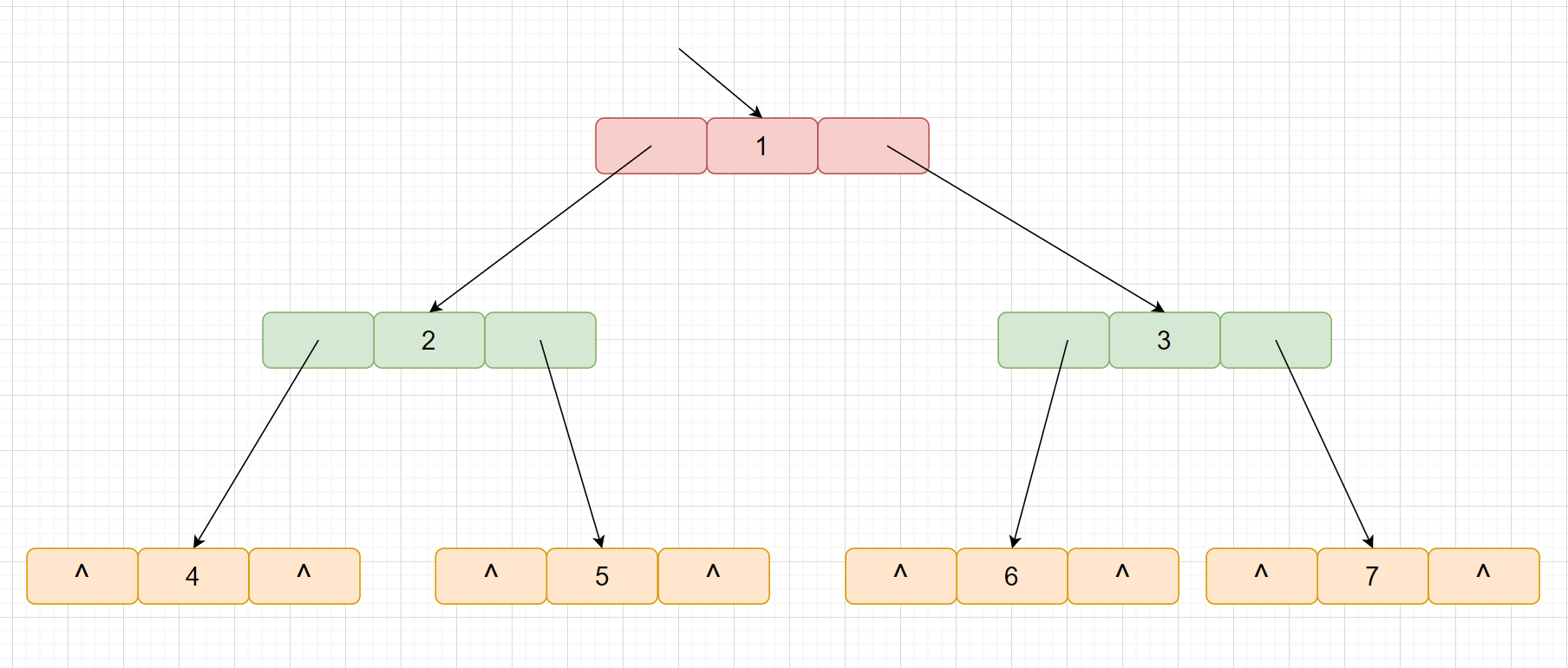
**二叉链表的节点结构定义代码**
```java
public class BinaryTree {
int val;
BinaryTree left;
BinaryTree right;
BinaryTree() {}
BinaryTree(int val) { this.val = val; }
BinaryTree(int val, BinaryTree left, BinaryTree right) {
this.val = val;
this.left = left;
this.right = right;
}
}
```
另外我们在刷题的时候, 可以`自己实现一下数据结构`, 加深我们的理解, 提升基本功, 而且面试考的也越来越多.
好啦,下面我们说一下树的遍历,
下面我会用动图的形式进行描述,很容易理解, 我也会为大家总结对应的题目,欢迎各位阅读.
## 遍历二叉树
二叉树的遍历指`从根节点出发,按照某种次序依次访问二叉树的所有节点`,使得每个节点都被访问且访问一次.
我们下面介绍二叉树的几种遍历方法及其对应的题目, 前序遍历, 中序遍历 , 后序遍历 , 层序遍历 .
### 前序遍历
前序遍历的顺序是, 对于树中的某节点,`先遍历该节点,然后再遍历其左子树,最后遍历其右子树`.
只看文字有点生硬, 下面我们直接看动画吧
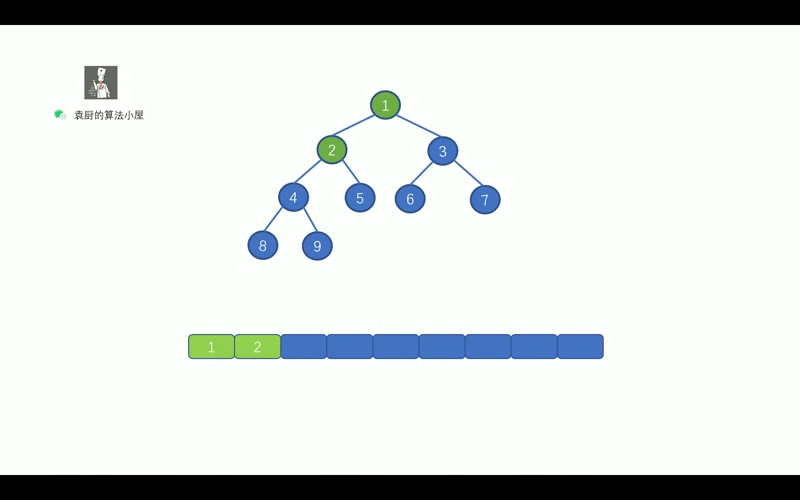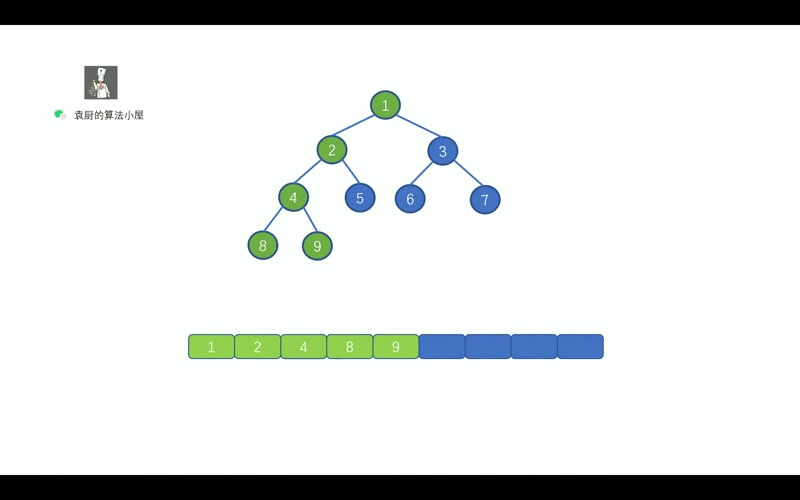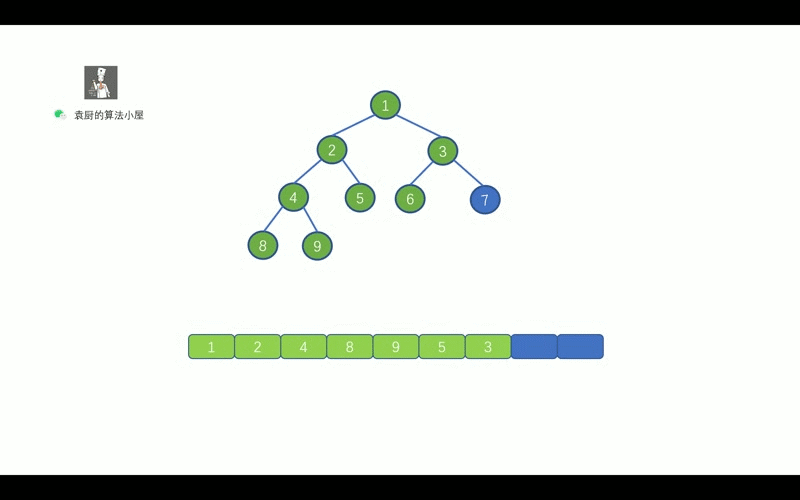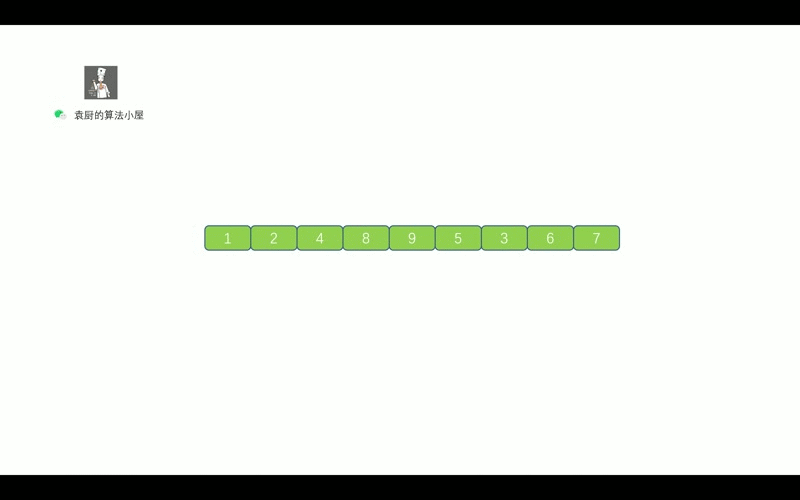
**测试题目: leetcode 144. 二叉树的前序遍历**
**代码实现(递归版)**
```java
class Solution {
public List<Integer> preorderTraversal(TreeNode root) {
List<Integer> arr = new ArrayList<>();
preorder(root,arr);
return arr;
}
public void preorder(TreeNode root,List<Integer> arr) {
if (root == null) {
return;
}
arr.add(root.val);
preorder(root.left,arr);
preorder(root.right,arr);
}
}
```
时间复杂度 : O(n) 空间复杂度 : O(n) 为递归过程中栈的开销,平均为 O(logn),但是当二叉树为斜树时则为 O(n)
为了控制文章篇幅, 二叉树的迭代遍历形式, 会在下篇文章进行介绍。
### 中序遍历
中序遍历的顺序是, `对于树中的某节点,先遍历该节点的左子树, 然后再遍历该节点, 最后遍历其右子树`
继续看动画吧, 如果有些遗忘或者刚开始学数据结构的同学可以自己模拟一下执行步骤.

**测试题目: leetcode 94 题 二叉树的中序遍历**
**代码实现(递归版)**
```java
class Solution {
public List<Integer> inorderTraversal(TreeNode root) {
List<Integer> res = new ArrayList<>();
inorder(root, res);
return res;
}
public void inorder (TreeNode root, List<Integer> res) {
if (root == null) {
return;
}
inorder(root.left, res);
res.add(root.val);
inorder(root.right, res);
}
}
```
时间复杂度 : O(n) 空间复杂度 : O(n)
### 后序遍历
后序遍历的顺序是,` 对于树中的某节点, 先遍历该节点的左子树, 再遍历其右子树, 最后遍历该节点`.
哈哈,继续看动画吧,看完动画就懂啦.
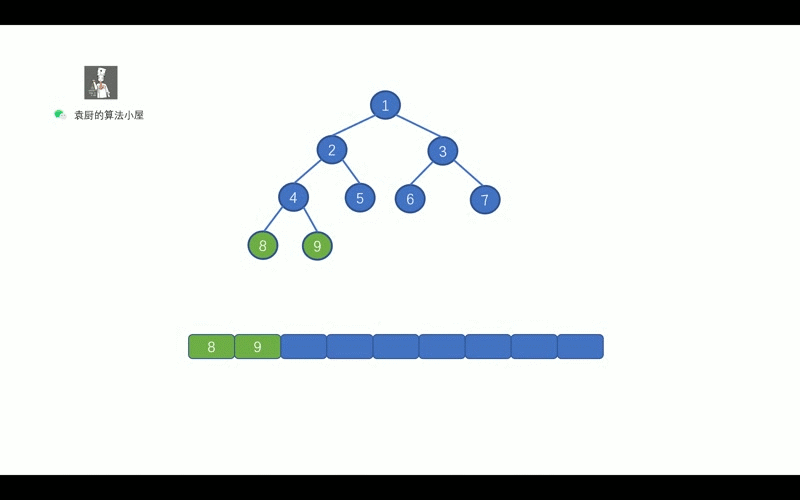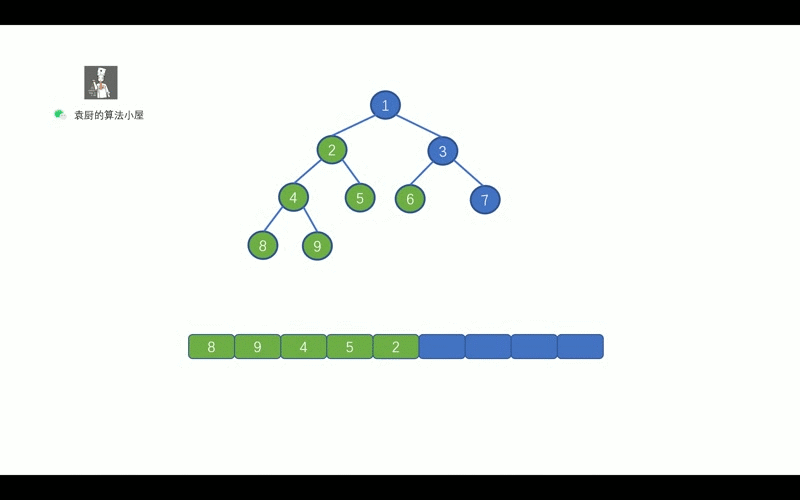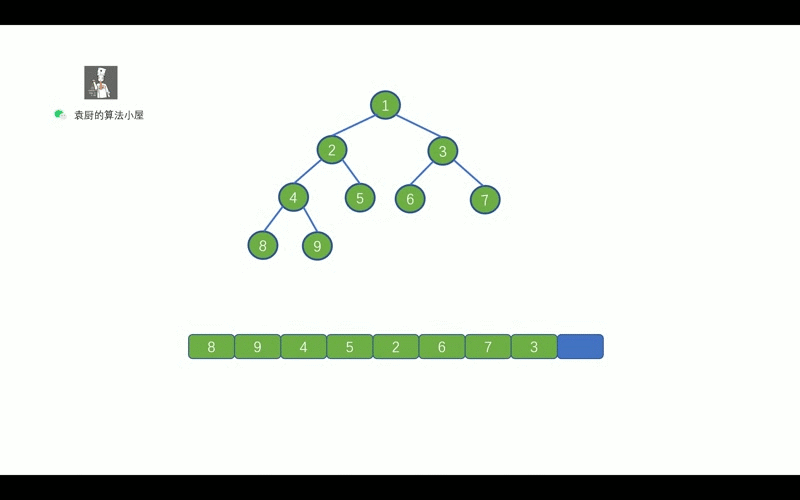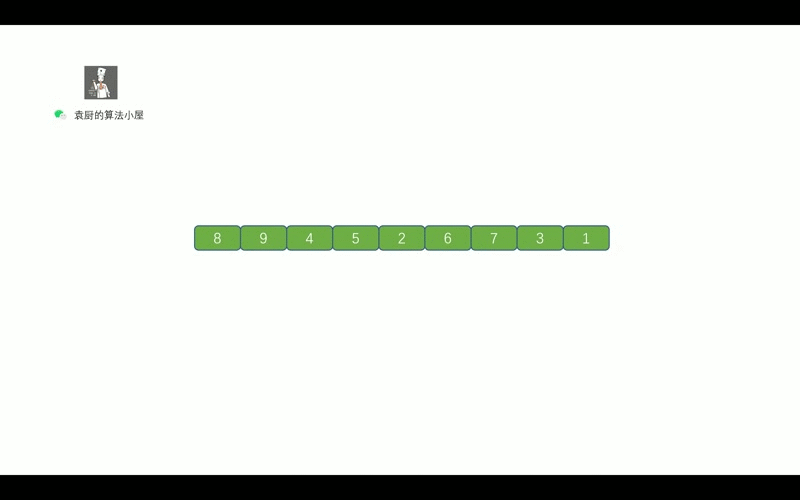
**测试题目: leetcode 145 题 二叉树的后序遍历**
**代码实现(递归版)**
```java
class Solution {
public List<Integer> postorderTraversal(TreeNode root) {
List<Integer> res = new ArrayList<>();
postorder(root,res);
return res;
}
public void postorder(TreeNode root, List<Integer> res) {
if (root == null) {
return;
}
postorder(root.left, res);
postorder(root.right, res);
res.add(root.val);
}
}
```
时间复杂度 : O(n) 空间复杂度 : O(n)
### 层序遍历
顾名思义,一层一层的遍历.
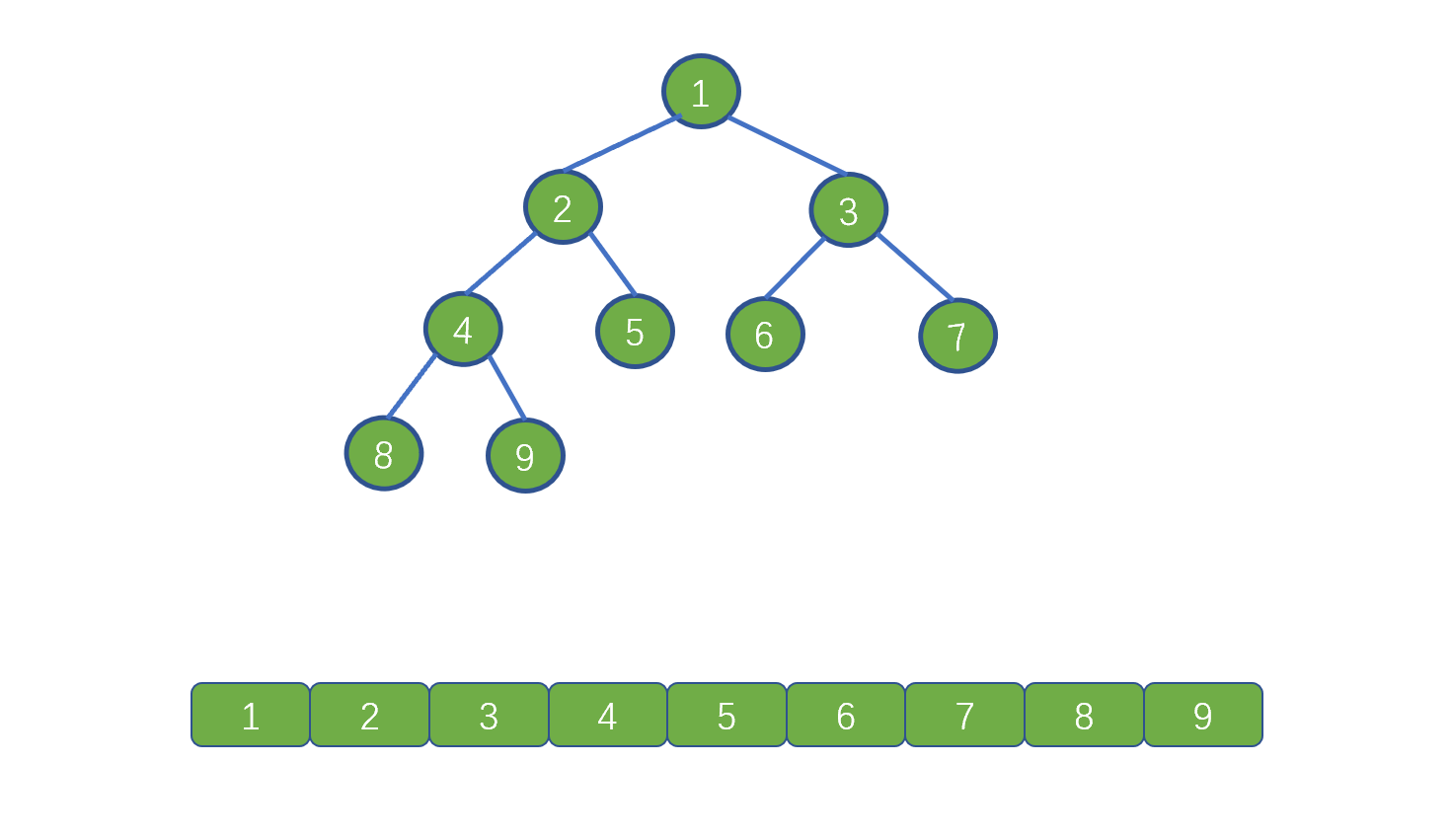
比如刚才那棵二叉树的层序遍历序列即为 1 ~ 9.
二叉树的层序, 这里我们需要借助其他数据结构来实现, 我们思考一下, 我们需要对二叉树进行层次遍历, 从上往下进行遍历, 我们可以借助什么数据结构来帮我们呢 ?
我们可以利用队列先进先出的特性,使用队列来帮助我们完成层序遍历, 具体操作如下
让二叉树的每一层入队, 然后再依次执行出队操作,
对`该层节点执行出队操作时, 需要将该节点的左孩子节点和右孩子节点进行入队操作`,
这样当该层的所有节点出队结束后, 下一层也就入队完毕,
不过我们需要考虑的就是, 我们`需要通过一个变量来保存每一层节点的数量`.
这样做是为了防止, 一直执行出队操作, 使输出不能分层
好啦,下面我们直接看动画吧,
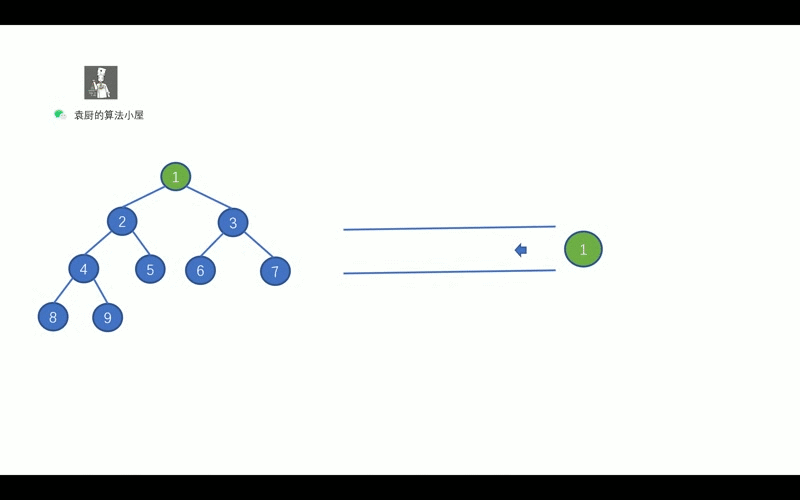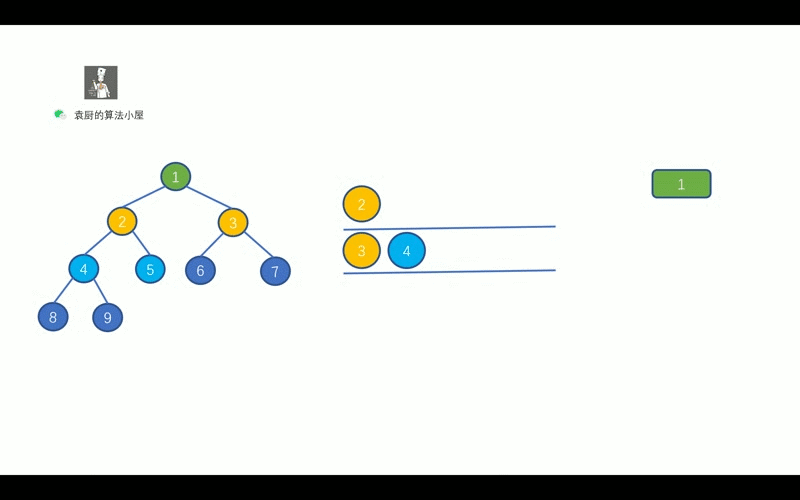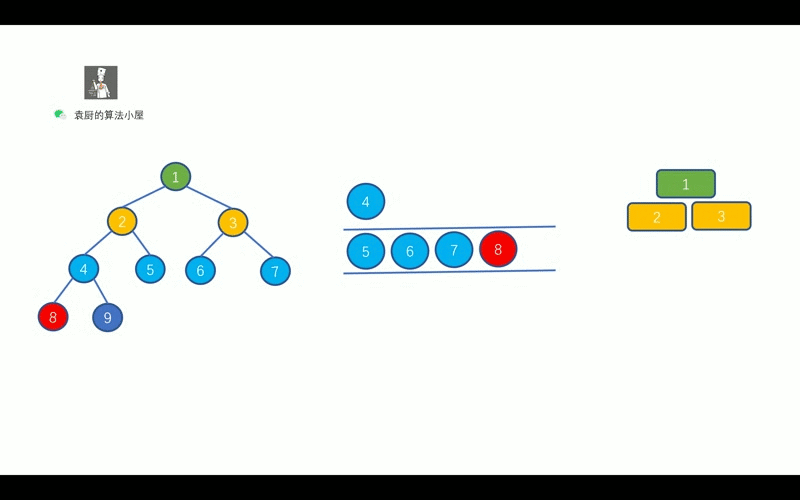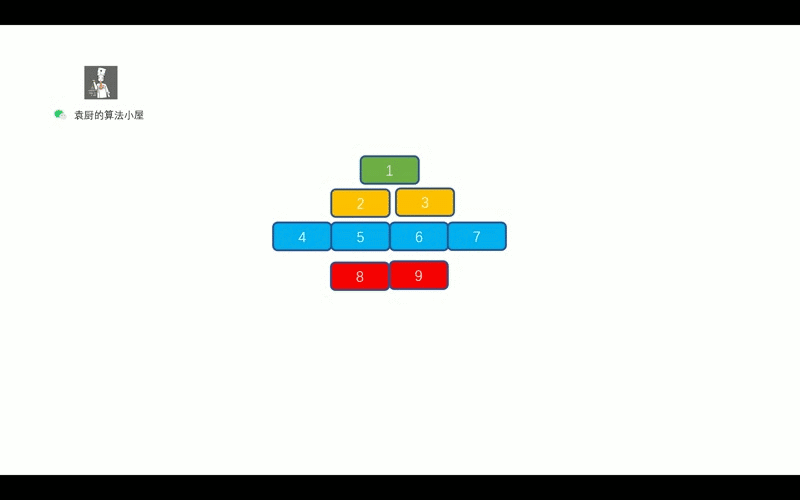
**测试题目: leetcode 102 二叉树的层序遍历**
Java Code:
```java
class Solution {
public List<List<Integer>> levelOrder(TreeNode root) {
List<List<Integer>> res = new ArrayList<>();
if (root == null) {
return res;
}
//入队 root 节点,也就是第一层
Queue<TreeNode> queue = new LinkedList<>();
queue.offer(root);
while (!queue.isEmpty()) {
List<Integer> list = new ArrayList<>();
int size = queue.size();
for (int i = 0; i < size; ++i) {
TreeNode temp = queue.poll();
//孩子节点不为空,则入队
if (temp.left != null) queue.offer(temp.left);
if (temp.right != null) queue.offer(temp.right);
list.add(temp.val);
}
res.add(list);
}
return res;
}
}
```
C++ Code:
```cpp
class Solution {
public:
vector<vector<int>> levelOrder(TreeNode* root) {
vector<vector<int>> res;
if (!root) return res;
queue<TreeNode *> q;
q.push(root);
while (!q.empty()) {
vector <int> t;
int size = q.size();
for (int i = 0; i < size; ++i) {
TreeNode * temp = q.front();
q.pop();
if (temp->left != nullptr) q.push(temp->left);
if (temp->right != nullptr) q.push(temp->right);
t.emplace_back(temp->val);
}
res.push_back(t);
}
return res;
}
};
```
Swift Code:
```swift
class Solution {
func levelOrder(_ root: TreeNode?) -> [[Int]] {
var res:[[Int]] = []
guard root != nil else {
return res
}
var queue:[TreeNode?] = []
queue.append(root!)
while !queue.isEmpty {
let size = queue.count
var list:[Int] = []
for i in 0..<size {
guard let node = queue.removeFirst() else {
continue
}
if node.left != nil {
queue.append(node.left)
}
if node.right != nil {
queue.append(node.right);
}
list.append(node.val)
}
res.append(list)
}
return res
}
}
```
Go Code:
```go
func levelOrder(root *TreeNode) [][]int {
res := [][]int{}
if root == nil {
return res
}
// 初始化队列时,记得把root节点加进去。
que := []*TreeNode{root}
for len(que) != 0 {
t := []int{}
// 这里一定要先求出来que的长度,因为在迭代的过程中,que的长度是变化的。
l := len(que)
for i := 0; i < l; i++ {
temp := que[0]
que = que[1:]
// 子节点不为空,就入队
if temp.Left != nil { que = append(que, temp.Left) }
if temp.Right != nil { que = append(que, temp.Right) }
t = append(t, temp.Val)
}
res = append(res, t)
}
return res
}
```
时间复杂度:O(n) 空间复杂度:O(n)
大家如果吃透了二叉树的层序遍历的话,可以顺手把下面几道题目解决掉,思路一致,甚至都不用拐弯
- **leetcode 107. 二叉树的层序遍历 II**
- **leetcode 103. 二叉树的锯齿形层序遍历**
上面两道题仅仅是多了翻转
- **leetcode 199. 二叉树的右视图**
- **leetcode 515. 在每个树行中找最大值**
- **leetcode 637. 二叉树的层平均值**
这三道题,仅仅是加了一层的一些操作
- **leetcode 116 填充每个节点的下一个右侧**
- **leetcode 117 填充每个节点的下一个右侧 2**
这两个题对每一层的节点进行链接即可。
大家可以去顺手解决这些题目,但是也要注意一下其他解法,把题目吃透。不要为了数目而刷题,好啦,今天的节目就到这里啦,我们下期见!
================================================
FILE: animation-simulation/二叉树/二叉树的前序遍历(Morris).md
================================================
### Morris
Morris 遍历利用树的左右孩子为空(大量空闲指针),实现空间开销的极限缩减。这个遍历方法,稍微有那么一丢丢难理解,不过结合动图,也就一目了然啦,下面我们先看动画吧。

看完视频,是不是感觉自己搞懂了,又感觉自己没搞懂,哈哈,咱们继续往下看。
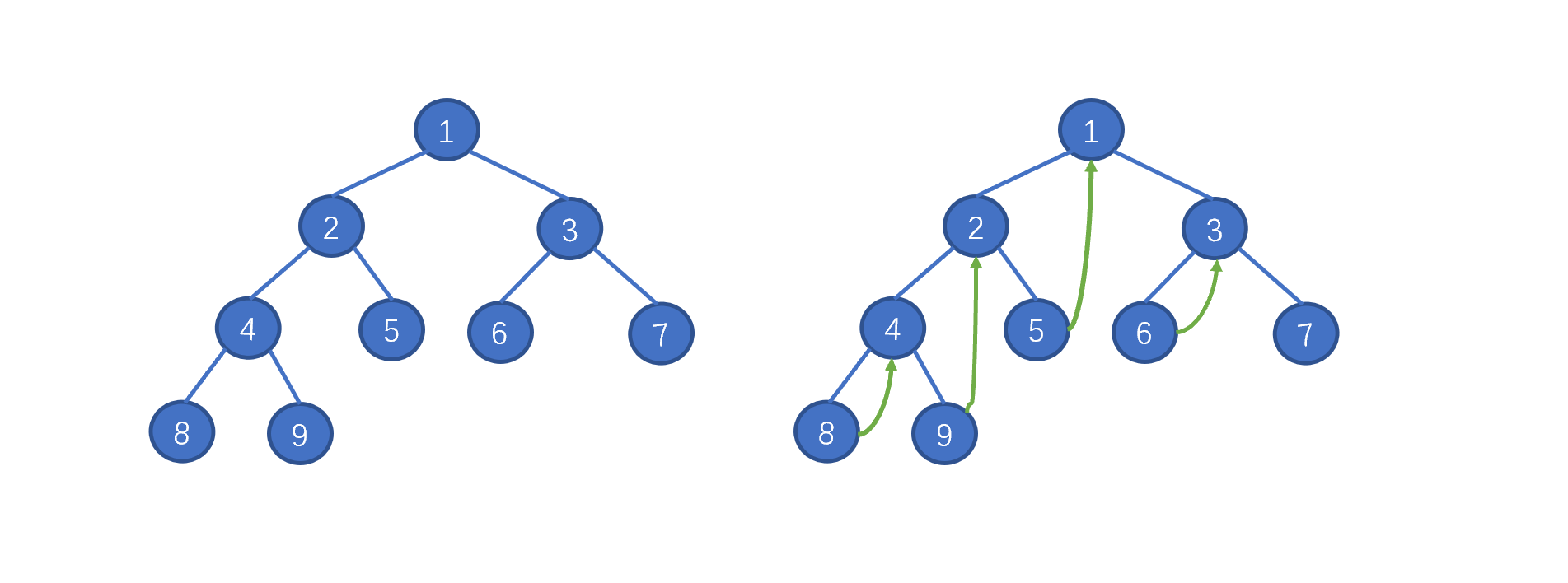
我们之前说的,Morris 遍历利用了`树中大量空闲指针的特性`,我们需要`找到当前节点的左子树中的最右边的叶子节点`,将该叶子节点的 right 指向当前节点。例如当前节点为 2,其左子树中的最右节点为 9 ,则在 9 节点添加一个 right 指针指向 2。
其实上图中的 Morris 遍历遵循两个原则,我们在动画中也能够得出。
1. 当 p1.left == null 时,p1 = p1.right。(这也就是我们为什么要给叶子节点添加 right 指针的原因)
2. 如果 p1.left != null,找到 p1 左子树上最右的节点。(也就是我们的 p2 最后停留的位置),此时我们又可以分为两种情况,一种是叶子节点添加 right 指针的情况,一种是去除叶子节点 right 指针的情况。
3. - 如果 p2 的 right 指针指向空,让其指向 p1,p1 向左移动,即 p1 = p1.left
- 如果 p2 的 right 指针指向 p1,让其指向空,(为了防止重复执行,则需要去掉 right 指针)p1 向右移动,p1 = p1.right。
这时你可以结合咱们刚才提到的两个原则,再去看一遍动画,并代入规则进行模拟,差不多就能完全搞懂啦。
下面我们来对动画中的内容进行拆解 ,
首先 p1 指向 root 节点
p2 = p1.left,下面我们需要通过 p2 找到 p1 的左子树中的最右节点。即节点 5,然后将该节点的 right 指针指向 root。并记录 root 节点的值。

向左移动 p1,即 p1 = p1.left
p2 = p1.left ,即节点 4 ,找到 p1 的左子树中的最右叶子节点,也就是 9,并将该节点的 right 指针指向 2。
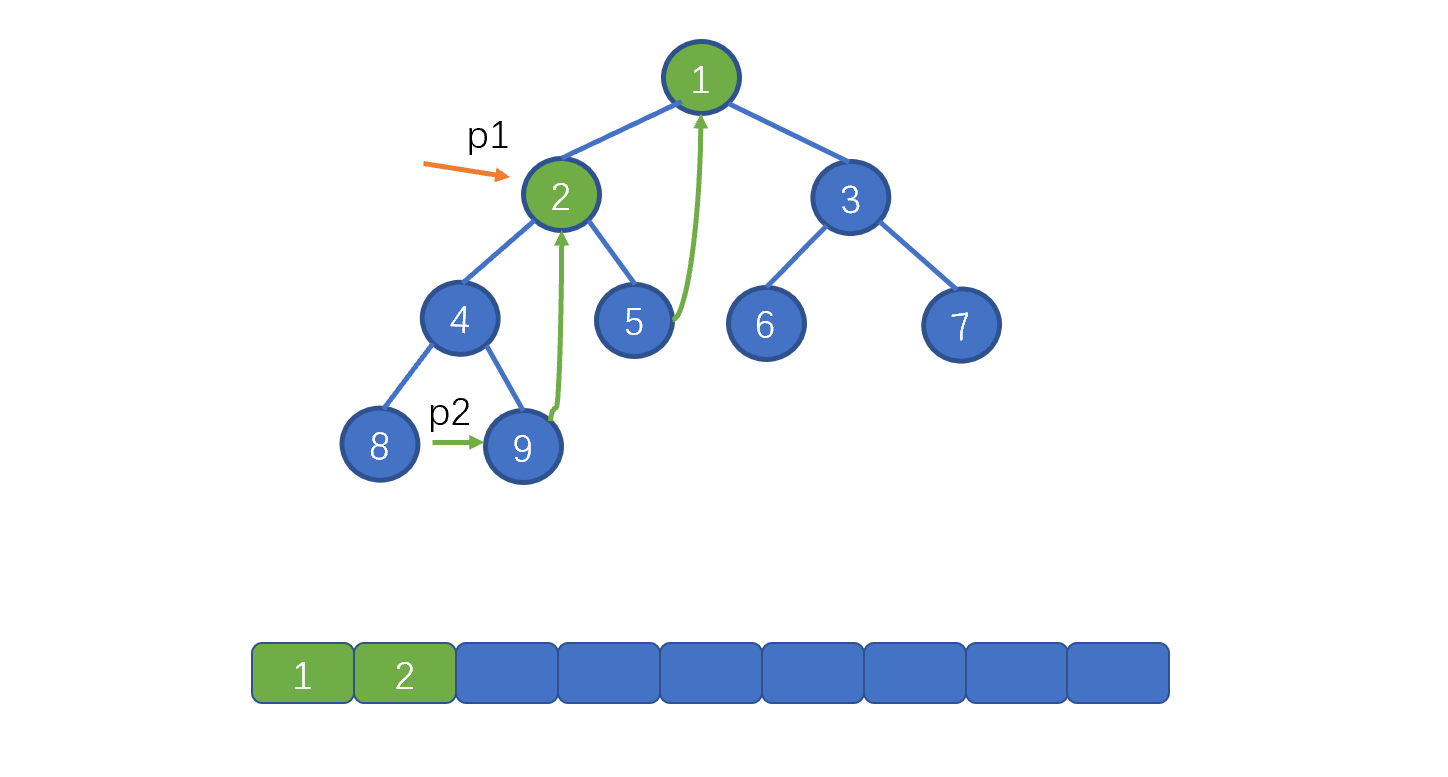
继续向左移动 p1,即 p1 = p1.left,p2 = p1.left。 也就是节点 8。并将该节点的 right 指针指向 p1。
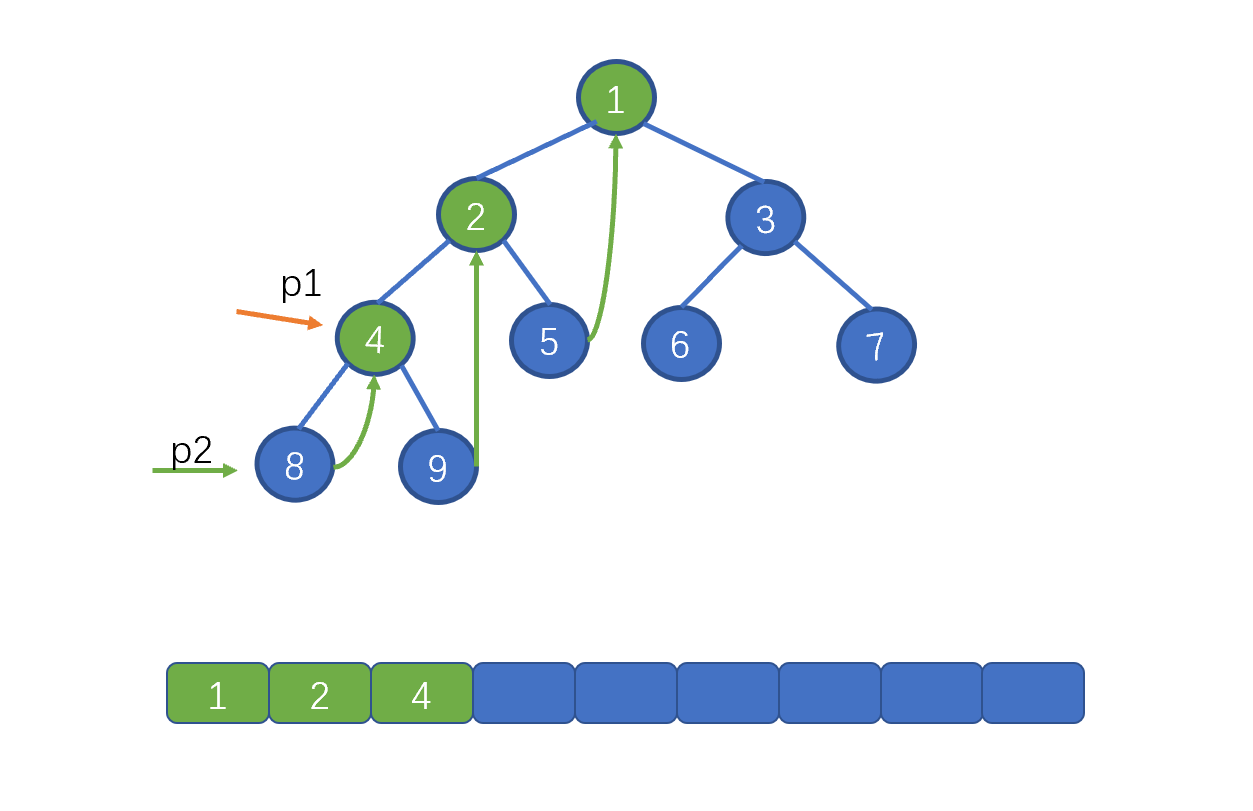
我们发现这一步给前两步是一样的,都是找到叶子节点,将其 right 指针指向 p1,此时我们完成了添加 right 指针的过程,下面我们继续往下看。
我们继续移动 p1 指针,p1 = p1.left。p2 = p.left。此时我们发现 p2 == null,即下图
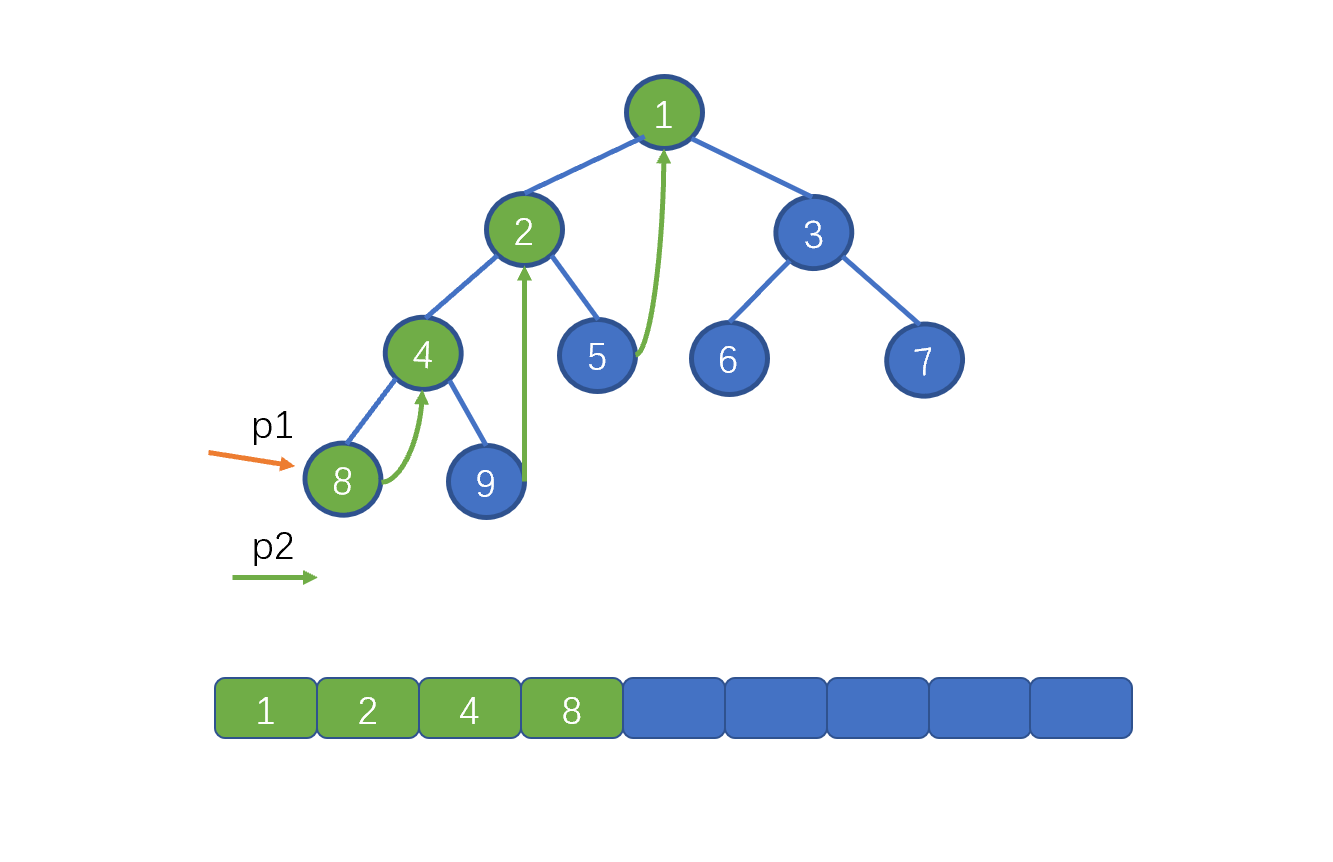
此时我们需要移动 p1, 但是不再是 p1 = p1.left 而是 p1 = p1.right。也就是 4,继续让 p2 = p1.left。此时则为下图这种情况
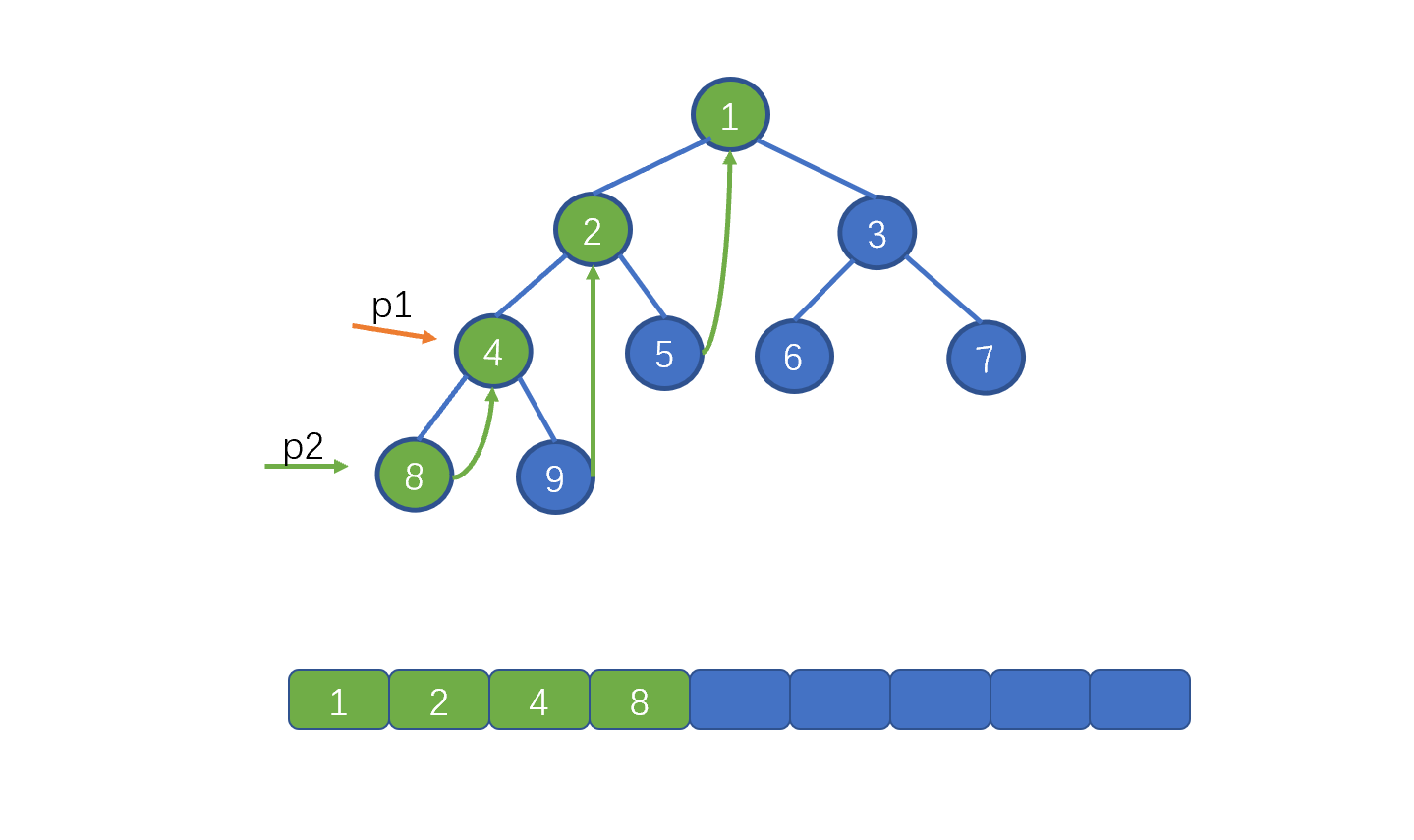
此时我们发现 p2.right != null 而是指向 4,说明此时我们已经添加过了 right 指针,所以去掉 right 指针,并让 p1 = p1.right
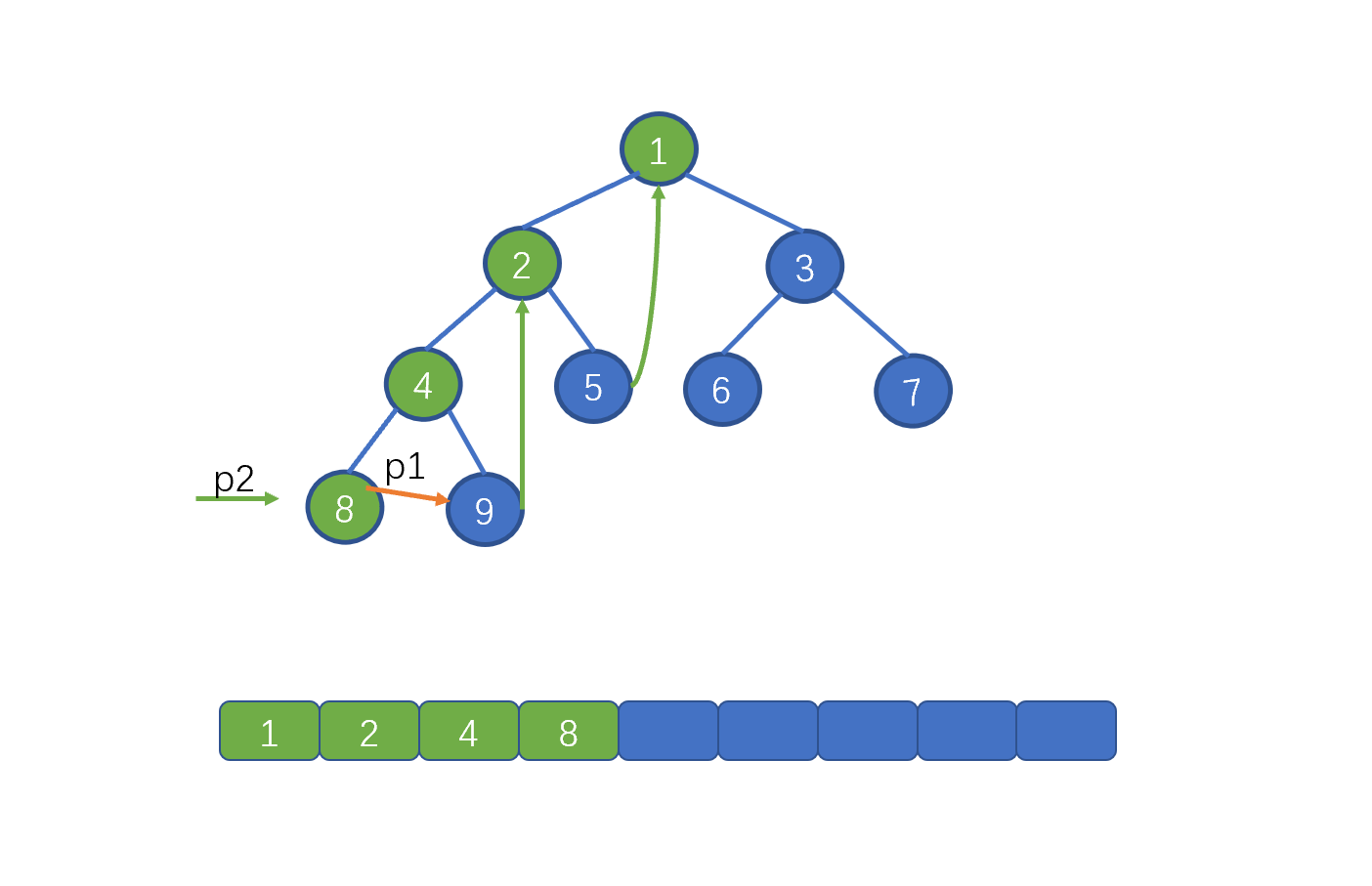
下面则继续移动 p1 ,按照规则继续移动即可,遇到的情况已经在上面做出了举例,所以下面我们就不继续赘述啦,如果还不是特别理解的同学,可以再去看一遍动画加深下印象。
时间复杂度 O(n),空间复杂度 O(1)
下面我们来看代码吧。
#### 代码
```java
class Solution {
public List<Integer> preorderTraversal(TreeNode root) {
List<Integer> list = new ArrayList<>();
if (root == null) {
return list;
}
TreeNode p1 = root; TreeNode p2 = null;
while (p1 != null) {
p2 = p1.left;
if (p2 != null) {
//找到左子树的最右叶子节点
while (p2.right != null && p2.right != p1) {
p2 = p2.right;
}
//添加 right 指针,对应 right 指针为 null 的情况
if (p2.right == null) {
list.add(p1.val);
p2.right = p1;
p1 = p1.left;
continue;
}
//对应 right 指针存在的情况,则去掉 right 指针
p2.right = null;
} else {
list.add(p1.val);
}
//移动 p1
p1 = p1.right;
}
return list;
}
}
```
Swift Code:
```swift
class Solution {
func preorderTraversal(_ root: TreeNode?) -> [Int] {
var list:[Int] = []
guard root != nil else {
return list
}
var p1 = root, p2: TreeNode?
while p1 != nil {
p2 = p1!.left
if p2 != nil {
//找到左子树的最右叶子节点
while p2!.right != nil && p2!.right !== p1 {
p2 = p2!.right
}
//添加 right 指针,对应 right 指针为 null 的情况
if p2!.right == nil {
list.append(p1!.val)
p2!.right = p1
p1 = p1!.left
continue
}
//对应 right 指针存在的情况,则去掉 right 指针
p2!.right = nil
} else {
list.append(p1!.val)
}
//移动 p1
p1 = p1!.right
}
return list
}
}
```
好啦,今天就看到这里吧,咱们下期见!
================================================
FILE: animation-simulation/二叉树/二叉树的前序遍历(栈).md
================================================
我们之前说了二叉树基础及二叉的几种遍历方式及练习题,今天我们来看一下二叉树的前序遍历非递归实现。
前序遍历的顺序是, 对于树中的某节点,`先遍历该节点,然后再遍历其左子树,最后遍历其右子树`.
我们先来通过下面这个动画复习一下二叉树的前序遍历。

### 迭代
我们试想一下,之前我们借助队列帮我们实现二叉树的层序遍历,
那么可不可以,也借助数据结构,帮助我们实现二叉树的前序遍历。
见下图
假设我们的二叉树为 [1,2,3]。我们需要对其进行前序遍历。其遍历顺序为
当前节点 1,左孩子 2,右孩子 3。
这里可不可以用栈,帮我们完成前序遍历呢?
> 栈和队列的那些事
我们都知道栈的特性是先进后出,我们借助栈来帮助我们完成前序遍历的时候。
则需要注意的一点是,我们应该`先将右子节点入栈,再将左子节点入栈`。
这样出栈时,则会先出左节点,再出右子节点,则能够完成树的前序遍历。
见下图。
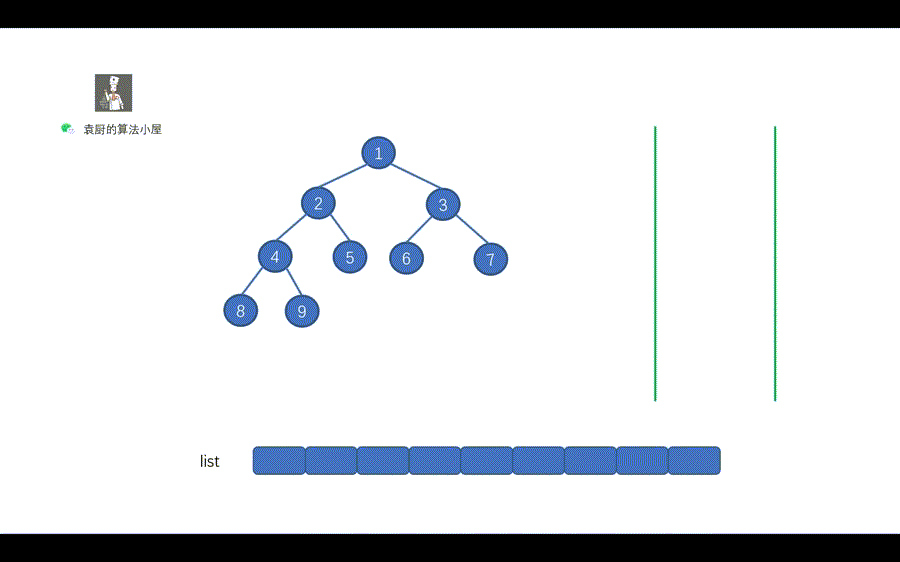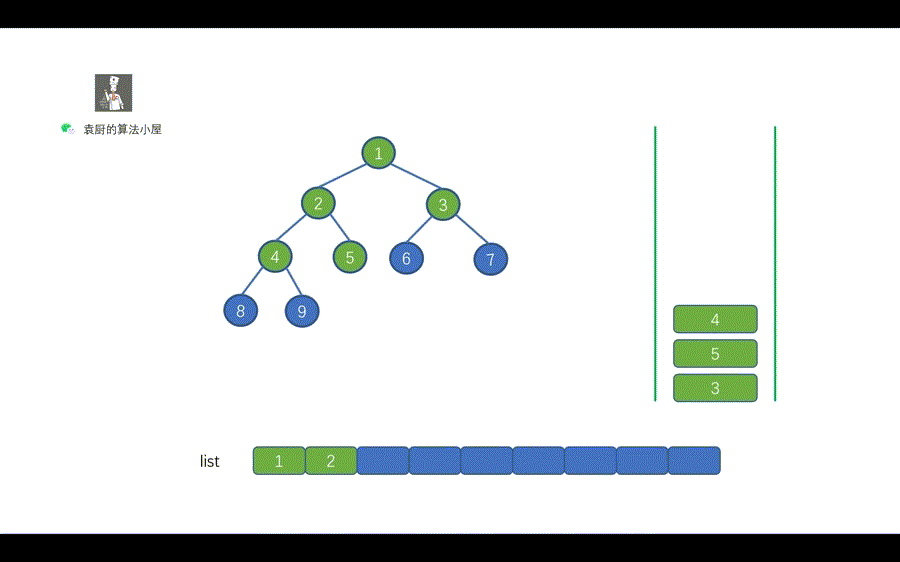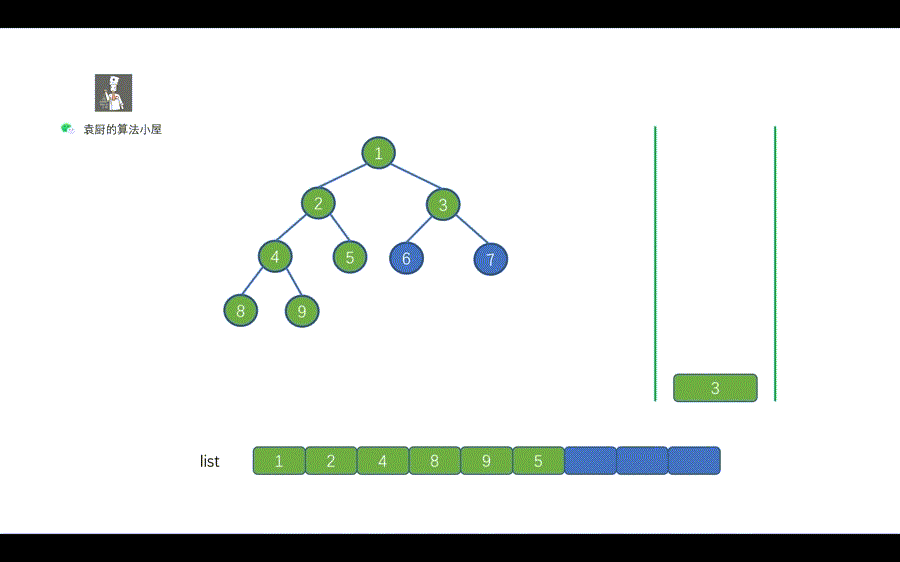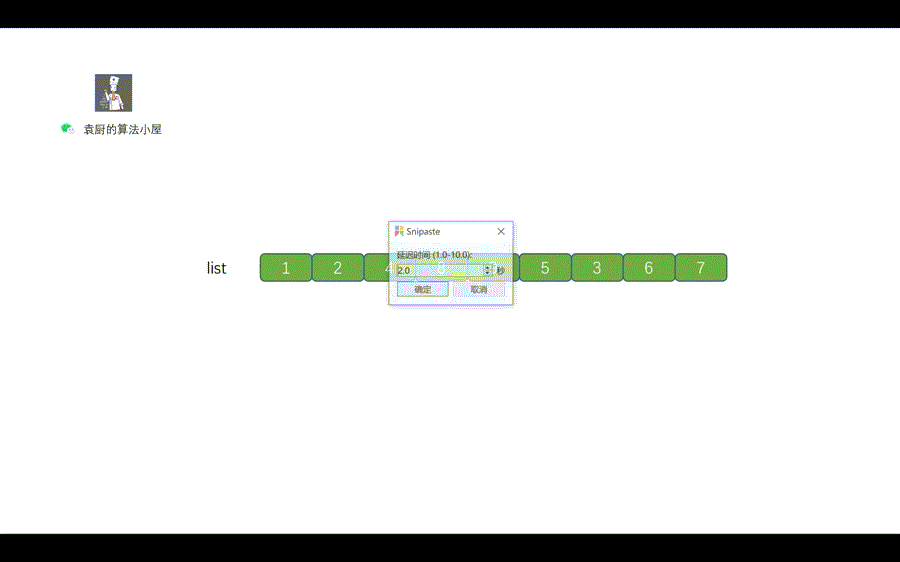
我们用一句话对上图进行总结,`当栈不为空时,栈顶元素出栈,如果其右孩子不为空,则右孩子入栈,其左孩子不为空,则左孩子入栈`。还有一点需要注意的是,我们和层序遍历一样,需要先将 root 节点进行入栈,然后再执行 while 循环。
看到这里你已经能够自己编写出代码了,不信你去试试。
时间复杂度:O(n) 需要对所有节点遍历一次
空间复杂度:O(n) 栈的开销,平均为 O(logn) 最快情况,即斜二叉树时为 O(n)
**参考代码**
```java
class Solution {
public List<Integer> preorderTraversal(TreeNode root) {
List<Integer> list = new ArrayList<>();
Stack<TreeNode> stack = new Stack<>();
if (root == null) return list;
stack.push(root);
while (!stack.isEmpty()) {
TreeNode temp = stack.pop();
if (temp.right != null) {
stack.push(temp.right);
}
if (temp.left != null) {
stack.push(temp.left);
}
//这里也可以放到前面
list.add(temp.val);
}
return list;
}
}
```
Swift Code:
```swift
class Solution {
func preorderTraversal(_ root: TreeNode?) -> [Int] {
var list:[Int] = []
var stack:[TreeNode] = []
guard root != nil else {
return list
}
stack.append(root!)
while !stack.isEmpty {
let temp = stack.popLast()
if let right = temp?.right {
stack.append(right)
}
if let left = temp?.left {
stack.append(left)
}
//这里也可以放到前面
list.append((temp?.val)!)
}
return list
}
}
```
Go Code:
```go
func preorderTraversal(root *TreeNode) []int {
res := []int{}
if root == nil {
return res
}
stk := []*TreeNode{root}
for len(stk) != 0 {
temp := stk[len(stk) - 1]
stk = stk[: len(stk) - 1]
if temp.Right != nil {
stk = append(stk, temp.Right)
}
if temp.Left != nil {
stk = append(stk, temp.Left)
}
res = append(res, temp.Val)
}
return res
}
```
================================================
FILE: animation-simulation/二叉树/二叉树的后续遍历 (迭代).md
================================================
之前给大家介绍了二叉树的[前序遍历](),[中序遍历]()的迭代法和 Morris 方法,今天咱们来说一下二叉后序遍历的迭代法及 Morris 方法。
注:阅读该文章前,建议各位先阅读之前的三篇文章,对该文章的理解有很大帮助。
## 迭代
后序遍历的相比前两种方法,难理解了一些,所以这里我们需要认真思考一下,每一行的代码的作用。
我们先来复习一下,二叉树的后序遍历

我们知道后序遍历的顺序是,` 对于树中的某节点, 先遍历该节点的左子树, 再遍历其右子树, 最后遍历该节点`。
那么我们如何利用栈来解决呢?
我们直接来看动画,看动画之前,但是我们`需要带着问题看动画`,问题搞懂之后也就搞定了后序遍历。
1.动画中的橙色指针发挥了什么作用
2.为什么动画中的某节点,为什么出栈后又入栈呢?
好啦,下面我们看动画吧!
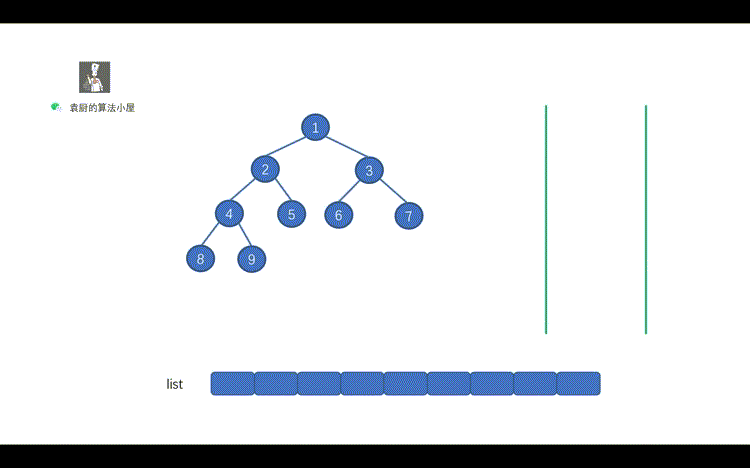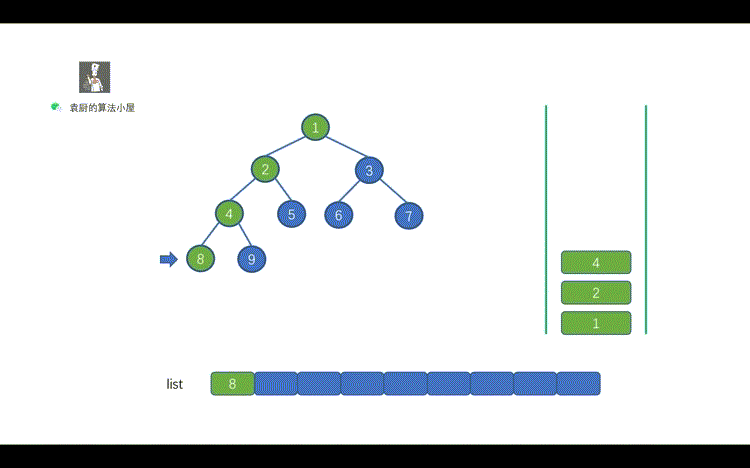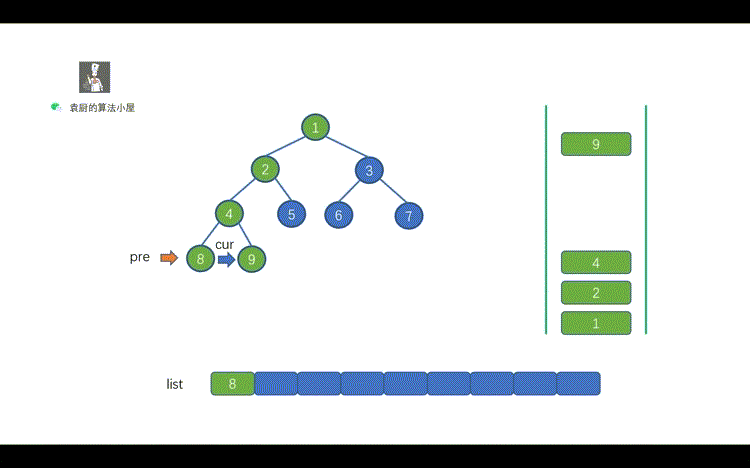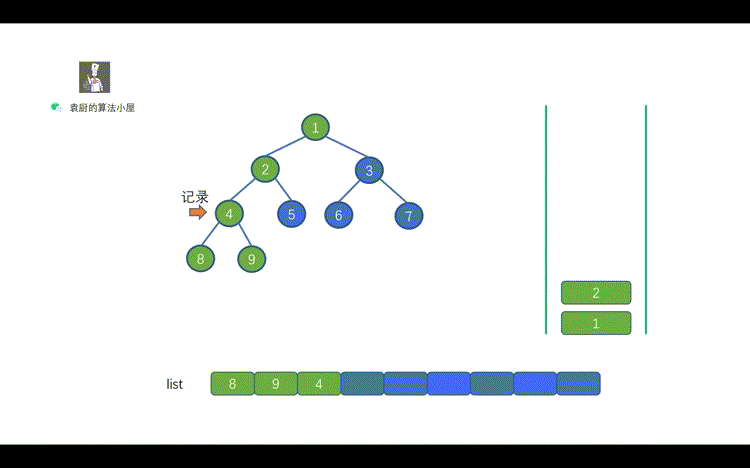
相信大家看完动画之后,也能够发现其中规律。
我们来对其中之前提出的问题进行解答
1.动画中的橙色箭头的作用?
> 用来定位住上一个访问节点,这样我们就知道 cur 节点的 right 节点是否被访问,如果被访问,我们则需要遍历 cur 节点。
2.为什么有的节点出栈后又入栈了呢?
> 出栈又入栈的原因是,我们发现 cur 节点的 right 不为 null ,并且 cur.right 也没有被访问过。因为 `cur.right != preNode `,所以当前我们还不能够遍历该节点,应该先遍历其右子树中的节点。
>
> 所以我们将其入栈后,然后`cur = cur.right`
```java
class Solution {
public List<Integer> postorderTraversal(TreeNode root) {
Stack<TreeNode> stack = new Stack<>();
List<Integer> list = new ArrayList<>();
TreeNode cur = root;
//这个用来记录前一个访问的节点,也就是橙色箭头
TreeNode preNode = null;
while (cur != null || !stack.isEmpty()) {
//和之前写的中序一致
while (cur != null) {
stack.push(cur);
cur = cur.left;
}
//1.出栈,可以想一下,这一步的原因。
cur = stack.pop();
//2.if 里的判断语句有什么含义?
if (cur.right == null || cur.right == preNode) {
list.add(cur.val);
//更新下 preNode,也就是定位住上一个访问节点。
preNode = cur;
cur = null;
} else {
//3.再次压入栈,和上面那条 1 的关系?
stack.push(cur);
cur = cur.right;
}
}
return list;
}
}
```
Swift Code:
```swift
class Solution {
func postorderTraversal(_ root: TreeNode?) -> [Int] {
var list:[Int] = []
var stack:[TreeNode] = []
var cur = root, preNode: TreeNode?
while !stack.isEmpty || cur != nil {
//和之前写的中序一致
while cur != nil {
stack.append(cur!)
cur = cur!.left
}
//1.出栈,可以想一下,这一步的原因。
cur = stack.popLast()
//2.if 里的判断语句有什么含义?
if cur!.right === nil || cur!.right === preNode {
list.append(cur!.val)
//更新下 preNode,也就是定位住上一个访问节点。
preNode = cur
cur = nil
} else {
//3.再次压入栈,和上面那条 1 的关系?
stack.append(cur!)
cur = cur!.right
}
}
return list
}
}
```
Go Code:
```go
func postorderTraversal(root *TreeNode) []int {
res := []int{}
if root == nil {
return res
}
stk := []*TreeNode{}
cur := root
var pre *TreeNode
for len(stk) != 0 || cur != nil {
for cur != nil {
stk = append(stk, cur)
cur = cur.Left
}
// 这里符合本文最后的说法,使用先获取栈顶元素但是不弹出,根据栈顶元素的情况进行响应的处理。
temp := stk[len(stk) - 1]
if temp.Right == nil || temp.Right == pre {
stk = stk[: len(stk) - 1]
res = append(res, temp.Val)
pre = temp
} else {
cur = temp.Right
}
}
return res
}
```
当然也可以修改下代码逻辑将 `cur = stack.pop()` 改成 `cur = stack.peek()`,下面再修改一两行代码也可以实现,这里这样写是方便动画模拟,大家可以随意发挥。
时间复杂度 O(n), 空间复杂度 O(n)
这里二叉树的三种迭代方式到这里就结束啦,大家可以进行归纳总结,三种遍历方式大同小异,建议各位,掌握之后,自己手撕一下,从搭建二叉树开始。
================================================
FILE: animation-simulation/二叉树/二叉树的后续遍历(Morris).md
================================================
之前给大家介绍了二叉树的[前序遍历](),[中序遍历]()的迭代法和 Morris 方法,今天咱们来说一下二叉后序遍历的迭代法及 Morris 方法。
注:阅读该文章前,建议各位先阅读之前的三篇文章,对该文章的理解有很大帮助。
## Morris
后序遍历的 Morris 方法也比之前两种代码稍微长一些,看着挺唬人,其实不难,和我们之前说的没差多少。下面我们一起来干掉它吧。
我们先来复习下之前说过的[中序遍历](),见下图。

另外我们来对比下,中序遍历和后序遍历的 Morris 方法,代码有哪里不同。

由上图可知,仅仅有三处不同,后序遍历里少了 `list.add()`,多了一个函数`postMorris()` ,那后序遍历的 list.add() 肯定是在 postMorris 函数中的。所以我们搞懂了 postMorris 函数,也就搞懂了后序遍历的 Morris 方法(默认大家看了之前的文章,没有看过的同学,可以点击文首的链接)
下面我们一起来剖析下 postMorris 函数.代码如下
```java
public void postMorris(TreeNode root) {
//反转转链表,详情看下方图片
TreeNode reverseNode = reverseList(root);
//遍历链表
TreeNode cur = reverseNode;
while (cur != null) {
list.add(cur.val);
cur = cur.right;
}
//反转回来
reverseList(reverseNode);
}
//反转链表
public TreeNode reverseList(TreeNode head) {
TreeNode cur = head;
TreeNode pre = null;
while (cur != null) {
TreeNode next = cur.right;
cur.right = pre;
pre = cur;
cur = next;
}
return pre;
}
```
上面的代码,是不是贼熟悉,和我们的倒序输出链表一致,步骤为,反转链表,遍历链表,将链表反转回原样。只不过我们将 ListNode.next 写成了 TreeNode.right 将树中的遍历右子节点的路线,看成了一个链表,见下图。
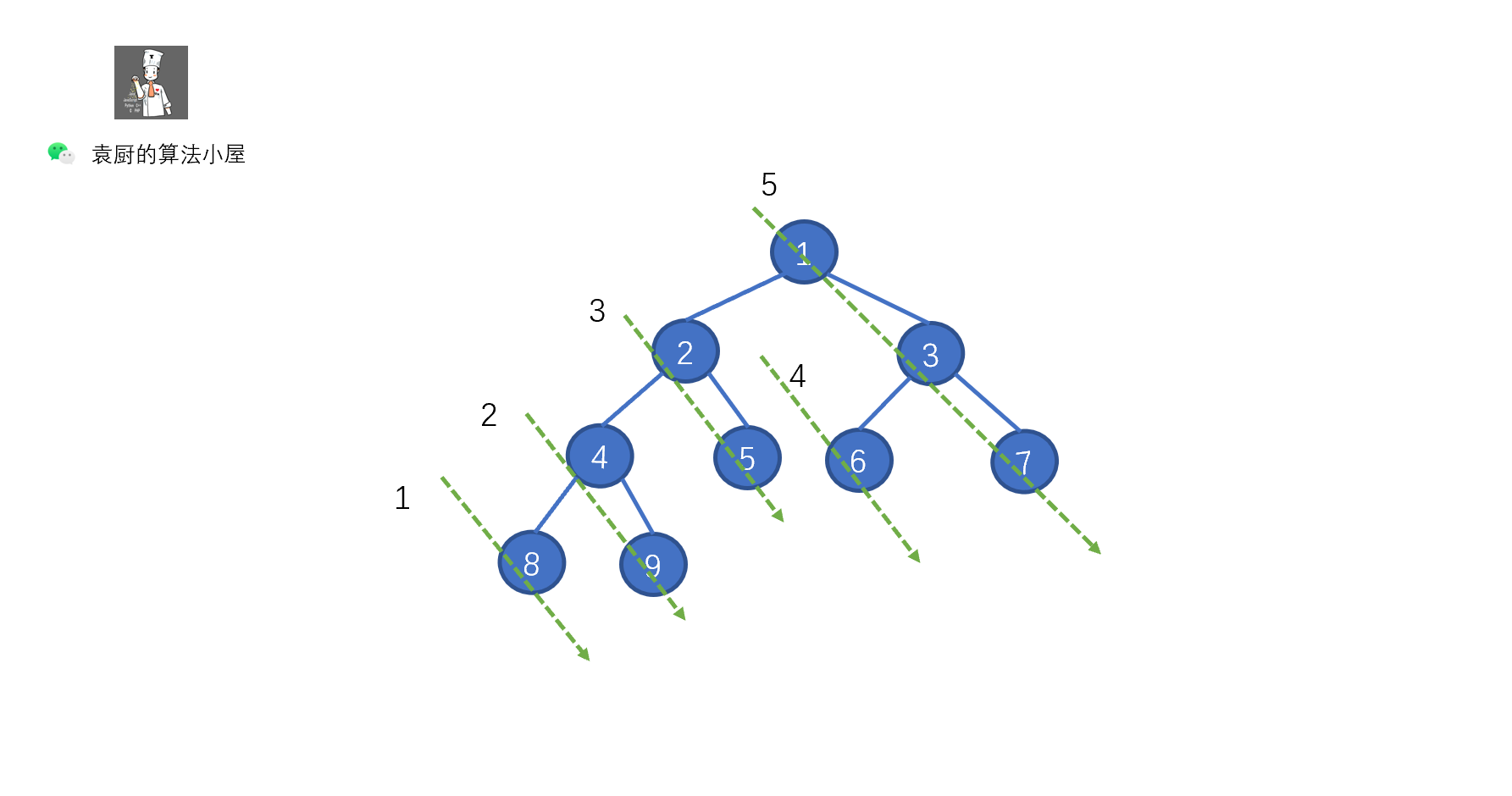
上图中的一个绿色虚线,代表一个链表,我们根据序号进行倒序遍历,看下是什么情况
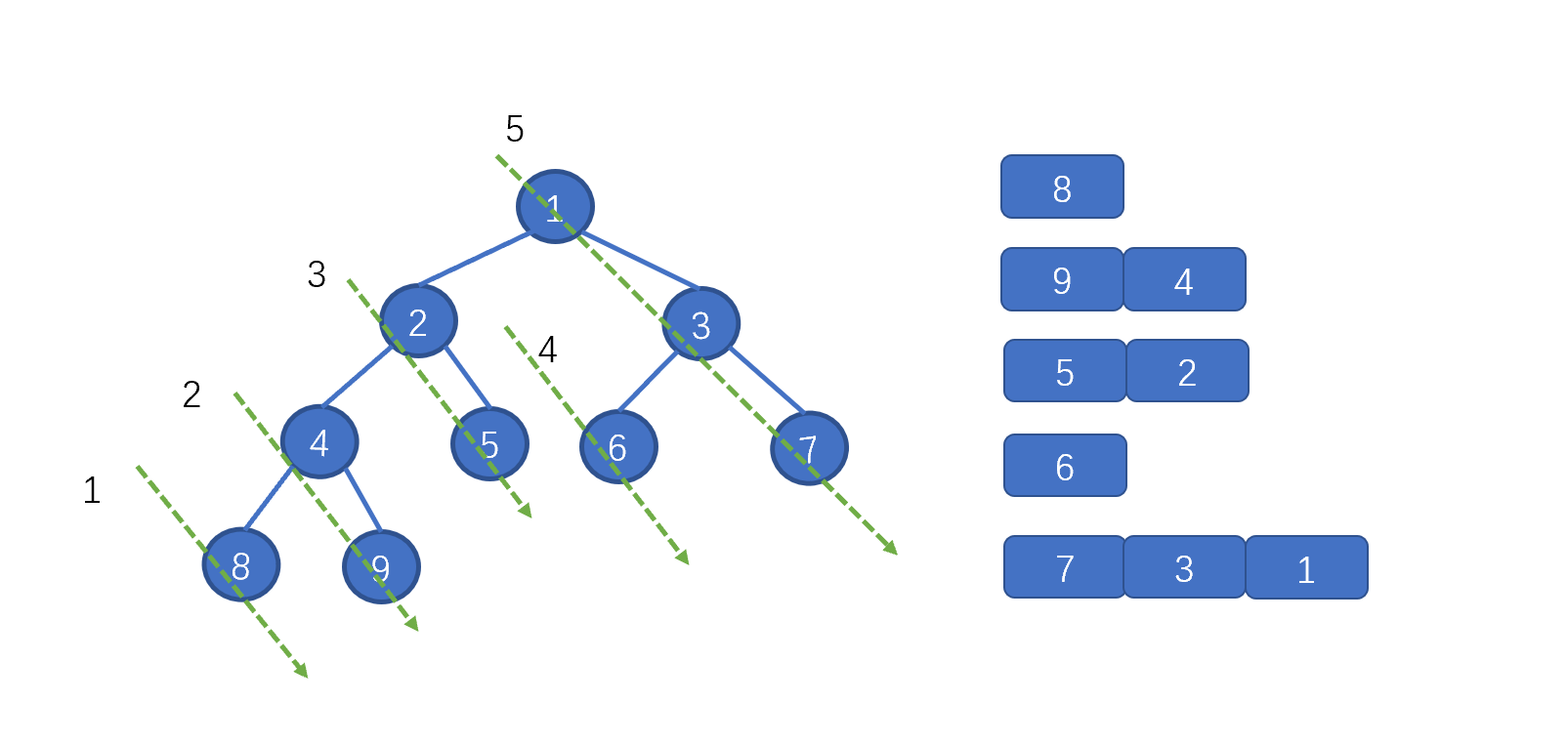

到这块是不是就整懂啦,打完收工!
```java
class Solution {
List<Integer> list;
public List<Integer> postorderTraversal(TreeNode root) {
list = new ArrayList<>();
if (root == null) {
return list;
}
TreeNode p1 = root;
TreeNode p2 = null;
while (p1 != null) {
p2 = p1.left;
if (p2 != null) {
while (p2.right != null && p2.right != p1) {
p2 = p2.right;
}
if (p2.right == null) {
p2.right = p1;
p1 = p1.left;
continue;
} else {
p2.right = null;
postMorris(p1.left);
}
}
p1 = p1.right;
}
//以根节点为起点的链表
postMorris(root);
return list;
}
public void postMorris(TreeNode root) {
//翻转链表
TreeNode reverseNode = reverseList(root);
//从后往前遍历
TreeNode cur = reverseNode;
while (cur != null) {
list.add(cur.val);
cur = cur.right;
}
//翻转回来
reverseList(reverseNode);
}
public TreeNode reverseList(TreeNode head) {
TreeNode cur = head;
TreeNode pre = null;
while (cur != null) {
TreeNode next = cur.right;
cur.right = pre;
pre = cur;
cur = next;
}
return pre;
}
}
```
Swift Code:
```swift
class Solution {
var list:[Int] = []
func postorderTraversal(_ root: TreeNode?) -> [Int] {
guard root != nil else {
return list
}
var p1 = root, p2: TreeNode?
while p1 != nil {
p2 = p1!.left
if p2 != nil {
while p2!.right != nil && p2!.right !== p1 {
p2 = p2!.right
}
if p2!.right == nil {
p2!.right = p1
p1 = p1!.left
continue
} else {
p2!.right = nil
postMorris(p1!.left)
}
}
p1 = p1!.right
}
//以根节点为起点的链表
postMorris(root!)
return list
}
func postMorris(_ root: TreeNode?) {
let reverseNode = reverseList(root)
//从后往前遍历
var cur = reverseNode
while cur != nil {
list.append(cur!.val)
cur = cur!.right
}
reverseList(reverseNode)
}
func reverseList(_ head: TreeNode?) -> TreeNode? {
var cur = head, pre: TreeNode?
while cur != nil {
let next = cur?.right
cur?.right = pre
pre = cur
cur = next
}
return pre
}
}
```
时间复杂度 O(n)空间复杂度 O(1)
总结:后序遍历比起前序和中序稍微复杂了一些,所以我们解题的时候,需要好好注意一下,迭代法的核心是利用一个指针来定位我们上一个遍历的节点,Morris 的核心是,将某节点的右子节点,看成是一条链表,进行反向遍历。
好啦,今天就唠到这吧,拜了个拜。
================================================
FILE: animation-simulation/二叉树/前序序列和中序构建二叉树.md
================================================
================================================
FILE: animation-simulation/位运算/空.md
================================================
================================================
FILE: animation-simulation/写写水文/书单.md
================================================
================================================
FILE: animation-simulation/写写水文/如何学习.md
================================================
如何面向面试学习?
我们提到面试,大多数人脑子里蹦出的第一个词,那就是八股文。但是面试真的可以**只**靠八股文吗?
那面试八股文重要吗?重要,非常重要!
那你这不是前后矛盾吗?一会说不能只靠八股文,一会又说八股文非常重要。
哎嘛,不要着急,听我慢慢说。
以下仅仅是我的一家之言。
我们先来看一下,一位 Javaer 校招需要准备的东西有哪些。
- 数据结构与算法
- 操作系统
- 计算机网络
- Java 基础
- MySQL
- Redis
- Java 并发编程
- Spring 全家桶
- Linux
- 设计模式
- 1-2 两个能拿得出手的项目。
上面的内容或多或少会在面试中问到,有的面试官侧重于项目,有的面试官喜欢问基础知识,也就是我们常说的八股,还有的面试官喜欢问实际开发中遇到的问题也就是场景题。但是我认为面试官在提问之前,他们心里已经有他们的答案,你如果能说出他心里的那个点,然后再对其延伸,则有可能让面试官眼前一亮的。但是如果你一直没有说出他想要的那个点,一昧的对其拓展,这个答案或许就有点些冗余。
或许面试时,面试官想要的状态是,看到你对技术的自信,知其然知其所以然。这样自然而然能够得到一个好的面评。
那么我们如何才能做到上面提到的呢?那就是看书,你会发现看过某个科目 2-3 遍书之后,你对这个科目是有自信的,因为你有这门科目的知识架构,有自己的理解,知道它们之间的联系,那么你回答时则会得心应手。记住是看 2-3 遍哦,一遍的话,只能大概了解大致脉络,不能让自己深刻理解,所以到重复看,你会发现那些好书,每次看的时候都会有新的收获。
那么面向面试,我们应该如何学习一项新科目呢?我们就以 MySQL(高频考点)来举例吧。
第一步:调研
这一步很好理解,我们需要了解该项技术的经典书籍,这样能我们学习时,事半功倍。我一般是自己进行搜索。现在是开源的时代,大家都很喜欢分享自己的心得,你可以通过知乎,论坛等搜索到某项科目的经典书籍,但是不要只看一个帖子,多看几个,这些帖子中多次提到的书籍。就是我们的学习目标。
另外你也可以问师兄师姐们,毕竟他们是过来人,知道哪些书籍值得读。
这里给大家推荐几本我读过的 MySQL 书籍,没有基础的同学可以按这个路线学习。
- MySQL 必知必会
一本小册子,一天就能搞定,帮你快速入门 MySQL,另外大家在学习时,可以自己下载一下 MySQL 官方的学习库,然后自己动手实践一下,虽然速度慢了一些,但是能够让你学习的更加扎实。

官方的 employees 库,我们可以用来练习一下,连接,explains 命令等。
- 数据库系统概论
玫红色书皮的那本书,很多学校用来当作教材,这本书对数据库基础知识,查询语句,范式等讲的比较详细。这本书因为我之前学过几遍,后面再看的时候很快就读完了。个人认为还不错的一本书。有的学校研究生复试会考数据库,那么可以看下这本书,考点全面覆盖。
- 高性能 MySQL
非常牛皮的一本书,很多知识点在里面讲的很细,适合进阶的同学,如果你看了这本书,面试时,常考的那些知识点,你就可以得心应手啦。
- MySQL 技术内幕
这本书我没有完整的看下来,看了部分章节,比如那些常考的知识点,事务,索引等。也是非常棒的一本书,推荐给面试的同学。
- MySQL 45 讲
这门课我看了大概百分之七十,前面的十几讲 看了大概 3-4 遍,每次都有新收获,这门课适合有一定基础的同学,如果没有学过 MySQL 的话,看的时候可能会有些吃力。
- 从根上理解 MySQL
这个是掘金小册,也非常棒,但是我发现的有点晚了,后面抽着看了大概 1/2 吧。小册子对某个知识点说的很细,很透。
视频的话,我看的比较少,之前看过 MOOC 哈工大,战德臣 老师的课程,非常牛的一位老师,讲课风格也很棒,没有基础的同学可以看一下这个视频。
好啦,第一步一不小心扯多了,下面我们来说第二步。
第二步:看面经(八股)
啥?你刚才还说不能只看八股,这刚调研完经典书籍,就开始看八股了?这不是自己打自己脸吗?先别骂,先别骂,听我接着往下说。
这时的八股和面试题,是为了让你知道面试时的重点,哪些知识点常考,这样我们就可以重点看那些常考的章节。
那些不常考的知识点就不用看了吗?当然也是需要看的,因为每个章节之间是有联系的,通过前面的章节引出后面的,可以帮助我们更好的理解,形成自己的体系结构。不过这些不是重点的章节,可以粗略学习,了解即可。
第三步:看书
这一步我建议大家看纸质书,我们可以在书上标注,后面二刷三刷的时候,也可以根据标注帮我们回忆。大家可以在看书的时候,自己做一下思维导图,帮助我们构建自己的知识体系。推荐的软件是 Xmind,ProcessOn。
第四步:看面经和八股
注意,这里是看不是背,我们通过面经里的问题来进行归纳整理,对面经的问题进行分类,然后自己通过翻阅书籍和文章来找到答案进行整理,记住哈,记得分类,后面便于补充,也有利于搭建我们的知识体系。比如下面这样

第五步:回溯
哈哈,这个回溯不是我们刷题的那个回溯,而是我们对每次面试的总结,建议大家刚开始面试的时候可以对自己的面试过程进行录屏,面试结束后,查看录像,看看自己的言行举止等,是否有摇头晃脑,回答不自信等情况。
后面的话则只需录音即可,思考一下自己哪块回答的不太好,需要迭代,思考一下某个问题,面试官想要考察的点是什么。经历几次之后,就能找到自己的面试节奏和风格。
大家是不是发现学好一门课并不容易,也比较耗时,所以我们需要尽早的准备面试,早就是优势!
好啦,我要说的大概就这些啦,希望可以对学弟学妹们有一丢丢帮助。大家可以在评论区进行补充,推荐一下自己认为不错的书籍,今天就唠到这吧,拜了个拜。如果你需要我整理的面经 PDF ,可以添加我的微信,备注你需要的科目和 PDF ,例如 数据库 PDF。
================================================
FILE: animation-simulation/写写水文/学弟问了我一个问题.md
================================================
一位学弟,问了我一个问题。
我在这里说一下我的看法,希望能够对有相同问题的学弟学妹,有一丢丢帮助。
回想自身
我似乎从来没想过这个问题?
读大学的时候,每天的想法不是,不是今天学点啥,吃点啥,玩个啥游戏开心开心,每天想的是,我怎么练球才能把我哥们打爆,斗牛时,说垃圾话,怎么才能不落下风。寒暑假的时候,能够大冬天搁水泥地(不是篮球场,是一块空地)拍球,拍两三个小时,就是为了开学的时候,把他们斩于马下。
就这样打着打着篮球,忽然就到大三下学期了,然后就听到谁谁谁去哪个大厂实习啦,谁谁谁参加什么比赛得奖啦。
好家伙,我慌了啊。
突然不知道自己该干啥了,打球打球,打个锤子球,马上就毕业啦,心里咋就没数呢?
那天晚上我失眠了,也在那天晚上,做了一个可能影响我一生的决定。
嗯,我决定考研!
其实说白了,也就是为了逃避就业,为自己的菜找个借口。
第二天醒来,就直接背着书去了自习室,开始了朝 8 晚 10 的复习之路。从决定考研到考研前夕,为期八个多月的备考,我打球的次数不会超过 5 次,休息的总天数不会超过 3 天。
每次哥们叫我打球,我总是找一些借口推掉了,渐渐的他们打球的时候也就不喊我了,我也就安心准备考研啦。
备考的这段时间,我一直没有忘记锻炼,我会隔一天去一次健身房,每次锻炼一个半小时。我觉得我能坚持到考研,健身房也有很大的功劳。
毕竟备考还是很累的,一坐就是一整天,中午也不回宿舍睡觉,就在桌子上趴一会。所以要有一个好身体,才能扛得住。
读者:你这说了一堆,和你学弟问的问题也没啥关系啊!
厨子:哎嘛,别急别急,即然说啦,肯定是有用的的,马上就说到重点啦。
通过上面我的例子,我认为完成某个目标需要具备这几个特点。
- 抹平信息差
- 执行力
- 持之以恒
**抹平信息差**
其实很多时候,我们和别人都有信息差距,进而导致思维上的差距,然而思维上的差距是最难缩短的。
我们为什么考大学考研究生时,想要考好大学,毕业后想去大公司。
大公司好呀,钱多,福利好,技术氛围好。
嗯是的,进入好学校和好公司都可以理解成进入了一个好的平台。之前和一位 HR 聊了挺久,交谈中的一句话,让我仍记忆犹新。
应届生入职时,平台带给你的,远远大于你自身技术带给你的。
暂且不论这句话是对是错,聊天结束后我思考了这句话的含义,以下是我对这句话,某一个方面的理解。
在好的平台里,你会多了很多和大牛们交流的机会,相当于进入了一个好的圈子。**在什么样的圈子里,以后就做什么样的事情,但是你现在所做的事,决定你以后能够进入什么样的圈子。**
这个过程中,你可能意识不到你的进步,但是如果你养成记录的习惯,回过头来再看的话,你会发现自己真的进步很大,而且进步的过程本来就是悄无声息,而是在之后的某一时刻,你才会发现你进步了。
当然好的平台带给我们的远远不止这一点,而且我们每个人对 “好” 的定义也不相同,就不在这详细说啦。
我认为抹平信息差是完成某个目标的要做的第一件事,完成目标前,我们要先定下目标。
本科的时候,我们很多人甚至都不知道有保研,秋招,比赛这一说,你敢信?
**作为大学生的你们则可以通过一下几种方法帮助你们抹平信息差**
1.请教往届的师兄师姐,他们的经验分享或许对你帮助很大。
2.通过某些途径,看一些前辈的分享求职分享或者学习路线等,比如知乎,牛客,脉脉等。
就拿考研来说,如果你看过,其他师兄师姐的考研心得,那么你就有可能少走很多弯路,复习的更加充分,上岸的几率则更大。
有的时候,我们缺少和前辈面对面交流的机会,但是从他们的文字中,也能够学到很多。
3.多和比你优秀的人交流。
就比如《孔子家语》中的一句话,与善人居,如入芝兰之室,久而不闻其香,即与之化矣。这句话的意思是,与品行优良的人共同居住,就好比是进入栽满了芝兰香草的雅室,时间久了就闻不到香味了,因为他已经被同化了,变得同样的品行优良。
思维高度亦是如此。
**执行力**
如果我们将抹平信息差,看成是通过前辈们的指导,找到了满是成熟果实的果园,那么执行力就可以比做摘果子的竹竿。
我们不要想着我们找到了果园,就能够硕果累累。果实是有成熟期的,如果在特定的时间不摘的话,就会腐烂(机会流逝)。
所以我们想到什么事有搞头,就抓紧去做吧,不然,只会让机会白白流走。
种一棵树最好的时间是十年前,其次是现在。
这句话,没毛病,但是我们为什么不把握最好的时间,而是要退而求其次呢?
很多时候,我们都是通过和身边人的比较,而知道自身水平。
所以如果身边的人都在进步,你停滞不前,到你发现的时候, 欲望更大,需要的更多,所承受的压力则会更大。
所以现在觉得有搞头,就快闷着头往前冲吧!
**持之以恒**
写到这的时候,感觉要写不下去了,说的这些感觉大家都知道,但是没有经历过的话,很难有深刻理解。本科时,我浪费掉了太多时间,所以真的希望学弟学妹们能够把握当下,这四年真的能够学到太多东西。
还是接着往下说吧。
我们现在已经在**满是成熟果实**的果园里打果子啦。如果我们三天打鱼两天晒网,别人果园的果实都打完了,开始找下一个果园了,你的这个还没打一半,这可咋整。
所以我们在给自己定下目标之后,坚持下去。
我们可以通过一下几种方法帮助我们坚持。
**正反馈**
设立奖励机制,我们完成某个小目标之后,则可以奖励给自己某些东西,比如吃些自己想吃的,买些自己之前想买,但是没买的东西。就比如我之前考研的时候,我会在每天早上,给自己设定好,自己今天要做的题目。
设定过今天的学习目标之后,则能让我学习效率大幅度提升,努力完成今天的目标,完成之后,则会在回宿舍的时候,奖励自己好吃的。
**闭关**
是的,闭关。无论是考研的时候,还是准备秋招的时候,我都是自己一人去图书馆,然后将手机锁机,开始学习。
我觉得最好的学习状态就是,保证作息规律,每天重复同样的事,吃饭,学习,睡觉。
进入这个状态之后,你会非常的想学习,对学习之外的事,兴趣就变得没有之前那么大,自然而然的就坚持下来啦。
**回溯**
其实这个也和正反馈一致,我们可以每天晚上,整理今日所学。整理过后,你会发现你今天学到了很多东西,就会非常充实和踏实。感觉今天一天没有白过。自然而然的形成良性循环,帮助你坚持下去。
当然我们一定要注意锻炼,身体是革命的本钱,身体和脑子有一个动就好啦。
授人以鱼,不如授人以渔。希望这篇文章,能够对迷茫的学弟学妹有一丢丢帮助。这篇文章不是假大空,是我经历过,感觉浪费掉的大把时间真的可惜。
虽然人生是个长跑,不是冲刺跑。某个时期对你的影响,没有你想象的那么大,只要我们保持向上的心就好。
如果给我重新读大学的机会,我仍然会和哥们们好好打球,不过我会努力抹平信息差,对自己的职业生涯好好规划。
如果觉得这篇文章对你有点用,那就帮忙转发给你的朋友吧。好啦,今天就唠到这吧,拜了个拜。
================================================
FILE: animation-simulation/写写水文/常看的UP主.md
================================================
今天不和大家吹牛玩了,唠唠嗑吧,说几个我逛 B 站经常看的几位 UP 主吧。看看里面有没有你关注滴。我知道在做的各位,很多都是在 B 站学跳舞的 🐶,我看的比较多的则是搞笑区 UP,他们可都太逗了。
### 导演小策
入坑作品,是那个贼牛的《一块劳力士的回家路》,现在已经一千多万播放了,当时感觉小策真的太有才了,短短三分钟,剧情跌宕起伏,既隐晦又深刻。

后面他又拍了《广场往事》系列,每个视频都让我笑出鹅叫,甚至连恰饭都恰的那么清新脱俗。

广场舞巨头鹅姨,鹅姨的跟班二花,会说 rap 的烫嘴阿姨,爱和三舅合影的三炮。每个人物都个性鲜明,绝了。

### 才疏学浅的才浅
这个真的是巨佬,也是我关注特别久的 UP 刚开始关注的时候才几千粉丝,现在已经 350 万了。
当时还跟着他的视频,给女朋友做了两个印章,(不知道咋回事,视频找不到了)。

可是后来,他开始做刀了。

再后来,他开始做面具,开始制杖了!

这下我真的搞不定了,才浅做面具和制杖的视频还登上了央视,真的太牛了,也喜欢手工的老哥可以去看一哈,非常牛的一位 UP 主。
### 小潮院长
哈哈,小潮 TEAM 的大哥大,他的不要做挑战真的太好笑啦,来回看了好几遍,每次都笑的肚子痛。
这个还掀起了 B 站的模仿热潮。真的是一个既有才又有趣的 UP。
### 张若宇
张若宇一个喜欢敷面膜的老哥,他的视频有一个特点,那就是短,短短一分钟的视频,节奏把握的特别好,BGM 配的也恰到好处,属实让他玩明白了。视频中最喜欢看的就是陶陶,一个酷爱吃肘子的 “活宝”。

亲切的口音和热闹的家庭氛围,让我很喜欢看他们的视频。也是一个非常有才 UP 主。
### 野球帝
很久很久之前就关注了野球帝,当时的我还很小,一看就看到现在。
野球帝团队的人也越来越多,也越来越热闹。
说实话真的很羡慕他们那种氛围,既可以和兄弟们一起打球,又能一起工作。
和喵哥说的似的,等退休之后,开个篮球场和烧烤店,和兄弟们打完球,一起撸撸串吹吹牛,好不惬意。

依旧干货满满,另外多说一句,别让通演傻子啦,他快改不过来啦。哈哈
喜欢篮球的哥们可以关注一波。
KBT 篮球训练营
这不和喵哥约了国庆节决一死战,我俩每天都在群里说一些垃圾话,都觉得能把对方打爆。不能光吹牛批不干活,所以咱们得把训练安排上。一位干货满满的 UP ,为你指出平常没有注意到的细节。都是很实用的动作,打喵哥应该足够了。

好啦,今天是纯唠嗑局,大家也可以把自己常看的优质 UP 打在评论区。
后面会继续给大家更新一些关于面试事,另外多说一句,2023 秋招的学弟学妹们,要尽快准备起来啦,早就是优势。
今天就唠到这吧,拜了个拜。
================================================
FILE: animation-simulation/写写水文/送书.md
================================================
好久不见
哈喽大家好,我是厨子,好久不见啊。
主要是这段时间太忙啦,所以没有进行更新,不过后面会慢慢更新起来,继续更之前的专题。
那么我今天是来干什么的呢?给大家送点福利,送几本我们经常用的《剑指 offer》。呐,就是下面这一本啦。
《剑指 offer 专项突破版》
感谢博文视点杨老师的赠书
大概翻了一下,这本书的目录和内容,这本书不仅仅是根据专题来进行编写,另外还将每个专题的解题方法进行了总结,个人感觉是非常不错的,能够帮助我们高效刷题。书中的题目也都是比较经典,高频的题目,对于我们面试也很有帮助。
下面是专项版和经典版的一些对比。
杨老师这里赞助了我六本,送给读者朋友,大家需要的可以参与下。
================================================
FILE: animation-simulation/分治/空.md
================================================
================================================
FILE: animation-simulation/前缀和/leetcode1248寻找优美子数组.md
================================================
> 如果阅读时,发现错误,或者动画不可以显示的问题可以添加我微信好友 **[tan45du_one](https://raw.githubusercontent.com/tan45du/tan45du.github.io/master/个人微信.15egrcgqd94w.jpg)** ,备注 github + 题目 + 问题 向我反馈
>
> 感谢支持,该仓库会一直维护,希望对各位有一丢丢帮助。
>
> 另外希望手机阅读的同学可以来我的 <u>[**公众号:程序厨**](https://raw.githubusercontent.com/tan45du/test/master/微信图片_20210320152235.2pthdebvh1c0.png)</u> 两个平台同步,想要和题友一起刷题,互相监督的同学,可以在我的小屋点击<u>[**刷题小队**](https://raw.githubusercontent.com/tan45du/test/master/微信图片_20210320152235.2pthdebvh1c0.png)</u>进入。
#### [1248. 统计「优美子数组」](https://leetcode-cn.com/problems/count-number-of-nice-subarrays/)
**题目描述**
> 给你一个整数数组 nums 和一个整数 k。
>
> 如果某个 连续 子数组中恰好有 k 个奇数数字,我们就认为这个子数组是「优美子数组」。
>
> 请返回这个数组中「优美子数组」的数目。
**示例 1:**
> 输入:nums = [1,1,2,1,1], k = 3
> 输出:2
> 解释:包含 3 个奇数的子数组是 [1,1,2,1] 和 [1,2,1,1] 。
**示例 2:**
> 输入:nums = [2,4,6], k = 1
> 输出:0
> 解释:数列中不包含任何奇数,所以不存在优美子数组。
**示例 3:**
> 输入:nums = [2,2,2,1,2,2,1,2,2,2], k = 2
> 输出:16
如果上面那个题目我们完成了,这个题目做起来,分分钟的事,不信你去写一哈,百分百就整出来了,我们继续按上面的思想来解决。
**HashMap**
**解析**
上个题目我们是求和为 K 的子数组,这个题目是让我们求 恰好有 k 个奇数数字的连续子数组,这两个题几乎是一样的,上个题中我们将前缀区间的和保存到哈希表中,这个题目我们只需将前缀区间的奇数个数保存到区间内即可,只不过将 sum += x 改成了判断奇偶的语句,见下图。
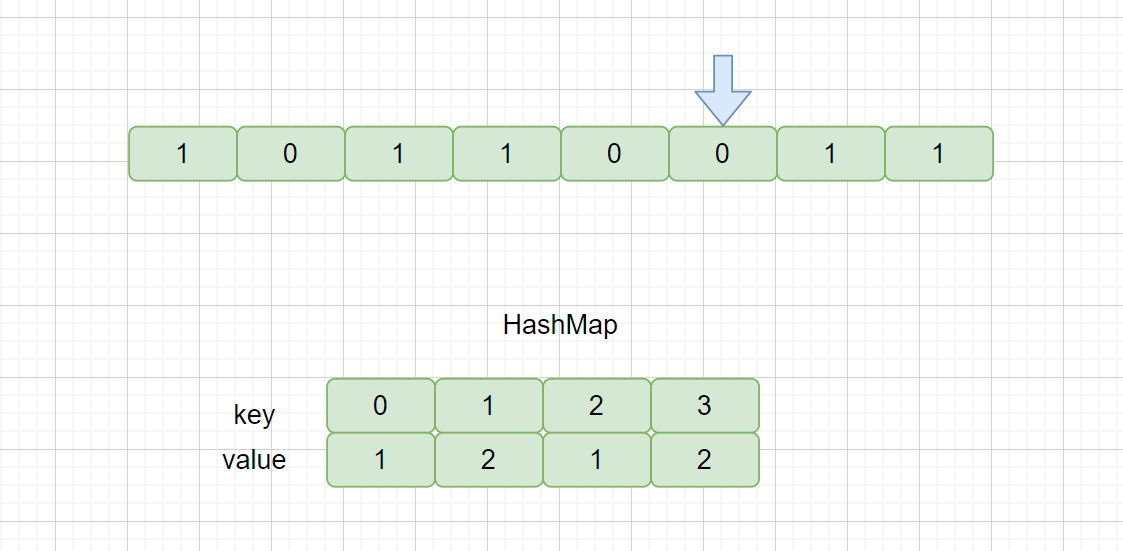
我们来解析一下哈希表,key 代表的是含有 1 个奇数的前缀区间,value 代表这种子区间的个数,含有两个,也就是 nums[0],nums[0,1].后面含义相同,那我们下面直接看代码吧,一下就能读懂。
Java Code:
```java
class Solution {
public int numberOfSubarrays(int[] nums, int k) {
if (nums.length == 0) {
return 0;
}
HashMap<Integer,Integer> map = new HashMap<>();
//统计奇数个数,相当于我们的 presum
int oddnum = 0;
int count = 0;
map.put(0,1);
for (int x : nums) {
// 统计奇数个数
oddnum += x & 1;
// 发现存在,则 count增加
if (map.containsKey(oddnum - k)) {
count += map.get(oddnum - k);
}
//存入
map.put(oddnum,map.getOrDefault(oddnum,0)+1);
}
return count;
}
}
```
C++ Code:
```cpp
class Solution {
public:
int numberOfSubarrays(vector<int>& nums, int k) {
if (nums.size() == 0) {
return 0;
}
map <int, int> m;
//统计奇数个数,相当于我们的 presum
int oddnum = 0;
int count = 0;
m.insert({0,1});
for (int & x : nums) {
// 统计奇数个数
oddnum += x & 1;
// 发现存在,则 count增加
if (m.find(oddnum - k) != m.end()) {
count += m[oddnum - k];
}
//存入
if(m.find(oddnum) != m.end()) m[oddnum]++;
else m[oddnum] = 1;
}
return count;
}
};
```
但是也有一点不同,就是我们是统计奇数的个数,数组中的奇数个数肯定不会超过原数组的长度,所以这个题目中我们可以用数组来模拟 HashMap ,用数组的索引来模拟 HashMap 的 key,用值来模拟哈希表的 value。下面我们直接看代码吧。
Java Code:
```java
class Solution {
public int numberOfSubarrays(int[] nums, int k) {
int len = nums.length;
int[] map = new int[len + 1];
map[0] = 1;
int oddnum = 0;
int count = 0;
for (int i = 0; i < len; ++i) {
//如果是奇数则加一,偶数加0,相当于没加
oddnum += nums[i] & 1;
if (oddnum - k >= 0) {
count += map[oddnum-k];
}
map[oddnum]++;
}
return count;
}
}
```
C++ Code:
```cpp
class Solution {
public:
int numberOfSubarrays(vector<int>& nums, int k) {
int len = nums.size();
vector <int> map(len + 1, 0);
map[0] = 1;
int oddnum = 0;
int count = 0;
for (int i = 0; i < len; ++i) {
//如果是奇数则加一,偶数加0,相当于没加
oddnum += nums[i] & 1;
if (oddnum - k >= 0) {
count += map[oddnum-k];
}
map[oddnum]++;
}
return count;
}
};
```
================================================
FILE: animation-simulation/前缀和/leetcode523连续的子数组和.md
================================================
> 如果阅读时,发现错误,或者动画不可以显示的问题可以添加我微信好友 **[tan45du_one](https://raw.githubusercontent.com/tan45du/tan45du.github.io/master/个人微信.15egrcgqd94w.jpg)** ,备注 github + 题目 + 问题 向我反馈
>
> 感谢支持,该仓库会一直维护,希望对各位有一丢丢帮助。
>
> 另外希望手机阅读的同学可以来我的 <u>[**公众号:程序厨**](https://raw.githubusercontent.com/tan45du/test/master/微信图片_20210320152235.2pthdebvh1c0.png)</u> 两个平台同步,想要和题友一起刷题,互相监督的同学,可以在我的小屋点击<u>[**刷题小队**](https://raw.githubusercontent.com/tan45du/test/master/微信图片_20210320152235.2pthdebvh1c0.png)</u>进入。
#### [523. 连续的子数组和](https://leetcode-cn.com/problems/continuous-subarray-sum/)
**题目描述**
> 给定一个包含 非负数 的数组和一个目标 整数 k,编写一个函数来判断该数组是否含有连续的子数组,其大小至少为 2,且总和为 k 的倍数,即总和为 n\*k,其中 n 也是一个整数。
**示例 1:**
> 输入:[23,2,4,6,7], k = 6
> 输出:True
解释:[2,4] 是一个大小为 2 的子数组,并且和为 6。
**示例 2:**
> 输入:[23,2,6,4,7], k = 6
> 输出:True
解释:[23,2,6,4,7]是大小为 5 的子数组,并且和为 42。
**前缀和 + HashMap**
这个题目算是对刚才那个题目的升级,前半部分是一样的,都是为了让你找到能被 K 整除的子数组,但是这里加了一个限制,那就是子数组的大小至少为 2,那么我们应该怎么判断子数组的长度呢?我们可以根据索引来进行判断,见下图。

此时我们 K = 6, presum % 6 = 4 也找到了相同余数的前缀子数组 [0,1] 但是我们此时指针指向为 2,我们的前缀子区间 [0,1]的下界为 1,所以 2 - 1 = 1,但我们的中间区间的长度小于 2,所以不能返回 true,需要继续遍历,那我们有两个区间[0,1],[0,2]都满足 presum % 6 = 4,那我们哈希表中保存的下标应该是 1 还是 2 呢?我们保存的是 1,如果我们保存的是较大的那个索引,则会出现下列情况,见下图。
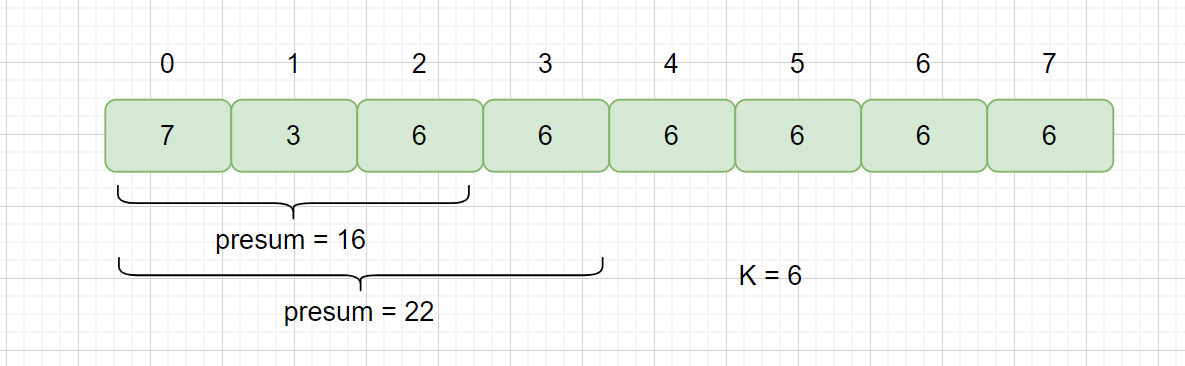
此时,仍会显示不满足子区间长度至少为 2 的情况,仍会继续遍历,但是我们此时的 [2,3]区间已经满足该情况,返回 true,所以我们往哈希表存值时,只存一次,即最小的索引即可。下面我们看一下该题的两个细节
细节 1:我们的 k 如果为 0 时怎么办,因为 0 不可以做除数。所以当我们 k 为 0 时可以直接存到数组里,例如输入为 [0,0] , K = 0 的情况
细节 2:另外一个就是之前我们都是统计个数,value 里保存的是次数,但是此时我们加了一个条件就是长度至少为 2,保存的是索引,所以我们不能继续 map.put(0,1),应该赋初值为 map.put(0,-1)。这样才不会漏掉一些情况,例如我们的数组为[2,3,4],k = 1,当我们 map.put(0,-1) 时,当我们遍历到 nums[1] 即 3 时,则可以返回 true,因为 1-(-1)= 2,5 % 1=0 , 同时满足。
**视频解析**

**题目代码**
Java Code:
```java
class Solution {
public boolean checkSubarraySum(int[] nums, int k) {
HashMap<Integer,Integer> map = new HashMap<>();
//细节2
map.put(0,-1);
int presum = 0;
for (int i = 0; i < nums.length; ++i) {
presum += nums[i];
//细节1,防止 k 为 0 的情况
int key = k == 0 ? presum : presum % k;
if (map.containsKey(key)) {
if (i - map.get(key) >= 2) {
return true;
}
//因为我们需要保存最小索引,当已经存在时则不用再次存入,不然会更新索引值
continue;
}
map.put(key,i);
}
return false;
}
}
```
C++ Code:
```cpp
class Solution {
public:
bool checkSubarraySum(vector<int>& nums, int k) {
map <int, int> m;
//细节2
m.insert({0,-1});
int presum = 0;
for (int i = 0; i < nums.size(); ++i) {
presum += nums[i];
//细节1,防止 k 为 0 的情况
int key = k == 0 ? presum : presum % k;
if (m.find(key) != m.end()) {
if (i - m[key] >= 2) {
return true;
}
//因为我们需要保存最小索引,当已经存在时则不用再次存入,不然会更新索引值
continue;
}
m.insert({key, i});
}
return false;
}
};
```
Go Code:
```go
func checkSubarraySum(nums []int, k int) bool {
m := map[int]int{}
// 由于前缀和%k可能为0,所以需要给出没有元素的时候,索引位置,即-1
m[0] = -1
sum := 0
for i, num := range nums {
sum += num
key := sum % k
/*
// 题目中告诉k >= 1
key := sum
if k != 0 {
key = sum % k
}
*/
if v, ok := m[key]; ok {
if i - v >= 2 {
return true
}
// 避免更新最小索引
continue
}
// 保存的是最小的索引
m[key] = i
}
return false
}
```
================================================
FILE: animation-simulation/前缀和/leetcode560和为K的子数组.md
================================================
> 如果阅读时,发现错误,或者动画不可以显示的问题可以添加我微信好友 **[tan45du_one](https://raw.githubusercontent.com/tan45du/tan45du.github.io/master/个人微信.15egrcgqd94w.jpg)** ,备注 github + 题目 + 问题 向我反馈
>
> 感谢支持,该仓库会一直维护,希望对各位有一丢丢帮助。
>
> 另外希望手机阅读的同学可以来我的 <u>[**公众号:程序厨**](https://raw.githubusercontent.com/tan45du/test/master/微信图片_20210320152235.2pthdebvh1c0.png)</u> 两个平台同步,想要和题友一起刷题,互相监督的同学,可以在我的小屋点击<u>[**刷题小队**](https://raw.githubusercontent.com/tan45du/test/master/微信图片_20210320152235.2pthdebvh1c0.png)</u>进入。
#### [560. 和为 K 的子数组](https://leetcode-cn.com/problems/subarray-sum-equals-k/)
**题目描述**
> 给定一个整数数组和一个整数 k,你需要找到该数组中和为 k 的连续的子数组的个数。
**示例 1 :**
> 输入:nums = [1,1,1], k = 2
> 输出: 2 , [1,1] 与 [1,1] 为两种不同的情况。
**暴力法**
**解析**
这个题目的题意很容易理解,就是让我们返回和为 k 的子数组的个数,所以我们直接利用双重循环解决该题,这个是很容易想到的。我们直接看代码吧。
```java
class Solution {
public int subarraySum(int[] nums, int k) {
int len = nums.length;
int sum = 0;
int count = 0;
for (int i = 0; i < len; ++i) {
for (int j = i; j < len; ++j) {
sum += nums[j];
if (sum == k) {
count++;
}
}
sum = 0;
}
return count;
}
}
```
下面我们我们使用前缀和的方法来解决这个题目,那么我们先来了解一下前缀和是什么东西。其实这个思想我们很早就接触过了。见下图
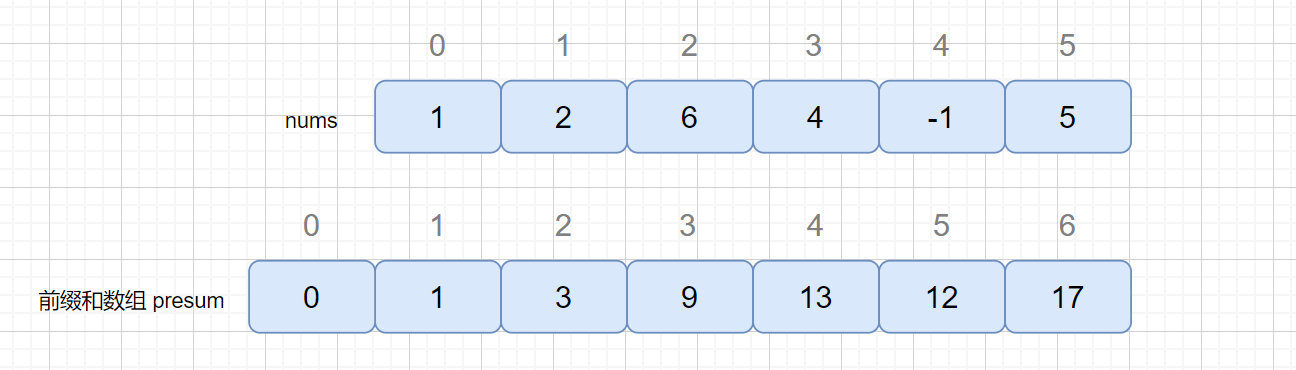
我们通过上图发现,我们的 presum 数组中保存的是 nums 元素的和,presum[1] = presum[0] + nums[0];
presum [2] = presum[1] + nums[1],presum[3] = presum[2] + nums[2] ... 所以我们通过前缀和数组可以轻松得到每个区间的和,
例如我们需要获取 nums[2] 到 nums[4] 这个区间的和,我们则完全根据 presum 数组得到,是不是有点和我们之前说的字符串匹配算法中 BM,KMP 中的 next 数组和 suffix 数组作用类似。
那么我们怎么根据 presum 数组获取 nums[2] 到 nums[4] 区间的和呢?见下图

所以我们 nums[2] 到 nums[4] 区间的和则可以由 presum[5] - presum[2] 得到。
也就是前 5 项的和减去前 2 项的和,得到第 3 项到第 5 项的和。那么我们可以遍历 presum 就能得到和为 K 的子数组的个数啦。
直接上代码。
```java
class Solution {
public int subarraySum(int[] nums, int k) {
//前缀和数组
int[] presum = new int[nums.length+1];
for (int i = 0; i < nums.length; i++) {
//这里需要注意,我们的前缀和是presum[1]开始填充的
presum[i+1] = nums[i] + presum[i];
}
//统计个数
int count = 0;
for (int i = 0; i < nums.length; ++i) {
for (int j = i; j < nums.length; ++j) {
//注意偏移,因为我们的nums[2]到nums[4]等于presum[5]-presum[2]
//所以这样就可以得到nums[i,j]区间内的和
if (presum[j+1] - presum[i] == k) {
count++;
}
}
}
return count;
}
}
```
我们通过上面的例子我们简单了解了前缀和思想,那么我们如果继续将其优化呢?
**前缀和 + HashMap**
**解析**
其实我们在之前的两数之和中已经用到了这个方法,我们一起来回顾两数之和 HashMap 的代码.
```java
class Solution {
public int[] twoSum(int[] nums, int target) {
HashMap<Integer,Integer> map = new HashMap<>();
//一次遍历
for (int i = 0; i < nums.length; ++i) {
//存在时,我们用数组得值为 key,索引为 value
if (map.containsKey(target - nums[i])){
return new int[]{i,map.get(target-nums[i])};
}
//存入值
map.put(nums[i],i);
}
//返回
return new int[]{};
}
}
```
上面代码中,我们将数组的值和索引存入 map 中,当我们遍历到某一值 x 时,判断 map 中是否含有 target - x,即可。其实我们现在这个题目和两数之和原理是一致的,只不过我们是将**所有的前缀和**该**前缀和出现的次数**存到了 map 里。下面我们来看一下代码的执行过程。
**动图解析**

**题目代码**
Java Code:
```java
class Solution {
public int subarraySum(int[] nums, int k) {
if (nums.length == 0) {
return 0;
}
HashMap<Integer,Integer> map = new HashMap<>();
//细节,这里需要预存前缀和为 0 的情况,会漏掉前几位就满足的情况
//例如输入[1,1,0],k = 2 如果没有这行代码,则会返回0,漏掉了1+1=2,和1+1+0=2的情况
//输入:[3,1,1,0] k = 2时则不会漏掉
//因为presum[3] - presum[0]表示前面 3 位的和,所以需要map.put(0,1),垫下底
map.put(0, 1);
int count = 0;
int presum = 0;
for (int x : nums) {
presum += x;
//当前前缀和已知,判断是否含有 presum - k的前缀和,那么我们就知道某一区间的和为 k 了。
if (map.containsKey(presum - k)) {
count += map.get(presum - k);//获取presum-k前缀和出现次数
}
//更新
map.put(presum,map.getOrDefault(presum,0) + 1);
}
return count;
}
}
```
C++ Code:
```cpp
public:
int subarraySum(vector<int>& nums, int k) {
if (nums.size() == 0) {
return 0;
}
map <int, int> m;
//细节,这里需要预存前缀和为 0 的情况,会漏掉前几位就满足的情况
//例如输入[1,1,0],k = 2 如果没有这行代码,则会返回0,漏掉了1+1=2,和1+1+0=2的情况
//输入:[3,1,1,0] k = 2时则不会漏掉
//因为presum[3] - presum[0]表示前面 3 位的和,所以需要m.insert({0,1}),垫下底
m.insert({0, 1});
int count = 0;
int presum = 0;
for (int x : nums) {
presum += x;
//当前前缀和已知,判断是否含有 presum - k的前缀和,那么我们就知道某一区间的和为 k 了。
if (m.find(presum - k) != m.end()) {
count += m[presum - k];//获取presum-k前缀和出现次数
}
//更新
if(m.find(presum) != m.end()) m[presum]++;
else m[presum] = 1;
}
return count;
}
};
```
Go Code:
```GO
func subarraySum(nums []int, k int) int {
m := map[int]int{}
// m存的是前缀和,没有元素的时候,和为0,且有1个子数组(空数组)满足条件,即m[0] = 1
m[0] = 1
sum := 0
cnt := 0
for _, num := range nums {
sum += num
if v, ok := m[sum - k]; ok {
cnt += v
}
// 更新满足前缀和的子数组数量
m[sum]++
}
return cnt
}
```
================================================
FILE: animation-simulation/前缀和/leetcode724寻找数组的中心索引.md
================================================
> 如果阅读时,发现错误,或者动画不可以显示的问题可以添加我微信好友 **[tan45du_one](https://raw.githubusercontent.com/tan45du/tan45du.github.io/master/个人微信.15egrcgqd94w.jpg)** ,备注 github + 题目 + 问题 向我反馈
>
> 感谢支持,该仓库会一直维护,希望对各位有一丢丢帮助。
>
> 另外希望手机阅读的同学可以来我的 <u>[**公众号:程序厨**](https://raw.githubusercontent.com/tan45du/test/master/微信图片_20210320152235.2pthdebvh1c0.png)</u> 两个平台同步,想要和题友一起刷题,互相监督的同学,可以在我的小屋点击<u>[**刷题小队**](https://raw.githubusercontent.com/tan45du/test/master/微信图片_20210320152235.2pthdebvh1c0.png)</u>进入。
### 前缀和详解
今天我们来说一下刷题时经常用到的前缀和思想,前缀和思想和滑动窗口会经常用在求子数组和子串问题上,当我们遇到此类问题时,则应该需要想到此类解题方式,该文章深入浅出描述前缀和思想,读完这个文章就会有属于自己的解题框架,遇到此类问题时就能够轻松应对。
下面我们先来了解一下什么是前缀和。
前缀和其实我们很早之前就了解过的,我们求数列的和时,Sn = a1+a2+a3+...an; 此时 Sn 就是数列的前 n 项和。例 S5 = a1 + a2 + a3 + a4 + a5; S2 = a1 + a2。所以我们完全可以通过 S5-S2 得到 a3+a4+a5 的值,这个过程就和我们做题用到的前缀和思想类似。我们的前缀和数组里保存的就是前 n 项的和。见下图

我们通过前缀和数组保存前 n 位的和,presum[1]保存的就是 nums 数组中前 1 位的和,也就是 **presum[1]** = nums[0], **presum[2]** = nums[0] + nums[1] = **presum[1]** + nums[1]. 依次类推,所以我们通过前缀和数组可以轻松得到每个区间的和。
例如我们需要获取 nums[2] 到 nums[4] 这个区间的和,我们则完全根据 presum 数组得到,是不是有点和我们之前说的字符串匹配算法中 BM,KMP 中的 next 数组和 suffix 数组作用类似。那么我们怎么根据 presum 数组获取 nums[2] 到 nums[4] 区间的和呢?见下图

好啦,我们已经了解了前缀和的解题思想了,我们可以通过下面这段代码得到我们的前缀和数组,非常简单
```java
for (int i = 0; i < nums.length; i++) {
presum[i+1] = nums[i] + presum[i];
}
```
好啦,我们开始实战吧。
#### [724. 寻找数组的中心下标](https://leetcode-cn.com/problems/find-pivot-index/)
**题目描述**
> 给定一个整数类型的数组 nums,请编写一个能够返回数组 “中心索引” 的方法。
>
> 我们是这样定义数组 中心索引 的:数组中心索引的左侧所有元素相加的和等于右侧所有元素相加的和。
>
> 如果数组不存在中心索引,那么我们应该返回 -1。如果数组有多个中心索引,那么我们应该返回最靠近左边的那一个。
**示例 1:**
> 输入:
> nums = [1, 7, 3, 6, 5, 6]
> 输出:3
解释:
索引 3 (nums[3] = 6) 的左侧数之和 (1 + 7 + 3 = 11),与右侧数之和 (5 + 6 = 11) 相等。
同时, 3 也是第一个符合要求的中心索引。
**示例 2:**
> 输入:
> nums = [1, 2, 3]
> 输出:-1
解释:
数组中不存在满足此条件的中心索引。
理解了我们前缀和的概念(不知道好像也可以做,这个题太简单了哈哈)。我们可以一下就能把这个题目做出来,先遍历一遍求出数组的和,然后第二次遍历时,直接进行对比左半部分和右半部分是否相同,如果相同则返回 true,不同则继续遍历。
Java Code:
```java
class Solution {
public int pivotIndex(int[] nums) {
int presum = 0;
//数组的和
for (int x : nums) {
presum += x;
}
int leftsum = 0;
for (int i = 0; i < nums.length; ++i) {
//发现相同情况
if (leftsum == presum - nums[i] - leftsum) {
return i;
}
leftsum += nums[i];
}
return -1;
}
}
```
C++ Code:
```cpp
class Solution {
public:
int pivotIndex(vector<int>& nums) {
int presum = 0;
//数组的和
for (int x : nums) {
presum += x;
}
int leftsum = 0;
for (int i = 0; i < nums.size(); ++i) {
//发现相同情况
if (leftsum == presum - nums[i] - leftsum) {
return i;
}
leftsum += nums[i];
}
return -1;
}
};
```
Go Code:
```go
func pivotIndex(nums []int) int {
presum := 0
for _, num := range nums {
presum += num
}
var leftsum int
for i, num := range nums {
// 比较左半和右半是否相同
if presum - leftsum - num == leftsum {
return i
}
leftsum += num
}
return -1
}
```
================================================
FILE: animation-simulation/前缀和/leetcode974和可被K整除的子数组.md
================================================
> 如果阅读时,发现错误,或者动画不可以显示的问题可以添加我微信好友 **[tan45du_one](https://raw.githubusercontent.com/tan45du/tan45du.github.io/master/个人微信.15egrcgqd94w.jpg)** ,备注 github + 题目 + 问题 向我反馈
>
> 感谢支持,该仓库会一直维护,希望对各位有一丢丢帮助。
>
> 另外希望手机阅读的同学可以来我的 <u>[**公众号:程序厨**](https://raw.githubusercontent.com/tan45du/test/master/微信图片_20210320152235.2pthdebvh1c0.png)</u> 两个平台同步,想要和题友一起刷题,互相监督的同学,可以在我的小屋点击<u>[**刷题小队**](https://raw.githubusercontent.com/tan45du/test/master/微信图片_20210320152235.2pthdebvh1c0.png)</u>进入。
#### [974. 和可被 K 整除的子数组](https://leetcode-cn.com/problems/subarray-sums-divisible-by-k/)
**题目描述**
> 给定一个整数数组 A,返回其中元素之和可被 K 整除的(连续、非空)子数组的数目。
**示例:**
> 输入:A = [4,5,0,-2,-3,1], K = 5
> 输出:7
**解释:**
> 有 7 个子数组满足其元素之和可被 K = 5 整除:
> [4, 5, 0, -2, -3, 1], [5], [5, 0], [5, 0, -2, -3], [0], [0, -2, -3], [-2, -3]
**前缀和+HashMap**
**解析**
我们在该文的第一题 **和为 K 的子数组 **中,我们需要求出满足条件的区间,见下图
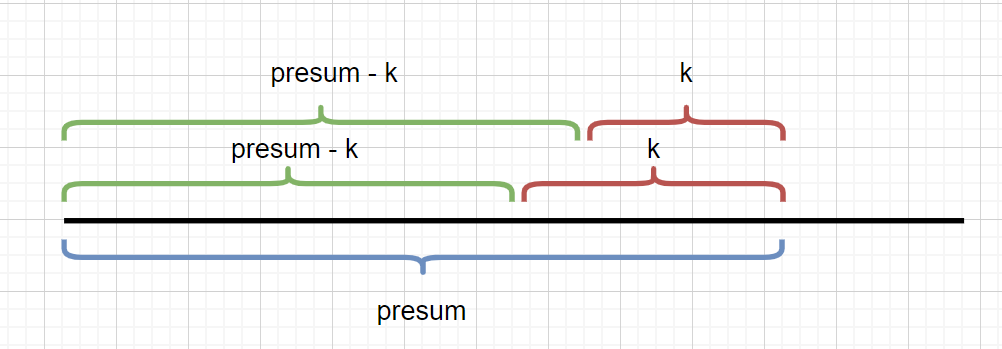
我们需要找到满足,和为 K 的区间。我们此时 presum 是已知的,k 也是已知的,我们只需要找到 presum - k 区间的个数,就能得到 k 的区间个数。但是我们在当前题目中应该怎么做呢?见下图。

我们在之前的例子中说到,presum[j+1] - presum[i] 可以得到 nums[i] + nums[i+1]+.... nums[j],也就是[i,j]区间的和。
那么我们想要判断区间 [i,j] 的和是否能整除 K,也就是上图中紫色那一段是否能整除 K,那么我们只需判断
(presum[j+1] - presum[i] ) % k 是否等于 0 即可,
我们假设 (presum[j+1] - presum[i] ) % k == 0;则
presum[j+1] % k - presum[i] % k == 0;
presum[j +1] % k = presum[i] % k ;
我们 presum[j +1] % k 的值 key 是已知的,则是当前的 presum 和 k 的关系,我们只需要知道之前的前缀区间里含有相同余数 (key)的个数。则能够知道当前能够整除 K 的区间个数。见下图
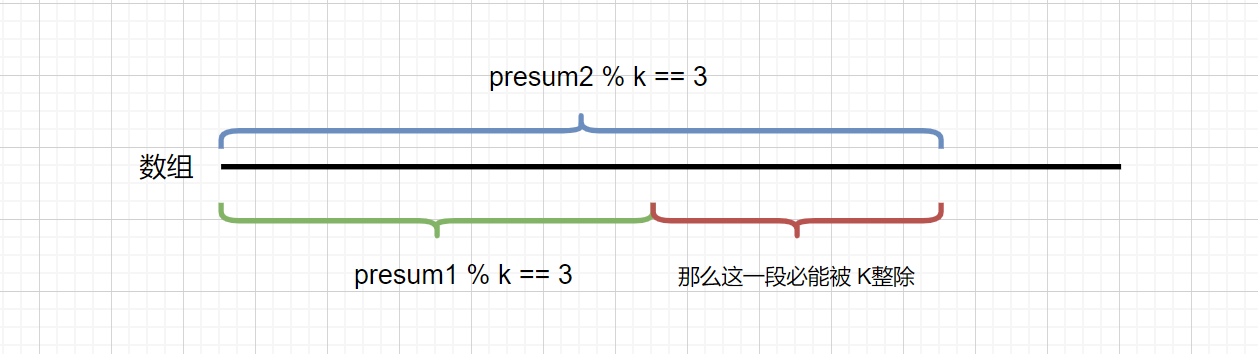
**题目代码**
```java
class Solution {
public int subarraysDivByK(int[] A, int K) {
HashMap<Integer,Integer> map = new HashMap<>();
map.put(0,1);
int presum = 0;
int count = 0;
for (int x : A) {
presum += x;
//当前 presum 与 K的关系,余数是几,当被除数为负数时取模结果为负数,需要纠正
int key = (presum % K + K) % K;
//查询哈希表获取之前key也就是余数的次数
if (map.containsKey(key)) {
count += map.get(key);
}
//存入哈希表当前key,也就是余数
map.put(key,map.getOrDefault(key,0)+1);
}
return count;
}
}
```
我们看到上面代码中有一段代码是这样的
```java
int key = (presum % K + K) % K;
```
这是为什么呢?不能直接用 presum % k 吗?
这是因为当我们 presum 为负数时,需要对其纠正。纠正前(-1) %2 = (-1),纠正之后 ( (-1) % 2 + 2) % 2=1 保存在哈希表中的则为 1.则不会漏掉部分情况,例如输入为 [-1,2,9],K = 2 如果不对其纠正则会漏掉区间 [2] 此时 2 % 2 = 0,符合条件,但是不会被计数。
那么这个题目我们可不可以用数组,代替 map 呢?当然也是可以的,因为此时我们的哈希表存的是余数,余数最大也只不过是 K-1 所以我们可以用固定长度 K 的数组来模拟哈希表。
Java Code:
```java
class Solution {
public int subarraysDivByK(int[] A, int K) {
int[] map = new int[K];
map[0] = 1;
int len = A.length;
int presum = 0;
int count = 0;
for (int i = 0; i < len; ++i) {
presum += A[i];
//求key
int key = (presum % K + K) % K;
//count添加次数,并将当前的map[key]++;
count += map[key]++;
}
return count;
}
}
```
C++ Code:
```cpp
class Solution {
public:
int subarraysDivByK(vector<int>& A, int K) {
vector <int> map (K, 0);
int len = A.size();
int count = 0;
int presum = 0;
map[0] = 1;
for (int i = 0; i < len; ++i) {
presum += A[i];
//求key
int key = (presum % K + K) % K;
//count添加次数,并将当前的map[key]++;
count += (map[key]++);
}
return count;
}
};
```
Go Code:
```go
func subarraysDivByK(nums []int, k int) int {
m := make(map[int]int)
cnt := 0
sum := 0
m[0] = 1
for _, num := range nums {
sum += num
key := (sum % k + k) % k
cnt += m[key]
m[key]++
}
return cnt
}
```
================================================
FILE: animation-simulation/剑指offer/1的个数.md
================================================
# 我太喜欢这个题了
> 如果阅读时,发现错误,或者动画不可以显示的问题可以添加我微信好友 **[tan45du_one](https://raw.githubusercontent.com/tan45du/tan45du.github.io/master/个人微信.15egrcgqd94w.jpg)** ,备注 github + 题目 + 问题 向我反馈
>
> 感谢支持,该仓库会一直维护,希望对各位有一丢丢帮助。
>
> 另外希望手机阅读的同学可以来我的 <u>[**公众号:程序厨**](https://raw.githubusercontent.com/tan45du/test/master/微信图片_20210320152235.2pthdebvh1c0.png)</u> 两个平台同步,想要和题友一起刷题,互相监督的同学,可以在我的小屋点击<u>[**刷题小队**](https://raw.githubusercontent.com/tan45du/test/master/微信图片_20210320152235.2pthdebvh1c0.png)</u>进入。
今天我们来看一道贼棒的题目,题目不长,很经典,也很容易理解,我们一起来看一哈吧,
大家也可能做过这道题,那就再复习一下,如果没做过的话,可以看完文章,自己去 AC 一下,不过写代码的时候,要自己完全写出来,这样才能有收获,下面我们看题目吧。
## leetcode 233. 数字 1 的个数
**题目描述**
给定一个整数 n,计算所有小于等于 n 的非负整数中数字 1 出现的个数。
示例 1:
> 输入:n = 13
> 输出:6
示例 2:
> 输入:n = 0
> 输出:0
太喜欢这种简洁的题目啦,言简意赅,就是让咱们找出**小于等于 n 的非负整数中数字 1 出现的个数**。
大家看到这个题目的第一印象,可能会这样想,哦,让我们求 1 的个数。
呐我们直接逐位遍历每个数的每一位,当遇到 1 的时候,计数器 +1,不就行了。
嗯,很棒的方法,可惜会超时。(我试了)
或者说,我们可以先将所有数字拼接起来,然后再逐位遍历,这样仍会超时。(我也试了)
大家再思考一下还有没有别的方法呢?
既然题目让我们统计小于等于 n 的非负整数中数字 1 出现的个数。
那我们可以不可这样统计。
我们假设 n = abcd,某个四位数。
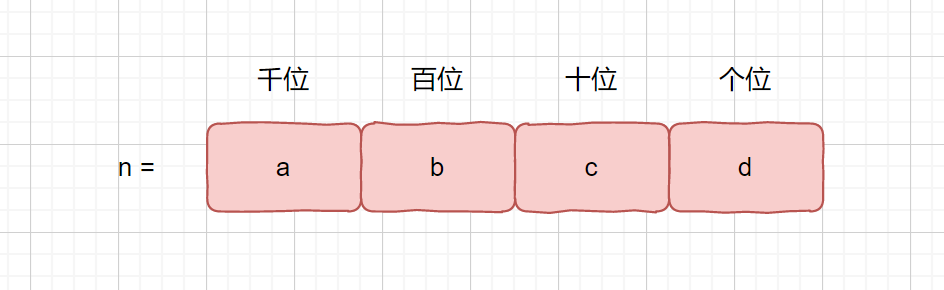
那我们完全可以统计每一位上 1 出现的次数,个数上 1 出现的次数,十位上 1 出现的次数,百位 ,千位。。。
也就是说**小于等于 n 的所有数字中**,个位上出现 1 的次数 + 十位出现 1 的次数 + 。。。最后得到的就是总的出现次数。
见下图
我们假设 n = 13 (用个小点的数,比较容易举例)
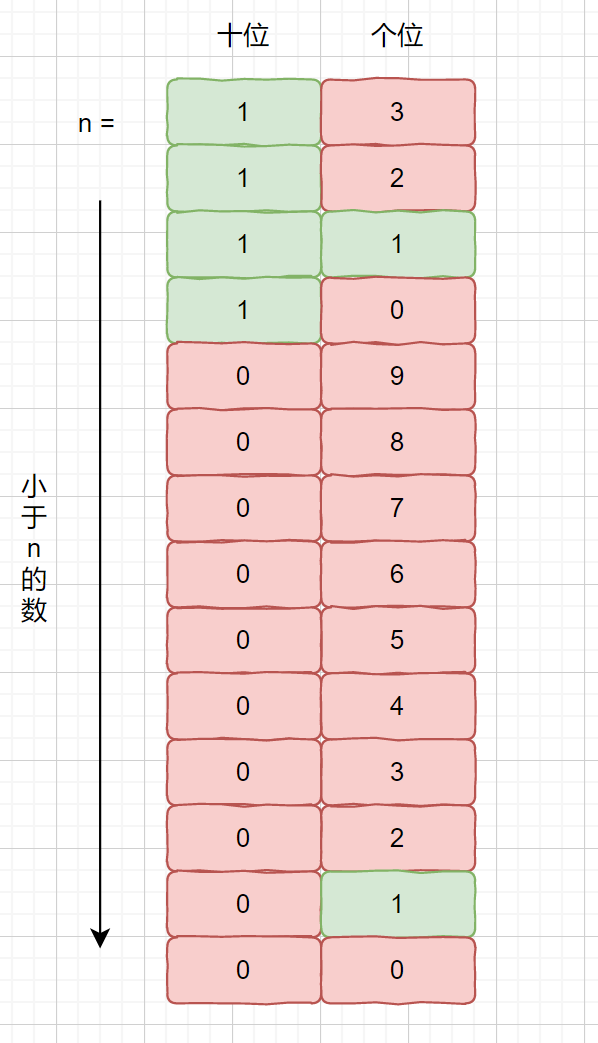
我们需要统计小于等于 13 的数中,出现 1 的次数,
通过上图可知,个位上 1 出现 2 次,十位上 1 出现 4 次
那么总次数为 2 + 4 = 6 次。
> 另外我们发现 11 这个数,会被统计 2 次,它的十位和个位都为 1 ,
>
> 而我们这个题目是要统计 1 出现的次数,而不是统计包含 1 的整数,所以上诉方法不会出现重复统计的情况。
我们题目已经有大概思路啦,下面的难点就是如何统计每一位中 1 出现的次数呢?
我们完全可以通过遍历 n 的每一位来得到总个数,见下图
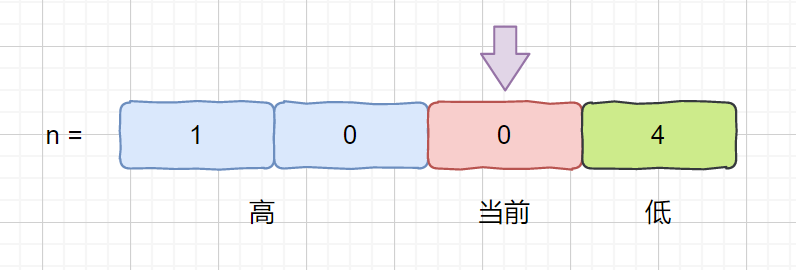
假设我们想要得到十位上 1 出现的次数,当前我们指针指向十位,
我们称之为当前位。num 则代表当前位的位因子,当前位为个位时 num = 1,十位时为 10,百位时为 100....
那我们将**当前位左边的定义为高位**,**当前位右边的定义位低位**。
> 例:n = 1004 ,此时指针指向十位(当前位)num = 10,高位为百位,千位,低位为个位
而且我们某一位的取值范围为 0 ~ 9,那么我们可以将这 10 个数分为 3 类,小于 1 (当前位数字为 0 ),等于 1(当前位数字为 1 ) ,大于 1(当前位上数字为 2 ~ 9),下面我们就来分别考虑三种情况。
> **我们进行举例的 n 为 1004,1014,1024。重点讨论十位上 3 种不同情况**。大家阅读下方文字之前,先想象自己脑子里有一个行李箱的滚轮密码锁,我们固定其中的某一位,然后可以随意滑动其他位,这样可以帮助大家理解。
>
> 注:该比喻来自与网友 ryan0414,看到的时候,不禁惊呼可太贴切了!
### **n = 1004**
我们想要计算出**小于等于 1004 的非负整数中**,十位上出现 1 的次数。
也就是当前位为十位,数字为 0 时,十位上出现 1 的次数。
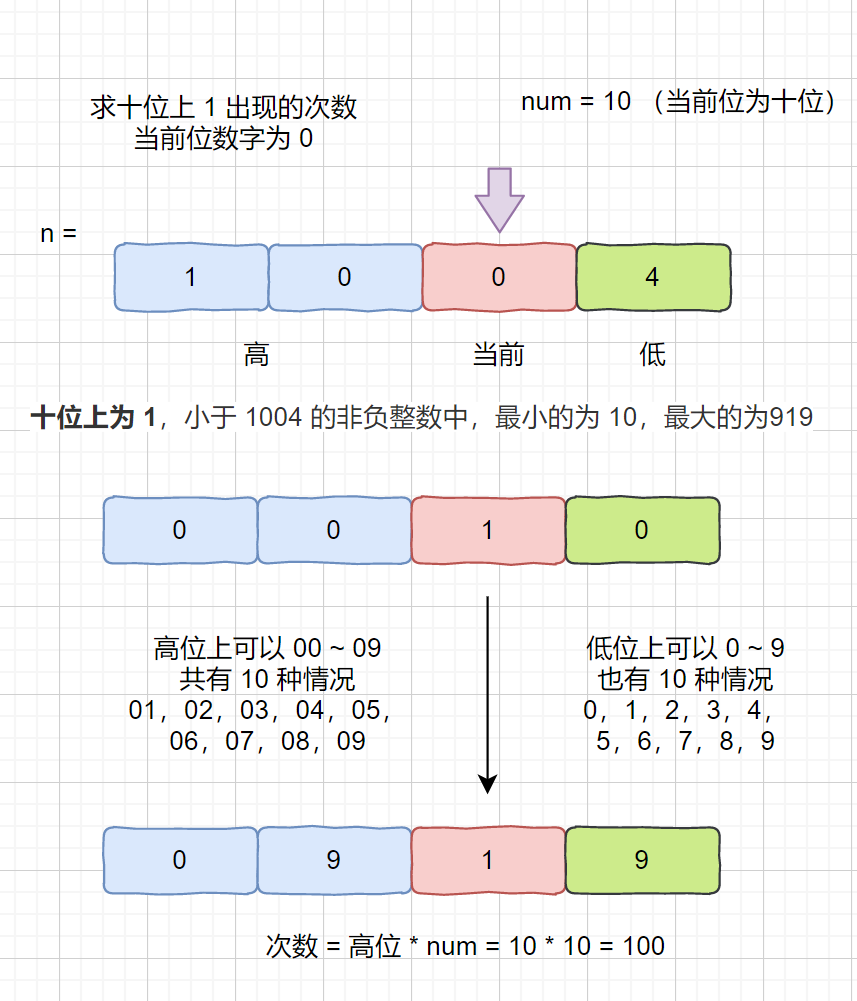
> 解析:为什么我们可以直接通过高位数字 \* num,得到 1 出现的次数
>
> 因为我们高位为 10,可变范围为 0 ~ 10,但是我们的十位为 0 ,所以高位为 10 的情况取不到,所以共有 10 种情况。
>
> 又当前位为十位,低位共有 1 位,可选范围为 0 ~ 9 共有 10 种情况,所以直接可以通过 10 \* 10 得到。
其实不难理解,我们可以设想成行李箱的密码盘,在一定范围内,也就是上面的 0010 ~ 0919 , 固定住一位为 1 ,只能移动其他位,看共有多少种组合。
好啦,这个情况我们已经搞明白啦,下面我们看另一种情况。
### n = 1014
我们想要计算出**小于等于 1014 的非负整数中**,十位上出现 1 的次数。
也就是当前位为十位,数字为 1 时,十位上出现 1 的次数。
我们在小于 1014 的非负整数中,十位上为 1 的最小数字为 10,最大数字为 1014,所以我们需要在 10 ~ 1014 这个范围内固定住十位上的 1 ,移动其他位。
其实然后我们可以将 1014 看成是 1004 + 10 = 1014
则可以将 10 ~ 1014 拆分为两部分 0010 ~ 0919 (小于 1004 ),1010 ~ 1014。
见下图
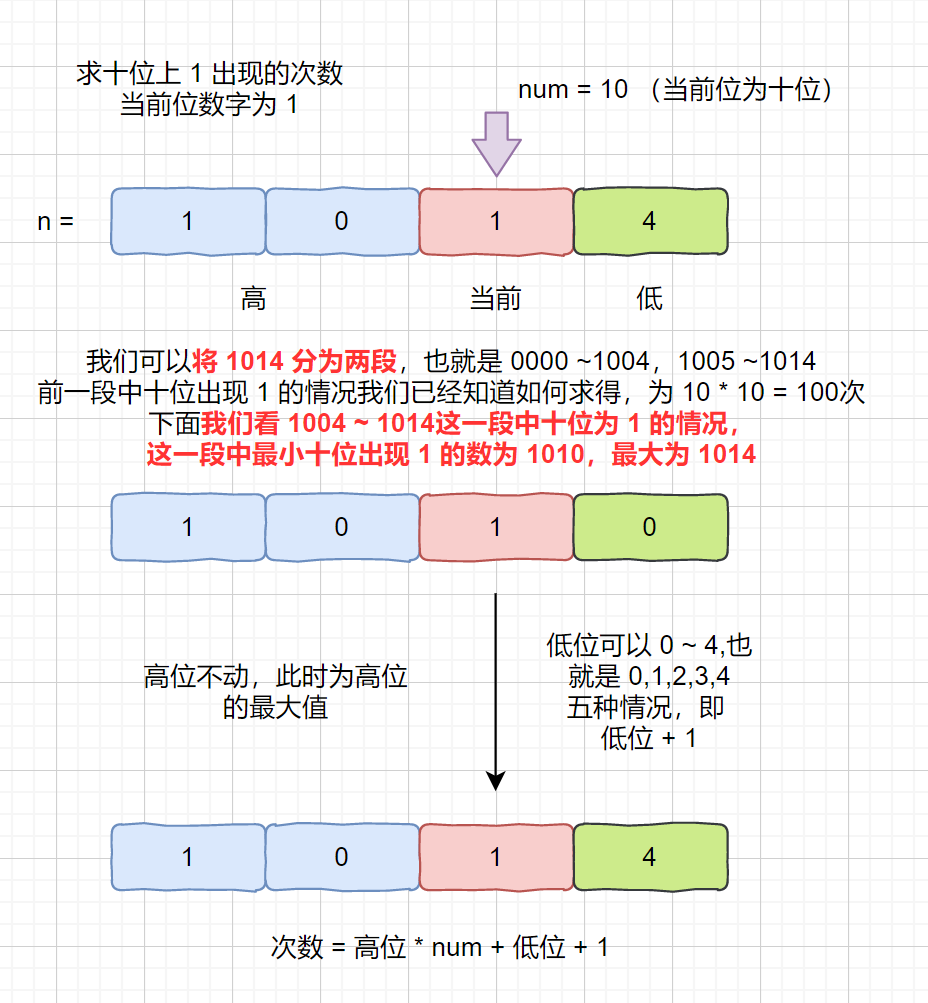
> 解析:为什么我们可以直接通过 高位数字 _ num + 低位数字 + 1 即 10 _ 10 + 4 + 1
>
> 得到 1 出现的次数
>
> 高位数字 \* num 是得到第一段的次数,第二段为 低位数字 + 1,求第二段时我们高位数字和当前位已经固定,
>
> 我们可以改变的只有低位。
可以继续想到密码盘,求第二段时,把前 3 位固定,只能改变最后一位。最后一位最大能到 4 ,那么共有几种情况?
### n = 1024
我们想要计算出**小于等于 1024 的非负整数中**,十位上出现 1 的次数。
也就是当前位为十位,数字为 2 ~ 9 时,十位上出现 1 的次数。其中最小的为 0010,最大的为 1019
我们也可以将其拆成两段 0010 ~ 0919,1010 ~ 1019
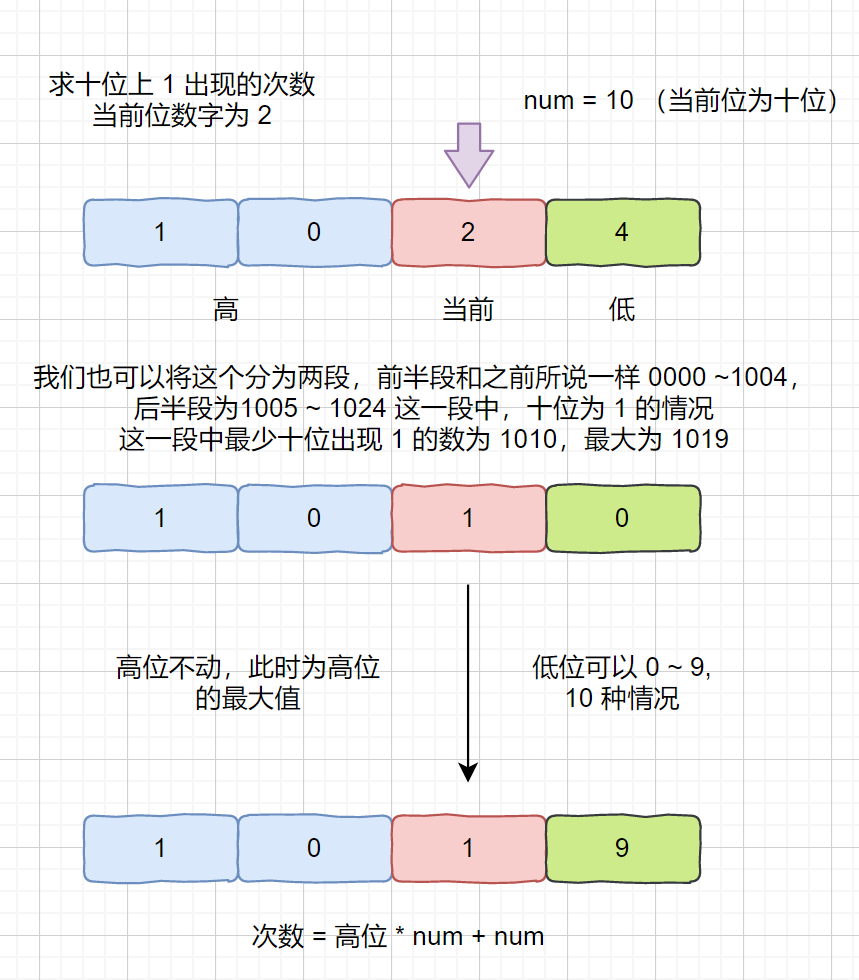
> 解析:为什么我们可以直接通过高位数字 _ num + num, 10 _ 10 + 10 得到 1 出现的次数
>
> 第一段和之前所说一样,第二段的次数,我们此时已经固定了高位和当前位,当前位为 1,低位可以随意取值,上诉例子中,当前位为 10,低位为位数为 1,则可以取值 0 ~ 9 的任何数,则共有 10 (num) 种可能。
好啦,这个题目大家应该理解的差不多啦,
下面我们通过动画模拟一下,是怎样一步一步的计算出,小于等于 1014 的数中 1 出现的次数。
> 注:蓝色高位,橙色当前位,绿色低位
>
> 初始化:low = 0, cur = n % 10, num = 1, count = 0, high = n / 10;

好啦,下面我们看一下题目代码吧
注:下方代码没有简写,也都标有注释,大家可以结合动画边思考边阅读。
**题目代码**
```java
class Solution {
public int countDigitOne(int n) {
//高位
int high = n;
//低位
int low = 0;
//当前位
int cur = 0;
int count = 0;
int num = 1;
while (high != 0 || cur != 0) {
cur = high % 10;
high /= 10;
//这里我们可以提出 high * num 因为我们发现无论为几,都含有它
if (cur == 0) count += high * num;
else if (cur == 1) count += high * num + 1 + low;
else count += (high + 1) * num;
//低位
low = cur * num + low;
num *= 10;
}
return count;
}
}
```
Swift Code:
```swift
class Solution {
func countDigitOne(_ n: Int) -> Int {
var high = n, low = 0, cur = 0, count = 0, num = 1
while high != 0 || cur != 0 {
cur = high % 10
high /= 10
//这里我们可以提出 high * num 因为我们发现无论为几,都含有它
if cur == 0 {
count += high * num
} else if cur == 1 {
count += high * num + 1 + low
} else {
count += (high + 1) * num
}
low = cur * num + low
num *= 10
}
return count
}
}
```
时间复杂度 : O(logn) 空间复杂度 O(1)
C++ Code:
```C++
class Solution
{
public:
int countDigitOne(int n)
{
// 高位, 低位, 当前位
int high = n, low = 0, cur = 0;
int count = 0, num = 1;
//数字是0的时候完全没必要继续计算
while (high != 0)
{
cur = high % 10;
high /= 10;
//这里我们可以提出 high * num 因为我们发现无论为几,都含有它
if (cur == 0)
count += (high * num);
else if (cur == 1)
count += (high * num + 1 + low);
else
count += ((high + 1) * num);
//低位
low = cur * num + low;
//提前检查剩余数字, 以免溢出
if (high != 0)
num *= 10;
}
return count;
}
};
```
================================================
FILE: animation-simulation/动态规划/空.md
================================================
================================================
FILE: animation-simulation/单调队列单调栈/leetcode739每日温度.md
================================================
> 如果阅读时,发现错误,或者动画不可以显示的问题可以添加我微信好友 **[tan45du_one](https://raw.githubusercontent.com/tan45du/tan45du.github.io/master/个人微信.15egrcgqd94w.jpg)** ,备注 github + 题目 + 问题 向我反馈
>
> 感谢支持,该仓库会一直维护,希望对各位有一丢丢帮助。
>
> 另外希望手机阅读的同学可以来我的 <u>[**公众号:程序厨**](https://raw.githubusercontent.com/tan45du/test/master/微信图片_20210320152235.2pthdebvh1c0.png)</u> 两个平台同步,想要和题友一起刷题,互相监督的同学,可以在我的小屋点击<u>[**刷题小队**](https://raw.githubusercontent.com/tan45du/test/master/微信图片_20210320152235.2pthdebvh1c0.png)</u>进入。
#### [739. 每日温度](https://leetcode-cn.com/problems/daily-temperatures/)
题目描述:
> 请根据每日 气温 列表,重新生成一个列表。对应位置的输出为:要想观测到更高的气温,至少需要等待的天数。如果气温在这之后都不会升高,请在该位置用 0 来代替。
示例 1:
> 输入: temperatures = [73, 74, 75, 71, 69, 72, 76, 73]
>
> 输出:arr = [1, 1, 4, 2, 1, 1, 0, 0]
示例 2:
> 输入:temperatures = [30,30,31,45,31,34,56]
>
> 输出:arr = [2,1,1,3,1,1,0]
#### 题目解析
其实我们可以换种方式理解这个题目,比如我们 temperatures[0] = 30,则我们需要找到后面第一个比 30 大的数,也就是 31,31 的下标为 2,30 的下标为 0 ,则我们的返回数组 arr[0] = 2。
理解了题目之后我们来说一下解题思路。
遍历数组,数组中的值为待入栈元素,待入栈元素入栈时会先跟栈顶元素进行对比,如果小于该值则入栈,如果大于则将栈顶元素出栈,新的元素入栈。
例如栈顶为 69,新的元素为 72,则 69 出栈,72 入栈。并赋值给 arr,69 的索引为 4,72 的索引为 5,则 arr[4] = 5 - 4 = 1,这个题目用到的是单调栈的思想,下面我们来看一下视频解析。

注:栈中的括号内的值,代表索引对应的元素,我们的入栈的为索引值,为了便于理解将其对应的值写在了括号中
```java
class Solution {
public int[] dailyTemperatures(int[] T) {
int len = T.length;
if (len == 0) {
return T;
}
Stack<Integer> stack = new Stack<>();
int[] arr = new int[len];
int t = 0;
for (int i = 0; i < len; i++) {
//单调栈
while (!stack.isEmpty() && T[i] > T[stack.peek()]){
arr[stack.peek()] = i - stack.pop();
}
stack.push(i);
}
return arr;
}
}
```
GO Code:
```go
func dailyTemperatures(temperatures []int) []int {
l := len(temperatures)
if l == 0 {
return temperatures
}
stack := []int{}
arr := make([]int, l)
for i := 0; i < l; i++ {
for len(stack) != 0 && temperatures[i] > temperatures[stack[len(stack) - 1]] {
idx := stack[len(stack) - 1]
arr[idx] = i - idx
stack = stack[: len(stack) - 1]
}
// 栈保存的是索引
stack = append(stack, i)
}
return arr
}
```
================================================
FILE: animation-simulation/单调队列单调栈/剑指offer59队列的最大值.md
================================================
> 如果阅读时,发现错误,或者动画不可以显示的问题可以添加我微信好友 **[tan45du_one](https://raw.githubusercontent.com/tan45du/tan45du.github.io/master/个人微信.15egrcgqd94w.jpg)** ,备注 github + 题目 + 问题 向我反馈
>
> 感谢支持,该仓库会一直维护,希望对各位有一丢丢帮助。
>
> 另外希望手机阅读的同学可以来我的 <u>[**公众号:程序厨**](https://raw.githubusercontent.com/tan45du/test/master/微信图片_20210320152235.2pthdebvh1c0.png)</u> 两个平台同步,想要和题友一起刷题,互相监督的同学,可以在我的小屋点击<u>[**刷题小队**](https://raw.githubusercontent.com/tan45du/test/master/微信图片_20210320152235.2pthdebvh1c0.png)</u>进入。
今天我们好好说说单调栈和单调队列。其实很容易理解,单调栈就是单调递增或单调递减的栈,栈内元素是有序的,单调队列同样也是。
下面我们通过几个题目由浅入深,一点一点挖透他们吧!
## 单调队列
#### [剑指 Offer 59 - II. 队列的最大值](https://leetcode-cn.com/problems/dui-lie-de-zui-da-zhi-lcof/)
#### 题目描述
请定义一个队列并实现函数 max_value 得到队列里的最大值
若队列为空,pop_front 和 max_value 需要返回 -1
**示例 1:**
> 输入: ["MaxQueue","push_back","push_back","max_value","pop_front","max_value"] > [[],[1],[2],[],[],[]]
> 输出: [null,null,null,2,1,2]
**示例 2:**
> 输入:
> ["MaxQueue","pop_front","max_value"] > [[],[],[]]
> 输出: [null,-1,-1]
#### 题目解析:
我们先来拆解下上面的示例 1

其实我觉得这个题目的重点在理解题意上面,可能刚开始刷题的同学,对题意理解不够透彻,做起来没有那么得心应手,通过上面的图片我们简单了解了一下题意,那我们应该怎么做才能实现上述要求呢?
下面我们来说一下双端队列。我们之前说过的队列,遵守先进先出的规则,双端队列则可以从队头出队,也可以从队尾出队。我们先通过一个视频来简单了解下双端队列。

我们可以用双端队列做辅助队列,用辅助队列来保存当前队列的最大值。我们同时定义一个普通队列和一个双端单调队列。普通队列就正常执行入队,出队操作。max_value 操作则返回咱们的双端队列的队头即可。下面我们来看一下代码的具体执行过程吧。

我们来对视频进行解析
1.我们需要维护一个单调双端队列,上面的队列则执行正常操作,下面的队列队头元素则为上面队列的最大值
2.出队时,我们需要进行对比两个队列的队头元素是否相等,如果相等则同时出队,则出队后的双端队列的头部仍未上面队列中的最大值。
3.入队时,我们需要维持一个单调递减的双端队列,因为我们需要确保队头元素为最大值嘛。
```java
class MaxQueue {
//普通队列
Queue<Integer> que;
//双端队列
Deque<Integer> deq;
public MaxQueue() {
que = new LinkedList<>();
deq = new LinkedList<>();
}
//获取最大值值,返回我们双端队列的对头即可,因为我们双端队列是单调递减的嘛
public int max_value() {
return deq.isEmpty() ? -1 : deq.peekFirst();
}
//入队操作
public void push_back(int value) {
que.offer(value);
//维护单调递减
while (!deq.isEmpty() && value > deq.peekLast()){
deq. pollLast();
}
deq.offerLast(value);
}
//返回队头元素,此时有个细节,我们需要用equals
//这里需要使用 equals() 代替 == 因为队列中存储的是 int 的包装类 Integer
public int pop_front() {
if(que.isEmpty()) return -1;
if (que.peek().equals(deq.peekFirst())) {
deq.pollFirst();
}
return que.poll();
}
}
```
GO Code:
```go
type MaxQueue struct {
que []int // 普通队列
deq []int // 双端队列
size int // que的队列长度
}
func Constructor() MaxQueue {
return MaxQueue{
que: []int{},
deq: []int{},
}
}
// Is_empty 表示队列是否为空
func (mq *MaxQueue) Is_empty() bool {
return mq.size == 0
}
// Max_value 取最大值值,返回我们双端队列的对头即可,因为我们双端队列是单调递减的嘛
func (mq *MaxQueue) Max_value() int {
if mq.Is_empty() { return -1 }
return mq.deq[0]
}
// Push_back 入队
func (mq *MaxQueue) Push_back(value int) {
mq.que = append(mq.que, value)
// 维护单调递减队列
for len(mq.deq) != 0 && mq.deq[len(mq.deq) - 1] < value {
mq.deq = mq.deq[:len(mq.deq) - 1]
}
mq.deq = append(mq.deq, value)
mq.size++
}
// Pop_front 弹出队列头元素,并且返回其值。
func (mq *MaxQueue) Pop_front() int {
if mq.Is_empty() { return -1 }
ans := mq.que[0]
mq.que = mq.que[1:]
if mq.deq[0] == ans {
mq.deq = mq.deq[1:]
}
mq.size--
return ans
}
```
###
================================================
FILE: animation-simulation/单调队列单调栈/接雨水.md
================================================
> 如果阅读时,发现错误,或者动画不可以显示的问题可以添加我微信好友 **[tan45du_one](https://raw.githubusercontent.com/tan45du/tan45du.github.io/master/个人微信.15egrcgqd94w.jpg)** ,备注 github + 题目 + 问题 向我反馈
>
> 感谢支持,该仓库会一直维护,希望对各位有一丢丢帮助。
>
> 另外希望手机阅读的同学可以来我的 <u>[**公众号:程序厨**](https://raw.githubusercontent.com/tan45du/test/master/微信图片_20210320152235.2pthdebvh1c0.png)</u> 两个平台同步,想要和题友一起刷题,互相监督的同学,可以在我的小屋点击<u>[**刷题小队**](https://raw.githubusercontent.com/tan45du/test/master/微信图片_20210320152235.2pthdebvh1c0.png)</u>进入。
#### [42. 接雨水](https://leetcode-cn.com/problems/trapping-rain-water/)
这道接雨水也是一道特别经典的题目,一道必刷题目,我们也用单调栈来解决。下面我们来看一下题目吧
给定 n 个非负整数表示每个宽度为 1 的柱子的高度图,计算按此排列的柱子,下雨之后能接多少雨水。
示例 1:
```
输入:height = [0,1,0,2,1,0,1,3,2,1,2,1]
输出:6
```
示例 2:
```
输入:height = [4,2,0,3,2,5]
输出:9
```
示例 3:
```
输入:[4,3,2,0,1,1,5]
输出:13
```
> 上面是由数组 [4,3,2,0,1,1,5]表示的高度图,在这种情况下,可以接 13 个单位的雨水(见下图)。
### 题目解析:
看了上面的示例刚开始刷题的同学可能有些懵逼,那我们结合图片来理解一下,我们就用示例 3 的例子进行举例,他的雨水到底代表的是什么。

上图则为我们的题目描述,是不是理解了呢?你也可以这样理解我们在地上放置了若干高度的黄色箱子,他们中间有空隙,然后我们想在他们里面插入若干蓝色箱子,并保证插入之后,这些箱子的左视图和右视图都不能看到蓝色箱子。
好啦题目我们已经理解了,下面我们看一下解题思路。做这个这前我们可以先去看一下我们之前做过的另一道题目每日温度。这两道题目的思路差不多,都是利用了单调栈的思想,下面我们来看一下具体思路吧。
这里我们也系统的说一下单调栈,单调栈含义就是栈内的元素是单调的,我们这两个题目用到的都是递减栈(相同也可以),我们依次将元素压入栈,如果当前元素小于等于栈顶元素则入栈,如果大于栈顶元素则先将栈顶不断出栈,直到当前元素小于或等于栈顶元素为止,然后再将当前元素入栈。就比如下图的 4,想入栈的话则需要 2,3 出栈之后才能入栈,因为 4 大于他俩。
<img src="https://img-blog.csdnimg.cn/20210320134154434.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzMzODg1OTI0,size_16,color_FFFFFF,t_70" alt="在这里插入图片描述" style="zoom:80%;" />
我们了解单调栈的含义下面我们来看一下接雨水问题到底该怎么做,其实原理也很简单,我们通过我们的例 3 来进行说明。
首先我们依次入栈 4,3,2,0 我们的数组前四个元素是符合单调栈规则的。但是我们的第五个 1,是大于 0 的。那我们就需要 0 出栈 1 入栈。但是我们这样做是为了什么呢?有什么意义呢?别急我们来看下图。

上图我们的,4,3,2,0 已经入栈了,我们的另一个元素为 1,栈顶元素为 0,栈顶下的元素为 2。那么我们在这一层接到的雨水数量怎么算呢?2,0,1 这三个元素可以接住的水为一个单位(见下图)这是我们第一层接到水的数量。
注:能接到水的情况,肯定是中间低两边高,这样才可以。

因为我们需要维护一个单调栈,所以我们则需要将 0 出栈 1 入栈,那么此时栈内元素为 4,3,2,1。下一位元素为 1,我们入栈,此时栈内元素为 4,3,2,1,1。下一元素为 5,栈顶元素为 1,栈顶的下一元素仍为 1,则需要再下一个元素,为 2,那我们求当前层接到的水的数量。

我们是通过 2,1,1,5 这四个元素求得第二层的接水数为 1\*3=3;1 是因为 min(2-1,5-1)=min(1,4)得来的,大家可以思考一下木桶效应。装水的多少,肯定是按最短的那个木板来的,所以高度为 1,3 的话是因为 5 的索引为 6,2 的索引为 2,他们之间共有三个元素(3,4,5)也就是 3 个单位。所以为 6-2-1=3。
将 1 出栈之后,我们栈顶元素就变成了 2,下一元素变成了 3,那么 3,2,5 这三个元素同样也可以接到水。

这是第三层的接水情况,能够接到 4 个单位的水,下面我们继续出栈 2,那么我们的 4,3,5 仍然可以接到水啊。

这是我们第四层接水的情况,一共能够接到 5 个单位的水,那么我们总的接水数加起来,那就是
1+3+4+5=13。你学会了吗?别急还有视频我们,我们再来深入理解一哈。

### 题目代码:
```java
class Solution {
public int trap(int[] height) {
Stack<Integer> stack = new Stack<Integer>();
int water = 0;
//特殊情况
if(height.length <3){
return 0;
}
for(int i = 0; i < height.length; i++){
while(!stack.isEmpty() && height[i] > height[stack.peek()]){
//栈顶元素
int popnum = stack.pop();
//相同元素的情况例1,1
while(!stack.isEmpty()&&height[popnum] == height[stack.peek()]){
stack.pop();
}
//计算该层的水的单位
if(!stack.isEmpty()){
int temp = height[stack.peek()];//栈顶元素值
//高
int hig = Math.min(temp-height[popnum],height[i]-height[popnum]);
//宽
int wid = i-stack.peek()-1;
water +=hig * wid;
}
}
//这里入栈的是索引
stack.push(i);
}
return water;
}
}
```
GO Code:
```go
func trap(height []int) int {
stack := []int{}
water := 0
// 最左边部分不会接雨水,左边持续升高时,stack都会弹出所有元素。
for i := 0; i< len(height); i++ {
for len(stack) != 0 && height[i] > height[stack[len(stack) - 1]] {
popnum := stack[len(stack) - 1]
// 出现相同高度的情况(其实也可以不用处理,如果不处理,相同高度时后面的hig为0,会产生很多无效的计算)
for len(stack) != 0 && height[popnum] == height[stack[len(stack) - 1]] {
stack = stack[:len(stack) - 1]
}
if len(stack) == 0 { break }
le, ri := stack[len(stack) - 1], i
hig := min(height[ri], height[le]) - height[popnum]
wid := ri - le - 1
water += wid * hig
}
stack = append(stack, i)
}
return water
}
func min(a, b int) int {
if a < b { return a }
return b
}
```
###
================================================
FILE: animation-simulation/单调队列单调栈/最小栈.md
================================================
> 如果阅读时,发现错误,或者动画不可以显示的问题可以添加我微信好友 **[tan45du_one](https://raw.githubusercontent.com/tan45du/tan45du.github.io/master/个人微信.15egrcgqd94w.jpg)** ,备注 github + 题目 + 问题 向我反馈
>
> 感谢支持,该仓库会一直维护,希望对各位有一丢丢帮助。
>
> 另外希望手机阅读的同学可以来我的 <u>[**公众号:程序厨**](https://raw.githubusercontent.com/tan45du/test/master/微信图片_20210320152235.2pthdebvh1c0.png)</u> 两个平台同步,想要和题友一起刷题,互相监督的同学,可以在我的小屋点击<u>[**刷题小队**](https://raw.githubusercontent.com/tan45du/test/master/微信图片_20210320152235.2pthdebvh1c0.png)</u>进入。
#### [155. 最小栈](https://leetcode-cn.com/problems/min-stack/)
设计一个支持 push ,pop ,top 操作,并能在常数时间内检索到最小元素的栈。
- push(x) —— 将元素 x 推入栈中。
- pop() —— 删除栈顶的元素。
- top() —— 获取栈顶元素。
- getMin() —— 检索栈中的最小元素。
输入:
> ["MinStack","push","push","push","getMin","pop","top","getMin"] > [[],[-2],[0],[-3],[],[],[],[]]
输出:
> [null,null,null,null,-3,null,0,-2]
#### 题目解析
感觉这个题目的难度就在读懂题意上面,读懂之后就没有什么难的了,我们在上面的滑动窗口的最大值已经进行了详细描述,其实这个题目和那个题目思路一致。该题让我们设计一个栈,该栈具有的功能有,push,pop,top 等操作,并且能够返回栈的最小值。比如此时栈中的元素为 5,1,2,3。我们执行 getMin() ,则能够返回 1。这块是这个题目的精髓所在,见下图。

我们一起先通过一个视频先看一下具体解题思路,通过视频一定可以整懂的,我们注意观察栈 B 内的元素。

我们来对视频进行解析 1.我们执行入栈操作时,先观察需要入栈的元素是否小于栈 B 的栈顶元素,如果小于则两个栈都执行入栈操作。
2.栈 B 的栈顶元素则是栈 A 此时的最小值。则 getMin() 只需返回栈 B 的栈顶元素即可。
3.出栈时,需要进行对比,若栈 A 和栈 B 栈顶元素相同,则同时出栈,出栈好 B 的栈顶保存的仍为此时栈 A 的最小元素
#### 题目代码
```java
class MinStack {
//初始化
Stack<Integer> A,B;
public MinStack() {
A = new Stack<>();
B = new Stack<>();
}
//入栈,如果插入值,当前插入值小于栈顶元素,则入栈,栈顶元素保存的则为当前栈的最小元素
public void push(int x) {
A.push(x);
if (B.isEmpty() || B.peek() >= x) {
B.push(x);
}
}
//出栈,如果A出栈等于B栈顶元素,则说明此时栈内的最小元素改变了。
//这里需要使用 equals() 代替 == 因为 Stack 中存储的是 int 的包装类 Integer
public void pop() {
if (A.pop().equals(B.peek()) ) {
B.pop();
}
}
//A栈的栈顶元素
public int top() {
return A.peek();
}
//B栈的栈顶元素
public int getMin() {
return B.peek();
}
}
```
GO Code:
```go
type MinStack struct {
stack []int
minStk []int
}
/** initialize your data structure here. */
func Constructor() MinStack {
return MinStack{
stack: []int{},
minStk: []int{},
}
}
// Push 入栈,如果插入值,当前插入值小于栈顶元素,则入栈,栈顶元素保存的则为当前栈的最小元素
func (m *MinStack) Push(x int) {
m.stack = append(m.stack, x)
if len(m.minStk) == 0 || m.minStk[len(m.minStk) - 1] >= x {
m.minStk = append(m.minStk, x)
}
}
// Pop 出栈,如果stack出栈等于minStk栈顶元素,则说明此时栈内的最小元素改变了。
func (m *MinStack) Pop() {
temp := m.stack[len(m.stack) - 1]
m.stack = m.stack[: len(m.stack) - 1]
if temp == m.minStk[len(m.minStk) - 1] {
m.minStk = m.minStk[: len(m.minStk) - 1]
}
}
// Top stack的栈顶元素
func (m *MinStack) Top() int {
return m.stack[len(m.stack) - 1]
}
// GetMin minStk的栈顶元素
func (m *MinStack) GetMin() int {
return m.minStk[len(m.minStk) - 1]
}
```
###
================================================
FILE: animation-simulation/单调队列单调栈/滑动窗口的最大值.md
================================================
> 如果阅读时,发现错误,或者动画不可以显示的问题可以添加我微信好友 **[tan45du_one](https://raw.githubusercontent.com/tan45du/tan45du.github.io/master/个人微信.15egrcgqd94w.jpg)** ,备注 github + 题目 + 问题 向我反馈
>
> 感谢支持,该仓库会一直维护,希望对各位有一丢丢帮助。
>
> 另外希望手机阅读的同学可以来我的 <u>[**公众号:程序厨**](https://raw.githubusercontent.com/tan45du/test/master/微信图片_20210320152235.2pthdebvh1c0.png)</u> 两个平台同步,想要和题友一起刷题,互相监督的同学,可以在我的小屋点击<u>[**刷题小队**](https://raw.githubusercontent.com/tan45du/test/master/微信图片_20210320152235.2pthdebvh1c0.png)</u>进入。
#### [剑指 Offer 59 - I. 滑动窗口的最大值](https://leetcode-cn.com/problems/hua-dong-chuang-kou-de-zui-da-zhi-lcof/)
这个题目,算是很经典的类型,我们的滑动窗口主要分为两种,一种的可变长度的滑动窗口,一种是固定长度的滑动窗口,这个题目算是固定长度的代表。今天我们用双端队列来解决我们这个题目,学会了这个题目的解题思想你可以去解决一下两道题目 [剑指 Offer 59 - II. 队列的最大值](https://leetcode-cn.com/problems/dui-lie-de-zui-da-zhi-lcof/),[155. 最小栈](https://leetcode-cn.com/problems/min-stack/),虽然这两个题目和该题类型不同,但是解题思路是一致的,都是很不错的题目,我认为做题,那些考察的很细的,解题思路很难想,即使想到,也不容易完全写出来的题目,才是能够大大提高我们编码能力的题目,希望能和大家一起进步。
这个题目我们用到了**双端队列**,队列里面保存的则为每段滑动窗口的最大值,我给大家做了一个动图,先来看一下代码执行过程吧。
我们先来了解下双端队列吧,队列我们都知道,是先进先出,双端队列呢?既可以从队头出队,也可以从队尾出队,则不用遵循先进先出的规则。
下面我们通过一个动图来了解一下吧。

好啦,我们了解双端队列是什么东东了,下面我们通过一个动画,来看一下代码的执行过程吧,相信各位一下就能够理解啦。
我们就通过题目中的例子来表述。nums = [1,3,-1,-3,5,3,6,7], k = 3

不知道通过上面的例子能不能给各位描述清楚,如果不能的话,我再加把劲,各位看官,请接着往下看。
我们将执行过程进行拆解。
1.想将我们第一个窗口的所有值存入单调双端队列中,单调队列里面的值为单调递减的。如果发现队尾元素小于要加入的元素,则将队尾元素出队,直到队尾元素大于新元素时,再让新元素入队,目的就是维护一个单调递减的队列。
2.我们将第一个窗口的所有值,按照单调队列的规则入队之后,因为队列为单调递减,所以队头元素必为当前窗口的最大值,则将队头元素添加到数组中。
3.移动窗口,判断当前**窗口前的元素**是否和队头元素相等,如果相等则出队。
4.继续然后按照规则进行入队,维护单调递减队列。
5.每次将队头元素存到返回数组里。
5.返回数组
是不是懂啦,再回去看一遍视频吧。祝大家新年快乐,天天开心呀!
```java
class Solution {
public int[] maxSlidingWindow(int[] nums, int k) {
int len = nums.length;
if (len == 0) {
return nums;
}
int[] arr = new int[len - k + 1];
int arr_index = 0;
//我们需要维护一个单调递增的双向队列
Deque<Integer> deque = new LinkedList<>();
for (int i = 0; i < k; i++) {
while (!deque.isEmpty() && deque.peekLast() < nums[i]) {
deque.removeLast();
}
deque.offerLast(nums[i]);
}
arr[arr_index++] = deque.peekFirst();
for (int j = k; j < len; j++) {
if (nums[j - k] == deque.peekFirst()) {
deque.removeFirst();
}
while (!deque.isEmpty() && deque.peekLast() < nums[j]) {
deque.removeLast();
}
deque.offerLast(nums[j]);
arr[arr_index++] = deque.peekFirst();
}
return arr;
}
}
```
GO Code:
```go
func maxSlidingWindow(nums []int, k int) []int {
l := len(nums)
if l == 0 {
return nums
}
arr := []int{}
// 维护一个单调递减的双向队列
deque := []int{}
for i := 0; i < k; i++ {
for len(deque) != 0 && deque[len(deque) - 1] < nums[i] {
deque = deque[:len(deque) - 1]
}
deque = append(deque, nums[i])
}
arr = append(arr, deque[0])
for i := k; i < l; i++ {
if nums[i - k] == deque[0] {
deque = deque[1:]
}
for len(deque) != 0 && deque[len(deque) - 1] < nums[i] {
deque = deque[:len(deque) - 1]
}
deque = append(deque, nums[i])
arr = append(arr, deque[0])
}
return arr
}
```
================================================
FILE: animation-simulation/哈希表篇/空.md
================================================
================================================
FILE: animation-simulation/回溯/空.md
================================================
================================================
FILE: animation-simulation/并查集/空.md
================================================
================================================
FILE: animation-simulation/数据结构和算法/BF算法.md
================================================
> 如果阅读时,发现错误,或者动画不可以显示的问题可以添加我微信好友 **[tan45du_one](https://raw.githubusercontent.com/tan45du/tan45du.github.io/master/个人微信.15egrcgqd94w.jpg)** ,备注 github + 题目 + 问题 向我反馈
>
> 感谢支持,该仓库会一直维护,希望对各位有一丢丢帮助。
>
> 另外希望手机阅读的同学可以来我的 <u>[**公众号:程序厨**](https://raw.githubusercontent.com/tan45du/test/master/微信图片_20210320152235.2pthdebvh1c0.png)</u> 两个平台同步,想要和题友一起刷题,互相监督的同学,可以在我的小屋点击<u>[**刷题小队**](https://raw.githubusercontent.com/tan45du/test/master/微信图片_20210320152235.2pthdebvh1c0.png)</u>进入。
> 为保证代码严谨性,文中所有代码均在 leetcode 刷题网站 AC ,大家可以放心食用。
皇上生辰之际,举国同庆,袁记菜馆作为天下第一饭店,所以被选为这次庆典的菜品供应方,这次庆典对于袁记菜馆是一项前所未有的挑战,毕竟是第一次给皇上庆祝生辰,稍有不慎就是掉脑袋的大罪,整个袁记菜馆内都在紧张的布置着。此时突然有一个店小二慌慌张张跑到袁厨面前汇报,到底发生了什么事,让店小二如此慌张呢?
袁记菜馆内
店小二:不好了不好了,掌柜的,出大事了。
袁厨:发生什么事了,慢慢说,如此慌张,成何体统。(开店开久了,架子出来了哈)
店小二:皇上按照咱们菜单点了 666 道菜,但是咱们做西湖醋鱼的师傅请假回家结婚了,不知道皇上有没有点这道菜,如果点了这道菜,咱们做不出来,那咱们店可就完了啊。
(袁厨听了之后,吓得一屁股坐地上了,缓了半天说道)
袁厨:别说那么多了,快给我找找皇上点的菜里面,有没有这道菜!
找了很久,并且核对了很多遍,最后确认皇上没有点这道菜。菜馆内的人都松了一口气
通过上面的一个例子,让我们简单了解了字符串匹配。
字符串匹配:设 S 和 T 是给定的两个串,在主串 S 中找到模式串 T 的过程称为字符串匹配,如果在主串 S 中找到 模式串 T ,则称匹配成功,函数返回 T 在 S 中首次出现的位置,否则匹配不成功,返回 -1。
例:

在上图中,我们试图找到模式 T = baab,在主串 S = abcabaabcabac 中第一次出现的位置,即为红色阴影部分, T 第一次在 S 中出现的位置下标为 4 ( 字符串的首位下标是 0 ),所以返回 4。如果模式串 T 没有在主串 S 中出现,则返回 -1。
解决上面问题的算法我们称之为字符串匹配算法,今天我们来介绍三种字符串匹配算法,大家记得打卡呀,说不准面试的时候就问到啦。
## BF 算法(Brute Force)
这个算法很容易理解,就是我们将模式串和主串进行比较,一致时则继续比较下一字符,直到比较完整个模式串。不一致时则将模式串后移一位,重新从模式串的首位开始对比,重复刚才的步骤下面我们看下这个方法的动图解析,看完肯定一下就能搞懂啦。

通过上面的代码是不是一下就将这个算法搞懂啦,下面我们用这个算法来解决下面这个经典题目吧。
### leetcdoe 28. 实现 strStr()
#### 题目描述
给定一个 haystack 字符串和一个 needle 字符串,在 haystack 字符串中找出 needle 字符串出现的第一个位置 (从 0 开始)。如果不存在,则返回 -1。
示例 1:
> 输入: haystack = "hello", needle = "ll"
> 输出: 2
示例 2:
> 输入: haystack = "aaaaa", needle = "bba"
> 输出: -1
#### 题目解析
其实这个题目很容易理解,但是我们需要注意的是一下几点,比如我们的模式串为 0 时,应该返回什么,我们的模式串长度大于主串长度时,应该返回什么,也是我们需要注意的地方。下面我们来看一下题目代码吧。
#### 题目代码
Java Code:
```java
class Solution {
public int strStr(String haystack, String needle) {
int haylen = haystack.length();
int needlen = needle.length();
//特殊情况
if (haylen < needlen) {
return -1;
}
if (needlen == 0) {
return 0;
}
//主串
for (int i = 0; i < haylen - needlen + 1; ++i) {
int j;
//模式串
for (j = 0; j < needlen; j++) {
//不符合的情况,直接跳出,主串指针后移一位
if (haystack.charAt(i+j) != needle.charAt(j)) {
break;
}
}
//匹配成功
if (j == needlen) {
return i;
}
}
return -1;
}
}
```
Python Code:
```python
from typing import List
class Solution:
def strStr(self, haystack: str, needle: str)->int:
haylen = len(haystack)
needlen = len(needle)
# 特殊情况
if haylen < needlen:
return -1
if needlen == 0:
return 0
# 主串
for i in range(0, haylen - needlen + 1):
# 模式串
j = 0
while j < needlen:
if haystack[i + j] != needle[j]:
break
j += 1
# 匹配成功
if j == needlen:
return i
return -1
```
我们看一下 BF 算法的另一种算法(显示回退),其实原理一样,就是对代码进行了一下修改,只要是看完咱们的动图,这个也能够一下就能看懂,大家可以结合下面代码中的注释和动图进行理解。
Java Code:
```java
class Solution {
public int strStr(String haystack, String needle) {
//i代表主串指针,j模式串
int i,j;
//主串长度和模式串长度
int halen = haystack.length();
int nelen = needle.length();
//循环条件,这里只有 i 增长
for (i = 0 , j = 0; i < halen && j < nelen; ++i) {
//相同时,则移动 j 指针
if (haystack.charAt(i) == needle.charAt(j)) {
++j;
} else {
//不匹配时,将 j 重新指向模式串的头部,将 i 本次匹配的开始位置的下一字符
i -= j;
j = 0;
}
}
//查询成功时返回索引,查询失败时返回 -1;
int renum = j == nelen ? i - nelen : -1;
return renum;
}
}
```
Python Code:
```python
from typing import List
class Solution:
def strStr(self, haystack: str, needle: str)->int:
# i代表主串指针,j模式串
i = 0
j = 0
# 主串长度和模式串长度
halen = len(haystack)
nelen = len(needle)
# 循环条件,这里只有 i 增长
while i < halen and j < nelen:
# 相同时,则移动 j 指针
if haystack[i] == needle[j]:
j += 1
else:
# 不匹配时,将 j 重新只想模式串的头部,将 i 本次匹配的开始位置的下一字符
i -= j
j = 0
i += 1
# 查询成功时返回索引,查询失败时返回 -1
renum = i - nelen if j == nelen else -1
return renum
```
================================================
FILE: animation-simulation/数据结构和算法/BM.md
================================================
## BM 算法(Boyer-Moore)
> 如果阅读时,发现错误,或者动画不可以显示的问题可以添加我微信好友 **[tan45du_one](https://raw.githubusercontent.com/tan45du/tan45du.github.io/master/个人微信.15egrcgqd94w.jpg)** ,备注 github + 题目 + 问题 向我反馈
>
> 感谢支持,该仓库会一直维护,希望对各位有一丢丢帮助。
>
> 另外希望手机阅读的同学可以来我的 <u>[**公众号:程序厨**](https://raw.githubusercontent.com/tan45du/test/master/微信图片_20210320152235.2pthdebvh1c0.png)</u> 两个平台同步,想要和题友一起刷题,互相监督的同学,可以在我的小屋点击<u>[**刷题小队**](https://raw.githubusercontent.com/tan45du/test/master/微信图片_20210320152235.2pthdebvh1c0.png)</u>进入。
我们刚才说过了 BF 算法,但是 BF 算法是有缺陷的,比如我们下面这种情况

如上图所示,如果我们利用 BF 算法,遇到不匹配字符时,每次右移一位模式串,再重新从头进行匹配,我们观察一下,我们的模式串 abcdex 中每个字符都不一样,但是我们第一次进行字符串匹配时,abcde 都匹配成功,到 x 时失败,又因为模式串每位都不相同,所以我们不需要再每次右移一位,再重新比较,我们可以直接跳过某些步骤。如下图

我们可以跳过其中某些步骤,直接到下面这个步骤。那我们是依据什么原则呢?

### 坏字符规则
我们之前的 BF 算法是从前往后进行比较 ,BM 算法是从后往前进行比较,我们来看一下具体过程,我们还是利用上面的例子。
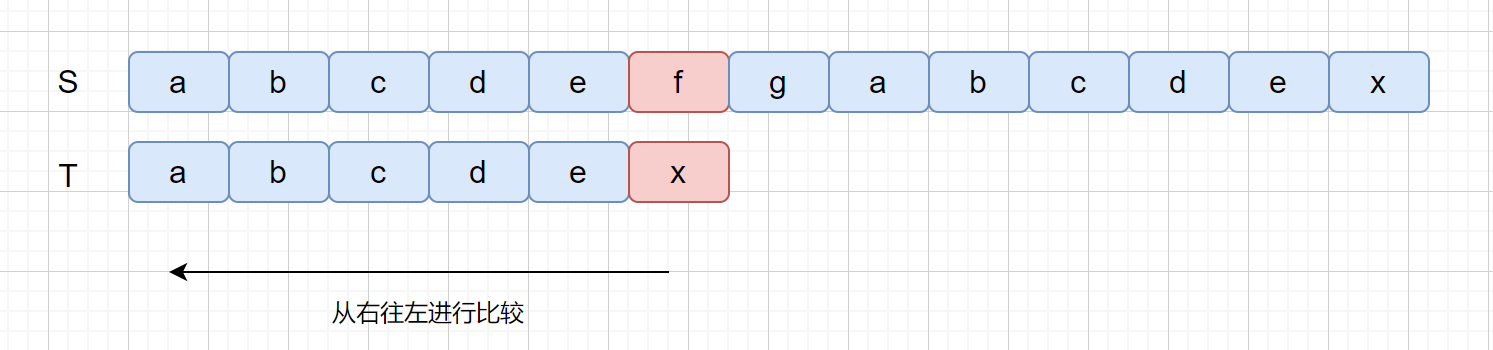
BM 算法是从后往前进行比较,此时我们发现比较的第一个字符就不匹配,我们将**主串**这个字符称之为**坏字符**,也就是 f ,我们发现坏字符之后,模式串 T 中查找是否含有该字符(f),我们发现并不存在 f,此时我们只需将模式串右移到坏字符的后面一位即可。如下图

那我们在模式串中找到坏字符该怎么办呢?
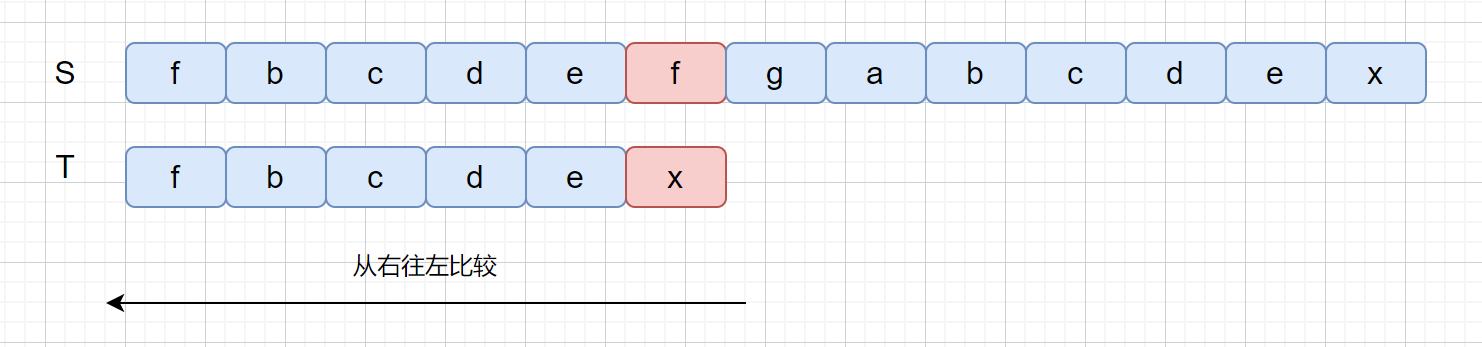
此时我们的坏字符为 f ,我们在模式串中,查找发现含有坏字符 f,我们则需要移动模式串 T ,将模式串中的 f 和坏字符对齐。见下图。

然后我们继续从右往左进行比较,发现 d 为坏字符,则需要将模式串中的 d 和坏字符对齐。


那么我们在来思考一下这种情况,那就是模式串中含有多个坏字符怎么办呢?
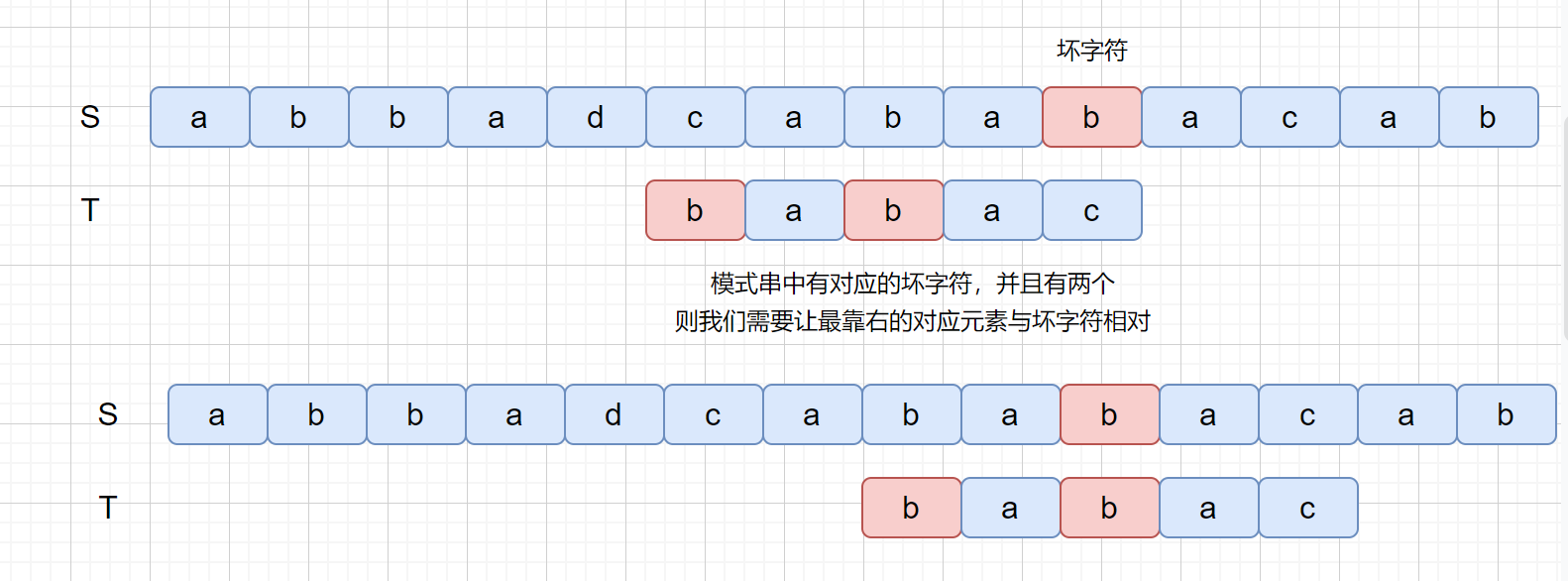
那么我们为什么要让**最靠右的对应元素与坏字符匹配**呢?如果上面的例子我们没有按照这条规则看下会产生什么问题。
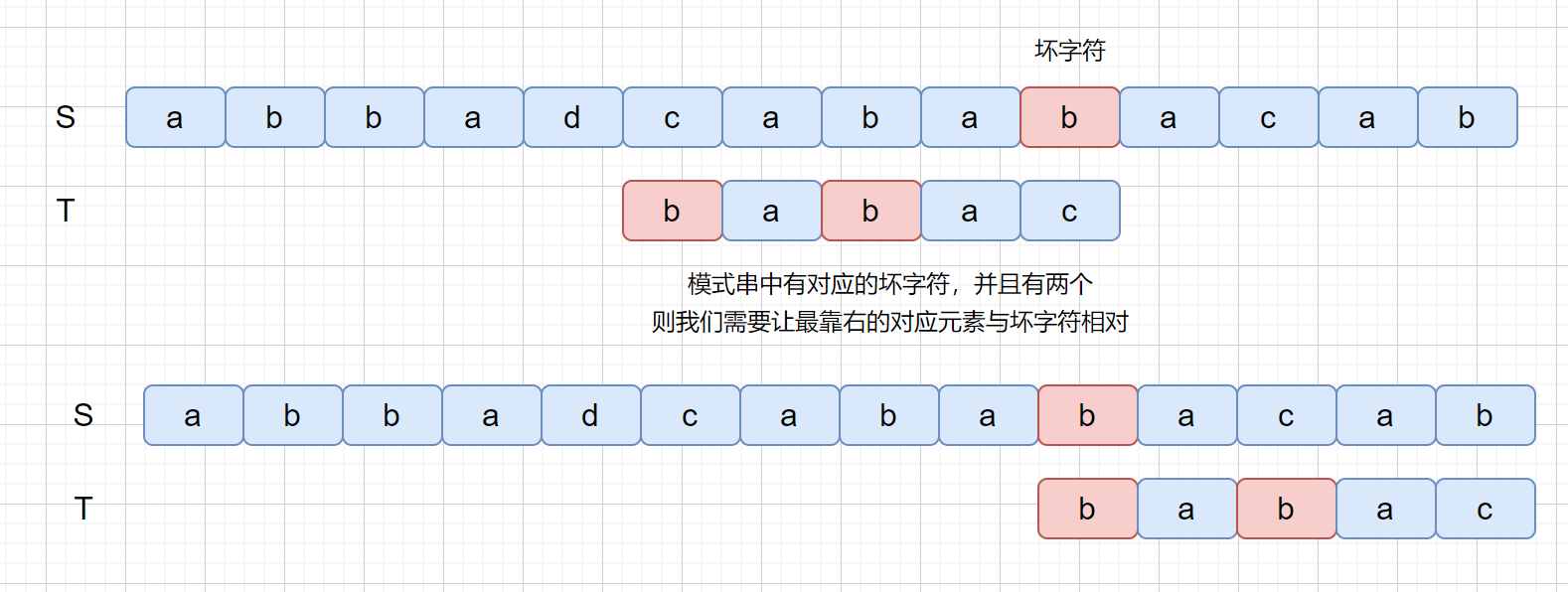
如果没有按照我们上述规则,则会**漏掉我们的真正匹配**。我们的主串中是**含有 babac** 的,但是却**没有匹配成功**,所以应该遵守**最靠右的对应字符与坏字符相对**的规则。
我们上面一共介绍了三种移动情况,分别是下方的模式串中没有发现与坏字符对应的字符,发现一个对应字符,发现两个。这三种情况我们分别移动不同的位数,那我们是根据依据什么来决定移动位数的呢?下面我们给图中的字符加上下标。见下图

下面我们来考虑一下这种情况。
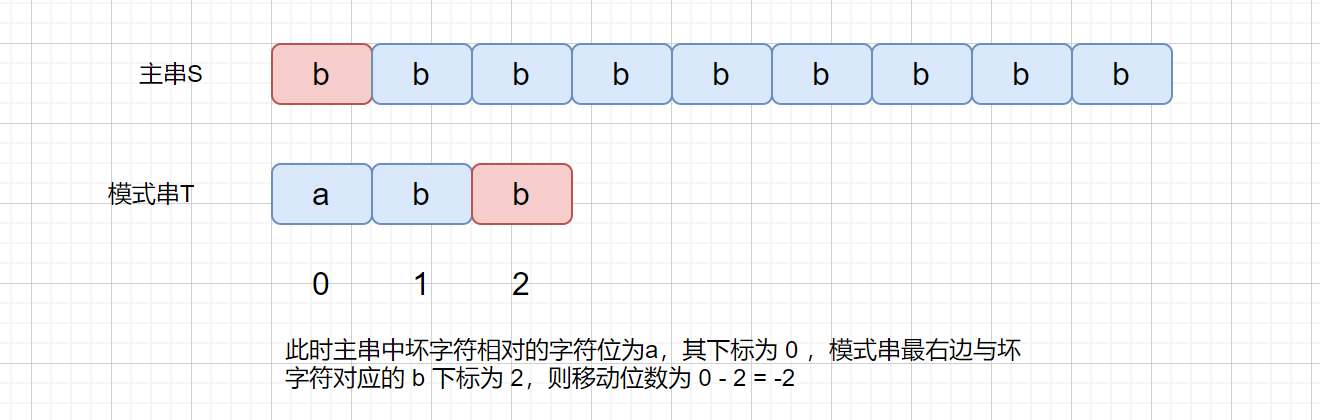
此时这种情况肯定是不行的,不往右移动,甚至还有可能左移,那么我们有没有什么办法解决这个问题呢?继续往下看吧。
### 好后缀规则
好后缀其实也很容易理解,我们之前说过 BM 算法是从右往左进行比较,下面我们来看下面这个例子。

这里如果我们按照坏字符进行移动是不合理的,这时我们可以使用好后缀规则,那么什么是好后缀呢?
BM 算法是从右往左进行比较,发现坏字符的时候此时 cac 已经匹配成功,在红色阴影处发现坏字符。此时已经匹配成功的 cac 则为我们的好后缀,此时我们拿它在模式串中查找,如果找到了另一个和好后缀相匹配的串,那我们就将另一个和**好后缀相匹配**的串 ,滑到和好后缀对齐的位置。
是不是感觉有点拗口,没关系,我们看下图,红色代表坏字符,绿色代表好后缀
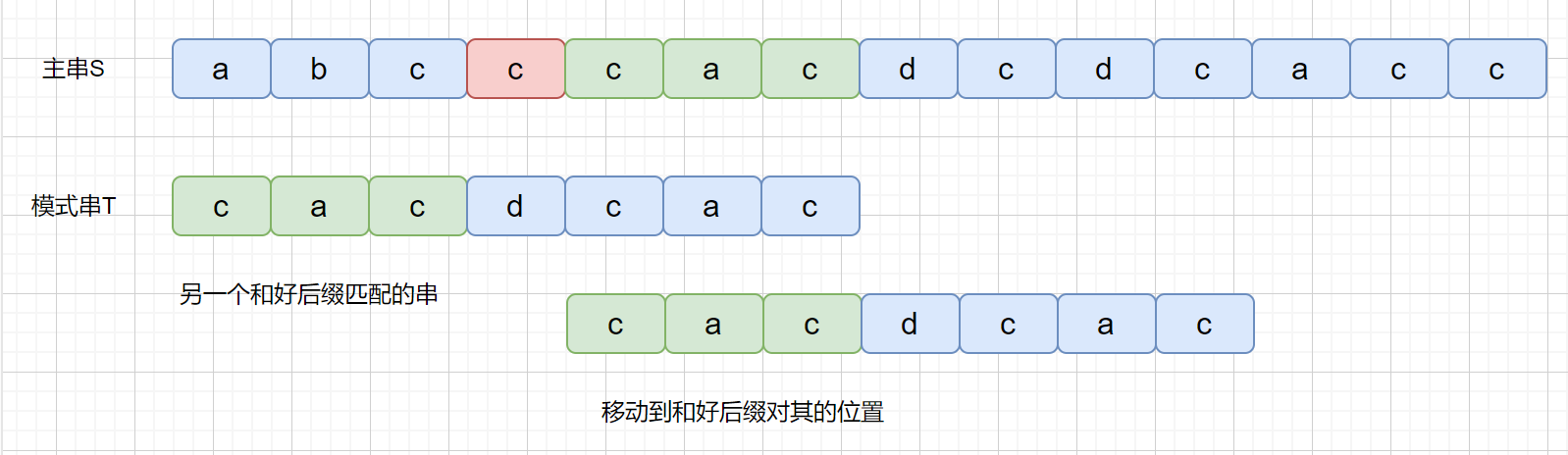
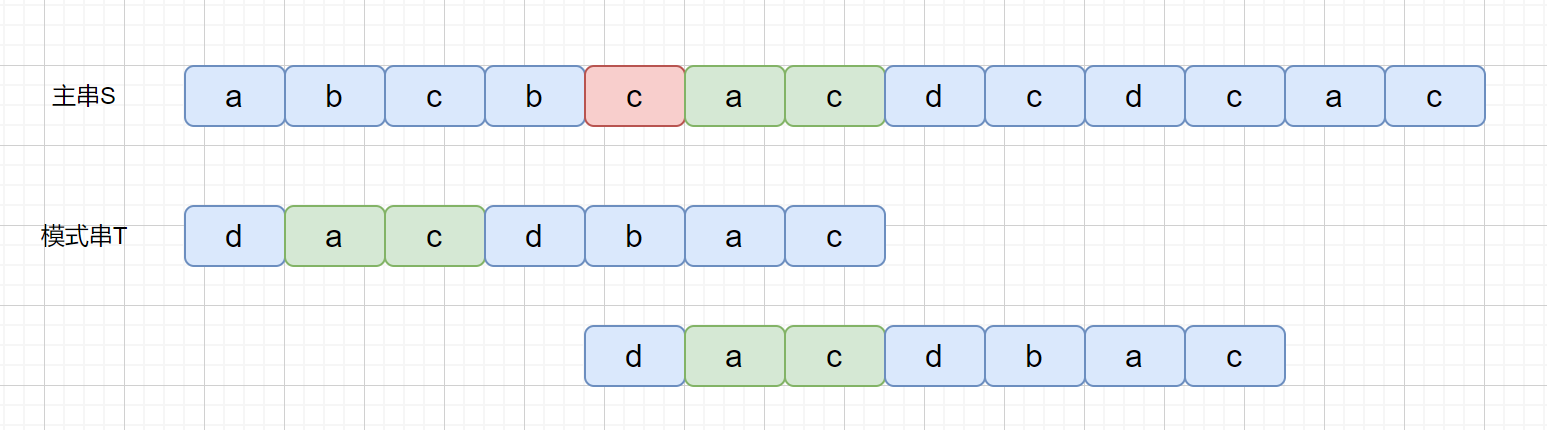
上面那种情况搞懂了,但是我们思考一下下面这种情况
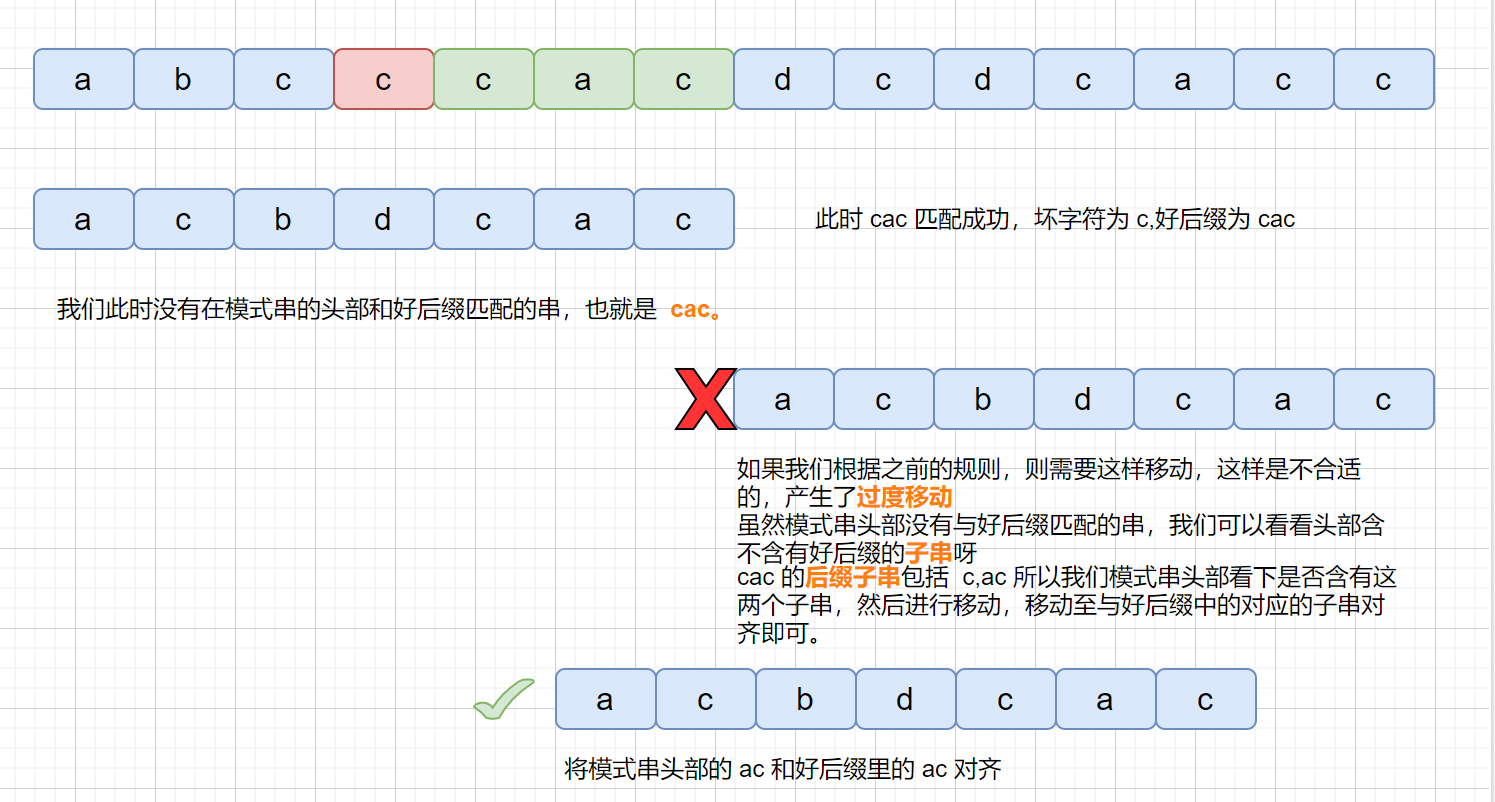
上面我们说到了,如果在模式串的**头部**没有发现好后缀,发现好后缀的子串也可以。但是为什么要强调这个头部呢?
我们下面来看一下这种情况
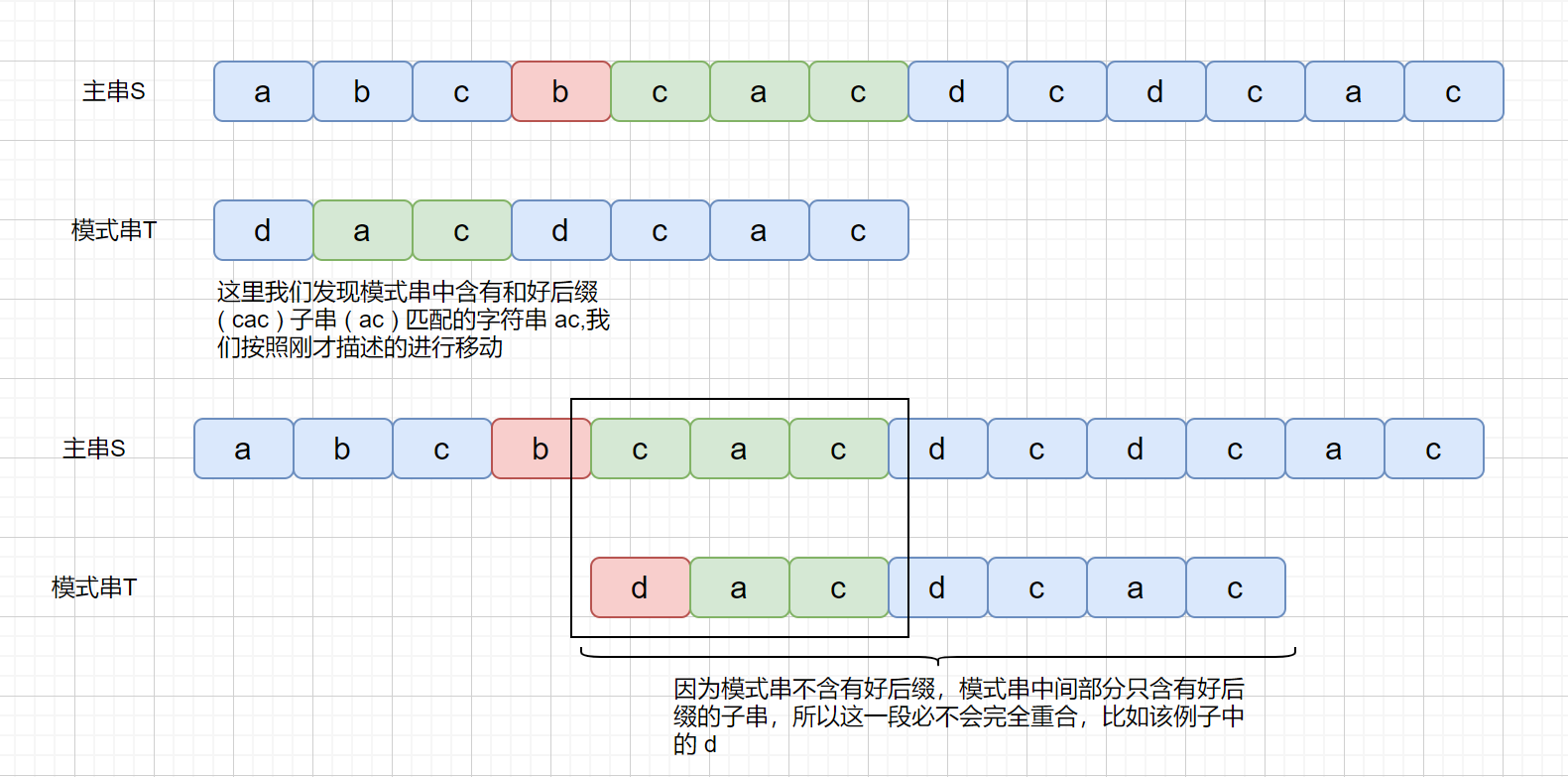
但是当我们在头部发现好后缀的子串时,是什么情况呢?
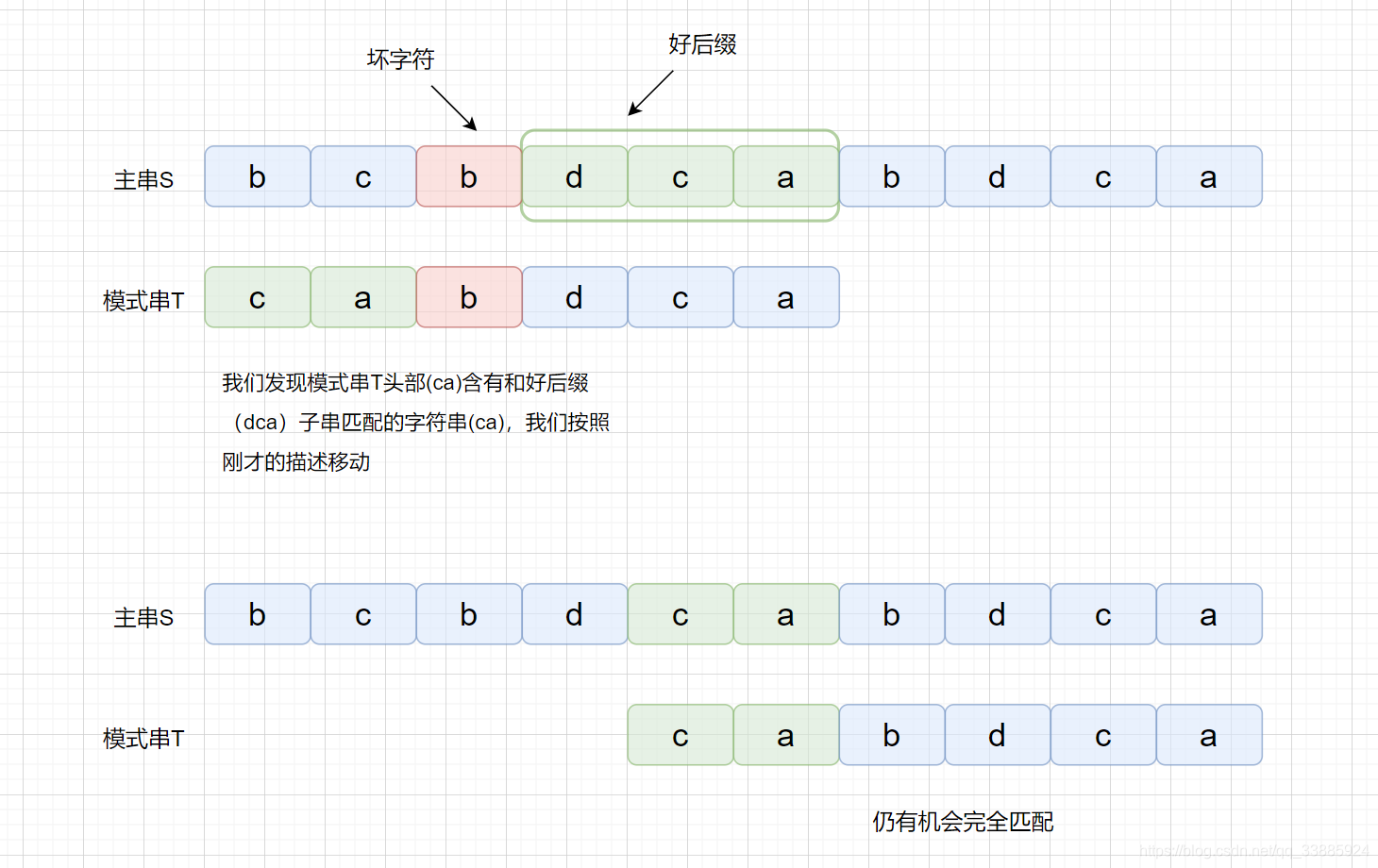
下面我们通过动图来看一下某一例子的具体的执行过程

说到这里,坏字符和好后缀规则就算说完了,坏字符很容易理解,我们对好后缀总结一下
1.如果模式串**含有好后缀**,无论是中间还是头部可以按照规则进行移动。如果好后缀在模式串中出现多次,则以**最右侧的好后缀**为基准。
2.如果模式串**头部含有**好后缀子串则可以按照规则进行移动,中间部分含有好后缀子串则不可以。
3.如果在模式串尾部就出现不匹配的情况,即不存在好后缀时,则根据坏字符进行移动,这里有的文章没有提到,是个需要特别注意的地方,我是在这个论文里找到答案的,感兴趣的同学可以看下。
> Boyer R S,Moore J S. A fast string searching algorithm[J]. Communications of the ACM,1977,10: 762-772.
之前我们刚开始说坏字符的时候,是不是有可能会出现负值的情况,即往左移动的情况,所以我们为了解决这个问题,我们可以分别计算好后缀和坏字符往后滑动的位数**(好后缀不为 0 的情况)**,然后取两个数中最大的,作为模式串往后滑动的位数。
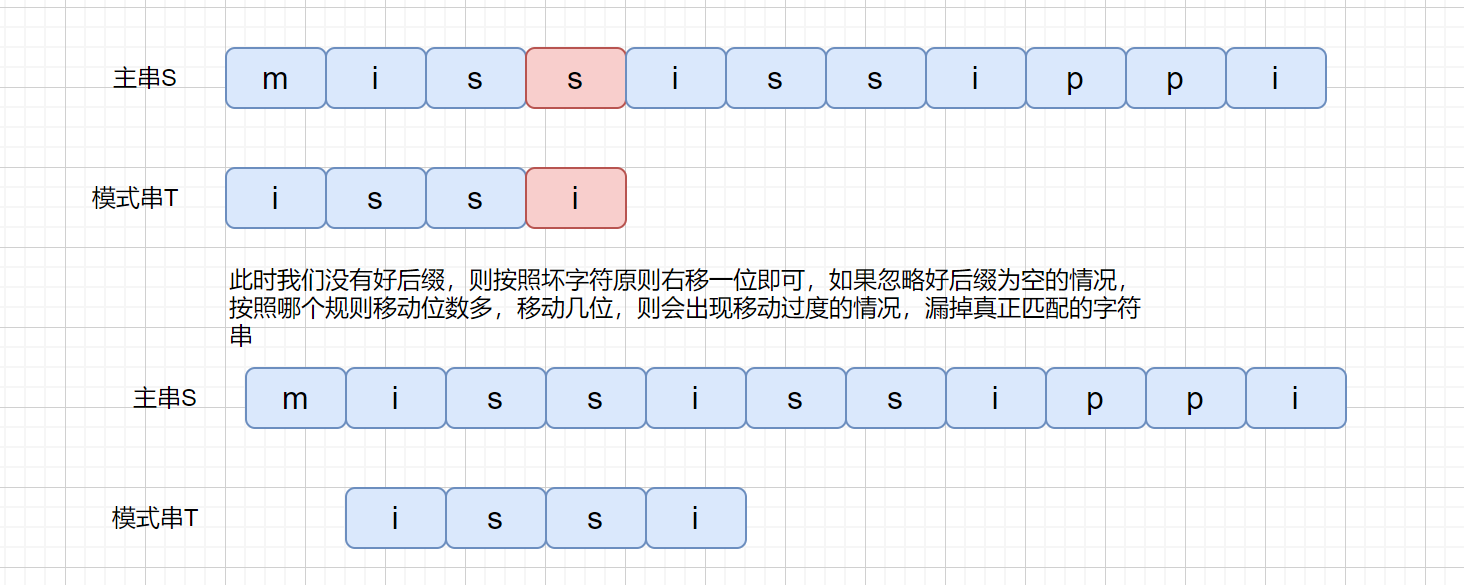
这破图画起来是真费劲啊。下面我们来看一下算法代码,代码有点长,我都标上了注释也在网站上 AC 了,如果各位感兴趣可以看一下,不感兴趣理解坏字符和好后缀规则即可。可以直接跳到 KMP 部分
Java Code:
```java
class Solution {
public int strStr(String haystack, String needle) {
char[] hay = haystack.toCharArray();
char[] need = needle.toCharArray();
int haylen = haystack.length();
int needlen = need.length;
return bm(hay,haylen,need,needlen);
}
//用来求坏字符情况下移动位数
private static void badChar(char[] b, int m, int[] bc) {
//初始化
for (int i = 0; i < 256; ++i) {
bc[i] = -1;
}
//m 代表模式串的长度,如果有两个 a,则后面那个会覆盖前面那个
for (int i = 0; i < m; ++i) {
int ascii = (int)b[i];
bc[ascii] = i;//下标
}
}
//用来求好后缀条件下的移动位数
private static void goodSuffix (char[] b, int m, int[] suffix,boolean[] prefix) {
//初始化
for (int i = 0; i < m; ++i) {
suffix[i] = -1;
prefix[i] = false;
}
for (int i = 0; i < m - 1; ++i) {
int j = i;
int k = 0;
while (j >= 0 && b[j] == b[m-1-k]) {
--j;
++k;
suffix[k] = j + 1;
}
if (j == -1) prefix[k] = true;
}
}
public static int bm (char[] a, int n, char[] b, int m) {
int[] bc = new int[256];//创建一个数组用来保存最右边字符的下标
badChar(b,m,bc);
//用来保存各种长度好后缀的最右位置的数组
int[] suffix_index = new int[m];
//判断是否是头部,如果是头部则true
boolean[] ispre = new boolean[m];
goodSuffix(b,m,suffix_index,ispre);
int i = 0;//第一个匹配字符
//注意结束条件
while (i <= n-m) {
int j;
//从后往前匹配,匹配失败,找到坏字符
for (j = m - 1; j >= 0; --j) {
if (a[i+j] != b[j]) break;
}
//模式串遍历完毕,匹配成功
if (j < 0) {
return i;
}
//下面为匹配失败时,如何处理
//求出坏字符规则下移动的位数,就是我们坏字符下标减最右边的下标
int x = j - bc[(int)a[i+j]];
int y = 0;
//好后缀情况,求出好后缀情况下的移动位数,如果不含有好后缀的话,则按照坏字符来
if (y < m-1 && m - 1 - j > 0) {
y = move(j, m, suffix_index,ispre);
}
//移动
i = i + Math.max(x,y);
}
return -1;
}
// j代表坏字符的下标
private static int move (int j, int m, int[] suffix_index, boolean[] ispre) {
//好后缀长度
int k = m - 1 - j;
//如果含有长度为 k 的好后缀,返回移动位数,
if (suffix_index[k] != -1) return j - suffix_index[k] + 1;
//找头部为好后缀子串的最大长度,从长度最大的子串开始
for (int r = j + 2; r <= m-1; ++r) {
//如果是头部
if (ispre[m-r] == true) {
return r;
}
}
//如果没有发现好后缀匹配的串,或者头部为好后缀子串,则移动到 m 位,也就是匹配串的长度
return m;
}
}
```
Python Code:
```python
from typing import List
class Solution:
def strStr(self, haystack: str, needle: str)->int:
haylen = len(haystack)
needlen = len(needle)
return self.bm(haystack, haylen, needle, needlen)
# 用来求坏字符情况下移动位数
def badChar(self, b: str, m: int, bc: List[int]):
# 初始化
for i in range(0, 256):
bc[i] = -1
# m 代表模式串的长度,如果有两个 a,则后面那个会覆盖前面那个
for i in range(0, m,):
ascii = ord(b[i])
bc[ascii] = i# 下标
# 用来求好后缀条件下的移动位数
def goodSuffix(self, b: str, m: int, suffix: List[int], prefix: List[bool]):
# 初始化
for i in range(0, m):
suffix[i] = -1
prefix[i] = False
for i in range(0, m - 1):
j = i
k = 0
while j >= 0 and b[j] == b[m - 1 - k]:
j -= 1
k += 1
suffix[k] = j + 1
if j == -1:
prefix[k] = True
def bm(self, a: str, n: int, b: str, m: int)->int:
bc = [0] * 256# 创建一个数组用来保存最右边字符的下标
self.badChar(b, m, bc)
# 用来保存各种长度好后缀的最右位置的数组
suffix_index = [0] * m
# 判断是否是头部,如果是头部则True
ispre = [False] * m
self.goodSuffix(b, m, suffix_index, ispre)
i = 0# 第一个匹配字符
# 注意结束条件
while i <= n - m:
# 从后往前匹配,匹配失败,找到坏字符
j = m - 1
while j >= 0:
if a[i + j] != b[j]:
break
j -= 1
# 模式串遍历完毕,匹配成功
if j < 0:
return i
# 下面为匹配失败时,如何处理
# 求出坏字符规则下移动的位数,就是我们坏字符下标减最右边的下标
x = j - bc[ord(a[i + j])]
y = 0
# 好后缀情况,求出好后缀情况下的移动位数,如果不含有好后缀的话,则按照坏字符来
if y < m - 1 and m - 1 - j > 0:
y = self.move(j, m, suffix_index, ispre)
# 移动
i += max(x, y)
return -1
# j代表坏字符的下标
def move(j: int, m: int, suffix_index: List[int], ispre: List[bool])->int:
# 好后缀长度
k = m - 1 - j
# 如果含有长度为 k 的好后缀,返回移动位数
if suffix_index[k] != -1:
return j - suffix_index[k] + 1
# 找头部为好后缀子串的最大长度,从长度最大的子串开始
for r in range(j + 2, m):
# //如果是头部
if ispre[m - r] == True:
return r
# 如果没有发现好后缀匹配的串,或者头部为好后缀子串,则移动到 m 位,也就是匹配串的长度
return m
```
我们来理解一下我们代码中用到的两个数组,因为两个规则的移动位数,只与模式串有关,与主串无关,所以我们可以提前求出每种情况的移动情况,保存到数组中。
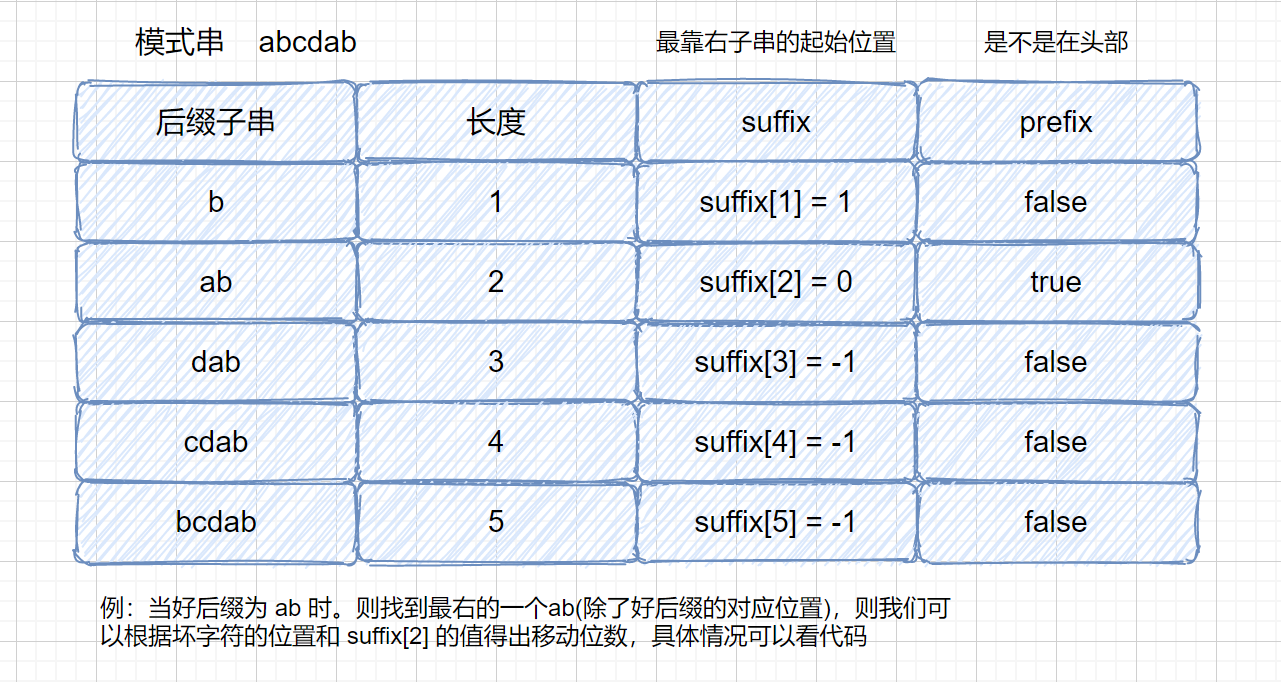
================================================
FILE: animation-simulation/数据结构和算法/Hash表的那些事.md
================================================
> 如果阅读时,发现错误,或者动画不可以显示的问题可以添加我微信好友 **[tan45du_one](https://raw.githubusercontent.com/tan45du/tan45du.github.io/master/个人微信.15egrcgqd94w.jpg)** ,备注 github + 题目 + 问题 向我反馈
>
> 感谢支持,该仓库会一直维护,希望对各位有一丢丢帮助。
>
> 另外希望手机阅读的同学可以来我的 <u>[**公众号:程序厨**](https://raw.githubusercontent.com/tan45du/test/master/微信图片_20210320152235.2pthdebvh1c0.png)</u> 两个平台同步,想要和题友一起刷题,互相监督的同学,可以在我的小屋点击<u>[**刷题小队**](https://raw.githubusercontent.com/tan45du/test/master/微信图片_20210320152235.2pthdebvh1c0.png)</u>进入。
# 散列(哈希)表总结
之前给大家介绍了**链表**,**栈和队列**今天我们来说一种新的数据结构散列(哈希)表,散列是应用非常广泛的数据结构,在我们的刷题过程中,散列表的出场率特别高。所以我们快来一起把散列表的内些事给整明白吧。文章框架如下
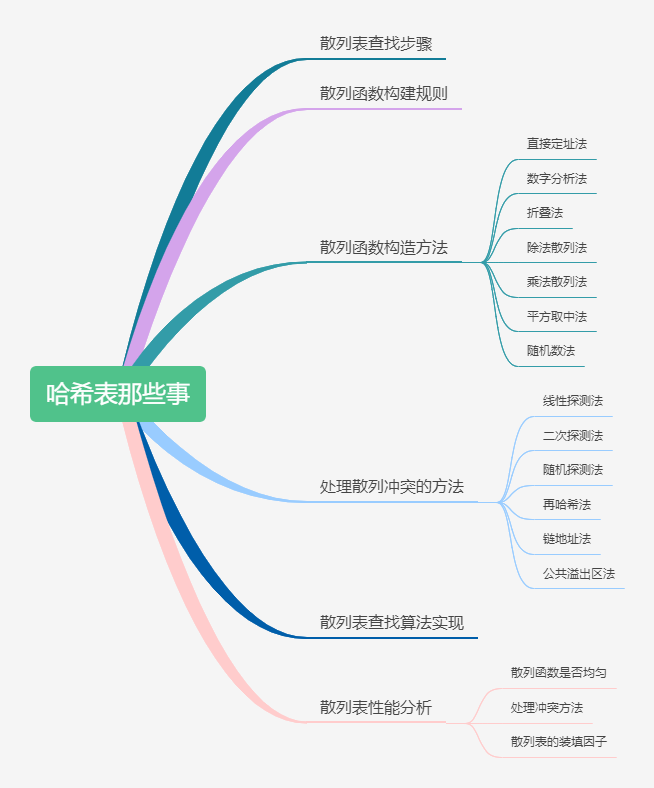
说散列表之前,我们先设想以下场景。
> 袁厨穿越回了古代,凭借从现代学习的做饭手艺,开了一个袁记菜馆,正值开业初期,店里生意十分火爆,但是顾客结账时就犯难了,每当结账的时候,老板娘总是按照菜单一个一个找价格(遍历查找),每次都要找半天,所以结账的地方总是排起长队,顾客们表示用户体验不咋滴。袁厨一想这不是办法啊,让顾客老是等着,太影响客户体验啦。所以袁厨就先把菜单按照首字母排序(二分查找),然后查找的时候根据首字母查找,这样结账的时候就能大大提高检索效率啦!但是呢?工作日顾客不多,老板娘完全应付的过来,但是每逢节假日,还是会排起长队。那么有没有什么更好的办法呢?对呀!我们把所有的价格都背下来不就可以了吗?每个菜的价格我们都了如指掌,结账的时候我们只需简单相加即可。所以袁厨和老板娘加班加点的进行背诵。下次再结账的时候一说吃了什么菜,我们立马就知道价格啦。自此以后收银台再也没有出现过长队啦,袁记菜馆开着开着一不小心就成了天下第一饭店了。
下面我们来看一下袁记菜馆老板娘进化史。
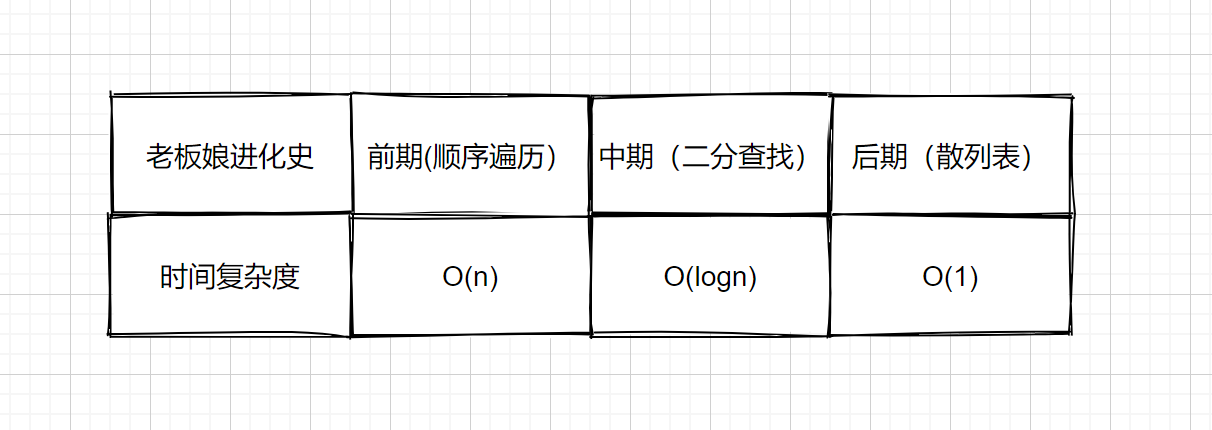
上面的后期结账的过程则模拟了我们的散列表查找,那么在计算机中是如何使用进行查找的呢?
### 散列表查找步骤
散列表-------最有用的基本数据结构之一。是根据关键码的值儿直接进行访问的数据结构,散列表的实现常常叫做**散列(hasing)**。散列是一种用于以**常数平均时间**执行插入、删除和查找的技术,下面我们来看一下散列过程。
我们的整个散列过程主要分为两步
(1)通过**散列函数**计算记录的散列地址,并按此**散列地址**存储该记录。就好比麻辣鱼我们就让它在川菜区,糖醋鱼,我们就让它在鲁菜区。但是我们需要注意的是,无论什么记录我们都需要用**同一个散列函数**计算地址,再存储。
(2)当我们查找时,我们通过**同样的散列函数**计算记录的散列地址,按此散列地址访问该记录。因为我们存和取得时候用的都是一个散列函数,因此结果肯定相同。
刚才我们在散列过程中提到了散列函数,那么散列函数是什么呢?
我们假设某个函数为 **f**,使得
**存储位置 = f (关键字)**
**输入:关键字** **输出:存储位置(散列地址)**
那样我们就能通过查找关键字**不需要比较**就可获得需要的记录的存储位置。这种存储技术被称为散列技术。散列技术是在通过记录的存储位置和它的关键字之间建立一个确定的对应关系 **f** ,使得每个关键字 **key** 都对应一个存储位置 **f(key)**。见下图
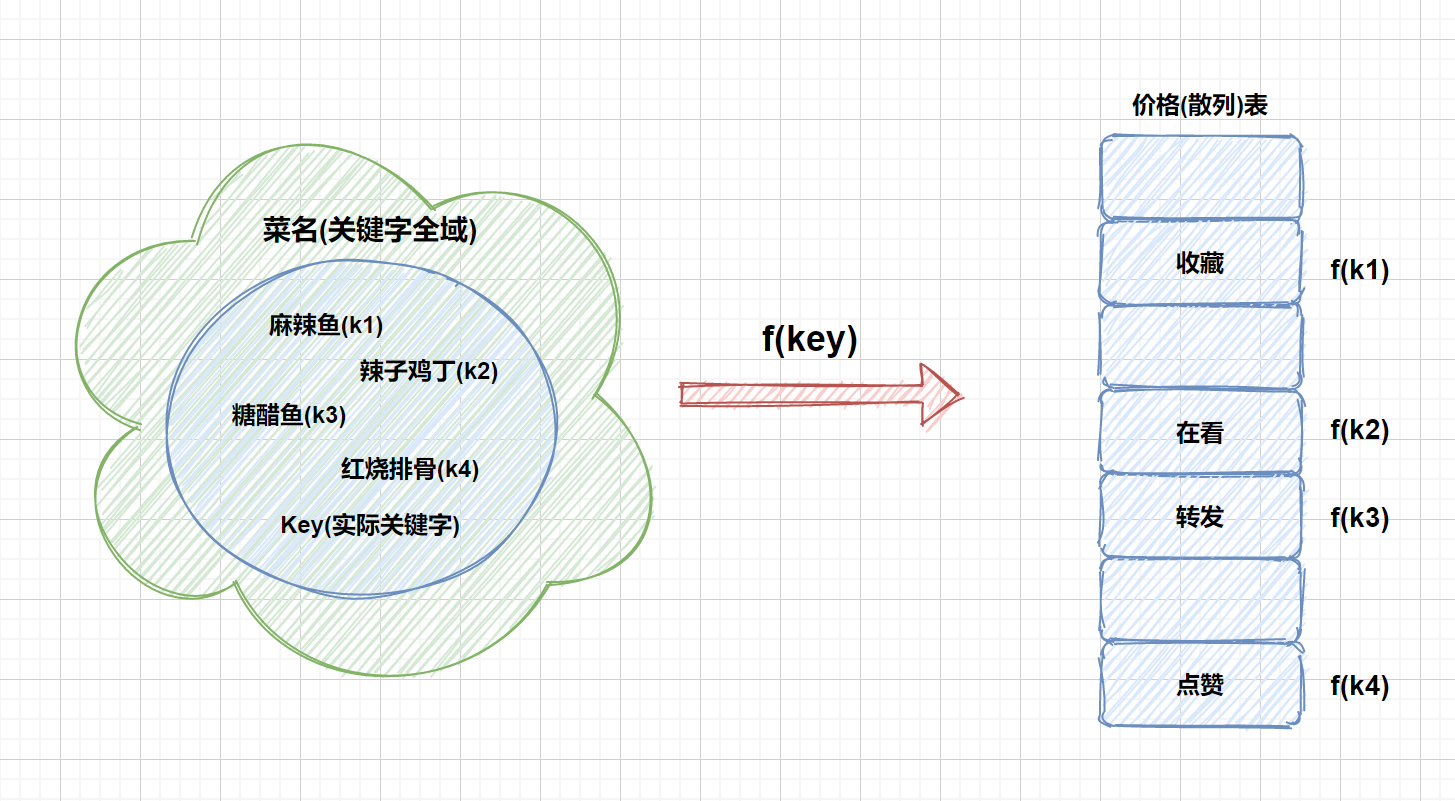
这里的 **f** 就是我们所说的散列函数(哈希)函数。我们利用散列技术将记录存储在一块连续的存储空间中,这块连续存储空间就是我们本文的主人公------**散列(哈希)表**
上图为我们描述了用散列函数将关键字映射到散列表,但是大家有没有考虑到这种情况,那就是将关键字映射到同一个槽中的情况,即 **f(k4) = f(k3)** 时。这种情况我们将其称之为**冲突**,**k3** 和 **k4**则被称之为散列函数 **f** 的**同义词**,如果产生这种情况,则会让我们查找错误。幸运的是我们能找到有效的方法解决冲突。
首先我们可以对哈希函数下手,我们可以精心设计哈希函数,让其尽可能少的产生冲突,所以我们创建哈希函数时应遵循以下规则
(1)**必须是一致的**,假设你输入辣子鸡丁时得到的是**在看**,那么每次输入辣子鸡丁时,得到的也必须为**在看**。如果不是这样,散列表将毫无用处。
(2)**计算简单**,假设我们设计了一个算法,可以保证所有关键字都不会冲突,但是这个算法计算复杂,会耗费很多时间,这样的话就大大降低了查找效率,反而得不偿失。所以咱们**散列函数的计算时间不应该超过其他查找技术与关键字的比较时间**,不然的话我们干嘛不使用其他查找技术呢?
(3)**散列地址分布均匀**我们刚才说了冲突的带来的问题,所以我们最好的办法就是让**散列地址尽量均匀分布在存储空间中**,这样即保证空间的有效利用,又减少了处理冲突而消耗的时间。
现在我们已经对散列表,散列函数等知识有所了解啦,那么我们来看几种常用的散列函数构造规则。这些方法的共同点为都是将原来的数字按某种规律变成了另一个数字。
### 散列函数构造方法
#### 直接定址法
如果我们对盈利为 0-9 的菜品设计哈希表,我们则直接可以根据作为地址,则 **f(key) = key**;
即下面这种情况。
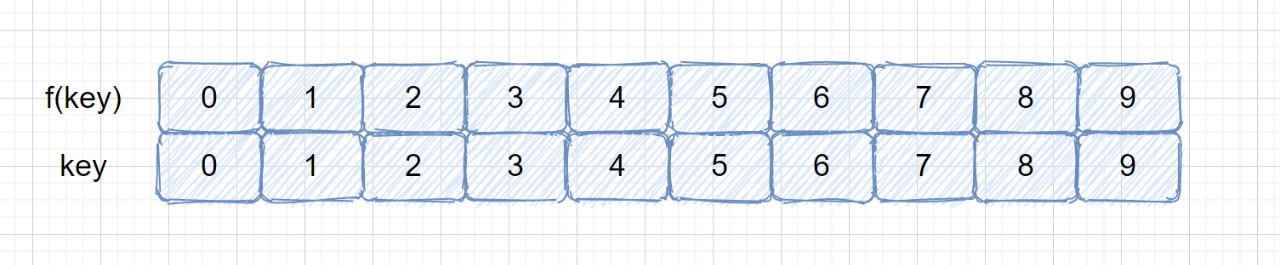
有没有感觉上面的图很熟悉,没错我们经常用的数组其实就是一张哈希表,关键码就是数组的索引下标,然后我们通过下标直接访问数组中的元素。
另外我们假设每道菜的成本为 50 块,那我们还可以根据盈利+成本来作为地址,那么则 f(key) = key + 50。也就是说我们可以根据线性函数值作为散列地址。
**f(key) = a \* key + b** **a,b 均为常数**
优点:简单、均匀、无冲突。
应用场景:需要事先知道关键字的分布情况,适合查找表较小且连续的情况
#### 数字分析法
该方法也是十分简单的方法,就是分析我们的关键字,取其中一段,或对其位移,叠加,用作地址。比如我们的学号,前 6 位都是一样的,但是后面 3 位都不相同,我们则可以用学号作为键,后面的 3 位做为我们的散列地址。如果我们这样还是容易产生冲突,则可以对抽取数字再进行处理。我们的目的只有一个,提供一个散列函数将关键字合理的分配到散列表的各位置。这里我们提到了一种新的方式,抽取,这也是在散列函数中经常用到的手段。
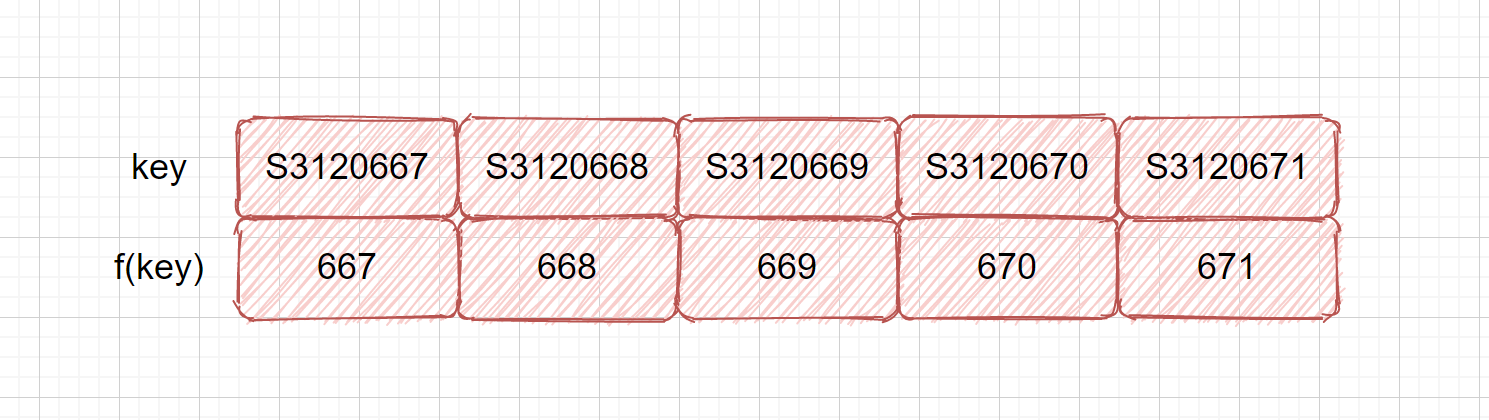
优点:简单、均匀、适用于关键字位数较大的情况
应用场景:关键字位数较大,知道关键字分布情况且关键字的若干位较均匀
#### 折叠法
其实这个方法也很简单,也是处理我们的关键字然后用作我们的散列地址,主要思路是将关键字从左到右分割成位数相等的几部分,然后叠加求和,并按散列表表长,取后几位作为散列地址。
比如我们的关键字是 123456789,则我们分为三部分 123 ,456 ,789 然后将其相加得 1368 然后我们再取其后三位 368 作为我们的散列地址。
优点:事先不需要知道关键字情况
应用场景:适合关键字位数较多的情况
#### 除法散列法
在用来设计散列函数的除法散列法中,通过取 key 除以 p 的余数,将关键字映射到 p 个槽中的某一个上,对于散列表长度为 m 的散列函数公式为
**f(k) = k mod p (p <= m)**
例如,如果散列表长度为 12,即 m = 12 ,我们的参数 p 也设为 12,**那 k = 100 时 f(k) = 100 % 12 = 4**
由于只需要做一次除法操作,所以除法散列法是非常快的。
由上面的公式可以看出,该方法的重点在于 p 的取值,如果 p 值选的不好,就可能会容易产生同义词。见下面这种情况。我们哈希表长度为 6,我们选择 6 为 p 值,则有可能产生这种情况,所有关键字都得到了 0 这个地址数。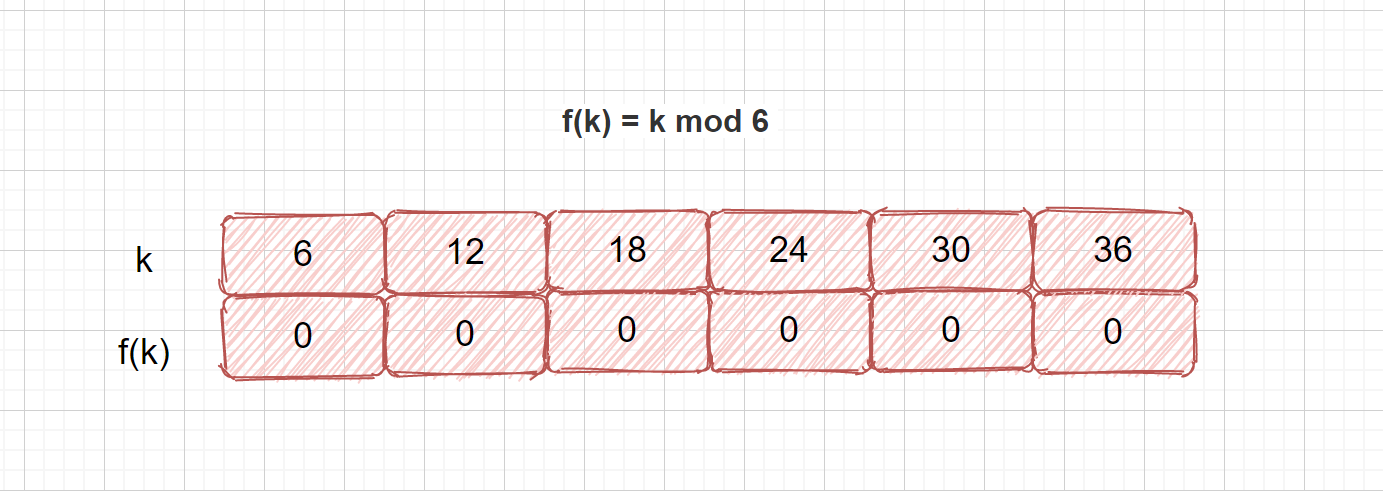
那我们在选用除法散列法时选取 p 值时应该遵循怎样的规则呢?
- m 不应为 2 的幂,因为如果 m = 2^p ,则 f(k) 就是 k 的 p 个最低位数字。例 12 % 8 = 4 ,12 的二进制表示位 1100,后三位为 100。
- 若散列表长为 m ,通常 p 为 小于或等于表长(最好接近 m)的最小质数或不包含小于 20 质因子的合数。
> **合数:**合数是指在大于 1 的整数中除了能被 1 和本身整除外,还能被其他数(0 除外)整除的数。
>
> **质因子**:质因子(或质因数)在数论里是指能整除给定正整数的质数。
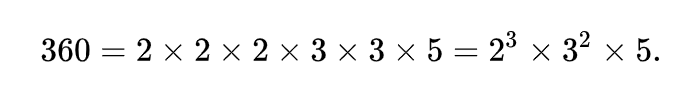
这里的 2,3,5 为质因子
还是上面的例子,我们根据规则选择 5 为 p 值,我们再来看。这时我们发现只有 6 和 36 冲突,相对来说就好了很多。
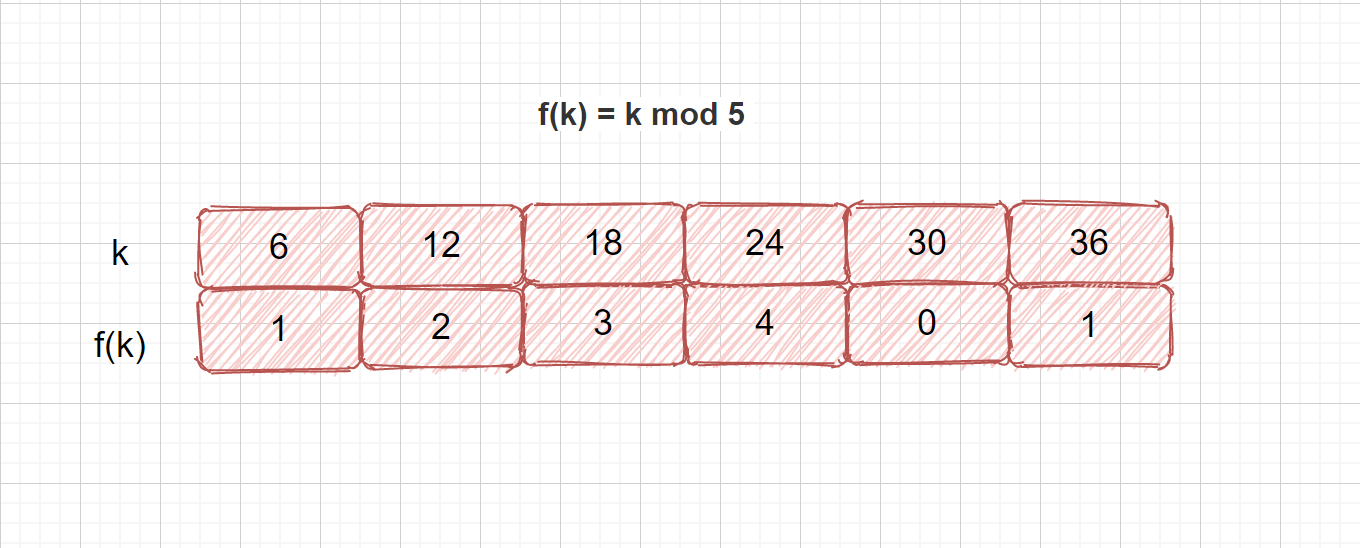
优点:计算效率高,灵活
应用场景:不知道关键字分布情况
#### 乘法散列法
构造散列函数的乘法散列法主要包含两个步骤
- 用关键字 k 乘上常数 A(0 < A < 1),并提取 k A 的小数部分
- 用 m 乘以这个值,再向下取整
散列函数为
**f (k) = ⌊ m(kA mod 1) ⌋**
这里的 **kA mod 1** 的含义是取 keyA 的小数部分,即 **kA - ⌊kA⌋** 。
优点:对 m 的选择不是特别关键,一般选择它为 2 的某个幂次(m = 2 ^ p ,p 为某个整数)
应用场景:不知道关键字情况
#### 平方取中法
这个方法就比较简单了,假设关键字是 321,那么他的平方就是 103041,再抽取中间的 3 位就是 030 或 304 用作散列地址。再比如关键字是 1234 那么它的平方就是 1522756 ,抽取中间 3 位就是 227 用作散列地址.
优点:灵活,适用范围广泛
适用场景:不知道关键字分布,而位数又不是很大的情况。
#### 随机数法
故名思意,取关键字的随机函数值为它的散列地址。也就是 **f(key) = random(key)**。这里的 random 是 随机函数。
优点:易实现
适用场景:关键字的长度不等时
上面我们的例子都是通过数字进行举例,那么如果是字符串可不可以作为键呢?当然也是可以的,各种各样的符号我们都可以转换成某种数字来对待,比如我们经常接触的 ASCII 码,所以是同样适用的。
以上就是常用的散列函数构造方法,其实他们的中心思想是一致的,将关键字经过加工处理之后变成另外一个数字,而这个数字就是我们的存储位置,是不是有一种间谍传递情报的感觉。
一个好的哈希函数可以帮助我们尽可能少的产生冲突,但是也不能完全避免产生冲突,那么遇到冲突时应该怎么做呢?下面给大家带来几种常用的处理散列冲突的方法。
### 处理散列冲突的方法
我们在使用 hash 函数之后发现关键字 key1 不等于 key2 ,但是 f(key1) = f(key2),即有冲突,那么该怎么办呢?不急我们慢慢往下看。
#### 开放地址法
了解开放地址法之前我们先设想以下场景。
> 袁记菜馆内,铃铃铃,铃铃铃 电话铃响了
>
> 大鹏:老袁,给我订个包间,我今天要去带几个客户去你那谈生意。
>
> 袁厨:大鹏啊,你常用的那个包间被人订走啦。
>
> 大鹏:老袁你这不仗义呀,咋没给我留住呀,那你给我找个**空房间**吧。
>
> 袁厨:好滴老哥
哦,穿越回古代就没有电话啦,那看来穿越的时候得带着几个手机了。
上面的场景其实就是一种处理冲突的方法-----开放地址法
**开放地址法**就是一旦发生冲突,就去寻找下一个空的散列地址,只要列表足够大,空的散列地址总能找到,并将记录存入,为了使用开放寻址法插入一个元素,需要连续地检查散列表,或称为**探查**,我们常用的有**线性探测,二次探测,随机探测**。
##### 线性探测法
下面我们先来看一下线性探测,公式:
> **f,(key) = ( f(key) + di ) MOD m(di = 1,2,3,4,5,6....m-1)**
我们来看一个例子,我们的关键字集合为{12,67,56,16,25,37,22,29,15,47,48,21},表长为 12,我们再用散列函数 **f(key) = key mod 12。**
我们求出每个 key 的 f(key)见下表

我们查看上表发现,前五位的 **f(key)** 都不相同,即没有冲突,可以直接存入,但是到了第六位 **f(37) = f(25) = 1**,那我们就需要利用上面的公式 **f(37) = f (f(37) + 1 ) mod 12 = 2**,这其实就是我们的订包间的做法。下面我们看一下将上面的所有数存入哈希表是什么情况吧。
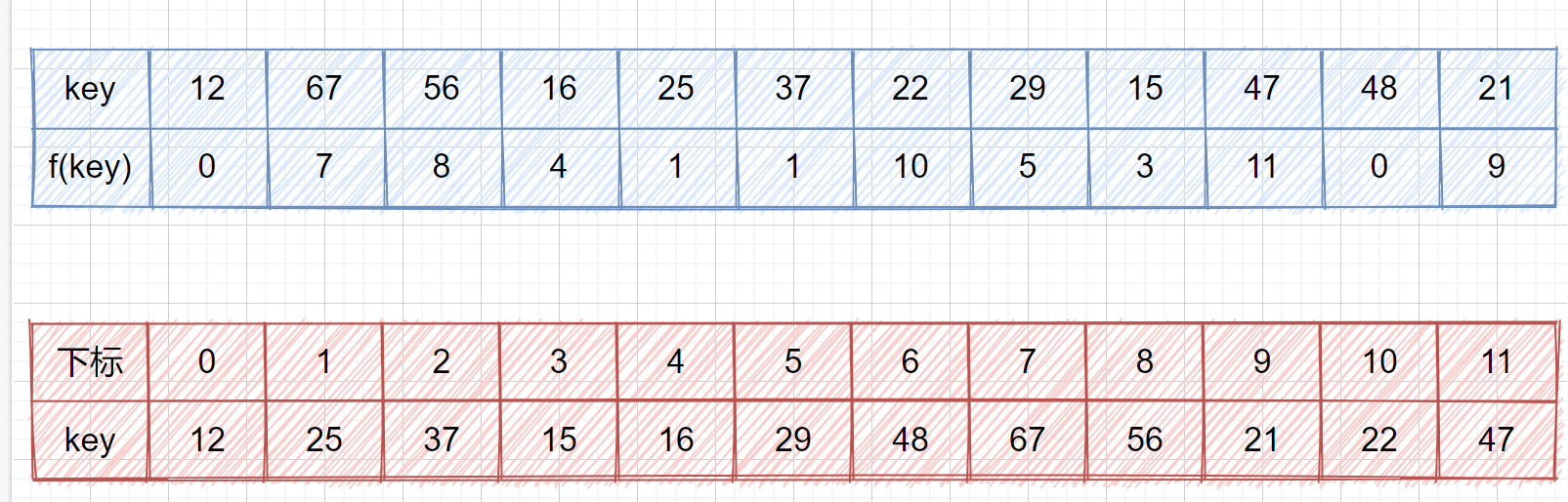
我们把这种解决冲突的开放地址法称为**线性探测法**。下面我们通过视频来模拟一下线性探测法的存储过程。
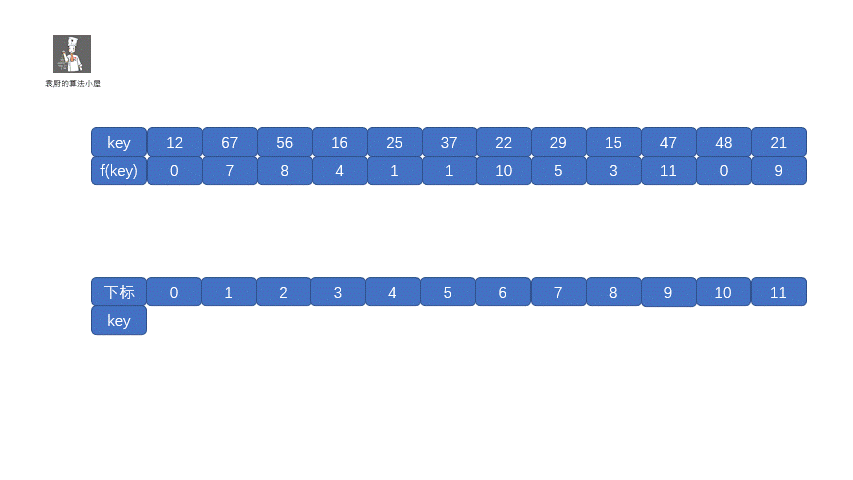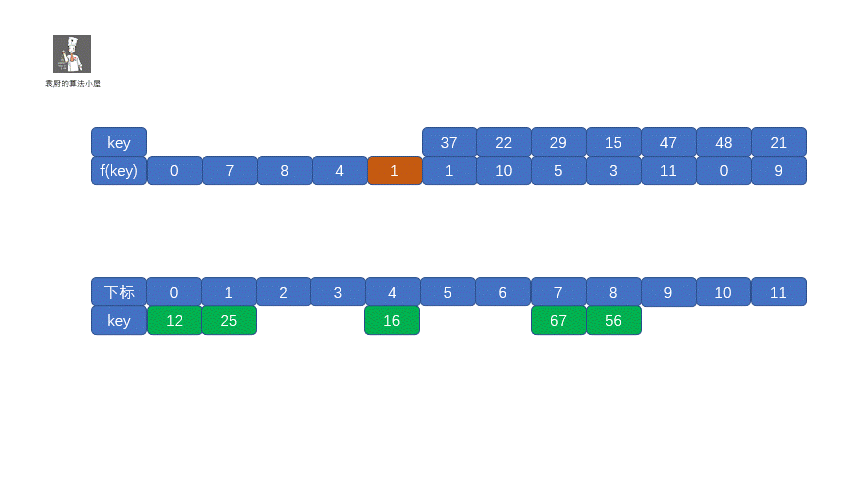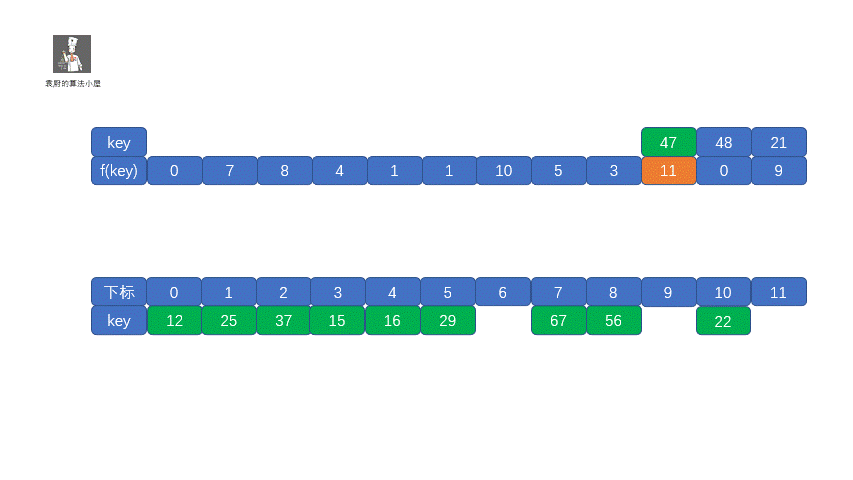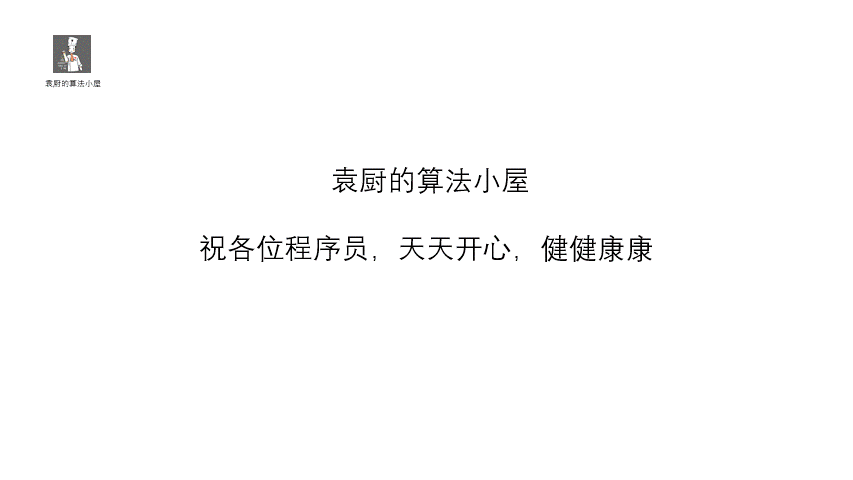
另外我们在解决冲突的时候,会遇到 48 和 37 虽然不是同义词,却争夺一个地址的情况,我们称其为**堆积**。因为堆积使得我们需要不断的处理冲突,插入和查找效率都会大大降低。
通过上面的视频我们应该了解了线性探测的执行过程了,那么我们考虑一下这种情况,若是我们的最后一位不为 21,为 34 时会有什么事情发生呢?
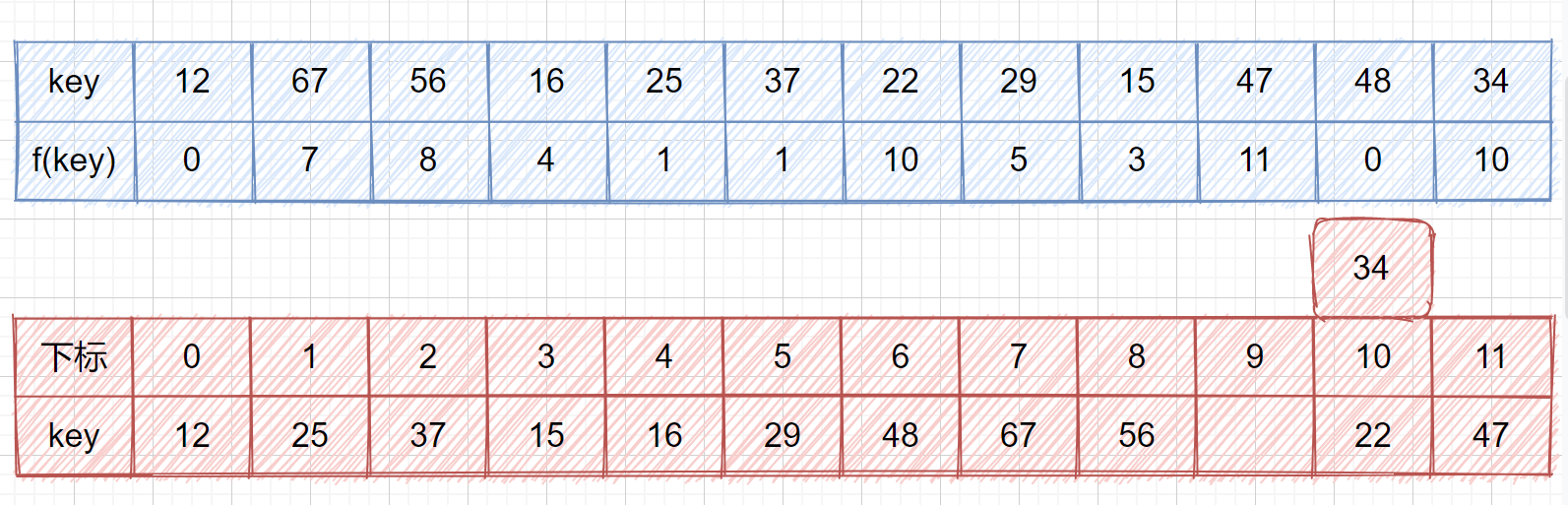
此时他第一次会落在下标为 10 的位置,那么如果继续使用线性探测的话,则需要通过不断取余后得到结果,数据量小还好,要是很大的话那也太慢了吧,但是明明他的前面就有一个空房间呀,如果向前移动只需移动一次即可。不要着急,前辈们已经帮我们想好了解决方法
##### 二次探测法
其实理解了我们的上个例子之后,这个一下就能整明白了,根本不用费脑子,这个方法就是更改了一下 di 的取值
> **线性探测: f,(key) = ( f(key) + di ) MOD m(di = 1,2,3,4,5,6....m-1)**
>
> **二次探测:** **f,(key) = ( f(key) + di ) MOD m(di =1^2 , -1^2 , 2^2 , -2^2 .... q^2, -q^2, q<=m/2)**
**注:这里的是 -1^2 为负值 而不是 (-1)^2**
所以对于我们的 34 来说,当 di = -1 时,就可以找到空位置了。
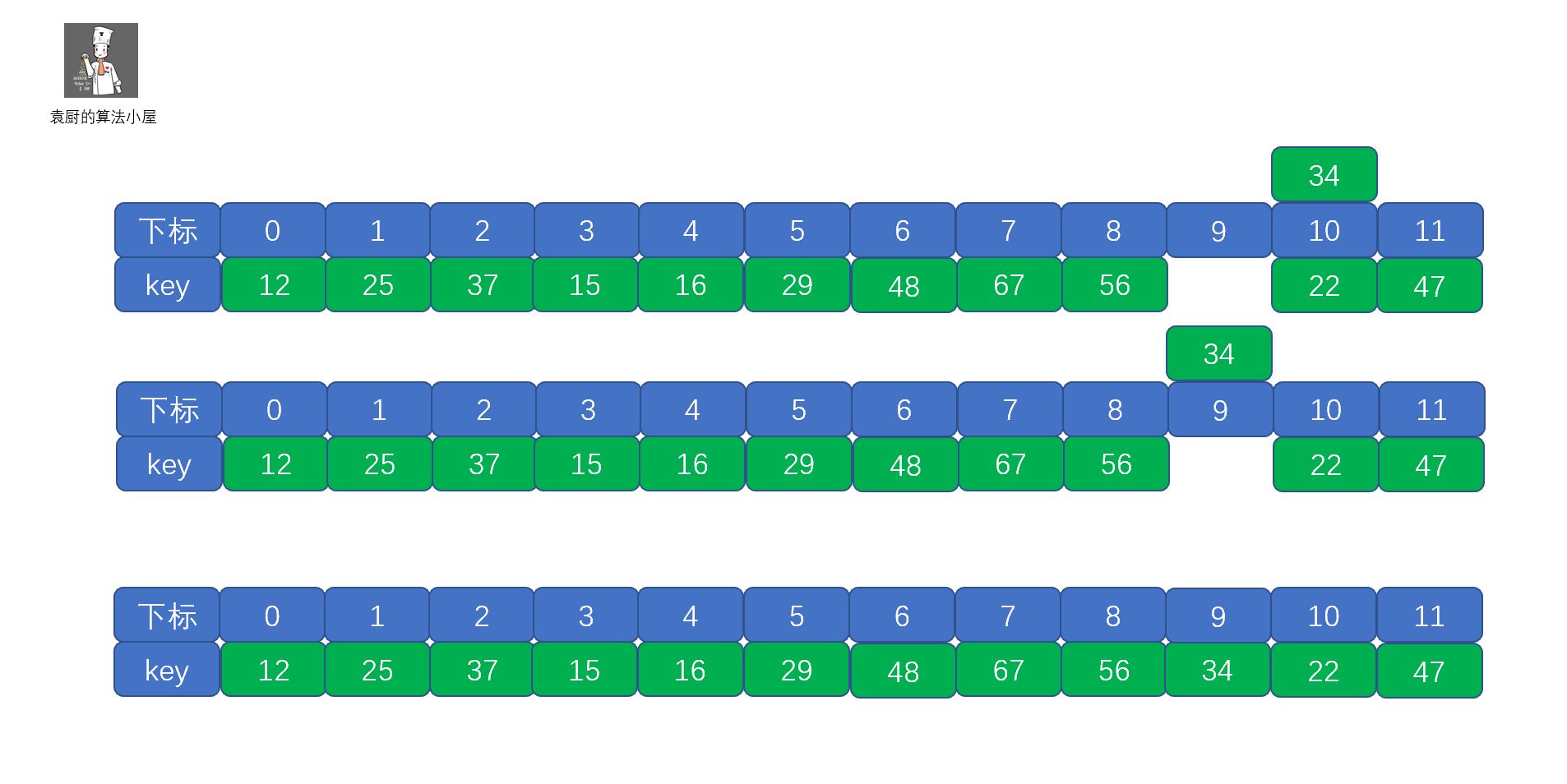
二次探测法的目的就是为了不让关键字聚集在某一块区域。另外还有一种有趣的方法,位移量采用随机函数计算得到,接着往下看吧.
##### 随机探测法
大家看到这是不又有新问题了,刚才我们在散列函数构造规则的第一条中说
> (1)**必须是一致的**,假设你输入辣子鸡丁时得到的是**在看**,那么每次输入辣子鸡丁时,得到的也必须为**在看**。如果不是这样,散列表将毫无用处。
咦?怎么又是**在看**哈哈,那么问题来了,我们使用随机数作为他的偏移量,那么我们查找的时候岂不是查不到了?因为我们 di 是随机生成的呀,这里的随机其实是伪随机数,伪随机数含义为,我们设置**随机种子**相同,则不断调用随机函数可以生成**不会重复的数列**,我们在查找时,**用同样的随机种子**,**它每次得到的数列是相同的**,那么相同的 di 就能得到**相同的散列地址**。
> 随机种子(Random Seed)是计算机专业术语,一种以随机数作为对象的以真随机数(种子)为初始条件的随机数。一般计算机的随机数都是伪随机数,以一个真随机数(种子)作为初始条件,然后用一定的算法不停迭代产生随机数

通过上面的测试是不是一下就秒懂啦,为什么我们可以使用随机数作为它的偏移量,理解那句,相同的随机种子,他每次得到的数列是相同的。
下面我们再来看一下其他的函数处理散列冲突的方法
#### 再哈希法
这个方法其实也特别简单,利用不同的哈希函数再求得一个哈希地址,直到不出现冲突为止。
> **f,(key) = RH,( key ) (i = 1,2,3,4.....k)**
这里的 RH,就是不同的散列函数,你可以把我们之前说过的那些散列函数都用上,每当发生冲突时就换一个散列函数,相信总有一个能够解决冲突的。这种方法能使关键字不产生聚集,但是代价就是增加了计算时间。是不是很简单啊。
#### 链地址法
下面我们再设想以下情景。
> 袁记菜馆内,铃铃铃,铃铃铃电话铃又响了,那个大鹏又来订房间了。
>
> 大鹏:老袁啊,我一会去你那吃个饭,还是上回那个包间
>
> 袁厨:大鹏你下回能不能早点说啊,又没人订走了,这回是老王订的
>
> 大鹏:老王这个老东西啊,反正也是熟人,你再给我整个桌子,我拼在他后面吧
不好意思啊各位同学,信鸽最近太贵了还没来得及买。上面的情景就是模拟我们的新的处理冲突的方法链地址法。
上面我们都是遇到冲突之后,就换地方。那么我们有没有不换地方的办法呢?那就是我们现在说的链地址法。
还记得我们说过得同义词吗?就是 key 不同 f(key) 相同的情况,我们将这些同义词存储在一个单链表中,这种表叫做同义词子表,散列表中只存储同义词子表的头指针。我们还是用刚才的例子,关键字集合为{12,67,56,16,25,37,22,29,15,47,48,21},表长为 12,我们再用散列函数 **f(key) = key mod 12。**我们用了链地址法之后就再也不存在冲突了,无论有多少冲突,我们只需在同义词子表中添加结点即可。下面我们看下链地址法的存储情况。
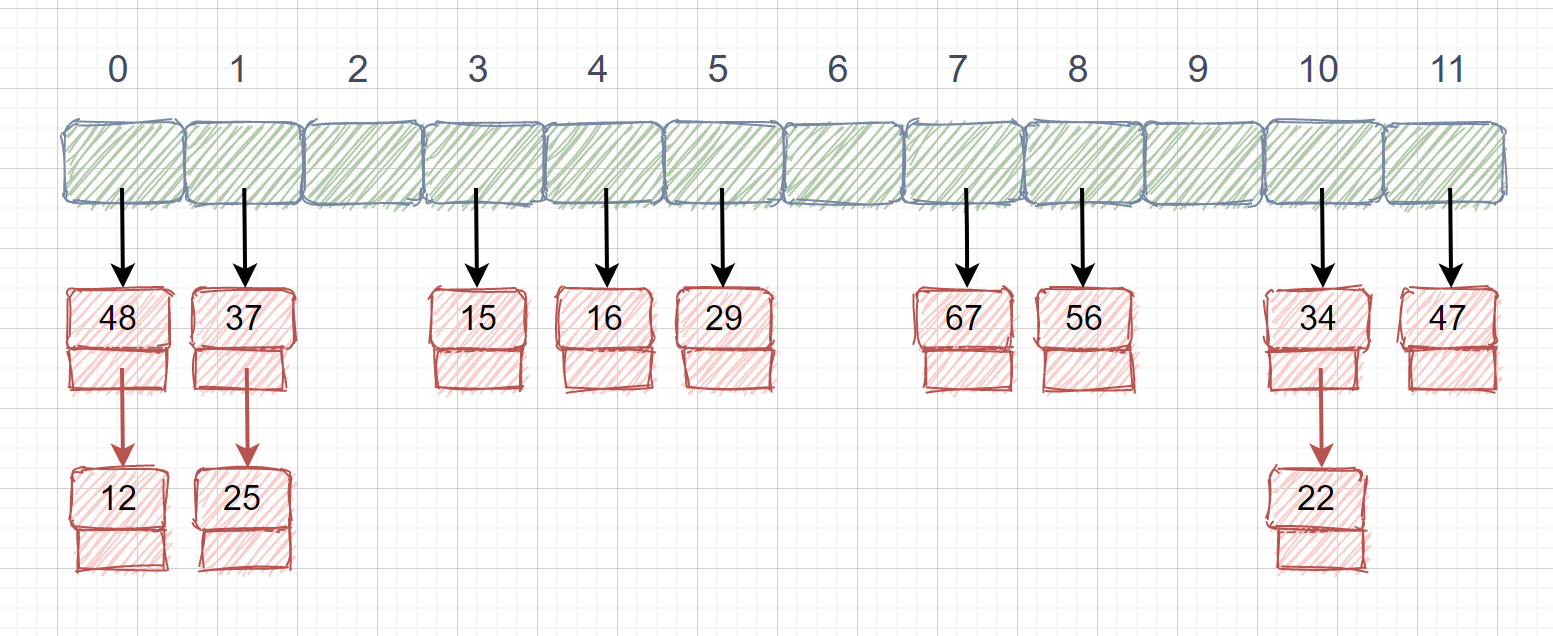
链地址法虽然能够不产生冲突,但是也带来了查找时需要遍历单链表的性能消耗,有得必有失嘛。
#### 公共溢出区法
下面我们再来看一种新的方法,这回大鹏又要来吃饭了。
> 袁记菜馆内.....
>
> 袁厨:呦,这是什么风把你给刮来了,咋没开你的大奔啊。
>
> 大鹏:哎呀妈呀,别那么多废话了,我快饿死了,你快给我找个位置,我要吃点饭。
>
> 袁厨:你来的,太不巧了,咱们的店已经满了,你先去旁边的小屋看会电视,等有空了我再叫你。小屋里面还有几个和你一样来晚的,你们一起看吧。
>
> 大鹏:电视?看电视?
上面得情景就是模拟我们的公共溢出区法,这也是很好理解的,你不是冲突吗?那冲突的各位我先给你安排个地方呆着,这样你就有地方住了。我们为所有冲突的关键字建立了一个公共的溢出区来存放。
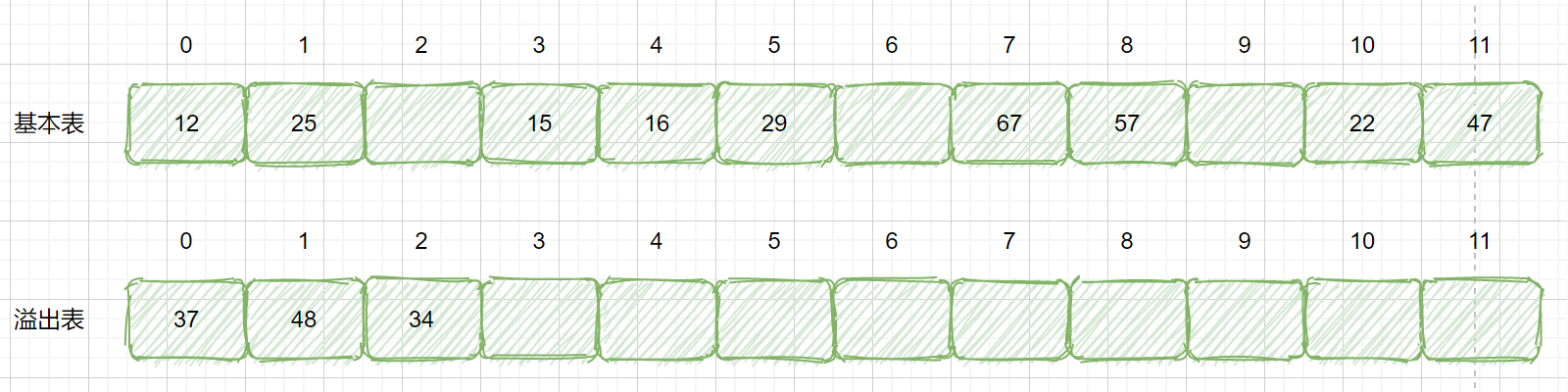
那么我们怎么进行查找呢?我们首先通过散列函数计算出散列地址后,先于基本表对比,如果不相等再到溢出表去顺序查找。这种解决冲突的方法,对于冲突很少的情况性能还是非常高的。
### 散列表查找算法(线性探测法)
下面我们来看一下散列表查找算法的实现
首先需要定义散列列表的结构以及一些相关常数,其中 elem 代表散列表数据存储数组,count 代表的是当前插入元素个数,size 代表哈希表容量,NULLKEY 散列表初始值,然后我们如果查找成功就返回索引,如果不存在该元素就返回元素不存在。
我们将哈希表初始化,为数组元素赋初值。

插入操作的具体步骤:
(1)通过哈希函数(除法散列法),将 key 转化为数组下标
(2)如果该下标中没有元素,则插入,否则说明有冲突,则利用线性探测法处理冲突。详细步骤见注释

查找操作的具体步骤:
(1)通过哈希函数(同插入时一样),将 key 转成数组下标
(2)通过数组下标找到 key 值,如果 key 一致,则查找成功,否则利用线性探测法继续查找。

下面我们来看一下完整代码
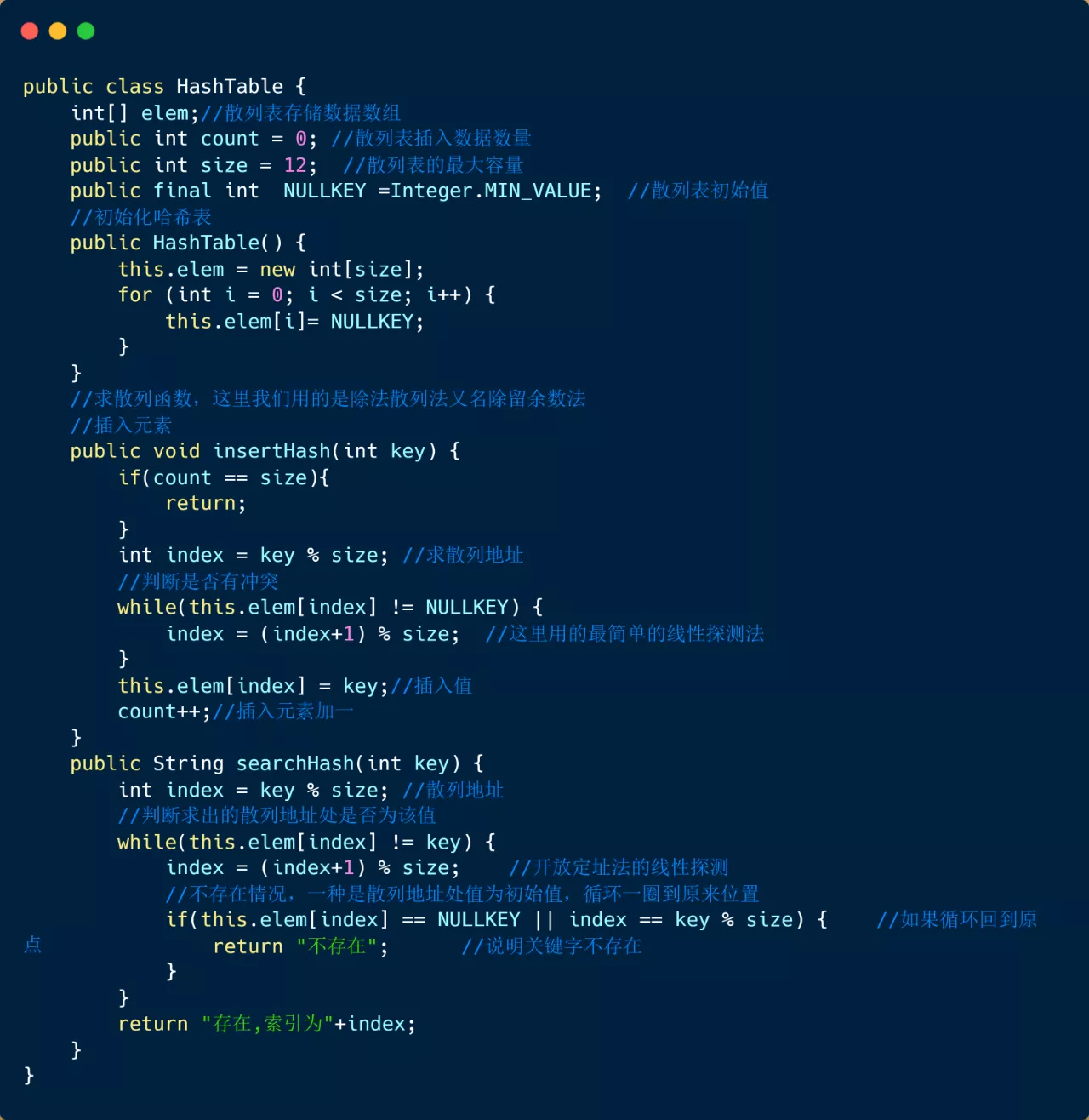
### 散列表性能分析
如果没有冲突的话,散列查找是我们查找中效率最高的,时间复杂度为 O(1),但是没有冲突的情况是一种理想情况,那么散列查找的平均查找长度取决于哪些方面呢?
**1.散列函数是否均匀**
我们在上文说到,可以通过设计散列函数减少冲突,但是由于不同的散列函数对一组关键字产生冲突可能性是相同的,因此我们可以不考虑它对平均查找长度的影响。
**2.处理冲突的方法**
相同关键字,相同散列函数,不同处理冲突方式,会使平均查找长度不同,比如我们线性探测有时会堆积,则不如二次探测法好,因为链地址法处理冲突时不会产生任何堆积,因而具有最佳的平均查找性能
**3.散列表的装填因子**
本来想在上文中提到装填因子的,但是后来发现即使没有说明也不影响我们对哈希表的理解,下面我们来看一下装填因子的总结
> 装填因子 α = 填入表中的记录数 / 散列表长度
散列因子则代表着散列表的装满程度,表中记录越多,α 就越大,产生冲突的概率就越大。我们上面提到的例子中 表的长度为 12,填入记录数为 6,那么此时的 α = 6 / 12 = 0.5 所以说当我们的 α 比较大时再填入元素那么产生冲突的可能性就非常大了。所以说散列表的平均查找长度取决于装填因子,而不是取决于记录数。所以说我们需要做的就是选择一个合适的装填因子以便将平均查找长度限定在一个范围之内。
================================================
FILE: animation-simulation/数据结构和算法/KMP.md
================================================
## KMP 算法(Knuth-Morris-Pratt)
> 如果阅读时,发现错误,或者动画不可以显示的问题可以添加我微信好友 **[tan45du_one](https://raw.githubusercontent.com/tan45du/tan45du.github.io/master/个人微信.15egrcgqd94w.jpg)** ,备注 github + 题目 + 问题 向我反馈
>
> 感谢支持,该仓库会一直维护,希望对各位有一丢丢帮助。
>
> 另外希望手机阅读的同学可以来我的 <u>[**公众号:程序厨**](https://raw.githubusercontent.com/tan45du/test/master/微信图片_20210320152235.2pthdebvh1c0.png)</u> 两个平台同步,想要和题友一起刷题,互相监督的同学,可以在我的小屋点击<u>[**刷题小队**](https://raw.githubusercontent.com/tan45du/test/master/微信图片_20210320152235.2pthdebvh1c0.png)</u>进入。
我们刚才讲了 BM 算法,虽然不是特别容易理解,但是如果你用心看的话肯定可以看懂的,我们再来看一个新的算法,这个算法是考研时必考的算法。实际上 BM 和 KMP 算法的本质是一样的,你理解了 BM 再来理解 KMP 那就是分分钟的事啦。
我们先来看一个实例

为了让读者更容易理解,我们将指针移动改成了模式串移动,两者相对与主串的移动是一致的,重新比较时都是从指针位置继续比较。
通过上面的实例是不是很快就能理解 KMP 算法的思想了,但是 KMP 的难点不是在这里,不过多思考,认真看理解起来也是很轻松的。
在上面的例子中我们提到了一个名词,**最长公共前后缀**,这个是什么意思呢?下面我们通过一个较简单的例子进行描述。

此时我们在红色阴影处匹配失败,绿色为匹配成功部分,则我们观察匹配成功的部分。
我们来看一下匹配成功部分的所有前缀
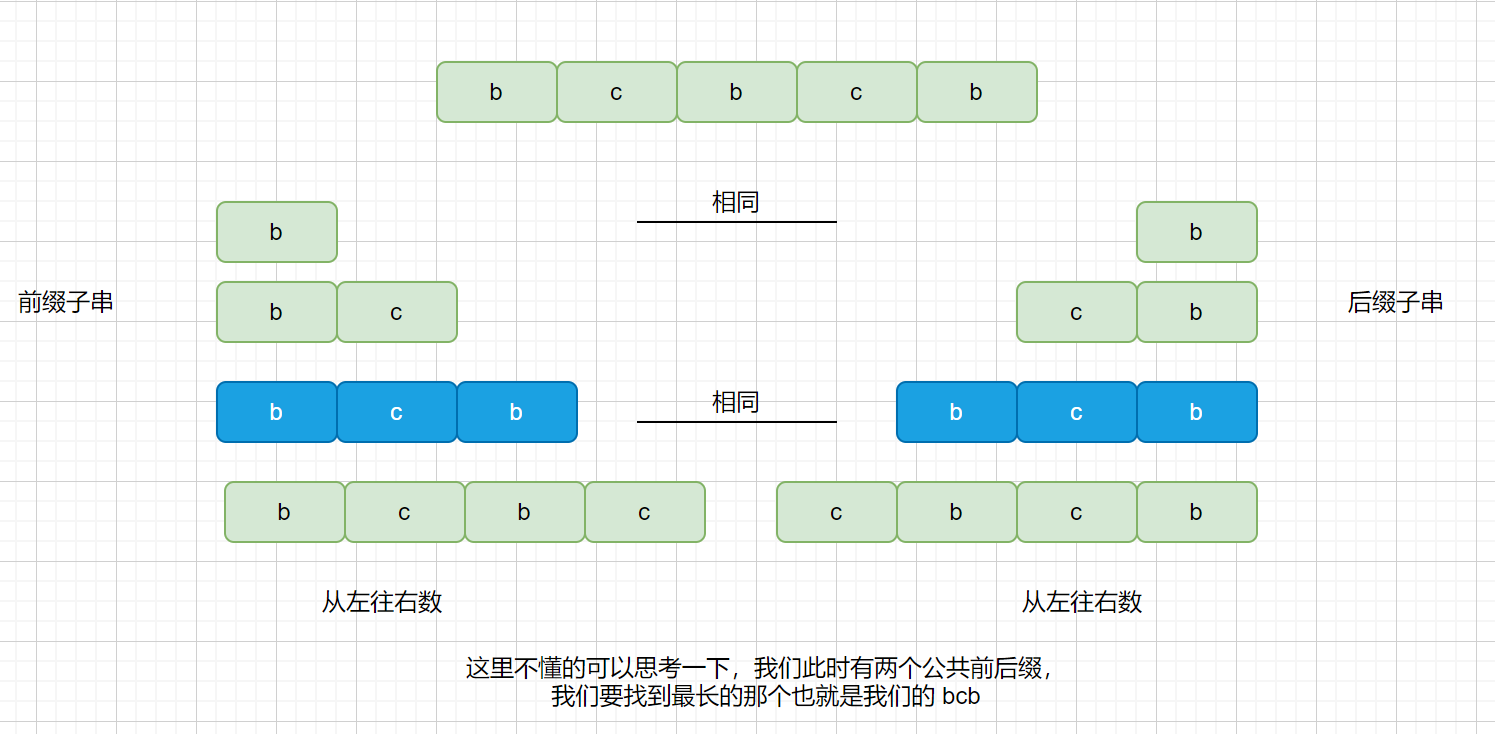
我们的最长公共前后缀如下图,则我们需要这样移动

好啦,看完上面的图,KMP 的核心原理已经基本搞定了,但是我们现在的问题是,我们应该怎么才能知道他的最长公共前后缀的长度是多少呢?怎么知道移动多少位呢?
刚才我们在 BM 中说到,我们移动位数跟主串无关,只跟模式串有关,跟我们的 bc,suffix,prefix 数组的值有关,我们通过这些数组就可以知道我们每次移动多少位啦,其实 KMP 也有一个数组,这个数组叫做 next 数组,那么这个 next 数组存的是什么呢?
next 数组存的咱们最长公共前后缀中,前缀的结尾字符下标。是不是感觉有点别扭,我们通过一个例子进行说明。
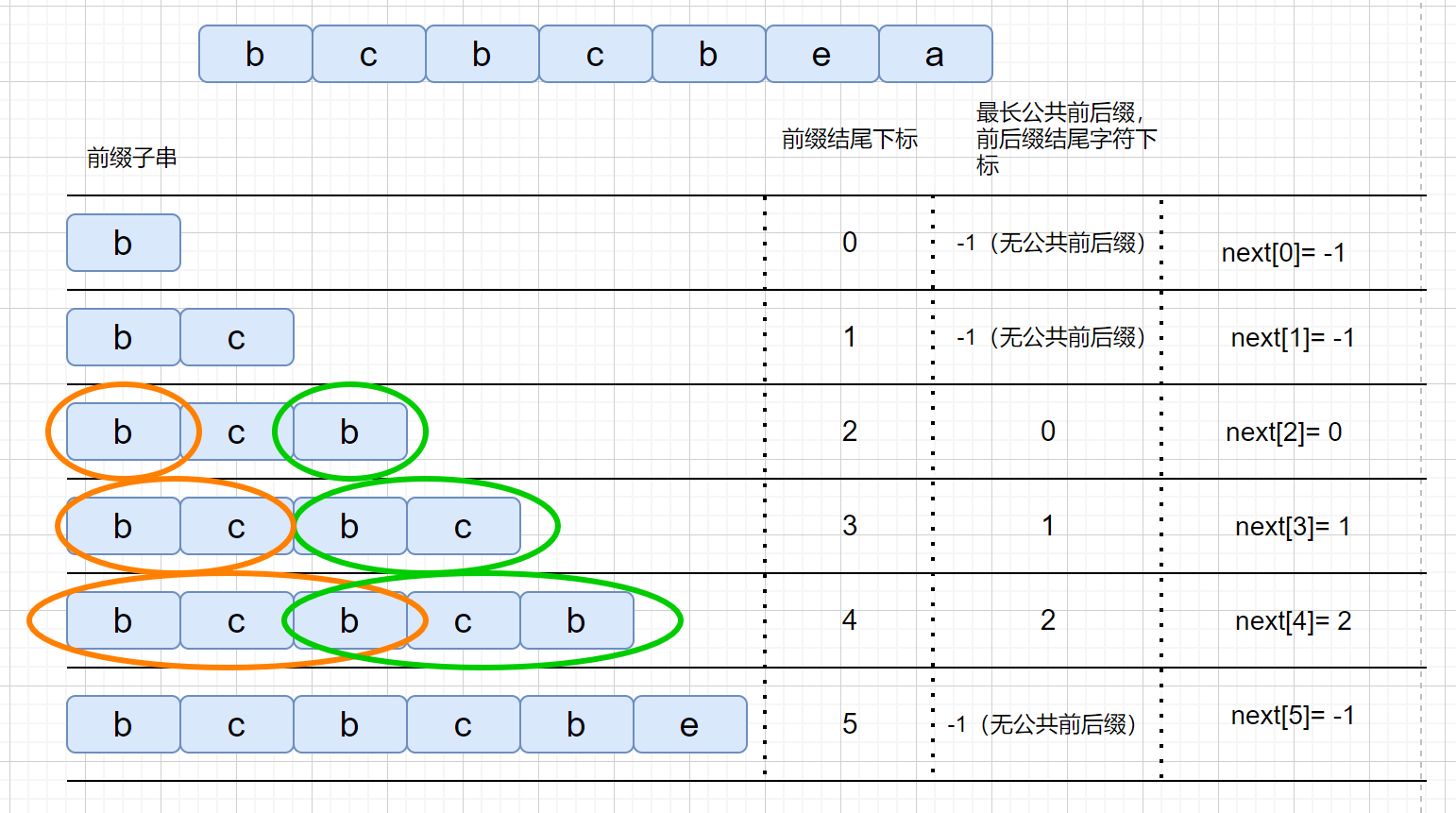
我们知道 next 数组之后,我们的 KMP 算法实现起来就很容易啦,另外我们看一下 next 数组到底是干什么用的。
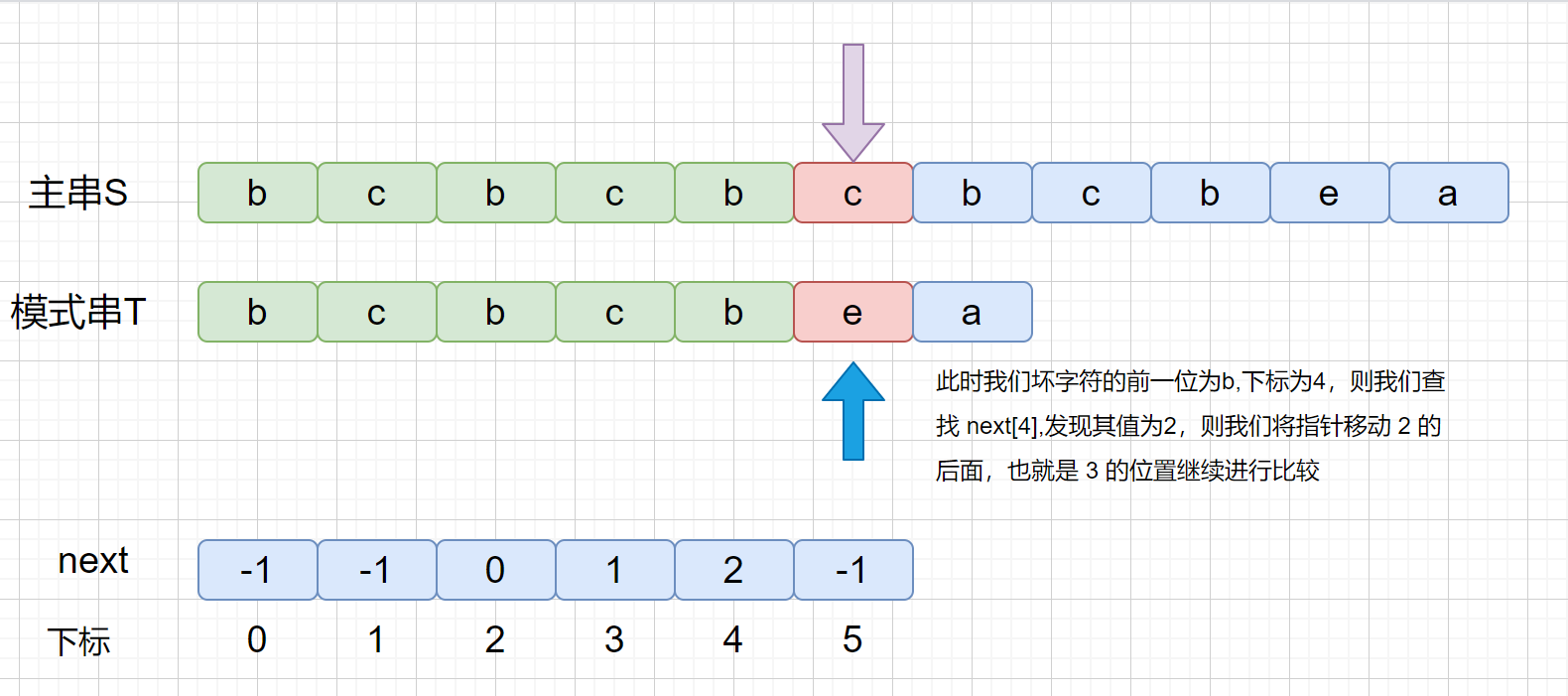
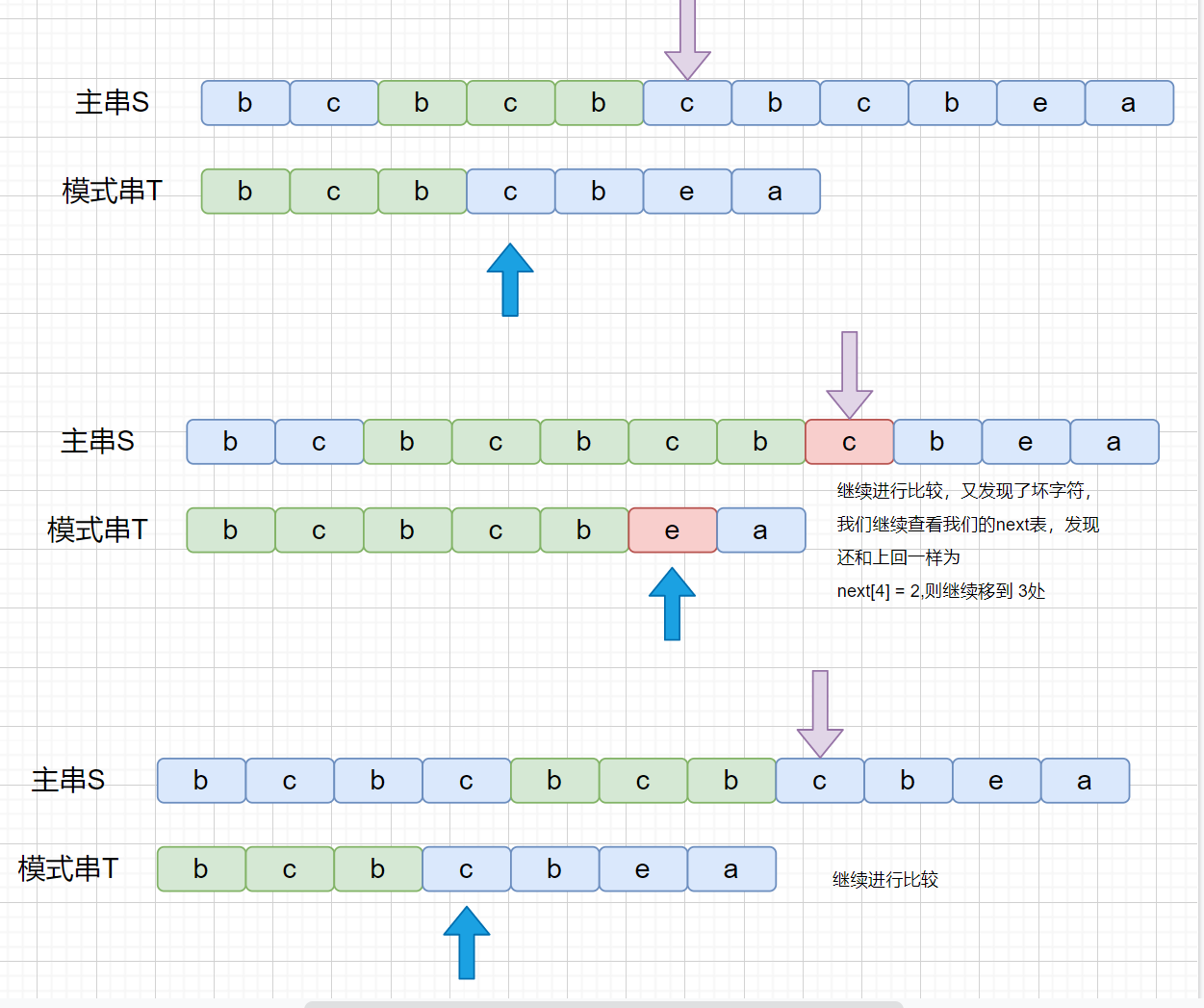
剩下的就不用说啦,完全一致啦,咱们将上面这个例子,翻译成和咱们开头对应的动画大家看一下。

下面我们看一下代码,标有详细注释,大家认真看呀。
**注:很多教科书的 next 数组表示方式不一致,理解即可**
```java
class Solution {
public int strStr(String haystack, String needle) {
//两种特殊情况
if (needle.length() == 0) {
return 0;
}
if (haystack.length() == 0) {
return -1;
}
// char 数组
char[] hasyarr = haystack.toCharArray();
char[] nearr = needle.toCharArray();
//长度
int halen = hasyarr.length;
int nelen = nearr.length;
//返回下标
return kmp(hasyarr,halen,nearr,nelen);
}
public int kmp (char[] hasyarr, int halen, char[] nearr, int nelen) {
//获取next 数组
int[] next = next(nearr,nelen);
int j = 0;
for (int i = 0; i < halen; ++i) {
//发现不匹配的字符,然后根据 next 数组移动指针,移动到最大公共前后缀的,
//前缀的后一位,和咱们移动模式串的含义相同
while (j > 0 && hasyarr[i] != nearr[j]) {
j = next[j - 1] + 1;
//超出长度时,可以直接返回不存在
if (nelen - j + i > halen) {
return -1;
}
}
//如果相同就将指针同时后移一下,比较下个字符
if (hasyarr[i] == nearr[j]) {
++j;
}
//遍历完整个模式串,返回模式串的起点下标
if (j == nelen) {
return i - nelen + 1;
}
}
return -1;
}
//这一块比较难懂,不想看的同学可以忽略,了解大致含义即可,或者自己调试一下,看看运行情况
//我会每一步都写上注释
public int[] next (char[] needle,int len) {
//定义 next 数组
int[] next = new int[len];
// 初始化
next[0] = -1;
int k = -1;
for (int i = 1; i < len; ++i) {
//我们此时知道了 [0,i-1]的最长前后缀,但是k+1的指向的值和i不相同时,我们则需要回溯
//因为 next[k]就时用来记录子串的最长公共前后缀的尾坐标(即长度)
//就要找 k+1前一个元素在next数组里的值,即next[k
gitextract_xq6x2zva/
├── .gitattributes
├── .github/
│ └── workflows/
│ ├── check_dead_links.yml
│ └── restructure_files.yml
├── LICENSE
├── README.md
└── animation-simulation/
├── Leetcode常用类和函数.md
├── 一些分享/
│ ├── 区块链详解.md
│ ├── 厨子的2020.md
│ ├── 学习.md
│ ├── 考研分享.md
│ └── 软件分享.md
├── 二分查找及其变种/
│ ├── leetcode 81不完全有序查找目标元素(包含重复值) .md
│ ├── leetcode153搜索旋转数组的最小值.md
│ ├── leetcode33不完全有序查找目标元素(不包含重复值).md
│ ├── leetcode34查找第一个位置和最后一个位置.md
│ ├── leetcode35搜索插入位置.md
│ ├── 二分查找详解.md
│ ├── 二维数组的二分查找.md
│ └── 找出第一个大于或小于目标的索引.md
├── 二叉树/
│ ├── 二叉树中序遍历(Morris).md
│ ├── 二叉树中序遍历(迭代).md
│ ├── 二叉树基础.md
│ ├── 二叉树的前序遍历(Morris).md
│ ├── 二叉树的前序遍历(栈).md
│ ├── 二叉树的后续遍历 (迭代).md
│ ├── 二叉树的后续遍历(Morris).md
│ └── 前序序列和中序构建二叉树.md
├── 位运算/
│ └── 空.md
├── 写写水文/
│ ├── 书单.md
│ ├── 如何学习.md
│ ├── 学弟问了我一个问题.md
│ ├── 常看的UP主.md
│ └── 送书.md
├── 分治/
│ └── 空.md
├── 前缀和/
│ ├── leetcode1248寻找优美子数组.md
│ ├── leetcode523连续的子数组和.md
│ ├── leetcode560和为K的子数组.md
│ ├── leetcode724寻找数组的中心索引.md
│ └── leetcode974和可被K整除的子数组.md
├── 剑指offer/
│ └── 1的个数.md
├── 动态规划/
│ └── 空.md
├── 单调队列单调栈/
│ ├── leetcode739每日温度.md
│ ├── 剑指offer59队列的最大值.md
│ ├── 接雨水.md
│ ├── 最小栈.md
│ └── 滑动窗口的最大值.md
├── 哈希表篇/
│ └── 空.md
├── 回溯/
│ └── 空.md
├── 并查集/
│ └── 空.md
├── 数据结构和算法/
│ ├── BF算法.md
│ ├── BM.md
│ ├── Hash表的那些事.md
│ ├── KMP.md
│ ├── read.md
│ ├── 关于栈和队列的那些事.md
│ ├── 关于链表的那些事.md
│ ├── 冒泡排序.md
│ ├── 合成.md
│ ├── 基数排序.md
│ ├── 堆排序.md
│ ├── 字符串匹配算法.md
│ ├── 希尔排序.md
│ ├── 归并排序.md
│ ├── 快速排序.md
│ ├── 桶排序.md
│ ├── 直接插入排序.md
│ ├── 简单选择排序.md
│ ├── 翻转对.md
│ ├── 荷兰国旗.md
│ ├── 计数排序.md
│ └── 逆序对问题.md
├── 数组篇/
│ ├── leetcode1052爱生气的书店老板.md
│ ├── leetcode1438绝对值不超过限制的最长子数组.md
│ ├── leetcode1两数之和.md
│ ├── leetcode219数组中重复元素2.md
│ ├── leetcode27移除元素.md
│ ├── leetcode41缺失的第一个正数.md
│ ├── leetcode485最大连续1的个数.md
│ ├── leetcode54螺旋矩阵.md
│ ├── leetcode560和为K的子数组.md
│ ├── leetcode59螺旋矩阵2.md
│ ├── leetcode66加一.md
│ ├── leetcode75颜色分类.md
│ ├── 剑指offer3数组中重复的数.md
│ └── 长度最小的子数组.md
├── 栈和队列/
│ ├── 225.用队列实现栈.md
│ ├── leetcode1047 删除字符串中的所有相邻重复项.md
│ ├── leetcode20有效的括号.md
│ ├── leetcode402移掉K位数字.md
│ └── 剑指Offer09用两个栈实现队列.md
├── 求和问题/
│ ├── 三数之和.md
│ ├── 两数之和.md
│ └── 四数之和.md
├── 求次数问题/
│ ├── 只出现一次的数.md
│ ├── 只出现一次的数2.md
│ └── 只出现一次的数3.md
├── 滑动窗口/
│ └── 空.md
├── 缓存淘汰算法/
│ ├── LFU.md
│ └── LRU.md
├── 设计/
│ └── LRU.md
├── 贪心/
│ └── 空.md
├── 递归/
│ └── 空.md
└── 链表篇/
├── 234. 回文链表.md
├── leetcode141环形链表.md
├── leetcode142环形链表2.md
├── leetcode147对链表进行插入排序.md
├── leetcode206反转链表.md
├── leetcode328奇偶链表.md
├── leetcode82删除排序链表中的重复元素II.md
├── leetcode86分隔链表.md
├── leetcode92反转链表2.md
├── 剑指Offer25合并两个排序的链表.md
├── 剑指Offer52两个链表的第一个公共节点.md
├── 剑指offer22倒数第k个节点.md
├── 面试题 02.03. 链表中间节点.md
└── 面试题 02.05. 链表求和.md
Condensed preview — 116 files, each showing path, character count, and a content snippet. Download the .json file or copy for the full structured content (551K chars).
[
{
"path": ".gitattributes",
"chars": 16,
"preview": "*.md text=auto\n\n"
},
{
"path": ".github/workflows/check_dead_links.yml",
"chars": 407,
"preview": "name: Check Markdown links\n\non:\n push:\n branches: [ main ]\n pull_request:\n branches: [ main ]\n workflow_dispatc"
},
{
"path": ".github/workflows/restructure_files.yml",
"chars": 915,
"preview": "name: Restructure files\n\non:\n push:\n branches: [ main ]\n workflow_dispatch:\n\njobs:\n test-and-build:\n runs-on: u"
},
{
"path": "LICENSE",
"chars": 1061,
"preview": "MIT License\n\nCopyright (c) 2021 算法基地\n\nPermission is hereby granted, free of charge, to any person obtaining a copy\nof th"
},
{
"path": "README.md",
"chars": 21575,
"preview": "# **algorithm-base**\n\n<div align=\"left\"> <a href = \"https://www.zhihu.com/people/suan-fa-ji-di\"><img src=\"https://img"
},
{
"path": "animation-simulation/Leetcode常用类和函数.md",
"chars": 8992,
"preview": "# Leetcode 常用函数\n\n## 链表篇\n\n一些节点,除了最后一个节点以外的每一个节点都存储着下一个节点的地址,依据这种方法依次连接, 构成一个链式结构。\n\n### ListNode\n\n```java\nListNode list=ne"
},
{
"path": "animation-simulation/一些分享/区块链详解.md",
"chars": 6612,
"preview": "最近总是能在一些网站上看到比特币大涨的消息,诺,这不都涨破 20000 美元啦。\n\n最近比特币涨势喜人,牵动着每一位股民的心,持有的老哥后悔说当时我咋就没多买点呢,不然明天早饭又能多加个鸡蛋啦,没持有的呢,就在懊恼后悔当时为啥就没买入呢?这"
},
{
"path": "animation-simulation/一些分享/厨子的2020.md",
"chars": 1881,
"preview": "## 我的那些牛 X 的事\n\n在火车上无聊,写下了这篇随笔,2020 年已经过去了一段时间,这篇年度总结好像来的略微晚了一些,因为实在不知道写些什么,感觉这一年没有特别突出的成绩,也没有特别大的突破,平平淡淡。下面我试着说一下我的 2020"
},
{
"path": "animation-simulation/一些分享/学习.md",
"chars": 3368,
"preview": "不知道各位有没有遇到过下面这种情况\n\n每天早上醒来,先给自己打个气,今天我一定要好好学习。打完气之后,就开始躺在床上玩手机。吃了睡,睡了吃,好不容易打开电脑学个习,看了半个小时就再次倒下。\n\n还有的时候呢?2:45 啦,我再玩一会吧,凑个整"
},
{
"path": "animation-simulation/一些分享/考研分享.md",
"chars": 4385,
"preview": "## 终于轮到我了,关于计算机考研的一点点经验\n\n之前有虎扑老哥让我写一下考研经验分享,但是距离我考研已经好几年了,记忆有些模糊,所以就请了一位跨考浙大计算机并成功上岸的学弟为大家分享。希望对准备考研的学弟学妹有一丢丢帮助。\n\n下面是学弟的"
},
{
"path": "animation-simulation/一些分享/软件分享.md",
"chars": 2261,
"preview": "这两天读者让我介绍一下写东西用到的工具,那咱们就来看看我都用了什么工具吧。\n\nPS:这期很多利器,大家不要错过哈,总有一款适合你。\n\n---\n\n## **Typora**\n\n这个大家肯定都不陌生,我的所有文章都是用这个软件写出来的,非常喜欢"
},
{
"path": "animation-simulation/二分查找及其变种/leetcode 81不完全有序查找目标元素(包含重复值) .md",
"chars": 2488,
"preview": "> 如果阅读时,发现错误,或者动画不可以显示的问题可以添加我微信好友 **[tan45du_one](https://raw.githubusercontent.com/tan45du/tan45du.github.io/master/个人"
},
{
"path": "animation-simulation/二分查找及其变种/leetcode153搜索旋转数组的最小值.md",
"chars": 2642,
"preview": "> 如果阅读时,发现错误,或者动画不可以显示的问题可以添加我微信好友 **[tan45du_one](https://raw.githubusercontent.com/tan45du/tan45du.github.io/master/个人"
},
{
"path": "animation-simulation/二分查找及其变种/leetcode33不完全有序查找目标元素(不包含重复值).md",
"chars": 4237,
"preview": "> 如果阅读时,发现错误,或者动画不可以显示的问题可以添加我微信好友 **[tan45du_one](https://raw.githubusercontent.com/tan45du/tan45du.github.io/master/个人"
},
{
"path": "animation-simulation/二分查找及其变种/leetcode34查找第一个位置和最后一个位置.md",
"chars": 5037,
"preview": "> 如果阅读时,发现错误,或者动画不可以显示的问题可以添加我微信好友 **[tan45du_one](https://raw.githubusercontent.com/tan45du/tan45du.github.io/master/个人"
},
{
"path": "animation-simulation/二分查找及其变种/leetcode35搜索插入位置.md",
"chars": 1581,
"preview": "> 如果阅读时,发现错误,或者动画不可以显示的问题可以添加我微信好友 **[tan45du_one](https://raw.githubusercontent.com/tan45du/tan45du.github.io/master/个人"
},
{
"path": "animation-simulation/二分查找及其变种/二分查找详解.md",
"chars": 5353,
"preview": "> 如果阅读时,发现错误,或者动画不可以显示的问题可以添加我微信好友 **[tan45du_one](https://raw.githubusercontent.com/tan45du/tan45du.github.io/master/个"
},
{
"path": "animation-simulation/二分查找及其变种/二维数组的二分查找.md",
"chars": 2814,
"preview": "> 如果阅读时,发现错误,或者动画不可以显示的问题可以添加我微信好友 **[tan45du_one](https://raw.githubusercontent.com/tan45du/tan45du.github.io/master/个人"
},
{
"path": "animation-simulation/二分查找及其变种/找出第一个大于或小于目标的索引.md",
"chars": 3803,
"preview": "> 如果阅读时,发现错误,或者动画不可以显示的问题可以添加我微信好友 **[tan45du_one](https://raw.githubusercontent.com/tan45du/tan45du.github.io/master/个人"
},
{
"path": "animation-simulation/二叉树/二叉树中序遍历(Morris).md",
"chars": 3478,
"preview": "### **Morris**\n\n我们之前说过,前序遍历的 Morris 方法,如果已经掌握,今天中序遍历的 Morris 方法也就没有什么难度,仅仅修改了一丢丢。\n\n我们先来回顾一下前序遍历 Morris 方法的代码部分。\n\n**前序遍历 "
},
{
"path": "animation-simulation/二叉树/二叉树中序遍历(迭代).md",
"chars": 2529,
"preview": "哈喽大家好,我是厨子,之前我们说了二叉树前序遍历的迭代法和 Morris,今天咱们写一下中序遍历的迭代法和 Morris。\n\n> 注:数据结构掌握不熟练的同学,阅读该文章之前,可以先阅读这两篇文章,二叉树基础,前序遍历另外喜欢电脑阅读的同学"
},
{
"path": "animation-simulation/二叉树/二叉树基础.md",
"chars": 10800,
"preview": "> 如果阅读时,发现错误,或者动画不可以显示的问题可以添加我微信好友 **[tan45du_one](https://raw.githubusercontent.com/tan45du/tan45du.github.io/master/个人"
},
{
"path": "animation-simulation/二叉树/二叉树的前序遍历(Morris).md",
"chars": 3961,
"preview": "### Morris\n\nMorris 遍历利用树的左右孩子为空(大量空闲指针),实现空间开销的极限缩减。这个遍历方法,稍微有那么一丢丢难理解,不过结合动图,也就一目了然啦,下面我们先看动画吧。\n\n.md",
"chars": 2522,
"preview": "我们之前说了二叉树基础及二叉的几种遍历方式及练习题,今天我们来看一下二叉树的前序遍历非递归实现。\n\n前序遍历的顺序是, 对于树中的某节点,`先遍历该节点,然后再遍历其左子树,最后遍历其右子树`.\n\n我们先来通过下面这个动画复习一下二叉树的前"
},
{
"path": "animation-simulation/二叉树/二叉树的后续遍历 (迭代).md",
"chars": 3471,
"preview": "之前给大家介绍了二叉树的[前序遍历](),[中序遍历]()的迭代法和 Morris 方法,今天咱们来说一下二叉后序遍历的迭代法及 Morris 方法。\n\n注:阅读该文章前,建议各位先阅读之前的三篇文章,对该文章的理解有很大帮助。\n\n## 迭"
},
{
"path": "animation-simulation/二叉树/二叉树的后续遍历(Morris).md",
"chars": 4510,
"preview": "之前给大家介绍了二叉树的[前序遍历](),[中序遍历]()的迭代法和 Morris 方法,今天咱们来说一下二叉后序遍历的迭代法及 Morris 方法。\n\n注:阅读该文章前,建议各位先阅读之前的三篇文章,对该文章的理解有很大帮助。\n\n## M"
},
{
"path": "animation-simulation/二叉树/前序序列和中序构建二叉树.md",
"chars": 0,
"preview": ""
},
{
"path": "animation-simulation/位运算/空.md",
"chars": 0,
"preview": ""
},
{
"path": "animation-simulation/写写水文/书单.md",
"chars": 0,
"preview": ""
},
{
"path": "animation-simulation/写写水文/如何学习.md",
"chars": 2720,
"preview": "如何面向面试学习?\n\n我们提到面试,大多数人脑子里蹦出的第一个词,那就是八股文。但是面试真的可以**只**靠八股文吗?\n\n那面试八股文重要吗?重要,非常重要!\n\n那你这不是前后矛盾吗?一会说不能只靠八股文,一会又说八股文非常重要。\n\n哎嘛,"
},
{
"path": "animation-simulation/写写水文/学弟问了我一个问题.md",
"chars": 2957,
"preview": "一位学弟,问了我一个问题。\n\n\n\n我在这里说一下我的看法,希望能够对有相同问题的学弟学妹,有一"
},
{
"path": "animation-simulation/写写水文/常看的UP主.md",
"chars": 1903,
"preview": "今天不和大家吹牛玩了,唠唠嗑吧,说几个我逛 B 站经常看的几位 UP 主吧。看看里面有没有你关注滴。我知道在做的各位,很多都是在 B 站学跳舞的 🐶,我看的比较多的则是搞笑区 UP,他们可都太逗了。\n\n### 导演小策\n\n入坑作品,是那个贼"
},
{
"path": "animation-simulation/写写水文/送书.md",
"chars": 391,
"preview": "好久不见\n\n哈喽大家好,我是厨子,好久不见啊。\n\n主要是这段时间太忙啦,所以没有进行更新,不过后面会慢慢更新起来,继续更之前的专题。\n\n那么我今天是来干什么的呢?给大家送点福利,送几本我们经常用的《剑指 offer》。呐,就是下面这一本啦。"
},
{
"path": "animation-simulation/分治/空.md",
"chars": 0,
"preview": ""
},
{
"path": "animation-simulation/前缀和/leetcode1248寻找优美子数组.md",
"chars": 3782,
"preview": "> 如果阅读时,发现错误,或者动画不可以显示的问题可以添加我微信好友 **[tan45du_one](https://raw.githubusercontent.com/tan45du/tan45du.github.io/master/个人"
},
{
"path": "animation-simulation/前缀和/leetcode523连续的子数组和.md",
"chars": 3810,
"preview": "> 如果阅读时,发现错误,或者动画不可以显示的问题可以添加我微信好友 **[tan45du_one](https://raw.githubusercontent.com/tan45du/tan45du.github.io/master/个人"
},
{
"path": "animation-simulation/前缀和/leetcode560和为K的子数组.md",
"chars": 5509,
"preview": "> 如果阅读时,发现错误,或者动画不可以显示的问题可以添加我微信好友 **[tan45du_one](https://raw.githubusercontent.com/tan45du/tan45du.github.io/master/个人"
},
{
"path": "animation-simulation/前缀和/leetcode724寻找数组的中心索引.md",
"chars": 3315,
"preview": "> 如果阅读时,发现错误,或者动画不可以显示的问题可以添加我微信好友 **[tan45du_one](https://raw.githubusercontent.com/tan45du/tan45du.github.io/master/个人"
},
{
"path": "animation-simulation/前缀和/leetcode974和可被K整除的子数组.md",
"chars": 3962,
"preview": "> 如果阅读时,发现错误,或者动画不可以显示的问题可以添加我微信好友 **[tan45du_one](https://raw.githubusercontent.com/tan45du/tan45du.github.io/master/个人"
},
{
"path": "animation-simulation/剑指offer/1的个数.md",
"chars": 5846,
"preview": "# 我太喜欢这个题了\n\n> 如果阅读时,发现错误,或者动画不可以显示的问题可以添加我微信好友 **[tan45du_one](https://raw.githubusercontent.com/tan45du/tan45du.github."
},
{
"path": "animation-simulation/动态规划/空.md",
"chars": 0,
"preview": ""
},
{
"path": "animation-simulation/单调队列单调栈/leetcode739每日温度.md",
"chars": 2287,
"preview": "> 如果阅读时,发现错误,或者动画不可以显示的问题可以添加我微信好友 **[tan45du_one](https://raw.githubusercontent.com/tan45du/tan45du.github.io/master/个人"
},
{
"path": "animation-simulation/单调队列单调栈/剑指offer59队列的最大值.md",
"chars": 3496,
"preview": "> 如果阅读时,发现错误,或者动画不可以显示的问题可以添加我微信好友 **[tan45du_one](https://raw.githubusercontent.com/tan45du/tan45du.github.io/master/个人"
},
{
"path": "animation-simulation/单调队列单调栈/接雨水.md",
"chars": 5581,
"preview": "> 如果阅读时,发现错误,或者动画不可以显示的问题可以添加我微信好友 **[tan45du_one](https://raw.githubusercontent.com/tan45du/tan45du.github.io/master/个人"
},
{
"path": "animation-simulation/单调队列单调栈/最小栈.md",
"chars": 3019,
"preview": "> 如果阅读时,发现错误,或者动画不可以显示的问题可以添加我微信好友 **[tan45du_one](https://raw.githubusercontent.com/tan45du/tan45du.github.io/master/个人"
},
{
"path": "animation-simulation/单调队列单调栈/滑动窗口的最大值.md",
"chars": 3389,
"preview": "> 如果阅读时,发现错误,或者动画不可以显示的问题可以添加我微信好友 **[tan45du_one](https://raw.githubusercontent.com/tan45du/tan45du.github.io/master/个人"
},
{
"path": "animation-simulation/哈希表篇/空.md",
"chars": 0,
"preview": ""
},
{
"path": "animation-simulation/回溯/空.md",
"chars": 0,
"preview": ""
},
{
"path": "animation-simulation/并查集/空.md",
"chars": 0,
"preview": ""
},
{
"path": "animation-simulation/数据结构和算法/BF算法.md",
"chars": 4784,
"preview": "> 如果阅读时,发现错误,或者动画不可以显示的问题可以添加我微信好友 **[tan45du_one](https://raw.githubusercontent.com/tan45du/tan45du.github.io/master/个人"
},
{
"path": "animation-simulation/数据结构和算法/BM.md",
"chars": 9606,
"preview": "## BM 算法(Boyer-Moore)\n\n> 如果阅读时,发现错误,或者动画不可以显示的问题可以添加我微信好友 **[tan45du_one](https://raw.githubusercontent.com/tan45du/tan4"
},
{
"path": "animation-simulation/数据结构和算法/Hash表的那些事.md",
"chars": 11572,
"preview": "> 如果阅读时,发现错误,或者动画不可以显示的问题可以添加我微信好友 **[tan45du_one](https://raw.githubusercontent.com/tan45du/tan45du.github.io/master/个人"
},
{
"path": "animation-simulation/数据结构和算法/KMP.md",
"chars": 5816,
"preview": "## KMP 算法(Knuth-Morris-Pratt)\n\n> 如果阅读时,发现错误,或者动画不可以显示的问题可以添加我微信好友 **[tan45du_one](https://raw.githubusercontent.com/tan4"
},
{
"path": "animation-simulation/数据结构和算法/read.md",
"chars": 1233,
"preview": "**大家刚开始刷题时,会有不知道该从何刷起,也看不懂别人题解的情况**\n\n**不要着急,这是正常的。**\n\n**当你刷题一定数量之后,你就会有自己的刷题思维。**\n\n**知道这个题目属于何种类型,使用什么解题方法。**\n\n**刷题速度也会大"
},
{
"path": "animation-simulation/数据结构和算法/关于栈和队列的那些事.md",
"chars": 4414,
"preview": "# 希望这篇文章能合你的胃口\n\n> 如果阅读时,发现错误,或者动画不可以显示的问题可以添加我微信好友 **[tan45du_one](https://raw.githubusercontent.com/tan45du/tan45du.git"
},
{
"path": "animation-simulation/数据结构和算法/关于链表的那些事.md",
"chars": 3020,
"preview": "# 链表详解\n\n> 如果阅读时,发现错误,或者动画不可以显示的问题可以添加我微信好友 **[tan45du_one](https://raw.githubusercontent.com/tan45du/tan45du.github.io/m"
},
{
"path": "animation-simulation/数据结构和算法/冒泡排序.md",
"chars": 6679,
"preview": "> 如果阅读时,发现错误,或者动画不可以显示的问题可以添加我微信好友 **[tan45du_one](https://raw.githubusercontent.com/tan45du/tan45du.github.io/master/个人"
},
{
"path": "animation-simulation/数据结构和算法/合成.md",
"chars": 5616,
"preview": "> 如果阅读时,发现错误,或者动画不可以显示的问题可以添加我微信好友 **[tan45du_one](https://raw.githubusercontent.com/tan45du/tan45du.github.io/master/个人"
},
{
"path": "animation-simulation/数据结构和算法/基数排序.md",
"chars": 0,
"preview": ""
},
{
"path": "animation-simulation/数据结构和算法/堆排序.md",
"chars": 8550,
"preview": "### **堆排序**\n\n> 如果阅读时,发现错误,或者动画不可以显示的问题可以添加我微信好友 **[tan45du_one](https://raw.githubusercontent.com/tan45du/tan45du.github"
},
{
"path": "animation-simulation/数据结构和算法/字符串匹配算法.md",
"chars": 19335,
"preview": "> 如果阅读时,发现错误,或者动画不可以显示的问题可以添加我微信好友 **[tan45du_one](https://raw.githubusercontent.com/tan45du/tan45du.github.io/master/个人"
},
{
"path": "animation-simulation/数据结构和算法/希尔排序.md",
"chars": 4156,
"preview": "> 如果阅读时,发现错误,或者动画不可以显示的问题可以添加我微信好友 **[tan45du_one](https://raw.githubusercontent.com/tan45du/tan45du.github.io/master/个人"
},
{
"path": "animation-simulation/数据结构和算法/归并排序.md",
"chars": 8837,
"preview": "### **归并排序**\n\n> 如果阅读时,发现错误,或者动画不可以显示的问题可以添加我微信好友 **[tan45du_one](https://raw.githubusercontent.com/tan45du/tan45du.githu"
},
{
"path": "animation-simulation/数据结构和算法/快速排序.md",
"chars": 14410,
"preview": "> 如果阅读时,发现错误,或者动画不可以显示的问题可以添加我微信好友 **[tan45du_one](https://raw.githubusercontent.com/tan45du/tan45du.github.io/master/个人"
},
{
"path": "animation-simulation/数据结构和算法/桶排序.md",
"chars": 2137,
"preview": "我们之前介绍了计数排序,大家应该已经完全搞定了吧,\n\n趁着今天没啥大事咱们再来搞点其他的,如果忘记计数排序的彦祖可以先去复习一下\n\n大家还记不记得咱们上回说的,我们的计数排序在数字范围较小,且全为整数时才可以使用,\n\n但是当我们遇到 dou"
},
{
"path": "animation-simulation/数据结构和算法/直接插入排序.md",
"chars": 2655,
"preview": "> 如果阅读时,发现错误,或者动画不可以显示的问题可以添加我微信好友 **[tan45du_one](https://raw.githubusercontent.com/tan45du/tan45du.github.io/master/个人"
},
{
"path": "animation-simulation/数据结构和算法/简单选择排序.md",
"chars": 2916,
"preview": "> 如果阅读时,发现错误,或者动画不可以显示的问题可以添加我微信好友 **[tan45du_one](https://raw.githubusercontent.com/tan45du/tan45du.github.io/master/个人"
},
{
"path": "animation-simulation/数据结构和算法/翻转对.md",
"chars": 4620,
"preview": "#### [leetcode 493 翻转对](https://leetcode-cn.com/problems/reverse-pairs/)\n\n> 如果阅读时,发现错误,或者动画不可以显示的问题可以添加我微信好友 **[tan45du_"
},
{
"path": "animation-simulation/数据结构和算法/荷兰国旗.md",
"chars": 6348,
"preview": "> 如果阅读时,发现错误,或者动画不可以显示的问题可以添加我微信好友 **[tan45du_one](https://raw.githubusercontent.com/tan45du/tan45du.github.io/master/个人"
},
{
"path": "animation-simulation/数据结构和算法/计数排序.md",
"chars": 6254,
"preview": "# 计数排序\n\n> 如果阅读时,发现错误,或者动画不可以显示的问题可以添加我微信好友 **[tan45du_one](https://raw.githubusercontent.com/tan45du/tan45du.github.io/m"
},
{
"path": "animation-simulation/数据结构和算法/逆序对问题.md",
"chars": 4531,
"preview": "> 如果阅读时,发现错误,或者动画不可以显示的问题可以添加我微信好友 **[tan45du_one](https://raw.githubusercontent.com/tan45du/tan45du.github.io/master/个人"
},
{
"path": "animation-simulation/数组篇/leetcode1052爱生气的书店老板.md",
"chars": 5845,
"preview": "> 如果阅读时,发现错误,或者动画不可以显示的问题可以添加我微信好友 **[tan45du_one](https://raw.githubusercontent.com/tan45du/tan45du.github.io/master/个人"
},
{
"path": "animation-simulation/数组篇/leetcode1438绝对值不超过限制的最长子数组.md",
"chars": 8954,
"preview": "> 如果阅读时,发现错误,或者动画不可以显示的问题可以添加我微信好友 **[tan45du_one](https://raw.githubusercontent.com/tan45du/tan45du.github.io/master/个人"
},
{
"path": "animation-simulation/数组篇/leetcode1两数之和.md",
"chars": 4976,
"preview": "> 如果阅读时,发现错误,或者动画不可以显示的问题可以添加我微信好友 **[tan45du_one](https://raw.githubusercontent.com/tan45du/tan45du.github.io/master/个人"
},
{
"path": "animation-simulation/数组篇/leetcode219数组中重复元素2.md",
"chars": 5682,
"preview": "> 如果阅读时,发现错误,或者动画不可以显示的问题可以添加我微信好友 **[tan45du_one](https://raw.githubusercontent.com/tan45du/tan45du.github.io/master/个人"
},
{
"path": "animation-simulation/数组篇/leetcode27移除元素.md",
"chars": 4507,
"preview": "> 如果阅读时,发现错误,或者动画不可以显示的问题可以添加我微信好友 **[tan45du_one](https://raw.githubusercontent.com/tan45du/tan45du.github.io/master/个人"
},
{
"path": "animation-simulation/数组篇/leetcode41缺失的第一个正数.md",
"chars": 7281,
"preview": "> 如果阅读时,发现错误,或者动画不可以显示的问题可以添加我微信好友 **[tan45du_one](https://raw.githubusercontent.com/tan45du/tan45du.github.io/master/个人"
},
{
"path": "animation-simulation/数组篇/leetcode485最大连续1的个数.md",
"chars": 5339,
"preview": "> 如果阅读时,发现错误,或者动画不可以显示的问题可以添加我微信好友 **[tan45du_one](https://raw.githubusercontent.com/tan45du/tan45du.github.io/master/个人"
},
{
"path": "animation-simulation/数组篇/leetcode54螺旋矩阵.md",
"chars": 5776,
"preview": "> 如果阅读时,发现错误,或者动画不可以显示的问题可以添加我微信好友 **[tan45du_one](https://raw.githubusercontent.com/tan45du/tan45du.github.io/master/个人"
},
{
"path": "animation-simulation/数组篇/leetcode560和为K的子数组.md",
"chars": 5838,
"preview": "> 如果阅读时,发现错误,或者动画不可以显示的问题可以添加我微信好友 **[tan45du_one](https://raw.githubusercontent.com/tan45du/tan45du.github.io/master/个人"
},
{
"path": "animation-simulation/数组篇/leetcode59螺旋矩阵2.md",
"chars": 10279,
"preview": "> 如果阅读时,发现错误,或者动画不可以显示的问题可以添加我微信好友 **[tan45du_one](https://raw.githubusercontent.com/tan45du/tan45du.github.io/master/个人"
},
{
"path": "animation-simulation/数组篇/leetcode66加一.md",
"chars": 3139,
"preview": "> 如果阅读时,发现错误,或者动画不可以显示的问题可以添加我微信好友 **[tan45du_one](https://raw.githubusercontent.com/tan45du/tan45du.github.io/master/个人"
},
{
"path": "animation-simulation/数组篇/leetcode75颜色分类.md",
"chars": 7690,
"preview": "> 如果阅读时,发现错误,或者动画不可以显示的问题可以添加我微信好友 **[tan45du_one](https://raw.githubusercontent.com/tan45du/tan45du.github.io/master/个人"
},
{
"path": "animation-simulation/数组篇/剑指offer3数组中重复的数.md",
"chars": 4439,
"preview": "> 如果阅读时,发现错误,或者动画不可以显示的问题可以添加我微信好友 **[tan45du_one](https://raw.githubusercontent.com/tan45du/tan45du.github.io/master/个人"
},
{
"path": "animation-simulation/数组篇/长度最小的子数组.md",
"chars": 3584,
"preview": "> 如果阅读时,发现错误,或者动画不可以显示的问题可以添加我微信好友 **[tan45du_one](https://raw.githubusercontent.com/tan45du/tan45du.github.io/master/个人"
},
{
"path": "animation-simulation/栈和队列/225.用队列实现栈.md",
"chars": 2392,
"preview": "> 如果阅读时,发现错误,或者动画不可以显示的问题可以添加我微信好友 **[tan45du_one](https://raw.githubusercontent.com/tan45du/tan45du.github.io/master/个人"
},
{
"path": "animation-simulation/栈和队列/leetcode1047 删除字符串中的所有相邻重复项.md",
"chars": 2405,
"preview": "> 如果阅读时,发现错误,或者动画不可以显示的问题可以添加我微信好友 **[tan45du_one](https://raw.githubusercontent.com/tan45du/tan45du.github.io/master/个人"
},
{
"path": "animation-simulation/栈和队列/leetcode20有效的括号.md",
"chars": 2805,
"preview": "> 如果阅读时,发现错误,或者动画不可以显示的问题可以添加我微信好友 **[tan45du_one](https://raw.githubusercontent.com/tan45du/tan45du.github.io/master/个人"
},
{
"path": "animation-simulation/栈和队列/leetcode402移掉K位数字.md",
"chars": 2661,
"preview": "> 如果阅读时,发现错误,或者动画不可以显示的问题可以添加我微信好友 **[tan45du_one](https://raw.githubusercontent.com/tan45du/tan45du.github.io/master/个人"
},
{
"path": "animation-simulation/栈和队列/剑指Offer09用两个栈实现队列.md",
"chars": 2626,
"preview": "> 如果阅读时,发现错误,或者动画不可以显示的问题可以添加我微信好友 **[tan45du_one](https://raw.githubusercontent.com/tan45du/tan45du.github.io/master/个人"
},
{
"path": "animation-simulation/求和问题/三数之和.md",
"chars": 6046,
"preview": "> 如果阅读时,发现错误,或者动画不可以显示的问题可以添加我微信好友 **[tan45du_one](https://raw.githubusercontent.com/tan45du/tan45du.github.io/master/个人"
},
{
"path": "animation-simulation/求和问题/两数之和.md",
"chars": 2707,
"preview": "> 如果阅读时,发现错误,或者动画不可以显示的问题可以添加我微信好友 **[tan45du_one](https://raw.githubusercontent.com/tan45du/tan45du.github.io/master/个人"
},
{
"path": "animation-simulation/求和问题/四数之和.md",
"chars": 4592,
"preview": "> 如果阅读时,发现错误,或者动画不可以显示的问题可以添加我微信好友 **[tan45du_one](https://raw.githubusercontent.com/tan45du/tan45du.github.io/master/个人"
},
{
"path": "animation-simulation/求次数问题/只出现一次的数.md",
"chars": 12331,
"preview": "> 如果阅读时,发现错误,或者动画不可以显示的问题可以添加我微信好友 **[tan45du_one](https://raw.githubusercontent.com/tan45du/tan45du.github.io/master/个人"
},
{
"path": "animation-simulation/求次数问题/只出现一次的数2.md",
"chars": 6523,
"preview": "> 如果阅读时,发现错误,或者动画不可以显示的问题可以添加我微信好友 **[tan45du_one](https://raw.githubusercontent.com/tan45du/tan45du.github.io/master/个人"
},
{
"path": "animation-simulation/求次数问题/只出现一次的数3.md",
"chars": 5972,
"preview": "> 如果阅读时,发现错误,或者动画不可以显示的问题可以添加我微信好友 **[tan45du_one](https://raw.githubusercontent.com/tan45du/tan45du.github.io/master/个人"
},
{
"path": "animation-simulation/滑动窗口/空.md",
"chars": 0,
"preview": ""
},
{
"path": "animation-simulation/缓存淘汰算法/LFU.md",
"chars": 0,
"preview": ""
},
{
"path": "animation-simulation/缓存淘汰算法/LRU.md",
"chars": 0,
"preview": ""
},
{
"path": "animation-simulation/设计/LRU.md",
"chars": 680,
"preview": "说起缓存我们都不陌生\n\n浏览器缓存,数据库缓存等。\n\n说起**缓存淘汰策略**我们也很熟悉。\n\n例如先进先出策略 FIFO(First In,First Out),最少使用策略 LFU(Least Frequently Used),最近最少"
},
{
"path": "animation-simulation/贪心/空.md",
"chars": 0,
"preview": ""
},
{
"path": "animation-simulation/递归/空.md",
"chars": 0,
"preview": ""
},
{
"path": "animation-simulation/链表篇/234. 回文链表.md",
"chars": 12659,
"preview": "> 如果阅读时,发现错误,或者动画不可以显示的问题可以添加我微信好友 **[tan45du_one](https://raw.githubusercontent.com/tan45du/tan45du.github.io/master/个人"
},
{
"path": "animation-simulation/链表篇/leetcode141环形链表.md",
"chars": 3109,
"preview": "> 如果阅读时,发现错误,或者动画不可以显示的问题可以添加我微信好友 **[tan45du_one](https://raw.githubusercontent.com/tan45du/tan45du.github.io/master/个人"
},
{
"path": "animation-simulation/链表篇/leetcode142环形链表2.md",
"chars": 8259,
"preview": "> 如果阅读时,发现错误,或者动画不可以显示的问题可以添加我微信好友 **[tan45du_one](https://raw.githubusercontent.com/tan45du/tan45du.github.io/master/个人"
},
{
"path": "animation-simulation/链表篇/leetcode147对链表进行插入排序.md",
"chars": 8109,
"preview": "> 如果阅读时,发现错误,或者动画不可以显示的问题可以添加我微信好友 **[tan45du_one](https://raw.githubusercontent.com/tan45du/tan45du.github.io/master/个人"
},
{
"path": "animation-simulation/链表篇/leetcode206反转链表.md",
"chars": 6416,
"preview": "> 如果阅读时,发现错误,或者动画不可以显示的问题可以添加我微信好友 **[tan45du_one](https://raw.githubusercontent.com/tan45du/tan45du.github.io/master/个人"
},
{
"path": "animation-simulation/链表篇/leetcode328奇偶链表.md",
"chars": 4109,
"preview": "> 如果阅读时,发现错误,或者动画不可以显示的问题可以添加我微信好友 **[tan45du_one](https://raw.githubusercontent.com/tan45du/tan45du.github.io/master/个人"
},
{
"path": "animation-simulation/链表篇/leetcode82删除排序链表中的重复元素II.md",
"chars": 5894,
"preview": "> 如果阅读时,发现错误,或者动画不可以显示的问题可以添加我微信好友 **[tan45du_one](https://raw.githubusercontent.com/tan45du/tan45du.github.io/master/个人"
},
{
"path": "animation-simulation/链表篇/leetcode86分隔链表.md",
"chars": 5086,
"preview": "> 如果阅读时,发现错误,或者动画不可以显示的问题可以添加我微信好友 **[tan45du_one](https://raw.githubusercontent.com/tan45du/tan45du.github.io/master/个人"
},
{
"path": "animation-simulation/链表篇/leetcode92反转链表2.md",
"chars": 7464,
"preview": "> 如果阅读时,发现错误,或者动画不可以显示的问题可以添加我微信好友 **[tan45du_one](https://raw.githubusercontent.com/tan45du/tan45du.github.io/master/个人"
},
{
"path": "animation-simulation/链表篇/剑指Offer25合并两个排序的链表.md",
"chars": 4414,
"preview": "> 如果阅读时,发现错误,或者动画不可以显示的问题可以添加我微信好友 **[tan45du_one](https://raw.githubusercontent.com/tan45du/tan45du.github.io/master/个人"
},
{
"path": "animation-simulation/链表篇/剑指Offer52两个链表的第一个公共节点.md",
"chars": 7410,
"preview": "> 如果阅读时,发现错误,或者动画不可以显示的问题可以添加我微信好友 **[tan45du_one](https://raw.githubusercontent.com/tan45du/tan45du.github.io/master/个人"
},
{
"path": "animation-simulation/链表篇/剑指offer22倒数第k个节点.md",
"chars": 4135,
"preview": "> 如果阅读时,发现错误,或者动画不可以显示的问题可以添加我微信好友 **[tan45du_one](https://raw.githubusercontent.com/tan45du/tan45du.github.io/master/个人"
},
{
"path": "animation-simulation/链表篇/面试题 02.03. 链表中间节点.md",
"chars": 3265,
"preview": "> 如果阅读时,发现错误,或者动画不可以显示的问题可以添加我微信好友 **[tan45du_one](https://raw.githubusercontent.com/tan45du/tan45du.github.io/master/个人"
},
{
"path": "animation-simulation/链表篇/面试题 02.05. 链表求和.md",
"chars": 7838,
"preview": "> 如果阅读时,发现错误,或者动画不可以显示的问题可以添加我微信好友 **[tan45du_one](https://raw.githubusercontent.com/tan45du/tan45du.github.io/master/个人"
}
]
About this extraction
This page contains the full source code of the chefyuan/algorithm-base GitHub repository, extracted and formatted as plain text for AI agents and large language models (LLMs). The extraction includes 116 files (511.1 KB), approximately 222.5k tokens. Use this with OpenClaw, Claude, ChatGPT, Cursor, Windsurf, or any other AI tool that accepts text input. You can copy the full output to your clipboard or download it as a .txt file.
Extracted by GitExtract — free GitHub repo to text converter for AI. Built by Nikandr Surkov.